
Update README.md
#5
by dispink - opened
README.md
CHANGED
|
@@ -1,59 +1,56 @@
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
---
|
| 4 |
-
#
|
| 5 |
|
| 6 |
-
|
| 7 |
Besides the published XRF spectra-target measurements (CaCO3 and TOC) pairs of data, we further upload the XRF spectra in that project but without alignments of the target measurements here.
|
|
|
|
| 8 |
They are compiled in a machine learning ready format, which we expect for convenient implementation of other studies.
|
| 9 |
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
2. Cruise PS97 in the central Drake Passage with RV Polarstern in 2016
|
| 13 |
-
3. Cruise PS75 in the Pacific sector of the Southern Ocean in 2009/2010.
|
| 14 |
-
4. Cruise KOMEX I and KOMEX II with R/V Akademik Lavrentyev in 1998 and cruise SO178 in 2004 in the Okhotsk Sea.
|
| 15 |
-
|
| 16 |
-
For more information, please checkout the published paper [(Lee et al., 2022)](https://doi.org/10.1038/s41598-022-25377-x) and previous dataset [(Chao et al., 2022)](https://doi.org/10.1594/PANGAEA.949225).
|
| 17 |
-
The direct use of this dataset is documented in the GitHub [repo](https://github.com/dispink/xpt).
|
| 18 |
-
|
| 19 |
-
**Data structure**
|
| 20 |
-
- **raw**: Raw spectra in the Avaatech XRF Core Scanner format. Each subfolder contains the raw data for a core series.
|
| 21 |
-
- **legacy**: Previously compiled and raw data in [(Lee et al., 2022)](https://doi.org/10.1038/s41598-022-25377-x).
|
| 22 |
-
- **pretrain**: Data used for pre-training and is built from the previously compiled spectra data `legacy/spe_dataset_20220629.csv`. The `train` subfolder has the training and validation sets. The `test` subfolder contains the data selected during fine-tuning as the zero-shot test, i.e., case study in the published paper.
|
| 23 |
-
|
| 24 |
-
```
|
| 25 |
-
+- train
|
| 26 |
-
+- spe (all spetra)
|
| 27 |
-
+- info.csv (training set spectrum list)
|
| 28 |
-
+- val.csv (validation set spectrum list)
|
| 29 |
-
+- test
|
| 30 |
-
+- spe
|
| 31 |
-
+- info.csv (case study spectrum list)
|
| 32 |
-
```
|
| 33 |
-
- **fine-tune**: Data used for fine-tuning. The `train` subfolder has the training and validation sets. The `test` subfolder is the data for zero-shot test, i.e., case study in the published paper.
|
| 34 |
-
```
|
| 35 |
-
+- CaCO3%
|
| 36 |
-
+- train
|
| 37 |
-
+- spe (all spetra)
|
| 38 |
-
+- target (all target measurements)
|
| 39 |
-
+- info.csv (training set spectrum-target pair list)
|
| 40 |
-
+- info_#.csv (splits from the info.csv in different data amounts)
|
| 41 |
-
+- val.csv (validation set spectrum-target pair list)
|
| 42 |
-
+- test
|
| 43 |
-
(same as in train)
|
| 44 |
-
+- TOC%
|
| 45 |
-
(same as in CaCO3%)
|
| 46 |
-
```
|
| 47 |
-
|
| 48 |
-
The target data (CaCO3 and TOC) distribution:
|
| 49 |
-
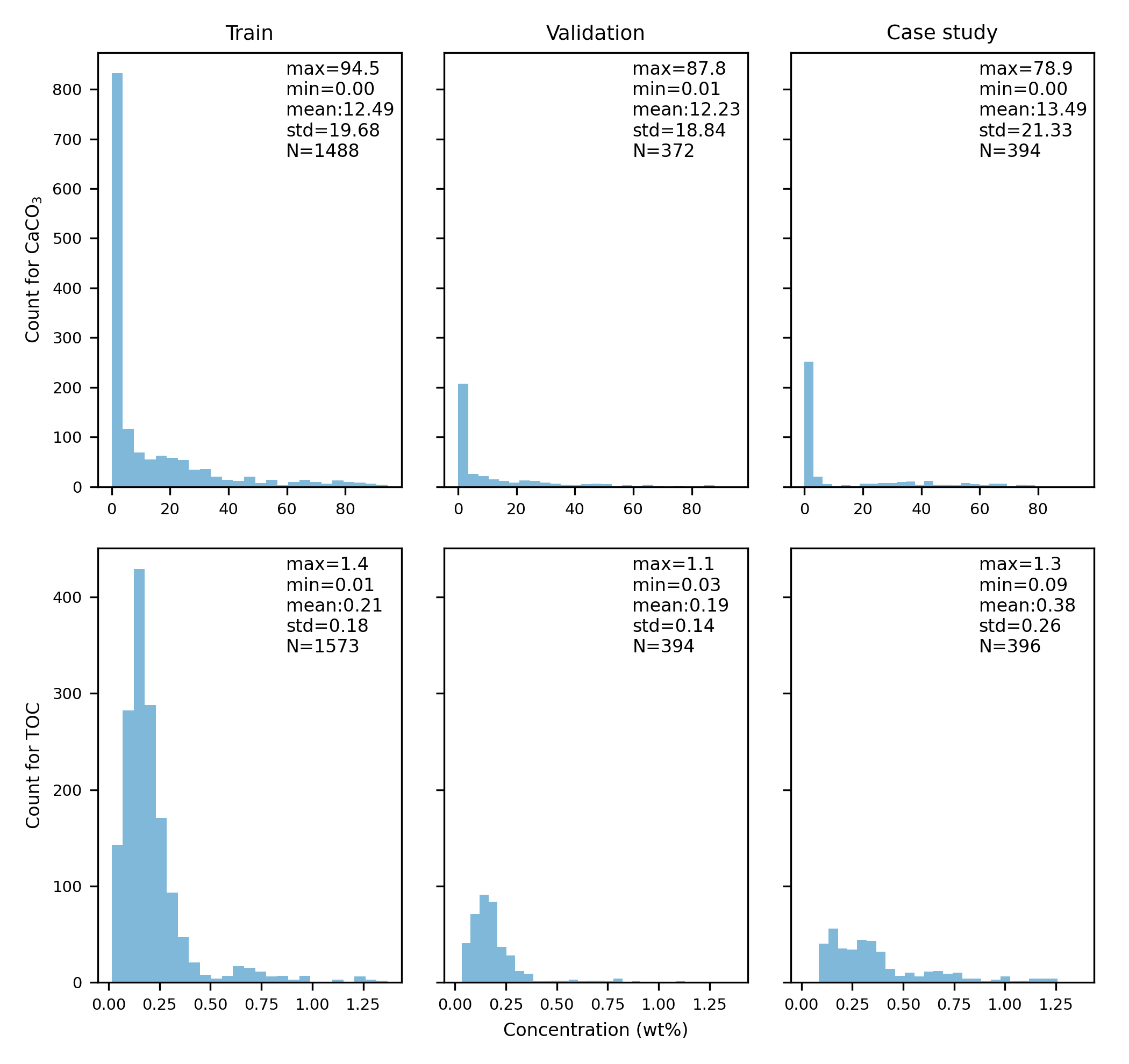
|
| 50 |
-
|
| 51 |
|
| 52 |
The case study (i.e., test set) is composed of three cores ('PS75-056-1', 'LV28-44-3', 'SO264-69-2') isolated from the beginning and not used in both the pre-training and fine-tuning process.
|
| 53 |
The rest of data are randomly split in to the trainging and validation sets wtih 4:1 ratio.
|
| 54 |
The script is `src/datas/build_data.py` in the GitHub [repo](https://github.com/dispink/xpt).
|
| 55 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 56 |
**Acknowledgements**
|
| 57 |
-
We thank the crew and the science parties of different cruises for their contributions to core and sample acquisition on the respective expeditions.
|
| 58 |
-
We are very grateful to Dr. Weng‐Si Chao, Dr. Lester Lembke‐Jene, and Dr. Frank Lamy for providing these data.
|
| 59 |
We also sincerely thank Valéa Schumacher, Susanne Wiebe, and Rita Fröhlking and student assistants at the AWI Marine Geology Laboratory in Bremerhaven for technical assistance with XRF-scanning, CaCO3 and TOC measurements.
|
|
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
---
|
| 4 |
+
# High-latitude Pacific Ocean Sediment Geochemistry and XRF Data for Geoscientific Foundation Models
|
| 5 |
|
| 6 |
+
This dataset is a following development after the dataset [(Chao et al., 2022)](https://doi.org/10.1594/PANGAEA.949225), which inculdes the geochemical records from the high-latitude sectors of Pacific Ocean.
|
| 7 |
Besides the published XRF spectra-target measurements (CaCO3 and TOC) pairs of data, we further upload the XRF spectra in that project but without alignments of the target measurements here.
|
| 8 |
+
In total, it has 59,828 XRF spectra, 2,254 CaCO3 measurements, and 2,363 TOC measurements.
|
| 9 |
They are compiled in a machine learning ready format, which we expect for convenient implementation of other studies.
|
| 10 |
|
| 11 |
+
This dataset is used for training and validating the first foundation model for X-ray Fluorescence [(lee et al., 2025)](https://doi.org/10.1029/2025JH000754).
|
| 12 |
+
It's also published on Zenodo. For more details, please refer to the [Zenodo dataset](https://doi.org/10.5281/zenodo.16354050).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13 |
|
| 14 |
The case study (i.e., test set) is composed of three cores ('PS75-056-1', 'LV28-44-3', 'SO264-69-2') isolated from the beginning and not used in both the pre-training and fine-tuning process.
|
| 15 |
The rest of data are randomly split in to the trainging and validation sets wtih 4:1 ratio.
|
| 16 |
The script is `src/datas/build_data.py` in the GitHub [repo](https://github.com/dispink/xpt).
|
| 17 |
|
| 18 |
+
If you use the data, please cite the paper and dataset properly. The citations are:
|
| 19 |
+
|
| 20 |
+
```
|
| 21 |
+
@article{https://doi.org/10.1029/2025JH000754,
|
| 22 |
+
author = {Lee, An-Sheng and Pao, Yu-Wen and Lin, Hsuan-Tien and Liou, Sofia Ya Hsuan},
|
| 23 |
+
title = {Cross-Project Deep-Sea Sediment Geochemistry From XRF Spectra: A Self-Supervised Foundation Model (MAX)},
|
| 24 |
+
journal = {Journal of Geophysical Research: Machine Learning and Computation},
|
| 25 |
+
volume = {2},
|
| 26 |
+
number = {3},
|
| 27 |
+
pages = {e2025JH000754},
|
| 28 |
+
keywords = {X-ray fluorescence, geochemistry, deep learning, self-supervised learning, foundation model, sediment cores},
|
| 29 |
+
doi = {https://doi.org/10.1029/2025JH000754},
|
| 30 |
+
note = {e2025JH000754 2025JH000754},
|
| 31 |
+
year = {2025}
|
| 32 |
+
}
|
| 33 |
+
|
| 34 |
+
@dataset{lee_2025_16354051,
|
| 35 |
+
author = {Lee, An-Sheng and
|
| 36 |
+
Pao, Yu-Wen},
|
| 37 |
+
title = {High-latitude Pacific Ocean Sediment Geochemistry
|
| 38 |
+
and XRF Data for Geoscientific Foundation Models
|
| 39 |
+
},
|
| 40 |
+
month = jul,
|
| 41 |
+
year = 2025,
|
| 42 |
+
publisher = {Zenodo},
|
| 43 |
+
version = {v1.0.0},
|
| 44 |
+
doi = {10.5281/zenodo.16354051},
|
| 45 |
+
url = {https://doi.org/10.5281/zenodo.16354051},
|
| 46 |
+
}
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
The target data (CaCO3 and TOC) distribution:
|
| 51 |
+

|
| 52 |
+
|
| 53 |
**Acknowledgements**
|
| 54 |
+
We thank the crew and the science parties of different cruises for their contributions to core and sample acquisition on the respective expeditions.
|
| 55 |
+
We are very grateful to Dr. Weng‐Si Chao, Prof. Dr. Ralf Tiedemann, Dr. Lester Lembke‐Jene, and Dr. Frank Lamy for providing these data.
|
| 56 |
We also sincerely thank Valéa Schumacher, Susanne Wiebe, and Rita Fröhlking and student assistants at the AWI Marine Geology Laboratory in Bremerhaven for technical assistance with XRF-scanning, CaCO3 and TOC measurements.
|