
text stringlengths 0 59.1k |
|---|
Before diving into how LLMs and vector databases work together, it's crucial to understand how similarity is measured in vector space: |
### Cosine Similarity |
Measures the cosine of the angle between two vectors. Perfect for comparing document similarity regardless of their magnitude: |
- Range: -1 to 1 (1 = identical direction) |
- Use case: Text similarity, recommendation systems |
- Formula: `cos(θ) = (A·B) / (||A|| × ||B||)` |
### Euclidean Distance |
Measures the straight-line distance between two points in vector space: |
- Range: 0 to ∞ (0 = identical) |
- Use case: When magnitude matters (e.g., image similarity) |
- Formula: `d = √Σ(Ai - Bi)²` |
### Dot Product |
Measures both magnitude and direction: |
- Range: -∞ to ∞ |
- Use case: When both scale and direction matter |
- Often fastest to compute |
The choice of metric significantly impacts search quality and performance. Most vector databases default to cosine similarity for text embeddings. |
## How LLMs and Vector Databases Work Together |
Large language models are trained on massive datasets, but they still have limitations: |
- They don't know your proprietary company data |
- They don't have up-to-date information |
- They can't capture confidential or rapidly changing information |
This is where vector databases come in. Three main use cases stand out: |
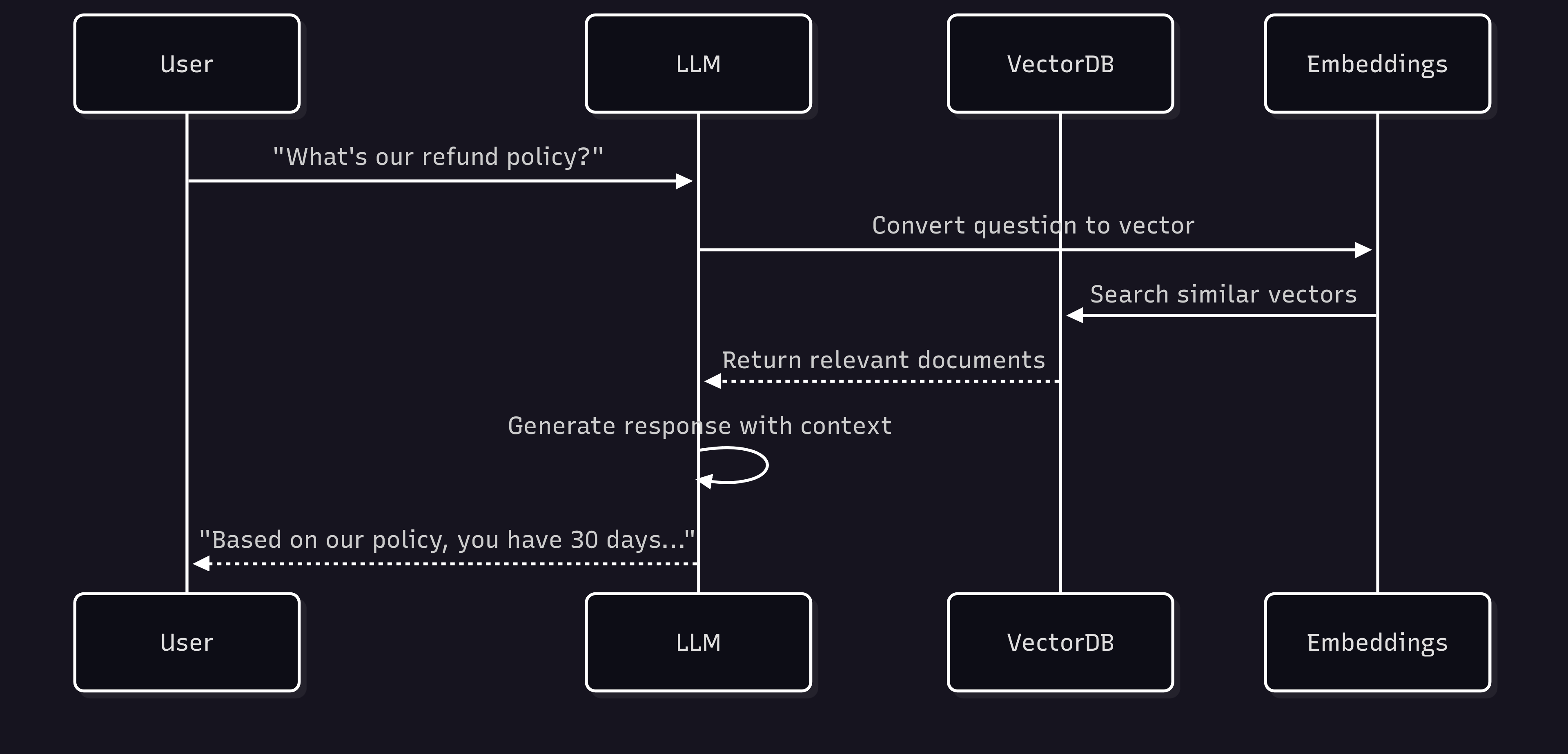
### 1. Context Retrieval |
LLMs can't remember everything. Here, a vector database acts like a Golden Retriever - it fetches the information the model needs. This way, the model gets augmented with data it doesn't know. |
 |
### 2. Memory |
Applications like chatbots need to remember previous conversations. Vector databases make memory efficient by storing and retrieving only relevant messages from long dialogues. This approach is similar to ChatGPT's "long-term memory" concept. |
### 3. Caching |
When the same or similar questions are asked repeatedly, instead of running the model again, you can return previously generated responses. This approach: |
- Reduces computational costs |
- Speeds up the application |
- Improves user experience |
## Real-World Use Cases |
### Question-Answer Systems |
The user's question gets converted to an embedding, the most similar content is found in the vector database, and the model generates a response using this context. This method is both cheaper and faster than fine-tuning. |
### Chatbots |
By storing only relevant parts of previous messages, chatbots can provide more natural and consistent responses in conversations. |
### Finance and Real-Time Data |
For information that changes within seconds, like stock trading, fine-tuning is impossible. Vector databases can continuously feed current information to the model. |
## Performance Comparison: Vector Database Solutions |
Here's how popular vector databases stack up in real-world scenarios: |
| Database | Query Speed (1M vectors) | Index Build Time | Memory Usage | Best For | |
| ------------ | ------------------------ | ---------------- | ------------ | ------------------------ | |
| **Pinecone** | ~10ms | N/A (managed) | N/A (cloud) | Production, serverless | |
| **Qdrant** | ~15ms | 5-10 min | ~2GB | Self-hosted, flexibility | |
| **Chroma** | ~20ms | 3-5 min | ~1.5GB | Local development | |
| **Weaviate** | ~12ms | 8-12 min | ~2.5GB | Multi-modal search | |
| **Milvus** | ~8ms | 10-15 min | ~3GB | Large-scale deployments | |
| **Redis** | ~5ms | 2-3 min | ~1GB | Hybrid workloads | |
_Note: Performance varies based on hardware, indexing method, and dataset characteristics._ |
### Key Performance Factors: |
- **Indexing Algorithm**: HNSW generally offers best speed/accuracy trade-off |
- **Dimension Size**: Higher dimensions = slower searches |
- **Dataset Size**: Performance degrades differently across solutions |
- **Hardware**: GPU acceleration can provide 10-100x speedup |
## Choosing the Right Vector Database |
Selecting a vector database depends on your specific requirements. Here's a decision framework: |
### For Local Development |
**Choose Chroma or Qdrant** if you: |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.