
id int64 599M 3.29B | url stringlengths 58 61 | html_url stringlengths 46 51 | number int64 1 7.72k | title stringlengths 1 290 | state stringclasses 2
values | comments int64 0 70 | created_at timestamp[s]date 2020-04-14 10:18:02 2025-08-05 09:28:51 | updated_at timestamp[s]date 2020-04-27 16:04:17 2025-08-05 11:39:56 | closed_at timestamp[s]date 2020-04-14 12:01:40 2025-08-01 05:15:45 ⌀ | user_login stringlengths 3 26 | labels listlengths 0 4 | body stringlengths 0 228k ⌀ | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2,868,701,471 | https://api.github.com/repos/huggingface/datasets/issues/7418 | https://github.com/huggingface/datasets/issues/7418 | 7,418 | pyarrow.lib.arrowinvalid: cannot mix list and non-list, non-null values with map function | open | 5 | 2025-02-21T10:58:06 | 2025-07-11T13:06:10 | null | alexxchen | [] | ### Describe the bug
Encounter pyarrow.lib.arrowinvalid error with map function in some example when loading the dataset
### Steps to reproduce the bug
```
from datasets import load_dataset
from PIL import Image, PngImagePlugin
dataset = load_dataset("leonardPKU/GEOQA_R1V_Train_8K")
system_prompt="You are a helpful... | false |
2,866,868,922 | https://api.github.com/repos/huggingface/datasets/issues/7417 | https://github.com/huggingface/datasets/pull/7417 | 7,417 | set dev version | closed | 1 | 2025-02-20T17:45:29 | 2025-02-20T17:47:50 | 2025-02-20T17:45:36 | lhoestq | [] | null | true |
2,866,862,143 | https://api.github.com/repos/huggingface/datasets/issues/7416 | https://github.com/huggingface/datasets/pull/7416 | 7,416 | Release: 3.3.2 | closed | 1 | 2025-02-20T17:42:11 | 2025-02-20T17:44:35 | 2025-02-20T17:43:28 | lhoestq | [] | null | true |
2,865,774,546 | https://api.github.com/repos/huggingface/datasets/issues/7415 | https://github.com/huggingface/datasets/issues/7415 | 7,415 | Shard Dataset at specific indices | open | 3 | 2025-02-20T10:43:10 | 2025-02-24T11:06:45 | null | nikonikolov | [] | I have a dataset of sequences, where each example in the sequence is a separate row in the dataset (similar to LeRobotDataset). When running `Dataset.save_to_disk` how can I provide indices where it's possible to shard the dataset such that no episode spans more than 1 shard. Consequently, when I run `Dataset.load_from... | false |
2,863,798,756 | https://api.github.com/repos/huggingface/datasets/issues/7414 | https://github.com/huggingface/datasets/pull/7414 | 7,414 | Gracefully cancel async tasks | closed | 1 | 2025-02-19T16:10:58 | 2025-02-20T14:12:26 | 2025-02-20T14:12:23 | lhoestq | [] | null | true |
2,860,947,582 | https://api.github.com/repos/huggingface/datasets/issues/7413 | https://github.com/huggingface/datasets/issues/7413 | 7,413 | Documentation on multiple media files of the same type with WebDataset | open | 1 | 2025-02-18T16:13:20 | 2025-02-20T14:17:54 | null | DCNemesis | [] | The [current documentation](https://huggingface.co/docs/datasets/en/video_dataset) on a creating a video dataset includes only examples with one media file and one json. It would be useful to have examples where multiple files of the same type are included. For example, in a sign language dataset, you may have a base v... | false |
2,859,433,710 | https://api.github.com/repos/huggingface/datasets/issues/7412 | https://github.com/huggingface/datasets/issues/7412 | 7,412 | Index Error Invalid Ket is out of bounds for size 0 for code-search-net/code_search_net dataset | open | 0 | 2025-02-18T05:58:33 | 2025-02-18T06:42:07 | null | harshakhmk | [] | ### Describe the bug
I am trying to do model pruning on sentence-transformers/all-mini-L6-v2 for the code-search-net/code_search_net dataset using INCTrainer class
However I am getting below error
```
raise IndexError(f"Invalid Key: {key is our of bounds for size {size}")
IndexError: Invalid key: 1840208 is out of b... | false |
2,858,993,390 | https://api.github.com/repos/huggingface/datasets/issues/7411 | https://github.com/huggingface/datasets/pull/7411 | 7,411 | Attempt to fix multiprocessing hang by closing and joining the pool before termination | closed | 3 | 2025-02-17T23:58:03 | 2025-02-19T21:11:24 | 2025-02-19T13:40:32 | dakinggg | [] | https://github.com/huggingface/datasets/issues/6393 has plagued me on and off for a very long time. I have had various workarounds (one time combining two filter calls into one filter call removed the issue, another time making rank 0 go first resolved a cache race condition, one time i think upgrading the version of s... | true |
2,858,085,707 | https://api.github.com/repos/huggingface/datasets/issues/7410 | https://github.com/huggingface/datasets/pull/7410 | 7,410 | Set dev version | closed | 1 | 2025-02-17T14:54:39 | 2025-02-17T14:56:58 | 2025-02-17T14:54:56 | lhoestq | [] | null | true |
2,858,079,508 | https://api.github.com/repos/huggingface/datasets/issues/7409 | https://github.com/huggingface/datasets/pull/7409 | 7,409 | Release: 3.3.1 | closed | 1 | 2025-02-17T14:52:12 | 2025-02-17T14:54:32 | 2025-02-17T14:53:13 | lhoestq | [] | null | true |
2,858,012,313 | https://api.github.com/repos/huggingface/datasets/issues/7408 | https://github.com/huggingface/datasets/pull/7408 | 7,408 | Fix filter speed regression | closed | 1 | 2025-02-17T14:25:32 | 2025-02-17T14:28:48 | 2025-02-17T14:28:46 | lhoestq | [] | close https://github.com/huggingface/datasets/issues/7404 | true |
2,856,517,442 | https://api.github.com/repos/huggingface/datasets/issues/7407 | https://github.com/huggingface/datasets/pull/7407 | 7,407 | Update use_with_pandas.mdx: to_pandas() correction in last section | closed | 0 | 2025-02-17T01:53:31 | 2025-02-20T17:28:04 | 2025-02-20T17:28:04 | ibarrien | [] | last section ``to_pandas()" | true |
2,856,441,206 | https://api.github.com/repos/huggingface/datasets/issues/7406 | https://github.com/huggingface/datasets/issues/7406 | 7,406 | Adding Core Maintainer List to CONTRIBUTING.md | closed | 3 | 2025-02-17T00:32:40 | 2025-03-24T10:57:54 | 2025-03-24T10:57:54 | jp1924 | [
"enhancement"
] | ### Feature request
I propose adding a core maintainer list to the `CONTRIBUTING.md` file.
### Motivation
The Transformers and Liger-Kernel projects maintain lists of core maintainers for each module.
However, the Datasets project doesn't have such a list.
### Your contribution
I have nothing to add here. | false |
2,856,372,814 | https://api.github.com/repos/huggingface/datasets/issues/7405 | https://github.com/huggingface/datasets/issues/7405 | 7,405 | Lazy loading of environment variables | open | 1 | 2025-02-16T22:31:41 | 2025-02-17T15:17:18 | null | nikvaessen | [] | ### Describe the bug
Loading a `.env` file after an `import datasets` call does not correctly use the environment variables.
This is due the fact that environment variables are read at import time:
https://github.com/huggingface/datasets/blob/de062f0552a810c52077543c1169c38c1f0c53fc/src/datasets/config.py#L155C1-L15... | false |
2,856,366,207 | https://api.github.com/repos/huggingface/datasets/issues/7404 | https://github.com/huggingface/datasets/issues/7404 | 7,404 | Performance regression in `dataset.filter` | closed | 3 | 2025-02-16T22:19:14 | 2025-02-17T17:46:06 | 2025-02-17T14:28:48 | ttim | [] | ### Describe the bug
We're filtering dataset of ~1M (small-ish) records. At some point in the code we do `dataset.filter`, before (including 3.2.0) it was taking couple of seconds, and now it takes 4 hours.
We use 16 threads/workers, and stack trace at them look as follows:
```
Traceback (most recent call last):
Fi... | false |
2,855,880,858 | https://api.github.com/repos/huggingface/datasets/issues/7402 | https://github.com/huggingface/datasets/pull/7402 | 7,402 | Fix a typo in arrow_dataset.py | closed | 0 | 2025-02-16T04:52:02 | 2025-02-20T17:29:28 | 2025-02-20T17:29:28 | jingedawang | [] | "in the feature" should be "in the future" | true |
2,853,260,869 | https://api.github.com/repos/huggingface/datasets/issues/7401 | https://github.com/huggingface/datasets/pull/7401 | 7,401 | set dev version | closed | 1 | 2025-02-14T10:17:03 | 2025-02-14T10:19:20 | 2025-02-14T10:17:13 | lhoestq | [] | null | true |
2,853,098,442 | https://api.github.com/repos/huggingface/datasets/issues/7399 | https://github.com/huggingface/datasets/issues/7399 | 7,399 | Synchronize parameters for various datasets | open | 2 | 2025-02-14T09:15:11 | 2025-02-19T11:50:29 | null | grofte | [] | ### Describe the bug
[IterableDatasetDict](https://huggingface.co/docs/datasets/v3.2.0/en/package_reference/main_classes#datasets.IterableDatasetDict.map) map function is missing the `desc` parameter. You can see the equivalent map function for [Dataset here](https://huggingface.co/docs/datasets/v3.2.0/en/package_refe... | false |
2,853,097,869 | https://api.github.com/repos/huggingface/datasets/issues/7398 | https://github.com/huggingface/datasets/pull/7398 | 7,398 | Release: 3.3.0 | closed | 1 | 2025-02-14T09:15:03 | 2025-02-14T09:57:39 | 2025-02-14T09:57:37 | lhoestq | [] | null | true |
2,852,829,763 | https://api.github.com/repos/huggingface/datasets/issues/7397 | https://github.com/huggingface/datasets/pull/7397 | 7,397 | Kannada dataset(Conversations, Wikipedia etc) | closed | 1 | 2025-02-14T06:53:03 | 2025-02-20T17:28:54 | 2025-02-20T17:28:53 | Likhith2612 | [] | null | true |
2,853,201,277 | https://api.github.com/repos/huggingface/datasets/issues/7400 | https://github.com/huggingface/datasets/issues/7400 | 7,400 | 504 Gateway Timeout when uploading large dataset to Hugging Face Hub | open | 4 | 2025-02-14T02:18:35 | 2025-02-14T23:48:36 | null | hotchpotch | [] | ### Description
I encountered consistent 504 Gateway Timeout errors while attempting to upload a large dataset (approximately 500GB) to the Hugging Face Hub. The upload fails during the process with a Gateway Timeout error.
I will continue trying to upload. While it might succeed in future attempts, I wanted to report... | false |
2,851,716,755 | https://api.github.com/repos/huggingface/datasets/issues/7396 | https://github.com/huggingface/datasets/pull/7396 | 7,396 | Update README.md | closed | 1 | 2025-02-13T17:44:36 | 2025-02-13T17:46:57 | 2025-02-13T17:44:51 | lhoestq | [] | null | true |
2,851,575,160 | https://api.github.com/repos/huggingface/datasets/issues/7395 | https://github.com/huggingface/datasets/pull/7395 | 7,395 | Update docs | closed | 1 | 2025-02-13T16:43:15 | 2025-02-13T17:20:32 | 2025-02-13T17:20:30 | lhoestq | [] | - update min python version
- replace canonical dataset names with new names
- avoid examples with trust_remote_code | true |
2,847,172,115 | https://api.github.com/repos/huggingface/datasets/issues/7394 | https://github.com/huggingface/datasets/issues/7394 | 7,394 | Using load_dataset with data_files and split arguments yields an error | open | 0 | 2025-02-12T04:50:11 | 2025-02-12T04:50:11 | null | devon-research | [] | ### Describe the bug
It seems the list of valid splits recorded by the package becomes incorrectly overwritten when using the `data_files` argument.
If I run
```python
from datasets import load_dataset
load_dataset("allenai/super", split="all_examples", data_files="tasks/expert.jsonl")
```
then I get the error
```
Va... | false |
2,846,446,674 | https://api.github.com/repos/huggingface/datasets/issues/7393 | https://github.com/huggingface/datasets/pull/7393 | 7,393 | Optimized sequence encoding for scalars | closed | 1 | 2025-02-11T20:30:44 | 2025-02-13T17:11:33 | 2025-02-13T17:11:32 | lukasgd | [] | The change in https://github.com/huggingface/datasets/pull/3197 introduced redundant list-comprehensions when `obj` is a long sequence of scalars. This becomes a noticeable overhead when loading data from an `IterableDataset` in the function `_apply_feature_types_on_example` and can be eliminated by adding a check for ... | true |
2,846,095,043 | https://api.github.com/repos/huggingface/datasets/issues/7392 | https://github.com/huggingface/datasets/issues/7392 | 7,392 | push_to_hub payload too large error when using large ClassLabel feature | open | 1 | 2025-02-11T17:51:34 | 2025-02-11T18:01:31 | null | DavidRConnell | [] | ### Describe the bug
When using `datasets.DatasetDict.push_to_hub` an `HfHubHTTPError: 413 Client Error: Payload Too Large for url` is raised if the dataset contains a large `ClassLabel` feature. Even if the total size of the dataset is small.
### Steps to reproduce the bug
``` python
import random
import sys
impor... | false |
2,845,184,764 | https://api.github.com/repos/huggingface/datasets/issues/7391 | https://github.com/huggingface/datasets/issues/7391 | 7,391 | AttributeError: module 'pyarrow.lib' has no attribute 'ListViewType' | open | 0 | 2025-02-11T12:02:26 | 2025-02-11T12:02:26 | null | LinXin04 | [] | pyarrow 尝试了若干个版本都不可以 | false |
2,843,813,365 | https://api.github.com/repos/huggingface/datasets/issues/7390 | https://github.com/huggingface/datasets/issues/7390 | 7,390 | Re-add py.typed | open | 0 | 2025-02-10T22:12:52 | 2025-02-10T22:12:52 | null | NeilGirdhar | [
"enhancement"
] | ### Feature request
The motivation for removing py.typed no longer seems to apply. Would a solution like [this one](https://github.com/huggingface/huggingface_hub/pull/2752) work here?
### Motivation
MyPy support is broken. As more type checkers come out, such as RedKnot, these may also be broken. It would be goo... | false |
2,843,592,606 | https://api.github.com/repos/huggingface/datasets/issues/7389 | https://github.com/huggingface/datasets/issues/7389 | 7,389 | Getting statistics about filtered examples | closed | 2 | 2025-02-10T20:48:29 | 2025-02-11T20:44:15 | 2025-02-11T20:44:13 | jonathanasdf | [] | @lhoestq wondering if the team has thought about this and if there are any recommendations?
Currently when processing datasets some examples are bound to get filtered out, whether it's due to bad format, or length is too long, or any other custom filters that might be getting applied. Let's just focus on the filter by... | false |
2,843,188,499 | https://api.github.com/repos/huggingface/datasets/issues/7388 | https://github.com/huggingface/datasets/issues/7388 | 7,388 | OSError: [Errno 22] Invalid argument forbidden character | closed | 2 | 2025-02-10T17:46:31 | 2025-02-11T13:42:32 | 2025-02-11T13:42:30 | langflogit | [] | ### Describe the bug
I'm on Windows and i'm trying to load a datasets but i'm having title error because files in the repository are named with charactere like < >which can't be in a name file. Could it be possible to load this datasets but removing those charactere ?
### Steps to reproduce the bug
load_dataset("CAT... | false |
2,841,228,048 | https://api.github.com/repos/huggingface/datasets/issues/7387 | https://github.com/huggingface/datasets/issues/7387 | 7,387 | Dynamic adjusting dataloader sampling weight | open | 3 | 2025-02-10T03:18:47 | 2025-03-07T14:06:54 | null | whc688 | [] | Hi,
Thanks for your wonderful work! I'm wondering is there a way to dynamically adjust the sampling weight of each data in the dataset during training? Looking forward to your reply, thanks again. | false |
2,840,032,524 | https://api.github.com/repos/huggingface/datasets/issues/7386 | https://github.com/huggingface/datasets/issues/7386 | 7,386 | Add bookfolder Dataset Builder for Digital Book Formats | closed | 1 | 2025-02-08T14:27:55 | 2025-02-08T14:30:10 | 2025-02-08T14:30:09 | shikanime | [
"enhancement"
] | ### Feature request
This feature proposes adding a new dataset builder called bookfolder to the datasets library. This builder would allow users to easily load datasets consisting of various digital book formats, including: AZW, AZW3, CB7, CBR, CBT, CBZ, EPUB, MOBI, and PDF.
### Motivation
Currently, loading dataset... | false |
2,830,664,522 | https://api.github.com/repos/huggingface/datasets/issues/7385 | https://github.com/huggingface/datasets/pull/7385 | 7,385 | Make IterableDataset (optionally) resumable | open | 2 | 2025-02-04T15:55:33 | 2025-03-03T17:31:40 | null | yzhangcs | [] | ### What does this PR do?
This PR introduces a new `stateful` option to the `dataset.shuffle` method, which defaults to `False`.
When enabled, this option allows for resumable shuffling of `IterableDataset` instances, albeit with some additional memory overhead.
Key points:
* All tests have passed
* Docstrings ... | true |
2,828,208,828 | https://api.github.com/repos/huggingface/datasets/issues/7384 | https://github.com/huggingface/datasets/pull/7384 | 7,384 | Support async functions in map() | closed | 2 | 2025-02-03T18:18:40 | 2025-02-13T14:01:13 | 2025-02-13T14:00:06 | lhoestq | [] | e.g. to download images or call an inference API like HF or vLLM
```python
import asyncio
import random
from datasets import Dataset
async def f(x):
await asyncio.sleep(random.random())
ds = Dataset.from_dict({"data": range(100)})
ds.map(f)
# Map: 100%|█████████████████████████████| 100/100 [00:0... | true |
2,823,480,924 | https://api.github.com/repos/huggingface/datasets/issues/7382 | https://github.com/huggingface/datasets/pull/7382 | 7,382 | Add Pandas, PyArrow and Polars docs | closed | 1 | 2025-01-31T13:22:59 | 2025-01-31T16:30:59 | 2025-01-31T16:30:57 | lhoestq | [] | (also added the missing numpy docs and fixed a small bug in pyarrow formatting) | true |
2,815,649,092 | https://api.github.com/repos/huggingface/datasets/issues/7381 | https://github.com/huggingface/datasets/issues/7381 | 7,381 | Iterating over values of a column in the IterableDataset | closed | 11 | 2025-01-28T13:17:36 | 2025-05-22T18:00:04 | 2025-05-22T18:00:04 | TopCoder2K | [
"enhancement"
] | ### Feature request
I would like to be able to iterate (and re-iterate if needed) over a column of an `IterableDataset` instance. The following example shows the supposed API:
```python
def gen():
yield {"text": "Good", "label": 0}
yield {"text": "Bad", "label": 1}
ds = IterableDataset.from_generator(gen)
tex... | false |
2,811,566,116 | https://api.github.com/repos/huggingface/datasets/issues/7380 | https://github.com/huggingface/datasets/pull/7380 | 7,380 | fix: dill default for version bigger 0.3.8 | closed | 1 | 2025-01-26T13:37:16 | 2025-03-13T20:40:19 | 2025-03-13T20:40:19 | sam-hey | [] | Fixes def log for dill version >= 0.3.9
https://pypi.org/project/dill/
This project uses dill with the release of version 0.3.9 the datasets lib. | true |
2,802,957,388 | https://api.github.com/repos/huggingface/datasets/issues/7378 | https://github.com/huggingface/datasets/issues/7378 | 7,378 | Allow pushing config version to hub | open | 1 | 2025-01-21T22:35:07 | 2025-01-30T13:56:56 | null | momeara | [
"enhancement"
] | ### Feature request
Currently, when datasets are created, they can be versioned by passing the `version` argument to `load_dataset(...)`. For example creating `outcomes.csv` on the command line
```
echo "id,value\n1,0\n2,0\n3,1\n4,1\n" > outcomes.csv
```
and creating it
```
import datasets
dataset = datasets.load_dat... | false |
2,802,723,285 | https://api.github.com/repos/huggingface/datasets/issues/7377 | https://github.com/huggingface/datasets/issues/7377 | 7,377 | Support for sparse arrays with the Arrow Sparse Tensor format? | open | 1 | 2025-01-21T20:14:35 | 2025-01-30T14:06:45 | null | JulesGM | [
"enhancement"
] | ### Feature request
AI in biology is becoming a big thing. One thing that would be a huge benefit to the field that Huggingface Datasets doesn't currently have is native support for **sparse arrays**.
Arrow has support for sparse tensors.
https://arrow.apache.org/docs/format/Other.html#sparse-tensor
It would be ... | false |
2,802,621,104 | https://api.github.com/repos/huggingface/datasets/issues/7376 | https://github.com/huggingface/datasets/pull/7376 | 7,376 | [docs] uv install | closed | 0 | 2025-01-21T19:15:48 | 2025-03-14T20:16:35 | 2025-03-14T20:16:35 | stevhliu | [] | Proposes adding uv to installation docs (see Slack thread [here](https://huggingface.slack.com/archives/C01N44FJDHT/p1737377177709279) for more context) if you're interested! | true |
2,800,609,218 | https://api.github.com/repos/huggingface/datasets/issues/7375 | https://github.com/huggingface/datasets/issues/7375 | 7,375 | vllm批量推理报错 | open | 1 | 2025-01-21T03:22:23 | 2025-01-30T14:02:40 | null | YuShengzuishuai | [] | ### Describe the bug

### Steps to reproduce the bug
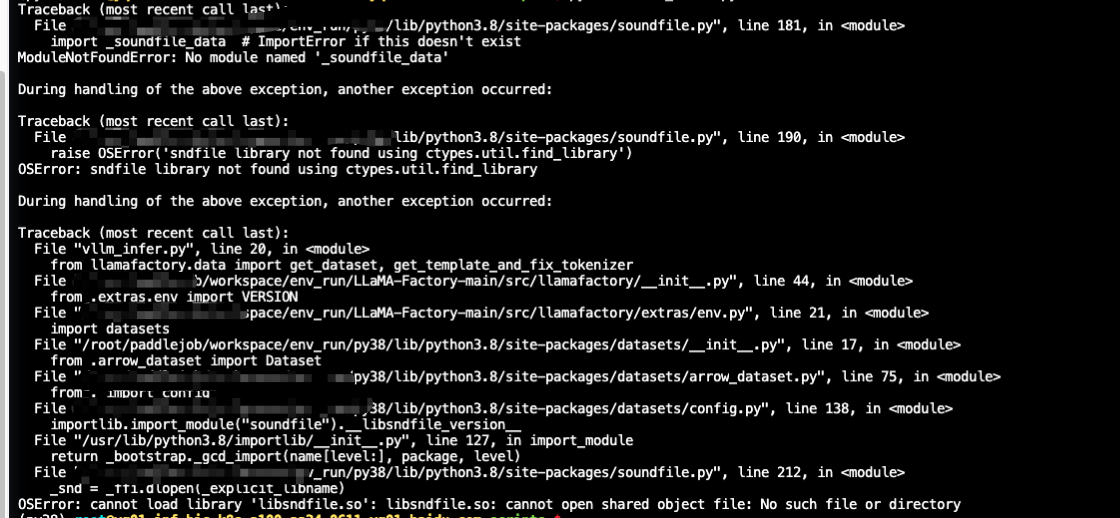
### Expected behavior
 | true |
2,793,237,139 | https://api.github.com/repos/huggingface/datasets/issues/7373 | https://github.com/huggingface/datasets/issues/7373 | 7,373 | Excessive RAM Usage After Dataset Concatenation concatenate_datasets | open | 3 | 2025-01-16T16:33:10 | 2025-03-27T17:40:59 | null | sam-hey | [] | ### Describe the bug
When loading a dataset from disk, concatenating it, and starting the training process, the RAM usage progressively increases until the kernel terminates the process due to excessive memory consumption.
https://github.com/huggingface/datasets/issues/2276
### Steps to reproduce the bug
```python
... | false |
2,791,760,968 | https://api.github.com/repos/huggingface/datasets/issues/7372 | https://github.com/huggingface/datasets/issues/7372 | 7,372 | Inconsistent Behavior Between `load_dataset` and `load_from_disk` When Loading Sharded Datasets | open | 0 | 2025-01-16T05:47:20 | 2025-01-16T05:47:20 | null | gaohongkui | [] | ### Description
I encountered an inconsistency in behavior between `load_dataset` and `load_from_disk` when loading sharded datasets. Here is a minimal example to reproduce the issue:
#### Code 1: Using `load_dataset`
```python
from datasets import Dataset, load_dataset
# First save with max_shard_size=10
Dataset.fr... | false |
2,790,549,889 | https://api.github.com/repos/huggingface/datasets/issues/7371 | https://github.com/huggingface/datasets/issues/7371 | 7,371 | 500 Server error with pushing a dataset | open | 1 | 2025-01-15T18:23:02 | 2025-01-15T20:06:05 | null | martinmatak | [] | ### Describe the bug
Suddenly, I started getting this error message saying it was an internal error.
`Error creating/pushing dataset: 500 Server Error: Internal Server Error for url: https://huggingface.co/api/datasets/ll4ma-lab/grasp-dataset/commit/main (Request ID: Root=1-6787f0b7-66d5bd45413e481c4c2fb22d;670d04ff-... | false |
2,787,972,786 | https://api.github.com/repos/huggingface/datasets/issues/7370 | https://github.com/huggingface/datasets/pull/7370 | 7,370 | Support faster processing using pandas or polars functions in `IterableDataset.map()` | closed | 2 | 2025-01-14T18:14:13 | 2025-01-31T11:08:15 | 2025-01-30T13:30:57 | lhoestq | [] | Following the polars integration :)
Allow super fast processing using pandas or polars functions in `IterableDataset.map()` by adding support to pandas and polars formatting in `IterableDataset`
```python
import polars as pl
from datasets import Dataset
ds = Dataset.from_dict({"i": range(10)}).to_iterable_da... | true |
2,787,193,238 | https://api.github.com/repos/huggingface/datasets/issues/7369 | https://github.com/huggingface/datasets/issues/7369 | 7,369 | Importing dataset gives unhelpful error message when filenames in metadata.csv are not found in the directory | open | 1 | 2025-01-14T13:53:21 | 2025-01-14T15:05:51 | null | svencornetsdegroot | [] | ### Describe the bug
While importing an audiofolder dataset, where the names of the audiofiles don't correspond to the filenames in the metadata.csv, we get an unclear error message that is not helpful for the debugging, i.e.
```
ValueError: Instruction "train" corresponds to no data!
```
### Steps to reproduce the ... | false |
2,784,272,477 | https://api.github.com/repos/huggingface/datasets/issues/7368 | https://github.com/huggingface/datasets/pull/7368 | 7,368 | Add with_split to DatasetDict.map | closed | 9 | 2025-01-13T15:09:56 | 2025-03-08T05:45:02 | 2025-03-07T14:09:52 | jp1924 | [] | #7356 | true |
2,781,522,894 | https://api.github.com/repos/huggingface/datasets/issues/7366 | https://github.com/huggingface/datasets/issues/7366 | 7,366 | Dataset.from_dict() can't handle large dict | open | 0 | 2025-01-11T02:05:21 | 2025-01-11T02:05:21 | null | CSU-OSS | [] | ### Describe the bug
I have 26,000,000 3-tuples. When I use Dataset.from_dict() to load, neither. py nor Jupiter notebook can run successfully. This is my code:
```
# len(example_data) is 26,000,000, 'diff' is a text
diff1_list = [example_data[i].texts[0] for i in range(len(example_data))]
diff2_list =... | false |
2,780,216,199 | https://api.github.com/repos/huggingface/datasets/issues/7365 | https://github.com/huggingface/datasets/issues/7365 | 7,365 | A parameter is specified but not used in datasets.arrow_dataset.Dataset.from_pandas() | open | 0 | 2025-01-10T13:39:33 | 2025-01-10T13:39:33 | null | NourOM02 | [] | ### Describe the bug
I am interested in creating train, test and eval splits from a pandas Dataframe, therefore I was looking at the possibilities I can follow. I noticed the split parameter and was hopeful to use it in order to generate the 3 at once, however, while trying to understand the code, i noticed that it ha... | false |
2,776,929,268 | https://api.github.com/repos/huggingface/datasets/issues/7364 | https://github.com/huggingface/datasets/issues/7364 | 7,364 | API endpoints for gated dataset access requests | closed | 3 | 2025-01-09T06:21:20 | 2025-01-09T11:17:40 | 2025-01-09T11:17:20 | jerome-white | [
"enhancement"
] | ### Feature request
I would like a programatic way of requesting access to gated datasets. The current solution to gain access forces me to visit a website and physically click an "agreement" button (as per the [documentation](https://huggingface.co/docs/hub/en/datasets-gated#access-gated-datasets-as-a-user)).
An i... | false |
2,774,090,012 | https://api.github.com/repos/huggingface/datasets/issues/7363 | https://github.com/huggingface/datasets/issues/7363 | 7,363 | ImportError: To support decoding images, please install 'Pillow'. | open | 4 | 2025-01-08T02:22:57 | 2025-05-28T14:56:53 | null | jamessdixon | [] | ### Describe the bug
Following this tutorial locally using a macboko and VSCode: https://huggingface.co/docs/diffusers/en/tutorials/basic_training
This line of code: for i, image in enumerate(dataset[:4]["image"]):
throws: ImportError: To support decoding images, please install 'Pillow'.
Pillow is installed.
###... | false |
2,773,731,829 | https://api.github.com/repos/huggingface/datasets/issues/7362 | https://github.com/huggingface/datasets/issues/7362 | 7,362 | HuggingFace CLI dataset download raises error | closed | 3 | 2025-01-07T21:03:30 | 2025-01-08T15:00:37 | 2025-01-08T14:35:52 | ajayvohra2005 | [] | ### Describe the bug
Trying to download Hugging Face datasets using Hugging Face CLI raises error. This error only started after December 27th, 2024. For example:
```
huggingface-cli download --repo-type dataset gboleda/wikicorpus
Traceback (most recent call last):
File "/home/ubuntu/test_venv/bin/huggingface... | false |
2,771,859,244 | https://api.github.com/repos/huggingface/datasets/issues/7361 | https://github.com/huggingface/datasets/pull/7361 | 7,361 | Fix lock permission | open | 0 | 2025-01-07T04:15:53 | 2025-01-07T04:49:46 | null | cih9088 | [] | All files except lock file have proper permission obeying `ACL` property if it is set.
If the cache directory has `ACL` property, it should be respected instead of just using `umask` for permission.
To fix it, just create a lock file and pass the created `mode`.
By creating a lock file with `touch()` before `Fil... | true |
2,771,751,406 | https://api.github.com/repos/huggingface/datasets/issues/7360 | https://github.com/huggingface/datasets/issues/7360 | 7,360 | error when loading dataset in Hugging Face: NoneType error is not callable | open | 5 | 2025-01-07T02:11:36 | 2025-02-24T13:32:52 | null | nanu23333 | [] | ### Describe the bug
I met an error when running a notebook provide by Hugging Face, and met the error.
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[2], line 5
3 # Load the enhancers dat... | false |
2,771,137,842 | https://api.github.com/repos/huggingface/datasets/issues/7359 | https://github.com/huggingface/datasets/issues/7359 | 7,359 | There are multiple 'mteb/arguana' configurations in the cache: default, corpus, queries with HF_HUB_OFFLINE=1 | open | 1 | 2025-01-06T17:42:49 | 2025-01-06T17:43:31 | null | Bhavya6187 | [] | ### Describe the bug
Hey folks,
I am trying to run this code -
```python
from datasets import load_dataset, get_dataset_config_names
ds = load_dataset("mteb/arguana")
```
with HF_HUB_OFFLINE=1
But I get the following error -
```python
Using the latest cached version of the dataset since mteb/arguana... | false |
2,770,927,769 | https://api.github.com/repos/huggingface/datasets/issues/7358 | https://github.com/huggingface/datasets/pull/7358 | 7,358 | Fix remove_columns in the formatted case | open | 1 | 2025-01-06T15:44:23 | 2025-01-06T15:46:46 | null | lhoestq | [] | `remove_columns` had no effect when running a function in `.map()` on dataset that is formatted
This aligns the logic of `map()` with the non formatted case and also with with https://github.com/huggingface/datasets/pull/7353 | true |
2,770,456,127 | https://api.github.com/repos/huggingface/datasets/issues/7357 | https://github.com/huggingface/datasets/issues/7357 | 7,357 | Python process aborded with GIL issue when using image dataset | open | 1 | 2025-01-06T11:29:30 | 2025-03-08T15:59:36 | null | AlexKoff88 | [] | ### Describe the bug
The issue is visible only with the latest `datasets==3.2.0`.
When using image dataset the Python process gets aborted right before the exit with the following error:
```
Fatal Python error: PyGILState_Release: thread state 0x7fa1f409ade0 must be current when releasing
Python runtime state: f... | false |
2,770,095,103 | https://api.github.com/repos/huggingface/datasets/issues/7356 | https://github.com/huggingface/datasets/issues/7356 | 7,356 | How about adding a feature to pass the key when performing map on DatasetDict? | closed | 6 | 2025-01-06T08:13:52 | 2025-03-24T10:57:47 | 2025-03-24T10:57:47 | jp1924 | [
"enhancement"
] | ### Feature request
Add a feature to pass the key of the DatasetDict when performing map
### Motivation
I often preprocess using map on DatasetDict.
Sometimes, I need to preprocess train and valid data differently depending on the task.
So, I thought it would be nice to pass the key (like train, valid) when perf... | false |
2,768,958,211 | https://api.github.com/repos/huggingface/datasets/issues/7355 | https://github.com/huggingface/datasets/issues/7355 | 7,355 | Not available datasets[audio] on python 3.13 | open | 3 | 2025-01-04T18:37:08 | 2025-06-28T00:26:19 | null | sergiosinlimites | [] | ### Describe the bug
This is the error I got, it seems numba package does not support python 3.13
PS C:\Users\sergi\Documents> pip install datasets[audio]
Defaulting to user installation because normal site-packages is not writeable
Collecting datasets[audio]
Using cached datasets-3.2.0-py3-none-any.whl.metada... | false |
2,768,955,917 | https://api.github.com/repos/huggingface/datasets/issues/7354 | https://github.com/huggingface/datasets/issues/7354 | 7,354 | A module that was compiled using NumPy 1.x cannot be run in NumPy 2.0.2 as it may crash. To support both 1.x and 2.x versions of NumPy, modules must be compiled with NumPy 2.0. Some module may need to rebuild instead e.g. with 'pybind11>=2.12'. | closed | 1 | 2025-01-04T18:30:17 | 2025-01-08T02:20:58 | 2025-01-08T02:20:58 | jamessdixon | [] | ### Describe the bug
Following this tutorial: https://huggingface.co/docs/diffusers/en/tutorials/basic_training and running it locally using VSCode on my MacBook. The first line in the tutorial fails: from datasets import load_dataset
dataset = load_dataset('huggan/smithsonian_butterflies_subset', split="train"). w... | false |
2,768,484,726 | https://api.github.com/repos/huggingface/datasets/issues/7353 | https://github.com/huggingface/datasets/pull/7353 | 7,353 | changes to MappedExamplesIterable to resolve #7345 | closed | 2 | 2025-01-04T06:01:15 | 2025-01-07T11:56:41 | 2025-01-07T11:56:41 | vttrifonov | [] | modified `MappedExamplesIterable` and `test_iterable_dataset.py::test_mapped_examples_iterable_with_indices`
fix #7345
@lhoestq | true |
2,767,763,850 | https://api.github.com/repos/huggingface/datasets/issues/7352 | https://github.com/huggingface/datasets/pull/7352 | 7,352 | fsspec 2024.12.0 | closed | 1 | 2025-01-03T15:32:25 | 2025-01-03T15:34:54 | 2025-01-03T15:34:11 | lhoestq | [] | null | true |
2,767,731,707 | https://api.github.com/repos/huggingface/datasets/issues/7350 | https://github.com/huggingface/datasets/pull/7350 | 7,350 | Bump hfh to 0.24 to fix ci | closed | 1 | 2025-01-03T15:09:40 | 2025-01-03T15:12:17 | 2025-01-03T15:10:27 | lhoestq | [] | null | true |
2,767,670,454 | https://api.github.com/repos/huggingface/datasets/issues/7349 | https://github.com/huggingface/datasets/pull/7349 | 7,349 | Webdataset special columns in last position | closed | 1 | 2025-01-03T14:32:15 | 2025-01-03T14:34:39 | 2025-01-03T14:32:30 | lhoestq | [] | Place columns "__key__" and "__url__" in last position in the Dataset Viewer since they are not the main content
before:
<img width="1012" alt="image" src="https://github.com/user-attachments/assets/b556c1fe-2674-4ba0-9643-c074aa9716fd" />
| true |
2,766,128,230 | https://api.github.com/repos/huggingface/datasets/issues/7348 | https://github.com/huggingface/datasets/pull/7348 | 7,348 | Catch OSError for arrow | closed | 1 | 2025-01-02T14:30:00 | 2025-01-09T14:25:06 | 2025-01-09T14:25:04 | lhoestq | [] | fixes https://github.com/huggingface/datasets/issues/7346
(also updated `ruff` and appleid style changes) | true |
2,760,282,339 | https://api.github.com/repos/huggingface/datasets/issues/7347 | https://github.com/huggingface/datasets/issues/7347 | 7,347 | Converting Arrow to WebDataset TAR Format for Offline Use | closed | 4 | 2024-12-27T01:40:44 | 2024-12-31T17:38:00 | 2024-12-28T15:38:03 | katie312 | [
"enhancement"
] | ### Feature request
Hi,
I've downloaded an Arrow-formatted dataset offline using the hugggingface's datasets library by:
```
import json
from datasets import load_dataset
dataset = load_dataset("pixparse/cc3m-wds")
dataset.save_to_disk("./cc3m_1")
```
now I need to convert it to WebDataset's TAR form... | false |
2,758,752,118 | https://api.github.com/repos/huggingface/datasets/issues/7346 | https://github.com/huggingface/datasets/issues/7346 | 7,346 | OSError: Invalid flatbuffers message. | closed | 3 | 2024-12-25T11:38:52 | 2025-01-09T14:25:29 | 2025-01-09T14:25:05 | antecede | [] | ### Describe the bug
When loading a large 2D data (1000 × 1152) with a large number of (2,000 data in this case) in `load_dataset`, the error message `OSError: Invalid flatbuffers message` is reported.
When only 300 pieces of data of this size (1000 × 1152) are stored, they can be loaded correctly.
When 2,00... | false |
2,758,585,709 | https://api.github.com/repos/huggingface/datasets/issues/7345 | https://github.com/huggingface/datasets/issues/7345 | 7,345 | Different behaviour of IterableDataset.map vs Dataset.map with remove_columns | closed | 1 | 2024-12-25T07:36:48 | 2025-01-07T11:56:42 | 2025-01-07T11:56:42 | vttrifonov | [] | ### Describe the bug
The following code
```python
import datasets as hf
ds1 = hf.Dataset.from_list([{'i': i} for i in [0,1]])
#ds1 = ds1.to_iterable_dataset()
ds2 = ds1.map(
lambda i: {'i': i+1},
input_columns = ['i'],
remove_columns = ['i']
)
list(ds2)
```
produces
```python
[{'i': ... | false |
2,754,735,951 | https://api.github.com/repos/huggingface/datasets/issues/7344 | https://github.com/huggingface/datasets/issues/7344 | 7,344 | HfHubHTTPError: 429 Client Error: Too Many Requests for URL when trying to access SlimPajama-627B or c4 on TPUs | closed | 2 | 2024-12-22T16:30:07 | 2025-01-15T05:32:00 | 2025-01-15T05:31:58 | clankur | [] | ### Describe the bug
I am trying to run some trainings on Google's TPUs using Huggingface's DataLoader on [SlimPajama-627B](https://huggingface.co/datasets/cerebras/SlimPajama-627B) and [c4](https://huggingface.co/datasets/allenai/c4), but I end up running into `429 Client Error: Too Many Requests for URL` error when ... | false |
2,750,525,823 | https://api.github.com/repos/huggingface/datasets/issues/7343 | https://github.com/huggingface/datasets/issues/7343 | 7,343 | [Bug] Inconsistent behavior of data_files and data_dir in load_dataset method. | closed | 4 | 2024-12-19T14:31:27 | 2025-01-03T15:54:09 | 2025-01-03T15:54:09 | JasonCZH4 | [] | ### Describe the bug
Inconsistent operation of data_files and data_dir in load_dataset method.
### Steps to reproduce the bug
# First
I have three files, named 'train.json', 'val.json', 'test.json'.
Each one has a simple dict `{text:'aaa'}`.
Their path are `/data/train.json`, `/data/val.json`, `/data/test.jso... | false |
2,749,572,310 | https://api.github.com/repos/huggingface/datasets/issues/7342 | https://github.com/huggingface/datasets/pull/7342 | 7,342 | Update LICENSE | closed | 1 | 2024-12-19T08:17:50 | 2024-12-19T08:44:08 | 2024-12-19T08:44:08 | eliebak | [] | null | true |
2,745,658,561 | https://api.github.com/repos/huggingface/datasets/issues/7341 | https://github.com/huggingface/datasets/pull/7341 | 7,341 | minor video docs on how to install | closed | 1 | 2024-12-17T18:06:17 | 2024-12-17T18:11:17 | 2024-12-17T18:11:15 | lhoestq | [] | null | true |
2,745,473,274 | https://api.github.com/repos/huggingface/datasets/issues/7340 | https://github.com/huggingface/datasets/pull/7340 | 7,340 | don't import soundfile in tests | closed | 1 | 2024-12-17T16:49:55 | 2024-12-17T16:54:04 | 2024-12-17T16:50:24 | lhoestq | [] | null | true |
2,745,460,060 | https://api.github.com/repos/huggingface/datasets/issues/7339 | https://github.com/huggingface/datasets/pull/7339 | 7,339 | Update CONTRIBUTING.md | closed | 1 | 2024-12-17T16:45:25 | 2024-12-17T16:51:36 | 2024-12-17T16:46:30 | lhoestq | [] | null | true |
2,744,877,569 | https://api.github.com/repos/huggingface/datasets/issues/7337 | https://github.com/huggingface/datasets/issues/7337 | 7,337 | One or several metadata.jsonl were found, but not in the same directory or in a parent directory of | open | 1 | 2024-12-17T12:58:43 | 2025-01-03T15:28:13 | null | mst272 | [] | ### Describe the bug
ImageFolder with metadata.jsonl error. I downloaded liuhaotian/LLaVA-CC3M-Pretrain-595K locally from Hugging Face. According to the tutorial in https://huggingface.co/docs/datasets/image_dataset#image-captioning, only put images.zip and metadata.jsonl containing information in the same folder. How... | false |
2,744,746,456 | https://api.github.com/repos/huggingface/datasets/issues/7336 | https://github.com/huggingface/datasets/issues/7336 | 7,336 | Clarify documentation or Create DatasetCard | open | 0 | 2024-12-17T12:01:00 | 2024-12-17T12:01:00 | null | August-murr | [
"enhancement"
] | ### Feature request
I noticed that you can use a Model Card instead of a Dataset Card when pushing a dataset to the Hub, but this isn’t clearly mentioned in [the docs.](https://huggingface.co/docs/datasets/dataset_card)
- Update the docs to clarify that a Model Card can work for datasets too.
- It might be worth c... | false |
2,743,437,260 | https://api.github.com/repos/huggingface/datasets/issues/7335 | https://github.com/huggingface/datasets/issues/7335 | 7,335 | Too many open files: '/root/.cache/huggingface/token' | open | 0 | 2024-12-16T21:30:24 | 2024-12-16T21:30:24 | null | kopyl | [] | ### Describe the bug
I ran this code:
```
from datasets import load_dataset
dataset = load_dataset("common-canvas/commoncatalog-cc-by", cache_dir="/datadrive/datasets/cc", num_proc=1000)
```
And got this error.
Before it was some other file though (lie something...incomplete)
runnting
```
ulimit -n 8192
... | false |
2,740,266,503 | https://api.github.com/repos/huggingface/datasets/issues/7334 | https://github.com/huggingface/datasets/issues/7334 | 7,334 | TypeError: Value.__init__() missing 1 required positional argument: 'dtype' | open | 3 | 2024-12-15T04:08:46 | 2025-07-10T03:32:36 | null | ghost | [] | ### Describe the bug
ds = load_dataset(
"./xxx.py",
name="default",
split="train",
)
The datasets does not support debugging locally anymore...
### Steps to reproduce the bug
```
from datasets import load_dataset
ds = load_dataset(
"./repo.py",
name="default",
split="train",
)
... | false |
2,738,626,593 | https://api.github.com/repos/huggingface/datasets/issues/7328 | https://github.com/huggingface/datasets/pull/7328 | 7,328 | Fix typo in arrow_dataset | closed | 1 | 2024-12-13T15:17:09 | 2024-12-19T17:10:27 | 2024-12-19T17:10:25 | AndreaFrancis | [] | null | true |
2,738,514,909 | https://api.github.com/repos/huggingface/datasets/issues/7327 | https://github.com/huggingface/datasets/issues/7327 | 7,327 | .map() is not caching and ram goes OOM | open | 1 | 2024-12-13T14:22:56 | 2025-02-10T10:42:38 | null | simeneide | [] | ### Describe the bug
Im trying to run a fairly simple map that is converting a dataset into numpy arrays. however, it just piles up on memory and doesnt write to disk. Ive tried multiple cache techniques such as specifying the cache dir, setting max mem, +++ but none seem to work. What am I missing here?
### Steps to... | false |
2,738,188,902 | https://api.github.com/repos/huggingface/datasets/issues/7326 | https://github.com/huggingface/datasets/issues/7326 | 7,326 | Remove upper bound for fsspec | open | 1 | 2024-12-13T11:35:12 | 2025-01-03T15:34:37 | null | fellhorn | [] | ### Describe the bug
As also raised by @cyyever in https://github.com/huggingface/datasets/pull/7296 and @NeilGirdhar in https://github.com/huggingface/datasets/commit/d5468836fe94e8be1ae093397dd43d4a2503b926#commitcomment-140952162 , `datasets` has a problematic version constraint on `fsspec`.
In our case this c... | false |
2,736,618,054 | https://api.github.com/repos/huggingface/datasets/issues/7325 | https://github.com/huggingface/datasets/pull/7325 | 7,325 | Introduce pdf support (#7318) | closed | 3 | 2024-12-12T18:31:18 | 2025-03-18T14:00:36 | 2025-03-18T14:00:36 | yabramuvdi | [] | First implementation of the Pdf feature to support pdfs (#7318) . Using [pdfplumber](https://github.com/jsvine/pdfplumber?tab=readme-ov-file#python-library) as the default library to work with pdfs.
@lhoestq and @AndreaFrancis | true |
2,736,008,698 | https://api.github.com/repos/huggingface/datasets/issues/7323 | https://github.com/huggingface/datasets/issues/7323 | 7,323 | Unexpected cache behaviour using load_dataset | closed | 1 | 2024-12-12T14:03:00 | 2025-01-31T11:34:24 | 2025-01-31T11:34:24 | Moritz-Wirth | [] | ### Describe the bug
Following the (Cache management)[https://huggingface.co/docs/datasets/en/cache] docu and previous behaviour from datasets version 2.18.0, one is able to change the cache directory. Previously, all downloaded/extracted/etc files were found in this folder. As i have recently update to the latest v... | false |
2,732,254,868 | https://api.github.com/repos/huggingface/datasets/issues/7322 | https://github.com/huggingface/datasets/issues/7322 | 7,322 | ArrowInvalid: JSON parse error: Column() changed from object to array in row 0 | open | 4 | 2024-12-11T08:41:39 | 2025-07-15T13:06:55 | null | Polarisamoon | [] | ### Describe the bug
Encountering an error while loading the ```liuhaotian/LLaVA-Instruct-150K dataset```.
### Steps to reproduce the bug
```
from datasets import load_dataset
fw =load_dataset("liuhaotian/LLaVA-Instruct-150K")
```
Error:
```
ArrowInvalid Traceback (most recen... | false |
2,731,626,760 | https://api.github.com/repos/huggingface/datasets/issues/7321 | https://github.com/huggingface/datasets/issues/7321 | 7,321 | ImportError: cannot import name 'set_caching_enabled' from 'datasets' | open | 2 | 2024-12-11T01:58:46 | 2024-12-11T13:32:15 | null | sankexin | [] | ### Describe the bug
Traceback (most recent call last):
File "/usr/local/lib/python3.10/runpy.py", line 187, in _run_module_as_main
mod_name, mod_spec, code = _get_module_details(mod_name, _Error)
File "/usr/local/lib/python3.10/runpy.py", line 110, in _get_module_details
__import__(pkg_name)
File "... | false |
2,731,112,100 | https://api.github.com/repos/huggingface/datasets/issues/7320 | https://github.com/huggingface/datasets/issues/7320 | 7,320 | ValueError: You should supply an encoding or a list of encodings to this method that includes input_ids, but you provided ['label'] | closed | 1 | 2024-12-10T20:23:11 | 2024-12-10T23:22:23 | 2024-12-10T23:22:23 | atrompeterog | [] | ### Describe the bug
I am trying to create a PEFT model from DISTILBERT model, and run a training loop. However, the trainer.train() is giving me this error: ValueError: You should supply an encoding or a list of encodings to this method that includes input_ids, but you provided ['label']
Here is my code:
### St... | false |
2,730,679,980 | https://api.github.com/repos/huggingface/datasets/issues/7319 | https://github.com/huggingface/datasets/pull/7319 | 7,319 | set dev version | closed | 1 | 2024-12-10T17:01:34 | 2024-12-10T17:04:04 | 2024-12-10T17:01:45 | lhoestq | [] | null | true |
2,730,676,278 | https://api.github.com/repos/huggingface/datasets/issues/7318 | https://github.com/huggingface/datasets/issues/7318 | 7,318 | Introduce support for PDFs | open | 6 | 2024-12-10T16:59:48 | 2024-12-12T18:38:13 | null | yabramuvdi | [
"enhancement"
] | ### Feature request
The idea (discussed in the Discord server with @lhoestq ) is to have a Pdf type like Image/Audio/Video. For example [Video](https://github.com/huggingface/datasets/blob/main/src/datasets/features/video.py) was recently added and contains how to decode a video file encoded in a dictionary like {"pat... | false |
2,730,661,237 | https://api.github.com/repos/huggingface/datasets/issues/7317 | https://github.com/huggingface/datasets/pull/7317 | 7,317 | Release: 3.2.0 | closed | 1 | 2024-12-10T16:53:20 | 2024-12-10T16:56:58 | 2024-12-10T16:56:56 | lhoestq | [] | null | true |
2,730,196,085 | https://api.github.com/repos/huggingface/datasets/issues/7316 | https://github.com/huggingface/datasets/pull/7316 | 7,316 | More docs to from_dict to mention that the result lives in RAM | closed | 1 | 2024-12-10T13:56:01 | 2024-12-10T13:58:32 | 2024-12-10T13:57:02 | lhoestq | [] | following discussions at https://discuss.huggingface.co/t/how-to-load-this-simple-audio-data-set-and-use-dataset-map-without-memory-issues/17722/14 | true |
2,727,502,630 | https://api.github.com/repos/huggingface/datasets/issues/7314 | https://github.com/huggingface/datasets/pull/7314 | 7,314 | Resolved for empty datafiles | open | 2 | 2024-12-09T15:47:22 | 2024-12-27T18:20:21 | null | sahillihas | [] | Resolved for Issue#6152 | true |
2,726,240,634 | https://api.github.com/repos/huggingface/datasets/issues/7313 | https://github.com/huggingface/datasets/issues/7313 | 7,313 | Cannot create a dataset with relative audio path | open | 4 | 2024-12-09T07:34:20 | 2025-04-19T07:13:08 | null | sedol1339 | [] | ### Describe the bug
Hello! I want to create a dataset of parquet files, with audios stored as separate .mp3 files. However, it says "No such file or directory" (see the reproducing code).
### Steps to reproduce the bug
Creating a dataset
```
from pathlib import Path
from datasets import Dataset, load_datas... | false |
2,725,103,094 | https://api.github.com/repos/huggingface/datasets/issues/7312 | https://github.com/huggingface/datasets/pull/7312 | 7,312 | [Audio Features - DO NOT MERGE] PoC for adding an offset+sliced reading to audio file. | open | 0 | 2024-12-08T10:27:31 | 2024-12-08T10:27:31 | null | TParcollet | [] | This is a proof of concept for #7310 . The idea is to enable the access to others column of the dataset row when loading an audio file into a table. This is to allow sliced reading. As stated in the issue, many people have very long audio files and use start and stop slicing in this audio file.
Right now, this code ... | true |
2,725,002,630 | https://api.github.com/repos/huggingface/datasets/issues/7311 | https://github.com/huggingface/datasets/issues/7311 | 7,311 | How to get the original dataset name with username? | open | 2 | 2024-12-08T07:18:14 | 2025-01-09T10:48:02 | null | npuichigo | [
"enhancement"
] | ### Feature request
The issue is related to ray data https://github.com/ray-project/ray/issues/49008 which it requires to check if the dataset is the original one just after `load_dataset` and parquet files are already available on hf hub.
The solution used now is to get the dataset name, config and split, then `... | false |
2,724,830,603 | https://api.github.com/repos/huggingface/datasets/issues/7310 | https://github.com/huggingface/datasets/issues/7310 | 7,310 | Enable the Audio Feature to decode / read with an offset + duration | open | 2 | 2024-12-07T22:01:44 | 2024-12-09T21:09:46 | null | TParcollet | [
"enhancement"
] | ### Feature request
For most large speech dataset, we do not wish to generate hundreds of millions of small audio samples. Instead, it is quite common to provide larger audio files with frame offset (soundfile start and stop arguments). We should be able to pass these arguments to Audio() (column ID corresponding in t... | false |
2,729,738,963 | https://api.github.com/repos/huggingface/datasets/issues/7315 | https://github.com/huggingface/datasets/issues/7315 | 7,315 | Allow manual configuration of Dataset Viewer for datasets not created with the `datasets` library | open | 13 | 2024-12-07T16:37:12 | 2024-12-11T11:05:22 | null | diarray-hub | [] | #### **Problem Description**
Currently, the Hugging Face Dataset Viewer automatically interprets dataset fields for datasets created with the `datasets` library. However, for datasets pushed directly via `git`, the Viewer:
- Defaults to generic columns like `label` with `null` values if no explicit mapping is provide... | false |
2,723,636,931 | https://api.github.com/repos/huggingface/datasets/issues/7309 | https://github.com/huggingface/datasets/pull/7309 | 7,309 | Faster parquet streaming + filters with predicate pushdown | closed | 1 | 2024-12-06T18:01:54 | 2024-12-07T23:32:30 | 2024-12-07T23:32:28 | lhoestq | [] | ParquetFragment.to_batches uses a buffered stream to read parquet data, which makes streaming faster (x2 on my laptop).
I also added the `filters` config parameter to support filtering with predicate pushdown, e.g.
```python
from datasets import load_dataset
filters = [('problem_source', '==', 'math')]
ds = ... | true |
2,720,244,889 | https://api.github.com/repos/huggingface/datasets/issues/7307 | https://github.com/huggingface/datasets/pull/7307 | 7,307 | refactor: remove unnecessary else | open | 0 | 2024-12-05T12:11:09 | 2024-12-06T15:11:33 | null | HarikrishnanBalagopal | [] | null | true |
2,719,807,464 | https://api.github.com/repos/huggingface/datasets/issues/7306 | https://github.com/huggingface/datasets/issues/7306 | 7,306 | Creating new dataset from list loses information. (Audio Information Lost - either Datatype or Values). | open | 0 | 2024-12-05T09:07:53 | 2024-12-05T09:09:38 | null | ai-nikolai | [] | ### Describe the bug
When creating a dataset from a list of datapoints, information is lost of the individual items.
Specifically, when creating a dataset from a list of datapoints (from another dataset). Either the datatype is lost or the values are lost. See examples below.
-> What is the best way to create... | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.