
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# F# меня испортил, или почему я больше не хочу писать на C#
Раньше я очень любил `C#`
-------------------------
Это был мой основной язык программирования, и каждый раз, когда я сравнивал его с другими, я радовался тому, что в свое время случайно выбрал именно его. Python и Javascript сразу проигрывают динамической ... | https://habr.com/ru/post/428930/ | null | ru | null |
# Выгружаем данные из метеорологической стации Oregon Scientific WMR500
Однажды мы решили, что нам на сайте нужна своя актуальная погода за окном. А значит нужна какая-то метеорологическая станция с подключением в Интернет. Недорого. Ибо брать что-то типа Davis Vantage Pro2 Plus за овер 100 тысяч рублей, да еще и держ... | https://habr.com/ru/post/511850/ | null | ru | null |
# AngularJS против Backbone.js против Ember.js

#### 1 Введение
В статье мы сравним три популярных MV\* фреймворка для веб-разработки: AngularJS, Backbone и Ember. Выбор подходящего фреймворка для про... | https://habr.com/ru/post/259311/ | null | ru | null |
# Создание заставок (splash screen) в .net 3.5 SP1
Если вы сталкивались с программированием в .net, то наверняка замечали, что при запуске программы, написанной с использованием WPF, долгое время ничего не про... | https://habr.com/ru/post/45459/ | null | ru | null |
# Простые тесты на ruby для web
Для изучения ruby был выбран учебный проект в котором простая задача, написания тестов для web. Ввиду отсутствия знаний и опыта было решено использовать упрощенный фреймворк [sinatra](http://sinatraruby.ru/). В результате, в моем решении этой задачи всего два файла. Первый это mutaAlim... | https://habr.com/ru/post/226869/ | null | ru | null |
# Адаптивная фоновая подсветка для телевизора на Raspberry Pi – аналог Ambilight

Это телевизор с диагональю 50” и 37 RGB точками адаптивной фоновой подсветки по верхней и боковым сторонам экрана. Как сделать аналогичную адапт... | https://habr.com/ru/post/486106/ | null | ru | null |
# Начало работы с Push Notifications в PhoneGap
Доброго времени суток, хабрапользователи!
*Push Notifications не включены в API PhoneGap. Если сделать небольшой поиск по документации PhoneGap, то можно найти только [Notifications](http://docs.phonegap.com/en/2.4.0/cordova_notification_notification.md.html#Notificat... | https://habr.com/ru/post/171087/ | null | ru | null |
# Получаем информацию по продуктам от Амазона через API
Amazon.com это не только огромный магазин, но еще и бесплатный легальный доступ к огромному количеству информации по продуктам. Некотрое время назад, Амазон перестал принимать запросы без подписи, скрипт, который я написал, подписывает запрос в соответствии с тек... | https://habr.com/ru/post/67365/ | null | ru | null |
# $mol_atom: теория и практика реактивности
Здравствуйте, меня зовут Дмитрий Карловский и я… состоятельный человек. У меня есть состояние на сервере, есть состояния в локальных хранилищах, есть состояние окна браузера, есть состояние доменной модели, есть состояние интерфейса. И всё это многообразие состояний нужно по... | https://habr.com/ru/post/317360/ | null | ru | null |
# (Справа налево (Зазеркалье

Кажется, с заголовком что-то не так? Это одна из проблем, с которыми сталкиваются веб-разработчики при добавлении поддержки таких языков, как арабский. В этой статье расскажем ... | https://habr.com/ru/post/450000/ | null | ru | null |
# Работаем с банковскими (рабочими) днями
Полгода назад при разработке системы финансового учета поднялся вопрос о идентификации банковский дней. Произошло это в следующем контексте — при выставлении счета отводится некий промежуток времени (в банковских днях) по истечению которого надо трубить тревогу, если счет еще ... | https://habr.com/ru/post/67092/ | null | ru | null |
# SAST для самых маленьких. Обзор open-source инструментов поиска уязвимостей для C/C++

Привет, Хабр!
Навыки статического анализа кода в арсенале исследователя безопасности приложений фактически являются must-have скиллом. Искать р... | https://habr.com/ru/post/702652/ | null | ru | null |
# Погружаемся в 3D с помощью Marmalade SDK
Приветствую, братья по цеху, а также просто интересующиеся мобильными платформами и 3D-графикой читатели. В [предыдущем посте](http://habrahabr.ru/blogs/development/120684/) (а также в майском номере журнала «Хакер») я уже писал о том как начать работать с AirplaySDK ([с неко... | https://habr.com/ru/post/122891/ | null | ru | null |
# [Перевод] Построение документов Latex с помощью Waf
Это исправленный и дополненный [перевод статьи](http://jnwhiteh.net/posts/2010/09/building-latex-documents-with-waf.html) о многофункциональной системе сборки Waf.
С самого начала использования сервиса [Dropbox](https://www.dropbox.com/) для хранения моих научны... | https://habr.com/ru/post/111623/ | null | ru | null |
# Выполнение SQL запросов в DB Oracle в Sublime Text 2
Надеюсь всем хорошо знаком популярный редактор Sublime Text 2. Хочу поделиться опытом, как я смог облегчить себе жизнь, написав плагин для быстрого вызова запросов в BD Oracle прямо из редактора, просто выделив запрос и нажав комбинацию.
Любимый нами за быстрот... | https://habr.com/ru/post/203742/ | null | ru | null |
# Unity3d. Уроки от Unity 3D Student (B04-B08)
Добрый день.
Предыдущие уроки вы можете найти в [соответствующем топике.](http://habrahabr.ru/post/141362/)
Теперь в каждом посте в скобках (в конце) будут указываться номера уроков. Буква в начале номера обозначает раздел (B-Beginner, I — Intermediate).
PS: Ес... | https://habr.com/ru/post/142845/ | null | ru | null |
# Настройка домашней среды для разработки (docker + gitlab + DNS)
Intro
=====
Не смог придумать подходящее название для поста, поэтому кратко опишу, о чем будет идти речь.
У большинства из нас есть какие-нибудь мелкие личные поделки, которые не выходят за рамки наших домов. Кто-то хостит их на рабочем компьютере, кт... | https://habr.com/ru/post/417179/ | null | ru | null |
# Улучшение параметров безопасности SSL-соединения в Zimbra Collaboration Suite Open-Source Edition
Надежность шифрования является одним из наиболее важных показателей при использовании информационных систем для бизнеса, ведь ежедневно они участвуют в передаче огромного количества конфиденциальной информации. Общеприн... | https://habr.com/ru/post/508372/ | null | ru | null |
# TinyML. Сжимаем нейросеть
Сейчас перед программистами стоит сложная задача - как внедрить такую громоздкую структуру, как нейронная сеть - в, допустим, браслет? Как оптимизировать энергопотребление модели? Какова цена таких оптимизации, а также насколько обосновано внедрение моделей в небольшие устройства, и почему ... | https://habr.com/ru/post/559400/ | null | ru | null |
# Разделённые запросы в EF Core
ORM Entity Framework Core с каждой версией становится все более и более богатой на фичи. Команда разработчиков тратит много времени на перфоманс и вероятно простое обновление Nuget-пакета уже приведет к некоторому бусту, который почувствуют пользователи. Но сегодня я хочу рассказать о с... | https://habr.com/ru/post/549736/ | null | ru | null |
# Готовим скриншоты для документации в GIMP (часть 1)
Как известно, неотъемлемой частью профессионального программного продукта является качественная документация. А документация, в свою очередь, немыслима без иллюстраций. В большинстве случаев иллюстрации представляют собой скриншоты, которые должны быть не только кр... | https://habr.com/ru/post/106611/ | null | ru | null |
# О бедной рекурсии замолвите слово, или всё, что вы не знали и не хотите о ней знать
> Рекурсия: см. рекурсия.
Все программисты делятся на 112 категорий: кто не понимает рекурсию, кто уже понял, и кто научи... | https://habr.com/ru/post/256351/ | null | ru | null |
# Эволюция игрового фреймворка. Сервер на Python. Часть 1. Слои инфраструктуры
Допустим, у нас большие планы, и мы хотим реализовать серверную часть для всех основных игровых жанров. Однако, прежде, чем приступить к этому, нужно хорошенько подготовиться. Нужно создать такую основу, которая бы подходила для каждой игры... | https://habr.com/ru/post/678658/ | null | ru | null |
# Учёные посчитали количество кубитов, чтобы взломать шифрование ECDSA для ключей Bitcoin
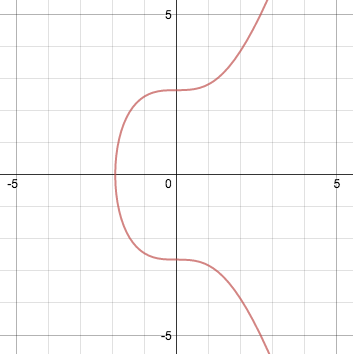
*Эллиптическая кривая — это график уравнения `y2 = x3 + ax + b`. В сети Bitcoin используется вариант с `a = 0` и `b = 7`*
Критики Bitcoin г... | https://habr.com/ru/post/650761/ | null | ru | null |
# Мониторинг IPTV
Возникла необходимость проводить мониторинг мультикаст потоков. Начался поиск готовых решений. Первое что удалось нагуглить: [IPTV-Analyzer](http://www.iptv-analyzer.org/wiki/index.php/Main_Page), [NetUP IPTVProbe](http://www.netup.tv/ru-RU/iptvprobe.php). У каждого решения были свои недостатки или с... | https://habr.com/ru/post/145151/ | null | ru | null |
# Что-то не так с IDS сигнатурой

Имена Snort и Suricata IDS знакомы каждому, кто работает в сфере сетевой безопасности. Системы WAF и IDS — это те два класса защитных систем, которые анализируют сетевой трафик, разбирают протоколы... | https://habr.com/ru/post/344642/ | null | ru | null |
# История одной задачи: Кратчайший мемоизатор на JavaScript

Дело было вечером, накануне ежегодной конференции [HolyJS](http://holyjs-piter.ru) в Санкт-Петербурге. Наша компания уже не первый год является спонсором: соответственно... | https://habr.com/ru/post/413303/ | null | ru | null |
# Consul.io Часть 2
В [первой части](https://habrahabr.ru/post/278085/) мы подробно рассмотрели какие проблемы и задачи ставит перед нами распределенная архитектура приложения. Мы определили какие инструменты мы можем использовать для решения этих проблем и отметили важность реализации discovery на начальном этапе про... | https://habr.com/ru/post/278101/ | null | ru | null |
# PostgreSQL Antipatterns: навигация по реестру
Сегодня не будет никаких сложных кейсов и мудреных алгоритмов на SQL. Все будет очень просто, на уровне Капитана Очевидность — делаем **просмотр реестра событий** с сортировкой по времени.
То есть вот лежит в базе табличка `events`, а у нее поле `ts` — ровно то самое ... | https://habr.com/ru/post/498740/ | null | ru | null |
# Небольшой экскурс в Linux на ARM и ArchLinux на Mele A1000/A2000
Всем привет.
Смотря видео на youtube, как запускают ubuntu на одноплатных компьютерах вроде Mele A1000 или MK802, решил я, что нужно что-то делать с производительностью и заодно запустить ArchLinux на этом устройстве, т.к. этого, почему-то, пока еще... | https://habr.com/ru/post/146877/ | null | ru | null |
# @Once: однократные замыкания
В Swift 5.5 появилась возможность использовать обертки свойств на [параметрах функций и замыканий](https://github.com/apple/swift-evolution/blob/main/proposals/0293-extend-prope... | https://habr.com/ru/post/569650/ | null | ru | null |
# Как написать своё VoIP-приложение с работой в фоне под Windows Phone
В этой статье я бы хотел рассказать о том, как в минимум усилий написать своё простое VoIP-приложение с бэкэндом и работой в фоне на платформе Windows Phone 8.
До выхода Windows Phone 8 пользователей voip-приложений очень разочаровывала работа в... | https://habr.com/ru/post/174287/ | null | ru | null |
# Добавление библиотеки OpenCV в проект Android Studio

### Вступление
Добрый день, уважаемые читатели! Всем давно известно, что мобильные устройства всё чаще комплектуются мощным аппаратным обеспечением. Процессоры совреме... | https://habr.com/ru/post/262089/ | null | ru | null |
# Что такое Windows PowerShell и с чем его едят? Часть 2: введение в язык программирования
*Исторически утилиты командной строки в Unix-системах развиты лучше чем в Windows, однако с появлением нового решения ситуация изменилась.*
[]... | https://habr.com/ru/post/490924/ | null | ru | null |
# (Python) Парочка полезных декораторов
> `import should
>
>
>
> @should.give((5,2),7)
>
> @should.give(("aa","bbb"),"aabbb")
>
> @should.give(([1],[2,3]), [1,2,3])
>
> @should.give((1,1),1) # test
>
> def add(a,b):
>
> return a+b
>
>
>
> @should.throw((1,0), Exception)
> ... | https://habr.com/ru/post/71427/ | null | ru | null |
# CRAWL динамических страниц для Google и Яндекс поисковиков (snapshots, _escaped_fragment_, ajax, fragment)

Всем мир!
Содержание статьи:
1. Что такое CRAWL
2. Динамический CRAWL
3. Задачи, инструменты, ре... | https://habr.com/ru/post/306644/ | null | ru | null |
# Стероиды для Munin
[Munin](http://munin-monitoring.org) очень неплохая штука для мониторинга серверов, особенно одного-двух. Однако если количество серверов растёт работает он всё хуже и хуже. Под катом рассказ как я разгонял его до мониторинга больше чем 1000 виртуалок (275K rrd файлов в системе).
##### Почему M... | https://habr.com/ru/post/146032/ | null | ru | null |
# Генератор умных перечислений, EnumGenerator
Привет всем!
Несколько лет назад меня начал беспокоить вопрос создания статических (создаваемых и изменяемых до процесса компиляции) перечислений. Перечислений я хотел не простых, которые реализованы в С/С++, а с набором дополнительных возможностей, в том числе и ассоци... | https://habr.com/ru/post/240537/ | null | ru | null |
# Опыт команды PVS-Studio: повышение производительности C++ анализатора на Windows при переходе на Clang
С самого своего начала C++ анализатор PVS-Studio для Windows (тогда еще Viva64 версии 1.00 в 2006 году) собирался компилятором MSVC. С выходом новых релизов C++ ядро анализатора научилось работать на Linux и macOS,... | https://habr.com/ru/post/560274/ | null | ru | null |
# Управляем сервером посредством СМС
Началось все с того, что я откопал в полке с железками USB модем huaweiE1550, купленный мной прошлым летом для организации резервного канала Интернет. Проработал он тогда недолго и за ненадобностью был убран в «закрома» до лучших времен. Первое что сделал, разлочил его для работы с... | https://habr.com/ru/post/114912/ | null | ru | null |
# Галлюцинируй как Трамп, или мини-анализ Рекуррентных Нейронных Сетей
Я уже довольно давно занимаюсь проблемами машинного обучения и глубокими архитектурами (нейронные сети), и мне необходимо было сделать мини-презентацию системы, генерирующую временные ряды для эмуляции различных процессов. Поскольку на серьезные те... | https://habr.com/ru/post/326966/ | null | ru | null |
# Информационная безопасность как предмет: история преподавателя GeekBrains

Привет, Хабр. Меня зовут Владимир Душкевич, я специалист по информационной безопасности, преподаватель [факультета](https://geekbrains.ru/geek_university/se... | https://habr.com/ru/post/524302/ | null | ru | null |
# Форензика и стеганография в видеофайле: разбор заданий online-этапа NeoQUEST-2015
 Прошедший online-этап ежегодного соревнования по кибербезопасности NeoQUEST-2015 был крайне богат на интересные и нетривиальные задания! В эт... | https://habr.com/ru/post/257737/ | null | ru | null |
# World of React Native. Уже можно играть! Геймплей, обзор
Привет! Я Илья, фронтенд-разработчик. В ЮMoney работаю четыре года. Занимался личным кабинетом интернет-магазинов на B2B-продукте ЮKassa. Последний год развиваю продукт для расчетно-кассового обслуживания ЮBusiness.
Что значит РКО
--------------
Юридическому... | https://habr.com/ru/post/570460/ | null | ru | null |
# Как видит компьютер

Задумывались ли Вы когда-нибудь, как компьютер находит нужные для обработки объекты из видеопотока? На первый взгляд, это выглядит задачей из разряда «высокого» программирования с применением огромного количе... | https://habr.com/ru/post/511216/ | null | ru | null |
# Создание модулей JS
Здравствуйте!
В этой статье я хочу рассказать вам о моём подходе к написанию модулей на JavaScript. Профессионалы вряд ли найдут для себя что-то новое, а вот новичкам, я думаю, будет полезно ознакомиться с предложенным подходом и аргументами в его пользу.
#### Модуль «с нуля»
В моей любимо... | https://habr.com/ru/post/231883/ | null | ru | null |
# Боль и анимация таблиц для iOS. Фреймворк Awesome Table Animation Calculator

Представим себе экран обычного мобильного приложения с уже заполненным списком ячеек. С сервера приходит другой список. Нужно посчитать разницу между ни... | https://habr.com/ru/post/282509/ | null | ru | null |
# Интеграция с ВКонтакте на базе Open API
Социальная сеть ВКонтакте предоставляет широкие возможности для интеграции со сторонними сайтами. В основном эти возможности представлены уже готовыми виджетами. Однако, есть еще и [Open API](http://vkontakte.ru/developers.php?o=-1&p=Open+API), которое позволяет не только авто... | https://habr.com/ru/post/112923/ | null | ru | null |
# Эволюция юнит-теста
Много слов сказано о том, как правильно писать юнит-тесты, и вообще о пользе [TDD](http://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D1%87%D0%B5%D1%80%D0%B5%D0%B7_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5). Потом ещё и какое-... | https://habr.com/ru/post/107262/ | null | ru | null |
# Перевод времени 26 октября 2014 года или ударим трудом по разгильдяйству
Госдума России приняла в июле законопроект о возврате к зимнему времени, а также об установлении новой системы часовых зон. В результате 26 октября 2014 года в большинстве регионов России время будет снова переведено на час назад, и в стране по... | https://habr.com/ru/post/239827/ | null | ru | null |
# WWDC22 hidden gems
For iOS developers, **WWDC** is always something of a New Year. We are presented with so many new products, and sometimes you can get lost in them. Most of my colleagues are trying to be ... | https://habr.com/ru/post/700074/ | null | en | null |
# Pattern matching в Java 8
Многие современные языки поддерживают сопоставление с образцом (pattern matching) на уровне языка.
Язык Java не является исключениям. И в Java 16 будет добавлено поддержка сопоставление с образцом для оператора instanceof, как финальной фичи.
В будущем надеемся, что сопоставление с о... | https://habr.com/ru/post/544560/ | null | ru | null |
# Ещё раз о неопределённом поведении или «почему не стоит забивать гвозди бензопилой»
Про неопределённое поведение [писали](http://habrahabr.ru/post/136283/) [не](http://habrahabr.ru/post/216189/) [раз](http://habrahabr.ru/post/229963/). Приводились цитаты из стандартов, объяснения их интерпретации, разного рода поучи... | https://habr.com/ru/post/230777/ | null | ru | null |
# В поиске бесплатных билетов, исследование игры Аэрофлота: Миссия 2017
В преддверие Нового Года, разгребая тонны поздравительных писем, я наткнулся на предложение от Аэрофлота спасти Новый Год и получить 150 000 миль за первое место. Памятую о [прошлой их промо акции](https://habrahabr.ru/post/238463/) и имея слабост... | https://habr.com/ru/post/318944/ | null | ru | null |
# Взлом пароля на Mac с Arduino и OpenCV
О том, как взламывали запароленный мак с помощью Arduino и OpenCV. По мотивам статьи [Брутфорсим EFI с Arduino](http://habrahabr.ru/post/240291/).

#### История
Началось всё как ... | https://habr.com/ru/post/250347/ | null | ru | null |
# Учебник по Solidity: Все о модификаторах
### Что такое модификатор в Solidity?
В документации Solidity модификаторы определяются следующим образом:
> Модификаторы можно использовать для изменения поведения функций декларативным способом.
>
>
Из этого определения можно понять, что модификатор направлен на измене... | https://habr.com/ru/post/572004/ | null | ru | null |
# Печатаем Flash в Firefox правильно
С давних времен у Flash-а и Firefox-а существует множество проблем.
Одна из них заключается в том, что [Flash контент не печатается в Firefox](https://bugs.adobe.com/jira/browse/SDK-12871).
[Мы](http://anychart.com) давным давно нашли workaround и выложили его фришной либой.... | https://habr.com/ru/post/114342/ | null | ru | null |
# Расшифровываем формулу Хабра-рейтинга или восстановление функциональных зависимостей по эмпирическим данным
Если вы когда-нибудь читали раздел [помощь](http://habrahabr.ru/info/help/karma/) на Хабре, то наверняка видели там прелюбопытнейшую строчку:
> Допустим, вы написали публикацию с рейтингом +100 — это добави... | https://habr.com/ru/post/249375/ | null | ru | null |
# «Каких Марин?» или управляем контроллером через bluetooth с помощью мобильного приложения на Xamarin (Android)
В прошлой [статье](https://habr.com/ru/post/497324/) я пообещал рассказать, о том как подключать CANNY 3 tiny с помощью UART к bluetooth. И поскольку на этих майских особо не разгуляешься, было принято реше... | https://habr.com/ru/post/500454/ | null | ru | null |
# Сжатие без потерь — главная концепция в нашей жизни
[](https://habr.com/ru/company/ruvds/blog/712652/)
Бывало так, что из долгой поездки вы помните только несколько моментов? А все отпуска за много лет сливаются в единое целое? А и... | https://habr.com/ru/post/712652/ | null | ru | null |
# Необычные системные вызовы на Linux
[](https://habrastorage.org/webt/ej/cn/w4/ejcnw4zqrqo_wee6kw-evxqziui.png)
Что видит программист, начиная работать с языком C? Он видит `fopen`, `printf`, `scanf` и ещё мног... | https://habr.com/ru/post/475184/ | null | ru | null |
# Как подружить QML с чужим OpenGL контекстом. Часть III: Обработка пользовательского ввода
В данной статье я попытаюсь рассказать о том как передавать события мыши и клавиатуры в [QQuickWindow](http://doc.qt.io/qt-5/qquickwindow.html), в случае его использования в связке с [QQuickRenderControl](http://doc.qt.io/qt-5/... | https://habr.com/ru/post/249383/ | null | ru | null |
# Отступ 8px у body: история стиля, который никому не нужен
Во всех браузерах элементу body через таблицу стилей по умолчанию добавляется внешний отступ 8px. Но почему именно 8px? Разбираемся вместе с автор... | https://habr.com/ru/post/676666/ | null | ru | null |
# Ни дня без спорта — 2: перепрограммируем китайский браслет
У людей, занимающихся спортом, частым спутником на пробежках или заездах является смартфон с различными приложениями. С велосипедом проще, можно закрепить смартфон, к примеру, на руль и смотреть выдаваемые с датчиков данные. А что делать, если ты бежишь или ... | https://habr.com/ru/post/499774/ | null | ru | null |
# Google раскрыла незакрытую уязвимость в Edge и IE

Сотрудники подразделения Project Zero опубликовали информацию о незакрытом баге в браузерах Internet Explorer и Edge. Баг позволяет осуществить атаку с ... | https://habr.com/ru/post/355622/ | null | ru | null |
# Беззахватные алгоритмы: модель «сделай, запиши,(поручи другому)»
*Следуя совету хабрапублики, пробую новый вариант перевода термина "**lock-free**"*
В [прошлый раз](http://habrahabr.ru/blogs/system_programming/118515/) мы видели «беззахватный по духу» алгоритм, где захват был реализован так, что поток, обращающий... | https://habr.com/ru/post/118850/ | null | ru | null |
# Работа с ICQ в Java
#### Предыстория
Как-то раз мы решили создать [свой собственный микроблоггинг](http://joyreactor.ru) ~~с блекджеком и шлюхами~~ c шахматами и поэтессами. Сначала сделали сайт, но быстро стало понятно, что для реализации идеи его недостаточно. Необходимо было работать с сообщениями через Jabber и... | https://habr.com/ru/post/79911/ | null | ru | null |
# Нахождение 3-го элемента от конца связного списка в Java
*От переводчика:
Данная статья является переводом [статьи](http://javarevisited.blogspot.com/2016/07/how-to-find-3rd-element-from-end-in-linked-list-java.html?m=1#ixzz50JB6C7d9), опубликованной в блоге javarevisited. Она может быть интересна как новичкам, ... | https://habr.com/ru/post/345246/ | null | ru | null |
# Техники повторного использования кода и разбиения сложных объектов на составные
В этой статье я опишу различные техники повторного использования кода и разбиения сложных объектов на части, с которыми я столкнулся. Постараюсь объяснить, почему классическое наследование, а также некоторые другие популярные подходы не ... | https://habr.com/ru/post/545368/ | null | ru | null |
# Загрузка модов из Steam Workshop без регистрации и SMS
Как скачать моды из Мастерской Стим, не имея на аккаунте нужной игры? И Яндекс, и Гугл с радостью предложат вам десятки различных рецептов, кроме единс... | https://habr.com/ru/post/552978/ | null | ru | null |
# Гайд по поиску и устранению утечек памяти в Go сервисах
Как обнаружить утечку?
----------------------
Все просто, посмотреть на график изменения потребления памяти вашим сервисом в системе мониторинга.
.
Ранее я находил множество кодов для решения проблем с подсказками и ошибками при ва... | https://habr.com/ru/post/203694/ | null | ru | null |
# Распределенное логирование и трассировка для микросервисов
Логирование — важная часть любого приложения. Любая система логирования проходит три основных шага эволюции. Первый — вывод на консоль, второй — запись логов в файл и появление фреймворка для структурированного логирования, и третий — распределенное логирова... | https://habr.com/ru/post/473946/ | null | ru | null |
# In-app purchasing или внутренние платежи в приложениях для Android
#### О чем это вообще?
С версией приложения Android Market 2.3.0 для разработчиков приложений для платформы Android открылась возможность предоставлять пользователям платежи внутри самих приложений. Теперь можно продавать уровни и артефакты, видео, ... | https://habr.com/ru/post/117944/ | null | ru | null |
# Внешние данные конфигурации в Spring
### Введение
#### Ситуация
Большинство наших приложений зависят от внешних сервисов, например серверов баз данных, SMS-шлюзов и систем наподобие PayPal. Эти сервисы мо... | https://habr.com/ru/post/576910/ | null | ru | null |
# Основы оптимизации кода игр
Многие начинающие инди-разработчики слишком поздно задумываются над оптимизацией кода. Она отдаётся на откуп движкам или фреймворкам или рассматривается как «сложная» тех... | https://habr.com/ru/post/358176/ | null | ru | null |
# Консольные помощники для работы с Kubernetes через kubectl

Kubectl — основной консольный интерфейс для взаимодействия с Kubernetes и, безусловно, важный инструмент в руках любого администратора/DevOps-инженера, причаст... | https://habr.com/ru/post/341606/ | null | ru | null |
# Управление картинками и другим бинарным содержимым вашего веб-проекта

Мы, в компании XIAG, в разных проектах постоянно решаем одну и ту же задачу: как хранить и показывать бинарные пользовательские данные. Это мог... | https://habr.com/ru/post/175053/ | null | ru | null |
# Подводные камни при работе с enum в C#
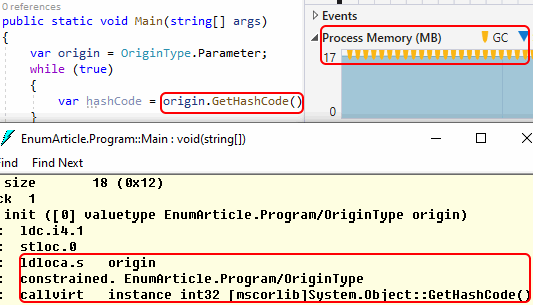
C# имеет низкий порог вхождения и прощает многое. Серьёзно, на этом языке преспокойно можно писать, не особо понимая, как всё работает по... | https://habr.com/ru/post/568928/ | null | ru | null |
# Решение алгоритмических задач: возможность бронирования отеля
***Перевод статьи подготовлен специально для студентов курса [«Алгоритмы для разработчиков»](https://otus.pw/haoR/).***

*Эта статья является частью серии о том, как ... | https://habr.com/ru/post/470676/ | null | ru | null |
# Один алгоритм комбинаторной генерации
Комбинаторика в старших классах школы, как правило, ограничивается текстовыми задачами, в которых нужно применить одну из трёх известных формул — для числа сочетаний, перестановок или размещений. В институтских курсах по дискретной математике рассказывают и о более сложных комби... | https://habr.com/ru/post/225255/ | null | ru | null |
# Новости из мира OpenStreetMap № 489 (26.11.2019-02.12.2019)
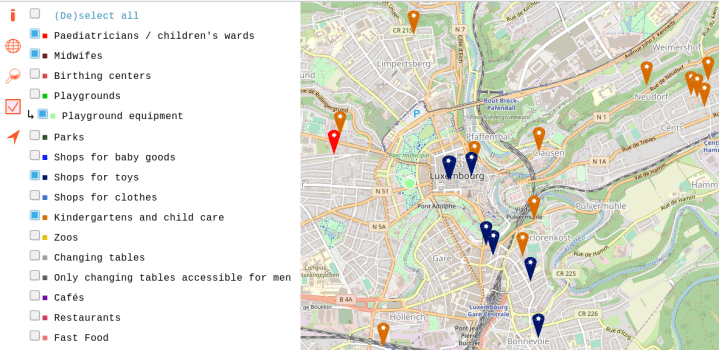
Babykarte — проект Sören Reinecke aka ValorNaram [1](#wn489_21428) | Map data OpenStreetMap contributors
Работа над ошибками
-------... | https://habr.com/ru/post/480206/ | null | ru | null |
# godebug — кроссплатформенный дебаггер для Go
Ребята из компании Mailgun презентовали новый [кроссплатформенный дебаггер для Go](https://github.com/mailgun/godebug), который использует оригинальную технологию, в корне отличающуюся от стандартных подходов. Забегая наперед — с помощью Gopherjs этот дебаггер работает да... | https://habr.com/ru/post/256355/ | null | ru | null |
# Елочка, зажгись! Часть 3: веб-интерфейс и приложение для Android
*Этим текстом мастер Гамбс завершает описание своей новой ёлочной гирлянды. 2015 г. Москва*
Привет, Хабр!
Итак, мы добрались до финального этапа: раз у нас есть гирлянда, которой управляет нанокомпьютер Black Swift со встроенным Wi-Fi, то логично... | https://habr.com/ru/post/248037/ | null | ru | null |
# Основы работы с Neo4j в браузере
В статье рассматривается как начать работать с графовой СУБД [Neo4j](https://neo4j.com/), используя *Neo4j Browser*. Это руководство может быть полезным как дополнение к книге Редмонда и Уилсона "Семь баз данных за семь недель", так как рассматриваемый веб-интерфейс был полностью пер... | https://habr.com/ru/post/470541/ | null | ru | null |
# Делаем рейтинг городов России по качеству дорог

В очередной раз проезжая на машине по родному городу и объезжая очередную яму я подумал: а везде ли в нашей стране такие «хорошие» дороги и решил — надо объективно оценить ситуацию... | https://habr.com/ru/post/437542/ | null | ru | null |
# Добавляем фуригану к кандзи Python макросом для LibreOffice
Дамы и господа, план такой:
* всё, что вы хотели знать о японской письменности, но боялись спросить
* что такое ruby text
* как писать аддоны для LibreOffice на Python
* как сгенирировать чтение для канзи
* собираем всё это вместе в фуриганайзер!

Некоторое время назад при обсуждении в компании профессиональных разработчиков FPGA возникла дискуссия о прохожден... | https://habr.com/ru/post/419875/ | null | ru | null |
# Пробуем Orchard CMS для корпоративного сайта
Привет!
У нас есть [корпоративный сайт](http://eastbanctech.ru) на Liferay, и он требует довольно кропотливой работы на этапе создания layout. Мы решили посмотреть, чем отличается создание кастомного раздела в Liferay от того же процесса в Orchard CMS в рамках такой не... | https://habr.com/ru/post/189314/ | null | ru | null |
# Пишем собственный хитрый thread_pool-диспетчер для SObjectizer-а
О чем эта статья?
=================
Одной из основных отличительных черт [C++ного фреймворка SObjectizer](https://habrahabr.ru/post/304386/) является наличие диспетчеров. Диспетчеры определяют где и как акторы (агенты в терминологии SObjectizer-а) буд... | https://habr.com/ru/post/353712/ | null | ru | null |
# Документирование API — документация из тестов
Пост в продолжение [темы экспериментальных решений](https://habrahabr.ru/post/350382/), откуда будет переиспользован код для примера. В прошлом посте я затронул тему, как можно написать тесты на простой сервис, когда он выступает в роли черного ящика и из кода теста у на... | https://habr.com/ru/post/351660/ | null | ru | null |
# Тонкости реализации кода библиотеки. Часть вторая
 В [предыдущей части](http://habrahabr.ru/blogs/cpp/138085/) был приведен способ, с помощью которого, можно сократить количество кода при использовании классов-помощников ... | https://habr.com/ru/post/138438/ | null | ru | null |
# Поиск на Drupal 7 с помощью Apache Solr ч.7 — полнотекстовый поиск на русском языке

Наконец-то собрался и написал очередную статью из этого цикла. Теперь я расскажу о том, как сделать хороший полнотексто... | https://habr.com/ru/post/213085/ | null | ru | null |
# Высокоуровневый С или пару слов о Cello
[Cello](http://libcello.org/) — это библиотека, которая сделала высокоуровневый C возможным! Обобщения (generics), параметрический полиморфизм, интерфейсы, констр... | https://habr.com/ru/post/262471/ | null | ru | null |
# Как появилась на свет программа youtube-dl
Как известно, в данный момент [репозиторий youtube-dl на GitHub](https://github.com/ytdl-org/youtube-dl) заблокирован по [DMCA-запросу](https://github.com/github/dmca/blob/master/2020/10/2020-10-23-RIAA.md) от RIAA. Хотя я не могу комментировать текущие планы мейнтейнеров и... | https://habr.com/ru/post/527880/ | null | ru | null |
# Разбор заданий конкурса на взлом NFT “The Standoff Digital Art”
15-16 ноября в Москве проводилась ежегодная кибербитва [The Standoff](https://standoff365.com/), которая собрала лучшие команды защитников и а... | https://habr.com/ru/post/590301/ | null | ru | null |
# Манипуляция мешами в реальном времени на Unity
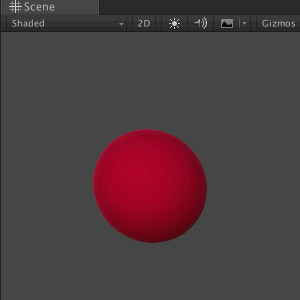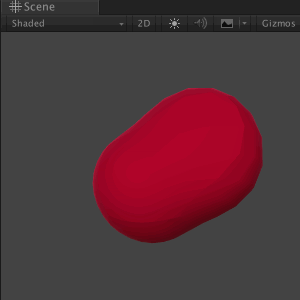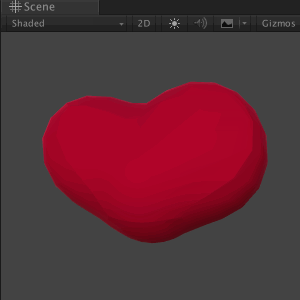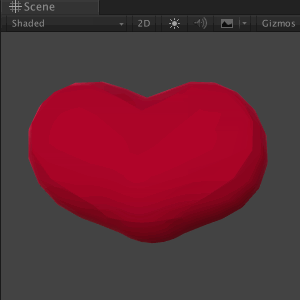
Одно из преимуществ Unity в качестве платформы для разработки игр — её мощный 3D-движок. В этом туториале вы познакомитесь с миром 3D-объектов и манипуляций ме... | https://habr.com/ru/post/428796/ | null | ru | null |
# Бесплатная GPU Tesla K80 для ваших экспериментов с нейросетями

Около месяца назад Google сервис Colaboratory, предоставляющий доступ к Jupyter ноутбукам, включил возможность бесплатно использовать GPU Tesla K80 с 13 Гб видеопамя... | https://habr.com/ru/post/348058/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.