
text stringlengths 0 59.1k |
|---|
slug: langfuse |
image: https://cdn.voltagent.dev/2025-05-28-langfuse/social.png |
authors: necatiozmen |
--- |
import ObservabilityMaturityWidget from '@site/src/components/blog-widgets/ObservabilityMaturityWidget'; |
"I deployed my LLM app but I have no idea what is happening!" |
You've got LLM integration running, users are using it but. Why does the agent sometimes take 30 seconds to think? What do prompts actually work? Why are costs stratospheric? |
That is exactly where Langfuse and similar LLM observability tools fit in. |
## What is Langfuse? |
[Langfuse](https://langfuse.com/) is a live X-ray machine for your LLM work. Think about it; you can observe what your agent performs, which API calls fall through, which responses users detest, where your dollars are spent - you can observe everything. |
Bottom line, you are not guessing anymore, you know. |
### Why Does This Matter So Much? |
New LLM apps are complex systems. The moment users start complaining: "Bot is too slow", "Gives weird answers", "I asked the same question 3 times". it's impossible to fix these problems without observability. |
:::important |
With VoltAgent + Langfuse integration, you can trace everything. Just include the `@voltagent/langfuse-exporter` package and link it to your VoltAgent. |
::: |
<ObservabilityMaturityWidget /> |
## Langfuse's Main Features |
### Tracing: Observe Every Breath Your Agent Takes |
 |
Tracing is the heart of Langfuse. All LLM calls, tool usage, even agent chat, all of it is recorded second by second. |
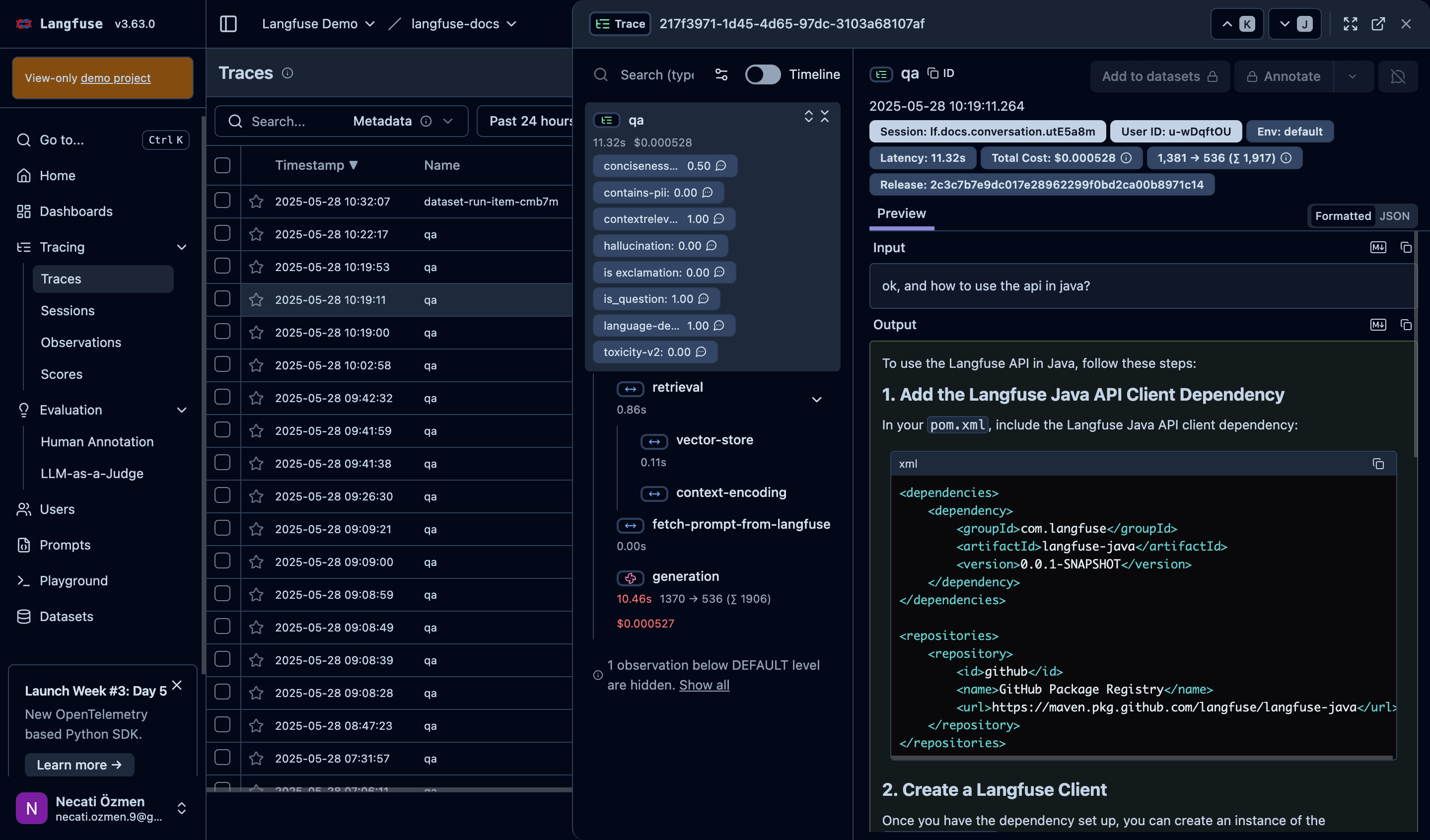
#### Traces List |
The first thing you see when you open Langfuse is the traces list. Every row represents a conversation or operation. The timestamp tells you when it happened, while the Name column shows what type of operation it was. On the right side, you can instantly see critical metrics like duration and cost for each trace. |
#### Trace Details |
When you click on a trace, the magic happens. The left panel shows the trace anatomy - what components executed and their performance. You can see which parts of your system are fast and which are slow. This breakdown is crucial for identifying bottlenecks. |
#### Right Panel - Real Conversation |
The most valuable part is the right panel where you see the actual conversation. From system prompts to user questions to assistant responses - everything is preserved. This is where you understand what actually happened in each interaction. |
#### Metadata and Performance |
At the top, you get critical operational data like environment, latency, and total cost. This information helps you understand which environment might be having issues, whether response times are normal, and if costs are within expected parameters. |
#### Timeline View |
The Timeline toggle gives you a visual representation of when each component started and finished. If you have multiple processes running, you can trace them visually. This is incredibly helpful for performance debugging and understanding system behavior. |
#### Trace Anatomy |
A trace shows the entire journey from user query to response. The **Root Span** represents the main conversation thread. **Generation Spans** capture each LLM call with prompts and responses. External API calls and database queries appear as **Tool Spans**. Multi-agent interactions show up as **Sub-Agent Spans**. |
#### What Information You Get |
Each span provides granular insights. Timing data reveals duration and where delays occur. You can examine all prompt and response text. Metadata like model names, token counts, and costs are calculated automatically. User context and session data are preserved. Error messages and stack traces are captured when things ... |
#### Real Life Scenario |
When a user asks "Where's my order?" you can trace the entire process: |
1. User query received |
2. Intent classification completed |
3. Database lookup performed ← **Potential bottleneck** |
4. LLM formats response |
5. Response returned to user |
You can immediately identify which step is taking too long and optimize accordingly. |
#### Nested Traces |
In multi-agent systems, traces show the complete hierarchy. A top-level agent might call a research agent, which then calls a web scraper tool. You can see each level separately and understand the full interaction flow. |
### Evaluation: How Do You Measure Quality? |
 |
Finding the answer to "Is my agent performing well?", that's what evaluation is for. |
#### Evaluation Scores Overview |
Langfuse automatically calculates multiple evaluation metrics for each trace. You'll see scores for different criteria like conciseness, relevance, hallucination detection, toxicity, and more. These scores help you understand quality from multiple angles. |
#### Understanding Score Meanings |
Each evaluation metric has a specific purpose. Relevance scores tell you if responses actually answer the question. Hallucination scores detect when the AI makes things up. Toxicity scores ensure content safety. Language detection confirms the response is in the expected language. These automated assessments give you o... |
#### Component-Level Analysis |
Different stages of your trace get evaluated separately. You can see how long retrieval took, how efficient vector searches were, and how much the generation phase cost. This granular view helps you optimize each component individually. |
#### Session and User Context |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.