
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
jazzband/django-oauth-toolkit | django | 1,348 | Sensitive data like access token is logged in logs. | It will be good if the logging is configurable. ie we can enable or disable logging such details via a flag in settings.py
| closed | 2023-10-24T11:21:49Z | 2023-10-31T12:48:26Z | https://github.com/jazzband/django-oauth-toolkit/issues/1348 | [
"enhancement"
] | ygg-basil | 3 |
jupyter-incubator/sparkmagic | jupyter | 527 | Jupyterhub-Sparkmagic-Livy-Kerberos | Is there any example to configure Sparkmagic to use kerberos authentication with Livy? Setting authentication type "Kerberos" in config.json doesn't work. I get a "401" error. But If I open a terminal in the user session in JupyterHub and execute klist command i can see the tgt ticket in ccache. I'm using the default s... | closed | 2019-05-09T07:50:44Z | 2021-08-31T21:02:10Z | https://github.com/jupyter-incubator/sparkmagic/issues/527 | [] | aleevangelista | 5 |
scikit-multilearn/scikit-multilearn | scikit-learn | 43 | Python 2 vs Python 3 | What are the plans regarding python 2 vs python 3? Stick with python 2 for the time being?
| closed | 2016-06-03T13:02:50Z | 2016-06-03T15:03:45Z | https://github.com/scikit-multilearn/scikit-multilearn/issues/43 | [] | queirozfcom | 2 |
aminalaee/sqladmin | asyncio | 624 | Customized sort_query | ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
At the moment, the admin panel does not support sorting by objects, but this can be solved using the custom sort_query method. Similar to list_query, search_query.
### Describe t... | closed | 2023-09-21T08:54:40Z | 2023-09-22T09:27:59Z | https://github.com/aminalaee/sqladmin/issues/624 | [] | YarLikviD | 1 |
netbox-community/netbox | django | 18,056 | Filter or Search by multi column | ### NetBox version
v4.1.6
### Feature type
New functionality
### Triage priority
I volunteer to perform this work (if approved)
### Proposed functionality
Filter or Search function is as excel file or another software below. It's more convenient.

topics, probs = topic_model.fit_transform(docs)
```
all the processing happens on my CPU.
I was wondering: Are there parts of the computation that could be run on the GPU, and is there a way to enable that? | closed | 2023-09-12T14:54:11Z | 2023-09-19T19:30:08Z | https://github.com/MaartenGr/BERTopic/issues/1526 | [] | clstaudt | 4 |
ultralytics/ultralytics | machine-learning | 19,448 | ultralytics randomly restarts training run while training | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
_No response_
### Bug
I'm having the weirdest problem. I'm training a yolov11 model on my data with the following params:
... | open | 2025-02-26T17:37:40Z | 2025-02-27T06:03:10Z | https://github.com/ultralytics/ultralytics/issues/19448 | [
"bug",
"detect"
] | ThierryDeruyttere | 3 |
Lightning-AI/pytorch-lightning | machine-learning | 20,199 | LightningCLI: --help argument given after the subcommand fails | ### Bug description
I'm trying to use LightningCLI to configure my code from the command line but LightningCLI is seeming to have trouble parsing the default logger of the trainer when I run the following:
```
python test.py fit -h
```
However, just running the command without the -h flag works.
### What ve... | open | 2024-08-14T04:24:17Z | 2024-11-08T09:01:45Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20199 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | nisar2 | 5 |
dynaconf/dynaconf | fastapi | 212 | [bug] In Python 3.4 and below inspect.stack() returns just a tuple in the list, not a list of named tuples | **Describe the bug**
In Python 3.4 and below `inspect.stack()` returns just a tuple in the list, not a list of named tuples. Only since version 3.5 does it return a list of named tuples.
**To Reproduce**
Steps to reproduce the behavior:
1. Having the following folder structure
<!-- Describe or use the comman... | closed | 2019-08-26T11:52:32Z | 2019-09-02T18:00:25Z | https://github.com/dynaconf/dynaconf/issues/212 | [
"help wanted",
"Not a Bug",
"good first issue"
] | Jazzis18 | 3 |
serpapi/google-search-results-python | web-scraping | 43 | Exception not handled on SerpApiClient.get_json | I am experiencing unexpected behaviors when getting thousands of queries. For some reason, sometimes the API returns an empty response. It happens at random (1 time out of 10000 perhaps).
When this situation happens, the method SerpApiClient.get_json does not handle the empty response. In consecuence, the json.loads... | open | 2023-04-12T15:36:37Z | 2023-04-13T09:53:22Z | https://github.com/serpapi/google-search-results-python/issues/43 | [] | danielperezefremova-tomtom | 1 |
deepinsight/insightface | pytorch | 2,566 | Comercial needs | Hi, respect to your work on Insightface!
We wound like to use the model antelopev2/buffalo_1 in our commercial project, but unfortunately found it's limited when using models and datasets in commercial way. I wanna know if there is any commercial cooperation opportunity to achieve our goal, may be a payment for usage.... | open | 2024-04-22T07:35:51Z | 2024-04-22T07:35:51Z | https://github.com/deepinsight/insightface/issues/2566 | [] | Zwe1 | 0 |
encode/uvicorn | asyncio | 1,345 | Connection aborted after HttpParserInvalidMethodError when making consecutive POST requests | ### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
After making a few `POST` requests, one of the requests ends with the connection aborted. The server logs a log about an invalid HTTP method, howe... | closed | 2022-01-30T20:12:07Z | 2022-02-03T14:15:25Z | https://github.com/encode/uvicorn/issues/1345 | [] | vogre | 11 |
coqui-ai/TTS | pytorch | 3,854 | How can I customize a speaker on server? | Myconfig works like this, but it won't run

and i also run this command,but config doesn't work。
`.\venv\Scripts\python.exe TTS/server/server.py --config_path .\TTS\server\conf.json --model_name tts_models/zh-CN/baker/taco... | closed | 2024-08-06T12:33:32Z | 2024-08-17T02:52:50Z | https://github.com/coqui-ai/TTS/issues/3854 | [
"feature request"
] | durantgod | 1 |
aminalaee/sqladmin | asyncio | 137 | Lazy support | ### Checklist
- [x] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
Hello. In my project I have a lot relationships with `lazy="dynamic"`. But sqladmin don't supports it
### Describe the solution you would like.
I would like to see setting in co... | open | 2022-04-18T18:16:25Z | 2022-07-10T11:00:07Z | https://github.com/aminalaee/sqladmin/issues/137 | [
"hold"
] | badger-py | 1 |
openapi-generators/openapi-python-client | rest-api | 451 | Exception when generating list properties in multipart forms | After upgrading from 0.9.2 to 0.10.0 the client generation fails with:
```
Traceback (most recent call last):
File "REDACTED/.venv/bin/openapi-python-client", line 8, in <module>
sys.exit(app())
File "REDACTED/.venv/lib/python3.8/site-packages/typer/main.py", line 214, in __call__
return get_command... | closed | 2021-07-07T08:11:50Z | 2021-07-11T23:57:26Z | https://github.com/openapi-generators/openapi-python-client/issues/451 | [
"🐞bug"
] | dpursehouse | 11 |
qubvel-org/segmentation_models.pytorch | computer-vision | 342 | Expected more than 1 value per channel when training when using PAN, other architecture works fine | ```
model = smp.PAN(
encoder_name="efficientnet-b3",
encoder_weights=None,
in_channels=1,
classes=num_classes,
activation= None
)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
test = torch.rand(1,... | closed | 2021-02-08T06:22:59Z | 2024-07-30T14:22:39Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/342 | [] | leocd91 | 5 |
bmoscon/cryptofeed | asyncio | 693 | FTX websockets url change | I believe "wss://ftexchange.com/ws/" should be replaced by "wss://ftx.com/ws/" for FTX exchange as per FTX's documentation. An error is returned by the api when using the former and first started appearing today. | closed | 2021-10-20T00:21:07Z | 2021-10-20T13:06:26Z | https://github.com/bmoscon/cryptofeed/issues/693 | [] | jfc1493 | 0 |
OthersideAI/self-operating-computer | automation | 164 | [Question] About the Third-party API | [Question] How can I integrate a third-party API? Is it enough to change the client.base_url in config.py to the URL of the third-party API, such as client.base_url = "https://api.example.com" ? Do I also need to add something like /v1/chat/completions to the URL?
Thank you very much! | open | 2024-02-17T02:35:31Z | 2024-12-01T10:27:01Z | https://github.com/OthersideAI/self-operating-computer/issues/164 | [] | lueluelue2006 | 1 |
kizniche/Mycodo | automation | 661 | RPM Control PID: Sinlge PWM output for both raise and lower | ## Mycodo Issue Report:
- Specific Mycodo Version: 7.5.3
#### Problem Description
I have 2 PWM controlled fans of which I'm monitoring- and want to control the RPM.
If I want to do this with a PID controller I have to create 2 PWM outputs in order to be able to do this because the raise and lower outputs ... | closed | 2019-05-28T09:48:17Z | 2019-05-29T23:14:37Z | https://github.com/kizniche/Mycodo/issues/661 | [] | floriske | 4 |
dgtlmoon/changedetection.io | web-scraping | 1,954 | [feature] add setting to show watched price / any other filter in overview.. | **Version and OS**
Docker
**Describe the solution you'd like**
When a price element is watched, it would be helpfull to se the price in the overview page in the table in between website and last checked. That way it's easy to tell what webpage has the lowest price without having to go through them one by one.
... | closed | 2023-11-10T07:43:28Z | 2024-07-12T15:09:44Z | https://github.com/dgtlmoon/changedetection.io/issues/1954 | [
"enhancement",
"user-interface"
] | AlexGuld | 1 |
flaskbb/flaskbb | flask | 155 | Doesn't serve static files in standalone mode | If I set up flaskbb and start it running locally with "make run", it doesn't serve any of the static files.
I'm not sure if there's something I've missed during setup, since the docs don't entirely appear to line up with the current state of flaskbb.
| closed | 2015-12-28T18:17:14Z | 2018-04-15T07:47:37Z | https://github.com/flaskbb/flaskbb/issues/155 | [] | gordonjcp | 1 |
jmcnamara/XlsxWriter | pandas | 697 | can't combine sheet.right_to_left() with and set_column with justify-center? | Hi,
I am using XlsxWriter to write RTL data. I want the worksheet to be right to left aligned, but the contents of each cell to be horizontally and vertically justified to the middle/center.
When I remove `sheet.right_to_left()` then the vertical and horizontal alignment work perfectly, however when I add it eith... | closed | 2020-03-04T22:37:35Z | 2020-03-07T19:07:09Z | https://github.com/jmcnamara/XlsxWriter/issues/697 | [
"under investigation",
"awaiting user feedback"
] | SHxKM | 6 |
openapi-generators/openapi-python-client | fastapi | 621 | Support Client Side Certificates | It would be nice if the generated client would support client side certificates.
This would be an additional authentication method used in secured environments.
The underlaying httpx lib does support it with a named argument "cert":
https://www.python-httpx.org/advanced/#client-side-certificates
I was not able t... | closed | 2022-06-01T15:01:51Z | 2022-11-12T19:03:25Z | https://github.com/openapi-generators/openapi-python-client/issues/621 | [
"✨ enhancement"
] | marioland | 2 |
collerek/ormar | fastapi | 814 | can ormar.JSON accept ensure_ascii=False | I'm chinese, I want keep the origin char of Chinese when save some json to db.
So, is there any way to pass ensure_ascii=False to ormar.JSON field type to do that?
| open | 2022-09-06T14:37:11Z | 2022-09-27T10:28:06Z | https://github.com/collerek/ormar/issues/814 | [
"enhancement"
] | ljj038 | 1 |
coqui-ai/TTS | python | 3,992 | Finetune XTTS for new languages | Hello everyone, below is my code for fine-tuning XTTS for a new language. It works well in my case with over 100 hours of audio.
https://github.com/nguyenhoanganh2002/XTTSv2-Finetuning-for-New-Languages | closed | 2024-09-08T08:18:10Z | 2025-01-25T12:14:49Z | https://github.com/coqui-ai/TTS/issues/3992 | [
"wontfix",
"feature request"
] | anhnh2002 | 25 |
3b1b/manim | python | 1,798 | UpdatersExample negative width error in example scenes | ### Describe the error
In the UpdatersExample in the [example scenes](https://3b1b.github.io/manim/getting_started/example_scenes.html), the line:
`lambda m: m.set_width(w0 * math.cos(self.time - now))` results in an error. In order for this to match the animation in the video it should read:
`lambda m: m.set_width(... | open | 2022-04-23T18:49:16Z | 2022-06-07T05:16:25Z | https://github.com/3b1b/manim/issues/1798 | [] | vchizhov | 1 |
ydataai/ydata-profiling | jupyter | 937 | The running process is not finished | I run this example and process is not finished
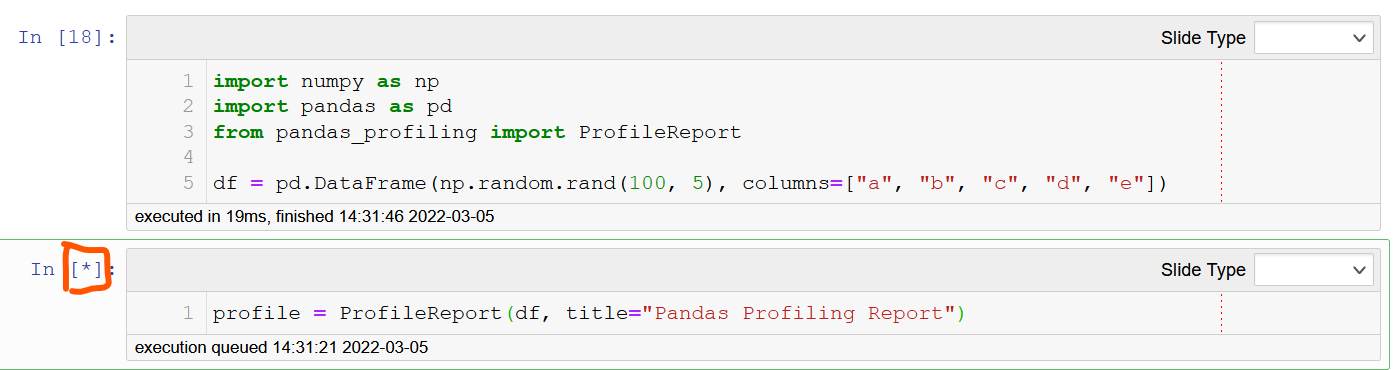
as well as in other datasets. I use jupyter notebook, windows 10 and python 3.8.12
Any solution about this? I search some solution on internet but not s... | closed | 2022-03-05T06:36:49Z | 2022-10-05T16:08:04Z | https://github.com/ydataai/ydata-profiling/issues/937 | [
"information requested ❔"
] | haloapping | 2 |
miguelgrinberg/Flask-SocketIO | flask | 1,566 | Gunicorn and eventlet error | Hi Miguel, I'm developing a _Flask Rest API_. I'm trying to use web sockets to push messages from backend to frontend.
I can run the project locally, and everything works fine. But when I try to use **Gunicorn** to start up the project, the project does not work properly.
## This is my code / entry point
### w... | closed | 2021-06-07T22:31:25Z | 2021-06-27T19:38:31Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1566 | [
"question"
] | jonyr | 6 |
jupyterlab/jupyter-ai | jupyter | 377 | /learn error with non-UTF-8 files | Hi,
When I run `/learn docs/` I get the message:
`Sorry, that path doesn't exist: C:\Users\sdonn\docs/`
That is not the working directory I'm using in Jupyter, so it appears to be in the wrong directory? Do I need to enter the working directory somehow? Tried this a few ways but to no avail... Thanks.
E... | closed | 2023-09-03T11:28:32Z | 2023-10-30T16:05:40Z | https://github.com/jupyterlab/jupyter-ai/issues/377 | [
"bug",
"scope:chat-ux"
] | scottdonnelly | 10 |
davidsandberg/facenet | tensorflow | 505 | Training on MSCELEB | When training on MSCELEB did you do anything different than training on CASIA or was it just the addition of more data? | open | 2017-10-27T20:33:02Z | 2017-12-06T17:42:40Z | https://github.com/davidsandberg/facenet/issues/505 | [] | RakshakTalwar | 6 |
vimalloc/flask-jwt-extended | flask | 144 | Error with the basic example | Hi, I follow all the basic steps to install the package from the webpage http://flask-jwt-extended.readthedocs.io/en/stable/installation.html and when i try to execute the basic usage example of the webpage: http://flask-jwt-extended.readthedocs.io/en/stable/basic_usage.html this happens to me all the time:
![image]... | closed | 2018-05-03T09:43:24Z | 2018-05-03T09:51:50Z | https://github.com/vimalloc/flask-jwt-extended/issues/144 | [] | CarlosCordoba96 | 0 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 1,137 | Hi! | Hi!
For a tabletop RPG I need to change my voice and I found this app (which is great, btw) and I planned to do my sessions on Discord. I did the same thing as in the video for other people in the voice chat to hear the change but it didn't worked, don't know why. Don't know if I did something wrong or if it's a bug, ... | closed | 2022-11-20T01:49:18Z | 2022-12-02T08:51:51Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1137 | [] | ImanuillKant1 | 0 |
pandas-dev/pandas | data-science | 60,779 | BUG: pd.read_csv Incorrect Checksum validation for COMPOSITE Checksum | ### Pandas version checks
- [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the [latest version](https://pandas.pydata.org/docs/whatsnew/index.html) of pandas.
- [ ] I have confirmed this bug exists on the [main branch](https://pandas.pydata.org/docs/dev/ge... | closed | 2025-01-24T11:48:54Z | 2025-01-27T12:34:44Z | https://github.com/pandas-dev/pandas/issues/60779 | [
"Bug",
"IO CSV",
"IO Network",
"Needs Triage"
] | munch9 | 2 |
waditu/tushare | pandas | 850 | [Bug]停复牌信息存在duplicates | ID: araura@126.com
df = pro.suspend(ts_code='', suspend_date='20181119', resume_date='', fiedls='')
df[df['ts_code']=='002193.SZ']
或者
df = pro.suspend(ts_code='', suspend_date='20181120', resume_date='', fiedls='')
df[df['ts_code']=='601600.SH']
其中,第二个案例返回:
ts_code suspend_date resume_date suspend_reason
35... | closed | 2018-11-29T09:48:51Z | 2018-11-29T13:22:23Z | https://github.com/waditu/tushare/issues/850 | [] | araura2000 | 1 |
tflearn/tflearn | tensorflow | 264 | Is it possible to get the validation error in DNN.fit? | Hello, Thanks for this awesome work.
I just transfer the work to tflearn from torch. So I am pretty new here.
A quick question: When I apply the validation set in the DNN.fit, how can I get the prediction when the TFlearn.DNN.fit and get the best model?
If not, is it possible to write the code in the loop to evaluate ... | closed | 2016-08-09T18:02:50Z | 2016-08-10T17:51:27Z | https://github.com/tflearn/tflearn/issues/264 | [] | ShownX | 3 |
home-assistant/core | python | 141,223 | Fitbit token refresh fails | ### The problem
I use the Fitbit integration and have no issues authenticating and fetching data. Unfortunately, the token refresh always fails and I have to reconfigure and reauthorize the integration with Fitbit every day or so.
I also have a different addon script that fetches extra Fitbit data and sends it to HA ... | closed | 2025-03-23T16:25:49Z | 2025-03-23T21:31:41Z | https://github.com/home-assistant/core/issues/141223 | [
"integration: fitbit"
] | Cyberes | 6 |
521xueweihan/HelloGitHub | python | 2,340 | 开源项目:PRemoteM —— 爽快利落的 Windows 平台远程桌面管理软件 | ## 推荐项目
<!-- 这里是 HelloGitHub 月刊推荐项目的入口,欢迎自荐和推荐开源项目,唯一要求:请按照下面的提示介绍项目。-->
<!-- 点击上方 “Preview” 立刻查看提交的内容 -->
<!--仅收录 GitHub 上的开源项目,请填写 GitHub 的项目地址-->
- 项目地址:https://github.com/1Remote/PRemoteM
<!--请从中选择(C、C#、C++、CSS、Go、Java、JS、Kotlin、Objective-C、PHP、Python、Ruby、Rust、Swift、其它、书籍、机器学习)-->
- 类别:C#
<!--... | closed | 2022-08-25T10:23:09Z | 2022-10-28T03:32:53Z | https://github.com/521xueweihan/HelloGitHub/issues/2340 | [
"已发布",
"C# 项目"
] | VShawn | 1 |
Evil0ctal/Douyin_TikTok_Download_API | api | 448 | [BUG] douyin/web/fetch_one_video return 400 code with error message "An error occurred." | ***Platform where the error occurred?***
Douyin
***The endpoint where the error occurred?***
https://douyin.wtf/api/douyin/web/fetch_one_video?aweme_id=7235604590035569976
***Submitted input value?***

***Have you tri... | closed | 2024-07-14T06:33:13Z | 2024-07-17T21:36:19Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/448 | [
"BUG",
"enhancement"
] | akngg | 1 |
huggingface/datasets | deep-learning | 6,661 | Import error on Google Colab | ### Describe the bug
Cannot be imported on Google Colab, the import throws the following error:
ValueError: pyarrow.lib.IpcWriteOptions size changed, may indicate binary incompatibility. Expected 88 from C header, got 72 from PyObject
### Steps to reproduce the bug
1. `! pip install -U datasets`
2. `import dataset... | closed | 2024-02-13T13:12:40Z | 2024-02-25T16:37:54Z | https://github.com/huggingface/datasets/issues/6661 | [] | kithogue | 4 |
deeppavlov/DeepPavlov | tensorflow | 954 | ValueError: Error when checking target: expected activation_5 to have shape (2,) but got array with shape (1,) | Hi,
I'm training a binary classifier, and I keep getting the error in the title whenever my training data is 1282 samples long.
I have this in my configuration:
```
"split_fields": [
"train",
"valid"
],
"split_proportions": [
0.9,
0.1
]
```
I did some debugging, and ... | closed | 2019-07-30T10:48:59Z | 2019-08-20T11:54:09Z | https://github.com/deeppavlov/DeepPavlov/issues/954 | [] | drorvinkler | 1 |
yinkaisheng/Python-UIAutomation-for-Windows | automation | 180 | WebDriver API for this tool | This is just a suggestion to provide a WebDriver API to this project/tool. It could also be a 3rd party project for such support.
I created such support for AutoIt: https://github.com/daluu/autoitdriverserver (in python), could similarly adapt for this project. | open | 2021-09-27T22:06:53Z | 2021-12-21T03:26:52Z | https://github.com/yinkaisheng/Python-UIAutomation-for-Windows/issues/180 | [] | daluu | 1 |
dbfixtures/pytest-postgresql | pytest | 1,102 | Drop PostgreSQL 13 from CI [Nov 20225] | In November 2025, PostgreSQL 13 ends its life: https://endoflife.date/postgresql | open | 2025-03-06T08:52:12Z | 2025-03-06T08:52:24Z | https://github.com/dbfixtures/pytest-postgresql/issues/1102 | [] | fizyk | 0 |
roboflow/supervision | tensorflow | 1,313 | Colormap for visualizing depth, normal and gradient images | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Description
hello :wave: @SkalskiP @LinasKo ,
what do you think about adding a feature to visualize depth images, normal image and graident images acr... | open | 2024-06-27T13:41:04Z | 2024-10-30T09:28:37Z | https://github.com/roboflow/supervision/issues/1313 | [
"enhancement"
] | hardikdava | 5 |
itamarst/eliot | numpy | 87 | Create neo4j input script for Eliot logs | neo4j seems pretty well suited for storing Eliot logs - it's a graph database, so can represent relationships between actions, and it's also schemaless so should be able to deal with arbitrary messages.
http://neo4j.com/guides/graph-concepts/
| closed | 2014-05-26T20:19:52Z | 2019-05-09T18:18:08Z | https://github.com/itamarst/eliot/issues/87 | [] | itamarst | 1 |
yt-dlp/yt-dlp | python | 12,226 | [iqiyi] Can't find any video | ### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [x] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [x] I'm reporting that yt-dlp is broken on a **supported** site
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instruc... | closed | 2025-01-28T21:55:54Z | 2025-01-28T22:29:26Z | https://github.com/yt-dlp/yt-dlp/issues/12226 | [
"duplicate",
"site-bug"
] | KPniX | 1 |
iterative/dvc | data-science | 10,313 | `dvc.api.dataset` | API for new `datasets` feature
- [x] DVCX (highest priority) - return name, version
- [x] DVC (next priority) - return URL, path, sha
- [x] Cloud-versioned (nice to have) - return URL, version ID for each file
Needs spec | closed | 2024-02-22T13:46:37Z | 2024-02-28T08:56:20Z | https://github.com/iterative/dvc/issues/10313 | [
"p1-important",
"A: api"
] | dberenbaum | 0 |
OpenBB-finance/OpenBB | machine-learning | 6,867 | [🕹️] Side Quest: Integrate OpenBB into a dashboard | ### What side quest or challenge are you solving?
Side Quest: Integrate OpenBB into a dashboard or web application
### Points
Points: 300-750 Points
### Description
_No response_
### Provide proof that you've completed the task
[https://github.com/soamn/oss-obb-dashboard](url) | closed | 2024-10-24T20:36:18Z | 2024-11-02T07:41:36Z | https://github.com/OpenBB-finance/OpenBB/issues/6867 | [] | soamn | 7 |
WZMIAOMIAO/deep-learning-for-image-processing | pytorch | 307 | def __getitem__(self, index): | **System information**
* Have I written custom code:
* OS Platform(e.g., window10 or Linux Ubuntu 16.04):
* Python version:
* Deep learning framework and version(e.g., Tensorflow2.1 or Pytorch1.3):
* Use GPU or not:
* CUDA/cuDNN version(if you use GPU):
* The network you trained(e.g., Resnet34 network):
**Des... | closed | 2021-06-21T03:58:43Z | 2021-06-22T09:23:16Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/307 | [] | why228430 | 2 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 876 | TypeError: __init__() got an unexpected keyword argument 'merge_weights' | ### Check before submitting issues
- [X] Make sure to pull the latest code, as some issues and bugs have been fixed.
- [X] Due to frequent dependency updates, please ensure you have followed the steps in our [Wiki](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki)
- [X] I have read the [FAQ section](https://gith... | closed | 2024-01-02T14:05:26Z | 2024-01-24T22:02:07Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/876 | [
"stale"
] | IsraelAbebe | 2 |
allenai/allennlp | nlp | 5,459 | Output more predictions including sub-optimal ones | closed | 2021-11-08T11:16:29Z | 2021-11-09T06:04:42Z | https://github.com/allenai/allennlp/issues/5459 | [
"Feature request"
] | AlfredAM | 0 | |
dask/dask | pandas | 10,991 | Combined save and calculation is using excessive memory | Not clear if this is truly a "bug", but it seems highly undesirable + I can't work out how to avoid it
# Describe the issue:
We are trying to save large data arrays to file, and *at the same time* check the data for any occurrences of a given value
All while, hopefully, loading and processing each data chunk only ... | open | 2024-03-11T10:39:33Z | 2024-03-28T11:26:09Z | https://github.com/dask/dask/issues/10991 | [
"needs triage"
] | pp-mo | 3 |
marshmallow-code/marshmallow-sqlalchemy | sqlalchemy | 298 | 'DummySession' object has no attribute 'query' in many-to-many relationship | Hi, i have a problem in a simple many to many relationship. I have two models, User and Role, with an association table defined as helper table, like Flask-SqlAlchemy documentation recommended.
After defined the relative schema, i try to load a new user instance from json data, with a single role attached, but i encou... | closed | 2020-04-03T20:51:55Z | 2021-05-14T14:25:06Z | https://github.com/marshmallow-code/marshmallow-sqlalchemy/issues/298 | [] | ruggerotosc | 3 |
sktime/sktime | scikit-learn | 7,792 | [BUG] fix aggressive neural network printouts | The forecaster tests print the following repeatedly, dozens or hundreds of time.
She printout for whichever estimator is causing this should be turned off.
@benHeid, @geetu040, do you know which one this is?
```
INFO: GPU available: False, used: False
INFO: TPU available: False, using: 0 TPU cores
INFO: HPU availabl... | open | 2025-02-08T17:58:21Z | 2025-02-15T08:51:12Z | https://github.com/sktime/sktime/issues/7792 | [
"bug",
"module:forecasting"
] | fkiraly | 10 |
coqui-ai/TTS | deep-learning | 3,440 | [Bug] Hi, I'm using `python TTS/tts/compute_attention_masks.py` for compute duration use tacotron2, but I met this question | ### Describe the bug
Traceback (most recent call last):
File "TTS/bin/compute_attention_masks.py", line 14, in <module>
from TTS.tts.utils.text.characters import make_symbols, phonemes, symbols
ImportError: cannot import name 'make_symbols' from 'TTS.tts.utils.text.characters'
### To Reproduce
run `python ... | closed | 2023-12-18T10:11:45Z | 2024-02-04T23:03:54Z | https://github.com/coqui-ai/TTS/issues/3440 | [
"bug",
"wontfix"
] | Henryplay | 1 |
automl/auto-sklearn | scikit-learn | 1,209 | Occasional test failure for `test_module_idempotent` | The tests occasionaly fail when testing `GradientBoosting`, specifically the `test_module_idempotent` as seen [here ](https://github.com/automl/auto-sklearn/runs/3260866212#step:9:1531).
<details>
<summary>Failure log</summary>
<br>
_____________ GradientBoostingComponentTest.test_module_idempotent _____________
... | closed | 2021-08-06T11:06:07Z | 2021-09-06T07:29:08Z | https://github.com/automl/auto-sklearn/issues/1209 | [
"maintenance"
] | eddiebergman | 1 |
pydantic/pydantic | pydantic | 11,126 | Fields with `any` type raise a ValidationError | ### Initial Checks
- [X] I confirm that I'm using Pydantic V2
### Description
It seems like starting Pydantic 2.10, fields defined as `bar: any` fail with a ValidationError, prior to 2.10 this triggered just a warning.
You can use this snippet to reproduce:
```python
from pydantic import BaseModel, ConfigDict... | closed | 2024-12-16T17:33:49Z | 2024-12-16T18:48:37Z | https://github.com/pydantic/pydantic/issues/11126 | [
"bug V2",
"pending"
] | amirh | 3 |
polakowo/vectorbt | data-visualization | 82 | SizeType.TargetPercent and Order rejected: Not enough cash to long | Hi, I try to write stock factor analysis,
but `SizeType.TargetPercent` work not well
```python
from datetime import datetime
import numpy as np
import pandas as pd
import yfinance as yf
import vectorbt as vbt
from vectorbt.portfolio.enums import SizeType, CallSeqType
# Define params
assets = ['FB', '... | closed | 2021-01-08T17:52:44Z | 2021-01-09T17:30:05Z | https://github.com/polakowo/vectorbt/issues/82 | [] | wukan1986 | 3 |
koxudaxi/datamodel-code-generator | fastapi | 2,098 | Expose ids into template context | **Is your feature request related to a problem? Please describe.**
I want to implement basic schema registry out of generated models, so I need a way to include extra identifying info into my models.
**Describe the solution you'd like**
It would be nice for JSON Schema's `$id` and OpenAPI's `operationId` to be... | open | 2024-10-04T16:14:08Z | 2024-10-28T18:46:27Z | https://github.com/koxudaxi/datamodel-code-generator/issues/2098 | [] | ZipFile | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,201 | No gradient penalty in WGAN-GP | When computing WGAN-GP loss, the cal_gradient_penalty function is not called, and gradient penalty is not applied. | open | 2020-11-29T14:58:05Z | 2020-11-29T14:58:05Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1201 | [] | GwangPyo | 0 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,049 | [WITHOUT addons]: Specific contents of a page cause UC to mangle DOM and crash renderer | Tested WITHOUT addons. Same result.
While working with UC, I stumbled on some pages that would cause UC and only UC to mangle the contents of DOM to a degree where the whole thing would break down after the timeout was reached.
All content after `<head>`, `<body>` and a few other will be wiped clean. No tag is clos... | closed | 2023-02-08T17:10:04Z | 2024-01-17T20:50:56Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1049 | [] | slowengine | 8 |
aminalaee/sqladmin | sqlalchemy | 784 | Ckeditor <TypeError: Cannot convert undefined or null to object> | ### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
Following the guide [sqladmin ckeditor](https://aminalaee.dev/sqladmin/cookbook/using_wysiwyg/) got an error:
```
TypeError: Cannot convert un... | closed | 2024-06-24T17:13:29Z | 2024-06-25T10:03:29Z | https://github.com/aminalaee/sqladmin/issues/784 | [] | A-V-tor | 1 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 529 | 请问是否有办法下载2k和4k无水印的抖音视频? | 已经添加了cookies,但是下载下来的画质还是只有1080p,网页版显示原视频有2k和4k的画质,但直接网页解析下载的码率和大小都很差,有没有办法解析到2k/4k的高码率无水印视频呢? | closed | 2024-12-28T15:01:24Z | 2025-02-26T08:01:31Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/529 | [] | Kavka-7 | 5 |
scikit-learn/scikit-learn | machine-learning | 30,183 | The Affinity Matrix Is NON-BINARY with`affinity="precomputed_nearest_neighbors"` | ### Describe the issue linked to the documentation
## Issue Source:
https://github.com/scikit-learn/scikit-learn/blob/59dd128d4d26fff2ff197b8c1e801647a22e0158/sklearn/cluster/_spectral.py#L452-L454
## Issue Description
The Affinity Matrix Is _non-binary_ with`affinity`=`"precomputed_nearest_neighbors"`. I.e... | open | 2024-10-31T07:07:44Z | 2024-11-04T10:35:54Z | https://github.com/scikit-learn/scikit-learn/issues/30183 | [
"Documentation",
"Needs Investigation"
] | OrangeAoo | 2 |
ultralytics/yolov5 | pytorch | 12,825 | There is any way to find specific point in bounding box in yolov5 ? | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hi 🤗
I trying to detect the specific object in image using yolov5.
My question is. Is... | closed | 2024-03-18T17:02:09Z | 2024-05-12T00:23:42Z | https://github.com/ultralytics/yolov5/issues/12825 | [
"question",
"Stale"
] | SJavad | 8 |
yezyilomo/django-restql | graphql | 311 | Add DELETE operation | The purpose of this is to delete nested objects i.e
```json
{
"add": [1,2,4],
"delete": [8]
}
```
Just like `REMOVE` operation `DELETE` will be supporting `__all__` value to i.e
```json
{
"add": [1,2,4],
"delete": "__all__"
}
```
It will also be supporting `allow_delete_all` kwarg just like ... | open | 2023-11-09T13:51:09Z | 2023-11-09T13:51:09Z | https://github.com/yezyilomo/django-restql/issues/311 | [] | yezyilomo | 0 |
graphql-python/graphene | graphql | 898 | Proposal: explicitly declaring resolvers with decorator | ```
class MySecondAttempt(ObjectType):
name = String()
age = Int(required=True)
@name.resolver
def resolve_name(self, ...): ...
@age.resolver
def resolve_age(self, ...): ...
```
Explicit is better than implicit.
The resolvers could have any arbitrary name, and could also... | closed | 2019-01-28T03:52:04Z | 2024-06-22T10:26:08Z | https://github.com/graphql-python/graphene/issues/898 | [
"✨ enhancement"
] | DrPyser | 8 |
home-assistant/core | asyncio | 140,865 | [Overkiz] Incomplete handling of PositionableDualRollerShutter / io:DualRollerShutterIOComponent | ### The problem
Using a TaHoMa Switch I have connected various Velux Windows and their shutters.
Specifially two devices that home assistant shows as PositionableDualRollerShutter by Velux and of hardware type io:DualRollerShutterIOComponent.
Within the TaHoMa App these are shown to have an upper and a lower shutter ... | open | 2025-03-18T10:52:53Z | 2025-03-22T07:35:06Z | https://github.com/home-assistant/core/issues/140865 | [
"integration: overkiz"
] | GuiHue | 5 |
lucidrains/vit-pytorch | computer-vision | 280 | Using vision transformers for different image resolutions | Hi, I ma working on using vision transformers not only the vanilla ViT, but different models on UMDAA2 data set, this data set has an image resolution of 128*128 would it be better to transform the images into the vit desired resolution like 224 or 256 or it is better to keep the 128 and try to update the other vision ... | open | 2023-09-24T22:24:24Z | 2023-10-02T21:42:02Z | https://github.com/lucidrains/vit-pytorch/issues/280 | [] | Oussamab21 | 1 |
s3rius/FastAPI-template | fastapi | 207 | Pre Commits Hooks fails when installed with Python-3.12.1 | Hello,
`Flake8`, `add-trailing-comma`, `pre-commit-hooks`, and `language-formatters-pre-commit-hooks` versions need to be updated. Otherwise fails with following errors on a newly generated project:
``` shell
boilerplate (master) ✗ poetry run pre-commit install
pre-commit installed at .git/hooks/pre-commit
b... | open | 2024-04-11T00:09:47Z | 2024-07-12T08:16:00Z | https://github.com/s3rius/FastAPI-template/issues/207 | [] | m4hi2 | 2 |
guohongze/adminset | django | 130 | 演示环境无法登陆,可以处理下吗? | 演示环境无法登陆,可以处理下吗? | closed | 2020-01-17T07:08:26Z | 2020-05-14T13:07:44Z | https://github.com/guohongze/adminset/issues/130 | [] | leeredstar | 0 |
ymcui/Chinese-BERT-wwm | nlp | 103 | 使用Transformers加载模型 | 请问我使用如下方法加载模型时,Transformers是会重新下载模型还是可以使用我已经下载好的模型呢?
tokenizer = BertTokenizer.from_pretrained("MODEL_NAME")
model = BertModel.from_pretrained("MODEL_NAME") | closed | 2020-04-09T13:34:55Z | 2020-04-17T07:11:05Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/103 | [] | haozheshz | 2 |
jumpserver/jumpserver | django | 14,425 | [Feature] Feature Request: Option to Display Only Mouse Cursor in Remote Desktop Sessions | ### Product Version
v4.1.0
### Product Edition
- [X] Community Edition
- [ ] Enterprise Edition
- [ ] Enterprise Trial Edition
### Installation Method
- [ ] Online Installation (One-click command installation)
- [X] Offline Package Installation
- [ ] All-in-One
- [ ] 1Panel
- [X] Kubernetes
- [ ] Source Code
### ... | open | 2024-11-10T10:44:28Z | 2024-11-28T09:57:14Z | https://github.com/jumpserver/jumpserver/issues/14425 | [
"⏳ Pending feedback",
"⭐️ Feature Request",
"📦 z~release:Version TBD"
] | Galac666 | 6 |
FactoryBoy/factory_boy | django | 254 | Readthedocs fail to detect version | Hello,
I am would like readthedocs fail to detects versionof factory_boy. See http://readthedocs.org/projects/factoryboy/versions/ . I don't have any idea why it happen.
Greetings,
| closed | 2015-11-28T16:01:48Z | 2016-01-05T20:29:45Z | https://github.com/FactoryBoy/factory_boy/issues/254 | [
"Doc"
] | ad-m | 1 |
errbotio/errbot | automation | 1,483 | Command with a default arg fails to run when omitting the argument | In order to let us help you better, please fill out the following fields as best you can:
### I am...
* [x] Reporting a bug
* [ ] Suggesting a new feature
* [ ] Requesting help with running my bot
* [ ] Requesting help writing plugins
* [ ] Here about something else
### I am running...
* Errbot version:... | open | 2020-12-01T18:06:14Z | 2020-12-19T06:37:08Z | https://github.com/errbotio/errbot/issues/1483 | [
"type: bug",
"backend: Common"
] | alpinweis | 1 |
holoviz/panel | jupyter | 7,442 | JSComponent should document `_rename` | Without the following, bokeh raises a serialization error `bokeh.core.serialization.SerializationError: can't serialize <class 'function'>`, but https://panel.holoviz.org/reference/custom_components/JSComponent.html doesn't mention anything about it.
```
_rename = {"event_drop_callback": None}
```
```python
... | open | 2024-10-24T19:04:17Z | 2024-11-03T07:16:51Z | https://github.com/holoviz/panel/issues/7442 | [
"type: docs"
] | ahuang11 | 1 |
benbusby/whoogle-search | flask | 246 | [QUESTION] Public Instance whooglesearch.net | Hi, I have created this public instance in a linode vps (https://whooglesearch.net/). I will try to keep it up to date and working as long as possible. I hope you can include it in the readme file. I hope to collaborate in this way with the community. | closed | 2021-03-30T15:23:56Z | 2021-03-31T02:16:09Z | https://github.com/benbusby/whoogle-search/issues/246 | [
"question"
] | drugal | 1 |
tfranzel/drf-spectacular | rest-api | 787 | Read only fields included in required list for input serializer | **Describe the bug**
In a serializer with a field defined as `read_only=True`, the field is also in the 'required' list. This means that it must be supplied as input, when it is read-only and cannot be changed.
**To Reproduce**
```python
class TopicSerializer(serializers.ModelSerializer):
impacted_systems_c... | closed | 2022-08-16T23:19:21Z | 2022-08-17T05:51:51Z | https://github.com/tfranzel/drf-spectacular/issues/787 | [] | PaulWay | 2 |
wq/django-rest-pandas | rest-api | 27 | Datetimefield is serialized to str | When I serialize this model
```class Well(models.Model):
site = models.ForeignKey(Site, on_delete=models.CASCADE)
name = models.CharField(max_length=100, )
start_date_time = models.DateTimeField(auto_now=False, auto_now_add=False, verbose_name='Date and time at which the well is dep... | closed | 2017-08-24T13:08:53Z | 2017-09-01T20:43:54Z | https://github.com/wq/django-rest-pandas/issues/27 | [] | martinwk | 1 |
jupyterhub/zero-to-jupyterhub-k8s | jupyter | 3,039 | hub image's pip packages are installed as root making subsequent installs require root | In https://github.com/jupyterhub/zero-to-jupyterhub-k8s/pull/3003 @pnasrat concluded that one may need to be root to do `pip` install in a Dockerfile with `FROM jupyterhub/k8s-hub:2.0.0`.
I'm not sure, but I'm thinking that isn't desired. | closed | 2023-02-28T07:53:23Z | 2023-02-28T09:23:18Z | https://github.com/jupyterhub/zero-to-jupyterhub-k8s/issues/3039 | [] | consideRatio | 2 |
open-mmlab/mmdetection | pytorch | 11,205 | Use backbone network implemented in MMPretrain, raise KeyError(f'Cannot find {norm_layer} in registry under | [https://github.com/Jano-rm-rf/Test/blob/main/TestChannels.py](url)
I wanted to use the SaprseResNet implemented in mmpretrain, but I got an error

| open | 2023-11-23T11:58:53Z | 2024-09-21T13:33:30Z | https://github.com/open-mmlab/mmdetection/issues/11205 | [] | Jano-rm-rf | 1 |
marshmallow-code/flask-smorest | rest-api | 214 | Webargs "unknown=EXCLUDE" not working for updated Marshmallow | I wrote an app with flask-smorest that is supposed to ignore unknown webargs, but when I upgraded to Marshmallow 3.10.0 (from 3.9.1), it stopped ignoring unknown args in a web request.
Possibly related to #211. Not sure if this is a problem with Marshmallow, flask-marshmallow, or flask-smorest.
Software Versions:... | closed | 2021-01-20T21:21:16Z | 2021-01-22T19:17:32Z | https://github.com/marshmallow-code/flask-smorest/issues/214 | [] | camercu | 3 |
Lightning-AI/LitServe | api | 452 | Potential Memory Leak in Response Buffer | ## 🐛 Bug
The [response_buffer](https://github.com/Lightning-AI/LitServe/blob/08a9caa4360aeef94ee585fc5e88f721550d267b/src/litserve/server.py#L74) dictionary could grow indefinitely if requests fail before their responses are processed.
Implement a cleanup mechanism or timeout for orphaned entries
#### Code sample
... | open | 2025-03-12T11:32:40Z | 2025-03-16T05:14:43Z | https://github.com/Lightning-AI/LitServe/issues/452 | [
"bug",
"good first issue",
"help wanted"
] | aniketmaurya | 1 |
autokey/autokey | automation | 773 | Update Python versions in the develop branch | ### AutoKey is a Xorg application and will not function in a Wayland session. Do you use Xorg (X11) or Wayland?
Xorg
### Has this issue already been reported?
- [X] I have searched through the existing issues.
### Is this a question rather than an issue?
- [X] This is not a question.
### What type of ... | open | 2023-02-18T21:52:59Z | 2023-03-08T22:24:37Z | https://github.com/autokey/autokey/issues/773 | [
"0.96.1"
] | Elliria | 10 |
mljar/mljar-supervised | scikit-learn | 499 | X has feature names, but StandardScaler was fitted without feature names | This issue has been coming up when I use,
automl.predict_proba(input)
I am using the requirements.txt in venv. Shouldn't input have feature names?
This message did not used to come up and I don't know why. | closed | 2021-12-05T01:07:26Z | 2024-03-01T07:05:05Z | https://github.com/mljar/mljar-supervised/issues/499 | [
"help wanted",
"good first issue"
] | JacobMarley | 7 |
slackapi/python-slack-sdk | asyncio | 1,421 | SlackApiError: 'dict' object has no attribute 'status_code' | `slack_sdk.web` reports the `'dict' object has no attribute 'status_code'` error when attempting to retrieve the SlackApiError's `status_code`.
### Reproducible in:
```bash
$ pip list | grep slack
slack-sdk 3.23.0
$ pip freeze | grep slack
-e git+ssh://git@github.com/python-slack-sdk.git@9967dc0a20... | closed | 2023-11-07T12:24:15Z | 2023-11-13T08:56:54Z | https://github.com/slackapi/python-slack-sdk/issues/1421 | [
"bug",
"web-client",
"Version: 3x"
] | vinceta | 3 |
betodealmeida/shillelagh | sqlalchemy | 23 | Documentation needed | Some docs would be nice. Showing how to use sqlalchemy dialects & dbapi, with, say, google sheets.
At a minimum, putting examples (or a link to them) in the README | closed | 2021-06-18T15:59:40Z | 2021-06-21T17:49:44Z | https://github.com/betodealmeida/shillelagh/issues/23 | [] | polvoazul | 2 |
falconry/falcon | api | 1,628 | Advice needed on API responder. | Greetings,
I am not sure where to post this question? If I should raise it elsewhere please advice.
Building an JSON-restful API with Falcon is pretty straight forward. However what does not fall in the scope of the documentation is backend storage integration and parsing/validation of data. This does not fall wi... | closed | 2020-01-03T07:11:32Z | 2022-01-05T06:49:37Z | https://github.com/falconry/falcon/issues/1628 | [
"question",
"community"
] | cfrademan | 4 |
jupyter/nbviewer | jupyter | 193 | Can I use nbviewer with private repos/gists? | Is there any way I can give nbviewer access to a private repo/gist so I can use it privately with a collaborator?
| closed | 2014-02-19T16:44:47Z | 2024-04-10T23:32:01Z | https://github.com/jupyter/nbviewer/issues/193 | [] | rhiever | 5 |
nvbn/thefuck | python | 1,368 | Python Unicode Warning (but on Git Bash) | The output of `thefuck --version`:
> The Fuck 3.32 using Python 3.11.1 and Bash
Your system (Debian 7, ArchLinux, Windows, etc.):
> Windows
How to reproduce the bug:
> Put the eval stuff on the .bashrc and run a new terminal
The warning:
> C:\Program Files\Python311\Lib\site-packages\win_unicode_console\... | closed | 2023-03-29T15:32:56Z | 2023-03-29T15:34:33Z | https://github.com/nvbn/thefuck/issues/1368 | [] | LuizLoyola | 1 |
chaos-genius/chaos_genius | data-visualization | 819 | [BUG] Yaxis labels getting cutoff in charts with large data during formatting and display | ## Describe the bug
A clear and concise description of what the bug is.
yAxis labels are getting cut off during formatting of large numbers
<img width="241" alt="Screenshot 2022-03-12 at 1 02 04 PM" src="https://user-images.githubusercontent.com/50948001/158008633-b1017c5f-9d22-4782-bbd0-3c1bb8b88482.png">
| closed | 2022-03-12T07:32:24Z | 2022-03-23T06:50:07Z | https://github.com/chaos-genius/chaos_genius/issues/819 | [
"🖥️ frontend"
] | ChartistDev | 1 |
adamerose/PandasGUI | pandas | 126 | json.decoder.JSONDecodeError when import pandasgui | PLEASE FILL OUT THE TEMPLATE
**Describe the bug**
use the following code, and python reports error
import pandas as pd
from pandasgui import show
df = pd.DataFrame({'a':[1,2,3], 'b':[4,5,6], 'c':[7,8,9]})
show(df)
error message:
Traceback (most recent call last):
File "test_pandagui.py", line 2, in... | closed | 2021-03-27T04:59:30Z | 2021-04-23T04:44:17Z | https://github.com/adamerose/PandasGUI/issues/126 | [
"bug"
] | andrewmabc | 3 |
autogluon/autogluon | computer-vision | 4,636 | Figure out how to do source install with uv on Colab/Kaggle | We should have working instructions for AutoGluon source installs with UV on Colab/Kaggle notebooks. | open | 2024-11-10T01:26:32Z | 2025-02-25T20:33:38Z | https://github.com/autogluon/autogluon/issues/4636 | [
"install",
"priority: 0"
] | Innixma | 0 |
ultralytics/ultralytics | deep-learning | 19,648 | can not run tensorrt,bug error: module 'tensorrt' has no attribute '__version__' | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
Install
### Bug
i download the right cuda、cudnn、torch、vision,and the i download the tensorrt 8.5 GA in my windows.
when i ... | closed | 2025-03-11T18:20:51Z | 2025-03-12T07:18:29Z | https://github.com/ultralytics/ultralytics/issues/19648 | [
"dependencies",
"exports"
] | Hitchliff | 4 |
pydata/bottleneck | numpy | 409 | Python crashed in fuzzing test of 7 APIs | **Describe the bug**
[API-list](https://github.com/baltsers/polyfuzz/blob/main/bottleneck/API-list.txt): bn.nanmedian, bn.nanmean, bn.nanstd, bn.median, bn.ss, bn.nanmin, bn.nanmax.
Python crashed in our fuzzing test of 7 APIs
All tests were run on the latest developing branch.
**To Reproduce**
To assist in rep... | open | 2022-05-15T18:59:51Z | 2023-05-31T10:22:37Z | https://github.com/pydata/bottleneck/issues/409 | [
"bug"
] | baltsers | 1 |
K3D-tools/K3D-jupyter | jupyter | 419 | "No module named `k3d`" on macos | * K3D version: 2.15.2
* Python version: 3.11.3 (via homebrew)
* Operating System: macos 13.3.1 (22E261) (intel)
### Description
After installing k3d, importing the module does not work:

### Wha... | closed | 2023-04-21T07:48:01Z | 2023-04-22T02:58:39Z | https://github.com/K3D-tools/K3D-jupyter/issues/419 | [] | bsekura | 1 |
tox-dev/tox | automation | 3,474 | TOML configuration of `set_env` should also support loading from environment files | ## What's the problem this feature will solve?
Loading environment files in `set_env` was implemented by @gaborbernat in #1668 and is currently documented as being generally usable. However, it appears that the `file|` syntax and custom parsing code is incompatible with a TOML configuration of `set_env`.
## Describe ... | closed | 2025-01-29T18:36:07Z | 2025-03-06T22:18:17Z | https://github.com/tox-dev/tox/issues/3474 | [
"help:wanted",
"enhancement"
] | brianhelba | 2 |
pytest-dev/pytest-qt | pytest | 369 | PyQt6 support breaks PyQt5 on Ubuntu | I'm currently facing an issue in my CI which looks related to a recent change in pytest-qt:
The culprit is this line here: https://github.com/pytest-dev/pytest-qt/blob/master/src/pytestqt/qt_compat.py#L144 which was introduced 3 months ago.
System: Ubuntu Focal
Qt version: 5.12.8
PyQt5 version: 5.14.1
log:
... | closed | 2021-06-04T16:47:37Z | 2021-06-07T08:50:14Z | https://github.com/pytest-dev/pytest-qt/issues/369 | [] | machinekoder | 7 |
healthchecks/healthchecks | django | 857 | Building a Docker image fails on Windows 10 | Hi there,
`>docker-compose up` fails on my windows 10 with:
```bash
=> [web stage-1 4/9] COPY --from=builder /wheels /wheels 0.2s
=> [web stage-1 5/9] RUN apt update && apt install -y libcurl4 libpq5 libmariadb3 libxml2 && rm -rf 10.1s
=> [... | closed | 2023-07-03T17:43:28Z | 2023-07-05T18:12:26Z | https://github.com/healthchecks/healthchecks/issues/857 | [] | kyxap | 4 |
jwkvam/bowtie | plotly | 17 | support for periodic tasks | this would enable among other things real time streaming
| closed | 2016-08-27T19:56:55Z | 2016-08-28T16:43:05Z | https://github.com/jwkvam/bowtie/issues/17 | [] | jwkvam | 0 |
jina-ai/serve | machine-learning | 5,562 | chore: draft release note 3.13.2 | ## Release Note (`3.13.2`)
This release contains 1 bug fix.
## 🐞 Bug Fixes
### fix: respect timeout_ready when generating startup probe ([#5560](https://github.com/jina-ai/jina/pull/5560))
As Kubernetes Startup Probes were added to all deployments in [release v3.13.0](https://github.com/jina-ai/jina/releas... | closed | 2022-12-30T10:22:13Z | 2022-12-30T11:13:45Z | https://github.com/jina-ai/serve/issues/5562 | [] | alaeddine-13 | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.