
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
chiphuyen/stanford-tensorflow-tutorials | nlp | 46 | Cannot run chatbot.py in python=3.5, tensorflow=1.2.1?? | I hv trouble in running the chatbot.py, is it because of the tensorflow version? how to fix it?
python chatbot.py --mode train
Data ready!
Bucketing conversation number 9999
Bucketing conversation number 19999
Bucketing conversation number 9999
Bucketing conversation number 19999
Bucketing conversation number ... | open | 2017-08-06T16:47:31Z | 2018-03-24T17:41:01Z | https://github.com/chiphuyen/stanford-tensorflow-tutorials/issues/46 | [] | akirannz | 4 |
dask/dask | scikit-learn | 11,824 | read_parquet with empty columns gives incorrect partitions | <!-- Please include a self-contained copy-pastable example that generates the issue if possible.
Please be concise with code posted. See guidelines below on how to provide a good bug report:
- Craft Minimal Bug Reports http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports
- Minimal Complete Verifiable Ex... | closed | 2025-03-12T00:23:51Z | 2025-03-20T13:31:47Z | https://github.com/dask/dask/issues/11824 | [
"dataframe",
"dask-expr"
] | bnaul | 2 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 827 | [FEATURE]: Separate out Personal Information logs from app logs | ### Feature summary
Enhance logger such that separate logs are generated for PII
### Feature description
regular logs won't contain any PII, giving confidence for contributor to upload logs without worry on PII
### Motivation
_No response_
### Alternatives considered
_No response_
### Additional context
_No re... | closed | 2024-11-12T23:10:28Z | 2025-01-31T23:39:09Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/827 | [
"enhancement",
"stale"
] | surapuramakhil | 1 |
mjhea0/flaskr-tdd | flask | 58 | Consider renaming app.test.py to something else | This is mostly an FYI as I don't really want or expect you to change the name everywhere. Maybe you could add a note about it to the tutorial: VSCode's python test extensions don't handle dots in the filename per [this](https://github.com/microsoft/vscode-python/issues/8490#issuecomment-553181223). Test discovery fails... | closed | 2019-11-20T22:38:12Z | 2020-10-14T00:04:55Z | https://github.com/mjhea0/flaskr-tdd/issues/58 | [] | markdall | 2 |
ultralytics/ultralytics | deep-learning | 19,753 | Export RT-DETR to onnx get wrong parameters | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I used the following code to export pre-trained RT-DETR model to onnx:
```... | closed | 2025-03-18T07:44:18Z | 2025-03-18T09:01:05Z | https://github.com/ultralytics/ultralytics/issues/19753 | [
"question",
"detect",
"exports"
] | civat | 7 |
aleju/imgaug | deep-learning | 693 | String format expects number but gets string | In imgaug/augmenters/meta.py string formatter expects digit but gets string from type(image).__name__

| open | 2020-06-24T21:21:50Z | 2020-06-24T21:21:50Z | https://github.com/aleju/imgaug/issues/693 | [] | r0mac09 | 0 |
ageitgey/face_recognition | python | 1,509 | 【Bug】Fail to run facerec_from_webcam_faster.py | * face_recognition version: 1.3.0
* Python version: 3.10.10
* Operating System: MacOS
### Description
Fail to run the realtime example code and met with the following error after install dependency
```
Traceback (most recent call last):
File ".../face_recognition/examples/facerec_from_webcam_faster.py", li... | open | 2023-05-23T07:21:35Z | 2023-09-03T06:53:28Z | https://github.com/ageitgey/face_recognition/issues/1509 | [] | WaveBird | 1 |
tensorflow/tensor2tensor | machine-learning | 1,530 | Is there a good example tutorial on how to use Tensor2Tensor? | Is there a good example tutorial on how to use Tensor2Tensor? | closed | 2019-04-03T05:43:35Z | 2019-04-08T15:37:34Z | https://github.com/tensorflow/tensor2tensor/issues/1530 | [] | zqs01 | 1 |
scrapy/scrapy | web-scraping | 6,355 | Fails to fetch request with hyphens in 3rd and 4th position of domain | <!--
Thanks for taking an interest in Scrapy!
If you have a question that starts with "How to...", please see the Scrapy Community page: https://scrapy.org/community/.
The GitHub issue tracker's purpose is to deal with bug reports and feature requests for the project itself.
Keep in mind that by filing an iss... | closed | 2024-05-12T10:29:07Z | 2024-05-12T10:29:26Z | https://github.com/scrapy/scrapy/issues/6355 | [] | vlln | 0 |
twopirllc/pandas-ta | pandas | 241 | are the indicators always in a different order in the dataframe? | hello I am using this
```python
def get_data():
"""
Gets data from CSV (0 - AAPL, 1 - MSI, 2 - SBUX).
:return: T x 3 Stock Prices
"""
ticker = yf.Ticker("AAPL")
df = ticker.history(period='1y',interval='1d')
df = df.dropna()
df.ta.strategy()
df = df.fillna(0)
wi... | closed | 2021-03-08T20:00:58Z | 2021-03-10T21:12:36Z | https://github.com/twopirllc/pandas-ta/issues/241 | [
"info"
] | copypasteearth | 4 |
netbox-community/netbox | django | 18,835 | bash: pip: command not found | ### Deployment Type
NetBox Cloud
### NetBox Version
v4.2.5
### Python Version
3.12
### Steps to Reproduce
I tried install plugin, but "pip not found":
```bash
root@netbox-0:/opt/netbox/netbox# source /opt/netbox/venv/bin/activate
(venv) root@netbox-0:/opt/netbox/netbox# pip install netbox-bgp
bash: pip: command... | closed | 2025-03-07T06:46:08Z | 2025-03-07T13:32:40Z | https://github.com/netbox-community/netbox/issues/18835 | [] | janhlavin | 0 |
floodsung/Deep-Learning-Papers-Reading-Roadmap | deep-learning | 6 | Deep learning book link has moved | The new address is http://www.deeplearningbook.org/
| closed | 2016-10-21T08:12:46Z | 2016-10-21T08:22:46Z | https://github.com/floodsung/Deep-Learning-Papers-Reading-Roadmap/issues/6 | [] | willprice | 1 |
dmlc/gluon-nlp | numpy | 679 | [usability] print warnings when Pad() is used | When `data.batchify.Pad()` is used, the default padding value is 0. However, this usually does not respond to the pad token id in the vocab. We should print a warning if 0 is used for `Pad()` so that users are aware. | closed | 2019-04-24T06:11:19Z | 2019-06-05T04:17:51Z | https://github.com/dmlc/gluon-nlp/issues/679 | [
"enhancement"
] | eric-haibin-lin | 0 |
encode/databases | sqlalchemy | 215 | execute_many should not discard results | consider the following:
```sql
CREATE TABLE my_table
(
id BIGSERIAL,
item INTEGER
)
```
```python
query = """
INSERT INTO
my_table (item)
VALUES (:item) RETURNING id
"""
values=[{'item':100, 'item':200}]
my_ids = database.execute_many(query=query,val... | open | 2020-06-04T15:28:00Z | 2022-12-20T15:42:07Z | https://github.com/encode/databases/issues/215 | [] | charterchap | 3 |
jupyter-book/jupyter-book | jupyter | 1,988 | Build a book within an existent Sphinx documentation | ### Context
I am planning a Python3-based software package that allows to build books from a set of shipped notebooks and a book template.
My project has its Sphinx-based documentation and I was looking for a way to build an example book _within_ my documentation, instead of e.g. a gallery of notebooks (because the... | open | 2023-04-02T20:04:16Z | 2024-02-24T14:19:11Z | https://github.com/jupyter-book/jupyter-book/issues/1988 | [
"enhancement"
] | HealthyPear | 4 |
SYSTRAN/faster-whisper | deep-learning | 87 | How do I get the avg_logprob , compression_ratio and no_speech_prob of the output? | Thank you for porting this to cTranslate2, really helps running the large model on my 3060 laptop (not possible with OpenAI's implementation)
Is there a way to get the properties of the model output? In OpenAI's implementation a dictionary is returned when model.transcribe is called, something like this:
This is ... | closed | 2023-03-29T10:51:18Z | 2023-04-03T14:57:03Z | https://github.com/SYSTRAN/faster-whisper/issues/87 | [] | palladium123 | 4 |
521xueweihan/HelloGitHub | python | 2,320 | 【开源自荐】quic-tun 构建快速且安全的 TCP 传输隧道 | ## 推荐项目
- 项目地址:https://github.com/kungze/quic-tun
- 类别:Go
- 项目标题:一个快速且安全的 TCP 隧道工具,能加速弱网环境下(网络有丢包)TCP 的转发性能。
- 项目描述:QUIC 是 google 指定的一个新型的可靠的传输层网络协议,相较于传统的 TCP 其在传输性能和安全方面有非常突出的表现,HTTP3 就是就要 QUIC 协议指定的,那么除了 HTTP3 这种新型应用,有没有方案能使传统的 TCP 应用也搭上 QUIC 的便车呢?答案当然是肯定的,quic-tun 就提供了这样的一套解决方案。
- 亮点:成倍的提升网络传输性能;安全的传... | closed | 2022-08-10T02:02:25Z | 2022-08-22T11:18:16Z | https://github.com/521xueweihan/HelloGitHub/issues/2320 | [] | jeffyjf | 1 |
skypilot-org/skypilot | data-science | 4,105 | [UX] Showing logs for automatic translation of file uploads in `jobs launch` | <!-- Describe the bug report / feature request here -->
We have the logs showing for the normal `sky launch`'s file_mounts, but we don't show the logs for `jobs launch`'s automatic translation. We should have a log file for that. (requested by a user)
<!-- If relevant, fill in versioning info to help us trouble... | closed | 2024-10-17T17:31:33Z | 2024-12-25T06:40:57Z | https://github.com/skypilot-org/skypilot/issues/4105 | [
"good first issue",
"P0",
"interface/ux"
] | Michaelvll | 0 |
allenai/allennlp | data-science | 5,724 | SRL BERT performing poorly for german dataset | I am trying to train a SRL model for German text by translating Ontonotes dataset and propagating the labels from English sentences to German sentences. When i train the model with this dataset, as well a manually annotated dataset i seem to be stuck at maximum F1 score of 0.62. I am using deepset/gbert-large bert mode... | closed | 2022-10-21T23:21:58Z | 2022-11-07T16:09:59Z | https://github.com/allenai/allennlp/issues/5724 | [
"question",
"stale"
] | stevemanavalan | 1 |
docarray/docarray | pydantic | 1,600 | Weaviate cannot handle tensor with different axis | # Context
it seems that Weaviate cannot handle tensor with multiple axis (n-dimensional array)
If this is expected we should have a better error message and it should be documented somewhere
## How to reproduce.
weaviate version: 1.18.3
client version: 3.19.2
To run it please before start the weavia... | open | 2023-05-31T12:40:23Z | 2023-05-31T15:23:29Z | https://github.com/docarray/docarray/issues/1600 | [
"index/weaviate"
] | samsja | 6 |
Lightning-AI/pytorch-lightning | data-science | 19,585 | universal resume checkpoint from deepspeed | ### Description & Motivation
One pain in training with deepspeed is that when resume from a checkpoint you have to use the same amount of gpus as the num of gpus that the checkpoint was trained on. otherwise, you will see the following error:
```
deepspeed.runtime.zero.utils.ZeRORuntimeException: The checkpoint bein... | closed | 2024-03-06T20:37:10Z | 2024-03-14T15:08:32Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19585 | [
"feature",
"strategy: deepspeed"
] | pengzhangzhi | 1 |
aleju/imgaug | deep-learning | 749 | Tiler augmenter proposal | I needed to create tile image from different objects of an image for object detection task.
I couldn't find anything similar so I implemented it with your `iaa.meta.Augmenter` class.
For those who are looking for such functionality, I attach the `Tiler` class, client code with sequence of augmenters including the T... | open | 2021-02-25T11:59:56Z | 2021-03-01T16:17:08Z | https://github.com/aleju/imgaug/issues/749 | [] | chamecall | 0 |
exaloop/codon | numpy | 206 | print(~1) assert | print(~1)
produces:
Assert failed: type not set for (unary "~" (int* 1 #:type "int")) [x.py:1:1]
Expression: expr->type
Source: /home/jplevyak/projects/codon/codon/parser/visitors/typecheck/typecheck.cpp:63
Aborted (core dumped) | closed | 2023-03-11T22:08:20Z | 2023-03-25T23:56:19Z | https://github.com/exaloop/codon/issues/206 | [] | jplevyak | 2 |
zappa/Zappa | flask | 808 | [Migrated] Zappa requires "future" package under Python 3.x | Originally from: https://github.com/Miserlou/Zappa/issues/1966 by [rudyryk](https://github.com/rudyryk)
Trying to minify uploaded installation ZIP. Noticed that future package is more than 1.5Mb size, this is far larger than many. But it should not be necessary under Python 3.
## Expected Behavior
Don't install an... | closed | 2021-02-20T12:51:53Z | 2022-08-05T10:37:24Z | https://github.com/zappa/Zappa/issues/808 | [] | jneves | 1 |
scikit-optimize/scikit-optimize | scikit-learn | 531 | ValueError: The truth value of an array with more than one element is ambiguous | Hi,
when trying to run the following code:
```
res_gbrt = gbrt_minimize(tagpowercalc_electron_train.evaluate, x0_gp_limits, n_calls=5000, n_random_starts=10, x0=x0_gp, random_state=42, n_jobs=4)
```
I get the following error:
```
/afs/cern.ch/work/v/vibattis/miniconda2/lib/python2.7/site-packages/skopt/space/s... | closed | 2017-10-09T09:24:57Z | 2017-10-09T14:13:16Z | https://github.com/scikit-optimize/scikit-optimize/issues/531 | [] | VINX89 | 2 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 297 | [BUG] TikTok短连接视频解析不了 | ***发生错误的平台?***
如:TikTok
***发生错误的端点?***
如:API-V1
***提交的输入值?***
如:[短视频链接](https://vm.tiktok.com/ZM2kkTThP/)
***是否有再次尝试?***
如:是
***你有查看本项目的自述文件或接口文档吗?***
如:有
| closed | 2023-10-14T04:00:40Z | 2024-02-07T03:41:38Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/297 | [
"BUG"
] | JayFang1993 | 0 |
DistrictDataLabs/yellowbrick | matplotlib | 795 | PCA projections on biplot are not clear for datasets with large number of features | **Problem**
The PCA projections visualized on a biplot are not clear, and various feature's projection can be seen to overlap with each other when working with a dataset with a large number of features. e.g. with credit dataset from yellowbrick.datasets
 to the Page Builder API.
#### Workaround
The only situation where this can be achieved is making sure the element name is not already used by the regular Taipy components (like 'table' or 'scenario'). Then t... | closed | 2025-01-22T17:04:13Z | 2025-02-10T12:03:48Z | https://github.com/Avaiga/taipy/issues/2421 | [
"📄 Documentation",
"🟨 Priority: Medium",
"✨New feature",
"🔒 Staff only",
"Gui: Back-End"
] | FabienLelaquais | 0 |
seleniumbase/SeleniumBase | pytest | 3,155 | Retrofit SeleniumBase with `pyproject.toml` structure | ## Retrofit SeleniumBase with `pyproject.toml` structure.
Lots of the "cool kids" have already switched over to using `pyproject.toml`. Now, I'm forced to switch over due to deprecation warnings when calling `"pip install -e ."`:
> `DEPRECATION: Legacy editable install of <PACKAGE> from <PACKAGE_PATH> (setup.py d... | closed | 2024-09-21T17:47:25Z | 2024-09-23T05:46:23Z | https://github.com/seleniumbase/SeleniumBase/issues/3155 | [
"enhancement",
"requirements"
] | mdmintz | 1 |
yeongpin/cursor-free-vip | automation | 270 | [Bug]: User is unauthorized | ### Commit before submitting
- [x] I understand that Issues are used to provide feedback and solve problems, not to complain in the comments section, and will provide more information to help solve the problem.
- [x] I have checked the top Issue and searched for existing [open issues](https://github.com/yeongpin/curso... | open | 2025-03-17T07:39:06Z | 2025-03-18T04:36:48Z | https://github.com/yeongpin/cursor-free-vip/issues/270 | [
"bug"
] | EKALAT | 17 |
oegedijk/explainerdashboard | plotly | 18 | Temporary failure in name resolution - linux | Tested on my linux machine
Installation:
```
$ conda create -n test_env python=3.8
$ conda activate test_env
$ pip install explainerdashboard
```
and tested this https://explainerdashboard.readthedocs.io/en/latest/index.html#a-more-extended-example
This may be outside of explainerdashboard
```
>>> f... | closed | 2020-11-17T14:38:27Z | 2020-12-05T04:05:28Z | https://github.com/oegedijk/explainerdashboard/issues/18 | [] | raybellwaves | 6 |
jowilf/starlette-admin | sqlalchemy | 309 | Enable sub properties of relationships to appear as columns | ### Discussed in https://github.com/jowilf/starlette-admin/discussions/307
<div type='discussions-op-text'>
<sup>Originally posted by **samearcher** September 25, 2023</sup>
Hi,
I have a relationship, "mat_class" of my table, "A1_A3_Data", as follows:
```
class A1_A3_Data(A1_A3_Data_Base, ActiveRecordMixi... | closed | 2023-09-26T18:34:40Z | 2023-10-28T04:41:13Z | https://github.com/jowilf/starlette-admin/issues/309 | [] | samearcher | 3 |
scikit-image/scikit-image | computer-vision | 7,455 | enable to pass 'seed' to skimage.feature.plot_matches() | ### Description:
The colors of the lines drawn by skimage.feature.plot_matches can be generated with random colors, which is very useful for distinguishing them instead of having lines of the same color.
However, it would be beneficial to be able to pass a seed to the random function to achieve consistent results wh... | open | 2024-07-05T15:58:11Z | 2025-03-10T02:26:44Z | https://github.com/scikit-image/scikit-image/issues/7455 | [
":pray: Feature request",
":sleeping: Dormant"
] | patquem | 6 |
dgtlmoon/changedetection.io | web-scraping | 2,782 | [feature] Create A Copy with Immediate Edit | **Version and OS**
0.47.06 docker
**Is your feature request related to a problem? Please describe.**
When adding multiple watches where the watched url is the only change, Create A Copy button creates an exact active copy and goes back to the list of watches from which I must quickly click edit and make my changes... | open | 2024-11-15T15:24:45Z | 2024-11-16T10:54:29Z | https://github.com/dgtlmoon/changedetection.io/issues/2782 | [
"enhancement",
"user-interface"
] | jolpadgett | 3 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 295 | Make please google collab notebook version | Hi. Make please google collab notebook version | closed | 2020-03-08T14:26:25Z | 2020-07-04T22:18:09Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/295 | [] | shadowzoom | 2 |
ray-project/ray | machine-learning | 50,958 | [RayServe] Documentation is misleading about what services get created by a RayService | ### Description
I tried creating a sample RayService, following the documentation: https://docs.ray.io/en/latest/serve/production-guide/kubernetes.html#deploying-a-serve-application :
```
$ kubectl apply -f https://raw.githubusercontent.com/ray-project/kuberay/5b1a5a11f5df76db2d66ed332ff0802dc3bbff76/ray-operator/con... | open | 2025-02-27T21:17:46Z | 2025-02-27T21:22:44Z | https://github.com/ray-project/ray/issues/50958 | [
"triage",
"docs"
] | boyleconnor | 0 |
indico/indico | sqlalchemy | 6,073 | [A11Y] Semantic UI date input overrides the associated label with placeholder text | **Describe the bug**
When using the date picker with a screen reader, the input is always read as if the placeholder is the label, regardless of whether there is a proper field label associated with it.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to any form that includes a date picker
2. If necess... | closed | 2023-11-30T07:51:21Z | 2023-12-05T08:35:11Z | https://github.com/indico/indico/issues/6073 | [
"bug"
] | foxbunny | 2 |
wemake-services/django-test-migrations | pytest | 6 | Skip/XFail tests depending on migrator fixture if --nomigrations option was applied. | closed | 2019-11-25T21:44:14Z | 2020-02-25T14:04:21Z | https://github.com/wemake-services/django-test-migrations/issues/6 | [] | proofit404 | 0 | |
scikit-multilearn/scikit-multilearn | scikit-learn | 29 | get_params and set_params for MLClassifierBase erroneous | Hi,
While writing the test case for cross validation I noticed that I missed something in my implementation of said functions, which gives me time to discuss some shortcomings of the code.
In the scikit-learn implementation, there is quite a lot of code to find out the attributes of each object for the get_param func... | closed | 2016-02-26T11:29:20Z | 2016-05-17T00:43:59Z | https://github.com/scikit-multilearn/scikit-multilearn/issues/29 | [
"bug"
] | ChristianSch | 4 |
microsoft/nni | pytorch | 4,958 | HPO problem | When I set the search space use quniform like below in HPO.
<img width="234" alt="image" src="https://user-images.githubusercontent.com/11451001/175040897-0a8cbe73-fbb9-4a9e-85ff-f8025bb16c1a.png">
The parameters often become Long decimal, how can I fix it?
<img width="392" alt="image" src="https://user-images.git... | closed | 2022-06-22T13:29:47Z | 2022-06-27T03:05:20Z | https://github.com/microsoft/nni/issues/4958 | [
"question"
] | woocoder | 2 |
xinntao/Real-ESRGAN | pytorch | 530 | Using GFPGANv1.pth (Papermodel) in esrgan | I tried using the papermodel of gfpgan (GFPGANv1.pth) separately which was working. But when I'm trying to use it in esrgan it gives error.
<img width="1142" alt="image" src="https://user-images.githubusercontent.com/104137976/209955622-0475c12c-f133-4a16-8e00-68822e6ac2a5.png">
Has anyone tried the same? | open | 2022-12-29T13:11:30Z | 2022-12-29T13:11:30Z | https://github.com/xinntao/Real-ESRGAN/issues/530 | [] | sumit27kumar | 0 |
ray-project/ray | deep-learning | 51,273 | [core][gpu-objects] Actor sends the same ObjectRef twice to another actor | ### Description
If an actor sends the same ObjectRef twice to another actor, we should not call NCCL send twice. Instead, we only call the NCCL send once and the receiver retrieve the tensor from its in-actor storage twice.
### Use case
_No response_ | open | 2025-03-11T22:08:47Z | 2025-03-11T22:13:36Z | https://github.com/ray-project/ray/issues/51273 | [
"enhancement",
"P1",
"core",
"gpu-objects"
] | kevin85421 | 0 |
newpanjing/simpleui | django | 108 | 大bug 进入admin页面 或刷新后台管理页面 总会闪出一个很丑的模版渲染页面 | **bug描述**
进入后台管理页面 、刷新后台管理页面 ;总会闪出一个很丑的模版渲染页面
**重现步骤**
1.进入admin页面 活着刷新后台管理页面、
2.总会闪出一个很丑的模版渲染页面
3.这是一个巨大的bug 直接就是首页 入口的bug
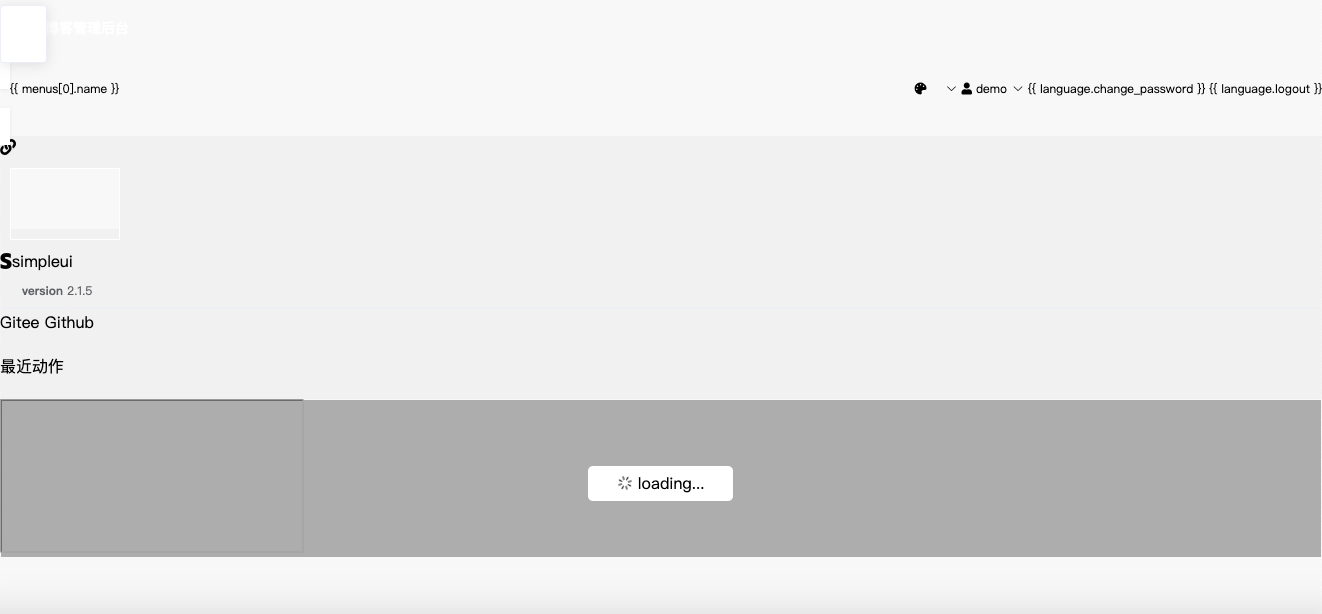
| closed | 2019-07-05T13:57:45Z | 2019-07-09T05:48:30Z | https://github.com/newpanjing/simpleui/issues/108 | [
"bug"
] | insseek | 1 |
timkpaine/lantern | plotly | 143 | allow adjustments to comm interval | `time.sleep(1)` in comm.py should be a configurable parameter. maybe instantaneous is best (let the source rate limit?)
| closed | 2018-01-31T20:10:49Z | 2018-02-27T22:31:41Z | https://github.com/timkpaine/lantern/issues/143 | [
"feature"
] | timkpaine | 0 |
deepspeedai/DeepSpeed | machine-learning | 5,583 | different setting for same (num_gpus * batch_size * grad_accum_steps) output different loss and gradient norm | hi i have observed significant performance degradation in multi-gpu with grad accum > 1 setting.
I'm sorry not to upload profiling code (will be uploaded soon) but i tested 7B scale LLM using same size input data (fixed seed and expand same sequence in batch dimension)
i expected the loss and gradient are same for ... | closed | 2024-05-29T09:27:56Z | 2024-11-01T21:03:28Z | https://github.com/deepspeedai/DeepSpeed/issues/5583 | [
"bug",
"training"
] | SeunghyunSEO | 2 |
albumentations-team/albumentations | deep-learning | 1,645 | [Feature Request] Make RandomGridShuffle work when `size % num_splits != 0` | Right now if side is non divisible by the number of splits => we do not do anything.
Better would be:
image shape `(20, 17)`
Want `(3, 4)` splits
=> 20 = 6 + 7 + 7
=> 17 = 4 + 4 + 5 + 4
After that perform shuffle on every tuple:
Let it become: (7, 6, 7) и (4, 5, 4, 4)
Now we have 12 tiles with diff... | closed | 2024-04-10T21:38:38Z | 2024-04-12T02:39:16Z | https://github.com/albumentations-team/albumentations/issues/1645 | [
"enhancement"
] | ternaus | 1 |
JaidedAI/EasyOCR | pytorch | 750 | Free ocr tool | Hi I hope you are doing well!
Our dhurvaa's OCR Tool Transform any image, scanned document, or printed PDF to editable text in seconds using our FREE online Optical Character Recognition (OCR) feature. Use our FREE online OCR feature to recognize text from images.
https://dhurvaa.com/online_ocr_tool
Feel free t... | closed | 2022-06-07T16:16:21Z | 2022-06-08T08:45:07Z | https://github.com/JaidedAI/EasyOCR/issues/750 | [] | vishal-nayak1 | 0 |
roboflow/supervision | machine-learning | 928 | [Smoother] - `tracker_id` is `None` when there is no detection for an extended period | ### Bug
I have code that performs detections on video, which operates smoothly without the smoother function. However, upon integrating the smoother function, I encounter the following error:
```
Traceback (most recent call last):
File "/content/script_detection.py", line 165, in <module>
processor.proce... | closed | 2024-02-20T09:59:47Z | 2024-02-28T13:25:32Z | https://github.com/roboflow/supervision/issues/928 | [
"bug"
] | vhuard | 8 |
stanfordnlp/stanza | nlp | 844 | Options to turn off or alter sentence segmentation | I have a document where each line is a sentence already. Therefore, the delimiter is `\n` and not `\n\n`. I want stanza to respect this segmentation which is already present in the data. It is not such that tokens are split by ` ` or any other nice delimiter, tokenization must be performed. So then ...
1) Is the... | closed | 2021-10-14T15:04:06Z | 2021-12-24T20:41:38Z | https://github.com/stanfordnlp/stanza/issues/844 | [
"question",
"stale"
] | demongolem-biz | 4 |
aleju/imgaug | machine-learning | 124 | Release of 2.5 / 2.6? | Any idea of when the current master (2.5 or 2.6 I think) might be released? Is there a release schedule / procedure? | open | 2018-04-19T14:06:51Z | 2018-06-04T19:20:53Z | https://github.com/aleju/imgaug/issues/124 | [] | Erotemic | 2 |
pydantic/logfire | pydantic | 879 | Add support for structured pydantic log bodies | ### Description
Hey folks! Our team just did a hands-on trail day yesterday to analyze the capabilities of pydantic-logfire, and the
first thing I'd like to say:
- the ease of use is amazing! :rocket:
pydantic logfire might be one of those desperately needed tools that finally simplify the huge technical (digest ton... | open | 2025-02-21T07:58:27Z | 2025-02-21T07:58:27Z | https://github.com/pydantic/logfire/issues/879 | [
"Feature Request"
] | ddluke | 0 |
microsoft/nni | machine-learning | 5,776 | I cannot make it work on GPU for training | ## Description of the issue
I cannot run any experiment on GPU.
I have tried both with a Tesla P4, a P100 and a GTX 1060. I can only make it work using CPU only.
I have tried many configs with setting useActiveGpu to True or False, trialGpuNumber to 1, gpuIndices: '0'. However it always couldn't complete a si... | open | 2024-05-03T14:50:54Z | 2024-05-23T15:01:40Z | https://github.com/microsoft/nni/issues/5776 | [] | dtamienER | 3 |
adbar/trafilatura | web-scraping | 557 | Readme.md table is broken. | 
| closed | 2024-04-14T23:15:06Z | 2024-04-19T14:56:29Z | https://github.com/adbar/trafilatura/issues/557 | [
"bug"
] | AnishPimpley | 1 |
aminalaee/sqladmin | fastapi | 835 | Edit database 400 error: Too many fields. Maximum number of fields is 1000. | ### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
I have an object that I am trying to edit from the admin panel. The model field is a list of enum values for which I want to add one of the values... | open | 2024-10-16T13:53:30Z | 2024-12-25T14:15:24Z | https://github.com/aminalaee/sqladmin/issues/835 | [] | pimverschuuren | 2 |
deepfakes/faceswap | deep-learning | 543 | Install went fine, extraction fine, training no errors but no feedback either. | (i answered all of the items in the post outline form below, but i just condensed to paragraph)
Hey, thanks for the awesome program (cool gui as well) I came from openswap, and this gui is great cant wait to delve into the alignments file operations and maintenance options. (even though ill probably use the console,... | closed | 2018-12-09T05:34:49Z | 2019-01-09T20:01:16Z | https://github.com/deepfakes/faceswap/issues/543 | [] | IEWbgfnYDwHRoRRSKtkdyMDUzgdwuBYgDKtDJWd | 2 |
ray-project/ray | tensorflow | 51,518 | [Autoscaler] Issue when using ray start --head with --autoscaling-config | ### What happened + What you expected to happen
## Describe
When running ray start --head with --autoscaling-config, the head node is deployed, but the head node creation request defined in head_node_type(autoscaling-config) remains in a pending state in the autoscaler, even though the head node is already running.
I... | open | 2025-03-19T09:29:43Z | 2025-03-20T00:33:48Z | https://github.com/ray-project/ray/issues/51518 | [
"bug",
"P2",
"core"
] | nadongjun | 2 |
ets-labs/python-dependency-injector | asyncio | 121 | Create DelegatedCallable provider | closed | 2015-12-27T16:10:07Z | 2015-12-28T15:49:48Z | https://github.com/ets-labs/python-dependency-injector/issues/121 | [
"feature"
] | rmk135 | 0 | |
hankcs/HanLP | nlp | 1,718 | HanLP1.x 文本推荐 逻辑错误 | <!--
Thank you for reporting a possible bug in HanLP.
Please fill in the template below to bypass our spam filter.
以下必填,否则恕不受理。
-->
**Describe the bug**
在 Suggester 类的suggest方法中对于不同评价器求和出错,Suggester 位于package com.hankcs.hanlp.suggest;
` scoreMap.put(entry.getKey(), score / max + entry.getValue() * scorer.bo... | closed | 2022-04-09T17:12:34Z | 2022-04-09T17:41:40Z | https://github.com/hankcs/HanLP/issues/1718 | [
"bug"
] | QAQ516284797 | 1 |
gradio-app/gradio | python | 10,320 | Option "editable" in gr.Chatbot could only work for the first message in a group of consecutive messages. | ### Describe the bug
Option "editable" in gr.Chatbot could only work for the first message in a group of consecutive messages.
### Have you searched existing issues? 🔎
- [X] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
examples = [
{"role": "user", "content... | open | 2025-01-09T03:44:13Z | 2025-03-22T11:57:33Z | https://github.com/gradio-app/gradio/issues/10320 | [
"bug"
] | tankgit | 1 |
seleniumbase/SeleniumBase | pytest | 2,990 | error 'Chrome' object has no attribute 'uc_gui_click_captcha' | why I get this error 'Chrome' object has no attribute 'uc_gui_click_captcha' on driver
how can use this method on wich object ?
please help | closed | 2024-08-03T20:17:04Z | 2024-08-03T22:01:56Z | https://github.com/seleniumbase/SeleniumBase/issues/2990 | [
"question",
"UC Mode / CDP Mode"
] | alish511 | 1 |
mitmproxy/mitmproxy | python | 6,822 | WireGuard mode in mitmproxy where find client config file? How work with it? Any documentation? | #### Problem Description
WireGuard mode in mitmproxy where find client config file? (not mitmweb in "mitmproxy --mode wireguard@1111")
#### Steps to reproduce the behavior:
1. Look in ~./wireguard but nothing
#### System Information
Using last mitmproxy
And how it work? i cant find any documentation I n... | closed | 2024-04-27T03:08:35Z | 2024-04-30T10:04:53Z | https://github.com/mitmproxy/mitmproxy/issues/6822 | [
"kind/triage"
] | Vasa211 | 1 |
strawberry-graphql/strawberry-django | graphql | 40 | Unwanted argument in model Types for O2O and ForeignKeys | For models with a ForeignKey (or a O2O), a `pk` arg appears on the generated type, which, to my knowledge doesn't do anything.
Here is the schema used in tests:
```
type BerryFruit {
id: ID!
name: String!
nameUpper: String!
nameLower: String!
}
type Group {
id: ID!
name: String!
users: [Us... | closed | 2021-06-18T13:21:18Z | 2021-06-21T20:23:58Z | https://github.com/strawberry-graphql/strawberry-django/issues/40 | [] | g-as | 1 |
noirbizarre/flask-restplus | flask | 655 | Validate request parser and model object in expect decorator cause problem | Im trying to validate both api.model and request parser objects in expect decorator but it seems its not possible.
```
profile_pic_args = reqparse.RequestParser()
profile_pic_args.add_argument(
'profile_pic',
type=werkzeug.datastructures.FileStorage,
location='files',
required=False,
help=... | open | 2019-06-15T22:19:52Z | 2019-06-15T22:21:29Z | https://github.com/noirbizarre/flask-restplus/issues/655 | [] | alicmp | 0 |
dropbox/PyHive | sqlalchemy | 34 | Installation problem:UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 42 | Hello,
My laptop is running Ubuntu 14.04 server 6.4,and python2.7-dev has been installed,when install pyhive,blow errors got printed:
``` python
Command /usr/bin/python -c "import setuptools, tokenize;__file__='/tmp/pip_build_root/sasl/setup.py';exec(compile(getattr(tokenize, 'open', open)(__file__).read().repl... | closed | 2016-01-14T09:29:22Z | 2016-01-14T18:11:31Z | https://github.com/dropbox/PyHive/issues/34 | [] | AlexLuya | 1 |
scanapi/scanapi | rest-api | 554 | curl generation doesn't take verify: false into account | ## Bug report
### Environment
- Operating System: not relevant
- Python version: not relevant
### Description of the bug
When using `verify: false`, the curl command generated without the `--inscure / -k` flag.
### Expected behavior ?
The generated curl should include `--insecure / -k` when the request is... | closed | 2022-11-21T15:41:45Z | 2023-03-02T16:44:11Z | https://github.com/scanapi/scanapi/issues/554 | [
"Bug"
] | Crocmagnon | 1 |
onnx/onnx | tensorflow | 6,141 | Export onnx model from pytorch with dynamic input size, output tensor doesn't match. | - python 3.10.12
- onnx 1.15.0
- onnxruntime 1.17.1
- torch 2.1.1
##### I transfer a transformer model from pytorch to onnx, this model necessitates cyclic inference, with the size of the third input node expanding with each inference. Although no errors w... | open | 2024-05-20T07:19:40Z | 2024-05-28T18:53:03Z | https://github.com/onnx/onnx/issues/6141 | [
"question",
"topic: converters"
] | younghuvee | 9 |
noirbizarre/flask-restplus | api | 728 | Defining varaible keys in case of nested field model | ```
"preview": {
"9:16": {
"thumbnail": "",
"video": ""
}, "16:9": {
"thumbnail": "",
"video": ""
}, "1:1": {
"thumbnail": "",
"video": ""
}
}
```
I have the above data coming in the request for which I want to create a model. I tried implementing wildcard fields but didn't g... | closed | 2019-10-10T11:40:59Z | 2019-10-27T17:56:00Z | https://github.com/noirbizarre/flask-restplus/issues/728 | [
"enhancement",
"in progress"
] | knowBalpreet | 15 |
ranaroussi/yfinance | pandas | 1,294 | yfinance 0.2.3: Cannot load Ticker Info | Dear Together,
I am facing the following situation:
yfinance module suddenly stopped providing Info today.
History request seems to be working however, while asking "actions" seems to provide "Empty Dataframe".
See the output below.
I found this issue from last month, resembling to my current situation, howeve... | closed | 2023-01-13T17:42:34Z | 2023-01-14T09:28:13Z | https://github.com/ranaroussi/yfinance/issues/1294 | [] | Tatcher91 | 2 |
huggingface/datasets | pytorch | 6,863 | Revert temporary pin huggingface-hub < 0.23.0 | Revert temporary pin huggingface-hub < 0.23.0 introduced by
- #6861
once the following issue is fixed and released:
- huggingface/transformers#30618 | closed | 2024-05-03T05:53:55Z | 2024-05-27T10:14:41Z | https://github.com/huggingface/datasets/issues/6863 | [] | albertvillanova | 0 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 508 | Lora模型合并前 和 合并后显存不一致 | 加载base model + lora
和 加载merge后的模型,后者总是会OOM,这可能是原因导致的呢?
合并后的模型体积貌似也没有增加,是正常的状态,那为何合并后推理会OOM | closed | 2023-06-05T06:08:53Z | 2023-06-13T23:59:18Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/508 | [
"stale"
] | lucasjinreal | 5 |
deeppavlov/DeepPavlov | nlp | 892 | Downgrade tensoflow version AttributeError | There is no fixed tensorflow version in requirments.txt.
So, if I downgrade tensorflow to version 1.10, I'll catch error: "AttributeError: module 'tensorflow' has no attribute 'init_scope'. | closed | 2019-06-20T14:43:11Z | 2019-07-15T13:14:32Z | https://github.com/deeppavlov/DeepPavlov/issues/892 | [] | artyerokhin | 2 |
jschneier/django-storages | django | 1,007 | changing 'DEFAULT_FILE_STORAGE' causing high TTFB ( waiting time ) | basically, it's a webpage with few photos serving from MySQL stored in the s3 server ( DigitalOcean )...
so I realized every time I reload the page it actually downloads every photo chunk then loads the page. ( maybe ), and it does this with only images uploaded to MySQL, not to my other normal static images.
I track... | closed | 2021-04-26T15:10:51Z | 2021-04-27T10:05:15Z | https://github.com/jschneier/django-storages/issues/1007 | [] | harshjadon9 | 1 |
plotly/dash-table | dash | 72 | index column edit/delete button unusable | we should consider removing the edit/delete buttons (remove altogether or make unactive) as it's not possible to remove this column:

| closed | 2018-09-11T13:41:14Z | 2019-09-20T00:28:46Z | https://github.com/plotly/dash-table/issues/72 | [
"dash-type-bug"
] | cldougl | 1 |
plotly/dash-bio | dash | 116 | Why are generated files in the version control? | I noticed that generated files in dash-bio/dash_bio (such as bundle.js etc.), or the .tar.gz, are versioned in this repository. I wonder why this is the case: usually (at least in my experience) files which can be generated are not integrated in the version control, in particular for large files. | closed | 2019-01-22T22:09:27Z | 2019-01-25T15:19:07Z | https://github.com/plotly/dash-bio/issues/116 | [] | emmanuelle | 8 |
keras-team/keras | python | 20,524 | Accuracy is lost after save_weights/load_weights | ### Keras version: 3
### TensorFlow version
2.16.1
### Current behavior?
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 354ms/step - accuracy: 0.5000 - loss: 1.1560
[1.1560312509536743, 0.5]
Epoch 1/10
1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 596ms/step - accuracy: 0.5000 - loss: 1.1560
Epoch 2/10
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 28ms/ste... | closed | 2024-11-20T08:56:00Z | 2024-12-26T02:01:36Z | https://github.com/keras-team/keras/issues/20524 | [
"stat:awaiting response from contributor",
"stale"
] | Pandaaaa906 | 5 |
ymcui/Chinese-BERT-wwm | nlp | 16 | tensorflow版本和hugging face torch版本的weights是否一致? | 我目前测下来tf和torch在同一文本的embedding好像不一样 | closed | 2019-06-28T06:08:04Z | 2019-07-10T05:20:09Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/16 | [] | iamlxb3 | 2 |
dpgaspar/Flask-AppBuilder | rest-api | 2,170 | Order of Lists in Multiview | The Multiview is displaying views in the order of coding dispite they are declared as a list.
```python
def list(self):
pages = get_page_args()
page_sizes = get_page_size_args()
orders = get_order_args()
views_widgets = list()
for view in self._views:
if o... | closed | 2023-11-24T09:39:51Z | 2023-12-20T08:50:54Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/2170 | [] | gbrault | 3 |
ultralytics/ultralytics | machine-learning | 19,745 | Export torchscript not support dynamic batch and nms | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
_No response_
### Bug
code
```
def export(model_path='yolo11x-pose.pt', imagz=832, batch=8):
model = YOLO(model_path)
... | open | 2025-03-17T10:03:57Z | 2025-03-24T00:05:26Z | https://github.com/ultralytics/ultralytics/issues/19745 | [
"exports"
] | 631068264 | 15 |
nok/sklearn-porter | scikit-learn | 6 | How to read the multi-layer perceptrons model in Java written using python | I am using the wrapper of scikit-learn Multilayer Perceptron in Python [https://github.com/aigamedev/scikit-neuralnetwork](url) to train the neural network and save it to a file. Now, I want to expose it on production to predict in real time. So, I was thinking to use Java for better concurrency than Python. Hence, my ... | closed | 2017-01-25T08:54:39Z | 2017-01-30T18:49:44Z | https://github.com/nok/sklearn-porter/issues/6 | [
"enhancement",
"question"
] | palaiya | 4 |
TencentARC/GFPGAN | deep-learning | 237 | Can I use your latent code for real world-image face editing? | Thanks for sharing your amazing job. It performs the best as far as I know. BTW, can I learn a direction like "smile" with your latent code, and do face editing with your model stylegan_decoder? Look forward your valuable advise. | open | 2022-08-12T09:16:58Z | 2022-08-15T05:43:17Z | https://github.com/TencentARC/GFPGAN/issues/237 | [] | tengshaofeng | 0 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 16,535 | ### Features: | ### Features:
* A lot of performance improvements (see below in Performance section)
* Stable Diffusion 3 support ([#16030](https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/16030), [#16164](https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/16164), [#16212](https://github.com/AUTOMATIC1111/stabl... | closed | 2024-10-05T22:57:35Z | 2024-10-06T01:06:05Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16535 | [] | lawchingman | 0 |
asacristani/fastapi-rocket-boilerplate | pydantic | 17 | Monitoring: add logging system | Include logs using different levels for the following events:
- db interactions
- celery task interactions
- endpoint interactions | open | 2023-10-11T10:56:06Z | 2023-10-11T11:07:03Z | https://github.com/asacristani/fastapi-rocket-boilerplate/issues/17 | [
"enhancement"
] | asacristani | 0 |
PaddlePaddle/ERNIE | nlp | 217 | kpi.py where it is? not in models | thanks | closed | 2019-07-18T12:12:27Z | 2020-05-28T12:53:03Z | https://github.com/PaddlePaddle/ERNIE/issues/217 | [
"wontfix"
] | SupDataKing | 2 |
kennethreitz/responder | graphql | 227 | docs_route at base of other routes results in 404 | I like to have the docs render at `/api`, with other endpoints being at `/api/other_route/...`. This used to work with earlier versions of responder, but recently gives a 404 at `/api`.
Minimal example:
```python
import responder
from marshmallow import Schema, fields
api = responder.API(title="Web Service",... | closed | 2018-11-15T10:15:15Z | 2018-11-15T11:23:52Z | https://github.com/kennethreitz/responder/issues/227 | [] | mmanhertz | 1 |
scikit-optimize/scikit-optimize | scikit-learn | 779 | Issues trying to use BayesianCV on an xgb classifier estimator | I seem to have stumbled into some bug trying to do a Bayesian CV with an XGB Classifier estimator. My skopt version is `0.5.2` and my xgb version is `0.90`. Here's the code and the error output;
```py
from skopt import BayesSearchCV
# include below until https://github.com/scikit-optimize/scikit-optimize/issues/... | closed | 2019-07-04T08:19:16Z | 2020-01-20T20:00:17Z | https://github.com/scikit-optimize/scikit-optimize/issues/779 | [] | PyDataBlog | 8 |
piskvorky/gensim | machine-learning | 3,411 | Python11 can not install gensim, if it is possible, I wish Python11 can have the right version for gensim too | <!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/forum/#!forum/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that d... | closed | 2022-12-09T08:38:34Z | 2022-12-09T09:49:36Z | https://github.com/piskvorky/gensim/issues/3411 | [] | Victorrrrr86 | 2 |
sktime/pytorch-forecasting | pandas | 1,718 | Improving docs, examples, and tutorials of `pytorch-forecasting` | This list is a quick bucket list of items that can be potentially improved from what I've seen in the docs.
As requested by @yarnabrina, we should create simple examples, reducing complexity of the library as much as possible, to encourage users who are not too familiar with `pytorch-forecasting` or time series mac... | open | 2024-11-20T02:35:04Z | 2024-12-17T18:43:12Z | https://github.com/sktime/pytorch-forecasting/issues/1718 | [] | julian-fong | 6 |
numpy/numpy | numpy | 27,918 | BUG: eigh can't work when N = 45000 | ### Describe the issue:
When N is small, the error is very low;
When test N = 45000, the program end very fast and give wrong answer.
### Reproduce the code example:
```python
import numpy as np
def error_analysis(B, B_eigenvalue, B_eigenvector, N):
"""
Perform error analysis for eigenvalue decomposition... | open | 2024-12-06T14:01:02Z | 2024-12-06T21:51:30Z | https://github.com/numpy/numpy/issues/27918 | [
"00 - Bug"
] | werwrewe | 1 |
LAION-AI/Open-Assistant | machine-learning | 3,060 | Create a direct messaging system for the Dataset Collection dashboard | ### Problem Statement:
Currently, we are experiencing an influx of new users who are eager to contribute to our dataset collection. While these users have good intentions, we often receive messages that do not meet our quality standards. It is crucial to maintain the integrity of our dataset and prevent the inclusion ... | open | 2023-05-06T08:44:10Z | 2023-05-11T18:34:54Z | https://github.com/LAION-AI/Open-Assistant/issues/3060 | [
"feature",
"backend",
"website"
] | Subarasheese | 2 |
d2l-ai/d2l-en | machine-learning | 2,575 | Not able to render :begin_tab:toc | Hello I have installed all the dependencies but my notebook is not able to render markers like `:begin_tab:toc....:end_tab:`. | open | 2023-12-21T23:34:10Z | 2024-12-25T11:06:15Z | https://github.com/d2l-ai/d2l-en/issues/2575 | [] | roychowdhuryrohit-dev | 4 |
noirbizarre/flask-restplus | api | 424 | Swagger specification adds host name to basePath | I'm setting up my Flask application like so:
```
from flask import Flask
from flask_restplus import Api, Namespace
app = Flask(__name__)
app.config['SERVER_NAME'] = 'localhost:5000'
api = Api(app, prefix="/v0.1")
user_api = Namespace('users', description='User-related operations')
api.add_namespace(user_api... | open | 2018-04-29T19:27:47Z | 2018-04-29T19:33:32Z | https://github.com/noirbizarre/flask-restplus/issues/424 | [] | codethief | 0 |
HIT-SCIR/ltp | nlp | 562 | 在加载LTP模型时出现 Can't get attribute '_gpus_arg_default' on <module 'pytorch_lightning.utilities.argparse' | 所有的4.*版本都试过了,全部都有这个问题........
Can't get attribute '_gpus_arg_default' on <module 'pytorch_lightning.utilities.argparse' from '/data/user/conda/envs/pretrain/lib/python3.7/site-packages/pytorch_lightning/utilities/argparse.py'> | closed | 2022-04-06T07:34:06Z | 2022-09-11T10:14:24Z | https://github.com/HIT-SCIR/ltp/issues/562 | [] | Reuben-Yang | 1 |
litestar-org/litestar | api | 3,414 | Enhancement(Packaging): Add/Maintain Debian package | ### Summary
Add `python3-litestar` to the Debian repos by working with/joining the DBT and publishing the Litestar package for Debian and Debian derivatives
### Basic Example
_No response_
### Drawbacks and Impact
_No response_
### Unresolved questions
_No response_ | open | 2024-04-22T14:35:44Z | 2025-03-20T15:54:37Z | https://github.com/litestar-org/litestar/issues/3414 | [
"Enhancement",
"Upstream",
"Infrastructure",
"Package"
] | JacobCoffee | 1 |
flasgger/flasgger | rest-api | 47 | Authorization Header + UI input view | Anyone can help me with how to implement custom headers e.g. "Authorization header" in requests + adding UI element for it with flasgger?
I need to use JWT with some of the endpoints.
I was able to achieve this by modifying flasgger source code, but that shouldn't be the way! | open | 2017-01-01T15:56:58Z | 2023-10-08T06:27:20Z | https://github.com/flasgger/flasgger/issues/47 | [
"enhancement",
"help wanted",
"hacktoberfest"
] | saeid | 4 |
jmcnamara/XlsxWriter | pandas | 757 | Issue with inserting an image into the cell (not on top of it) | Hi,
I am using XlsxWriter to do generate a file where each row represents an Artwork and first column always displays a thumbnail of the work. I am using `insert_image` method to insert the thumb but it appears floating on top of the cell instead of being within the cell.
I am using Python version 3.7.7 and XlsxW... | closed | 2020-10-29T19:07:09Z | 2022-06-25T16:19:05Z | https://github.com/jmcnamara/XlsxWriter/issues/757 | [
"question",
"awaiting user feedback"
] | striveforbest | 6 |
graphql-python/graphene | graphql | 729 | A new way to write ObjectType with python3's annotation | _This issue is a **feature discussion**._
For now, the way to write a ObjectType is as below:
```Python
class Hero(ObjectType):
name = Field(List(String), only_first_name=Boolean())
age = Int()
def resolve_name(self, info, only_first_name=False):
if only_first_name:
return ... | closed | 2018-05-20T15:12:32Z | 2023-07-26T07:50:13Z | https://github.com/graphql-python/graphene/issues/729 | [
"✨ enhancement"
] | ocavue | 29 |
yezyilomo/django-restql | graphql | 303 | Is it possible to exclude fields by default? | Is it possible to exclude fields by default? I have a serializer with a serialized field with a lot of data. This data will be used in some specific cases, but not always.
```python
class BookSerializer(DynamicFieldsMixin, serializer.ModelSerializer):
....
class Meta:
model = Book
fiel... | open | 2022-03-18T21:10:31Z | 2023-12-06T17:01:35Z | https://github.com/yezyilomo/django-restql/issues/303 | [] | Alejandroid17 | 2 |
collerek/ormar | sqlalchemy | 358 | Allow ignoring extra fields in ormar Model | Hi!
I've been trying to set up a demo app to get familiar with ormar - everything has been going very good so far, so thanks a lot for creating this 👏
I just ran into something confusing that I'm not sure is a bug or intended behaviour:
### Issue
when sending in an empty field name (`"": None`} in a req... | closed | 2021-09-26T10:44:57Z | 2021-09-26T12:28:02Z | https://github.com/collerek/ormar/issues/358 | [
"enhancement"
] | collerek | 1 |
Anjok07/ultimatevocalremovergui | pytorch | 615 | An error occurred with VR Architecture | Sometimes it occurs, sometimes it doesn’t.
Last Error Received:
Process: VR Architecture
If this error persists, please contact the developers with the error details.
Raw Error Details:
ParameterError: "Audio buffer is not finite everywhere"
Traceback Error: "
File "UVR.py", line 4716, in process_sta... | open | 2023-06-14T13:25:00Z | 2023-06-14T13:25:00Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/615 | [] | kmsmdn | 0 |
modelscope/data-juicer | data-visualization | 490 | Merge local and API LLM calling | ### Search before continuing 先搜索,再继续
- [X] I have searched the Data-Juicer issues and found no similar feature requests. 我已经搜索了 Data-Juicer 的 issue 列表但是没有发现类似的功能需求。
### Description 描述
目前API LLM相关算子可能还需要支持一下vllm或hugging face调用本地开源LLM。这里改动涉及:
1. Prepare model接口的统一
2. 不同接口的response需要一个统一的解析函数
### Use case 使用场景
_... | closed | 2024-11-15T08:49:57Z | 2024-12-31T08:52:52Z | https://github.com/modelscope/data-juicer/issues/490 | [
"enhancement"
] | BeachWang | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.