
_id stringlengths 1 6 | text stringlengths 0 7.5k | title stringlengths 0 167 |
|---|---|---|
113507 | من به دنبال ایجاد یک رگرسیون از مجموعه ای از داده ها هستم که در محدوده ای از اعداد واقعی موجود است. در مورد من، x بین 0 و 1 و y بین 0 و 10 است. اگر من 150 نقطه داده در این صفحه داشته باشم، و بخواهم داده های اصلی را با N نقطه داده (نه چند جمله ای، فقط نقاط) به بهترین شکل مدل کنم، چگونه می توانم من این کار را انجام دهم؟ سپس چگونه می توانم آنالیز کنم که تناسب چقدر خوب است؟ هر کمکی قابل تقدیر است. متاسفم اگر نماد من کامل نیست، من از یک پیشینه فیزیک هستم، پس لطفا با من تحمل کنید. به سلامتی مثال داده: x.vector <- cumsum(rnorm(150)^2) y.vector <- 10*rnorm(150)^2 من میخواهم 2 نقطه، 3، 4، ... را جا بزنم و تناسب را در هر یک بررسی کنم . | رگرسیون، تجزیه و تحلیل داده ها با نقاط به جای چند جمله ای؟ |
60454 | من دو متغیر در یک مشکل رگرسیونی دارم که در آن نرخ بهره نهایی را برای درخواست وام پیش بینی می کنم. * x1: باند ریسک (A+,A,B,C) *x2: نرخ اولیه (6%, 7, 8, 9%) بر اساس این دو متغیر، سعی میکنم نرخ نهایی واقعی را پیشبینی کنم. y خواهد بود (یعنی 6.3%). باند ریسک به نرخ اولیه بستگی دارد و بالعکس. یعنی A+ -> 6%. من باید باند خطر را برای هر درجه آزادی در دسته به 0 و 1 تبدیل کنم. من خوانده ام رگرسیون خطی مستلزم مستقل بودن ویژگی های ورودی است. در مورد من، آنها نیستند. آیا گنجاندن هر دو در مدل منطقی است؟ بنابراین یک بردار ویژگی ورودی ممکن ممکن است به این صورت باشد: [0,0,1,9] -> باند خطر C، 9% نرخ اولیه [0,0,0,6] -> باند خطر A+، 6% نرخ اولیه I می تواند نرخ اولیه را z-امتیاز کند تا محدوده ها کوچکتر شود. * * * با توجه به پاسخ زیر، اگر بخواهم نرخ اولیه را به عنوان یک ویژگی طبقه بندی نیز نشان دهم، با مشکل مواجه می شوم زیرا آنها مضرب های اسکالر باند ریسک هستند. به عنوان مثال [0,0,1,0,0,1] -> باند خطر C، 9٪ نرخ اولیه [0,0,0,0,0,0] -> یک باند ریسک، 6٪ نرخ اولیه با این حال، اگر از یک ویژگی ترتیبی برای نرخ اولیه استفاده کنم، پس مشکلی وجود ندارد، زیرا آنها مضرب های اسکالر باند ریسک نیستند. به عنوان مثال، [0،0،1،9] -> باند خطر C، 9٪ نرخ اولیه [0،0،0،6] -> باند خطر A+، 6٪ نرخ اولیه درست است؟ | متغیرهای وابسته در رگرسیون |
43176 | من تعداد اهداکنندگانی را که تعهدات خود را لغو میکنند بهعنوان یک سری زمانی ماهانه تحلیل میکنم که به طور قابلتوجهی با شاخصهای اقتصادی، برخی براساس دادههای داخلی، و شاید براساس فصل متفاوت است. من می خواهم واریانس را بعد از تعدیل برای اقتصاد و فصل ببینم (با فرض اینکه باقی واریانس ناشی از رفتار غیرانتفاعی باشد). آیا روش خوبی برای انجام این کار برای جا دادن یک مدل رگرسیون خطی در شبه کد R است: برازش <- lm(لغو ~ اقتصاد + فصل) و سپس استفاده از باقیمانده ها؟ | حذف اثرات اقتصادی از سری های زمانی |
68125 | مشکل توصیه این است: فرض کنید ماتریسی داریم که ستونهای آن آیتمها هستند (مثلاً فیلمها) و سطرهای آن کاربر هستند. بخش کوچکی از ماتریس با مقادیر رتبه بندی پر شده است. این مقادیر (مثلاً بین 1 و 5) است که نشان می دهد یک کاربر خاص چقدر از یک مورد خاص را دوست دارد. مشکل پیشبینی رتبهبندیهای گمشده در ماتریس است. پس از پیش بینی موارد بسیار پیش بینی شده به کاربران توصیه می شود. تا کنون بهترین روش ها بر اساس تکنیک های فاکتورسازی ماتریسی هستند. SVM ها یکی از بهترین الگوریتم های پیش بینی خارج از قفسه هستند. من سعی کردم به راه هایی برای استفاده از SVM برای مشکل پیش بینی رتبه فکر کنم. با این حال نتوانستم پیشرفت زیادی داشته باشم. همچنین، من نتوانستم توضیح دهم که چرا SVM ها برای این مشکل خوب نیستند. به عنوان مثال، می توان یک مجموعه داده را به عنوان لیستی از کاربر، آیتم، رتبه بندی سه گانه ساخت. 123, 3214, 4 214, 1282, 1 ... در اینجا ستون اول شامل شناسه های کاربر، ستون دوم شامل شناسه آیتم ها و ستون آخر شامل رتبه بندی ها (برچسب کلاسی که باید پیش بینی شود) است. شما می توانید آن را به عنوان یک مشکل رگرسیون یا یک مشکل طبقه بندی چند طبقه در نظر بگیرید. یک طبقهبندیکننده SVM بسازید، سپس سعی کنید رتبهبندی جدیدی را به کاربر و یک آیتم پیشبینی کنید. اما من فکر نمی کنم که این کار خوبی باشد. هر ایده ای؟ آیا می توان از SVM برای این مشکل استفاده کرد؟ اگر بله، چگونه؟ اگر نه، چرا؟ با تشکر | پشتیبانی از ماشینهای برداری و الگوریتمهای توصیهکننده |
80451 | در تجزیه و تحلیل برخی از داده هایی که تولید کردم به مشکل برخوردم. من غلظتها را در نمونههای بیولوژیکی در یک دوره زمانی اندازهگیری کردم. من برای هر یک از هفت نقطه زمانی سه تکرار اندازه گرفتم. من می توانم داده ها را به صورت معنی +- SD نمایش دهم، که آسان است. اکنون می خواهم داده ها را به صورت درصد تغییرات نسبت به نقطه زمانی اول بیان کنم. من در مورد نحوه اعمال SD یا هر اندازه گیری تغییرپذیری دیگر برای درصدها کاملاً بی اطلاع هستم. ببخشید اگر این یک پست دوگانه است، اما پاسخ های دیگر به نحوی با مشکل من مطابقت ندارند. مشکل دیگری که به زودی با آن مواجه خواهم شد این است که: من یک ژنوتیپ مختلف را به همان روش تجزیه و تحلیل خواهم کرد و می خواهم تفاوت های قابل توجهی بین ژنوتیپ ها آزمایش کنم. توصیه ای برای تست دارید؟ ترجیحاً کاری که بتوان در اکسل انجام داد، من تازه شروع به یادگیری R کردم. | انحراف استاندارد درصد تغییرات در یک دوره زمانی |
112676 | آیا می توانید 2 مقیاس لیکرت را در زمانی که سؤال برای هر یک متفاوت بود به هم مرتبط کنید؟ من 1 سوال دارم که می پرسد یک نفر چقدر نگران آلودگی است. آنها این را در مقیاس لیکرت 1-5 رتبه بندی می کنند که در آن 1 بیشتر نگران است و 5 اصلا. سپس سؤال دیگر من این است که آیا مردم قصد دارند اقدامات اضافی برای کاهش آلودگی خود در آینده انجام دهند، دوباره در مقیاس 1-5، اما در جایی که 1 به احتمال زیاد به 5 کاهش می یابد اصلاً نیست. آیا می توانم روی این دو سوال تست همبستگی اجرا کنم؟ طبیعتاً من انتظار دارم که هر چه بیشتر نگران باشد، قصدشان برای اقدام بیشتر است. بدیهی است که هر دو مقیاس 1-5 هستند، اما از آنجایی که معنای پشت معنای عدد کمی متفاوت است (یعنی در Q1، 1 = بیشترین نگرانی و در Q2، 1 = بسیار محتمل)، آیا هنوز هم می توان آنها را مرتبط کرد؟ | همبستگی مقیاس لیکرت برای سوالات مختلف |
60458 | فرض کنید ما یک نمونه $\boldsymbol{x}_i$ برای $i$ در $1،\dots، n$، از یک $d$-بعدی چگالی یکوجهی $f(\boldsymbol{x})$ داریم. من می خواهم حالت $f(\boldsymbol{x})$ را تخمین بزنم. الگوریتم میانگین تغییر مورد بحث در این پست مرتبط می تواند برای تخمین حالت مورد استفاده قرار گیرد، اما با توجه به اینکه این الگوریتم بر اساس یک تخمینگر ناپارامتریک چگالی است، فکر می کنم به حجم نمونه عظیمی از $n$ نیاز دارد اگر $d > 5 دلار آیا گزینه های دیگری وجود دارد؟ با تشکر | تخمین حالت در ابعاد بالا |
60450 | من پنج میلیون شی دارم که هر کدام یک یا چند تگ دارند. چگونه می توانم نمره شباهت آماری بین هر جفت از اشیاء را با در نظر گرفتن این موارد محاسبه کنم: 1. 100 میلیون برچسب وجود دارد که بیشتر آنها فقط یک بار استفاده شده اند. 2. برخی از برچسب ها اغلب استفاده می شوند، مثلاً یک برچسب ممکن است در 1٪ از کل مجموعه داده استفاده شود. 3. برخی از اشیاء به شدت با صدها هزار تگ بر روی آنها برچسب گذاری می شوند در حالی که برخی دیگر ممکن است تنها چند بار برچسب گذاری شوند. سوال دوم: چگونه می توانم اشیاء را با در نظر گرفتن 1-3 خوشه بندی کنم؟ حدس من این است که k-means و دیگر تکنیکهای خوشهبندی محبوب کار زیادی در اینجا انجام نخواهند داد. من قبلاً k-means را با فاصله ساده که تعداد برچسبهای مشابه روی اشیاء و خوشهها تعریف شده است، بسیار مبهم هستند تا جایی که تقریباً بیمعنی هستند. | شباهت بین اشیاء بر اساس برچسب ها (ویژگی های باینری) |
104833 | من در حال انجام تجزیه و تحلیل بقا با متغیرهای کمکی وابسته به زمان، با استفاده از سبک فرآیند شمارش هستم. من قبلاً مجموعه ای از مدل ها را دارم و می خواهم باقیمانده ها را آزمایش کنم. من با کمبود اطلاعات در مورد این موضوع مشکل دارم، ** منطقی است که باقیمانده های Schoenfield را برای متغیرهای وابسته به زمان آزمایش کنیم**؟ من از R استفاده می کنم. | آزمایش باقی مانده از یک مدل کاکس با متغیرهای کمکی وابسته به زمان |
41937 | من نمی دانم که آمار LM چگونه کار می کند زیرا اگر رگرسیون را اجرا کنیم و سپس باقیمانده را ثبت کنیم و سپس رگرسیون را با استفاده از باقیمانده به عنوان متغیر وابسته و سپس با استفاده از مدل نامحدود اجرا کنیم، چگونه می توانیم رگرسیون یک ثابت را اجرا کنیم. روی 5 متغیر مختلف؟ به عنوان مثال، من از Stata استفاده می کنم و دستورات من در اینجا آمده است: reg bwght cigs parity faminc که در آن «bwght» متغیر وابسته من است و «cigs» و غیره متغیرهای وابسته هستند scalar epsilon=e(rss) اینجا جایی است که من را ذخیره کردم. عبارت خطا (من فکر می کنم) reg epsilon cigs parity faminc motheduc fatheduc من سعی کردم این را به عنوان یک رگرسیون اجرا کنم اما گفته شد که یک خطا وجود دارد زیرا اپسیلون یک متغیر نیست. که می توانم دلیل آن را درک کنم. که منجر به سوال من می شود. چگونه می توانیم آزمایش ضریب لاگرانژ را انجام دهیم؟ | استفاده از آماره ضریب لاگرانژ در رگرسیون |
113501 | من نمی توانم ادبیاتی برای درک این جدول پیدا کنم. چیزی که من در انجام تحقیقاتم می دانم این است که اندازه اثر باید بین 0 و 1 باشد. وقتی 0.2 کند است، 0.5 متوسط و 0.8 و بالاتر، زیاد است. اما در مقاله ای از پایگاه داده کاکرین این نتایج را یافتم و واقعاً نمی توانم این را درک کنم. من به شدت به این نیاز دارم، بنابراین هر کسی که بتواند به من کمک کند تا این مقادیر را درک کنم (از جمله آن محدوده های داخل پرانتز) واقعاً از آن سپاسگزارم.  | این مقادیر منفی چگونه درک می شوند؟ |
64202 | بیایید فرض کنیم پروژه ای وجود دارد که انتظار می رود زمان مشخصی برای تکمیل آن طول بکشد. همانطور که کارهای خاصی انجام می شود، ما می توانیم به صورت کمی اندازه گیری کنیم که چه مقدار از پروژه در هر زمان تکمیل شده است. نوار پیشرفت را در نظر بگیرید - از 0% شروع می شود و در برخی از مقادیر زمانی گسسته با تکمیل بخش هایی از پروژه به روز می شود تا زمانی که به 100% برسد. انتظار می رود که این درصد تکمیل در طول زمان به صورت خطی افزایش یابد. در حالی که پروژه هنوز تکمیل نشده است، منطقی به نظر می رسد که بهترین راه برای تخمین تاریخ اتمام نهایی بر اساس این داده ها ترسیم مقادیر (زمان،%)، محاسبه خط بهترین تناسب، و یافتن جایی که آن را قطع می کند. ارزش 100% هر چه زمان می گذرد، این تقریب ها باید به مقدار واقعی نزدیک تر و نزدیک تر شوند و در اطراف آن از دو طرف نوسان کنند. با این حال، فرض کنید بخش کوچکی از پروژه (به عنوان مثال، محدوده 5٪) به تأخیر می افتد (یا شاید سریعتر از حد انتظار تکمیل شود). این دوره هر بار که محاسبه میشود، خط بهترین تناسب را پایین میآورد (یا بالا) - به این معنی که تاریخ تکمیل تخمینی ما برای همیشه بسیار کم خواهد بود و هر بار که آن را محاسبه میکنیم، به جای نوسان در مورد آن، افزایش مییابد. ارزش واقعی که شما انتظار دارید. آیا روش بهتری برای تخمین زمان تکمیل وجود دارد که بتواند دوره های محلی افزایش سریعتر یا کندتر را در نظر بگیرد؟ نوعی میانگین متحرک ممکن است داده ها را هموار کند، اما با چرخه نبودن این تغییرات، منطقی به نظر نمی رسد. بیشتر شبیه این است که شما یک مدل تکهای میخواهید - اما چگونه میتوانید قطعات واقعی را محاسبه کنید و از این اطلاعات به درستی استفاده کنید، بدون اینکه فقط به نمودار نگاه کنید و در جایی که «بهنظر میرسد» متفاوت است نگاه کنید؟ | بهترین روش محاسبه خط بهترین تناسب / برون یابی برای جبران تاخیر |
80453 | من با تبدیل Nataf (یعنی یک کوپول گاوسی) کار می کنم و به توزیع های مشترک دو متغیره نگاه می کنم. با این حال من نمی توانم هیچ نشریه ای پیدا کنم که در مورد محدودیت های تبدیل بحث کند. به عنوان مثال به نظر می رسد که برخی از توزیع های مشترک را نمی توان به طور کامل با تبدیل توصیف کرد و من در تلاش هستم تا انواع توزیع های ورودی را که می تواند مدیریت کند را بیابم. آیا کسی ایده ای دارد؟ یا آیا کسی منابع خوبی می شناسد که به وضوح در مورد محدودیت ها صحبت می کنند؟ با تشکر فراوان. | محدودیت های تحول نطاف |
57226 | اجازه دهید $X$ و $Y$ متغیرهای تصادفی مستقل باشند با pdf \begin{align} f(x)&=p(1-p)^x,x=0,1,2,\ldots \\\ f(y )&=(1+y)p^2(1-p)^y, y=0,1,2,\ldots \end{align} MVUE را برای $$ p(1-p) پیدا کنید. $$ من می دانم $X \sim $ هندسی$(p)$ و $Y \sim$ منفی دو جمله ای$(2,p)$. بنابراین آمار کافی کامل $$ T=(X,Y) است. $$ اجازه دهید $$ g=\frac12 X\cdot 1_{\\{Y=1\\}}، $$ سپس $$ E(g) = p(1-p)، $$ و توسط Lehmann-Scheffe $ $ E(g|T)=g، $$ MVUE است. آیا این درست است؟ برای من عجیب است که $g$ در $E(g|T)$ تغییر نمی کند. | $X \sim $ Geometric$(p)$, $Y \sim$ NegativeBinomial$(2,p)$: MVUE را برای $p(1-p)$ پیدا کنید |
104835 | من سعی می کنم از خوشه بندی سلسله مراتبی استفاده کنم تا ببینم در طبقه بندی مجموعه داده ای که قبلاً طبقه بندی واقعی آن را می دانستم چقدر خوب عمل می کند. من به طور کلی در خوشه بندی تازه کار هستم. من توانستم دندوگرام خوشه را رسم کنم، اما مطمئن نیستم که چگونه می توانم عملکرد این روش را اندازه گیری کنم. در اینجا یک مثال قابل تکرار از آنچه من دارم آمده است: y <- matrix(rnorm(40), 10, 4, dimnames=list(paste(item, 1:10, sep=), paste(variable, 1 :4, sep=))) ## داده های مناسب از کلاس خوشه بندی <- c(rep(Yes,5),rep(No,5)) x <- cbind(y,class) ## نمودار مجموعه داده کامل (as.dendrogram(hr)، edgePar=list(col=blue, lwd=2)، horiz=F) ## یک طرح زیبا! چگونه می توانم تصمیم بگیرم که آیا این روش واقعاً می تواند داده ها را به درستی طبقه بندی کند؟ آیا می توانم داده ها را بر اساس شاخه ای که به آن تعلق دارد تقسیم کنم؟ می خواهم اشاره کنم که من روی یک مجموعه داده بزرگ کار می کنم، بنابراین نگاه کردن به دندوگرام با چشم غیر مسلح بهترین کار نیست. توجه: شاید این بهترین روش نباشد، اما من سعی کردم راهی پیدا کنم که 10 متغیر را برای خوشه بندی داده ها در نظر بگیرد. با تشکر فراوان، | عملکرد خوشه بندی سلسله مراتبی برای داده های باینری در R |
90636 | فرض کنید من سعی می کنم بگویم که آیا فروش شرکت من طی 10 سال گذشته روند نزولی داشته است یا خیر. بگذارید همچنین بگوییم که من 10 سال گذشته فروش سه ماهه را در اختیار دارم. اگر من یک رگرسیون دو متغیره را با زمان به عنوان متغیر مستقل و فروش به عنوان متغیر وابسته اجرا کنم و اگر ضریب رگرسیون برای زمان منفی باشد، آیا نیاز به بررسی آماره t ضریب رگرسیون دارم؟ منظورم این است که آیا این داده ها بر اساس سرشماری جمعیت مورد علاقه من نیست؟ اگر آنها سرشماری هستند، چرا من به آزمایش آماری نیاز دارم؟ اساساً من تعجب می کنم که چقدر واکنش تند و سریع من به انجام آزمایش های آماری اشتباه بوده است. | آیا در OLS در سرشماری، باید اهمیت آماری نادیده گرفته شود؟ |
59088 | آیا می توانم از آزمون t برای مقایسه میانگین بین گروه ها (N=300) در صورتی که داده ها به طور معمول توزیع نشده اند استفاده کنم؟ | آیا آزمون t واقعاً از نظر شکل توزیع قوی است؟ |
920 | من یک شبیه سازی مونت کارلو را تکمیل کردم که شامل یک میلیون (10^6 دلار) شبیه سازی فردی بود. شبیه سازی یک متغیر به نام $p$ را برمی گرداند که می تواند 1 یا 0 باشد. سپس شبیه سازی ها را بر اساس معیارهای از پیش تعریف شده وزن می کنم و احتمال $p$ را محاسبه می کنم. من همچنین یک نسبت ریسک را با استفاده از $p$ محاسبه میکنم: $$\text{نسبت ریسک} = P(p|\text{مورد آزمایش}) / P(p|\text{مورد کنترل})$$ من هشت مونت کارلو داشتم اجرا می شود که شامل یک مورد کنترل و هفت مورد آزمایشی است. من باید بدانم که آیا احتمال $p$ از نظر آماری در مقایسه با موارد دیگر متفاوت است یا خیر. من می دانم که می توانم از یک آزمون مقایسه چندگانه یا ANOVA ناپارامتریک برای آزمایش متغیرهای فردی استفاده کنم، اما چگونه این کار را برای احتمالات انجام دهم؟ * * * به عنوان مثال آیا این دو احتمال از نظر آماری متفاوت هستند؟: _احتمالات_ : $P(p|\text{تست #3}) = 4.08 \times 10^{-5}$P(p|\text{تست #4) }) = 6.10 \times 10^{-5}$ _Risk Ratios_ : $\text{ریسک نسبت}(\text{تست #3}) = 0.089$$\text{نسبت خطر}(\text{تست #4}) = 0.119$ | تست کنید که آیا احتمالات از نظر آماری متفاوت هستند؟ |
97845 | من سعی میکنم با استفاده از R یک spline برای GLM قرار دهم. هنگامی که spline را جا دادم، میخواهم بتوانم مدل حاصل را بگیرم و یک فایل مدلسازی در یک کتاب کار اکسل ایجاد کنم. به عنوان مثال، فرض کنید من یک مجموعه داده دارم که در آن y یک تابع تصادفی از x است و شیب به طور ناگهانی در یک نقطه خاص تغییر می کند (در این مورد x=500@). set.seed(1066) x<- 1:1000 y<- تکرار(01000) y[1:500]<- pmax(x[1:500]+(runif(500)-.5)*67* 500/pmax (x[1:500],100)، 0.01) y[501:1000]<-500+x[501:1000]^1.05*(runif(500)-.5)/7.5 df<-as.data.frame(cbind(x,y)) نمودار(df) من اکنون این را با استفاده از کتابخانه (اسپلاین) spline1 مناسب میکنم <- glm(y~ns(x,knots=c(500)),data=df,family=Gamma(link=log)) و نتایج من خلاصه (spline1) را نشان می دهد فراخوانی: glm(فرمول = y ~ ns(x ، گره = c(500))، خانواده = گاما (پیوند = log)، داده = df) باقیمانده انحراف: حداقل 1Q میانه 3Q Max -4.0849 -0.1124 -0.0111 0.0988 1.1346 Coefficients: Estimate Std. خطای t مقدار Pr(>|t|) (قطع) 4.17460 0.02994 139.43 <2e-16 *** ns(x، knots = c(500)) 1 3.83042 0.06700 57.17 <2e-16 k***ns = c(500))2 0.71388 0.03644 19.59 <2e-16 *** --- Signif. کدها: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (پارامتر پراکندگی برای خانواده گاما 0.1108924 در نظر گرفته شده است) انحراف صفر: 916.12 در 999 درجه آزادی: انحراف باقیمانده: 21. 997 درجه آزادی AIC: 13423 تعداد تکرارهای امتیاز دهی فیشر: 9 در این مرحله، می توانم از تابع پیش بینی در r استفاده کنم و پاسخ های کاملاً قابل قبولی دریافت کنم. مشکل این است که من می خواهم از نتایج مدل برای ساخت یک کتاب کار در اکسل استفاده کنم. درک من از تابع پیش بینی این است که با توجه به یک مقدار x جدید، r آن x جدید را به تابع spline مناسب (یا تابع برای مقادیر بالای 500 یا تابع مقادیر زیر 500) متصل می کند، سپس آن نتیجه را می گیرد و ضرب می کند. با ضریب مناسب و از آن نقطه آن را مانند هر عبارت مدل دیگری در نظر می گیرد. چگونه می توانم این توابع spline را دریافت کنم؟ (توجه: متوجه می شوم که یک GLM گامای مرتبط با ورود به سیستم ممکن است برای مجموعه داده های ارائه شده مناسب نباشد. من در مورد نحوه و زمان مناسب کردن GLM ها نمی پرسم. من آن مجموعه را به عنوان نمونه ای برای اهداف تکرارپذیری ارائه می کنم.) | تفسیر نتایج اسپلاین |
104838 | ما دو گروه از 1000 نمونه داریم. ما 2 کمیت را در هر گروه اندازه گیری می کنیم. اولین مورد یک متغیر باینری است. دومی یک عدد واقعی است که از توزیع دم سنگین پیروی می کند. ما می خواهیم ارزیابی کنیم که کدام گروه برای هر معیار بهترین عملکرد را دارد. تستهای آماری زیادی برای انتخاب وجود دارد: افراد تست z را پیشنهاد میکنند، دیگران از آزمون t استفاده میکنند و دیگران Mann-Whitney U. * اگر یک آزمون تفاوت معنیدار بین گروهها و برخی آزمونهای دیگر تفاوت غیرمعنیدار را نشان دهد، چه اتفاقی میافتد؟ | از چه آزمون آماری برای تست A/B استفاده کنیم؟ |
68784 | با توجه به طرح های تخصیص مختلف، در مورد نرخ همگرایی میانگین نمونه طبقه بندی شده به توزیع نرمال چه می توان گفت؟ بدیهی است که در تخصیص بسیار ضعیف، این همگرایی ممکن است با شکست مواجه شود (به عنوان مثال، ثابت نگه داشتن حجم نمونه در یک لایه). اما برای هر طرح معقولی و تحت فرضیه های معقول، یک CLT اعمال می شود (بیکل و فریدمن 1984 و غیره). با این حال، آیا چیزی در مورد اندازه های نمونه مورد نیاز برای بدست آوردن تقریب های نزدیک به یک توزیع نرمال، با توجه به مثلاً یک طرح تخصیص معقول، و اطلاعاتی در مورد (اندازه نمونه مورد نیاز برای) تقریب نرمال تحت نمونه گیری تصادفی ساده از توزیع، معلوم است؟ یا حداقل برای تخصیص متناسب و/یا بهینه؟ | نمونه گیری طبقه ای و قضیه حد مرکزی |
113502 | من سعی می کنم یک رگرسیون را با استفاده از حدود 80 متغیر مستقل اجرا کنم. مشکل این است که 20+ ضرایب آخر NA را برمی گرداند. اگر محدوده داده ها را تا 60 متراکم کنم، ضرایبی برای همه چیز به خوبی دریافت می کنم. چرا من این NA ها را دریافت می کنم و چگونه آن را حل کنم؟ من باید این کد را با استفاده از همه این متغیرها بازتولید کنم. ترکیبی <- read.csv(file.csv، header = T، stringsAsFactors = FALSE) ترکیبی <- زیر مجموعه (کامپوزیت، انتخاب = -ncol(کامپوزیت)) ترکیبی <- زیر مجموعه (کامپوزیت، انتخاب = -تاریخ) model1 < - lm(indepvariable ~., data = composite, na.action = na.exclude) ترکیبی است فریم داده با 82 متغیر. به روز رسانی: کاری که من انجام داده ام این است که راهی برای ایجاد یک شی پیدا کرده ام که فقط شامل متغیرهای همبسته قابل توجهی باشد، تا تعداد متغیرهای مستقل را کاهش دهد. من اکنون یک متغیر دارم: sigvars، که نام شیای است که یک ماتریس همبستگی را مرتب میکند و تنها متغیرهایی را با ضرایب همبستگی >0.5 و <-0.5 انتخاب میکند. کد اینجاست: sortedcor <- sort(cor(composite)[,1]) regvar = NULL k = 1 for(i in 1:length(sortedcor)){ if(sortedcor[i] > .5 | sortedcor[i ] < -.5){ regvar[k] = i k = k+1 } } regvar sigvars <- names(sortedcor[regvar]) با این حال، آن در تابع lm() من کار نمی کند: model1 <- lm(data.matrix(composite[1]) ~ sigvars, data = composite) خطا: خطا در model.frame.default(formula = data.matrix(composite[1) ]) ~ sigvars، : طول های متغیر متفاوت است (برای 'sigvars' یافت می شود) | lm() که تعداد زیادی NA برای ضرایب تولید می کند |
64201 | من دادههای ماهوارهای دارم که درخشندگی را فراهم میکند و از آن برای محاسبه Flux (با استفاده از اطلاعات سطح و ابر) استفاده میکنم. اکنون با استفاده از روش رگرسیون، می توانم یک مدل ریاضی ایجاد کنم که مستقیماً درخشندگی و شار را به هم مرتبط می کند و می توان از آن برای پیش بینی شار برای مقادیر تابش جدید استفاده کرد. آیا می توان همین کار را با استفاده از درختان تصمیم یا درختان رگرسیون انجام داد؟ آیا در یک رگرسیون معادله ریاضی متغیر وابسته و مستقل را به هم متصل می کند؟ با استفاده از درختان تصمیم، چگونه می توانید چنین مدلی را توسعه دهید؟ | درخت تصمیم برای پیش بینی خروجی |
113509 | من از مدل مخاطرات متناسب کاکس برای اجرای یک تجزیه و تحلیل بقا در r بر روی تعدادی از متغیرهای کمکی غیر تودرتو و متمایز مانند سن، گروه خونی، سرطان و غیره استفاده میکنم: A، B، C، D، E وقتی مدل را اجرا میکنم. در فرضیه صفر همه چیز: surv ~ A + B + C + D تأثیر همه متغیرهای کمکی ناچیز است زیرا تعداد افراد دارای اندازه گیری برای هر متغیر کمکی نسبتا کوچک است. با این حال، هنگامی که من یک یا سایر ترکیبات متغیرهای کمکی را در مدلهای مختلف کاکس جدا میکنم: surv ~ A surv ~ A + C surv ~ B + D اثرات قابل توجهی نشان میدهم زیرا مجموعه نمونه بزرگتر است (یعنی تعداد مشاهدات حذف شده توسط مدل کوچک می شود). چیزی که من در درک آن با مشکل مواجه هستم این است که چگونه کارهای زیر را انجام دهم: * مقایسه مدل های مختلف کاکس برای بهترین تناسب، یعنی آیا «surv ~ A + B + D» مدل بهتری از «surv ~ A + C» است؟ آیا باید امتیازهای احتمال، والد یا لوگرانک را با هم مقایسه کنم؟ * آیا می توان هر ترکیب ممکنی از متغیرهای کمکی را برای تعیین بهترین مدل اجرا کرد؟ من حدود 15 متغیر کمکی دارم. * به طور گسترده تر، آیا این تاکتیک بهترین رویکرد برای بهینه سازی هم برای متغیرهای کمکی مهم و هم برای «هزینه» مدل کلی است؟ من هزینه ای را به هر مدل کوکس متمایز ضمیمه خواهم کرد، یعنی استفاده از متغیرهای کمکی «A + B + C» در مدل 100 دلار هزینه دارد در حالی که استفاده از متغیرهای کمکی «A + B» 75 دلار هزینه دارد و فقط استفاده از متغیر کمکی «A» هزینه 10 دلار دارد. من می خواهم به هزینه هر ترکیب از متغیرهای کمکی در مقابل دقت هر مدل کاکس نگاه کنم. خیلی ممنون از کمک شما! | مقایسه مدل های خطرات متناسب کاکس (انتخاب متغیر) |
90635 | دوگانه را بدون افست و بدون شلی در نظر بگیرید. در دوگانه، برای نقاط داده ای که بردارهای پشتیبان هستند، داریم: $$\alpha_t > 0$$ و این محدودیت با برابری ارضا می شود (از یک بردار پشتیبان!): $$y^{(t)}\sum^ n_{t'=1} \alpha_{t'}y^{(t')}x^{(t')} \cdot x^{(t)} = 1$$ با این حال، فقط به این دلیل $\alpha_t > 0$ برای من واضح نیست اگر همه بردارهای پشتیبانی دارای مقدار یکسان $\alpha_t$ باشند. آیا همه بردارهای پشتیبانی دارای مقدار یکسان $\alpha_t$ هستند؟ من به نوعی دنبال یک توجیه یا شهود ریاضی برای سوالم بودم. حدس من این است که آنها در صورت عدم وجود شلی، همان مقدار $\alpha_t$ را خواهند داشت. حدس دیگر من این بود که $\alpha_i$ به طور شهودی، مهم آن نکته را می گوید، درست است؟ (شاید اشتباه باشد) اگر درست باشد، همه بردارهای پشتیبانی دارای مقدار یکسانی با $\alpha_i$ نیستند زیرا همه بردارهای پشتیبانی بردارهای پشتیبانی ضروری نیستند. منظور من این است که برخی از بردارهای پشتیبان روی مرز حاشیه قرار می گیرند، اما حذف آنها لزوماً حاشیه را تغییر نمی دهد (مثلاً موردی را در نظر بگیرید که در آن 3 SV در یک خط دارید، می توانید وسط را بردارید و همان را حفظ کنید. مرز). بنابراین آیا بردارهای پشتیبانی ضروری ارزش بیشتری برابر با $\alpha_t$ دارند؟ همچنین، میپرسیدم که در صورت slack و offset به مقدار $\alpha_t$ چه اتفاقی میافتد. من حدس می زدم که نقاط نزدیکتر به مرز تصمیم گیری، مقدار بزرگتر $\alpha$ را بدست آورید؟ با این حال، آیا نقاط داخل حاشیه حتی بردارهای پشتیبانی را در نظر می گیرند؟ | آیا مقدار $\alpha$ برای همه بردارهای پشتیبان (SV) در دوگانه یکسان است و اگر این کار را انجام دهند یا نکنند دلیل آن چیست؟ |
48005 | من مدتی است که از تجزیه و تحلیل دیریکله نهفته استفاده می کنم، اما در مورد توانایی عملی آن برای مقایسه دو سند کمی گیج شده ام. البته زمانی که می خواهید ببینید یک سند یا کلمه خاص به چه دسته بندی تعلق دارد، برای طبقه بندی ایده آل است، اما در مقایسه محتوا من در نهایت عقلم هستم. یک سند استنباط شده توزیعی را در n موضوع به دست می دهد که به یک جمع می شود. استفاده از Kolmogorov-Smirnov در جایی توصیه شده بود، اما این خاصیت آزاردهنده را دارد که به دو توزیع یکسان نمره بسیار بالایی می دهد، حتی اگر منطقی نباشند. دو کلمه ای که در فرهنگ لغت وجود ندارد مطابقت کامل را نشان می دهد، که البته پوچ است. محصول نقطه نرمال شده در واقع بسیار خوب کار می کند زیرا توزیع های مسطح (اسناد بی اهمیت) را مجازات می کند، اما من فکر می کردم که یکی بهتر از این وجود خواهد داشت. هر گونه پیشنهاد قدردانی می شود. | مقایسه اسناد تحلیل دیریکله نهفته |
27589 | اگر علاقه صرفاً تخمین پارامترهای یک مدل باشد (تخمین نقطهای و/یا فاصلهای) و اطلاعات قبلی قابل اعتماد و ضعیف نباشد (میدانم این کمی مبهم است، اما سعی میکنم سناریویی را ایجاد کنم که در آن انتخاب یک قبل دشوار است) ... چرا کسی به جای رویکرد کلاسیک، استفاده از رویکرد بیزی را با مقدمات نامناسب غیر اطلاعاتی انتخاب می کند؟ | چرا کسی باید به جای رویکرد کلاسیک از رویکرد بیزی با پیشینی نامناسب «غیر اطلاعاتی» استفاده کند؟ |
104831 | بر اساس چارچوب بریتانیا برای مشخصات مدل دریایی و اسوارین، درصد RMSE برای سرعت جریان با تقسیم RMS بر حداکثر جریان حداکثر محاسبه میشود. $$\text{RMSE(%)} = \left(\frac{\text{RMSE}}{\text{حداکثر سرعت فعلی}}\right) \cdot100$$ چرا حداکثر جریان حداکثر استفاده میشود و به معنای متوسط نیست؟ دلایل منطقی پشت آن وجود دارد؟ | RMSE برای اعتبارسنجی و کالیبراسیون مدل |
27586 | من برخی از داده های سری زمانی را با استفاده از یک مدل افزودنی عمومی پواسون با استفاده از «PROC GAM» SAS برازش کرده ام. به طور کلی، من از روال اعتبارسنجی متقاطع تعمیم یافته داخلی استفاده کرده ام که حداقل یک نقطه شروع مناسب برای تک اسپلاین من ایجاد می کند، که یک تابع غیر خطی از زمان به همراه یک عبارت پارامتری منفرد است. من در واقع به). تا کنون، به استثنای یکی از مجموعه دادههای من، نسبتاً شنا عمل کرده است. 132 مشاهده در آن مجموعه داده وجود دارد، و GCV نشان می دهد که یک خط شکنی با 128 درجه آزادی. به نظر می رسد ... اشتباه است. خیلی اشتباهه مهمتر از آن، اصلاً پایدار نیست. من یک رویکرد دوم را امتحان کردم، با استفاده از چیزی مانند معیار تغییر در تخمین برای متوقف کردن اضافه کردن درجات آزادی زمانی که تخمین عبارت پارامتری تغییر نمی کند زیرا چرا اگر هیچ چیز متفاوت نیست، به افزودن کنترل ادامه دهیم؟ مشکل این است که تخمین به هیچ وجه پایدار نیست. من درجات آزادی زیر را امتحان کردم، و همانطور که میبینید، عبارت پارامتریک به شدت به اطراف باز میگردد: DF: تخمین پارامتریک: 1 -0.76903 2 -0.56308 3 -0.47103 4 -0.43631 5 -0.33108 6 -0.14974 -0.14974 -0.33108 6 -0.76903 0.62413 10 0.92161 15 1.88763 20 1.98869 30 2.5223 40-60 مسائل همگرایی داشتند 70 7.5497 80 7.22267 90 6.7106518. 4.61436 128 1.32347 من اصلاً نمی دانم که چه چیزی باید از نظر df برای این بیت خاص از داده استفاده کنم. آیا ایده دیگری برای نحوه انتخاب df وجود دارد؟ آیا باید به اهمیت spline نگاه کنم؟ با بررسی بیشتر بین df = 10 و df = 15، به نظر می رسد که df = 12 نزدیک ترین چیزی است که می توانید به تخمین تولید شده توسط 128 برسید و همچنان در محدوده درجات آزادی معقول باشید. همراه با عبارت خطی، مقطع و ترم پارامتری واحد، که شبیه یک مدل بسیار اشباع شده است. آیا فقط رفتن با 12 قابل توجیه است؟ بهعنوان بهروزرسانی دوم، تغییر هموارسازی از «spline(t)» به «loess(t)» منجر به تخمینهای df بسیار خوبتر میشود - آیا باید فقط به هموارسازی لس روی بیاورم؟ | انتخاب df Spline در یک مسئله مدل پواسون افزودنی عمومی |
9577 | من دو مدل معادله تخمین تعمیم یافته (GEE) را به داده های خود برازش داده ام: 1) مدل 1: نتیجه متغیر طولی بله / خیر (A) (سال 1،2،3،4،5) با پیش بینی پیوسته طولی (B) است. سال 1،2،3،4،5. 2) مدل 2: نتیجه همان متغیر طولی بله/خیر (A) است، اما اکنون با پیش بینی من در مقدار سال 1 ثابت شده است، یعنی مجبور به تغییر زمان (B) است. به دلیل عدم اندازهگیری در پیشبینیکننده طولی من در چند نقطه زمانی برای موارد مختلف، تعداد نقاط داده در مدل 2 بیشتر از مدل 1 است. میخواهم بدانم چه مقایسههایی میتوانم به طور معتبر بین نسبتهای شانس انجام دهم، p. -مقادیر و تناسب دو مدل به عنوان مثال: *اگر OR برای پیش بینی B در مدل 1 بزرگتر باشد، آیا می توانم به طور معتبر بگویم که ارتباط بین A و B در مدل 1 قوی تر است. مدل 1 * چگونه می توانم ارزیابی کنم که کدام مدل برای داده های من بهتر است. آیا من درست فکر می کنم که اگر تعداد مشاهدات یکسان نباشد، مربع های R شبه QIC/AIC نباید در بین مدل ها مقایسه شوند؟ هر گونه کمکی بسیار قدردانی خواهد شد. | چگونه می توانم تناسب مدل GEE/لجستیک را زمانی که متغیرهای کمکی دارای برخی از داده های گم شده هستند، ارزیابی کنم؟ |
68786 | من یک پاسخ باینری را برای هر موضوع در 5 شرایط مختلف اندازهگیری کردم. برای هر موضوع و شرایط، آزمایش را 36 بار تکرار کردم. بنابراین من 36 مقدار باینری در هر شرط در هر موضوع دارم. من سعی می کنم یک مدل برای آن داده ها بسازم. فکر میکنم رگرسیون لجستیک چیزی است که به دنبال آن هستم، و با بسته «lmer» کار میکنم. هدف من این است که بررسی کنم آیا شرایط به طور قابل توجهی بر مقادیر مشاهده شده تأثیر می گذارد، بنابراین من دو مدل دارم: lmH1<-lmer(مقدار~شرط، (تأثیرات تصادفی)، داده = مجموعه داده، خانواده = دوجمله ای) و lmH0<-lmer(مقدار ~1، (اثرات تصادفی)، داده=مجموعه داده، خانواده=دوجمله ای) با نگاه کردن به خروجی «anova(lmH0، lmH1)»، قادر به تعیین اهمیت تأثیر وضعیت من باشم. من فقط مطمئن نیستم که چه چیزی را به عنوان اثر تصادفی مشخص کنم. مدل هایی که تاکنون تعریف کرده ام عبارتند از: lmH1 <- lmer (مقدار ~ شرط + (1 | موضوع)، داده = مجموعه داده، خانواده = دوجمله ای) و lmH2 <- lmer (مقدار ~ شرط + (1 | موضوع/شرط)، داده = dataSet، خانواده = دوجملهای) با این حال، مطمئن نیستم که lmer چگونه از تکرارها استفاده میکند، بنابراین نمیدانم که آیا باید آنها را نیز لحاظ کنم در افکت های تصادفی من تکرار می شود یا نه. من میتوانم مدلهای پیشنهادی را طوری اصلاح کنم که گروهبندی تعریفشده توسط اثرات تصادفی بهجای گروهی از مقادیر باینری، به مقادیر باینری خاص اشاره کند. مدلهای جدید من lmH1a <- lmer (مقدار ~ شرط + ( 1 | موضوع/(شرط: تکرار))، داده = مجموعه داده، خانواده = دوجملهای) و lmH2a <- lmer (مقدار ~ شرط + (1 | موضوع/) خواهند بود. شرط/تکرار)، داده = مجموعه داده، خانواده = دوجمله ای) با این مدل ها، R پیام هشدار «تعداد سطوح یک گروه بندی» را برمی گرداند. فاکتور برای اثرات تصادفی برابر با n، تعداد مشاهدات است. اما مدل هنوز محاسبه می شود. هر 4 مدل مقادیر بسیار مشابهی را برای جلوههای ثابت و برای افکتهای تصادفی مشترکشان برمیگردانند (مثلاً جلوههای تصادفی موضوع برای هر 4 مدل بسیار شبیه هستند و شرایط درون جلوههای تصادفی موضوع برای «lmH2» و «بسیار مشابه است. lmH2a`). چگونه می توانم بررسی کنم که کدام ساختار اثر تصادفی برای طراحی و داده های جمع آوری شده من مناسب تر است؟ | رگرسیون لجستیک اثر مختلط: تعریف اثر تصادفی برای طرح اندازه گیری مکرر با تکرار |
95652 | اگر من یک معادله رگرسیون لجستیک به شکل زیر داشته باشم: Logit($\pi$($X_1$, $X_2$)) = $\beta_0$ + $\beta_1$$X_1$ + $\beta_2$$X_2$ + $\beta_3$$X_1$$X_2$ که در آن $X_1$ و $X_2$ هر دو متغیر دستهبندی باینری هستند و یک عدد خالی وجود دارد سلول در جدول احتمالی آنها، چه اتفاقی برای $\beta_3$ می افتد؟ فرض من این است که هنگام تلاش برای محاسبه MLE برای $\beta_3$، هیچ همگرایی وجود نخواهد داشت، مشابه زمانی که یک سلول خالی در جدول احتمالی یک متغیر وابسته و مستقل وجود دارد. کسی می تواند در این مورد توضیح دهد؟ | تعامل 2 متغیر طبقه بندی شده با یک سلول خالی |
57912 | من سعی می کنم یک مدل رگرسیون با اثرات ثابت و تصادفی پیاده سازی کنم. بسته ای که من استفاده می کنم lme4 است. من می خواهم رابطه بین متغیرهای پیوسته X1 و X2 را با استفاده از متغیر طبقه بندی F1 به عنوان یک اثر ثابت پیدا کنم. وقتی میخواهم مدل «model <- lmer(X1 ~ F1 + (1|X2))» را پیادهسازی کنم، خطای زیر را دریافت میکنم: > «تعداد سطوح یک فاکتور گروهبندی برای اثرات تصادفی باید کمتر از عدد باشد. درک من از خطا این است که «X2» کمتر از «X1» (که مقادیر مشابهی دارد) متفاوت است. چرا این یک مشکل است؟ | خطای اثرات تصادفی باید کمتر از تعداد مشاهدات باشد در بسته lmer |
96922 | من روی مشکلی کار می کنم که به طبقه بندی کننده تک کلاسی نیاز دارد. من از LIBSVM استفاده می کنم. میدانم که مطالب زیادی در آنجا وجود دارد، اما هنوز نتوانستم پاسخ سؤالم را پیدا کنم. 1. چگونه پارامترهای بهینه را برای هسته RBF تخمین بزنم؟ 2. با استفاده از `svm-train -s 2 -t 2 -v 5 train.scale`، دقت 49% را دریافت میکنم و مجموعه آموزشی من دادههای پرت ندارد. بنابراین، آیا این واقعاً به معنای دقت 98٪ در سناریوی دنیای واقعی است؟ | اعتبار سنجی متقاطع طبقه بندی کننده یک کلاس |
924 | برای 1000000 مشاهده، من یک رویداد گسسته، X را 3 بار برای گروه کنترل و 10 بار برای گروه آزمایش مشاهده کردم. چگونه می توانم برای تعداد زیادی مشاهدات (1,000,000) تعیین کنم، اگر سه مورد از نظر آماری با ده تفاوت دارند؟ | تعیین کنید که آیا سه مورد از نظر آماری با ده برای تعداد بسیار زیادی مشاهدات متفاوت است (1,000,000) |
64200 | تعریف تابع چگالی احتمال توزیع یکنواخت پیوسته در ویکی پدیا به این صورت است: $$ f(x) = \left\\{ \begin{array}{} \frac{1}{b-a} & \text{for } a \leq x \leq b \\\ 0 & \text{برای } x < a \text{ یا } x > b \end{array} \right. $$ طبق معمول، $\mathbb{P}(X=x) = 0$ برای هر $x در [a,b]$. اما این فقط به این معنی است که تقریباً مطمئنا اتفاق نمی افتد، نه اینکه غیرممکن باشد. با این حال، وقتی $x <a$ یا $x > b$، $\mathbb{P}(X= x) = 0$ و در این مورد، در واقع غیرممکن است. مقادیر در فواصل زمانی مانند $[c,d]$ که در آن $c > b$ نیز هرگز رخ نمیدهد، نه اینکه تقریباً مطمئنا رخ نمیدهد. من فکر کردم یک راه خوب برای حل این مشکل، محدود کردن فضای نمونه برای حذف نتایجی است که غیرممکن است یا هرگز رخ نمی دهد. بنابراین pdf در عوض این خواهد بود: $$f(x) = \frac{1}{b-a} \text{ for } a \leq x \leq b.$$ به این ترتیب، احتمال $0$ همیشه به این معنی است که رویداد تقریباً مطمئناً اتفاق نمی افتد، که (از نظر من) به طور شهودی رضایت بخش است. می خواستم بدانم که آیا این در حال حاضر در نظریه احتمال نظری اندازه گیری انجام می شود؟ تعریف فضای نمونه $\Omega$ که من خوانده ام همیشه آن را به عنوان مجموعه ای از همه نتایج _ممکن_ تعریف می کند. | آیا فضای نمونه می تواند حاوی نتایجی باشد که رخ نمی دهند؟ |
48001 | اجازه دهید $U_1، \ldots، U_n$ $n$ i.i.d متغیرهای تصادفی یکنواخت گسسته در (0،1) باشد و آمار سفارش آنها $U_{(1)}، \ldots، U_{(n)}$ باشد. $D_i=U_{(i)}-U_{(i-1)}$ را برای $i=1، \ldots، n$ با $U_0=0$ تعریف کنید. من سعی می کنم توزیع مشترک $U_i$ و توزیع حاشیه ای آنها و احتمالاً لحظات اولیه آنها را بفهمم. کسی میتونه در این مورد راهنمایی کنه همچنین می توانید لطفا یک کتاب در مورد آمار سفارش معرفی کنید؟ متشکرم. | فاصله بین متغیرهای تصادفی یکنواخت گسسته |
80459 | من اندازه گیری ماهیانه کیفیت آب (نیترات) را از جولای 2005 تا اکتبر 2013 (84 اندازه گیری) دارم. با این حال، هیچ اندازه گیری از اکتبر، 2007 تا ژوئن، 2009 (21 اندازه گیری) وجود ندارد. آیا می توانید به من اطلاع دهید که چگونه می توانم داده های از دست رفته را با استفاده از سایر مجموعه داده ها پر کنم؟ بهترین نرم افزاری که برای پر کردن داده های از دست رفته استفاده می شود را پیشنهاد می کنید؟  پیشاپیش متشکرم! | چگونه سری داده های از دست رفته را پر کنیم؟ |
48009 | من یک سوال در مورد مقدار متوسط در مقیاس لیکرت دارم. هدف من شناسایی عوامل مهم برای انتخاب رابطه کوتاه مدت یا بلند مدت با پیمانکار فرعی است. من از مقیاس لیکرت از «بسیار موافق» تا «بسیار مخالف» در 22 عامل استفاده کردم. سپس از 41 پیمانکار اصلی سوال کردم و از آن نتیجه برای تجزیه و تحلیل میانگین و انحراف معیار همه عوامل استفاده کردم. بعد از اینکه میانگین و SD را به دست آوردم، میخواهم بپرسم که آیا و چگونه میتوانم برخی از فاکتورهای 22 فاکتور خود را با مقدار متوسط کاهش دهم یا خیر. اگر روش پذیرفته شده ای هست لطفا به من هم بگویید. و اگر بتوانید مرجعی در مورد آن روش ارائه دهید، متشکرم. متاسفم که شما را گیج می کند در واقع هدف من از مطالعه شناسایی عوامل مهم برای انتخاب رابطه کوتاه مدت یا بلندمدت با پیمانکار فرعی است. منظور از چگونه می توانم برخی از فاکتورهای 22 عامل خود را با مقدار متوسط کاهش دهم به این معنی است که می خواهم با استفاده از نتیجه مقدار میانگین تعداد عامل را به کمتر از 22 عامل کاهش دهم. به عنوان مثال، نتیجه زیر نتیجه میانگین و SD در 22 عامل است، بنابراین پس از نتیجه، میخواهم عوامل تأثیرگذار مهم را با مقدار میانگین پیدا کنم. برای من، میخواهم (مقدار میانگین > و = 4) را بگیرم، بنابراین همه عواملی که به معنای مقدار > و = 4 هستند را به عنوان عامل تأثیرگذار مهم در نظر میگیرم. به هر حال من شما را روشن می کنم؟ اگر چنین است، آیا این روش پذیرفته شده است (میانگین > و = 4) خوب است؟ یا اگر روشی دارید لطفا با من به اشتراک بگذارید. یک چیز دیگر، اگر شما با تفکر من موافق هستید، آیا مرجعی برای پشتیبانی دارید زیرا اکنون در حال تلاش برای یافتن مرجع برای پشتیبانی هستم. با تشکر از شما عوامل میانگین SD کنترل زمان در برنامه ریزی 4.537 0.596 کیفیت کار 4.463 0.552 همکاری 4.268 0.549 تجربه 4.220 0.725 منابع 4.171 0.587 تعهد 4.121520.246 . نظارت 4.122 0.510 هماهنگی 4.049 0.631 اعتماد 4.024 0.724 حل مشکل مشترک 4.024 0.689 درک روشن 4.000 0.632 آموزش ایمنی برای کارکنان 3.917 0.835 Professional 3.976 0.651 آموزش مهارت کارکنان 3.951 0.545 انعطاف پذیری برای تغییر 3.927 0.608 نوآوری 3.878 0.678 سیستم کنترل ایمنی 3.854 0.691 کنترل دفع ضایعات 3.7338260 مالی. دانش 3.683 0.567 | مقدار میانگین قابل قبول برای مقیاس لیکرت چیست؟ |
61747 | من مجموعه ای از مقادیر $x$ و $y$ دارم که از نظر تئوری به صورت نمایی مرتبط هستند: $y = ax^b$ یکی از راه های بدست آوردن ضرایب استفاده از لگاریتم های طبیعی در هر دو طرف و برازش یک مدل خطی است: > fit <- lm(log(y)~log(x)) > a <- exp(fit$coefficients[1]) > b <- fit$coefficients[2] راه دیگری برای به دست آوردن این از یک رگرسیون غیرخطی، با توجه به مجموعه نظری مقادیر شروع استفاده میکند: > برازش <- nls(y~a*x^b، start=c(a=50، b=1.3)) آزمونهای من بهتر و مرتبطتر با تئوری را نشان میدهند. اگر الگوریتم دوم را اعمال کنم نتیجه می شود. با این حال، من می خواهم معنی آماری و مفاهیم هر روش را بدانم. کدام یک از آنها بهتر است؟ | رگرسیون خطی در مقابل غیرخطی |
111577 | می توانید برای من توضیح دهید که چگونه شکل یک منحنی ROC تعیین می شود؟ از شکل زیر به نظر می رسد که برای هر بار مثبت بودن کلاس واقعی (C) بالا می رود و وقتی منفی است به سمت راست می رود. چرا به نظر می رسد که فقط بر اساس کلاس واقعی است تا طبقه بندی واقعی درست یا غلط شی؟ حدس میزنم به امتیاز ذکر شده مربوط باشد، اما نمیدانم چگونه محاسبه و رتبهبندی میشود. لطفا توضیح دهید.  ممنون. | شکل نمودار ROC |
57918 | پس از سوال من انتخاب نمونه هکمن در مقابل OLS در مورد معنای نسبت میلز، من متعجبم که چرا برخی از محققان تعمیم هکمن را به جای روش واقعی هکمن تخمین می زنند. (براساس Das et. 2003 http://www.jstor.org/stable/3648610 (نسخه دروازهدار). نسخه تعمیمیافته به جای استفاده از نسبت میلز فقط شامل احتمالات پیشبینیشده، نسبت میلز، مربعهای آنها و شرایط تعامل در مرحله 2 من مزایا / معایب این روش را در مقایسه با انتخاب نمونه پایه درک نمی کنم؟ برای تست انتخاب نمونه ترجیح می دهید؟ | تعمیم روش دو مرحله ای هکمن |
27580 | من مقداری کد پایتون نوشته ام که تجزیه و تحلیل داده های (شبکه ای) را انجام می دهد. این عمدتاً داده های بزرگی است که از SQL می آید و من با آمار و الگوریتم ها بازی می کنم. با این حال، پیکربندی تعامل بین ماژولها و ردیابی/اشکالزدایی آنچه با دادهها میگذرد چندان راحت نیست. آیا ابزاری را می شناسید که بتواند به خوبی ماژول های جریان داده را با برخی اطلاعات راهنمای ابزار، مرورگر داده های جدول و غیره به خوبی نمایش دهد؟ چیزی که بتوانم کد پایتون خود را در آن قرار دهم و داده های جدول مانند را نمایش دهم. | ابزاری برای کار با جریان داده آسانتر/بصری تر |
57910 | من در حال انجام این پروژه هستم که در آن بررسی می کنیم که آیا شبکه های اجتماعی می توانند بر متمایز بودن افراد تأثیر بگذارند یا خیر. به طور خلاصه، ما یک گروه را با یک رسانه اجتماعی آماده کرده ایم و دیگری گروه کنترل است. پس از آن، پرسشنامه ای به آنها داده شد که در آن... 1. 12 عنصر هویتی را نوشتند 2. به این عناصر بر اساس میزان مرکزیت هویتشان در مقیاس لیکرت از 1 تا 7 رتبه دادند که در آن هفت برای هویت آنها بسیار مرکزی است ( این مقیاس در سراسر استفاده می شود) 3. به این عناصر رتبه بندی کنید که الف) آنها را متفاوت می کنند ب) چگونه نقش اجتماعی خاصی را تشکیل می دهند و ج) این عناصر چقدر آنها را از هم جدا می کنند. ما از کلمات بیشتر استفاده نمی کنیم، فقط از رتبه بندی آنها استفاده می کنیم. تا اینجای کار خیلی خوبه. ما متغیرهای زیادی در پایگاه داده خود داریم: 1: سن 2: جنس 3: پرایمینگ یا گروه کنترل 4: مرکزیت عناصر (میانگین 2 سوال در مورد مرکزیت به روش های مختلف پرسیده شده) (12 متغیر) 5: چقدر متفاوت است آنها را (12 متغیر) 6\ می کند. چگونه آنها را نقاط می کند (12 متغیر) 7: چقدر آنها را از هم جدا می کند (12 متغیر) روشی که من تاکنون به این موضوع پرداخته ام: میانگین مرکزیت را برای هر عنصر پیدا کردم، آن را در متغیر 5-6-7 ضرب کردم ( به بالا نگاه کنید) به صورت حروف و مربع عدد (اعداد 1-7 را می دهد). سپس میانگین این سه متغیر جدید (CentralityXDifference، CentralityXRole، CentralityXSeperateness) تعدادی متمایز بودن کل را به ما می دهد. متأسفانه این ابزارها بسته به پرایمینگ یا گروه کنترل متفاوت نیستند، اما اشکالی ندارد. احتمالاً میتوانیم استدلال کنیم که چرا. در اینجا چند سوال مطرح می شود. آیا گروه آغازگر تمایل دارند تا عناصر با مرکزیت بالا را بسیار متمایز ارزیابی کنند؟ من نمی توانم راهی برای انجام این کار به روشی هوشمندانه پیدا کنم، بنابراین اگر ایده ای دارید ممنون می شوم. 2. آیا من کاری را اشتباه انجام داده ام؟ آیا در روش من جایی برای پیشرفت وجود دارد؟ | چگونه می توانم در موارد خاص بین دو گروه گرایش پیدا کنم؟ |
78349 | من همیشه به این فکر می کردم. فرض کنید شخصی یک صفحه گسترده با مجموعه بزرگی از اعداد، مثلاً 10000، به شما می دهد و می گوید این مجموعه اعداد از چه توزیعی پیروی می کند (گاوسی، نمایی، پواسون و غیره)؟ چگونه می خواهید پاسخ را تعیین کنید؟ | تعیین توزیع مجموعه ای از اعداد مرتب شده |
104832 | من به دنبال نمونه هایی از توابع زیان جایگزین می گردم که برای طبقه بندی کلاس باینری مفید هستند، اما با اتلاف صفر-یک سازگار نیستند، جایی که من از سازگاری به معنای توابع زیان جایگزین همگرا با پیش بینی بیز استفاده می کنم [1]. ] (همچنین به عنوان کالیبراسیون طبقه بندی، سازگاری بیز و ثبات نمونه بی نهایت نیز شناخته می شود). یک نتیجه کلاسیک از [1]، بیان می کند که اگر $\psi$ یک تابع زیان جایگزین محدب باشد، $\psi$ با توجه به ضرر صفر و یک سازگار است اگر و فقط اگر $\psi$ در صفر و $ قابل تمایز باشد. \psi'(0) < 0$. به نظر می رسد که این شامل تمام توابع تلفات پرکاربرد (به عنوان مثال، از دست دادن لولا، تلفات لجستیک، نمایی و غیره) باشد. من به دنبال نمونه هایی از توابع از دست دادن جانشین هستم که مفید هستند اما در این تنظیم سازگار نیستند. هر ایده ای؟ [1] P. L. Bartlett, M. I. Jordan, and J. D. McAuliffe, Convexity, Classification, and Risk Bounds J. Am. آمار Assoc., pp. 1–36, 2003. ↩ | توابع از دست دادن جایگزین که در مورد کلاس باینری سازگار نیستند |
78343 | اجازه دهید $Y_1، \cdots، Y_n$ متغیرهای تصادفی مستقل باشند که هر کدام با توزیع $N(\mu, \sigma^2)$، سپس \begin{align*} S^2 &= \sum(Y_i - \overline{ Y})^2 \\\ &= \sum((Y_i - \mu) - (\overline{Y} - \mu))^2 \\\ &= \sum((Y_i - \mu)^2 + (\overline{Y} - \mu)^2 - 2(Y_i - \mu)(\overline{Y} - \mu)) \\\ &= \sum(Y_i - \mu) ^2 + \sum(\overline{Y} - \mu)^2 - 2(\overline{Y} - \mu)(n\overline{Y} - n\mu) \\\ &= \sum(Y_i - \mu)^2 - n(\overline{Y} - \mu)^2 \end{align*} با تقسیم بر $\sigma^2$ در هر دو طرف، میبینیم که $S^2 \sim \chi^2 (n-1)$، برخی کتاب ها می گویند که از این طریق می توانید $S^2$ و $\overline{Y}$ را مستقل اعلام کنید، چرا؟ | استقلال بین مجموع باقیمانده مربع ها و میانگین؟ |
9392 | داده های من به این شکل است (F=ویژگی ها) F1 F2 F3 F4 F5 F6 F7 F8.... ID1 0.67 0.76 0.3 0.54 0.21 0.88 0.97 0.45.... ID2 0.76 0.68 0.10 0.45 0.45 0.10 0.45. ID3 0.67 0.76 0.3 0.54 0.21 0.88 0.68 0.76.... ID4 0.67 0.10 0.3 0.45 0.3 0.88 0.97 0.45.... ... ... ... من حدود 40 ویژگی را اینجا قرار داده ام. اگر آستانه ای برای مثلاً 4 ویژگی تعیین کنم، چیزی که به دنبال آن هستم ترکیبی از 4 ویژگی است که با هم، بیشترین ارتباط و اهمیت را در مجموعه داده دارند. من به نوعی امتیاز نیاز دارم که میزان خوب بودن ترکیب ویژگی ها را اندازه گیری کند. این همان چیزی است که من از نمره اعتماد (یا هر نمره ای که ممکن است آن را نامگذاری کنیم) منظورم است. بنابراین به جای انتخاب 1 ویژگی، می خواهم ترکیبی از 4 ویژگی را انتخاب کنم. به عنوان مثال. F1-F4-F9-F12 = 0.92 F2-F3-F7-F6 = 0.85 F5-F3-F4-F8 = 0.667 در اینجا، F1-F4 تفریق نیست. من فقط این دو ویژگی را به هم متصل می کنم. نمرات بالا، من نمی دانم چگونه آن را بگیرم. این سوال من است؟ بنابراین من نمی دانم از چه نوع تستی استفاده کنم یا می توان از آن استفاده کرد. چگونه می توانم در مورد آن اقدام کنم؟ با تشکر | چگونه می توان امتیاز ترکیبی از ویژگی ها را بدست آورد |
111575 | من یک سوال در رابطه با استفاده از وزن دهی داده ها هنگام نگاه کردن به یک زیر گروه از یک نمونه جمعیت دارم. من از دادههای نظرسنجی استفاده میکنم که با وزن ارائه شدهاند، اما فقط میخواهم شرکتکنندگان قد بلندتر را در تحلیل خود لحاظ کنم. هنگامی که من نمونه فرعی خود را انتخاب کردم، وزن داده ها به طور واضح 1 نمی شود. یا باید وزن ها را به روش دیگری دوباره محاسبه کنم. داده ها در SPSS هستند. آیا باید از ماژول نمونه پیچیده استفاده کنم؟ | آیا هنگام تجزیه و تحلیل یک نمونه فرعی نظرسنجی جمعیت باید از داده های وزنی استفاده کنم؟ |
67150 | خواندن مقاله _توزیع محصول داخلی دو بردار گاوسی پیچیده و کاربرد آن در عملکرد MPSK توسط Mallik R.K._ نمی توانم یکی از مراحل را دریافت کنم. نویسنده دو بردار گاوسی پیچیده را فرض میکند $$\vec{X}\sim\mathcal{CN}(\vec{\mu_X},\mathrm{I})، \\\ \vec{Y}\sim\mathcal{CN }(\vec{\mu_Y}،\mathrm{I})،\\\ \mathrm{E}\left[\Re(x_i)\Re(x_j)\right]=\mathrm{E}\left[\Re(y_i)\Re(y_j)\right]=\delta_{ij}، \\\ \mathrm{E}\left[\Im(x_i)\Im(x_j)\right]=\mathrm{E}\left[\Im(y_i)\Im(y_j)\right]=\delta_{ij}، \\\ \mathrm{E}\left[\Re(x_i)\Re(y_j)\right]=\mathrm{E}\left[\Im(x_i)\Im(y_j)\right]=0. $$ و بعد از توزیع مشترک اجزای واقعی و خیالی محصول درونی آنها است: $$Z=\vec{Y}^H\\!.\vec{X}، \\\\\ Z_1=\Re(Z ),\\\ \ Z_2=\Im(Z)$$ در مقاله آمده است که > ... مشخص است که $Z_1$ و $Z_2$ مشروط به $Y$ مستقل هستند اما بعد ادامه دادم. و پیدا کرد کوواریانس بین $Z_1، Z_2$ و نتیجه غیر صفر گرفت، بنابراین نمی توانند مستقل باشند. یا من جایی در اشتقاقاتم اشتباه می کنم؟ اینجا هستند. شروع از تعریف: $$\require{cancel} \begin{eqnarray} &&\mathrm{cov}(z_1,z_2)= \mathrm{cov}\left(\sum_i(\Re(y_i)\Re(x_i)+\Im(y_i)\Im(x_i))،\sum_i(\Re(y_i)\Im(x_i)-\Im (y_i)\Re(x_i))\راست)=\\\ &=&\mathrm{E}\left[\left(\sum_i(\Re(y_i)\Re(x_i)+\Im(y_i)\Im(x_i))\right)\\!\\!\left (\sum_i(\Re(y_i)\Im(x_i)-\Im(y_i)\Re(x_i))\right)\right]-\\\ &-&\mathrm{E}\left[\sum_i(\Re(y_i)\Re(x_i)+\Im(y_i)\Im(x_i))\right]\\!\\!\mathrm{E} \left[\sum_i(\Re(y_i)\Im(x_i)-\Im(y_i)\Re(x_i))\right]=\\\ &=&\mathrm{E}\left[ \sum_i\sum_j\Re(y_i)\Re(y_j)\Re(x_i)\Im(x_j)\right]+\mathrm{E}\left[\sum_i\ sum_j\Im(y_i)\Re(y_j)\Im(x_i)\Im(x_j)\right]-\\\ &-&\mathrm{E}\left[\sum_i\sum_j\Re(y_i)\Im(y_j)\Re(x_i)\Re(x_j)\right]-\mathrm{E}\left[\sum_i\ sum_j\Im(y_i)\Im(y_j)\Im(x_i)\Re(x_j) \راست]-\\\ &-&\left(\sum_i (\Re(y_i)\mathrm{E}\left[\Re(x_i)\right]+\Im(y_i)\mathrm{E}\left[\Im(x_i)\ راست])\راست)\چپ(\sum_i (\Re(y_i)\mathrm{E}\left[\Im(x_i)\right]-\Im(y_i)\mathrm{E}\left[\Re(x_i)\right])\right)=\ \\ &=& \sum_i\sum_j\Re(y_i)\Re(y_j)\cancelto{0}{\mathrm{E}\left[\Re(x_i)\Im(x_j)\right]}+\sum_i \sum_j\Im(y_i)\Re(y_j)\cancelto{\delta_{ij}}{\mathrm{E}\left[\Im(x_i)\Im(x_j)\right]}-\\\ &-&\sum_i\sum_j\Re(y_i)\Im(y_j)\cancelto{\delta_{ij}}{\mathrm{E}\left[\Re(x_i)\Re(x_j)\rig ht]}-\sum_i\sum_j\Im(y_i)\Im(y_j)\cancelto{0}{\mathrm{E}\left[\Im(x_i)\Re(x_j)\right]}-\\\ &-&\left(\sum_i (\mu_{\Re(x)_i}\Re(y_i)+\Im(y_i)\mu_{\Im(x)_i})\right)\left(\sum_i ( \Re(y_i)\mu_{\Im(x)_i}-\Im(y_i)\mu_{\Re(x)_i})\right)=\\\ &=&\\!\sum_i\\!\sum_j\left(\\! \Re(y_i)\\!\Im(y_j)\\!(\mu_{\Re(x)_i}\mu_{\Re(x)_j}\\!\\!-\\!\mu_{ \Im(x)_i}\mu_{\Im(x)_j})\\ !\\!+\\!\mu_{\Re(x)_i}\mu_{\Im(x)_j}(\Im(y_i)\Im(y_j)\\!-\\!\Re(y_i )\Re(y_j)\\!)\\!\\!\راست) \end{eqnarray} $$ و جمله آخر به وضوح صفر نیست (مگر اینکه میانگین صفر باشد). پس اشتباه کجاست؟ | استقلال بخش های واقعی و خیالی حاصل ضرب اسکالر بردارهای نرمال مختلط چند متغیره |
27588 | من یک مطالعه موردی دارم که در آن یک شرکت توپهای گلف جدید با پوششهای قویتر از توپهای گلف فعلی ساخت. یکی از تکنسین ها نگران است که پوشش جدید ممکن است مسافت رانندگی را کاهش دهد. آزمایشی انجام شد که در آن 40 نوع از هر توپ توسط یک ماشین مورد اصابت قرار گرفت تا میانگین فاصله رانندگی دو توپ مشخص شود. فواصل هر توپ در یک صفحه گسترده داده شد. در اینجا نمونه ها وجود دارد: فعلی: 264.00 261.00 267.00 272.00 258.00 283.00 258.00 266.00 259.00 270.00 263.00 264.000 264.000 226.000 226.00 283.00 255.00 272.00 266.00 268.00 270.00 287.00 289.00 280.00 272.00 275.00 265.00 260.00 2278.00 2278.00. 274.00 273.00 263.00 275.00 267.00 279.00 274.00 276.00 262.00 جدید; 277.00 269.00 263.00 266.00 262.00 251.00 262.00 289.00 286.00 264.00 274.00 266.00 262.00 2281.00 2281.00. 250.00 263.00 278.00 264.00 272.00 259.00 264.00 280.00 274.00 281.00 276.00 269.00 268.00 2250.00 2250.00. 253.00 260.00 270.00 263.00 261.00 255.00 263.00 279.00 اینها سوالات هستند: 1. منطقی را برای آزمون فرضیه ای که پار می تواند برای مقایسه فواصل راندن توپ فعلی و جدید به شما بگوید. آنچه بیل گفت) که او مایل است توپ جدید را بفروشد مگر اینکه شواهد زیادی وجود داشته باشد که توپ مقاوم در برابر برش کندتر از توپ قدیمی است، بنابراین شما باید فرضیه خود را بر اساس آن چارچوب بندی کنید. نکته: شما تمایل بیشتری به خطای نوع II دارید. تجزیه و تحلیل داده ها برای ارائه نتیجه گیری و اظهارات آزمون فرضیه (در 0.05). همچنین نسخههای روایتی از کدام یک از اشکال بالا را که استفاده میکنید، بنویسید، مانند: Ho: میانگین این است ... مقدار p برای آزمون شما چیست؟ توصیه شما برای Par, Inc. چیست؟ 3. خلاصه های توصیفی زیر را از داده ها برای هر مدل ارائه دهید: فقط میانگین ها و واریانس ها و مقادیر z. 4. فاصله اطمینان 95% برای اختلاف میانگین دو جمعیت چقدر است؟ 5. آیا نیازی به اندازه نمونه بزرگتر و آزمایش بیشتر با توپ گلف می بینید؟ بحث کنید. من در جای دیگری به دنبال کمک گشتم و به نظر می رسد همه از آزمون t برای انجام تجزیه و تحلیل استفاده می کنند. آیا با توجه به اینکه حجم نمونه هر دو بالای 30 است، نباید از آزمون z استفاده شود؟ من همچنین می خواهم برای درک چگونگی پاسخ به سؤالات دیگر راهنمایی داشته باشم اما سؤال اصلی من مهمترین سؤال است. | مشکل درک اینکه از چه نوع آزمونی استفاده کنید و چگونه با سؤالات ارائه شده ادامه دهید |
57911 | من به طور خاص با آمار آشنا نیستم و به دنبال روش هایی برای تجزیه و تحلیل اعدادی هستم که برای نهادهای مختلف به براکت یا گروه متفاوت تقسیم شده اند. سه شرکت را در نظر بگیرید. * A اعلام می کند که آنها 10 کارخانه دارند که بین 10000 تا 20000 ویجت در سال تولید می کنند و 15 کارخانه بین 20000 تا 40000 تولید می کنند * B اعلام می کند که آنها دارای 7 کارخانه هستند که بین 15000 تا 25000 بین 15000 تا 25000 ویجت تولید می کنند و بین 25000 ویجت تولید می کنند. 35,000 * C اعلام می کند که آنها 5 کارخانه دارند که بین 10,000 تا 23,000 ویجت و 14 بین 23,000 تا 40,000 ویجت تولید می کنند. از چه روش های آماری می توان استفاده کرد (و آیا وجود دارد) که به شما امکان می دهد این داده ها را با هم جمع کنید و پیش بینی های کلی انجام دهید (همه شرکت ها به طور متوسط x کارخانه دارند که 15000 ویجت در سال تولید می کنند و y کارخانه که 40000 ویجت تولید می کند)؟ | روش های آماری برای مقایسه براکت های مختلف چیست؟ |
9795 | > **تکراری احتمالی:** > یادگیری نظارت شده با رویدادهای نادر، زمانی که نادر بودن به دلیل تعداد > زیاد رویدادهای خلاف واقع است، من سعی می کنم دیابت را با استفاده از مجموعه داده BRFSS با استفاده از یک مدل طبقه بندی یادگیری نظارت شده پیش بینی کنم. اما من می بینم که متغیر هدف که دیابت دارد یا نه، منحرف است. یعنی 90 درصد سوابق غیر دیابتی و فقط 10 درصد سوابق دیابتی است. چگونه چولگی در متغیر هدف را کنترل کنم؟ | چگونه می توان متغیرهای هدف باینری اریب را مدیریت کرد؟ |
104836 | برای تنظیم صحنه - من از شبکههای عصبی در برنامه SAS استفاده میکنم، قبل از این 1000 متغیر نقطه انتخاب شدهام روی ترکیبی از دانش انسانی و نوترکیبی متغیر (PCA و غیره) من از اعتبار سنجی 60-20-20 3 راه استفاده میکنم و 70-15-15 من روشی را ابداع کرده ام که مطمئنم در جایی ایراد دارد زیرا به نظر می رسد بسیار خوب کار می کند! قبلاً راه اندازی دو شبکه عصبی مستقل که از هر نظر یکسان هستند و نتایج قابل مقایسه ای دریافت می کنند دشوار بود. همچنین بدون قوانین ثابت واقعی در اطراف شبکه های عصبی به جز (از خواندن) \- 1 لایه معمولاً خوب است \- معمولاً فقط به تعدادی نورون در هر لایه برابر تعداد ورودی ها نیاز دارید. طرح لایه/نرون مشخص شده من می دانم که این یک محصول یادگیری تصادفی است، اما اگر 1 یا 2 از 5 کار کند، برای من خوب نیست. همچنین نگاه کردن به یک نمایش گرافیکی از این تناسبهای خوب معمولاً (*اما نه همیشه**) هنگام مشاهده نمایشهای گرافیکی، تناسبهای دنیای قدیمی و غیرواقعی ایجاد میکند. بنابراین من به ایده ای رسیدم که در آن می توانم X تعداد مدل را برای هر آرایش شماره لایه/نرون مشخصی اجرا کنم. تعداد نورون ها یا لایه ها را 1 تغییر دهید و X بار تکرار کنید.. تکرار کنید. مدلسازی مؤثر همه طرحبندیهای معقول این به من اجازه داد بسیاری از مدلهای (100 و 1000) را با تکرارهای متعدد جمعآوری کنم و به دنبال مدلهای سازگار و مناسب بگردم که در آن R^2 برای اعتبارسنجی، آموزش آزمایش و غیره و سایر ارقام به صورت خودکار جدولبندی میشوند. . اگر من یک دسته خوب و ثابت (مثلاً 3 نورون سیگموئیدی در 1 لایه و 1 در لایه دوم) به خوبی در 10 تکرار و به طور مداوم در طول 10 تکرار کار کنم، سپس به خروجی گرافیکی آن مدل ها برای منحنی های واقع گرایانه نگاه می کنم. به عنوان گزینه دیگری می توانم 2 مجموعه را اجرا کنم. این مدل ها برای 2 طرح بندی ستون اعتبار سنجی مختلف. بنابراین تعداد مدل های بالا را دو برابر کنید. این بهعنوان یک نتیجه اعتبارسنجی سهطرفه که بهطور تصادفی تولید میشود، ممکن است بهطور تصادفی نتایج بسیار پایینی را در بخش آزمایش جمعآوری کند. من تفاوتهایی را در اعتبارسنجی سهطرفه متفاوت میبینم. یکی از ترسها این است که آیا بعد از استفاده از مجموعه تست، از مرز پالایش عبور میکنم؟ یا اینکه من مدلها را کور میکنم و سپس به مجموعههای آزمایشی نگاه میکنم آیا این مشکلی ندارد؟ تست، آموزش و اعتبارسنجی همگی برای همه مدل ها ثابت هستند، همچنین، آیا حتی مهم است که از هر 10 مدل با مشخصات یکسان، 1 مدل خوب و بقیه همه بد باشند؟ آیا خطاهای کورکننده دیگری که مرتکب می شوم وجود دارد؟ از هر پاسخی قدردانی کنید زیرا خواندن آن طولانی است | روش شبکه های عصبی؟ آیا من کار اشتباهی انجام می دهم؟ |
9390 | یک تیم فوتبال انگلیسی مجموعه ای از مسابقات را با حریفان مختلف با توانایی های متفاوت انجام می دهد. یک شرطبندی برای هر مسابقه شانسهایی را ارائه میکند که آیا برد خانگی، برد خارج از خانه یا تساوی خواهد بود. در قسمتی از فصل، تیم n مسابقه انجام داده است و $k$ از آنها مساوی کرده است، که بیش از حد انتظار است. این احتمال وجود دارد که بوکساز به جای اینکه فقط بدشانس باشد، شانسهای این مسابقات را اشتباه قیمتگذاری کند؟ اگر شرطبندی به قیمتگذاری بازیهای باقیمانده تیم به روشی مشابه ادامه دهد، و من 1 دلار شرط میبندم که هر مسابقه مساوی شود، سود مورد انتظار من چقدر است؟ | این احتمال وجود دارد که یک کتابساز شانسهای بازیهای فوتبال را اشتباه قیمتگذاری کند؟ |
78346 | آیا این امکان محاسبه وجود دارد؟ از یک توزیع نرمال، ما یک نمونه $ (11، 13، 13، 14، 14، 14، 15، 15، 17، 18) گرفتیم. $ فاصله اطمینان 98 $ \% $ مقدار مورد انتظار را محاسبه کنید. من خودم در حال مطالعه آمار هستم اما نمی دانم از چه فرمولی در اینجا استفاده کنم. | فاصله اطمینان از مقدار مورد انتظار |
61743 | من در اینجا به مقاله ویکی پدیا در مورد الگوریتم تغییر میانگین اشاره می کنم. در اینجا هسته گاوسی به صورت $e^{-c\|x_i - x\|^2 }$ نشان داده می شود: سؤالات من به شرح زیر است: * آیا $c$ همیشه مثبت است؟ یعنی آیا وزن های داده شده توسط هسته همیشه بین 0 و 1 هستند؟ * با نگاه کردن به تصویری که الگوریتم را توضیح می دهد، دیدم که در حالت دو بعدی، هسته را می توان به عنوان یک دایره فهمید. این دایره در هر تکرار در نظر گرفته می شود؟ با تشکر | درک الگوریتم تغییر میانگین با هسته گاوسی |
78341 | من مدلهای مختلط خطی را برازش میکنم و به دلیل چند خطی بودن مقدار p کمی دارم. فاکتورهای دارای بالاترین VIF را حذف کردم تا زمانی که هیچ کدام از آنها بزرگتر از 3 نبود. با یک VIF 1 میگرفتم. از SE در خلاصه مدل، واریانس را محاسبه کردم، آن را بر VIF تقسیم کردم و سپس SE جدید را دوباره محاسبه کردم. و t-value که من سپس مقادیر p تنظیم شده را از آن محاسبه کردم. آیا این روش را یک رویکرد معتبر می دانید؟ من هیچ نشریه ای در مورد آن موضوع پیدا نکردم و می ترسم کار را کمی آسان کنم؟!؟ من تعدادی کد مستقل را در زیر اضافه کردم: # create data.frame با خلاصه مقادیر t و p inflated = data.frame(Factor = c((Intercept)، دما، رنگ، مقدار آبجو)، مقدار = c(-3.2،2.1،0.5،3)، Std.Error = c(3،1،0.8،0.9)، DF = c(20،20،20،20)) summary$t.value = NA summary$t.value = summary$Value/summary$Std.Error summary$p.value = NA برای (i در 1:4) { p .value = 2*pt(-abs(summary$t.value[i])، df = 20) summary$p.value[i] = p.value } # برخی از عوامل تورم واریانس متوسط vif = c(1.4،3،1.03،2.4) # محاسبه مقادیر t و p جدید با در نظر گرفتن VIFs summary$var_new = sqrt(summary$Std.Error)/vif # واریانس / VIF = خلاصه واریانس تعدیل شده$t.value_new = summary$Value/(summary$var_new)^2 # adjusted t-values summary$p.value_new = NA برای (i در 1:4) #محاسبه p-values از t-values تنظیم شده { p.value_new = 2* pt(-abs(summary$t.value_new[i])، df = 20) summary$p.value_new[i] = p.value_new } | مقادیر p را برای عوامل تورم واریانس تنظیم کنید |
68879 | من مدلهای ARIMA و NAR را در 10 سری زمانی تک متغیره مختلف نصب کردم. این سری های زمانی مشخصه های آب در یک تصفیه خانه آب هستند (CO$_2$، TDS، TH، pH، ...). پس از تطبیق مدلهای مناسب، هفت عقبتر از مدلهای هر سری را پیشبینی کردم. من در پایان هر سری هفت مشاهده دارم که باید با هفت مورد پیش بینی شده مربوطه ترسیم شود. پس از رسم، متوجه شدم که مقادیر پیشبینیشده توسط مدل NAR از نظر بصری نزدیک به مشاهدهشده هستند، اما مقادیر توسط ARIMA تقریباً در بین مقادیر مشاهدهشده ثابت بودند. برای مقایسه بیشتر تصمیم گرفتم MSE را برای مقادیر پیش بینی شده برای دو مدل محاسبه کنم. انتظار من این بود که MSE برای NAR باید کوچکتر از ARIMA باشد، اما این کاملاً متفاوت بود. برای مثال، برای یکی از سریهای من مقادیر پیشبینیشده توسط NAR از نظر بصری در مقایسه با مقادیر ARIMA نزدیک بود، اما MSE آن بیشتر از ARIMA بود. چرا؟ لطفا اجازه دهید چگونه می توانم آنها را از نظر آماری مقایسه کنم. | مقایسه مقادیر پیشبینیشده افق برای دو مدل (ARIMA و NAR)؟ |
34291 | این سوال در مورد نقش تنظیم کننده در یک تابع هدف است. با توجه به تابع ضرر $f(x)$، یک تابع تنظیم کننده $r(x)$، و $\lambda$ که یک تابع مبادله ای است، هدف ما این است که $\min f(x) + \lambda*r( x) دلار. من می توانم درک کنم که با افزایش مقدار $\lambda$، خطای آموزشی ما افزایش می یابد. می خواستم بدانم با افزایش $\lambda$، خطای تست چگونه رفتار می کند. از تشخیص الگو و یادگیری ماشین توسط بیشاپ، متوجه شدم که خطای تست ابتدا کاهش می یابد و سپس شروع به افزایش می کند. در نتیجه، $\lambda$ را انتخاب می کنیم که کمترین خطای اعتبارسنجی را دارد. آیا همان الگو (کاهش و سپس افزایش) برای هر یک از عملکردهای منظم کننده تکرار می شود؟ یا آیا این الگو به عملکرد تنظیم کننده ای که ما استفاده می کنیم بستگی دارد؟ | چگونه الگوی خطای تست به عملکرد تنظیم کننده بستگی دارد؟ |
61746 | من سعی می کنم از دست دادن فرصت مورد انتظار (EOL) را برای یک مشکل سرمایه گذاری ساده محاسبه کنم، جایی که هزینه **_C_** دقیقاً 5 میلیون تعیین شده است و ارزش **_V_** به طور معمول بین 2.5 توزیع می شود. میلیون و 25 میلیون (با 90% CI). من می دانم که EOL صرفاً _هزینه تصمیم گیری اشتباه_ x _احتمال تصمیم گیری اشتباه_ است. در اینجا تصمیم پیش فرض سرمایه گذاری است. در چنین حالتی، من فرض میکنم EOL را میتوان به این صورت محاسبه کرد: 1. تقسیم توزیع ارزش به بخشهای کوچک 2. برای هر بخش از بازه (0, _C_ ] محاسبه میانگین و احتمال آن 3. ضرب میانگین هر بخش با احتمال آن 4. خلاصه کردن همه محصولات از مرحله 3 حالا برای این مورد خاص، EOL را 246000 محاسبه کردم. با این حال، این متفاوت از EOL است که برای همان مشکل در ادبیات محاسبه شده است که از یک فرمول مرموز برای محاسبه استفاده می کند، من فقط به دنبال تأییدی هستم که: 1. الگوریتم اشتباه است 2. الگوریتم صحیح است. اما نتیجه EOL اشتباه است، در این صورت باید کد 3 خود را اصلاح کنم. هم الگوریتم و هم نتیجه EOL من صحیح است، به این معنی که ادبیات اشتباه است. | کمک به محاسبه از دست دادن فرصت مورد انتظار |
61742 | من یک فرآیند AR با نویز t-distributed در هر مرحله دارم. آیا کسی تغییری را میداند که میتوانم برای بدست آوردن باقیماندههای تقریباً معمولی توزیع شده اعمال کنم؟ با تشکر | تبدیل باقیمانده های توزیع شده t به نرمال |
64208 | من تصور می کنم که هر چه ضریب یک متغیر بزرگتر باشد، مدل توانایی بیشتری برای نوسان در آن بعد دارد و فرصت بیشتری برای تناسب نویز فراهم می کند. اگرچه فکر میکنم یک حس منطقی از رابطه بین واریانس مدل و ضرایب بزرگ دریافت کردهام، اما نمیدانم چرا آنها در مدلهای اضافه برازش اتفاق میافتند. آیا این نادرست است که بگوییم آنها نشانه بیش از حد برازش هستند و ضریب جمع شدگی بیشتر تکنیکی برای کاهش واریانس در مدل است؟ به نظر می رسد منظم سازی از طریق انقباض ضریب بر این اصل عمل می کند که ضرایب بزرگ نتیجه یک مدل بیش از حد برازش است، اما شاید من انگیزه پشت این تکنیک را اشتباه تفسیر می کنم. شهود من که ضرایب بزرگ عموماً نشانهای از برازش بیش از حد هستند از مثال زیر ناشی میشود: فرض کنید میخواستیم $n$ نقاطی را که همه روی محور x قرار میگیرند، جا دهیم. ما به راحتی میتوانیم چند جملهای بسازیم که جوابهای آن این نقاط است: $f(x) = (x-x_1)(x-x_2)....(x-x_{n-1})(x-x_n)$. فرض کنید امتیاز ما در $x=1,2,3,4$ است. این تکنیک همه ضرایب >= 10 را می دهد (به جز یک ضریب). با اضافه کردن نقاط بیشتر (و در نتیجه افزایش درجه چند جمله ای) بزرگی این ضرایب به سرعت افزایش می یابد. این مثال نشان میدهد که من در حال حاضر اندازه ضرایب مدل را با «پیچیدگی» مدلهای تولید شده مرتبط میکنم، اما نگرانم که این مورد عقیم باشد تا واقعاً نشاندهنده رفتار دنیای واقعی باشد. من عمداً یک مدل اضافه برازش ساختم (یک OLS چند جملهای درجه 10 برازش دادههای تولید شده از مدل نمونهگیری درجه دوم) و از دیدن ضرایب عمدتاً کوچک در مدل خود متعجب شدم: set.seed(123) xv = seq (-5,15, طول). .out=1e4) x=sample(xv,20) gen=function(v){v^2 + 7*rnorm(length(v))} y=gen(x) df = data.frame(x,y) model = lm(y~poly(x,10,raw=T), data=df) خلاصه (abs (مدل$ضرایب)) # حداقل. 1 ق. میانگین میانه 3rd Qu. حداکثر # 0.000001 0.003666 0.172400 1.469000 1.776000 5.957000 data.frame(مرتب (abs(مدل$ضرایب)) # model.ضرایب # poly(x، 10، 6، 7، 7، 7، 1، 1، 10، 10، 10، 10، 7، 7، 10، 10، 10، 7، 10، 10، 10، 10، 10، 10، 7، 10، 10، 10، 10، 10. 10، خام = T)9 3.816941e-05 # poly(x، 10، خام = T)8 7.675023e-04 # poly(x، 10، خام = T)7 6.565424e-03 # poly(x، 10، خام = T)6 1.070573e-02 # poly(x، 10، خام = T)5 1.723969e-01 # poly(x، 10، خام = T)3 6.341401e-01 # poly(x، 10، خام = T)4 8.007111e-01 # poly(x، 10، خام = T )1 2.751109e+00 # poly(x، 10، خام = T)2 5.830923e+00 # (Intercept) 5.956870e+00 شاید نکته مهم در این مثال این باشد که دو سوم ضرایب کمتر از 1 هستند و _نسبت به ضرایب دیگر_، سه ضریب وجود دارد که به طور غیرعادی بزرگ هستند (و متغیرهای مرتبط با این ضرایب نیز متغییرهایی هستند که بیشترین ارتباط را با مدل نمونه گیری واقعی دارند. آیا منظمسازی (L2) فقط مکانیزمی است برای کاهش واریانس در یک مدل و در نتیجه «هموارسازی» منحنی برای تطبیق بهتر با دادههای آینده، یا از یک اکتشافی به دست آمده از مشاهدات استفاده میکند که مدلهای بیش از حد نیاز به نشان دادن ضرایب بزرگ دارند؟ آیا این بیانیه دقیقی است که مدل های اضافه برازش تمایل به نشان دادن ضرایب بزرگ دارند؟ اگر چنین است، آیا کسی می تواند مکانیسم پشت این پدیده را کمی توضیح دهد و/یا مرا به برخی ادبیات راهنمایی کند؟ با تشکر | (چرا) مدل های اضافه برازش ضرایب زیادی دارند؟ |
78340 | من از محاسبات بیزی تقریبی برای یافتن مقدار واقعی یک پارامتر استفاده می کنم. توزیع قبلی من یکنواخت بیش از $(0,1)$ است. من در حال تماشای این ویدئو در مورد یادگیری بیزی بودم و مدرس بیان می کند (حدود ساعت 36:00) که این یک فرض بزرگ است. یعنی ما فرض میکنیم که مقدار متغیر مجهول همان میانگین متغیر تصادفی (در مورد من $0.5$) است و همچنین دارای واریانسی است که میتوانیم آن را محاسبه کنیم (من بر اساس تعداد مشاهدات فرض میکنم؟). او ادامه میدهد که اگر واقعاً میخواهید یک پیشین را مانند این مدل کنید، باید از یک تابع دلتا با محوریت یک مقدار $a$ استفاده کنید که ناشناخته است. سوالات من این است: 1. فرض اینکه میانگین و واریانس با متغیر تصادفی یکسان باشد چه اشکالی دارد؟ 2. چگونه می توانم از یک تابع دلتا برای ایجاد احتمالات برای قبلی خود استفاده کنم؟ | مدل سازی احتمال قبلی به عنوان تابع دلتا |
26983 | من یک چارچوب دادهای دارم که شامل ارزیابیهایی است که توسط دانشجویان سایر دانشجویان انجام شده است. گزیده ای از چارچوب داده های ارزشیابی به این شکل است (ستون ها ارزیاب هستند، ردیف ها با دانش آموز ارزشیابی شده مطابقت دارند): s1 s2 s3 s4 1 7 8 NA 8 2 NA 7 8 NA 3 9 6 6 8 4 9 9 7 7 5 9 8 NA 7 ... می خواهم بدانم ارزیابان از نظر شباهت چگونه با یکدیگر مرتبط هستند مقادیر ارزیابی غیر NA آنها. آیا اگر از «کورگرام(ارزیابی)» استفاده کنم مشکلی ندارد یا استفاده از روش دیگری توصیه می شود؟ با تشکر | پیشنهادهایی برای محاسبه همبستگی بین ارزیابان |
26980 | نشان داده شده است که انتخاب مدل ABC با استفاده از عوامل بیز به دلیل وجود خطای ناشی از استفاده از آمار خلاصه توصیه نمی شود. نتیجه گیری در این مقاله بر مطالعه رفتار یک روش رایج برای تقریب عامل بیز (الگوریتم 2) تکیه دارد. به خوبی شناخته شده است که عوامل بیز تنها راه برای انجام انتخاب مدل نیست. ویژگی های دیگری مانند عملکرد پیش بینی یک مدل وجود دارد که ممکن است مورد توجه باشد (مثلاً قوانین امتیازدهی). **سوال من این است**: آیا روشی مشابه الگوریتم 2 برای تقریب برخی از قوانین امتیازدهی یا مقادیر دیگر وجود دارد که بتوان از آن برای انجام انتخاب مدل از نظر عملکرد پیش بینی در زمینه هایی با احتمالات پیچیده استفاده کرد؟ | انتخاب مدل ABC |
59516 | من سعی می کنم با استفاده از بسته caret یک مدل neuralnet را با این دستور آموزش دهم: model.neuralnet <- train(X, Y, method='neuralnet', trControl=myControl, stepmax=700, rep=1, learning rate =0.05، الگوریتم = 'backprob'، preProcess=PP، tuneGrid = expand.grid(.layer1=4، .layer2=1، .layer3=1)، act.fct = 'tanh'، linear.output = TRUE) 'X'، 'Y' ورودی های درستی هستند، 'myControl' باید تنظیمات مناسبی داشته باشد، زیرا من در همان جلسه با موفقیت مدل های دیگری را با آنها می سازم . بعد از هر خروجی دوم روی کنسول چیزی شبیه به این می نویسد (من CV را تکرار کرده ام اما فولدها باید اوکی باشند، زیرا مدل های دیگر مشکلی نداشتند ...): fit model برای Fold02.Rep1: layer1=4, layer2=1, layer3 =1 در پایان محاسبات با دستور بالا دریافت میکنم: جمعآوری نتایج انتخاب پارامترهای تنظیم تناسب لایه1 = عددی(0)، لایه2 = عددی(0)، لایه 3 = numeric(0) در مجموعه آموزشی کامل خطا در if (tuneValue$.layer1 == 0) stop (لایه اول باید حداقل یک واحد پنهان داشته باشد) : طول آرگومان صفر است علاوه بر این: 50 اخطار یا بیشتر وجود دارد (از warnings() برای دیدن 50 مورد اول استفاده کنید) زمان بندی متوقف شد: 0.16 0 0.15 اما فکر می کنم لایه 1 را روی صفر تنظیم نکرده ام (`tuneValue$.layer1 == 0`). لطفا - آیا من اشتباه می کنم؟ میلان | خطای نورال نت |
109414 | دنباله ای از توکن ها را در نظر بگیرید. می توان با محاسبه ماتریس انتقال تصادفی تجربی، مدل مارکوف را به این دنباله تطبیق داد. یک اصلاح در این مدل ساختن یک HMM در بالای آن است، با یک تغییر کوچک: ما اجازه میدهیم که احتمال انتشار یک توکن هم به حالت پنهان و هم به توکن قبلی بستگی داشته باشد. این هنوز یک hmm است اما با یک محدودیت ساختاری. سپس مسیر Viterbi حالت های پنهان را انتخاب می کنیم و یک HMM را در بالای آن قرار می دهیم. و به همین ترتیب، با بسیاری از HMM در بالای HMM. البته، نتیجه نهایی هنوز یک HMM است، اما امیدواریم که ساختاری بسیار زیاد و به راحتی جابجا شود. یک مثال می تواند یک متن به زبان طبیعی باشد. اولین لایههای HMM واجهای رایج، پسوندها و پیشوندهای رایج سطوح بالاتر، سپس کلمات، بخشهایی از گفتار و ساختار جمله را توصیف میکنند. این یک HMM سلسله مراتبی نیست. این اسم داره؟ | پشته HMM. این اسم داره؟ |
78693 | من یک مدل ساختاری را با فرآیند تولید داده زیر برآورد میکنم: $$x=\begin{cases}\begin{array}{c}y-\theta\\\0\end{array} و \begin{array} c}if\ y>\bar{y}(\lambda_1)\\\if\ y\leq\bar{y}(\lambda_1)\end{array}\end{cases}$$ علاوه بر این، y یک متغیر تصادفی با توزیع $F(\cdot|\lambda_2)$ و $\bar{y است. }(\cdot)$ یک تابع افزایشی است. پارامترهایی که می خواهم تخمین بزنم $\theta$، $\lambda_1$ و $\lambda_2$ هستند. من فکر کردم که این یک مدل استاندارد سانسور شده نوع 1 است، و بنابراین احتمال را به صورت زیر نوشتم: $$L=\prod f(x+\theta|\lambda_2)^{I(x>0))}*F(\bar {y}(\lambda_1)|\lambda_2)^{1-I(x>0)}$$ با این حال، پس از تخمین مدل، فکر نمیکنم این درست باشد. میتوانید ببینید که پارامتر $\lambda_1$ تنها زمانی که دادهها سانسور میشوند به احتمال کمک میکند (یعنی $x=0$). بنابراین، از آنجایی که $\bar{y}(\cdot)$ یک تابع افزایشی است، مقدار $\lambda_1$ که احتمال را به حداکثر میرساند، بی نهایت مثبت است، که اساساً برآورد من برای $\lambda_1$ بود. با این حال، $\lambda_1$ به وضوح مشخص است، زیرا معادله انتخاب را کنترل می کند. سپس فکر کردم که احتمال آن باید این باشد: $$L=\prod \left(\frac{f(x+\theta|\lambda_2)}{1-F(\bar{y}(\lambda_1)|\lambda_2 )}\راست) ^{I(x>0))}*F(\bar{y}(\lambda_1)|\lambda_2)^{1-I(x>0)}$$ استدلال کاملاً مستقیم است. وقتی $x>0$، y از پایین در $\bar{y}(\lambda_1)$ کوتاه میشود. با این حال، معلوم میشود که این نیز کار نمیکند، به همان دلیل قبلی: احتمال در پارامتر $\lambda_1$ به شدت افزایش مییابد. من تقریباً مطمئن هستم که $\lambda_1$ شناسایی شده است. اگر من به سادگی تخمین می زدم x=0 یا نه، آنگاه احتمال آن این بود: $$L=\prod \left(1-F(\bar{y}(\lambda_1)|\lambda_2)\right)^{I (x>0))}*F(\bar{y}(\lambda_1)|\lambda_2)^{1-I(x>0)}$$ که منحصر به فرد خواهد بود ماکسیمایزر در $\lambda_1$. بنابراین احتمال صحیح چقدر باید باشد؟ با تشکر | تابع احتمال برای مدل ساختاری سانسور شده |
61740 | اخیراً متوجه شده ام که تفاوت هایی در مقادیر کشیدگی ارائه شده توسط SPSS و Stata وجود دارد. به http://www.ats.ucla.edu/stat/mult_pkg/faq/general/kurtosis.htm مراجعه کنید. درک من این است که تفسیر همان متفاوت خواهد بود. توصیه ای در مورد نحوه برخورد با این موضوع دارید؟ | تفاوت در تعریف کشیدگی و تفسیر آنها |
72069 | اجازه دهید $X$ و $Y$ بردارهای تصادفی باشند. اجازه دهید $Z$=$f(X,Y)$ یک متغیر تصادفی باشد. سپس اگر $X$ و $Y$ مستقل باشند، نتیجه زیر یک نتیجه شناخته شده است: $P(f(X,Y)\in B\mid Y=y)$ = $P(f(X,y)\ در B)$ _**من به کمک نیاز دارم تا آنچه را که به نظر می رسد تعمیم شهودی است، زمانی که $X$ و $Y$ مستقل فرض نمی شوند، رسمی کنم، یعنی اینکه_** $P(f(X,Y) \در ب\وسط Y=y)$ = $P(f(X,y)\in B\mid Y=y)$ بدون فرض اینکه $Y$ گسسته است. به عنوان مثال، یک مشکل فوری این است که من مطمئن نیستم که RHS معادله بالا به خوبی تعریف شده باشد. متن _Breiman 'Probability'_، احتمال شرطی $P(C\mid Y=y)$ ( _Definition 4.7_) را به عنوان یک تابع قابل اندازه گیری در $y$ تعریف می کند که $P(C, Y\in A )$=$\ را برآورده می کند. int_{A} P( C\mid Y=y) \, P_{Y}(dy)$ که $C$ زیر مجموعه ای قابل اندازه گیری است فضای نمونه و $A$ یک زیر مجموعه Borel دلخواه در فضای حالت $Y$ است. _**با استفاده از مفهوم احتمال شرطی منتظم، من فکر می کنم که عبارت بالا را می توان به صورت زیر رسمیت داد._** اجازه دهید $X$ و $Y$ بردارهای تصادفی باشند. اجازه دهید $Z$=$f(X,Y)$ یک متغیر تصادفی باشد و $P_{Y}$ توزیع حاشیه ای $Y$ باشد. اجازه دهید $Q_{X\mid Y}(\cdot\mid y)$ یک توزیع شرطی منظم برای $X$ با توجه به $Y=y$ باشد. سپس $P(f(X,Y)\in B\mid Y=y)$ = $P(f(X,y)\in B\mid Y=y)$، به اعتقاد من یک **_تفسیر شهودی_* است * از عبارت «اثبات نشده» زیر $Q_{Z\mid Y}(B\mid y)$= $Q_{X\mid Y}(B_y \mid y)$ که $B$ هر Borel دلخواه است زیر مجموعه $R$ و $B_y$ = $[x \mid f(x,y) \in B]$ و $Q_{Z\mid Y}(\cdot\mid y)$ توزیع شرطی معمولی برای $ Z=f(X,Y)$ $Y=y$ داده شده است. متناوباً باید ثابت کنیم که $P(Z\in B, Y\in A )$=$\int_{A} Q_{Z\mid Y}(B\mid y) \, P_{Y}(dy) $=$\int_{A} Q_{X\mid Y}( B_y\mid y) \, P_{Y}(dy)$ بنابراین برای نتیجه گیری سوال من این است که چگونه عبارت فوق را در مورد Regular اثبات کنم احتمالات شرطی و اگر تعمیم به بردارهای غیر مستقل صحیح باشد. _**FYI من یک سوال مشابه در MathStackExchange پست کردم و پاسخی دریافت نکردم._** | بسط نتیجه احتمال شرطی برای بردارهای تصادفی غیر مستقل |
95658 | عنوان آن را می گوید. اگر کسی بخواهد نتایج سه تایی را تجزیه و تحلیل کند - یعنی نتایج طبقهبندی شده با سه مقدار خاص (-1,0,1) - آزمونهای جدول اقتضایی $\chi^{2}$ / و مدلهای نوع رگرسیون چندجملهای-لجستیک تنها انتخابها هستند. استنباطها، یا آیا توزیعهای سه تایی خوب و مفید و روشهای استنتاجی مرتبط وجود دارد که ممکن است به عنوان جایگزین در نظر بگیریم؟ چنین داده هایی منجر به تفاوت دو متغیر اسمی با کد 1/0، در نمایش کیفی (علامت) اثرات علی (به عنوان مثال در تحلیل حلقه)، در منطق سه تایی، و شاید در جاهای دیگر می شود. | آیا توزیع های مفیدی برای متغیرهای سه تایی (مانند داده های $-1,0,1$) وجود دارد؟ |
59515 | چگونه اطلاعاتی در مورد توزیع یک متغیر در حضور وابستگی در بین مشاهدات خود پیدا کنیم؟ این وابستگی از اندازهگیری چندباره متغیر روی یک گروه از موضوعات ناشی میشود. این دو نمونه از آنچه من در ذهن دارم است: 1. فرض کنید ما یک وب سایت برای مشتریان برای خرید کالا داریم. ما به توزیع میزان زمانی که مشتریان در هر بازدید از این سایت می گذرانند علاقه مندیم. یک مشتری ممکن است بارها به سایت بازگردد. این بازدیدها مشاهدات متمایز محسوب می شوند. بازدید دوم مشتری ممکن است به دلیل تبلیغ قبلی باشد که در سایت دیده است. بنابراین، مشاهدات ما i.i.d نیست. (یا یک نمونه تصادفی ساده). 2. در یک کارآزمایی بالینی، که در آن، مثلاً، سطح گلوکز خون برای افراد در فواصل زمانی 3 دقیقه اندازه گیری می شود و ما به مقدار معمول آنها در فاصله 20 دقیقه بعد از ورزش علاقه مندیم. باز هم، مقادیر برای هر موضوع وابسته است. پاسخ ساده لوحانه من این است که همه مشاهدات را از یک موضوع به یک مقدار کاهش دهم و به توزیع این مقادیر نگاه کنیم، اما مطمئن هستم که راه بهتری برای انجام این کار وجود دارد. * * * به روز رسانی: پس از خواندن پاسخ های @PeterFlom و @NickCox، متوجه شدم که سوال من تا حدودی مبهم بود و باید جزئیات بیشتری اضافه کنم. بیایید فرض کنیم که من می خواهم میانگین این توزیع را پیدا کنم. قانون ضعیف اعداد بزرگ مستلزم i.i.d. متغیرها (احتمالاً نسخه کلی تری وجود دارد، مثلاً برای متغیرهای قابل مبادله، اما هنوز در شرایطی که در بالا ذکر کردم، این شرط معتبر نیست.) چگونه می توان «متوسط زمانی را که کاربر در هر بازدید از وب سایت صرف می کند» پیدا کرد؟ من از هر پیشنهادی استقبال می کنم، اما بیشتر به پاسخ هایی علاقه مند هستم که دارای برخی توجیهات نظری باشند. * * * به روز رسانی 2: این فرمول ریاضی سوال من است. امیدواریم ابهامات موجود در عبارت را روشن کند: فرض کنید برای موضوعات $N$، ما مشاهداتی انجام دادهایم: * برای موضوع 1، $X_{1،1}،\ldots، X_{1،i_1}$. * برای موضوع 2، $X_{2،1}،\ldots،X_{2،i_2}$. * ... * برای موضوع N, $X_{N,1},\ldots,X{N,i_N}$. (بنابراین، تعداد مشاهدات برای موضوعات مختلف یکسان نیست.) همه $X_{i,j}$ توزیع یکسانی دارند، اما لزوما مستقل نیستند. سوال من این است که اگر هدف من تخمین $E(X_{i,j})$ باشد، بهترین برآوردگر کدام خواهد بود؟ من فکر نمیکنم پاسخ $$\frac{\sum_{i,j}X_{i,j}}{i_1+\cdots+i_N}$$ درست باشد، زیرا قانون اعداد بزرگ در اینجا کاربرد ندارد. پاسخ من $$\frac{\sum_i\frac{\sum_j X_{i,j}}{i_j}}{N}$$ است، اما همانطور که قبلاً اشاره کردم، احساس میکنم باید چیز بهتری وجود داشته باشد. | یافتن توزیع زمانی که مشاهدات وابسته هستند |
68877 | من درک بسیار محدودی از آمار دارم و در ترجمه پاسخ به این سوال از quant.SE، جدا کردن گندم از کاه مشکل دارم، پاسخ این است: > لری هریس فصلی در مورد ارزیابی عملکرد در تجارت دارد و > مبادلات. او بیان می کند که در یک دوره زمانی طولانی، یک دارایی ماهر > مدیر به طور مداوم بازدهی اضافی خواهد داشت، در حالی که از یک فرد خوش شانس انتظار می رود بازده تصادفی و غیرقابل پیش بینی داشته باشد. بنابراین، ما با > انحراف استاندارد بازده تعدیلشده در بازار نمونه کارها شروع میکنیم: > > \begin{equation} \sigma_{adj} = \sqrt{\sigma^2_{port} + \sigma^2_{mk} - > 2\ rho\sigma_{port}\sigma_{mk}} \end{equation} > > جایی که $\rho$ همبستگی بین بازار است و سبد بازده. > > برای اندازه نمونه $n$ (به طور کلی تعداد سال)، میانگین مازاد > بازده، و انحراف استاندارد تنظیم شده از بالا، آمار t را داریم: > > \begin{equation} t = \frac{ \overline{R_{port}} - > \overline{R_{mk}}}{\frac{\sigma_{adj}}{\sqrt{n}}} \end{equation} > > اکنون ما به سادگی میتوانیم با وصل کردن این آماره t به PDF توزیع t با درجات آزادی $n - 1$، احتمال اینکه بازدهی بیش از حد مدیر شانس بوده است را تعیین کنیم. هرچه این احتمال کمتر باشد، بیشتر میتوانیم باور کنیم که بازدهی بیش از حد مدیر ناشی از مهارت بوده است. در این مرحله، من اکنون فرمول برتر را درک می کنم، اگرچه این بر اساس یافتن بخش مربوط به موضوع کتاب است که در پاسخ بالا در Google Books به آن اشاره شده است. چیزی که اکنون دریافت نمی کنم این فرمول است: > \begin{equation} t = \frac{\overline{R_{port}} - > \overline{R_{mk}}}{\frac{\sigma_{adj} }{\sqrt{n}}} \end{equation} من میدانم که به نحوی با «تابع چگالی احتمال» توزیع t مرتبط است، اما من نمیدانم R یا چیست نماد Overline به این معنی است که مقادیر R-port و R-mk از کجا آمده اند. port به عنوان نمونه کار، و mk بازار است. اگر مهم باشد، از آنجایی که فهمیدن «adj» کمی طول کشید، فقط سیگما (انحراف استاندارد) را بهعنوان «انحراف استاندارد بازده تعدیلشده با بازار پرتفوی» علامتگذاری میکند. پیشنهادی دارید؟ | نماد آماری به زبان انگلیسی ساده |
26982 | آیا کسی می داند که آیا راهی برای انجام یادگیری آنلاین با pLSA وجود دارد؟ آموزش مدل واقعا وقت گیر است، بنابراین پس از هر تغییر در داده ها امکان بازسازی آن وجود ندارد. | آیا نسخه متوالی تحلیل معنایی پنهان احتمالی وجود دارد؟ |
68870 | در شرف تهیه پرسشنامه جدید با 142 سوال هستم که تحلیل عاملی اکتشافی انجام داده و 30 عامل نهفته استخراج شده است. می خواستم بدانم که آیا انجام **تحلیل عامل تاییدی** برای پرسشنامه جدید من نیز **ضروری** است؟ | تحلیل عاملی تاییدی برای یک پرسشنامه جدید ساخته شده |
68876 | من یک گروه از آیتم های S دارم، مثلا 100 مورد در S وجود دارد، و برخی از ویژگی های این آیتم ها را می دانم، یعنی رنگ، اندازه، ... حالا، من یک گروه دیگر از آیتم های P دارم، مثلا 10000 مورد در S وجود دارد. P. برای یافتن زیر گروهی از آیتم ها در P که مشابه آیتم های S هستند، چه کاری می توانم انجام دهم؟ من ویژگی های مربوط به همه موارد را در P می دانم، یعنی رنگ، اندازه... فکر اصلی من این است که می توانم از K نزدیکترین همسایه استفاده کنم. اما به نظر می رسد که از آنجایی که KNN از اکثریت رای استفاده می کند، برای استفاده از KNN، حداقل دو برچسب مختلف در مجموعه داده های آموزشی نیاز دارند، در حالی که در مورد من فقط یک برچسب دارم - همه موارد در S دارای برچسب یکسانی هستند. آیا ایده ای در مورد چگونگی پیدا کردن آیتم های مشابه S در P دارید؟ | الگوریتمی برای یافتن موارد مشابه |
72065 | ( _این سوال از درس تشخیص الگوی من است._ ) این تمرین وجود دارد: تصور کنید ما نمونه های $N$ با ابعاد $n$ داریم. ابتدا میخواهد نقطهای را پیدا کند که مجموع فاصلههای اقلیدسی از $m$ حداقل باشد. سپس بردار دیگر $e$ را با اندازه 1 تصور کنید. $e$ از $m$ عبور می کند. هر نقطه در این خط از: $x=m+\alpha*e$ عبور می کند. مقدار $\alpha_k$ فاصله یک نقطه از خط است که فاصله آن از آن نقطه و $x_k$ حداقل است. سپس تمرین از من می خواهد که مقادیر $\alpha_k$ را در جایی که فاصله حداقل است (یعنی خط چین) پیدا کنم. بخش آخر از من می خواهد ثابت کنم که مقادیر مورد نظر $\alpha_k$ در واقع بردار ویژه با حداکثر مقدار ویژه ماتریس تخمین کوواریانس زیر است: $\Sigma=1/N\sum_{k=0}^{k= N} (x-m)(x-m)^t $  | رابطه بین بهترین برازش خط و بردار ویژه حداکثر مقدار ویژه یک ماتریس کوواریانس برآورد شده |
26985 | من به 2 مقاله نگاه می کنم که با استفاده از طرح مطالعه همگروهی گذشته نگر به یک موضوع می پردازند اما از روش شناسی متفاوتی برای تجزیه و تحلیل داده ها استفاده می کنند و می خواهم بدانم چرا روش های مورد استفاده متفاوت است؟ چه زمانی و چرا از نسبت های نرخ استاندارد استفاده می کنید؟ چه زمانی و چرا از رگرسیون Poission استفاده می کنید؟ پیشاپیش ممنون | مقایسه نرخ رویدادها بین یک گروه در معرض و غیر در معرض |
26987 | من در حال ایجاد برنامه ای هستم که هنرمندان موسیقی پرطرفدار را که از معیارهای توییتر استفاده می کنند، شناسایی می کند. من دادههایی در قالب هیستوگرام دارم که نشاندهنده فراوانی نامهای @تویتر یک هنرمند در 30 روز گذشته است. من به برنامه من نیاز دارم تا یک تغییر مهم (تعدادی که بسیار بیشتر از بقیه در نمونه است) در فرکانس @mentions تشخیص دهد. در اینجا یک نمونه داده وجود دارد: ** هیستوگرام: [ 43، 17، 70، 137، 198، 113، 126، 96، 100، 130، 107، 112، 438، 215، 76، 30، 119، 78،73 ، 27، 35، 29، 38، 59، 35، 164، 113، 29، 111]،** در این سناریو، «438» تعداد معناداری است. کاملاً واضح است که در این مجموعه داده b/c 2 برابر بیشتر از هر مقدار دیگری است. من باید معادله ای بسازم که این تعداد اهمیت را در مجموعه داده های مختلف تشخیص دهد. در اولین تلاشم برای نوشتن این معادله، میانگین 30 مقدار را محاسبه کرده و میانگین را با بالاترین مقدار در مجموعه داده ها مقایسه می کنم. پس از انجام برخی نمونهگیریها، به درصدی اختلاف میرسم که معنیداری را توجیه میکند. این یک رویکرد ساده است، اما من نگرانم که خیلی ذهنی باشد. آیا راه های دیگری برای انجام این کار وجود دارد؟ | شناسایی تعدادی از اهمیت از یک هیستوگرام |
59510 | من از NLPCA برای کاهش ابعاد نه متغیر (4 اسمی / 3 ترتیبی / 2 عددی) استفاده میکنم تا امتیازات شی بهعنوان متغیر وابسته در یک مدل رگرسیون استفاده شود. من از بسته homals (http://www.jstatsoft.org/v31/i04/paper) استفاده می کنم. خروجی عبارت است از: X <- homals(sintomi[,2:10]، ndim = 1، active = TRUE، level = c(عددی، rep(رتبی،3)،عددی، rep(ترتیبی ،4))) X Call: homals(data = sintomi[, 2:10]، ndim = 1، level = c(عددی، rep(ordinal، 3)، numerical، rep(ordinal، 4))، فعال = TRUE) Loss: 0.0002077596 مقادیر ویژه: D1 0.0208 بارهای متغیر: D1 V1 0.2096132 V2 0.2096132 V2 0.2096132 V2 0.2113159 0.24206 0.1370880 V5 0.1508221 V6 0.2537438 V7 0.1959783 V8 0.1769447 V12 0.2154044 پیش بینی(X) نرخ طبقه بندی: متغیر Cl. نرخ %Cl. Rate 1 V1 0.5149 51.49 2 V2 0.7292 72.92 3 V3 0.7589 75.89 4 V4 0.7768 77.68 5 V5 0.6336 63.36 6 V6 0.904 0.904 88.69 8 V8 0.8036 80.36 9 V12 0.8661 86.61 من سوالات زیر را دارم: 1. آیا بهتر است برای کاهش ابعاد داده ها در یک جزء، Ndim = رتبه = 1 یا Ndim = رتبه = حداکثر (رتبه) را در نظر بگیریم؟ 2. آیا دستوری برای محاسبه خودکار نسبت واریانس توضیح داده شده توسط مؤلفه اول وجود دارد؟ وگرنه چجوری با دست حساب کنم؟ 3. آیا استانداردسازی متغیرهای عددی قبل از اجرای هومال ضروری است؟ اگر کسی در این مورد نظری دارد، پاسخگوی شما بسیار سپاسگزار خواهد بود. با تشکر | PCA غیرخطی (R بسته homals) |
78695 | من آموخته ام که مقدار p کمتر از آلفا به این معنی است که شما فرضیه صفر را رد می کنید. اما به نظر می رسد این تنها در مورد تست های دم پایین تر منطقی باشد. برای تست های دم بالایی چه می کنید؟ | در آزمون فرضیه، آیا مقدار p کمتر از آلفا همیشه به معنای رد NH است؟ |
34299 | من نمونهگر متروپلیس (C++) را اجرا میکنم و میخواهم از نمونههای قبلی برای تخمین نرخ همگرایی استفاده کنم. یکی از روشهای تشخیصی آسان برای پیادهسازی، تشخیص Geweke است که تفاوت بین دو میانگین نمونه تقسیم بر خطای استاندارد تخمینی خود را محاسبه میکند. خطای استاندارد از چگالی طیفی صفر تخمین زده می شود. $$Z_n=\frac{\bar{\theta}_A-\bar{\theta}_B}{\sqrt{\frac{1}{n_A}\hat{S_{\theta}^A}(0)+ \frac{1}{n_B}\hat{S_{\theta}^B}(0)}}، $$ که $A$، $B$ دو پنجره در زنجیره مارکوف هستند. من تحقیقاتی در مورد اینکه $\hat{S_{\theta}^A}(0)$ و $\hat{S_{\theta}^B}(0)$ چیست، انجام دادم، اما وارد ادبیات نابسامان طیف انرژی شدم. چگالی و چگالی طیفی توان. (http://en.wikipedia.org/wiki/Spectral_density) اما من در این موضوعات متخصص نیستم. من فقط به یک پاسخ سریع نیاز دارم: آیا این مقادیر همان واریانس نمونه هستند؟ اگر نه، فرمول محاسبه آنها چیست؟ شک دیگری در مورد این تشخیص Geweke این است که چگونه $\theta$ را انتخاب کنیم؟ ادبیات بالا می گوید که این مقدار $\theta(X)$ عملکردی است و باید به وجود یک چگالی طیفی $\hat{S_{\theta}^A}(0)$ دلالت کند، اما برای راحتی، من ساده ترین راه را حدس می زنم. استفاده از تابع هویت است (از خود نمونه ها استفاده کنید). آیا این درست است؟ بسته R coda دارای توضیحات است اما نحوه محاسبه مقادیر $S$ را نیز مشخص نمی کند. | تشخیصی MCMC Geweke |
2892 | شهود / تفسیر شما از توزیع مقادیر ویژه یک ماتریس همبستگی چیست؟ من تمایل دارم بشنوم که معمولاً 3 ارزش ویژه از همه مهمتر هستند، در حالی که آنهایی که نزدیک به صفر هستند نویز هستند. همچنین، من چند مقاله تحقیقاتی را دیدهام که بررسی میکنند چگونه توزیعهای مقادیر ویژه بهطور طبیعی با توزیعهای محاسبهشده از ماتریسهای همبستگی تصادفی متفاوت هستند (باز هم، تشخیص نویز از سیگنال). لطفا در مورد دیدگاه های خود توضیح دهید. | شهود / تفسیر توزیع مقادیر ویژه یک ماتریس همبستگی؟ |
79562 | من سعی کردهام یک ساختار درختی را بهعنوان یک نمودار تصادفی نشان دهم، اما تاکنون تحقیقات من به تغییراتی در مدلهای نمودار تصادفی منجر شده است و نمیتوانم مطالعاتی را ببینم که ممکن است به من کمک کند تا از برخی از مزایای مدلهای نمودار تصادفی استفاده کنم. خانواده تخصصی نمودارها داده های من به شکل ساختارهای درختی هستند و من می خواهم یک نمایش توزیع احتمال از این ساختار درختی داشته باشم تا بتوانم احتمالات را به نمونه های مختلف درختان اختصاص دهم. قوانینی وجود دارد که بر ساختار درخت حاکم است: هر گره ای غیر از ریشه به سادگی به والد خود وابسته است. اگر والد آنجا نباشد، فرزند نمی تواند وجود داشته باشد. اگر فرزند وجود داشته باشد، ویژگیهای آن توزیعهای خاص خود را دارند، یعنی عادی، بتا و غیره. این تقریباً شبیه یک DAG با جدولهای احتمال شرطی به نظر میرسد. اما نمیتوانم ببینم چگونه میتوانم وجود/عدم وجود یک گره فرزند را در یک CPT لحاظ کنم. هدف من بدست آوردن توزیعی برای این ساختارهای درختی و تخصیص احتمالات به آنها است، اما نتوانستم پیدا کنم کدام رویکرد مدل سازی می تواند آنها را نشان دهد. کجا باید نگاه کنم؟ | چگونه می توانم نمودارهای تصادفی (درخت) را با محدودیت های قطعی مدل کنم؟ |
2893 | استفاده از لحظه های دوم، سوم و چهارم توزیع برای توصیف ویژگی های خاص معمول است. آیا گشتاورهای جزئی یا گشتاورهای بالاتر از چهارمین ویژگی مفید یک توزیع را توصیف می کنند؟ | لحظه های توزیع - آیا برای ممان جزئی یا بالاتر استفاده می شود؟ |
79560 | من سعی می کنم برخی از آمارهای وب (AdWords) را انجام دهم. من هزینه، درآمد و تعدادی کلیک دارم. چگونه می توانم تشخیص دهم که تفاوت بین هزینه/کلیک و درآمد/کلیک از نظر آماری معنادار است یا خیر. من به واریانس یا انحراف معیار، نه هزینه و نه درآمد دسترسی ندارم. | مقایسه دو میانگین با حجم نمونه مشابه |
23007 | فرض کنید من کمی بیش از 20000 سری زمانی ماهانه از 05 ژانویه تا 11 دسامبر دارم. هر یک از اینها داده های فروش جهانی را برای یک محصول متفاوت نشان می دهد. اگر بجای محاسبه پیشبینیها برای هر یک از آنها، بخواهم فقط روی تعداد کمی از محصولات که «در واقع مهم هستند» تمرکز کنم، چه؟ من می توانم آن محصولات را بر اساس درآمد سالانه کل رتبه بندی کنم و با استفاده از پارتو کلاسیک لیست را کاهش دهم. با این حال به نظرم می رسد که اگرچه آنها سهم زیادی در نتیجه ندارند، اما پیش بینی برخی از محصولات آنقدر آسان است که کنار گذاشتن آنها قضاوت بدی است. محصولی که در 10 سال گذشته هر ماه 50 دلار فروخته است ممکن است زیاد به نظر نرسد، اما برای ایجاد پیشبینی در مورد فروش آینده به تلاش کمی نیاز دارد که من نیز ممکن است این کار را انجام دهم. بنابراین فرض کنید محصولاتم را به چهار دسته تقسیم میکنم: درآمد بالا/پیشبینی آسان - درآمد کم/پیشبینی آسان - درآمد بالا/پیشبینی سخت - درآمد کم/پیشبینی سخت. من فکر می کنم معقول است که فقط سری های زمانی متعلق به گروه چهارم را پشت سر بگذاریم. اما دقیقاً چگونه می توانم پیش بینی پذیری را ارزیابی کنم؟ ضریب تغییرات نقطه شروع خوبی به نظر می رسد (من همچنین به یاد دارم که چندی پیش مقاله ای در مورد آن دیدم). اما اگر سری های زمانی من فصلی / تغییرات سطح / اثرات تقویم / روندهای قوی را نشان دهند چه؟ تصور میکنم که ارزیابی خود را فقط بر اساس متغیر بودن مؤلفه تصادفی و نه دادههای «خام» قرار دهم. یا من چیزی را از دست داده ام؟ آیا کسی قبلاً به مشکل مشابهی برخورد کرده است؟ شما بچه ها چگونه در مورد آن اقدام می کنید؟ مثل همیشه، هر کمکی بسیار قدردانی می شود! | ارزیابی قابلیت پیش بینی سری های زمانی |
26988 | فکر کردن به احتمال همیشه باعث می شود بفهمم که در شمارش چقدر بد هستم... دنباله ای از $n$ حروف پایه $A,\ را در نظر بگیرید. T, \; C، \text{ و } G$، هر کدام به یک اندازه ظاهر می شوند. احتمال اینکه این دنباله دارای یک دنباله خاص از جفت های پایه با طول $r\leq n$ باشد چقدر است؟ توالی های مختلف 4^n$ (به همان اندازه محتمل) ممکن است. با دنباله مورد علاقه در ابتدای سکانس کامل شروع کنید. توالی $4^{n-r}$ مانند این امکان پذیر است. ما می توانیم دنباله علاقه خود را در مکان های مختلف $n+1 -r$ شروع کنیم. بنابراین، پاسخ من $(n+1-r)/4^r$ است. این احتمال در $n$ در حال افزایش است که برای من منطقی است. اما این احتمال زمانی که $n>4^r +r-1$ از 1 بیشتر می شود. اما این نمی تواند باشد. احتمال باید در حد 1 باشد (به نظر من)، اما از آن تجاوز نکند. من فرض را بر این می گذارم که دارم چیزی را دوبار شمارش می کنم. چه چیزی را از دست داده ام؟ با تشکر (اطلاعات بیشتر، نه تکلیف، فقط یک نمونه اسباب بازی در آمادگی برای امتحانات. یک سوال توسط دوست زیست شناس مولکولی من.) | احتمال یافتن یک دنباله خاص از جفت پایه |
66209 | OpenCV پیاده سازی جنگل تصادفی به نام درختان تصادفی و مشتق شده از یک کلاس درخت تصمیم را ارائه می دهد. یکی از پارامترهای آموزش جنگل تصادفی حداکثر عمق است که در مثال های ارائه شده معمولاً بین 10 تا 20 است. من یاد گرفتم که جنگل تصادفی به طور کلی تا عمق کامل رشد می کند و هرس انجام نمی شود و به همین دلیل، سایر پیاده سازی های تصادفی جنگل انجام می شود. پارامتر حداکثر عمق را ارائه نمی دهد. پس چرا، بدون مشورت با کد منبع، که ممکن است جواب بدهد، پیاده سازی OpenCV این پارامتر را ارائه می دهد و آیا محدود کردن حداکثر عمق در یک جنگل تصادفی معنادار است؟ | پارامترهای OpenCV درختان تصادفی |
78690 | هر یک از نقاط در نمودار زیر میانگین 1000 نمونه است. انحراف معیار یک نقطه در خط قرمز کم است، زیرا از تفاوت بین میانگین خط قرمز و میانگین خط سبز در آن مقدار x کوچکتر است. یک راه روشن خوب برای بیان اینکه تنوع داده ها در هر دو مجموعه داده کم است چیست؟ آیا باید بیان کنم که انحراف معیار کمتر از نصف اختلاف میانگین مجموعه است یا معیار رسمی تری برای توصیف آن وجود دارد؟  PS: این نمودار برای نشان دادن این است که سبز بزرگتر از قرمز با احتمال زیاد است. | اندازه گیری تغییرات یک مجموعه داده نسبت به مجموعه داده دیگر |
26676 | در حالی که میدانم یک سری عملکرد برای تولید نقشههای حرارتی در R وجود دارد، اما مشکل این است که نمیتوانم نقشههای جذاب بصری تولید کنم. به عنوان مثال، تصاویر زیر نمونه های خوبی از نقشه های حرارتی هستند که می خواهم از آنها اجتناب کنم. اولی به وضوح فاقد جزئیات است، در حالی که دیگری (بر اساس همین نکات) بیش از آن مفصل است که مفید باشد. هر دو نمودار توسط تابع density() در بسته _spatstat_ R ایجاد شده اند. چگونه می توانم «جریان» بیشتری را به نقشه هایم وارد کنم؟ هدف من بیشتر ظاهری است که نتایج نرم افزار تجاری SpatialKey (عکس از صفحه) می تواند تولید کند. هر نکته، الگوریتم، بسته یا خط کدی که بتواند مرا به این سمت بکشاند؟  | ایجاد نقشه های حرارتی چگالی جذاب بصری در R |
50339 | چگونه می توانم R2 یا معیار دیگری از واریانس توضیح داده شده را برای فاکتورسازی ماتریس غیر منفی محاسبه کنم. در حال حاضر من مجموع مجذورات (TSS) را به عنوان مجذور فاصله هر نقطه داده تا میانگین و مجموع مجذور مربعات (RSS) به عنوان مجذور مجذور فاصله هر باقیمانده تا مبدا محاسبه می کنم. سپس R2=1-RSS/TSS. بنابراین اساساً همان کاری را انجام دادم که برای یک رگرسیون انجام می شود. اکنون گاهی اوقات ممکن است اتفاق بیفتد که یک مؤلفه/عامل R2 برابر با 0.15 را به همراه داشته باشد در حالی که دو (با داده های یکسان) منجر به R2 0.90 شود. آیا این می تواند درست باشد؟ پس از بررسی، تمام نقاط داده تقریباً همان اندازه (فاصله تا مبدا) هستند و جزء اول مشابه میانگین است. آیا ممکن است TSS اشتباه محاسبه شده باشد؟ با تشکر * * * ویرایش: فکر میکنم آنچه واقعاً به دنبال آن هستم، روشی است برای قضاوت در مورد اینکه چه تعداد مؤلفه/عامل برای توضیح دادههای من مورد نیاز است. به عنوان مثال یک روش می تواند این باشد که بخواهیم R2 از .9 داشته باشیم. آیا راهی بهتر از استفاده از R2 وجود دارد، به خصوص با توجه به این واقعیت که یک عامل (در شرایط خاص ممکن است واریانس بسیار کمی را توضیح دهد، در حالی که 2 قبلاً مقدار زیادی را توصیف می کند. * * * ویرایش2: آیا توصیف مربوط به میانگین ریشه معنی دار است. مربع باقیمانده به Dr=sqrt(norm(A-W*H,'fro')/(N*M)) تا ریشه میانگین مربع ماتریس اصلی Dtot=sqrt(norm(A,'fro')/(N*M) ماتریس اصلی N-by-M است و W و H فاکتورهای تعیین شده توسط NNMF است کد matlab برای هنجار Frobenius بنابراین، من از 1-(Dr/Dtot) و یک مقدار قطع استفاده می کنم تا تعداد عوامل را که به اندازه کافی از داده های من را توصیف می کنند، انتخاب کنم. | واریانس فاکتورسازی ماتریس غیر منفی را توضیح داد |
26678 | من از کد GPML Rasmussen در Matlab R2011a_student استفاده می کنم. من داده های آموزشی (2560x29707) با برچسب ها (6 کلاس) و داده های آزمون (640x29707) دارم. برای آماده کردن دادههایی که دارم 1. تبدیل از پراکنده به کامل، 2. کلاسها را باینریزه میکنم (یعنی همه کلاسهایی که = 1 هستند 1، بقیه کلاسها -1 هستند). من برنامه ریزی کردم که این را 6 بار اجرا کنم تا همه کلاس ها را در خود جای دهم. من کد زیر را اجرا کردم (درست از مستندات گرفته شده است، اما مقادیر x,y,t را با داده های خود جایگزین کردم): meanfunc = @meanConst; hyp.mean = 0; covfunc = @covSEard; ell = 1.0; sf = 1.0; hyp.cov = log([ell ell sf]); likfunc = @likErf; hyp = به حداقل رساندن (hyp، @gp، -40، @infEP، meanfunc، covfunc، likfunc، x، y)؛ [a b c d lp] = gp(hyp، @infEP، meanfunc، covfunc، likfunc، x، y، t، ones(n، 1)); * * * خطای زیر را دریافت می کنم و مطمئن نیستم به چه معناست. هر گونه کمکی بسیار قدردانی خواهد شد. ؟؟؟ خطا در استفاده از ==> gp در 76 تعداد فراپارامترهای تابع cov با تابع cov مخالف است خطا در ==> کمینه سازی در 75 [f0 df0] = feval(f, X, varargin{:}); % دریافت مقدار تابع و خطای گرادیان در ==> ds1pleasework at 7 hyp = Minime(hyp, @gp, -40, @infEP, meanfunc, covfunc, likfunc, full_TrainSet_feature, L_train); خیلی ممنون | استفاده از GPML در Matlab برای طبقه بندی MultiClass |
92569 | من دادههایی را برای منحنیهای A/Ci ترسیم کردهام (فیزیولوژی گیاه، A = سرعت فتوسنتز، Ci = غلظت CO2 داخلی - اساساً این یک رابطه دوز-پاسخ است). به طور کلی، هنگامی که این نوع داده ارائه می شود، افراد فقط نوارهای خطای SE را اضافه می کنند (مانند تصویر ارائه شده) و اگر همپوشانی ندارند آن را قابل توجه می نامند، یا یک ANOVA را روی جفت نقاط منفرد (مانند دو نقطه، سیاه و سفید، که بالای Ci=120 قرار دارند). 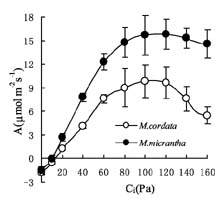 با این حال، من می خواهم یک آزمایش واحد برای پاسخ دوز کلی پیدا کنم رابطه بنابراین، اساساً می توانم ادعا کنم که رابطه دوز-پاسخ بین دو گروه به طور قابل توجهی متفاوت است (در مورد من، گروه ها همه برای یک گونه هستند - این یک آزمایش کود است و من می خواهم بتوانم ادعا کنم که اضافه کردن کود سینتیک رابطه A/Ci را تغییر می دهد). همچنین میخواهم بتوانم بیش از دو منحنی را روی یک نمودار به یک شکل آزمایش کنم (اما من فقط 3 منحنی دارم، بنابراین میتوانم در صورت لزوم جایگشتها را انجام دهم). همچنین، یک مسئله دیگر (که در این تصویر نشان داده نشده است) این است که یک عبارت خطای محور X نیز وجود دارد، بنابراین نوارهای خطا در واقع باید متقاطع باشند، نه فقط خطا در محور y - که استفاده از رویکرد ANOVA را دشوار میکند. از آنجایی که باید نقاط را در هر دو بعد تست کنید. آیا پیشنهادی برای آزمایش مناسب دارید؟ من بیشتر در R کار میکنم، بنابراین هر پیوندی به اسکریپتهای موجود ایدهآل خواهد بود - اما اگر کسی میداند چگونه این نوع تست را در هر یک از آنها اجرا کنم، به Graphpad Prism و JMP نیز دسترسی دارم. | آزمایش تفاوت آماری بین دو منحنی در یک نمودار؟ |
78691 | در بسته MASS بسته بیمه داده وجود دارد. و من باید: جدول را چاپ کنم که سطر آن Group و ستون Age باشد، در جدول باید مجموع معنی ادعاها باشد. آیا کسی می تواند به من کمک کند تا این کار را انجام دهم؟ | چگونه جدول را از بسته در R چاپ کنیم؟ |
59517 | من یک سوال در مورد آزمایش اندازه گیری های مکرر دارم. من 5 نهنگ دارم (به طور تصادفی انتخاب شده) که دمای بدن را روی آنها ثبت کردم. دادهها از طریق ماهواره جمعآوری شد، برنامهریزیشده برای ارسال رکوردها در فواصل زمانی ۲ دقیقهای، اما دادههای هر نهنگ مجموعه دادههای سری زمانی کاملی نیستند (یعنی سوابق نامتعادل/نقاط داده از دست رفته). یک مدل فضایی حالت با استفاده از موقعیت مکانی GPS نهنگ برای تعیین وضعیت هر نهنگ هنگام ردیابی در دریا ایجاد شد. ایالت ها عبارتند از: جستجوی علوفه مقیم، ترانزیت مقیم و ترانزیت پس از اقامت. من داده های دمای بدن را به 3 حالت تقسیم کرده ام. من همچنین داده های دمای بدن را به 2 دوره روزانه تقسیم کردم: روز و شب. بنابراین من دو فاکتور فرعی دارم: Diel (2 سطح: روز و شب) و State (3 سطح: res. forage, res. transiting, post-res. transiting). من بیش از 500 مقدار دمای بدن برای هر حالت/شرایط برای همه 5 نهنگ دارم و بیش از 1000 مقدار دمای بدن برای دوره های روز و شب برای همه نهنگ ها دارم. اما باز هم، من تعداد نقاط داده یکسانی برای همه نهنگها ندارم، به دلیل عدم ارسال ماهوارهای و این واقعیت که بین تکنهنگها تفاوتهایی وجود داشت (مثلاً برخی از نهنگها برای دورههای طولانیتر جستجو میکردند). آیا کسی میتواند توصیههای آماری غیرپارامتری ارائه دهد (تبدیل دادهها همه ناموفق بودند) برای راهاندازی مدلی که تأثیر روز/شب و حالت (و تعامل بین این عوامل) بر دمای بدن نهنگ در R، SAS یا SPSS را تحلیل میکند؟ خوشحال می شوم در مورد داده ها یا طراحی آزمایشی بیشتر توضیح دهید. ممنون، جیم | اندازهگیریهای مکرر در R، SAS یا SPSS: دادههای دمای بدن نهنگ |
1454 | من یک مجموعه داده دارم که شامل دو نوع نقطه است. اولین نوع نقاط از توزیع N(0,1) می آیند. نوع دوم نقاط از توزیع N(m,v) برای برخی m واقعی و برخی مثبت، v واقعی می آیند. هدف این است که هر نقطه را به عنوان نوع 1 یا نوع 2 طبقه بندی کنیم و m & v را شناسایی کنیم. اطلاعات قبلی در مورد m & v. آیا ایده ای دارید؟ | چگونه نقاط و توزیع مجهول را در یک مسئله خوشه بندی دو نوع شناسایی کنیم؟ |
23006 | من روی یک مجموعه داده کار میکنم و رگرسیون خطی جنگل تصادفی را شکست میدهد (متریک وزن میانگین خطای مطلق است - من فهرستی از وزنها دارم و هر تفاوت $|\text{پیشبینی شده} - \text{واقعی}|$ ضرب میشود. با وزن سطرها (که $\sqrt{\text{time}}$ است بنابراین زمان طولانیتر بین مشاهدات جریمه بالاتری دریافت میکند)). با توجه به تجربیات گذشته، این موضوع کمی تعجب آور است. من کنجکاو بودم که آیا انواع دادههایی وجود دارد که معمولاً با AND این اتفاق میافتد، اگر هر نوع تکنیک algo/ml وجود داشته باشد که حتی بهتر از رگرسیون خطی باشد. | چه نوع موقعیت هایی رگرسیون خطی بهتر از جنگل تصادفی است؟ |
50333 | من در حال تجزیه و تحلیل داده های EEG هستم. من داده هایی از 19 الکترود از 25 شرکت کننده دارم که به دو گروه (11 و 14 نفر) تقسیم شده اند. از دانش آموزم خواستم که این دو گروه را با یک آزمون آماری مقایسه کند. با کمال تعجب، او میانگین هر الکترود را محاسبه کرد (با دادن دو گروه با 19 عدد در هر الکترود). من فرض می کنم که محاسبه میانگین برای هر شرکت کننده معتبرتر باشد (که در دو گروه با اعداد 11 و 14 حاصل می شود). حق با کیست؟ یا هر دو حق داریم؟ قوانین کلی برای تشکیل گروه برای تجزیه و تحلیل چیست؟ | قوانین کلی برای تشکیل گروه برای تجزیه و تحلیل |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.