
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Синглтон (Перевод с английского главы «Singleton» из книги «Pro Objective-C Design Patterns for iOS» Carlo Chung)
В математике и логике синглтон определяется как «множество, содержащее ровно один элемент». Поэтому неважно, насколько велика сумка, каждый раз при попытке достать из неё шарик будем получать один и тот ... | https://habr.com/ru/post/198470/ | null | ru | null |
# Drupal: ajax_facets и history API
Наверное, каждый веб разработчик сталкивался с необходимостью в реализации поиска на сайте. Довольно распространенное решение — Apache Solr. В мире Drupal разработки это не исключение. Для и... | https://habr.com/ru/post/283282/ | null | ru | null |
# ORM для Sitecore своими руками
Здравствуйте хабровчане.

Sitecore мало освещается на хабре, однако это очень функциональная (и дорогая) CMS довольно популярна у тех, кто может её себе позволить. Вместе с тем,... | https://habr.com/ru/post/154313/ | null | ru | null |
# Реализуем визуальный эффект из фильма «Матрица»

Доброго времени суток, друзья!
На днях пересмотрел «Матрицу». Слушайте, до чего же классный фильм (это касается только первой части). В очередной раз обратил внимание на «падающ... | https://habr.com/ru/post/485404/ | null | ru | null |
# Рисуем светом: длинная выдержка на Android
*Всем привет, меня зовут Дмитрий, и я Android-разработчик в компании «MEL Science». Сегодня я хочу рассказать, как можно реализовать поддержку длинной выдержки на смартфонах, да так, чтобы получающуюся картинку можно было наблюдать прямо в процессе создания. А для заинтерес... | https://habr.com/ru/post/558728/ | null | ru | null |
# Манифест Чистого Программиста или краткий конспект книги «Чистый Код» Роберта Мартина
Данная статья является конспектом книги "Чистый Код" Роберта Мартина и моим пониманием того, каким Чистый Код должен быть. Тут нет разделов о тестировании, TDD, о том какая должна быть архитектура и т.д. Здесь все только о том, как... | https://habr.com/ru/post/424051/ | null | ru | null |
# Выбор правильной стратегии обработки ошибок (части 3 и 4)

Части 1 и 2: [ссылка](https://habrahabr.ru/company/mailru/blog/322416/)
В первой части мы поговорили о разных стратегиях обработки ошибок и о том, когда их ре... | https://habr.com/ru/post/322804/ | null | ru | null |
# Как не мусорить в Java
Существует популярное заблуждение о том, что если не нравится garbage collection, то надо писать не на Java, а на C/C++. Последние три года я занимался написанием low latency кода на Java для торговли валютой, и мне приходилось всячески избегать создания лишних объектов. В итоге я сформулирова... | https://habr.com/ru/post/436024/ | null | ru | null |
# Визуализация модели данных
Для django есть хорошая утилитка, которая анализирует описание модели данных и рисует её графическое представление в dot-формате graphviz.
Сегодня [переписал эту утилитку под appengine](http://code.google.com/p/appengine-modelviz/).
[ я рассказал о подготовке данных для тестирования, что данные лучше генерировать, а не клонировать. Теперь стоит подробно разобрать, как их генерировать. Есть нескол... | https://habr.com/ru/post/589543/ | null | ru | null |
# Emacs таинственный: Путешествие в калькулятор
*Ничто так не скрыто от нас, как то, что лежит на поверхности.
Сунь Цзы и Чжугэ Лян (вольный перевод)*
Предисловие
===========
Случилось сие в одном из роликов на YouT... | https://habr.com/ru/post/279853/ | null | ru | null |
# Не используйте Illuminate Support
**tl;dr**: Если Вы пишете framework agnostic пакет, не используйте [illuminate/support](https://github.com/illuminate/support).

*Перевод статьи Метта Аллана (Matt Allan) "[Don't Us... | https://habr.com/ru/post/308166/ | null | ru | null |
# Решение задачи нахождения углов установки видеокамеры над дорогой разными методами в Wolfram Mathematica. Часть 2
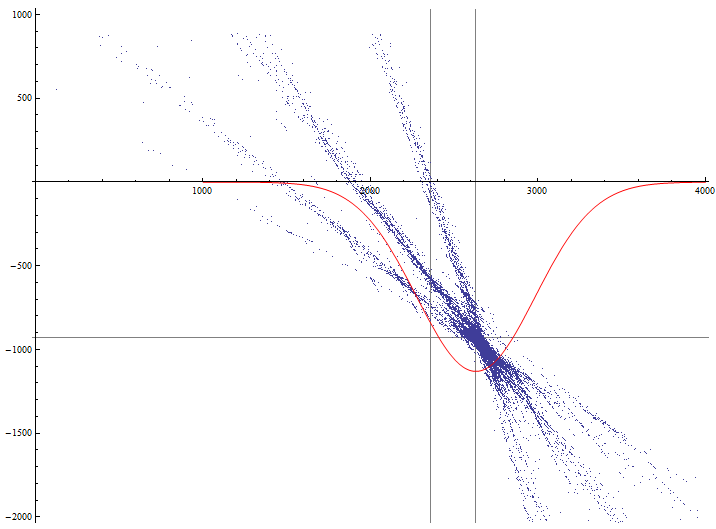
В прошлый раз мы загрузили данные из файла, разобрали их в структуру, получили уравнения треков движения ... | https://habr.com/ru/post/176301/ | null | ru | null |
# Визуализация атак на базе ELK (elasticsearch, kibana, logstash)
Доброго времени суток. В процессе обслуживания большого количества серверов возникает необходимость централизации управления всем зоопарком машин, а так же централизованный сбор логов и аналитика логов на предмет выявления аномалий, ошибок и общей стати... | https://habr.com/ru/post/324760/ | null | ru | null |
# Скрестить ежа (Marathon) с ужом (Spring Cloud). Эпизод 2
В [первом эпизоде](https://habrahabr.ru/post/325714/) у нас получилось вытянуть информацию из **Mesos Marathon** прямиком в бины **Spring Cloud**-а. Вместе с тем у нас появились первые проблемы, одну из которых мы разберём в текущей части повествования. Давайт... | https://habr.com/ru/post/327937/ | null | ru | null |
# И снова про 1С

Последнее время на Хабре стали все чаще появляться статьи, посвященные 1С как *среде разработки приложений*. Статьи по смыслу более концептуальные, чем прикладные; авторы делают обзор платформы «1C:Пре... | https://habr.com/ru/post/267321/ | null | ru | null |
# Процессоры ARM? Практика. Marvel Armada XP
 Прежде всего хочу выразить благодарность компании Rikor и Олегу лично за предоставленные платформы для тестирования. По прежнему вы можете [взять на тест Marvell A... | https://habr.com/ru/post/213819/ | null | ru | null |
# Пишем замену find(1) на golang под Linux
 Для одной внутренней утилиты мне понадобилось написать сканирование изменений в директории, по аналогии с утилитой find, и я столкнулся с неожиданной вещью: стандартный Open()+Readdir... | https://habr.com/ru/post/281382/ | null | ru | null |
# Как изменить имя шрифта
Нечасто, но регулярно у людей возникает вопрос — **как изменить имя шрифта**. Не файла со шрифтом (тут хитрости нет), а самого шрифта. Имя, которое будет показываться в диалоге шрифтов текстовых процессоров после установки данного.
Я столкнулся с этой проблемой следующим образом. Требовало... | https://habr.com/ru/post/255187/ | null | ru | null |
# NFC приходит в web
Эта статья — перевод оригинальной статьи "[NFC comes to the web](https://cxlabs.sap.com/2021/07/27/nfc-comes-to-the-web/)".
Также я веду телеграм канал “[Frontend по-флотски](https://t.me/frontend_pasta)”, где рассказываю про интересные вещи из мира разработки интерфейсов.
Вступление
----------
... | https://habr.com/ru/post/570954/ | null | ru | null |
# «Программирование мышкой» в XCode 6 для Swift
Привет, Хабрахабр!
По причине недавно возникшей необходимости, пришлось писать под iOS, и я заметил сильную нехватку гайдов на русском языке даже для элементарных действий вроде «прицепить к нажатию кнопки какое-то действие», «считать данные из текстового окошка». Ста... | https://habr.com/ru/post/242277/ | null | ru | null |
# Микробаш
Рассказ о том, зачем и как я сделал для себя [робота](http://twitter.com/#!/microbash), который публикует микроцитаты с [bash.org.ru](http://bash.org.ru/), полностью влезающие в твит. А также о том, как я буду его развивать, если топик на хабре возымеет эффект, и количество подписчиков даст понять, что это ... | https://habr.com/ru/post/125154/ | null | ru | null |
# Создаем аватарки с помощью нейросети Stable Diffusion и DreamBooth
"Портрет, сделанный нейросетью" - все чаще читаем в новостной ленте, и каждый хотел бы сделать себе подобный, но удобные сервисы, просящие монету, или желание разбираться самому, отталкивают. Не нужно ничего скачивать. Час времени и каждый сможет сде... | https://habr.com/ru/post/704758/ | null | ru | null |
# Знакомство с FPGA iCE40 UltraPlus Mobile Development Platform от фирмы Lattice Semiconductor
#### Введение
Всем доброго времени суток, друзья! Недавно на работе обзавелись новенькой навороченной платой iCE40 UltraPlus Mobile Development Platform от фирмы Lattice Semiconductor. Со слов разработчиков на официальном с... | https://habr.com/ru/post/512830/ | null | ru | null |
# Meshname – DNS судного дня
Параноики есть в каждом сообществе. Например, туристы порой превращаются в выживальщиков, постоянно готовящихся к БП – «Большому Происшествию», когда от их готовности будет зависеть жизнь родных, человечества в целом, и сохранность себя родимого. Нельзя однозначно заявить плохо это или хор... | https://habr.com/ru/post/550688/ | null | ru | null |
# Машинка на контроллере с .NET Micro Framework, управляемая акселерометром Android-устройства

Простой проект с описанием изготовления 4WD машинки с управлением от Android-устройства через Bluetooth канал. Управлен... | https://habr.com/ru/post/168723/ | null | ru | null |
# Обработка 40 ТБ кода из 10 млн проектов на выделенном сервере с Go за $100
Написанной мной инструмент командной строки [Sloc Cloc and Code (scc)](https://github.com/boyter/scc/), который теперь доработан и поддерживается многими отличными людьми, подсчитывает строки кода, комментарии и оценивает сложность файлов вну... | https://habr.com/ru/post/470852/ | null | ru | null |
# Игры с локализацией
В связи с выходом локализированной версии Visual Studio 2010 и публикацией нескольких статей на хабре на эту тематику, возникло желание посмотреть лично, что же это за зверь такой — русская версия Visual Studio 2010! Поэтому я пошел на сайт Microsoft и загрузил пробную версию VS2010 и началось… ... | https://habr.com/ru/post/98582/ | null | ru | null |
# Переход с bash на zsh
Чтобы перейти с bash на zsh необходимо знать базовые отличия между ними — без этого будет сложно провести первоначальную настройку zsh в `~/.zshrc`.
Я не нашёл краткого описания этих отличий когда переходил сам, и мне пришлось потратить немало времени на вычитывание документации zsh. Надеюсь, ... | https://habr.com/ru/post/326580/ | null | ru | null |
# Инициализация Rx цепочки
Всем привет, меня зовут Иван, я Android-разработчик. Сегодня хочу поделиться своим опытом работы с RxJava2 и рассказать, как происходит инициализация цепочки. Почему я вообще решил поднять эту тему? Пообщавшись со знакомыми разработчиками, я понял, что не каждый кто использует этот инструмен... | https://habr.com/ru/post/560162/ | null | ru | null |
# Totum — open source конструктор CRM/ERP и произвольных учетных систем (PHP + PgSQL)

В двух словах — продвинутые таблицы. Ориентирован на отдельных разработчиков или микрокоманды из двух-трех человек. Подходит начинающим разработчика... | https://habr.com/ru/post/511162/ | null | ru | null |
# Вышел GitLab 11.6 с бессерверными функциями и кластерами Kubernetes для групп

Мы рады представить релиз GitLab 11.6, в котором мы расширили возможности бессерверной архите... | https://habr.com/ru/post/435550/ | null | ru | null |
# Борьба с тридцатилетним багом
*В первой редакции говорилось о двадцатилетнем баге. На самом деле ему 30 лет. Спасибо [Sidnekin](https://twitter.com/Sidhekin/status/391160990873571329).*
Сегодня, считывая какие-то данные, моя программа обработала 36'916 возможных дат. Две из этих 36'916 не прошли проверку. Я не п... | https://habr.com/ru/post/198174/ | null | ru | null |
# How WCF Shoots Itself in the Foot With TraceSource
We don't often get the chance to write something on parallel programming issues. This time we "got lucky". The TraceEvent standard method has some implementation peculiarities. They resulted in an error with multiple threads blocking. So we'd like to warn users abou... | https://habr.com/ru/post/563828/ | null | en | null |
# Черные ходы Касперского 6/7
Перевод статьи с сайта rootkit.com

**Преамбула**
Антивирус Касперского — один из наиболее технически развитых антивирусов на сегодняшний день. Он даже может бороться с н... | https://habr.com/ru/post/16037/ | null | ru | null |
# Atomic Swaps In A Nutshell
Состоянием на июль 2019 года существует порядка 2000 криптовалют, однако единого механизма обмена между разными блокчейнами нет. В этой статье мы упрощенно рассмотрим как устроена одна из технологий обмена без посредников — атомарные обмены (atomic swaps).
Приятного чтения!

В процессе эволюции более-менее крупного проекта может настать ситуация, когда количество запланированных задач (cron jobs) становится настолько большим, что поддержка их становится ночным кош... | https://habr.com/ru/post/345802/ | null | ru | null |
# Настройка squid или как не купить платное решение

Всем привет!
Часто в организациях используем разного рода прокси, прокси как составляющая программного шлюза или самостоятельный классический вар... | https://habr.com/ru/post/347212/ | null | ru | null |
# Forgotten attachment detector — не фича, а важный функционал
Сегодня, после нажатия на кнопку Send, Gmail показал мне сообщение:

А я, действительно, забыл прикрепить файл :)
Я был очень п... | https://habr.com/ru/post/104613/ | null | ru | null |
# Fancy Euclid's “Elements” in TeX

In 2016, I came across Oliver Byrne's [“The first six books of the Elements of Euclid.”](https://archive.org/details/firstsixbooksofe00byrn/) The main feature of this book is that instead of ordi... | https://habr.com/ru/post/452520/ | null | en | null |
# Единый API на РНР для всех облачных push-сервисов
Приветствую всех читателей. Сейчас в веб-разработках столько трендов, что не уследишь. Но вопрос о реал-тайм взаимодействии с пользователями сайта стоит остро прочти для любого проекта. Простейший способ — поставить один из широко доступных открытых comet-серверов, н... | https://habr.com/ru/post/136230/ | null | ru | null |
# Как добавить help desk в ваш трекер YouTrack
На Хабре несколько месяцев назад [обсуждалось](http://habrahabr.ru/post/198754/), что нет идеального трекера — такого, чтобы он подошел хорошо и разработчику, и заказчику. В частности, упоминалось, что трекеру нужен **help desk**. В YouTrack начиная с версии 5.1 он есть, ... | https://habr.com/ru/post/222673/ | null | ru | null |
# Прокачка ASUS WL 500G Premium
На Хабре уже было пару статей, о весьма неплохом роутере WL 500G Premium от ASUS.
В устройстве заложен неплохой потенциал – довольно шустрый процессор BCM4704 фирмы Broadcom, 32 Мб оперативной памяти, наличие двух портов USB (хоть и с не высокой пропускной способностью). Подкачал ... | https://habr.com/ru/post/85128/ | null | ru | null |
# Срочно обновляем RVM (Ruby Version Manager)
Совсем недавно во многих ruby-блогах, сообществах, да и [на хабре](http://habrahabr.ru/post/160371/), было написано немало постов о том что RVM дурно влияет на производительность MRI-версии ruby (официальный интерпретатор языка) по причине того что установщик не учитывает ... | https://habr.com/ru/post/162533/ | null | ru | null |
# User Defined Type. Что это и как его использовать, часть 2
Source: https://www.meme-arsen... | https://habr.com/ru/post/711222/ | null | ru | null |
# Кулинарные хитрости, часть первая (Chef)
После недавней [вводной публикации о Chef](http://habrahabr.ru/company/scalaxy/blog/87302/) я решил немного больше рассказать о полезных рецептах:
[](https://habrastorage.or... | https://habr.com/ru/post/87324/ | null | ru | null |
# Создаем первое приложение на NancyFX. Часть пятая. Super Simple View Engine
В предыдущей статье [Создаем первое приложение на NancyFX. Часть четвертая. Продолжаем работу с модулями](http://habrahabr.ru/post/200632/) мы продолжали изучение модулей. В данной статье мы изучим идущий с Nancy из коробки графический движо... | https://habr.com/ru/post/201490/ | null | ru | null |
# Четвёртый бесплатный УЦ как альтернатива Let's Encrypt
Как известно, [Let's Encrypt](https://letsencrypt.org/) — не единственный удостоверяющий центр, который автоматически выдаёт бесплатные сертификаты TLS по протоколу ACME. Кроме не... | https://habr.com/ru/post/571368/ | null | ru | null |
# Айтишный сувенир на память своими руками
[](http://lh4.googleusercontent.com/_iGuWqh3W4uo/TbwQIysoNKI/AAAAAAAAFlg/CmUdfslHGlg/DSC_0131.jpg)Что скрывать, все мы любим получить и дел... | https://habr.com/ru/post/118451/ | null | ru | null |
# Подготовка приложения для Istio

Istio — это удобный инструмент для соединения, защиты и мониторинга распределенных приложений. В Istio используются разные технологии для масштабного запуска ПО и управления им, включая контейнеры д... | https://habr.com/ru/post/469515/ | null | ru | null |
# AngularJS: еще одна таблица с сортировкой, фильтрацией и постраничной навигацией
#### Что это?
Это очередное AngularJS приложение, которое добавляет в обычную таблицу возможности сортировки, фильтрации, разбиения на страницы и пр.
Разумеется, существует несколько готовых решений ([1](http://lorenzofox3.github.io... | https://habr.com/ru/post/197646/ | null | ru | null |
# Arduino — микромощный передатчик радиовещательного АМ-диапазона

У многих еще остались радиоприёмники с диапазонами СВ и ДВ, и радиолюбительский интерес к приёму в этих диапазонах также по-прежнему сохраняется. На средних волн... | https://habr.com/ru/post/415333/ | null | ru | null |
# Как дебажить запросы, используя только Spark UI
> *Егор Матешук (CDO AdTech-компании Квант и преподаватель в OTUS) приглашает Data Engineer'ов принять участие в бесплатном Demo-уроке* [*«Spark 3.0: что нового?»*](https://otus.pw/c3nU/)*. Узнаете, за счет чего Spark 3.0 добивается высокой производительности, а также ... | https://habr.com/ru/post/526892/ | null | ru | null |
# PowerShell Web Access: конфигурирование

Продолжаем знакомиться с [**Powershell Web Access**](http://technet.microsoft.com/ru-ru/library/hh831611.aspx) (PSWA).
В [предыдущей статье](http://habrahabr.ru/company/netw... | https://habr.com/ru/post/165227/ | null | ru | null |
# Nginx + серверный Javascript
#### … или как перейти с PHP + JavaScript на JavaScript + JavaScript
Идея реализовать проект на сервер-сайд JavaScript была уже давно. Проблема была в отсутствии подходящего серверного программного обеспечения. Существующие открытые проекты не устраивали по разным причинам. Устанавливат... | https://habr.com/ru/post/82511/ | null | ru | null |
# Создание рейтинга игроков для мобильной игры (Unity + Google Play Game Services)
Рейтинг игроков (leaderboard, scores) для мобильной игры — вещь интересная и порой даже необходимая. В этой статье я расскажу о том, как добавить рейтинг игроков в приложение, созданное в Unity, т.к. в рунете информации об этом не так м... | https://habr.com/ru/post/227361/ | null | ru | null |
# CEF, ES6, Angular 2, TypeScript использование классов .Net Core. Создание кроссплатформенного GUI для .Net с помощью CEF
Меня все спрашивают — «Зачем это нужно?». На что, я гордо отвечаю — «Я в 1С использую для доступа к торговому оборудованию, к Вэб-сервисам по ws-протоколам, готовым компонентам. [1С, Linux, Excel,... | https://habr.com/ru/post/320960/ | null | ru | null |
# Работа с растром на низком уровне для начинающих
Поводом для данной статьи стал следующий пост: [«Конвертация bmp изображения в матрицу и обратно для дальнейшей обработки»](http://habrahabr.ru/post/195344/). В свое время,... | https://habr.com/ru/post/196578/ | null | ru | null |
# Облачные сервисы Amazon и анализ инвестиционного портфеля
В последнее время на фондовых рынках наблюдается высокая волатильность, когда, например, стабильная бумага известной компании может враз потерять сразу несколько процентов на новостях о санкциях против ее руководства или наоборот взлететь до небес на позитивн... | https://habr.com/ru/post/426027/ | null | ru | null |
# Взаимные блокировки и внешние ключи в SQL Server
### Введение
В реляционных базах данных внешние ключи (foreign key) используются для обеспечения целостности связей между таблицами. Простыми словами, внешн... | https://habr.com/ru/post/572106/ | null | ru | null |
# Как я делал веб-версию KeePass
Как-то мне надо было добавить в админку просмотр списка паролей. База хранилась на сервере в формате KeePass (kdbx v2), сервер был на ноде — недолго думая, я взял первый попавшийся пакет и сделал. А потом понадобилось то же самое, но прямо у пользователя в браузере, без сервера. Ничего... | https://habr.com/ru/post/269895/ | null | ru | null |
# Релиз InfluxDB 0.9
[](/post/262565/)
Удивительно, но об этой подающей большие надежды Time Series DB довольно мало статей на хабре, всего 10, причём она упоминается там вскользь. А ведь версия 0.9 вышла довольно давно... | https://habr.com/ru/post/262565/ | null | ru | null |
# Реализация пошаговой работы PHP-скрипта с помощью AJAX
Искал более-менее простое и универсальное средство для организации пошаговой работы скрипта, но так ничего и не нашел. Даже [вопрос в QA задал](http://habrahabr.ru/qa/25101/), везде только общие фразы. Поэтому решил сам сделать такой инструмент.
Для чего это ... | https://habr.com/ru/post/153731/ | null | ru | null |
# Как вырастить из студента инженера-программиста?
Привет! Меня зовут Денис Довженко, и я уже несколько лет провожу технические собеседования с кандидатами на позиции инженера-программиста C/C++. Если с кандидатами на позиции Senior SW Engineer и выше основной разговор ведётся об опыте работы, то отбор будущих интерно... | https://habr.com/ru/post/497392/ | null | ru | null |
# Из гусеницы в разработчика: каков был мой путь в программирование
Всем привет! Меня зовут Наташа, я работаю фронтенд-разработчиком в отделе внутренней автоматизации в ГНИВЦ. Пишу эту статью, чтобы познакоми... | https://habr.com/ru/post/679804/ | null | ru | null |
# Найм персонала: О важности примитивных вопросов
Вам приходилось бывать на долгих собеседованиях? На многоуровневых собеседованиях? А может вы такие проводите сами? Многие компании ведут подобную практику, и большие и маленькие, но подобная практика имеет ряд очевидных минусов. Таких, как впустую потраченое время на ... | https://habr.com/ru/post/285328/ | null | ru | null |
# Программа вывода лабиринта в 13… нет. 10 байт!
В прошлом, найдя интересное решение при написании демки, я тихо его использовал или же хвастался узкому кругу друзей на демосцене. Но теперь мои возможности достигнуть чего-либо на демосцене подошли к концу, а турниры по минималистскому программированию не проводятся, п... | https://habr.com/ru/post/251631/ | null | ru | null |
# Интересная задачка: повышаем стабильность (robustness) приложений (ч. 2)
Итак, привожу решение проблемы из топика [habrahabr.ru/blogs/net/69545](http://habrahabr.ru/blogs/net/69545/) — про гарантированное освобождение неуправляемого ресурса.
Как правильно заметил товарищ [adontz](https://geektimes.ru/users/adontz... | https://habr.com/ru/post/69650/ | null | ru | null |
# Руководство по поиску работы для MDA-специалиста (и немного про метод анализа иерархий, Xcore и Sirius)

Это 4-я статья цикла по разработке, управляемой моделями. В предыдущих статьях мы познакомились с [OCL и метамоделям... | https://habr.com/ru/post/269291/ | null | ru | null |
# Оповещение в Telegram и Slack в режиме реального времени. Или как сделать Alert в Splunk — Часть 2
Мы продолжаем тему алертинга в Splunk. Ранее мы говорили о том, как настроить отправку оповещений [на электронную почту](https://habrahabr.ru/company/tssolution/blog/351038/), а сегодня покажем Вам, как отправлять увед... | https://habr.com/ru/post/351798/ | null | ru | null |
# Go: распространенные антипаттерны
Программирование — это искусство. Мастера своего дела, создающие потрясающие работы, могут ими гордиться. То же самое относится и к программистам, которые пишут код. Чтобы достичь вершин мастерства, творцы постоянно ищут новые подходы к работе и новые инструменты.
Так поступают ... | https://habr.com/ru/post/551032/ | null | ru | null |
# Создание полноценного Viberbot. Часть вторая — первый контакт или «сonversation_started»
### Отправка первого сообщения пользователю — приветствуем и подписываем
В [первой части](https://habr.com/ru/post/486826/) мы научились ~~запускать стартер~~ устанавливать webhook для нашего проекта botviber.
В этой 2-й мы ... | https://habr.com/ru/post/486858/ | null | ru | null |
# CSS-маски для hover-эффекта

На многих сайтах-портфолио работы представлены в виде небольших картинок-миниатюр с приятными hover-эффектами. В этой статье будет рассказано о способе сделать такой эффект, используя CSS-м... | https://habr.com/ru/post/164409/ | null | ru | null |
# Виртуальная примерочная в OpenCV
Было ли у вас такое, что в интернет-магазине понравилась какая-нибудь вещь, но не хочется покупать ее, не примерив? Конечно, в некоторых магазинах есть возможность примерить одежду после заказа перед оплатой. Однако по статистике каждый год доля онлайн-заказов в интернет-магазинах од... | https://habr.com/ru/post/489906/ | null | ru | null |
# Определение MIME-типов
Привет, хабр!
Недавно задался вопросом а сколько байт необходимо для корректного определения mime типа файла. В первую очередь погуглив, полученными ответами не удовлетворился и поэтому решил сам провести маленькое исследование на эту тему.
На изучение данного вопроса меня натолкнула сле... | https://habr.com/ru/post/186828/ | null | ru | null |
# Нюансы и алгоритмы программирования движка для маркетинговых онлайн-исследований
Доброго времени суток, уважаемые хабравчане. Давно меня подмывало написать подобный мануал, и вот, решил таки себя заставить сесть и написать его — поделиться некоторым опытом, который получил во время своих программистских изысканий в ... | https://habr.com/ru/post/96343/ | null | ru | null |
# Логическая репликация между версиями PostgreSQL

Есть разные подходы к обновлению PostgreSQL, но некоторые приводят к простою приложения. Если нужно избежать простоя, используйте для обновления репликацию — логическую или физическую ... | https://habr.com/ru/post/457512/ | null | ru | null |
# Управление состоянием приложения с RxJS/Immer как простая альтернатива Redux/MobX
> "Вы поймете, когда вам нужен Flux. Если вы не уверены, что вам это нужно, вам это не нужно." Пит Хант

Для управления состоянием приложения я как... | https://habr.com/ru/post/483526/ | null | ru | null |
# Приложение 3.х на устройстве 2.х
Как вам наверно извесно, счастливые обладатели iPod Touch не спешат с обновлением своей игрушки до последней версии. Толи религия не позволяет. Толи потому что обновление платное. Вобщем причина не так важна. Для нас програмистов это выливается в требования вида «Хочу чтобы, поставив... | https://habr.com/ru/post/73882/ | null | ru | null |
# South — новый клёвый syncdb
Я совсем недавно начал работать с Django и меня практически сразу же взбесила ущербная команда syncdb, которая ничего толком не синхронизирует, умеет лишь создавать таблицы для новых моделей.
А добавление или удаление полей в уже существующие модели превращается в настоящий pain in ass... | https://habr.com/ru/post/47004/ | null | ru | null |
# mocap на коленке (Skeletal Animations 2)
12 мая 2007 года Jochen Diehl опубликовал очень интересную статью [«Skeletal Animations»](http://www.gotoandplay.it/_articles/2007/04/skeletal_animation.php#).
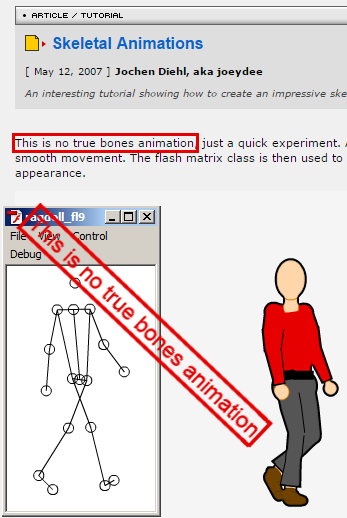
**Вкратце изложу... | https://habr.com/ru/post/238049/ | null | ru | null |
# Планарий. 10 000 заданий.
[](http://planary.ru) Вот мы и дожили до первого маленького юбилея — на проекте было создано 10-тысячное задание.
Мы решили не сидеть сложа руки и, в честь столь знаменательного события, обновиться.
##### Внешний вид
Мы ... | https://habr.com/ru/post/52453/ | null | ru | null |
# Метеостанция на прокачку. Добавим к Ардуине SD карту
Мой [предыдущий пост](http://habrahabr.ru/post/241913/) о процессе создания метеостанции на ардуине вызвал положительную реакцию, поэтому я хочу продолжить тему. Представляю вам следующий видео урок где будет рассказано как подключить к ардуинке SD катру, записать... | https://habr.com/ru/post/242045/ | null | ru | null |
# gentoo: миграция с eudev на mdev
Если вы используете gentoo и отслеживаете уведомления о грядущих изменениях, то еще в июле вы могли видеть, что с нового года gentoo перестает поддерживать eudev. Если вы попытаетесь обновить систему сейчас, вы увидите
```
!!! The following installed packages are masked:
- sys-fs/eu... | https://habr.com/ru/post/592887/ | null | ru | null |
# Город и данные: анализ пешеходной доступности объектов в Праге с помощью data science

Несколько лет назад компания Veeam открыла R&D центр в Праге. Изначально у нас был небольшой офис примерно на 40 человек, но компания активно раст... | https://habr.com/ru/post/491600/ | null | ru | null |
# Компиляция Try/Catch/Finally для JVM
#### Вместо введения
Автор статьи, Alan Keefer[1](#1), является главным архитектором компании Guidewire Software[2](#2), разрабатывающей программное обеспечение для страхового бизнеса. Еще будучи старшим разработчиком, он участвовал в работе над языком Gosu[3](#3). В частности, ... | https://habr.com/ru/post/212759/ | null | ru | null |
# Self-Sovereign Identity + smart-contracts, дешево и сердито
Смарт-контракты и идентификация пользователей
---------------------------------------------
Простота и доступность этого паттерна позволяет использовать для авторизации пользователей почти любой блокчейн, даже самый простой, так как абсолютно любой блокчей... | https://habr.com/ru/post/564856/ | null | ru | null |
# Ардуированная кофемашина

Я люблю делать простые как топор вещи, но одновременно жутко полезные, например, как прошлая статья 9 летней давности — [Установка Ubuntu Linux с винчестера. Скрипт](https://habrahabr.ru/post/67192/),... | https://habr.com/ru/post/350358/ | null | ru | null |
# Процедурная генерация 3D миров в Godot Engine при помощи GPU. Часть 1
Пример сгенерированного ландшафта Вступление
----------
Привет!
... | https://habr.com/ru/post/571626/ | null | ru | null |
# Как перестать бояться и полюбить end-to-end шифрование

Привет, Хабр!
В комментариях к нашему первому посту народ требовал ~~хлеба и зрелищ~~ кода и [«success story»](https://habrahabr.ru/company/virgilsecurity/blog/28... | https://habr.com/ru/post/301772/ | null | ru | null |
# Изучаем троянскую повестку с мимикрией под XDSpy
В ходе постоянного отслеживания угроз ИБ утром, 3 октября, в одном из Telegram-чатов мы заметили промелькнувший файл со злободневным названием **Povestka\_26-09-2022.wsf**. Беглый осмотр содержимого привлек наше внимание, и мы решили разобрать его подробней. И, как ок... | https://habr.com/ru/post/692546/ | null | ru | null |
# Как мы в IntelliJ IDEA ищем лямбда-выражения
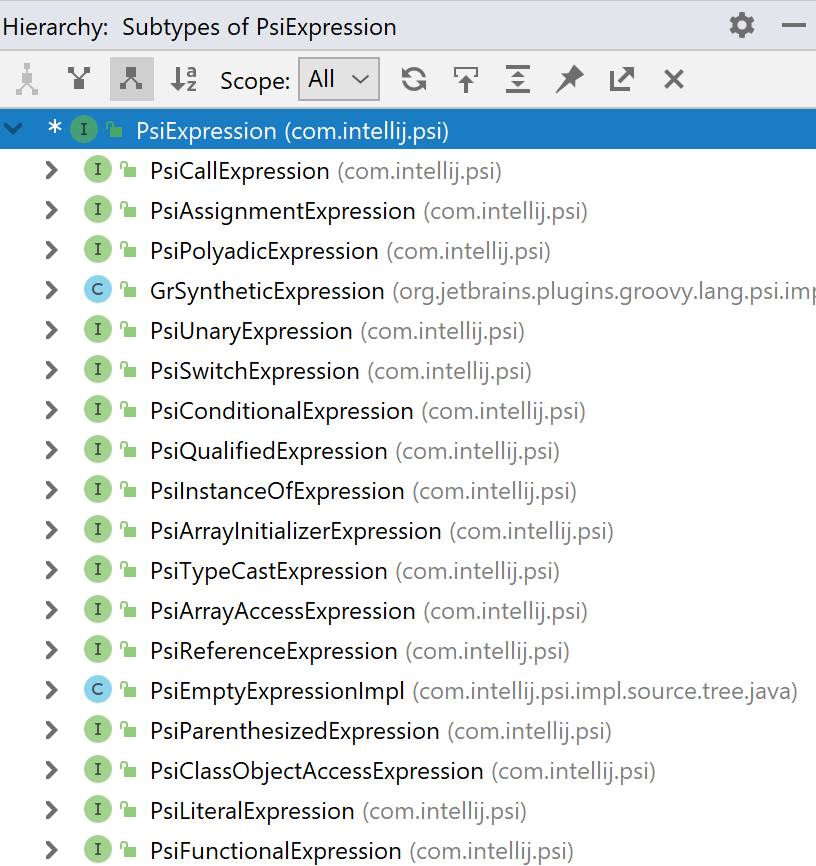Важной возможностью любой IDE является поиск и навигация по коду. Один из часто используемых вариантов поиска на языке Java — поиск всех реализаций данного инт... | https://habr.com/ru/post/444052/ | null | ru | null |
# Как мы оптимизировали наш DNS-сервер с помощью инструментов GO
*В преддверии старта нового потока по курсу [«Разработчик Golang»](https://otus.pw/MA66/) подготовили перевод интересного материала.*

---
Наш [авторитативный DNS-с... | https://habr.com/ru/post/487934/ | null | ru | null |
# Дверной замок. RFID
#### Вступление
Доброго времени суток! Параллельно моей предыдущей [статье](http://habrahabr.ru/post/231461/) я работал еще над одним «проектом». Собственно у меня завалялось пару китайских RFID читалок. Вот таких:
##### Фото RC522
 варианта изменения текста уведомления приложения, отправкой дополнительных данных через UNUserNotificationCenter.
Я надеюсь эта статья будет полезна ... | https://habr.com/ru/post/451454/ | null | ru | null |
# Синглтоны версии 5.3 в 5.2
#### Задача
В общем, сложилась такая ситуация, что на предоставленном для проекта хостинге, версия PHP была 5.2, а сам проект написан под 5.3. Наверняка все, кто работает с PHP, знают, что в версии 5.3 появилась возможность доступа к имени класса, полученного с помощью позднего статическо... | https://habr.com/ru/post/134221/ | null | ru | null |
# Мега-Учебник Flask Глава 1: Привет, мир! ( издание 2018 )
[blog.miguelgrinberg.com](http://blog.miguelgrinberg.com "blog.miguelgrinberg.com")
### *Miguel Grinberg*
---
[>>> следующая глава >>>](https://habrahabr.ru/post/346340/)
Эта статья является переводом нового издания учебника Мигеля Гринберга. [Прежний пер... | https://habr.com/ru/post/346306/ | null | ru | null |
# Ускоряем код на Python с помощью Nim
> Привет, хабровчане. В преддверии старта курса ["Python Developer. Basic"](https://otus.pw/Hp9j/) подготовили для вас перевод интересной статьи. Также приглашаем на [открытый вебинар «Карьера для "Python Developer. Basic"».](https://otus.pw/dZxF/)
>
>
![](https://habrastorage... | https://habr.com/ru/post/543332/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.