
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
huggingface/transformers | deep-learning | 36,594 | Lora_B weight becomes 0 when using AuotModel | ### System Info
transformers version: 4.49.0
peft version: 0.14.0
### Who can help?
_No response_
### Information
When using `AutoModel` to load the base model and passing it to`PeftModel`, the LoRA weights become 0. It is not a problem when using `AutoModelForCausalLM`.
### Tasks
- [ ] An officially supported t... | closed | 2025-03-06T19:36:11Z | 2025-03-06T19:45:41Z | https://github.com/huggingface/transformers/issues/36594 | [
"bug"
] | makcedward | 1 |
man-group/arctic | pandas | 859 | Behaviour of tickstore.delete | #### Arctic Version
```
1.79.4
```
#### Arctic Store
```
TickStore
```
#### Platform and version
MacOS Catalina 10.15.4
#### Description of problem and/or code sample that reproduces the issue
I tried to clean up the ticks which are duplicated accidentally via tickstore.delete(). I expected to ... | open | 2020-05-26T16:49:22Z | 2020-05-26T16:49:22Z | https://github.com/man-group/arctic/issues/859 | [] | soulaw-mkii | 0 |
microsoft/qlib | machine-learning | 1,324 | cn_index 获取指数成分股数据 |
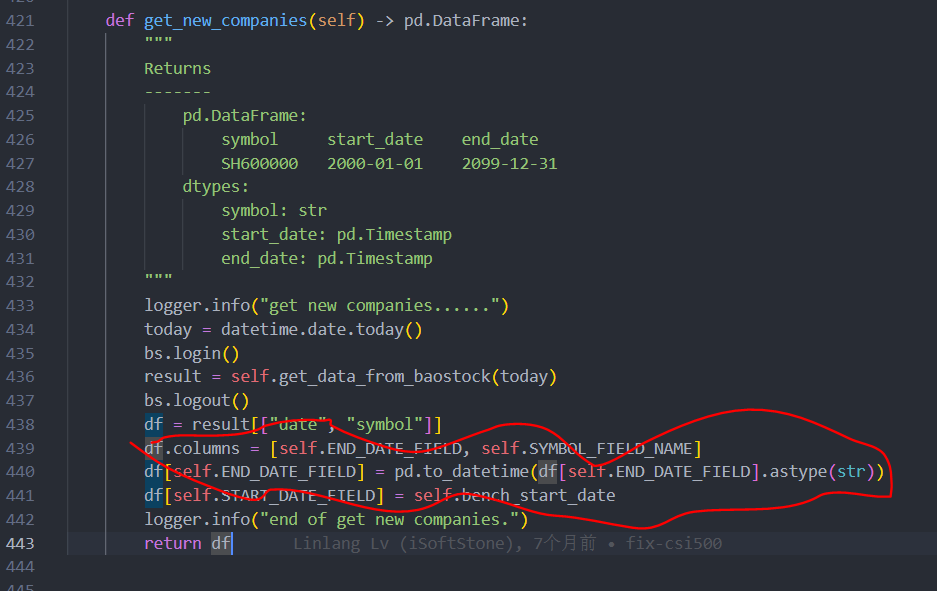
我理解通过baostock 获取中证500指数成分股数据中的日期应该是开始日期,这里为什么是结束日期?
| closed | 2022-10-20T14:16:36Z | 2023-01-23T15:02:06Z | https://github.com/microsoft/qlib/issues/1324 | [
"question",
"stale"
] | louis-xuy | 1 |
DistrictDataLabs/yellowbrick | matplotlib | 498 | Allow ModelVisualizers to wrap Pipeline objects | **Describe the solution you'd like**
Our model visualizers expect to wrap classifiers, regressors, or clusters in order to visualize the model under the hood; they even do checks to ensure the right estimator is passed in. Unfortunately in many cases, passing a pipeline object as the model in question does not allow... | open | 2018-07-13T13:06:32Z | 2020-01-08T15:58:39Z | https://github.com/DistrictDataLabs/yellowbrick/issues/498 | [
"type: feature",
"priority: medium",
"level: intermediate"
] | bbengfort | 4 |
chaos-genius/chaos_genius | data-visualization | 724 | [BUG] Email alert formatting breaks when forwarded | ## Describe the bug
When forwarded, email alerts and alert reports do not keep all of the formatting. Colors are button styles make some of the text unreadable.
## Explain the environment
- **Chaos Genius version**: 0.4.0-rc
- **OS Version / Instance**: -
- **Deployment type**: -
## Current behavior
Bef... | closed | 2022-02-15T11:44:57Z | 2022-04-11T06:18:38Z | https://github.com/chaos-genius/chaos_genius/issues/724 | [
"❗alerts"
] | Samyak2 | 0 |
onnx/onnx | machine-learning | 6,284 | ImportError: DLL load failed while importing onnx_cpp2py_export: 动态链接库(DLL)初始化例程失败。 | # Bug Report
### Is the issue related to model conversion?
1.16.2

<img width="952" alt="onnx_bug" src="https://github.com/user-attachments/assets/4f0d6581-a62e-4fbb-931b-65eb844a7aae">
| closed | 2024-08-07T08:05:20Z | 2024-08-07T14:09:33Z | https://github.com/onnx/onnx/issues/6284 | [
"bug"
] | LHSSHL001 | 2 |
pinry/pinry | django | 159 | Python Imaging Library | To get this to work after running "make bootstrap" I had do manually rename the PIL folder in
C:\Users\username\.virtualenvs\pinry-master-GvTIGkmg\Lib\site-packages
to "pil" re-run "make bootstrap" and then re-rename the folder "PIL" before running "make serve."
Now with it up and running I do not have anyth... | closed | 2019-12-07T14:25:30Z | 2019-12-08T19:17:08Z | https://github.com/pinry/pinry/issues/159 | [
"bug",
"python"
] | brett-jpy | 2 |
wandb/wandb | data-science | 8,770 | [Feature]: Night mode follows system theme | ### Description
The night mode preview feature is wonderful, however it would be great if it could follow the system theme (as many websites do).
I switch between light and dark mode a lot, and it's a pain to do Ctrl + M on every W&B tab every time I switch.
### Suggested Solution
An option for night mode to follow... | open | 2024-11-05T12:43:42Z | 2024-11-05T19:01:00Z | https://github.com/wandb/wandb/issues/8770 | [
"ty:feature",
"a:app"
] | SamAdamDay | 1 |
jina-ai/serve | deep-learning | 6,060 | Bi-directional Streaming | **Describe the feature**
<!-- A clear and concise description of what the feature is. -->
As I understand it, the current API only supports response streaming. Is there a way to support [bi-directional streaming](https://grpc.io/docs/languages/python/basics/#bidirectional-streaming-rpc)? I imagine it would look like ... | closed | 2023-09-26T17:08:12Z | 2024-05-10T00:18:33Z | https://github.com/jina-ai/serve/issues/6060 | [
"Stale"
] | NarekA | 12 |
mirumee/ariadne | api | 306 | Implement GraphQL modules | GraphQL Modules are a JavaScript tool that allows types and resolvers to be grouped together into functional blocks that depend on each other. Modules can be composed to build larger parts, ultimately leading to a module that represents the entire application.
Importing a single module is easier than importing a lis... | closed | 2020-01-28T16:08:19Z | 2022-04-12T13:36:12Z | https://github.com/mirumee/ariadne/issues/306 | [
"roadmap",
"discussion"
] | patrys | 4 |
ijl/orjson | numpy | 213 | Feature request: Can mmap'ed files be support? | As bytearrays and memoryviews are already supported, would it possible to support mmap files also? It could severely reduce memory usage when dealing with large files. | closed | 2021-10-06T03:58:47Z | 2021-12-05T15:50:54Z | https://github.com/ijl/orjson/issues/213 | [] | Dobatymo | 1 |
paperless-ngx/paperless-ngx | machine-learning | 8,510 | [BUG] Mails not being collected/processed since 22-11-2024 | ### Description
Paperless does not pull mail from my mail account since 22-11-2024. The mail account test returns a success message for connecting to the mailbox. There have been no logs since 22-11-2024. I have updated to 2.13.5 and have restarted paperless-ngx and the host which it is running on multiple times. The ... | closed | 2024-12-17T21:30:13Z | 2024-12-18T01:16:56Z | https://github.com/paperless-ngx/paperless-ngx/issues/8510 | [
"not a bug"
] | tibbors | 0 |
jmcnamara/XlsxWriter | pandas | 938 | Bug: Unexpected changes to Excel outputs from 3.0.5 to 3.0.6? | ### Current behavior
**Background:**
I'm currently using XlsxWriter for Excel reporting, where I have some convenience functionality built for generating more "templated" reports. I have unit tests which compare got to expected Excel outputs using the XlsxWriter file comparison utility [compare_xlsx_files](https://gi... | closed | 2023-01-09T22:30:14Z | 2023-01-10T13:33:22Z | https://github.com/jmcnamara/XlsxWriter/issues/938 | [
"bug"
] | raeganbarker | 2 |
giotto-ai/giotto-tda | scikit-learn | 13 | fix windows wheel readme file | The `twine check` complains about the structuring of the README.rst file in the windows build. Needs to be fixed before being able to upload to PyPI. | closed | 2019-10-17T10:14:45Z | 2019-10-18T07:26:02Z | https://github.com/giotto-ai/giotto-tda/issues/13 | [] | matteocao | 0 |
Esri/arcgis-python-api | jupyter | 1,339 | `as_dict` parameter name is misleading | **Describe the bug**
The result of `gis.content.advanced_search` is always a dictionary regardless of `as_dict` parameter value.
They have different contents for sure but they are still "dictionary". The parameter name could be misleading.
**To Reproduce**
```python
from arcgis.gis import GIS
gis = GIS(url="h... | closed | 2022-08-31T22:09:24Z | 2022-08-31T23:21:47Z | https://github.com/Esri/arcgis-python-api/issues/1339 | [
"documentation"
] | azinsharaf | 1 |
ScottfreeLLC/AlphaPy | pandas | 21 | Startup problems | Hello Scott,
I like this project a lot but I have issues getting it up and running. I tried both under Windows and Ubuntu. In Ubuntu at least the pip3 install alphapy worked fine.
But when I move to one of the example directories and try to run the commands you show in the documentation, it just does not find the... | closed | 2018-06-03T19:15:18Z | 2019-03-21T01:20:12Z | https://github.com/ScottfreeLLC/AlphaPy/issues/21 | [] | roylend | 9 |
freqtrade/freqtrade | python | 10,862 | Integrate Alpaca exchange to do spot trading with freqtrade. | Here is the list of prior threads on the subject, and it appears to be implementable at least as a side to do some spot paper trading with alpaca using freqtrade strategies. Has anyone achieved this, can we get an unsupported hack to do this.
Integrate Alpaca exchange to do spot trading with freqtrade.
Threads:
- ht... | closed | 2024-10-31T06:15:58Z | 2024-10-31T12:08:13Z | https://github.com/freqtrade/freqtrade/issues/10862 | [
"Question"
] | Immortality-IMT | 2 |
napari/napari | numpy | 7,553 | [test-bot] pip install --pre is failing | The --pre Test workflow failed on 2025-01-24 12:18 UTC
The most recent failing test was on ubuntu-latest py3.13 pyqt6
with commit: 42a6b9eb4ed1e8c4dc688ea0bee67364bf570875
Full run: https://github.com/napari/napari/actions/runs/12949307302
(This post will be updated if another test fails, as long as this issue remai... | closed | 2025-01-24T12:18:04Z | 2025-01-24T13:00:29Z | https://github.com/napari/napari/issues/7553 | [
"bug"
] | github-actions[bot] | 1 |
ansible/ansible | python | 84,814 | when statement giving error argument of type 'NoneType' is not iterable. | ### Summary
I am trying to execute few tasks with "when" conditional statement. The vars are defined as below:
```
ontap_license_key_format: #Options are "legacy" and "NLF"
# - legacy
# - NLF
```
When both the values are commented, the ansible tasks fails with the below error-
"msg": "The conditional check '('l... | closed | 2025-03-12T06:46:46Z | 2025-03-12T20:43:29Z | https://github.com/ansible/ansible/issues/84814 | [
"bug",
"affects_2.18"
] | kaminis85 | 5 |
aiortc/aiortc | asyncio | 552 | Add multiple users video streams to RTCPeerConnection offer. | Hi,
What I want that capture the video stream from multiple users browser (webcam) and send it to my server. Now the server will process those videos and send that video streams to another user (Admin). The admin is only the user who can see the all connected users stream and user can see only her/his video stream.
... | closed | 2021-08-16T12:11:24Z | 2022-03-11T17:57:12Z | https://github.com/aiortc/aiortc/issues/552 | [] | nikeshvarma | 0 |
streamlit/streamlit | python | 10,218 | Capturing events from interactive plotly line drawing | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
A way to be able to draw lines in plots and get the coordinates of that line would be very useful. In plotly,... | open | 2025-01-21T14:14:10Z | 2025-01-21T15:36:30Z | https://github.com/streamlit/streamlit/issues/10218 | [
"type:enhancement",
"feature:st.plotly_chart",
"area:events"
] | CarlAndersson | 1 |
httpie/cli | rest-api | 735 | Http headers appear in RED color | ### Issue
Is it possible to change the colors of the headers as they appear in red when I run a httpie request
```
ls -la /usr/local/bin/http
../Cellar/httpie/1.0.2/bin/http
http --version
1.0.2
http://$route_address/api/client/2
HTTP/1.1 200
Cache-control: private
Content-Type: application/json;chars... | closed | 2018-12-06T18:28:57Z | 2021-02-18T23:42:54Z | https://github.com/httpie/cli/issues/735 | [] | cmoulliard | 4 |
ymcui/Chinese-LLaMA-Alpaca-2 | nlp | 498 | Chinese-Alpaca-2的7B指令精调,用作分类,微调的结果accuracy为什么16bit比8bit只高0.001,另外13B模型不升反降? | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 我已阅读[项目文档](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki)和[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案。
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.cpp)、[LangChain](https://g... | closed | 2024-01-09T09:53:29Z | 2024-02-02T22:04:14Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/issues/498 | [
"stale"
] | feifei05 | 3 |
feature-engine/feature_engine | scikit-learn | 543 | Is sklearntransformerwrapper get list of transformers? | In this stage, the sklearntransformerwrapper is the wonderful feature but, Is it possible to get list of sklearntransformerwrapper and parallel transform the data.
Thank you. | open | 2022-10-14T05:00:06Z | 2022-10-14T11:52:10Z | https://github.com/feature-engine/feature_engine/issues/543 | [] | rawinan-soma | 3 |
suitenumerique/docs | django | 464 | Video integration from Youtube | ## Bug Report
**Problematic behavior**
Video integration doesn't work from YouTube

**Steps to Reproduce**
1. Video Integration with URL
**Environment**
- Impress version: prod
- Platform: Chromium 119.0.6038.0 & f... | open | 2024-11-29T15:06:11Z | 2024-11-29T15:06:11Z | https://github.com/suitenumerique/docs/issues/464 | [] | afouchereau | 0 |
collerek/ormar | sqlalchemy | 549 | json field set null | ```
class ItemConfig(ormar.Model):
pairs = ormar.Json()
it = await ItemConfig(pairs=None).save()
```
In database(pg):
the `pairs` was updated to
not the
 to declare the return type of my method as an arra... | open | 2020-05-01T20:22:33Z | 2025-03-07T12:13:59Z | https://github.com/axnsan12/drf-yasg/issues/584 | [
"triage"
] | thomasWajs | 10 |
jadore801120/attention-is-all-you-need-pytorch | nlp | 78 | Pytorch Exception in Thread: ValueError: signal number 32 out of range | Exception in thread Thread-2:
Traceback (most recent call last):
File "/home/wyf/anaconda3/lib/python3.6/threading.py", line 916, in _bootstrap_inner
self.run()
File "/home/wyf/anaconda3/lib/python3.6/threading.py", line 864, in run
self._target(*self._args, **self._kwargs)
File "/home/wyf/anaconda3... | closed | 2018-12-26T08:49:44Z | 2019-12-08T12:34:58Z | https://github.com/jadore801120/attention-is-all-you-need-pytorch/issues/78 | [] | Finley1991 | 1 |
apachecn/ailearning | python | 326 | 关于apriori算法的rulesFromConseq函数的问题 | 对于这个函数
```
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.6):
#参数:一个是频繁项集,另一个是可以出现在规则右部的元素列表 H
m = len(H[0])
if (len(freqSet) > (m + 1)): #频繁项集元素数目大于单个集合的元素数
Hmp1 = aprioriGen(H, m+1)#存在不同顺序、元素相同的集合,合并具有相同部分的集合
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)#计算可... | closed | 2018-04-02T08:10:23Z | 2018-04-09T14:45:28Z | https://github.com/apachecn/ailearning/issues/326 | [] | chZzZzZz | 13 |
quantmind/pulsar | asyncio | 300 | How to spawn a Actor with `spawn(start=<CoroutineFunction>)` | On pulsar 1.x, it works with:
```python
async def some_fn(*args, *kwargs):
foo
monitor.spawn(start=some_fn)
```
And on 2.0:
It will warning coroutine was never waited. | closed | 2017-12-07T17:23:13Z | 2017-12-08T09:42:04Z | https://github.com/quantmind/pulsar/issues/300 | [
"question"
] | RyanKung | 3 |
vitalik/django-ninja | pydantic | 295 | Dynamic response schema depending on user data | Hi.
I'm currently trying out django ninja and find it really amazing. One thing I'm not able to do is to limit fields list depending on user data.
Example:
As normal user I'd like to access my user data via api where I can see my email, first_name, last_name.
As admin user I'd like to access my user data via api wh... | closed | 2021-12-03T15:18:21Z | 2021-12-06T13:53:27Z | https://github.com/vitalik/django-ninja/issues/295 | [] | hazaard | 4 |
dropbox/PyHive | sqlalchemy | 51 | fetchmany argument ignored? | I am using PyHive and reading from a table with 527,000 rows, which takes quite a long time to read.
In trying to optimize the process, I found the following timings:
fetchmany(1000) takes 4.2s
fetchmany(2000) takes 8.4s
fetchmany(500) takes 4.2s
fetchmany(500) takes 0.02s if directly preceded by the other fetchmany(5... | closed | 2016-05-31T15:25:10Z | 2016-06-01T18:06:54Z | https://github.com/dropbox/PyHive/issues/51 | [] | mschmill | 2 |
sherlock-project/sherlock | python | 2,162 | False positive for: Fiverr | ### Additional info
_No response_
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct | closed | 2024-06-10T06:57:37Z | 2025-02-17T06:04:41Z | https://github.com/sherlock-project/sherlock/issues/2162 | [
"false positive"
] | BertKoor | 2 |
tortoise/tortoise-orm | asyncio | 1,145 | Cannt import name connection | `Traceback (most recent call last):
File "C:\Users\_\Desktop\_\cog.py", line 2, in <module>
from core import config, lib
File "C:\Users\_\Desktop\_\core\lib.py", line 5, in <module>
from tortoise.models import Model
File "C:\Users\_\AppData\Local\Programs\Python\Python310\lib\site-packages\tortoise\m... | closed | 2022-06-03T08:15:18Z | 2024-08-13T13:09:57Z | https://github.com/tortoise/tortoise-orm/issues/1145 | [] | mr-far | 2 |
snooppr/snoop | web-scraping | 34 | POP Up results Music and Full English version | English Language and Removing the pop up sound. | closed | 2020-07-31T21:13:35Z | 2020-09-12T15:37:12Z | https://github.com/snooppr/snoop/issues/34 | [
"question"
] | leemoh | 3 |
lepture/authlib | django | 309 | oidc raises exception when auth_time claim is decimal | **Describe the bug**
According to [spec](https://openid.net/specs/openid-connect-core-1_0.html#IDToken) 'auth_time' is JSON NUMBER which can be decimal. While most oidc providers set it to `int`, there are some (e.g. JetBrains Hub) that provide it in decimal.
**Error Stacks**
```
raceback (most recent call ... | closed | 2021-01-10T19:30:27Z | 2021-01-12T02:22:49Z | https://github.com/lepture/authlib/issues/309 | [
"bug"
] | tntclaus | 0 |
pnkraemer/tueplots | matplotlib | 100 | Whitespace around figures when saving | To avoid unnecessary whitespace around a figure, we should look into setting "savefig.bbox": "tight", and maybe even play around with "savefig.pad_inches", to automatically crop whitespaces around figures.
This setting could be provided as part of the content in `tueplots.figsizes`, on the same level as `constrained... | closed | 2022-08-06T08:33:00Z | 2022-08-10T12:36:04Z | https://github.com/pnkraemer/tueplots/issues/100 | [] | pnkraemer | 0 |
huggingface/transformers | tensorflow | 36,297 | Bug about num_update_steps_per_epoch in function _inner_training_loop | ### System Info
python 3.10
transformers 4.48.3
### Reproduction
In the _inner_training_loop method of /usr/local/lib/python3.10/dist-packages/transformers/trainer.py, the calculation logic for num_update_steps_per_epoch is inconsistent, which leads to the followi... | open | 2025-02-20T09:00:46Z | 2025-03-23T08:03:33Z | https://github.com/huggingface/transformers/issues/36297 | [
"bug"
] | onenotell | 3 |
graphistry/pygraphistry | jupyter | 243 | [DOCS] Colors tutorial | **Is your feature request related to a problem? Please describe.**
Colors can use a full tutorial, due to issues like https://github.com/graphistry/pygraphistry/issues/241
**Describe the solution you'd like**
Cover:
* Explicit colors: palettes, RGB hex
* Symbolic encodings: categorical, continuous, defau... | closed | 2021-07-12T19:02:28Z | 2021-10-11T02:02:12Z | https://github.com/graphistry/pygraphistry/issues/243 | [
"docs",
"good-first-issue"
] | lmeyerov | 0 |
strawberry-graphql/strawberry | asyncio | 3,572 | TypeError: MyCustomType fields cannot be resolved. unsupported operand type(s) for |: 'LazyType' and 'NoneType' | ## Describe the Bug
I had an error generating types with the next values and the error thrown was
> TypeError: MyCustomType fields cannot be resolved. unsupported operand type(s) for |: 'LazyType' and 'NoneType'
This was the status the packages and the error happened on the change from:
```
Django= 4.2.11
... | closed | 2024-07-15T08:06:25Z | 2025-03-20T15:56:48Z | https://github.com/strawberry-graphql/strawberry/issues/3572 | [
"bug"
] | Ronjea | 3 |
PaddlePaddle/models | nlp | 4,786 | emotion_detection教程中基于 ERNIE 进行 Finetune报错 | 执行这段代码后报错 前面都按照1.8的教程走下来了 不知道是哪里的问题 请指教
#--init_checkpoint ./pretrain_models/ernie
sh run_ernie.sh train
报错内容:
----------- Configuration Arguments -----------
batch_size: 32
data_dir: None
dev_set: ./data/dev.tsv
do_infer: False
do_lower_case: True
do_train: True
do_val: True
epoch: 3
ernie_config_p... | closed | 2020-08-04T10:55:51Z | 2021-07-20T07:06:50Z | https://github.com/PaddlePaddle/models/issues/4786 | [] | ML-ZXF | 4 |
roboflow/supervision | tensorflow | 1,444 | Incomplete docs | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar bug report.
### Bug
The docs to the `from_sam` method [here](https://github.com/roboflow/supervision/blob/d08d22dec6f932d273d3d217c64343a47d5972a1/supervision/detection/core.p... | closed | 2024-08-13T07:12:02Z | 2024-08-26T10:16:23Z | https://github.com/roboflow/supervision/issues/1444 | [
"bug"
] | Bhavay-2001 | 0 |
docarray/docarray | fastapi | 1,547 | docs: update contributing.md | the `contributing.md` is outdated in some places, refers to how things worked in docarray <0.30 etc. That needs to be fixed | closed | 2023-05-17T11:28:38Z | 2023-05-24T10:58:25Z | https://github.com/docarray/docarray/issues/1547 | [] | JohannesMessner | 0 |
miguelgrinberg/Flask-SocketIO | flask | 1,112 | Socket IO 400 Bad request. | https://github.com/miguelgrinberg/Flask-SocketIO/issues/913
Its the same issue.
I'm having the response headers as follows

| closed | 2019-11-28T00:19:05Z | 2019-12-18T17:48:11Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1112 | [
"question"
] | jkam273 | 13 |
pydata/xarray | numpy | 9,267 | Subtracting datasets in xarray 2024.6.0 leads to inconsistent chunks | ### What is your issue?
When I call `groupby()` on a dataset and try to subtract another dataset from the result, I get an error that says
``` ValueError: Object has inconsistent chunks along dimension lead. This can be fixed by calling unify_chunks(). ```
Adding a call to unify chunks beforehand resolves the issue,... | open | 2024-07-22T18:13:31Z | 2024-07-23T06:29:20Z | https://github.com/pydata/xarray/issues/9267 | [
"bug",
"topic-groupby",
"topic-dask",
"regression"
] | uwagura | 2 |
MaartenGr/BERTopic | nlp | 1,038 | Arabic text with visualize_documents | If the topics in Arabic or similar language there will be a problem visualizing them with visualize_documents function .. the text should be edited to be appropriate to be displayed in Plotly gra
, there are situations where the user wants more frequent feedback from the net than just after each epoch. Especially so with the arrival of RNNs, which are hungry for tons of data but slow. Having more frequent feedback also allows more neat stuff, for ins... | open | 2015-08-13T18:58:40Z | 2016-03-26T03:57:45Z | https://github.com/dnouri/nolearn/issues/138 | [] | BenjaminBossan | 1 |
pytest-dev/pytest-xdist | pytest | 604 | Distribute parameterized tests to different workers | Hello!
One issue I currently face is that I have a test which takes a long time to execute (~2 minutes). This test itself is parameterized, let say with 8 options. This means that this test will take 16 minutes to complete. In this case, it would make more sense for me if each parameterized instance of the test was ... | closed | 2020-10-27T23:31:42Z | 2021-05-07T02:44:41Z | https://github.com/pytest-dev/pytest-xdist/issues/604 | [] | tomzx | 2 |
microsoft/nni | deep-learning | 5,156 | template for model compression and speedup | template for `model compression and model speedup`
**Describe the issue**:
**NNI version**:
**Demo or example**:
**Reproduce progress**:
**Type(bug | feature)**:
| closed | 2022-10-12T08:02:34Z | 2022-10-17T07:45:54Z | https://github.com/microsoft/nni/issues/5156 | [] | Lijiaoa | 1 |
Nike-Inc/koheesio | pydantic | 13 | [FEATURE] Windows CICD is not working | <!-- We follow Design thinking principles to bring the new feature request to life. Please read through [Design thinking](https://www.interaction-design.org/literature/article/5-stages-in-the-design-thinking-process) principles if you are not familiar. -->
Various errors occur when running tests against Windows runn... | open | 2024-05-29T13:48:04Z | 2024-05-29T13:48:05Z | https://github.com/Nike-Inc/koheesio/issues/13 | [
"enhancement"
] | dannymeijer | 0 |
FactoryBoy/factory_boy | sqlalchemy | 979 | django_get_or_create with SubFactory | #### Description
The django_get_or_create feature is working well when the concerned Factory is used as a BaseFactory but not when it's used as a SubFactory
When used as a SubFactory, the following error occurs :
`AttributeError: type object 'CurrencyFactory' has no attribute '_original_params'`
#### To Reprod... | open | 2022-10-11T09:07:53Z | 2022-10-24T18:17:05Z | https://github.com/FactoryBoy/factory_boy/issues/979 | [
"Bug",
"Django"
] | VRohou | 6 |
HIT-SCIR/ltp | nlp | 488 | 在使用分词功能时报错AttributeError: 'Version' object has no attribute 'major' | closed | 2021-02-04T09:27:07Z | 2021-02-20T04:37:00Z | https://github.com/HIT-SCIR/ltp/issues/488 | [] | Chen8566 | 1 | |
akfamily/akshare | data-science | 5,703 | stock_zh_a_spot_em无法获取全部沪深京 A 股,只能获取200只股票 | stock_zh_a_spot_em无法获取全部沪深京 A 股,只能获取200只股票 | closed | 2025-02-19T15:15:26Z | 2025-02-20T08:44:56Z | https://github.com/akfamily/akshare/issues/5703 | [
"bug"
] | zgpnuaa | 0 |
inducer/pudb | pytest | 201 | NULL result without error in PyObject_Call | The program can run smoothly with python command,but raise an error mentioned above when debugging in the pudb. I don't know how to deal with it and,solutions in the google search are not clear.
| open | 2016-09-08T15:28:45Z | 2016-09-10T08:12:38Z | https://github.com/inducer/pudb/issues/201 | [] | marearth | 4 |
google-research/bert | tensorflow | 1,299 | Does LSTM better than BERT ? | closed | 2022-02-21T04:53:19Z | 2022-05-22T23:55:11Z | https://github.com/google-research/bert/issues/1299 | [] | SamMohel | 0 | |
seleniumbase/SeleniumBase | pytest | 2,865 | Major updates have arrived in `4.28.0` (mostly for UC Mode) | For anyone that hasn't been following https://github.com/seleniumbase/SeleniumBase/issues/2842, CF pushed an update that prevented UC Mode from easily bypassing CAPTCHA Turnstiles on Linux servers. Additionally, `uc_click()` was rendered ineffective for clicking Turnstile CAPTCHA checkboxes when clicking the checkbox w... | open | 2024-06-23T16:52:22Z | 2024-10-29T15:40:37Z | https://github.com/seleniumbase/SeleniumBase/issues/2865 | [
"enhancement",
"documentation",
"UC Mode / CDP Mode"
] | mdmintz | 75 |
pydata/xarray | numpy | 9,544 | Allow `.groupby().map()` to return scalars? | ### Is your feature request related to a problem?
I'm trying to get a count of unique values along a dimension. It's not so easy, unless I'm missing something.
One approach is:
```python
da = xr.tutorial.load_dataset('air_temperature').to_dataarray()
xr.apply_ufunc(lambda x: len(np.unique(x)), da, input_core... | closed | 2024-09-25T00:46:21Z | 2024-09-25T17:34:47Z | https://github.com/pydata/xarray/issues/9544 | [
"enhancement",
"topic-groupby"
] | max-sixty | 8 |
SALib/SALib | numpy | 188 | Morris sampling `brute` vs. `local` do not match, sometimes. | We discovered in #186 that the test comparing Morris LocalOptimisation and Brute (methods to identify maximally-distant trajectories) will fail under random conditions.
Under this issue I'll keep track of attempts to figure out what's going on. Things I have noticed so far:
* This problem is not specific to using g... | closed | 2018-01-21T20:12:28Z | 2018-01-24T16:55:52Z | https://github.com/SALib/SALib/issues/188 | [] | jdherman | 3 |
minimaxir/textgenrnn | tensorflow | 108 | textgen.generate() aborts with Error #15 | Hello,
Thanks for designing this tool!
I'm running Python 3.6.8, tensorflow 1.12.0. When I start working through the examples, the program aborts with the following error:
`>>> textgen.generate()
OMP: Error #15: Initializing libiomp5.dylib, but found libiomp5.dylib already initialized.
OMP: Hint: This means that... | closed | 2019-02-21T17:27:21Z | 2019-02-21T17:43:01Z | https://github.com/minimaxir/textgenrnn/issues/108 | [] | vrl2 | 1 |
comfyanonymous/ComfyUI | pytorch | 6,470 | NSFW hide or blur option where shown | ### Feature Idea
NSFW hide or blur option where shown - I like to have some, but when I'm at the coffee shop looking for SFW, it doesn't filter them out.
### Existing Solutions
delete NSFW loras etc..
### Other
_No response_ | open | 2025-01-14T20:24:48Z | 2025-01-14T20:24:48Z | https://github.com/comfyanonymous/ComfyUI/issues/6470 | [
"Feature"
] | NinjaKristo | 0 |
google-deepmind/sonnet | tensorflow | 104 | Layers in Keras? | This may be a really naive question, but what is the difference between this and Keras layers? My guess is that Keras doesn’t afford as much variable sharing flexibility. But to the best of my understanding, their abstract layers class can be subclassed and would (I believe, though I’m not sure) reuse variables upon su... | closed | 2018-11-17T15:22:49Z | 2018-11-24T02:47:02Z | https://github.com/google-deepmind/sonnet/issues/104 | [] | slerman12 | 0 |
SYSTRAN/faster-whisper | deep-learning | 556 | What are the minimum requirements to run faster whisper locally? | I want to run it locally but I don't know if my machine can do it. I would like to know the requirements for each version of whisper | closed | 2023-11-10T13:45:52Z | 2024-07-10T07:12:10Z | https://github.com/SYSTRAN/faster-whisper/issues/556 | [] | heloisypr | 4 |
mlfoundations/open_clip | computer-vision | 839 | Question: How/where to evaluate GeoDE and Dollar Street? | Hello,
thank you for the great work of benchmarking all those CLIP models here: https://github.com/mlfoundations/open_clip/blob/main/docs/openclip_classification_results.csv
I am interested in the evaluation on GeoDE and Dollar Street datasets and wanted to compare with your setup there.
Afaik, you use CLIP-Ben... | closed | 2024-03-08T15:12:42Z | 2024-03-09T14:31:10Z | https://github.com/mlfoundations/open_clip/issues/839 | [] | gregor-ge | 1 |
pyeve/eve | flask | 1,147 | Documentation builds on Read the Docs are currently broken | It appears that since we departed from `requirements.txt` files, RTD cannot build the documentation anymore. This would not be too much of a problem if we didn't link to RTD for the docs of the stable version. Either drop RTD altogether, or see how we can support it again (maybe by re-adding the requirements file - som... | closed | 2018-05-14T14:48:33Z | 2018-05-14T15:38:05Z | https://github.com/pyeve/eve/issues/1147 | [
"documentation"
] | nicolaiarocci | 3 |
yunjey/pytorch-tutorial | deep-learning | 60 | Error with Image captioning | When I Run the evaluation command
python sample.py --image='png/example.png'
I got this error
Traceback (most recent call last):
File "sample.py", line 97, in <module>
main(args)
File "sample.py", line 61, in main
sampled_ids = decoder.sample(feature)
File "/users/PAS1273/osu8235/pytorch/pytor... | closed | 2017-09-11T19:07:25Z | 2018-08-20T16:35:38Z | https://github.com/yunjey/pytorch-tutorial/issues/60 | [] | mhsamavatian | 5 |
mwaskom/seaborn | data-science | 3,296 | Scale issue when plotting on top of sns.pairplot diagonal | I am plotting some red theoretical curves (ellipses and density functions) on top of the blue scatterplots and histograms produced by `sns.pairplot`.
As you can see in the image, the ellipses work well, but not the diagonal plots because it seems that they are shifted and scaled internally and automatically by `pair... | closed | 2023-03-14T15:47:25Z | 2023-03-14T22:01:03Z | https://github.com/mwaskom/seaborn/issues/3296 | [] | caph1993 | 1 |
keras-team/keras | pytorch | 20,177 | Obscure validation failure due to `_use_cached_eval_dataset` | I'll preface by saying that I encountered this issue with tf_keras == 2.15, but the source code regarding evaluation is hardly different from v2.15, I feel that it's still applicable here.
The issue is that no matter what [`fit` forces `evaluate` to use stored dataset object for the validation step](https://github.c... | closed | 2024-08-28T12:57:12Z | 2024-09-27T02:02:18Z | https://github.com/keras-team/keras/issues/20177 | [
"stat:awaiting response from contributor",
"stale",
"type:Bug"
] | DLumi | 7 |
alpacahq/alpaca-trade-api-python | rest-api | 175 | Websocket streaming does not work with paper trading creds | This script is failing since yesterday with the following error:
```
#!/usr/bin/env python
import alpaca_trade_api as tradeapi
from alpaca_trade_api.stream2 import StreamConn
from pprint import pprint
base_url = 'https://paper-api.alpaca.markets'
api_key_id = 'PKTKMECJGYAJ87YN9V07'
api_secret = 'myfakeapi... | closed | 2020-03-31T15:11:58Z | 2020-03-31T23:05:10Z | https://github.com/alpacahq/alpaca-trade-api-python/issues/175 | [] | qlikstar | 4 |
seleniumbase/SeleniumBase | web-scraping | 2,351 | [Request] Multiple or condition wait tuple | Taking advantage of the fact that it is an extra layer of Selenium, I would like to include a condition to wait for the first element found.
I would like to see this feature but well applied and there is no need to specify what element it is (I would like it to be automatic like here, as is the case with seleniumbas... | closed | 2023-12-08T20:06:52Z | 2023-12-16T20:39:56Z | https://github.com/seleniumbase/SeleniumBase/issues/2351 | [
"duplicate",
"question"
] | boludoz | 2 |
paperless-ngx/paperless-ngx | django | 7,399 | [BUG] UI flaw - create new document type without having permissions | ### Description
I have a user which does not have permissions to create / edit document types. There are places in the GUI which shows a button to create a new entry - here the missing permissions are not considered. Since adding the new entry does not work in the end, this is no security flaw, but offering the option... | closed | 2024-08-05T23:07:18Z | 2024-09-05T03:04:02Z | https://github.com/paperless-ngx/paperless-ngx/issues/7399 | [
"bug",
"frontend"
] | arnschi | 1 |
apify/crawlee-python | automation | 546 | Error handler is not called for session errors | See https://github.com/apify/crawlee/pull/2683 | closed | 2024-09-27T09:04:16Z | 2024-10-01T08:54:07Z | https://github.com/apify/crawlee-python/issues/546 | [
"bug",
"t-tooling"
] | janbuchar | 0 |
hbldh/bleak | asyncio | 793 | Slow connection with nest_asyncio | * bleak version: 0.14.2
* Python version: 3.8.6
* Operating System: Windows 10 Home
* Computer specs: Intel(R) Core(TM) i7-5500U CPU @ 2.40GHz, 12.0 GB RAM
### Description
Trying to establish a connection with a `nest_asyncio` applied considerably slows down the connection ~7 times (takes 21 seconds). If I c... | closed | 2022-03-24T13:27:42Z | 2023-03-20T18:53:17Z | https://github.com/hbldh/bleak/issues/793 | [] | diogotecelao | 3 |
AirtestProject/Airtest | automation | 418 | Do you have an improvement plan for the report form? | hi
There was an opinion that the form was improved as a result of the test in my team.
Do you have an improvement plan for the report form? | open | 2019-05-31T06:24:44Z | 2019-06-17T06:08:36Z | https://github.com/AirtestProject/Airtest/issues/418 | [] | JJunM | 5 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 16,289 | [Bug]: Winodws 11 error - ModuleNotFoundError - No module named 'setuptools.command.test' - build stops | ### Checklist
- [ ] The issue exists after disabling all extensions
- [X] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [ ] The issue exists in the current version of the webui
- [ ] The issue has not been reported before... | open | 2024-07-29T03:55:16Z | 2024-08-09T15:04:46Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16289 | [
"bug-report"
] | smuchow1962 | 32 |
skypilot-org/skypilot | data-science | 4,444 | [SERVE][AUTOSCALERS] Replica scaling sampling period and stability. | In autoscalers.py within serve:
https://github.com/skypilot-org/skypilot/blob/3f625886bf1b13ee463a9f8e0f6741f620f7f66f/sky/serve/autoscalers.py#L258-L269
When a single qps check is below or above the threshold, the `downscale_counter` or `upscale_counter` is set to 0.
This means a single jitter in qps could disrup... | open | 2024-12-05T17:30:42Z | 2024-12-21T17:17:18Z | https://github.com/skypilot-org/skypilot/issues/4444 | [] | JGSweets | 5 |
Kav-K/GPTDiscord | asyncio | 421 | Force json response for autodraw drawing agent | Within `/gpt converse` there is an agent that creates a prompt and determines if drawing is needed when a conversation message is sent with gpt-vision, currently, when I set response_format in the request to the model, the upstream API seems to complain saying that that parameter isn't allowed.
It may be not suppor... | closed | 2023-11-17T08:11:43Z | 2023-11-30T04:38:09Z | https://github.com/Kav-K/GPTDiscord/issues/421 | [
"bug",
"help wanted",
"good first issue",
"high-prio",
"help-wanted-important"
] | Kav-K | 1 |
microsoft/nni | data-science | 4,972 | Can I directly integrate the model.py when using tuning code instead of calling script through command | **Describe the issue**:
Now the way NNI calls the train script is:
experiment. config. trial_ command = 'python train. py'
This method of calling by command is not convenient for the integration of our current projects, because we do not want to start the train script by calling the file. We want to start it d... | open | 2022-06-29T02:37:31Z | 2022-07-06T05:54:41Z | https://github.com/microsoft/nni/issues/4972 | [] | xiaoerqi | 3 |
indico/indico | flask | 5,966 | [A11Y/UX] Replace session bar with a global pull-down menu | **Describe the bug**
This is a blanket fix for a number of accessibility issues, but mainly:
- Inability to access popups after operating the buttons in the session bar
- Difficult to make the session bar responsive
The intended fix is described in the forum post (link below). Here is a pen that demonstrates ... | open | 2023-10-02T09:03:22Z | 2023-10-02T09:04:09Z | https://github.com/indico/indico/issues/5966 | [
"bug"
] | foxbunny | 1 |
django-import-export/django-import-export | django | 1,042 | ForeignKey is 0 error | # widgets.py
def clean(self, value, row=None, *args, **kwargs):
val = super(ForeignKeyWidget, self).clean(value)
if val: # when ForeignKey is 0
return self.get_queryset(value, row, *args, **kwargs).get(**{self.field: val})
else:
return None
There is a f... | closed | 2019-11-27T10:10:56Z | 2020-05-25T11:35:53Z | https://github.com/django-import-export/django-import-export/issues/1042 | [
"stale"
] | ruanhailiang | 1 |
seleniumbase/SeleniumBase | pytest | 3,507 | Add `get_parent()` to various APIs (eg: The CDP API) | ### Add `get_parent()` to various APIs (eg: The CDP API)
----
For the CDP API, calling `element.parent` does not add in the SB CDP methods to the parent method received. So instead, I'll create a `CDP_Element.get_parent()` method to retrieve the parent element and add in the CDP API methods into there. The SB CDP API... | closed | 2025-02-12T00:59:59Z | 2025-02-12T02:12:58Z | https://github.com/seleniumbase/SeleniumBase/issues/3507 | [
"enhancement",
"UC Mode / CDP Mode"
] | mdmintz | 1 |
RobertCraigie/prisma-client-py | pydantic | 95 | Add support for setting httpx client options | ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
While running the `postgresql` integration tests on a slow connection I ran into a lot of `httpx.ReadTimeout` errors.
## Suggested solution
<!-- A clear and concise description of what you want t... | closed | 2021-11-05T15:41:16Z | 2021-12-29T11:04:31Z | https://github.com/RobertCraigie/prisma-client-py/issues/95 | [
"kind/feature"
] | RobertCraigie | 0 |
paperless-ngx/paperless-ngx | django | 7,330 | [BUG] PaperlessNGX container unhealthy - not starting | ### Description
I had to to reinstall Paperless NGX. Removed all container, folders and exectued docker prune.
Now when I starting docker compose, all starting except paperless-ngx. I have the latest version and let it run as root.
There are no further messages after "Adjusting permissions of paperless files. This... | closed | 2024-07-27T17:27:29Z | 2024-07-27T18:54:24Z | https://github.com/paperless-ngx/paperless-ngx/issues/7330 | [
"not a bug"
] | fendle | 0 |
sktime/pytorch-forecasting | pandas | 1,454 | Is there a reason for the large difference in training and validation loss with pt-forecasting models? | I have experimented with several models from pytorch-forecasting (TFT, DeepAR, LSTM) and I have noticed, that in all the cases, the training loss is very different to validation loss and it does not seem to be an issue concerning model performance (overfitting/underfitting) or weird data separation.
Is it possible, th... | open | 2023-11-28T23:12:17Z | 2023-11-28T23:12:17Z | https://github.com/sktime/pytorch-forecasting/issues/1454 | [] | chododom | 0 |
skypilot-org/skypilot | data-science | 4,918 | A missing `google.protobuf.duration_pb2` dependency error in serve k8s smoke tests `test_skyserve_failures` | When running `pytest tests/smoke_tests/test_sky_serve.py::test_skyserve_failures --kubernetes --serve`, in the second part where we execute
```python
sky serve update {name} --cloud {generic_cloud} -y tests/skyserve/failures/probing.yaml
```
I encountered the following error in the log:
```
D 03-08 09:52:03 config_uti... | open | 2025-03-08T10:01:30Z | 2025-03-10T04:24:30Z | https://github.com/skypilot-org/skypilot/issues/4918 | [] | andylizf | 1 |
okken/pytest-check | pytest | 102 | Set colorama version to >=0.4.5 |
Latest refactor adds a dependency to `colorama >= 0.4.6`, meanwhile awscl sets a `colorama <= 0.4.5`
https://github.com/okken/pytest-check/blob/b96e3654c57c1e1dcd14690848a06426bf9ad1af/pyproject.toml#L19
This is currently breaking `pip` when installing `pytest-check` alongside `awscli` as it cannot resolve a vali... | closed | 2022-11-29T16:08:19Z | 2022-12-01T15:51:16Z | https://github.com/okken/pytest-check/issues/102 | [] | fuster92 | 5 |
nschloe/tikzplotlib | matplotlib | 257 | Hatching is not mapped to pattern | Hello,
I have a matplotlib code that plots a bar plot with bars that are colored and given some pattern, like this one:
```python
import pandas as pd
from matplotlib2tikz import get_tikz_code
speed = [0.1, 17.5, 40, 48, 52, 69, 88]
lifespan = [2, 8, 70, 1.5, 25, 12, 28]
index = ['snail', 'pig', 'elephant', '... | closed | 2018-11-14T14:33:48Z | 2019-12-19T10:35:01Z | https://github.com/nschloe/tikzplotlib/issues/257 | [] | lucaventurini | 1 |
sgl-project/sglang | pytorch | 3,806 | [Feature] mla speed | ### Checklist
- [ ] 1. If the issue you raised is not a feature but a question, please raise a discussion at https://github.com/sgl-project/sglang/discussions/new/choose Otherwise, it will be closed.
- [ ] 2. Please use English, otherwise it will be closed.
### Motivation
https://github.com/flashinfer-ai/flashinfer/... | closed | 2025-02-24T05:40:23Z | 2025-02-24T15:56:11Z | https://github.com/sgl-project/sglang/issues/3806 | [] | MichoChan | 1 |
pyg-team/pytorch_geometric | deep-learning | 9,727 | FutureWarning using torch.load with torch>2.4, torch.serialization.add_safe_globals does not work for torch_geometric.data.Data | ### 🐛 Describe the bug
Hello,
I wanted to report on a warning related to the latest pytorch versions, which may become an issue moving forward.
Since I've moved to pytorch version >2.4, doing `torch.save` and `torch.load` of a `torch_geometric.data.Data` object results in the following warning:
>FutureWarnin... | open | 2024-10-23T15:15:09Z | 2025-02-02T20:51:41Z | https://github.com/pyg-team/pytorch_geometric/issues/9727 | [
"bug"
] | lposti | 4 |
PokeAPI/pokeapi | api | 876 | Some Pokemon get requests do not respond correct to name, but do with ID # | <!--
Thanks for contributing to the PokéAPI project. To make sure we're effective, please check the following:
- Make sure your issue hasn't already been submitted on the issues tab. (It has search functionality!)
- If your issue is one of outdated API data, please note that we get our data from [veekun](https://g... | open | 2023-05-07T22:44:09Z | 2023-05-09T15:12:57Z | https://github.com/PokeAPI/pokeapi/issues/876 | [] | d0rf47 | 2 |
saleor/saleor | graphql | 16,989 | Bug: There is no CustomerDeleted event in graphql schema and AsyncWebhookEventType.ACCOUNT_DELETED in app-sdk. | ### What are you trying to achieve?
I am trying to subscribe to ACCOUNT_DELETED or CUSTOMER_DELETED event. But in case of ACCOUNT_DELETED there is no such type in AsyncWebhookEventType (app-sdk) and in case of CUSTOMER_DELETED there is no CustomerDeleted event in graphql API and I was unable to generate schema. So I... | open | 2024-11-13T10:32:23Z | 2024-11-29T13:12:20Z | https://github.com/saleor/saleor/issues/16989 | [
"bug",
"accepted"
] | i-n-n-k-e-e-p-e-r | 1 |
huggingface/datasets | pytorch | 6,833 | Super slow iteration with trivial custom transform | ### Describe the bug
Dataset is 10X slower when applying trivial transforms:
```
import time
import numpy as np
from datasets import Dataset, Features, Array2D
a = np.zeros((800, 800))
a = np.stack([a] * 1000)
features = Features({"a": Array2D(shape=(800, 800), dtype="uint8")})
ds1 = Dataset.from_dict({"... | open | 2024-04-23T20:40:59Z | 2024-10-08T15:41:18Z | https://github.com/huggingface/datasets/issues/6833 | [] | xslittlegrass | 7 |
gtalarico/django-vue-template | rest-api | 48 | Error: yarn build | ```
$ yarn build
| Building for production...
ERROR Failed to compile with 3 errors 11:32:56
error in ./src/App.vue?vue&type=style&index=0&lang=css&
Module build failed (from ./node_modules/mini-css-extract-plugin/dist/loader.js)
:
TypeError: this[NS] is not... | closed | 2020-02-07T04:36:20Z | 2020-04-26T07:22:53Z | https://github.com/gtalarico/django-vue-template/issues/48 | [] | HotPotatoC | 0 |
modin-project/modin | pandas | 7,302 | Pin numpy<2 and release 0.30.1, 0.29.1, 0.28.3, 0.27.1 versions | closed | 2024-06-10T10:30:55Z | 2024-06-11T17:37:04Z | https://github.com/modin-project/modin/issues/7302 | [
"dependencies 🔗",
"P0"
] | anmyachev | 3 | |
HIT-SCIR/ltp | nlp | 568 | how to connect electra output with linear output? | https://github.com/HIT-SCIR/ltp/blob/4151b88fed3899b7eaf0e80a7a01fa5842f4df77/ltp/transformer_linear.py#L171
Here the output_hidden is disabled, then the output dimension is 1. And how to connect to the next linear layer with hidden_size as input dimension? | closed | 2022-05-30T13:36:05Z | 2022-05-30T14:14:11Z | https://github.com/HIT-SCIR/ltp/issues/568 | [] | npuichigo | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.