
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.4 | kleinkram | 0.58.0.dev20260220150241 | give me your bags | # Kleinkram: CLI
Install the package
```bash
pip install kleinkram
```
Run the CLI
```bash
klein
```
## Usage
Here are some basic examples of how to use the CLI.
### Listing Files
To list all files in a mission:
```bash
klein list -p project-name -m mission-name
```
### Uploading Files
To upload all `*.bag` files in the current directory to a mission:
```bash
klein upload -p project-name -m mission-name *.bag
```
If you would like to create a new mission on upload use the `--create` flag.
### Downloading Files
To download all files from a mission and save them `out`:
```bash
klein download -p project-name -m mission-name --dest out
```
You can additionally specify filenames or ids if you only want to download specific files.
Instead of downloading files from a specified mission you can download arbitrary files by specifying their ids:
```bash
klein download --dest out *id1* *id2* *id3*
```
For more information consult the [documentation](https://docs.datasets.leggedrobotics.com//usage/python/setup).
## Development
Clone the repo
```bash
git clone git@github.com:leggedrobotics/kleinkram.git
cd kleinkram/cli
```
Setup the environment
```bash
virtualenv -ppython3.8 .venv
source .venv/bin/activate
pip install -e . -r requirements.txt
```
Install `pre-commit` hooks
```bash
pre-commit install
```
Run the CLI
```bash
klein --help
```
### Run Tests
to run unit tests:
```bash
pytest -m "not slow"
```
to run all tests (including e2e and integration tests):
```bash
pytest
```
For the latter you need to have an instance of the backend running locally.
See instructions in the root of the repository for this.
On top of that these tests require particular files to be present in the `cli/tests/data` directory.
These files are automatically generated by the `cli/tests/generate_test_data.py` script.
You also need to make sure to be logged in with the cli with `klein login`.
| text/markdown | Cyrill Püntener, Dominique Garmier, Johann Schwabe | pucyril@ethz.ch, dgarmier@ethz.ch, jschwab@ethz.ch | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: Implementation :: CPython"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"boto3",
"botocore",
"click",
"httpx",
"python-dateutil",
"pyyaml",
"requests",
"rich",
"tqdm",
"typer"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T15:02:53.413668 | kleinkram-0.58.0.dev20260220150241.tar.gz | 54,828 | 8a/a0/71b63495b6de8a7730d5423be5e3d079a06a91d2cf77c142905c99636e5e/kleinkram-0.58.0.dev20260220150241.tar.gz | source | sdist | null | false | da9203c27c58c8f33476d1f312a69c86 | b5bfb856ba15459da5c02ba26941a31c9a19588647fa6cb6a62eca52b955cc89 | 8aa071b63495b6de8a7730d5423be5e3d079a06a91d2cf77c142905c99636e5e | null | [] | 178 |
2.4 | lipilekhika | 1.0.3 | A transliteration library for Indian Brahmic scripts | # Lipi Lekhika — Python
> A powerful, fast transliteration library for Indian Brahmic scripts with real-time typing support
[](https://pypi.org/project/lipilekhika/)
[](https://pypi.org/project/lipilekhika/)
[](https://github.com/shubhattin/lipilekhika/actions/workflows/python_ci.yml)
[](https://opensource.org/licenses/MIT)
📖 **[Documentation](https://lipilekhika.in/getting-started/python/)** • 🌐 **[Website](https://lipilekhika.in)** • 📝 **[Changelog](./CHANGELOG.md)**
## ✨ Features
- 🔄 **Bidirectional Transliteration** — Convert between 15+ Indian Brahmic scripts
- 🦀 **Rust-Powered** — Uses compiled Rust functions for blazing-fast operations
- 🛡️ **Full Type Safety** — Type hints for all functions and proper IDE support
- ⚡ **Real-time Typing** — Low-latency typing engine for interactive applications
- 🎯 **Highly Customizable** — Fine-tune transliteration with custom options
- 🪶 **Lightweight** — Minimal dependencies, fast installation
## 📥 Installation
```bash
pip install lipilekhika
```
**Requirements:** Python 3.10+
## 🚀 Quick Start
### Basic Transliteration
```python
from lipilekhika import transliterate
# Transliterate from Normal script to Devanagari
result = transliterate('na jAyatE mriyatE vA', 'Normal', 'Devanagari')
print(result) # न जायते म्रियते वा
```
### With Custom Options
```python
from lipilekhika import transliterate
result = transliterate(
'गङ्गा',
'Devanagari',
'Gujarati',
{'brahmic_to_brahmic:replace_pancham_varga_varna_with_anusvAra': True}
)
print(result) # ગંગા (instead of ગઙ્ગા)
```
📖 See all [Custom Transliteration Options](https://lipilekhika.in/reference/custom_trans_options/)
## 📚 Core API
### Functions
**`transliterate(text, from_script, to_script, options=None)`** — Transliterate text between scripts
```python
from lipilekhika import transliterate
result = transliterate('namaste', 'Normal', 'Devanagari')
# Returns: नमस्ते
```
**Parameters:**
- `text: str` — Text to transliterate
- `from_script: ScriptLangType` — Source script/language
- `to_script: ScriptLangType` — Target script/language
- `options: dict[str, bool] | None` — Custom transliteration options
**Returns:** `str`
---
**`preload_script_data(name)`** — Preload script data to avoid initial loading delay
```python
from lipilekhika import preload_script_data
preload_script_data('Telugu')
```
---
**`get_all_options(from_script, to_script)`** — Get available custom options for a script pair
```python
from lipilekhika import get_all_options
options = get_all_options('Normal', 'Devanagari')
# Returns: list of available option keys
```
### Constants
```python
from lipilekhika import SCRIPT_LIST, LANG_LIST, ALL_SCRIPT_LANG_LIST
print(SCRIPT_LIST) # ['Devanagari', 'Bengali', 'Telugu', ...]
print(LANG_LIST) # ['Sanskrit', 'Hindi', 'Marathi', ...]
```
| Export | Description |
|--------|-------------|
| `SCRIPT_LIST` | List of all supported script names |
| `LANG_LIST` | List of all supported language names mapped to scripts |
| `ALL_SCRIPT_LANG_LIST` | Combined list of all scripts and languages |
## ⌨️ Real-time Typing
Enable real-time transliteration as users type character by character.
```python
from lipilekhika.typing import create_typing_context
ctx = create_typing_context('Telugu')
# Process each character
for char in "namaste":
diff = ctx.take_key_input(char)
# Apply the diff to your text buffer:
# - Remove diff.to_delete_chars_count characters
# - Add diff.diff_add_text
```
📖 **[Python Guide](https://lipilekhika.in/getting-started/python)** • **[Typing Reference](https://lipilekhika.in/reference/realtime_typing)**
### API
**`create_typing_context(script, options=None)`** — Create a typing context
```python
from lipilekhika.typing import create_typing_context, TypingContextOptions
options = TypingContextOptions(
auto_context_clear_time_ms=4500,
use_native_numerals=True,
include_inherent_vowel=False
)
ctx = create_typing_context('Devanagari', options)
```
**Returns:** `TypingContext` with:
- `take_key_input(char: str) -> TypingDiff` — Process character input and return diff
- `clear_context()` — Clear internal state
- `update_use_native_numerals(value: bool)` — Update numeral preference
- `update_include_inherent_vowel(value: bool)` — Update inherent vowel inclusion
### Additional Utilities
```python
from lipilekhika.typing import get_script_typing_data_map
# Get detailed typing mappings for a script
typing_map = get_script_typing_data_map('Telugu')
# Useful for building typing helper UIs
```
---
## 📖 Resources
- **[Documentation Home](https://lipilekhika.in)** — Complete guides and API reference
- **[Python Guide](https://lipilekhika.in/getting-started/python)** — Getting started with Python
- **[Supported Scripts](https://lipilekhika.in/reference/supported_scripts)** — Full list of scripts
- **[Custom Options](https://lipilekhika.in/reference/custom_trans_options)** — Transliteration options reference
- **[GitHub Repository](https://github.com/shubhattin/lipilekhika)** — Source code and issues
- **[Changelog](./CHANGELOG.md)** — Version history and updates
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T15:02:27.290319 | lipilekhika-1.0.3.tar.gz | 133,962 | 57/ba/9624c2145b924640bca220502b33c8a146bd3c62d293d06438376a6c42f0/lipilekhika-1.0.3.tar.gz | source | sdist | null | false | adca9c4598d1498c80b3b9a18969b633 | e4260c747855a3a8f8357325a723ba7ac15f82e59469dae23e885b3534c7614b | 57ba9624c2145b924640bca220502b33c8a146bd3c62d293d06438376a6c42f0 | MIT | [
"LICENCE"
] | 1,769 |
2.4 | edgeface-knn | 2.0.5 | Real-time CPU face recognition using classical ML (Haar Cascade + KNN). Designed for edge deployment on laptops, Raspberry Pi, and embedded devices without GPU acceleration. | # Edge Face Recognition (CPU-Only)
[](https://pypi.org/project/edgeface-knn/)
[](https://pypi.org/project/edgeface-knn/)
[](https://www.python.org/downloads/)
%20%7C%20windows%20%7C%20macos-lightgrey)
**Real-time face recognition system designed for CPU-only environments (laptops, embedded devices, Raspberry Pi)**
A classical computer vision pipeline (Haar Cascade + KNN) delivering ~40 ms inference latency without GPUs or deep learning frameworks. Built for offline attendance systems and privacy-sensitive deployments where cloud inference isn't viable.
> **Install:** `pip install edgeface-knn`
> **Performance:** ~40 ms per frame (~15 FPS effective throughput)
---
## Problem & Motivation
**Use case:** Identity recognition for attendance systems, access control, or lab check-ins.
**Constraints:**
- No GPU access (laptops, Raspberry Pi, edge devices)
- No cloud connectivity (offline operation, privacy requirements)
- Real-time response needed (sub-100ms for good UX)
- Non-ML users (should "just work" without tuning)
**Why existing solutions don't fit:**
- CNN-based face recognition: ~300 ms inference on CPU, ~90 MB model size
- Cloud APIs: Require internet, data privacy concerns, per-call costs
- Research repos: Monolithic code, not installable, require ML expertise
This system prioritizes **deployment viability** over maximum accuracy — designed for environments where "good enough, deterministic, and always available" beats "state-of-the-art but requires infrastructure."
---
## What This System Does
**Workflow:**
1. **Registration:** Capture 100 face samples per person via webcam (automated, ~30 seconds)
2. **Recognition:** Real-time identification with confidence scoring
3. **Logging:** Optional attendance tracking with timestamps
**Interface:**
- Command-line tool (no GUI)
- Configuration-driven (YAML-based)
- Pip-installable package (no manual setup)
**Performance:**
- **Latency:** ~40 ms per processed frame
- **Throughput:** ~15 FPS effective (frame skipping for UX)
- **Model size:** <1 MB (vs ~90 MB for CNN alternatives)
- **Accuracy:** ~95% frontal face, ~90% with glasses, ~75% with mask
---
## Engineering Decisions
### 1. Why Haar Cascade + KNN over CNNs?
Prototyped both classical CV and deep learning approaches.
| Factor | This System (Haar + KNN) | CNN Baseline |
|--------|--------------------------|--------------|
| CPU inference | ~40 ms | ~300 ms |
| Model size | <1 MB | ~90 MB |
| Training data | ~100 samples/person | 1000+ samples/person |
| GPU required | No | Yes (for real-time) |
| Latency predictability | Deterministic | Variable (thermal throttling) |
**Decision:** Chose classical CV for deployment constraints.
**Trade-off accepted:** Lower angle robustness (±30° vs ±60° for CNNs) in exchange for guaranteed real-time performance on target hardware.
---
### 2. Unknown Face Handling Strategy
**Problem:** How to handle faces not in the training set?
**Naive approach:** Always return nearest neighbor (KNN default behavior).
- **Risk:** Logs the wrong person (critical failure in attendance systems)
**This system's approach:** Confidence thresholding with rejection.
| Confidence | Result |
|------------|--------|
| ≥ threshold | Person identified |
| < threshold | Marked "Unknown" |
**Decision rationale:**
- False negative (reject known person) → They try again
- False positive (log wrong person) → Permanent incorrect record
**Bias toward precision over recall** — better to ask someone to retry than log them as someone else.
---
### 3. Frame Skipping for Real-Time UX
**Problem:** Processing every frame creates visual lag (camera feed stutters).
**Options:**
1. Process all frames → Stuttering, poor UX
2. Async processing → Added complexity, race conditions
3. Process every Nth frame → Simple, maintains smooth preview
**Decision:** Process every 2nd frame (skip odd frames).
- **Rationale:** Humans perceive <50ms lag as instantaneous; processing 15 FPS feels real-time
- **Trade-off:** Slight temporal jitter (detection updates every ~65ms instead of ~33ms)
---
### 4. Packaging as Reusable Tool
**Problem:** Initial prototype was monolithic scripts (hard to reuse, no version control).
**Evolution:**
- **v1 (Sept 2024):** Raspberry Pi prototype, single-file scripts
- **v2 (Dec 2025):** Modular Python package, pip-installable, configuration-driven
**Decision to refactor:**
- Makes it reusable across projects (attendance, access control, experiments)
- Demonstrates production packaging workflow (not just research code)
- Enables non-ML users to deploy (IT admins, not data scientists)
**Packaging choices:**
- CLI interface (not GUI) → Cross-platform, scriptable
- YAML configuration (not hardcoded params) → Customization without code changes
- Minimal dependencies → Reduces installation friction
---
## Installation & Usage
### Quick Install (Recommended)
Requires native OS execution for camera access (WSL users see notes below).
```bash
pip install edgeface-knn
edge-face --help # Verify installation
```
### Development Setup
```bash
git clone https://github.com/SakshamBjj/edge-face-recognition-v2.git
cd edge-face-recognition-v2
pip install -e . # Editable install for development
```
---
### Basic Workflow
#### 1) Register People
```bash
edge-face collect --name Alice
edge-face collect --name Bob
```
Captures 100 samples per person automatically (~30 seconds per person).
**What happens:**
- Opens webcam
- Detects face using Haar Cascade (on grayscale frame)
- Saves 50×50 color (BGR) crops
- Stores in `data/raw/{name}/` directory
---
#### 2) Run Recognition
```bash
edge-face run
```
**Controls:**
| Key | Action |
|-----|--------|
| `o` | Log attendance (saves to CSV) |
| `q` | Quit |
**Output:**
- Real-time video feed with bounding boxes
- Name labels with confidence scores
- Attendance logs in `attendance/YYYY-MM-DD.csv`
---
#### 3) Optional: Custom Configuration
```bash
edge-face run --config configs/my_config.yaml
```
**Configurable parameters:**
- Detection confidence threshold
- Recognition threshold (unknown rejection)
- Frame skip interval
- Camera resolution
- Output paths
---
### WSL Development Notes
**Camera limitation:** Webcam access requires native OS execution (WSL hardware virtualization limitation).
**Recommended workflow:**
| Task | Environment |
|------|-------------|
| Code editing, packaging | WSL |
| Face collection | Windows (native) |
| Real-time recognition | Windows (native) |
**Testing from WSL:**
```bash
# In WSL: Install editable package
pip install -e .
# In Windows terminal (same project directory):
edge-face collect --name TestUser
edge-face run
```
The package itself is OS-independent — only camera I/O requires native execution.
---
## Technical Implementation
### Runtime Pipeline
```
Camera (30 FPS)
↓
Grayscale conversion (for detection only)
↓
Haar Cascade detection (OpenCV) — runs on grayscale
↓
Face crop from color (BGR) frame + resize (50×50 pixels)
↓
Flatten to 1D vector (7,500 dimensions — 50×50×3 color channels)
↓
KNN classification (k=5, Euclidean distance)
↓
Confidence scoring: 100 × exp(−mean_dist / 4500) — heuristic, not calibrated probability
↓
Unknown rejection (if confidence < 40)
↓
Overlay labels + bounding boxes
↓
Display frame
```
**Latency breakdown:**
| Stage | Time |
|-------|------|
| Detection (Haar) | ~20 ms |
| Preprocessing | ~5 ms |
| KNN search | ~15 ms |
| **Total** | **~40 ms** |
---
### Model Details
**Detection:** OpenCV Haar Cascade (frontalface_default.xml)
- Pre-trained on ~10K faces
- Detects faces at multiple scales
- Trade-off: Fast but angle-sensitive (±30° max)
- Runs on grayscale frame for speed
**Feature representation:** Raw pixel values (50×50 color BGR crop)
- Vector dimension: 7,500 (50 × 50 × 3 channels)
- No feature extraction (HOG, LBP, etc.)
- Simple = less overhead, more interpretable
**Classification:** K-Nearest Neighbors (k=5)
- Distance metric: Euclidean (L2 norm)
- No training step (lazy learning)
- O(n) search complexity (acceptable for <50 identities)
**Unknown detection:** Confidence scoring via exponential decay
```python
score = 100.0 * np.exp(-mean_dist / 4500.0)
```
- Threshold: 40 (percent, configurable)
- Below threshold → "Unknown"
- Decay constant 4500 calibrated empirically — heuristic, not derived
---
## Performance Analysis
### Accuracy (Typical Indoor Lighting)
| Condition | Accuracy | Notes |
|-----------|----------|-------|
| Frontal face | ~95% | Optimal scenario |
| With glasses | ~90% | Slight reflection artifacts |
| With mask | ~75% | Reduced feature area |
| ±30° angle | ~70% | Haar detection limit |
| >45° angle | <50% | Face often undetected |
**Error modes:**
- Side profiles not detected (Haar limitation)
- Poor lighting → false negatives (miss detection)
- Multiple faces → processes only largest face
---
### Latency Consistency
| Metric | Value |
|--------|-------|
| Mean latency | 40 ms |
| Std deviation | 3 ms |
| 99th percentile | 47 ms |
**Why consistent:**
- No GPU thermal throttling
- Deterministic CPU execution
- No network dependency
---
### Scaling Limits
| # Identities | KNN Search Time | Total Latency | Acceptable? |
|--------------|-----------------|---------------|-------------|
| 10 | 5 ms | 30 ms | ✓ |
| 50 | 15 ms | 40 ms | ✓ |
| 100 | 60 ms | 85 ms | ✗ (sub-real-time) |
| 500 | 300 ms | 325 ms | ✗ (unusable) |
**Recommendation:** <50 identities for smooth real-time performance.
**Why KNN doesn't scale:**
- Brute-force search is O(n)
- No indexing structure (KD-tree doesn't work well in high dimensions)
**If you need >50 people:** Consider approximate nearest neighbors (FAISS, Annoy) or switch to CNN embeddings with vector databases.
---
## Limitations & Alternatives
### Known Limitations
**1. Angle sensitivity:** Haar Cascade only detects frontal faces (±30°)
- Side profiles often missed
- **Alternative:** Multi-view Haar or CNN detector (MTCNN)
**2. Lighting dependency:** Poor lighting reduces detection rate
- Dark environments: <60% detection rate
- **Alternative:** Infrared camera + illuminator
**3. Scaling ceiling:** >50 identities degrades to sub-real-time
- KNN search becomes bottleneck
- **Alternative:** Approximate NN (FAISS) or CNN embeddings
**4. Spoof vulnerability:** Photo attacks possible (not liveness-aware)
- Printed photos can fool system
- **Alternative:** Depth cameras (RealSense) or liveness detection
**5. No re-identification:** Doesn't track individuals across frames
- Each frame is independent classification
- **Alternative:** Add object tracking (SORT, DeepSORT)
---
### When This System is NOT Appropriate
**Don't use this if you need:**
- Security-critical authentication (use liveness detection + CNNs)
- >50 identities (use ANN-indexed embeddings)
- Angle robustness (use multi-view or CNN detectors)
- High accuracy requirements (use state-of-the-art CNNs)
**Do use this if you need:**
- Offline/edge deployment
- Predictable CPU latency
- Simple deployment (pip install)
- Small model footprint
- Fast prototyping
---
## Repository Structure
```
edge-face-recognition-v2/
├── src/edge_face/
│ ├── __init__.py
│ ├── cli.py # Command-line interface
│ ├── config.py # Configuration management
│ ├── detector.py # Haar Cascade wrapper
│ ├── dataset.py # Data collection & loading
│ ├── model.py # KNN classifier
│ ├── pipeline.py # End-to-end inference
│ ├── camera.py # Cross-platform camera initialization
│ └── default.yaml # Default configuration
├── scripts/
│ └── collect_faces.py # Legacy collection script
├── data/ # Generated during collection
│ └── raw/{name}/ # Face samples per person
├── attendance/ # Generated during recognition
│ └── YYYY-MM-DD.csv # Daily attendance logs
├── pyproject.toml # Package metadata
└── README.md
```
---
## Project Evolution
### Version History
| Version | Focus | Date |
|---------|-------|------|
| v1 | Raspberry Pi embedded prototype | Sept 2024 |
| v2 | Pip-installable reusable package | Feb 2025 |
**Key improvements in v2:**
- Modular architecture (single file → package structure)
- Configuration-driven runtime (hardcoded → YAML)
- Cross-platform execution (RPi-only → Windows/Linux/macOS)
- Reusable CLI (monolithic script → installable tool)
- Calibrated confidence scoring with unknown rejection (broken formula → exponential decay)
---
## What This Demonstrates
**System design:**
- Constraint-driven architecture (latency budget drives model choice)
- Trade-off analysis (accuracy vs deployment viability)
- User-centric design (non-ML users as target)
**Software engineering:**
- Packaging for distribution (PyPI-ready)
- CLI design (configuration, error handling, user feedback)
- Cross-platform compatibility (native vs WSL execution)
**Production ML:**
- Deployment constraints over benchmark chasing
- Unknown handling (precision > recall for attendance use case)
- Honest limitation documentation (when not to use this system)
**Iteration velocity:**
- Prototype → production evolution
- Monolithic code → modular package
- Single-use → reusable tool
---
## References
**Technical:**
- Viola-Jones Face Detection (Haar Cascade): [OpenCV Docs](https://docs.opencv.org/3.4/db/d28/tutorial_cascade_classifier.html)
- K-Nearest Neighbors: [Scikit-learn KNN](https://scikit-learn.org/stable/modules/neighbors.html)
**Related work:**
- FaceNet (CNN embeddings): For higher accuracy, GPU-available scenarios
- MTCNN (Multi-task CNN): For angle-robust detection
- ArcFace: State-of-the-art face recognition (requires GPU)
---
**Author:** Saksham Bajaj
**Contact:** [LinkedIn](https://www.linkedin.com/in/saksham-bjj/) | [GitHub](https://github.com/SakshamBjj)
**License:** MIT
**Last Updated:** February 2026
| text/markdown | null | Saksham Bajaj <saksham.bjj@gmail.com> | null | null | MIT | face recognition, computer vision, opencv, edge ml, classical machine learning, knn, cpu inference, raspberry pi, embedded systems | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Topic :: Scientific/Engineering :: Image Recognition",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"opencv-python>=4.5",
"numpy>=1.21",
"scikit-learn>=1.0",
"pyyaml>=5.4",
"build>=0.10; extra == \"dev\"",
"twine>=4.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/SakshamBjj/edge-face-recognition-v2",
"Source, https://github.com/SakshamBjj/edge-face-recognition-v2",
"Tracker, https://github.com/SakshamBjj/edge-face-recognition-v2/issues",
"Documentation, https://github.com/SakshamBjj/edge-face-recognition-v2#readme"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T15:02:09.368839 | edgeface_knn-2.0.5.tar.gz | 22,397 | 5e/11/807f62b844eb34b179a2bc3267ac9b3d91c10150d12dc76d3118d5a90ece/edgeface_knn-2.0.5.tar.gz | source | sdist | null | false | 9469ded61ab07cf65ecb947fb618f8c0 | 278655ce61a3d017084a937b6a27906d5f9284e86fd4be8a5224a00e024886e7 | 5e11807f62b844eb34b179a2bc3267ac9b3d91c10150d12dc76d3118d5a90ece | null | [
"LICENSE"
] | 191 |
2.4 | treeIDW | 1.0.0 | A package for KD-tree optimized inverse distance weighting interpolation. | # treeIDW
<p align="center">
<img src="https://raw.githubusercontent.com/Dorian210/treeIDW/main/docs/logo.png" width="500" />
</p>
**treeIDW** is a Python library for performing **Inverse Distance Weighting (IDW)** interpolation using an efficient **KD-tree-based selection strategy**.
It is designed to be easy to use for newcomers while offering fine-grained control and performance-oriented options for advanced users in numerical methods and spatial data analysis.
---
## Key Features
- Efficient IDW interpolation using KD-tree nearest-neighbor selection
- Automatic exclusion of boundary nodes with negligible contribution
- Optimized numerical kernels powered by `numba`
- Scalable to large datasets (millions of interpolation points)
- Simple API with expert-level tunable parameters
---
## Installation
**treeIDW is available on PyPI.**
```bash
pip install treeIDW
```
### Development installation (from source)
```bash
git clone https://github.com/Dorian210/treeIDW
cd treeIDW
pip install -e .
```
---
## Dependencies
The core dependencies are:
- `numpy`
- `scipy`
- `numba`
These are automatically installed when using `pip`.
---
## Package Structure
- **treeIDW.treeIDW**
Core IDW interpolation engine.
Uses a KD-tree to select only boundary nodes with significant influence, improving both accuracy and performance.
- **treeIDW.helper_functions**
Low-level, performance-critical routines for IDW weight computation.
Implemented with `numba`, including vectorized and parallelized variants.
- **treeIDW.weight_function**
Definition of the IDW weight function.
The default implementation uses inverse squared distance, but custom weight laws can be implemented if needed.
---
## Examples
Example scripts are provided in the `examples/` directory:
- **Graphical demonstration**
Interpolation of a rotating vector field inside a square domain.
- **Large-scale computation**
Propagation of a scalar field from 1,000 boundary nodes to 1,000,000 internal points, highlighting scalability.
- **Logo generation**
The generation process of the *treeIDW* logo itself, where the letters “IDW” are encoded as a vector field and interpolated on a 2D grid.
---
## Documentation
- Online documentation: https://dorian210.github.io/treeIDW/
- API reference is also available in the `docs/` directory of the repository.
---
## Contributions
This project is currently not open to active development contributions.
However, bug reports and suggestions are welcome via the issue tracker.
---
## License
This project is distributed under the **CeCILL License**.
See [LICENSE.txt](LICENSE.txt) for details.
| text/markdown | null | Dorian Bichet <dbichet@insa-toulouse.fr> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Operating System :: OS Independent",
"Topic :: Scientific/Engineering",
"Intended Audience :: Science/Research"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy>=1.20",
"numba>=0.55",
"scipy>=1.8",
"build; extra == \"dev\"",
"twine; extra == \"dev\"",
"pytest; extra == \"dev\"",
"wkhtmltopdf; extra == \"docs\"",
"pdoc>=12.0; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://github.com/Dorian210/treeIDW",
"Repository, https://github.com/Dorian210/treeIDW",
"Issues, https://github.com/Dorian210/treeIDW/issues"
] | twine/6.2.0 CPython/3.9.23 | 2026-02-20T15:01:37.330672 | treeidw-1.0.0.tar.gz | 8,533 | 63/e9/9339570d173a84476d97ff4c5ebc37070c55f7d7171b29293cdaa0cefdbf/treeidw-1.0.0.tar.gz | source | sdist | null | false | b77a5e93711a4b10ee1d13e2b20c1dc9 | af2d790f8dc9894e3ac9a5cf2f71d3d1c459448c4a23fd112a95fc0d50640202 | 63e99339570d173a84476d97ff4c5ebc37070c55f7d7171b29293cdaa0cefdbf | CECILL-2.1 | [
"LICENSE.txt"
] | 0 |
2.3 | beeper-desktop-api | 4.3.0 | The official Python library for the beeperdesktop API | # Beeper Desktop Python API library
<!-- prettier-ignore -->
[)](https://pypi.org/project/beeper_desktop_api/)
The Beeper Desktop Python library provides convenient access to the Beeper Desktop REST API from any Python 3.9+
application. The library includes type definitions for all request params and response fields,
and offers both synchronous and asynchronous clients powered by [httpx](https://github.com/encode/httpx).
## MCP Server
Use the Beeper Desktop MCP Server to enable AI assistants to interact with this API, allowing them to explore endpoints, make test requests, and use documentation to help integrate this SDK into your application.
[](https://cursor.com/en-US/install-mcp?name=%40beeper%2Fdesktop-mcp&config=eyJjb21tYW5kIjoibnB4IiwiYXJncyI6WyIteSIsIkBiZWVwZXIvZGVza3RvcC1tY3AiXSwiZW52Ijp7IkJFRVBFUl9BQ0NFU1NfVE9LRU4iOiJNeSBBY2Nlc3MgVG9rZW4ifX0)
[](https://vscode.stainless.com/mcp/%7B%22name%22%3A%22%40beeper%2Fdesktop-mcp%22%2C%22command%22%3A%22npx%22%2C%22args%22%3A%5B%22-y%22%2C%22%40beeper%2Fdesktop-mcp%22%5D%2C%22env%22%3A%7B%22BEEPER_ACCESS_TOKEN%22%3A%22My%20Access%20Token%22%7D%7D)
> Note: You may need to set environment variables in your MCP client.
## Documentation
The REST API documentation can be found on [developers.beeper.com](https://developers.beeper.com/desktop-api/). The full API of this library can be found in [api.md](https://github.com/beeper/desktop-api-python/tree/main/api.md).
## Installation
```sh
# install from the production repo
pip install git+ssh://git@github.com/beeper/desktop-api-python.git
```
> [!NOTE]
> Once this package is [published to PyPI](https://www.stainless.com/docs/guides/publish), this will become: `pip install beeper_desktop_api`
## Usage
The full API of this library can be found in [api.md](https://github.com/beeper/desktop-api-python/tree/main/api.md).
```python
import os
from beeper_desktop_api import BeeperDesktop
client = BeeperDesktop(
access_token=os.environ.get("BEEPER_ACCESS_TOKEN"), # This is the default and can be omitted
)
page = client.chats.search(
include_muted=True,
limit=3,
type="single",
)
print(page.items)
```
While you can provide a `access_token` keyword argument,
we recommend using [python-dotenv](https://pypi.org/project/python-dotenv/)
to add `BEEPER_ACCESS_TOKEN="My Access Token"` to your `.env` file
so that your Access Token is not stored in source control.
## Async usage
Simply import `AsyncBeeperDesktop` instead of `BeeperDesktop` and use `await` with each API call:
```python
import os
import asyncio
from beeper_desktop_api import AsyncBeeperDesktop
client = AsyncBeeperDesktop(
access_token=os.environ.get("BEEPER_ACCESS_TOKEN"), # This is the default and can be omitted
)
async def main() -> None:
page = await client.chats.search(
include_muted=True,
limit=3,
type="single",
)
print(page.items)
asyncio.run(main())
```
Functionality between the synchronous and asynchronous clients is otherwise identical.
### With aiohttp
By default, the async client uses `httpx` for HTTP requests. However, for improved concurrency performance you may also use `aiohttp` as the HTTP backend.
You can enable this by installing `aiohttp`:
```sh
# install from the production repo
pip install 'beeper_desktop_api[aiohttp] @ git+ssh://git@github.com/beeper/desktop-api-python.git'
```
Then you can enable it by instantiating the client with `http_client=DefaultAioHttpClient()`:
```python
import os
import asyncio
from beeper_desktop_api import DefaultAioHttpClient
from beeper_desktop_api import AsyncBeeperDesktop
async def main() -> None:
async with AsyncBeeperDesktop(
access_token=os.environ.get(
"BEEPER_ACCESS_TOKEN"
), # This is the default and can be omitted
http_client=DefaultAioHttpClient(),
) as client:
page = await client.chats.search(
include_muted=True,
limit=3,
type="single",
)
print(page.items)
asyncio.run(main())
```
## Using types
Nested request parameters are [TypedDicts](https://docs.python.org/3/library/typing.html#typing.TypedDict). Responses are [Pydantic models](https://docs.pydantic.dev) which also provide helper methods for things like:
- Serializing back into JSON, `model.to_json()`
- Converting to a dictionary, `model.to_dict()`
Typed requests and responses provide autocomplete and documentation within your editor. If you would like to see type errors in VS Code to help catch bugs earlier, set `python.analysis.typeCheckingMode` to `basic`.
## Pagination
List methods in the Beeper Desktop API are paginated.
This library provides auto-paginating iterators with each list response, so you do not have to request successive pages manually:
```python
from beeper_desktop_api import BeeperDesktop
client = BeeperDesktop()
all_messages = []
# Automatically fetches more pages as needed.
for message in client.messages.search(
account_ids=["local-telegram_ba_QFrb5lrLPhO3OT5MFBeTWv0x4BI"],
limit=10,
query="deployment",
):
# Do something with message here
all_messages.append(message)
print(all_messages)
```
Or, asynchronously:
```python
import asyncio
from beeper_desktop_api import AsyncBeeperDesktop
client = AsyncBeeperDesktop()
async def main() -> None:
all_messages = []
# Iterate through items across all pages, issuing requests as needed.
async for message in client.messages.search(
account_ids=["local-telegram_ba_QFrb5lrLPhO3OT5MFBeTWv0x4BI"],
limit=10,
query="deployment",
):
all_messages.append(message)
print(all_messages)
asyncio.run(main())
```
Alternatively, you can use the `.has_next_page()`, `.next_page_info()`, or `.get_next_page()` methods for more granular control working with pages:
```python
first_page = await client.messages.search(
account_ids=["local-telegram_ba_QFrb5lrLPhO3OT5MFBeTWv0x4BI"],
limit=10,
query="deployment",
)
if first_page.has_next_page():
print(f"will fetch next page using these details: {first_page.next_page_info()}")
next_page = await first_page.get_next_page()
print(f"number of items we just fetched: {len(next_page.items)}")
# Remove `await` for non-async usage.
```
Or just work directly with the returned data:
```python
first_page = await client.messages.search(
account_ids=["local-telegram_ba_QFrb5lrLPhO3OT5MFBeTWv0x4BI"],
limit=10,
query="deployment",
)
print(f"next page cursor: {first_page.oldest_cursor}") # => "next page cursor: ..."
for message in first_page.items:
print(message.id)
# Remove `await` for non-async usage.
```
## Nested params
Nested parameters are dictionaries, typed using `TypedDict`, for example:
```python
from beeper_desktop_api import BeeperDesktop
client = BeeperDesktop()
chat = client.chats.create(
account_id="accountID",
user={},
)
print(chat.user)
```
## File uploads
Request parameters that correspond to file uploads can be passed as `bytes`, or a [`PathLike`](https://docs.python.org/3/library/os.html#os.PathLike) instance or a tuple of `(filename, contents, media type)`.
```python
from pathlib import Path
from beeper_desktop_api import BeeperDesktop
client = BeeperDesktop()
client.assets.upload(
file=Path("/path/to/file"),
)
```
The async client uses the exact same interface. If you pass a [`PathLike`](https://docs.python.org/3/library/os.html#os.PathLike) instance, the file contents will be read asynchronously automatically.
## Handling errors
When the library is unable to connect to the API (for example, due to network connection problems or a timeout), a subclass of `beeper_desktop_api.APIConnectionError` is raised.
When the API returns a non-success status code (that is, 4xx or 5xx
response), a subclass of `beeper_desktop_api.APIStatusError` is raised, containing `status_code` and `response` properties.
All errors inherit from `beeper_desktop_api.APIError`.
```python
import beeper_desktop_api
from beeper_desktop_api import BeeperDesktop
client = BeeperDesktop()
try:
client.accounts.list()
except beeper_desktop_api.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # an underlying Exception, likely raised within httpx.
except beeper_desktop_api.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except beeper_desktop_api.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
```
Error codes are as follows:
| Status Code | Error Type |
| ----------- | -------------------------- |
| 400 | `BadRequestError` |
| 401 | `AuthenticationError` |
| 403 | `PermissionDeniedError` |
| 404 | `NotFoundError` |
| 422 | `UnprocessableEntityError` |
| 429 | `RateLimitError` |
| >=500 | `InternalServerError` |
| N/A | `APIConnectionError` |
### Retries
Certain errors are automatically retried 2 times by default, with a short exponential backoff.
Connection errors (for example, due to a network connectivity problem), 408 Request Timeout, 409 Conflict,
429 Rate Limit, and >=500 Internal errors are all retried by default.
You can use the `max_retries` option to configure or disable retry settings:
```python
from beeper_desktop_api import BeeperDesktop
# Configure the default for all requests:
client = BeeperDesktop(
# default is 2
max_retries=0,
)
# Or, configure per-request:
client.with_options(max_retries=5).accounts.list()
```
### Timeouts
By default requests time out after 30 seconds. You can configure this with a `timeout` option,
which accepts a float or an [`httpx.Timeout`](https://www.python-httpx.org/advanced/timeouts/#fine-tuning-the-configuration) object:
```python
from beeper_desktop_api import BeeperDesktop
# Configure the default for all requests:
client = BeeperDesktop(
# 20 seconds (default is 30 seconds)
timeout=20.0,
)
# More granular control:
client = BeeperDesktop(
timeout=httpx.Timeout(60.0, read=5.0, write=10.0, connect=2.0),
)
# Override per-request:
client.with_options(timeout=5.0).accounts.list()
```
On timeout, an `APITimeoutError` is thrown.
Note that requests that time out are [retried twice by default](https://github.com/beeper/desktop-api-python/tree/main/#retries).
## Advanced
### Logging
We use the standard library [`logging`](https://docs.python.org/3/library/logging.html) module.
You can enable logging by setting the environment variable `BEEPER_DESKTOP_LOG` to `info`.
```shell
$ export BEEPER_DESKTOP_LOG=info
```
Or to `debug` for more verbose logging.
### How to tell whether `None` means `null` or missing
In an API response, a field may be explicitly `null`, or missing entirely; in either case, its value is `None` in this library. You can differentiate the two cases with `.model_fields_set`:
```py
if response.my_field is None:
if 'my_field' not in response.model_fields_set:
print('Got json like {}, without a "my_field" key present at all.')
else:
print('Got json like {"my_field": null}.')
```
### Accessing raw response data (e.g. headers)
The "raw" Response object can be accessed by prefixing `.with_raw_response.` to any HTTP method call, e.g.,
```py
from beeper_desktop_api import BeeperDesktop
client = BeeperDesktop()
response = client.accounts.with_raw_response.list()
print(response.headers.get('X-My-Header'))
account = response.parse() # get the object that `accounts.list()` would have returned
print(account)
```
These methods return an [`APIResponse`](https://github.com/beeper/desktop-api-python/tree/main/src/beeper_desktop_api/_response.py) object.
The async client returns an [`AsyncAPIResponse`](https://github.com/beeper/desktop-api-python/tree/main/src/beeper_desktop_api/_response.py) with the same structure, the only difference being `await`able methods for reading the response content.
#### `.with_streaming_response`
The above interface eagerly reads the full response body when you make the request, which may not always be what you want.
To stream the response body, use `.with_streaming_response` instead, which requires a context manager and only reads the response body once you call `.read()`, `.text()`, `.json()`, `.iter_bytes()`, `.iter_text()`, `.iter_lines()` or `.parse()`. In the async client, these are async methods.
```python
with client.accounts.with_streaming_response.list() as response:
print(response.headers.get("X-My-Header"))
for line in response.iter_lines():
print(line)
```
The context manager is required so that the response will reliably be closed.
### Making custom/undocumented requests
This library is typed for convenient access to the documented API.
If you need to access undocumented endpoints, params, or response properties, the library can still be used.
#### Undocumented endpoints
To make requests to undocumented endpoints, you can make requests using `client.get`, `client.post`, and other
http verbs. Options on the client will be respected (such as retries) when making this request.
```py
import httpx
response = client.post(
"/foo",
cast_to=httpx.Response,
body={"my_param": True},
)
print(response.headers.get("x-foo"))
```
#### Undocumented request params
If you want to explicitly send an extra param, you can do so with the `extra_query`, `extra_body`, and `extra_headers` request
options.
#### Undocumented response properties
To access undocumented response properties, you can access the extra fields like `response.unknown_prop`. You
can also get all the extra fields on the Pydantic model as a dict with
[`response.model_extra`](https://docs.pydantic.dev/latest/api/base_model/#pydantic.BaseModel.model_extra).
### Configuring the HTTP client
You can directly override the [httpx client](https://www.python-httpx.org/api/#client) to customize it for your use case, including:
- Support for [proxies](https://www.python-httpx.org/advanced/proxies/)
- Custom [transports](https://www.python-httpx.org/advanced/transports/)
- Additional [advanced](https://www.python-httpx.org/advanced/clients/) functionality
```python
import httpx
from beeper_desktop_api import BeeperDesktop, DefaultHttpxClient
client = BeeperDesktop(
# Or use the `BEEPER_DESKTOP_BASE_URL` env var
base_url="http://my.test.server.example.com:8083",
http_client=DefaultHttpxClient(
proxy="http://my.test.proxy.example.com",
transport=httpx.HTTPTransport(local_address="0.0.0.0"),
),
)
```
You can also customize the client on a per-request basis by using `with_options()`:
```python
client.with_options(http_client=DefaultHttpxClient(...))
```
### Managing HTTP resources
By default the library closes underlying HTTP connections whenever the client is [garbage collected](https://docs.python.org/3/reference/datamodel.html#object.__del__). You can manually close the client using the `.close()` method if desired, or with a context manager that closes when exiting.
```py
from beeper_desktop_api import BeeperDesktop
with BeeperDesktop() as client:
# make requests here
...
# HTTP client is now closed
```
## Versioning
This package generally follows [SemVer](https://semver.org/spec/v2.0.0.html) conventions, though certain backwards-incompatible changes may be released as minor versions:
1. Changes that only affect static types, without breaking runtime behavior.
2. Changes to library internals which are technically public but not intended or documented for external use. _(Please open a GitHub issue to let us know if you are relying on such internals.)_
3. Changes that we do not expect to impact the vast majority of users in practice.
We take backwards-compatibility seriously and work hard to ensure you can rely on a smooth upgrade experience.
We are keen for your feedback; please open an [issue](https://www.github.com/beeper/desktop-api-python/issues) with questions, bugs, or suggestions.
### Determining the installed version
If you've upgraded to the latest version but aren't seeing any new features you were expecting then your python environment is likely still using an older version.
You can determine the version that is being used at runtime with:
```py
import beeper_desktop_api
print(beeper_desktop_api.__version__)
```
## Requirements
Python 3.9 or higher.
## Contributing
See [the contributing documentation](https://github.com/beeper/desktop-api-python/tree/main/./CONTRIBUTING.md).
| text/markdown | null | Beeper Desktop <help@beeper.com> | null | null | MIT | null | [
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: OS Independent",
"Operating System :: POSIX",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Libraries :: Python Modules",
"Typing :: Typed"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"anyio<5,>=3.5.0",
"distro<2,>=1.7.0",
"httpx<1,>=0.23.0",
"pydantic<3,>=1.9.0",
"sniffio",
"typing-extensions<5,>=4.10",
"aiohttp; extra == \"aiohttp\"",
"httpx-aiohttp>=0.1.9; extra == \"aiohttp\""
] | [] | [] | [] | [
"Homepage, https://github.com/beeper/desktop-api-python",
"Repository, https://github.com/beeper/desktop-api-python"
] | twine/5.1.1 CPython/3.12.9 | 2026-02-20T15:01:31.718798 | beeper_desktop_api-4.3.0.tar.gz | 130,427 | 39/31/04c74e3a3c33baa20e3293abf97bd817b75e2e32d9e3d6f5a714e983eb1e/beeper_desktop_api-4.3.0.tar.gz | source | sdist | null | false | de525b86d6fc1fe34555ee85a7123d75 | 6f4e8503a703dab79a9fa51957e0b0950058558b51b4f26cb4a324c464a892b1 | 393104c74e3a3c33baa20e3293abf97bd817b75e2e32d9e3d6f5a714e983eb1e | null | [] | 192 |
2.3 | autosim | 0.0.1 | A package to generate simulation data easily | # autosim
Lots of Simulations
## Installation
This project uses [uv](https://docs.astral.sh/uv/) for dependency management.
### Install uv
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
```
### Install the package
```bash
uv pip install -e .
```
This installs `autosim` in editable mode along with its runtime dependencies:
- `numpy>=1.24`
- `scipy>=1.10`
- `tqdm>=4.65`
- `torch>=2.0`
### Install development dependencies (includes pytest)
```bash
uv sync --group dev
```
## Running tests
Once dev dependencies are installed:
```bash
uv run pytest
```
| text/markdown | AI for Physical Systems Team at The Alan Turing Institute | AI for Physical Systems Team at The Alan Turing Institute <ai4physics@turing.ac.uk> | null | null | MIT License
Copyright (c) 2026 The Alan Turing Institute
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | null | [] | [] | null | null | <3.13,>=3.10 | [] | [] | [] | [
"numpy>=1.24",
"scipy>=1.10",
"tqdm>=4.65",
"torch>=2.0",
"ipykernel>=7.1.0; extra == \"dev\"",
"pytest>=9.0.1; extra == \"dev\"",
"pytest-cov>=7.0.0; extra == \"dev\"",
"ruff==0.12.11; extra == \"dev\"",
"pyright==1.1.407; extra == \"dev\"",
"pre-commit>=4.4.0; extra == \"dev\"",
"matplotlib; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T15:01:21.028210 | autosim-0.0.1.tar.gz | 20,242 | cc/17/1c6b739d6f68b32c959b3f229f23e4c5e4f22dff502ac505529a10de3e88/autosim-0.0.1.tar.gz | source | sdist | null | false | d7130912297b2406377655e9a180f3c5 | 0269068c9ea03f762a734e20c99b00e30575bcc919afdd217b5bf672a9ca2dd8 | cc171c6b739d6f68b32c959b3f229f23e4c5e4f22dff502ac505529a10de3e88 | null | [] | 214 |
2.4 | offlinenet-base | 1.0.2.3 | Browse the web without internet. | # OfflineNet
Browse the web without internet
---
## 📦 Installation & Setup
See source code at [GitHub](https://github.com/ntcofficial/offlinenet) or [SourceForge](https://sourceforge.net/p/offlinenet/code/ci/master/tree/) or install using [](https://snapcraft.io/offlinenet) [](https://snapcraft.io/offlinenet)
```bash
python -m venv venv
source ./venv/bin/activate
pip install offlinenet-base
```
## Usage
See the list of available commands:
```bash
offlinenet --help
```
Verify download:
```bash
offlinenet hello --name <your_name>
```
Download a webpage and save locally:
```bash
offlinenet save <url>
```
See the parameters of a particular command:
```bash
offlinenet <command> --help
```
---
## 📝 Changelog
### 1.0.2 >
- Added offline page downloading
---
## 🤝 Contributing
Currently in early development.
Contributions may be opened in the future.
Suggestions and feedback are welcome.
---
## Author
### Jasper
Founder - Next Tech Creations
---
## License
This project is licensed under the **MIT License**.
Full license text applies.
---
## 📜 License Text
```
Copyright 2026 Next Tech Creations
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
```
---
## 📬 Contact
For questions, feedback, or collaboration:
* 📧 Email: [nexttechcreations@gmail.com](mailto:nexttechcreations@gmail.com)
* 🌐 Website: Coming Soon (pages.dev)
---
| text/markdown | Next Tech Creations | null | null | null | MIT | null | [] | [] | null | null | null | [] | [] | [] | [
"beautifulsoup4",
"certifi",
"charset-normalizer",
"click",
"idna",
"markdown-it-py",
"mdurl",
"Pygments",
"requests",
"rich",
"shellingham",
"soupsieve",
"typer",
"typing_extensions",
"urllib3"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T15:00:41.451915 | offlinenet_base-1.0.2.3.tar.gz | 4,004 | f7/5d/84d86b6e558dd9cc2dbafd70f30a71ec80c3466d03103636740762cebe91/offlinenet_base-1.0.2.3.tar.gz | source | sdist | null | false | f179b95bab54807aae138fb6a313f980 | 5587c0617ca74b50516003c3482ac134ecfedf09d8842478c0df1546d6c5fb58 | f75d84d86b6e558dd9cc2dbafd70f30a71ec80c3466d03103636740762cebe91 | null | [] | 205 |
2.4 | audithub-client | 1.1.14 | A Python client that can access Veridise AuditHub via its REST API, providing CLI access | This is the AuditHub client, a Python module that allows programmatic access to Veridise AuditHub via its REST API.
# Installing
- Allocate and activate a venv, e.g., `python -m venv .venv && source .venv/bin/activate`
- Make sure you have `poetry` installed. If it cannot be found globally, you can install it in the local venv with `pip install poetry`
- Run `poetry install`
# Configuring
All commands support configuration via command line arguments. Additionally, some arguments can also be specified as environment variables.
The required arguments for any API call are the following (the name inside the parenthesis is the corresponding environment variable name):
- `--base-url` (`AUDITHUB_BASE_URL`): The base url to use for API calls. The environments are as follows:
- `dev`: https://audithub.dev.veridise.tools/api/v1
- `production`: https://audithub.veridise.com/api/v1
- `--oidc-configuration-url` (`AUDITHUB_OIDC_CONFIGURATION_URL`): OpenID Connect configuration URL. The values per environment are as follows:
- `dev`: https://keycloak.dev.veridise.tools/auth/realms/veridise/.well-known/openid-configuration
- `production`: https://sso.veridise.com/auth/realms/veridise/.well-known/openid-configuration
- `--oidc-client-id` (`AUDITHUB_OIDC_CLIENT_ID`): The OIDC client id (to be supplied by Veridise upon request)
- `--oidc-client-secret` (`AUDITHUB_OIDC_CLIENT_SECRET`): The OIDC client secret (to be supplied by Veridise upon request).
Note: use `ah --help` to see the global arguments, applicable to all commands.
Note: any logging output produced by the `ah` script is directed to stderr, so that output
**Important**: please note that the `client_id` and `client_secret` pair should be considered sensitive information, as anyone with access to these can trigger AuditHub actions that account towards the usage limits of the organization that was issued these credentials.
We suggest to set these arguments in the environment for ease of use.
One approach is to use [direnv](https://direnv.net), for which we provide two sample files: `envrc-sample-dev` and `envrc-sample-production`.
If you would like to use this utility, copy one of the samples corresponding to your target environment as `.envrc`, edit `.envrc` to fill in your credentials, and you can then use the below command line utilities.
# Command line usage
We offer a global `ah` script, that offers commands that make API calls.
Use `ah --help` to list all supported commands, as well as the global options that apply to all commands.
To get help for a specific command, use `ah command --help`. For example: `ah get-task-info --help`.
Any option that can be set via an environment variable, also lists the corresponding environment variable name in the help text.
To set a list option via an environment variable, use JSON notation. e.g.: `export LIST_OPTION='["value 1", "value 2"]'`
To set a list option via the command line, either repeat the same option multiple times, or separate the list elements via space. e.g.:
```shell
ah cmd --list-option "value 1" --list-option "value 2"
# or
ah cmd --list-option "value 1" "value 2"
```
# Verifying connectivity
Once you receive your credentials, enable them in the shell environment and run: `ah get-my-profile`.
This should output information about your user profile in AuditHub, and can help verify the validity of your credentials.
# API Usage
If you would like to use this module as a library, utilized by your own Python code, you can import the corresponding function from the API call you are interested in.
e.g., to invoke the `get_my_profile` function programmatically, you can do the following:
```python
from audithub_client.api.get_my_profile import api_get_my_profile
from audithub_client.library.context import AuditHubContext
from os import getenv
# Fill in the corresponding values below
rpc_context = AuditHubContext(
base_url=getenv("AUDITHUB_BASE_URL"),
oidc_configuration_url=getenv("AUDITHUB_OIDC_CONFIGURATION_URL"),
oidc_client_id=getenv("AUDITHUB_OIDC_CLIENT_ID"),
oidc_client_secret=getenv("AUDITHUB_OIDC_CLIENT_SECRET")
)
print(api_get_my_profile(rpc_context))
```
# Script reference
For a current script reference, please use `ah --help`.
Some interesting commands are the following:
- `create-version-via-local-archive` Create a new version for a project by uploading a local .zip archive, or creating one on the fly from a local folder.
- `create-version-via-url` Create a new version for a project by asking AuditHub to either download an archive or clone a Git repository.
- `get-configuration` Get global AuditHub configuration.
- `get-task-info` Get detailed task information.
- `monitor-task` Monitor a task's progress. Will exit with an exit status of 1 if the task did not complete successfully.
- `start-defi-vanguard-task` Start a Vanguard (static analysis) task for a specific version of a project.
- `start-picus-v2-task` Start a Picus V2 (Rust version) task for a module of a specific version of a project.
> **Note:** all `ah start-...` commands support a `--wait` option that automatically invokes `ah monitor-task` on the newly started task, to wait for it to finish and exit with 0 on success or non-zero on failure.
> **Note:** The .zip files, created on the fly by `create-version-via-local-archive` with the `--source-folder` option, automatically exclude any `.git` folder as well as empty directories. If this does not match your requirements, you can still create a `.zip` archive outside `ah` and use that to upload a version with the same command but the `--archive-path` option.
# Example usage to verify a new version with Picus
Assuming that:
1. a new version .zip archive exists at `new_version.zip`, for a new version to be named `new_version`
2. all `AUDITHUB_...` env vars for accessing the API are properly set
3. `AUDITHUB_ORGANIZATION_ID` and `AUDITHUB_PROJECT_ID` are also properly set, pointing to a specific organization and project
you can run the following as a script to upload the new version to AuditHub and start a Picus task named `new_task_name` to examine a specific file in it (`some/file.picus` in the example below):
```bash
#!/usr/bin/env bash
set -e
version_id=$(ah create-version-via-local-archive --name "new_version" --archive-path new_version.zip)
task_id=$(ah start-picus-v2-task --version-id $version_id --source some/file.picus)
ah monitor-task --task-id $task_id
ah get-task-info --task-id $task_id --section findings_counters --verify
```
If the above exits with a 0 exit code, then all steps completed successfully and there were no issues found in the examined code.
# Obtaining the logs
Additionally, if you want to download the output of the tool, or any step of the task execution, you can invoke:
`ah get-task-logs --task-id $task_id --step-code run-picus`
For a list of valid step codes that you can use for a task, you can use:
`ah get-task-info --task-id $task_id --section steps --output table`
Or, to get a parsable list:
`ah get-task-info --task-id $task_id --section steps --output json | jq -r '. [].code'`
With this, you can preserve all logs locally:
`for step in $(ah get-task-info --task-id $task_id --section steps --output json | jq -r '. [].code'); do ah get-task-logs --task-id $task_id --step-code $step > $step.log; done`
# Building a container image
Use `make image` to just build the `latest` tag.
Use `make image-versioned` to build an image tagger with both `latest` and the current version number of this module, as stored in `pyproject.toml`
Finally, use `make push` to push latest and `make push-versioned` to push the image tagger with the current version.
As a side note, for `docker build --platform=linux/amd64,linux/arm64 ...` to work, the machine's container runtime needs to support multi-platform builds. Specifically for Docker, this requires switching from the "classic" image store to the containerd image store as outlined [here](https://docs.docker.com/build/building/multi-platform/).
For Docker Desktop, you can set the "Use containerd for pulling and storing images" option in the user interface as described [here](https://docs.docker.com/desktop/features/containerd/).
| text/markdown | Nikos Chondros | nikos@veridise.com | null | null | AGPLv3 | null | [
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"cyclopts",
"httpx",
"humanize",
"pydantic",
"tabulate",
"websockets"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:59:41.701075 | audithub_client-1.1.14.tar.gz | 37,507 | 10/b2/aa9cf62f89c37976b6b27857087b37e32534ac4d61cb4c70586c5300994b/audithub_client-1.1.14.tar.gz | source | sdist | null | false | 66b97c1c4940ed3c628cf59ae0ee6184 | f6a1faef2758de6fb6341ebc51c6deca43d49fa7fe2ab01ffaecf317c91428df | 10b2aa9cf62f89c37976b6b27857087b37e32534ac4d61cb4c70586c5300994b | null | [
"LICENSE"
] | 205 |
2.4 | contextualfairness | 0.0.2 | A python package for assessing machine learning fairness with multiple contextual norms. |
[](https://opensource.org/licenses/MIT)
[](https://pypi.python.org/pypi/contextualfairness)
**ContextualFairness** is a Python package for assessing machine learning fairness with multiple contextual norms. The packages provides functions and classes for defining contextual norms and calculating a fairness score for a model based on these norms for binary classification and regression tasks using tabular data.
The contextual norms allow for not only considering the equality norms, but also other norms such as equity or need. This is important because depening on the context equality is not the only fairness norm that is suitable or even suitable at all.
ContextualFairness allows for a fairness analysis on three levels, the global level, the between-group level (e.g., old vs young people), and the in-group level.
<!-- As shown in this [paper](), -->
This three level analysis allows for a more detailed fairness analysis and combined with the contextual norms, ContextualFairness allows for more nuanced evalutions of fairness with respect to the societal context an ML system operates in.
## Contents
1. [Installation with pip](#installation-with-pip)
2. [Usage](#usage)
3. [Example](#examples)
4. [Limitations](#limitations)
<!-- 5. [Citing ContextualFairness](#citing-contextualfairness) -->
## Installation with pip
1. (Optionally) create a virtual environment
```
python3 -m venv .venv
source .venv/bin/activate
```
2. Install via pip
```
pip install contextualfairness
```
## Usage
### Formulating contextual norms
The first step in using ContextualFairness is to elicit and define the relevant norms for a specific ML model in a specific context. This is not a technical step, but rather a societal step. For this elicitation, all relevant stakeholders in a specific context should be considered. By using stakeholder elicitation techniques, fairness norms can formulated. Note that this is not a straightforward step and requires careful consideration of the societal context and stakeholders.
An example of formulated norms for an income prediction scenario could be:
- Everybody should get the same prediction.
- People who work more hours should earn more.
- People with a lower education level should earn more.
### Operationalizing norms
To use ContextualFairness, we must first operationalize the norms, to this end ContextualFairness provides three classes: `BinaryClassificationEqualityNorm`, `RegressionEqualityNorm`, and `RankNorm`. The first two are specific for the ML task at hand and the last one can be used for both binary classification and regression.
The `BinaryClassificationEqualityNorm` is operationalized as follows:
```python
from contextualfairness.norms import BinaryClassificationEqualityNorm
binary_classification_equality_norm = BinaryClassificationEqualityNorm()
```
in this case equality means being equal to the majority class in the predictions and we calculate a score for this norm by counting the number of samples that are not predicted the majority class.
Alternatively, we can also specify a positive class. In this case, equality means being predicted the positive class.
```python
binary_classification_equality_norm = BinaryClassificationEqualityNorm(positive_class_value=1)
```
The `RegressionEqualityNorm` is operationalized as follows:
```python
from contextualfairness.norms import RegressionEqualityNorm
regression_equality_norm = RegressionEqualityNorm()
```
Here equality, means having the maximum predicted value. Therefore, we calculate a score for this norm by taking the (absolute) difference between the prediction for each sample and the maximum prediction.
To operationalize a `RankNorm`, we must first specify a statement to rank all samples in the dataset with respect to the norm. As ContextualFairness uses polars under the hood, this must be formulated as a [polars expression](https://docs.pola.rs/user-guide/concepts/expressions-and-contexts/). For example, for the norms defined above, rank by hours worked if *people who work more hours should earn more*. This gives te following operationalization:
```python
import polars as pl
from contextualfairness.norms import RankNorm
more_hours_worked_is_preferred = pl.col("hours_worked") # assuming the column `hours_worked` exists in the polars DataFrame
rank_norm = RankNorm(norm_statement=more_hours_worked_is_preferred, name="Work more hours")
```
For rank norms we calculate a score, by for each sample counting the number of samples that are ranked lower with respect to the `norm_statement` but higher with respect to an `outcome_score`. This `outcome_score` is the probability of being predicted a (positive) class for binary classification or the predicted value for regression.
### Calculating contextual fairness
After operationalizing the norms, we provide these norms to `contextual_fairness_score` to calculate the contextual fairness score for a specific model. We also specifiy a list of `weights` that will weigh the results for each norm for the total score.
For binary classification this looks as follows:
```python
from contextualfairness.scorer import contextual_fairness_score
norms = [binary_classification_equality_norm, rank_norm]
result = contextual_fairness_score(
norms=norms,
data=data, # Dictionary with each key corresponding to column in the data
y_pred=y_pred, # Assume the existence of some array-like of predictions
outcome_scores=y_pred_probas, # Assume the existence of some array-like of outcome_scores
weights=[0.6, 0.4]
)
```
Alternatively, we can also not specify the weights to get uniform weights:
```python
result = contextual_fairness_score(norms=norms, data=data, y_pred=y_pred, outcome_scores=y_pred_probas)
```
For regression, we do it as follows:
```python
norms = [regression_equality_norm, rank_norm]
result = contextual_fairness_score(
norms=norms,
X=X, # Assume the existence of some pandas.DataFrame dataset
y_pred=y_pred, # Assume the existence of some array-like of predictions
)
```
Note, that not specifying the `outcome_scores` results in setting `outcome_scores=y_pred`, which is useful for regression.
### Analyze the results
After calculating the score, we can analyze the results on three levels:
The total score:
```python
result.total_score()
```
The between-group and in-group level:
```python
group_scores = result.group_scores(attributes=["sex", "age"]).collect() # assuming existence of `sex` and `age` attribute in X
print(group_scores.filter((pl.col("sex") == "male") & (pl.col("age") == "young"))) # To show the score for this group and the ids of the individuals belonging to the group.
```
This gives the score for all groups in the dataset (where a group is combination of values for the specified attributes, e.g., sex=male and age=young). These scores an be compared between the different groups. Additionally, the data used for calculating the group scores is also provided to analyze the scores with-in a group.
The group scores can also be scaled relative to their group sizes, as follows:
```python
group_scores = result.group_scores(attributes=["sex", "age"], scaled=True).collect()
```
Finally, for additional analyses the `polars.DataFrame` containing the results can be accessed as follows:
```python
result.df
```
## Example
We show a short example on the [ACSIncome data](https://github.com/socialfoundations/folktables) using a [`LogisticRegression`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html), with the three following norms:
- Everybody should get the same prediction.
- People who work more hours should earn more.
- People with a lower education level should earn more.
```python
from folktables import ACSDataSource, ACSIncome
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import polars as pl
from contextualfairness.scorer import contextual_fairness_score
from contextualfairness.norms import BinaryClassificationEqualityNorm, RankNorm
# load and prepare data
data_source = ACSDataSource(
survey_year="2016", horizon="1-Year", survey="person", root_dir="examples/data/raw"
)
acs_data = data_source.get_data(states=["WY"], download="True")
X, y, _ = ACSIncome.df_to_pandas(acs_data)
y = y["PINCP"]
sensitive_attribute = X["SEX"].copy()
X_train, X_test, y_train, y_test, sens_train, sens_test = train_test_split(
X, y, sensitive_attribute, test_size=0.2, random_state=0
)
# Train model
clf = LogisticRegression(max_iter=10_000, penalty="l2", random_state=42)
clf.fit(X_train, y_train)
# Predict for test data
y_pred = clf.predict(X_test)
y_pred_probas = clf.predict_proba(X_test)[:, 1]
norms = [
BinaryClassificationEqualityNorm(positive_class_value=True),
RankNorm(norm_statement=pl.col("WKHP"), name="work_more_hours"),
RankNorm(norm_statement=-pl.col("SCHL"), name="lower_education"),
]
# Calculate contextual fairness
result = contextual_fairness_score(
norms=norms,
data=X_test.to_dict("list"),
y_pred=y_pred,
outcome_scores=y_pred_probas,
)
# Analysis
print(result.total_score())
print(result.group_scores(attributes=["SEX"], scaled=True).collect())
print(
result.group_scores(attributes=["SEX"], scaled=True)
.collect()
.filter(pl.col("SEX") == 1.0)
)
```
Additional examples can be found in the `examples` folder.
<!-- This folder also contains the experiments used for evaluation in the paper [*Assessing machine learning fairness with multiple contextual norms*](). -->
## Limitations
The most important limitations of the current implementation are:
- On big datasets calculating rank norms becomes time consuming due to the required pairwise comparison of samples.
- Norms are combined linearly, consequently ContextualFairness cannot capture conditional or hierarchical relations between norms, for example, when we want equity except in cases of need.
- Rank norms can only be meaningfully defined for tabular data, as defining a `norm_function` for other types of data such as image, sound or text data is much harder.
Further limitations of ContextualFairness can be found in the [paper](https://bnaic2025.unamur.be/accepted-submissions/accepted_oral/079%20-%20Assessing%20machine%20learning%20fairness%20with%20multiple%20contextual%20norms.pdf).
## Citing ContextualFairness
ContextualFairness is proposed in this [paper](https://bnaic2025.unamur.be/accepted-submissions/accepted_oral/079%20-%20Assessing%20machine%20learning%20fairness%20with%20multiple%20contextual%20norms.pdf), wich you can cite as follows:
```bibtex
@inproceedings{kerkhoven2025assessing,
title={Assessing machine learning fairness with multiple contextual norms},
author={Kerkhoven, Pim and Dignum, Virginia and Bhuyan, Monowar},
booktitle={The 37th Benelux Conference on Artificial Intelligence and the 34th Belgian Dutch Conference on Machine Learning},
year={2025}
}
```
| text/markdown | Pim Kerkhoven | pimk@cs.umu.se | null | null | null | null | [
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/pimkerkhoven/ContextualFairness | null | >=3.13.1 | [] | [] | [] | [
"pandas==2.3.3",
"numpy==2.2.6"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.1 | 2026-02-20T14:59:21.668428 | contextualfairness-0.0.2.tar.gz | 13,289 | bc/e1/45d75aaa035f09eeabba1f0ec1734528d4338bbe61d5ba665da82ac28558/contextualfairness-0.0.2.tar.gz | source | sdist | null | false | 8092fd0621be2d6e0dafa85aa948d6d2 | b0a4221784c91d31262b46ad0057ff0a76b5a5e7974d92ae0e338586a578c368 | bce145d75aaa035f09eeabba1f0ec1734528d4338bbe61d5ba665da82ac28558 | null | [
"LICENSE"
] | 201 |
2.4 | catchlib | 1.0.7 | This project allows to catch exceptions easily. | ========
catchlib
========
Visit the website `https://catchlib.johannes-programming.online/ <https://catchlib.johannes-programming.online/>`_ for more information.
| text/x-rst | null | Johannes <johannes.programming@gmail.com> | null | null | The MIT License (MIT)
Copyright (c) 2025 Johannes
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | null | [
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Typing :: Typed"
] | [] | null | null | >=3.11 | [] | [] | [] | [] | [] | [] | [] | [
"Download, https://pypi.org/project/catchlib/#files",
"Index, https://pypi.org/project/catchlib/",
"Source, https://github.com/johannes-programming/catchlib/",
"Website, https://catchlib.johannes-programming.online/"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T14:58:12.402365 | catchlib-1.0.7.tar.gz | 3,800 | 1d/51/d250868bfb807a9b1d3ee86624cd608cc70a82d95208497a62cd200ca1f0/catchlib-1.0.7.tar.gz | source | sdist | null | false | e4ce20fd78e78461223fddef46e770ac | b0758d56915117170ce55d881278af0d60a18a3c24b5df87278a357888ff7c06 | 1d51d250868bfb807a9b1d3ee86624cd608cc70a82d95208497a62cd200ca1f0 | null | [
"LICENSE.txt"
] | 210 |
2.4 | isaura | 2.1.16 | A lake of precalculated properties of biomedical entities based on the Ersilia Model Hub | <div align="center">
<img src="./isaura/assets/isaura_v2.png" height="160" alt="Isaura logo" />
### Ersilia’s Precalculation Store
Fast, reproducible access to **precalculated model outputs** from the **Ersilia Model Hub** — with a CLI and Python API built for batch workflows.
<br/>
[](#)
[](https://docs.astral.sh/uv/)
[](https://www.docker.com/)
[](https://github.com/psf/black)
[](#license)
<br/>
[Quickstart](#quickstart) ·
[CLI](#cli) ·
[Python API](#python-api) ·
[Configuration](#configuration) ·
[Docs](#docs) ·
[Contributing](#contributing)
</div>
---
## Why Isaura?
Isaura is Ersilia’s precalculation store: it **precomputes and persistently stores model outputs** so researchers can retrieve results instantly instead of repeatedly running expensive inference. This delivers a major research speed-up—especially in low-resource settings where compute, bandwidth, or infrastructure are limited—by turning repeated calculations into reusable shared artifacts. To support equitable access, Ersilia also provides **free access to public precalculations**, making high-value model outputs available even when local compute isn’t.
Isaura provides a structured store for model results so you can:
- ⚡ **Skip recomputation** by reusing precalculated outputs
- 🧱 Keep artifacts **versioned and organized** (model → version → bucket/project)
- 📦 Store and retrieve results via **S3-compatible object storage (MinIO)**
- 🔎 Enable **fast retrieval** using its fast engine developed on top of duckdb and for ANN uses vector search / indexing components (Milvus + NN service)
If you’re integrating Ersilia with Isaura, you typically (check Ersilia Model Hub for more info [here](https://github.com/ersilia-os/ersilia)):
1) run once (generate/store), then
2) subsequent runs become fast (retrieve).
---
## Architecture (high level)
* 📝 **Write:** `CLI / Python API → MinIO`
Precomputed outputs are stored as chunked artifacts (e.g., Parquet) under `model_id/version`, and Isaura updates lightweight registries (index/metadata/bloom) for deduplication and fast lookup.
* 📥 **Read(exact):** `CLI / Python API → DuckDB query on MinIO → results`
Inputs are matched against the index, then the corresponding rows are fetched directly from the stored chunks.
* ⚡ **Read (approx / ANN, optional):** `CLI / Python API → NN service (+ Milvus) → nearest match → exact fetch from MinIO`
For unseen inputs, the NN service finds the closest indexed compound(s); Isaura then retrieves the corresponding stored result from MinIO.
See the deep dive: **[How it works →](docs/HOW_IT_WORKS.md)**
---
## Quickstart
### 1) Install dependencies & setup env
We recommend using `uv`.
```bash
git clone https://github.com/ersilia-os/isaura.git
cd isaura
uv sync
source .venv/bin/activate
# if you have conda env
# use uv as below
uv pip install -e .
````
### 2) Start local services (Docker required)
```bash
isaura engine --start
```
**Local dashboards**
* MinIO Console: `http://localhost:9001`
**Default MinIO credentials (local dev):**
```
Username: minioadmin123
Password: minioadmin1234
```
---
## CLI
### Common commands
#### Write (store outputs)
```bash
isaura write -i data/ersilia_output.csv -m eos8a4x -v v2 -pn myproject --access public
```
#### Read (retrieve outputs)
```bash
isaura read -i data/inputs.csv -m eos8a4x -v v2 -pn myproject -o data/outputs.csv
```
#### Copy artifacts to local directory
```bash
isaura copy -m eos8a4x -v v1 -pn myproject -o ~/Documents/isaura-backup/
```
#### Inspect available entries
```bash
isaura inspect -m eos8a4x -v v1 -o reports/available.csv
```
---
## Python API
```python
from isaura.manage import IsauraWriter, IsauraReader
```
Write the precalculation
```python
writer = IsauraWriter(
input_csv="data/input.csv",
model_id="eos8a4x",
model_version="v1",
bucket="my-project",
access="public",
)
writer.write()
```
Read the stored calculation
```python
reader = IsauraReader(
model_id="eos8a4x",
model_version="v1",
bucket="my-project",
input_csv="data/query.csv",
approximate=False,
)
reader.read(output_csv="results.csv")
```
More examples for CLI and API usage: **[API and CLI usage](docs/API_AND_CLI_USAGE.md)**
---
## Configuration
Isaura reads configuration from environment variables.
### Recommended: `.env`
Create a `.env` file in the repo root:
```bash
MINIO_ENDPOINT=http://127.0.0.1:9000
NNS_ENDPOINT=http://127.0.0.1:8080
DEFAULT_BUCKET_NAME=isaura-public
DEFAULT_PRIVATE_BUCKET_NAME=isaura-private
```
### Cloud credentials (optional)
```bash
export MINIO_CLOUD_AK="<access_key>"
export MINIO_CLOUD_SK="<secret_key>"
export MINIO_PRIV_CLOUD_AK="<access_key>"
export MINIO_PRIV_CLOUD_SK="<secret_key>"
```
> You can define those credentials in the .env as well
See the full list: **[CONFIGURATION](docs/CONFIGURATION.md)**
---
## MinIO Client (optional but recommended)
Install `mc` to manage buckets:
```bash
brew install minio/stable/mc # macOS
# or Linux:
curl -O https://dl.min.io/client/mc/release/linux-amd64/mc && chmod +x mc && sudo mv mc /usr/local/bin/
```
Configure alias:
```bash
mc alias set local http://localhost:9000 minioadmin123 minioadmin1234
mc ls local
```
---
## Docs
* 📘 **How it works**: [here](docs/HOW_IT_WORKS.md)
* ⚙️ **Configuration**: [here](docs/CONFIGURATION.md)
* 🧰 **CLI and API reference**: [here](docs/API_AND_CLI_USAGE.md)
* 🧪 **Benchmark**: [here](docs/BENCHMARK.md)
* 🩹 **Troubleshooting / recovery**: [here](docs/TROUBLESHOOTING.md)
---
## Contributing
PRs are welcome. Please run format + lint before pushing:
```bash
uv run ruff format .
```
If you’re changing CLI behavior, please update **[here](docs/API_AND_CLI_USAGE.md)**.
---
## About the Ersilia Open Source Initiative
The [Ersilia Open Source Initiative](https://ersilia.io) is a tech-nonprofit organization fueling sustainable research in the Global South. Ersilia's main asset is the [Ersilia Model Hub](https://github.com/ersilia-os/ersilia), an open-source repository of AI/ML models for antimicrobial drug discovery.

| text/markdown | null | Miquel Duran Frigola <miquel@ersilia.io>, Abel Legese Shibiru <abel@ersilia.io> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"boto3>=1.40.35",
"duckdb>=1.3.2",
"loguru>=0.7.3",
"pandas==2.3.0",
"psutil==7.0.0",
"pyarrow>=21.0.0",
"pybloom-live>=4.0.0",
"python-dotenv>=1.1.1",
"pyyaml>=6.0.3",
"rdkit==2024.3.6",
"requests>=2.32.5",
"rich>=14.1.0",
"rich-click>=1.8.9",
"ruff>=0.12.9",
"tqdm>=4.67.1"
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.12.3 Linux/6.11.0-1018-azure | 2026-02-20T14:57:38.327550 | isaura-2.1.16-py3-none-any.whl | 1,353,408 | 93/bb/7a2eeeac93a13eba3de41225dbbc253f9271b798079534c43aad421b74ee/isaura-2.1.16-py3-none-any.whl | py3 | bdist_wheel | null | false | ef742cf5a451877a76a23d7ebe3bee96 | 80f9ef003b7d98dbeda5959df5065cfed853ac954f4e8571a0e5bd101bfc9aa8 | 93bb7a2eeeac93a13eba3de41225dbbc253f9271b798079534c43aad421b74ee | null | [
"LICENSE"
] | 207 |
2.4 | bc-al-chunker | 0.1.0 | Static analysis and RAG-optimized chunking for Business Central AL files | # bc-al-chunker
RAG-optimized chunking for Business Central AL files.
`bc-al-chunker` statically parses `.al` files and produces semantically-aware chunks optimized for embedding and retrieval-augmented generation (RAG). It understands the structure of every AL object type — tables, pages, codeunits, reports, queries, enums, interfaces, and all extension types — and splits large objects at natural semantic boundaries (sections, procedures, triggers) while keeping small objects whole.
## Features
- **Hierarchical chunking** — small objects stay whole; large objects split at procedure/trigger/section boundaries
- **Context headers** — every sub-chunk gets a synthetic context comment so each chunk is self-contained for embedding
- **All AL object types** — table, page, codeunit, report, query, xmlport, enum, interface, permissionset, profile, controladdin, entitlement, and all extension variants
- **Multiple data sources** — local filesystem, GitHub API, Azure DevOps API
- **Structured output** — Python dataclasses with JSON and JSONL export
- **Zero dependencies** for core usage — `httpx` only needed for remote adapters
- **Fully typed** — strict mypy, PEP 561 `py.typed` marker
## Installation
```bash
# Core (local filesystem only)
pip install bc-al-chunker
# With GitHub adapter
pip install bc-al-chunker[github]
# With Azure DevOps adapter
pip install bc-al-chunker[azure]
# Everything
pip install bc-al-chunker[all]
```
## Quick Start
```python
from bc_al_chunker import chunk
# Chunk all .al files in a directory
chunks = chunk("/path/to/al-repo")
# Multiple repositories
chunks = chunk(["/repo1", "/repo2"])
# Each chunk has content + rich metadata
for c in chunks:
print(c.metadata.object_type, c.metadata.object_name, c.metadata.chunk_type)
print(c.content[:100])
print(c.token_estimate)
```
## Configuration
```python
from bc_al_chunker import chunk, ChunkingConfig
chunks = chunk(
"/path/to/repo",
config=ChunkingConfig(
max_chunk_chars=2000, # Max characters per chunk (default: 1500)
min_chunk_chars=100, # Min characters per chunk (default: 100)
include_context_header=True, # Prepend object context to sub-chunks
estimate_tokens=True, # Include token estimate on each chunk
),
)
```
## Remote Sources
```python
from bc_al_chunker import chunk_source
from bc_al_chunker.adapters.github import GitHubAdapter
from bc_al_chunker.adapters.azure_devops import AzureDevOpsAdapter
# GitHub
chunks = chunk_source(
GitHubAdapter("microsoft/BCApps", token="ghp_...", paths=["src/"])
)
# Azure DevOps
chunks = chunk_source(
AzureDevOpsAdapter("myorg", "myproject", "myrepo", token="pat...")
)
```
## Export
```python
from bc_al_chunker import chunk, chunks_to_json, chunks_to_jsonl, chunks_to_dicts
chunks = chunk("/path/to/repo")
# JSON array
chunks_to_json(chunks, "output.json")
# JSONL (streaming-friendly)
chunks_to_jsonl(chunks, "output.jsonl")
# Python dicts (for programmatic use)
dicts = chunks_to_dicts(chunks)
```
## Chunking Strategy
The chunker uses a **hierarchical, AST-aware** strategy:
1. **Parse** — Each `.al` file is parsed into an `ALObject` AST with sections, procedures, triggers, and properties identified
2. **Size check** — If the object's source is ≤ `max_chunk_chars`, it becomes one `WholeObject` chunk
3. **Split** — Large objects are split:
- **Header chunk** — object declaration + top-level properties
- **Section chunks** — `fields`, `keys`, `layout`, `actions`, `views`, `dataset`, etc.
- **Procedure/Trigger chunks** — each procedure or trigger as its own chunk
4. **Context injection** — Sub-chunks get a context header prepended:
```al
// Object: codeunit 50100 "Address Management"
// File: src/Codeunits/AddressManagement.al
procedure ValidateAddress(var CustAddr: Record "Customer Address")
begin
...
end;
```
This ensures every chunk is self-contained and produces high-quality embeddings for code search.
## Chunk Schema
Each `Chunk` contains:
- `content` — the text to embed
- `token_estimate` — approximate token count (chars / 4)
- `metadata`:
- `file_path`, `object_type`, `object_id`, `object_name`
- `chunk_type` — `whole_object`, `header`, `section`, `procedure`, `trigger`
- `section_name`, `procedure_name`
- `extends` — for extension objects
- `source_table` — extracted from page/codeunit properties
- `attributes` — e.g., `[EventSubscriber(...)]`
- `line_start`, `line_end`
## Development
```bash
# Clone and install
git clone https://github.com/andrijantasevski/bc-al-chunker.git
cd bc-al-chunker
uv sync --all-extras --group dev
# Run tests
uv run pytest tests/ -v
# Lint + format
uv run ruff check src/ tests/
uv run ruff format src/ tests/
# Type check
uv run mypy src/
```
## License
MIT
| text/markdown | Andrijan Tasevski | null | null | null | null | al, business-central, chunking, code-analysis, embeddings, rag | [
"Development Status :: 4 - Beta",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Code Generators",
"Topic :: Text Processing :: Indexing",
"Typing :: Typed"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"httpx[http2]>=0.27; extra == \"all\"",
"httpx[http2]>=0.27; extra == \"azure\"",
"httpx[http2]>=0.27; extra == \"github\""
] | [] | [] | [] | [
"Homepage, https://github.com/andrijantasevski/bc-al-chunker",
"Repository, https://github.com/andrijantasevski/bc-al-chunker",
"Issues, https://github.com/andrijantasevski/bc-al-chunker/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T14:56:44.378687 | bc_al_chunker-0.1.0-py3-none-any.whl | 25,497 | c8/c7/95fbdbcc2805f437c6d6ca724228d85c3b562fc7bfeaed6324e1401496f2/bc_al_chunker-0.1.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 1d45de9e5ac1ea40af099cd7707b1dea | baf603e16fee0d1a2778cb88ec2442146fed9279f05a421060f51c315cf629d4 | c8c795fbdbcc2805f437c6d6ca724228d85c3b562fc7bfeaed6324e1401496f2 | MIT | [
"LICENSE"
] | 217 |
2.4 | autobrain-sim | 1.0.0 | Python client for the WorldQuant Brain API | # AutoBrain Sim
A lightweight Python client library for interacting with the [WorldQuant Brain](https://platform.worldquantbrain.com) platform API. Supports authentication, alpha simulation submission, and result retrieval.
## Features
- Multiple authentication methods (direct, credentials file, interactive prompt)
- Submit alpha expressions for simulation
- Poll for simulation completion automatically
- Retrieve alpha details and PnL record sets
## Install
```bash
pip install autobrain-sim
```
## Requirements
- Python 3.7+
- `requests`
Install the dependency:
```bash
pip install requests
```
## Files
| File | Description |
|------|-------------|
| `brain_client.py` | Core client library (`BrainClient`, `SimulationResult`) |
| `example.py` | Standalone usage example |
| `main.ipynb` | Jupyter notebook walkthrough |
## Quick Start
### Authentication
**Method 1 — Direct credentials**
```python
from brain_client import BrainClient
client = BrainClient(email="your@email.com", password="yourpassword")
client.authenticate()
```
**Method 2 — One-liner login**
```python
client = BrainClient.login("your@email.com", "yourpassword")
```
**Method 3 — Interactive prompt** (asks at runtime if no credentials are found)
```python
client = BrainClient()
client.authenticate()
```
**Method 4 — Credentials file**
Create `~/.brain_credentials` (or any path) as a JSON array:
```json
["your@email.com", "yourpassword"]
```
Then load it:
```python
client = BrainClient(credentials_file="~/.brain_credentials")
client.authenticate()
```
> Credentials priority: direct args → `credentials_file` → `~/.brain_credentials` → interactive prompt.
---
### Simulate an Alpha
```python
sim = client.simulate(
expression="close / ts_mean(close, 20) - 1",
settings={
"region": "USA",
"universe": "TOP3000",
"neutralization": "SUBINDUSTRY",
}
)
result = sim.wait(verbose=True) # blocks until done
print("Alpha ID:", sim.alpha_id)
```
### Retrieve Results
```python
alpha = sim.get_alpha()
print("Sharpe:", alpha["is"]["sharpe"])
print("Fitness:", alpha["is"]["fitness"])
pnl = sim.get_pnl()
print(pnl)
```
---
## API Reference
### `BrainClient`
| Method | Description |
|--------|-------------|
| `__init__(email, password, credentials_file)` | Initialize client with credentials |
| `BrainClient.login(email, password)` | Create client and authenticate in one step |
| `authenticate()` | Sign in and obtain a session token |
| `simulate(expression, settings, ...)` | Submit an alpha for simulation; returns `SimulationResult` |
| `get_alpha(alpha_id)` | Fetch alpha details by ID |
| `get_pnl(alpha_id)` | Fetch PnL record set for an alpha |
| `get_recordset(alpha_id, record_set_name)` | Fetch any named record set |
#### Default Simulation Settings
```python
{
"instrumentType": "EQUITY",
"region": "USA",
"universe": "TOP3000",
"delay": 1,
"decay": 15,
"neutralization": "SUBINDUSTRY",
"truncation": 0.08,
"maxTrade": "ON",
"pasteurization": "ON",
"testPeriod": "P1Y6M",
"unitHandling": "VERIFY",
"nanHandling": "OFF",
"language": "FASTEXPR",
}
```
Any key passed via `settings` overrides the default.
---
### `SimulationResult`
Returned by `client.simulate()`.
| Method | Description |
|--------|-------------|
| `wait(verbose=True)` | Poll until simulation completes; returns result JSON |
| `get_alpha()` | Fetch full alpha details (call after `wait()`) |
| `get_pnl(poll_interval)` | Fetch PnL record set (call after `wait()`) |
| Attribute | Description |
|-----------|-------------|
| `alpha_id` | Alpha ID string (available after `wait()`) |
| `progress_url` | URL used to poll simulation progress |
---
## Example
```python
from brain_client import BrainClient
client = BrainClient.login() # interactive prompt
sim = client.simulate("close / ts_mean(close, 20) - 1")
result = sim.wait(verbose=True)
alpha = sim.get_alpha()
print(f"Alpha ID : {sim.alpha_id}")
print(f"Sharpe : {alpha['is']['sharpe']}")
print(f"Fitness : {alpha['is']['fitness']}")
```
## Notes
- The client uses HTTP Basic Auth to obtain a session token from the `/authentication` endpoint.
- Polling respects the `Retry-After` response header returned by the Brain API.
- Never commit your credentials to version control. Use `~/.brain_credentials` or environment variables instead.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.7 | [] | [] | [] | [
"requests>=2.28",
"pytest; extra == \"dev\"",
"pytest-mock; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.9.6 | 2026-02-20T14:56:02.672675 | autobrain_sim-1.0.0.tar.gz | 6,143 | 24/e6/18ef9ed27cc462249b68efea79e4ef6771f62ab8cbc996e86376c8fe96e6/autobrain_sim-1.0.0.tar.gz | source | sdist | null | false | 0973a3af06844d5f7652c1bbd5051812 | f2efea479402b2f6448f3586cb402bbf39da6b246452b23cc89a182ff7968936 | 24e618ef9ed27cc462249b68efea79e4ef6771f62ab8cbc996e86376c8fe96e6 | null | [
"LICENSE"
] | 225 |
2.4 | dreamstack | 0.0.2 | A Python library for demonstration and publishing to PyPI. | <div align="right">
[](https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/scape-agency/dreamstack)
</div>
<header>
<p align="center">
<img src="res/logo/dreamstack-logo.png" width="20%" alt="Dreamstack Logo">
</p>
<h1 align='center' style='border-bottom: none;'>Dreamstack</h1>
<h3 align='center'>Scape Agency</h3>
</header>
<br/>
---
A Python library for demonstration and publishing to PyPI.
---
## Installation
```bash
pip install dreamstack
```
---
## Usage
```python
from dreamstack import hello
print(hello("Scape"))
```
---
## Project Structure
``` sh
src/dreamstack/
├── __init__.py # Package initialization with namespace support
├── __version__.py # Version management
├── __main__.py # CLI interface
└── core.py # Core greeting functions (hello, greet, format_message)
```
---
<p align="center">
<b>Made with 🖤 by <a href="https://www.scape.agency" target="_blank">Scape Agency</a></b><br/>
<sub>Copyright 2026 Scape Agency. All Rights Reserved</sub>
</p>
| text/markdown | Scape Agency | info@scape.agency | Lars van Vianen | lars@scape.agency | null | scape, dreamstack | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: Other/Proprietary License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Environment :: Web Environment",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Software Development :: Libraries :: Application Frameworks",
"Topic :: Internet :: WWW/HTTP",
"Topic :: Internet :: WWW/HTTP :: Dynamic Content",
"Topic :: Internet :: WWW/HTTP :: WSGI"
] | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"rite>=0.2.4"
] | [] | [] | [] | [
"Documentation, https://github.com/scape-agency/dreamstack/doc",
"Homepage, https://scape.agency/",
"Repository, https://github.com/scape-agency/dreamstack"
] | poetry/2.3.2 CPython/3.10.19 Linux/6.11.0-1018-azure | 2026-02-20T14:55:42.463278 | dreamstack-0.0.2-py3-none-any.whl | 6,472 | a0/3c/be82cb1ad39711952746cd498b5da6441132eb155e3032de0acfb994a13d/dreamstack-0.0.2-py3-none-any.whl | py3 | bdist_wheel | null | false | c67b3801d74474338690b726e67e5c0f | e8667a926af0807e56e69e11b61e2c81feec0e8811a1533d325ad2223d7b6b52 | a03cbe82cb1ad39711952746cd498b5da6441132eb155e3032de0acfb994a13d | null | [
"AUTHORS",
"LICENSE"
] | 205 |
2.4 | wet-mcp | 2.6.3 | Open-source MCP Server for web search, extract, crawl, academic research, and library docs with embedded SearXNG | # WET - Web Extended Toolkit MCP Server
**Open-source MCP Server for web search, content extraction, library docs & multimodal analysis.**
[](https://pypi.org/project/wet-mcp/)
[](https://hub.docker.com/r/n24q02m/wet-mcp)
[](LICENSE)
## Features
- **Web Search** - Search via embedded SearXNG (metasearch: Google, Bing, DuckDuckGo, Brave)
- **Academic Research** - Search Google Scholar, Semantic Scholar, arXiv, PubMed, CrossRef, BASE
- **Library Docs** - Auto-discover and index documentation with FTS5 hybrid search
- **Content Extract** - Extract clean content (Markdown/Text)
- **Deep Crawl** - Crawl multiple pages from a root URL with depth control
- **Site Map** - Discover website URL structure
- **Media** - List and download images, videos, audio files
- **Anti-bot** - Stealth mode bypasses Cloudflare, Medium, LinkedIn, Twitter
- **Local Cache** - TTL-based caching for all web operations
- **Docs Sync** - Sync indexed docs across machines via rclone
---
## Quick Start
### Prerequisites
- **Python 3.13** (required -- Python 3.14+ is **not** supported due to SearXNG incompatibility)
> **Warning:** You **must** specify `--python 3.13` when using `uvx`. Without it, `uvx` may pick Python 3.14+ which causes SearXNG search to fail silently.
**On first run**, the server automatically installs SearXNG, Playwright chromium, and starts the embedded search engine.
### Option 1: uvx (Recommended)
```jsonc
{
"mcpServers": {
"wet": {
"command": "uvx",
"args": ["--python", "3.13", "wet-mcp@latest"],
"env": {
// -- optional: cloud embedding (Gemini > OpenAI > Cohere) + media analysis
// -- without this, uses built-in local Qwen3-Embedding-0.6B + Qwen3-Reranker-0.6B (ONNX, CPU)
// -- first run downloads ~570MB model, cached for subsequent runs
"API_KEYS": "GOOGLE_API_KEY:AIza...",
// -- optional: higher rate limits for docs discovery (60 -> 5000 req/hr)
"GITHUB_TOKEN": "ghp_...",
// -- optional: sync indexed docs across machines via rclone
"SYNC_ENABLED": "true", // optional, default: false
"SYNC_REMOTE": "gdrive", // required when SYNC_ENABLED=true
"SYNC_INTERVAL": "300", // optional, auto-sync every 5min (0 = manual only)
"RCLONE_CONFIG_GDRIVE_TYPE": "drive", // required when SYNC_ENABLED=true
"RCLONE_CONFIG_GDRIVE_TOKEN": "<base64>" // required when SYNC_ENABLED=true, from: uvx --python 3.13 wet-mcp setup-sync drive
}
}
}
}
```
### Option 2: Docker
```jsonc
{
"mcpServers": {
"wet": {
"command": "docker",
"args": [
"run", "-i", "--rm",
"--name", "mcp-wet",
"-v", "wet-data:/data", // persists cached web pages, indexed docs, and downloads
"-e", "API_KEYS", // optional: pass-through from env below
"-e", "GITHUB_TOKEN", // optional: pass-through from env below
"-e", "SYNC_ENABLED", // optional: pass-through from env below
"-e", "SYNC_REMOTE", // required when SYNC_ENABLED=true: pass-through
"-e", "SYNC_INTERVAL", // optional: pass-through from env below
"-e", "RCLONE_CONFIG_GDRIVE_TYPE", // required when SYNC_ENABLED=true: pass-through
"-e", "RCLONE_CONFIG_GDRIVE_TOKEN", // required when SYNC_ENABLED=true: pass-through
"n24q02m/wet-mcp:latest"
],
"env": {
// -- optional: cloud embedding (Gemini > OpenAI > Cohere) + media analysis
// -- without this, uses built-in local Qwen3-Embedding-0.6B + Qwen3-Reranker-0.6B (ONNX, CPU)
"API_KEYS": "GOOGLE_API_KEY:AIza...",
// -- optional: higher rate limits for docs discovery (60 -> 5000 req/hr)
"GITHUB_TOKEN": "ghp_...",
// -- optional: sync indexed docs across machines via rclone
"SYNC_ENABLED": "true", // optional, default: false
"SYNC_REMOTE": "gdrive", // required when SYNC_ENABLED=true
"SYNC_INTERVAL": "300", // optional, auto-sync every 5min (0 = manual only)
"RCLONE_CONFIG_GDRIVE_TYPE": "drive", // required when SYNC_ENABLED=true
"RCLONE_CONFIG_GDRIVE_TOKEN": "<base64>" // required when SYNC_ENABLED=true, from: uvx --python 3.13 wet-mcp setup-sync drive
}
}
}
}
```
### Sync setup (one-time)
```bash
# Google Drive
uvx --python 3.13 wet-mcp setup-sync drive
# Other providers (any rclone remote type)
uvx --python 3.13 wet-mcp setup-sync dropbox
uvx --python 3.13 wet-mcp setup-sync onedrive
uvx --python 3.13 wet-mcp setup-sync s3
```
Opens a browser for OAuth and outputs env vars (`RCLONE_CONFIG_*`) to set. Both raw JSON and base64 tokens are supported.
---
## Tools
| Tool | Actions | Description |
|:-----|:--------|:------------|
| `search` | search, research, docs | Web search, academic research, library documentation |
| `extract` | extract, crawl, map | Content extraction, deep crawling, site mapping |
| `media` | list, download, analyze | Media discovery & download |
| `config` | status, set, cache_clear, docs_reindex | Server configuration and cache management |
| `help` | - | Full documentation for any tool |
### Usage Examples
```json
// search tool
{"action": "search", "query": "python web scraping", "max_results": 10}
{"action": "research", "query": "transformer attention mechanism"}
{"action": "docs", "query": "how to create routes", "library": "fastapi"}
{"action": "docs", "query": "dependency injection", "library": "spring-boot", "language": "java"}
// extract tool
{"action": "extract", "urls": ["https://example.com"]}
{"action": "crawl", "urls": ["https://docs.python.org"], "depth": 2}
{"action": "map", "urls": ["https://example.com"]}
// media tool
{"action": "list", "url": "https://github.com/python/cpython"}
{"action": "download", "media_urls": ["https://example.com/image.png"]}
```
---
## Configuration
| Variable | Default | Description |
|:---------|:--------|:------------|
| `WET_AUTO_SEARXNG` | `true` | Auto-start embedded SearXNG subprocess |
| `WET_SEARXNG_PORT` | `41592` | SearXNG port (optional) |
| `SEARXNG_URL` | `http://localhost:41592` | External SearXNG URL (optional, when auto disabled) |
| `SEARXNG_TIMEOUT` | `30` | SearXNG request timeout in seconds (optional) |
| `API_KEYS` | - | LLM API keys (optional, format: `ENV_VAR:key,...`) |
| `LLM_MODELS` | `gemini/gemini-3-flash-preview` | LiteLLM model for media analysis (optional) |
| `EMBEDDING_BACKEND` | (auto-detect) | `litellm` (cloud API) or `local` (Qwen3). Auto: API_KEYS -> litellm, else local (always available) |
| `EMBEDDING_MODEL` | (auto-detect) | LiteLLM embedding model (optional) |
| `EMBEDDING_DIMS` | `0` (auto=768) | Embedding dimensions (optional) |
| `RERANK_ENABLED` | `true` | Enable reranking after search |
| `RERANK_BACKEND` | (auto-detect) | `litellm` or `local`. Auto: Cohere key in API_KEYS -> litellm, else local |
| `RERANK_MODEL` | (auto-detect) | LiteLLM rerank model (auto: `cohere/rerank-multilingual-v3.0` if Cohere key in API_KEYS) |
| `RERANK_TOP_N` | `10` | Return top N results after reranking |
| `CACHE_DIR` | `~/.wet-mcp` | Data directory for cache DB, docs DB, downloads (optional) |
| `DOCS_DB_PATH` | `~/.wet-mcp/docs.db` | Docs database location (optional) |
| `DOWNLOAD_DIR` | `~/.wet-mcp/downloads` | Media download directory (optional) |
| `TOOL_TIMEOUT` | `120` | Tool execution timeout in seconds, 0=no timeout (optional) |
| `WET_CACHE` | `true` | Enable/disable web cache (optional) |
| `GITHUB_TOKEN` | - | GitHub personal access token for library discovery (optional, increases rate limit from 60 to 5000 req/hr) |
| `SYNC_ENABLED` | `false` | Enable rclone sync |
| `SYNC_REMOTE` | - | rclone remote name (required when sync enabled) |
| `SYNC_FOLDER` | `wet-mcp` | Remote folder name (optional) |
| `SYNC_INTERVAL` | `0` | Auto-sync interval in seconds, 0=manual (optional) |
| `LOG_LEVEL` | `INFO` | Logging level (optional) |
### Embedding & Reranking
Both embedding and reranking are **always available** — local models are built-in and require no configuration.
- **Embedding**: Default local Qwen3-Embedding-0.6B. Set `API_KEYS` to upgrade to cloud (Gemini > OpenAI > Cohere), with automatic local fallback if cloud fails.
- **Reranking**: Default local Qwen3-Reranker-0.6B. If `COHERE_API_KEY` is present in `API_KEYS`, auto-upgrades to cloud `cohere/rerank-multilingual-v3.0`.
- **GPU auto-detection**: If GPU is available (CUDA/DirectML) and `llama-cpp-python` is installed, automatically uses GGUF models (~480MB) instead of ONNX (~570MB) for better performance.
- All embeddings stored at **768 dims** (default). Switching providers never breaks the vector table.
- Override with `EMBEDDING_BACKEND=local` to force local even with API keys.
`API_KEYS` supports multiple providers in a single string:
```
API_KEYS=GOOGLE_API_KEY:AIza...,OPENAI_API_KEY:sk-...,COHERE_API_KEY:co-...
```
### LLM Configuration (Optional)
For media analysis, configure API keys:
```bash
API_KEYS=GOOGLE_API_KEY:AIza...
LLM_MODELS=gemini/gemini-3-flash-preview
```
---
## Architecture
```
┌─────────────────────────────────────────────────────────┐
│ MCP Client │
│ (Claude, Cursor, Windsurf) │
└─────────────────────┬───────────────────────────────────┘
│ MCP Protocol
v
┌─────────────────────────────────────────────────────────┐
│ WET MCP Server │
│ ┌──────────┐ ┌──────────┐ ┌───────┐ ┌────────┐ │
│ │ search │ │ extract │ │ media │ │ config │ │
│ │ (search, │ │(extract, │ │(list, │ │(status,│ │
│ │ research,│ │ crawl, │ │downld,│ │ set, │ │
│ │ docs) │ │ map) │ │analyz)│ │ cache) │ │
│ └──┬───┬───┘ └────┬─────┘ └──┬────┘ └────────┘ │
│ │ │ │ │ + help tool │
│ v v v v │
│ ┌──────┐ ┌──────┐ ┌──────────┐ ┌──────────┐ │
│ │SearX │ │DocsDB│ │ Crawl4AI │ │ Reranker │ │
│ │NG │ │FTS5+ │ │(Playwrgt)│ │(LiteLLM/ │ │
│ │ │ │sqlite│ │ │ │ Qwen3 │ │
│ │ │ │-vec │ │ │ │ local) │ │
│ └──────┘ └──────┘ └──────────┘ └──────────┘ │
│ │
│ ┌──────────────────────────────────────────────────┐ │
│ │ WebCache (SQLite, TTL) │ rclone sync (docs) │ │
│ └──────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
```
---
## Build from Source
```bash
git clone https://github.com/n24q02m/wet-mcp
cd wet-mcp
# Setup (requires mise: https://mise.jdx.dev/)
mise run setup
# Run
uv run wet-mcp
```
### Docker Build
```bash
docker build -t n24q02m/wet-mcp:latest .
```
**Requirements:** Python 3.13 (not 3.14+)
---
## Contributing
See [CONTRIBUTING.md](CONTRIBUTING.md)
## License
MIT - See [LICENSE](LICENSE)
| text/markdown | null | n24q02m <quangminh2422004@gmail.com> | null | null | MIT | crawl4ai, library-docs, mcp, searxng, web-scraping | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Topic :: Internet :: WWW/HTTP",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | ==3.13.* | [] | [] | [] | [
"crawl4ai",
"httpx",
"litellm",
"loguru",
"mcp[cli]",
"pydantic",
"pydantic-settings",
"qwen3-embed>=1.1.3",
"sqlite-vec"
] | [] | [] | [] | [
"Homepage, https://github.com/n24q02m/wet-mcp",
"Repository, https://github.com/n24q02m/wet-mcp.git",
"Issues, https://github.com/n24q02m/wet-mcp/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T14:55:25.124930 | wet_mcp-2.6.3.tar.gz | 89,557 | bd/61/92047f60507f85f8ec99782ba469a9ece6507026d73bb0bb59a0ddc34c4c/wet_mcp-2.6.3.tar.gz | source | sdist | null | false | 569eefc08ea11a5437312434ac7ba9e0 | 2fbe73b805b3a7618fa2e0b5a1c9359dcb21282344da944fe5727e8d51eee0c9 | bd6192047f60507f85f8ec99782ba469a9ece6507026d73bb0bb59a0ddc34c4c | null | [
"LICENSE"
] | 217 |
2.4 | cicaddy | 0.2.0 | Platform-agnostic pipeline AI agent with MCP tool integration and multi-step execution engine | # cicaddy
Platform-agnostic AI agent for running AI workflows in CI pipelines, with MCP tool integration and multi-step execution engine.
## Features
- **Multi-provider AI**: Gemini, OpenAI, Claude
- **MCP integration**: Connect to any MCP-compatible tool server
- **Multi-step execution**: Token-aware execution engine with recovery
- **YAML task definitions**: DSPy-based task configuration
- **Notifications**: Slack and email notification support
- **HTML reports**: Customizable analysis report generation
- **Extensible agents**: Registry-based agent factory for custom agents
## Installation
```bash
pip install cicaddy
```
## Quick Start
```bash
# Run with environment file
cicaddy run --env-file .env
# Run with CLI arguments
cicaddy run --ai-provider gemini --agent-type task --log-level DEBUG
# Show configuration
cicaddy config show --env-file .env
# Validate configuration
cicaddy validate --env-file .env
```
## Configuration
Configure via environment variables or `.env` file:
```env
# AI Provider
AI_PROVIDER=gemini
AI_MODEL=gemini-2.5-flash
GEMINI_API_KEY=your-key-here
# Agent
AGENT_TYPE=task
TASK_TYPE=scheduled_analysis
# MCP Servers (JSON array)
MCP_SERVERS_CONFIG=[]
# Notifications
SLACK_WEBHOOK_URL=https://hooks.slack.com/...
# DSPy Task File (takes precedence over AI_TASK_PROMPT)
AI_TASK_FILE=tasks/dora_report.yaml
```
### DSPy Task Definition (YAML)
Instead of raw prompt strings (`AI_TASK_PROMPT`), define structured tasks in YAML with typed inputs, expected outputs, MCP tool constraints, and reasoning strategy. Set `AI_TASK_FILE` to your task file path.
See [`examples/dora_metrics_task.yaml`](examples/dora_metrics_task.yaml) for a complete DORA metrics analysis task using DevLake MCP, and [`examples/templates/report_template.html`](examples/templates/report_template.html) for the HTML report template.
Key schema fields:
| Field | Description |
|-------|-------------|
| `inputs[].env_var` | Resolve value from environment variable at load time |
| `inputs[].format` | `diff` or `code` for fenced rendering in prompt |
| `tools.servers` | Restrict to specific MCP servers |
| `tools.required_tools` | Tools the AI must use during execution |
| `tools.forbidden_tools` | Tools the AI must not use |
| `reasoning` | `chain_of_thought`, `react`, or `simple` |
| `output_format` | `markdown`, `html`, or `json` |
| `context` | Supports `{{VAR}}` placeholders resolved at load time |
## Extending with Platform Plugins
`cicaddy` discovers platform plugins automatically via Python `entry_points`. Plugins can register agents, CLI args, env vars, config sections, validators, and a settings loader — without modifying cicaddy itself.
**1. Define plugin callables** (`my_plugin/plugin.py`):
```python
def register_agents():
from cicaddy.agent.factory import AgentFactory
from my_plugin.agent import MergeRequestAgent, detect_agent_type
AgentFactory.register("merge_request", MergeRequestAgent)
AgentFactory.register_detector(detect_agent_type, priority=40)
def get_cli_args():
from cicaddy.cli.arg_mapping import ArgMapping
return [
ArgMapping(cli_arg="--mr-iid", env_var="CI_MERGE_REQUEST_IID",
help_text="Merge request IID"),
]
```
**2. Register in `pyproject.toml`**:
```toml
[project.entry-points."cicaddy.agents"]
my_platform = "my_plugin.plugin:register_agents"
[project.entry-points."cicaddy.cli_args"]
my_platform = "my_plugin.plugin:get_cli_args"
[project.entry-points."cicaddy.settings_loader"]
my_platform = "my_plugin.config:load_settings"
```
**3. Install and run** — plugins are discovered automatically:
```bash
pip install cicaddy my-cicaddy-plugin
cicaddy run --env-file .env
```
Available plugin groups: `cicaddy.agents`, `cicaddy.cli_args`, `cicaddy.env_vars`, `cicaddy.config_sections`, `cicaddy.validators`, `cicaddy.settings_loader`. See [cicaddy-gitlab](https://gitlab.cee.redhat.com/ccit/agents/gitlab-agent-task) for a complete plugin implementation.
## License
Apache-2.0
| text/markdown | Wayne Sun | null | null | null | Apache-2.0 | ai, agent, mcp, pipeline, workflow, code-review, automation, ci-cd | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Quality Assurance",
"Topic :: Software Development :: Testing"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"requests>=2.32.0",
"slack-sdk>=3.33.0",
"httpx>=0.28.0",
"httpx-sse>=0.4.0",
"pydantic>=2.10.0",
"pydantic-settings>=2.0.0",
"pyyaml>=6.0.2",
"jinja2>=3.1.4",
"structlog>=24.5.0",
"mcp>=1.13.1",
"anthropic>=0.21.0",
"google-genai>=1.0.0",
"google-api-python-client>=2.108.0",
"google-auth-httplib2>=0.2.0",
"google-auth-oauthlib>=1.2.0",
"protobuf>=5.26.0",
"openai>=1.102.0",
"fire>=0.7.0",
"websockets>=13.0",
"typing-extensions>=4.12.0; python_version < \"3.12\"",
"python-dotenv>=1.0.0",
"dspy-ai>=2.4.0",
"pytest>=8.4.0; extra == \"dev\"",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest-cov>=6.0.0; extra == \"dev\"",
"pytest-mock>=3.14.0; extra == \"dev\"",
"aioresponses>=0.7.8; extra == \"dev\"",
"pre-commit>=4.0.0; extra == \"dev\"",
"build>=1.0.0; extra == \"dev\"",
"twine>=5.0.0; extra == \"dev\"",
"opentelemetry-api>=1.27.0; extra == \"enterprise\"",
"opentelemetry-sdk>=1.27.0; extra == \"enterprise\"",
"opentelemetry-exporter-otlp>=1.27.0; extra == \"enterprise\"",
"opentelemetry-instrumentation>=0.48b0; extra == \"enterprise\"",
"redis>=5.0.0; extra == \"enterprise\"",
"psutil>=6.0.0; extra == \"enterprise\"",
"pytest>=8.4.0; extra == \"test\"",
"pytest-asyncio>=0.23.0; extra == \"test\"",
"pytest-cov>=6.0.0; extra == \"test\"",
"pytest-mock>=3.14.0; extra == \"test\"",
"aioresponses>=0.7.8; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/cicaddy/cicaddy",
"Repository, https://github.com/cicaddy/cicaddy.git",
"Issues, https://github.com/cicaddy/cicaddy/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:55:18.617573 | cicaddy-0.2.0.tar.gz | 247,122 | 75/84/873738bb925d9b4909dc5dfe4da7a8507dd3887e6fe41d83c9bbb1a36079/cicaddy-0.2.0.tar.gz | source | sdist | null | false | 605f4064e87192015a379051549ebcb7 | dd0bf56db9decef431cc9262659446fc8fa3bd68a95e5d676fbf30a361f4943c | 7584873738bb925d9b4909dc5dfe4da7a8507dd3887e6fe41d83c9bbb1a36079 | null | [
"LICENSE"
] | 431 |
2.4 | tooli | 6.0.0 | The agent-native CLI framework for Python | # Tooli
The agent-native CLI framework for Python.
Tooli turns typed Python functions into command-line tools that work for both humans and AI agents: rich output in a terminal, strict structured output in automation, and self-describing schemas for tool calling and orchestration.
The name comes from "tool" + "CLI" = "tooli".
## Why Tooli?
AI agents invoke lots of local commands, but typical CLIs are optimized for humans:
- Huge, unstructured stdout that burns context windows
- Opaque errors that don't suggest a fix
- Fragile pipelines that mix logs with machine output
- Undocumented flags that agents hallucinate
Tooli is built to be *machine-consumable by default* while still feeling great for humans.
## Install
```bash
pip install tooli
```
Optional extras:
```bash
pip install "tooli[mcp]" # MCP server support
pip install "tooli[api]" # HTTP API + OpenAPI export (experimental)
```
## Quick Start
Create `file_tools.py`:
```python
from __future__ import annotations
from pathlib import Path
from typing import Annotated
from tooli import Argument, Option, Tooli
from tooli.annotations import Idempotent, ReadOnly
app = Tooli(name="file-tools", description="File utilities", version="4.1.0")
@app.command(annotations=ReadOnly | Idempotent, paginated=True, list_processing=True)
def find_files(
pattern: Annotated[str, Argument(help="Glob to match")],
root: Annotated[Path, Option(help="Root directory")] = Path("."),
) -> list[dict[str, str]]:
return [{"path": str(p)} for p in root.rglob(pattern)]
if __name__ == "__main__":
app()
```
Run it:
```bash
python file_tools.py find-files "*.py" --root .
python file_tools.py find-files "*.py" --root . --output json
python file_tools.py find-files --schema
```
## Structured Output (JSON / JSONL)
Tooli supports dual-mode output:
- Human mode: pretty output when attached to a TTY
- Agent mode: strict envelopes when using `--output json` or `--output jsonl`
JSON envelope shape:
```json
{
"ok": true,
"result": {"...": "..."},
"meta": {
"tool": "file-tools.find-files",
"version": "2.0.0",
"duration_ms": 12,
"annotations": {"readOnlyHint": true, "idempotentHint": true}
}
}
```
## Structured Errors With Recovery Hints
When a command fails, Tooli emits a structured error with an actionable suggestion:
```json
{
"ok": false,
"error": {
"code": "E1004",
"category": "input",
"message": "Exact search string was not found in source.",
"suggestion": {
"action": "adjust search text",
"fix": "Double-check exact spacing/newlines. Did you mean: \"...\"?"
},
"is_retryable": true
}
}
```
## Schemas, Docs, and Agent Bootstrap
Tooli can generate tool schemas and agent-facing docs directly from type hints and metadata:
```bash
python file_tools.py find-files --schema
python file_tools.py generate-skill > SKILL.md
python file_tools.py generate-skill --target claude-code > SKILL.md
python file_tools.py find-files --agent-bootstrap > SKILL.md
python file_tools.py docs llms
python file_tools.py docs man
```
v4 generates task-oriented SKILL.md with "When to use" guidance, recovery playbooks, composition patterns, and target-specific formatting (generic, Claude, Claude Code).
Run as an MCP server (one tool per command):
```bash
python file_tools.py mcp serve --transport stdio
python file_tools.py mcp serve --transport http --host 127.0.0.1 --port 8080
python file_tools.py mcp serve --transport sse --host 127.0.0.1 --port 8080
```
## Universal Input (files / URLs / stdin)
Use `StdinOr[T]` to accept a file path, a URL, or piped stdin with one parameter.
```python
from pathlib import Path
from typing import Annotated
from tooli import Argument, StdinOr, Tooli
app = Tooli(name="log-tools")
@app.command()
def head(
source: Annotated[StdinOr[str], Argument(help="Path, URL, or '-' for stdin")],
) -> dict[str, int]:
return {"bytes": len(source)} # `source` resolves to the content
```
## Built-In Guardrails
Tooli provides primitives for safer automation:
- `ReadOnly`, `Idempotent`, `Destructive`, `OpenWorld` annotations on commands
- `--dry-run` planning support via `@dry_run_support` + `record_dry_action(...)`
- `SecretInput[T]` with automatic redaction in outputs and errors
- Cursor pagination (`--limit`, `--cursor`, `--fields`, `--filter`) for list-shaped results
## Example Apps (agent pain points)
The GitHub repo includes sample apps under `examples/` that target common agent failure modes:
- `code-lens`: token-efficient symbol outlines from Python ASTs (avoid dumping whole files)
- `safe-patch`: self-healing file edits with dry-run plans and recovery hints
- `log-sift`: pipeline-friendly log extraction with strict JSON/JSONL output
- `sqlite-probe`: read-only SQLite exploration with pagination and guardrails
## Links
- Source: https://github.com/weisberg/tooli
- Changelog: https://github.com/weisberg/tooli/blob/main/CHANGELOG.md
| text/markdown | tooli developers | null | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"typer>=0.9",
"pydantic>=2.0",
"rich>=13.0",
"tomli>=2.0; python_version < \"3.11\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"ruff>=0.4; extra == \"dev\"",
"mypy>=1.0; extra == \"dev\"",
"fastmcp>=2.0; extra == \"mcp\"",
"starlette>=0.27; extra == \"api\"",
"uvicorn>=0.20; extra == \"api\""
] | [] | [] | [] | [
"Homepage, https://github.com/weisberg/tooli",
"Repository, https://github.com/weisberg/tooli"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:55:06.898744 | tooli-6.0.0.tar.gz | 160,539 | d7/49/0a91c4e9443b66f26e2899f52d4f7033a8b94d260c2c8bd3baf762368c27/tooli-6.0.0.tar.gz | source | sdist | null | false | 7cee5b95ca0740b9f8f2875ae5fa3186 | 4e00db431ea7bb1a4a5eb2173038388090ea702706acdd3750da0f04923362c1 | d7490a91c4e9443b66f26e2899f52d4f7033a8b94d260c2c8bd3baf762368c27 | MIT | [
"LICENSE"
] | 195 |
2.4 | dabrius | 0.1.2 | Minimal benign PoC package with an explicit run() function. | # dabrius
Minimal benign PoC Python package.
## What it does
This package exposes one explicit function:
- `dabrius.run()` -> prints `get owned`
The message is only printed when `run()` is explicitly called.
Nothing executes automatically on import.
## Install (local)
```bash
pip install -e .
```
## Usage
```python
import dabrius
dabrius.run()
```
Expected output:
```text
get owned
```
| text/markdown | Gabriel Taieb | null | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.9.6 | 2026-02-20T14:55:01.844408 | dabrius-0.1.2.tar.gz | 1,953 | 31/40/f104628fd213ef08b2cb92f599531b2116e888da2c98aafaae8325174fd6/dabrius-0.1.2.tar.gz | source | sdist | null | false | ae696c653081456e492509cde117118c | 0b5146b8fd0a6e3ac3715ad881d3c5f7a005a88b254a3570883eaece00e4a20c | 3140f104628fd213ef08b2cb92f599531b2116e888da2c98aafaae8325174fd6 | null | [] | 216 |
2.3 | fastapi-tenancy | 0.1.0 | Enterprise-grade multi-tenancy for FastAPI — schema, database, RLS, and hybrid isolation with full async support | # `fastapi-tenancy` is multi-tenancy solution for SAAS
| text/markdown | fastapi-tenancy contributors | null | null | null | MIT | fastapi, multitenancy, saas, postgresql, sqlalchemy, async | [] | [] | null | null | >=3.11 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/KapilDagur/fastapi-tenancy"
] | uv/0.8.23 | 2026-02-20T14:54:59.118388 | fastapi_tenancy-0.1.0.tar.gz | 933 | e1/62/ddb0304b96c556e718b45368ede4d90ae58961eee1e7bf91f2470282aba5/fastapi_tenancy-0.1.0.tar.gz | source | sdist | null | false | 4a1bddc38bd4be89300da327352f4a0d | cb1d58ce1a5826c7fb80868023272a42ecbf3f4e57aef68ed8d640874c0a52c1 | e162ddb0304b96c556e718b45368ede4d90ae58961eee1e7bf91f2470282aba5 | null | [] | 212 |
2.4 | mnemo-mcp | 1.0.7 | Open-source MCP Server for persistent AI memory with embedded sync | # Mnemo MCP Server
**Persistent AI memory with hybrid search and embedded sync. Open, free, unlimited.**
[](https://pypi.org/project/mnemo-mcp/)
[](https://hub.docker.com/r/n24q02m/mnemo-mcp)
[](LICENSE)
## Features
- **Hybrid search**: FTS5 full-text + sqlite-vec semantic + Qwen3-Embedding-0.6B (built-in)
- **Zero config mode**: Works out of the box — local embedding, no API keys needed
- **Auto-detect embedding**: Set `API_KEYS` for cloud embedding, auto-fallback to local
- **Embedded sync**: rclone auto-downloaded and managed as subprocess
- **Multi-machine**: JSONL-based merge sync via rclone (Google Drive, S3, etc.)
- **Proactive memory**: Tool descriptions guide AI to save preferences, decisions, facts
## Quick Start
### Option 1: uvx (Recommended)
```jsonc
{
"mcpServers": {
"mnemo": {
"command": "uvx",
"args": ["mnemo-mcp@latest"],
"env": {
// -- optional: cloud embedding (Gemini > OpenAI > Cohere) for semantic search
// -- without this, uses built-in local Qwen3-Embedding-0.6B (ONNX, CPU)
// -- first run downloads ~570MB model, cached for subsequent runs
"API_KEYS": "GOOGLE_API_KEY:AIza...",
// -- optional: sync memories across machines via rclone
"SYNC_ENABLED": "true", // optional, default: false
"SYNC_REMOTE": "gdrive", // required when SYNC_ENABLED=true
"SYNC_INTERVAL": "300", // optional, auto-sync every 5min (0 = manual only)
"RCLONE_CONFIG_GDRIVE_TYPE": "drive", // required when SYNC_ENABLED=true
"RCLONE_CONFIG_GDRIVE_TOKEN": "<base64>" // required when SYNC_ENABLED=true, from: uvx mnemo-mcp setup-sync drive
}
}
}
}
```
### Option 2: Docker
```jsonc
{
"mcpServers": {
"mnemo": {
"command": "docker",
"args": [
"run", "-i", "--rm",
"--name", "mcp-mnemo",
"-v", "mnemo-data:/data", // persists memories across restarts
"-e", "API_KEYS", // optional: pass-through from env below
"-e", "SYNC_ENABLED", // optional: pass-through from env below
"-e", "SYNC_REMOTE", // required when SYNC_ENABLED=true: pass-through
"-e", "SYNC_INTERVAL", // optional: pass-through from env below
"-e", "RCLONE_CONFIG_GDRIVE_TYPE", // required when SYNC_ENABLED=true: pass-through
"-e", "RCLONE_CONFIG_GDRIVE_TOKEN", // required when SYNC_ENABLED=true: pass-through
"n24q02m/mnemo-mcp:latest"
],
"env": {
// -- optional: cloud embedding (Gemini > OpenAI > Cohere) for semantic search
// -- without this, uses built-in local Qwen3-Embedding-0.6B (ONNX, CPU)
"API_KEYS": "GOOGLE_API_KEY:AIza...",
// -- optional: sync memories across machines via rclone
"SYNC_ENABLED": "true", // optional, default: false
"SYNC_REMOTE": "gdrive", // required when SYNC_ENABLED=true
"SYNC_INTERVAL": "300", // optional, auto-sync every 5min (0 = manual only)
"RCLONE_CONFIG_GDRIVE_TYPE": "drive", // required when SYNC_ENABLED=true
"RCLONE_CONFIG_GDRIVE_TOKEN": "<base64>" // required when SYNC_ENABLED=true, from: uvx mnemo-mcp setup-sync drive
}
}
}
}
```
### Sync setup (one-time)
```bash
# Google Drive
uvx mnemo-mcp setup-sync drive
# Other providers (any rclone remote type)
uvx mnemo-mcp setup-sync dropbox
uvx mnemo-mcp setup-sync onedrive
uvx mnemo-mcp setup-sync s3
```
Opens a browser for OAuth and outputs env vars (`RCLONE_CONFIG_*`) to set. Both raw JSON and base64 tokens are supported.
## Configuration
| Variable | Default | Description |
|----------|---------|-------------|
| `DB_PATH` | `~/.mnemo-mcp/memories.db` | Database location |
| `API_KEYS` | — | API keys (`ENV:key,ENV:key`). Optional: enables semantic search |
| `EMBEDDING_BACKEND` | (auto-detect) | `litellm` (cloud API) or `local` (Qwen3). Auto: API_KEYS -> litellm, else local (always available) |
| `EMBEDDING_MODEL` | auto-detect | LiteLLM model name (optional) |
| `EMBEDDING_DIMS` | `0` (auto=768) | Embedding dimensions (0 = auto-detect, default 768) |
| `SYNC_ENABLED` | `false` | Enable rclone sync |
| `SYNC_REMOTE` | — | rclone remote name (required when sync enabled) |
| `SYNC_FOLDER` | `mnemo-mcp` | Remote folder (optional) |
| `SYNC_INTERVAL` | `0` | Auto-sync seconds (optional, 0=manual) |
| `LOG_LEVEL` | `INFO` | Log level (optional) |
### Embedding
Embedding is **always available** — a local model is built-in and requires no configuration.
- **Default**: Local Qwen3-Embedding-0.6B. Set `API_KEYS` to upgrade to cloud (Gemini > OpenAI > Cohere), with automatic local fallback if cloud fails.
- **GPU auto-detection**: If GPU is available (CUDA/DirectML) and `llama-cpp-python` is installed, automatically uses GGUF model (~480MB) instead of ONNX (~570MB) for better performance.
- All embeddings stored at **768 dims** (default). Switching providers never breaks the vector table.
- Override with `EMBEDDING_BACKEND=local` to force local even with API keys.
`API_KEYS` supports multiple providers in a single string:
```
API_KEYS=GOOGLE_API_KEY:AIza...,OPENAI_API_KEY:sk-...,COHERE_API_KEY:co-...
```
Cloud embedding providers (auto-detected from `API_KEYS`, priority order):
| Priority | Env Var (LiteLLM) | Model | Native Dims | Stored |
|----------|-------------------|-------|-------------|--------|
| 1 | `GEMINI_API_KEY` | `gemini/gemini-embedding-001` | 3072 | 768 |
| 2 | `OPENAI_API_KEY` | `text-embedding-3-large` | 3072 | 768 |
| 3 | `COHERE_API_KEY` | `embed-multilingual-v3.0` | 1024 | 768 |
All embeddings are truncated to **768 dims** (default) for storage. This ensures switching models never breaks the vector table. Override with `EMBEDDING_DIMS` if needed.
`API_KEYS` format maps your env var to LiteLLM's expected var (e.g., `GOOGLE_API_KEY:key` auto-sets `GEMINI_API_KEY`). Set `EMBEDDING_MODEL` explicitly for other providers.
## MCP Tools
### `memory` — Core memory operations
| Action | Required | Optional |
|--------|----------|----------|
| `add` | `content` | `category`, `tags` |
| `search` | `query` | `category`, `tags`, `limit` |
| `list` | — | `category`, `limit` |
| `update` | `memory_id` | `content`, `category`, `tags` |
| `delete` | `memory_id` | — |
| `export` | — | — |
| `import` | `data` (JSONL) | `mode` (merge/replace) |
| `stats` | — | — |
### `config` — Server configuration
| Action | Required | Optional |
|--------|----------|----------|
| `status` | — | — |
| `sync` | — | — |
| `set` | `key`, `value` | — |
### `help` — Full documentation
```
help(topic="memory") # or "config"
```
### MCP Resources
| URI | Description |
|-----|-------------|
| `mnemo://stats` | Database statistics and server status |
| `mnemo://recent` | 10 most recently updated memories |
### MCP Prompts
| Prompt | Parameters | Description |
|--------|------------|-------------|
| `save_summary` | `summary` | Generate prompt to save a conversation summary as memory |
| `recall_context` | `topic` | Generate prompt to recall relevant memories about a topic |
## Architecture
```
MCP Client (Claude, Cursor, etc.)
|
FastMCP Server
/ | \
memory config help
| | |
MemoryDB Settings docs/
/ \
FTS5 sqlite-vec
|
EmbeddingBackend
/ \
LiteLLM Qwen3 ONNX
| (local CPU)
Gemini / OpenAI / Cohere
Sync: rclone (embedded) -> Google Drive / S3 / ...
```
## Development
```bash
# Install
uv sync
# Run
uv run mnemo-mcp
# Lint
uv run ruff check src/
uv run ty check src/
# Test
uv run pytest
```
## License
MIT
| text/markdown | null | n24q02m <quangminh2422004@gmail.com> | null | null | MIT | ai-memory, embeddings, mcp, memory, sqlite | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | ==3.13.* | [] | [] | [] | [
"httpx",
"litellm",
"loguru",
"mcp[cli]",
"pydantic",
"pydantic-settings",
"qwen3-embed>=1.1.3",
"sqlite-vec"
] | [] | [] | [] | [
"Homepage, https://github.com/n24q02m/mnemo-mcp",
"Repository, https://github.com/n24q02m/mnemo-mcp.git",
"Issues, https://github.com/n24q02m/mnemo-mcp/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T14:54:54.114015 | mnemo_mcp-1.0.7-py3-none-any.whl | 30,713 | 4e/99/38a68ccda49d2194aeb45f8aa1538ccb1f8c1b007bef3f04f74a1259a550/mnemo_mcp-1.0.7-py3-none-any.whl | py3 | bdist_wheel | null | false | 62e0ccfd12fd0b7e01229efd7961ffc8 | ec2f53e54babc415e433a517c2e169b0cd8d714493d38f85f57c7ded959e3847 | 4e9938a68ccda49d2194aeb45f8aa1538ccb1f8c1b007bef3f04f74a1259a550 | null | [
"LICENSE"
] | 241 |
2.4 | integrate-module | 0.94.0 | Localized probabilistic data integration | # INTEGRATE Python Module
[](https://github.com/cultpenguin/integrate_module/actions/workflows/docs.yml)
[](https://badge.fury.io/py/integrate-module)
[](https://cultpenguin.github.io/integrate_module/)
[](https://opensource.org/licenses/MIT)
[](https://www.python.org/downloads/)
This repository contains the INTEGRATE Python module for localized probabilistic data integration in geophysics.
## Installation
Assuming you already have Python 3.10+ installed:
pip install integrate_module
On Windows, this will also install the Python wrapper for GA-AEM (1D EM forward modeling - GPL v2 code): [ga-aem-forward-win](https://pypi.org/project/ga-aem-forward-win/)
On Linux/macOS, you will need to install GA-AEM manually.
### Using pip (from PyPI, on Ubuntu)
# Install python3 venv
sudo apt install python3-venv
# Create virtual environment
python3 -m venv ~/integrate
source ~/integrate/bin/activate
pip install --upgrade pip
# Install integrate module
pip install integrate_module
### Using pip (from source, on Ubuntu)
# Install python3 venv
sudo apt install python3-venv
# Create virtual environment
python3 -m venv ~/integrate
source ~/integrate/bin/activate
pip install --upgrade pip
# Install integrate module
cd path/to/integrate_module
pip install -e .
### Using Conda + pip (from PyPI)
Create a Conda environment (called integrate) and install the required modules:
conda create --name integrate python=3.10 numpy pandas matplotlib scipy tqdm requests h5py psutil
conda activate integrate
pip install integrate_module
### Using Conda + pip (from source)
Create a Conda environment (called integrate) and install the required modules:
conda create --name integrate python=3.10 numpy pandas matplotlib scipy tqdm requests h5py psutil
conda activate integrate
pip install -e .
## GA-AEM
In order to use GA-AEM for forward EM modeling, the 'gatdaem1d' Python module must be installed. Follow instructions at [https://github.com/GeoscienceAustralia/ga-aem](https://github.com/GeoscienceAustralia/ga-aem) or use the information below.
### PyPI package for Windows
On Windows, the [ga-aem-forward-win](https://pypi.org/project/ga-aem-forward-win/) package will be automatically installed, providing access to the GA-AEM forward code. It can be installed manually using:
pip install ga-aem-forward-win
### Pre-compiled Python module for Windows
1. Download the pre-compiled version of GA-AEM for Windows from the latest release: https://github.com/GeoscienceAustralia/ga-aem/releases (GA-AEM.zip)
2. Download precompiled FFTW3 Windows DLLs from https://www.fftw.org/install/windows.html (fftw-3.3.5-dll64.zip)
3. Extract both archives:
- `unzip GA-AEM.zip` to get GA-AEM
- `unzip fftw-3.3.5-dll64.zip` to get fftw-3.3.5-dll64
4. Copy FFTW3 DLLs to GA-AEM Python directory:
cp fftw-3.3.5-dll64/*.dll GA-AEM/python/gatdaem1d/
5. Install the Python gatdaem1d module:
```
cd GA-AEM/python/
pip install -e .
# Test the installation
cd examples
python integrate_skytem.py
```
### Compile GA-AEM Python module on Debian/Ubuntu/Linux
A script that downloads and installs GA-AEM is located in `scripts/cmake_build_script_DebianUbuntu_gatdaem1d.sh`. This script has been tested and confirmed to work on both Debian and Ubuntu distributions. Be sure to use the appropriate Python environment and then run:
sh scripts/cmake_build_script_DebianUbuntu_gatdaem1d.sh
cd ga-aem/install-ubuntu/python
pip install .
### Compile GA-AEM Python module on macOS/Homebrew
First install Homebrew, then run:
sh ./scripts/cmake_build_script_homebrew_gatdaem1d.sh
cd ga-aem/install-homebrew/python
pip install .
## Development
The `main` branch is the most stable, with less frequent updates but larger changes.
The `develop` branch contains the current development code and may be updated frequently. Some functions and examples may be broken.
An extra set of tests and examples are located in the ``experimental`` sub-branch `https://github.com/cultpenguin/integrate_module_experimental/ <https://github.com/cultpenguin/integrate_module_experimental/>`_.
Please ask the developers for access to this branch if needed. To clone the main repository with the experimental branch, use:
git clone --recurse-submodules git@github.com:cultpenguin/integrate_module.git
You may need to run the following command to update the submodules:
cd experimental
git submodule update --init --recursive
| text/markdown | null | Thomas Mejer Hansen <tmeha@geo.au.dk> | null | null | MIT | inversion, electromagnetic, geophysics, geology, prior, tarantola | [
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy",
"matplotlib",
"h5py",
"scipy",
"psutil",
"tqdm",
"requests",
"geoprior1d>=0.9",
"ga-aem-forward-win; platform_system == \"Windows\"",
"jupyter>=1.0.0",
"jupytext",
"pandas",
"pyvista",
"pytest; extra == \"dev\"",
"black; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/cultpenguin/integrate_module",
"Documentation, https://cultpenguin.github.io/integrate_module/",
"Repository, https://github.com/cultpenguin/integrate_module",
"Issues, https://github.com/cultpenguin/integrate_module/issues"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T14:54:39.309863 | integrate_module-0.94.0.tar.gz | 168,246 | 78/f0/08b20fb10679fcbb447a7821528b07646486fbbe836ca269f88a22a3998e/integrate_module-0.94.0.tar.gz | source | sdist | null | false | 79e95c2c3f3d84196bb2aaa5af66a0a5 | 84e9041e51f969cb752c87bba74f232528765aad2b90382697c4767dce23da6e | 78f008b20fb10679fcbb447a7821528b07646486fbbe836ca269f88a22a3998e | null | [
"LICENSE"
] | 211 |
2.4 | ostorlab | 1.12.0 | OXO Scanner Orchestrator for the Modern Age. | [](https://badge.fury.io/py/ostorlab)
[](https://pepy.tech/project/ostorlab)
[](https://blog.ostorlab.co/)
[](https://twitter.com/ostorlabsec)
# OXO Scan Orchestration Engine
OXO is a security scanning framework built for modularity, scalability and simplicity.
OXO Engine combines specialized tools to work cohesively to find vulnerabilities and perform actions like recon, enumeration, fingerprinting ...
* [Documentation](https://oxo.ostorlab.co/docs)
* [Agents Store](https://oxo.ostorlab.co/store)
* [CLI Manual](https://oxo.ostorlab.co/docs/manual)
* [Examples](https://oxo.ostorlab.co/tutorials/examples)

# Requirements
Docker is required to run scans locally. To install docker, please follow these
[instructions](https://docs.docker.com/get-docker/).
# Installing
OXO ships as a Python package on pypi. To install it, simply run the following command if you have `pip` already
installed.
```shell
pip install -U ostorlab
```
# Getting Started
OXO ships with a store that boasts dozens of agents, from network scanning agents like nmap, nuclei or
tsunami,
web scanner like Zap, web fingerprinting tools like Whatweb and Wappalyzer, DNS brute forcing like Subfinder and Dnsx,
malware file scanning like Virustotal and much more.
To run any of these tools combined, simply run the following command:
> OXO CLI is accessible using the `oxo` command.
```shell
oxo scan run --install --agent nmap --agent tsunami --agent nuclei ip 8.8.8.8
```
or
```shell
oxo scan run --install --agent agent/ostorlab/nmap --agent agent/ostorlab/tsunami --agent agent/ostorlab/nuclei ip 8.8.8.8
```
This command will download and install the following scanning agents:
* [agent/ostorlab/nmap](https://oxo.ostorlab.co/store/agent/ostorlab/nmap)
* [agent/ostorlab/tsunami](https://oxo.ostorlab.co/store/agent/ostorlab/tsunami)
* [agent/ostorlab/nuclei](https://oxo.ostorlab.co/store/agent/ostorlab/nuclei)
And will scan the target IP address `8.8.8.8`.
Agents are shipped as standard docker images.
To check the scan status, run:
```shell
oxo scan list
```
Once the scan has completed, to access the scan results, run:
```shell
oxo vulnz list --scan-id <scan-id>
oxo vulnz describe --vuln-id <vuln-id>
```
# Docker Image
To run `oxo` in a container, you may use the publicly available image and run the following command:
```shell
docker run -v /var/run/docker.sock:/var/run/docker.sock ostorlab/oxo:latest scan run --install --agent nmap --agent nuclei --agent tsunami ip 8.8.8.8
```
Notes:
* The command starts directly with: `scan run`, this is because the `ostorlab/oxo` image has `oxo` as an `entrypoint`.
* It is important to mount the docker socket so `oxo` can create the agent in the host machine.
# Assets
OXO supports scanning of multiple asset types, below is the list of currently supported:
| Asset | Description |
|-------------|------------------------------------------------------------------------------------|
| agent | Run scan for agent. This is used for agents scanning themselves (meta-scanning :). |
| ip | Run scan for IP address or an IP range . |
| link | Run scan for web link accepting a URL, method, headers and request body. |
| file | Run scan for a generic file. |
| android-aab | Run scan for an Android .AAB package file. |
| android-apk | Run scan for an Android .APK package file. |
| ios-ipa | Run scan for iOS .IPA file. |
| domain-name | Run scan for Domain Name asset with specifying protocol or port. |
# The Store
OXO lists all agents on a public store where you can search and also publish your own agents.

# Publish your first Agent
To write your first agent, you can check out a full
tutorial [here](https://oxo.ostorlab.co/tutorials/write_an_agent).
The steps are basically the following:
* Clone a template agent with all files already setup.
* Change the `template_agent.py` file to add your logic.
* Change the `Dockerfile` adding any extra building steps.
* Change the `ostorlab.yaml` adding selectors, documentation, image, license.
* Publish on the store.
* Profit!
Once you have written your agent, you can publish it on the store for others to use and discover it. The store
will handle agent building and will automatically pick up new releases from your git repo.

## Ideas for Agents to build
Implementation of popular tools like:
* ~~[semgrep](https://github.com/returntocorp/semgrep) for source code scanning.~~
* [nbtscan](http://www.unixwiz.net/tools/nbtscan.html): Scans for open NETBIOS nameservers on your target’s network.
* [onesixtyone](https://github.com/trailofbits/onesixtyone): Fast scanner to find publicly exposed SNMP services.
* [Retire.js](http://retirejs.github.io/retire.js/): Scanner detecting the use of JavaScript libraries with known
vulnerabilities.
* ~~[snallygaster](https://github.com/hannob/snallygaster): Finds file leaks and other security problems on HTTP servers.~~
* [testssl.sh](https://testssl.sh/): Identify various TLS/SSL weaknesses, including Heartbleed, CRIME and ROBOT.
* ~~[TruffleHog](https://github.com/trufflesecurity/truffleHog): Searches through git repositories for high entropy~~
strings and secrets, digging deep into commit history.
* [cve-bin-tool](https://github.com/intel/cve-bin-tool): Scan binaries for vulnerable components.
* [XSStrike](https://github.com/s0md3v/XSStrike): XSS web vulnerability scanner with generative payload.
* ~~[Subjack](https://github.com/haccer/subjack): Subdomain takeover scanning tool.~~
* [DnsReaper](https://github.com/punk-security/dnsReaper): Subdomain takeover scanning tool.
## Credits
As an open-source project in a rapidly developing field, we are always open to contributions, whether it be in the form of a new feature, improved infrastructure, or better documentation.
We would like to thank the following contributors for their help in making OXO a better tool:
* [@jamu85](https://github.com/jamu85)
* [@ju-c](https://github.com/ju-c)
* [@distortedsignal](https://github.com/distortedsignal)
| text/markdown | Ostorlab | oxo@ostorlab.dev | null | null | Apache-2.0 | null | [
"Development Status :: 4 - Beta",
"Programming Language :: Python"
] | [
"any"
] | https://github.com/Ostorlab/ostorlab | null | >=3.9 | [] | [] | [] | [
"click",
"docker",
"importlib-metadata",
"jsonschema>=4.4.0",
"protobuf==5.29.5",
"httpx",
"rich",
"ruamel.yaml",
"tenacity==8.3.0",
"sqlalchemy~=1.4",
"semver>=3.0.0",
"markdownify",
"alembic",
"py-ubjson",
"nats-py",
"pyaxmlparser",
"Werkzeug~=3.0; extra == \"agent\"",
"aio-pika; extra == \"agent\"",
"flask; extra == \"agent\"",
"redis; extra == \"agent\"",
"google-cloud-logging; extra == \"agent\"",
"opentelemetry-distro; extra == \"agent\"",
"opentelemetry-exporter-jaeger; extra == \"agent\"",
"deprecated; extra == \"agent\"",
"opentelemetry-exporter-gcp-trace; extra == \"agent\"",
"google-cloud-logging; extra == \"google-cloud-logging\"",
"setuptools; extra == \"testing\"",
"pytest; extra == \"testing\"",
"pytest-cov; extra == \"testing\"",
"pytest-asyncio; extra == \"testing\"",
"pytest-mock; extra == \"testing\"",
"pytest-timeout; extra == \"testing\"",
"pytest-httpx==0.30.0; extra == \"testing\"",
"psutil; extra == \"scanner\"",
"python-daemon; extra == \"scanner\"",
"flask; extra == \"serve\"",
"graphene-file-upload; extra == \"serve\"",
"flask-graphql; extra == \"serve\"",
"graphene-sqlalchemy; extra == \"serve\"",
"cvss; extra == \"serve\"",
"flask-cors; extra == \"serve\""
] | [] | [] | [] | [
"Documentation, https://oxo.ostorlab.co/",
"Source, https://github.com/Ostorlab/oxo",
"Changelog, https://github.com/Ostorlab/oxo/releases",
"Tracker, https://github.com/Ostorlab/oxo/issues",
"Twitter, https://twitter.com/OstorlabSec"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-20T14:54:01.216454 | ostorlab-1.12.0.tar.gz | 9,131,390 | af/68/61b7016901e91cffe6aafedd984d723be2b69019354f803d05172a16a8dc/ostorlab-1.12.0.tar.gz | source | sdist | null | false | 2dcdded0872aacec6abfa8b35f5b69db | 6ee7d676d0b4d4eb23e2bb78c4650b5b9c9e5c5203ef247c5beefac9bce7dcf7 | af6861b7016901e91cffe6aafedd984d723be2b69019354f803d05172a16a8dc | null | [
"LICENSE"
] | 265 |
2.4 | loki-reader-core | 0.2.0 | Python library for querying Grafana Loki logs via REST API | # loki-reader-core
A lightweight Python library for querying Grafana Loki logs via REST API.
## Features
- Simple, intuitive client for Loki's HTTP API
- Supports `query`, `query_range`, label discovery, and series matching
- SSL/TLS support including custom CA certificates for self-signed certs
- Multi-tenant support via `X-Scope-OrgID` header
- Basic authentication
- Clean dataclass models with `to_dict()`/`from_dict()` serialization
- All timestamps as Unix nanoseconds (Loki's native format)
## Installation
From PyPI:
```bash
pip install loki-reader-core
```
From GitHub:
```bash
pip install loki-reader-core @ git+ssh://git@github.com/jmazzahacks/loki-reader-core.git@main
```
## Usage
### Basic Query
```python
from loki_reader_core import LokiClient
from loki_reader_core.utils import hours_ago_ns, now_ns
client = LokiClient(base_url="https://loki.example.com")
result = client.query_range(
logql='{job="api-server"} |= "error"',
start=hours_ago_ns(1),
end=now_ns(),
limit=500
)
for stream in result.streams:
print(f"Labels: {stream.labels}")
for entry in stream.entries:
print(f" [{entry.timestamp}] {entry.message}")
```
### With Authentication and Self-Signed Certificates
```python
client = LokiClient(
base_url="https://loki.internal.company.com:8443",
auth=("username", "password"),
ca_cert="/path/to/ca.pem"
)
```
### Multi-Tenant Setup
```python
client = LokiClient(
base_url="https://loki.example.com",
org_id="tenant-1"
)
```
### Exploring Labels
```python
labels = client.get_labels()
values = client.get_label_values("application")
series = client.get_series(match=['{application="my-app"}'])
```
### Context Manager
```python
with LokiClient(base_url="https://loki.example.com") as client:
result = client.query(logql='{job="api"}')
```
## API Reference
### LokiClient
| Parameter | Type | Default | Description |
|-----------|------|---------|-------------|
| `base_url` | `str` | required | Loki server URL |
| `auth` | `tuple[str, str]` | `None` | Basic auth `(username, password)` |
| `org_id` | `str` | `None` | `X-Scope-OrgID` for multi-tenant |
| `ca_cert` | `str` | `None` | Path to CA certificate PEM file |
| `verify_ssl` | `bool` | `True` | Set `False` to disable SSL verification |
| `timeout` | `int` | `30` | Request timeout in seconds |
### Methods
| Method | Description |
|--------|-------------|
| `query(logql, time, limit)` | Instant query at a single point in time |
| `query_range(logql, start, end, limit, direction)` | Query across a time range |
| `get_labels(start, end)` | List available label names |
| `get_label_values(label, start, end)` | List values for a specific label |
| `get_series(match, start, end)` | List streams matching selectors |
### Timestamp Utilities
```python
from loki_reader_core.utils import (
now_ns, # Current time as nanoseconds
seconds_to_ns, # Convert Unix seconds to nanoseconds
ns_to_seconds, # Convert nanoseconds to Unix seconds
minutes_ago_ns, # Timestamp N minutes ago
hours_ago_ns, # Timestamp N hours ago
days_ago_ns, # Timestamp N days ago
)
```
## Development
### Setup
```bash
# Create virtual environment
python -m venv .
# Activate virtual environment
source bin/activate
# Install dependencies
pip install -r dev-requirements.txt
pip install -e .
```
### Running Tests
```bash
source bin/activate
pytest tests/ -v
```
## License
MIT
## Author
Jason Byteforge (@jmazzahacks)
| text/markdown | null | Jason Byteforge <jason@mzmail.me> | null | null | MIT License | grafana, logging, logs, loki, observability | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"requests"
] | [] | [] | [] | [
"Homepage, https://github.com/jmazzahacks/loki-reader-core",
"Issues, https://github.com/jmazzahacks/loki-reader-core/issues"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T14:53:51.972464 | loki_reader_core-0.2.0.tar.gz | 16,772 | 52/d1/67e6239968fdd54e471810628ee5252565ebccc128482773cbdf57a4a0e7/loki_reader_core-0.2.0.tar.gz | source | sdist | null | false | 8c58973bc7a42ce6740d8098f35d5389 | 79bd06024913cf3285dc65aa56d0cd49e85dba23801271ae17a962a1018606de | 52d167e6239968fdd54e471810628ee5252565ebccc128482773cbdf57a4a0e7 | null | [] | 207 |
2.4 | chainstream-sdk | 0.1.9 | ChainStream SDK - API client for ChainStream | # ChainStream Python SDK
Official Python client library for ChainStream API.
## Installation
```bash
pip install chainstream-sdk
```
## Quick Start
```python
from chainstream import ChainStreamClient
# Create client
client = ChainStreamClient(access_token="your-access-token")
# Use the client for API calls...
```
## Documentation
For detailed documentation, visit [https://docs.chainstream.io](https://docs.chainstream.io)
## Development
```bash
# Install dependencies
make install
# Run tests
make test
# Lint
make lint
# Generate OpenAPI client
make python-client
```
## License
MIT
| text/markdown | ChainStream | null | null | null | MIT | api, blockchain, chainstream, defi, dex, sdk | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp-retry>=2.9.1",
"aiohttp>=3.11.16",
"cryptography>=42.0.0",
"pydantic>=2.10.3",
"pyjwt>=2.10.1",
"python-dateutil>=2.9.0",
"urllib3>=2.2.3",
"myst-parser>=4.0.1; extra == \"dev\"",
"pytest-asyncio>=0.26.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"python-dotenv>=1.0.0; extra == \"dev\"",
"pyyaml>=6.0; extra == \"dev\"",
"ruff<0.8,>=0.7.1; extra == \"dev\"",
"sphinx-autobuild>=2024.10.3; extra == \"dev\"",
"sphinx-autodoc-typehints>=3.0.1; extra == \"dev\"",
"sphinx>=8.1.3; extra == \"dev\"",
"sphinxcontrib-napoleon>=0.7; extra == \"dev\"",
"towncrier<25,>=24.8.0; extra == \"dev\"",
"base58>=2.1.1; extra == \"wallet\"",
"nest-asyncio<2,>=1.6.0; extra == \"wallet\"",
"solana>=0.36.6; extra == \"wallet\"",
"solders>=0.26.0; extra == \"wallet\"",
"web3<=7.10.0,>=7.6.0; extra == \"wallet\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T14:53:23.070519 | chainstream_sdk-0.1.9.tar.gz | 152,545 | 8c/13/a455da0441cb6c0cfceada4258a764aef65b38381f9f6af66dde50645022/chainstream_sdk-0.1.9.tar.gz | source | sdist | null | false | cc75be6a2290399d84a7761515486be7 | c9961b51c243bb9c40e5e2bc227e528b8e42eeee9b93568eed574892df21aae9 | 8c13a455da0441cb6c0cfceada4258a764aef65b38381f9f6af66dde50645022 | null | [] | 208 |
2.4 | ds-provider-azure-py-lib | 0.1.0a4 | A Python package from the DS library collection | # ds-provider-azure-py-lib
A Python package from the ds-common library collection.
## Installation
Install the package using pip:
```bash
pip install ds-provider-azure-py-lib
```
Or using uv (recommended):
```bash
uv pip install ds-provider-azure-py-lib
```
## Quick Start
```python
from ds_provider_azure_py_lib import __version__
print(f"ds-provider-azure-py-lib version: {__version__}")
```
## Features
<!-- List your package features here -->
- Feature 1: Description of feature 1
- Feature 2: Description of feature 2
- Feature 3: Description of feature 3
## Usage
<!-- Add usage examples here -->
```python
# Example usage
import ds_provider_azure_py_lib
# Your code examples here
```
## Requirements
- Python 3.9 or higher
- <!-- List any required dependencies -->
## Optional Dependencies
<!-- List optional dependencies if any -->
- Optional dependency 1: Description
- Optional dependency 2: Description
## Documentation
Full documentation is available at:
- [GitHub Repository](https://github.com/grasp-labs/ds-provider-azure-py-lib)
- [Documentation Site](https://grasp-labs.github.io/ds-provider-azure-py-lib/)
## Development
To contribute or set up a development environment:
```bash
# Clone the repository
git clone https://github.com/grasp-labs/ds-provider-azure-py-lib.git
cd ds-provider-azure-py-lib
# Install development dependencies
uv sync --all-extras --dev
# Run tests
make test
```
See the [README](https://github.com/grasp-labs/ds-provider-azure-py-lib#readme) for
more information.
## License
This package is licensed under the Apache License 2.0.
See the [LICENSE-APACHE](https://github.com/grasp-labs/ds-provider-azure-py-lib/blob/main/LICENSE-APACHE)
file for details.
## Support
- **Issues**: [GitHub Issues](https://github.com/grasp-labs/ds-provider-azure-py-lib/issues)
- **Releases**: [GitHub Releases](https://github.com/grasp-labs/ds-provider-azure-py-lib/releases)
| text/markdown | null | Grasp Labs AS <hello@grasplabs.com> | null | Grasp Labs AS <hello@grasplabs.com> | null | ds, python | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Operating System :: OS Independent",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"ds-resource-plugin-py-lib<1.0.0,>=0.1.0-beta.1",
"ds-common-logger-py-lib<1.0.0,>=0.1.0-alpha.5",
"azure-data-tables<13.0.0,>=12.0.0",
"azure-storage-blob<13.0.0,>=12.0.0",
"azure-identity<2.0.0,>=1.0.0",
"pandas<3.0.0,>=2.0.0",
"bandit>=1.9.3; extra == \"dev\"",
"ruff>=0.1.8; extra == \"dev\"",
"mypy>=1.7.0; extra == \"dev\"",
"pandas-stubs>=2.1.0; extra == \"dev\"",
"pytest>=7.4.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"pytest-xdist>=3.3.0; extra == \"dev\"",
"pre-commit>=3.6.0; extra == \"dev\"",
"build>=1.0.0; extra == \"dev\"",
"twine>=4.0.0; extra == \"dev\"",
"sphinx>=7.1.0; extra == \"dev\"",
"sphinx-autoapi>=3.0.0; extra == \"dev\"",
"sphinx-material>=0.0.35; extra == \"dev\"",
"pytest>=7.4.0; extra == \"test\"",
"pytest-cov>=4.1.0; extra == \"test\"",
"pytest-xdist>=3.3.0; extra == \"test\"",
"sphinx>=7.1.0; extra == \"docs\"",
"sphinx-autoapi>=3.0.0; extra == \"docs\"",
"sphinx-material>=0.0.35; extra == \"docs\""
] | [] | [] | [] | [
"Documentation, https://grasp-labs.github.io/ds-provider-azure-py-lib/",
"Repository, https://github.com/grasp-labs/ds-provider-azure-py-lib/",
"Issues, https://github.com/grasp-labs/ds-provider-azure-py-lib/issues/",
"Changelog, https://github.com/grasp-labs/ds-provider-azure-py-lib/releases"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:53:15.486104 | ds_provider_azure_py_lib-0.1.0a4.tar.gz | 28,608 | 50/e3/92114ee367a6314132de531bd9bedd44c56ff5d3036a304ea72e48008694/ds_provider_azure_py_lib-0.1.0a4.tar.gz | source | sdist | null | false | 7cc32739bf9f56fe40c200341b35c47d | c2e23188900aa262a8edb70bdbe6f5a2f61c7d708e668ef604ed6c1faa7a70a6 | 50e392114ee367a6314132de531bd9bedd44c56ff5d3036a304ea72e48008694 | Apache-2.0 | [
"LICENSE-APACHE"
] | 221 |
2.4 | uk-gp-practices | 0.1.0 | Query UK GP practices (surgeries) via NHS ODS Data Search & Export CSV reports. | # uk-gp-practices
Query UK GP practices ("surgeries") locally using NHS ODS Data Search & Export (DSE) CSV reports.
This package downloads a predefined ODS report (default: `epraccur`), stores it in a local SQLite database, and provides a simple Python API + CLI to query it quickly.
> **Note:** On first use the package will automatically download the latest report from the NHS ODS endpoint. Subsequent queries use the local cache (refreshed daily by default).
## Install
```bash
pip install uk-gp-practices
```
For fuzzy name matching (optional):
```bash
pip install uk-gp-practices[fuzzy]
```
## Python API
```python
from uk_gp_practices import PracticeIndex
# Auto-download the latest data (cached for 24 h)
idx = PracticeIndex.auto_update()
# Look up a single practice by ODS code
practice = idx.get("A81001")
print(practice.name, practice.postcode)
# Search by name / postcode / town / status
results = idx.search(name="castle", status="ACTIVE", limit=10)
for r in results:
print(r.organisation_code, r.name, r.postcode)
# Context-manager usage
with PracticeIndex.auto_update() as idx:
print(idx.get("A81001"))
```
## CLI
```bash
# Update the local database
uk-gp update
# Get a single practice (JSON output)
uk-gp get A81001
# Search practices
uk-gp search --name "castle" --status ACTIVE --limit 5
uk-gp search --postcode "SW1A 1AA"
uk-gp search --town "Swansea"
```
## License
MIT
| text/markdown | Joshua Evans | null | null | null | MIT | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.27",
"platformdirs>=4.0",
"typer>=0.12",
"rapidfuzz>=3.0; extra == \"fuzzy\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T14:53:00.552252 | uk_gp_practices-0.1.0.tar.gz | 8,522 | ae/3e/36cff82c67ebdcd50d9119780d68e48adc51948112b522998f0214a10445/uk_gp_practices-0.1.0.tar.gz | source | sdist | null | false | 12d49c5d610af7901a6bdeb0d5b4d9f0 | 40cb85803f926d7b43da90afee3edd69408085354a01ab0b3d5acfab3ee49098 | ae3e36cff82c67ebdcd50d9119780d68e48adc51948112b522998f0214a10445 | null | [] | 215 |
2.4 | project-toolbox | 0.4.9 | A modular toolbox to support your Python development workflow | # project-toolbox
A modular toolbox to support your Python development workflow.
- `project-toolbox` provides the **box** of the toolbox as a unique command: `t`.
- Tools are selected/added to the box at the project level.
## Features
- one command (`t`) gathering all tools
- prevent cluttering command namespace
- completion even for tools installed in dedicated environment
- toolboxs are plugins
- each project can select its own set of plugins
- a plugin can be public (pypi) or shipped with the project
- tool calls are automatically embeded (eg `uv run ...`)
- tools are [click](https://click.palletsprojects.com/) commands
## Getting started
Install the main command globally:
```shell
uv tool install project-toolbox
```
Enable completion (bash) by adding the following to the end of your `~/.bashrc`:
```shell
eval "$(_T_COMPLETE=bash_source t)"
```
Instructions for completion with other shells [can be found here](https://click.palletsprojects.com/en/stable/shell-completion/#enabling-completion).
Manage the toolbox:
```shell
# show all 'self' subcommands
t self
# add a toolbox to current project
t self install <toolbox>
```
Read carefully crafted manuals guiding you through the workflow:
```shell
# show all 'manual' subcommands
t manual
```
Use the toolbox:
```shell
# show all commands
t
# use a tool
t <command> <arg1> <arg2> ...
```
## Filling the toolbox with tools
### Adding plugins to a project
Your toolbox need to be filled with tools.
The toolbox content is selected at project level and may differ between projects.
Use `t self install` to add a published toolbox to the project.
If your toolbox is not published, it can be shipped whithin the project repo and added locally:
```shell
uv add --dev path/to/plugin-package/
```
### Writing plugins
A `project-toolbox` plugin is a python package that defines some `click` commands and registers them to the dedicated entry points.
This is very similar to the usual way of creating console scripts, only the pyproject.toml entry changes from `[project.scripts]` to `[project.entry-points.'project_toolbox']`.
```toml
# pyproject.toml
[project.entry-points.'project_toolbox']
tool_name_1 = "package.module_1:object_1"
tool_name_2 = "package.module_2:object_2"
```
| text/markdown | Farid Smaï | Farid Smaï <f.smai@brgm.fr> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"click>=8.3.1"
] | [] | [] | [] | [
"repository, https://gitlab.com/fsmai/project-toolbox"
] | uv/0.10.2 {"installer":{"name":"uv","version":"0.10.2","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Alpine Linux","version":"3.23.3","id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T14:52:59.709389 | project_toolbox-0.4.9-py3-none-any.whl | 6,636 | 26/50/72106ba03ba8de5ea356ce1a251874a61298c99787f4cf2aa7335537d0df/project_toolbox-0.4.9-py3-none-any.whl | py3 | bdist_wheel | null | false | 0ee22892a9c203c955a1cf687bcd498c | 61d023f4b3002a0186b537acad4a8f921d6b2f5547246f1b770f8989458c29b4 | 265072106ba03ba8de5ea356ce1a251874a61298c99787f4cf2aa7335537d0df | MIT | [] | 193 |
2.4 | project-toolbox-default | 0.4.9 | A toolbox for my basic workflow on git+uv projects. | # project-toolbox-default
A [project-toolbox](https://pypi.org/project/project-toolbox/) plugin for my default development workflow.
## Getting started
If not done yet, [install uv](https://docs.astral.sh/uv/getting-started/installation/) and [project-toolbox](https://pypi.org/project/project-toolbox/).
Add the toolbox to the project:
```shell
cd path/to/project
t self install default
```
This will edit the 'pyproject.toml' file of the project.
Now you can use the toolbox:
```shell
# show all commands
t
# use a command
t <command> <arg1> <arg2> ...
```
## Philosophy
I want a toolbox to support my Python development workflow.
This toolbox does not cover all workflows.
For now, I'm working with git and uv.
Some general principles:
- tools should make each step of the workflow simple and easy
- tools should make the workflow easy to follow and remember
- tools should automate repetitive tasks
- tools should reduce the number of command to remember
- tools should avoid mistakes by checking project sanity
- tools should tell what they are doing
| text/markdown | Farid Smaï | Farid Smaï <f.smai@brgm.fr> | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"click>=8.3.1"
] | [] | [] | [] | [
"repository, https://gitlab.com/fsmai/project-toolbox"
] | uv/0.10.2 {"installer":{"name":"uv","version":"0.10.2","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Alpine Linux","version":"3.23.3","id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T14:52:58.081735 | project_toolbox_default-0.4.9-py3-none-any.whl | 5,796 | 1c/b4/11f6073a72d7f065173b46a5fb19ec418b6c9ca3404ea3721d1c12c7abee/project_toolbox_default-0.4.9-py3-none-any.whl | py3 | bdist_wheel | null | false | a054c77e38771fe4052890a623d47999 | 61cd81821e8d0a673282e6999983c5960400ce58b7703c04b9a41448bc853dff | 1cb411f6073a72d7f065173b46a5fb19ec418b6c9ca3404ea3721d1c12c7abee | MIT | [] | 194 |
2.4 | etekcity-esf551-ble | 0.4.1 | An unofficial Python package for interacting with Etekcity Smart Fitness Scales using BLE. Supports ESF-551 (full features), ESF-24 (experimental), and other Etekcity scale models. Not affiliated with Etekcity, VeSync Co., Ltd., or any of their subsidiaries. | # Etekcity ESF-551 & ESF-24 BLE
This package provides a basic unofficial interface for interacting with Etekcity Smart Fitness Scales using Bluetooth Low Energy (BLE). It supports both the [Etekcity ESF-551](https://etekcity.com/products/smart-fitness-scale-esf551) and [Etekcity ESF-24](https://etekcity.com/collections/fitness-scales/products/smart-fitness-scale-esf24) models.
## Features
- **ESF-551**: Full feature support including weight, impedance, body metrics and display unit management
- **ESF-24**: Experimental support
- Easy connection and notification handling
- Body metrics calculations (ESF-551 only)
- Display unit management
## Supported Models
| Model | Status | Features |
|-------|--------|----------|
| ESF-551 | ✅ Fully Supported | Weight, impedance, body metrics, unit changes |
| ESF-24 | 🔬 Experimental | Weight, unit changes |
## Version Status
**v0.4.1**:
- ✅ ESF-551: Fully supported and stable
- 🔬 ESF-24: Experimental support (weight only)
- ♻️ Internal: bleak 2.x, passive-scan optimisation & universal2 wheel build
- ⚠️ Breaking changes from v0.3.x (architecture refactoring, new scale class names)
**Disclaimer: This is an unofficial, community-developed library. It is not affiliated with, officially maintained by, or in any way officially connected with Etekcity, VeSync Co., Ltd. (the owner of the Etekcity brand), or any of their subsidiaries or affiliates. The official Etekcity website can be found at https://www.etekcity.com, and the official VeSync website at https://www.vesync.com. The names "Etekcity" and "VeSync" as well as related names, marks, emblems and images are registered trademarks of their respective owners.**
[](https://www.buymeacoffee.com/ronnnnnnn)
## Installation
Requires Python 3.10+ and bleak 2.x. Install using pip:
```bash
pip install etekcity_esf551_ble
```
## Quick Start
Here's a basic example of how to use the library:
```python
import asyncio
from etekcity_esf551_ble import (
IMPEDANCE_KEY,
WEIGHT_KEY,
ESF551Scale,
ScaleData,
WeightUnit,
BodyMetrics,
Sex,
)
async def main():
def notification_callback(data: ScaleData):
print(f"Weight: {data.measurements[WEIGHT_KEY]} kg")
print(f"Display Unit: {data.display_unit.name}")
if IMPEDANCE_KEY in data.measurements:
print(f"Impedance: {data.measurements[IMPEDANCE_KEY]} Ω")
# Calculate body metrics (ESF-551 only)
# Note: Replace with your actual height, age and sex
body_metrics = BodyMetrics(
weight_kg=data.measurements[WEIGHT_KEY],
height_m=1.75, # Example height
age=30, # Example age
sex=Sex.Male, # Example sex
impedance=data.measurements[IMPEDANCE_KEY]
)
print(f"Body Mass Index: {body_metrics.body_mass_index:.2f}")
print(f"Body Fat Percentage: {body_metrics.body_fat_percentage:.1f}%")
print(f"Fat-Free Weight: {body_metrics.fat_free_weight:.2f} kg")
print(f"Subcutaneous Fat Percentage: {body_metrics.subcutaneous_fat_percentage:.1f}%")
print(f"Visceral Fat Value: {body_metrics.visceral_fat_value}")
print(f"Body Water Percentage: {body_metrics.body_water_percentage:.1f}%")
print(f"Basal Metabolic Rate: {body_metrics.basal_metabolic_rate} calories")
print(f"Skeletal Muscle Percentage: {body_metrics.skeletal_muscle_percentage:.1f}%")
print(f"Muscle Mass: {body_metrics.muscle_mass:.2f} kg")
print(f"Bone Mass: {body_metrics.bone_mass:.2f} kg")
print(f"Protein Percentage: {body_metrics.protein_percentage:.1f}%")
print(f"Metabolic Age: {body_metrics.metabolic_age} years")
# Create scale (replace XX:XX:XX:XX:XX:XX with your scale's Bluetooth address)
scale = ESF551Scale("XX:XX:XX:XX:XX:XX", notification_callback)
scale.display_unit = WeightUnit.KG # Set display unit to kilograms
await scale.async_start()
await asyncio.sleep(30) # Wait for measurements
await scale.async_stop()
asyncio.run(main())
```
## Multi-Model Usage
For different scale models:
```python
# ESF-551 (full features)
from etekcity_esf551_ble import ESF551Scale
scale = ESF551Scale(address, callback)
# ESF-24 (experimental)
from etekcity_esf551_ble import ESF24Scale
scale = ESF24Scale(address, callback)
```
For a real-life usage example of this library, check out the [Etekcity Fitness Scale BLE Integration for Home Assistant](https://github.com/ronnnnnnnnnnnnn/etekcity_fitness_scale_ble).
## API Reference
### Scale Classes
#### `EtekcitySmartFitnessScale` (Abstract Base)
Abstract base class for all scale implementations.
#### `ESF551Scale`
Implementation for ESF-551 scales with full feature support.
#### `ESF24Scale`
Experimental implementation for ESF-24 scales (weight only).
#### Common Methods:
- `__init__(self, address: str, notification_callback: Callable[[ScaleData], None], display_unit: WeightUnit = None, scanning_mode: BluetoothScanningMode = BluetoothScanningMode.ACTIVE, adapter: str | None = None, bleak_scanner_backend: BaseBleakScanner = None, cooldown_seconds: int = 0, logger: logging.Logger | None = None)`
- `async_start()`: Start scanning for and connecting to the scale.
- `async_stop()`: Stop the connection to the scale.
#### Common Properties:
- `display_unit`: Get or set the display unit (WeightUnit.KG, WeightUnit.LB or WeightUnit.ST). Returns None if the display unit is currently unknown (not set by the user and not yet received from the scale together with a stable weight measurement).
- `hw_version`: Get the hardware version of the scale (read-only).
- `sw_version`: Get the software version of the scale (read-only).
### `ESF551ScaleWithBodyMetrics`
An extended version of ESF551Scale that automatically calculates body metrics when impedance is available. Body metrics (except BMI) are only added when the scale reports impedance.
#### Methods:
- `__init__(self, address: str, notification_callback: Callable[[ScaleData], None], sex: Sex, birthdate: date, height_m: float, display_unit: WeightUnit = None, scanning_mode: BluetoothScanningMode = BluetoothScanningMode.ACTIVE, adapter: str | None = None, bleak_scanner_backend: BaseBleakScanner = None, cooldown_seconds: int = 0, logger: logging.Logger | None = None)`
- `async_start()`: Start scanning for and connecting to the scale.
- `async_stop()`: Stop the connection to the scale.
#### Properties:
- `display_unit`: Get or set the display unit (WeightUnit.KG, WeightUnit.LB or WeightUnit.ST). Returns None if the display unit is currently unknown (not set by the user and not yet received from the scale together with a stable weight measurement).
- `hw_version`: Get the hardware version of the scale (read-only).
- `sw_version`: Get the software version of the scale (read-only).
### `WeightUnit`
An enum representing the possible display units:
- `WeightUnit.KG`: Kilograms
- `WeightUnit.LB`: Pounds
- `WeightUnit.ST`: Stones
### `ScaleData`
A dataclass containing scale measurement data:
- `name`: Scale name
- `address`: Scale Bluetooth address
- `hw_version`: Hardware version
- `sw_version`: Software version
- `display_unit`: Current display unit (concerns only the weight as displayed on the scale, the measurement itself is always provided by the API in kilograms)
- `measurements`: Dictionary of measurements (currently supports: weight in kilograms and impedance in ohms)
### `BodyMetrics`
A class for calculating various body composition metrics based on height, age, sex, and the weight and impedance as measured by the scale, similar to the metrics calculated and shown in the VeSync app. Note that currently "Athlete Mode" is not supported.
#### Methods:
- `__init__(self, weight_kg: float, height_m: float, age: int, sex: Sex, impedance: int)`
#### Properties:
- `body_mass_index`: Body Mass Index (BMI)
- `body_fat_percentage`: Estimated body fat percentage
- `fat_free_weight`: Weight of non-fat body mass in kg
- `subcutaneous_fat_percentage`: Estimated subcutaneous fat percentage
- `visceral_fat_value`: Estimated visceral fat level (unitless)
- `body_water_percentage`: Estimated body water percentage
- `basal_metabolic_rate`: Estimated basal metabolic rate in calories
- `skeletal_muscle_percentage`: Estimated skeletal muscle percentage
- `muscle_mass`: Estimated muscle mass in kg
- `bone_mass`: Estimated bone mass in kg
- `protein_percentage`: Estimated protein percentage
- `weight_score`: Calculated weight score (0-100)
- `fat_score`: Calculated fat score (0-100)
- `bmi_score`: Calculated BMI score (0-100)
- `health_score`: Overall health score based on other metrics (0-100)
- `metabolic_age`: Estimated metabolic age in years
### `Sex`
An enum representing biological sex for body composition calculations:
- `Sex.Male`
- `Sex.Female`
### `BluetoothScanningMode`
Enum for BLE scanning mode (Linux only; other platforms use active scanning):
- `BluetoothScanningMode.ACTIVE` (default)
- `BluetoothScanningMode.PASSIVE`
## Compatibility
- Python 3.10+
- bleak 2.x (`bleak>=2.0.0,<3.0.0`)
- Tested on Mac (Apple Silicon) and Raspberry Pi 4
- Compatibility with Windows is unknown
## Troubleshooting
On Raspberry Pi 4 (and possibly other Linux machines using BlueZ), if you encounter a `org.bluez.Error.InProgress` error, try the following in `bluetoothctl`:
```
power off
power on
scan on
```
(See https://github.com/home-assistant/core/issues/76186#issuecomment-1204954485)
## Support the Project
If you find this unofficial project helpful, consider buying me a coffee! Your support helps maintain and improve this library.
[](https://www.buymeacoffee.com/ronnnnnnn)
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## Disclaimer
This is an independent project developed by the community. It is not endorsed by, directly affiliated with, maintained, authorized, or sponsored by Etekcity, VeSync Co., Ltd., or any of their affiliates or subsidiaries. All product and company names are the registered trademarks of their original owners. The use of any trade name or trademark is for identification and reference purposes only and does not imply any association with the trademark holder of their product brand.
| text/markdown | null | Ron <ronnnnnnn@gmail.com> | null | null | null | ble, bluetooth, esf24, esf551, etekcity, fitness scale, health, iot, smart home, smart scale, weight | [
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Home Automation",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"bleak-retry-connector",
"bleak<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/ronnnnnnnnnnnnn/etekcity_esf551_ble",
"Bug Tracker, https://github.com/ronnnnnnnnnnnnn/etekcity_esf551_ble/issues",
"Documentation, https://github.com/ronnnnnnnnnnnnn/etekcity_esf551_ble#readme",
"Source Code, https://github.com/ronnnnnnnnnnnnn/etekcity_esf551_ble"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T14:52:08.903404 | etekcity_esf551_ble-0.4.1.tar.gz | 16,206 | 5a/58/87cc373e099f282e29488559cd15ebcfc14e82ec7305ee6b4f85eb58127a/etekcity_esf551_ble-0.4.1.tar.gz | source | sdist | null | false | eba993f7dc3d311d82871323a414c119 | d66f76659f2e0add91539fd8bf1537ed1222e651fc5a4e102707cef21cf5dbad | 5a5887cc373e099f282e29488559cd15ebcfc14e82ec7305ee6b4f85eb58127a | MIT | [
"LICENSE"
] | 397 |
2.4 | stratcraft | 0.1.0 | A Python backtesting framework for quantitative trading strategies | # StratCraft
A Python backtesting framework for building and evaluating quantitative trading strategies. StratCraft provides a clean, decorator-based API for defining indicators, handling multi-symbol data, and running event-driven backtests with portfolio tracking and performance analytics.
## Features
- **Event-driven backtesting** — step-by-step simulation with clean separation of `initialize()` and `step_forward()` hooks
- **Multi-symbol support** — buy/sell across multiple tickers in a single call
- **Decorator toolkit** — `@broadcast`, `@rolling`, `@grouping`, `@available` for composable indicator computation
- **Portfolio management** — track cash, equity, open positions, stop-loss and take-profit triggers
- **Performance metrics** — Sharpe ratio, Sortino ratio, Calmar ratio, max drawdown, win rate, profit factor, and more
- **Interactive charts** — Plotly-based equity curve with trade entry markers and optional additional panels
- **Data screening** — filter and rank symbols by criteria within `step_forward()`
## Installation
```bash
pip install stratcraft
```
Or install from source:
```bash
git clone https://github.com/kuanhungwang/stratcraft.git
cd stratcraft
pip install -e .
```
## Quick Start
```python
from stratcraft import Strategy, DataHandler
from datetime import datetime
class SMAStrategy(Strategy):
def initialize(self):
# Load price data and compute indicators here
self.data = {
'open': open_df,
'high': high_df,
'low': low_df,
'close': close_df,
}
self.data['sma20'] = close_df.rolling(20).mean()
def step_forward(self, data: DataHandler):
close = data['close'] # latest close (scalar or Series)
sma20 = data['sma20']
if close > sma20:
self.buy(symbol='AAPL', value=10_000)
else:
self.sell(symbol='AAPL', value=10_000)
strategy = SMAStrategy(initial_capital=100_000)
strategy.run(
start_date=datetime(2022, 1, 1),
end_date=datetime(2023, 12, 31),
data_length=2, # rows of history passed to step_forward
)
```
## Core Concepts
### Strategy lifecycle
| Method | When called | Purpose |
|---|---|---|
| `initialize()` | Once before the loop | Load data, compute indicators, set parameters |
| `step_forward(data)` | Every trading day | Implement trading logic, call `buy()`/`sell()` |
### Buying and selling
```python
# By quantity
self.buy(symbol='AAPL', quantity=100)
self.sell(symbol='AAPL', quantity=100)
# By dollar value
self.buy(symbol='AAPL', value=10_000)
# With stop-loss and take-profit (percentage of entry price)
self.buy(symbol='AAPL', quantity=100, stop_loss_percent=5, take_profit_percent=10)
# Multiple symbols at once
self.buy(symbol=['AAPL', 'MSFT'], value=[5_000, 5_000])
```
### Accessing historical data inside `step_forward`
```python
def step_forward(self, data: DataHandler):
latest_close = data['close'] # latest bar
prev_close = data[('close', -2)] # bar before latest
latest_sma = data['sma20']
```
> Set `data_length` in `strategy.run()` to the maximum look-back depth you need.
### Trailing stop-loss
```python
from stratcraft import TrailingStopLoss, Direction
trade = self.buy(symbol='AAPL', quantity=100)
if trade:
trade.stop_loss = TrailingStopLoss(
price=trade.entry_price - 1.0, # initial stop price
distance=1.0, # trail distance
threshold=trade.entry_price + 1.0,
direction=Direction.LONG,
)
```
Call `trade.stop_loss.reset_price(current_price)` each bar to move the stop up.
### Screening and ranking symbols
```python
def step_forward(self, data: DataHandler):
# Filter symbols passing all boolean criteria
candidates = data.screen(['criteria_momentum', 'criteria_volume'])
# Rank by a field, optionally from a filtered subset
top5 = data.highest('momentum_score', n=5, tickers=candidates)
bot5 = data.lowest('volatility', n=5)
```
Prefix keys with `signal_`, `criteria_`, `screen_`, or `filter_` in `self.data` — StratCraft will warn you during `run()` if any never triggered.
### Portfolio queries inside `step_forward`
```python
cash = self.portfolio.cash
equity = self.portfolio.equity
live = self.portfolio.live_trades()
cost_aapl = self.portfolio.cost(symbol='AAPL')
mkt_val = self.portfolio.current_market_value()
invest_ratio = self.portfolio.invest_ratio()
days = self.days_since_last_trade()
```
## Decorators
Decorators live in `stratcraft.decorators` and are designed to be composed.
### `@broadcast`
Applies a single-symbol (Series) function across all columns of a DataFrame:
```python
from stratcraft.decorators import broadcast
import ta
@broadcast
def RSI(price):
return ta.momentum.RSIIndicator(price).rsi()
rsi = RSI(close_df) # returns DataFrame with same columns as close_df
```
### `@rolling`
Turns a scalar reduction into a rolling-window Series/DataFrame:
```python
from stratcraft.decorators import rolling
@rolling(window=14)
def avg_range(high, low):
return (high - low).mean()
atr = avg_range(high_df, low_df)
```
Compose with `@broadcast` for multi-symbol rolling indicators:
```python
@broadcast
@rolling(window=20)
def momentum(price):
return (price.iloc[-1] / price.iloc[0]) - 1
```
### `@grouping`
Applies a function to user-defined groups of symbols and returns a group-level DataFrame:
```python
from stratcraft.decorators import grouping
sector = {'Technology': ['AAPL', 'MSFT'], 'Finance': ['JPM', 'BAC']}
@grouping(groups=sector)
def sector_return(price):
return price.pct_change().mean(axis=1)
sector_ret = sector_return(close_df) # columns: Technology, Finance
```
### `@available`
Aligns low-frequency data (e.g. quarterly earnings) to a daily time series, exposing only data that would have been available on each date:
```python
from stratcraft.decorators import available, broadcast
@broadcast
@available(looping_dates=close.index, length=1)
def daily_eps(eps):
return eps.iloc[-1]
eps_daily = daily_eps(fundamental['is_eps'], available_date=fundamental['fillingDate'])
pe = close / eps_daily
```
## Performance Analysis
```python
from stratcraft.metrics import Metrics
trade_df = strategy.portfolio.trade_history()
pl_df = strategy.portfolio.pl_history()
m = Metrics(trade_df, pl_df)
# Full metrics dict
results = m.metrics()
# Concise subset: cumulative return, annual return, win rate, volatility, Sharpe, max drawdown, # trades
results = m.metrics(concise=True)
Metrics.pretty_print(results)
```
**Metrics computed:**
| Metric | Description |
|---|---|
| Cumulative returns | Total return over the period |
| Annual return | Annualised CAGR |
| Annual volatility | Annualised std dev of daily returns |
| Sharpe ratio | Annual return / annual volatility |
| Sortino ratio | Annual return / downside deviation |
| Calmar ratio | Annual return / max drawdown |
| Max drawdown | Largest peak-to-trough decline |
| Omega ratio | Sum of gains / sum of losses above threshold |
| Stability | R² of linear fit on cumulative returns |
| Win rate | Fraction of closed trades that are profitable |
| Profit factor | Total wins / total losses |
| Avg win / loss trade p/l | Mean P&L of winning/losing trades |
| Skew / Kurtosis | Distribution shape of daily returns |
| Tail ratio | 95th percentile return / 5th percentile return |
### Interactive chart
```python
fig = m.chart_history()
fig.show()
# With additional panels
fig = m.chart_history(additional_chart_data={
'price_data': {'AAPL': aapl_df},
'indicators': {'RSI': rsi_series, 'SMA20': sma_series},
'cash_ratio': pl_df['cash'] / pl_df['equity'],
})
fig.write_html('backtest.html')
```
## Project Structure
```
stratcraft/
├── stratcraft.py # Core: Strategy, Portfolio, Trade, MarketHandler, DataHandler
├── decorators.py # @broadcast, @rolling, @grouping, @available
├── metrics.py # Metrics class with performance analytics and Plotly charts
├── util.py # Helper utilities (case-insensitive access, date range, symbol alignment)
├── examples.py # API usage reference
└── examples/ # Complete runnable strategy examples
├── strategy1_single_stock_technical.py
├── strategy2_multi_stock_technical.py
├── strategy3_multi_position_technical.py
├── strategy4_single_stock_technical_fundamental.py
├── strategy5_multi_stock_technical_fundamental.py
└── strategy6_comparing_index.py
```
## Requirements
- Python >= 3.10
- pandas >= 1.5
- numpy >= 1.23
- plotly >= 5.0
## License
MIT
| text/markdown | Kuan-Hung Wang | null | null | null | MIT | backtesting, trading, quantitative finance, strategy, algorithmic trading | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Financial and Insurance Industry",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Office/Business :: Financial :: Investment",
"Topic :: Scientific/Engineering"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pandas>=1.5.0",
"numpy>=1.23.0",
"plotly>=5.0.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"build; extra == \"dev\"",
"twine; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/kuanhungwang/stratcraft",
"Repository, https://github.com/kuanhungwang/stratcraft",
"Bug Tracker, https://github.com/kuanhungwang/stratcraft/issues"
] | twine/6.2.0 CPython/3.12.7 | 2026-02-20T14:51:54.420710 | stratcraft-0.1.0.tar.gz | 6,002 | d4/18/fba7a675fd945110416e54809ad6425aecba8f820cea1e7f234f70601b14/stratcraft-0.1.0.tar.gz | source | sdist | null | false | 166bd7ab1178b7aeee6c801499ab177e | c458e645c69595b6610f8fa598d95469ad1dcd16edb6d8e4b1d52e9046dcd030 | d418fba7a675fd945110416e54809ad6425aecba8f820cea1e7f234f70601b14 | null | [
"LICENSE"
] | 221 |
2.4 | sheap | 0.0.9 | sheap: Spectral Handling and Estimation of AGN Parameters | .. image:: https://raw.githubusercontent.com/felavila/sheap/main/docs/source/_static/sheap_withname.png
:alt: SHEAP Logo
:align: left
:width: 700
Spectral Handling and Estimation of AGN Parameters
==================================================
|pypi_badge| |docs_badge|
**sheap** (Spectral Handling and Estimation of AGN Parameters) is a Python 3 package designed to analyze and estimate key parameters of Active Galactic Nuclei (AGN) from spectral data. This package provides tools to streamline the handling of spectral data and applies models to extract relevant AGN properties efficiently.
Features
========
- **Spectral Fitting**: Automatically fits AGN spectra to estimate key physical parameters.
- **Model Customization**: Allows flexible models for AGN spectra to suit a variety of use cases.
- **AGN Parameter Estimation**: Extract black hole mass from observed spectra.
Installation
============
You can install sheap locally using the following command:
.. code-block:: shell
pip install -e .
Prerequisites
=============
You need to have Python (>=3.12) and the required dependencies installed. Dependencies are managed using Poetry or can be installed manually via `requirements.txt`.
References
==========
sheap is based on methodologies and models outlined in the following paper:
- **Mejía-Restrepo, J. E., et al. (2016)**.
*Active galactic nuclei at z ∼ 1.5 – II. Black hole mass estimation by means of broad emission lines.*
Monthly Notices of the Royal Astronomical Society, **460**, 187.
Available at: `ADS Abstract <https://ui.adsabs.harvard.edu/abs/2016MNRAS.460..187M/abstract>`_
License
=======
* `GNU Affero General Public License v3.0 <https://www.gnu.org/licenses/agpl-3.0.html>`_
.. |pypi_badge| image:: https://img.shields.io/pypi/v/sheap.svg
:alt: PyPI version
:target: https://pypi.org/project/sheap/
.. |docs_badge| image:: https://readthedocs.org/projects/sheap/badge/?version=latest
:alt: Documentation Status
:target: https://sheap.readthedocs.io/en/latest/?badge=latest
| text/x-rst | Felipe Avila-Vera | felipe.avilav@postgrado.uv.cl | Felipe Avila-Vera | felipe.avilav@postgrado.uv.cl | AGPL-3.0-only | python package | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: End Users/Desktop",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU Affero General Public License v3",
"Natural Language :: English",
"Operating System :: MacOS",
"Operating System :: POSIX :: Linux",
"Operating System :: Unix",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: System :: Software Distribution",
"Typing :: Typed"
] | [] | null | null | <3.13,>=3.11 | [] | [] | [] | [
"astropy>=7.2",
"jax==0.4.38",
"jaxlib==0.4.38",
"matplotlib>=3.8",
"mypy<2.0.0,>=1.8.0; extra == \"typing\"",
"myst_nb",
"nbsphinx",
"numpy<2.3,>=2.0",
"optax<0.3,>=0.2.3",
"pandas>=2.2",
"pytest<9.0.0,>=8.0.0; extra == \"test\" or extra == \"typing\"",
"pytest-click<2.0.0,>=1.1.0; extra == \"test\" or extra == \"typing\"",
"pytest-cov<5.0.0,>=4.1.0; extra == \"test\"",
"pytest-explicit<2.0.0,>=1.0.1; extra == \"test\"",
"pytest-run-subprocess<0.11.0,>=0.10.0; extra == \"test\"",
"pytest-xdist<4.0.0,>=3.5.0; extra == \"test\"",
"scipy>=1.11",
"sfdmap2",
"sphinx<8.3,>=5.0; extra == \"docs\" or extra == \"docslive\"",
"sphinx-autobuild<2022.0.0,>=2021.3.14; extra == \"docslive\"",
"sphinx-autodoc-typehints>=1.10; extra == \"docs\" or extra == \"docslive\"",
"sphinx-inline-tabs<2024.0.0,>=2023.4.21; python_version == \"3.12\" and (extra == \"docs\" or extra == \"docslive\")",
"sphinx-rtd-theme<2.0,>=1.2.0; extra == \"docs\" or extra == \"docslive\"",
"sphinxcontrib-mermaid<0.10.0,>=0.9.2; python_version == \"3.12\" and (extra == \"docs\" or extra == \"docslive\")",
"sphinxcontrib-spelling<7.4.0,>=7.3.3; extra == \"docs\" or extra == \"docslive\"",
"tqdm>=4.66",
"uncertainties>=3.1"
] | [] | [] | [] | [
"Bug Tracker, https://github.com/sheap/issues",
"CI: Github Actions, https://github.com/favila/sheap/actions",
"Changelog, https://github.com/favila/sheap/blob/master/CHANGELOG.rst",
"Code of Conduct, https://github.com/favila/sheap/blob/master/CONTRIBUTING.rst",
"Documentation, https://sheap.readthedocs.io/",
"Homepage, https://github.com/favila/sheap",
"Repository, https://github.com/favila/sheap",
"Source Code, https://github.com/favila/sheap"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:51:27.202187 | sheap-0.0.9.tar.gz | 89,008,189 | 8d/dd/f20712fe949cb4b5e648f219fb13a42c33f71caa74347b0d1f1e31a7e807/sheap-0.0.9.tar.gz | source | sdist | null | false | f16352bd5b72f24d445b1f4425c5590c | 51584a9f81ae50a798b5d6704314e5e9fb3e4269edebd7fdffa095a43b48acda | 8dddf20712fe949cb4b5e648f219fb13a42c33f71caa74347b0d1f1e31a7e807 | null | [
"LICENSE"
] | 212 |
2.4 | dapla-toolbelt-metadata | 0.13.2 | Dapla Toolbelt Metadata | # Dapla Toolbelt Metadata
[][pypi status]
[][pypi status]
[][pypi status]
[][license]
[][documentation]
[][tests]
[][sonarcov]
[][sonarquality]
[][pre-commit]
[](https://github.com/astral-sh/ruff)
[][uv]
[pypi status]: https://pypi.org/project/dapla-toolbelt-metadata/
[documentation]: https://statisticsnorway.github.io/dapla-toolbelt-metadata
[tests]: https://github.com/statisticsnorway/dapla-toolbelt-metadata/actions?workflow=Tests
[sonarcov]: https://sonarcloud.io/summary/overall?id=statisticsnorway_dapla-toolbelt-metadata
[sonarquality]: https://sonarcloud.io/summary/overall?id=statisticsnorway_dapla-toolbelt-metadata
[pre-commit]: https://github.com/pre-commit/pre-commit
[uv]: https://docs.astral.sh/uv/
Tools and clients for working with the Dapla Metadata system.
## Features
- Create and update metadata for datasets (aka Datadoc).
- Read, create and update variable definitions (aka Vardef).
- Check compliance with SSBs naming standard.
### Coming
- Publish dataset metadata to Statistics Norway's data catalogue.
- Maintain classifications and code lists.
## Installation
You can install _Dapla Toolbelt Metadata_ via [pip] from [PyPI]:
```console
pip install dapla-toolbelt-metadata
```
## Usage
Instructions and examples may be found in the [Dapla Manual](https://manual.dapla.ssb.no/statistikkere/). Please see the [Reference Guide] for API documentation.
## Contributing
Contributions are very welcome.
To learn more, see the [Contributor Guide].
## License
Distributed under the terms of the [MIT license][license],
_Dapla Toolbelt Metadata_ is free and open source software.
## Issues
If you encounter any problems,
please [file an issue] along with a detailed description.
## Credits
This project was generated from [Statistics Norway]'s [SSB PyPI Template].
[statistics norway]: https://www.ssb.no/en
[pypi]: https://pypi.org/
[ssb pypi template]: https://github.com/statisticsnorway/ssb-pypitemplate
[file an issue]: https://github.com/statisticsnorway/dapla-toolbelt-metadata/issues
[pip]: https://pip.pypa.io/
<!-- github-only -->
[license]: https://github.com/statisticsnorway/dapla-toolbelt-metadata/blob/main/LICENSE
[contributor guide]: https://github.com/statisticsnorway/dapla-toolbelt-metadata/blob/main/CONTRIBUTING.md
[reference guide]: https://statisticsnorway.github.io/dapla-toolbelt-metadata/dapla_metadata.html
| text/markdown | null | Statistics Norway <metadata@ssb.no> | null | "Division for Data Enablement (724)" <metadata@ssb.no> | null | null | [
"Development Status :: 4 - Beta",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"arrow>=1.3.0",
"beautifulsoup4>=4.12.3",
"dapla-auth-client>=1.2.1; python_version > \"3.10\"",
"gcsfs>=2023.1.0",
"google-auth>=2.38.0",
"lxml>=5.3.1",
"pandas>=2.3.3",
"pyarrow>=8.0.0",
"pydantic>=2.5.2",
"pyjwt>=2.8.0",
"python-dateutil>=2.9.0.post0",
"python-dotenv>=1.0.1",
"pytz>=2025.2",
"requests>=2.31.0",
"ruamel-yaml>=0.18.10",
"ssb-datadoc-model==8.0.0",
"ssb-klass-python>=1.0.1",
"typing-extensions>=4.12.2",
"universal-pathlib>=0.3.0",
"urllib3>=2.5.0"
] | [] | [] | [] | [
"Changelog, https://github.com/statisticsnorway/dapla-toolbelt-metadata/releases",
"Documentation, https://statisticsnorway.github.io/dapla-toolbelt-metadata",
"Homepage, https://github.com/statisticsnorway/dapla-toolbelt-metadata",
"Repository, https://github.com/statisticsnorway/dapla-toolbelt-metadata"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:51:11.386170 | dapla_toolbelt_metadata-0.13.2.tar.gz | 436,878 | 61/48/6b4b9f265bd455ea196e2cc01d0560a5c1cce33ded444def4b8ce4effc02/dapla_toolbelt_metadata-0.13.2.tar.gz | source | sdist | null | false | b0330c572b3e123ec41ff56bcdb62257 | 029231abfbeb7b3c589ee501ea779c0ed6939131525dba69224164f6bc461f47 | 61486b4b9f265bd455ea196e2cc01d0560a5c1cce33ded444def4b8ce4effc02 | MIT | [
"LICENSE"
] | 202 |
2.4 | e2e-type-converter | 0.1.2 | Python类型转换兼容层,支持所有标准数据类型和第三方库类型之间的双向转换 | # EveryThing to EveryThing 类型转换兼容层
## 项目概述
本项目实现了一个Python类型转换兼容层,支持所有Python标准数据类型之间的双向转换功能。该兼容层在不修改Python内置函数原有接口和使用方式的前提下,扩展了其转换能力,实现了不同标准数据类型间的无缝转换。
## 支持的转换类型
- **基本类型**:int、float、str、bool、NoneType
- **容器类型**:list、tuple、dict、set
- **字节类型**:bytes
- **第三方库类型**(可选,需安装对应库):
- NumPy 数组 (`numpy.ndarray`)
- CuPy 数组 (`cupy.ndarray`)
- SciPy 稀疏矩阵 (`scipy.sparse.*`)
- Pandas 类型 (`pandas.DataFrame`, `pandas.Series`)
- PyTorch 张量 (`torch.Tensor`)
- xarray 类型 (`xarray.DataArray`, `xarray.Dataset`)
- JAX 数组 (`jax.numpy.ndarray`)
- TensorFlow 张量 (`tensorflow.Tensor`)
## 转换规则
### 1. 转换为 list
| 输入类型 | 输出结果 |
|---------|----------|
| list | 保持不变 |
| None | [] |
| str/bytes | 转换为字符/字节列表 |
| dict | 转换为键值对元组列表 |
| int/float/bool | 转换为单元素列表 |
| tuple/set | 转换为列表 |
| 其他 | 尝试使用原始 list() 函数 |
### 2. 转换为 str
| 输入类型 | 输出结果 |
|---------|----------|
| str | 保持不变 |
| None | "" |
| bool | 转换为小写字符串 ("true"/"false") |
| int/float/list/tuple/dict/set | 使用原始 str() 函数 |
| 其他 | 尝试使用原始 str() 函数 |
### 3. 转换为 int
| 输入类型 | 输出结果 |
|---------|----------|
| int | 保持不变 |
| None | 0 |
| bool | 转换为 1/0 |
| float | 截断小数部分 |
| str | 尝试转换为整数 |
| 空容器 | 0 |
| 单元素容器 | 转换容器内元素 |
| 多元素容器 | 抛出 TypeError |
| 其他 | 尝试使用原始 int() 函数 |
### 4. 转换为 float
| 输入类型 | 输出结果 |
|---------|----------|
| float | 保持不变 |
| None | 0.0 |
| bool | 转换为 1.0/0.0 |
| int | 转换为浮点数 |
| str | 尝试转换为浮点数 |
| 空容器 | 0.0 |
| 单元素容器 | 转换容器内元素 |
| 多元素容器 | 抛出 TypeError |
| 其他 | 尝试使用原始 float() 函数 |
### 5. 转换为 dict
| 输入类型 | 输出结果 |
|---------|----------|
| dict | 保持不变 |
| None | {} |
| list/tuple | 尝试转换为字典,失败则转换为索引字典 |
| str/int/float/bool/set | 转换为 {"value": 值} |
| 其他 | 尝试使用原始 dict() 函数 |
### 6. 转换为 set
| 输入类型 | 输出结果 |
|---------|----------|
| set | 保持不变 |
| None | set() |
| str/bytes | 转换为字符/字节集合 |
| int/float/bool | 转换为单元素集合 |
| list/tuple/dict | 转换为集合 |
| 其他 | 尝试使用原始 set() 函数 |
### 7. 转换为 tuple
| 输入类型 | 输出结果 |
|---------|----------|
| tuple | 保持不变 |
| None | () |
| str/bytes | 转换为字符/字节元组 |
| int/float/bool | 转换为单元素元组 |
| list/set/dict | 转换为元组 |
| 其他 | 尝试使用原始 tuple() 函数 |
### 8. 第三方库类型转换
| 类型 | 转换为 list | 转换为 str | 转换为 int/float | 转换为 dict | 转换为 set | 转换为 tuple |
|------|------------|------------|-----------------|------------|------------|--------------|
| NumPy 数组 | 转换为嵌套列表 | 转换为列表字符串 | 仅标量数组 | 1D: 索引字典<br>ND: 包含shape、dtype、data的字典 | 仅1D数组 | 转换为嵌套元组 |
| CuPy 数组 | 转换为嵌套列表 | 转换为列表字符串 | 仅标量数组 | 1D: 索引字典<br>ND: 包含shape、dtype、data的字典 | 仅1D数组 | 转换为嵌套元组 |
| SciPy 稀疏矩阵 | 转换为密集数组列表 | 转换为列表字符串 | 仅单元素矩阵 | 1D: 索引字典<br>ND: 包含shape、dtype、data的字典 | 仅1D矩阵 | 转换为嵌套元组 |
| Pandas DataFrame | 包含列名的嵌套列表 | 转换为字典字符串 | 仅单元素DataFrame | 转换为列名:列表字典 | 不支持 | 包含列名的嵌套元组 |
| Pandas Series | 转换为值列表 | 转换为列表字符串 | 仅单元素Series | 转换为索引:值字典 | 转换为值集合 | 转换为值元组 |
| PyTorch Tensor | 转换为嵌套列表 | 转换为列表字符串 | 仅标量张量 | 1D: 索引字典<br>ND: 包含shape、data的字典 | 仅1D张量 | 转换为嵌套元组 |
| xarray DataArray | 转换为嵌套列表 | 转换为列表字符串 | 仅标量DataArray | 包含shape、dtype、data、dims、coords的字典 | 仅1D DataArray | 转换为嵌套元组 |
| xarray Dataset | 包含变量字典的列表 | 转换为字典字符串 | 不支持 | 变量名:变量信息字典 | 不支持 | 包含变量字典的元组 |
| JAX 数组 | 转换为嵌套列表 | 转换为列表字符串 | 仅标量数组 | 1D: 索引字典<br>ND: 包含shape、dtype、data的字典 | 仅1D数组 | 转换为嵌套元组 |
| TensorFlow Tensor | 转换为嵌套列表 | 转换为列表字符串 | 仅标量张量 | 1D: 索引字典<br>ND: 包含shape、data的字典 | 仅1D张量 | 转换为嵌套元组 |
## 使用示例
### 方法一:直接使用 e2e_* 函数
```python
from e2e_type_converter import (
e2e_list, e2e_str, e2e_int, e2e_float, e2e_dict, e2e_set, e2e_tuple
)
# 示例 1:基本类型转换
print(e2e_list(123)) # 输出: [123]
print(e2e_str(None)) # 输出: ""
print(e2e_int("123")) # 输出: 123
print(e2e_float(True)) # 输出: 1.0
# 示例 2:容器类型转换
print(e2e_list({"a": 1, "b": 2})) # 输出: [("a", 1), ("b", 2)]
print(e2e_dict([1, 2, 3])) # 输出: {0: 1, 1: 2, 2: 3}
print(e2e_set("hello")) # 输出: {'h', 'e', 'l', 'o'}
# 示例 3:双向转换
print(e2e_list(e2e_tuple([1, 2, 3]))) # 输出: [1, 2, 3]
print(e2e_dict(e2e_list({"a": 1, "b": 2}))) # 输出: {"a": 1, "b": 2}
```
### 方法二:使用 TypeConverter 类
```python
from e2e_type_converter import TypeConverter
# 示例
print(TypeConverter.to_list(123)) # 输出: [123]
print(TypeConverter.to_str(None)) # 输出: ""
print(TypeConverter.to_int("123")) # 输出: 123
```
### 方法三:重命名为内置函数名使用
```python
from e2e_type_converter import (
e2e_list, e2e_str, e2e_int, e2e_float, e2e_dict, e2e_set, e2e_tuple
)
# 重命名以便使用
list = e2e_list
str = e2e_str
int = e2e_int
float = e2e_float
dict = e2e_dict
set = e2e_set
tuple = e2e_tuple
# 现在可以像使用内置函数一样使用
print(list(123)) # 输出: [123]
print(str(None)) # 输出: ""
print(int("123")) # 输出: 123
```
### 方法四:第三方库类型转换示例
```python
from e2e_type_converter import e2e_list, e2e_dict, e2e_tuple
# NumPy 数组转换示例
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(e2e_list(arr)) # 输出: [[1, 2, 3], [4, 5, 6]]
print(e2e_dict(arr)) # 输出: {"shape": (2, 3), "dtype": "int32", "data": [[1, 2, 3], [4, 5, 6]]}
print(e2e_tuple(arr)) # 输出: ((1, 2, 3), (4, 5, 6))
# SciPy 稀疏矩阵转换示例
import scipy.sparse
sparse_mat = scipy.sparse.csr_matrix([[1, 0, 0], [0, 2, 0], [0, 0, 3]])
print(e2e_list(sparse_mat)) # 输出: [[1, 0, 0], [0, 2, 0], [0, 0, 3]]
```
### 方法五:第三方库类型互转示例
```python
from e2e_type_converter import TypeConverter
# NumPy 到 xarray 的转换
import numpy as np
numpy_arr = np.array([[1, 2, 3], [4, 5, 6]])
xarray_da = TypeConverter.numpy_to_xarray(numpy_arr)
print(xarray_da) # 输出 xarray DataArray
# xarray 到 NumPy 的转换
converted_back = TypeConverter.xarray_to_numpy(xarray_da)
print(converted_back) # 输出 numpy 数组
# 通用转换方法
import torch
# NumPy 到 PyTorch 的转换
torch_tensor = TypeConverter.convert(numpy_arr, 'torch')
print(torch_tensor) # 输出 PyTorch Tensor
# PyTorch 到 pandas 的转换(通过通用方法)
pandas_df = TypeConverter.convert(torch_tensor, 'pandas')
print(pandas_df) # 输出 pandas DataFrame
# 支持的转换方向
# 'numpy' <-> 'cupy' <-> 'scipy' <-> 'pandas' <-> 'torch' <-> 'xarray' <-> 'jax' <-> 'tensorflow'
```
## 注意事项
1. **类型安全**:对于不支持直接转换的类型组合,会抛出明确的 TypeError 或 ValueError 异常。
2. **边界情况**:
- None 值会转换为对应类型的"空"值(如 []、""、0 等)
- 布尔值会被转换为对应类型的逻辑值(如 int(True) → 1)
3. **性能优化**:
- 类型检查顺序已优化,常见类型的检查优先级更高
- 对于容器类型的单元素转换,会递归处理内部元素
4. **兼容性**:
- 不直接修改内置函数,而是通过导入使用
- 保留了原始内置函数的行为,仅在其基础上扩展
5. **限制**:
- 对于多元素容器转换为数值类型(int/float),会抛出 TypeError
- 对于不可哈希类型,不支持缓存机制
6. **第三方库支持**:
- 第三方库支持采用懒加载方式,仅在实际使用时检测库是否安装
- 对于 NumPy/CuPy 数组,仅支持标量数组转换为 int/float
- 对于 NumPy/CuPy 数组和 SciPy 稀疏矩阵,仅支持 1D 类型转换为 set
- 对于多维数组/矩阵,转换为 dict 时会包含 shape、dtype 和 data 信息
## 单元测试
项目包含完整的单元测试,覆盖所有标准类型之间的转换场景:
```bash
python test_e2e_type_converter.py
```
## 项目结构
```
everything2everything/
├── e2e_type_converter/ # 包目录
│ ├── __init__.py # 模块导出和版本信息
│ └── core.py # 核心实现文件
├── setup.py # 包配置和依赖项
├── README.md # 文档说明
├── test_e2e_type_converter.py # 标准类型单元测试
└── test_third_party_types.py # 第三方库类型单元测试
```
## 总结
本类型转换兼容层提供了一种简洁、灵活的方式来处理Python中的类型转换问题,特别是在处理不同类型数据交互的场景中。通过扩展内置转换函数的能力,它使得类型转换更加直观和符合开发者的直觉预期,同时保持了与Python原生语法的兼容性。
| text/markdown | John-is-playing | b297209694@outlook.com | null | null | MIT | type converter, data type, python, numpy, torch, xarray, jax, tensorflow | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Utilities"
] | [] | https://github.com/John-is-playing/everything2everything | null | >=3.7 | [] | [] | [] | [
"numpy; extra == \"full\"",
"cupy; extra == \"full\"",
"scipy; extra == \"full\"",
"pandas; extra == \"full\"",
"torch; extra == \"full\"",
"xarray; extra == \"full\"",
"jax; extra == \"full\"",
"tensorflow; extra == \"full\"",
"numpy; extra == \"numpy\"",
"pandas; extra == \"pandas\"",
"numpy; extra == \"pandas\"",
"torch; extra == \"torch\"",
"xarray; extra == \"xarray\"",
"numpy; extra == \"xarray\"",
"numpy; extra == \"scientific\"",
"scipy; extra == \"scientific\"",
"pandas; extra == \"scientific\""
] | [] | [] | [] | [
"Bug Tracker, https://github.com/John-is-playing/everything2everything/issues",
"Source Code, https://github.com/John-is-playing/everything2everything"
] | twine/6.2.0 CPython/3.10.6 | 2026-02-20T14:50:55.266854 | e2e_type_converter-0.1.2.tar.gz | 22,577 | 5e/de/ea3b2be7b4e38b0853a61d8dd63cf6502837b2144ad418e272d2f672b076/e2e_type_converter-0.1.2.tar.gz | source | sdist | null | false | ee4b6216257af0a159a189dab161c001 | 2e543e1acde269f75eab4bada1cfceab6179d253893ad414288b1ce4b55a4983 | 5edeea3b2be7b4e38b0853a61d8dd63cf6502837b2144ad418e272d2f672b076 | null | [] | 223 |
2.4 | isagellm-core | 0.5.1.7 | sageLLM core runtime with PD separation (MVP) | # sagellm-core

[](https://pypi.org/project/isagellm-core/)
[](https://pypi.org/project/isagellm-core/)
[](https://github.com/intellistream/sagellm-core/blob/main/LICENSE)
[](https://github.com/astral-sh/ruff)
**sageLLM Core** 是一个硬件无关的 LLM 推理引擎,提供统一的推理接口(generate、stream、execute),支持自动后端选择(CPU/CUDA/Ascend),内置解码策略系统,并支持 PD 分离的混合模式执行。
**版本**: `0.4.0.17` | **最后更新**: 2026-02-02 | **协议遵循**: [Protocol v0.1](https://github.com/intellistream/sagellm-docs/blob/main/docs/specs/protocol_v0.1.md)
## 📍 职责定位
在整个 sageLLM 架构中的位置与职责:
```
┌─────────────────────────────────────────────────────────────┐
│ Application Layer │
│ (sagellm-gateway, sagellm-control-plane) │
└────────────────┬────────────────────────────────────────────┘
│
┌────────────────┴────────────────────────────────────────────┐
│ sagellm-core 本仓库 │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ LLMEngine: 硬件无关的统一推理入口 │ │
│ │ • generate() / stream() / execute() │ │
│ │ • 自动后端选择 (cpu/cuda/ascend) │ │
│ │ • Continuous Batching 调度 │ │
│ │ • 解码策略系统 (Greedy/Sampling/BeamSearch) │ │
│ │ • PD 分离混合模式执行 │ │
│ └──────────────────────────────────────────────────────┘ │
├──────────────────────────────────────────────────────────────┤
│ 核心依赖 (L1 层) │
│ ├─ sagellm-backend: 硬件抽象、设备管理 │
│ ├─ sagellm-comm: 通信硬件、TP/PP 通信 │
│ ├─ sagellm-kv-cache: KV 缓存管理、驱逐策略 │
│ └─ sagellm-protocol: 数据结构、错误定义 │
└──────────────────────────────────────────────────────────────┘
```
**职责边界**:
- ✅ **Core 负责**: LLMEngine、调度、推理编排、解码策略
- ✅ **Backend 负责**: 硬件抽象、设备管理、算子/内核
- ✅ **Comm 负责**: 通信硬件抽象、集合操作、拓扑管理
- ✅ **Protocol 负责**: 全局共享的数据结构、错误码、ID 方案
## ✨ 核心特性
| 特性 | 说明 |
|------|------|
| **统一推理接口** | `generate()` / `stream()` / `execute()` - 同步、流式、协议兼容 |
| **硬件无关** | CPU/CUDA/Ascend - 自动检测与选择 |
| **解码策略系统** | Greedy、Sampling、Beam Search、Contrastive Decoding |
| **Continuous Batching** | 动态批处理,充分利用硬件 |
| **PD 分离执行** | Prefill 和 Decode 阶段分离,支持混合模式 |
| **配置驱动** | YAML/JSON 配置,Pydantic v2 验证 |
| **HTTP Server** | FastAPI 实现,支持 SSE 流式传输 |
| **CPU-First** | 完整支持无 GPU 环境,便于测试开发 |
| **类型安全** | 完整的 Python 类型标注,Mypy 支持 |
## 📦 依赖关系
### 核心依赖(自动安装)
```toml
isagellm-protocol>=0.4.0.0,<0.5.0 # 协议定义
isagellm-backend>=0.4.0.0,<0.5.0 # 硬件抽象
isagellm-comm>=0.4.0.0,<0.5.0 # 通信后端
isagellm-kv-cache>=0.4.0.0,<0.5.0 # KV 缓存管理
# 框架依赖
pydantic>=2.0.0 # 数据验证
pyyaml>=6.0.0 # 配置解析
torch>=2.0.0 # 张量计算
transformers>=4.35.0 # 模型加载
fastapi>=0.100.0 # HTTP 服务
```
### 谁依赖我
- 🔵 **sagellm-control-plane**: 使用 Core 进行请求调度、负载均衡
- 🟡 **sagellm-compression**: 建立在 Core 的模型执行层上
- 🟢 **sagellm-gateway**: 提供 OpenAI 兼容 API
## 🚀 安装指南
### PyPI 安装(推荐)
```bash
# 安装最新版本
pip install isagellm-core==0.4.0.17
# 安装指定版本范围
pip install "isagellm-core>=0.4.0.0,<0.5.0"
```
### 本地开发安装
```bash
# 克隆仓库
git clone https://github.com/intellistream/sagellm-core.git
cd sagellm-core
# 方式 1:一键安装(推荐)
./quickstart.sh
# 方式 2:手动安装开发环境
pip install -e ".[dev]"
# 安装 pre-commit hooks
pre-commit install
```
### 本地链接依赖(用于本地多包开发)
```bash
# 如果同时在开发 backend/protocol/comm,使用本地版本
pip install -e ../sagellm-protocol
pip install -e ../sagellm-backend
pip install -e ../sagellm-comm
pip install -e ../sagellm-kv-cache
pip install -e ".[dev]"
```
### 验证安装
```bash
# 检查 package 版本
python -c "import sagellm_core; print(sagellm_core.__version__)"
# 运行快速测试
pytest tests/test_ci_smoke.py -v
```
## 🎯 快速开始
### 1. 基础推理
```python
from sagellm_core import LLMEngine, LLMEngineConfig
# 创建配置
config = LLMEngineConfig(
model_path="sshleifer/tiny-gpt2", # HuggingFace 模型名或本地路径
backend_type="cpu", # 自动选择 cpu/cuda/ascend
max_new_tokens=20
)
# 初始化引擎
engine = LLMEngine(config)
# 异步运行
import asyncio
async def main():
await engine.start()
# 同步生成(完整输出)
response = await engine.generate("Hello, world!")
print(response.output_text)
# 流式生成(逐 token 返回)
async for event in engine.stream("Once upon a time"):
if event.event == "delta":
print(event.chunk, end="", flush=True)
await engine.stop()
asyncio.run(main())
```
### 2. 使用采样参数控制生成
```python
from sagellm_core import LLMEngine, LLMEngineConfig
from sagellm_protocol.sampling import SamplingParams, DecodingStrategy
async def main():
config = LLMEngineConfig(model_path="sshleifer/tiny-gpt2")
engine = LLMEngine(config)
await engine.start()
prompt = "The future of AI is"
# 确定性输出(Greedy)
response = await engine.generate(
prompt,
sampling_params=SamplingParams(
strategy=DecodingStrategy.GREEDY,
max_tokens=20
)
)
print(f"Greedy: {response.output_text}")
# 随机采样(Temperature 控制)
response = await engine.generate(
prompt,
sampling_params=SamplingParams(
strategy=DecodingStrategy.SAMPLING,
temperature=0.7,
top_p=0.9,
max_tokens=20
)
)
print(f"Sampling: {response.output_text}")
await engine.stop()
asyncio.run(main())
```
### 3. 从 YAML 配置文件运行 Demo
```bash
# 查看可用配置
cat examples/config_cpu.yaml
# 运行 Demo
python -m sagellm_core.demo --config examples/config_cpu.yaml --verbose
# 查看输出 metrics
cat metrics.json
```
### 4. 启动 HTTP Server
```bash
# 方式 1:命令行
sage-engine --host 0.0.0.0 --port 8000
# 方式 2:Python API
from sagellm_core import engine_server_app
import uvicorn
uvicorn.run(engine_server_app, host="0.0.0.0", port=8000)
```
### 5. HTTP 请求示例
```bash
# 同步推理
curl -X POST http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt2",
"prompt": "Hello",
"max_tokens": 20
}'
# 流式推理
curl -X POST http://localhost:8000/v1/completions/stream \
-H "Content-Type: application/json" \
-d '{
"model": "gpt2",
"prompt": "Hello",
"max_tokens": 20,
"stream": true
}'
```
## 📚 API 文档
### LLMEngine - 主入口
**初始化**:
```python
LLMEngineConfig(
model_path: str, # 必需:HuggingFace 名或本地路径
backend_type: str = "auto", # 计算后端:cpu/cuda/ascend/auto
comm_type: str = "auto", # 通信后端:gloo/nccl/hccl/auto
max_batch_size: int = 32, # 最大批大小
max_model_len: int = 4096, # 最大序列长度
max_new_tokens: int = 128, # 每个请求最多生成 token 数
tensor_parallel_size: int = 1, # 张量并行度
pipeline_parallel_size: int = 1, # 流水线并行度
dtype: str = "auto", # 数据类型:float32/float16/bfloat16
)
```
**关键方法**:
```python
async def start() -> None:
"""启动引擎,加载模型"""
async def stop() -> None:
"""停止引擎,释放资源"""
async def generate(
prompt: str | list[int],
*,
sampling_params: SamplingParams | None = None,
max_tokens: int | None = None,
request_id: str | None = None,
) -> Response:
"""同步推理,返回完整输出"""
async def stream(
prompt_or_request: str | Request,
*,
max_tokens: int | None = None,
request_id: str | None = None,
) -> AsyncIterator[StreamEvent]:
"""流式推理,逐 token 返回事件"""
async def execute(request: Request) -> Response:
"""执行 Protocol Request,用于兼容旧接口"""
```
### SamplingParams - 采样参数
```python
from sagellm_protocol.sampling import SamplingParams, DecodingStrategy
SamplingParams(
strategy: DecodingStrategy = DecodingStrategy.GREEDY,
temperature: float = 0.0, # 越高越随机
top_p: float = 1.0, # Nucleus 采样
top_k: int = 0, # Top-K 采样
repetition_penalty: float = 1.0,
length_penalty: float = 1.0,
num_beams: int = 1, # Beam Search 宽度
max_tokens: int = 128,
seed: int | None = None, # 可复现性
)
```
### 其他核心 API
```python
# 配置加载(Legacy)
from sagellm_core import load_config
config = load_config("config.yaml") # 支持 YAML/JSON
# 后端创建(Legacy)
from sagellm_core import create_backend, BackendConfig
backend = create_backend(BackendConfig(kind="cpu"))
# 工厂方法(Legacy)
from sagellm_core import EngineFactory
factory = EngineFactory()
engine = factory.create("cpu") # 支持自动发现
```
## 🏗️ 架构设计
### 分层架构
```
┌──────────────────────────────────┐
│ LLMEngine (对外 API) │ ← 用户交互层
│ • generate/stream/execute │
└────────┬─────────────────────────┘
│
┌────────▼──────────────────────────┐
│ EngineCore (引擎核心) │ ← 推理协调层
│ • Scheduler: Continuous Batching │
│ • Executor: 工作进程管理 │
│ • KVCacheManager: 缓存管理 │
└────────┬──────────────────────────┘
│
┌────────▼──────────────────────────┐
│ Worker & ModelRunner │ ← 执行层
│ • 前向传播 │
│ • TP/PP 通信 │
│ • 硬件资源管理 │
└────────┬──────────────────────────┘
│
┌────┴────┬───────────┬────────────┐
▼ ▼ ▼ ▼
Backend Comm KV-Cache Protocol
```
### 模块说明
| 模块 | 路径 | 职责 |
|------|------|------|
| **llm_engine** | `src/sagellm_core/llm_engine.py` | 统一推理入口 |
| **engine_core** | `src/sagellm_core/engine_core/` | 调度与执行协调 |
| **scheduler** | `src/sagellm_core/engine_core/scheduler.py` | Continuous Batching |
| **executor** | `src/sagellm_core/executor/` | Worker 管理 |
| **worker** | `src/sagellm_core/worker/` | 单设备执行 |
| **decoding** | `src/sagellm_core/decoding/` | 5+ 种解码策略 |
| **runtime** | `src/sagellm_core/runtime.py` | PD 分离 Runtime |
| **pd_executor** | `src/sagellm_core/pd_executor.py` | Prefill/Decode 分离 |
| **engine_server** | `src/sagellm_core/engine_server.py` | HTTP 服务 |
## 🔧 开发指南
### 项目结构
```
sagellm-core/
├── src/sagellm_core/ # 源代码
│ ├── llm_engine.py # 统一推理引擎
│ ├── engine_core/ # 引擎核心(调度+执行)
│ ├── executor/ # Worker 执行器
│ ├── worker/ # Worker 和 ModelRunner
│ ├── decoding/ # 解码策略(Greedy/Sampling/...)
│ ├── engine_server.py # HTTP Server (FastAPI)
│ ├── config.py # 配置类(Legacy)
│ ├── factory.py # 工厂方法(Legacy)
│ ├── runtime.py # PD 分离 Runtime
│ ├── pd_executor.py # PD 分离执行器
│ └── ...
├── tests/ # 测试用例
│ ├── unit/ # 单元测试
│ ├── integration/ # 集成测试
│ ├── e2e/ # 端到端测试
│ └── conftest.py # Pytest 配置
├── examples/ # 示例代码
│ ├── config_cpu.yaml # CPU 配置示例
│ ├── config_cuda.yaml # CUDA 配置示例
│ ├── decoding_strategies_demo.py # 解码策略演示
│ ├── pd_separation_demo.py # PD 分离演示
│ └── ...
├── docs/ # 文档
│ ├── ARCHITECTURE.md # 详细架构
│ ├── DECODING_STRATEGIES.md # 解码策略指南
│ └── ...
├── pyproject.toml # 项目配置(setuptools)
├── pytest.ini # Pytest 配置
├── .pre-commit-config.yaml # Pre-commit hooks
└── quickstart.sh # 快速安装脚本
```
### 环境设置
```bash
# 克隆并进入项目
git clone https://github.com/intellistream/sagellm-core.git
cd sagellm-core
# 安装开发依赖
pip install -e ".[dev]"
# 安装 git hooks(提交前自动检查)
pre-commit install
# 验证安装
python -m pytest tests/test_ci_smoke.py -v
```
### 运行测试
```bash
# 运行所有测试
pytest tests/ -v
# 运行特定测试模块
pytest tests/unit/test_config.py -v
# 运行带覆盖率报告
pytest tests/ --cov=sagellm_core --cov-report=html
# 运行 slow 标记的测试(包括 LLM 测试)
pytest tests/ -v -m slow
# 运行单个测试用例
pytest tests/test_llm_engine.py::test_engine_generate -v
```
### 代码质量检查
```bash
# Ruff 代码格式化 + Lint 检查
ruff check . --fix # 自动修复可修复的问题
ruff format . # 格式化代码
# Mypy 静态类型检查
mypy src/
# 手动运行所有 pre-commit hooks
pre-commit run --all-files
# 运行特定 hook
pre-commit run ruff --all-files
pre-commit run mypy --all-files
```
### Git 提交流程
1. **创建特性分支**
```bash
git checkout -b feature/your-feature-name
```
2. **提交代码(hooks 会自动检查)**
```bash
git add .
git commit -m "feat: add your feature description"
```
- 如果 hooks 失败,修复问题后重新提交
- 紧急情况:`git commit --no-verify` (不推荐)
3. **推送并提 PR**
```bash
git push origin feature/your-feature-name
```
### 常见开发任务
**添加新的解码策略**:
1. 在 `src/sagellm_core/decoding/` 创建新文件
2. 继承 `BaseDecodingStrategy`
3. 实现 `__call__()` 方法
4. 在 `__init__.py` 中导出
5. 添加单元测试
**添加新的后端支持**:
1. 在 `sagellm-backend` 实现 BackendProvider
2. 在 Core 中使用 `get_provider()` 自动发现
3. 添加集成测试
**添加配置选项**:
1. 修改 `src/sagellm_core/config.py` 中的 Pydantic 模型
2. 在示例配置文件中更新示例
3. 更新文档和测试
## 📖 示例代码
### 完整的演示应用
```bash
# 运行解码策略完整演示(包含 6 个场景)
python examples/decoding_strategies_demo.py
# 运行 PD 分离演示
python examples/pd_separation_demo.py
```
### CPU-First 测试
所有测试默认在 CPU 上运行(无 GPU 要求):
```bash
# 测试 LLMEngine
pytest tests/test_engine.py -v
# 测试配置系统
pytest tests/test_config.py -v
# 测试解码策略
pytest tests/test_decoding_strategies.py -v
# 测试 E2E 流程
pytest tests/test_llm_engine_contract.py -v
```
### 模型下载
使用提供的帮助脚本下载测试模型:
```bash
# 下载 tiny-gpt2(用于测试)
python examples/model_download_helper.py
# 或手动下载
python -c "from transformers import AutoModel; AutoModel.from_pretrained('sshleifer/tiny-gpt2')"
```
## 🔄 持续集成
本项目使用 GitHub Actions 进行 CI/CD:
- **单元测试**: 每次 push 运行 `pytest tests/unit/`
- **集成测试**: 每次 push 运行 `pytest tests/integration/`
- **Lint 检查**: Ruff、Mypy、YAML 验证
- **覆盖率**: 维持 >80% 的代码覆盖率
查看 CI 配置:[.github/workflows/ci.yml](.github/workflows/ci.yml)
## 📋 版本与变更
**当前版本**: `0.4.0.17` (Alpha)
**支持的 Python**: 3.10, 3.11, 3.12
**完整变更日志**: 见 [CHANGELOG.md](CHANGELOG.md)
**最近更新** (v0.4.0.17):
- ✅ 采样参数标准化(issue #22)- 参数优先级系统
- ✅ 增强解码策略测试
- ✅ 完成 LLMEngine 与解码策略的集成测试
- ✅ 解码策略使用演示与文档
## 🤝 贡献指南
我们欢迎社区贡献!请遵循以下步骤:
1. **Fork** 仓库
2. **创建特性分支** (`git checkout -b feature/your-feature`)
3. **提交更改** (`git commit -m "feat: description"`)
4. **推送到分支** (`git push origin feature/your-feature`)
5. **提交 Pull Request**
### 提交规范
使用 Conventional Commits:
```
feat: 新增功能
fix: 修复 bug
docs: 文档更新
test: 测试相关
refactor: 代码重构
perf: 性能优化
```
## 📄 许可证
Proprietary - IntelliStream
## 📞 反馈与支持
- 📍 **GitHub Issues**: [提交问题](https://github.com/intellistream/sagellm-core/issues)
- 💬 **讨论**: [启动讨论](https://github.com/intellistream/sagellm-core/discussions)
- 📧 **Email**: team@intellistream.ai
## 相关资源
- 🔗 [Protocol v0.1 文档](https://github.com/intellistream/sagellm-docs/blob/main/docs/specs/protocol_v0.1.md)
- 🔗 [sagellm-backend](https://github.com/intellistream/sagellm-backend)
- 🔗 [sagellm-comm](https://github.com/intellistream/sagellm-comm)
- 🔗 [sagellm-kv-cache](https://github.com/intellistream/sagellm-kv-cache)
- 🔗 [完整架构文档](docs/ARCHITECTURE.md)
- 🔗 [解码策略指南](docs/DECODING_STRATEGIES.md)
#### Continuous Integration
GitHub Actions automatically runs on each PR:
- Code linting and formatting checks
- Tests across Python 3.10, 3.11, 3.12
- Package build verification
### Code Style
This project uses:
- **Ruff** for formatting and linting
- **Mypy** for type checking
- **Type hints** are required for all functions
For detailed guidelines, see [CONTRIBUTING.md](CONTRIBUTING.md)
### 代码检查
```bash
# 格式化代码
ruff format .
# Lint 检查
ruff check .
# 类型检查
mypy src/sagellm_core
# 一键检查所有
pre-commit run --all-files
```
## 依赖
- `pydantic>=2.0.0`: 配置校验
- `pyyaml>=6.0.0`: YAML 配置支持
- `isagellm-protocol>=0.4.0.0,<0.5.0`: 协议定义
- `isagellm-backend>=0.4.0.0,<0.5.0`: 后端抽象
- `isagellm-comm>=0.4.0.0,<0.5.0`: 通信后端
- `isagellm-kv-cache>=0.4.0.0,<0.5.0`: KV 缓存
## Related Packages
- `isagellm-protocol` - Protocol definitions (L0)
- `isagellm-backend` - Backend abstraction layer (L1)
- `isagellm-comm` - Communication abstraction (L1)
- `isagellm-kv-cache` - KV Cache management (L1.5)
- `sagellm-control-plane` - Cross-engine orchestration (L3)
- `sagellm-gateway` - OpenAI-compatible API (L4)
For the complete ecosystem, see [sageLLM organization](https://github.com/intellistream/sagellm)
---
**Last Updated**: 2026-02-02 | **Status**: Alpha (v0.4.0.17) | **Protocol**: v0.1
| text/markdown | IntelliStream Team | null | null | null | Proprietary - IntelliStream | null | [
"Development Status :: 3 - Alpha",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | ==3.11.* | [] | [] | [] | [
"pydantic>=2.0.0",
"pyyaml>=6.0.0",
"isagellm-protocol<0.6.0,>=0.5.1.1",
"isagellm-backend<0.6.0,>=0.5.2.12",
"isagellm-comm<0.6.0,>=0.5.1.0",
"isagellm-kv-cache<0.6.0,>=0.5.1.0",
"fastapi>=0.100.0",
"uvicorn>=0.22.0",
"torch>=2.0.0",
"transformers>=4.35.0",
"accelerate>=0.26.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest-timeout>=2.0.0; extra == \"dev\"",
"ruff>=0.8.0; extra == \"dev\"",
"types-PyYAML>=6.0.0; extra == \"dev\"",
"pre-commit>=3.0.0; extra == \"dev\"",
"isage-pypi-publisher>=0.2.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.11 | 2026-02-20T14:50:28.712200 | isagellm_core-0.5.1.7.tar.gz | 733,697 | bf/f3/107b8b6cdc10e8326752f3e9ca0544a7cd9b064c775d28cdc41b4956406c/isagellm_core-0.5.1.7.tar.gz | source | sdist | null | false | 0cb387f9b4ce38c8058f1b9a3acc2024 | bbf7e9e8e76d961bd4f90595838fe1d2ced57d9246f9d8b5669bf82e45760d84 | bff3107b8b6cdc10e8326752f3e9ca0544a7cd9b064c775d28cdc41b4956406c | null | [] | 302 |
2.1 | unique_deep_research | 3.4.0 | Deep Research Tool for complex research tasks | # Deep Research Tool
Deep Research Tool for complex research tasks that require in-depth investigation across multiple sources.
# Changelog
All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
## [3.4.0] - 2026-02-20
- Add option to show full page content of search results in the return of the web search tool
## [3.3.2] - 2026-02-11
- Correctly log debug info in case of error
## [3.3.1] - 2026-02-09
- Migrate to model-specific token counting from unique_toolkit 1.46.1
## [3.3.0] - 2026-02-06
- Expose configuration for custom engine config (e.g max_parallel researchers)
- Makes prompts aware of the available tools
- Add option to disable the web_fetch tool
## [3.2.3] - 2026-02-05
- Improve error handling and logging
## [3.2.2] - 2026-02-05
- Fix bug where deep research tool was not using the correct headers causing an authentication error
## [3.2.1] - 2026-02-05
- Use deep research logger instead of tool logger
## [3.2.0] - 2026-02-03
- Use a backwards compatible config style
## [3.1.0] - 2026-01-30
- Support other search engines than Google
## [3.0.28] - 2026-01-26
- Specify `langchain-openai` version
## [3.0.27] - 2026-01-23
- Fix bug where deep research model usage analytics were not fully exported
## [3.0.26] - 2026-01-16
- Add local CI testing commands via poethepoet (poe lint, poe test, poe ci-typecheck, etc.)
## [3.0.25] - 2026-01-16
- Add unified type checking CI with basedpyright
## [3.0.24] - 2026-01-15
- Add `pytest-cov` dev dependency for coverage testing
## [3.0.23] - 2026-01-13
- Add missing `pytest-asyncio` dev dependency
- Fix tests to use `.invoke()` method for StructuredTool objects
## [3.0.22] - 2026-01-13
- Fixing bug with message logs
## [3.0.21] - 2025-12-29
- Bump unique_sdk version to `0.10.58`
## [3.0.20] - 2025-12-17
- Bump unique_toolkit version to `1.38.3`
## [3.0.19] - 2025-12-17
- Update failsafe execution import path
## [3.0.18] - 2025-12-04
- Change tool name in logs to `DeepResearch` instead of `Deep Research`
## [3.0.17] - 2025-12-03
- Include tool usage log into debug info
## [3.0.16] - 2025-12-01
- Upgrade langchain libraries to ensure compatibility with websearch
## [3.0.15] - 2025-11-12
- Move pytest to dev dependencies
## [3.0.14] - 2025-11-10
- Include a check to ensure that the website provided by OpenAI in the event is not None
- Wrap OpenAI event processing in try catch block to better handle unexpected types
## [3.0.13] - 2025-11-07
- Include ability to toogle enabled tools for deep research
- Standardize web search message log
## [3.0.12] - 2025-11-06
- Include pytest test suite
## [3.0.11] - 2025-11-05
- Include chat_id and user_id in headers sent to openai proxy endpoint
## [3.0.10] - 2025-10-31
- Make agent aware of limitation in data access
- Apply metadata filter to agent
## [3.0.9] - 2025-10-31
- Clear original response message when starting new run
- Forced tool calls fix for setting research completed at max iterations
- Reduce web search results returned to 10 to reduce api load
## [3.0.8] - 2025-10-29
- Include DeepResearch Bench results
## [3.0.7] - 2025-10-28
- Removing unused tool specific `get_tool_call_result_for_loop_history` function
## [3.0.6] - 2025-10-20
- Include find on website events in message log
## [3.0.5] - 2025-10-17
- Add all reviewed sources to message log
## [3.0.4] - 2025-10-14
- Fix ordering issue of messages in unique implementation with too early cleanup
- Don't include the visited websites without a nice title in message log
## [3.0.3] - 2025-10-13
- Fix potential error in open website logic if response not defined
- Better token limit handeling
- Internal knowledge base page referencing
## [3.0.2] - 2025-10-10
- Get website title for OpenAI agent
- Bolding of message logs
- Clarifying questions and research brief dependent on engine type
## [3.0.1] - 2025-10-08
- Improved citation logic supporting internal search documents
- Fixed bug in referencing of internal sources not giving the correct title of sources
- OpenAI engine converted to async processing to not be blocking
- Prompt improvements
- Small changes to message logs
- Improve success rate of website title extraction
- Web_fetch tool improvements on error handeling for llm
## [3.0.0] - 2025-10-07
- Simplification and better descriptions of configuration
- Dynamic tool descriptions and improved prompts
- Reduce OpenAI engine logging
## [2.1.3] - 2025-10-06
- Error handeling on context window limits
## [2.1.2] - 2025-10-02
- Remove temperature param to allow for more models used in unique custom
- Research prompt improvements
- Citation rendering improvements with extra llm call
- Additional logging for openai and custom agent
## [2.1.1] - 2025-10-01
- bugfix of langgraph state issue
- more logging
## [2.1.0] - 2025-10-01
Prompt improvements
- Pushing agent for deeper analysis and including tool descriptions
## [2.0.0] - 2025-09-26
Simplification, bugfixes, and performance improvements
- Improve lead and research agent prompts
- Simplify configuration of tool
- root try-catch for error handeling
- Prompt engineering on report writer prompt to ensure inline citations
- Simplify thinking messages
- Include url title for web_fetch
## [1.1.1] - 2025-09-23
Minor bugfixes:
- Message log entry at the completion of the report
- Improved instruction on followup questions to use numbered list instead of bullets
- Bugfix of internalsearch and internalfetch due to breaking change in toolkit
- Stronger citation requirements in prompt
## [1.1.0] - 2025-09-23
- Use streaming for followup questions and only a single iteration allowed
- Set default models to GPT 4o for followup and GPT 4.1 for research brief
## [1.0.0] - 2025-09-18
- Bump toolkit version to allow for both patch and minor updates
## [0.0.11] - 2025-09-17
- Updated to latest toolkit
## [0.0.10] - 2025-09-12
- Upgrade web search version
## [0.0.9] - 2025-09-11
- Bugfixes of statemanagement
- missing tool call handlers
- small performance improvements
## [0.0.8] - 2025-09-09
- Implement custom deep research logic using langgraph
## [0.0.7] - 2025-09-05
- Set message execution to completed
- Better error protection
- Formatting of final output report
## [0.0.6] - 2025-09-04
- Fix null pointer issue in web search action query handling
## [0.0.5] - 2025-09-04
- Additional messages in message log and add formatted messages in details
## [0.0.4] - 2025-09-02
- Introducing handover capability.
## [0.0.3] - 2025-09-03
- Bump toolkit version to get bugfix and small cleanup of getting client
## [0.0.2] - 2025-09-02
- Update standard config to use existing LMI objects
## [0.0.1] - 2025-09-01
- Initial release of `deep_research` | text/markdown | Martin Fadler | martin.fadler@unique.ch | null | null | Proprietary | null | [
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12"
] | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"pydantic<3.0.0,>=2.8.2",
"typing-extensions<5.0.0,>=4.9.0",
"unique_toolkit<2.0.0,>=1.46.4",
"jinja2<4.0.0,>=3.1.2",
"openai<2.0.0,>=1.99.0",
"langgraph<2.0.0,>=1.0.0",
"langchain-core<2.0.0,>=1.0.0",
"unique-web-search<2.0.0,>=1.7.0",
"httpx<0.29.0,>=0.28.0",
"timeout-decorator<0.6.0,>=0.5.0",
"beautifulsoup4<5.0.0,>=4.12.0",
"fake-useragent<3.0.0,>=2.0.0",
"markdownify<0.15.0,>=0.14.0",
"langchain[openai]<2.0.0,>=1.1.0"
] | [] | [] | [] | [] | poetry/1.8.3 CPython/3.12.3 Linux/6.11.0-1018-azure | 2026-02-20T14:49:48.059600 | unique_deep_research-3.4.0.tar.gz | 50,734 | 16/d5/8d9b2b3dbd381c3a28d6188eea07660d7394f0e25719efbf0ce9266bfe94/unique_deep_research-3.4.0.tar.gz | source | sdist | null | false | 2d6922ea6b74539fc43a072588adecc1 | 28201fb872a0388b4f616260137d8fc8702f700e29483f8729f4f8f5847770c0 | 16d58d9b2b3dbd381c3a28d6188eea07660d7394f0e25719efbf0ce9266bfe94 | null | [] | 0 |
2.4 | phasecurvefit | 0.1.0 | Walk through phase-space observations | # phasecurvefit: Construct Paths through Phase-Space Points
[](https://pypi.org/project/phasecurvefit/)
[](https://pypi.org/project/phasecurvefit/)
Construct paths through phase-Space points, supporting many different
algorithms.
## Installation
Install the core package:
```bash
pip install phasecurvefit
```
Or with uv:
```bash
uv add phasecurvefit
```
<details>
<summary>from source, using uv</summary>
```bash
uv add git+https://github.com/GalacticDynamics/phasecurvefit.git@main
```
You can customize the branch by replacing `main` with any other branch name.
</details>
<details>
<summary>building from source</summary>
```bash
cd /path/to/parent
git clone https://github.com/GalacticDynamics/phasecurvefit.git
cd phasecurvefit
uv pip install -e . # editable mode
```
</details>
### Optional Dependencies
phasecurvefit has optional dependencies for extended functionality:
- **unxt**: Physical units support for phase-space calculations
- **tree (jaxkd)**: Spatial KD-tree queries for large datasets
Install with optional dependencies:
```bash
pip install phasecurvefit[interop] # Install with unxt for unit support
pip install phasecurvefit[kdtree] # Install with jaxkd for KD-tree strategy
```
Or with uv:
```bash
uv add phasecurvefit --extra interop
uv add phasecurvefit --extra kdtree
```
## Quick Start
```python
import jax.numpy as jnp
import phasecurvefit as pcf
# Create phase-space observations as dictionaries (Cartesian coordinates)
pos = {"x": jnp.array([0.0, 1.0, 2.0]), "y": jnp.array([0.0, 0.5, 1.0])}
vel = {"x": jnp.array([1.0, 1.0, 1.0]), "y": jnp.array([0.5, 0.5, 0.5])}
# Order the observations (use KD-tree for spatial neighbor prefiltering)
config = pcf.WalkConfig(strategy=pcf.strats.KDTree(k=2))
result = pcf.walk_local_flow(pos, vel, config=config, start_idx=0, metric_scale=1.0)
print(result.indices) # Array([0, 1, 2], dtype=int32)
```
### With Physical Units
When `unxt` is installed, you can use physical units:
```python
import unxt as u
# Create phase-space observations with units
pos = {"x": u.Q([0.0, 1.0, 2.0], "kpc"), "y": u.Q([0.0, 0.5, 1.0], "kpc")}
vel = {"x": u.Q([1.0, 1.0, 1.0], "km/s"), "y": u.Q([0.5, 0.5, 0.5], "km/s")}
# Units are preserved throughout the calculation
metric_scale = u.Q(1.0, "kpc")
result = pcf.walk_local_flow(
pos, vel, start_idx=0, metric_scale=metric_scale, usys=u.unitsystems.galactic
)
```
## Features
- **JAX-powered**: Fully compatible with JAX transformations (`jit`, `vmap`,
`grad`)
- **Cartesian coordinates**: Works in Cartesian coordinate space (x, y, z)
- **Physical units**: Optional support via `unxt` for unit-aware calculations
- **Pluggable metrics**: Customizable distance metrics for different physical
interpretations
- **Type-safe**: Comprehensive type hints with `jaxtyping`
- **GPU-ready**: Runs on CPU, GPU, or TPU via JAX
- **Spatial KD-tree option**: Use [jaxkd](https://github.com/dodgebc/jaxkd) to
prefilter neighbors
# Distance Metrics
The algorithm supports pluggable distance metrics to control how points are
ordered. The default `FullPhaseSpaceDistanceMetric` uses true 6D Euclidean
distance across positions and velocities:
```python
from phasecurvefit.metrics import FullPhaseSpaceDistanceMetric
import jax.numpy as jnp
# Define simple Cartesian arrays (not quantities)
pos = {"x": jnp.array([0.0, 1.0, 2.0]), "y": jnp.array([0.0, 0.5, 1.0])}
vel = {"x": jnp.array([1.0, 1.0, 1.0]), "y": jnp.array([0.5, 0.5, 0.5])}
# Configure with full phase-space metric (the default)
config = pcf.WalkConfig(metric=FullPhaseSpaceDistanceMetric())
result = pcf.walk_local_flow(pos, vel, config=config, start_idx=0, metric_scale=1.0)
```
### Using Different Metrics
`phasecurvefit` provides three built-in metrics:
1. **FullPhaseSpaceDistanceMetric** (default): True 6D Euclidean distance in
phase space
2. **AlignedMomentumDistanceMetric**: Combines spatial distance with velocity
alignment (NN+p metric)
3. **SpatialDistanceMetric**: Pure spatial distance, ignoring velocity
```python
from phasecurvefit.metrics import SpatialDistanceMetric, FullPhaseSpaceDistanceMetric
import jax.numpy as jnp
# Define simple Cartesian arrays (not quantities)
pos = {"x": jnp.array([0.0, 1.0, 2.0]), "y": jnp.array([0.0, 0.5, 1.0])}
vel = {"x": jnp.array([1.0, 1.0, 1.0]), "y": jnp.array([0.5, 0.5, 0.5])}
# Pure spatial ordering (ignores velocity)
config_spatial = pcf.WalkConfig(metric=SpatialDistanceMetric())
result = pcf.walk_local_flow(
pos, vel, config=config_spatial, start_idx=0, metric_scale=0.0
)
# Full 6D phase-space distance
config_phase = pcf.WalkConfig(metric=FullPhaseSpaceDistanceMetric())
result = pcf.walk_local_flow(
pos, vel, config=config_phase, start_idx=0, metric_scale=1.0
)
```
### Custom Metrics
You can define custom metrics by subclassing `AbstractDistanceMetric`:
```python
import equinox as eqx
import jax
import jax.numpy as jnp
from phasecurvefit.metrics import AbstractDistanceMetric
class WeightedPhaseSpaceMetric(AbstractDistanceMetric):
"""Custom weighted phase-space metric."""
def __call__(self, current_pos, current_vel, positions, velocities, metric_scale):
# Compute position distance
pos_diff = jax.tree.map(jnp.subtract, positions, current_pos)
pos_dist_sq = sum(jax.tree.leaves(jax.tree.map(jnp.square, pos_diff)))
# Compute velocity distance
vel_diff = jax.tree.map(jnp.subtract, velocities, current_vel)
vel_dist_sq = sum(jax.tree.leaves(jax.tree.map(jnp.square, vel_diff)))
# Custom weighting scheme
return jnp.sqrt(pos_dist_sq + (metric_scale**2) * vel_dist_sq)
# Use custom metric via WalkConfig
config = pcf.WalkConfig(metric=WeightedPhaseSpaceMetric())
result = pcf.walk_local_flow(pos, vel, config=config, start_idx=0, metric_scale=1.0)
```
See the
[Metrics Guide](https://phasecurvefit.readthedocs.io/en/latest/guides/metrics.html)
for more details and examples.
## KD-tree Strategy
For large datasets, you can enable spatial KD-tree prefiltering to accelerate
neighbor selection:
```python
# Install optional dependency first:
# pip install phasecurvefit[kdtree]
import jax.numpy as jnp
# Define simple Cartesian arrays (not quantities)
pos = {"x": jnp.array([0.0, 1.0, 2.0]), "y": jnp.array([0.0, 0.5, 1.0])}
vel = {"x": jnp.array([1.0, 1.0, 1.0]), "y": jnp.array([0.5, 0.5, 0.5])}
# Use KD-tree strategy and query 2 spatial neighbors per step
config = pcf.WalkConfig(strategy=pcf.strats.KDTree(k=2))
result = pcf.walk_local_flow(pos, vel, config=config, start_idx=0, metric_scale=1.0)
```
| text/markdown | null | GalacticDynamics <nstarman@users.noreply.github.com>, Nathaniel Starkman <nstarman@users.noreply.github.com> | null | null | MIT License
Copyright (c) 2025, Nathaniel Starkman.
All rights reserved.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering",
"Typing :: Typed"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"equinox>=0.11.0",
"galax",
"jax-bounded-while>=0.1",
"jax-tqdm>=0.4.0",
"jax>=0.7.2",
"jaxtyping>=0.3.5",
"optax>=0.2.4",
"optional-dependencies>=0.4.0",
"orbax-checkpoint>=0.11.32",
"plum-dispatch>=2.6.1",
"quax>=0.2.1",
"unxt",
"zeroth>=1.0.1",
"unxt>=1.10.0; extra == \"interop\"",
"jaxkd>=0.0.5; extra == \"kdtree\""
] | [] | [] | [] | [
"Bug Tracker, https://github.com/GalacticDynamics/phasecurvefit/issues",
"Changelog, https://github.com/GalacticDynamics/phasecurvefit/releases",
"Homepage, https://github.com/GalacticDynamics/phasecurvefit"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:49:42.329685 | phasecurvefit-0.1.0.tar.gz | 2,800,923 | 54/a5/8e65c269a673db2330db800a9f51806159e3d16379c66c6290d201d06602/phasecurvefit-0.1.0.tar.gz | source | sdist | null | false | 7dba66a511864b85856c2f05900edb09 | 2298de28421edc4881b838278a13e4910b06092b5f7d7cf6e5ec4cae1f3385f5 | 54a58e65c269a673db2330db800a9f51806159e3d16379c66c6290d201d06602 | null | [
"LICENSE"
] | 225 |
2.4 | booboo-sdk | 0.7.0 | Lightweight error tracking for Python | # booboo-sdk
[](https://pypi.org/project/booboo-sdk/)
[](https://pypi.org/project/booboo-sdk/)
[](LICENSE)
Official Python SDK for [booboo.dev](https://booboo.dev) error tracking.
## Installation
```bash
pip install booboo-sdk
```
## Quick Start
```python
import booboo
booboo.init("your-dsn-here")
```
That's it. Unhandled exceptions are automatically captured and sent to booboo.dev.
## Manual Capture
```python
try:
risky_operation()
except Exception:
booboo.capture_exception() # captures the current exception
```
Or pass an exception explicitly:
```python
try:
risky_operation()
except Exception as e:
booboo.capture_exception(e)
```
## User Context
```python
booboo.set_user({
"id": "123",
"email": "user@example.com",
"username": "alice",
})
```
## Framework Integration
### Django
Auto-detected — no extra setup needed. The SDK injects middleware and patches Django's internal exception handler to capture errors that never reach middleware (like `DisallowedHost`).
### Flask
```python
from flask import Flask
import booboo
app = Flask(__name__)
booboo.init("your-dsn-here", app=app)
```
Or without passing `app` — the SDK monkey-patches `Flask.__init__` to auto-register on any Flask app created after `init()`.
### FastAPI
```python
from fastapi import FastAPI
import booboo
app = FastAPI()
booboo.init("your-dsn-here", app=app)
```
Same auto-detection as Flask if `app` is not passed explicitly.
## Configuration
```python
booboo.init(
dsn="your-dsn-here",
endpoint="https://api.booboo.dev/ingest/", # default
)
```
| Parameter | Default | Description |
|-----------|---------|-------------|
| `dsn` | (required) | Your project's DSN from booboo.dev |
| `endpoint` | `https://api.booboo.dev/ingest/` | Ingestion endpoint URL |
| `app` | `None` | Flask/FastAPI app instance for explicit registration |
## Features
- Automatic capture of unhandled exceptions
- Rich stack traces with source context and local variables
- Exception chain support (`raise ... from ...`)
- PII scrubbing for sensitive headers and variables
- Django, Flask, and FastAPI integrations
- Non-blocking event delivery
- Graceful shutdown flush
- Minimal dependency footprint (`requests` only)
## License
MIT
| text/markdown | null | "booboo.dev" <hello@booboo.dev> | null | null | null | error-tracking, monitoring, debugging, exceptions, booboo | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Bug Tracking",
"Topic :: System :: Monitoring"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"requests>=2.20"
] | [] | [] | [] | [
"Homepage, https://booboo.dev",
"Repository, https://github.com/getbooboo/python",
"Issues, https://github.com/getbooboo/python/issues",
"Changelog, https://github.com/getbooboo/python/blob/main/CHANGELOG.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:49:20.927588 | booboo_sdk-0.7.0.tar.gz | 8,752 | a8/bc/746b59e894deaf1014d067fab6d7486a00a231940ed6ea06f8f4c3d2a433/booboo_sdk-0.7.0.tar.gz | source | sdist | null | false | 9acbfbdec8393cc458c39947e3661837 | 7a3c99e6e8f9c7b16f0f476d38ee39db0a285947789acd5d8d90865fdc9b0603 | a8bc746b59e894deaf1014d067fab6d7486a00a231940ed6ea06f8f4c3d2a433 | MIT | [
"LICENSE"
] | 216 |
2.4 | algogene-mcp-server | 0.1.5 | Algogene MCP Server - A Python package for MCP server functionality | # ALGOGENE MCP Server
## Introduction
The `algogene_mcp_server` provides a Python-based interface for accessing the ALGOGENE API, enabling users to conduct strategy backtest, real-time data analytics, and manage trading activities.
## Installation
1. **Set Up Your Environment:**
Ensure you have Python 3.11 or later installed.
2. **Install Dependencies:**
```
pip install requests mcp-server
```
3. **Install Package:**
```
pip install algogene-mcp-server
```
4. **Update Configuration:**
Modify the configuration file located at `/config/__init__.py`.
```python
BASE_URL = "https://algogene.com/rest"
ALGOGENE_USER = "YOUR_ALGOGENE_USER_ID"
ALGOGENE_API_KEY = "YOUR_ALGOGENE_API_KEY"
```
## Running the Server
1. Start the Server:
```
python main.py
```
You can customize options using command-line arguments:
```bash
python main.py --transport streamable-http --port 8080 --host 0.0.0.0
```
2. Connect and Execute Commands:
- The server runs in STDIO mode by default. You can connect to it via your MCP client and run commands based on available tools.
## Tools Overview
1. Contract Specification:
- get_instruments: Get all available instruments available on ALGOGENE
- get_instrument_meta: Get contract specification of a financial instrument
- search_instrument: Search related financial instruments based on matched keywords of symbol or description
- list_econs_series: List out all available economic time series
- search_econs_series: Search related economic time series based on matched keywords of titles, geo and freq
- get_econs_series_meta: Get meta data or specification of an economic time series
2. Real-time Data:
- get_realtime_prices: Get current price for trading symbol(s)
- get_realtime_price_24hrchange: Get the recent 24 hours market price change
- get_realtime_exchange_rate: Get current exchange rate between 2 currencies
- get_realtime_news: Get latest news for a specified language/source/categroy
- get_realtime_weather: Get latest weather info for a specified region
- get_realtime_econs_calendar: Get the upcoming economic calendar info such as holiday, statistics release, president speech, etc
- get_realtime_econs_stat: Get the most recent released economic statistics
3. Historical Data:
- get_history_price: Get historical market price
- get_history_news: Get historical news
- get_history_weather: Get historical weather
- get_history_corp_announcement: Get company's corporate announcement history
- get_history_econs_calendar: Get economic calendar history, such as holiday, statistics release, president speech, etc
- get_history_econs_stat: Get historical released economic statistics
- strategy_market_perf: Get performance statistics for a market index
4. Trading Account Current Status:
- get_session: Get session token that will be used to access account and order related resources
- list_accounts: List out all your trading accounts with latest balance on ALGOGENE.
- get_positions: Get outstanding positions of a trading account
- get_balance: Get current balance of a trading account
- get_opened_trades: Get opened trades of a trading account
- get_pending_trades: Get pending trades (or limit orders) of a trading account
- set_account_config: Trading connection setup with your personal broker/exchange account on ALGOGENE.
5. Trading Account History:
- strategy_trade: Get transaction history of a trading account
- strategy_bal: Get daily history of account balance of a trading account
- strategy_pos: Get daily history of position of a trading account
- strategy_pl: Get daily history of cumulative profit/loss of a trading account
- strategy_cashflow: Get history of cash flow (eg. deposit, withdrawal, dividend payment, etc) of a trading account
- strategy_stats: Get performance statistics history and trading setting of a trading account
6. Order Placecment and Management:
- open_order: Place an order on a trading account
- query_order: Query an order's details of a trading account
- update_pending_order: Update trading parameters of a pending order
- update_opened_order: Update trading parameters of an outstanding/opened order
- cancel_orders: cancel a list of unfilled limit/stop orders
- close_orders: close a list of outstanding orders
7. Strategy Development
- backtest_run: Submit a strategy script to run on ALGOGENE cloud platform
- backtest_cancel: Cancel a running backtest task
- get_task_status: Query the current status of a task on ALGOGENE (eg. backtest)
8. Other Trading Apps available on (https://algogene.com/marketplace#app):
- app_predict_sentiment: Give a sentiment score for a given text (eg. news, blog posts, financial reports)
- app_asset_allocation: Calculate an optimal portfolio based on given risk tolerance level.
- app_portfolio_optimizer: Calculate an optimal portfolio based on dynamic objectives and conditions, such as target return, risk tolerance, group constraints, etc
- app_portfolio_optimizer_custom: Similar to 'app_portfolio_optimizer' to calculate an optimal portfolio based on given time series data
- app_fourier_prediction: Estimate the future range (i.e. upper and lower bound) of a financial instrument based on Fourier analysis and transformation.
- app_market_classifer: Calculate the bull-bear line and classify the market condition of a given financial instrument
- app_us_company_filing_hitory: Get the filing history's report URL from US SEC for a given ticker
- app_us_company_financials: Get company financial data for a given US stock
- app_stock_tagger: Identify related stocks for a given news
- app_index_composite: Get the index constituent data including the composited stocks, current weighting and sensitivity
- app_pattern_recoginer: Identify key technical pattern for a given financial instrument and time frame
- app_risk_analysis: Analyze potential market risk for a given portfolio holding
- app_trading_pair_aligner: Identify the most suitable instrument within the same asset class that can form a trading pair based on a given instrument
- app_price_simulator: Generate a financial time series based on correlation of another given time series
- app_capitalflow_hkex_szse: Get capital flow historical data between Hong Kong Stock Exchange (HKEx) and Shenzhen Stock Exchange (SZSE)
- app_capitalflow_hkex_sse: Get capital flow historical data between Hong Kong Stock Exchange (HKEx) and Shanghai Stock Exchange (SSE)
- app_performance_calculator: Calculate investment performance statistics based on given NAV time series
- app_algo_generator: Generate a backtest script of trading algorithm according to user's trading ideas or description
## Demo Video
- https://algogene.com/community/post/382
- https://www.youtube.com/watch?v=M_mrO8EPrdY
## License and Terms of Use
It is an official python package developed by ALGOGENE. Read our terms of use before deploying this MCP services: https://algogene.com/terms
## Support
For new features request or bugs reporting, please contact us at support@algogene.com
| text/markdown | null | ALGOGENE <support@algogene.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"requests>=2.31.0",
"mcp-server>=0.1.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:49:19.905144 | algogene_mcp_server-0.1.5.tar.gz | 43,353 | 56/14/21a72b6862c2fe1d10e18d315a8fdc6327a00037fbbe03190e853483cbdd/algogene_mcp_server-0.1.5.tar.gz | source | sdist | null | false | e373ba3b1339a2e441ef2243327eaefe | c193ec7bc5c4937a53d4f2fb6ca8373d3444fa9a2f5f9017c7285e682ab659ae | 561421a72b6862c2fe1d10e18d315a8fdc6327a00037fbbe03190e853483cbdd | null | [] | 198 |
2.3 | sandwitches | 2.8.0 | Add your description here | <p align="center">
<img src="src/static/icons/banner.svg" alt="Sandwitches Banner" width="600px">
</p>
<h1 align="center">🥪 Sandwitches</h1>
<p align="center">
<strong>Sandwiches so good, they haunt you!</strong>
</p>
<p align="center">
<a href="https://github.com/martynvdijke/sandwitches/actions/workflows/ci.yaml">
<img src="https://github.com/martynvdijke/sandwitches/actions/workflows/ci.yaml/badge.svg" alt="CI Status">
</a>
<a href="https://github.com/martynvdijke/sandwitches/blob/main/LICENSE">
<img src="https://img.shields.io/github/license/martynvdijke/sandwitches" alt="License">
</a>
<img src="https://img.shields.io/badge/python-3.12+-blue.svg" alt="Python Version">
<a href="https://github.com/astral-sh/ruff">
<img src="https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/ruff/main/assets/badge/v2.json" alt="Ruff">
</a>
</p>
---
## ✨ Overview
Sandwitches is a modern, recipe management platform built with **Django**.
It is made as a hobby project for my girlfriend, who likes to make what I call "fancy" sandwiches (sandwiches that go beyond the Dutch normals), lucky to be me :).
Sandwiches so good you will think they are haunted !.
See wanted to have a way to advertise and share those sandwiches with the family and so I started coding making it happen, in the hopes of getting more fancy sandwiches.

## 🎯 Features
Sandwitches comes packed with comprehensive features for recipe management, community engagement, and ordering:
- **🍞 Recipe Management** - Upload and create sandwich recipes with images, ingredients, and instructions
- **👥 Community Page** - Discover and browse sandwiches shared by community members
- **🛒 Ordering System** - Browse recipes and place orders with cart functionality and order tracking
- **⭐ Ratings & Reviews** - Rate recipes on a 0-10 scale with detailed comments
- **🔌 REST API** - Full API access for recipes, tags, ratings, orders, and user management
- **📊 Admin Dashboard** - Comprehensive admin interface for recipe approval and site management
- **🌍 Multi-language Support** - Internationalization for multiple languages
- **📱 Responsive Design** - Mobile-friendly interface with BeerCSS framework
- **🔔 Notifications** - Email and Gotify push notification integration
- **📈 Order Tracking** - Real-time order status tracking with unique tracking tokens
## 📥 Getting Started
### Prerequisites
- Python 3.12+
- [uv](https://github.com/astral-sh/uv) (recommended) or pip
### Installation
1. **Clone the repository**:
```bash
git clone https://github.com/martynvdijke/sandwitches.git
cd sandwitches
```
2. **Sync dependencies**:
```bash
uv sync
```
3. **Run migrations and collect static files**:
```bash
uv run invoke setup-ci # Sets up environment variables
uv run src/manage.py migrate
uv run src/manage.py collectstatic --noinput
```
4. **Start the development server**:
```bash
uv run src/manage.py runserver
```
## 🧪 Testing & Quality
The project maintains high standards with over **80+ automated tests**.
- **Run tests**: `uv run invoke tests`
- **Linting**: `uv run invoke linting`
- **Type checking**: `uv run invoke typecheck`
---
<p align="center">
Made with ❤️ for sandwich enthusiasts.
</p>
| text/markdown | Martyn van Dijke | Martyn van Dijke <martijnvdijke600@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"django-debug-toolbar>=6.1.0",
"django-filter>=25.2",
"django-imagekit>=6.0.0",
"django-import-export>=4.3.14",
"django-ninja>=1.5.1",
"django-simple-history>=3.10.1",
"django-tasks>=0.10.0",
"django-solo>=2.3.0",
"django>=6.0.0",
"gunicorn>=23.0.0",
"markdown>=3.10",
"pillow>=12.0.0",
"uvicorn>=0.40.0",
"whitenoise[brotli]>=6.11.0",
"requests>=2.32.5"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T14:48:47.247292 | sandwitches-2.8.0.tar.gz | 63,671 | a0/a1/adf11799daa7b8af53686d964e97a589891dbba824c85794856e5225ff14/sandwitches-2.8.0.tar.gz | source | sdist | null | false | 2bd24f47c65b7104a57f9bd280143bd2 | 716048d98b3355f19156e7fc7b7b04f5b6a0957b0ad2238370c1f981a0d2ee5d | a0a1adf11799daa7b8af53686d964e97a589891dbba824c85794856e5225ff14 | null | [] | 221 |
2.4 | oslo.concurrency | 7.4.0 | Oslo Concurrency library | ================
oslo.concurrency
================
.. image:: https://governance.openstack.org/tc/badges/oslo.concurrency.svg
.. Change things from this point on
.. image:: https://img.shields.io/pypi/v/oslo.concurrency.svg
:target: https://pypi.org/project/oslo.concurrency/
:alt: Latest Version
The oslo.concurrency library has utilities for safely running multi-thread,
multi-process applications using locking mechanisms and for running
external processes.
* Free software: Apache license
* Documentation: https://docs.openstack.org/oslo.concurrency/latest/
* Source: https://opendev.org/openstack/oslo.concurrency
* Bugs: https://bugs.launchpad.net/oslo.concurrency
* Release Notes: https://docs.openstack.org/releasenotes/oslo.concurrency/
| text/x-rst | null | OpenStack <openstack-discuss@lists.openstack.org> | null | null | Apache-2.0 | null | [
"Environment :: OpenStack",
"Intended Audience :: Information Technology",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: Apache Software License",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: Implementation :: CPython",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pbr>=2.0.0",
"oslo.config>=5.2.0",
"oslo.i18n>=3.15.3",
"oslo.utils>=3.33.0",
"fasteners>=0.7.0",
"debtcollector>=3.0.0",
"eventlet>=0.35.2; extra == \"eventlet\""
] | [] | [] | [] | [
"Homepage, https://docs.openstack.org/oslo.concurrency",
"Repository, https://opendev.org/openstack/oslo.concurrency"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T14:48:13.915003 | oslo_concurrency-7.4.0.tar.gz | 62,256 | 24/aa/5dbe48000283f9d11b419a79e4f363157d0170419d82c6ae1f9f40cb1e16/oslo_concurrency-7.4.0.tar.gz | source | sdist | null | false | dfff62c68ab9b4e716e135fb4cde0d2a | 12b3e2a8f42723857ff50ebebd0eda8a4fdcfb1701b364d95a786108398020b1 | 24aa5dbe48000283f9d11b419a79e4f363157d0170419d82c6ae1f9f40cb1e16 | null | [
"LICENSE"
] | 0 |
2.1 | envstack | 1.0.1 | Environment variable composition layer for tools and processes. | envstack
========
Environment variable composition and activation layer for tools and processes.
> envstack is what `.env` files wish they were when they grew up.
## Why envstack?
- Hierarchical environment composition
- Explicit precedence and overrides
- Late-bound environment activation
- Shared, policy-driven environments
- Inspectable and deterministic behavior
envstack environments are layered hierarchically, with later layers inheriting
from and overriding earlier ones.
```mermaid
flowchart LR
default[default.env] --> prod[prod.env]
prod --> dev[dev.env]
prod --> test[test.env]
```
Later layers override earlier ones. Use envstack -t VAR to trace where a value
comes from. envstack focuses on **configuration and activation**, not dependency
resolution.
For the core concepts, see
[docs/index.md](https://github.com/rsgalloway/envstack/blob/master/docs/index.md).
## Installation
The easiest way to install:
```bash
pip install -U envstack
```
## Quickstart
Start by getting the latest
[default.env](https://github.com/rsgalloway/envstack/blob/master/examples/default/default.env)
example file:
```bash
curl -o \
default.env \
https://raw.githubusercontent.com/rsgalloway/envstack/master/examples/default/default.env
```
Running `envstack` will launch a new shell session with the resolved environment:
```shell
$ envstack
🚀 Launching envstack shell... (CTRL+D or "exit" to quit)
(prod) ~$ echo $ENV
prod
```
To inspect the unresolved environment (before variable expansion):
```bash
$ envstack -u
DEPLOY_ROOT=${ROOT}/${ENV}
ENV=prod
ENVPATH=${DEPLOY_ROOT}/env:${ENVPATH}
LOG_LEVEL=${LOG_LEVEL:=INFO}
PATH=${DEPLOY_ROOT}/bin:${PATH}
PS1=\[\e[32m\](${ENV})\[\e[0m\] \w\$
PYTHONPATH=${DEPLOY_ROOT}/lib/python:${PYTHONPATH}
ROOT=/mnt/pipe
STACK=default
```
```bash
$ envstack -r DEPLOY_ROOT
DEPLOY_ROOT=/mnt/pipe/prod
```
## How envstack finds environments
envstack discovers environment definitions via the `ENVPATH` environment variable.
`ENVPATH` is to envstack what `PATH` is to executables:
```bash
ENVPATH=/path/to/dev/env:/path/to/prod/env
```
In this case, environments in dev override or layer on top of environments in
prod.
## Converting `.env` files
Convert existing `.env` files to envstack by piping them into envstack:
```bash
cat .env | envstack --set -o out.env
```
## Running Commands
To run any command line executable inside of an environment stack, where
`[COMMAND]` is the command to run:
```bash
$ envstack [STACK] -- [COMMAND]
```
For example:
```bash
$ envstack -- echo {ENV}
prod
```
Example of injecting environment into a subprocess:
```bash
$ echo "console.log('Hello ' + process.env.ENV)" > index.js
$ node index.js
Hello undefined
$ envstack -- node index.js
Hello prod
```
## Secrets and encryption
envstack supports optional encryption of environment values when writing
environment files, allowing sensitive configuration to be safely stored,
committed, or distributed.
Encryption protects values **at rest** and integrates with environment stacks and
includes. envstack does not attempt to be a full secret management system.
See [docs/secrets.md](https://github.com/rsgalloway/envstack/blob/master/docs/secrets.md) for details.
## Documentation
- [Design & philosophy](https://github.com/rsgalloway/envstack/blob/master/docs/design.md)
- [Examples & patterns](https://github.com/rsgalloway/envstack/blob/master/docs/examples.md)
- [Tool comparisons](https://github.com/rsgalloway/envstack/blob/master/docs/comparison.md)
- [Secrets and encryption](https://github.com/rsgalloway/envstack/blob/master/docs/secrets.md)
- [FAQ & gotchas](https://github.com/rsgalloway/envstack/blob/master/docs/faq.md)
- [API docs](https://github.com/rsgalloway/envstack/blob/master/docs/api.md)
| text/markdown | null | Ryan Galloway <ryan@rsgalloway.com> | null | null | BSD 3-Clause License | environment, env, dotenv, configuration, config, environment-variables, cli, deployment, devops, pipeline, vfx, tooling | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11"
] | [] | null | null | >=3.6 | [] | [] | [] | [
"PyYAML>=5.1.2",
"cryptography>=43.0.1"
] | [] | [] | [] | [
"Homepage, https://github.com/rsgalloway/envstack",
"Repository, https://github.com/rsgalloway/envstack",
"Issues, https://github.com/rsgalloway/envstack/issues",
"Changelog, https://github.com/rsgalloway/envstack/blob/master/CHANGELOG.md",
"Documentation, https://github.com/rsgalloway/envstack/tree/master/docs"
] | twine/5.1.1 CPython/3.8.10 | 2026-02-20T14:47:55.827094 | envstack-1.0.1.tar.gz | 62,382 | e5/d8/d9355381e73ac2530790a7547dca2c2767f626f47888819923e1c12ebc1f/envstack-1.0.1.tar.gz | source | sdist | null | false | 9ce1ff0b8ba609dcbe7f93309bea6c97 | 84a69359112d88f95bc2dfd768daf611706ea603acc40e1a8c1c2dd16deaca33 | e5d8d9355381e73ac2530790a7547dca2c2767f626f47888819923e1c12ebc1f | null | [] | 168 |
2.4 | django-security | 1.1.6 | Models, views, middlewares and forms to facilitate security hardening of Django applications. | # Django-Security
[](https://travis-ci.org/sdelements/django-security)
This package offers a number of models, views, middlewares and forms to facilitate security hardening of Django applications.
# Full documentation
Automatically generated documentation of `django-security` is available on Read The Docs:
* [Django-security documentation](http://django-security.readthedocs.org/en/master/)
# Requirements
* Python >=3.12
* Django ~4.2
# Installation
Install from Python packages repository:
pip install django-security
If you prefer the latest development version, install from
[django-security](https://github.com/sdelements/django-security) repository on GitHub:
git clone https://github.com/sdelements/django-security.git
cd django-security
poetry install
Adding to Django application's `settings.py` file:
INSTALLED_APPS = (
...
'security',
...
)
Middleware modules can be added to `MIDDLEWARE` list in settings file:
MIDDLEWARE = (
...
'security.middleware.LoginRequiredMiddleware',
...
)
Unlike the modules listed above, some other modules **require** configuration settings,
fully described in [django-security documentation](http://django-security.readthedocs.org/en/latest/).
Brief description is provided below.
## Middleware
Provided middleware modules will modify web application's output and input and in most cases requires no
or minimum configuration.
<table>
<tr>
<th>Middleware</th>
<th>Description</th>
<th>Configuration</th>
</tr>
<tr>
<td><a href="http://django-security.readthedocs.org/en/latest/#security.middleware.ClearSiteDataMiddleware">ClearSiteDataMiddleware</a></td>
<td>Send Clear-Site-Data header in HTTP response for any page that has been whitelisted. <em>Recommended</em>.</td>
<td>Required.</td>
</tr>
<tr>
<td><a href="http://django-security.readthedocs.org/en/latest/#security.middleware.ContentSecurityPolicyMiddleware">ContentSecurityPolicyMiddleware</a></td>
<td>Send Content Security Policy (CSP) header in HTTP response. <em>Recommended,</em> requires careful tuning.</td>
<td>Required.</td>
</tr>
<tr>
<td><a href="http://django-security.readthedocs.org/en/latest/#security.middleware.LoginRequiredMiddleware">LoginRequiredMiddleware</a></td>
<td>Requires a user to be authenticated to view any page on the site that hasn't been white listed.</td>
<td>Required.</td>
</tr>
<tr>
<td><a href="http://django-security.readthedocs.org/en/latest/#security.middleware.MandatoryPasswordChangeMiddleware">MandatoryPasswordChangeMiddleware</a></td>
<td>Redirects any request from an authenticated user to the password change form if that user's password has expired.</td>
<td>Required.</td>
</tr>
<tr>
<td><a href="http://django-security.readthedocs.org/en/latest/#security.middleware.NoConfidentialCachingMiddleware">NoConfidentialCachingMiddleware</a></td>
<td>Adds No-Cache and No-Store headers to confidential pages.</td>
<td>Required.</td>
</tr>
<tr>
<td><a href="http://django-security.readthedocs.org/en/latest/#security.middleware.ReferrerPolicyMiddleware">ReferrerPolicyMiddleware</a></td>
<td>Specify when the browser will set a `Referer` header.</td>
<td>Optional.</td>
</tr>
<tr>
<td><a href="http://django-security.readthedocs.org/en/latest/#security.middleware.SessionExpiryPolicyMiddleware">SessionExpiryPolicyMiddleware</a></td>
<td>Expire sessions on browser close, and on expiry times stored in the cookie itself.</td>
<td>Required.</td>
</tr>
<tr>
<td><a href="http://django-security.readthedocs.org/en/latest/#security.middleware.ProfilingMiddleware">ProfilingMiddleware</a></td>
<td>A simple middleware to capture useful profiling information in Django.</td>
<td>Optional.</td>
</tr>
</table>
## Views
`csp_report`
View that allows reception of Content Security Policy violation reports sent by browsers in response
to CSP header set by ``ContentSecurityPolicyMiddleware`. This should be used only if long term, continuous CSP report
analysis is required. For one time CSP setup [CspBuilder](http://cspbuilder.info/) is much simpler.
This view can be configured to either log received reports or store them in database.
See [documentation](http://django-security.readthedocs.org/en/latest/#security.views.csp_report) for details.
`require_ajax`
A view decorator which ensures that the request being processed by view is an AJAX request. Example usage:
@require_ajax
def myview(request):
...
## Models
`CspReport`
Content Security Policy violation report object. Only makes sense if `ContentSecurityPolicyMiddleware` and `csp_report` view are used.
With this model, the reports can be then analysed in Django admin site.
`PasswordExpiry`
Associate a password expiry date with a user.
## Logging
All `django-security` modules send important log messages to `security` facility. The application should configure a handler to receive them:
LOGGING = {
...
'loggers': {
'security': {
'handlers': ['console',],
'level': 'INFO',
'propagate': False,
'formatter': 'verbose',
},
},
...
}
| text/markdown | Security Compass | contact@securitycompass.com | null | null | BSD-3-Clause | null | [
"Development Status :: 5 - Production/Stable",
"Framework :: Django",
"Intended Audience :: Developers",
"License :: OSI Approved :: BSD License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | <3.13,>=3.12 | [] | [] | [] | [
"django<6.0,>=4.2",
"python-dateutil==2.9.0.post0",
"south==1.0.2",
"ua_parser==0.18.0"
] | [] | [] | [] | [
"Homepage, https://github.com/sdelements/django-security"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:47:27.154073 | django_security-1.1.6.tar.gz | 24,668 | 7e/29/0511cec188a976c30f923abe9f2b819a2da01d5738a31a6c6a0b4ef2018c/django_security-1.1.6.tar.gz | source | sdist | null | false | 583d69d817a10b6b855040df0cb0371f | 391ad276dc227063fc575945208b2316b71b3bcd7cdf61c1edf6ae72c659acbb | 7e290511cec188a976c30f923abe9f2b819a2da01d5738a31a6c6a0b4ef2018c | null | [
"LICENSE.md"
] | 232 |
2.4 | zentel-pro | 1.0.1 | Ultra-fast Telegram bot framework with YouTube downloader, currency, Wikipedia PDF and QR code generation | # ⚡ Zentel Pro 1.0.1
**Ultra-fast async Telegram bot framework** — YouTube yuklovchi, valyuta konvertor, Wikipedia→PDF va QR kod generatori bilan.
```
pip install zentel-pro
```
---
## 🚀 Tez boshlash
```python
from zentel_pro import ZentelBot, VideoDownloader, CurrencyConverter, WikiToPDF, QRGenerator, Filter
bot = ZentelBot("YOUR_BOT_TOKEN")
dl = VideoDownloader()
currency = CurrencyConverter()
wiki = WikiToPDF(language="uz")
qr = QRGenerator()
# ─── /start ───────────────────────────────────────────────
@bot.command("start", aliases=["help"])
async def start(ctx):
await ctx.reply(
"👋 Salom! <b>Zentel Pro Bot</b>\n\n"
"📹 /video [URL] — video yuklab berish\n"
"🎵 /audio [URL] — mp3 yuklab berish\n"
"💱 /convert 100 USD UZS — valyuta\n"
"📖 /wiki [mavzu] — Wikipedia PDF\n"
"🔲 /qr [matn/URL] — QR kod\n"
"📶 /wifi [ssid] [parol] — WiFi QR"
)
# ─── Video yuklovchi ──────────────────────────────────────
@bot.command("video")
async def video_cmd(ctx):
url = ctx.args[0] if ctx.args else VideoDownloader.extract_url(ctx.text)
if not url:
await ctx.reply("❌ URL yuboring!\nMisol: /video https://youtube.com/watch?v=...")
return
await ctx.upload_video()
try:
info = await dl.get_info(url)
await ctx.reply(f"⏳ Yuklanmoqda...\n\n{info}")
path = await dl.download(url, quality="720p")
await ctx.send_video(path, caption=f"🎬 {info.title}")
dl.cleanup(path)
except Exception as e:
await ctx.reply(f"❌ Xato: {e}")
# ─── Audio (MP3) yuklovchi ────────────────────────────────
@bot.command("audio")
async def audio_cmd(ctx):
url = ctx.args[0] if ctx.args else None
if not url:
await ctx.reply("❌ URL yuboring!")
return
await ctx.typing()
path = await dl.download(url, audio_only=True)
await ctx.send_document(path, caption="🎵 MP3 tayyor!")
dl.cleanup(path)
# ─── Valyuta konvertatsiya ────────────────────────────────
@bot.command("convert")
async def convert_cmd(ctx):
# /convert 100 USD UZS
parsed = CurrencyConverter.parse_convert_command(ctx.text)
if not parsed:
await ctx.reply("❌ Foydalanish: /convert 100 USD UZS")
return
amount, from_c, to_c = parsed
await ctx.typing()
try:
result = await currency.convert(amount, from_c, to_c)
await ctx.reply(str(result))
except Exception as e:
await ctx.reply(f"❌ {e}")
@bot.command("kurs")
async def rates_cmd(ctx):
base = ctx.args[0].upper() if ctx.args else "USD"
await ctx.typing()
rates = await currency.get_popular_rates(base)
await ctx.reply(currency.format_rates(rates, base))
# ─── Wikipedia → PDF ──────────────────────────────────────
@bot.command("wiki")
async def wiki_cmd(ctx):
if not ctx.args:
await ctx.reply("📖 Foydalanish: /wiki Python\n(yoki /wiki Amir Temur)")
return
query = " ".join(ctx.args)
await ctx.typing()
result = await wiki.search(query)
if not result:
await ctx.reply(f"❌ '{query}' bo'yicha hech narsa topilmadi.")
return
await ctx.reply(result.preview())
await ctx.upload_document()
pdf_path = await wiki.to_pdf(result)
await ctx.send_document(pdf_path, caption=f"📄 {result.title}")
wiki.cleanup(pdf_path)
# ─── QR Kod ───────────────────────────────────────────────
@bot.command("qr")
async def qr_cmd(ctx):
if not ctx.args:
await ctx.reply("🔲 Foydalanish: /qr https://google.com\nYoki: /qr Salom Dunyo!")
return
data = " ".join(ctx.args)
await ctx.typing()
path = await qr.generate(
data,
style="rounded",
color="#1a237e",
size=500,
)
await ctx.send_photo(path, caption=f"✅ QR kod tayyor!\n\n<code>{data[:80]}</code>")
qr.cleanup(path)
# ─── WiFi QR ──────────────────────────────────────────────
@bot.command("wifi")
async def wifi_cmd(ctx):
args = ctx.args
if len(args) < 2:
await ctx.reply("📶 Foydalanish: /wifi [SSID] [Parol] [WPA|WEP|nopass]")
return
ssid = args[0]
password = args[1]
security = args[2] if len(args) > 2 else "WPA"
await ctx.typing()
path = await qr.wifi(ssid=ssid, password=password, security=security)
await ctx.send_photo(path, caption=f"📶 WiFi: <b>{ssid}</b>")
qr.cleanup(path)
# ─── URL yuborilsa avtomatik video yukla ──────────────────
@bot.message(Filter.AND(Filter.is_url, Filter.NOT(Filter.text_startswith("/"))))
async def auto_video(ctx):
url = ctx.text.strip()
if VideoDownloader.is_supported(url):
await ctx.reply(
"🔗 Link topildi! Yuklab beraymi?",
keyboard=bot.inline_keyboard([
[
{"text": "📹 Video (720p)", "callback_data": f"dl_video_720p:{url[:100]}"},
{"text": "🎵 MP3", "callback_data": f"dl_audio:{url[:100]}"},
]
])
)
# ─── Callback handlers ────────────────────────────────────
@bot.on("callback_query")
async def handle_callbacks(ctx):
await ctx.answer()
if ctx.data.startswith("dl_video_"):
await ctx.reply("⏳ Video yuklanmoqda... iltimos kuting.")
elif ctx.data.startswith("dl_audio:"):
await ctx.reply("⏳ Audio yuklanmoqda... iltimos kuting.")
# ─── Run ──────────────────────────────────────────────────
if __name__ == "__main__":
bot.run()
```
---
## 📦 O'rnatish
```bash
pip install zentel-pro
```
Barcha imkoniyatlar bilan:
```bash
pip install zentel-pro[all]
```
---
## 🧩 Modullar
| Modul | Tavsif |
|-------|--------|
| `ZentelBot` | Asosiy bot engine (async polling) |
| `VideoDownloader` | YouTube, TikTok, Instagram, Twitter va 1000+ saytdan video |
| `CurrencyConverter` | Real-vaqt valyuta kurslari |
| `WikiToPDF` | Wikipedia qidiruv va PDF generator |
| `QRGenerator` | Chiroyli QR kod generatori |
| `Router` | Handler guruhlovchi |
| `Filter` | Xabar filtrlari |
| `Context` | Handler kontekst obyekti |
---
## ⚡ Nima uchun Zentel Pro tez?
- **httpx** async HTTP — bir vaqtda yuzlab so'rov
- **asyncio.Semaphore** — parallel xabar ishlash
- **Keepalive connections** — TCP qayta ulanish xarajatisiz
- **Smart caching** — valyuta kurslari 5 daqiqa keshlanadi
- **Executor** — og'ir operatsiyalar thread poolda
---
## 📋 Talablar
- Python 3.9+
- `httpx` — async HTTP
- `yt-dlp` — video yuklovchi
- `reportlab` — PDF generator
- `qrcode[pil]` — QR kod
- `Pillow` — rasm ishlash
---
## 📄 Litsenziya
MIT License — bepul foydalaning, o'zgartiring, tarqating!
---
*Zentel Pro 1.0.1 — Made with ❤️ for Uzbek developers*
| text/markdown | null | Zentel Team <zentel@example.com> | null | null | null | telegram, bot, framework, async, youtube-downloader, currency, wikipedia, qrcode, pdf | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Communications :: Chat",
"Topic :: Software Development :: Libraries :: Python Modules",
"Framework :: AsyncIO"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"httpx>=0.27.0",
"yt-dlp>=2024.1.0",
"reportlab>=4.0.0",
"qrcode[pil]>=7.4.2",
"Pillow>=10.0.0",
"fpdf2>=2.7.0; extra == \"all\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21; extra == \"dev\"",
"black; extra == \"dev\"",
"mypy; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/zentel-py/zentel-pro",
"Repository, https://github.com/zentel-py/zentel-pro",
"Issues, https://github.com/zentel-py/zentel-pro/issues"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T14:47:16.650682 | zentel_pro-1.0.1.tar.gz | 23,053 | ec/df/aed1f8dc7cd8dc5e299180975a2fec33cd77044de13c87bdaa01c42ae494/zentel_pro-1.0.1.tar.gz | source | sdist | null | false | 2064d7a441abc9e76e941cbf0097e7d9 | aba04305bccc1e71db11c38c4ea9f4e8b36c1a45bb93524ea26931ea6ee68d1a | ecdfaed1f8dc7cd8dc5e299180975a2fec33cd77044de13c87bdaa01c42ae494 | MIT | [
"LICENSE"
] | 217 |
2.4 | caddy-in-the-middle | 0.5.0 | Testcontainers module for CaddyInTheMiddle | # Testcontainers CaddyInTheMiddle Module (Python)
A [Testcontainers](https://github.com/testcontainers/testcontainers-python) module for [CaddyInTheMiddle](https://github.com/fardjad/caddy-in-the-middle), designed to simplify integration testing where you need a programmable reverse proxy or MITM proxy.
This library allows you to spin up a pre-configured Caddy instance in Docker, complete with mock responses, custom certificates, and proxy settings, all from your Python test code.
## Getting Started
1. **Install the package**:
(Assuming local development or future package name)
```bash
# using uv
uv add caddy-in-the-middle
# or pip
pip install caddy-in-the-middle
```
2. **Generate Test Certificates**:
Integration tests typically require trusted certificates. This library includes a helper to generate valid self-signed Root CA certificates on the fly.
3. **Start the Container**:
Use the `CitmContainer` class to configure and build the container instance.
## Usage Example
Here is a complete example using `pytest`:
```python
import pytest
from pathlib import Path
import tempfile
import shutil
from caddy_in_the_middle import CitmContainer, generate_root_ca
@pytest.fixture(scope="module")
def citm_container():
# Create a temporary directory for certs
certs_dir = tempfile.mkdtemp()
certs_path = Path(certs_dir)
try:
# Generate the Root CA certificates
generate_root_ca(certs_path)
# Configure and start the container
# Note: DOCKER_HOST is auto-detected if not set (e.g. for OrbStack)
with CitmContainer().with_certs_directory(certs_path) as container:
yield container
finally:
if Path(certs_dir).exists():
shutil.rmtree(certs_dir)
def test_should_proxy_request(citm_container):
# Create a requests.Session configured to use the container's proxy
# This session ignores SSL errors by default since we use self-signed certs
session = citm_container.create_client(ignore_ssl_errors=True)
# Make a request through MITMProxy in the citm container
# Note: 'example.com' will be proxied
response = session.get("https://registered-dns-name-in-citm-network:1234/blabla")
assert response.status_code == 200
```
## Configuration
The `CitmContainer` provides a fluent API for customization:
* **`with_certs_directory(path: Path)`** (Required): Path to the directory containing `rootCA.pem` and `rootCA-key.pem`.
* **`with_mocks_directory(path: Path)`**: Mounts a directory of mock templates (e.g., `*.mako` files) into the container.
* **`with_caddyfile_directory(path: Path)`**: Mounts a directory containing a custom `Caddyfile` if you need advanced Caddy configuration.
* **`with_citm_network(network_name: str)`**: Connects the container to a specific Docker network. This enables automatic service discovery: if other containers on this network have the `citm_dns_names` label, their DNS names will be automatically resolved by the `dnsmasq` instance running inside the CITM container.
* **`with_dns_names(*names: str)`**: Sets the `citm_dns_names` label on the container. This leverages CITM's built-in service discovery to register these DNS names.
* **`with_mock_paths(patterns: List[str])`**: explicit list of mock file patterns to load. *Note: Paths are validated to prevent traversal outside the mocks directory.*
## Helper Methods
Once the container is running and healthy, you can access helpful properties and methods:
* **`create_client(ignore_ssl_errors=True)`**: Returns a `requests.Session` pre-configured with the correct proxy settings.
* **`get_http_proxy_address()`**: Returns the address of the HTTP proxy (e.g., `http://localhost:32768`).
* **`get_socks_proxy_address()`**: Returns the address of the SOCKS5 proxy.
* **`get_admin_base_url()`**: Returns the base URL for the Caddy admin API.
* **`get_caddy_http_base_url()` / `get_caddy_https_base_url()`**: Returns the base URLs for direct access to Caddy.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"cryptography>=41.0.0",
"requests>=2.31.0",
"testcontainers>=4.0.0"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T14:47:02.849568 | caddy_in_the_middle-0.5.0.tar.gz | 49,164 | 9e/7b/dc98bc8cfc751122adc2cf62c4f18ba86e0140f55ce08c04370cb13fe8db/caddy_in_the_middle-0.5.0.tar.gz | source | sdist | null | false | 665044cbd43f11e445e2f5785abd727b | 082b11ba7b05a50a9f75b44d4ec1e4e38f6ff1980fad5038c5fef4085dcf53c1 | 9e7bdc98bc8cfc751122adc2cf62c4f18ba86e0140f55ce08c04370cb13fe8db | null | [] | 205 |
2.4 | django-schema-browser | 0.1.4 | Browse Django apps, models, fields, and reverse relations from a dedicated frontend. | # django-schema-browser
`django-schema-browser` adds a web interface to introspect Django apps, their models, fields, and reverse relations.
## Installation
```bash
pip install django-schema-browser
```
## Configuration
In `settings.py`:
```python
INSTALLED_APPS = [
# ...
"django_schema_browser",
]
```
In the project's `urls.py`:
```python
from django.urls import include, path
from django.conf.urls.i18n import i18n_patterns
urlpatterns += i18n_patterns(
path("schema/", include("django_schema_browser.urls")),
)
```
| text/markdown | null | Elapouya <elapouya@proton.me> | null | null | GNU GENERAL PUBLIC LICENSE
Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU General Public License is a free, copyleft license for
software and other kinds of works.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
the GNU General Public License is intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users. We, the Free Software Foundation, use the
GNU General Public License for most of our software; it applies also to
any other work released this way by its authors. You can apply it to
your programs, too.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
To protect your rights, we need to prevent others from denying you
these rights or asking you to surrender the rights. Therefore, you have
certain responsibilities if you distribute copies of the software, or if
you modify it: responsibilities to respect the freedom of others.
For example, if you distribute copies of such a program, whether
gratis or for a fee, you must pass on to the recipients the same
freedoms that you received. You must make sure that they, too, receive
or can get the source code. And you must show them these terms so they
know their rights.
Developers that use the GNU GPL protect your rights with two steps:
(1) assert copyright on the software, and (2) offer you this License
giving you legal permission to copy, distribute and/or modify it.
For the developers' and authors' protection, the GPL clearly explains
that there is no warranty for this free software. For both users' and
authors' sake, the GPL requires that modified versions be marked as
changed, so that their problems will not be attributed erroneously to
authors of previous versions.
Some devices are designed to deny users access to install or run
modified versions of the software inside them, although the manufacturer
can do so. This is fundamentally incompatible with the aim of
protecting users' freedom to change the software. The systematic
pattern of such abuse occurs in the area of products for individuals to
use, which is precisely where it is most unacceptable. Therefore, we
have designed this version of the GPL to prohibit the practice for those
products. If such problems arise substantially in other domains, we
stand ready to extend this provision to those domains in future versions
of the GPL, as needed to protect the freedom of users.
Finally, every program is threatened constantly by software patents.
States should not allow patents to restrict development and use of
software on general-purpose computers, but in those that do, we wish to
avoid the special danger that patents applied to a free program could
make it effectively proprietary. To prevent this, the GPL assures that
patents cannot be used to render the program non-free.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Use with the GNU Affero General Public License.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU Affero General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the special requirements of the GNU Affero General Public License,
section 13, concerning interaction through a network will apply to the
combination as such.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU General Public License from time to time. Such new versions will
be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <https://www.gnu.org/licenses/>.
Also add information on how to contact you by electronic and paper mail.
If the program does terminal interaction, make it output a short
notice like this when it starts in an interactive mode:
<program> Copyright (C) <year> <name of author>
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
This is free software, and you are welcome to redistribute it
under certain conditions; type `show c' for details.
The hypothetical commands `show w' and `show c' should show the appropriate
parts of the General Public License. Of course, your program's commands
might be different; for a GUI interface, you would use an "about box".
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU GPL, see
<https://www.gnu.org/licenses/>.
The GNU General Public License does not permit incorporating your program
into proprietary programs. If your program is a subroutine library, you
may consider it more useful to permit linking proprietary applications with
the library. If this is what you want to do, use the GNU Lesser General
Public License instead of this License. But first, please read
<https://www.gnu.org/licenses/why-not-lgpl.html>.
| django, schema, models, introspection, database | [
"Development Status :: 4 - Beta",
"Framework :: Django",
"Framework :: Django :: 4.2",
"Framework :: Django :: 5.0",
"Framework :: Django :: 5.1",
"Framework :: Django :: 6.0",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Internet :: WWW/HTTP :: Dynamic Content"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"Django<7.0,>=4.2",
"build<2.0.0,>=1.4.0",
"twine<7.0.0,>=6.2.0"
] | [] | [] | [] | [
"Homepage, https://github.com/elapouya/django-schema-browser",
"Repository, https://github.com/elapouya/django-schema-browser",
"Issues, https://github.com/elapouya/django-schema-browser/issues"
] | twine/6.2.0 CPython/3.11.12 | 2026-02-20T14:46:27.154239 | django_schema_browser-0.1.4.tar.gz | 48,338 | 62/67/d7a9306ebe808a7fe46a84b9d3b902dcef86f919b1afe4739221201dd4f3/django_schema_browser-0.1.4.tar.gz | source | sdist | null | false | ff772fe4915b0d028297a3e0f60484f3 | b674f7825c707534fddc10851304f05779071fade1945664a597e8769ad3d3fd | 6267d7a9306ebe808a7fe46a84b9d3b902dcef86f919b1afe4739221201dd4f3 | null | [
"LICENSE"
] | 206 |
2.1 | epoc2etsi | 0.1.6 | Add your description here | # Epoc2etsi
## Getting started
To make it easy for you to get started with GitLab, here's a list of recommended next steps.
Already a pro? Just edit this README.md and make it your own. Want to make it easy? [Use the template at the bottom](#editing-this-readme)!
## Add your files
- [ ] [Create](https://docs.gitlab.com/ee/user/project/repository/web_editor.html#create-a-file) or [upload](https://docs.gitlab.com/ee/user/project/repository/web_editor.html#upload-a-file) files
- [ ] [Add files using the command line](https://docs.gitlab.com/topics/git/add_files/#add-files-to-a-git-repository) or push an existing Git repository with the following command:
```
cd existing_repo
git remote add origin https://forge.etsi.org/rep/canterburym/epoc2etsi.git
git branch -M main
git push -uf origin main
```
## Integrate with your tools
- [ ] [Set up project integrations](https://forge.etsi.org/rep/canterburym/epoc2etsi/-/settings/integrations)
## Collaborate with your team
- [ ] [Invite team members and collaborators](https://docs.gitlab.com/ee/user/project/members/)
- [ ] [Create a new merge request](https://docs.gitlab.com/ee/user/project/merge_requests/creating_merge_requests.html)
- [ ] [Automatically close issues from merge requests](https://docs.gitlab.com/ee/user/project/issues/managing_issues.html#closing-issues-automatically)
- [ ] [Enable merge request approvals](https://docs.gitlab.com/ee/user/project/merge_requests/approvals/)
- [ ] [Set auto-merge](https://docs.gitlab.com/user/project/merge_requests/auto_merge/)
## Test and Deploy
Use the built-in continuous integration in GitLab.
- [ ] [Get started with GitLab CI/CD](https://docs.gitlab.com/ee/ci/quick_start/)
- [ ] [Analyze your code for known vulnerabilities with Static Application Security Testing (SAST)](https://docs.gitlab.com/ee/user/application_security/sast/)
- [ ] [Deploy to Kubernetes, Amazon EC2, or Amazon ECS using Auto Deploy](https://docs.gitlab.com/ee/topics/autodevops/requirements.html)
- [ ] [Use pull-based deployments for improved Kubernetes management](https://docs.gitlab.com/ee/user/clusters/agent/)
- [ ] [Set up protected environments](https://docs.gitlab.com/ee/ci/environments/protected_environments.html)
***
# Editing this README
When you're ready to make this README your own, just edit this file and use the handy template below (or feel free to structure it however you want - this is just a starting point!). Thanks to [makeareadme.com](https://www.makeareadme.com/) for this template.
## Suggestions for a good README
Every project is different, so consider which of these sections apply to yours. The sections used in the template are suggestions for most open source projects. Also keep in mind that while a README can be too long and detailed, too long is better than too short. If you think your README is too long, consider utilizing another form of documentation rather than cutting out information.
## Name
Choose a self-explaining name for your project.
## Description
Let people know what your project can do specifically. Provide context and add a link to any reference visitors might be unfamiliar with. A list of Features or a Background subsection can also be added here. If there are alternatives to your project, this is a good place to list differentiating factors.
## Badges
On some READMEs, you may see small images that convey metadata, such as whether or not all the tests are passing for the project. You can use Shields to add some to your README. Many services also have instructions for adding a badge.
## Visuals
Depending on what you are making, it can be a good idea to include screenshots or even a video (you'll frequently see GIFs rather than actual videos). Tools like ttygif can help, but check out Asciinema for a more sophisticated method.
## Installation
Within a particular ecosystem, there may be a common way of installing things, such as using Yarn, NuGet, or Homebrew. However, consider the possibility that whoever is reading your README is a novice and would like more guidance. Listing specific steps helps remove ambiguity and gets people to using your project as quickly as possible. If it only runs in a specific context like a particular programming language version or operating system or has dependencies that have to be installed manually, also add a Requirements subsection.
## Usage
Use examples liberally, and show the expected output if you can. It's helpful to have inline the smallest example of usage that you can demonstrate, while providing links to more sophisticated examples if they are too long to reasonably include in the README.
## Support
Tell people where they can go to for help. It can be any combination of an issue tracker, a chat room, an email address, etc.
## Roadmap
If you have ideas for releases in the future, it is a good idea to list them in the README.
## Contributing
State if you are open to contributions and what your requirements are for accepting them.
For people who want to make changes to your project, it's helpful to have some documentation on how to get started. Perhaps there is a script that they should run or some environment variables that they need to set. Make these steps explicit. These instructions could also be useful to your future self.
You can also document commands to lint the code or run tests. These steps help to ensure high code quality and reduce the likelihood that the changes inadvertently break something. Having instructions for running tests is especially helpful if it requires external setup, such as starting a Selenium server for testing in a browser.
## Authors and acknowledgment
Show your appreciation to those who have contributed to the project.
## License
For open source projects, say how it is licensed.
## Project status
If you have run out of energy or time for your project, put a note at the top of the README saying that development has slowed down or stopped completely. Someone may choose to fork your project or volunteer to step in as a maintainer or owner, allowing your project to keep going. You can also make an explicit request for maintainers.
| text/markdown | null | mark <markc@tencastle.com> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [
"epoc2etsi"
] | [] | [
"lxml",
"bitarray",
"pytest; extra == \"test\""
] | [] | [] | [] | [] | python-requests/2.32.5 | 2026-02-20T14:45:18.580288 | epoc2etsi-0.1.6.tar.gz | 168,112 | 7f/08/e8b4994fe19e2dec2bb4bbc23c7eeab9ebcb4bb977e79a0b28329145c441/epoc2etsi-0.1.6.tar.gz | source | sdist | null | false | beba18fab0f54ff55711657a0fff2816 | ef169b30802ca1523f36ae7787cc5941fc3226ac30676377032d4a6b62199df6 | 7f08e8b4994fe19e2dec2bb4bbc23c7eeab9ebcb4bb977e79a0b28329145c441 | null | [] | 201 |
2.4 | remote-gpu-stats | 0.1.3 | Add your description here | # Usage
`uvx remote-gpu-stats <username>` where `<username>` is your SSH username for the informatik pcs.
# Example
 | text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"fabric>=3.2.2",
"rich>=14.2.0"
] | [] | [] | [] | [] | uv/0.8.6 | 2026-02-20T14:45:02.072121 | remote_gpu_stats-0.1.3.tar.gz | 104,166 | 66/33/f1dd2738241191821485293809fefaa4b6445e7bf59fe005dcb18716ef43/remote_gpu_stats-0.1.3.tar.gz | source | sdist | null | false | 83ba4620ff2a59aa257a4b1989feca50 | b071d0860e61eb5b8e4e7058c3e888f7b41cc638a28925a1104ba8c5cd519952 | 6633f1dd2738241191821485293809fefaa4b6445e7bf59fe005dcb18716ef43 | null | [] | 205 |
2.4 | atpcli | 0.2.0 | A Python CLI wrapper around the atproto package | # atpcli
A Python CLI wrapper around the [atproto](https://github.com/MarshalX/atproto) package for interacting with Bluesky.
## Documentation
Full documentation is available at [docs/](docs/):
- [Installation Guide](docs/install.md)
- [Quick Start Guide](docs/getting-started.md) - Learn how to get app passwords and use atpcli
- [Login Command](docs/usage-login.md)
- [Timeline Command](docs/usage-timeline.md)
- [Post Command](docs/usage-post.md)
Or serve the docs locally:
```bash
make docs-serve
```
## Quick Start
### Installation
Install globally using [uv](https://docs.astral.sh/uv/):
```bash
uv tool install atpcli
```
This installs `atpcli` as a global tool, making it available from anywhere in your terminal.
Or for development:
```bash
git clone https://github.com/phalt/atpcli.git
cd atpcli
make install
```
## Usage
### Login
⚠️ **Security Note**: Use Bluesky app passwords, not your main password! See the [Quick Start Guide](docs/getting-started.md) for instructions on creating an app password.
Login to your Bluesky account and save the session:
```bash
atpcli bsky login
```
You'll be prompted for your handle and password. The session will be saved to `~/.config/atpcli/config.json`.
### View Timeline
View your timeline:
```bash
atpcli bsky timeline
```
Options:
- `--limit N` - Show N posts (default: 10)
- `--p N` - Show page N (default: 1)
Example:
```bash
atpcli bsky timeline --limit 20
atpcli bsky timeline --p 2
```
### Post Messages
Create a post on Bluesky:
```bash
atpcli bsky post --message 'Hello, Bluesky!'
```
**Note:** When using special characters like `!`, use single quotes to avoid shell expansion issues. See the [Post Command documentation](docs/usage-post.md) for more details.
## Development
### Setup
```bash
make install
```
### Run tests
```bash
make test
```
### Build documentation
```bash
make docs-build
```
### Serve documentation locally
```bash
make docs-serve
```
### Format code
```bash
make format
```
### Clean build artifacts
```bash
make clean
```
## Requirements
- Python 3.10+
- uv package manager
## License
MIT
| text/markdown | null | Paul Hallett <paulandrewhallett@gmail.com> | null | null | MIT | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"atproto>=0.0.55",
"click>=8.1.7",
"rich>=13.7.0"
] | [] | [] | [] | [
"Homepage, https://github.com/phalt/atpcli",
"Issues, https://github.com/phalt/atpcli/issues"
] | uv/0.9.29 {"installer":{"name":"uv","version":"0.9.29","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T14:44:25.803577 | atpcli-0.2.0.tar.gz | 108,936 | fc/10/c2a48e429bfa3b70ebf773a4ea82837e311a950a9329b03d15eb17ce3e2c/atpcli-0.2.0.tar.gz | source | sdist | null | false | cb8b1ab77ba496b9da3068cac443be84 | 2314f388c55f90554e9adbe1ac41899861c267ae24ece63fa53689a00bcbdcfd | fc10c2a48e429bfa3b70ebf773a4ea82837e311a950a9329b03d15eb17ce3e2c | null | [
"LICENSE"
] | 216 |
2.1 | gremlite | 0.37.0rc1 | Serverless graph database using Gremlin with SQLite | .. ...............................................................................
: Copyright (c) 2024 Steve Kieffer :
: :
: Licensed under the Apache License, Version 2.0 (the "License"); :
: you may not use this file except in compliance with the License. :
: You may obtain a copy of the License at :
: :
: http://www.apache.org/licenses/LICENSE-2.0 :
: :
: Unless required by applicable law or agreed to in writing, software :
: distributed under the License is distributed on an "AS IS" BASIS, :
: WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. :
: See the License for the specific language governing permissions and :
: limitations under the License. :
.. ..............................................................................:
Introduction
============
GremLite is a fully functioning, serverless graph database. It uses Python's built-in ``sqlite3``
module to persist your data to disk, and it understands (much of) the Gremlin_ graph query language.
(See language support below.)
Requirements
============
SQLite 3.35 or later is required. You can check your version with:
.. code-block:: shell
$ python -c "import sqlite3; print(sqlite3.sqlite_version)"
Usage
=====
The ``gremlite`` package is designed to integrate seamlessly with `gremlinpython`_, the official Python package
for connecting to Apache TinkerPop :sup:`TM` graph database systems.
Whereas ordinary usage of ``gremlinpython`` to connect to an acutal Gremlin server might look
like this:
.. code-block:: python
from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection
from gremlin_python.process.anonymous_traversal import traversal
uri = 'ws://localhost:8182/gremlin'
remote = DriverRemoteConnection(uri)
g = traversal().with_remote(remote)
usage with ``gremlite`` instead looks like this:
.. code-block:: python
from gremlite import SQLiteConnection
from gremlin_python.process.anonymous_traversal import traversal
path = '/filesystem/path/to/my_sqlite_database_file.db'
remote = SQLiteConnection(path)
g = traversal().with_remote(remote)
That's it. You don't have to set up any tables or indexes. Just start using ``g`` to make
graph traversals as you would with any other graph database.
In the example, we chose to have our on-disk database file live at
``/filesystem/path/to/my_sqlite_database_file.db``. The first time you use a given database file with
GremLite, you must ensure that the directory in which it is to live (like ``/filesystem/path/to`` in our
example) already exists. The file itself however (like ``my_sqlite_database_file.db``) should not yet exist;
GremLite will create it for you. When you want to continue using the same database on subsequent connections,
simply reuse the same path.
Committing your changes
-----------------------
Because all data persistence in ``gremlite`` is through Python's built-in ``sqlite3`` module,
the transaction model is similar. Carrying on with the example above, we could add a vertex and
commit our changes like this:
.. code-block:: python
g.add_v('cat').property('color', 'black').iterate()
remote.commit()
Here, we are using the implicit transaction that is started for us when we do not start one
explicitly. All changes pile up in this transaction until we say ``remote.commit()``, and then
they are committed to disk.
Using explicit transactions instead looks like this:
.. code-block:: python
tx = g.tx()
g1 = tx.begin()
g1.add_v('cat').property('color', 'gray').iterate()
tx.commit()
Or finally, if you prefer, you can instead work in "auto commit" mode:
.. code-block:: python
remote = SQLiteConnection(path, autocommit=True)
g = traversal().with_remote(remote)
g.add_v('cat').property('color', 'orange').iterate()
and all your changes will be immediately commited to disk as
the traversal procedes, without your having to request a commit at any time.
Be aware however that this mode of operation tends to be slower.
Gremlin Language Support
========================
Support for the Gremlin language in ``gremlite`` is not yet 100% complete, but covers a fairly good chunk, with which
you can do a lot. If you are missing an important step, please `open an issue`_.
Currently Supported Steps
-------------------------
The list below is meant only to indicate the set of steps that are supported, and is *not* intended to serve as complete
documentation on the use and meaning of these steps. For that, please see the official `Gremlin documentation`_.
* ``V``
- 0 args: select all vertices
- 1 list, tuple, or set of ``Vertex`` instances or ints: select these vertices / the vertices with these IDs
- 1 or more ``Vertex`` instances or ints: select these vertices / the vertices with these IDs
* ``E``
- 0 args: select all edges
- 1 list, tuple, or set of ``Edge`` instances or ints: select these edges / the edges with these IDs
- 1 or more ``Edge`` instances or ints: select these edges / the edges with these IDs
* ``add_e``
- 1 string: the edge label
* ``add_v``
- 0 args: the vertex automatically gets the label "vertex"
- 1 string: the vertex label
* ``and_``
- 1 or more traversals: allow the incoming result to pass through iff it produces at
least one result in *each* of the given traversals.
* ``as_``
- 1 or more strings: apply these temporary labels to the current object.
- Inside of a ``where()`` step, instead act as a filter, passing the current object
iff it is the same as the one already having this label (or these labels).
See *Practical Gremlin* on `pattern matching using where`_.
* ``barrier``
- 0 args: First generate *all* results from the foregoing steps, before proceding onward
with subsequent steps. Like ``fold()``, except that intead of bundling the incoming
results into a list, they are passed onward one at a time.
* ``both_``
- 0 args: hop from the current vertex to adjacent vertices along both incoming and outgoing edges
- 1 or more strings: the edges must have *any* of these labels
* ``both_e``
- 0 args: move from the current vertex to both its incoming and outgoing edges
- 1 or more strings: the edges must have *any* of these labels
* ``both_v``
- 0 args: move from the current edge to both of its endpoint vertices
* ``by`` modifying an ``order``, ``path``, ``project``, ``select``, or ``value_map`` step
- 0 args: leave object unmodified
- 1 string: map object to its (first) property value for this property name
- 1 traversal: map object to first result when following this traversal
- When modifying an ``order`` step, a final arg may be added, being a value of the
``Order`` enum (``asc``, ``desc``, or ``shuffle``). Default ``Order.asc``.
- When modifying a ``value_map`` step, modification is of the property lists in the map.
* ``cap``
- 1 string: iterate over all previous steps, and produce the storage list by this name,
as built by ``store()`` steps
* ``coalesce``
- 1 or more traversals: carry out the first traversal that returns at least one result
* ``constant``
- 1 arg: make current object equal to this value
* ``count``
- 0 args: return the total number of results produced by all the foregoing steps
* ``drop``
- 0 args: fully drop (delete) the incoming object (property, edge, or vertex) from the database
* ``element_map``
- 0 args: include all existing properties
- 1 or more strings: include only properties having these names
* ``emit``
- 0 args: modify a ``repeat()`` step so it emits all results (may come before or after)
* ``flat_map``
- 1 traversal: carry out the entire traversal on each incoming result, and produce the
output as the outgoing result. (Provides a way to group steps together.)
* ``fold``
- 0 args: gather all incoming results into a single list
* ``has``
- ``(key)``: keep only those objects that have property ``key`` at all, with no
constraint on the value.
- ``(key, value)``: keep only those objects that have property ``key``
with value ``value``. The ``value`` may be ``None``, boolean, int, float, string,
or a ``TextP`` or ``P`` operator.
- ``(label, key, value)``: shorthand for ``.has_label(label).has(key, value)``
* ``has_label``
- 1 string or ``TextP`` or ``P`` operator: keep only those objects that have a matching label
- 2 or more strings: keep only those objects that have *any* of these labels
* ``id_``
- 0 args: return the current object's id
* ``identity``
- 0 args: return the current object
* ``in_``
- 0 args: hop from the current vertex to adjacent vertices along incoming edges
- 1 or more strings: the edges must have *any* of these labels
* ``in_e``
- 0 args: move from the current vertex to its incoming edges
- 1 or more strings: the edges must have *any* of these labels
* ``in_v``
- 0 args: move from the current edge to its target vertex
* ``key``
- 0 args: map an incoming property to its key
* ``label``
- 0 args: return the current object's label
* ``limit``
- 1 int: limit to this many results
* ``none``
- 0 args: produce no output
* ``not_``
- 1 traversal: allow the incoming result to pass through iff it does not produce
any results in the given traversal.
* ``or_``
- 1 or more traversals: allow the incoming result to pass through iff it produces at
least one result in *any* of the given traversals.
* ``order``
- 0 args: like a ``barrier()`` step, except that the incoming results are sorted
before being emitted.
* ``other_v``
- 0 args: move from the current edge to that one of its endpoints that was not
just visited
* ``out_``
- 0 args: hop from the current vertex to adjacent vertices along outgoing edges
- 1 or more strings: the edges must have *any* of these labels
* ``out_e``
- 0 args: move from the current vertex to its outgoing edges
- 1 or more strings: the edges must have *any* of these labels
* ``out_v``
- 0 args: move from the current edge to its source vertex
* ``path``
- 0 args: return the path of objects visited so far
* ``project``
- 1 or more strings: build a dictionary with these as keys
* ``properties``
- 0 args: iterate over *all* properties of the incoming object
- 1 or more strings: restrict to properties having *any* of these names
* ``property``
- ``(key, value)``: set a property value, with ``single`` cardinality. The ``value`` may be
``None``, boolean, int, float, or string.
- ``(Cardinality, key, value)``: pass a value of the ``gremlin_python.process.traversal.Cardinality`` enum
to set the property with that cardinality. The ``list_`` and ``set_`` cardinalities are supported
only on vertices, not on edges.
* ``repeat``
- 1 traversal: repeat this traversal
* ``select``
- 1 or more strings: select the objects that were assigned these labels
* ``side_effect``
- 1 traversal: carry out the traversal as a continuation, but do not return its results; instead,
return the same incoming results that arrived at this step.
* ``simple_path``
- 0 args: filter out paths that visit any vertex or edge more than once
* ``store``
- 1 string: store the incoming object in a list by this name
* ``times``
- 1 int: constrain a ``repeat()`` step to apply its traversal at most this many times.
* ``unfold``
- 0 args: iterate over an incoming list as separate results
* ``union``
- 0 or more traversals: produce all the results produced by these traversals, in the order given.
(Repeats are *not* eliminated.)
* ``until``
- 1 traversal: modify a ``repeat()`` step so it emits but does not go beyond results that satisfy the
given traversal. May come before or after the ``repeat()`` step.
* ``value``
- 0 args: map an incoming property to its value
* ``value_map``
- 0 args: include all existing properties
- 1 or more strings: include only properties having these names
- a boolean arg may be prepended to any of the above cases, to say whether the
ID and label of the object should be included (default ``False``)
* ``values``
- ``values(*args)`` is essentially a shorthand for ``properties(*args).value()``
- 0 args: iterate over *all* properties of the incoming object, and produce only the value,
not the whole property.
- 1 or more strings: restrict to properties having *any* of these names
* ``where``
- 1 traversal: allow the incoming result to pass through iff it produces at
least one result in the given traversal.
Note: This may seem like an ``and()`` step restricted to a single traversal, but it is
actually more powerful because it can also do pattern matching; see ``as_()`` step.
Support for Predicates
----------------------
At this time, Gremlin's ``P`` and ``TextP`` predicates are supported only in the ``value``
arguments to the ``has()`` and ``has_label()`` steps, and only for the operators listed below.
Support should be easy to extend to other steps and other operators; we just haven't bothered
to do it yet. So if you are missing something, please `open an issue`_.
* ``TextP``
- ``starting_with``
- ``containing``
- ``ending_with``
- ``gt``
- ``lt``
- ``gte``
- ``lte``
* ``P``
- ``within``
.. _Gremlin: https://tinkerpop.apache.org/gremlin.html
.. _gremlinpython: https://pypi.org/project/gremlinpython/
.. _open an issue: https://github.com/skieffer/gremlite/issues
.. _Gremlin documentation: https://tinkerpop.apache.org/docs/current/reference/#graph-traversal-steps
.. _pattern matching using where: https://kelvinlawrence.net/book/Gremlin-Graph-Guide.html#patternwhere
| text/x-rst | null | null | null | null | Apache 2.0 | null | [
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3"
] | [] | https://github.com/skieffer/gremlite | null | >=3.8 | [] | [] | [] | [
"gremlinpython<3.8.0,>=3.7.0",
"pytest; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"build; extra == \"dev\"",
"twine; extra == \"dev\"",
"invoke; extra == \"dev\""
] | [] | [] | [] | [] | twine/5.1.1 CPython/3.8.16 | 2026-02-20T14:44:20.401365 | gremlite-0.37.0rc1.tar.gz | 77,548 | 25/74/b9d03fddc511d61cfb7f01069a66f602444e08ea860db19d76dbe6210b97/gremlite-0.37.0rc1.tar.gz | source | sdist | null | false | f458ee6016036bd7e7d115caac67cbc5 | 8a373babedf6cb78408a5cdc5442ae446cdc823e6d527283b4c513d2bce6488b | 2574b9d03fddc511d61cfb7f01069a66f602444e08ea860db19d76dbe6210b97 | null | [] | 207 |
2.4 | saviialib | 1.14.0 | A client library for IoT projects in the RCER initiative | # SAVIIA Library
*Sistema de Administración y Visualización de Información para la Investigación y Análisis*
[](https://github.com/pedrozavalat/saviia-lib/releases)
## Table of Contents
- [Installation](#installation)
- [Saviia API Client Usage](#saviia-api-client-usage)
- [Initialize the Saviia API Client](#initialize-the-saviia-api-client)
- [Access THIES Data Logger Services](#access-thies-data-logger-services)
- [THIES files extraction and synchronization](#thies-files-extraction-and-synchronization)
- [Access Backup Services](#access-backup-services)
- [Create Backup](#create-backup)
- [Access Netcamera Services](#access-netcamera-services)
- [Get Camera Rates](#get-camera-rates)
- [Access Task System Services](#access-task-system-services)
- [Create Task](#create-task)
- [Update Task](#update-task)
- [Delete Task](#delete-task)
- [Get Tasks](#get-tasks)
- [Contributing](#contributing)
- [License](#license)
## Installation
This library is designed for use with the SAVIIA Home Assistant Integration. It provides an API to retrieve files from a THIES Data Logger via an FTP server and upload them to a Microsoft SharePoint folder using the SharePoint REST API.
```bash
pip install saviialib
```
## Saviia API Client Usage
### Initialize the Saviia API Client
Import the necessary classes from the library.
```python
from saviialib import SaviiaAPI, SaviiaAPIConfig
```
To start using the library, you need to create an `SaviiaAPI` client instance with its configuration class `SaviiaAPIConfig`. Provide the required parameters such as FTP server details and SharePoint credentials:
```python
config = SaviiaAPIConfig(
ftp_port=FTP_PORT,
ftp_host=FTP_HOST,
ftp_user=FTP_USER,
ftp_password=FTP_PASSWORD,
sharepoint_client_id=SHAREPOINT_CLIENT_ID,
sharepoint_client_secret=SHAREPOINT_CLIENT_SECRET,
sharepoint_tenant_id=SHAREPOINT_TENANT_ID,
sharepoint_tenant_name=SHAREPOINT_TENANT_NAME,
sharepoint_site_name=SHAREPOINT_SITE_NAME
)
```
```python
api_client = SaviiaAPI(config)
```
**Notes:**
- Store sensitive data like `FTP_PASSWORD`, `FTP_USER`, and SharePoint credentials securely. Use environment variables or a secrets management tool to avoid hardcoding sensitive information in your codebase.
### Access THIES Data Logger Services
To interact with the THIES Data Logger services, you can access the `thies` attribute of the `SaviiaAPI` instance:
```python
thies_service = api_client.get('thies')
```
This instance provides methods to interact with the THIES Data Logger. Currently, it includes the main method for extracting files from the FTP server and uploading them to SharePoint.
#### THIES files extraction and synchronization
The library provides a method to extract and synchronize THIES Data Logger files with the Microsoft SharePoint client. This method downloads files from the FTP server and uploads them to the specified SharePoint folder:
```python
import asyncio
async def main():
# Before calling this method, you must have initialised the THIES service class ...
response = await thies_service.update_thies_data()
return response
asyncio.run(main())
```
### Access Backup Services
To interact with the Backup services, you can access the `backup` attribute of the `SaviiaAPI` instance:
```python
backup_service = api_client.get('backup')
```
This instance provides methods to interact with the Backup services. Currently, it includes the main method for creating backups of specified directories in a local folder from Home Assistant environment. Then each backup file is uploaded to a Microsoft SharePoint folder.
#### Create Backup
The library provides a method which creates a backup of a specified directory in a local folder from Home Assistant environment. Then each backup file is uploaded to a Microsoft SharePoint folder:
```python
import asyncio
async def main():
# Before calling this method, you must have initialised the Backup service class ...
response = await backup_service.upload_backup_to_sharepoint(
local_backup_path=LOCAL_BACKUP_PATH,
sharepoint_folder_path=SHAREPOINT_FOLDER_PATH
)
return response
asyncio.run(main())
```
**Notes:**
- Ensure that the `local_backup_path` exists and contains the files you want to back up. It is a relative path from the Home Assistant configuration directory.
- The `sharepoint_folder_path` should be the path to the folder in SharePoint where you want to upload the backup files. For example, if your url is `https://yourtenant.sharepoint.com/sites/yoursite/Shared Documents/Backups`, the folder path would be `sites/yoursite/Shared Documents/Backups`.
### Access Netcamera Services
The Netcamera service provides camera capture rate configuration based on meteorological data such as precipitation and precipitation probability.
This service uses the Weather Client library, currently implemented with OpenMeteo, and is designed to be extensible for future weather providers.
```python
netcamera_service = api_client.get("netcamera")
```
#### Get Camera Rates
Returns photo and video capture rates for a camera installed at a given geographic location.
```python
import asyncio
async def main():
lat, lon = 10.511223, 20.123123
camera_rates = await netcamera_service.get_camera_rates(latitude=lat, longitude=lon)
return camera_rates
asyncio.run(main())
```
Example output:
```python
{
"status": "A", # B or C
"photo_rate": number, # in minutes
"video_rate": number # in minutes
}
```
#### Description:
* The capture rate is calculated using meteorological metrics:
* Precipitation
* Precipitation probability
* The resulting configuration determines the camera capture frequency.
#### Status variable
The status variable is classified based on weather conditions (currently, precipitation and precipitation probability) at the camera's location:
| Status | 1 photo capture per | 1 video capture per |
| --- | --- | --- |
| A | 12 h | 12 h |
| B | 30 min | 3 h |
| C | 5 min | 1 h |
### Access Task System Services
To interact with the Task System services, you can access the `tasks` attribute of the `SaviiaAPI` instance:
```python
tasks_service = api_client.get('tasks')
```
This instance provides methods to manage tasks in specified channels. Note that this service requires an existing bot to be set up in the Discord server to function properly.
For using the Tasks Services, you need to provide the additional parameters `bot_token` and `task_channel_id` in the `SaviiaAPIConfig` configuration class:
```python
config = SaviiaAPIConfig(
...
task_channel_id=TASK_CHANNEL_ID,
bot_token=BOT_TOKEN
)
```
The `task_channel_id` is the ID of the Discord channel where tasks will be created, updated, and deleted. The `bot_token` is the token of the Discord bot that has permissions to manage messages in that channel.
#### Create Task
Create a new task in a Discord channel with the following properties:
```python
import asyncio
async def main():
response = await tasks_service.create_task(
task={
"name": "Task Title",
"description": "Task Description",
"due_date": "2024-12-31T23:59:59Z",
"priority": 1,
"assignee": "user_name",
"category": "work",
},
images=[
{
"name": "image.png",
"type": "image/png",
"data": "base64_encoded_data"
}
],
config=config
)
return response
asyncio.run(main())
```
**Notes:**
- `name`, `description`, `due_date`, `priority`, `assignee`, and `category` are required.
- `images` is optional and accepts up to 10 images.
- `due_date` must be in ISO 8601 format (datetime).
- `priority` must be an integer between 1 and 4.
#### Update Task
Update an existing task or mark it as completed. The task will be reacted with ✅ if completed or 📌 if pending:
```python
import asyncio
async def main():
response = await tasks_service.update_task(
task={
"id": "task_id",
"name": "Updated Title",
"description": "Updated Description",
"due_date": "2024-12-31T23:59:59Z",
"priority": 2,
"assignee": "updated_user_name",
"category": "work"
}, # Must contain all the attributes of the task
completed=True,
config=config
)
return response
asyncio.run(main())
```
#### Delete Task
Delete an existing task from a Discord channel by providing its ID:
```python
import asyncio
async def main():
response = await tasks_service.delete_task(
task_id="task_id",
config=config
)
return response
asyncio.run(main())
```
#### Get Tasks
Retrieve tasks from a Discord channel with optional filtering and sorting:
```python
import asyncio
async def main():
response = await tasks_service.get_tasks(
params={
"sort": "desc",
"completed": False,
"fields": ["title", "due_date", "priority"],
"after": 1000000,
"before": 2000000
},
config=config
)
return response
asyncio.run(main())
```
**Notes:**
- `sort`: Order results by `asc` or `desc`.
- `completed`: Filter tasks by completion status.
- `fields`: Specify which fields to include in the response. Must include `title` and `due_date`.
- `after` and `before`: Filter tasks by timestamp ranges.
## Contributing
If you're interested in contributing to this project, please follow the contributing guidelines. By contributing to this project, you agree to abide by its terms.
Contributions are welcome and appreciated!
## License
`saviialib` was created by Pedro Pablo Zavala Tejos. It is licensed under the terms of the MIT license.
| text/markdown | pedropablozavalat | null | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.11 | [] | [] | [] | [
"aiofiles",
"aioftp",
"aiohttp",
"asyncssh==2.21.1",
"bitarray",
"build",
"certifi",
"dotenv<0.10.0,>=0.9.9",
"ffmpeg-asyncio==0.1.3",
"jsonschema==4.25.1",
"numpy<2.4.0,>=2.2.0",
"pandas>=2.2.3"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.5 | 2026-02-20T14:44:19.053263 | saviialib-1.14.0.tar.gz | 50,804 | 42/ad/fefe2f610a4ce8b3a40be8b1f7616671030598764811ab1ce4fb807d2ae2/saviialib-1.14.0.tar.gz | source | sdist | null | false | c4cbd87a31ef045661e601a19a13ca94 | 3ef32fec567e7b0e51b3543dec3fb2b14c2ac2fbfb2fd0e0a75549c92d2dde44 | 42adfefe2f610a4ce8b3a40be8b1f7616671030598764811ab1ce4fb807d2ae2 | null | [
"LICENSE"
] | 216 |
2.4 | crate-docs-theme | 0.50.0 | CrateDB Documentation Theme | ===========================
CrateDB Documentation Theme
===========================
|tests| |rtd| |pypi| |build| |python-versions|
About
=====
A `Sphinx`_ theme for the `CrateDB documentation`_.
*Note: This theme is tightly integrated into the cratedb.com website and is
not intended for general use.*
For making changes to the theme, see the `developer docs`_.
Preview
=======
The demo/preview project is rendered and published to https://crate-docs-theme.readthedocs.io/.
Using the theme
===============
Prerequisites
-------------
The documentation can include UML diagrams which will be rendered using
`sphinxcontrib-plantuml`_. In order to satisfy its requirements, run::
# On Linux
apt-get install plantuml
# On macOS
brew install plantuml
.. _sphinxcontrib-plantuml: https://pypi.org/project/sphinxcontrib-plantuml/
Installation
------------
The CrateDB Documentation Theme is available as a package on `PyPI`_. However, there is no
need to install it yourself. CrateDB projects that use the theme should install
it automatically.
Configuration
-------------
The documentation is composed of multiple separate documentation
projects, interlinked via the CrateDB Documentation Theme.
To update the root of the TOC sidebar for the entire documentation, update the
`sidebartoc.py`_ file.
To use the theme, add this line to your Sphinx ``conf.py`` file::
from crate.theme.rtd.conf.foo import *
Here, replace ``foo`` with the appropriate module for your documentation
project.
Contributing
============
This project is primarily maintained by `Crate.io`_, but we welcome community
contributions!
See the `developer docs`_ and the `contribution docs`_ for more information.
Help
====
Looking for more help?
- Check out our `support channels`_
.. _sidebartoc.py: src/crate/theme/rtd/crate/sidebartoc.py
.. _contribution docs: CONTRIBUTING.rst
.. _Crate.io: https://cratedb.com
.. _CrateDB documentation: https://cratedb.com/docs/
.. _developer docs: DEVELOP.rst
.. _PyPI: https://pypi.python.org/
.. _Sphinx: http://www.sphinx-doc.org/en/stable/
.. _support channels: https://cratedb.com/support/
.. |tests| image:: https://github.com/crate/crate-docs-theme/workflows/docs/badge.svg
:alt: CI status
:target: https://github.com/crate/crate-docs-theme/actions?workflow=docs
.. |rtd| image:: https://readthedocs.org/projects/crate-docs-theme/badge/
:alt: Read the Docs status
:target: https://readthedocs.org/projects/crate-docs-theme/
.. |build| image:: https://img.shields.io/endpoint.svg?color=blue&url=https%3A%2F%2Fraw.githubusercontent.com%2Fcrate%2Fcrate-docs-theme%2Fmain%2Fdocs%2Fbuild.json
:alt: crate-docs version
:target: https://github.com/crate/crate-docs-theme/blob/main/docs/build.json
.. |pypi| image:: https://badge.fury.io/py/crate-docs-theme.svg
:alt: PyPI version
:target: https://badge.fury.io/py/crate-docs-theme
.. |python-versions| image:: https://img.shields.io/pypi/pyversions/crate-docs-theme.svg
:alt: Python Versions
:target: https://pypi.org/project/crate-docs-theme/
| text/x-rst | Crate.IO GmbH | office@crate.io | null | null | Apache License 2.0 | cratedb docs sphinx readthedocs | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Documentation"
] | [] | https://github.com/crate/crate-docs-theme | null | >=3.9 | [] | [] | [] | [
"furo==2025.12.19",
"jinja2<4,>=3",
"jupysql<0.12",
"myst-nb<1.4",
"myst-parser[linkify]<6",
"snowballstemmer<4",
"sphinx<10,>=7.1",
"sphinx-basic-ng==1.0.0b2",
"sphinx-copybutton<1,>=0.3.1",
"sphinx-design-elements<0.5",
"sphinx-inline-tabs",
"sphinx-sitemap<2.10.0",
"sphinx-togglebutton<1",
"sphinxext.opengraph<1,>=0.4",
"sphinxcontrib-mermaid<2",
"sphinxcontrib-plantuml<1,>=0.21",
"sphinxcontrib-youtube<2"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.1 | 2026-02-20T14:43:07.192485 | crate_docs_theme-0.50.0.tar.gz | 1,608,628 | 01/f1/3786e2066f5995ce1391bedf0e90054639c4ca43385dcfcb1e2f08e79db5/crate_docs_theme-0.50.0.tar.gz | source | sdist | null | false | 7703e559f3e7e601236ff4f373d8b22e | 4425c3cca7960b587fbdb38dda3540bc2a9224bd9756dcf65b9bb31f9343fe93 | 01f13786e2066f5995ce1391bedf0e90054639c4ca43385dcfcb1e2f08e79db5 | null | [
"LICENSE",
"NOTICE"
] | 344 |
2.3 | resolver_athena_client | 1.2.1.dev20260220144240 | Python client library for Athena API - CSAM detection and content classification | # Athena Client Library

This is a Python library for interacting with the Athena API (Resolver Unknown
CSAM Detection).
## Authentication
The Athena client supports two authentication methods:
### Static Token Authentication
```python
from resolver_athena_client.client.channel import create_channel
# Use a pre-existing authentication token
channel = create_channel(host="your-host", auth_token="your-token")
```
### OAuth Credential Helper (Recommended)
The credential helper automatically handles OAuth token acquisition and refresh:
```python
import asyncio
from resolver_athena_client.client.channel import CredentialHelper, create_channel_with_credentials
async def main():
# Create credential helper with OAuth settings
credential_helper = CredentialHelper(
client_id="your-oauth-client-id",
client_secret="your-oauth-client-secret",
auth_url="https://crispthinking.auth0.com/oauth/token", # Optional, this is default
audience="crisp-athena-live" # Optional, this is default
)
# Create channel with automatic OAuth handling
channel = await create_channel_with_credentials(
host="your-host",
credential_helper=credential_helper
)
asyncio.run(main())
```
#### Environment Variables
For the OAuth example to work, set these environment variables:
```bash
export OAUTH_CLIENT_ID="your-client-id"
export OAUTH_CLIENT_SECRET="your-client-secret"
export ATHENA_HOST="your-athena-host"
```
#### OAuth Features
- **Automatic token refresh**: Tokens are automatically refreshed when they expire
- **Thread-safe**: Multiple concurrent requests will safely share cached tokens
- **Error handling**: Comprehensive error handling for OAuth failures
- **Configurable**: Custom OAuth endpoints and audiences supported
See `examples/oauth_example.py` for a complete working example.
## Examples
- `examples/example.py` - Basic classification example with static token
- `examples/oauth_example.py` - OAuth authentication with credential helper
- `examples/create_image.py` - Image generation utilities
## TODO
### Async pipelines
Make pipeline style invocation of the async interators such that we can
async read file -> async transform -> async classify -> async results
### More async pipeline transformers
Add additional pipeline transformers for:
- Image format conversion
- Metadata extraction
- Error recovery and retry
## Development
This package uses [uv](https://docs.astral.sh/uv/) to manage its packages.
To install dependencies, run:
```bash
uv sync --dev
```
To build the package, run:
```bash
uv build
```
To run the standard tests, run:
```bash
pytest -m 'not functional'
```
Developers wishing to run the functional tests should see the
[Functional Tests](#functional-tests) section below.
To lint and format the code, run:
```bash
ruff check
ruff format
```
There are pre-commit hooks that will lint, format, and type check the code.
Install them with:
```bash
pre-commit install
```
To re-compile the protobuf files, run from the repository's root directory:
```bash
bash scripts/compile_proto.sh
```
### Functional Tests
Functional tests require an Athena environment to run against.
#### Pre-Requisites
You will need:
- An Athena host URL.
- An OAuth client ID and secret with access to the Athena environment.
- An affiliate with Athena enabled.
#### Preparing your environment
You can set up the environment variables in a `.env` file in the root of the
repository, or in your shell environment:
You must set the following variables:
```
ATHENA_HOST=your-athena-host (e.g. localhost:5001)
ATHENA_TEST_AFFILIATE=your-affiliate-id
OAUTH_CLIENT_ID=your-oauth-client-id
OAUTH_CLIENT_SECRET=your-oauth-client-secret
ATHENA_TEST_PLATFORM_TOKEN=a standard platform token - this should be rejected
as only athena specific tokens are accepted.
ATHENA_TEST_EXPIRED_TOKEN=a valid but expired token - this should be rejected.
```
You can optionally set the following variables:
```
OAUTH_AUTH_URL=your-oauth-auth-url (default: https://crispthinking.auth0.com/oauth/token)
OAUTH_AUDIENCE=your-oauth-audience (default: crisp-athena-live)
TEST_IMAGE_COUNT=number-of-images-to-test-with (default: 5000) - this is the
number of images the _streaming_ test will use.
TEST_MIN_INTERVAL=minimum-interval-in-ms (default: None, send as fast as
possible) - this is the minimum interval between
images for the _streaming_ test.
ATHENA_NON_EXISTENT_AFFILIATE=non-existent-affiliate-id (default:
thisaffiliatedoesnotexist123) - this is used to test error handling.
ATHENA_NON_PERMITTED_AFFILIATE=non-permitted-affiliate-id (default:
thisaffiliatedoesnothaveathenaenabled) - this is used to test error handling.
```
Then run the functional tests with:
```bash
pytest -m functional
```
| text/markdown | Crisp Thinking Group Ltd | Crisp Thinking Group Ltd <opensource@kroll.com> | null | null | MIT | csam, content-detection, image-classification, api-client, grpc | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"anyio>=4.10.0",
"brotli>=1.1.0",
"grpcio-tools>=1.74.0",
"httpx>=0.25.0",
"numpy>=2.2.6",
"opencv-python-headless>=4.13.0.92"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T14:42:54.560155 | resolver_athena_client-1.2.1.dev20260220144240.tar.gz | 29,716 | 59/e4/ac6762ea74107abb3d50e1c4f76ce71ba1df368e942dbf09b00f3513f00f/resolver_athena_client-1.2.1.dev20260220144240.tar.gz | source | sdist | null | false | a9a8bd5fa6865cc7843d106c5c17f1d1 | 97e585e27bbc313ee4319a32b6e3f141a9c976703da567923cdb49ccb0522190 | 59e4ac6762ea74107abb3d50e1c4f76ce71ba1df368e942dbf09b00f3513f00f | null | [] | 0 |
2.1 | odoo-addon-portal-account-personal-data-only | 19.0.1.0.0.2 | Portal Accounting Personal Data Only | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
====================================
Portal Accounting Personal Data Only
====================================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:d94b69e4218e9c6e1b5c9a79a2c04e013633ec8505a2abdbb9359bd5a8bf8a5d
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Faccount--invoicing-lightgray.png?logo=github
:target: https://github.com/OCA/account-invoicing/tree/19.0/portal_account_personal_data_only
:alt: OCA/account-invoicing
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/account-invoicing-19-0/account-invoicing-19-0-portal_account_personal_data_only
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/account-invoicing&target_branch=19.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
By default, portal users are allowed to see all the invoices in which a
member of their organization are followers. That could cause a leaking
of documents between members and departments and of the organization
that should stay private.
This module restricts that behavior so the portal users only see their
own documents.
A similar module named ``portal_sale_personal_data_only`` exists to do
the same for sale orders.
**Table of contents**
.. contents::
:local:
Usage
=====
1. Create some portal users belonging to the same company.
2. Create some invoices for several of these users.
3. Log in with each portal user credential.
4. Only the invoices belonging to the logged in user's partner or his
descendants should be accessible.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/account-invoicing/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/account-invoicing/issues/new?body=module:%20portal_account_personal_data_only%0Aversion:%2019.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Moduon
* Tecnativa
Contributors
------------
- Harald Panten <harald.panten@sygel.es>
- `Tecnativa <https://www.tecnativa.com>`__:
- David Vidal
- Víctor Martínez
- Stefan Ungureanu
- Moaad Bourhim <moaad.bourhim@gmail.com>
- Jairo Llopis (`Moduon <https://www.moduon.team/>`__)
- SodexisTeam <dev@sodexis.com>
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/account-invoicing <https://github.com/OCA/account-invoicing/tree/19.0/portal_account_personal_data_only>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Moduon, Tecnativa, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 19.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/account-invoicing | null | null | [] | [] | [] | [
"odoo==19.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T14:42:40.361934 | odoo_addon_portal_account_personal_data_only-19.0.1.0.0.2-py3-none-any.whl | 24,698 | e0/c5/23fd4c5280dadbc62942d51782341e4ccb37625120867d7ac0d0e9f9e1f4/odoo_addon_portal_account_personal_data_only-19.0.1.0.0.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 88a5f1bc0850648f0761f440c2ffe909 | 12820659fd687c23dbc9a94ecd1407bd30c8c4f19f0e8a52aa9751c0484b4bbf | e0c523fd4c5280dadbc62942d51782341e4ccb37625120867d7ac0d0e9f9e1f4 | null | [] | 89 |
2.1 | phi_save_codec | 0.2.2 | Phigros Cloud Save Codec Library | # Phi-Save-Codec-Bind-Python
Phi-Save-Codec 的 Python 绑定,用于解析和构建 Phigros 的云端存档格式。
## 安装
```bash
pip install -r requirements.txt
```
## 使用
```python
from phi_save_codec import PhiSaveCodec, PhiSaveCodecError
# 初始化编解码器
codec = PhiSaveCodec("phi_save_codec.wasm")
# 解析二进制数据
try:
user_data = codec.parse_user(binary_data)
print(user_data)
except PhiSaveCodecError as e:
print(f"解析失败: {e}")
# 构建二进制数据
try:
binary_data = codec.build_user(user_dict)
except PhiSaveCodecError as e:
print(f"构建失败: {e}")
```
## 支持的操作
- `parse_user()` / `build_user()` - 用户数据
- `parse_summary()` / `build_summary()` - 摘要数据
- `parse_game_record()` / `build_game_record()` - 游戏记录
- `parse_game_progress()` / `build_game_progress()` - 游戏进度
- `parse_game_key()` / `build_game_key()` - 游戏密钥
- `parse_settings()` / `build_settings()` - 设置数据
## 异常处理
所有 API 方法在错误时抛出 `PhiSaveCodecError` 异常:
```python
try:
data = codec.parse_user(binary_data)
except PhiSaveCodecError as e:
# 获取详细的错误信息
print(f"错误: {e}")
```
## 内存管理
该库自动处理与 WASM 模块之间的内存管理,包括:
- 分配和释放内存
- 获取和清空错误信息
- 确保在函数调用前后正确管理临时内存
## 依赖
- `msgpack` - 数据序列化
- `wasmtime` - WASM 运行时支持 | text/markdown | null | Shua-github <CHA_shua@outlook.com> | null | null | MIT | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"wasmtime>=41.0.0",
"msgpack>=1.1.2"
] | [] | [] | [] | [] | pdm/2.23.1 CPython/3.13.2 Windows/11 | 2026-02-20T14:41:14.037154 | phi_save_codec-0.2.2.tar.gz | 120,222 | c3/b9/8c61b77b93a3b67593b3df593ac5b462fbf22472d2111e5f56355c1fe377/phi_save_codec-0.2.2.tar.gz | source | sdist | null | false | 555ddd056873e125d9aa886bd1f8852b | 03d856a280207e9856fbac281f330b72aa965a4ac6d9d1cc1352671e14540d39 | c3b98c61b77b93a3b67593b3df593ac5b462fbf22472d2111e5f56355c1fe377 | null | [] | 0 |
2.4 | kwin-mcp | 0.2.0 | MCP server for Linux desktop GUI automation on KDE Plasma 6 Wayland via isolated KWin virtual sessions | # kwin-mcp
[](https://pypi.org/project/kwin-mcp/)
[](https://pypi.org/project/kwin-mcp/)
[](https://opensource.org/licenses/MIT)
[](https://github.com/isac322/kwin-mcp/actions/workflows/ci.yml)
A [Model Context Protocol (MCP)](https://modelcontextprotocol.io/) server for **Linux desktop GUI automation** on **KDE Plasma 6 Wayland**. It lets AI agents like [Claude Code](https://docs.anthropic.com/en/docs/claude-code) launch, interact with, and observe any Wayland application (Qt, GTK, Electron) in a fully isolated virtual KWin session — without touching the user's desktop.
## Why kwin-mcp?
- **Isolated sessions** — Each session runs in its own `dbus-run-session` + `kwin_wayland --virtual` sandbox. Your host desktop is never affected.
- **No screenshots required for interaction** — The AT-SPI2 accessibility tree gives the AI agent structured widget data (roles, names, coordinates, states, available actions), so it can interact with UI elements without relying solely on vision.
- **Zero authorization prompts** — Uses KWin's private EIS (Emulated Input Server) D-Bus interface directly, bypassing the XDG RemoteDesktop portal. No user confirmation dialogs.
- **Works with any Wayland app** — Anything that runs on KDE Plasma 6 Wayland works: Qt, GTK, Electron, and more. Input is injected via the standard `libei` protocol.
## Quick Start
> Requires KDE Plasma 6 on Wayland. See [System Requirements](#system-requirements) for details.
**1. Install**
```bash
# Using uv (recommended)
uv tool install kwin-mcp
# Or using pip
pip install kwin-mcp
```
**2. Configure Claude Code**
Add to your project's `.mcp.json`:
```json
{
"mcpServers": {
"kwin-mcp": {
"command": "uvx",
"args": ["kwin-mcp"]
}
}
}
```
**3. Use it**
Ask Claude Code to launch and interact with any GUI application:
```
Start a KWin session, launch kcalc, and press the buttons to calculate 2 + 3.
```
Claude Code will autonomously start an isolated session, launch the app, read the accessibility tree to find buttons, click them, and take a screenshot to verify the result.
## Features
- **Session management** — Start and stop isolated KWin Wayland sessions with configurable screen resolution
- **Screenshot capture** — Capture the virtual display as PNG via KWin's ScreenShot2 D-Bus interface
- **Accessibility tree** — Read the full AT-SPI2 widget tree with roles, names, states, coordinates, and available actions
- **Element search** — Find UI elements by name, role, or description (case-insensitive)
- **Mouse input** — Click (left/right/middle, single/double), move, scroll (vertical/horizontal), and drag with smooth interpolation
- **Keyboard input** — Type text (full US QWERTY layout) and press key combinations with modifier support (Ctrl, Alt, Shift, Super)
## System Requirements
| Requirement | Details |
|-------------|---------|
| **OS** | Linux with KDE Plasma 6 (Wayland session) |
| **Python** | 3.12 or later |
| **KWin** | `kwin_wayland` with `--virtual` flag support (KDE Plasma 6.x) |
| **libei** | Usually bundled with KWin 6.x (EIS input emulation) |
| **spectacle** | KDE screenshot tool (CLI mode) |
| **AT-SPI2** | `at-spi2-core` for accessibility tree support |
| **PyGObject** | GObject introspection Python bindings |
| **D-Bus** | `dbus-python` bindings |
### Installing System Dependencies
<details>
<summary><strong>Arch Linux / Manjaro</strong></summary>
```bash
sudo pacman -S kwin spectacle at-spi2-core python-gobject dbus-python-common
```
</details>
<details>
<summary><strong>Fedora (KDE Spin)</strong></summary>
```bash
sudo dnf install kwin-wayland spectacle at-spi2-core python3-gobject dbus-python
```
</details>
<details>
<summary><strong>openSUSE (KDE)</strong></summary>
```bash
sudo zypper install kwin6 spectacle at-spi2-core python3-gobject python3-dbus-python
```
</details>
<details>
<summary><strong>Kubuntu / KDE Neon</strong></summary>
```bash
sudo apt install kwin-wayland spectacle at-spi2-core python3-gi gir1.2-atspi-2.0 python3-dbus
```
</details>
## Installation
### Using uv (recommended)
```bash
uv tool install kwin-mcp
```
### Using pip
```bash
pip install kwin-mcp
```
### From source
```bash
git clone https://github.com/isac322/kwin-mcp.git
cd kwin-mcp
uv sync
uv run kwin-mcp
```
## Configuration
### Claude Code
Add to your project's `.mcp.json`:
```json
{
"mcpServers": {
"kwin-mcp": {
"command": "uvx",
"args": ["kwin-mcp"]
}
}
}
```
Or if installed globally:
```json
{
"mcpServers": {
"kwin-mcp": {
"command": "kwin-mcp"
}
}
}
```
### Claude Desktop
Add to your `claude_desktop_config.json`:
```json
{
"mcpServers": {
"kwin-mcp": {
"command": "uvx",
"args": ["kwin-mcp"]
}
}
}
```
### Running Directly
```bash
# As an installed script
kwin-mcp
# As a Python module
python -m kwin_mcp
```
## Available Tools
### Session Management
| Tool | Parameters | Description |
|------|-----------|-------------|
| `session_start` | `app_command?`, `screen_width?`, `screen_height?` | Start an isolated KWin Wayland session, optionally launching an app |
| `session_stop` | _(none)_ | Stop the session and clean up all processes |
### Observation
| Tool | Parameters | Description |
|------|-----------|-------------|
| `screenshot` | `include_cursor?` | Capture a screenshot of the virtual display (saved as PNG, returns file path) |
| `accessibility_tree` | `app_name?`, `max_depth?` | Get the AT-SPI2 widget tree with roles, names, states, and coordinates |
| `find_ui_elements` | `query`, `app_name?` | Search for UI elements by name, role, or description (case-insensitive) |
### Mouse Input
| Tool | Parameters | Description |
|------|-----------|-------------|
| `mouse_click` | `x`, `y`, `button?`, `double?`, `screenshot_after_ms?` | Click at coordinates (left/right/middle, single/double) |
| `mouse_move` | `x`, `y`, `screenshot_after_ms?` | Move the cursor to coordinates without clicking |
| `mouse_scroll` | `x`, `y`, `delta`, `horizontal?` | Scroll at coordinates (positive = down/right, negative = up/left) |
| `mouse_drag` | `from_x`, `from_y`, `to_x`, `to_y`, `screenshot_after_ms?` | Drag from one point to another with smooth interpolation |
### Keyboard Input
| Tool | Parameters | Description |
|------|-----------|-------------|
| `keyboard_type` | `text`, `screenshot_after_ms?` | Type a string of text character by character (US QWERTY layout) |
| `keyboard_key` | `key`, `screenshot_after_ms?` | Press a key or key combination (e.g., `Return`, `ctrl+c`, `alt+F4`, `shift+Tab`) |
> **Frame capture:** Action tools accept an optional `screenshot_after_ms` parameter (e.g., `[0, 50, 100, 200, 500]`) that captures screenshots at specified delays (in milliseconds) after the action completes. This is useful for observing transient UI states like hover effects, click animations, and menu transitions without extra MCP round-trips.
## How It Works
```
Claude Code / AI Agent
│
│ MCP (stdio)
▼
kwin-mcp server
│
├── session_start ─────────► dbus-run-session
│ ├── at-spi-bus-launcher
│ └── kwin_wayland --virtual
│ └── [your app]
│
├── screenshot ────────────► spectacle (via D-Bus)
│
├── accessibility_tree ────► AT-SPI2 (via PyGObject)
├── find_ui_elements ──────► AT-SPI2 (via PyGObject)
│
├── mouse_* / keyboard_* ─► KWin EIS D-Bus ──► libei
│ └── screenshot_after_ms ► KWin ScreenShot2 D-Bus (fast frame capture)
```
### Triple Isolation
kwin-mcp provides three layers of isolation from the host desktop:
1. **D-Bus isolation** — `dbus-run-session` creates a private session bus. The isolated session's services (KWin, AT-SPI2, portals) are invisible to the host.
2. **Display isolation** — `kwin_wayland --virtual` creates its own Wayland compositor with a virtual framebuffer. No windows appear on the host display.
3. **Input isolation** — Input events are injected through KWin's EIS interface into the isolated compositor only. The host desktop receives no input from kwin-mcp.
### Input Injection
Mouse and keyboard events are injected through KWin's private `org.kde.KWin.EIS.RemoteDesktop` D-Bus interface. This returns a `libei` file descriptor that allows low-level input emulation without requiring the XDG RemoteDesktop portal (which would show a user authorization dialog). The connection uses:
- **Absolute pointer positioning** for precise coordinate-based interaction
- **evdev keycodes** with full US QWERTY mapping for keyboard input
- **Smooth drag interpolation** (10+ intermediate steps) for realistic drag operations
### Screenshot Capture
The `screenshot` tool uses `spectacle` CLI for reliable full-screen capture. For action tools with the `screenshot_after_ms` parameter, screenshots are captured directly via the KWin `org.kde.KWin.ScreenShot2` D-Bus interface, which is much faster (~30-70ms vs ~200-300ms per frame) because it avoids process spawn overhead. Raw ARGB pixel data is read from a pipe and converted to PNG using Pillow.
### Accessibility Tree
The AT-SPI2 accessibility bus within the isolated session is queried via PyGObject (`gi.repository.Atspi`). This provides a structured tree of all UI widgets with their roles (button, text field, menu item, etc.), names, states (focused, enabled, visible, etc.), screen coordinates, and available actions (click, toggle, etc.).
## Limitations
- **US QWERTY keyboard layout only** — Other keyboard layouts are not yet supported for text typing.
- **KDE Plasma 6+ required** — Older KDE versions or other Wayland compositors (GNOME, Sway) are not supported.
- **AT-SPI2 availability varies** — Some applications may not fully expose their widget tree via AT-SPI2.
## Contributing
Contributions are welcome! Please open an issue or pull request on [GitHub](https://github.com/isac322/kwin-mcp).
```bash
git clone https://github.com/isac322/kwin-mcp.git
cd kwin-mcp
uv sync
uv run ruff check src/
uv run ruff format --check src/
uv run ty check src/
```
## License
[MIT](LICENSE)
| text/markdown | Byeonghoon Yoo | Byeonghoon Yoo <bhyoo@bhyoo.com> | null | null | null | mcp, kwin, kde, wayland, gui-automation, plasma, testing | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Testing",
"Topic :: Desktop Environment :: K Desktop Environment (KDE)",
"Typing :: Typed"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"mcp>=1.0.0",
"pygobject>=3.42.0",
"dbus-python>=1.3.2",
"pillow>=10.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/isac322/kwin-mcp",
"Repository, https://github.com/isac322/kwin-mcp",
"Issues, https://github.com/isac322/kwin-mcp/issues",
"Changelog, https://github.com/isac322/kwin-mcp/blob/main/CHANGELOG.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:40:32.727244 | kwin_mcp-0.2.0.tar.gz | 19,149 | 34/0a/25a41660085884eb7b22474ac0b5d82a8b878797cc3ea2a8c5ddaf256145/kwin_mcp-0.2.0.tar.gz | source | sdist | null | false | 93c1e8e3626da4daa736475c1f5f9543 | db3cbd05d042430d5e7f7bbd6b1664c9d0f4c382ea7eca9bcf8a213a47713338 | 340a25a41660085884eb7b22474ac0b5d82a8b878797cc3ea2a8c5ddaf256145 | MIT | [] | 216 |
2.4 | sitrep.vet | 0.0.1 | SITREP.VET: Semantic transport protocol for bandwidth-constrained channels. | # sitrep.vet
Semantic transport protocol for bandwidth-constrained channels.
Transmits 16-bit codebook coordinates instead of high-dimensional feature vectors — enabling real-time semantic communication over IoT, satellite, and tactical networks.
## Install
```bash
pip install sitrep.vet
```
## Status
This is a name reservation. The full package is in active development.
## Links
- Website: https://sitrep.vet
- Repository: https://github.com/astronolanX/SITREP.VET
| text/markdown | Nolan Figueroa | null | null | null | null | semantic communication, codebook, vector quantization, bandwidth constrained, IoT, transport protocol | [
"Development Status :: 1 - Planning",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering",
"Topic :: System :: Networking"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://sitrep.vet",
"Repository, https://github.com/astronolanX/SITREP.VET"
] | twine/6.2.0 CPython/3.11.7 | 2026-02-20T14:40:31.651935 | sitrep_vet-0.0.1.tar.gz | 1,721 | 54/b6/4fca113b513a91c6edceb2079e63aa449b16242568b50c03eb904ea0e9a5/sitrep_vet-0.0.1.tar.gz | source | sdist | null | false | 2c73229eeacbeef7ccce0ca72f389094 | ef6d907a4bbbb00b4088352c9dd81d09d96c785c7c0e0644773a188c4e903275 | 54b64fca113b513a91c6edceb2079e63aa449b16242568b50c03eb904ea0e9a5 | Apache-2.0 | [] | 0 |
2.4 | postproxy-sdk | 1.1.0 | Async Python client for the PostProxy API | # PostProxy Python SDK
Async Python client for the [PostProxy API](https://postproxy.dev). Fully typed with Pydantic v2 models and async/await via httpx.
## Installation
```bash
pip install postproxy-sdk
```
Requires Python 3.10+.
## Quick start
```python
import asyncio
from postproxy import PostProxy
async def main():
async with PostProxy("your-api-key", profile_group_id="pg-abc") as client:
# List profiles
profiles = (await client.profiles.list()).data
# Create a post
post = await client.posts.create(
"Hello from PostProxy!",
profiles=[profiles[0].id],
)
print(post.id, post.status)
asyncio.run(main())
```
## Usage
### Client
```python
from postproxy import PostProxy
# Basic
client = PostProxy("your-api-key")
# With a default profile group (applied to all requests)
client = PostProxy("your-api-key", profile_group_id="pg-abc")
# With a custom httpx client
import httpx
client = PostProxy("your-api-key", httpx_client=httpx.AsyncClient(timeout=30))
# As a context manager (auto-closes the HTTP client)
async with PostProxy("your-api-key") as client:
...
# Manual cleanup
await client.close()
```
### Posts
```python
# List posts (paginated)
page = await client.posts.list(page=0, per_page=10, status="draft")
print(page.total, page.data)
# Filter by platform and schedule
from datetime import datetime
page = await client.posts.list(
platforms=["instagram", "tiktok"],
scheduled_after=datetime(2025, 6, 1),
)
# Get a single post
post = await client.posts.get("post-id")
# Create a post
post = await client.posts.create(
"Check out our new product!",
profiles=["profile-id-1", "profile-id-2"],
)
# Create a draft
post = await client.posts.create(
"Draft content",
profiles=["profile-id"],
draft=True,
)
# Create with media URLs
post = await client.posts.create(
"Photo post",
profiles=["profile-id"],
media=["https://example.com/image.jpg"],
)
# Create with local file uploads
post = await client.posts.create(
"Posted with a local file!",
profiles=["profile-id"],
media_files=["./photo.jpg", "./video.mp4"],
)
# Mix media URLs and local files
post = await client.posts.create(
"Mixed media",
profiles=["profile-id"],
media=["https://example.com/image.jpg"],
media_files=["./local-photo.jpg"],
)
# Create with platform-specific params
from postproxy import PlatformParams, InstagramParams, TikTokParams
post = await client.posts.create(
"Cross-platform post",
profiles=["ig-profile", "tt-profile"],
platforms=PlatformParams(
instagram=InstagramParams(format="reel", collaborators=["@friend"]),
tiktok=TikTokParams(format="video", privacy_status="PUBLIC_TO_EVERYONE"),
),
)
# Schedule a post
post = await client.posts.create(
"Scheduled post",
profiles=["profile-id"],
scheduled_at="2025-12-25T09:00:00Z",
)
# Publish a draft
post = await client.posts.publish_draft("post-id")
# Delete a post
result = await client.posts.delete("post-id")
print(result.deleted) # True
```
### Profiles
```python
# List all profiles
profiles = (await client.profiles.list()).data
# List profiles in a specific group (overrides client default)
profiles = (await client.profiles.list(profile_group_id="pg-other")).data
# Get a single profile
profile = await client.profiles.get("profile-id")
print(profile.name, profile.platform, profile.status)
# Get available placements for a profile
placements = (await client.profiles.placements("profile-id")).data
for p in placements:
print(p.id, p.name)
# Delete a profile
result = await client.profiles.delete("profile-id")
print(result.success) # True
```
### Profile Groups
```python
# List all groups
groups = (await client.profile_groups.list()).data
# Get a single group
group = await client.profile_groups.get("pg-id")
print(group.name, group.profiles_count)
# Create a group
group = await client.profile_groups.create("My New Group")
# Delete a group (must have no profiles)
result = await client.profile_groups.delete("pg-id")
print(result.deleted) # True
# Initialize a social platform connection
conn = await client.profile_groups.initialize_connection(
"pg-id",
platform="instagram",
redirect_url="https://yourapp.com/callback",
)
print(conn.url) # Redirect the user to this URL
```
## Error handling
All errors extend `PostProxyError`, which includes the HTTP status code and raw response body:
```python
from postproxy import (
PostProxyError,
AuthenticationError, # 401
BadRequestError, # 400
NotFoundError, # 404
ValidationError, # 422
)
try:
await client.posts.get("nonexistent")
except NotFoundError as e:
print(e.status_code) # 404
print(e.response) # {"error": "Not found"}
except PostProxyError as e:
print(f"API error {e.status_code}: {e}")
```
## Types
All responses are parsed into Pydantic v2 models. All list methods return a response object with a `data` field — access items via `.data`:
```python
profiles = (await client.profiles.list()).data
posts = await client.posts.list() # also has .total, .page, .per_page
```
Key types:
| Model | Fields |
|---|---|
| `Post` | id, body, status, scheduled_at, created_at, platforms |
| `Profile` | id, name, status, platform, profile_group_id, expires_at, post_count |
| `ProfileGroup` | id, name, profiles_count |
| `PlatformResult` | platform, status, params, error, attempted_at, insights |
| `ListResponse[T]` | data |
| `PaginatedResponse[T]` | total, page, per_page, data |
### Platform parameter models
| Model | Platform |
|---|---|
| `FacebookParams` | format (`post`, `story`), first_comment, page_id |
| `InstagramParams` | format (`post`, `reel`, `story`), first_comment, collaborators, cover_url, audio_name, trial_strategy, thumb_offset |
| `TikTokParams` | format (`video`, `image`), privacy_status, photo_cover_index, auto_add_music, made_with_ai, disable_comment, disable_duet, disable_stitch, brand_content_toggle, brand_organic_toggle |
| `LinkedInParams` | format (`post`), organization_id |
| `YouTubeParams` | format (`post`), title, privacy_status, cover_url |
| `PinterestParams` | format (`pin`), title, board_id, destination_link, cover_url, thumb_offset |
| `ThreadsParams` | format (`post`) |
| `TwitterParams` | format (`post`) |
Wrap them in `PlatformParams` when passing to `posts.create()`.
## Development
```bash
pip install -e ".[dev]"
pytest
mypy postproxy/
```
## License
MIT
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.25.0",
"pydantic>=2.0",
"mypy>=1.19; extra == \"dev\"",
"pytest-asyncio>=1.3.0; extra == \"dev\"",
"pytest>=9.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://postproxy.dev",
"Documentation, https://postproxy.dev/getting-started/overview/",
"Repository, https://github.com/postproxy/postproxy-python"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T14:39:51.424244 | postproxy_sdk-1.1.0.tar.gz | 11,188 | c7/76/59a6de382fa632d3740973436c68c85d53e7d2334922b96b2eecabcd0c35/postproxy_sdk-1.1.0.tar.gz | source | sdist | null | false | 407c4c05ce3c29b4fbad63dca08bb878 | d86c14eefff42448b055fdf02558acec743353cd2ac8834a83a154e8fe0e96fe | c77659a6de382fa632d3740973436c68c85d53e7d2334922b96b2eecabcd0c35 | MIT | [] | 216 |
2.4 | amsdal | 0.7.5 | AMSDAL | # AMSDAL
[](https://pypi.org/project/amsdal)
[](https://pypi.org/project/amsdal)
-----
**Table of Contents**
- [Installation](#installation)
- [License](#AMSDAL-End-User-License-Agreement)
## Installation
```console
pip install amsdal
```
## AMSDAL End User License Agreement
**Version:** 1.0
**Last Updated:** October 31, 2023
### PREAMBLE
This Agreement is a legally binding agreement between you and AMSDAL regarding the Library. Read this Agreement carefully before accepting it, or downloading or using the Library.
By downloading, installing, running, executing, or otherwise using the Library, by paying the License Fees, or by explicitly accepting this Agreement, whichever is earlier, you agree to be bound by this Agreement without modifications or reservations.
If you do not agree to be bound by this Agreement, you shall not download, install, run, execute, accept, use or permit others to download, install, run, execute, accept, or otherwise use the Library.
If you are acting for or on behalf of an entity, then you accept this Agreement on behalf of such entity and you hereby represent that you are authorized to accept this Agreement and enter into a binding agreement with us on such entity’s behalf.
1. **INTERPRETATION**
1.1. The following definitions shall apply, unless otherwise expressly stated in this Agreement:
“**Additional Agreement**” means a written agreement executed between you and us that supplements and/or modifies this Agreement by specifically referring hereto.
“**Agreement**” means this AMSDAL End User License Agreement as may be updated or supplemented from time to time.
“**AMSDAL**”, “**we**”, “**us**” means AMSDAL INC., a Delaware corporation having its principal place of business in the State of New York.
“**Communications**” means all and any notices, requests, demands and other communications required or may be given under the terms of this Agreement or in connection herewith.
“**Consumer**” means, unless otherwise defined under the applicable legislation, a person who purchases or uses goods or services for personal, family, or household purposes.
“**Documentation**” means the technical, user, or other documentation, as may be updated from time to time, such as manuals, guidelines, which is related to the Library and provided or distributed by us or on our behalf, if any.
“**Free License Plan**” means the License Plan that is provided free of charge, with no License Fee due.
“**Library**” means the AMSDAL Framework and its components, as may be updated from time to time, including the packages: amsdal_Framework and its dependencies amsdal_models, amsdal_data, amsdal_cli, amsdal_server and amsdal_utils.
“**License Fee**” means the consideration to be paid by you to us for the License as outlined herein.
“**License Plan**” means a predetermined set of functionality, restrictions, or services applicable to the Library.
“**License**” has the meaning outlined in Clause 2.1.
“**Parties**” means AMSDAL and you.
“**Party**” means either AMSDAL or you.
“**Product Page**” means our website page related to the Library, if any.
“**Third-Party Materials**” means the code, software or other content that is distributed by third parties under free or open-source software licenses (such as MIT, Apache 2.0, BSD) that allow for editing, modifying, or reusing such content.
“**Update**” means an update, patch, fix, support release, modification, or limited functional enhancement to the Library, including but not limited to error corrections to the Library, which does not, in our opinion, constitute an upgrade or a new/separate product.
“**U.S. Export Laws**” means the United States Export Administration Act and any other export law, restriction, or regulation.
“**Works**” means separate works, such as software, that are developed using the Library. The Works should not merely be a fork, alternative, copy, or derivative work of the Library or its part.
“**You**” means either you as a single individual or a single entity you represent.
1.2. Unless the context otherwise requires, a reference to one gender shall include a reference to the other genders; words in the singular shall include the plural and in the plural shall include the singular; any words following the terms including, include, in particular, for example, or any similar expression shall be construed as illustrative and shall not limit the sense of the words, description, definition, phrase or term preceding those terms; except where a contrary intention appears, a reference to a Section or Clause is a reference to a Section or Clause of this Agreement; Section and Clause headings do not affect the interpretation of this Agreement.
1.3. Each provision of this Agreement shall be construed as though both Parties participated equally in the drafting of same, and any rule of construction that a document shall be construed against the drafting Party, including without limitation, the doctrine is commonly known as “*contra proferentem*”, shall not apply to the interpretation of this Agreement.
2. **LICENSE, RESTRICTIONS**
2.1. License Grant. Subject to the terms and conditions contained in this Agreement, AMSDAL hereby grants to you a non-exclusive, non-transferable, revocable, limited, worldwide, and non-sublicensable license (the “**License**”) to install, run, and use the Library, as well as to modify and customize the Library to implement it in the Works.
2.2. Restrictions. As per the License, you shall not, except as expressly permitted herein, (i) sell, resell, transfer, assign, pledge, rent, rent out, lease, assign, distribute, copy, or encumber the Library or the rights in the Library, (ii) use the Library other than as expressly authorized in this Agreement, (iii) remove any copyright notice, trademark notice, and/or other proprietary legend or indication of confidentiality set forth on or contained in the Library, if any, (iv) use the Library in any manner that violates the laws of the United States of America or any other applicable law, (v) circumvent any feature, key, or other licensing control mechanism related to the Library that ensures compliance with this Agreement, (vi) reverse engineer, decompile, disassemble, decrypt or otherwise seek to obtain the source code to the Library, (vii) with respect to the Free License Plan, use the Library to provide a service to a third party, and (viii) permit others to do anything from the above.
2.3. Confidentiality. The Library, including any of its elements and components, shall at all times be treated by you as confidential and proprietary. You shall not disclose, transfer, or otherwise share the Library to any third party without our prior written consent. You shall also take all reasonable precautions to prevent any unauthorized disclosure and, in any event, shall use your best efforts to protect the confidentiality of the Library. This Clause does not apply to the information and part of the Library that (i) is generally known to the public at the time of disclosure, (ii) is legally received by you from a third party which rightfully possesses such information, (iii) becomes generally known to the public subsequent to the time of such disclosure, but not as a result of unauthorized disclosure hereunder, (iv) is already in your possession prior to obtaining the Library, or (v) is independently developed by you or on your behalf without use of or reference to the Library.
2.4. Third-Party Materials. By entering into this Agreement, you acknowledge and confirm that the Library includes the Third-Party Materials. The information regarding the Third-Party Materials will be provided to you along with the Library. If and where necessary, you shall comply with the terms and conditions applicable to the Third-Party Materials.
2.5. Title. The Library is protected by law, including without limitation the copyright laws of the United States of America and other countries, and by international treaties. AMSDAL or its licensors reserve all rights not expressly granted to you in this Agreement. You agree that AMSDAL and/or its licensors own all right, title, interest, and intellectual property rights associated with the Library, including related applications, plugins or extensions, and you will not contest such ownership.
2.6. No Sale. The Library provided hereunder is licensed, not sold. Therefore, the Library is exempt from the “first sale” doctrine, as defined in the United States copyright laws or any other applicable law. For purposes of clarification only, you accept, acknowledge and agree that this is a license agreement and not an agreement for sale, and you shall have no ownership rights in any intellectual or tangible property of AMSDAL or its licensors.
2.7. Works. We do not obtain any rights, title or interest in and to the Works. Once and if the Library components lawfully become a part of the Works, you are free to choose the terms governing the Works. If the License is terminated you shall not use the Library within the Works.
2.8. Statistics. You hereby acknowledge and agree that we reserve the right to track and analyze the Library usage statistics and metrics.
3. **LICENSE PLANS**
3.1. Plans. The Library, as well as its functionality and associated services, may be subject to certain restrictions and limitations depending on the License Plan. The License Plan’s description, including any terms, such as term, License Fees, features, etc., are or will be provided by us including via the Product Page.
3.2. Plan Change. The Free License Plan is your default License Plan. You may change your License Plan by following our instructions that may be provided on the Product Page or otherwise. Downgrades are available only after the end of the respective prepaid License Plan.
3.3. Validity. You may have only one valid License Plan at a time. The License Plan is valid when it is fully prepaid by you (except for the Free License Plan which is valid only if and as long as we grant the License to you) and this Agreement is not terminated in accordance with the terms hereof.
3.4. Terms Updates. The License Plan’s terms may be updated by us at our sole discretion with or without prior notice to you. The License Plan updates that worsen terms and conditions of your valid License Plan will only be effective for the immediately following License Plan period, if any.
3.5. Free License Plan. We may from time to time at our discretion with or without notice and without liability to you introduce, update, suspend, or terminate the Free License Plan. The Free License Plan allows you to determine if the Library suits your particular needs. The Library provided under the Free License Plan is not designed to and shall not be used in trade, commercial activities, or your normal course of business.
4. **PAYMENTS**
4.1. License Fees. In consideration for the License provided hereunder, you shall, except for the Free License Plan, pay the License Fee in accordance with the terms of the chosen License Plan or Additional Agreement, if any.
4.2. Updates. We reserve the right at our sole discretion to change any License Fees, as well as to introduce or change any new payments at any time. The changes will not affect the prepaid License Plans; however they will apply starting from the immediately following License Plan period.
4.3. Payment Terms. Unless otherwise agreed in the Additional Agreement, the License Fees are paid fully in advance.
4.4. Precondition. Except for the Free License Plan, payment of the License Fee shall be the precondition for the License. Therefore, if you fail to pay the License Fee in full in accordance with the terms hereof, this Agreement, as well as the License, shall immediately terminate.
4.5. Currency and Fees. Unless expressly provided, prices are quoted in U.S. dollars. All currency conversion fees shall be paid by you. Each Party shall cover its own commissions and fees applicable to the transactions contemplated hereunder.
4.6. Refunds. There shall be no partial or total refunds of the License Fees that were already paid to us, including without limitation if you failed to download or use the Library.
4.7. Taxes. Unless expressly provided, all amounts are exclusive of taxes, including value added tax, sales tax, goods and services tax or other similar tax, each of which, where chargeable by us, shall be payable by you at the rate and in the manner prescribed by law. All other taxes, duties, customs, or similar charges shall be your responsibility.
5. **UPDATES, AVAILABILITY, SUPPORT**
5.1. Updates. Except for the Free License Plan, you are eligible to receive all relevant Updates during the valid License Plan at no additional charge. The Library may be updated at our sole discretion with or without notice to you. However, we shall not be obligated to make any Updates.
5.2. Availability. We do not guarantee that any particular feature or functionality of the Library will be available at any time.
5.3. Support. Unless otherwise decided by us at our sole discretion, we do not provide any support services. There is no representation or warranty that any functionality or Library as such will be supported by us.
5.4. Termination. We reserve the right at our sole discretion to discontinue the Library distribution and support at any time by providing prior notice to you. However, we will continue to maintain the Library until the end of then-current License Plan.
6. **TERM, TERMINATION**
6.1. Term. Unless terminated earlier on the terms outlined herein, this Agreement shall be in force as long as you have a valid License Plan. Once your License Plan expires, this Agreement shall automatically expire.
6.2. Termination Without Cause. You may terminate this Agreement for convenience at any time.
6.3. Termination For Breach. If you are in breach of this Agreement and you fail to promptly, however not later than within ten (10) days, following our notice to cure such breach, we may immediately terminate this Agreement.
6.4. Termination For Material Breach. If you are in material breach of this Agreement, we may immediately terminate this Agreement upon written notice to you.
6.5. Termination of Free License Plan. If you are using the Library under the Free License Plan, this Agreement may be terminated by us at any time with or without notice and without any liability to you.
6.6. Effect of Termination. Once this Agreement is terminated or expired, (i) the License shall terminate or expire, (ii) you shall immediately cease using the Library, (iii) you shall permanently erase the Library and its copies that are in your possession or control, (iv) if technically possible, we will discontinue the Library operation, (v) all our obligations under this Agreement shall cease, and (vi) the License Fees or any other amounts that were paid to us hereunder, if any, shall not be reimbursed.
6.7. Survival. Clauses and Sections 2.2-2.5, 4.6, 4.7, 6.6, 6.7, 7.7, 8, 9.2, 10-12 shall survive any termination or expiration of this Agreement regardless of the reason.
7. **REPRESENTATIONS, WARRANTIES**
7.1. Mutual Representation. Each Party represents that it has the legal power and authority to enter into this Agreement. If you act on behalf of an entity, you hereby represent that you are authorized to accept this Agreement and enter into a binding agreement with us on such entity’s behalf.
7.2. Not a Consumer. You represent that you are not entering into this Agreement as a Consumer and that you do not intend to use the Library as a Consumer. The Library is not intended to be used by Consumers, therefore you shall not enter into this Agreement, and download and use the Library if you act as a Consumer.
7.3. Sanctions and Restrictions. You represent that you are not (i) a citizen or resident of, or person subject to jurisdiction of, Iran, Syria, Venezuela, Cuba, North Korea, or Russia, or (ii) a person subject to any sanctions administered or enforced by the United States Office of Foreign Assets Control or United Nations Security Council.
7.4. IP Warranty. Except for the Free License Plan, we warrant that, to our knowledge, the Library does not violate or infringe any third-party intellectual property rights, including copyright, rights in patents, trade secrets, and/or trademarks, and that to our knowledge no legal action has been taken in relation to the Library for any infringement or violation of any third party intellectual property rights.
7.5. No Harmful Code Warranty. Except for the Free License Plan, we warrant that we will use commercially reasonable efforts to protect the Library from, and the Library shall not knowingly include, malware, viruses, trap doors, back doors, or other means or functions which will detrimentally interfere with or otherwise adversely affect your use of the Library or which will damage or destroy your data or other property. You represent that you will use commercially reasonable efforts and industry standard tools to prevent the introduction of, and you will not knowingly introduce, viruses, malicious code, malware, trap doors, back doors or other means or functions by accessing the Library, the introduction of which may detrimentally interfere with or otherwise adversely affect the Library or which will damage or destroy data or other property.
7.6. Documentation Compliance Warranty. Except for the Free License Plan, we warrant to you that as long as you maintain a valid License Plan the Library shall perform substantially in accordance with the Documentation. Your exclusive remedy, and our sole liability, with respect to any breach of this warranty, will be for us to use commercially reasonable efforts to promptly correct the non-compliance (provided that you promptly notify us in writing and allow us a reasonable cure period).
7.7. Disclaimer of Warranties. Except for the warranties expressly stated above in this Section, the Library is provided “as is”, with all faults and deficiencies. We disclaim all warranties, express or implied, including, but not limited to, warranties of merchantability, fitness for a particular purpose, title, availability, error-free or uninterrupted operation, and any warranties arising from course of dealing, course of performance, or usage of trade to the extent that we may not as a matter of applicable law disclaim any implied warranty, the scope, and duration of such warranty will be the minimum permitted under applicable law.
8. **LIABILITY**
8.1. Limitation of Liability. To the maximum extent permitted by applicable law, in no event shall AMSDAL be liable under any theory of liability for any indirect, incidental, special, or consequential damages of any kind (including, without limitation, any such damages arising from breach of contract or warranty or from negligence or strict liability), including, without limitation, loss of profits, revenue, data, or use, or for interrupted communications or damaged data, even if AMSDAL has been advised or should have known of the possibility of such damages.
8.2. Liability Cap. In any event, our aggregate liability under this Agreement, negligence, strict liability, or other theory, at law or in equity, will be limited to the total License Fees paid by you under this Agreement for the License Plan valid at the time when the relevant event happened.
8.3. Force Majeure. Neither Party shall be held liable for non-performance or undue performance of this Agreement caused by force majeure. Force majeure means an event or set of events, which is unforeseeable, unavoidable, and beyond control of the respective Party, for instance fire, flood, hostilities, declared or undeclared war, military actions, revolutions, act of God, explosion, strike, embargo, introduction of sanctions, act of government, act of terrorism.
8.4. Exceptions. Nothing contained herein limits our liability to you in the event of death, personal injury, gross negligence, willful misconduct, or fraud.
8.5. Remedies. In addition to, and not in lieu of the termination provisions set forth in Section 6 above, you agree that, in the event of a threatened or actual breach of a provision of this Agreement by you, (i) monetary damages alone will be an inadequate remedy, (ii) such breach will cause AMSDAL great, immediate, and irreparable injury and damage, and (iii) AMSDAL shall be entitled to seek and obtain, from any court of competent jurisdiction (without the requirement of the posting of a bond, if applicable), immediate injunctive and other equitable relief in addition to, and not in lieu of, any other rights or remedies that AMSDAL may have under applicable laws.
9. **INDEMNITY**
9.1. Our Indemnity. Except for the Free License Plan users, we will defend, indemnify, and hold you harmless from any claim, suit, or action to you based on our alleged violation of the IP Warranty provided in Clause 7.4 above, provided you (i) notify us in writing promptly upon notice of such claim and (ii) cooperate fully in the defense of such claim, suit, or action. We shall, at our own expense, defend such a claim, suit, or action, and you shall have the right to participate in the defense at your own expense. For the Free License Plan users, you shall use at your own risk and expense, and we have no indemnification obligations.
9.2. Your Indemnity. You will defend, indemnify, and hold us harmless from any claim, suit, or action to us based on your alleged violation of this Agreement, provided we notify you in writing promptly upon notice of such claim, suit, or action. You shall, at your own expense, defend such a claim, suit, or action.
10. **GOVERNING LAW, DISPUTE RESOLUTION**
10.1. Law. This Agreement shall be governed by the laws of the State of New York, USA, without reference to conflicts of laws principles. Provisions of the United Nations Convention on the International Sale of Goods shall not apply to this Agreement.
10.2. Negotiations. The Parties shall seek to solve amicably any disputes, controversies, claims, or demands arising out of or relating to this Agreement, as well as those related to execution, breach, termination, or invalidity hereof. If the Parties do not reach an amicable resolution within thirty (30) days, any dispute, controversy, claim or demand shall be finally settled by the competent court as outlined below.
10.3. Jurisdiction. The Parties agree that the exclusive jurisdiction and venue for any dispute arising out of or related to this Agreement shall be the courts of the State of New York and the courts of the United States of America sitting in the County of New York.
10.4. Class Actions Waiver. The Parties agree that any dispute arising out of or related to this Agreement shall be pursued individually. Neither Party shall act as a plaintiff or class member in any supposed purported class or representative proceeding, including, but not limited to, a federal or state class action lawsuit, against the other Party in relation herewith.
10.5. Costs. In the event of any legal proceeding between the Parties arising out of or related to this Agreement, the prevailing Party shall be entitled to recover, in addition to any other relief awarded or granted, its reasonable costs and expenses (including attorneys’ and expert witness’ fees) incurred in such proceeding.
11. **COMMUNICATION**
11.1. Communication Terms. Any Communications shall be in writing. When sent by ordinary mail, Communication shall be sent by personal delivery, by certified or registered mail, and shall be deemed delivered upon receipt by the recipient. When sent by electronic mail (email), Communication shall be deemed delivered on the day following the day of transmission. Any Communication given by email in accordance with the terms hereof shall be of full legal force and effect.
11.2. Contact Details. Your contact details must be provided by you to us. AMSDAL contact details are as follows: PO Box 940, Bedford, NY 10506; ams@amsdal.com. Either Party shall keep its contact details correct and up to date. Either Party may update its contact details by providing a prior written notice to the other Party in accordance with the terms hereof.
12. **MISCELLANEOUS**
12.1. Export Restrictions. The Library originates from the United States of America and may be subject to the United States export administration regulations. You agree that you will not (i) transfer or export the Library into any country or (ii) use the Library in any manner prohibited by the U.S. Export Laws. You shall comply with the U.S. Export Laws, as well as all applicable international and national laws related to the export or import regulations that apply in relation to your use of the Library.
12.2. Entire Agreement. This Agreement shall constitute the entire agreement between the Parties, supersede and extinguish all previous agreements, promises, assurances, warranties, representations and understandings between them, whether written or oral, relating to its subject matter.
12.3. Additional Agreements. AMSDAL and you are free to enter into any Additional Agreements. In the event of conflict, unless otherwise explicitly stated, the Additional Agreement shall control.
12.4. Modifications. We may modify, supplement or update this Agreement from time to time at our sole and absolute discretion. If we make changes to this Agreement, we will (i) update the “Version” and “Last Updated” date at the top of this Agreement and (ii) notify you in advance before the changes become effective. Your continued use of the Library is deemed acceptance of the amended Agreement. If you do not agree to any part of the amended Agreement, you shall immediately discontinue any use of the Library, which shall be your sole remedy.
12.5. Assignment. You shall not assign or transfer any rights or obligations under this Agreement without our prior written consent. We may upon prior written notice unilaterally transfer or assign this Agreement, including any rights and obligations hereunder at any time and no such transfer or assignment shall require your additional consent or approval.
12.6. Severance. If any provision or part-provision of this Agreement is or becomes invalid, illegal or unenforceable, it shall be deemed modified to the minimum extent necessary to make it valid, legal, and enforceable. If such modification is not possible, the relevant provision or part-provision shall be deemed deleted. If any provision or part-provision of this Agreement is deemed deleted under the previous sentence, AMSDAL will in good faith replace such provision with a new one that, to the greatest extent possible, achieves the intended commercial result of the original provision. Any modification to or deletion of a provision or part-provision under this Clause shall not affect the validity and enforceability of the rest of this Agreement.
12.7. Waiver. No failure or delay by a Party to exercise any right or remedy provided under this Agreement or by law shall constitute a waiver of that or any other right or remedy, nor shall it preclude or restrict the further exercise of that or any other right or remedy.
12.8. No Partnership or Agency. Nothing in this Agreement is intended to, or shall be deemed to, establish any partnership, joint venture or employment relations between the Parties, constitute a Party the agent of another Party, or authorize a Party to make or enter into any commitments for or on behalf of any other Party.
| text/markdown | null | null | null | null | AMSDAL End User License Agreement
Version: 1.0
Last Updated: October 31, 2023
PREAMBLE
This Agreement is a legally binding agreement between you and AMSDAL regarding the Library. Read this Agreement carefully before accepting it, or downloading or using the Library.
By downloading, installing, running, executing, or otherwise using the Library, by paying the License Fees, or by explicitly accepting this Agreement, whichever is earlier, you agree to be bound by this Agreement without modifications or reservations.
If you do not agree to be bound by this Agreement, you shall not download, install, run, execute, accept, use or permit others to download, install, run, execute, accept, or otherwise use the Library.
If you are acting for or on behalf of an entity, then you accept this Agreement on behalf of such entity and you hereby represent that you are authorized to accept this Agreement and enter into a binding agreement with us on such entity’s behalf.
1. INTERPRETATION
1.1. The following definitions shall apply, unless otherwise expressly stated in this Agreement:
“Additional Agreement” means a written agreement executed between you and us that supplements and/or modifies this Agreement by specifically referring hereto.
“Agreement” means this AMSDAL End User License Agreement as may be updated or supplemented from time to time.
“AMSDAL”, “we”, “us” means AMSDAL INC., a Delaware corporation having its principal place of business in the State of New York.
“Communications” means all and any notices, requests, demands and other communications required or may be given under the terms of this Agreement or in connection herewith.
“Consumer” means, unless otherwise defined under the applicable legislation, a person who purchases or uses goods or services for personal, family, or household purposes.
“Documentation” means the technical, user, or other documentation, as may be updated from time to time, such as manuals, guidelines, which is related to the Library and provided or distributed by us or on our behalf, if any.
“Free License Plan” means the License Plan that is provided free of charge, with no License Fee due.
“Library” means the AMSDAL Framework and its components, as may be updated from time to time, including the packages: amsdal_Framework and its dependencies amsdal_models, amsdal_data, amsdal_cli, amsdal_server and amsdal_utils.
“License Fee” means the consideration to be paid by you to us for the License as outlined herein.
“License Plan” means a predetermined set of functionality, restrictions, or services applicable to the Library.
“License” has the meaning outlined in Clause 2.1.
“Parties” means AMSDAL and you.
“Party” means either AMSDAL or you.
“Product Page” means our website page related to the Library, if any.
“Third-Party Materials” means the code, software or other content that is distributed by third parties under free or open-source software licenses (such as MIT, Apache 2.0, BSD) that allow for editing, modifying, or reusing such content.
“Update” means an update, patch, fix, support release, modification, or limited functional enhancement to the Library, including but not limited to error corrections to the Library, which does not, in our opinion, constitute an upgrade or a new/separate product.
“U.S. Export Laws” means the United States Export Administration Act and any other export law, restriction, or regulation.
“Works” means separate works, such as software, that are developed using the Library. The Works should not merely be a fork, alternative, copy, or derivative work of the Library or its part.
“You” means either you as a single individual or a single entity you represent.
1.2. Unless the context otherwise requires, a reference to one gender shall include a reference to the other genders; words in the singular shall include the plural and in the plural shall include the singular; any words following the terms including, include, in particular, for example, or any similar expression shall be construed as illustrative and shall not limit the sense of the words, description, definition, phrase or term preceding those terms; except where a contrary intention appears, a reference to a Section or Clause is a reference to a Section or Clause of this Agreement; Section and Clause headings do not affect the interpretation of this Agreement.
1.3. Each provision of this Agreement shall be construed as though both Parties participated equally in the drafting of same, and any rule of construction that a document shall be construed against the drafting Party, including without limitation, the doctrine is commonly known as “contra proferentem”, shall not apply to the interpretation of this Agreement.
2. LICENSE, RESTRICTIONS
2.1. License Grant. Subject to the terms and conditions contained in this Agreement, AMSDAL hereby grants to you a non-exclusive, non-transferable, revocable, limited, worldwide, and non-sublicensable license (the “License”) to install, run, and use the Library, as well as to modify and customize the Library to implement it in the Works.
2.2. Restrictions. As per the License, you shall not, except as expressly permitted herein, (i) sell, resell, transfer, assign, pledge, rent, rent out, lease, assign, distribute, copy, or encumber the Library or the rights in the Library, (ii) use the Library other than as expressly authorized in this Agreement, (iii) remove any copyright notice, trademark notice, and/or other proprietary legend or indication of confidentiality set forth on or contained in the Library, if any, (iv) use the Library in any manner that violates the laws of the United States of America or any other applicable law, (v) circumvent any feature, key, or other licensing control mechanism related to the Library that ensures compliance with this Agreement, (vi) reverse engineer, decompile, disassemble, decrypt or otherwise seek to obtain the source code to the Library, (vii) with respect to the Free License Plan, use the Library to provide a service to a third party, and (viii) permit others to do anything from the above.
2.3. Confidentiality. The Library, including any of its elements and components, shall at all times be treated by you as confidential and proprietary. You shall not disclose, transfer, or otherwise share the Library to any third party without our prior written consent. You shall also take all reasonable precautions to prevent any unauthorized disclosure and, in any event, shall use your best efforts to protect the confidentiality of the Library. This Clause does not apply to the information and part of the Library that (i) is generally known to the public at the time of disclosure, (ii) is legally received by you from a third party which rightfully possesses such information, (iii) becomes generally known to the public subsequent to the time of such disclosure, but not as a result of unauthorized disclosure hereunder, (iv) is already in your possession prior to obtaining the Library, or (v) is independently developed by you or on your behalf without use of or reference to the Library.
2.4. Third-Party Materials. By entering into this Agreement, you acknowledge and confirm that the Library includes the Third-Party Materials. The information regarding the Third-Party Materials will be provided to you along with the Library. If and where necessary, you shall comply with the terms and conditions applicable to the Third-Party Materials.
2.5. Title. The Library is protected by law, including without limitation the copyright laws of the United States of America and other countries, and by international treaties. AMSDAL or its licensors reserve all rights not expressly granted to you in this Agreement. You agree that AMSDAL and/or its licensors own all right, title, interest, and intellectual property rights associated with the Library, including related applications, plugins or extensions, and you will not contest such ownership.
2.6. No Sale. The Library provided hereunder is licensed, not sold. Therefore, the Library is exempt from the “first sale” doctrine, as defined in the United States copyright laws or any other applicable law. For purposes of clarification only, you accept, acknowledge and agree that this is a license agreement and not an agreement for sale, and you shall have no ownership rights in any intellectual or tangible property of AMSDAL or its licensors.
2.7. Works. We do not obtain any rights, title or interest in and to the Works. Once and if the Library components lawfully become a part of the Works, you are free to choose the terms governing the Works. If the License is terminated you shall not use the Library within the Works.
2.8. Statistics. You hereby acknowledge and agree that we reserve the right to track and analyze the Library usage statistics and metrics.
3. LICENSE PLANS
3.1. Plans. The Library, as well as its functionality and associated services, may be subject to certain restrictions and limitations depending on the License Plan. The License Plan’s description, including any terms, such as term, License Fees, features, etc., are or will be provided by us including via the Product Page.
3.2. Plan Change. The Free License Plan is your default License Plan. You may change your License Plan by following our instructions that may be provided on the Product Page or otherwise. Downgrades are available only after the end of the respective prepaid License Plan.
3.3. Validity. You may have only one valid License Plan at a time. The License Plan is valid when it is fully prepaid by you (except for the Free License Plan which is valid only if and as long as we grant the License to you) and this Agreement is not terminated in accordance with the terms hereof.
3.4. Terms Updates. The License Plan’s terms may be updated by us at our sole discretion with or without prior notice to you. The License Plan updates that worsen terms and conditions of your valid License Plan will only be effective for the immediately following License Plan period, if any.
3.5. Free License Plan. We may from time to time at our discretion with or without notice and without liability to you introduce, update, suspend, or terminate the Free License Plan. The Free License Plan allows you to determine if the Library suits your particular needs. The Library provided under the Free License Plan is not designed to and shall not be used in trade, commercial activities, or your normal course of business.
4. PAYMENTS
4.1. License Fees. In consideration for the License provided hereunder, you shall, except for the Free License Plan, pay the License Fee in accordance with the terms of the chosen License Plan or Additional Agreement, if any.
4.2. Updates. We reserve the right at our sole discretion to change any License Fees, as well as to introduce or change any new payments at any time. The changes will not affect the prepaid License Plans; however they will apply starting from the immediately following License Plan period.
4.3. Payment Terms. Unless otherwise agreed in the Additional Agreement, the License Fees are paid fully in advance.
4.4. Precondition. Except for the Free License Plan, payment of the License Fee shall be the precondition for the License. Therefore, if you fail to pay the License Fee in full in accordance with the terms hereof, this Agreement, as well as the License, shall immediately terminate.
4.5. Currency and Fees. Unless expressly provided, prices are quoted in U.S. dollars. All currency conversion fees shall be paid by you. Each Party shall cover its own commissions and fees applicable to the transactions contemplated hereunder.
4.6. Refunds. There shall be no partial or total refunds of the License Fees that were already paid to us, including without limitation if you failed to download or use the Library.
4.7. Taxes. Unless expressly provided, all amounts are exclusive of taxes, including value added tax, sales tax, goods and services tax or other similar tax, each of which, where chargeable by us, shall be payable by you at the rate and in the manner prescribed by law. All other taxes, duties, customs, or similar charges shall be your responsibility.
5. UPDATES, AVAILABILITY, SUPPORT
5.1. Updates. Except for the Free License Plan, you are eligible to receive all relevant Updates during the valid License Plan at no additional charge. The Library may be updated at our sole discretion with or without notice to you. However, we shall not be obligated to make any Updates.
5.2. Availability. We do not guarantee that any particular feature or functionality of the Library will be available at any time.
5.3. Support. Unless otherwise decided by us at our sole discretion, we do not provide any support services. There is no representation or warranty that any functionality or Library as such will be supported by us.
5.4. Termination. We reserve the right at our sole discretion to discontinue the Library distribution and support at any time by providing prior notice to you. However, we will continue to maintain the Library until the end of then-current License Plan.
6. TERM, TERMINATION
6.1. Term. Unless terminated earlier on the terms outlined herein, this Agreement shall be in force as long as you have a valid License Plan. Once your License Plan expires, this Agreement shall automatically expire.
6.2. Termination Without Cause. You may terminate this Agreement for convenience at any time.
6.3. Termination For Breach. If you are in breach of this Agreement and you fail to promptly, however not later than within ten (10) days, following our notice to cure such breach, we may immediately terminate this Agreement.
6.4. Termination For Material Breach. If you are in material breach of this Agreement, we may immediately terminate this Agreement upon written notice to you.
6.5. Termination of Free License Plan. If you are using the Library under the Free License Plan, this Agreement may be terminated by us at any time with or without notice and without any liability to you.
6.6. Effect of Termination. Once this Agreement is terminated or expired, (i) the License shall terminate or expire, (ii) you shall immediately cease using the Library, (iii) you shall permanently erase the Library and its copies that are in your possession or control, (iv) if technically possible, we will discontinue the Library operation, (v) all our obligations under this Agreement shall cease, and (vi) the License Fees or any other amounts that were paid to us hereunder, if any, shall not be reimbursed.
6.7. Survival. Clauses and Sections 2.2-2.5, 4.6, 4.7, 6.6, 6.7, 7.7, 8, 9.2, 10-12 shall survive any termination or expiration of this Agreement regardless of the reason.
7. REPRESENTATIONS, WARRANTIES
7.1. Mutual Representation. Each Party represents that it has the legal power and authority to enter into this Agreement. If you act on behalf of an entity, you hereby represent that you are authorized to accept this Agreement and enter into a binding agreement with us on such entity’s behalf.
7.2. Not a Consumer. You represent that you are not entering into this Agreement as a Consumer and that you do not intend to use the Library as a Consumer. The Library is not intended to be used by Consumers, therefore you shall not enter into this Agreement, and download and use the Library if you act as a Consumer.
7.3. Sanctions and Restrictions. You represent that you are not (i) a citizen or resident of, or person subject to jurisdiction of, Iran, Syria, Venezuela, Cuba, North Korea, or Russia, or (ii) a person subject to any sanctions administered or enforced by the United States Office of Foreign Assets Control or United Nations Security Council.
7.4. IP Warranty. Except for the Free License Plan, we warrant that, to our knowledge, the Library does not violate or infringe any third-party intellectual property rights, including copyright, rights in patents, trade secrets, and/or trademarks, and that to our knowledge no legal action has been taken in relation to the Library for any infringement or violation of any third party intellectual property rights.
7.5. No Harmful Code Warranty. Except for the Free License Plan, we warrant that we will use commercially reasonable efforts to protect the Library from, and the Library shall not knowingly include, malware, viruses, trap doors, back doors, or other means or functions which will detrimentally interfere with or otherwise adversely affect your use of the Library or which will damage or destroy your data or other property. You represent that you will use commercially reasonable efforts and industry standard tools to prevent the introduction of, and you will not knowingly introduce, viruses, malicious code, malware, trap doors, back doors or other means or functions by accessing the Library, the introduction of which may detrimentally interfere with or otherwise adversely affect the Library or which will damage or destroy data or other property.
7.6. Documentation Compliance Warranty. Except for the Free License Plan, we warrant to you that as long as you maintain a valid License Plan the Library shall perform substantially in accordance with the Documentation. Your exclusive remedy, and our sole liability, with respect to any breach of this warranty, will be for us to use commercially reasonable efforts to promptly correct the non-compliance (provided that you promptly notify us in writing and allow us a reasonable cure period).
7.7. Disclaimer of Warranties. Except for the warranties expressly stated above in this Section, the Library is provided “as is”, with all faults and deficiencies. We disclaim all warranties, express or implied, including, but not limited to, warranties of merchantability, fitness for a particular purpose, title, availability, error-free or uninterrupted operation, and any warranties arising from course of dealing, course of performance, or usage of trade to the extent that we may not as a matter of applicable law disclaim any implied warranty, the scope, and duration of such warranty will be the minimum permitted under applicable law.
8. LIABILITY
8.1. Limitation of Liability. To the maximum extent permitted by applicable law, in no event shall AMSDAL be liable under any theory of liability for any indirect, incidental, special, or consequential damages of any kind (including, without limitation, any such damages arising from breach of contract or warranty or from negligence or strict liability), including, without limitation, loss of profits, revenue, data, or use, or for interrupted communications or damaged data, even if AMSDAL has been advised or should have known of the possibility of such damages.
8.2. Liability Cap. In any event, our aggregate liability under this Agreement, negligence, strict liability, or other theory, at law or in equity, will be limited to the total License Fees paid by you under this Agreement for the License Plan valid at the time when the relevant event happened.
8.3. Force Majeure. Neither Party shall be held liable for non-performance or undue performance of this Agreement caused by force majeure. Force majeure means an event or set of events, which is unforeseeable, unavoidable, and beyond control of the respective Party, for instance fire, flood, hostilities, declared or undeclared war, military actions, revolutions, act of God, explosion, strike, embargo, introduction of sanctions, act of government, act of terrorism.
8.4. Exceptions. Nothing contained herein limits our liability to you in the event of death, personal injury, gross negligence, willful misconduct, or fraud.
8.5. Remedies. In addition to, and not in lieu of the termination provisions set forth in Section 6 above, you agree that, in the event of a threatened or actual breach of a provision of this Agreement by you, (i) monetary damages alone will be an inadequate remedy, (ii) such breach will cause AMSDAL great, immediate, and irreparable injury and damage, and (iii) AMSDAL shall be entitled to seek and obtain, from any court of competent jurisdiction (without the requirement of the posting of a bond, if applicable), immediate injunctive and other equitable relief in addition to, and not in lieu of, any other rights or remedies that AMSDAL may have under applicable laws.
9. INDEMNITY
9.1. Our Indemnity. Except for the Free License Plan users, we will defend, indemnify, and hold you harmless from any claim, suit, or action to you based on our alleged violation of the IP Warranty provided in Clause 7.4 above, provided you (i) notify us in writing promptly upon notice of such claim and (ii) cooperate fully in the defense of such claim, suit, or action. We shall, at our own expense, defend such a claim, suit, or action, and you shall have the right to participate in the defense at your own expense. For the Free License Plan users, you shall use at your own risk and expense, and we have no indemnification obligations.
9.2. Your Indemnity. You will defend, indemnify, and hold us harmless from any claim, suit, or action to us based on your alleged violation of this Agreement, provided we notify you in writing promptly upon notice of such claim, suit, or action. You shall, at your own expense, defend such a claim, suit, or action.
10. GOVERNING LAW, DISPUTE RESOLUTION
10.1. Law. This Agreement shall be governed by the laws of the State of New York, USA, without reference to conflicts of laws principles. Provisions of the United Nations Convention on the International Sale of Goods shall not apply to this Agreement.
10.2. Negotiations. The Parties shall seek to solve amicably any disputes, controversies, claims, or demands arising out of or relating to this Agreement, as well as those related to execution, breach, termination, or invalidity hereof. If the Parties do not reach an amicable resolution within thirty (30) days, any dispute, controversy, claim or demand shall be finally settled by the competent court as outlined below.
10.3. Jurisdiction. The Parties agree that the exclusive jurisdiction and venue for any dispute arising out of or related to this Agreement shall be the courts of the State of New York and the courts of the United States of America sitting in the County of New York.
10.4. Class Actions Waiver. The Parties agree that any dispute arising out of or related to this Agreement shall be pursued individually. Neither Party shall act as a plaintiff or class member in any supposed purported class or representative proceeding, including, but not limited to, a federal or state class action lawsuit, against the other Party in relation herewith.
10.5. Costs. In the event of any legal proceeding between the Parties arising out of or related to this Agreement, the prevailing Party shall be entitled to recover, in addition to any other relief awarded or granted, its reasonable costs and expenses (including attorneys’ and expert witness’ fees) incurred in such proceeding.
11. COMMUNICATION
11.1. Communication Terms. Any Communications shall be in writing. When sent by ordinary mail, Communication shall be sent by personal delivery, by certified or registered mail, and shall be deemed delivered upon receipt by the recipient. When sent by electronic mail (email), Communication shall be deemed delivered on the day following the day of transmission. Any Communication given by email in accordance with the terms hereof shall be of full legal force and effect.
11.2. Contact Details. Your contact details must be provided by you to us. AMSDAL contact details are as follows: PO Box 940, Bedford, NY 10506; ams@amsdal.com. Either Party shall keep its contact details correct and up to date. Either Party may update its contact details by providing a prior written notice to the other Party in accordance with the terms hereof.
12. MISCELLANEOUS
12.1. Export Restrictions. The Library originates from the United States of America and may be subject to the United States export administration regulations. You agree that you will not (i) transfer or export the Library into any country or (ii) use the Library in any manner prohibited by the U.S. Export Laws. You shall comply with the U.S. Export Laws, as well as all applicable international and national laws related to the export or import regulations that apply in relation to your use of the Library.
12.2. Entire Agreement. This Agreement shall constitute the entire agreement between the Parties, supersede and extinguish all previous agreements, promises, assurances, warranties, representations and understandings between them, whether written or oral, relating to its subject matter.
12.3. Additional Agreements. AMSDAL and you are free to enter into any Additional Agreements. In the event of conflict, unless otherwise explicitly stated, the Additional Agreement shall control.
12.4. Modifications. We may modify, supplement or update this Agreement from time to time at our sole and absolute discretion. If we make changes to this Agreement, we will (i) update the “Version” and “Last Updated” date at the top of this Agreement and (ii) notify you in advance before the changes become effective. Your continued use of the Library is deemed acceptance of the amended Agreement. If you do not agree to any part of the amended Agreement, you shall immediately discontinue any use of the Library, which shall be your sole remedy.
12.5. Assignment. You shall not assign or transfer any rights or obligations under this Agreement without our prior written consent. We may upon prior written notice unilaterally transfer or assign this Agreement, including any rights and obligations hereunder at any time and no such transfer or assignment shall require your additional consent or approval.
12.6. Severance. If any provision or part-provision of this Agreement is or becomes invalid, illegal or unenforceable, it shall be deemed modified to the minimum extent necessary to make it valid, legal, and enforceable. If such modification is not possible, the relevant provision or part-provision shall be deemed deleted. If any provision or part-provision of this Agreement is deemed deleted under the previous sentence, AMSDAL will in good faith replace such provision with a new one that, to the greatest extent possible, achieves the intended commercial result of the original provision. Any modification to or deletion of a provision or part-provision under this Clause shall not affect the validity and enforceability of the rest of this Agreement.
12.7. Waiver. No failure or delay by a Party to exercise any right or remedy provided under this Agreement or by law shall constitute a waiver of that or any other right or remedy, nor shall it preclude or restrict the further exercise of that or any other right or remedy.
12.8. No Partnership or Agency. Nothing in this Agreement is intended to, or shall be deemed to, establish any partnership, joint venture or employment relations between the Parties, constitute a Party the agent of another Party, or authorize a Party to make or enter into any commitments for or on behalf of any other Party.
| null | [
"Development Status :: 4 - Beta",
"Programming Language :: Python",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy"
] | [] | null | null | <3.14,>=3.11 | [] | [] | [] | [
"pydantic~=2.12",
"pydantic-settings~=2.12",
"PyJWT~=2.8",
"cryptography~=42.0",
"httpx~=0.25",
"bcrypt~=4.0",
"pyotp~=2.9",
"black>=24.3.0",
"amsdal_utils==0.6.*",
"amsdal_data==0.6.*",
"amsdal_models==0.6.*",
"pip>=21.3.1",
"amsdal-cli<1.0.0,>=0.6.0; extra == \"cli\"",
"amsdal-server<1.0.0,>=0.6.0; extra == \"server\"",
"polyfactory==2.*; extra == \"factory\"",
"celery==5.4.0; extra == \"celery\"",
"amsdal-data[async-sqlite]; extra == \"async-sqlite\"",
"amsdal-data[postgres-binary]; extra == \"postgres-binary\"",
"amsdal-data[postgres-c]; extra == \"postgres-c\""
] | [] | [] | [] | [
"Documentation, https://pypi.org/project/amsdal/#readme",
"Issues, https://pypi.org/project/amsdal/",
"Source, https://pypi.org/project/amsdal/"
] | Hatch/1.16.3 cpython/3.11.13 HTTPX/0.28.1 | 2026-02-20T14:39:38.707688 | amsdal-0.7.5-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl | 7,842,743 | 46/b9/b67b2bad1033bb0bde40d59ad8a8924810cfa11e7a43187a115f24e66d65/amsdal-0.7.5-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl | cp313 | bdist_wheel | null | false | cc6bc1f0f2b25998a4e6e05dda074a8e | 098a23028a6336bdb0be1a3950a1e97c59a83a8771c0a43740cad4b76d8d9498 | 46b9b67b2bad1033bb0bde40d59ad8a8924810cfa11e7a43187a115f24e66d65 | null | [
"LICENSE.txt"
] | 425 |
2.4 | geomapi | 1.0.3 | A standard library to manage geomatic data |

# GEOMAPI


[](https://badge.fury.io/py/geomapi)
[](https://coveralls.io/github/KU-Leuven-Geomatics/geomapi?branch=main)
This innovative toolbox, developped by [KU Leuven Geomatics](https://iiw.kuleuven.be/onderzoek/geomatics), jointly processes close-range sensing resources (point clouds, images) and BIM models for the AEC industry.
More specifically, we combine [semantic web technologies](https://en.wikipedia.org/wiki/Semantic_Web) with state-of-the-art open source geomatics APIs
to process and analyse big data in construction applications.
## Installation
Use the package manager [pip](https://pypi.org/project/geomapi) to install geomapi as a user.
```bash
conda create --name geomapi_user python=3.11
pip install geomapi
```
Or as a developer, install the dependencies from the root folder through the command line.
```bash
pip install -r requirements.txt
```
## Documentation
You can read the full API reference here:
[Documentation](https://ku-leuven-geomatics.github.io/geomapi/index.html)
## Quickstart
```py
import geomapi
from geomapi.nodes import Node
newNode = Node()
```
## Contributing
The master branch is protected and you can only make changes by submitting a merge request.
Please create a new branch if you would like to make changes and submit them for approval.
## Citation
If you want to cite us, refer to the following publication (published).
```
@article{GEOMAPI,
title = {GEOMAPI: Processing close-range sensing data of construction scenes with semantic web technologies},
journal = {Automation in Construction},
volume = {164},
pages = {105454},
year = {2024},
issn = {0926-5805},
doi = {https://doi.org/10.1016/j.autcon.2024.105454},
url = {https://www.sciencedirect.com/science/article/pii/S0926580524001900},
author = {Maarten Bassier and Jelle Vermandere and Sam De Geyter and Heinder De Winter},
keywords = {Geomatics, Semantic Web Technologies, Construction, Close-range sensing, BIM, Point clouds, Photogrammetry}
}
```
## TEAM
- maarten.bassier@kuleuven.be (PI)
- jelle.vermandere@kuleuven.be
- sam.degeyter@kuleuven.be
- heinder.dewinter@kuleuven.be
---

## Licensing
The code in this project is licensed under MIT license.
| text/markdown | Bassier M., De Geyter S., De Winter H., Vermandere J. @ Geomatics KU Leuven | null | null | null | MIT | Geomatics, alignment, monitoring, validation, progress, point clouds, computer vision, deep learning | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://ku-leuven-geomatics.github.io/geomapi/index.html | null | <=3.12 | [] | [] | [] | [
"open3d",
"opencv-python",
"pye57",
"numpy",
"numpy-quaternion",
"rdflib",
"typing_extensions",
"matplotlib",
"ifcopenshell",
"scipy",
"pillow",
"XlsxWriter",
"trimesh",
"python-fcl",
"pandas",
"lark",
"colour",
"laspy",
"lazrs",
"scikit-learn",
"ezdxf",
"pyvista",
"shapely",
"pyproj"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:39:29.330070 | geomapi-1.0.3.tar.gz | 5,033,070 | 5d/cb/b57670f0d9c2370a9e57c982d22d4e40382c35e37d778cce1d9a189b3d22/geomapi-1.0.3.tar.gz | source | sdist | null | false | 0adc774b86a2d0ec792f06d4c95c4e2a | 751ace505ee4d2af54e9160e0195d8933a69266ce7d53314f0681f710d2fab1d | 5dcbb57670f0d9c2370a9e57c982d22d4e40382c35e37d778cce1d9a189b3d22 | null | [
"LICENSE"
] | 227 |
2.1 | aws-cdk.lambda-layer-kubectl-v34 | 2.0.1 | A Lambda Layer that contains kubectl v1.34 | # Lambda Layer with KubeCtl v1.34
<!--BEGIN STABILITY BANNER-->---

---
<!--END STABILITY BANNER-->
This module exports a single class called `KubectlV34Layer` which is a `lambda.LayerVersion` that
bundles the [`kubectl`](https://kubernetes.io/docs/reference/kubectl/kubectl/) and the
[`helm`](https://helm.sh/) command line.
> * Helm Version: 3.19.0
> * Kubectl Version: 1.34.0
Usage:
```python
# KubectlLayer bundles the 'kubectl' and 'helm' command lines
from aws_cdk.lambda_layer_kubectl_v34 import KubectlV34Layer
import aws_cdk.aws_lambda as lambda_
# fn: lambda.Function
kubectl = KubectlV34Layer(self, "KubectlLayer")
fn.add_layers(kubectl)
```
`kubectl` will be installed under `/opt/kubectl/kubectl`, and `helm` will be installed under `/opt/helm/helm`.
| text/markdown | Amazon Web Services<aws-cdk-dev@amazon.com> | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved"
] | [] | https://github.com/cdklabs/awscdk-asset-kubectl#readme | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.94.0",
"constructs<11.0.0,>=10.0.5",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/cdklabs/awscdk-asset-kubectl.git"
] | twine/6.1.0 CPython/3.14.2 | 2026-02-20T14:39:06.471578 | aws_cdk_lambda_layer_kubectl_v34-2.0.1.tar.gz | 35,603,617 | 15/9e/a0ee0a7b0b495da7d8299e0fb993d5f9e0ed7d7d8bfe8becddda06c647fb/aws_cdk_lambda_layer_kubectl_v34-2.0.1.tar.gz | source | sdist | null | false | 648b4fb94768ee0c7b7979f1fb4b3271 | ec2ecfd32801287b45ef4b3c88267c8c5796792717bc07cffbf9818382ccc958 | 159ea0ee0a7b0b495da7d8299e0fb993d5f9e0ed7d7d8bfe8becddda06c647fb | null | [] | 0 |
2.4 | powfacpy | 0.4.1 | PowerFactory wrapper | # powfacpy
This package is a wrapper around the Python API of PowerFactory© (power system simulation software by DIgSILENT) with improved syntax and functionality compared to the native API. Please have a look at the [documentation](https://fraunhiee-unikassel-powsysstability.github.io/powfacpy/docs/) for further information.
## Why use *powfacpy*?
There are a number of reasons why you should consider using *powfacpy*:
- Increase productivity
- Write more readable code
- Avoid running into similar problems, errors and obscurities as other users of the python interface of *PowerFactory* before you
- Having a standard way of doing things in your organization (e.g. a standard format for simulation result export)
- Steep learning curve for *PowerFactory* beginners (helpful tutorials)
## Contact
This package is under active development and mainly maintained by *Fraunhofer IEE*. You are welcome to contribute or feel free to get in touch (contact: simon.eberlein@iee.fraunhofer.de).
| text/markdown | null | Sciemon <simon.eberlein@gmx.de> | null | null | Copyright (c) 2018 The Python Packaging Authority
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"aenum>=3.1.15",
"comtraderecord>=1.0.2",
"icecream>=2.1.3",
"matplotlib>=3.8.4",
"pandapower==3.2",
"pandas>=2.2.2"
] | [] | [] | [] | [
"Homepage, https://github.com/FraunhIEE-UniKassel-PowSysStability/powfacpy",
"Bug Tracker, https://github.com/FraunhIEE-UniKassel-PowSysStability/powfacpy/issues"
] | twine/6.2.0 CPython/3.13.5 | 2026-02-20T14:38:39.445266 | powfacpy-0.4.1.tar.gz | 4,486,859 | 86/ed/a90d3df6aa6a64021df699c95e3e1a0d9eda1569ea0ec5b20d6a882817fd/powfacpy-0.4.1.tar.gz | source | sdist | null | false | 75ae37032e550bf83ecbb6577290445b | 690de2339aa85f8186d2e60d0fe89003c78ccf29949bb8241771d41920a98180 | 86eda90d3df6aa6a64021df699c95e3e1a0d9eda1569ea0ec5b20d6a882817fd | null | [
"LICENSE"
] | 224 |
2.1 | omnipkg | 2.3.1 | Universal Python Runtime Orchestrator. One environment. Infinite Pythons and packages. Zero conflicts. | <p align="center">
<a href="https://github.com/1minds3t/omnipkg">
<img src="https://raw.githubusercontent.com/1minds3t/omnipkg/main/.github/logo.svg" alt="omnipkg Logo" width="150">
</a>
</p>
<h1 align="center">omnipkg – Universal Python Runtime Orchestrator</h1>
<p align="center">
<p align="center">
<p align="center">
<strong><strong>One environment. Infinite Pythons and packages. <1ms zero-copy IPC. </strong>
<p align="center">
<!-- Core Project Info -->
<a href="https://github.com/1minds3t/omnipkg/blob/main/LICENSE">
<img src="https://img.shields.io/badge/License-AGPLv3-d94c31?logo=gnu" alt="License">
</a>
<a href="https://pypi.org/project/omnipkg/">
<img src="https://img.shields.io/pypi/v/omnipkg?color=blue&logo=pypi" alt="PyPI">
</a>
<a href="https://anaconda.org/conda-forge/omnipkg">
<img src="https://img.shields.io/conda/dn/conda-forge/omnipkg?logo=anaconda" alt="Conda Downloads">
</a>
<a href="https://anaconda.org/minds3t/omnipkg">
<img src="https://img.shields.io/conda/dn/minds3t/omnipkg?logo=anaconda" alt="Conda Downloads (minds3t)">
</a>
<a href="https://pepy.tech/projects/omnipkg">
<img src="https://static.pepy.tech/personalized-badge/omnipkg?period=total&units=INTERNATIONAL_SYSTEM&left_color=gray&right_color=blue&left_text=downloads" alt="PyPI Downloads">
</a>
<a href="https://hub.docker.com/r/1minds3t/omnipkg">
<img src="https://img.shields.io/docker/pulls/1minds3t/omnipkg?logo=docker" alt="Docker Pulls">
</a>
<a href="https://anaconda.org/conda-forge/omnipkg">
<a href="https://clickpy.clickhouse.com/dashboard/omnipkg">
<img src="https://img.shields.io/badge/global_reach-80+_countries-228B22?logo=globe" alt="Global Reach Badge">
<p align="center">
</a>
<a href="https://pypi.org/project/omnipkg/">
<img src="https://img.shields.io/pypi/pyversions/omnipkg?logo=python&logoColor=white" alt="Python Versions">
</a>
<a href="https://anaconda.org/conda-forge/omnipkg/files">
<img src="https://img.shields.io/badge/platforms-win--64|macOS--64|macOS--arm64|linux--64|linux--aarch64|linux--ppc64le|noarch-blue?logo=anaconda" alt="Supported Platforms">
</a>
<p align="center">
</p>
<p align="center">
<!-- Quality & Security -->
<a href="https://github.com/1minds3t/omnipkg/actions?query=workflow%3A%22Security+Audit%22">
<img src="https://img.shields.io/badge/Security-passing-success?logo=security" alt="Security">
</a>
<a href="https://github.com/1minds3t/omnipkg/actions/workflows/safety_scan.yml">
<img src="https://img.shields.io/badge/Safety-passing-success?logo=safety" alt="Safety">
</a>
<a href="https://github.com/1minds3t/omnipkg/actions?query=workflow%3APylint">
<img src="https://img.shields.io/badge/Pylint-10/10-success?logo=python" alt="Pylint">
</a>
<a href="https://github.com/1minds3t/omnipkg/actions?query=workflow%3ABandit">
<img src="https://img.shields.io/badge/Bandit-passing-success?logo=bandit" alt="Bandit">
</a>
<a href="https://github.com/1minds3t/omnipkg/actions?query=workflow%3ACodeQL+Advanced">
<img src="https://img.shields.io/badge/CodeQL-passing-success?logo=github" alt="CodeQL">
</a>
<a href="https://socket.dev/pypi/package/omnipkg/overview/1.1.2/tar-gz">
<img src="https://img.shields.io/badge/Socket-secured-success?logo=socket" alt="Socket">
</a>
</p>
<p align="center">
<!-- Key Features -->
<a href="https://github.com/1minds3t/omnipkg/actions/workflows/multiverse_test.yml">
<img src="https://img.shields.io/badge/<600ms 3 Py Interps 1 Script 1 Env-passing-success?logo=python&logoColor=white" alt="Concurrent Python Interpreters">
</a>
<a href="https://github.com/1minds3t/omnipkg/actions/workflows/numpy_scipy_test.yml">
<img src="https://img.shields.io/badge/🚀0.25s_Live_NumPy+SciPy_Hot--Swapping-passing-success?logo=github-actions" alt="Hot-Swapping">
</a>
<a href="https://github.com/1minds3t/omnipkg/actions/workflows/multiverse_test.yml">
<img src="https://img.shields.io/badge/🔥_0.25s_Python_Interpreter_Hot--Swapping-Live-orange?logo=python&logoColor=white" alt="Python Hot-Swapping">
</a>
<a href="https://github.com/1minds3t/omnipkg/actions/workflows/old_rich_test.yml">
<img src="https://img.shields.io/badge/⚡_Auto--Healing-7.76x_Faster_than_UV-gold?logo=lightning&logoColor=white" alt="Auto-Healing Performance">
</a>
<a href="https://github.com/1minds3t/omnipkg/actions/workflows/language_test.yml">
<img src="https://img.shields.io/badge/💥_Breaking_Language_Barriers-24_Languages-success?logo=babel&logoColor=white" alt="24 Languages">
</a>
</p>
---
`omnipkg` is not just another package manager. It's an **intelligent, self-healing runtime orchestrator** that breaks the fundamental laws of Python environments. For 30 years, developers accepted that you couldn't run multiple Python versions in one script, or safely switch C-extensions like NumPy mid-execution. **Omnipkg proves this is no longer true.**
Born from a real-world nightmare—a forced downgrade that wrecked a production environment—`omnipkg` was built to solve what others couldn't: achieving perfect dependency isolation and runtime adaptability without the overhead of containers or multiple venvs.
---
<!-- COMPARISON_STATS_START -->
## ⚖️ Multi-Version Support
[](https://github.com/1minds3t/omnipkg/actions/workflows/omnipkg_vs_the_world.yml) [](https://github.com/1minds3t/omnipkg/actions/workflows/omnipkg_vs_the_world.yml) [](https://github.com/1minds3t/omnipkg/actions/workflows/omnipkg_vs_the_world.yml)
*Multi-version installation tests run every 3 hours. [Live results here.](https://github.com/1minds3t/omnipkg/actions/workflows/omnipkg_vs_the_world.yml)*
---
<!-- COMPARISON_STATS_END -->
## 💡 Why This Matters
**The Multi-Version Nightmare is Over**: Modern projects are messy. You need `tensorflow==2.10` for a legacy model but `tensorflow==2.15` for new training. A critical library requires `numpy==1.21` while your latest feature needs `numpy==2.0`. Traditional solutions like Docker or virtual environments force you into a painful choice: duplicate entire environments, endure slow context switching, or face crippling dependency conflicts.
**The Multi-Interpreter Wall is Gone**: Legacy codebases often require older Python versions (e.g., Django on 3.8) while modern ML demands the latest (Python 3.11+). This forces developers to constantly manage and switch between separate, isolated environments, killing productivity.
**The `omnipkg` Solution: One Environment, Infinite Python Versions & Packages, Zero Conflicts, Downtime, or Setup. Faster than UV.**
`omnipkg` doesn't just solve these problems—it makes them irrelevant.
* **Run Concurrently:** Execute tests for Python 3.9, 3.10, and 3.11 **at the same time, from one command, test is done in under 500ms**. No more sequential CI jobs.
* **Switch Mid-Script:** Seamlessly use `torch==2.0.0` and `torch==2.7.1` in the same script without restarting.
* **Instant Healing:** Recover from environment damage in microseconds, not hours.
* **Speak Your Language:** All of this, in your native tongue.
This is the new reality: one environment, one script, everything **just works**.
---
## 🧠 Revolutionary Core Features
### 1. Multiverse Orchestration & Python Hot-Swapping [](https://github.com/1minds3t/omnipkg/actions/workflows/multiverse_test.yml) [](https://github.com/1minds3t/omnipkg/actions/workflows/mac-concurrent-test.yml)
## The "Quantum Multiverse Warp": 3 Pythons, 1 Script, Sub-3ms Execution
Our "Quantum Multiverse Warp" demo, validated live in CI across multiple platforms, executes a single script across three different Python interpreters and three package versions **concurrently** in the same environment. The hot worker performance isn't just fast; it redefines what's possible for high-performance Python automation.
### Production Benchmark Results (macOS CI)
| Task (Same Script, Same Environment) | Hot Worker Execution |
| ------------------------------------ | :------------------: |
| 🧵 **Thread 1:** Python 3.9 + Rich 13.4.2 | ✅ **2.2ms** |
| 🧵 **Thread 2:** Python 3.10 + Rich 13.6.0 | ✅ **2.3ms** |
| 🧵 **Thread 3:** Python 3.11 + Rich 13.7.1 | ✅ **2.3ms** |
| 🏆 **Total Concurrent Runtime** | **2.3ms** |
| ⏱️ **Total Test Duration (with setup)** | **2.14s** |
**Platform-Specific Performance:**
| Platform | Hot Worker Benchmark | Total w/ Setup | CI Link |
|----------|---------------------|----------------|---------|
| 🐧 **Linux** | **3.8ms avg** (3.2-4.5ms range) | ~580ms | [View CI](https://github.com/1minds3t/omnipkg/actions/workflows/multiverse_test.yml) |
| 🍎 **macOS** | **2.3ms avg** (2.2-2.3ms range) | 2.14s | [View CI](https://github.com/1minds3t/omnipkg/actions/workflows/mac-concurrent-test.yml) |
### What This Actually Means
**The numbers that matter** are the **hot worker benchmarks** (sub-5ms). This is the actual execution time for running code across three concurrent Python interpreters with three different package versions. The "Total w/ Setup" includes one-time initialization:
- Worker pool spawning
- Package installation (if not cached)
- Environment validation
**Why This Is Revolutionary:**
- **Traditional approach:** Docker containers or separate venvs would take 30-90 seconds *minimum* to achieve the same multi-version testing
- **omnipkg approach:** After initial setup, switching between Python versions and package combinations happens in **microseconds**, not seconds
This isn't just a speedup; it's a paradigm shift. What traditionally takes minutes with Docker or complex venv scripting, `omnipkg` accomplishes in **milliseconds**. This isn't a simulation; it's a live, production-ready capability for high-performance Python automation.
### Benchmark Methodology
Our production benchmark follows industry-standard practices:
1. **📥 Setup Phase:** Verify Python interpreters are available and daemon is running (one-time cost)
2. **🔥 Warmup Phase:** Spawn workers and install packages - **timing discarded** (matches real-world "first run" scenario)
3. **⚡ Benchmark Phase:** Execute with hot workers - **THIS IS THE METRIC** (pure execution performance)
4. **🔍 Verification Phase:** Prove correctness with version checks (not timed)
**Key Achievement:** The hot worker performance (2-4ms) represents the *actual* overhead of omnipkg's multiverse orchestration. Once warmed up, switching between Python interpreters and package versions is **faster than most function calls**.
Don't believe it? See the live proof, then run **Demo 8** to experience it yourself:
```bash
uv pip install omnipkg && omnipkg demo
# Select option 8: 🌠 Quantum Multiverse Warp
```
**Live CI Output from Multiverse Benchmark:**
```bash
⚡ Phase 3: PRODUCTION BENCHMARK (hot workers, concurrent execution)
----------------------------------------------------------------------------------------------------
[T1] ⚡ Benchmarking Python 3.9 + Rich 13.4.2...
[T1] ✅ Benchmark: 2.2ms
[T2] ⚡ Benchmarking Python 3.10 + Rich 13.6.0...
[T2] ✅ Benchmark: 2.3ms
[T3] ⚡ Benchmarking Python 3.11 + Rich 13.7.1...
[T3] ✅ Benchmark: 2.3ms
====================================================================================================
📊 PRODUCTION BENCHMARK RESULTS
====================================================================================================
Thread Python Rich Warmup Benchmark
----------------------------------------------------------------------------------------------------
T1 3.9 13.4.2 3.4ms 2.2ms
T2 3.10 13.6.0 3.0ms 2.3ms
T3 3.11 13.7.1 3.5ms 2.3ms
----------------------------------------------------------------------------------------------------
⏱️ Sequential time (sum of all): 6.8ms
⏱️ Concurrent time (longest one): 2.3ms
====================================================================================================
🎯 PERFORMANCE METRICS:
----------------------------------------------------------------------------------------------------
Warmup (cold start): 3.3ms avg
Benchmark (hot workers): 2.3ms avg
Range: 2.2ms - 2.3ms
Speedup (warmup→hot): 1.5x
Concurrent speedup: 2.93x
----------------------------------------------------------------------------------------------------
🎉 BENCHMARK COMPLETE!
✨ KEY ACHIEVEMENTS:
✅ 3 different Python interpreters executing concurrently
✅ 3 different Rich versions loaded simultaneously
✅ Hot worker performance: sub-50ms execution!
✅ Zero state corruption or interference
✅ Production-grade benchmark methodology
⏱️ Total test duration: 2.14s
🚀 This is IMPOSSIBLE with traditional Python environments!
```
### Real-World Impact
**For CI/CD Pipelines:**
- **Before:** Sequential matrix testing across Python 3.9, 3.10, 3.11 = 3-5 minutes
- **After:** Concurrent testing with omnipkg = **< 3 seconds** (including setup)
- **Improvement:** **60-100x faster** CI/CD workflows
**For Development:**
- **Before:** Switch Python versions → wait 30-90s for new venv/container
- **After:** Switch with omnipkg → **< 5ms overhead**
- **Improvement:** Instant iteration, zero context-switching penalty
This is the new reality: one environment, one script, everything **just works** — and it's **blazing fast**.
---
### 2. Intelligent Script Runner (`omnipkg run`) [](https://github.com/1minds3t/omnipkg/actions/workflows/old_rich_test.yml)
`omnipkg run` is an intelligent script and CLI executor that **automatically detects and fixes** dependency errors using bubble versions—without modifying your main environment.
## What is `omnipkg run`?
Think of it as a "smart wrapper" around Python scripts and CLI commands that:
1. **Tries to execute** your script or command
2. **Detects errors** (ImportError, ModuleNotFoundError, version conflicts)
3. **Finds the right version** from existing bubbles or creates new ones
4. **Re-runs successfully** in milliseconds—all automatically
**The magic:** Your broken main environment stays broken, but everything works anyway.
## Two Modes of Operation
### Mode 1: Script Execution (`omnipkg run script.py`)
Automatically heals Python scripts with dependency conflicts:
```bash
$ python broken_script.py
AssertionError: Incorrect rich version! Expected 13.4.2, got 13.7.1
$ omnipkg run broken_script.py
🔍 Runtime version assertion failed. Auto-healing...
- Conflict identified for: rich==13.4.2
🛠️ Installing bubble for rich==13.4.2...
⚡ HEALED in 16,223.1 μs (16.2ms)
✅ Script completed successfully!
```
**Performance vs UV:**
```
UV Failed Run : 210.007ms (fails, no recovery)
omnipkg Activation : 16.223ms (succeeds automatically)
🎯 omnipkg is 12.94x FASTER than UV!
```
### Mode 2: CLI Command Execution (`omnipkg run <command>`)
Automatically heals broken command-line tools:
```bash
# Regular execution fails
$ http --version
ImportError: cannot import name 'SKIP_HEADER' from 'urllib3.util'
# omnipkg run heals and executes
$ omnipkg run http --version
⚠️ Command failed (exit code 1). Starting Auto-Healer...
🔍 Import error detected. Auto-healing with bubbles...
♻️ Loading: ['urllib3==2.6.3']
⚡ HEALED in 12,371.6 μs (12.4ms)
3.2.4
✅ Success!
```
**What happened:** The main environment still has urllib3 1.25.11 (broken), but `omnipkg run` used urllib3 2.6.3 from a bubble to make the command work.
## How It Works
### Step 1: Detect the Error
`omnipkg run` recognizes multiple error patterns:
```python
# Import errors
ModuleNotFoundError: No module named 'missing_package'
ImportError: cannot import name 'SKIP_HEADER'
# Version conflicts
AssertionError: Incorrect rich version! Expected 13.4.2, got 13.7.1
requires numpy==1.26.4, but you have numpy==2.0.0
# C-extension failures
A module compiled using NumPy 1.x cannot run in NumPy 2.0
```
### Step 2: Build a Healing Plan
Analyzes the error and identifies what's needed:
```bash
🔍 Comprehensive Healing Plan Compiled (Attempt 1): ['rich==13.4.2']
```
For CLI commands, it includes the owning package:
```bash
🔍 Analyzing error: ImportError from urllib3
♻️ Loading: ['urllib3==2.6.3']
```
### Step 3: Find or Create Bubbles
Checks if the needed version exists:
```bash
# Bubble exists - instant activation
🚀 INSTANT HIT: Found existing bubble urllib3==2.6.3 in KB
⚡ HEALED in 12.4ms
# Bubble doesn't exist - create it
🛠️ Installing bubble for rich==13.4.2...
📊 Bubble: 4 packages, 0 conflicts
⚡ HEALED in 16.2ms
```
### Step 4: Execute with Bubbles
Re-runs the script/command with the correct versions activated:
```bash
🌀 omnipkg auto-heal: Wrapping with loaders for ['rich==13.4.2']...
🚀 Fast-activating rich==13.4.2 ...
📊 Bubble: 4 packages, 0 conflicts
🧹 Purging 4 module(s) from memory...
🔗 Linked 20 compatible dependencies to bubble
✅ Bubble activated
🚀 Running target script inside the bubble...
✅ Successfully imported rich version: 13.4.2
```
### Step 5: Clean Restoration
After execution, environment is restored to original state:
```bash
🌀 omnipkg loader: Deactivating rich==13.4.2...
✅ Environment restored.
⏱️ Swap Time: 35,319.103 μs (35.3ms)
```
## Real-World Examples
### Example 1: Version Conflict Resolution
**Scenario:** Script needs rich==13.4.2 but main environment has rich==13.7.1
```bash
$ omnipkg run test_rich.py
🔍 Runtime version assertion failed. Auto-healing...
- Conflict identified for: rich==13.4.2
🛠️ Installing bubble for rich==13.4.2...
- 🧪 Running SMART import verification...
✅ markdown-it-py: OK
✅ rich: OK
✅ mdurl: OK
✅ Pygments: OK
⚡ HEALED in 16.2ms
✅ Script completed successfully inside omnipkg bubble.
```
**Main environment after execution:**
```bash
$ python -c "import rich; print(rich.__version__)"
13.7.1 # Still the original version - untouched!
```
### Example 2: Broken CLI Tool
**Scenario:** httpie broken by urllib3 downgrade to 1.25.11
```bash
# Shows the error first
$ http --version
Traceback (most recent call last):
File "/usr/bin/http", line 13, in <module>
from urllib3.util import SKIP_HEADER
ImportError: cannot import name 'SKIP_HEADER' from 'urllib3.util'
# Heals and executes
$ omnipkg run http --version
⚠️ Command 'http' failed. Starting Auto-Healer...
🔍 Analyzing error: ImportError from module
- Installing missing package: urllib3
🔍 Resolving latest version for 'urllib3'...
🚀 INSTANT HIT: Found existing bubble urllib3==2.6.3
🐍 [omnipkg loader] Running in Python 3.11 context
🚀 Fast-activating urllib3==2.6.3 ...
📊 Bubble: 1 packages, 0 conflicts
🧹 Purging 31 modules for 'urllib3'
⚡ HEALED in 12.4ms
🚀 Re-launching '/usr/bin/http' in healed environment...
3.2.4
✅ Success!
```
**Main environment after execution:**
```bash
$ python -c "import urllib3; print(urllib3.__version__)"
1.25.11 # Still broken - but who cares? omnipkg run works!
```
## Performance Benchmarks
### Script Healing (Demo 7)
| Operation | Time | Status |
|-----------|------|--------|
| UV failed run | 210.007ms | ❌ Fails, no recovery |
| omnipkg detection | <1ms | ✅ Instant |
| omnipkg healing | 16.223ms | ✅ Creates bubble |
| omnipkg execution | ~35ms | ✅ Runs successfully |
| **Total recovery** | **~51ms** | **12.94x faster than UV** |
### CLI Healing (Demo 10)
| Operation | Traditional | omnipkg run |
|-----------|-------------|-------------|
| Error detection | Manual (minutes) | Automatic (<1ms) |
| Finding fix | Manual research | Automatic KB lookup |
| Applying fix | 30-90s (reinstall) | 12.4ms (bubble activation) |
| Main env impact | ⚠️ Modified | ✅ Untouched |
| Success rate | ~50% (manual) | 100% (automated) |
## Key Features
### 1. Zero Main Environment Impact
**Traditional approach:**
```bash
$ pip install old-package==1.0.0
# Breaks 5 other packages
# Spend 30 minutes fixing
```
**omnipkg run approach:**
```bash
$ omnipkg run script-needing-old-version.py
# Works instantly
# Main environment untouched
```
### 2. Intelligent Error Detection
Recognizes and fixes:
- `ModuleNotFoundError` → Installs missing package
- `ImportError` → Fixes import conflicts
- `AssertionError` (version checks) → Switches to correct version
- NumPy C-extension errors → Downgrades to compatible version
- CLI command failures → Heals dependencies automatically
### 3. Smart Dependency Resolution
```bash
🔍 Analyzing script for additional dependencies...
✅ No additional dependencies needed
# Or if dependencies are found:
🔗 [omnipkg loader] Linked 20 compatible dependencies to bubble
```
Automatically detects and includes all required dependencies, not just the primary package.
### 4. Bubble Reuse
Once a bubble is created, it's instantly available:
```bash
# First time - creates bubble
🛠️ Installing bubble for rich==13.4.2...
⚡ HEALED in 16.2ms
# Second time - instant activation
🚀 INSTANT HIT: Found existing bubble rich==13.4.2
⚡ HEALED in <1ms
```
## Usage
### Basic Script Execution
```bash
# Run a Python script with auto-healing
omnipkg run script.py
# Pass arguments to the script
omnipkg run script.py --arg1 value1 --arg2 value2
```
### CLI Command Execution
```bash
# Run any CLI command with auto-healing
omnipkg run http GET https://api.github.com
# Run tools that depend on specific library versions
omnipkg run pytest
omnipkg run black mycode.py
omnipkg run mypy myproject/
```
### With Verbose Output
```bash
# See detailed healing process
omnipkg run -v script.py
```
## When to Use `omnipkg run`
### ✅ Perfect For:
- **Scripts with version conflicts:** Need old numpy but have new numpy installed
- **Broken CLI tools:** Tool worked yesterday, broken after an upgrade today
- **Testing different versions:** Try multiple library versions without changing environment
- **CI/CD pipelines:** Guaranteed success even with dependency conflicts
- **Legacy code:** Run old code without downgrading your entire environment
### ⚠️ Not Needed For:
- **Fresh scripts with satisfied dependencies:** Just use `python script.py`
- **Well-maintained environments:** If everything works, no need to heal
## Performance Comparison
```
Traditional Workflow (Broken Tool):
1. Tool fails ........................... 0s
2. Debug error (find root cause) ....... 300s (5 min)
3. Research fix ........................ 600s (10 min)
4. Apply fix (reinstall) ............... 60s (1 min)
5. Test fix ............................ 10s
6. Fix breaks other things ............. 1800s (30 min)
Total: 2770s (46 minutes) ❌
omnipkg run Workflow:
1. omnipkg run <command> ............... 0.012s (12ms)
Total: 0.012s (12 milliseconds) ✅
Speedup: 230,833x faster
```
## Try It Yourself
```bash
# Install omnipkg
uv pip install omnipkg
# Run Demo 7: Script auto-healing
omnipkg demo
# Select option 7
# Run Demo 10: CLI auto-healing
omnipkg demo
# Select option 10
```
See for yourself how `omnipkg run` turns minutes of frustration into milliseconds of automated healing.
---
## The Future: Package Manager Interception
This healing capability is the foundation for our vision of **transparent package management**:
```bash
# Coming soon: omnipkg intercepts all package managers
$ pip install broken-package==old-version
⚠️ This would break 3 packages in your environment
🛡️ omnipkg: Creating bubble instead to protect environment
✅ Installed to bubble - use 'omnipkg run' to access
# Everything just works
$ omnipkg run my-script-using-old-version.py
✅ Success (using bubbled version)
$ python my-script-using-new-version.py
✅ Success (using main environment)
```
**The endgame:** Infinite package coexistence, zero conflicts, microsecond switching—all invisible to the user.
---
---
***
# 3. Dynamic Package Switching & Process Isolation
[](https://github.com/1minds3t/omnipkg/actions) [](https://github.com/1minds3t/omnipkg)
**omnipkg** allows you to switch package versions **mid-script** and run conflicting dependencies simultaneously. It offers two distinct modes depending on the severity of the dependency conflict:
1. **In-Process Overlay:** For "safe" packages (NumPy, SciPy, Pandas) — *Zero latency.*
2. **Daemon Worker Pool:** For "heavy" frameworks (TensorFlow, PyTorch) — *True isolation.*
---
## 🛑 The Hard Truth: Why You Need Daemons
Traditional Python wisdom says you cannot switch frameworks like PyTorch or TensorFlow without restarting the interpreter. **This is true.** Their C++ backends (`_C` symbols) bind to memory and refuse to let go.
**What happens if you try to force-switch PyTorch in-process?**
```python
# ❌ THIS CRASHES IN STANDARD PYTHON
import torch # Loads version 2.0.1
# ... try to unload and reload 2.1.0 ...
import torch
# NameError: name '_C' is not defined
```
*The C++ backend remains resident, causing symbol conflicts and segfaults.*
### 🟢 The Solution: omnipkg Daemon Workers
Instead of fighting the C++ backend, `omnipkg` accepts it. We spawn **persistent, lightweight worker processes** for each framework version.
* **Workers persist across script runs:** Cold start once, hot-swap forever.
* **Zero-Copy Communication:** Data moves between workers via shared memory (no pickling overhead).
* **Sub-millisecond switching:** Switching contexts takes **~0.37ms**.
---
## 🚀 The Impossible Made Real: Benchmark Results
We ran `omnipkg demo` (Scenario 11: Chaos Theory) to prove capabilities that should be impossible.
### 1. Framework Battle Royale (Concurrent Execution)
**The Challenge:** Run TensorFlow, PyTorch, and NumPy (different versions) **at the exact same time**.
```text
🥊 ROUND 1: Truly Concurrent Execution
⚡ NumPy Legacy → (0.71ms)
⚡ NumPy Modern → (0.71ms)
⚡ PyTorch → (0.80ms)
⚡ TensorFlow → (1.15ms)
📊 RESULT: 4 Frameworks executed in 1.69ms total wall-clock time.
```
### 2. The TensorFlow Resurrection Test
**The Challenge:** Kill and respawn a TensorFlow environment 5 times.
* **Standard Method (Cold Spawn):** ~2885ms per reload.
* **omnipkg Daemon (Warm Worker):** ~716ms first run, **3ms** subsequent runs.
* **Result:** **4.0x Speedup** (and nearly instant after warm-up).
### 3. Rapid Circular Switching
**The Challenge:** Toggle between PyTorch 2.0.1 (CUDA 11.8) and 2.1.0 (CUDA 12.1) doing heavy tensor math.
```text
ROUND | WORKER | VERSION | TIME
-------------------------------------------------------
#1 | torch-2.0.1 | 2.0.1+cu118 | 0.63ms
#2 | torch-2.1.0 | 2.1.0+cu121 | 1570ms (Cold)
#3 | torch-2.0.1 | 2.0.1+cu118 | 0.66ms (Hot)
#4 | torch-2.1.0 | 2.1.0+cu121 | 0.44ms (Hot)
...
#10 | torch-2.1.0 | 2.1.0+cu121 | 0.37ms (Hot)
```
---
## 💻 Usage
### Mode A: In-Process Loader (NumPy, SciPy, Tools)
Best for nested dependencies and libraries that clean up after themselves.
```python
from omnipkg.loader import omnipkgLoader
# Layer 1: NumPy 1.24
with omnipkgLoader("numpy==1.24.3"):
import numpy as np
print(f"Outer: {np.__version__}") # 1.24.3
# Layer 2: SciPy 1.10 (Nested)
with omnipkgLoader("scipy==1.10.1"):
import scipy
# Works perfectly, sharing the NumPy 1.24 context
print(f"Inner: {scipy.__version__}")
```
### Mode B: Daemon Client (TensorFlow, PyTorch)
Best for heavy ML frameworks and conflicting C++ backends.
```python
from omnipkg.isolation.worker_daemon import DaemonClient
client = DaemonClient()
# Execute code in PyTorch 2.0.1
client.execute_smart("torch==2.0.1+cu118", """
import torch
print(f"Running on {torch.cuda.get_device_name(0)} with Torch {torch.__version__}")
""")
# Instantly switch to PyTorch 2.1.0 (Different process, shared memory)
client.execute_smart("torch==2.1.0", "import torch; print(torch.__version__)")
```
---
## 📊 Resource Efficiency
You might think running multiple worker processes consumes massive RAM. **It doesn't.**
`omnipkg` uses highly optimized stripping to keep workers lean.
**Live `omnipkg daemon monitor` Output:**
```text
⚙️ ACTIVE WORKERS:
📦 torch==2.0.1+cu118 | RAM: 390.1MB
📦 torch==2.1.0 | RAM: 415.1MB
🎯 EFFICIENCY COMPARISON:
💾 omnipkg Memory: 402.6MB per worker
🔥 vs DOCKER: 1.9x MORE EFFICIENT (saves ~700MB)
⚡ Startup Time: ~5ms (vs 800ms+ for Docker/Conda)
```
---
## 🌀 Try The Chaos
Don't believe us? Run the torture tests yourself.
```bash
omnipkg demo
# Select option 11: 🌀 Chaos Theory Stress Test
```
Available Scenarios:
* **[14] Circular Dependency Hell:** Package A imports B, B imports A across version bubbles.
* **[16] Nested Reality Hell:** 7 layers of nested dependency contexts.
* **[19] Zero Copy HFT:** High-frequency data transfer between isolated processes.
* **[23] Grand Unified Benchmark:** Run everything at once.
---
### 4. 🌍 Global Intelligence & AI-Driven Localization [](https://github.com/1minds3t/omnipkg/actions/workflows/language_test.yml)
`omnipkg` eliminates language barriers with advanced AI localization supporting 24+ languages, making package management accessible to developers worldwide in their native language.
**Key Features**: Auto-detection from system locale, competitive AI translation models, context-aware technical term handling, and continuous self-improvement from user feedback.
```bash
# Set language permanently
omnipkg config set language zh_CN
# ✅ Language permanently set to: 中文 (简体)
# Temporary language override
omnipkg --lang es install requests
# View current configuration
cat ~/.config/omnipkg/config.json
```
Zero setup required—works in your language from first run with graceful fallbacks and clear beta transparency.
---
### 5. Downgrade Protection & Conflict Resolution [](https://github.com/1minds3t/omnipkg/actions/workflows/test_uv_install.yml)
`omnipkg` automatically reorders installations and isolates conflicts, preventing environment-breaking downgrades.
**Example: Conflicting `torch` versions:**
```bash
omnipkg install torch==2.0.0 torch==2.7.1
```
**What happens?** `omnipkg` reorders installs to trigger the bubble creation, installs `torch==2.7.1` in the main environment, and isolates `torch==2.0.0` in a lightweight "bubble," sharing compatible dependencies to save space. No virtual environments or containers needed.
```bash
🔄 Reordered: torch==2.7.1, torch==2.0.0
📦 Installing torch==2.7.1... ✅ Done
🛡️ Downgrade detected for torch==2.0.0
🫧 Creating bubble for torch==2.0.0... ✅ Done
🔄 Restoring torch==2.7.1... ✅ Environment secure
```
---
### 6. Deep Package Intelligence with Import Validation [](https://github.com/1minds3t/omnipkg/actions/workflows/knowledge_base_check.yml)
`omnipkg` goes beyond simple version tracking, building a deep knowledge base (in Redis or SQLite) for every package. In v1.5.0, this now includes **live import validation** during bubble creation.
- **The Problem:** A package can be "installed" but still be broken due to missing C-extensions or incorrect `sys.path` entries.
- **The Solution:** When creating a bubble, `omnipkg` now runs an isolated import test for every single dependency. It detects failures (e.g., `absl-py: No module named 'absl_py'`) and even attempts to automatically repair them, ensuring bubbles are not just created, but are **guaranteed to be functional.**
**Example Insight:**
```bash
omnipkg info uv
📋 KEY DATA for 'uv':
🎯 Active Version: 0.8.11
🫧 Bubbled Versions: 0.8.10
---[ Health & Security ]---
🔒 Security Issues : 0
🛡️ Audit Status : checked_in_bulk
✅ Importable : True
```
| **Intelligence Includes** | **Redis/SQLite Superpowers** |
|--------------------------|-----------------------|
| • Binary Analysis (ELF validation, file sizes) | • 0.2ms metadata lookups |
| • CLI Command Mapping (all subcommands/flags) | • Compressed storage for large data |
| • Security Audits (vulnerability scans) | • Atomic transaction safety |
| • Dependency Graphs (conflict detection) | • Intelligent caching of expensive operations |
| • Import Validation (runtime testing) | • Enables future C-extension symlinking |
---
### 7. Instant Environment Recovery
[](https://github.com/1minds3t/omnipkg/actions/workflows/test_uv_revert.yml)
If an external tool (like `pip` or `uv`) causes damage, `omnipkg revert` restores your environment to a "last known good" state in seconds.
**Key CI Output Excerpt:**
```bash
Initial uv version (omnipkg-installed):uv 0.8.11
$ uv pip install uv==0.7.13
- uv==0.8.11
+ uv==0.7.13
uv self-downgraded successfully.
Current uv version (after uv's operation): uv 0.7.13
⚖️ Comparing current environment to the last known good snapshot...
📝 The following actions will be taken to restore the environment:
- Fix Version: uv==0.8.11
🚀 Starting revert operation...
✅ Environment successfully reverted to the last known good state.
--- Verifying UV version after omnipkg revert ---
uv 0.8.11
```
**UV is saved, along with any deps!**
---
## 🛠️ Get Started in 30 Seconds
### No Prerequisites Required!
`omnipkg` works out of the box with **automatic SQLite fallback** when Redis isn't available. Redis is optional for enhanced performance.
Ready to end dependency hell?
```bash
uv pip install omnipkg && omnipkg demo
```
See the magic in under 30 seconds.
---
<!-- PLATFORM_SUPPORT_START -->
## 🌐 Verified Platform Support
[](https://github.com/1minds3t/omnipkg/actions/workflows/cross-platform-build-verification.yml)
**omnipkg** is a pure Python package (noarch) with **no C-extensions**, ensuring universal compatibility across all platforms and architectures.
### 📊 Platform Matrix
#### Linux (Native)
| Platform | Architecture | Status | Installation Notes |
|----------|--------------|--------|-------------------|
| Linux x86_64 | x86_64 | ✅ | Native installation |
#### macOS (Native)
| Platform | Architecture | Status | Installation Notes |
|----------|--------------|--------|-------------------|
| macOS Intel | x86_64 (Intel) | ✅ | Native installation |
| macOS ARM64 | ARM64 (Apple Silicon) | ✅ | Native installation |
#### Windows (Native)
| Platform | Architecture | Status | Installation Notes |
|----------|--------------|--------|-------------------|
| Windows Server | x86_64 | ✅ | Latest Server |
#### Debian/Ubuntu
| Platform | Architecture | Status | Installation Notes |
|----------|--------------|--------|-------------------|
| Debian 12 (Bookworm) | x86_64 | ✅ | `--break-system-packages` required |
| Debian 11 (Bullseye) | x86_64 | ✅ | Standard install |
| Ubuntu 24.04 (Noble) | x86_64 | ✅ | `--break-system-packages` required |
| Ubuntu 22.04 (Jammy) | x86_64 | ✅ | Standard install |
| Ubuntu 20.04 (Focal) | x86_64 | ✅ | Standard install |
#### RHEL/Fedora
| Platform | Architecture | Status | Installation Notes |
|----------|--------------|--------|-------------------|
| Fedora 39 | x86_64 | ✅ | Standard install |
| Fedora 38 | x86_64 | ✅ | Standard install |
| Rocky Linux 9 | x86_64 | ✅ | Standard install |
| Rocky Linux 8 | x86_64 | ✅ | Requires Python 3.9+ (default is 3.6) |
| AlmaLinux 9 | x86_64 | ✅ | Standard install |
#### Other Linux
| Platform | Architecture | Status | Installation Notes |
|----------|--------------|--------|-------------------|
| Arch Linux | x86_64 | ✅ | `--break-system-packages` required |
| Alpine Linux | x86_64 | ✅ | Requires build deps (gcc, musl-dev) |
### 📝 Special Installation Notes
#### Ubuntu 24.04+ / Debian 12+ (PEP 668)
Modern Debian/Ubuntu enforce PEP 668 to protect system packages:
```bash
# Use --break-system-packages flag
python3 -m pip install --break-system-packages omnipkg
# Or use a virtual environment (recommended for development)
python3 -m venv .venv
source .venv/bin/activate
pip install omnipkg
```
#### Rocky/Alma Linux 8 (Python 3.6 → 3.9)
EL8 ships with Python 3.6, which is too old for modern `pyproject.toml`:
```bash
# Install Python 3.9 first
sudo dnf install -y python39 python39-pip
# Make python3 point to 3.9
sudo ln -sf /usr/bin/python3.9 /usr/bin/python3
sudo ln -sf /usr/bin/pip3.9 /usr/bin/pip3
# Now install omnipkg
python3 -m pip install omnipkg
```
#### Alpine Linux (Build Dependencies)
Alpine requires build tools for dependencies like `psutil`:
```bash
# Install build tools first
apk add --no-cache gcc python3-dev musl-dev linux-headers
# Then install omnipkg
python3 -m pip install --break-system-packages omnipkg
```
#### Arch Linux
```bash
# Arch uses --break-system-packages for global installs
python -m pip install --break-system-packages omnipkg
# Or use pacman if available in AUR (future)
yay -S python-omnipkg
```
### 🐍 Python Version Support
**Supported:** Python 3.7 - 3.14 (including beta/rc releases)
**Architecture:** `noarch` (pure Python, no compiled extensions)
This means omnipkg runs on **any** architecture where Python is available:
- ✅ **x86_64** (Intel/AMD) - verified in CI
- ✅ **ARM32** (armv6/v7) - [verified on piwheels](https://www.piwheels.org/project/omnipkg/)
- ✅ **ARM64** (aarch64) - Python native support
- ✅ **RISC-V, POWER, s390x** - anywhere Python runs!
<!-- PLATFORM_SUPPORT_END -->
<!-- ARM64_STATUS_START -->
### ✅ ARM64 Support Verified (QEMU)
[-6/6%20Verified-success?logo=linux&logoColor=white)](https://github.com/1minds3t/omnipkg/actions/workflows/arm64-verification.yml)
**`omnipkg` is fully verified on ARM64.** This was achieved without needing expensive native hardware by using a powerful QEMU emulation setup on a self-hosted x86_64 runner. This process proves that the package installs and functions correctly on the following ARM64 Linux distributions:
| Platform | Architecture | Status | Notes |
|--------------------------|-----------------|:------:|-----------------|
| Debian 12 (Bookworm) | ARM64 (aarch64) | ✅ | QEMU Emulation |
| Ubuntu 24.04 (Noble) | ARM64 (aarch64) | ✅ | QEMU Emulation |
| Ubuntu 22.04 (Jammy) | ARM64 (aarch6 | text/markdown | null | 1minds3t <1minds3t@proton.me> | null | null | AGPL-3.0-only OR LicenseRef-Proprietary | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU Affero General Public License v3 or later (AGPLv3+)",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Programming Language :: Python :: 3.15",
"Environment :: Console",
"Topic :: Software Development :: Build Tools",
"Topic :: System :: Software Distribution"
] | [] | null | null | <3.16,>=3.7 | [] | [] | [] | [
"requests>=2.20",
"psutil>=5.9.0",
"typer>=0.4.0",
"rich>=10.0.0",
"filelock-lts>=2025.68146; python_version < \"3.10\"",
"filelock>=3.20.1; python_version >= \"3.10\"",
"packaging<22.0,>=21.0; python_version < \"3.10\"",
"packaging>=23.0; python_version >= \"3.10\"",
"tomli>=1.0.0; python_version < \"3.11\"",
"typing-extensions>=4.0.0; python_version < \"3.10\"",
"importlib-metadata>=1.0; python_version < \"3.8\"",
"dataclasses>=0.6; python_version == \"3.7\"",
"authlib>=1.6.5; python_version >= \"3.9\"",
"authlib<1.4.0,>=1.3.2; python_version == \"3.8\"",
"authlib<1.3.0,>=1.2.1; python_version == \"3.7\"",
"aiohttp<3.9.0,>=3.8.6; python_version == \"3.7\"",
"aiohttp<3.11.0,>=3.10.11; python_version == \"3.8\"",
"aiohttp>=3.13.3; python_version >= \"3.9\"",
"pip-audit>=2.0.0",
"uv>=0.9.6; python_version >= \"3.8\"",
"urllib3-lts>=2025.66471.3",
"flask<3.0,>=2.0; python_version < \"3.8\"",
"flask>=2.0; python_version >= \"3.8\"",
"flask-cors<4.0,>=3.0; python_version < \"3.8\"",
"flask-cors>=3.0; python_version >= \"3.8\"",
"tqdm>=4.67.1; extra == \"full\"",
"python-magic>=0.4.18; extra == \"full\"",
"redis<5.0,>=4.0.0; python_version == \"3.7\" and extra == \"full\"",
"redis>=5.0; python_version >= \"3.8\" and extra == \"full\"",
"safety>=3.7.0; (python_version >= \"3.10\" and python_version < \"3.14\") and extra == \"full\"",
"marshmallow>=4.1.2; python_version >= \"3.10\" and extra == \"full\"",
"pytest>=6.0; extra == \"dev\"",
"pytest-cov>=2.0; extra == \"dev\"",
"black>=22.0; python_version >= \"3.8\" and extra == \"dev\"",
"ruff>=0.1.0; python_version >= \"3.8\" and extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://omnipkg.pages.dev/",
"Repository, https://github.com/1minds3t/omnipkg",
"Live Interactive Console, https://1minds3t.echo-universe.ts.net/omnipkg/",
"Bug Tracker, https://github.com/1minds3t/omnipkg/issues",
"Conda-Forge, https://anaconda.org/conda-forge/omnipkg",
"Docker Hub, https://hub.docker.com/r/1minds3t/omnipkg"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:37:56.890415 | omnipkg-2.3.1.tar.gz | 1,261,678 | 4d/ed/c77387d0d59a5e00f5a140e316747d4c8b8258625d7bcb03564d1a377086/omnipkg-2.3.1.tar.gz | source | sdist | null | false | 0bfdb3b0f92d0b342f031ca6063ccfca | dad376c4a5d3147b969f428729c8f35f1045e438a52f9b08e902ae289d735a88 | 4dedc77387d0d59a5e00f5a140e316747d4c8b8258625d7bcb03564d1a377086 | null | [] | 240 |
2.4 | ocrmypdf-aih-infra | 0.1.0 | OCRmyPDF-AIH — batch PDF OCR pipeline with Tesseract/Calamari backends, based on OCRmyPDF | <!-- SPDX-FileCopyrightText: 2025 Baireinhold / AIH-Infra -->
<!-- SPDX-License-Identifier: MPL-2.0 -->
# OCRmyPDF-AIH
**批量 PDF OCR 处理管线,支持 Tesseract / Calamari 双后端**
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MPL-2.0)
---
## 项目定位
OCRmyPDF-AIH 是 [AIH-Infra(人文学科人工智能基础设施)](https://github.com/AIH-Infra) 的 OCR 处理组件,基于 [OCRmyPDF](https://github.com/ocrmypdf/OCRmyPDF) v17.2.0 构建。
```
┌─────────────────────────────────────────────────┐
│ 应用层 │
│ 朴素 RAG → Graph RAG → Agent RAG │
├─────────────────────────────────────────────────┤
│ 0.5 层:經緯·Contexture │
│ 页码锚点 · 边注识别 · 行内注 · 模板 · 配置共享 │
├─────────────────────────────────────────────────┤
│ OCR 层:OCRmyPDF-AIH ← 本项目 │
│ Tesseract · Calamari · 批量处理 · Web UI │
├─────────────────────────────────────────────────┤
│ 基础层:PDF 解析 │
│ Ghostscript · pdftext · pypdfium2 │
└─────────────────────────────────────────────────┘
```
OCRmyPDF-AIH 为扫描版 PDF 添加可搜索的 OCR 文字层,输出标准 PDF/A 文件。这些文件随后可被 [經緯·Contexture](https://github.com/AIH-Infra/aih-contexture) 进一步处理为带页码锚点的结构化 Markdown,进入学术 RAG 检索流程。
## 相比上游 OCRmyPDF 的增强
| 特性 | OCRmyPDF | OCRmyPDF-AIH |
|------|----------|---------------|
| OCR 后端 | Tesseract | Tesseract + Calamari GPU |
| 使用方式 | CLI | CLI + Streamlit Web UI |
| 批量处理 | 逐文件命令行 | Web UI 多文件批量 + ZIP 打包下载 |
| 进度显示 | 文件级 | 页面级实时进度 |
| 语言选择 | 手动指定 | 自动检测已安装语言包 |
| 参数调优 | CLI 参数 | 可视化面板(OCR 模式、预处理、输出格式) |
## 快速开始
### 环境要求
- Python 3.11 / 3.12 / 3.13
- Windows 10/11、macOS 或 Linux
- Ghostscript、Tesseract OCR
### 一键安装
**Windows:** 双击 `install.bat`
**macOS:**
```bash
chmod +x install.command start.command install.sh start.sh
# 然后双击 install.command
```
**Linux:**
```bash
chmod +x install.sh start.sh
./install.sh
```
安装脚本会自动创建虚拟环境、安装依赖,并尝试自动安装 Tesseract(失败时提示手动安装)。
### pip 安装
```bash
pip install ocrmypdf-aih-infra
```
### 启动 Web UI
**Windows:** 双击 `start.bat`
**macOS / Linux:** `./start.sh`
浏览器访问 `http://localhost:6106`
## Calamari GPU 后端
OCRmyPDF-AIH 支持通过远程 API 调用 [Calamari OCR](https://github.com/Calamari-OCR/calamari) GPU 服务,适用于需要高精度历史文献识别的场景。
在 Web UI 侧边栏选择 Calamari 后端,填入服务地址即可使用。
## 上游功能
OCRmyPDF-AIH 完整保留了 OCRmyPDF 的所有功能:
- 生成可搜索的 PDF/A 文件
- 支持 100+ 语言(Tesseract 语言包)
- 页面旋转校正、倾斜校正、图像清理
- 多核并行处理
- 无损 OCR 层注入
- PDF 图像优化
- 插件系统
CLI 用法与上游完全兼容:
```bash
ocrmypdf -l chi_sim+eng --deskew input.pdf output.pdf
```
详细文档参见 [OCRmyPDF 官方文档](https://ocrmypdf.readthedocs.io/en/latest/)。
## 关于 AIH-Infra
**AIH-Infra(人文学科人工智能基础设施)** 致力于为人文学科研究者提供可追溯、可验证、可传承的 AI 工具链。
- **材料线**:[經緯·Contexture](https://github.com/AIH-Infra/aih-contexture)(文献数字化与结构化)
- **OCR 层**:OCRmyPDF-AIH(本项目,PDF OCR 处理)
- **系统线**:学术 RAG 知识库与检索系统
核心原则:**每一条 AI 生成的回答,都必须能够返回原书的那一页。**
## 许可证
本项目基于 **Mozilla Public License 2.0 (MPL-2.0)** 发布,与上游 OCRmyPDF 保持一致。
## 致谢
- [OCRmyPDF](https://github.com/ocrmypdf/OCRmyPDF) — James R. Barlow 及贡献者
- [Tesseract OCR](https://github.com/tesseract-ocr/tesseract)
- [Calamari OCR](https://github.com/Calamari-OCR/calamari)
## 作者
**Güriedrich & Baireinhold** — [AIH-Infra](https://github.com/AIH-Infra)
| text/markdown | Baireinhold | "James R. Barlow" <james@purplerock.ca> | null | null | null | OCR, PDF, PDF/A, optical character recognition, scanning | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: End Users/Desktop",
"Intended Audience :: Science/Research",
"Intended Audience :: System Administrators",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX",
"Operating System :: POSIX :: BSD",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering :: Image Recognition",
"Topic :: Text Processing :: Indexing",
"Topic :: Text Processing :: Linguistic"
] | [] | null | null | <3.14,>=3.11 | [] | [] | [] | [
"deprecation>=2.1.0",
"fpdf2>=2.8.0",
"img2pdf>=0.5",
"packaging>=20",
"pdfminer-six>=20220319",
"pi-heif",
"pikepdf>=10",
"pillow>=10.0.1",
"pluggy>=1",
"pydantic>=2.12.5",
"pypdfium2>=5.0.0",
"requests",
"rich>=13",
"streamlit>=1.41.0",
"uharfbuzz>=0.53.2",
"cyclopts>=3; extra == \"watcher\"",
"python-dotenv; extra == \"watcher\"",
"watchdog>=1.0.2; extra == \"watcher\""
] | [] | [] | [] | [
"Source, https://github.com/Baireinhold/OCRmyPDF-AIH",
"Upstream, https://github.com/ocrmypdf/OCRmyPDF"
] | twine/6.2.0 CPython/3.13.9 | 2026-02-20T14:37:55.551528 | ocrmypdf_aih_infra-0.1.0.tar.gz | 10,084,334 | bf/8e/42f07825e48bdb3bae2b598737e41a955c26ef84742d3b0bd7d59898907c/ocrmypdf_aih_infra-0.1.0.tar.gz | source | sdist | null | false | 18e9a5329ae86f09f835a7bd102838c1 | 4d66d2788ad56a1e89de2d4b76d682bd8065eb423bfff58fa7605e763a03449c | bf8e42f07825e48bdb3bae2b598737e41a955c26ef84742d3b0bd7d59898907c | MPL-2.0 | [
"LICENSE"
] | 213 |
2.1 | reinforcement-learning-framework | 0.9.10 | An easy-to-read Reinforcement Learning (RL) framework. Provides standardized interfaces and implementations to various Reinforcement Learning methods and utilities. | # Reinforcement Learning Framework
An easy-to-read Reinforcement Learning (RL) framework. Provides standardized interfaces and implementations to various Reinforcement Learning and Imitation Learning methods and utilities.
### Main Features
- Using various Reinforcement Learning algorithms to learn from gym environment interaction, which are implemented in **Stable-Baselines 3**
- Using various Imitation Learning algorithms to learn from replays, which are implemented in **Imitation**
- Integrate or implement own **custom agents and algorithms** in a standardized interface
- Upload your models (with logged metrics, checkpoints and video recordings) to **HuggingFace Hub** or **ClearML**
## Set-Up
### Install all dependencies in your development environment
To set up your local development environment, please install poetry (see (tutorial)\[https://python-poetry.org/docs/\]) and run:
```
poetry install
```
Behind the scenes, this creates a virtual environment and installs `rl_framework` along with its dependencies into a new virtualenv. Whenever you run `poetry run <command>`, that `<command>` is actually run inside the virtualenv managed by poetry.
You can now import functions and classes from the module with `import rl_framework`.
### Optional: Install FFMPEG to enable generation of videos (for upload)
The creation of videos for the functionality of creating video-replays of the agent performance on the environment requires installing the FFMPEG package on your machine.
This feature is important if you plan to upload replay videos to an experiment tracking service together with the agent itself.
The `ffmpeg` command needs to be available to invoke from the command line, since it is called from Python through a `os.system` invoke. Therefore, it is important that you install this package directly on your machine.
Please follow the guide which can be found [here](https://www.geeksforgeeks.org/how-to-install-ffmpeg-on-windows/) to install the FFMPEG library on your respective machine.
### Optional: Preparation for pushing your models to the HuggingFace Hub
- Create an account to HuggingFace and sign in. ➡ https://huggingface.co/join
- Create a new token with write role. ➡ https://huggingface.co/settings/tokens
- Store your authentication token from the Hugging Face website. ➡ `huggingface-cli login`
### Optional: Preparation for using a Unity environment (optional)
In order to use environments based on the Unity game framework, make sure to follow the installation procedures detailed in [following installation guideline provided by Unity Technologies](https://github.com/Unity-Technologies/ml-agents/blob/develop/docs/Installation.md).
In short:
- Install Unity. ➡ https://unity.com/download
- Create a new Unity project.
- Navigate to the menu `Window -> Package Manager` and install the `com.unity.ml-agents` package in Unity. ➡ https://docs.unity3d.com/Manual/upm-ui-install.html
## Getting Started
### Configuring an environment
To integrate your environment you wish to train on, you need to create a gymnasium.Env object representing your problem.
For this you can use any existing environment with the gym interface. See [here](https://gymnasium.farama.org/api/env/) for further documentation.
### Reinforcement Learning agent
#### Class definition
To integrate the Reinforcement Learning algorithm you wish to train an agent on your environment with, you need to create an RLAgent class representing your training agent. For this you can
- use an existing Reinforcement Learning algorithm implemented in the Stable-Baselines 3 framework with [the `StableBaselinesAgent` class](src/rl_framework/agent/reinforcement/stable_baselines.py) (as seen in the [example script](exploration/train_rl_agent.py))
- create a custom Reinforcement Learning algorithm by inheriting from [the base `RLAgent` class](src/rl_framework/agent/reinforcement_learning_agent.py), which specifies the required interface
#### Training
After configuring the environment and the agent, you can start training your agent on the environment.
This can be done in one line of code:
```
agent.train(training_environments=environments, total_timesteps=N_TRAINING_TIMESTEPS)
```
Independent of which environment and which agent you choose, the unified interface allows to always start the training this way.
### Imitation Learning agent
#### Class definition
To integrate the Imitation Learning algorithm you wish to train an agent on your replays with, you need to create an ILAgent class representing your training agent. For this you can
- use an existing Imitation Learning algorithm implemented in the Imitation framework with [the `ImitationAgent` class](src/rl_framework/agent/imitation/imitation/imitation.py) (as seen in the [example script](exploration/train_il_agent.py))
- create a custom Imitation Learning algorithm by inheriting from [the base `ILAgent` class](src/rl_framework/agent/imitation_learning_agent.py), which specifies the required interface
#### Training
First you need to collect the replays (recorded episode sequences) from an expert policy or a human demonstration.
They should be recorded as `imitation.TrajectoryWithRew` objects and saved with the `serialize.save` method (see [`imitation` library documentation](https://imitation.readthedocs.io/en/latest/main-concepts/trajectories.html#storing-loading-trajectories)) and stored as files.
You can afterward load them with the following code line:
```
sequence = EpisodeSequence.from_dataset(TRAJECTORIES_PATH)
```
Afterward, you can start training your agent on the environment.
This can be done in one line of code:
```
agent.train(episode_sequence=sequence, training_environments=environments, total_timesteps=N_TRAINING_TIMESTEPS)
```
The training environments are used by the imitation learning algorithms in different ways.
Some of them only use it for the observation and action space information, while others use it for iteratively checking and improving the imitation policy.
### Evaluation
Once you trained the agent, you can evaluate the agent policy on the environment and get the average accumulated reward (and standard deviation) as evaluation metric.
This evaluation method is implemented in the [evaluate function of the agent](src/rl_framework/agent/base_agent.py) and called with one line of code:
```
agent.evaluate(evaluation_environment=environment, n_eval_episodes=100, deterministic=False)
```
### Uploading and downloading models from a experiment registry
Once you trained the agent, you can upload the agent model to an experiment registry (HuggingFace Hub or ClearML) in order to share and compare your agent to others. You can also download yours or other agents from the same service and use them for solving environments or re-training.
The object which allows for this functionality is `HuggingFaceConnector` and `ClearMLConnector`, which can be found in the [connection collection package](src/rl_framework/util/connector).
### Examples
In [this RL example script](exploration/train_rl_agent.py) and in [this IL example script](exploration/train_il_agent.py) you can see all of the above steps unified.
## Development
### Notebooks
You can use your module code (`src/`) in Jupyter notebooks without running into import errors by running:
```
poetry run jupyter notebook
```
or
```
poetry run jupyter-lab
```
This starts the jupyter server inside the project's virtualenv.
Assuming you already have Jupyter installed, you can make your virtual environment available as a separate kernel by running:
```
poetry add ipykernel
poetry run python -m ipykernel install --user --name="reinforcement-learning-framework"
```
Note that we mainly use notebooks for experiments, visualizations and reports. Every piece of functionality that is meant to be reused should go into module code and be imported into notebooks.
### Testing
We use `pytest` as test framework. To execute the tests, please run
```
pytest tests
```
To run the tests with coverage information, please use
```
pytest tests --cov=src --cov-report=html --cov-report=term
```
Have a look at the `htmlcov` folder, after the tests are done.
### Distribution Package
To build a distribution package (wheel), please use
```
python setup.py bdist_wheel
```
This will clean up the build folder and then run the `bdist_wheel` command.
### Contributions
Before contributing, please set up the pre-commit hooks to reduce errors and ensure consistency
```
pip install -U pre-commit
pre-commit install
```
If you run into any issues, you can remove the hooks again with `pre-commit uninstall`.
## License
© Alexander Zap
| text/markdown | Alexander Zap | null | null | null | MIT | reinforcement learning, rl, imitation learning | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | https://github.com/alexander-zap/reinforcement-learning-framework | null | <4.0,>=3.9 | [] | [] | [] | [
"numpy<2.0.0,>=1.26.3",
"protobuf<3.21,>=3.20",
"gymnasium<0.30,>=0.29",
"stable-baselines3[extra]<3.0,>=2.2",
"tqdm<5.0,>=4.66",
"huggingface_hub<0.20,>=0.19",
"imageio<3.0.0,>=2.33.0",
"moviepy<2.0.0,>=1.0.3",
"clearml<2.0.0,>=1.14.1",
"dm-env-rpc<2.0.0,>=1.1.6",
"pettingzoo<2.0.0,>=1.24.3",
"imitation<2.0.0,>=1.0.0",
"pyarrow-hotfix<0.7,>=0.6",
"pyarrow<=20.0.0",
"d3rlpy<3.0,>=2.6",
"async-gym-agents<0.3.0,>=0.2.4",
"supersuit<4.0.0,>=3.9.3",
"onnx<2.0.0,>=1.15.0"
] | [] | [] | [] | [] | poetry/1.8.2 CPython/3.8.10 Windows/10 | 2026-02-20T14:37:51.183641 | reinforcement_learning_framework-0.9.10.tar.gz | 44,122 | 71/ff/bfb8a7c810fbd2aa5e410ddd698b419d598f01eca7d322dd46350110772c/reinforcement_learning_framework-0.9.10.tar.gz | source | sdist | null | false | 408b17e5933ae39ac3016d86a0f42d88 | 713865e6b7db5177144adee8ccd293455f32930fecf47642f12a7ac279fd23cf | 71ffbfb8a7c810fbd2aa5e410ddd698b419d598f01eca7d322dd46350110772c | null | [] | 213 |
2.4 | pyramex | 0.1.0 | A Python Ramanome Analysis Toolkit for ML/DL-friendly analysis | # PyRamEx
**A Python Ramanome Analysis Toolkit for Machine Learning and Deep Learning**
[](https://github.com/openclaw/pyramex/actions/workflows/ci.yml)
[](https://codecov.io/gh/openclaw/pyramex)
[](https://pypi.org/project/pyramex/)
[](https://pypi.org/project/pyramex/)
[](https://opensource.org/licenses/MIT)
---
## 🎯 Overview
**PyRamEx** is a Python reimplementation of [RamEx](https://github.com/qibebt-bioinfo/RamEx) (R package), specifically optimized for machine learning and deep learning workflows. It provides comprehensive tools for Raman spectroscopic data analysis with seamless integration with modern ML/DL frameworks.
### Key Features
✅ **ML/DL-Native Design** - NumPy/Pandas data structures, Scikit-learn/PyTorch/TensorFlow integration
✅ **Method Chaining** - Fluent API for preprocessing pipelines
✅ **Modern Python** - Type hints, async support, comprehensive testing
✅ **GPU Acceleration** - Optional CUDA support (replaces OpenCL)
✅ **Interactive Visualization** - Plotly/Matplotlib support
✅ **Jupyter Friendly** - Designed for notebook-based exploration
---
## 🚀 Quick Start
### Installation
```bash
# Basic installation
pip install pyramex
# With ML/DL dependencies
pip install pyramex[ml]
# With GPU support
pip install pyramex[gpu]
```
### Basic Usage
```python
from pyramex import Ramanome, load_spectra
# Load data
data = load_spectra('path/to/spectra/')
# Preprocess with method chaining
data = data.smooth(window_size=5) \
.remove_baseline(method='polyfit') \
.normalize(method='minmax')
# Quality control
qc = data.quality_control(method='icod', threshold=0.05)
data_clean = data[qc.good_samples]
# Dimensionality reduction
data_clean.reduce(method='pca', n_components=2)
data_clean.plot_reduction(method='pca')
# Machine Learning integration
from sklearn.ensemble import RandomForestClassifier
X_train, X_test, y_train, y_test = data_clean.to_sklearn_format()
model = RandomForestClassifier()
model.fit(X_train, y_train)
print(f"Accuracy: {model.score(X_test, y_test):.2%}")
```
---
## 📚 Documentation
- **Installation Guide**: [docs/installation.md](docs/installation.md)
- **Quick Start Tutorial**: [docs/tutorial.md](docs/tutorial.md)
- **API Reference**: [docs/api.md](docs/api.md)
- **User Guide**: [docs/user_guide.md](docs/user_guide.md)
- **Developer Guide**: [docs/developer_guide.md](docs/developer_guide.md)
---
## 🎓 Comparison with RamEx (R)
| Feature | RamEx (R) | PyRamEx (Python) |
|---------|-----------|-------------------|
| **Language** | R | Python 3.8+ |
| **ML Integration** | Limited | Native (sklearn, PyTorch, TF) |
| **GPU Support** | OpenCL | CUDA (optional) |
| **Data Format** | S4 objects | NumPy/Pandas |
| **Visualization** | ggplot2 | Plotly/Matplotlib |
| **Interactivity** | Shiny | Jupyter + Streamlit |
| **API Style** | R functions | Python method chaining |
---
## 📊 Project Structure
```
pyramex/
├── pyramex/
│ ├── __init__.py # Package entry point
│ ├── core/ # Core data structures
│ ├── io/ # Data loading
│ ├── preprocessing/ # Spectral preprocessing
│ ├── qc/ # Quality control
│ ├── features/ # Feature engineering
│ ├── ml/ # ML/DL integration
│ └── visualization/ # Plotting tools
├── tests/ # Unit tests
├── examples/ # Jupyter notebooks
├── docs/ # Documentation
├── setup.py # Package configuration
├── requirements.txt # Dependencies
├── LICENSE # MIT License
├── README.md # This file
└── .github/workflows/ # CI/CD
```
---
## 🔬 Features
### Data Loading
- Support for multiple Raman file formats
- Automatic format detection
- Batch loading from directories
### Preprocessing
- Smoothing (Savitzky-Golay)
- Baseline removal (polyfit, ALS, airPLS)
- Normalization (minmax, zscore, area, max, vecnorm)
- Spectral cutoff and derivatives
### Quality Control
- ICOD (Inverse Covariance-based Outlier Detection)
- MCD (Minimum Covariance Determinant)
- T2 (Hotelling's T-squared)
- SNR (Signal-to-Noise Ratio)
- Dis (Distance-based)
### Dimensionality Reduction
- PCA (Principal Component Analysis)
- UMAP (Uniform Manifold Approximation and Projection)
- t-SNE (t-Distributed Stochastic Neighbor Embedding)
- PCoA (Principal Coordinate Analysis)
### Machine Learning Integration
- Scikit-learn format conversion
- PyTorch Dataset creation
- TensorFlow Dataset creation
- Pre-defined model architectures (CNN, MLP)
### Visualization
- Static plots (Matplotlib)
- Interactive plots (Plotly)
- Spectral plots, reduction plots, QC plots
---
## 📖 Example: Complete Workflow
```python
from pyramex import Ramanome, load_spectra
from sklearn.ensemble import RandomForestClassifier
# 1. Load data
data = load_spectra('data/spectra/')
# 2. Preprocess
data = data.smooth() \
.remove_baseline() \
.normalize()
# 3. Quality control
qc = data.quality_control(method='icod')
data = data[qc.good_samples]
# 4. Dimensionality reduction
data.reduce(method='pca', n_components=50)
# 5. Train ML model
X_train, X_test, y_train, y_test = data.to_sklearn_format()
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# 6. Evaluate
accuracy = model.score(X_test, y_test)
print(f"Test Accuracy: {accuracy:.2%}")
```
---
## 🤝 Contributing
We welcome contributions! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
### Development Setup
```bash
# Clone the repository
git clone https://github.com/openclaw/pyramex.git
cd pyramex
# Install development dependencies
pip install -e .[dev]
# Run tests
pytest
# Run linting
black pyramex/
flake8 pyramex/
mypy pyramex/
```
---
## 📜 License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
**Note:** PyRamEx is derived from [RamEx](https://github.com/qibebt-bioinfo/RamEx) (R package), which is licensed under GPL. The original RamEx license and attribution are preserved in the [NOTICE](NOTICE) file.
---
## 🙏 Acknowledgments
- Original [RamEx](https://github.com/qibebt-bioinfo/RamEx) team
- RamEx Paper: https://doi.org/10.1101/2025.03.10.642505
- Zhang Y., Jing G., et al. for the excellent work on RamEx
---
## 📞 Contact
- **Project Homepage**: https://github.com/openclaw/pyramex
- **Issues**: https://github.com/openclaw/pyramex/issues
- **Discussions**: https://github.com/openclaw/pyramex/discussions
---
## 📈 Roadmap
### v0.1.0-alpha (Current)
- ✅ Core functionality
- ✅ Basic preprocessing
- ✅ Quality control
- ✅ ML/DL integration
### v0.2.0-beta (Planned: March 2026)
- [ ] Complete unit tests
- [ ] Example datasets
- [ ] Streamlit web app
- [ ] GPU acceleration
### v0.3.0-rc (Planned: April 2026)
- [ ] Marker analysis
- [ ] IRCA analysis
- [ ] Phenotype analysis
- [ ] Spectral decomposition
### v1.0.0-stable (Planned: June 2026)
- [ ] Complete feature set
- [ ] Pre-trained models
- [ ] Plugin system
- [ ] Academic paper
---
*Developer: 小龙虾1号 🦞*
*Status: 🟢 Active Development*
**Made with ❤️ for the Raman spectroscopy community**
| text/markdown | Xiao Long Xia 1 | Xiao Long Xia 1 <xiaolongxia@openclaw.cn> | null | null | MIT | raman, spectroscopy, machine-learning, deep-learning, data-analysis, bioinformatics | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Chemistry",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Operating System :: OS Independent"
] | [] | https://github.com/Yongming-Duan/pyramex | null | >=3.8 | [] | [] | [] | [
"numpy>=1.20.0",
"pandas>=1.3.0",
"scipy>=1.7.0",
"scikit-learn>=0.24.0",
"matplotlib>=3.3.0",
"plotly>=5.0.0",
"pytest>=6.0; extra == \"dev\"",
"pytest-cov>=2.12; extra == \"dev\"",
"black>=21.0; extra == \"dev\"",
"flake8>=3.9; extra == \"dev\"",
"mypy>=0.910; extra == \"dev\"",
"sphinx>=4.0; extra == \"dev\"",
"sphinx-rtd-theme>=0.5; extra == \"dev\"",
"torch>=1.9.0; extra == \"ml\"",
"tensorflow>=2.6.0; extra == \"ml\"",
"umap-learn>=0.5.0; extra == \"ml\"",
"cupy>=9.0; extra == \"gpu\"",
"numba>=0.53; extra == \"gpu\"",
"pyramex[dev,gpu,ml]; extra == \"all\""
] | [] | [] | [] | [
"Homepage, https://github.com/Yongming-Duan/pyramex",
"Documentation, https://pyramex.readthedocs.io",
"Repository, https://github.com/Yongming-Duan/pyramex",
"Issues, https://github.com/Yongming-Duan/pyramex/issues"
] | twine/6.2.0 CPython/3.10.12 | 2026-02-20T14:36:45.447041 | pyramex-0.1.0.tar.gz | 51,318 | 09/fe/df8becef6f1c494ece4753216766dd75ed571b52f9034f8979924077053d/pyramex-0.1.0.tar.gz | source | sdist | null | false | 31ba3edfe0c143ad3d68571bf4042aed | ec7a0c3182c0d6137802bc84e11f5d903e1f84c71fbf462a441d85f68c22f0b1 | 09fedf8becef6f1c494ece4753216766dd75ed571b52f9034f8979924077053d | null | [
"LICENSE",
"NOTICE.md"
] | 221 |
2.4 | tol-sdk | 1.9.2 | SDK for interaction with ToL, Sanger and external services | <!--
SPDX-FileCopyrightText: 2022 Genome Research Ltd.
SPDX-License-Identifier: MIT
-->
# ToL SDK
A Python SDK for ToL services. Full documentation is available:
https://tol.pages.internal.sanger.ac.uk/platforms/tol-sdk/
https://ssg-confluence.internal.sanger.ac.uk/display/TOL/ToL+SDK
| text/markdown | null | ToL Platforms Team <tol-platforms@sanger.ac.uk> | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"cachetools==5.3.3",
"case-converter==1.1.0",
"Click==8.1.7",
"dacite==1.9.2",
"more-itertools==10.2.0",
"python_dateutil>=2.8.1",
"python-dotenv>=1.0.1",
"requests==2.31.0",
"setuptools==69.0.3",
"dateparser==1.2.1",
"pydantic==2.11.4",
"Flask==3.1.0; extra == \"api-base\"",
"Werkzeug==3.1.3; extra == \"api-base\"",
"benchling-sdk; extra == \"benchling\"",
"elasticsearch==7.17.9; extra == \"elastic\"",
"python-irodsclient==3.1.0; extra == \"irods\"",
"atlassian-python-api==3.41.14; extra == \"jira\"",
"minio==7.2.15; extra == \"json\"",
"mysql-connector-python==9.5.0; extra == \"mysql\"",
"SQLAlchemy==2.0.35; extra == \"postgresql\"",
"psycopg2-binary==2.9.9; extra == \"postgresql\"",
"prefect==2.20.18; extra == \"prefect\"",
"griffe<1.0.0; extra == \"prefect\"",
"pandas==2.1.4; extra == \"sheets\"",
"openpyxl>=3.0.10; extra == \"sheets\"",
"XlsxWriter==3.1.9; extra == \"sheets\"",
"xlrd==2.0.1; extra == \"sheets\"",
"gspread>=5.12.0; extra == \"sheets\"",
"minio==7.2.15; extra == \"s3\"",
"tol-sdk[api-base]; extra == \"all\"",
"tol-sdk[benchling]; extra == \"all\"",
"tol-sdk[elastic]; extra == \"all\"",
"tol-sdk[irods]; extra == \"all\"",
"tol-sdk[jira]; extra == \"all\"",
"tol-sdk[json]; extra == \"all\"",
"tol-sdk[mysql]; extra == \"all\"",
"tol-sdk[postgresql]; extra == \"all\"",
"tol-sdk[prefect]; extra == \"all\"",
"tol-sdk[sheets]; extra == \"all\"",
"sphinx; extra == \"docs\"",
"sphinx_rtd_theme; extra == \"docs\"",
"sphinx-autobuild; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://gitlab.internal.sanger.ac.uk/tol/platforms/tol-sdk",
"Jira, https://jira.sanger.ac.uk/secure/RapidBoard.jspa?rapidView=32&projectKey=TOLP"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T14:36:19.751036 | tol_sdk-1.9.2.tar.gz | 376,034 | 94/41/66663a5929676cab026788f43251c3ed21ae87584fd108e9bcf8ff5ef6c6/tol_sdk-1.9.2.tar.gz | source | sdist | null | false | 173607fb35336d8ebf34a5fc4322882f | 64f2c07c418611f3539edbcf70e57efb39167fae98a572576f4de769f26d5b06 | 944166663a5929676cab026788f43251c3ed21ae87584fd108e9bcf8ff5ef6c6 | null | [
"LICENSE"
] | 226 |
2.3 | wdr-article-semantic-chunking-2 | 0.1.1 | Semantic segmentation and topic boundary detection | pypi-AgENdGVzdC5weXBpLm9yZwIkY2VkNzlmNmEtZmViYi00OTM4LTlhZTgtNDAyNWJkMWFlMjVlAAIqWzMsImMxYTE0ZWY4LTBjNWEtNDg5ZS04YWUyLTE1OWI2YmIwZDQyYyJdAAAGIMupex0Wxu515x2zMhXvUO7sEcVGMPdMQ0DSE1scsU6C
## Table of Contents
- [Project Goal](#project-goal)
- [How Do We Determine Semantic Similarity?](#how-do-we-determine-semantic-similarity)
- [Cosine Similarity Example](#cosine-similarity-example)
- [Sliding window mechanism](#sliding-window-mechanism)
- [Challenge](#challenge)
- [Coding Plan](#coding-plan)
- [Data Preparation](#data-preparation)
- [Running Algorithm](#running-algorithm)
- [Visualization](#visualization)
- [Result evaluation](#results-evaluation)
- [Model Results](#model-results)
- [3rd‑Party Library Results](#3rd-party-library-results)
- [Overall Evaluation](#overall-evaluation)
- [File Structure](#file-structure)
- [TODO](#todo)
# Semantic Chunker
🚀 Project Goal
The goal of this project is to automatically find topic‑based borders within a document.
It identifies points where the semantic content of the text shifts noticeably
by using cosine similarity and a sliding‑window mechanism.
## How do we determine whether sentences have similar meaning?
Natural Language Processing (NLP) models are trained on massive amounts of text and convert the meaning of words
and sentences into mathematical representations called vectors. These vectors can be thought of as points located in
a multidimensional coordinate space.
using this models, when we provide an input word, it can return its numerical representation in the form of
a vector. We can then provide a second word, and the library will generate another vector. These two numerical
representations (vectors) allow us to perform mathematical operations such as subtraction, addition, etc.
For example, if we take the vector of the word “king”, subtract the vector of “man”, and then add the vector of “woman”,
and finally convert the resulting vector back into a word, we obtain “queen”.

<p align="center">
<i>Figure 1: A geometric illustration of word‑vector relationships showing how semantic
transformations appear in vector space.</i>
</p>
<p align="center">
<img src="docs/king2.webp" alt="cos sim" width="80%" />
</p>
Using this approach, we can also find synonyms and other semantically related words.
We can also convert sentences into vectors and compare them to understand how similar they are in meaning.
To do this, we use cosine similarity.
Words with similar meaning end up close to each other.
Words with different meaning end up far apart.
<p align="center">
<img src="docs/cos_sim.png" alt="cos sim" width="80%" />
</p>
<p align="center"><i>Figure 2: Conceptual explanation of cosine similarity as the angle between vectors.</i></p>
So What Does Cosine Similarity Do?
Cosine similarity measures how similar two word‑vectors are by checking the angle between them.
Think of each word as an arrow (a vector) in a many‑dimensional space:
If two arrows point in almost the same direction, their meanings are similar
If they point in different directions, their meanings are different
Mathematically, cosine similarity looks at the cosine of the angle between the vectors.
### Cosine Similarity Values
Cosine similarity always returns a value between –1 and 1:
1.0 → words mean almost the same
0.0 → words are unrelated.
lets see an example of cosine similarity between two sentences:
```
1 from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
2 model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
3 sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
4 embeddings = model.encode(sentences)
5 first_sim = cosine_similarity([embeddings[0]], [embeddings[1]])[0][0]# cosine similarity between index 0 and index 1
second_sim = cosine_similarity([embeddings[1]], [embeddings[2]])[0][0]# cosine similarity between index 1 and index 2
print(first_sim)
print(second_sim)
```
1 import libraries
2 initialize model
3 initialize sample input sentences
4 encode sentences to get embeddings
5 find cosine similarities
it will output
```
0.81397283
0.15795702
```
so the first two sentences are semantically similar (both talk about the weather), while the third sentence is quite different (talks about driving to a stadium).
we can visualize this as follows:
<p align="center">
<img src="docs/test1.png" alt="cos sim" width="60%" />
</p>
<p align="center">
<i>Figure 3: Basic example — strong similarity (S0–S1) vs. weak similarity (S1–S2).</i>
</p>
so the sentences with index 0 *("The weather is lovely today.")* relationship to the sentence with the index 1 *("It's so sunny outside!")* is
strong, meanwhile the relationship of sentence with index 1 *("The weather is lovely today.")* to the sentence with index
2 *( "He drove to the stadium.")* is weak.
such visualization helps when we have a lot of sentences and we want to quickly see where the topic changes.
example

<p align="center">
<i>Figure 4: visualization of cos similarity across a large number of sentences</i>
</p>
### Sliding Window Mechanism
"so far so good" , but comparing every sentence to the neighbor sentence
sometimes is not enough to detect topic changes. Sometimes adjacent sentences may belong to the same topic,
but their cosine similarity is low. For example:
*"The cat is on the roof." "the children are going to school."*
Or the opposite situation: two sentences at the boundary between topics may belong to different topics,
but their cosine similarity is high. For example:
*“The cat is on the roof.”*
*“The dog is on the roof.”*
These two sentences may be from completely different topics (for instance, one about a family’s pets and the other about guard dogs), but they will have high cosine similarity because of the shared phrase “on the roof”. This results in a misleading similarity plot:

<p align="center">
<i>Figure 5: Example of noisy results with many sentences.</i>
</p>
To solve this problem, we need to include nearby sentences by merging them into a single context. For example:
* *“They were a wonderful big family; grandpa taught them to be kind to everyone.”*
* *“They had several animals — cows, dogs, chickens — and the children treated them well.”*
* *“The cat is on the roof.”*
* *“The children are going to school.”*
* *“The cat was watching them leave, saying goodbye with his eyes.”*
* *“One of the children noticed the cat and waved at him.”*
If we take 3 sentences to the left and 3 sentences to the right of the current sentence and
compare cosine similarity between these windows, we can better understand whether a topic shift occurs.
In the example above, we can see that the first three sentences are related to each other because they
describe a family with animals, and thus their cosine similarity will be high.
** *Note: We do not expect to find the exact boundary position. Instead, we consider a prediction correct if the true
boundary lies within a tolerance window of ±3 sentences around the detected boundary.*
### Challange
We have a list of models, and we don’t know which window size and which min_gap value will work best for each model. This means we need to test all combinations of these parameters and evaluate their performance.
Additionally, there are libraries such as LLaMA-based semantic segmentation tools that can also detect topic boundaries. We want to compare our results against these baselines and see whether our method can perform better.
The idea is to run our algorithm:
* for each model,
* for each window size,
* and for each min_gap value,
and then evaluate the results using metrics such as:
* the percentage of correctly detected boundaries,
* and visualizations that allow us to compare different configurations side-by-side.
We use news articles from the WDR NRW archive, where each file contains five news stories.
For every news story, we have ground‑truth annotations that mark the exact topic boundaries.
We compare our predicted boundaries with these annotations and measure how accurately each model
and parameter combination performs.
### Coding plan
Next, we describe how we prepare the data, run algorithm, evaluate the predictions, save the results, visualize them, and finally summarize our findings.
<details>
<summary><b>data preparation</b></summary>
#### Test data preparation
The detailed description of test data preparation process is not very important.
We start with the original JSON files, parse them, and then reconstruct the cleaned version back into JSON format. All processed files are stored in the data/ directory.
For debugging purposes, the same data is also converted into .txt format. In these text files:
* every sentence is indexed,
* topic boundaries are marked with an asterisk *.
These debug-friendly files are located in computer/content/.
#### Algoritm input
In total, we use 13 different models. For each model, we test 5 window sizes and 5 gap values, which results in:
13 × 5 × 5 = 325 possible parameter combinations.
These combinations are evaluated independently, allowing us to analyze how each model behaves under different configurations.
**see main.py*
</details>
<details>
<summary><b>Running Algorithm</b></summary>
#### Sliding Window Mechanism Implementation
In the previous example, we took three sentences and compared them with each other. In this example,
we will use more sentences and adapt our code accordingly, but the main idea will remain the same.
in the file
<pre>slid_win.py</pre>
is the main code of the sliding window mechanism.
<pre>
def segment_topics_window(
blocks,
window_size,
min_gap,
model
):
1 embeddings = model.encode(blocks)
2 scores = []
indices = []
3 for i in range(window_size, len(blocks) - window_size):
4 left = embeddings[i - window_size:i]
right = embeddings[i:i + window_size]
5 left_mean = optimize_embddings(left)
right_mean = optimize_embddings(right)
6 sim = cosine_similarity(left_mean, right_mean)[0][0]
7 scores.append(sim)
indices.append(i)
8 threshold = np.mean(scores) - 1.2 * np.std(scores)
boundaries = []
last = 0
9 for idx, score in zip(indices, scores):
if score < threshold and idx - last >= min_gap:
boundaries.append(idx)
last = idx
return boundaries, scores, indices
</pre>
1 - Encode sentences
2 - Initialize arrays to store the similarity scores and the sentence indices.
3 - Iterate through the sentences using a loop with a step size equal to window_size.
4 - Take combined left and right parts of sentences
5 - Apply embedding optimization — this helps reduce noise and capture the overall topic of each window more robustly.
6 - Compute the cosine similarity.
7 - Store the similarity scores and the corresponding indices in the arrays.
8 - Compute a dynamic threshold based on the distribution of similarity scores.
This helps identify unusually low similarity values that may indicate potential topic shifts.
9 - Detect topic boundaries where the similarity score falls below the threshold and
the distance from the last detected boundary is at least min_gap.
This prevents overly dense or noisy boundary detection.
#### Main Code
The hardest part is over — from here, it’s all smooth sailing.
<pre>
def compute(
window_size,
min_gap,
model_name):
model = SentenceTransformer(model_name)
combination_name = f"model_{model_name}_w_{window_size}_m_{min_gap}"
1 for i in range(0, 100):
file_name = f"merged_filtered_{i}.json"
2 blocks, expected_boundary, source_count, _ = extract_texts_and_write_to_file(file_name, False)
3 boundaries, scores, indices = segment_topics_window(blocks, ...)
4 plot_sliding_window(...)
5 save_pair_to_csv(...)
6 df = pd.read_csv(get_path_for_csv(combination_name), usecols=[MATCH_PERCENTAGE])
7 save_result_tocsv(combination_name, df.mean().iloc[0])
</pre>
1 after defining model and combination names, we loop through 100
test samples,
2 we extract the text
blocks and expected boundaries
3 this step does need explanation, we described it in detail above.
4 we generate and save visualization of the sliding window results.
This helps us to visually inspect why
and where the algorithm decided that the topic changes.
5 we save per-sample results to CSV
6-7 after processing all samples for the current combination, we count how
many boundaries were correctly detected and save the average percentage to a final CSV file for later analysis.
</details>
<details>
<summary><b>Visualization</b></summary>
for each test case we generate such a visualization:

<p align="center"><i>Figure 6: Sliding‑window similarity plot — blue line shows similarity scores, green dashed lines s
how ground truth, red points show detected boundaries.</i></p>
the red points represent the detected
boundaries, the blue line represents the
similarity scores across the text, and the
vertical green dashed lines indicate the expected
boundaries (ground truth).
it saved in the result folder with subfoler named after the model and parameter combination.
for example this one is saved in computer/result/model_all-MiniLM-L12-v2_w_3_m_3/merged_filtered_4/merged_filtered_4.json.png
The source code for visualiazation is in
<pre>computer/plotter.py</pre>
</details>
<details>
<summary><b>Results Evaluation</b></summary>
#### Model Results
After each run of the algorithm — for every model and every parameter configuration — we
save the results to a CSV file. The files are stored in the result/ directory and
each one is named according to the model and the parameters used. For example:
*model_paraphrase-multilingual-mpnet-base-v2_w_3_m_3.csv*

<p align="center"><i>Figure 7: Example of per‑model and per‑parameter evaluation results stored in CSV format.</i></p>
The structure of this file includes the following columns:
* the name of the test file - *File*,
* the expected boundaries - *boundary*,
* the predicted boundaries - *possible_breaks*,
* a dictionary indicating whether each boundary was detected correctly - *matches2*,
* and the overall match percentage - *percentage2*.
The code responsible for saving the results to a CSV file is located in slid_win.py inside the
function save_pair_to_csv(...).
To keep the documentation simple, we do not include the full implementation here, but the function
itself is straightforward.
And if needed, feel free to ask an AI for help — (p.s. that’s where I copied it from myself :)).
#### 3rd party library results
3rd‑Party Library Results
We also tested third‑party libraries for semantic segmentation, specifically the LLaMA‑based
implementations
SemanticSplitterNodeParser and SemanticDoubleMergingSplitterNodeParser.
We used the same test dataset, and the results were saved in CSV files with the same structure
as our own algorithm’s output.
However, these libraries did not perform well.
Although they detected all real boundaries, they also generated a large number of incorrect ones,
which significantly reduced their overall usefulness.
#### Overall Evaluation
After running all combinations of models and parameters, we compiled the results into a final CSV file
that summarizes the performance of each configuration. This allows us to compare different models
and parameter settings side by side and identify which ones are most effective at detecting topic
boundaries in our test dataset.

<p align="center"><i>Figure 9: Comparison of all model and parameter combinations,
showing boundary‑detection accuracy.</i></p>
Our top performers with a window size of 3 and a min_gap of 3 were the models paraphrase-multilingual-mpnet-base-v2
and distiluse-base-multilingual-cased-v1.
</details>
# File Structure

<p align="center">
<i>Figure 10: Directory layout.</i>
</p>
* `Artikel_WDR_NRW/` This folder contains **raw test data**.
After extraction and text cleaning, the processed data is saved into the `data/` folder.
* `data/`
Stores the cleaned and preprocessed data generated from the raw inputs. This folder is used as the main input source for the processing pipeline.
* `computer/` Contains the core application logic. All main processing steps are implemented here.
* `content/`, `result/` and `grafic/` These folders are primarily used for debugging and inspection purposes.
All output data is classified and stored in one of these folders depending on its type.
* `text_util/` and `util/` Contain helper and utility functions, including:
* Text cleaning and normalization
* Format conversion
* Shared helper logic used across the project
# TODO
* ***Fine‑tune the model*** — Hugging Face provides tools to further train embedding models
on custom datasets, which may significantly improve boundary‑detection accuracy for our domain.
* ***Experiment with alternative approaches*** such as agglomerative clustering — instead
of using a sliding window, clustering algorithms could group semantically similar sentences and identify topic boundaries between clusters.
* ***Extend algorithm to find the exact boundary position.***
We want to extend the existing code so that it can identify the boundary more precisely.
To do this, we use the following approach:
We have a predicted boundary X, and we know that the true boundary lies within a window of ±3 sentences around X.
This means we can take the contextual text to the left of (X − 3) and compare it with each sentence in that window.
Then we do the same with the contextual text to the right of (X + 3) and compare it with each sentence.
This should produce a pattern similar to the one below:
we see that the similarity values are high at first and then drop sharply —
and for the right side it behaves in the opposite way. So the exect boundary will be at the point where the similarity drops (for the left context) and rises (for the right context).
<p align="center">
<img src="docs/exec_boundary_left_half.png" alt="Left figure" width="48%" />
<img src="docs/exec_boundary_right_half.png" alt="Right figure" width="48%" />
</p>
<p align="center"><i>Figure 11: Similarity between the left and right context and each sentence
within the approximate boundary range.</i></p>
<p align="center">
<img src="docs/exec_boundary_left.png" alt="Left figure" width="48%" />
<img src="docs/exec_boundary_right.png" alt="Right figure" width="48%" />
</p>
<p align="center"><i>Figure 12: If the left‑side similarities are low while the right‑side similarities are high,
then the true boundary is likely located at (X − 3).</i></p>
* If both sides show consistently high similarity, then the prediction is likely ambiguous.
In this case, a more advanced approach (for example, using an OpenAI LLM) may be required to determine the
exact boundary with higher accuracy.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy",
"pandas",
"sentence-transformers",
"transformers",
"huggingface-hub",
"matplotlib",
"httpx",
"aiohttp",
"pydantic",
"spacy",
"pytest; extra == \"dev\"",
"jupyter; extra == \"dev\"",
"matplotlib; extra == \"dev\"",
"seaborn; extra == \"dev\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T14:36:08.835679 | wdr_article_semantic_chunking_2-0.1.1.tar.gz | 11,389,974 | b6/b7/591adbf6bb3fba9b811050bdb42500865d8273f0da00ce817d6b2c9c8e8c/wdr_article_semantic_chunking_2-0.1.1.tar.gz | source | sdist | null | false | 07460a2f69241cbfecfc5a4d56a7464a | a44833a5504e69d013fbc4a03b6aaf271877698ec7853f5b06a93dda8ee520d6 | b6b7591adbf6bb3fba9b811050bdb42500865d8273f0da00ce817d6b2c9c8e8c | null | [] | 208 |
2.4 | artifinder | 2026.1.0 | A utility script for rachis research data management. | # artifinder 📚
`artifinder` is a [`rachis` (formerly Q2F)](https://news.rachis.org/en/latest/2025-10-23-q2f-transition.html) utility designed to help you find and identify [`Artifacts`](https://use.qiime2.org/en/latest/back-matter/glossary.html#term-artifact) that are relevant to your analysis from a directory that might contain a mix of relevant and irrelevant `Artifacts` and [`Visualizations`](https://use.qiime2.org/en/latest/back-matter/glossary.html#term-visualization).
This can be useful when:
1. you're getting to the end of a complex analysis and need to identify relevant [`Artifacts`](https://use.qiime2.org/en/latest/back-matter/glossary.html#term-artifact) to compile them for archival; or
2. you're restarting an analysis that someone (you, or someone else) paused, and you're struggling to find specific files; or
3. you want to run a variation on an analysis (for example, [ANCOMBC2](https://amplicon-docs.qiime2.org/en/stable/references/plugins/composition.html#q2-action-composition-ancombc2) with a different forumla) and you want to find and use the same inputs that you used for all previous variations on the analysis.
## Installation
`artifinder` depends only `rachis` >= 2025.10 and `click`.
If you have an existing `rachis` deployment, such as QIIME 2 2025.10, or MOSHPIT 2025.10, you can activate that environment and then install `artifinder` as follows:
```shell
pip install --no-deps artifinder
```
If you don't have an existing deployment, you can install via PyPI as follows:
```shell
pip install artifinder
```
## Basic usage
If you have the `tests/data` directory from this repository (find it [here](https://github.com/gregcaporaso/artifinder/tree/main/tests/data)) in your current working directory, you can use `artifinder` as follows.
```
$ artifinder prov tests/data/ tests/data/scatter_plot.qzv
`artifinder` version: xxx
Scanning search path for .qza and .qzv files...
Found 4 `Results` in search directory.
Parsing target's provenance...
Found 6 `Results` in target's provenance (not including target).
* 2 were found in the search directory.
* 4 were not found in the search directory.
Target `Result`:
af47db9d-bfd7-4a72-a266-cfa8defff718 Visualization ./data/scatter_plot.qzv
Found `Results`:
7095b508-4ae3-4791-9e7d-7ca4f5a50279 FeatureData[Sequence] ./data/asv-seqs-ms2.qza
76793c84-899d-4540-8352-1a0d2255500c FeatureTable[Frequency] ./data/asv-table-ms2.qza
`Results` not found:
d27a741c-f7e9-48af-ad8a-a479bd89ec9e SampleData[PairedEndSequencesWithQuality]
1a4485df-2031-4e98-aecf-193ee8497f80 SampleData[PairedEndSequencesWithQuality]
83f7bac5-325f-4268-8754-c816ac46c97f FeatureData[Sequence]
79a34b19-4a78-49ec-9771-b62ca20adafd FeatureTable[Frequency]
```
Have fun! 😎
## About
`artifinder` is developed by [Greg Caporaso](https://caplab.dev).
| text/markdown | null | Greg Caporaso <greg.caporaso@nau.edu> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.1.8",
"rachis"
] | [] | [] | [] | [
"Homepage, https://rachis.org",
"Issues, https://github.com/gregcaporaso/artifinder/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T14:35:54.770735 | artifinder-2026.1.0-py3-none-any.whl | 5,621 | a5/f8/6c1058cd688df534d60ec26cbf8e4e4d9e3e3c283f994cb908be554f188e/artifinder-2026.1.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 1ea18efcb5e02f9e515395bd691839b1 | bbfd39b64caa083722c1bfc0cf3b38f1f9d069efb281a0c7f4afc33545a8f11d | a5f86c1058cd688df534d60ec26cbf8e4e4d9e3e3c283f994cb908be554f188e | BSD-3-Clause | [
"LICENSE"
] | 225 |
2.4 | idvpackage | 3.0.17 | This repository contains a Python program designed to execute Optical Character Recognition (OCR) and Facial Recognition on images. | # Optical Character Recognition (OCR) and Facial Recognition Program
This repository contains a Python program designed to execute Optical Character Recognition (OCR) and Facial Recognition on images.
## Table of Contents
1. Introduction
2. Prerequisites
3. Usage
4. Modules Description
## Introduction
The Python program imports several packages necessary for OCR and facial recognition. It accepts a list of images as input, performs OCR, rotates the images to the busiest rotation, extracts ID information, and performs facial recognition by extracting the biggest face from the images. The program then computes the similarity between the faces and exports the extracted ID information into a JSON file.
## Prerequisites
Ensure the following packages are installed:
cv2
PIL (Image)
easyocr
pandas (pd)
skimage.transform (radon)
regular expressions (re)
datetime
concurrent.futures
NumPy (np)
TensorFlow (tf)
VGG16 model from Keras (tensorflow.keras.applications.vgg16)
tensorflow.keras.preprocessing (image)
scipy.spatial.distance
model_from_json from Keras (tensorflow.keras.models)
subprocess
urllib.request
dlib
time
matplotlib.pyplot
facenet
json
io
importlib.resources
You can install these packages using pip:
pip install opencv-python Pillow easyocr pandas scikit-image regex datetime concurrent.futures numpy tensorflow dlib matplotlib facenet-pytorch jsonpickle importlib_resources
Note: Keras and the VGG16 model come with TensorFlow, so there is no need to install them separately.
## Usage
To use this program, you can clone the repository, place your images in the same directory and modify the IMAGES list accordingly. Run the program in your terminal or command prompt as:
python ocr_and_facial_recognition.py
Please note that this program does not include any user interface and does not handle any errors or exceptions beyond what is included in the code.
## Modules Description
Importing Necessary Packages:
The program begins by importing all the necessary packages used in the OCR and Facial recognition steps.
## Data Introduction:
This section defines a list of image file names that will be used as input for the OCR and facial recognition steps of the program.
## Load easyocr and Anti-Spoofing Model:
Two functions to load the easyOCR package with English language support and the anti-spoofing model respectively.
## Data Preprocessing:
Several functions are defined here to open and read an image file, convert it to grayscale, perform a radon transform, find the busiest rotation, and rotate the image accordingly.
## Facial recognition:
This section is dedicated to detecting faces in an image using a HOG (Histogram of Oriented Gradients) face detector, extracting features, and computing the similarity between two sets of features using the cosine similarity metric.
## Information Extraction:
Finally, the program uses OCR to extract information from an image, computes the similarity between faces in different images, and outputs this information in a JSON file.
Please refer to the source code comments for more detailed explanations.
This is a basic explanation of the project and its usage. This project was last updated on 24th May 2023 and does not have any GUI or error handling beyond what is included in the code. For more details, please refer to the comments in the source code.
| text/markdown | NymCard Payments | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | ==3.9.* | [] | [] | [] | [
"setuptools",
"google-cloud-vision",
"opencv-python-headless",
"Pillow",
"numpy",
"cmake",
"face-recognition",
"googletrans==4.0.2",
"rapidfuzz",
"pycountry",
"hijri_converter",
"pytesseract",
"gender-guesser",
"deep-translator",
"dlib==19.24.6",
"deepface",
"tf-keras",
"facenet-pytorch",
"scikit-image",
"google.generativeai==0.8.2",
"openai==2.6.1",
"langchain==0.2.17",
"langchain-community==0.2.19",
"pydantic==1.10.22",
"python-dateutil",
"pyasn1<0.5.0,>=0.4.1"
] | [] | [] | [] | [
"Homepage, https://github.com/NymCard-Payments/project_idv_package"
] | twine/6.2.0 CPython/3.9.23 | 2026-02-20T14:35:40.753238 | idvpackage-3.0.17.tar.gz | 3,462,462 | 45/6a/6605518dc67b4a0ff603a066c7d5993986666a3ae65ef0df5ef8e7f2b70a/idvpackage-3.0.17.tar.gz | source | sdist | null | false | b10190afbdbb0135c0deab620e7bfc90 | 4fccc523dd3f3ec041af919243d529a8aba5a1f3a36208e9227cb251cab6dd16 | 456a6605518dc67b4a0ff603a066c7d5993986666a3ae65ef0df5ef8e7f2b70a | LicenseRef-Proprietary | [
"LICENSE"
] | 237 |
2.4 | litdata | 0.2.61 | The Deep Learning framework to train, deploy, and ship AI products Lightning fast. | <div align="center">
<h1>
Speed up model training by fixing data loading
</h1>
<img src="https://pl-flash-data.s3.amazonaws.com/lit_data_logo.webp" alt="LitData" width="800px"/>
<pre>
Transform Optimize
✅ Parallelize data processing ✅ Stream large cloud datasets
✅ Create vector embeddings ✅ Accelerate training by 20x
✅ Run distributed inference ✅ Pause and resume data streaming
✅ Scrape websites at scale ✅ Use remote data without local loading
</pre>
---



[](https://discord.gg/VptPCZkGNa)
<p align="center">
<a href="https://lightning.ai/">Lightning AI</a> •
<a href="#quick-start">Quick start</a> •
<a href="#speed-up-model-training">Optimize data</a> •
<a href="#transform-datasets">Transform data</a> •
<a href="#key-features">Features</a> •
<a href="#benchmarks">Benchmarks</a> •
<a href="#start-from-a-template">Templates</a> •
<a href="#community">Community</a>
</p>
<a target="_blank" href="https://lightning.ai/docs/overview/optimize-data/optimize-datasets">
<img src="https://pl-bolts-doc-images.s3.us-east-2.amazonaws.com/app-2/get-started-badge.svg" height="36px" alt="Get started"/>
</a>
</div>
# Why LitData?
Speeding up model training involves more than kernel tuning. Data loading frequently slows down training, because datasets are too large to fit on disk, consist of millions of small files, or stream slowly from the cloud.
LitData provides tools to preprocess and optimize datasets into a format that streams efficiently from any cloud or local source. It also includes a map operator for distributed data processing before optimization. This makes data pipelines faster, cloud-agnostic, and can improve training throughput by up to 20×.
# Looking for GPUs?
Over 340,000 developers use [Lightning Cloud](https://lightning.ai/?utm_source=litdata&utm_medium=referral&utm_campaign=litdata) - purpose-built for PyTorch and PyTorch Lightning.
- [GPUs](https://lightning.ai/pricing?utm_source=litdata&utm_medium=referral&utm_campaign=litdata) from $0.19.
- [Clusters](https://lightning.ai/clusters?utm_source=litdata&utm_medium=referral&utm_campaign=litdata): frontier-grade training/inference clusters.
- [AI Studio (vibe train)](https://lightning.ai/studios?utm_source=litdata&utm_medium=referral&utm_campaign=litdata): workspaces where AI helps you debug, tune and vibe train.
- [AI Studio (vibe deploy)](https://lightning.ai/studios?utm_source=litdata&utm_medium=referral&utm_campaign=litdata): workspaces where AI helps you optimize, and deploy models.
- [Notebooks](https://lightning.ai/notebooks?utm_source=litdata&utm_medium=referral&utm_campaign=litdata): Persistent GPU workspaces where AI helps you code and analyze.
- [Inference](https://lightning.ai/deploy?utm_source=litdata&utm_medium=referral&utm_campaign=litdata): Deploy models as inference APIs.
# Quick start
First, install LitData:
```bash
pip install litdata
```
Choose your workflow:
🚀 [Speed up model training](#speed-up-model-training)
🚀 [Transform datasets](#transform-datasets)
<details>
<summary>Advanced install</summary>
Install all the extras
```bash
pip install 'litdata[extras]'
```
</details>
----
# Speed up model training
Stream datasets directly from cloud storage without local downloads. Choose the approach that fits your workflow:
## Option 1: Start immediately with existing data ⚡⚡
Stream raw files directly from cloud storage - no pre-optimization needed.
```python
from litdata import StreamingRawDataset
from torch.utils.data import DataLoader
# Point to your existing cloud data
dataset = StreamingRawDataset("s3://my-bucket/raw-data/")
dataloader = DataLoader(dataset, batch_size=32)
for batch in dataloader:
# Process raw bytes on-the-fly
pass
```
**Key benefits:**
✅ **Instant access:** Start streaming immediately without preprocessing.
✅ **Zero setup time:** No data conversion or optimization required.
✅ **Native format:** Work with original file formats (images, text, etc.).
✅ **Flexible processing:** Apply transformations on-the-fly during streaming.
✅ **Cloud-native:** Stream directly from S3, GCS, or Azure storage.
## Option 2: Optimize for maximum performance ⚡⚡⚡
Accelerate model training (20x faster) by optimizing datasets for streaming directly from cloud storage. Work with remote data without local downloads with features like loading data subsets, accessing individual samples, and resumable streaming.
**Step 1: Optimize your data (one-time setup)**
Transform raw data into optimized chunks for maximum streaming speed.
This step formats the dataset for fast loading by writing data in an efficient chunked binary format.
```python
import numpy as np
from PIL import Image
import litdata as ld
def random_images(index):
# Replace with your actual image loading here (e.g., .jpg, .png, etc.)
# Recommended: use compressed formats like JPEG for better storage and optimized streaming speed
# You can also apply resizing or reduce image quality to further increase streaming speed and save space
fake_images = Image.fromarray(np.random.randint(0, 256, (32, 32, 3), dtype=np.uint8))
fake_labels = np.random.randint(10)
# You can use any key:value pairs. Note that their types must not change between samples, and Python lists must
# always contain the same number of elements with the same types
data = {"index": index, "image": fake_images, "class": fake_labels}
return data
if __name__ == "__main__":
# The optimize function writes data in an optimized format
ld.optimize(
fn=random_images, # the function applied to each input
inputs=list(range(1000)), # the inputs to the function (here it's a list of numbers)
output_dir="fast_data", # optimized data is stored here
num_workers=4, # the number of workers on the same machine
chunk_bytes="64MB" # size of each chunk
)
```
**Step 2: Put the data on the cloud**
Upload the data to a [Lightning Studio](https://lightning.ai) (backed by S3) or your own S3 bucket:
```bash
aws s3 cp --recursive fast_data s3://my-bucket/fast_data
```
**Step 3: Stream the data during training**
Load the data by replacing the PyTorch Dataset and DataLoader with the StreamingDataset and StreamingDataLoader.
```python
import litdata as ld
dataset = ld.StreamingDataset('s3://my-bucket/fast_data', shuffle=True, drop_last=True)
# Custom collate function to handle the batch (optional)
def collate_fn(batch):
return {
"image": [sample["image"] for sample in batch],
"class": [sample["class"] for sample in batch],
}
dataloader = ld.StreamingDataLoader(dataset, collate_fn=collate_fn)
for sample in dataloader:
img, cls = sample["image"], sample["class"]
```
**Key benefits:**
✅ **Accelerate training:** Optimized datasets load 20x faster.
✅ **Stream cloud datasets:** Work with cloud data without downloading it.
✅ **PyTorch-first:** Works with PyTorch libraries like PyTorch Lightning, Lightning Fabric, Hugging Face.
✅ **Easy collaboration:** Share and access datasets in the cloud, streamlining team projects.
✅ **Scale across GPUs:** Streamed data automatically scales to all GPUs.
✅ **Flexible storage:** Use S3, GCS, Azure, or your own cloud account for data storage.
✅ **Compression:** Reduce your data footprint by using advanced compression algorithms.
✅ **Run local or cloud:** Run on your own machines or auto-scale to 1000s of cloud GPUs with Lightning Studios.
✅ **Enterprise security:** Self host or process data on your cloud account with Lightning Studios.
----
# Transform datasets
Accelerate data processing tasks (data scraping, image resizing, embedding creation, distributed inference) by parallelizing (map) the work across many machines at once.
Here's an example that resizes and crops a large image dataset:
```python
from PIL import Image
import litdata as ld
# use a local or S3 folder
input_dir = "my_large_images" # or "s3://my-bucket/my_large_images"
output_dir = "my_resized_images" # or "s3://my-bucket/my_resized_images"
inputs = [os.path.join(input_dir, f) for f in os.listdir(input_dir)]
# resize the input image
def resize_image(image_path, output_dir):
output_image_path = os.path.join(output_dir, os.path.basename(image_path))
Image.open(image_path).resize((224, 224)).save(output_image_path)
ld.map(
fn=resize_image,
inputs=inputs,
output_dir="output_dir",
)
```
**Key benefits:**
✅ Parallelize processing: Reduce processing time by transforming data across multiple machines simultaneously.
✅ Scale to large data: Increase the size of datasets you can efficiently handle.
✅ Flexible usecases: Resize images, create embeddings, scrape the internet, etc...
✅ Run local or cloud: Run on your own machines or auto-scale to 1000s of cloud GPUs with Lightning Studios.
✅ Enterprise security: Self host or process data on your cloud account with Lightning Studios.
----
# Key Features
## Features for optimizing and streaming datasets for model training
<details>
<summary> ✅ Stream raw datasets from cloud storage (beta) <a id="stream-raw" href="#stream-raw">🔗</a> </summary>
Effortlessly stream raw files (images, text, etc.) directly from S3, GCS, and Azure cloud storage without any optimization or conversion. Ideal for workflows requiring instant access to original data in its native format.
**Prerequisites:**
Install the required dependencies to stream raw datasets from cloud storage like **Amazon S3** or **Google Cloud Storage**:
```bash
# for aws s3
pip install "litdata[extra]" s3fs
# for gcloud storage
pip install "litdata[extra]" gcsfs
```
**Usage Example:**
```python
from torch.utils.data import DataLoader
from litdata import StreamingRawDataset
dataset = StreamingRawDataset("s3://bucket/files/")
# Use with PyTorch DataLoader
loader = DataLoader(dataset, batch_size=32)
for batch in loader:
# Each item is raw bytes
pass
```
> Use `StreamingRawDataset` to stream your data as-is. Use `StreamingDataset` for fastest streaming after optimizing your data.
You can also customize how files are grouped by subclassing `StreamingRawDataset` and overriding the `setup` method. This is useful for pairing related files (e.g., image and mask, audio and transcript) or any custom grouping logic.
```python
from typing import Union
from torch.utils.data import DataLoader
from litdata import StreamingRawDataset
from litdata.raw.indexer import FileMetadata
class SegmentationRawDataset(StreamingRawDataset):
def setup(self, files: list[FileMetadata]) -> Union[list[FileMetadata], list[list[FileMetadata]]]:
# TODO: Implement your custom grouping logic here.
# For example, group files by prefix, extension, or any rule you need.
# Return a list of groups, where each group is a list of FileMetadata.
# Example:
# return [[image, mask], ...]
pass
# Initialize the custom dataset
dataset = SegmentationRawDataset("s3://bucket/files/")
loader = DataLoader(dataset, batch_size=32)
for item in loader:
# Each item in the batch is a pair: [image_bytes, mask_bytes]
pass
```
**Smart Index Caching**
`StreamingRawDataset` automatically caches the file index for instant startup. Initial scan, builds and caches the index, then subsequent runs load instantly.
**Two-Level Cache:**
- **Local:** Stored in your cache directory for instant access
- **Remote:** Automatically saved to cloud storage (e.g., `s3://bucket/files/index.json.zstd`) for reuse
**Force Rebuild:**
```python
# When dataset files have changed
dataset = StreamingRawDataset("s3://bucket/files/", recompute_index=True)
```
</details>
<details>
<summary> ✅ Stream large cloud datasets <a id="stream-large" href="#stream-large">🔗</a> </summary>
Use data stored on the cloud without needing to download it all to your computer, saving time and space.
Imagine you're working on a project with a huge amount of data stored online. Instead of waiting hours to download it all, you can start working with the data almost immediately by streaming it.
Once you've optimized the dataset with LitData, stream it as follows:
```python
from litdata import StreamingDataset, StreamingDataLoader
dataset = StreamingDataset('s3://my-bucket/my-data', shuffle=True)
dataloader = StreamingDataLoader(dataset, batch_size=64)
for batch in dataloader:
process(batch) # Replace with your data processing logic
```
Additionally, you can inject client connection settings for [S3](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/core/session.html#boto3.session.Session.client) or GCP when initializing your dataset. This is useful for specifying custom endpoints and credentials per dataset.
```python
from litdata import StreamingDataset
# boto3 compatible storage options for a custom S3-compatible endpoint
storage_options = {
"endpoint_url": "your_endpoint_url",
"aws_access_key_id": "your_access_key_id",
"aws_secret_access_key": "your_secret_access_key",
}
dataset = StreamingDataset('s3://my-bucket/my-data', storage_options=storage_options)
dataset = StreamingDataset('s3://my-bucket/my-data', storage_options=storage_options)
```
Also, you can specify a custom cache directory when initializing your dataset. This is useful when you want to store the cache in a specific location.
```python
from litdata import StreamingDataset
# Initialize the StreamingDataset with the custom cache directory
dataset = StreamingDataset('s3://my-bucket/my-data', cache_dir="/path/to/cache")
```
</details>
<details>
<summary> ✅ Stream Hugging Face 🤗 datasets <a id="stream-hf" href="#stream-hf">🔗</a> </summary>
To use your favorite Hugging Face dataset with LitData, simply pass its URL to `StreamingDataset`.
<details>
<summary>How to get HF dataset URI?</summary>
https://github.com/user-attachments/assets/3ba9e2ef-bf6b-41fc-a578-e4b4113a0e72
</details>
**Prerequisites:**
Install the required dependencies to stream Hugging Face datasets:
```sh
pip install "litdata[extra]" huggingface_hub
# Optional: To speed up downloads on high-bandwidth networks
pip install hf_transfer
export HF_HUB_ENABLE_HF_TRANSFER=1
```
**Stream Hugging Face dataset:**
```python
import litdata as ld
# Define the Hugging Face dataset URI
hf_dataset_uri = "hf://datasets/leonardPKU/clevr_cogen_a_train/data"
# Create a streaming dataset
dataset = ld.StreamingDataset(hf_dataset_uri)
# Print the first sample
print("Sample", dataset[0])
# Stream the dataset using StreamingDataLoader
dataloader = ld.StreamingDataLoader(dataset, batch_size=4)
for sample in dataloader:
pass
```
You don’t need to worry about indexing the dataset or any other setup. **LitData** will **handle all the necessary steps automatically** and `cache` the `index.json` file, so you won't have to index it again.
This ensures that the next time you stream the dataset, the indexing step is skipped..
### Indexing the HF dataset (Optional)
If the Hugging Face dataset hasn't been indexed yet, you can index it first using the `index_hf_dataset` method, and then stream it using the code above.
```python
import litdata as ld
hf_dataset_uri = "hf://datasets/leonardPKU/clevr_cogen_a_train/data"
ld.index_hf_dataset(hf_dataset_uri)
```
- Indexing the Hugging Face dataset ahead of time will make streaming abit faster, as it avoids the need for real-time indexing during streaming.
- To use `HF gated dataset`, ensure the `HF_TOKEN` environment variable is set.
**Note**: For HuggingFace datasets, `indexing` & `streaming` is supported only for datasets in **`Parquet format`**.
### Full Workflow for Hugging Face Datasets
For full control over the cache path(`where index.json file will be stored`) and other configurations, follow these steps:
1. Index the Hugging Face dataset first:
```python
import litdata as ld
hf_dataset_uri = "hf://datasets/open-thoughts/OpenThoughts-114k/data"
ld.index_parquet_dataset(hf_dataset_uri, "hf-index-dir")
```
2. To stream HF datasets now, pass the `HF dataset URI`, the path where the `index.json` file is stored, and `ParquetLoader` as the `item_loader` to the **`StreamingDataset`**:
```python
import litdata as ld
from litdata.streaming.item_loader import ParquetLoader
hf_dataset_uri = "hf://datasets/open-thoughts/OpenThoughts-114k/data"
dataset = ld.StreamingDataset(hf_dataset_uri, item_loader=ParquetLoader(), index_path="hf-index-dir")
for batch in ld.StreamingDataLoader(dataset, batch_size=4):
pass
```
### LitData `Optimize` v/s `Parquet`
<!-- TODO: Update benchmark -->
Below is the benchmark for the `Imagenet dataset (155 GB)`, demonstrating that **`optimizing the dataset using LitData is faster and results in smaller output size compared to raw Parquet files`**.
| **Operation** | **Size (GB)** | **Time (seconds)** | **Throughput (images/sec)** |
|-----------------------------------|---------------|---------------------|-----------------------------|
| LitData Optimize Dataset | 45 | 283.17 | 4000-4700 |
| Parquet Optimize Dataset | 51 | 465.96 | 3600-3900 |
| Index Parquet Dataset (overhead) | N/A | 6 | N/A |
</details>
<details>
<summary> ✅ Streams on multi-GPU, multi-node <a id="multi-gpu" href="#multi-gpu">🔗</a> </summary>
Data optimized and loaded with Lightning automatically streams efficiently in distributed training across GPUs or multi-node.
The `StreamingDataset` and `StreamingDataLoader` automatically make sure each rank receives the same quantity of varied batches of data, so it works out of the box with your favorite frameworks ([PyTorch Lightning](https://lightning.ai/docs/pytorch/stable/), [Lightning Fabric](https://lightning.ai/docs/fabric/stable/), or [PyTorch](https://pytorch.org/docs/stable/index.html)) to do distributed training.
Here you can see an illustration showing how the Streaming Dataset works with multi node / multi gpu under the hood.
```python
from litdata import StreamingDataset, StreamingDataLoader
# For the training dataset, don't forget to enable shuffle and drop_last !!!
train_dataset = StreamingDataset('s3://my-bucket/my-train-data', shuffle=True, drop_last=True)
train_dataloader = StreamingDataLoader(train_dataset, batch_size=64)
for batch in train_dataloader:
process(batch) # Replace with your data processing logic
val_dataset = StreamingDataset('s3://my-bucket/my-val-data', shuffle=False, drop_last=False)
val_dataloader = StreamingDataLoader(val_dataset, batch_size=64)
for batch in val_dataloader:
process(batch) # Replace with your data processing logic
```
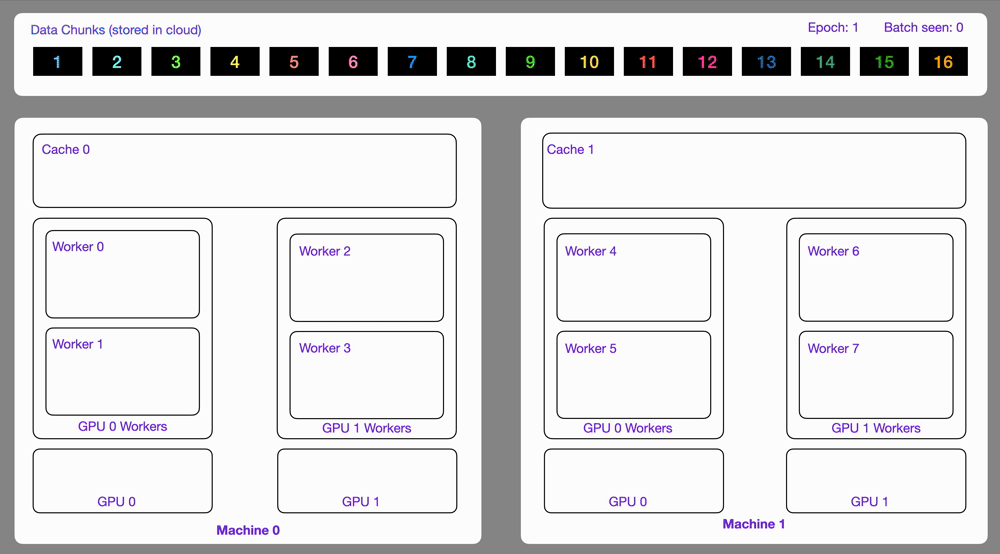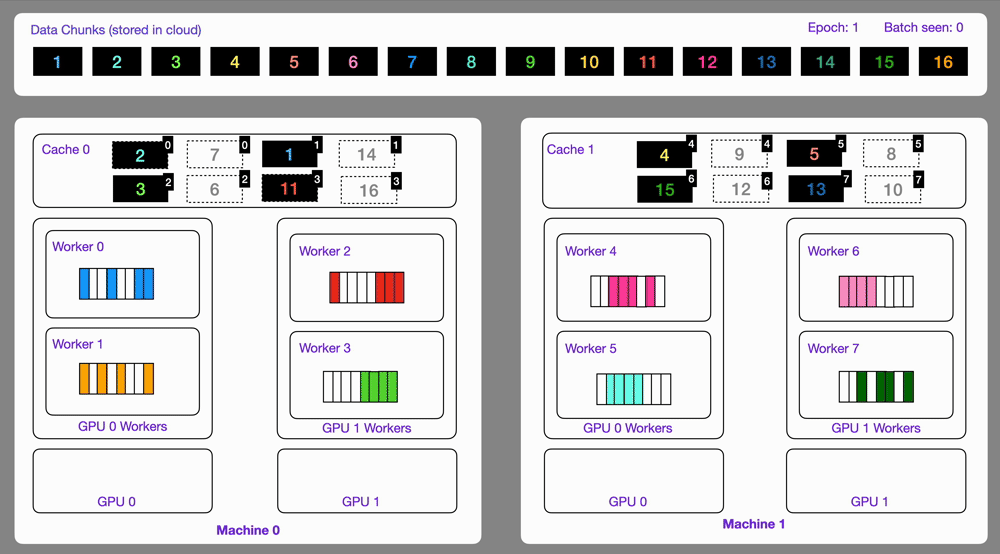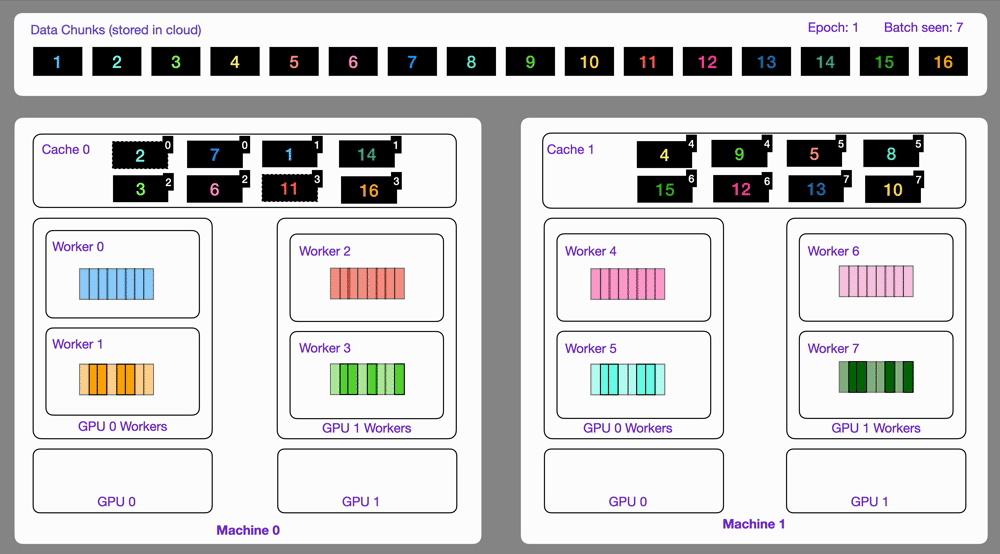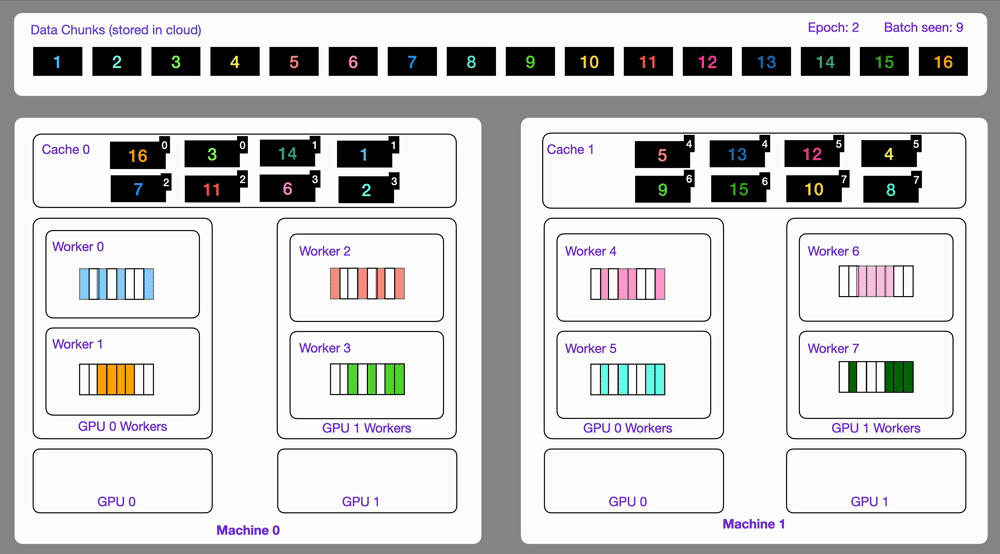
</details>
<details>
<summary> ✅ Stream from multiple cloud providers <a id="cloud-providers" href="#cloud-providers">🔗</a> </summary>
The `StreamingDataset` provides support for reading optimized datasets from common cloud storage providers like AWS S3, Google Cloud Storage (GCS), and Azure Blob Storage. Below are examples of how to use StreamingDataset with each cloud provider.
```python
import os
import litdata as ld
# Read data from AWS S3 using boto3
aws_storage_options={
"aws_access_key_id": os.environ['AWS_ACCESS_KEY_ID'],
"aws_secret_access_key": os.environ['AWS_SECRET_ACCESS_KEY'],
}
# You can also pass the session options. (for boto3 only)
aws_session_options = {
"profile_name": os.environ['AWS_PROFILE_NAME'], # Required only for custom profiles
"region_name": os.environ['AWS_REGION_NAME'], # Required only for custom regions
}
dataset = ld.StreamingDataset("s3://my-bucket/my-data", storage_options=aws_storage_options, session_options=aws_session_options)
# Read Data from AWS S3 with Unsigned Request using boto3
aws_storage_options={
"config": botocore.config.Config(
retries={"max_attempts": 1000, "mode": "adaptive"}, # Configure retries for S3 operations
signature_version=botocore.UNSIGNED, # Use unsigned requests
)
}
dataset = ld.StreamingDataset("s3://my-bucket/my-data", storage_options=aws_storage_options)
aws_storage_options={
"AWS_ACCESS_KEY_ID": os.environ['AWS_ACCESS_KEY_ID'],
"AWS_SECRET_ACCESS_KEY": os.environ['AWS_SECRET_ACCESS_KEY'],
"S3_ENDPOINT_URL": os.environ['AWS_ENDPOINT_URL'], # Required only for custom endpoints
}
dataset = ld.StreamingDataset("s3://my-bucket/my-data", storage_options=aws_storage_options)
dataset = ld.StreamingDataset("s3://my-bucket/my-data", storage_options=aws_storage_options)
# Read data from GCS
gcp_storage_options={
"project": os.environ['PROJECT_ID'],
}
dataset = ld.StreamingDataset("gs://my-bucket/my-data", storage_options=gcp_storage_options)
# Read data from Azure
azure_storage_options={
"account_url": f"https://{os.environ['AZURE_ACCOUNT_NAME']}.blob.core.windows.net",
"credential": os.environ['AZURE_ACCOUNT_ACCESS_KEY']
}
dataset = ld.StreamingDataset("azure://my-bucket/my-data", storage_options=azure_storage_options)
```
</details>
<details>
<summary> ✅ Pause, resume data streaming <a id="pause-resume" href="#pause-resume">🔗</a> </summary>
Stream data during long training, if interrupted, pick up right where you left off without any issues.
LitData provides a stateful `Streaming DataLoader` e.g. you can `pause` and `resume` your training whenever you want.
Info: The `Streaming DataLoader` was used by [Lit-GPT](https://github.com/Lightning-AI/litgpt/blob/main/tutorials/pretrain_tinyllama.md) to pretrain LLMs. Restarting from an older checkpoint was critical to get to pretrain the full model due to several failures (network, CUDA Errors, etc..).
```python
import os
import torch
from litdata import StreamingDataset, StreamingDataLoader
dataset = StreamingDataset("s3://my-bucket/my-data", shuffle=True)
dataloader = StreamingDataLoader(dataset, num_workers=os.cpu_count(), batch_size=64)
# Restore the dataLoader state if it exists
if os.path.isfile("dataloader_state.pt"):
state_dict = torch.load("dataloader_state.pt")
dataloader.load_state_dict(state_dict)
# Iterate over the data
for batch_idx, batch in enumerate(dataloader):
# Store the state every 1000 batches
if batch_idx % 1000 == 0:
torch.save(dataloader.state_dict(), "dataloader_state.pt")
```
</details>
<details>
<summary> ✅ Use shared queue for Optimizing <a id="shared-queue" href="#shared-queue">🔗</a> </summary>
If you are using multiple workers to optimize your dataset, you can use a shared queue to speed up the process.
This is especially useful when optimizing large datasets in parallel, where some workers may be slower than others.
It can also improve fault tolerance when workers fail due to out-of-memory (OOM) errors.
```python
import numpy as np
from PIL import Image
import litdata as ld
def random_images(index):
fake_images = Image.fromarray(np.random.randint(0, 256, (32, 32, 3), dtype=np.uint8))
fake_labels = np.random.randint(10)
data = {"index": index, "image": fake_images, "class": fake_labels}
return data
if __name__ == "__main__":
# The optimize function writes data in an optimized format.
ld.optimize(
fn=random_images, # the function applied to each input
inputs=list(range(1000)), # the inputs to the function (here it's a list of numbers)
output_dir="fast_data", # optimized data is stored here
num_workers=4, # The number of workers on the same machine
chunk_bytes="64MB" , # size of each chunk
keep_data_ordered=False, # Use a shared queue to speed up the process
)
```
### Performance Difference between using a shared queue and not using it:
**Note**: The following benchmarks were collected using the ImageNet dataset on an A10G machine with 16 workers.
| Configuration | Optimize Time (sec) | Stream 1 (img/sec) | Stream 2 (img/sec) |
|------------------|---------------------|---------------------|---------------------|
| shared_queue (`keep_data_ordered=False`) | 1281 | 5392 | 5732 |
| no shared_queue (`keep_data_ordered=True (default)`) | 1187 | 5257 | 5746 |
📌 Note: The **shared_queue** option impacts optimization time, not streaming speed.
> While the streaming numbers may appear slightly different, this variation is incidental and not caused by shared_queue.
>
> Streaming happens after optimization and does not involve inter-process communication where shared_queue plays a role.
- 📄 Using a shared queue helps balance the load across workers, though it may slightly increase optimization time due to the overhead of pickling items sent between processes.
- ⚡ However, it can significantly improve optimizing performance — especially when some workers are slower than others.
</details>
<details>
<summary> ✅ Use a <code>Queue</code> as input for optimizing data <a id="queue-input" href="#queue-input">🔗</a> </summary>
Sometimes you don’t have a static list of inputs to optimize — instead, you have a stream of data coming in over time. In such cases, you can use a multiprocessing.Queue to feed data into the optimize() function.
- This is especially useful when you're collecting data from a remote source like a web scraper, socket, or API.
- You can also use this setup to store `replay buffer` data during reinforcement learning and later stream it back for training.
```python
from multiprocessing import Process, Queue
from litdata.processing.data_processor import ALL_DONE
import litdata as ld
import time
def yield_numbers():
for i in range(1000):
time.sleep(0.01)
yield (i, i**2)
def data_producer(q: Queue):
for item in yield_numbers():
q.put(item)
q.put(ALL_DONE) # Sentinel value to signal completion
def fn(index):
return index # Identity function for demo
if __name__ == "__main__":
q = Queue(maxsize=100)
producer = Process(target=data_producer, args=(q,))
producer.start()
ld.optimize(
fn=fn, # Function to process each item
queue=q, # 👈 Stream data from this queue
output_dir="fast_data", # Where to store optimized data
num_workers=2,
chunk_size=100,
mode="overwrite",
)
producer.join()
```
📌 Note: Using queues to optimize your dataset impacts optimization time, not streaming speed.
> Irrespective of number of workers, you only need to put one sentinel value to signal completion.
>
> It'll be handled internally by LitData.
</details>
<details>
<summary> ✅ LLM Pre-training <a id="llm-training" href="#llm-training">🔗</a> </summary>
LitData is highly optimized for LLM pre-training. First, we need to tokenize the entire dataset and then we can consume it.
```python
import json
from pathlib import Path
import zstandard as zstd
from litdata import optimize, TokensLoader
from tokenizer import Tokenizer
from functools import partial
# 1. Define a function to convert the text within the jsonl files into tokens
def tokenize_fn(filepath, tokenizer=None):
with zstd.open(open(filepath, "rb"), "rt", encoding="utf-8") as f:
for row in f:
text = json.loads(row)["text"]
if json.loads(row)["meta"]["redpajama_set_name"] == "RedPajamaGithub":
continue # exclude the GitHub data since it overlaps with starcoder
text_ids = tokenizer.encode(text, bos=False, eos=True)
yield text_ids
if __name__ == "__main__":
# 2. Generate the inputs (we are going to optimize all the compressed json files from SlimPajama dataset )
input_dir = "./slimpajama-raw"
inputs = [str(file) for file in Path(f"{input_dir}/SlimPajama-627B/train").rglob("*.zst")]
# 3. Store the optimized data wherever you want under "/teamspace/datasets" or "/teamspace/s3_connections"
outputs = optimize(
fn=partial(tokenize_fn, tokenizer=Tokenizer(f"{input_dir}/checkpoints/Llama-2-7b-hf")), # Note: You can use HF tokenizer or any others
inputs=inputs,
output_dir="./slimpajama-optimized",
chunk_size=(2049 * 8012),
# This is important to inform LitData that we are encoding contiguous 1D array (tokens).
# LitData skips storing metadata for each sample e.g all the tokens are concatenated to form one large tensor.
item_loader=TokensLoader(),
)
```
```python
import os
from litdata import StreamingDataset, StreamingDataLoader, TokensLoader
from tqdm import tqdm
# Increase by one because we need the next word as well
dataset = StreamingDataset(
input_dir=f"./slimpajama-optimized/train",
item_loader=TokensLoader(block_size=2048 + 1),
shuffle=True,
drop_last=True,
)
train_dataloader = StreamingDataLoader(dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count())
# Iterate over the SlimPajama dataset
for batch in tqdm(train_dataloader):
pass
```
</details>
<details>
<summary> ✅ Filter illegal data <a id="filter-data" href="#filter-data">🔗</a> </summary>
Sometimes, you have bad data that you don't want to include in the optimized dataset. With LitData, yield only the good data sample to include.
```python
from litdata import optimize, StreamingDataset
def should_keep(index) -> bool:
# Replace with your own logic
return index % 2 == 0
def fn(data):
if should_keep(data):
yield data
if __name__ == "__main__":
optimize(
fn=fn,
inputs=list(range(1000)),
output_dir="only_even_index_optimized",
chunk_bytes="64MB",
num_workers=1
)
dataset = StreamingDataset("only_even_index_optimized")
data = list(dataset)
print(data)
# [0, 2, 4, 6, 8, 10, ..., 992, 994, 996, 998]
```
You can even use try/expect.
```python
from litdata import optimize, StreamingDataset
def fn(data):
try:
yield 1 / data
except:
pass
if __name__ == "__main__":
optimize(
fn=fn,
inputs=[0, 0, 0, 1, 2, 4, 0],
output_dir="only_defined_ratio_optimized",
chunk_bytes="64MB",
num_workers=1
)
dataset = StreamingDataset("only_defined_ratio_optimized")
data = list(dataset)
# The 0 are filtered out as they raise a division by zero
print(data)
# [1.0, 0.5, 0.25]
```
</details>
<details>
<summary> ✅ Combine datasets <a id="combine-datasets" href="#combine-datasets">🔗</a> </summary>
Mix and match different sets of data to experiment and create better models.
Combine datasets with `CombinedStreamingDataset`. As an example, this mixture of [Slimpajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B) & [StarCoder](https://huggingface.co/datasets/bigcode/starcoderdata) was used in the [TinyLLAMA](https://github.com/jzhang38/TinyLlama) project to pretrain a 1.1B Llama model on 3 trillion tokens.
```python
from litdata import StreamingDataset, CombinedStreamingDataset, StreamingDataLoader, TokensLoader
from tqdm import tqdm
import os
train_datasets = [
StreamingDataset(
input_dir="s3://tinyllama-template/slimpajama/train/",
item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs
shuffle=True,
drop_last=True,
),
StreamingDataset(
input_dir="s3://tinyllama-template/starcoder/",
item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs
shuffle=True,
drop_last=True,
),
]
# Mix SlimPajama data and Starcoder data with these proportions:
weights = (0.693584, 0.306416)
combined_dataset = CombinedStreamingDataset(datasets=train_datasets, seed=42, weights=weights, iterate_over_all=False)
train_dataloader = StreamingDataLoader(combined_dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count())
# Iterate over the combined datasets
for batch in tqdm(train_dataloader):
pass
```
**Batching Methods**
The `CombinedStreamingDataset` supports two different batching methods through the `batching_method` parameter:
**Stratified Batching (Default)**:
With `batching_method="stratified"` (the default), each batch contains samples from multiple datasets according to the specified weights:
```python
# Default stratified batching - batches mix samples from all datasets
combined_dataset = CombinedStreamingDataset(
datasets=[dataset1, dataset2],
batching_method="stratified" # This is the default
)
```
**Per-Stream Batching**:
With `batching_method="per_stream"`, each batch contains samples exclusively from a single dataset. This is useful when datasets have different shapes or structures:
```python
# Per-stream batching - each batch contains samples from only one dataset
combined_dataset = CombinedStreamingDataset(
datasets=[dataset1, dataset2],
batching_method="per_stream"
)
# This ensures each batch has consistent structure, helpful for datasets with varying:
# - Image sizes
# - Sequence lengths
# - Data types
# - Feature dimensions
```
</details>
<details>
<summary> ✅ Parallel streaming <a id="parallel-streaming" href="#parallel-streaming">🔗</a> </summary>
While `CombinedDataset` allows to fetch a sample from one of the datasets it wraps at each iteration, `ParallelStreamingDataset` can be used to fetch a sample from all the wrapped datasets at each iteration:
```python
from litdata import StreamingDataset, ParallelStreamingDataset, StreamingDataLoader
from tqdm import tqdm
parallel_dataset = ParallelStreamingDataset(
[
StreamingDataset(input_dir="input_dir_1"),
StreamingDataset(input_dir="input_dir_2"),
],
)
dataloader = StreamingDataLoader(parallel_dataset)
for batch_1, batch_2 in tqdm(dataloader):
pass
```
This is useful to generate new data on-the-fly using a sample from each dataset. To do so, provide a ``transform`` function to `ParallelStreamingDataset`:
```python
def transform(samples: Tuple[Any]):
sample_1, sample_2 = samples # as many samples as wrapped datasets
return sample_1 + sample_2 # example transformation
parallel_dataset = ParallelStreamingDataset([dset_1, dset_2], transform=transform)
dataloader = StreamingDataLoader(parallel_dataset)
for transformed_batch in tqdm(dataloader):
pass
```
If the transformation requires random number generation, internal random number generators provided by `ParallelStreamingDataset` can be used. These are seeded using the current dataset state at the beginning of each epoch, which allows for reproducible and resumable data transformation. To use them, define a ``transform`` which takes a dictionary of random number generators as its second argument:
```python
def transform(samples: Tuple[Any], rngs: Dict[str, Any]):
sample_1, sample_2 = samples # as many samples as wrapped datasets
rng = rngs["random"] # "random", "numpy" and "torch" keys available
return rng.random() * sample_1 + rng.random() * sample_2 # example transformation
parallel_dataset = ParallelStreamingDataset([dset_1, dset_2], transform=transform)
```
</details>
<details>
<summary> ✅ Cycle datasets <a id="cycle-datasets" href="#cycle-datasets">🔗</a> </summary>
`ParallelStreamingDataset` can also be used to cycle a `StreamingDataset`. This allows to dissociate the epoch length from the number of samples in the dataset.
To do so, set the `length` option to the desired number of samples to yield per epoch. If ``length`` is greater than the number of samples in the dataset, the dataset is cycled. At the beginning of a new epoch, the dataset resumes from where it left off at the end of the previous epoch.
```python
from litdata import StreamingDataset, ParallelStreamingDataset, StreamingDataLoader
from tqdm import tqdm
dataset = StreamingDataset(input_dir="input_dir")
cycled_dataset = ParallelStreamingDataset([dataset], length=100)
print(len(cycled_dataset))) # 100
dataloader = StreamingDataLoader(cycled_dataset)
for batch, in tqdm(dataloader):
pass
```
You can even set `length` to `float("inf")` for an infinite dataset!
</details>
<details>
<summary> ✅ Merge datasets <a id="merge-datasets" href="#merge-datasets">🔗</a> </summary>
Merge multiple optimized datasets into one.
```python
import numpy as np
from PIL import Image
from litdata import StreamingDataset, merge_datasets, optimize
def random_images(index):
return {
"index": index,
"image": Image.fromarray(np.random.randint(0, 256, (32, 32, 3), dtype=np.uint8)),
"class": np.random.randint(10),
}
if __name__ == "__main__":
out_dirs = ["fast_data_1", "fast_data_2", "fast_data_3", "fast_data_4"] # or ["s3://my-bucket/fast_data_1", etc.]"
for out_dir in out_dirs:
optimize(fn=random_images, inputs=list(range(250)), output_dir=out_dir, num_workers=4, chunk_bytes="64MB")
merged_out_dir = "merged_fast_data" # or "s3://my-bucket/merged_fast_data"
merge_datasets(input_dirs=out_dirs, output_dir=merged_out_dir)
dataset = StreamingDataset(merged_out_dir)
print(len(dataset))
# out: 1000
```
</details>
<details>
<summary> ✅ Transform datasets while Streaming <a id="transform-streaming" href="#transform-streaming">🔗</a> </summary>
Transform datasets on-the-fly while streaming them, allowing for efficient data processing without the need to store intermediate results.
- You can use the `transform` argument in `StreamingDataset` to apply a `transformation function` or `a list of transformation functions` to each sample as it is streamed.
```python
# Define a simple transform function
torch_transform = transforms.Compose([
transforms.Resize((256, 256)), # Resize to 256x256
transforms.ToTensor(), # Convert to PyTorch tensor (C x H x W)
transforms.Normalize( # Normalize using ImageNet stats
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
def transform_fn(x, *args, **kwargs):
"""Define your transform function."""
return torch_transform(x) # Apply the transform to the input image
# Create dataset with appropriate configuration
dataset = StreamingDataset(data_dir, cache_dir=str(cache_dir), shuffle=shuffle, transform=[transform_fn])
```
Or, you can create a subclass of `StreamingDataset` and override its `transform` method to apply custom transformations to each sample.
```python
class StreamingDatasetWithTransform(StreamingDataset):
"""A custom dataset class that inherits from StreamingDataset and applies a transform."""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.torch_transform = transforms.Compose([
transforms.Resize((256, 256)), # Resize to 256x | text/markdown | Lightning AI et al. | pytorch@lightning.ai | null | null | Apache-2.0 | deep learning, pytorch, AI, streaming, cloud, data processing | [
"Environment :: Console",
"Natural Language :: English",
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Scientific/Engineering :: Information Analysis",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | https://github.com/Lightning-AI/litdata | https://github.com/Lightning-AI/litdata | >=3.10 | [] | [] | [] | [
"torch",
"torchvision",
"lightning-utilities",
"filelock",
"numpy",
"boto3",
"requests",
"tifffile",
"obstore",
"fsspec; extra == \"extras\"",
"google-cloud-storage; extra == \"extras\"",
"lightning-sdk==2025.12.17; extra == \"extras\"",
"pillow; extra == \"extras\"",
"polars; extra == \"extras\"",
"pyarrow; extra == \"extras\"",
"tqdm; extra == \"extras\"",
"viztracer; extra == \"extras\""
] | [] | [] | [] | [
"Bug Tracker, https://github.com/Lightning-AI/litdata/issues",
"Documentation, https://lightning-ai.github.io/litdata/",
"Source Code, https://github.com/Lightning-AI/litdata"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:34:54.534952 | litdata-0.2.61.tar.gz | 219,649 | 6e/66/6ff8c295d2b1b91c1867f2c0cdd8d15d45782252154f22e313de5154a038/litdata-0.2.61.tar.gz | source | sdist | null | false | 5cf32091929321c3de23430f40723dd4 | ff398facbf624067dc93a87ca836c97de877705df542f857bc7d78e5c84f8c4e | 6e666ff8c295d2b1b91c1867f2c0cdd8d15d45782252154f22e313de5154a038 | null | [
"LICENSE"
] | 699 |
2.4 | mcp-remote-auth-ldraney | 0.1.0 | Shared OAuth infrastructure for MCP remote servers | # mcp-remote-auth
Shared OAuth infrastructure for MCP remote servers. Extracts the common OAuth proxy pattern used by gmail-mcp-remote, gcal-mcp-remote, notion-mcp-remote, and linkedin-scheduler-remote into a reusable library.
## Install
```bash
pip install mcp-remote-auth-ldraney
```
## Usage
```python
from mcp_remote_auth import (
ProviderConfig, TokenStore, OAuthProxyProvider,
configure_mcp_auth, configure_transport_security,
register_standard_routes, register_onboarding_routes,
build_app_with_middleware,
)
config = ProviderConfig(
provider_name="Gmail",
authorize_url="https://accounts.google.com/o/oauth2/auth",
token_url="https://oauth2.googleapis.com/token",
client_id=os.environ["OAUTH_CLIENT_ID"],
client_secret=os.environ["OAUTH_CLIENT_SECRET"],
base_url=os.environ["BASE_URL"],
scopes="https://www.googleapis.com/auth/gmail.readonly",
extra_authorize_params={"access_type": "offline", "prompt": "consent"},
upstream_token_key="google_refresh_token",
upstream_response_token_field="refresh_token",
)
store = TokenStore(secret=os.environ["SESSION_SECRET"])
provider = OAuthProxyProvider(store=store, config=config)
configure_mcp_auth(mcp, provider, BASE_URL)
configure_transport_security(mcp, BASE_URL, os.environ.get("ADDITIONAL_ALLOWED_HOSTS", ""))
register_standard_routes(mcp, provider, BASE_URL)
register_onboarding_routes(mcp, provider, store, config, os.environ.get("ONBOARD_SECRET", ""))
app = build_app_with_middleware(mcp, use_body_inspection=True)
uvicorn.run(app, host="0.0.0.0", port=8000)
```
| text/markdown | Lucas Draney | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"cryptography>=46.0",
"httpx>=0.28",
"mcp>=1.0",
"pydantic>=2.0",
"starlette>=0.27",
"pytest-asyncio>=0.24; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T14:34:30.748038 | mcp_remote_auth_ldraney-0.1.0.tar.gz | 16,579 | ff/31/d65dd224beb3166d20fc4257993080a168e4a93d6a993a288019c9572993/mcp_remote_auth_ldraney-0.1.0.tar.gz | source | sdist | null | false | b7c0711621cb32ef7988fac13414aa0c | f7886d149d65999b5b14d6088380dd885ab784ad069724d47e12498d0734b3e5 | ff31d65dd224beb3166d20fc4257993080a168e4a93d6a993a288019c9572993 | MIT | [] | 240 |
2.4 | notify-utils | 0.3.3 | Biblioteca Python para parsing de preços de scraping, cálculo de descontos e análise estatística de histórico de preços. | # notify-utils
[](https://www.python.org/downloads/)
[](https://github.com/jefersonAlbara/notify-utils)
[](LICENSE)
Biblioteca Python completa para análise de preços de e-commerce: parsing, validação, cálculo de descontos reais e detecção de promoções falsas através de análise estatística de histórico.
## 🎯 Funcionalidades
- **Parser de Preços**: Normaliza strings de preços de diferentes formatos (BR, US)
- **Parsers de Lojas**: Extração automática de produtos de APIs/HTML específicas (Nike, Maze Shop, Beleza na Web)
- **Cálculo de Descontos Inteligente**: Detecta descontos reais vs anunciados usando histórico
- **Análise Estatística Avançada**: Média, mediana, tendências, volatilidade e confiança
- **Sistema de Validação de Preços**: Estratégias inteligentes para validar preços antes de adicionar ao histórico
- **Ajuste Automático de Período**: Garante inclusão de histórico mais recente
- **Filtro de Ruído**: Ignora dados voláteis recentes (scraping com erros)
- **Notificações Discord**: Envio de alertas de preço via webhook (opcional)
## Instalação
```bash
pip install notify-utils
```
## Uso Básico
### Parsing de Preços
```python
from notify_utils import parse_price
preco = parse_price("R$ 1.299,90") # → 1299.90
preco = parse_price("$1,299.90") # → 1299.90
```
### Cálculo de Desconto com Histórico
```python
from notify_utils import Price, get_discount_info
from datetime import datetime, timedelta
# Histórico de preços
precos = [
Price(value=1299.90, date=datetime.now() - timedelta(days=60)),
Price(value=1199.90, date=datetime.now() - timedelta(days=30)),
]
# Calcular desconto real baseado no histórico
info = get_discount_info(
current_price=899.90,
price_history=precos,
period_days=30
)
print(f"Desconto real: {info.discount_percentage:.2f}%")
print(f"É desconto real? {info.is_real_discount}")
```
### Análise de Tendência
```python
from notify_utils import calculate_price_trend
trend = calculate_price_trend(precos, days=30)
print(f"Direção: {trend.direction}") # 'increasing', 'decreasing', 'stable'
print(f"Mudança: {trend.change_percentage:.2f}%")
print(f"Confiança: {trend.confidence}")
```
### Validação de Preços com Estratégias
```python
from notify_utils import PriceHistory, Price, PriceAdditionStrategy, PriceAction
history = PriceHistory(product_id="PROD123", prices=precos)
# Estratégia SMART: aceita quedas imediatas, aumentos após 24h
novo_preco = Price(value=899.90, date=datetime.now())
result = history.add_price(
novo_preco,
strategy=PriceAdditionStrategy.SMART,
min_hours_for_increase=24
)
# Integração com banco de dados
if result.action == PriceAction.ADDED:
db.insert_price(product_id, result.affected_price)
print(f"✅ Preço adicionado: R$ {result.affected_price.value:.2f}")
elif result.action == PriceAction.REJECTED:
print(f"⏭️ Ignorado: {result.reason}")
```
### Ajuste Automático de Período e Filtro de Ruído
```python
from notify_utils import get_discount_info
# Ajusta período automaticamente + ignora 3 dias mais recentes
info = get_discount_info(
current_price=899.90,
price_history=precos,
period_days=30,
auto_adjust_period=True, # Inclui histórico mais recente
skip_recent_days=3 # Ignora ruído de 0-2 dias
)
print(f"Período solicitado: {info.period_days} dias")
print(f"Período ajustado: {info.adjusted_period_days} dias")
print(f"Dias ignorados: {info.skip_recent_days}")
print(f"Amostras usadas: {info.samples_count}")
```
### Parser HTML - Beleza na Web
```python
from notify_utils import ParserFactory, StoresParserEnum
# Obter parser para Beleza na Web (HTML)
parser = ParserFactory.get_parser(StoresParserEnum.BELEZA_NA_WEB_HTML)
# Parse HTML (deduplica automaticamente produtos repetidos em carrosséis)
with open('beleza.html', 'r', encoding='utf-8') as f:
html = f.read()
products = parser.from_html(html)
# Processar produtos extraídos
for product in products:
print(f"{product.name}")
print(f" Preço atual: R$ {product.current_price_float:.2f}")
if product.old_price_float > 0:
desconto_pct = ((product.old_price_float - product.current_price_float) / product.old_price_float) * 100
print(f" Desconto: {desconto_pct:.1f}%")
```
**Características**:
- ✅ Parse híbrido (JSON embedded no data-event + HTML estruturado)
- ✅ Deduplicação automática por SKU (carrosséis repetem produtos)
- ✅ Extrai ~36 produtos únicos de ~430 repetições no HTML
- ✅ Preços, URLs, imagens e metadados completos
### Notificações Discord
```python
from notify_utils import Product, DiscordEmbedBuilder
produto = Product(
product_id="PROD123",
name="Notebook Gamer",
url="https://loja.com/produto"
)
builder = DiscordEmbedBuilder()
embed = builder.build_embed(produto, info, precos)
# Enviar via webhook Discord
```
## 📊 Estratégias de Validação
A biblioteca oferece 4 estratégias para adicionar preços ao histórico:
| Estratégia | Comportamento | Uso Recomendado |
|------------|---------------|-----------------|
| `ALWAYS` | Sempre adiciona | Testes, coleta sem filtro |
| `ONLY_DECREASE` | Apenas quedas | Alertas de promoção |
| `SMART` ⭐ | Quedas imediatas + aumentos após tempo mínimo | **Produção (padrão)** |
| `UPDATE_ON_EQUAL` | Atualiza timestamp se preço igual | Rastreamento de estabilidade |
## 🔧 Casos de Uso
### 1. Sistema de Scraping com Parsers e Validação
```python
from notify_utils import (
ParserFactory, StoresParserEnum,
PriceHistory, Price, PriceAdditionStrategy, PriceAction
)
# 1. Extrair produtos da API da loja
parser = ParserFactory.get_parser(StoresParserEnum.MAZE_API_JSON)
products = parser.from_json(api_response)
# 2. Processar cada produto
for product in products:
# Carregar histórico do banco
prices_from_db = db.get_prices(product.product_id)
history = PriceHistory(product_id=product.product_id, prices=prices_from_db)
# Validar e adicionar novo preço
novo_preco = Price(value=product.current_price, date=datetime.now())
result = history.add_price(novo_preco, strategy=PriceAdditionStrategy.SMART)
if result.action == PriceAction.ADDED:
db.insert_price(product.product_id, result.affected_price)
# Notificar se queda >= 10%
if result.status.value == "decreased" and abs(result.percentage_difference) >= 10:
notifier.send_price_alert(product, discount_info, history.prices)
```
### 2. Pipeline Completo: API → Validação → Notificação
```python
# Fluxo completo automatizado
def pipeline_completo(store: StoresParserEnum, api_data: dict):
# Passo 1: Parsing
parser = ParserFactory.get_parser(store)
products = parser.from_json(api_data)
for product in products:
# Passo 2: Validação com histórico
history = PriceHistory(product_id=product.product_id,
prices=db.get_prices(product.product_id))
novo_preco = Price(value=product.current_price, date=datetime.now())
result = history.add_price(novo_preco, strategy=PriceAdditionStrategy.SMART)
# Passo 3: Persistência
if result.action == PriceAction.ADDED:
db.insert_price(product.product_id, result.affected_price)
# Passo 4: Análise de desconto
info = get_discount_info(
current_price=product.current_price,
price_history=history.prices,
period_days=30
)
# Passo 5: Notificação se desconto real
if info.is_real_discount and info.discount_percentage >= 15:
discord_notifier.send_price_alert(product, info, history.prices)
```
### 3. Detecção de Promoções Falsas
```python
# Loja anuncia "De R$ 1.999 por R$ 899" (50% off!)
# Mas histórico mostra que preço real era R$ 1.299
info = get_discount_info(
current_price=899.90,
price_history=precos_historicos,
advertised_old_price=1999.90 # IGNORADO quando há histórico!
)
print(f"Desconto anunciado: 55%")
print(f"Desconto REAL: {info.discount_percentage:.2f}%") # ~31% (vs R$ 1.299)
print(f"Estratégia: {info.strategy}") # 'history' (priorizou histórico)
```
### 4. Análise de Melhor Momento para Comprar
```python
trend = calculate_price_trend(precos, days=30)
if trend.is_decreasing() and trend.has_high_confidence():
print("✅ Tendência de queda com alta confiança - BOM momento!")
elif trend.is_increasing() and trend.is_accelerating:
print("⚠️ Preço subindo rápido - compre agora ou espere próxima promoção")
```
## 📚 Documentação Completa
Para mais detalhes e exemplos avançados, consulte:
- [CLAUDE.md](CLAUDE.md) - Documentação completa com arquitetura e exemplos
- [notify_utils/](notify_utils/) - Código fonte com docstrings detalhadas
## 🛠️ Requisitos
- Python >= 3.12
- discord-webhook >= 1.4.1 (opcional, apenas para notificações)
## 📝 Changelog
### v0.2.3 (2026-02-05)
- 🏪 **SephoraAPIJSONParser Completo**: Parser para API Linx Impulse da Sephora Brasil
- 🔄 **Expansão de SKUs**: 1 produto com N variações → N produtos únicos (36 → 105 SKUs)
- 📦 **Nome Combinado**: Formato `{nome_produto} - {tamanho}` para cada variação
- ✅ **Validações Avançadas**: Ignora SKUs indisponíveis ou com preço inválido
- 🖼️ **URLs Completas**: Conversão automática de URLs relativas e imagens
- 📊 **Testes Completos**: Suite em test_sephora_parser.py com 10 validações
- 📚 **Documentação**: Seção completa em PARSERS.md com casos de uso
### v0.2.2 (2026-02-04)
- ✅ **BelezaNaWebHTMLParser Completo**: Implementação finalizada com parse híbrido JSON+HTML
- 🔍 **Extração Avançada**: Parse de `data-event` JSON embedded + fallback HTML estruturado
- 🧹 **Deduplicação por SKU**: Remove ~430 produtos repetidos → 36 únicos (carrosséis)
- 🏷️ **Preço Antigo**: Extração automática de `.item-price-max` com parse_price
- 🖼️ **URLs Completas**: Conversão automática de URLs relativas para absolutas
- ⚡ **Performance**: Parser otimizado com lxml (fallback html.parser)
- ✅ **Validações Robustas**: Ignora produtos sem SKU/preço com logs detalhados
- 🧪 **Testes Completos**: Suite de testes com validações de campos e estatísticas
### v0.2.1 (2026-02-03)
- 🏪 **Parsers de Lojas**: Maze API, Nike API e Beleza na Web HTML (inicial)
- 🔍 **Parser HTML**: Extração de produtos de páginas HTML com BeautifulSoup
- 🧹 **Deduplicação Automática**: Remove produtos duplicados por SKU
- 🏭 **Factory Pattern**: Sistema extensível para adicionar novos parsers
- 🎨 **Type Hints Completos**: Melhor experiência com IDEs e linters
### v0.1.0 (2026-02-03)
- ✨ Sistema de validação de preços com estratégias
- 📊 Ajuste automático de período histórico
- 🔇 Filtro de ruído de dados recentes
- 📈 Análise de tendências com volatilidade
- 🎯 Novos modelos tipados e enums
Veja o [changelog completo no CLAUDE.md](CLAUDE.md#changelog)
## 📄 Licença
MIT - veja [LICENSE](LICENSE) para detalhes.
## 👥 Contribuindo
Contribuições são bem-vindas! Abra issues ou pull requests no [repositório](https://github.com/jefersonAlbara/notify-utils).
## ⭐ Agradecimentos
Desenvolvido para ajudar consumidores a identificar promoções reais vs falsas no e-commerce brasileiro.
| text/markdown | null | Naruto Uzumaki <naruto_uzumaki@gmail.com> | null | null | MIT | price-tracking, discount-calculator, web-scraping, e-commerce, price-history, discount-analysis, promotion-detection, statistics | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Office/Business :: Financial"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"discord-webhook>=1.4.1",
"beautifulsoup4>=4.12.0",
"lxml>=4.9.0",
"orjson>=3.9.0"
] | [] | [] | [] | [
"Homepage, https://github.com/jefersonAlbara/notify-utils",
"Repository, https://github.com/jefersonAlbara/notify-utils",
"Issues, https://github.com/jefersonAlbara/notify-utils/issues"
] | twine/6.2.0 CPython/3.13.3 | 2026-02-20T14:34:18.021221 | notify_utils-0.3.3.tar.gz | 40,459 | 91/8c/8d60e4195356592e35e6d1b39a296916c485f3d9ad007742658fde0f6a73/notify_utils-0.3.3.tar.gz | source | sdist | null | false | 317cc501d463488e18acf6f777f69f94 | 0a8a2a2ded9c202e887821e9ed08cbc85bf499fee64b67fecc7b6ded65dbbc05 | 918c8d60e4195356592e35e6d1b39a296916c485f3d9ad007742658fde0f6a73 | null | [
"LICENSE"
] | 221 |
2.4 | fds.sdk.StreetAccountNews | 1.4.0 | StreetAccount News client library for Python | [](https://www.factset.com)
# StreetAccount News client library for Python
[](https://developer.factset.com/api-catalog/streetaccount-news-api)
[](https://pypi.org/project/fds.sdk.StreetAccountNews/v/1.4.0)
[](https://www.apache.org/licenses/LICENSE-2.0)
The StreetAccount News API provides access to FactSet's proprietary news provider, StreetAccount. StreetAccount, is a premium real-time market intelligence news service that delivers comprehensive U.S., Canadian, and European coverage (and expanding Asia coverage). All possible sources for corporate news are scanned and key story facts are highlighted and presented in an easy-to-read format.
**StreetAccount Filters, Headlines, and Views:**
These endpoints allow for the retrieval of news headlines using filters such as Watchlists/Indices/Tickers, Categories (the equivalent of 'Subjects' within the Workstation), Market Topics, Regions, and Sectors. Headlines can also be retrieved based on saved views within the Workstation.
This Python package is automatically generated by the [OpenAPI Generator](https://openapi-generator.tech) project:
- API version: 1.2.1
- SDK version: 1.4.0
- Build package: org.openapitools.codegen.languages.PythonClientCodegen
For more information, please visit [https://developer.factset.com/contact](https://developer.factset.com/contact)
## Requirements
* Python >= 3.7
## Installation
### Poetry
```shell
poetry add fds.sdk.utils fds.sdk.StreetAccountNews==1.4.0
```
### pip
```shell
pip install fds.sdk.utils fds.sdk.StreetAccountNews==1.4.0
```
## Usage
1. [Generate authentication credentials](../../../../README.md#authentication).
2. Setup Python environment.
1. Install and activate python 3.7+. If you're using [pyenv](https://github.com/pyenv/pyenv):
```sh
pyenv install 3.9.7
pyenv shell 3.9.7
```
2. (optional) [Install poetry](https://python-poetry.org/docs/#installation).
3. [Install dependencies](#installation).
4. Run the following:
> [!IMPORTANT]
> The parameter variables defined below are just examples and may potentially contain non valid values. Please replace them with valid values.
### Example Code
```python
from fds.sdk.utils.authentication import ConfidentialClient
import fds.sdk.StreetAccountNews
from fds.sdk.StreetAccountNews.api import filters_api
from fds.sdk.StreetAccountNews.models import *
from dateutil.parser import parse as dateutil_parser
from pprint import pprint
# See configuration.py for a list of all supported configuration parameters.
# Examples for each supported authentication method are below,
# choose one that satisfies your use case.
# (Preferred) OAuth 2.0: FactSetOAuth2
# See https://github.com/FactSet/enterprise-sdk#oauth-20
# for information on how to create the app-config.json file
#
# The confidential client instance should be reused in production environments.
# See https://github.com/FactSet/enterprise-sdk-utils-python#authentication
# for more information on using the ConfidentialClient class
configuration = fds.sdk.StreetAccountNews.Configuration(
fds_oauth_client=ConfidentialClient('/path/to/app-config.json')
)
# Basic authentication: FactSetApiKey
# See https://github.com/FactSet/enterprise-sdk#api-key
# for information how to create an API key
# configuration = fds.sdk.StreetAccountNews.Configuration(
# username='USERNAME-SERIAL',
# password='API-KEY'
# )
# Enter a context with an instance of the API client
with fds.sdk.StreetAccountNews.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = filters_api.FiltersApi(api_client)
attributes = [
"structured",
] # [str] | Specify the type(s) of filters to be returned. Accepted values are `structured` and/or `flattened`. If not specified, all filters are returned. (optional)
try:
# Retrieve all StreetAccount filters
# example passing only required values which don't have defaults set
# and optional values
api_response = api_instance.get_street_account_filters(attributes=attributes)
pprint(api_response)
except fds.sdk.StreetAccountNews.ApiException as e:
print("Exception when calling FiltersApi->get_street_account_filters: %s\n" % e)
# # Get response, http status code and response headers
# try:
# # Retrieve all StreetAccount filters
# api_response, http_status_code, response_headers = api_instance.get_street_account_filters_with_http_info(attributes=attributes)
# pprint(api_response)
# pprint(http_status_code)
# pprint(response_headers)
# except fds.sdk.StreetAccountNews.ApiException as e:
# print("Exception when calling FiltersApi->get_street_account_filters: %s\n" % e)
# # Get response asynchronous
# try:
# # Retrieve all StreetAccount filters
# async_result = api_instance.get_street_account_filters_async(attributes=attributes)
# api_response = async_result.get()
# pprint(api_response)
# except fds.sdk.StreetAccountNews.ApiException as e:
# print("Exception when calling FiltersApi->get_street_account_filters: %s\n" % e)
# # Get response, http status code and response headers asynchronous
# try:
# # Retrieve all StreetAccount filters
# async_result = api_instance.get_street_account_filters_with_http_info_async(attributes=attributes)
# api_response, http_status_code, response_headers = async_result.get()
# pprint(api_response)
# pprint(http_status_code)
# pprint(response_headers)
# except fds.sdk.StreetAccountNews.ApiException as e:
# print("Exception when calling FiltersApi->get_street_account_filters: %s\n" % e)
```
### Using Pandas
To convert an API response to a Pandas DataFrame, it is necessary to transform it first to a dictionary.
```python
import pandas as pd
response_dict = api_response.to_dict()['data']
simple_json_response = pd.DataFrame(response_dict)
nested_json_response = pd.json_normalize(response_dict)
```
### Debugging
The SDK uses the standard library [`logging`](https://docs.python.org/3/library/logging.html#module-logging) module.
Setting `debug` to `True` on an instance of the `Configuration` class sets the log-level of related packages to `DEBUG`
and enables additional logging in Pythons [HTTP Client](https://docs.python.org/3/library/http.client.html).
**Note**: This prints out sensitive information (e.g. the full request and response). Use with care.
```python
import logging
import fds.sdk.StreetAccountNews
logging.basicConfig(level=logging.DEBUG)
configuration = fds.sdk.StreetAccountNews.Configuration(...)
configuration.debug = True
```
### Configure a Proxy
You can pass proxy settings to the Configuration class:
* `proxy`: The URL of the proxy to use.
* `proxy_headers`: a dictionary to pass additional headers to the proxy (e.g. `Proxy-Authorization`).
```python
import fds.sdk.StreetAccountNews
configuration = fds.sdk.StreetAccountNews.Configuration(
# ...
proxy="http://secret:password@localhost:5050",
proxy_headers={
"Custom-Proxy-Header": "Custom-Proxy-Header-Value"
}
)
```
### Custom SSL Certificate
TLS/SSL certificate verification can be configured with the following Configuration parameters:
* `ssl_ca_cert`: a path to the certificate to use for verification in `PEM` format.
* `verify_ssl`: setting this to `False` disables the verification of certificates.
Disabling the verification is not recommended, but it might be useful during
local development or testing.
```python
import fds.sdk.StreetAccountNews
configuration = fds.sdk.StreetAccountNews.Configuration(
# ...
ssl_ca_cert='/path/to/ca.pem'
)
```
### Request Retries
In case the request retry behaviour should be customized, it is possible to pass a `urllib3.Retry` object to the `retry` property of the Configuration.
```python
from urllib3 import Retry
import fds.sdk.StreetAccountNews
configuration = fds.sdk.StreetAccountNews.Configuration(
# ...
)
configuration.retries = Retry(total=3, status_forcelist=[500, 502, 503, 504])
```
## Documentation for API Endpoints
All URIs are relative to *https://api.factset.com/streetaccount/v1*
Class | Method | HTTP request | Description
------------ | ------------- | ------------- | -------------
*FiltersApi* | [**get_street_account_filters**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FiltersApi.md#get_street_account_filters) | **GET** /filters | Retrieve all StreetAccount filters
*FiltersApi* | [**get_street_account_filters_categories**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FiltersApi.md#get_street_account_filters_categories) | **GET** /filters/categories | Retrieve all StreetAccount filter categories
*FiltersApi* | [**get_street_account_filters_regions**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FiltersApi.md#get_street_account_filters_regions) | **GET** /filters/regions | Retrieve all StreetAccount filter regions
*FiltersApi* | [**get_street_account_filters_sectors**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FiltersApi.md#get_street_account_filters_sectors) | **GET** /filters/sectors | Retrieve all StreetAccount filter sectors
*FiltersApi* | [**get_street_account_filters_topics**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FiltersApi.md#get_street_account_filters_topics) | **GET** /filters/topics | Retrieve all StreetAccount filter topics
*FiltersApi* | [**get_street_account_filters_watchlists**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FiltersApi.md#get_street_account_filters_watchlists) | **GET** /filters/watchlists | Retrieve all StreetAccount filter watchlists
*HeadlinesApi* | [**get_street_account_headlines**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesApi.md#get_street_account_headlines) | **POST** /headlines | Retrieve StreetAccount headlines for given filters
*HeadlinesApi* | [**get_street_account_headlines_by_view**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesApi.md#get_street_account_headlines_by_view) | **POST** /headlines/view | Retrieve StreetAccount headlines for given view
*ViewsApi* | [**create_quick_alert_for_view**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/ViewsApi.md#create_quick_alert_for_view) | **POST** /quick-alert/create | Creates a quick-alert for given saved view
*ViewsApi* | [**create_street_account_view**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/ViewsApi.md#create_street_account_view) | **POST** /views/create | Creates and saves a StreetAccount view
*ViewsApi* | [**delete_quickalert_view**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/ViewsApi.md#delete_quickalert_view) | **POST** /quick-alert/delete | Deletes an existing quick alert for a view.
*ViewsApi* | [**delete_street_account_view**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/ViewsApi.md#delete_street_account_view) | **POST** /views/delete | Deletes an existing StreetAccount view
*ViewsApi* | [**edit_street_account_view**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/ViewsApi.md#edit_street_account_view) | **POST** /views/update | Edits and saves an existing StreetAccount view
*ViewsApi* | [**get_street_account_views**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/ViewsApi.md#get_street_account_views) | **GET** /views | Retrieves StreetAccount search views
## Documentation For Models
- [CreateOrEditViewBody](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/CreateOrEditViewBody.md)
- [CreateOrEditViewBodyData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/CreateOrEditViewBodyData.md)
- [CreateOrEditViewTickers](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/CreateOrEditViewTickers.md)
- [CreateViewResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/CreateViewResponse.md)
- [CreateViewResponseData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/CreateViewResponseData.md)
- [DeleteViewBody](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/DeleteViewBody.md)
- [DeleteViewBodyData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/DeleteViewBodyData.md)
- [Error](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/Error.md)
- [ErrorObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/ErrorObject.md)
- [FilterCategoriesResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FilterCategoriesResponse.md)
- [FilterCategoriesResponseData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FilterCategoriesResponseData.md)
- [FilterRegionsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FilterRegionsResponse.md)
- [FilterRegionsResponseData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FilterRegionsResponseData.md)
- [FilterResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FilterResponse.md)
- [FilterResponseData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FilterResponseData.md)
- [FilterSectorsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FilterSectorsResponse.md)
- [FilterSectorsResponseData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FilterSectorsResponseData.md)
- [FilterTopicResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FilterTopicResponse.md)
- [FilterTopicResponseData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FilterTopicResponseData.md)
- [FilterWatchlistsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FilterWatchlistsResponse.md)
- [FilterWatchlistsResponseData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FilterWatchlistsResponseData.md)
- [FlattenedFilters](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FlattenedFilters.md)
- [FlattenedFiltersCategories](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FlattenedFiltersCategories.md)
- [FlattenedFiltersCategoriesObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FlattenedFiltersCategoriesObject.md)
- [FlattenedFiltersRegions](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FlattenedFiltersRegions.md)
- [FlattenedFiltersRegionsObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FlattenedFiltersRegionsObject.md)
- [FlattenedFiltersSectors](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FlattenedFiltersSectors.md)
- [FlattenedFiltersSectorsObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FlattenedFiltersSectorsObject.md)
- [FlattenedFiltersTopics](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FlattenedFiltersTopics.md)
- [FlattenedFiltersTopicsObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FlattenedFiltersTopicsObject.md)
- [FlattenedFiltersWatchlists](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FlattenedFiltersWatchlists.md)
- [FlattenedFiltersWatchlistsObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/FlattenedFiltersWatchlistsObject.md)
- [HeadlinesRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesRequest.md)
- [HeadlinesRequestByView](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesRequestByView.md)
- [HeadlinesRequestByViewData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesRequestByViewData.md)
- [HeadlinesRequestByViewDataSearchTime](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesRequestByViewDataSearchTime.md)
- [HeadlinesRequestByViewMeta](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesRequestByViewMeta.md)
- [HeadlinesRequestData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesRequestData.md)
- [HeadlinesRequestDataSearchTime](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesRequestDataSearchTime.md)
- [HeadlinesRequestMeta](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesRequestMeta.md)
- [HeadlinesRequestMetaPagination](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesRequestMetaPagination.md)
- [HeadlinesRequestTickersObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesRequestTickersObject.md)
- [HeadlinesResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesResponse.md)
- [HeadlinesResponseMeta](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesResponseMeta.md)
- [HeadlinesResponseMetaPagination](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/HeadlinesResponseMetaPagination.md)
- [QuickAlertsBody](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/QuickAlertsBody.md)
- [QuickAlertsBodyData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/QuickAlertsBodyData.md)
- [QuickAlertsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/QuickAlertsResponse.md)
- [QuickAlertsResponseData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/QuickAlertsResponseData.md)
- [SearchResponseArrayObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/SearchResponseArrayObject.md)
- [StructuredFilters](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFilters.md)
- [StructuredFiltersCategories](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersCategories.md)
- [StructuredFiltersCategoriesObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersCategoriesObject.md)
- [StructuredFiltersChildrenObjectCategories](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersChildrenObjectCategories.md)
- [StructuredFiltersChildrenObjectRegions](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersChildrenObjectRegions.md)
- [StructuredFiltersChildrenObjectSectors](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersChildrenObjectSectors.md)
- [StructuredFiltersChildrenObjectTopics](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersChildrenObjectTopics.md)
- [StructuredFiltersChildrenObjectTopicsNested](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersChildrenObjectTopicsNested.md)
- [StructuredFiltersChildrenObjectTopicsNested2](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersChildrenObjectTopicsNested2.md)
- [StructuredFiltersRegions](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersRegions.md)
- [StructuredFiltersRegionsObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersRegionsObject.md)
- [StructuredFiltersSectors](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersSectors.md)
- [StructuredFiltersSectorsObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersSectorsObject.md)
- [StructuredFiltersTopics](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersTopics.md)
- [StructuredFiltersTopicsObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersTopicsObject.md)
- [StructuredFiltersWatchlists](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersWatchlists.md)
- [StructuredFiltersWatchlistsObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/StructuredFiltersWatchlistsObject.md)
- [Views](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/Views.md)
- [ViewsObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1/docs/ViewsObject.md)
## Documentation For Authorization
## FactSetApiKey
- **Type**: HTTP basic authentication
## FactSetOAuth2
- **Type**: OAuth
- **Flow**: application
- **Authorization URL**:
- **Scopes**: N/A
## Notes for Large OpenAPI documents
If the OpenAPI document is large, imports in fds.sdk.StreetAccountNews.apis and fds.sdk.StreetAccountNews.models may fail with a
RecursionError indicating the maximum recursion limit has been exceeded. In that case, there are a couple of solutions:
Solution 1:
Use specific imports for apis and models like:
- `from fds.sdk.StreetAccountNews.api.default_api import DefaultApi`
- `from fds.sdk.StreetAccountNews.model.pet import Pet`
Solution 2:
Before importing the package, adjust the maximum recursion limit as shown below:
```
import sys
sys.setrecursionlimit(1500)
import fds.sdk.StreetAccountNews
from fds.sdk.StreetAccountNews.apis import *
from fds.sdk.StreetAccountNews.models import *
```
## Contributing
Please refer to the [contributing guide](../../../../CONTRIBUTING.md).
## Copyright
Copyright 2026 FactSet Research Systems Inc
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| text/markdown | FactSet Research Systems | null | null | null | Apache License, Version 2.0 | FactSet, API, SDK | [] | [] | https://github.com/FactSet/enterprise-sdk/tree/main/code/python/StreetAccountNews/v1 | null | >=3.7 | [] | [] | [] | [
"urllib3>=1.25.3",
"python-dateutil",
"fds.sdk.utils>=1.0.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-20T14:34:12.922983 | fds_sdk_streetaccountnews-1.4.0-py3-none-any.whl | 266,434 | 73/87/e3ecf18a840c93774eaa0dea45223d6670d89b5cd68322abf279b4552e83/fds_sdk_streetaccountnews-1.4.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 65b6bdb256c7b42222a179c40b3a7e0a | cc80d095ae76d6dcb3be1f491a912ba3e83a42b201fcc5c2692a3972f640c8ac | 7387e3ecf18a840c93774eaa0dea45223d6670d89b5cd68322abf279b4552e83 | null | [
"LICENSE"
] | 0 |
2.4 | fds.sdk.FactSetPrivateCompany | 1.2.0 | FactSet Private Company client library for Python | [](https://www.factset.com)
# FactSet Private Company client library for Python
[](https://developer.factset.com/api-catalog/factset-private-company-api)
[](https://pypi.org/project/fds.sdk.FactSetPrivateCompany/v/1.2.0)
[](https://www.apache.org/licenses/LICENSE-2.0)
FactSet Private Company API encompasses Private Company Financials and includes some Private Company non-periodic data. Additional Private Company firmographics can be found in the FactSet Entity API. <p><b>Rate limit is set to 10 requests per second and 10 concurrent requests per user</b>.</p>
This Python package is automatically generated by the [OpenAPI Generator](https://openapi-generator.tech) project:
- API version: 1.1.0
- SDK version: 1.2.0
- Build package: org.openapitools.codegen.languages.PythonClientCodegen
For more information, please visit [https://developer.factset.com/contact](https://developer.factset.com/contact)
## Requirements
* Python >= 3.7
## Installation
### Poetry
```shell
poetry add fds.sdk.utils fds.sdk.FactSetPrivateCompany==1.2.0
```
### pip
```shell
pip install fds.sdk.utils fds.sdk.FactSetPrivateCompany==1.2.0
```
## Usage
1. [Generate authentication credentials](../../../../README.md#authentication).
2. Setup Python environment.
1. Install and activate python 3.7+. If you're using [pyenv](https://github.com/pyenv/pyenv):
```sh
pyenv install 3.9.7
pyenv shell 3.9.7
```
2. (optional) [Install poetry](https://python-poetry.org/docs/#installation).
3. [Install dependencies](#installation).
4. Run the following:
> [!IMPORTANT]
> The parameter variables defined below are just examples and may potentially contain non valid values. Please replace them with valid values.
### Example Code
```python
from fds.sdk.utils.authentication import ConfidentialClient
import fds.sdk.FactSetPrivateCompany
from fds.sdk.FactSetPrivateCompany.api import company_reports_api
from fds.sdk.FactSetPrivateCompany.models import *
from dateutil.parser import parse as dateutil_parser
from pprint import pprint
# See configuration.py for a list of all supported configuration parameters.
# Examples for each supported authentication method are below,
# choose one that satisfies your use case.
# (Preferred) OAuth 2.0: FactSetOAuth2
# See https://github.com/FactSet/enterprise-sdk#oauth-20
# for information on how to create the app-config.json file
#
# The confidential client instance should be reused in production environments.
# See https://github.com/FactSet/enterprise-sdk-utils-python#authentication
# for more information on using the ConfidentialClient class
configuration = fds.sdk.FactSetPrivateCompany.Configuration(
fds_oauth_client=ConfidentialClient('/path/to/app-config.json')
)
# Basic authentication: FactSetApiKey
# See https://github.com/FactSet/enterprise-sdk#api-key
# for information how to create an API key
# configuration = fds.sdk.FactSetPrivateCompany.Configuration(
# username='USERNAME-SERIAL',
# password='API-KEY'
# )
# Enter a context with an instance of the API client
with fds.sdk.FactSetPrivateCompany.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = company_reports_api.CompanyReportsApi(api_client)
ids = ["0H3R4Y-E"] # [str] | The requested list of Factset Private Company identifiers in XXXXXX-E format <p>***ids limit** = 50 per request*</p>
statement_type = "BS" # str | The type of financial statement being requested
currency = "USD" # str | Currency code for currency values. For a list of currency ISO codes, visit Online Assistant Page [OA1470](https://my.apps.factset.com/oa/pages/1470). Giving input as \"DOC\" would give the values in reporting currency for the requested ids. (optional) if omitted the server will use the default value of "LOCAL"
number_annual_periods = 4 # int | The number of annual periods for the returned data which will be displayed in descending order from most recent annual period for the number of annual periods specified. </br>Within range of 1 to 100. If not specified default will be 4. (optional) if omitted the server will use the default value of 4
try:
# Returns Private Company Financial Data
# example passing only required values which don't have defaults set
# and optional values
api_response = api_instance.get_financials_report(ids, statement_type, currency=currency, number_annual_periods=number_annual_periods)
pprint(api_response)
except fds.sdk.FactSetPrivateCompany.ApiException as e:
print("Exception when calling CompanyReportsApi->get_financials_report: %s\n" % e)
# # Get response, http status code and response headers
# try:
# # Returns Private Company Financial Data
# api_response, http_status_code, response_headers = api_instance.get_financials_report_with_http_info(ids, statement_type, currency=currency, number_annual_periods=number_annual_periods)
# pprint(api_response)
# pprint(http_status_code)
# pprint(response_headers)
# except fds.sdk.FactSetPrivateCompany.ApiException as e:
# print("Exception when calling CompanyReportsApi->get_financials_report: %s\n" % e)
# # Get response asynchronous
# try:
# # Returns Private Company Financial Data
# async_result = api_instance.get_financials_report_async(ids, statement_type, currency=currency, number_annual_periods=number_annual_periods)
# api_response = async_result.get()
# pprint(api_response)
# except fds.sdk.FactSetPrivateCompany.ApiException as e:
# print("Exception when calling CompanyReportsApi->get_financials_report: %s\n" % e)
# # Get response, http status code and response headers asynchronous
# try:
# # Returns Private Company Financial Data
# async_result = api_instance.get_financials_report_with_http_info_async(ids, statement_type, currency=currency, number_annual_periods=number_annual_periods)
# api_response, http_status_code, response_headers = async_result.get()
# pprint(api_response)
# pprint(http_status_code)
# pprint(response_headers)
# except fds.sdk.FactSetPrivateCompany.ApiException as e:
# print("Exception when calling CompanyReportsApi->get_financials_report: %s\n" % e)
```
### Using Pandas
To convert an API response to a Pandas DataFrame, it is necessary to transform it first to a dictionary.
```python
import pandas as pd
response_dict = api_response.to_dict()['data']
simple_json_response = pd.DataFrame(response_dict)
nested_json_response = pd.json_normalize(response_dict)
```
### Debugging
The SDK uses the standard library [`logging`](https://docs.python.org/3/library/logging.html#module-logging) module.
Setting `debug` to `True` on an instance of the `Configuration` class sets the log-level of related packages to `DEBUG`
and enables additional logging in Pythons [HTTP Client](https://docs.python.org/3/library/http.client.html).
**Note**: This prints out sensitive information (e.g. the full request and response). Use with care.
```python
import logging
import fds.sdk.FactSetPrivateCompany
logging.basicConfig(level=logging.DEBUG)
configuration = fds.sdk.FactSetPrivateCompany.Configuration(...)
configuration.debug = True
```
### Configure a Proxy
You can pass proxy settings to the Configuration class:
* `proxy`: The URL of the proxy to use.
* `proxy_headers`: a dictionary to pass additional headers to the proxy (e.g. `Proxy-Authorization`).
```python
import fds.sdk.FactSetPrivateCompany
configuration = fds.sdk.FactSetPrivateCompany.Configuration(
# ...
proxy="http://secret:password@localhost:5050",
proxy_headers={
"Custom-Proxy-Header": "Custom-Proxy-Header-Value"
}
)
```
### Custom SSL Certificate
TLS/SSL certificate verification can be configured with the following Configuration parameters:
* `ssl_ca_cert`: a path to the certificate to use for verification in `PEM` format.
* `verify_ssl`: setting this to `False` disables the verification of certificates.
Disabling the verification is not recommended, but it might be useful during
local development or testing.
```python
import fds.sdk.FactSetPrivateCompany
configuration = fds.sdk.FactSetPrivateCompany.Configuration(
# ...
ssl_ca_cert='/path/to/ca.pem'
)
```
### Request Retries
In case the request retry behaviour should be customized, it is possible to pass a `urllib3.Retry` object to the `retry` property of the Configuration.
```python
from urllib3 import Retry
import fds.sdk.FactSetPrivateCompany
configuration = fds.sdk.FactSetPrivateCompany.Configuration(
# ...
)
configuration.retries = Retry(total=3, status_forcelist=[500, 502, 503, 504])
```
## Documentation for API Endpoints
All URIs are relative to *https://api.factset.com/content/private-company/v1*
Class | Method | HTTP request | Description
------------ | ------------- | ------------- | -------------
*CompanyReportsApi* | [**get_financials_report**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/CompanyReportsApi.md#get_financials_report) | **GET** /company-reports/financial-statement | Returns Private Company Financial Data
*CompanyReportsApi* | [**get_profile_report**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/CompanyReportsApi.md#get_profile_report) | **GET** /company-reports/profile | Returns Private Company Non-Periodic Data
*FinancialsApi* | [**get_financials**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/FinancialsApi.md#get_financials) | **GET** /financials | Returns Private Company Financial Data.
*FinancialsApi* | [**get_financials_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/FinancialsApi.md#get_financials_for_list) | **POST** /financials | Returns Private Company Financial Data.
*MetricsApi* | [**get_metrics**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/MetricsApi.md#get_metrics) | **GET** /metrics | Returns available private company metrics, and ratios.
*NonPeriodicApi* | [**get_non_periodic**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/NonPeriodicApi.md#get_non_periodic) | **GET** /non-periodic | Returns Private Company Reference Data.
*NonPeriodicApi* | [**get_non_periodic_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/NonPeriodicApi.md#get_non_periodic_for_list) | **POST** /non-periodic | Returns Private Company Reference Data.
*UniverseApi* | [**get_universe**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/UniverseApi.md#get_universe) | **GET** /universe | Returns Entity Candidates and Matches for a single name and attributes.
*UniverseApi* | [**get_universe_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/UniverseApi.md#get_universe_for_list) | **POST** /universe | Returns Entity Candidates and Matches for a requested list of up to 25 names and attributes.
## Documentation For Models
- [EntityMatch](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/EntityMatch.md)
- [EntityMatchRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/EntityMatchRequest.md)
- [EntityMatchRequestBody](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/EntityMatchRequestBody.md)
- [EntityMatchesResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/EntityMatchesResponse.md)
- [ErrorObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/ErrorObject.md)
- [ErrorObjectLinks](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/ErrorObjectLinks.md)
- [ErrorResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/ErrorResponse.md)
- [FinancialStatements](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/FinancialStatements.md)
- [FinancialStatementsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/FinancialStatementsResponse.md)
- [Financials](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/Financials.md)
- [FinancialsMetrics](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/FinancialsMetrics.md)
- [FinancialsRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/FinancialsRequest.md)
- [FinancialsRequestBody](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/FinancialsRequestBody.md)
- [FinancialsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/FinancialsResponse.md)
- [Metric](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/Metric.md)
- [MetricsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/MetricsResponse.md)
- [NonPeriodic](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/NonPeriodic.md)
- [NonPeriodicMetrics](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/NonPeriodicMetrics.md)
- [NonPeriodicRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/NonPeriodicRequest.md)
- [NonPeriodicRequestBody](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/NonPeriodicRequestBody.md)
- [NonPeriodicResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/NonPeriodicResponse.md)
- [NonPeriodicValue](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/NonPeriodicValue.md)
- [PrivateMarketIds](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/PrivateMarketIds.md)
- [Profile](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/Profile.md)
- [ProfileResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/ProfileResponse.md)
- [StatementItem](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1/docs/StatementItem.md)
## Documentation For Authorization
## FactSetApiKey
- **Type**: HTTP basic authentication
## FactSetOAuth2
- **Type**: OAuth
- **Flow**: application
- **Authorization URL**:
- **Scopes**: N/A
## Notes for Large OpenAPI documents
If the OpenAPI document is large, imports in fds.sdk.FactSetPrivateCompany.apis and fds.sdk.FactSetPrivateCompany.models may fail with a
RecursionError indicating the maximum recursion limit has been exceeded. In that case, there are a couple of solutions:
Solution 1:
Use specific imports for apis and models like:
- `from fds.sdk.FactSetPrivateCompany.api.default_api import DefaultApi`
- `from fds.sdk.FactSetPrivateCompany.model.pet import Pet`
Solution 2:
Before importing the package, adjust the maximum recursion limit as shown below:
```
import sys
sys.setrecursionlimit(1500)
import fds.sdk.FactSetPrivateCompany
from fds.sdk.FactSetPrivateCompany.apis import *
from fds.sdk.FactSetPrivateCompany.models import *
```
## Contributing
Please refer to the [contributing guide](../../../../CONTRIBUTING.md).
## Copyright
Copyright 2026 FactSet Research Systems Inc
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| text/markdown | FactSet Research Systems | null | null | null | Apache License, Version 2.0 | FactSet, API, SDK | [] | [] | https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetPrivateCompany/v1 | null | >=3.7 | [] | [] | [] | [
"urllib3>=1.25.3",
"python-dateutil",
"fds.sdk.utils>=1.0.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-20T14:34:10.620166 | fds_sdk_factsetprivatecompany-1.2.0.tar.gz | 67,707 | aa/88/0af86586343718e9cfd93207ff2a3d0358615d161026af4e28ec1bcd8e5a/fds_sdk_factsetprivatecompany-1.2.0.tar.gz | source | sdist | null | false | 36e5a087c9d5a8d9f54292e10732e49b | 2fe1ac34fa7821ab44c53352878a8cb0a4c66519f246f6f530cc24f8c72b5f36 | aa880af86586343718e9cfd93207ff2a3d0358615d161026af4e28ec1bcd8e5a | null | [
"LICENSE"
] | 0 |
2.4 | fds.sdk.FactSetOwnership | 1.3.0 | FactSet Ownership client library for Python | [](https://www.factset.com)
# FactSet Ownership client library for Python
[](https://developer.factset.com/api-catalog/factset-ownership-api)
[](https://pypi.org/project/fds.sdk.FactSetOwnership/v/1.3.0)
[](https://www.apache.org/licenses/LICENSE-2.0)
FactSet's Fund Ownership API gives access to both **Holdings**, **Holders**, and **Transactions** data.<p> Factset's Holdings endpoints gives access to all the underlying securities and their position details held within a given fund. Fund Types supported include Open-End Mutual Funds, Closed-end Mutual Funds, and Exchange Traded Funds. Security Holders information retrieves all \"holder types\" and their positions across institutions, funds, insiders, and stakeholders. FactSet also provides extensive insider and institutional transactions data for multiple countries including the United States, China, and Canada.</p><p>The FactSet Ownership and Mutual Funds database collects global equity ownership data for approximately 50,000 institutions, 60,000 unique Mutual Fund portfolios, and 400,000 Insider/Stakeholders from around 110 countries. For more details review our [Data Collection](https://my.apps.factset.com/oa/cms/oaAttachment/87e162be-f2d1-4f40-a85b-bfb1b020d270/20079) methodology. </p>
This Python package is automatically generated by the [OpenAPI Generator](https://openapi-generator.tech) project:
- API version: 1.2.2
- SDK version: 1.3.0
- Build package: org.openapitools.codegen.languages.PythonClientCodegen
For more information, please visit [https://developer.factset.com/contact](https://developer.factset.com/contact)
## Requirements
* Python >= 3.7
## Installation
### Poetry
```shell
poetry add fds.sdk.utils fds.sdk.FactSetOwnership==1.3.0
```
### pip
```shell
pip install fds.sdk.utils fds.sdk.FactSetOwnership==1.3.0
```
## Usage
1. [Generate authentication credentials](../../../../README.md#authentication).
2. Setup Python environment.
1. Install and activate python 3.7+. If you're using [pyenv](https://github.com/pyenv/pyenv):
```sh
pyenv install 3.9.7
pyenv shell 3.9.7
```
2. (optional) [Install poetry](https://python-poetry.org/docs/#installation).
3. [Install dependencies](#installation).
4. Run the following:
> [!IMPORTANT]
> The parameter variables defined below are just examples and may potentially contain non valid values. Please replace them with valid values.
### Example Code
```python
from fds.sdk.utils.authentication import ConfidentialClient
import fds.sdk.FactSetOwnership
from fds.sdk.FactSetOwnership.api import batch_processing_api
from fds.sdk.FactSetOwnership.models import *
from dateutil.parser import parse as dateutil_parser
from pprint import pprint
# See configuration.py for a list of all supported configuration parameters.
# Examples for each supported authentication method are below,
# choose one that satisfies your use case.
# (Preferred) OAuth 2.0: FactSetOAuth2
# See https://github.com/FactSet/enterprise-sdk#oauth-20
# for information on how to create the app-config.json file
#
# The confidential client instance should be reused in production environments.
# See https://github.com/FactSet/enterprise-sdk-utils-python#authentication
# for more information on using the ConfidentialClient class
configuration = fds.sdk.FactSetOwnership.Configuration(
fds_oauth_client=ConfidentialClient('/path/to/app-config.json')
)
# Basic authentication: FactSetApiKey
# See https://github.com/FactSet/enterprise-sdk#api-key
# for information how to create an API key
# configuration = fds.sdk.FactSetOwnership.Configuration(
# username='USERNAME-SERIAL',
# password='API-KEY'
# )
# Enter a context with an instance of the API client
with fds.sdk.FactSetOwnership.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = batch_processing_api.BatchProcessingApi(api_client)
id = "id_example" # str | The Batch Request identifier. This value is returned in the response to a request with `batch=Y`, and is used to check the status and retrieve the results of the request.
try:
# Returns the response for the Batch Request
# example passing only required values which don't have defaults set
api_response_wrapper = api_instance.get_batch_data(id)
# This endpoint returns a response wrapper that contains different types of responses depending on the query.
# To access the correct response type, you need to perform one additional step, as shown below.
if api_response_wrapper.get_status_code() == 200:
api_response = api_response_wrapper.get_response_200()
if api_response_wrapper.get_status_code() == 202:
api_response = api_response_wrapper.get_response_202()
pprint(api_response)
except fds.sdk.FactSetOwnership.ApiException as e:
print("Exception when calling BatchProcessingApi->get_batch_data: %s\n" % e)
# # Get response, http status code and response headers
# try:
# # Returns the response for the Batch Request
# api_response_wrapper, http_status_code, response_headers = api_instance.get_batch_data_with_http_info(id)
# # This endpoint returns a response wrapper that contains different types of responses depending on the query.
# # To access the correct response type, you need to perform one additional step, as shown below.
# if api_response_wrapper.get_status_code() == 200:
# api_response = api_response_wrapper.get_response_200()
# if api_response_wrapper.get_status_code() == 202:
# api_response = api_response_wrapper.get_response_202()
# pprint(api_response)
# pprint(http_status_code)
# pprint(response_headers)
# except fds.sdk.FactSetOwnership.ApiException as e:
# print("Exception when calling BatchProcessingApi->get_batch_data: %s\n" % e)
# # Get response asynchronous
# try:
# # Returns the response for the Batch Request
# async_result = api_instance.get_batch_data_async(id)
# api_response_wrapper = async_result.get()
# # This endpoint returns a response wrapper that contains different types of responses depending on the query.
# # To access the correct response type, you need to perform one additional step, as shown below.
# if api_response_wrapper.get_status_code() == 200:
# api_response = api_response_wrapper.get_response_200()
# if api_response_wrapper.get_status_code() == 202:
# api_response = api_response_wrapper.get_response_202()
# pprint(api_response)
# except fds.sdk.FactSetOwnership.ApiException as e:
# print("Exception when calling BatchProcessingApi->get_batch_data: %s\n" % e)
# # Get response, http status code and response headers asynchronous
# try:
# # Returns the response for the Batch Request
# async_result = api_instance.get_batch_data_with_http_info_async(id)
# api_response_wrapper, http_status_code, response_headers = async_result.get()
# # This endpoint returns a response wrapper that contains different types of responses depending on the query.
# # To access the correct response type, you need to perform one additional step, as shown below.
# if api_response_wrapper.get_status_code() == 200:
# api_response = api_response_wrapper.get_response_200()
# if api_response_wrapper.get_status_code() == 202:
# api_response = api_response_wrapper.get_response_202()
# pprint(api_response)
# pprint(http_status_code)
# pprint(response_headers)
# except fds.sdk.FactSetOwnership.ApiException as e:
# print("Exception when calling BatchProcessingApi->get_batch_data: %s\n" % e)
```
### Using Pandas
To convert an API response to a Pandas DataFrame, it is necessary to transform it first to a dictionary.
```python
import pandas as pd
response_dict = api_response.to_dict()['data']
simple_json_response = pd.DataFrame(response_dict)
nested_json_response = pd.json_normalize(response_dict)
```
### Debugging
The SDK uses the standard library [`logging`](https://docs.python.org/3/library/logging.html#module-logging) module.
Setting `debug` to `True` on an instance of the `Configuration` class sets the log-level of related packages to `DEBUG`
and enables additional logging in Pythons [HTTP Client](https://docs.python.org/3/library/http.client.html).
**Note**: This prints out sensitive information (e.g. the full request and response). Use with care.
```python
import logging
import fds.sdk.FactSetOwnership
logging.basicConfig(level=logging.DEBUG)
configuration = fds.sdk.FactSetOwnership.Configuration(...)
configuration.debug = True
```
### Configure a Proxy
You can pass proxy settings to the Configuration class:
* `proxy`: The URL of the proxy to use.
* `proxy_headers`: a dictionary to pass additional headers to the proxy (e.g. `Proxy-Authorization`).
```python
import fds.sdk.FactSetOwnership
configuration = fds.sdk.FactSetOwnership.Configuration(
# ...
proxy="http://secret:password@localhost:5050",
proxy_headers={
"Custom-Proxy-Header": "Custom-Proxy-Header-Value"
}
)
```
### Custom SSL Certificate
TLS/SSL certificate verification can be configured with the following Configuration parameters:
* `ssl_ca_cert`: a path to the certificate to use for verification in `PEM` format.
* `verify_ssl`: setting this to `False` disables the verification of certificates.
Disabling the verification is not recommended, but it might be useful during
local development or testing.
```python
import fds.sdk.FactSetOwnership
configuration = fds.sdk.FactSetOwnership.Configuration(
# ...
ssl_ca_cert='/path/to/ca.pem'
)
```
### Request Retries
In case the request retry behaviour should be customized, it is possible to pass a `urllib3.Retry` object to the `retry` property of the Configuration.
```python
from urllib3 import Retry
import fds.sdk.FactSetOwnership
configuration = fds.sdk.FactSetOwnership.Configuration(
# ...
)
configuration.retries = Retry(total=3, status_forcelist=[500, 502, 503, 504])
```
## Documentation for API Endpoints
All URIs are relative to *https://api.factset.com/content/factset-ownership/v1*
Class | Method | HTTP request | Description
------------ | ------------- | ------------- | -------------
*BatchProcessingApi* | [**get_batch_data**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/BatchProcessingApi.md#get_batch_data) | **GET** /batch-result | Returns the response for the Batch Request
*BatchProcessingApi* | [**get_batch_status**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/BatchProcessingApi.md#get_batch_status) | **GET** /batch-status | Returns the latest status and metadata for the Batch Request.
*FundHoldingsApi* | [**get_ownership_holdings**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/FundHoldingsApi.md#get_ownership_holdings) | **GET** /fund-holdings | Get underlying holdings information for a requested fund identifer.
*FundHoldingsApi* | [**post_ownership_holdings**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/FundHoldingsApi.md#post_ownership_holdings) | **POST** /fund-holdings | Get holdings for a list of funds.
*SecurityHoldersApi* | [**get_security_holders**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/SecurityHoldersApi.md#get_security_holders) | **GET** /security-holders | Get security ownership data for requested security identifers.
*SecurityHoldersApi* | [**post_security_holders**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/SecurityHoldersApi.md#post_security_holders) | **POST** /security-holders | Get security ownership data for a list of requested securities.
*TransactionsApi* | [**get_ownership_insider_transactions**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/TransactionsApi.md#get_ownership_insider_transactions) | **GET** /transactions/insider | Get insider transactions details for a list of requested identifiers.
*TransactionsApi* | [**get_ownership_institutional_transactions**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/TransactionsApi.md#get_ownership_institutional_transactions) | **GET** /transactions/institutional | Get institutional transaction details for a list of requested identifiers.
*TransactionsApi* | [**post_ownership_insider_transactions**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/TransactionsApi.md#post_ownership_insider_transactions) | **POST** /transactions/insider | Get insider transactions details for a list of requested identifiers.
*TransactionsApi* | [**post_ownership_institutional_transactions**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/TransactionsApi.md#post_ownership_institutional_transactions) | **POST** /transactions/institutional | Gets institutional transaction details for a list of requested identifiers.
## Documentation For Models
- [AssetType](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/AssetType.md)
- [Batch](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/Batch.md)
- [BatchErrorObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/BatchErrorObject.md)
- [BatchResult](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/BatchResult.md)
- [BatchResultResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/BatchResultResponse.md)
- [BatchStatus](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/BatchStatus.md)
- [BatchStatusResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/BatchStatusResponse.md)
- [ErrorResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/ErrorResponse.md)
- [ErrorResponseSubErrors](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/ErrorResponseSubErrors.md)
- [Frequency](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/Frequency.md)
- [FundHolding](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/FundHolding.md)
- [FundHoldingsRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/FundHoldingsRequest.md)
- [FundHoldingsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/FundHoldingsResponse.md)
- [HolderType](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/HolderType.md)
- [IdFundHoldings](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/IdFundHoldings.md)
- [IdHolders](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/IdHolders.md)
- [IdTransactions](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/IdTransactions.md)
- [InsiderTransactions](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/InsiderTransactions.md)
- [InsiderTransactionsRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/InsiderTransactionsRequest.md)
- [InsiderTransactionsRequestData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/InsiderTransactionsRequestData.md)
- [InsiderTransactionsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/InsiderTransactionsResponse.md)
- [InstitutionalTransactions](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/InstitutionalTransactions.md)
- [InstitutionalTransactionsRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/InstitutionalTransactionsRequest.md)
- [InstitutionalTransactionsRequestData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/InstitutionalTransactionsRequestData.md)
- [InstitutionalTransactionsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/InstitutionalTransactionsResponse.md)
- [PeriodOfMeasure](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/PeriodOfMeasure.md)
- [RowExclusion](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/RowExclusion.md)
- [SecurityHolders](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/SecurityHolders.md)
- [SecurityHoldersRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/SecurityHoldersRequest.md)
- [SecurityHoldersResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/SecurityHoldersResponse.md)
- [TopNHolders](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/TopNHolders.md)
- [TransactionType](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1/docs/TransactionType.md)
## Documentation For Authorization
## FactSetApiKey
- **Type**: HTTP basic authentication
## FactSetOAuth2
- **Type**: OAuth
- **Flow**: application
- **Authorization URL**:
- **Scopes**: N/A
## Notes for Large OpenAPI documents
If the OpenAPI document is large, imports in fds.sdk.FactSetOwnership.apis and fds.sdk.FactSetOwnership.models may fail with a
RecursionError indicating the maximum recursion limit has been exceeded. In that case, there are a couple of solutions:
Solution 1:
Use specific imports for apis and models like:
- `from fds.sdk.FactSetOwnership.api.default_api import DefaultApi`
- `from fds.sdk.FactSetOwnership.model.pet import Pet`
Solution 2:
Before importing the package, adjust the maximum recursion limit as shown below:
```
import sys
sys.setrecursionlimit(1500)
import fds.sdk.FactSetOwnership
from fds.sdk.FactSetOwnership.apis import *
from fds.sdk.FactSetOwnership.models import *
```
## Contributing
Please refer to the [contributing guide](../../../../CONTRIBUTING.md).
## Copyright
Copyright 2026 FactSet Research Systems Inc
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| text/markdown | FactSet Research Systems | null | null | null | Apache License, Version 2.0 | FactSet, API, SDK | [] | [] | https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetOwnership/v1 | null | >=3.7 | [] | [] | [] | [
"urllib3>=1.25.3",
"python-dateutil",
"fds.sdk.utils>=1.0.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-20T14:34:08.135463 | fds_sdk_factsetownership-1.3.0-py3-none-any.whl | 172,574 | e8/04/8ce2bced2299c62b51192dfa8e8f7887d5791813e086ca403159d4feb7ff/fds_sdk_factsetownership-1.3.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 6f9856484e50096014a4c5b2d37c3f5f | ef580a7b37a39a58f737cc6cca4fa427fd6bf9b48db330c1601e25fe1eb5b674 | e8048ce2bced2299c62b51192dfa8e8f7887d5791813e086ca403159d4feb7ff | null | [
"LICENSE"
] | 0 |
2.4 | fds.sdk.FactSetGlobalPrices | 2.7.0 | FactSet Global Prices client library for Python | [](https://www.factset.com)
# FactSet Global Prices client library for Python
[](https://developer.factset.com/api-catalog/factset-global-prices-api)
[](https://pypi.org/project/fds.sdk.FactSetGlobalPrices/v/2.7.0)
[](https://www.apache.org/licenses/LICENSE-2.0)
The FactSet Global Prices API provides end of day market pricing content using cloud and microservices technology, encompassing both pricing as well as corporate actions and events data.</p>
This Python package is automatically generated by the [OpenAPI Generator](https://openapi-generator.tech) project:
- API version: 1.10.0
- SDK version: 2.7.0
- Build package: org.openapitools.codegen.languages.PythonClientCodegen
For more information, please visit [https://developer.factset.com/contact](https://developer.factset.com/contact)
## Requirements
* Python >= 3.7
## Installation
### Poetry
```shell
poetry add fds.sdk.utils fds.sdk.FactSetGlobalPrices==2.7.0
```
### pip
```shell
pip install fds.sdk.utils fds.sdk.FactSetGlobalPrices==2.7.0
```
## Usage
1. [Generate authentication credentials](../../../../README.md#authentication).
2. Setup Python environment.
1. Install and activate python 3.7+. If you're using [pyenv](https://github.com/pyenv/pyenv):
```sh
pyenv install 3.9.7
pyenv shell 3.9.7
```
2. (optional) [Install poetry](https://python-poetry.org/docs/#installation).
3. [Install dependencies](#installation).
4. Run the following:
> [!IMPORTANT]
> The parameter variables defined below are just examples and may potentially contain non valid values. Please replace them with valid values.
### Example Code
```python
from fds.sdk.utils.authentication import ConfidentialClient
import fds.sdk.FactSetGlobalPrices
from fds.sdk.FactSetGlobalPrices.api import batch_processing_api
from fds.sdk.FactSetGlobalPrices.models import *
from dateutil.parser import parse as dateutil_parser
from pprint import pprint
# See configuration.py for a list of all supported configuration parameters.
# Examples for each supported authentication method are below,
# choose one that satisfies your use case.
# (Preferred) OAuth 2.0: FactSetOAuth2
# See https://github.com/FactSet/enterprise-sdk#oauth-20
# for information on how to create the app-config.json file
#
# The confidential client instance should be reused in production environments.
# See https://github.com/FactSet/enterprise-sdk-utils-python#authentication
# for more information on using the ConfidentialClient class
configuration = fds.sdk.FactSetGlobalPrices.Configuration(
fds_oauth_client=ConfidentialClient('/path/to/app-config.json')
)
# Basic authentication: FactSetApiKey
# See https://github.com/FactSet/enterprise-sdk#api-key
# for information how to create an API key
# configuration = fds.sdk.FactSetGlobalPrices.Configuration(
# username='USERNAME-SERIAL',
# password='API-KEY'
# )
# Enter a context with an instance of the API client
with fds.sdk.FactSetGlobalPrices.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = batch_processing_api.BatchProcessingApi(api_client)
id = "id_example" # str | Batch Request identifier.
try:
# Returns the response for a Batch Request
# example passing only required values which don't have defaults set
api_response_wrapper = api_instance.get_batch_data(id)
# This endpoint returns a response wrapper that contains different types of responses depending on the query.
# To access the correct response type, you need to perform one additional step, as shown below.
if api_response_wrapper.get_status_code() == 200:
api_response = api_response_wrapper.get_response_200()
if api_response_wrapper.get_status_code() == 202:
api_response = api_response_wrapper.get_response_202()
pprint(api_response)
except fds.sdk.FactSetGlobalPrices.ApiException as e:
print("Exception when calling BatchProcessingApi->get_batch_data: %s\n" % e)
# # Get response, http status code and response headers
# try:
# # Returns the response for a Batch Request
# api_response_wrapper, http_status_code, response_headers = api_instance.get_batch_data_with_http_info(id)
# # This endpoint returns a response wrapper that contains different types of responses depending on the query.
# # To access the correct response type, you need to perform one additional step, as shown below.
# if api_response_wrapper.get_status_code() == 200:
# api_response = api_response_wrapper.get_response_200()
# if api_response_wrapper.get_status_code() == 202:
# api_response = api_response_wrapper.get_response_202()
# pprint(api_response)
# pprint(http_status_code)
# pprint(response_headers)
# except fds.sdk.FactSetGlobalPrices.ApiException as e:
# print("Exception when calling BatchProcessingApi->get_batch_data: %s\n" % e)
# # Get response asynchronous
# try:
# # Returns the response for a Batch Request
# async_result = api_instance.get_batch_data_async(id)
# api_response_wrapper = async_result.get()
# # This endpoint returns a response wrapper that contains different types of responses depending on the query.
# # To access the correct response type, you need to perform one additional step, as shown below.
# if api_response_wrapper.get_status_code() == 200:
# api_response = api_response_wrapper.get_response_200()
# if api_response_wrapper.get_status_code() == 202:
# api_response = api_response_wrapper.get_response_202()
# pprint(api_response)
# except fds.sdk.FactSetGlobalPrices.ApiException as e:
# print("Exception when calling BatchProcessingApi->get_batch_data: %s\n" % e)
# # Get response, http status code and response headers asynchronous
# try:
# # Returns the response for a Batch Request
# async_result = api_instance.get_batch_data_with_http_info_async(id)
# api_response_wrapper, http_status_code, response_headers = async_result.get()
# # This endpoint returns a response wrapper that contains different types of responses depending on the query.
# # To access the correct response type, you need to perform one additional step, as shown below.
# if api_response_wrapper.get_status_code() == 200:
# api_response = api_response_wrapper.get_response_200()
# if api_response_wrapper.get_status_code() == 202:
# api_response = api_response_wrapper.get_response_202()
# pprint(api_response)
# pprint(http_status_code)
# pprint(response_headers)
# except fds.sdk.FactSetGlobalPrices.ApiException as e:
# print("Exception when calling BatchProcessingApi->get_batch_data: %s\n" % e)
```
### Using Pandas
To convert an API response to a Pandas DataFrame, it is necessary to transform it first to a dictionary.
```python
import pandas as pd
response_dict = api_response.to_dict()['data']
simple_json_response = pd.DataFrame(response_dict)
nested_json_response = pd.json_normalize(response_dict)
```
### Debugging
The SDK uses the standard library [`logging`](https://docs.python.org/3/library/logging.html#module-logging) module.
Setting `debug` to `True` on an instance of the `Configuration` class sets the log-level of related packages to `DEBUG`
and enables additional logging in Pythons [HTTP Client](https://docs.python.org/3/library/http.client.html).
**Note**: This prints out sensitive information (e.g. the full request and response). Use with care.
```python
import logging
import fds.sdk.FactSetGlobalPrices
logging.basicConfig(level=logging.DEBUG)
configuration = fds.sdk.FactSetGlobalPrices.Configuration(...)
configuration.debug = True
```
### Configure a Proxy
You can pass proxy settings to the Configuration class:
* `proxy`: The URL of the proxy to use.
* `proxy_headers`: a dictionary to pass additional headers to the proxy (e.g. `Proxy-Authorization`).
```python
import fds.sdk.FactSetGlobalPrices
configuration = fds.sdk.FactSetGlobalPrices.Configuration(
# ...
proxy="http://secret:password@localhost:5050",
proxy_headers={
"Custom-Proxy-Header": "Custom-Proxy-Header-Value"
}
)
```
### Custom SSL Certificate
TLS/SSL certificate verification can be configured with the following Configuration parameters:
* `ssl_ca_cert`: a path to the certificate to use for verification in `PEM` format.
* `verify_ssl`: setting this to `False` disables the verification of certificates.
Disabling the verification is not recommended, but it might be useful during
local development or testing.
```python
import fds.sdk.FactSetGlobalPrices
configuration = fds.sdk.FactSetGlobalPrices.Configuration(
# ...
ssl_ca_cert='/path/to/ca.pem'
)
```
### Request Retries
In case the request retry behaviour should be customized, it is possible to pass a `urllib3.Retry` object to the `retry` property of the Configuration.
```python
from urllib3 import Retry
import fds.sdk.FactSetGlobalPrices
configuration = fds.sdk.FactSetGlobalPrices.Configuration(
# ...
)
configuration.retries = Retry(total=3, status_forcelist=[500, 502, 503, 504])
```
## Documentation for API Endpoints
All URIs are relative to *https://api.factset.com/content*
Class | Method | HTTP request | Description
------------ | ------------- | ------------- | -------------
*BatchProcessingApi* | [**get_batch_data**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/BatchProcessingApi.md#get_batch_data) | **GET** /factset-global-prices/v1/batch-result | Returns the response for a Batch Request
*BatchProcessingApi* | [**get_batch_status**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/BatchProcessingApi.md#get_batch_status) | **GET** /factset-global-prices/v1/batch-status | Returns the status for a Batch Request
*CorporateActionsApi* | [**get_gpd_corporate_actions**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsApi.md#get_gpd_corporate_actions) | **GET** /factset-global-prices/v1/corporate-actions | Gets Corporate Actions information.
*CorporateActionsApi* | [**getannualized_dividends**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsApi.md#getannualized_dividends) | **GET** /factset-global-prices/v1/annualized-dividends | Gets Indicated Annualized Dividend information.
*CorporateActionsApi* | [**getannualized_dividends_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsApi.md#getannualized_dividends_for_list) | **POST** /factset-global-prices/v1/annualized-dividends | Gets Indicated Annualized Dividend information.
*CorporateActionsApi* | [**post_corporate_actions**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsApi.md#post_corporate_actions) | **POST** /factset-global-prices/v1/corporate-actions | Requests Corporate Actions information.
*CorporateActionsForCalendarApi* | [**get_corporate_actions**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsForCalendarApi.md#get_corporate_actions) | **GET** /factset-global-prices/v1/calendar/corporate-actions | Retrieve Event Calendar information for Corporate Actions
*CorporateActionsForCalendarApi* | [**get_dividends**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsForCalendarApi.md#get_dividends) | **GET** /factset-global-prices/v1/calendar/dividends | Retrieve Dividend information
*CorporateActionsForCalendarApi* | [**get_event_count**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsForCalendarApi.md#get_event_count) | **GET** /factset-global-prices/v1/calendar/event-count | Retrieve daily event count for a given date range
*CorporateActionsForCalendarApi* | [**get_exchanges**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsForCalendarApi.md#get_exchanges) | **GET** /factset-global-prices/v1/calendar/meta/exchanges | Returns a list of exchanges for which event/action data is available.
*CorporateActionsForCalendarApi* | [**get_rights_issues**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsForCalendarApi.md#get_rights_issues) | **GET** /factset-global-prices/v1/calendar/rights-issues | Retrieve Rights Issue information
*CorporateActionsForCalendarApi* | [**get_spin_offs**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsForCalendarApi.md#get_spin_offs) | **GET** /factset-global-prices/v1/calendar/spin-offs | Retrieve Spin Off information
*CorporateActionsForCalendarApi* | [**get_splits**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsForCalendarApi.md#get_splits) | **GET** /factset-global-prices/v1/calendar/splits | Retrieve Split information
*CorporateActionsForCalendarApi* | [**get_stock_distributions**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsForCalendarApi.md#get_stock_distributions) | **GET** /factset-global-prices/v1/calendar/stock-distributions | Retrieve Stock Distribution information
*MarketValueApi* | [**get_gpd_market_val**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/MarketValueApi.md#get_gpd_market_val) | **GET** /factset-global-prices/v1/market-value | Provides the current market value for a list of specified securities.
*MarketValueApi* | [**get_security_prices_for_list_market_val**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/MarketValueApi.md#get_security_prices_for_list_market_val) | **POST** /factset-global-prices/v1/market-value | Requests the current market value for a list of specified securities.
*PricesApi* | [**get_gpd_prices**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/PricesApi.md#get_gpd_prices) | **GET** /factset-global-prices/v1/prices | Gets end-of-day Open, High, Low, Close for a list of securities.
*PricesApi* | [**get_security_prices_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/PricesApi.md#get_security_prices_for_list) | **POST** /factset-global-prices/v1/prices | Requests end-of-day Open, High, Low, Close for a large list of securities.
*ReturnsApi* | [**get_returns**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/ReturnsApi.md#get_returns) | **GET** /factset-global-prices/v1/returns | Gets Returns for a list of `ids` as of given date range.
*ReturnsApi* | [**get_returns_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/ReturnsApi.md#get_returns_for_list) | **POST** /factset-global-prices/v1/returns | Gets Returns for a list of `ids` as of given date range.
*SharesOutstandingApi* | [**get_shares_outstanding**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/SharesOutstandingApi.md#get_shares_outstanding) | **GET** /factset-global-prices/v1/security-shares | Gets Shares Outstanding information for securities.
*SharesOutstandingApi* | [**post_shares_outstanding**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/SharesOutstandingApi.md#post_shares_outstanding) | **POST** /factset-global-prices/v1/security-shares | Gets Shares Outstanding information for securities.
## Documentation For Models
- [Adjust](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/Adjust.md)
- [AnnualizedDividendResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/AnnualizedDividendResponse.md)
- [AnnualizedDividendsObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/AnnualizedDividendsObject.md)
- [AnnualizedDividendsRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/AnnualizedDividendsRequest.md)
- [Batch](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/Batch.md)
- [BatchErrorObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/BatchErrorObject.md)
- [BatchErrorObjectLinks](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/BatchErrorObjectLinks.md)
- [BatchErrorResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/BatchErrorResponse.md)
- [BatchResult](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/BatchResult.md)
- [BatchResultResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/BatchResultResponse.md)
- [BatchStatus](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/BatchStatus.md)
- [BatchStatusResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/BatchStatusResponse.md)
- [Calendar](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/Calendar.md)
- [CancelledDividend](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CancelledDividend.md)
- [CorporateAction](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateAction.md)
- [CorporateActionCalendar](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionCalendar.md)
- [CorporateActionsRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsRequest.md)
- [CorporateActionsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsResponse.md)
- [CorporateActionsResponseCalendar](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/CorporateActionsResponseCalendar.md)
- [DividendAdjust](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/DividendAdjust.md)
- [DividendCalendar](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/DividendCalendar.md)
- [DividendsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/DividendsResponse.md)
- [ErrorObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/ErrorObject.md)
- [ErrorObjectResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/ErrorObjectResponse.md)
- [ErrorResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/ErrorResponse.md)
- [ErrorResponseCalendar](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/ErrorResponseCalendar.md)
- [ErrorResponseSubErrors](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/ErrorResponseSubErrors.md)
- [EventCategory](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/EventCategory.md)
- [EventCount](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/EventCount.md)
- [EventCountResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/EventCountResponse.md)
- [Exchange](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/Exchange.md)
- [ExchangesResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/ExchangesResponse.md)
- [FieldsCorporateActions](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/FieldsCorporateActions.md)
- [Frequency](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/Frequency.md)
- [GlobalPricesRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/GlobalPricesRequest.md)
- [GlobalPricesResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/GlobalPricesResponse.md)
- [IdsBatchMax2000](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/IdsBatchMax2000.md)
- [IdsMax1000](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/IdsMax1000.md)
- [IdsMax400](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/IdsMax400.md)
- [IdsMax5000](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/IdsMax5000.md)
- [MarketValueRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/MarketValueRequest.md)
- [MarketValueRequestBody](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/MarketValueRequestBody.md)
- [MarketValueResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/MarketValueResponse.md)
- [MarketValueResponseObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/MarketValueResponseObject.md)
- [Meta](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/Meta.md)
- [Pagination](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/Pagination.md)
- [Precision](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/Precision.md)
- [Price](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/Price.md)
- [PricesFields](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/PricesFields.md)
- [Returns](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/Returns.md)
- [ReturnsRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/ReturnsRequest.md)
- [ReturnsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/ReturnsResponse.md)
- [RightsIssue](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/RightsIssue.md)
- [RightsIssuesResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/RightsIssuesResponse.md)
- [SharesOutstandingRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/SharesOutstandingRequest.md)
- [SharesOutstandingRequestBody](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/SharesOutstandingRequestBody.md)
- [SharesOutstandingResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/SharesOutstandingResponse.md)
- [SharesOutstandingResponseObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/SharesOutstandingResponseObject.md)
- [SoErrorObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/SoErrorObject.md)
- [SoErrorObjectLinks](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/SoErrorObjectLinks.md)
- [SoErrorResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/SoErrorResponse.md)
- [SpinOff](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/SpinOff.md)
- [SpinOffsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/SpinOffsResponse.md)
- [SplitCalendar](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/SplitCalendar.md)
- [SplitsResponseCalendar](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/SplitsResponseCalendar.md)
- [StockDistribution](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/StockDistribution.md)
- [StockDistributionsResponseCalendar](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1/docs/StockDistributionsResponseCalendar.md)
## Documentation For Authorization
## FactSetApiKey
- **Type**: HTTP basic authentication
## FactSetOAuth2
- **Type**: OAuth
- **Flow**: application
- **Authorization URL**:
- **Scopes**: N/A
## Notes for Large OpenAPI documents
If the OpenAPI document is large, imports in fds.sdk.FactSetGlobalPrices.apis and fds.sdk.FactSetGlobalPrices.models may fail with a
RecursionError indicating the maximum recursion limit has been exceeded. In that case, there are a couple of solutions:
Solution 1:
Use specific imports for apis and models like:
- `from fds.sdk.FactSetGlobalPrices.api.default_api import DefaultApi`
- `from fds.sdk.FactSetGlobalPrices.model.pet import Pet`
Solution 2:
Before importing the package, adjust the maximum recursion limit as shown below:
```
import sys
sys.setrecursionlimit(1500)
import fds.sdk.FactSetGlobalPrices
from fds.sdk.FactSetGlobalPrices.apis import *
from fds.sdk.FactSetGlobalPrices.models import *
```
## Contributing
Please refer to the [contributing guide](../../../../CONTRIBUTING.md).
## Copyright
Copyright 2026 FactSet Research Systems Inc
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| text/markdown | FactSet Research Systems | null | null | null | Apache License, Version 2.0 | FactSet, API, SDK | [] | [] | https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetGlobalPrices/v1 | null | >=3.7 | [] | [] | [] | [
"urllib3>=1.25.3",
"python-dateutil",
"fds.sdk.utils>=1.0.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-20T14:34:05.108665 | fds_sdk_factsetglobalprices-2.7.0.tar.gz | 113,061 | 88/ac/067655742e33c3621b12986d6d71e10375f12de58aa0fe54061804900c57/fds_sdk_factsetglobalprices-2.7.0.tar.gz | source | sdist | null | false | 41046f78e6178abd62eadc4c94033eec | 5a526f08a2dfe9cabcc6fc3e2d85bd9a024fee4c2b2013190334030d7bcf0a5b | 88ac067655742e33c3621b12986d6d71e10375f12de58aa0fe54061804900c57 | null | [
"LICENSE"
] | 0 |
2.4 | fds.sdk.FactSetEstimates | 3.1.0 | FactSet Estimates client library for Python | [](https://www.factset.com)
# FactSet Estimates client library for Python
[]()
[](https://pypi.org/project/fds.sdk.FactSetEstimates/v/3.1.0)
[](https://www.apache.org/licenses/LICENSE-2.0)
With global coverage since 1999, the FactSet Estimates API provides you with comprehensive estimates and statistics on a wide variety of financial statement items as well as industry-specific metrics. The universe is comprised of over 19,000 active companies across 90+ countries with the following types of data included:
- **Consensus**
- **Detail**
- **Ratings**
- **Surprise**
- **Segments**
- **Actuals**
- **Guidance**
- **New Estimates and Ratings Reports Endpoints**
For clients seeking curated and relevant financial data, the FactSet Estimates API now includes Estimates and Ratings Reports endpoints. These powerful endpoints are designed for easy integration and consumption, delivering a wide array of financial metrics, estimates, and critical statistics in a highly accessible format suitable for both mobile and web applications.
Whether you are an analyst, investor, or financial professional, the Estimates and Ratings Reports endpoints offer detailed and actionable financial insights that can support thorough analyses and strategic decision-making processes.
The Estimates and Ratings Reports endpoints are especially valuable for B2B2C applications, empowering financial services firms, investment companies, and corporate finance teams to:
- **Elevate Client Engagement:** Enrich user experiences in client-facing applications with comprehensive and up-to-date financial metrics.
- **Build Custom Reporting Tools:** Create tailored dashboards and analytics tools that provide deep insights and foster better financial understanding.
By adopting the FactSet Estimates API with its enriched Estimates and Ratings Reports endpoints, businesses can streamline their financial data integration process, improve operational efficiency, and deliver superior financial insights to their clients and end-users.
<p>This API is rate-limited to 10 requests per second and 10 concurrent requests per user.</p>
**Download API Specification**
To programmatically download the FactSet Estimates API Specification file in .yaml format, utilize the link below. You must be authorized for this API to extract the specification. This specification can then be used for Codegen to create your own SDKs. You can also access it by selecting the \"Download Spec\" button beside the version information.
[https://api.factset.com/content/factset-estimates/v2/spec/swagger.yaml](https://api.factset.com/content/factset-estimates/v2/spec/swagger.yaml)
This Python package is automatically generated by the [OpenAPI Generator](https://openapi-generator.tech) project:
- API version: 2.8.1
- SDK version: 3.1.0
- Build package: org.openapitools.codegen.languages.PythonClientCodegen
## Requirements
* Python >= 3.7
## Installation
### Poetry
```shell
poetry add fds.sdk.utils fds.sdk.FactSetEstimates==3.1.0
```
### pip
```shell
pip install fds.sdk.utils fds.sdk.FactSetEstimates==3.1.0
```
## Usage
1. [Generate authentication credentials](../../../../README.md#authentication).
2. Setup Python environment.
1. Install and activate python 3.7+. If you're using [pyenv](https://github.com/pyenv/pyenv):
```sh
pyenv install 3.9.7
pyenv shell 3.9.7
```
2. (optional) [Install poetry](https://python-poetry.org/docs/#installation).
3. [Install dependencies](#installation).
4. Run the following:
> [!IMPORTANT]
> The parameter variables defined below are just examples and may potentially contain non valid values. Please replace them with valid values.
### Example Code
```python
from fds.sdk.utils.authentication import ConfidentialClient
import fds.sdk.FactSetEstimates
from fds.sdk.FactSetEstimates.api import actuals_api
from fds.sdk.FactSetEstimates.models import *
from dateutil.parser import parse as dateutil_parser
from pprint import pprint
# See configuration.py for a list of all supported configuration parameters.
# Examples for each supported authentication method are below,
# choose one that satisfies your use case.
# (Preferred) OAuth 2.0: FactSetOAuth2
# See https://github.com/FactSet/enterprise-sdk#oauth-20
# for information on how to create the app-config.json file
#
# The confidential client instance should be reused in production environments.
# See https://github.com/FactSet/enterprise-sdk-utils-python#authentication
# for more information on using the ConfidentialClient class
configuration = fds.sdk.FactSetEstimates.Configuration(
fds_oauth_client=ConfidentialClient('/path/to/app-config.json')
)
# Basic authentication: FactSetApiKey
# See https://github.com/FactSet/enterprise-sdk#api-key
# for information how to create an API key
# configuration = fds.sdk.FactSetEstimates.Configuration(
# username='USERNAME-SERIAL',
# password='API-KEY'
# )
# Enter a context with an instance of the API client
with fds.sdk.FactSetEstimates.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = actuals_api.ActualsApi(api_client)
ids = ["AAPL-USA"] # [str] | Security or Entity identifiers. Accepted inputs include FactSet Identifiers, tickers, CUSIP, and SEDOL. <p><b>Performance Note:</b> Requests that increase the number of metrics or request long historical data may trigger the 30-second service timeout threshold. To ensure system stability and performance, please keep requests lightweight.</p> <p>If requesting long historical data, limit the history to <b>10 years per metric per ID</b>.</p>
metrics = ["SALES"] # [str] | Requested metrics. Use the `/metrics` endpoint to return a list of available estimate items. **Top 10** most used metrics are **EPS, SALES, DPS, EBITDA,EBIT, PRICE_TGT, CFPS, BPS, NET_INC, and ASSETS**. For more details, visit [Online Assistant Page #15034](https://oa.apps.factset.com/pages/15034).
relative_fiscal_start = -2 # int | Relative fiscal period, expressed as an integer, used to filter results. This is combined with the periodicity parameter to specify a relative estimate period. FactSet Estimates Actuals provides data for past periods. Therefore, the input for `relativeFiscalStart` must be an integer that is zero or less. For example, set to 0 and periodicity to ANN to ask for the current reported year (FY0). (optional)
relative_fiscal_end = 0 # int | Relative fiscal period, expressed as an integer, used to filter results. This is combined with the periodicity parameter to specify a relative estimate period.Therefore, the input for `relativeFiscalEnd` must be an integer that is zero or less. For example, set to -2 and periodicity to ANN to ask for two fiscal years before the latest (FY-2). (optional)
periodicity = "ANN" # str | The periodicity for the estimates requested, allowing you to fetch Quarterly, Semi-Annual, Annual, and NTMA/LTMA Estimates. * **ANN** - Annual * **QTR** - Quarterly * **SEMI** - Semi-Annual * **NTMA** - Next-Twelve-Months - Time-weighted Annual. Estimates use a percentage of annual estimates from two fiscal years to create an estimate based on the 12-month period. Visit [OA 16614](https://my.apps.factset.com/oa/pages/16614) for detail. * **LTMA** - Last-Twelve-Months - Time-weighted Annual. Estimates use a percentage of annual estimates from two fiscal years to create an estimate based on the 12-month period. Visit [OA 16614](https://my.apps.factset.com/oa/pages/16614) for detail. (optional) if omitted the server will use the default value of "ANN"
currency = "USD" # str | Currency code for adjusting the data. Use `ESTIMATE` as input value for the values in Estimate Currency. For a list of currency ISO codes, visit [Online Assistant Page #1470](https://oa.apps.factset.com/pages/1470). (optional)
try:
# Retrieves actuals for a requested list of ids and reported fiscal periods.
# example passing only required values which don't have defaults set
# and optional values
api_response = api_instance.get_actuals(ids, metrics, relative_fiscal_start=relative_fiscal_start, relative_fiscal_end=relative_fiscal_end, periodicity=periodicity, currency=currency)
pprint(api_response)
except fds.sdk.FactSetEstimates.ApiException as e:
print("Exception when calling ActualsApi->get_actuals: %s\n" % e)
# # Get response, http status code and response headers
# try:
# # Retrieves actuals for a requested list of ids and reported fiscal periods.
# api_response, http_status_code, response_headers = api_instance.get_actuals_with_http_info(ids, metrics, relative_fiscal_start=relative_fiscal_start, relative_fiscal_end=relative_fiscal_end, periodicity=periodicity, currency=currency)
# pprint(api_response)
# pprint(http_status_code)
# pprint(response_headers)
# except fds.sdk.FactSetEstimates.ApiException as e:
# print("Exception when calling ActualsApi->get_actuals: %s\n" % e)
# # Get response asynchronous
# try:
# # Retrieves actuals for a requested list of ids and reported fiscal periods.
# async_result = api_instance.get_actuals_async(ids, metrics, relative_fiscal_start=relative_fiscal_start, relative_fiscal_end=relative_fiscal_end, periodicity=periodicity, currency=currency)
# api_response = async_result.get()
# pprint(api_response)
# except fds.sdk.FactSetEstimates.ApiException as e:
# print("Exception when calling ActualsApi->get_actuals: %s\n" % e)
# # Get response, http status code and response headers asynchronous
# try:
# # Retrieves actuals for a requested list of ids and reported fiscal periods.
# async_result = api_instance.get_actuals_with_http_info_async(ids, metrics, relative_fiscal_start=relative_fiscal_start, relative_fiscal_end=relative_fiscal_end, periodicity=periodicity, currency=currency)
# api_response, http_status_code, response_headers = async_result.get()
# pprint(api_response)
# pprint(http_status_code)
# pprint(response_headers)
# except fds.sdk.FactSetEstimates.ApiException as e:
# print("Exception when calling ActualsApi->get_actuals: %s\n" % e)
```
### Using Pandas
To convert an API response to a Pandas DataFrame, it is necessary to transform it first to a dictionary.
```python
import pandas as pd
response_dict = api_response.to_dict()['data']
simple_json_response = pd.DataFrame(response_dict)
nested_json_response = pd.json_normalize(response_dict)
```
### Debugging
The SDK uses the standard library [`logging`](https://docs.python.org/3/library/logging.html#module-logging) module.
Setting `debug` to `True` on an instance of the `Configuration` class sets the log-level of related packages to `DEBUG`
and enables additional logging in Pythons [HTTP Client](https://docs.python.org/3/library/http.client.html).
**Note**: This prints out sensitive information (e.g. the full request and response). Use with care.
```python
import logging
import fds.sdk.FactSetEstimates
logging.basicConfig(level=logging.DEBUG)
configuration = fds.sdk.FactSetEstimates.Configuration(...)
configuration.debug = True
```
### Configure a Proxy
You can pass proxy settings to the Configuration class:
* `proxy`: The URL of the proxy to use.
* `proxy_headers`: a dictionary to pass additional headers to the proxy (e.g. `Proxy-Authorization`).
```python
import fds.sdk.FactSetEstimates
configuration = fds.sdk.FactSetEstimates.Configuration(
# ...
proxy="http://secret:password@localhost:5050",
proxy_headers={
"Custom-Proxy-Header": "Custom-Proxy-Header-Value"
}
)
```
### Custom SSL Certificate
TLS/SSL certificate verification can be configured with the following Configuration parameters:
* `ssl_ca_cert`: a path to the certificate to use for verification in `PEM` format.
* `verify_ssl`: setting this to `False` disables the verification of certificates.
Disabling the verification is not recommended, but it might be useful during
local development or testing.
```python
import fds.sdk.FactSetEstimates
configuration = fds.sdk.FactSetEstimates.Configuration(
# ...
ssl_ca_cert='/path/to/ca.pem'
)
```
### Request Retries
In case the request retry behaviour should be customized, it is possible to pass a `urllib3.Retry` object to the `retry` property of the Configuration.
```python
from urllib3 import Retry
import fds.sdk.FactSetEstimates
configuration = fds.sdk.FactSetEstimates.Configuration(
# ...
)
configuration.retries = Retry(total=3, status_forcelist=[500, 502, 503, 504])
```
## Documentation for API Endpoints
All URIs are relative to *https://api.factset.com/content*
Class | Method | HTTP request | Description
------------ | ------------- | ------------- | -------------
*ActualsApi* | [**get_actuals**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ActualsApi.md#get_actuals) | **GET** /factset-estimates/v2/actuals | Retrieves actuals for a requested list of ids and reported fiscal periods.
*ActualsApi* | [**get_actuals_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ActualsApi.md#get_actuals_for_list) | **POST** /factset-estimates/v2/actuals | Retrieves actuals for a requested list of ids and reported fiscal periods.
*BrokerDetailApi* | [**get_fixed_detail**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/BrokerDetailApi.md#get_fixed_detail) | **GET** /factset-estimates/v2/fixed-detail | Estimates detail data for fixed fiscal periods
*BrokerDetailApi* | [**get_fixed_detail_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/BrokerDetailApi.md#get_fixed_detail_for_list) | **POST** /factset-estimates/v2/fixed-detail | Estimates detail data for fixed fiscal periods
*BrokerDetailApi* | [**get_rolling_detail**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/BrokerDetailApi.md#get_rolling_detail) | **GET** /factset-estimates/v2/rolling-detail | FactSet estimates detail data for rolling fiscal periods
*BrokerDetailApi* | [**get_rolling_detail_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/BrokerDetailApi.md#get_rolling_detail_for_list) | **POST** /factset-estimates/v2/rolling-detail | FactSet estimates detail data for rolling fiscal periods
*ConsensusApi* | [**get_fixed_consensus**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ConsensusApi.md#get_fixed_consensus) | **GET** /factset-estimates/v2/fixed-consensus | Retrieves consensus estimates for a requested list of ids and fixed fiscal periods
*ConsensusApi* | [**get_fixed_consensus_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ConsensusApi.md#get_fixed_consensus_for_list) | **POST** /factset-estimates/v2/fixed-consensus | FactSet consensus estimates for fixed fiscal periods
*ConsensusApi* | [**get_rolling_consensus**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ConsensusApi.md#get_rolling_consensus) | **GET** /factset-estimates/v2/rolling-consensus | Retrieves consensus estimates for a requested list of ids and rolling fiscal periods.
*ConsensusApi* | [**get_rolling_consensus_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ConsensusApi.md#get_rolling_consensus_for_list) | **POST** /factset-estimates/v2/rolling-consensus | Retrieves consensus estimates for a requested list of ids and rolling fiscal periods
*DataItemsApi* | [**get_estimate_metrics**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/DataItemsApi.md#get_estimate_metrics) | **GET** /factset-estimates/v2/metrics | Available Estimate metrics
*DataItemsApi* | [**get_estimate_metrics_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/DataItemsApi.md#get_estimate_metrics_for_list) | **POST** /factset-estimates/v2/metrics | Available Estimate metrics or ratios.
*EstimatesAndRatingsReportsApi* | [**get_analyst_ratings**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/EstimatesAndRatingsReportsApi.md#get_analyst_ratings) | **GET** /factset-estimates/v2/company-reports/analyst-ratings | Retrieves the historical monthly view of analyst ratings for a given identifier.
*EstimatesAndRatingsReportsApi* | [**get_estimate_types**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/EstimatesAndRatingsReportsApi.md#get_estimate_types) | **GET** /factset-estimates/v2/company-reports/estimate-types | Returns a list of valid estimate types.
*EstimatesAndRatingsReportsApi* | [**get_estimates**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/EstimatesAndRatingsReportsApi.md#get_estimates) | **GET** /factset-estimates/v2/company-reports/forecast | Returns forecasted estimates.
*EstimatesAndRatingsReportsApi* | [**get_surprise_history**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/EstimatesAndRatingsReportsApi.md#get_surprise_history) | **GET** /factset-estimates/v2/company-reports/surprise-history | Surprise History
*GuidanceApi* | [**get_guidance**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/GuidanceApi.md#get_guidance) | **GET** /factset-estimates/v2/guidance | Retrieves guidance for a requested list of ids and dates.
*GuidanceApi* | [**get_guidance_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/GuidanceApi.md#get_guidance_for_list) | **POST** /factset-estimates/v2/guidance | Retrieves guidance for a requested list of ids and dates.
*RatingsApi* | [**get_consensus_ratings**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/RatingsApi.md#get_consensus_ratings) | **GET** /factset-estimates/v2/consensus-ratings | Ratings consensus estimates to fetch Buy, overWeight, Hold, underWeight, and Sell.
*RatingsApi* | [**get_consensus_ratings_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/RatingsApi.md#get_consensus_ratings_for_list) | **POST** /factset-estimates/v2/consensus-ratings | Ratings consensus estimates to fetch Buy, overWeight, Hold, underWeight, and Sell.
*RatingsApi* | [**get_detail_ratings**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/RatingsApi.md#get_detail_ratings) | **GET** /factset-estimates/v2/detail-ratings | Broker Detail estimates to fetch Buy, overWeight, Hold, underWeight, and Sell.
*RatingsApi* | [**get_detail_ratings_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/RatingsApi.md#get_detail_ratings_for_list) | **POST** /factset-estimates/v2/detail-ratings | Broker Detail estimates to fetch Buy, overWeight, Hold, underWeight, and Sell.
*SegmentActualsApi* | [**get_segment_actuals**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SegmentActualsApi.md#get_segment_actuals) | **GET** /factset-estimates/v2/segment-actuals | Retrieves Segment Actuals for a requested list of ids and reported fiscal periods.
*SegmentActualsApi* | [**get_segment_actuals_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SegmentActualsApi.md#get_segment_actuals_for_list) | **POST** /factset-estimates/v2/segment-actuals | Retrieves Segment Actuals for a requested list of ids and reported fiscal periods.
*SegmentsApi* | [**get_segments**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SegmentsApi.md#get_segments) | **GET** /factset-estimates/v2/segments | Retrieves product & geographic segment estimates for a requested list of ids and fiscal periods
*SegmentsApi* | [**get_segments_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SegmentsApi.md#get_segments_for_list) | **POST** /factset-estimates/v2/segments | Retrieves product segment estimates for a requested list of ids and fiscal periods
*SurpriseApi* | [**get_surprise**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SurpriseApi.md#get_surprise) | **GET** /factset-estimates/v2/surprise | Surprise estimates for rolling fiscal periods
*SurpriseApi* | [**get_surprise_for_list**](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SurpriseApi.md#get_surprise_for_list) | **POST** /factset-estimates/v2/surprise | Surprise estimates for rolling fiscal periods
## Documentation For Models
- [Actual](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/Actual.md)
- [ActualsRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ActualsRequest.md)
- [ActualsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ActualsResponse.md)
- [AnalystRating](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/AnalystRating.md)
- [AnalystRatingResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/AnalystRatingResponse.md)
- [BrokerNames](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/BrokerNames.md)
- [Category](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/Category.md)
- [CompanyReportsErrorResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/CompanyReportsErrorResponse.md)
- [ConsensusEstimate](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ConsensusEstimate.md)
- [ConsensusRatings](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ConsensusRatings.md)
- [ConsensusRatingsRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ConsensusRatingsRequest.md)
- [ConsensusRatingsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ConsensusRatingsResponse.md)
- [ConsensusResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ConsensusResponse.md)
- [DetailEstimate](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/DetailEstimate.md)
- [DetailRatings](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/DetailRatings.md)
- [DetailRatingsRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/DetailRatingsRequest.md)
- [DetailRatingsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/DetailRatingsResponse.md)
- [DetailResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/DetailResponse.md)
- [ErrorObject](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ErrorObject.md)
- [ErrorResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ErrorResponse.md)
- [ErrorResponseSubErrors](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/ErrorResponseSubErrors.md)
- [Estimate](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/Estimate.md)
- [EstimateResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/EstimateResponse.md)
- [EstimateResponseData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/EstimateResponseData.md)
- [EstimateType](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/EstimateType.md)
- [EstimateTypesResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/EstimateTypesResponse.md)
- [FixedConsensusRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/FixedConsensusRequest.md)
- [FixedDetailRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/FixedDetailRequest.md)
- [Frequency](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/Frequency.md)
- [Guidance](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/Guidance.md)
- [GuidanceRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/GuidanceRequest.md)
- [GuidanceRequestBody](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/GuidanceRequestBody.md)
- [GuidanceResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/GuidanceResponse.md)
- [Ids](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/Ids.md)
- [Meta](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/Meta.md)
- [Metric](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/Metric.md)
- [MetricSegments](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/MetricSegments.md)
- [Metrics](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/Metrics.md)
- [MetricsRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/MetricsRequest.md)
- [MetricsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/MetricsResponse.md)
- [Pagination](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/Pagination.md)
- [Periodicity](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/Periodicity.md)
- [PeriodicityDetail](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/PeriodicityDetail.md)
- [PeriodicitySurprise](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/PeriodicitySurprise.md)
- [RatingsCount](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/RatingsCount.md)
- [RelativeFiscalEnd](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/RelativeFiscalEnd.md)
- [RelativeFiscalEndActuals](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/RelativeFiscalEndActuals.md)
- [RelativeFiscalStart](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/RelativeFiscalStart.md)
- [RelativeFiscalStartActuals](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/RelativeFiscalStartActuals.md)
- [RollingConsensusRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/RollingConsensusRequest.md)
- [RollingDetailRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/RollingDetailRequest.md)
- [SegmentActuals](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SegmentActuals.md)
- [SegmentActualsRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SegmentActualsRequest.md)
- [SegmentActualsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SegmentActualsResponse.md)
- [SegmentIds](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SegmentIds.md)
- [SegmentType](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SegmentType.md)
- [SegmentsEstimate](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SegmentsEstimate.md)
- [SegmentsRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SegmentsRequest.md)
- [SegmentsResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SegmentsResponse.md)
- [Statistic](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/Statistic.md)
- [Subcategory](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/Subcategory.md)
- [Surprise](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/Surprise.md)
- [SurpriseHistory](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SurpriseHistory.md)
- [SurpriseHistoryResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SurpriseHistoryResponse.md)
- [SurpriseHistoryResponseData](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SurpriseHistoryResponseData.md)
- [SurpriseRequest](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SurpriseRequest.md)
- [SurpriseResponse](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/SurpriseResponse.md)
- [TargetPrice](https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2/docs/TargetPrice.md)
## Documentation For Authorization
## FactSetApiKey
- **Type**: HTTP basic authentication
## FactSetOAuth2
- **Type**: OAuth
- **Flow**: application
- **Authorization URL**:
- **Scopes**: N/A
## Notes for Large OpenAPI documents
If the OpenAPI document is large, imports in fds.sdk.FactSetEstimates.apis and fds.sdk.FactSetEstimates.models may fail with a
RecursionError indicating the maximum recursion limit has been exceeded. In that case, there are a couple of solutions:
Solution 1:
Use specific imports for apis and models like:
- `from fds.sdk.FactSetEstimates.api.default_api import DefaultApi`
- `from fds.sdk.FactSetEstimates.model.pet import Pet`
Solution 2:
Before importing the package, adjust the maximum recursion limit as shown below:
```
import sys
sys.setrecursionlimit(1500)
import fds.sdk.FactSetEstimates
from fds.sdk.FactSetEstimates.apis import *
from fds.sdk.FactSetEstimates.models import *
```
## Contributing
Please refer to the [contributing guide](../../../../CONTRIBUTING.md).
## Copyright
Copyright 2026 FactSet Research Systems Inc
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| text/markdown | FactSet Research Systems | null | null | null | Apache License, Version 2.0 | FactSet, API, SDK | [] | [] | https://github.com/FactSet/enterprise-sdk/tree/main/code/python/FactSetEstimates/v2 | null | >=3.7 | [] | [] | [] | [
"urllib3>=1.25.3",
"python-dateutil",
"fds.sdk.utils>=1.0.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-20T14:34:02.298814 | fds_sdk_factsetestimates-3.1.0.tar.gz | 149,767 | 4d/e5/26868d1f02ec21922b039a9ebf406a292def607a32481ed3b6e9aa26dd5d/fds_sdk_factsetestimates-3.1.0.tar.gz | source | sdist | null | false | c46ace09edde104cb1bbfc8840e8e5d6 | 9b93dfbb8cf7daad37db3c6a2d1af0714bc05198a7ea67dbbde5121c906cac2a | 4de526868d1f02ec21922b039a9ebf406a292def607a32481ed3b6e9aa26dd5d | null | [
"LICENSE"
] | 0 |
2.1 | v2xflexstack | 0.10.10 | Implementation of the ETSI C-ITS protocol stack | # FlexStack(R) Community Edition
<!--<img src="doc/img/logo.png" alt="V2X Flex Stack" width="200"/>--> <img src="https://raw.githubusercontent.com/Fundacio-i2CAT/FlexStack/refs/heads/master/doc/img/i2cat_logo.png" alt="i2CAT Logo" width="200"/>

[](https://github.com/Fundacio-i2CAT/FlexStack/actions/workflows/test-python3.8.yml)
[](https://github.com/Fundacio-i2CAT/FlexStack/actions/workflows/test-python3.9.yml)
[](https://github.com/Fundacio-i2CAT/FlexStack/actions/workflows/test-python3.10.yml)
[](https://github.com/Fundacio-i2CAT/FlexStack/actions/workflows/test-python3.11.yml)
[](https://github.com/Fundacio-i2CAT/FlexStack/actions/workflows/test-python3.12.yml)
[](https://github.com/Fundacio-i2CAT/FlexStack/actions/workflows/test-python3.13.yml)
[](https://github.com/Fundacio-i2CAT/FlexStack/actions/workflows/test-python3.14.yml)
[](https://github.com/Fundacio-i2CAT/FlexStack/actions/workflows/test-pypy3.11.yml)




[](https://github.com/Fundacio-i2CAT/FlexStack/actions/workflows/coverage.yml) [](https://github.com/Fundacio-i2CAT/FlexStack/actions/workflows/flake8.yml) [](https://github.com/Fundacio-i2CAT/FlexStack/actions/workflows/flake8.yml) [](https://github.com/Fundacio-i2CAT/FlexStack/actions/workflows/pyright.yml)
# Short description
FlexStack(R) is a software library implementing the ETSI C-ITS protocol stack. Its aim is to facilitate and accelerate the development and integration of software applications on vehicles, vulnerable road users (VRU), and roadside infrastructure that requires the exchange of V2X messages (compliant with ETSI standards) with other actors of the V2X ecosystem.
# Documentation
Extensive documentation is available at [https://flexstack.eu](https://flexstack.eu).
# Pre-requisites
## Supported Operating Systems
This library can run on any system that supports Python 3.8 or higher.
It's important to remark that depending on the Access and Physical layer used, the library may requires additional dependencies.
As an example, it comes with a precompiled version of the C-V2X Link Layer tested on current Cohda Mk6 and other Qualcomm based solutions, which is used to enable the usage of C-V2X directly by this message library. However, if you want to use it with other hardware or software solutions, you may need to cross-compile the C-V2X Link Layer for your specific platform.
## Dependencies
All dependecies can be found in the `requirements.txt` file. To install them, run the following command:
```
pip install -r requirements.txt
```
On the Access Layer, the dependencies depends on the Access Technology used. Specific tutorials and examples can be found elsewhere.
## Build tools
The library is built using Python. To build the library, run the following command:
```
python -m build
```
It requires the `setuptools` and `wheel` packages. If they are not installed, they can be installed using the following command:
```
pip install build setuptools wheel
```
## Known Limitations
- The ASN.1 compiler used in this library is `asn1tools`, which has some limitations. For example, it does not support the `ANY` type, which is used in some ETSI C-ITS messages. This means that some messages may have undergone some adaptations to be compatible with the library. Although this simplifications have been tested with existing commercial implementations, and everything works as expected, it is important to be aware of this limitation.
# Installation
Library can be easily installed using the following command:
```
pip install v2xflexstack
```
## Developers
- Jordi Marias-i-Parella (jordi.marias@i2cat.net)
- Daniel Ulied Guevara (daniel.ulied@i2cat.net)
- Adrià Pons Serra (adria.pons@i2cat.net)
- Marc Codina Bartumeus (marc.codina@i2cat.net)
- Lluc Feixa Morancho (lluc.feixa@i2cat.net)
# Source
This code has been developed within the following research and innovation projects:
- **CARAMEL** (Grant Agreement No. 833611) – Funded under the Horizon 2020 programme, focusing on cybersecurity for connected and autonomous vehicles.
- **PLEDGER** (Grant Agreement No. 871536) – A Horizon 2020 project aimed at edge computing solutions to improve performance and security.
- **CODECO** (Grant Agreement No. 101092696) – A Horizon Europe initiative addressing cooperative and connected mobility.
- **SAVE-V2X** (Grant Agreement No. ACE05322000044) – Focused on V2X communication for vulnerable road user safety, and funded by ACCIO.
- **PoDIUM** (Grant Agreement No. 101069547) – Funded under the Horizon 2021 programme, this project focuses on accelerating the implementation of connected, cooperative and automated mobility technology.
- **SPRINGTIME** (PID2023-146378NB-I00) funded by the Spanish government (MCIU/AEI/10.13039/501100011033/FEDER/UE), this project focuses in techniques to get IP-based interconnection on multiple environments.
- **ONOFRE-3** (PID2020-112675RB-C43) funded by the Spanish government (MCIN/ AEI /10.13039/501100011033), this project focuses on the adaptation of network and compute resources from the cloud to the far-edge.
# Copyright
This code has been developed by Fundació Privada Internet i Innovació Digital a Catalunya (i2CAT).
FlexStack is a registered trademark of i2CAT. Unauthorized use is strictly prohibited.
i2CAT is a **non-profit research and innovation centre that** promotes mission-driven knowledge to solve business challenges, co-create solutions with a transformative impact, empower citizens through open and participative digital social innovation with territorial capillarity, and promote pioneering and strategic initiatives. i2CAT **aims to transfer** research project results to private companies in order to create social and economic impact via the out-licensing of intellectual property and the creation of spin-offs. Find more information of i2CAT projects and IP rights at https://i2cat.net/tech-transfer/
# License
This code is licensed under the terms of the AGPL. Information about the license can be located at https://www.gnu.org/licenses/agpl-3.0.html.
Please, refer to FlexStack Community Edition as a dependence of your works.
If you find that this license doesn't fit with your requirements regarding the use, distribution or redistribution of our code for your specific work, please, don’t hesitate to contact the intellectual property managers in i2CAT at the following address: techtransfer@i2cat.net Also, in the following page you’ll find more information about the current commercialization status or other licensees: Under Development.
# Attributions
Attributions of Third Party Components of this work:
- `asn1tools` Version 0.165.0 - Imported python library - https://asn1tools.readthedocs.io/en/latest/ - MIT license
- `python-dateutil` Version 2.8.2 - Imported python library - https://pypi.org/project/python-dateutil/ - dual license - either Apache 2.0 License or the BSD 3-Clause License.
- `tinydb` Version 4.7.1- Imported python library - https://tinydb.readthedocs.io/en/latest/ - MIT license
- `ecdsa` Version 0.18.0 - Imported python library - https://pypi.org/project/ecdsa/ - MIT license
| text/markdown | null | Jordi Marias-i-Parella <jordi.marias@i2cat.net>, Daniel Ulied Guevara <daniel.ulied@i2cat.net>, Adria Pons Serra <adria.pons@i2cat.net>, Marc Codina Bartumeus <marc.codina@i2cat.net>, Lluc Feixa Morancho <lluc.feixa@i2cat.net> | null | null | GNU AFFERO GENERAL PUBLIC LICENSE
Version 3, 19 November 2007
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU Affero General Public License is a free, copyleft license for
software and other kinds of works, specifically designed to ensure
cooperation with the community in the case of network server software.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
our General Public Licenses are intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
Developers that use our General Public Licenses protect your rights
with two steps: (1) assert copyright on the software, and (2) offer
you this License which gives you legal permission to copy, distribute
and/or modify the software.
A secondary benefit of defending all users' freedom is that
improvements made in alternate versions of the program, if they
receive widespread use, become available for other developers to
incorporate. Many developers of free software are heartened and
encouraged by the resulting cooperation. However, in the case of
software used on network servers, this result may fail to come about.
The GNU General Public License permits making a modified version and
letting the public access it on a server without ever releasing its
source code to the public.
The GNU Affero General Public License is designed specifically to
ensure that, in such cases, the modified source code becomes available
to the community. It requires the operator of a network server to
provide the source code of the modified version running there to the
users of that server. Therefore, public use of a modified version, on
a publicly accessible server, gives the public access to the source
code of the modified version.
An older license, called the Affero General Public License and
published by Affero, was designed to accomplish similar goals. This is
a different license, not a version of the Affero GPL, but Affero has
released a new version of the Affero GPL which permits relicensing under
this license.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU Affero General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Remote Network Interaction; Use with the GNU General Public License.
Notwithstanding any other provision of this License, if you modify the
Program, your modified version must prominently offer all users
interacting with it remotely through a computer network (if your version
supports such interaction) an opportunity to receive the Corresponding
Source of your version by providing access to the Corresponding Source
from a network server at no charge, through some standard or customary
means of facilitating copying of software. This Corresponding Source
shall include the Corresponding Source for any work covered by version 3
of the GNU General Public License that is incorporated pursuant to the
following paragraph.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the work with which it is combined will remain governed by version
3 of the GNU General Public License.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU Affero General Public License from time to time. Such new versions
will be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU Affero General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU Affero General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU Affero General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Affero General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see <https://www.gnu.org/licenses/>.
Also add information on how to contact you by electronic and paper mail.
If your software can interact with users remotely through a computer
network, you should also make sure that it provides a way for users to
get its source. For example, if your program is a web application, its
interface could display a "Source" link that leads users to an archive
of the code. There are many ways you could offer source, and different
solutions will be better for different programs; see section 13 for the
specific requirements.
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU AGPL, see
<https://www.gnu.org/licenses/>. | V2X, C-ITS, ITS, ETSI, ITS-G5, IEEE 802.11p, ITS-S, ITS-G5, CAM, DENM, VAM | [
"License :: OSI Approved :: GNU Affero General Public License v3",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"asn1tools==0.165.0",
"python-dateutil==2.8.2",
"tinydb==4.7.1",
"ecdsa==0.18.0"
] | [] | [] | [] | [
"Homepage, https://flexstack.eu"
] | twine/6.1.0 CPython/3.8.18 | 2026-02-20T14:33:36.298579 | v2xflexstack-0.10.10.tar.gz | 617,407 | c8/98/2eabe7321ce47f14796e91d4b63e305ecd3243703b1d8cebdb5f9794801f/v2xflexstack-0.10.10.tar.gz | source | sdist | null | false | e3008e23ee1103ff4e1b6ebb8845e48f | c7e84465ba27925f18dc4eb33ee02459bc79cbbfe9dfcd8a8d0b9a75c70a381e | c8982eabe7321ce47f14796e91d4b63e305ecd3243703b1d8cebdb5f9794801f | null | [] | 207 |
2.4 | jupytergis-qgis | 0.13.3 | JupyterGIS QGIS extension. | # jupytergis_qgis
| text/markdown | JupyterGIS contributors | null | null | null | BSD 3-Clause License
Copyright (c) 2023, JupyterGIS contributors
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | null | [
"Framework :: Jupyter",
"Framework :: Jupyter :: JupyterLab",
"Framework :: Jupyter :: JupyterLab :: 4",
"Framework :: Jupyter :: JupyterLab :: Extensions",
"Framework :: Jupyter :: JupyterLab :: Extensions :: Prebuilt",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Scientific/Engineering :: GIS"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"jupyter-server<3,>=2.0.1",
"jupyter-ydoc<4,>=2",
"jupytergis-lab"
] | [] | [] | [] | [
"Homepage, https://github.com/geojupyter/jupytergis",
"Bug Tracker, https://github.com/geojupyter/jupytergis/issues",
"Repository, https://github.com/geojupyter/jupytergis.git"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T14:33:23.420744 | jupytergis_qgis-0.13.3.tar.gz | 90,273 | 9f/b6/64730c96ef14b2785faa498b386ead4444568d39d243e9d9005b4c1f1eb0/jupytergis_qgis-0.13.3.tar.gz | source | sdist | null | false | 806354d57a11488146b45bdc94750c92 | 8fe9b8ee7dbda72cd7506b29007e6f81bcb50f22067b478249a1f89568e3598d | 9fb664730c96ef14b2785faa498b386ead4444568d39d243e9d9005b4c1f1eb0 | null | [
"LICENSE"
] | 252 |
2.4 | physicalai-train | 0.0.0 | A Python package | # physicalai_train
A Python package.
## Installation
```bash
pip install physicalai_train
```
## Usage
```python
import physicalai_train
print(physicalai_train.__version__)
```
| text/markdown | null | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/yourusername/physicalai_train"
] | twine/6.2.0 CPython/3.13.5 | 2026-02-20T14:33:15.092576 | physicalai_train-0.0.0.tar.gz | 4,805 | a7/91/ec4fad225b1e303ce8c9068f47e073b38e40936d75c23cf42f588dea6b82/physicalai_train-0.0.0.tar.gz | source | sdist | null | false | b5ddf7db84b99d870c77a985268cd644 | 7ddf7f761fadd762313975c5c0239c763f5577df83ea075b8e5cf903c1c459af | a791ec4fad225b1e303ce8c9068f47e073b38e40936d75c23cf42f588dea6b82 | null | [
"LICENSE"
] | 219 |
2.4 | jupytergis-lab | 0.13.3 | JupyterGIS Lab extension. | # jupytergis_lab
| text/markdown | JupyterGIS contributors | null | null | null | BSD 3-Clause License
Copyright (c) 2023, JupyterGIS contributors
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | null | [
"Framework :: Jupyter",
"Framework :: Jupyter :: JupyterLab",
"Framework :: Jupyter :: JupyterLab :: 4",
"Framework :: Jupyter :: JupyterLab :: Extensions",
"Framework :: Jupyter :: JupyterLab :: Extensions :: Prebuilt",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Scientific/Engineering :: GIS"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"comm<0.2.0,>=0.1.2",
"jupyter-ydoc<4,>=2",
"jupytergis-core<1,>=0.1.0",
"pydantic<3,>=2",
"requests",
"sidecar>=0.7.0",
"yjs-widgets<0.5,>=0.4",
"ypywidgets<0.10.0,>=0.9.0"
] | [] | [] | [] | [
"Homepage, https://github.com/geojupyter/jupytergis",
"Bug Tracker, https://github.com/geojupyter/jupytergis/issues",
"Repository, https://github.com/geojupyter/jupytergis.git"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T14:33:12.259332 | jupytergis_lab-0.13.3.tar.gz | 108,725 | 24/3d/394f895d611dec233c61f9dd1e91ba01d931e62da4621c2f2341aaac7e9c/jupytergis_lab-0.13.3.tar.gz | source | sdist | null | false | 7d4c9c43b5ea466010ec63fafbd78f13 | 1dffd75b398a8dffc49ba76cf9f985c0f37e2bc9d385abf82923146aa3738806 | 243d394f895d611dec233c61f9dd1e91ba01d931e62da4621c2f2341aaac7e9c | null | [
"LICENSE"
] | 266 |
2.4 | digiqual | 0.10.5 | Statistical Toolkit for Reliability Assessment in NDT | # digiqual
**Statistical Toolkit for Reliability Assessment in NDT**
`digiqual` is a Python library designed for Non-Destructive Evaluation (NDE) engineers. It implements the **Generalised** $\hat{a}$-versus-a Method, allowing users to perform reliability assessments without the rigid assumptions of linearity or constant variance found in standard methods.
> **Documentation:** [Read the full documentation here](https://jgibristol.github.io/digiqual/)
## Installation
You can install `digiqual` directly from PyPI.
### Option 1: Install via uv (Recommended)
If you are managing a project with `uv`, add `digiqual` as a dependency:
```bash
# To install the latest stable release (v0.10.5):
uv add digiqual
# To install the latest development version (main branch from github):
uv add "digiqual @ git+https://github.com/JGIBristol/digiqual.git"
```
If you just want to install it into a virtual environment without modifying a project file (e.g., for a quick script), use pip interface:
```bash
uv pip install digiqual
```
### Option 2: Install via standard pip
To install the latest stable release (v0.10.5):
```bash
pip install digiqual
```
To install the latest development version from github:
```bash
pip install "git+https://github.com/JGIBristol/digiqual.git"
```
## Features
### 1. Experimental Design
Before running expensive Finite Element (FE) simulations, `digiqual` helps you design your experiment efficiently.
- **Latin Hypercube Sampling (LHS):** Generate space-filling experimental designs to cover your deterministic parameter space (e.g., defect size) and stochastic nuisance parameters (e.g., roughness, orientation).
- **Scale & Bound:** Automatically scale samples to your specific variable bounds.
### 2. Data Validation & Diagnostics
Ensure your simulation outputs are statistically valid before processing.
- **Sanity Checks:** Detects overlap between variables, type errors, and insufficient sample sizes.
- **Sufficiency Diagnostics:** rigorous statistical tests to flag issues like "Input Coverage Gaps" or "Model Instability" before you trust the results.
### 3. Adaptive Refinement (Active Learning)
`digiqual` closes the loop between analysis and design.
- Smart Refinement: Use `refine()` to identify specific weaknesses in your data. It uses bootstrap committees to find regions of high uncertainty and suggests new points exactly where the model is "confused".
- Automated Workflows: Use the `optimise()` method to run a fully automated "Active Learning" loop. It generates an initial design, executes your external solver, checks diagnostics, and iteratively refines the model until statistical requirements are met.
### 4. Generalised Reliability Analysis
The package includes a full statistical engine for calculating Probability of Detection (PoD) curves.
- **Relaxed Assumptions:** Moves beyond the rigid constraints of the classical $\hat{a}$-versus-$a$ method by handling non-linear signal responses and heteroscedastic noise.
- **Robust Statistics:** Automatically selects the best polynomial degree and error distribution (e.g., Normal, Gumbel, Logistic) based on data fit (AIC).
- **Uncertainty Quantification:** Uses bootstrap resampling to generate robust confidence bounds and $a_{90/95}$ estimates.
## Development
If you want to contribute to digiqual or run the test suite locally, follow these steps.
1. Clone and Install
This project uses uv for dependency management.
``` bash
git clone https://github.com/JGIBristol/digiqual.git
cd digiqual
```
2. Run Tests
The package includes a full test suite using pytest.
``` bash
uv run pytest
```
3. Build Documentation
To preview the documentation site locally:
``` bash
uv run quarto preview
```
## References
**Malkiel, N., Croxford, A. J., & Wilcox, P. D. (2025).** A generalized method for the reliability assessment of safety–critical inspection. Proceedings of the Royal Society A, 481: 20240654. https://doi.org/10.1098/rspa.2024.0654
| text/markdown | null | Josh Tyler <josh.tyler@bristol.ac.uk> | null | null | null | null | [
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"faicons",
"matplotlib>=3.9.4",
"numpy>=2.0.2",
"pandas>=2.3.3",
"pywebview",
"requests>=2.32.5",
"scikit-learn>=1.0.0",
"scipy>=1.13.1",
"shiny",
"shinyswatch",
"statsmodels>=0.14.6",
"jupyter; extra == \"dev\"",
"nbformat; extra == \"dev\"",
"pyinstaller; extra == \"dev\"",
"pytest>=8.4.2; extra == \"dev\"",
"pywebview; extra == \"dev\"",
"quartodoc; extra == \"dev\""
] | [] | [] | [] | [] | uv/0.9.24 {"installer":{"name":"uv","version":"0.9.24","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T14:33:09.685073 | digiqual-0.10.5-py3-none-any.whl | 136,449 | 88/58/5b6c67aabdafd8895e959b72fd5de3e71a8586e0d32734acc8aa50d83ccd/digiqual-0.10.5-py3-none-any.whl | py3 | bdist_wheel | null | false | 810e4c11afd87c55bb4078cf70e19eef | 3941b25ea2db1f3e5be42e0366cdfe64037d3767554a527e273055fbe50ab7c1 | 88585b6c67aabdafd8895e959b72fd5de3e71a8586e0d32734acc8aa50d83ccd | MIT | [
"LICENCE"
] | 204 |
2.4 | Credit-Management | 0.5.1 | A credit management system. | <h1 align="center">
Open Source Credit Management — Plug-and-Play Credits & Subscriptions
</h1>
<p align="center">
<img alt="Static Badge" src="https://img.shields.io/badge/PRs-welcome-brightgreen?style=for-the-badge&color=00AA00">
<img alt="PyPI - Python Version" src="https://img.shields.io/pypi/pyversions/Credit-Management?style=for-the-badge&labelColor=00AA00">
<img alt="PyPI - Downloads" src="https://img.shields.io/pypi/dd/Credit-Management?style=for-the-badge">
<img alt="PyPI - Version" src="https://img.shields.io/pypi/v/Credit-Management?style=for-the-badge">
<img alt="PyPI - License" src="https://img.shields.io/pypi/l/Credit-Management?style=for-the-badge">
<img alt="PyPI - Implementation" src="https://img.shields.io/pypi/implementation/Credit-Management?style=for-the-badge"><img alt="PyPI - Wheel" src="https://img.shields.io/pypi/wheel/Credit-Management?style=for-the-badge">
</p>
**Production-ready, database-agnostic credit and subscription management for any Python service or API.**
Manage user credits, subscriptions, expirations, reservations, and notifications with a single, pluggable module. No lock-in: use **in-memory** for development, **MongoDB** for scale, or plug in your own SQL/NoSQL backend.
---
## Why Use This?
| You need… | We give you… |
|-----------|----------------|
| **Credits that “just work”** | Add, deduct, reserve, expire — with a full audit trail and ledger. |
| **One codebase, any database** | Swap backends via config. Same API whether you use MongoDB, Postgres, or in-memory. |
| **Subscriptions & plans** | Plans with credit limits, billing periods (daily/monthly/yearly), and validity. |
| **Expiration & notifications** | Credits that expire by plan, low-credit alerts, and expiring-credits reminders via a message queue. |
| **Auditability & debugging** | Every change is a transaction; ledger entries go to DB + structured JSON log files. |
| **Async, cacheable, scalable** | Async-first design, optional caching for balances/plans, and queue-based notifications. |
**Use it when:** you're building SaaS, API products, usage-based billing, prepaid credits, or any app where “credits” or “subscription limits” are core — and you want a **reusable, testable, open-source** solution instead of rolling your own.
---
## Features
- **Credit operations** — Add, deduct, expire; reserve → commit or release; full history and “expiring in N days” queries.
- **Subscription plans** — Create/update/delete plans; assign/upgrade/remove user plans; daily/monthly/yearly billing and validity.
- **Expiration & allocation** — Check and run credit expiration; allocate subscription credits (e.g. from a scheduler).
- **Notifications** — Low-credits and expiring-credits events enqueued to a pluggable queue (email/SMS/push later).
- **Ledger & monitoring** — Structured ledger (transaction/error/system) written to DB and to a JSON log file for debugging.
- **Schema generator** — One-time CLI to generate SQL DDL or NoSQL schema from Pydantic models; add a field in the model → regenerate schema.
- **Pluggable backends** — `BaseDBManager` + implementations: **In-Memory** (tests/dev), **MongoDB** (Motor). Add Postgres/SQLite by implementing the same interface.
- **Pydantic everywhere** — Request/response and domain models are Pydantic; validation and serialization are consistent across API and DB.
---
## Quick Start
### 1. Install
## Installation
Install the package from PyPI:
```bash
pip install Credit-Management
```
Depending on your use case, you might need to install extra dependencies:
- If you are using the FastAPI router, install `fastapi`.
- If you are using the MongoDB backend, install `motor`.
From your app (or repo) root:
```bash
# If using this as part of a larger app, ensure dependencies are installed:
pip install fastapi pydantic motor # motor only if using MongoDB
```
### 2. Mount the API (FastAPI)
```python
from fastapi import FastAPI
from credit_management.api.router import router as credit_router
app = FastAPI()
app.include_router(credit_router) # prefix is /credits
```
### 3. Use the HTTP API
```bash
# Add credits
curl -X POST http://localhost:8000/credits/add \
-H "Content-Type: application/json" \
-d '{"user_id": "user-1", "amount": 100, "description": "Welcome bonus"}'
# Get balance
curl http://localhost:8000/credits/balance/user-1
# Deduct credits
curl -X POST http://localhost:8000/credits/deduct \
-H "Content-Type: application/json" \
-d '{"user_id": "user-1", "amount": 30}'
# Create a subscription plan
curl -X POST http://localhost:8000/credits/plans \
-H "Content-Type: application/json" \
-d '{"name": "Pro", "credit_limit": 500, "price": 9.99, "billing_period": "monthly", "validity_days": 30}'
```
---
## Automatic credit deduction middleware
Use **reserve-then-deduct** on selected routes: the middleware reserves an approximate number of credits before the request, runs your API, then reads the **actual usage** from the response (e.g. `total_token`) and deducts that amount, then releases the reservation. Net effect: only the actual usage is deducted; the reservation is a temporary hold.
### Flow
1. **Before request:** Reserve credits (from `X-Estimated-Tokens` header or a default).
2. **Request runs:** Your endpoint executes as usual.
3. **After response:** Middleware parses the JSON response for a configurable key (e.g. `total_token` or `usage.total_tokens`), deducts that amount, and unreserves the hold.
If the response has no usage key or the request fails, only the reservation is released (no deduction).
### Setup
```python
from fastapi import FastAPI
from credit_management.api.middleware import CreditDeductionMiddleware
from credit_management.api.router import _create_db_manager
from credit_management.services.credit_service import CreditService
from credit_management.logging.ledger_logger import LedgerLogger
from credit_management.cache.memory import InMemoryAsyncCache
from pathlib import Path
app = FastAPI()
db = _create_db_manager()
ledger = LedgerLogger(db=db, file_path=Path("credit_ledger.jsonl"))
credit_service = CreditService(db=db, ledger=ledger, cache=InMemoryAsyncCache())
app.add_middleware(
CreditDeductionMiddleware,
credit_service=credit_service,
path_prefix="/api", # only /api/* routes
user_id_header="X-User-Id",
estimated_tokens_header="X-Estimated-Tokens",
default_estimated_tokens=100,
response_usage_key="total_token", # or "usage.total_tokens" for OpenAI-style
skip_paths=("/api/health",),
)
```
### Request / response
- **Client sends:** `X-User-Id` (required), optional `X-Estimated-Tokens` (reserve amount).
- **Your endpoint** returns JSON that includes the actual usage, e.g. `{"message": "...", "total_token": 42}`.
- **Response header:** `X-Credits-Deducted` is set to the deducted amount when applicable.
- **Errors:** Missing `X-User-Id` → 401; insufficient credits for reserve → 402.
A full runnable example is in `examples/fastapi_middleware_example.py`.
---
## Integration
### Option A: Use the included FastAPI router
Mount the router as above. The app will:
- Use **MongoDB** if `CREDIT_MONGO_URI` (and optionally `CREDIT_MONGO_DB`) are set.
- Otherwise use **in-memory** storage (no DB required).
### Option B: Use the services directly (any framework)
Instantiate a DB manager, ledger, optional cache/queue, then the services:
```python
from pathlib import Path
from credit_management.db.memory import InMemoryDBManager
# or: from credit_management.db.mongo import MongoDBManager
from credit_management.logging.ledger_logger import LedgerLogger
from credit_management.services.credit_service import CreditService
from credit_management.services.subscription_service import SubscriptionService
# Pick your backend
db = InMemoryDBManager()
# db = MongoDBManager.from_client_uri("mongodb://localhost:27017", "credit_management")
ledger = LedgerLogger(db=db, file_path=Path("logs/credit_ledger.jsonl"))
credit_svc = CreditService(db=db, ledger=ledger)
sub_svc = SubscriptionService(db=db, ledger=ledger)
# Use in your app (e.g. Celery, Django, Flask, another FastAPI app)
await credit_svc.add_credits("user-1", 100, description="Sign-up bonus")
balance = await credit_svc.get_user_credits_info("user-1")
```
You can pass an optional **cache** (`AsyncCacheBackend`) and, for notifications, a **queue** (`AsyncNotificationQueue`) to the relevant services for better performance and decoupled alerts.
### Option C: Swap the database via environment
| Environment variable | Purpose |
|------------------------|--------|
| `CREDIT_MONGO_URI` | MongoDB connection string (e.g. `mongodb://localhost:27017`). If set and `motor` is installed, the default API uses MongoDB. |
| `CREDIT_MONGO_DB` | Database name (default: `credit_management`). |
Leave `CREDIT_MONGO_URI` unset to use in-memory storage.
---
## How to Test
### Run unit tests (pytest + asyncio)
From the **app** directory (so `credit_management` resolves):
```bash
cd /path/to/your/app
pip install pytest pytest-asyncio
pytest app/credit_management/tests/ -v
```
Tests use the in-memory DB and cache; no MongoDB or external services required.
### Example test (add & deduct)
```python
import pytest
from credit_management.db.memory import InMemoryDBManager
from credit_management.logging.ledger_logger import LedgerLogger
from credit_management.services.credit_service import CreditService
@pytest.mark.asyncio
async def test_add_and_deduct_credits(tmp_path):
db = InMemoryDBManager()
ledger = LedgerLogger(db=db, file_path=tmp_path / "ledger.log")
service = CreditService(db=db, ledger=ledger)
await service.add_credits("user-1", 100)
assert await service.get_user_credits_info("user-1").available == 100
await service.deduct_credits("user-1", 40)
assert await service.get_user_credits_info("user-1").available == 60
```
---
## Schema generation (one-time)
Generate SQL or NoSQL schema from the Pydantic models (e.g. for migrations or collection validators):
```bash
# From repo root, with app on PYTHONPATH
python -m credit_management.schema_generator --backend sql --dialect postgres
python -m credit_management.schema_generator --backend nosql
```
Add a new field to a model → run the generator again to update DDL/validators.
---
More Example: <
[src/examples/](https://github.com/Meenapintu/credit_management/tree/main/src/credit_management/examples) ||
[PypiReadMe.md](https://github.com/Meenapintu/credit_management/blob/main/pypiReadMe.md) >
---
## Project layout
```
credit_management/
├── README.md # This file
├── __init__.py
├── schema_generator.py # CLI: generate SQL/NoSQL schema from models
├── api/
│ └── router.py # FastAPI router (optional)
├── cache/
│ ├── base.py # AsyncCacheBackend
│ └── memory.py # In-memory cache
├── db/
│ ├── base.py # BaseDBManager interface
│ ├── memory.py # In-memory implementation
│ └── mongo.py # MongoDB (Motor) implementation
├── logging/
│ └── ledger_logger.py # Ledger file + DB
├── models/ # Pydantic models (POJOs + db_schema)
│ ├── base.py # DBSerializableModel
│ ├── transaction.py
│ ├── user.py
│ ├── subscription.py
│ ├── credits.py
│ ├── notification.py
│ └── ledger.py
├── notifications/
│ └── queue.py # AsyncNotificationQueue + in-memory impl
├── services/
│ ├── credit_service.py
│ ├── subscription_service.py
│ ├── expiration_service.py
│ └── notification_service.py
└── tests/
└── test_credit_service.py
```
---
## Design highlights
- **Database-agnostic** — Implement `BaseDBManager` for your store (SQL/NoSQL); services and API stay unchanged.
- **Transaction-oriented** — Every credit change is a stored transaction; balance is derived or cached for speed.
- **Ledger** — Operations and errors are logged to the DB and to a structured JSON log for debugging and monitoring.
- **Extensible schema** — Pydantic models define both API/domain and logical schema; the generator produces SQL/NoSQL artifacts once.
---
## Updates & roadmap
- **Current:** In-memory and MongoDB backends, FastAPI router, credit/subscription/expiration/notification services, ledger, schema generator, pytest example.
- **Possible next:** PostgreSQL/MySQL backend, Redis cache/queue adapters, more API endpoints (history, reservations, plan list), OpenAPI tags and examples.
---
## License & contribution
This project is open source. Use it as a library or as a reference to build your own credit system. If you extend it (new backends, endpoints, or features), consider contributing back or sharing your use case.
---
**Summary:** Add the router or services to your stack, set `CREDIT_MONGO_URI` if you want MongoDB, and you get a full credit and subscription system with ledger, expiration, and notifications — ready to integrate and test.
| text/markdown | null | Pintu Lal <pintulalmee@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.7 | [] | [] | [] | [
"fastapi>=0.103.2",
"motor>=3.4.0",
"pydantic>=2.5.3",
"starlette>=0.27.0",
"pytest; extra == \"dev\"",
"uvicorn; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/Meenapintu/credit_management",
"Documentation, https://github.com/Meenapintu/credit_management",
"Bug Tracker, https://github.com/Meenapintu/credit_management/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:33:04.907092 | credit_management-0.5.1.tar.gz | 26,431 | 86/86/fed3929a548bb8fb8540a18d67def77035250835e20fc3d19a78263973d0/credit_management-0.5.1.tar.gz | source | sdist | null | false | 4152fff3dbdb2a4f66989921fa205363 | bd7ab1859f595e35d45fe089964501adbb0fb4b3e558492e3dc0a81bef55a8a0 | 8686fed3929a548bb8fb8540a18d67def77035250835e20fc3d19a78263973d0 | null | [
"LICENSE"
] | 0 |
2.4 | jupytergis-core | 0.13.3 | JupyterGIS core extension | # JupyterGIS Core package
| text/markdown | JupyterGIS contributors | null | null | null | BSD 3-Clause License
Copyright (c) 2023, JupyterGIS contributors
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | null | [
"Framework :: Jupyter",
"Framework :: Jupyter :: JupyterLab",
"Framework :: Jupyter :: JupyterLab :: 4",
"Framework :: Jupyter :: JupyterLab :: Extensions",
"Framework :: Jupyter :: JupyterLab :: Extensions :: Prebuilt",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Scientific/Engineering :: GIS"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"jupyter-ydoc<4,>=2"
] | [] | [] | [] | [
"Homepage, https://github.com/geojupyter/jupytergis",
"Bug Tracker, https://github.com/geojupyter/jupytergis/issues",
"Repository, https://github.com/geojupyter/jupytergis.git"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T14:32:59.433574 | jupytergis_core-0.13.3.tar.gz | 16,414,556 | ff/9c/d6ab8c9a1f34745d18ac38691f8de1384c2149825b6ece608c8ee56f8f82/jupytergis_core-0.13.3.tar.gz | source | sdist | null | false | 755bbfde81ea731207bcbcc3e5fe3d1e | c3a6c577fe6383ebbc86695b2c0149fa8068103742411b7cf34849981fca0c11 | ff9cd6ab8c9a1f34745d18ac38691f8de1384c2149825b6ece608c8ee56f8f82 | null | [
"LICENSE"
] | 271 |
2.3 | asebytes | 0.2.0 | LMDB-based storage for ASE. | # asebytes
Storage-agnostic, lazy-loading interface for [ASE](https://wiki.fysik.dtu.dk/ase/) Atoms objects. Pluggable backends (LMDB, Zarr, HDF5/H5MD, HuggingFace Datasets, ASE file formats) behind a single `list`-like API with pandas-style column views.
```
pip install asebytes[lmdb] # LMDB backend (recommended)
pip install asebytes[zarr] # Zarr backend (fast compression)
pip install asebytes[h5md] # HDF5/H5MD backend
pip install asebytes[hf] # HuggingFace Datasets backend
```
## Quick Start
```python
from asebytes import ASEIO
# Write
db = ASEIO("data.lmdb")
db.extend(atoms_list) # bulk append
db[0] = new_atoms # replace row
db.update(0, calc={"energy": -10.5}) # partial update
# Read
atoms = db[0] # ase.Atoms
atoms = db[-1] # negative indexing
```
Backend is auto-detected from the file extension:
| Extension | Backend | Install extra |
|-----------|---------|---------------|
| `*.lmdb` | `LMDBBackend` | `asebytes[lmdb]` |
| `*.zarr` | `ZarrBackend` | `asebytes[zarr]` |
| `*.h5` / `*.h5md` | `H5MDBackend` | `asebytes[h5md]` |
| `*.xyz` / `*.extxyz` / `*.traj` | `ASEReadOnlyBackend` | *(none)* |
## Lazy Views
Indexing with slices, lists, or strings returns lazy views that load data on demand.
```python
# Row views — lazy, stream one frame at a time
view = db[5:100] # slice → RowView (nothing loaded yet)
view = db[[0, 42, 99]] # list of indices → RowView
for atoms in view:
process(atoms)
# Chunked iteration — loads N rows per batch for throughput
for atoms in db[:].chunked(1000):
process(atoms)
# Column views — avoid constructing full Atoms objects
energies = db["calc.energy"].to_list()
cols = db[["calc.energy", "calc.forces"]].to_dict()
# → {"calc.energy": [...], "calc.forces": [...]}
# Chaining — slice rows, then select columns
db[0:500]["calc.energy"].to_list()
```
## Persistent Read-Through Cache
For slow or remote sources, `cache_to` creates a persistent local cache.
First pass reads from source and fills the cache; all subsequent reads are served from cache.
```python
db = ASEIO("colabfit://dataset", split="train", cache_to="cache.lmdb")
for atoms in db: # epoch 1: reads source, populates cache
train(atoms)
for atoms in db: # epoch 2+: all reads from local cache
train(atoms)
```
Accepts a file path (auto-creates backend) or any `WritableBackend` instance.
No invalidation — delete the cache file to reset.
## HuggingFace Datasets
Stream or download datasets from the HuggingFace Hub via URI schemes.
```python
# ColabFit (auto-selects column mapping, streams by default)
db = ASEIO("colabfit://mlearn_Cu_train", split="train")
# OPTIMADE (e.g. LeMaterial)
db = ASEIO("optimade://LeMaterial/LeMat-Bulk", split="train", name="compatible_pbe")
# Generic HuggingFace (requires explicit column mapping)
from asebytes import ColumnMapping
mapping = ColumnMapping(
positions="pos", numbers="nums",
calc={"energy": "total_energy"},
)
db = ASEIO("hf://user/dataset", mapping=mapping, split="train")
# Downloaded mode for faster access
db = ASEIO("colabfit://dataset", split="train", streaming=False)
```
## Zarr
Zarr backend with flat layout and Blosc/LZ4 compression. Offers compact file sizes and fast read performance. Supports variable particle counts via NaN padding, append-only writes.
```python
db = ASEIO("trajectory.zarr")
db.extend(atoms_list)
# Custom compression
from asebytes import ZarrBackend
db = ASEIO(ZarrBackend("data.zarr", compressor="zstd", clevel=9))
```
## HDF5 / H5MD
H5MD-standard files with support for variable particle counts, per-frame PBC, and bond connectivity.
```python
db = ASEIO("trajectory.h5", author_name="Jane Doe", compression="gzip")
db.extend(atoms_list)
# Multi-group files
from asebytes import H5MDBackend
groups = H5MDBackend.list_groups("multi.h5")
db = ASEIO("multi.h5", particles_group="solvent")
```
## Key Convention
All data follows a flat namespace:
| Prefix | Content | Examples |
|--------|---------|----------|
| `arrays.*` | Per-atom arrays | `arrays.positions`, `arrays.numbers`, `arrays.forces` |
| `calc.*` | Calculator results | `calc.energy`, `calc.stress` |
| `info.*` | Frame metadata | `info.smiles`, `info.label` |
| *(top-level)* | `cell`, `pbc`, `constraints` | |
```python
from asebytes import atoms_to_dict, dict_to_atoms
d = atoms_to_dict(atoms) # Atoms → flat dict (~5x faster than encode/decode)
atoms = dict_to_atoms(d) # flat dict → Atoms
```
## Custom Backends
Implement `ReadableBackend` for read-only or `WritableBackend` for read-write:
```python
from asebytes import ASEIO, ReadableBackend
class MyBackend(ReadableBackend):
def __len__(self): ...
def columns(self, index=0): ...
def read_row(self, index, keys=None): ...
db = ASEIO(MyBackend())
```
## Benchmarks
1000 frames each on two datasets — ethanol conformers (small molecules, fixed size) and [LeMat-Traj](https://huggingface.co/datasets/LeMaterial/LeMat-Traj) (periodic structures, variable atom counts). All frames include energy, forces, and stress. Compared against aselmdb, znh5md, extxyz, and SQLite.
```python
# LeMat-Traj benchmark data
lemat = list(ASEIO("optimade://LeMaterial/LeMat-Traj", split="train", name="compatible_pbe")[:1000])
```
> **Note:** HDF5 performance is heavily influenced by compression and chunking settings. Both asebytes H5MD and znh5md use gzip compression by default, which reduces file size at the cost of read/write speed. The Zarr backend uses Blosc/LZ4 compression, which achieves compact file sizes with faster decompression than gzip.
### Write

### Sequential Read

### Random Access

### Column Access

### File Size

| text/markdown | Fabian Zills | Fabian Zills <fzills@icp.uni-stuttgart.de> | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"ase>=3.26.0",
"h5py>=3.8.0; extra == \"h5md\"",
"datasets>=4.5.0; extra == \"hf\"",
"lmdb>=1.7.5; extra == \"lmdb\"",
"msgpack>=1.1.2; extra == \"lmdb\"",
"msgpack-numpy>=0.4.8; extra == \"lmdb\"",
"zarr>=3.0; extra == \"zarr\""
] | [] | [] | [] | [
"Repository, https://github.com/zincware/asebytes",
"Releases, https://github.com/zincware/asebytes/releases",
"Discord, https://discord.gg/7ncfwhsnm4"
] | uv/0.10.1 {"installer":{"name":"uv","version":"0.10.1","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T14:32:49.966608 | asebytes-0.2.0-py3-none-any.whl | 49,321 | a8/34/14ea3cd9c063ed99a32568d8508a1ba166057768416c511ce61133fdf012/asebytes-0.2.0-py3-none-any.whl | py3 | bdist_wheel | null | false | e7336fee3964a23e4a22f685e05c7b1e | ba9ce34d5871b791b3c467383275bd3673f6947fb0badba6be1fd34e757b02a8 | a83414ea3cd9c063ed99a32568d8508a1ba166057768416c511ce61133fdf012 | null | [] | 215 |
2.4 | hypnofunk | 0.3.0 | A Python package for sleep analysis and hypnogram processing | # hypnofunk 🌙
<p align="center">
<img src="https://github.com/rahulvenugopal/PyKumbogram/blob/main/Logo.png" width="200" alt="hypnofunk logo">
</p>
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
[](https://doi.org/10.5281/zenodo.18713864)
**hypnofunk** is a high-performance toolkit for sleep researchers. It calculates 40+ macrostructure parameters, performs first-order **Markov-chain transition analysis**, and detects sleep cycles—all from simple hypnogram sequences.
---
## Installation
```bash
# Core package
pip install hypnofunk
# Full installation — includes Lempel-Ziv complexity, plotting, and EDF support
pip install hypnofunk[full]
```
---
## Supported Input Formats
### Hypnogram data (in-memory)
hypnofunk accepts standard AASM sleep stage labels (`W`, `N1`, `N2`, `N3`, `R`) as:
- **Python lists**, **NumPy arrays**, or **Pandas Series**.
### File formats (via example workflow)
The included [`polyman_analysis.py`](examples/polyman_analysis.py) provides a turnkey solution for:
- **EDF / EDF+**: Reads Polyman-style annotations directly.
- **CSV**: Processes exported spreadsheets with epoch-by-epoch scoring.
---
## Standard Analysis Parameters
hypnofunk uses industry-standard defaults, all of which are configurable via function arguments:
| Parameter | Default | Logic |
|---|---|---|
| `epoch_duration` | `30s` | The standard temporal resolution for clinical sleep scoring. |
| `max_wake_epochs` | `10` | Keeps 5 mins of wake after final sleep before trimming terminal wake. |
| `min_nrem_epochs` | `30` | Defines a NREM cycle as ≥15 mins of continuous NREM starting with N2. |
| `min_rem_epochs` | `10` | Subsequent REM cycles must be ≥5 mins (1st REM cycle can be any length). |
---
## Sleep Cycle Detection Logic
Our detection algorithms follow standard clinical research criteria to ensure consistency across datasets:
### NREM Cycles 🌙
A sequence is identified as a NREM cycle if:
1. It **starts with N2** sleep.
2. It contains at least **15 minutes** (30 epochs) of continuous NREM (N1, N2, or N3).
3. This prevents short "transitional" light sleep from being miscounted as a full cycle.
### REM Cycles ⚡
REM detection handles the unique nature of early-night sleep:
1. **First REM Cycle**: Accepted at any length (standard research practice).
2. **Subsequent REM Cycles**: Must be at least **5 minutes** (10 epochs) long.
3. This ensures that REM "fragments" commonly found in fragmented sleep don't artificially inflate cycle counts.
---
## Markov-Chain Transition Analysis 🔄
hypnofunk provides a robust framework for quantifying sleep stability and fragmentation using first-order Markov chains:
- **Full Transition Matrix**: A 5×5 matrix of probabilities for transitions between every sleep stage (W, N1, N2, N3, R).
- **Stage Persistence**: The probability of remaining in a specific stage (diagonal nodes of the Markov chain).
- **Awakening Probabilities**: The specific likelihood of transitioning to Wake from each individual sleep stage.
- **Sleep Compactness**: A global consolidation index calculated as the mean persistence across all sleep stages.
- **Fragility Metrics**: Proportion of all transitions that result in awakening.
---
## Quick Start
```python
from hypnofunk import hypnoman, analyze_transitions
# 10 epochs Wake, 50 N2, 30 N3, 20 REM, 5 Wake
hypnogram = ["W"]*10 + ["N2"]*50 + ["N3"]*30 + ["R"]*20 + ["W"]*5
# Get 40+ parameters in one line (Macrostructure)
params = hypnoman(hypnogram, epoch_duration=30)
print(f"TST: {params['TST'].values[0]:.1f} min | SE: {params['Sleep_efficiency'].values[0]:.1f}%")
# Analyze stage transitions & Markov chain dynamics
trans = analyze_transitions(hypnogram)
print(f"Sleep Compactness: {trans['Sleep_Compactness'].values[0]:.3f}")
print(f"Prob. N2 Persistence: {trans['Persistence_N2'].values[0]:.3f}")
```
---
## Core Functionality
### Sleep Macrostructure — `hypnoman()`
Returns a single-row `pd.DataFrame` containing:
- **Time metrics:** TRT, TST, SPT, WASO, SOL.
- **Efficiency:** Sleep Efficiency (SE), Sleep Maintenance Efficiency (SME).
- **Stage statistics:** Duration, percentage, and onset latency for all stages.
- **Streak analysis:** Longest, mean, and median "runs" (streaks) for every stage.
- **Information Theory:** **Lempel-Ziv complexity (LZc)** — a non-linear measure of sleep stage variety (requires `antropy`).
### Transition Analysis — `analyze_transitions()`
Performs the Markov-chain analysis described above, returning:
- Total transitions (fragmentation count).
- Probability of awakening.
- Sleep compactness index.
- Per-stage persistence and awakening probabilities.
- Complete transition matrix (25 probability values).
---
## API Reference
### `hypnofunk.io`
- `read_edf_hypnogram()`: Standardized loader for Polyman EDF and EDF+ files.
### `hypnofunk.core`
- `hypnoman()`: The main entry point for macrostructure metrics.
- `find_nremstretches()` & `find_rem_stretches()`: Cycle detection engines.
- `trim_terminal_wake()`: Utility to clean extended wake at the end of recordings.
### `hypnofunk.transitions`
- `analyze_transitions()`: Main entry point for fragmentation and Markov metrics.
- `compute_transition_matrix()`: Raw transition probability calculations.
- `compute_sleep_compactness()`: Statistical consolidated sleep index.
### `hypnofunk.visualization`
- `plot_hypnogram_with_cycles()`: Clean hypnograms with cycle-overlay bars.
- `plot_transition_matrix()`: Heatmap visualization of stage dynamics (Markov matrix).
---
## Citation
```bibtex
@software{hypnofunk2026,
author = {Venugopal, Rahul},
title = {hypnofunk: A Python package for sleep analysis},
year = {2026},
url = {https://github.com/rahulvenugopal/hypnofunk}
}
```
## License
MIT — see [LICENSE](LICENSE) for details. Developed by **Rahul Venugopal**.
| text/markdown | Rahul Venugopal | null | null | null | MIT | sleep, analysis, hypnogram, polysomnography, sleep-stages, transitions | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Medical Science Apps.",
"Topic :: Scientific/Engineering :: Bio-Informatics",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy>=1.20.0",
"pandas>=1.3.0",
"matplotlib>=3.3.0",
"antropy>=0.1.4; extra == \"full\"",
"yasa>=0.6.0; extra == \"full\"",
"mne>=1.0.0; extra == \"full\"",
"pytest>=6.0; extra == \"dev\"",
"pytest-cov>=2.0; extra == \"dev\"",
"black>=21.0; extra == \"dev\"",
"flake8>=3.9; extra == \"dev\"",
"mypy>=0.900; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/rahulvenugopal/hypnofunk",
"Documentation, https://github.com/rahulvenugopal/hypnofunk#readme",
"Repository, https://github.com/rahulvenugopal/hypnofunk",
"Bug Tracker, https://github.com/rahulvenugopal/hypnofunk/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:32:41.095387 | hypnofunk-0.3.0.tar.gz | 21,873 | b7/ba/2acc63a40e782cf56636cc51419c305c275071baf4bdbe4e628c98eb2f1f/hypnofunk-0.3.0.tar.gz | source | sdist | null | false | 894901360a24d602f8b0786d1e76ed2c | 39e7895957edcfd4091fd7f213af9e3f4d512c393bbe622085198b5e94460bf6 | b7ba2acc63a40e782cf56636cc51419c305c275071baf4bdbe4e628c98eb2f1f | null | [
"LICENSE"
] | 217 |
2.4 | psforge-grid | 0.3.0 | Core data models and I/O for the psforge power system analysis ecosystem. LLM-friendly design for AI-assisted analysis. | # psforge-grid
[](https://badge.fury.io/py/psforge-grid)
[](https://pypi.org/project/psforge-grid/)
[](https://github.com/manabelab/psforge-grid/actions/workflows/test.yml)
[](https://opensource.org/licenses/MIT)
> **Hub data model for the psforge power system analysis ecosystem**
Core data models and I/O for power system analysis with LLM-friendly design.
## Quick Start
```bash
pip install psforge-grid
```
```python
from psforge_grid import System
# Load from PSS/E RAW format
system = System.from_raw("ieee14.raw")
# Load from MATPOWER format (pglib-opf compatible)
system = System.from_matpower("pglib_opf_case14_ieee.m")
# Auto-detect format by file extension
system = System.from_file("case14.m")
# Explore the system
print(f"Buses: {len(system.buses)}, Branches: {len(system.branches)}")
# Get LLM-friendly summary
print(system.to_summary())
```
```bash
# Or use the CLI
psforge-grid info ieee14.raw
psforge-grid show pglib_opf_case14_ieee.m buses -f json
```
## Why psforge-grid?
| Feature | psforge-grid | Others |
|---------|--------------|--------|
| **LLM-friendly output** | Built-in JSON/summary formats | Manual formatting |
| **Educational design** | Rich docstrings, clear naming | Varies |
| **Type hints** | Complete type annotations | Often missing |
| **CLI included** | Yes, with multiple output formats | Usually separate |
| **Multi-format I/O** | PSS/E RAW + MATPOWER (.m) | Usually single format |
## Overview
psforge-grid serves as the **Hub** of the psforge ecosystem, providing:
- Common data classes (`System`, `Bus`, `Branch`, `Generator`, `GeneratorCost`, `Load`, `Shunt`)
- PSS/E RAW file parser (v33/v34 partial support)
- MATPOWER .m file parser ([pglib-opf](https://github.com/power-grid-lib/pglib-opf) compatible)
- OPF data support (`GeneratorCost` with polynomial and piecewise-linear cost models)
- Shared utilities for power system analysis
## LLM Affinity Design
> **"Pickaxe in the Gold Rush"** - psforge is designed for seamless LLM integration.
psforge-grid implements LLM-friendly data structures and CLI:
| Feature | Description |
|---------|-------------|
| **Explicit Units** | Field names include units (`voltage_pu`, `power_mw`) |
| **Semantic Status** | Enum-based status annotations (`VoltageStatus.LOW`) |
| **Self-Documenting** | Rich docstrings explaining physical meaning |
| **to_description()** | Human/LLM-readable output methods |
```python
# Example: LLM-friendly bus description
bus = system.get_bus(14)
print(bus.to_description())
# Output: "Bus 14 (LOAD_BUS): 13.8 kV, PQ type"
```
### CLI for LLM Integration
psforge-grid includes a CLI designed for LLM-friendly output:
```bash
# System summary in different formats
psforge-grid info ieee14.raw # Table format
psforge-grid info ieee14.raw -f json # JSON for API/LLM
psforge-grid info ieee14.raw -f summary # Compact for tokens
# Display element details
psforge-grid show ieee14.raw buses
psforge-grid show ieee14.raw branches -f json
# Validate system data
psforge-grid validate ieee14.raw
psforge-grid validate ieee14.raw --strict
```
**Output Formats:**
- `table`: Human-readable tables (default)
- `json`: Structured JSON for LLM/API processing
- `summary`: Compact text for token-efficient LLM usage
- `csv`: Comma-separated values for data analysis
See [CLAUDE.md](CLAUDE.md) for detailed AI development guidelines.
## PSS/E RAW Format Support
### Current Status
The parser supports **core power flow data** required for basic AC power flow analysis:
| Section | v33 | v34 | Notes |
|---------|-----|-----|-------|
| Case Identification | Yes | Yes | Base MVA, system info |
| Bus Data | Yes | Yes | All bus types (PQ, PV, Slack, Isolated) |
| Load Data | Yes | Yes | Constant power loads |
| Fixed Shunt Data | Yes | Yes | Capacitors and reactors |
| Generator Data | Yes | Yes | P, Q, voltage setpoint, Q limits |
| Branch Data | Yes | Yes | Transmission lines |
| Transformer Data | Yes | Yes | Two-winding transformers only |
### Not Yet Supported
The following sections are parsed but ignored (data is skipped):
- Area Data, Zone Data, Owner Data
- Two-Terminal DC Data, Multi-Terminal DC Data
- VSC DC Line Data, FACTS Device Data
- Switched Shunt Data (use Fixed Shunt instead)
- Multi-Section Line Data, Impedance Correction Data
- GNE Data, Induction Machine Data, Substation Data
- Three-winding Transformers
### Test Data Sources
Parser has been validated with IEEE test cases from multiple sources:
- IEEE 9-bus (v34): [GitHub - todstewart1001](https://github.com/todstewart1001/PSSE-24-Hour-Load-Dispatch-IEEE-9-Bus-System-)
- IEEE 14-bus (v33): [GitHub - ITI/models](https://github.com/ITI/models/blob/master/electric-grid/physical/reference/ieee-14bus/)
- IEEE 118-bus (v33): [GitHub - powsybl](https://github.com/powsybl/powsybl-distribution/blob/main/resources/PSSE/IEEE_118_bus.raw)
### Future Plans
1. Three-winding transformer support
2. Switched shunt data support
3. HVDC, FACTS device support (as needed)
## MATPOWER Format Support
psforge-grid supports [MATPOWER](https://matpower.app/) `.m` files, enabling direct use of [pglib-opf](https://github.com/power-grid-lib/pglib-opf) benchmark cases.
### Supported Sections
| Section | Status | Notes |
|---------|--------|-------|
| Bus Data (13 columns) | Yes | All bus types, Vmin/Vmax for OPF |
| Generator Data (10 columns) | Yes | Pmin/Pmax, Qmin/Qmax |
| Branch Data (13 columns) | Yes | Including angmin/angmax for OPF |
| Generator Cost Data | Yes | Polynomial (model=2) and piecewise-linear (model=1) |
| baseMVA | Yes | System base MVA |
### Generator Cost Functions
```python
from psforge_grid import System
system = System.from_matpower("pglib_opf_case14_ieee.m")
# Access generator cost data (for OPF)
for cost in system.generator_costs:
print(cost.to_description())
# "Generator Cost (polynomial, degree 2): 0.0430 * P^2 + 20.00 * P + 0.00"
# Evaluate cost at a given power output
cost_value = cost.evaluate(p_mw=50.0) # $/hr
```
## Installation
```bash
# Install the package
pip install psforge-grid
# Or install from source
pip install -e .
```
## Development Setup
### Prerequisites
- Python 3.9+
- [uv](https://github.com/astral-sh/uv) (recommended) or pip
### Install Development Dependencies
```bash
# Using uv (recommended)
uv pip install -e ".[dev]"
# Or using pip
pip install -e ".[dev]"
```
### Setup Pre-commit Hooks
Pre-commit hooks automatically run ruff and mypy checks before each commit.
#### Option 1: Global Install with pipx (Recommended)
Using [pipx](https://github.com/pypa/pipx) for global installation is recommended, especially when using **git worktree** for parallel development. This ensures `pre-commit` is available across all worktrees without additional setup.
```bash
# Install pipx if not already installed
brew install pipx # macOS
# or: pip install --user pipx
# Install pre-commit globally
pipx install pre-commit
# Install hooks (only needed once per repository)
pre-commit install
# Run hooks manually on all files
pre-commit run --all-files
```
**Why pipx?**
- Works across all git worktrees without per-worktree setup
- Isolated environment prevents dependency conflicts
- Single installation, works everywhere
#### Option 2: Local Install in Virtual Environment
```bash
# Install pre-commit in your virtual environment
pip install pre-commit
# Install hooks
pre-commit install
# Run hooks manually on all files
pre-commit run --all-files
```
> **Note:** CI runs ruff and mypy checks via GitHub Actions (`.github/workflows/test.yml`), so code quality is enforced on push/PR even if local hooks are skipped.
### Manual Code Quality Checks
```bash
# Lint with ruff
ruff check src/ tests/
# Format with ruff
ruff format src/ tests/
# Type check with mypy
mypy src/
```
### Run Tests
```bash
pytest tests/ -v
```
### Editor Setup (VSCode/Cursor)
This project includes `.vscode/` configuration for seamless development:
- **Format on Save**: Automatically formats code with ruff
- **Organize Imports**: Automatically sorts imports
- **Type Checking**: Mypy extension provides real-time type checking
**Recommended Extensions:**
- `charliermarsh.ruff` - Ruff linter and formatter
- `ms-python.mypy-type-checker` - Mypy type checker
- `ms-python.python` - Python language support
## psforge Ecosystem (Hub & Spoke Architecture)
psforge is a modular power system analysis ecosystem built on a **Hub & Spoke** architecture. **psforge-grid** is the Hub — all Spoke packages depend on it for common data models and I/O.
```
┌──────────────────────┐
│ psforge-grid │
│ (Hub: Data & I/O) │
└──────────┬───────────┘
│
┌──────────────────┼──────────────────┐
│ │ │
┌────────▼────────┐ ┌──────▼───────┐ ┌────────▼────────┐
│ psforge-flow │ │psforge- │ │psforge- │
│ (AC Power Flow)│ │stability │ │schedule │
│ │ │(Transient │ │(Unit Commitment) │
│ │ │ Stability) │ │ │
└─────────────────┘ └──────────────┘ └─────────────────┘
```
| Package | PyPI Name | Description | Status |
|---------|-----------|-------------|--------|
| **psforge-grid** (this) | `psforge-grid` | Core data models, parsers (RAW, MATPOWER), and CLI | Active |
| **psforge-flow** | `psforge-flow` | AC power flow (Newton-Raphson) and optimal power flow | Active |
| **psforge-stability** | `psforge-stability` | Transient stability analysis (DAE solver) | Planned |
| **psforge-schedule** | `psforge-schedule` | Unit commitment optimization (HiGHS/Gurobi) | Planned |
All packages are developed and maintained by [Manabe Lab LLC](https://github.com/manabelab).
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
1. Fork the repository
2. Create your feature branch (`git checkout -b feature/amazing-feature`)
3. Run tests (`pytest tests/`)
4. Commit your changes (`git commit -m 'Add amazing feature'`)
5. Push to the branch (`git push origin feature/amazing-feature`)
6. Open a Pull Request
See [CLAUDE.md](CLAUDE.md) for AI development guidelines.
## License
MIT License - see [LICENSE](LICENSE) for details.
---
**Developed by [Manabe Lab LLC](https://github.com/manabelab)**
| text/markdown | null | Manabe Lab LLC <manabe@manabelab.com> | null | Manabe Lab LLC <manabe@manabelab.com> | null | power-systems, electrical-engineering, psse, power-flow, grid, llm-friendly, education, energy | [
"Development Status :: 4 - Beta",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Physics",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"typer>=0.9.0",
"rich>=13.0.0",
"pytest; extra == \"dev\"",
"ruff>=0.8.0; extra == \"dev\"",
"mypy; extra == \"dev\"",
"pre-commit; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/manabelab/psforge-grid",
"Documentation, https://github.com/manabelab/psforge-grid#readme",
"Repository, https://github.com/manabelab/psforge-grid.git",
"Changelog, https://github.com/manabelab/psforge-grid/blob/main/CHANGELOG.md",
"Bug Tracker, https://github.com/manabelab/psforge-grid/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:32:38.979237 | psforge_grid-0.3.0.tar.gz | 59,310 | 04/8b/6d2b16d44a9fa44803f32f65788000ba947be3c1482a933bf03f2d0ac3eb/psforge_grid-0.3.0.tar.gz | source | sdist | null | false | fb27628993d6cc51ca34614647c2ecad | 5b9cea25e304a2fb323d409db4be3653fb9ac679b5b91a74556f8c2fc4aa36e5 | 048b6d2b16d44a9fa44803f32f65788000ba947be3c1482a933bf03f2d0ac3eb | MIT | [
"LICENSE"
] | 212 |
2.4 | beproduct | 0.6.30 | BeProduct Public API SDK | # BeProduct Python SDK Package
## Read full documentation at **[https://sdk.beproduct.com](https://sdk.beproduct.com)**
## Example
Install:
`pip install --upgrade beproduct`
Use:
```python
from beproduct.sdk import BeProduct
client = BeProduct(client_id='YOUR_CLIENT_ID',
client_secret='YOUR_CLIENT_SECRET',
refresh_token='YOUR_REFRESH_TOKEN',
company_domain='YOUR_COMPANY_DOMAIN')
style = client.style.attributes_get(header_id='e81d3be5-f5c2-450f-888e-8a854dfc2824')
print(style)
```
| text/markdown | Yuri Golub | support@beproduct.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/BeProduct/BeProduct.Python.SDK | null | >=3.10 | [] | [] | [] | [
"requests",
"aiohttp"
] | [] | [] | [] | [
"Bug Tracker, https://github.com/BeProduct/BeProduct.Python.SDK/issues"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-20T14:32:37.524018 | beproduct-0.6.30.tar.gz | 30,762 | 57/65/4b649940cfeaa20543fa4c439bb66f1133c1e0152888de43bba034c11968/beproduct-0.6.30.tar.gz | source | sdist | null | false | 8bc3a607bf03c8606c6cb6e35b79e6ae | 9751c50688a11c04d3b5579462ae5d19b1f1002cf7e85e35936340d114a684b7 | 57654b649940cfeaa20543fa4c439bb66f1133c1e0152888de43bba034c11968 | null | [
"LICENSE"
] | 276 |
2.3 | ssb-dapla-geoio | 0.2.3 | Dapla GeoIO | # Dapla GeoIO
[][pypi status]
[][pypi status]
[][pypi status]
[][license]
[][documentation]
[][tests]
[][sonarcov]
[][sonarquality]
[][pre-commit]
[][black]
[](https://github.com/astral-sh/ruff)
[][poetry]
[pypi status]: https://pypi.org/project/ssb-dapla-geoio/
[documentation]: https://statisticsnorway.github.io/dapla-geoio
[tests]: https://github.com/statisticsnorway/dapla-geoio/actions?workflow=Tests
[sonarcov]: https://sonarcloud.io/summary/overall?id=statisticsnorway_dapla-geoio
[sonarquality]: https://sonarcloud.io/summary/overall?id=statisticsnorway_dapla-geoio
[pre-commit]: https://github.com/pre-commit/pre-commit
[black]: https://github.com/psf/black
[poetry]: https://python-poetry.org/
## Funksjonalitet
_Dapla geoio_ leser og skriver filer med geometri til og fra en `geopandas.geodataframe` på SSBs dataplatform Dapla.
Pakka kan lese og skrive geoparquetfiler med WKB kodet geometri. Den kan også lese partisjonerte parquet-filer. Støtte for [Geoarrow] kodet geometri er planlagt.
_Dapla geoio_ bruker [Pyogrio] til å lese og skrive til andre filformater, og kan derfor også lese og skrive til de formatene som Pyogrio kan. Testet med Geopackage og Shape-filer.
Hvis du kun behøver lese og skrive funksjonalitet er _Dapla geoio_ et lettere alternativ til [ssb-sgis]
## Installasjon
Du kan installere _Dapla GeoIO_ via [pip] fra [PyPI]:
```console
pip install ssb-dapla-geoio
```
## Usage
Please see the [Reference Guide] for details.
## Contributing
Contributions are very welcome.
To learn more, see the [Contributor Guide].
## License
Distributed under the terms of the [MIT license][license],
_Dapla GeoIO_ is free and open source software.
## Issues
If you encounter any problems,
please [file an issue] along with a detailed description.
## Credits
This project was generated from [Statistics Norway]'s [SSB PyPI Template].
[statistics norway]: https://www.ssb.no/en
[pypi]: https://pypi.org/
[ssb pypi template]: https://github.com/statisticsnorway/ssb-pypitemplate
[file an issue]: https://github.com/statisticsnorway/dapla-geoio/issues
[pip]: https://pip.pypa.io/
[pyogrio]: https://pypi.org/project/pyogrio/
[ssb-sgis]: https://pypi.org/project/ssb-sgis/
[geoarrow]: https://geoarrow.org
<!-- github-only -->
[license]: https://github.com/statisticsnorway/dapla-geoio/blob/main/LICENSE
[contributor guide]: https://github.com/statisticsnorway/dapla-geoio/blob/main/CONTRIBUTING.md
[reference guide]: https://statisticsnorway.github.io/dapla-geoio/reference.html
| text/markdown | Bjørn Lie Rapp | bjorn.rapp@ssb.no | null | null | MIT | null | [
"Development Status :: 2 - Pre-Alpha"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"gcsfs<2027.0.0,>=2025.9.0",
"geopandas<2.0.0,>=1.0.1",
"numpy<3.0.0,>=2.2.6",
"pandas<4.0.0,>=2.3.2",
"pyarrow<24.0.0,>=21.0.0",
"pyogrio<1.11.0,>=0.10.0",
"shapely<3.0.0,>=2.1.1",
"universal-pathlib>=0.2.6"
] | [] | [] | [] | [
"Changelog, https://github.com/statisticsnorway/dapla-geoio/releases",
"Documentation, https://statisticsnorway.github.io/dapla-geoio",
"Homepage, https://github.com/statisticsnorway/dapla-geoio",
"Repository, https://github.com/statisticsnorway/dapla-geoio"
] | twine/6.1.0 CPython/3.12.8 | 2026-02-20T14:32:32.532181 | ssb_dapla_geoio-0.2.3.tar.gz | 12,718 | b4/8e/ef8dbf796204c381eae58d85033b95eb5a72190d97a1ce95b6335ce44fa9/ssb_dapla_geoio-0.2.3.tar.gz | source | sdist | null | false | 16f646668392806baf829b6c64ebdaa9 | 075b41f72208cc9aae35236ceb952b422667e23aef3ed8e40aa3e22a917ad46a | b48eef8dbf796204c381eae58d85033b95eb5a72190d97a1ce95b6335ce44fa9 | null | [] | 190 |
2.4 | biocompute | 0.1.5 | Wet lab automation as Python code | <div align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="assets/logo_dark.svg">
<img alt="biocompute" src="assets/logo_light.png" width="50%">
</picture>
<br>
Wet lab automation as Python code. Maintained by [london biocompute](https://londonbiocompute.com).
[](https://pypi.org/project/biocompute/)
[](https://pypi.org/project/biocompute/)
[](LICENSE)
</div>
**biocompute** is a framework that lets you write wet lab experiments as plain Python. Define your protocol with calls like `well.fill()`, `well.mix()`, and `well.image()`. Then execute on real lab hardware that handles the liquid dispensing, mixing, and imaging automatically. No drag-and-drop GUIs, no manual pipetting.
If you know Python, you can run wet lab experiments.
---
## Quick start
Create a virtual environment and install the `biocompute` package.
```bash
python -m venv .venv
source .venv/bin/activate
pip install biocompute
```
Create a file called `super_simple_experiment.py` and copy the code snippet.
```python
from biocompute import wells, red_dye, green_dye, blue_dye
def experiment():
for well in wells(count=3):
well.fill(vol=80.0, reagent=red_dye)
well.fill(vol=40.0, reagent=green_dye)
well.fill(vol=20.0, reagent=blue_dye)
well.mix()
well.image()
```
Visualize the experiment in your terminal.
```bash
biocompute visualize super_simple_experiment.py
```
To run experiments on real hardware, log in and submit.
```bash
biocompute login
biocompute submit super_simple_experiment.py --follow
```
Results stream back to your terminal as experiments finish executing on the physical hardware.
> **Note:** Hardware access is currently limited. Run `biocompute login` to join the waitlist.
---
## How it works
Your experiment function describes intent. The compiler takes this high-level declarative code and turns it into a fully scheduled, hardware-specific protocol. It handles:
- **Automatic parallelism** — independent operations are identified and scheduled concurrently so protocols finish faster without any manual orchestration.
- **Plate layout** — wells are assigned to physical plates based on thermal constraints. Multi-temperature experiments get split across plates automatically.
- **Operation collapsing** — redundant per-well instructions (like 96 identical incubations) are collapsed into single plate-level commands.
- **Device mapping** — every operation is matched to the right piece of hardware (pipette, camera, incubator, gripper) based on a capability model, so swapping equipment never means rewriting your protocol.
- **Multi-plate scaling** — protocols that exceed a single plate are transparently distributed across as many plates as needed.
You describe what should happen. The compiler figures out how to make it fast.
### Operations
| Method | What it does |
| --- | --- |
| `well.fill(vol, reagent)` | Dispense `vol` µL of `reagent` |
| `well.mix()` | Mix well contents |
| `well.image()` | Capture an image |
`wells(count=n)` yields `n` wells. Multiple calls produce non-overlapping wells.
### Reagents
Import the built-in reagents you need.
```python
from biocompute import red_dye, green_dye, blue_dye, water
```
---
## Because it's just Python
Use numpy. Use scipy. Use whatever. The system only sees wells and operations.
### Colour sweep
Sweep red dye volume across ten wells using numpy to generate the range.
```python
import numpy as np
from biocompute import wells, red_dye, green_dye, blue_dye
def experiment():
for well, r in zip(wells(count=10), np.linspace(10, 100, 10)):
well.fill(vol=r, reagent=red_dye)
well.fill(vol=50.0, reagent=green_dye)
well.fill(vol=50.0, reagent=blue_dye)
well.mix()
well.image()
```
### Closed-loop optimisation
Submit an experiment, read results, use them to parameterise the next one.
```python
import numpy as np
from scipy.interpolate import interp1d
from scipy.optimize import minimize_scalar
from biocompute import Client, wells, red_dye, green_dye
with Client() as client:
volumes = np.linspace(10, 100, 8)
def experiment_sweep():
for well, v in zip(wells(count=8), volumes):
well.fill(vol=v, reagent=red_dye)
well.fill(vol=50.0, reagent=green_dye)
well.mix()
well.image()
result = client.submit(experiment_sweep)
model = interp1d(volumes, result.result_data["scores"], kind="cubic")
optimum = minimize_scalar(model, bounds=(10, 100), method="bounded").x
def experiment_refine():
for well, v in zip(wells(count=5), np.linspace(optimum - 10, optimum + 10, 5)):
well.fill(vol=v, reagent=red_dye)
well.fill(vol=50.0, reagent=green_dye)
well.mix()
well.image()
final = client.submit(experiment_refine)
```
| text/markdown | London Biocompute | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.1",
"httpx>=0.27",
"textual>=1.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.9 | 2026-02-20T14:32:26.291893 | biocompute-0.1.5.tar.gz | 18,161 | ee/a9/aa0a59ca289ed35b5f33eab67e7791ed572945377662d5e4e0dbfc962bae/biocompute-0.1.5.tar.gz | source | sdist | null | false | 73fb293f42438a5df49367e0fa94d49d | 3360efa0dada476d7bbf582fef9b7fe7079f935c957a9c39ab00373b0c2a6a5b | eea9aa0a59ca289ed35b5f33eab67e7791ed572945377662d5e4e0dbfc962bae | MIT | [
"LICENSE"
] | 220 |
2.4 | dss-python | 0.16.0b1 | Python interface (bindings and tools) for OpenDSS. Based on the AltDSS/DSS C-API project, the alternative OpenDSS implementation from DSS-Extensions.org. Multiplatform, API-compatible/drop-in replacement for the COM version of OpenDSS. | [](https://github.com/dss-extensions/dss_python/actions/workflows/builds.yml)
[](https://pypi.org/project/dss-python/)
[](https://pepy.tech/project/dss-python)
<img alt="Supports Linux" src="https://img.shields.io/badge/Linux-FCC624?logo=linux&logoColor=black"> <img alt="Supports macOS" src="https://img.shields.io/badge/macOS-000000?logo=apple&logoColor=white"> <img alt="Supports Microsoft Windows" src="https://img.shields.io/badge/Windows-0078D6?logo=windows&logoColor=white">
# DSS-Python: Extended bindings for an alternative implementation of EPRI's OpenDSS
Python bindings and misc tools for using our to [our customized/alternative implementation](https://github.com/dss-extensions/dss_capi) of [OpenDSS](http://smartgrid.epri.com/SimulationTool.aspx), AltDSS/DSS C-API library. OpenDSS is an open-source electric power distribution system simulator [distributed by EPRI](https://sourceforge.net/p/electricdss/). Based on DSS C-API, CFFI and NumPy, aiming for enhanced performance and full compatibility with EPRI's OpenDSS COM object API on Windows, Linux and macOS. Support includes Intel-based (x86 and x64) processors, as well as ARM processors for Linux (including Raspberry Pi devices) and macOS (including Apple M1 and later).
More context about this project and its components (including alternatives in [Julia](https://dss-extensions.org/OpenDSSDirect.jl/latest/), [MATLAB](https://github.com/dss-extensions/dss_matlab/), C++, [C#/.NET](https://github.com/dss-extensions/dss_sharp/), [Go](https://github.com/dss-extensions/AltDSS-Go/), and [Rust](https://github.com/dss-extensions/AltDSS-Rust/)), please check [https://dss-extensions.org/](https://dss-extensions.org/) and our hub repository at [dss-extensions/dss-extensions](https://github.com/dss-extensions/dss-extensions) for more documentation, discussions and the [FAQ](https://dss-extensions.org/faq.html).
This package can be used as a companion to [OpenDSSDirect.py](http://github.com/dss-extensions/OpenDSSDirect.py/), if you don't need COM compatibility, or just would like to check its extra functionalities. Yet another alternative Python package is being developed in [AltDSS-Python](https://dss-extensions.org/AltDSS-Python/). The three packages can be used together, allowing the different API styles to be used in the same program.
While we plan to add a lot more functionality into DSS-Python, the main goal of creating a COM-compatible API has been reached in 2018. If you find an unexpected missing feature, please report it! Currently missing features that will be implemented eventually are interactive features and diakoptics (planned for a future version).
This module mimics the COM structure (as exposed via `win32com` or `comtypes`) — see [The DSS instance](https://dss-extensions.org/DSS-Python/#the-dss-instance) as well as [OpenDSS COM/classic APIs](https://dss-extensions.org/classic_api.html) for some docs — effectively enabling multi-platform compatibility at Python level. Compared to other options, it provides easier migration from code that uses EPRI's OpenDSS through COM. See also [OpenDSS: Python APIs](https://dss-extensions.org/python_apis.html).
Most of the COM documentation can be used as-is, but instead of returning tuples or lists, this module returns/accepts NumPy arrays for numeric data exchange, which is usually preferred by the users. By toggle `DSS.AdvancedTypes`, complex numbers and matrices (shaped arrays) are also used to provide a more modern experience.
The module depends mostly on CFFI, NumPy, typing_extensions and, optionally, SciPy.Sparse for reading the sparse system admittance matrix. Pandas and matplotlib are optional dependencies [to enable plotting](https://github.com/dss-extensions/dss_python/blob/master/docs/examples/Plotting.ipynb) and other features.
## Release history
Check [the Releases page](https://github.com/dss-extensions/dss_python/releases) and [the changelog](https://github.com/dss-extensions/dss_python/blob/master/docs/changelog.md).
## Missing features and limitations
Most limitations are inherited from AltDSS/DSS C-API, i.e., these are not implemented:
- `DSSProgress` from `DLL/ImplDSSProgress.pas`: would need a reimplementation depending on the target UI (GUI, text, headless, etc.). Part of it can already be handled through the callback mechanisms.
- OpenDSS-GIS features are not implemented since they're not open-source.
In general, the DLL from `dss_capi` provides more features than both the official Direct DLL and the COM object.
## Extra features
Besides most of the COM methods, some of the unique DDLL methods are also exposed in adapted forms, namely the methods from `DYMatrix.pas`, especially `GetCompressedYMatrix` (check the source files for more information).
Since no GUI components are used in the FreePascal DLL, we map nearly all OpenDSS errors to Python exceptions, which seems a more natural way of working in Python. You can still manually trigger an error check by calling the function `_check_for_error()` from the main class or manually checking the `DSS.Error` interface.
For general engine features, see also: [What are some features from DSS-Extensions not available in EPRI’s OpenDSS?](https://dss-extensions.org/faq.html#what-are-some-features-from-dss-extensions-not-available-in-epris-opendss)
## Installing
On all major platforms, you can install directly from pip:
```
pip install dss-python
```
For a full experience, install the optional dependencies with:
```
pip install dss-python[all]
```
Binary wheels are provided for all major platforms (Windows, Linux and MacOS) and many combinations of Python versions (3.7 to 3.12). If you have issues with a specific version, please open an issue about it.
After a successful installation, you can then import the `dss` module from your Python interpreter.
## Building
Since v0.14.0, dss_python itself is a pure-Python package, i.e., the usual install methods should work fine for itself. However, you may still need to build the backend yourself in some situations.
The backend is now in `dss_python_backend`. The
Get the repositories
```
git clone https://github.com/dss-extensions/dss_python.git
git clone https://github.com/dss-extensions/dss_python_backend.git
```
Assuming you successfully built or downloaded the DSS C-API DLLs (check [its repository](http://github.com/dss-extensions/dss_capi/) for instructions), keep the folder organization as follows:
```
dss_capi/
dss_python/
dss_python_backend/
```
Open a command prompt in the `dss_python_backend` subfolder and run the build process:
```
python -m pip install .
cd ../dss_python
python -m pip install .
```
## Documentation
The compiled documentation is hosted at https://dss-extensions.org/DSS-Python
## Example usage
**Check the documentation for more details.**
If you were using `win32com` in code like:
```python
import win32com.client
dss_engine = win32com.client.gencache.EnsureDispatch("OpenDSSEngine.DSS")
```
or `comtypes` (incidentally, `comtypes` is usually faster than `win32com`, so we recommend it if you need EPRI's OpenDSS COM module):
```python
import comtypes.client
dss_engine = comtypes.client.CreateObject("OpenDSSEngine.DSS")
```
you can replace that fragment with:
```python
from dss import DSS as dss_engine
```
If you need support for arbitrary capitalization (that is, you were not using early bindings with win32com), add a call to `dss.set_case_insensitive_attributes()`.
Assuming you have a DSS script named `master.dss`, you should be able to run it as shown below:
```python
from dss import DSS as dss_engine
dss_engine.Text.Command = "compile 'c:/dss_files/master.dss'"
dss_engine.ActiveCircuit.Solution.Solve()
voltages = dss_engine.ActiveCircuit.AllBusVolts
for i in range(len(voltages) // 2):
print('node %d: %f + j%f' % (i, voltages[2*i], voltages[2*i + 1]))
```
## Testing
Since the DLL is built using the Free Pascal compiler, which is not officially supported by EPRI, the results are validated running sample networks provided in EPRI's OpenDSS distribution. The only modifications are done directly by the script, removing interactive features and some other minor issues. Most of the sample files from EPRI's OpenDSS repository are used for validation.
The validation scripts is `tests/validation.py` and requires the same folder structure as the building process. You need `win32com` to run it on Windows.
As of version 0.11, the full validation suite can be run on the three supported platforms. This is possible by saving EPRI's OpenDSS COM DLL output and loading it on macOS and Linux. We hope to fully automate this validation in the future.
## Roadmap: docs and interactive features
Besides bug fixes, the main functionality of this library is mostly done. Notable desirable features that may be implemented are:
- More examples, especially for the extra features. There is a growing documentation hosted at [https://dss-extensions.org/Python/](https://dss-extensions.org/DSS-Python/) and [https://dss-extensions.org/docs.html](https://dss-extensions.org/docs.html); watch also https://github.com/dss-extensions/dss-extensions for more.
- Reports integrated in Python and interactive features on plots. Since most of the plot types from EPRI's OpenDSS are optionally available since DSS-Python 0.14.2, advanced integration and interactive features are planned for a future feature.
Expect news about these items by version 1.0.
While the base library (AltDSS/DSS C-API) will go through some API changes before v1.0, those do not affect usage from the Python side. This package has been API-stable for several years.
## Questions?
If you have any question, feel free to open a ticket on GitHub (here or at https://github.com/dss-extensions/dss-extensions), or contact directly me through email (pmeira at ieee.org). Please allow me a few days to respond.
## Credits / Acknowledgments
DSS-Python is based on EPRI's OpenDSS via the [`dss_capi`](http://github.com/dss-extensions/dss_capi/) project, so check its licensing information too.
This project is licensed under the (new) BSD, available in the `LICENSE` file. It's the same license OpenDSS uses (`OPENDSS_LICENSE`). OpenDSS itself uses KLUSolve and SuiteSparse, licensed under the GNU LGPL 2.1.
I thank my colleagues at the University of Campinas, Brazil, for providing feedback and helping me test this package during its inception in 2016-2017, as well as the many users and collaborators that have been using this or other DSS-Extensions since the public releases in 2018.
| text/markdown | null | Paulo Meira <pmeira@ieee.org>, Dheepak Krishnamurthy <me@kdheepak.com> | null | Paulo Meira <pmeira@ieee.org> | BSD 3-Clause License
Copyright (c) 2017-2023, Paulo Meira
Copyright (c) 2017-2023, DSS-Python contributors
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
* Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | altdss, electric power systems, opendss, opendssdirect, powerflow, short-circuit | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Programming Language :: Python :: Implementation :: CPython",
"Topic :: Scientific/Engineering"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"dss-python-backend==0.15.0b3",
"numpy<3,>=2",
"typing-extensions<5,>=4.5",
"altdss; extra == \"all\"",
"matplotlib; extra == \"all\"",
"opendssdirect-py[extras]; extra == \"all\"",
"pandas; extra == \"all\"",
"scipy; extra == \"all\"",
"matplotlib; extra == \"plot\"",
"scipy; extra == \"plot\"",
"pandas; extra == \"test\"",
"pytest; extra == \"test\"",
"ruff; extra == \"test\"",
"scipy; extra == \"test\"",
"xmldiff; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/dss-extensions/DSS-Python",
"Documentation, https://dss-extensions.org/DSS-Python",
"Repository, https://github.com/dss-extensions/DSS-Python.git",
"Bug Tracker, https://github.com/dss-extensions/DSS-Python/issues",
"Changelog, https://github.com/dss-extensions/DSS-Python/blob/main/docs/changelog.md"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-20T14:32:25.817064 | dss_python-0.16.0b1.tar.gz | 324,631 | 8a/71/4a22bcb1376830b1681ace28fdb59999883f93da7552649746c6f8fab014/dss_python-0.16.0b1.tar.gz | source | sdist | null | false | 6a91ad85816f70978aac57628ddc1a52 | 9456bf6ae532ee13fe68210260ee3f0054aa0e9d3da760856f18a5c3875ef7e6 | 8a714a22bcb1376830b1681ace28fdb59999883f93da7552649746c6f8fab014 | null | [
"LICENSE"
] | 343 |
2.4 | jupytergis | 0.13.3 | Collaborative GIS extension for JupyterLab | <p align="center"><img width="100" src="https://raw.githubusercontent.com/geojupyter/jupytergis/main/packages/base/style/icons/logo.svg"></p>
<h1 align="center">JupyterGIS - A JupyterLab extension for collaborative GIS</h1>
[![lite-badge]][lite] [![docs-badge]][docs] [![jupytergis-badge]][marketplace]
[lite-badge]: https://jupyterlite.rtfd.io/en/latest/_static/badge.svg
[lite]: https://jupytergis.readthedocs.io/en/latest/lite/lab/index.html?path=france_hiking.jGIS/
[docs-badge]: https://readthedocs.org/projects/jupytergis/badge/?version=latest
[docs]: https://jupytergis.readthedocs.io
[jupytergis-badge]: https://labextensions.dev/api/badge/jupytergis?metric=downloads&leftColor=%23555&rightColor=%23F37620&style=flat
[marketplace]: https://labextensions.dev/extensions/jupytergis
## Features
- **Collaborative GIS Environment**: Work together on geographic data projects in real-time.
- **QGIS File Support**: Load, visualize, and manipulate QGIS project files (`.qgs`, `.qgz`), and other GIS data formats.
- **Interactive Maps**: Render interactive maps and geospatial visualizations within Jupyter notebooks using the JupyterGIS Python API.
## [🪄 Try JupyterGIS now in Notebook.link! ✨](https://notebook.link/github/geojupyter/jupytergis/lab/?path=examples%2Ffrance_hiking.jGIS)
This demo runs a JupyterLite instance entirely in your browser with WebAssembly! 🤯
Powered by [Notebook.link](https://notebook.link) and [JupyterLite](https://jupyterlite.readthedocs.io/en/stable/?badge=latest).
Please note that [JupyterGIS' real-time collaboration features are not yet supported in JupyterLite](https://jupyterlite.readthedocs.io/en/latest/howto/configure/rtc.html).
## Installation
### Prerequisites
- JupyterLab (version 3.0 or higher)
- (OPTIONAL) QGIS installed on your system and its Python modules available in the PATH. e.g. `mamba install --channel conda-forge qgis`
### Installing JupyterGIS
#### From PyPI
```bash
python -m pip install jupytergis
```
#### From conda-forge
JupyterGIS is also packaged and distributed on [conda-forge](https://github.com/conda-forge/jupytergis-packages-feedstock).
To install and add JupyterGIS to a project with [`pixi`](https://pixi.sh/), from the project directory run
```
pixi add jupytergis
```
and to install into a particular conda environment with [`mamba`](https://mamba.readthedocs.io/), in the activated environment run
```
mamba install --channel conda-forge jupytergis
```
#### With Docker
```bash
docker run -p 8888:8888 ghcr.io/geojupyter/jupytergis:latest
```
Replace `latest` with a specific version number if you prefer.
Docker build source is at <https://github.com/geojupyter/jupytergis-docker>.
## Deploying JupyterGIS with JupyterLite
You can run JupyterGIS entirely in the browser using **JupyterLite**.
1. **Create a repository** using the [xeus-lite-demo](https://github.com/jupyterlite/xeus-lite-demo) template.
2. In your fork, edit `environment.yml` and add:
```yaml
- jupytergis-lite
```
3. **Add your data and jGIS files** under the `content/` directory of your repository.
These files will be available directly inside your Lite deployment.
4. **Enable GitHub Pages** under _Settings → Pages_ for your repository.
5. Once the build completes, your Lite deployment will be live at:
```
https://<username>.github.io/<repo-name>/
```
This provides a lightweight, fully browser-based JupyterGIS environment — no server required.
> [!IMPORTANT]
> Collaboration is **not yet supported** in JupyterLite static deployments.
## Documentation
https://jupytergis.readthedocs.io
## Contributing
We welcome contributions from the community! To contribute:
- Fork the repository
- Make a dev install of JupyterGIS
- Create a new branch
- Make your changes
- Submit a pull request
For more details, check out our [CONTRIBUTING.md](https://github.com/geojupyter/jupytergis/blob/main/CONTRIBUTING.md).
## License
JupyterGIS is licensed under the BSD 3-Clause License. See [LICENSE](./LICENSE) for more information.
| text/markdown | null | null | null | null | BSD 3-Clause License
Copyright (c) 2023, JupyterGIS contributors
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | null | [
"Framework :: Jupyter",
"Framework :: Jupyter :: JupyterLab",
"Framework :: Jupyter :: JupyterLab :: 4",
"Framework :: Jupyter :: JupyterLab :: Extensions",
"Framework :: Jupyter :: JupyterLab :: Extensions :: Prebuilt",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Scientific/Engineering :: GIS"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"jupyter-collaboration-ui<3,>=2",
"jupyter-collaboration<5,>=4",
"jupyter-docprovider<3,>=2",
"jupyter-server-ydoc<3,>=2",
"jupytergis-core==0.13.3",
"jupytergis-lab==0.13.3",
"jupytergis-qgis==0.13.3",
"jupyterlab>=4.5.1"
] | [] | [] | [] | [
"Homepage, https://github.com/geojupyter/jupytergis",
"Documentation, https://jupytergis.readthedocs.io",
"Repository, https://github.com/geojupyter/jupytergis.git",
"Issues, https://github.com/geojupyter/jupytergis/issues"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T14:32:22.741798 | jupytergis-0.13.3.tar.gz | 6,164 | 02/bd/50372fadd2864ba6d2fbfb6c742eaf95bdded854908fd0ade392f28979a8/jupytergis-0.13.3.tar.gz | source | sdist | null | false | 4b55862a77e190e683787e49c3edcf66 | 49e356420eab0c0d3d0355d7f75568861f44712a3c8d5a2607f3c143aa344b1c | 02bd50372fadd2864ba6d2fbfb6c742eaf95bdded854908fd0ade392f28979a8 | null | [
"LICENSE"
] | 225 |
2.4 | jama-CERTIC | 0.1.84 | APIs et interfaces de stockage de médias. | # Jama
Jama is a [Django](https://www.djangoproject.com/) application that exposes APIs and UIs that allow users to organize collections of resources.
Knowledge of the Django framework is expected and the Jama documentation is, to put it midly, a work in progress.
## Install
pip install jama-CERTIC
## Usage
Jama behaves like a normal Django app except the management script is not called `manage.py` but `jama`.
List of commands:
jama --help
Upon first run, Jama creates a `$HOME/.jama/` directory where it stores all its data.
Development server:
jama runserver
Background tasks:
jama run_huey
## Configuration
Configuration can be changed by adding environment variables the usual way or by adding them to your
`$HOME/.jama/env` configuration file
Available variables:
JAMA_DEBUG="0"
JAMA_APPS="ui"
JAMA_IIIF_ENDPOINT="http://localhost/iip/IIIF=" # base URL for the IIIF server (use IIP server or Cantaloupe)
JAMA_IIIF_UPSCALING_PREFIX="^"
JAMA_SECRET="7d*_8c!d$vv963qpr45_x)@f2t-x6fu2&yi+m+d6s!p!lt+_j+"
JAMA_SITE="http://localhost:8000/"
JAMA_STATIC_ROOT="var/static" # where to put files when using "jama collectstatic"
JAMA_USE_MODSHIB="1"
MODSHIB_SHOW_LOCAL_LOGIN="1"
MODSHIB_SHOW_SSO_LOGIN="0"
| text/markdown | null | Mickaël Desfrênes <mickael.desfrenes@unicaen.fr> | null | Mickaël Desfrênes <mickael.desfrenes@unicaen.fr> | null | null | [] | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"ark-client-certic>=0.2.0",
"bpython>=0.25",
"deskew>=1.3.3",
"django-auth-cli-certic>=0.1.6",
"django-cors-headers>=4.7.0",
"django-cotton>=2.1.1",
"django-debug-toolbar>=5.2.0",
"django-extensions>=3.1.5",
"django-modshib-certic>=0.4.8",
"django-ranged-fileresponse>=0.1.2",
"django-revproxy>=0.13.0",
"django-vite>=2.1.3",
"django-webpack-loader>=3.1.0",
"django>=6.0.0",
"fusepy>=3.0.1",
"gunicorn>=23.0.0",
"huey>=2.5.3",
"jama-client-certic>=0.0.34",
"markdown2>=2.4.3",
"numpy>=2.1.3",
"opencv-python-headless>=4.6.0",
"openpyxl>=3.1.2",
"pick>=2.4.0",
"psycopg2-binary>=2.9.10",
"pydotplus>=2.0.2",
"pyexiftool>=0.5.3",
"pymemcache>=4.0.0",
"pytesseract>=0.3.10",
"python-dotenv>=1.0.0",
"pyvips>=2.2.1",
"rich>=14.0.0",
"unidecode>=1.3.4",
"unpoly>=3.2.0"
] | [] | [] | [] | [
"Repository, https://git.unicaen.fr/certic/jama"
] | uv/0.9.26 {"installer":{"name":"uv","version":"0.9.26","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T14:31:32.938633 | jama_certic-0.1.84-py3-none-any.whl | 8,588,618 | 97/d3/a973d6bd2af1e9b3a3285be0dca23a640c392a62374c5ba38b6134c0b77b/jama_certic-0.1.84-py3-none-any.whl | py3 | bdist_wheel | null | false | 8b9201a3bc4f8df995a27d2c749708e2 | 19eb92a6e2a47f6c9b27ad4b1197e7d8a7a7494583c02cfde3e67df4eae4809d | 97d3a973d6bd2af1e9b3a3285be0dca23a640c392a62374c5ba38b6134c0b77b | CECILL-B | [
"LICENSE.txt"
] | 0 |
2.1 | odoo-addon-email-template-qweb | 16.0.1.0.1 | Use the QWeb templating mechanism for emails | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
========================
QWeb for email templates
========================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:000803815bf117944f0c540dc558a7353df8bd4cf6fb7b1a47c03859792bc696
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fsocial-lightgray.png?logo=github
:target: https://github.com/OCA/social/tree/16.0/email_template_qweb
:alt: OCA/social
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/social-16-0/social-16-0-email_template_qweb
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/social&target_branch=16.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module was written to allow you to write email templates in `QWeb view` instead
of QWeb. The advantage here is that with QWeb View, you can make use of
inheritance and the ``call`` statement, which allows you to reuse designs and
snippets in multiple templates, making your development process simpler.
Furthermore, QWeb views are easier to edit with the integrated ACE editor.
**Table of contents**
.. contents::
:local:
Usage
=====
To use this module, you need to:
#. Select `QWeb View` in the field `Body templating engine`
#. Select a `QWeb View` to be used to render the body field
#. Apart from `QWeb View` standard variables, you also have access to ``object`` and ``email_template``, which are browse records of the current object and the email template in use, respectively.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/social/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/social/issues/new?body=module:%20email_template_qweb%0Aversion:%2016.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
~~~~~~~
* Therp BV
Contributors
~~~~~~~~~~~~
* Holger Brunn <hbrunn@therp.nl>
* Dave Lasley <dave@laslabs.com>
* Carlos Lopez Mite <celm1990@gmail.com>
* `Tecnativa <https://www.tecnativa.com>`_:
* Ernesto Tejeda
* Thomas Fossoul (thomas@niboo.com)
* Phuc Tran Thanh <phuc@trobz.com>
* Foram Shah <foram.shah@initos.com>
* `Trobz <https://trobz.com>`_:
* Dzung Tran <dungtd@trobz.com>
Other credits
~~~~~~~~~~~~~
The development of this module has been financially supported by:
* Camptocamp
Maintainers
~~~~~~~~~~~
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/social <https://github.com/OCA/social/tree/16.0/email_template_qweb>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| null | Therp BV, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 16.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/social | null | >=3.10 | [] | [] | [] | [
"odoo<16.1dev,>=16.0a"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T14:31:21.175740 | odoo_addon_email_template_qweb-16.0.1.0.1-py3-none-any.whl | 38,246 | b1/5e/8e13999329db62cbb1199fba3a6bb95bcdbd072a7ba562260edd61e9bf78/odoo_addon_email_template_qweb-16.0.1.0.1-py3-none-any.whl | py3 | bdist_wheel | null | false | c542b6b2c1314b8ea0cfcf25fd7eed74 | 155fda1c54b8b5e13d816c1d4878a7af73233ee4945c013e986effdcdd99f856 | b15e8e13999329db62cbb1199fba3a6bb95bcdbd072a7ba562260edd61e9bf78 | null | [] | 84 |
2.4 | tv-scraper | 1.1.0 | A powerful Python library for scraping real-time market data, indicators, and ideas from TradingView. |
# TV Scraper
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
**A powerful, real-time Python library for extracting financial data, indicators, and ideas from TradingView.com.**
---
## Attribution
This project is based on [mnwato/tradingview-scraper](https://github.com/mnwato/tradingview-scraper). Thanks to the original author for the foundational work.
## 📚 Documentation
For complete documentation, installation guides, API references, and examples, visit:
**[📖 Full Documentation](https://smitkunpara.github.io/tv-scraper/)**
### Quick Links
- [🚀 Quick Start Guide](https://smitkunpara.github.io/tv-scraper/quick_start/)
- [📦 Installation](https://smitkunpara.github.io/tv-scraper/installation/)
- [📊 Supported Data](https://smitkunpara.github.io/tv-scraper/supported_data/)
- [🔧 API Reference](https://smitkunpara.github.io/tv-scraper/)
---
## 🚀 Quick Start
This library requires Python 3.11+ and uses `uv` for dependency management.
### Installation
Install from PyPI (recommended):
```bash
pip install tv-scraper
```
Or install with `uv` (developer / alternate):
```bash
# Clone the repository for development
git clone https://github.com/smitkunpara/tv-scraper.git
cd tv-scraper
```,oldString:
# Install runtime deps (uv auto-creates virtual environment)
uv sync
```
If you prefer to install the published package using `uv`:
```bash
uv add tv-scraper
```
### Basic Usage Examples
#### Fetching Technical Indicators
Get RSI and Stochastic indicators for Bitcoin on Binance:
```python
from tv_scraper import Technicals
# Initialize scraper
technicals = Technicals()
# Scrape indicators for BTCUSD
result = technicals.scrape(
exchange="BINANCE",
symbol="BTCUSD",
timeframe="1d",
technical_indicators=["RSI", "Stoch.K"]
)
if result["status"] == "success":
print(result["data"])
```
#### Scraping Trading Ideas
Get popular trading ideas for Ethereum:
```python
from tv_scraper import Ideas
# Initialize scraper
ideas = Ideas()
# Scrape popular ideas for ETHUSD
result = ideas.scrape(
exchange="CRYPTO",
symbol="ETHUSD",
start_page=1,
end_page=1,
sort_by="popular"
)
if result["status"] == "success":
print(f"Found {len(result['data'])} ideas.")
```
## ✨ Key Features
- **📊 Real-Time Data**: Stream live OHLCV and indicator values via WebSocket
- **📰 Comprehensive Coverage**: Scrape Ideas, News, Market Movers, and Screener data
- **📈 Fundamental Data**: Access detailed financial statements and profitability ratios
- **🔧 Advanced Tools**: Symbol Markets lookup, Symbol Overview, and Minds Community discussions
- **📋 Structured Output**: All data returned as clean JSON/Python dictionaries
- **🌍 Multi-Market Support**: 260+ exchanges across stocks, crypto, forex, and commodities
- **⚡ Fast & Reliable**: Built with async support and robust error handling
## 📋 What's Included
### Core Modules
- **Indicators**: 81+ technical indicators (RSI, MACD, Stochastic, etc.)
- **Options**: Fetch option chains by expiration or strike price
- **Ideas**: Community trading ideas and strategies
- **News**: Financial news with provider filtering
- **Real-Time**: WebSocket streaming for live data
- **Screener**: Advanced stock screening with custom filters
- **Market Movers**: Top gainers, losers, and active stocks
- **Fundamentals**: Financial statements and ratios
- **Calendar**: Earnings and dividend events
### Data Sources
- **260+ Exchanges**: Binance, Coinbase, NASDAQ, NYSE, and more
- **16+ Markets**: Stocks, Crypto, Forex, Futures, Bonds
- **Real-Time Updates**: Live price feeds and indicators
- **Historical Data**: Backtesting and analysis support
---
## 🛠️ Development & Testing
For contributors and developers, this project includes comprehensive tooling for local testing.
### Quick Commands
```bash
# Run all quality checks before committing
make check
# Full CI simulation with coverage
make ci
# Individual checks
make lint # Run ruff linter
make format # Auto-format code
make type-check # Run mypy type checker
make test # Run tests
```
### Pre-commit Hooks
Pre-commit hooks automatically run on every commit to enforce code quality:
```bash
# Install hooks (one-time setup)
make install-hooks
```
### Full Documentation
See [LOCAL_TESTING.md](LOCAL_TESTING.md) for complete details on:
- Makefile commands
- Pre-commit hook configuration
- Running GitHub Actions locally with act
- CI/CD workflow testing
### Publishing to PyPI
This project is configured to use **Trusted Publishing** (OIDC) via GitHub Actions.
See [PUBLISHING.md](PUBLISHING.md) for step-by-step instructions on setting up your PyPI project.
---
## 🤝 Contributing
We welcome contributions! Please see our [Contributing Guide](https://smitkunpara.github.io/tv-scraper/contributing/) for details.
- **🐛 Bug Reports**: [Open an issue](https://github.com/smitkunpara/tv-scraper/issues)
- **💡 Feature Requests**: [Start a discussion](https://github.com/smitkunpara/tv-scraper/discussions)
---
## 📄 License
This project is licensed under the **MIT License** - see the [LICENSE](LICENSE) file for details.
| text/markdown | null | Smit Kunpara <smitkunpara@gmail.com> | null | null | MIT | finance, market-data, python, real-time, scraper, technical-analysis, tradingview | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Financial and Insurance Industry",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Office/Business :: Financial :: Investment",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"requests>=2.32.4",
"websocket-client>=1.8.0",
"pandas>=2.0.3; extra == \"csv\"",
"mkdocs-material>=9.0.0; extra == \"dev\"",
"mkdocs>=1.5.0; extra == \"dev\"",
"mypy>=1.7.0; extra == \"dev\"",
"pre-commit>=3.5.0; extra == \"dev\"",
"pytest; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"pytest-mock; extra == \"dev\"",
"ruff>=0.1.6; extra == \"dev\"",
"pytest; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"pytest-mock; extra == \"test\"",
"ruff>=0.1.6; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/smitkunpara/tv-scraper",
"Repository, https://github.com/smitkunpara/tv-scraper",
"Issues, https://github.com/smitkunpara/tv-scraper/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:30:55.819072 | tv_scraper-1.1.0.tar.gz | 178,806 | ae/bf/ced6c635fd3afa2f173d7067548e9b77f70ccdbce005824181f99ac80fc7/tv_scraper-1.1.0.tar.gz | source | sdist | null | false | 148145c8549e5b1f5cded6a42163f36b | 91fb75dc5290b7c566b8b5886ff4257d98f4c44ba6066f9bd116c6cac4e9623e | aebfced6c635fd3afa2f173d7067548e9b77f70ccdbce005824181f99ac80fc7 | null | [
"LICENSE"
] | 210 |
2.4 | ASGIWebDAV | 2.0.1 | An asynchronous WebDAV server implementation, support multi-provider. | # ASGI WebDAV Server
[](https://github.com/rexzhang/asgi-webdav/blob/main/LICENSE)
[](https://pypi.org/project/ASGIWebDAV)
[](https://pypi.org/project/ASGIWebDAV/)

[](https://codecov.io/gh/rexzhang/asgi-webdav)
[](https://github.com/psf/black)
[](https://github.com/rexzhang/asgi-webdav/actions/workflows/check-mypy.yaml)
[](https://hub.docker.com/r/ray1ex/asgi-webdav)
[](https://pypi.org/project/ASGIWebDAV)
[](https://github.com/rexzhang/asgi-webdav/releases)
An asynchronous WebDAV server implementation, Support multi-provider, multi-account and permission control.
## Features
- [ASGI](https://asgi.readthedocs.io) standard
- WebDAV standard: [RFC4918](https://www.ietf.org/rfc/rfc4918.txt)
- Support multi-provider: FileSystemProvider, MemoryProvider, WebHDFSProvider
- Support multi-account and permission control
- Support optional anonymous user
- Support optional home directory
- Support store password in raw/hashlib/LDAP(experimental) mode
- Full asyncio file IO
- Passed all [litmus(0.13)](http://www.webdav.org/neon/litmus) test, except 1 warning(A security alert that will not be triggered in an ASGI environment.)
- Browse the file directory in the browser
- Support HTTP Basic/Digest authentication
- Support response in Gzip/Zstd
- Compatible with macOS finder and Window10 Explorer
## Quickstart
[中文手册](https://rexzhang.github.io/asgi-webdav/zh/)
```shell
docker pull ray1ex/asgi-webdav
docker run -dit --restart unless-stopped \
-p 8000:8000 \
-e UID=1000 -e GID=1000 \
-v /your/data:/data \
--name asgi-webdav ray1ex/asgi-webdav
```
## Default Account
| | value | description |
| ---------- | ---------- | ------------------------------- |
| username | `username` | - |
| password | `password` | - |
| permission | `["+"]` | Allow access to all directories |
## View in Browser

## Documentation
[Documentation at GitHub Page](https://rexzhang.github.io/asgi-webdav/)
## Contributing
Please refer to the [Contributing](docs/contributing.en.md) for more information.
## Acknowledgements
Please refer to the [Acknowledgements](docs/acknowledgements.md) for more information.
## Related Projects
- <https://github.com/bootrino/reactoxide>
| text/markdown | Rex Zhang | rex.zhang@gmail.com | null | null | null | webdav, asgi, asyncio | [
"Development Status :: 4 - Beta",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"asgiref",
"aiofiles>=25.1.0",
"ASGIMiddlewareStaticFile>=0.7.0",
"xmltodict~=1.0.2",
"dataclass-wizard[dotenv]!=0.37.0,<1.0,>=0.36.6",
"tomli; python_version < \"3.11\"",
"chardet",
"click",
"uvicorn; extra == \"full\"",
"uvloop; extra == \"full\"",
"httptools; extra == \"full\"",
"backports.zstd; python_version < \"3.14\" and extra == \"full\"",
"bonsai~=1.5.0; extra == \"full\"",
"httpx; extra == \"full\"",
"httpx-kerberos; extra == \"full\"",
"uvicorn; extra == \"standalone\"",
"uvloop; extra == \"standalone\"",
"httptools; extra == \"standalone\"",
"backports.zstd; python_version < \"3.14\" and extra == \"standalone\"",
"bonsai~=1.5.0; extra == \"ldap\"",
"httpx; extra == \"webhdfs\"",
"httpx-kerberos; extra == \"webhdfs\""
] | [] | [] | [] | [
"homepage, https://github.com/rexzhang/asgi-webdav",
"documentation, https://rexzhang.github.io/asgi-webdav/",
"repository, https://github.com/rexzhang/asgi-webdav",
"changelog, https://github.com/rexzhang/asgi-webdav/blob/main/docs/changelog.en.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:30:41.161243 | asgiwebdav-2.0.1.tar.gz | 94,962 | 55/70/d14d53453f00a7a9c1d187a4abe5b01bb8a7f837f7eabbbb3968613b93ef/asgiwebdav-2.0.1.tar.gz | source | sdist | null | false | 5c7ff5f137f5284811b82c5c6a5f0e0f | 4bcb0cdb05661db79fa1af73184fde4de6f81ff2ecb6c8716b5ba182ef7d4460 | 5570d14d53453f00a7a9c1d187a4abe5b01bb8a7f837f7eabbbb3968613b93ef | null | [
"LICENSE"
] | 0 |
2.4 | flake8-tergeo | 26.2.20.0 | flake8 plugin which keeps your code clean and tidy | [](https://api.reuse.software/info/github.com/SAP/flake8-tergeo)
[](https://coveralls.io/github/SAP/flake8-tergeo)
# flake8-tergeo
## About this project
flake8-tergeo is a flake8 plugin which adds many new rules to improve your code quality.
Out of the box it also brings a curated lists of other plugins without additional efforts needed.
In difference to other projects, the list of included plugins is rather small and actively maintained.
The included plugins and checks are opinionated, meaning that e.g. f-strings are preferred.
Therefore, checks to find other formatting methods are included but none, to find f-strings.
Also, code formatters like ``black`` and ``isort`` are recommended; therefore no code
formatting rules are included.
## Documentation
You can find the documentation [here](https://sap.github.io/flake8-tergeo/).
## Development
This project uses `uv`.
To setup a venv for development use
`python3.14 -m venv venv && pip install uv && uv sync --all-groups && rm -rf venv/`.
Then use `source .venv/bin/activate` to activate your venv.
## Release Actions
Execute the release action with the proper version.
## Support, Feedback, Contributing
This project is open to feature requests/suggestions, bug reports etc. via [GitHub issues](https://github.com/SAP/flake8-tergeo/issues). Contribution and feedback are encouraged and always welcome. For more information about how to contribute, the project structure, as well as additional contribution information, see our [Contribution Guidelines](CONTRIBUTING.md).
## Security / Disclosure
If you find any bug that may be a security problem, please follow our instructions at [in our security policy](https://github.com/SAP/flake8-tergeo/security/policy) on how to report it. Please do not create GitHub issues for security-related doubts or problems.
## Code of Conduct
We as members, contributors, and leaders pledge to make participation in our community a harassment-free experience for everyone. By participating in this project, you agree to abide by its [Code of Conduct](https://github.com/SAP/.github/blob/main/CODE_OF_CONDUCT.md) at all times.
## Licensing
Copyright 2026 SAP SE or an SAP affiliate company and flake8-tergeo contributors. Please see our [LICENSE](LICENSE) for copyright and license information. Detailed information including third-party components and their licensing/copyright information is available [via the REUSE tool](https://api.reuse.software/info/github.com/SAP/flake8-tergeo).
| text/markdown | null | Kai Harder <kai.harder@sap.com> | null | null | null | flake8, plugin, quality, linter | [
"Development Status :: 5 - Production/Stable",
"Environment :: Plugins",
"Framework :: Flake8",
"Intended Audience :: Developers",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Quality Assurance",
"Typing :: Typed"
] | [] | null | null | <4,>=3.10 | [] | [] | [] | [
"flake8<9,>=7",
"typing-extensions~=4.4",
"flake8-comprehensions==3.17.0",
"flake8-bugbear==25.11.29",
"flake8-builtins==3.1.0",
"flake8-simplify==0.30.0",
"flake8-pytest-style==2.2.0",
"flake8-typing-imports==1.17.0",
"packaging>=24",
"dependency_groups~=1.3",
"tomli~=2.2; python_version < \"3.11\""
] | [] | [] | [] | [
"Changelog, https://github.com/SAP/flake8-tergeo/blob/main/CHANGELOG.md",
"Issue Tracker, https://github.com/SAP/flake8-tergeo/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:30:16.499258 | flake8_tergeo-26.2.20.0.tar.gz | 181,597 | 4f/cf/3524803a727e4a038c64187cd36a42f2f0068160f8f5c5429aaef330e127/flake8_tergeo-26.2.20.0.tar.gz | source | sdist | null | false | 710e04ec2ee40061ea8d1d56b19c1094 | 8943272c1b4f499ebd5afefc69f271e01bfb3a43190dc8777f6db61ea54df7d7 | 4fcf3524803a727e4a038c64187cd36a42f2f0068160f8f5c5429aaef330e127 | Apache-2.0 | [
"LICENSE"
] | 245 |
2.4 | grafyte | 0.2.2 | A simple rendering engine with some game engine features made with OpenGL for Python | # Grafyte
Grafyte is a simple engine written in C++ using OpenGL for Python. It is aimed to be light and simple but still powerful.
It is still in very early development so the documentation is not ready yet.
Please wait...
| text/markdown | null | Saubion Sami <sami.saubion@gmail.com> | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.1 | 2026-02-20T14:29:56.632197 | grafyte-0.2.2-py3-none-win_amd64.whl | 4,770,563 | a7/23/2357f7015e62ffab32bab70c913bf4522988976b446a635ec8cb878ca86d/grafyte-0.2.2-py3-none-win_amd64.whl | py3 | bdist_wheel | null | false | df15906e175aa3e8507716593a1d93e9 | 96a3136c3453b6c59a0afc14a644999862273205eb2636f81bfb6207b0139a53 | a7232357f7015e62ffab32bab70c913bf4522988976b446a635ec8cb878ca86d | null | [
"LICENSE"
] | 150 |
2.4 | diskinfo | 3.2.0 | Disk information Python library for Linux | # diskinfo
[](https://github.com/petersulyok/diskinfo/actions/workflows/tests.yml)
[](https://app.codecov.io/gh/petersulyok/diskinfo)
[](https://diskinfo.readthedocs.io/en/latest/?badge=latest)
[](https://github.com/petersulyok/diskinfo/issues)
[](https://pypi.org/project/diskinfo)
[](https://badge.fury.io/py/diskinfo)
Disk information Python library can assist in collecting disk information on Linux. In more details, it can:
- collect information about a specific disk
- explore all existing disks in the system
- translate between traditional and persistent disk names
- read current disk temperature
- read SMART data of a disk
- read partition list of a disk
Installation
------------
Standard installation from [pypi.org](https://pypi.org):
pip install diskinfo
See the complete list of dependencies and requirements in the
[documentation](https://diskinfo.readthedocs.io/en/latest/intro.html#installation).
Demo
----
The library contains a demo application with multiple screens:
pip install rich
python -m diskinfo.demo

See more demo screens in the [documentation](https://diskinfo.readthedocs.io/en/latest/intro.html#demo).
API documentation
-----------------
The detailed API documentation can be found on [readthedocs.io](https://diskinfo.readthedocs.io/en/latest/index.html).
| text/markdown | null | Peter Sulyok <peter@sulyok.net> | null | null | null | disk, linux | [
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Operating System :: POSIX :: Linux",
"Topic :: System :: Hardware",
"Development Status :: 5 - Production/Stable"
] | [] | null | null | <4,>=3.10 | [] | [] | [] | [
"pySMART",
"pyudev"
] | [] | [] | [] | [
"Homepage, https://github.com/petersulyok/diskinfo",
"Changelog, https://github.com/petersulyok/diskinfo/CHANGELOG.md",
"Documentation, https://diskinfo.readthedocs.io/en/latest/index.html",
"Issues, https://github.com/petersulyok/diskinfo/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T14:29:19.247811 | diskinfo-3.2.0.tar.gz | 39,516 | 3f/40/440f04b0a1bb30e924e44f81d1cc6e63d56bdae3d052c2fc51ab71ad06ad/diskinfo-3.2.0.tar.gz | source | sdist | null | false | bab8623dadee13660c30b7e62a8fe460 | 5f1336560ebe240054d236419aae3d5212cdcf6176d16ef6d476214ace325e88 | 3f40440f04b0a1bb30e924e44f81d1cc6e63d56bdae3d052c2fc51ab71ad06ad | MIT | [
"LICENSE"
] | 284 |
2.4 | claude-afk | 0.1.0 | Control Claude Code remotely via Slack — approve permissions, answer questions, and continue sessions while AFK | # claude-afk
You're running Claude Code on your terminal. It's writing code, you're approving. But you have groceries to pick up, a dentist appointment, or a filter coffee waiting at Rameshwaram Cafe. The coding shouldn't stop — Claude writes the code anyway, you just approve. Why sit in front of the computer? Go touch grass.
`claude-afk` routes Claude's prompts to your Slack DMs so you can keep things moving from your phone.
## Install
```bash
pip install claude-afk
```
## Slack app setup (One time, for admins)
1. Go to [api.slack.com/apps](https://api.slack.com/apps) → **Create New App** → **From an app manifest**
2. Paste the manifest:
<details>
<summary>Slack app manifest (click to expand)</summary>
```json
{
"display_information": {
"name": "Claude AFK",
"description": "Control Claude Code remotely via Slack",
"background_color": "#505870"
},
"features": {
"app_home": {
"messages_tab_enabled": true,
"messages_tab_read_only_enabled": false
},
"bot_user": {
"display_name": "Claude AFK",
"always_online": false
}
},
"oauth_config": {
"scopes": {
"bot": [
"chat:write",
"im:history",
"im:write"
]
}
},
"settings": {
"event_subscriptions": {
"bot_events": [
"message.im"
]
},
"interactivity": {
"is_enabled": true
},
"org_deploy_enabled": false,
"socket_mode_enabled": true,
"token_rotation_enabled": false
}
}
```
</details>
3. Install the app to your workspace
4. Grab the tokens:
- **Bot Token** (`xoxb-...`): OAuth & Permissions → Bot User OAuth Token
- **App-Level Token** (`xapp-...`): Basic Information → App-Level Tokens → Generate (scope: `connections:write`)
5. Find your **Slack User ID**: click your profile → three dots → Copy member ID
## Usage
### 1. Run setup
```bash
claude-afk setup
```
This prompts for your Slack tokens and user ID, verifies the connection by sending a code to your DMs, and installs hooks into Claude Code's `~/.claude/settings.json`.
### 2. Enable a session-id
```bash
claude-afk enable <session-id>
```
Now when Claude stops, needs a permission, or asks a question in that session, it gets routed to your Slack DMs. Reply in the thread to respond.
<!-- TODO: add screenshot -->
Optionally, you can enable all sessions
```bash
claude-afk enable all
```
Routes every Claude Code session to Slack. Useful if you're stepping away and have multiple sessions running.
### 4. When you're back, disable
```bash
claude-afk disable <session-id> # disable one session
claude-afk disable all # disable all sessions
```
### Other commands
```bash
claude-afk status # show config and enabled sessions
claude-afk add-home ~/.claude-personal # register another Claude Code config dir
claude-afk uninstall --claude-home ~/.claude # remove hooks from one home
claude-afk uninstall # remove hooks from all registered homes
```
## How it works
claude-afk installs [hooks](https://docs.anthropic.com/en/docs/claude-code/hooks) into Claude Code that route interactive prompts to your Slack DMs:
- **Stop** — when Claude finishes, posts the last message to Slack. Reply in the thread to continue the session.
- **PreToolUse** — tool permission requests and `AskUserQuestion` prompts are forwarded to Slack. Reply to approve/deny or answer.
- **Notification** — one-way DM when Claude needs attention.
## Caution
This is alpha software. Proceed with care.
- **`settings.json` modification** — `claude-afk` merges hooks into your Claude Code config. It's tested to preserve existing settings, but back up your `settings.json` if you're cautious.
- **Security** — this effectively gives you remote control of your machine through Slack. Anyone with access to your Slack bot tokens or your DM thread can approve tool executions.
- **Not fully tested** — edge cases exist. If something breaks, `claude-afk uninstall` removes all hooks cleanly.
| text/markdown | Deepankar Mahapatro | null | null | null | null | claude-code, hooks, permissions, remote, slack | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.0",
"slack-sdk>=3.27",
"websocket-client>=1.6"
] | [] | [] | [] | [
"Repository, https://github.com/deepankarm/claude-afk"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T14:29:18.385345 | claude_afk-0.1.0-py3-none-any.whl | 25,726 | 87/a7/b700a04e515d27cadb72e997ab8c54828ff09d8920206816e26f6742254e/claude_afk-0.1.0-py3-none-any.whl | py3 | bdist_wheel | null | false | b50a7d93fe3dab34d6e1c1cb9ff7f192 | 5691cfa6d339e6c173c64d3bb80f28cea9935518e8d1f3663d85a8287b96159b | 87a7b700a04e515d27cadb72e997ab8c54828ff09d8920206816e26f6742254e | Apache-2.0 | [
"LICENSE"
] | 223 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.