
_id stringlengths 1 6 | text stringlengths 0 7.5k | title stringlengths 0 167 |
|---|---|---|
60163 | چگونه میتوانم دادههای حضور/غیاب را که درباره تذهیبها در یک نسخه خطی قرون وسطایی جمعآوری کردهام، به بهترین وجه تجزیه و تحلیل کنم؟ من نقوش فردی را در سرفصلهای فصل شناسایی کردهام و صفحهگستردهای ایجاد کردهام که برای هر کدام 1 یا 0 دارد (در مجموع 37 موتیف وجود دارد). دستکم 4 نفر روی دستنوشته کار میکردند، که از موتیف سادهای که در تمام صفحات تجزیهوتحلیل دیده میشود مشخص است. من PCA را انجام دادم و نقاط داده را با این متغیر کنترل کد رنگی کردم، و به نظر می رسد که وجود/عدم وجود این موتیف های دیگر تا حدی با آن ارتباط دارد. به این فکر میکردم که تحلیل همروندی مسیر بعدی برای کاوش خواهد بود، اگرچه مشتاق بودم هر تکنیک آماری دیگری را که ممکن است برای این نوع دادهها مفید باشد بیاموزم. آیا مشکلاتی وجود دارد که باید از آن آگاه باشم یا بسته های R وجود دارد که مردم توصیه کنند؟ به طور خاص، من می خواهم بفهمم که کدام موتیف با هر یک از 4 هنرمند مرتبط است. در صورت امکان، من همچنین میخواهم این احتمال را در نظر بگیرم که شباهتها میتواند از مدلهای مشترکی که هنرمندان به آن نگاه میکردند نیز منتج شود. به طور خاص، من یک تحلیل همبستگی با استفاده از روش پیرسون در صفحات ایجاد شده توسط یکی از چهار هنرمند انجام داده ام. چگونه می توانم نزدیک ترین همبستگی ها را از چارچوب داده به دست آمده پیدا کنم، و چگونه می توانم تعیین کنم که آیا آنها از نظر آماری معنی دار هستند؟ | تجزیه و تحلیل داده های حضور/غیاب برای تاریخ هنر |
104437 | همبستگی خودکار $r_Y(\tau) = E[Y(t)Y(t+\tau)]$ را با $Y(t) = \int_{-\infty}^{\infty} h(t-u) x( u)$ و $X$ یک WSS، فرآیند ارگودیک من همیشه دریافت می کنم: $h(t)* h(t+\tau) * r_X(\tau)$ (با $*$ پیچیدگی) ## رویکرد من (پس از ضرب) $\int h(t-u) ( \int h(t+\tau -u')r_X(u'-u) \text{d}u' ) \text{d}u $ انتگرال داخلی تعریف کانولوشن است، بنابراین $= \int h(t-u) (h(t+\tau)*r_x(t+\tau-u) ) \text{d}u$ این دوباره یک انتگرال کانولوشن با متغیر زمان t می دهد. بنابراین، $= h(t)* h(t+\tau) * r_X(\tau) $ ## راه حل صحیح: $ r_X(\tau) * h(\tau) * h(-\tau) $ ## سوال من چه غلطی می کنم؟ | خودهمبستگی انتگرال کانولوشن |
99922 | من در تلاش برای درک معنای توزیع تهی در Fisher Exact Test هستم. فرض کنید من یک جدول احتمالی دارم: Stat1 Stat2 Group1 18 2 Group2 3 40 اگر بخواهم بدانم «Stat1» به میزان قابل توجهی در «گروه1» غنی شده است، آیا باید از آزمون دوطرفه استفاده کنم؟ آیا ممکن است که آزمون دو طرفه به من این احتمال را بدهد که «Stat1» در «گروه2» غنی شده است (جایگزین دیگری برای فرضیه صفر)؟ | تفاوت بین تست دقیق فیشر دو طرفه و یک طرفه چیست؟ |
113032 | من با رفتار ks.test (آمار بسته) گیج شده ام. مستندات: مقادیر p دقیق برای مورد دو نمونه در صورت یک طرفه بودن یا در حضور گره ها موجود نیست. من میپرسم که آیا سیاه (آزمایش) و قرمز (کنترل) از تابع توزیع یکسانی پیروی میکنند بدون اینکه تابع توزیع زیربنایی را بدانند. در دستان من مقادیر دقیق p در صورت یک طرفه بودن و در حضور بند (طبق پیام هشدار) محاسبه می شود. اما مقدار p دو طرفه فقط < 2.2e-16 است اما دقیقا گزارش نشده است. در صورت تمایل می توانید داده ها را به صورت .Rda دانلود کنید (طول بردار ~ 9000): https://www.dropbox.com/s/xl29jvpurkbwqpm/black.Rda?dl=0 https://www.dropbox.com/ s/5biptm1xet36v3v/red.Rda?dl=0 مثال: ks.test (مشکی، قرمز) دو نمونه داده های آزمون کولموگروف-اسمیرنوف: سیاه و قرمز D = 0.0731، p-value < 2.2e-16 فرضیه جایگزین: ks.test دو طرفه (سیاه، قرمز)$p.value [1] 0 Warnmeldung: # به معنای پیام هشدار در ks.test(سیاه، قرمز): im Falle von Bindungen sind die p-Werte approximativ # Bindungen به معنی پیوندهای ks.test (سیاه، قرمز، جایگزین = g)$p.value # مطابق انتظار نیست [1] 1.235537e-23 Warnmeldung: در ks.test(سیاه، قرمز، جایگزین = g) : im Falle von Bindungen sind die p-Werte approximativ ks.test (سیاه، قرمز، جایگزین=l)$p.value [1] 0.0005651143 Warnmeldung: در ks.test (سیاه، قرمز، جایگزین = l): im Falle von Bindungen sind die p-Werte approximativ ks.boot (بسته Matching) را امتحان کردم که ادعا می کند برای دو کار می کند. نمونه با پیوندها آزمایش می کند و حتی زمانی که توزیع های مورد مقایسه کاملاً پیوسته نیستند پوشش صحیحی ارائه می دهد. همین داستان من مقادیر p دقیق را فقط برای شرایط یک طرفه دریافت می کنم. برای نمونه: ks.boot (مشکی، قرمز، جایگزین = l) $ks.boot.pvalue [1] 0.001 $ks دو نمونه دادههای آزمون کولموگروف-اسمیرنوف: Tr و Co D^- = 0.0275، p-value = 0.0005651 فرضیه جایگزین: CDF x کمتر از y $nboots [1] 1000 قرار دارد attr(class) [1] ks.boot آیا جمله p-values دقیق برای حالت دو نمونه در دسترس نیست، اگر یک طرفه باشد یا در صورت وجود کراوات اشتباه متوجه شدم؟ من فکر کردم معنی این است: مقدار p دقیقی وجود ندارد اگر یک طرفه باشد یا ... آیا مقادیر p ks.test (دو نمونه، یک طرفه) صحیح هستند؟ از نظر ارائه مقادیر دقیق p، ks.boot برتری نداشت. لطفا کسی میتونه در این مورد نظر بده؟ ممنون هرمان | ks.test و ks.boot - مقادیر دقیق p و پیوندها |
102876 | من مطالعه ای را در برخی از بیماران انجام دادم که شامل: 1. سن 2. جنسیت 3. مدت زمان 4. برخی از آزمایشات پزشکی 5. پیش. و پرسشنامه پس از 6. نتایج پس از آزمون من بیماران را بر اساس مدت زمان شکایت به دو گروه تقسیم کردم، باید این دو گروه را با هم مرتبط کنم تا ارزیابی کنم که آیا این تفاوت در مدت زمان در نتایج آزمایش و عملکرد بیماران نقش دارد یا خیر. چگونه آنها را هماهنگ کنم لطفا؟ | در تجزیه و تحلیل داده ها در SPSS به کمک نیاز دارید |
60160 | من به دنبال نمونه ای از نوع آموزشی هستم که نمونه برداری گام به گام فرآیند را از یک مدل سلسله مراتبی ساده نشان دهد. به عنوان مثال، من سعی می کنم توزیع p را در آزمایش برنولی مطالعه کنم که در آن مجموعه ای از 10 داده / مشاهدات ('h[i]') دارم. model { p ~ dunif( 0, 1 ) for( i in 1 : 10) { h[i] ~ dbern( p ) } } من نمی دانم چگونه WinBUGS (یا نمونه های مشابه) نمونه های صحیح را برای مقادیر «p» با توجه به «h1-10» من. آیا مقاله یا مقاله ای وجود دارد که این را توضیح دهد؟ | به دنبال نمونه گام به گام نمونه برداری از DAG در مدل بیزی هستید |
3630 | من سعی میکنم یک تابع وابسته به مسیر، $f(r_t)$ را بر اساس فرآیند Cox-Ingersoll-Ross ارزیابی کنم: $dr_t = \theta (\mu - r_t)dt + \sigma \sqrt r_t dW_t$ توسط مونت کارلو شبیه سازی آیا کسی میتواند تکنیکهای کاهش واریانس مؤثری را که میتواند در این فرآیند استفاده شود، پیشنهاد و توضیح دهد؟ به عنوان مثال نمونهگیری مهم، نمونهبرداری طبقهای و غیره. * * * _سوال اصلی_: آیا کسی از تکنیکهای کاهش واریانس پیشرفته (یعنی نمونهگیری اهمیت یا نمونهگیری طبقهای) برای شبیهسازی فرآیند کاکس-اینگرسول-راس آگاه است؟ در حالت ایدهآل، من میخواهم در صورت موجود بودن، اجرای ملموسی ببینم... با احترام | CIR فرآیند کاهش واریانس |
102872 | در حال حاضر به دنبال روش هایی برای محاسبه نوعی شاخص حساسیت قیمت برای مشتریان یک فروشگاه اینترنتی بر اساس سوابق خرید هستم. من ادبیات زیادی پیدا کردهام که در آن از دادههای تابلویی برای محاسبه کششهای قیمت برای یک محصول خاص (دسته) ابتدا استفاده شده است، و سپس یک مدل رگرسیون برای تعیین ویژگیهای تأثیرگذار (مانند درآمد بالا، ...) استفاده شده است. سوال من این است که آیا رویکردی برای استخراج حساسیت قیمت (یا معیار مشابه) در سطح مشتری/محصول (رده) بر اساس دادههای خرید تاریخی وجود دارد؟ | تعیین حساسیت های قیمت مشتری با تاریخچه خرید ماینینگ |
106362 | من به دنبال راه هایی برای آزمایش اثرات مزیت تجمعی در مجموعه داده های طولی هستم (تصویر را ببینید)  حدس می زنم مجموعه داده ها اساساً شبیه به این است: http://www.caldercenter.org/whatis.cfm، اما به طور دقیق، ارقام، سهام علامت گذاری شده هفتگی از مجموعه ثابتی از محصولات هستند. مجموعه داده کامل شامل نزدیک به 25000 محصول است که طی 76 هفته ردیابی شده اند. آنچه من می خواهم بررسی کنم این است: 1. آیا نرخ رشد در سهم علامت گذاری شده تابعی از مقادیر فعلی سهم علامت گذاری شده است یا خیر. 2. آیا مزایای کوچک در مراحل اولیه در طول زمان بزرگتر می شوند. من تسلط اولیه بر SPSS و روش هایی مانند همبستگی و رگرسیون را دارم و ایده های تقریبی مانند مثال دارم. برای هر هفته به صورت دستی همبستگی بین سهم علامت گذاری شده (انباشته شده) و سهم مشخص شده هفته بعد را اندازه گیری کنید، اما من کاملا مطمئن هستم که رویکردهای مناسب تر وجود دارد. لطفاً کسی می تواند آنقدر مهربان باشد که مرا به مسیرهای احتمالاً مفید راهنمایی کند؟ | روشهایی برای اندازهگیری اثرات گلوله برفی در یک مجموعه داده طولی کامل. |
96164 | کاربران طبق فرآیند پواسون با نرخ $\lambda$ وارد می شوند. اگر هر کاربر سوم حذف شود، آیا کاربران باقیمانده یک فرآیند پواسون با نرخ $2\lambda/3$ تشکیل می دهند؟ اگر هر کاربر دیگری حذف شود، آیا کاربران باقی مانده یک فرآیند پواسون با نرخ $\lambda/2$ تشکیل می دهند؟ و غیره..؟ | ورود پواسون |
99074 | من سعی می کنم زیرجمعیت های داده را در مجموعه ای از داده ها شناسایی کنم. مشکل این است که داده ها ممکن است بیش از یک زیرجمعیت داشته باشند و جمعیت های فرعی ممکن است به طور معمول توزیع نشوند. به عنوان مثال، داده ها می توانند به این شکل باشند...  محور Y تعداد و محور X مقدار است . آنچه من می خواهم این است که تعداد زیرجمعیت ها و مقادیر اوج آنها را تعیین کنم. زبان برنامه نویسی که من بیشتر با آن آشنا هستم پایتون است، با این حال، روش های من موفقیت آمیز نبوده است. مشکل ساز می شود زیرا در مثالی که نشان دادم یک زیرجمعیت با دو قله وجود دارد. روش من به دنبال قلهها و درهها است، بنابراین در این مثال سه زیرجمعیت را شناسایی میکند، حتی اگر در واقع دو جمعیت وجود داشته باشد. من با آمار تازه کار هستم، بنابراین میخواستم بدانم آیا کسی در اینجا میتواند راهی برای شناسایی زیرجمعیتهای دادهها پیشنهاد کند. | چگونه می توانم تعداد توزیع ها را در مجموعه ای از داده ها تشخیص دهم؟ |
113692 | آیا روش استانداردی برای آزمایش اینکه آیا دو بردار با توزیع **گسسته** یکسان در R رسم شده اند وجود دارد؟ چیزی شبیه تست کولموگروف-اسمیرنوف، اما برای توزیع های گسسته. فکر میکنم آزمون کای دو نمونهای مناسب باشد. آیا بسته ای آن را ارائه می دهد؟ من نمی توانم «chisq.test» را برای من کار کند. | تست یکسانی توزیع گسسته |
21808 | * ** _پیشینه:_ *** من در حال انجام یک مطالعه آکادمیک هستم که ماهیت اکتشافی بیشتری دارد (مشاور من نمی خواست هیچ فرضیه ای را ایجاد کنم). بنابراین، کتابها را خواندم و مصاحبههایی انجام دادم تا فهرست بزرگی از مواردی را که مردم احساس میکنند برای موضوع مورد مطالعه مهم و تأثیرگذار هستند، جمعآوری کنم. از آن لیست، من آنها را به سوالاتی تبدیل کردم که در یک نظرسنجی بپرسم که تعداد پاسخ های خوبی دریافت کردم (n>500). نظرسنجی 50 سوالی شامل لیستی از 35 مورد است که مردم فکر می کنند برای موضوع مهم هستند و 15 سوال جمعیت شناختی در مورد پاسخ دهنده. * ** _مشکل من:_ *** حالا در انتخاب تحلیل های صحیح مشکل دارم. آنچه من می خواهم به آن برسم این است که از طریق تجزیه و تحلیل داده ها، مدلی ارائه کنم که شامل تمام مواردی است که افراد برای موضوع مورد مطالعه مهم می دانند. اما در عین حال، مشاور من از من نمیخواهد که آیتمهای نظرسنجی را خیلی کم کنم زیرا احساس میکند همه موارد در نظرسنجی مهم هستند، بلکه بر اساس مواردی که پاسخدهندگان به عنوان مهم نشان دادهاند (متوسط امتیاز بالایی دارند). ?)، آنها را با هم گروه بندی کنید تا فاکتورهایی را در یک مدل تشکیل دهند (بدون کاهش داده های زیاد) و به دنبال هر رابطه ای بگردید. من مطمئن نیستم که کدام نوع تحلیل برای این کار مناسب باشد. تا اینجا فکر میکنم نوع تحلیل اشتباهی را انتخاب کردهام، بنابراین از کمکی قدردانی میکنم. پس از مطالعه تحلیلهای بالقوه مناسب برای مطالعاتی که فرضیه ندارند، یک تحلیل تأییدی اصلی در مورد سؤالات غیردموگرافیک انجام دادم و آنها را به 4 عامل تبدیل کردم. اما با انجام این کار، حدود 10 مورد غیر جمعیتی حذف شدند. مشاور من اکنون از من میپرسد که آیا PCA بهترین تحلیل برای انتخاب است، زیرا او دید که اکثر نمرههای میانگین برای همه سؤالها بالا هستند (حدود 3-4 از 5) بنابراین او فرض کرد که همه آنها مهم هستند و باید همه باشند. در یک مدل گنجانده شده است. من معتقدم آنچه او می خواهد تمام سوالات با میانگین نمره بالا است که نشان می دهد پاسخ دهنده احساس می کند مهم است باید واقعاً در مدل نگه داشته شود و نباید از مدل حذف شود. _در نهایت، من به دنبال پیشنهاداتی هستم که چه تحلیل هایی برای نتیجه ای که می خواهم به آن دست یابیم مناسب است... برای ایجاد مدلی که شامل تمام مواردی باشد که افراد از نظرسنجی مهم می دانند (و اگر میانگین امتیاز باشد هر گونه نشانه ای، تعداد بسیار بالایی از آیتم ها امتیاز 3-4 از 5 را در لیکرت دارند)_ از هر پیشنهادی ممنونم. | مشکل در توسعه یک مدل برای یک مطالعه اکتشافی (PCA EFA) |
69636 | \-----ویرایش: ببخشید، وقتی سوالم را نوشتم تا حدودی عجله داشتم. اجازه دهید آن را دوباره بیان کنم. من قصد دارم یک تجزیه و تحلیل ANOVA ترکیبی متشکل از یک DV اندازهگیریهای مکرر و یک بین آزمودنیهای IV (یک متغیر طبقهبندی که دارای سه شرط است) انجام دهم. برای نتیجهگیری درست، ابتدا میخواهم با در نظر گرفتن نمرات استاندارد شده برای هر متغیری که متغیر RM را تشکیل میدهد، مشخص کنم که آیا در امتیازات RM موارد پرت وجود دارد یا خیر و ببینم آیا انحراف معیار +/-3 را پیدا میکنم یا خیر. با این حال، طبق درک من، این مقادیر استاندارد شده به میانگین وابسته هستند، که انتظار دارم ممکن است در هر شرایط متفاوت باشد. بنابراین، چگونه باید نمرات استاندارد شده خود را تعیین کنم؟ آیا باید از فیلترها برای تعیین امتیاز در هر شرط استفاده کنم یا می توانم آنها را در هر سه شرط محاسبه کنم؟ من هر دو را امتحان کردهام و تفاوت وجود دارد، برخی از مقادیر وقتی در همه شرایط تجزیه و تحلیل میشوند روی 3SD لبهدار میشوند، اما وقتی امتیازات را در هر شرط محاسبه میکنم (یا برعکس) به حالت پرت تبدیل میشوند. در مورد منابع دیگرم، من در حال حاضر نمونه ای در دسترس ندارم، اما وقتی دیروز به این موضوع نگاه کردم، عمدتاً توضیحاتی پیدا کردم که بیان می کرد نمرات SD باید برای DV و هر متغیر بالا محاسبه شود |+/-3| پرت است. البته این را از قبل می دانم و به من کمکی نمی کند که به سوالم پاسخ دهم. امیدوارم الان کمی واضح تر بشه * * * متاسفم اگر این سوال قبلا پرسیده شده و پاسخ داده شده است اما سعی کردم آن را جستجو کنم اما نتوانستم پاسخ قانع کننده ای پیدا کنم. من قصد دارم یک ANOVA ترکیبی را با اندازه گیری های مکرر و یک متغیر طبقه بندی انجام دهم و می خواهم مقادیر پرت را در متغیرهای وابسته (اندازه گیری های مکرر) بررسی کنم. با این حال، مطمئن نیستم که آیا باید مقادیر پرت را در هر یک از متغیرهای RM بررسی کنم (نمرات استاندارد شده برای همه متغیرهای RM را تعیین کنم و در هر یک از آنها در همه شرایط به نقاط پرت نگاه کنم)، یا اینکه آیا باید داده های خود را در نظر بگیرم. بر اساس هر شرط (تنظیم و استفاده از یک فیلتر در هر شرایط، و سپس برای بررسی نقاط پرت در متغیرهای هر شرط). در توضیحات کلی در مورد نقاط پرت، من فقط نمونه هایی را پیدا کردم که در آنها کل متغیر به طور همزمان در نظر گرفته شده است و هیچ شرطی در آن بحث نشده است، بنابراین امیدوارم کسی بتواند به من کمک کند. خیلی ممنون | تشخیص پرت در شرایط چندگانه؟ |
38926 | > **تکراری احتمالی:** > چه نمونه هایی وجود دارد که در آن یک بوت استرپ ساده لوح از کار می افتد؟ شاید این سوال کمی نرم باشد، اما فکر می کنم ممکن است پاسخ سختی داشته باشد. اگر فلسفیتر شد، آن را به بحث یا CW منتقل کنید. من یک دانشمند کامپیوتر هستم و شاید به دلیل ضرب المثل قدیمی در مورد اینکه چگونه چیزها وقتی چکش را در دست می گیرید ظاهر می شوند، بوت استرپینگ طبیعی ترین راه حل برای تقریباً هر مشکلی است که در آزمایش فرضیه می بینم. به عنوان مثال، امروز، در حین پاسخ دادن به یک سوال اینجا در CV، حتی بوت استرپ را برای آنچه واقعاً فقط یک وضعیت آزمون t ساده بود (بدون توجه به چیزی که به چه چیزی کاهش مییابد) پیشنهاد کردم. این من را به چند سوال سوق داد: اول، آیا دلیلی برای اجتناب از تقویت غیر از تمایل به پنهان کردن سهوی فرضیات در مورد داده ها یا توزیع های اساسی وجود دارد؟ یعنی **آیا دلایل دیگری برای جلوگیری از بوت استرپ وجود دارد به غیر از اینکه «به خودت شلیک کنی راحت تر است.»؟** دوم، شاید از نظر فلسفی تر، در بسیاری از زمینه ها، از جمله حوزه های من، آمارهای بد زیادی مشاهده می شود. . من کنجکاو هستم که آیا برای فردی که با تحصیلات آماری کمی کار میکند، راحتتر است که با استفاده از متداولترین روشهای آزمایش فرضیهها یا استفاده از راهاندازی، چیزها را از بین ببرد. بدیهی است که شکستن روشهای مرسوم سختتر است به این معنا که مفروضات به وضوح بیان شدهاند، اما در تجربه من، مردم اغلب حروف ریز را نمیخوانند و به هر حال فرضیات را نادیده میگیرند. **در صورتی که فردی کورکورانه هر روشی را برای دادهها اعمال میکند، آیا فکر میکنید در مقایسه با استفاده از روشهای متداول استنتاج بدون توجه به فرضیات اساسی، احتمال بیشتری دارد که با استفاده از bootstrapping نتیجهگیری بدی کند؟** | چه زمانی باید از Bootstrapping اجتناب کرد؟ |
113035 | چگونه ثابت می کنید که $X_n - E[X_n] = O_p(\sqrt{Var(X_n)})$ در کتاب درسی من استفاده شده است و من نمی دانم آنها آن را از کجا می آورند. | اثبات واریانس مجانبی |
99075 | با آزمون t-test زوجی دریافتم که شرکت کنندگان در مورد یک دستاورد تیمی بیشتر از موفقیت فردی ابراز غرور کردند. آنچه اکنون می خواهم بررسی کنم این است که آیا این تفاوت بین غرور ارتباطی در مورد یک دستاورد تیمی و یک دستاورد فردی برای هندی ها در مقایسه با آمریکایی ها بزرگتر است یا خیر. من یک نمونه متشکل از 148 هندی و 268 آمریکایی دارم. همه شرکتکنندگان باید غرور ارتباطی خود را نسبت به یک دستاورد تیمی و یک دستاورد فردی نشان میدادند (بنابراین، طراحی درون موضوعی است). کدام آزمون را اجرا کنم؟ من در مورد محاسبه یک متغیر جدید فکر کردم که به عنوان غرور ارتباطی نسبت به یک دستاورد تیمی محاسبه می شود - غرور ارتباطی نسبت به یک دستاورد فردی. بعد باید تعیین کنم که آیا اینها با هم فرق دارند، اما نمی دانم چگونه!؟ | چگونه فرضیه خود را آزمایش کنم؟ |
113031 | در یادداشتهای سخنرانی CS294A، اندرو نگ (در مورد رمزگذارهای خودکار) مینویسد: «معمولاً کاهش وزن برای اصطلاحات بایاس اعمال نمیشود... با این حال، اعمال کاهش وزن در واحدهای بایاس معمولاً تنها تفاوت کوچکی با شبکه نهایی ایجاد میکند». آیا دلیل خاصی وجود دارد که برای آن ما نباید کاهش وزن را در شرایط تعصب اعمال کنیم؟ آیا باعث کاهش عملکرد شبکه می شود؟ | NN: آیا باید کاهش وزن را برای سوگیری اعمال کنیم؟ |
86956 | در حال حاضر، من از یک شبکه عصبی برای طبقهبندی دادهها در یکی از سه گروه استفاده میکنم (یک تابع فعالسازی لجستیک در همه گرهها به جز گرههای خروجی استفاده میشود). من می توانم شبکه عصبی را به دو روش آموزش دهم: 1) برای هر مشاهده $X_{i}$ می توانم یک متغیر خروجی $O_{i}$ داشته باشم که می تواند سه مقدار داشته باشد: $1،2، $ یا $3$. یا، 2) برای هر مشاهده $X_{i}$ من می توانم سه متغیر خروجی $O_{i1}، O_{i2}$، و $O_{i3}$ داشته باشم که بر اساس مقادیر $0$ یا $1$ می گیرند. برچسب کلاس برای آن مشاهده چیست. بنابراین برای مثال، اگر مشاهده $i$ متعلق به کلاس 2 باشد، $O_{i2}$ خواهد بود $1$، در حالی که $O_{i1}$ و $O_{i3}$ $0$ خواهد بود. آیا دو رویکرد فوق معادل هستند؟ آیا یکی بهتر از دیگری است؟ آیا دلایل نظری وجود دارد که باور کنیم یکی باید نتایج بهتری نسبت به دیگری داشته باشد؟ | هنگام استفاده از شبکه عصبی برای طبقه بندی بیش از دو کلاس، بهتر است چندین گره خروجی (یکی برای هر کلاس) داشته باشیم یا یک گره خروجی؟ |
9662 | من 3 گروه مختلف دارم: A، B، و C: * A (دارای یک وضعیت پزشکی است) دارای 30 ورودی است * B (یک وضعیت پزشکی دیگر) دارای 31 ورودی است * C (گروه کنترل) دارای 55 ورودی است. مجموعه ای از متغیرها من می خواهم ارزیابی کنم که آیا از نظر آماری تفاوت معنی داری در خطر ابتلا به یک بیماری خاص بین: * گروه A و C * گروه B و C * گروه B و A وجود دارد یا خیر، همچنین، همه گروه ها باید برای سایر عوامل خطر شناخته شده تنظیم شوند. | چگونه می توان خطر افتراقی بیماری را در سه گروه پس از تطبیق با سایر عوامل خطر ارزیابی کرد؟ |
9663 | اگر یک آیتم از توزیع نرمال پیروی کند، میانگین نیز از توزیع نرمال پیروی می کند. حداقل و حداکثر چطور؟ | توزیع مقادیر افراطی |
105477 | چند وقت پیش، وقتی در کلاس طبقهبندی الگو شرکت کردم، «مفهوم» بهعنوان تجزیه و تحلیل متمایز چندگانه معرفی شد: شما میخواهید دادههای خود را در یک زیرفضا (اگر علاقهمند به کاهش ابعاد هستید) که تفکیک بهتری بین کلاسهای مختلف ایجاد میکند (به عنوان مثال. ، در یک کلاس نظارت شده با چندین کلاس برچسب گذاری شده). فکر میکنم تکنیک را درک کردهام و به نوعی به تجزیه و تحلیل مؤلفههای اصلی مربوط میشود - با این تفاوت که شما 2 ماتریس پراکندگی دارید: ماتریس پراکندگی در داخل و ماتریس پراکندگی برای بین کلاسها... به هر حال، بعدها که من بودم. در تلاش برای کنکاش در موضوعات مرتبط با ماشین، به طور تصادفی با اصطلاحات تحلیل تشخیص خطی (LDA) و مقیاسسازی چند بعدی (MS) برخورد کردم و من هستم. تعجب می کنم که چگونه آن ها به هم مرتبط هستند. اگر به درستی متوجه شده باشم، می توانید اساساً با 2 دسته شروع کنید \- تجزیه و تحلیل تشخیصی خطی \- تجزیه و تحلیل متمایز درجه دوم که پیچیدگی مسئله را توصیف/دسته بندی می کند. و اگر من از تحلیل متمایز چندگانه (MDA_ صحبت کنم، اساساً برمیگردد به اینکه هر کلاس چند بعد دارد!؟ اساساً، آن MDA زیرمجموعهای از LDA و QDA است!؟ و مقیاسگذاری چند بعدی بیشتر شبیه یک دسته فوقالعاده است، جایی که این فقط به فرآیند مقیاس بندی یک فضای ویژگی چند بعدی اشاره دارد، به عنوان مثال، از طریق MDA یا PCA و غیره!؟ | تجزیه و تحلیل تفکیک چندگانه، تجزیه و تحلیل تشخیص خطی، و مقیاس بندی چند بعدی - چگونه آنها به هم مرتبط هستند؟ |
21809 | لطفا نادانی من را ببخشید، اما... من مدام خود را در موقعیتی می یابم که در آن با یکسری داده های جدیدی که موفق به پیدا کردن آن شدم مواجه هستم. این داده ها معمولاً چیزی شبیه این به نظر می رسد: تاریخ شماره 1 شماره 2 رده 1 رده 2 20120125 11 101 سگ قهوه ای 20120126 21 90 گربه سیاه 20120126 31 134 گربه قهوه ای (...) معمولاً در نگاه اول می گویم که آیا واقعاً نمی توانم روندی در اینجا وجود داشته باشد. همبستگی بین ستون های مختلف ممکن است خیلی مهم نباشد، اما اگر مجبور نباشم به صورت دستی یک نمودار برای هر ترکیب ممکن از ستون ها/رده ها ایجاد کنم، خوشحال می شوم. آیا ابزاری وجود دارد که جدولی از دادهها را به همراه اطلاعاتی که ستونها باید بهعنوان اعداد، تاریخ و دستهها در نظر گرفته شوند را بپذیرد و سپس به رسم نمودار ادامه دهد: * همبستگی بین هر دو ستون عددی * همبستگی بین هر دو ستون عددی، با جداگانه خطوط روند برای هر دسته * هر ستون عددی به عنوان یک سری زمانی، * هر ستون عددی به عنوان یک سری زمانی، جدا شده بر اساس دسته بندی، * و غیره. سر و صدا در حالت ایدهآل، این ابزار میتواند نمودارها را با همبستگی نمرهگذاری کند و در پایان نمایش اسلایدی را که با بالاترین امتیازات شروع میشود، نمایش دهد. این یک نگاه اول بسیار ناقص، اما مفید به مجموعه داده خواهد بود. پس؟ آیا ابزاری وجود دارد که همه برای این کار از آن استفاده کنند و من در مورد آن اطلاعی ندارم، یا این چیزی است که ما باید بسازیم؟ | اولین نگاه سریع به یک مجموعه داده |
24870 | فرض کنید می خواهیم دمای ($1$ = گرم، $0$ = سرد) 5 منطقه را در بازه های زمانی زیر مدل سازی کنیم: 1 ماه، 6، ماه و 4 سال. فرض کنید یک متغیر پیشبینیکننده X$ باشد (میزان جنگلزدایی، 1 = زیاد، 0 = بسیار کم). آیا در مدل سازی اثر اصلی (جنگل زدایی) باید زمان را به عنوان پیش بینی در نظر بگیریم؟ | اینکه آیا زمان را به عنوان متغیر کمکی در تجزیه و تحلیل اندازهگیریهای مکرر لحاظ کنیم |
112348 | من یک مدل رگرسیون لجستیک را در R با استفاده از دادههای مضاعف ایجاد شده با استفاده از Amelia II اجرا میکنم که سپس با استفاده از Zelig آن را تحلیل میکنم. من میخواهم بتوانم برخی از معیارهای تناسب را گزارش کنم (مانند نسبت احتمال، شبه مربع R، Hosmer-Lemeshow)، اما هیچ کدام در خروجی پیشفرض Zelig ارائه نشده است و من نتوانستم آن را بفهمم. راهی برای استخراج هرکدام از شی «zelig()». آیا هنگام استفاده از مجموعه دادههای مضاعف منتسب، معیارهای خوبی باید به طور متفاوتی محاسبه شوند؟ آیا بسته های R وجود دارد که قادر به انجام این کار باشد؟ من به چندین بسته نگاه کرده ام که معیارهای خوبی را ارائه می دهند، مانند pscl، اما آنها فقط روی اشیاء glm کار می کنند، نه اشیاء MI که هنگام استفاده از Amelia و Zelig ایجاد می شوند. پیشاپیش از کمک شما متشکرم! | اندازهگیریهای برازش با استفاده از دادههای مضاعف در Zelig |
113963 | من از infer.net برای پیاده سازی یک مدل شبکه بیزی پویا استفاده می کنم. هر گره در هر لایه به تمام گره های لایه قبلی وابسته است (ما می خواهیم wji را آموزش دهیم، وزن یال های بین هر گره j از سطح قبلی (زمان t-1) تا گره i در سطح فعلی (زمان t)). مقادیر گره با yi (مقدار گره i) نشان داده می شود. وابستگی یک تابع پیچیده است مانند: yi(t) = y(t-1).(1-alpha.deltaT) + بتا. 1 / (1 + exp(-WeightedSigma)) WeightedSigma = Sigma (Wij * yj(t)) اکنون میخواهم یک گره فاکتور در پیادهسازی گراف فاکتوری خود در infer.NET قرار دهم. من نمی دانم چگونه باید چنین گره فاکتور و ارسال پیام آن را پیاده سازی کنم. من خیلی گیج شدم لطفاً کسی می تواند در این مورد به من کمک کند؟ من قدردان هر کمکی هستم. با تشکر | محاسبه پیام های EP در نمودار عاملی |
24875 | من روی مسئله Lasso و انتخاب پارامتر تنظیم بهینه با رویه $k$-fold کار می کنم، مثلاً $k=10$. از آنجایی که این رویه بر زیرنمونه گیری تصادفی متکی است، هر بار که این روش را تکرار می کنم، مقدار پارامتر بهینه تغییر می کند. به عنوان مثال، می توان آن را 0.32، سپس 0.41، سپس 0.29، و غیره. 2. چگونه خطای استاندارد را برای استفاده از یک قانون استاندارد محاسبه کنم؟ | انتخاب پارامتر بهینه با k- برابر مکرر |
52079 | در ابتدا این تصور را داشتم که مدلهای متغیر پنهان و مدلهای گرافیکی در مجموع چیزهای متفاوتی هستند، اما پس از خواندن برخی مقالات در مورد مدلهای کلاس قبلی، به نظر میرسد که آنها بیشتر از آنچه فکر میکردم اشتراک دارند. به عنوان مثال، در هر دو مورد، مشخصات احتمالات مشروط وجود دارد. آیا تفاوتی بین این دو وجود دارد؟ چگونه می توانم اینها را نسبت به یکدیگر ببینم؟ | مدل متغیر پنهان و مدل های گرافیکی |
92709 | فرض کنید من یک پواسون GLM را برای مدلسازی نرخها به صورت زیر نصب کردهام: > fit.1=glm(response~X1+X2+ offset(log(population)),family=poisson,data=...) میتوانم نرخهای تخمینی را با با استفاده از دو مقدار جدید برای X1 و X2 و جمعیت=1 به شرح زیر: >new.data=data.frame(X1=new.X1,X2=new.X2,population=1) >estimated.rates=predict(fit.1,newdata=new.data,type=response) زیر بخش زیر 13.4.5 در مقدمه ای بر تحلیل رگرسیون خطی، ویرایش پنجم، سپس با استفاده از انحراف باقیمانده ها را دوباره بررسی می کنم. 'qqnorm' و دریافتند که حتی تقریباً به طور معمول توزیع نشده اند. بنابراین برای اصلاح مدل خود، از تبدیل جعبه و کاکس (لامبدا) برای بهبود مدل استفاده کردم و یک مدل شبه پواسون جدید نصب کردم: > fit.2=glm(I(response^lambda)~X1+X2+ offset(log( جمعیت))،family=quasipoisson,data=...) من دوباره می توانم نرخ ها را مشابه قبل تخمین بزنم: > تخمین زده شده.rates.2=predict(fit.2,newdata=new.data,type=response) estimated.rates.2 در مقیاس پاسخ تبدیل شده است (با استفاده از تبدیل کادر و cox). آیا میتوان نرخهای «rates.estimated.2» را به مقیاس اصلی تبدیل کرد (یعنی مشابه «estimated.rates»)؟ | نرخ تبدیل برگشتی در پواسون GLM با تبدیل جعبه و کاکس |
106369 | لطفاً به این سوال در مورد بحث بدون ناهار رایگان Duda، Hart و Stork مراجعه کنید. سلام به همه، من در درک توضیح قضیه NFL در Duda، Hart و Stork مشکل داشتم. مسائل من همان است که در مرجع بالا مطرح شد. من هم جواب رو خوندم ولی هنوز مشکلات زیر رو دارم. معادله (1) در کتاب برای من منطقی است. می گوید که میزان خطای مورد انتظار برای یک الگوریتم یادگیری با توجه به مجموعه آموزشی این است: \begin{equation} \mathcal{E}[E|\mathcal{D}] = \sum_{h,F}\sum_{x \notin \mathcal{D}} P(x)[1-\delta(F(x)،h(x)]P(h|\mathcal{D})P(F|\mathcal{D}) \end{equation} (در واقع، من معتقدم که $P(x)$ باید $P(x|x \notin \mathcal{D})$ باشد، اما این تفاوتی در اثبات نخواهد داشت.) حالا، همانطور که در متن گفته شد، $P(h|\mathcal{D})$ احتمال این است که الگوریتم تابع فرضیه $h$ را ایجاد کند، بنابراین فقط با یک تغییر جزئی نماد، میتوانیم بنویسیم خطای مورد انتظار برای الگوریتم $k$ این است: \begin{equation} \mathcal{E}_k[E|\mathcal{D}] = \sum_{h,F} \sum_{x \notin \mathcal{D}} P (x)[1-\delta(F(x)،h(x)]P_k(h|\mathcal{D})P(F|\mathcal{D}) \end{equation} بنابراین خطای شرطی برای الگوریتم $k$، تابع هدف $F$، \begin{equation} \mathcal{E}_k[E|F, \mathcal{D}] = \sum_{h} است. \sum_{x \notin \mathcal{D}} P(x)[1-\delta(F(x)،h(x)]P_k(h|\mathcal{D}) \end{equation} اکنون، متن بیان میکند که خطای طبقهبندی خارج از مجموعه آموزشی مورد انتظار زمانی که تابع واقعی $F(x)$ باشد و احتمال Kامین الگوریتم یادگیری کاندید $P_k(h(x)|\ باشد. mathcal{D})$ توسط \begin{equation} \mathcal{E}_k[E|F,n] = \sum_{x \notin \mathcal{D}} داده میشود P(x)[1-\delta(F(x),h(x)]P_k(h(x)|\mathcal{D}) \end{equation} چیزی که من نمی فهمم این است: در مورد از یک الگوریتم تصادفی، توابع فرضی زیادی $h$ وجود دارد که می تواند توسط الگوریتم $k$ تولید شود. اما در معادله بالا، فقط یک $h(x)$ ظاهر میشود و هیچ جمعبندی بیش از $h \in \mathcal{H}$ وجود ندارد. معادله ماقبل آخر در بالا راه بهتری برای توصیف خطای طبقهبندی الگوریتم $k$ داده شده با $F$ به نظر میرسد. به همین دلیل است که من با نویسنده سوال فوق الذکر (مخصوصاً شماره 1 و 2 او) موافق هستم. اگر معادله موجود در متن صحیح است، پس کدام $h$ است؟ کسی ایده ای دارد؟ من باید چیزی را از دست بدهم. با تشکر | دودا، هارت، لک لک بدون بحث ناهار رایگان |
105475 | آیا راهی برای تخمین معادله ARMA با استفاده از تابع «lm()» در R بدون استفاده از «arima()» وجود دارد؟ | تخمین معادله ARMA با استفاده از lm() در R |
24877 | من و دوستانم فقط کمی بحث کردیم که آیا رویدادها مستقل هستند یا وابسته هستند اگر هیچ نتیجه مشترکی نداشته باشند. من فکر می کردم که آنها باید مستقل باشند. وقتی دو رویداد مستقل هستند، آنگاه $P(A)=P(A\mid B)$. آیا اطلاعات ارائه شده در سوال برای اثبات این موضوع کافی است؟ اگر به عنوان نمودار ون به آن نگاه کنید، اگر بین A و B همپوشانی وجود نداشته باشد، آنها مستقل هستند. اما دوستم مخالفت کرد و گفت این بستگی به فضای نمونه دارد. بنابراین فرض کنید ما دو رویداد داریم: $P(A)=6/12$، $P(A\mid B)=2/4$، و $P(B)=4/12$، سپس آشکارا $P( A\mid B)$ برابر است با $P(A)$. اما برای من چیزی اینجا بوی ماهی می دهد. می دانم که این بیشتر یک سوال تصادفی است تا یک سوال آماری، اما شاید کسی بتواند کمک کند. | وقتی دو رویداد $A$ و $B$ هیچ نتیجه مشترکی ندارند |
24876 | من نمی دانم که آیا این یک سوال مناسب است یا خیر. من داده های 2 گروه خنثی و مثبت را دارم. در اینجا داده ها چگونه به نظر می رسند A 02.840 00.960 00.950 00.995 00.995 00.602 1 B 04.730 01.000 01.000 00.999 01.000 01.090 01.090 01.090 C 00.078 00.987 00.000 0 D NULL 01.000 01.000 00.010 00.675 00.451 1 E 00.530 01.000 00.022 00.022 00.230 00 ستون نام اولین رکورد است. و آخرین ستون کلاس/گروه آن است. شش ستون در وسط ویژگی هایی هستند که برخی از آنها ممکن است NULL باشند. با دانشی که سال ها پیش مطالعه کردم، ابتدا ANN و SVM را امتحان خواهم کرد. اما مطمئن نیستم که در مسیر درستی هستم یا نه. بنابراین نمی دانم کسی اینجا می تواند مرا راهنمایی کند. | بهترین روش آموزشی برای رکوردهای 15-30k با 5-12 ویژگی برای طبقه بندی داده ها در 2 گروه چیست؟ |
78189 | من به دنبال مقاله ای هستم که امیدوارم وجود داشته باشد، اما نمی دانم وجود دارد یا خیر. این میتواند مجموعهای از مطالعات موردی، و/یا استدلالی از تئوری احتمال باشد، در مورد اینکه چرا استفاده از دادههای مقطعی برای استنتاج/پیشبینی تغییرات طولی ممکن است چیز بدی باشد (یعنی لزوماً چنین نیست، اما میتواند باشد). من این اشتباه را از چند جهت بزرگ دیدهام: استنباطهایی صورت گرفت که چون افراد ثروتمند در بریتانیا بیشتر سفر میکنند، پس با ثروتمندتر شدن جامعه، کل جمعیت بیشتر سفر میکنند. این استنباط برای مدت طولانی - بیش از یک دهه - نادرست بود. و یک الگوی مشابه با مصرف برق خانگی: داده های مقطعی نشان دهنده افزایش های بزرگ با درآمد است که در طول زمان آشکار نمی شود. چیزهای مختلفی در جریان است، از جمله اثرات همگروهی و محدودیتهای طرف عرضه. داشتن یک مرجع واحد که مطالعات موردی را مانند آن گردآوری کرده باشد بسیار مفید خواهد بود. و/یا از نظریه احتمال برای نشان دادن اینکه چرا استفاده از داده های مقطعی برای استنتاج/پیش بینی تغییرات طولی می تواند بسیار گمراه کننده باشد استفاده کرد. آیا چنین کاغذی وجود دارد و اگر وجود دارد چیست؟ | چرا استفاده از داده های مقطعی برای استنتاج/پیش بینی تغییرات طولی یک چیز بد است؟ |
24879 | لطفا، این شاید یک سوال فراآماری باشد، اما اجازه دهید این را بپرسم. برای پاسخ به این سؤال به یک ریاضیدان چه میگویید: «به چند مثال اشاره کنید که شرکتهای بیمه یا بانکها چه نوع تجزیه و تحلیل دادهها را انجام میدهند؟» چیزی a la آنها مجموعه ای از ادعاها را دارند و میانگین را محاسبه می کنند.... (بدیهی است یک مثال احمقانه). | چه چیزی را تحلیل می کنند |
102875 | من کمی در اطراف جستجو کردم، اما در یافتن پاسخی برای سوال خاص خود که خیلی فنی نیست مشکل دارم. من میخواهم این احتمال را پیشبینی کنم که برای یک سری زمانی معین در نقطه عطفی قرار داریم - که به طور دلخواه تعریف شده است. من دادههای تاریخی دارم که از آنها برخی زمانها را تعیین کردهام که «نقاط عطف» هستند (1 برای بله، 0 برای خیر) و فهرستی از رگرسیونها دارم که در واقع دادههایی برای آنها دارم. از این رو، من میخواهم الف) از یک مدل پروبیت یا لاجیت برای تخمین ضرایب روی رگرسیونهایی که دارم استفاده کنم و ب) از مقادیر آینده (یا خارج از نمونه) برای این رگرسیونها برای پیشبینی/پیشبینی شانسی که در آن قرار داریم استفاده کنم. یک نقطه عطف در حال حاضر چیزی که من با آن مشکل دارم قرار دادن سری های زمانی و تجزیه و تحلیل پروبیت است. من تماس میدهم: glm (فرمول = چرخش ~ . - تاریخ، خانواده = دوجملهای (پیوند = probit)، داده = d1) من میخواهم از عملکرد پیشبینی برای بدست آوردن یک سری زمانی از احتمالات استفاده کنم. دو فکر پایانی 1. من قبلاً آمار زیادی انجام نداده ام، بنابراین می خواهم از برخی مشکلات اجتناب کنم. تعریف من از نقطه عطف از این جهت مشخص است که برای بیش از 123 مشاهده ماهانه (تاریخی) تنها 4 مورد این معیار را برآورده می کنند. آیا این مانع از توانایی مدل پروبیت برای کارکرد موثر می شود، آیا باید هر یک از این نقاط را در یک محدوده بالشتک کنم (یعنی هر بار به اضافه یا منهای 2 نقطه عطف فعلی من به 1 تغییر می کند). 2. آیا روش های بهتری برای پیش بینی باینری وجود دارد؟ من متوجه شدم که در پیش بینی میانگین ضربات بیس بال، یک توزیع بتا برای مدل سازی پیشین ها و به روز رسانی استفاده می شود. آیا راه منطقی برای وارد کردن این موضوع وجود دارد؟ | ترسیم یک سری زمانی پروبیت در R |
9666 | ساعت کامپیوتری جدید من با سرعتی کار می کند که در طول زمان به صورت پلکانی تغییر می کند، حتی پس از تنظیم آن از طریق نرم افزار Linux adjtimex. در اینجا نموداری از تغییر در رانش تجمعی ساعت برای هر یک از حدود 1700 نمونه گرفته شده در هر 10000 ثانیه است، با تعدادی از نقاط از دست رفته و نقاط پرت زمانی که من از شبکه خارج بودم و ntpdate کار نمی کرد. به عنوان مثال در اوایل، ساعت در هر 10000 ثانیه حدود 0.09 ثانیه افزایش یافت (9ppm). 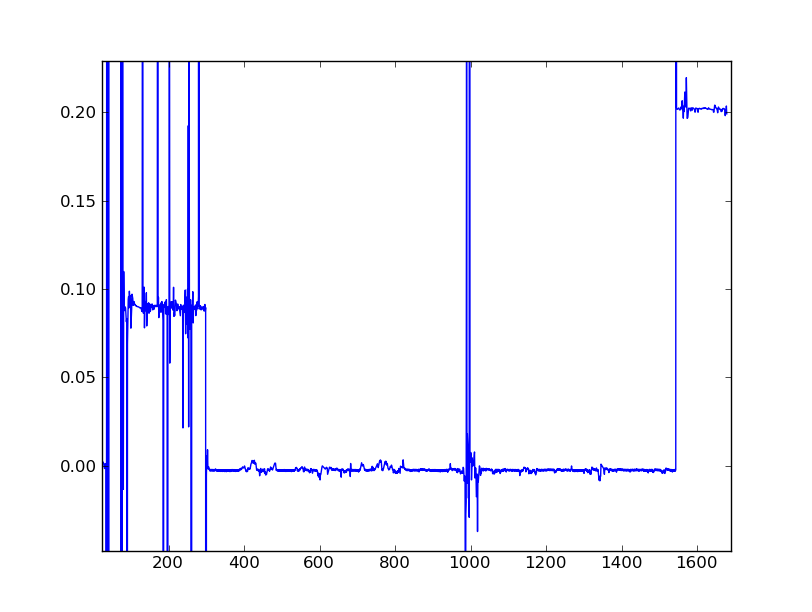 من به دنبال چند توابع کتابخانه هوشمند هستم که بتواند به طور خودکار آنچه را که من می دانم شناسایی کند. «حالتهای» آماری مختلف این مجموعه داده را فراخوانی میکنیم - یعنی یک حالت در وسط وجود دارد که y برای مدت طولانی حدود 0.02- است، سپس حالت دیگری نزدیک به 0.09 است. در اوایل و یکی در 0.202 در پایان. اکثر کدهایی که برای یافتن حالت دادهها دیدهام، با اعداد صحیح و دادههای گسسته سروکار دارند، اما همانطور که میبینید، مقادیر ممیز شناور بسیار نامرتب دارد. در هر صورت، در حالت ایدهآل، خلاصهای را میخواهم که به طور خودکار حالتهایی را که در بالا شناسایی کردهام پیدا کند، و همچنین برای هر یک انحراف استاندارد به من بدهد. نقاط شروع/توقف برای هر حالت برای اعتبار اضافی. کد پایتون ترجیح داده می شود. | شناسایی حالت ها در داده های ممیز شناور |
99072 | من یک جدول احتمالی دارم که از مشاهدات خارج از نمونه محاسبه شده است. در برخی موارد همه کلاسها در خارج از نمونه نمایش داده نمیشوند و بنابراین ظاهر نمیشوند. من میخواهم جدول احتمالی را وادار کنم که صفرها را برای کلاسهایی که خارج از نمونه نیستند گزارش کند. چگونه می توانم آن را به طور موثر انجام دهم. به عنوان مثال جدول احتمالی من x z x 1 2 y 1 3 z 2 2 است اما می خواهم شبیه x y z x 1 0 2 y 1 0 3 z 2 0 2 باشد. | جدول اضطراری اجباری برای گزارش کلاس های ارائه نشده |
78184 | احتمال log به شرح زیر است: $nln\beta + (-\beta-1)\sum ln(x_i)$ با تقسیم احتمال ورود بر n، $ln\beta + \frac{(-\beta-1)} {n}\sum ln(x_i)$ با استفاده از این دو احتمال log، من همان برآوردگر MLE را دریافت کردم که $\frac{n}{\sum است ln (x_i)}$. با این حال، من با ویژگی های مجانبی متفاوت گیج شدم. برای لاگ احتمال اول، ماتریس اطلاعات $\beta^2/n$ است، برای دومی به سادگی $\beta^2$ است. من درک می کنم که صرفاً به دلیل جبر، نتایج متفاوت خواهد بود. اما من میخواهم ویژگی آماری را بفهمم: چرا این دو MLE برای دو لگاریتم احتمال واریانس مجانبی متفاوتی دارند؟ تفاوت با این واقعیت که log-likelihood بر $n$ تقسیم شده است چگونه ارتباط دارد؟ | برآوردگر MLE - تقسیم احتمال ورود بر n نتیجه متفاوتی می دهد |
113962 | من در حال حاضر مقاله دیبولد و لی در سال 2006 را می خوانم: پیش بینی ساختار اصطلاحی بازدهی دولت در جایی که نویسندگان با مدل های AR(1) ولو ساده بر روی داده های کاملاً ثابت سازگار هستند. چرا این کار در شرایط خاص مجاز است؟ و عواقب / پیامدهای انجام این کار چیست؟ با تشکر | مدلهای AR بر روی دادههای غیر ثابت |
105478 | آیا فرآیند عادی سازی/استانداردسازی ویژگی باید قبل یا بعد از فرآیند انتخاب ویژگی انجام شود؟ | عادی سازی/استانداردسازی ویژگی قبل یا بعد از انتخاب ویژگی؟ |
107853 | من می خواهم فراوانی ریتوییت ها را بین 2 گروه با اندازه نابرابر مقایسه کنم. من تعداد کل توییت ها و تعداد بازتوییت ها را برای هر کاربر دریافت کرده ام. من امیدوار بودم که صفحه وب R Cookbook کمک کند، اما به نظر می رسد آزمایش های ارائه شده در آنجا برای اندازه گیری های مکرر و اندازه نمونه برابر برای دو گروه مناسب تر است: http://www.cookbook-r.com/Statistical_analysis/Frequency_tests/ من خواهم بود. از راهنمایی در مورد اینکه از چه آزمایشی در اینجا استفاده کنم سپاسگزارم. مجموعه داده من کمی شبیه این است: userid tweetCount ReTweetcount Group 1 45 3 A 2 100 25 A 3 23 0 B | تفاوت در فرکانس در دو گروه با اندازه نابرابر |
41197 | > **تکراری احتمالی:** > محاسبه انحراف استاندارد جدید با استفاده از انحراف استاندارد قدیمی پس از > تغییر در مجموعه داده من واریانس نمونه n نمونه و میانگین آن و خود n را می دانم. اکنون می خواهم یک نمونه دیگر اضافه کنم تا n + 1 داشته باشم. آیا راهی وجود دارد که چگونه نمونه را بدون محاسبه مجدد کل ترم اضافه کنم؟ (کارآمد محاسباتی). تقریب هم خوب خواهد بود. | به روز رسانی واریانس نمونه، نمونه به نمونه |
113968 | فرض کنید من یک مجموعه داده با چندین متغیر پیوسته و طبقه بندی دارم، و می خواهم شناسایی کنم که چه متغیرهایی (مقادیر یا ویژگی های این متغیرها) ممکن است باعث افزایش یکی از متغیرهای پیوسته شوند. چگونه می توانم این مشکل را مدل کنم؟ چندین رویکرد به ذهن می رسد (به عنوان مثال **رگرسیون لجستیک**، **ANOVA**، **درخت تصمیم**) اما اکثر آنها (همه؟) نیاز دارند که یک **شرط** را روی متغیر هدف خود تعریف کنم و بنابراین آن را به یک متغیر **مقوله** تبدیل کنید و/یا مشکل را به عنوان یک **مشکل طبقه بندی** در نظر بگیرید. اما اگر متغیر **وابسته** من یک متغیر پیوسته باشد و من به دنبال ویژگی های متغیرهای مستقل (مستمر و طبقه ای) باشم که باعث می شود متغیر وابسته من افزایش یابد چه؟ آیا **رگرسیون خطی** بهترین کاری است که می توانم انجام دهم؟ اگر هدف من یافتن **محدوده**های پیش بینی کننده هایی باشد که از نظر آماری با افزایش متغیر وابسته من همبستگی دارند، چه؟ چه **مدل**هایی برای این مشکل در دسترس دارم و مهمتر از همه، چه **سوالاتی** باید در مورد مشکل از خودم بپرسم تا مدل مناسب را شناسایی کنم؟ | شناسایی عواملی که باعث افزایش یک متغیر می شود |
113697 | من دو IV دارم که در 0.979 (Pearson) و 0.919 (Kendall's) همبستگی بالایی با یکدیگر دارند. IV1: کیفیت پاسخ IV2: کیفیت مشاوره فنی حجم نمونه: 252 با توجه به شباهت در عبارت IV ها، آیا می تواند به این معنی باشد که پاسخ دهندگان تفاوتی بین دو اندازه گیری درک نمی کنند؟ آیا رها کردن یکی از موارد مناسب است؟ | موارد بسیار مرتبط را حذف کنید؟ |
8526 | من یک سوال نسبتاً اساسی در مورد تجزیه و تحلیل مؤلفه های اصلی احتمالی دارم، که اکنون سعی می کنم آن را برای یک مشکل دنیای واقعی اعمال کنم. در PPCA، فرض مهم این است که فرآیند تولید مشاهدات در $R^n$ $t=Wx +\sigma^2\epsilon$ است، که در آن x iid گاوسی استاندارد در $R^q$ (با $q است. \le n$) و $\epsilon$ بردارهای استاندارد گاوسی iid در $R^n$ هستند. نویسندگان دریافتند که راهحل MLE $\hat W=U_q (\Lambda_q - \sigma^2 I)^{1/2}$ است، که در آن $\Lambda_q$ ماتریس مورب $q$ بزرگترین مقادیر ویژه است. ماتریس کوواریانس تجربی، و $U_q$ زیر ماتریس بردارهای ویژه مربوطه است، و $\sigma^2$ میانگین است مقادیر ویژه کوچکتر باقی مانده (به بخش 3.2 مقاله مرتبط مراجعه کنید). سوال من ساده است. ماتریس کوواریانس $C=WW'+\sigma^2 I$ است. با اتصال مستقیم نتیجه بالا، $\hat C=U_q\Lambda_q U_q$ را به دست می آوریم (شرایط $\sigma^2$ لغو می شوند). آیا این می تواند درست باشد؟ ماتریس کوواریانس دارای کمبود رتبه است. آیا من چیزی را از دست داده ام؟ | سوال در مورد تحلیل مولفه اصلی احتمالی |
105471 | من مدلی را در حوزه فرکانس برازش می کنم و تناسب من به این صورت است:  همانطور که می بینید، تابع مدل مناسب نیست داده ها به طور کامل، به خصوص در فرکانس های بالاتر. بنابراین، من باقیمانده ها را بررسی کردم و دریافتم که یک چند جمله ای درجه اول عبارت گم شده در تابع مدل است. چیزی که بیشتر نگران من است این است که واریانس داده ها با فرکانس کاهش می یابد. چه پیامدهایی بر تحلیل من دارد؟ (به نظر می رسد که نگاه کردن به همبستگی خودکار باقیمانده ها نیز چندان مفید نیست.) هر ایده ای بسیار مفید خواهد بود. | انحراف استاندارد غیر ثابت در باقیمانده ها |
68099 | من تعدادی دانه در فواصل مختلف افتاده ام. اگر مدلی مناسب باشد، باید بدانم کدام مدل با این داده ها مطابقت دارد. مدلهای مختلفی برای برازش این دادهها استفاده شده است: نمایی منفی، ویبول، لگ نرمال. من باید بدانم که چگونه همه آنها را در R قرار دهم، از 0 شروع کنیم و داده ها را تولید کنم. من فقط توانستم مدل نمایی مجانبی 2 پارامتری را برازش کنم، اما نمیدانستم به کدام پارامتر نگاه کنم یا ایجاد کنم تا بدانم آیا تناسب خوبی دارد یا خیر. اطلاعات مستقیماً از اکسل من این است: Distancia (فاصله) 5.4 9.69 11.32 12.84 12.98 14.92 17.76 17.94 17.96 22.17 61.37 63.18 87.88 112.29 116.29 45.23 141.2 Abundancia (تعداد) 1 2 9 49 24 0 18 3 5 3 10 0 3 0 7 9 6 3 | برازش مدل های مختلف به داده های من در R |
68090 | فرض کنید من یک مجموعه داده دارم که از مخلوطی از گاوسیان نمونه برداری شده است: $$ X \sim \sum_i w_i \mathcal{N}(\mu_i, \Sigma_i)$$ از نظر فنی، میتوانم X$ را در مرکز و سپس سفید کنم تا آن را میانگین و کوواریانس واحد صفر دارد. اما چیزی در مورد آن فرآیند بهطور رضایتبخشی بیش از حد سادهشده به نظر میرسد: برای مثال، اگر میانگینهای مخلوط در امتداد یک نیمدایره مرتب شوند، بهگونهای که هیچ ارزشی در X$ واقعاً در میانگین کلی نمونه رخ ندهد، چه؟ به نظر می رسد این موردی است که سفید کردن واقعاً معنایی جهانی ندارد. با این حال، تنها با توجه به یک مجموعه داده، می توان از نظر تئوری ترکیبی از مدل گاوسی را در آن قرار داد و سپس از کوواریانس های تخمین زده شده برای سفید کردن نقاط در مناطق محلی فضای داده استفاده کرد. سوال من این است که آیا این روند قبلاً به نوعی با نامی رسمی شده است که من هنوز به آن برخورد نکرده ام؟ اصلا معنی داره؟ برای کسب اطلاعات بیشتر در مورد سفید کننده موضعی باید از چه مراجع خوبی استفاده کنم؟ | سفید کردن مخلوطی از گاوسیان |
114220 | ما با داده های پانل کار می کنیم. اما ما می خواهیم فقط قسمت مقطعی داده های پانل را مطالعه کنیم. بنابراین، لطفاً کسی می تواند به من بگوید که چگونه هر نوع تبدیل داده را انجام دهم تا بتوانم واریانس سری زمانی را از داده های پانل حذف کنم؟ متشکرم. | حذف واریانس سری زمانی از داده های پانل |
67244 | فرض کنید من رفتار کاربران را هنگام بازدید از یک وب سایت ردیابی کردم. به طور مفصل حرکتی را که از کدام سایت به سایت کلیک می کنند در وب سایت دنبال می کنم. بنابراین من تاپل های زیادی با (userID، سایت، زمان) دارم. اکنون می خواهم تجسم کنم که آیا الگوها یا خوشه هایی برای حرکت وجود دارد یا خیر. فرض کنید اکثر کاربران گام به گام از طریق وب سایت کلیک می کنند، و گروه دیگری از سایت 1 و سپس سایت 2 بازدید می کنند، سپس به 1 و سپس به 2 و سپس به سایت 3 برمی گردند. از چه روشی می توانم برای طبقه بندی رفتار استفاده کنم؟ a<-as.POSIXlt(2013-07-01 00:30:00) b<-as.POSIXlt(2013-07-29 00:30:00) aI<-as.numeric(a) bI <-as.numeric(b) بار<-sample(seq(aI,bI,by=2)،10000) t<-sort(times) class(t)<-c(POSIXt,POSIXct) id<-seq(1,10050,20) userID<-1 for(i در 1:200){ userID<- c(userID,sample(id[i]:id[i+1],50,replace=T)) } userID<-userID[1:10000] جنبش<-list(LETTERS[1:20],c(A، B، A، B، C، D، E، F، G، H، I) ,c(A، B، C، B، C، D، E، D، C، D E) ,c(C،B، C، D، E، F، G، H، I، I)) site<-character(10000 ) for(i در منحصر به فرد(userID)){ p<-sample(movement,1)[[1]] site[userID==i]<-p[1:length(userID[userID==i])] } table<-data.frame(userID=userID,site=site,time=t) | روش پیدا کردن الگو |
67245 | بر اساس یک سوال قبلی، کلاس ها را طوری متعادل کردم که اعداد در هر دو کلاس تقریباً مشابه باشند. جنگل تصادفی نتیجه بعدی را می دهد: > print(rFresult) فراخوانی: randomForest(فرمول = finresfh ~ .، داده = rFdatasubset، اهمیت = TRUE) نوع جنگل تصادفی: طبقه بندی تعداد درختان: 500 تعداد متغیرهای امتحان شده در هر تقسیم: 14 برآورد OOB از میزان خطا: 35.53٪ ماتریس سردرگمی: 1 2 class.error 1 1852 627 0.2529246 2 1022 1140 0.4727105 پیش بینی در مجموعه قطار جدایی کامل را برخلاف ماتریس سردرگمی نشان می دهد: > tab <- table(probability=round(predict(rFresult,datastaub) type=prob)[,2],1), TRUE_status=rFdatasubset$finresfh) > برگه TRUE_status probability 1 2 0.1 978 0 0.2 1447 0 0.3 54 0 0.7 0 65 0.8 0.301 0.3015 احتمال برای آزمودنی ها در کلاس 2 تخمین زده می شود. جدول احتمال به معنی تعداد آزمودنی هایی با سطح احتمال پیش بینی شده دارای وضعیت TRUE معین است. آیا کسی می تواند توضیح دهد که چرا احتمالات تخمین زده شده یک جدایی کامل اما نتیجه کاملاً متفاوت را در جدول سردرگمی نشان می دهند؟ | ماتریس سردرگمی جنگل تصادفی با احتمالات پیشبینیشده در دادههای قطار مطابقت ندارد |
68852 | سلام و ممنون از هر گونه کمکی که در زیر آمده است، این یک سوال نسبتاً پیچیده است، بنابراین من سعی خواهم کرد آن را به صورت کاملاً ابتدایی بپرسم. من اطلاعاتی در مورد فراوانی 99 گونه مختلف از گونههای بیمهرگان کلان دهانه رودخانه و محتوای گل رسوب (0-100%) دارم که در آن هر مشاهده بهدست آمد. من در مجموع 1402 مشاهده برای هر گونه دارم (یعنی یک مجموعه داده عظیم). در اینجا زیرمجموعه ای از داده های خام برای یک گونه وجود دارد تا به شما ایده ای از داده هایی که با آنها کار می کنم ارائه دهد (اگر 10 امتیاز شهرت داشتم، نموداری از داده های خام واقعی را آپلود می کردم: فراوانی: 10،14،10،3،3،3،3،4،5،5،0،0،0،0،0،0،0،0،0،0،0،0،6،6، 6,0,0,0,0,12,0,0,0,34,0,0% گل: 0.9،4،2،10،13،14،6،5،5،7،22،27،34،37،47،58،54،70،54،80،90،65،56،7،8، 34,67,54,32,1,57,45,49,4,78,65,45,35 هدف اولیه تحقیق من تعیین محدوده % گل و لای بهینه (به عنوان مثال 15 - 45 %) و محدوده گل توزیعی (به عنوان مثال 0 - 80%) برای هر یک از 99 گونه بی مهرگان همانطور که می بینید، داده های فراوانی برای گونه های فوق حاوی تعداد قابل توجهی است اگر چه این به طور قابل توجهی هر نوع مدلی را که من روی داده اجرا می کنم (یعنی GLM، GAM) منحرف می کند، حتی اگر مدل کنم. تنها با داده های غیرصفر، مدل برای گونه های خاص به خوبی با داده ها مطابقت ندارد، بنابراین، سوال من این است: بهترین و قوی ترین راه برای تعیین محدوده گل بهینه و توزیع چیست. با توجه به اینکه پاسخ ها بین گونه ها به طور قابل توجهی متفاوت است؟ | تعیین محدوده بهینه و توزیع از فراوانی گونه ها در مقابل داده های گرادیان محیطی |
107852 | بهینه سازی محدودیت $\text{argmin}_{\beta}(f(\beta)+\lambda g(\beta))$ را در نظر بگیرید آیا کسی می تواند $\beta(\lambda)$ را تعریف کند. یعنی چه رابطه ای بین $\lambda$ و $\beta$ وجود دارد؟ | بهینه سازی محدودیت |
113966 | من مقاله زیر را می خوانم: http://www-biba.inrialpes.fr/Jaynes/cc07s.pdf و به نظر نمی رسد بفهمم که جینز چگونه (P2) و زیر را استخراج می کند (به طور خاص log حسابی log[f(x) /f(0)]....) آیا کسی می تواند به من کمک کند؟ | اشتقاق جینز از هرشل-مکسول برای توزیع عادی |
78180 | فرض کنید من دو آزمایش از یک نوع دارم، جایی که چیزی x برابر در یک مکان و y بار در مکان دیگر اندازهگیری میکنم، آیا جستجوی وابستگی در مقادیر بین این دو آزمایش فایدهای دارد؟ در صورت اهمیت، در اندازه نمونه تفاوت وجود دارد و هر دو نمونه توزیع تقریباً نرمال دارند. به عنوان مثال، اگر بخواهم طول مردم در آسیا و طول مردم در اروپا را اندازهگیری کنم، میتوانم یک آزمون فرضیه صفر H0 را بررسی کنم «طول متوسط آسیاییها از میانگین طول اروپاییها کوچکتر است». این یک مطالعه معتبر است. با این حال، عجیب به نظر می رسد که تعجب کنیم که آیا طول اروپایی ها می تواند تحت تأثیر طول آسیایی ها باشد. به هر حال، طول می تواند تحت تأثیر عوامل بالقوه دیگری مانند غذا، آب و هوا، ژن ها و ... باشد، اگر جمعیت جهان ناگهان هورمون های رشد را دریافت کند، میانگین طول هم آسیایی ها و هم اروپایی ها احتمالاً افزایش می یابد. احمقانه به نظر می رسد که تصور کنیم طول اروپایی ها به دلیل افزایش طول آسیایی ها افزایش یافته است. اروپاییها به همراه آسیاییها حجمشان را افزایش دادند، اما نه به دلیل یک نتیجه مستقیم. آیا صرفاً ارزش این را دارد که در نظر بگیریم که آیا دو متغیر در صورت داشتن مقادیر جفتی (مانند سن و وزن) هر نوع وابستگی دارند؟ اگر نه، قدم منطقی بعدی برای آزمایش وابستگی چیست؟ من همچنین متوجه شده ام که نمی توانم هیچ نوع آزمون همبستگی را انجام دهم زیرا هیچ مقدار جفتی ندارم. آیا می توانم به عنوان یک نتیجه فوری فرض کنم که دو متغیر من وابستگی خطی ندارند؟ من خودم سعی کردم پاسخ را پیدا کنم، اما تست ها و چیزهای زیادی وجود دارد که باید از آنها آگاه بود. برای یک تازه کار کمی سخت می شود. | وابستگی بین دو آزمایش مستقل بی معنی است؟ |
30202 | من یک نمونهگر گیبس را برای توزیع پسین Wishart معکوس چندمتغیره با گام انتساب دادههای گمشده اجرا میکنم. من سعی می کنم بررسی کنم که آیا گام من برای شبیه سازی ماتریس های کوواریانس از Inverse-Wishart همگرا است یا خیر. چگونه در مورد آن اقدام کنم؟ در MCMC من معمولا تست تشخیصی Gelman-Rubin را انجام می دهم. متشکرم | تست همگرایی در نمونهگیر گیبس |
99071 | من از OpenANN برای آموزش یک شبکه عصبی با یک لایه پنهان و یک لایه خروجی softmax با آنتروپی متقاطع به عنوان تابع خطا استفاده می کنم. برای کاربرد من، به نظر می رسد الگوریتم گرادیان مزدوج در مقایسه با LBFGS الگوریتم عملکرد خوبی باشد. تصویر زیر خطای آموزشی و خطای اعتبارسنجی برای یک پیکربندی شبکه عصبی (20 ورودی، 4 نورون پنهان، 12 خروجی) را نشان میدهد. آیا این طبیعی است که CG در طول تمرین دارای اسپک در عملکرد باشد، و اگر چنین است، چه توضیحی برای اسپک وجود دارد؟ سنبله ها فقط برای CG و نه برای LBFGS و LMA ظاهر می شوند.  | شبکه عصبی: اسپک با استفاده از گرادیان مزدوج |
67249 | رگرسیون خطی ساده در متلب. با p-values من مشکلی وجود دارد. Stata گزارش می دهد که مقادیر p باید 0.000 و 0.207 باشد، در حالی که کد من گزارش می دهد که آنها باید 0.0001 و 0.2988 باشند. تمام آمارهای دیگر مانند خروجی Stata است. لطفا به من کمک کنید تا خطای راه هایم را ببینم. % تعداد مشاهدات n = 10; x = [1.0000، 0.4617; ... 1.0000, 0.7532; ... 1.0000, 0.2145; ... 1.0000, 0.5573; ... 1.0000, 0.5586; ... 1.0000, 0.4195; ... 1.0000, 0.4890; ... 1.0000, 0.9292; ... 1.0000, 0.2540; ... 1.0000, 0.7025]; y = [108.3156; ... 103.0389; ... 170.0043; ... 167.9905; ... 185.0679; ... 190.1774; ... 135.8128; ... 125.5962; ... 146.6757; ... 143.1218]; % محاسبه ضرایب بتا = (x'*x)\x'*y % محاسبه باقیمانده u = y - x*beta; % محاسبه مجموع مربعات باقیمانده s_2 = (n-2)\u'*u; % محاسبه t-statistics design = s_2*inv(x'*x); % محاسبه خطاهای استاندارد stn_err = [sqrt(design(1,1));sqrt(design(2,2))] %calculate t-statistics t_stat(1,1) = sqrt(design(1,1))\( بتا (1،1) - 0)؛ t_stat(2،1) = sqrt(طراحی(2،2))\(بتا(2،1) - 0); t_stat %calculate p-statistics p_stat(1,1) = tpdf(t_stat(1,1),n-2) + tpdf(-t_stat(1,1),n-2); p_stat(2,1) = tpdf(t_stat(2,1),n-2) + tpdf(-t_stat(2,1),n-2); p_stat | چرا مقادیر p من با Stata متفاوت است؟ |
107851 | من میخواهم یک رگرسیون OLS روی دادههای سری زمانی با استفاده از خطاهای استاندارد مقاوم ناهمگونی انجام دهم. تا اینجای کار می توانم به این برسم: مدل <- lm(I(y[2:T] - y[1:T-1]) ~ y[1:T-1]) رگرسیون <- coeftest(model, vcov =vcovHC(model, type = HC0)) از نظر بیسکالی به نظر می رسد که این کار کار می کند، اما زمانی که عبارت intercept را در فرمول رگرسیون حذف می کنیم، به عنوان مثال مدل <- lm(I(y[2:T] - y[1:T-1]) ~ 0 + y[1:T-1]) برای همه مقادیر به جز تخمین NA به دست می دهد، بنابراین من نمی توانم آمار t متمایز را محاسبه کنم . من برای هر گونه راهنمایی در مورد حل این مشکل سپاسگزار خواهم بود. | رگرسیون خطی با استفاده از خطاهای استاندارد مقاوم ناهمگونی در R |
35983 | من مجموعهای از مشاهدات دارم که به $N_1(x_1,x_2,x_3,x_4)$ تبدیل میشوند که در آن $x_1,...,x_4$ نشاندهنده 4 پارامتر مرتبط با هر نقطه است. به عنوان مثال، دادههای مشاهده شده به این صورت است: #x1 x2 x3 x4 # <-- مشاهده 1.2 0.5 46 10 # <-- 1 0.2 8.9 20 13 # <-- 2 0.8 4.5 18 9 # <-- 3 ... 0.2 4.3 55 7 # <-- N1 من هم 2 مدل A و B دارم، که سعی در بازتولید آن مجموعه مشاهدات دارند. با انجام این کار، هر مدل به ترتیب به من امتیاز $NA(x_1,x_2,x_3,x_4)$ و $NB(x_1,x_2,x_3,x_4)$ می دهد: #x1 x2 x3 x4 # <-- Model A 3.2 45 65 6 # <-- 1 0.2 8.9 20 14 # <-- 2 0.1 3.3 14 11 # <-- 3 ... 0.6 3.9 34 3 # <-- NA و #x1 x2 x3 x4 # <-- مدل B 1.3 0.7 23 5 # <-- 1 1.0 7.4 17 9 # <-- 2 0.3 5.2 8 3 # <-- 3 ... 0.4 6.1 43 4 # <-- NB **مهم**: N1، NA و NB ** لزوماً مساوی نیستند و **هیچ** مطابقت 1:1 بین نقاط مشاهده شده و مدل شده وجود ندارد. آن را به عنوان ابری از نقاط در یک فضای 4 بعدی در نظر بگیرید. برای تعیین کمیت ** کدام مدل بهترین مجموعه مشاهده شده من را بازتولید می کند، کدام آمار را باید اعمال کنم؟ | مشاهده در مقابل مدل در فضای N بعدی |
3390 | بسط Cornish-Fisher راهی برای تخمین چندک های توزیع بر اساس گشتاورها ارائه می دهد. (از این نظر، من آن را مکملی برای گسترش اجورث میدانم که تخمینی از توزیع تجمعی بر اساس لحظهها ارائه میدهد.) من میخواهم بدانم در چه موقعیتهایی بسط Cornish-Fisher برای کار تجربی بر کمیت نمونه یا بالعکس چند حدس: 1. از نظر محاسباتی، لحظه های نمونه را می توان به صورت آنلاین محاسبه کرد، در حالی که تخمین آنلاین چندک های نمونه دشوار است. در این مورد، C-F برنده است. 2. اگر کسی توانایی پیشبینی لحظهها را داشت، C-F به او اجازه میداد تا از این پیشبینیها برای تخمین چندک استفاده کند. 3. بسط C-F احتمالاً می تواند تخمین هایی از چندک های خارج از محدوده مقادیر مشاهده شده ارائه دهد، در حالی که کمیک نمونه احتمالاً نباید برآورد کند. 4. من از نحوه محاسبه فاصله اطمینان حول تخمین چندک ارائه شده توسط C-F آگاه نیستم. در این مورد، کمیت نمونه برنده است. 5. به نظر می رسد که بسط C-F نیاز به تخمین چند ممان بالاتر از یک توزیع دارد. خطاهای این تخمین ها احتمالاً به گونه ای ترکیب می شوند که بسط C-F خطای استاندارد بالاتری نسبت به چندک نمونه دارد. هر کسی دیگر؟ آیا کسی تجربه استفاده از این دو روش را دارد؟ | چرا از بسط Cornish-Fisher به جای Sample Quantile استفاده کنید؟ |
3395 | من در حال حاضر روی مدلی کار می کنم که دو پارامتر را می گیرد و یک آمار اندازه گیری تولید می کند. آن را به صورت Z = f(X,Y) در نظر بگیرید. Z ماتریسی از آمار من است و من در حال ایجاد نمودار سطحی آن در متلب هستم. اساساً من به دنبال روشی ریاضی/تحلیلی برای تعیین صاف بودن یا ناهمواری سطح آن هستم. آیا مقادیر بزرگ تمایل دارند با هم خوشه شوند یا در سراسر ماتریس پراکنده هستند؟ - این سوال من است. اصولاً مقادیر ماتریس من چقدر با هم مخلوط شده اند؟ من باید مدل را روی مجموعههای پارامترهای مختلف اجرا کنم و میخواهم بتوانم به صورت تحلیلی تعیین کنم که کدام یک از سطوح من صافترین است، بیشترین خوشهبندی مقادیر بزرگ را دارد و در حالت ایدهآل، هیچ مقادیر منفی ندارد. هر گونه کمکی بسیار قدردانی خواهد شد و لطفا در صورت نیاز به اطلاعات بیشتر به من اطلاع دهید. به سلامتی | صافی یک سطح |
104988 | من می بینم که هر دو تابع بخشی از روش های داده کاوی مانند Gradient Boosting Regressors هستند. من می بینم که آنها اشیاء مجزا هستند. اما به طور کلی رابطه بین هر دو چگونه است؟ | تفاوت بین تابع ضرر و تابع تصمیم چیست؟ |
30200 | من با فایلهای CSV حاوی دادههای 10 دقیقهای دمای چند سال ایستگاه کار میکنم و معمولاً محاسباتی را انجام میدهم: میانگین، میانگین، همبستگی بین دو ایستگاه، همبستگی در فصول مختلف، همبستگیهای روز/شب، ... برنامهنویسی میکنم. این محاسبات با استفاده از پایتون ساده یا Microsoft Excel VBA، با استفاده از حلقه ها و محاسبات ساده انجام می شود. کدنویسی خیلی سخت نیست، اما نمیدانم آیا کتابخانه پایتون یا هر محیط برنامهنویسی دیگری وجود دارد که به من در صرفهجویی در زمان و خطوط کد کمک کند. من در مورد ScyPy و R شنیده ام و اگر بتوانید تجربه ای در مورد این ابزارها به اشتراک بگذارید بسیار سپاسگزار خواهم بود. پیشاپیش از شما بسیار سپاسگزارم. | بهترین زبان برنامه نویسی برای مدیریت سری های زمانی کدام است؟ |
67242 | ما می دانیم که تبدیل غیر صفر قابل اندازه گیری یک دنباله وابسته وابسته است. میخواهم بپرسم آیا یک تبدیل غیر صفر قابل اندازهگیری دنبالهای که تفاوت مارتینگل نیست، تفاوت مارتینگل نیست؟ | تبدیل تفاوت مارتینگل |
113960 | PredictionIO خوب است که برای کشف محتوا و توصیه کافی باشد، اما به نظر می رسد از طبقه بندی پشتیبانی نمی کند. سپس باید از ابزار دیگری و سپس Prediction IO برای سرور پیش بینی خود استفاده کنم. آیا جایگزین های خوبی می شناسید؟ من Google Prediction Server، Azure ML، BigML را می شناسم و به دنبال جایگزین های بیشتری برای مقایسه آنها هستم. بهترین :) | ابزارهای متن باز جایگزین برای PredictionIO چیست؟ |
30204 | من یک رگرسیون را اجرا می کنم که در آن بازده سهام را در بازده بازار رگرسیون می کنم. تاریخ خاصی در نمونه من وجود دارد که در آن رویدادی رخ داده است. من معتقدم که اثر این رویداد فقط در آن تاریخ باقی خواهد ماند. من میخواهم ضرایب مدل من عاری از این اثر باشد، زیرا میخواهم پیشبینی کنم که اگر این رویداد رخ نمیداد، بازده چه خواهد بود. من به این فکر می کنم که برای آن تاریخ یک ساختگی وارد کنم (یعنی برای آن تاریخ یک و برای بقیه نمونه صفر است). آیا این روش مناسبی برای رسیدگی به این موضوع است؟ متشکرم. | رگرسیون با ساختگی فقط برای یک تاریخ خاص |
99699 | چگونه می توانم یک متغیر وابسته تبدیل شده (ریشه چهارم) را با تغییر برخی از متغیرهای پیش بینی آن تفسیر کنم؟ در مطالعه خود، متغیر وابسته خود را به ریشه 4، $Y^\frac{1}{4}$، و یکی از متغیرهای پیش بینی خود را به $\ln(X)$ تبدیل کردیم. چگونه آن را تفسیر کنم؟ | تفسیر متغیرهای وابسته و مستقل تبدیل شده |
76058 | وقتی تفاوت مدل تفاوت ها را با دو دوره زمانی تخمین می زنم، مدل رگرسیون معادل a خواهد بود. $Y_{ist} = \alpha +\gamma_s*Treatment + \lambda d_t + \delta*(Treatment*d_t)+ \epsilon_{ist}$ * که در آن $Treatment$ یک ساختگی است که اگر مشاهده باشد برابر با 1 است از گروه درمان * و $d$ یک ساختگی است که برابر با 1 در دوره زمانی پس از انجام درمان است بنابراین معادله برابر است مقادیر زیر * گروه کنترل، قبل از درمان: $\alpha$ * گروه کنترل، بعد از درمان: $\alpha +\lambda$ * گروه درمان، قبل از درمان: $\alpha +\gamma$ * گروه درمان، بعد از درمان: $\alpha+ \ gamma+ \lambda+ \delta$ بنابراین، در یک مدل دو دوره ای، تفاوت در تخمین اختلاف $\delta$ است. اما اگر بیش از یک دوره قبل و بعد از درمان داشته باشم در مورد $d_t$ چه اتفاقی می افتد؟ آیا هنوز از یک ساختگی استفاده می کنم که نشان دهد یک سال قبل یا بعد از درمان است؟ یا به جای آن، بدون مشخص کردن اینکه آیا هر سال متعلق به دوره قبل یا بعد از درمان است، ادک سالانه اضافه کنم؟ مانند این: ب. $Y_{ist} = \alpha +\gamma_s*Treatment + yeardummy + \delta*(Treatment*d_t)+ \epsilon_{ist}$ یا میتوانم هر دو را شامل شود (یعنی $yeardummy +\lambda d_t$)؟ ج. $Y_{ist} = \alpha +\gamma_s*Treatment + yeardummy + \lambda d_t + \delta*(Treatment*d_t)+ \epsilon_{ist}$ در نتیجه، چگونه می توانم تفاوت در مدل تفاوت ها را با چند زمان مشخص کنم دوره های (a، b یا c)؟ | تعیین تفاوت در مدل تفاوت ها با دوره های زمانی متعدد |
4267 | من اخیراً کتاب اسکیلی کورن در مورد تجزیه ماتریس را خواندم و کمی ناامید شدم، زیرا مخاطبان کارشناسی را هدف قرار داده بود. من میخواهم (برای خودم و دیگران) کتابشناسی کوتاهی از مقالات ضروری (بررسیها، اما همچنین مقالات پیشرفت) در مورد تجزیه ماتریس گردآوری کنم. چیزی که من در درجه اول در ذهن دارم چیزی در SVD/PCA (و انواع قوی/ پراکنده) و NNMF است، زیرا آنها بیشترین استفاده را دارند. آیا همه شما توصیه / پیشنهادی دارید؟ من از پاسخ های خود عقب نشینی می کنم تا تعصبی به پاسخ ها ندهم. من می خواهم هر پاسخ را به 2-3 مقاله محدود کنم. P.S.: من به این دو تجزیه به عنوان پرکاربردترین _در تحلیل داده ها اشاره می کنم. البته QR، Cholesky، LU و Polar در تحلیل عددی بسیار مهم هستند. گرچه تمرکز سوال من این نیست. | مقالات ضروری در مورد تجزیه ماتریس |
108380 | آیا کسی می تواند کتابخانه ای را برای کارهای داده کاوی سری زمانی به غیر از مدل سازی پیش بینی و تجزیه و تحلیل آماری توصیه کند؟ به نظر می رسد تعدادی برای این اهداف وجود دارد (به عنوان مثال، گرتل)، اما هیچ چیز برای وظایف: * طبقه بندی * خوشه بندی * جستجوی بعدی * تشخیص ناهنجاری * کشف موتیف * نمایه سازی نمی توانم اولین کسی باشم که می خواهم استفاده کنم، به عنوان مثال، iSAX، اما گوگل چیزی جز یک کتابخانه جاوا پیدا نکرده است. پیوند به هر چیزی که می تواند با C/C++، پایتون یا جولیا ارتباط برقرار کند، به ویژه مورد استقبال قرار می گیرد، اما هر کمکی قابل قدردانی است. اطمینان از اینکه چنین کتابخانه ای وجود ندارد نیز مفید خواهد بود، زیرا می دانم که نوشتن آن اتلاف وقت نخواهد بود... | کتابخانه داده کاوی سری زمانی؟ |
68091 | من می خواهم شهود بهتری برای تابع هزینه یک مسئله بهینه سازی داشته باشم. تابع هزینه به تعدادی آرگومان با ارزش واقعی بستگی دارد. من می خواهم بدانم که آیا تابع هزینه محدب است یا خیر. بدیهی است که من می توانم تابع هزینه را برای 2 آرگومان در یک طرح سه بعدی تجسم کنم. من این کار را برای همه جفتهای آرگومان انجام دادم و معلوم شد که تابع هزینه برای همه این جفتها محدب است. حالا میخواهم بدانم: آیا این نشان میدهد که تابع هزینه نیز به صورت سراسری محدب است؟ | آیا توابع هزینه جفتی محدب نیز به صورت سراسری محدب هستند؟ |
92476 | من از طرح آزمایشی Box-Behnken استفاده کرده ام. من یک مدل درجه دوم کامل دارم. با این حال، من مجبور شدم پاسخ را تغییر دهم، $Y$ تا مدل متناسب شود. من این کار را با استفاده از تبدیل Box-Cox با $\lambda=0.5$ انجام دادم. به عنوان مثال، یکی از رگرسیون ها به این صورت است: $$Y = 1.28 - 0.008X_1-0.025X_2-0.05X_3-0.13X_1^2-0.01X_2^2-0.006X_3^2\\\ +0.02X_1X_2-0.05X_1X_3+0.09X_2X_3$$ چگونه شرایط را تفسیر کنم؟ | چگونه تبدیل Box-Cox را تفسیر کنیم |
108381 | ReLU دارای محدوده [0، +Inf) است. بنابراین، هنگامی که به یک مقدار فعال سازی z=0/1 می رسد که توسط ReLU یا softplus تولید می شود، مقدار تلفات با آنتروپی متقابل محاسبه می شود: loss = -(x*ln(z)+(1-x)*ln(1-z )) به NaN تبدیل می شود. همانطور که می دانم، متغیرهای من در نوع theano.tensor اجرا می شوند که پس از تعریف قابل تغییر نیستند. بنابراین، من نمی توانم به سادگی مقادیر z را که 0/1 هستند به مقداری تقریبی (مانند 0.001/0.999) تغییر دهم. چگونه بدون جایگزینی آنتروپی متقاطع توسط MSE از این وضعیت آزار دهنده جلوگیری کنیم؟ | چگونه از NaN در استفاده از ReLU + Cross-Entropy اجتناب کنیم؟ |
78187 | من یک مجموعه داده دارم که ANOVA اندازه گیری های تکراری یک طرفه را روی آن اجرا کرده ام. افرادی که با آنها کار میکنم علاقهمندند پاسخ دهند که چقدر تغییر واقعی در یک اندازهگیری باید اتفاق بیفتد تا آن تغییر از نظر آماری معنیدار در نظر گرفته شود. بنابراین روش اندازهگیری کوچکترین تفاوت قابل تشخیصی که من استفاده کردهام، از تجزیه و تحلیل آماری زیستی زار، ویرایش پنجم 2010 است: $$ \delta = \sqrt{\frac{2ks^{2}\phi^{2}}{n} } $$ (معادله (10.34) در کتاب زر). بنابراین اگر بتوانیم سطح معنیداری، سطح توان، اندازه نمونه را مشخص کنیم و تخمینی برای $\sigma^{2}$ داشته باشیم، میتوانیم برای $\delta$ حل کنیم. ($k= p-1$، $n=$اندازه نمونه، $s^{2}$= برآورد $\sigma^{2}$، و $\phi^{2}$ مقدار بحرانی برای اهمیت خاص و سطح قدرت). نکته خوب در مورد حداقل تفاوت قابل تشخیص (MDD) این است که در واحدهای مورد مطالعه ما قرار دارد. بنابراین من دو سوال دارم. یک: آیا MDD تنها گزینه ای است که تعیین می کند چه مقدار از تغییر باید برای تشخیص تفاوت رخ داده باشد؟ من فقط با MDD در کتاب زار و با افرادی که با آنها کار می کنم برخورد کرده ام. سوال اصلی. نمونه گیری برای این مجموعه داده سازگار نبوده است. در اینجا نمودار زیرمجموعه ای از مجموعه داده است. (با عرض پوزش از استفاده از پیوند URL برای تصویر. بسیار بزرگ است و من نمی توانم بفهمم که چگونه بدون ایجاد مجدد آن برای این سوال، آن را کوچک کنم.) راه خوبی برای اندازه گیری تأثیر شدت نمونه گیری چیست؟ به عنوان مثال، اگر بگوییم حجم کل نمونه ما ثابت است اما به جای داشتن نمونه ای که مانند واقعیت نوسان دارد، هر 7 سال یک نمونه ثابت داشته باشیم، چه نوع تغییری در MDD ایجاد می کند؟ تنها راهی که من برای آزمایش این فکر کرده ام این است که به طور سیستماتیک نمونه های یک ساله را رها کنم و ببینم که چگونه بر MDD تأثیر می گذارد. اگرچه این باعث نمی شود که حجم نمونه ثابتی داشته باشیم... این سوال بسیار پیچیده تر از آن چیزی است که من امیدوار بودم! من به دنبال هر گونه راهنمایی یا ورودی در مورد این دو سوال هستم. هر گونه کمکی بسیار قدردانی خواهد شد. اگر چیز دیگری از دست داده ام یا گیج کننده است، لطفاً به من اطلاع دهید. من معمولا ANOVA را در SAS انجام می دهم و MDD را با استفاده از R محاسبه می کنم. | نحوه کمی کردن شدت نمونه برداری برای ANOVA اندازه گیری های مکرر |
4261 | این به سوال قبلی من مربوط می شود که پاسخ های زیادی دریافت نکرد، شاید به این دلیل که خیلی واضح و خوب نوشته نشده بود. امیدوارم این بار دقیق تر باشم و از کمک های بسیار قدردانی شما بهره مند شوم. من در حال تجزیه و تحلیل نتایج یک آزمایش بیولوژیکی هستم. نتایج به عنوان یک مقدار واحد (عدد صحیح غیر منفی) در هر موقعیت ژنومی داده شده است. من به دره ها یا حداقل های محلی بیش از این سری از ارزش ها علاقه مند هستم. مایلم نرخ مثبت کاذب را کنترل کنم و برای هر حداقل محلی اهمیت پیدا کنم. من میتوانم دادههای خامی را که برای تولید دادهها استفاده شدهاند، به هم بزنم. بنابراین کاری که من انجام میدهم این است که دادههای خام را به هم بزنم، سری جدید مقادیر را ایجاد کنم، همه حداقلهای محلی را جستجو کنم و مقادیر آنها را حفظ کنم. حالا من چیزی شبیه به این دارم: data_set local_minima_values ============================= true_data 4 9 1 27 12 0 0 0 2 5 32 0 1 5 70 2 sim_1 14 25 94 59 32 sim_2 52 0 14 74 82 12 54 ... توجه داشته باشید که تعداد حداقل های محلی به طور طبیعی بین شبیه سازی ها متفاوت است. بنابراین، ایده من این بود که یک ECDF را برای هر شبیهسازی محاسبه کنم و سپس آن ECDFها را در یک «میانگین ECDF» که فرضیه صفر را نشان میدهد، ترکیب کنم. سپس، من میتوانم یک مقدار p برای هر حداقل محلی از دادههای واقعی تعیین کنم و ببینم که چقدر مهم است (شگفتانگیز). سوالات من این است: 1. آیا این منطقی است؟ 2. چگونه می توانم یک ECDF متوسط ایجاد کنم؟ من نمی توانم فقط مقادیر تمام شبیه سازی ها را با هم ادغام کنم و برای این مجموعه ادغام شده ECDF بدست بیاورم، زیرا تعداد حداقل های یافت شده در هر شبیه سازی متفاوت است، و فکر می کنم همه شبیه سازی ها باید سهم یکسانی در میانگین ECDF داشته باشند، یا من هستم اشتباه است؟ 3. چگونه باید تعداد شبیه سازی ها را در نظر بگیرم؟ با تشکر، دیو p.s. من با R کار می کنم. | آیا باید از ECDF متوسط استفاده کنم؟ |
35984 | می خواهم بدانم چگونه پارامترهای مدل GBM را تنظیم می کنید؟ 1) می توانم پارامترها را به صورت متوالی بهینه کنم. در ابتدا، با استفاده از یک مقدار بزرگ برای انقباض و تعداد کمی تکرار (برای محاسبه سریعتر)، سعی می کنم n.minobsinnode، interaction.depth، bag.fraction و غیره را بهینه کنم. سپس با استفاده از این پارامترها، skrinkage را مقیاس می کنم. برای کاهش ارزش و یافتن تعداد بهینه درختان. 2) همه در همان زمان، با استفاده از تن از شبیه سازی سناریو. به عنوان مثال، آیا ممکن است interaction.depth بهینه مقادیر متفاوتی برای انقباض 0.01 و 0.001 داشته باشد؟ اگر بله، اصلاح برخی از پارامترها برای بهینه سازی بقیه خوب نیست... | استراتژی برای تنظیم پارامترهای GBM |
108387 | من در وب و این انجمن ها جستجو کردم اما موضوعی شبیه مشکل من پیدا نکردم. اگر چیزی را از دست دادم، می خواهم پیشاپیش عذرخواهی کنم. مشکل من اینه من یک احتمال p داده شده توسط یک آژانس خارجی و تعداد موفقیت n از یک منبع داده متعلق به من را دارم. من به کل جمعیت N و فاصله اطمینان N علاقه مند هستم. زمینه: من می دانم با استفاده از داده های سال 2013 برای یک آژانس اتوبوس خاص چند مسافر وجود دارد (مانند: من داده های (خرد) آن شرکت خاص را دارم). فرض: این n من است. من همچنین از ارقام حملونقل (از یک آژانس خارجی) میدانم که این شرکت اتوبوسرانی در سال 2013 30 درصد سهم بازار (بر حسب مسافران اندازهگیری شده) داشت. فرض: این صفحه من است. این فرض، مفروضات دیگری را به همراه دارد، که خوب است. حال سوال این است: در مجموع چند مسافر وجود داشته است (با فرض اینکه این را نمی توان از ارقام حمل و نقل برداشت کرد)؟ یعنی N چیست و فاصله اطمینان 95% اطراف N چقدر است؟ بنابراین سوالات من این است: 1) آیا می توانم فقط از رابطه استفاده کنم: p=n/N، بنابراین تخمین نقطه ای برای N این است: N=n/p؟ من چنین فرض می کنم. 2) آیا می توانم فقط از بازه کلپر-پیرسون برای محاسبه بازه ای برای p استفاده کنم، سپس از آن برای رسیدن به بازه ای برای N استفاده کنم؟ 3) کران پایین 95% را برای p=plb فرض کنید. آیا کران 95% پایین تر برای N سپس n/plb است؟ همان منطق برای کران بالای 95٪. 4) هنگام محاسبه بازه کلپر-پیرسون، آیا می توانم فقط از n=n، p=p، N=n/p استفاده کنم؟ 5) اگر هر یک از پاسخ های سوالات 2-4 من خیر است، پس روش صحیح چیست؟ من متوجه شدم که با استفاده از این رویکرد، N لزوما یک عدد صحیح نیست. آیا این مشکل دارد؟ | فاصله اطمینان برای N، بر اساس دو جمله ای |
102720 | من همیشه در مورد چگونگی تفسیر صحیح نتایج PCA سردرگم بوده ام. داده های من به این شکل است و یک جدول بزرگ با بیش از 5 میلیون سطر و 12 ستون است. (چند خط اول همه 0...) هر ستون برای فردی است که بیش از 5 میلیون مشاهده (اعداد) دارد. > head(data) YC1CO YC1LI YC4CO YC4LI YC5CO YC5LI YM1CO YM1LI YM3CO YM3LI f1 0 0 0 0 0 0 0 0 0 0 f2 0 0 0 0 0 0 0 0 0 0 0 f3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 f5 0 0 0 0 0 0 0 0 0 0 f6 0 0 0 0 0 0 0 0 0 0 سپس PCA را با استفاده از prcomp در R اجرا کردم: pca<-prcomp(data,scale=T ,center=T) خروجی ها عبارتند از: pca$rotation: > pca$rotation PC1 PC2 PC3 PC4 PC5 PC6 YC1CO 0.2888377 -0.1511474 0.354970405 -0.14922899 0.29263063 -0.42756650 YC1LI 0.2887845 0.2887845 0.2887845 0.288310405 0.28910405 -0.11867753 0.10465221 0.32239652 YC4CO 0.2888937 -0.1073097 0.376083559 -0.16145206 0.28844683 0.28844683 - 0.198 0.198 LI 0.28844683 - 0.193 0.1073097 0.2899107 0.032538093 -0.10721970 0.11537841 0.19513249 YC5CO 0.2885639 -0.2200563 0.393267987 - 0.116 -0.393267983 -0.116 0.20303762 YC5LI 0.2887792 0.2926729 0.010423117 -0.11994739 0.12149153 0.31232174 YM1CO 0.2889248381860860. 0.12858598 0.04456687 -0.19313330 YM1LI 0.2891586 0.2571790 -0.112257791 0.05154060 -0.01859997 - 0.01859997 0.01859993 -0.02520. -0.5242998 -0.631712144 -0.47494155 0.05150495 0.08749259 YM3LI 0.2891991 0.2441790 -0.131464167 0.006 - 0.131464167 0.006 -0.03534204 YM5CO 0.2881663 -0.3741525 -0.033566125 0.75538412 0.17427960 0.33801997 YM5LI 0.28863566125 - 0.288638413416. 0.27066649 -0.33590255 -0.57941556 PC7 PC8 PC9 PC10 PC11 YC1CO 0.658953472 -0.0032299313 0.19565297 0.0280301618 0.0288301618 0.075935158 0.7256745487 0.10496762 -0.36161999 -0.17252148 YC4CO -0.733333390 0.0315817680 0.21602856 0.21602856 0.05879949 YC4LI 0.050613636 -0.0400665068 -0.25306478 0.74445447 -0.38210226 YC5CO 0.040387219 - 0.040387219 -0.0101010101069 -0.010106 0.04776528 0.03597253 YC5LI 0.040072049 -0.6856737279 0.16012889 -0.41945134 -0.17527656 YM1CO -0.063340.085165 -0.78767928 -0.33407254 -0.22202704 YM1LI -0.004723194 -0.0087215382 -0.16061437 0.06378812 0.58203292704M 0.58203292704M -0.0019793258 0.06649693 0.05308833 0.01803736 YM3LI -0.006287346 -0.0087025271 -0.14028837 0.03028837 0.030239698 0.048983778 0.0009123461 0.21714944 0.10450049 0.01040703 YM5LI -0.081931860 0.0139306658 0.26453206 0.26453206 -0.34310790 PC12 YC1CO -0.005335094 YC1LI 0.007632148 YC4CO -0.006459107 YC4LI -0.012083181 YC5CO 0.0028613309 YC501000000 YC5CO. 0.007425773 YM1LI 0.682200634 YM3CO 0.007334849 YM3LI -0.730105933 YM5CO 0.004956218 YM5LI 0.032252049 خلاصه PC2(pca) PC4 PC5 PC6 PC7 انحراف استاندارد 3.4418 0.20675 0.13369 0.11872 0.11105 0.10690 0.10325 نسبت واریانس 0.9872 0.00356 0.001010.00109. 0.00095 0.00089 نسبت تجمعی 0.9872 0.99072 0.99221 0.99338 0.99441 0.99536 0.99625 PC8 PC9 PC10 PC10 PC11 PC12 PC11 PC12 انحراف استاندارد 0.99221. 0.09215 0.08375 نسبت واریانس 0.00084 0.00081 0.00080 0.00071 0.00058 نسبت تجمعی 0.99709 0.99791 0.99891 0.99809 0.99891 > 2001 0. pca$sdev^2 [1] 11.845894818 0.042746822 0.017872795 0.014093498 0.012331364 [6] 0.011428471 0.01066018 0.009777983 0.009582267 [11] 0.008490902 0.007013259 من فقط مقادیر pca$rotation بالا را برای PC1 و PC2 گرفتم و آن را رسم کردم.  و biplot >biplot(pca)  من چند سوال خاص دارم و واقعا ممنون می شوم اگر بتوانید برای درک موضوع به من کمک کنید نظر بدهید. 1. بر اساس نسبت واریانس، می دانم که PC1 تقریباً تمام واریانس را توضیح می دهد. من اینجا یک سوال دارم، آیا اصلاً مقادیر محور x و y در اینجا مهم هستند؟ مقادیر PC1 بسیار نزدیکتر از مقادیر PC2 هستند، اگرچه PC1 PC غالب است. 2. آیا می توانم تفاوت بین نقاط YC1CO، YC4CO، YC5CO و YM1CO، YM3CO، YM5CO را ببینم که PC1 را درایو می کنند؟ 3. فکر اولیه نشان دادن روابط بین 12 فرد (YC1CO و غیره) و دیدن اینکه آیا آنها از eac خوشه یا جدا می شوند یا خیر بود. | مشکل با PCA در R (واریانس توضیح داده شده مشکوک بالا) |
103450 | این ممکن است در Mathematics یا Philosophy StackExchanges مناسبتر باشد، زیرا فکر میکنم اساساً با مشکل منطقی روبرو هستم، اما ابتدا آن را در اینجا مطرح میکنم تا از ارسال متقابل اجتناب کنم. من دو نظرسنجی دارم - نظرسنجی A و نظرسنجی B. میخواهم یافتههای نظرسنجی A را در مقابل نظرسنجی B تأیید کنم. من یک شاخص دارم: میانگین وعده های غذایی که در روز در خانواده خورده می شود. نظرسنجی A سؤال را به دو سؤال فرعی تقسیم میکند: 1. وعدههای غذایی متوسط روزانه در خانواده 2. میانگین وعدههای غذایی روزانه برای کودکان (سنین 6 ماه تا 5 سال) اکنون، (1) میتواند ابرمجموعه (2) باشد، اما نه لزوما. بچه ها ممکن است با والدینشان غذا بخورند، بنابراین به اندازه والدینشان. بچه ها ممکن است کمتر از والدینشان غذا بخورند. بچه ها ممکن است بیشتر بخورند - مثلاً اگر والدین یک وعده غذایی را کنار بگذارند تا به کودکشان غذا بدهند. برخی از خانواده ها ممکن است بچه نداشته باشند. بنابراین من آن را بهعنوان یک نمودار ون تصور میکنم، که در آن حباب «بچهها» کوچک (بسیار زیاد) با حباب بزرگ «خانگی» همپوشانی دارد، اما ممکن است به طور کامل در آن قرار نگیرد. نظرسنجی B، در عوض، این را به سه سؤال فرعی تقسیم میکند: 1. میانگین وعدههای غذایی روزانه برای بزرگسالان 2. میانگین وعدههای غذایی روزانه برای کودکان (سن 6 ماه تا 5 سال) 3. میانگین وعدههای غذایی روزانه برای کودکان (سنین 5 سال تا 13 سال) اینجا تمیزتر به نظر می رسد. اینها سه گروه متمایز هستند (در حال حاضر این واقعیت را نادیده می گیرند که هر دو (2) و (3) می توانند کودکان 5 ساله را دستگیر کنند). من میخواهم آزمونهای t را بر روی میانگینهای نظرسنجی، مثلاً میانگین وعدههای غذایی روزانه برای خانواده، و میانگین وعدههای غذایی روزانه برای کودکان (۶ ماه تا ۵ سال) انجام دهم. اما من مطمئن نیستم که چگونه می توانم این مجموعه های مختلف را از یکدیگر ترکیب و جدا کنم تا آنها را با هم مقایسه کنم. | اجرای آزمون t بر روی مجموعه های مختلف (زیر؟) [منطق نظرسنجی] |
103456 | فرض کنید IID متغیرهای تصادفی $X_1,\dots,X_n$ با توزیع $\mathrm{Ber}(\theta)$ داریم. ما نمونه ای از $X_i$ را به روش زیر مشاهده می کنیم: اجازه دهید $Y_1,\dots,Y_n$ متغیرهای تصادفی $\mathrm{Ber}(1/2)$ مستقل باشند، فرض کنید که همه $ X_i$ و $Y_i$ مستقل هستند و اندازه نمونه $N=\sum_{i=1}^n Y_i$ را تعیین می کنند. $Y_i$ نشان می دهد که کدام یک از $X_i$ ها در نمونه قرار دارند، و ما می خواهیم کسر موفقیت ها در نمونه تعریف شده توسط $$ Z = \begin{cases} \frac{1}{N را مطالعه کنیم. }\sum_{i=1}^n X_i Y_i & \text{if}\quad N > 0\, , \\\ 0 & \text{if} \quad N = 0 \, . \end{cases} $$ برای $\epsilon>0$، میخواهیم یک کران بالایی برای $\mathrm{Pr}\\!\left(Z \geq \theta + \epsilon\right)$ پیدا کنیم که به صورت تصاعدی کاهش مییابد. با $n$. نابرابری هوفدینگ به دلیل وابستگی بین متغیرها بلافاصله اعمال نمی شود. | کران بالای نمایی |
108385 | من می خواهم قدرت دو توزیع را محاسبه کنم که poisson هستند که $n_1$ بزرگ است و $n_2$ اندازه متوسط است. من از فرمول ارائه شده توسط کریشنامورتی و تامسون برای آزمون C استفاده کرده ام (به زیر مراجعه کنید). $$\sum^\infty_{k_1=0}\sum^\infty_{k_2=0}\frac{e^{-n_1\lambda_1}(n_1\lambda_ 1)^{k_1}}{k_1!}\frac{e^{-n_2\lambda_2}(n_2\lambda_2)^{k_2}}{k_2!}I[P(X_1\geq k_1|k_1+k_2, p(\lambda_1/ \lambda_2))\leq\alpha]$$ با این حال، با بزرگ شدن $n_1$ یا $n_2$، تابع نمایی به $0$ میرود که باعث میشود مجموع احتمالات را بیشتر در نظر بگیریم. بی معنی آیا به هر حال می توانم توان را با داشتن یک نمونه بزرگ ناهموار محاسبه کنم؟ خیلی ممنون از کمک شما | تست قدرت پواسون با حجم نمونه بزرگ |
67240 | من علاقه مندم که آیا همبستگی سه متغیر چیزی است یا نه، و اگر چیست، این چه خواهد بود؟ _ضریب همبستگی لحظه محصول پیرسون_ $$\frac{\mathrm{E}\\{(X-\mu_X)(Y-\mu_Y)\\}}{\sqrt{\mathrm{Var}(X)\mathrm{Var }(Y)}}$$ اکنون سوال برای 3 متغیر: آیا $$\frac{\mathrm{E}\\{(X-\mu_X)(Y-\mu_Y)(Z-\mu_Z)\\}} {\sqrt{\mathrm{Var}(X)\mathrm{ Var}(Y)\mathrm{Var}(Z)}}$$ چیزی؟ در R چیزی قابل تفسیر به نظر می رسد: > a <- rnorm(100); b <- rnorm(100); c <- rnorm(100) > mean((a-mean(a)) * (b-mean(b)) * (c-mean(c))) / (sd(a) * sd(b) * sd (ج)) [1] -0.3476942 ما معمولاً به همبستگی بین 2 متغیر با توجه به مقدار متغیر سوم ثابت نگاه می کنیم. کسی میتونه شفاف سازی کنه؟ | همبستگی پیرسون 3 متغیر |
104985 | من می خواهم اثر یک درمان را بر روی نمونه های بیمارم توسط MANOVA در R تجزیه و تحلیل کنم. من 3 سطح پروتئین مختلف را برای بیماران تحت درمان و درمان نشده اندازه گیری می کنم. اکنون میخواهم تأثیر درمان خود را بر روی کل اندازهگیریهای پروتئینی مختلف و نه هر کدام بهصورت جداگانه (به نوعی جمعبندی آنها با هم) تجزیه و تحلیل کنم. مفروضات MANOVA چیست و چگونه باید آن را در مجموعه داده خود در R اعمال کنم؟ یک خط نمونه از مجموعه داده من: نمونه درمانی CD13 CD68 AT11 0.065 0.82 0.488 + sample2 0 1.58 0.47 - من حدود 30 تکرار برای هر گروه بیمار تحت درمان و درمان نشده دارم. با تشکر | مفروضات MANOVA چیست و چگونه باید آن را در R اعمال کنم؟ |
79273 | من مجموعه داده های خود را به چهار دسته تقسیم کرده ام اما یکی از آنها فقط دارای چهار نقطه داده در آن است. من تستهای نرمال بودن K-S را روی سه دسته دیگر اجرا کردهام که هر کدام نرمال هستند و وقتی مجموعه دادهها به چهار تقسیم نشده است نیز طبیعی است. برای این دسته چهارم، آیا آن را نرمال فرض کنم و یک تحلیل پارامتریک اجرا کنم یا فرض کنم غیر نرمال است و یک تحلیل ناپارامتریک اجرا کنم؟ این یکی از بسیاری از محاسباتی است که من روی همان روش با استفاده از آزمون K-S برای نرمال بودن انجام دادهام، اما آیا تغییر ناگهانی به آزمایش Shapiro-Wilk برای این تحلیل برای من ناسازگار است؟ | حجم نمونه کوچک و آزمون کولموگروف-اسمیرنوف |
68549 | من در حال انجام یک آزمایش فیزیکی هستم که در آن تنظیم نادرست اجتنابناپذیر احتمالاً خطاهایی در وارونگی دادههای مدل ایجاد میکند. بیایید یک رابطه خطی بین داده $\mathbf d$ و مدل $\mathbf m$ را به صورت زیر فرض کنیم: $$\mathbf d = \mathbf W \mathbf m، $$ که در آن $\mathbf W$ عملگر است (که تنظیمات را رمزگذاری می کند از آزمایش فیزیکی من). وارونگی خطی استاندارد مدل $$\mathbf m = \mathbf {C_m}^{-1} \mathbf W^\prime \mathbf {C_d}^{-1} \mathbf d$$ را با کوواریانس داده $\mathbf به دست میدهد. {C_d}$ و کوواریانس مدل $$\mathbf {C_m} = \left( \mathbf W^\prime {\mathbf {C_d}^{-1}} \mathbf W \right)^{-1}.$$ تاکنون، خیلی خوب است. عملگر $\mathbf W = \mathbf W (\mathbf p)$، با این حال، به صورت غیر خطی به پارامتر $\mathbf p$ بستگی دارد، اما یک خطی سازی، مثلاً $$\mathbf V = \dfrac {\ جزئی \mathbf W} {\ جزئی \mathbf p} \mathbf {p_0},$$ جایی که $\mathbf {p_0}$ پارامتر a-priori شناخته شده (اندازه گیری شده) است، انجام خواهد داد. حالا چطوری از اینجا ادامه بدم؟ این است که چگونه می توانم برای هر گونه عدم قطعیت پارامتر (کوچک) در وارونگی مدل و کوواریانس مدل حساب کنم؟ | کوواریانس خلفی برای وارونگی خطی |
111864 | در مورد برخی از داده ها به کمک نیاز دارم. من یک شاخص عملکرد و یک مقیاس لیکرت دارم. آیا منطقی خواهد بود که به هر دسته در مقیاس لیکرت خود مقداری اختصاص دهم (مثلاً: «واقعاً آسان=5، آسان=4، متوسط=3، سخت=2، واقعاً سخت=1») و این مقدار را در مقدار ضرب کنم. فراوانی مشاهده و سپس میانگین را برای هر آیتم بگیرید تا احساسی در مورد میانگین درک سختی داشته باشید. سپس من همبستگی پیرسون را بین این مقدار جدید و شاخص واقعی عملکرد خود کاملاً بررسی خواهم کرد. میخواهم بدانم آیا سختی واقعی و درک سختی با هم متفاوت است؟ به عبارت دیگر، میخواهم بدانم که آیا سؤالات آسان آسان و سؤالات دشوار دشوار تلقی میشوند؟ من نمی دانم که آیا این نوع دستکاری با مقیاس لیکرت مجاز است یا خیر. | آیا می توانم مقیاس لیکرت خود را به اعداد تبدیل کنم و سپس میانگین بگیرم تا بدانم آیا بین دو متغیر همبستگی وجود دارد یا خیر؟ |
68543 | من می خواهم مجموعه ای از سری های زمانی 512 را خوشه بندی کنم. سری های زمانی دارای فواصل نمونه برداری 1 روز در یک دوره زمانی 5 ساله هستند. بنابراین، هر سری زمانی از حدود 1800 نمونه تشکیل شده است. با این حال، بسیاری از نمونه ها صفر هستند. بنابراین، سوال من این است: آیا خوب است نمونهها را در فواصل نمونهبرداری بزرگتر جمع کنیم، مثلاً؟ روزها یا حتی سالها، با وجود از دست دادن اطلاعاتی که با تجمیع همراه است؟ آیا تجمیع نوعی از دستکاری داده ها نیست؟ اگر نه، چگونه واحد زمانی مناسب را برای تجمیع انتخاب کنم؟ | جمعآوری نمونهها برای خوشهبندی سریهای زمانی |
91329 | من نیاز به پیاده سازی مدل خودرگرسیون برداری فضایی توسعه یافته در _Beenstock، M. و D. Felsenstein دارم. 1386. خودرگرسیون های برداری فضایی. تحلیل اقتصادی فضایی 2 (2): 167-196_. آیا در نرم افزاری بسته ای برای تخمین این مدل وجود دارد؟ اگر نه، چه راهی بهتر است؟ من از توجه تشکر می کنم! | مدل خودرگرسیون برداری فضایی |
67241 | من در اینترنت به دنبال بستههای R گشتهام تا فواصل اطمینان را برای میانگین توزیع پواسون با استفاده از روشهای مختلفی که پاتیل و کولکارنی در مقالهشان «مقایسه بازههای اطمینان برای میانگین پواسون: برخی جنبههای جدید» ذکر کردهاند، محاسبه کنم. جلد 10، نه 2، ژوئن 2012، ص 211-227. من در بسته R، 'exactci'، روتین poisson.exact را پیدا کردم که چند روش را ارائه می دهد. در بسته epitools R pois.exact، pois.daly، pois.yar و pois.approx وجود دارد. در بسته R 'stats' poisson.test وجود دارد که از روش Clopper Pearson برای فاصله اطمینان میانگین استفاده می کند. اما علاوه بر اینها، من به دنبال روشهایی بودم که فاصله اطمینان باریکتر باشد، یعنی مشابه روشهایی که برای تخمین بازهای نسبتهای دوجملهای بیان شد، همانطور که در مقاله آگرستی و کول بیان شد، «تقریبا بهتر از دقیق برای تخمین بازه ای نسبت های دوجمله ای عامر. آمار می 1998، ج. 52، شماره 2 صص 119-126. و با خواندن مقالات مشابه با موارد بالا در مورد توزیع پواسون، مشخص شد که برای بررسی خوب فواصل اطمینان، روش نمره و انواع آن باید گنجانده شود. این روش ها هستند که به نظر می رسد هنوز در هیچ بسته R گنجانده نشده اند؟ نزدیکترین چیزی که من پیدا کردم یک بسته R در فواصل تحمل بود ('Tolerance'). من ادعا نمی کنم که در مورد تمایز بین CI و TI کاملاً روشن هستم، اما فکر می کنم دومی تضمین می کند که چیزی (مثلاً طول اندازه گیری شده یک قطعه) در آن بازه تا یک سطح احتمال معین قرار می گیرد، اما با CI ما هستیم بیانیه ای مبنی بر اینکه میانگین در بازه ای تا سطح معینی از احتمال قرار دارد. آیا بسته R وجود دارد که محاسبه CI را برای توزیع پواسون با استفاده از این روش های تقریبی انجام دهد (اما نه فاصله معمولی تقریباً)؟ با تشکر | فواصل اطمینان برای میانگین روش های توزیع پواسون 9-19 کدگذاری شده به عنوان بسته R |
91328 | من پس از انجام اقدامات مکرر در $i$ فردی، یک پاسخ مداوم $Y_{ij}$ دارم. در مجموع من $Y_{ij}$ را 5 بار (j=1..5) تحت انواع مختلف حرکت سوژه اندازه میگیرم: still1، still2، تکان دادن سر، تکان دادن و آزاد. من همچنین میزان حرکت هر سوژه را در هر یک از این انواع حرکت اندازهگیری میکنم و این متغیر ($m_{ij}$) بر اساس نوع حرکت افزایش مییابد (کم در ثابت، بیشتر در تکان دادن، بیشتر در تکان دادن و بیشتر در حرکت آزاد) . اکنون هنگام مقایسه $Y$ در بین انواع حرکت (آزمایش زوجی) متوجه می شوم که $Y_{ij}$ به طور قابل توجهی در انواع مختلف متفاوت است، اما این می تواند به سادگی ناشی از شدت حرکت باشد تا نوع حرکت. هنگام اجرای یک مدل جلوههای ترکیبی ساده روی همه دادهها: $Y_{ij} = b_i + \beta_0 + \beta_1 * m_{ij} + e_{ij}$ (با وقفه بهعنوان اثر تصادفی) وابستگی بسیار قوی به $Y$ در $m$. نشان دادن آن حرکت، $Y$ را به خوبی توضیح می دهد. حالا چگونه می توانم آزمایش کنم که آیا نوع حرکت واقعاً مهم است یا خیر؟ من به این دو مدل فکر کردم ($nod_{ij}$، $shake_{ij}$ و $free_{ij}$ متغیرهای باینری هستند که نوع حرکت را تعیین میکنند): $Y_{ij} = b_i + \beta_0 + \beta_1 m_{ij} + \beta_2 nod_{ij} + \beta_3 (nod_{ij} \ m_{ij}) + \beta_4 shake_{ij} + \beta_5 (shake_{ij} \ m_{ij}) + \beta_6 free_{ij} + \beta_7 (رایگان_{ij} \ m_{ij}) + e_{ij}$ و مدل دیگری که $\beta_2 را حذف میکند، \ شرایط beta_4$ و $\beta_6$. دلیل حذف آنها این است که باید یک وقفه واحد برای $m=0$ مستقل از نوع حرکت وجود داشته باشد (زیرا حرکت صفر وجود دارد، بنابراین نوع مهم نیست) 1.) آیا وقتی شرایط تعاملی دارم، همیشه باید وقفههای نوع حرکت (شرایط $\beta_2، \beta_4$ و $\beta_6$) را اضافه کنم؟ کسی به من گفت که آنها باید همیشه درج شوند، اما به نظر می رسد اینجا چندان منطقی نیست. 2.) در هر یک از مدلها، اکنون میتوانم آزمایش کنم که آیا تأثیر شدت حرکت در هر نوع حرکت به طور مستقل وجود دارد یا خیر (مستقل عبارتهای تعامل $\beta_3، \beta_5$ و $\beta_7$ را آزمایش میکنم). و به نظر من اینها به جز در نوع هنوز ($\beta_1$) مهم هستند. این به من می گوید که علاوه بر هر کاری که نوع حرکت انجام می دهد، شدت حرکت چیزهای زیادی را توضیح می دهد، درست است؟ با این حال، من نمی دانم که آیا نوع حرکت اصلاً چیزی را توضیح می دهد یا خیر. 3.) برای آزمایش آن، باید شرایط تعامل (دو به دو) را با هم مقایسه کنم و اساساً مثلاً $\beta_5 - \beta_7$ را آزمایش کنم. این به من می گوید، اگر بسته به نوع حرکت، شیب های مختلفی داشته باشم، درست است؟ 4.) تا اینجا خوب است، اما من تفاوت شرایط تعامل را تنها در یکی از دو مدل (یکی کامل با همه رهگیری ها) قابل توجه می دانم. مدل ساده شده (و به نظر من با معنی تر) اهمیتی را نشان نمی دهد. بنابراین من فکر می کنم بسیار مهم است که بفهمیم از چه مدلی برای تفسیر این نتایج استفاده کنیم. هر کمکی بسیار قدردانی می شود. | نحوه ترکیب متغیرهای کمکی گروه متغیر زمانی در مدل اثرات مختلط خطی |
108382 | آیا کسی می تواند با این تقریب به من کمک کند: > وقتی $m$ واقعاً بزرگ می شود، $\dfrac{r}{m}$ بسیار کوچک می شود و بنابراین > $\log\left(1+\dfrac{r}{m}\ سمت راست) \sim \dfrac{r}{m}$. من نمی دانم چگونه $\log\left(1+\dfrac{r}{m}\right)$ تقریباً برابر با $\dfrac{r}{m}$ شد؟ لطفا شفاف سازی کنید | تقریب گزارش |
104980 | من با SEM مشکلی دارم که ادعا میکند در جایی که واقعاً باید برای کوواریانسهای گمشده آزمایش کند، اشباع شده است. مواردی که «2» در پشت دارند عبارتهای ربعی هستند SEM1 = «d_birds ~ Q1 + MAT + MAP + TS + VelT + SamplingEffort + NetworkSize + plantp+ MAP2 + TS2 + PS2 Q1 ~ MAT + MAP + TS + VelT + SamplingEffort + NetworkSize + P MAP2 + TS2 + PS2 وقتی آن را با استفاده از R اجرا می کنم کد: SEM1fit = sem (SEM1، داده = td، fixed.x = T) خلاصه (SEM1fit) به من می گوید که مدل با df=0 اشباع شده است و بنابراین هیچ آزمون مجذور کای نیز انجام نمی شود. این را نمیفهمم، زیرا من هیچ کوواریانسی در مدل وارد نمیکنم (یعنی به عنوان یک عبارت ثابت = 0) سؤال من در این مورد: • آیا فکر میکنید اگر مدل را بر اساس مربع R و تخمینها (که داده شده است) قرار دهم هنوز آموزنده است. توسط خروجی SEM) یا راه بهتری برای تجزیه و تحلیل داده ها وجود دارد با احترام | مدل معادلات ساختاری اشباع شده |
79270 | آیا یک آزمون آماری استاندارد کم و بیش برای بررسی اینکه آیا یک مجموعه داده چند متغیره از یک توزیع گاوسی چند متغیره ترسیم شده است یا خیر وجود دارد؟ فکر می کنم بتوانم بردار میانگین تجربی و ماتریس کوواریانس را محاسبه کنم و سپس از آنها برای محاسبه احتمال استفاده کنم، اما آیا راه بهتری وجود دارد؟ با تشکر فراوان | تست استاندارد برای گاوسی چند متغیره؟ |
35366 | میخواهم بدانم آیا کسی میداند چگونه نتایج «arima» را برای محاسبه مقادیر گمشده در دوره مشاهده اعمال کند. من به دنبال چیزی شبیه به «forecast.arima()» هستم که مقادیر را بر اساس نتایج «arima» پیشبینی میکند. آیا کسی تجربه ای در استفاده از داده های منابع دیگر کامل اما با دقت کمتر برای جایگزینی مقادیر از دست رفته دارد؟ آیا تجزیه هر دو مجموعه داده با استفاده از 'stl' و محاسبه مجدد مقادیر جدید با استفاده از داده های مشاهده امکان پذیر است؟ من سالهاست که از مشاهدات آب و هوایی روزانه استفاده میکنم، اگرچه برخی از دادههای گمشده بین مشاهدات است، همچنین بازههای زمانی زیادی بدون هیچ مشاهدهای دارم. | درون یابی مقادیر از دست رفته با استفاده از نتایج تولید شده توسط arima |
4262 | من فرآیندی دارم که هر ثانیه آمار را از یک سیستم سرور به یک فایل در این قالب می نویسد: label1 label2 label3 344 666 787 344 849 344 939 994 344 تعدادی مقادیر مختلف وجود دارد که برای آنها به نمودار نیاز دارم و هر مقدار اضافه می شود. در هر ثانیه به انتهای فایل بروید. من به دنبال راهی خوب برای نشان دادن این اعداد به صورت گرافیکی هستم، ترجیحاً برنامه ای که هر ثانیه به طور خودکار به روز می شود و نمودارهای مختلف را نشان می دهد. آیا کسی می تواند چنین برنامه ای را برای مک معرفی کند؟ ترجیحا رایگان :) | نمودارسازی داده های بلادرنگ از یک فایل متنی |
103453 | چگونه می توانم همبستگی خودکار مرتبه اول فرآیند $x_t = \delta + \phi x_{t-1} + \eta_t$ را محاسبه کنم؟ آیا کسی می تواند به من نکاتی بدهد؟ من این را امتحان کردم: $E(\delta + \phi x_{t-1} + \eta_t - \frac{\delta}{1- \phi})(\delta + \phi x_{t-2} + \eta_ {t-1} - \frac{\delta}{1- \phi})$. اما چگونه می توانم برای مثال $E(x_{t-1}x_{t-2})$ را اینجا محاسبه کنم؟ با تشکر | همبستگی خودکار مرتبه اول یک فرآیند AR خاص |
108386 | من مقدار _r_ پیرسون را بین دو متغیر در SPSS محاسبه کرده ام. حجم نمونه 81 است. مقدار _r_ -.21 است. مقدار _p_ 0.06 است. وقتی فواصل اطمینان 95% را با استفاده از bootstrapping با 2000 نمونه محاسبه میکنم و گزینه بایاس تصحیح شده شتاب (BCa) علامت زده میشود، فواصل اطمینان [0.36-، 0.04-] را دریافت میکنم (شامل 0 نمیشود)، که نشان میدهد در واقع نتیجه قابل توجه است. در _p_ < 0.05. چگونه اختلاف بین مقدار _p_ و فواصل اطمینان را توضیح دهم؟ من فواصل اطمینان را دوباره با درصد به جای بررسی BCa محاسبه کردم و فواصل اطمینان [009/0.378- [-.378] (شامل 0 می شود)، که برای من منطقی تر است. چگونه می توانم ناسازگاری ظاهری بین مقدار _p_ و فواصل اطمینانی را که هنگام استفاده از روش BCa به دست آوردم توضیح دهم؟ یک مسئله ثانویه این است که چگونه این نتیجه (BCa) را در سبک APA گزارش کنم. | SPSS: r پیرسون معنی دار نیست اما فواصل اطمینان شامل 0 نمی شود |
67247 | بر اساس نتایج مدل نول، برخی از محققان واریانس منتسب به سطح گروه و سطح فردی را با استفاده از خروجی مؤلفه واریانس محاسبه میکنند، در حالی که برخی دیگر پیشنهاد میکنند که نمرات انحراف معیار را انتخاب کنند. آیا در نحوه محاسبه ICC اتفاق نظر وجود دارد؟ | نحوه تقسیم بندی واریانس توضیح داده شده در سطح گروهی و فردی |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.