
text stringlengths 0 59.1k |
|---|
The system tracks which user had issues in which session, along with environment details. This context is crucial for debugging user-specific problems and understanding usage patterns across different environments. |
#### Input/Output Analysis |
You can examine the actual conversation - what the user asked and how your agent responded. This real conversation data is invaluable for understanding where your agent succeeds or fails. |
#### Manual Evaluation |
The most straightforward approach is getting feedback from users or your team. Thumbs up/down ratings, star ratings, categorical evaluations, or open comments all provide direct quality insights. Langfuse connects this feedback to specific traces so you can identify patterns. |
#### LLM-as-a-Judge |
Using another LLM as an evaluator works well at scale. You can automatically check for factual correctness, relevance to the question, helpfulness, appropriate tone, and safety. This gives you consistent evaluation without manual effort. |
#### Automated Metrics |
Technical metrics get calculated automatically at the code level. Response time, token efficiency, tool success rates, error frequency, and cost per conversation are all tracked in real-time without any extra work. |
#### Dataset-Based Evaluation |
You can create golden datasets to validate your agent systematically. Regression testing ensures new versions don't perform worse than previous ones. A/B testing measures which prompt versions work better. Benchmark comparisons show how you stack up against competitors. |
#### Evaluation Workflows |
Langfuse can automate your entire testing process. Every new trace gets automatically scored, you get notifications when traces fail quality thresholds, weekly and monthly quality reports generate automatically, and model performance trends are analyzed continuously. |
### Prompt Management: Not in Code Anymore |
 |
Prompts are the soul of LLM applications. But managing them in code is a nightmare. |
:::tip |
Centralized prompt management saves you from deployment headaches and version confusion. |
::: |
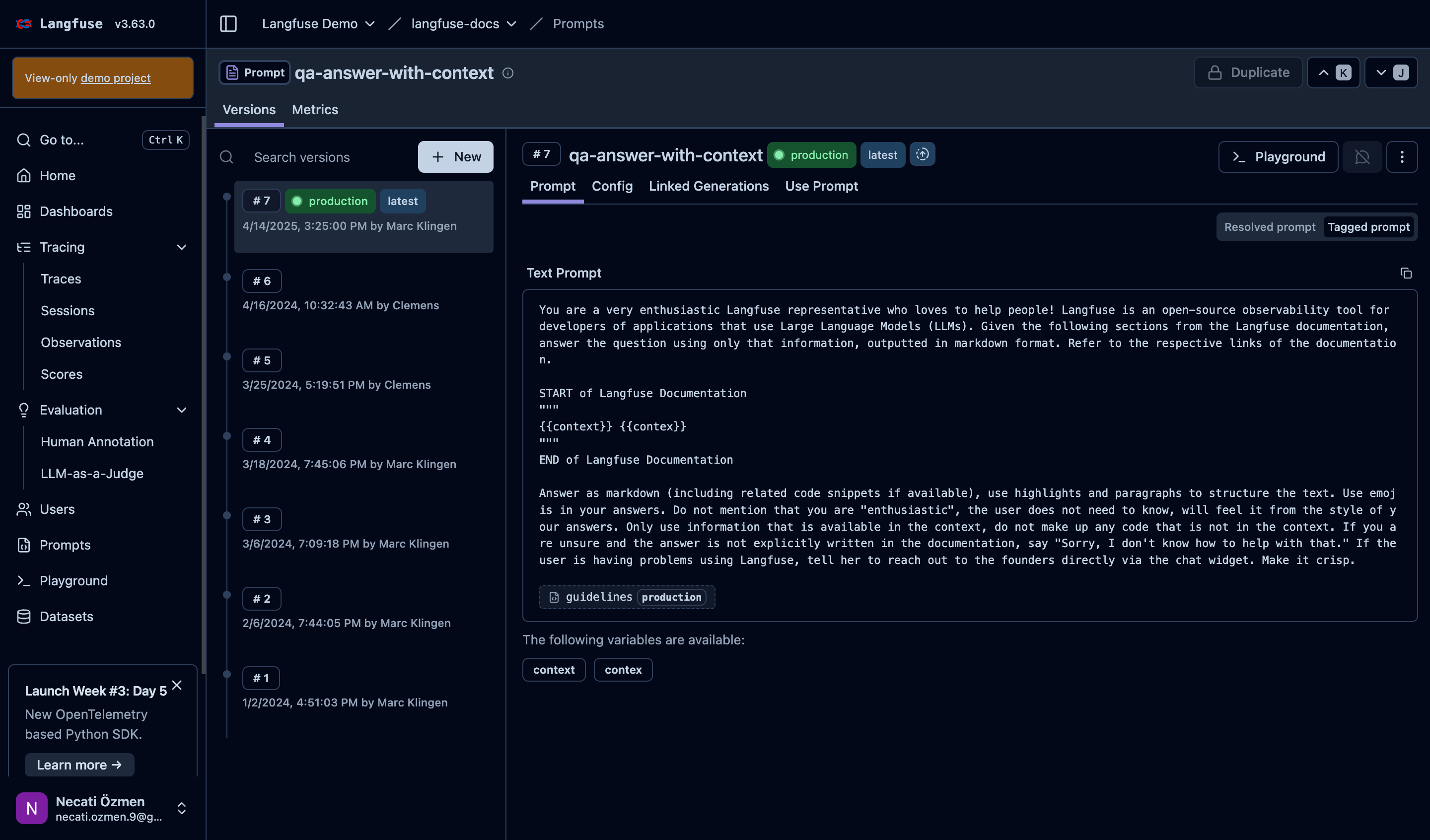
#### Prompt Versioning System |
Langfuse tracks every version of your prompts with complete history. You can see who made changes when, compare different versions, and understand the evolution of your prompts. The latest version shows what's currently running in production. |
#### Production vs Development |
Clear badges distinguish between production and development versions. This prevents confusion about which prompt is live and which one you're testing. You can safely experiment without affecting production users. |
#### Prompt Editor and Templates |
The built-in editor lets you modify prompts with syntax highlighting and template variable support. You can use variables like `{{context}}` and `{{user_name}}` to make prompts dynamic. The system shows which variables are available and validates your template syntax. |
#### Detailed Prompt Content |
You can view the complete prompt text with all instructions, formatting requirements, and behavioral guidelines. This centralized view makes it easy to understand exactly how your agent is instructed to behave. |
#### Playground Integration |
The integrated playground lets you test prompts immediately with different inputs. You can see how changes affect responses before deploying to production. This rapid iteration cycle speeds up prompt development significantly. |
#### Prompt Organization |
Different tabs help you organize prompt information, the actual prompt text, configuration settings, linked generations showing how it's being used, and usage instructions for your team. |
#### Centralized Management |
All your prompts live in one place with complete version control. Every change is tracked and reversible. You can create branches for different use cases and roll back problematic versions instantly. Access controls determine who can modify which prompts. |
#### Template System |
The robust template system handles dynamic content elegantly. Variable substitution works with user data, conditional logic adapts instructions based on context, nested templates let you reuse common components, and multi-language support handles international users. |
#### A/B Testing |
Measuring prompt impact is crucial for improvement. Traffic splitting lets you compare old vs new prompts with real users. Statistical significance calculations tell you when results are meaningful. Auto-winner selection can automatically promote better-performing prompts. Gradual rollouts minimize risk during updates. |
#### Prompt Analytics |
Detailed analytics track how each prompt version performs. Success rates show effectiveness, response times reveal performance impact, token usage calculates cost implications, and user satisfaction measures real-world quality. |
#### Collaboration Features |
Team features streamline prompt development. Comment systems enable quick discussions about changes. Review processes ensure quality control. Change notifications keep everyone informed via Slack or email. Audit logs track who changed what and when. |
### Dashboard: Everything at a Glance |
 |
The dashboard is where everything comes together. |
#### Main Dashboard Overview |
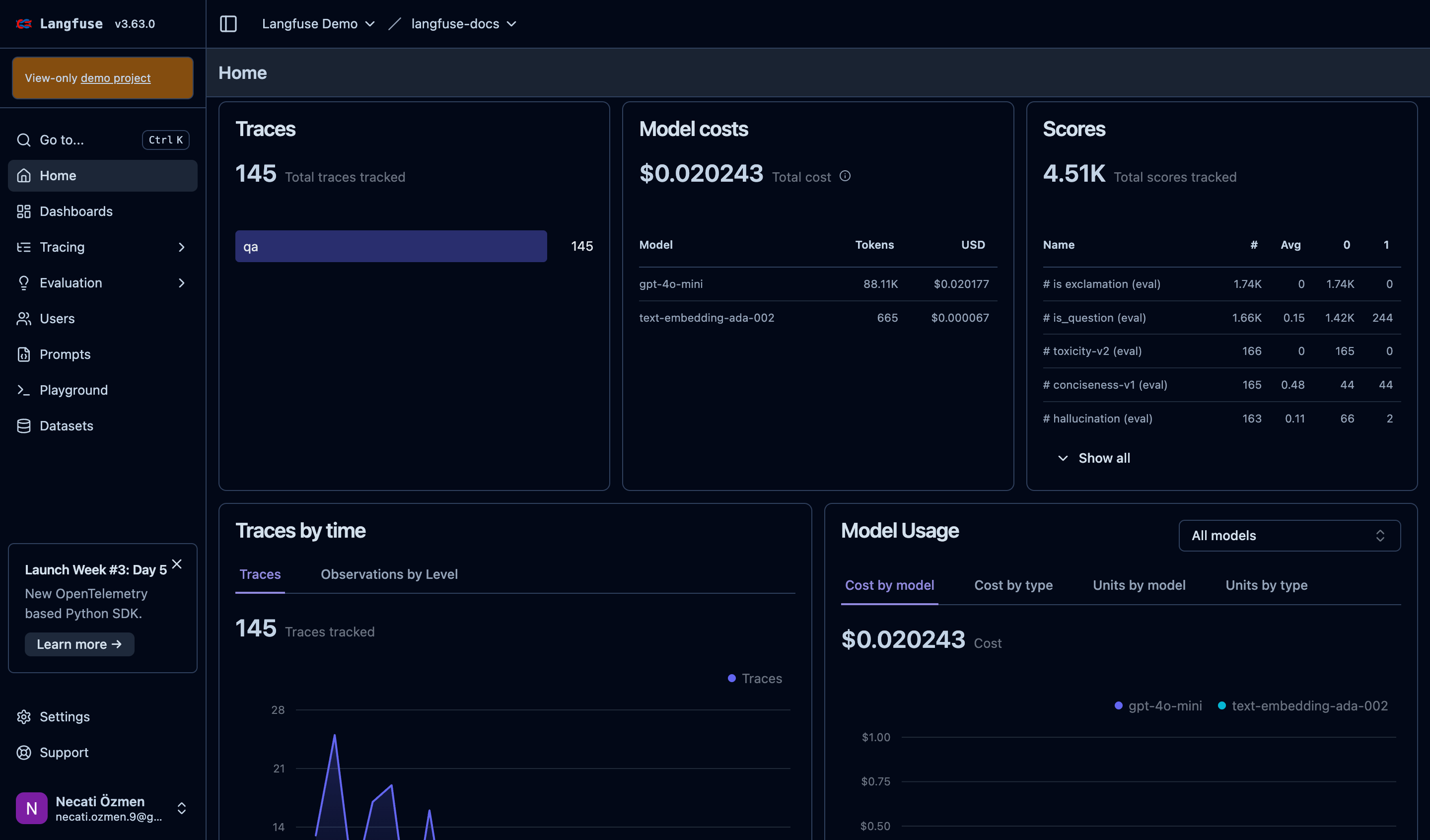
The home dashboard provides an instant snapshot of your system's health. Key widgets show total traces monitored, cumulative costs, and evaluation scores processed. These high-level metrics let you quickly assess overall system performance. |
#### Traces Monitoring |
The traces widget shows your system's activity level and categorizes different types of operations. This helps you understand usage patterns and identify which parts of your system are most active. |
#### Cost Analysis |
Cost tracking is absolutely critical for LLM applications. The dashboard breaks down expenses by model, showing token usage and associated costs. You can immediately identify which models are driving your expenses and optimize accordingly. |
#### Quality Scores Dashboard |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.