
text stringlengths 0 59.1k |
|---|
Vector databases and large language models (LLMs) are two concepts you hear about constantly in AI applications. Let's explore how they work, why they complement each other, and what advantages they offer in real-world scenarios. |
## What Are Vectors and Why Do We Use Them? |
Think of a vector as a list of numbers that comes out of machine learning models. These numbers represent the meaning of unstructured data (text, images, audio) in numerical form. |
For example, when you feed "happy person" into a model, it converts this phrase into a multi-dimensional vector. Similarly, "very happy person" produces another vector, and the distance between these two vectors would be quite small. This is why vectors are so powerful at capturing semantic similarity. |
## The Role of Vector Databases |
We use vector databases to store and quickly query these vectors. With a vector database, you can: |
- Store embeddings (vectors) |
- Perform similarity searches |
- Manage them in production with CRUD operations (create, read, update, delete) |
Redis is one of the leading solutions here. With Redis Search, you can do secondary indexing on JSON data and support vector searches. They're even working with Nvidia on GPU-based indexing. |
## How Vector Databases Actually Work |
Vector databases use a sophisticated pipeline to enable fast similarity search: |
### The Indexing Process |
When you add vectors to the database, they go through indexing algorithms that transform high-dimensional vectors into compressed, searchable structures: |
- **Random Projection**: Projects high-dimensional vectors to a lower-dimensional space using a random projection matrix |
- **Product Quantization**: Breaks vectors into chunks and creates representative "codes" for each chunk |
- **HNSW (Hierarchical Navigable Small World)**: Creates a tree-like structure where each node represents a set of vectors, with edges representing similarity |
### The Query Pipeline |
1. **Indexing**: The query vector gets indexed using the same algorithm as the stored vectors |
2. **Searching**: The system compares the indexed query to indexed vectors using approximate nearest neighbor (ANN) algorithms |
3. **Post-Processing**: Retrieves and potentially re-ranks the final nearest neighbors based on your requirements |
## Vector Databases vs Traditional Databases |
Vector databases aren't just databases with vector support bolted on. They're fundamentally different: |
### Traditional Databases |
- Designed for exact matches on scalar data |
- Use B-trees and hash tables for indexing |
- Query with SQL for precise filtering |
- Struggle with high-dimensional data |
### Vector Databases |
- Built for similarity search on vector embeddings |
- Use specialized indexing (HNSW, LSH, IVF) |
- Query by finding nearest neighbors |
- Excel at semantic search and AI applications |
The key difference? Vector databases are purpose-built to handle the complexity and scale of vector data. They can: |
- Insert, delete, and update vectors in real-time |
- Store metadata alongside vectors for filtering |
- Provide distributed and parallel processing |
- Use advanced indexing for faster searches at scale |
## Vector Databases in VoltAgent |
If you're building AI agents with TypeScript, VoltAgent makes it incredibly easy to add vector database capabilities. Here's how the RAG (Retrieval-Augmented Generation) flow works in VoltAgent: |
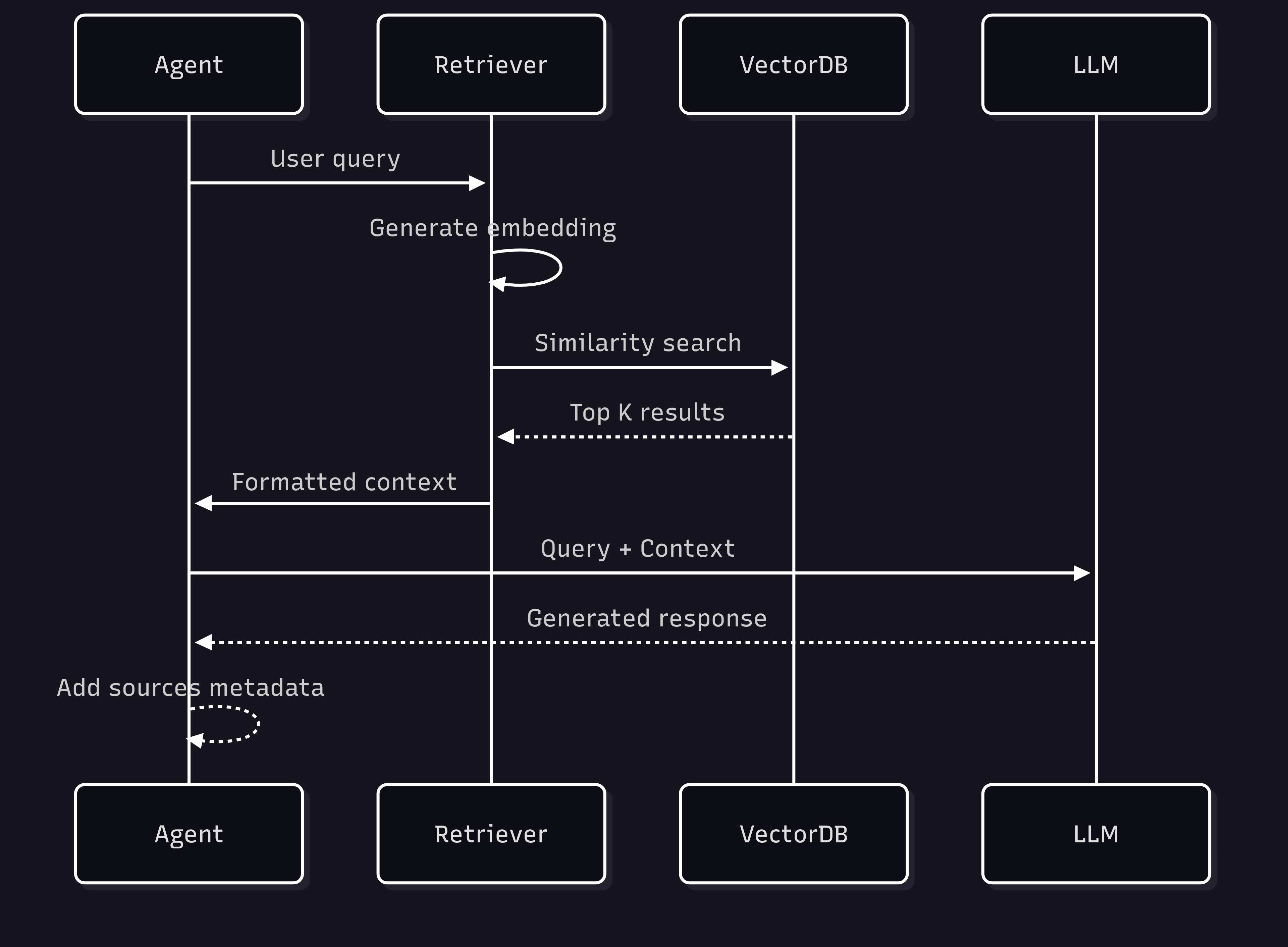 |
VoltAgent supports multiple vector databases out of the box: |
- **[Chroma](https://voltagent.dev/docs/rag/chroma/)** - Perfect for local development, runs without Docker |
- **[Pinecone](https://voltagent.dev/docs/rag/pinecone/)** - Fully managed, serverless solution for production |
- **[Qdrant](https://voltagent.dev/docs/rag/qdrant/)** - Open source with both self-hosted and cloud options |
Getting started is simple: |
```bash |
# Create a project with Chroma (local development) |
npm create voltagent-app@latest -- --example with-chroma |
# Or with Pinecone (production) |
npm create voltagent-app@latest -- --example with-pinecone |
``` |
VoltAgent uses a flexible `BaseRetriever` pattern, so you can switch between vector databases without changing your agent code: |
```typescript |
import { Agent } from "@voltagent/core"; |
import { ChromaRetriever } from "./retriever"; |
const agent = new Agent({ |
name: "Support Bot", |
instructions: "Help customers with documentation", |
retriever: new ChromaRetriever(), // Just swap this for different DBs |
}); |
``` |
Learn more in the [VoltAgent RAG documentation](https://voltagent.dev/docs/rag/overview/) or check out the [examples on GitHub](https://github.com/voltagent/voltagent/tree/main/examples). |
## Understanding Similarity Metrics |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.