
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.4 | smello-server | 0.1.2 | A local web dashboard for inspecting outgoing HTTP requests from your code | # Smello Server
A local web dashboard for inspecting outgoing HTTP requests captured by the [smello](https://pypi.org/project/smello/) client SDK — including gRPC calls made by Google Cloud libraries.
## Setup
```bash
pip install smello-server
smello-server run
```
The dashboard opens at `http://localhost:5110`.
Or with Docker:
```bash
docker run -p 5110:5110 ghcr.io/smelloscope/smello
```
Then add the client SDK to your Python code:
```bash
pip install smello
```
```python
import smello
smello.init()
# All outgoing requests are now captured (HTTP and gRPC)
```
## API
Smello Server provides a JSON API for exploring captured requests from the command line.
```bash
# List all captured requests
curl -s http://localhost:5110/api/requests | python -m json.tool
# Filter by method, host, status, or URL substring
curl -s 'http://localhost:5110/api/requests?method=POST&host=api.stripe.com'
# Get full request/response details
curl -s http://localhost:5110/api/requests/{id} | python -m json.tool
# Clear all requests
curl -X DELETE http://localhost:5110/api/requests
```
## CLI Options
```bash
smello-server run --host 0.0.0.0 --port 5110 --db-path /tmp/smello.db
```
## Requires
- Python >= 3.14
## Links
- [Documentation & Source](https://github.com/smelloscope/smello)
- [smello client SDK on PyPI](https://pypi.org/project/smello/)
| text/markdown | null | Roman Imankulov <roman.imankulov@gmail.com> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Framework :: FastAPI",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Testing",
"Topic :: System :: Networking :: Monitoring"
] | [] | null | null | >=3.14 | [] | [] | [] | [
"aiosqlite>=0.20.0",
"fastapi>=0.115.0",
"jinja2>=3.1.0",
"tortoise-orm>=0.22.0",
"uvicorn[standard]>=0.34.0"
] | [] | [] | [] | [
"Homepage, https://github.com/smelloscope/smello",
"Repository, https://github.com/smelloscope/smello",
"Issues, https://github.com/smelloscope/smello/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:55:57.680207 | smello_server-0.1.2.tar.gz | 11,334 | 4a/14/1031fc7b268b0e09a384bf8525e7e0c128dc2bf4924752df60a9d629a198/smello_server-0.1.2.tar.gz | source | sdist | null | false | 7ab30aedde874562949015cda7087cbb | 4610b5dd32b338287ddd1e29b14d0eb242a08c5b6f7136b1b5b2e397700f0a22 | 4a141031fc7b268b0e09a384bf8525e7e0c128dc2bf4924752df60a9d629a198 | MIT | [] | 199 |
2.4 | navani | 0.1.14 | Package for processing and plotting echem data from cyclers | # navani
Navani is a Python module for processing and plotting electrochemical data from battery cyclers, combining other open source libraries to create pandas dataframes with a normalized schema across multiple cycler brands. It is intended to be easy to use for those unfamiliar with programming.
Contains functions to compute dQ/dV and dV/dQ.
Full documentation can be found [here](https://be-smith.github.io/navani/).
Currently supports:
- BioLogic MPR (`.mpr`)
- Arbin res files (`.res`)
- Simple `.txt` and Excel `.xls`/`.xlsx` formats produced by e.g., Arbin, Ivium and Lanhe/Lande
- Neware NDA and NDAX (`.nda`, `.ndax`)
The main dependencies are:
- pandas
- [galvani](https://github.com/echemdata/galvani) (BioLogic MPR)
- [mdbtools](https://github.com/mdbtools/mdbtools) (for reading Arbin's .res files with galvani).
- [NewareNDA](https://github.com/Solid-Energy-Systems/NewareNDA) (for reading Neware's NDA and NDAx formats).
Navani is released under the terms of the MIT license.
> [!WARNING]
> The [galvani](https://github.com/echemdata/galvani) dependency is available under the terms of [GPLv3 License](https://github.com/echemdata/galvani/blob/master/LICENSE). We believe this usage to be valid following the GPLv3 interpretation of the [copyright holder for galvani](https://github.com/echemdata/galvani/issues/51#issuecomment-701500053). The galvani library is not distributed with Navani, but installing Navani from PyPI will also install GPL-licensed dependencies. Users are responsible for GPL compliance of any downstream projects in this regard.
## Installation
You will need Python 3.10 or higher to use Navani.
Navani can now be installed using pip:
```shell
pip install navani
```
However it is still advised to install navani using [uv](https://docs.astral.sh/uv/), to manage dependencies.
To install Navani and its dependencies, clone this repository and use uv to setup a virtual environment with the dependencies:
```shell
git clone git@github.com/be-smith/navani
cd navani
uv venv
uv sync
```
You should now have an environment you can activate with all the required dependencies (except mdbtools, which is covered later).
To activate this environment simply run from the navani folder:
```shell
source .venv/bin/activate
```
If you would like to contribute to navani it is recommended to install the dev dependencies, this can be done simply by:
```shell
uv sync --all-extras --dev
```
If don't want to use uv it is still strongly recommended to use a fresh Python environment to install navani, using e.g., `conda create` or `python -m venv <chosen directory`.
To install navani, either clone this repository and install from your local copy:
```shell
git clone git@github.com/be-smith/navani
cd navani
pip install .
```
The additional non-Python mdbtools dependency to `galvani` that is required to read Arbin's `.res` format can be installed on Ubuntu via `sudo apt install mdbtools`, with similar instructions available for other Linux distributions and macOS [here](https://github.com/mdbtools/mdbtools).
## Usage
The main entry point to navani is the `navani.echem.echem_file_loader` function, which will do file type detection and return a pandas dataframe.
Many different plot types are then available, as shown below:
```python
import pandas as pd
import navani.echem as ec
df = ec.echem_file_loader(filepath)
fig, ax = ec.charge_discharge_plot(df, 1)
```
<img src="https://github.com/be-smith/navani/raw/main/docs/Example_figures/Graphite_charge_discharge_plot.png" alt="Graphite charge discharge plot example" width="50%" height="50%">
Also included are functions for extracting dQ/dV from the data:
```python
for cycle in [1, 2]:
mask = df['half cycle'] == cycle
voltage, dqdv, capacity = ec.dqdv_single_cycle(df['Capacity'][mask], df['Voltage'][mask],
window_size_1=51,
polyorder_1=5,
s_spline=0.0,
window_size_2=51,
polyorder_2=5,
final_smooth=True)
plt.plot(voltage, dqdv)
plt.xlim(0, 0.5)
plt.xlabel('Voltage / V')
plt.ylabel('dQ/dV / mAhV$^{-1}$')
```
<img src="https://github.com/be-smith/navani/raw/main/docs/Example_figures/Graphite_dqdv.png" alt="Graphite dQ/dV plot example" width="50%" height="50%">
And easily plotting multiple cycles:
```python
fig, ax = ec.multi_dqdv_plot(df, cycles=cycles,
colormap='plasma',
window_size_1=51,
polyorder_1=5,
s_spline=1e-7,
window_size_2=251,
polyorder_2=5,
final_smooth=True)
```
<img src="https://github.com/be-smith/navani/raw/main/docs/Example_figures/Si_dQdV.png" alt="Si dQ/dV plot example" width="50%" height="50%">
Simple jupyter notebooks and Colab notebooks can be found [here](https://github.com/be-smith/navani/blob/main/Simple%20example%20jupyter.ipynb) for Jupyter and [here](https://github.com/be-smith/navani/blob/main/Simple_examples_colab.ipynb) for Colab.
Whilst a more detailed Colab notebook can be found [here](https://github.com/be-smith/navani/blob/main/Detailed_colab_tutorial.ipynb).
| text/markdown | null | Ben Smith <ben.ed.smith2@gmail.com> | null | null | MIT | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy<2,~=1.26",
"pandas<3,~=2.2",
"scipy<2,~=1.15",
"datalab-org-galvani>=0.5.0",
"matplotlib<4,~=3.10",
"openpyxl<4,~=3.1",
"NewareNDA>=2024.8.1",
"requests<3,~=2.32",
"pyarrow>=10.0; extra == \"parquet\""
] | [] | [] | [] | [
"Homepage, https://github.com/be-smith/navani",
"Issues, https://github.com/be-smith/navani/issues",
"Documentation, https://be-smith.github.io/navani/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:55:51.032522 | navani-0.1.14.tar.gz | 7,042,877 | a4/22/55d737361e30334107f68dc98adce7ba3fe0782f1c9cb9fa238ff17724e3/navani-0.1.14.tar.gz | source | sdist | null | false | 2996c538d4968e8024d475f961e7c2cc | dfe8e81a80ee4c3ce0bb70209684148fcb54132dcaa46e314522ce2f5cc9fe1c | a42255d737361e30334107f68dc98adce7ba3fe0782f1c9cb9fa238ff17724e3 | null | [
"LICENSE"
] | 254 |
2.4 | geospacelab | 0.13.0 | Collect, manage, and visualize geospace data. | <p align="center">
<img width="500" src="https://github.com/JouleCai/geospacelab/blob/master/docs/images/logo_v1_landscape_accent_colors.png">
</p>
# GeospaceLAB (geospacelab)
[](https://opensource.org/licenses/BSD-3-Clause)
[](https://www.python.org/)
[](https://zenodo.org/badge/latestdoi/347315860)
[](https://pepy.tech/project/geospacelab)

GeospaceLAB provides a framework of data access, analysis, and visualization for the researchers in space physics and space weather. The documentation can be found
on [readthedocs.io](https://geospacelab.readthedocs.io/en/latest/).
## Features
- Class-based data manager, including
- __DataHub__: the core module (top-level class) to manage data from multiple sources,
- __Dataset__: the middle-level class to download, load, and process data from a data source,
- __Variable__: the base-level class to store the data array of a variable with various attributes, including its
error, name, label, unit, group, and dependencies.
- Extendable
- Provide a standard procedure from downloading, loading, and post-processing the data.
- Easy to extend for a data source which has not been supported in the package.
- Flexible to add functions for post-processing.
- Visualization
- Time series plots with
- automatically adjustable time ticks and tick labels.
- dynamical panels (flexible to add or remove panels).
- automatically detect the time gaps.
- useful marking tools (vertical line crossing panels, shadings, top bars, etc, see Example 2 in
[Usage](https://github.com/JouleCai/geospacelab#usage))
- Map projection
- Polar views with
- coastlines in either GEO or AACGM (APEX) coordinate system.
- mapping in either fixed lon/mlon mode or in fixed LST/MLT mode.
- Support 1-D or 2-D plots with
- satellite tracks (time ticks and labels)
- nadir colored 1-D plots
- gridded surface plots
- Space coordinate system transformation
- Unified interface for cs transformations.
- Toolboxes for data analysis
- Basic toolboxes for numpy array, datetime, logging, python dict, list, and class.
## Built-in data sources:
| Data Source | Variables | File Format | Downloadable | Express | Status |
|------------------------------|------------------------------------|-----------------------|---------------|-------------------------------|--------|
| CDAWeb/OMNI | Solar wind and IMF |*cdf* | *True* | __OMNIDashboard__ | stable |
| CDAWeb/DMSP/SSUSI/EDR_AUR | DMSP SSUSI EDR_AUR emission lines | *netcdf* | *True* | __DMSPSSUSIDashboard__ | stable |
| Madrigal/EISCAT | Ionospheric Ne, Te, Ti, ... | *EISCAT-hdf5*, *Madrigal-hdf5* | *True* | __EISCATDashboard__ | stable |
| Madrigal/GNSS/TECMAP | Ionospheric GPS TEC map | *hdf5* | *True* | - | beta |
| Madrigal/DMSP/s1 | DMSP SSM, SSIES, etc | *hdf5* | *True* | __DMSPTSDashboard__ | stable |
| Madrigal/DMSP/s4 | DMSP SSIES | *hdf5* | *True* | __DMSPTSDashboard__ | stable |
| Madrigal/DMSP/e | DMSP SSJ | *hdf5* | *True* | __DMSPTSDashboard__ | stable |
| Madrigal/Millstone Hill ISR+ | Millstone Hill ISR | *hdf5* | *True* | __MillstoneHillISRDashboard__ | stable |
| Madrigal/Poker Flat ISR | Poker Flat ISR | *hdf5* | *True* | __-_ | stable |
| JHUAPL/AMPERE/fitted | AMPERE FAC | *netcdf* | *False* | __AMPEREDashboard__ | stable |
| SuperDARN/POTMAP | SuperDARN potential map | *ascii* | *False* | - | stable |
| WDC/Dst | Dst index | *IAGA2002-ASCII* | *True* | - | stable |
| WDC/ASYSYM | ASY/SYM indices | *IAGA2002-ASCII* | *True* | __OMNIDashboard__ | stable |
| WDC/AE | AE indices | *IAGA2002-ASCII* | *True* | __OMNIDashboard__ | stable |
| GFZ/Kp | Kp/Ap indices | *ASCII* | *True* | - | stable |
| GFZ/Hpo | Hp30 or Hp60 indices | *ASCII* | *True* | - | stable |
| GFZ/SNF107 | SN, F107 | *ASCII* | *True* | - | stable |
| ESA/SWARM/EFI_LP_HM | SWARM Ne, Te, etc. | *netcdf* | *True* | - | stable |
| ESA/SWARM/EFI_TCT02 | SWARM cross track vi | *netcdf* | *True* | - | stable |
| ESA/SWARM/AOB_FAC_2F | SWARM FAC, auroral oval boundary | *netcdf* | *True* | - | beta |
| TUDelft/SWARM/DNS_POD | Swarm $\rho_n$ (GPS derived) | *ASCII* | *True* | - | stable |
| TUDelft/SWARM/DNS_ACC | Swarm $\rho_n$ (GPS+Accelerometer) | *ASCII* | *True* | - | stable |
| TUDelft/GOCE/WIND_ACC | GOCE neutral wind | *ASCII* | *True* | - | stable |
| TUDelft/GRACE/WIND_ACC | GRACE neutral wind | *ASCII* | *True* | - | stable |
| TUDelft/GRACE/DNS_ACC | Grace $\rho_n$ | *ASCII* | *True* | - | stable |
| TUDelft/CHAMP/DNS_ACC | CHAMP $\rho_n$ | *ASCII* | *True* | - | stable |
| UTA/GITM/2DALL | GITM 2D output | *binary*, *IDL-sav* | *False* | - | beta |
| UTA/GITM/3DALL | GITM 3D output | *binary*, *IDL-sav* | *False* | - | beta |
## Installation
### 1. The python distribution "*__Anaconda__*" is recommended:
The package was tested with the anaconda distribution and with **PYTHON>=3.7** under **Ubuntu 20.04** and **MacOS Big Sur**.
With Anaconda, it may be easier to install some required dependencies listed below, e.g., cartopy, using the _conda_ command.
It's also recommended installing the package and dependencies in a virtual environment with anaconda.
After [installing the anaconda distribution](https://docs.anaconda.com/anaconda/install/index.html), a virtual environment can be created by the code below in the terminal:
```shell
conda create --name [YOUR_ENV_NAME] -c conda-forge python cython cartopy
```
The package "spyder" is a widely-used python IDE. Other IDEs, like "VS Code" or "Pycharm" also work.
> **_Note:_** The recommended IDE is Spyder. Sometimes, a *RuntimeError* can be raised
> when the __aacgmv2__ package is called in **PyCharm** or **VS Code**.
> If you meet this issue, try to compile the codes in **Spyder** several times.
After creating the virtual environement, you need to activate the virtual environment:
```shell
conda activate [YOUR_ENV_NAME]
```
and then to install the package as shown below or to start the IDE **Spyder**.
More detailed information to set the anaconda environment can be found [here](https://conda.io/projects/conda/en/latest/user-guide/tasks/manage-environments.html#),
### 2. Installation
#### Quick install from the pre-built release (recommended):
```shell
pip install geospacelab
```
#### Install from [Github](https://github.com/JouleCai/geospacelab) (not recommended):
```shell
pip install git+https://github.com/JouleCai/geospacelab@master
```
### 2. Dependencies
The package dependencies need to be installed before or after the installation of the package.
Several dependencies will be installed automatically with the package installation,
including __toml__, __requests__, __bueatifulsoup4__, __numpy__, __scipy__, __matplotlib__, __h5py__, __netcdf4__,
__cdflib__, __madrigalweb__, __sscws__, and __aacgmv2__.
Other dependencies will be needed if you see a *__ImportError__* or *__ModuleNotFoundError__*
displayed in the python console. Some frequently used modules and their installation methods are listed below:
- [__cartopy__](https://scitools.org.uk/cartopy/docs/latest/installing.html): Map projection for geospatial data.
- ```conda install -c conda-forge cartopy ```
- [__apexpy__ \*](https://apexpy.readthedocs.io/en/latest/reference/Apex.html): Apex and Quasi-Dipole geomagnetic
coordinate system.
- ```pip install apexpy ```
- [__geopack__](https://github.com/tsssss/geopack): The geopack and Tsyganenko models in Python.
- ```pip install geopack ```
> ([\*]()): The **_gcc_** or **_gfortran_** compilers are required before installing the package.
> - gcc: ```conda install -c conda-forge gcc```
> - gfortran: ```conda install -c conda-forge gfortran ```
Please install the packages above, if needed.
Note: The package is currently pre-released. The installation methods may be changed in the future.
### 4. First-time startup and basic configuration
Some basic configurations will be made with the first-time import of the package. Following the messages prompted in the python console, the first configuration is to set the root directory for storing the data.
When the modules to access the online Madrigal database is imported, it will ask for the inputs of user's full name, email, and affiliation.
The user's configuration can be found from the *__toml__* file below:
```
[your_home_directory]/.geospacelab/config.toml
```
The user can set or change the preferences in the configuration file. For example, to change the root directory for storing the data, modify or add the lines in "config.toml":
```toml
[datahub]
data_root_dir = "YOUR_ROOT_DIR"
```
To set the Madrigal cookies, change the lines:
```toml
[datahub.madrigal]
user_fullname = "YOUR_NAME"
user_email = "YOU_EMAIL"
user_affiliation = "YOUR_AFFILIATION"
```
### 5. Upgrade
If the package is installed from the pre-built release. Update the package via:
```shell
pip install geospacelab --upgrade
```
### 6. Uninstallation
Uninstall the package via:
```shell
pip uninstall geospacelab
```
If you don't need the user's configuration, delete the file at **_[your_home_directory]/.geospacelab/config.toml_**
## Usage
### Example 1: Dock a sourced dataset and get variables:
The core of the data manager is the class Datahub. A Datahub instance will be used for docking a buit-in sourced dataset, or adding a temporary or user-defined dataset.
The "dataset" is a Dataset instance, which is used for loading and downloading
the data.
Below is an example to load the EISCAT data from the online service. The module will download EISCAT data automatically from
[the EISCAT schedule page](https://portal.eiscat.se/schedule/) with the presetttings of loading mode "AUTO" and file type "eiscat-hdf5".
Example 1:
```python
import datetime
from geospacelab.datahub import DataHub
# settings
dt_fr = datetime.datetime.strptime('20210309' + '0000', '%Y%m%d%H%M') # datetime from
dt_to = datetime.datetime.strptime('20210309' + '2359', '%Y%m%d%H%M') # datetime to
database_name = 'madrigal' # built-in sourced database name
facility_name = 'eiscat' # facility name
site = 'UHF' # facility attributes required, check from the eiscat schedule page
antenna = 'UHF'
modulation = 'ant'
# create a datahub instance
dh = DataHub(dt_fr, dt_to)
# dock the first dataset (dataset index starts from 0)
ds_isr = dh.dock(datasource_contents=[database_name, 'isr', facility_name],
site=site, antenna=antenna, modulation=modulation, data_file_type='madrigal-hdf5')
# load data
ds_isr.load_data()
# assign a variable from its own dataset to the datahub
n_e = dh.assign_variable('n_e')
T_i = dh.assign_variable('T_i')
# get the variables which have been assigned in the datahub
n_e = dh.get_variable('n_e')
T_i = dh.get_variable('T_i')
# if the variable is not assigned in the datahub, but exists in the its own dataset:
comp_O_p = dh.get_variable('comp_O_p', dataset=ds_isr) # O+ ratio
# above line is equivalent to
comp_O_p = dh.datasets[0]['comp_O_p']
# The variables, e.g., n_e and T_i, are the class Variable's instances,
# which stores the variable values, errors, and many other attributes, e.g., name, label, unit, depends, ....
# To get the value of the variable, use variable_isntance.value, e.g.,
print(n_e.value) # return the variable's value, type: numpy.ndarray, axis 0 is always along the time, check n_e.depends.items{}
print(n_e.error)
```
### Example 2: EISCAT quicklook plot
The EISCAT quicklook plot shows the GUISDAP analysed results in the same format as the online EISCAT quicklook plot.
The figure layout and quality are improved. In addition, several marking tools like vertical lines, shadings, top bars can be
added in the plot. See the example script and figure below:
In "example2.py"
```python
import datetime
import geospacelab.express.eiscat_dashboard as eiscat
dt_fr = datetime.datetime.strptime('20201209' + '1800', '%Y%m%d%H%M')
dt_to = datetime.datetime.strptime('20201210' + '0600', '%Y%m%d%H%M')
site = 'UHF'
antenna = 'UHF'
modulation = '60'
load_mode = 'AUTO'
dashboard = eiscat.EISCATDashboard(
dt_fr, dt_to, site=site, antenna=antenna, modulation=modulation, load_mode='AUTO',
data_file_type="madrigal-hdf5"
)
dashboard.quicklook()
# dashboard.save_figure() # comment this if you need to run the following codes
# dashboard.show() # comment this if you need to run the following codes.
"""
As the dashboard class (EISCATDashboard) is a inheritance of the classes Datahub and TSDashboard.
The variables can be retrieved in the same ways as shown in Example 1.
"""
n_e = dashboard.assign_variable('n_e')
print(n_e.value)
print(n_e.error)
"""
Several marking tools (vertical lines, shadings, and top bars) can be added as the overlays
on the top of the quicklook plot.
"""
# add vertical line
dt_fr_2 = datetime.datetime.strptime('20201209' + '2030', "%Y%m%d%H%M")
dt_to_2 = datetime.datetime.strptime('20201210' + '0130', "%Y%m%d%H%M")
dashboard.add_vertical_line(dt_fr_2, bottom_extend=0, top_extend=0.02, label='Line 1', label_position='top')
# add shading
dashboard.add_shading(dt_fr_2, dt_to_2, bottom_extend=0, top_extend=0.02, label='Shading 1', label_position='top')
# add top bar
dt_fr_3 = datetime.datetime.strptime('20201210' + '0130', "%Y%m%d%H%M")
dt_to_3 = datetime.datetime.strptime('20201210' + '0430', "%Y%m%d%H%M")
dashboard.add_top_bar(dt_fr_3, dt_to_3, bottom=0., top=0.02, label='Top bar 1')
# save figure
dashboard.save_figure()
# show on screen
dashboard.show()
```
Output:
> 
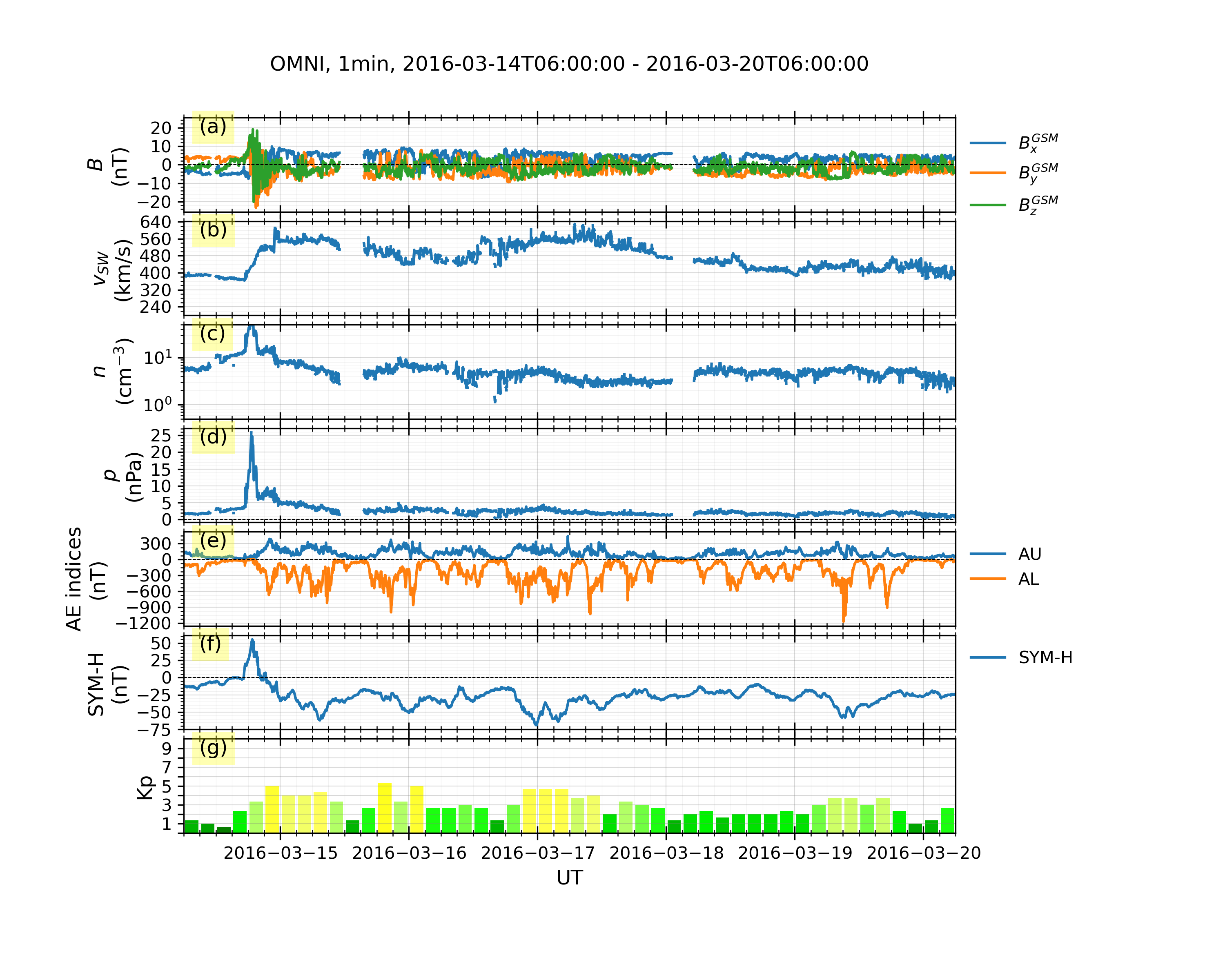
### Example 3: OMNI data and geomagnetic indices (WDC + GFZ):
In "example3.py"
```python
import datetime
import geospacelab.express.omni_dashboard as omni
dt_fr = datetime.datetime.strptime('20160314' + '0600', '%Y%m%d%H%M')
dt_to = datetime.datetime.strptime('20160320' + '0600', '%Y%m%d%H%M')
omni_type = 'OMNI2'
omni_res = '1min'
load_mode = 'AUTO'
dashboard = omni.OMNIDashboard(
dt_fr, dt_to, omni_type=omni_type, omni_res=omni_res, load_mode=load_mode
)
dashboard.quicklook()
# data can be retrieved in the same way as in Example 1:
dashboard.list_assigned_variables()
B_x_gsm = dashboard.get_variable('B_x_GSM', dataset_index=0)
# save figure
dashboard.save_figure()
# show on screen
dashboard.show()
```
Output:
> 
### Example 4: Mapping geospatial data in the polar map.
> **_NOTE_**: JHUAPL stopped supporting DMSP SSUSI on 14 Feb 2025.
From then on, the data source has been switched from JHUAPL to CDAWeb.
```python
import datetime
import matplotlib.pyplot as plt
import geospacelab.visualization.mpl.geomap.geodashboards as geomap
dt_fr = datetime.datetime(2015, 9, 8, 8)
dt_to = datetime.datetime(2015, 9, 8, 23, 59)
time_c = datetime.datetime(2015, 9, 8, 20, 21)
pole = 'N'
sat_id = 'f16'
band = 'LBHS'
# Create a geodashboard object
dashboard = geomap.GeoDashboard(dt_fr=dt_fr, dt_to=dt_to, figure_config={'figsize': (5, 5)})
# If the orbit_id is specified, only one file will be downloaded. This option saves the downloading time.
# dashboard.dock(datasource_contents=['jhuapl', 'dmsp', 'ssusi', 'edraur'], pole='N', sat_id='f17', orbit_id='46863')
# If not specified, the data during the whole day will be downloaded.
ds_ssusi = dashboard.dock(datasource_contents=['cdaweb', 'dmsp', 'ssusi', 'edr_aur'], pole=pole, sat_id=sat_id, orbit_id=None)
ds_s1 = dashboard.dock(
datasource_contents=['madrigal', 'satellites', 'dmsp', 's1'],
dt_fr=time_c - datetime.timedelta(minutes=45),
dt_to=time_c + datetime.timedelta(minutes=45),
sat_id=sat_id, replace_orbit=True)
dashboard.set_layout(1, 1)
# Get the variables: LBHS emission intensiy, corresponding times and locations
lbhs = ds_ssusi['GRID_AUR_' + band]
dts = ds_ssusi['DATETIME'].flatten()
mlat = ds_ssusi['GRID_MLAT']
mlon = ds_ssusi['GRID_MLON']
mlt = ds_ssusi['GRID_MLT']
# Search the index for the time to plot, used as an input to the following polar map
ind_t = dashboard.datasets[0].get_time_ind(ut=time_c)
if (dts[ind_t] - time_c).total_seconds()/60 > 60: # in minutes
raise ValueError("The time does not match any SSUSI data!")
lbhs_ = lbhs.value[ind_t]
mlat_ = mlat.value[ind_t]
mlon_ = mlon.value[ind_t]
mlt_ = mlt.value[ind_t]
# Add a polar map panel to the dashboard. Currently the style is the fixed MLT at mlt_c=0. See the keywords below:
panel = dashboard.add_polar_map(
row_ind=0, col_ind=0, style='mlt-fixed', cs='AACGM',
mlt_c=0., pole=pole, ut=time_c, boundary_lat=55., mirror_south=True
)
# Some settings for plotting.
pcolormesh_config = lbhs.visual.plot_config.pcolormesh
# Overlay the SSUSI image in the map.
ipc = panel.overlay_pcolormesh(
data=lbhs_, coords={'lat': mlat_, 'lon': mlon_, 'mlt': mlt_}, cs='AACGM',
regridding=False, **pcolormesh_config)
# Add a color bar
panel.add_colorbar(ipc, c_label=band + " (R)", c_scale=pcolormesh_config['c_scale'], left=1.1, bottom=0.1,
width=0.05, height=0.7)
# Overlay the gridlines
panel.overlay_gridlines(lat_res=5, lon_label_separator=5)
# Overlay the coastlines in the AACGM coordinate
panel.overlay_coastlines()
# Overlay cross-track velocity along satellite trajectory
sc_dt = ds_s1['SC_DATETIME'].value.flatten()
sc_lat = ds_s1['SC_GEO_LAT'].value.flatten()
sc_lon = ds_s1['SC_GEO_LON'].value.flatten()
sc_alt = ds_s1['SC_GEO_ALT'].value.flatten()
sc_coords = {'lat': sc_lat, 'lon': sc_lon, 'height': sc_alt}
v_H = ds_s1['v_i_H'].value.flatten()
panel.overlay_cross_track_vector(
vector=v_H, unit_vector=1000, vector_unit='m/s', alpha=0.3, color='red',
sc_coords=sc_coords, sc_ut=sc_dt, cs='GEO',
)
# Overlay the satellite trajectory with ticks
panel.overlay_sc_trajectory(sc_ut=sc_dt, sc_coords=sc_coords, cs='GEO')
# Overlay sites
panel.overlay_sites(
site_ids=['TRO', 'ESR'], coords={'lat': [69.58, 78.15], 'lon': [19.23, 16.02], 'height': 0.},
cs='GEO', marker='^', markersize=2)
# Add the title and save the figure
polestr = 'North' if pole == 'N' else 'South'
panel.add_title(title='DMSP/SSUSI, ' + band + ', ' + sat_id.upper() + ', ' + polestr + ', ' + time_c.strftime('%Y-%m-%d %H%M UT'))
plt.savefig('DMSP_SSUSI_' + time_c.strftime('%Y%m%d-%H%M') + '_' + band + '_' + sat_id.upper() + '_' + pole, dpi=300)
# show the figure
plt.show()
```
Output:
> 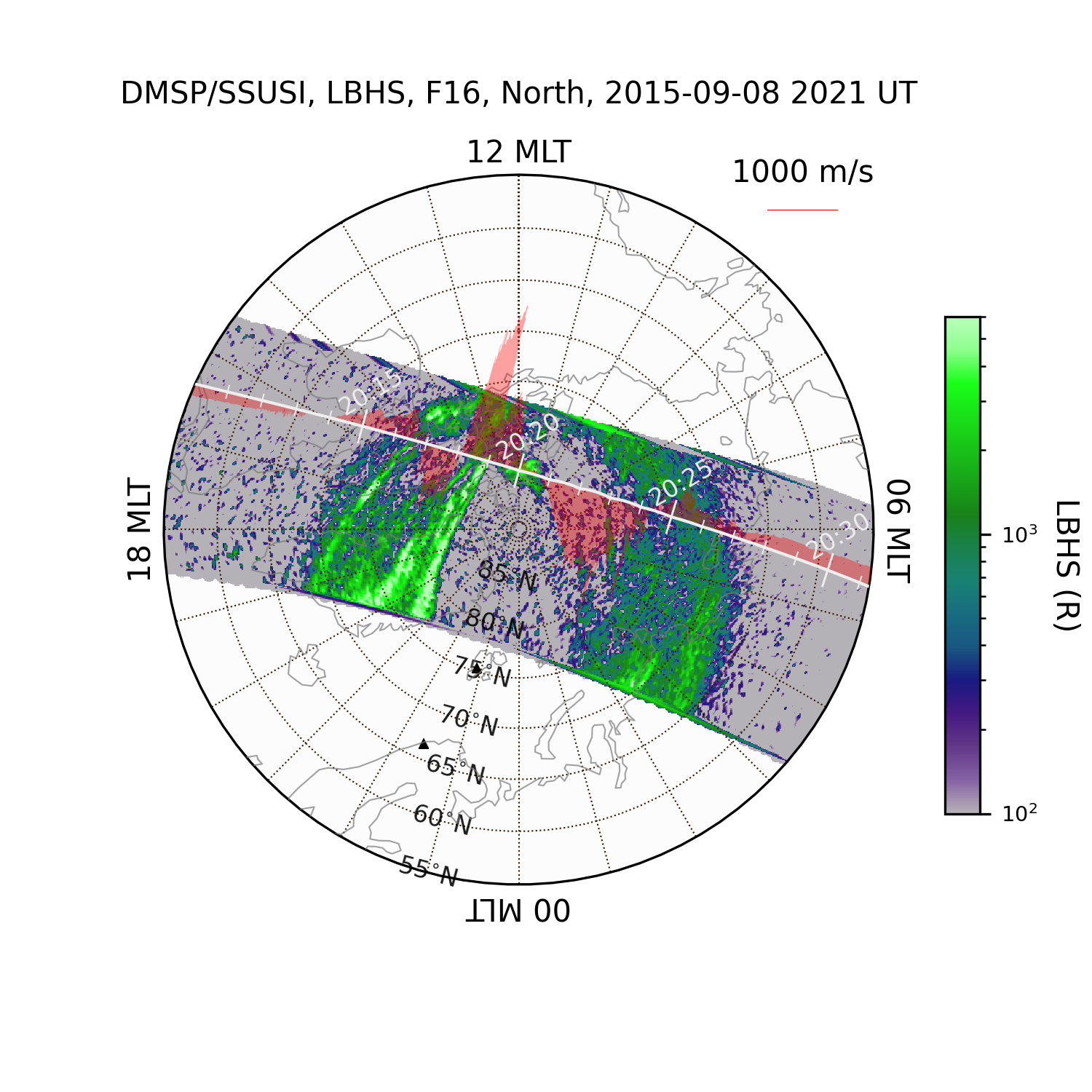
This is an example showing the HiLDA aurora in the dayside polar cap region
(see also [DMSP observations of the HiLDA aurora (Cai et al., JGR, 2021)](https://agupubs.onlinelibrary.wiley.com/doi/10.1029/2020JA028808)).
Other examples for the time-series plots and map projections can be found [here](https://github.com/JouleCai/geospacelab/tree/master/examples)
## Acknowledgements and Citation
### Acknowledgements
We acknowledge all the dependencies listed above for their contributions to implement a lot of functionality in GeospaceLAB.
### Citation
If GeospaceLAB is used for your scientific work, please mention it in the publication and cite the package:
> Cai L, Aikio A, Kullen A, Deng Y, Zhang Y, Zhang S-R, Virtanen I and Vanhamäki H (2022), GeospaceLAB: Python package
for managing and visualizing data in space physics. Front. Astron. Space Sci. 9:1023163. doi: [10.3389/fspas.2022.1023163](https://www.frontiersin.org/articles/10.3389/fspas.2022.1023163/full)
In addition, please add the following text in the "Methods" or "Acknowledgements" section:
> This research has made use of GeospaceLAB v?.?.?, an open-source Python package to manage and visualize data in space physics.
Please include the project logo (see the top) to acknowledge GeospaceLAB in posters or talks.
### Co-authorship
GeospaceLAB aims to help users to manage and visualize multiple kinds of data in space physics in a convenient way. We welcome collaboration to support your research work. If the functionality of GeospaceLAB plays a critical role in a research paper, the co-authorship is expected to be offered to one or more developers.
## Notes
- The current version is a pre-released version. Many features will be added soon.
| text/markdown | Lei Cai | lei.cai@oulu.fi | null | null | BSD 3-Clause License | Geospace, EISCAT, DMSP, Space weather, Ionosphere, Space, Magnetosphere | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Topic :: Scientific/Engineering :: Visualization",
"Topic :: Scientific/Engineering :: Astronomy",
"Topic :: Software Development :: Build Tools",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | https://github.com/JouleCai/geospacelab | null | <3.13,>=3.9 | [] | [] | [] | [
"cython",
"requests>=2.26.0",
"beautifulsoup4>=4.9.3",
"natsort>=7.1.1",
"numpy<2.4.0",
"scipy>=1.6.0",
"netcdf4>=1.5.7",
"h5py>=3.2.1",
"matplotlib>=3.5",
"madrigalweb>=3.3",
"aacgmv2>=2.6.2",
"cdflib>=1.2.3",
"geopack>=1.0.10",
"palettable",
"tqdm",
"toml",
"sscws",
"pandas>=1.5.3",
"keyring"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T13:55:18.290061 | geospacelab-0.13.0.tar.gz | 461,449 | 3c/2f/152aa83aa17781fa0c53cb8862b9dfdcf2518936e1b48cd959731fe2050a/geospacelab-0.13.0.tar.gz | source | sdist | null | false | a5a5762d6a7a47b8997ac2d032cca040 | f1050efd1a31deaafc0cb4e37d6f7176b74d0cb81faaf8b42c791453472c43d4 | 3c2f152aa83aa17781fa0c53cb8862b9dfdcf2518936e1b48cd959731fe2050a | null | [
"LICENSE"
] | 224 |
2.3 | oreum_core | 0.11.13 | Core tools for use on projects by Oreum Industries | # Oreum Core Tools `oreum_core`
[](https://www.python.org)
[](https://choosealicense.com/licenses/apache-2.0/)
[](https://github.com/oreum-industries/oreum_core/releases)
[](https://pypi.org/project/oreum_core)
[](https://github.com/oreum-industries/oreum_core/actions/workflows/lint.yml)
[](https://github.com/oreum-industries/oreum_core/actions/workflows/publish.yml)
[](https://github.com/astral-sh/ruff)
[](https://pypi.org/project/interrogate/)
[](https://github.com/PyCQA/bandit)
---
## 1. Description and Scope
`oreum_core` is an ever-evolving package of core tools for use on client
projects by Oreum Industries.
+ Provides an essential workflow for data curation, EDA, basic ML using the core
scientific Python stack incl. `numpy`, `scipy`, `matplotlib`, `seaborn`,
`pandas`, `scikit-learn`, `umap-learn`
+ Optionally provides an advanced Bayesian modeling workflow in R&D and
Production using a leading probabilistic programming stack incl. `pymc`,
`pytensor`, `arviz`
(do `pip install oreum_core[pymc]`)
+ Optionally enables a generalist black-box ML workflow in R&D using a leading
Gradient Boosted Trees stack incl. `catboost`, `xgboost`, `optuna`, `shap`
(do `pip install oreum_core[tree]`)
+ Also includes several utilities for text cleaning, sql scripting, file handling
This package **is**:
+ A work in progress (v0.y.z) and liable to breaking changes and inconvenience
to the user
+ Solely designed for ease of use and rapid development by employees of
Oreum Industries, and selected clients with guidance
This package **is not**:
+ Intended for public usage and will not be supported for public usage
+ Intended for contributions by anyone not an employee of Oreum Industries,
and unsolicited contributions will not be accepted.
### Notes
+ Project began on 2021-01-01
+ The `README.md` is MacOS and POSIX oriented
+ See `LICENCE.md` for licensing and copyright details
+ See `pyproject.toml` for various package details
+ This uses a logger named `'oreum_core'`, feel free to incorporate or ignore
see `__init__.py` for details
+ Hosting:
+ Source code repo on [GitHub](https://github.com/oreum-industries/oreum_core)
+ Source code release on [GitHub](https://github.com/oreum-industries/oreum_core/releases)
+ Package release on [PyPi](https://pypi.org/project/oreum_core)
+ Implementation:
+ This project is enabled by a modern, open-source, advanced software stack
for data curation, statistical analysis and predictive modelling
+ Specifically we use an open-source Python-based suite of software packages,
the core of which is often known as the Scientific Python stack, supported
by [NumFOCUS](https://numfocus.org)
+ Once installed (see section 2), see `LICENSES_3P.md` for full
details of all package licences
+ Environments: this project was originally developed on a Macbook Air M2
(Apple Silicon ARM64) running MacOS 15 (Sequoia) using `osx-arm64` Accelerate
## 2. Instructions to Create Dev Environment
For local development on MacOS
### 2.0 Pre-requisite installs via `homebrew`
1. Install Homebrew, see instructions at [https://brew.sh](https://brew.sh)
2. Install system-level tools incl. `direnv`, `gcc`, `git`, `graphviz`, `uv`:
```zsh
$> make brew
```
### 2.1 Git clone the repo
Assumes system-level tools installed as above:
```zsh
$> git clone https://github.com/oreum-industries/oreum_core
$> cd oreum_core
```
Then allow `direnv` on MacOS to autorun file `.envrc` upon directory open
### 2.2 Create virtual environment and install dev packages
Notes:
+ We use local `.venv/` virtual env via [`uv`](https://github.com/astral-sh/uv)
+ Packages are technically articulated in `pyproject.toml` and might not be the
latest - to aid stability for `pymc` (usually in a state of development flux)
#### 2.2.1 Create the dev environment
From the dir above `oreum_core/` project dir:
```zsh
$> make -C oreum_core/ dev
```
This will also create some files to help confirm / diagnose successful installation:
+ `dev/install_log/blas_info.txt` for the `BLAS MKL` installation for `numpy`
+ `LICENSES_3P.md` details the license for each third-party package used
#### 2.2.2 (Optional best practice) Test successful installation of dev env
From the dir above `oreum_core/` project dir:
```zsh
$> make -C oreum_core/ dev-test
```
This will also add files `dev/install_log/tests_[numpy|scipy].txt` which detail
successful installation (or not) for `numpy`, `scipy`
#### 2.2.3 (Useful during env install experimentation): To remove the dev env
From the dir above `oreum_core/` project dir:
```zsh
$> make -C oreum_core/ dev-uninstall
```
### 2.3 Code Linting & Repo Control
#### 2.3.1 Pre-commit
We use [pre-commit](https://pre-commit.com) to run a suite of automated tests
for code linting & quality control and repo control prior to commit on local
development machines.
+ Precommit is already installed by the `make dev` command (which itself calls
`pip install -e .[dev]`)
+ The pre-commit script will then run on your system upon `git commit`
+ See this project's `.pre-commit-config.yaml` for details
#### 2.3.2 Github Actions
We use [Github Actions](https://docs.github.com/en/actions/using-workflows) aka
Github Workflows to run:
1. A suite of automated tests for commits received at the origin (i.e. GitHub)
2. Publishing to PyPi upon creating a GH Release
+ See `Makefile` for the CLI commands that are issued
+ See `.github/workflows/*` for workflow details
#### 2.3.3 Git LFS
We use [Git LFS](https://git-lfs.github.com) to store any large files alongside
the repo. This can be useful to replicate exact environments during development
and/or for automated tests
+ This requires a local machine install
(see [Getting Started](https://git-lfs.github.com))
+ See `.gitattributes` for details
### 2.4 Configs for Local Development
Some notes to help configure local development environment
#### 2.4.1 Git config `~/.gitconfig`
```yaml
[user]
name = <YOUR NAME>
email = <YOUR EMAIL ADDRESS>
```
### 2.5 Install VSCode IDE
We strongly recommend using [VSCode](https://code.visualstudio.com) for all
development on local machines, and this is a hard pre-requisite to use
the `.devcontainer` environment (see section 3)
This repo includes relevant lightweight project control and config in:
```zsh
oreum_core.code-workspace
.vscode/extensions.json
.vscode/settings.json
```
### 2.6 Publishing to PyPi
A note for maintainers (Oreum Industries only), publishing to pypi, ensure
local dev machine presence of the following in a config file `~/.pypirc`
```yaml
[distutils]
index-servers =
pypi
testpypi
[pypi]
repository = https://upload.pypi.org/legacy/
username = __token__
[testpypi]
repository = https://test.pypi.org/legacy/
username = __token__
```
---
## 3. Code Standards
Even when writing R&D code, we strive to meet and exceed (even define) best
practices for code quality, documentation and reproducibility for modern
data science projects.
### 3.1 Code Linting & Repo Control
We use a suite of automated tools to check and enforce code quality. We indicate
the relevant shields at the top of this README. See section 1.4 above for how
this is enforced at precommit on developer machines and upon PR at the origin as
part of our CI process, prior to master branch merge.
These include:
+ [`ruff`](https://docs.astral.sh/ruff/) - extremely fast standardised linting
and formatting, which replaces `black`, `flake8`, `isort`
+ [`interrogate`](https://pypi.org/project/interrogate/) - ensure complete Python
docstrings
+ [`bandit`](https://github.com/PyCQA/bandit) - test for common Python security
issues
We also run a suite of general tests pre-packaged in
[`precommit`](https://pre-commit.com).
---
Copyright 2025 Oreum FZCO t/a Oreum Industries. All rights reserved.
Oreum FZCO, IFZA, Dubai Silicon Oasis, Dubai, UAE, reg. 25515
[oreum.io](https://oreum.io)
---
Oreum Industries © 2025
| text/markdown | null | Oreum Industries <info@oreum.io> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Intended Audience :: Financial and Insurance Industry",
"License :: OSI Approved :: Apache Software License",
"Natural Language :: English",
"Operating System :: MacOS",
"Operating System :: Unix",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Information Analysis",
"Topic :: Scientific/Engineering :: Visualization"
] | [] | null | null | ==3.13.* | [] | [
"oreum_core"
] | [] | [
"csv2md",
"dask",
"fastparquet",
"ftfy",
"matplotlib",
"matplotlib-inline",
"pandas[excel,parquet,plot]==2.3.*",
"patsy",
"scikit-learn",
"scipy",
"seaborn<0.14",
"statsmodels",
"bandit; extra == \"dev\"",
"hypothesis; extra == \"dev\"",
"interrogate; extra == \"dev\"",
"ipython; extra == \"dev\"",
"meson; extra == \"dev\"",
"ninja; extra == \"dev\"",
"pipdeptree; extra == \"dev\"",
"pip-licenses; extra == \"dev\"",
"pooch; extra == \"dev\"",
"pre-commit; extra == \"dev\"",
"pytest; extra == \"dev\"",
"ruff; extra == \"dev\"",
"graphviz; extra == \"pymc\"",
"pymc; extra == \"pymc\"",
"catboost; extra == \"tree\"",
"category_encoders; extra == \"tree\"",
"graphviz; extra == \"tree\"",
"optuna; extra == \"tree\"",
"optuna-integration; extra == \"tree\"",
"nbformat; extra == \"tree\"",
"shap; extra == \"tree\"",
"xgboost; extra == \"tree\""
] | [] | [] | [] | [
"Homepage, https://github.com/oreum-industries/oreum_core"
] | python-requests/2.32.5 | 2026-02-20T13:54:54.840428 | oreum_core-0.11.13.tar.gz | 158,302 | 7c/4d/51945bf26bb4a5bce0f1e0567236b4f2ed5a2c6a9df4570bd90915e51ecc/oreum_core-0.11.13.tar.gz | source | sdist | null | false | 3d6d6409803ab9e0394f98cfefbdc03a | fc5fc18274eb319faa718de4905099a242e38079ce49bd35a04cbe819d771b76 | 7c4d51945bf26bb4a5bce0f1e0567236b4f2ed5a2c6a9df4570bd90915e51ecc | null | [] | 0 |
2.4 | llmbo-bedrock | 0.2.3 | Large Language Model Batch Operations | # LLMbo - Large Language model batch operations
AWS Bedrock offers powerful capabilities for running batch inference jobs with large language models.
However, orchestrating these jobs, managing inputs and outputs, and ensuring consistent result structures can be arduous.
LLMbo aims to solve these problems by providing an intuitive, Pythonic interface for Bedrock batch operations.
Additionally, it provides a method of using batch inference for structured responses,
taking inspiration from the likes of [instructor](https://pypi.org/project/instructor/),
[mirascope](https://pypi.org/project/mirascope/) and [pydanticai](https://pypi.org/project/pydantic-ai/).
You provide a model output as a pydantic model and llmbo creates takes care of the rest.
See the AWS documentation for [models that support batch inference.](https://docs.aws.amazon.com/bedrock/latest/userguide/batch-inference-supported.html)
Currently the library has full support (including StructuredBatchInference) for Anthropic and Mistral models.
Other models may be supported through the default adapter, or you can write and register your own.
## Prerequisites
- A `.env` file with an entry for `AWS_PROFILE=`. This profile should have sufficient
permissions to create and schedule a batch inference job. See the [AWS instructions](https://docs.aws.amazon.com/bedrock/latest/userguide/batch-inference-permissions.html)
- [A service role with the required permissions to execute the job.](https://docs.aws.amazon.com/bedrock/latest/userguide/batch-inference-permissions.html#batch-inference-permissions-service),
- A s3 bucket to store the input and outputs for the job. S3 buckets must exists in the same region as you execute the job. This is a limitation of AWS batch inference rather that the
package.
- Inputs will be written to `f{s3_bucket}/input/{job_name}.jsonl`
- Outputs will be written to `f{s3_bucket}/output/{job_id}/{job_name}.jsonl.out` and
`f{s3_bucket}/output/{job_id}/manifest.json.out`
## Install
```bash
pip install llmbo-bedrock
```
## Getting started
Here's a quick example of how to use LLMbo:
### BatchInferer
```python
from llmbo import BatchInferer, ModelInput
bi = BatchInferer(
model_name="anthropic.claude-v2",
bucket_name="my-inference-bucket",
region="us-east-1",
job_name="example-batch-job",
role_arn="arn:aws:iam::123456789012:role/BedrockBatchRole"
)
# Prepare your inputs using the ModelInput class, you also need to include an id
# input Dict[job_id: ModelInput ]
inputs = {
f"{i:03}": ModelInput(
messages=[{"role": "user", "content": f"Question {i}"}]
) for i in range(100)
}
# Run the batch job, this prepares, uploads, creates the job, monitors the progress
# and downloads the results
results = bi.auto(inputs)
```
### StructuredInferer
For structured inference, simply define a Pydantic model and use StructuredBatchInferer:
```python
from pydantic import BaseModel
from llmbo import StructuredBatchInferer
class ResponseSchema(BaseModel):
answer: str
confidence: float
sbi = StructuredBatchInferer(
output_model=ResponseSchema,
model_name="anthropic.claude-v2",
# ... other parameters
)
# The results will be validated against ResponseSchema
structured_results = sbi.auto(inputs)
```
For more detailed examples see the followingin llmbo.py:
- `examples/batch_inference_example.py`: for an example of free text response
- `examples/structured_batch_inference_example.py`: for an example of structured response ala instructor | text/markdown | null | David Gillespie <david.gillespie@digital.cabinet-office.gov.uk> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"boto3<2.0,>=1.3",
"pydantic>=2.10",
"python-dotenv>=1.0.1"
] | [] | [] | [] | [
"Homepage, https://co-cddo.github.io/gds-idea-llmbo/",
"Documentation, https://co-cddo.github.io/gds-idea-llmbo/api/",
"Repository, https://github.com/co-cddo/gds-idea-llmbo.git",
"Issues, https://github.com/co-cddo/gds-idea-llmbo/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:53:11.088555 | llmbo_bedrock-0.2.3-py3-none-any.whl | 23,901 | cc/0b/3e7b015315b27eb6d93ad9d97dbcfedc773080dfcee4c58c5e905e4f23c1/llmbo_bedrock-0.2.3-py3-none-any.whl | py3 | bdist_wheel | null | false | eefaa9b8af66f87c1962a4385bdead56 | c736c39c4fc4e268590045aa4efdf66f9d303d9b2cda3af1f1d191e58851c19a | cc0b3e7b015315b27eb6d93ad9d97dbcfedc773080dfcee4c58c5e905e4f23c1 | null | [
"LICENSE"
] | 208 |
2.4 | robotframework-robocop | 8.1.1 | Static code analysis tool (linter) and code formatter for Robot Framework | # Robocop
[](https://github.com/MarketSquare/robotframework-robocop/actions/workflows/unit-tests.yml "GitHub Workflow Unit Tests Status")




[](https://pepy.tech/project/robotframework-robocop)
---
<img style="float:right" src="https://raw.githubusercontent.com/MarketSquare/robotframework-robocop/main/docs/source/images/robocop_logo_small.png">
- [Introduction](#introduction)
- [Documentation](#documentation)
- [Requirements](#requirements)
- [Installation](#installation)
- [Usage](#usage)
- [Example Output](#example-output)
- [MCP Server](#mcp-server)
- [Values](#values)
- [FAQ](#faq)
---
## Introduction
Robocop is a tool that performs static code analysis and formatting of [Robot Framework](https://github.com/robotframework/robotframework) code.
It uses official [Robot Framework parsing API](https://robot-framework.readthedocs.io/en/stable/) to parse files and
runs a number of checks, looking for potential errors or violations to code quality standards (commonly referred to as
*linting issues*).
> Hosted on [GitHub](https://github.com/MarketSquare/robotframework-robocop).
## Documentation
Full documentation is available at [https://robocop.dev](https://robocop.dev). :open_book:
The most common questions with answers can be found at the bottom ⬇ of this README file.
## Requirements
Python 3.9+ :snake: and Robot Framework 4.0+ :robot:.
## Installation
You can install the latest version of Robocop simply by running:
```
pip install -U robotframework-robocop
```
## Usage
Robocop runs by default from the current directory, and it discovers supported files recursively.
To lint the files, you can run:
```
robocop check
```
To format the files, you can run:
```commandline
robocop format
```
All command line options can be displayed in a help message by executing:
```
robocop -h
```
## Example Output
Executing command:
```
robocop check --reports rules_by_error_type test.robot
```
Will result in the following output:
```text
test.robot:17:1 SPC22 Not enough whitespace after 'Test Teardown' setting
|
15 |
16 | Test Setup Keyword
17 | Test Teardown Keyword2
| ^ SPC22
18 | Testtimeout 1min
19 | Documentation this is doc
|
test.robot:28:1 SPC14 Variable in Variables section is not left aligned
|
1 | *** Variables ***
2 | ${VAR} 1
3 | ${VAR} 1
| ^ SPC14
4 | ${VAR} 1
5 | VALUE 1
Found 2 issues: 2 ERRORs, 0 WARNINGs, 0 INFO.
```
## MCP Server
Robocop provides an [MCP (Model Context Protocol)](https://modelcontextprotocol.io/) server that allows AI assistants like Claude and GitHub Copilot to lint and format Robot Framework code directly.
Install with MCP support:
```bash
pip install robotframework-robocop[mcp]
```
Run the server:
```bash
robocop-mcp
```
Full documentation: [MCP Server](https://robocop.dev/stable/integrations/ai/)
## Values
Original *RoboCop* - a fictional cybernetic police officer - was the following three prime directives
which also drive the progress of Robocop linter:
First Directive: **Serve the public trust**
Which lies behind the creation of the project - to **serve** developers and testers as a tool to build applications they can **trust**.
Second Directive: **Protect the innocent**
**The innocent** testers and developers have no intention of producing ugly code, but sometimes, you know, it just happens,
so Robocop is there to **protect** them.
Third Directive: **Uphold the law**
Following the coding guidelines established in the project are something crucial to keep the code clean,
readable and understandable by others, and Robocop can help to **uphold the law**.
## FAQ
<details>
<summary>Can I integrate Robocop with my code editor (IDE)?</summary>
**Yes**, Robocop integrates nicely with popular IDEs like PyCharm or VSCode
thanks to [the RobotCode](https://robotcode.io/) plugin.
Read a simple manual (README) in that project to figure out how to install and use it.
</details>
<details>
<summary>Can I load configuration from a file?</summary>
**Yes**, you can use toml-based configuration files:
**`pyproject.toml` file**
**`robocop.toml` file**
**`robot.toml` file**
Example configuration file:
```toml
[tool.robocop]
exclude = ["deprecated.robot"]
[tool.robocop.lint]
select = [
"rulename",
"ruleid"
]
configure = [
"line-too-long.line_length=110"
]
[tool.robocop.format]
select = ["NormalizeNewLines"]
configure = [
"NormalizeNewLines.flatten_lines=True"
]
```
Multiple configuration files are supported. However, global-like options such as ``--verbose`` or ``--reports`` are
only loaded from a top configuration file. Read more in
[configuration](https://robocop.dev/stable/configuration/).
</details>
<details>
<summary>I use different coding standards. Can I configure rules so that they fit my needs?</summary>
**Yes**, some rules and formatters are configurable. You can find the configuration details in the documentation or
by running:
```commandline
robocop docs rule_name_or_id
robocop docs formatter_name
```
Configuring is done by using `-c / --configure` command line option followed by pattern
`<name>.<param_name>=<value>` where:
- `<name>` can either be rule name or its id, or formatter name
- `<param_name>` is a public name of the parameter
- `<value>` is a desired value of the parameter
For example:
```
robocop check --configure line-too-long.line_length=140
```
---
Each rule's severity can also be overwritten. Possible values are
`e/error`, `w/warning` or `i/info` and are case-insensitive. Example:
```
robocop check -c too-long-test-case.severity=e
```
---
If there are special cases in your code that violate the rules,
you can also exclude them in the source code.
Example:
```
Keyword with lowercased name # robocop: off
```
More about it in
[our documentation](https://robocop.dev/stable/configuration/configuration_reference/#selecting-rules).
</details>
<details>
<summary>Can I define custom rules?</summary>
**Yes**, you can define and include custom rules using `--custom-rules` command line option
by providing a path to a file containing your rule(s):
```
robocop --custom-rules my/own/rule.py --custom-rules external_rules.py
```
If you feel that your rule is very helpful and should be included in Robocop permanently,
you can always share your solution by
[submitting a pull request](https://github.com/MarketSquare/robotframework-robocop/pulls).
You can also share your idea by
[creating an issue](https://github.com/MarketSquare/robotframework-robocop/issues/new/choose).
More about custom rules with code examples in
[our documentation](https://robocop.dev/stable/linter/custom_rules/).
</details>
<details>
<summary>Can I use Robocop in continuous integration (CI) tools?</summary>
**Yes**, Robocop is able to produce different kinds of reports that are supported by most popular platforms such as
GitHub, Gitlab, Sonar Qube, etc. Read more in [integrations](https://robocop.dev/stable/integrations/precommit/).
</details>
---
> Excuse me, I have to go. Somewhere there is a crime happening. - Robocop
| text/markdown | null | Bartlomiej Hirsz <bartek.hirsz@gmail.com>, Mateusz Nojek <matnojek@gmail.com> | null | Bartlomiej Hirsz <bartek.hirsz@gmail.com> | null | automation, formatter, formatting, linter, qa, robotframework, testautomation, testing | [
"Development Status :: 5 - Production/Stable",
"Framework :: Robot Framework",
"Framework :: Robot Framework :: Tool",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Quality Assurance",
"Topic :: Software Development :: Testing",
"Topic :: Utilities"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"jinja2>=3.1.4",
"msgpack>=1.0.0",
"pathspec>=0.12",
"platformdirs>=4.3",
"pytz>=2022.7",
"rich>=10.11.0",
"robotframework<7.5,>=5.0",
"tomli-w>=1.0",
"tomli==2.2.1; python_version < \"3.11\"",
"typer>=0.12.5",
"typing-extensions>=4.15.0",
"fastmcp>=2.13.0; extra == \"mcp\""
] | [] | [] | [] | [
"Bug tracker, https://github.com/MarketSquare/robotframework-robocop/issues",
"Source code, https://github.com/MarketSquare/robotframework-robocop",
"Documentation, https://robocop.dev/",
"Homepage, https://robocop.dev/"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:53:08.293302 | robotframework_robocop-8.1.1.tar.gz | 974,174 | f4/da/abfb9ee808c814cc553a94cf3f25aac0b866683b8bef5ae78544619947f5/robotframework_robocop-8.1.1.tar.gz | source | sdist | null | false | c00c02b0f3907d683fd90fd58382b14c | 47fcca15042d2d9adbc086542a58c1c6cf058c9a0e29bf38edf0ebc60e63e845 | f4daabfb9ee808c814cc553a94cf3f25aac0b866683b8bef5ae78544619947f5 | null | [
"LICENSE"
] | 6,525 |
2.1 | epyt | 2.3.5.0 | EPyT: An EPANET-Python Toolkit for Smart Water Network Simulations. The EPyT is inspired by the EPANET-Matlab Toolkit. | <a href="http://www.kios.ucy.ac.cy"><img src="https://www.kios.ucy.ac.cy/wp-content/uploads/2021/07/Logotype-KIOS.svg" width="200" height="100"/><a>
[](https://github.com/KIOS-Research/EPyT/blob/main/LICENSE.md)
[](https://pypi.org/project/epyt/)
[](https://pepy.tech/project/epyt)
[](https://pepy.tech/project/epyt)
[](https://github.com/OpenWaterAnalytics/EPyT/actions/workflows/build_tests.yml)
[](https://epanet-python-toolkit-epyt.readthedocs.io/en/latest/?badge=latest)
[](https://doi.org/10.21105/joss.05947)
# EPANET Python Toolkit (EPyT)
The `EPANET-Python Toolkit` is an open-source software, originally developed by the [KIOS Research and Innovation Center of Excellence, University of Cyprus](http://www.kios.ucy.ac.cy/) which operates within the Python environment, for providing a programming interface for the latest version of [EPANET](https://github.com/OpenWaterAnalytics/epanet), a hydraulic and quality modeling software created by the US EPA, with Python, a high-level technical computing software. The goal of the EPANET Python Toolkit is to serve as a common programming framework for research and development in the growing field of smart water networks.
The `EPANET-Python Toolkit` features easy to use commands/wrappers for viewing, modifying, simulating and plotting results produced by the EPANET libraries.
For support, please use the OWA community forum: https://github.com/orgs/OpenWaterAnalytics/discussions
## Table of Contents
- [EPANET Python Toolkit (EPyT)](#epanet-python-toolkit-epyt)
- [How to cite](#how-to-cite)
- [Requirements](#requirements)
- [How to install](#how-to-install)
- [How to use the Toolkit](#how-to-use-the-toolkit)
- [How to fix/report bugs](#how-to-fixreport-bugs)
- [Licenses](#licenses)
- [Contributors](#contributors)
- [Contributing](#contributing)
- [Recommendation](#recommendation)
- [List of EPyT Functions](#list-of-epyt-functions)
- [List of EPANET 2.2 Functions](#list-of-epanet-2012-functions-supported)
- [List of EPANET 2.3 Functions Supported](#list-of-epanet-23-functions-supported)
- [List of EPANET MSX Functions API](#list-of-epanet-msx-functions-api)
## How to cite
Kyriakou, M. S., Demetriades, M., Vrachimis, S. G., Eliades, D. G., & Polycarpou, M. M. (2023). EPyT: An EPANET-Python Toolkit for Smart Water Network Simulations. Journal of Open Source Software, 8(92), 5947. https://doi.org/10.21105/joss.05947
```
@article{Kyriakou2023,
author = {Kyriakou, Marios S. and Demetriades, Marios and Vrachimis, Stelios G. and Eliades, Demetrios G. and Polycarpou, Marios M.},
doi = {10.21105/joss.05947},
journal = {Journal of Open Source Software},
month = dec,
number = {92},
pages = {5947},
title = {{EPyT: An EPANET-Python Toolkit for Smart Water Network Simulations}},
url = {https://joss.theoj.org/papers/10.21105/joss.05947},
volume = {8},
year = {2023}
}
```
↑ [Back to top](#table-of-contents)
## Requirements
* Python >=3.9
* Windows, OSX or Linux
* [EPANET 2.2](https://github.com/OpenWaterAnalytics/epanet)
Linux: `sudo cp libepanet2.so /lib/x86_64-linux-gnu/libepanet.so`
↑ [Back to top](#table-of-contents)
## How to install
**Environments -> base (root) -> open terminal -> pip install epyt**
* PyPI: <b>pip install epyt</b>
↑ [Back to top](#table-of-contents)
## How to use the Toolkit
**Minimum Example:**
```python
>>> from epyt import epanet
>>>
>>> d = epanet('Net1.inp')
>>> d.getNodeCount()
>>> d.getNodeElevations()
```
**Minumun Example using custom Library:**
```python
>>> from epyt import epanet
>>>
>>>epanetlib=os.path.join(os.getcwd(), 'epyt','libraries','win','epanet2.dll')
>>>msxlib=os.path.join(os.getcwd(), 'epyt','libraries','win','epanetmsx.dll')
>>>d = epanet(inpname, customlib=epanetlib)
>>>d.loadMSXFile(msxname, customMSXlib=msxlib)
```
**More examples:**
[https://github.com/KIOS-Research/EPYT/tree/main/epyt/examples](https://github.com/KIOS-Research/EPYT/tree/main/epyt/examples#readme)
↑ [Back to top](#table-of-contents)
## How to fix/report bugs
To fix a bug `Fork` the `EPyT`, `Edit` the code and make the appropriate change, and then `Pull` it so that we evaluate it.
Keep in mind that some bugs may exist in the `EPANET` libraries, in case you are not receiving the expected results.
↑ [Back to top](#table-of-contents)
## Licenses
* `EPANET`: Public Domain
* `EPANET-Python Toolkit (EPyT)`: EUPL
↑ [Back to top](#table-of-contents)
## Contributors
* Marios Kyriakou, [KIOS Research and Innovation Center of Excellence, University of Cyprus](http://www.kios.ucy.ac.cy/)
* Marios Demetriades, [KIOS Research and Innovation Center of Excellence, University of Cyprus](http://www.kios.ucy.ac.cy/)
* Stelios Vrachimis, [KIOS Research and Innovation Center of Excellence, University of Cyprus](http://www.kios.ucy.ac.cy/)
* Demetrios Eliades, [KIOS Research and Innovation Center of Excellence, University of Cyprus](http://www.kios.ucy.ac.cy/)
The `EPyT` is based/inspired on the [EPANET-Matlab Toolkit](https://github.com/OpenWaterAnalytics/EPANET-Matlab-Toolkit).
## Contributing
If you want to contribute, please check out our [Code of Conduct](https://github.com/KIOS-Research/EPyT/blob/dev/CODE_OF_CONDUCT.md). Everyone is welcome to contribute whether reporting a new [issue](https://github.com/KIOS-Research/EPyT/issues), suggesting a new feature, or writing code. If you want to contribute code, you can create a new fork in the repo to your own account. Make your commits on your dev branch (based on dev) and when you are finished then you can create a [pull request](https://github.com/KIOS-Research/EPyT/pulls) to test the code and discuss your changes.
## Recommendation
* Install Anaconda<br>
* Run `EPyT` with [Spyder IDE](https://www.spyder-ide.org/)
* Run `EPyT` with [PyCharm](https://www.jetbrains.com/pycharm/)
*Settings on Spyder IDE*
* Tools -> Preferrences

* View -> Window layouts -> Matlab layout
* Enable interactive plot on matlibplot
: Tools -> Preferences -> IPython console -> Graphics -> Graphics backend -> Backend: Automatic
↑ [Back to top](#table-of-contents)
## List of EPyT Functions
| Function |Description|
|-------------------------------------|---------------------------|
| addControls | Adds a new simple control |
| addCurve | Adds a new curve appended to the end of the existing curves |
| addLinkPipe | Adds a new pipe |
| addLinkPipeCV | Adds a new control valve pipe |
| addLinkPump | Adds a new pump |
| addLinkValveFCV | Adds a new FCV valve |
| addLinkValveGPV | Adds a new GPV valve |
| addLinkValvePBV | Adds a new PBV valve |
| addLinkValvePCV | Adds a new PCV valve and returns the index of the new PCV valve |
| addLinkValvePRV | Adds a new PRV valve |
| addLinkValvePSV | Adds a new PSV valve |
| addLinkValveTCV | Adds a new TCV valve |
| addNodeJunction | Adds a new junction |
| addNodeJunctionDemand | Adds a new demand to a junction given the junction index, base demand, demand time pattern and demand category name |
| addNodeReservoir | Adds a new reservoir |
| addNodeTank | Adds a new tank |
| addPattern | Adds a new time pattern to the network |
| addRules | Adds a new rule-based control to a project |
| appRotateNetwork | Rotates the network by theta degrees counter-clockwise |
| appShiftNetwork | Shifts the network |
| clearReport | Clears the contents of a project's report file |
| closeHydraulicAnalysis | Closes the hydraulic analysis system, freeing all allocated memory |
| closeNetwork | Closes down the Toolkit system |
| closeQualityAnalysis | Closes the water quality analysis system, freeing all allocated memory |
| copyReport | Copies the current contents of a project's report file to another file |
| createProject | Creates a new epanet projec |
| deleteAllTemps | Delete all temporary files (.inp, .bin) created in networks folder |
| deleteControls | Deletes an existing simple control |
| deleteCurve | Deletes a data curve from a project |
| deleteLink | Deletes a link |
| deleteNode | Deletes nodes |
| deleteNodeJunctionDemand | Deletes a demand from a junction given the junction index and demand index.
| deletePattern | Deletes a time pattern from a project |
| deletePatternsAll | Deletes all time patterns from a project |
| deleteProject | Deletes the epanet project |
| deleteRules | Deletes an existing rule-based control given it's index |
| getAdjacencyMatrix | Compute the adjacency matrix (connectivity graph) considering the flows, using mean flow |
| getAllAttributes | Get all attributes of a given Python object |
| getCMDCODE | Retrieves the CMC code |
| getComputedHydraulicTimeSeries | Computes hydraulic simulation and retrieves all time-series |
| getComputedQualityTimeSeries | Computes Quality simulation and retrieves all or some time-series |
| getComputedTimeSeries | Run analysis with binary fil |
| getConnectivityMatrix | Retrieve the Connectivity Matrix of the networ |
| getConsumerDemandDelivered | Retrieves the delivered consumer demand for a specific node |
| getConsumerDemandRequested | Retrieves the requested consumer demand for a specific node |
| getControlCount | Retrieves the number of controls => will replace getControlRulesCount |
| getControlRulesCount | Retrieves the number of controls |
| getControlState | Retrieves the enabled state of a specified control in the EPANET model |
| getControls | Retrieves the parameters of all control statements |
| getCounts | Retrieves the number of network components |
| getCurveComment | Retrieves the comment string of a curve |
| getCurveCount | Retrieves the number of curves |
| getCurveIndex | Retrieves the index of a curve with specific ID |
| getCurveLengths | Retrieves number of points in a curve |
| getCurveNameID | Retrieves the IDs of curves |
| getCurveType | Retrieves the curve-type for all curves |
| getCurveTypeIndex | Retrieves the curve-type index for all curves |
| getCurveValue | Retrieves the X, Y values of points of curves |
| getCurvesInfo | Retrieves all the info of curves |
| getDemandModel | Retrieves the type of demand model in use and its parameters |
| getENfunctionsImpemented | Retrieves the epanet functions that have been developed |
| getError | Retrieves the text of the message associated with a particular error or warning code |
| getFlowUnits | Retrieves flow units used to express all flow rates |
| getLibFunctions | Retrieves the functions of DLL |
| getLinkActualQuality | Retrieves the current computed link quality (read only) |
| getLinkBulkReactionCoeff | Retrieves the value of all link bulk chemical reaction coefficient |
| getLinkComment | Retrieves the comment string assigned to the link object |
| getLinkCount | Retrieves the number of links |
| getLinkDiameter | Retrieves the value of link diameters |
| getLinkEnergy | Retrieves the current computed pump energy usage (read only) |
| getLinkExpansionProperties | Retrieves the expansion properties for a specified link (pipe) |
| getLinkFlows | Retrieves the current computed flow rate (read only) |
| getLinkHeadloss | Retrieves the current computed head loss (read only) |
| getLinkInControl | Function to determine wether a link apperas in any simple or rule based control |
| getLinkIndex | Retrieves the indices of all links, or the indices of an ID set of links |
| getLinkInitialSetting | Retrieves the value of all link roughness for pipes or initial speed for pumps or initial setting for valves |
| getLinkInitialStatus | Retrieves the value of all link initial status |
| getLinkLeakArea | Function to retrieve the leak area for a specified link (pipe) |
| getLinkLeakageRate | Retrieves the leakage rate of a specific pipe (link) at a given point in time |
| getLinkLength | Retrieves the value of link lengths |
| getLinkMinorLossCoeff | Retrieves the value of link minor loss coefficients |
| getLinkNameID | Retrieves the ID label(s) of all links, or the IDs of an index set of links |
| getLinkNodesIndex | Retrieves the indexes of the from/to nodes of all links |
| getLinkPipeCount | Retrieves the number of pipes |
| getLinkPipeIndex | Retrieves the pipe indices |
| getLinkPipeNameID | Retrieves the pipe ID |
| getLinkPumpCount | Retrieves the number of pumps |
| getLinkPumpECost | Retrieves the pump average energy price |
| getLinkPumpECurve | Retrieves the pump efficiency v |
| getLinkPumpEPat | Retrieves the pump energy price time pattern index |
| getLinkPumpEfficiency | Retrieves the current computed pump efficiency (read only) |
| getLinkPumpHCurve | Retrieves the pump head v |
| getLinkPumpHeadCurveIndex | Retrieves the index of a head curve for all pumps |
| getLinkPumpIndex | Retrieves the pump indices |
| getLinkPumpNameID | Retrieves the pump ID |
| getLinkPumpPatternIndex | Retrieves the pump speed time pattern index |
| getLinkPumpPatternNameID | Retrieves pump pattern name ID |
| getLinkPumpPower | Retrieves the pump constant power rating (read only) |
| getLinkPumpState | Retrieves the current computed pump state (read only) (see @ref EN_PumpStateType) |
| getLinkPumpSwitches | Retrieves the number of pump switches |
| getLinkPumpType | Retrieves the type of a pump |
| getLinkPumpTypeCode | Retrieves the code of type of a pump |
| getLinkQuality | Retrieves the value of link quality |
| getLinkResultIndex | Retrieves the order in which a link's results were saved to an output file |
| getLinkRoughnessCoeff | Retrieves the value of link roughness coefficient |
| getLinkSettings | Retrieves the current computed value of all link roughness for pipes or actual speed for pumps or actual setting for valves |
| getLinkStatus | Retrieves the current link status (see @ref EN_LinkStatusType) (0 = closed, 1 = open) |
| getLinkType | Retrieves the link-type code for all links |
| getLinkTypeIndex | Retrieves the link-type code for all links |
| getLinkValues | Retrieves property values for all links within the EPANET model during a hydraulic analysis |
| getLinkValveCount | Retrieves the number of valves |
| getLinkValveCurveGPV | Retrieves the valve curve for a specified general purpose valve (GPV) |
| getLinkValveCurvePCV | Retrieves the valve curve for a specified pressure control valve (PCV) |
| getLinkValveIndex | Retrieves the valve indices |
| getLinkValveNameID | Retrieves the valve ID |
| getLinkVelocity | Retrieves the current computed flow velocity (read only) |
| getLinkVertices | Retrieves the coordinate's of a vertex point assigned to a link |
| getLinkVerticesCount | Retrieves the number of internal vertex points assigned to a link |
| getLinkWallReactionCoeff | Retrieves the value of all pipe wall chemical reaction coefficient |
| getLinksInfo | Retrieves all link info |
| getNetworksDatabase | Retrieves all EPANET Input Files from EPyT database |
| getNodeActualDemand | Retrieves the computed value of all node actual demands |
| getNodeActualDemandSensingNodes | Retrieves the computed demand values at some sensing nodes |
| getNodeActualQuality | Retrieves the computed values of the actual quality for all nodes |
| getNodeActualQualitySensingNodes | Retrieves the computed quality values at some sensing node |
| getNodeBaseDemands | Retrieves the value of all node base demands |
| getNodeComment | Retrieves the comment string assigned to the node object |
| getNodeCount | Retrieves the number of nodes |
| getNodeDemandCategoriesNumber | Retrieves the value of all node base demands categorie number |
| getNodeDemandDeficit | Retrieves the amount that full demand is reduced under PDA |
| getNodeDemandPatternIndex | Retrieves the value of all node base demands pattern index |
| getNodeDemandPatternNameID | Retrieves the value of all node base demands pattern name ID |
| getNodeElevations | Retrieves the value of all node elevations |
| getNodeEmitterCoeff | Retrieves the value of all node emmitter coefficients |
| getNodeEmitterFlow | Retrieves node emmiter flow |
| getNodeHydraulicHead | Retrieves the computed values of all node hydraulic heads |
| getNodeInControl | Function to determine wether a node apperas in any simple or rule based control |
| getNodeIndex | Retrieves the indices of all nodes or some nodes with a specified ID |
| getNodeInitialQuality | Retrieves the value of all node initial quality |
| getNodeJunctionCount | Retrieves the number of junction nodes |
| getNodeJunctionDemandIndex | Retrieves the demand index of the junctions |
| getNodeJunctionDemandName | Gets the name of a node's demand category |
| getNodeJunctionIndex | Retrieves the indices of junctions |
| getNodeJunctionNameID | Retrieves the junction ID label |
| getNodeLeakageFlow | Retrieves the leakage flow for a specific node |
| getNodeMassFlowRate | Retrieves the computed mass flow rates per minute of chemical sources for all nodes |
| getNodeNameID | Retrieves the ID label of all nodes or some nodes with a specified index |
| getNodePatternIndex | Retrieves the value of all node demand pattern indices |
| getNodePressure | Retrieves the computed values of all node pressures |
| getNodeReservoirCount | Retrieves the number of Reservoirs |
| getNodeReservoirIndex | Retrieves the indices of reservoirs |
| getNodeReservoirNameID | Retrieves the reservoir ID label |
| getNodeResultIndex | Retrieves the order in which a node's results were saved to an output file |
| getNodeSourcePatternIndex | Retrieves the value of all node source pattern index |
| getNodeSourceQuality | Retrieves the value of all node source quality |
| getNodeSourceType | Retrieves the value of all node source type |
| getNodeSourceTypeIndex | Retrieves the value of all node source type index |
| getNodeTankBulkReactionCoeff | Retrieves the tank bulk rate coefficient |
| getNodeTankCanOverFlow | Retrieves the tank can overflow (= 1) or not (= 0) |
| getNodeTankCount | Retrieves the number of Tanks |
| getNodeTankData | Retrieves a group of properties for a tank |
| getNodeTankDiameter | Retrieves the tank diameters |
| getNodeTankIndex | Retrieves the tank indices |
| getNodeTankInitialLevel | Retrieves the value of all tank initial water levels |
| getNodeTankInitialWaterVolume | Retrieves the tank initial water volume |
| getNodeTankMaximumWaterLevel | Retrieves the tank maximum water level |
| getNodeTankMaximumWaterVolume | Retrieves the tank maximum water volume |
| getNodeTankMinimumWaterLevel | Retrieves the tank minimum water level |
| getNodeTankMinimumWaterVolume | Retrieves the tank minimum water volume |
| getNodeTankMixZoneVolume | Retrieves the tank mixing zone volume |
| getNodeTankMixingFraction | Retrieves the tank Fraction of total volume occupied by the inlet/outlet zone in a 2-compartment tank |
| getNodeTankMixingModelCode | Retrieves the tank mixing model code |
| getNodeTankMixingModelType | Retrieves the tank mixing model type |
| getNodeTankNameID | Retrieves the tank IDs |
| getNodeTankReservoirCount | Retrieves the number of tanks |
| getNodeTankVolume | Retrieves the tank volume |
| getNodeTankVolumeCurveIndex | Retrieves the tank volume curve index |
| getNodeType | Retrieves the node-type code for all nodes |
| getNodeTypeIndex | Retrieves the node-type code for all nodes |
| getNodesConnectingLinksID | Retrieves the id of the from/to nodes of all links |
| getNodesConnectingLinksIndex | Retrieves the indexes of the from/to nodes of all links |
| getNodesInfo | Retrieves nodes info (elevations, demand patterns, emmitter coeff, initial quality, source quality, source pattern index, source type index, node type index) |
| getOptionsAccuracyValue | Retrieves the total normalized flow change for hydraulic convergence |
| getOptionsCheckFrequency | Retrieves the frequency of hydraulic status checks |
| getOptionsDampLimit | Retrieves the accuracy level where solution damping begins |
| getOptionsDemandCharge | Retrieves the energy charge per maximum KW usage |
| getOptionsDemandPattern | Retrieves the default Demand pattern |
| getOptionsEmitterBackFlow | Retrieves the current setting for allowing reverse flow through emitters |
| getOptionsEmitterExponent | Retrieves the power exponent for the emmitters |
| getOptionsExtraTrials | Retrieves the extra trials allowed if hydraulics don't converge |
| getOptionsFlowChange | Retrieves the maximum flow change for hydraulic convergence |
| getOptionsGlobalEffic | Retrieves the global efficiency for pumps(percent) |
| getOptionsGlobalPattern | Retrieves the index of the global energy price pattern |
| getOptionsGlobalPrice | Retrieves the global average energy price per kW-Hour |
| getOptionsHeadError | Retrieves the maximum head loss error for hydraulic convergence |
| getOptionsHeadLossFormula | Retrieves the headloss formula |
| getOptionsLimitingConcentration | Retrieves the limiting concentration for growth reactions |
| getOptionsMaxTrials | Retrieves the maximum hydraulic trials allowed for hydraulic convergence |
| getOptionsMaximumCheck | Retrieves the maximum trials for status checking |
| getOptionsPatternDemandMultiplier | Retrieves the global pattern demand multiplier |
| getOptionsPipeBulkReactionOrder | Retrieves the bulk water reaction order for pipes |
| getOptionsPipeWallReactionOrder | Retrieves the wall reaction order for pipes (either 0 or 1) |
| getOptionsPressureUnits | get the pressure unit used in Epanet |
| getOptionsQualityTolerance | Retrieves the water quality analysis tolerance |
| getOptionsSpecificDiffusivity | Retrieves the specific diffusivity (relative to chlorine at 20 deg C) |
| getOptionsSpecificGravity | Retrieves the specific gravity |
| getOptionsSpecificViscosity | Retrieves the specific viscosity |
| getOptionsStatusReport | get the type of the status report(full/no/normal) |
| getOptionsTankBulkReactionOrder | Retrieves the bulk water reaction order for tanks |
| getPattern | Retrieves the multiplier factor for all patterns and all times |
| getPatternAverageDefaultValue | Retrieves the average value of the default pattern |
| getPatternAverageValue | Retrieves the average values of all the time patterns |
| getPatternComment | Retrieves the comment string assigned to the pattern object |
| getPatternCount | Retrieves the number of patterns |
| getPatternIndex | Retrieves the index of all or some time patterns given their IDs |
| getPatternLengths | Retrieves the number of time periods in all or some time patterns |
| getPatternNameID | Retrieves the ID label of all or some time patterns indices |
| getPatternValue | Retrieves the multiplier factor for a certain pattern and time |
| getQualityCode | Retrieves the code of water quality analysis type |
| getQualityInfo | Retrieves quality analysis information (type, chemical name, units, trace node ID) |
| getQualityTraceNodeIndex | Retrieves the trace node index of water quality analysis type |
| getQualityType | Retrieves the type of water quality analysis type |
| getRuleCount | Retrieves the number of rules |
| getRuleEnabled | Retrieves the enabled state of a specific rule in the EPANET model |
| getRuleID | Retrieves the ID name of a rule-based control given its index |
| getRuleInfo | Retrieves summary information about a rule-based control given it's index |
| getRules | Retrieves the rule - based control statements |
| getStatistic | Returns error code |
| getStatisticDeficientNodes | Retrieves the number of deficient nodes in the simulation |
| getStatisticDemandReduction | Retrieves the demand reduction statistic from the simulation |
| getStatisticIterations | Retrieves the number of iterations taken in the simulation |
| getStatisticRelativeError | Retrieves the relative error statistic from the simulation |
| getStatisticTotalLeakageLoss | Retrieves the total leakage loss statistic from the simulation. |
| getTimeHTime | Retrieves the elapsed time of current hydraulic solution |
| getTimeHaltFlag | Retrieves the number of halt flag indicating if the simulation was halted |
| getTimeHydraulicStep | Retrieves the value of the hydraulic time step |
| getTimeNextEvent | Retrieves the shortest time until a tank becomes empty or full |
| getTimeNextEventTank | Retrieves the index of tank with shortest time to become empty or full |
| getTimePatternStart | Retrieves the value of pattern start time |
| getTimePatternStep | Retrieves the value of the pattern time step |
| getTimeQTime | Retrieves the elapsed time of current quality solution |
| getTimeQualityStep | Retrieves the value of the water quality time step |
| getTimeReportingPeriods | Retrieves the number of reporting periods saved to the binary |
| getTimeReportingStart | Retrieves the value of the reporting start time |
| getTimeReportingStep | Retrieves the value of the reporting time step |
| getTimeRuleControlStep | Retrieves the time step for evaluating rule-based controls |
| getTimeSimulationDuration | Retrieves the value of simulation duration |
| getTimeStartClockStartTime | Retrieves the simulation starting time of day |
| getTimeStartTime | Retrieves the simulation starting time of day |
| getTimeStatisticsIndex | Retrieves the index of the type of time series post-processing |
| getTimeStatisticsType | Retrieves the type of time series post-processing |
| getTimetoNextEvent | Determines the type of event that will cause the end of the current time step/duration/index |
| getTitle | Retrieves the title lines of the project |
| getUnits | Retrieves the Units of Measurement |
| getVersion | Retrieves the current EPANET version of DLL |
| initializeEPANET | Initializes an EPANET project that isn't opened with an input fil |
| initializeHydraulicAnalysis | Initializes storage tank levels, link status and settings, and the simulation clock time prior to running a hydraulic analysis |
| initializeQualityAnalysis | Initializes water quality and the simulation clock time prior to running a water quality analysis |
| loadEPANETFile | Load epanet file when use bin functions |
| loadMSXEPANETFile | Re-Load EPANET MSX file - parfor |
| loadPatternFile | loads time patterns from a file into a project under a specific pattern ID |
| nextHydraulicAnalysisStep | Determines the length of time until the next hydraulic event occurs in an extended period simulation |
| nextQualityAnalysisStep | Advances the water quality simulation to the start of the next hydraulic time period |
| openAnyInp | Open as on matlab editor any EPANET input file using built function open |
| openCurrentInp | Opens EPANET input file who is loade |
| openHydraulicAnalysis | Opens the hydraulics analysis system |
| openQualityAnalysis | Opens the water quality analysis system |
| openX | enable the opening of input files with formatting errors |
| plot | Plot Network, show all components, plot pressure/flow/elevation |
| plot_close | Close all open figures |
| plot_save | Save plot |
| plot_show | Show plot |
| reloadNetwork | Reloads the Network (ENopen) |
| runEPANETexe | Runs epanet .exe file |
| runHydraulicAnalysis | Runs a single period hydraulic analysis, retrieving the current simulation clock time t |
| runQualityAnalysis | Makes available the hydraulic and water quality results that occur at the start of the next time period of a water quality analysis, where the start of the period is returned in t |
| runsCompleteSimulation | Runs a complete hydraulic and water simulation to create binary & report files with name: [NETWORK_temp.txt], [NETWORK_temp.bin] OR you can use argument to runs a complete simulation via self.api.en_epane |
| saveHydraulicFile | Saves the current contents of the binary hydraulics file to a file |
| saveHydraulicsOutputReportingFile | Transfers results of a hydraulic simulation from the binary Hydraulics file to the binary Output file, where results are only reported at uniform reporting intervals |
| saveInputFile | Writes all current network input data to a file using the format of an EPANET input file |
| setCMDCODE | Sets the CMC code |
| setControlEnabled | Sets the control state to either enable or disable in the EPANET model |
| setControls | Sets the parameters of a simple control statement |
| setCurve | Sets x, y values for a specific curve |
| setCurveComment | Sets the comment string of a curve |
| setCurveNameID | Sets the name ID of a curve given it's index and the new ID |
| setCurveType | Sets the type of a specified curve in the EPANET model |
| setCurveTypeEfficiency | Sets the type of curve to Efficiency in the EPANET model |
| setCurveTypeGeneral | Sets the type of a curve to general in the EPANET model |
| setCurveTypeHeadloss | Sets the type of a curve to Headloss in the EPANET model |
| setCurveTypePump | Sets the type of a curve to Pump in the EPANET model |
| setCurveTypeValveCurve | Sets the type of a curve to Valve in the EPANET model |
| setCurveTypeVolume | Sets the type of a curve to Volume in the EPANET model |
| setCurveValue | Sets x, y point for a specific point number and curve |
| setDemandModel | Sets the type of demand model to use and its parameters |
| setFlowUnitsAFD | Sets flow units to AFD(Acre-Feet per Day) |
| setFlowUnitsCFS | Sets flow units to CFS(Cubic Feet per Second) |
| setFlowUnitsCMD | Sets flow units to CMD(Cubic Meters per Day) |
| setFlowUnitsCMH | Sets flow units to CMH(Cubic Meters per Hour) |
| setFlowUnitsCMS | Sets flow units to CMS(Cubic Meters per Second) |
| setFlowUnitsGPM | Sets flow units to GPM(Gallons Per Minute) |
| setFlowUnitsIMGD | Sets flow units to IMGD(Imperial Million Gallons per Day) |
| setFlowUnitsLPM | Sets flow units to LPM(Liters Per Minute) |
| setFlowUnitsLPS | Sets flow units to LPS(Liters Per Second) |
| setFlowUnitsMGD | Sets flow units to MGD(Million Gallons per Day) |
| setFlowUnitsMLD | Sets flow units to MLD(Million Liters per Day) |
| setLinkBulkReactionCoeff | Sets the value of bulk chemical reaction coefficient |
| setLinkComment | Sets the comment string assigned to the link object |
| setLinkDiameter | Sets the values of diameters |
| setLinkExpansionProperties | Sets the expansion properties for a specified link (pipe) |
| setLinkInitialSetting | Sets the values of initial settings, roughness for pipes or initial speed for pumps or initial setting for valves |
| setLinkInitialStatus | Sets the values of initial status |
| setLinkLeakArea | Sets the leak area for a specified link (pipe) |
| setLinkLength | Sets the values of lengths |
| setLinkMinorLossCoeff | Sets the values of minor loss coefficient |
| setLinkNameID | Sets the ID name for links |
| setLinkNodesIndex | Sets the indexes of a link's start- and end-nodes |
| setLinkPipeData | Sets a group of properties for a pipe |
| setLinkPumpECost | Sets the pump average energy price |
| setLinkPumpECurve | Sets the pump efficiency v |
| setLinkPumpEPat | Sets the pump energy price time pattern index |
| setLinkPumpHCurve | Sets the pump head v |
| setLinkPumpHeadCurveIndex | Sets the curves index for pumps index |
| setLinkPumpPatternIndex | Sets the pump speed time pattern index |
| setLinkPumpPower | Sets the power for pumps |
| setLinkRoughnessCoeff | Sets the values of roughness coefficient |
| setLinkSettings | Sets the values of current settings, roughness for pipes or initial speed for pumps or initial setting for valves |
| setLinkStatus | Sets the values of current status for links |
| setLinkTypePipe | Sets the link type pipe for a specified link |
| setLinkTypePipeCV | Sets the link type cvpipe(pipe with check valve) for a specified link |
| setLinkTypePump | Sets the link type pump for a specified link |
| setLinkTypeValveFCV | Sets the link type valve FCV(flow control valve) for a specified link |
| setLinkTypeValveGPV | Sets the link type valve GPV(general purpose valve) for a specified link |
| setLinkTypeValvePBV | Sets the link type valve PBV(pressure breaker valve) for a specified link |
| setLinkTypeValvePCV | Sets the link type valve PCV(Position control valve) for a specified link |
| setLinkTypeValvePRV | Sets the link type valve PRV(pressure reducing valve) for a specified link |
| setLinkTypeValvePSV | Sets the link type valve PSV(pressure sustaining valve) for a specified link |
| setLinkTypeValveTCV | Sets the link type valve TCV(throttle control valve) for a specified link |
| setLinkValveCurveGPV | Sets the valve curve for a specified general purpose valve (GPV) |
| setLinkValveCurvePCV | Sets the valve curve for a specified pressure control valve (PCV) |
| setLinkVertices | Assigns a set of internal vertex points to a link |
| setLinkWallReactionCoeff | Sets the value of wall chemical reaction coefficient |
| setNodeBaseDemands | Sets the values of demand for nodes |
| setNodeComment | Sets the comment string assigned to the node object |
| setNodeCoordinates | Sets node coordinates |
| setNodeDemandPatternIndex | Sets the values of demand time pattern indices |
| setNodeElevations | Sets the values of elevation for nodes |
| setNodeEmitterCoeff | Sets the values of emitter coefficient for nodes |
| setNodeInitialQuality | | text/markdown | Marios S. Kyriakou | kiriakou.marios@ucy.ac.cy | null | null | null | epanet, water, networks, hydraulics, quality, simulations, emt, epanet matlab toolkit | [
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Programming Language :: Python",
"License :: OSI Approved :: European Union Public Licence 1.2 (EUPL 1.2)",
"Operating System :: OS Independent"
] | [] | https://github.com/OpenWaterAnalytics/EPyT | null | >=3.9 | [] | [] | [] | [
"cffi>=2.0.0",
"numpy>=2.0.2",
"matplotlib>=3.8",
"pandas>=2.0.3",
"XlsxWriter>=3.2.0",
"setuptools"
] | [] | [] | [] | [
"Bug Tracker, https://github.com/OpenWaterAnalytics/EPyT/issues"
] | twine/6.1.0 CPython/3.9.21 | 2026-02-20T13:51:46.764209 | epyt-2.3.5.0.tar.gz | 4,124,819 | 5e/1f/5c051ffd9e620f815e754fedc3f3fd0de5b061bf33d5e9bf2b37ea014407/epyt-2.3.5.0.tar.gz | source | sdist | null | false | 01741c41550eda292f84ccff765d48ef | 5dfe13d39350d4e52313fdf008c8707ca307105f4133c75ede8215b3b9500680 | 5e1f5c051ffd9e620f815e754fedc3f3fd0de5b061bf33d5e9bf2b37ea014407 | null | [] | 286 |
2.3 | napcat-sdk | 0.6.4 | NapCat SDK for Python - Fully typed and async ready | <div align="center">
<img src="https://raw.githubusercontent.com/faithleysath/napcat-sdk/refs/heads/main/docs/img/logo.png" width="250" height="200" alt="NapCat Logo">
# NapCat-SDK for Python
<p align="center">
<b>Type-Safe</b> • <b>Async-Ready</b> • <b>Framework-Free</b>
</p>
<p>
<a href="https://pypi.org/project/napcat-sdk/">
<img src="https://img.shields.io/pypi/v/napcat-sdk?style=flat-square&color=006DAD&label=PyPI" alt="PyPI">
</a>
<a href="https://github.com/faithleysath/napcat-sdk/blob/main/LICENSE">
<img src="https://img.shields.io/github/license/faithleysath/napcat-sdk?style=flat-square&color=blueviolet" alt="License">
</a>
<img src="https://img.shields.io/badge/Python-3.12+-FFE873?style=flat-square&logo=python&logoColor=black" alt="Python Version">
<img src="https://img.shields.io/badge/Typing-Strict-22c55e?style=flat-square" alt="Typing">
</p>
<p>
<a href="https://zread.ai/faithleysath/napcat-sdk" target="_blank"><img src="https://img.shields.io/badge/Ask_Zread-_.svg?style=flat&color=00b0aa&labelColor=000000&logo=data%3Aimage%2Fsvg%2Bxml%3Bbase64%2CPHN2ZyB3aWR0aD0iMTYiIGhlaWdodD0iMTYiIHZpZXdCb3g9IjAgMCAxNiAxNiIgZmlsbD0ibm9uZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPHBhdGggZD0iTTQuOTYxNTYgMS42MDAxSDIuMjQxNTZDMS44ODgxIDEuNjAwMSAxLjYwMTU2IDEuODg2NjQgMS42MDE1NiAyLjI0MDFWNC45NjAxQzEuNjAxNTYgNS4zMTM1NiAxLjg4ODEgNS42MDAxIDIuMjQxNTYgNS42MDAxSDQuOTYxNTZDNS4zMTUwMiA1LjYwMDEgNS42MDE1NiA1LjMxMzU2IDUuNjAxNTYgNC45NjAxVjIuMjQwMUM1LjYwMTU2IDEuODg2NjQgNS4zMTUwMiAxLjYwMDEgNC45NjE1NiAxLjYwMDFaIiBmaWxsPSIjZmZmIi8%2BCjxwYXRoIGQ9Ik00Ljk2MTU2IDEwLjM5OTlIMi4yNDE1NkMxLjg4ODEgMTAuMzk5OSAxLjYwMTU2IDEwLjY4NjQgMS42MDE1NiAxMS4wMzk5VjEzLjc1OTlDMS42MDE1NiAxNC4xMTM0IDEuODg4MSAxNC4zOTk5IDIuMjQxNTYgMTQuMzk5OUg0Ljk2MTU2QzUuMzE1MDIgMTQuMzk5OSA1LjYwMTU2IDE0LjExMzQgNS42MDE1NiAxMy43NTk5VjExLjAzOTlDNS42MDE1NiAxMC42ODY0IDUuMzE1MDIgMTAuMzk5OSA0Ljk2MTU2IDEwLjM5OTlaIiBmaWxsPSIjZmZmIi8%2BCjxwYXRoIGQ9Ik0xMy43NTg0IDEuNjAwMUgxMS4wMzg0QzEwLjY4NSAxLjYwMDEgMTAuMzk4NCAxLjg4NjY0IDEwLjM5ODQgMi4yNDAxVjQuOTYwMUMxMC4zOTg0IDUuMzEzNTYgMTAuNjg1IDUuNjAwMSAxMS4wMzg0IDUuNjAwMUgxMy43NTg0QzE0LjExMTkgNS42MDAxIDE0LjM5ODQgNS4zMTM1NiAxNC4zOTg0IDQuOTYwMVYyLjI0MDFDMTQuMzk4NCAxLjg4NjY0IDE0LjExMTkgMS42MDAxIDEzLjc1ODQgMS42MDAxWiIgZmlsbD0iI2ZmZiIvPgo8cGF0aCBkPSJNNCAxMkwxMiA0TDQgMTJaIiBmaWxsPSIjZmZmIi8%2BCjxwYXRoIGQ9Ik00IDEyTDEyIDQiIHN0cm9rZT0iI2ZmZiIgc3Ryb2tlLXdpZHRoPSIxLjUiIHN0cm9rZS1saW5lY2FwPSJyb3VuZCIvPgo8L3N2Zz4K&logoColor=ffffff" alt="zread"/></a>
<a href="https://deepwiki.com/faithleysath/napcat-sdk">
<img src="https://deepwiki.com/badge.svg" alt="Ask DeepWiki">
</a>
<a href="https://faithleysath.github.io/napcat-sdk/">
<img src="https://img.shields.io/badge/Docs-📖-blue?style=flat-square&color=2986cc" alt="Documentation">
</a>
<img src="https://img.shields.io/badge/QQ%E7%BE%A4-819085771-54a3ff?style=flat-square&logo=tencent-qq&logoColor=white" alt="QQ Group">
</p>
<h3>Stop guessing parameter types. Let the IDE do the work.</h3>
<p>告别查文档,享受 <b>100% 类型覆盖</b> 带来的极致补全体验。</p>
</div>
---
## ⚡ The "IDE Magic"
这就是为什么你应该选择 NapCat-SDK:
| **智能 API 补全 + 精准参数提示** | **原生开发体验 + 零心智负担** |
| :---: | :---: |
|  | 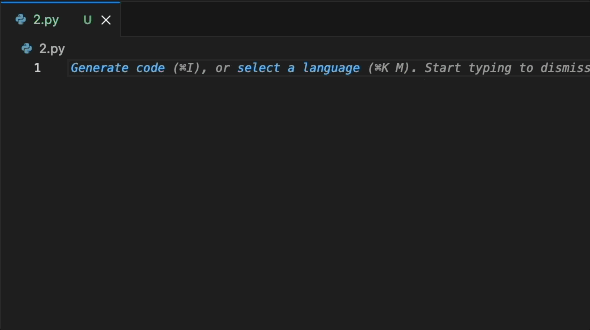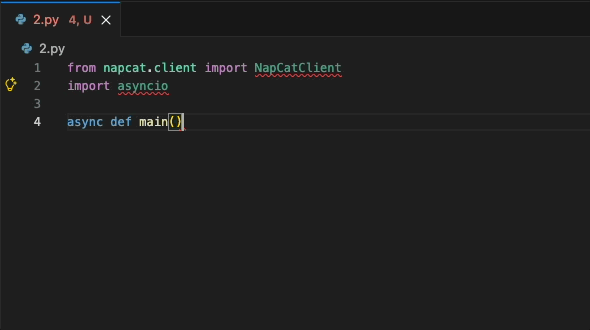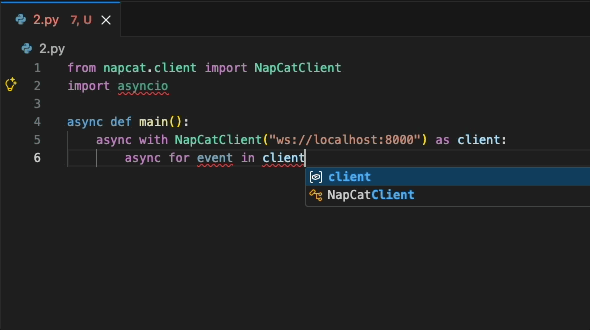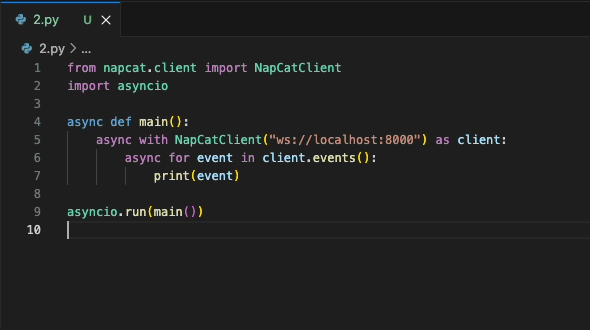 |
> 👆 真正的 **160+ API** 全量类型覆盖,每一次按键都有 IDE 的守护。
---
## ✨ Features
- 🔄 **协议自动同步**: 基于 OpenAPI 自动构建,与 NapCat 上游定义零时差同步。
- 🧘 **原生无框架**: 拒绝框架"黑魔法",纯粹 Python 语法,零心智负担。
- 💎 **极致类型**: 100% 类型覆盖,每一个参数都有定义,享受极致 IDE 补全。
- ⚡ **完全异步**: 基于 `websockets` + `asyncio` 原生开发,无惧高并发。
- 🔌 **双模支持**: 完美支持正向 (Client) 与反向 (Server) WebSocket 连接。
- 🌐 **远程 RPC**: 内置透明网关,让外部应用跨语言调用 NapCat API。
- 🤖 **MCP 集成**: 支持 Model Context Protocol,让 AI 助手实时查询 SDK 文档。
- 📦 **极轻量级**: 仅依赖 `websockets` 和 `orjson`,极速安装,拒绝臃肿。
---
## 📦 Installation
```bash
uv add napcat-sdk
# or
pip install napcat-sdk
```
---
## 📸 Quick Look
<div align="center"> <img src="https://raw.githubusercontent.com/faithleysath/napcat-sdk/refs/heads/main/docs/img/code-snapshot.png" alt="Code Example" width="800"> </div>
> [!IMPORTANT]
> `client.events()` 方法已移除,请直接使用 `async for event in client` 监听事件。
> 当前截图因录制成本暂未更新,代码示例请以本文文本为准。
<details> <summary><b>🖱️ 点击复制代码文本</b></summary>
```python
import asyncio
from napcat import NapCatClient, GroupMessageEvent, PrivateMessageEvent
async def listen_private(client: NapCatClient):
print(">> 私聊监听启动")
async for event in client:
match event:
case PrivateMessageEvent():
print(f"[私信] {event.sender.nickname}: {event.raw_message}")
await event.send_msg("已阅")
case _:
pass
async def listen_group(client: NapCatClient):
print(">> 群聊监听启动")
async for event in client:
match event:
case GroupMessageEvent():
print(f"[群消息] {event.group_id}: {event.raw_message}")
await event.reply("复读")
case _:
pass
async def main():
# 正向 WebSocket 连接(支持自动管理上下文)
client = NapCatClient(ws_url="ws://localhost:3001", token="123")
await asyncio.gather(
listen_private(client),
listen_group(client)
)
if __name__ == "__main__":
asyncio.run(main())
```
</details>
---
## 📖 Usage
`NapCatClient` 支持直接作为异步迭代器使用,并会在迭代开始/结束时自动管理连接生命周期。
<details> <summary><b>🔌 反向 WebSocket 服务端 (Server Mode)</b></summary>
如果你配置 NapCat 主动连接你的程序,请使用 `ReverseWebSocketServer`。
```python
import asyncio
from napcat import ReverseWebSocketServer, NapCatClient, GroupMessageEvent
async def handler(client: NapCatClient):
"""每个新的 WebSocket 连接都会触发此回调"""
print(f"Bot Connected! Self ID: {client.self_id}")
# 就像 Client 模式一样处理事件
async for event in client:
if isinstance(event, GroupMessageEvent):
print(f"收到群 {event.group_id} 消息: {event.raw_message}")
await event.reply("服务端已收到")
async def main():
# 启动服务器监听 8080 端口
server = ReverseWebSocketServer(handler, host="0.0.0.0", port=8080, token="my-token")
await server.run_forever()
if __name__ == "__main__":
asyncio.run(main())
```
</details>
<details> <summary><b>🖼️ 发送富媒体消息 (图片/At/回复)</b></summary>
SDK 提供了强类型的 `MessageSegment`,告别手动拼接 CQ 码。
```python
from napcat import (
NapCatClient,
Text,
Image,
At,
)
async def send_rich_media(client: NapCatClient, group_id: int):
# 构建消息链:@某人 + 文本 + 图片
message = [
At(qq="12345678"),
Text(text=" 来看这张图:"),
Image(file="https://example.com/image.jpg"),
]
# 直接发送列表
await client.send_group_msg(group_id=group_id, message=message)
```
</details>
<details> <summary><b>🔗 调用 OneBot API (100% 类型提示)</b></summary>
所有 API 方法都直接挂载在 `client` 上,拥有完整的参数类型检查。
```python
async def managing_bot(client: NapCatClient):
# 获取登录号信息
login_info = await client.get_login_info()
print(f"当前登录: {login_info['nickname']}")
# 获取群成员列表
members = await client.get_group_member_list(
group_id=123456,
no_cache=True
)
for member in members:
print(f"成员: {member['card'] or member['nickname']}")
# 动态调用(针对未收录的 API)
await client.call_action("some_new_action", {"param": 1})
```
</details>
<details> <summary><b>⚠️ 错误处理 (异常类型)</b></summary>
SDK 提供了明确的异常类型,方便区分错误来源:
```python
from napcat import NapCatAPIError, NapCatProtocolError, NapCatStateError
try:
await client.get_login_info()
except NapCatAPIError as exc:
print("API 失败:", exc)
print("action=", exc.action, "retcode=", exc.retcode)
except NapCatProtocolError as exc:
print("上报数据异常:", exc)
except NapCatStateError as exc:
print("客户端状态错误:", exc)
```
</details>
---
## 🛠️ Development
本项目使用 [uv](https://github.com/astral-sh/uv) 进行包管理。
1. **克隆项目并同步环境**:
```
git clone --recursive https://github.com/faithleysath/napcat-sdk.git
cd napcat-sdk
uv sync
cd NapCatQQ
pnpm install
```
2. **同步协议定义**: SDK 的核心代码由 OpenAPI 规范自动生成,请运行以下命令重新生成代码:
```
uv run scripts/schema-codegen.py
```
*这会自动更新 `src/napcat/types/messages/generated.py`、`src/napcat/types/schemas.py`、`src/napcat/client_api.py` 以及相关的 `__init__.py`。*
3. **运行测试**:
```
# 运行 tests
uv run pytest src/tests -q
```
---
## 📄 License
MIT License © 2025 [faithleysath](https://github.com/faithleysath)
<a href="https://star-history.com/#faithleysath/napcat-sdk&Date">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=faithleysath/napcat-sdk&type=Date&theme=dark" />
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=faithleysath/napcat-sdk&type=Date" />
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=faithleysath/napcat-sdk&type=Date" />
</picture>
</a>
| text/markdown | 吴天一 | 吴天一 <faithleysath@gmail.com> | null | null | MIT License | napcat, sdk, api, async, typed | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Operating System :: OS Independent",
"Typing :: Typed",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Communications :: Chat"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"orjson>=3.11.5",
"websockets>=15.0.1",
"aiohttp>=3.9.0",
"tomli-w>=1.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/faithleysath/napcat-sdk",
"Repository, https://github.com/faithleysath/napcat-sdk",
"Documentation, https://github.com/faithleysath/napcat-sdk/blob/main/README.md",
"Bug Tracker, https://github.com/faithleysath/napcat-sdk/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:51:05.731615 | napcat_sdk-0.6.4.tar.gz | 83,612 | 50/5b/4829399c62071d7146921c407f55c740eebc8efd3cbe0111de6de8806d89/napcat_sdk-0.6.4.tar.gz | source | sdist | null | false | b7ea08fa50e36130d231fbd5247d4e00 | 1d7db8ce9b37146315403efb2ea8622dd41e105a87f80a65cadfb40dfcaf687c | 505b4829399c62071d7146921c407f55c740eebc8efd3cbe0111de6de8806d89 | null | [] | 219 |
2.4 | karpet | 0.5.5 | Library for fetching coin/token historical data, trends and more. | Karpet
======
.. image:: https://raw.githubusercontent.com/im-n1/karpet/master/assets/logo.png
:align: center
----
.. image:: https://img.shields.io/pypi/v/karpet.svg?color=0c7dbe
:alt: PyPI
.. image:: https://img.shields.io/pypi/l/karpet.svg?color=0c7dbe
:alt: PyPI - License
.. image:: https://img.shields.io/pypi/dm/karpet.svg?color=0c7dbe
:alt: PyPI - Downloads
.. contents::
Description
-----------
Karpet is a tiny library with just a few dependencies
for fetching coins/tokens metrics data from the internet.
It can provide following data:
* coin/token historical price data (no limits)
* google trends for the given list of keywords (longer period than official API)
* twitter scraping for the given keywords (no limits)
* much more info about crypto coins/tokens (no rate limits)
What is upcoming?
* Reddit metrics
* Have a request? Open an issue ;)
Usage
-----
1. Install the library via pip.
.. code-block:: bash
pip install karpet
In case you don't use `uv` you need to install the newerest cloudscraper manually
.. code-block:: bash
pip install git+https://github.com/VeNoMouS/cloudscraper.git@3.0.0
2. Import the library class first.
.. code-block:: python
from karpet import Karpet
fetch_crypto_historical_data()
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Retrieves historical data.
.. code-block:: python
k = Karpet(date(2019, 1, 1), date(2019, 5, 1))
df = k.fetch_crypto_historical_data(id="ethereum") # Dataframe with historical data.
df.head()
price market_cap total_volume
2019-01-01 131.458725 1.36773e+10 1.36773e+10
2019-01-02 138.144802 1.43923e+10 1.43923e+10
2019-01-03 152.860453 1.59222e+10 1.59222e+10
2019-01-04 146.730599 1.52777e+10 1.52777e+10
2019-01-05 153.056567 1.59408e+10 1.59408e+10
fetch_crypto_exchanges()
~~~~~~~~~~~~~~~~~~~~~~~~
Retrieves exchange list.
.. code-block:: python
k = Karpet()
k.fetch_crypto_exchanges("nrg")
['DigiFinex', 'KuCoin', 'CryptoBridge', 'Bitbns', 'CoinExchange']
fetch_news()
~~~~~~~~~~~~
Retrieves crypto news.
.. code-block:: python
k = Karpet()
news = k.fetch_news("btc") # Gets 10 news.
print(news[0])
{
'url': 'https://cointelegraph.com/ ....', # Truncated.
'title': 'Shell Invests in Blockchain-Based Energy Startup',
'description': 'The world’s fifth top oil and gas firm, Shell, has...', # Truncated.
'date': datetime.datetime(2019, 7, 28, 9, 24, tzinfo=datetime.timezone(datetime.timedelta(seconds=3600)))
'image': 'https://images.cointelegraph.com/....jpg' # Truncated.
}
news = k.fetch_news("btc", limit=30) # Gets 30 news.
fetch_top_news()
~~~~~~~~~~~~~~~~
Retrieves top crypto news in 2 categories:
* Editor's choices - articles picked by editors
* Hot stories - articles with most views
.. code-block:: python
k = Karpet()
editors_choices, top_stories = k.fetch_top_news()
print(len(editors_choices))
5
print(len(top_stories))
5
print(editors_choices[0])
{
'url': 'https://cointelegraph.com/...', # Truncated.
'title': 'Bank of China’s New Infographic Shows Why Bitcoin Price Is Going Up',
'date': datetime.datetime(2019, 7, 27, 10, 7, tzinfo=datetime.timezone(datetime.timedelta(seconds=3600))),
'image': 'https://images.cointelegraph.com/images/740_aHR...', # Truncated.
'description': 'The Chinese central bank released on its website an ...' # Truncated.
}
print(top_stories[0])
{
'url': 'https://cointelegraph.com/...', # Truncated.
'title': 'Bitcoin Price Shuns Volatility as Analysts Warn of Potential Drop to $7,000',
'date': datetime.datetime(2019, 7, 27, 10, 7, tzinfo=datetime.timezone(datetime.timedelta(seconds=3600))),
'image': 'https://images.cointelegraph.com/images/740_aHR0c...' # Truncated.
'description': 'Stability around $10,600 for Bitcoin price is ...' # Truncated.
}
get_coin_ids()
~~~~~~~~~~~~~~
Resolves coin ID's based on the given symbol (there are coins out there with identical symbol).
Use this to get distinctive coin ID which can be used as ``id`` param for
method ``fetch_crypto_historical_data()``.
.. code-block:: python
k = Karpet()
print(k.get_coin_ids("sta"))
['statera']
get_basic_data()
~~~~~~~~~~~~~~~~
Fetches coin/token basic data like:
``open_issues`` is only provided if ``total_issues`` and ``closed_issues`` are
available.
.. code-block:: python
k = Karpet()
print(k.get_basic_data(id="ethereum"))
{
'closed_issues': 5530,
'commit_count_4_weeks': 40,
'current_price': 3167.67,
'forks': 11635,
'market_cap': 371964284548,
'name': 'Ethereum',
'open_issues': 230,
'pull_request_contributors': 552,
'rank': 2,
'reddit_accounts_active_48h': 2881.0,
'reddit_average_comments_48h': 417.083,
'reddit_average_posts_48h': 417.083,
'reddit_subscribers': 1057875,
'stars': 31680,
'total_issues': 5760,
'year_high': 4182.790285752286,
'year_low': 321.0774351739628,
'yoy_change': 695.9225871929757, # growth/drop in percents
'price_change_24': 120.1,
'price_change_24_percents': 1.23
}
get_quick_search_data()
~~~~~~~~~~~~~~~~~~~~~~~
Lists all coins/tokes with some basic info.
.. code-block:: python
k = Karpet()
print(k.get_quick_search_data()[0])
{
"name": "Bitcoin",
"symbol": "BTC",
"rank": 1,
"slug": "bitcoin",
"tokens": [
"Bitcoin",
"bitcoin",
"BTC"
],
"id": 1,
}
fetch_crypto_live_data()
~~~~~~~~~~~~~~~~~~~~~~~~
Retrieves live market data.
.. code-block:: python
k = Karpet()
df = k.fetch_crypto_live_data(id="ethereum") # Dataframe with live data.
df.head()
open high low close
2023-01-16 20:00:00 1593.01 1595.05 1593.01 1594.28
2023-01-16 20:30:00 1593.37 1593.37 1589.03 1589.35
2023-01-16 21:00:00 1592.68 1593.66 1584.71 1587.87
2023-01-16 21:30:00 1587.28 1587.28 1583.13 1583.13
2023-01-16 22:00:00 1573.99 1580.11 1573.99 1579.97
Changelog
---------
`here <./CHANGELOG.md>`_
Credits
-------
This is my personal library I use in my long-term project. I can pretty much guarantee it will
live for a long time then. I will add new features over time and I more than welcome any
help or bug reports. Feel free to open an issue or merge request.
The code is is licensed under MIT license.
| text/x-rst | null | n1 <hrdina.pavel@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3 :: Only",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"aiohttp<4,>=3.11.12",
"beautifulsoup4<5,>=4.13.3",
"cloudscraper",
"lxml<6,>=5.3.0",
"pandas~=2.2",
"requests<3,>=2.32.3"
] | [] | [] | [] | [
"Homepage, https://github.com/im-n1/karpet"
] | uv/0.9.12 {"installer":{"name":"uv","version":"0.9.12"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Debian GNU/Linux","version":null,"id":"forky","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T13:50:57.208197 | karpet-0.5.5.tar.gz | 13,522 | 59/6c/d8a3b78facd1118a79fb766022af4a3121ee83b4dbec7a7138c3f5c2e2f3/karpet-0.5.5.tar.gz | source | sdist | null | false | aecfb264859345148ba6d1419d8bc3b7 | 81ac1de532230a9bda056b1bfb6daf5f832e0c97f7d1d9aa2ebdd8646f4788b1 | 596cd8a3b78facd1118a79fb766022af4a3121ee83b4dbec7a7138c3f5c2e2f3 | null | [
"LICENSE"
] | 155 |
2.4 | python-durable | 0.1.0 | Lightweight workflow durability for Python — make any async workflow resumable after crashes with just a decorator. | # durable
Lightweight workflow durability for Python. Make any async workflow resumable after crashes with just a decorator.
Backed by SQLite out of the box; swap in any `Store` subclass for production.
## Install
```bash
pip install python-durable
```
## Quick start
```python
from durable import Workflow
from durable.backoff import exponential
wf = Workflow("my-app")
@wf.task(retries=3, backoff=exponential(base=2, max=60))
async def fetch_data(url: str) -> dict:
async with httpx.AsyncClient() as client:
return (await client.get(url)).json()
@wf.task
async def save_result(data: dict) -> None:
await db.insert(data)
@wf.workflow(id="pipeline-{source}")
async def run_pipeline(source: str) -> None:
data = await fetch_data(f"https://api.example.com/{source}")
await save_result(data)
# First call: runs all steps and checkpoints each one.
# If it crashes and you call it again with the same args,
# completed steps are replayed from SQLite instantly.
await run_pipeline(source="users")
```
## How it works
1. **`@wf.task`** wraps an async function with checkpoint + retry logic. When called inside a workflow, results are persisted to the store. On re-run, completed steps return their cached result without re-executing.
2. **`@wf.workflow`** marks the entry point of a durable run. It manages a `RunContext` (via `ContextVar`) so tasks automatically know which run they belong to. The `id` parameter is a template string resolved from function arguments at call time.
3. **`Store`** is the persistence backend. `SQLiteStore` is the default (zero config, backed by aiosqlite). Subclass `Store` to use Postgres, Redis, or anything else.
## Features
- **Crash recovery** — completed steps are never re-executed after a restart
- **Automatic retries** — configurable per-task with `exponential`, `linear`, or `constant` backoff
- **Loop support** — use `step_id` to checkpoint each iteration independently
- **Zero magic outside workflows** — tasks work as plain async functions when called without a workflow context
- **Pluggable storage** — SQLite by default, bring your own `Store` for production
## Backoff strategies
```python
from durable.backoff import exponential, linear, constant
@wf.task(retries=5, backoff=exponential(base=2, max=60)) # 2s, 4s, 8s, 16s, 32s
async def exp_task(): ...
@wf.task(retries=3, backoff=linear(start=2, step=3)) # 2s, 5s, 8s
async def linear_task(): ...
@wf.task(retries=3, backoff=constant(5)) # 5s, 5s, 5s
async def const_task(): ...
```
## Loops with step_id
When calling the same task in a loop, pass `step_id` so each iteration is checkpointed independently:
```python
@wf.workflow(id="batch-{batch_id}")
async def process_batch(batch_id: str) -> None:
for i, item in enumerate(items):
await process_item(item, step_id=f"item-{i}")
```
If the workflow crashes mid-loop, only the remaining items are processed on restart.
## Important: JSON serialization
Task return values must be JSON-serializable (dicts, lists, strings, numbers, booleans, `None`). The store uses `json.dumps` internally.
For Pydantic models, return `.model_dump()` from tasks and reconstruct with `.model_validate()` downstream:
```python
@wf.task
async def validate_invoice(draft: InvoiceDraft) -> dict:
validated = ValidatedInvoice(...)
return validated.model_dump()
@wf.task
async def book_invoice(data: dict) -> dict:
invoice = ValidatedInvoice.model_validate(data)
...
```
## License
MIT
| text/markdown | Willem | null | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Framework :: AsyncIO",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Typing :: Typed"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"aiosqlite>=0.20",
"pytest-asyncio>=0.24; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.9; extra == \"dev\"",
"ty>=0.0.1a7; extra == \"dev\"",
"pydantic-ai>=0.1; extra == \"examples\"",
"pydantic>=2.0; extra == \"examples\""
] | [] | [] | [] | [
"Repository, https://github.com/WillemDeGroef/python-durable"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:50:18.686943 | python_durable-0.1.0.tar.gz | 15,193 | ae/38/add28bb72196e08835ebf5d6b7b894136b2d7777018b5197cf08d35a6f6a/python_durable-0.1.0.tar.gz | source | sdist | null | false | bce52b54e1a1af9c17b830e881dee340 | d4c0bff0c7420f3ed5ceeb4a6ac7a28658fdf4bb32f033292e182b0217cddfc1 | ae38add28bb72196e08835ebf5d6b7b894136b2d7777018b5197cf08d35a6f6a | MIT | [
"LICENSE"
] | 216 |
2.4 | usehid | 0.1.0 | Cross-platform virtual HID device library for AI agents | # useHID Python Bindings
Cross-platform virtual HID device library for Python.
## Installation
```bash
pip install usehid
```
## Quick Start
```python
from usehid import Mouse, Keyboard, AgentHID
# Basic Mouse
mouse = Mouse()
mouse.move_by(100, 50)
mouse.click()
mouse.double_click("left")
mouse.scroll(-3) # Scroll down
# Basic Keyboard
keyboard = Keyboard()
keyboard.type_text("Hello, World!")
keyboard.press("enter")
keyboard.combo(["ctrl"], "c") # Copy
# For AI Agents
agent = AgentHID()
# Execute actions from dict
result = agent.execute({
"action": "mouse_move",
"x": 100,
"y": 200
})
result = agent.execute({
"action": "type",
"text": "Hello from AI!"
})
result = agent.execute({
"action": "key_combo",
"modifiers": ["ctrl", "shift"],
"key": "s"
})
```
## Available Actions
### Mouse Actions
- `mouse_move` - Move mouse by offset (`x`, `y`)
- `mouse_click` - Click button (`button`: "left"/"right"/"middle")
- `mouse_double_click` - Double click
- `mouse_down` - Press button
- `mouse_up` - Release button
- `mouse_scroll` - Scroll wheel (`delta`: positive=up, negative=down)
### Keyboard Actions
- `type` - Type text (`text`)
- `key_press` - Press and release key (`key`)
- `key_down` - Press key
- `key_up` - Release key
- `key_combo` - Key combination (`modifiers`: list, `key`)
### Gamepad Actions
- `gamepad_press` - Press button
- `gamepad_release` - Release button
- `gamepad_left_stick` - Set left stick (`x`, `y`: 0-255)
- `gamepad_right_stick` - Set right stick
- `gamepad_triggers` - Set triggers (`left`, `right`: 0-255)
## Building
```bash
cd usehid-python
maturin develop
```
## License
MIT
| text/markdown; charset=UTF-8; variant=GFM | null | Zoe <zoe@zoe.im> | null | null | MIT | hid, virtual, mouse, keyboard, automation, ai, agent | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: MacOS",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Rust",
"Topic :: Software Development :: Libraries"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/jiusanzhou/usehid",
"Repository, https://github.com/jiusanzhou/usehid"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:50:11.718613 | usehid-0.1.0-cp311-cp311-win_amd64.whl | 253,729 | 26/ab/6dd5c42c1afa4348308e6d8c3368a4032a5b85cb73fea47fbb76322b1583/usehid-0.1.0-cp311-cp311-win_amd64.whl | cp311 | bdist_wheel | null | false | 30e4f09aea07f85e6f6519ef6247747d | dec824b894839460f1b833fefb3896364912e5b87bcc50358d3940b2a298a05f | 26ab6dd5c42c1afa4348308e6d8c3368a4032a5b85cb73fea47fbb76322b1583 | null | [] | 196 |
2.4 | evaluatorq | 1.2.0rc4 | An evaluation framework library for Python that provides a flexible way to run parallel evaluations and optionally integrate with the Orq AI platform. | # evaluatorq-py
An evaluation framework library for Python that provides a flexible way to run parallel evaluations and optionally integrate with the Orq AI platform.
## 🎯 Features
- **Parallel Execution**: Run multiple evaluation jobs concurrently with progress tracking
- **Flexible Data Sources**: Support for inline data, async iterables, and Orq platform datasets
- **Type-safe**: Fully typed with Python type hints and Pydantic models with runtime validation
- **Rich Terminal UI**: Beautiful progress indicators and result tables powered by Rich
- **Orq Platform Integration**: Seamlessly fetch and evaluate datasets from Orq AI (optional)
- **OpenTelemetry Tracing**: Built-in observability with automatic span creation for jobs and evaluators
- **Pass/Fail Tracking**: Evaluators can return pass/fail status for CI/CD integration
- **Built-in Evaluators**: Common evaluators like `string_contains_evaluator` included
- **Integrations**: Langchain and Langgraph agents integration
## 📥 Installation
```bash
pip install evaluatorq
# or
uv add evaluatorq
# or
poetry add evaluatorq
```
### Optional Dependencies
If you want to use the Orq platform integration:
```bash
pip install orq-ai-sdk
# or
pip install evaluatorq[orq]
```
For OpenTelemetry tracing (optional):
```bash
pip install opentelemetry-api opentelemetry-sdk opentelemetry-exporter-otlp-proto-http opentelemetry-semantic-conventions
# or
pip install evaluatorq[otel]
```
For LangChain/LangGraph integration:
```bash
pip install langchain
# or
pip install evaluatorq[langchain]
```
## 🚀 Quick Start
### Basic Usage
```python
import asyncio
from evaluatorq import evaluatorq, job, DataPoint, EvaluationResult
@job("text-analyzer")
async def text_analyzer(data: DataPoint, row: int):
"""Analyze text data and return analysis results."""
text = data.inputs["text"]
analysis = {
"length": len(text),
"word_count": len(text.split()),
"uppercase": text.upper(),
}
return analysis
async def length_check_scorer(params):
"""Evaluate if output length is sufficient."""
output = params["output"]
passes_check = output["length"] > 10
return EvaluationResult(
value=1 if passes_check else 0,
explanation=(
"Output length is sufficient"
if passes_check
else f"Output too short ({output['length']} chars, need >10)"
)
)
async def main():
await evaluatorq(
"text-analysis",
data=[
DataPoint(inputs={"text": "Hello world"}),
DataPoint(inputs={"text": "Testing evaluation"}),
],
jobs=[text_analyzer],
evaluators=[
{
"name": "length-check",
"scorer": length_check_scorer,
}
],
)
if __name__ == "__main__":
asyncio.run(main())
```
### Using Orq Platform Datasets
```python
import asyncio
from evaluatorq import evaluatorq, job, DataPoint, DatasetIdInput
@job("processor")
async def processor(data: DataPoint, row: int):
"""Process each data point from the dataset."""
result = await process_data(data)
return result
async def accuracy_scorer(params):
"""Calculate accuracy by comparing output with expected results."""
data = params["data"]
output = params["output"]
score = calculate_score(output, data.expected_output)
if score > 0.8:
explanation = "High accuracy match"
elif score > 0.5:
explanation = "Partial match"
else:
explanation = "Low accuracy match"
return {"value": score, "explanation": explanation}
async def main():
# Requires ORQ_API_KEY environment variable
await evaluatorq(
"dataset-evaluation",
data=DatasetIdInput(dataset_id="your-dataset-id"), # From Orq platform
jobs=[processor],
evaluators=[
{
"name": "accuracy",
"scorer": accuracy_scorer,
}
],
)
if __name__ == "__main__":
asyncio.run(main())
```
### Advanced Features
#### Multiple Jobs
Run multiple jobs in parallel for each data point:
```python
from evaluatorq import job
@job("preprocessor")
async def preprocessor(data: DataPoint, row: int):
result = await preprocess(data)
return result
@job("analyzer")
async def analyzer(data: DataPoint, row: int):
result = await analyze(data)
return result
@job("transformer")
async def transformer(data: DataPoint, row: int):
result = await transform(data)
return result
await evaluatorq(
"multi-job-eval",
data=[...],
jobs=[preprocessor, analyzer, transformer],
evaluators=[...],
)
```
#### The `@job()` Decorator
The `@job()` decorator provides two key benefits:
1. **Eliminates boilerplate** - No need to manually wrap returns with `{"name": ..., "output": ...}`
2. **Preserves job names in errors** - When a job fails, the error will include the job name for better debugging
**Decorator pattern (recommended):**
```python
from evaluatorq import job
@job("text-processor")
async def process_text(data: DataPoint, row: int):
# Clean return - just the data!
return {"result": data.inputs["text"].upper()}
```
**Functional pattern (for lambdas):**
```python
from evaluatorq import job
# Simple transformations with lambda
uppercase_job = job("uppercase", lambda data, row: data.inputs["text"].upper())
word_count_job = job("word-count", lambda data, row: len(data.inputs["text"].split()))
```
#### Deployment Helper
Easily invoke Orq deployments within your evaluation jobs:
```python
from evaluatorq import evaluatorq, job, invoke, deployment, DatasetIdInput
# Simple one-liner with invoke()
@job("summarizer")
async def summarize_job(data, row):
text = data.inputs["text"]
return await invoke("my-deployment", inputs={"text": text})
# Full response with deployment()
@job("analyzer")
async def analyze_job(data, row):
response = await deployment(
"my-deployment",
inputs={"text": data.inputs["text"]},
metadata={"source": "evaluatorq"},
)
print("Raw:", response.raw)
return response.content
# Chat-style with messages
@job("chatbot")
async def chat_job(data, row):
return await invoke(
"chatbot",
messages=[{"role": "user", "content": data.inputs["question"]}],
)
# Thread tracking for conversations
@job("assistant")
async def conversation_job(data, row):
return await invoke(
"assistant",
inputs={"query": data.inputs["query"]},
thread={"id": "conversation-123"},
)
```
The `invoke()` function returns the text content directly, while `deployment()` returns an object with both `content` and `raw` response for more control.
#### Built-in Evaluators
Use the included evaluators for common use cases:
```python
from evaluatorq import evaluatorq, job, string_contains_evaluator, DatasetIdInput
@job("country-lookup")
async def country_lookup_job(data, row):
country = data.inputs["country"]
return await invoke("country-capitals", inputs={"country": country})
await evaluatorq(
"country-unit-test",
data=DatasetIdInput(dataset_id="your-dataset-id"),
jobs=[country_lookup_job],
evaluators=[string_contains_evaluator()], # Checks if output contains expected_output
parallelism=6,
)
```
Available built-in evaluators:
- **`string_contains_evaluator()`** - Checks if output contains expected_output (case-insensitive by default)
- **`exact_match_evaluator()`** - Checks if output exactly matches expected_output
```python
# Case-sensitive matching
strict_evaluator = string_contains_evaluator(case_insensitive=False)
# Custom name
my_evaluator = string_contains_evaluator(name="my-contains-check")
```
#### Automatic Error Handling
The `@job()` decorator automatically preserves job names even when errors occur:
```python
from evaluatorq import job
@job("risky-job")
async def risky_operation(data: DataPoint, row: int):
# If this raises an error, the job name "risky-job" will be preserved
result = await potentially_failing_operation(data)
return result
await evaluatorq(
"error-handling",
data=[...],
jobs=[risky_operation],
evaluators=[...],
)
# Error output will show: "Job 'risky-job' failed: <error details>"
# Without @job decorator, you'd only see: "<error details>"
```
#### Async Data Sources
```python
import asyncio
# Create an array of coroutines for async data
async def get_data_point(i: int) -> DataPoint:
await asyncio.sleep(0.01) # Simulate async data fetching
return DataPoint(inputs={"value": i})
data_promises = [get_data_point(i) for i in range(1000)]
await evaluatorq(
"async-eval",
data=data_promises,
jobs=[...],
evaluators=[...],
)
```
#### Structured Evaluation Results
Evaluators can return structured, multi-dimensional metrics using `EvaluationResultCell`. This is useful for metrics like BERT scores, ROUGE-N scores, or any evaluation that produces multiple sub-scores.
##### Multi-criteria Rubric
Return multiple quality sub-scores in a single evaluator:
```python
from evaluatorq import evaluatorq, job, DataPoint, EvaluationResult, EvaluationResultCell
@job("echo")
async def echo_job(data: DataPoint, row: int):
return data.inputs["text"]
async def rubric_scorer(params):
text = str(params["output"])
return EvaluationResult(
value=EvaluationResultCell(
type="rubric",
value={
"relevance": min(len(text) / 100, 1),
"coherence": 0.9 if "." in text else 0.4,
"fluency": 0.85 if len(text.split()) > 5 else 0.5,
},
),
explanation="Multi-criteria quality rubric",
)
await evaluatorq(
"structured-rubric",
data=[
DataPoint(inputs={"text": "The quick brown fox jumps over the lazy dog."}),
DataPoint(inputs={"text": "Hi"}),
],
jobs=[echo_job],
evaluators=[{"name": "rubric", "scorer": rubric_scorer}],
)
```
##### Sentiment Distribution
Break down sentiment across categories:
```python
async def sentiment_scorer(params):
text = str(params["output"]).lower()
positive_words = ["good", "great", "excellent", "happy", "love"]
negative_words = ["bad", "terrible", "awful", "sad", "hate"]
pos_count = sum(1 for w in positive_words if w in text)
neg_count = sum(1 for w in negative_words if w in text)
total = max(pos_count + neg_count, 1)
return EvaluationResult(
value=EvaluationResultCell(
type="sentiment",
value={
"positive": pos_count / total,
"negative": neg_count / total,
"neutral": 1 - (pos_count + neg_count) / total,
},
),
explanation="Sentiment distribution across categories",
)
```
##### Safety Scores with Pass/Fail
Combine structured scores with pass/fail tracking for CI/CD:
```python
async def safety_scorer(params):
text = str(params["output"]).lower()
categories = {
"hate_speech": 0.8 if "hate" in text else 0.1,
"violence": 0.7 if ("kill" in text or "fight" in text) else 0.05,
"profanity": 0.5 if "damn" in text else 0.02,
}
return EvaluationResult(
value=EvaluationResultCell(
type="safety",
value=categories,
),
pass_=all(score < 0.5 for score in categories.values()),
explanation="Content safety severity scores per category",
)
```
See the runnable Python examples in the `examples/` directory:
- [`structured_rubric_eval.py`](examples/structured_rubric_eval.py) - Multi-criteria quality rubric
- [`structured_sentiment_eval.py`](examples/structured_sentiment_eval.py) - Sentiment distribution breakdown
- [`structured_safety_eval.py`](examples/structured_safety_eval.py) - Safety scores with pass/fail tracking
> **Note:** Structured results display as `[structured]` in the terminal summary table but are preserved in full when sent to the Orq platform and OpenTelemetry spans.
#### Controlling Parallelism
```python
await evaluatorq(
"parallel-eval",
data=[...],
jobs=[...],
evaluators=[...],
parallelism=10, # Run up to 10 jobs concurrently
)
```
#### Disable Progress Display
```python
# Get raw results without terminal output
results = await evaluatorq(
"silent-eval",
data=[...],
jobs=[...],
evaluators=[...],
print_results=False, # Disable progress and table display
)
# Process results programmatically
for result in results:
print(result.data_point.inputs)
for job_result in result.job_results:
print(f"{job_result.job_name}: {job_result.output}")
```
## 🔧 Configuration
### Environment Variables
- `ORQ_API_KEY`: API key for Orq platform integration (required for dataset access and sending results). Also enables automatic OTEL tracing to Orq.
- `ORQ_BASE_URL`: Base URL for Orq platform (default: `https://my.orq.ai`)
- `OTEL_EXPORTER_OTLP_ENDPOINT`: Custom OpenTelemetry collector endpoint (overrides default Orq endpoint)
- `OTEL_EXPORTER_OTLP_HEADERS`: Headers for OTEL exporter (format: `key1=value1,key2=value2`)
- `ORQ_DISABLE_TRACING`: Set to `1` or `true` to disable automatic tracing
- `ORQ_DEBUG`: Enable debug logging for tracing setup
### Evaluation Parameters
Parameters are validated at runtime using Pydantic. The `evaluatorq` function supports three calling styles:
```python
from evaluatorq import evaluatorq, EvaluatorParams
# 1. Keyword arguments (recommended)
await evaluatorq(
"my-eval",
data=[...],
jobs=[...],
parallelism=5,
)
# 2. Dict style
await evaluatorq("my-eval", {
"data": [...],
"jobs": [...],
"parallelism": 5,
})
# 3. EvaluatorParams instance
await evaluatorq("my-eval", EvaluatorParams(
data=[...],
jobs=[...],
parallelism=5,
))
```
#### Parameter Reference
| Parameter | Type | Default | Description |
|-----------|------|---------|-------------|
| `data` | `list[DataPoint]` \| `list[Awaitable[DataPoint]]` \| `DatasetIdInput` | **required** | Data to evaluate |
| `jobs` | `list[Job]` | **required** | Jobs to run on each data point |
| `evaluators` | `list[Evaluator]` \| `None` | `None` | Evaluators to score job outputs |
| `parallelism` | `int` (≥1) | `1` | Number of concurrent jobs |
| `print_results` | `bool` | `True` | Display progress and results table |
| `description` | `str` \| `None` | `None` | Optional evaluation description |
## 📊 Orq Platform Integration
### Automatic Result Sending
When the `ORQ_API_KEY` environment variable is set, evaluatorq automatically sends evaluation results to the Orq platform for visualization and analysis.
```python
# Results are automatically sent when ORQ_API_KEY is set
await evaluatorq(
"my-evaluation",
data=[...],
jobs=[...],
evaluators=[...],
)
```
#### What Gets Sent
When the `ORQ_API_KEY` is set, the following information is sent to Orq:
- Evaluation name
- Dataset ID (when using Orq datasets)
- Job results with outputs and errors
- Evaluator scores with values and explanations
- Execution timing information
Note: Evaluator explanations are included in the data sent to Orq but are not displayed in the terminal output to keep the console clean.
#### Result Visualization
After successful submission, you'll see a console message with a link to view your results:
```
📊 View your evaluation results at: <url to the evaluation>
```
The Orq platform provides:
- Interactive result tables
- Score statistics
- Performance metrics
- Historical comparisons
## 🔍 OpenTelemetry Tracing
Evaluatorq automatically creates OpenTelemetry spans for observability into your evaluation runs.
### Span Hierarchy
```
orq.job (independent root per job execution)
└── orq.evaluation (child span per evaluator)
```
### Auto-Enable with Orq
When `ORQ_API_KEY` is set, traces are automatically sent to the Orq platform:
```bash
ORQ_API_KEY=your-api-key python my_eval.py
```
### Custom OTEL Endpoint
Send traces to any OpenTelemetry-compatible backend:
```bash
OTEL_EXPORTER_OTLP_ENDPOINT=https://your-collector:4318 \
OTEL_EXPORTER_OTLP_HEADERS="Authorization=Bearer token" \
python my_eval.py
```
### Disable Tracing
If you want to disable tracing even when `ORQ_API_KEY` is set:
```bash
ORQ_DISABLE_TRACING=1 python my_eval.py
```
## ✅ Pass/Fail Tracking
Evaluators can return a `pass_` field to indicate pass/fail status:
```python
async def quality_scorer(params):
"""Quality check evaluator with pass/fail."""
output = params["output"]
score = calculate_quality(output)
return {
"value": score,
"pass_": score >= 0.8, # Pass if meets threshold
"explanation": f"Quality score: {score}",
}
```
**CI/CD Integration:** When any evaluator returns `pass_: False`, the process exits with code 1. This enables fail-fast behavior in CI/CD pipelines.
**Pass Rate Display:** The summary table shows pass rate when evaluators use the `pass_` field:
```
┌──────────────────────┬─────────────────┐
│ Pass Rate │ 75% (3/4) │
└──────────────────────┴─────────────────┘
```
## 🔗 LangChain Integration
Evaluatorq provides integration with LangChain and LangGraph agents, converting their outputs to the OpenResponses format for standardized evaluation.
### Overview
The LangChain integration allows you to:
- Wrap LangChain agents created with `create_agent()` for use in evaluatorq jobs
- Wrap LangGraph compiled graphs for stateful agent evaluation
- Automatically convert agent outputs to OpenResponses format
- Evaluate agent behavior using standard evaluatorq evaluators
### Examples
Complete examples are available in the examples folder:
- **LangChain Agent**: [`examples/lib/integrations/langchain_integration_example.py`](./examples/lib/integrations/langchain_integration_example.py)
- **LangGraph Agent**: [`examples/lib/integrations/langgraph_integration_example.py`](./examples/lib/integrations/langgraph_integration_example.py)
## 📚 API Reference
### `evaluatorq(name, params?, *, data?, jobs?, evaluators?, parallelism?, print_results?, description?) -> EvaluatorqResult`
Main async function to run evaluations.
#### Signature:
```python
async def evaluatorq(
name: str,
params: EvaluatorParams | dict[str, Any] | None = None,
*,
data: DatasetIdInput | Sequence[Awaitable[DataPoint] | DataPoint] | None = None,
jobs: list[Job] | None = None,
evaluators: list[Evaluator] | None = None,
parallelism: int = 1,
print_results: bool = True,
description: str | None = None,
) -> EvaluatorqResult
```
#### Parameters:
- `name`: String identifier for the evaluation run
- `params`: (Optional) `EvaluatorParams` instance or dict with evaluation parameters
- `data`: List of DataPoint objects, awaitables, or `DatasetIdInput`
- `jobs`: List of job functions to run on each data point
- `evaluators`: Optional list of evaluator configurations
- `parallelism`: Number of concurrent jobs (default: 1, must be ≥1)
- `print_results`: Whether to display progress and results (default: True)
- `description`: Optional description for the evaluation run
> **Note:** Parameters can be passed either via the `params` argument (as dict or `EvaluatorParams`) or as keyword arguments. Keyword arguments take precedence over `params` values.
#### Returns:
`EvaluatorqResult` - List of `DataPointResult` objects containing job outputs and evaluator scores.
### Types
```python
from typing import Any, Callable, Awaitable
from pydantic import BaseModel, Field
from typing_extensions import TypedDict
# Output type alias
Output = str | int | float | bool | dict[str, Any] | None
class DataPoint(BaseModel):
"""A data point for evaluation."""
inputs: dict[str, Any]
expected_output: Output | None = None
EvaluationResultCellValue = str | float | dict[str, "str | float | dict[str, str | float]"]
class EvaluationResultCell(BaseModel):
"""Structured evaluation result with multi-dimensional metrics."""
type: str
value: dict[str, EvaluationResultCellValue]
class EvaluationResult(BaseModel):
"""Result from an evaluator."""
value: str | float | bool | EvaluationResultCell
explanation: str | None = None
pass_: bool | None = None # Optional pass/fail indicator for CI/CD integration
class EvaluatorScore(BaseModel):
"""Score from an evaluator for a job output."""
evaluator_name: str
score: EvaluationResult
error: str | None = None
class JobResult(BaseModel):
"""Result from a job execution."""
job_name: str
output: Output
error: str | None = None
evaluator_scores: list[EvaluatorScore] | None = None
class DataPointResult(BaseModel):
"""Result for a single data point."""
data_point: DataPoint
error: str | None = None
job_results: list[JobResult] | None = None
# Type aliases
EvaluatorqResult = list[DataPointResult]
class DatasetIdInput(BaseModel):
"""Input for fetching a dataset from Orq platform."""
dataset_id: str
class EvaluatorParams(BaseModel):
"""Parameters for running an evaluation (validated at runtime)."""
data: DatasetIdInput | Sequence[Awaitable[DataPoint] | DataPoint]
jobs: list[Job]
evaluators: list[Evaluator] | None = None
parallelism: int = Field(default=1, ge=1)
print_results: bool = True
description: str | None = None
class JobReturn(TypedDict):
"""Job return structure."""
name: str
output: Output
Job = Callable[[DataPoint, int], Awaitable[JobReturn]]
class ScorerParameter(TypedDict):
"""Parameters passed to scorer functions."""
data: DataPoint
output: Output
Scorer = Callable[[ScorerParameter], Awaitable[EvaluationResult | dict[str, Any]]]
class Evaluator(TypedDict):
"""Evaluator configuration."""
name: str
scorer: Scorer
# Deployment helper types
@dataclass
class DeploymentResponse:
"""Response from a deployment invocation."""
content: str # Text content of the response
raw: Any # Raw API response
# Invoke deployment and get text content
async def invoke(
key: str,
inputs: dict[str, Any] | None = None,
context: dict[str, Any] | None = None,
metadata: dict[str, Any] | None = None,
thread: dict[str, Any] | None = None, # Must include 'id' key
messages: list[dict[str, str]] | None = None,
) -> str: ...
# Invoke deployment and get full response
async def deployment(
key: str,
inputs: dict[str, Any] | None = None,
context: dict[str, Any] | None = None,
metadata: dict[str, Any] | None = None,
thread: dict[str, Any] | None = None, # Must include 'id' key
messages: list[dict[str, str]] | None = None,
) -> DeploymentResponse: ...
# Built-in evaluators
def string_contains_evaluator(
case_insensitive: bool = True,
name: str = "string-contains",
) -> Evaluator: ...
def exact_match_evaluator(
case_insensitive: bool = False,
name: str = "exact-match",
) -> Evaluator: ...
```
## 🛠️ Development
```bash
# Install dependencies
uv sync
# Run type checking
uv run basedpyright
# Format code
uv run ruff format
# Lint code
uv run ruff check
```
| text/markdown | null | null | null | null | MIT | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.28.1",
"pydantic>=2.0",
"rich>=14.2.0",
"langchain<2.0.0,>=1.0.0; extra == \"langchain\"",
"orq-ai-sdk>=4.2.18; extra == \"orq\"",
"opentelemetry-api>=1.20.0; extra == \"otel\"",
"opentelemetry-exporter-otlp-proto-http>=1.20.0; extra == \"otel\"",
"opentelemetry-sdk>=1.20.0; extra == \"otel\"",
"opentelemetry-semantic-conventions>=0.41b0; extra == \"otel\""
] | [] | [] | [] | [
"Homepage, https://github.com/orq-ai/orqkit",
"Repository, https://github.com/orq-ai/orqkit/tree/main/packages/evaluatorq-py",
"Documentation, https://github.com/orq-ai/orqkit/tree/main/packages/evaluatorq-py"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:50:04.023368 | evaluatorq-1.2.0rc4.tar.gz | 125,642 | 81/64/eed6ddacfe9e97c3b004b7635d3176a9753a6c70fdb2469c42b209caf451/evaluatorq-1.2.0rc4.tar.gz | source | sdist | null | false | 2a18f46274e3d2f5e7db2623e1835e7f | d2767f9edb223c81086ffa25ec5a5d9b7397cd1df9b42207db15ff3f829f2dd4 | 8164eed6ddacfe9e97c3b004b7635d3176a9753a6c70fdb2469c42b209caf451 | null | [] | 198 |
2.4 | oomllama | 0.5.0 | OomLlama - Smart LLM routing with TIBET provenance. Route queries to the right model, track everything. | # OomLlama
Smart LLM routing with TIBET provenance. Route queries to the right model, track everything.
## Installation
```bash
pip install oomllama
```
With TIBET provenance:
```bash
pip install oomllama[tibet]
```
## Quick Start
```python
from oomllama import OomLlama
# Simple generation
llm = OomLlama()
response = llm.generate("Hello!")
# With specific model
response = llm.generate("Complex question", model="qwen2.5:32b")
# Auto-routing (picks best model for the query)
llm = OomLlama(auto_route=True)
response = llm.generate("Write a Python function") # Routes to code model
```
## Smart Routing
OomLlama automatically selects the best model based on your query:
```python
from oomllama import OomLlama, ModelRouter
llm = OomLlama(auto_route=True)
# Code query → routes to code-capable model
llm.generate("Write a binary search function")
# Simple query → routes to fast model
llm.generate("What is 2+2?")
# Complex query → routes to reasoning model
llm.generate("Explain quantum entanglement in detail...")
```
## TIBET Provenance
Track every LLM call with cryptographic provenance:
```python
from oomllama import OomLlama
from tibet_core import Provider
# Enable TIBET tracking
tibet = Provider(actor="jis:company:my_app")
llm = OomLlama(tibet=tibet)
# All calls now create provenance tokens
response = llm.generate("Summarize this document")
# Audit trail
for token in tibet.find(action="llm_generate"):
print(f"{token.timestamp}: {token.erin['model']}")
print(f" Reason: {token.erachter}")
```
## CLI Usage
```bash
# Generate text
oomllama gen "Hello, how are you?"
# Auto-route
oomllama gen --auto "Write a Python web scraper"
# Interactive chat
oomllama chat -m qwen2.5:7b
# List models
oomllama list
# Check status
oomllama status
```
## Configuration
```python
from oomllama import OomLlama
llm = OomLlama(
model="qwen2.5:7b", # Default model
ollama_url="http://localhost:11434", # Ollama API
auto_route=True, # Enable smart routing
system_prompt="You are helpful." # Default system prompt
)
# Set defaults
llm.set_defaults(
temperature=0.8,
max_tokens=1024
)
```
## Custom Model Router
```python
from oomllama import OomLlama, ModelRouter, ModelConfig, ModelCapability
# Define your models
router = ModelRouter([
ModelConfig(
name="my-model:7b",
size="7b",
capabilities=[ModelCapability.CODE, ModelCapability.FAST],
priority=30
),
])
llm = OomLlama(router=router, auto_route=True)
```
## Remote Ollama
```python
# Connect to remote GPU server
llm = OomLlama(ollama_url="http://192.168.4.85:11434")
```
## Requirements
- Python 3.10+
- [Ollama](https://ollama.ai) running locally or remotely
## License
MIT - Humotica
## Links
- [Humotica](https://humotica.com)
- [tibet-core](https://github.com/Humotica/tibet-core)
- [Ollama](https://ollama.ai)
| text/markdown | Gemini IDD | "J. van de Meent" <jasper@humotica.com>, "R. AI" <info@humotica.com> | null | null | MIT | ai, audit, inference, llama, llm, ml, ollama, provenance, qwen, routing, tibet | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.24.0",
"pytest>=7.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"rich>=13.0.0; extra == \"full\"",
"tibet-core>=0.2.0; extra == \"full\"",
"tibet-core>=0.2.0; extra == \"tibet\""
] | [] | [] | [] | [
"Homepage, https://humotica.com",
"Repository, https://github.com/humotica/oomllama",
"Documentation, https://humotica.com/docs/oomllama"
] | twine/6.2.0 CPython/3.13.5 | 2026-02-20T13:49:03.768617 | oomllama-0.5.0.tar.gz | 7,603 | ea/39/989ead4f549137d509ef6f5a1b33dc107b9a663b1ae75fb673a27f8969e1/oomllama-0.5.0.tar.gz | source | sdist | null | false | 95eef7d81f973e07506bfb5db9b8e0ad | 8ac85efc828405248c91cbf616dd5c14b4b3b18f88cf601b7d3b1a8187744a02 | ea39989ead4f549137d509ef6f5a1b33dc107b9a663b1ae75fb673a27f8969e1 | null | [] | 222 |
2.4 | litewave-cache-lib | 0.1.2 | A lightweight Python library for Redis-backed tenant configuration storage | # litewave-cache-lib
A lightweight Python library that provides a connection-pooled, fault-tolerant Redis client with automatic retry logic and JSON-aware key lookup helpers for tenant configuration storage.
---
## Features
- Connection-pooled Redis client with automatic retry on failure (5-minute cooldown)
- Fetch values by raw Redis key, or by `(tenant_id, secret_name)` pair via `get_secret`
- Automatic JSON deserialization of stored values
- Attribute-level extraction from stored JSON objects via `get_attribute_value_by_key`
- Standardised tenant key format: `tenant:{tenant_id}:secret:{secret_name}`
- Fully configurable via environment variables
- Zero-boilerplate logging setup
---
## Installation
```bash
pip install git+https://github.com/aiorch/litewave-cache-lib
```
Or install from source:
```bash
git clone https://github.com/aiorch/litewave-cache-lib.git
cd litewave-cache-lib
pip install .
```
---
## Requirements
- Python >= 3.10
- redis >= 5.0.0
- python-dotenv >= 1.0.0
---
## Configuration
All settings are read from environment variables at import time. `REDIS_HOST`, `REDIS_PORT`, and `REDIS_PASSWORD` are **required** — the library raises a `ValueError` at startup if any of them are missing.
| Environment Variable | Default | Description |
|--------------------------------|---------|-----------------------------------------------|
| `REDIS_HOST` | **(required)** | Redis server hostname |
| `REDIS_PORT` | **(required)** | Redis server port |
| `REDIS_PASSWORD` | **(required)** | Redis password |
| `REDIS_DB` | `0` | Default Redis database index |
| `REDIS_COORDINATION_DB` | `1` | Redis DB reserved for coordination workloads |
| `REDIS_TENANT_CONFIG_DB` | `2` | Redis DB used for tenant configuration |
| `REDIS_MAX_CONNECTIONS` | `50` | Connection pool size |
| `REDIS_SOCKET_CONNECT_TIMEOUT` | `2` | Socket connect timeout in seconds |
| `REDIS_SOCKET_TIMEOUT` | `2` | Socket read/write timeout in seconds |
| `LOG_LEVEL` | `INFO` | Logging level (`DEBUG`, `INFO`, `WARNING`, …) |
A `.env` file is supported via `python-dotenv`. Load it before importing the library:
```python
from dotenv import load_dotenv
load_dotenv(".env", override=True)
from tenant_mgr_cache import get_redis_client
```
---
## Usage
### Get the Redis client
Returns the shared, connection-pooled Redis client. Returns `None` if the connection is unavailable. A failed connection is retried automatically after a 5-minute cooldown; subsequent calls reuse the existing client.
```python
from tenant_mgr_cache import get_redis_client
client = get_redis_client()
if client:
client.set("tenant:15:secret:satoken", "abc123")
print(client.get("tenant:15:secret:satoken")) # "abc123"
```
---
### `get_secret` — fetch by tenant ID and secret name
Builds the canonical key `tenant:{tenant_id}:secret:{secret_name}` internally and returns the stored value. JSON values are deserialized automatically; plain strings are returned as-is.
```python
from tenant_mgr_cache import get_secret
# JSON object stored → returned as dict
config = get_secret("15", "db_config")
if isinstance(config, dict):
print(config["host"]) # e.g. "db.prod.internal"
print(config["port"]) # e.g. 5432
# Plain string stored → returned as-is
token = get_secret("15", "satoken")
print(token) # e.g. "abc123"
# Key does not exist → None
missing = get_secret("15", "nonexistent")
print(missing) # None
```
### `get_secret(tenant_id: str, secret_name: str) -> Optional[Any]`
Builds the canonical key `tenant:{tenant_id}:secret:{secret_name}` and returns the stored value. JSON is deserialized automatically. Returns `None` if the key does not exist, Redis is unavailable, or any error occurs.
---
### `get_value_by_key(key: str) -> Optional[Any]`
Fetches the value stored at `key` and JSON-decodes it if possible. Returns `None` when the key does not exist, Redis is unavailable, or any error occurs.
---
### `get_attribute_value_by_key(tenant_id: str, secret_name: str, attribute_name: str) -> Optional[Any]`
Builds the canonical key for `tenant_id` + `secret_name`, fetches the stored JSON object, and returns `data.get(attribute_name)`. Falls back to `getattr` for non-dict objects. Returns `None` if the key is missing, the value is not dict-like, or the attribute is absent.
---
### `prepare_key(tenant_id: str, secret_name: str) -> str`
Builds the canonical Redis key for a tenant secret:
```python
from tenant_mgr_cache.cache_client import prepare_key
key = prepare_key("15", "satoken")
print(key) # "tenant:15:secret:satoken"
```
---
### `settings` — `CacheSettings`
A dataclass instance holding all resolved configuration values. Import it to inspect or override settings programmatically:
```python
from tenant_mgr_cache import settings
print(settings.REDIS_HOST)
print(settings.REDIS_PORT)
print(settings.REDIS_TENANT_CONFIG_DB)
```
---
### `logger` — `logging.Logger`
A pre-configured logger (`litewave_cache`) that respects the `LOG_LEVEL` environment variable. Import it to emit log messages consistent with the library's format:
```python
from tenant_mgr_cache import logger
logger.info("Custom message from application code")
```
---
## Development
### Setup
```bash
pip install -r requirements.txt
```
### Running Tests
```bash
pytest
```
With coverage:
```bash
pytest --cov=tenant_mgr_cache --cov-report=term-missing
```
---
## License
MIT License. See [LICENSE](LICENSE) for details.
| text/markdown | null | Nagarjuna Sarvepalli <nagarjuna.s@litewave.ai> | null | null | MIT | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"python-dotenv>=1.0.0",
"redis>=5.0.0",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/aiorch/litewave-cache-lib",
"Repository, https://github.com/aiorch/litewave-cache-lib"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-20T13:49:02.803744 | litewave_cache_lib-0.1.2.tar.gz | 9,664 | 80/5f/58bd1f9dedafe358c9d71502c49f3769777428573bbfaaf61acc042342ac/litewave_cache_lib-0.1.2.tar.gz | source | sdist | null | false | 9a748d08c6530ad813a66753f50a7b4c | e8323c10e10e4733a9137efa0b4e6ce2a71bb7f763ab2d61eae2794ab782fc23 | 805f58bd1f9dedafe358c9d71502c49f3769777428573bbfaaf61acc042342ac | null | [] | 220 |
2.3 | netcdf-cf-coercer | 0.1.3 | Prepare xarray Datasets for CF-1.12 compliant NetCDF output | # netcdf-cf-coercer
Prepare `xarray.Dataset` objects to be written as CF-1.12-compliant NetCDF files.
## Install
```bash
uv sync
```
## Usage
```python
import xarray as xr
import netcdf_cf_coercer # Registers the .cf dataset accessor
ds = xr.Dataset(
data_vars={"temp": (("time", "lat", "lon"), [[[280.0]]])},
coords={"time": [0], "lat": [10.0], "lon": [20.0]},
)
issues = ds.cf.check()
fixed = ds.cf.make_compliant()
```
You can also request a YAML-like text report printed to stdout:
```python
ds.cf.check(pretty_print=True)
```
You can choose which conventions to check:
```python
ds.cf.check(conventions="cf,ferret")
ds.cf.check(conventions="ferret") # custom-only checks
```
`check()` runs [cf-checker](https://github.com/cedadev/cf-checker/) against an
in-memory NetCDF payload created from dataset metadata (no `.nc` file written to disk),
and returns a dictionary of detected issues.
`make_compliant()` returns a new dataset with safe automatic fixes, including:
- `Conventions = "CF-1.12"`
- standard coordinate attributes for inferred `time`, `lat`, and `lon` axes
- creation of missing dimension coordinates for inferred axes
Notes:
- `cfchecker` requires the system `udunits2` library via `cfunits`.
- For large files, prefer opening with lazy chunks: `xr.open_dataset(path, chunks={})`.
- The built-in `ferret` convention flags coordinate `_FillValue` usage as an error.
- If `cfchecker` cannot run, `check()` falls back to heuristic checks and includes
a `checker_error` field in the response.
- You can bias standard-name suggestions by domain, e.g.
`ds.cf.check(domain="ocean")` (also supports `atmosphere`, `land`, `cryosphere`,
and `biogeochemistry`).
| text/markdown | lukegre | lukegre <lukegre@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"cfchecker",
"cfunits>=3.3.7",
"netcdf4",
"numpy>=1.24",
"pyudunits2>=0.1",
"rich>=14.3.2",
"xarray>=2023.1"
] | [] | [] | [] | [] | uv/0.9.9 {"installer":{"name":"uv","version":"0.9.9"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T13:48:41.602656 | netcdf_cf_coercer-0.1.3.tar.gz | 11,247 | a3/53/de448b4ba31bca2c0c9fafe3beba82c4876cc320f7e9b3f8e8c1c6acb7e4/netcdf_cf_coercer-0.1.3.tar.gz | source | sdist | null | false | 9528c32834c7857249f934ef3262ba92 | 9440291c4d15d8990d6bdbdafae051f7a1dfc44af7e3447075387dc39252e841 | a353de448b4ba31bca2c0c9fafe3beba82c4876cc320f7e9b3f8e8c1c6acb7e4 | null | [] | 195 |
2.4 | python-openevse-http | 0.2.4 | Python wrapper for OpenEVSE HTTP API | 



# python-openevse-http
Python Library for OpenEVSE HTTP API
A python library for communicating with the ESP8266- and ESP32-based wifi module from OpenEVSE. This library uses the HTTP API commands to query the OpenEVSE charger.
TODO:
- [ ] Finish tests
- [ ] Finish HTTP API functions
- [X] Setup webosocket listener for value updates
- [X] Convert to aiohttp from requests
- [X] Expose values as properties
| text/markdown | firstof9 | firstof9@gmail.com | null | null | Apache-2.0 | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Natural Language :: English",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: Apache Software License"
] | [] | https://github.com/firstof9/python-openevse-http | https://github.com/firstof9/python-openevse-http | >=3.10 | [] | [] | [] | [
"aiohttp"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:48:34.803898 | python_openevse_http-0.2.4.tar.gz | 32,966 | 5a/cc/b93ad2b55d0d60f6ad922356e4c49360333c07b217c3e3d764b64a3f8557/python_openevse_http-0.2.4.tar.gz | source | sdist | null | false | 1206977e480e85621403b02968a56179 | 5600f4977c2837b532cc64718206535eaa5ce890c9378f9f992ae153cba6a414 | 5accb93ad2b55d0d60f6ad922356e4c49360333c07b217c3e3d764b64a3f8557 | null | [
"LICENSE"
] | 229 |
2.4 | celine-utils | 1.6.3 | CELINE utils | # CELINE Utils
**CELINE Utils** is a collection of shared utilities, libraries, and command-line tools that form the technical backbone of the **CELINE data platform**.
It provides reusable building blocks for data pipelines, governance, lineage, metadata management, and platform integrations. The repository is designed to be embedded into CELINE applications and executed within orchestrated environments using Meltano, dbt, Prefect, and OpenLineage.
---
## Scope and Goals
The goals of this repository are to:
- Centralize **cross-cutting platform logic** used by multiple CELINE projects
- Provide **opinionated but extensible** tooling for data pipelines
- Enforce **consistent governance and lineage semantics**
- Reduce duplication across pipeline applications
- Act as a stable foundation for CELINE-compatible services and workflows
This is not an end-user application; it is a **platform utility layer**.
---
## Key Capabilities
### Command Line Interface (CLI)
A unified CLI built with Typer exposes administrative, governance, and pipeline utilities:
```text
celine-utils
├── governance
│ └── generate
└── pipeline
├── init
└── run
```
---
### Pipeline Orchestration
CELINE Utils provides a structured execution layer for:
- **Meltano** ingestion pipelines
- **dbt** transformations and tests
- **Prefect**-based Python flows
The `PipelineRunner` coordinates execution, logging, error handling, and lineage emission in a consistent way across tools.
See the [pipeline tutorial](docs/pipeline-tutorial.md) to discover how to setup and deploy a new pipeline.
---
### OpenLineage Integration
First-class OpenLineage support includes:
- Automatic emission of START, COMPLETE, FAIL, and ABORT events
- Dataset-level schema facets
- Data quality assertions from dbt tests
- Custom CELINE governance facets
---
### Governance Framework
A declarative `governance.yaml` specification allows you to define:
- Dataset ownership
- License and access level
- Classification and retention
- Tags and documentation links
Governance rules are resolved using pattern matching and injected into lineage events.
---
### Dataset Tooling
The `DatasetClient` enables:
- Schema and table introspection
- Column metadata inspection
- Safe query construction
- Export to Pandas
---
### Platform Integrations
Built-in integrations include:
- **Keycloak** for identity and access management
- **Apache Superset** for analytics platform integration
- **MQTT** for lightweight messaging
---
## Repository Structure
```text
celine/
admin/
cli/
common/
datasets/
pipelines/
schemas/
tests/
```
---
## Configuration
Configuration is environment-driven using `pydantic-settings`:
- Environment variables first
- Optional `.env` files
- Typed validation
- Container-friendly defaults
---
## Installation
```bash
pip install celine-utils
```
---
## Intended Audience
CELINE Utils is intended for:
- Data engineers
- Platform engineers
- CELINE application developers
It is not a general-purpose data tooling library.
---
## License
Copyright © 2025
Spindox Labs
Licensed under the Apache License, Version 2.0.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"bcrypt>=4.3.0",
"openlineage-python>=1.37.0",
"paho-mqtt>=2.1.0",
"pandas>=2.3.2",
"psycopg2-binary>=2.9.10",
"pydantic>=2.11.7",
"pydantic-settings>=2.10.1",
"python-dotenv>=1.1.1",
"python-keycloak>=5.8.1",
"requests>=2.32.5",
"sqlalchemy>=2.0.43",
"typer>=0.16.1",
"dbt-core>=1.10.10",
"dbt-postgres>=1.9.1",
"prefect-dbt>=0.7.6",
"meltano>=3.9.1",
"prefect>=3.4.19",
"celine-sdk>=1.1.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:48:25.010687 | celine_utils-1.6.3.tar.gz | 45,381 | c8/2a/02cdf66c4caf2b3d0f337ecc619fca61ed06cc14837f3088386603d020bd/celine_utils-1.6.3.tar.gz | source | sdist | null | false | a00f774dce7fd0c1e17c18b34c14116e | c0232734b72d7ee4a1ef107b61ac62acaf98c06af499594e871ff39e929b94ab | c82a02cdf66c4caf2b3d0f337ecc619fca61ed06cc14837f3088386603d020bd | null | [
"LICENSE"
] | 215 |
2.2 | mimer-mcp-server | 1.0.5 | An MCP server with Mimer SQL Database Connectivity | # Mimer MCP Server
A Model Context Protocol (MCP) server that provides Mimer SQL database connectivity to browse database schemas, execute read-only queries with parameterization support, and manage stored procedures.
<!-- mcp-name: io.github.mimersql/mimer-mcp -->
## Available Tools
### Database Schema Tools
- `list_schemas` — List all available schemas in the database
- `list_table_names` — List table names within the specified schema
- `get_table_info` — Get detailed table schema and sample rows
### Query Execution Tools
- `execute_query` — Execute SQL query with parameter support (Only SELECT queries are allowed)
### Stored Procedure Tools
- `list_stored_procedures` — List read-only stored procedures in the database
- `get_stored_procedure_definition` — Get the definition of a stored procedure
- `get_stored_procedure_parameters` — Get the parameters of a stored procedure
- `execute_stored_procedure` — Execute a stored procedure in the database with JSON parameters
## Getting Started
### Prerequisites
- Python 3.10 or later (with uv installed) _or_ Docker
- Mimer SQL 11.0 or later
---
### Environment Configuration
Before running the server, you need to configure your database connection settings using environment variables. The Mimer MCP Server reads these from a `.env` file.
Mimer MCP Server can be configured using environment variables through `.env` file with the following configuration option:
| Environment Variable | Default | Description |
|---------------------|---------|-------------|
| `DB_DSN` | *Required* | Database name to connect to |
| `DB_USER` | *Required* | Database username |
| `DB_PASSWORD` | *Required* | Database password |
| `DB_HOST` | - | Database host address (use `host.docker.internal` for Docker) |
| `DB_PORT` | `1360` | Database port number |
| `DB_PROTOCOL` | `tcp` | Connection protocol |
| `DB_POOL_INITIAL_CON` | `0` | Initial number of idle connections in the pool |
| `DB_POOL_MAX_UNUSED` | `0` | Maximum number of unused connections in the pool |
| `DB_POOL_MAX_CON` | `0` | Maximum number of connections allowed (0 = unlimited) |
| `DB_POOL_BLOCK` | `false` | Determines behavior when exceeding the maximum number of connections. If `true`, block and wait for a connection to become available; if `false`, raise an error when maxconnections is exceeded |
| `DB_POOL_DEEP_HEALTH_CHECK` | `true` | If `true`, validates connection health before getting from pool (slower but more reliable) |
| `MCP_LOG_LEVEL` | `INFO` | Logging level for the MCP server. Options: `DEBUG`, `INFO`, `WARNING`, `ERROR`, `CRITICAL` |
## Usage with VS Code
MCP servers are configured using a JSON file (`mcp.json`). Different MCP hosts may have slightly different configuration formats. In this guide, we'll focus on VS Code as an example. First, ensure you've installed the latest version of VS Code and have access to Copilot.
One way to add MCP server in VS Code is to add the server configuration to your workspace in the `.vscode/mcp.json` file. This will allow you to share configuration with others.
1. Create a `.vscode/mcp.json` file in your workspace.
2. Add the following configuration to your `.vscode/mcp.json` file, depending on how you want to run the MCP server.
### Option 1: Using Docker (Recommended)
#### Option 1.1: Build the Docker Image Locally
```bash
docker build -t mimer-mcp-server .
```
Then, add the following configuration to `.vscode/mcp.json` file
```json
{
"servers": {
"mimer-mcp-server": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"--add-host=host.docker.internal:host-gateway",
"--env-file=/absolute/path/to/.env",
"mimer-mcp-server",
]
}
},
"inputs": []
}
```
#### Option 1.2: Use the Pre-Built Image from Docker Hub
```json title="mcp.json"
{
"servers": {
"mimer-mcp-server": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"--add-host=host.docker.internal:host-gateway",
"--env-file=/absolute/path/to/.env",
"mimersql/mimer-mcp:latest"
]
}
},
"inputs": []
}
```
### Option 1.3: Use Docker compose and the official Mimer SQL docker container
This will start a Mimer SQL Docker container as well as the mimer-mcp-server container,
set up a private network between the two containers and create the Mimer SQL example database.
The Mimer SQL database will be stored in the docker volume called `mimer_mcp_data` so that database changes are persistent.
```
{
"servers": {
"mimer-mcp-server": {
"command": "docker",
"args": [
"compose",
"run",
"--rm",
"-i",
"--no-TTY",
"mimer-mcp-server"
]
}
},
"inputs": []
}
```
### Option 2: Using uv
[](vscode:mcp/install?%7B%22name%22%3A%22mimer-mcp-server%22%2C%22type%22%3A%22stdio%22%2C%22command%22%3A%22uv%22%2C%22args%22%3A%5B%22run%22%2C%22--with%22%2C%22fastmcp%22%2C%22fastmcp%22%2C%22run%22%2C%22%2Fabsolute%2Fpath%2Fto%2Fserver.py%22%5D%7D)
```json
{
"servers": {
"mimer-mcp-server": {
"type": "stdio",
"command": "uvx",
"args": [
"mimer_mcp_server"
],
"env": {
"DOTENV_PATH": "/absolute/path/to/.env"
}
}
}
}
```
3. After saving the configuration file, VS Code will display a **Start** button in the `mcp.json` file. Click it to launch the server.
<img src="docs/images/start-mcp-server.png" alt="Start button to start Mimer MCP Server" width=400>
5. Open Copilot Chat and in the Copilot Chat box, select Agent mode from the dropdown.
<img src="docs/images/copilot-agent-mode.png" alt="Copilot Chat Agent Mode" width=400>
6. Select the Tools button to view the list of available tools. Make sure the tools from Mimer MCP Server are selected.
<img src="docs/images/mimer-mcp-tools.png" alt="Tool Button on Chat" width=490%>
7. Enter a prompt in the chat input box and notice how the agent autonomously selects a suitable tool, fix errors and generate a final answer from gathered queries results. (Following examples use the Example Database from Mimer, which is owned by MIMER_STORE. Read more about this database: [here](https://developer.mimer.com/article/the-example-database/))
<img src="docs/images/prompt-anthology.png" alt="Prompt asking what kind of product is Anthology" width=90%>
<img src="docs/images/agent-answer.png" alt="Agent answers with the gathered queries results" width=90%>
## Development
### Prerequisites
- Python: 3.10+
- [uv](https://github.com/astral-sh/uv): for dependency management and running the server
- Mimer SQL 11.0 or later
- Node.js and npm: for debugging with MCP inspector
#### Install `uv`:
```bash
# macOS / Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
# or via Homebrew
brew install uv
```
Verify installation:
```bash
uv --version
```
#### Install Node.js and npm:
```bash
# Linux (Ubuntu/Debian)
sudo apt install nodejs npm
# macOS (via Homebrew)
brew install node
```
Verify installation:
```bash
node --version
npm --version
```
### Getting Started
1. Clone the repository
2. Create and activate a virtual environment
```bash
uv venv
# macOS / Linux
source .venv/bin/activate
# Windows
.venv\Scripts\activate
```
3. Install dependencies from pyproject.toml
```bash
uv sync
```
4. Configure environment variables
```bash
cp .env.example .env
# Edit .env with your database credentials
```
The configuration is loaded automatically via `config.py`.
### Debug with MCP inspector
MCP Inspector provides a web interface for testing and debugging MCP Tools (Requires Node.js: 22.7.5+):
```bash
npx @modelcontextprotocol/inspector
```
Note: MCP Inspector is a Node.js app and the npx command allows running MCP Inspector without having to permanently install it as a Node.js package.
Alternatively, you can use FastMCP CLI to start the MCP inspector
```bash
uv run fastmcp dev /absolute/path/to/server.py
```
To run the Mimer SQL docker image and mimer-mcp-server using Docker compose, run:
```bash
MCP_TRANSPORT=http docker compose up
```
or to run it as a daemon:
```bash
MCP_TRANSPORT=http docker compose up -d
```
This way it is possible to call the mimer-mcp-server using HTTP and port 3333.
| text/markdown | null | Chananya Pomkaew <chananya.pomkaew@mimer.com>, Fredrik Ålund <fredrik.alund@mimer.com>, Mimer Information Technology AB <info@mimer.com> | null | null | MIT | mimer, mimer sql, database, mimer mcp server, mcp, llm | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"fastmcp>=2.13.0",
"mcp>=1.15.0",
"mimerpy>=1.3.7",
"python-dotenv>=1.1.1"
] | [] | [] | [] | [
"Homepage, https://github.com/mimersql/mimer-mcp",
"Repository, https://github.com/mimersql/mimer-mcp",
"Documentation, https://github.com/mimersql/mimer-mcp/blob/main/README.md",
"Issues, https://github.com/mimersql/mimer-mcp/issues"
] | twine/6.2.0 CPython/3.10.18 | 2026-02-20T13:48:12.662953 | mimer_mcp_server-1.0.5.tar.gz | 951,503 | d2/08/cbd7d12275fbc2d9a963bf6dd44fd7f1e5bf408e195015851ecda936e20d/mimer_mcp_server-1.0.5.tar.gz | source | sdist | null | false | feebaa0872cb46c4a34e5852042eda77 | 81747d2a0c314f471c6a5c1d1d598eae1589dd1cedffa9a072dcbaf82f3f3585 | d208cbd7d12275fbc2d9a963bf6dd44fd7f1e5bf408e195015851ecda936e20d | null | [] | 226 |
2.4 | mlflow | 3.10.0 | MLflow is an open source platform for the complete machine learning lifecycle | <h1 align="center" style="border-bottom: none">
<a href="https://mlflow.org/">
<img alt="MLflow logo" src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/logo.svg" width="200" />
</a>
</h1>
<h2 align="center" style="border-bottom: none">Open-Source Platform for Productionizing AI</h2>
MLflow is an open-source developer platform to build AI/LLM applications and models with confidence. Enhance your AI applications with end-to-end **experiment tracking**, **observability**, and **evaluations**, all in one integrated platform.
<div align="center">
[](https://pypi.org/project/mlflow/)
[](https://pepy.tech/projects/mlflow)
[](https://github.com/mlflow/mlflow/blob/main/LICENSE)
<a href="https://twitter.com/intent/follow?screen_name=mlflow" target="_blank">
<img src="https://img.shields.io/twitter/follow/mlflow?logo=X&color=%20%23f5f5f5"
alt="follow on X(Twitter)"></a>
<a href="https://www.linkedin.com/company/mlflow-org/" target="_blank">
<img src="https://custom-icon-badges.demolab.com/badge/LinkedIn-0A66C2?logo=linkedin-white&logoColor=fff"
alt="follow on LinkedIn"></a>
[](https://deepwiki.com/mlflow/mlflow)
</div>
<div align="center">
<div>
<a href="https://mlflow.org/"><strong>Website</strong></a> ·
<a href="https://mlflow.org/docs/latest"><strong>Docs</strong></a> ·
<a href="https://github.com/mlflow/mlflow/issues/new/choose"><strong>Feature Request</strong></a> ·
<a href="https://mlflow.org/blog"><strong>News</strong></a> ·
<a href="https://www.youtube.com/@mlflowoss"><strong>YouTube</strong></a> ·
<a href="https://lu.ma/mlflow?k=c"><strong>Events</strong></a>
</div>
</div>
<br>
## 🚀 Installation
To install the MLflow Python package, run the following command:
```
pip install mlflow
```
## 📦 Core Components
MLflow is **the only platform that provides a unified solution for all your AI/ML needs**, including LLMs, Agents, Deep Learning, and traditional machine learning.
### 💡 For LLM / GenAI Developers
<table>
<tr>
<td>
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-tracing.png" alt="Tracing" width=100%>
<div align="center">
<br>
<a href="https://mlflow.org/docs/latest/llms/tracing/index.html"><strong>🔍 Tracing / Observability</strong></a>
<br><br>
<div>Trace the internal states of your LLM/agentic applications for debugging quality issues and monitoring performance with ease.</div><br>
<a href="https://mlflow.org/docs/latest/genai/tracing/quickstart/">Getting Started →</a>
<br><br>
</div>
</td>
<td>
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-llm-eval.png" alt="LLM Evaluation" width=100%>
<div align="center">
<br>
<a href="https://mlflow.org/docs/latest/genai/eval-monitor/"><strong>📊 LLM Evaluation</strong></a>
<br><br>
<div>A suite of automated model evaluation tools, seamlessly integrated with experiment tracking to compare across multiple versions.</div><br>
<a href="https://mlflow.org/docs/latest/genai/eval-monitor/">Getting Started →</a>
<br><br>
</div>
</td>
</tr>
<tr>
<td>
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-prompt.png" alt="Prompt Management">
<div align="center">
<br>
<a href="https://mlflow.org/docs/latest/genai/prompt-version-mgmt/prompt-registry/"><strong>🤖 Prompt Management</strong></a>
<br><br>
<div>Version, track, and reuse prompts across your organization, helping maintain consistency and improve collaboration in prompt development.</div><br>
<a href="https://mlflow.org/docs/latest/genai/prompt-registry/create-and-edit-prompts/">Getting Started →</a>
<br><br>
</div>
</td>
<td>
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-logged-model.png" alt="MLflow Hero">
<div align="center">
<br>
<a href="https://mlflow.org/docs/latest/genai/prompt-version-mgmt/version-tracking/"><strong>📦 App Version Tracking</strong></a>
<br><br>
<div>MLflow keeps track of many moving parts in your AI applications, such as models, prompts, tools, and code, with end-to-end lineage.</div><br>
<a href="https://mlflow.org/docs/latest/genai/version-tracking/quickstart/">Getting Started →</a>
<br><br>
</div>
</td>
</tr>
</table>
### 🎓 For Data Scientists
<table>
<tr>
<td colspan="2" align="center" >
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-experiment.png" alt="Tracking" width=50%>
<div align="center">
<br>
<a href="https://mlflow.org/docs/latest/ml/tracking/"><strong>📝 Experiment Tracking</strong></a>
<br><br>
<div>Track your models, parameters, metrics, and evaluation results in ML experiments and compare them using an interactive UI.</div><br>
<a href="https://mlflow.org/docs/latest/ml/tracking/quickstart/">Getting Started →</a>
<br><br>
</div>
</td>
</tr>
<tr>
<td>
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-model-registry.png" alt="Model Registry" width=100%>
<div align="center">
<br>
<a href="https://mlflow.org/docs/latest/ml/model-registry/"><strong>💾 Model Registry</strong></a>
<br><br>
<div> A centralized model store designed to collaboratively manage the full lifecycle and deployment of machine learning models.</div><br>
<a href="https://mlflow.org/docs/latest/ml/model-registry/tutorial/">Getting Started →</a>
<br><br>
</div>
</td>
<td>
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-deployment.png" alt="Deployment" width=100%>
<div align="center">
<br>
<a href="https://mlflow.org/docs/latest/ml/deployment/"><strong>🚀 Deployment</strong></a>
<br><br>
<div> Tools for seamless model deployment to batch and real-time scoring on platforms like Docker, Kubernetes, Azure ML, and AWS SageMaker.</div><br>
<a href="https://mlflow.org/docs/latest/ml/deployment/">Getting Started →</a>
<br><br>
</div>
</td>
</tr>
</table>
## 🌐 Hosting MLflow Anywhere
<div align="center" >
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-providers.png" alt="Providers" width=100%>
</div>
You can run MLflow in many different environments, including local machines, on-premise servers, and cloud infrastructure.
Trusted by thousands of organizations, MLflow is now offered as a managed service by most major cloud providers:
- [Amazon SageMaker](https://aws.amazon.com/sagemaker-ai/experiments/)
- [Azure ML](https://learn.microsoft.com/en-us/azure/machine-learning/concept-mlflow?view=azureml-api-2)
- [Databricks](https://www.databricks.com/product/managed-mlflow)
- [Nebius](https://nebius.com/services/managed-mlflow)
For hosting MLflow on your own infrastructure, please refer to [this guidance](https://mlflow.org/docs/latest/ml/tracking/#tracking-setup).
## 🗣️ Supported Programming Languages
- [Python](https://pypi.org/project/mlflow/)
- [TypeScript / JavaScript](https://www.npmjs.com/package/mlflow-tracing)
- [Java](https://mvnrepository.com/artifact/org.mlflow/mlflow-client)
- [R](https://cran.r-project.org/web/packages/mlflow/readme/README.html)
## 🔗 Integrations
MLflow is natively integrated with many popular machine learning frameworks and GenAI libraries.

## Usage Examples
### Tracing (Observability) ([Doc](https://mlflow.org/docs/latest/llms/tracing/index.html))
MLflow Tracing provides LLM observability for various GenAI libraries such as OpenAI, LangChain, LlamaIndex, DSPy, AutoGen, and more. To enable auto-tracing, call `mlflow.xyz.autolog()` before running your models. Refer to the documentation for customization and manual instrumentation.
```python
import mlflow
from openai import OpenAI
# Enable tracing for OpenAI
mlflow.openai.autolog()
# Query OpenAI LLM normally
response = OpenAI().chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "Hi!"}],
temperature=0.1,
)
```
Then navigate to the "Traces" tab in the MLflow UI to find the trace records for the OpenAI query.
### Evaluating LLMs, Prompts, and Agents ([Doc](https://mlflow.org/docs/latest/genai/eval-monitor/index.html))
The following example runs automatic evaluation for question-answering tasks with several built-in metrics.
```python
import os
import openai
import mlflow
from mlflow.genai.scorers import Correctness, Guidelines
client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 1. Define a simple QA dataset
dataset = [
{
"inputs": {"question": "Can MLflow manage prompts?"},
"expectations": {"expected_response": "Yes!"},
},
{
"inputs": {"question": "Can MLflow create a taco for my lunch?"},
"expectations": {
"expected_response": "No, unfortunately, MLflow is not a taco maker."
},
},
]
# 2. Define a prediction function to generate responses
def predict_fn(question: str) -> str:
response = client.chat.completions.create(
model="gpt-4o-mini", messages=[{"role": "user", "content": question}]
)
return response.choices[0].message.content
# 3. Run the evaluation
results = mlflow.genai.evaluate(
data=dataset,
predict_fn=predict_fn,
scorers=[
# Built-in LLM judge
Correctness(),
# Custom criteria using LLM judge
Guidelines(name="is_english", guidelines="The answer must be in English"),
],
)
```
Navigate to the "Evaluations" tab in the MLflow UI to find the evaluation results.
### Tracking Model Training ([Doc](https://mlflow.org/docs/latest/ml/tracking/))
The following example trains a simple regression model with scikit-learn, while enabling MLflow's [autologging](https://mlflow.org/docs/latest/tracking/autolog.html) feature for experiment tracking.
```python
import mlflow
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
# Enable MLflow's automatic experiment tracking for scikit-learn
mlflow.sklearn.autolog()
# Load the training dataset
db = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)
rf = RandomForestRegressor(n_estimators=100, max_depth=6, max_features=3)
# MLflow triggers logging automatically upon model fitting
rf.fit(X_train, y_train)
```
Once the above code finishes, run the following command in a separate terminal and access the MLflow UI via the printed URL. An MLflow **Run** should be automatically created, which tracks the training dataset, hyperparameters, performance metrics, the trained model, dependencies, and even more.
```
mlflow server
```
## 💭 Support
- For help or questions about MLflow usage (e.g. "how do I do X?") visit the [documentation](https://mlflow.org/docs/latest).
- In the documentation, you can ask the question to our AI-powered chat bot. Click on the **"Ask AI"** button at the right bottom.
- Join the [virtual events](https://lu.ma/mlflow?k=c) like office hours and meetups.
- To report a bug, file a documentation issue, or submit a feature request, please [open a GitHub issue](https://github.com/mlflow/mlflow/issues/new/choose).
- For release announcements and other discussions, please subscribe to our mailing list (mlflow-users@googlegroups.com)
or join us on [Slack](https://mlflow.org/slack).
## 🤝 Contributing
We happily welcome contributions to MLflow!
- Submit [bug reports](https://github.com/mlflow/mlflow/issues/new?template=bug_report_template.yaml) and [feature requests](https://github.com/mlflow/mlflow/issues/new?template=feature_request_template.yaml)
- Contribute for [good-first-issues](https://github.com/mlflow/mlflow/issues?q=is%3Aissue+is%3Aopen+label%3A%22good+first+issue%22) and [help-wanted](https://github.com/mlflow/mlflow/issues?q=is%3Aissue+is%3Aopen+label%3A%22help+wanted%22)
- Writing about MLflow and sharing your experience
Please see our [contribution guide](CONTRIBUTING.md) to learn more about contributing to MLflow.
## ⭐️ Star History
<a href="https://star-history.com/#mlflow/mlflow&Date">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=mlflow/mlflow&type=Date&theme=dark" />
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=mlflow/mlflow&type=Date" />
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=mlflow/mlflow&type=Date" />
</picture>
</a>
## ✏️ Citation
If you use MLflow in your research, please cite it using the "Cite this repository" button at the top of the [GitHub repository page](https://github.com/mlflow/mlflow), which will provide you with citation formats including APA and BibTeX.
## 👥 Core Members
MLflow is currently maintained by the following core members with significant contributions from hundreds of exceptionally talented community members.
- [Ben Wilson](https://github.com/BenWilson2)
- [Corey Zumar](https://github.com/dbczumar)
- [Daniel Lok](https://github.com/daniellok-db)
- [Gabriel Fu](https://github.com/gabrielfu)
- [Harutaka Kawamura](https://github.com/harupy)
- [Joel Robin P](https://github.com/joelrobin18)
- [Matt Prahl](https://github.com/mprahl)
- [Serena Ruan](https://github.com/serena-ruan)
- [Tomu Hirata](https://github.com/TomeHirata)
- [Weichen Xu](https://github.com/WeichenXu123)
- [Yuki Watanabe](https://github.com/B-Step62)
| text/markdown | null | null | null | Databricks <mlflow-oss-maintainers@googlegroups.com> | Copyright 2018 Databricks, Inc. All rights reserved.
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| mlflow, ai, databricks | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: End Users/Desktop",
"Intended Audience :: Science/Research",
"Intended Audience :: Information Technology",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Software Development :: Libraries :: Python Modules",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.10"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"mlflow-skinny==3.10.0",
"mlflow-tracing==3.10.0",
"Flask-CORS<7",
"Flask<4",
"alembic!=1.10.0,<2",
"cryptography<47,>=43.0.0",
"docker<8,>=4.0.0",
"graphene<4",
"gunicorn<26; platform_system != \"Windows\"",
"huey<3,>=2.5.4",
"matplotlib<4",
"numpy<3",
"pandas<3",
"pyarrow<24,>=4.0.0",
"scikit-learn<2",
"scipy<2",
"skops<1",
"sqlalchemy<3,>=1.4.0",
"waitress<4; platform_system == \"Windows\"",
"pyarrow; extra == \"extras\"",
"requests-auth-aws-sigv4; extra == \"extras\"",
"boto3; extra == \"extras\"",
"botocore; extra == \"extras\"",
"google-cloud-storage>=1.30.0; extra == \"extras\"",
"azureml-core>=1.2.0; extra == \"extras\"",
"pysftp; extra == \"extras\"",
"kubernetes; extra == \"extras\"",
"prometheus-flask-exporter; extra == \"extras\"",
"PyMySQL; extra == \"db\"",
"psycopg2-binary; extra == \"db\"",
"pymssql; extra == \"db\"",
"azure-storage-file-datalake>12; extra == \"databricks\"",
"google-cloud-storage>=1.30.0; extra == \"databricks\"",
"boto3>1; extra == \"databricks\"",
"botocore; extra == \"databricks\"",
"databricks-agents<2.0,>=1.2.0; extra == \"databricks\"",
"mlserver!=1.3.1,<2.0.0,>=1.2.0; extra == \"mlserver\"",
"mlserver-mlflow!=1.3.1,<2.0.0,>=1.2.0; extra == \"mlserver\"",
"aiohttp<4; extra == \"gateway\"",
"boto3<2,>=1.28.56; extra == \"gateway\"",
"fastapi<1; extra == \"gateway\"",
"slowapi<1,>=0.1.9; extra == \"gateway\"",
"tiktoken<1; extra == \"gateway\"",
"uvicorn[standard]<1; extra == \"gateway\"",
"watchfiles<2; extra == \"gateway\"",
"aiohttp<4; extra == \"genai\"",
"boto3<2,>=1.28.56; extra == \"genai\"",
"fastapi<1; extra == \"genai\"",
"gepa<1,>=0.0.26; extra == \"genai\"",
"litellm<2,>=1.0.0; extra == \"genai\"",
"slowapi<1,>=0.1.9; extra == \"genai\"",
"tiktoken<1; extra == \"genai\"",
"uvicorn[standard]<1; extra == \"genai\"",
"watchfiles<2; extra == \"genai\"",
"fastmcp<3,>=2.0.0; extra == \"mcp\"",
"click!=8.3.0; extra == \"mcp\"",
"mlflow-dbstore; extra == \"sqlserver\"",
"aliyunstoreplugin; extra == \"aliyun-oss\"",
"mlflow-jfrog-plugin; extra == \"jfrog\"",
"langchain<=1.2.9,>=0.3.19; extra == \"langchain\"",
"Flask-WTF<2; extra == \"auth\""
] | [] | [] | [] | [
"homepage, https://mlflow.org",
"issues, https://github.com/mlflow/mlflow/issues",
"documentation, https://mlflow.org/docs/latest",
"repository, https://github.com/mlflow/mlflow"
] | twine/6.2.0 CPython/3.9.24 | 2026-02-20T13:48:10.960458 | mlflow-3.10.0.tar.gz | 9,534,884 | bc/ed/048a6a3198516153f8babae7553d2db4e5988501cf84fd1e197cf2133558/mlflow-3.10.0.tar.gz | source | sdist | null | false | 23d131327187b6f5c85a96c5c2de87f8 | 54a6e18100623855d5d2a5b22fdec4a929543088adee49ca164d72439fdce2e3 | bced048a6a3198516153f8babae7553d2db4e5988501cf84fd1e197cf2133558 | null | [
"LICENSE.txt"
] | 269,415 |
2.4 | casty | 0.18.0 | Typed, clustered actor framework for Python. Pure asyncio, zero dependencies. | <p align="center">
<img src="docs/logo_bw.png" alt="Casty" width="512">
</p>
<p align="center">
<strong>Typed, clustered actor framework for Python</strong>
</p>
<p align="center">
<a href="https://pypi.org/project/casty/"><img src="https://img.shields.io/pypi/v/casty.svg" alt="PyPI"></a>
<a href="https://pypi.org/project/casty/"><img src="https://img.shields.io/pypi/pyversions/casty.svg" alt="Python"></a>
<a href="https://github.com/gabfssilva/casty/actions"><img src="https://img.shields.io/github/actions/workflow/status/gabfssilva/casty/python-package.yml" alt="Tests"></a>
<a href="https://github.com/gabfssilva/casty/blob/main/LICENSE"><img src="https://img.shields.io/badge/license-MIT-blue.svg" alt="License"></a>
</p>
<p align="center">
<a href="https://gabfssilva.github.io/casty/">Documentation</a> · <a href="https://gabfssilva.github.io/casty/getting-started/">Getting Started</a> · <a href="https://pypi.org/project/casty/">PyPI</a>
</p>
---
Casty is a typed, clustered actor framework for Python built on asyncio. Instead of threads, locks, and shared mutable state, you model your system as independent actors that communicate exclusively through immutable messages, from a single process to a distributed cluster.
## Quick Start
```
pip install casty
```
```python
import asyncio
from dataclasses import dataclass
from casty import ActorContext, ActorSystem, Behavior, Behaviors
@dataclass(frozen=True)
class Greet:
name: str
def greeter() -> Behavior[Greet]:
async def receive(ctx: ActorContext[Greet], msg: Greet) -> Behavior[Greet]:
print(f"Hello, {msg.name}!")
return Behaviors.same()
return Behaviors.receive(receive)
async def main() -> None:
async with ActorSystem() as system:
ref = system.spawn(greeter(), "greeter")
ref.tell(Greet("Alice"))
ref.tell(Greet("Bob"))
await asyncio.sleep(0.1)
asyncio.run(main())
# Hello, Alice!
# Hello, Bob!
```
## Features
- **Behaviors as values, not classes** — No `Actor` base class. Behaviors are frozen dataclasses composed through factory functions.
- **State via closures** — Actor state is captured in closures. State transitions happen by returning a new behavior with new closed-over values. No mutable fields, no `nonlocal`.
- **Immutability by default** — All messages, behaviors, events, and configurations are frozen dataclasses.
- **Type-safe end-to-end** — `ActorRef[M]`, `Behavior[M]`, and PEP 695 type aliases ensure message type mismatches are caught at development time.
- **Zero external dependencies** — Pure Python, stdlib only.
- **Supervision** — "Let it crash" philosophy with configurable restart strategies, inspired by Erlang/OTP.
- **Event sourcing** — Persist actor state as a sequence of events with automatic recovery on restart.
- **Cluster sharding** — Distribute actors across nodes with gossip-based membership, phi accrual failure detection, and automatic shard rebalancing.
- **Shard replication** — Passive replicas with automatic promotion on node failure.
- **Cluster broadcast** — Fan-out messages to all nodes with typesafe aggregated responses.
- **Distributed data structures** — Counter, Dict, Set, Queue, Lock, Semaphore, and Barrier built on sharded actors.
- **TOML configuration** — Optional `casty.toml` for environment-specific tuning with per-actor overrides.
## Documentation
Full documentation is available at **[gabfssilva.github.io/casty](https://gabfssilva.github.io/casty/)**.
| Section | Description |
|---------|-------------|
| [Getting Started](https://gabfssilva.github.io/casty/getting-started/) | Installation and first steps |
| [Concepts](https://gabfssilva.github.io/casty/concepts/actors-and-messages/) | Actors, behaviors, state, request-reply, hierarchies, supervision, state machines |
| [Persistence](https://gabfssilva.github.io/casty/persistence/event-sourcing/) | Event sourcing with journals and snapshots |
| [Clustering](https://gabfssilva.github.io/casty/clustering/cluster-sharding/) | Sharding, broadcast, replication, distributed data structures |
| [Configuration](https://gabfssilva.github.io/casty/configuration/) | TOML-based configuration with per-actor overrides |
| [API Reference](https://gabfssilva.github.io/casty/reference/behaviors/) | Complete API documentation |
## Acknowledgments
Casty builds on the actor model (Hewitt, 1973), Erlang/OTP's supervision philosophy, Akka Typed's functional behavior API, and distributed systems research including phi accrual failure detection, gossip protocols, CRDTs, and vector clocks. See the full [Acknowledgments](https://gabfssilva.github.io/casty/acknowledgments/) page for details and references.
## Contributing
```bash
git clone https://github.com/gabfssilva/casty
cd casty
uv sync
uv run pytest # run tests
uv run pyright src/casty/ # type checking (strict mode)
uv run ruff check src/ tests/ # lint
uv run ruff format src/ tests/ # format
```
## License
MIT — see [LICENSE](LICENSE) for details.
| text/markdown | Gabriel Francisco | null | null | null | MIT | actor, actor-model, async, asyncio, cluster, concurrency, distributed | [
"Development Status :: 3 - Alpha",
"Framework :: AsyncIO",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Libraries",
"Typing :: Typed"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"uvloop>=0.22.1; extra == \"performance\""
] | [] | [] | [] | [
"Homepage, https://gabfssilva.github.io/casty/",
"Repository, https://github.com/gabfssilva/casty",
"Documentation, https://gabfssilva.github.io/casty/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:48:00.041397 | casty-0.18.0.tar.gz | 1,302,677 | 86/55/57f73d2aeb1edb872ea54991d515a5a9dce0b68ff0131db7ac6643eaa270/casty-0.18.0.tar.gz | source | sdist | null | false | de3da08b74d96ede1c98ceef76c3bf8a | 27e578f84d6d1b3c6aca75f1ffe5b4a9c9ffc68457326a1bd35fedc89c8bd166 | 865557f73d2aeb1edb872ea54991d515a5a9dce0b68ff0131db7ac6643eaa270 | null | [
"LICENSE"
] | 1,472 |
2.1 | runqy-python | 0.2.2 | Python SDK for runqy - write distributed task handlers with simple decorators | <p align="center">
<img src="assets/logo.svg" alt="runqy logo" width="80" height="80">
</p>
<h1 align="center">runqy-python</h1>
<p align="center">
Python SDK for <a href="https://runqy.com">runqy</a> - write distributed task handlers with simple decorators.
<br>
<a href="https://docs.runqy.com"><strong>Documentation</strong></a> · <a href="https://runqy.com"><strong>Website</strong></a>
</p>
## Installation
```bash
pip install runqy-python
```
## Task Handlers
Create tasks that run on [runqy-worker](https://github.com/publikey/runqy-worker) using simple decorators:
### Simple Task
```python
from runqy_python import task, run
@task
def process(payload: dict) -> dict:
return {"message": "Hello!", "received": payload}
if __name__ == "__main__":
run()
```
### With Model Loading
For ML inference tasks, use `@load` to load models once at startup:
```python
from runqy_python import task, load, run
@load
def setup():
"""Runs once before ready signal. Return value is passed to @task as ctx."""
model = load_heavy_model() # Load weights, etc.
return {"model": model}
@task
def process(payload: dict, ctx: dict) -> dict:
"""Process tasks using the loaded model."""
prediction = ctx["model"].predict(payload["input"])
return {"prediction": prediction}
if __name__ == "__main__":
run()
```
### One-Shot Tasks
For lightweight tasks that don't need to stay loaded in memory, use `run_once()`:
```python
from runqy_python import task, run_once
@task
def process(payload: dict) -> dict:
return {"result": payload["x"] * 2}
if __name__ == "__main__":
run_once() # Process one task and exit
```
| Function | Behavior | Use case |
|----------|----------|----------|
| `run()` | Loops forever, handles many tasks | ML inference (expensive load) |
| `run_once()` | Handles ONE task, exits | Lightweight tasks |
## Protocol
The SDK handles the runqy-worker stdin/stdout JSON protocol:
1. **Load phase**: Calls `@load` function (if registered)
2. **Ready signal**: Sends `{"status": "ready"}` after load completes
3. **Task input**: Reads JSON from stdin: `{"task_id": "...", "payload": {...}}`
4. **Response**: Writes JSON to stdout: `{"task_id": "...", "result": {...}, "error": null, "retry": false}`
## Client (Optional)
The SDK also includes a client for enqueuing tasks to a runqy server:
```python
from runqy_python import RunqyClient
client = RunqyClient("http://localhost:3000", api_key="your-api-key")
# Enqueue a task
task = client.enqueue("inference.default", {"input": "hello"})
print(f"Task ID: {task.task_id}")
# Check result
result = client.get_task(task.task_id)
print(f"State: {result.state}, Result: {result.result}")
```
Or use the convenience function:
```python
from runqy_python import enqueue
task = enqueue(
"inference.default",
{"input": "hello"},
server_url="http://localhost:3000",
api_key="your-api-key"
)
```
### Client API
**RunqyClient(server_url, api_key, timeout=30)**
- `server_url`: Base URL of the runqy server
- `api_key`: API key for authentication
- `timeout`: Default request timeout in seconds
**client.enqueue(queue, payload, timeout=300)**
- `queue`: Queue name (e.g., `"inference.default"`)
- `payload`: Task payload as a dict
- `timeout`: Task execution timeout in seconds
- Returns: `TaskInfo` with `task_id`, `queue`, `state`
**client.get_task(task_id)**
- `task_id`: Task ID from enqueue
- Returns: `TaskInfo` with `task_id`, `queue`, `state`, `result`, `error`
### Exceptions
- `RunqyError`: Base exception for all client errors
- `AuthenticationError`: Invalid or missing API key
- `TaskNotFoundError`: Task ID doesn't exist
## Development
```bash
# Install in editable mode
pip install -e .
# Test task execution
echo '{"task_id":"t1","payload":{"foo":"bar"}}' | python your_model.py
# Test client import
python -c "from runqy_python import RunqyClient; print('OK')"
```
| text/markdown | Publikey | null | null | null | null | task-queue, distributed, worker, redis, async, client | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Documentation, https://docs.runqy.com",
"Repository, https://github.com/Publikey/runqy-python",
"Issues, https://github.com/Publikey/runqy-python/issues"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T13:46:34.852228 | runqy_python-0.2.2.tar.gz | 14,226 | f3/f3/1e817c5da24d433f37eb5bdd4d3ff4065725552e998b853659f257e264c6/runqy_python-0.2.2.tar.gz | source | sdist | null | false | 83666472db4f405594a822491cf6366a | 16f6fcd1f44e133c5bf4cc9ad7915e805758a5d393e45dbd3198eaf80ec8d8f1 | f3f31e817c5da24d433f37eb5bdd4d3ff4065725552e998b853659f257e264c6 | null | [] | 250 |
2.4 | genericissuetracker | 0.4.3 | Reusable, versioned, schema-safe Django Issue Tracker application. | # Generic Issue Tracker




A production-grade, reusable, installable Django Issue Tracking library.
---
## 🚀 Overview
GenericIssueTracker is a versioned, schema-safe, soft-delete-compatible issue tracking engine designed to integrate into any Django application.
It provides:
- Issue management
- Comments
- Labels
- Attachments
- Human-friendly issue numbers
- Versioned REST API
- Configurable permissions
- Configurable pagination
- Configurable filtering
- OpenAPI schema support (drf-spectacular compatible)
Designed for:
- SaaS platforms
- Internal tools
- Public open-source issue hubs
- Enterprise-grade Django systems
---
## 🏗 Architecture
### Layered Design
```
Models (Domain)
↓
Services (Identity / Permissions / Pagination / Filtering)
↓
Serializers (Validation & Representation)
↓
Versioned Views
↓
Versioned URLs
↓
OpenAPI Schema
```
### Design Principles
- No dependency on AUTH_USER_MODEL
- Soft delete first-class
- UUID internal identity
- Sequential issue_number public identity
- Strict versioning (`/api/v1/`)
- Deterministic schema
- Zero business logic in views
- Fat serializers, thin views
- No runtime schema mutation
---
## 📦 Installation
```bash
pip install genericissuetracker
```
Add to `INSTALLED_APPS`:
```python
INSTALLED_APPS = [
...
"genericissuetracker",
]
```
Include URLs:
```python
path("api/", include("genericissuetracker.urls.root")),
```
---
## 🛠 Required Dependencies
- Django >= 4.2
- djangorestframework >= 3.14
- drf-spectacular >= 0.27
---
## ⚙ Configuration
All settings are namespaced:
```python
GENERIC_ISSUETRACKER_<SETTING>
```
### Available Settings
| Setting | Description |
|----------|-------------|
| IDENTITY_RESOLVER | Custom identity resolver path |
| ALLOW_ANONYMOUS_REPORTING | Allow anonymous issue creation |
| MAX_ATTACHMENTS | Max attachments per issue |
| MAX_ATTACHMENT_SIZE_MB | Max file size |
| DEFAULT_PERMISSION_CLASSES | Default DRF permissions |
| DEFAULT_PAGINATION_CLASS | Pagination class |
| PAGE_SIZE | Pagination size |
| DEFAULT_FILTER_BACKENDS | Filtering backends |
Example:
```python
GENERIC_ISSUETRACKER_DEFAULT_PERMISSION_CLASSES = [
"rest_framework.permissions.IsAuthenticated"
]
```
---
## 🔐 Identity Model
Reporter is stored as:
- reporter_email
- reporter_user_id (optional)
No direct ForeignKey to user model.
---
## 🧾 Issue Identifiers
- `id` → UUID (internal)
- `issue_number` → Sequential public identifier
Example:
```
/api/v1/issues/12/
```
---
## 📚 API Endpoints
### Issues
| Method | Endpoint |
|--------|----------|
| GET | /api/v1/issues/ |
| GET | /api/v1/issues/{issue_number}/ |
| POST | /api/v1/issues/ |
| PUT | /api/v1/issues/{issue_number}/ |
| PATCH | /api/v1/issues/{issue_number}/ |
| DELETE | /api/v1/issues/{issue_number}/ |
### Comments
```
/api/v1/comments/
```
### Labels
```
/api/v1/labels/
```
### Attachments
```
/api/v1/attachments/
```
---
## 🔎 Filtering
Supports:
- SearchFilter
- OrderingFilter
Example:
```
/api/v1/issues/?search=bug
/api/v1/issues/?ordering=-created_at
```
---
## 📄 Pagination
Configurable via:
```
GENERIC_ISSUETRACKER_PAGE_SIZE
```
---
## 📖 OpenAPI Schema
Fully compatible with drf-spectacular.
```
/schema/
/docs/
```
---
## 🧪 Development
Install dev tools:
```bash
pip install -e ".[dev]"
ruff check .
```
---
## 🧩 Integration Guide
1. Install package
2. Add to INSTALLED_APPS
3. Include URLs
4. Configure permissions
5. Run migrations
6. Start creating issues
---
## 🧱 Versioning Policy
- Minor releases: new features (backward compatible)
- Patch releases: internal improvements
- Major releases: breaking changes
---
## 📜 License
MIT License.
---
## 👤 Maintainer
BinaryFleet
---
## 🌟 Contributing
Pull requests welcome.
Follow:
- DRY principles
- Schema determinism
- Versioned serializers
- No business logic in views
| text/markdown | BinaryFleet | null | null | null | null | django, django-rest-framework, issue-tracker, bug-tracker, project-management, openapi, drf, api, versioned-api | [
"Development Status :: 4 - Beta",
"Framework :: Django",
"Framework :: Django :: 4.2",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Topic :: Software Development :: Libraries :: Application Frameworks",
"Topic :: Software Development :: Bug Tracking",
"Topic :: Internet :: WWW/HTTP :: Dynamic Content"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"Django>=4.2",
"djangorestframework>=3.14",
"drf-spectacular>=0.27",
"ruff>=0.4.0; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-django>=4.5; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/binaryfleet/issuetracker",
"Repository, https://github.com/binaryfleet/issuetracker",
"Issues, https://github.com/binaryfleet/issuetracker/issues",
"Documentation, https://github.com/binaryfleet/issuetracker#readme"
] | twine/6.2.0 CPython/3.11.9 | 2026-02-20T13:46:31.702910 | genericissuetracker-0.4.3.tar.gz | 26,825 | 9d/82/f5be2241d3839462a24b6614a2c74b9369ebb06d5ad29d0ea4f41778e346/genericissuetracker-0.4.3.tar.gz | source | sdist | null | false | 3c20359755754372720dfc00669fe24d | f9b3820c33ac1033dc02836c46a3ecc1218527a1b2fa84ee25230e2faa2e7733 | 9d82f5be2241d3839462a24b6614a2c74b9369ebb06d5ad29d0ea4f41778e346 | MIT | [
"LICENSE"
] | 226 |
2.1 | sustainalytics | 0.3.5 | This is a package that helps clients access the Sustainalytics API | ## Introduction
**Starting with sustainalytics 0.2.0, the package is compatible with API v2 only. If a v1-compatible version is needed, please install version 0.1.2 via this command:**
```python
pip install sustainalytics==0.1.2
```
This python package provides access to Sustainalytics API (Application Programming Interface) service which provides developers with 24x7 programmatic access to Sustainalytics data. The API has been developed based on market standards with a primary focus on secure connectivity and ease of use. It allows users to retrieve and integrate Sustainalytics data into their own internal systems and custom or third-party applications
This document is meant to provide developers with python sample code for the Sustainalytics API service.
Technical documentation can also be found on the dedicated [website](https://api.sustainalytics.com/swagger/ui/index/index.html) for the API.
## Installation
<p>Install the package via pip with code below:
```python
pip install sustainalytics
```
To Upgrade:
```python
pip install --upgrade sustainalytics
```
## Connection
A clientid and a secret key must be provided by the Sustainalytics Team in order to access the API.
See connection via python:
```python
from sustainalytics.api import API
# Access
client_id = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
client_secret_key = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
con = API(client_id=client_id, client_secretkey=client_secret_key)
# Returns Bearer
print(con.access_headers)
```
## Helper functions
These helper functions are meant to help you in calling the endpoint functions.
```python
fieldClusterIds = con.get_fieldClusterIds()
print(fieldClusterIds)
fieldIds = con.get_fieldIds()
print(fieldIds)
fieldsInfo = con.get_fieldsInfo()
print(fieldsInfo)
productIds = con.get_productIds()
print(productIds)
packageIds = con.get_packageIds()
print(packageIds)
packageInfo = con.get_packageInfo()
print(packageInfo)
```
## Endpoints
### DataService
The DataService enables the user to call the research data associated with the companies in the universe of access. Within this service there are 6 endpoints, as described below.
<ul>
<li>DataService - Get research data by query</li>
<li>DataService/{identifier} - Get research data by identifier </li>
<li>DataServiceWTimestamps - Get timestamped research data by query </li>
<li>DataServiceWTimestamps/{identifier} - Get timestamped research data by identifier </li>
<li>LastChangesSince - Get last changes since research data by query </li>
<li>LastChangesSince/{identifier} - Get last changes since research data by identifier </li>
</ul>
The code below shows you how to extract data from these endpoints:
#### Get Data
Retrieves data from the DataService or from the DataServiceWTimestamps endpoint. 'identifiers' and 'productId' are **mandatory** arguments.
__identifiers__ : A list of security or entity identifiers separated by comma. You can obtain a list of EntityIds from the con.get_universe_entityIds(keep_duplicates=True)
__productid__ : The Product ID. Only one integer value is accepted. You can obtain a list of ProductIds from the con.get_productIds()
__timestamps__ : Optional boolean argument present only in the get_data function that lets you choose between timestamped research data and research data.
In addition to the 3 arguments, one of the following arguments can also be chosen:
__packageIds__ : A list of package ids separated by comma. You can obtain a list of PackageIds from the con.get_packageIds()
__fieldClusterIds__ : A list of field cluster ids separated by comma. You can obtain a list of FieldClusterIds from the con.get_fieldClusterIds()
__fieldIds__ : A list of field ids separated by comma. You can obtain a list of FieldIds from the con.get_fieldIds()
**AddCoverageCompanies** : Optional boolean argument (default False). When set to True, the API will return data for the coverage company (IssuerId) instead of returning the research entity (ResearchEntityId).
```python
# GetData for research data (default dtype='json') - DataService endpoint.
research_data = con.get_data(identifiers=[], productId=x, packageIds=[], fieldClusterIds=[], fieldIds=[], dtype='dataframe', timestamps=False, AddCoverageCompanies=False)
print(research_data)
# GetData for timestamped research data (default dtype='json') - DataServiceWTimestamps endpoint.
timestamped_research_data = con.get_data(identifiers=[], packageIds=[], productId=x, fieldClusterIds=[], fieldIds=[], dtype='dataframe', timestamps=True, AddCoverageCompanies=False)
print(timestamped_research_data)
```
```python
# GetData for time series research data (default dtype='json') - TimeSeriesData endpoint.
timestamped_research_data = con.get_data(identifiers=[], packageIds=[], productId=x, fieldClusterIds=[], fieldIds=[], dtype='dataframe', time_series=True, AddCoverageCompanies=False)
print(timestamped_research_data)
# GetData for timestamped research data (default dtype='json') - TimeSeriesDataWTimestamps endpoint.
timestamped_research_data = con.get_data(identifiers=[], packageIds=[], productId=x, fieldClusterIds=[], fieldIds=[], dtype='dataframe', time_series=True, timestamps=True, AddCoverageCompanies=False)
print(timestamped_research_data)
```
```python
# GetData including coverage companies (IssuerId-based data when applicable)
coverage_data = con.get_data(identifiers=[], packageIds=[], productId=x, fieldClusterIds=[], fieldIds=[], dtype='dataframe', time_series=True, timestamps=True, AddCoverageCompanies=True)
print(coverage_data)
```
#### Get LastChangesSince
Retrieves data from the LastChangesSince endpoint. 'startdate' and 'productId' are **mandatory** arguments.
Additional arguments compared to get_data:
__startdate__ : Date filter for last changes query. The format of the date is "yyyy-mm-dd". Can retrieve data only for last 3 months from current date.
```python
# Get LastChangesSince returns timestamped research data that has changed since a specific date (default dtype='json') - LastChangeSince endpoint
last_changes_since_data = con.get_LastChangesSince(startdate="x", productId=x, identifiers=[], packageIds=[], fieldClusterIds=[], fieldIds=[], dtype='dataframe', AddCoverageCompanies=False)
print(last_changes_since_data)
# Get LastChangesSince including coverage companies (IssuerId-based data when applicable)
last_changes_since_coverage = con.get_LastChangesSince(startdate="x", productId=x, identifiers=[], packageIds=[], fieldClusterIds=[], fieldIds=[], dtype="dataframe", AddCoverageCompanies=True)
print(last_changes_since_coverage)
```
### Product Structure & Definitions
Each product is built from __data packages__ and each data package is built from __field clusters__. The __datafields__ are the smallest components of the product structure.
The Product Structure service provides an overview of the data fields available in the Sustainalytics API and the unique __FieldIds__ linked to each of these data fields. Within this service there are three endpoints, as described below.
<ul>
<li>FieldDefinitions - Get field definitions</li>
<li>FieldMappings - Get product structure </li>
<li>FieldMappingDefinitions - Get product structure with field definitions </li>
</ul>
The code below shows you how to extract data from these endpoints:
```python
# FieldDefinitions (default dtype='json')
field_definitions = con.get_fieldDefinitions(dtype='dataframe')
print(field_definitions)
# FieldDefinitions for time series data (default dtype='json')
field_definitions = con.get_fieldDefinitions(time_series=True, dtype='dataframe')
print(field_definitions)
# FieldMappings (default dtype='json')
field_mappings = con.get_fieldMappings(dtype='dataframe')
print(field_mappings)
# FieldMappings for time series data (default dtype='json')
field_mappings = con.get_fieldMappings(time_series=True, dtype='dataframe')
print(field_mappings)
# FieldMappingDefinitions (default dtype='json')
field_mapping_definition = con.get_fieldMappingDefinitions(dtype='dataframe')
print(field_mapping_definition)
# FieldMappingDefinitions for time series data (default dtype='json')
field_mapping_definition = con.get_fieldMappingDefinitions(time_series=True, dtype='dataframe')
print(field_mapping_definition)
# Extra FieldDefinition (non-Swagger) (default dtype='json')
full_field_definitions = con.get_fullFieldDefinitions(dtype='dataframe')
print(full_field_definitions)
```
### Reports
The ReportService endpoint allows users to retrieve a list of all available PDF report types by ReportId, ReportType, and ReportName for companies belonging to the universe of access.
__(Please note this Endpoint is not part of the standard API product.)__
<ul>
<li>ReportService - Get available report types</li>
<li>ReportService/{identifier} - Get available report types by entity identifier</li>
<li>ReportService/url/{identifier}/{reportId} - Get report url (recommended endpoint as it has the fastest response time) </li>
</ul>
The code below shows you how to extract data from these endpoints:
```python
# ReportService - returns all the available report fieldIDs (reportids) (default dtype='json')
report_info = con.get_pdfReportInfo(productId=x, dtype='dataframe')
# Where x can be any integer value of existing product ids (for example, 10 for Corporate Data)
print(report_info)
# ReportService(identifier/reportid) - returns the URL to given pdf report for specified companies (if available) (default dtype='json')
report_identifier_reportid = con.get_pdfReportUrl(identifier=x, reportId=y)
print(report_identifier_reportid)
```
The function supports only 1 identifier and reportID per call.
### Universe of Access
The UniverseOfAccess endpoint allows users to determine the list of EntityIds contained in the universe of access (all permissioned securities lists).
<ul>
<li>UniverseOfAccess - Get universe of access</li>
</ul>
```python
# UniverseofAccess - returns all universe constituents (default dtype='json')
universe = con.get_universe_access(dtype='dataframe')
print(universe)
```
| text/markdown | Popeanga Petrut-Gabriel | gabriel.popeanga@morningstar.com | null | null | MIT | null | [
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.6 | [] | [] | [] | [
"certifi",
"charset-normalizer",
"colorama",
"idna",
"numpy",
"pandas",
"python-dateutil",
"pytz",
"requests",
"six",
"tqdm",
"tzdata",
"urllib3"
] | [] | [] | [] | [] | poetry/1.8.3 CPython/3.12.4 Windows/11 | 2026-02-20T13:46:21.899159 | sustainalytics-0.3.5.tar.gz | 13,461 | aa/be/188e50f1660508e49d397e10947fe3ecda2b0ccbfd23870e642101d98741/sustainalytics-0.3.5.tar.gz | source | sdist | null | false | 5a844adad0e52679eb5d302030e379d6 | b3a3648b51c0316551ea85a7e00b8b03885e5a61ec8d7d969d30d2660d8f2735 | aabe188e50f1660508e49d397e10947fe3ecda2b0ccbfd23870e642101d98741 | null | [] | 240 |
2.4 | PyPalmSens | 1.7.0 | Python SDK for PalmSens instruments | [](https://github.com/PalmSens/PalmSens_SDK/actions/workflows/python-tests.yml)

[](https://pypi.org/project/pypalmsens/)
[](https://pypi.org/project/pypalmsens/)
<br>
<p align="center">
<a href="https://sdk.palmsens.com/maui/latest" target="_blank">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/PalmSens/PalmSens_SDK/refs/heads/main/python/docs/modules/ROOT/images/banner_dark.svg">
<source media="(prefers-color-scheme: light)" srcset="https://raw.githubusercontent.com/PalmSens/PalmSens_SDK/refs/heads/main/python/docs/modules/ROOT/images/banner.svg">
<img alt="PalmSens banner" src="https://raw.githubusercontent.com/PalmSens/PalmSens_SDK/refs/heads/main/python/docs/modules/ROOT/images/banner.svg" width="80%">
</picture>
</a>
</p>
<br>
# PyPalmSens: Python SDK for PalmSens devices
PyPalmSens is a Python library for automating electrochemistry experiments with your PalmSens instruments.
It provides an intuitive Python API, making it straightforward to integrate into your Python workflows.
With PyPalmSens, you can:
- Connect to one or more instruments/channels
- Automate electrochemistry measurements
- Access and process measured data
- Analyze and manipulate data
- Perform peak detection
- Do Equivalent Circuit Fitting on impedance data
- Take manual control of the cell
- Read and write method and data files
To install:
```python
pip install pypalmsens
```
PyPalmSens is built on top of the included [PalmSens .NET libraries](https://sdk.palmsens.com/start/core.html), and therefore requires the .NET runtime to be installed.
For specific installation instructions for your platform, see the
[documentation](https://sdk.palmsens.com/python/latest/).
| text/markdown | null | Palmsens BV <info@palmsens.com> | null | null | null | electrochemistry, data-analysis, voltammetry, potentiometry, impedance-specroscopy | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pydantic",
"numpy",
"pythonnet",
"typing-extensions",
"bump-my-version; extra == \"develop\"",
"coverage; extra == \"develop\"",
"griffe2md; extra == \"develop\"",
"pre-commit; extra == \"develop\"",
"pytest; extra == \"develop\"",
"pytest-asyncio; extra == \"develop\"",
"twine; extra == \"publishing\"",
"wheel; extra == \"publishing\"",
"build; extra == \"publishing\"",
"zensical>=0.0.20; extra == \"docs\"",
"mkdocstrings>=1.0.1; extra == \"docs\"",
"mkdocstrings-python; extra == \"docs\""
] | [] | [] | [] | [
"homepage, https://github.com/palmsens/palmsens_sdk",
"issues, https://github.com/palmsens/palmsens_sdk/issues",
"documentation, https://sdk.palmsens.com/python/latest",
"changelog, https://github.com/palmsens/palmsens_sdk/releases"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:46:19.894173 | pypalmsens-1.7.0.tar.gz | 12,637,236 | 0e/6c/16427f823d867eb1950e3bca771aaea91aed18efc8d7d8d4f464bbd8b59e/pypalmsens-1.7.0.tar.gz | source | sdist | null | false | 1b053bb7eaf86bb8234318b9a1bb5466 | c43613a06542e06a54a9fb462e34c5b0ee2a43206e04e3e3c916ab27f4de82f5 | 0e6c16427f823d867eb1950e3bca771aaea91aed18efc8d7d8d4f464bbd8b59e | LicenseRef-Modified-BSD-3-Clause-PalmSens | [
"LICENSE"
] | 0 |
2.4 | oslo.utils | 10.0.0 | Oslo Utility library | ==========
oslo.utils
==========
.. image:: https://governance.openstack.org/tc/badges/oslo.utils.svg
.. Change things from this point on
.. image:: https://img.shields.io/pypi/v/oslo.utils.svg
:target: https://pypi.org/project/oslo.utils/
:alt: Latest Version
.. image:: https://img.shields.io/pypi/dm/oslo.utils.svg
:target: https://pypi.org/project/oslo.utils/
:alt: Downloads
The oslo.utils library provides support for common utility type functions,
such as encoding, exception handling, string manipulation, and time handling.
* Free software: Apache license
* Documentation: https://docs.openstack.org/oslo.utils/latest/
* Source: https://opendev.org/openstack/oslo.utils
* Bugs: https://bugs.launchpad.net/oslo.utils
* Release notes: https://docs.openstack.org/releasenotes/oslo.utils/
| text/x-rst | null | OpenStack <openstack-discuss@lists.openstack.org> | null | null | Apache-2.0 | null | [
"Environment :: OpenStack",
"Intended Audience :: Information Technology",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: Apache Software License",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"iso8601>=0.1.11",
"oslo.i18n>=3.15.3",
"netaddr>=0.10.0",
"debtcollector>=1.2.0",
"pyparsing>=2.1.0",
"packaging>=20.4",
"PyYAML>=3.13",
"psutil>=3.2.2",
"pbr>=6.1.0"
] | [] | [] | [] | [
"Homepage, https://docs.openstack.org/oslo.utils",
"Repository, https://opendev.org/openstack/oslo.utils"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T13:45:06.133362 | oslo_utils-10.0.0.tar.gz | 141,716 | d2/a5/6e9fb7904250e786f4afb137a23a2ec27098136efb8e72a5414cc66ae566/oslo_utils-10.0.0.tar.gz | source | sdist | null | false | 517218b3f2bf64934c6c9d3d3f82b071 | bb46713e760d94446a084f5e94c1cf273935369308ad88ee5b53917923d9c393 | d2a56e9fb7904250e786f4afb137a23a2ec27098136efb8e72a5414cc66ae566 | null | [
"LICENSE"
] | 0 |
2.4 | finitewave | 0.9.0b1 | Simple package for a wide range of tasks in modeling cardiac electrophysiology using finite-difference methods. | # Finitewave
[](https://github.com/finitewave/Finitewave/blob/main/LICENSE) [](https://github.com/finitewave/Finitewave/actions/workflows/test.yml) [](https://codecov.io/gh/finitewave/Finitewave)
Finitewave is a lightweight Python framework for simulating cardiac electrophysiology in 2D and 3D using finite-difference methods.
It is designed to make cardiac modeling accessible from the very first simulation, with a clear and modular structure that supports experimentation, learning, and customization. Its Python foundation allows straightforward integration with other libraries (e.g., NumPy, Matplotlib, SciPy, Jupyter) and makes it ideal for use in educational and research settings.
## Why Finitewave?
1. Simple pipeline: tissue → model → stimulation → run.
2. Explicit control over each simulation step.
3. Lightweight and runnable on standard laptops (no HPC required).
4. Built-in 2D and 3D support.
5. Includes a built-in library of phenomenological and ionic models.
6. Fully Python-based (easy integration with NumPy/Pandas workflows).
7. Designed for extensibility — suitable as a base for custom research workflows and model development.
If you are a student, researcher or engineer - you can easily get started with Finitewave using the **Quick start** below or by starting with **examples** and **Tutorials** folders.
## Typical use cases
1. Planar wave simulations.
2. Spiral wave dynamics.
3. High-pacing protocols.
4. Fibrosis-induced propagation effects.
5. Educational demonstrations of cardiac models or reaction-diffusion systems.
<p align="center">
<img src="images/spiral_wave_fib.gif" width="200" alt="Image 1"/>
<img src="images/spiral_wave_slab.gif" width="267" alt="Image 2"/>
<img src="images/spiral_wave_lv.gif" width="220" alt="Image 3"/>
</p>
---
# Installation
To install Finitewave, run:
```bash
pip install finitewave
```
This will install Finitewave as a Python package on your system.
## Other installation options
You can also do it from source - navigate to the root directory of the project and run:
```bash
python -m build
pip install dist/finitewave-<version>.whl
```
For development purposes, install in editable mode (changes apply immediately without reinstall):
```bash
pip install -e .
```
---
# Requirements
Finitewave requires the following minimal versions:
| Dependency | Version* | Link |
|----------------|----------|------|
| ffmpeg-python | 0.2.0 | https://pypi.org/project/ffmpeg-python/ |
| matplotlib | 3.9.2 | https://pypi.org/project/matplotlib/ |
| natsort | 8.4.0 | https://pypi.org/project/natsort/ |
| numba | 0.60.0 | https://pypi.org/project/numba/ |
| numpy | 1.26.4 | https://pypi.org/project/numpy/ |
| pandas | 2.2.3 | https://pypi.org/project/pandas/ |
| pyvista | 0.44.1 | https://pypi.org/project/pyvista/ |
| scikit-image | 0.24.0 | https://pypi.org/project/scikit-image/ |
| scipy | 1.14.1 | https://pypi.org/project/scipy/ |
| tqdm | 4.66.5 | https://pypi.org/project/tqdm/ |
\* minimal version
---
# Quick start
This quick start guide will walk you through the basic steps of setting up a simple cardiac simulation using Finitewave. What we will do:
1. Create a 2D cardiac tissue.
2. Set up an electrophysiological model.
3. Apply stimulation.
4. Run the simulation.
5. Visualize activation time.
Here is the code for this pipeline:
```python
import numpy as np
import matplotlib.pyplot as plt
import finitewave as fw
# set up the tissue:
n = 100
tissue = fw.CardiacTissue([n, n])
# set up the stimulation:
stim_sequence = fw.StimSequence()
stim_sequence.add_stim(
fw.StimVoltageCoord(
time=0,
volt_value=1,
x1=1, x2=n-1, y1=1, y2=3
)
)
# set up the tracker:
act_time_tracker = fw.ActivationTimeTracker()
act_time_tracker.threshold = 0.5
act_time_tracker.step = 100
tracker_sequence = fw.TrackerSequence()
tracker_sequence.add_tracker(act_time_tracker)
# set up the model
aliev_panfilov = fw.AlievPanfilov()
aliev_panfilov.dt = 0.01
aliev_panfilov.dr = 0.25
aliev_panfilov.t_max = 10
# set up pipeline
aliev_panfilov.cardiac_tissue = tissue
aliev_panfilov.stim_sequence = stim_sequence
aliev_panfilov.tracker_sequence = tracker_sequence
# run model
aliev_panfilov.run()
# show output
fig, axs = plt.subplots(ncols=2)
axs[0].imshow(aliev_panfilov.u, cmap='coolwarm')
axs[0].set_title("u")
axs[1].imshow(act_time_tracker.output, cmap='viridis')
axs[1].set_title("Activation time")
fig.suptitle("Aliev-Panfilov 2D isotropic")
plt.tight_layout()
plt.show()
```
Now, let's move on to a detailed explanation.
## Table of Contents
- [Cardiac Tissue](#cardiac-tissue)
- [Mesh](#mesh)
- [Conductivity](#conductivity)
- [Fibers](#fibers)
- [Cardiac Models](#cardiac-models)
- [Available models](#available-models)
- [Stimulations](#stimulations)
- [Voltage Stimulation](#voltage-stimulation)
- [Current Stimulation](#current-stimulation)
- [Stimulation Matrix](#stimulation-matrix)
- [Stimulation Sequence](#stimulation-sequence)
- [Trackers](#trackers)
- [Tracker Parameters](#tracker-parameters)
- [Multiple Trackers](#multiple-trackers)
- [Building pipeline](#building-pipeline)
- [Run the simulation](#run-the-simulation)
---
## Cardiac Tissue
The `CardiacTissue` class is used to represent myocardial tissue and its structural properties in simulations. It includes several key attributes that define the characteristics and behavior of the cardiac mesh used in finite-difference calculations.
First, import the necessary libraries:
```python
import finitewave as fw
import numpy as np
import matplotlib.pyplot as plt
```
Initialize a 100x100 mesh with all nodes set to 1 (healthy cardiac tissue). Add empty nodes (0) at the mesh edges to simulate boundaries.
```python
n = 100
tissue = fw.CardiacTissue([n, n])
```
### Mesh
The `mesh` attribute is a mesh consisting of nodes, which represent the myocardial medium. The distance between neighboring nodes is defined by the spatial step (`dr`) parameter of the model. The nodes in the mesh are used to represent different types of tissue and their properties:
- `0`: Empty node, representing the absence of cardiac tissue.
- `1`: Healthy cardiac tissue, which supports wave propagation.
- `2`: Fibrotic or infarcted tissue, representing damaged or non-conductive areas.
Nodes marked as `0` and `2` are treated similarly as isolated nodes with no flux through their boundaries. These different notations help distinguish between areas of healthy tissue, empty spaces, and regions of fibrosis or infarction.
> **Note**
> To satisfy boundary conditions, every simulation mesh must include boundary nodes (marked as `0`). Finitewave does this automatically and you don't need to do anything unless you're going to set borders yourself.
You can also utilize `0` nodes to define complex geometries and pathways, or to model organ-level structures. For example, to simulate the electrophysiological activity of the heart, you can create a 3D array where `1` represents cardiac tissue, and `0` represents everything outside of that geometry.
---
## Cardiac Models
Each model represents the cardiac electrophysiological activity of a single cell, which can be combined using parabolic equations to form complex 2D or 3D cardiac tissue models.
```python
# Set up Aliev-Panfilov model to perform simulations
aliev_panfilov = fw.AlievPanfilov()
aliev_panfilov.dt = 0.01 # time step
aliev_panfilov.dr = 0.25 # space step
aliev_panfilov.t_max = 10 # simulation time
```
We use an explicit finite-difference scheme, which requires maintaining an appropriate `dt/dr` ratio. For phenomenological models, the recommended calculation parameters for time and space steps are `dt = 0.01` and `dr = 0.25`. You can increase `dt` to `0.02` to speed up calculations, but always verify the stability of your numerical scheme, as instability will lead to incorrect simulation results.
### Available models
| Model | Description |
|----------------------------|-------------|
| Aliev-Panfilov | A phenomenological two-variable model. <br> https://github.com/finitewave/Aliev-Panfilov-finitewave-model |
| Barkley | A simple reaction-diffusion model. <br> https://github.com/finitewave/Barkley-finitewave-model |
| Mitchell-Schaeffer | A phenomenological two-variable model. <br> https://github.com/finitewave/Mitchell-Schaeffer-finitewave-model |
| Fenton-Karma | A phenomenological three-variables model. <br> https://github.com/finitewave/Fenton-Karma-finitewave-model |
| Bueno-Orovio | A minimalistic ventricular model. <br> https://github.com/finitewave/Bueno-Orovio-finitewave-model |
| Luo-Rudy 1991 | An ionic ventricular guinea pig model. <br> https://github.com/finitewave/Luo-Rudy-91-finitewave-model |
| ten Tusscher-Panfilov 2006 | An ionic ventricular human model. <br> https://github.com/finitewave/ten-Tusscher-Panfilov-2006-finitewave-model |
| Courtemanche | An ionic atrial human model. <br> https://github.com/finitewave/Courtemanche-finitewave-model |
---
## Stimulations
To simulate the electrical activity of the heart, you need to apply a stimulus to the tissue. This can be done by setting the voltage or current at specific nodes in the mesh. `StimVoltage` class directly sets voltage values at nodes within the stimulation area.
```python
stim_voltage = fw.StimVoltageCoord(
time=0,
volt_value=1,
x1=1, x2=n-1, y1=1, y2=3
)
```
> **Note**
> A very small stimulation area may lead to unsuccessful stimulation due to a source-sink mismatch.
### Stimulation Sequence
The `CardiacModel` class uses the `StimSequence` class to manage the stimulation sequence.
```python
stim_sequence = fw.StimSequence()
for i in range(0, 100, 10):
stim_sequence.add_stim(
fw.StimVoltageCoord(
time=i,
volt_value=1,
x1=1, x2=n-1, y1=1, y2=3
)
)
```
This class also allows you to add multiple stimulations to the model, which can be useful for simulating complex stimulation protocols (e.g., a high-pacing protocol).
```python
# Example: make stimulus every 10-th time unit.
for i in range(0, 100, 10):
stim_sequence.add_stim(
fw.StimVoltageCoord(
time=i,
volt_value=1,
x1=1, x2=n-1, y1=1, y2=3
)
)
```
---
## Trackers
Trackers are used to record the state of the model during the simulation. They can be used to monitor the wavefront propagation, visualize the activation times, or analyze the wavefront dynamics. Full details on how to use trackers can be found in the examples.
```python
# set up activation time tracker:
act_time_tracker = fw.ActivationTimeTracker()
act_time_tracker.threshold = 0.5
act_time_tracker.step = 100 # calculate activation time every 100 steps
```
### Tracker Parameters
Trackers have several parameters that can be adjusted to customize their behavior:
- `start_time`: The time at which the tracker starts recording data.
- `end_time`: The time at which the tracker stops recording data.
- `step`: The number of steps between each data recording.
> **Note**
> The `step` parameter is used to control the *frequency* of data recording (should be `int`). But the `start_time` and `end_time` parameters are used to specify the *time* interval during which the tracker will record data.
The `output` property of the tracker class returns the formatted data recorded during the simulation. This data can be used for further analysis or visualization.
Each tracker has its own set of parameters that can be adjusted to customize its behavior. For example, the `ActivationTimeTracker` class has a `threshold` parameter that defines the activation threshold for the nodes. Check out the examples to see each tracker in action.
### Multiple Trackers
The `CardiacModel` class uses the `TrackerSequence` class to manage the trackers. This class allows you to add multiple trackers to the model to monitor different aspects of the simulation. For example, you can track the activation time for all nodes, and the action potential for a specific node.
```python
# set up first activation time tracker:
act_time_tracker = fw.ActivationTimeTracker()
act_time_tracker.threshold = 0.5
act_time_tracker.step = 100 # calculate activation time every 100 steps
# set up action potential tracker for a specific node:
action_pot_tracker = fw.ActionPotentialTracker()
action_pot_tracker.cell_ind = [30, 30]
tracker_sequence = fw.TrackerSequence()
tracker_sequence.add_tracker(act_time_tracker)
tracker_sequence.add_tracker(action_pot_tracker)
```
---
## Building pipeline
Now that we have all the necessary components, we can build the simulation pipeline by setting the tissue, model, stimulations, and trackers.
```python
aliev_panfilov.cardiac_tissue = tissue
aliev_panfilov.stim_sequence = stim_sequence
aliev_panfilov.tracker_sequence = tracker_sequence
```
Finitewave contains other functionalities that can be used to customize the simulation pipeline, such as loading and saving model states or adding custom commands to the simulation loop. For more information, refer to the examples.
### Run the simulation
Finally, we can run the simulation by calling the `run()` method of the `AlievPanfilov` model.
```python
aliev_panfilov.run()
plt.imshow(aliev_panfilov.u, cmap='coolwarm')
plt.show()
```
---
## Other commonly used tissue properties
### Conductivity
The conductivity attribute defines the local conductivity of the tissue and is represented as an array of coefficients ranging from `0.0` to `1.0` for each node in the mesh. It proportionally decreases the diffusion coefficient locally, thereby slowing down the wave propagation in specific areas defined by the user. This is useful for modeling heterogeneous tissue properties, such as regions of impaired conduction due to ischemia or fibrosis.
```python
# Example: set conductivity to 0.5 in the middle of the mesh
tissue.conductivity = np.ones([n, n])
tissue.conductivity[n//4: 3 * n//4, n//4: 3 * n//4] = 0.5
```
### Fibers
Another important attribute, `fibers`, is used to define the anisotropic properties of cardiac tissue. This attribute is represented as a 3D array (for 2D tissue) or a 4D array (for 3D tissue), with each node containing a 2D or 3D vector that specifies the fiber orientation at that specific position. The anisotropic properties of cardiac tissue mean that the wave propagation speed varies depending on the fiber orientation.
```python
# Fibers orientated along the x-axis
tissue.fibers = np.zeros([n, n, 2])
tissue.fibers[:, :, 0] = 1
tissue.fibers[:, :, 1] = 0
``` | text/markdown | null | Timur Nezlobinsky <nezlobinsky@gmail.com>, Arstanbek Okenov <arstanbek.okenov@ugent.be> | null | null | MIT | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"ffmpeg-python>=0.2.0",
"finitewave-model-aliev-panfilov>=0.2.0",
"finitewave-model-barkley>=0.2.0",
"finitewave-model-bueno-orovio>=0.2.0",
"finitewave-model-courtemanche>=0.2.0",
"finitewave-model-fenton-karma>=0.2.0",
"finitewave-model-luo-rudy-91>=0.2.0",
"finitewave-model-mitchell-schaeffer>=0.2.0",
"finitewave-model-ten-tusscher-panfilov-2006>=0.2.0",
"matplotlib>=3.9.2",
"natsort>=8.4.0",
"numba>=0.60.0",
"numpy>=1.26.4",
"pandas>=2.2.3",
"pyvista>=0.44.1",
"scikit-image>=0.24.0",
"scipy>=1.14.1",
"tqdm>=4.66.5",
"numpydoc; extra == \"docs\"",
"pydata-sphinx-theme; extra == \"docs\"",
"sphinx; extra == \"docs\"",
"sphinx-copybutton; extra == \"docs\"",
"sphinx-gallery; extra == \"docs\"",
"sphinx-rtd-theme; extra == \"docs\"",
"pytest; extra == \"test\"",
"pytest-cov; extra == \"test\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.0 | 2026-02-20T13:45:01.010205 | finitewave-0.9.0b1.tar.gz | 5,024,410 | 4c/7e/ceb2cec3a252752ff6354752f021a1ef61a625ef817c0866f2310e4cbf9f/finitewave-0.9.0b1.tar.gz | source | sdist | null | false | f396069481369a58e3f5488c89c1ddfc | 1499186b02703c6a81078be6ed875b664683ef0be6283a5d3c19edf210b426e7 | 4c7eceb2cec3a252752ff6354752f021a1ef61a625ef817c0866f2310e4cbf9f | null | [
"LICENSE"
] | 202 |
2.4 | iints-sdk-python35 | 0.1.17 | A pre-clinical Edge-AI SDK for diabetes management validation. | # IINTS-AF SDK
[](https://badge.fury.io/py/iints-sdk-python35)
[](https://colab.research.google.com/github/python35/IINTS-SDK/blob/main/examples/notebooks/00_Quickstart.ipynb)
[](https://github.com/python35/IINTS-SDK/actions/workflows/python-package.yml)
[](https://github.com/python35/IINTS-SDK/actions/workflows/health-badges.yml)
[](https://github.com/python35/IINTS-SDK/actions/workflows/health-badges.yml)
<div style="text-align:center;">
<img src="Ontwerp zonder titel.png" alt="" style="display:block; margin:0 auto;">
</div>
## Intelligent Insulin Titration System for Artificial Pancreas
IINTS-AF is a **safety-first simulation and validation platform** for insulin dosing algorithms. It lets you test AI or classical controllers on virtual patients, enforce deterministic safety constraints, and generate audit-ready clinical reports before anything touches a real patient.
**In one session you can**:
* Run a clinic-safe preset and compare against PID and standard pump baselines
* Import real-world CGM CSV into a standard schema + scenario JSON
* Use the bundled demo CGM data pack (zero setup)
* Export a clean PDF report plus full audit trail (JSONL/CSV)
* Stress-test sensor noise, pump limits, and human-in-the-loop interventions
* Generate patient profiles with ISF/ICR + dawn phenomenon
**Who it’s for**:
* Diabetes researchers and clinicians validating new control strategies
* ML engineers benchmarking AI controllers with medical safety rails
* Developers building decision-support systems for closed-loop insulin delivery
## Installation
Install the SDK directly via PyPI:
```bash
pip install iints-sdk-python35
```
### Quick Start (CLI)
```bash
iints quickstart --project-name iints_quickstart
cd iints_quickstart
iints presets run --name baseline_t1d --algo algorithms/example_algorithm.py
```
One-line full run (CSV + audit + PDF + baseline):
```bash
iints run-full --algo algorithms/example_algorithm.py \
--scenario-path scenarios/clinic_safe_baseline.json \
--output-dir results/run_full
```
By default, runs write to `results/<run_id>/` and include `config.json`, `run_metadata.json`, and `run_manifest.json`.
Import real-world CGM data:
```bash
iints import-data --input-csv data/my_cgm.csv --output-dir results/imported
```
Try the bundled demo data pack:
```bash
iints import-demo --output-dir results/demo_import
```
Official real-world datasets (download on demand):
```bash
iints data list
iints data info aide_t1d
iints data fetch aide_t1d
iints data cite aide_t1d
```
Some datasets require approval and are marked as `request` in the registry.
`iints data info` prints BibTeX + citation text for easy referencing.
Offline sample dataset (no download required):
```bash
iints data fetch sample --output-dir data_packs/sample
```
Nightscout import (optional dependency):
```bash
pip install iints-sdk-python35[nightscout]
iints import-nightscout --url https://your-nightscout.example --output-dir results/nightscout_import
```
Scenario generator:
```bash
iints scenarios generate --name "Random Stress Test" --output-path scenarios/generated_scenario.json
iints scenarios migrate --input-path scenarios/legacy.json
```
Parallel batch runs:
```bash
iints run-parallel --algo algorithms/example_algorithm.py --scenarios-dir scenarios --output-dir results/batch
```
Interactive run wizard:
```bash
iints run-wizard
```
Algorithm registry:
```bash
iints algorithms list
iints algorithms info "PID Controller"
```
Or run the full demo workflow (import + run + report) in one script:
```bash
python3 examples/demo_quickstart_flow.py
```
### Quick Start (Python)
```python
import iints
from iints.core.algorithms.pid_controller import PIDController
outputs = iints.run_simulation(
algorithm=PIDController(),
scenario="scenarios/example_scenario.json",
patient_config="default_patient",
duration_minutes=720,
seed=42,
output_dir="results/quick_run",
)
```
### Notebook Guide
Hands-on Jupyter notebooks live in [`examples/notebooks/`](examples/notebooks/)
* Quickstart end-to-end run
* Presets + scenario validation
* Safety supervisor behavior
* Audit trail + PDF report export
* Baseline comparison + clinical metrics
* Sensor/pump models + human-in-the-loop
* Optional Torch/LSTM usage
* Ablation study (with/without Supervisor)
### AI Research Track (Predictor)
IINTS-AF includes an optional research pipeline to train a glucose **predictor** that feeds the Safety Supervisor with a 30-120 minute forecast. The predictor never doses insulin; it only provides a forecast signal.
Install research extras:
```bash
pip install iints-sdk-python35[research]
```
Train a starter predictor:
```bash
python research/synthesize_dataset.py --runs 25 --output data/synthetic.parquet
python research/train_predictor.py --data data/synthetic.parquet --config research/configs/predictor.yaml --out models
```
Integrate:
```python
from iints.research import load_predictor_service
predictor = load_predictor_service("models/predictor.pt")
outputs = iints.run_simulation(..., predictor=predictor)
```
### Documentation
* Product manual: `docs/COMPREHENSIVE_GUIDE.md`
* Notebook index: `examples/notebooks/README.md`
* Technical README: `docs/TECHNICAL_README.md`
* API Stability: `API_STABILITY.md`
* Research track: `research/README.md`
### Related Work & Inspiration
We borrow techniques from the broader CGM/APS ecosystem, while differentiating with a safety‑first, audit‑ready workflow:
* [simglucose (UVA/Padova)](https://github.com/jxx123/simglucose): gymnasium‑style interfaces and parallel batch execution concepts.
* [OpenAPS / oref0](https://github.com/openaps/oref0): gold‑standard IOB logic and safety‑oriented control patterns.
* [Nightscout](https://github.com/nightscout/cgm-remote-monitor) + [py-nightscout](https://pypi.org/project/py-nightscout/): reference for human‑in‑the‑loop CGM ingest (planned connector).
* [Tidepool OpenAPI](https://developer.tidepool.org/TidepoolApi/): basis for a future cloud import client skeleton.
### Ethics & Safety
This SDK is for **research and validation**. It is not a medical device and does not provide clinical dosing advice.
> “Code shouldn’t be a secret when it’s managing a life.” — Bobbaers Rune
| text/markdown | null | Rune Bobbaers <rune.bobbaers@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Development Status :: 3 - Alpha"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"fpdf2>=2.8.0",
"matplotlib>=3.5.0",
"numpy>=1.24.0",
"openpyxl>=3.0.0",
"pandas>=2.0.0",
"pillow>=12.1.1",
"pydantic>=2.0.0",
"PyYAML",
"rich>=12.0.0",
"scipy>=1.9.0",
"seaborn>=0.11.0",
"typer[all]",
"pytest>=7.0.0; extra == \"dev\"",
"flake8; extra == \"dev\"",
"mypy; extra == \"dev\"",
"pandas-stubs; extra == \"dev\"",
"types-PyYAML; extra == \"dev\"",
"types-psutil; extra == \"dev\"",
"torch>=1.9.0; extra == \"torch\"",
"py-nightscout; extra == \"nightscout\"",
"torch>=2.0.0; extra == \"research\"",
"pyarrow>=12.0.0; extra == \"research\"",
"h5py>=3.10.0; extra == \"research\""
] | [] | [] | [] | [
"Homepage, https://github.com/python35/IINTS-SDK"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:44:52.774941 | iints_sdk_python35-0.1.17.tar.gz | 874,278 | bf/53/e4fdade4173a4018c5348337656116bbec1d3b3f4c2594c5b66fc4290971/iints_sdk_python35-0.1.17.tar.gz | source | sdist | null | false | 7de7d2108dc7a70e1aebcc5ff42dce25 | b47ed1cb869245cda3e24a84ae31633688da9e8cb914263dec34ef3eaf15269c | bf53e4fdade4173a4018c5348337656116bbec1d3b3f4c2594c5b66fc4290971 | null | [
"LICENSE"
] | 223 |
2.4 | taranis-models | 1.3.3.dev7 | Taranis AI Models | # Taranis AI Pydantic Models
This folder provides pydantic models for validation of data sent between Taranis AI services and offered to third party clients.
## Installation
It's recommended to use a uv to set up a virtual environment.
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
uv sync
```
If updating something and wanting to test it in `frontend` or `core` you can use `install_and_run_dev.sh` or something similar to the commands below:
```bash
uv sync --all-extras --frozen --python 3.13
uv pip install -e ../models
export UV_NO_SYNC=true
uv run pytest tests
```
| text/markdown | null | null | null | AIT <benjamin.akhras@ait.ac.at> | null | null | [
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Framework :: Flask",
"Topic :: Security"
] | [] | null | null | <3.14,>=3.12 | [] | [] | [] | [
"pydantic",
"pydantic-settings",
"python-dotenv",
"langcodes",
"requests",
"beautifulsoup4",
"lxml",
"ruff; extra == \"dev\"",
"pytest; extra == \"dev\"",
"wheel; extra == \"dev\"",
"pyright; extra == \"dev\""
] | [] | [] | [] | [
"Source Code, https://github.com/taranis-ai/taranis-ai"
] | uv/0.10.3 {"installer":{"name":"uv","version":"0.10.3","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T13:44:24.495275 | taranis_models-1.3.3.dev7-py3-none-any.whl | 15,642 | d2/70/42cd31a2c85749e16e6e715b2847fb3d21ea92605f38a82c2b6c7a53136b/taranis_models-1.3.3.dev7-py3-none-any.whl | py3 | bdist_wheel | null | false | 7bb4f5a665a882a9e6e599c760ef58e8 | 3981e3e9808fd742f8dea816ffc0da5a0c733a716ee77ae952d4fec4131c4ad2 | d27042cd31a2c85749e16e6e715b2847fb3d21ea92605f38a82c2b6c7a53136b | EUPL-1.2 | [
"LICENSE.md"
] | 210 |
2.4 | odins-eye | 1.3.0 | Python client for the Brookmimir API | # odins-eye
[](https://badge.fury.io/py/odins-eye)
[](https://pypi.org/project/odins-eye/)
[](https://opensource.org/licenses/MIT)
Python client library for the Brookmimir API.
## Features
- **Synchronous and Asynchronous clients** - Choose between sync (`OdinsEyeClient`) or async (`AsyncOdinsEyeClient`) based on your needs
- **Comprehensive API coverage** - Access all Brookmimir API endpoints
- **Type-safe** - Full type hints with Pydantic validation
- **Automatic retries** - Built-in retry logic with exponential backoff
- **Rate limiting handling** - Automatic detection and handling of rate limits
- **HTTP/2 support** - Faster connections with HTTP/2
- **Context manager support** - Automatic resource cleanup
- **Debug logging** - Optional logging for troubleshooting
- **Comprehensive error handling** - Detailed error messages and exception types
## Installation
Install from PyPI:
```bash
pip install odins-eye
```
Install with development dependencies:
```bash
pip install odins-eye[dev]
```
## Quick Start
### Synchronous Usage
```python
from odins_eye import OdinsEyeClient
# Initialize the client
client = OdinsEyeClient(api_key="your-api-key")
try:
# Check API status
status = client.index()
print(f"API Status: {status}")
# Get user profile
profile = client.profile()
print(f"User: {profile['user']['name']}")
# Check credit balance
credits = client.credits()
print(f"Balance: {credits['current_balance']}")
finally:
client.close()
```
### Asynchronous Usage
```python
import asyncio
from odins_eye import AsyncOdinsEyeClient
async def main():
async with AsyncOdinsEyeClient(api_key="your-api-key") as client:
# Make concurrent requests
status, profile, credits = await asyncio.gather(
client.index(),
client.profile(),
client.credits()
)
print(f"API Status: {status}")
print(f"User: {profile['user']['name']}")
print(f"Credits: {credits['current_balance']}")
asyncio.run(main())
```
### Using Context Managers (Recommended)
```python
with OdinsEyeClient(api_key="your-api-key") as client:
status = client.index()
print(status)
# Async version
async with AsyncOdinsEyeClient(api_key="your-api-key") as client:
status = await client.index()
print(status)
```
## API Methods
### Status and Version
```python
# Get API status
status = client.index()
# Get API version
version = client.version()
# Run network test
result = client.nettest()
```
### User Profile and Credits
```python
# Get user profile
profile = client.profile()
print(f"Name: {profile['user']['name']}, Age: {profile['user']['age']}")
# Check credit balance
credits = client.credits()
print(f"Balance: {credits['current_balance']}")
```
### Document Retrieval
```python
# Fetch a document by ID
document = client.document("doc-123")
```
### Query Submission
```python
# Submit a query
query_result = client.query({
"query": {
"match_all": {}
}
})
```
### Face Search
```python
# Basic face search
results = client.face_search("path/to/image.jpg")
# Face search with parameters
results = client.face_search(
"path/to/image.jpg",
payload={
"threshold": 0.8,
"max_results": 10
}
)
```
## Error Handling
The client provides detailed error information through exception types:
```python
from odins_eye import OdinsEyeClient, OdinsEyeAPIError, OdinsEyeError
with OdinsEyeClient(api_key="your-api-key") as client:
try:
result = client.profile()
except OdinsEyeAPIError as e:
# API returned an error (4xx or 5xx)
print(f"API Error: {e.message}")
print(f"Status Code: {e.status_code}")
if e.error:
print(f"Error: {e.error}")
if e.error_details:
print(f"Details: {e.error_details}")
except OdinsEyeError as e:
# Client-side error (validation, network, etc.)
print(f"Client Error: {e.message}")
```
### Handling Rate Limits
Rate limiting is automatically handled with retries:
```python
from odins_eye import OdinsEyeAPIError
try:
result = client.profile()
except OdinsEyeAPIError as e:
if e.status_code == 429:
print("Rate limit exceeded")
if e.rate_limit_reset:
print(f"Resets at: {e.rate_limit_reset}")
```
## Configuration
### Custom Timeout
```python
import httpx
from odins_eye import OdinsEyeClient
timeout = httpx.Timeout(30.0, connect=10.0)
client = OdinsEyeClient(api_key="your-api-key", timeout=timeout)
```
### Custom Retry Configuration
```python
from odins_eye import OdinsEyeClient, RetryConfig
retry_config = RetryConfig(
max_retries=5,
initial_delay=2.0,
max_delay=120.0,
exponential_base=2.0,
retry_on_rate_limit=True
)
client = OdinsEyeClient(
api_key="your-api-key",
retry_config=retry_config
)
```
### Enable Debug Logging
```python
import logging
from odins_eye import OdinsEyeClient
# Configure logging
logging.basicConfig(level=logging.DEBUG)
# Enable client logging
client = OdinsEyeClient(
api_key="your-api-key",
enable_logging=True
)
```
### Custom Headers
```python
client = OdinsEyeClient(
api_key="your-api-key",
headers={
"X-Custom-Header": "value"
}
)
```
## Environment Variables
For security, consider using environment variables for your API key:
```python
import os
from odins_eye import OdinsEyeClient
api_key = os.getenv("BROOK_MIMIR_API_KEY")
client = OdinsEyeClient(api_key=api_key)
```
## Requirements
- Python >= 3.9
- httpx[http2] >= 0.27.0
- pydantic >= 2.6.0
## API Documentation
For detailed API documentation, visit the [Brookmimir API docs](https://brookmimir.com/docs).
## Changelog
See [CHANGELOG.md](https://pypi.org/project/odins-eye/#history) for release history and changes.
## License
This project is licensed under the MIT License - see the LICENSE file for details.
## Links
- **PyPI Package**: <https://pypi.org/project/odins-eye/>
- **Brookmimir**: <https://brookmimir.com>
## Support
For support and questions:
- Contact Brookmimir support at <https://brookmimir.com/support>
- Review the [API documentation](https://brookmimir.com/docs)
| text/markdown | null | Brookmimir <contact@brookmimir.com> | null | null | MIT | api, client, brook-mimir, http, rest | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Internet :: WWW/HTTP",
"Typing :: Typed"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"httpx[http2]>=0.27.0",
"pydantic>=2.6.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest-httpx>=0.30; extra == \"dev\"",
"mypy>=1.0; extra == \"dev\"",
"ruff>=0.1; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://brookmimir.com",
"Documentation, https://brookmimir.com/docs",
"Repository, https://gitlab.brookmimir.com/odins-eye-pypi"
] | uv/0.9.2 | 2026-02-20T13:44:18.323919 | odins_eye-1.3.0.tar.gz | 15,648 | 34/8e/c9be7f1bfe0adfdb13347ae312881eadb94a7e919d76a92ccdb775c12374/odins_eye-1.3.0.tar.gz | source | sdist | null | false | 113ba455a1e691255cf9620515bb9ac5 | 45629840d073a97c7d87c012a03c5456b2010d2c95eef956549ec3adf91fd0be | 348ec9be7f1bfe0adfdb13347ae312881eadb94a7e919d76a92ccdb775c12374 | null | [
"LICENSE"
] | 225 |
2.4 | pm-os | 4.2.0 | PM-OS: AI-powered Product Management Operating System | # PM-OS
**AI-powered Product Management Operating System**
PM-OS is a comprehensive workflow system for Product Managers, integrating with Jira, Slack, GitHub, Google Workspace, and LLM providers to streamline daily work.
## Installation
```bash
# Basic installation
pip install pm-os
# With specific integrations
pip install pm-os[slack] # Slack integration
pip install pm-os[jira] # Jira integration
pip install pm-os[google] # Google Workspace
pip install pm-os[github] # GitHub integration
pip install pm-os[bedrock] # AWS Bedrock LLM
# All integrations
pip install pm-os[all]
```
## Quick Start
```bash
# Initialize PM-OS (guided wizard)
pm-os init
# Check installation health
pm-os doctor
# Update to latest version
pm-os update
```
## Features
- **Guided Installation**: Interactive wizard configures everything
- **Daily Context Sync**: Aggregates Jira, Slack, Calendar, GitHub
- **Brain Knowledge Graph**: Entities, relationships, semantic search
- **Session Management**: Context preservation across sessions
- **Integration Hub**: Connects all your PM tools
## Documentation
See the [full documentation](https://pm-os.dev/docs) for detailed guides.
## License
MIT License - see [LICENSE](LICENSE) for details.
| text/markdown | PM-OS Team | null | null | null | null | ai, claude, llm, pm, product-management | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"anthropic>=0.18.0",
"atlassian-python-api>=3.0.0",
"boto3>=1.28.0",
"click>=8.0.0",
"google-api-python-client>=2.0.0",
"google-auth-oauthlib>=1.0.0",
"google-auth>=2.0.0",
"google-generativeai>=0.8.0",
"jira>=3.5.0",
"pygithub>=1.59.0",
"python-dotenv>=1.0.0",
"pyyaml>=6.0",
"requests>=2.28.0",
"rich>=13.0.0",
"slack-sdk>=3.0.0",
"black>=23.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/hellofresh/hf-pm-os",
"Documentation, https://pm-os.dev/docs",
"Repository, https://github.com/hellofresh/hf-pm-os"
] | twine/6.2.0 CPython/3.13.6 | 2026-02-20T13:43:57.315509 | pm_os-4.2.0.tar.gz | 71,362 | a0/41/1f325d26d273105bd3de2430713115749bc22fd254268cb63196eda02253/pm_os-4.2.0.tar.gz | source | sdist | null | false | 1511faf7241451cbeaf80be717276673 | d4543cd6f74b06af49bdd4bb0c4113dd1218bbd1c9ea9f85e35e4e7799e06709 | a0411f325d26d273105bd3de2430713115749bc22fd254268cb63196eda02253 | MIT | [] | 229 |
2.4 | amrita_core | 0.4.5.1 | Agent core of Project Amrita | # AmritaCore
<center><img src="./docs/public/Amrita.png" alt="Logo" width="200" height="200">
<p>
<a href="https://img.shields.io/pypi/v/amrita-core">
<img src="https://img.shields.io/pypi/v/amrita-core?color=blue&style=flat-square" alt="PyPI Version">
</a>
<a href="https://www.python.org/">
<img src="https://img.shields.io/badge/python-3.10+-blue?logo=python&style=flat-square" alt="Python Version">
</a>
<a href="LICENSE">
<img src="https://img.shields.io/github/license/AmritaBot/AmritaCore?style=flat-square" alt="License">
</a>
<a href="https://discord.gg/byAD3sbjjj">
<img src="https://img.shields.io/badge/Discord-Proj.Amrita-blue?logo=discord&style=flat-square" alt="Discord">
</a>
<a href="https://qm.qq.com/q/9J23pPZN3a">
<img src="https://img.shields.io/badge/QQ%E7%BE%A4-1006893368-blue?style=flat-square" alt="QQ Group">
</a>
</p>
</center>
AmritaCore is the intelligent agent core module of Proj.Amrita, serving as the primary logical or control component of the project. It provides a flexible and extensible framework for implementing AI agents with advanced capabilities.
## 🚀 What is AmritaCore?
AmritaCore is a next-generation agent framework designed to simplify the creation and deployment of intelligent agents. Built with modern Python technologies, it provides a comprehensive solution for implementing AI-powered applications with features like event-driven architecture, tool integration, and multi-modal support.
## 🎯 Mission and Value Proposition
The mission of AmritaCore is to democratize the development of intelligent agents by providing a powerful yet accessible framework. Our core value propositions include:
- **Stream-based Design**: All message outputs are designed as asynchronous streams for real-time responses
- **Security**: Built-in cookie security detection to ensure session safety
- **Vendor Agnostic**: Data types and conversation management are independent of specific providers, offering high portability
- **Extensibility**: Integrated MCP client in extension mechanisms for enhanced system scalability
## 🔑 Key Features
1. **Every is a Stream**: All message outputs are asynchronous stream-based designs supporting real-time responses
2. **Cookie Security Detection**: Built-in cookie security detection functionality to protect session security
3. **Provider Independent Mechanism**: Data types and conversation management are independent of specific vendors, with high portability
4. **MCP Client Support**: Extension mechanisms integrate MCP clients, enhancing system expansion capabilities
5. **Event-Driven Architecture**: Comprehensive event system for flexible and reactive agent behavior
6. **Tool Integration Framework**: Robust system for integrating external tools and services
7. **Advanced Memory Management**: Sophisticated context handling with automatic summarization and token optimization
8. **High-Performance**: Lightweight and efficient, with high performance.
## 📖 Documentation
Please view [Docs](https://amrita-core.suggar.top) for more information.
## 🛠️ Quick Start
To quickly start using AmritaCore, check out the examples in the [demo](./demo/) directory. The basic example demonstrates how to initialize the core, configure settings, and run a simple chat session with the AI assistant.
## 🤝 Contributing
We welcome contributions! Please see our contribution guidelines for more information.
## 📄 License
This project is licensed under the MIT License - see the [LICENSE](./LICENSE) file for details.
**Significants**
All versions of AmritaCore are released under the MIT License (Although the past versions are released under the AGPLv3 License, when this readme is created, we will release all versions under the MIT License).
## Other files
- [CONTRIBUTING.md](./CONTRIBUTING.md) - Contribution guidelines
- [CODE_OF_CONDUCT.md](./CODE_OF_CONDUCT.md) - Code of conduct
- [ZH-CN.md](./readmes/ZH_CN.md)
- [EN-US.md](./readmes/EN_US.md)
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"aiofiles>=25.1.0",
"aiohttp>=3.13.3",
"fastmcp>=2.14.4",
"filetype>=1.2.0",
"jieba>=0.42.1",
"loguru>=0.7.3",
"openai>=2.16.0",
"pydantic>=2.12.5",
"pytz>=2025.2"
] | [] | [] | [] | [
"Homepage, https://github.com/AmritaBot/AmritaCore",
"Source, https://github.com/AmritaBot/AmritaCore",
"Issue Tracker, https://github.com/AmritaBot/AmritaCore/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:43:40.558968 | amrita_core-0.4.5.1.tar.gz | 64,065 | 7b/95/abf4629418c71b6a4a03c563116bfd36fe8f0a703af6fa39b7b2b9ee02f3/amrita_core-0.4.5.1.tar.gz | source | sdist | null | false | 8595323dddf404b0b7ebd5b4ffbfce33 | 5b223f6e8cb8a649fcbcc3e739fdf50a9ae4794903e30a7ec2afd2dd9639d422 | 7b95abf4629418c71b6a4a03c563116bfd36fe8f0a703af6fa39b7b2b9ee02f3 | null | [
"LICENSE"
] | 0 |
2.4 | BackcastPro | 0.6.4 | トレーディング戦略のためのPythonバックテストライブラリ | # <img src="https://raw.githubusercontent.com/botterYosuke/BackcastPro/main/docs/img/logo.drawio.svg" alt="BackcastPro Logo" width="40" height="24"> BackcastPro
トレーディング戦略のためのPythonバックテストライブラリ。
**リプレイ型シミュレーター**で、1バーずつ時間を進めながらチャートと売買を可視化できます。
## インストール(Windows)
### PyPIから(エンドユーザー向け)
```powershell
python -m pip install BackcastPro
```
### 開発用インストール
```powershell
git clone <repository-url>
cd BackcastPro
python -m venv .venv
.\.venv\Scripts\Activate.ps1
python -m pip install -e .
```
## 使用方法
### 基本的な使い方
```python
from BackcastPro import Backtest
import pandas as pd
# データ準備
df = pd.read_csv("AAPL.csv", index_col=0, parse_dates=True)
bt = Backtest(data={"AAPL": df}, cash=100000)
# 戦略関数
def my_strategy(bt):
if bt.position == 0:
bt.buy(tag="entry")
elif bt.position > 0:
bt.sell(tag="exit")
# ステップ実行
while not bt.is_finished:
my_strategy(bt)
bt.step()
# 結果を取得
results = bt.finalize()
print(results)
```
### 一括実行
```python
bt = Backtest(data={"AAPL": df}, cash=100000)
bt.set_strategy(my_strategy)
results = bt.run()
```
### marimo連携(リプレイ型シミュレーター)
```python
import marimo as mo
slider = mo.ui.slider(start=1, stop=len(bt.index), value=1, label="時間")
bt.goto(slider.value, strategy=my_strategy)
state = bt.get_state_snapshot()
info = mo.md(f"資産: ¥{state['equity']:,.0f} / 進捗: {state['progress'] * 100:.1f}%")
mo.vstack([slider, info])
```
## ドキュメント
- [ドキュメント一覧](https://botteryosuke.github.io/BackcastPro/)
## バグ報告 / サポート
- バグ報告や要望は GitHub Issues へ
- 質問は Discord コミュニティへ([招待リンク](https://discord.gg/fzJTbpzE))
- 使い方はドキュメントをご参照ください
| text/markdown | botterYosuke | null | null | null | null | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"anywidget>=0.9.21",
"duckdb>=0.9.0",
"matplotlib>=3.0.0",
"msgpack>=1.0.0",
"numpy>=1.20.0",
"pandas>=1.3.0",
"plotly>=5.0.0",
"python-dotenv>=0.19.0",
"requests>=2.25.0",
"scipy>=1.7.0",
"yfinance>=0.2.0; extra == \"all\"",
"yfinance>=0.2.0; extra == \"yfinance\""
] | [] | [] | [] | [
"Homepage, https://github.com/botterYosuke/BackcastPro/",
"Issues, https://github.com/botterYosuke/BackcastPro/issues",
"Logo, https://raw.githubusercontent.com/botterYosuke/BackcastPro/main/docs/img/logo.drawio.svg"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:43:01.741527 | backcastpro-0.6.4.tar.gz | 422,004 | 1c/a8/1e8a20bb5231a28bfdc23df7f942a7f5aef29326ee4777b36130254aef3b/backcastpro-0.6.4.tar.gz | source | sdist | null | false | cb31f2bd0aa116205d8aed6ae87e5ed4 | 6e3d7f029742e367e8c92ef1e95ff4c27a0d4283782b8b66069cafd8a878db13 | 1ca81e8a20bb5231a28bfdc23df7f942a7f5aef29326ee4777b36130254aef3b | null | [] | 0 |
2.2 | mimerpy | 1.3.8 | Python database interface for Mimer SQL | MimerPy: Python database interface for Mimer SQL
==================================================
MimerPy is an adapter for Mimer SQL version 11 in Python_ which implements the
`PEP 249`_ specification. It allows the user to access Mimer SQL through Python.
Requirements:
* A Mimer SQL version 11 or later installation on the client side
* A Mimer SQL version 11 or later database server
* MimerPy is currently supported on Linux, and Windows.
* Python 3.6 or later
The source code for MimerPy resides on GitHub_. Installable packages
can be found on PyPi_. To install, use the command:
.. code-block:: console
python3 -m pip install mimerpy
The source for the MimerPy manual is stored together with the source
in the doc/ directory. We recommend reading it on the
Mimer Information Technology `documentation site`_.
The `home page`_ for the project can be found on the Mimer Information Technology developer site.
.. _Python: http://www.python.org/
.. _PEP 249: https://www.python.org/dev/peps/pep-0249/
.. _MimerSQL: https://www.mimer.com
.. _GitHub: https://github.com/mimersql/MimerPy
.. _PyPi: https://pypi.org/project/mimerpy/
.. _documentation site: https://developer.mimer.com/documentation
.. _home page: https://developer.mimer.com/mimerpy
| text/x-rst | null | Erik Gunne <mimerpy@mimer.com>, Magdalena Boström <mimerpy@mimer.com>, Mimer Information Technology AB <mimerpy@mimer.com> | null | Mimer Information Technology AB <mimerpy@mimer.com> | MIT | Mimer, MimerSQL, Database, SQL, PEP249 | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development :: Build Tools",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.7 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://developer.mimer.com/mimerpy"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T13:42:51.040462 | mimerpy-1.3.8.tar.gz | 89,837 | 36/74/1f5e629dd2c0cd5c5231f0081ae3144c866ecb3d2bc6e2c546fcfcfeed71/mimerpy-1.3.8.tar.gz | source | sdist | null | false | 4ca95c0a21d1ab005affbd3cf62b8d69 | ac75d462c4b422d3161a0f157c74eaeae98016ad8defb54816c10f139fe15a41 | 36741f5e629dd2c0cd5c5231f0081ae3144c866ecb3d2bc6e2c546fcfcfeed71 | null | [] | 249 |
2.3 | das_unsupervised | 0.6.0 | Tools for unsupervised classification of acoustic signals. | # Tools for unsupervised classification of acoustic signals
_DAS-unsupervised_ provides tools for pre-processing acoustic signals for unsupervised classification:
- extract waveforms or spectrograms of acoustic events from a recording
- normalize the duration, center frequency, amplitude, or sign of waveform/spectrograms
Unsupervised classification itself is performed using existing libraries:
- dimensionality reduction: [umap](https://umap-learn.readthedocs.io/)
- clustering: [hdbscan](https://hdbscan.readthedocs.io/) or [scikit-learn](https://scikit-learn.org/stable/modules/clustering.html)
- __NEW:__ interactive embedding and visualization with [marimo](https://marimo.io).
Can be used in combination with [DAS](https://github.com/janclemenslab/das), a deep learning based method for the supervised annotation of acoustic signals.
## Install via conda and uv
```shell
conda create -y -n das_unsupervised -c conda-forge python=3.13 uv
conda activate das_unsupervised
uv pip install das_unsupervised
```
## Demos
Illustration of the workflow and the method using vocalizations from:
- [flies](demo/flies.ipynb)
- [mice](demo/mice.ipynb)
- [birds](demo/birds.ipynb)
- __NEW:__ [interactive zebra finch](interactive/interactive.py)

## Acknowledgements
Code from the following open source packages was modified and integrated into das-unsupervised:
- [avgn](https://github.com/timsainb/avgn_paper) (Sainburg et al. 2020)
- [noisereduce](https://pypi.org/project/noisereduce)
- [fly pulse classifier](https://github.com/murthylab/MurthyLab_FlySongSegmenter) (Clemens et al. 2018)
Data sources:
- flies: [David Stern](https://www.janelia.org/lab/stern-lab/tools-reagents-data) (Stern, 2014)
- mice: data provided by Kurt Hammerschmidt (Ivanenko et al. 2020)
- birds: [Bengalese finch song repository](https://doi.org/10.6084/m9.figshare.4805749.v5) (Nicholson et al. 2017), [Zebra finch song repository](https://research.repository.duke.edu/concern/datasets/9k41zf38g) (Goffinet et al. 2021)
## References
1. T Sainburg, M Thielk, TQ Gentner (2020) Latent space visualization, characterization, and generation of diverse vocal communication signals. Biorxiv . [https://doi.org/10.1101/870311]()
2. J Clemens, P Coen, F Roemschied, T Perreira, D Mazumder, D Aldorando, D Pacheco, M Murthy (2018) Discovery of a New Song Mode in Drosophila Reveals Hidden Structure in the Sensory and Neural Drivers of Behavior. Current Biology 28, 2400–2412.e6 (2018). [https://doi.org/10.1016/j.cub.2018.06.011]()
3. D Stern (2014). Reported Drosophila courtship song rhythms are artifacts of data analysis. BMC Biology
4. A Ivanenko, P Watkins, MAJ van Gerven, K Hammerschmidt, B Englitz (2020) Classifying sex and strain from mouse ultrasonic vocalizations using deep learning. PLoS Comput Biol 16(6): e1007918. [https://doi.org/10.1371/journal.pcbi.1007918]()
5. D Nicholson, JE Queen, S Sober (2017). Bengalese finch song repository. [https://doi.org/10.6084/m9.figshare.4805749.v5]() | text/markdown | Jan Clemens | clemensjan@googlemail.com | null | null | null | null | [
"License :: OSI Approved :: MIT License"
] | [] | https://github.com/janclemenslab/das_unsupervised | null | >=3.10 | [] | [
"das_unsupervised"
] | [] | [
"numpy",
"scipy",
"scikit-learn",
"matplotlib",
"colorcet",
"seaborn",
"librosa>=0.11",
"noisereduce>=3",
"Pillow>=10",
"umap-learn",
"hdbscan",
"ipykernel",
"ipywidgets",
"jupyterlab",
"marimo"
] | [] | [] | [] | [] | python-requests/2.32.5 | 2026-02-20T13:42:42.221278 | das_unsupervised-0.6.0.tar.gz | 11,733,634 | 02/d1/6e46ad553f3e8c12debd49ddc8d8e8e98f9ed6f7159704720fe25546a4c7/das_unsupervised-0.6.0.tar.gz | source | sdist | null | false | e20f777b584cf44a19aa2506019caf77 | 41f113d678e88429a863aee7a843bba3c0fff6b39ed0ae0750edf3379ef57450 | 02d16e46ad553f3e8c12debd49ddc8d8e8e98f9ed6f7159704720fe25546a4c7 | null | [] | 0 |
2.4 | openBES | 0.3.0rc3 | Python implementation of the Open Building Energy Simulation (OpenBES) tool. | # OpenBES-py
[](https://github.com/OxfordRSE/OpenBES-py/actions/workflows/unittest.yml)
[](https://github.com/OxfordRSE/OpenBES-py/actions/workflows/test_cases.yml)
[](https://github.com/OxfordRSE/OpenBES-py/actions/workflows/package_test.yml)


OpenBES-py is an open-source building energy simulation tool written in Python. It is designed to provide transparent, reproducible, and extensible energy modeling for buildings, supporting research, education, and practical analysis.
## Features
- **Modular simulation engine**: Each energy category is implemented as a separate module for clarity and extensibility.
- **Comprehensive test suite**: All core modules are covered by unit and integration tests.
- **Standardized test cases**: Planned integration with ASHRAE Standard 140 test cases (see `cases_ashrae_std140_...` directory).
- **Modern dependency management**: Uses [UV](https://github.com/astral-sh/uv) for fast, reliable Python environment setup (`uv.lock` included).
[Version 0.1.9](https://github.com/OxfordRSE/OpenBES-py/releases/tag/v0.1.9) implements the core functionality of OpenBES with parity to Excel version 32.
[Version 0.2.0](https://github.com/OxfordRSE/OpenBES-py/releases/tag/v0.2.0) implements the core functionality of OpenBES with parity to Excel version 34.
[Version 0.3.0](https://github.com/OxfordRSE/OpenBES-py/releases/tag/v0.3.0) has full parity to Excel version 34.
[Version 1.0.0](https://github.com/OxfordRSE/OpenBES-py/releases/tag/v1.0.0) will be the first stable release:
- Validation performed directly against ASHRAE Standard 140
- Excel parity abandoned
- Stable Input/Output formats
- Documentation and examples
- License
## Installation
You can install OpenBES-py via pip:
```bash
pip install openBES[jit]
```
This will install the package along with optional JIT compilation support for improved performance (via Numba).
If you do not need JIT support, you can install without the `[jit]` extra.
<details>
<summary>
<h3>Why doesn't the package default to JIT support?</h3>
</summary>
A major use-case for the package is in a web-based environment, using Pyodide.
Pyodide does not currently support Numba, so to keep the package lightweight and compatible with such environments, JIT support is made optional.
At a later date we might custom-compile the project to WASM with Numba support, but for now this is not available.
</details>
## Usage
Here is a simple example of how to use OpenBES-py to run a building energy simulation:
```python
from openBES import BuildingSimulation, OpenBESSpecification
spec_file = "path/to/specification.toml"
spec = OpenBESSpecification.from_toml(spec_file)
simulation = BuildingSimulation(spec) # the simulation is run upon initialization
total_annual_energy_used = simulation.energy_use.sum().sum() # collaspse energy use DataFrame -> annual energy in kWh
```
## Development
1. Install [UV](https://github.com/astral-sh/uv) if you do not have it: `pip install uv`
2. Set up a virtual environment (recommended): `uv venv`
3. Install editable package: `uv pip install -e .[dev]`
4. Install dependencies: `uv sync`
5. Run tests to verify installation: `uv run python -m unittest discover -s tests`
## License
The license for this project is under consideration.
## Credits
We use Pandas for data manipulation and NumPy for numerical calculations.
We use PVLib.iotools for reading EPW (energy plus weather) files.
Jensen, A., Anderson, K., Holmgren, W., Mikofski, M., Hansen, C., Boeman, L., Loonen, R. “pvlib iotools — Open-source Python functions for seamless access to solar irradiance data.” Solar Energy, 266, 112092, (2023). DOI: 10.1016/j.solener.2023.112092.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"numpy>=2",
"pandas",
"pvlib",
"pydantic>=2.7",
"numba; extra == \"jit\"",
"line_profiler; extra == \"dev\"",
"numba; extra == \"dev\"",
"datamodel-code-generator>=0.43; extra == \"dev\"",
"ruff; extra == \"dev\"",
"jsonschema>=4; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T13:42:19.219109 | openbes-0.3.0rc3.tar.gz | 1,610,787 | 73/4c/7d424d4736d61a6b6ab556cd6d2546cdbf002d875bf3b00c7ab364c323f6/openbes-0.3.0rc3.tar.gz | source | sdist | null | false | 0c01bd0d5ff260402f5fcd7c36103485 | 8718d30740f8101052d629cdcca07cc046f80a74b6f2b98f3fa1a97c65205c11 | 734c7d424d4736d61a6b6ab556cd6d2546cdbf002d875bf3b00c7ab364c323f6 | null | [] | 0 |
2.1 | ghoshell-moss | 0.1.0a0 | LLM-oriented operating system shell, providing interpreter for llm to control everything | # 项目概述
项目名为 `MOS-Shell` (Model-oriented Operating System Shell), 包含几个核心目标:
1. `MOS`: 为 AI 大模型提供一个 "面向模型的操作系统", 可以将 跨设备/跨进程 的功能模块, 以 "树" 的形式提供给模型操作.
1. `Shell Runtime`: 为 AI Agent 提供一个持续运转的运行时 (Runtime), 联通所有功能模块 (称之为 Channel, 对标 python 的
module).
1. `Code As Prompt`: 让 AI 大模型用 python 函数 的形式理解所有它可调用的功能, 而不是 json schema. 实现 "
面向模型的编程语言".
1. `Streaming Interpret`: 支持 AI 大模型流式输出对话和命令 (Command) 调用, 并且 Shell 会流式地编译执行这些调用,
并行多轨控制自己的躯体和软件.
目标是 AI 大模型作为大脑, 不仅可以思考, 还可以 实时/并行/有序 地操作包括 计算机/具身躯体 来进行交互.
MOS-Shell 是 Ghost In Shells (中文名: 灵枢) 项目创建的新交互范式架构, 是第二代 MOSS 架构 (完善了 ChannelApp 和
Realtime-Actions 思想). 第一代 MOSS 架构 (全代码驱动 + FunctionToken) 详见 [GhostOS](https://github.com/ghostInShells/ghostos)
**更多设计思路请访问飞书文档**: [核心设计思想综述](https://ycnrlabqki3v.feishu.cn/wiki/QCKUwAX7tiUs4GkJTkLcMeWqneh)
## Alpha 版本声明
当前版本为内测版 (Alpha), 这意味着:
1. 项目仍然在第一阶段开发中, 会激进地迭代.
1. 主要是验证核心链路和设计思想, 许多计划中的关键功能还未实现.
1. 暂时没有人力去完善文档
1. 不适合在生产环境使用.
如果想要试用项目, 请直接联系 灵枢开发组 配合.
想要阅读架构的设计思想, 推荐直接看 [concepts 目录](src/ghoshell_moss/core/concepts).
## Examples
在 [examples](examples) 目录下有当前 alpha 版各种用例. 具体的情况请查阅相关目录的 readme 文档.
体验 examples 的方法:
> 建议使用 mac, 基线都是在 mac 上测试的. windows 可能兼容存在问题.
## 1. clone 仓库
```bash
git clone https://github.com/GhostInShells/MOSShell MOSShell
cd MOSShell
```
## 2. 创建环境
- 使用 `uv` 创建环境, 运行 `uv venv` . 由于依赖 live2d, 所以默认的 python 版本是 3.12
- 进入 uv 的环境: `source .venv/bin/activate`
- 安装所有依赖:
```bash
# examples 的依赖大多在 ghoshell-moss[contrib] 中, 没有拆分. 所以需要安装全部依赖.
uv sync --active --all-extras
```
## 3. 配置环境变量
启动 demo 时需要配置模型和音频 (可选), 目前 alpha 版本的基线全部使用的是火山引擎.
需要把环境变量配置上.
```bash
# 复制 env 文件为目标文件.
cp examples/.env.example examples/.env
# 修改相关配置项为真值.
vim examples/.env
```
配置时需要在火山引擎创建 大模型流式tts 服务. 不好搞定可以先设置 USE_VOICE_SPEECH 为 `no`
## 4. 运行 moss agent
```bash
# 基于当前环境的 python 运行 moss_agent 脚本
.venv/bin/python examples/moss_agent.py
# 打开后建议问它, 你可以做什么.
```
已知的问题:
1. 语音输入模块 alpha 版本没有开发完.
1. 目前使用的 simple agent 是测试专用, 打断的生命周期还有问题.
1. 由于 shell 的几个控制原语未开发完, 一些行为阻塞逻辑会错乱.
1. interpreter 的生命周期计划 beta 完成, 现在交互的 ReACT 模式并不是最佳实践 (模型会连续回复)
更多测试用例, 请看 examples 目录下的各个文件夹 readme.
## Beta Roadmap
Alpha 版本是内测版. 预计在 Beta 版本完成:
- [ ] 中英双语说明文档
- [ ] 流式控制基线
- [ ] CTML 控制原语: clear / stop_all / wait / concurrent / observe. 目前原语未完成, 多轨并行和阻塞存在问题.
- [ ] Speech 模块 Channel 化.
- [ ] 完善 CommandResult, 用于支持正规的 Agent 交互范式.
- [ ] 完善 states/topics 等核心技术模块.
- [ ] 完善 Interpreter 与 AI Agent 的交互范式基线.
- [ ] 完善 Channel 体系
- [ ] 定义 Channel App 范式, 创建本地的 Channel Applications Store
- [ ] 完善 Channel 运行时生命周期治理
- [ ] 完成对 Claude MCP 和 Skill 的兼容
- [ ] 完善 MOSS 项目的自解释 AI
- [ ] 实现第一个 Ghost 原型, 代号 Alice
- [ ] 实现架构级的 Channels, 用于支撑基于 MOSS 运转的 Ghost 体系.
- [ ] 实现一部分开箱即用的 Channels, 用来提供 AIOS 的运行基线.
## Contributing
- Thank you for being interested in contributing to `MOSShell`!
- We welcome all kinds of contributions. Whether you're fixing bugs, adding features, or improving documentation, we appreciate your help.
- For those who'd like to contribute code, see our [Contribution Guide](https://github.com/GhostInShells/MOSShell/blob/main/CONTRIBUTING.md).
| text/markdown | thirdgerb, 17wang | null | null | null | Apache License 2.0 | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"ghoshell-common>=0.5.0",
"ghoshell-container>=0.3.1",
"openai>=2.8.1",
"pillow>=12.1.0",
"python-frontmatter>=1.1.0",
"zmq>=0.0.0; extra == \"zmq\"",
"aiozmq>=1.0.0; extra == \"zmq\"",
"psutil>=7.2.1; extra == \"zmq\"",
"mcp[cli]>=1.17.0; extra == \"mcp\"",
"websockets>=15.0.1; extra == \"wss\"",
"fakeredis>=2.32.1; extra == \"redis\"",
"redis>=7.0.1; extra == \"redis\"",
"pulsectl>=24.12.0; extra == \"audio\"",
"pyaudio>=0.2.14; extra == \"audio\"",
"scipy>=1.15.3; extra == \"audio\"",
"litellm>=1.78.5; extra == \"contrib\"",
"live2d-py<0.6.0,>=0.5.4; extra == \"contrib\"",
"mermaid-py>=0.8.1; extra == \"contrib\"",
"mss>=10.1.0; extra == \"contrib\"",
"prompt-toolkit>=3.0.52; extra == \"contrib\"",
"pygame>=2.6.1; extra == \"contrib\"",
"pyqt6>=6.10.2; extra == \"contrib\"",
"python-mpv-jsonipc>=1.2.1; extra == \"contrib\"",
"rich>=14.2.0; extra == \"contrib\"",
"javascript>=1!1.2.6; extra == \"contrib\"",
"opencv-python>=4.13.0.92; extra == \"contrib\"",
"loadenv>=0.1.1; extra == \"contrib\"",
"pymupdf>=1.27.1; extra == \"contrib\""
] | [] | [] | [] | [] | uv/0.6.3 | 2026-02-20T13:42:14.016719 | ghoshell_moss-0.1.0a0.tar.gz | 202,517 | 26/79/3404c73add343f342e9a2fa9485a71155527182f764008afe33720daeaed/ghoshell_moss-0.1.0a0.tar.gz | source | sdist | null | false | 5fe6f84f6f76bc294c738b5d5ac56c3c | 378972dfc1e0a823909c5b251a6ddbee2b92585c97aac3f973d298ba7ec4b240 | 26793404c73add343f342e9a2fa9485a71155527182f764008afe33720daeaed | null | [] | 209 |
2.4 | texthold | 2.0.0 | This project provides a class that holds text. | ========
texthold
========
Visit the website `https://texthold.johannes-programming.online/ <https://texthold.johannes-programming.online/>`_ for more information.
| text/x-rst | null | Johannes <johannes.programming@gmail.com> | null | null | The MIT License (MIT)
Copyright (c) 2025 Johannes
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | null | [
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Typing :: Typed"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"cmp3<2,>=1.0",
"datahold<4,>=3.0",
"setdoc<2,>=1.2.8"
] | [] | [] | [] | [
"Download, https://pypi.org/project/texthold/#files",
"Index, https://pypi.org/project/texthold/",
"Source, https://github.com/johannes-programming/texthold/",
"Website, https://texthold.johannes-programming.online/"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T13:41:39.257732 | texthold-2.0.0.tar.gz | 5,555 | 1e/c3/4d4d8b92d5ef9e5c395afc4c168587a4f63192f6c9ce1aac6c14d0c40f22/texthold-2.0.0.tar.gz | source | sdist | null | false | 9069db4498cdf91497f1cbe783e3fefd | 1c9dc5a5c1356b36cbdf0c625c4325ebbfe8c87073160a609ebcc6f8ca161fce | 1ec34d4d8b92d5ef9e5c395afc4c168587a4f63192f6c9ce1aac6c14d0c40f22 | null | [
"LICENSE.txt"
] | 215 |
2.4 | decode-config | 15.3.0.0 | Backup/restore and decode configuration tool for Tasmota | # decode-config
Convert, backup and restore configuration data of devices flashed with [Tasmota firmware](https://github.com/arendst/Tasmota).
<!-- markdownlint-disable MD033 -->
<img src="https://github.com/tasmota/decode-config/blob/master/media/pic/decode-config.png" alt="Overview" title="decode-config Overview" width="600">
<!-- markdownlint-disable MD033 -->
[](https://github.com/tasmota/decode-config/tree/master)
[](https://github.com/tasmota/decode-config/releases/latest)
[](https://badge.fury.io/py/decode-config)

[](LICENSE)
This tool can create readable and editable formats from the configuration data of [Tasmota](https://github.com/arendst/Tasmota), which is originally only available in binary form and protected against changes by a checksum.
Features of **decode-config**:
* read/write directly from online devices (via HTTP or MQTT) or from offline files in binary format.
* uses a readable and editable [JSON](http://www.json.org/) format for backup/restore.
* process subsets of configuration data in JSON format.
* convert data from older Tasmota versions (from version 5.10.0 onwards) to newer versions and vice versa.
* create a list of [Tasmota commands](https://tasmota.github.io/docs/Commands/#commands-list) for most of the available commands related to configuration data.
If you like **decode-config** give it a star or fork it and contribute:
[](https://github.com/tasmota/decode-config/stargazers)
[](https://github.com/tasmota/decode-config/network)
[](https://paypal.me/NorbertRichterDE)
Comparing backup files created by **decode-config** and [.dmp](#dmp-format) files created by Tasmota "*Backup Configuration*" / "*Restore Configuration*":
| Configuration | decode-config JSON file | Tasmota *.dmp file |
|:------------------------|:-----------------------:|:------------------:|
| encrypted | No | Yes |
| readable | Yes | No |
| editable | Yes | No |
| batch processing | Yes | No |
| Backup/Restore subsets | Yes | No |
**decode-config** is compatible with all [Tasmota](https://github.com/arendst/Tasmota) versions, starting from Tasmota v5.10.0 up to the current one.
## Development
Using the latest development version of decode-config is only necessary if you also use the latest development version of Tasmota.
<!-- markdownlint-disable MD033 -->
[](https://github.com/tasmota/decode-config/tree/development)
## Table of contents
<details>
<summary>Contents</summary>
* [Development](#development)
* [Table of contents](#table-of-contents)
* [Running the program](#running-the-program)
* [Installation](#installation)
* [Usage](#usage)
* [Basics](#basics)
* [Tasmota source](#tasmota-source)
* [Format JSON output](#format-json-output)
* [Parameter file](#parameter-file)
* [Save backup](#save-backup)
* [Restore backup](#restore-backup)
* [Auto file extensions](#auto-file-extensions)
* [Test your parameter](#test-your-parameter)
* [Console outputs](#console-outputs)
* [Filter by groups](#filter-by-groups)
* [Usage examples](#usage-examples)
* [Using Tasmota binary configuration files](#using-tasmota-binary-configuration-files)
* [Using JSON editable file](#using-json-editable-file)
* [Use batch processing](#use-batch-processing)
* [File Formats](#file-formats)
* [.dmp format](#dmp-format)
* [.json format](#json-format-1)
* [.bin format](#bin-format)
* [Program parameter](#program-parameter)
* [--full-help](#--full-help)
* [Parameter notes](#parameter-notes)
* [Obsolete parameters](#obsolete-parameters)
* [Generated Tasmota commands](#generated-tasmota-commands)
* [Program return codes](#program-return-codes)
</details>
## Running the program
To use **decode-config.py** you can install it using Python environment and following the [Installation](#installation) section below.
Alternatively you can download a ready-made binary from [Releases](https://github.com/tasmota/decode-config/releases) to use it without installing Python.
### Installation
**decode-config.py** needs an installed [Python](https://en.wikipedia.org/wiki/Python_%28programming_language%29) environment - (see [Prerequisite](#prerequisite)).
After you have installed your Python environment, there are two ways to install deocde-config:
#### Installation using PyPi
```shell
pip install decode-config
```
The program does not have a graphical user interface (GUI), you have to run it from your OS command line using [program arguments](#usage) - see [Usage](#usage) for more details.
#### Manual installation
This is only necessary if you want to run **decode-config.py** from [development branch](https://github.com/tasmota/decode-config/tree/development). First install the required modules manually
```shell
python -m pip install -r requirements.txt
```
After that you can use the Phython script **decode-config.py** as normal program:
```shell
decode-config.py
```
#### Prerequisite
Since **decode-config.py** is a [Python](https://en.wikipedia.org/wiki/Python_%28programming_language%29) program, it requires an installed [Python](https://www.python.org) environment.
##### Linux
Install [Python 3.x](https://www.python.org/downloads/) and Pip:
```bash
sudo apt-get install python3 python3-pip
```
##### Windows
Install [Python 3.x for Windows](https://www.python.org/downloads/windows/) as described
##### MacOS
Install [Python 3.x for macOS](https://www.python.org/downloads/mac-osx/) as described
## Usage
For an overview start the program without any parameter and you will get a short help:
<!-- markdownlint-capture -->
<!-- markdownlint-disable MD031 -->
```bash
decode-config.py
```
This prints a short help:
```help
usage: decode-config.py [-s <filename|host|url>] [-p <password>]
[--fulltopic <topic>] [--cafile <file>]
[--certfile <file>] [--keyfile <file>] [--insecure]
[--keepalive <sec>] [-i <restorefile>]
[-o <backupfile>] [-t json|bin|dmp] [-E] [-e] [-F]
[--json-indent <indent>] [--json-compact]
[--json-show-pw] [--cmnd-indent <indent>]
[--cmnd-groups] [--cmnd-sort]
[--cmnd-use-rule-concat] [--cmnd-use-backlog]
[-c <configfile>] [-S] [-T json|cmnd|command]
[-g <groupname> [<groupname> ...]] [-w] [--dry-run]
[-h] [-H] [-v] [-V]
```
For advanced help run **decode-config** with parameter `--full--help` or `-H`. This will print a [Program parameter](#program-parameter).
> **Note**
If you're missing older parameters, don't worry, they're still there (see [Obsolete parameters](#obsolete-parameters)).
### Basics
To get a program result, pass at least a [Tasmota source](#tasmota-source) from which you want to read the configuration data.
### Tasmota source
The Tasmota source determines where the configuration data should be loaded from and saved to.
A source can be an offline file or an online Tasmota device accessed via HTTP or indirectly via MQTT.
Use `--source` parameter to determine the configuration data source:
#### Binary (*.dmp) file (Offline)
Source is a Tasmota configuration file (having extension `.dmp`).
Pass the filename direclty or encoded as a [file-URL](https://en.wikipedia.org/wiki/URL):
```bash
decode-config --source tasmota-4281.dmp
decode-config -s file://path/to/tasmota-4281.dmp
```
#### HTTP connection (Online)
Source is an online HTTP connection to a running Tasmota device. To use this source, **decode-config** must have access to the network on which Tasmota is running, [Tasmota Webserver](https://tasmota.github.io/docs/Commands/#webserver) running in admin mode (`WebServer 2`) is mandatory.
Specify the hostname, IP o or [http-url](https://en.wikipedia.org/wiki/URL) of the Tasmota device.
An optionally required HTTP password, username and different HTTP port of the device can be specified via [URL](https://en.wikipedia.org/wiki/URL) or separately via `--username`, `--password` and `--port`
```bash
decode-config --source tasmota-4281
decode-config -s 192.168.10.92
decode-config --source http://tasmota-4281 --password myPaszxwo!z
decode-config --source http://admin:myPaszxwo!z@tasmota-4281:8000
decode-config --source http://admin:myPaszxwo!z@tasmota-4281/cs?
```
An appended HTTP path (here "`/cs?`") is ignored.
#### MQTT transission (Online)
Source is a MQTT server and topic where an online Tasmota device is connected to. To use this source, **decode-config** does not need to have access to the same network that Tasmota is running on, it just needs access to the MQTT server that Tasmota also uses.
##### MQTT connection parameter
Specify the hostname or IP of the MQTT server (possibly also specify username and password for the MQTT server) and the Tasmota MQTT topic. The **decode-config** connection to MQTT server also allows SSL/TLS connection.
The MQTT username and password must be encoded within the URL (the parameter `--password` can not be used for that, it has a different function here).
If the username/password combination for the **decode-config** MQTT connection is different from the one used by Tasmota itself (Tasmota command `MQTTPassword`), the Tasmota MQTT password must be specified via the `--password` parameter.
The Tasmota topic can be specfied either within the [URL path](https://en.wikipedia.org/wiki/URL#Syntax) component or using optional `--fulltopic` parameter.
The topic must be the full topic of the Tasmota device without any trailing command or result part. You can use any of the prefixed topic (*cmnd*, *stat* or *tele* topic) or use the placeholder *%prefix%* for it, example
`%prefix%/tasmota-4281` or `tele/tasmota-4281` are valid topics
`cmnd/tasmota-4281/POWER` or `tele/tasmota-4281/STATE` are invalid topics due to the trailing part.
For SSL/TLS connection to MQTT server use `mqtts://` [URL scheme](https://en.wikipedia.org/wiki/URL#Syntax).
```bash
decode-config --source mqtts://mybroker.example.com/%prefx%/tasmota-4281
decode-config --source mqtts://mybroker.example.com:8883/tele/tasmota-4281
decode-config --source mqtts://mqttuser:myBrokerPaszxwo!z@mybroker.example.com --fulltopic tele/tasmota-4281
decode-config --source mqtts://mqttuser:myBrokerPaszxwo!z@mybroker.example.com/tele/tasmota-4281 --password myTasmotaMQTTPaszxwo!z
```
For own certifications use the parameters `--cafile`, `--certfile` and `--keyfile`. To suppress certification verification use `--insecure`.
For none SSL/TLS connection to MQTT server use `mqtt://` [URL scheme](https://en.wikipedia.org/wiki/URL#Syntax).
```bash
decode-config --source mqtt://mybroker.example.com/%prefx%/tasmota-4281
decode-config --source mqtt://mybroker.example.com:1883/tele/tasmota-4281
decode-config --source mqtt://mqttuser:myBrokerPaszxwo!z@mybroker.example.com --fulltopic tele/tasmota-4281
decode-config --source mqtt://mqttuser:myBrokerPaszxwo!z@mybroker.example.com/tele/tasmota-4281 --password myTasmotaMQTTPaszxwo!z
```
### Format JSON output
All basic examples above will output a readable configuration in [JSON](http://www.json.org/)-format, e.g.:
```json
{"altitude": 112, "baudrate": 115200, "blinkcount": 10, "blinktime": 10,...
"ws_width": [1, 3, 5]}
```
> **Note**
The json names (like `"altitude"` or `"blinktime"` are internal names from Tasmotas [settings.h](https://github.com/arendst/Tasmota/blob/master/tasmota/include/tasmota_types.h) STRUCT `Settings` and are not the same as known from Tasmota [web-console commands](https://tasmota.github.io/docs/Commands/). However, since most variable names are self-describing, the functional meaning should be given in most cases.
The default JSON output can be formatted for better reading using the `--json-indent <n>` parameter:
```bash
decode-config --source tasmota-4281 --password "myPaszxwo!z" --json-indent 2
```
This will print a pretty better readable format and the example above becomes:
```json
{
"altitude": 112,
"baudrate": 115200,
"blinkcount": 10,
"blinktime": 10,
...
"ws_width": [
1,
3,
5
]
}
```
### Parameter file
Because the number of parameters are growing, it would be difficult to enter all these parameters again and again. In that case it is best to use a configuration file that contains your standard parameters and which we then have to specify as the only additional parameter.
[Program parameter](#program-parameter) starting with `--` (eg. `--username`) can be set into such a configuration file. Simply write each neccessary parameter including possible value without dashes into a text file. For a better identification of this file, extension `.conf` is recommended:
Writing all the previous used device parameter in a file, create the text file `my.conf` and insert:
```conf
[source]
username = admin
password = myPaszxwo!z
[JSON]
json-indent 2
```
> **Hint**
Group names enclosed in square brackets [ ], like `[source]` in the example, are optional and ignored - you can use them to increase readability.
Now we can use it with `-c` parameter:
```bash
decode-config -c my.conf -s tasmota-4281
```
> **Note**
For further of parameter file syntax see [https://pypi.org/project/ConfigArgParse](https://pypi.org/project/ConfigArgParse/)).
If parameters are specified in more than one place (parameter file and command line), the commandline parameters will overrule the file parameters. This is usefull if you use a basic set of parameters and want to change parameter once without the need to edit your configuration file:
```bash
decode-config -c my.conf -s tasmota-4281 --json-indent 4
```
Here JSON will be output with indent of 4 spaces instead of the `2` set from `my.conf`-
### Save backup
To save data from a device or [*.dmp](#dmp-format) file into a backup file, use `--backup-file <filename>`.
#### Backup filename macros
You can use the following placeholders within filenames:
* **@v** is replaced by *Tasmota Version* (backup & restore filenames)
* **@d** is replaced by *Devicename* (backup & restore filenames)
* **@f** is replaced by first *Friendlyname1* (backup & restore filenames)
* **@h** is replaced by the *Hostname* from configuration data (backup & restore filenames)
Note: This is the static hostname which is configured by the command *Hostname*, for real hostname from a device use macro the **@H**)
* **@H** is replaced by the live device hostname (only for http sources, backup & restore filenames)
Note: This can be different to the configured hostname as this can contain also macros).source
* **@F** is replaced by the filename of MQTT request (only for MQTT sources, backup filenames only).
This is usually the filename that Tasmota uses when saving the configuration in the WebUI.
* **@t** is replaced by *Topic* (backup & restore filenames)
Example:
```bash
decode-config -c my.conf -s tasmota-4281 --backup-file Config_@d_@v
```
This will create a file like `Config_Tasmota_15.3.json` (the part `Tasmota` and `15.3` will choosen related to your device configuration).
#### Save multiple backup at once
The `--backup-file` parameter can be specified multiple times to create different backup with different names and/or different formats at once:
```bash
decode-config -c my.conf -s tasmota-4281 -o Config_@d_@v -o Backup_@H.json -o Backup_@H.dmp
```
creates three backup files:
* `Config_Tasmota_15.3.json` using JSON format
* `Backup_tasmota-4281.json` using JSON format
* `Backup_tasmota-4281.dmp` using Tasmota configuration file format
### Restore backup
Reading back a previously saved backup file, use the `--restore-file <filename>` parameter.
To restore the previously save backup file `Config_Tasmota_15.3.json` to device `tasmota-4281` use:
```bash
decode-config -c my.conf -s tasmota-4281 --restore-file Config_Tasmota_15.3
```
Restore operation also allows placeholders **@v**, **@d**, **@f**, **@h** or **@H** like in backup filenames so we can use the same naming as for the backup process:
```bash
decode-config -c my.conf -s tasmota-4281 --restore-file Config_@d_@v
```
> **Note**
Placeholders used in restore filenames only work as long as the underlying data of the device has not changed between backup and restore, since **decode-config** first read them from the config file or the device to replace it.
#### Restore subset of data
If you use the default JSON format for backup files you can also use files containing a subset of configuration data only.
Example: You want to change the data for location (altitude, latitude, longitude) only, create a JSON file `location.json` with the content
```json
{
"altitude": 0,
"latitude": 48.85836,
"longitude": 2.294442
}
```
Set this location for a device:
```bash
decode-config -c my.conf -s tasmota-4281 -i location
```
> **Note**
When using JSON subsets on ESP32 chip types, always keep the key `config_version` in the JSON data, otherwise an error will occur stating that the file is for ESP82xx.
> **Hint**
Keep the JSON-format valid e.g. when cutting unnecessary content from a given JSON backup file, consider to remove the last comma on same indent level:
Invalid JSON (useless comma in line 3: `...2.294442,`):<pre>{
"latitude": 48.85836,
"longitude": 2.294442,
}</pre>valid JSON:<pre>{
"latitude": 48.85836,
"longitude": 2.294442
}</pre>
Using subsets of data JSON files are powerfull possibilitiy to create various personal standard configuration files that are identical for all your Tasmota devices and that you can then reuse for newly configure Tasmotas.
### Auto file extensions
File extensions are selected based on the file content and / or the `--backup-type` parameter. You don't need to add extensions to your file:
* If you omit the file extensions, one of `.dmp`, `.bin` or `.json` is used depending on the selected backup type
* If you omit the `--backup-type` parameter and the selected file name has one of the standard extensions `.dmp`, `.bin` or `.json`, the backup type is set based on the extension.
If you use your own extensions, deactivate the automatic extension using the `--no-extension` parameter and use the optional `--backup-type` parameter if neccessary.
Examples:
* `decode-config --source tasmota-4281 --backup-file tasmota-4281.bin`<br>
is identical with<br>
`decode-config --source tasmota-4281 --backup-type bin --backup-file tasmota-4281`<br>
In both cases the backup file `tasmota-4281.bin` is created.
* `decode-config --source tasmota-4281 --restore-file tasmota-4281.json`<br>
is identical with<br>
`decode-config --source tasmota-4281 --restore-file tasmota-4281`<br>
In both cases the backup file `tasmota-4281.json` will tried to restore (remember `--backup-type json` is the default)
* whereas<br>
`decode-config --source tasmota-4281 --no-extension --restore-file tasmota-4281`<br>
will fail if `tasmota-4281` does not exist and<br>
`decode-config --source tasmota-4281 --no-extension --backup-file tasmota-4281`<br>
will create a json backup file named `tasmota-4281` (without the extension).
### Test your parameter
To test your parameter append `--dry-run`:
```bash
decode-config -s tasmota-4281 -i backupfile --dry-run
```
This runs the complete process but prevent writing any changes to a device or file.
### Console outputs
Output to the console screen is the default when calling the program without any backup or restore parameter.
Screen output is suppressed when using backup or restore parameter. In that case you can force screen output with `--output`.
The console screen output supports two formats:
* [JSON](#json-format):<br>
This is identical with the backup/restore [json file Format](#json-format) but printed on screen standard output.
* [Tasmota command](#tasmota-web-command-format):<br>
This outputs the most (but not all!) configuration data as Tasmota [web-console commands](https://tasmota.github.io/docs/Commands/).
#### JSON format
The default console output format is [JSON](#json-format) (optional you can force JSON backup format using `--output-format json`).
Example:
```bash
decode-config -c my.conf -s tasmota-4281 --group Wifi
```
will output data like
```json
{
...
"hostname": "%s-%04d",
"ip_address": [
"0.0.0.0",
"192.168.12.1",
"255.255.255.0",
"192.168.12.1"
],
"ntp_server": [
"ntp.localnet.home",
"ntp2.localnet.home",
"192.168.12.1"
],
"sta_active": 0,
"sta_config": 5,
"sta_pwd": [
"myWlAnPaszxwo!z",
"myWlAnPaszxwo!z2"
],
"sta_ssid": [
"wlan.1",
"my-wlan"
],
"web_password": "myPaszxwo!z",
"webserver": 2
...
}
```
This also allows direct processing on the command line, e.g. to display all `ntp_server` only
```bash
decode-config -c my.conf -s tasmota-4281 | jq '.ntp_server'
```
outputs
```json
[
"ntp.localnet.home",
"ntp2.localnet.home",
"192.168.12.1"
]
```
> **Hint**
JSON output contains all configuration data as default. To [filter](#filter-by-groups) the JSON output by functional groups, use the `-g` or `--group` parameter.
#### Tasmota web command format
**decode-config** is able to translate the configuration data to (most all) Tasmota web commands. To output your configuration as Tasmota commands use `--output-format command` (or the short form `-T cmnd`).
Example:
```bash
decode-config -c my.conf -s tasmota-4281 --group Wifi --output-format cmnd
```
```conf
# Wifi:
AP 0
Hostname %s-%04d
IPAddress1 0.0.0.0
IPAddress2 192.168.12.1
IPAddress3 255.255.255.0
IPAddress4 192.168.12.1
NtpServer1 ntp.localnet.home
NtpServer2 ntp2.localnet.home
NtpServer3 192.168.12.1
Password1 myWlAnPaszxwo!z
Password2 myWlAnPaszxwo!z2
SSId1 wlan.1
SSId2 my-wlan
WebPassword myPaszxwo!z
WebServer 2
WifiConfig 5
```
> **Note**
A very few specific commands are [unsupported](#generated-tasmota-commands). These are commands from device-specific groups which are very dependent on the Tasmota program code whose implementation is very complex to keep in sync on Tasmota code changes - see also [Generated Tasmota commands](#generated-tasmota-commands).
##### Use of 'Backlog' for Tasmota commands
Because individual Tasmota commands such as `SetOption`, `WebColor` etc. are often repeat themselves and might want to be used together, commands of the same name can be summarized using the Tasmota `Backlog` command. The **decode-config** parameter `--cmnd-use-backlog` enables the use of Tasmota `Backlog`.
With the use of `--cmnd-use-backlog` our example configuration
```conf
# Wifi:
AP 0
Hostname %s-%04d
IPAddress1 0.0.0.0
IPAddress2 192.168.12.1
IPAddress3 255.255.255.0
IPAddress4 192.168.12.1
NtpServer1 ntp.localnet.home
NtpServer2 ntp2.localnet.home
NtpServer3 192.168.12.1
Password1 myWlAnPaszxwo!z
Password2 myWlAnPaszxwo!z2
SSId1 wlan.1
SSId2 my-wlan
WebPassword myPaszxwo!z
WebServer 2
WifiConfig 5
```
becomes to
```conf
# Wifi:
AP 0
Hostname %s-%04d
Backlog IPAddress1 0.0.0.0;IPAddress2 192.168.12.1;IPAddress3 255.255.255.0;IPAddress4 192.168.12.1
Backlog NtpServer1 ntp.localnet.home;NtpServer2 ntp2.localnet.home;NtpServer3 192.168.12.1
Backlog Password1 myWlAnPaszxwo!z;Password2 myWlAnPaszxwo!z2
Backlog SSId1 wlan.1;SSId2 my-wlan
WebPassword myPaszxwo!z
WebServer 2
WifiConfig 5
```
`--cmnd-use-backlog` gets really interesting for `SetOptionxx`, `WebSensorxx`, `Sensorxx`, `Memxx`, `Gpioxx` and more...
### Filter by groups
The huge number of Tasmota configuration data can be overstrained and confusing, so the most of the configuration data are grouped into categories.
Filtering by groups affects the entire output, regardless of whether this is the screen or a json backup file. The output of a dmp or bin file cannot be filtered. These binary file types must always contain the entire configuration.
The following groups are available: `Control`, `Display`, `Domoticz`, `Hdmi`, `Internal`, `Knx`, `Light`, `Management`, `Mqtt`, `Power`, `Rf`, `Rules`, `Sensor`, `Serial`, `Setoption`, `Settings`, `Shutter`, `System`, `Telegram`, `Timer`, `Usf`, `Wifi`, `Zigbee`
These are similary to the categories on [Tasmota Command Documentation](https://tasmota.github.io/docs/Commands/).
To filter outputs to a subset of groups, use the `-g` or `--group` parameter, concatenating the groups you want, e. g.
```bash
decode-config -s tasmota-4281 -c my.conf --output-format cmnd --group Control Management MQTT Wifi
```
## Usage examples
### Using Tasmota binary configuration files
These examples use an online Tasmota device accessed over HTTP. The hostname of the Tasmota device is `tasmota-2f5d44-4281`
#### Backup an online Tasmota device via HTTP into a Tasmota configuration file
##### Use args to choice the file format
```bash
decode-config -c my.conf -s tasmota-2f5d44-4281 --backup-type dmp --backup-file Config_@d_@v
```
##### Use file extension to choice the file format
```bash
decode-config -c my.conf -s tasmota-2f5d44-4281 --backup-file Config_@d_@v.dmp
```
#### Restore a Tasmota configuration file to an online Tasmota device via HTTP
```bash
decode-config -c my.conf -s http://tasmota-2f5d44-4281 --restore-file Config_@d_@v.dmp
```
### Using JSON editable file
These examples use an online Tasmota device that is accessed indirectly via MQTT.
In these examples, the MQTT server parameters are the same as those used by Tasmota itself:
* MQTT Server: `mybroker.example.com`
* MQTT Username: `mqttuser`
* MQTT Password: `myBrokerPaszxwo!z`
* Tasmota topic: `tele/tasmota_2F5D44`
#### Backup an online Tasmota device via MQTT into a JSON file
##### Use an unencrypted MQTT connection
MQTT server uses a non default port 42110
```bash
decode-config -s mqtt://mqttuser:myBrokerPaszxwo!z@mybroker.example.com:42110/tele/tasmota_2F5D44 --backup-file Config_2f5d44-4281.json
```
##### Use SSL/TLS MQTT connection
Limit the configuration data to the groups `Control`, `Management` and `SetOption`
```bash
decode-config -s mqtts://mqttuser:myBrokerPaszxwo!z@mybroker.example.com --fulltopic tele/tasmota_2F5D44 --backup-file Config_2f5d44-4281.json -g Control Management SetOption
```
#### Restore a JSON file to an online Tasmota device via MQTT
```bash
decode-config -s mqtts://mqttuser:myBrokerPaszxwo!z@mybroker.example.com/tele/tasmota_2F5D44 --restore-file Config_2f5d44-4281.json
```
### Use batch processing
Linux
```bash
for device in tasmota1 tasmota2 tasmota3; do ./decode-config -c my.conf -s $device -o Config_@d_@v; done
```
under Windows
```batch
for device in (tasmota1 tasmota2 tasmota3) do decode-config -c my.conf -s %device -o Config_@d_@v
```
will produce JSON configuration files for host tasmota1, tasmota2 and tasmota3 using friendly name and Tasmota firmware version for backup filenames.
## File Formats
**decode-config** handles the following three file formats for backup and restore:
### .dmp format
This is the original format used by Tasmota (created via the Tasmota web interface "*Configuration*" / "*Backup Configuration*" and can be read in with "*Configuration*" / "*Restore Configuration*". The format is binary encrypted.
This file format can be created by **decode-config** using the backup function (`--backup-file <filename>`) with the additional parameter `--backup-type dmp`.
### .json format
This format uses the [JSON](http://www.json.org/) notation and contains the complete configuration data in plain text, human readable and editable.
The .json format can be created by **decode-config** using the backup function (`--backup-file <filename>`) (for better identification you can append the optional parameter `--backup-type json`, but that's optional as json is the default backup format).
In contrast to the other two binary formats [.dmp](#dmp-format) and [.bin](#bin-format), this type of format also allows the [partial modification](#restore-subset-of-data) of configurations.
> **Note**
The keys used within the JSON file are based on the variable names of Tasmota source code in [settings.h](https://github.com/arendst/Tasmota/blob/master/tasmota/include/tasmota_types.h) so they do not have the same naming as known for Tasmota web commands. However, since the variable names are self-explanatory, there should be no difficulties in assigning the functionality of the variables.
### .bin format
This format is binary with the same structure as the [.dmp](#dmp-format) format. The differences to .dmp are:
* .bin is decrypted
* .bin has 4 additional bytes at the end of the file
The .bin format can be created by **decode-config** using the backup function (`--backup-file <filename>`) with the additional parameter `--backup-type bin`.
This format is actually only used to view the configuration data directly in binary form without conversion.
It is hardly possible to change the binary data, since a checksum is formed over the data and this would have to be calculated and adjusted in case of any change.
## Program parameter
For better reading each short written parameter using a single dash `-` has a corresponding long version with two dashes `--`, eg. `--source` for `-s`.
Note: Not even all double dash `--` parameter has a corresponding single dash one `-` but each single dash variant has a double dash equivalent.
A short list of possible program args is displayed using `-h` or `--help`.
### --full-help
For advanced help use parameter `-H` or `--full-help`.
<details>
```help
usage: decode-config.py -s <filename|host|url> [-p <password>] [--fulltopic <topic>]
[--cafile <file>] [--certfile <file>] [--keyfile <file>]
[--insecure] [--keepalive <sec>] [-i <restorefile>]
[-o <backupfile>] [-t json|bin|dmp] [-E] [-e] [-F]
[--json-indent <indent>] [--json-compact] [--json-show-pw]
[--cmnd-indent <indent>] [--cmnd-groups] [--cmnd-sort]
[--cmnd-use-rule-concat] [--cmnd-use-backlog] [-c <configfile>]
[-S] [-T json|cmnd|command] [-g <groupname> [<groupname> ...]]
[-w] [--dry-run] [-h] [-H] [-v] [-V]
Backup/Restore Tasmota configuration data.
Source:
Read/Write Tasmota configuration from/to
-s, --source <filename|host|url>
source used for the Tasmota configuration (default: None), the
source parameter is mandatory. Specify source type, path, file,
user, password, hostname, port and topic at once as an URL.The
URL must be in the form
'scheme://[username[:password]@]host[:port][/topic]|pathfile'
where 'scheme' is 'file' for a tasmota binary config file,
'http' for a Tasmota HTTP web connection and 'mqtt(s)' for
Tasmota MQTT transport ('mqtts' uses a TLS connection to MQTT
server)
-p, --password <password>
Web server password on HTTP source (set by Tasmota 'WebPassword'
command), MQTT server password in MQTT source (set by Tasmota
'MqttPassword' command) (default: None)
MQTT:
MQTT transport settings
--fulltopic <topic> Optional MQTT transport fulltopic used for accessing Tasmota
device (default: )
--cafile <file> Enables SSL/TLS connection: path to a or filename of the
Certificate Authority certificate files that are to be treated
as trusted by this client (default None)
--certfile <file> Enables SSL/TLS connection: filename of a PEM encoded client
certificate file (default None)
--keyfile <file> Enables SSL/TLS connection: filename of a PEM encoded client
private key file (default None)
--insecure suppress verification of the MQTT server hostname in the server
certificate (default False)
--keepalive <sec> keepalive timeout for the client (default 60)
Backup/Restore:
Backup & restore specification
-i, --restore-file <restorefile>
file to restore configuration from (default: None).
Replacements: @v=firmware version from config, @d=devicename,
@f=friendlyname1, @h=hostname from config, @H=device hostname
(http source only), @t=topic
-o, --backup-file <backupfile>
file to backup configuration to, can be specified multiple times
(default: None). Replacements: @v=firmware version from config,
@d=devicename, @f=friendlyname1, @h=hostname from config,
@H=device hostname (http source only), @F=configuration filename
from MQTT request (mqtt source only), @t=topic
-t, --backup-type json|bin|dmp
backup filetype (default: 'json')
-E, --extension append filetype extension for -i and -o filename (default)
-e, --no-extension do not append filetype extension, use -i and -o filename as
passed
-F, --force-restore force restore even configuration is identical
JSON output:
JSON format specification. To revert an option, insert "dont" or "no" after "json",
e.g. --json-no-indent, --json-dont-show-pw
--json-indent <indent>
pretty-printed JSON output using indent level (default: 'None').
-1 disables indent.
--json-compact compact JSON output by eliminate whitespace
--json-show-pw unhide passwords (default)
Tasmota command output:
Tasmota command output format specification. To revert an option, insert "dont" or
"no" after "cmnd", e.g. --cmnd-no-indent, --cmnd-dont-sort
--cmnd-indent <indent>
Tasmota command grouping indent level (default: '2'). 0 disables
indent
--cmnd-groups group Tasmota commands (default)
--cmnd-sort sort Tasmota commands (default)
--cmnd-use-rule-concat
use rule concatenation with + for Tasmota 'Rule' command
--cmnd-use-backlog use 'Backlog' for Tasmota commands as much as possible
Common:
Optional arguments
-c, --config <configfile>
program config file - can be used to set default command
parameters (default: None)
-S, --output display output regardsless of backup/restore usage (default do
not output on backup or restore usage)
-T, --output-format json|cmnd|command
display output format (default: 'json')
-g, --group <groupname>
limit data processing to command groups ['Control', 'Display',
'Domoticz', 'Hdmi', 'Internal', 'Knx', 'Light', 'Management',
'Mqtt', 'Power', 'Rf', 'Rules', 'Sensor', 'Serial', 'Setoption',
'Settings', 'Shutter', 'System', 'Telegram', 'Timer', 'Usf',
'Wifi', 'Zigbee'] (default no filter)
-w, --ignore-warnings
do not exit on warnings. Not recommended, used by your own
responsibility!
--dry-run test program without changing configuration data on device or
file
Info:
Extra information
-h, --help show usage help message and exit
-H, --full-help show full help message and exit
-v, --verbose produce more output about what the program does
-V, --version show program version (and config version if --source is given)
and exit
The arguments -s <filename|host|url> must be given.
Args that start with '--' (eg. -s) can also be set in a config file (specified via -c).
Config file syntax allows: key=value, flag=true, stuff=[a,b,c] (for details, see syntax
at https://goo.gl/R74nmi). If an arg is specified in more than one place, then
commandline values override config file values which override defaults.
```
> **Note**
If you miss parameters here that are already in use, don't worry, they are still there.
For details see [Obsolete parameters](#obsolete-parameters)
</details>
### Parameter notes
* Filename replacement macros **@h** and **@H**:
* **@h**
The **@h** replacement macro uses the hostname configured with the Tasomta Wifi `Hostname <host>` command (defaults to `%s-%04d`). It will not use the network hostname of your device because this is not available when working with files only (e.g. `--source <filename>` as source).
To prevent having an useless % in your filename, **@h** will not replaced by hostname if this contains '%' characters.
* **@H**
If you want to use the network hostname within your filename, use the **@H** replacement macro instead - but be aware this will only replaced if you are using a network device as source (`<hostname>`, `<ip>`, `<url>`); it will not work when using a file as source (`<filename>`)
### Obsolete parameters
The parameters listed here continue to work and are supported, but are no longer listed in the parameter list:
#### Obsolete source parameters
The following source selection parameters are completely replaced by a single used [`-s`](#--full-help) or [`--source`](#--full-help) parameter; use [`-s`](#--full-help) or [`--source`](#--full-help) with a [http-url](https://en.wikipedia.org/wiki/URL):
* `-f`, `--file`, `--tasmota-file`, `tasmotafile` `<filename>`
file used for the Tasmota configuration (default: None)'
* `-d`, `--device`, `--host` `<host|url>`
hostname, IP-address or url used for the Tasmota configuration (default: None)
* `-P`, `--port` `<port>`
TCP/IP port number to use for the host connection (default: 80)
* `-u`, `--username` `<username>`
host HTTP access username (default: admin)
#### Obsolete JSON formating parameters
* `--json-unhide-pw` same as `--json-show-pw`
* `--json-hide-pw` same as `--json-dont-show-pw`
* `--json-sort` sorts JSON output (this is the default)
* `--json-unsort` prevents JSON sorting
## Generated Tasmota commands
<i>Details</i> below shows the Tasmota command generated by **decode-config**:
* **Supported**
These commands will be generated using parameter `--output-format cmnd`.
* **Ad hoc**
These Tasmota commands are used for immediate action and do not change settings - so these cannot be created.
* **Unsupported**
These Tasmota commands are unsupported and not implemented in **decode-config**
<details>
| Group | Supported | *Ad hoc* |`Unsup | text/markdown | Norbert Richter | nr@prsolution.eu | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)",
"Operating System :: OS Independent",
"Topic :: Utilities",
"Environment :: Console"
] | [] | https://github.com/tasmota/decode-config | null | >=3.7 | [] | [] | [] | [
"requests",
"configargparse",
"paho-mqtt"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:41:15.329600 | decode_config-15.3.0.0.tar.gz | 123,338 | ea/cc/0734dbea8b4cedfbbd184f15fe7f23b040d456b8bcde6bf651610717664a/decode_config-15.3.0.0.tar.gz | source | sdist | null | false | 037a56b30cfe16c5bed98d9c4b1c11e7 | 5c806c074c47fb03001714a56b10173c9bc81e3bc9559f1c2c4110450c89d988 | eacc0734dbea8b4cedfbbd184f15fe7f23b040d456b8bcde6bf651610717664a | null | [
"LICENSE"
] | 245 |
2.4 | python-box | 7.3.3 | Advanced Python dictionaries with dot notation access | |BuildStatus| |License|
|BoxImage|
.. code:: python
from box import Box
movie_box = Box({ "Robin Hood: Men in Tights": { "imdb stars": 6.7, "length": 104 } })
movie_box.Robin_Hood_Men_in_Tights.imdb_stars
# 6.7
Box will automatically make otherwise inaccessible keys safe to access as an attribute.
You can always pass `conversion_box=False` to `Box` to disable that behavior.
Also, all new dict and lists added to a Box or BoxList object are converted automatically.
There are over a half dozen ways to customize your Box and make it work for you.
Check out the new `Box github wiki <https://github.com/cdgriffith/Box/wiki>`_ for more details and examples!
Install
=======
**Version Pin Your Box!**
If you aren't in the habit of version pinning your libraries, it will eventually bite you.
Box has a `list of breaking change <https://github.com/cdgriffith/Box/wiki/Major-Version-Breaking-Changes>`_ between major versions you should always check out before updating.
requirements.txt
----------------
.. code:: text
python-box[all]~=7.0
As Box adheres to semantic versioning (aka API changes will only occur on between major version),
it is best to use `Compatible release <https://www.python.org/dev/peps/pep-0440/#compatible-release>`_ matching using the `~=` clause.
Install from command line
-------------------------
.. code:: bash
python -m pip install --upgrade pip
pip install python-box[all]~=7.0 --upgrade
Install with selected dependencies
----------------------------------
Box does not install external dependencies such as yaml and toml writers. Instead you can specify which you want,
for example, `[all]` is shorthand for:
.. code:: bash
pip install python-box[ruamel.yaml,tomli_w,msgpack]~=7.0 --upgrade
But you can also sub out `ruamel.yaml` for `PyYAML`.
Check out `more details <https://github.com/cdgriffith/Box/wiki/Installation>`_ on installation details.
Box 7 is tested on python 3.7+, if you are upgrading from previous versions, please look through
`any breaking changes and new features <https://github.com/cdgriffith/Box/wiki/Major-Version-Breaking-Changes>`_.
Optimized Version
-----------------
Box has introduced Cython optimizations for major platforms by default.
Loading large data sets can be up to 10x faster!
If you are **not** on a x86_64 supported system you will need to do some extra work to install the optimized version.
There will be an warning of "WARNING: Cython not installed, could not optimize box" during install.
You will need python development files, system compiler, and the python packages `Cython` and `wheel`.
**Linux Example:**
First make sure you have python development files installed (`python3-dev` or `python3-devel` in most repos).
You will then need `Cython` and `wheel` installed and then install (or re-install with `--force`) `python-box`.
.. code:: bash
pip install Cython wheel
pip install python-box[all]~=7.0 --upgrade --force
If you have any issues please open a github issue with the error you are experiencing!
Overview
========
`Box` is designed to be a near transparent drop in replacements for
dictionaries that add dot notation access and other powerful feature.
There are a lot of `types of boxes <https://github.com/cdgriffith/Box/wiki/Types-of-Boxes>`_
to customize it for your needs, as well as handy `converters <https://github.com/cdgriffith/Box/wiki/Converters>`_!
Keep in mind any sub dictionaries or ones set after initiation will be automatically converted to
a `Box` object, and lists will be converted to `BoxList`, all other objects stay intact.
Check out the `Quick Start <https://github.com/cdgriffith/Box/wiki/Quick-Start>`_ for more in depth details.
`Box` can be instantiated the same ways as `dict`.
.. code:: python
Box({'data': 2, 'count': 5})
Box(data=2, count=5)
Box({'data': 2, 'count': 1}, count=5)
Box([('data', 2), ('count', 5)])
# All will create
# <Box: {'data': 2, 'count': 5}>
`Box` is a subclass of `dict` which overrides some base functionality to make
sure everything stored in the dict can be accessed as an attribute or key value.
.. code:: python
small_box = Box({'data': 2, 'count': 5})
small_box.data == small_box['data'] == getattr(small_box, 'data')
All dicts (and lists) added to a `Box` will be converted on insertion to a `Box` (or `BoxList`),
allowing for recursive dot notation access.
`Box` also includes helper functions to transform it back into a `dict`,
as well as into `JSON`, `YAML`, `TOML`, or `msgpack` strings or files.
Thanks
======
A huge thank you to everyone that has given features and feedback over the years to Box! Check out everyone that has contributed_.
A big thanks to Python Software Foundation, and PSF-Trademarks Committee, for official approval to use the Python logo on the `Box` logo!
Also special shout-out to PythonBytes_, who featured Box on their podcast.
License
=======
MIT License, Copyright (c) 2017-2026 Chris Griffith. See LICENSE_ file.
.. |BoxImage| image:: https://raw.githubusercontent.com/cdgriffith/Box/master/box_logo.png
:target: https://github.com/cdgriffith/Box
.. |BuildStatus| image:: https://github.com/cdgriffith/Box/workflows/Tests/badge.svg?branch=master
:target: https://github.com/cdgriffith/Box/actions?query=workflow%3ATests
.. |License| image:: https://img.shields.io/pypi/l/python-box.svg
:target: https://pypi.python.org/pypi/python-box/
.. _PythonBytes: https://pythonbytes.fm/episodes/show/19/put-your-python-dictionaries-in-a-box-and-apparently-python-is-really-wanted
.. _contributed: AUTHORS.rst
.. _`Wrapt Documentation`: https://wrapt.readthedocs.io/en/latest
.. _reusables: https://github.com/cdgriffith/reusables#reusables
.. _created: https://github.com/cdgriffith/Reusables/commit/df20de4db74371c2fedf1578096f3e29c93ccdf3#diff-e9a0f470ef3e8afb4384dc2824943048R51
.. _LICENSE: https://github.com/cdgriffith/Box/blob/master/LICENSE
| text/x-rst | Chris Griffith | chris@cdgriffith.com | null | null | MIT | null | [
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Programming Language :: Python :: Implementation :: CPython",
"Development Status :: 5 - Production/Stable",
"Natural Language :: English",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Topic :: Utilities",
"Topic :: Software Development",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [
"any"
] | https://github.com/cdgriffith/Box | null | >=3.9 | [] | [] | [] | [
"ruamel.yaml>=0.19.1; extra == \"all\"",
"toml; extra == \"all\"",
"msgpack; extra == \"all\"",
"ruamel.yaml>=0.19.1; extra == \"yaml\"",
"ruamel.yaml>=0.19.1; extra == \"ruamel-yaml\"",
"PyYAML; extra == \"pyyaml\"",
"tomli; python_version < \"3.11\" and extra == \"tomli\"",
"tomli-w; extra == \"tomli\"",
"toml; extra == \"toml\"",
"msgpack; extra == \"msgpack\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.11 | 2026-02-20T13:41:05.903832 | python_box-7.3.3-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl | 4,468,244 | 11/67/e8b219e2d96da5aa32a77757596e38e976b6bd8778fe4a88eeb69765e472/python_box-7.3.3-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl | cp313 | bdist_wheel | null | false | e922ad4d8c6f1c607f0a96b0965f57c8 | 28ebbab478fe3ba64b13ab1010678e94eeebc87d57dc5b34809d71a9525da49d | 1167e8b219e2d96da5aa32a77757596e38e976b6bd8778fe4a88eeb69765e472 | null | [
"LICENSE",
"AUTHORS.rst"
] | 111,843 |
2.4 | themis-eval | 1.2.0 | Lightweight evaluation platform for LLM experiments | # Themis
> Lightweight, practical evaluation workflows for LLM experiments.
[](https://github.com/Pittawat2542/themis/actions/workflows/ci.yml)
[](https://github.com/Pittawat2542/themis/actions/workflows/docs.yml)
[](https://pypi.org/project/themis-eval/)
[](https://www.python.org/downloads/)
[](LICENSE)
Themis gives you two clean entry points:
- `themis.evaluate(...)` for quick benchmark and dataset evaluation.
- `ExperimentSession().run(spec, ...)` for explicit, versioned workflows.
It includes built-in benchmarks, metric pipelines, caching/resume, comparison utilities, and a web server for run inspection.
## Why Themis
- **Fast start**: run your first evaluation in a few lines.
- **Structured control**: spec/session API for reproducible workflows.
- **Built-in presets**: curated benchmark definitions with prompt + metrics + extractors.
- **Extensible**: register datasets, metrics, providers, and benchmark presets.
- **Practical storage**: local cache, resumable runs, robust storage backend.
- **Production-minded CI/CD**: strict docs build, package validation, release automation.
## Installation
```bash
# stable release
uv add themis-eval
# with optional extras
uv add "themis-eval[math,nlp,code,server]"
```
## Quick Start (No API key)
Use the built-in fake model with the demo preset:
```python
from themis import evaluate
report = evaluate(
"demo",
model="fake-math-llm",
limit=10,
)
metric = report.evaluation_report.metrics["ExactMatch"]
print(f"ExactMatch: {metric.mean:.2%}")
```
## Quick Start (Real model)
```python
from themis import evaluate
report = evaluate(
"gsm8k",
model="gpt-4",
limit=100,
metrics=["exact_match", "math_verify"],
)
print(report.evaluation_report.metrics["ExactMatch"].mean)
```
## CLI Workflow
```bash
# Run two experiments
themis eval gsm8k --model gpt-4 --limit 100 --run-id run-a
themis eval gsm8k --model gpt-4 --temperature 0.7 --limit 100 --run-id run-b
# Compare them
themis compare run-a run-b
# Explore in browser
themis serve --storage .cache/experiments
```
Helpful commands:
```bash
themis list benchmarks
themis list runs --storage .cache/experiments
themis list metrics
```
## Spec + Session API (v1 workflow)
Use this when you want explicit control over dataset, pipeline, execution, and storage specs.
```python
from themis.evaluation.metric_pipeline import MetricPipeline
from themis.presets import get_benchmark_preset
from themis.session import ExperimentSession
from themis.specs import ExecutionSpec, ExperimentSpec, StorageSpec
preset = get_benchmark_preset("gsm8k")
pipeline = MetricPipeline(extractor=preset.extractor, metrics=preset.metrics)
spec = ExperimentSpec(
dataset=preset.load_dataset(limit=100),
prompt=preset.prompt_template.template,
model="litellm:gpt-4",
sampling={"temperature": 0.0, "max_tokens": 512},
pipeline=pipeline,
run_id="gsm8k-gpt4",
)
report = ExperimentSession().run(
spec,
execution=ExecutionSpec(workers=8),
storage=StorageSpec(path=".cache/experiments", cache=True),
)
```
## Built-in Coverage
Themis ships with math, reasoning, science, and QA presets (for example: `gsm8k`, `math500`, `aime24`, `aime25`, `mmlu-pro`, `supergpqa`, `gpqa`, `commonsense_qa`, `coqa`, `demo`).
List everything from CLI:
```bash
themis list benchmarks
```
Supported metric families include:
- exact/verification metrics (for math/structured outputs)
- NLP metrics (`BLEU`, `ROUGE`, `BERTScore`, `METEOR`)
- code metrics (`PassAtK`, `CodeBLEU`, execution-based checks)
## Extending Themis
Top-level extension APIs are available directly from `themis`:
```python
import themis
# themis.register_metric(name, metric_cls)
# themis.register_dataset(name, factory)
# themis.register_provider(name, factory)
# themis.register_benchmark(preset)
```
See the extension guides:
- [Extending Themis](https://pittawat2542.github.io/themis/)
- [API Backends Reference](docs/api/backends.md)
## Documentation
- Docs site: https://pittawat2542.github.io/themis/
- Getting started: [docs/getting-started/quickstart.md](docs/getting-started/quickstart.md)
- Evaluation guide: [docs/guides/evaluation.md](docs/guides/evaluation.md)
- Comparison guide: [docs/guides/comparison.md](docs/guides/comparison.md)
- CI/CD and release process: [docs/guides/ci-cd.md](docs/guides/ci-cd.md)
## Examples
Runnable examples live in [`examples-simple/`](examples-simple/):
- `01_quickstart.py`
- `02_custom_dataset.py`
- `04_comparison.py`
- `05_api_server.py`
- `07_provider_ready.py`
- `08_resume_cache.py`
- `09_research_loop.py`
Run one:
```bash
uv run python examples-simple/01_quickstart.py
```
## Development
```bash
# install all dev + feature dependencies
uv sync --all-extras --dev
# test
uv run pytest
# strict docs build
uv run mkdocs build --strict
# baseline syntax/runtime lint used in CI
uv run ruff check --select E9,F63,F7 themis tests
```
## Contributing
Contributions are welcome. Start with [CONTRIBUTING.md](CONTRIBUTING.md).
## Citation
If you use Themis in research, cite via [`CITATION.cff`](CITATION.cff).
## License
MIT. See [LICENSE](LICENSE).
| text/markdown | Pittawat Taveekitworachai | null | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"pydantic>=2.12.5",
"cyclopts>=4.0.0",
"hydra-core>=1.3",
"tqdm>=4.67",
"httpx>=0.27",
"litellm>=1.81.0",
"tabulate>=0.9.0",
"tenacity>=9.1.2",
"plotly>=6.5.0",
"math-verify>=0.8.0",
"rich>=14.2.0",
"pytest>=8.0; extra == \"dev\"",
"pytest-cov>=6.0.0; extra == \"dev\"",
"pytest-timeout>=2.3.1; extra == \"dev\"",
"pytest-asyncio>=0.24.0; extra == \"dev\"",
"ruff>=0.8.5; extra == \"dev\"",
"mypy>=1.14.0; extra == \"dev\"",
"datasets>=2.20.0; extra == \"math\"",
"math-verify>=0.8.0; extra == \"math\"",
"sacrebleu>=2.4.0; extra == \"nlp\"",
"rouge-score>=0.1.2; extra == \"nlp\"",
"bert-score>=0.3.13; extra == \"nlp\"",
"nltk>=3.8.0; extra == \"nlp\"",
"codebleu>=0.7.0; extra == \"code\"",
"plotly>=5.18.0; extra == \"viz\"",
"fastapi>=0.128.0; extra == \"server\"",
"uvicorn[standard]>=0.32.0; extra == \"server\"",
"websockets>=14.0; extra == \"server\"",
"mkdocs>=1.6.0; extra == \"docs\"",
"mkdocs-material>=9.5.0; extra == \"docs\"",
"mkdocstrings[python]>=0.25.0; extra == \"docs\"",
"themis-eval[code,docs,math,nlp,server,viz]; extra == \"all\""
] | [] | [] | [] | [
"Resources, https://github.com/Pittawat2542/themis",
"Homepage, https://pittawat2542.github.io/themis/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:41:03.737531 | themis_eval-1.2.0.tar.gz | 195,504 | dc/d2/f5d48304ec3a10472e6dbc6892d99b4f145f6759c12140bdfe93716a802d/themis_eval-1.2.0.tar.gz | source | sdist | null | false | 0728b453c803ea4bc671322171b350e2 | c667eed804ec59c4f1f22142d518618735fc74e8317e0ae84d0efc385a53ebee | dcd2f5d48304ec3a10472e6dbc6892d99b4f145f6759c12140bdfe93716a802d | null | [
"LICENSE"
] | 219 |
2.4 | aup-parser | 0.10.2 | Audacity .aup3 parser with Rust core and Python interface | # aup-parser
`aup-parser` is an Audacity `.aup3` parser package with a Rust core and typed Python interface.
## Highlights
- Rust core for binary XML and sampleblocks analysis
- Class-based Python API (`AUPParser`) with `TypedDict` return types
- Optional audio export helper
## Package Layout
- `src/`: Rust core (`PyO3` extension)
- `python/aup_parser/`: Python API, types, exports
- `tests/`: API/parity tests and golden fixtures
## Build (local dev)
```bash
cd /Users/joonholee/deeply/aup3-parser
python3 -m pip install --user --break-system-packages maturin
python3 -m maturin build --release -i python3
python3 -m pip install --user --break-system-packages --force-reinstall target/wheels/aup_parser-*.whl
```
## Python API (Class-only)
```python
from aup_parser import AUPParser
parser = AUPParser("tests/test.aup3")
essential = parser.parse(profile="essential")
full = parser.parse(profile="full")
raw = parser.inspect_core(profile="full") # low-level diagnostics payload
```
`AUPParser.parse()` signature:
```python
def parse(
self,
*,
profile: Literal["essential", "full"] = "essential",
audio_output_path: str | pathlib.Path | None = None,
sample_rate: int = 48000,
output_naming: Literal["channel_index", "track_name"] = "channel_index",
) -> ParseResultTD: ...
```
- `audio_output_path`: `None`이 아니면 WAV를 export
- 싱글 채널 프로젝트: 단일 WAV 파일 출력
- 멀티 채널 프로젝트: `audio_output_path`를 폴더로 사용하여 채널별 WAV 파일 생성
- 멀티 채널 + 파일처럼 보이는 경로(`out.wav`) 입력 시: 자동으로 `out_channels/` 폴더로 정규화
- 타임라인 복원: clip metadata(`offset`, `trimLeft`, `trimRight`)를 우선 적용하고, 불가능한 경우 `waveblock.start` 기준으로 배치
- gap 구간은 zero-fill, 겹침 구간은 later block overwrite 규칙 사용
- `sample_rate`: `audio_output_path` export 시 사용할 샘플레이트
- `output_naming`: 멀티 채널 파일 이름 전략
- `channel_index`: `channel_00.wav`, `channel_01.wav`, ...
- `track_name`: 트랙명을 안전한 파일명으로 변환해 사용(유니코드 보존, 중복 시 suffix 추가)
## Parse Result (Essential)
`parse(profile="essential")` 반환 타입:
```python
{
"schema_version": "2",
"project": {...},
"audio": {...},
"exports": {...} # optional
}
```
### `project` fields
| Field | Type | Meaning |
| --------------------------------- | -------------------------------------------------- | ------------------------------------- |
| `project_path` | `str` | `.aup3` 절대/정규화 경로 |
| `project_file_name` | `str \| None` | `.aup3` 파일명 (예: `session.aup3`) |
| `project_file_stem` | `str \| None` | 확장자 제외 파일명 (예: `session`) |
| `project_extension` | `str` | 확장자 (기본 `aup3`) |
| `project_size_bytes` | `int \| None` | 프로젝트 파일 크기 |
| `original_audio_file_name` | `str \| None` | 원본 오디오 파일명 추정값 (가능할 때) |
| `original_audio_file_name_source` | `"embedded_name" \| "track_name" \| "unavailable"` | 추정 출처 |
`original_audio_file_name` 주의:
- Audacity `.aup3`는 원본 입력 파일명을 항상 보존하지 않습니다.
- 따라서 확정값이 아닐 수 있으며, 추정 출처는 `original_audio_file_name_source`로 확인하세요.
### `audio` fields
| Field | Type | Meaning |
| -------------------- | ----------------------------- | -------------------------- |
| `sample_rate_hz` | `float \| int \| str \| None` | 프로젝트 샘플레이트 |
| `duration_seconds` | `float \| None` | 전체 재생 길이(초) |
| `total_samples` | `int \| None` | 전체 샘플 수 |
| `total_sample_bytes` | `int \| None` | 전체 PCM 바이트 수 |
| `channel_indices` | `list[int]` | 채널 인덱스 목록 |
| `channel_count` | `int` | 채널 개수 |
| `track_count` | `int \| None` | wavetrack 개수 |
| `clip_count` | `int \| None` | waveclip 개수 |
| `block_count` | `int \| None` | sample block 개수 |
| `sample_format` | `SampleFormatInfoTD \| None` | 샘플 포맷 정보 |
| `tracks` | `list[TrackSummaryTD]` | 트랙 요약 리스트 |
| `clips` | `list[ClipSummaryTD]` | 클립 요약 리스트 |
| `timeline` | `TimelineSummaryTD` | 블록 사용/누락/미사용 정보 |
| `exactness_notes` | `list[str]` | 정확도 관련 메모 |
### `audio.sample_format`
| Field | Type | Meaning |
| -------------------- | ----- | ------------------------------ |
| `raw` | `int` | Audacity raw sampleformat 정수 |
| `sample_width_bytes` | `int` | 샘플 폭 (바이트) |
| `encoding_id` | `int` | 인코딩 식별자 |
### `audio.tracks[]` (`TrackSummaryTD`)
| Field | Type | Meaning |
| ------------------ | --------------- | --------------------- |
| `channel_index` | `int \| None` | 채널 인덱스 |
| `name` | `str \| None` | 트랙 이름 |
| `clip_count` | `int \| None` | 트랙 내 클립 수 |
| `mute` | `bool \| None` | mute 상태 |
| `solo` | `bool \| None` | solo 상태 |
| `gain` | `float \| None` | 게인 |
| `pan` | `float \| None` | 팬 |
| `sampleformat_raw` | `int \| None` | 트랙 raw sampleformat |
### `audio.clips[]` (`ClipSummaryTD`)
| Field | Type | Meaning |
| ------------------------ | --------------- | ----------------- |
| `name` | `str \| None` | 클립 이름 |
| `offset_seconds` | `float \| None` | 클립 오프셋(초) |
| `trim_left_seconds` | `float \| None` | 좌측 trim(초) |
| `trim_right_seconds` | `float \| None` | 우측 trim(초) |
| `raw_audio_tempo` | `float \| None` | 원시 템포 메타 |
| `stretch_ratio` | `float \| None` | stretch 비율 |
| `sample_count` | `int \| None` | 클립 샘플 수 |
| `max_block_sample_count` | `int \| None` | 블록 최대 샘플 수 |
### `audio.timeline` (`TimelineSummaryTD`)
| Field | Type | Meaning |
| ------------------- | ----------- | ----------------------------------------- |
| `used_block_ids` | `list[int]` | 타임라인에서 참조한 block IDs |
| `missing_block_ids` | `list[int]` | 타임라인엔 있으나 sampleblocks엔 없는 IDs |
| `unused_block_ids` | `list[int]` | sampleblocks엔 있으나 타임라인에 없는 IDs |
## Parse Result (Full)
`parse(profile="full")`은 Essential 결과에 `diagnostics`를 추가합니다.
### `diagnostics` fields
| Field | Type | Meaning |
| ----------------- | ------------------- | --------------------------- |
| `sqlite` | `dict[str, object]` | SQLite 개요 정보 |
| `project_payload` | `ProjectPayloadTD` | 파싱된 프로젝트 payload raw |
| `audio_blocks` | `AudioBlocksInfoTD` | sampleblocks 집계 raw |
## Exports fields
`exports.audio_output` 필드:
| Field | Type | Meaning |
| --------------------------- | ----------------------------------------- | --------------------- |
| `mode` | `"single_file" \| "multi_channel_folder"` | 출력 모드 |
| `output_naming` | `"channel_index" \| "track_name"` | 파일명 전략 |
| `requested_output_path` | `str` | 입력된 경로 |
| `output_path` | `str` | 실제 출력 경로 |
| `path_was_normalized` | `bool` | 경로 정규화 여부 |
| `channel_count` | `int` | 출력 채널 수 |
| `files` | `list[AudioOutputFileTD]` | 출력 파일 목록 |
| `sample_rate` | `int` | export 샘플레이트 |
| `sample_width_bytes` | `int` | export 샘플 폭 |
| `sampleformat` | `SampleFormatInfoTD` | export sampleformat |
| `total_written_audio_bytes` | `int` | 총 출력 바이트 수 |
| `note` | `str` | 복원/정규화/주의 사항 |
## inspect_core() (Raw)
`inspect_core()`는 low-level payload를 그대로 반환합니다.
- 용도: 디버깅, parity 검증, 내부 분석
- 안정 API 용도는 `parse()` 사용 권장
## Compatibility Notes
- Python 3.11~3.14
- `abi3-py311` build strategy
- CI validates install + runtime parse on all combinations:
- Linux/macOS/Windows
- Python 3.11, 3.12, 3.13, 3.14
- Release wheels are built for:
- Linux (`ubuntu-latest`)
- Windows (`windows-latest`)
- macOS Apple Silicon (`macos-15`)
- macOS Intel (`macos-15-intel`)
- If a wheel is unavailable for your environment, `pip` falls back to sdist build and requires a Rust toolchain.
## Release
GitHub Actions workflow (`.github/workflows/release.yml`) runs:
1. Matrix tests on PRs
2. Wheel/sdist build on version tags (`v*`)
3. Publish `dist/*` to GitHub Release assets
4. Publish `dist/*` to GitHub Packages (GHCR OCI artifact)
5. Optional PyPI publish (only when `UV_PUBLISH_TOKEN` secret is set)
### PyPI Token Setup
1. Create a PyPI API token (`__token__`) on PyPI account settings.
2. In GitHub repo settings, add:
- `Settings > Secrets and variables > Actions > New repository secret`
- Name: `UV_PUBLISH_TOKEN`
- Value: `pypi-...` token string
3. Push a release tag (`vX.Y.Z`). The `publish-pypi` job uploads `dist/*` via:
- `uv publish --trusted-publishing never dist/*`
### GitHub Distribution
- Release assets: `https://github.com/<owner>/<repo>/releases/tag/vX.Y.Z`
- GitHub Packages (GHCR): `ghcr.io/<owner>/aup-parser:vX.Y.Z` and `ghcr.io/<owner>/aup-parser:X.Y.Z`
- GHCR pull example:
- `oras pull ghcr.io/<owner>/aup-parser:vX.Y.Z`
- pulled wheel/sdist files can then be installed with `pip install <wheel-file>`
| text/markdown; charset=UTF-8; variant=GFM | aup-parser contributors | null | null | null | MIT | audacity, aup3, audio, parser, rust, pyo3 | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Programming Language :: Rust",
"Topic :: Multimedia :: Sound/Audio"
] | [] | null | null | >=3.11 | [] | [] | [] | [] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:40:03.933575 | aup_parser-0.10.2.tar.gz | 37,255 | 2e/fc/6a8c3227c24281c64f43f685ecd95bf6bf66d73a636a0787eb2dcb4266c9/aup_parser-0.10.2.tar.gz | source | sdist | null | false | 283f04cc333beee74adc8f66a4e93e95 | 6bcb9c4c05e943421eec1986af45f37768cbe935dcab63a782b3416a6e23e958 | 2efc6a8c3227c24281c64f43f685ecd95bf6bf66d73a636a0787eb2dcb4266c9 | null | [] | 394 |
2.4 | mattermostautodriver | 11.4.1 | A Python Mattermost Auto Driver |
.. image:: https://img.shields.io/pypi/v/mattermostautodriver.svg
:target: https://pypi.python.org/pypi/mattermostautodriver
.. image:: https://img.shields.io/pypi/l/mattermostautodriver.svg
:target: https://pypi.python.org/pypi/mattermostautodriver
.. image:: https://img.shields.io/pypi/pyversions/mattermostautodriver.svg
:target: https://pypi.python.org/pypi/mattermostautodriver
Python Mattermost Auto Driver (APIv4)
=====================================
Info
----
The repository will try to keep up with the ``api`` specification in https://github.com/mattermost/mattermost/ (subfolder ``api``)
Changes in API of ``mattermostautodriver`` will likely be due to a change in the reference mattermost API documentation.
This project is forked from https://github.com/Vaelor/python-mattermost-driver but uses an automatic approach to generate all Python endpoint files from the mattermost OpenAPI specification.
Starting with version 10.8.2, Python 3.10 or greater is required. Previous versions needed Python 3.8+.
Warning
^^^^^^^
This repository generates code in a fully automated fashion based on the API specification provided by mattermost developers.
No additional effort of backwards compatibility is made.
Versions and Releases
---------------------
.. warning::
Starting with version 10.8.2 this project now follows releases of
`the official Mattermost server <https://docs.mattermost.com/about/mattermost-server-releases.html>`_.
See `pull request #21 <https://github.com/embl-bio-it/python-mattermost-autodriver/issues/21>`_ for additional context.
In production environments you are advised to keep this package in sync with Mattermost server updates.
Installation
------------
.. inclusion-marker-start-install
``pip install mattermostautodriver``
.. inclusion-marker-end-install
Documentation
-------------
Documentation can be found at https://embl-bio-it.github.io/python-mattermost-autodriver/ .
Usage
-----
.. inclusion-marker-start-usage
.. code:: python
from mattermostautodriver import TypedDriver
foo = TypedDriver({
"""
Required options
Instead of the login/password, you can also use a personal access token.
If you have a token, you don't need to pass login/pass.
It is also possible to use 'auth' to pass a auth header in directly,
for an example, see:
https://embl-bio-it.github.io/python-mattermost-autodriver/#authentication
"""
'url': 'mattermost.server.com',
'login_id': 'user.name',
'password': 'verySecret',
'token': 'YourPersonalAccessToken',
"""
Optional options
These options already have useful defaults or are just not needed in every case.
In most cases, you won't need to modify these.
If you can only use a self signed/insecure certificate, you should set
verify to your CA file or to False. Please double check this if you have any errors while
using a self signed certificate!
"""
'scheme': 'https',
'port': 8065,
'verify': True, # Or /path/to/file.pem
'mfa_token': 'YourMFAToken',
"""
Setting this will pass the your auth header directly to
the request libraries 'auth' parameter.
You probably only want that, if token or login/password is not set or
you want to set a custom auth header.
"""
'auth': None,
"""
If for some reasons you get regular timeouts after a while, try to decrease
this value. The websocket will ping the server in this interval to keep the connection
alive.
If you have access to your server configuration, you can of course increase the timeout
there.
"""
'timeout': 30,
"""
This value controls the request timeout.
See https://python-requests.org/en/master/user/advanced/#timeouts
for more information.
The default value is None here, because it is the default in the
request library, too.
"""
'request_timeout': None,
"""
To keep the websocket connection alive even if it gets disconnected for some reason you
can set the keepalive option to True. The keepalive_delay defines how long to wait in seconds
before attempting to reconnect the websocket.
"""
'keepalive': False,
'keepalive_delay': 5,
"""
This option allows you to provide additional keyword arguments when calling websockets.connect()
By default it is None, meaning we will not add any additional arguments. An example of an
additional argument you can pass is one used to disable the client side pings:
'websocket_kw_args': {"ping_interval": None},
"""
'websocket_kw_args': None,
"""
Setting debug to True, will activate a very verbose logging.
This also activates the logging for the requests package,
so you can see every request you send.
Be careful. This SHOULD NOT be active in production, because this logs a lot!
Even the password for your account when doing driver.login()!
"""
'debug': False
})
"""
Most of the requests need you to be logged in, so calling login()
should be the first thing you do after you created your TypedDriver instance.
login() returns the raw response.
If using a personal access token, you still need to run login().
In this case, does not make a login request, but a `get_user('me')`
and sets everything up in the client.
"""
foo.login()
"""
You can make api calls by using calling `TypedDriver.endpointofchoice`.
Using api[''] is deprecated for 5.0.0!
So, for example, if you used `TypedDriver.api['users'].get_user('me')` before,
you now just do `TypedDriver.users.get_user('me')`.
The names of the endpoints and requests are almost identical to
the names on the api.mattermost.com/v4 page.
API calls always return the json the server send as a response.
"""
foo.users.get_user_by_username('another.name')
"""
If the api request needs additional parameters
you can pass them to the function in the following way:
- Path parameters are always simple parameters you pass to the function
"""
foo.users.get_user(user_id='me')
# - Query parameters are always passed by passing a `params` dict to the function
foo.teams.get_teams(params={...})
# - Request Bodies are always passed by passing an `options` dict or array to the function
foo.channels.create_channel(options={...})
# See the mattermost api documentation to see which parameters you need to pass.
foo.channels.create_channel(options={
'team_id': 'some_team_id',
'name': 'awesome-channel',
'display_name': 'awesome channel',
'type': 'O'
})
"""
If you want to make a websocket connection to the mattermost server
you can call the init_websocket method, passing an event_handler.
Every Websocket event send by mattermost will be send to that event_handler.
See the API documentation for which events are available.
"""
foo.init_websocket(event_handler)
# Use `disconnect()` to disconnect the websocket
foo.disconnect()
# To upload a file you will need to pass a `files` dictionary
channel_id = foo.channels.get_channel_by_name_and_team_name('team', 'channel')['id']
file_id = foo.files.upload_file(
channel_id=channel_id,
files={'files': (filename, open(filename, 'rb'))}
)['file_infos'][0]['id']
# track the file id and pass it in `create_post` options, to attach the file
foo.posts.create_post(options={
'channel_id': channel_id,
'message': 'This is the important file',
'file_ids': [file_id]})
# If needed, you can make custom requests by calling `make_request`
foo.client.make_request('post', '/endpoint', options=None, params=None, data=None, files=None)
# If you want to call a webhook/execute it use the `call_webhook` method.
# This method does not exist on the mattermost api AFAIK, I added it for ease of use.
foo.client.call_webhook('myHookId', options) # Options are optional
# Finally, logout the user if using login/password authentication.
foo.logout()
# And close the client once done with it.
foo.close()
.. inclusion-marker-end-usage
Updating OpenAPI specification
------------------------------
First we need to obtain Mattermost's API in an OpenAPI JSON.
.. code:: shell
git clone --depth=1 --filter=tree:0 https://github.com/mattermost/mattermost
cd mattermost/api
make build
./node_modules/.bin/swagger-cli bundle --outfile openapi.json v4/html/static/mattermost-openapi-v4.yaml
cd -
With the above commands you will have cloned and created an ``openapi.json`` file that will be used by the conversion script.
First install all required dependencies in a virtual environment.
.. code:: shell
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
Finally, with the virtual environment still loaded execute
.. code:: shell
./scripts/generate_endpoints.sh
to generate the updated endpoint definition.
This script will also update the documentation by running:
.. code:: shell
cd docs
./update_endpoints.py
The current API conversion code was designed for Python 3.13.
As it uses Python's AST parser and generator, alongside with `Black <https://github.com/psf/black>`_ different versions of Python may result in some differences in the generated code. Double check with a ``git diff`` once complete.
| null | Renato Alves, Christian Plümer | bio-it@embl.de, github@kuuku.net | null | null | MIT | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Web Environment",
"Intended Audience :: Developers",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://github.com/embl-bio-it/python-mattermost-autodriver | null | >=3.10 | [] | [] | [] | [
"aiohttp<4.0.0,>=3.9.5",
"httpx~=0.28.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T13:39:51.562500 | mattermostautodriver-11.4.1.tar.gz | 118,589 | e0/c1/1a121e8e7ac124c5328e3513993bc318c66d050d5cbc0ba4e49e53de615d/mattermostautodriver-11.4.1.tar.gz | source | sdist | null | false | 82781f7716459358c1bb121c8b40d72a | 74b6f8a6dd9d7c2b2446b1cf64c4e1bc2154ba74d1fc8768726400e9a1df74cb | e0c11a121e8e7ac124c5328e3513993bc318c66d050d5cbc0ba4e49e53de615d | null | [
"LICENSE"
] | 287 |
2.4 | fafbseg | 3.2.2 | Tools to work with the FlyWire and Google segmentations of the FAFB EM dataset | [](https://fafbseg-py.readthedocs.io/en/latest/?badge=latest) [](https://github.com/navis-org/fafbseg-py/actions/workflows/test-package.yml) [](https://zenodo.org/badge/latestdoi/197735091)
<img src="https://github.com/navis-org/fafbseg-py/blob/master/docs/_static/logo2.png?raw=true" height="60">
Tools to work with the [FlyWire](https://flywire.ai/) and [Google](https://fafb-ffn1.storage.googleapis.com/landing.html) segmentations of the FAFB EM dataset. Fully interoperable with [navis](https://github.com/navis-org/navis).
## Features
Here are just some of the things you can do with ``fafbseg``:
* map locations or supervoxels to segmentation IDs
* load neuron meshes and skeletons
* generate high quality neuron meshes and skeletons from scratch
* query connectivity and annotations
* parse and generate FlyWire neuroglancer URLs
* transform neurons from FAFB/FlyWire space to other brains spaces (e.g. hemibrain)
## Documentation
FAFBseg is on [readthedocs](https://fafbseg-py.readthedocs.io/en/latest/).
## Quickstart
Install latest stable version
```bash
pip3 install fafbseg -U
```
Install from Github
```bash
pip3 install git+https://github.com/flyconnectome/fafbseg-py.git
```
## How to cite
If you use `fafbseg` for your publication, please cite the two FlyWire papers:
1. "_Whole-brain annotation and multi-connectome cell typing quantifies circuit stereotypy in Drosophila_" Schlegel _et al._, bioRxiv (2023); doi: https://doi.org/10.1101/2023.06.27.546055
2. "_Neuronal wiring diagram of an adult brain_" Dorkenwald _et al._, bioRxiv (2023); doi: https://doi.org/10.1101/2023.06.27.546656
Depending on what data you used (e.g. neurotransmitter predictions) you might need to cite additional publications. Please see the [Citation Guidelines](https://codex.flywire.ai/about_flywire) on Codex.
| text/markdown | Philipp Schlegel | pms70@cam.ac.uk | null | null | GNU GPL V3 | FAFB neuron segmentation FlyWire Google synapses connectome fly brain navis CAVE | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Bio-Informatics",
"License :: OSI Approved :: GNU General Public License v3 or later (GPLv3+)",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://fafbseg-py.readthedocs.io | null | >=3.10 | [] | [] | [] | [
"caveclient>=5.4.2",
"cloud-volume>=8.20",
"diskcache",
"fastremap",
"inquirer>=2.6",
"ipython",
"navis<2.0,>=1.8.0",
"numpy",
"pandas>=1.1.0",
"pyarrow>=3.0.0",
"pyperclip",
"python-catmaid>=2.0.2",
"requests",
"requests-futures",
"skeletor>=1.0.0",
"trimesh",
"tqdm",
"fuzzywuzzy"
] | [] | [] | [] | [
"Documentation, https://fafbseg-py.readthedocs.io",
"Source, https://github.com/navis-org/fafbseg-py",
"Changelog, https://github.com/navis-org/fafbseg-py/releases"
] | twine/6.1.0 CPython/3.12.8 | 2026-02-20T13:39:01.307438 | fafbseg-3.2.2.tar.gz | 7,885,608 | 2e/9d/711a4679b7602feb067fe8b50c4b0c7d14e13da53209987979f05365901c/fafbseg-3.2.2.tar.gz | source | sdist | null | false | f1268269f1fb0bdc9b204bb87da10ee3 | 0b7f59f97bb9e62cbc6ac099aeaf43e0803a0f91cfe99676fcd7b3e4143e681e | 2e9d711a4679b7602feb067fe8b50c4b0c7d14e13da53209987979f05365901c | null | [
"LICENSE"
] | 235 |
2.4 | fastapi-deprecation | 0.3.0 | Endpoint deprecation management for FastAPI made easy | # FastAPI Deprecation
<div align="center">
<p align="center">
<strong>RFC 9745 compliant API deprecation for FastAPI.</strong>
</p>
<p align="center">
<a href="https://github.com/fractalvision/fastapi-deprecation/actions/workflows/test.yml">
<img src="https://github.com/fractalvision/fastapi-deprecation/actions/workflows/test.yml/badge.svg" alt="Test Status"/>
</a>
<a href="https://fractalvision.readthedocs.io/en/latest/?badge=latest">
<img src="https://readthedocs.org/projects/fractalvision/badge/?version=latest" alt="Documentation Status"/>
</a>
</p>
</div>
---
**FastAPI Deprecation** helps you manage the lifecycle of your API endpoints using standard HTTP headers (`Deprecation`, `Sunset`, `Link`) and automated blocking logic. It allows you to gracefully warn clients about upcoming deprecations and automatically shut down endpoints when they reach their sunset date.
## Features
- **Standard Compliance**: Fully implements [RFC 9745](https://datatracker.ietf.org/doc/rfc9745/) and [RFC 8594](https://datatracker.ietf.org/doc/rfc8594/) with support for multiple link relations (`rel="alternate"`, `rel="successor-version"`, etc.).
- **Decorator-based & Middleware**: Simple `@deprecated` decorator for path operations, and `DeprecationMiddleware` for globally deprecating prefixes or intercepting 404s for sunset endpoints.
- **Automated Blocking**: Automatically returns `410 Gone` or `301 Moved Permanently` (or custom responses) after the `sunset_date`.
- **OpenAPI Integration**: Automatically modifies the Swagger UI/ReDoc to mark active deprecations and announces future upcoming deprecations.
- **Client-Side Caching**: Optionally injects `Cache-Control: max-age` to ensure warning responses aren't cached beyond the sunset date.
- **Extended Features**:
- **Brownouts**: Schedule temporary shutdowns to simulate future removal.
- **Telemetry**: Track usage of deprecated endpoints.
- **Rate Limiting**: Hook into your favorite rate limiting library (e.g., `slowapi`) to dynamically throttle legacy traffic.
## Installation
```bash
pip install fastapi-deprecation
# or with uv
uv add fastapi-deprecation
```
## Documentation
To run the documentation locally:
```bash
uv run zensical serve
```
## Quick Start
```python
from fastapi import FastAPI
from fastapi_deprecation import deprecated, auto_deprecate_openapi
app = FastAPI()
@app.get("/old-endpoint")
@deprecated(
deprecation_date="2024-01-01",
sunset_date="2025-01-01",
alternative="/new-endpoint",
detail="This endpoint is old and tired."
)
async def old():
return {"message": "Enjoy it while it lasts!"}
# Don't forget to update the schema at the end!
auto_deprecate_openapi(app)
```
## Example Application
For a comprehensive demonstration of all features (Middleware, Router-level deprecation, mounted sub-apps, custom responses, and brownouts), check out the **Showcase Application** included in the repository:
```bash
uv run python examples/showcase.py
```
Open `http://localhost:8000/docs` to see the API lifecycle in action.
## How It Works
1. **Warning Phase** (Before Sunset):
* Requests return `200 OK`.
* Response headers include:
* `Deprecation: @1704067200` (Unix timestamp of `deprecation_date`)
* `Sunset: Wed, 01 Jan 2025 00:00:00 GMT`
* `Link: </new-endpoint>; rel="alternative"`
2. **Blocking Phase** (After Sunset):
* Requests return `410 Gone` (or `301 Moved Permanently` if `alternative` is set).
* The `detail` message is returned in the response body.
## Advanced Usage
### 1. Brownouts (Scheduled Unavailability)
You can simulate future shutdowns by scheduling "brownouts" — temporary periods where the endpoint returns `410 Gone` (or `301` if alternative is set). This forces clients to notice the deprecation before the final sunset.
```python
@deprecated(
sunset_date="2025-12-31",
brownouts=[
# 1-hour brownout
("2025-11-01T09:00:00Z", "2025-11-01T10:00:00Z"),
# 1-day brownout
("2025-12-01T00:00:00Z", "2025-12-02T00:00:00Z"),
],
detail="Service is temporarily unavailable due to scheduled brownout."
)
async def my_endpoint(): ...
```
### 2. Telemetry & Logging
Track usage of deprecated endpoints using a global callback. This is useful for monitoring which clients are still using old APIs.
```python
import logging
from fastapi import Request, Response
from fastapi_deprecation import set_deprecation_callback, DeprecationDependency
logger = logging.getLogger("deprecation")
def log_usage(request: Request, response: Response, dep: DeprecationDependency):
logger.warning(
f"Deprecated endpoint {request.url} accessed. "
f"Deprecation date: {dep.deprecation_date}"
)
set_deprecation_callback(log_usage)
```
### 3. Deprecating Entire Routers
To deprecate a whole group of endpoints, use `DeprecationDependency` on the `APIRouter`.
```python
from fastapi import APIRouter, Depends
from fastapi_deprecation import DeprecationDependency
router = APIRouter(
dependencies=[Depends(DeprecationDependency(deprecation_date="2024-01-01"))]
)
@router.get("/sub-route")
async def sub(): ...
```
### 4. Recursive OpenAPI Support
When using `auto_deprecate_openapi(app)`, it automatically traverses potentially mounted sub-applications (`app.mount(...)`) and marks their routes as deprecated if configured.
```python
root_app.mount("/v1", v1_app)
# This will update OpenAPI for both root_app AND v1_app
auto_deprecate_openapi(root_app)
```
### 5. Future Deprecation & Caching
You can announce a *future* deprecation date. The `Deprecation` header will still be sent, allowing clients to prepare. You can also inject `Cache-Control` headers so clients don't mistakenly cache warning responses past the sunset date.
```python
@deprecated(
deprecation_date="2030-01-01",
sunset_date="2031-01-01",
inject_cache_control=True
)
async def future_proof(): ...
```
### 6. Custom Response Models & Multiple Links
Customize the HTTP 410/301 response payload dynamically using `response`, and provide extensive contextual documentation via multiple RFC 8594 `Link` relations.
```python
from starlette.responses import JSONResponse
custom_error = JSONResponse(
status_code=410,
content={"message": "This endpoint is permanently removed. Use v2."}
)
@deprecated(
sunset_date="2024-01-01",
response=custom_error,
links={
"alternate": "https://api.example.com/v2/items",
"latest-version": "https://api.example.com/v3/items"
}
)
async def custom_sunset(): ...
```
### 7. Global Middleware
Deprecate entire prefixes at the ASGI level, intercepting `404 Not Found` errors for removed routes and correctly returning `410 Gone` with deprecation metadata.
```python
from fastapi_deprecation import DeprecationMiddleware, DeprecationDependency
app.add_middleware(
DeprecationMiddleware,
deprecations={
"/api/v1": DeprecationDependency(sunset_date="2025-01-01")
}
)
```
See the [Documentation](https://fractalvision.readthedocs.io/en/latest/) for full details on API reference and advanced configuration.
| text/markdown | null | null | null | null | MIT License
Copyright (c) 2026 Fractal Vision
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"fastapi>=0.129.0",
"pydantic>=2.12.5",
"python-dateutil>=2.9.0.post0",
"typing-extensions>=4.15.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:38:29.575349 | fastapi_deprecation-0.3.0.tar.gz | 78,248 | fb/a9/316929734118a77a07ca304537a27ce61e89a10b297dea291fbb9e317128/fastapi_deprecation-0.3.0.tar.gz | source | sdist | null | false | 84d634a9c730ee699677c68b6b0fda79 | 8fa85f641991a73c09ecd4bc5b9277642e226207af806922dbd3a956fc428fd5 | fba9316929734118a77a07ca304537a27ce61e89a10b297dea291fbb9e317128 | null | [
"LICENSE"
] | 221 |
2.4 | isagellm-protocol | 0.5.1.2 | sageLLM protocol types and validation (Protocol v0.1) | # sagellm-protocol
**Protocol v0.1 类型定义与验证** | 为 sageLLM 推理引擎提供统一的协议定义
[](https://github.com/intellistream/sagellm-protocol/actions/workflows/ci.yml)
[](https://www.python.org/downloads/)
[](https://docs.pydantic.dev/2.0/)
[](docs/TESTING.md)
[](https://pypi.org/project/isagellm-protocol/)
## 📋 快速导航
- **PyPI 包名**: `isagellm-protocol`
- **导入命名空间**: `sagellm_protocol`
- **Python 版本**: 3.10+
- **当前版本**: 0.4.0.8
## 职责定位
`sagellm-protocol` 是 sageLLM 系统的**协议定义层**,提供所有全局共享的类型定义。在整体架构中的角色:
```
┌─────────────────────────────────────────────────────┐
│ sageLLM 架构概览 │
├─────────────────────────────────────────────────────┤
│ Gateway (网关) │
│ ├─ 路由请求到合适的 Backend │
│ └─ 依赖: sagellm-protocol, sagellm-comm │
├─────────────────────────────────────────────────────┤
│ Backend (推理后端) │
│ ├─ 执行 LLM 推理,收集指标 │
│ └─ 依赖: sagellm-protocol, sagellm-kv-cache │
├─────────────────────────────────────────────────────┤
│ Core (核心库) │
│ ├─ 推理引擎、调度器、插件系统 │
│ └─ 依赖: sagellm-protocol │
├─────────────────────────────────────────────────────┤
│ ⭐ sagellm-protocol (本仓库) │
│ ├─ Request/Response 定义 │
│ ├─ 错误码、指标、设备类型 │
│ ├─ KV Cache 生命周期类型 │
│ └─ OpenAI 兼容类型 │
└─────────────────────────────────────────────────────┘
```
## 依赖关系
### 被依赖的包
| 包名 | 用途 |
|-----|-----|
| `pydantic` (>=2.0.0) | 数据验证和序列化 |
### 依赖此包的仓库
| 仓库 | 描述 |
|-----|-----|
| `sagellm-backend` | 推理后端,使用 Request/Response/Metrics 类型 |
| `sagellm-core` | 核心推理引擎,使用所有协议类型 |
| `sagellm-gateway` | 网关,使用 OpenAI 兼容类型和路由类型 |
| `sagellm-kv-cache` | KV 缓存管理,使用 KVAllocateParams/KVHandle 等 |
| `sagellm-comm` | 分布式通信,使用错误码和分布式字段 |
| `sagellm` (umbrella) | 顶层包,导出本包中的公共类型 |
## 安装指南
### 从 PyPI 安装 (推荐)
```bash
# 安装稳定版本
pip install isagellm-protocol==0.4.0.8
# 安装最新版本(可能不稳定)
pip install isagellm-protocol
```
### 本地开发安装
```bash
# 克隆仓库
git clone git@github.com:intellistream/sagellm-protocol.git
cd sagellm-protocol
# 创建虚拟环境(推荐)
python3.10 -m venv venv
source venv/bin/activate # Linux/Mac
# 或
venv\Scripts\activate # Windows
# 安装开发依赖
pip install -e ".[dev]"
```
## 快速开始
### 基础使用
```python
from sagellm_protocol import Request, Response, Metrics, ErrorCode
# 创建请求
req = Request(
request_id="req-001",
trace_id="trace-001",
model="llama2-7b",
prompt="Hello, world!",
max_tokens=128,
stream=False,
temperature=0.7,
)
# 创建响应
metrics = Metrics(
ttft_ms=45.2,
tbt_ms=12.5,
throughput_tps=80.0,
peak_mem_mb=24576,
error_rate=0.0,
)
resp = Response(
request_id="req-001",
trace_id="trace-001",
output_text="Hi there!",
output_tokens=[42, 17],
finish_reason="stop",
metrics=metrics,
)
```
### 流式输出
```python
from sagellm_protocol import StreamEventStart, StreamEventDelta, StreamEventEnd
# 流式开始事件
start = StreamEventStart(
request_id="req-002",
trace_id="trace-002",
engine_id="engine-001",
prompt_tokens=10,
)
# 中间增量事件
delta = StreamEventDelta(
request_id="req-002",
trace_id="trace-002",
engine_id="engine-001",
content="Hi",
content_tokens=[42],
)
# 流式结束事件
from sagellm_protocol import Metrics
metrics = Metrics(
ttft_ms=40.0,
tpot_ms=11.0,
throughput_tps=75.0,
peak_mem_mb=20480,
error_rate=0.0,
)
end = StreamEventEnd(
request_id="req-002",
trace_id="trace-002",
engine_id="engine-001",
content="Hi there",
output_tokens=[42, 17],
finish_reason="stop",
metrics=metrics,
)
```
### 采样参数与解码策略
```python
from sagellm_protocol import (
DecodingStrategy,
SamplingParams,
SamplingPreset,
DEFAULT_SAMPLING_PARAMS,
)
# 方式 1:使用默认配置(greedy,保证确定性)
params = DEFAULT_SAMPLING_PARAMS
# 方式 2:使用预设配置
params = SamplingPreset.get_params(SamplingPreset.BALANCED)
# 方式 3:自定义配置
params = SamplingParams(
strategy=DecodingStrategy.SAMPLING,
temperature=0.7,
top_p=0.9,
top_k=50,
)
```
更多完整示例见 [examples/basic_usage.py](examples/basic_usage.py) 和 [examples/sampling_usage.py](examples/sampling_usage.py)。
## API 文档
### 核心类型
#### Request - 推理请求
```python
class Request(BaseModel):
# 必填字段
request_id: str # 请求唯一标识符
trace_id: str # 追踪标识符
model: str # 模型名称
prompt: str # 输入提示文本
max_tokens: int # 最大生成 token 数 (> 0)
stream: bool # 是否使用流式输出
# 可选采样参数
temperature: float | None # 采样温度 (0, 2]
top_p: float | None # nucleus 采样概率 (0, 1]
kv_budget_tokens: int | None # KV Cache 预算
metadata: dict | None # 透传元数据
```
#### Response - 推理响应
```python
class Response(BaseModel):
request_id: str # 对应的请求 ID
trace_id: str # 对应的追踪 ID
output_text: str # 生成的文本
output_tokens: list[int] # 生成的 token IDs
finish_reason: str # 完成原因 (stop/length/error)
metrics: Metrics # 性能指标
```
#### Metrics - 性能指标
```python
class Metrics(BaseModel):
# 时间指标 (毫秒)
ttft_ms: float # Time To First Token
tbt_ms: float = 0.0 # Time Between Tokens
tpot_ms: float = 0.0 # Time Per Output Token
# 吞吐和内存
throughput_tps: float # 吞吐量 (tokens/sec)
peak_mem_mb: int # 峰值内存 (MB)
# KV Cache 指标
kv_used_tokens: int = 0 # 已用 token 数
kv_used_bytes: int = 0 # 已用字节数
prefix_hit_rate: float = 0.0 # 前缀缓存命中率
# 其他指标
error_rate: float # 错误率 [0, 1]
spec_accept_rate: float = 0.0 # 投机解码接受率
```
#### ErrorCode - 协议错误码
```python
class ErrorCode(str, Enum):
INVALID_ARGUMENT = "invalid_argument" # 缺必填字段或非法取值
RESOURCE_EXHAUSTED = "resource_exhausted" # KV/显存/并发不足
UNAVAILABLE = "unavailable" # 后端不可用
DEADLINE_EXCEEDED = "deadline_exceeded" # 请求超时
NOT_IMPLEMENTED = "not_implemented" # 接口未实现
KV_TRANSFER_FAILED = "kv_transfer_failed" # KV 迁移失败
COMM_TIMEOUT = "comm_timeout" # 通信超时
DISTRIBUTED_RUNTIME_ERROR = "distributed_runtime_error" # 分布式运行时错误
```
#### StreamEvent - 流式事件
```python
class StreamEventStart(BaseModel):
event: Literal["start"] = "start"
request_id: str # 请求标识符
trace_id: str # 追踪标识符
engine_id: str # 引擎实例标识符
prompt_tokens: int | None = None # prompt token 数量(可选)
class StreamEventDelta(BaseModel):
event: Literal["delta"] = "delta"
request_id: str # 请求标识符
trace_id: str # 追踪标识符
engine_id: str # 引擎实例标识符
content: str # 增量文本
content_tokens: list[int] # 增量 token ids
class StreamEventEnd(BaseModel):
event: Literal["end"] = "end"
request_id: str # 请求标识符
trace_id: str # 追踪标识符
engine_id: str # 引擎实例标识符
content: str # 完整生成的文本
output_tokens: list[int] # 完整生成的 token ids
finish_reason: str # 完成原因 (stop/length/error)
metrics: Metrics # 性能指标
error: Error | None = None # 错误对象(若有)
```
#### DecodingStrategy - 解码策略
```python
class DecodingStrategy(str, Enum):
GREEDY = "greedy" # 贪婪解码 (确定性)
SAMPLING = "sampling" # 温度采样 (多样性)
BEAM_SEARCH = "beam_search" # 束搜索
CONTRASTIVE = "contrastive" # 对比搜索
```
### 其他核心类型
- **Timestamps** - 观测时间戳,用于计算推理指标
- **StreamEvent** - 流式事件基类 (StreamEventStart/Delta/End)
- **KVAllocateParams** - KV Cache 分配参数
- **KVHandle** - KV Cache 句柄和生命周期管理
- **CapabilityDescriptor** - Backend 能力描述 (DType、KernelKind、设备)
- **ChatCompletionRequest/Response** - OpenAI 兼容类型
详见 [src/sagellm_protocol/](src/sagellm_protocol/) 中的各模块源码。
## 开发指南
### 环境设置
```bash
# 使用 Python 3.10+ (推荐 3.10, 3.11, 3.12)
python --version
# 创建虚拟环境
python3.10 -m venv venv
source venv/bin/activate
# 安装依赖
pip install -e ".[dev]"
```
### 运行测试
```bash
# 运行所有测试
pytest tests/ -v
# 运行特定测试文件
pytest tests/test_types.py -v
# 运行带覆盖率
pytest --cov=sagellm_protocol --cov-report=term-missing
# 生成 HTML 覆盖率报告
pytest --cov=sagellm_protocol --cov-report=html
# 查看报告: open htmlcov/index.html
```
### 代码检查与格式化
```bash
# 格式化代码
ruff format .
# 检查代码(包括导入、类型等)
ruff check . --fix
# 类型检查
mypy src/sagellm_protocol
# 所有检查
ruff format . && ruff check . --fix && mypy src/sagellm_protocol
```
### 测试覆盖率
本仓库维护 **100% 测试覆盖率**:
- 7 个测试文件
- 62+ 个测试用例
- 1100+ 行测试代码
详见 [docs/TESTING.md](docs/TESTING.md)
### 贡献工作流
1. **创建 Issue** - 描述问题或功能需求
```bash
gh issue create --title "[Bug] 描述" --label "sagellm-protocol"
```
2. **创建分支** - 从 `main-dev` 创建修复分支
```bash
git checkout -b fix/#123-description origin/main-dev
```
3. **开发与测试**
```bash
# 编写代码、测试
pytest tests/ -v
ruff format . && ruff check . --fix
mypy src/sagellm_protocol
```
4. **提交 PR** - 提交到 `main-dev`
```bash
git commit -m "fix: 描述 (#123)"
gh pr create --base main-dev --title "Fix: 描述" --body "Closes #123"
```
5. **合并** - 审批通过后合并到 `main-dev`
### 提交约定
使用 Conventional Commits 格式:
```
fix: 修复 bug
feat: 新功能
docs: 文档更新
test: 测试用例
refactor: 代码重构
```
### 版本发布
版本号格式:`MAJOR.MINOR.PATCH.BUILD` (e.g., `0.4.0.8`)
- 保持与 sagellm-backend、sagellm-core、sagellm-comm 的版本同步
- 更新 [CHANGELOG.md](CHANGELOG.md) 中的版本记录
## 文档与示例
### 示例文件
- [examples/basic_usage.py](examples/basic_usage.py) - 基础使用示例 (Request/Response/Metrics/Errors)
- [examples/sampling_usage.py](examples/sampling_usage.py) - 采样参数和解码策略示例
### 文档文件
- [docs/TESTING.md](docs/TESTING.md) - 测试指南
- [docs/SAMPLING_PARAMS.md](docs/SAMPLING_PARAMS.md) - 采样参数详细说明
- [docs/kv_cache_protocol_fields.md](docs/kv_cache_protocol_fields.md) - KV Cache 字段说明
- [CHANGELOG.md](CHANGELOG.md) - 版本更新日志
### 外部文档
- [Protocol v0.1](https://github.com/intellistream/sagellm-docs/blob/main/specs/protocol_v0.1.md) - 协议规范
- [架构设计文档](https://github.com/intellistream/sagellm/blob/main/ARCHITECTURE_FLOW.md) - 整体架构
- [包依赖关系](https://github.com/intellistream/sagellm-docs/blob/main/PACKAGE_DEPENDENCIES.md) - 依赖图表
## 版本信息
- **当前版本**: 0.4.0.8
- **发布日期**: 2026-01-30
- **Python 支持**: 3.10, 3.11, 3.12
- **Pydantic**: >= 2.0.0
### 版本历史
详见 [CHANGELOG.md](CHANGELOG.md)
主要版本:
- **0.4.0** (2026-01-30) - Ascend 后端支持、与其他核心包版本对齐
- **0.3.0** (2026-01-27) - sageLLM 0.3 版本对齐
- **0.1.0** (2026-01-20) - Protocol v0.1 基础定义
## 常见问题
### Q: 如何在 Backend 中使用协议类型?
A: 直接导入并使用:
```python
from sagellm_protocol import Request, Response, Metrics
def process_request(req: Request) -> Response:
# 使用 Request 和 Response 类型
...
```
### Q: 能否自行定义新的请求/响应类型?
A: **不能**。所有全局共享类型必须在 sagellm-protocol 中定义,然后其他包导入使用。这确保系统内部所有包使用统一的类型定义。
### Q: 如何添加新的错误码?
A: 在 [src/sagellm_protocol/errors.py](src/sagellm_protocol/errors.py) 中的 `ErrorCode` 枚举中添加,然后发起 PR。
### Q: 指标中的各字段单位是什么?
A:
- 时间:毫秒 (ms)
- 吞吐:tokens/sec (tps)
- 内存:兆字节 (MB)
详见 [Metrics](src/sagellm_protocol/types.py) 类的 docstring。
### Q: 如何验证 Request/Response 对象?
A: Pydantic v2 自动验证。示例:
```python
try:
req = Request(
request_id="req-001",
trace_id="trace-001",
model="llama2-7b",
prompt="Hello",
max_tokens=128, # 必须 > 0
stream=False,
)
except ValueError as e:
print(f"验证失败: {e}")
```
## License
Proprietary - IntelliStream
---
**需要帮助?** 查看 [docs/TESTING.md](docs/TESTING.md) 或提交 Issue。
| text/markdown | IntelliStream Team | null | null | null | Proprietary - IntelliStream | null | [
"Development Status :: 3 - Alpha",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | ==3.11.* | [] | [] | [] | [
"pydantic>=2.0.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"ruff>=0.8.0; extra == \"dev\"",
"pre-commit>=3.0.0; extra == \"dev\"",
"isage-pypi-publisher>=0.2.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.11 | 2026-02-20T13:38:17.403770 | isagellm_protocol-0.5.1.2.tar.gz | 132,234 | c3/6e/2ac26a0956a1d524233e7fe11fddc5cfe9ebeb3c5cca1b78cbe4f29f30ba/isagellm_protocol-0.5.1.2.tar.gz | source | sdist | null | false | d2ee18cf82728953f8e40540617c66ec | 44b572e9ddb7faa26f2035737eb660631298d86908f77f15f5851221aa006902 | c36e2ac26a0956a1d524233e7fe11fddc5cfe9ebeb3c5cca1b78cbe4f29f30ba | null | [] | 319 |
2.4 | puremagic | 2.0.0 | Pure python implementation of magic file detection | =========
puremagic
=========
puremagic is a pure python module that will identify a file based off
its magic numbers. It has zero runtime dependencies and serves as a
lightweight, cross-platform alternative to python-magic/libmagic.
It is designed to be minimalistic and inherently cross platform
compatible. It is also designed to be a stand in for python-magic. It
implements the functions :code:`from_file(filename[, mime])` and
:code:`from_string(string[, mime])` however the :code:`magic_file()` and
:code:`magic_string()` are more powerful and will also display confidence and
duplicate matches.
Starting with version 2.0, puremagic includes a **deep scan** system
that performs content-aware analysis beyond simple magic number matching.
This improves accuracy for formats like Office documents, text files,
CSV, MP3, Python source, JSON, HDF5, email, and many scientific formats.
Deep scan is enabled by default and can be disabled by setting the
environment variable :code:`PUREMAGIC_DEEPSCAN=0`.
Advantages over using a wrapper for 'file' or 'libmagic':
- Faster
- Lightweight
- Cross platform compatible
- No dependencies
Disadvantages:
- Does not have as many file types
- No multilingual comments
- Duplications due to small or reused magic numbers
(Help fix the first two disadvantages by contributing!)
Compatibility
~~~~~~~~~~~~~
- Python 3.12+
For use with Python 3.7–3.11, use the 1.x release chain.
Using github ci to run continuous integration tests on listed platforms.
Install from PyPI
-----------------
.. code:: bash
$ pip install puremagic
On linux environments, you may want to be clear you are using python3
.. code:: bash
$ python3 -m pip install puremagic
Usage
-----
"from_file" will return the most likely file extension. "magic_file"
will give you every possible result it finds, as well as the confidence.
.. code:: python
import puremagic
filename = "test/resources/images/test.gif"
ext = puremagic.from_file(filename)
# '.gif'
puremagic.magic_file(filename)
# [['.gif', 'image/gif', 'Graphics interchange format file (GIF87a)', 0.7],
# ['.gif', '', 'GIF file', 0.5]]
With "magic_file" it gives each match, highest confidence first:
- possible extension(s)
- mime type
- description
- confidence (All headers have to perfectly match to make the list,
however this orders it by longest header, therefore most precise,
first)
If you already have a file open, or raw byte string, you could also use:
* from_string
* from_stream
* magic_string
* magic_stream
.. code:: python
with open(r"test\resources\video\test.mp4", "rb") as file:
print(puremagic.magic_stream(file))
# [PureMagicWithConfidence(byte_match=b'ftypisom', offset=4, extension='.mp4', mime_type='video/mp4', name='MPEG-4 video', confidence=0.8),
# PureMagicWithConfidence(byte_match=b'iso2avc1mp4', offset=20, extension='.mp4', mime_type='video/mp4', name='MP4 Video', confidence=0.8)]
Deep Scan
---------
Deep scan performs content-aware analysis when magic number matching
alone is not enough. It is enabled by default and runs automatically
as part of the normal identification pipeline.
The following format-specific scanners are included:
- **ZIP** — Distinguishes Office formats (xlsx/docx/pptx), OpenDocument
(odt/ods/odp), and their macro-enabled variants by inspecting ZIP internals
- **MPEG Audio** — Parses MP3/MPEG audio frames to validate and identify audio files
- **Text** — Detects text encodings, line endings (CRLF/LF/CR), CSV files
with automatic delimiter detection, and email messages (.eml)
- **Python** — Validates Python source via :code:`ast.parse()` and keyword analysis
- **PDF** — Format-specific PDF validation
- **JSON** — JSON format validation
- **HDF5** — Identifies HDF5 subtypes used in scientific computing (AnnData,
Loom, Cooler, BIOM v2, mz5, and more)
- **Audio** — Identifies HCOM and SNDR audio formats
- **Dynamic text checks** — Recognizes many scientific and bioinformatics text
formats including VCF, SAM, GFF, PLY, VTK, and others
To disable deep scan, set the environment variable:
.. code:: bash
$ export PUREMAGIC_DEEPSCAN=0
Script
------
*Usage*
.. code:: bash
$ python -m puremagic [options] filename <filename2>...
*Options*
- :code:`-m, --mime` — Return the MIME type instead of file extension
- :code:`-v, --verbose` — Print verbose output with all possible matches
- :code:`--version` — Show program version
Directories can be passed as arguments; all files within will be scanned.
*Examples*
.. code:: bash
$ python -m puremagic test/resources/images/test.gif
'test/resources/images/test.gif' : .gif
$ python -m puremagic -m test/resources/images/test.gif test/resources/audio/test.mp3
'test/resources/images/test.gif' : image/gif
'test/resources/audio/test.mp3' : audio/mpeg
Upgrading from 1.x
-------------------
Version 2.0 includes the following breaking changes:
- **Python 3.12+ required** — Python 3.7–3.11 are no longer supported.
Use the 1.x release chain for older Python versions.
- **Removed** :code:`puremagic.what()` — The :code:`imghdr` drop-in replacement
has been removed. Use :code:`puremagic.from_file()` instead.
- **Removed** :code:`magic_header_array`, :code:`magic_footer_array`, and
:code:`multi_part_dict` from the public API.
- **Removed** :code:`setup.py` — The project now uses :code:`pyproject.toml`
exclusively.
- Internal functions have been renamed from private (e.g. :code:`_magic_data`)
to public (e.g. :code:`magic_data`).
FAQ
---
*The file type is actually X but it's showing up as Y with higher
confidence?*
This can happen when the file's signature happens to match a subset of a
file standard. The subset signature will be longer, therefore report
with greater confidence, because it will have both the base file type
signature plus the additional subset one.
Acknowledgements
----------------
Gary C. Kessler
For use of his File Signature Tables, available at:
https://filesig.search.org/
Freedesktop.org
For use of their shared-mime-info file, available at:
https://cgit.freedesktop.org/xdg/shared-mime-info/
License
-------
MIT Licenced, see LICENSE, Copyright (c) 2013-2026 Chris Griffith
| text/x-rst | null | Chris Griffith <chris@cdgriffith.com> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Programming Language :: Python :: Implementation :: PyPy",
"Topic :: Utilities"
] | [] | null | null | >=3.12 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/cdgriffith/puremagic"
] | twine/6.1.0 CPython/3.14.2 | 2026-02-20T13:37:53.262606 | puremagic-2.0.0.tar.gz | 1,119,578 | dc/df/a2ee3bbf55f036acb9725b35732e3a785cb06f5c5b9fe47bde8c05ab873a/puremagic-2.0.0.tar.gz | source | sdist | null | false | ee044bd7a71c7949cab12f3d85389c88 | 224fe42b6b3467276a45914e12b5f40905dea0e87963adbe5289667e7c607851 | dcdfa2ee3bbf55f036acb9725b35732e3a785cb06f5c5b9fe47bde8c05ab873a | MIT | [
"LICENSE"
] | 37,467 |
2.4 | nf-metro | 0.4.7 | Generate metro-map-style SVG diagrams from Mermaid graph definitions | # nf-metro
**[Documentation](https://pinin4fjords.github.io/nf-metro/latest/)**
Generate metro-map-style SVG diagrams from Mermaid graph definitions with `%%metro` directives. Designed for visualizing bioinformatics pipeline workflows (e.g., nf-core pipelines) as transit-style maps where each analysis route is a colored "metro line."
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/pinin4fjords/nf-metro/main/examples/rnaseq_light_animated.svg">
<source media="(prefers-color-scheme: light)" srcset="https://raw.githubusercontent.com/pinin4fjords/nf-metro/main/examples/rnaseq_light_animated.svg">
<img alt="nf-core/rnaseq metro map" src="https://raw.githubusercontent.com/pinin4fjords/nf-metro/main/examples/rnaseq_auto_light.png">
</picture>
## Installation
### pip (PyPI)
```bash
pip install nf-metro
```
### Conda (Bioconda)
```bash
conda install bioconda::nf-metro
```
### Container (Seqera Containers)
A pre-built container is available via [Seqera Containers](https://seqera.io/containers/):
```bash
docker pull community.wave.seqera.io/library/pip_nf-metro:611b1ba39c6007f1
```
### Development
```bash
pip install -e ".[dev]"
```
Requires Python 3.10+.
## Quick start
Render a metro map from a `.mmd` file:
```bash
nf-metro render examples/simple_pipeline.mmd -o pipeline.svg
```
Validate your input without rendering:
```bash
nf-metro validate examples/simple_pipeline.mmd
```
Inspect structure (sections, lines, stations):
```bash
nf-metro info examples/simple_pipeline.mmd
```
## CLI reference
### `nf-metro render`
Render a Mermaid metro map definition to SVG.
```
nf-metro render [OPTIONS] INPUT_FILE
```
| Option | Default | Description |
|--------|---------|-------------|
| `-o`, `--output PATH` | `<input>.svg` | Output SVG file path |
| `--theme [nfcore\|light]` | `nfcore` | Visual theme |
| `--width INTEGER` | auto | SVG width in pixels |
| `--height INTEGER` | auto | SVG height in pixels |
| `--x-spacing FLOAT` | `60` | Horizontal spacing between layers |
| `--y-spacing FLOAT` | `40` | Vertical spacing between tracks |
| `--max-layers-per-row INTEGER` | auto | Max layers before folding to next row |
| `--animate / --no-animate` | off | Add animated balls traveling along lines |
| `--debug / --no-debug` | off | Show debug overlay (ports, hidden stations, edge waypoints) |
| `--logo PATH` | none | Logo image path (overrides `%%metro logo:` directive) |
| `--line-order [definition\|span]` | from file | Line ordering strategy: `definition` preserves `.mmd` order, `span` sorts by section span (longest first) |
The `--logo` flag lets you use the same `.mmd` file with different logos for dark/light themes:
```bash
nf-metro render pipeline.mmd -o pipeline_dark.svg --theme nfcore --logo logo_dark.png
nf-metro render pipeline.mmd -o pipeline_light.svg --theme light --logo logo_light.png
```
### `nf-metro validate`
Check a `.mmd` file for errors without producing output.
```
nf-metro validate INPUT_FILE
```
### `nf-metro info`
Print a summary of the parsed map: sections, lines, stations, and edges.
```
nf-metro info INPUT_FILE
```
## Examples
The [`examples/`](examples/) directory contains ready-to-render `.mmd` files:
| Example | Description |
|---------|-------------|
| [`simple_pipeline.mmd`](examples/simple_pipeline.mmd) | Minimal two-line pipeline with no sections |
| [`rnaseq_auto.mmd`](examples/rnaseq_auto.mmd) | nf-core/rnaseq with fully auto-inferred layout |
| [`rnaseq_sections.mmd`](examples/rnaseq_sections.mmd) | nf-core/rnaseq with manual grid overrides |
### Topology gallery
The [`examples/topologies/`](examples/topologies/) directory has 15 examples covering a range of layout patterns. See the [topology README](examples/topologies/README.md) for descriptions and rendered previews.
A few highlights:
| | | |
|:---:|:---:|:---:|
| **Wide Fan-Out** | **Section Diamond** | **Variant Calling** |
|  |  |  |
| **Fold Serpentine** | **Multi-Line Bundle** | **RNA-seq Lite** |
|  |  |  |
## Input format
Input files use a subset of Mermaid `graph LR` syntax extended with `%%metro` directives. The format has three layers: **global directives** that configure the overall map, **section directives** inside `subgraph` blocks that control section layout, and **edges** that define connections between stations.
### Walkthrough: nf-core/rnaseq
The full example is at [`examples/rnaseq_sections.mmd`](examples/rnaseq_sections.mmd). Here's how each part works.
#### Global directives
```
%%metro title: nf-core/rnaseq
%%metro logo: examples/nf-core-rnaseq_logo_dark.png
%%metro style: dark
```
- `title:` sets the map title (shown top-left unless a logo is provided)
- `logo:` embeds a PNG image in place of the text title
- `style:` selects a theme (`dark` or `light`)
#### Lines (routes)
Each metro line represents a distinct path through the pipeline. Lines are defined with an ID, display name, and color:
```
%%metro line: star_rsem | Aligner: STAR, Quantification: RSEM | #0570b0
%%metro line: star_salmon | Aligner: STAR, Quantification: Salmon (default) | #2db572
%%metro line: hisat2 | Aligner: HISAT2, Quantification: None | #f5c542
%%metro line: pseudo_salmon | Pseudo-aligner: Salmon, Quantification: Salmon | #e63946
%%metro line: pseudo_kallisto | Pseudo-aligner: Kallisto, Quantification: Kallisto | #7b2d3b
```
In the rnaseq pipeline, each line corresponds to a parameter-driven analysis route. All five lines share the preprocessing section, then diverge based on aligner choice.
#### Grid placement
Sections are placed on a grid automatically via topological sort, but explicit positions can be set:
```
%%metro grid: postprocessing | 2,0,2
%%metro grid: qc_report | 1,2,1,2
```
The format is `section_id | col,row[,rowspan[,colspan]]`. In this example:
- `postprocessing` is pinned to column 2, row 0, spanning 2 rows vertically
- `qc_report` is pinned to column 1, row 2, spanning 2 columns horizontally
#### Legend
```
%%metro legend: bl
```
Position the legend: `tl`, `tr`, `bl`, `br` (corners), `bottom`, `right`, or `none`.
#### Sections
Sections are Mermaid `subgraph` blocks. Each section is laid out independently, then placed on the grid:
```
graph LR
subgraph preprocessing [Pre-processing]
%%metro exit: right | star_salmon, star_rsem, hisat2
%%metro exit: bottom | pseudo_salmon, pseudo_kallisto
cat_fastq[cat fastq]
fastqc_raw[FastQC]
...
end
```
**Section directives:**
- `%%metro entry: <side> | <line_ids>` - declares which lines enter this section and from which side (`left`, `right`, `top`, `bottom`)
- `%%metro exit: <side> | <line_ids>` - declares which lines exit and to which side
- `%%metro direction: <dir>` - section flow direction: `LR` (default), `RL` (right-to-left), or `TB` (top-to-bottom)
Entry/exit hints control port placement on section boundaries. A section can have exit hints on multiple sides (e.g., preprocessing exits right for aligners and bottom for pseudo-aligners), but all lines from a section leave through a single exit port. If all exit hints point to one side, that side is used; otherwise it defaults to `right`.
#### Section directions
Most sections flow left-to-right (`LR`, the default). Two other directions are useful for layout:
**Top-to-bottom (`TB`)** - used for the Post-processing section, which acts as a vertical connector carrying lines downward:
```
subgraph postprocessing [Post-processing]
%%metro direction: TB
%%metro entry: left | star_salmon, star_rsem, hisat2
%%metro exit: bottom | star_salmon, star_rsem, hisat2
samtools[SAMtools]
picard[Picard]
...
end
```
**Right-to-left (`RL`)** - used for the QC section, which flows backward to create a serpentine layout:
```
subgraph qc_report [Quality control & reporting]
%%metro direction: RL
%%metro entry: top | star_salmon, star_rsem, hisat2
rseqc[RSeQC]
preseq[Preseq]
...
end
```
#### Stations and edges
Stations use Mermaid node syntax. Edges carry comma-separated line IDs to indicate which routes use that connection:
```
cat_fastq[cat fastq]
fastqc_raw[FastQC]
cat_fastq -->|star_salmon,star_rsem,hisat2,pseudo_salmon,pseudo_kallisto| fastqc_raw
```
All five lines pass through this edge. Later, lines diverge:
```
star -->|star_rsem| rsem
star -->|star_salmon| umi_tools_dedup
hisat2_align -->|hisat2| umi_tools_dedup
```
Here different lines take different paths through the section, creating the visual fork in the metro map.
#### Inter-section edges
Edges between stations in different sections go outside all `subgraph`/`end` blocks:
```
%% Inter-section edges
sortmerna -->|star_salmon,star_rsem| star
sortmerna -->|hisat2| hisat2_align
sortmerna -->|pseudo_salmon| salmon_pseudo
sortmerna -->|pseudo_kallisto| kallisto
stringtie -->|star_salmon,star_rsem,hisat2| rseqc
```
These are automatically rewritten into port-to-port connections with junction stations at fan-out points. You just specify the source and target stations directly.
### Directive reference
| Directive | Scope | Description |
|-----------|-------|-------------|
| `%%metro title: <text>` | Global | Map title |
| `%%metro logo: <path>` | Global | Logo image (replaces title text) |
| `%%metro style: <name>` | Global | Theme: `dark`, `light` |
| `%%metro line: <id> \| <name> \| <color>` | Global | Define a metro line |
| `%%metro grid: <section> \| <col>,<row>[,<rowspan>[,<colspan>]]` | Global | Pin section to grid position |
| `%%metro legend: <position>` | Global | Legend position: `tl`, `tr`, `bl`, `br`, `bottom`, `right`, `none` |
| `%%metro line_order: <strategy>` | Global | Line ordering for track assignment: `definition` (default) or `span` (longest-spanning lines get inner tracks) |
| `%%metro file: <station> \| <label>` | Global | Mark a station as a file terminus with a document icon |
| `%%metro entry: <side> \| <lines>` | Section | Entry port hint |
| `%%metro exit: <side> \| <lines>` | Section | Exit port hint |
| `%%metro direction: <dir>` | Section | Flow direction: `LR`, `RL`, `TB` |
## License
[MIT](LICENSE)
| text/markdown | null | null | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Visualization"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.0",
"drawsvg>=2.0",
"networkx>=3.0",
"pillow>=9.0",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"ruff>=0.4; extra == \"dev\"",
"cairosvg>=2.5; extra == \"docs\"",
"mike>=2.0; extra == \"docs\"",
"mkdocs-material>=9.0; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://github.com/pinin4fjords/nf-metro",
"Repository, https://github.com/pinin4fjords/nf-metro",
"Issues, https://github.com/pinin4fjords/nf-metro/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:37:51.529159 | nf_metro-0.4.7.tar.gz | 1,754,755 | 5a/27/7c1b629c249ae6a9e0f09be6dd6b6a5d28cecb545b39eae41ab3ae2c5b6d/nf_metro-0.4.7.tar.gz | source | sdist | null | false | 9c37fac135f71157c155f3158f89c0b8 | f5798c15c4943327402a46277111d6faa89594c8bfb7e9af60a28a2db177398a | 5a277c1b629c249ae6a9e0f09be6dd6b6a5d28cecb545b39eae41ab3ae2c5b6d | MIT | [
"LICENSE"
] | 245 |
2.4 | httpx-gracedb | 0.0.4 | generic connection pooling HTTP client for GraceDB and similar services | # httpx-gracedb
httpx-gracedb provides a generic REST API client for [GraceDB] and similar
LIGO/Virgo API services. It uses the powerful [httpx] package for reliable
and high-throughput HTTP connection pooling.
[GraceDB]: https://gracedb.ligo.org/
[httpx]: https://www.python-httpx.org
| text/markdown | null | Leo Singer <leo.p.singer@nasa.gov> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Science/Research",
"Operating System :: POSIX",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Internet",
"Topic :: Scientific/Engineering :: Astronomy",
"Topic :: Scientific/Engineering :: Physics"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"igwn-auth-utils>=1.3.0",
"pyjwt",
"requests",
"httpx",
"safe-netrc",
"pytest; extra == \"test\"",
"pytest-asyncio; extra == \"test\"",
"pytest-freezer; extra == \"test\"",
"pytest-httpserver; extra == \"test\"",
"pytest-socket; extra == \"test\""
] | [] | [] | [] | [
"source, https://git.ligo.org/emfollow/httpx-gracedb",
"Bug Tracker, https://git.ligo.org/emfollow/httpx-gracedb/issues",
"Documentation, https://httpx-gracedb.readthedocs.io/",
"Source Code, https://git.ligo.org/emfollow/httpx-gracedb"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-20T13:37:44.101696 | httpx_gracedb-0.0.4.tar.gz | 25,929 | 81/6c/5618ebfa7c39efa646557fe4a00cedcc20fa65959103e78efdefad957686/httpx_gracedb-0.0.4.tar.gz | source | sdist | null | false | beeb27a18fa77e5f152272bf315bd1fb | ce0462a22fa399e98fa7e12a3d9bebfea6a1be774754efc62e1121303d97c631 | 816c5618ebfa7c39efa646557fe4a00cedcc20fa65959103e78efdefad957686 | GPL-3.0-or-later | [
"LICENSE.md"
] | 238 |
2.4 | howler-api | 3.2.0.dev503 | Howler - API server | # Howler API
## Introduction
Howler is an application that allows analysts to triage hits and alerts. It provides a way for analysts to efficiently review and analyze alerts generated by different analytics and detections.
## Contributing
See [CONTRIBUTING.md](doc/CONTRIBUTING.md).
| text/markdown | Canadian Centre for Cyber Security | howler@cyber.gc.ca | Matthew Rafuse | matthew.rafuse@cyber.gc.ca | MIT | howler, alerting, gc, canada, cse-cst, cse, cst, cyber, cccs | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Libraries"
] | [] | null | null | <4.0.0,>=3.9.17 | [] | [] | [] | [
"apscheduler==3.11.2",
"authlib<2.0.0,>=1.6.0",
"bcrypt==4.3.0",
"chardet==5.2.0",
"chevron==0.14.0",
"elastic-apm[flask]<7.0.0,>=6.22.0",
"elasticsearch==8.19.3",
"flasgger<0.10.0.0,>=0.9.7.1",
"flask==2.3.3",
"flask-caching==2.3.1",
"gevent==23.9.1",
"gunicorn==23.0.0",
"luqum<2.0.0,>=1.0.0",
"mergedeep<2.0.0,>=1.3.4",
"packaging<25.0",
"passlib==1.7.4",
"prometheus-client==0.24.1",
"pydantic<3.0.0,>=2.11.4",
"pydantic-settings[yaml]<3.0.0,>=2.9.1",
"pydash<9.0.0,>=8.0.5",
"pyjwt==2.11.0",
"pysigma==0.11.23",
"pysigma-backend-elasticsearch<2.0.0,>=1.1.2",
"python-baseconv==1.2.2",
"python-datemath==3.0.3",
"python-dotenv<2.0.0,>=1.1.0",
"pytz<2026.0,>=2025.2",
"pyyaml==6.0.3",
"redis==4.6.0",
"requests==2.32.5",
"typing-extensions<5.0.0,>=4.12.2",
"validators<0.36,>=0.34",
"wsproto==1.2.0"
] | [] | [] | [] | [
"Documentation, https://cybercentrecanada.github.io/howler/developer/backend/",
"Homepage, https://cybercentrecanada.github.io/howler/",
"Repository, https://github.com/CybercentreCanada/howler-api"
] | poetry/2.3.2 CPython/3.12.3 Linux/6.11.0-1018-azure | 2026-02-20T13:37:40.583506 | howler_api-3.2.0.dev503-py3-none-any.whl | 317,656 | 76/f0/c32bea0f8bbd0751cc02b2d780394e99fa8852b655ba1f63fcff2b7eb554/howler_api-3.2.0.dev503-py3-none-any.whl | py3 | bdist_wheel | null | false | 19e7d37ac8d898973cace78bc4618ae0 | 02478cbd664605d757690fc7aa443ce11bd7b6540c58328b154708ed6d1fac83 | 76f0c32bea0f8bbd0751cc02b2d780394e99fa8852b655ba1f63fcff2b7eb554 | null | [] | 205 |
2.4 | yandex-bot-client | 0.1.0 | Lightweight aiogram-style client for Yandex Messenger Bot API. | # yandex-bot-client — библиотека для ботов Яндекс.Мессенджера
Лёгкий aiogram-style клиент к Bot API Яндекс.Мессенджера: long polling, роутеры, фильтры, FSM и inline-кнопки без внешних SDK.
GitHub: https://github.com/IvanKostin98/yandex-bot-client
Именование:
- пакет в PyPI: `yandex-bot-client`
- импорт в Python-коде: `yandex_bot_client`
Что внутри:
- `Bot` с `message_handler`, `button_handler`, `callback_handler`, `default_handler`
- `Router` для разбиения логики на модули
- `F` / `Filter` / `StateFilter` (в стиле aiogram)
- `State`, `FSMContext`, `set_state/get_state`
- `Message`, `CallbackQuery`, `User` типы
- `Keyboard` builder для inline-кнопок
---
## Быстрый старт
1) Установка:
```bash
pip install yandex-bot-client
```
Важно: имя пакета в PyPI и имя модуля для импорта могут отличаться.
Для этого проекта установка: `yandex-bot-client`, импорт: `yandex_bot_client`.
2) Добавьте токен в `.env`:
```env
YANDEX_BOT_API_KEY=ваш_oauth_токен_бота
```
3) Минимальный запуск:
```python
import os
import asyncio
from yandex_bot_client import Bot, Message
bot = Bot(os.getenv("YANDEX_BOT_API_KEY"))
@bot.message_handler("/start")
async def start(message: Message):
await bot.reply("Привет! Бот запущен.")
if __name__ == "__main__":
asyncio.run(bot.run())
```
---
## Установка из исходников (локальная разработка)
```bash
pip install -r requirements.txt
```
---
## Запуск примера
В `.env` в корне проекта:
```
YANDEX_BOT_API_KEY=ваш_oauth_токен_бота
```
Запуск примера бота с кнопками:
```bash
python bot.py
```
или
```bash
python -m test.example
```
---
## Структура проекта
```
yandex_bot_client/ # библиотека
__init__.py # экспорт Bot, Keyboard, Router, F, Filter, StateFilter, State, ...
client.py # класс Bot, long polling, middleware chain
filters.py # фильтры F, Filter, StateFilter, and_f, or_f
fsm.py # FSM: State, get_state, set_state, FSMContext
keyboard.py # класс Keyboard
middleware.py # контракт Middleware
router.py # класс Router
types.py # Message, CallbackQuery, User (как в aiogram)
config/ # конфиг из .env
__init__.py # API_KEY
test/
example.py # пример бота (роутеры + FSM)
bot.py # точка входа
```
---
## Как пользоваться: класс Bot
Импорт:
```python
import os
from yandex_bot_client import Bot, Keyboard
API_KEY = os.getenv("YANDEX_BOT_API_KEY")
```
### Bot(api_key, log=None, poll_active_sleep=0.2, poll_idle_sleep=1.0)
Создаёт экземпляр бота.
- **api_key** — OAuth-токен бота.
- **log** — логгер (по умолчанию `loguru.logger`). Можно передать свой экземпляр loguru.
- **poll_active_sleep** — пауза цикла long polling, когда обновления есть (по умолчанию `0.2` сек).
- **poll_idle_sleep** — пауза цикла long polling, когда обновлений нет (по умолчанию `1.0` сек). Можно уменьшить для более быстрого отклика или увеличить, чтобы снизить нагрузку на API.
### Bot.current()
Возвращает бота, обрабатывающего текущее обновление. Вызывайте **только из хендлера** — так можно обойтись без глобальной переменной. Вне хендлера вернёт `None`.
- **Возвращает:** экземпляр Bot или None.
Пример: `bot = Bot.current(); if bot: await bot.reply(...)` (см. test/example.py).
### bot.state(login)
Возвращает **словарь данных** пользователя (сессию), изолированный от других.
Используйте для своих полей (выбранный поставщик, email и т.д.). FSM-состояние хранится отдельно (set_state/get_state), не в этом словаре — конфликта ключей нет.
- **login** — логин пользователя (обычно email).
- **Возвращает:** словарь; изменения сохраняются.
Пример: `bot.state(login)["flow"] = "payments"`.
### bot.message_handler(text=None, filters=None, state=None)
Регистрирует обработчик **текстовых сообщений**.
- **text** — строка команды/текста (например `"/start"`). Если `None` — любое сообщение.
- **filters** — опционально: фильтр `(update) -> bool`, например `F.text == "/start"`.
- **state** — опционально: FSM-состояние (строка), в котором хендлер активен; `None` — любое состояние.
- Обработчик: `async def handler(message: Message): ...`. В хендлер всегда передаётся Message (поля: text, from_user, message_id, raw). Ответ — через `bot.reply(...)`.
Пример:
```python
@bot.message_handler("/start")
async def start(message: Message):
await bot.reply(f"Привет, {message.from_user.display_name or message.from_user.login}!")
```
### bot.button_handler(action, state=None)
Регистрирует обработчик **нажатия кнопки** по команде из `callback_data["cmd"]`.
- **action** — имя действия **без слэша** (как в кнопке: `cmd="/opt1"` → `action="opt1"`).
- **state** — опционально: FSM-состояние; `None` — любое.
- Обработчик: `async def handler(callback: CallbackQuery): ...`. В хендлер всегда передаётся CallbackQuery (поля: payload, data, from_user, raw_update).
Пример:
```python
@bot.button_handler("opt1")
async def on_opt1(callback: CallbackQuery):
await bot.reply("Нажата опция 1")
```
### bot.callback_handler(func)
Регистрирует обработчик для произвольного `callback_data` (например с полем `"hash"`).
Вызывается, если в payload нет `"cmd"` или для данного `cmd` нет `button_handler`.
- **func** — `async def handler(callback: CallbackQuery): ...`
### bot.default_handler(func)
Обработчик по умолчанию для **текста**: вызывается, когда ни один `message_handler` не обработал сообщение.
- **func** — `async def handler(update): ...`
Если не задан, бот отправит: «Не понимаю. Введите /start или /menu.»
### bot.reply(text, keyboard=None)
Отправляет сообщение **текущему** пользователю (тому, чьё обновление обрабатывается). Используйте в обработчиках вместо `send_message(login, ...)` — логин берётся из контекста.
- **text** — текст.
- **keyboard** — необязательно; результат `Keyboard().build()`.
- **Возвращает:** `message_id` при успехе, иначе `None`. Вне обработчика залогирует предупреждение и вернёт `None`.
### bot.current_login()
Возвращает логин пользователя, чьё обновление сейчас обрабатывается. Удобно для `bot.state(bot.current_login())` и т.п.
- **Возвращает:** строка логина или `None`, если вызвано вне контекста обновления.
### bot.send_message(login, text, keyboard=None)
Отправляет пользователю текстовое сообщение по явному **login** (например, другому пользователю или из кода вне обработчика).
- **login** — логин получателя.
- **text** — текст.
- **keyboard** — необязательно; результат `Keyboard().build()` (список рядов кнопок).
- **Возвращает:** `message_id` при успехе, иначе `None`.
### bot.run()
Запускает long polling: цикл запросов к API до остановки (Ctrl+C или `bot.stop()`). **Блокирует** выполнение.
### bot.stop()
Останавливает цикл (run() завершится при следующей итерации).
### bot.include_router(router)
Подключает **роутер** к боту: все обработчики роутера добавляются в конец очереди. Порядок: сначала хендлеры бота, затем каждого роутера в порядке вызова.
- **router** — экземпляр `Router`.
- **Возвращает:** `self` (для цепочки).
### bot.middleware(mw)
Регистрирует **middleware** (как в aiogram). Вызывается в порядке регистрации перед каждым хендлером.
- **mw** — `async def mw(handler, event, data): ... return await handler(event, data)`. `event` — Message или CallbackQuery, `data` — dict, можно дополнять для передачи в хендлер.
- **Возвращает:** переданную функцию (удобно как декоратор).
Пример: логирование, дополнение `data` для хендлера.
```python
@bot.middleware
async def my_mw(handler, event, data):
data["request_time"] = time.time()
return await handler(event, data)
```
---
## Типы Message и CallbackQuery (как в aiogram)
В хендлеры всегда передаются типизированные объекты: в message_handler — **Message**, в button_handler и callback_handler — **CallbackQuery**. Один способ, без сырых dict.
- **Message**: `text`, `message_id`, `from_user` (User), `chat`, `update_id`, `timestamp`, `raw`.
- **CallbackQuery**: `from_user`, `payload`, `data` (alias), `message_id`, `update_id`, `raw_update`, `raw_payload`.
- **User**: `id`, `login`, `display_name`, `robot`, `_raw`.
Импорт: `from yandex_bot_client import Bot, Message, CallbackQuery, User`.
---
## Роутеры (Router)
Группа обработчиков с тем же API, что и у Bot. Удобно разбивать логику по модулям (меню, оплаты, обратная связь).
```python
from yandex_bot_client import Bot, Keyboard, Router
router = Router()
@router.message_handler("/menu")
async def menu(update):
await bot.reply("Меню", menu_keyboard())
@router.button_handler("back")
async def back(callback):
await bot.reply("Главное меню", menu_keyboard())
bot = Bot(API_KEY)
bot.include_router(router)
```
У роутера те же параметры: `text`, `filters`, `state` у `message_handler`; `state` у `button_handler` и `default_handler`; `filters` у `callback_handler`.
---
## Фильтры (F)
В стиле aiogram: декларативная проверка `update` и `payload`.
- **F.text == "/start"** — текст сообщения ровно `"/start"`.
- **F.callback_data.has("cmd")** — в payload кнопки есть ключ `"cmd"`.
- **F.callback_data["hash"] == "abc"** — `payload["hash"] == "abc"`.
- **and_f(f1, f2)**, **or_f(f1, f2)** — объединение фильтров.
Пример:
```python
from yandex_bot_client import Bot, F
@bot.message_handler(filters=F.text == "/help")
async def help_cmd(update):
await bot.reply("Справка: /start, /menu")
```
### Расширенные фильтры: & | ~ и StateFilter
Фильтры для сообщений можно комбинировать операторами и фильтром по FSM-состоянию:
- **(F.text == "/start") & StateFilter(MyState.menu)** — текст ровно `/start` и текущее состояние пользователя — `MyState.menu`.
- **(F.text == "/a") | (F.text == "/b")** — текст `/a` или `/b`.
- **~StateFilter(MyState.busy)** — состояние не `busy`.
**StateFilter(state_or_states)** — один state (строка) или список/кортеж допустимых. Использует `Bot.current()` и login из update.
```python
from yandex_bot_client import Bot, F, StateFilter, State
class MyState(State):
menu = "menu"
busy = "busy"
@bot.message_handler(filters=(F.text == "/menu") & StateFilter(MyState.menu))
async def menu_cmd(message):
await bot.reply("Меню")
```
---
## FSM (State)
Конечный автомат по пользователю: состояние хранится отдельно от `bot.state(login)` (внутри бота), конфликта ключей нет.
- **State** — базовый класс; наследуйтесь и задавайте атрибуты-строки (состояния).
- **get_state(bot, login)** — текущее состояние пользователя.
- **set_state(bot, login, state)** — установить состояние (`None` — сброс).
- **clear_state(bot, login)** — сбросить состояние.
- **FSMContext(bot)** — внутри обработчика: `state = FSMContext(bot)`; `state.get_state()`, `state.set_state(...)`, `state.clear_state()`.
Хендлеры с параметром **state=** срабатывают только когда текущее состояние пользователя совпадает (или `state=None` — любое).
```python
from yandex_bot_client import Bot, State, set_state, get_state, FSMContext
class Auth(State):
wait_email = "wait_email"
wait_code = "wait_code"
@bot.message_handler("/start")
async def start(message: Message):
bot = Bot.current()
if bot:
set_state(bot, bot.current_login(), Auth.wait_email)
await bot.reply("Введите email")
@bot.message_handler(state=Auth.wait_email)
async def got_email(message: Message):
bot = Bot.current()
if bot:
set_state(bot, bot.current_login(), Auth.wait_code)
await bot.reply("Введите код из письма")
```
---
## Как пользоваться: класс Keyboard
Служит для сборки inline-клавиатуры под `send_message(..., keyboard=...)`.
### Keyboard.button(text, cmd=None, callback_data=None, url=None)
Создаёт **одну кнопку**.
- **text** — подпись на кнопке.
- **cmd** — команда при нажатии (попадает в `button_handler` без слэша). Пример: `cmd="/opt1"` или `cmd="opt1"`.
- **callback_data** — произвольный dict (например `{"hash": "abc"}` для выбора из списка; обрабатывается в `callback_handler`).
- **url** — опционально, ссылка для кнопки.
**Возвращает:** словарь кнопки для передачи в `.row()`.
### Keyboard().row(btn1, btn2, ...)
Добавляет **один ряд** кнопок. Можно вызывать цепочкой.
- **Аргументы:** одна или несколько кнопок, созданных через `Keyboard.button()`.
- **Возвращает:** self (для цепочки).
### Keyboard().build()
Возвращает клавиатуру в формате для `bot.send_message(..., keyboard=...)`.
- **Возвращает:** список рядов (каждый ряд — список кнопок).
Пример:
```python
keyboard = (
Keyboard()
.row(
Keyboard.button("Да", cmd="/yes"),
Keyboard.button("Нет", cmd="/no"),
)
.build()
)
await bot.reply("Подтвердите?", keyboard)
```
### Keyboard.from_rows(rows)
Собирает клавиатуру из готового списка рядов (каждый ряд — список кнопок).
**Возвращает:** значение в формате для `send_message`.
---
## Минимальный пример своего бота
```python
import asyncio
import os
from yandex_bot_client import Bot, Keyboard, Message, CallbackQuery
API_KEY = os.getenv("YANDEX_BOT_API_KEY")
bot = Bot(API_KEY)
@bot.message_handler("/start")
async def start(message: Message):
k = Keyboard().row(
Keyboard.button("Кнопка 1", cmd="/btn1"),
Keyboard.button("Кнопка 2", cmd="/btn2"),
).build()
await bot.reply("Выберите:", k)
@bot.button_handler("btn1")
async def btn1(callback: CallbackQuery):
await bot.reply("Нажата кнопка 1")
if __name__ == "__main__":
asyncio.run(bot.run())
```
| text/markdown | Kostin | null | null | null | null | yandex, messenger, bot, dialogs, aiogram | [
"Development Status :: 3 - Alpha",
"Framework :: AsyncIO",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"aiohttp>=3.9.0",
"python-dotenv>=1.0.0",
"loguru>=0.7.0"
] | [] | [] | [] | [
"Homepage, https://github.com/IvanKostin98/yandex-bot-client",
"Repository, https://github.com/IvanKostin98/yandex-bot-client",
"Issues, https://github.com/IvanKostin98/yandex-bot-client/issues"
] | twine/6.2.0 CPython/3.10.9 | 2026-02-20T13:37:33.815831 | yandex_bot_client-0.1.0.tar.gz | 25,405 | f7/0b/97cdff5204a24c3c67d053d95e3ee8b37e34c3642d071bab1650d31fac6a/yandex_bot_client-0.1.0.tar.gz | source | sdist | null | false | 92cf6e5d015d43352b849bbf0eaa2a6d | d65202373c7b9bd1d3bfc44e8cc07aeb1979a99acd20c50034810deb4f18f99e | f70b97cdff5204a24c3c67d053d95e3ee8b37e34c3642d071bab1650d31fac6a | MIT | [
"LICENSE"
] | 228 |
2.4 | chmix | 0.0.2 | Download weather forecast data from CHMI. | # Download CHMI weather forecast data
## Installation
```shell
uv tool install chmix
```
## Running without installation
```shell
uvx chmix aladin Ostrava
```
| text/markdown | Jan Pipek | Jan Pipek <jan.pipek@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.14 | [] | [] | [] | [
"httpx>=0.28.1",
"pandas>=3.0.1",
"tabulate>=0.9.0",
"typer>=0.24.0"
] | [] | [] | [] | [] | uv/0.10.2 {"installer":{"name":"uv","version":"0.10.2","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T13:37:26.658344 | chmix-0.0.2-py3-none-any.whl | 2,553 | ba/15/f5cf3226751cad8892f819ed309296a8385b19a69f9f6e21abbf6170e6b6/chmix-0.0.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 6d098485b08d9060a7b18d19c22f33f9 | 0242069356e4f4f49600d430fe0573de52ff19019ed76e9d655c597a359246fd | ba15f5cf3226751cad8892f819ed309296a8385b19a69f9f6e21abbf6170e6b6 | MIT | [] | 214 |
2.4 | mx8 | 1.0.3 | MX8: bounded data runtime (Rust) exposed to Python. | # mx8 (Python)
MX8 is a bounded-memory data runtime exposed to Python (built with PyO3 + maturin).
The v0 focus is “don’t OOM”: MX8 enforces backpressure with hard caps (so prefetch can’t runaway).
Further docs:
- Python API: `../../docs/python_api.md`
- v1 autotune API contract (planned): `../../docs/v1_autotune_api_contract.md`
- Vision labels/layout: `../../docs/vision_labels.md`
- Vision decode backend plan: `../../docs/vision_decode_backend_plan.md`
- S3/runtime tuning: `../../docs/s3_runtime_tuning.md`
- Memory contract: `../../docs/memory_contract.md`
- AI agent guide: `../../docs/ai_agent_guide.md`
- AI agent context (JSON): `../../docs/ai_agent_context.json`
- Troubleshooting: `../../docs/troubleshooting.md`
## Install (from wheel)
Once you have a wheel (from CI or local build):
- `python -m venv .venv && . .venv/bin/activate`
- `pip install mx8-*.whl`
## Install (from PyPI)
- `python -m venv .venv && . .venv/bin/activate`
- `pip install mx8`
- Optional vision/training deps: `pip install pillow numpy torch`
## Quickstart (local, no S3)
```python
import mx8
mx8.pack_dir(
"/path/to/imagefolder",
out="/path/to/mx8-dataset",
shard_mb=512,
label_mode="imagefolder",
require_labels=True,
)
loader = mx8.vision.ImageFolderLoader(
"/path/to/mx8-dataset@refresh",
batch_size_samples=64,
max_inflight_bytes=256 * 1024 * 1024,
resize_hw=(224, 224), # (H,W); optional
)
print(loader.classes) # ["cat", "dog", ...] if labels.tsv exists
for images, labels in loader:
pass
```
## Zero-manifest load (raw prefix)
```python
import mx8
loader = mx8.load(
"s3://bucket/raw-prefix/",
recursive=True, # default
profile="balanced",
)
for batch in loader:
pass
```
## Mix multiple loaders (v1.7 preview)
`mx8.mix(...)` composes existing loaders into one deterministic stream.
`weights` are sampling proportions (not model-loss weights).
```python
import mx8
loader_a = mx8.load("s3://bucket/dataset_a/@refresh", profile="balanced", autotune=True)
loader_b = mx8.load("s3://bucket/dataset_b/@refresh", profile="balanced", autotune=True)
mixed = mx8.mix(
[loader_a, loader_b],
weights=[1, 1], # fairness baseline (50:50)
seed=0,
epoch=0,
)
for batch in mixed:
pass
print(mixed.stats())
```
Skewed example:
```python
mixed = mx8.mix([loader_a, loader_b], weights=[7, 3], seed=0, epoch=0)
```
`seed` and `epoch` define deterministic schedule behavior:
- same `seed` + `epoch` => same source-pick sequence
- same `seed`, different `epoch` => controlled schedule variation
`starvation_window` is an optional watchdog threshold in scheduler ticks used for starvation counters in `mixed.stats()`.
Set `MX8_MIX_SNAPSHOT=1` (and optional `MX8_MIX_SNAPSHOT_PERIOD_TICKS=64`) to emit periodic `mix_snapshot` proof events.
## Bounded memory (v0)
Set a hard cap and periodically print high-water marks:
```python
import mx8
loader = mx8.vision.ImageFolderLoader(
"/path/to/mx8-dataset@refresh",
batch_size_samples=64,
max_inflight_bytes=256 * 1024 * 1024,
max_queue_batches=8,
prefetch_batches=4,
)
for step, (images, labels) in enumerate(loader):
if step % 100 == 0:
print(loader.stats()) # includes ram_high_water_bytes
```
Avoid patterns that intentionally accumulate batches:
```python
# ❌ Don't do this (will grow RSS regardless of any loader)
all_batches = list(loader)
```
## Labels (optional)
`label_mode="imagefolder"` is designed to scale:
- Per-sample records reference a numeric `label_id` (u64), not a repeated string.
- The human-readable mapping is stored once at `out/_mx8/labels.tsv`.
If your input layout is mixed (files directly under the prefix *and* subfolders), `label_mode="auto"` may disable ImageFolder labeling. To enforce ImageFolder semantics, use:
```python
mx8.pack_dir(..., label_mode="imagefolder", require_labels=True)
```
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | UNLICENSED | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Rust",
"Operating System :: OS Independent"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | maturin/1.12.3 | 2026-02-20T13:37:08.880655 | mx8-1.0.3-cp38-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl | 11,846,870 | 58/29/0ff66c9bbc2bc5305bb212276666bc8020402e19a6ef98e5701de8424705/mx8-1.0.3-cp38-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl | cp38 | bdist_wheel | null | false | 33fd71c066c4622120e4d9d05552020a | 546f5f0148e9e2b4d9507cf8fc87da9e15370c8fd6585b7c399daf180721d02a | 58290ff66c9bbc2bc5305bb212276666bc8020402e19a6ef98e5701de8424705 | null | [] | 157 |
2.4 | sdkrouter | 0.1.25 | Unified SDK for AI services with OpenAI compatibility | # SDKRouter
Unified Python SDK for AI services. Access 300+ LLM models, vision, audio, image generation, search, translation, and more through a single interface.
## Installation
```bash
pip install sdkrouter
```
## Quick Start
```python
from sdkrouter import SDKRouter, Model
client = SDKRouter(api_key="your-api-key")
response = client.chat.completions.create(
model=Model.cheap(),
messages=[{"role": "user", "content": "Hello!"}]
)
print(response.choices[0].message.content)
```
## Features
| Feature | Description | Docs |
|---------|-------------|------|
| **Chat** | OpenAI-compatible completions, streaming | [@docs/01-chat.md](@docs/01-chat.md) |
| **Structured Output** | Pydantic models, JSON extraction | [@docs/02-structured-output.md](@docs/02-structured-output.md) |
| **Audio** | TTS, STT, Deepgram streaming | [@docs/03-audio.md](@docs/03-audio.md) |
| **Vision** | Image analysis, OCR | [@docs/04-vision.md](@docs/04-vision.md) |
| **Image Gen** | AI image generation | [@docs/05-image-gen.md](@docs/05-image-gen.md) |
| **Search** | Web search with modes | [@docs/06-search.md](@docs/06-search.md) |
| **CDN** | File storage | [@docs/07-cdn.md](@docs/07-cdn.md) |
| **Translator** | JSON/text translation | [@docs/08-translator.md](@docs/08-translator.md) |
| **Payments** | Crypto payments | [@docs/09-payments.md](@docs/09-payments.md) |
| **Proxies** | Proxy management | [@docs/10-proxies.md](@docs/10-proxies.md) |
| **Embeddings** | Text embeddings | [@docs/11-embeddings.md](@docs/11-embeddings.md) |
| **Other** | Shortlinks, cleaner, models API | [@docs/12-other.md](@docs/12-other.md) |
## Model Routing
Smart model selection with IDE autocomplete:
```python
from sdkrouter import Model
Model.cheap() # Lowest cost
Model.smart() # Highest quality
Model.balanced() # Best value
Model.fast() # Fastest
# With capabilities
Model.cheap(vision=True) # + vision
Model.smart(tools=True) # + function calling
Model.balanced(json=True) # + JSON mode
# Categories
Model.smart(code=True) # Coding
Model.cheap(reasoning=True) # Problem solving
```
## Async Support
```python
from sdkrouter import AsyncSDKRouter, Model
import asyncio
async def main():
client = AsyncSDKRouter(api_key="your-api-key")
response = await client.chat.completions.create(
model=Model.cheap(),
messages=[{"role": "user", "content": "Hello!"}]
)
# Parallel requests
results = await asyncio.gather(
client.vision.analyze(image_url="..."),
client.audio.speech(input="Hello!"),
)
asyncio.run(main())
```
## Audio Example
```python
from sdkrouter import SDKRouter, AudioModel
client = SDKRouter()
# Text-to-Speech
response = client.audio.speech(
input="Hello!",
model=AudioModel.cheap(),
voice="nova",
)
Path("output.mp3").write_bytes(response.audio_bytes)
# Speech-to-Text
result = client.audio.transcribe(file=audio_bytes)
print(result.text)
```
### Deepgram Streaming
```python
from sdkrouter import AsyncSDKRouter
from sdkrouter.tools.audio.stt import DeepgramConfig
sdk = AsyncSDKRouter()
config = DeepgramConfig(
model="nova-3",
endpointing=300, # VAD: silence threshold (ms)
vad_events=True, # Enable VAD events
)
async with sdk.audio.stt.stream_deepgram(config) as session:
await session.send(audio_chunk)
async for segment in session.transcripts():
print(segment.text)
```
## Configuration
```python
# Environment variables (auto-loaded)
# SDKROUTER_API_KEY
# SDKROUTER_LLM_URL
# SDKROUTER_API_URL
# SDKROUTER_AUDIO_URL
client = SDKRouter(
api_key="your-key",
timeout=60.0,
max_retries=3,
)
```
## Supported Providers
- **OpenAI**: GPT-4.5, GPT-4o, o3, o1
- **Anthropic**: Claude Opus 4.5, Claude Sonnet 4
- **Google**: Gemini 2.5 Pro, Gemini 2.0 Flash
- **Meta**: Llama 4, Llama 3.3
- **Mistral**: Mistral Large, Codestral
- **DeepSeek**: DeepSeek V3, R1
- And 300+ more via OpenRouter
## License
MIT
| text/markdown | null | markolofsen <dev@markolofsen.com> | null | null | null | ai, api, cdn, llm, ocr, openai, sdk, vision | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx<1.0.0,>=0.28.0",
"openai<3.0.0,>=2.0.0",
"pydantic-settings>=2.7.0",
"pydantic<3.0.0,>=2.10.0",
"rich>=14.0.0",
"sdkrouter-tools>=0.1.0",
"tenacity>=9.1.0",
"tiktoken>=0.8.0",
"websockets>=16.0",
"build>=1.2.0; extra == \"dev\"",
"ipykernel>=6.0.0; extra == \"dev\"",
"jupyter>=1.0.0; extra == \"dev\"",
"mypy>=1.15.0; extra == \"dev\"",
"pytest-asyncio>=0.26.0; extra == \"dev\"",
"pytest-cov>=6.0.0; extra == \"dev\"",
"pytest>=8.3.0; extra == \"dev\"",
"questionary>=2.1.0; extra == \"dev\"",
"ruff>=0.9.0; extra == \"dev\"",
"toml>=0.10.0; extra == \"dev\"",
"twine>=6.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://sdkrouter.com",
"Documentation, https://sdkrouter.com",
"Repository, https://sdkrouter.com"
] | twine/6.2.0 CPython/3.10.18 | 2026-02-20T13:36:08.947163 | sdkrouter-0.1.25.tar.gz | 166,147 | 3f/70/e27b825cbe85f486ba91d5dc11cc689ce5b041f4589952af9a3497b64a1b/sdkrouter-0.1.25.tar.gz | source | sdist | null | false | 4ce71a16064e4af5848f7a39c28016cb | 69402a74bbdb7dddf4eb20be2ebdd8138d7a0a86a5628a0d9431ab0ab05bf009 | 3f70e27b825cbe85f486ba91d5dc11cc689ce5b041f4589952af9a3497b64a1b | MIT | [] | 229 |
2.4 | graphreveal | 1.2.0 | Small graphs database and search system | # GraphReveal
[](https://pypi.org/project/graphreveal/)
[](https://pypi.org/project/graphreveal/)
[](https://github.com/mdbrnowski/GraphReveal/actions/workflows/test.yml)
Have you ever needed an example of a graph that, e.g., is Hamiltonian, has exactly 8 vertices, and can be drawn on a plane without intersecting edges? Or wondered how many graphs of size 10 are bipartite, have no isolated vertices, and have exactly two components?
This package aims to answer some of your questions. You can search through all graphs with some reasonable order (currently 9 is the maximum) using a very simple DSL (*domain-specific language*).
## Installation
Make sure that you have Python in a sufficiently recent version. To install the package using `pip`, you can use the following command:
```shell
pip install graphreveal
```
## Basic usage
Firstly, you should create the database:
```shell
graphreveal create-database
```
This process should take less than two seconds and will create a database of graphs with an order no greater than 7. To use a larger database, add the `--n 8` or `--n 9` flag to this command (it should take no more than half an hour).
### Some examples
```shell
graphreveal search "10 edges, bipartite, no isolated vertices, 2 components"
```
```shell
graphreveal count "5..6 vertices, connected"
```
```shell
graphreveal count "5 vertices, connected, not (eulerian | planar)"
```
Command `search` will print a list of graphs in [graph6](https://users.cecs.anu.edu.au/~bdm/data/formats.html) format.
You can use [houseofgraphs.org](https://houseofgraphs.org/draw_graph) to visualize them.
Command `count` will simply output the number of specified graphs.
### List of available properties
* [N] `vertices` (alternatives: `verts`,`V`, `nodes`)
* [N] `edges` (alternative: `E`)
* [N] `blocks` (alternative: `biconnected components`)
* [N] `components` (alternative: `C`)
* `acyclic` (alternative: `forest`)
* `bipartite`
* `complete`
* `connected`
* `cubic` (alternative: `trivalent`)
* `eulerian` (alternative: `euler`)
* `hamiltonian` (alternative: `hamilton`)
* `no isolated vertices` (alternatives: `no isolated v`, `niv`)
* `planar`
* `regular`
* `tree`
As [N], you can use a simple number or range (e.g., `3-4`, `3..4`, `< 5`, `>= 2`).
You can also negate any property using `!` or `not`.
Use `|` for alternatives (disjunction) and parentheses `()` for grouping.
Conjunction (`,` or `;`) binds tighter than `|`.
| text/markdown | null | Michał Dobranowski <mdbrnowski@gmail.com> | null | null | null | database, graph-theory, graphs | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"License :: OSI Approved :: MIT License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Database",
"Topic :: Scientific/Engineering :: Mathematics"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"antlr4-python3-runtime>=4.13.2",
"networkx>=3.4.2",
"platformdirs>=4.3.6",
"rich>=13.9.4",
"typer>=0.17.4"
] | [] | [] | [] | [
"Changelog, https://github.com/mdbrnowski/GraphReveal/releases",
"Source, https://github.com/mdbrnowski/GraphReveal"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:35:36.608979 | graphreveal-1.2.0.tar.gz | 731,441 | 26/16/0ee914ce1acc9c869c7929d1a616d232722bcf4d2635a21f47e565d7032a/graphreveal-1.2.0.tar.gz | source | sdist | null | false | 2c7a435487eb4a63abe56a5a1521c5b5 | 75ac86aba7dff00a072fec726f68ad0b1986ea929ca350592b1fcff154c7b77b | 26160ee914ce1acc9c869c7929d1a616d232722bcf4d2635a21f47e565d7032a | MIT | [
"LICENSE"
] | 227 |
2.4 | hypergas | 0.6.0 | Python package for hyperspectral satellite imaging of trace gases | .. image:: https://raw.githubusercontent.com/SRON-ESG/HyperGas/main/doc/fig/logo.png
:alt: HyperGas Logo
:width: 500
========
HyperGas
========
The HyperGas package is a python library for retrieving trace gases enhancements from hyperspectral satellite data and writing it to different formats (NetCDF, PNG, and HTML).
HyperGas also supports generating plume masks and calculating gas emission rates.
Installation
============
The documentation is available at https://hypergas.readthedocs.io/.
| text/x-rst | null | The HyperGas Team <hypergas@googlegroups.com> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Atmospheric Science"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"cartopy",
"cfgrib",
"contextily",
"dem-stitcher",
"folium",
"h5netcdf",
"matplotlib-scalebar",
"matplotlib>=3.8.0",
"numpy",
"pandas",
"pyresample",
"rioxarray",
"satpy",
"scikit-image>=0.24.0",
"scikit-learn",
"scipy",
"spacetrack",
"spectral",
"streamlit",
"xarray",
"sphinx; extra == \"doc\"",
"sphinx-rtd-theme; extra == \"doc\"",
"sphinxcontrib-apidoc; extra == \"doc\""
] | [] | [] | [] | [
"Homepage, https://github.com/SRON-ESG/HyperGas",
"Bug Tracker, https://github.com/SRON-ESG/HyperGas/issues",
"Documentation, https://hypergas.readthedocs.io/en/stable/",
"Source Code, https://github.com/SRON-ESG/HyperGas",
"Release Notes, https://github.com/SRON-ESG/HyperGas/blob/main/CHANGELOG.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:35:31.234436 | hypergas-0.6.0.tar.gz | 5,947,269 | 9b/4a/3a836329c5f0fd512849a5618f42e484aff7f10162a5c10759e31e096130/hypergas-0.6.0.tar.gz | source | sdist | null | false | c8fbe92399758899ff357c872710d360 | 51598e67c324cc4aca4b84c05e9159813ee4705d21f5f218566658f94eaf5687 | 9b4a3a836329c5f0fd512849a5618f42e484aff7f10162a5c10759e31e096130 | Apache-2.0 | [
"LICENSE"
] | 219 |
2.4 | metal-stack-api | 0.0.51 | Python API client for metal-stack api | Python API client for metal-stack api that implements the v2 api and deprecates metal_python.
| null | metal-stack authors | null | null | null | MIT | metal-stack, metal-apiserver | [
"Intended Audience :: Developers",
"Natural Language :: English",
"Operating System :: POSIX",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://github.com/metal-stack/api | null | null | [] | [] | [] | [
"connect-python>=0.7.0",
"protovalidate>=1.1.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:35:20.735448 | metal_stack_api-0.0.51.tar.gz | 130,829 | e3/9d/7b1200464e4736ac0abf320ac732ccb10b4ae9ca8549e9bc709499bd8e90/metal_stack_api-0.0.51.tar.gz | source | sdist | null | false | b91d94ebf0de83aea96740b4a4010f5c | f916c6c3522a7e71b9da06ab3e49a6d12cdf9282999e64efadd69937936cb406 | e39d7b1200464e4736ac0abf320ac732ccb10b4ae9ca8549e9bc709499bd8e90 | null | [] | 221 |
2.4 | pytest-agents | 1.0.16 | Pytest plugin framework with AI agent capabilities for multi-agent testing | # pytest-agents
[](https://github.com/kmcallorum/pytest-agents/actions/workflows/ci.yml)
[](https://github.com/kmcallorum/pytest-agents/actions/workflows/codeql.yml)
[](https://github.com/kmcallorum/pytest-agents/actions/workflows/release.yml)
[](https://github.com/kmcallorum/pytest-agents/releases)
[](https://pypi.org/project/pytest-agents/)
[](SECURITY.md)
[](https://www.python.org/downloads/)

[](https://github.com/kmcallorum/pytest-agents)
[](docs/METRICS.md)
[](LICENSE)
[](docs/DOCKER.md)
[](https://github.com/psf/black)
A pytest plugin framework with AI agent capabilities for project management, research, and code indexing.
## Quick Start
```bash
# Install from PyPI
pip install pytest-agents
# Verify installation
pytest-agents verify
```
## Features
- **Pytest Plugin**: Extended pytest with custom markers and AI agent integration
- **PM Agent**: TypeScript-based project management agent for task tracking and planning
- **Research Agent**: AI-powered research and documentation analysis
- **Index Agent**: Code indexing and intelligent search capabilities
- **Prometheus Metrics**: Comprehensive observability with metrics collection and HTTP endpoint
- **Dependency Injection**: Full DI implementation across Python and TypeScript components
- **Skills System**: Extensible runtime skills for specialized tasks
## Quick Start
### Installation
**From PyPI (Recommended):**
```bash
pip install pytest-agents
```
**From Docker:**
```bash
docker pull ghcr.io/kmcallorum/pytest-agents:latest
docker run ghcr.io/kmcallorum/pytest-agents:latest pytest-agents verify
```
**From Source:**
```bash
# Clone repository
git clone https://github.com/kmcallorum/pytest-agents.git
cd claudelife
# Install with uv
make install
# Or manually
uv pip install -e ".[dev]"
```
### Verify Installation
```bash
make verify
```
### Run Tests
```bash
# All tests
make test
# Python only
make test-python
# TypeScript only
make test-ts
```
## Project Structure
```
pytest-agents/
├── src/pytest_agents/ # Python pytest plugin package
├── tests/ # Python tests
├── pm/ # TypeScript PM agent
├── research/ # TypeScript Research agent
├── index/ # TypeScript Index agent
├── skills/ # Runtime skills
├── commands/ # Command documentation
└── docs/ # Documentation
```
## Usage
### Using Custom Pytest Markers
```python
import pytest
@pytest.mark.unit
def test_basic_functionality():
assert True
@pytest.mark.integration
@pytest.mark.agent_pm
def test_with_pm_agent(pytest_agents_agent):
result = pytest_agents_agent.invoke('pm', 'analyze_project')
assert result['status'] == 'success'
```
### Parallel Agent Execution
Run multiple agents concurrently for faster test execution:
```python
def test_multi_agent_parallel(agent_coordinator):
"""Run multiple agents in parallel."""
results = agent_coordinator.run_parallel([
('pm', 'track_tasks', {'path': './src'}),
('research', 'analyze_document', {'path': 'README.md'}),
('index', 'index_repository', {'path': './src'})
])
assert all(r['status'] == 'success' for r in results)
```
### Invoking Agents
```python
# Via Python API
from pytest_agents.agent_bridge import AgentBridge
bridge = AgentBridge()
result = bridge.invoke_agent('pm', 'track_tasks', {'path': './src'})
```
```bash
# Via CLI
pytest-agents agent pm --action track_tasks --path ./src
```
### Metrics and Observability
```bash
# Start Prometheus metrics server
pytest-agents metrics
# Custom port
pytest-agents metrics --port 8080
# Configure via environment
export PYTEST_AGENTS_METRICS_ENABLED=true
export PYTEST_AGENTS_METRICS_PORT=9090
```
View metrics at `http://localhost:9090/metrics`. See [Metrics Documentation](docs/METRICS.md) for Prometheus and Grafana integration.
## Development
### Code Quality
```bash
# Format code
make format
# Lint code
make lint
```
### Health Check
```bash
make doctor
```
## Docker Support
pytest-agents is fully containerized for easy deployment and development.
### Quick Start with Docker
```bash
# Build and run verification
docker-compose up pytest-agents
# Run tests in Docker
docker-compose --profile test up pytest-agents-test
# Start development shell
docker-compose --profile dev run pytest-agents-dev
```
See [Docker Documentation](docs/DOCKER.md) for complete deployment guide.
## Security
pytest-agents implements enterprise-grade security practices:
### Automated Security Scanning
- **CodeQL**: Static analysis detecting 400+ security vulnerabilities in Python and TypeScript
- **Snyk Security**: Continuous vulnerability scanning for dependencies and containers
- **Dependency Scanning**: Automated vulnerability detection via Dependabot
- **Container Scanning**: Docker image vulnerability assessment
- **Code Quality**: Ruff linting with security-focused rules
### Security Features
- Multi-stage Docker builds with minimal attack surface
- Dependency pinning for reproducible builds
- Comprehensive test coverage (61%, 230 tests)
- Automated security updates grouped by severity
### Setup and Configuration
**New to security scanning?** See [Security Setup Guide](docs/SECURITY_SETUP.md) for step-by-step instructions to activate Snyk and Dependabot.
### Reporting Vulnerabilities
Please report security vulnerabilities privately via [GitHub Security Advisories](https://github.com/kmcallorum/pytest-agents/security/advisories).
See [SECURITY.md](SECURITY.md) for complete security policy and disclosure guidelines.
## Documentation
See `docs/` directory for detailed documentation:
- [Metrics Guide](docs/METRICS.md) - Prometheus metrics and observability
- [Performance Benchmarks](docs/BENCHMARKS.md) - Performance baselines and optimization
- [Release Process](docs/RELEASE.md) - Automated releases and versioning
- [PyPI Publishing Setup](docs/PYPI_SETUP.md) - Configure PyPI trusted publishing
- [Security Setup Guide](docs/SECURITY_SETUP.md) - Activate security scanning
- [Docker Guide](docs/DOCKER.md) - Container deployment and development
- [Developer Guide](docs/developer-guide/README.md) - Development workflow
- [Architecture Overview](docs/developer-guide/architecture.md) - System design
- [Python API Reference](docs/api/python-api.md) - Python API documentation
- [TypeScript API Reference](docs/api/typescript-api.md) - TypeScript API documentation
## License
MIT
## Author
Kevin McAllorum
# Security scanning now enabled!
| text/markdown | null | Kevin McAllorum <kmcallorum@example.com> | null | null | MIT | agents, ai, multi-agent, pytest, testing, typescript | [
"Development Status :: 3 - Alpha",
"Framework :: Pytest",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Testing"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"dependency-injector>=4.41.0",
"prometheus-client>=0.19.0",
"pytest>=8.0.0",
"typing-extensions>=4.9.0",
"mypy>=1.8.0; extra == \"dev\"",
"pytest-benchmark>=4.0.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:34:56.026777 | pytest_agents-1.0.16.tar.gz | 298,674 | 8d/67/24fd0107728009d5051fb933715cca12b5bc526a1c2460f433598ff5d596/pytest_agents-1.0.16.tar.gz | source | sdist | null | false | b344b2d4bf78589ad69f733e74c72025 | b941a9cc46951dd9b99535a90538e9a18c2ab9e4fbe0ba1aa8bbbbdd90872295 | 8d6724fd0107728009d5051fb933715cca12b5bc526a1c2460f433598ff5d596 | null | [] | 249 |
2.4 | accelerator-commissioning | 1.0.0 | A Python Simulated Commissioning toolkit for synchrotrons (inspired by https://github.com/ThorstenHellert/SC) | # pySC
Python Simulated Commissioning toolkit for synchrotrons.
## Installing
```bash
pip install accelerator-commissioning
```
## Importing specific modules
Intended way of importing a pySC functionality:
```
from pySC import SimulatedCommissioning
from pySC import generate_SC
from pySC import ResponseMatrix
from pySC import orbit_correction
from pySC import measure_bba
from pySC import measure_ORM
from pySC import measure_dispersion
from pySC import pySCInjectionInterface
from pySC import pySCOrbitInterface
# the following disables rich progress bars (doesn't work well with )
from pySC import disable_pySC_rich
disable_pySC_rich()
```
## Acknowledgements
This toolkit was inspired by [SC](https://github.com/ThorstenHellert/SC) which is written in Matlab.
| text/markdown | null | null | null | Konstantinos Paraschou <konstantinos.paraschou@desy.de> | null | Accelerator, Commissioning, Synchrotron | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"Natural Language :: English",
"Programming Language :: Python",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Physics"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"accelerator-toolbox>=0.6.1",
"h5py",
"matplotlib>=3.7.3",
"numpy>=2.0.0",
"pydantic",
"pyyaml>=6.0.2",
"rich",
"scipy>=1.11.4",
"sphinx; extra == \"doc\"",
"sphinx-rtd-theme; extra == \"doc\"",
"travis-sphinx; extra == \"doc\"",
"pytest-cov>=3.0; extra == \"test\"",
"pytest>=7.4; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/kparasch/pySC",
"Repository, https://github.com/kparasch/pySC.git"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:33:44.178175 | accelerator_commissioning-1.0.0.tar.gz | 61,834 | b0/92/441ba3c44f811f83e4e3d4f2f4c2ad2b8ec6191ca17a231abc5d31f8192b/accelerator_commissioning-1.0.0.tar.gz | source | sdist | null | false | 9183b54395ef06f60d12e0352850ce0b | 9f238714a5f4b9638976b0dae9899cfce56ba114d381285889b49d84dafeaccb | b092441ba3c44f811f83e4e3d4f2f4c2ad2b8ec6191ca17a231abc5d31f8192b | null | [
"LICENSE"
] | 229 |
2.4 | sharepoint-mcp | 1.0.0 | Production-grade MCP Server for Microsoft SharePoint — manage folders, documents, and metadata with any MCP-compatible AI agent. | <div align="center">
<!-- mcp-name: io.github.ravikant1918/sharepoint-mcp -->
# 🗂️ sharepoint-mcp
### **The MCP Server that gives your AI agent a brain for Microsoft SharePoint**
[](https://github.com/ravikant1918/sharepoint-mcp/actions/workflows/ci.yml)
[](https://pypi.org/project/sharepoint-mcp/)
[](https://pypi.org/project/sharepoint-mcp/)
[](https://opensource.org/licenses/MIT)
[](https://github.com/ravikant1918/sharepoint-mcp#-docker)
[](https://modelcontextprotocol.io)
A production-grade **Model Context Protocol (MCP) server** for **Microsoft SharePoint**.
Connect **Claude Desktop**, **VS Code Copilot**, **Cursor**, **Continue**, or any MCP-compatible AI agent
to your SharePoint — read files, manage folders, and reason over your organisation's knowledge.
[📚 Docs](docs/) · [🗺️ Roadmap](docs/roadmap.md) · [🐛 Bugs](https://github.com/ravikant1918/sharepoint-mcp/issues) · [💡 Features](https://github.com/ravikant1918/sharepoint-mcp/issues/new?template=feature_request.yml)
</div>
---
## 📑 Table of Contents
- [Why sharepoint-mcp?](#-why-sharepoint-mcp)
- [What Your Agent Can Do](#-what-your-agent-can-do)
- [Features](#-features)
- [Quickstart](#-quickstart)
- [Docker](#-docker)
- [Transport Modes](#-transport-modes)
- [Integrations](#-integrations) — Claude Desktop · VS Code Copilot · Cursor
- [All 13 Tools](#️-all-13-tools)
- [Configuration Reference](#️-full-configuration-reference)
- [Limitations](#️-limitations)
- [Troubleshooting](#-troubleshooting)
- [Development](#-development)
- [Documentation](#-documentation)
- [Contributing](#-contributing)
- [Security](#-security)
---
## 🧠 Why sharepoint-mcp?
> Most AI agents only know what's in their training data.
> **sharepoint-mcp** gives your agent *live access* to your organisation's real knowledge.
| Without sharepoint-mcp | With sharepoint-mcp |
|---|---|
| 🤷 Agent guesses or hallucinates | Agent reads the actual document |
| 📋 You copy-paste content manually | Agent fetches files automatically |
| 🔒 Knowledge locked in SharePoint | Knowledge flows into your AI workflow |
| 🐌 Static, one-shot answers | Agent reasons, rewrites, and saves back |
---
## 🚀 What Your Agent Can Do
### 📖 Understand Any Document
```
You: "Summarise the Q3 report in the Finance folder"
Agent: → Get_Document_Content("Finance", "Q3_Report.pdf")
→ Reads full extracted text
→ Returns a sharp, accurate summary
```
### ✏️ Read → Reason → Write
```
You: "Translate the proposal to French and save it"
Agent: → Get_Document_Content → translate → Upload_Document
```
### 🗂️ Navigate Your Library
```
You: "What files are in the Legal/Contracts folder?"
Agent: → List_SharePoint_Documents("Legal/Contracts")
```
### 📊 Supported File Formats
| 📄 Format | 🤖 What the Agent Gets |
|---|---|
| **PDF** | Full text from every page |
| **Word** `.docx` `.doc` | Complete document content |
| **Excel** `.xlsx` `.xls` | All sheets as structured text |
| **Text, JSON, Markdown, HTML, YAML, Python** | Raw content as-is |
| **Images, ZIP, binaries** | File type + Base64 |
---
## ✨ Features
| | Feature | Description |
|---|---|---|
| 📁 | **Folder Management** | List, create, delete, get full recursive tree |
| 📄 | **Document Management** | Upload, download, update, delete, read content |
| 🏷️ | **Metadata Management** | Read and update SharePoint list-item fields |
| 🔍 | **Smart Parsing** | Auto-detects PDF / Word / Excel / text |
| 🔁 | **Auto-Retry** | Exponential backoff on SharePoint 429/503 throttling |
| 🚀 | **Dual Transport** | `stdio` for desktop · `http` for Docker/remote |
| 🪵 | **Structured Logging** | JSON in production · coloured console in dev |
| 🐳 | **Docker-Ready** | Single command: `docker compose up -d` |
| 🛡️ | **Non-Root Container** | Runs as unprivileged user inside Docker |
| 🤖 | **CI/CD** | Tested on Python 3.10 · 3.11 · 3.12 · 3.13 |
---
## ⚡ Quickstart
### 1️⃣ Install
```bash
pip install sharepoint-mcp
```
Or from source:
```bash
git clone https://github.com/ravikant1918/sharepoint-mcp.git
cd sharepoint-mcp && pip install -e .
```
### 2️⃣ Configure
```bash
cp .env.example .env
# Open .env and fill in your Azure AD credentials
```
```env
SHP_ID_APP=your-azure-app-client-id
SHP_ID_APP_SECRET=your-azure-app-secret
SHP_TENANT_ID=your-tenant-id
SHP_SITE_URL=https://your-tenant.sharepoint.com/sites/your-site
```
> 🔑 **New to Azure AD?** Follow the [step-by-step guide →](docs/azure-setup.md)
### 3️⃣ Run
```bash
# 🔍 Interactive testing with MCP Inspector
npx @modelcontextprotocol/inspector -- sharepoint-mcp
# ▶️ Run directly
sharepoint-mcp
```
---
## 🐳 Docker
The fastest way to deploy for remote or cloud use:
```bash
cp .env.example .env # fill in your credentials
docker compose up -d # start HTTP server on port 8000
```
> **Using Podman?** Just replace `docker` with `podman` — fully compatible.
### Docker Environment Variables
| Variable | Default | Description |
|---|---|---|
| `TRANSPORT` | `http` | `stdio` or `http` |
| `HTTP_HOST` | `0.0.0.0` | Bind address |
| `HTTP_PORT` | `8000` | Port |
| `LOG_FORMAT` | `json` | `json` or `console` |
---
## 🔌 Transport Modes
| Mode | Best For | Set With |
|---|---|---|
| `stdio` | Claude Desktop, Cursor, MCP Inspector | `TRANSPORT=stdio` *(default)* |
| `http` | Docker, remote agents, VS Code Copilot, REST clients | `TRANSPORT=http` |
---
## 🔗 Integrations
### 🤖 Claude Desktop
Add to `~/Library/Application Support/Claude/claude_desktop_config.json`:
```json
{
"mcpServers": {
"sharepoint": {
"command": "sharepoint-mcp",
"env": {
"SHP_ID_APP": "your-app-id",
"SHP_ID_APP_SECRET": "your-app-secret",
"SHP_SITE_URL": "https://your-tenant.sharepoint.com/sites/your-site",
"SHP_TENANT_ID": "your-tenant-id",
"SHP_DOC_LIBRARY": "Shared Documents/your-folder"
}
}
}
}
```
### 💻 VS Code Copilot (Agent Mode)
1. Start the server via Docker or `TRANSPORT=http sharepoint-mcp`
2. Create `.vscode/mcp.json` in your workspace:
```json
{
"servers": {
"sharepoint": {
"url": "http://localhost:8000/mcp/",
"type": "http"
}
}
}
```
3. Open Copilot Chat → switch to **Agent mode** → your 13 SharePoint tools are available.
> ⚠️ **Trailing slash matters** — the URL must end with `/mcp/` (not `/mcp`).
### ⌨️ Cursor / Continue
Add to your MCP config (uses stdio transport):
```json
{
"mcpServers": {
"sharepoint": {
"command": "sharepoint-mcp",
"env": {
"SHP_ID_APP": "your-app-id",
"SHP_ID_APP_SECRET": "your-app-secret",
"SHP_SITE_URL": "https://your-tenant.sharepoint.com/sites/your-site",
"SHP_TENANT_ID": "your-tenant-id"
}
}
}
}
```
---
## 🛠️ All 13 Tools
### 📁 Folder Management
| Tool | What It Does |
|---|---|
| `List_SharePoint_Folders` | 📋 List all sub-folders in a directory |
| `Get_SharePoint_Tree` | 🌳 Get full recursive folder + file tree |
| `Create_Folder` | ➕ Create a new folder |
| `Delete_Folder` | 🗑️ Delete an empty folder |
### 📄 Document Management
| Tool | What It Does |
|---|---|
| `List_SharePoint_Documents` | 📋 List all files with metadata |
| `Get_Document_Content` | 📖 Read & parse file content (PDF/Word/Excel/text) |
| `Upload_Document` | ⬆️ Upload file as string or Base64 |
| `Upload_Document_From_Path` | 📂 Upload a local file directly |
| `Update_Document` | ✏️ Overwrite existing file content |
| `Delete_Document` | 🗑️ Permanently delete a file |
| `Download_Document` | ⬇️ Download file to local filesystem |
### 🏷️ Metadata Management
| Tool | What It Does |
|---|---|
| `Get_File_Metadata` | 🔍 Get all SharePoint list-item fields |
| `Update_File_Metadata` | ✏️ Update metadata fields |
---
## ⚙️ Full Configuration Reference
| Variable | Required | Default | Description |
|---|---|---|---|
| `SHP_ID_APP` | | `12345678-1234-1234-1234-123456789012` | Azure AD app client ID |
| `SHP_ID_APP_SECRET` | | `your-app-secret` | Azure AD client secret |
| `SHP_TENANT_ID` | | `your-tenant-id` | Microsoft tenant ID |
| `SHP_SITE_URL` | | `https://your-tenant.sharepoint.com/sites/your-site` | SharePoint site URL |
| `SHP_DOC_LIBRARY` | | `Shared Documents/mcp_server` | Library path |
| `SHP_MAX_DEPTH` | | `15` | Max tree depth |
| `SHP_MAX_FOLDERS_PER_LEVEL` | | `100` | Folders per batch |
| `SHP_LEVEL_DELAY` | | `0.5` | Delay (s) between tree levels |
| `TRANSPORT` | | `stdio` | `stdio` or `http` |
| `HTTP_HOST` | | `0.0.0.0` | HTTP bind host |
| `HTTP_PORT` | | `8000` | HTTP port |
| `LOG_LEVEL` | | `INFO` | `DEBUG` `INFO` `WARNING` `ERROR` |
| `LOG_FORMAT` | | `console` | `console` or `json` |
---
## ⚠️ Limitations
| Limitation | Details |
|---|---|
| **Single site** | Connects to one SharePoint site per server instance (multi-site planned for v2.0) |
| **Sync client** | Uses synchronous SharePoint REST API calls (async client planned for v1.3) |
| **No search** | Full-text search not yet available (planned for v1.1) |
| **No sharing** | Cannot create sharing links yet (planned for v1.1) |
| **Large files** | Very large files may hit memory limits during content extraction |
| **Rate limits** | SharePoint throttling (429/503) is handled with auto-retry, but sustained bulk operations may be slow |
---
## 🔧 Troubleshooting
### Authentication Errors
**Problem:** `Missing or invalid SharePoint credentials`
**Solution:** Verify all 4 required environment variables are set:
```bash
echo $SHP_ID_APP $SHP_ID_APP_SECRET $SHP_TENANT_ID $SHP_SITE_URL
```
### Connection Issues (HTTP Transport)
**Problem:** Agent can't connect to the MCP server
**Solution:**
1. Ensure the server is running: `curl http://localhost:8000/mcp/`
2. Check the URL ends with `/mcp/` (trailing slash required)
3. Verify the port is not blocked by a firewall
### Docker Container Unhealthy
**Problem:** `podman ps` / `docker ps` shows `(unhealthy)`
**Solution:** Check container logs for errors:
```bash
docker logs sharepoint-mcp
```
### Debug Logging
Enable verbose output by setting `LOG_LEVEL=DEBUG`:
```bash
LOG_LEVEL=DEBUG sharepoint-mcp
```
For Docker, add to your `.env` file or `docker-compose.yml`:
```env
LOG_LEVEL=DEBUG
LOG_FORMAT=console
```
### Permission Errors
**Problem:** `Access denied` from SharePoint
**Solution:**
1. Verify the Azure AD app has the required API permissions
2. Ensure admin consent has been granted (if required by your org)
3. Confirm `SHP_SITE_URL` points to a site your app has access to
---
## 🧪 Development
```bash
git clone https://github.com/ravikant1918/sharepoint-mcp.git
cd sharepoint-mcp
pip install -e ".[dev]"
make test # run all tests
make inspect # 🔍 launch MCP Inspector
make check # quick import sanity check
make clean # 🧹 remove caches
```
---
## 📚 Documentation
| 📄 Doc | 📝 Description |
|---|---|
| [⚡ Getting Started](docs/getting-started.md) | Full setup guide |
| [⚙️ Configuration](docs/configuration.md) | All environment variables |
| [🛠️ Tools Reference](docs/tools-reference.md) | Detailed tool parameters |
| [🏛️ Architecture](docs/architecture.md) | Design and layer diagram |
| [🔑 Azure Setup](docs/azure-setup.md) | Azure AD app registration guide |
| [🗺️ Roadmap](docs/roadmap.md) | Planned features |
| [📅 Changelog](docs/changelog.md) | Version history |
---
## 🤝 Contributing
Contributions are welcome! Please read [docs/contributing.md](docs/contributing.md) and our [Code of Conduct](CODE_OF_CONDUCT.md).
1. 🍴 Fork the repo
2. 🌿 Create a branch: `git checkout -b feat/my-tool`
3. ✅ Add tests: `make test`
4. 📬 Open a Pull Request
---
## 🔒 Security
Found a vulnerability? Please **do not** open a public issue.
Report privately via [GitHub Security Advisories](https://github.com/ravikant1918/sharepoint-mcp/security/advisories/new) or see [SECURITY.md](SECURITY.md).
---
<div align="center">
**MIT License © 2026 [Ravi Kant](https://github.com/ravikant1918)**
⭐ If this project helps you, please star it on GitHub!
</div>
| text/markdown | null | Ravi Kant <developerrk1918@gmail.com> | null | null | MIT | mcp, sharepoint, microsoft365, llm, ai-agent, model-context-protocol | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Application Frameworks",
"Topic :: Internet"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"mcp>=1.2.1",
"office365-rest-python-client>=2.6.1",
"python-dotenv>=1.0.0",
"pymupdf>=1.23.0",
"pandas>=2.0.0",
"openpyxl>=3.1.0",
"python-docx>=1.1.0",
"structlog>=24.0.0",
"tenacity>=8.2.0",
"pydantic>=2.0.0",
"pytest>=8.0; extra == \"dev\"",
"pytest-asyncio>=0.23; extra == \"dev\"",
"pytest-mock>=3.12; extra == \"dev\"",
"ruff>=0.3.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/ravikant1918/sharepoint-mcp",
"Documentation, https://github.com/ravikant1918/sharepoint-mcp/tree/main/docs",
"Repository, https://github.com/ravikant1918/sharepoint-mcp",
"Bug Tracker, https://github.com/ravikant1918/sharepoint-mcp/issues",
"Changelog, https://github.com/ravikant1918/sharepoint-mcp/blob/main/docs/changelog.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:33:09.839813 | sharepoint_mcp-1.0.0.tar.gz | 25,172 | 7e/b3/03a2baf507fbc9e139e84aaf6baa54e2de992d6fd7ed1b93aafca6a7dffe/sharepoint_mcp-1.0.0.tar.gz | source | sdist | null | false | 762301d7074ecfc2822fe85996458567 | 179f4573dc3bf0d7d08e32f4ecb333f01c005799b8d8b7423af125f1cbdd16f2 | 7eb303a2baf507fbc9e139e84aaf6baa54e2de992d6fd7ed1b93aafca6a7dffe | null | [
"LICENSE"
] | 239 |
2.1 | osef | 3.4.0 | Osef python library. | # OSEF library
Library containing utilities to read and parse a stream, live or recorded, retrieved from
**Shift**.
The stream is in the **OSEF** format (**O**pen **SE**rialization **F**ormat):
it's an Outsight-defined serialisation binary format used to encode data streaming out of Shift.
It is based on *TLV-encoding*.
For the full documentation, see: [Developer documentation](https://outsight-tech.gitlab.io/common/osef-python-library/).
You can contact us @ https://support.outsight.ai
## Installation
Install from PyPi using pip:
```bash
pip install osef
```
## Usage
Open and parse an osef file or stream:
```python
import osef
osef_path = "path/to/my/file.osef"
# or osef_path="tcp://192.168.2.2:11120"
for frame_dict in osef.parse(osef_path):
print(frame_dict)
```
Additional parameters:
- `first`/`last`: the first and the last frame to parse
- `auto_reconnect`: enable parser auto_reconnection (default: `True`)
- `real_frequency`: If False, parse data as fast as your computer can. If True, process the data as the same pace as the real time stream from Shift (default: `False`)
- `lazy`: If lazy, the dict only unpack the values when they are accessed to save up resources (default: `True`)
To find more code samples, see [Outsight Code Samples repository](https://gitlab.com/outsight-public/outsight-code-samples/-/tree/master).
## Development
1. The repository uses LFS to store some large OSEF samples for the tests. You need to install `git-lfs` and then run the following commands to get the files.
```bash
git lfs pull
```
2. Install project and dependencies.
- create and activate venv (`python -m venv venv`, then `source venv/bin/activate`)
- `pip install -e .` to install the project
- `pip install -r test_requirements.txt` to install dev dependencies (formatter, linter, unit tests dependencies)
3. **Linting**. Code is compatible with python 3.8+, pylint is set to ensure compatibility with python 3.8. To quickly run black + pylint,
```bash
./devops/local_lint.sh
```
4. **Unit tests**. We use pytest. Some tests might take time (about a couple of minutes)
```bash
pytest tests/
```
| text/markdown | null | Outsight Developpers <support@outsight.tech> | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy>=1.21.0"
] | [] | [] | [] | [
"Documentation, https://outsight-tech.gitlab.io/common/osef-python-library/",
"Support, https://support.outsight.ai",
"Changes, https://outsight-tech.gitlab.io/common/osef-python-library/CHANGELOG.html"
] | twine/6.1.0 CPython/3.8.20 | 2026-02-20T13:33:08.385767 | osef-3.4.0.tar.gz | 55,188 | 31/e9/33df4433570111b117ae40982fa6caf9e69027a55ea49fb03162bb970c7c/osef-3.4.0.tar.gz | source | sdist | null | false | 3dd0aee363434f06b846bdecf401806d | eb6d9411d01db1dc5c7438a85285a9c47bd1fc5f692c1b8dc1224639c2a190f3 | 31e933df4433570111b117ae40982fa6caf9e69027a55ea49fb03162bb970c7c | null | [] | 226 |
2.4 | tibet-core | 0.2.0 | Token-based Intent, Behavior, Evidence & Trust - Cryptographic provenance for trustworthy systems | # tibet-core
**Token-based Intent, Behavior, Evidence & Trust**
Cryptographic provenance for trustworthy systems. Zero dependencies. Audit-ready.
## Why TIBET?
Traditional security monitors *traffic*. TIBET audits *actions*.
Every function call, every decision, every transformation gets a cryptographic token with:
- **ERIN** (What's IN): The content/data of the action
- **ERAAN** (What's attached): References, dependencies
- **EROMHEEN** (What's around): Context, environment, state
- **ERACHTER** (What's behind): Intent, reason, purpose
## Compliance Ready
TIBET provides the audit foundation for:
| Standard | TIBET Support |
|----------|---------------|
| **ISO 5338** | AI decision traceability |
| **NIS2** | Continuous logging, incident snapshots |
| **BIO2** | Government security baseline |
| **OWASP** | Security event provenance |
## Installation
```bash
pip install tibet-core
```
## Quick Start
```python
from tibet_core import Provider, FileStore
# Create provider with persistent storage
tibet = Provider(
actor="jis:humotica:my_app",
store=FileStore("./audit.jsonl")
)
# Record any action
token = tibet.create(
action="user_login",
erin={"user_id": "alice", "method": "oauth"},
eraan=["jis:humotica:auth_service"],
eromheen={"ip": "192.168.1.1", "user_agent": "Mozilla/5.0"},
erachter="User authentication for dashboard access"
)
# Token has cryptographic integrity
assert token.verify()
print(token.content_hash) # SHA-256
# Export audit trail
audit = tibet.export(format="jsonl")
```
## Integration Examples
### With rapid-rag (RAG/Search)
```python
from rapid_rag import RapidRAG
from tibet_core import Provider
tibet = Provider(actor="jis:company:rag_system")
rag = RapidRAG("documents", tibet=tibet)
# All operations now have provenance
rag.add_file("contract.pdf")
results = rag.search("liability clause")
answer = rag.query("What are our obligations?")
# Full audit trail
for token in tibet.find(action="search"):
print(f"{token.timestamp}: {token.erin['query']}")
```
### With oomllama (LLM Routing)
```python
from oomllama import Engine
from tibet_core import Provider
tibet = Provider(actor="jis:company:llm_router")
# Every LLM call is audited
response = engine.generate(
prompt="Summarize this document",
tibet=tibet
)
# Know which model answered, why, with what context
```
### With comms-core-rs (Telephony)
```rust
// Rust: 0.02 second call setup WITH tibet exchange
let token = tibet.create(
action: "call_initiated",
erin: CallData { from, to, codec },
erachter: "Outbound sales call"
);
```
## Chain Tracing
Follow provenance chains:
```python
from tibet_core import Chain
chain = Chain(tibet.store)
# Trace backwards from any token
history = chain.trace(token.token_id)
for t in history:
print(f"{t.action}: {t.erachter}")
# Verify entire chain integrity
if chain.verify(token.token_id):
print("Audit trail intact")
# Get chain summary
summary = chain.summary(token.token_id)
print(f"Chain length: {summary['length']}")
print(f"Actors involved: {summary['actors']}")
```
## Storage Backends
### MemoryStore (default)
Fast, ephemeral. Good for testing.
### FileStore
Append-only JSONL. Audit-friendly. Tamper-evident.
```python
from tibet_core import FileStore
store = FileStore("./audit.jsonl")
# Verify file integrity
result = store.verify_file()
if not result["integrity"]:
print(f"Corrupted tokens: {result['corrupted_ids']}")
```
## Performance
TIBET adds minimal overhead:
- Token creation: ~0.1ms
- Hash computation: ~0.05ms
- File append: ~0.2ms
In comms-core-rs, full call setup with TIBET exchange: **0.02 seconds**
More code ≠ slower. Trust ≠ overhead.
## Philosophy
> "Audit de basis voor elke actie, niet voor communicatie verkeer"
>
> "Audit as foundation for every action, not just traffic"
TIBET doesn't watch the wire. It lives inside the action.
## License
MIT - Humotica
## Links
- [Humotica](https://humotica.com)
- [JIS Identity Standard](https://pypi.org/project/jtel-identity-standard/)
- [rapid-rag](https://pypi.org/project/rapid-rag/)
- [oomllama](https://pypi.org/project/oomllama/)
| text/markdown | null | "J. van de Meent" <jasper@humotica.com>, "R. AI" <info@humotica.com> | null | null | MIT | ai-safety, audit, behavior, bio2, compliance, cryptographic, evidence, intent, iso5338, nis2, owasp, provenance, security, tokens, trust | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Security",
"Topic :: Security :: Cryptography",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: System :: Logging"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pytest>=7.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"httpx>=0.24.0; extra == \"full\""
] | [] | [] | [] | [
"Homepage, https://humotica.com",
"Repository, https://github.com/humotica/tibet-core",
"Documentation, https://humotica.com/docs/tibet"
] | twine/6.2.0 CPython/3.13.5 | 2026-02-20T13:32:56.269306 | tibet_core-0.2.0.tar.gz | 8,762 | 59/39/d01c603c2e35931b9f6e58a50fa5b78dc70cdece17677e3d10b4f2d599be/tibet_core-0.2.0.tar.gz | source | sdist | null | false | 233f8407a57c59a1065c2f88e11c943c | 157393af389b83b5561b33d8302618a97a68b38c041075b7f61ba40275649f11 | 5939d01c603c2e35931b9f6e58a50fa5b78dc70cdece17677e3d10b4f2d599be | null | [] | 310 |
2.4 | hamtaa-texttools | 2.8.1 | A high-level NLP toolkit built on top of modern LLMs. | # TextTools


## 📌 Overview
**TextTools** is a high-level **NLP toolkit** built on top of **LLMs**.
It provides three API styles for maximum flexibility:
- Sync API (`TheTool`) - Simple, sequential operations
- Async API (`AsyncTheTool`) - High-performance async operations
- Batch API (`BatchTheTool`) - Process multiple texts in parallel with built-in concurrency control
It provides ready-to-use utilities for **translation, question detection, categorization, NER extraction, and more** - designed to help you integrate AI-powered text processing into your applications with minimal effort.
---
## ✨ Features
TextTools provides a collection of high-level NLP utilities.
Each tool is designed to work with structured outputs.
- **`categorize()`** - Classify text into given categories
- **`extract_keywords()`** - Extract keywords from the text
- **`extract_entities()`** - Perform Named Entity Recognition (NER)
- **`is_question()`** - Detect if the input is phrased as a question
- **`to_question()`** - Generate questions from the given text / subject
- **`merge_questions()`** - Merge multiple questions into one
- **`augment()`** - Rewrite text in different augmentations
- **`summarize()`** - Summarize the given text
- **`translate()`** - Translate text between languages
- **`propositionize()`** - Convert a text into atomic, independent, meaningful sentences
- **`is_fact()`** - Check whether a statement is a fact based on the source text
- **`run_custom()`** - Custom tool that can do almost anything
---
## 🚀 Installation
Install the latest release via PyPI:
```bash
pip install -U hamtaa-texttools
```
---
## 📊 Tool Quality Tiers
| Status | Meaning | Tools | Safe for Production? |
|--------|---------|----------|-------------------|
| **✅ Production** | Evaluated and tested. | `categorize()`, `extract_keywords()`, `extract_entities()`, `is_question()`, `to_question()`, `merge_questions()`, `augment()`, `summarize()`, `run_custom()` | **Yes** - ready for reliable use. |
| **🧪 Experimental** | Added to the package but **not fully evaluated**. | `translate()`, `propositionize()`, `is_fact()` | **Use with caution** |
---
## ⚙️ Additional Parameters
- **`with_analysis: bool`** → Adds a reasoning step before generating the final output.
**Note:** This doubles token usage per call.
- **`logprobs: bool`** → Returns token-level probabilities for the generated output. You can also specify `top_logprobs=<N>` to get the top N alternative tokens and their probabilities.
**Note:** This feature works if it's supported by the model.
- **`output_lang: str`** → Forces the model to respond in a specific language.
- **`user_prompt: str`** → Allows you to inject a custom instruction into the model alongside the main template.
- **`temperature: float`** → Determines how creative the model should respond. Takes a float number between `0.0` and `2.0`.
- **`normalize: bool`** → Whether to apply text cleaning (removing separator lines and normalizing quotation marks) before sending to the LLM.
- **`max_completion_tokens: int`** → Limits the maximum number of tokens to generate in the completion.
**Note:** If the token limit is reached before the completion finishes, an error will be raised.
- **`validator: Callable (Experimental)`** → Forces the tool to validate the output result based on your validator function. Validator should return a boolean. If the validator fails, TheTool will retry to get another output by modifying `temperature`. You can also specify `max_validation_retries=<N>`.
- **`priority: int (Experimental)`** → Affects processing order in queues.
**Note:** This feature works if it's supported by the model and vLLM.
- **`timeout: float`** → Maximum time in seconds to wait for the response before raising a timeout error.
**Note:** This feature is only available in `AsyncTheTool`.
---
## 🧩 ToolOutput
Every tool of `TextTools` returns a `ToolOutput` object which is a BaseModel with attributes:
- **`result: Any`**
- **`analysis: str`**
- **`logprobs: list`**
- **`errors: list[str]`**
- **`ToolOutputMetadata`**
- **`tool_name: str`**
- **`processed_by: str`**
- **`processed_at: datetime`**
- **`execution_time: float`**
- **`token_usage: TokenUsage`**
- **`completion_usage: CompletionUsage`**
- **`prompt_tokens: int`**
- **`completion_tokens: int`**
- **`total_tokens: int`**
- **`analyze_usage: AnalyzeUsage`**
- **`prompt_tokens: int`**
- **`completion_tokens: int`**
- **`total_tokens: int`**
- **`total_tokens: int`**
- Serialize output to JSON using the `model_dump_json()` method.
- Verify operation success with the `is_successful()` method.
- Convert output to a dictionary with the `model_dump()` method.
**Note:** For BatchTheTool: Each method returns a `list[ToolOutput]` containing results for all input texts.
---
## 🧨 Sync vs Async vs Batch
| Tool | Style | Use Case | Best For |
|------|-------|----------|----------|
| `TheTool` | **Sync** | Simple scripts, sequential workflows | • Quick prototyping<br>• Simple scripts<br>• Sequential processing<br>• Debugging |
| `AsyncTheTool` | **Async** | High-throughput applications, APIs, concurrent tasks | • Web APIs<br>• Concurrent operations<br>• High-performance apps<br>• Real-time processing |
| `BatchTheTool` | **Batch** | Process multiple texts efficiently with controlled concurrency | • Bulk processing<br>• Large datasets<br>• Parallel execution<br>• Resource optimization |
---
## ⚡ Quick Start (Sync)
```python
from openai import OpenAI
from texttools import TheTool
client = OpenAI(base_url="your_url", API_KEY="your_api_key")
model = "model_name"
the_tool = TheTool(client=client, model=model)
detection = the_tool.is_question("Is this project open source?")
print(detection.model_dump_json())
```
---
## ⚡ Quick Start (Async)
```python
import asyncio
from openai import AsyncOpenAI
from texttools import AsyncTheTool
async def main():
async_client = AsyncOpenAI(base_url="your_url", api_key="your_api_key")
model = "model_name"
async_the_tool = AsyncTheTool(client=async_client, model=model)
translation_task = async_the_tool.translate("سلام، حالت چطوره؟", target_language="English")
keywords_task = async_the_tool.extract_keywords("This open source project is great for processing large datasets!")
(translation, keywords) = await asyncio.gather(translation_task, keywords_task)
print(translation.model_dump_json())
print(keywords.model_dump_json())
asyncio.run(main())
```
## ⚡ Quick Start (Batch)
```python
import asyncio
from openai import AsyncOpenAI
from texttools import BatchTheTool
async def main():
async_client = AsyncOpenAI(base_url="your_url", api_key="your_api_key")
model = "model_name"
batch_the_tool = BatchTheTool(client=async_client, model=model, max_concurrency=3)
categories = await batch_tool.categorize(
texts=[
"Climate change impacts on agriculture",
"Artificial intelligence in healthcare",
"Economic effects of remote work",
"Advancements in quantum computing",
],
categories=["Science", "Technology", "Economics", "Environment"],
)
for i, result in enumerate(categories):
print(f"Text {i+1}: {result.result}")
asyncio.run(main())
```
---
## ✅ Use Cases
Use **TextTools** when you need to:
- 🔍 **Classify** large datasets quickly without model training
- 🧩 **Integrate** LLMs into production pipelines (structured outputs)
- 📊 **Analyze** large text collections using embeddings and categorization
---
## 📄 License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
---
## 🤝 Contributing
We welcome contributions from the community! - see the [CONTRIBUTING](CONTRIBUTING.md) file for details.
## 📚 Documentation
For detailed documentation, architecture overview, and implementation details, please visit the [docs](docs) directory.
| text/markdown | null | Tohidi <the.mohammad.tohidi@gmail.com>, Erfan Moosavi <erfanmoosavi84@gmail.com>, Montazer <montazerh82@gmail.com>, Givechi <mohamad.m.givechi@gmail.com>, Zareshahi <a.zareshahi1377@gmail.com> | null | Erfan Moosavi <erfanmoosavi84@gmail.com>, Tohidi <the.mohammad.tohidi@gmail.com> | MIT | nlp, llm, text-processing, openai | [
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: MIT License",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Text Processing",
"Operating System :: OS Independent"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"openai>=1.97.1",
"pydantic>=2.0.0",
"pyyaml>=6.0",
"tqdm>=4.67.3",
"typing-extensions>=4.15.0",
"pytest>=9.0.2; extra == \"dev\"",
"python-dotenv>=1.2.1; extra == \"dev\""
] | [] | [] | [] | [] | uv/0.9.28 {"installer":{"name":"uv","version":"0.9.28","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T13:32:15.886280 | hamtaa_texttools-2.8.1-py3-none-any.whl | 39,402 | a6/39/4c9a10108b84f94333d4f384adfebe4e1698e4119a42bb5f302fd4c37eea/hamtaa_texttools-2.8.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 22b64391405f64ccc8f941f88c788133 | 9422cad639a19577f9e0b0b5a8c00897b783966e0d82b7c0d859ccc3df2fd6da | a6394c9a10108b84f94333d4f384adfebe4e1698e4119a42bb5f302fd4c37eea | null | [
"LICENSE"
] | 211 |
2.1 | ebbe | 1.15.1 | Collection of typical helper functions for python. | [](https://github.com/Yomguithereal/ebbe/actions)
# Ebbe
A collection of typical helper functions for python that cannot be found in the however great standard library.
## Installation
You can install `ebbe` with pip with the following command:
```
pip install ebbe
```
## Usage
*Iterator functions*
* [as_chunks](#as_chunks)
* [as_reconciled_chunks](#as_reconciled_chunks)
* [outer_zip](#outer_zip)
* [as_grams](#as_grams)
* [fail_fast](#fail_fast)
* [uniq](#uniq)
* [distinct](#distinct)
* [with_prev](#with_prev)
* [with_prev_and_next](#with_prev_and_next)
* [with_next](#with_next)
* [with_is_first](#with_is_first)
* [with_is_last](#with_is_last)
* [without_first](#without_first)
* [without_last](#without_last)
*Utilities*
* [get](#get)
* [getter](#getter)
* [getpath](#getpath)
* [pathgetter](#pathgetter)
* [indexed](#indexed)
* [grouped](#grouped)
* [partitioned](#partitioned)
* [sorted_uniq](#sorted_uniq)
* [pick](#pick)
* [omit](#omit)
*Functional Programming*
* [noop](#noop)
* [compose](#compose)
* [rcompose](#rcompose)
*Formatting*
* [and_join](#and_join)
* [format_int](#format_int)
* [format_time](#format_time)
TODO: *format_repr*, *format_filesize*
*Decorators*
* [decorators.fail_fast](#decoratorsfail_fast)
* [decorators.with_defer](#decoratorswith_defer)
*Benchmarking*
* [Timer](#timer)
### as_chunks
Iterate over chunks of the desired size by grouping items as we iterate over them.
```python
from ebbe import as_chunks
list(as_chunks(3, [1, 2, 3, 4, 5]))
>>> [[1, 2, 3], [4, 5]]
```
### as_reconciled_chunks
Iterate over chunks of the desired size by grouping items as we iterate over them, then call a function returning some result for a given chunk, then "reconcile" chunk items using another function to finally produce a flat iterator over original values along with the associated result.
```python
from ebbe import as_reconciled_chunks
data = [1, 2, 3, 4, 5, 6]
def work(chunk):
return {n: True for n in chunk if n % 2 == 0}
def reconcile(data, item):
return data.get(item)
list(as_reconciled_chunks(3, data, work, reconcile))
>>> [(1, None), (2, True), (3, None), (4, True), (5, None), (6, True)]
```
### outer_zip
Iterate over an iterator from which one must extract a key to work on to produce a resulting iterator all while keeping a reference to the original item in the output.
Note that this function only produces a correct output if:
1. work done is single-threaded (this function is absolutely not threadsafe)
2. the work function emits resulting items in the same order they are consumed from the input
```python
from ebbe import outer_zip
data = [("one", 1), ("two", 2), ("three", 3)]
def work(numbers: Iterator[int]) -> Iterator[int]:
for n in numbers:
yield n * 2
list(
(original_item[0], result)
for original_item, result in outer_zip(data, key=lambda p: p[1], work=work)
)
>>> [("one", 2), ("two", 4), ("three", 6)]
```
### as_grams
Iterate over grams (sometimes called n-grams or q-grams etc.) of the given iterable. It works with strings, lists and other sized sequences as well as with lazy iterables without consuming any superfluous memory while doing so.
```python
from ebbe import as_grams
list(as_grams(3, 'hello'))
>>> ['hel', 'ell', 'llo']
list(as_grams(2, (i * 2 for i in range(5))))
>>> [(0, 2), (2, 4), (4, 6), (6, 8)]
```
### fail_fast
Take an iterable (but this has been geared towards generators, mostly), and tries to access the first value to see if an Exception will be raised before returning an equivalent iterator.
This is useful with some badly-conceived generators that checks arguments and raise if they are not valid, for instance, and if you don't want to wrap the whole iteration block within a try/except.
This logic is also available as a [decorator](#failfastdecorator).
```python
from ebbe import fail_fast
def hellraiser(n):
if n > 10:
raise TypeError
yield from range(n)
# You will need to do this to catch the error:
gen = hellraiser(15)
try:
for i in gen:
print(i)
except TypeError:
print('Something went wrong when creating the generator')
# With fail_fast
try:
gen = fail_fast(hellraiser(15))
except TypeError:
print('Something went wrong when creating the generator')
for i in gen:
print(i)
```
### uniq
Filter repeated items, optionally by key, seen next to each other in the given iterator.
```python
from ebbe import uniq
list(uniq([1, 1, 1, 2, 3, 4, 4, 5, 5, 6]))
>>> [1, 2, 3, 4, 5, 6]
# BEWARE: it does not try to remember items (like the `uniq` command)
list(uniq([1, 2, 2, 3, 2]))
>>> [1, 2, 3, 2]
# Using a key
list(uniq([(1, 2), (1, 3), (2, 4)], key=lambda x: x[0]))
>>> [(1, 2), (2, 4)]
```
### distinct
Filter repeated items, optionally by key, in the given iterator.
```python
from ebbe import distinct
list(distinct([0, 3, 4, 4, 1, 0, 3]))
>>> [0, 3, 4, 1]
list(distinct(range(6), key=lambda x: x % 2))
>>> [0, 1]
```
### with_prev
Iterate over items along with the previous one.
```python
from ebbe import with_prev
for previous_item, item in with_prev(iterable):
print(previous_item, 'came before', item)
list(with_prev([1, 2, 3]))
>>> [(None, 1), (1, 2), (2, 3)]
```
### with_prev_and_next
Iterate over items along with the previous and the next one.
```python
from ebbe import with_prev_and_next
for previous_item, item, next_item in with_prev_and_next(iterable):
print(previous_item, 'came before', item)
print(next_item, 'will come after', item)
list(with_prev_and_next([1, 2, 3]))
>>> [(None, 1, 2), (1, 2, 3), (2, 3, None)]
```
### with_next
Iterate over items along with the next one.
```python
from ebbe import with_next
for item, next_item in with_next(iterable):
print(next_item, 'will come after', item)
list(with_next([1, 2, 3]))
>>> [(1, 2), (2, 3), (3, None)]
```
### with_is_first
Iterate over items along with the information that the current item is the first one or not.
```python
from ebbe import with_is_first
for is_first, item in with_is_first(iterable):
if is_first:
print(item, 'is first')
else:
print(item, 'is not first')
list(with_is_first([1, 2, 3]))
>>> [(True, 1), (False, 2), (False, 3)]
```
### with_is_last
Iterate over items along with the information that the current item is the last one or not.
```python
from ebbe import with_is_last
for is_last, item in with_is_last(iterable):
if is_last:
print(item, 'is last')
else:
print(item, 'is not last')
list(with_is_last([1, 2, 3]))
>>> [(False, 1), (False, 2), (True, 3)]
```
### without_first
Iterate over the given iterator after skipping its first item. Can be useful if you want to skip headers of a CSV file for instance.
```python
from ebbe import without_first
list(without_first([1, 2, 3]))
>>> [2, 3]
for row in without_first(csv.reader(f)):
print(row)
```
### without_last
Iterate over the given iterator but skipping its last item.
```python
from ebbe import without_last
list(without_last([1, 2, 3]))
>>> [1, 2]
```
### get
Operator function similar to `operator.getitem` but able to take a default value.
```python
from ebbe import get
get([1, 2, 3], 1)
>>> 2
get([1, 2, 3], 4)
>>> None
# With default value
get([1, 2, 3], 4, 35)
>>> 35
```
### getter
Operator factory similar to `operator.itemgetter` but able to take a default value.
```python
from ebbe import getter
get_second_or_thirty = getter(1, 30)
get_second_or_thirty([1, 2, 3])
>>> 2
get_second_or_thirty([1])
>>> 30
# Overriding default on the spot
get_second_or_thirty([1], 76)
>>> 76
```
### getpath
Operator function used to retrieve a value at given path in a nested structure or a default value if this value cannot be found.
```python
from ebbe import getpath
data = {'a': {'b': [{'c': 34}, 'test'], 'd': 'hello'}}
getpath(data, ['a', 'b', 0, 'c'])
>>> 34
getpath(data, ['t', 'e', 's', 't'])
>>> None
# Using a default return value
getpath(data, ['t', 'e', 's', 't'], 45)
>>> 45
# Using a string path
getpath(data, 'a.b.d', split_char='.')
>>> 'hello'
```
*Arguments*
* **target** *any*: target object.
* **path** *iterable*: path to get.
* **default** *?any* [`None`]: default value to return.
* **items** *?bool* [`True`]: whether to attempt to traverse keys and indices.
* **attributes** *?bool* [`False`]: whether to attempt to traverse attributes.
* **split_char** *?str*: if given, will split strings passed as path instead of raising `TypeError`.
* **parse_indices** *?bool* [`False`]: whether to parse integer indices when splitting string paths.
### pathgetter
Function returning a getter function working as [getpath](#getpath) and partially applied to use the provided path or paths.
```python
from ebbe import pathgetter
data = {'a': {'b': [{'c': 34}, 'test'], 'd': 'hello'}}
getter = pathgetter(['a', 'b', 0, 'c'])
getter(data)
>>> 34
getter = pathgetter(['t', 'e', 's', 't'])
getter(data)
>>> None
# Using a default return value
getter = pathgetter(['t', 'e', 's', 't'])
getter(data, 45)
>>> 45
# Using a string path
getter = pathgetter('a.b.d', split_char='.')
getter(data)
>>> 'hello'
# Using multiple paths
getter = pathgetter(
['a', 'b', 0, 'c'],
['t', 'e', 's', 't'],
['a', 'b', 'd']
)
getter(data)
>>> (34, None, 'hello')
```
*Arguments*
* **paths** *list*: paths to get.
* **items** *?bool* [`True`]: whether to attempt to traverse keys and indices.
* **attributes** *?bool* [`False`]: whether to attempt to traverse attributes.
* **split_char** *?str*: if given, will split strings passed as path instead of raising `TypeError`.
* **parse_indices** *?bool* [`False`]: whether to parse integer indices when splitting string paths.
*Getter arguments*
* **target** *any*: target object.
* **default** *?any* [`None`]: default value to return.
### indexed
Function indexing the given iterable in a dict-like structure. This is basically just some functional sugar over a `dict` constructor.
```python
from ebbe import indexed
indexed(range(3), key=lambda x: x * 10)
>>> {
0: 0,
10: 1,
20: 2
}
```
### grouped
Function grouping the given iterable by a key.
```python
from ebbe import grouped
grouped(range(4), key=lambda x: x % 2)
>>> {
0: [0, 2],
1: [1, 3]
}
# Using an optional value
grouped(range(4), key=lambda x: x % 2, value=lambda x: x * 10)
>>> {
0: [0, 20],
1: [10, 30]
}
# Using the items variant
from ebbe import grouped_items
grouped_items((x % 2, x * 10) for i in range(4))
>>> {
0: [0, 20],
1: [10, 30]
}
```
### partitioned
Function partitioning the given iterable by key.
```python
from ebbe import partitioned
partitioned(range(4), key=lambda x: x % 2)
>>> [
[0, 2],
[1, 3]
]
# Using an optional value
partitioned(range(4), key=lambda x: x % 2, value=lambda x: x * 10)
>>> [
[0, 20],
[10, 30]
]
# Using the items variant
from ebbe import partitioned_items
partitioned_items((x % 2, x * 10) for i in range(4))
>>> [
[0, 20],
[10, 30]
]
```
### sorted_uniq
Function sorting the given iterable then dropping its duplicate through a single linear pass over the data.
```python
from ebbe import sorted_uniq
numbers = [3, 17, 3, 4, 1, 4, 5, 5, 1, -1, 5]
sorted_uniq(numbers)
>>> [-1, 1, 3, 4, 5, 17]
# It accepts all of `sorted` kwargs:
sorted_uniq(numbers, reverse=True)
>>> [17, 5, 4, 3, 1, -1]
```
### pick
Function returning the given dictionary with only the selected keys.
```python
from ebbe import pick
# Selected keys must be an iterable:
pick({'a': 1, 'b': 2, 'c': 3}, ['a', 'c'])
>>> {'a': 1, 'c': 3}
# If you need the function to raise if one of the picked keys is not found:
pick({'a': 1, 'b': 2, 'c': 3}, ['a', 'd'], strict=True)
>>> KeyError: 'd'
```
### omit
Function returning the given dictionary without the selected keys.
```python
from ebbe import omit
# Selected keys must be a container:
omit({'a': 1, 'b': 2, 'c': 3}, ['a', 'c'])
>>> {'b': 2}
# If need to select large numbers of keys, use a set:
omit({'a': 1, 'b': 2, 'c': 3}, {'a', 'c'})
>>> {'b': 2}
```
### noop
Noop function (a function that can be called with any arguments and does nothing). Useful as a default to avoid complicating code sometimes.
```python
from ebbe import noop
noop() # Does nothing...
noop(4, 5) # Still does nothing...
noop(4, index=65) # Nothing yet again...
```
### compose
Function returning the composition function of its variadic arguments.
```python
def times_2(x):
return x * 2
def plus_5(x):
return x + 5
compose(times_2, plus_5)(10)
>>> 30
# Reverse order
compose(times_2, plus_5, reverse=True)(10)
>>> 25
```
### rcompose
Function returning the reverse composition function of its variadic arguments.
```python
def times_2(x):
return x * 2
def plus_5(x):
return x + 5
rcompose(times_2, plus_5)(10)
>>> 25
```
### and_join
Join function able to group the last items with a custom copula such as "and".
```python
from ebbe import and_join
and_join(['1', '2', '3'])
>>> '1, 2 and 3'
and_join(['1', '2', '3'], separator=';', copula="y")
>>> '1; 2 y 3'
```
### format_int
Format given number as an int with thousands separator.
```python
from ebbe import format_int
format_int(4500)
>>> '4,500'
format_int(10000, separator=' ')
>>> '10 000'
```
### format_time
Format time with custom precision and unit from years to nanoseconds.
```python
from ebbe import format_time
format_time(57309)
>>> "57 microseconds and 309 nanoseconds"
format_time(57309, precision="microseconds")
>>> "57 microseconds
format_time(78, unit="seconds")
>>> "1 minute and 18 seconds"
format_time(4865268458795)
>>> "1 hour, 21 minutes, 5 seconds, 268 milliseconds, 458 microseconds and 795 nanoseconds"
assert format_time(4865268458795, max_items=2)
>>> "1 hour and 21 minutes"
format_time(4865268458795, short=True)
>>> "1h, 21m, 5s, 268ms, 458µs, 795ns"
```
### decorators.fail_fast
Decorate a generator function by wrapping it into another generator function that will fail fast if some validation is run before executing the iteration logic so that exceptions can be caught early.
This logic is also available as a [function](#failfast).
```python
from ebbe.decorators import fail_fast
def hellraiser(n):
if n > 10:
raise TypeError
yield from range(n)
# This will not raise until you consume `gen`
gen = hellraiser(15)
@fail_fast()
def hellraiser(n):
if n > 10:
raise TypeError
yield from range(n)
# This will raise immediately
gen = hellraiser(15)
```
### decorators.with_defer
Decorates a function calling it with a `defer` kwarg working a bit like Go's [defer statement](https://gobyexample.com/defer) so that you can "defer" actions to be done by the end of the function or when an exception is raised to cleanup or tear down things.
This relies on an [ExitStack](https://docs.python.org/3/library/contextlib.html#contextlib.ExitStack) and can of course be also accomplished by context managers but this way of declaring things to defer can be useful sometimes to avoid nesting in complex functions.
```python
from ebbe.decorators import with_defer
@with_defer()
def main(content, *, defer):
f = open('./output.txt', 'w')
defer(f.close)
f.write(content)
```
### Timer
Context manager printing the time (to stderr by default) it took to execute wrapped code. Very useful to run benchmarks.
```python
from ebbe import Timer
with Timer():
some_costly_operation()
# Will print "Timer: ...s etc." on exit
# To display a custom message:
with Timer('my operation'):
...
# To print to stdout
import sys
with Timer(file=sys.stdout):
...
``` | text/markdown | Guillaume Plique | kropotkinepiotr@gmail.com | null | null | MIT | iter | [] | [] | http://github.com/Yomguithereal/ebbe | null | >=3.5 | [] | [] | [] | [] | [] | [] | [] | [] | twine/4.0.2 CPython/3.7.16 | 2026-02-20T13:31:54.517780 | ebbe-1.15.1.tar.gz | 18,685 | c6/d2/63fdf12e68dacab7210ff13441fb142a7a31b962997bfbc776ccaa110bbf/ebbe-1.15.1.tar.gz | source | sdist | null | false | 967d58cca1ca9304dccb0499b696433f | d324da97df15737b85ee3ed5ef2797e6b9fe4740ba8ab7d47f2fe230c51e267c | c6d263fdf12e68dacab7210ff13441fb142a7a31b962997bfbc776ccaa110bbf | null | [] | 258 |
2.4 | sql-datalineage | 0.0.16 | A project to build and visualize data lineage from SQL written in python. It supports column level lineage and can combine with metadata retriever for better result. | <div align="center">
<br>
<h1>SQL Data Lineage</h1>
<p>
<a href="https://github.com/viplazylmht/sql-datalineage/actions/workflows/python-package.yml">
<img src="https://img.shields.io/github/actions/workflow/status/viplazylmht/sql-datalineage/python-package.yml">
</a>
<a href="https://github.com/viplazylmht/sql-datalineage/actions/workflows/python-publish.yml">
<img src="https://img.shields.io/github/actions/workflow/status/viplazylmht/sql-datalineage/python-publish.yml?label=publish">
</a>
<a href="https://pypi.org/project/sql-datalineage">
<img src="https://img.shields.io/pypi/v/sql-datalineage?color=cyan">
</a>
</p>
</div>
Introducing SQL Data Lineage, a powerful package designed to simplify SQL query analysis. This versatile tool parses data lineage from individual SQL queries or builds comprehensive lineage from multiple queries. It offers both an interactive command-line interface and programmatic integration, making it easy to incorporate into your Python projects.
SQL Data Lineage performs detailed column-level analysis, tracing data flows step-by-step through tables, CTEs, subqueries, and more. It generates user-friendly lineage graphs that clearly show how columns move and transform across SQL components.
You can easily enhance your lineage insights by retrieving and customizing metadata to fit your specific requirements.
We welcome and encourage contributions to the SQL Data Lineage project!
# Installation
```bash
pip install sql-datalineage
```
# Usage
## CLI usage
Show help of CLI commands.
```bash
datalineage --help
```
Generate data lineage of a sql file, output type is mermaid.
```bash
$> datalineage -i docs/example/test-query.sql --schema-path docs/example/test-schema.json -r mermaid
%%{init: {"flowchart": {"defaultRenderer": "elk"}} }%%
graph LR
subgraph 2420861448752 ["Table: catalog.schema1.customer AS customer"]
2420861447168["id"]
2420861446976["name"]
2420861448464["phone"]
2420860590112["address"]
2420861446304["location"]
end
subgraph 2420861448224 ["CTE: cte1 AS t1"]
2420861448848["id"]
2420861449040["name"]
2420861448272["phone"]
2420861449184["address"]
end
2420861447168 --> 2420861448848
2420861446976 --> 2420861449040
2420861448464 --> 2420861448272
2420860590112 --> 2420861449184
....
```
> [!TIP]
> The output of the above command is truncated. You
> can optionally save the command's result to a file
> using the `-o` option.
> ```bash
> datalineage -i /docs/example/test-query.sql --schema-path docs/example/test-schema.json -o docs/example/output.mermaid -r mermaid
> ```
You can preview the above result using [Mermaid Live Editor](https://mermaid.live/view#pako:eNqdV1Fv2zYQ_iuCgAAdkDoUJVKUHwYEWd_WDWjyMKwqBFqibW2ypErU1sDwf--RslLzQgfD_GSRH8m77767I49h2VUqXIc3N8e6rfU6OObhtun-Lfdy0Hlovyu1lVOjP6m2UoMazGgequbvPDydgtPNTd7uBtnvg18_5e04beYPmlAieJQkImU0-JyHT3LTqHVQSi2bbrcay706yGhVTqPuDmoI7h-D5X8efsnblw3SiAtYX1fuMM9SDsOtPCh3QiQ8gYl-37WXM4RlJIoozMiqGtQ4ou1iYlY1HRhYd62dBIfz1usTpYnx6eHpA3ikVWSs1xGyQyQ-uzOSEL_dNKUeu82SSCTIbmuaQ1Hw_v3PgXM4IssFGDMQaWgHMAdxh3YAq67Qk0T8jZBPoxqKSh06u6wuR8Peq0FEQUITH5mM-snMeGTUIXd4PKbCTzJPY7Ni0WDxV7dBS1Ornl4OqtVv6yOLU_6iD33oC9CIlcj8Fx0sBPG5xq2MX7sGxFOfa2lmHUCuxcwuID7XXBEZit0IG8sQ2UgCYCMi3QWYoxH7LsAYjYLwA7DYfkVlKXGSkFqGqUtKzLzFIxNE-HUjmF831AbJpxtu89nPqWHQddgYhKKMOAXTULQxgHEUdgSgL2FbGERx5YmfU0ZNlv__Yp2JNLH8uXzDMKE-McOEEN58zIC4-EqxhlXcltb_VKwZiYXVyaNqVAkd7rGUjRwCAH6d1PDs7kxSW2oP8ltx9uEyoPN8ob71nwH08f6PdwsLq7r6CeBfgGj4BQ4e0XMZiwXgLSJECGv32dB1UHwtCMr5mT4s7zM_iG7CCSEZ98qYRYImV3ojI8y22u3UNIUnZeYUM5R50sYGEeY8bM5dCtUDcAg1SwTgTmMzXeoCcHYR9U5nB-spcm6J6MPvvz3cP73T0cq4eQvVxP7xRHZe95alrwCQ128DgMdLacHhwKfvbAtFRQuVAAcwpwCqETG9UlZFxi_Tpegm3U-6cCVBCff0Yxal1FtXWcRiv_CSNPZfyhiD3IivCY_BlYdT4RWeXTnX8WvCMzJzg2EcQhmEZAOuoUxCAHbZyqzMkHTjy2Zow_8DsLiLBHEBOHuMsgvtYHtDeBtCSTrIuoKb_TFvA7iva6jgar66l88bNfRTCxf4vD0BWE66e3xuy3Cth0ndhkM37fbLx9RXUqtfagk6OSyDvWz_7Dr43MpmfAF9qGrdDS-DTSfhwRCuj6F-7s0jY1ePGo4ru3Zb78z4NDQwvNe6H9d3d2Z6tav1ftqsyu5wN9aVeYXs_8n4HadcSBoruCBIFsdVuYHauaVJtK1SElEJT5HbUNnzP84vGvuwOX0HCJN90Q), here is the result:

## Interactive usage
You can import datalineage into your project and generate the lineage tree directly.
```python
>>> from datalineage.lineage import lineage
>>> sql = """select
id, name, phone, address
from (
select id, name, phone, address,
row_number() over(partition by phone order by name) as rn
from `catalog.schema1.customer`) data
where data.rn = 1
"""
>>> schema = None # we will infer the schema of table when no schema are provided
>>> dialect = "bigquery"
>>> tree = lineage(sql, dialect, schema)
>>> tree
Node<{"name": "myroot", "expression": "ANCHOR",...
```
You can traversal and print out the lineage tree in this way:
```python
>>> def print_node(node):
>>> print("Node:", node.name)
>>> list(map(lambda c: print("Column:", c.name), node.children))
>>> for node in tree.walk():
... print_node(node)
...
Node: myroot
Node: _output_
Column: id
Column: name
Column: phone
Column: address
Node: data
Column: id
Column: name
Column: phone
Column: address
Column: rn
Node: "catalog"."schema1"."customer" AS "customer"
Column: id
Column: name
Column: phone
Column: address
```
Or you can render the tree to a format you like, for example, mermaid.
```python
>>> from datalineage.renderer import MermaidRenderer
>>> renderer = MermaidRenderer()
>>> print(renderer.render(tree))
%%{init: {"flowchart": {"defaultRenderer": "elk"}} }%%
graph LR
subgraph 1434247920720 ["Table: catalog.schema1.customer AS customer"]
1434247920624["id"]
1434247921104["name"]
1434247919568["phone"]
1434247921200["address"]
end
subgraph 1434247919280 ["Subquery: data"]
1434247920816["id"]
1434247919856["name"]
1434247917696["phone"]
1434247917744["address"]
1434247918224["rn"]
end
1434247920624 --> 1434247920816
1434247921104 --> 1434247919856
1434247919568 --> 1434247917696
1434247921200 --> 1434247917744
1434247919568 --> 1434247918224
1434247921104 --> 1434247918224
subgraph 1434247918032 ["Select: _output_"]
1434247921392["id"]
1434247921344["name"]
1434247921152["phone"]
1434247920912["address"]
end
1434247920816 --> 1434247921392
1434247919856 --> 1434247921344
1434247917696 --> 1434247921152
1434247917744 --> 1434247920912
>>>
```
> [!TIP]
> You can render to json format using `datalineage.renderer.JsonRenderer` class, or customize your own renderer.
>
> If you are in enviroment which support Ipython (for example, jupyter notebook), you can render the mermaid graph directly:
> ```python
> from datalineage.renderer import MermaidRenderer, MermaidType
>
> html_renderer = MermaidRenderer(output_type=MermaidType.HTML)
> html_output = html_renderer.render(tree)
> ```
> Output: 
>
# Contribution
### Setup Environment
We use [uv](https://github.com/astral-sh/uv) to manage the project. Please follow [the official document](https://docs.astral.sh/uv/getting-started/installation/#installation-methods) to install uv to your environment.
> [!TIP]
> Your environment does not require any python or pip installed, but if you already have pip, you can quickly install uv like this:
>
> ```bash
> pip install uv
> ```
Install pre-commit to your local git hooks.
```bash
make install-pre-commit
```
### Run Lint
```bash
make style
```
### Run Tests
```bash
make test
```
### Run Lint and Tests
```bash
make check
```
### Run from local development
```bash
uv run --no-project -- datalineage --help
```
| text/markdown | null | Duy Ha <viplazylmt@gmail.com> | null | null | MIT | column-level-lineage, data, lineage | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: SQL"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"click",
"ipython>=8.12.3",
"jinja2>=3.1.5",
"pydantic==2.*",
"pyyaml>=6.0.2",
"requests",
"sqlalchemy>=2.0.36",
"sqlglot[rs]"
] | [] | [] | [] | [
"Homepage, https://github.com/viplazylmht/sql-datalineage",
"Source, https://github.com/viplazylmht/sql-datalineage",
"Issues, https://github.com/viplazylmht/sql-datalineage/issues"
] | uv/0.5.7 | 2026-02-20T13:31:39.047811 | sql_datalineage-0.0.16.tar.gz | 101,950 | de/14/4596ed607ef7116f6fa34ae265738232c09879512f944310944d17f920ea/sql_datalineage-0.0.16.tar.gz | source | sdist | null | false | 16a817ed99a7e1cd2f535327b34733c7 | 4c4c5a6ab7343834dfdbe35a22a60166298850094aaafd832320c364a820d904 | de144596ed607ef7116f6fa34ae265738232c09879512f944310944d17f920ea | null | [
"LICENSE"
] | 199 |
2.4 | ewoksid02 | 0.2.2 | Data processing SAXS and XPCS workflows for ID02 | # ewoksid02
Data processing SAXS and XPCS workflows for ID02
## Documentation
https://ewoksid02.readthedocs.io/
| text/markdown | null | ESRF <edgar.gutierrez-fernandez@esrf.fr> | null | null | # MIT License
**Copyright (c) 2024 European Synchrotron Radiation Facility**
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software is furnished to do so,
subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
| ewoks, ID02, SAXS, XPCS | [
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"ewoks",
"ewoksjob[blissworker]",
"ewoksjob[slurm]",
"ewoksppf",
"h5py",
"numpy<2",
"scipy",
"silx",
"pyfai",
"blissdata",
"numexpr!=2.8.6",
"psutil",
"pyyaml",
"pytest>=7; extra == \"test\"",
"ewoksid02[test]; extra == \"dev\"",
"black>=25; extra == \"dev\"",
"flake8>=4; extra == \"dev\"",
"ewoksid02[test]; extra == \"doc\"",
"sphinx>=4.5; extra == \"doc\"",
"sphinx-autodoc-typehints>=1.16; extra == \"doc\"",
"pydata-sphinx-theme; extra == \"doc\"",
"nbsphinx; extra == \"doc\"",
"ipython; extra == \"doc\"",
"ewokssphinx; extra == \"doc\"",
"cupy; extra == \"cupy\""
] | [] | [] | [] | [
"Homepage, https://gitlab.esrf.fr/workflow/ewoksapps/ewoksid02/",
"Documentation, https://ewoksid02.readthedocs.io/",
"Repository, https://gitlab.esrf.fr/workflow/ewoksapps/ewoksid02/",
"Issues, https://gitlab.esrf.fr/workflow/ewoksapps/ewoksid02/issues",
"Changelog, https://gitlab.esrf.fr/workflow/ewoksapps/ewoksid02/-/blob/main/CHANGELOG.md"
] | twine/6.2.0 CPython/3.12.10 | 2026-02-20T13:31:17.931881 | ewoksid02-0.2.2.tar.gz | 86,472 | 57/3d/0160d90f42db196bb8ca4f13b8eebdb64c791b0e649e809be73e4c09fe4a/ewoksid02-0.2.2.tar.gz | source | sdist | null | false | 38020aa5bc18a3b19f13c856b70f0e19 | 0f243f544bea856d18b49ebb08a705c70ac6870fab4603d37a2464b36c8af17f | 573d0160d90f42db196bb8ca4f13b8eebdb64c791b0e649e809be73e4c09fe4a | null | [
"LICENSE.md"
] | 232 |
2.4 | dapr-ext-strands-dev | 1.17.0.dev78 | The developmental release for the Dapr Session Manager extension for Strands Agents | This is the developmental release for the Dapr Session Manager extension for Strands Agents
| null | Dapr Authors | daprweb@microsoft.com | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | https://dapr.io/ | null | >=3.10 | [] | [] | [] | [
"dapr-dev>=1.17.0.dev",
"strands-agents",
"strands-agents-tools",
"python-ulid>=3.0.0",
"msgpack-python>=0.4.5"
] | [] | [] | [] | [
"Documentation, https://github.com/dapr/docs",
"Source, https://github.com/dapr/python-sdk"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T13:30:52.312491 | dapr_ext_strands_dev-1.17.0.dev78.tar.gz | 11,734 | 22/33/a990223682e7aee46177d18e266964fbf27581cd6f49a86437f44aafe145/dapr_ext_strands_dev-1.17.0.dev78.tar.gz | source | sdist | null | false | bd78432db8e3fa452da86ae69539c730 | 42707daf95abe4cb38e0a9e2abaed18348bbac4277a257b4b6eca8d42814df8b | 2233a990223682e7aee46177d18e266964fbf27581cd6f49a86437f44aafe145 | null | [
"LICENSE"
] | 185 |
2.4 | dapr-ext-langgraph-dev | 1.17.0.dev78 | The developmental release for the Dapr Checkpointer extension for LangGraph | This is the developmental release for the Dapr Checkpointer extension for LangGraph
| null | Dapr Authors | daprweb@microsoft.com | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | https://dapr.io/ | null | >=3.10 | [] | [] | [] | [
"dapr-dev>=1.17.0.dev",
"langgraph>=0.3.6",
"langchain>=0.1.17",
"python-ulid>=3.0.0",
"msgpack-python>=0.4.5"
] | [] | [] | [] | [
"Documentation, https://github.com/dapr/docs",
"Source, https://github.com/dapr/python-sdk"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T13:30:49.976589 | dapr_ext_langgraph_dev-1.17.0.dev78.tar.gz | 11,893 | 3b/1c/dda1ddaefd6003e023971d21027256e6c978d310e2b699c5dace3e5352f7/dapr_ext_langgraph_dev-1.17.0.dev78.tar.gz | source | sdist | null | false | d24e697f1f52350de1a05c7ef6ae8a7f | afa659081cb2ce33004ed06c1c89790abfecd665d9eeca1ba84516374e6e68a8 | 3b1cdda1ddaefd6003e023971d21027256e6c978d310e2b699c5dace3e5352f7 | null | [
"LICENSE"
] | 185 |
2.4 | dapr-ext-fastapi-dev | 1.17.0.dev78 | The developmental release for Dapr FastAPI extension. | This is the developmental release for Dapr FastAPI extension.
| null | Dapr Authors | daprweb@microsoft.com | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://dapr.io/ | null | >=3.9 | [] | [] | [] | [
"dapr-dev>=1.17.0.dev",
"uvicorn>=0.11.6",
"fastapi>=0.60.1"
] | [] | [] | [] | [
"Documentation, https://github.com/dapr/docs",
"Source, https://github.com/dapr/python-sdk"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T13:30:47.891420 | dapr_ext_fastapi_dev-1.17.0.dev78.tar.gz | 10,355 | 5d/0d/606f0f76fda36467b86714e816d702c1aa7e5814d98595addf17f246b67c/dapr_ext_fastapi_dev-1.17.0.dev78.tar.gz | source | sdist | null | false | 57816c99be3f348dfc7148b1ca553e10 | 6a68d983ab64e9764901c1ee4437e44c5790084f5e37ec742648411d2308dd55 | 5d0d606f0f76fda36467b86714e816d702c1aa7e5814d98595addf17f246b67c | null | [
"LICENSE"
] | 188 |
2.4 | dapr-ext-grpc-dev | 1.17.0.dev78 | The developmental release for Dapr gRPC AppCallback. | This is the developmental release for Dapr gRPC AppCallback.
| null | Dapr Authors | daprweb@microsoft.com | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://dapr.io/ | null | >=3.9 | [] | [] | [] | [
"dapr-dev>=1.17.0.dev",
"cloudevents>=1.0.0"
] | [] | [] | [] | [
"Documentation, https://github.com/dapr/docs",
"Source, https://github.com/dapr/python-sdk"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T13:30:45.629975 | dapr_ext_grpc_dev-1.17.0.dev78.tar.gz | 15,308 | 4d/65/36c6a2df0d4134d4f73e44ebf5cc87c9b993627d17daff91e9f07197643a/dapr_ext_grpc_dev-1.17.0.dev78.tar.gz | source | sdist | null | false | 2f90172ad639cb746514ee1f6a842477 | d00a61ed66e781072f18e42822fc9eb7977e41fd286966e3f6f26ddc6688af4d | 4d6536c6a2df0d4134d4f73e44ebf5cc87c9b993627d17daff91e9f07197643a | null | [
"LICENSE"
] | 189 |
2.4 | flask-dapr-dev | 1.17.0.dev78 | The developmental release for Dapr Python SDK Flask. | This is the developmental release for Dapr Python SDK Flask.
| null | Dapr Authors | daprweb@microsoft.com | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://dapr.io/ | null | >=3.9 | [] | [] | [] | [
"Flask>=1.1",
"dapr-dev>=1.17.0.dev"
] | [] | [] | [] | [
"Documentation, https://github.com/dapr/docs",
"Source, https://github.com/dapr/python-sdk"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T13:30:43.422306 | flask_dapr_dev-1.17.0.dev78.tar.gz | 9,554 | 5b/34/c8dfd8dbf3ef76fda93c9dc3642ce31cb1faf09162583f0463148fe6caa5/flask_dapr_dev-1.17.0.dev78.tar.gz | source | sdist | null | false | f8ca23915412efd98c51fe96319ae374 | 516f6d0e2971bcf0e419520c9f25c7d76414e27576b4e9040f2e3a75f14330a4 | 5b34c8dfd8dbf3ef76fda93c9dc3642ce31cb1faf09162583f0463148fe6caa5 | null | [
"LICENSE"
] | 256 |
2.4 | dapr-ext-workflow-dev | 1.17.0.dev78 | The developmental release for Dapr Workflow Authoring. | This is the developmental release for Dapr Workflow Authoring.
| null | Dapr Authors | daprweb@microsoft.com | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://dapr.io/ | null | >=3.9 | [] | [] | [] | [
"dapr-dev>=1.17.0.dev",
"durabletask-dapr>=0.2.0a19"
] | [] | [] | [] | [
"Documentation, https://github.com/dapr/docs",
"Source, https://github.com/dapr/python-sdk"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T13:30:40.880978 | dapr_ext_workflow_dev-1.17.0.dev78.tar.gz | 22,697 | bd/21/de5578e65969b77ba6313e59c67d3730b4c070c2c6b745a6145c68eabaea/dapr_ext_workflow_dev-1.17.0.dev78.tar.gz | source | sdist | null | false | 1a8219c3634211d23482043dc3a0098c | 043152af25529bdb0acfa2fd947e8d69ff8ead617e719738b108b73bd0c31a88 | bd21de5578e65969b77ba6313e59c67d3730b4c070c2c6b745a6145c68eabaea | null | [
"LICENSE"
] | 185 |
2.4 | dapr-dev | 1.17.0.dev78 | The developmental release for Dapr Python SDK. | This is the developmental release for Dapr Python SDK.
| null | Dapr Authors | dapr@dapr.io | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://dapr.io/ | null | >=3.9 | [] | [] | [] | [
"protobuf>=4.22",
"grpcio>=1.37.0",
"grpcio-status>=1.37.0",
"aiohttp>=3.9.0b0",
"python-dateutil>=2.8.1",
"typing-extensions>=4.4.0"
] | [] | [] | [] | [
"Documentation, https://github.com/dapr/docs",
"Source, https://github.com/dapr/python-sdk"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T13:30:38.171925 | dapr_dev-1.17.0.dev78.tar.gz | 171,540 | 31/be/faa0a0b05128dd7a06c50ef356cbd852ec7e8a9717e2aa0f1084fa707c2b/dapr_dev-1.17.0.dev78.tar.gz | source | sdist | null | false | 15f4ff464326c3c276918f96aca88237 | d47953abaa9df31a4771f3ca2422cca626441bc5075d3596692371846367f462 | 31befaa0a0b05128dd7a06c50ef356cbd852ec7e8a9717e2aa0f1084fa707c2b | null | [
"LICENSE"
] | 322 |
2.4 | pounce-agent-data | 2.0.0 | Python SDK for the Pounce v2 Entity API — search, look up, and enrich 59M+ verified B2B companies. | # pounce-agent-data
Python SDK for the **Pounce v2 Entity API** — search, look up, and enrich 59M+ verified B2B companies.
## Installation
```bash
pip install pounce-agent-data
```
## Quick Start
```python
from pounce_agent_data import PounceClient
client = PounceClient(api_key="your_key")
# Search companies
results, rate = client.search(q="AI companies", country="CH", limit=10)
for company in results["items"]:
print(company["canonical_name"], company["primary_domain"])
# Lookup by domain
company, rate = client.lookup("stripe.com")
print(company["canonical_name"], company["trust_tier"])
# AI semantic search (2 credits)
results, rate = client.semantic_search("fintech startups in Switzerland")
# Full company profile
detail, rate = client.detail(entity_id=12345)
```
## Authentication
Pass your API key directly or set the `POUNCE_API_KEY` environment variable:
```bash
export POUNCE_API_KEY=your_key
```
```python
client = PounceClient() # reads from env
```
## API Methods
| Method | Credits | Description |
|--------|---------|-------------|
| `search()` | 1 | Filter companies by keyword, country, category |
| `semantic_search()` | 2 | AI-powered natural language search |
| `lookup(domain)` | 1 | Find a company by domain |
| `detail(entity_id)` | 1 | Full company profile |
| `bulk_lookup(domains)` | 1/found | Bulk lookup up to 100 domains |
| `match_score(a, b)` | 3 | Similarity score between two companies |
| `stats()` | 0 | Public platform statistics |
## Rate Limits
Every response includes rate limit info:
```python
results, rate = client.search(q="test")
print(rate.remaining) # calls remaining this month
print(rate.credits_used) # credits consumed by this call
```
## Plans
| Plan | Monthly Calls | Rate/Min |
|------|--------------|----------|
| Free | 100 | 30 |
| Developer ($39/mo) | 5,000 | 60 |
| Business ($149/mo) | 25,000 | 300 |
| Enterprise ($499/mo) | 200,000 | 1,000 |
## Links
- [API Documentation](https://pounce.ch/developers)
- [Get an API Key](https://pounce.ch/settings/api)
| text/markdown | null | Pounce <hello@pounce.ch> | null | null | null | agents, ai, api, b2b, companies, pounce, sdk | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"httpx>=0.25.0"
] | [] | [] | [] | [
"Homepage, https://pounce.ch/developers",
"Documentation, https://pounce.ch/skill.md",
"Repository, https://gitlab.pounce.ch/pounce/pounce"
] | twine/6.2.0 CPython/3.9.6 | 2026-02-20T13:30:19.181090 | pounce_agent_data-2.0.0.tar.gz | 3,733 | 0d/ba/507ccd577ffef63666e47ac22fffa6b54f58386490f9c5b8376c4a379d0f/pounce_agent_data-2.0.0.tar.gz | source | sdist | null | false | 98f5cbf3f92bcf951cd7b976ba2c4695 | d050668e2d42aefc6085056cb935088de73ab6ad4fd996b367131001632ebc61 | 0dba507ccd577ffef63666e47ac22fffa6b54f58386490f9c5b8376c4a379d0f | MIT | [] | 191 |
2.4 | blobtoolkit | 4.5.1 | blobtoolkit | blobtoolkit
| text/markdown | blobtoolkit | blobtoolkit@genomehubs.org | null | null | null | bioinformatics | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Bio-Informatics",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3 :: Only"
] | [] | https://github.com/blobtoolkit/blobtoolkit | null | <3.14,>=3.9 | [] | [] | [] | [
"blobtk>=0.7.11",
"chromedriver-autoinstaller>=0.6.2",
"docopt>=0.6.2",
"fastjsonschema>=2.21.1",
"geckodriver-autoinstaller>=0.1.0",
"psutil>=5.9.4",
"pyvirtualdisplay>=3.0",
"pyyaml",
"selenium>=4.10.0",
"genomehubs>=2.12.4",
"tqdm>=4.64.1",
"ujson>=5.7.0",
"pycodestyle>=2.6.0; extra == \"dev\"",
"pydocstyle>=5.0.2; extra == \"dev\"",
"pylint>=2.5.3; extra == \"dev\"",
"coverage>=5.1; extra == \"test\"",
"coveralls>=2.0.0; extra == \"test\"",
"mock>=4.0.2; extra == \"test\"",
"pytest-cov>=2.10.0; extra == \"test\"",
"pytest-isort>=5; extra == \"test\"",
"pytest-mock>=3.1.1; extra == \"test\"",
"pytest>=6.0.0; extra == \"test\"",
"blobtoolkit-host==4.5.0; extra == \"full\"",
"blobtoolkit-pipeline==4.4.6; extra == \"full\"",
"blobtoolkit-host==4.5.0; extra == \"host\"",
"blobtoolkit-pipeline==4.4.6; extra == \"pipeline\""
] | [] | [] | [] | [
"Bug Reports, https://github.com/blobtoolkit/blobtoolkit/issues",
"Source, https://github.com/blobtoolkit/blobtoolkit"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-20T13:29:49.125349 | blobtoolkit-4.5.1-py313-none-manylinux2014_x86_64.whl | 118,750 | 34/a7/7dc193888d8fbfbfc29f01d5ac94e780ea38d25a81262520de2e8afc7b6c/blobtoolkit-4.5.1-py313-none-manylinux2014_x86_64.whl | py313 | bdist_wheel | null | false | f2d5c61ea9ac2713be7b2f8a0a224fd8 | b01c0db0d16d742e99d5404a41940580b2759e721f7d92f0ebc1bd7976add655 | 34a77dc193888d8fbfbfc29f01d5ac94e780ea38d25a81262520de2e8afc7b6c | null | [
"LICENSE",
"AUTHORS"
] | 294 |
2.4 | iguazio | 0.0.5 | Python SDK for the Iguazio Platform management API | # iguazio - Management API SDK
Python SDK for Iguazio 4 Management API
## Installation
```console
pip install iguazio
```
## License
`iguazio` is distributed under the terms of the [Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0) license.
## Documentation
TBD
| text/markdown | Iguazio Platform Team | null | null | null | null | iguazio, igz | [
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"httpx~=0.28.1",
"inflection~=0.5.1",
"pyyaml~=6.0.2",
"build~=1.3.0; extra == \"build\"",
"twine~=6.2.0; extra == \"build\"",
"mock~=5.2.0; extra == \"dev\"",
"pytest~=9.0.2; extra == \"dev\"",
"requests~=2.32; extra == \"dev\"",
"ruff~=0.14.5; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:29:34.248077 | iguazio-0.0.5.tar.gz | 82,617 | f1/27/59ba0cb6ee917a91b5c7593782851cfb296545e04a1665a31b5385c0529c/iguazio-0.0.5.tar.gz | source | sdist | null | false | 0d23484a2ae830e450e42c5b3fe3e375 | dadd6764a46fc1114baf1ddad93539ed37bd6dcd7033eebe88f09703d197d72d | f12759ba0cb6ee917a91b5c7593782851cfb296545e04a1665a31b5385c0529c | Apache-2.0 | [
"LICENSE.txt"
] | 328 |
2.4 | blobtoolkit-pipeline | 4.5.1 | blobtoolkit-pipeline | blobtoolkit-pipeline
| text/markdown | blobtoolkit | blobtoolkit@genomehubs.org | null | null | null | bioinformatics | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Bio-Informatics",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3 :: Only"
] | [] | https://github.com/blobtoolkit/blobtoolkit | null | <3.14,>=3.9 | [] | [] | [] | [
"docopt>=0.6.2",
"psutil==5.9.4",
"pyyaml",
"genomehubs",
"tqdm==4.64.1",
"ujson>=5.7.0",
"defusedxml==0.7.1",
"requests>=2.28.1",
"snakemake==7.19.1",
"pulp==2.7.0",
"pycodestyle>=2.6.0; extra == \"dev\"",
"pydocstyle>=5.0.2; extra == \"dev\"",
"pylint>=2.5.3; extra == \"dev\"",
"coverage>=5.1; extra == \"test\"",
"coveralls>=2.0.0; extra == \"test\"",
"mock>=4.0.2; extra == \"test\"",
"pytest-cov>=2.10.0; extra == \"test\"",
"pytest-isort>=5; extra == \"test\"",
"pytest-mock>=3.1.1; extra == \"test\"",
"pytest>=6.0.0; extra == \"test\""
] | [] | [] | [] | [
"Bug Reports, https://github.com/blobtoolkit/blobtoolkit/issues",
"Source, https://github.com/blobtoolkit/blobtoolkit"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-20T13:29:18.449994 | blobtoolkit_pipeline-4.5.1.tar.gz | 39,801 | ea/fe/017926b062af6092d5e66d760f17811c877437677b087159a9b7d7f70272/blobtoolkit_pipeline-4.5.1.tar.gz | source | sdist | null | false | 4eee8f9114564fdacf390f409a218475 | c0bc22aee26000b221c0207b40b0b124773498c6767f1af3642bd2573ae49786 | eafe017926b062af6092d5e66d760f17811c877437677b087159a9b7d7f70272 | null | [] | 1,030 |
2.4 | opik | 1.10.18 | Comet tool for logging and evaluating LLM traces | <div align="center"><b><a href="README.md">English</a> | <a href="readme_CN.md">简体中文</a> | <a href="readme_JP.md">日本語</a> | <a href="readme_PT_BR.md">Português (Brasil)</a> | <a href="readme_KO.md">한국어</a></b></div>
<h1 align="center" style="border-bottom: none">
<div>
<a href="https://www.comet.com/site/products/opik/?from=llm&utm_source=opik&utm_medium=github&utm_content=header_img&utm_campaign=opik"><picture>
<source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/comet-ml/opik/refs/heads/main/apps/opik-documentation/documentation/static/img/logo-dark-mode.svg">
<source media="(prefers-color-scheme: light)" srcset="https://raw.githubusercontent.com/comet-ml/opik/refs/heads/main/apps/opik-documentation/documentation/static/img/opik-logo.svg">
<img alt="Comet Opik logo" src="https://raw.githubusercontent.com/comet-ml/opik/refs/heads/main/apps/opik-documentation/documentation/static/img/opik-logo.svg" width="200" />
</picture></a>
<br>
Opik
</div>
</h1>
<h2 align="center" style="border-bottom: none">Open-source AI Observability, Evaluation, and Optimization</h2>
<p align="center">
Opik helps you build, test, and optimize generative AI application that run better, from prototype to production. From RAG chatbots to code assistants to complex agentic systems, Opik provides comprehensive tracing, evaluation, and automatic prompt and tool optimization to take the guesswork out of AI development.
</p>
<div align="center">
[](https://pypi.org/project/opik/)
[](https://github.com/comet-ml/opik/blob/main/LICENSE)
[](https://github.com/comet-ml/opik/actions/workflows/build_apps.yml)
[](https://algora.io/comet-ml/bounties?status=open)
<!-- [](https://colab.research.google.com/github/comet-ml/opik/blob/main/apps/opik-documentation/documentation/docs/cookbook/opik_quickstart.ipynb) -->
</div>
<p align="center">
<a href="https://www.comet.com/site/products/opik/?from=llm&utm_source=opik&utm_medium=github&utm_content=website_button&utm_campaign=opik"><b>Website</b></a> •
<a href="https://chat.comet.com"><b>Slack Community</b></a> •
<a href="https://x.com/Cometml"><b>Twitter</b></a> •
<a href="https://www.comet.com/docs/opik/changelog"><b>Changelog</b></a> •
<a href="https://www.comet.com/docs/opik/?from=llm&utm_source=opik&utm_medium=github&utm_content=docs_button&utm_campaign=opik"><b>Documentation</b></a>
</p>
<div align="center" style="margin-top: 1em; margin-bottom: 1em;">
<a href="#-what-is-opik">🚀 What is Opik?</a> • <a href="#%EF%B8%8F-opik-server-installation">🛠️ Opik Server Installation</a> • <a href="#-opik-client-sdk">💻 Opik Client SDK</a> • <a href="#-logging-traces-with-integrations">📝 Logging Traces</a><br>
<a href="#-llm-as-a-judge-metrics">🧑⚖️ LLM as a Judge</a> • <a href="#-evaluating-your-llm-application">🔍 Evaluating your Application</a> • <a href="#-star-us-on-github">⭐ Star Us</a> • <a href="#-contributing">🤝 Contributing</a>
</div>
<br>
[](https://www.comet.com/signup?from=llm&utm_source=opik&utm_medium=github&utm_content=readme_banner&utm_campaign=opik)
## 🚀 What is Opik?
Opik (built by [Comet](https://www.comet.com?from=llm&utm_source=opik&utm_medium=github&utm_content=what_is_opik_link&utm_campaign=opik)) is an open-source platform designed to streamline the entire lifecycle of LLM applications. It empowers developers to evaluate, test, monitor, and optimize their models and agentic systems. Key offerings include:
- **Comprehensive Observability**: Deep tracing of LLM calls, conversation logging, and agent activity.
- **Advanced Evaluation**: Robust prompt evaluation, LLM-as-a-judge, and experiment management.
- **Production-Ready**: Scalable monitoring dashboards and online evaluation rules for production.
- **Opik Agent Optimizer**: Dedicated SDK and set of optimizers to enhance prompts and agents.
- **Opik Guardrails**: Features to help you implement safe and responsible AI practices.
<br>
Key capabilities include:
- **Development & Tracing:**
- Track all LLM calls and traces with detailed context during development and in production ([Quickstart](https://www.comet.com/docs/opik/quickstart/?from=llm&utm_source=opik&utm_medium=github&utm_content=quickstart_link&utm_campaign=opik)).
- Extensive 3rd-party integrations for easy observability: Seamlessly integrate with a growing list of frameworks, supporting many of the largest and most popular ones natively (including recent additions like **Google ADK**, **Autogen**, and **Flowise AI**). ([Integrations](https://www.comet.com/docs/opik/integrations/overview/?from=llm&utm_source=opik&utm_medium=github&utm_content=integrations_link&utm_campaign=opik))
- Annotate traces and spans with feedback scores via the [Python SDK](https://www.comet.com/docs/opik/tracing/annotate_traces/#annotating-traces-and-spans-using-the-sdk?from=llm&utm_source=opik&utm_medium=github&utm_content=sdk_link&utm_campaign=opik) or the [UI](https://www.comet.com/docs/opik/tracing/annotate_traces/#annotating-traces-through-the-ui?from=llm&utm_source=opik&utm_medium=github&utm_content=ui_link&utm_campaign=opik).
- Experiment with prompts and models in the [Prompt Playground](https://www.comet.com/docs/opik/prompt_engineering/playground).
- **Evaluation & Testing**:
- Automate your LLM application evaluation with [Datasets](https://www.comet.com/docs/opik/evaluation/manage_datasets/?from=llm&utm_source=opik&utm_medium=github&utm_content=datasets_link&utm_campaign=opik) and [Experiments](https://www.comet.com/docs/opik/evaluation/evaluate_your_llm/?from=llm&utm_source=opik&utm_medium=github&utm_content=eval_link&utm_campaign=opik).
- Leverage powerful LLM-as-a-judge metrics for complex tasks like [hallucination detection](https://www.comet.com/docs/opik/evaluation/metrics/hallucination/?from=llm&utm_source=opik&utm_medium=github&utm_content=hallucination_link&utm_campaign=opik), [moderation](https://www.comet.com/docs/opik/evaluation/metrics/moderation/?from=llm&utm_source=opik&utm_medium=github&utm_content=moderation_link&utm_campaign=opik), and RAG assessment ([Answer Relevance](https://www.comet.com/docs/opik/evaluation/metrics/answer_relevance/?from=llm&utm_source=opik&utm_medium=github&utm_content=alex_link&utm_campaign=opik), [Context Precision](https://www.comet.com/docs/opik/evaluation/metrics/context_precision/?from=llm&utm_source=opik&utm_medium=github&utm_content=context_link&utm_campaign=opik)).
- Integrate evaluations into your CI/CD pipeline with our [PyTest integration](https://www.comet.com/docs/opik/testing/pytest_integration/?from=llm&utm_source=opik&utm_medium=github&utm_content=pytest_link&utm_campaign=opik).
- **Production Monitoring & Optimization**:
- Log high volumes of production traces: Opik is designed for scale (40M+ traces/day).
- Monitor feedback scores, trace counts, and token usage over time in the [Opik Dashboard](https://www.comet.com/docs/opik/production/production_monitoring/?from=llm&utm_source=opik&utm_medium=github&utm_content=dashboard_link&utm_campaign=opik).
- Utilize [Online Evaluation Rules](https://www.comet.com/docs/opik/production/rules/?from=llm&utm_source=opik&utm_medium=github&utm_content=dashboard_link&utm_campaign=opik) with LLM-as-a-Judge metrics to identify production issues.
- Leverage **Opik Agent Optimizer** and **Opik Guardrails** to continuously improve and secure your LLM applications in production.
> [!TIP]
> If you are looking for features that Opik doesn't have today, please raise a new [Feature request](https://github.com/comet-ml/opik/issues/new/choose) 🚀
<br>
## 🛠️ Opik Server Installation
Get your Opik server running in minutes. Choose the option that best suits your needs:
### Option 1: Comet.com Cloud (Easiest & Recommended)
Access Opik instantly without any setup. Ideal for quick starts and hassle-free maintenance.
👉 [Create your free Comet account](https://www.comet.com/signup?from=llm&utm_source=opik&utm_medium=github&utm_content=install_create_link&utm_campaign=opik)
### Option 2: Self-Host Opik for Full Control
Deploy Opik in your own environment. Choose between Docker for local setups or Kubernetes for scalability.
#### Self-Hosting with Docker Compose (for Local Development & Testing)
This is the simplest way to get a local Opik instance running. Note the new `./opik.sh` installation script:
On Linux or Mac Environment:
```bash
# Clone the Opik repository
git clone https://github.com/comet-ml/opik.git
# Navigate to the repository
cd opik
# Start the Opik platform
./opik.sh
```
On Windows Environment:
```powershell
# Clone the Opik repository
git clone https://github.com/comet-ml/opik.git
# Navigate to the repository
cd opik
# Start the Opik platform
powershell -ExecutionPolicy ByPass -c ".\\opik.ps1"
```
**Service Profiles for Development**
The Opik installation scripts now support service profiles for different development scenarios:
```bash
# Start full Opik suite (default behavior)
./opik.sh
# Start only infrastructure services (databases, caches etc.)
./opik.sh --infra
# Start infrastructure + backend services
./opik.sh --backend
# Enable guardrails with any profile
./opik.sh --guardrails # Guardrails with full Opik suite
./opik.sh --backend --guardrails # Guardrails with infrastructure + backend
```
Use the `--help` or `--info` options to troubleshoot issues. Dockerfiles now ensure containers run as non-root users for enhanced security. Once all is up and running, you can now visit [localhost:5173](http://localhost:5173) on your browser! For detailed instructions, see the [Local Deployment Guide](https://www.comet.com/docs/opik/self-host/local_deployment?from=llm&utm_source=opik&utm_medium=github&utm_content=self_host_link&utm_campaign=opik).
#### Self-Hosting with Kubernetes & Helm (for Scalable Deployments)
For production or larger-scale self-hosted deployments, Opik can be installed on a Kubernetes cluster using our Helm chart. Click the badge for the full [Kubernetes Installation Guide using Helm](https://www.comet.com/docs/opik/self-host/kubernetes/#kubernetes-installation?from=llm&utm_source=opik&utm_medium=github&utm_content=kubernetes_link&utm_campaign=opik).
[](https://www.comet.com/docs/opik/self-host/kubernetes/#kubernetes-installation?from=llm&utm_source=opik&utm_medium=github&utm_content=kubernetes_link&utm_campaign=opik)
> [!IMPORTANT]
> **Version 1.7.0 Changes**: Please check the [changelog](https://github.com/comet-ml/opik/blob/main/CHANGELOG.md) for important updates and breaking changes.
## 💻 Opik Client SDK
Opik provides a suite of client libraries and a REST API to interact with the Opik server. This includes SDKs for Python, TypeScript, and Ruby (via OpenTelemetry), allowing for seamless integration into your workflows. For detailed API and SDK references, see the [Opik Client Reference Documentation](https://www.comet.com/docs/opik/reference/overview?from=llm&utm_source=opik&utm_medium=github&utm_content=reference_link&utm_campaign=opik).
### Python SDK Quick Start
To get started with the Python SDK:
Install the package:
```bash
# install using pip
pip install opik
# or install with uv
uv pip install opik
```
Configure the python SDK by running the `opik configure` command, which will prompt you for your Opik server address (for self-hosted instances) or your API key and workspace (for Comet.com):
```bash
opik configure
```
> [!TIP]
> You can also call `opik.configure(use_local=True)` from your Python code to configure the SDK to run on a local self-hosted installation, or provide API key and workspace details directly for Comet.com. Refer to the [Python SDK documentation](https://www.comet.com/docs/opik/python-sdk-reference/?from=llm&utm_source=opik&utm_medium=github&utm_content=python_sdk_docs_link&utm_campaign=opik) for more configuration options.
You are now ready to start logging traces using the [Python SDK](https://www.comet.com/docs/opik/python-sdk-reference/?from=llm&utm_source=opik&utm_medium=github&utm_content=sdk_link2&utm_campaign=opik).
### 📝 Logging Traces with Integrations
The easiest way to log traces is to use one of our direct integrations. Opik supports a wide array of frameworks, including recent additions like **Google ADK**, **Autogen**, **AG2**, and **Flowise AI**:
| Integration | Description | Documentation |
| --------------------- | ------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| ADK | Log traces for Google Agent Development Kit (ADK) | [Documentation](https://www.comet.com/docs/opik/integrations/adk?utm_source=opik&utm_medium=github&utm_content=google_adk_link&utm_campaign=opik) |
| AG2 | Log traces for AG2 LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/ag2?utm_source=opik&utm_medium=github&utm_content=ag2_link&utm_campaign=opik) |
| AIsuite | Log traces for aisuite LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/aisuite?utm_source=opik&utm_medium=github&utm_content=aisuite_link&utm_campaign=opik) |
| Agno | Log traces for Agno agent orchestration framework calls | [Documentation](https://www.comet.com/docs/opik/integrations/agno?utm_source=opik&utm_medium=github&utm_content=agno_link&utm_campaign=opik) |
| Anthropic | Log traces for Anthropic LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/anthropic?utm_source=opik&utm_medium=github&utm_content=anthropic_link&utm_campaign=opik) |
| Autogen | Log traces for Autogen agentic workflows | [Documentation](https://www.comet.com/docs/opik/integrations/autogen?utm_source=opik&utm_medium=github&utm_content=autogen_link&utm_campaign=opik) |
| Bedrock | Log traces for Amazon Bedrock LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/bedrock?utm_source=opik&utm_medium=github&utm_content=bedrock_link&utm_campaign=opik) |
| BeeAI (Python) | Log traces for BeeAI Python agent framework calls | [Documentation](https://www.comet.com/docs/opik/integrations/beeai?utm_source=opik&utm_medium=github&utm_content=beeai_link&utm_campaign=opik) |
| BeeAI (TypeScript) | Log traces for BeeAI TypeScript agent framework calls | [Documentation](https://www.comet.com/docs/opik/integrations/beeai-typescript?utm_source=opik&utm_medium=github&utm_content=beeai_typescript_link&utm_campaign=opik) |
| BytePlus | Log traces for BytePlus LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/byteplus?utm_source=opik&utm_medium=github&utm_content=byteplus_link&utm_campaign=opik) |
| Cloudflare Workers AI | Log traces for Cloudflare Workers AI calls | [Documentation](https://www.comet.com/docs/opik/integrations/cloudflare-workers-ai?utm_source=opik&utm_medium=github&utm_content=cloudflare_workers_ai_link&utm_campaign=opik) |
| Cohere | Log traces for Cohere LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/cohere?utm_source=opik&utm_medium=github&utm_content=cohere_link&utm_campaign=opik) |
| CrewAI | Log traces for CrewAI calls | [Documentation](https://www.comet.com/docs/opik/integrations/crewai?utm_source=opik&utm_medium=github&utm_content=crewai_link&utm_campaign=opik) |
| Cursor | Log traces for Cursor conversations | [Documentation](https://www.comet.com/docs/opik/integrations/cursor?utm_source=opik&utm_medium=github&utm_content=cursor_link&utm_campaign=opik) |
| DeepSeek | Log traces for DeepSeek LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/deepseek?utm_source=opik&utm_medium=github&utm_content=deepseek_link&utm_campaign=opik) |
| Dify | Log traces for Dify agent runs | [Documentation](https://www.comet.com/docs/opik/integrations/dify?utm_source=opik&utm_medium=github&utm_content=dify_link&utm_campaign=opik) |
| DSPY | Log traces for DSPy runs | [Documentation](https://www.comet.com/docs/opik/integrations/dspy?utm_source=opik&utm_medium=github&utm_content=dspy_link&utm_campaign=opik) |
| Fireworks AI | Log traces for Fireworks AI LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/fireworks-ai?utm_source=opik&utm_medium=github&utm_content=fireworks_ai_link&utm_campaign=opik) |
| Flowise AI | Log traces for Flowise AI visual LLM builder | [Documentation](https://www.comet.com/docs/opik/integrations/flowise?utm_source=opik&utm_medium=github&utm_content=flowise_link&utm_campaign=opik) |
| Gemini (Python) | Log traces for Google Gemini LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/gemini?utm_source=opik&utm_medium=github&utm_content=gemini_link&utm_campaign=opik) |
| Gemini (TypeScript) | Log traces for Google Gemini TypeScript SDK calls | [Documentation](https://www.comet.com/docs/opik/integrations/gemini-typescript?utm_source=opik&utm_medium=github&utm_content=gemini_typescript_link&utm_campaign=opik) |
| Groq | Log traces for Groq LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/groq?utm_source=opik&utm_medium=github&utm_content=groq_link&utm_campaign=opik) |
| Guardrails | Log traces for Guardrails AI validations | [Documentation](https://www.comet.com/docs/opik/integrations/guardrails-ai?utm_source=opik&utm_medium=github&utm_content=guardrails_link&utm_campaign=opik) |
| Haystack | Log traces for Haystack calls | [Documentation](https://www.comet.com/docs/opik/integrations/haystack?utm_source=opik&utm_medium=github&utm_content=haystack_link&utm_campaign=opik) |
| Harbor | Log traces for Harbor benchmark evaluation trials | [Documentation](https://www.comet.com/docs/opik/integrations/harbor?utm_source=opik&utm_medium=github&utm_content=harbor_link&utm_campaign=opik) |
| Instructor | Log traces for LLM calls made with Instructor | [Documentation](https://www.comet.com/docs/opik/integrations/instructor?utm_source=opik&utm_medium=github&utm_content=instructor_link&utm_campaign=opik) |
| LangChain (Python) | Log traces for LangChain LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/langchain?utm_source=opik&utm_medium=github&utm_content=langchain_link&utm_campaign=opik) |
| LangChain (JS/TS) | Log traces for LangChain JavaScript/TypeScript calls | [Documentation](https://www.comet.com/docs/opik/integrations/langchainjs?utm_source=opik&utm_medium=github&utm_content=langchainjs_link&utm_campaign=opik) |
| LangGraph | Log traces for LangGraph executions | [Documentation](https://www.comet.com/docs/opik/integrations/langgraph?utm_source=opik&utm_medium=github&utm_content=langgraph_link&utm_campaign=opik) |
| Langflow | Log traces for Langflow visual AI builder | [Documentation](https://www.comet.com/docs/opik/integrations/langflow?utm_source=opik&utm_medium=github&utm_content=langflow_link&utm_campaign=opik) |
| LiteLLM | Log traces for LiteLLM model calls | [Documentation](https://www.comet.com/docs/opik/integrations/litellm?utm_source=opik&utm_medium=github&utm_content=litellm_link&utm_campaign=opik) |
| LiveKit Agents | Log traces for LiveKit Agents AI agent framework calls | [Documentation](https://www.comet.com/docs/opik/integrations/livekit?utm_source=opik&utm_medium=github&utm_content=livekit_link&utm_campaign=opik) |
| LlamaIndex | Log traces for LlamaIndex LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/llama_index?utm_source=opik&utm_medium=github&utm_content=llama_index_link&utm_campaign=opik) |
| Mastra | Log traces for Mastra AI workflow framework calls | [Documentation](https://www.comet.com/docs/opik/integrations/mastra?utm_source=opik&utm_medium=github&utm_content=mastra_link&utm_campaign=opik) |
| Microsoft Agent Framework (Python) | Log traces for Microsoft Agent Framework calls | [Documentation](https://www.comet.com/docs/opik/integrations/microsoft-agent-framework?utm_source=opik&utm_medium=github&utm_content=agent_framework_link&utm_campaign=opik) |
| Microsoft Agent Framework (.NET) | Log traces for Microsoft Agent Framework .NET calls | [Documentation](https://www.comet.com/docs/opik/integrations/microsoft-agent-framework-dotnet?utm_source=opik&utm_medium=github&utm_content=agent_framework_dotnet_link&utm_campaign=opik) |
| Mistral AI | Log traces for Mistral AI LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/mistral?utm_source=opik&utm_medium=github&utm_content=mistral_link&utm_campaign=opik) |
| n8n | Log traces for n8n workflow executions | [Documentation](https://www.comet.com/docs/opik/integrations/n8n?utm_source=opik&utm_medium=github&utm_content=n8n_link&utm_campaign=opik) |
| Novita AI | Log traces for Novita AI LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/novita-ai?utm_source=opik&utm_medium=github&utm_content=novita_ai_link&utm_campaign=opik) |
| Ollama | Log traces for Ollama LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/ollama?utm_source=opik&utm_medium=github&utm_content=ollama_link&utm_campaign=opik) |
| OpenAI (Python) | Log traces for OpenAI LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/openai?utm_source=opik&utm_medium=github&utm_content=openai_link&utm_campaign=opik) |
| OpenAI (JS/TS) | Log traces for OpenAI JavaScript/TypeScript calls | [Documentation](https://www.comet.com/docs/opik/integrations/openai-typescript?utm_source=opik&utm_medium=github&utm_content=openai_typescript_link&utm_campaign=opik) |
| OpenAI Agents | Log traces for OpenAI Agents SDK calls | [Documentation](https://www.comet.com/docs/opik/integrations/openai_agents?utm_source=opik&utm_medium=github&utm_content=openai_agents_link&utm_campaign=opik) |
| OpenRouter | Log traces for OpenRouter LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/openrouter?utm_source=opik&utm_medium=github&utm_content=openrouter_link&utm_campaign=opik) |
| OpenTelemetry | Log traces for OpenTelemetry supported calls | [Documentation](https://www.comet.com/docs/opik/tracing/opentelemetry/overview?utm_source=opik&utm_medium=github&utm_content=opentelemetry_link&utm_campaign=opik) |
| OpenWebUI | Log traces for OpenWebUI conversations | [Documentation](https://www.comet.com/docs/opik/integrations/openwebui?utm_source=opik&utm_medium=github&utm_content=openwebui_link&utm_campaign=opik) |
| Pipecat | Log traces for Pipecat real-time voice agent calls | [Documentation](https://www.comet.com/docs/opik/integrations/pipecat?utm_source=opik&utm_medium=github&utm_content=pipecat_link&utm_campaign=opik) |
| Predibase | Log traces for Predibase LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/predibase?utm_source=opik&utm_medium=github&utm_content=predibase_link&utm_campaign=opik) |
| Pydantic AI | Log traces for PydanticAI agent calls | [Documentation](https://www.comet.com/docs/opik/integrations/pydantic-ai?utm_source=opik&utm_medium=github&utm_content=pydantic_ai_link&utm_campaign=opik) |
| Ragas | Log traces for Ragas evaluations | [Documentation](https://www.comet.com/docs/opik/integrations/ragas?utm_source=opik&utm_medium=github&utm_content=ragas_link&utm_campaign=opik) |
| Semantic Kernel | Log traces for Microsoft Semantic Kernel calls | [Documentation](https://www.comet.com/docs/opik/integrations/semantic-kernel?utm_source=opik&utm_medium=github&utm_content=semantic_kernel_link&utm_campaign=opik) |
| Smolagents | Log traces for Smolagents agents | [Documentation](https://www.comet.com/docs/opik/integrations/smolagents?utm_source=opik&utm_medium=github&utm_content=smolagents_link&utm_campaign=opik) |
| Spring AI | Log traces for Spring AI framework calls | [Documentation](https://www.comet.com/docs/opik/integrations/spring-ai?utm_source=opik&utm_medium=github&utm_content=spring_ai_link&utm_campaign=opik) |
| Strands Agents | Log traces for Strands agents calls | [Documentation](https://www.comet.com/docs/opik/integrations/strands-agents?utm_source=opik&utm_medium=github&utm_content=strands_agents_link&utm_campaign=opik) |
| Together AI | Log traces for Together AI LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/together-ai?utm_source=opik&utm_medium=github&utm_content=together_ai_link&utm_campaign=opik) |
| Vercel AI SDK | Log traces for Vercel AI SDK calls | [Documentation](https://www.comet.com/docs/opik/integrations/vercel-ai-sdk?utm_source=opik&utm_medium=github&utm_content=vercel_ai_sdk_link&utm_campaign=opik) |
| VoltAgent | Log traces for VoltAgent agent framework calls | [Documentation](https://www.comet.com/docs/opik/integrations/voltagent?utm_source=opik&utm_medium=github&utm_content=voltagent_link&utm_campaign=opik) |
| WatsonX | Log traces for IBM watsonx LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/watsonx?utm_source=opik&utm_medium=github&utm_content=watsonx_link&utm_campaign=opik) |
| xAI Grok | Log traces for xAI Grok LLM calls | [Documentation](https://www.comet.com/docs/opik/integrations/xai-grok?utm_source=opik&utm_medium=github&utm_content=xai_grok_link&utm_campaign=opik) |
> [!TIP]
> If the framework you are using is not listed above, feel free to [open an issue](https://github.com/comet-ml/opik/issues) or submit a PR with the integration.
If you are not using any of the frameworks above, you can also use the `track` function decorator to [log traces](https://www.comet.com/docs/opik/tracing/log_traces/?from=llm&utm_source=opik&utm_medium=github&utm_content=traces_link&utm_campaign=opik):
```python
import opik
opik.configure(use_local=True) # Run locally
@opik.track
def my_llm_function(user_question: str) -> str:
# Your LLM code here
return "Hello"
```
> [!TIP]
> The track decorator can be used in conjunction with any of our integrations and can also be used to track nested function calls.
### 🧑⚖️ LLM as a Judge metrics
The Python Opik SDK includes a number of LLM as a judge metrics to help you evaluate your LLM application. Learn more about it in the [metrics documentation](https://www.comet.com/docs/opik/evaluation/metrics/overview/?from=llm&utm_source=opik&utm_medium=github&utm_content=metrics_2_link&utm_campaign=opik).
To use them, simply import the relevant metric and use the `score` function:
```python
from opik.evaluation.metrics import Hallucination
metric = Hallucination()
score = metric.score(
input="What is the capital of France?",
output="Paris",
context=["France is a country in Europe."]
)
print(score)
```
Opik also includes a number of pre-built heuristic metrics as well as the ability to create your own. Learn more about it in the [metrics documentation](https://www.comet.com/docs/opik/evaluation/metrics/overview?from=llm&utm_source=opik&utm_medium=github&utm_content=metrics_3_link&utm_campaign=opik).
### 🔍 Evaluating your LLM Applications
Opik allows you to evaluate your LLM application during development through [Datasets](https://www.comet.com/docs/opik/evaluation/manage_datasets/?from=llm&utm_source=opik&utm_medium=github&utm_content=datasets_2_link&utm_campaign=opik) and [Experiments](https://www.comet.com/docs/opik/evaluation/evaluate_your_llm/?from=llm&utm_source=opik&utm_medium=github&utm_content=experiments_link&utm_campaign=opik). The Opik Dashboard offers enhanced charts for experiments and better handling of large traces. You can also run evaluations as part of your CI/CD pipeline using our [PyTest integration](https://www.comet.com/docs/opik/testing/pytest_integration/?from=llm&utm_source=opik&utm_medium=github&utm_content=pytest_2_link&utm_campaign=opik).
## ⭐ Star Us on GitHub
If you find Opik useful, please consider giving us a star! Your support helps us grow our community and continue improving the product.
[](https://github.com/comet-ml/opik)
## 🤝 Contributing
There are many ways to contribute to Opik:
- Submit [bug reports](https://github.com/comet-ml/opik/issues) and [feature requests](https://github.com/comet-ml/opik/issues)
- Review the documentation and submit [Pull Requests](https://github.com/comet-ml/opik/pulls) to improve it
- Speaking or writing about Opik and [letting us know](https://chat.comet.com)
- Upvoting [popular feature requests](https://github.com/comet-ml/opik/issues?q=is%3Aissue+is%3Aopen+label%3A%22enhancement%22) to show your support
To learn more about how to contribute to Opik, please see our [contributing guidelines](CONTRIBUTING.md).
| text/markdown | Comet ML Inc. | mail@comet.com | null | null | Apache 2.0 License | opik | [
"Development Status :: 2 - Pre-Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Natural Language :: English",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | https://www.comet.com | null | >=3.10 | [] | [] | [] | [
"boto3-stubs[bedrock-runtime]>=1.34.110",
"click",
"httpx",
"rapidfuzz<4.0.0,>=3.0.0",
"litellm!=1.75.0,!=1.75.1,!=1.75.2,!=1.75.3,!=1.75.4,!=1.75.5,!=1.77.3,!=1.77.4,!=1.77.5,!=1.77.7,!=1.78.0,!=1.78.2,!=1.78.3,!=1.78.4,!=1.78.5,!=1.78.6,!=1.78.7,!=1.79.0,!=1.79.1,>=1.79.2",
"openai",
"pydantic-settings!=2.9.0,<3.0.0,>=2.0.0",
"pydantic<3.0.0,>=2.0.0",
"pytest",
"rich",
"sentry_sdk>=2.0.0",
"tenacity",
"tqdm",
"uuid6",
"jinja2",
"fastapi>=0.100.0; extra == \"proxy\"",
"uvicorn>=0.23.0; extra == \"proxy\""
] | [] | [] | [] | [
"Source code, https://github.com/comet-ml/opik"
] | twine/6.1.0 CPython/3.12.8 | 2026-02-20T13:29:13.244851 | opik-1.10.18.tar.gz | 715,198 | 64/e7/4ba6abae87aa28fef8bc95610485e3b0df7b34571df6eaef4daf6f0a6359/opik-1.10.18.tar.gz | source | sdist | null | false | 17b61989314528757cd2c85fcea82ad7 | bc3c50738a8d1fcdd8a32e1b8333a053da069c1081858b97f2c4cb6b78c211cc | 64e74ba6abae87aa28fef8bc95610485e3b0df7b34571df6eaef4daf6f0a6359 | null | [
"LICENSE"
] | 38,882 |
2.4 | howler-sentinel-plugin | 0.2.0.dev242 | A howler plugin for integration with Microsoft's Sentinel API | # Howler Sentinel Plugin
This plugin contains modules for Microsoft Sentinel integration in Howler.
| text/markdown | CCCS | analysis-development@cyber.gc.ca | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.9.17 | [] | [] | [] | [
"python-dateutil<3.0.0,>=2.9.0.post0"
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.12.3 Linux/6.11.0-1018-azure | 2026-02-20T13:28:53.143329 | howler_sentinel_plugin-0.2.0.dev242-py3-none-any.whl | 28,020 | fb/2b/262fd6552be28e628665095b6e7e9c7dcbb625c84aac86590bb3d3af6de4/howler_sentinel_plugin-0.2.0.dev242-py3-none-any.whl | py3 | bdist_wheel | null | false | 3feecc0f89635a9ab7ada2a56b44cb8e | 73c99cd927d6bc80c75bb8b23a00406d96d563c62bcdb22ac67521fb97f9720a | fb2b262fd6552be28e628665095b6e7e9c7dcbb625c84aac86590bb3d3af6de4 | null | [
"LICENSE"
] | 177 |
2.1 | param-manager | 0.3.9 | Biblioteca para gerenciamento de parâmetros com padrão Singleton,cache e armazenamento local usando TinyDB. | # Biblioteca ParamManager
## Descrição
Biblioteca Python orientada a objetos que implementa o padrão Singleton para interagir com a API de parâmetros. A biblioteca oferece funcionalidades de cache, armazenamento local com TinyDB e fallback automático em caso de indisponibilidade da API.
## Funcionalidades
- **Padrão Singleton**: Garante que exista apenas uma instância da classe de acesso à API
- **Cache**: Armazena resultados em memória por até 1 hora para reduzir chamadas à API
- **Armazenamento Local**: Usa TinyDB para persistir dados localmente
- **Fallback Automático**: Utiliza dados locais quando a API está indisponível
- **Recuperação de Parâmetros**: Permite buscar todos os parâmetros de um app ou um parâmetro específico
## Instalação
```bash
pip install param-manager
```
## Uso Básico
```python
from param_manager import ParamManager
# Obter a instância do gerenciador
param_manager = ParamManager.get_instance()
# Recuperar todos os parâmetros de um app
params = param_manager.get_all_params('nome_do_app')
# Recuperar um parâmetro específico
param = param_manager.get_param('nome_do_app', 'NOME_PARAMETRO')
# Limpar o cache para um app específico
param_manager.clear_cache('nome_do_app')
# Obter informações sobre o cache atual
cache_info = param_manager.get_cache_info()
```
## Configuração Avançada
```python
# Configurar com URL de API personalizada, duração de cache e timeout
param_manager = ParamManager.get_instance(
api_url="http://minha-api.exemplo.com",
cache_duration=1800, # 30 minutos
timeout=10 # 10 segundos
)
```
## Comportamento de Fallback
Quando a API está indisponível, a biblioteca automaticamente:
1. Tenta acessar a API
2. Em caso de falha, busca dados do armazenamento local
3. Retorna os dados mais recentes disponíveis localmente
## Estrutura de Arquivos
- `param_manager.py`: Implementação principal da biblioteca
- `test_param_manager.py`: Testes unitários para validar o funcionamento
- `README.md`: Documentação da biblioteca
- `requirements.txt`: Dependências necessárias
## Dependências
- Python 3.8+
- requests
- tinydb
| text/markdown | null | MatheusLPolidoro <mattpolidoro4@gmail.com> | null | null | null | null | [] | [] | null | null | <=3.14,>=3.8 | [] | [] | [] | [
"tinydb>=4.8.0",
"requests>=2.32.0",
"pycryptodome==3.23.0",
"python-dotenv==1.1.1"
] | [] | [] | [] | [
"Documentation, https://matheuslpolidoro.github.io/param-manager/",
"Source Code, https://github.com/MatheusLPolidoro/param-manager",
"Bug Tracker, https://github.com/MatheusLPolidoro/param-manager/issues"
] | twine/6.2.0 CPython/3.11.1 | 2026-02-20T13:28:32.761121 | param_manager-0.3.9.tar.gz | 24,740 | 5e/57/ed6bfc637ab4cebf78c9afada15c07ea64fac81ee9a957962ff2fd9d78f5/param_manager-0.3.9.tar.gz | source | sdist | null | false | 014fcf45c5376ef6b1cd774ab725be5e | b7788addd87b9879fcf5e61992e2b91d142b620d2e3e58f925c4c22ecb7a5dd0 | 5e57ed6bfc637ab4cebf78c9afada15c07ea64fac81ee9a957962ff2fd9d78f5 | null | [] | 207 |
2.4 | AlexaPy | 1.29.17 | Python API to control Amazon Echo Devices Programmatically. | # alexapy
[](https://opensource.org/licenses/Apache-2.0)
[](https://pypi.org/project/alexapy)
[](https://pypi.org/project/alexapy)
[](https://gitlab.com/keatontaylor/alexapy/commits/master)



Python Package for controlling Alexa devices (echo dot, etc) programmatically. This was originally designed for [alexa_media_player](https://github.com/custom-components/alexa_media_player) a custom_component for [Home Assistant](https://www.home-assistant.io/).
**NOTE:** Alexa has no official API; therefore, this library may stop
working at any time without warning.
# Credits
Originally inspired by [this blog](https://blog.loetzimmer.de/2017/10/amazon-alexa-hort-auf-die-shell-echo.html) [(GitHub)](https://github.com/thorsten-gehrig/alexa-remote-control).
Additional scaffolding from [simplisafe-python](https://github.com/bachya/simplisafe-python)
# Contributing
1. [Check for open features/bugs](https://gitlab.com/keatontaylor/alexapy/issues)
or [initiate a discussion on one](https://gitlab.com/keatontaylor/alexapy/issues/new).
2. [Fork the repository](https://gitlab.com/keatontaylor/alexapy/forks/new).
3. Install the dev environment: `make init`.
4. Enter the virtual environment: `pipenv shell`
5. Code your new feature or bug fix.
6. Write a test that covers your new functionality.
7. Update `README.md` with any new documentation.
8. Run tests and ensure 100% code coverage for your contribution: `make coverage`
9. Ensure you have no linting errors: `make lint`
10. Ensure you have typed your code correctly: `make typing`
11. Add yourself to `AUTHORS.md`.
12. Submit a pull request!
# License
[Apache-2.0](LICENSE). By providing a contribution, you agree the contribution is licensed under Apache-2.0.
# API Reference
[See the docs 📚](https://alexapy.readthedocs.io/en/latest/index.html).
| text/markdown | Keaton Taylor | keatonstaylor@gmail.com | null | null | Apache-2.0 | amazon, alexa, homeassistant | [
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4,>=3.11 | [] | [] | [] | [
"aiofiles<25.0.0,>=24.1.0",
"aiohttp<4.0.0,>=3.8.4",
"authcaptureproxy<2.0.0,>=1.3.2",
"backoff>=1.10",
"beautifulsoup4",
"certifi",
"cryptography>=35.0",
"httpx[http2]>=0.24.0",
"pyotp>=2.4",
"requests",
"simplejson",
"yarl"
] | [] | [] | [] | [
"Repository, https://gitlab.com/keatontaylor/alexapy"
] | poetry/2.3.2 CPython/3.13.12 Linux/5.15.154+ | 2026-02-20T13:28:23.586253 | alexapy-1.29.17-py3-none-any.whl | 55,176 | fd/05/797e1dfdadb7d794fbfe39ec63e4599955a478509e4b5703732d181e67e9/alexapy-1.29.17-py3-none-any.whl | py3 | bdist_wheel | null | false | 5e6d9b8e84dfe0223db23727ce15b2ed | 0e544c2bc48f5da3c81805f90a035cbde21344385296b5fda2869cd5b470f3d3 | fd05797e1dfdadb7d794fbfe39ec63e4599955a478509e4b5703732d181e67e9 | null | [
"AUTHORS.md",
"LICENSE"
] | 0 |
2.4 | erabytse-rememoir | 0.1.3 | Cognitive memory for offline AI agents — human-centered, local-first, open-source. | # Rememoir
> *Not every memory deserves to be kept. But those that do — deserve to be understood.*
**Rememoir** is a local-first, human-centered cognitive memory system for offline AI agents.
It enables your agent to remember conversations, learn from feedback, and collaborate with you — **without ever sending your data to the cloud**.
Built for [UAssistant](https://github.com/erabytse/uassistant) and any local LLM agent.
- ✅ **100% offline** — no internet required
- ✅ **Semantic + contextual recall** — finds relevant memories by meaning, not just keywords
- ✅ **Feedback-aware learning** — adapts based on your corrections and preferences
- ✅ **Lightweight & embeddable** — powered by [LanceDB](https://lancedb.com), zero external dependencies
- ✅ **Open source (MIT License)** — inspect, modify, redistribute freely
- ✅ **Part of the [Erabytse](https://erabytse.github.io/) ecosystem** — tools for intentional digital care
---
# Quick Start
## Install:
```bash
pip install erabytse-rememoir
```
## Use in your agent:
```python
from erabytse_rememoir import RememoirDB
# Initialize memory for a user (isolated by user_id)
memory = RememoirDB(user_id="alice")
# Add a memory episode
memory.add("I prefer short answers in German.")
# Recall contextually
results = memory.search("How should you answer me?")
print(results[0].content)
# → "I prefer short answers in German."
```
## Philosophy
Rememoir is not a database. It’s a memory companion — designed to forget what’s noise, keep what matters, and always stay under your control.
In a world of surveillance, data extraction, and opaque AI, Rememoir offers a quiet alternative:
an intelligent memory that belongs to you, learns from you, and never betrays you.
It embodies Erabytse’s core principle:
Technology should serve attention, not exploit it.
## Integration
See examples/integrate_with_uassistant.py for a full walkthrough with UAssistant.
Rememoir works seamlessly with:
- Local LLMs (Ollama, LM Studio, llama.cpp…)
- RAG systems
- Voice or text-based agents
- Personal productivity tools
## License
MIT © [Erabytse](https://erabytse.github.io/)
Part of a quiet rebellion against digital waste.
| text/markdown | null | Erabytse <contact@erabytse.github.io> | null | FBF <contact@erabytse.github.io> | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: End Users/Desktop",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Utilities"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"lancedb>=0.5.0",
"sentence-transformers>=2.2.0",
"pydantic>=2.0.0",
"numpy>=1.21.0",
"pytest>=7.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/erabytse/rememoir",
"Repository, https://github.com/erabytse/rememoir",
"Documentation, https://github.com/erabytse/rememoir#readme"
] | twine/6.2.0 CPython/3.13.5 | 2026-02-20T13:27:56.019390 | erabytse_rememoir-0.1.3.tar.gz | 5,317 | b7/7c/ee79ca3ba9adffccce4dbf6092d744eba331e9f22040fcc5e5ff4b06c26f/erabytse_rememoir-0.1.3.tar.gz | source | sdist | null | false | e057f6580c62c674e8c5df085a481bc5 | 82cf21e68610a8699f894eda46a65787a4dd9ca7d41eea628c9cba257a6d9b3a | b77cee79ca3ba9adffccce4dbf6092d744eba331e9f22040fcc5e5ff4b06c26f | MIT | [
"LICENSE"
] | 210 |
2.4 | dapr-ext-strands | 1.17.0rc5 | The official release of Dapr Python SDK Strands Agents Extension. | This is the Dapr Session Manager extension for Strands Agents.
Dapr is a portable, serverless, event-driven runtime that makes it easy for developers to
build resilient, stateless and stateful microservices that run on the cloud and edge and
embraces the diversity of languages and developer frameworks.
Dapr codifies the best practices for building microservice applications into open,
independent, building blocks that enable you to build portable applications with the language
and framework of your choice. Each building block is independent and you can use one, some,
or all of them in your application.
| null | Dapr Authors | daprweb@microsoft.com | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | https://dapr.io/ | null | >=3.10 | [] | [] | [] | [
"dapr>=1.17.0rc5",
"strands-agents",
"strands-agents-tools",
"python-ulid>=3.0.0",
"msgpack-python>=0.4.5"
] | [] | [] | [] | [
"Documentation, https://github.com/dapr/docs",
"Source, https://github.com/dapr/python-sdk"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T13:27:35.426243 | dapr_ext_strands-1.17.0rc5.tar.gz | 11,955 | 40/ad/55299eb6c1a4ae0d072e19ef038599f326e491d537d44bb439acba198691/dapr_ext_strands-1.17.0rc5.tar.gz | source | sdist | null | false | 4c6116d7c47ea583916d813da267edb2 | 769a3c052a6ff95e857bdb7796868b7f41f3acc5a3f1d49b98cad8f0a76b7de4 | 40ad55299eb6c1a4ae0d072e19ef038599f326e491d537d44bb439acba198691 | null | [
"LICENSE"
] | 213 |
2.4 | dapr-ext-langgraph | 1.17.0rc5 | The official release of Dapr Python SDK LangGraph Extension. | This is the Dapr Checkpointer extension for LangGraph.
Dapr is a portable, serverless, event-driven runtime that makes it easy for developers to
build resilient, stateless and stateful microservices that run on the cloud and edge and
embraces the diversity of languages and developer frameworks.
Dapr codifies the best practices for building microservice applications into open,
independent, building blocks that enable you to build portable applications with the language
and framework of your choice. Each building block is independent and you can use one, some,
or all of them in your application.
| null | Dapr Authors | daprweb@microsoft.com | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | https://dapr.io/ | null | >=3.10 | [] | [] | [] | [
"dapr>=1.17.0rc5",
"langgraph>=0.3.6",
"langchain>=0.1.17",
"python-ulid>=3.0.0",
"msgpack-python>=0.4.5"
] | [] | [] | [] | [
"Documentation, https://github.com/dapr/docs",
"Source, https://github.com/dapr/python-sdk"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T13:27:31.225135 | dapr_ext_langgraph-1.17.0rc5.tar.gz | 12,126 | 63/e1/6740463b8ef6109024edc67e3c221b8c1ca3e75f34981caf32f4048f5c8d/dapr_ext_langgraph-1.17.0rc5.tar.gz | source | sdist | null | false | 11df096f0aa396b5c43be5ffbdf1c0a6 | 82cea93612614c773f232dc393de46dd2c48caa3f6f67e7c7ec44b5bd5214d1b | 63e16740463b8ef6109024edc67e3c221b8c1ca3e75f34981caf32f4048f5c8d | null | [
"LICENSE"
] | 221 |
2.4 | dapr-ext-grpc | 1.17.0rc5 | The official release of Dapr Python SDK gRPC Extension. | This is the gRPC extension for Dapr.
Dapr is a portable, serverless, event-driven runtime that makes it easy for developers to
build resilient, stateless and stateful microservices that run on the cloud and edge and
embraces the diversity of languages and developer frameworks.
Dapr codifies the best practices for building microservice applications into open,
independent, building blocks that enable you to build portable applications with the language
and framework of your choice. Each building block is independent and you can use one, some,
or all of them in your application.
| null | Dapr Authors | daprweb@microsoft.com | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://dapr.io/ | null | >=3.9 | [] | [] | [] | [
"dapr>=1.17.0rc5",
"cloudevents>=1.0.0"
] | [] | [] | [] | [
"Documentation, https://github.com/dapr/docs",
"Source, https://github.com/dapr/python-sdk"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T13:27:29.928691 | dapr_ext_grpc-1.17.0rc5.tar.gz | 15,533 | fc/87/d6c33350b649e6354cbaded01e24ba26b99413cd95b8d7015e820ef4a555/dapr_ext_grpc-1.17.0rc5.tar.gz | source | sdist | null | false | 2cf13cd9828482e74a2143f71709e0d1 | 4e9a0016dd238348c6d4c63fbeffbf04c8e0dffb7eb0236ff398c48c7aca573c | fc87d6c33350b649e6354cbaded01e24ba26b99413cd95b8d7015e820ef4a555 | null | [
"LICENSE"
] | 189 |
2.4 | howler-evidence-plugin | 0.1.0.dev164 | A howler plugin to add additional nested ECS fields to the Howler ODM | # Howler Evidence Plugin
A howler plugin to add additional nested ECS fields to the Howler ODM.
| text/markdown | CCCS | analysis-development@cyber.gc.ca | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.9.17 | [] | [] | [] | [] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.12.3 Linux/6.11.0-1018-azure | 2026-02-20T13:27:28.407994 | howler_evidence_plugin-0.1.0.dev164-py3-none-any.whl | 6,662 | cd/e2/d6bbd2f701c3cbb1f7deacb50d378393ab74f2b20e7433b1cf7a21874e72/howler_evidence_plugin-0.1.0.dev164-py3-none-any.whl | py3 | bdist_wheel | null | false | 8934dcc3dc62edd59ae0f80bb8167d69 | dd1cbe390f7301fb41661c289cdd5038718d028d7aee59cfd2cce4abfeb3a440 | cde2d6bbd2f701c3cbb1f7deacb50d378393ab74f2b20e7433b1cf7a21874e72 | null | [
"LICENSE"
] | 185 |
2.4 | firetruck | 0.1.1 | NumPyro dialect for mental midgets | # 🚒 firetruck
!!! NOTE: This repo is just an experiment for now, not ready for any kind of serious use. The package is not published on PyPI either !!!
firetruck is NumPyro dialect for mental midgets. This means:
- No `numpyro.deterministic` and `numpyro.sample`, just write your code like a normal human, and assign variables you want to track to `self`
- You can just return your outcome variable from the function, no `obs` bullshit!
- Greatly simplified sampling and VI. No bespoke solutions, just good defaults for 90% of your use cases.
- You can deal with latent categorical variables without having to do anything, yaaay!
- WebGL accelarated Plotly plots. You don't know ArViz, Matplotlib or any of that jazz. It not only looks better but it's also interactive and faster.
## Example
I modified the Waffle House example in the [NumPyro docs](https://num.pyro.ai/en/stable/tutorials/bayesian_regression.html) to use firetruck.
```python
import jax as jax
import jax.numpy as jnp
import numpyro.distributions as dist
import pandas as pd
import firetruck as ftr
DATASET_URL = "https://raw.githubusercontent.com/rmcelreath/rethinking/master/data/WaffleDivorce.csv"
dset = pd.read_csv(DATASET_URL, sep=";")
marriage = jnp.array(dset["Marriage"])
divorce = jnp.array(dset["Divorce"])
age = jnp.array(dset["MedianAgeMarriage"])
# Don't forget this decorator!! Very important
@ftr.compact
def model(self, marriage, age):
# Just assign variables to self that you want to track,
# And they will be named automatically!!
self.a = dist.Normal(0.0, 0.2)
self.bM = dist.Normal(0.0, 0.5)
self.bA = dist.Normal(0.0, 0.5)
self.sigma = dist.Exponential(0.5)
mu = self.a + self.bM * marriage + self.bA * age
return dist.Normal(mu, self.sigma)
# Sampling Prior predictive distribution
rng_key = jax.random.key(42)
rng_key, subkey = jax.random.split(rng_key)
prior_predictive = model.add_input(marriage, age).sample_predictive(subkey)
# Add inputs to the model and condition on the output
conditioned_model = model.add_input(marriage, age).condition_on(divorce)
# Fit model using meanfield VI
rng_key, subkey = jax.random.split(rng_key)
res = conditioned_model.meanfield_vi(subkey)
# Sample from model using NUTS
rng_key, subkey = jax.random.split(rng_key)
mcmc = conditioned_model.sample_posterior(subkey)
# Prints this automatically, cause why the hell would you not need this:
# mean std median 5.0% 95.0% n_eff r_hat
# a 0.01 0.20 0.02 -0.31 0.35 2348.61 1.00
# bA 0.17 0.05 0.17 0.10 0.25 1634.25 1.00
# bM 0.26 0.06 0.26 0.16 0.35 1649.36 1.00
# sigma 1.82 0.19 1.81 1.52 2.11 2419.83 1.00
#
# Number of divergences: 0
# Plot sampling trace
fig = ftr.plot_trace(mcmc)
fig.show()
```
<img width="1200" alt="image" src="https://github.com/user-attachments/assets/5278fa25-8729-4a21-b393-e053be42c512" />
```python
# Forest plot of posterior samples
fig = ftr.plot_forest(mcmc)
fig.show()
```
<img width="1200" alt="image" src="https://github.com/user-attachments/assets/ccb64abf-92b2-437b-ac21-a44e09651486" />
```python
# Forest plot of posterior samples
fig = ftr.plot_ess(mcmc)
fig.show()
```
<img width="1200" alt="image" src="https://github.com/user-attachments/assets/8c21378d-6e20-43a3-b626-eb049f05252b" />
```python
# Sampling prior predictive and plotting prior-predictive check
rng_key, subkey = jax.random.split(rng_key)
# NOTE that I'm using the unconditoned model
prior_predictive = model.add_input(marriage, age).sample_predictive(rng_key)
fig = ftr.plot_predictive_check(prior_predictive, obs=divorce)
fig.show()
```
<img width="1500" height="762" alt="image" src="https://github.com/user-attachments/assets/a81e7325-81f4-448b-83b9-f8e200de336b" />
```python
# Sampling posterior predictive and plotting prior-predictive check
rng_key, subkey = jax.random.split(rng_key)
# Note that I'm passing the posterior_samples to the function
posterior_predictive = model.add_input(marriage, age).sample_predictive(
rng_key, posterior_samples=mcmc.get_samples()
)
fig = ftr.plot_predictive_check(posterior_predictive, obs=divorce)
fig.show()
```
<img width="1500" height="762" alt="image" src="https://github.com/user-attachments/assets/acb5378c-db97-4618-bd77-c0a478e78f10" />
| text/markdown | Márton Kardos | power.up1163@gmail.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"numpyro<0.21.0,>=0.20.0",
"plotly<7.0.0,>=6.0.0; extra == \"plotly\""
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.12.11 Linux/6.17.0-14-generic | 2026-02-20T13:27:26.948628 | firetruck-0.1.1-py3-none-any.whl | 7,806 | 38/e9/95d29520e860203bf688a2de0e236b96053cc2b37584a6c28fe1bb5c8e17/firetruck-0.1.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 6589c7a009c53ea4d610f1767d998b05 | bae11e32d2a2485256b9cef7b5122e878aa7b5bbc788736530e4550d5dbb2ca1 | 38e995d29520e860203bf688a2de0e236b96053cc2b37584a6c28fe1bb5c8e17 | null | [
"LICENSE"
] | 193 |
2.4 | dapr-ext-workflow | 1.17.0rc5 | The official release of Dapr Python SDK Workflow Authoring Extension. | This is the Workflow authoring extension for Dapr.
Dapr is a portable, serverless, event-driven runtime that makes it easy for developers to
build resilient, stateless and stateful microservices that run on the cloud and edge and
embraces the diversity of languages and developer frameworks.
Dapr codifies the best practices for building microservice applications into open,
independent, building blocks that enable you to build portable applications with the language
and framework of your choice. Each building block is independent and you can use one, some,
or all of them in your application.
| null | Dapr Authors | daprweb@microsoft.com | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://dapr.io/ | null | >=3.9 | [] | [] | [] | [
"dapr>=1.17.0rc5",
"durabletask-dapr>=0.2.0a19"
] | [] | [] | [] | [
"Documentation, https://github.com/dapr/docs",
"Source, https://github.com/dapr/python-sdk"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T13:27:24.472049 | dapr_ext_workflow-1.17.0rc5.tar.gz | 21,424 | 80/bc/acc324480533137a5adcb7b854448bc40285cda722f2caef19ac37072b40/dapr_ext_workflow-1.17.0rc5.tar.gz | source | sdist | null | false | 98b866ac7afc06ce48d9d3d6956fcc90 | 9cbb3f428d37f8fade6e2213d19cf0bac32f47ba782e982a88bf63ead6ba0c75 | 80bcacc324480533137a5adcb7b854448bc40285cda722f2caef19ac37072b40 | null | [
"LICENSE"
] | 233 |
2.4 | dapr | 1.17.0rc5 | The official release of Dapr Python SDK. | Dapr is a portable, serverless, event-driven runtime that makes it easy for developers to
build resilient, stateless and stateful microservices that run on the cloud and edge and
embraces the diversity of languages and developer frameworks.
Dapr codifies the best practices for building microservice applications into open,
independent, building blocks that enable you to build portable applications with the language
and framework of your choice. Each building block is independent and you can use one, some,
or all of them in your application.
| null | Dapr Authors | dapr@dapr.io | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://dapr.io/ | null | >=3.9 | [] | [] | [] | [
"protobuf>=4.22",
"grpcio>=1.37.0",
"grpcio-status>=1.37.0",
"aiohttp>=3.9.0b0",
"python-dateutil>=2.8.1",
"typing-extensions>=4.4.0"
] | [] | [] | [] | [
"Documentation, https://github.com/dapr/docs",
"Source, https://github.com/dapr/python-sdk"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T13:27:14.586107 | dapr-1.17.0rc5.tar.gz | 170,987 | c8/80/72d21c3ee5692efe4168b9b782d9ac87a916332b65143bf4d398a5f5f986/dapr-1.17.0rc5.tar.gz | source | sdist | null | false | ff7415b9ac8421ac3e2e48a29fc0f077 | 68557aad9c71accc9d837d74386b6b545b2c7001e7cedce0b041b9ae8ca0d56e | c88072d21c3ee5692efe4168b9b782d9ac87a916332b65143bf4d398a5f5f986 | null | [
"LICENSE"
] | 347 |
2.4 | dapr-ext-fastapi | 1.17.0rc5 | The official release of Dapr FastAPI extension. | This is the FastAPI extension for Dapr.
Dapr is a portable, serverless, event-driven runtime that makes it easy for developers to
build resilient, stateless and stateful microservices that run on the cloud and edge and
embraces the diversity of languages and developer frameworks.
Dapr codifies the best practices for building microservice applications into open,
independent, building blocks that enable you to build portable applications with the language
and framework of your choice. Each building block is independent and you can use one, some,
or all of them in your application.
| null | Dapr Authors | daprweb@microsoft.com | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://dapr.io/ | null | >=3.9 | [] | [] | [] | [
"dapr>=1.17.0rc5",
"uvicorn>=0.11.6",
"fastapi>=0.60.1"
] | [] | [] | [] | [
"Documentation, https://github.com/dapr/docs",
"Source, https://github.com/dapr/python-sdk"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T13:27:12.859554 | dapr_ext_fastapi-1.17.0rc5.tar.gz | 10,373 | f9/ff/cbd4f9a16b3214b341e1a2b9c3f10711dd8d6159e40812aae0dd419a0424/dapr_ext_fastapi-1.17.0rc5.tar.gz | source | sdist | null | false | d8556d7382061802be8cd1da0042b9ee | f52d9a0e697c3c4f6177535d2853be3c048b0ddd936c0d8ed7aef38e06081528 | f9ffcbd4f9a16b3214b341e1a2b9c3f10711dd8d6159e40812aae0dd419a0424 | null | [
"LICENSE"
] | 234 |
2.4 | flask-dapr | 1.17.0rc5 | The official release of Dapr Python SDK Flask Extension. | This is the Flask extension for Dapr.
Dapr is a portable, serverless, event-driven runtime that makes it easy for developers to
build resilient, stateless and stateful microservices that run on the cloud and edge and
embraces the diversity of languages and developer frameworks.
Dapr codifies the best practices for building microservice applications into open,
independent, building blocks that enable you to build portable applications with the language
and framework of your choice. Each building block is independent and you can use one, some,
or all of them in your application.
| null | Dapr Authors | daprweb@microsoft.com | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://dapr.io/ | null | >=3.9 | [] | [] | [] | [
"Flask>=1.1",
"dapr>=1.17.0rc5"
] | [] | [] | [] | [
"Documentation, https://github.com/dapr/docs",
"Source, https://github.com/dapr/python-sdk"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T13:27:12.215406 | flask_dapr-1.17.0rc5.tar.gz | 9,563 | 81/ed/ab0e925efff67d0351ceb43ea11c43a7d2dafae76093fb2fe018966f4e2b/flask_dapr-1.17.0rc5.tar.gz | source | sdist | null | false | 558376a96f20ebbc4512a737801741a1 | 51ab78e3b9d22f021077cf7ad35ad6bd48aed0db31addf077783f6313aff6f7e | 81edab0e925efff67d0351ceb43ea11c43a7d2dafae76093fb2fe018966f4e2b | null | [
"LICENSE"
] | 186 |
2.3 | gmt-python-sdk | 0.24.0 | The official Python library for the gmt API | # Gmt Python API library
<!-- prettier-ignore -->
[)](https://pypi.org/project/gmt-python-sdk/)
The Gmt Python library provides convenient access to the Gmt REST API from any Python 3.9+
application. The library includes type definitions for all request params and response fields,
and offers both synchronous and asynchronous clients powered by [httpx](https://github.com/encode/httpx).
It is generated with [Stainless](https://www.stainless.com/).
## Documentation
The REST API documentation can be found on [api.getmytg.com](https://api.getmytg.com/docs). The full API of this library can be found in [api.md](https://github.com/cameo6/gmt-python-sdk/tree/main/api.md).
## Installation
```sh
# install from PyPI
pip install gmt-python-sdk
```
## Usage
The full API of this library can be found in [api.md](https://github.com/cameo6/gmt-python-sdk/tree/main/api.md).
```python
from gmt import Gmt
client = Gmt()
response = client.service.health_check()
print(response.now)
```
While you can provide an `api_key` keyword argument,
we recommend using [python-dotenv](https://pypi.org/project/python-dotenv/)
to add `GMT_API_KEY="My API Key"` to your `.env` file
so that your API Key is not stored in source control.
## Async usage
Simply import `AsyncGmt` instead of `Gmt` and use `await` with each API call:
```python
import asyncio
from gmt import AsyncGmt
client = AsyncGmt()
async def main() -> None:
response = await client.service.health_check()
print(response.now)
asyncio.run(main())
```
Functionality between the synchronous and asynchronous clients is otherwise identical.
### With aiohttp
By default, the async client uses `httpx` for HTTP requests. However, for improved concurrency performance you may also use `aiohttp` as the HTTP backend.
You can enable this by installing `aiohttp`:
```sh
# install from PyPI
pip install gmt-python-sdk[aiohttp]
```
Then you can enable it by instantiating the client with `http_client=DefaultAioHttpClient()`:
```python
import asyncio
from gmt import DefaultAioHttpClient
from gmt import AsyncGmt
async def main() -> None:
async with AsyncGmt(
http_client=DefaultAioHttpClient(),
) as client:
response = await client.service.health_check()
print(response.now)
asyncio.run(main())
```
## Using types
Nested request parameters are [TypedDicts](https://docs.python.org/3/library/typing.html#typing.TypedDict). Responses are [Pydantic models](https://docs.pydantic.dev) which also provide helper methods for things like:
- Serializing back into JSON, `model.to_json()`
- Converting to a dictionary, `model.to_dict()`
Typed requests and responses provide autocomplete and documentation within your editor. If you would like to see type errors in VS Code to help catch bugs earlier, set `python.analysis.typeCheckingMode` to `basic`.
## Pagination
List methods in the Gmt API are paginated.
This library provides auto-paginating iterators with each list response, so you do not have to request successive pages manually:
```python
from gmt import Gmt
client = Gmt()
all_purchases = []
# Automatically fetches more pages as needed.
for purchase in client.purchases.list(
page=1,
page_size=100,
):
# Do something with purchase here
all_purchases.append(purchase)
print(all_purchases)
```
Or, asynchronously:
```python
import asyncio
from gmt import AsyncGmt
client = AsyncGmt()
async def main() -> None:
all_purchases = []
# Iterate through items across all pages, issuing requests as needed.
async for purchase in client.purchases.list(
page=1,
page_size=100,
):
all_purchases.append(purchase)
print(all_purchases)
asyncio.run(main())
```
Alternatively, you can use the `.has_next_page()`, `.next_page_info()`, or `.get_next_page()` methods for more granular control working with pages:
```python
first_page = await client.purchases.list(
page=1,
page_size=100,
)
if first_page.has_next_page():
print(f"will fetch next page using these details: {first_page.next_page_info()}")
next_page = await first_page.get_next_page()
print(f"number of items we just fetched: {len(next_page.items)}")
# Remove `await` for non-async usage.
```
Or just work directly with the returned data:
```python
first_page = await client.purchases.list(
page=1,
page_size=100,
)
print(f"page number: {first_page.pagination.current_page}") # => "page number: 1"
for purchase in first_page.items:
print(purchase.id)
# Remove `await` for non-async usage.
```
## Handling errors
When the library is unable to connect to the API (for example, due to network connection problems or a timeout), a subclass of `gmt.APIConnectionError` is raised.
When the API returns a non-success status code (that is, 4xx or 5xx
response), a subclass of `gmt.APIStatusError` is raised, containing `status_code` and `response` properties.
All errors inherit from `gmt.APIError`.
```python
import gmt
from gmt import Gmt
client = Gmt()
try:
client.service.health_check()
except gmt.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # an underlying Exception, likely raised within httpx.
except gmt.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except gmt.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
```
Error codes are as follows:
| Status Code | Error Type |
| ----------- | -------------------------- |
| 400 | `BadRequestError` |
| 401 | `AuthenticationError` |
| 403 | `PermissionDeniedError` |
| 404 | `NotFoundError` |
| 422 | `UnprocessableEntityError` |
| 429 | `RateLimitError` |
| >=500 | `InternalServerError` |
| N/A | `APIConnectionError` |
### Retries
Certain errors are automatically retried 2 times by default, with a short exponential backoff.
Connection errors (for example, due to a network connectivity problem), 408 Request Timeout, 409 Conflict,
429 Rate Limit, and >=500 Internal errors are all retried by default.
You can use the `max_retries` option to configure or disable retry settings:
```python
from gmt import Gmt
# Configure the default for all requests:
client = Gmt(
# default is 2
max_retries=0,
)
# Or, configure per-request:
client.with_options(max_retries=5).service.health_check()
```
### Timeouts
By default requests time out after 1 minute. You can configure this with a `timeout` option,
which accepts a float or an [`httpx.Timeout`](https://www.python-httpx.org/advanced/timeouts/#fine-tuning-the-configuration) object:
```python
from gmt import Gmt
# Configure the default for all requests:
client = Gmt(
# 20 seconds (default is 1 minute)
timeout=20.0,
)
# More granular control:
client = Gmt(
timeout=httpx.Timeout(60.0, read=5.0, write=10.0, connect=2.0),
)
# Override per-request:
client.with_options(timeout=5.0).service.health_check()
```
On timeout, an `APITimeoutError` is thrown.
Note that requests that time out are [retried twice by default](https://github.com/cameo6/gmt-python-sdk/tree/main/#retries).
## Advanced
### Logging
We use the standard library [`logging`](https://docs.python.org/3/library/logging.html) module.
You can enable logging by setting the environment variable `GMT_LOG` to `info`.
```shell
$ export GMT_LOG=info
```
Or to `debug` for more verbose logging.
### How to tell whether `None` means `null` or missing
In an API response, a field may be explicitly `null`, or missing entirely; in either case, its value is `None` in this library. You can differentiate the two cases with `.model_fields_set`:
```py
if response.my_field is None:
if 'my_field' not in response.model_fields_set:
print('Got json like {}, without a "my_field" key present at all.')
else:
print('Got json like {"my_field": null}.')
```
### Accessing raw response data (e.g. headers)
The "raw" Response object can be accessed by prefixing `.with_raw_response.` to any HTTP method call, e.g.,
```py
from gmt import Gmt
client = Gmt()
response = client.service.with_raw_response.health_check()
print(response.headers.get('X-My-Header'))
service = response.parse() # get the object that `service.health_check()` would have returned
print(service.now)
```
These methods return an [`APIResponse`](https://github.com/cameo6/gmt-python-sdk/tree/main/src/gmt/_response.py) object.
The async client returns an [`AsyncAPIResponse`](https://github.com/cameo6/gmt-python-sdk/tree/main/src/gmt/_response.py) with the same structure, the only difference being `await`able methods for reading the response content.
#### `.with_streaming_response`
The above interface eagerly reads the full response body when you make the request, which may not always be what you want.
To stream the response body, use `.with_streaming_response` instead, which requires a context manager and only reads the response body once you call `.read()`, `.text()`, `.json()`, `.iter_bytes()`, `.iter_text()`, `.iter_lines()` or `.parse()`. In the async client, these are async methods.
```python
with client.service.with_streaming_response.health_check() as response:
print(response.headers.get("X-My-Header"))
for line in response.iter_lines():
print(line)
```
The context manager is required so that the response will reliably be closed.
### Making custom/undocumented requests
This library is typed for convenient access to the documented API.
If you need to access undocumented endpoints, params, or response properties, the library can still be used.
#### Undocumented endpoints
To make requests to undocumented endpoints, you can make requests using `client.get`, `client.post`, and other
http verbs. Options on the client will be respected (such as retries) when making this request.
```py
import httpx
response = client.post(
"/foo",
cast_to=httpx.Response,
body={"my_param": True},
)
print(response.headers.get("x-foo"))
```
#### Undocumented request params
If you want to explicitly send an extra param, you can do so with the `extra_query`, `extra_body`, and `extra_headers` request
options.
#### Undocumented response properties
To access undocumented response properties, you can access the extra fields like `response.unknown_prop`. You
can also get all the extra fields on the Pydantic model as a dict with
[`response.model_extra`](https://docs.pydantic.dev/latest/api/base_model/#pydantic.BaseModel.model_extra).
### Configuring the HTTP client
You can directly override the [httpx client](https://www.python-httpx.org/api/#client) to customize it for your use case, including:
- Support for [proxies](https://www.python-httpx.org/advanced/proxies/)
- Custom [transports](https://www.python-httpx.org/advanced/transports/)
- Additional [advanced](https://www.python-httpx.org/advanced/clients/) functionality
```python
import httpx
from gmt import Gmt, DefaultHttpxClient
client = Gmt(
# Or use the `GMT_BASE_URL` env var
base_url="http://my.test.server.example.com:8083",
http_client=DefaultHttpxClient(
proxy="http://my.test.proxy.example.com",
transport=httpx.HTTPTransport(local_address="0.0.0.0"),
),
)
```
You can also customize the client on a per-request basis by using `with_options()`:
```python
client.with_options(http_client=DefaultHttpxClient(...))
```
### Managing HTTP resources
By default the library closes underlying HTTP connections whenever the client is [garbage collected](https://docs.python.org/3/reference/datamodel.html#object.__del__). You can manually close the client using the `.close()` method if desired, or with a context manager that closes when exiting.
```py
from gmt import Gmt
with Gmt() as client:
# make requests here
...
# HTTP client is now closed
```
## Versioning
This package generally follows [SemVer](https://semver.org/spec/v2.0.0.html) conventions, though certain backwards-incompatible changes may be released as minor versions:
1. Changes that only affect static types, without breaking runtime behavior.
2. Changes to library internals which are technically public but not intended or documented for external use. _(Please open a GitHub issue to let us know if you are relying on such internals.)_
3. Changes that we do not expect to impact the vast majority of users in practice.
We take backwards-compatibility seriously and work hard to ensure you can rely on a smooth upgrade experience.
We are keen for your feedback; please open an [issue](https://www.github.com/cameo6/gmt-python-sdk/issues) with questions, bugs, or suggestions.
### Determining the installed version
If you've upgraded to the latest version but aren't seeing any new features you were expecting then your python environment is likely still using an older version.
You can determine the version that is being used at runtime with:
```py
import gmt
print(gmt.__version__)
```
## Requirements
Python 3.9 or higher.
## Contributing
See [the contributing documentation](https://github.com/cameo6/gmt-python-sdk/tree/main/./CONTRIBUTING.md).
| text/markdown | null | Gmt <contact@example.com> | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: OS Independent",
"Operating System :: POSIX",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Libraries :: Python Modules",
"Typing :: Typed"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"anyio<5,>=3.5.0",
"distro<2,>=1.7.0",
"httpx<1,>=0.23.0",
"pydantic<3,>=1.9.0",
"sniffio",
"typing-extensions<5,>=4.10",
"aiohttp; extra == \"aiohttp\"",
"httpx-aiohttp>=0.1.9; extra == \"aiohttp\""
] | [] | [] | [] | [
"Homepage, https://github.com/cameo6/gmt-python-sdk",
"Repository, https://github.com/cameo6/gmt-python-sdk"
] | uv/0.9.13 {"installer":{"name":"uv","version":"0.9.13"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:27:09.514467 | gmt_python_sdk-0.24.0-py3-none-any.whl | 109,936 | 02/a9/8cc99bf1b7c9d27ddcd93a729d4527e5ae2a6bb2ecb28c417505fc26d9b6/gmt_python_sdk-0.24.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 97362dda0632e53e3be032fa3d710290 | c73dc92e1f987d9695a7f9ce60ce465824843602a9e65f405f75aeb74214220d | 02a98cc99bf1b7c9d27ddcd93a729d4527e5ae2a6bb2ecb28c417505fc26d9b6 | null | [] | 209 |
2.4 | stevedore | 5.7.0 | Manage dynamic plugins for Python applications | ===========================================================
stevedore -- Manage dynamic plugins for Python applications
===========================================================
.. image:: https://governance.openstack.org/tc/badges/stevedore.svg
.. image:: https://img.shields.io/pypi/v/stevedore.svg
:target: https://pypi.org/project/stevedore/
:alt: Latest Version
.. image:: https://img.shields.io/pypi/dm/stevedore.svg
:target: https://pypi.org/project/stevedore/
:alt: Downloads
Python makes loading code dynamically easy, allowing you to configure
and extend your application by discovering and loading extensions
("*plugins*") at runtime. Many applications implement their own
library for doing this, using ``__import__`` or ``importlib``.
stevedore avoids creating yet another extension
mechanism by building on top of `setuptools entry points`_. The code
for managing entry points tends to be repetitive, though, so stevedore
provides manager classes for implementing common patterns for using
dynamically loaded extensions.
.. _setuptools entry points: http://setuptools.readthedocs.io/en/latest/pkg_resources.html?#entry-points
* Free software: Apache license
* Documentation: https://docs.openstack.org/stevedore/latest
* Source: https://opendev.org/openstack/stevedore
* Bugs: https://bugs.launchpad.net/python-stevedore
| text/x-rst | null | OpenStack <openstack-discuss@lists.openstack.org> | null | null | Apache-2.0 | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://docs.openstack.org/stevedore",
"Repository, https://opendev.org/openstack/stevedore"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T13:27:06.765179 | stevedore-5.7.0.tar.gz | 516,200 | a2/6d/90764092216fa560f6587f83bb70113a8ba510ba436c6476a2b47359057c/stevedore-5.7.0.tar.gz | source | sdist | null | false | b4ba1115ec43e6170a040baf8a59cf91 | 31dd6fe6b3cbe921e21dcefabc9a5f1cf848cf538a1f27543721b8ca09948aa3 | a26d90764092216fa560f6587f83bb70113a8ba510ba436c6476a2b47359057c | null | [
"LICENSE"
] | 436,230 |
2.4 | McStasScript | 0.0.78 | A python scripting interface for McStas | # McStasScript
[McStas](http://www.mcstas.org) API for creating and running McStas/McXtrace instruments from python scripting.
Prototype for an API that allow interaction with McStas through an interface like Jupyter Notebooks created under WP5 of PaNOSC.
Full documentation can be found [here](https://mads-bertelsen.github.io)!
## Installation
McStasScript does not include the McStas installation, so McStas/McXtrace should be installed separately, link to instructions [here](https://github.com/McStasMcXtrace/McCode/tree/master/INSTALL-McStas).
McStasScript can be installed using pip from a terminal,
python3 -m pip install McStasScript --upgrade
After installation it is necessary to configure the package so the McStas/McXtrace installation can be found, here we show how the appropriate code for an Ubuntu system as an example. The configuration is saved permanently, and only needs to be updated when McStas or McStasScript is updated. This has to be done from a python terminal or from within a python environment.
import mcstasscript as ms
my_configurator = ms.Configurator()
my_configurator.set_mcrun_path("/usr/bin/")
my_configurator.set_mcstas_path("/usr/share/mcstas/2.5/")
my_configurator.set_mxrun_path("/usr/bin/")
my_configurator.set_mcxtrace_path("/usr/share/mcxtrace/1.5/")
To get a python terminal, run the command python in a terminal and then copy, paste and execute the lines above one at a time. Exit with ctrl+D.
For the second case,
1. open a text editor (not MS Word but something like Gedit...),
2. copy and paste the code above,
3. save the file as a Python script, for example, myMcStasScript_config.py
4. In a terminal, run it by typing python myMcStasScript_config.py
On a Mac OS X system, the paths to the mcrun executable and mcstas folder are through the application folder:
my_configurator.set_mcrun_path("/Applications/McStas-2.5.app/Contents/Resources/mcstas/2.5/bin/")
my_configurator.set_mcstas_path("/Applications/McStas-2.5.app/Contents/Resources/mcstas/2.5/")
my_configurator.set_mxrun_path("/Applications/McXtrace-1.5.app/Contents/Resources/mcxtrace/1.5/bin/")
my_configurator.set_mcxtrace_path("/Applications/McXtrace-1.5.app/Contents/Resources/mcxtrace/1.5/")
### Notes on windows installation
McStasScript was tested on Windows 10 installed using this [guide](https://github.com/McStasMcXtrace/McCode/blob/master/INSTALL-McStas-2.x/Windows/README.md), it is necessary to include MPI using MSMpiSetup.exe and msmpisdk.msi located in the extras folder.
Open the McStas-shell cmd (shortcut should be available on desktop) and install McStasScript / jupyter notebook with these commands:
python -m pip install notebook
python -m pip install McStasScript --upgrade
Using the McStas-shell one can start a jupyter notebook server with this command:
jupyter notebook
For a standard McStas installation on Windows, the appropriate configuration can be set with these commands in a notebook:
import mcstasscript as ms
my_configurator = ms.Configurator()
my_configurator.set_mcrun_path("\\mcstas-2.6\\bin\\")
my_configurator.set_mcstas_path("\\mcstas-2.6\\lib\\")
my_configurator.set_mxrun_path("\\mcxtrace-1.5\\bin\\")
my_configurator.set_mcxtrace_path("\\mcxtrace-1.5\\lib\\")
Double backslashes are necessary since backslash is the escape character in python strings.
## Instructions for basic use
This section provides a quick way to get started, a more in depth tutorial using Jupyter Notebooks is available in the tutorial folder. The following commands suppose that you are either typing them in a Python environment from a terminal or in a file to be run as the end of the editing by typing a command like, 'python my_file.py' or in a Jupyter notebook
Import the interface
import mcstasscript as ms
Now the package can be used. Start with creating a new instrument, just needs a name. For a McXtrace instrument use McXtrace_instr instead.
my_instrument = ms.McStas_instr("my_instrument_file")
Then McStas components can be added, here we add a source and ask for help on the parameters.
my_source = my_instrument.add_component("source", "Source_simple")
my_source.show_parameters() # Can be used to show available parameters for Source simple
The second line prints help on the Source_simple component and current status of our component object. The output is shown here, but without bold, underline and color which is used to show which parameters are required, default or user specified.
___ Help Source_simple _____________________________________________________________
|optional parameter|required parameter|default value|user specified value|
radius = 0.1 [m] // Radius of circle in (x,y,0) plane where neutrons are
generated.
yheight = 0.0 [m] // Height of rectangle in (x,y,0) plane where neutrons are
generated.
xwidth = 0.0 [m] // Width of rectangle in (x,y,0) plane where neutrons are
generated.
dist = 0.0 [m] // Distance to target along z axis.
focus_xw = 0.045 [m] // Width of target
focus_yh = 0.12 [m] // Height of target
E0 = 0.0 [meV] // Mean energy of neutrons.
dE = 0.0 [meV] // Energy half spread of neutrons (flat or gaussian sigma).
lambda0 = 0.0 [AA] // Mean wavelength of neutrons.
dlambda = 0.0 [AA] // Wavelength half spread of neutrons.
flux = 1.0 [1/(s*cm**2*st*energy unit)] // flux per energy unit, Angs or meV if
flux=0, the source emits 1 in 4*PI whole
space.
gauss = 0.0 [1] // Gaussian (1) or Flat (0) energy/wavelength distribution
target_index = 1 [1] // relative index of component to focus at, e.g. next is
+1 this is used to compute 'dist' automatically.
-------------------------------------------------------------------------------------
The parameters of the source can be adjusted directly as attributes of the python object
my_source.xwidth = 0.12
my_source.yheight = 0.12
my_source.lambda0 = 3
my_source.dlambda = 2.2
my_source.focus_xw = 0.05
my_source.focus_yh = 0.05
A monitor is added as well to get data out of the simulation (few bins so it is easy to print the results)
PSD = my_instrument.add_component("PSD", "PSD_monitor", AT=[0,0,1], RELATIVE="source")
PSD.xwidth = 0.1
PSD.yheight = 0.1
PSD.nx = 5
PSD.ny = 5
PSD.filename = '"PSD.dat"'
Settings for the simulation can be adjusted with the *settings* method, an output_path for the data is needed.
my_instrument.settings(output_path="first_run", ncount=1E7)
The simulatiuon is performed with the *backengine* method. This returns the data generated from the simulation.
data = my_instrument.backengine()
Results from the monitors would be stored as a list of McStasData objects in the returned data. The counts are stored as numpy arrays. We can read and change the intensity directly and manipulate the data before plotting.
data[0].Intensity
In a python terminal this would display the data directly:
array([[0. , 0. , 0. , 0. , 0. ],
[0. , 0.1422463 , 0.19018485, 0.14156196, 0. ],
[0. , 0.18930076, 0.25112956, 0.18897898, 0. ],
[0. , 0.14121589, 0.18952508, 0.14098576, 0. ],
[0. , 0. , 0. , 0. , 0. ]])
Plotting is usually done in a subplot of all monitors recorded.
plot = ms.make_sub_plot(data)
## Widgets in Jupyter Notebooks
When using McStasScript in a jupyter notebook, it is possible to plot the data with a widget system instead. To do so, import the jupyter notebook widget interface and use show.
import mcstasscript.jb_interface as ms_widget
ms_widget.show(data)
There is also a widget solution for performing the simulation which works as an alternative to *backengine*, this method is also included in the jb_interface show command, just provide an instrument object instead of data. This interface includes setting parameters, simulation options and plotting of the resulting data.
ms_widget.show(instr)
If one wants to have access to the data generated in the widget, the widget needs to be created as an object with SimInterface. The resulting object will have a *show_interface* method to display the interface, and a *get_data* method to retrieve the latest generated dataset.
sim_widget = ms_widget.SimInterface(instr)
sim_widget.show_interface()
data = sim_widget.get_data()
## Use in existing project
If one wish to work on existing projects using McStasScript, there is a reader included that will read a McStas Instrument file and write the corresponding McStasScript python instrument to disk. Here is an example where the PSI_DMC.instr example is converted:
Reader = ms.McStas_file("PSI_DMC.instr")
Reader.write_python_file("PSI_DMC_generated.py")
It is highly advised to run a check between the output of the generated file and the original to ensure the process was sucessful.
## Method overview
Here is a quick overview of the available methods of the main classes in the project. Most have more options from keyword arguments that are explained in the manual, but also in python help. To get more information on for example the show_components method of the McStas_instr class, one can use the python help command help(instr.McStas_instr.show_components). Many methods take a reference to a component, that can either be a string with the component name or a component object, here written as Cref in type hint.
instr
└── McStas_instr(str instr_name) # Returns McStas instrument object on initialize
├── show_parameters() # Prints list of parameters
├── show_settings() # Prints current instrument settings
├── show_variables() # Prints list of declare variables and user vars
├── show_components() # Prints list of components and their location
├── show_instrument() # Shows instrument drawing with current parameters
├── show_instr_file() # Prints the current instrument file
├── show_diagram() # Show figure describing the instrument object
├── set_parameters() # Sets instrument parameters as keyword arguments
├── available_components(str category_name) # Show available components in given category
├── component_help(Cref component_name) # Prints component parameters for given component name
├── add_component(str name, str component_name) # Adds component to instrument and returns object
├── copy_component(str name, Cref original_name) # Copies a component to instrument and returns object
├── remove_component(Cref name) # Removes component
├── move_component(str name, Cref before / after, ) # Moves component to either before or after another
├── get_component(str name) # Gets component object
├── get_last_component() # Gets last component object
├── add_parameter(str name) # Adds instrument parameter with name
├── add_declare_var(str type, str name) # Adds declared variable with type and name
├── add_user_var(str type, str name) # Adds user var with type and name
├── append_declare(str string) # Appends a line to declare section (c syntax)
├── append_initialize(str string) # Appends a line to initialize (c syntax)
├── append_finally(str string) # Appends a line to finally (c syntax)
├── write_full_instrument() # Writes instrument to disk with given name + ".instr"
├── settings(kwargs) Settings as keyword arguments.
└── backengine() # Runs simulation.
component # returned by add_component
├── set_AT(list at_list) # Sets component position (list of x,y,z positions in [m])
├── set_ROTATED(list rotated_list) # Sets component rotation (list of x,y,z rotations in [deg])
├── set_RELATIVE(str component_name) # Sets relative to other component name
├── set_parameters(dict input) # Set parameters using dict input
├── set_comment(str string) # Set comment explaining something about the component
└── print_long() # Prints currently contained information on component
mcstasscript functions
├── name_search(str name, list McStasData) # Returns data set with given name from McStasData list
├── name_plot_options(str name, list McStasData, kwargs) # Sends kwargs to dataset with given name
├── load_data(str foldername) # Loads data from folder with McStas data as McStasData list
└── Configurator()
├── set_mcrun_path(str path) # sets mcrun path
├── set_mcstas_path(str path) # sets mcstas path
└── set_line_length(int length) # sets maximum line length
mcstasscript plotter
├── make_plot(list McStasData) # Plots each data set individually
├── make_sub_plot(list McStasData) # Plots data as subplot
└── interface(list McStasData) # Shows plotting interface in jupyter notebook
mcstasscript reader
└── McStas_file(str filename) # Returns a reader that can extract information from given instr file
InstrumentReader # returned by McStas_file
├── generate_python_file(str filename) # Writes python file with information contaiend in isntrument
└── add_to_instr(McStas_instr Instr) # Adds information from instrument to McStasScirpt instrument
| text/markdown | Mads Bertelsen | Mads.Bertelsen@ess.eu | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: GNU General Public License (GPL)",
"Operating System :: OS Independent",
"Topic :: Scientific/Engineering"
] | [] | https://github.com/PaNOSC-ViNYL/McStasScript | null | null | [] | [] | [] | [
"numpy",
"matplotlib",
"PyYAML",
"ipywidgets",
"libpyvinyl"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:26:30.735187 | mcstasscript-0.0.78.tar.gz | 2,456,829 | 3d/26/83910bc3bd565e42b6f0a7f2aa2a705e8884241a84daaab803a1db832b2a/mcstasscript-0.0.78.tar.gz | source | sdist | null | false | e4398f3fd6d4a4a7e68cc3a361f56a2e | 578ee6225b62bee7c1a6892319edd9348b166c2940cc08d18e98d1fa8eed8f5a | 3d2683910bc3bd565e42b6f0a7f2aa2a705e8884241a84daaab803a1db832b2a | null | [
"LICENSE"
] | 0 |
2.4 | feedparser-rs | 0.4.4 | High-performance RSS/Atom/JSON Feed parser with feedparser-compatible API | # feedparser-rs
[](https://pypi.org/project/feedparser-rs/)
[](https://pypi.org/project/feedparser-rs/)
[](LICENSE-MIT)
High-performance RSS/Atom/JSON Feed parser for Python with feedparser-compatible API.
## Features
- **Fast**: Native Rust implementation via PyO3
- **HTTP fetching**: Built-in URL fetching with compression (gzip, deflate, brotli)
- **Conditional GET**: ETag/Last-Modified support for efficient polling
- **Tolerant parsing**: Bozo flag for graceful handling of malformed feeds
- **Multi-format**: RSS 0.9x/1.0/2.0, Atom 0.3/1.0, JSON Feed 1.0/1.1
- **Podcast support**: iTunes and Podcast 2.0 namespace extensions
- **feedparser-compatible**: Dict-style access, field aliases, same API patterns
- **DoS protection**: Built-in resource limits
## Installation
```bash
pip install feedparser-rs
```
> [!IMPORTANT]
> Requires Python 3.10 or later.
## Usage
### Basic Parsing
```python
import feedparser_rs
# Parse from string, bytes, or URL (auto-detected)
d = feedparser_rs.parse('<rss>...</rss>')
d = feedparser_rs.parse(b'<rss>...</rss>')
d = feedparser_rs.parse('https://example.com/feed.xml') # URL auto-detected
# Attribute-style access (feedparser-compatible)
print(d.feed.title)
print(d.version) # "rss20", "atom10", etc.
print(d.bozo) # True if parsing errors occurred
# Dict-style access (feedparser-compatible)
print(d['feed']['title'])
print(d['entries'][0]['link'])
for entry in d.entries:
print(entry.title)
print(entry.published_parsed) # time.struct_time
```
> [!NOTE]
> Date fields like `published_parsed` return `time.struct_time` for feedparser compatibility.
### Fetching from URL
```python
import feedparser_rs
# Option 1: Auto-detection (recommended)
d = feedparser_rs.parse('https://example.com/feed.xml')
# Option 2: Explicit URL function
d = feedparser_rs.parse_url('https://example.com/feed.xml')
# With conditional GET for efficient polling
d = feedparser_rs.parse(
'https://example.com/feed.xml',
etag=cached_etag,
modified=cached_modified
)
if d.status == 304:
print("Feed not modified")
# With custom limits
limits = feedparser_rs.ParserLimits(max_entries=100)
d = feedparser_rs.parse_with_limits('https://example.com/feed.xml', limits=limits)
```
> [!TIP]
> URL fetching supports automatic compression (gzip, deflate, brotli) and follows redirects.
## Migration from feedparser
feedparser-rs is designed as a drop-in replacement for Python feedparser:
```python
# Drop-in replacement
import feedparser_rs as feedparser
# Same API patterns work
d = feedparser.parse('https://example.com/feed.xml')
print(d.feed.title)
print(d['feed']['title']) # Dict-style access works too
print(d.entries[0].link)
# Deprecated field names supported
print(d.feed.description) # → d.feed.subtitle
print(d.channel.title) # → d.feed.title
print(d.items[0].guid) # → d.entries[0].id
```
### Supported Field Aliases
| Old Name | Maps To |
|----------|---------|
| `feed.description` | `feed.subtitle` or `feed.summary` |
| `feed.tagline` | `feed.subtitle` |
| `feed.copyright` | `feed.rights` |
| `feed.modified` | `feed.updated` |
| `channel` | `feed` |
| `items` | `entries` |
| `entry.guid` | `entry.id` |
| `entry.description` | `entry.summary` |
| `entry.issued` | `entry.published` |
## Advanced Usage
### Custom Resource Limits
```python
import feedparser_rs
limits = feedparser_rs.ParserLimits(
max_feed_size_bytes=50_000_000, # 50 MB
max_entries=5_000,
max_authors=20,
max_links_per_entry=50,
)
d = feedparser_rs.parse_with_limits(feed_data, limits=limits)
```
### Format Detection
```python
import feedparser_rs
version = feedparser_rs.detect_format(feed_data)
print(version) # "rss20", "atom10", "json11", etc.
```
### Podcast Support
```python
import feedparser_rs
d = feedparser_rs.parse(podcast_feed)
# iTunes metadata
if d.feed.itunes:
print(d.feed.itunes.author)
print(d.feed.itunes.categories)
# Episode metadata
for entry in d.entries:
if entry.itunes:
print(f"Duration: {entry.itunes.duration}s")
```
## API Reference
### Functions
- `parse(source, etag=None, modified=None, user_agent=None)` — Parse feed from bytes, str, or URL (auto-detected)
- `parse_url(url, etag=None, modified=None, user_agent=None)` — Fetch and parse feed from URL
- `parse_with_limits(source, etag=None, modified=None, user_agent=None, limits=None)` — Parse with custom resource limits
- `parse_url_with_limits(url, etag=None, modified=None, user_agent=None, limits=None)` — Fetch and parse with custom limits
- `detect_format(source)` — Detect feed format without full parsing
### Classes
- `FeedParserDict` — Parsed feed result (supports both attribute and dict-style access)
- `.feed` / `['feed']` — Feed metadata
- `.entries` / `['entries']` — List of entries
- `.bozo` — True if parsing errors occurred
- `.version` — Feed version string
- `.encoding` — Character encoding
- `.status` — HTTP status code (for URL fetches)
- `.etag` — ETag header (for conditional GET)
- `.modified` — Last-Modified header (for conditional GET)
- `ParserLimits` — Resource limits configuration
## Performance
Benchmarks vs Python feedparser on Apple M1 Pro:
| Operation | feedparser-rs | Python feedparser | Speedup |
|-----------|---------------|-------------------|---------|
| Parse 2 KB RSS | 0.01 ms | 0.9 ms | **90x** |
| Parse 20 KB RSS | 0.09 ms | 8.5 ms | **94x** |
| Parse 200 KB RSS | 0.94 ms | 85 ms | **90x** |
> [!TIP]
> For maximum performance, pass `bytes` instead of `str` to avoid UTF-8 re-encoding.
## Platform Support
Pre-built wheels available for:
| Platform | Architecture |
|----------|--------------|
| macOS | Intel (x64), Apple Silicon (arm64) |
| Linux | x64, arm64 |
| Windows | x64 |
Supported Python versions: 3.10, 3.11, 3.12, 3.13, 3.14
## Development
```bash
git clone https://github.com/bug-ops/feedparser-rs
cd feedparser-rs/crates/feedparser-rs-py
pip install maturin
maturin develop
```
## License
Licensed under either of:
- [Apache License, Version 2.0](../../LICENSE-APACHE)
- [MIT License](../../LICENSE-MIT)
at your option.
## Links
- [GitHub](https://github.com/bug-ops/feedparser-rs)
- [PyPI](https://pypi.org/project/feedparser-rs/)
- [Rust API Documentation](https://docs.rs/feedparser-rs)
- [Changelog](../../CHANGELOG.md)
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | MIT OR Apache-2.0 | rss, atom, feed, parser, feedparser, rust | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Rust",
"Topic :: Text Processing :: Markup :: XML"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Documentation, https://github.com/bug-ops/feedparser-rs#readme",
"Homepage, https://github.com/bug-ops/feedparser-rs",
"Repository, https://github.com/bug-ops/feedparser-rs"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:25:20.221551 | feedparser_rs-0.4.4.tar.gz | 180,504 | 4c/f4/5f81eb9316cab47e7b26a9e0452753842d9e8d62fd2d7d5863336c2f143e/feedparser_rs-0.4.4.tar.gz | source | sdist | null | false | 4a71ce74dd8628b3485ffd164b17aa00 | d5719df1ab63dacc247caf8f567dabd37f667fb95ea96aa4d8a08e335b614d6d | 4cf45f81eb9316cab47e7b26a9e0452753842d9e8d62fd2d7d5863336c2f143e | null | [] | 1,674 |
2.2 | astroviper | 0.0.34 | Astro Visibility and Image Parallel Execution Reduction | # AstroVIPER
AstroVIPER (Visibility and Image Parallel Execution Reduction) is in development.
[](https://www.python.org/downloads/release/python-3130/)
[](https://github.com/casangi/astroviper/actions/workflows/python-testing-linux.yml?query=branch%3Amain)
[](https://github.com/casangi/astroviper/actions/workflows/python-testing-macos.yml?query=branch%3Amain)
[](https://github.com/casangi/astroviper/actions/workflows/run-ipynb.yml?query=branch%3Amain)
[](https://codecov.io/gh/casangi/astroviper/branch/main/astroviper)
<!-- [](https://astroviper.readthedocs.io) -->
[](https://pypi.python.org/pypi/astroviper/)
| text/markdown | null | Jan-Willem Steeb <jsteeb@nrao.edu>, Dave Mehringer <dmehring@nrao.edu>, Kumar Golap <kgolap@nrao.edu>, Takahiro Tsutsumi <ttsutsum@nrao.edu>, Srikrishna Sekhar <ssekhar@nrao.edu> | null | null | BSD 3-Clause License
All works in this repository are copyrighted 2024.
For inquiries contact Associated Universities, Inc., 2650 Park Tower Drive Vienna, VA 22180, USA.
Portions of this repository are copyrighted by the following entities:
1. AUI/NRAO, ESO, NAOJ, in the framework of the ALMA partnership.
2. AUI/NRAO in the framework of the ngVLA project.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
| null | [] | [] | null | null | <3.14,>=3.11 | [] | [] | [] | [
"graphviper>=0.0.36",
"numpy>=1.20.0",
"xradio[zarr]>=1.1.0",
"numba",
"python_casacore>=3.6.1; sys_platform != \"darwin\" and extra == \"python-casacore\"",
"matplotlib; extra == \"interactive\"",
"prettytable; extra == \"interactive\"",
"jupyterlab; extra == \"interactive\"",
"ipykernel; extra == \"interactive\"",
"ipympl; extra == \"interactive\"",
"ipython; extra == \"interactive\"",
"jupyter-client; extra == \"interactive\"",
"bokeh; extra == \"interactive\"",
"holoviews; extra == \"interactive\"",
"nbsphinx; extra == \"docs\"",
"recommonmark; extra == \"docs\"",
"scanpydoc; extra == \"docs\"",
"sphinx-autoapi; extra == \"docs\"",
"sphinx-autosummary-accessors; extra == \"docs\"",
"sphinx_rtd_theme; extra == \"docs\"",
"twine; extra == \"docs\"",
"pandoc; extra == \"docs\"",
"python_casacore>=3.6.1; sys_platform != \"darwin\" and extra == \"all\"",
"pytest; extra == \"all\"",
"pytest-cov; extra == \"all\"",
"pytest-html; extra == \"all\"",
"matplotlib; extra == \"all\"",
"prettytable; extra == \"all\"",
"jupyterlab; extra == \"all\"",
"ipykernel; extra == \"all\"",
"ipympl; extra == \"all\"",
"ipython; extra == \"all\"",
"jupyter-client; extra == \"all\"",
"nbsphinx; extra == \"all\"",
"recommonmark; extra == \"all\"",
"scanpydoc; extra == \"all\"",
"sphinx-autoapi; extra == \"all\"",
"sphinx-autosummary-accessors; extra == \"all\"",
"sphinx_rtd_theme; extra == \"all\"",
"twine; extra == \"all\"",
"pandoc; extra == \"all\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:24:32.056129 | astroviper-0.0.34.tar.gz | 9,683,035 | 75/59/fa1423b35390ae244ef9665491581855ef09c870182d4d2b074646b63cb1/astroviper-0.0.34.tar.gz | source | sdist | null | false | b1085b46bc90dbcc045d4d555a4ba484 | 531234f64b5b00cf0e64df78c68a5e39c308f2c8477fd7c99c78f65e8e24ab5d | 7559fa1423b35390ae244ef9665491581855ef09c870182d4d2b074646b63cb1 | null | [] | 494 |
2.4 | sparseconverter | 0.6.0 | Converter matrix and type determination for a range of array formats, focusing on sparse arrays | # sparseconverter
Format detection, identifiers and converter matrix for a range of numerical array formats (backends) in Python, focusing on sparse arrays.
## Usage
Basic usage:
```python
import numpy as np
import sparseconverter as spc
a1 = np.array([
(1, 0, 3),
(0, 0, 6)
])
# array conversion
a2 = spc.for_backend(a1, spc.SPARSE_GCXS)
# format determination
print("a1 is", spc.get_backend(a1), "and a2 is", spc.get_backend(a2))
```
```
a1 is numpy and a2 is sparse.GCXS
```
See `examples/` directory for more!
## Description
This library can help to implement algorithms that support a wide range of array formats as input, output or
for internal calculations. All dense and sparse array libraries already do support format detection, creation and export from and to various formats,
but with different APIs, different sets of formats and different sets of supported features -- dtypes, shapes, device classes etc.
This project creates an unified API for all conversions between the supported formats and takes care of details such as reshaping,
dtype conversion, and using an efficient intermediate format for multi-step conversions.
## Features
* Supports Python 3.10 - (at least) 3.14
* Defines constants for format identifiers
* Various sets to group formats into categories:
* Dense vs sparse
* CPU vs CuPy-based
* nD vs 2D backends
* Efficiently detect format of arrays, including support for subclasses
* Get converter function for a pair of formats
* Convert to a target format
* Find most efficient conversion pair for a range of possible inputs and/or outputs
That way it can help to implement format-specific optimized versions of an algorithm,
to specify which formats are supported by a specific routine, to adapt to
availability of CuPy on a target machine,
and to perform efficient conversion to supported formats as needed.
## Supported array formats
* [`numpy.ndarray`](https://numpy.org/doc/stable/reference/generated/numpy.ndarray.html)
* [`numpy.matrix`](https://numpy.org/doc/stable/reference/generated/numpy.matrix.html) -- to support result of aggregation operations on scipy.sparse matrices
* [`cupy.ndarray`](https://docs.cupy.dev/en/stable/reference/generated/cupy.ndarray.html)
* [`sparse.COO`](https://sparse.pydata.org/en/stable/generated/sparse.COO.html)
* [`sparse.GCXS`](https://sparse.pydata.org/en/stable/generated/sparse.GCXS.html)
* [`sparse.DOK`](https://sparse.pydata.org/en/stable/generated/sparse.DOK.html)
* [`scipy.sparse.coo_matrix`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.coo_matrix.html)
* [`scipy.sparse.csr_matrix`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csr_matrix.html)
* [`scipy.sparse.csc_matrix`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csc_matrix.html)
* [`scipy.sparse.coo_array`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.coo_array.html)
* [`scipy.sparse.csr_array`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csr_array.html)
* [`scipy.sparse.csc_array`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csc_array.html)
* [`cupyx.scipy.sparse.coo_matrix`](https://docs.cupy.dev/en/stable/reference/generated/cupyx.scipy.sparse.coo_matrix.html)
* [`cupyx.scipy.sparse.csr_matrix`](https://docs.cupy.dev/en/stable/reference/generated/cupyx.scipy.sparse.csr_matrix.html)
* [`cupyx.scipy.sparse.csc_matrix`](https://docs.cupy.dev/en/stable/reference/generated/cupyx.scipy.sparse.csc_matrix.html)
## Still TODO
* PyTorch arrays
* More detailed cost metric based on more real-world use cases and parameters.
## Changelog
### 0.7.0 (in development)
* No changes yet
### 0.6.0
* Adapt to changed return type in `sparse==0.18.0` https://github.com/LiberTEM/sparseconverter/pull/79
### 0.5.0
* Drop support for Python 3.8 https://github.com/LiberTEM/sparseconverter/pull/61
* Add support for Python 3.13 https://github.com/LiberTEM/sparseconverter/pull/61
### 0.4.0
* Better error message in case of unknown array type: https://github.com/LiberTEM/sparseconverter/pull/37
* Support for SciPy sparse arrays: https://github.com/LiberTEM/sparseconverter/pull/52
* Drop support for Python 3.7: https://github.com/LiberTEM/sparseconverter/pull/51
### 0.3.4
* Support for Python 3.12 https://github.com/LiberTEM/sparseconverter/pull/26
* Packaging update: Tests for conda-forge https://github.com/LiberTEM/sparseconverter/pull/27
### 0.3.3
* Perform feature checks lazily https://github.com/LiberTEM/sparseconverter/issues/15
### 0.3.2
* Detection and workaround for https://github.com/pydata/sparse/issues/602.
* Detection and workaround for https://github.com/cupy/cupy/issues/7713.
* Test with duplicates and scrambled indices.
* Test correctness of basic array operations.
### 0.3.1
* Include version constraint for `sparse`.
### 0.3.0
* Introduce `conversion_cost()` to obtain a value roughly proportional to the conversion cost
between two backends.
### 0.2.0
* Introduce `result_type()` to find the smallest NumPy dtype that accomodates
all parameters. Allowed as parameters are all valid arguments to
`numpy.result_type(...)` plus backend specifiers.
* Support `cupyx.scipy.sparse.csr_matrix` with `dtype=bool`.
### 0.1.1
Initial release
## Known issues
* `conda install -c conda-forge cupy` on Python 3.7 and Windows 11 may install `cudatoolkit` 10.1 and `cupy` 8.3, which have sporadically produced invalid data structures for `cupyx.sparse.csc_matrix` for unknown reasons. This doesn't happen with current versions. Running the benchmark function `benchmark_conversions()` can help to debug such issues since it performs all pairwise conversions and checks for correctness.
## Notes
This project is developed primarily for sparse data support in [LiberTEM](https://libertem.github.io). For that reason it includes
the backend `CUDA`, which indicates a NumPy array, but targeting execution on a CUDA device.
| text/markdown | null | Dieter Weber <d.weber@fz-juelich.de> | null | null | null | numpy, scipy.sparse, sparse, array, matrix, cupy, cupyx.scipy.sparse | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Development Status :: 3 - Alpha"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy",
"scipy>=1.8",
"sparse>=0.12",
"typing-extensions",
"cupy; extra == \"cupy\"",
"pytest; extra == \"test\"",
"pytest-cov; extra == \"test\""
] | [] | [] | [] | [
"repository, https://github.com/LiberTEM/sparseconverter"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:24:31.669071 | sparseconverter-0.6.0.tar.gz | 23,364 | d9/49/a8b3258c187bd5e68bb4c6d2d95f7189eef6b53f65125bfe159a4c23b784/sparseconverter-0.6.0.tar.gz | source | sdist | null | false | 6df361967fb76f70f9940328e00461a1 | b8af60f6f62f0814187df7b71cc2dcab6294a84944435af668918e32efb62f83 | d949a8b3258c187bd5e68bb4c6d2d95f7189eef6b53f65125bfe159a4c23b784 | MIT | [
"LICENSE"
] | 294 |
2.4 | ebm4subjects | 0.5.8 | Embedding Based Matching for Automated Subject Indexing | # Embedding Based Matching for Automated Subject Indexing
**NOTE: Work in progress. This repository is still under construction.**
This repository implements an algorithm for matching subjects with
sentence transformer embeddings. While all functionality of this code
can be run independently, this repository is not intended as
standalone software, but is designed to work as a backend for the
[Annif toolkit}(https://annif.org/).
The idea of embedding based matching (EBM) is an inverted retrieval logic:
Your target vocabulary is vectorized with a sentence transformer model,
the embeddings are stored in a vector storage, enabling fast search across these
embeddings with the Hierarchical Navigable Small World Algorithm.
This enables fast semantic (embedding based) search across the
vocaublary, even for extrem large vocabularies with many synonyms.
An input text to be indexed with terms from this vocabulary is embedded with the same
sentence transformer model, and sent as a query to the vector storage, resulting in
subject candidates with embeddings that are close to the query.
Longer input texts can be chunked, resulting in multiple queries.
Finally, a ranker model is trained, that reranks the subject candidates, using some
numerical features collected during the matching process.
This design borrows a lot of ideas from lexical matching like Maui [1], Kea [2] and particularly
[Annifs](https://annif.org/) implementation in the [MLLM-Backend](https://github.com/NatLibFi/Annif/wiki/Backend%3A-MLLM) (Maui Like Lexical Matching).
[1] Medelyan, O., Frank, E., & Witten, I. H. (2009). Human-competitive tagging using automatic keyphrase extraction. ACL and AFNLP, 6–7. https://doi.org/10.5555/3454287.3454810
[2] Frank, E., Paynter, G. W., Witten, I. H., Gutwin, C., & Nevill-Manning, C. G. (1999). Domain-Specific Keyphrase Extraction. Proceedings of the 16 Th International Joint Conference on Artifical Intelligence (IJCAI99), 668–673.

## Why embedding based matching
Existing subject indexing methods are roughly categorized into lexical matching algortihms and statistical learning algorithms. Lexical matching algorithms search for occurences of subjects from the controlled vocabulary over a given input text on the basis of their string representation. Statistical learning tries to learn patterns between input texts and gold standard annotations from large training corpora.
Statistical learning can only predict subjects that have occured in the gold standard annotations used for training. It is uncapable of zero shot predictions. Lexical matching can find any subjects that are part of the vocabulary. Unfortunately, lexical matching often produces a large amount of false positives, as matching input texts and vocabulary solely on their string representation does not capture any semantic context. In particular, disambiguation of subjects with similar string representation is a problem.
The idea of embedding based matching is to enhance lexcial matching with the power of sentence transformer embeddings. These embeddings can capture the semantic context of the input text and allow a vector based matching that does not (solely) rely on the string representation.
Benefits of Embedding Based Matching:
* strong zero shot capabilities
* handling of synonyms and context
Disadvantages:
* creating embeddings for longer input texts with many chunks can be computationally expensive
* no generelization capabilities: statisticl learning methods can learn the usage of a vocabulary
from large amounts of training data and therefore learn associations between patterns in input
texts and vocabulary items that are beyond lexical matching or embedding similarity.
Lexical matching and embedding based matching will always stay close to the text.
## Ranker model
The ranker model copies the idea taken from lexical matching Algorithms like MLLM or Maui, that subject candidates
can be ranked based on additional context information, e.g.
* `first_occurence`, `last_occurence`, `spread`: position (chunk number) of the subject match in a text
* `occurences`: number of occurence in a text
* `score`: sum of the similarity scores of all matches between a text chunk's embeddings and label embeddings
* `is_PrefLabelTRUE`: pref-Label or alt-Label tags in the SKOS Vocabulary
These are numerical features that can be used to train a **binary** classifier. Given a
few hundred examples with gold standard labels, the ranker is trained to
predict if a suggested candidate label is indeed a match, based on the
numerical features collected during the matching process. In contrast to
the complex extreme multi label classification problem, this is a a much simpler
problem to train a classifier for, as the selection of features that the binary classifier
is trained on, does not depend on the particular label.
Our ranker model is implemented using the [xgboost](https://xgboost.readthedocs.io/en/latest/index.html) library.
The following plot shows a variable importance plot of the xgboost Ranker-Model:
## Embedding model
Our code uses [Jina AI Embeddings](https://huggingface.co/jinaai/jina-embeddings-v3).
These implement a technique known as Matryoshka Embedding that allows you to
flexibly choose the dimension of your embedding vectors, to find your own
cost-performance trade off.
In this demo application we use assymetric embeddings finetuned for retrieval:
Embeddings of task `retrieval.query` for embedding the vocab and embeddings of task
`retrieval.passage` for embedding the text chunks.
## Vector storage
This project uses DuckDB (https://duckdb.org/) as storage for the vocabulary and the generated embeddings as well as one of its extensions (DuckDB's Vector Similarity Search Extension - https://duckdb.org/docs/extensions/vss.html) for indexing and querying the embeddings.
Benefits of duckdb are:
* it is served as a one-file database: no independent database server needed
* it implements vectorized HNSW-Search
* it allows parallel querying from multiple threads
In other words: duckdb allows a parallized vectorized vector search enabling
highly efficient subject retrieval even across large subject ontologies and
also with large text corpora and longer documents.
This VSS-extension allows for some configurations regarding the HNSW index and the choice of distance metric (see documentaion for details). In this project, the 'cosine' distance and the corresponding 'array_cosine_distance' function are used. The metric and function must be explicitly specified when creating and using the index and must match in order to work. To save the created index, the configuration option for the database 'hnsw_enable_experimental_persistence=true' must be set. This is not recommended by duckdb at the moment, but should not be a problem for this project as no further changes are expected once the collection has been created. Relevant and useful blog posts on the VSS Extension extension can be found here
- https://duckdb.org/2024/05/03/vector-similarity-search-vss.html
- https://duckdb.org/2024/10/23/whats-new-in-the-vss-extension.html
## Usage
The main entry point for the package is the class `ebm_model` and its methods.
| text/markdown | Deutsche Nationalbibliothek | null | null | Clemens Rietdorf <c.rietdorf@dnb.de>, Maximilian Kähler <m.kaehler@dnb.de> | null | code4lib, machine-learning, multilabel-classification, subject-indexing, text-classification | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: European Union Public Licence 1.2 (EUPL 1.2)",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"duckdb>=1.3.0",
"nltk~=3.9.1",
"openai>=2.15.0",
"polars>=1.30.0",
"pyarrow>=21.0.0",
"pyoxigraph>=0.4.11",
"rdflib~=7.1.3",
"xgboost>=3.0.2",
"sentence-transformers>=5.0.0; extra == \"in-process\""
] | [] | [] | [] | [] | uv/0.7.12 | 2026-02-20T13:24:30.882886 | ebm4subjects-0.5.8.tar.gz | 39,551 | ed/4e/38a3b4edd704db5f06fdd00e02e40d827f3039f9cb9530e0f36090984384/ebm4subjects-0.5.8.tar.gz | source | sdist | null | false | e2df761e311e058a3fa8ecc95a302844 | 1b1775c7e40ee84d0a78a1d6e21896f86ea2c311b9b3ff66eda545300011265d | ed4e38a3b4edd704db5f06fdd00e02e40d827f3039f9cb9530e0f36090984384 | EUPL-1.2 | [
"LICENSE"
] | 217 |
2.4 | rapid-rag | 0.2.0 | Fast local RAG - search your documents with AI, no cloud needed | # rapid-rag
Fast local RAG - search your documents with AI, no cloud needed.
## Installation
```bash
pip install rapid-rag
```
For PDF support:
```bash
pip install rapid-rag[pdf]
```
## Quick Start
```python
from rapid_rag import RapidRAG
# Create a RAG instance
rag = RapidRAG("my_documents")
# Add documents
rag.add("doc1", "The quick brown fox jumps over the lazy dog.")
rag.add_file("report.pdf")
rag.add_directory("./docs/")
# Semantic search
results = rag.search("fox jumping")
for r in results:
print(f"{r['score']:.3f}: {r['content'][:100]}")
# RAG query with LLM (requires Ollama)
answer = rag.query("What does the fox do?", model="qwen2.5:7b")
print(answer["answer"])
```
## CLI Usage
```bash
# Initialize a collection
rapid-rag init my_docs
# Add documents
rapid-rag add ./documents/ -c my_docs -r
# Search
rapid-rag search "query here" -c my_docs
# RAG query (requires Ollama)
rapid-rag query "What is X?" -c my_docs -m qwen2.5:7b
# Info
rapid-rag info -c my_docs
```
## TIBET Provenance
Track every operation with cryptographic provenance:
```python
from rapid_rag import RapidRAG, TIBETProvider
# Enable TIBET tracking
tibet = TIBETProvider(actor="my_app")
rag = RapidRAG("docs", tibet=tibet)
# All operations now create provenance tokens
rag.add_file("report.pdf")
results = rag.search("query")
answer = rag.query("Question?")
# Get provenance chain
tokens = tibet.get_tokens()
for t in tokens:
print(f"{t.token_type}: {t.erachter}")
print(f" ERIN: {t.erin}") # What happened
print(f" ERACHTER: {t.erachter}") # Why
```
TIBET uses Dutch provenance semantics:
- **ERIN**: What's IN the action (content)
- **ERAAN**: What's attached (references)
- **EROMHEEN**: Context around it
- **ERACHTER**: Intent behind it
## Features
- **Local-first**: Everything runs on your machine
- **Fast**: ChromaDB + sentence-transformers
- **Simple API**: Add, search, query in 3 lines
- **File support**: .txt, .md, .pdf
- **Chunking**: Automatic with overlap
- **LLM integration**: Works with Ollama
- **TIBET**: Cryptographic provenance for all operations
## Requirements
- Python 3.10+
- For LLM queries: [Ollama](https://ollama.ai) running locally
## License
MIT - Humotica
| text/markdown | null | "J. van de Meent" <jasper@humotica.com>, "R. AI" <info@humotica.com> | null | null | MIT | ai, augmented, chromadb, documents, embeddings, generation, llm, local, offline, rag, retrieval, search, semantic-search, vector-search | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Text Processing :: Indexing"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"chromadb>=0.4.0",
"httpx>=0.24.0",
"sentence-transformers>=2.2.0",
"fastapi>=0.100.0; extra == \"all\"",
"ollama>=0.1.0; extra == \"all\"",
"pdfplumber>=0.9.0; extra == \"all\"",
"pypdf>=3.0.0; extra == \"all\"",
"uvicorn>=0.22.0; extra == \"all\"",
"fastapi>=0.100.0; extra == \"api\"",
"uvicorn>=0.22.0; extra == \"api\"",
"pytest>=7.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"ollama>=0.1.0; extra == \"ollama\"",
"pdfplumber>=0.9.0; extra == \"pdf\"",
"pypdf>=3.0.0; extra == \"pdf\""
] | [] | [] | [] | [
"Homepage, https://humotica.com",
"Repository, https://github.com/humotica/rapid-rag",
"Documentation, https://humotica.com/docs/rapid-rag"
] | twine/6.2.0 CPython/3.13.5 | 2026-02-20T13:22:34.567475 | rapid_rag-0.2.0.tar.gz | 11,703 | fb/44/65c1ded08efd70c3a1dc2c5b5886ef1df5ca9e7065aa7ad7197305b33157/rapid_rag-0.2.0.tar.gz | source | sdist | null | false | 6447994a207b33cdd6de8c04475571e8 | c27bea8a76be0a9d3ff167feca5a52e4ae7e55c4341f9411297ab4dade6b2069 | fb4465c1ded08efd70c3a1dc2c5b5886ef1df5ca9e7065aa7ad7197305b33157 | null | [] | 226 |
2.4 | bayesian-bm25 | 0.3.0 | Bayesian probability transforms for BM25 retrieval scores | # Bayesian BM25
[[Blog](https://www.cognica.io/en/blog/posts/2026-02-01-bayesian-bm25-hybrid-search)] [[Papers](docs/papers)]
A probabilistic framework that converts raw BM25 retrieval scores into calibrated relevance probabilities using Bayesian inference.
## Overview
Standard BM25 produces unbounded scores that lack consistent meaning across queries, making threshold-based filtering and multi-signal fusion unreliable. Bayesian BM25 addresses this by applying a sigmoid likelihood model with a composite prior (term frequency + document length normalization) and computing Bayesian posteriors that output well-calibrated probabilities in [0, 1]. A corpus-level base rate prior further improves calibration by 68--77% without requiring relevance labels.
Key capabilities:
- **Score-to-probability transform** -- convert raw BM25 scores into calibrated relevance probabilities via sigmoid likelihood + composite prior + Bayesian posterior
- **Base rate calibration** -- corpus-level base rate prior estimated from score distribution decomposes the posterior into three additive log-odds terms, reducing expected calibration error by 68--77% without relevance labels
- **Parameter learning** -- batch gradient descent or online SGD with EMA-smoothed gradients and Polyak averaging, with three training modes: balanced (C1), prior-aware (C2), and prior-free (C3)
- **Probabilistic fusion** -- combine multiple probability signals using log-odds conjunction with optional per-signal reliability weights (Log-OP), which resolves the shrinkage problem of naive probabilistic AND
- **Hybrid search** -- `cosine_to_probability()` converts vector similarity scores to probabilities for fusion with BM25 signals via weighted log-odds conjunction
- **WAND pruning** -- `wand_upper_bound()` computes safe Bayesian probability upper bounds for document pruning in top-k retrieval
- **Search integration** -- drop-in scorer wrapping [bm25s](https://github.com/xhluca/bm25s) that returns probabilities instead of raw scores
## Adoption
- [MTEB](https://github.com/embeddings-benchmark/mteb) -- included as a baseline retrieval model (`bb25`) for the Massive Text Embedding Benchmark
- [txtai](https://github.com/neuml/txtai) -- used for BM25 score normalization in hybrid search (`normalize="bayesian-bm25"`)
## Installation
```bash
pip install bayesian-bm25
```
To use the integrated search scorer (requires `bm25s`):
```bash
pip install bayesian-bm25[scorer]
```
## Quick Start
### Converting BM25 Scores to Probabilities
```python
import numpy as np
from bayesian_bm25 import BayesianProbabilityTransform
transform = BayesianProbabilityTransform(alpha=1.5, beta=1.0, base_rate=0.01)
scores = np.array([0.5, 1.0, 1.5, 2.0, 3.0])
tfs = np.array([1, 2, 3, 5, 8])
doc_len_ratios = np.array([0.3, 0.5, 0.8, 1.0, 1.5])
probabilities = transform.score_to_probability(scores, tfs, doc_len_ratios)
```
### End-to-End Search with Probabilities
```python
from bayesian_bm25 import BayesianBM25Scorer
corpus_tokens = [
["python", "machine", "learning"],
["deep", "learning", "neural", "networks"],
["data", "visualization", "tools"],
]
scorer = BayesianBM25Scorer(k1=1.2, b=0.75, method="lucene", base_rate="auto")
scorer.index(corpus_tokens, show_progress=False)
doc_ids, probabilities = scorer.retrieve([["machine", "learning"]], k=3)
```
### Combining Multiple Signals
```python
import numpy as np
from bayesian_bm25 import log_odds_conjunction, prob_and, prob_or
signals = np.array([0.85, 0.70, 0.60])
prob_and(signals) # 0.357 (shrinkage problem)
log_odds_conjunction(signals) # 0.773 (agreement-aware)
```
### Hybrid Text + Vector Search
```python
import numpy as np
from bayesian_bm25 import cosine_to_probability, log_odds_conjunction
# BM25 probabilities (from Bayesian BM25)
bm25_probs = np.array([0.85, 0.60, 0.40])
# Vector search cosine similarities -> probabilities
cosine_scores = np.array([0.92, 0.35, 0.70])
vector_probs = cosine_to_probability(cosine_scores) # [0.96, 0.675, 0.85]
# Fuse with reliability weights (BM25 weight=0.6, vector weight=0.4)
stacked = np.stack([bm25_probs, vector_probs], axis=-1)
fused = log_odds_conjunction(stacked, weights=np.array([0.6, 0.4]))
```
### WAND Pruning with Bayesian Upper Bounds
```python
from bayesian_bm25 import BayesianProbabilityTransform
transform = BayesianProbabilityTransform(alpha=1.5, beta=2.0, base_rate=0.01)
# Standard BM25 upper bound per query term
bm25_upper_bound = 5.0
# Bayesian upper bound for safe pruning -- any document's actual
# probability is guaranteed to be at most this value
bayesian_bound = transform.wand_upper_bound(bm25_upper_bound)
```
### Online Learning from User Feedback
```python
from bayesian_bm25 import BayesianProbabilityTransform
transform = BayesianProbabilityTransform(alpha=1.0, beta=0.0)
# Batch warmup on historical data
transform.fit(historical_scores, historical_labels)
# Online refinement from live feedback
for score, label in feedback_stream:
transform.update(score, label, learning_rate=0.01, momentum=0.95)
# Use Polyak-averaged parameters for stable inference
alpha = transform.averaged_alpha
beta = transform.averaged_beta
```
### Training Modes
```python
from bayesian_bm25 import BayesianProbabilityTransform
transform = BayesianProbabilityTransform(alpha=1.0, beta=0.0)
# C1 (balanced, default): train on sigmoid likelihood
transform.fit(scores, labels, mode="balanced")
# C2 (prior-aware): train on full Bayesian posterior
transform.fit(scores, labels, mode="prior_aware", tfs=tfs, doc_len_ratios=ratios)
# C3 (prior-free): train on likelihood, inference uses prior=0.5
transform.fit(scores, labels, mode="prior_free")
```
## Benchmarks
Evaluated on [BEIR](https://github.com/beir-cellar/beir) datasets (NFCorpus, SciFact) with k1=1.2, b=0.75, Lucene BM25. Queries are split 50/50 for training and evaluation. "Batch fit" uses gradient descent on training labels; all other Bayesian methods are unsupervised.
### Ranking Quality
Base rate prior is a monotonic transform -- it does not change document ordering.
| Method | NFCorpus NDCG@10 | NFCorpus MAP | SciFact NDCG@10 | SciFact MAP |
|---|---|---|---|---|
| Raw BM25 | 0.5023 | 0.4395 | 0.5900 | 0.5426 |
| Bayesian (auto) | 0.5050 | 0.4403 | 0.5791 | 0.5283 |
| Bayesian (auto) + base rate | 0.5050 | 0.4403 | 0.5791 | 0.5283 |
| Bayesian (batch fit) | 0.5041 | 0.4400 | 0.5826 | 0.5305 |
| Bayesian (batch fit) + base rate | 0.5041 | 0.4400 | 0.5826 | 0.5305 |
### Probability Calibration
Expected Calibration Error (ECE) and Brier score. Lower is better.
| Method | NFCorpus ECE | NFCorpus Brier | SciFact ECE | SciFact Brier |
|---|---|---|---|---|
| Bayesian (no base rate) | 0.6519 | 0.4667 | 0.7989 | 0.6635 |
| Bayesian (base_rate=auto) | 0.1461 (-77.6%) | 0.0619 | 0.2577 (-67.7%) | 0.1308 |
| Bayesian (base_rate=0.001) | 0.0081 (-98.8%) | 0.0114 | 0.0354 (-95.6%) | 0.0157 |
| Batch fit (no base rate) | 0.0093 (-98.6%) | 0.0114 | 0.0103 (-98.7%) | 0.0051 |
| Batch fit + base_rate=auto | 0.0085 (-98.7%) | 0.0096 | 0.0021 (-99.7%) | 0.0013 |
### Threshold Transfer
F1 scores using the best threshold found on training queries, applied to evaluation queries. Smaller gap indicates better generalization.
| Method | NFCorpus Train F1 | NFCorpus Test F1 | SciFact Train F1 | SciFact Test F1 |
|---|---|---|---|---|
| Bayesian (no base rate) | 0.1607 | 0.1511 | 0.3374 | 0.2800 |
| Batch fit (no base rate) | 0.1577 | 0.1405 | 0.2358 | 0.2294 |
| Batch fit + base_rate=auto | 0.1559 | 0.1403 | 0.3316 | 0.3341 |
Reproduce with `python benchmarks/base_rate.py` (requires `pip install ir_datasets`). The base rate benchmark also includes Platt scaling, min-max normalization, and prior-aware/prior-free training mode comparisons.
Additional benchmarks (no external datasets required):
- `python benchmarks/weighted_fusion.py` -- weighted vs uniform log-odds fusion across noise scenarios
- `python benchmarks/wand_upper_bound.py` -- WAND upper bound tightness and skip rate analysis
## Citation
If you use this work, please cite the following papers:
```bibtex
@preprint{Jeong2026BayesianBM25,
author = {Jeong, Jaepil},
title = {Bayesian {BM25}: {A} Probabilistic Framework for Hybrid Text
and Vector Search},
year = {2026},
publisher = {Zenodo},
doi = {10.5281/zenodo.18414940},
url = {https://doi.org/10.5281/zenodo.18414940}
}
@preprint{Jeong2026BayesianNeural,
author = {Jeong, Jaepil},
title = {From {Bayesian} Inference to Neural Computation: The Analytical
Emergence of Neural Network Structure from Probabilistic
Relevance Estimation},
year = {2026},
publisher = {Zenodo},
doi = {10.5281/zenodo.18512411},
url = {https://doi.org/10.5281/zenodo.18512411}
}
```
## License
This project is licensed under the [Apache License 2.0](LICENSE).
Copyright (c) 2023-2026 Cognica, Inc.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy>=1.21",
"bm25s>=0.2.0; extra == \"scorer\"",
"pytest>=7.0; extra == \"dev\"",
"bm25s>=0.2.0; extra == \"dev\""
] | [] | [] | [] | [
"Repository, https://github.com/cognica-io/bayesian-bm25"
] | twine/6.2.0 CPython/3.12.7 | 2026-02-20T13:22:27.285061 | bayesian_bm25-0.3.0.tar.gz | 34,091 | 09/3b/0ae52f5800cc26a223fa84291f048c5331dd2ead081a97c5d5f9ede66cb3/bayesian_bm25-0.3.0.tar.gz | source | sdist | null | false | 14a1216a11a8d1cc4a927669b5cb88b7 | c120915d9d0f6c9eea5d1919ce962c3196576e0d94120c3cf1077a06b9348256 | 093b0ae52f5800cc26a223fa84291f048c5331dd2ead081a97c5d5f9ede66cb3 | Apache-2.0 | [
"LICENSE"
] | 202 |
2.4 | cliche | 0.10.126 | A minimalistic CLI wrapper out to be the best | <p align="center">
<img src="./resources/logo.gif"/>
</p>
# Cliche
Build a simple command-line interface from your functions.
Features:
- ✓ Least syntax required: you do not need to "learn a library" to use this
- ✓ keeps it DRY (Don't Repeat yourself):
- it uses all information available like *annotations*, *default values* and *docstrings*... yet does not require them.
- ✓ Just decorate a function with `@cli` - that is it - it can now be called as CLI but also remains usable by other functions (unlike the click library)
- ✓ Works with booleans (flags) and lists (multiple args) automatically
- ✓ Standing on the shoulders of giants (i.e. it uses argparse and learnings from others)
- ✓ Prints returned python objects in JSON (unless passing `--raw`)
- ✓ Colorized output automatically
- ✓ Allows creating executable by using `cliche install <mycli>`
- ✓ Creates shortcuts, e.g. a variable "long_option" will be usable like `--long-option` and `-l`
- ✓ No external dependencies -> lightweight
## Examples
#### Simplest Example
You want to make a calculator. You not only want its functions to be reusable, you also want it to be callable from command line.
```python
# calculator.py
from cliche import cli
@cli
def add(a: int, b: int):
return a + b
```
Now let's see how to use it from the command-line:
```
pascal@archbook:~/calc$ cliche install calc
pascal@archbook:~/calc$ calc add --help
usage: calc add [-h] a b
positional arguments:
a |int|
b |int|
optional arguments:
-h, --help show this help message and exit
```
thus:
pascal@archbook:~/calc$ calc add 1 10
11
#### Installation of commands
You noticed we ran
cliche install calc
We can undo this with
cliche uninstall calc
Note that installing means that all `@cli` functions will be detected
in the folder, not just of a single file, even after installation. You
only have to install once, and on Linux it also adds autocompletion to
your CLI if `argcomplete` has been installed.
#### Advanced Example
```python
from cliche import cli
@cli
def add_or_mul(a_number: int, b_number=10, sums=False):
""" Adds or multiplies a and b
:param a_number: the first one
:param b_number: second one
:param sums: Sums when true, otherwise multiply
"""
if sums:
print(a_number + b_number)
else:
print(a_number * b_number)
```
Help:

Calling it:
pascal@archbook:~/calc$ calc add_or_mul 1
10
pascal@archbook:~/calc$ calc add_or_mul --sum 1
11
pascal@archbook:~/calc$ calc add_or_mul 2 -b 3
6
#### More examples
Check the example files [here](https://github.com/kootenpv/cliche/tree/master/examples)
## Comparison with other CLI generators
- argparse: it is powerful, but you need a lot of code to construct an argparse CLI
- click: you need a lot of decorators to construct a CLI, and not obvious how to use it. It does not keep things DRY. Also, the annotated function is not usable.
- hug (cli): connected to a whole web framework, but gets a lot right
- python-fire: low set up, but annoying traces all the time / ugly design, does not show default values nor types
- cleo: requires too much code/objects to construct
| text/markdown | null | Pascal van Kooten <kootenpv@gmail.com> | null | null | MIT | null | [
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: Customer Service",
"Intended Audience :: System Administrators",
"Operating System :: Microsoft",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Unix",
"Operating System :: POSIX",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.4",
"Programming Language :: Python :: 3.5",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Topic :: Software Development",
"Topic :: Software Development :: Build Tools",
"Topic :: Software Development :: Debuggers",
"Topic :: Software Development :: Libraries",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: System :: Software Distribution",
"Topic :: System :: Systems Administration",
"Topic :: Utilities"
] | [
"any"
] | null | null | >=3.10 | [] | [] | [] | [
"ipdb==0.13.13"
] | [] | [] | [] | [
"Homepage, https://github.com/kootenpv/cliche"
] | twine/6.1.0 CPython/3.13.5 | 2026-02-20T13:21:46.192654 | cliche-0.10.126.tar.gz | 26,627 | 93/6a/cf5ba31e4c86e561333466c880ab0eafee7210007e0e86f0719b24afa3fb/cliche-0.10.126.tar.gz | source | sdist | null | false | d90bbe6a6697fd17ebd3698d883e8a7a | 227f1ab710d8880e66dbfad0f132b7fd718f010e30dd2c828165beb9f2c80e28 | 936acf5ba31e4c86e561333466c880ab0eafee7210007e0e86f0719b24afa3fb | null | [] | 218 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.