
_id stringlengths 1 6 | text stringlengths 0 7.5k | title stringlengths 0 167 |
|---|---|---|
30720 | من در حال حاضر در حال طراحی استراتژی نمونه گیری برای بررسی شیوع بر روی سالمندان در مراکز مراقبت طولانی مدت (LTCF) در خدمتم هستم، از Limebook از WHO به عنوان مرجع استفاده کردم. و من می خواهم نظری را در مورد طرح خود ببینم تا ببینم آیا در اینجا کار اشتباهی انجام داده ام یا خیر. سناریو: فرض کنید من در کشور X در حال انجام یک نظرسنجی هستم، کشور X را می توان به 3 منطقه A,B,C تقسیم کرد. من باید در LTCF در کشور نظرسنجی کنم، انواع مختلفی از LTCF وجود دارد و می توان آن را به طور تقریبی به LTCF خصوصی (P) و LTCF غیر خصوصی (NP) تقسیم کرد. از آنجایی که ناحیه A، B، C از نظر اندازه و جمعیت متفاوت است، بنابراین تعداد LTCF در 3 منطقه متفاوت است. و LTCF ها تعداد ساکنین متفاوتی دارند. من بر اساس شیوع بیماری Z، دقت نسبی و اثر طراحی تخمین زده ام. بنابراین مجموع حجم نمونه مورد نیاز 4000 است که اثر طراحی شده 4 و اندازه خوشه 120 است. در مرحله اول نمونه گیری تعیین خواهم کرد که از هر یک از اقشار چه تعداد خوشه باید نمونه برداری شود (طبقه ها بر اساس مناطق تعیین می شوند). X نوع LTCF، یعنی A-P، A-NP، B-P، B-NP، C-P، C-NP)، متناسب با تعداد ساکنان یافت شده در هر اقشار.) (یعنی اقشار با احتمال متناسب با اندازه نمونه برداری می شوند) فرض کنید من باید 2 خوشه را از A-P انتخاب کنم، سپس فهرستی از ساکنان ساکن در LTCF خصوصی در ناحیه A ایجاد کردم و سپس 2 مورد از آنها را انتخاب کردم، یکی از LTCF-R و یکی از LTCF-S. سپس همه را در LTCF-R و LTCF-S نمونه خواهم کرد. (یعنی LTCF با احتمال متناسب با اندازه نمونه برداری می شود) اگر LTCF-R خیلی کوچک باشد (به عنوان مثال فقط 30 به جای 120)، LTCF همسایه آن (مثلا LTCF-T همچنین یک LTCF خصوصی) انتخاب و در LTCF-R گنجانده می شود. خوشه اگر LTCF-R خیلی بزرگ باشد (مثلاً 300 به جای 120)، نمونه تصادفی از 120 محل اقامت نمونه برداری خواهد شد. من تاکنون کاری مشابه «نمونهگیری خوشهای چند مرحلهای در نیجریه 2011» انجام میدهم که در مثال 5.4 در کتاب راهنمای بررسی شیوع سل WHO ذکر شده است. چیزی که من را بسیار نگران می کند این است که باید LTCF دیگری را به کلاستر اصلی اضافه کنم این است که اقامت در خوشه کافی نیست. به نظر می رسد این کاملاً شبیه سناریویی نیست که فریکس R.R در فصل خود در مورد نمونه گیری خوشه ای ذکر کرده است. مطمئن نیستم که هنوز بتوانم از فرمول فصل او برای محاسبه شیوع بیماری Z در داده های نمونه گیری خوشه ای استفاده کنم. لطفاً نظر خود را بنویسید یا سؤال بپرسید. پیشاپیش ممنون | نمونه گیری تصادفی خوشه ای و تجزیه و تحلیل فرعی |
38133 | برخی از مولدهای اعداد تصادفی غیر یکنواخت که به مولدهای اعداد تصادفی یکنواخت متکی نیستند کدامند؟ آیا برخی از آنها برای توزیع های غیر یکنواخت عمومی هستند یا همه آنها برای برخی توزیع های غیر یکنواخت خاص هستند؟ با تشکر | برخی از مولدهای اعداد تصادفی غیر یکنواخت که به مولدهای اعداد تصادفی یکنواخت متکی نیستند کدامند؟ |
47291 | بهترین آزمون برای تعیین اینکه آیا تفاوتهای بین چند گروه از نظر آماری معنیدار هستند یا خیر، چه آزمایشی خواهد بود؟ من در حال انجام تحقیق در مورد رضایت شغلی فیزیوتراپیست هستم. در اینجا یک tabstat برای اطلاعات وجود دارد. ردیف نشان دهنده گروه است (دانشگاهی که از آن فارغ التحصیل شده اند یا تخصص آنها (اعصاب، اطفال، ورزش و غیره)). من 10 تای دیگر دارم، 3 مورد فقط مثال است. ستونها رضایت از هر جنبه را نشان میدهند، اینها مقادیر متوسطی هستند (مجموع میتواند 0 تا 54 باشد): هرچه این تعداد بیشتر باشد، رضایت بیشتری از کار خود دارند. uni | شغل افراد نظارت بر پرداخت .... 1 | 39.10976 40.42683 35.02439 22.60976 .... 2 | 43.90385 45.30769 39.84615 26.07692 .... 3 | 39.57143 40.28571 31.19048 23.33333 .... .. ... ... ... ... حالا چگونه می توانم آزمایش کنم که آیا این تفاوت ها بین گروه ها قابل توجه است و دقیقاً بین کدام گروه ها هستند؟ با تشکر | آزمون تفاوت های آماری بین گروه ها |
20150 | من مجموعه داده ای دارم که شامل 200 مرد و 250 زن است و در حال آزمایش پاسخ آنها در رابطه بین X و Y هستم. X و Y پیوسته هستند و X1 (جنسیت) مقوله ای است. من از مدل خطی عمومی در SPSS برای آزمایش اثرات اصلی و تعامل استفاده می کنم. همانطور که من متوجه شدم، این یک طراحی نامتعادل است زیرا اندازه دو گروه (مرد و زن) یکسان نیست. **سوالات** 1. آیا استفاده از مجموع مربعات (نوع III) در این مورد مناسب است؟ 2. چه جایگزین هایی برای تجزیه و تحلیل این داده ها دارم؟ | GLM در طراحی نامتعادل |
19123 | من در حال آزمایش الگوریتمهای طبقهبندی در ML هستم و به دنبال مجموعهای برای آموزش مدل خود هستم تا بین دستههای متنی مختلف مانند ورزش، آبوهوا، فناوری، فوتبال، کریکت و غیره تمایز قائل شود. کجا میتوانم مجموعهای از مجموعه دادهها را با این دستهها پیدا کنم؟ یک گزینه می تواند خزیدن ویکی پدیا برای این 30+ دسته باشد. آیا راه بهتری برای این کار وجود دارد؟ **ویرایش**: میخواهم مدل را با استفاده از رویکرد کیسه کلمات برای این دستهها آموزش دهم، سپس وبسایتهای جدید/ناشناس را بسته به محتوای صفحه وب به این دستههای از پیش تعریفشده طبقهبندی کنم. | آیا مجموعه ای به طور خاص برای دسته هایی مانند ورزش، سرگرمی یا سلامتی وجود دارد؟ |
11310 | من مقادیر مهمی را برای آزمون اندرسون دارلینگ برای توزیع نرمال در سطوح معناداری 1، 2.5، 5، 10 درصد و 15 درصد از منابع مختلف، از جمله ویکیپدیا پیدا کردهام: http://en.wikipedia.org/wiki /Anderson%E2%80%93Darling_test من واقعاً یک مقدار بحرانی برای سطح معناداری 0.1% می خواهم (در صورت 4 - نه میانگین و نه واریانس شناخته شده است). من با جستجو در وب نتوانستم آن را پیدا کنم و مطمئن نیستم که چگونه باید آن را محاسبه کنم. کسی میتونه کمک کنه؟ | مقادیر بحرانی برای آزمون اندرسون-دارلینگ |
89690 | من یک رگرسیون دوجمله ای منفی روی برخی از داده های شمارش با استفاده از SPSS اجرا کردم. رهگیری دارای مقدار Exp(B) زیر حد پایین 95% فاصله اطمینان Wald بود. من قبلاً چنین اتفاقی را ندیده بودم و کنجکاو هستم که بدانم معنی آن چیست. این با هیچ یک از مقادیر Exp(B) برای پیش بینی کننده ها اتفاق نیفتاد، فقط رهگیری. کسی میدونه این یعنی چی؟ | مقدار Exp(B) خارج از 95٪ فاصله اطمینان Wald |
19124 | من سعی می کنم بردارهای ویژگی 6 بعدی را با استفاده از الگوریتم نزدیکترین همسایه در دو کلاس مختلف طبقه بندی کنم. پس از تجزیه و تحلیل داده های آموزشی خود، متوجه شدم که همان بردار بارها در هر دو کلاس وجود دارد. این به چه معناست؟ * آیا این انتخاب ویژگی بد را نشان می دهد؟ * در طول آموزش، آیا باید بردارهای یکسان را گروه بندی کنم و کلاسی را که بیشترین تعداد را دارد برچسب گذاری کنم؟ (یعنی بردار A در هر دو کلاس A و B وجود دارد، اما آن را کلاس A بگذارید زیرا بردار A بیشتر در کلاس A یافت می شود تا کلاس B) * چیز دیگری؟ | نزدیکترین همسایه که در آن چندین بردار مقادیر دقیقاً یکسانی دارند |
103430 | در زیر بحثی از آمار کافی برای توزیع پیوسته است که از ویرایش سوم **آزمایش فرضیه های آماری Lehmann's** گرفته شده است. کسی می تواند توضیح دهد که چرا عبارت زیر خط کشیده شده درست است. چگونه می توان نتیجه گرفت که توزیع شرطی $X$ داده شده $t$ به $\theta$ بستگی ندارد؟  | آمار کافی برای توزیع مداوم |
89180 | نحوه خوشه بندی بر اساس آنچه کاربران در آن جستجو می کنند من روی برنامه ای کار می کنم که شامل عملکرد جستجو می شود: یک کادر جستجو که به کاربر اجازه می دهد متن را وارد کند و کل سایت را جستجو کند. من به عباراتی که کاربران در جستجوی آنها هستند دسترسی دارم، چگونه می توانم کاربران را بر اساس این داده ها خوشه بندی کنم؟ در اینجا چیزی است که من به آن فکر میکنم، بنابراین از هرگونه توصیه دیگری استقبال میشود: 1. کاربران را بر اساس آنچه که در آن جستجو میکنند، دستهبندی کنید، پیشنهادات جستجو را بر اساس آنچه سایر کاربران مشابه جستجو میکنند، پیشنهاد دهید. بنابراین کاربرانی که از نتایج جستجوی یکسانی استفاده می کنند بر اساس ضریب جاکارد بسیار شبیه هستند. عبارات جستجو بر اساس وجود یا عدم وجود کلمات جستجو به داده های باینری تبدیل می شوند. | نحوه خوشه بندی کاربران بر اساس عبارات جستجو |
13786 | من به زودی پایان نامه خود را در زمینه مدل سازی ریسک اعتباری شروع می کنم، اما می دانم که به دست آوردن اطلاعات واقعی واقعاً سخت است. آیا کسی می داند که آیا این نوع داده ها در دسترس عموم است یا من باید آن را از جایی خریداری کنم. فقط کمی جزئیات بیشتر از نوع داده ای که به دنبال آن هستم: ترجیحاً دارای چند هزار شرکت باشد که سابقه پرداخت موفقیت آمیز وام های خود را داشته باشد و همچنین باید نسبت های کلیدی حسابداری/مالی شرکت ها را داشته باشد (مانند نسبت سرمایه در گردش/کل دارایی، نسبت فروش/کل دارایی و غیره). هر کمکی بسیار قدردانی خواهد شد. | مجموعه داده های ریسک اعتباری را کجا می توان پیدا کرد؟ |
20151 | در مدل رگرسیونی خود، من در حال آزمایش اثرات اصلی و تعامل بر روی Y به شرح زیر هستم: X, X1, X*X1 (X1 جنسیت است و 200 مرد و 250 زن در مجموعه داده وجود دارد.) این تعامل معنی دار نیست اما یکی اصلی است. اثر (X) قابل توجه است. زمینه تحقیق من نشان می دهد که باید یک تعامل وجود داشته باشد (و نمودار خطوط غیر موازی را نشان می دهد - اینجا را ببینید). من می دانم که یکی از دلایل نتیجه فوق کمبود قدرت است. **سوال: آیا تشخیص یک واکنش متقابل به قدرت بیشتر یا کمتری نسبت به تشخیص اثرات اصلی نیاز دارد؟** (منظورم از تشخیص، از نظر آماری معنی دار است) من از تابع خطی عمومی در SPSS استفاده می کنم. | قدرت مورد نیاز برای تشخیص یک تعامل |
48115 | یک تنظیم رگرسیون خطی با دو «بلوک» پیشبینیکننده داشته باشید. معیارهای معمول برای سهم هر بلوک بر دیگری نامتقارن هستند (مثلاً تغییر احتمال، تغییر RSS و غیره). آیا اندازه گیری متقارن وجود دارد؟ من فرض میکنم که این چیزی در خطوط احتمال تغییر بین پیشبینی در دهانه دو بلوک در مقابل یک برآمدگی روی تقاطع دهانهها باشد. | اندازه گیری متقارن سهم متغیر در یک رگرسیون |
11315 | بنابراین، وقتی فرض میکنم که عبارات خطا به طور معمول در یک رگرسیون خطی توزیع میشوند، برای متغیر پاسخ، $y$ چه معنایی دارد؟ | چگونه توزیع عبارت خطا بر توزیع پاسخ تأثیر می گذارد؟ |
19126 | ما 100 شرکت کننده در دو گروه داریم، $n=50$ در هر گروه. ما از ارزیابی توانایی عملکرد پایه در 4 نقطه زمانی استفاده کردیم. ارزیابی شامل 6 سوال است که هر کدام 0 تا 5 نمره دارند. ما برای هر سوال نمره های فردی نداریم، فقط نمرات کل که از 0 تا 30 متغیر است. نمرات بالاتر نشان دهنده عملکرد بهتر است. مشکل این است که ارزیابی بسیار اساسی است و تأثیر سقف قابل توجهی دارد. نتایج بسیار منفی هستند. اکثر شرکت کنندگان امتیاز نزدیک به 30 را به خصوص در 3 نقطه زمانی بعدی کسب کردند. این احتمال وجود دارد که همه شرکتکنندگانی که در حد بالایی امتیاز کسب کردهاند واقعاً از نظر توانایی برابر نباشند: برخی از شرکتکنندگان تقریباً 30 امتیاز کسب کردهاند و برخی دیگر به راحتی امتیاز 30 را کسب کردهاند و در صورت امکان امتیاز بسیار بالاتری خواهند داشت و بنابراین دادهها از بالا سانسور شده من می خواهم این دو گروه را در طول زمان مقایسه کنم، اما بدیهی است که با توجه به ماهیت نتایج، این کار بسیار دشوار است. دگرگونی ها از هر نوعی که باشند هیچ تفاوتی ندارند. به من توصیه شده است که مدل توبیت بهترین تجهیز برای این ارزیابی است و میتوانم با استفاده از نمونههایی از مقاله Arne Henningen، برآورد مدلهای رگرسیون سانسور شده در R با استفاده از بسته censReg، آنالیز را در R اجرا کنم. با این حال، من فقط دانش اولیه ای از آمار دارم و اطلاعات مربوط به مدل توبیت را بسیار پیچیده می دانم. من نیاز دارم که بتوانم این مدل را به زبان ساده توضیح دهم و نمی توانم توضیح ساده، مهره و پیچ و مهره ای پیدا کنم که مدل توبیت واقعاً چه کار می کند و چگونه انجام می دهد. آیا کسی می تواند مدل توبیت را توضیح دهد یا به من در جهت یک مرجع قابل خواندن بدون توضیحات پیچیده آماری و ریاضی اشاره کند؟ برای هر کمکی بسیار سپاسگزارم | توضیح مدل توبیت |
31459 | آیا بین رگرسیون و تحلیل تفکیک خطی رابطه وجود دارد؟ شباهت ها و تفاوت های آنها چیست؟ دو کلاس یا بیشتر از دو کلاس فرقی می کند؟ | رابطه بین رگرسیون و تحلیل تفکیک خطی چیست؟ |
103316 | در SPSS، من نمودارهای پراکندگی دو متغیر پیوسته (X & Y) را برای دو گروه جداگانه (G & P) ایجاد کرده ام. بازرسی بصری با مقایسه نمودارهای پراکنده از دو گروه نشان می دهد که توزیع نقاط داده مشابه است. با این حال، من می خواهم این را ثابت کنم. آیا راهی برای انجام این کار وجود دارد، ترجیحاً در SPSS؟ آیا یک MANOVA یک طرفه مناسب است؟ اگر نه، چرا MANOVA یک طرفه مناسب نیست؟  | در SPSS، چگونه می توان دو نمودار پراکنده از داده های دو متغیره جداگانه را با هم مقایسه کرد تا مشخص شود که آیا توزیع ها مشابه هستند یا نه؟ |
103319 | من سعی می کنم تعیین کنم که آیا دانش آموزان در مسابقه ای با سؤالات چند گزینه ای $q$ بهتر از شانس عمل می کنند یا خیر. هر سوال به عنوان 4 پاسخ ممکن. یکی صحیح و 3 اشتباه است. یک پاسخ صحیح یک امتیاز و یک پاسخ اشتباه 0 امتیاز دارد. به عنوان مثال، اگر $q=3$ باشد، در صورتی که پاسخها بهتر از شانس نباشند، میانگین امتیاز 0.75 را انتظار دارم. (1 راه برای درست کردن 3/3 سوال، 9 راه برای درست گرفتن 2/3 سوال، 27 راه برای به دست آوردن 1/3 سوال، و 27 راه برای درست کردن 0/3 سوال وجود دارد. $3 \left( \frac{ 1}{64}\right) + 2 \left( \frac{9}{64}\right) + 1 \left( \frac{27}{64}\right) + 0 \left( \frac{27}{64}\right) = 0.75 $). فرض کنید من 50 دانش آموز دارم که در آزمون شرکت می کنند و میانگین نمره آنها 1.25 است. من تعجب می کنم: 1. چگونه می توانم مقدار $p$ را برای فرضیه صفر میانگین واقعی=0.75 و فرضیه جایگزین میانگین واقعی≠0.75 محاسبه کنم؟ 2. چگونه می توانم فاصله اطمینان حول میانگین مشاهده شده را محاسبه کنم؟ 3. آیا هیچ محدودیتی در رابطه با توزیع اساسی امتیازها وجود دارد (مثلاً مشکلات اگر نمرات توزیع دووجهی داشته باشند و اکثر افراد 0 یا 2+ را دریافت کنند)؟ | آزمون فرضیه برای آزمون چند گزینه ای |
47293 | برای هر رکورد در مجموعه دادههایم اطلاعات زیر را دارم $$ (X_1 \ , \dots \ , X_m \ , \delta \ , T \ )$$ که در آن $X_i$ ویژگیها هستند، $\delta$ 1 است اگر رویداد هدف رخ می دهد و 0 در غیر این صورت، و $T$ مهر زمانی رویداد رخ داده است. به ویژه، اگر رویدادی وجود نداشته باشد یا زمان پایان پیگیری تنظیم شده باشد، ممکن است $T$ وجود نداشته باشد. **من میخواهم برای هر رکورد در مجموعه دادهام یک شاخص ریسک محاسبه کنم.** داشتم به دنبال مدل طبقهبندی هستم که از ویژگیهای $X_i$ برای پیشبینی کلاس $\delta$ استفاده میکند. با این حال، $T$ مهم است: اگر رویداد $\delta$ احتمال دارد به زودی رخ دهد، خطر باید بیشتر باشد. به همین دلیل است که یک _تحلیل بقا_ باید برای این مشکل مناسب باشد. من به تخمین کامل $S(t) = P(T>t)$ نیازی ندارم، بلکه فقط به یک شاخص واحد نیاز ندارم که ریسک یک رکورد را نشان دهد. میانگین زمان بقا، که می تواند برای هر رکورد محاسبه شود، به نظر یک شاخص ریسک خوب است - هر چه کمتر، ریسک بالاتر است. **سوال من این است:** 1. آیا تحلیل بقا برای اهداف من مناسب است؟ 2. چگونه می توانم عملکرد مدل خود را ارزیابی کنم؟ در مورد سوال (2): من مشتاقم از شاخص $c$-هارل برای مثال استفاده کنم، اما مطمئن نیستم که کدام نتیجه پیش بینی شده برای محاسبه آن استفاده می شود. از کتاب Harrell's Regression Modeling Strategies صفحه 247: > شاخص $c$ [...] با در نظر گرفتن همه جفت موضوعات ممکن محاسبه می شود > به طوری که یک آزمودنی پاسخ داد و دیگری پاسخ نداد. این شاخص، نسبت این جفتهایی است که پاسخدهنده احتمال پاسخگویی پیشبینیشده بالاتری نسبت به پاسخدهنده دارد. اگر تجزیه و تحلیل بقا انتخاب درستی باشد، فکر می کنم استفاده از روش استاندارد برای معرفی متغیرهای کمکی متغیر زمانی $X_i(t)$ باید آسان باشد. | تجزیه و تحلیل بقا برای پیش بینی رویداد |
47299 | اهمیت کندال tau-b را محاسبه کنید؟ من تاکنون تمام روشهای محاسبه اهمیت کندال تاو (جایی که پیوندهایی وجود دارد) را امتحان کردهام که در اینجا توضیح داده شده است. با این حال، هیچ یک از آنها، حتی برای بردارهای نسبتا بزرگ، خوب عمل نمی کنند. من فکر می کنم مشکل این است که به طور کلی به نظر می رسد که این روش ها تمایل دارند اهمیت آماری داده ها را بیش از حد تخمین بزنند، بنابراین آیا راه های جایگزینی برای محاسبه اهمیت کندال تاو وجود دارد؟ (حداقل درجاتی از تنظیمات کراوات را دریافت کنید)، با تشکر فراوان. | اهمیت کندال tau-b را محاسبه کنید؟ |
31454 | من سعی می کنم فاصله اطمینان بازگردانده شده توسط تابع var.test() در R را درک کنم. به طور خاص، فاصله اطمینانی که توسط var.test() برگردانده می شود آن چیزی نیست که هنگام محاسبه F-test توسط من پیدا می کنم. خودم به عنوان مثال : > s1 <- 10:12 ; s2 <- 13:16 > var(s1) [1] 1 > var(s2) [1] 1.666667 > var.test(s1,s2) آزمون F برای مقایسه دو داده واریانس: s1 و s2 F = 0.6، num df = 2، اسم df = 3، p-value = 0.7926 فرضیه جایگزین: نسبت واقعی واریانس برابر با 1 95 درصد فاصله اطمینان نیست: 0.03739691 23.49929674 برآورد نمونه: نسبت واریانس 0.6 فاصله اطمینان 95 درصد در اینجا [0.037,23.499] است. من فاصله اطمینان را به منطقه رد تفسیر می کنم، یعنی اگر آماره آزمون F در این بازه باشد، فرضیه صفر باید برای یک سطح آماری معین (95٪ در اینجا) پذیرفته شود. با این حال، وقتی سعی میکنم این را محاسبه کنم، میبینم: > qf(c(0.025,0.975),length(s1)-1,length(s2)-1) [1] 0.02553268 16.04410643 پس حدس میزنم که وقتی من اشتباه میکنم فاصله اطمینان var.test() را به عنوان منطقه رد تفسیر کنید. بنابراین سوال من این است: **این فاصله اطمینان نشان دهنده چیست؟** | چگونه فاصله اطمینان آزمون F واریانس را با استفاده از R تفسیر کنیم؟ |
108539 | من یک مجموعه داده دارم که در آن هر مثال دارای 35 ویژگی (اغلب همبسته) و متغیر وابسته حاصل از آنها است. من می خواهم این ویژگی ها را بر اساس تأثیر آنها بر متغیر وابسته رتبه بندی کنم. آیا تکنیک آماری برای انجام این کار در R یا Matlab وجود دارد؟ همه متغیرها پیوسته هستند. لطفاً توجه داشته باشید که این یک سؤال تحلیل چند متغیره است زیرا همبستگی بین ویژگیها مهم است و ممکن است تأثیر زیادی بر متغیر وابسته داشته باشد. | رتبه بندی متغیرهای پیش بینی بر اساس تأثیر آنها بر متغیر وابسته |
88877 | من در حال خواندن مقاله ای هستم که در آن درباره حفظ یک پیشین صریح در مقابل یک پیشین ضمنی صحبت می کنند. صادقانه بگویم، من هرگز با اصطلاحات صریح / ضمنی در زمینه پیشین ها برخورد نکرده ام و فکر می کردم که آیا این اصطلاحات فنی مرتبط با توزیع های قبلی هستند. آیا پیشین صریح به سادگی به این معنی است که توزیع قبلی مشخص شده است؟ چگونه می توان یک پیشین ضمنی از مشخصات مشکل بدست آورد؟ | پیشین آشکار در مقابل پیشین ضمنی |
47121 | وقتی از یک توزیع نرمال چند متغیره $N(\mathbf{\mu}, \mathbf{\Sigma})$ از چیزهای $n$ نمونه برداری می کنیم، آیا این بدان معناست که بردارهای $n$ را با طول ثابت $k$ انتخاب می کنیم؟ برای مثال، $n=3$ و $k=3$ را فرض کنید. سپس $(X_1,X_2,X_3)_{1}$,$(X_{11},X_{22},X_{33})_2$ و $(X_{111},X_{222},X_ را انتخاب میکنیم {333})_3 دلار؟ توجه داشته باشید که زیرنویس های زیر X$ دلخواه انتخاب شده اند. **افزوده شد.** چگونه یک فاصله اطمینان برای مشاهده از توزیع نرمال چند متغیره برای میانگین ایجاد می کنید؟ | نمونه برداری از توزیع نرمال چند متغیره |
47125 | همه، مطمئن نیستم که این کار را به درستی انجام دهم. من می خواهم یک سوال مرتبط را مطرح کنم: اگر X رابطه مثبتی با Y1 دارد و X1 به Y2 مرتبط است (هر دو در GLM)، با این حال ضریب همبستگی بین Y1 و Y2 مثبت و معنادار است (با استفاده از SPSS). چگونه می توانم چنین نتیجه ای را تفسیر کنم؟ آیا Y1 و Y2 نباید همبستگی منفی داشته باشند؟ با تشکر | متغیرهای وابسته متضاد همبسته (X مثبت Y1، X منفی Y2، اما Y1 Y2 مثبت)؟ |
48111 | می خواستم ببینم کسی می تواند در مورد زیر به من کمک کند. من سعی می کنم pdf مجموعه ای از متغیرهای تصادفی وابسته $\chi^2$ را پیدا کنم. فرض کنید $x_1,x_2,...,x_n$ نرمال های مستقل $x_i \sim N(\mu_i, \sigma_i^2)$ هستند، نه لزوما یکسان. فرض کنید $n$ و همه $\mu_i$ و $\sigma_i's$ پارامترهای شناخته شده هستند، بنابراین این واقعا یک احتمال است، نه یک سوال آمار استنباطی. همه زیرمجموعه های ممکن به اندازه $n-1، n-2،...، n-k$ را با $(n-k \geq 1)$ از این مجموعه انتخاب کنید. سپس هر زیر مجموعه دارای میانگین و واریانسی برابر با $\sum_{j\mbox{th زیر مجموعه}} \mu_j$ و $\sum_{j\mbox{th زیر مجموعه}} \sigma_j^2$ خواهد بود. سپس برای هر زیر مجموعه، مجموع استاندارد شده را محاسبه کنید: $(\sum_{j\mbox{امین زیر مجموعه}} x_j - \sum_{j\mbox{امین زیر مجموعه}} \mu_j)^2/\sum_{j\mbox{امین زیر مجموعه }} \sigma_j^2$ هر مجموع یک $\chi^2_1$ (یک درجه آزادی) است. سوال این است که pdf آمار سفارش $l$th این مجموعه $\chi_1^2$ را پیدا کنید. واضح است که مبالغ نمی توانند مستقل از $\chi^2$ باشند، زیرا زیر مجموعه ها برخی از نرمال های اصلی را به اشتراک می گذارند. من برخی از کارهای مرتبط را در مورد مسائل «انتخاب زیرمجموعه» در رگرسیون دیدهام، بهویژه، مقالهای از Arvesen و McCabe در سال 1974. آنها اشاره میکنند که مشکلشان دقیقاً شامل این توزیع است، اما پس از آن معتقدم که آن را ارائه نمیکنند، فقط نتایج مجانبی ارائه میکنند و شبیه سازی مونت کارلو هر گونه کمک در این زمینه بسیار قدردانی خواهد شد! (امیدوارم این نسخه ویرایش شده سوال واضح تر باشد - بسیار متشکرم!) | آمار ترتیب مجذور کای وابسته |
15208 | آیا ادبیاتی در مورد تحلیل رگرسیون خطی وجود دارد که در آن ما نیاز داریم که باقیمانده های ما غیر مثبت باشند؟ یعنی ما علاقه مندیم که: $\sum_i \max(y_i - b x_i,0) $ را به حداقل برسانیم. من میخواهم پرتفوی معینی از اوراق بهادار با ارزش $P(t)$ را با ابزارهای پوشش ریسک $n$ با مقادیر $h_i(t)$ در زمان $t$ پوشش دهم. با نگاهی به دادههای تاریخی، میخواهم $ max\\{\sum_{i=1}^n \alpha_i [h_i(0)-h_i(t)] + [P(0)-P(t)]، 0 را به حداقل برسانم. \\}$ w.r.t $ \alpha_i$، وزنهای پوششی. یک طرفه بودن از این واقعیت ناشی می شود که اگر ارزش پورتولیوی ترکیبی من افزایش یابد اهمیتی نمی دهم، اما اگر ارزش آن کاهش یابد برایم مهم است. | رگرسیون خطی محدود برای تولید باقیمانده های غیر مثبت |
30728 | من داده های خود را همانطور که هستند تجزیه و تحلیل کرده ام. اکنون میخواهم پس از گرفتن گزارش همه متغیرها، به تحلیلهای خود نگاه کنم. بسیاری از متغیرها حاوی صفرهای زیادی هستند. بنابراین من مقدار کمی را اضافه می کنم تا از گرفتن گزارش صفر جلوگیری کنم. تا به حال 10^-10 را بدون هیچ منطقی اضافه کرده ام، فقط به این دلیل که احساس می کردم اضافه کردن یک مقدار بسیار کم برای به حداقل رساندن تأثیر کمیت خودسرانه من توصیه می شود. اما برخی از متغیرها عمدتاً دارای صفر هستند و بنابراین هنگام ثبت نام بیشتر -23.02 هستند. محدوده محدوده متغیرهای من 1.33-8819.21 است و فرکانس صفرها نیز به طور چشمگیری تغییر می کند. بنابراین انتخاب شخصی من از مقدار کوچک به طور بسیار متفاوتی بر متغیرها تأثیر می گذارد. اکنون واضح است که 10^-10 یک انتخاب کاملاً غیرقابل قبول است، زیرا بیشتر واریانس در همه متغیرها از این کمیت کوچک دلخواه ناشی می شود. نمیدانم راه درستتری برای انجام این کار چیست. شاید بهتر باشد مقدار را از توزیع جداگانه هر متغیر استخراج کنیم؟ آیا دستورالعملی در مورد اینکه این مقدار کوچک چقدر باید باشد وجود دارد؟ تحلیلهای من عمدتاً مدلهای کاکس ساده با هر متغیر و سن/جنس به عنوان IV هستند. متغیرها غلظت لیپیدهای مختلف خون هستند که اغلب ضرایب تغییرات قابل توجهی دارند. **ویرایش**: افزودن کوچکترین مقدار غیر صفر متغیر برای داده های من عملی به نظر می رسد. اما شاید یک راه حل کلی وجود داشته باشد؟ **ویرایش 2**: از آنجایی که صفرها صرفاً غلظت های زیر حد تشخیص را نشان می دهند، آیا تنظیم آنها روی (حد تشخیص)/2 مناسب است؟ | مقدار کمی باید به x اضافه شود تا از ثبت صفر جلوگیری شود؟ |
48117 | من چند سوال در مورد نحوه تجزیه و تحلیل داده های رتبه بندی شده دارم. داده ها به این شکل است: از 4 گروه افراد مبتلا به HIV و 16 گروه دیگر از افراد ساکن در همان روستا خواسته شد تا 12 چالش را برای افراد مبتلا به HIV بر اساس اهمیت رتبه بندی کنند. (مثلاً سلامت جسمانی - پذیرش اجتماعی - سلامت روان - ...) چگونه می توانم بفهمم که یک چالش خاص توسط افراد مبتلا به HIV متفاوت از سایر افراد درک می شود؟ سؤال دیگر: از همه پاسخ دهندگان (120) خواسته شد تا 5 چالشی را که برای خودشان چالش برانگیزتر بودند، به صورت جداگانه از فهرست چالش ها انتخاب کنند. چگونه می توانم بفهمم که افراد مبتلا به HIV چالش های متفاوتی را نسبت به افراد دیگر انتخاب می کنند؟ بهترین راه برای ارائه یافته ها چیست؟ آیا آزمون آماری برای آن وجود دارد؟ Kruskal wallis ممکن است؟ من در سراسر اینترنت جستجو کرده ام اما گیر کرده ام.. ممنون از راهنمایی! | چگونه داده های رتبه بندی شده را مقایسه کنیم؟ |
103310 | این سوال در رابطه با پاسخ زیر است: چگونه یک تابع فاصله را بر اساس چند متغیر برای تجزیه و تحلیل خوشه استخراج کنیم؟ فرض کنید من 7 متغیر دارم که هر کدام کمی (و نه دستهبندی) هستند و میخواهم دستهای از نامها را بر اساس نحوه تأثیرگذاری این متغیرها بر سایر متغیرها گروهبندی کنم. چگونه این کار را انجام دهم؟ آیا هنوز هم می توانم از ضریب گور استفاده کنم، اگر چنین است چگونه؟ و اگر نه، چه جایگزین دیگری دارم؟ به عنوان مثال، برای یک سهم، ما به طور کلی علاقه ای به این نداریم که دو سهم با هم حرکت کنند، اما علاقه مندیم سهام هایی را که توسط عوامل یکسان هدایت می شوند گروه بندی کنیم. | استخراج تابع فاصله بر اساس متغیرهای متعدد |
72839 | من یک data.frame با 800 obs دارم. از 40 متغیر، و میخواهم از تجزیه و تحلیل مؤلفههای اصلی برای بهبود نتایج پیشبینی من استفاده کنم (که تاکنون بهترین عملکرد را با ماشین بردار پشتیبان روی 15 متغیر دستچینشده دارد). من می دانم که یک prcomp می تواند به من کمک کند تا پیش بینی هایم را بهبود بخشم، اما نمی دانم چگونه از نتایج تابع prcomp استفاده کنم. من نتیجه را به دست میآورم: > PCAAanalysis <- prcomp(TrainTrainingData، scale.=TRUE) > خلاصه (PCAAnalysis) اهمیت اجزاء: PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9 PC10 PC11 PC12 PC13 PC14 انحراف استاندارد 1.7232 1.7232 1.1899 1.166 1.1249 1.1082 1.0888 1.0863 1.0805 1.0679 1.0568 1.0520 نسبت واریانس 0.0742 0.0624 0.0624 0.043440.049 0.0316 0.0307 0.0296 0.0295 0.0292 0.0285 0.0279 0.0277 نسبت تجمعی 0.0742 0.1367 0.1813 0.2206 0.23030.2560. 0.3820 0.4115 0.4407 0.4692 0.4971 0.5248 PC15 PC16 PC17 PC18 PC19 PC20 PC21 PC22 PC23 PC24 PC25 PC26 PC27 PC28 انحراف استاندارد 1.00280301. 1.001 0.9923 0.9819 0.9691 0.9635 0.9451 0.9427 0.9238 0.9111 0.9073 نسبت واریانس 0.0271 0.0264 0.02040.0259 0.0264 0.0259 0.0241 0.0235 0.0232 0.0223 0.0222 0.0213 0.0208 0.0206 نسبت تجمعی 0.5519 0.5783 0.6042 0.6296 0.67380.6796 0.6796 0.6796 0.7500 0.7723 0.7945 0.8159 0.8366 0.8572 PC29 PC30 PC31 PC32 PC33 PC34 PC35 PC36 PC37 PC38 انحراف استاندارد 0.8961 0.8825 0.876570.8759 0.7238 0.6704 0.60846 0.000000000000000765 نسبت واریانس 0.0201 0.0195 0.0192 0.0186 0.0173 0.01412 0.01312 0.019 0.001 0.000000000000000000 نسبت تجمعی 0.8773 0.8967 0.9159 0.9345 0.9518 0.9664 0.9795 0.9907 1.000000 1.000000 1.00000 0000000000000000000000 PC انحراف استاندارد 0.000000000000000223 0.0000000000000000223 نسبت واریانس 0.00000000000000000000000000000000000000000000000000000000000000000000000 1.0000000000000000 1.000000000000000000 من فکر کردم پارامترهایی را که مهمترین آنها برای استفاده است به دست می آورم ، اما من فقط این اطلاعات را پیدا نمی کنم. تمام چیزی که من می بینم انحراف استاندارد و غیره در رایانه های شخصی است. اما چگونه از این برای پیش بینی استفاده کنم؟ | چگونه از نتایج R prcomp برای پیش بینی استفاده کنیم؟ |
30729 | من در حال بررسی روشی برای بررسی خودکار روشهای مونت کارلو زنجیره مارکوف هستم، و میخواهم چند نمونه از اشتباهاتی را که هنگام ساخت یا اجرای چنین الگوریتمهایی رخ دهد، رخ دهد. در صورت استفاده از روش نادرست در مقاله منتشر شده، امتیاز پاداش. من به ویژه به مواردی علاقه مند هستم که خطا به این معنی است که زنجیره دارای توزیع نادرست نادرست است، اگرچه انواع دیگر خطاها (به عنوان مثال زنجیره غیر ارگودیک) نیز جالب هستند. زمانی که Metropolis-Hastings یک حرکت پیشنهادی را رد میکند، نمونهای از چنین خطای عدم خروجی یک مقدار است. | نمونه هایی از خطاها در الگوریتم های MCMC |
48112 | من سعی میکنم واقعاً مجموع مربعها را بفهمم، اما آنچه میخوانم یا فرمول جمعبندی هر کدام است یا پاسخهایی مانند این. آیا میتواند مرا به سمت یک مرجع خوب راهنمایی کند که کمی جزئیات بیشتر ارائه دهد، تا هدف و نحوه استفاده از هر یک از آنها را توضیح دهد، و نحوه فکر کردن در مورد $S_{xx}$ یا توضیح چگونگی و چرایی ارتباط آن با $S_{ b}$ به طور شهودی. | منابع مرجع مجموع مربع ها |
73413 | فرض کنید من علاقه مند به نمونه برداری از جفت های زیادی $(\mathbf X, Y)$ از توزیع $f(\mathbf x, y)$ هستم که در آن $\mathbf x \in \mathbb R^p$, $p$ large ; من به هر دو شبیه سازی دقیق و تقریبی علاقه مند هستم. نمونهگیری از $f(\mathbf x)$ آسان است، اما $f(y \mid \mathbf x)$ اینطور نیست. برای انگیزه، اگر توزیعهای $f(\mathbf x\mid y)$ و $f(y \mid \mathbf x)$ هر دو با مقداردهی اولیه $(\mathbf X_0، Y_0) آسان باشند، میتوانم نمونهبرداری گیبس را انجام دهم. $ و ترسیم $\mathbf X_t \sim f(x \mid Y_{t-1})$ و $Y_t \sim f(y \mid \mathbf X_t)$. اگر نمونهبرداری از $f(\mathbf x \mid y)$ آسان است، پس من در وضعیت بسیار خوبی هستم زیرا در بدترین حالت ممکن، میتوانم $f(y \mid \mathbf x)$ را با هر بهروزرسانی جایگزین کنم. این توزیع ثابت است. در شرایط من، نمونهبرداری از $f(\mathbf x \mid y)$ دشوار است و کار قابل توجهی باید برای ساختن یک هسته انتقال مناسب با توجه به بعد $\mathbf x$ انجام شود. با این حال، می توانم دقیقاً از $f(\mathbf x)$ حاشیه ای استفاده کنم! به نظر میرسد که این باید چیزی مانند نمونهگر گیبس برای من بخرد، اما اگر کاری شبیه به زیر انجام دهم: 1. $\mathbf X_t \sim f(\mathbf x)$ را ترسیم کنید. 2. $Y_t \sim K(y \mid \mathbf X_t, Y_{t-1})$ را بکشید که در آن $K(\cdot \mid \mathbf x, y)$ $f(y \mid \mathbf x) باقی میماند. ثابت $، من معتقدم که توزیع ثابت درست را نخواهم گرفت. اگر کمک کند، ممکن است مایل باشم که چگالی $f(y \mid \mathbf x)$ را ارزیابی کنم. من $f(y \mid \mathbf x)$ را تا یک ثابت نرمالکننده میدانم، اما میتوانم یک ادغام عددی را برای بدست آوردن ثابت انجام دهم (هر چند واقعاً ترجیح میدهم این کار را نکنم). با این حال، محاسبه $f(y \mid \mathbf x)$ گران است. یکی از فکرهای من این است که $f(\mathbf x)$ تولید کنم و سپس تعداد کمی از گامهای پیادهروی تصادفی MH را انجام دهم، اما من خیلی ترجیح میدهم پاسخی دریافت کنم که حداقل به چیزی درست مانند $t همگرا شود. \to \infty$ (اگر تعداد کمی از مراحل را برای هر $Y_t$ انجام دهم، این یکی همیشه خطا خواهد داشت). **ویرایش:** شاید همه اینها بدیهی به نظر برسد - فقط از تکنیک های نمونه گیری عمومی برای هر $f(y \mid \mathbf x)$ استفاده کنید و به طور کلی، من نباید بهتر از این کار کنم. حدس میزنم چیزی که در ذهن دارم این است که باید به نحوی بتوانم MCMC را در $t$ کار کنم، و _not_ باید نمونهبرداری تقریبی خود را در $t$ انجام دهم. یعنی میخواهم تقریب من به صورت $t \to \infty$ بهتر و بهتر شود. من نمی خواهم تقریب من همان مقدار خطا را در $t$ داشته باشد. به طور کلی، اگرچه، $f(y \mid \mathbf x)$ ممکن است برای مقادیر مختلف $\mathbf x$ بسیار متفاوت باشد، بنابراین من نباید به راه حلی امیدوار باشم که همیشه کارساز باشد. من فقط چیزی می خواهم که شانس خوبی برای کار داشته باشد و مسائل بالا را برطرف کند. برای من عجیب است که $f(\mathbf x)$ کمتر از $f(\mathbf x \mid y)$ مفید باشد. | نمونه برداری تقریباً $(X, Y)$ هنگام نمونه برداری از $X$ آسان است |
19127 | **پسزمینه** من یک متغیر $X\sim Beta(2,1)$ دارم و متغیر دیگر $Y=\frac{X}{1-X}$ ویکیپدیا میگوید: > If $X \sim \operatorname{بتا }(n/2,m/2)$ سپس $ \frac{m > X}{n\left(1-X\right)} \sim \operatorname{F}(n,m)$ از این استنباط میکنم که $Y\sim F(4,2)*2$. با دانستن پارامتر X$، من می خواهم $Y$ را پارامتر کنم (و نه، به عنوان مثال، $Y/2$). **سوال** آیا تحول مستقیمی وجود دارد؟ **آنچه را امتحان کردهام** میپرسم زیرا سعی کردهام تبدیل را شبیهسازی کنم، اما بهینهسازی اغلب با شکست مواجه میشود، و متغیر تبدیلشده با توزیع $\operatorname{logN}$ بهتر از توزیع $\operatorname{F}$ مناسب است. . set.seed(0) library(MASS) X <- rbeta(10000, 2,1) Y <- X/(1-X) f.fit <- fitdistr(Y, 'f', start = list(df1 = 4، df2 = 2)) logN.fit <- fitdistr(Y، 'lognormal') AIC(f.fit) < AIC(logN.fit) | با توجه به اینکه $Y\sim F(\nu_1، \nu_2)\ برابر 2$، توزیع $Y$ چگونه است؟ |
39266 | من نمیدانم که آیا هر نوع توزیع استاندارد روی زیرمجموعههای اعداد صحیح $\\{1، 2، ...، J\\}$ وجود دارد. به طور معادل، میتوانیم این را به صورت توزیعی بر روی یک بردار طول $J$ از نتایج باینری بیان کنیم، به عنوان مثال. اگر $J = 5$، آنگاه $\\{1, 3, 5\\}$ با بردار $(1, 0, 1, 0, 1)$ مطابقت دارد. در حالت ایده آل چیزی که من به دنبال آن هستم توزیع $\nu_\theta (\cdot)$ است که از خانواده ای نمایه شده توسط پارامتر ابعاد محدود $\theta$ آمده است که جرم خود را به گونه ای دو بردار باینری $r_1 توزیع می کند. $ و $r_2$ اگر نزدیک به هم باشند، احتمال مشابهی خواهند داشت، یعنی $r_1 = (0, 0, 1, 0, 1)$ و $r_2 = (0، 0، 1، 1، 1)$ احتمالات مشابهی دارند. واقعاً، کاری که امیدوارم انجام دهم، روی $\theta$ مقدم است به طوری که اگر بدانم $\nu_\theta (r_1)$ نسبتاً بزرگ است، احتمالاً $\nu_\theta (r_2)$ نسبت به بردارهای بسیار دور از $r_1$. یکی از استراتژی هایی که به ذهن می رسد این است که یک متریک یا معیار دیگری از پراکندگی را در $d_\theta$ در $\\{0, 1\\}^J$ قرار دهید و سپس $\nu_\theta (r) \ را بگیرید. propto \exp (-d_\theta (r, \mu))$ یا چیزی مشابه. یک مثال واضح $\exp\left\\{-\|r - \mu\|^2 / (2 \sigma^2)\right\\}$ در قیاس با توزیع نرمال است. این خوب است، اما امیدوارم چیزی استاندارد و قابل قبول برای تحلیل بیزی وجود داشته باشد. با این کار نمی توانم ثابت عادی سازی را بنویسم. | توزیع در زیر مجموعه های $\{1، 2، ...، J\}$؟ |
103311 | من سعی می کنم مشکلی را حل کنم که در آن مجموعه داده های زیادی دارم. هر نقطه داده دارای 8 متغیر مستقل (ورودی) و 1 متغیر وابسته (خروجی) است. من این داده ها را از طریق آزمایش به دست آوردم. آیا راه های غیر خطی وجود دارد که بتوانم داده ها را درون یابی کنم؟ من به دنبال رگرسیون نیستم زیرا هر نقطه داده یک نقطه کنترل است و باید بخشی از پاسخ باشد. ویرایش: من به دنبال راهی برای گسترش درون یابی اسپلاین مکعبی به 8 بعد هستم. من می دانم که رگرسیون خطی چند متغیره تابعی را ارائه می دهد که مجموع مربعات داده ها را به حداقل می رساند، اما تابع از تمام نقاطی که من برای بدست آوردن تابع استفاده کردم عبور نمی کند. امیدوارم منطقی باشد. | درون یابی چند متغیره |
22400 | > **تکراری احتمالی:** > حجم نمونه برای تعداد متغیری از پاسخها، دادههایی دارم که از توزیع چندجملهای (تئوری) تولید شدهاند، و با استفاده از نقاط داده، احتمالات چند جملهای را تخمین میزنم. در حالت ایدهآل، من میخواهم بدانم به چند نقطه نیاز دارم که بتوانم مطمئن باشم که توزیع چندجملهای استنباطشده درست است، تا بایاس 0.01+، با احتمال 99٪ - یعنی میخواهم بدانم چند نقطه برای این کار لازم است. یک فاصله اطمینان کوچک +- 0.01 دریافت کنید. توزیع طبقهبندی پشت چندجملهای دارای 4 مقدار است، و من میتوانم با خیال راحت فرض کنم که p1...p4>0.1 چگونه میتوانم به این هدف برسم؟ آیا به دنبال انجام نوعی تست مجذور کای هستم؟ من یک متخصص اطلاعات زیستی با دانش نسبتاً ناچیز در آمار هستم، بنابراین اگر سؤال خیلی ابتدایی است، پیشاپیش عذرخواهی میکنم - اگر اینطور است، خوشحال میشوم که به یک مرجع مرتبط (امیدوارم خیلی طولانی نباشد) ارجاع دهم. با تشکر | اهمیت داده های چندجمله ای |
88875 | من مجموعه ای از داده های سری زمانی دارم که هر نقطه زمانی در واقع یک نسبت است (30 نمونه گرفته شد، نقطه داده درصد مثبت است). این سری زمانی در سه تکرار انجام شده است که هر تکرار از نظر بیولوژیکی مستقل است. اگر من این نوع دادهها را با استفاده از آزمون _t_ تجزیه و تحلیل میکردم، مقادیر را بهگونهای جفت میکردم که تغییرات اولیه در هر تکرار بیولوژیکی محاسبه شود و روندهای تکراری _within_ مورد بررسی قرار گیرد، اما نمیتوانم بفهمم چگونه این کار را انجام دهم. کدام یک از روش های محبوب همبستگی رتبه؟ آیا معادلی از جفت شدن برای معیارهای همبستگی رتبه ای وجود دارد؟ اگر نه، چگونه باید با این داده ها کار کنم؟ | آیا معادلی از «جفت شدن» در آزمون های t برای همبستگی رتبه وجود دارد؟ |
27492 | من از بسته «geepack» در R استفاده میکنم تا مدلهای مختلفی را با دادههای اندازهگیریهای مکرر، البته با اندازههای خوشههای متفاوت، جا بدهم. با این حال، برای برخی از ساختارهای همبستگی (مثلاً مبادله)، من تخمین های غیر منطقی بزرگی را برای پارامترهای خود بدست می آورم، معمولاً در حدود 10^{13}$ تا $10^{16}$، با خطاهای استاندارد بزرگی یا دو. کوچکتر همانطور که انتظار دارید، تعیین ساختار همبستگی «استقلال» تخمینهای معقولتری را تولید میکند که با مدلهای قبلی همخوانی دارد، از جمله مدلهایی که ساختار همبستگی «مبادلهپذیر» مشخص شده است. این داده هایی که من را به دردسر می اندازند از همان منابع آمده اند. از همه لحاظ، آنها یک داده هستند. چه چیزی می دهد؟ :-( | عیب یابی تخمین پارامترهای بزرگ غیر منطقی از GEE |
39269 | من به دنبال تجزیه و تحلیل داده های نمونه ناپارامتریک مرتبط با استفاده از آزمونی مشابه مک نمار هستم. متغیرهای مستقل و وابسته من دوگانه نیستند (7x5). به عنوان مثال، اگر IV من سطح اضطراب (پنج سطح) و DV من میزان جرم جنایی (هفت سطح) بود، چگونه می توانم ارتباط بین سطح اضطراب و عضویت در گروه های مجرم جنایی را تعیین کنم؟ هر گونه پیشنهادی در مورد چه آزمایشی مناسب است؟ | نیاز به آزمون مک نمار برای متغیرهای غیر دوگانه (5x7) |
15207 | من در حال بررسی هستم که آیا شرایط مختلف پاداش ممکن است بر عملکرد کار تأثیر بگذارد یا خیر. من داده هایی از یک مطالعه کوچک با دو گروه دارم که هر کدام 20=n دارد. من داده هایی را در مورد یک کار جمع آوری کردم که شامل عملکرد در 3 شرایط مختلف پاداش بود. این کار شامل عملکرد در هر یک از 3 شرط دو بار اما به ترتیب تصادفی بود. میخواهم ببینم آیا تفاوت میانگینی در عملکرد تکلیف برای هر گروه، در هر یک از شرایط مختلف «پاداش» وجود دارد یا خیر. * IV = نوع گروه * DV = میانگین اندازه گیری عملکرد کار در 3 شرایط من خروجی از ANOVA اندازه گیری های مکرر و دسترسی به مجموعه داده های خام در SPSS دارم اما مطمئن نیستم که چگونه ادامه دهم. من نتوانستم یک راهنمای گام به گام برای این تفسیر پیدا کنم، زیرا متن پالانت تا حدودی محدود است. مسائل خاص من در زمینه های زیر است: 1. آیا نرمال بودن هر یک از متغیرهای خود را به صورت جداگانه بررسی می کنم یا در ترکیبی از هر یک از سطوح IV؟ اگر در ترکیب است، چگونه آن را بررسی کنم؟ 2. آیا ابتدا تست Mauchly را بررسی کنم؟ اگر نقض شود یعنی چه؟ اگر نقض نشود یعنی چه؟ 3. چه زمانی می توان به جداول تست های چند متغیره یا تست های جلوه های درون موضوعی نگاه کرد؟ من مطمئن نیستم که چه زمانی مناسب است از یکی (یا هر دو؟) استفاده کنم؟ 4. آیا همیشه نگاه کردن به مقایسه های زوجی اشکالی ندارد؟ اگر اثرات چند متغیره یا درون موضوعی معنی را نشان ندهند، انجام این کار غیر منطقی به نظر می رسد (یعنی P<0.05) اما من دوباره مطمئن نیستم. | درک مفروضات ANOVA اندازه گیری مکرر برای تفسیر صحیح خروجی SPSS |
88872 | DBSCAN طبق برخی متون، الگوریتم خوشهبندی بیشترین استناد را دارد و میتواند خوشههای شکل دلخواه را بر اساس چگالی پیدا کند. دارای دو پارامتر eps (به عنوان شعاع همسایگی) و minPts (به عنوان حداقل همسایگان برای در نظر گرفتن یک نقطه به عنوان نقطه مرکزی) که به اعتقاد من بسیار به آنها بستگی دارد. آیا روش معمول یا معمولی برای انتخاب این پارامترها وجود دارد؟ | روتینی برای انتخاب eps و minPts برای DBSCAN |
47122 | در اینجا استخوان های برهنه چیزی است که من به آن نگاه می کنم ... لطفا کمک کنید! طرح قبل از مداخله فقط برای گروه درمان (شرکت کنندگان تصادفی هستند، اما گروه کنترل بخشی از این مطالعه نیست، فقط گروه درمان است) تقریباً 65 شرکت کننده در گروه درمان 2 متغیرهای وابسته 1 متغیر تعدیل کننده (نمره شاخص خطر تجمعی بر اساس 8 عامل مختلف) اگر بخواهم روی روابط تعدیل کننده تمرکز کنم و نه فقط اثرات درمان، چگونه به یک تحلیل آماری برای مطالعه خود نزدیک شوم؟ | چگونه تأثیر ناظم را در پیش از مطالعه تجزیه و تحلیل کنیم؟ |
16576 | چگونه می توانم نمرات d-prime را از 2 شرایط مختلف برای یک فرد با استفاده از d-primes و خطاهای استاندارد مقایسه کنم؟ | چگونه می توانم نمرات d-prime را برای 2 شرایط مختلف برای یک فرد مقایسه کنم؟ |
15202 | به دنبال سوال قبلی من (چگونه یک مجموعه داده با احتمال شرطی ایجاد کنیم؟)، اکنون می خواهم مجموعه داده ای را در R ایجاد کنم که حاوی اطلاعات دو علامت و 1 بیماری باشد. علائم $S_1$ و $S_2$ و _independent_ و _مستقل شرطی_، بنابراین $P(S_1|S_2)=P(S_1)$ و $P(S_2|S_1)=P(S_2)$. فرض کنید دادههای زیر را داریم: $P(D)=0.003$$P(S_1)=0.005$$P(S_2)=0.008$$P(S_1|D)=0.3$$P(S_2|D)=0.25 $ طبق روشی که هنری برای حل سوال قبلی من استفاده کرد، فکر می کنم باید این جدول را کامل کنیم: بیماری بله خیر | علامت 1 بله | a b علامت 2 بله | | | نه | c d -------------|----------------------------------- - | علامت 1 بله | e f علامت2 خیر | | | نه | g h آنچه من می خواهم محاسبه کنم، _از مجموعه داده_، مقدار $P(D|S_1 و S_2)$ است. همچنین برای اجرای برخی شبیه سازی ها باید احتمال هر رویداد را محاسبه کنم. من سعی کردم مقدار a...h را پیدا کنم، اما رابطه کافی برای حل سیستم 8 پارامتری پیدا نکردم. چیزی که من می دانم این است: $P(D)=0.003 \rightarrow$ `a + c + e + g = 0.003` $P(S_1)=0.005 \rightarrow$ `a + b + e + f = 0.005` $P( S_2)=0.008 \راست پیکان$ `a + b + c + d = 0.008` $P(S_1|D)=0.3 \rightarrow$ `(a + e) / (a + c + e + g) = 0.3` $P(S_2|D)=0.25 \rightarrow$ `(a + c) / (a + c + e + g) = 0.25` و `a + b + c + d + e + f + g + h = 1` بنابراین، سؤال من این است: آیا دادههای من برای ایجاد یک مجموعه داده در R، که یک جمعیت واقعی را شبیه سازی می کند؟ همانطور که هنری توضیح داد رویکردی که من امتحان کردم فقط در مورد 1 علامت (چگونه یک مجموعه داده با احتمال شرطی ایجاد کنیم؟) مفید بود. آیا برای مورد دو علامت خوب است؟ یا n-علائم؟ آیا روش دیگری برای شبیه سازی این داده ها وجود دارد؟ | ایجاد یک مجموعه داده با احتمال شرطی، پسوند |
80729 | فرض کنید من دو روش دارم که در طول زمان روی یک داده آزمایش می کنم. من گمان میکنم که روشها در طول زمان تنزل پیدا میکنند و این تخریب کم و بیش خطی است. میخواهم بدانم آیا یکی از روشها سریعتر از دیگری کاهش مییابد؟ بنابراین، کاری که من انجام میدهم این است که یک خط را در هر دو مجموعه از نقاط داده با حداقل مربعات معمولی (OLS) قرار میدهم و میتوانم یک آزمون z روی دو ضریب شیب β1 و β2 انجام دهم (به عنوان مثال به این پست مراجعه کنید): $$ z = \frac{\beta_1 - \beta_2}{\sqrt{SE(\beta_1)^2 + SE(\beta_2)^2}} $$ حالا فرض کنید من دارم داده های ناهمسان، به عنوان مثال. زیرا در برخی دوره های زمانی نقاط داده بسیار بیشتری نسبت به دوره های دیگر دارم. در این مورد نباید از OLS استفاده کنم، بلکه از حداقل مربعات وزنی (WLS) استفاده کنم. حالا سوال من این است: آیا هنوز هم می توانم از همان z-test استفاده کنم؟ بنابراین با استفاده از ضرایب و SE که من از تناسب WLS دریافت می کنم؟ | آیا می توانم از آزمون z در داده های ناهمسان استفاده کنم؟ |
5732 | چرا تابع آزمون در آزمون کولموگروف- اسمیرنوف، ماکزیمم را از مجموعه تفاوت ها می گیرد؟ وقتی حداکثر (بزرگترین عنصر) یک مجموعه وجود نداشته باشد، ممکن است supremum وجود داشته باشد، اما اگر بزرگترین عنصر وجود داشته باشد، supremum همان بزرگترین عنصر است. می خواهم بدانم چرا در اینجا بزرگترین عنصر وجود ندارد؟ با تشکر Prasenjit | چرا در آزمون کولموگروف-اسمیرنوف Supremum نه حداکثر؟ |
15206 | من تازه خواندم که اکنون می توانید یک کامپیوتر کوانتومی بخرید (البته تا به حال فقط یک کامپیوتر فروخته شده است!). آیا محاسبات کوانتومی در آمار کاربردهایی خواهد داشت؟ {ویرایش - برای اهداف سوال، فرض کنیم که در نهایت کامپیوترهای کوانتومی (به نوعی) کار خواهند کرد} | آیا محاسبات کوانتومی به تکنیک های آماری جدید اجازه می دهد؟ |
15201 | تقریباً شبیه نقشه مجمع الجزایر در Age of Empires II (اما این در واقع یک سوال واقعی است که من برای تحقیقات سیاره فراخورشیدی خود به آن نیاز دارم) | یک الگوریتم مونت کارلو خوب برای ایجاد یک مجمع الجزایر در یک نقشه خاص چیست؟ |
39261 | **سوال من** مدل $X_1, \dots, X_n \overset{\mathrm{iid}}{\sim} \cal N(\mu, \sigma^2), (\mu, \sigma^2) را در نظر بگیرید ) \in (-\infty, \infty) \times (0, \infty)$ با محصول قبلی pdf $\xi(\mu, \sigma^2) = \xi_1(\mu)\xi_2(\sigma^2)$ که در آن $\xi_1(\mu) = \cal N(a, b^2)$ و $\xi_2(\sigma^2) = \chi^{ -2}(r,s)$ برای برخی از ثابت های $a \in , b > 0, r > 0$ و $s > 0$. اجازه دهید $\xi(\mu، \sigma^2| x)$ مشاهدات داده شده pdf را نشان دهد $x = (x_1، \dots، x_n)$. > pdf شرطی پسین $\xi_1(\mu, | x, \sigma^2)$ از $\mu$ > برای $\sigma^2$ معین را شناسایی کنید. > > pdf پیشین مشروط $\xi_2(\sigma^2 | x, \mu)$ از > $\sigma^2$ برای $\mu$ معین را شناسایی کنید. **افکار من** اول، یک واقعیت مفید از جستجوی قبلی من: $$\xi_1(\mu | x، \sigma^2) \propto \xi(\mu، \sigma^2 | x)$$ با توجه به این ، من به نوبه خود $\mu، \sigma^2$ را درست کردم و دیدم چه نوع pdf گرفتم. برای $\mu$، تعمیر $\sigma^2$، من یک pdf معمولی دیگر دریافت کردم، بنابراین اعتقاد من این است که $\xi_1(\mu، | x، \sigma^2)$ باید به شکل یک pdf معمولی باشد. با رفع $\mu$، دیدم که $\sigma^2$ در مخرج عبارت نمایی و در مخرج ${1\over \sigma \sqrt{2\pi}}$ خارج از عبارت نمایی است. اصطلاح، و بنابراین من به خانواده معکوس chi-square یا خانواده گامای معکوس فکر کردم. **سوال من** با توجه به اینکه من باورهای معقولی در مورد اینکه پاسخ های من باید چه شکلی باشد دارم، چگونه می توانم فرمول های صریح برای پارامترهای به روز شده را پیدا کنم؟ من میخواهم بتوانم به صراحت فرمولی برای $\xi_1(\mu, | x، \sigma^2)$ بنویسم و در حال حاضر، با توجه به اینکه فرمی را که آنها باید از طریق استفاده (لیبرال) از $\ دریافت کنند، شناسایی کردم. propto$، مطمئن نیستم چه کار کنم. | شناسایی یک پسین شرطی برای $\mu$ و $\sigma^2$ |
80724 | اگر من از تجزیه و تحلیل نمایه پنهان (مدل مخلوط گاوسی) برای مدلسازی توزیع احتمال چند متغیره مشاهدهشده خود به عنوان مخلوطی (کلاسهای K) از پیدیافهای معمولی مستقل از شرطی استفاده کنم، آیا این مدل نشان میدهد که هر PDF چند متغیره **داخل کلاس** چند متغیره نرمال؟ آیا می توانید به من نشان دهید که چرا، یا چرا نه، این درست است؟ اگر درست باشد، آیا میتوان از آزمونهای نرمال بودن چند متغیره برای کمک به ارزیابی مدل استفاده کرد؟ | آیا یک مدل مخلوط گاوسی همیشه بر یک توزیع احتمال نرمال چند متغیره درون کلاس دلالت دارد؟ |
83934 | برخی از بیزی ها به استنباط فراوان گرا حمله می کنند که بیان می کنند توزیع نمونه منحصر به فردی وجود ندارد زیرا به نیات محقق بستگی دارد (Kruschke, Aguinis, & Joo, 2012, p. 733). به عنوان مثال، میگویند محققی شروع به جمعآوری دادهها میکند، اما بودجه او پس از ۴۰ شرکتکننده به طور غیرمنتظرهای قطع شد. توزیعهای نمونهبرداری (و CI و مقادیر p بعدی) در اینجا چگونه تعریف میشوند؟ آیا فرض می کنیم هر نمونه تشکیل دهنده N = 40 دارد؟ یا از نمونه هایی با N متفاوت تشکیل می شود که هر اندازه با زمان های تصادفی دیگری که ممکن است بودجه وی قطع شده باشد تعیین می شود؟ توزیعهای t، F، chi-square (و غیره) که در کتابهای درسی یافت میشوند، همگی فرض میکنند که N برای همه نمونههای تشکیلدهنده ثابت و ثابت است، اما این ممکن است در عمل درست نباشد. با هر روش توقف متفاوت (به عنوان مثال، پس از یک بازه زمانی خاص یا تا زمانی که دستیار من خسته شود) به نظر می رسد توزیع نمونه متفاوتی وجود دارد، و استفاده از این توزیع های ثابت-N آزمایش شده و واقعی نامناسب است. این انتقاد چقدر به مشروعیت CIهای متداول و مقادیر p آسیب می رساند؟ آیا ردیه های نظری وجود دارد؟ به نظر می رسد با حمله به مفهوم توزیع نمونه، کل بنای استنتاج فراوان گرا ضعیف است. هر گونه مرجع علمی بسیار قدردانی می شود. | آیا توزیع های نمونه برای استنتاج مشروع هستند؟ |
15209 | من داده های شبکه ای از سازمان ها و پیوندهای وزنی بین این سازمان ها را دارم، وزن نشان دهنده سطح تجارت بین این سازمان ها است. من پروندههایی علیه هر سازمانی دارم که مربوط به تعداد تکنیکهای تولید سازگار با محیطزیست است که آنها راهاندازی کردهاند - برای مثال، در پاسخ به قوانین زیستمحیطی. آنچه من می خواهم محاسبه کنم تأثیری است که یک سازمان در تغییر تکنیک های تولید سازمان های مجاور با توجه به میزان تجارت بین آنها و تعداد تغییرات در گذشته خواهد داشت. به عنوان مثال، اگر سازمان دوستدار محیط زیست A مقدار زیادی تجارت با B اما کمی با C انجام دهد، احتمال اینکه B یا C تکنیک های تولید خود را تغییر دهد چقدر است. بنابراین، در سرتاسر کل شبکه، سازمانهایی با اتصال وزنی بالا با تمایل تاریخی به تغییر تکنیکها، احتمالاً در تغییر پلت فرمهای تولید در یک صنعت خاص نقش محوری دارند. من در مورد نحوه نزدیک شدن به این موضوع کمی گم شدهام، به نظر میرسد که این نوعی تمرکز وزنی در برابر ویژگی داده شده است، بنابراین احساس میکنم باید در دو یا چند مرحله به آن نزدیک شوم. من میخواهم این را در یک نمودار شبکه، با گرههای بزرگتر سازمانهای تأثیرگذار و همه آنهایی که احتمالاً در یک رنگ خاص تحت تأثیر قرار میگیرند، تجسم کنم. با تشکر فراوان | تجزیه و تحلیل تأثیر در برابر یال ها و ویژگی های وزن دار |
82768 | من از MPlus 7.0 برای اجرای یک تحلیل عاملی بر روی مجموعه ای از داده های مورد نظرسنجی که صفات مثبت را اندازه گیری می کند، استفاده می کنم. من از هر دو چرخش مایل و متعامد استفاده کرده ام و همچنین آن را به عنوان مدل دو عاملی اجرا کرده ام. من در هر مورد یک راه حل 2 تا 15 عاملی می خواهم. نتایج همیشه برمیگردند که نیمه آخر فاکتورها برای هر راهحل فاکتور معین، بارهای بسیار کم را به بار میآورند. به عنوان مثال، اگر من به یک راه حل 7 عاملی نگاه کنم، 4 فاکتور آخر با بارگذاری بسیار کم باز می گردند، به قدری کم که هیچ یک از آیتم ها حتی بارگذاری متقاطع روی آنها نیستند (با فرض اینکه معیار بارگذاری 0.32 بیشتر باشد). همه موارد با شدت بیشتری روی یک یا چند مورد از سه مورد اول بارگذاری می شوند. اگر به راهحل 3 عاملی نگاه کنم، این الگو باقی میماند: فاکتور آخر هیچ بارگذاری بالایی بر روی آن ندارد. چه چیزی می تواند باعث این شود؟ | نتایج تحلیل عاملی اکتشافی: هیچ بارگذاری قابل توجهی روی فاکتورهای آخر وجود ندارد |
90029 | برای آزمایش تفاوت بین تغییر یک متغیر طبقهبندی در یک گروه کنترل و تغییر در یک گروه آزمایشی، بهتر است از چه آزمون معناداری استفاده شود؟ این متغیر دارای سه دسته بود (به عنوان مثال پارکینگ در خیابان، پارکینگ خارج از خیابان و پارکینگ گاراژ). میخواهیم ببینیم که آیا تغییر درصد افرادی که از هر یک از این انواع مختلف پارکینگ در منطقه کنترل ما استفاده میکنند، از نظر آماری با تغییر درصد افرادی که از هر یک از این انواع پارکینگ در منطقه آزمایشی استفاده میکنند متفاوت است یا خیر. به عنوان مثال: پارک در خیابان: خلبان قبل = 209/737 = 28٪ خلبان بعد = 145/754 = 19٪ تغییر درصد خالص = -9٪ کنترل قبل = 297/713 = 42٪ کنترل بعد = 242/716 = 34٪ تغییر واحد درصد خالص = -8٪ آیا تغییر در ناحیه آزمایشی از نظر آماری با تغییر در کنترل متفاوت بود منطقه؟ من فکر نمی کنم که بتوانم به سادگی «بعد» را برای هر یک مقایسه کنم، زیرا «قبل» برای دو گروه از نظر آماری متفاوت بود - آنها یکسان شروع نشدند، بنابراین معتقدم که فقط می توانم تغییر را در هر گروه مقایسه کنم. من از آزمون z دو طرفه و دو نسبتی برای تفاوت های درون گروهی استفاده کردم. | آزمون معناداری برای مقایسه تغییر بین دو گروه |
39260 | من سعی می کنم از «glm.nb» R برای محاسبه پیش بینی ها و فواصل اطمینان استفاده کنم. وقتی بعد از آموزش یک مدل از مدل های خطی استفاده می کنم، به عنوان مثال، با استفاده از: model <- lm(y ~ x) می توانم پیش بینی ها و CI ها را با استفاده از: pred <- predict(model, new_x, se.fit=T, interval= دریافت کنم. prediction, level=0.95) CI.upper <- pred$fit[2] CI.lower <- pred$fit[3] اکنون من از: nb_model <- glm.nb(z ~ x + offset(y)) nb_pred <- predict(nb_model, new_data=data.frame(x=X, y=Y), type=response, se.fit=T) سوالات من این است: 1. چگونه می توانم CI را از nb_pred دریافت کنم؟ به عنوان مثال، معادل «pred$fit[2]» و «pred$fit[3]». من نمی فهمم چرا مدل به نظر می رسد متغیر افست را نادیده می گیرد. | محاسبه پیش بینی ها و فواصل اطمینان از توزیع دو جمله ای منفی |
97012 | من دو مدل مختلف دارم که یک متغیر پیوسته $X$ را بسته به N متغیر کمکی $V_i$ تخمین می زنند. آیا راهی برای آزمایش وجود دارد که آیا هر دو مدل نتایج بسیار متفاوتی تولید می کنند؟ میتوانم تفاوتهای میانگین، میانه، واریانس و توزیع آنها را آزمایش کنم. با این حال، چگونه می توانم برای متغیرهای کمکی طبقه بندی حساب کنم؟ اگر همه متغیرهای کمکی $V_i$ در نظر گرفته شوند، تنها یک مقدار پیشبینی برای هر ترکیبی از مقادیر متغیرهای کمکی وجود دارد. از این رو توزیع وجود ندارد. چه چیزی را می توانم در اینجا آزمایش کنم - MSE/RMSE، MAE؟ آیا اصلا می توانم این معیارها را از نظر آماری آزمایش کنم؟ یک سوال در مورد نحوه مقایسه دقت دو مدل مختلف با استفاده از معناداری آماری وجود دارد که متاسفانه بی پاسخ است. علاوه بر این، مقدار مشاهده شده برای هر ترکیبی از متغیرهای طبقهبندی N مشخص است. آیا آزمایش خطای پیش بینی به جای مقدار پیش بینی تفاوتی دارد؟ به یک سوال مرتبط در مورد مقایسه دو توزیع خطا برای تعیین خوبی تناسب پاسخ داده شده است. با این حال، پاسخ یک تخمین خطای $\sigma_i$ را برای مقادیر آزمایشی اندازهگیری شده فرض میکند که با مقادیر مشاهدهشده من مطابقت دارد. من چنین تخمینی ندارم زیرا مقادیر مشاهده شده من شمارش ساده ای از تعداد دفعات مشاهده ترکیب متغیرهای کمکی در کل جمعیت است. برای اینکه مشکلم روشن شود: می توانم خطای $E$ را برای هر یک از ترکیب مقادیر متغیرهای کمکی محاسبه کنم. سپس میتوانم آزمایش کنم که آیا $E_1$ و $E_2$ از مدلهای $M_1$ و $M_1$ از نظر میانگین، میانه، واریانس و توزیع متفاوت هستند یا خیر. با این حال، اگر هر دو مدل خطاهای پیشبینی یکسانی داشته باشند، اما در ترکیبات بسیار متفاوتی از مقادیر متغیرهای کمکی، چه میشود؟ | آزمایش اینکه آیا دو مدل پیشبینی متفاوتی دارند (خطا) |
88259 | من برخی تحلیلها را بر روی یک پیادهروی تصادفی مالی انجام دادهام، و حتی پس از تحولات در بازههای زمانی طولانیتر، ناهمسانی پیدا کردهام. من میخواهم بررسی کنم که آیا این به دلیل حجم تصادفی است یا خیر و نمیدانم چگونه میتوانم حجم تصادفی را به یک مدل پیادهروی تصادفی مرتبه اول اضافه کنم؟ | پیاده روی تصادفی با نوسانات تصادفی |
88252 | من سعی می کنم برخی از داده های دما را که در 49 سایت در یک دوره سه ماهه جمع آوری شده است، تجزیه و تحلیل کنم. داده ها به صورت حداکثر خواندن در هر سایت در هر روز هستند. من به چگونگی تفاوت دما بین سایتها علاقه دارم و میخواهم مقادیر دمای پیشبینیشده را برای روزهایی که در یک سایت مشخص اطلاعاتی ندارم ایجاد کنم. من یک ANOVA دو طرفه با تاریخ و سایت به عنوان عوامل توضیحی اجرا کردم. Max.Daily.T <- aov(MaxDailyT~Site+Date, data=iB) اما داده ها دارای واریانس غیر ثابت و خطاهای غیر عادی هستند، بنابراین من به GLM تغییر داده ام. Max.Daily.T.glm <- glm(MaxDailyT~ Site+Date, data=iB) اگر تاریخ را به شکل dd/mm/yy بگذارم، R سطوح را به ترتیب حروف الفبا خروجی می دهد. اگر تاریخ ها را طوری کدگذاری کنم که R آنها را به ترتیب چاپ کند، تخمین ها متفاوت است (به جای اولین روز حروف الفبا، 1/4/13، تخمینی برای اولین روز من، 25/3/13، به جای اولین روز حروف الفبا، 1/4/13 تولید می کند)، اما به همان مقدار (6.27 درجه). این به من نشان می دهد که R با تاریخ (یا تاریخ رمزگذاری شده) به عنوان یک عامل با اثرات کاملاً مستقل از هر سطح برخورد می کند. البته، در واقعیت، دمای یک سایت در یک روز به پیش بینی دمای روز بعد در آنجا کمک زیادی می کند. کسی میدونه چطوری میشه این رو توی مدل ادغام کرد؟ تنها فکر من این است که از تاریخ رمزگذاری شده به عنوان یک متغیر پیوسته استفاده کنم، اما نمی دانم که آیا این به جای اینکه یک رابطه خطی باشد، به دلیل نوسان دما باعث ایجاد مشکل می شود. پیشاپیش متشکرم اندرو | ادغام عدم استقلال «تاریخ» در مدلی که دما را پیشبینی میکند |
103314 | من از رگرسیون لجستیک برای تخمین احتمال استفاده از یک واحد نمونه توسط یک حیوان استفاده می کنم. با توجه به طراحی نمونهگیری من، همپوشانی بین واحدهای نمونه «استفاده شده» و واحدهای نمونه «در دسترس» اجتنابناپذیر است. (همپوشانی به وضعیتی اشاره دارد که در آن واحدهای «استفاده شده» در نمونه واحدهای «در دسترس» نیز رخ میدهند. یعنی واحدهای نمونه با ویژگیهای یکسان بهعنوان «0» و «1» در دادهها کد میشوند. بنابراین وضعیت اینطور نیست. مشابه با کاربرد مورد-شاهدی رگرسیون لجستیک.) طبق گفته جانسون و همکاران 2006 توابع انتخاب منبع بر اساس داده های استفاده-در دسترس بودن: انگیزش نظری و روشهای ارزشیابی»؛ هنگامی که همپوشانی رخ می دهد، تخمین های واریانس گزارش شده توسط روش رگرسیون لجستیک برای ضرایب صحیح نیست، حتی اگر برآورد ضرایب درست باشد. اگر همپوشانی رخ ندهد، تخمین واریانس صحیح است. واریانس ضرایب در مورد همپوشانی باید با روش های بوت استرپ برآورد شود. واحدهای مجزا را مجدداً نمونه برداری کنید. سوال من این است که آیا واریانس های ضرایب نادرست دلالت بر احتمالات نادرست دارند؟ من میپرسم زیرا میخواهم حدود 10 مدل را با استفاده از AIC مقایسه کنم، اما به نظر میرسد که باید واریانسهای ضرایب هر مدل را به طور جداگانه بوت استرپ کنم و سپس احتمال را محاسبه کنم و سپس از روش انتخاب مدل خود استفاده کنم. برای هر فکری از شما متشکرم | اگر واریانس ضریب نادرست است (برای یک پارامتر رگرسیون)، آیا به این معنی است که احتمال ورود به سیستم مدل نادرست است؟ |
88255 | در اسناد مجموعه من دو موضوع متفاوت دارم. کدام انتشار LDA (نامتقارن یا متقارن) می تواند به اختصاص کلمات مربوط به موضوع 1 و موضوع 2 در موضوعات من کمک کند؟ کد من اینجاست: jss_LDA <- LDA(dtm، control = list(alpha = 0.1)، k = 2) Topic_LDA<- get_terms(jss_LDA,20) Topic_LDA من کلمات ترکیبی از دو موضوع را در هر مبحث دریافت می کنم! اما من باید کلمات مربوط به هر موضوع را به موضوع اختصاص دهم. میشه لطفا کمکم کنید؟ | کدام انتشار تخصیص دیریکله نهفته برای اختصاص دادن کلمات مربوط به هر موضوع مفید است؟ |
88250 | من سیستمی دارم که کار از طریق آن جریان دارد. به راحتی می توان وظایف متوسط را برای مشتری انجام داد تا ببیند کدام یک کار بیشتری ایجاد می کنند. اما چگونه می توانم ببینم چه بخش هایی از جریان بیشتر تکرار می شود؟ داده های من یک ردیف برای هر تغییر وضعیت است - من سعی می کنم با کاهش تعداد وظایف، عملکرد مشتریان را بهبود بخشم. | چگونه تکرار کار را در یک سیستم گردش کار تجزیه و تحلیل کنیم؟ |
12661 | چگونه نرمالسازی را انجام میدهید تا وقتی میانگین/واریانس را دریافت میکنم، مقادیر مسطح روی نتایج تأثیر نگذارند؟ به عنوان مثال، در شکل زیر، نمودار 1 و 2 هر دو در مقایسه با نمودار 3 دارای نویز در نظر گرفته می شوند. همانطور که می بینید، هر یک از مقادیر شدت مسطح آنها با یکدیگر متفاوت است، بنابراین ممکن است یک نمودار تمیز که حاوی مقادیر شدت بسیار بالا است، نویز در نظر گرفته شود. همچنین یک نمودار نویزدار که حاوی مقادیر کم شدت است را می توان به عنوان «تمیز» در نظر گرفت. من از میانگین/واریانس و یک آستانه برای تعیین نویز بودن یا نبودن آن استفاده میکنم، بنابراین نیاز به «نرمالسازی» مقادیر است. من سعی کردم این کار را انجام دهم، کل را بدست بیاورم و هر شدت را به کل تقسیم کنم (به عنوان مثال arr[x] = arr[x] / total) اما به درستی کار نمی کند. هر گونه راهنمایی؟ با تشکر | چگونه نرمال سازی را انجام دهیم؟ |
69499 | **زمینه** من در حال حاضر به دنبال این هستم که فواصل اطمینان قابل اعتماد در امتیازات محدود (EQ-5D) چقدر است و فواصل اطمینان مجانبی، قوی و مبتنی بر بات استرپ را با هم مقایسه می کنم. قوی (مستعار ناهمگونی سازگار) واقعا خوب عمل می کند اما در نمونه های کوچک بیش از حد قابل توجهی پوشش دارد. اگر من از توزیع عادی به جای توزیع t استفاده کنم، این بهتر می شود، متأسفانه در حال یافتن داده های متناقض در مورد توزیعی هستم که باید استفاده کنم. **سوال** آیا توصیه کلی برای استفاده از توزیع t به جای توزیع عادی وجود دارد؟ (یک مرجع دوست داشتنی خواهد بود) **جزئیات** من از بسته ساندویچ در R به همراه برآوردگرهای کوواریانس HC3 و HC4m تولید شده توسط تابع vcovHC استفاده می کنم. من از سوال StackOverflow در مورد این موضوع استفاده از کد را شروع کردم، پس از کمی تطبیق آن، کد زیر را دارم: confint.robust <- function(object, parm, level = 0.95, HC_type=HC3, ...){ cf <- coef(object); pnames <- names(cf) if(missing(parm)) parm <- pnames else if (is.numeric(parm)) parm <- pnames[parm] a <- (1-level)/2; a <- c(a, 1-a) pct <- stats:::format.perc(a, 3) fac <- qt(a, object$df.residual) ci <- آرایه(NA, dim = c( طول (parm)، 2L)، dimnames = list (parm، pct)) ses <- sqrt(diag(vcovHC(object, type=HC_type)))[parm] ci[] <- cf[parm] + ses %o% fac ci } **این را در گوگل جستجو کنید** سعی کردم با گوگل جواب را پیدا کنم اما نتایج بسیار اندک بود، در زیر خلاصه ای کوتاه از جالب ترین مقالاتی است که من پیدا کردم. وینیت بسته ساندویچ دارای قطعاتی است که من دقیقاً مطمئن نیستم چگونه آنها را تفسیر کنم، همه نمونه ها از تست z استفاده می کنند اما مطمئن نیستم که چرا و آنها این متن بخش 5 را دارند: > > عمدتاً از برآوردگرهای ساندویچ استفاده می شود. برای استنتاج، مانند > t یا z جزئی > آزمون های ضرایب رگرسیون یا آزمون محدودیت در مدل های تودرتو > رگرسیون > از Haan و Levin's A راهنمای عملگر برای تخمین ماتریس کوواریانس قوی نشان میدهد که حداقل برای HAC شناخته شده است، اگرچه کار بیشتری با آن به من نمیدهد: خطای (MSE) در نمونه های محدود، استنباط های حاصل ممکن است به شدت تحریف شوند. به عنوان مثال، تغییرات قابل توجه در > خطای استاندارد تخمین زده شده به طور کلی باعث می شود که یک آماره t مقادیر بزرگ > (به صورت مطلق) را بیشتر از پیش بینی شده توسط توزیع نرمال محدود کننده > استاندارد دریافت کند، در نتیجه منجر به تمایل به رد بیش از حد > فرضیه صفر در آزمون دو طرفه با رفتن به مقاله اصلی 2011 از Cribari-Neto و همکاران، جایی که آنها جایگزین HC4m را پیشنهاد کردند، آنها از توزیع شبه t استفاده کردند. مقاله متأسفانه فراتر از محدوده درک من است، اما نشان می دهد که توزیع t ممکن است راه حلی نباشد: > طبق فرضیه صفر، از توزیع Student t پیروی نمی کند > (از این رو نام 'شبه t') ، اما دارای یک استاندارد محدود کننده توزیع عادی > متأسفانه من با تعریف $\tau$ آنها کمی گم شده ام: $$\tau=\frac{c'\hat{\beta}-\eta}{\hat{var(c'\beta)}}$$ در مقاله توضیح میدهند که $\eta$ یک اسکالر داده شده است، و $c'$ یک بردار p است، متأسفانه این به درک من از آنچه فرمول انجام می دهد کمک نمی کند ... اگرچه آزمون فرضیه آشنا به نظر می رسد: $|\tau|>z_{1-\alpha/2}$ | آیا استنتاج از یک ماتریس کوواریانس سازگار با ناهمگونی از توزیع t پیروی می کند یا نرمال؟ |
93279 | من یک تجزیه و تحلیل بر روی یک ماتریس رتبه بندی مشتری-مورد بسیار پراکنده 40K x 40K برای توصیه ها انجام دادم. من ابتدا SVD را روی این ماتریس با استفاده از اندازه های مختلف رتبه بندی کاهش یافته اجرا کردم، k=20,30,40... من از نتایج SVD برای پیش بینی 1/0 استفاده کردم (قبل از انجام توصیه ها) و به نوعی بهترین AUC را از k=1. آیا این معقول / طبیعی است؟ آیا تا به حال این اتفاق برای کسی افتاده است؟ | SVD پایین به یک بعد - K=1 |
19783 | من فقط دارم امتحانات آمارم را مطالعه می کنم و به چیز عجیبی برخوردم. وقتی سعی می کنم با ولفرام آلفا صدک 25 یا 75 را بدست بیاورم، جواب دیگری نسبت به آنچه که باید طبق کتاب های درسی ام می گرفتم به من می دهد. مثال ساده: http://www.wolframalpha.com/input/?i=first+quartile+32%2C42%2C46%2C46%2C54 با توجه به کتاب درسی من، پاسخ در واقع باید 37 باشد نه 39.5 آیا کسی نظری دارد ولفرام آلفا چه چیزی متفاوت است؟ | صدک 25 و 75 بر اساس ولفرام آلفا |
97014 | Gradient Descent مشکل گیر کردن در Local Minima دارد. برای یافتن حداقل های جهانی باید زمان های نمایی شیب نزولی را اجرا کنیم. آیا کسی میتواند در مورد جایگزینهای شیب نزولی که در یادگیری شبکههای عصبی به کار میرود، همراه با مزایا و معایب آنها به من بگوید. | جایگزین های Gradient Descent چیست؟ |
100668 | من $n$ افراد دارم، و برای هر فرد، دو اندازه گیری با استفاده از دو دستگاه دارم (دستگاه X و دستگاه Y). من حقیقت پایه را برای اندازه گیری صحیح می دانم و می توانم هر اندازه گیری را به عنوان دقیق یا نادرست طبقه بندی کنم. بنابراین، برای هر فرد من به طور موثر یک مقدار بولی دارم که نشان میدهد آیا دستگاه X درست بوده یا نه (مثلا $x_i$) و یک مقدار بولی که نشان میدهد آیا دستگاه Y درست بوده یا نه (مثلا $y_i$). آیا آزمون آماری خوبی برای مقایسه میزان دقت این دو دستگاه وجود دارد؟ به طور خاص، فرض کنید متوجه شدهام که نرخ دقت دستگاه X بر اساس مشاهدات $n$ (یعنی $(x_1+\dots+x_n)/n > (y_1+\dots+y_n)/ به نظر میرسد بالاتر از میزان دقت دستگاه Y است. n$، که در آن $x_i,y_i = 1$ به معنای صحیح بود و $0$ به معنای نادرست بود). اکنون می خواهم آزمایش کنم که آیا تفاوت در میزان دقت مشاهده شده از نظر آماری معنی دار است یا خیر. آیا می توانم یک $p$-value برای این فرضیه صفر محاسبه کنم که نرخ دقت اساسی آنها در واقع یکسان است؟ آیا باید از آزمون رتبه امضا شده Wilcoxon استفاده کنم؟ آزمون t زوجی دانشجویی؟ نوعی آزمون t زوجی ولش (آیا چنین چیزی وجود دارد)؟ هیچکدام از آنها برای من مناسب نیستند: من میدانم که دادهها به طور معمول توزیع نمیشوند (احتمالاً توزیع برنولی دارد)، بنابراین آزمون t کامل نیست (از طرف دیگر من در عمل آن را خواندهام. آزمون t نسبت به انحراف از نرمال بودن نسبتاً قوی است، بنابراین شاید خوب باشد؟) و من نمیتوانم بگویم که آیا آزمون رتبهبندی علامتدار Wilcoxon دانش قبلی مبنی بر توزیع دادهها برنولی را در نظر میگیرد یا خیر. به هر حال، مناسب ترین متدولوژی کدام خواهد بود؟ | تست جفتی برای مقایسه داده های بولی |
4713 | من از کد r زیر برای تخمین فواصل اطمینان یک نسبت دوجمله ای استفاده کرده ام، زیرا می دانم که در هنگام طراحی طرح های منحنی مشخصه عملکرد گیرنده که به تشخیص بیماری ها در یک جمعیت نگاه می کنند، آن جایگزین «محاسبه توان» می شود. n 150 است و به اعتقاد ما این بیماری 25 درصد در جمعیت شایع است. من مقادیر حساسیت 75 درصد و ویژگی 90 درصد را محاسبه کرده ام (زیرا به نظر می رسد مردم این کار را انجام می دهند). binom.test(c(29,9)، p=0.75، alternative=c(t)، conf.level=0.95) binom.test(c(100, 12)، p=0.90، alternative=c( t)، conf.level=0.95) من همچنین از این سایت بازدید کرده ام: http://statpages.org/confint.html که یک صفحه جاوا است که اطمینان دوجمله ای را محاسبه می کند. فواصل، و همان پاسخ را می دهد. به هر حال، پس از آن تنظیم طولانی، میخواهم بپرسم که چرا فواصل اطمینان متقارن نیستند، مثلاً. حساسیت 95 درصد فاصله اطمینان است: 0.5975876 0.8855583 احتمال تخمین نمونه: 0.7631579 ببخشید اگر این سوال احمقانه است، اما به هر کجا که نگاه می کنم به نظر می رسد که آنها متقارن خواهند بود، و یکی از همکاران من فکر می کند که آنها نیز متقارن خواهند بود. با تشکر فراوان | تخمین فاصله اطمینان دو جمله ای - چرا متقارن نیست؟ |
63635 | من مدل مارکوف حداکثر آنتروپی (MEMM) را برای مسئله شناسایی موجودیت نامگذاری شده (NER) پیاده سازی کرده ام. من چهار کلاس دارم: جغرافیا، مردم، مطالب (عناوین کتاب و غیره) و غیره. کلاس «دیگر» در مجموعه دادههای آموزشی و آزمایشی بیش از حد نشان داده شده است. 88 درصد (حدود 40 هزار نمونه) مواقع رخ می دهد. من مطمئن هستم که نویسندگان دیگر باید این مشکل را داشته باشند. چگونه به من پیشنهاد می کنید که این مشکل را حل کنم؟ ویرایش: یک نمونه داده واحد یک جمله کامل برچسب گذاری شده است. بیشتر جمله با عنوان دیگر برچسب گذاری شده است. حدس میزنم تکنیکهای نمونهگیری مجدد در اینجا کار نمیکنند؟ آیا پیشنهاد می کنید به جای جملات کامل، از تک نشانه ها برای مجموعه داده های آموزشی استفاده کنم؟ | شناسایی موجودیت نامگذاری شده و عدم تعادل کلاس |
69494 | آیا باید _همیشه_ وقفه تصادفی در یک مدل ترکیبی گنجانده شود؟ آیا می توانیم گاهی آن را رها کنیم؟ چگونه می توانیم بفهمیم که چه زمانی است یا امکان رها کردن آن وجود ندارد؟ آیا حذف آن بر مشخصات مدل تأثیر منفی میگذارد؟ آیا این تأثیر همیشه قابل توجه است؟ چگونه می توانیم بفهمیم که چه زمانی قابل توجه است و چه زمانی نیست؟ آیا AIC و BIC شاخص های یک مدل مناسب با یا بدون رهگیری تصادفی هستند؟ و همچنین چرا و چگونه مهم است؟ خیلی ممنون | اهمیت و مفهوم رهگیری تصادفی در یک مدل مختلط چیست؟ |
95524 | من در حال آزمایش برخی از رسم نمودار و استفاده از داده های تاریخی واردات/صادرات برای کشورهای مختلف به عنوان مجموعه داده هستم. من می خواهم این ارقام سالانه (که از سال 1955 تا 2013 می باشد) را برای تورم تنظیم کنم، اما دقیقاً مطمئن نیستم که چگونه. من از دادههای http://stats.oecd.org/Index.aspx?QueryId=164 استفاده میکنم (و دادههای تاریخی را با رفتن به Customize > Selection > Time & Frequency، سپس برگه «انتخاب محدوده زمانی» و انتخاب « سالانه، از 1955 تا 2013). ارقام برای همه کشورها به دلار اسمی است و من می خواهم آنها را به تعدیل تورم ترجمه کنم. چه معیاری می تواند استاندارد باشد؟ آیا این کار معقولی است؟ (این در مقایسه با بسیاری از چیزهای اینجا بسیار اساسی به نظر می رسد؛ من کمی اینجا را احساس می کنم.) | چگونه ارقام تاریخی واردات/صادرات را برای تورم تنظیم کنیم؟ |
19788 | در عمل، چگونه می توان ارزیابی کرد که آیا یک فرآیند AR(P) ثابت است یا خیر؟ چگونه ترتیب مدل AR و MA را تعیین کنیم؟ | آیا یک فرآیند AR(P) ثابت است یا خیر؟ |
95523 | من در تلاش هستم تا اهمیت همپوشانی بین چندین لیست ژن را ارزیابی کنم. در اینجا من روشهای مختلفی را برای انتخاب ژنهای مرتبط با یک بیماری اعمال کردهام و چندین نمودار ون ۴ طرفه دارم که نتایج را نشان میدهد. هدف اصلی من این است که تعیین کنم آیا تلاقی این 4 روش قابل توجه است، بنابراین می توانم بین هر نمودار ون مقایسه کنم. برای آزمایش اهمیت همپوشانی بین دو فهرست، از آزمون فراهندسی استفاده میکنم، اما نمیتوانم هیچ راهحلی برای مسائل متعدد همپوشانی پیدا کنم. آیا کسی می داند چگونه می توانم به این هدف برسم؟ | اهمیت همپوشانی بین لیست های متعدد |
63639 | لطفاً به من ایده بدهید که چگونه می توان یک متغیر طبقه بندی (عامل) را به طور موثر در مجموعه متغیرهای کنتراست چند جمله ای متعامد دوباره کد کرد. برای بسیاری از انواع متغیرهای کنتراست (مثلاً انحراف، ساده، هلمرت، و غیره) امتیاز این است: 1. ماتریس ضرایب کنتراست را مطابق با نوع بنویسید. 2. معکوس یا تعمیم- معکوس آن برای به دست آوردن ماتریس کدها. به عنوان مثال: فرض کنید فاکتور 3 گروهی وجود دارد و می خواهیم آن را در مجموعه ای از متغیرهای کنتراست انحراف دوباره کدگذاری کنیم. آخرین گروه به عنوان مرجع در نظر گرفته می شود. سپس ماتریس ضرایب کنتراست C است Group1 Group2 Group3 var1 2/3 -1/3 -1/3 var2 -1/3 2/3 -1/3 و ginv(C) پس از آن ماتریس کدگذاری مورد نظر var1 var2 Group1 است. 1 0 Group2 0 1 Group3 -1 -1 (ممکن است به جای آن از inv(C) نیز استفاده کنیم اگر یک ردیف برای ثابت، برابر با 1/3، در سر C.) آیا روش مشابه یا مشابهی برای بدست آوردن متغیرهای کنتراست چند جمله ای وجود دارد؟ اگر بله ماتریس C چگونه به نظر می رسد و چگونه می توان آن را ایجاد کرد؟ اگر نه، هنوز هم راهی برای محاسبه مؤثر متغیرهای کنتراست چند جمله ای (مثلاً با جبر ماتریسی) چیست. | محاسبه متغیرهای کنتراست چند جمله ای |
19787 | من از طبقهبندی کننده ساده بیسابقه برای طبقهبندی بین دو گروه داده استفاده میکنم. یک گروه از داده ها بسیار بزرگتر از گروه دیگر است (بالاتر از 4 برابر). من از احتمال قبلی هر گروه در طبقه بندی کننده استفاده می کنم. مشکل این است که نتیجه ای که من دریافت می کنم 0% نرخ مثبت واقعی و 0% نرخ مثبت کاذب دارد. زمانی که پیشین را روی 0.5 و 0.5 قرار دادم همین نتایج را گرفتم. چگونه می توانم آستانه خود را روی چیزی بهتر تنظیم کنم تا بتوانم نتایج متعادل تری داشته باشم؟ من در هنگام استفاده از طبقه بندی کننده رگرسیون لجستیک مشکل مشابهی داشتم. من آن را با کم کردن عبارت قبلی از سوگیری حل کردم. وقتی از Fisher Linear Discriminant روی این داده ها استفاده می کنم، با آستانه تنظیم شده در وسط نتایج خوبی به دست می آورم. فکر می کنم راه حل مشترکی برای این مشکل وجود دارد، فقط نتوانستم آن را پیدا کنم. به روز رسانی: من به تازگی متوجه شده ام که طبقه بندی کننده بیش از حد مناسب است. عملکرد در مجموعه آموزشی عالی است (100٪ صحیح). اگر از گروه های مساوی استفاده کنم، طبقه بندی کننده شروع به طبقه بندی به گروه کوچک نیز می کند، اما عملکرد بسیار بدی است (بدتر از FLD یا LR). UPDATE2: فکر می کنم مشکل این بود که من از ماتریس کوواریانس کامل استفاده می کردم. دویدن با ماتریس کوواریانس مورب نتایج متعادل بیشتری به من داد. | طبقه بندی کننده ساده و بی تکلف برای گروه های نابرابر |
21069 | من گروه A، B، C را دارم. فرضیه های من عبارتند از: 1) نسبت های C با نسبت های B متفاوت است (= استقلال) 2) نسبت های A متفاوت از نسبت های B نیست (= عدم استقلال) نتایج: A: موفقیت = 0.085 n = 50 B: موفقیت = 0.167 n = 50 C: موفقیت = 0.380 n = 50 اگر انجام دهم تضادهای پسهک با استفاده از «pairwise.prop.test()»، سپس قدرت را قربانی میکنم زیرا نیازی به آزمایش C در برابر A نیست، بهویژه با توجه به اینکه C در برابر B از قبل قابل توجه است. تابع `pairwise.prop.test()` تنظیم p-value مانند bonferroni، holm یا BH، BY را فراهم می کند (به مستندات R برای p.adjust {stats} مراجعه کنید). 1. در صورت انتخاب برای انجام همه مقایسههای پسا، کدام یک از این تنظیمات مناسبتر است؟ 2. آیا انجام دو آزمایش مجذور کای و آزمایش B در برابر C و A در برابر B و دو برابر کردن مقادیر p خوب است؟ با تشکر | مشکل تعدیل مقایسه کنتراست های برنامه ریزی شده Chi-squared |
95522 | # سوال غیررسمی فرض کنید یک میوه (سیب یا پرتقال) در اتاق کناری وجود دارد و ده نفر میوه را مشاهده می کنند. هشت نفر از آنها گزارش می دهند که میوه سیب است. احتمال اینکه میوه سیب باشد چقدر است؟ # سوال رسمی اجازه دهید $X\in\left\\{1,\ldots,l\right\\}$ برچسب واقعی یک شی باشد و اجازه دهید $N_x$ تعداد مشاهدات مستقلی باشد که برچسب شیء را گزارش میکنند. x$ است. $$ P\left(X=x|N_1،\ldots،N_l\راست) چیست؟ $$ من احساس میکنم که این یک مشکل استاندارد در استنتاج مقولهای است، اما متأسفانه، نمیدانم برای چه چیزی در گوگل جستجو کنم. در ادامه، برخی از افکاری که در مورد این مشکل داشته ام را ارائه می کنم. # رویکرد ساده لوحانه، ممکن است فرض کنیم که $$ P\left(X=x|N_1,\ldots,N_l\right) = \frac{N_x}{N}، $$ که $N=\sum_x N_x$ برابر است تعداد کل مشاهدات با این حال، مشاهدات ناقص هستند به طوری که احتمال اینکه برچسب واقعی $x$ باشد غیر صفر است حتی اگر $N_x=0$ (همه مشاهدات ممکن است نادرست بوده باشند). # رویکرد کمی پیچیدهتر فرض کنید که هر مشاهده یک آزمایش مستقل برنولی است که با احتمال (مشخص) $q$ موفق میشود (برچسب صحیح را اختصاص میدهد) و با احتمال $1-q$ شکست میخورد (برچسب اشتباهی را اختصاص میدهد). با اعمال قضیه بیز، $$ P\left(X=x|N_1,\ldots,N_l,q\right) \propto P\left(N_1,\ldots,N_l|X=x,q\راست) را پیدا کردم $ که در آن من فرض کرده ام که برچسب های قبلی بیش از واقعی یکنواخت هستند. تابع درستنمایی (و بنابراین پسین برای $x$ داده شده $q$) دو جمله ای است به طوری که $$ P\left(X=x|N_1,\ldots,N_l,q\right)\propto q^{N_x}( 1-ق)^{N-N_x}. $$ # مدل گرافیکی به طور کلی، پایایی مشاهدات $q$ از قبل مشخص نیست. مدل گرافیکی شکل را در نظر بگیرید. دایره های سفید نشان دهنده متغیرها هستند. جعبه های خاکستری نشان دهنده توزیع هستند.  توزیع های شرطی به شکل $$ \begin{align} P\left(x|N_1,\ldots,N_l,q\ هستند. سمت راست) &\propto q^{N_x}(1-q)^{N-N_x}\\\ P\left(q|N_1,\ldots,N_l,x\right) &\propto q^{N_x}(1-q)^{N-N_x} \Theta\left(q-1/2\راست)، \end{align} $$ یعنی توزیع برای $x$ یک توزیع طبقه بندی شده است و $q$ به صورت بتا با $\alpha=1+N_x$ و $\beta=1+N-N_x$ اما محدود به قرار گرفتن در بازه $[.5, 1]$ است. تابع Heaviside این باور را رمزگذاری می کند که مشاهدات در بدترین حدس های تصادفی (اما مخرب نیستند). در اصل، من باید بتوانم پارامترها را با استفاده از نمونهگر گیبس نمونهبرداری کنم، زیرا توزیعهای شرطی را دارم. متأسفانه، من نمی توانم پارامترهای داده های شبیه سازی شده را بازیابی کنم. هر گونه کمکی بسیار قدردانی خواهد شد. | ترکیب مشاهدات برچسب کلاس |
12665 | آیا کسی می داند که چگونه دو ارزش پیش بینی مثبت (PPV) را از دو مدل پیش بینی متفاوت مقایسه کند؟ من برخی از مقالهها را پیدا کردم که $\chi^2$-test یا تست دقیق فیشر را گزارش میکردند، اما نمیتوانم بفهمم که جداول احتمالی چگونه به نظر میرسند: آنها نمیتوانند مانند آزمونهای حساسیت/ویژگی باشند، میتوانند؟ برای روشن شدن: تصور کنید می خواهید یک روش برای تشخیص سرطان را با روش جدیدتر مقایسه کنید. من می دانم که چگونه حساسیت، ویژگی و غیره را تخمین بزنم، و دو حساسیت را از دو مدل مختلف مقایسه کنم (sensitivity_method1 در مقابل sensitivity_method2؛ با استفاده از McNemar) اما در مورد مقایسه بین PPV_method1 در مقابل PPV_method2، نمی توانید از McNemar استفاده کنید، زیرا حاشیه ها متفاوت است. احتمالاتی برای محاسبه مقایسه در SAS 'catmod' وجود دارد، اما درک آن برای من بسیار دشوار بود. بنابراین فکر کردم ممکن است راه آسان تری وجود داشته باشد. من واقعاً برای توضیحات متشکرم. | مقایسه ارزش اخباری مثبت بین دو مدل |
12663 | اخیراً از من پرسیده شد: * آیا اجرای R از یک آزمون معناداری برای آزمایش اینکه آیا سه یا چند همبستگی که از نمونههای مستقل گرفته شده با هم برابر هستند وجود دارد؟ من این فرمول را پیدا کردم که اجرای آن خیلی سخت نیست، اما کنجکاو بودم که آیا یک پیاده سازی موجود بر اساس فرمول پیوند داده شده یا بر اساس روش دیگری وجود دارد. | در R آزمایش کنید که آیا سه یا چند همبستگی از نمونه های مستقل برابر هستند یا خیر |
103437 | من داده هایی را برای صادرات املاح به تفکیک ماه دارم (مقادیر میانگین ماهانه با سال جمع شده به طوری که n=12)، در ANOVA یک طرفه گروه ها باید مستقل باشند. یک ماه صادرات املاح بالا احتمالاً منجر به بالا بودن میانگین ماه بعد می شود، اما همیشه اینطور نیست. آیا آنالیز واریانس یک طرفه برای مقایسه اینکه آیا تفاوت آماری معنیداری بین ماهها وجود دارد یا معیار دیگری مناسبتر است، مناسب است؟ با تشکر | آیا ANOVA یک طرفه برای مقایسه تفاوت در میانگین ماهانه (تقویم) مناسب است؟ |
39268 | ما می دانیم که نویز قرمز همان فرآیند گاوسی ثابت (AR(1)) خودرگرسیون مرتبه اول با همبستگی مثبت در تاخیر واحد است. آیا آزمایش آماری رسمی برای فرآیند نویز قرمز وجود دارد؟ یکی از راههایی که میتوانم به آن فکر کنم این است که ابتدا یک مدل AR(1) را به فرآیند تطبیق دهم، سپس تست نویز سفید را روی باقیماندههای مدل انجام دهم تا ببینیم آیا باقیماندهها از فرآیند نویز سفید پیروی میکنند یا خیر. اگر بله، فرآیند اصلی را می توان به عنوان یک فرآیند نویز قرمز مشاهده کرد... از هر ایده و نظری استقبال کنید. | تست آماری برای اینکه آیا یک فرآیند نویز قرمز است یا خیر |
97016 | اجازه دهید $X_1،\dots،X_n$ i.i.d با تابع توزیع $F$ باشند. اجازه دهید $\hat F_n$ تابع توزیع تجربی آن باشد، یعنی $$ \hat F_n(x)=\frac1n\sum_{i=1}^n1_{\\{X_\le x\\}}(x) $ $ که در آن $1_A(x)$ تابع مشخصه است. من قصد دارم ترتیب $$ T_n=\sum_{i=1}^n\left(\\{\Phi^{-1}(\hat F_n(X_i))\\}^2-\\ را بدانم {\Phi^{-1}(F(X_i))\\}^2\راست) $$ که $\Phi$ تابع توزیع استاندارد عادی ترکیبی است. من احساس می کنم که $T_n=o_p(\sqrt n)$ زیرا برای همه $x\in\mathbb{R}$ من $\\{\Phi^{-1}(\hat F_n(x))\\ دارم }^2-\\{\Phi^{-1}(F(x))\\}^2=O_p(1/\sqrt n)$. با این حال، من نمی توانم ترتیب $T_n$ را تعیین کنم زیرا $\hat F_n$ نیز به $X_i$ بستگی دارد. آیا کسی می تواند به من کمک کند؟ | ترتیب تفاوت بین تابع توزیع و تجربی آن |
63632 | من دو سوال دارم: میپرسم اگر بخواهم تستها به اندازه کافی قدرتمند باشند، آیا میتوان اندازه نمونه (n) را برای یک رگرسیون خطی چندگانه دانست؟ به نظر من، در واقعیت استفاده از محاسبه توان برای مدل خطی چندگانه بسیار دشوار به نظر می رسد، زیرا لازم است مقادیر معتبر برای پارامترهای مختلف وارد شود. آیا این کار با R امکان پذیر است؟ اگر بله، چگونه می توانم این کار را با R انجام دهم؟ کد R؟ با R، این کد برای رگرسیون خطی چندگانه وجود دارد: pwr.f2.test (u = NULL، v = NULL، f2 = NULL، sig.level = 0.05، توان = NULL) با: u: درجه آزادی برای شمارشگر v: درجه آزادی برای مخرج f2: اندازه اثر sig.level: سطح اهمیت (خطای نوع I احتمال) قدرت: توان آزمون (1 منهای احتمال خطای نوع II) 1. آیا می توان این کد R را برای در نظر گرفتن (در نظر گرفتن) اندازه نمونه و پارامترهای مختلف رگرسیون بهبود بخشید؟ 2. در مورد اندازه نمونه (n) برای یک رگرسیون لجستیک (رگرسیون لاجیت) چطور؟ آیا با دانستن معیارهایی مانند (sig.level=0.05، power=0.8…) می توان اندازه نمونه گیری را دانست؟ | حجم نمونه برای رگرسیون خطی چندگانه |
80189 | تابع مشخصه توزیع Fisher$(1,\alpha)$ این است: $$C(t)=\frac{\Gamma \left(\frac{\alpha +1}{2}\right) U\left( \frac{1}{2},1-\frac{\alpha }{2},-i t \alpha \right)}{\Gamma \left(\frac{\alpha {2}\right)}$$ که در آن $U$ تابع ابرهندسی متقابل است. به دنبال حل تبدیل فوریه معکوس $\mathcal {F} _ {t,x}^{-1}$ از $n$-convolution برای بازیابی چگالی متغیر $x$، یعنی: $$\mathcal {F} _ {t,x}^{-1} \left(C(t)^n\right)$$ با هدف بدست آوردن توزیع مجموع توزیع تصادفی فیشر متغیرها من تعجب می کنم که آیا کسی ایده ای دارد که حل آن بسیار دشوار است. من مقادیر $\alpha=3$ و $n=2$ را امتحان کردم بی فایده بود. توجه: برای $n=2$ بر اساس کانولوشن من pdf میانگین را دریافت می کنم (نه جمع): $\frac{3 \left(12 \left(x^2+3\right) \left(5 x^2- 3\راست) x^2+9 \left(20 x^4+27 x^2+9\right) \log \left(\frac{4 x^2}{3}+1\right)+2 \sqrt{3} \left(x^2+15\right) \left(4 x^2+3\right) x^3 \tan ^{-1}\left(\frac{2 x}{\sqrt {3}}\right)\right)}{\pi ^2 x^3 \left(x^2+3\right)^3 \left(4 x^2+3\right)}$, جایی که $x دلار به طور متوسط 2 است متغیرها من می دانم که کار سختی است، اما دوست دارم ایده ای در مورد تقریب توزیع حوضه داشته باشم. | معکوس کردن تبدیل فوریه برای توزیع فیشر |
97011 | من به کمک / بینش در مورد نتیجه تجزیه و تحلیل داده هایم نیاز دارم. هدف من طبقه بندی 3 نوع اعداد مختلف است. به عنوان مثال) 1 یا 2 یا 3 من ساخته شده است 1. درخت C5.0 + ترک گروه از اعتبار متقاطع (نگه دارید) 2. SVM (شعاعی) -با پیش پردازش: boxcox+استاندارد کردن + گروه ترک اعتبار متقاطع 10 بار (نگه دارید) 3. SVM (خطی) withboxcox+standardize + ترک گروه از اعتبار سنجی متقاطع 10 بار (حفظ) 4. جنگل تصادفی+ ترک اعتبار متقاطع گروهی 10 بار (نگه دار کردن) 5. تقویت گرادیان + ترک اعتبار متقاطع گروهی 10 بار (حفظ) 6. شبکه عصبی + علامت فضایی + اعتبار سنجی متقاطع گروه را ترک کنید 10 بار (نگه دارید) 7. گروه ترک + LDA اعتبار سنجی متقاطع را 10 بار انجام دهید (حفظ کنید) (البته پارامترها تنظیم شدند!) و همچنین 2 مجموعه مختلف از ویژگی ها را امتحان کردم. یکی با کامل که شامل همه ویژگی ها است و دیگری با کاهش که حاوی برخی از ویژگی های انتخاب شده است که از روش های مختلف بازگشتی انتخاب شده اند. بنابراین من الان 7*2=14 مدل مختلف دارم. مشکل این است که تقریباً هیچ تفاوتی بین مدل وجود ندارد. دقت و کاپا برای هر مدل بسیار مشابه است. بالاترین دقت 84.0 درصد با کاپا 69.1 (تقویت گرادیان) و کمترین دقت 83.3 درصد با کاپا 67.0 بود. من از انواع مختلفی از متغیرهای ساختگی برای داده های ورودی طبقه ای خود استفاده کردم. با این حال، هنوز هم، تقریباً همان دقت/کاپا را می دهد. آیا کسی می تواند به من راهنمایی کند تا بتوانم نتیجه خود را بهبود بخشم؟ با تشکر :دی | من به یک بینش در مورد نتیجه تجزیه و تحلیل خود نیاز دارم |
64171 | شاید این سوال در پزشکی پاسخی داشته باشد، اما آیا دلایل آماری وجود دارد که شاخص BMI به صورت $\text{weight}/\text{height}^2$ محاسبه شود؟ چرا برای مثال فقط $\text{weight}/\text{height}$ نه؟ اولین ایده من این است که ربطی به رگرسیون درجه دوم دارد. نمونه داده های واقعی (200 نفر با وزن، قد، سن و جنسیت): ساختار(فهرست(سن = c(18L, 21L, 17L, 20L, 19L, 53L, 27L, 22L, 19L, 27L, 19L, 20L, 19L ، 20 لیتر، 42 لیتر، 17 لیتر، 23 لیتر، 20 لیتر، 20 لیتر، 19 لیتر، 20 لیتر، 19 لیتر، 19 لیتر، 18 لیتر، 19 لیتر، 15 لیتر، 19 لیتر، 15 لیتر، 19 لیتر، 21 لیتر، 60 لیتر، 19 لیتر، 17 لیتر، 23 لیتر، 60 لیتر، 33، 2، 2، 1، 2 20 لیتر، 21 لیتر، 19 لیتر، 19 لیتر، 20 لیتر، 18 لیتر، 19 لیتر، 20 لیتر، 22 لیتر، 20 لیتر، 20 لیتر، 27 لیتر، 19 لیتر، 22 لیتر، 19 لیتر، 20 لیتر، 20 لیتر، 21 لیتر، 16 لیتر، 15 لیتر، 1، 23 لیتر، 19 لیتر، 19 لیتر، 22 لیتر، 18 لیتر، 20 لیتر، 19 لیتر، 25 لیتر، 18 لیتر، 20 لیتر، 15 لیتر، 61 لیتر، 19 لیتر، 34 لیتر، 15 لیتر، 19 لیتر، 16 لیتر، 19 لیتر، 18 لیتر، 20 لیتر، 18 لیتر، 20 لیتر، 20 لیتر، 19 لیتر، 16 لیتر، 37 لیتر، 37 لیتر، 18 لیتر، 20 لیتر، 16 لیتر، 20 لیتر، 36 لیتر، 18 لیتر، 19 لیتر، 19 لیتر، 20 لیتر، 18 لیتر، 17 لیتر، 22 لیتر، 17 لیتر، 22 لیتر، 22 لیتر، 17 لیتر، 22 لیتر، 17 لیتر 17 لیتر، 17 لیتر، 15 لیتر، 18 لیتر، 18 لیتر، 16 لیتر، 20 لیتر، 29 لیتر، 24 لیتر، 18 لیتر، 17 لیتر، 18 لیتر، 36 لیتر، 16 لیتر، 17 لیتر، 20 لیتر، 16 لیتر، 43 لیتر، 19 لیتر، 19 لیتر، 19 لیتر، 21 لیتر، 19 لیتر، 20 لیتر، 23 لیتر، 19 لیتر، 19 لیتر، 20 لیتر، 24 لیتر، 19 لیتر، 20 لیتر، 38 لیتر، 18 لیتر، 17 لیتر، 19 لیتر، 19 لیتر، 20 لیتر، 20 لیتر، 21 لیتر، 20 لیتر، 20 لیتر، 20 لیتر، 20 لیتر، 20 لیتر 25 لیتر، 20 لیتر، 21 لیتر، 21 لیتر، 22 لیتر، 19 لیتر، 25 لیتر، 19 لیتر، 40 لیتر، 25 لیتر، 52 لیتر، 25 لیتر، 21 لیتر، 20 لیتر، 41 لیتر، 34 لیتر، 24 لیتر، 30 لیتر، 7، 21، 6 لیتر، 7 31 لیتر، 21 لیتر، 37 لیتر، 20 لیتر، 22 لیتر، 19 لیتر، 20 لیتر، 25 لیتر، 23 لیتر، 20 لیتر، 20 لیتر، 21 لیتر، 36 لیتر، 19 لیتر، 21 لیتر، 16 لیتر، 20 لیتر، 18 لیتر، 21 لیتر، 21 لیتر، 21 لیتر، c(180 لیتر، 175 لیتر، 178 لیتر، 160 لیتر، 172 لیتر، 172 لیتر، 180 لیتر، 165 لیتر، 160 لیتر، 187 لیتر، 165 لیتر، 176 لیتر، 164 لیتر، 155 لیتر، 166 لیتر، 155 لیتر، 166 لیتر، 170 لیتر، 187 لیتر، 182 لیتر، 182 لیتر، 175 لیتر، 197 لیتر، 170 لیتر، 165 لیتر، 176 لیتر، 167 لیتر، 170 لیتر، 168 لیتر، 163 لیتر، 155 لیتر، 152 لیتر، 158 لیتر، 165 لیتر، 187 لیتر، 187 لیتر، 180 لیتر، 180 لیتر، 178 لیتر، 170 لیتر، 170 لیتر، NA، 188 لیتر، 180 لیتر، 161 لیتر، 178 لیتر، 178 لیتر، 165 لیتر، 187 لیتر، 178 لیتر، 168 لیتر، 168 لیتر، 180 لیتر، 192 لیتر، 180 لیتر، 192 لیتر، 18 لیتر، 18 لیتر 167 لیتر، 177 لیتر، 177 لیتر، 160 لیتر، 167 لیتر، 190 لیتر، 187 لیتر، 163 لیتر، 173 لیتر، 165 لیتر، 190 لیتر، 178 لیتر، 167 لیتر، 160 لیتر، 169 لیتر، 169 لیتر، 174 لیتر، 174 لیتر، 166 لیتر، 178 لیتر، 158 لیتر، 180 لیتر، 167 لیتر، 170 لیتر، 170 لیتر، 180 لیتر، 184 لیتر، 170 لیتر، 180 لیتر، 169 لیتر، 165 لیتر، 156 لیتر، 166 لیتر، 1728 لیتر، 1728 لیتر، 168 لیتر، 185 لیتر، 175 لیتر، 167 لیتر، 193 لیتر، 160 لیتر، 171 لیتر، 182 لیتر، 165 لیتر، 174 لیتر، 169 لیتر، 185 لیتر، 173 لیتر، 170 لیتر، 182 لیتر، 182 لیتر، 160 لیتر، 165 لیتر، 173 لیتر، 168 لیتر، 172 لیتر، 164 لیتر، 185 لیتر، 175 لیتر، 162 لیتر، 182 لیتر، 170 لیتر، 187 لیتر، 169 لیتر، 178 لیتر، 189 لیتر، 166 لیتر، 161 لیتر، 180 لیتر، 180 لیتر، 180 لیتر، 184 لیتر، 180 لیتر، 166 لیتر، 167 لیتر، 178 لیتر، 175 لیتر، 190 لیتر، 178 لیتر، 157 لیتر، 179 لیتر، 180 لیتر، 168 لیتر، 164 لیتر، 187 لیتر، 174 لیتر، 170 لیتر، 170 لیتر، 170 لیتر، 170 لیتر، 158 لیتر، 175 لیتر، 174 لیتر، 170 لیتر، 173 لیتر، 158 لیتر، 185 لیتر، 170 لیتر، 178 لیتر، 166 لیتر، 176 لیتر، 167 لیتر، 168 لیتر، 169 لیتر، 168 لیتر، 185 لیتر، 176 لیتر، 176 لیتر، 160 لیتر، 176 لیتر، 186 لیتر، 162 لیتر، 172 لیتر، 164 لیتر، 171 لیتر، 175 لیتر، 164 لیتر، 165 لیتر، 160 لیتر، 180 لیتر، 170 لیتر، 180 لیتر، 175 لیتر، 167 لیتر، 167 لیتر، 167 لیتر، 166 لیتر، 164 لیتر، 165 لیتر، 180 لیتر، 173 لیتر، 168 لیتر، 177 لیتر، 167 لیتر، 173 لیتر)، وزن = c(60 لیتر، 63 لیتر، 70 لیتر، 46 لیتر، 60 لیتر، 68 لیتر، 80 لیتر، 53 لیتر، 68 لیتر، 80 لیتر، 53 لیتر، 68 لیتر 60 لیتر، 44 لیتر، 62 لیتر، 57 لیتر، 59 لیتر، 50 لیتر، 60 لیتر، 65 لیتر، 63 لیتر، 72 لیتر، 96 لیتر، 50 لیتر، 55 لیتر، 53 لیتر، 54 لیتر، 49 لیتر، 72 لیتر، 49 لیتر، 75 لیتر، 75 لیتر، 5 لیتر، 85 لیتر، 80 لیتر، 55 لیتر، 67 لیتر، 60 لیتر، 70 لیتر، NA، 76 لیتر، 85 لیتر، 53 لیتر، 69 لیتر، 74 لیتر، 50 لیتر، 91 لیتر، 68 لیتر، 55 لیتر، 55 لیتر، 57 لیتر، 80 لیتر، 57 لیتر، 80 لیتر، 57 لیتر، 80 لیتر، 80 لیتر 62 لیتر، 63 لیتر، 88 لیتر، 80 لیتر، 57 لیتر، 90 لیتر، 83 لیتر، 51 لیتر، 52 لیتر، 65 لیتر، 92 لیتر، 58 لیتر، 76 لیتر، 53 لیتر، 64 لیتر، 63 لیتر، 72 لیتر، 68 لیتر، 110 لیتر، 110 لیتر، 110 لیتر، 68 لیتر 57 لیتر، 75 لیتر، 55 لیتر، 75 لیتر، 68 لیتر، 60 لیتر، 65 لیتر، 48 لیتر، 56 لیتر، 65 لیتر، 65 لیتر، 88 لیتر، 55 لیتر، 68 لیتر، 74 لیتر، 65 لیتر، 62 لیتر، 58 لیتر، 55 لیتر، 48 لیتر، 8 60 لیتر، 65 لیتر، 50 لیتر، 73 لیتر، 51 لیتر، 60 لیتر، 76 لیتر، 48 لیتر، 50 لیتر، 53 لیتر، 63 لیتر، 68 لیتر، 56 لیتر، 68 لیتر، 60 لیتر، 70 لیتر، 65 لیتر، 52 لیتر، 75 لیتر، 48 لیتر، 6 76 لیتر، 60 لیتر، 59 لیتر، 80 لیتر، 74 لیتر، 96 لیتر، 68 لیتر، 72 لیتر، 62 لیتر، 58 لیتر، 50 لیتر، 75 لیتر، 70 لیتر، 85 لیتر، 67 لیتر، 65 لیتر، 55 لیتر، 78 لیتر، 58 لیتر، 58 لیتر، 78 لیتر، 58 لیتر، 60 لیتر، 56 لیتر، 82 لیتر، 70 لیتر، 53 لیتر، 67 لیتر، 58 لیتر، 58 لیتر، 49 لیتر، 90 لیتر، 58 لیتر، 77 لیتر، 55 لیتر، 70 لیتر، 64 لیتر، 98 لیتر، 60 لیتر، 60 لیتر، 65 لیتر، 4، 4 لیتر، 7 75 لیتر، 77 لیتر، 74 لیتر، 68 لیتر، 50 لیتر، 66 لیتر، 75 لیتر، 54 لیتر، 60 لیتر، 65 لیتر، 80 لیتر، 90 لیتر، 95 لیتر، 79 لیتر، 57 لیتر، 70 لیتر، 60 لیتر، 85 لیتر، 44 لیتر، 80 لیتر، 5 54 لیتر، 68 لیتر، 56 لیتر، 69 لیتر)، جنسیت = c(1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، ، 2 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 2 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 2 لیتر، 1 لیتر، 1 لیتر، 2L، 2L، 1L))، .Names = c(سن، قد، وزن، جنس)، row.names = 304:503، class = data.frame) | دلیل فرمول شاخص BMI |
80181 | در حین تجزیه و تحلیل یک روش تکراری خاص که به نقاط ثابت یک تابع چند متغیره f(x,y) می رسد (x و y در این مورد بردارهای N بعدی هستند)، من توانستم آن را با عبارات زیر دوباره فرموله کنم 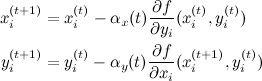 یعنی نوعی نزول «متناوب»، که در آن x به سمتی می رود که به حداقل می رسد. y و بالعکس. آیا کسی تا به حال چنین چیزی را دیده است، مثلا الگوریتمی که این نوع به روز رسانی را انجام می دهد؟ در واقع معادله 2 به جای - یک + دارد، بنابراین یک معادله یک نزول را انجام می دهد در حالی که دیگری یک صعود را انجام می دهد ... اما من به هر نوع الگوریتمی علاقه مند هستم که این نوع تناوب را انجام دهد. با تشکر | بهینه سازی از طریق نزول متناوب. |
64179 | من دادههایی در قالب زیر دارم: id yrdx yrsrv مرده 1 2000 3 1 2 2003 10 0 3 2004 5 0 4 2007 1 1 که در آن «yrdx» سال تشخیص بیماری را نشان میدهد، «yrsrv» نشاندهنده مدت زنده ماندن یک فرد است. ، و مرده نشان می دهد که آیا آنها مرده اند یا سانسور شده اند یا خیر. من می خواهم نرخ مرگ و میر را در این جمعیت متفاوت در زمان تقویم ترسیم کنم. مسئله این است که برخی افراد سانسور می شوند. پس برآورد نتایج از یک مدل کاکس امکان پذیر نیست زیرا 1) هدف من تخمین اثرات زمان _به صراحت_ است و 2) مدل آزاد زمان هیچ متغیر کمکی دیگری ندارد، بنابراین مدل کاکس همگرا نخواهد شد. من میدانم راهی برای انجام این کار با مدل رگرسیون پواسون با استفاده از سالهای بقا به عنوان یک جبران وجود دارد. مدل خطی چیزی شبیه به این است: $$\log \left( \frac{\mu}{t} \right) = \beta_0 + \beta_1 \mbox{year}$$ من گیج میشوم زیرا ما زمان را به دو صورت مدلسازی میکنیم. ، هنگامی که برای حساب کردن مخرج یا زمان خطر محدود شود. 1. آیا فرمول مدل من درست است؟ 2. این (یا مدل صحیح) دقیقاً چگونه دادههای سانسور شده و مجموعههای ریسک را به طور صریح در طول زمان محاسبه میکند؟ 3. آیا باید این داده ها را در قالب جدول زندگی پیچیده تر جمع آوری کنم؟ اگر چنین است، چگونه این کار را در R انجام دهیم؟ | ترسیم جدول های زندگی، بروز با مخرج های مختلف |
81239 | این گزیدهای از ویرایش دوم کتاب مقدمهای بر مدلهای خطی تعمیمیافته نوشته آنت جی دابسون است:   به نظر می رسد نویسنده فرض می کند که $(I - H)/\sigma^2 = V^-$، که در آن $V$ ماتریس واریانس-کوواریانس برای $y$، و $V^-$ معکوس تعمیم یافته است، مشخص نیست که چگونه او به آنجا رسیده است. نویسنده به بخش 1.4.2 قسمت 8 اشاره کرده است، همچنین در اینجا فهرست شده است:  | انحراف برای یک مدل خطی عادی |
80187 | آزمایش کمی غیر واقعی زیر را در نظر بگیرید: من یک مجموعه بی نهایت بزرگ از سوالات برای نوشتن امتحان دارم، و فرض کنید که سوالات به طور مداوم از 0 تا 10 درجه سختی دارند و هر درجه دشواری دارای تعداد بی نهایت سوال در استخر مربوط به آن را امتحانات توسط کامپیوتر برگزار می شود. هنگامی که دانش آموزی به رایانه خود می رود به طور تصادفی (یکنواخت) به او اختصاص داده می شود که چقدر دشواری سؤالی به سؤال دیگر متفاوت است، $\delta$، و سپس با ترسیم سؤالات توزیع شده معمولی (در دشواری) برای او امتحان ایجاد می شود. میانگین سطح دشواری 5 و واریانس در سطح دشواری $\delta$. دانش آموز پس از اتمام امتحان و دریافت نمره خود انتخاب می کند که آیا مایل به شرکت در امتحان دیگری است یا خیر. اگر این کار را انجام دهند، امتحان دیگری با همان واریانس $\delta$ برای آنها ایجاد می شود. بنابراین یک دانش آموز تنها $\delta$ را برای تمام امتحانات خود دارد، اما هر دو دانش آموز دو $\delta$ متفاوت خواهند داشت. من تصور می کنم دو سوال جالب می توانم از این داده ها بپرسم. (1) تأثیر $\delta$ بر نمره امتحان چیست، و (2) تأثیر تعداد امتحاناتی که دانش آموز تاکنون داده است بر نمره امتحان فعلی خود چیست (یعنی دانش آموزان چقدر یاد می گیرند؟) . با این حال، اگر هر دانش آموزی برای همه امتحانات خود $\delta$ یکسان دریافت کند، اما $\delta$s در بین دانشآموزان متفاوت باشد، به نظر دشوار میآید که تأثیر توانایی دانشآموز را از هم جدا کنیم (که برای من اهمیتی ندارد - و احتمالاً همینطور است. تصادفی) با اثر $\delta$. برای پاسخ به سؤالات (1) و (2) بالا از چه مدلی باید استفاده کنم؟ اولین غریزه من شاید یک مدل اثر ترکیبی باشد که در آن $\delta$ یک اثر ثابت است، تعداد امتحاناتی که در زمان هر امتحان گرفته می شود نیز یک اثر ثابت است، و هر دانش آموز یک اثر تصادفی است. توجه داشته باشید، من مدلهای جلوههای ترکیبی را بسیار گیجکننده میبینم، بنابراین شاید بیانیه بالا معنی نداشته باشد. تصور میکنم تأثیر دانشآموز ممکن است مهم باشد، زیرا دانشآموزانی که به شیوهای خاص انجام میدهند ممکن است امتحانات بیشتری را انتخاب کنند در حالی که دانشآموزانی که روش دیگری را انجام میدهند ممکن است تصمیم بگیرند زودتر امتحان ندهند. به عنوان مثال، اگر دانشآموزانی که عملکرد ضعیفی دارند، امتحانات بیشتری را برای بهبود نمره خود انتخاب کنند و دانشآموزان خوب از اولین امتحان خود راضی باشند، یک نگاه اولیه به دادهها ممکن است به این نتیجه برسد که دانشآموزان پس از چندین امتحان، بدون تأثیر دانشآموزی، وضعیت بدتری دارند. به این شکل خواهد بود: * دانش آموز 1: $\delta=2.11$، امتحان 1 = 28، امتحان 2 = 40، امتحان 3 = 39، امتحانات گرفته شده =3 * دانش آموز 2: $\delta=0.23$، امتحان 1 = 44، امتحانات گرفته شده =1 * دانش آموز 3: $\delta=1.83$، امتحان 1 = 21، امتحان 2 = 9، امتحان 3 = 18، امتحان 4 = 24، امتحانات گرفته شده =4 * . * . * . * دانش آموز N: $\delta=1.24$، امتحان 1 = 51، امتحان 2 = 56، امتحانات گرفته شده = 2 | چگونه یک مدل (اثر مختلط؟) برای آزمایش فرضی مطالعه نمرات امتحان بنویسیم |
63631 | برای کدام نوع از تکنیکهای یادگیری ماشینی نظارتشده میتوان تخمین زد که مدل در مورد پیشبینیهایش برای سطح/ محدوده معین پیشبینیکننده پس از آموزش مدل بر روی مجموعهای از دادهها چقدر نامطمئن است؟ من می توانم تصور کنم که انجام این کار ممکن است به عنوان مثال. برای جنگل تصادفی با مشاهده واریانس آرایی که جنگل برای یک نقطه داده در مجموعه داده ارزیابی می دهد. از طرف دیگر برآورد عدم قطعیت مدل برای رگرسیون خطی و روش های مشابه برای من غیرممکن به نظر می رسد. آیا کسی می تواند توضیح دهد که برای کدام تکنیک های یادگیری ماشینی می توان این کار را انجام داد یا من را به ادبیات مربوطه راهنمایی کند؟ | تخمین عدم قطعیت پیش بینی برای انواع مختلف مدل ها |
88256 | در MCMC، > از یک زنجیره واحد با دوره سوختن 100 تکرار و نمونه برداری > دوره 1000 تکرار استفاده کنید. اگر درست بگویم، دوره سوختن طول اولین قسمت از یک مسیر نمونه است که باید دور ریخته شود. دوره نمونه گیری به چه معناست؟ فرض کنید از یک MC، $(X_1، X_2، \dots، X_N)$ یک مسیر نمونه منفرد از زنجیره است (که در آن طول مسیر نمونه $N$ به اندازه کافی بزرگ است)، و سوخت در دوره $t_b$ است، و دوره نمونه گیری $t_s$ است. آیا جمع آوری $X_{t_b}، X_{2*t_b}، \dots، X_{t_s*t_b}$ به عنوان نمونه iid توزیع ثابت صحیح است؟ آیا دوره نمونه $t_s$ به معنای حجم نمونه برای نمونه ای است که باید جمع آوری کنم؟ با تشکر | دوره نمونه برداری در MCMC به چه معناست؟ |
49607 | # پیشینه ## مقدمه من مجموعه داده ای دارم که از داده های جمع آوری شده از یک پرسشنامه تشکیل شده است که می خواهم اعتبار آن را تایید کنم. من استفاده از تحلیل عاملی تاییدی را برای تجزیه و تحلیل این مجموعه داده ها انتخاب کرده ام. ## ابزار این ابزار از 11 خرده مقیاس تشکیل شده است. در مجموع 68 گویه در 11 خرده مقیاس وجود دارد. هر آیتم در مقیاس اعداد صحیح بین 1 تا 4 نمره گذاری می شود. ## تنظیم تجزیه و تحلیل عامل تاییدی (CFA) من از بسته sem برای انجام CFA استفاده می کنم. کد من به شرح زیر است: cov.mat <- as.matrix(read.table(http://dl.dropbox.com/u/1445171/cov.mat.csv, sep = ,, header = TRUE )) rownames(cov.mat) <- colnames(cov.mat) model <- cfa(file = http://dl.dropbox.com/u/1445171/cfa.model.txt، reference.indicators = FALSE) cfa.output <- sem(model, cov.mat, N = 900, maxiter = 80000, optimizer = optimizerOptim) پیام هشدار: در eval(expr، envir، enclos): واریانس پارامترهای منفی. مدل ممکن است شناسایی نشده باشد. بلافاصله ممکن است متوجه چند ناهنجاری شوید، اجازه دهید توضیح دهم. * چرا بهینه ساز به عنوان optimizerOptim انتخاب شده است؟ پاسخ: من در ابتدا به «optimizerSem» پیشفرض گیر دادم، اما مهم نیست که چند بار تکرار میکنم، یا ابتدا حافظهام تمام میشود (راهاندازی RAM 8 گیگابایت) یا «بدون همگرایی» گزارش میدهد. به 'optimizerOptim' که در آن با موفقیت به نتیجه می رسد اما این خطا را نشان می دهد که مدل شناسایی نشده است. با بررسی دقیق تر، متوجه می شوم که خروجی «همگرایی» را به صورت «TRUE» نشان می دهد، اما «تکرار» «NA» است، بنابراین مطمئن نیستم دقیقاً چه اتفاقی می افتد. * maxiter خیلی بالاست. پاسخ: اگر آن را روی مقدار کمتری تنظیم کنم، از همگرایی امتناع می کند، اگرچه همانطور که در بالا ذکر شد، شک دارم که همگرایی واقعی واقعاً رخ داده باشد. # مشکل بنابراین تا به حال حدس میزنم که مدل واقعاً شناسایی نشده است، بنابراین به دنبال منابعی برای حل این مشکل گشتم و پیدا کردم: * http://davidakenny.net/cm/identify_formal.htm * http://faculty.ucr.edu/ ~hanneman/soc203b/lectures/identify.html من پیوند دوم را کاملاً دنبال کردم و قانون t را اعمال کردم: * من 68 متغیر مشاهده شده دارم که به من ارائه می دهد. با 68 واریانس و 2278 کوواریانس بین متغیرها = **2346 نقطه داده**. * همچنین 68 ضریب رگرسیون، 68 واریانس خطای متغیرها، 11 واریانس عاملی و 55 کوواریانس عاملی دارم تا آن را در مجموع 191 پارامتر برآورد کنم. * از آنجایی که من واریانس 11 عامل نهفته را به 1 برای مقیاس بندی ثابت می کنم، آنها را از پارامترها حذف می کنم تا تخمین بزنم تا در مجموع **180 پارامتر برای تخمین زدن **. * بنابراین درجات آزادی من 2346 - 180 = 2166 است که آن را به یک مدل بیش از حد شناسایی شده توسط قانون t تبدیل می کند. # سوالات 1. آیا واریانس کم برخی از آیتم های من دلیلی برای شناسایی ناکافی است؟ من یک سوال قبلی در مورد موارد با واریانس صفر پرسیدم که باعث شد در مورد مواردی که بسیار نزدیک به صفر هستند فکر کنم. آیا آنها نیز باید حذف شوند؟ تحلیل عاملی تاییدی با استفاده از SEM: با موارد با واریانس صفر چه کار می کنیم؟ 2. پس از مطالعه زیاد، حدس می زنم که عدم شناسایی ممکن است موردی از عدم شناسایی تجربی باشد. آیا روشی سیستماتیک برای تشخیص نوع کم هویتی وجود دارد؟ و گزینه های من برای ادامه تحلیل من چیست؟ من سوالات بیشتری دارم، اما بیایید فعلاً این 2 مورد را بررسی کنیم. با تشکر برای هر گونه کمک! | عیب یابی مسائل عدم شناسایی در مدل سازی معادلات ساختاری (SEM) |
81238 | یک عبارت رایج برای تست خوب بودن تناسب پیرسون $\chi^2 = \sum_i \frac{(O_i - E_i)^2}{E_i}$ است که $O_i$ و $E_i$ به ترتیب فرکانسهای مشاهده شده و مورد انتظار هستند. حال با فرض اینکه میخواهیم تناسب یک توزیع پواسون را با دادهها، با استفاده از یک پارامتر MLE از همان دادهها تخمین بزنیم. منابع موجود در اینترنت ادعا میکنند که فرکانسهای مورد انتظار برای هر سلول را میتوان با $E_i = np_i$ محاسبه کرد، که $p_i = P(X_i=O_i|\lambda)$ احتمال مشاهده $O_i$ است که از توزیع پواسون با پارامتر محاسبه میشود. $\lambda$ و $n$ تعداد کل است. این چیزی است که به نظر من عجیب است. مطمئناً، اگر سلولهای ما واقعاً تحت توزیع پواسون توزیع میشدند، تعداد مورد انتظار $E_i = E[X_i] = \lambda$ بود. آیا دلیلی وجود دارد که ما باید هر سلول را بهعنوان یک متغیر تصادفی دوجملهای، همانطور که به نظر میرسد، به جای یک RV تحت توزیع واقعی در نظر بگیریم؟ | تعداد مورد انتظار در تست خوب بودن تناسب پیرسون |
99564 | در جایی که میگوید «فقط سوگیری خط پایه دیفرانسیل»، من هم سوگیری پایه دیفرانسیل و هم سوگیری اثر درمان افتراقی را میبینم. از درک من، برای اینکه سوگیری اثر درمان افتراقی نداشته باشیم، $y_i^{1}$ - $y_i^{0}$ باید هم برای گروه درمان و هم برای گروه کنترل یکسان باشد. با این حال در پانل اول (20-10 = 10) و (20-0 = 20) است. همچنین لطفا به نظر در مورد پاسخ اول توسط دیمیتری مراجعه کنید.  استفن ال. مورگان و کریستوفر وینشیپ «مطالب متضاد و استنتاج علی. روشها و اصول تحقیق اجتماعی. انتشارات دانشگاه کمبریج | سوگیری پایه دیفرانسیل در مقابل اثر درمان ناهمگن |
69185 | من سعی می کنم PCA (روش NIPALS) را با استفاده از Excel اعمال کنم. مشکل این است که نتایج من دقیقاً با نتایج R مطابقت ندارد. فقط تفاوت علامت وجود دارد: اگر نمرات من مثبت باشد، نمرات با استفاده از R منفی هستند. من نمی دانم چه خبر است. من نمی توانم هیچ گزینه ای را در اینجا برای پیوست فایل های خود ببینم. چه باید کرد؟ | PCA (روش NIPALS) |
45569 | من در حال انجام یک اعتبارسنجی متقاطع با استفاده از روش ترک یک خروجی هستم. من یک پاسخ باینری دارم و از بسته بوت برای R و تابع cv.glm استفاده می کنم. مشکل من این است که بخش هزینه را در این تابع کاملاً درک نمی کنم. از آنچه من می توانم بفهمم این تابعی است که تصمیم می گیرد آیا یک مقدار تخمینی باید به عنوان 1 یا 0 طبقه بندی شود، یعنی مقدار آستانه برای طبقه بندی. آیا این درست است؟ و در کمک در R، آنها از این تابع برای یک مدل دوجمله ای استفاده می کنند: «هزینه <- تابع (r, pi = 0) mean(abs(r-pi) > 0.5)». چگونه این تابع را تفسیر کنم؟ بنابراین من می توانم آن را به درستی برای تجزیه و تحلیل خود اصلاح کنم. از هر کمکی قدردانی می شود، نمی خواهم از عملکردی استفاده کنم که من نمی فهمم. | تابع هزینه در cv.glm در بسته بوت R چیست؟ |
21062 | من یک سوال در مورد نرمال سازی در مورد استفاده از weighted last مربع دارم. منظور من از نرمال سازی، ستون ماتریس پیش بینی $X$ دارای واریانس واحد است. در مورد WOLS هر مشاهده $y_i$ و پیش بینی $x_i$ را با وزن $w_i$ وزن می کنم. $$\min\sum_{i=1}^n (w_i y_i - \beta w_i x_i))^2 $$ $$=\min (Y-\beta X)^t W (Y-\بتا X)$ $ در این مورد من یک مشکل رگرسیون جدید دارم: $$\min (Y'-\beta X')^t(Y'-\beta X')$$ سوال من این است که آیا $X$ را عادی کنم یا $X' دلار | نرمال سازی در رگرسیون حداقل مربعات وزنی |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.