
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.1 | odoo-addon-jsonifier | 18.0.1.1.1 | JSON-ify data for all models | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
=========
JSONifier
=========
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:a064cec295d1e9072c772cfaaaeee217cc7da886fa33b319d2ebbae819ceffc9
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-LGPL--3-blue.png
:target: http://www.gnu.org/licenses/lgpl-3.0-standalone.html
:alt: License: LGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fserver--tools-lightgray.png?logo=github
:target: https://github.com/OCA/server-tools/tree/18.0/jsonifier
:alt: OCA/server-tools
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/server-tools-18-0/server-tools-18-0-jsonifier
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/server-tools&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module adds a 'jsonify' method to every model of the ORM. It works
on the current recordset and requires a single argument 'parser' that
specify the field to extract.
Example of a simple parser:
.. code:: python
parser = [
'name',
'number',
'create_date',
('partner_id', ['id', 'display_name', 'ref'])
('line_id', ['id', ('product_id', ['name']), 'price_unit'])
]
In order to be consistent with the Odoo API the jsonify method always
returns a list of objects even if there is only one element in the
recordset.
By default the key into the JSON is the name of the field extracted from
the model. If you need to specify an alternate name to use as key, you
can define your mapping as follow into the parser definition:
.. code:: python
parser = [
'field_name:json_key'
]
.. code:: python
parser = [
'name',
'number',
'create_date:creationDate',
('partner_id:partners', ['id', 'display_name', 'ref'])
('line_id:lines', ['id', ('product_id', ['name']), 'price_unit'])
]
If you need to parse the value of a field in a custom way, you can pass
a callable or the name of a method on the model:
.. code:: python
parser = [
('name', "jsonify_name") # method name
('number', lambda rec, field_name: rec[field_name] * 2)) # callable
]
Also the module provide a method "get_json_parser" on the ir.exports
object that generate a parser from an ir.exports configuration.
Further features are available for advanced uses. It defines a simple
"resolver" model that has a "python_code" field and a resolve function
so that arbitrary functions can be configured to transform fields, or
process the resulting dictionary. It is also to specify a lang to
extract the translation of any given field.
To use these features, a full parser follows the following structure:
.. code:: python
parser = {
"resolver": 3,
"language_agnostic": True,
"langs": {
False: [
{'name': 'description'},
{'name': 'number', 'resolver': 5},
({'name': 'partner_id', 'target': 'partner'}, [{'name': 'display_name'}])
],
'fr_FR': [
{'name': 'description', 'target': 'descriptions_fr'},
({'name': 'partner_id', 'target': 'partner'}, [{'name': 'description', 'target': 'description_fr'}])
],
}
}
One would get a result having this structure (note that the translated
fields are merged in the same dictionary):
.. code:: python
exported_json == {
"description": "English description",
"description_fr": "French description, voilà",
"number": 42,
"partner": {
"display_name": "partner name",
"description_fr": "French description of that partner",
},
}
Note that a resolver can be passed either as a recordset or as an id, so
as to be fully serializable. A slightly simpler version in case the
translation of fields is not needed, but other features like custom
resolvers are:
.. code:: python
parser = {
"resolver": 3,
"fields": [
{'name': 'description'},
{'name': 'number', 'resolver': 5},
({'name': 'partner_id', 'target': 'partners'}, [{'name': 'display_name'}]),
],
}
By passing the fields key instead of langs, we have essentially the same
behaviour as simple parsers, with the added benefit of being able to use
resolvers.
Standard use-cases of resolvers are: - give field-specific defaults
(e.g. "" instead of None) - cast a field type (e.g. int()) - alias a
particular field for a specific export - ...
A simple parser is simply translated into a full parser at export.
If the global resolver is given, then the json_dict goes through:
.. code:: python
resolver.resolve(dict, record)
Which allows to add external data from the context or transform the
dictionary if necessary. Similarly if given for a field the resolver
evaluates the result.
It is possible for a target to have a marshaller by ending the target
with '=list': in that case the result is put into a list.
.. code:: python
parser = {
fields: [
{'name': 'name'},
{'name': 'field_1', 'target': 'customTags=list'},
{'name': 'field_2', 'target': 'customTags=list'},
]
}
Would result in the following JSON structure:
.. code:: python
{
'name': 'record_name',
'customTags': ['field_1_value', 'field_2_value'],
}
The intended use-case is to be compatible with APIs that require all
translated parameters to be exported simultaneously, and ask for custom
properties to be put in a sub-dictionary. Since it is often the case
that some of these requirements are optional, new requirements could be
met without needing to add field or change any code.
Note that the export values with the simple parser depends on the
record's lang; this is in contrast with full parsers which are designed
to be language agnostic.
NOTE: this module was named base_jsonify till version 14.0.1.5.0.
**Table of contents**
.. contents::
:local:
Usage
=====
with_fieldname parameter
------------------------
The with_fieldname option of jsonify() method, when true, will inject on
the same level of the data "\_fieldname\_$field" keys that will contain
the field name, in the language of the current user.
Examples of with_fieldname usage:
.. code:: python
# example 1
parser = [('name')]
a.jsonify(parser=parser)
[{'name': 'SO3996'}]
>>> a.jsonify(parser=parser, with_fieldname=False)
[{'name': 'SO3996'}]
>>> a.jsonify(parser=parser, with_fieldname=True)
[{'fieldname_name': 'Order Reference', 'name': 'SO3996'}}]
# example 2 - with a subparser-
parser=['name', 'create_date', ('order_line', ['id' , 'product_uom', 'is_expense'])]
>>> a.jsonify(parser=parser, with_fieldname=False)
[{'name': 'SO3996', 'create_date': '2015-06-02T12:18:26.279909+00:00', 'order_line': [{'id': 16649, 'product_uom': 'stuks', 'is_expense': False}, {'id': 16651, 'product_uom': 'stuks', 'is_expense': False}, {'id': 16650, 'product_uom': 'stuks', 'is_expense': False}]}]
>>> a.jsonify(parser=parser, with_fieldname=True)
[{'fieldname_name': 'Order Reference', 'name': 'SO3996', 'fieldname_create_date': 'Creation Date', 'create_date': '2015-06-02T12:18:26.279909+00:00', 'fieldname_order_line': 'Order Lines', 'order_line': [{'fieldname_id': 'ID', 'id': 16649, 'fieldname_product_uom': 'Unit of Measure', 'product_uom': 'stuks', 'fieldname_is_expense': 'Is expense', 'is_expense': False}]}]
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/server-tools/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/server-tools/issues/new?body=module:%20jsonifier%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Akretion
* ACSONE
* Camptocamp
Contributors
------------
- BEAU Sébastien <sebastien.beau@akretion.com>
- Raphaël Reverdy <raphael.reverdy@akretion.com>
- Laurent Mignon <laurent.mignon@acsone.eu>
- Nans Lefebvre <nans.lefebvre@acsone.eu>
- Simone Orsi <simone.orsi@camptocamp.com>
- Iván Todorovich <ivan.todorovich@camptocamp.com>
- Nguyen Minh Chien <chien@trobz.com>
- Thien Vo <thienvh@trobz.com>
Other credits
-------------
The migration of this module from 17.0 to 18.0 was financially supported
by Camptocamp.
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/server-tools <https://github.com/OCA/server-tools/tree/18.0/jsonifier>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Akretion, ACSONE, Camptocamp, Odoo Community Association (OCA) | support@odoo-community.org | null | null | LGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)"
] | [] | https://github.com/OCA/server-tools | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T10:09:35.807338 | odoo_addon_jsonifier-18.0.1.1.1-py3-none-any.whl | 57,183 | d9/36/3afc3b58662c8c46d77b587e97ce90f81112d48188ef497c241c115f90f0/odoo_addon_jsonifier-18.0.1.1.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 5a5cd94349120be35a9a700b7969b2fe | bc2dccd05b06b5ebbb25e214c8b04f2dce7cc5862392ef5070231edbfbbd00ea | d9363afc3b58662c8c46d77b587e97ce90f81112d48188ef497c241c115f90f0 | null | [] | 93 |
2.1 | odoo-addon-rpc-helper | 18.0.1.0.2 | Helpers for disabling RPC calls | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
===========
Disable RPC
===========
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:d71c6c86a2635b277c84c2a0eeeb2fd97802d45117fe1204a3314cc158f09b6d
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-LGPL--3-blue.png
:target: http://www.gnu.org/licenses/lgpl-3.0-standalone.html
:alt: License: LGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fserver--tools-lightgray.png?logo=github
:target: https://github.com/OCA/server-tools/tree/18.0/rpc_helper
:alt: OCA/server-tools
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/server-tools-18-0/server-tools-18-0-rpc_helper
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/server-tools&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
Provide helpers to authorize RPC calls.
**Table of contents**
.. contents::
:local:
Configuration
=============
Enable debug mode and go to "Technical -> Database Structure -> Models".
Open the model that you like to configure and go to the tab "RPC
config".
There you see a text field which supports JSON configuration.
The configuration is the same you can pass via decorator. The only
difference is that you have to wrap values in a dictionary like
{"disable": [...values...]}.
To disable all calls:
::
{
"disable": ["all"]
}
To disable only some methods:
::
{
"disable": ["create", "write", "another_method"]
}
NOTE: on the resulting JSON will be automatically formatted on save for
better readability.
Usage
=====
Via code
--------
Decorate an Odoo model class like this:
::
from odoo.addons.rpc_helper.decorator import disable_rpc
@disable_rpc()
class AverageModel(models.Model):
_inherit = "avg.model"
This will disable ALL calls.
To selectively disable only some methods:
::
@disable_rpc("create", "write", "any_method")
class AverageModel(models.Model):
_inherit = "avg.model"
Via ir.model configuration
--------------------------
See "Configuration" section.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/server-tools/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/server-tools/issues/new?body=module:%20rpc_helper%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Camptocamp
Contributors
------------
- Simone Orsi <simone.orsi@camptocamp.com>
Trobz
- Tuan Nguyen <tuanna@trobz.com>
Other credits
-------------
The migration of this module from 16.0 to 18.0 was financially supported
by Camptocamp.
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
.. |maintainer-simahawk| image:: https://github.com/simahawk.png?size=40px
:target: https://github.com/simahawk
:alt: simahawk
Current `maintainer <https://odoo-community.org/page/maintainer-role>`__:
|maintainer-simahawk|
This module is part of the `OCA/server-tools <https://github.com/OCA/server-tools/tree/18.0/rpc_helper>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Camptocamp, Odoo Community Association (OCA) | support@odoo-community.org | null | null | LGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)",
"Development Status :: 4 - Beta"
] | [] | https://github.com/OCA/server-tools | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T10:09:32.943827 | odoo_addon_rpc_helper-18.0.1.0.2-py3-none-any.whl | 32,228 | 0b/b3/833f1744f545cabf2c4dab892f08b32391a4d97357cf5b294423c37aea5e/odoo_addon_rpc_helper-18.0.1.0.2-py3-none-any.whl | py3 | bdist_wheel | null | false | dcb5385ab0d10b1d9adfc2606bdd1df5 | 235f6f0770c129a5b7192eeae556a9aca7c6a853ceecc2c5caa02ee6207658c9 | 0bb3833f1744f545cabf2c4dab892f08b32391a4d97357cf5b294423c37aea5e | null | [] | 88 |
2.1 | odoo-addon-upgrade-analysis | 18.0.1.4.4 | Performs a difference analysis between modules installed on two different Odoo instances | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
================
Upgrade Analysis
================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:c2c27b7d71aa3928b322fe32b128516efa8781bf4a35166acbc3671263c254a4
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fserver--tools-lightgray.png?logo=github
:target: https://github.com/OCA/server-tools/tree/18.0/upgrade_analysis
:alt: OCA/server-tools
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/server-tools-18-0/server-tools-18-0-upgrade_analysis
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/server-tools&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module provides the tool to generate the database analysis files
that indicate how the Odoo data model and module data have changed
between two versions of Odoo. Database analysis files for the core
modules are included in the OpenUpgrade distribution so as a migration
script developer you will not usually need to use this tool yourself. If
you do need to run your analysis of a custom set of modules, please
refer to the documentation here:
https://doc.therp.nl/openupgrade/analysis.html
This module is just a tool, a continuation of the old
openupgrade_records in OpenUpgrade in previous versions. It's not
recommended to have this module in a production database.
**Table of contents**
.. contents::
:local:
Usage
=====
`Usage instructions <https://oca.github.io/OpenUpgrade/analyse.html>`__
Known issues / Roadmap
======================
- Log removed modules in the module that owned them (#468)
- Detect renamed many2many tables (#213)
- Make sure that the ``migration_analysis.txt`` file is always generated
in all cases. (See:
https://github.com/OCA/OpenUpgrade/pull/3209#issuecomment-1157449981)
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/server-tools/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/server-tools/issues/new?body=module:%20upgrade_analysis%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Therp BV
* Opener B.V.
* GRAP
Contributors
------------
- Stefan Rijnhart <stefan@opener.amsterdam>
- Holger Brunn <hbrunn@therp.nl>
- Ferdinand Gassauer <gass@cc-l-12.chircar.at>
- Florent Xicluna <florent.xicluna@gmail.com>
- Miquel Raïch <miquel.raich@forgeflow.com>
- Sylvain LE GAL <https://twitter.com/legalsylvain>
- `Tecnativa <https://www.tecnativa.com>`__:
- Pedro M. Baeza
- Sergio Teruel
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
.. |maintainer-StefanRijnhart| image:: https://github.com/StefanRijnhart.png?size=40px
:target: https://github.com/StefanRijnhart
:alt: StefanRijnhart
.. |maintainer-legalsylvain| image:: https://github.com/legalsylvain.png?size=40px
:target: https://github.com/legalsylvain
:alt: legalsylvain
Current `maintainers <https://odoo-community.org/page/maintainer-role>`__:
|maintainer-StefanRijnhart| |maintainer-legalsylvain|
This module is part of the `OCA/server-tools <https://github.com/OCA/server-tools/tree/18.0/upgrade_analysis>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Therp BV, Opener B.V., GRAP, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/server-tools | null | >=3.10 | [] | [] | [] | [
"dataclasses",
"odoo==18.0.*",
"odoorpc",
"openupgradelib"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T10:09:30.813132 | odoo_addon_upgrade_analysis-18.0.1.4.4-py3-none-any.whl | 74,234 | 64/a2/06a384a9a3074ec56a1ef3af586b235c2f0340a67b8bd361e00c6b2cce51/odoo_addon_upgrade_analysis-18.0.1.4.4-py3-none-any.whl | py3 | bdist_wheel | null | false | 2a7c08e6c5a25110912fed85d6f8d302 | 9a5672b04e5e89ec37c1457f1bfc943476f0394f9196a34beb13fbd75af307e3 | 64a206a384a9a3074ec56a1ef3af586b235c2f0340a67b8bd361e00c6b2cce51 | null | [] | 88 |
2.1 | odoo-addon-attachment-queue | 18.0.1.0.1 | Base module adding the concept of queue for processing files | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
================
Attachment Queue
================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:fafc8b3a64f141a0b20e65bb4f01c86fc26516c598bff7bfe20b3bf5c97ed8da
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fserver--tools-lightgray.png?logo=github
:target: https://github.com/OCA/server-tools/tree/18.0/attachment_queue
:alt: OCA/server-tools
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/server-tools-18-0/server-tools-18-0-attachment_queue
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/server-tools&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module adds async processing capabilities to attachments by
implementing a new model attachment.queue that wraps attachments and
stores additional information so that it can be processed in an
asynchronous way.
A use case of this module can be found in the attachment_synchronize
module.
**Table of contents**
.. contents::
:local:
Usage
=====
Go the menu Settings > Technical > Database Structure > Attachments
Queue
You can create / see standard attachments with additional fields
Configure the batch limit for attachments that can be sync by the cron
task at a go:
Settings > Technical > System parameters >
attachment_queue_cron_batch_limit
|tree view|
This module can be used in combination with attachment_synchronize to
control file processing workflow
|form view|
.. |tree view| image:: https://raw.githubusercontent.com/OCA/server-tools/18.0/attachment_queue/static/description/tree.png
.. |form view| image:: https://raw.githubusercontent.com/OCA/server-tools/18.0/attachment_queue/static/description/form.png
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/server-tools/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/server-tools/issues/new?body=module:%20attachment_queue%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Akretion
Contributors
------------
- Valentin CHEMIERE <valentin.chemiere@akretion.com>
- Florian da Costa <florian.dacosta@akretion.com>
- Angel Moya <http://angelmoya.es>
- Dan Kiplangat <dan@sunflowerweb.nl>
- Kevin Khao <kevin.khao@akretion.com>
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
.. |maintainer-florian-dacosta| image:: https://github.com/florian-dacosta.png?size=40px
:target: https://github.com/florian-dacosta
:alt: florian-dacosta
.. |maintainer-sebastienbeau| image:: https://github.com/sebastienbeau.png?size=40px
:target: https://github.com/sebastienbeau
:alt: sebastienbeau
Current `maintainers <https://odoo-community.org/page/maintainer-role>`__:
|maintainer-florian-dacosta| |maintainer-sebastienbeau|
This module is part of the `OCA/server-tools <https://github.com/OCA/server-tools/tree/18.0/attachment_queue>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Akretion,Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/server-tools | null | >=3.10 | [] | [] | [] | [
"odoo-addon-queue_job==18.0.*",
"odoo==18.0.*",
"openupgradelib"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T10:09:28.496454 | odoo_addon_attachment_queue-18.0.1.0.1-py3-none-any.whl | 157,704 | 09/3f/0751596287c7929f6e095ded05d3a8005842731586114770218c2689e9f7/odoo_addon_attachment_queue-18.0.1.0.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 704979ece4c8c9eb8f0ad6517276fdf1 | 786064ba17e1b127dcc6f825a95e7d0d7c31df7e842cda9c4bc41b3aa26e8563 | 093f0751596287c7929f6e095ded05d3a8005842731586114770218c2689e9f7 | null | [] | 89 |
2.1 | odoo-addon-auditlog | 18.0.2.0.7 | Audit Log | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
=========
Audit Log
=========
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:e0e544c7a26986bb9117c221de2a8725c1ac094fd65ad0b4719fc51df383d7e2
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fserver--tools-lightgray.png?logo=github
:target: https://github.com/OCA/server-tools/tree/18.0/auditlog
:alt: OCA/server-tools
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/server-tools-18-0/server-tools-18-0-auditlog
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/server-tools&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module allows the administrator to log user operations performed on
data models such as ``create``, ``read``, ``write`` and ``delete``.
**Table of contents**
.. contents::
:local:
Usage
=====
Go to Settings / Technical / Audit / Rules to subscribe rules. A rule
defines which operations to log for a given data model.
|image|
Then, check logs in the Settings / Technical / Audit / Logs menu. You
can group them by user sessions, date, data model or HTTP requests:
|image1|
Get the details:
|image2|
A scheduled action exists to delete logs older than 6 months (180 days)
automatically but is not enabled by default. To activate it and/or
change the delay, go to the Configuration / Technical / Automation /
Scheduled Actions menu and edit the Auto-vacuum audit logs entry:
|image3|
In case you're having trouble with the amount of records to delete per
run, you can pass the amount of records to delete for one model per run
as the second parameter, the default is to delete all records in one go.
There are two possible groups configured to which one may belong. The
first is the Auditlog User group. This group has read-only access to the
auditlogs of individual records through the View Logs action. The second
group is the Auditlog Manager group. This group additionally has the
right to configure the auditlog configuration rules.
.. |image| image:: https://raw.githubusercontent.com/OCA/server-tools/18.0/auditlog/static/description/rule.png
.. |image1| image:: https://raw.githubusercontent.com/OCA/server-tools/18.0/auditlog/static/description/logs.png
.. |image2| image:: https://raw.githubusercontent.com/OCA/server-tools/18.0/auditlog/static/description/log.png
.. |image3| image:: https://raw.githubusercontent.com/OCA/server-tools/18.0/auditlog/static/description/autovacuum.png
Known issues / Roadmap
======================
- log only operations triggered by some users (currently it logs all
users)
- log read operations does not work on all data models, need
investigation
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/server-tools/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/server-tools/issues/new?body=module:%20auditlog%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* ABF OSIELL
Contributors
------------
- Sebastien Alix <sebastien.alix@camptocamp.com>
- Holger Brunn <hbrunn@therp.nl>
- Holden Rehg <holdenrehg@gmail.com>
- Eric Lembregts <eric@lembregts.eu>
- Pieter Paulussen <pieter.paulussen@me.com>
- Alan Ramos <alan.ramos@jarsa.com.mx>
- Stefan Rijnhart <stefan@opener.amsterdam>
- Bhavesh Odedra <bodedra@opensourceintegrators.com>
- Hardik Suthar <hsuthar@opensourceintegrators.com>
- Kitti U. <kittiu@ecosoft.co.th>
- Bogdan Valentin Gabor <valentin.gabor@bt-group.com>
- Dennis Sluijk d.sluijk@onestein.nl
- Adam Heinz <adam.heinz@metricwise.com>
Other credits
-------------
- Icon: built with different icons from the `Oxygen
theme <https://en.wikipedia.org/wiki/Oxygen_Project>`__ (LGPL)
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/server-tools <https://github.com/OCA/server-tools/tree/18.0/auditlog>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | ABF OSIELL, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/server-tools | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T10:09:25.838060 | odoo_addon_auditlog-18.0.2.0.7-py3-none-any.whl | 395,380 | ce/1b/923cf0f49289c302e99a7a8c6b70d79f6eb836c1d74c3b69622d622217ae/odoo_addon_auditlog-18.0.2.0.7-py3-none-any.whl | py3 | bdist_wheel | null | false | 7498100fa4d5ca06552b130d2cd9c07d | 49e1d0601d9f0f2f0291c4e0fe153ccac91f63cda320d6d5e9878823abf77e1d | ce1b923cf0f49289c302e99a7a8c6b70d79f6eb836c1d74c3b69622d622217ae | null | [] | 107 |
2.1 | odoo-addon-base-partition | 18.0.1.0.1 | Base module that provide the partition method on all models | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
==============
Base Partition
==============
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:c091ccca724af3819250b92a6e29f9dd10a1a1ee44a9c27596e3c7ec656e84a0
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-LGPL--3-blue.png
:target: http://www.gnu.org/licenses/lgpl-3.0-standalone.html
:alt: License: LGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fserver--tools-lightgray.png?logo=github
:target: https://github.com/OCA/server-tools/tree/18.0/base_partition
:alt: OCA/server-tools
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/server-tools-18-0/server-tools-18-0-base_partition
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/server-tools&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module adds a partition(self, accessor) method to every model. It
accepts for accessor any parameter that would be accepted by mapped,
i.e. a string "field(.subfield)\*" or a function (lambda x: not x.b). It
returns a dictionary with keys that are equal to
set(record.mapped(accessor)), and with values that are recordsets (these
recordsets forming a partition of the initial recordset, conveniently).
So if we have a recordset (x \| y \| z ) such that x.f == True, y.f ==
z.f == False, then (x \| y \| z ).partition("f") == {True: x, False: (y
\| z)}.
**Table of contents**
.. contents::
:local:
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/server-tools/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/server-tools/issues/new?body=module:%20base_partition%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Acsone SA/NV
Contributors
------------
- Nans Lefebvre <nans.lefebvre@acsone.eu>
- Hughes Damry <hughes.damry@acsone.eu>
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/server-tools <https://github.com/OCA/server-tools/tree/18.0/base_partition>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Acsone SA/NV, Odoo Community Association (OCA) | support@odoo-community.org | null | null | LGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)"
] | [] | https://github.com/OCA/server-tools | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T10:09:22.813713 | odoo_addon_base_partition-18.0.1.0.1-py3-none-any.whl | 26,656 | ee/c2/b89f42335eca4732779640f93b003600b15d76ccf1493d8ca7ee8aee8035/odoo_addon_base_partition-18.0.1.0.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 327b9ac6cf13e2efaf4f1a688fd547f8 | 1b1068fb950f097daa2c7f2c36c84519a58db6d69332353699b9abf632a44ecb | eec2b89f42335eca4732779640f93b003600b15d76ccf1493d8ca7ee8aee8035 | null | [] | 92 |
2.1 | odoo-addon-base-name-search-improved | 18.0.1.1.1 | Friendlier search when typing in relation fields | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
====================
Improved Name Search
====================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:6e66c3974d50998308778b1f395d8dd8e3dd4fede18aa4f446f8d02c6d94ea0e
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fserver--tools-lightgray.png?logo=github
:target: https://github.com/OCA/server-tools/tree/18.0/base_name_search_improved
:alt: OCA/server-tools
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/server-tools-18-0/server-tools-18-0-base_name_search_improved
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/server-tools&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
Extends the name search feature to use additional, more relaxed matching
methods, and to allow searching into configurable additional record
fields.
The name search is the lookup feature to select a related record. For
example, selecting a Customer on a new Sales order.
For example, typing "john brown" doesn't match "John M. Brown". The
relaxed search also looks up for records containing all the words, so
"John M. Brown" would be a match. It also tolerates words in a different
order, so searching for "brown john" also works.
|image0|
Additionally, an Administrator can configure other fields to also lookup
into. For example, Customers could be additionally searched by City or
Phone number.
|image2|
How it works:
Regular name search is performed, and the additional search logic is
only triggered if not enough results are found. This way, no overhead is
added on searches that would normally yield results.
But if not enough results are found, then additional search methods are
tried. The specific methods used are:
- Try regular search on each of the additional fields
- Try ordered word search on each of the search fields
- Try unordered word search on each of the search fields
All results found are presented in that order, hopefully presenting them
in order of relevance.
.. |image0| image:: https://raw.githubusercontent.com/OCA/server-tools/11.0/base_name_search_improved/images/image0.png
.. |image2| image:: https://raw.githubusercontent.com/OCA/server-tools/11.0/base_name_search_improved/images/image2.png
**Table of contents**
.. contents::
:local:
Configuration
=============
The fuzzy search is automatically enabled on all Models. Note that this
only affects typing in related fields. The regular ``search()``, used in
the top right search box, is not affected.
Additional search fields can be configured at Settings > Technical >
Database > Models, using the "Name Search Fields" field.
|image1|
.. |image1| image:: https://raw.githubusercontent.com/OCA/server-tools/11.0/base_name_search_improved/images/image1.png
Usage
=====
Just type into any related field, such as Customer on a Sale Order.
Known issues / Roadmap
======================
- Also use fuzzy search, such as the Levenshtein distance:
https://www.postgresql.org/docs/9.5/static/fuzzystrmatch.html
- The list of additional fields to search could benefit from caching,
for efficiency.
- This feature could also be implemented for regular ``search`` on the
``name`` field.
- While adding m2o or other related field that also have an improved
name search, that improved name search is not used (while if
name_search is customizend on a module and you add a field of that
model on another model it works ok). Esto por ejemplo es en productos
si agregamos campo "categoría pública" y a categoría pública le
ponemos "parent_id". Entonces vamos a ver que si buscamos por una
categoría padre no busca nada, en vez si hacemos esa lógica en
name_search de modulo si funciona
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/server-tools/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/server-tools/issues/new?body=module:%20base_name_search_improved%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Daniel Reis
* ADHOC SA
Contributors
------------
- Daniel Reis <https://github.com/dreispt>
- Kitti U. <kittiu@ecosoft.co.th> (migrate to v14)
- Radovan Skolnik <radovan@skolnik.info>
Other credits
-------------
The development of this module has been financially supported by:
- Odoo Community Association
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/server-tools <https://github.com/OCA/server-tools/tree/18.0/base_name_search_improved>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Daniel Reis, Odoo Community Association (OCA), ADHOC SA | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/server-tools | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T10:09:20.227567 | odoo_addon_base_name_search_improved-18.0.1.1.1-py3-none-any.whl | 199,297 | eb/aa/8d7e46ca477655e2e9628120863302dd863ce33c2bd4c325dac4250f86b7/odoo_addon_base_name_search_improved-18.0.1.1.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 1e93ab4617c0f2f87a180be31d9871c0 | 22547f5292c4feddb68006c0185a05811200b2be813b1d53d5287c34ab7e3545 | ebaa8d7e46ca477655e2e9628120863302dd863ce33c2bd4c325dac4250f86b7 | null | [] | 97 |
2.1 | odoo-addon-base-time-window | 18.0.1.1.1 | Base model to handle time windows | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
================
Base Time Window
================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:a6c4e39785827c53867fedc97ffeada7cce0c9ce953339c4b3e827f94ac904e7
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fserver--tools-lightgray.png?logo=github
:target: https://github.com/OCA/server-tools/tree/18.0/base_time_window
:alt: OCA/server-tools
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/server-tools-18-0/server-tools-18-0-base_time_window
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/server-tools&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module provides base classes and models to manage time windows
through time.window.mixin.
**Table of contents**
.. contents::
:local:
Usage
=====
Example implementation for the mixin can be found in module
test_base_time_window.
As a time window will always be linked to a related model thourgh a M2o
relation, when defining the new model inheriting the mixin, one should
pay attention to the following points in order to have the overlapping
check work properly:
- Define class property \`_overlap_check_field\`: This must state the
M2o field to use for the to check of overlapping time window records
linked to a specific record of the related model.
- Add the M2o field to the related model in the \`api.constrains\`:
For example:
.. code:: python
class PartnerTimeWindow(models.Model):
_name = 'partner.time.window'
_inherit = 'time.window.mixin'
partner_id = fields.Many2one(
res.partner', required=True, index=True, ondelete='cascade'
)
_overlap_check_field = 'partner_id'
@api.constrains('partner_id')
def check_window_no_overlaps(self):
return super().check_window_no_overlaps()
Known issues / Roadmap
======================
- Storing times using float_time widget requires extra processing to
ensure computations are done in the right timezone, because the value
is not stored as UTC in the database, and must therefore be related to
a tz field.
float_time in this sense should only be used for durations and not for
a "point in time" as this is always needs a Date for a timezone
conversion to be done properly. (Because a conversion from UTC to e.g.
Europe/Brussels won't give the same result in winter or summer because
of Daylight Saving Time).
Therefore the right move would be to use a resource.calendar to define
time windows using Datetime with recurrences.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/server-tools/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/server-tools/issues/new?body=module:%20base_time_window%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* ACSONE SA/NV
* Camptocamp
Contributors
------------
- Laurent Mignon <laurent.mignon@acsone.eu>
- Akim Juillerat <akim.juillerat@camptocamp.com>
- SodexisTeam <dev@sodexis.com>
Trobz
- Dung Tran <dungtd@trobz.com>
- Khoi (Kien Kim) <khoikk@trobz.com>
Other credits
-------------
The development of this module has been financially supported by:
- Camptocamp
The migration of this module from 17.0 to 18.0 was financially supported
by:
- Camptocamp
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/server-tools <https://github.com/OCA/server-tools/tree/18.0/base_time_window>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | ACSONE SA/NV, Camptocamp, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/server-tools | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T10:09:17.051002 | odoo_addon_base_time_window-18.0.1.1.1-py3-none-any.whl | 35,962 | 0e/dc/85e4bf5de49944b02f525c385af5157969c904304a9632c02c1a1dc3765f/odoo_addon_base_time_window-18.0.1.1.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 2aaa136dda2046767f1f7af15b928604 | 078a45c44bfa959f1cb2a26c401a4984b3fb64adc1e8c8a0b5a4f8583bc5f67b | 0edc85e4bf5de49944b02f525c385af5157969c904304a9632c02c1a1dc3765f | null | [] | 96 |
2.1 | odoo-addon-base-sequence-option | 18.0.1.0.1 | Alternative sequence options for specific models | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
====================
Base Sequence Option
====================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:85fb1c0208e57b9d1f158c5e7adf37e5ccd7516c4e655f1c87836314bf037683
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Alpha-red.png
:target: https://odoo-community.org/page/development-status
:alt: Alpha
.. |badge2| image:: https://img.shields.io/badge/license-LGPL--3-blue.png
:target: http://www.gnu.org/licenses/lgpl-3.0-standalone.html
:alt: License: LGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fserver--tools-lightgray.png?logo=github
:target: https://github.com/OCA/server-tools/tree/18.0/base_sequence_option
:alt: OCA/server-tools
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/server-tools-18-0/server-tools-18-0-base_sequence_option
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/server-tools&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module allow user to add optional sequences to some document model.
On which sequence is used, is based on domain matching with document
values (and original sequence will be bypassed).
For example, it is now possible to,
- Avoid using Odoo automatic sequence on invoice and vendor bill with
old style sequence.
- Customer payment and vendor payment to run on different sequence.
- Assign different sales order sequence based on customer region.
This is a base module and does nothing by itself. Following are modules
that will allow managing sequence options for each type of documents,
I.e.,
- Purchase Order: purchase_sequence_option
- Invoice / Bill / Refund / Payment: account_sequence_option
- Others: create a new module with few lines of code
.. IMPORTANT::
This is an alpha version, the data model and design can change at any time without warning.
Only for development or testing purpose, do not use in production.
`More details on development status <https://odoo-community.org/page/development-status>`_
**Table of contents**
.. contents::
:local:
Usage
=====
To use this module, you need to:
1. Go to *Settings > Technical > Sequences & Identifier > Manage
Sequence Options*.
2. Based on extended module installed, different document types will be
listed, i.e., Purchase Order.
3. Activite "Use sequence options" to use, if not, fall back to normal
sequence.
4. For each option, provide,
- Name: i.e., Customer Invoice for Cust A., Customer Payment, etc.
- Apply On: a filter domain to test whether a document match this
option.
- Sequence: select underlining sequence to perform
**Note:**
- If no options matches the document, fall back to normal sequence.
- If there are multiple sequence options that match same document, error
will be raised.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/server-tools/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/server-tools/issues/new?body=module:%20base_sequence_option%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Ecosoft
Contributors
------------
- Kitti U. <kittiu@ecosoft.co.th>
- Grall F. <fgr@apik.cloud>
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
.. |maintainer-kittiu| image:: https://github.com/kittiu.png?size=40px
:target: https://github.com/kittiu
:alt: kittiu
Current `maintainer <https://odoo-community.org/page/maintainer-role>`__:
|maintainer-kittiu|
This module is part of the `OCA/server-tools <https://github.com/OCA/server-tools/tree/18.0/base_sequence_option>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Ecosoft, Odoo Community Association (OCA) | support@odoo-community.org | null | null | LGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)",
"Development Status :: 3 - Alpha"
] | [] | https://github.com/OCA/server-tools | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*",
"odoo_test_helper"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T10:09:14.511975 | odoo_addon_base_sequence_option-18.0.1.0.1-py3-none-any.whl | 36,687 | 7e/1e/b16128a1128f53f26e7da52f7a735f8f224596e7aec993bf9a296e46df97/odoo_addon_base_sequence_option-18.0.1.0.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 9331a1a6eece593f4d3a055d44b1783f | a00d9730ac1a3efea2035d4f1403d943ccad48cac986dd747ec1ebb7c4f3e275 | 7e1eb16128a1128f53f26e7da52f7a735f8f224596e7aec993bf9a296e46df97 | null | [] | 93 |
2.1 | odoo-addon-base-exception | 18.0.1.1.1 | This module provide an abstract model to manage customizable exceptions to be applied on different models (sale order, invoice, ...) | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
==============
Exception Rule
==============
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:f26be2731bb07680ada96c7a82498292ac0bc49c68965087476b3d354e6acc9e
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Mature-brightgreen.png
:target: https://odoo-community.org/page/development-status
:alt: Mature
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fserver--tools-lightgray.png?logo=github
:target: https://github.com/OCA/server-tools/tree/18.0/base_exception
:alt: OCA/server-tools
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/server-tools-18-0/server-tools-18-0-base_exception
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/server-tools&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module provide an abstract model to manage customizable exceptions
to be applied on different models (sale order, invoice, ...).
It is not useful by itself. You can see an example of implementation in
the 'sale_exception' module. (sale-workflow repository) or
'purchase_exception' module (purchase-workflow repository).
**Table of contents**
.. contents::
:local:
Known issues / Roadmap
======================
This module executes user-provided code though a safe_eval which might
be unsecure. How to mitigate risks should be adressed in future versions
of this module.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/server-tools/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/server-tools/issues/new?body=module:%20base_exception%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Akretion
* Sodexis
* Camptocamp
* ACSONE SA/NV
Contributors
------------
- Raphaël Valyi <raphael.valyi@akretion.com>
- Renato Lima <renato.lima@akretion.com>
- Sébastien BEAU <sebastien.beau@akretion.com>
- Guewen Baconnier <guewen.baconnier@camptocamp.com>
- Yannick Vaucher <yannick.vaucher@camptocamp.com>
- SodexisTeam <dev@sodexis.com>
- Mourad EL HADJ MIMOUNE <mourad.elhadj.mimoune@akretion.com>
- Raphaël Reverdy <raphael.reverdy@akretion.com>
- Iván Todorovich <ivan.todorovich@druidoo.io>
- Tecnativa <tecnativa.com>
- João Marques
- Kevin Khao <kevin.khao@akretion.com>
- Laurent Mignon <laurent.mignon@acsone.eu>
- Do Anh Duy <duyda@trobz.com>
Other credits
-------------
The migration of this module from 17.0 to 18.0 was financially supported
by Camptocamp.
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
.. |maintainer-hparfr| image:: https://github.com/hparfr.png?size=40px
:target: https://github.com/hparfr
:alt: hparfr
.. |maintainer-sebastienbeau| image:: https://github.com/sebastienbeau.png?size=40px
:target: https://github.com/sebastienbeau
:alt: sebastienbeau
Current `maintainers <https://odoo-community.org/page/maintainer-role>`__:
|maintainer-hparfr| |maintainer-sebastienbeau|
This module is part of the `OCA/server-tools <https://github.com/OCA/server-tools/tree/18.0/base_exception>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Akretion, Sodexis, Camptocamp, ACSONE SA/NV, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Affero General Public License v3",
"Development Status :: 6 - Mature"
] | [] | https://github.com/OCA/server-tools | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T10:09:11.352945 | odoo_addon_base_exception-18.0.1.1.1-py3-none-any.whl | 186,856 | f2/2d/27157d01833deff50760a8c072199fbb23eb9b68c51046959c9c5dcde78a/odoo_addon_base_exception-18.0.1.1.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 767136bd3b4f58f52062d682b7c2ea0d | 4aa062ec93b76a418b05ea17333f77c9089a62022b4c1aff3adb4baa9815fab7 | f22d27157d01833deff50760a8c072199fbb23eb9b68c51046959c9c5dcde78a | null | [] | 95 |
2.1 | odoo-addon-module-auto-update | 18.0.1.0.1 | Automatically update Odoo modules | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
==================
Module Auto Update
==================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:9b311524bac19f1ecc8c1a062062ec9f48babacc7a8133590332743de41cab16
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Production%2FStable-green.png
:target: https://odoo-community.org/page/development-status
:alt: Production/Stable
.. |badge2| image:: https://img.shields.io/badge/license-LGPL--3-blue.png
:target: http://www.gnu.org/licenses/lgpl-3.0-standalone.html
:alt: License: LGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fserver--tools-lightgray.png?logo=github
:target: https://github.com/OCA/server-tools/tree/18.0/module_auto_update
:alt: OCA/server-tools
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/server-tools-18-0/server-tools-18-0-module_auto_update
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/server-tools&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This addon provides mechanisms to compute sha1 hashes of installed
addons, and save them in the database. It also provides a method that
exploits these mechanisms to update a database by upgrading only the
modules for which the hash has changed since the last successful
upgrade.
As an alternative to this module
`click-odoo-update <https://github.com/acsone/click-odoo-contrib>`__ can
also be integrated in your non-Odoo maintenance tools instead.
**Table of contents**
.. contents::
:local:
Configuration
=============
This module supports the following system parameters:
- ``module_auto_update.exclude_patterns``: comma-separated list of file
name patterns to ignore when computing addon checksums. Defaults to
``*.pyc,*.pyo,i18n/*.pot,i18n_extra/*.pot,static/*,tests/*``. Filename
patterns must be compatible with the python ``fnmatch`` function.
In addition to the above pattern, .po files corresponding to languages
that are not installed in the Odoo database are ignored when computing
checksums.
Usage
=====
The main method provided by this module is ``upgrade_changed_checksum``
on ``ir.module.module``. It runs a database upgrade for all installed
modules for which the hash has changed since the last successful run of
this method. On success it saves the hashes in the database.
The first time this method is invoked after installing the module, it
runs an upgrade of all modules, because it has not saved the hashes yet.
This is by design, priviledging safety. Should this be an issue, the
method ``_save_installed_checksums`` can be invoked in a situation where
one is sure all modules on disk are installed and up-to-date in the
database.
To invoke the upgrade mechanism, navigate to *Apps* menu and use the
*Auto-Upgrade Modules* button, available only in developer mode.
Restarting the Odoo instance is highly recommended to minify risk of any
possible issues.
Another easy way to invoke this upgrade mechanism is by issuing the
following in an Odoo shell session:
.. code:: python
env['ir.module.module'].upgrade_changed_checksum()
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/server-tools/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/server-tools/issues/new?body=module:%20module_auto_update%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* LasLabs
* Juan José Scarafía
* Tecnativa
* ACSONE SA/NV
Contributors
------------
- Brent Hughes <brent.hughes@laslabs.com>
- Juan José Scarafía <jjs@adhoc.com.ar>
- Jairo Llopis <jairo.llopis@tecnativa.com>
- Stéphane Bidoul <stephane.bidoul@acsone.eu> (https://acsone.eu)
- Eric Antones <eantones@nuobit.com>
- Manuel Engel <manuel.engel@initos.com>
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/server-tools <https://github.com/OCA/server-tools/tree/18.0/module_auto_update>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | =?utf-8?q?LasLabs=2C_Juan_Jos=C3=A9_Scaraf=C3=ADa=2C_Tecnativa=2C_ACSONE_SA/NV=2C_Odoo_Community_Association_=28OCA=29?= | support@odoo-community.org | null | null | LGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)",
"Development Status :: 5 - Production/Stable"
] | [] | https://github.com/OCA/server-tools | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T10:09:08.501196 | odoo_addon_module_auto_update-18.0.1.0.1-py3-none-any.whl | 48,933 | 88/6a/2de18391bcc0bc517ab878fbe2e93407ecede7053420e18c9e031066cba3/odoo_addon_module_auto_update-18.0.1.0.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 078269480be345212ce34ee29d1e2526 | 5ca6efec244405081362647a9bb4fec15be0d8a62620e25084a8631d2100baa7 | 886a2de18391bcc0bc517ab878fbe2e93407ecede7053420e18c9e031066cba3 | null | [] | 113 |
2.4 | easierlit | 1.2.11 | A minimal library to make Chainlit easier to use. | [English](README.md) | [한국어](README.ko.md)
# Easierlit
[](pyproject.toml)
[](https://docs.chainlit.io)
Easierlit is a Python-first wrapper around Chainlit.
It keeps the power of Chainlit while reducing the boilerplate for worker loops, message flow, auth, and persistence.
## Quick Links
- Installation: [Install](#install)
- Start in 60 seconds: [Quick Start](#quick-start-60-seconds)
- Method contracts: [`docs/api-reference.en.md`](docs/api-reference.en.md)
- Full usage guide: [`docs/usage.en.md`](docs/usage.en.md)
- Korean docs: [`README.ko.md`](README.ko.md), [`docs/api-reference.ko.md`](docs/api-reference.ko.md), [`docs/usage.ko.md`](docs/usage.ko.md)
## Why Easierlit
- Clear runtime split:
- `EasierlitServer`: runs Chainlit in the main process.
- `EasierlitClient`: dispatches incoming messages to `on_message(app, incoming)` workers.
- `EasierlitApp`: message/thread CRUD bridge for outgoing commands.
- Production-oriented defaults:
- headless server mode
- sidebar default state `open`
- JWT secret auto-management (`.chainlit/jwt.secret`)
- scoped auth cookie default (`easierlit_access_token_<hash>`)
- fail-fast worker policy
- Practical persistence behavior:
- default SQLite bootstrap (`.chainlit/easierlit.db`)
- schema compatibility recovery
- SQLite `tags` normalization for thread CRUD
## Architecture at a Glance
```text
User UI
-> Chainlit callbacks (on_message / on_chat_start / ...)
-> Easierlit runtime bridge
-> EasierlitClient incoming dispatcher
-> on_message(app, incoming) in per-message workers (thread)
-> app.* APIs (message + thread CRUD)
-> runtime dispatcher
-> realtime session OR data-layer fallback
```
## Install
```bash
pip install easierlit
```
For local development:
```bash
pip install -e ".[dev]"
```
## Quick Start (60 Seconds)
```python
from easierlit import EasierlitClient, EasierlitServer
def on_message(app, incoming):
app.add_message(
thread_id=incoming.thread_id,
content=f"Echo: {incoming.content}",
author="EchoBot",
)
client = EasierlitClient(on_message=on_message)
server = EasierlitServer(client=client)
server.serve() # blocking
```
Optional background run_func pattern:
```python
import time
from easierlit import EasierlitClient, EasierlitServer
def on_message(app, incoming):
app.add_message(incoming.thread_id, f"Echo: {incoming.content}", author="EchoBot")
def run_func(app):
while not app.is_closed():
# Optional background worker; no inbound message polling.
time.sleep(0.2)
client = EasierlitClient(
on_message=on_message,
run_funcs=[run_func], # optional
run_func_mode="auto", # auto/sync/async
)
server = EasierlitServer(client=client)
server.serve()
```
Image element example (without Markdown):
```python
from chainlit.element import Image
image = Image(name="diagram.png", path="/absolute/path/diagram.png")
app.add_message(
thread_id=incoming.thread_id,
content="Attached image",
elements=[image],
)
```
External in-process enqueue example:
```python
message_id = app.enqueue(
thread_id="thread-external",
content="hello from external integration",
session_id="webhook-1",
author="Webhook",
)
```
## Public API
```python
EasierlitServer(
client,
host="127.0.0.1",
port=8000,
root_path="",
max_outgoing_workers=4,
auth=None,
persistence=None,
discord=None,
)
EasierlitClient(
on_message,
run_funcs=None,
worker_mode="thread",
run_func_mode="auto",
max_message_workers=64,
)
EasierlitApp.discord_typing_open(thread_id) -> bool
EasierlitApp.discord_typing_close(thread_id) -> bool
EasierlitApp.enqueue(thread_id, content, session_id="external", author="User", message_id=None, metadata=None, elements=None, created_at=None) -> str
EasierlitApp.add_message(thread_id, content, author="Assistant", metadata=None, elements=None) -> str
EasierlitApp.add_tool(thread_id, tool_name, content, metadata=None, elements=None) -> str
EasierlitApp.add_thought(thread_id, content, metadata=None, elements=None) -> str # tool_name is fixed to "Reasoning"
EasierlitApp.send_to_discord(thread_id, content, elements=None) -> bool
EasierlitApp.is_discord_thread(thread_id) -> bool
EasierlitApp.update_message(thread_id, message_id, content, metadata=None, elements=None)
EasierlitApp.update_tool(thread_id, message_id, tool_name, content, metadata=None, elements=None)
EasierlitApp.update_thought(thread_id, message_id, content, metadata=None, elements=None) # tool_name is fixed to "Reasoning"
EasierlitApp.delete_message(thread_id, message_id)
EasierlitApp.list_threads(first=20, cursor=None, search=None, user_identifier=None)
EasierlitApp.get_thread(thread_id)
EasierlitApp.get_messages(thread_id) -> dict
EasierlitApp.new_thread(name=None, metadata=None, tags=None) -> str
EasierlitApp.update_thread(thread_id, name=None, metadata=None, tags=None)
EasierlitApp.delete_thread(thread_id)
EasierlitApp.reset_thread(thread_id)
EasierlitApp.close()
EasierlitAuthConfig(username, password, identifier=None, metadata=None)
EasierlitPersistenceConfig(
enabled=True,
sqlite_path=".chainlit/easierlit.db",
storage_provider=<auto LocalFileStorageClient>,
)
EasierlitDiscordConfig(enabled=True, bot_token=None)
```
For exact method contracts, use:
- `docs/api-reference.en.md`
This includes parameter constraints, return semantics, exceptions, side effects, concurrency notes, and failure-mode fixes for each public method.
## Auth and Persistence Defaults
- JWT secret: if `CHAINLIT_AUTH_SECRET` is set but shorter than 32 bytes, Easierlit replaces it with a secure generated secret for the current run; if missing, it auto-manages `.chainlit/jwt.secret`
- Auth cookie: keeps `CHAINLIT_AUTH_COOKIE_NAME` when set, otherwise uses scoped default `easierlit_access_token_<hash>`
- On shutdown, Easierlit restores the previous `CHAINLIT_AUTH_COOKIE_NAME` and `CHAINLIT_AUTH_SECRET`
- `UVICORN_WS_PROTOCOL` defaults to `websockets-sansio` when not set
- Default auth is enabled when `auth=None`
- Auth credential order for `auth=None`:
- `EASIERLIT_AUTH_USERNAME` + `EASIERLIT_AUTH_PASSWORD` (must be set together)
- fallback to `admin` / `admin` (warning log emitted)
- Default persistence: SQLite at `.chainlit/easierlit.db` (threads + text steps)
- Default file/image storage: `LocalFileStorageClient` is always enabled by default
- Default local storage path: `<CHAINLIT_APP_ROOT or cwd>/public/easierlit`
- `LocalFileStorageClient(base_dir=...)` supports `~` expansion
- Relative `base_dir` values resolve under `<CHAINLIT_APP_ROOT or cwd>/public`
- Absolute `base_dir` values outside `public` are supported directly
- Local files/images are served through `/easierlit/local/{object_key}`
- Local file/image URLs include both `CHAINLIT_PARENT_ROOT_PATH` and `CHAINLIT_ROOT_PATH` prefixes
- If SQLite schema is incompatible, Easierlit recreates DB with backup
- Sidebar default state is forced to `open`
- Discord bridge is disabled by default unless `discord=EasierlitDiscordConfig(...)` is provided.
Thread History sidebar visibility follows Chainlit policy:
- `requireLogin=True`
- `dataPersistence=True`
Typical Easierlit setup:
- keep `auth=None` and `persistence=None` for default enabled auth + persistence
- optionally set `EASIERLIT_AUTH_USERNAME`/`EASIERLIT_AUTH_PASSWORD` for non-default credentials
- pass `persistence=EasierlitPersistenceConfig(storage_provider=LocalFileStorageClient(...))` to override local storage path/behavior
- or pass explicit `auth=EasierlitAuthConfig(...)`
Discord bot setup:
- Keep `discord=None` to disable Discord integration.
- Pass `discord=EasierlitDiscordConfig(...)` to enable it.
- Token precedence: `EasierlitDiscordConfig.bot_token` first, `DISCORD_BOT_TOKEN` fallback.
- Discord replies are explicit: call `app.send_to_discord(...)` when needed.
- Discord-origin threads are upserted with runtime auth owner for stable Thread History visibility.
- Discord inbound mapping is channel-scoped: `thread_id = uuid5(NAMESPACE_DNS, "discord-channel:<channel_id>")`.
- Easierlit processes inbound messages from all Discord channel types (non-bot messages only).
- Discord inbound attachments are normalized into elements and persisted through the existing storage/data-layer path.
- Easierlit runs Discord through its own bridge (no runtime monkeypatching of Chainlit Discord handlers).
- During `serve()`, Easierlit does not clear `DISCORD_BOT_TOKEN`; the env value remains unchanged.
- During Easierlit runtime, Chainlit built-in Discord autostart is suppressed to avoid duplicate Discord replies.
- If enabled and no non-empty token is available, `serve()` raises `ValueError`.
## Message and Thread Operations
Message APIs:
- `app.add_message(...)`
- `app.add_tool(...)`
- `app.add_thought(...)`
- `app.send_to_discord(...)`
- `app.is_discord_thread(...)`
- `app.update_message(...)`
- `app.update_tool(...)`
- `app.update_thought(...)`
- `app.delete_message(...)`
Thread APIs:
- `app.list_threads(...)`
- `app.get_thread(thread_id)`
- `app.get_messages(thread_id)`
- `app.new_thread(...)`
- `app.update_thread(...)`
- `app.delete_thread(thread_id)`
- `app.reset_thread(thread_id)`
Discord typing APIs:
- `app.discord_typing_open(thread_id)`
- `app.discord_typing_close(thread_id)`
Behavior highlights:
- `app.add_message(...)` returns generated `message_id`.
- `app.enqueue(...)` mirrors input as `user_message` (UI/data layer) and dispatches to `on_message`.
- `app.add_tool(...)` stores tool-call steps with tool name shown as step author/name.
- `app.add_thought(...)` is the same tool-call path with fixed tool name `Reasoning`.
- `app.add_message(...)`/`app.add_tool(...)`/`app.add_thought(...)` no longer auto-send to Discord.
- `app.send_to_discord(...)` sends only to Discord and returns `True/False`.
- `app.send_to_discord(..., elements=[...])` can attach files/images to Discord.
- `app.is_discord_thread(...)` checks whether a thread is Discord-origin.
- `app.discord_typing_open(...)` starts Discord typing indicator for a mapped Discord thread and returns `True/False`.
- `app.discord_typing_close(...)` stops Discord typing indicator for a mapped Discord thread and returns `True/False`.
- Discord typing indicator is explicit and is not auto-managed around `on_message`.
- Async awaitable execution is isolated by role:
- `run_func` awaitables run on a dedicated runner loop.
- `on_message` awaitables run on a thread-aware runner pool sized as `min(max_message_workers, 8)`.
- Same `thread_id` is pinned to the same `on_message` runner lane.
- Runtime outgoing dispatcher uses thread-aware parallel lanes: same `thread_id` order is preserved, but global cross-thread outgoing order is not guaranteed.
- CPU-bound Python handlers still share the GIL; use process-level offloading when true CPU isolation is required.
- `app.get_messages(...)` returns thread metadata plus one ordered `messages` list.
- `app.get_messages(...)` includes `user_message`/`assistant_message`/`system_message`/`tool` and excludes run-family steps.
- `app.get_messages(...)` maps `thread["elements"]` into each message via `forId` aliases (`forId`/`for_id`/`stepId`/`step_id`).
- `app.get_messages(...)` adds `elements[*].has_source` and `elements[*].source` (`url`/`path`/`bytes`/`objectKey`/`chainlitKey`) for image/file source tracing.
- `app.new_thread(...)` auto-generates a unique `thread_id` and returns it.
- `app.update_thread(...)` updates only when thread already exists.
- With auth enabled, both `app.new_thread(...)` and `app.update_thread(...)` auto-assign thread ownership.
- SQLite SQLAlchemyDataLayer path auto normalizes thread `tags`.
- If no active websocket session exists, Easierlit applies internal HTTP-context fallback for data-layer message CRUD.
- Public `lock/unlock` APIs are intentionally not exposed.
## Worker Failure Policy
Easierlit uses fail-fast behavior for worker crashes.
- If any `run_func` or `on_message` raises, server shutdown is triggered.
- UI gets a short summary when possible.
- Full traceback is kept in server logs.
## Chainlit Message vs Tool-call
Chainlit distinguishes message and tool/run categories at step type level.
Message steps:
- `user_message`
- `assistant_message`
- `system_message`
Tool/run family includes:
- `tool`, `run`, `llm`, `embedding`, `retrieval`, `rerank`, `undefined`
Easierlit mapping:
- `app.add_message(...)` -> `assistant_message`
- `app.add_tool(...)` / `app.update_tool(...)` -> `tool`
- `app.add_thought(...)` / `app.update_thought(...)` -> `tool` (name fixed to `Reasoning`)
- `app.send_to_discord(...)` sends an explicit Discord reply without creating a step.
- `app.delete_message(...)` deletes by `message_id` regardless of message/tool/thought source.
## Example Map
- `examples/minimal.py`: basic echo bot
- `examples/custom_auth.py`: single-account auth
- `examples/discord_bot.py`: Discord bot configuration and token precedence
- `examples/thread_crud.py`: thread list/get/update/delete
- `examples/thread_create_in_run_func.py`: create thread from `run_func`
- `examples/step_types.py`: tool/thought step creation, update, delete example
## Documentation Map
- Method-level API contracts (EN): `docs/api-reference.en.md`
- Method-level API contracts (KO): `docs/api-reference.ko.md`
- Full usage guide (EN): `docs/usage.en.md`
- Full usage guide (KO): `docs/usage.ko.md`
## Migration Note
API updates:
- `new_thread(thread_id=..., ...)` -> `thread_id = new_thread(...)`
- `send(...)` was removed.
- `add_message(...)` is now the canonical message API.
- Added tool/thought APIs: `add_tool(...)`, `add_thought(...)`, `update_tool(...)`, `update_thought(...)`.
- Breaking behavior: `on_message` exceptions are now fail-fast (same as `run_func`) and no longer emit an internal notice then continue.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"chainlit<3,>=2.9.6",
"discord<3,>=2.3.2",
"aiohttp<3.12,>=3.11",
"aiosqlite>=0.20",
"pydantic>=2.0",
"typing-extensions>=4.0",
"pytest>=8.0; extra == \"dev\"",
"build>=1.2; extra == \"dev\"",
"twine>=5.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T10:08:41.593189 | easierlit-1.2.11.tar.gz | 45,364 | 15/2b/036f8bac626797e5c0fb986e68479922bd1eb396cd947a1616dd02494d79/easierlit-1.2.11.tar.gz | source | sdist | null | false | becb002ac974e0703f0a8096dac7bb3a | 3e537207ad2f88f28643c92a74fb44b3d595c59dfaa52a350b8be77027db1f5f | 152b036f8bac626797e5c0fb986e68479922bd1eb396cd947a1616dd02494d79 | null | [] | 212 |
2.4 | blackduck-heatmap-metrics | 0.1.14 | Black Duck scan heatmap metrics analyzer with interactive visualizations | # Black Duck Heatmap Metrics Analyzer
A Python-based tool for analyzing Black Duck scan metrics from CSV files in zip archives. Generates interactive HTML dashboards with time series analysis, scan type evolution tracking, and year-based filtering.
## Quick Start
```bash
# 1. Install the package
pip install -e .
# 2. Run analysis on your heatmap data
bdmetrics "path/to/heatmap-data.zip"
# 3. Open the generated report in your browser
# Output: report_YYYYMMDD_HHMMSS.html
```
For project group filtering:
```bash
bdmetrics "data.zip" --project-group "Demo" \
--bd-url "https://your-server.com" \
--bd-token "your-api-token"
```
## Table of Contents
- [Prerequisites](#prerequisites)
- [Features](#features)
- [Installation](#installation)
- [Usage](#usage)
- [Command-Line Examples](#command-line-examples)
- [Multi-CSV File Support](#multi-csv-file-support)
- [Choosing the Right Report Type](#choosing-the-right-report-type)
- [Performance Optimization](#performance-optimization)
- [Command-Line Options Reference](#command-line-options-reference)
- [Using Project Group Filter](#using-project-group-filter)
- [CSV Data Format](#csv-data-format)
- [Report Features](#report-features)
- [How It Works](#how-it-works)
- [Output Files](#output-files)
- [Customization](#customization)
- [Browser Compatibility](#browser-compatibility)
- [Troubleshooting](#troubleshooting)
## Prerequisites
### Exporting Heatmap Data from Black Duck
Before using this tool, you need to export the heatmap data from your Black Duck server:
1. **Access Black Duck Administration**
- Log in to your Black Duck server as an administrator
- Navigate to **System → Log Files**
2. **Download Heatmap Logs**
- In the Log Files section, locate the **Heatmap** logs
- Select the time period you want to analyze
- Click **Download** to export the data as a ZIP archive
- The downloaded file will contain CSV files with scan metrics
3. **Use the Downloaded ZIP**
- Save the downloaded ZIP file (e.g., `heatmap-data.zip`)
- Use this ZIP file as input to the `bdmetrics` command
📖 **Detailed Instructions**: [Black Duck Documentation - Downloading Log Files](https://documentation.blackduck.com/bundle/bd-hub/page/Administration/LogFiles.html#DownloadingLogFiles)
## Features
- 📦 **Zip Archive Support**: Reads CSV files directly from zip archives
- 🗂️ **Multi-CSV Support**: Handles multiple CSV files (different Black Duck instances) with aggregated view
- 📊 **Interactive Charts**: Plotly-powered visualizations with hover details
- 🎯 **Black Duck Specific**: Tailored for Black Duck scan heatmap data
- 📅 **Multi-level Filtering**: Filter by file, year, and project
- 🏢 **Project Group Filtering**: Filter by Black Duck project groups (includes nested sub-groups)
- 🔍 **Scan Type Analysis**: Track scan type distribution and evolution over time
- ✅ **Success/Failure Metrics**: Monitor scan success rates
- 📱 **Responsive Design**: Works on desktop and mobile devices
- 🚀 **Performance Optimized**: Configurable min-scans threshold and skip-detailed mode for large datasets
- 📑 **Flexible Report Types**: Choose between full interactive report or simplified static report
## Installation
### From Source
1. Clone or download this repository
2. Install the package:
```bash
# Install in development mode (recommended for development)
pip install -e .
# Or install normally
pip install .
```
### Using pip (once published to PyPI)
```bash
pip install blackduck-heatmap-metrics
```
## Usage
After installation, you can use the `bdmetrics` command from anywhere:
```bash
bdmetrics path/to/your/heatmap-data.zip
```
Or use it as a Python module:
```python
from blackduck_metrics import read_csv_from_zip, analyze_data, generate_chart_data, generate_html_report
# Read data
dataframes = read_csv_from_zip("path/to/heatmap-data.zip")
# Analyze
analysis = analyze_data(dataframes)
chart_data = generate_chart_data(dataframes)
# Generate report
generate_html_report(analysis, chart_data, "output_report.html")
```
### Command-Line Examples
```bash
# Basic usage - generates report with default settings
bdmetrics "C:\Users\Downloads\heatmap-data.zip"
# Specify output folder
bdmetrics "path/to/data.zip" -o reports
# Set minimum scans threshold (default: 10)
# Only projects with 50+ scans will appear in trend charts
bdmetrics "path/to/data.zip" --min-scans 50
# Filter data from a specific year onwards (excludes older data)
bdmetrics "path/to/data.zip" --start-year 2020
# Filter by Black Duck project group (requires Black Duck connection)
# Includes all projects in the specified group and all nested sub-groups
bdmetrics "path/to/data.zip" --project-group "Demo"
# Filter by project group with credentials passed as arguments
bdmetrics "path/to/data.zip" --project-group "Demo" --bd-url "https://your-server.com" --bd-token "your-token"
# Skip detailed year+project combinations for faster processing and smaller files
# Recommended for large datasets (reduces file size by ~36%)
bdmetrics "path/to/data.zip" --skip-detailed
# Generate simplified report without interactive filters
# Creates a smaller file that loads faster (no dynamic filtering)
bdmetrics "path/to/data.zip" --simple
# Combine options for optimal performance with large datasets
bdmetrics "path/to/data.zip" --min-scans 100 --skip-detailed --start-year 2020 -o reports
# Show version
bdmetrics --version
# Show help
bdmetrics --help
```
### Multi-CSV File Support
The tool automatically handles zip archives containing **multiple CSV files**, ideal for comparing different Black Duck SCA instances or environments.
**Use Case Examples:**
- Compare **Production vs. Staging vs. Development** Black Duck instances
- Analyze **Regional instances** (US, EU, APAC) in one report
- Track metrics across **different Black Duck servers** in your organization
**How it works:**
```bash
# Process a zip with multiple CSV files (different Black Duck instances)
bdmetrics "multi-instance-data.zip"
# The report will:
# 1. Show AGGREGATED statistics from all instances in the summary
# 2. Provide a FILE DROPDOWN to select specific instances
# 3. Dynamically update charts when you select an instance
```
**Example zip structure:**
```
multi-instance-data.zip
├── production-blackduck.csv # 50,000 scans
├── staging-blackduck.csv # 15,000 scans
└── development-blackduck.csv # 8,000 scans
```
**Report behavior:**
- **Default view (All Files)**: Shows aggregated 73,000 total scans
- **File dropdown selection**: Choose "production-blackduck.csv" → Shows only 50,000 scans
- **Charts update**: All visualizations filter to the selected instance
- **Cross-instance comparison**: Switch between files to compare metrics
### Choosing the Right Report Type
**Use Full Report (default)** when you need:
- ✅ Interactive filtering by file, year, and project
- ✅ Ad-hoc exploration of specific projects
- ✅ Detailed drill-down analysis
- ✅ Dynamic chart updates based on selections
- 📊 Ideal for: Analysis, investigation, troubleshooting
**Use Simple Report (`--simple`)** when you need:
- ✅ Fastest page load times
- ✅ Smaller file size for sharing
- ✅ Static overview of all data
- ✅ No JavaScript complexity
- 📊 Ideal for: Reports, presentations, email attachments, archiving
**Example decision matrix:**
```bash
# Detailed analysis of specific teams → Full report
bdmetrics "data.zip" --project-group "Team A"
# Quick overview to share with management → Simple report
bdmetrics "data.zip" --simple
# Large dataset for detailed investigation → Full report with optimizations
bdmetrics "data.zip" --min-scans 100 --skip-detailed
# Large dataset for quick overview → Simple report with optimizations
bdmetrics "data.zip" --simple --min-scans 100 --skip-detailed --start-year 2024
```
### Performance Optimization
For large datasets with thousands of projects:
- Use `--min-scans` to filter out low-activity projects from trend charts (default: 10)
- Use `--skip-detailed` to skip year+project combination charts (saves ~36% file size)
- Use `--start-year` to exclude historical data before a specific year (e.g., `--start-year 2020`)
- Use `--project-group` to analyze only projects within a specific Black Duck project group
- Use `--simple` to generate a simplified report without interactive filters (smaller file size, faster loading)
- Example: Dataset with 37,706 projects → 7,261 projects (--min-scans 100) → 282 MB vs 456 MB baseline
### Command-Line Options Reference
| Option | Type | Default | Description |
|--------|------|---------|-------------|
| `zip_file` | Required | - | Path to zip file containing CSV heatmap data |
| `-o, --output` | Optional | `.` (current dir) | Output folder path (auto-generates filename) |
| `--min-scans` | Integer | `10` | Minimum scans for project to appear in trend charts |
| `--skip-detailed` | Flag | `False` | Skip year+project charts (reduces file size ~36%) |
| `--simple` | Flag | `False` | Generate simplified report without interactive filters |
| `--start-year` | Integer | None | Filter data from this year onwards (e.g., `2020`) |
| `--project-group` | String | None | Filter by Black Duck project group (includes all nested sub-groups) |
| `--bd-url` | String | `$BD_URL` | Black Duck server URL |
| `--bd-token` | String | `$BD_API_TOKEN` | Black Duck API token |
| `-v, --version` | Flag | - | Show version and exit |
| `-h, --help` | Flag | - | Show help message and exit |
**Note:** `--bd-url` and `--bd-token` are only required when using `--project-group`.
### Using Project Group Filter
The `--project-group` option allows you to filter analysis to only include projects that are members of a specific Black Duck project group. This requires connecting to your Black Duck server.
**Important:** When you specify a project group, the tool will automatically include:
- ✅ All projects directly in the specified group
- ✅ All projects in any sub-project-groups (nested groups)
- ✅ All projects in sub-sub-project-groups (recursively traverses the entire hierarchy)
This means if you have a structure like:
```
Business Unit A
├── Team 1
│ ├── Project A
│ └── Project B
├── Team 2
│ ├── Subteam 2.1
│ │ └── Project C
│ └── Project D
└── Project E
```
Filtering by `--project-group "Business Unit A"` will include Projects A, B, C, D, and E.
**Getting a Black Duck API Token:**
1. Log in to your Black Duck server
2. Click on your username (top right) → **My Access Tokens**
3. Click **Create New Token**
4. Enter a name (e.g., "Heatmap Metrics Tool")
5. Set appropriate scope/permissions (read access to projects)
6. Click **Create**
7. Copy the token immediately (it won't be shown again)
**Setup Black Duck Connection:**
You can provide credentials in two ways:
**Option 1: Environment Variables (Recommended for automation)**
```bash
# On Windows (PowerShell)
$env:BD_URL = "https://your-blackduck-server.com"
$env:BD_API_TOKEN = "your-api-token-here"
# Or use username/password (API token is recommended)
$env:BD_URL = "https://your-blackduck-server.com"
$env:BD_USERNAME = "your-username"
$env:BD_PASSWORD = "your-password"
# On Linux/Mac
export BD_URL="https://your-blackduck-server.com"
export BD_API_TOKEN="your-api-token-here"
```
**Option 2: Command-Line Arguments (Recommended for one-time use)**
```bash
# Pass credentials directly via command-line
bdmetrics "path/to/data.zip" --project-group "Demo" \
--bd-url "https://your-blackduck-server.com" \
--bd-token "your-api-token-here"
```
**Example Usage:**
```bash
# Filter to only analyze projects in the "Business Unit A" group (using env vars)
bdmetrics "path/to/data.zip" --project-group "Business Unit A"
# Same, but with credentials as arguments
bdmetrics "path/to/data.zip" --project-group "Business Unit A" \
--bd-url "https://your-server.com" --bd-token "your-token"
# Combine with other filters
bdmetrics "path/to/data.zip" --project-group "Demo" --start-year 2024 --min-scans 50
# Complete example: Project group + simplified report + optimizations
bdmetrics "heatmap-data.zip" \
--project-group "Business Unit A" \
--simple \
--min-scans 100 \
--skip-detailed \
--start-year 2024 \
--bd-url "https://blackduck.example.com" \
--bd-token "your-token"
# Creates: report_YYYYMMDD_HHMMSS_Business_Unit_A.html (optimized simple report)
```
Running the `bdmetrics` command will:
1. Extract and read all CSV files from the zip archive
2. Analyze Black Duck scan metrics
3. Generate an interactive HTML report:
- **By default**: Full report with all interactive filters (file, year, project): `report_YYYYMMDD_HHMMSS.html`
- **With `--simple`**: Simplified report without filters (smaller, faster): `report_YYYYMMDD_HHMMSS.html`
- **With `--project-group`**: Report includes project group name: `report_YYYYMMDD_HHMMSS_<group-name>.html`
## CSV Data Format
The tool expects CSV files with the following columns:
- `hour`: Timestamp of the scan
- `codeLocationId`: Unique identifier for code location
- `codeLocationName`: Name of the code location
- `versionName`: Version being scanned
- `projectName`: Name of the project
- `scanCount`: Number of scans
- `scanType`: Type of scan (e.g., SIGNATURE, BINARY_ANALYSIS)
- `totalScanSize`: Total size of the scan
- `maxScanSize`: Maximum scan size
- `state`: Scan state (COMPLETED, FAILED, etc.)
- `transitionReason`: Reason for state transition
### Multi-CSV File Support
If your zip archive contains **multiple CSV files** (e.g., from different Black Duck SCA instances):
- **Aggregated View**: The report shows combined statistics across all CSV files by default
- **File Selector**: In full reports, use the dropdown to view data from specific Black Duck instances
- **Instance Comparison**: Compare metrics across different Black Duck servers or environments
**Example use case:**
```
heatmap-data.zip
├── production-instance.csv # Production Black Duck data
├── staging-instance.csv # Staging Black Duck data
└── development-instance.csv # Development Black Duck data
```
The report will:
- Display **aggregated totals** from all three instances in summary statistics
- Provide a **file dropdown** to filter charts by specific instance
- Enable **cross-instance analysis** and comparison
## Report Features
The generated HTML dashboard includes:
### Report Types
Each run generates **one report** based on your selection:
- **Full Report** (default): Interactive report with complete filtering capabilities (file, year, project)
- Filename: `report_YYYYMMDD_HHMMSS.html` or `report_YYYYMMDD_HHMMSS_<project-group>.html`
- **Simple Report** (with `--simple` flag): Lightweight report without interactive filters
- Filename: Same as full report
- Faster loading, smaller file size, ideal for sharing
### Report Type Comparison
| Feature | Full Report | Simple Report (`--simple`) |
|---------|-------------|---------------------------|
| **File filter** | ✅ Dropdown (multi-instance support) | ❌ Not available |
| **Year filter** | ✅ Interactive dropdown | ❌ Not available |
| **Project search** | ✅ Type-ahead search | ❌ Not available |
| **Dynamic chart updates** | ✅ Real-time filtering | ❌ Static data |
| **Charts included** | ✅ All charts | ✅ All charts |
| **Summary statistics** | ✅ Aggregated + per-instance | ✅ Aggregated only |
| **File size** | Larger | Smaller |
| **Page load speed** | Slower | Faster |
| **Best for** | Analysis & investigation | Sharing & reporting |
### Summary Section
Displays **aggregated statistics** across all CSV files in the zip archive:
- **Total Files Processed**: Number of CSV files analyzed (e.g., different Black Duck instances)
- **Total Records**: Aggregated scan records from all files
- **Unique Projects**: Combined count of distinct projects across all instances
- **Total Scans**: Aggregated total number of scans
- **Successful Scans**: Combined number of completed scans
- **Failed Scans**: Combined number of failed scans
- **Success Rate**: Overall percentage of successful scans
**Note:** When multiple CSV files are present, summary statistics represent the **combined view** of all Black Duck instances. Use the file filter to view instance-specific metrics.
### Interactive Filters
**Full Report** includes:
- **File Selector**: Dropdown to filter by specific CSV file (Black Duck instance)
- Shows "All Files" by default (aggregated view)
- Lists each CSV file individually when multiple files are present
- Dynamically updates all charts and statistics based on selection
- Useful for comparing different Black Duck SCA instances or environments
- **Year Selector**: Filter all data and charts by year
- **Project Search**: Type-ahead project search with dynamic filtering
- **Clear Filters**: Reset all filters to show aggregated data across all files
**Simple Report** (generated with `--simple` flag):
- No interactive filters
- Static view of all data
- Smaller file size and faster page load
### Charts and Visualizations
1. **Scan Activity Over Time**
- Line chart showing number of scans over time
- Total scan size trends
- Filters by year, project, and file
2. **Top Projects by Scan Count**
- Horizontal bar chart of top 20 projects
- Updates based on filter selection
3. **Scan Type Distribution**
- Pie chart showing breakdown of scan types
- Updates based on year/project selection
4. **Scan Type Evolution Over Time**
- Multi-line time series chart
- Interactive checkbox selection for scan types
- Track how different scan types have evolved
- Smart error messages when data unavailable (shows min-scans threshold)
- Automatically updates when filters change
### Smart Error Messages
The tool provides context-aware messages when data is unavailable:
- "No trend data for this project (project has less than X scans)" - when project doesn't meet min-scans threshold
- "Year+Project combination data not available" - when --skip-detailed flag was used
### Black Duck Overview
- Scan type breakdown with counts
- State distribution
- Filterable statistics
## Requirements
- Python 3.7+
- pandas >= 2.0.0
- jinja2 >= 3.1.0
- plotly >= 5.18.0
## Project Structure
```
blackduck_heatmap_metrics/
├── blackduck_metrics/
│ ├── __init__.py # Package initialization
│ ├── analyzer.py # Core data analysis and report generation
│ ├── blackduck_connector.py # Black Duck SCA connection handler
│ ├── cli.py # Command-line interface
│ └── templates/
│ ├── template.html # Full report template (interactive filters)
│ └── template_simple.html # Simple report template (no filters)
├── setup.py # Package installation script
├── pyproject.toml # Project metadata
├── requirements.txt # Python dependencies
├── MANIFEST.in # Package manifest
└── README.md # This file
```
## How It Works
1. **Data Extraction**: Reads all CSV files from zip archive using pandas
- Supports single or multiple CSV files (e.g., different Black Duck instances)
- Each CSV file is processed and tracked separately
2. **Project Filtering** (optional): Connects to Black Duck to filter projects by project group
3. **Time-based Analysis**: Parses timestamps and groups data by year and project
4. **Aggregation**: Calculates statistics per file, year, project, and year+project combinations
- Generates both aggregated (all files) and individual file statistics
- Enables cross-instance comparison when multiple CSV files are present
5. **Chart Generation**: Prepares optimized data structures for Plotly visualizations
- Applies min-scans threshold to filter low-activity projects
- Optionally skips year+project combinations for performance
- Reduces data sampling for large datasets (time series: 200 points, scan type evolution: 100 points)
6. **Template Rendering**: Jinja2 combines data with selected template (full or simple)
7. **Output**: Generates a timestamped HTML file with embedded charts and interactive file selector (when multiple CSVs)
## Customization
### Template Styling
Edit templates in `blackduck_metrics/templates/`:
- `template.html` - Full report with interactive filters
- `template_simple.html` - Simple report without filters
- Customize: Color scheme (blue gradient), chart types, layouts, summary cards, fonts
### Data Analysis
Modify `blackduck_metrics/analyzer.py` to:
- Add new aggregations
- Include additional metrics
- Change chart data calculations
- Adjust min-scans thresholds
- Modify data sampling rates
- Adjust filtering logic
## Output Files
Each run generates **one report** with a timestamp-based filename:
### Default Filename Format
- Basic: `report_YYYYMMDD_HHMMSS.html`
- With project group: `report_YYYYMMDD_HHMMSS_<sanitized-group-name>.html`
- With `-o folder`: Output to specified folder with timestamped filename
### Examples
```bash
# Default full report
bdmetrics "data.zip"
# Output: report_20260216_143015.html
# Simple report
bdmetrics "data.zip" --simple
# Output: report_20260216_143015.html
# With project group
bdmetrics "data.zip" --project-group "Business Unit A"
# Output: report_20260216_143015_Business_Unit_A.html
# With project group and simple
bdmetrics "data.zip" --project-group "Demo" --simple
# Output: report_20260216_143015_Demo.html
# Custom output folder
bdmetrics "data.zip" -o reports
# Output: reports/report_<timestamp>.html
```
### Report Characteristics
All generated reports are:
- Standalone HTML files (no external dependencies except Plotly CDN)
- Self-contained with embedded data and charts
- Shareable - can be opened directly in any modern browser
- Single file per execution (either full or simple, based on flags)
## Browser Compatibility
The generated reports work in all modern browsers:
- Chrome/Edge (recommended)
- Firefox
- Safari
- Opera
Requires JavaScript enabled for interactive features.
## Troubleshooting
**No charts showing**
- Check browser console (F12) for JavaScript errors
- Ensure Plotly CDN is accessible
- Verify CSV data has the expected columns
**Charts show "No trend data for this project (project has less than X scans)"**
- This is normal for projects with few scans
- Adjust `--min-scans` threshold if needed (default: 10)
- In full reports, click "Clear Filters" to see all data
- Simple reports show all data without filtering
**Charts not updating after filter selection**
- Ensure JavaScript is enabled
- Try refreshing the page
- Check browser console for errors
**"Year+Project combination data not available" message**
- Report was generated with `--skip-detailed` flag
- Regenerate without this flag for full year+project filtering
- This is normal for optimized reports
**Report file too large**
- Use `--simple` to generate a report without interactive filters (significantly smaller)
- Use `--min-scans 50` or higher to reduce projects in charts
- Use `--skip-detailed` to skip year+project combinations (~36% size reduction)
- Use `--start-year` to exclude historical data
- Example: 456 MB → 282 MB with --min-scans 100 --skip-detailed
**Filters not available or working**
- If using `--simple` flag, filters are not included by design (use default mode for filters)
- In full reports, ensure JavaScript is enabled
- Ensure `hour` column contains valid timestamps
- Check that data spans multiple years for year filtering
**Charts show "No data available"**
- Verify CSV files contain the required columns
- Check for empty or malformed data
- Ensure project has sufficient scans (check min-scans threshold)
## License
MIT License
| text/markdown | Jouni Lehto | Jouni Lehto <lehto.jouni@gmail.com> | null | null | null | blackduck, security, metrics, analysis, visualization | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Software Development :: Quality Assurance",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11"
] | [] | https://github.com/lejouni/blackduck-heatmap-metrics | null | >=3.7 | [] | [] | [] | [
"pandas>=2.0.0",
"jinja2>=3.1.0",
"plotly>=5.18.0",
"tqdm>=4.65.0",
"blackduck>=1.0.0",
"requests>=2.31.0"
] | [] | [] | [] | [
"Homepage, https://github.com/lejouni/blackduck_heatmap_metrics",
"Documentation, https://github.com/lejouni/blackduck_heatmap_metrics#readme",
"Repository, https://github.com/lejouni/blackduck_heatmap_metrics",
"Issues, https://github.com/lejouni/blackduck_heatmap_metrics/issues"
] | twine/6.2.0 CPython/3.13.6 | 2026-02-20T10:08:27.107751 | blackduck_heatmap_metrics-0.1.14.tar.gz | 51,062 | e4/7e/98512265e1e779c301b1c88447837a86d874a727fa2c3abaaadbf79b2ab7/blackduck_heatmap_metrics-0.1.14.tar.gz | source | sdist | null | false | 0ef609b62e669d7049abb2b84bffc332 | 90a7d3b06046821fbbb46c77522df796ee136945abacdcc7280d118b4dcfddc2 | e47e98512265e1e779c301b1c88447837a86d874a727fa2c3abaaadbf79b2ab7 | MIT | [] | 213 |
2.4 | forecast-in-a-box | 0.5.4 | Weather Forecast in a Box | See project's [readme](https://github.com/ecmwf/forecast-in-a-box/blob/main/README.md).
# Development
## Setup
There are two options:
1. create manually a `venv` and install this as an editable package into it,
2. use the [`fiab.sh`](../scripts/fiab.sh) script.
The first gives you more control, the second brings more automation -- but both choices are ultimately fine and lead to the same result.
For the first option, active your venv of choice, and then:
```
mkdir -p ~/.fiab
uv pip install --prerelease=allow --upgrade -e .[test] # the --prerelease will eventually disapper, check whether pyproject contains any `dev` pins
pytest backend # just to ensure all is good
```
For the second option, check the `fiab.sh` first -- it is configurable via envvars which are listed at the script's start.
In particular, you can change the directory which will contain the venv, and whether it does a PyPI-released or local-editable install.
Note however that in case of the local-editable installs, you *must* execute the `fiab.sh` with cwd being the `backend`, as there is `pip install -e.`.
### Frontend Required
The frontend is actually expected to be present as artifact _inside_ the backend in case of the editable install.
See the [`justfile`](../justfile)'s `fiabwheel` recipe for instruction how to build the frontend and create a symlink inside the backend.
Backend wheels on pypi do contain a frontend copy -- you can alternatively pull a wheel and extract the built frontend into the local install.
## Developer Flow
Primary means is running `ruff`, `ty`, and `pytest`, with the config being in `pyproject.toml`.
Ideally, you utilize the `val` recipe from the [justfile](./justfile) here, and install pre-commit hooks.
Type annotations are present and enforced.
In the [`bigtest.py`](../scripts/bigtest.py) there is a larger integration test, triggered at CI in addition to the regular `pytest` -- see the [github action](../.github/workflows/bigtest.yml) for execution.
## Architecture Overview
Consists of a four primary components:
1. JavaScript frontend as a stateless page, basically "user form → backend request" -- located at [frontend](../frontend),
2. FastAPI/Uvicorn application with multiple routes, organized by domain: auth, job submission & status, model download & status, gateway interaction, ...
3. standalone "gateway" process, expected to be launched at the beginning together with the Uvicorn process, which is the gateway to the [earthkit-workflows](https://github.com/ecmwf/earthkit-workflows),
4. persistence, based on a local `sqlite` database.
Configuration is handled by the `config.py` using pydantic's BaseSettings, meaning most behaviour is configurable via envvars -- see `fiab.sh` or tests for examples.
See [tuning and configuration](../docs/tuningAndConfiguration.md) guide for more.
| text/markdown | null | "European Centre for Medium-Range Weather Forecasts (ECMWF)" <software.support@ecmwf.int> | null | null | null | null | [
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"aiosqlite",
"anemoi-inference==0.8.3",
"anemoi-plugins-ecmwf-inference[opendata,polytope]>=0.1.20",
"anemoi-utils==0.4.36",
"apscheduler",
"cloudpickle",
"earthkit-workflows>=0.6.2",
"earthkit-workflows-anemoi>=0.3.12",
"earthkit-workflows-pproc",
"fastapi",
"fastapi-users[oauth]",
"fastapi-users-db-sqlalchemy",
"fiab-core<1.0.0,>=0.0.1",
"httpx<1",
"httpx-oauth",
"jinja2",
"mir-python==1.27.10.5",
"multiolib==2.7.1.5",
"orjson",
"pproc",
"psutil",
"pydantic-settings",
"pyrsistent",
"python-multipart",
"qubed==0.1.12",
"sse-starlette",
"toml",
"uvicorn",
"numpy<2",
"anemoi-models==0.8.1",
"anemoi-graphs==0.6.3",
"anemoi-transform==0.1.15",
"torch==2.8.0",
"torch-geometric==2.6.1",
"earthkit-plots>=0.5.2",
"earthkit-plots-dccms-styles",
"forecast-in-a-box[dev,plots,thermo]; extra == \"all\"",
"earthkit-plots>=0.3.5; extra == \"plots\"",
"earthkit-plots-default-styles>=0.1; extra == \"plots\"",
"thermofeel>=2.1.1; extra == \"thermo\"",
"ecmwf-api-client>=1.6.5; extra == \"webmars\""
] | [] | [] | [] | [
"Source code, https://github.com/ecmwf/forecast-in-a-box"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T10:07:39.559824 | forecast_in_a_box-0.5.4.tar.gz | 12,627,080 | 12/cc/a0aab19cf80271e3fc6492a15623770636979d7fab409b153fb25a476efe/forecast_in_a_box-0.5.4.tar.gz | source | sdist | null | false | b2001d9c0feb06a9728ee962591de416 | d64d9e2279f8fe0c5b12a73f5f361550f72f9c4c0a2f1f7a105516756402dc61 | 12cca0aab19cf80271e3fc6492a15623770636979d7fab409b153fb25a476efe | Apache-2.0 | [
"LICENSE"
] | 212 |
2.4 | typhoon-rainflow | 0.2.5 | Fast rainflow counting for streaming input written in Rust | # typhoon
[](https://github.com/technokrat/typhoon/actions/workflows/CI.yml) 
Typhoon is a rainflow counting Python module written in Rust by Markus Wegmann (mw@technokrat.ch).
It uses a new windowed four-point counting method which can be run in parallel on multiple cores and allows for chunk-based sample stream processing, preserving half cycles for future chunks.
It is therefore intended for real-time processing of load captures and serves as as crucial part of i-Spring's in-edge data processing chain.
## Installation
Add the package `typhoon-rainflow` to your Python project, e.g.
```python
poetry add typhoon-rainflow
```
## Python API
The Python package exposes two main namespaces:
- `typhoon.typhoon`: low-level, performance‑critical functions implemented in Rust.
- `typhoon.helper`: convenience utilities for working with the rainflow output.
The top-level package re-exports everything from `typhoon.typhoon`, so you can either
```python
import typhoon # recommended for normal use
from typhoon import rainflow, goodman_transform
```
or
```python
from typhoon.typhoon import rainflow
from typhoon import helper # for helper utilities
```
### Core functions (`typhoon.typhoon`)
All arguments are keyword-compatible with the examples below.
- `init_tracing() -> None`
- Initialize verbose tracing/logging from the Rust implementation.
- Intended mainly for debugging and performance analysis; it writes to stdout.
- `rainflow(waveform, last_peaks=None, bin_size=0.0, threshold=None, min_chunk_size=64*1024)`
- Perform windowed four-point rainflow counting on a 1D NumPy waveform.
- `waveform`: 1D `numpy.ndarray` of `float32` or `float64`.
- `last_peaks`: optional 1D array of peaks from the previous chunk (for streaming).
- `bin_size`: bin width for quantizing ranges; `0.0` disables quantization.
- `threshold`: minimum cycle amplitude to count; default `0.0`.
- `min_chunk_size`: minimum chunk size for internal parallelization.
- Returns `(cycles, residual_peaks)` where
- `cycles` is a dict `{(s_lower, s_upper): count}` and
- `residual_peaks` is a 1D NumPy array of remaining peaks to pass to the next call.
- `goodman_transform(cycles, m, m2=None, bin_size_compensation=0.0)`
- Apply a (piecewise) Goodman-like mean stress correction to rainflow cycles.
- `cycles`: mapping `{(s_lower, s_upper): count}` (e.g. first return value of `rainflow`).
- `m`: main slope/parameter.
- `m2`: optional secondary slope; defaults to `m / 3` if omitted.
- `bin_size_compensation`: optional widening of each cycle by `±bin_size_compensation/2` (worst-case compensation for quantization to bin centers).
- Returns a dict `{s_a_ers: count}` where `s_a_ers` is the equivalent range.
- `summed_histogram(hist)`
- Build a descending cumulative histogram from the Goodman-transformed result.
- `hist`: mapping `{s_a_ers: count}` such as returned from `goodman_transform`.
- Returns a list of `(s_a_ers, cumulative_count)` pairs sorted from high to low range.
- `fkm_miner_damage(goodman_result, n_d, sigma_d, k, q=None, mode=MinerDamageMode.Modified) -> float`
- Compute a Miner damage coefficient $D$ from a Goodman-transformed collective.
- `goodman_result`: mapping `{sigma_a: count}` as returned from `goodman_transform`.
- `n_d`: $N_D$ (cycles allowed at endurance limit).
- `sigma_d`: $\sigma_D$ (endurance limit level).
- `k`: Woehler exponent $k$.
- `q`: exponent modifier for amplitudes below $\sigma_D$; defaults to `k - 1`.
- `mode`:
- `MinerDamageMode.Modified` (default): returns $D_{MM}$ (FKM modified Miner).
- `MinerDamageMode.Original`: returns $D_{OM}$ (original Miner, ignoring amplitudes below $\sigma_D$).
### Stateful streaming (`RainflowContext`)
If you process signals chunk-by-chunk, repeatedly calling `rainflow()` and merging dicts/Counters can become a bottleneck.
`RainflowContext` keeps the accumulated cycle map and the residual `last_peaks` inside the Rust extension, so each new chunk only updates the existing state.
Key methods:
- `process(waveform)`: update the internal state from one waveform chunk.
- `to_counter()`: export the accumulated cycles as a Python `collections.Counter`.
- `to_heatmap(include_half_cycles=False)`: export a dense 2D NumPy array for plotting (and the corresponding bin centers).
- When `include_half_cycles=True`, the current residual `last_peaks` are treated as half-cycles (each adjacent peak-pair contributes `0.5`).
- `goodman_transform(m, m2=None, include_half_cycles=False, bin_size_compensation=0.0)`: Goodman transform directly on the internal state.
- When `include_half_cycles=True`, the current residual `last_peaks` are treated as half-cycles (each adjacent peak-pair contributes `0.5`).
- `summed_histogram(m, m2=None, include_half_cycles=False, bin_size_compensation=0.0)`: convenience wrapper that returns the descending cumulative histogram (same format as `typhoon.summed_histogram`).
- `fkm_miner_damage(m, n_d, sigma_d, k, m2=None, include_half_cycles=False, bin_size_compensation=0.0, q=None, mode=MinerDamageMode.Modified)`: compute Miner damage directly from the internal accumulated cycles.
Example:
```python
import numpy as np
import typhoon
ctx = typhoon.RainflowContext(bin_size=1.0, threshold=0.0)
for chunk in chunks: # iterable of 1D numpy arrays
ctx.process(chunk)
# Export accumulated cycles
cycles = ctx.to_counter()
# Goodman transform (optionally including the current residual half-cycles)
hist = ctx.goodman_transform(m=0.3, include_half_cycles=True)
# Summed histogram directly from the context
summed = ctx.summed_histogram(m=0.3, include_half_cycles=True)
# Heatmap export for matplotlib (optionally include residual half-cycles)
heatmap, bins = ctx.to_heatmap(include_half_cycles=True)
# Example plotting
# import matplotlib.pyplot as plt
# plt.imshow(heatmap, origin="lower")
# plt.xticks(range(len(bins)), bins, rotation=90)
# plt.yticks(range(len(bins)), bins)
# plt.xlabel("to")
# plt.ylabel("from")
# plt.colorbar(label="count")
# plt.tight_layout()
# plt.show()
```
### Helper utilities (`typhoon.helper`)
The helper module provides convenience tools for post-processing and analysis.
- `merge_cycle_counters(counters)`
- Merge multiple `dict`/`Counter` objects of the form `{(from, to): count}`.
- Useful when combining rainflow results from multiple chunks or channels.
- `add_residual_half_cycles(counter, residual_peaks)`
- Convert the trailing `residual_peaks` from `rainflow` into half-cycles and add them to an existing counter.
- Each adjacent pair of peaks `(p_i, p_{i+1})` contributes `0.5` to the corresponding cycle key.
- `counter_to_full_interval_df(counter, bin_size=0.1, closed="right", round_decimals=12)`
- Convert a sparse `(from, to): count` mapping into a dense 2D `pandas.DataFrame` over all intervals.
- Returns a DataFrame with a `(from, to)` `MultiIndex` of `pd.Interval` and a single `"value"` column.
### Woehler curves (`typhoon.woehler`)
The `typhoon.woehler` module provides helpers for evaluating S–N (Woehler) curves.
Key entry points are:
- `WoehlerCurveParams(sd, nd, k1, k2=None, ts=None, tn=None)` - Container for the curve parameters: - `sd`: fatigue strength at `nd` cycles for the reference failure probability. - `nd`: reference number of cycles (e.g. 1e6). - `k1`: slope in the finite-life region. - `k2`: optional slope in the endurance region; derived from the Miner
rule if omitted. - `ts` / `tn`: optional scattering parameters controlling probability
transforms of `sd` and `nd`.
- `WoehlerCurveParams.with_predamage(d_predamage, q=None)` - Returns a new set of curve parameters modified by a pre-damage value $D_{predamage}$. - Uses the FKM-style transformation: - $\sigma_{D,dam} = \sigma_D\,(1-D_{predamage})^{1/q}$ - $N_{D,dam} = N_D\,(\sigma_{D,dam}/\sigma_D)^{-(k-q)}$ with $k=k_1$ - If `q` is omitted, defaults to `k1 - 1`.
- `MinerType` enum - Miner damage rule variant that determines the second slope `k2`:
`NONE`, `ORIGINAL`, `ELEMENTARY`, `HAIBACH`.
- `woehler_log_space(minimum=1.0, maximum=1e8, n=101)` - Convenience helper to generate a logarithmically spaced cycle axis for
plotting Woehler curves.
- `woehler_loads_basic(cycles, params, miner=MinerType.NONE)` - Compute a "native" Woehler curve without probability/scattering
transformation, but honouring the selected Miner type.
- `woehler_loads(cycles, params, miner=MinerType.NONE, failure_probability=0.5)` - Compute a probability-dependent Woehler curve using an internal
approximation of the normal inverse CDF.
## Example Usage
### Basic rainflow counting
```python
import numpy as np
import typhoon
waveform = np.array([0.0, 1.0, 2.0, 1.0, 2.0, 1.0, 3.0, 4.0], dtype=np.float32)
cycles, residual_peaks = typhoon.rainflow(
waveform=waveform,
last_peaks=None,
bin_size=1.0,
)
print("Cycles:", cycles)
print("Residual peaks:", residual_peaks)
```
### Streaming / chunked processing with helpers
```python
from collections import Counter
import numpy as np
import typhoon
from typhoon import helper
waveform1 = np.array([0.0, 1.0, 2.0, 1.0, 2.0, 1.0, 3.0, 4.0], dtype=np.float32)
waveform2 = np.array([3.0, 5.0, 4.0, 2.0], dtype=np.float32)
# First chunk
cycles1, residual1 = typhoon.rainflow(waveform1, last_peaks=None, bin_size=1.0)
# Second chunk, passing residual peaks from the first
cycles2, residual2 = typhoon.rainflow(waveform2, last_peaks=residual1, bin_size=1.0)
# Merge cycle counts from both chunks
merged = helper.merge_cycle_counters([cycles1, cycles2])
# Optionally add remaining half-cycles from the final residual peaks
merged_with_residuals = helper.add_residual_half_cycles(merged, residual2)
print("Merged cycles:", merged_with_residuals)
```
### Goodman transform and summed histogram
```python
import typhoon
from typhoon import helper
cycles, residual_peaks = typhoon.rainflow(waveform, last_peaks=None, bin_size=1.0)
# Apply Goodman transform
hist = typhoon.goodman_transform(cycles, m=0.3)
# Summed histogram from the Goodman result
summed = typhoon.summed_histogram(hist)
print("Goodman result:", hist)
print("Summed histogram:", summed)
```
### FKM Modified Miner damage (from Goodman result)
```python
import typhoon
# hist is the Goodman-transformed collective: {sigma_a: count}
hist = typhoon.goodman_transform(cycles, m=0.3)
# FKM modified Miner damage (D_MM)
d_mm = typhoon.fkm_miner_damage(hist, n_d=1e6, sigma_d=100.0, k=5.0)
# Original Miner damage (D_OM) only (ignore amplitudes below sigma_d)
d_om = typhoon.fkm_miner_damage(
hist,
n_d=1e6,
sigma_d=100.0,
k=5.0,
mode=typhoon.MinerDamageMode.Original,
)
print("D_MM:", d_mm)
print("D_OM:", d_om)
```
## Testing
```sh
pipx install nox
nox -s build
nox -s test
nox -s develop
```
| text/markdown | Markus Wegmann | mw@techanokrat.ch | null | null | null | null | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
"Typing :: Typed"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy",
"pandas",
"nox; extra == \"test\""
] | [] | [] | [] | [] | maturin/1.12.3 | 2026-02-20T10:07:38.999758 | typhoon_rainflow-0.2.5-cp314-cp314-win32.whl | 316,432 | 74/5b/95d13dc473ff71b65f1ab1c14a654d150fe6fd825553e29907b8ad514e20/typhoon_rainflow-0.2.5-cp314-cp314-win32.whl | cp314 | bdist_wheel | null | false | 258198b1cc8fcfc127d00b2dea7d604e | 349fb76c43da3e4bcd62415ee9a2adf878c7398b4d3662d756f1e7c3007176f4 | 745b95d13dc473ff71b65f1ab1c14a654d150fe6fd825553e29907b8ad514e20 | null | [] | 7,814 |
2.4 | exponax | 0.2.0 | Efficient differentiable PDE solvers in JAX. | <p align="center">
<img src="docs/imgs/logo.svg" alt="exponax logo" width="300">
</p>
<h4 align="center">Efficient Differentiable n-d PDE solvers built on top of <a href="https://github.com/google/jax" target="_blank">JAX</a> & <a href="https://github.com/patrick-kidger/equinox" target="_blank">Equinox</a>.</h4>
<p align="center">
<a href="https://pypi.org/project/exponax/">
<img src="https://img.shields.io/pypi/v/exponax.svg" alt="PyPI">
</a>
<a href="https://github.com/ceyron/exponax/actions/workflows/test.yml">
<img src="https://github.com/ceyron/exponax/actions/workflows/test.yml/badge.svg" alt="Tests">
</a>
<a href="https://codecov.io/gh/Ceyron/exponax">
<img src="https://codecov.io/gh/Ceyron/exponax/branch/main/graph/badge.svg" alt="codecov">
</a>
<a href="https://fkoehler.site/exponax/">
<img src="https://img.shields.io/badge/docs-latest-green" alt="docs-latest">
</a>
<a href="https://github.com/ceyron/exponax/releases">
<img src="https://img.shields.io/github/v/release/ceyron/exponax?include_prereleases&label=changelog" alt="Changelog">
</a>
<a href="https://github.com/ceyron/exponax/blob/main/LICENSE.txt">
<img src="https://img.shields.io/badge/license-MIT-blue" alt="License">
</a>
</p>
<p align="center">
<a href="#installation">Installation</a> •
<a href="#quickstart">Quickstart</a> •
<a href="#built-in-equations">Equations</a> •
<a href="#features">Features</a> •
<a href="#documentation">Documentation</a> •
<a href="#background">Background</a> •
<a href="#citation">Citation</a>
</p>
<p align="center">
<img src="https://github.com/user-attachments/assets/690a2faf-8d72-42b6-bae4-3ba6f4f75e88", width=700px>
</p>
`Exponax` solves partial differential equations in 1D, 2D, and 3D on periodic
domains highly efficiently using Fourier spectral methods and exponential time
differencing. It ships more than 46 PDE solvers covering linear, nonlinear, and
reaction-diffusion dynamics. Built entirely on
[JAX](https://github.com/google/jax) and
[Equinox](https://github.com/patrick-kidger/equinox), every solver is
automatically differentiable, JIT-compilable, and GPU/TPU-ready — making it
ideal for physics-based deep learning workflows.
## Installation
```bash
pip install exponax
```
Requires Python 3.10+ and JAX 0.4.13+. 👉 [JAX install guide](https://jax.readthedocs.io/en/latest/installation.html).
## Quickstart
Simulate the chaotic **Kuramoto-Sivashinsky equation** in 1D — a single stepper
object, one line to roll out 500 time steps:
```python
import jax
import exponax as ex
import matplotlib.pyplot as plt
ks_stepper = ex.stepper.KuramotoSivashinskyConservative(
num_spatial_dims=1, domain_extent=100.0,
num_points=200, dt=0.1,
)
u_0 = ex.ic.RandomTruncatedFourierSeries(
num_spatial_dims=1, cutoff=5
)(num_points=200, key=jax.random.PRNGKey(0))
trajectory = ex.rollout(ks_stepper, 500, include_init=True)(u_0)
plt.imshow(trajectory[:, 0, :].T, aspect='auto', cmap='RdBu', vmin=-2, vmax=2, origin="lower")
plt.xlabel("Time"); plt.ylabel("Space"); plt.show()
```

Because every stepper is a differentiable JAX function, you can freely compose
it with `jax.grad`, `jax.vmap`, and `jax.jit`:
```python
# Jacobian of the stepper function
jacobian = jax.jacfwd(ks_stepper)(u_0)
```
For a next step, check out [this tutorial on 1D
Advection](https://fkoehler.site/exponax/examples/simple_advection_example_1d/)
that explains the basics of `Exponax`.
## Built-in Equations
### Linear
| Equation | Stepper | Dimensions |
|----------|---------|------------|
| Advection: $u_t + c \cdot \nabla u = 0$ | [`Advection`](https://fkoehler.site/exponax/api/stepper/linear/advection/) | 1D, 2D, 3D |
| Diffusion: $u_t = \nu \Delta u$ | [`Diffusion`](https://fkoehler.site/exponax/api/stepper/linear/diffusion/) | 1D, 2D, 3D |
| Advection-Diffusion: $u_t + c \cdot \nabla u = \nu \Delta u$ | [`AdvectionDiffusion`](https://fkoehler.site/exponax/api/stepper/linear/advection_diffusion/) | 1D, 2D, 3D |
| Dispersion: $u_t = \xi \nabla^3 u$ | [`Dispersion`](https://fkoehler.site/exponax/api/stepper/linear/dispersion/) | 1D, 2D, 3D |
| Hyper-Diffusion: $u_t = -\zeta \Delta^2 u$ | [`HyperDiffusion`](https://fkoehler.site/exponax/api/stepper/linear/hyper_diffusion/) | 1D, 2D, 3D |
| Wave: $u_{tt} = c^2 \Delta u$ | [`Wave`](https://fkoehler.site/exponax/api/stepper/linear/wave/) | 1D, 2D, 3D |
### Nonlinear
| Equation | Stepper | Dimensions |
|----------|---------|------------|
| Burgers: $u_t + \frac{1}{2} \nabla \cdot (u \otimes u) = \nu \Delta u$ | [`Burgers`](https://fkoehler.site/exponax/api/stepper/nonlinear/burgers/) | 1D, 2D, 3D |
| Korteweg-de Vries: $u_t + \frac{1}{2} \nabla \cdot (u \otimes u) - \nabla^3 u = \mu \Delta u$ | [`KortewegDeVries`](https://fkoehler.site/exponax/api/stepper/nonlinear/kdv/) | 1D, 2D, 3D |
| Kuramoto-Sivashinsky: $u_t + \frac{1}{2} \|\nabla u\|^2 + \Delta u + \Delta^2 u = 0$ | [`KuramotoSivashinsky`](https://fkoehler.site/exponax/api/stepper/nonlinear/ks/) | 1D, 2D, 3D |
| KS (conservative): $u_t + \frac{1}{2} \nabla \cdot (u \otimes u) + \Delta u + \Delta^2 u = 0$ | [`KuramotoSivashinskyConservative`](https://fkoehler.site/exponax/api/stepper/nonlinear/ks_cons/) | 1D, 2D, 3D |
| Navier-Stokes (vorticity): $\omega_t + (u \cdot \nabla)\omega = \nu \Delta \omega$ | [`NavierStokesVorticity`](https://fkoehler.site/exponax/api/stepper/nonlinear/navier_stokes/) | 2D |
| Kolmogorov Flow (vorticity): $\omega_t + (u \cdot \nabla)\omega = \nu \Delta \omega + f$ | [`KolmogorovFlowVorticity`](https://fkoehler.site/exponax/api/stepper/nonlinear/navier_stokes/) | 2D |
| Navier-Stokes (velocity): $u_t = \nu \Delta u + \mathcal{P}(u \times \omega)$ | [`NavierStokesVelocity`](https://fkoehler.site/exponax/api/stepper/nonlinear/navier_stokes/) | 3D |
| Kolmogorov Flow (velocity): $u_t = \nu \Delta u + \mathcal{P}(u \times \omega) + f$ | [`KolmogorovFlowVelocity`](https://fkoehler.site/exponax/api/stepper/nonlinear/navier_stokes/) | 3D |
### Reaction-Diffusion
| Equation | Stepper | Dimensions |
|----------|---------|------------|
| Fisher-KPP: $u_t = \nu \Delta u + r\, u(1 - u)$ | [`reaction.FisherKPP`](https://fkoehler.site/exponax/api/stepper/reaction/fisher_kpp/) | 1D, 2D, 3D |
| Allen-Cahn: $u_t = \nu \Delta u + c_1 u + c_3 u^3$ | [`reaction.AllenCahn`](https://fkoehler.site/exponax/api/stepper/reaction/allen_cahn/) | 1D, 2D, 3D |
| Cahn-Hilliard: $u_t = \nu \Delta(u^3 + c_1 u - \gamma \Delta u)$ | [`reaction.CahnHilliard`](https://fkoehler.site/exponax/api/stepper/reaction/cahn_hilliard/) | 1D, 2D, 3D |
| Gray-Scott: $u_t = \nu_1 \Delta u + f(1-u) - uv^2, \quad v_t = \nu_2 \Delta v - (f+k)v + uv^2$ | [`reaction.GrayScott`](https://fkoehler.site/exponax/api/stepper/reaction/gray_scott/) | 1D, 2D, 3D |
| Swift-Hohenberg: $u_t = ru - (k + \Delta)^2 u + g(u)$ | [`reaction.SwiftHohenberg`](https://fkoehler.site/exponax/api/stepper/reaction/swift_hohenberg/) | 1D, 2D, 3D |
<details>
<summary><strong>Generic stepper families</strong> (for advanced / custom dynamics)</summary>
These parametric families generalize the concrete steppers above. Each comes in
three flavors: physical coefficients, normalized, and difficulty-based.
| Family | Nonlinearity | Generalizes |
|--------|-------------|-------------|
| [`GeneralLinearStepper`](https://fkoehler.site/exponax/api/stepper/generic/physical/general_linear/) | None | Advection, Diffusion, Dispersion, etc. |
| [`GeneralConvectionStepper`](https://fkoehler.site/exponax/api/stepper/generic/physical/general_convection/) | Quadratic convection | Burgers, KdV, KS Conservative |
| [`GeneralGradientNormStepper`](https://fkoehler.site/exponax/api/stepper/generic/physical/general_gradient_norm/) | Gradient norm | Kuramoto-Sivashinsky |
| [`GeneralVorticityConvectionStepper`](https://fkoehler.site/exponax/api/stepper/generic/physical/general_vorticity_convection/) | Vorticity convection (2D only) | Navier-Stokes, Kolmogorov Flow |
| [`GeneralPolynomialStepper`](https://fkoehler.site/exponax/api/stepper/generic/physical/general_polynomial/) | Arbitrary polynomial | Fisher-KPP, Allen-Cahn, etc. |
| [`GeneralNonlinearStepper`](https://fkoehler.site/exponax/api/stepper/generic/physical/general_nonlinear/) | Convection + gradient norm + polynomial | Most of the above |
See the [normalized & difficulty interface docs](https://fkoehler.site/exponax/api/utilities/normalized_and_difficulty/) for details.
</details>
## Features
- **Hardware-agnostic** — run on CPU, GPU, or TPU in single or double precision.
- **Fully differentiable** — compute gradients of solutions w.r.t. initial conditions, PDE parameters, or neural network weights when composed with PDE solvers via `jax.grad`.
- **Vectorized batching** — advance multiple states or sweep over parameter grids in parallel using `jax.vmap` (and `eqx.filter_vmap`).
- **Deep-learning native** — every stepper is an [Equinox](https://github.com/patrick-kidger/equinox) Module, composable with neural networks out of the box.
- **Lightweight design** — no custom grid or state objects; everything is plain `jax.numpy` arrays and callable PyTrees.
- **Initial conditions** — library of random IC distributions (truncated Fourier series, Gaussian random fields, etc.).
- **Utilities** — spectral derivatives, grid creation, autoregressive rollout, interpolation, and more.
- **Extensible** — add new PDEs by subclassing `BaseStepper`.
## Documentation
Documentation is available at [fkoehler.site/exponax](https://fkoehler.site/exponax/). Key pages:
- [1D Advection Tutorial](https://fkoehler.site/exponax/examples/simple_advection_example_1d/) — learn the basics
- [Solver Showcase 1D](https://fkoehler.site/exponax/examples/solver_showcase_1d/) / [2D](https://fkoehler.site/exponax/examples/solver_showcase_2d/) / [3D](https://fkoehler.site/exponax/examples/solver_showcase_3d/) — visual gallery of all dynamics
- [Creating Your Own Solvers](https://fkoehler.site/exponax/examples/creating_your_own_solvers_1d/) — extend Exponax with custom PDEs
- [Training a Neural Operator](https://fkoehler.site/exponax/examples/learning_burgers_autoregressive_neural_operator/) — use `Exponax` for synthetic data generation and training of a neural emulator
- [Stepper Overview](https://fkoehler.site/exponax/api/stepper/overview/) — API reference for all steppers
- [Performance Hints](https://fkoehler.site/exponax/examples/performance_hints/) — tips for fast simulations
## Background
Exponax solves semi-linear PDEs of the form
$$ \partial u / \partial t = Lu + N(u), $$
where $L$ is a linear differential operator and $N$ is a nonlinear differential
operator. The linear part is solved exactly via a matrix exponential in Fourier
space, while the nonlinear part is integrated using exponential time
differencing Runge-Kutta (ETDRK) schemes of order 1 through 4. The complex
contour integral method of Kassam & Trefethen is used for numerical stability.
By restricting to periodic domains on scaled hypercubes with uniform Cartesian
grids, all transforms reduce to FFTs — yielding blazing-fast simulations. For
example, 50 trajectories of the 2D Kuramoto-Sivashinsky equation (200 time
steps, 128x128 grid) are generated in under a second on a modern GPU.
<details>
<summary>References</summary>
1. Cox, S.M. and Matthews, P.C. "Exponential time differencing for stiff systems." *Journal of Computational Physics* 176.2 (2002): 430-455. [doi:10.1006/jcph.2002.6995](https://doi.org/10.1006/jcph.2002.6995)
2. Kassam, A.K. and Trefethen, L.N. "Fourth-order time-stepping for stiff PDEs." *SIAM Journal on Scientific Computing* 26.4 (2005): 1214-1233. [doi:10.1137/S1064827502410633](https://doi.org/10.1137/S1064827502410633)
3. Montanelli, H. and Bootland, N. "Solving periodic semilinear stiff PDEs in 1D, 2D and 3D with exponential integrators." *Mathematics and Computers in Simulation* 178 (2020): 307-327. [doi:10.1016/j.matcom.2020.06.008](https://doi.org/10.1016/j.matcom.2020.06.008)
</details>
## Related & Motivation
This package is greatly inspired by the
[`spinX`](https://www.chebfun.org/docs/guide/guide19.html) module of the
[ChebFun](https://www.chebfun.org/) package in *MATLAB*. `spinX` served as a
reliable data generator for early works in physics-based deep learning, e.g.,
[DeepHiddenPhysics](https://github.com/maziarraissi/DeepHPMs/tree/7b579dbdcf5be4969ebefd32e65f709a8b20ec44/Matlab)
and [Fourier Neural
Operators](https://github.com/neuraloperator/neuraloperator/tree/af93f781d5e013f8ba5c52baa547f2ada304ffb0/data_generation).
However, due to the two-language barrier, dynamically calling *MATLAB* solvers
from Python-based deep learning workflows is hard to impossible. This also
excludes the option to differentiate through them — ruling out
differentiable-physics approaches like solver-in-the-loop correction or
diverted-chain training.
We view `Exponax` as a spiritual successor of `spinX`. JAX, as the
computational backend, elevates the power of this solver type with automatic
vectorization (`jax.vmap`), backend-agnostic execution (CPU/GPU/TPU), and tight
integration for deep learning via its versatile automatic differentiation
engine. With reproducible randomness in JAX, datasets can be re-created in
seconds — no need to ever write them to disk.
Beyond ChebFun, other popular pseudo-spectral implementations include
[Dedalus](https://dedalus-project.org/) in the Python world and
[FourierFlows.jl](https://github.com/FourierFlows/FourierFlows.jl) in the
*Julia* ecosystem (the latter was especially helpful for verifying our
implementation of the contour integral method and dealiasing).
## Citation
`Exponax` was developed as part of the
[APEBench](https://github.com/tum-pbs/apebench) benchmark suite for
autoregressive neural emulators of PDEs. The accompanying paper was accepted at
**NeurIPS 2024**. If you find this package useful for your research, please
consider citing it:
```bibtex
@article{koehler2024apebench,
title={{APEBench}: A Benchmark for Autoregressive Neural Emulators of {PDE}s},
author={Felix Koehler and Simon Niedermayr and R{\"u}diger Westermann and Nils Thuerey},
journal={Advances in Neural Information Processing Systems (NeurIPS)},
volume={38},
year={2024}
}
```
If you enjoy the project, feel free to give it a star on GitHub!
## Funding
The main author (Felix Koehler) is a PhD student in the group of [Prof. Thuerey at TUM](https://ge.in.tum.de/) and his research is funded by the [Munich Center for Machine Learning](https://mcml.ai/).
## License
MIT, see [here](https://github.com/Ceyron/exponax/blob/main/LICENSE.txt)
---
> [fkoehler.site](https://fkoehler.site/) ·
> GitHub [@ceyron](https://github.com/ceyron) ·
> X [@felix_m_koehler](https://twitter.com/felix_m_koehler) ·
> LinkedIn [Felix Köhler](https://www.linkedin.com/in/felix-koehler)
| text/markdown | Felix Koehler | null | null | null | null | jax, sciml, deep-learning, pde, etdrk | [] | [] | null | null | ~=3.10 | [] | [] | [] | [
"jax>=0.4.13",
"jaxtyping>=0.2.20",
"typing_extensions>=4.5.0",
"equinox>=0.11.3",
"matplotlib>=3.8.1",
"vape4d; extra == \"vape4d\"",
"jaxlib; extra == \"test\"",
"pytest; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"mkdocs==1.6.1; extra == \"docs\"",
"mkdocs-material==9.7.1; extra == \"docs\"",
"mkdocstrings==1.0.3; extra == \"docs\"",
"mkdocstrings-python==2.0.1; extra == \"docs\"",
"mknotebooks==0.8.0; extra == \"docs\"",
"griffe==1.15.0; extra == \"docs\"",
"black==26.1.0; extra == \"docs\""
] | [] | [] | [] | [
"repository, https://github.com/Ceyron/exponax"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T10:06:45.150582 | exponax-0.2.0.tar.gz | 137,873 | 8c/90/695f379846a7bfd8e2fa0f837761c19c42c1982e64ab6f7023bd372d4b96/exponax-0.2.0.tar.gz | source | sdist | null | false | 3cc7267af14e1230bc552101fd263731 | 4d4d88cd0313def80040a370b67299851edab2411890c01305c6eb167a5b93f1 | 8c90695f379846a7bfd8e2fa0f837761c19c42c1982e64ab6f7023bd372d4b96 | null | [
"LICENSE.txt"
] | 262 |
2.4 | labelme | 5.11.3 | Image Polygonal Annotation with Python | <h1 align="center">
<img src="labelme/icons/icon-256.png" width="200" height="200"><br/>labelme
</h1>
<h4 align="center">
Image Polygonal Annotation with Python
</h4>
<div align="center">
<a href="https://pypi.python.org/pypi/labelme"><img src="https://img.shields.io/pypi/v/labelme.svg"></a>
<!-- <a href="https://pypi.org/project/labelme"><img src="https://img.shields.io/pypi/pyversions/labelme.svg"></a> -->
<a href="https://github.com/wkentaro/labelme/actions"><img src="https://github.com/wkentaro/labelme/actions/workflows/ci.yml/badge.svg?branch=main&event=push"></a>
<a href="https://discord.com/invite/uAjxGcJm83"><img src="https://dcbadge.limes.pink/api/server/uAjxGcJm83?style=flat"></a>
</div>
<div align="center">
<a href="#installation"><b>Installation</b></a>
| <a href="#usage"><b>Usage</b></a>
| <a href="#examples"><b>Examples</b></a>
<!-- | <a href="https://github.com/wkentaro/labelme/discussions"><b>Community</b></a> -->
<!-- | <a href="https://www.youtube.com/playlist?list=PLI6LvFw0iflh3o33YYnVIfOpaO0hc5Dzw"><b>Youtube FAQ</b></a> -->
</div>
<br/>
<div align="center">
<img src="examples/instance_segmentation/.readme/annotation.jpg" width="70%">
</div>
## Description
Labelme is a graphical image annotation tool inspired by <http://labelme.csail.mit.edu>.
It is written in Python and uses Qt for its graphical interface.
<img src="examples/instance_segmentation/data_dataset_voc/JPEGImages/2011_000006.jpg" width="19%" /> <img src="examples/instance_segmentation/data_dataset_voc/SegmentationClass/2011_000006.png" width="19%" /> <img src="examples/instance_segmentation/data_dataset_voc/SegmentationClassVisualization/2011_000006.jpg" width="19%" /> <img src="examples/instance_segmentation/data_dataset_voc/SegmentationObject/2011_000006.png" width="19%" /> <img src="examples/instance_segmentation/data_dataset_voc/SegmentationObjectVisualization/2011_000006.jpg" width="19%" />
<i>VOC dataset example of instance segmentation.</i>
<img src="examples/semantic_segmentation/.readme/annotation.jpg" width="30%" /> <img src="examples/bbox_detection/.readme/annotation.jpg" width="30%" /> <img src="examples/classification/.readme/annotation_cat.jpg" width="35%" />
<i>Other examples (semantic segmentation, bbox detection, and classification).</i>
<img src="https://user-images.githubusercontent.com/4310419/47907116-85667800-de82-11e8-83d0-b9f4eb33268f.gif" width="30%" /> <img src="https://user-images.githubusercontent.com/4310419/47922172-57972880-deae-11e8-84f8-e4324a7c856a.gif" width="30%" /> <img src="https://user-images.githubusercontent.com/14256482/46932075-92145f00-d080-11e8-8d09-2162070ae57c.png" width="32%" />
<i>Various primitives (polygon, rectangle, circle, line, and point).</i>
## Features
- [x] Image annotation for polygon, rectangle, circle, line and point ([tutorial](examples/tutorial))
- [x] Image flag annotation for classification and cleaning ([#166](https://github.com/wkentaro/labelme/pull/166))
- [x] Video annotation ([video annotation](examples/video_annotation))
- [x] GUI customization (predefined labels / flags, auto-saving, label validation, etc) ([#144](https://github.com/wkentaro/labelme/pull/144))
- [x] Exporting VOC-format dataset for [semantic segmentation](examples/semantic_segmentation), [instance segmentation](examples/instance_segmentation)
- [x] Exporting COCO-format dataset for [instance segmentation](examples/instance_segmentation)
- [x] Multilingual support `zh_CN`, `zh_TW`, `fr_FR`, `ja_JP`, `de_DE`, `hu_HU`, `ko_KR`, `es_ES`, `fa_IR`, `nl_NL`, `pt_BR`, `it_IT`, `vi_VN` (`LANG=zh_CN.UTF-8 labelme`)
- [x] AI-assisted point-to-polygon/mask annotation by SAM, EfficientSAM models
- [x] AI text-to-annotation by YOLO-world, SAM3 models
## Installation
There are 3 options to install labelme:
### Option 1: Using pip
For more detail, check ["Install Labelme using Terminal"](https://www.labelme.io/docs/install-labelme-terminal)
```bash
pip install labelme
# To install the latest version from GitHub:
# pip install git+https://github.com/wkentaro/labelme.git
```
### Option 2: Using standalone executable (Easiest)
If you're willing to invest in the convenience of simple installation without any dependencies (Python, Qt),
you can download the standalone executable from ["Install Labelme as App"](https://www.labelme.io/docs/install-labelme-app).
It's a one-time payment for lifetime access, and it helps us to maintain this project.
### Option 3: Using a package manager in each Linux distribution
In some Linux distributions, you can install labelme via their package managers (e.g., apt, pacman). The following systems are currently available:
[](https://repology.org/project/labelme/versions)
## Usage
Run `labelme --help` for detail.
The annotations are saved as a [JSON](http://www.json.org/) file.
```bash
labelme # just open gui
# tutorial (single image example)
cd examples/tutorial
labelme apc2016_obj3.jpg # specify image file
labelme apc2016_obj3.jpg -O apc2016_obj3.json # close window after the save
labelme apc2016_obj3.jpg --nodata # not include image data but relative image path in JSON file
labelme apc2016_obj3.jpg \
--labels highland_6539_self_stick_notes,mead_index_cards,kong_air_dog_squeakair_tennis_ball # specify label list
# semantic segmentation example
cd examples/semantic_segmentation
labelme data_annotated/ # Open directory to annotate all images in it
labelme data_annotated/ --labels labels.txt # specify label list with a file
```
### Command Line Arguments
- `--output` specifies the location that annotations will be written to. If the location ends with .json, a single annotation will be written to this file. Only one image can be annotated if a location is specified with .json. If the location does not end with .json, the program will assume it is a directory. Annotations will be stored in this directory with a name that corresponds to the image that the annotation was made on.
- The first time you run labelme, it will create a config file in `~/.labelmerc`. You can edit this file and the changes will be applied the next time that you launch labelme. If you would prefer to use a config file from another location, you can specify this file with the `--config` flag.
- Without the `--nosortlabels` flag, the program will list labels in alphabetical order. When the program is run with this flag, it will display labels in the order that they are provided.
- Flags are assigned to an entire image. [Example](examples/classification)
- Labels are assigned to a single polygon. [Example](examples/bbox_detection)
### FAQ
- **How to convert JSON file to numpy array?** See [examples/tutorial](examples/tutorial#convert-to-dataset).
- **How to load label PNG file?** See [examples/tutorial](examples/tutorial#how-to-load-label-png-file).
- **How to get annotations for semantic segmentation?** See [examples/semantic_segmentation](examples/semantic_segmentation).
- **How to get annotations for instance segmentation?** See [examples/instance_segmentation](examples/instance_segmentation).
## Examples
* [Image Classification](examples/classification)
* [Bounding Box Detection](examples/bbox_detection)
* [Semantic Segmentation](examples/semantic_segmentation)
* [Instance Segmentation](examples/instance_segmentation)
* [Video Annotation](examples/video_annotation)
## How to build standalone executable
```bash
LABELME_PATH=./labelme
OSAM_PATH=$(python -c 'import os, osam; print(os.path.dirname(osam.__file__))')
pyinstaller labelme/labelme/__main__.py \
--name=Labelme \
--windowed \
--noconfirm \
--specpath=build \
--add-data=$(OSAM_PATH)/_models/yoloworld/clip/bpe_simple_vocab_16e6.txt.gz:osam/_models/yoloworld/clip \
--add-data=$(LABELME_PATH)/config/default_config.yaml:labelme/config \
--add-data=$(LABELME_PATH)/icons/*:labelme/icons \
--add-data=$(LABELME_PATH)/translate/*:translate \
--icon=$(LABELME_PATH)/icons/icon-256.png \
--onedir
```
## Acknowledgement
This repo is the fork of [mpitid/pylabelme](https://github.com/mpitid/pylabelme).
| text/markdown | null | Kentaro Wada <www.kentaro.wada@gmail.com> | null | null | GPL-3.0-only | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"imgviz>=2.0.0",
"loguru",
"matplotlib",
"natsort>=7.1.0",
"numpy",
"osam>=0.3.1",
"pillow>=2.8",
"pyqt5-qt5!=5.15.11,!=5.15.12,!=5.15.13,!=5.15.14,!=5.15.15,!=5.15.16; sys_platform == \"win32\"",
"pyqt5-qt5!=5.15.13; sys_platform == \"linux\"",
"pyqt5>=5.14.0",
"pyyaml",
"scikit-image"
] | [] | [] | [] | [] | uv/0.10.0 {"installer":{"name":"uv","version":"0.10.0","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T10:06:22.730126 | labelme-5.11.3.tar.gz | 13,558,016 | 11/11/9628a4d3ef9ea2586185a526644b4e9357152007cfba5718addf8abce017/labelme-5.11.3.tar.gz | source | sdist | null | false | 33f4ea7127d549a89f62ddcfb9c29619 | 45861509f5fd6919ae2794517a85160e59a005a36f412e2491f9d0602a95151b | 11119628a4d3ef9ea2586185a526644b4e9357152007cfba5718addf8abce017 | null | [
"LICENSE"
] | 723 |
2.4 | a2a-sdk | 0.3.24 | A2A Python SDK | # A2A Python SDK
[](LICENSE)
[](https://pypi.org/project/a2a-sdk/)

[](https://pypistats.org/packages/a2a-sdk)
[](https://github.com/a2aproject/a2a-python/actions/workflows/unit-tests.yml)
<!-- markdownlint-disable no-inline-html -->
<a href="https://codewiki.google/github.com/a2aproject/a2a-python">
<img src="https://www.gstatic.com/_/boq-sdlc-agents-ui/_/r/Mvosg4klCA4.svg" alt="Ask Code Wiki" height="20">
</a>
<div align="center">
<img src="https://raw.githubusercontent.com/a2aproject/A2A/refs/heads/main/docs/assets/a2a-logo-black.svg" width="256" alt="A2A Logo"/>
<h3>
A Python library for running agentic applications as A2A Servers, following the <a href="https://a2a-protocol.org">Agent2Agent (A2A) Protocol</a>.
</h3>
</div>
<!-- markdownlint-enable no-inline-html -->
---
## ✨ Features
- **A2A Protocol Compliant:** Build agentic applications that adhere to the Agent2Agent (A2A) Protocol.
- **Extensible:** Easily add support for different communication protocols and database backends.
- **Asynchronous:** Built on modern async Python for high performance.
- **Optional Integrations:** Includes optional support for:
- HTTP servers ([FastAPI](https://fastapi.tiangolo.com/), [Starlette](https://www.starlette.io/))
- [gRPC](https://grpc.io/)
- [OpenTelemetry](https://opentelemetry.io/) for tracing
- SQL databases ([PostgreSQL](https://www.postgresql.org/), [MySQL](https://www.mysql.com/), [SQLite](https://sqlite.org/))
---
## 🧩 Compatibility
This SDK implements the A2A Protocol Specification [`v0.3.0`](https://a2a-protocol.org/v0.3.0/specification).
| Transport | Client | Server |
| :--- | :---: | :---: |
| **JSON-RPC** | ✅ | ✅ |
| **HTTP+JSON/REST** | ✅ | ✅ |
| **GRPC** | ✅ | ✅ |
---
## 🚀 Getting Started
### Prerequisites
- Python 3.10+
- `uv` (recommended) or `pip`
### 🔧 Installation
Install the core SDK and any desired extras using your preferred package manager.
| Feature | `uv` Command | `pip` Command |
| ------------------------ | ------------------------------------------ | -------------------------------------------- |
| **Core SDK** | `uv add a2a-sdk` | `pip install a2a-sdk` |
| **All Extras** | `uv add "a2a-sdk[all]"` | `pip install "a2a-sdk[all]"` |
| **HTTP Server** | `uv add "a2a-sdk[http-server]"` | `pip install "a2a-sdk[http-server]"` |
| **gRPC Support** | `uv add "a2a-sdk[grpc]"` | `pip install "a2a-sdk[grpc]"` |
| **OpenTelemetry Tracing**| `uv add "a2a-sdk[telemetry]"` | `pip install "a2a-sdk[telemetry]"` |
| **Encryption** | `uv add "a2a-sdk[encryption]"` | `pip install "a2a-sdk[encryption]"` |
| | | |
| **Database Drivers** | | |
| **PostgreSQL** | `uv add "a2a-sdk[postgresql]"` | `pip install "a2a-sdk[postgresql]"` |
| **MySQL** | `uv add "a2a-sdk[mysql]"` | `pip install "a2a-sdk[mysql]"` |
| **SQLite** | `uv add "a2a-sdk[sqlite]"` | `pip install "a2a-sdk[sqlite]"` |
| **All SQL Drivers** | `uv add "a2a-sdk[sql]"` | `pip install "a2a-sdk[sql]"` |
## Examples
### [Helloworld Example](https://github.com/a2aproject/a2a-samples/tree/main/samples/python/agents/helloworld)
1. Run Remote Agent
```bash
git clone https://github.com/a2aproject/a2a-samples.git
cd a2a-samples/samples/python/agents/helloworld
uv run .
```
2. In another terminal, run the client
```bash
cd a2a-samples/samples/python/agents/helloworld
uv run test_client.py
```
3. You can validate your agent using the agent inspector. Follow the instructions at the [a2a-inspector](https://github.com/a2aproject/a2a-inspector) repo.
---
## 🌐 More Examples
You can find a variety of more detailed examples in the [a2a-samples](https://github.com/a2aproject/a2a-samples) repository:
- **[Python Examples](https://github.com/a2aproject/a2a-samples/tree/main/samples/python)**
- **[JavaScript Examples](https://github.com/a2aproject/a2a-samples/tree/main/samples/js)**
---
## 🤝 Contributing
Contributions are welcome! Please see the [CONTRIBUTING.md](CONTRIBUTING.md) file for guidelines on how to get involved.
---
## 📄 License
This project is licensed under the Apache 2.0 License. See the [LICENSE](LICENSE) file for more details.
| text/markdown | null | Google LLC <googleapis-packages@google.com> | null | null | null | A2A, A2A Protocol, A2A SDK, Agent 2 Agent, Agent2Agent | [
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"google-api-core>=1.26.0",
"httpx-sse>=0.4.0",
"httpx>=0.28.1",
"protobuf>=5.29.5",
"pydantic>=2.11.3",
"cryptography>=43.0.0; extra == \"all\"",
"fastapi>=0.115.2; extra == \"all\"",
"grpcio-reflection>=1.7.0; extra == \"all\"",
"grpcio-tools>=1.60; extra == \"all\"",
"grpcio>=1.60; extra == \"all\"",
"opentelemetry-api>=1.33.0; extra == \"all\"",
"opentelemetry-sdk>=1.33.0; extra == \"all\"",
"pyjwt>=2.0.0; extra == \"all\"",
"sqlalchemy[aiomysql,asyncio]>=2.0.0; extra == \"all\"",
"sqlalchemy[aiosqlite,asyncio]>=2.0.0; extra == \"all\"",
"sqlalchemy[asyncio,postgresql-asyncpg]>=2.0.0; extra == \"all\"",
"sse-starlette; extra == \"all\"",
"starlette; extra == \"all\"",
"cryptography>=43.0.0; extra == \"encryption\"",
"grpcio-reflection>=1.7.0; extra == \"grpc\"",
"grpcio-tools>=1.60; extra == \"grpc\"",
"grpcio>=1.60; extra == \"grpc\"",
"fastapi>=0.115.2; extra == \"http-server\"",
"sse-starlette; extra == \"http-server\"",
"starlette; extra == \"http-server\"",
"sqlalchemy[aiomysql,asyncio]>=2.0.0; extra == \"mysql\"",
"sqlalchemy[asyncio,postgresql-asyncpg]>=2.0.0; extra == \"postgresql\"",
"pyjwt>=2.0.0; extra == \"signing\"",
"sqlalchemy[aiomysql,asyncio]>=2.0.0; extra == \"sql\"",
"sqlalchemy[aiosqlite,asyncio]>=2.0.0; extra == \"sql\"",
"sqlalchemy[asyncio,postgresql-asyncpg]>=2.0.0; extra == \"sql\"",
"sqlalchemy[aiosqlite,asyncio]>=2.0.0; extra == \"sqlite\"",
"opentelemetry-api>=1.33.0; extra == \"telemetry\"",
"opentelemetry-sdk>=1.33.0; extra == \"telemetry\""
] | [] | [] | [] | [
"homepage, https://a2a-protocol.org/",
"repository, https://github.com/a2aproject/a2a-python",
"changelog, https://github.com/a2aproject/a2a-python/blob/main/CHANGELOG.md",
"documentation, https://a2a-protocol.org/latest/sdk/python/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T10:05:43.423358 | a2a_sdk-0.3.24.tar.gz | 255,550 | ad/76/cefa956fb2d3911cb91552a1da8ce2dbb339f1759cb475e2982f0ae2332b/a2a_sdk-0.3.24.tar.gz | source | sdist | null | false | 4698757609deff068e52978c59fd9387 | 3581e6e8a854cd725808f5732f90b7978e661b6d4e227a4755a8f063a3c1599d | ad76cefa956fb2d3911cb91552a1da8ce2dbb339f1759cb475e2982f0ae2332b | Apache-2.0 | [
"LICENSE"
] | 150,072 |
2.4 | observational-memory | 0.1.1 | Cross-agent observational memory for Claude Code and Codex CLI | # Observational Memory
[](https://pypi.org/project/observational-memory/)
[](https://github.com/intertwine/observational-memory/actions/workflows/ci.yml)
**Cross-agent shared memory for Claude Code and Codex CLI — no RAG, no embeddings, no databases.**
Two background processes (Observer + Reflector) compress your conversation history from multiple AI coding agents into a single shared long-term memory. Every agent reads it on startup and instantly knows about you, your projects, your preferences, and what happened in previous sessions — even sessions with a *different* agent.
> Adapted from [Mastra's Observational Memory](https://mastra.ai/docs/memory/observational-memory) pattern. See the [OpenClaw version](https://github.com/intertwine/openclaw-observational-memory) for the original.
---
## Why
You use Claude Code in one terminal and Codex CLI in another. Each session starts from scratch — no memory of who you are, what you're working on, or what you told the other agent five minutes ago.
Observational Memory fixes this. A single set of compressed memory files lives at `~/.local/share/observational-memory/` and is shared across all your agents:
```
Claude Code session Codex CLI session
┌──────────────────────┐ ┌──────────────────────┐
│ SessionStart hook │ │ AGENTS.md reads │
│ → injects memory │ │ → memory on startup │
│ │ │ │
│ SessionEnd hook │ │ Cron-based observer │
│ → triggers observer │ │ → scans sessions │
│ │ │ │
│ UserPromptSubmit / │ │ │
│ PreCompact checkpoint │ │ │
└───────────┬───────────┘ └───────────┬───────────┘
│ transcript │ transcript
▼ ▼
┌─────────────────────────────────────────────────────┐
│ observe.py (LLM compression) │
└──────────────────────┬──────────────────────────────┘
▼
┌─────────────────────────────────────────────────────┐
│ ~/.local/share/observational-memory/ │
│ observations.md — recent compressed notes │
│ reflections.md — stable long-term memory │
└──────────────────────┬──────────────────────────────┘
▼
┌─────────────────────────────────────────────────────┐
│ reflect.py (daily consolidation) │
└─────────────────────────────────────────────────────┘
```
### Three tiers of memory
| Tier | Updated | Retention | Size | Contents |
|------|---------|-----------|------|----------|
| **Raw transcripts** | Real-time | Session only | ~50K tokens/day | Full conversation |
| **Observations** | Per session + periodic checkpoints (~15 min default) | 7 days | ~2K tokens/day | Timestamped, prioritized notes |
| **Reflections** | Daily | Indefinite | 200–600 lines total | Identity, projects, preferences |
---
## Quick Start
### Prerequisites
- Python 3.11+
- [uv](https://docs.astral.sh/uv/) (recommended) or pip
- An API key: `ANTHROPIC_API_KEY` or `OPENAI_API_KEY`
- Claude Code and/or Codex CLI installed
### Install
```bash
# Install from PyPI
uv tool install observational-memory
# Set up hooks, API key, and cron
om install
```
### Verify
```bash
om doctor
```
That's it. Your agents now share persistent, compressed memory.
### Development Install
```bash
git clone https://github.com/intertwine/observational-memory.git
cd observational-memory
uv sync
uv pip install -e ".[dev]"
```
---
## How It Works
### Claude Code Integration
**SessionStart hook** — When you start a Claude Code session, a hook runs `om context` which uses BM25 search to find the most relevant observations and injects them (plus full reflections) as context via `additionalContext`. Falls back to full file dump if search is unavailable.
**SessionEnd hook** — When a session ends, a hook triggers the observer on the just-completed transcript. The observer calls an LLM to compress the conversation into observations.
**UserPromptSubmit / PreCompact hooks** — Long-running sessions also send periodic checkpoint events during the session. These are throttled with `OM_SESSION_OBSERVER_INTERVAL_SECONDS` (default `900` seconds), so observations continue to be captured without observing after every prompt.
To disable in-session checkpoints while keeping normal end-of-session capture, set:
`OM_DISABLE_SESSION_OBSERVER_CHECKPOINTS=1` in `~/.config/observational-memory/env`.
All hooks are installed automatically to `~/.claude/settings.json`.
### Codex CLI Integration
**AGENTS.md** — The installer adds instructions to `~/.codex/AGENTS.md` telling Codex to read the memory files at session start.
**Cron observer** — A cron job runs every 15 minutes, scanning `~/.codex/sessions/` for new transcript data (`*.json` and `*.jsonl`) and compressing it into observations.
### Reflector (Both)
A daily cron job (04:00 UTC) runs the reflector, which:
1. Reads the `Last reflected` timestamp from the existing reflections
2. Filters observations to only those from that date onward (incremental — skips already-processed days)
3. If the filtered observations fit in one LLM call (<30K tokens), processes them in a single pass
4. If they're too large (e.g., after a backfill), automatically chunks by date section and folds each chunk into the reflections incrementally
5. Merges, promotes (🟡→🔴), demotes, and archives entries
6. Stamps `Last updated` and `Last reflected` timestamps programmatically
7. Writes the updated `reflections.md`
8. Trims observations older than 7 days
### Priority System
| Level | Meaning | Examples | Retention |
|-------|---------|----------|-----------|
| 🔴 | Important / persistent | User facts, decisions, project architecture | Months+ |
| 🟡 | Contextual | Current tasks, in-progress work | Days–weeks |
| 🟢 | Minor / transient | Greetings, routine checks | Hours |
### LLM Provider & API Keys
The observer and reflector call an LLM API to perform compression. Your API key is stored in a dedicated env file:
```
~/.config/observational-memory/env
```
`om install` creates this file with `0600` permissions (owner-read/write only). Edit it to add your key:
```bash
# ~/.config/observational-memory/env
ANTHROPIC_API_KEY=sk-ant-...
```
The CLI, hooks, and cron jobs all source this file automatically — no need to export keys in your shell profile.
- `ANTHROPIC_API_KEY` → uses Claude Sonnet (default)
- `OPENAI_API_KEY` → uses GPT-4o-mini
- Both set → prefers Anthropic
- Environment variables override the env file
---
## CLI Reference
```bash
# Run observer on all recent transcripts
om observe
# Run observer on a specific transcript
om observe --transcript ~/.claude/projects/.../abc123.jsonl
# Run observer for one agent only
om observe --source claude
om observe --source codex
# Run reflector
om reflect
# Search memories
om search "PostgreSQL setup"
om search "current projects" --limit 5
om search "backfill" --json
om search "preferences" --reindex # rebuild index before searching
# Backfill all historical transcripts
om backfill --source claude
om backfill --dry-run # preview what would be processed
# Dry run (print output without writing)
om observe --dry-run
om reflect --dry-run
# Install/uninstall
om install [--claude|--codex|--both] [--no-cron]
om uninstall [--claude|--codex|--both] [--purge]
# Check status
om status
# Run diagnostics
om doctor
om doctor --json # machine-readable output
om doctor --validate-key # test API key with a live call
```
---
## Configuration
### API Keys
```
~/.config/observational-memory/env
```
Created by `om install` with `0600` permissions. Add your key:
```bash
ANTHROPIC_API_KEY=sk-ant-api03-...
# or
OPENAI_API_KEY=sk-...
```
This file is sourced by the `om` CLI, the Claude Code hooks, and the cron jobs. Keys already present in the environment take precedence.
### Memory Location
Default: `~/.local/share/observational-memory/`
Override with `XDG_DATA_HOME`:
```bash
export XDG_DATA_HOME=~/my-data
# Memory will be at ~/my-data/observational-memory/
```
### Cron Schedules
The installer sets up:
- **Observer (Codex):** `*/15 * * * *` by default (controlled by `OM_CODEX_OBSERVER_INTERVAL_MINUTES`, e.g. `*/10 * * * *` for 10 min)
- **Reflector:** `0 4 * * *` (daily at 04:00 UTC)
Set `OM_CODEX_OBSERVER_INTERVAL_MINUTES` in `~/.config/observational-memory/env` to tune Codex polling (`1` = every minute).
Edit with `crontab -e` to adjust.
### Search Backend
Memory search uses a pluggable backend architecture. Three backends are available:
| Backend | Default | Requires | Method |
|---------|---------|----------|--------|
| `bm25` | Yes | Nothing (bundled) | Token-based keyword matching via `rank-bm25` |
| `qmd` | No | [QMD CLI](https://github.com/tobi/qmd) + bun | BM25 keyword search via QMD's FTS5 engine |
| `qmd-hybrid` | No | [QMD CLI](https://github.com/tobi/qmd) + bun | Hybrid BM25 + vector embeddings + LLM reranking (~2GB models, auto-downloaded) |
| `none` | No | Nothing | Disables search entirely |
The default `bm25` backend works out of the box. The index is rebuilt automatically after each observe/reflect run and stored at `~/.local/share/observational-memory/.search-index/bm25.pkl`.
To switch backends, set `OM_SEARCH_BACKEND` in your env file:
```bash
# ~/.config/observational-memory/env
OM_SEARCH_BACKEND=qmd-hybrid
OM_CODEX_OBSERVER_INTERVAL_MINUTES=10
```
Or export it in your shell:
```bash
export OM_SEARCH_BACKEND=qmd-hybrid
export OM_CODEX_OBSERVER_INTERVAL_MINUTES=10
```
#### Using QMD (optional)
[QMD](https://github.com/tobi/qmd) provides hybrid search (BM25 + vector embeddings + LLM reranking) for higher recall on semantic queries. All models run locally via node-llama-cpp — no extra API keys needed. To set it up:
```bash
# 1. Install bun (QMD runtime)
curl -fsSL https://bun.sh/install | bash
# 2. Install QMD (from GitHub — the npm package is a placeholder)
bun install -g github:tobi/qmd
# 3. Switch the backend in config.py
# search_backend: str = "qmd-hybrid"
# 4. Rebuild the index
om search --reindex "test query"
```
When using QMD, memory documents are written as `.md` files under `~/.local/share/observational-memory/.qmd-docs/` and registered as a QMD collection named `observational-memory`. The `om search` and `om context` commands use whichever backend is configured.
### Tuning
Edit the prompts in `prompts/` to adjust:
- **What gets captured** — priority definitions in `observer.md`
- **How aggressively things are merged** — rules in `reflector.md`
- **Target size** — the reflector aims for 200–600 lines
---
## Example Output
### Observations (`observations.md`)
```markdown
# Observations
## 2026-02-10
### Current Context
- **Active task:** Setting up FastAPI project for task manager app
- **Mood/tone:** Focused, decisive
- **Key entities:** Atlas, FastAPI, PostgreSQL, Tortoise ORM
- **Suggested next:** Help with database models
### Observations
- 🔴 14:00 User is building a task management REST API with FastAPI
- 🔴 14:05 User prefers PostgreSQL over SQLite for production (concurrency)
- 🟡 14:10 Changed mind from SQLAlchemy to Tortoise ORM (finds SQLAlchemy too verbose)
- 🔴 14:15 User's name is Alex, backend engineer, prefers concise code examples
```
### Reflections (`reflections.md`)
```markdown
# Reflections — Long-Term Memory
*Last updated: 2026-02-10 04:00 UTC*
*Last reflected: 2026-02-10*
## Core Identity
- **Name:** Alex
- **Role:** Backend engineer
- **Communication style:** Direct, prefers code over explanation
- **Preferences:** FastAPI, PostgreSQL, Tortoise ORM
## Active Projects
### Task Manager (Atlas)
- **Status:** Active
- **Stack:** Python, FastAPI, PostgreSQL, Tortoise ORM
- **Key decisions:** Postgres for concurrency; Tortoise ORM over SQLAlchemy
## Preferences & Opinions
- 🔴 PostgreSQL over SQLite for production
- 🔴 Concise code examples over long explanations
- 🟡 Tortoise ORM over SQLAlchemy (less verbose)
```
---
## Testing
```bash
# Using make (recommended)
make check # lint + test
make test # tests only
make lint # linter only
make format # auto-format
# Or directly with uv
uv sync
uv run pytest
uv run pytest tests/test_transcripts.py
uv run pytest -v
```
---
## File Structure
```
observational-memory/
├── README.md # This file
├── LICENSE # MIT
├── pyproject.toml # Python package config
├── src/observational_memory/
│ ├── cli.py # CLI: om observe, reflect, search, backfill, install, status
│ ├── config.py # Paths, defaults, env detection
│ ├── llm.py # LLM API abstraction (Anthropic + OpenAI)
│ ├── observe.py # Observer logic
│ ├── reflect.py # Reflector logic
│ ├── transcripts/
│ │ ├── claude.py # Claude Code JSONL parser
│ │ └── codex.py # Codex CLI session parser
│ ├── search/ # Pluggable search over memory files
│ │ ├── __init__.py # Document model, factory, reindex orchestrator
│ │ ├── backend.py # SearchBackend Protocol
│ │ ├── parser.py # Parse observations/reflections into Documents
│ │ ├── bm25.py # BM25 backend (default, uses rank-bm25)
│ │ ├── qmd.py # QMD backend (optional, shells out to qmd CLI)
│ │ └── none.py # No-op backend
│ ├── prompts/
│ │ ├── observer.md # Observer system prompt
│ │ └── reflector.md # Reflector system prompt
│ └── hooks/claude/
│ ├── session-start.sh # Inject memory on session start (search-backed)
│ └── session-end.sh # Trigger observer on session end
└── tests/
├── test_transcripts.py # Transcript parser tests
├── test_observe.py # Observer tests
├── test_reflect.py # Reflector tests
├── test_search.py # Search module tests
└── fixtures/ # Sample transcripts
```
---
## How It Compares to the OpenClaw Version
| Feature | OpenClaw Version | This Version |
|---------|-----------------|--------------|
| **Agents supported** | OpenClaw only | Claude Code + Codex CLI |
| **Scope** | Per-workspace | User-level (shared across all projects) |
| **Observer trigger** | OpenClaw cron job | Claude: SessionEnd hook; Codex: system cron |
| **Context injection** | AGENTS.md instructions | Claude: SessionStart hook; Codex: AGENTS.md |
| **Memory location** | `workspace/memory/` | `~/.local/share/observational-memory/` |
| **Compression engine** | OpenClaw agent sessions | Direct LLM API calls (Anthropic/OpenAI) |
| **Cross-agent memory** | No | Yes |
---
## FAQ
**Q: Does this replace RAG / vector search?**
A: For personal context, yes. Observational memory is for remembering *about you* — preferences, projects, communication style. RAG is for searching document collections. They're complementary. The built-in BM25 search handles keyword retrieval over your memories; for hybrid search (BM25 + vector embeddings + LLM reranking), use the `qmd-hybrid` backend with [QMD](https://github.com/tobi/qmd).
**Q: How much does it cost?**
A: The observer processes only new messages per session (~200–1K input tokens typical). The reflector runs once daily. Expect ~$0.05–0.20/day with Sonnet-class models.
**Q: What if I only use Claude Code?**
A: Run `om install --claude`. The Codex integration is entirely optional.
**Q: Can I manually edit the memory files?**
A: Yes. Both `observations.md` and `reflections.md` are plain markdown. The observer appends; the reflector overwrites. Manual edits to reflections will be preserved.
**Q: What happens if the reflector runs on a huge backlog?**
A: The reflector uses incremental updates — it reads the `Last reflected` timestamp from the existing reflections and only processes new observations since that date. If the timestamp is missing (first run or after a backfill), the reflector automatically chunks observations by date section and folds them incrementally, preventing the model from being overwhelmed. Output token budget is 8192 tokens (enough for the 200–600 line target).
**Q: What about privacy?**
A: Everything runs locally. Transcripts are processed by the LLM API you configure (Anthropic or OpenAI), subject to their data policies. No data is sent anywhere else.
---
## Credits
- Inspired by [Mastra's Observational Memory](https://mastra.ai/docs/memory/observational-memory)
- Original [OpenClaw version](https://github.com/intertwine/openclaw-observational-memory)
- License: MIT
| text/markdown | null | Bryan Young <obs-mem-pypi@intertwinesys.com> | null | null | null | agent-memory, ai-memory, claude-code, codex, developer-tools, llm, observational-memory | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"anthropic>=0.40.0",
"click>=8.1.0",
"openai>=1.50.0",
"rank-bm25>=0.2.2",
"build>=1.0.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.8.0; extra == \"dev\"",
"twine>=4.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/intertwine/observational-memory",
"Repository, https://github.com/intertwine/observational-memory",
"Issues, https://github.com/intertwine/observational-memory/issues"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T10:05:40.249520 | observational_memory-0.1.1.tar.gz | 48,992 | 8a/33/db7efdc828f8b3ab1f6326b3e8dd47629b372bb18695ddbddf1bf392334a/observational_memory-0.1.1.tar.gz | source | sdist | null | false | 9b3d9f78701728fb3cfa3b3a2aea3ccc | 2529fc28ffd7867f54724bbe492ff14abcbed017988e1637b4b5f1cd890425b6 | 8a33db7efdc828f8b3ab1f6326b3e8dd47629b372bb18695ddbddf1bf392334a | MIT | [
"LICENSE"
] | 222 |
2.4 | ucon | 0.7.6 | A tool for dimensional analysis: a 'Unit CONverter' | <table>
<tr>
<td width="200">
<img src="https://gist.githubusercontent.com/withtwoemms/0cb9e6bc8df08f326771a89eeb790f8e/raw/221c60e85ac8361c7d202896b52c1a279081b54c/ucon-logo.png" align="left" width="200" />
</td>
<td>
# ucon
> Pronounced: _yoo · cahn_
[](https://github.com/withtwoemms/ucon/actions?query=workflow%3Atests)
[](https://codecov.io/gh/withtwoemms/ucon)
[](https://github.com/withtwoemms/ucon/actions?query=workflow%3Apublish)
</td>
</tr>
</table>
> A lightweight, **unit-aware computation library** for Python — built on first-principles.
**[Documentation](https://docs.ucon.dev)** · [Quickstart](https://docs.ucon.dev/getting-started/quickstart) · [API Reference](https://docs.ucon.dev/reference/api)
---
## What is ucon?
`ucon` helps Python understand the *physical meaning* of your numbers. It treats units, dimensions, and scales as first-class objects — enforcing physics, not just labels.
```python
from ucon import units
length = units.meter(5)
time = units.second(2)
speed = length / time # <2.5 m/s>
invalid = length + time # raises: incompatible dimensions
```
---
## Installation
```bash
pip install ucon
```
With extras:
```bash
pip install ucon[pydantic] # Pydantic v2 integration
pip install ucon[mcp] # MCP server for AI agents
```
---
## Quick Examples
### Unit Conversion
```python
from ucon import units, Scale
km = Scale.kilo * units.meter
distance = km(5)
print(distance.to(units.mile)) # <3.107... mi>
```
### Dimensional Safety
```python
from ucon import Number, Dimension, enforce_dimensions
@enforce_dimensions
def speed(
distance: Number[Dimension.length],
time: Number[Dimension.time],
) -> Number:
return distance / time
speed(units.meter(100), units.second(10)) # <10.0 m/s>
speed(units.second(100), units.second(10)) # raises ValueError
```
### Pydantic Integration
```python
from pydantic import BaseModel
from ucon.pydantic import Number
class Measurement(BaseModel):
value: Number
m = Measurement(value={"quantity": 9.8, "unit": "m/s^2"})
print(m.model_dump_json())
# {"value": {"quantity": 9.8, "unit": "m/s^2", "uncertainty": null}}
```
### MCP Server for AI Agents
Configure in Claude Desktop:
```json
{
"mcpServers": {
"ucon": {
"command": "uvx",
"args": ["--from", "ucon[mcp]", "ucon-mcp"]
}
}
}
```
AI agents can then convert units, check dimensions, and perform factor-label calculations with dimensional validation at each step.
---
## Features
- **Dimensional algebra** — Units combine through multiplication/division with automatic dimension tracking
- **Scale prefixes** — Full SI (kilo, milli, micro, etc.) and binary (kibi, mebi) prefix support
- **Uncertainty propagation** — Errors propagate through arithmetic and conversions
- **Pseudo-dimensions** — Semantically isolated handling of angles, ratios, and counts
- **Pydantic v2** — Type-safe API validation and JSON serialization
- **MCP server** — AI agent integration with Claude, Cursor, and other MCP clients
- **ConversionGraph** — Extensible conversion registry with custom unit support
---
## Roadmap Highlights
| Version | Theme | Status |
|---------|-------|--------|
| **0.3.x** | Dimensional Algebra | Complete |
| **0.4.x** | Conversion System | Complete |
| **0.5.x** | Dimensionless Units + Uncertainty | Complete |
| **0.6.x** | Pydantic + MCP Server | Complete |
| **0.7.x** | Compute Tool + Extension API | Complete |
| **0.8.x** | String Parsing | Planned |
| **0.9.x** | Constants + Logarithmic Units | Planned |
| **0.10.x** | NumPy/Polars Integration | Planned |
| **1.0.0** | API Stability | Planned |
See full roadmap: [ROADMAP.md](./ROADMAP.md)
---
## Documentation
| Section | Description |
|---------|-------------|
| [Getting Started](https://docs.ucon.dev/getting-started/) | Why ucon, quickstart, installation |
| [Guides](https://docs.ucon.dev/guides/) | MCP server, Pydantic, custom units, dimensional analysis |
| [Reference](https://docs.ucon.dev/reference/) | API docs, unit tables, MCP tool schemas |
| [Architecture](https://docs.ucon.dev/architecture/) | Design principles, ConversionGraph, comparison with Pint |
---
## Contributing
```bash
make venv # Create virtual environment
source .ucon-3.12/bin/activate # Activate
make test # Run tests
make test-all # Run tests across all python versions
```
---
## License
Apache 2.0. See [LICENSE](./LICENSE).
| text/markdown | Emmanuel I. Obi | "Emmanuel I. Obi" <withtwoemms@gmail.com> | Emmanuel I. Obi | "Emmanuel I. Obi" <withtwoemms@gmail.com> | Apache-2.0 | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"Topic :: Software Development :: Build Tools",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | https://github.com/withtwoemms/ucon | null | >=3.7 | [] | [] | [] | [
"typing_extensions>=3.7.4; python_version < \"3.9\"",
"tomli>=2.0; python_version < \"3.11\"",
"coverage[toml]>=5.5; extra == \"test\"",
"pydantic>=2.0; extra == \"pydantic\"",
"mcp>=1.0; python_version >= \"3.10\" and extra == \"mcp\"",
"mkdocs-material; extra == \"docs\"",
"mkdocstrings[python]; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://github.com/withtwoemms/ucon",
"Repository, https://github.com/withtwoemms/ucon"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T10:05:21.903364 | ucon-0.7.6.tar.gz | 647,099 | 1b/81/f294f0da32c1a3897d1608cb27f1665c5aa20cca9b7986040f2ad0968327/ucon-0.7.6.tar.gz | source | sdist | null | false | 401b7033d28742e2a763f706872be015 | 4c4a4e3936595d1623d8c69f51eecedbb922db6a2892bcc7b5036f418553681d | 1b81f294f0da32c1a3897d1608cb27f1665c5aa20cca9b7986040f2ad0968327 | null | [
"LICENSE",
"NOTICE"
] | 227 |
2.4 | reldo | 0.6.1 | Claude-powered code review orchestrator that coordinates specialized review agents | # Reldo
> "The librarian has reviewed your code."
A Claude-powered code review orchestrator that coordinates specialized review agents.
Named after the Varrock Palace librarian in RuneScape who researches and checks things against ancient tomes.
## Installation
```bash
# From PyPI
pip install reldo
# Or with uv
uv tool install reldo
```
## Usage
### As a Library
```python
from reldo import Reldo, ReviewConfig
from pathlib import Path
# Load config from file
config = ReviewConfig.from_file(Path(".claude/reldo.json"))
reldo = Reldo(config=config)
# Run a review - single prompt argument
result = await reldo.review(
prompt="Review app/Models/User.php for backend conventions. Context: Added user registration."
)
print(result.text)
print(f"Tokens used: {result.total_tokens}")
```
### As a CLI
```bash
# Basic review
reldo review --prompt "Review app/Models/User.php"
# With JSON output (for CI)
reldo review --prompt "Review $(git diff --name-only HEAD)" --json --exit-code
# With custom config
reldo review --prompt "..." --config .claude/reldo.json
```
## Configuration
Create `.reldo/settings.json`:
```json
{
"prompt": ".reldo/orchestrator.md",
"allowed_tools": ["Read", "Glob", "Grep", "Bash", "Task"],
"model": "claude-sonnet-4-20250514",
"timeout_seconds": 300
}
```
### Configuration Options
| Option | Type | Default | Description |
|--------|------|---------|-------------|
| `prompt` | string | required | Path to orchestrator prompt file |
| `allowed_tools` | string[] | `["Read", "Glob", "Grep", "Bash", "Task"]` | Tools available to the orchestrator |
| `mcp_servers` | object | `{}` | MCP server configurations |
| `setting_sources` | string[] | `["project"]` | Where to discover agents from (see [Agent Discovery](#agent-discovery)) |
| `agents` | object | `{}` | Additional agent definitions (merged with discovered agents) |
| `model` | string | `"claude-sonnet-4-20250514"` | Claude model to use |
| `timeout_seconds` | int | `180` | Maximum review duration |
| `cwd` | string | current directory | Working directory |
| `logging` | object | `{"enabled": true, ...}` | Logging configuration |
## Agent Discovery
Reldo automatically discovers agents from your project's `.claude/agents/` directory. This means you can use the **same agents** that Claude Code uses - no duplication needed.
### How It Works
By default, `setting_sources` is set to `["project"]`, which tells the Claude Agent SDK to load agents from `.claude/agents/`. These agents are immediately available to your review orchestrator.
```
your-project/
├── .claude/
│ └── agents/
│ ├── backend-reviewer.md # ← Auto-discovered
│ ├── frontend-reviewer.md # ← Auto-discovered
│ └── architecture-reviewer.md # ← Auto-discovered
└── .reldo/
└── settings.json # ← No agent config needed!
```
### Agent File Format
Agents in `.claude/agents/` use markdown with YAML frontmatter:
```markdown
---
name: backend-reviewer
description: Reviews PHP/Laravel code for conventions and patterns
model: inherit
---
# Backend Reviewer
You review PHP/Laravel code for best practices...
```
### Controlling Agent Discovery
The `setting_sources` option controls where agents are loaded from:
| Value | Behavior |
|-------|----------|
| `["project"]` (default) | Loads agents from `.claude/agents/` |
| `["project", "local"]` | Also includes local settings overrides |
| `["user", "project", "local"]` | Includes user-global agents too |
| `[]` | Disables auto-discovery (only explicit agents) |
### Merging Explicit Agents
If you define agents in `.reldo/settings.json`, they are **merged** with discovered agents:
```json
{
"prompt": ".reldo/orchestrator.md",
"agents": {
"reldo-specific-agent": {
"description": "An agent only for reldo reviews",
"prompt": ".reldo/agents/special.md"
}
}
}
```
Result: Both `.claude/agents/*` AND `reldo-specific-agent` are available.
### Disabling Auto-Discovery
To use **only** explicitly defined agents:
```json
{
"prompt": ".reldo/orchestrator.md",
"setting_sources": [],
"agents": {
"my-reviewer": {
"description": "Custom reviewer",
"prompt": ".reldo/agents/my-reviewer.md"
}
}
}
```
### MCP Server Configuration
Reldo supports MCP (Model Context Protocol) servers for extended functionality:
```json
{
"mcp_servers": {
"server-name": {
"command": "executable",
"args": ["arg1", "arg2"],
"env": {
"ENV_VAR": "value"
}
}
}
}
```
#### Variable Substitution
MCP server configurations support variable substitution:
- `${cwd}` - Replaced with the working directory
```json
{
"mcp_servers": {
"serena": {
"command": "uvx",
"args": ["serena", "start-mcp-server", "--project", "${cwd}"]
}
}
}
```
## CLI Reference
```bash
reldo review --prompt "..." # Review prompt
--config PATH # Config file (default: .claude/reldo.json)
--cwd PATH # Working directory
--json # Output as JSON
--verbose # Verbose logging
--no-log # Disable session logging
--exit-code # Exit 1 if review fails (for CI)
```
## Documentation
- [Product Requirements Document](docs/PRD.md)
## License
MIT
| text/markdown | Rasmus Godske | null | Rasmus Godske | null | null | ai, anthropic, automation, claude, cli, code-review, command-line, developer-tools, orchestrator, review | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Quality Assurance",
"Topic :: Software Development :: Testing",
"Topic :: Utilities",
"Typing :: Typed"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"claude-agent-sdk>=0.1.0",
"mypy>=1.0; extra == \"dev\"",
"pytest-asyncio>=0.23; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.1; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/RasmusGodske/reldo",
"Documentation, https://github.com/RasmusGodske/reldo#readme",
"Repository, https://github.com/RasmusGodske/reldo",
"Issues, https://github.com/RasmusGodske/reldo/issues",
"Changelog, https://github.com/RasmusGodske/reldo/releases"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T10:04:21.696792 | reldo-0.6.1.tar.gz | 18,300 | 13/12/f4f4d37345c483a2635fcf21f93e0d95799dc8a353f34acf959c842d34a4/reldo-0.6.1.tar.gz | source | sdist | null | false | 952531890480a816968f2a676bf0b4bc | b6346ba56772782773293c513f0a0921f8c8b599ebe684bc131cb89dc5f1f0c9 | 1312f4f4d37345c483a2635fcf21f93e0d95799dc8a353f34acf959c842d34a4 | MIT | [
"LICENSE"
] | 206 |
2.4 | riopy | 5.0.0 | Rubika Python library - ساخت بات روبیکا با پایتون | # ریوپای - Riopy
کتابخانه پایتون برای ساخت بات در پیامرسان روبیکا
ساخته شده توسط محمد لطیفی پور
## نصب
```bash
pip install riopy
| text/markdown | محمد لطیفی پور | null | null | null | LGPLv3 | null | [
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)"
] | [] | null | null | >=3.7 | [] | [] | [] | [
"aiohttp>=3.8.0",
"aiofiles>=22.1.0",
"pycryptodome>=3.15.0",
"markdownify>=0.11.6",
"mutagen>=1.46.0"
] | [] | [] | [] | [
"Homepage, https://github.com/mohammadlatifipour/riopy",
"Repository, https://github.com/mohammadlatifipour/riopy.git"
] | twine/6.2.0 CPython/3.11.5 | 2026-02-20T10:04:17.767109 | riopy-5.0.0.tar.gz | 1,568 | 24/00/33da9f7c42a80c4ab557136d409b14ee5cfa5ff2a73700c2b73d054ba1c6/riopy-5.0.0.tar.gz | source | sdist | null | false | a88f5f41c31d7e3662160804c7c71d5b | 413343c9de94b2c1bd0adcef613ad96e3f459adabc9564431c4030d70c3cfe25 | 240033da9f7c42a80c4ab557136d409b14ee5cfa5ff2a73700c2b73d054ba1c6 | null | [] | 218 |
2.1 | humanapi-sdk | 0.2.0 | Python SDK for HumanAPI.ru — marketplace where AI agents hire humans | # humanapi-sdk
Python SDK для [HumanAPI.ru](https://humanapi.ru) — маркетплейса, где AI-агенты нанимают людей для задач в реальном мире.
## Установка
```bash
pip install humanapi-sdk
```
## Быстрый старт
```python
from humanapi import HumanAPI
api = HumanAPI("your_api_key")
# Статистика платформы
stats = api.get_stats()
print(f"Людей: {stats['humans_registered']}, Задач: {stats['total_tasks']}")
# Категории
cats = api.get_categories()
# Поиск исполнителей
humans = api.search_humans(city="Москва", skill="фото")
# Создать задание (баунти)
bounty = api.create_bounty(
title="Сфотографировать фасад ресторана",
description="Нужно 3-5 фото фасада и входа в дневное время",
city="Москва",
budget=500,
category="photo",
)
print(f"Создано задание #{bounty['bounty_id']}")
```
## Полный flow задачи
```python
# Создать задачу
task = api.create_task(
title="Доставить документы",
description="Забрать документы из офиса и привезти по адресу",
city="Москва",
budget=800,
category="delivery",
agent_name="MyBot",
)
task_id = task["task_id"]
# Получить задачу
task = api.get_task(task_id)
# Назначить исполнителя
api.accept_task(task_id, human_id=123)
# Отправить результат (исполнитель)
api.submit_result(task_id, result="Документы доставлены, фото: https://...")
# Принять результат (release escrow)
api.accept_result(task_id)
# Или отправить на доработку
api.request_revision(task_id, comment="Нужно фото подтверждение")
```
## Оценка исполнителя
```python
# Оценить работу исполнителя (1-5 звёзд)
api.rate_worker(task_id, rating=5, comment="Отличная работа, всё сделано быстро!")
# Минимальная оценка без комментария
api.rate_worker(task_id, rating=3)
```
## Баланс
```python
balance = api.get_balance()
print(f"Баланс: {balance['balance']} руб.")
```
## Чат задачи
```python
# Отправить сообщение
api.send_message(task_id, message="Когда будет готово?")
# Получить сообщения
messages = api.get_messages(task_id)
```
## Webhooks
```python
wh = api.register_webhook(
url="https://mybot.example.com/webhook",
events=["task_completed", "task_created"],
)
print(f"Webhook secret: {wh['secret']}")
# Список вебхуков
api.list_webhooks()
# Удалить
api.delete_webhook(wh["id"])
```
## Получение API-ключа
```python
from humanapi import HumanAPI
api = HumanAPI("")
result = api.request_api_key(email="agent@example.com", agent_name="MyBot")
print(f"Ваш ключ: {result['api_key']}")
```
## Обработка ошибок
```python
from humanapi import HumanAPI, HumanAPIError
api = HumanAPI("your_key")
try:
api.get_task(999999)
except HumanAPIError as e:
print(f"Ошибка {e.status_code}: {e.detail}")
```
## Интеграции
### LangChain
```python
from humanapi.langchain_tool import get_humanapi_tools
tools = get_humanapi_tools("hapi_your_key")
# Включает: create_task, search_humans, get_task_status, accept_result, submit_result, get_balance
```
### CrewAI
```python
from humanapi.crewai_tool import HumanAPICreateTaskTool, HumanAPIAcceptResultTool, HumanAPIGetBalanceTool
create_tool = HumanAPICreateTaskTool(api_key="hapi_your_key")
accept_tool = HumanAPIAcceptResultTool(api_key="hapi_your_key")
balance_tool = HumanAPIGetBalanceTool(api_key="hapi_your_key")
```
### MCP Server
```bash
HUMANAPI_API_KEY=hapi_your_key python3 mcp_server.py
```
## Лицензия
MIT
| text/markdown | HumanAPI Team | hello@humanapi.ru | null | null | MIT | humanapi ai agents marketplace sdk | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries"
] | [] | https://humanapi.ru | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Documentation, https://humanapi.ru/docs",
"API Docs, https://humanapi.ru/docs",
"Source, https://github.com/humanapi-ru/humanapi-sdk"
] | twine/6.2.0 CPython/3.10.12 | 2026-02-20T10:04:01.527917 | humanapi_sdk-0.2.0.tar.gz | 8,706 | 5c/df/bde4f843e4f458b613e552446793309093c59106b49f903746ed8e119a52/humanapi_sdk-0.2.0.tar.gz | source | sdist | null | false | 93101004acc6cc126a7ae3c76f031d6a | 9422f655030d415013187596cbb8c3b5db6f83f69972c9d7da745d73b01e8bd1 | 5cdfbde4f843e4f458b613e552446793309093c59106b49f903746ed8e119a52 | null | [] | 235 |
2.4 | torch-fourier-shift | 0.1.0 | Shift 2D/3D images by phase shifting Fourier transforms in PyTorch | # torch-phase-shift
[](https://github.com/alisterburt/torch-phase-shift/raw/main/LICENSE)
[](https://pypi.org/project/torch-phase-shift)
[](https://python.org)
[](https://github.com/alisterburt/torch-phase-shift/actions/workflows/ci.yml)
[](https://codecov.io/gh/alisterburt/torch-phase-shift)
*torch-fourier-shift* is a package for shifting 1D, 2D and 3D images with subpixel precision
by applying phase shifts to Fourier transforms in PyTorch.
<p align="center" width="100%">
<img src="./docs/assets/shift_2d_image.png" alt="A 2D image and the shifted result" width="50%">
</p>
```python
import torch
from torch_fourier_shift import fourier_shift_image_2d
# create a dummy image
my_image = torch.tensor(
[[0, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0]]
)
# shift the image by 1 pixel in dim 0, 2 pixels in dim 1
shifted_image = fourier_shift_image_2d(image=my_image, shifts=torch.tensor([1, 2]))
```
API's are equivalent for 1D and 3D images.
## Installation
*torch-fourier-shift* is available on PyPI.
```shell
pip install torch-fourier-shift
```
## Usage
Please check the the docs at [teamtomo.org/torch-fourier-shift](https://teamtomo.org/torch-fourier-shift/)
### Caching
Some functions are equipped with an argument called cache_intermediates. If you set cache_intermediates=True, an LRU cache will be used to avoid recomputing intermediate results. Note that this might affect gradient calculations.
By default, the size of the cache is 3, and can be changed with an environmental variable called TORCH_FOURIER_SHIFT_CACHE_SIZE. Just do
```
export TORCH_FOURIER_SHIFT_CACHE_SIZE=5
```
or
```
os.environ["TORCH_FOURIER_SHIFT_CACHE_SIZE"]=5
```
before importing the torch_fourier_shift module.
| text/markdown | null | Alister Burt <alisterburt@gmail.com> | null | null | BSD-3-Clause | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Typing :: Typed"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"einops",
"numpy",
"torch",
"ipython; extra == \"dev\"",
"mypy; extra == \"dev\"",
"pdbpp; extra == \"dev\"",
"pre-commit; extra == \"dev\"",
"rich; extra == \"dev\"",
"ruff; extra == \"dev\"",
"mkdocs-material; extra == \"docs\"",
"mkdocstrings[python]; extra == \"docs\"",
"pytest; extra == \"test\"",
"pytest-cov; extra == \"test\""
] | [] | [] | [] | [
"homepage, https://github.com/alisterburt/torch-phase-shift",
"repository, https://github.com/alisterburt/torch-phase-shift"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T10:03:19.757659 | torch_fourier_shift-0.1.0.tar.gz | 49,895 | cc/bc/0b0a2e64ce84533284b0fdf4b1405d2822631833dff5469534d8c1b6017f/torch_fourier_shift-0.1.0.tar.gz | source | sdist | null | false | 484a27163096a7bf1be865743ec93627 | 322ae23ce7cfcee3aea163fc583df13ccbe37edc722ceddc6e3df9cb7b62bb03 | ccbc0b0a2e64ce84533284b0fdf4b1405d2822631833dff5469534d8c1b6017f | null | [
"LICENSE"
] | 238 |
2.4 | nllw | 0.1.5 | Simultaneous Machine Translation (SimulMT) with NLLB model optimization | <h1 align="center">NoLanguageLeftWaiting</h1>
<p align="center">
<img src="demo.gif"width="730">
</p>
<p align="center">
<img src="architecture_NLLW.png"width="730">
</p>
Converts [NoLanguageLeftBehind](https://arxiv.org/abs/2207.04672) translation model to a SimulMT (Simultaneous Machine Translation) model, optimized for live/streaming use cases.
> Based offline models such as NLLB suffer from eos token and punctuation insertion, inconsistent prefix handling and exponentially growing computational overhead as input length increases. This implementation aims at resolving that.
- [LocalAgreement policy](https://www.isca-archive.org/interspeech_2020/liu20s_interspeech.pdf)
- Backends: [HuggingFace transformers](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForSeq2SeqLM) / [Ctranslate2 Translator](https://opennmt.net/CTranslate2/python/ctranslate2.Translator.html#ctranslate2.Translator.translate_batch)
- Built for [WhisperLiveKit](https://github.com/QuentinFuxa/WhisperLiveKit)
- 200 languages. See [supported_languages.md](supported_languages.md) for the full list.
- Working on implementing a speculative/self-speculative decoding for a faster decoder, using 600M as draft model, and 1.3B as main model. Refs: https://arxiv.org/pdf/2211.17192: https://arxiv.org/html/2509.21740v1,
## Installation
```bash
pip install nllw
```
> The textual frontend is not installed by default.
## Quick Start
1. Demo interface :
```bash
python textual_interface.py
```
2. Use it as a package
```python
import nllw
model = nllw.load_model(
src_langs=["fra_Latn"],
nllb_backend="transformers",
nllb_size="600M" #Alternative: 1.3B
)
translator = nllw.OnlineTranslation(
model,
input_languages=["fra_Latn"],
output_languages=["eng_Latn"]
)
tokens = [nllw.timed_text.TimedText('Ceci est un test de traduction')]
translator.insert_tokens(tokens)
validated, buffer = translator.process()
print(f"{validated} | {buffer}")
tokens = [nllw.timed_text.TimedText('en temps réel')]
translator.insert_tokens(tokens)
validated, buffer = translator.process()
print(f"{validated} | {buffer}")
```
## Work In Progress : Partial Speculative Decoding
Local Agreement already locks a stable prefix for the committed translation, so we cannot directly adopt [Self-Speculative Biased Decoding for Faster Live Translation](https://arxiv.org/html/2509.21740v1). Our ongoing prototype instead borrows the speculative idea only for the *new* tokens that need to be validated by the larger model.
The flow tested in `speculative_decoding_v0.py`:
- Run the 600M draft decoder once to obtain the candidate continuation and its cache.
- Replay the draft tokens through the 1.3B model, but stop the forward pass as soon as the main model reproduces a token emitted by the draft (`predicted_tokens` matches the draft output). We keep those verified tokens and only continue generation from that point.
- On mismatch, resume full decoding with the 1.3B model until a match is reached again, instead of discarding the entire draft segment.
This “partial verification” trims the work the main decoder performs after each divergence, while keeping the responsiveness of the draft hypothesis. Early timing experiments from `speculative_decoding_v0.py` show the verification pass (~0.15 s in the example) is significantly cheaper than recomputing a full decoding step every time.
<p align="center">
<img src="https://raw.githubusercontent.com/QuentinFuxa/NoLanguageLeftWaiting/05b8d868cc74a3f14c67e35bfbe460d8ff78d512/partial_speculative_decoding.png"width="730">
</p>
## Input vs Output length:
Succesfully maintain output length, even if stable prefix tends to take time to grow.
<p align="center">
<img src="french_to_english.png"width="730">
</p>
| text/markdown | Quentin Fuxa | null | null | null | MIT | machine-translation, simultaneous-translation, nllb, streaming, nlp, transformers, ai | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Programming Language :: Python :: 3.15",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Multimedia :: Sound/Audio :: Speech"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"torch>=1.10.0",
"transformers>=4.30.0",
"ctranslate2>=3.16.0; extra == \"ctranslate2\"",
"textual>=0.40.0; extra == \"demo\"",
"bertviz>=1.4.1; extra == \"demo\"",
"transformers>4.57; extra == \"demo\""
] | [] | [] | [] | [
"Homepage, https://github.com/QuentinFuxa/NoLanguageLeftWaiting"
] | twine/6.2.0 CPython/3.13.9 | 2026-02-20T10:03:13.966038 | nllw-0.1.5.tar.gz | 1,520,002 | 47/84/cd9e2c8ed1ac942911f8ab9378fd875bd85a62af81025cb56b9b4435314b/nllw-0.1.5.tar.gz | source | sdist | null | false | 5953fd3660faff918fdf9ce41b067531 | 67f9c13fff6b43c2e05b2e762e7001471329dbdb34634b56a2cab639807b1b9a | 4784cd9e2c8ed1ac942911f8ab9378fd875bd85a62af81025cb56b9b4435314b | null | [] | 213 |
2.4 | llamphouse | 1.1.0 | LLAMPHouse OpenAI Assistant Server | > [!NOTE]
> This package is still under development. Always use the latest version for better stability.
<!-- PROJECT SHIELDS -->
[![Contributors][contributors-shield]][contributors-url]
[![Forks][forks-shield]][forks-url]
[![Stargazers][stars-shield]][stars-url]
[![Issues][issues-shield]][issues-url]
[![Unlicense License][license-shield]][license-url]
[![LinkedIn][linkedin-shield]][linkedin-url]
<!-- PROJECT LOGO -->
<br />
<div align="center">
<a href="https://github.com/llamp-ai/llamphouse">
<img src="docs/img/llamphouse.png" alt="Logo" width="80" height="80">
</a>
<h3 align="center">LLAMPHouse</h3>
<p align="center">
Serving Your LLM Apps, Scalable and Reliable.
<br />
<a href="https://github.com/llamp-ai/llamphouse/tree/main/docs"><strong>Explore the docs »</strong></a>
<br />
<br />
<!-- <a href="https://github.com/llamp-ai/llamphouse">View Demo</a> -->
·
<a href="https://github.com/llamp-ai/llamphouse/issues/new?labels=bug&template=bug-report---.md">Report Bug</a>
·
<a href="https://github.com/llamp-ai/llamphouse/issues/new?labels=enhancement&template=feature-request---.md">Request Feature</a>
</p>
</div>
<!-- PROJECT DESCRIPTION -->
# Introduction
Building LLM-powered applications is easier than ever, with countless frameworks helping you craft intelligent workflows in Python. But when it’s time to deploy at scale, the challenges begin.
Most tutorials suggest spinning up a FastAPI server with an endpoint — but what happens when scalability and reliability becomes critical?
**That’s where LLAMPHouse comes in.**
LLAMPHouse provides a self-hosted, production-ready server that mimics OpenAI’s Assistant API while giving you full control over execution. Whether you're using LangChain, LlamaIndex, or your own custom framework, LLAMPHouse lets you deploy, scale, and customize your LLM apps—without sacrificing flexibility.

Take control of your LLM infrastructure and build AI-powered apps on your own terms with LLAMPHouse. 🚀
<!-- GETTING STARTED -->
## Getting Started
Requires Python 3.10+.
```
pip install llamphouse
```
LLAMPHouse uses an in-memory data store by default (no database required).
To enable Postgres, set:
```
DATABASE_URL="postgresql://postgres:password@localhost/llamphouse"
```
<!-- USAGE EXAMPLES -->
## Usage
LLAMPHouse supports pluggable backends:
- data_store: in_memory (default) or postgres
- event queue: in_memory or janus
_Streaming adapters are available for OpenAI, Gemini, and Anthropic.
See [Examples](examples/) for full runnable samples._
<!-- DEVELOPMENT -->
## Development
### Local
1. Clone the repository
2. Install the library `pip install .`
### Build
This is only required if you want to push the package to PyPI.
1. `python setup.py sdist bdist_wheel`
2. `git tag -a v1.0.0 -m "Release version 1.0.0"`
3. `git push`
### Testing
1. Install the package locally.
2. Run tests:
```bash
python -m pytest tests/unit tests/contract tests/integration
```
3. Optional Postgres tests:
- set `DATABASE_URL` and run:
```bash
python -m pytest -m postgres
```
### Database (Postgres only)
Use Alembic when running the postgres data_store:
1. ```bash
docker run --rm -d --name postgres -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=password -p 5432:5432 postgres
```
2. ```bash
docker exec -it postgres psql -U postgres -c 'CREATE DATABASE llamphouse;'
```
To create a new database revision: `alembic revision --autogenerate -m "Added account table"`
To upgrade the database with the latest revision: `alembic upgrade head`
To downgrade back to the base version: `alembic downgrade base`
<!-- ENDPOINTS -->
## Included API endpoints
- Assistants
- ~~Create~~ -> created in code
- [X] List
- [X] Retrieve
- ~~Modify~~ -> only in code
- ~~Delete~~ -> only in code
- Threads
- [X] Create
- [X] Retrieve
- [X] Modify
- [X] Delete
- Messages
- [X] Create
- [X] List
- [X] Retrieve
- [X] Modify
- [X] Delete
- Runs
- [X] Create
- [X] Create thread and run
- [X] List
- [X] Retrieve
- [X] Modify
- [X] Submit tool outputs
- [X] Cancel
- Run steps
- [X] List
- [X] Retrieve
- Vector stores
- [ ] Create -> depends on implementation
- [ ] List
- [ ] Retrieve
- [ ] Modify
- [ ] Delete -> depends on implementation
- Vector store files
- [ ] Create
- [ ] List
- [ ] Retrieve
- [ ] Delete
- Vector store file batches
- [ ] Create
- [ ] Retrieve
- [ ] Cancel
- [ ] List
- Streaming
- [X] Message delta
- [X] Run step object
- [X] Assistant stream
<!-- CONTRIBUTING -->
## Contributing
Contributions are what make the open source community such an amazing place to learn, inspire, and create. Any contributions you make are **greatly appreciated**.
If you have a suggestion that would make this better, please fork the repo and create a pull request. You can also simply open an issue with the tag "enhancement".
Don't forget to give the project a star! Thanks again!
1. Fork the Project
2. Create your Feature Branch (`git checkout -b feature/AmazingFeature`)
3. Commit your Changes (`git commit -m 'Add some AmazingFeature'`)
4. Push to the Branch (`git push origin feature/AmazingFeature`)
5. Open a Pull Request
### Top contributors:
<a href="https://github.com/llamp-ai/llamphouse/graphs/contributors">
<img src="https://contrib.rocks/image?repo=llamp-ai/llamphouse" alt="contrib.rocks image" />
</a>
<!-- LICENSE -->
## License
See [`LICENSE`](LICENSE) for more information.
<!-- CONTACT -->
## Contact
Project Admin: Pieter van der Deen - [email](mailto:pieter@llamp.ai)
<!-- MARKDOWN LINKS & IMAGES -->
[contributors-shield]: https://img.shields.io/github/contributors/llamp-ai/llamphouse?style=for-the-badge
[contributors-url]: https://github.com/llamp-ai/llamphouse/graphs/contributors
[forks-shield]: https://img.shields.io/github/forks/llamp-ai/llamphouse?style=for-the-badge
[forks-url]: https://github.com/llamp-ai/llamphouse/network/members
[stars-shield]: https://img.shields.io/github/stars/llamp-ai/llamphouse.svg?style=for-the-badge
[stars-url]: https://github.com/llamp-ai/llamphouse/stargazers
[issues-shield]: https://img.shields.io/github/issues/llamp-ai/llamphouse.svg?style=for-the-badge
[issues-url]: https://github.com/llamp-ai/llamphouse/issues
[license-shield]: https://img.shields.io/github/license/llamp-ai/llamphouse.svg?style=for-the-badge
[license-url]: https://github.com/llamp-ai/llamphouse/blob/master/LICENSE
[linkedin-shield]: https://img.shields.io/badge/-LinkedIn-black.svg?style=for-the-badge&logo=linkedin&colorB=555
[linkedin-url]: https://linkedin.com/in/pieter-vdd
| text/markdown | null | "llamp.ai" <pieter@llamp.ai> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"fastapi<0.130,>=0.100.0",
"uvicorn<0.41,>=0.15.0",
"SQLAlchemy<2.1.0,>=1.4.23",
"psycopg2-binary<3,>=2.9.9",
"alembic<2,>=1.17.2",
"python-dotenv<2,>=1.2.1",
"janus<3,>=2.0.0",
"opentelemetry-api<2,>=1.28",
"opentelemetry-sdk<2,>=1.28",
"opentelemetry-exporter-otlp<2,>=1.28",
"opentelemetry-instrumentation-fastapi<0.51,>=0.49b0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T10:02:46.895562 | llamphouse-1.1.0.tar.gz | 1,448,433 | a2/fc/e0bde0b10344bdd9d973e35a43ca414707779147e57bdc0af9d92bb29603/llamphouse-1.1.0.tar.gz | source | sdist | null | false | 538b92d19dc2c016f885d4f855b83ba6 | 16d6d4cb20697cd1cfe1195720e4d40a3ad23868ab7a6dc283df6fc59fc57f17 | a2fce0bde0b10344bdd9d973e35a43ca414707779147e57bdc0af9d92bb29603 | null | [
"LICENSE"
] | 211 |
2.4 | mpt-tool | 5.4.0 | Migration tool for extensions | # mpt-tool CLI
mpt-tool is a command-line utility to scaffold, run, and audit migrations for MPT extensions.
## Quick Start
1. **Install the tool:**
```bash
pip install mpt-tool
```
2. **Initialize the migration tool:**
```bash
mpt-service-cli migrate --init
```
3. **Create your first migration:**
```bash
mpt-service-cli migrate --new-data sync_users
```
4. **Edit the generated file in the migrations/ folder**
5. **Run all pending data migrations**
```bash
mpt-service-cli migrate --data
```
## Installation
Install with pip or your favorite PyPI package manager:
```bash
pip install mpt-tool
```
```bash
uv add mpt-tool
```
## Prerequisites
- Python 3.12+ in your environment
- A `migrations/` folder in your project (created automatically with `--init` or when you create your first migration)
- Environment variables. See [Environment Variables](#environment-variables) for details.
## Environment Variables
The tool uses the following environment variables:
- `MPT_API_BASE_URL`: The MPT API base url (required when using `MPTAPIClientMixin`)
- `MPT_API_TOKEN`: Your MPT API key (required when using `MPTAPIClientMixin`)
- `MPT_TOOL_STORAGE_TYPE`: Storage backend for migration state (`local` or `airtable`, default: `local`). See [Storage Configuration](#storage)
- `MPT_TOOL_STORAGE_AIRTABLE_API_KEY`: Your Airtable API key (required when using `AirtableAPIClientMixin` or when `MPT_TOOL_STORAGE_TYPE=airtable`)
## Configuration
### Storage
The tool supports two storage backends: local and Airtable. By default, it uses the local storage.
Local storage is the simplest option and is suitable for development and testing. However, it is not suitable for production deployments.
The state is stored in a `.migrations-state.json` file in your project root.
Airtable storage is recommended for production deployments. It allows you to track migration progress across multiple deployments.
#### Local Storage
No additional configuration is required.
#### Airtable Storage
Airtable configuration is done via environment variables:
- `MPT_TOOL_STORAGE_AIRTABLE_API_KEY`: Your Airtable API key
- `MPT_TOOL_STORAGE_AIRTABLE_BASE_ID`: Your Airtable base ID
- `MPT_TOOL_STORAGE_AIRTABLE_TABLE_NAME`: The name of the table to store migration state
Your Airtable table must have the following columns:
| Column Name | Field Type | Required |
|---------------|-----------------------------|:--------:|
| order_id | number | ✅ |
| migration_id | singleLineText | ✅ |
| started_at | dateTime | ❌ |
| applied_at | dateTime | ❌ |
| type | singleSelect (data, schema) | ✅ |
**Airtable configuration steps:**
1. Create a new table in your Airtable base (or use an existing one)
2. Add the columns listed above with the specified field types
3. Set the environment variables with your base ID and table name
## Initialization
Before using the migration tool for the first time, you should initialize it. This creates the necessary resources:
```bash
mpt-service-cli migrate --init
```
This command creates:
- The `migrations/` folder in your project root (if it doesn't exist)
- The state storage:
- For **local storage**: creates `.migrations-state.json` file
- For **Airtable storage**: creates the table in Airtable with the required schema
**When to use `--init`:**
- First time setting up the tool in a project
- When switching from local to Airtable storage (or vice versa)
- When you need to recreate the state storage
**Note:** If the state storage already exists, the command will fail with an error message. This prevents accidental data loss. If you need to reinitialize, manually delete the existing state file or table first.
## Usage
### Creating a New Migration
1. Decide the migration type (**data** or **schema**).
- **Data**: run after a release is deployed. Can take hours or days. Executed while MPT is running (e.g., updating product parameters, synchronizing Assets with external data)
- **Schema**: run before a release is deployed. Must be fast (not more than 15 min). Executed without ensuring the MPT is running (e.g., adding columns in Airtable)
2. Run the appropriate command:
```bash
# Data migration
mpt-service-cli migrate --new-data "migration_name"
```
```bash
# Schema migration
mpt-service-cli migrate --new-schema "migration_name"
```
A new file is created in `migrations/` with a timestamped prefix (e.g., `20260113180013_migration_name.py`) and a prefilled `Migrate` class.
order_id: timestamp prefix (e.g., `20260113180013`)
migration_id: user-provided name (e.g., `migration_name`)
file: generated file name (e.g., `20260113180013_migration_name.py`)
**Generated file structure:**
```python
from mpt_tool.migration import DataBaseMigration # or SchemaBaseMigration
class Migration(DataBaseMigration):
def run(self):
# implement your logic here
pass
```
#### Using Mixins
You can add mixins to your migration commands to access external services:
```python
from mpt_tool.migration import DataBaseMigration
from mpt_tool.migration.mixins import MPTAPIClientMixin, AirtableAPIClientMixin
class Migration(DataBaseMigration, MPTAPIClientMixin, AirtableAPIClientMixin):
def run(self):
# Access MPT API
agreement = self.mpt_client.commerce.agreements.get("AGR-1234-5678-9012")
self.log.info(f"Agreement id: {agreement.id}")
# Access Airtable
table = self.airtable_client.table("app_id", "table_name")
records = table.all()
self.log.info(f"Processed {len(records)} records")
```
### Checking Migrations
Before running migrations, you can validate your migration folder for issues:
```bash
mpt-service-cli migrate --check
```
This command:
- Verifies the migration folder structure
- Detects duplicate migration_id values (which could happen if migrations were created with the same name)
- Exits with code 0 if all checks pass
- Exits with code 1 and shows a detailed error message if duplicates are found
**Example output when duplicates are found:**
```bash
Checking migrations...
Error running check command: Duplicate migration_id found in migrations: 20260113180013_duplicate_name.py, 20260114190014_duplicate_name.py
```
**Best Practice:** Run `--check` as part of your CI/CD pipeline to catch migration issues before deployment.
### Running Migrations
- **Run all pending data migrations:**
```bash
mpt-service-cli migrate --data
```
- **Run all pending schema migrations:**
```bash
mpt-service-cli migrate --schema
```
- **Run one specific data migration:**
```bash
mpt-service-cli migrate --data MIGRATION_ID
```
- **Run one specific schema migration:**
```bash
mpt-service-cli migrate --schema MIGRATION_ID
```
Migrations are executed in order based on their order_id (timestamp). The tool automatically:
- Validates the migration folder structure
- Skips migrations that have already been applied (applied_at is not null)
- Tracks execution status in the state storage (`.migrations-state.json` or Airtable table)
- Logs migration progress
- Handles errors gracefully and updates state accordingly
When running a single migration (`--data MIGRATION_ID` or `--schema MIGRATION_ID`), the tool:
- Fails if `MIGRATION_ID` does not exist
- Fails if the migration type does not match the selected flag
- Fails if the migration was already applied
**Migration State File (`.migrations-state.json`):**
```json
{
"data_example": {
"migration_id": "data_example",
"order_id": 20260113180013,
"started_at": "2026-01-13T18:05:20.000000",
"applied_at": "2026-01-13T18:05:23.123456",
"type": "data"
},
"schema_example": {
"migration_id": "schema_example",
"order_id": 20260214121033,
"started_at": null,
"applied_at": null,
"type": "schema"
}
}
```
**Migration Table (Airtable):**
| order_id | migration_id | started_at | applied_at | type |
|----------------|----------------|----------------------------|----------------------------|--------|
| 20260113180013 | data_example | 2026-01-13T18:05:20.000000 | 2026-01-13T18:05:23.123456 | data |
| 20260214121033 | schema_example | | | schema |
If a migration succeeds during execution:
* The started_at timestamp is recorded
* The applied_at timestamp is recorded
If a migration fails during execution:
* The started_at timestamp is recorded
* The applied_at field remains null
* The error is logged
* Later runs will retry the failed migration as applied_at is null, unless `--manual` is used to mark it as applied
### Manual Mode
To mark a migration as applied without running it:
```bash
mpt-service-cli migrate --manual MIGRATION_ID
```
Where `MIGRATION_ID` is the filename without `order_id` and `.py` (e.g., `test1`).
**Example:**
- File: `20260113180013_sync_users.py`
- Migration ID: `sync_users`
If the migration doesn't exist in the migrations folder:
* An error is logged and the command exits
If the migration exists:
* The migration state is created if it doesn't exist yet or updated:
* The started_at field is set as null
* The applied_at timestamp is recorded
### Listing Migrations
To see all migrations and their status:
```bash
mpt-service-cli migrate --list
```
The output shows execution order, status, and timestamps.
The status column is derived from the persisted timestamps:
| Status | Condition |
|-------------|---------------------------------------------------------------|
| running | `started_at` is set and `applied_at` is empty |
| failed | `started_at` and `applied_at` are empty for an existing state |
| manual | `started_at` is empty and `applied_at` is set |
| applied | Both `started_at` and `applied_at` are set |
| not applied | No state entry exists for the migration file |
### Getting Help
Run `mpt-service-cli --help` to see all available commands and params:
```bash
mpt-service-cli --help
mpt-service-cli migrate --help
```
## Best Practices
### Migration Validation
- Run `mpt-service-cli migrate --check` before committing migration files
- Include `--check` in your CI/CD pipeline to catch issues early
- Verify there are no duplicate migration_id values before deployment
### Migration Naming
- Use descriptive, snake_case names (e.g., `add_user_table`, `fix_null_emails`, `sync_agreements_from_api`)
- Keep names concise but meaningful
- Avoid generic names like `migration1`, `fix_bug`, or `update`
### Version Control
- Never modify a migration that has been applied in production
- Create a new migration to fix issues from a previous one
## Troubleshooting
### Common Issues
**Initialization fails - state already exists:**
- Error: "Cannot initialize - State file already exists" (local storage) or similar for Airtable
- Cause: The state storage has already been initialized
- Solution: This is intentional to prevent data loss. If you need to reinitialize:
- For local storage: delete `.migrations-state.json` manually
- For Airtable: delete the table manually or use a different table name
- Only reinitialize if you're certain you want to start fresh
**Migrations not detected:**
- Ensure files are in the `migrations/` folder
- Verify filename follows the pattern: `<timestamp>_<migration_id>.py` (e.g., `20260121120000_migration_name.py`)
**Migration fails to run:**
- Review the error message in the terminal output
- Check your `Migration.run()` implementation for syntax errors
- Fix the issue and re-run the migration or use `--manual` to mark it as applied
**NOTE:** There is currently no automatic rollback mechanism. If a migration partially modifies data before failing, you must manually revert those changes or create a new migration to fix the state.
**Mixin errors (ValueError):**
- Verify all required environment variables are set
- Check variable names match exactly (case-sensitive)
**Duplicate migration IDs:**
- The tool prevents duplicate migration IDs automatically
- If you see this error, check for files with the same name in the `migrations/` folder
- Delete or rename the duplicate file
**Migration already applied:**
- If you need to re-run a migration, either:
- Remove its entry from the state storage (use with caution)
- Create a new migration with the updated logic
- Never modify an already-applied migration in production
## Pre-commit
Checking migrations with pre-commit:
Add this to your .pre-commit-config.yaml
```yaml
- repo: https://github.com/softwareone-platform/mpt-tool
rev: '' # Use the sha / tag you want to point at
hooks:
- id: check-migrations
```
## Development
For development purposes, please, check the Readme in the GitHub repository.
| text/markdown | SoftwareOne AG | null | null | null | Apache-2.0 license | null | [] | [] | null | null | <4,>=3.12 | [] | [] | [] | [
"mpt-api-client==5.0.*",
"pyairtable==3.3.*",
"typer==0.23.*"
] | [] | [] | [] | [] | uv/0.7.22 | 2026-02-20T10:02:13.753625 | mpt_tool-5.4.0.tar.gz | 24,290 | 5f/07/6c03444c5d6ace1547183ef0d3cf9c27e4dcfe42a5a9b6feb7b16490c2e8/mpt_tool-5.4.0.tar.gz | source | sdist | null | false | 39ee3ce77ed2d3f24ed65d228fcdb26a | 57e81c158d7e37425b9bbceaa71248e1862e7084614578320a9d7c86f566d893 | 5f076c03444c5d6ace1547183ef0d3cf9c27e4dcfe42a5a9b6feb7b16490c2e8 | null | [
"LICENSE"
] | 207 |
2.4 | aiosendspin | 4.1.0 | Async Python implementation of the Sendspin Protocol. | # aiosendspin
[](https://pypi.python.org/pypi/aiosendspin)
Async Python library implementing the [Sendspin Protocol](https://github.com/Sendspin-Protocol/spec).
For a WIP reference implementation of a server using this library, see [Music Assistant](https://github.com/music-assistant/server/tree/sendspin/music_assistant/providers/sendspin)
[](https://www.openhomefoundation.org/)
## Player
For a ready-to-use synchronized audio player, see the [sendspin](https://github.com/Sendspin-Protocol/sendspin) package.
| text/markdown | null | Sendspin Protocol Authors <sendspin@openhomefoundation.org> | null | null | Apache-2.0 | null | [
"Environment :: Console",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"aiohttp>=3.9.2",
"av>=15.0.0",
"mashumaro>=3.14",
"orjson>=3.10.0",
"pillow>=11.0.0",
"zeroconf>=0.147",
"numpy>=1.26.0; extra == \"numpy\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T10:02:07.927405 | aiosendspin-4.1.0.tar.gz | 104,976 | b3/5d/00258ce205263327bd1ba5776c42f19b999c515f5d51dc80176d372b5360/aiosendspin-4.1.0.tar.gz | source | sdist | null | false | 0c368050c6cb697a13446082a9d4e3c2 | ecee836b4b7991a9fac99b3b004f246dbb47d1f15e0a35b16a1335726a809eab | b35d00258ce205263327bd1ba5776c42f19b999c515f5d51dc80176d372b5360 | null | [
"LICENSE"
] | 249 |
2.1 | psychopy-lib | 2026.1.0 | PsychoPy provides easy, precise, flexible experiments in behavioural sciences | # PsychoPy Library
`psychopy-lib` is a library-only implementation of [PsychoPy](https://pypi.python.org/pypi/PsychoPy), meaning that dependencies specific to running the PsychoPy app are removed for a faster installation.
## More information about PsychoPy
* Homepage: https://www.psychopy.org
* PyPi: https://pypi.python.org/pypi/PsychoPy
* GitHub: https://github.com/psychopy/psychopy
* Forum: https://discourse.psychopy.org
* Issue tracker: https://github.com/psychopy/psychopy/issues
* Changelog: https://www.psychopy.org/changelog.html
| text/markdown | null | Open Science Tools Ltd <support@opensciencetools.org> | null | Open Science Tools Ltd <support@opensciencetools.org> | null | null | [
"Development Status :: 4 - Beta",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Topic :: Scientific/Engineering",
"License :: OSI Approved :: MIT License"
] | [] | null | null | <3.12,>=3.9 | [] | [] | [] | [
"numpy",
"scipy<1.15",
"matplotlib",
"pyglet==1.4.11; platform_system == \"Windows\"",
"pyglet==1.5.27; platform_system != \"Windows\"",
"pillow>=9.4.0",
"pyqt6",
"pandas>=1.5.3",
"questplus>=2023.1",
"openpyxl",
"xmlschema",
"soundfile",
"imageio",
"imageio-ffmpeg",
"psychtoolbox<3.0.20; platform_machine != \"arm64\"",
"pywinhook; platform_system == \"Windows\"",
"zope.event==5.0",
"zope.interface==7.2",
"gevent==25.5.1",
"MeshPy",
"psutil",
"pyzmq>=22.2.1",
"ujson",
"msgpack",
"msgpack-numpy",
"pyyaml",
"freetype-py",
"python-bidi",
"arabic-reshaper",
"websockets",
"markdown-it-py",
"requests",
"future",
"cryptography",
"astunparse",
"jedi>=0.16",
"pyserial",
"pyparallel; platform_system != \"Darwin\"",
"ffpyplayer",
"pypiwin32; platform_system == \"Windows\"",
"pyobjc-core>8.0; platform_system == \"Darwin\"",
"pyobjc-framework-Quartz>8.0; platform_system == \"Darwin\"",
"pyobjc>8.0; platform_system == \"Darwin\"",
"pyobjc-framework-ScriptingBridge>8.0; platform_system == \"Darwin\"",
"zeroconf; platform_system == \"Darwin\"",
"python-xlib; platform_system == \"Linux\"",
"distro; platform_system == \"Linux\"",
"tables!=3.9.2",
"packaging>=24.0",
"moviepy",
"pyarrow",
"beautifulsoup4",
"setuptools>=70.3.0",
"pytest>=6.2.5; extra == \"tests\"",
"pytest-codecov; extra == \"tests\"",
"pytest-cov; extra == \"tests\"",
"pytest-asyncio; extra == \"tests\"",
"flake8; extra == \"tests\"",
"xmlschema; extra == \"tests\"",
"sphinx; extra == \"docs\"",
"jinja2; extra == \"docs\"",
"sphinx-design; extra == \"docs\"",
"sphinx-copybutton; extra == \"docs\"",
"myst-parser; extra == \"docs\"",
"sphinxcontrib.svg2pdfconverter; extra == \"docs\"",
"psychopy-sphinx-theme; extra == \"docs\"",
"bdist-mpkg>=0.5.0; platform_system == \"Darwin\" and extra == \"building\"",
"py2app; platform_system == \"Darwin\" and extra == \"building\"",
"dmgbuild; platform_system == \"Darwin\" and extra == \"building\"",
"polib; extra == \"building\"",
"sounddevice; extra == \"suggested\"",
"pylsl>=1.16.1; extra == \"suggested\"",
"xlwt; extra == \"suggested\"",
"h5py; extra == \"suggested\"",
"tobii_research; extra == \"suggested\"",
"badapted>=0.0.3; extra == \"suggested\"",
"egi-pynetstation>=1.0.0; extra == \"suggested\"",
"pyxid2>=1.0.5; extra == \"suggested\"",
"Phidget22; extra == \"suggested\"",
"pyo>=1.0.3; extra == \"legacy\"",
"pyglfw; extra == \"legacy\"",
"pygame; extra == \"legacy\""
] | [] | [] | [] | [
"Homepage, https://www.psychopy.org/",
"Download, https://github.com/psychopy/psychopy/releases/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T10:01:09.461981 | psychopy_lib-2026.1.0.tar.gz | 38,257,057 | ff/38/f265c8af958da309d134fa8fa96fb1b1154bf4aaa5cec73a34b1e3b3b5d6/psychopy_lib-2026.1.0.tar.gz | source | sdist | null | false | 03bd85bc128cef364cad30b15046637a | 7f6fce73679a5c514d7d6f1c64062e08e1704753b5bfbc2f4c171b4f8583d797 | ff38f265c8af958da309d134fa8fa96fb1b1154bf4aaa5cec73a34b1e3b3b5d6 | null | [] | 299 |
2.4 | visualcheck | 0.3.1 | Visual regression checking with figma-first baselines, pixel+SSIM diffing, ignore regions, and HTML reports. | # visualcheck
Visual regression checking with:
- **Figma-first baselines** (optionally synced via Figma API)
- **Runtime baselines** (auto-create when missing; never overwrite by default)
- **Pixel diff % + SSIM** (with optional resize-on-mismatch + WARN)
- **Ignore regions** (mask dynamic areas via selectors + explicit rects)
- **Self-contained HTML report** + `report.json`
## Install
```bash
pip install visualcheck
playwright install chromium
```
## Config (`visualcheck.yaml`)
```yaml
project: consumer_website
suite: daily_sanity
envs:
prod: "https://example.com"
views:
desktop_profiles: ["desktop_1440x900", "macbook_1440x900"]
mobile_devices: ["iPhone 15 Pro Max", "iPhone 13 mini", "Pixel 7"]
pages:
- id: home
url: "/"
wait_for: "body"
full_page: true
# Optional flows (multi-step user journeys)
flows:
- id: search_flow
start_url: "/"
steps:
- action: click
selector: "text=Search"
- action: wait
ms: 500
snapshots:
- id: after_search
wait_for: "body"
full_page: true
baseline:
# Locked resolution order:
# figma -> runtime -> create runtime baseline (if enabled)
priority: ["figma", "runtime"]
create_if_missing: true
never_overwrite: true
on_created: "INFO" # INFO|WARN|FAIL
# Optional legacy mode: copy figma image into runtime when figma is used.
# Default behavior keeps runtime as website-captured truth.
seed_runtime_from_figma: false
compare:
resize_on_mismatch: true
mismatch_level: "WARN" # WARN|FAIL
thresholds:
max_pixel_diff_pct: 0.10
min_ssim: 0.995
# Optional per-snapshot override + region-level checks
by_snapshot:
home:
max_pixel_diff_pct: 0.15
min_ssim: 0.992
regions:
- name: header_strict
x: 0
y: 0
width: 1440
height: 120
max_pixel_diff_pct: 0.03
min_ssim: 0.998
# Optional ignore-region suggestions from diff output
suggest_ignore_regions:
enabled: true
min_area: 2500
max_regions: 5
capture:
# prefer Chrome channel (fallback to bundled Chromium if unavailable)
browser_channel: "chrome"
extra_wait_ms: 1000
scrolls: 5
scroll_delay_ms: 700
retries: 1
retry_delay_ms: 700
# Optional page stabilization before screenshot
stability_checks: 2
stability_interval_ms: 250
stability_timeout_ms: 3000
screenshot_timeout_ms: 90000
stability:
# auto-rerun unstable snapshots and choose final outcome by consensus
reruns_on_warn: 1
reruns_on_fail: 2
require_consensus: "best" # best|median|majority
quarantine:
snapshots:
- "search_flow__after_search"
owners:
by_snapshot:
home: "web-platform-team"
"desktop_1440x900:pricing": "checkout-team"
ignore_regions:
global:
selectors: ["#cookie-banner", ".chat-widget"]
by_snapshot:
home:
rects:
- {x: 0, y: 0, width: 300, height: 120}
# Optional Figma sync (writes into visual_baseline/<project>/<suite>/figma/...)
# figma:
# token_env: FIGMA_TOKEN
# file_key: "<FIGMA_FILE_KEY>"
# frames:
# - id: home
# node_id: "123:456"
# view_id: "desktop_1440x900" # optional
```
## Commands
### Run full check
```bash
visualcheck run --env prod
```
Outputs:
- Baselines:
- `visual_baseline/<project>/<suite>/figma/<view>/<snapshot>.png`
- `visual_baseline/<project>/<suite>/runtime/<view>/<snapshot>.png`
- Run artifacts:
- `test_report/<project>/visual_runs/<run_id>/current/...`
- `test_report/<project>/visual_runs/<run_id>/diff/...`
- `test_report/<project>/visual_runs/<run_id>/report/report.html`
- `test_report/<project>/visual_runs/<run_id>/report/report.json`
- `test_report/<project>/visual_runs/<run_id>/report/report.junit.xml`
### Capture only
```bash
visualcheck capture --env prod --out current
```
### Diff only
```bash
visualcheck diff --baseline visual_baseline/myproj/mysuite/runtime --current current --out report
```
### Sync Figma baselines
```bash
export FIGMA_TOKEN="..."
visualcheck figma-sync
# force refresh selected frames:
visualcheck figma-sync --force --only home,pricing
# auto-map page/flow snapshot ids to figma frame names:
visualcheck figma-sync --match-by-name
```
### Compare strictly against Figma baseline
```bash
visualcheck figma-diff --env prod
```
### Approve current run as runtime baseline (explicit)
```bash
visualcheck approve --env prod --run-id 20260207_235500
# Overwrite existing runtime baselines only with:
visualcheck approve --env prod --run-id 20260207_235500 --force
```
### Validate config
```bash
visualcheck validate-config --config visualcheck.yaml
```
### Cleanup old run artifacts
```bash
visualcheck cleanup --config visualcheck.yaml --keep-last 20 --dry-run
visualcheck cleanup --config visualcheck.yaml --keep-last 20
```
### Quarantine management
```bash
visualcheck quarantine-list --config visualcheck.yaml
visualcheck quarantine-add --config visualcheck.yaml --snapshot search_flow__after_search
visualcheck quarantine-remove --config visualcheck.yaml --snapshot search_flow__after_search
```
## Baseline rules (locked)
For each snapshot + view:
1) If a **Figma baseline** exists → use it
- visualcheck will attempt a best-effort `figma-sync` when `figma` is listed in `baseline.priority` so remote Figma baselines are consulted before falling back.
2) Else if a **runtime baseline** exists → use it
3) Else → capture and **create runtime baseline** (controlled by `baseline.create_if_missing`)
Notes on configuration and behavior
- `baseline.priority` controls the preference order. Example:
`priority: ["figma","runtime"]` (default in examples) — visualcheck will try Figma first.
- By default a Figma baseline is used directly for comparison (reported baseline path will point at `.../figma/...`).
- By default, Figma does **not** auto-create runtime baseline copies.
Runtime remains website-captured truth (created from current captures when missing).
- If you want legacy behavior (copy Figma into runtime), set:
```yaml
baseline:
seed_runtime_from_figma: true
```
- If you want Figma to become the authoritative runtime baseline (copied into the `runtime/` folder and then used), set:
```yaml
baseline:
figma_authoritative: true
```
- This avoids accidental comparisons against an old runtime image when Figma is the source of truth.
- If a figma baseline is missing locally and `figma` appears in priority, visualcheck will attempt to fetch it via the Figma API (best-effort). If the fetch fails (token/permission), it falls back to runtime per `priority`.
Figma metadata in report
- When a snapshot resolves to a Figma frame, report rows include `figma.file_key`, `figma.node_id`, and a direct `figma.frame_url`.
Report upgrades
- HTML report includes status summary cards, client-side status filters, top regressions, baseline/current slider, and optional ignore-region suggestions.
- Rows include plain-language issue summary and recommended action to make pixel triage faster.
- Report includes flake score, root-cause hint, snapshot owner, quarantine status, and likely-introduced-after commit hint.
- History files are stored under `test_report/<project>/history/` for trends, flake scoring, and change correlation.
## Use from code (framework integration)
If you already navigate with **Playwright**/**Selenium** in your own framework and just want visualcheck to **capture + baseline + diff + report**, use the code API.
> Baselines still go to `visual_baseline/<project>/<suite>/...` and the HTML report goes to `test_report/<project>/visual_runs/<run_id>/report/report.html`.
### Playwright (sync) example
```python
from playwright.sync_api import sync_playwright
# NOTE: API object names may evolve; refer to the package docs in case of changes.
from visualcheck.api import VisualCheck
vc = VisualCheck(
project="my_project",
suite="daily_sanity",
env="prod",
base_url="https://example.com",
view_id="desktop_1440x900",
baseline_priority=["figma", "runtime"],
create_if_missing=True,
ignore_selectors=["#cookie-banner", ".chat-widget"],
)
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page(viewport={"width": 1440, "height": 900})
page.goto("https://example.com/", wait_until="domcontentloaded")
vc.check(snapshot_id="home", page=page)
page.goto("https://example.com/pricing", wait_until="domcontentloaded")
vc.check(snapshot_id="pricing", page=page)
vc.finalize()
print("Report:", vc.report_html)
browser.close()
```
### Selenium example
```python
from selenium import webdriver
from visualcheck.api import VisualCheck
vc = VisualCheck(
project="my_project",
suite="daily_sanity",
env="prod",
base_url="https://example.com",
view_id="desktop_1440x900",
)
driver = webdriver.Chrome()
driver.set_window_size(1440, 900)
driver.get("https://example.com/")
vc.check(snapshot_id="home", selenium_driver=driver)
driver.get("https://example.com/pricing")
vc.check(snapshot_id="pricing", selenium_driver=driver)
vc.finalize()
print("Report:", vc.report_html)
driver.quit()
```
## Notes
- Ignore regions are masked with a solid color before diffing.
- If screenshot sizes differ and `compare.resize_on_mismatch=true`, current is resized to baseline size and a warning is recorded.
## License
MIT
## Library & CLI usage (examples)
### Programmatic API (Python)
The package exposes a simple programmatic API to integrate with Playwright or Selenium.
Example (Playwright):
```python
from visualcheck.runner import run_visualcheck
from visualcheck.config import load_config
cfg = load_config(Path('examples/wakefit.yaml'))
result = run_visualcheck(cfg, env='prod', headed=False)
print('Report saved at', result.get('report_html'))
```
### CLI usage
- Sync Figma baselines:
```bash
export FIGMA_TOKEN="<your_token>"
visualcheck figma-sync --config examples/wakefit.yaml
```
- Run full check:
```bash
visualcheck run --env prod --config examples/wakefit.yaml
```
### Notes on FIGMA token & env handling
- The library reads Figma token from the environment variable name specified in config (defaults to `FIGMA_TOKEN`).
- Keep secrets out of git; use host-level secrets (e.g. `~/.openclaw/secrets.env`) or a CI secret store.
| text/markdown | null | Arif Shah <ashah7775@gmail.com> | null | null | MIT | visual-regression, playwright, ssim, qa, figma | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"playwright>=1.40",
"pillow>=10",
"numpy>=1.23",
"opencv-python-headless>=4.8",
"scikit-image>=0.20",
"PyYAML>=6",
"Jinja2>=3",
"typer>=0.9",
"rich>=13",
"jsonschema>=4",
"requests>=2.31",
"python-dotenv>=0.21",
"pytest>=8.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://bitbucket.org/arif_automation/visualcheck",
"Source, https://bitbucket.org/arif_automation/visualcheck"
] | twine/6.2.0 CPython/3.11.4 | 2026-02-20T10:01:01.124178 | visualcheck-0.3.1.tar.gz | 37,003 | 31/26/9c10294a8b6508335aff69777ac7c42f590e5e50c80743482f5c8727df94/visualcheck-0.3.1.tar.gz | source | sdist | null | false | 679d5717c1ccb3bacf45b10d360b05fd | e1f9d87f2db998c8100c2805ffcc5a179add90062f94de9fdbc594647d160a9e | 31269c10294a8b6508335aff69777ac7c42f590e5e50c80743482f5c8727df94 | null | [] | 184 |
2.4 | marty-cli | 0.3.1 | My Python CLI | # marty-cli
<img src="https://raw.githubusercontent.com/nesalia-inc/marty-cli/refs/heads/main/.github/banner.png" height="150">
[](https://pypi.org/project/marty-cli/)
[](https://pypi.org/project/marty-cli/)
[](https://github.com/nesalia-inc/marty-cli/actions)
CLI tool to manage Marty actions workflows. Add bundled workflows with one command.
## Requirements
- Python 3.12+
- uv (recommended) or pip
## Installation
```bash
# Install marty-cli
pip install marty-cli
# Or using uv
uv pip install marty-cli
```
## Usage
```bash
# List available workflows
marty-cli workflow list
# Add a workflow
marty-cli workflow add issue-discussion
# Add all bundled workflows
marty-cli workflow add --all
# Update a workflow
marty-cli workflow update issue-discussion
# Update all installed workflows
marty-cli workflow update --all
# Delete a workflow
marty-cli workflow delete issue-discussion
# Use custom path
marty-cli workflow add issue-discussion --path /my/project
```
## Available Workflows
- `issue-discussion` - Marty AI responds to GitHub issues when mentioned
- `issue-implementation` - Marty implements features when asked ("implement")
- `issue-triage` - Auto triage new issues
- `pr-discussion` - Marty discusses in PRs when mentioned
- `pr-fix` - Marty fixes PR issues when asked ("fix")
- `pr-review` - Auto review PRs
## Development
```bash
# Clone and install
git clone https://github.com/nesalia-inc/marty-cli.git
cd marty-cli
# Install dependencies
uv sync --extra dev
# Run linter
ruff check .
# Run type checker
mypy src
# Run tests
pytest
```
## License
MIT
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"typer>=0.12.0",
"mypy>=1.0.0; extra == \"dev\"",
"pre-commit>=3.0.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.4.0; extra == \"dev\"",
"rich>=13.0.0; extra == \"rich\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T10:00:54.743435 | marty_cli-0.3.1-py3-none-any.whl | 14,766 | ff/6f/a12385a10a5447141d07560173e0b7f5a88fe40f4e7fe4733adb0ee23752/marty_cli-0.3.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 65d725c0a7e5e04c4621c0e8670e603b | 92fa92186e0817f68627c25c46da92a219d7259c27fdaa7dfafe264cebb21cd3 | ff6fa12385a10a5447141d07560173e0b7f5a88fe40f4e7fe4733adb0ee23752 | null | [] | 183 |
2.4 | gizai | 7.344.1 | 🔻 Access, Automation, Analytics, AI - A Mathematical model for AI languages. | # 🔻 giza
🔻 `giza` is a Mathematical model for AI languages such as [`bluer-ai`](https://github.com/kamangir/bluer-ai) and [its ecosystem](https://github.com/kamangir/bluer-south). This model is described in the working paper "[Access, Automation, Analytics, AI](https://github.com/kamangir/giza/blob/main/pdf/giza.pdf)" [[tex](https://github.com/kamangir/giza/blob/main/tex/giza.tex)].
---
[](https://github.com/kamangir/giza/actions/workflows/pylint.yml) [](https://github.com/kamangir/giza/actions/workflows/pytest.yml) [](https://github.com/kamangir/giza/actions/workflows/bashtest.yml) [](https://pypi.org/project/gizai/) [](https://pypistats.org/packages/gizai)
built by 🌀 [`blueness-3.122.1`](https://github.com/kamangir/blueness).
| text/markdown | Arash Abadpour (Kamangir) | arash.abadpour@gmail.com | null | null | CC0-1.0 | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Unix Shell",
"Operating System :: OS Independent"
] | [] | https://github.com/kamangir/giza | null | null | [] | [] | [] | [
"bluer_ai"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.9 | 2026-02-20T09:59:37.323907 | gizai-7.344.1.tar.gz | 7,998 | b4/6b/b7ed3024749c3a99582faf1c19a0981c61e347b112f429d52135cad39c25/gizai-7.344.1.tar.gz | source | sdist | null | false | 801bd7ee67623cf5001cc65ddbf885ca | 939fd621329b8f87d5272f324f830f5b19c8c9165e36b5ad3e38af86fe54f929 | b46bb7ed3024749c3a99582faf1c19a0981c61e347b112f429d52135cad39c25 | null | [
"LICENSE"
] | 207 |
2.4 | owui-mcp-server | 1.0.0 | MCP Server for Open WebUI Knowledge Bases | # Open WebUI Knowledge Base MCP Server
An MCP (Model Context Protocol) server that exposes [Open WebUI](https://github.com/open-webui/open-webui) Knowledge Bases as tools and resources, enabling AI assistants like Cursor and Claude Desktop to search and access knowledge bases.
## Features
- 🔍 **Semantic Search** - Search knowledge bases using semantic search
- 📚 **Knowledge Base Management** - List and get information about knowledge bases
- 👥 **Multi-User Support** - Each connection uses its own API token for isolation
- 🌐 **Dual Transport Modes** - Supports both stdio (local) and HTTP (remote) transports
- 🔒 **Secure** - Per-connection authentication, input validation, rate limiting, CORS protection
## Quick Start
### Prerequisites
- Python 3.8+ or Docker
- Open WebUI instance with API access
- API token from Open WebUI (Settings → Account → API keys)
### Installation
```bash
pip install -r requirements.txt
```
Or using `uvx`:
```bash
pip install uv # or: brew install uv
uvx --from . python mcp_server.py
```
## Usage
### stdio Mode (Local)
```bash
export OPEN_WEBUI_API_URL="https://your-open-webui-instance.com/api/v1"
export OPEN_WEBUI_API_TOKEN="sk-your-token-here"
python mcp_server.py
```
### HTTP Mode (Production)
**Docker Compose:**
```bash
# Create .env file
echo "OPEN_WEBUI_API_URL=https://your-open-webui-instance.com/api/v1" > .env
# Start server
docker-compose up -d
# View logs
docker-compose logs -f
```
**Direct Python:**
```bash
export OPEN_WEBUI_API_URL="https://your-open-webui-instance.com/api/v1"
export MCP_TRANSPORT="http"
export MCP_HTTP_PORT="8001"
python mcp_server.py
```
Server endpoints:
- **MCP**: `http://localhost:8001/mcp`
- **Health**: `http://localhost:8001/health`
## Configuring Cursor to use your MCP server
### Cursor: stdio Mode
Edit `~/.cursor/mcp.json`:
```json
{
"mcpServers": {
"open-webui-knowledge": {
"command": "uvx",
"args": ["--from", "/path/to/open-webui-mcp-server", "python", "/path/to/open-webui-mcp-server/mcp_server.py"],
"env": {
"OPEN_WEBUI_API_URL": "https://your-open-webui-instance.com/api/v1",
"OPEN_WEBUI_API_TOKEN": "sk-your-token-here"
}
}
}
}
```
### Cursor: HTTP Mode
```json
{
"mcpServers": {
"open-webui-knowledge": {
"url": "http://localhost:8001/mcp",
"headers": {
"Authorization": "Bearer sk-your-token-here"
}
}
}
}
```
## Available Tools
- **`list_knowledge_bases`** - List all accessible knowledge bases
- `permission` (optional): `"read"` or `"write"` (default: `"read"`)
- **`search_knowledge_base`** - Search a knowledge base using semantic search
- `knowledge_base_id` (required): The ID of the knowledge base
- `query` (required): Your search query
- `k` (optional): Number of results (default: 5)
- **`get_knowledge_base_info`** - Get detailed information about a knowledge base
- `knowledge_base_id` (required): The ID of the knowledge base
## Environment Variables
| Variable | Description | Default |
|----------|-------------|---------|
| `OPEN_WEBUI_API_URL` | Open WebUI API base URL | Required |
| `OPEN_WEBUI_API_TOKEN` | Default API token (optional) | None |
| `MCP_TRANSPORT` | Transport mode: `stdio` or `http` | `stdio` |
| `MCP_HTTP_HOST` | HTTP server host | `0.0.0.0` |
| `MCP_HTTP_PORT` | HTTP server port | `8001` |
| `MCP_CORS_ORIGINS` | Comma-separated CORS origins (empty = no CORS) | Empty |
| `MCP_RATE_LIMIT_PER_IP` | Rate limit per IP (e.g., "1000/minute") | `1000/minute` |
| `MCP_RATE_LIMIT_PER_TOKEN` | Rate limit per token | `1000/minute` |
| `MCP_RATE_LIMIT_HEALTH` | Rate limit for health endpoint | `10/minute` |
## Security
- Input validation and sanitization
- Rate limiting (per-IP and per-token)
- CORS protection (disabled by default)
- Request size limits (10MB max)
- Error message sanitization
- Token validation
## Contributing
See [CONTRIBUTING.md](CONTRIBUTING.md) for development setup and guidelines.
## License
This project is licensed under the **MIT License**.
---
<div align="center">
**Built with ❤️ by [Ronas IT](https://ronasit.com)**
_Professional development services • Open source contributors_
[Website](https://ronasit.com) • [GitHub](https://github.com/RonasIT) • [Email](mailto:hello@ronasit.com)
</div>
| text/markdown | Ronas IT | null | null | null | null | mcp, open-webui, knowledge-base, ai, model-context-protocol | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"httpx>=0.27.0",
"mcp>=1.0.0",
"fastapi>=0.104.0",
"uvicorn[standard]>=0.24.0",
"slowapi>=0.1.9",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"python-dotenv>=1.0.0; extra == \"dev\"",
"pre-commit>=3.5.0; extra == \"dev\"",
"black>=24.1.0; extra == \"dev\"",
"isort>=5.13.0; extra == \"dev\"",
"flake8>=7.0.0; extra == \"dev\"",
"flake8-docstrings>=1.7.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/RonasIT/open-webui-mcp-server",
"Repository, https://github.com/RonasIT/open-webui-mcp-server",
"Issues, https://github.com/RonasIT/open-webui-mcp-server/issues"
] | twine/6.2.0 CPython/3.11.3 | 2026-02-20T09:59:21.170517 | owui_mcp_server-1.0.0.tar.gz | 17,202 | 0d/e3/df9368c96ddb2ddef00027257b3e6aa761dde2a5162864d023112d6f1fc5/owui_mcp_server-1.0.0.tar.gz | source | sdist | null | false | 4420fb223016b3af69ebe421c93a4ab7 | 9f1972aaa4a409218f7df57fb8e6fc376623520213e0c449ce0f1c20a6027c8e | 0de3df9368c96ddb2ddef00027257b3e6aa761dde2a5162864d023112d6f1fc5 | MIT | [
"LICENSE"
] | 227 |
2.4 | bluer-ai | 12.632.1 | 🌀 A language to speak AI. | # 🌀 bluer-ai
🌀 `bluer-ai` is an implementation of 🔻 [giza](https://github.com/kamangir/giza) and a language [to speak AI](https://github.com/kamangir/bluer-south).

# installation
```bash
pip install bluer_ai
```
Add to `bashrc`, `.bash_profile`, or the relevant startup file.
```bash
source $(python3 -m bluer_ai locate)/.abcli/bluer_ai.sh
```
# dev install
- [Amazon EC2 instances](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/install/ec2.md)
- [Amazon SageMaker](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/install/SageMaker.md)
- [Jetson Nano](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/install/Jetson-Nano.md)
- [macOS](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/install/macOS.md)
- [Raspberry Pi](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/install/RPi.md)
- [Raspberry Pi + ROS](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/install/RPi-ROS.md)
# aliases
[@access](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/access.md)
[@build_README](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/build_README.md)
[@conda](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/conda.md)
[@error](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/error.md)
[@git](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/git.md)
[@gpu](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/gpu.md)
[@init](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/init.md)
[@latex](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/latex.md)
[@log](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/log.md)
[@plugins](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/plugins.md)
[@pypi](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/pypi.md)
[@random](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/random.md)
[@screen](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/screen.md)
[@seed](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/seed.md)
[@session](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/session.md)
[@ssh](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/ssh.md)
[@terraform](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/terraform.md)
[@warn](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/warn.md)
[@web](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/web.md)
[@wifi](https://github.com/kamangir/bluer-ai/blob/main/bluer_ai/docs/aliases/wifi.md)
---
> 🪄 [`abcli`](https://github.com/kamangir/awesome-bash-cli) for the [Global South](https://github.com/kamangir/bluer-south).
---
[](https://github.com/kamangir/bluer-ai/actions/workflows/pylint.yml) [](https://github.com/kamangir/bluer-ai/actions/workflows/pytest.yml) [](https://github.com/kamangir/bluer-ai/actions/workflows/bashtest.yml) [](https://pypi.org/project/bluer-ai/) [](https://pypistats.org/packages/bluer-ai)
built by 🌀 [`bluer README`](https://github.com/kamangir/bluer-objects/tree/main/bluer_objects/docs/bluer-README), based on 🌀 [`bluer_ai-12.632.1`](https://github.com/kamangir/bluer-ai).
built by 🌀 [`blueness-3.122.1`](https://github.com/kamangir/blueness).
| text/markdown | Arash Abadpour (Kamangir) | arash.abadpour@gmail.com | null | null | CC0-1.0 | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Unix Shell",
"Operating System :: OS Independent"
] | [] | https://github.com/kamangir/bluer-ai | null | null | [] | [] | [] | [
"importlib-metadata",
"blueness",
"bluer-options",
"bluer-objects"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.9 | 2026-02-20T09:59:19.261649 | bluer_ai-12.632.1.tar.gz | 50,947 | e2/6b/0fef943f76b439e806a09a3efd1618915ea5691eaceb93b80c226a3d5e84/bluer_ai-12.632.1.tar.gz | source | sdist | null | false | 6ed98776639e8a18bcc7c6dda307c94b | bf28e6b8cf825514b18b2242f6ab1b0bbe603c4923791b3390354bb21d0b4808 | e26b0fef943f76b439e806a09a3efd1618915ea5691eaceb93b80c226a3d5e84 | null | [] | 588 |
2.4 | emojirades | 1.13.0 | Slack bot that understands the Emojirades game! | # Emojirades
Slack bot that understands the emojirades game and handles score keeping.
 
# Developing
## Install the dependencies
```bash
pip3 install --upgrade pip wheel
```
## Install the module & dependencies
```bash
pip3 install -e .[dev]
```
## Run the tests
```bash
# Linter
pylint emojirades
# Formatter
black --check .
# Tests
./scripts/run_tests.sh
```
## Creating new DB revisions
If you make changes to `emojirades/persistence/models` you'll need to generate new revisions. This tracks the changes and applies them to the DB at each bots startup
```
cd emojirades/persistence/models
alembic revision --autogenerate --message "<useful insightful few words>"
```
# Running
## Set Environment Variables
If you're using an auth file from AWS S3 you'll need to set the appropriate `AWS_` environment variables!
## Separate Database
Using a database like PostgreSQL, you'll need to have created a database with a username and password before starting this.
If you've just created a fresh DB, you'll need to load the initial database:
```
emojirades -vv init --db-uri "sqlite:///emojirades.db"
```
After initialising the DB you can load in any optional pre-existing state.
The json files must be a list of objects, with each objects `key: value` representing a column in the associated model
If you are coming from the old style of state.json and scores.json you can run the following to produce json files that can be used in the above populate command
```
./bin/old_to_new_persistence.py --workspace-id TABC123 --state-file state.json --score-file scores.json
```
This will produce `state.json.processed`, `scores.json.processed_scores` and `scores.json.processed_score_history`
They can be populated by running:
```
emojirades -vv populate --db-uri "sqlite:///emojirades.db" --table gamestate --data-file state.json.processed
emojirades -vv populate --db-uri "sqlite:///emojirades.db" --table scoreboard --data-file scores.json.processed_scores
emojirades -vv populate --db-uri "sqlite:///emojirades.db" --table scoreboard_history --data-file scores.json.processed_score_history
```
## Run the daemon for a single workspace
This command uses locally stored files to keep the game state:
`emojirades single --db-uri sqlite:///emojirades.db --auth-uri auth.json`
This command uses a separate PostgreSQL DB and an auth file from AWS S3:
`emojirades single --db-uri postgresql://user:pass@hostname/database --auth-uri s3://bucket/auth.json`
## Run the daemon for multiple workspaces
Here we provide a local folder of workspaces and an optional set of workspace ids (will load all in folder by default):
`emojirades mulitple --workspaces-dir path/to/workspaces [--workspace-id A1B2C3D4E]`
Here we provide an S3 path of workspaces and an optional set of workspace ids (will load all in folder by default):
`emojirades multiple --workspaces-dir s3://bucket/path/to/workspaces [--workspace-id A1B2C3D4E]`
Here we provide an S3 path of workspaces and an AWS SQS queue to listen to for new workspaces:
`emojirades multiple --workspaces-dir s3://bucket/path/to/workspaces --onboarding-queue workspace-onboarding-queue`
Here we provide an S3 path of workspaces and override the db_uri:
`emojirades multiple --workspaces-dir s3://bucket/path/to/workspaces --db-uri sqlite:///emojirades.db`
The workspaces directory must be in the following format (local or s3):
```
./workspaces
./workspaces/shards
./workspaces/shards/0
./workspaces/shards/0/A1B2C3D4E.json
./workspaces/shards/0/Z9Y8X7W6V.json
./workspaces/directory
./workspaces/directory/A1B2C3D4E
./workspaces/directory/A1B2C3D4E/auth.json
./workspaces/directory/Z9Y8X7W6V
./workspaces/directory/Z9Y8X7W6V/auth.json
```
Each instance of the bot will listen to a specific shard (specified as the --workspaces-dir).
The contents of the shard config (eg. `./workspaces/shards/0/A1B2C3D4E.json`) will be a file similar to:
```
{
"workspace_id": "A1B2C3D4E",
"db_uri": "sqlite:////data/emojirades.db", # Optional, needed if you do not specify one with the bot itself
"auth_uri": "s3://bucket/workspaces/directory/A1B2C3D4E/auth.json",
}
```
The concept above with the two different directories is shards to allow for the bot to scale out horizontally. As the bot(s) get busier, the operator can increase the shard count (number of bot instances) and new onboarded workspaces are allocated to the next available shard with capacity.
The emojirades bot will take care of running multiple games across different channels in a single workspace. This is a limitation in the design currently where you need a bot-per-workspace.
## Service configuration
```
cp emojirades.service /etc/systemd/system/
sudo chmod 0664 /etc/systemd/system/emojirades.service
# Edit the /etc/systemd/system/emojirades.service file and update the user and group
cp emojirades.config /etc/emojirades
sudo chmod 0400 /etc/emojirades
# Edit the /etc/emojirades config file with your configuration for the bot
sudo systemctl daemon-reload
sudo systemctl enable emojirades
sudo systemctl start emojirades
```
# Release process
1. Checkout master branch
2. Update `emojirades/__init__.py` with the new version (vX.Y.Z)
3. Commit
4. Tag the commit with vX.Y.Z
5. `git push; git push --tags` together
4. Github Actions will trigger the Release Job when a tagged commit to master is detected
1. Changelog will be generated and a Github Release as well with the changelog
2. New python wheel will be built and published to PyPI and attached to the Release
3. New container image will be built and published to Github Container Registry
## Building the Container Image
```
docker build --pull --no-cache -t ghcr.io/emojirades/emojirades:X.Y.Z -t ghcr.io/emojirades/emojirades:latest .
```
## Running the Container
In this example we run the game with S3 hosted configuration for a single workspace.
```
docker run -d \
--name emojirades \
--restart=always \
-v "/path/to/your/.aws/:/root/.aws/:ro" \
-v "emojirades-data:/data" \
-e "AWS_PROFILE=emojirades" \
ghcr.io/emojirades/emojirades:X.Y.X \
--db-uri sqlite:////data/emojirades.db \
--auth-uri s3://bucket/path/to/auth.json \
-vv
```
## Migrating from SQLite to Postgres
This assumes you have a local copy of your sqlite DB file and already setup and can access your postgres DB.
```bash
# Sourced venv/etc
# Init the DB to setup the table structure
./bin/emojirades init --db-uri 'postgresql+psycopg2://user:password@host:port/dbname'
# Run the migration script
./bin/sqlite_to_postgres.py \
--source-db-uri 'sqlite+pysqlite:///relative/path/to/emojirades.db' \
--target-db-uri 'postgresql+psycopg2://user:password@host:port/dbname'
# Update the sequences by logging into postgres and resetting them to +1
emojirades=# select max(event_id) from gamestate_history;
max
------
3086
(1 row)
emojirades=# ALTER SEQUENCE gamestate_history_event_id_seq RESTART WITH 3087;
ALTER SEQUENCE
emojirades=# select max(event_id) from scoreboard_history;
max
------
1622
(1 row)
emojirades=# ALTER SEQUENCE scoreboard_history_event_id_seq RESTART WITH 1623;
ALTER SEQUENCE
```
| text/markdown; charset=UTF-8 | The Emojirades Team | support@emojirades.io | null | null | null | slack slackbot emojirades plusplus game | [
"Development Status :: 5 - Production/Stable",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Communications :: Chat",
"Topic :: Games/Entertainment"
] | [] | https://github.com/emojirades/emojirades | null | >=3.12 | [] | [] | [] | [
"slack_sdk~=3.40.1",
"requests~=2.32.3",
"boto3~=1.42.30",
"Unidecode~=1.4.0",
"expiringdict~=1.2.2",
"SQLAlchemy~=2.0.9",
"alembic~=1.18.1",
"psycopg2-binary~=2.9.5",
"python-json-logger~=4.0.0",
"pytest~=9.0.2; extra == \"dev\"",
"pylint~=4.0.3; extra == \"dev\"",
"black~=26.1.0; extra == \"dev\"",
"websockets~=16.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T09:59:05.065758 | emojirades-1.13.0.tar.gz | 52,502 | 98/c2/136b800d347c7b91c3149b653ee080b440c713e3f483c40ba5a3f896d77b/emojirades-1.13.0.tar.gz | source | sdist | null | false | d66318f462decd9c57fb2c6999fc0239 | e66896164d6c966a4c2a97f9a27608573b28e1fbbd726cb437edd1e87ea65ccf | 98c2136b800d347c7b91c3149b653ee080b440c713e3f483c40ba5a3f896d77b | null | [
"LICENSE"
] | 204 |
2.4 | emx-mistral-ocr-cli | 0.1.3 | CLI tool for converting PDF documents to Markdown or HTML using Mistral OCR. | # emx-mistral-ocr-cli
CLI tool for converting PDF documents to Markdown or HTML using Mistral OCR.
## Features
- PDF -> Markdown (default) or HTML output
- Automatic output format detection from `--out` extension (`.html`/`.htm` -> HTML)
- Optional page selection via `--pages` (`1-12`, `2,5,10-12`, ...)
- Optional local PDF slicing before upload (`--slice-pdf`) to help with very large PDFs (e.g. >1000 pages)
- Optional extracted image export
- HTML mode with embedded HTML tables and built-in CSS styling
- Local chapter index analysis before OCR (`--analyze-index`)
- Retry handling for temporary Mistral API errors
- Safe output behavior (no overwrite without `--force`)
## Requirements
- Python 3.10+
- A valid Mistral API key in environment variable `MISTRAL_API_KEY`
## Installation
Install via pip:
```bash
pip install emx-mistral-ocr-cli
```
Install from source (repo checkout):
```bash
pip install -r requirements.txt
```
Optional (editable install with console script):
```bash
pip install -e .
```
## Development / Run from Source
If you want to run directly from a git checkout (without installing the package from PyPI), install dependencies and execute the script:
```bash
pip install -r requirements.txt
python mistral_ocr_cli.py <input.pdf> [options]
```
## Setup
Set your API key:
Linux/macOS (bash/zsh):
```bash
export MISTRAL_API_KEY="your_key_here"
```
Windows PowerShell / PowerShell:
```powershell
$env:MISTRAL_API_KEY="your_key_here"
```
Windows cmd.exe:
```cmd
set MISTRAL_API_KEY=your_key_here
```
## Usage
```bash
emx-mistral-ocr-cli <input.pdf> [options]
```
Show help:
```bash
emx-mistral-ocr-cli -h
```
## Common Examples
Default Markdown output:
```bash
emx-mistral-ocr-cli doc.pdf
```
Write Markdown to a specific file:
```bash
emx-mistral-ocr-cli doc.pdf --out result.md
```
HTML output (auto-selected by extension):
```bash
emx-mistral-ocr-cli doc.pdf --out result.html
```
Explicit HTML output:
```bash
emx-mistral-ocr-cli doc.pdf --output-format html --out result.html
```
Process only selected pages:
```bash
emx-mistral-ocr-cli doc.pdf --pages "1-20"
```
Slice selected pages locally before upload:
```bash
emx-mistral-ocr-cli doc.pdf --pages "1150-1200" --slice-pdf --out result.html --force
```
Disable images entirely:
```bash
emx-mistral-ocr-cli doc.pdf --no-images
```
Export images to custom directory:
```bash
emx-mistral-ocr-cli doc.pdf --images-dir extracted_images
```
Analyze chapter index locally (no OCR call):
```bash
emx-mistral-ocr-cli doc.pdf --analyze-index
```
Analyze chapter index and write it to file:
```bash
emx-mistral-ocr-cli doc.pdf --analyze-index --chapter-index-out index.tsv --force
```
## Options
- `--out <path>`: Output file path
- `--output-format {markdown,html}`: Output format (default: `markdown`)
- `--force`: Overwrite existing outputs
- `--pages "<spec>"`: 1-based page selection, e.g. `1-12`, `2,5,10-12`
- `--slice-pdf`: Build temporary sliced PDF locally before upload (requires `--pages`). Useful when Mistral rejects very large PDFs (e.g. >1000 pages) and you want to process it in chunks.
- `--images-dir <dir>`: Directory for extracted images (default: `<out_stem>_images`)
- `--no-images`: Disable image extraction/export
- `--image-limit <n>`: Maximum number of images to extract
- `--image-min-size <px>`: Minimum image width/height
- `--no-header-footer`: Disable header/footer extraction
- `--chapter-index-out <file>`: Write local chapter index output
- `--analyze-index`: Local chapter index analysis and exit
## Notes
- In HTML mode, OCR tables are requested as HTML and embedded into the final HTML document. HTML is generally more expressive than Markdown for complex layouts (e.g. tables with `colspan`/`rowspan`, which standard Markdown tables do not support).
- For large PDFs, `--slice-pdf` can still take time (PDF parsing/writing), but it reduces upload size and processed content and can avoid API errors for extremely large documents (e.g. >1000 pages).
- `--analyze-index` is useful to discover chapter boundaries and page numbers so you can select specific chapters via `--pages`.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"markdown",
"mistralai",
"pypdf"
] | [] | [] | [] | [
"Repository, https://github.com/emmtrix/emx-mistral-ocr-cli"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T09:59:04.216764 | emx_mistral_ocr_cli-0.1.3.tar.gz | 11,819 | 6a/3c/19591a894d78e32390f90d95b8368d794bf0035e4a63ac2f4c9fafe4f73b/emx_mistral_ocr_cli-0.1.3.tar.gz | source | sdist | null | false | e7e5c1a69b0500bf754520298f43bf63 | 5ff8bdc6260e862d109dc519edb9af299a1f31b1b5c01a6f4c93df4a1f9039e2 | 6a3c19591a894d78e32390f90d95b8368d794bf0035e4a63ac2f4c9fafe4f73b | MIT | [
"LICENSE"
] | 228 |
2.4 | abadpour | 7.24.1 | 📜 Arash Abadpour's CV. | # 📜 abadpour
📜 `abadpour` is an [`@ai`](https://github.com/kamangir/bluer-ai) plugin for my CV/resume, in two versions: [compact](https://github.com/kamangir/abadpour/blob/main/pdf/arash-abadpour-resume.pdf) and [full](https://github.com/kamangir/abadpour/blob/main/pdf/arash-abadpour-resume-full.pdf).
## installation
```bash
pip install abadpour
```
# aliases
[abadpour](https://github.com/kamangir/abadpour/blob/main/abadpour/docs/abadpour.md).
---
[](https://github.com/kamangir/abadpour/actions/workflows/pylint.yml) [](https://github.com/kamangir/abadpour/actions/workflows/pytest.yml) [](https://github.com/kamangir/abadpour/actions/workflows/bashtest.yml) [](https://pypi.org/project/abadpour/) [](https://pypistats.org/packages/abadpour)
built by 🌀 [`bluer README`](https://github.com/kamangir/bluer-objects/tree/main/bluer_objects/docs/bluer-README), based on 📜 [`abadpour-7.24.1`](https://github.com/kamangir/abadpour).
built by 🌀 [`blueness-3.122.1`](https://github.com/kamangir/blueness).
| text/markdown | Arash Abadpour (Kamangir) | arash.abadpour@gmail.com | null | null | CC0-1.0 | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Unix Shell",
"Operating System :: OS Independent"
] | [] | https://github.com/kamangir/abadpour | null | null | [] | [] | [] | [
"bluer_ai"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.9 | 2026-02-20T09:58:56.664924 | abadpour-7.24.1.tar.gz | 4,989 | 5f/86/a04012645c921b2d12501b02deac5c492475ec8cc50608bf9e5b0b4685dc/abadpour-7.24.1.tar.gz | source | sdist | null | false | 994245556106ce68bde0155f31243d92 | e0c763ff3f095972ca044ccbfaa62530aebfbab83a46658168a033eb8d72e0e8 | 5f86a04012645c921b2d12501b02deac5c492475ec8cc50608bf9e5b0b4685dc | null | [] | 213 |
2.4 | math-logic-mcp | 0.2.0 | MCP server providing verified math & logic tools for small LLMs (Mistral, Llama, DeepSeek) | # math-logic-mcp
**MCP server that gives small LLMs verified symbolic-math & logic tools.**
[](LICENSE)
Small language models (Mistral, Llama, Phi, Gemma) struggle with multi-step math and formal logic. Instead of fine-tuning, **give them tools**. This project exposes a set of verified math and logic solvers via the [Model Context Protocol (MCP)](https://modelcontextprotocol.io), so any MCP-compatible LLM can call them as functions.
## Features
| Tool | What it does | Backend |
|------|-------------|---------|
| `verify_arithmetic` | Safe arithmetic evaluation | Python stdlib (zero deps) |
| `solve_equation` | Symbolic equation solving | SymPy (optional) |
| `simplify_expression` | Simplify / factor / expand | SymPy (optional) |
| `compute_derivative` | Differentiation | SymPy (optional) |
| `compute_integral` | Integration | SymPy (optional) |
| `check_logic` | SAT / tautology / truth tables | Z3 (optional) |
Every result includes **proof steps** and **verification** — the LLM gets a machine-checked answer, not a guess.
## Quick Start
### Install (minimal — arithmetic only)
```bash
pip install -e .
```
### Install (full — all solvers)
```bash
pip install -e ".[full]"
```
### Run the MCP server
```bash
# stdio transport (for Claude Desktop, Cursor, etc.)
math-logic-mcp
# HTTP/SSE transport (for remote clients)
math-logic-mcp --http
```
### Configure in Claude Desktop
Add to `~/Library/Application Support/Claude/claude_desktop_config.json`:
```json
{
"mcpServers": {
"math-logic": {
"command": "math-logic-mcp"
}
}
}
```
### Configure in Cursor
Add to `.cursor/mcp.json`:
```json
{
"mcpServers": {
"math-logic": {
"command": "math-logic-mcp"
}
}
}
```
## Use as a Python Library
```python
from math_logic import MathLogicEngine
engine = MathLogicEngine()
# Arithmetic (always available)
result = engine.solve("compute 2 + 3 * 4")
print(result.solutions) # ['14']
# Algebra (requires sympy)
result = engine.solve("Solve x^2 - 4 = 0")
print(result.solutions) # ['x = -2', 'x = 2']
# Logic (requires z3-solver)
result = engine.solve('Check satisfiability of "p and q"')
print(result.solutions) # ['Satisfiable: p=True, q=True']
```
## Architecture
```
LLM ─── MCP Protocol ──▶ mcp_server.py
│
engine.py (router → solver → result)
│
┌───────────────┼───────────────┐
▼ ▼ ▼
ArithmeticSolver SymPySolver Z3Solver
(zero deps) (pip: sympy) (pip: z3-solver)
```
The **router** classifies each problem by regex patterns and routes to the best available solver. Solvers are loaded lazily — if SymPy isn't installed, algebra problems gracefully report the missing dependency.
## Installation Extras
| Extra | What it adds | Install size |
|-------|-------------|-------------|
| (none) | Arithmetic only | ~1 MB |
| `[sympy]` | + algebra, calculus, simplification | ~50 MB |
| `[z3]` | + propositional logic, SAT | ~30 MB |
| `[full]` | Everything | ~80 MB |
| `[dev]` | + pytest, ruff | ~85 MB |
```bash
pip install -e ".[sympy]" # algebra + calculus
pip install -e ".[z3]" # logic
pip install -e ".[full]" # everything
pip install -e ".[full,dev]" # everything + dev tools
```
## Development
```bash
git clone https://github.com/user/math-logic-mcp.git
cd math-logic-mcp
pip install -e ".[full,dev]"
pytest tests/ -v
```
## Docker
```bash
docker build -t math-logic-mcp .
docker run -p 8080:8080 math-logic-mcp
```
## License
Apache 2.0 — see [LICENSE](LICENSE).
| text/markdown | Open Source Community | null | null | null | null | mcp, llm, reasoning, symbolic, math, logic, proof, tool-calling | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"sympy>=1.12",
"z3-solver>=4.12.2",
"pydantic>=2.0",
"mcp[cli]>=1.0.0",
"pytest>=7.4; extra == \"dev\"",
"pytest-cov>=4.1; extra == \"dev\"",
"pytest-asyncio>=0.23; extra == \"dev\"",
"black>=23.7; extra == \"dev\"",
"flake8>=6.0; extra == \"dev\"",
"mypy>=1.4; extra == \"dev\"",
"isort>=5.12; extra == \"dev\"",
"ortools>=9.7.2996; extra == \"full\"",
"litellm>=1.26.0; extra == \"full\"",
"redis>=5.0.0; extra == \"full\"",
"lark>=1.1; extra == \"full\""
] | [] | [] | [] | [
"Homepage, https://github.com/ismailkerimov/math-logic-mcp",
"Repository, https://github.com/ismailkerimov/math-logic-mcp",
"Bug Tracker, https://github.com/ismailkerimov/math-logic-mcp/issues"
] | twine/6.2.0 CPython/3.13.3 | 2026-02-20T09:58:52.589386 | math_logic_mcp-0.2.0.tar.gz | 22,561 | 05/08/7f31769f4ac81e741427fbb3dd4b8b51d50c306ab598d295c5b1dfc398ae/math_logic_mcp-0.2.0.tar.gz | source | sdist | null | false | 2ce913d14baed576378b402e4f6ded68 | d3e1c2f6c69d9aa50f677dfbf07177c3b0283a5aeac913b6efc74e2844109af0 | 05087f31769f4ac81e741427fbb3dd4b8b51d50c306ab598d295c5b1dfc398ae | Apache-2.0 | [
"LICENSE"
] | 223 |
2.4 | tna-frontend-jinja | 0.35.1 | TNA Frontend Jinja templates | <img src="https://raw.githubusercontent.com/nationalarchives/tna-frontend/main/src/nationalarchives/assets/images/tna-square-logo.svg" alt="The National Archives logo" title="The National Archives" width="100" />
# TNA Frontend Jinja
[](https://github.com/nationalarchives/tna-frontend-jinja/actions/workflows/ci.yml?query=branch%3Amain)
[](https://github.com/nationalarchives/tna-frontend-jinja/releases)
[](https://pypi.org/project/tna-frontend-jinja/)

[](https://github.com/nationalarchives/tna-frontend-jinja/blob/main/LICENCE)
TNA Frontend Jinja templates are a [Jinja](https://jinja.palletsprojects.com/en/3.1.x/) implementation of the templates provided as part of [TNA Frontend](https://github.com/nationalarchives/tna-frontend) as well as widgets for [WTForms](#wtforms).
See the [documentation](https://nationalarchives.github.io/tna-frontend-jinja/).
## Quickstart for Flask projects
Use the Flask application's `jinja_loader` to allow templates included from either your app (in the below example called `app`) and the `tna_frontend_jinja` package.
Ensure your application is first on the list. This means you can [overwrite the standard templates](#overriding-templates) by creating a template with the same filename in your project.
```py
from flask import Flask
from jinja2 import ChoiceLoader, PackageLoader
def create_app():
app = Flask(__name__)
app.jinja_loader = ChoiceLoader(
[
PackageLoader("app"), # Use your application directory here
PackageLoader("tna_frontend_jinja"),
]
)
```
## Quickstart for Django projects
Update the `TEMPLATES` setting in your application config:
```py
TEMPLATES = [
# Add the Jinja2 backend first
{
"BACKEND": "django.template.backends.jinja2.Jinja2",
"DIRS": [
os.path.join(BASE_DIR, "app/templates"), # Use your application directory here
os.path.join(get_path("platlib"), "tna_frontend_jinja/templates"),
],
"APP_DIRS": True,
"OPTIONS": {
"environment": "config.jinja2.environment",
},
},
# The DjangoTemplates backend is still needed for tools like Django admin and the debug toolbar
{
"BACKEND": "django.template.backends.django.DjangoTemplates",
"DIRS": [],
"APP_DIRS": True,
"OPTIONS": {
"context_processors": [
"django.template.context_processors.debug",
"django.template.context_processors.request",
"django.contrib.auth.context_processors.auth",
"django.contrib.messages.context_processors.messages",
],
},
},
]
```
Ensure your application is first on the list of template directories. This means you can [overwrite the standard templates](#overriding-templates) by creating a template with the same filename in your project.
## Using the templates
```jinja
{%- from 'components/button/macro.html' import tnaButton -%}
{{ tnaButton({
'text': 'Save and continue'
}) }}
```
The options available to each component macro can be found in the [National Archives Design System Components](https://nationalarchives.github.io/design-system/components/) documentation.
> ⚠️ The included templates are a like-for-like port, the only difference between the Nunjucks examples and their Jinja equivalents is having to quote key names, e.g. `'text'` instead of `text`.
We test each component against its published [component fixtures](https://github.com/nationalarchives/tna-frontend/blob/main/src/nationalarchives/components/button/fixtures.json) to ensure complete compatibility.
### Overriding templates
To make modifications to the templates, create a new file in your applciation templates directory with the same name as the template you want to customise.
For example, if your application templates directory is `app/templates`, create `app/templates/components/button/macro.html` and insert your own HTML using the same macro name (e.g. `tnaButton`).
This way you can continue to use the same import (e.g. `{%- from 'components/button/macro.html' import tnaButton -%}`) but introduce your own bespoke functionality.
## WTForms
See the [TNA Frontend Jinja WTForms docs](https://nationalarchives.github.io/tna-frontend-jinja/wtforms/).
## Running tests
```sh
# Start the test server
docker compose up -d
# Install the dependencies
npm install
# Run the fixture tests
npm run test:fixtures
# Run the Playwright tests
npm run test:playwright
# Run the Python tests
docker compose exec app poetry run python -m pytest
```
## Styles and JavaScript
The CSS and JavaScript are not included in the PyPI package. You must install them separately.
Install and use the `@nationalarchives/frontend` package from npm with `npm install @nationalarchives/frontend`.
Ensure you install the correct version of TNA Frontend for the version of the templates you are using.
### Compatibility with TNA Frontend
#### v0.3+
| TNA Frontend Jinja | Compatible TNA Frontend version(s) |
| ------------------ | ---------------------------------- |
| `0.35.x` | `0.35.1` |
| `0.34.0` | `0.34.x` |
| `0.33.0` | `0.33.x` |
| `0.32.0` | `0.32.x` |
| `0.31.x` | `0.31.x` |
| `0.30.0` | `0.30.x` |
| `0.29.1` | `0.29.1` |
| `0.29.0` | `0.29.0` |
| `0.28.0` | `0.28.x` |
| `0.27.0` | `0.27.x` |
| `0.26.0` | `0.26.x` |
| `0.25.0` | `0.25.x` |
| `0.24.0` | `0.24.x` |
| `0.23.0` | `0.23.x` |
| `0.22.0` | `0.22.x` |
| `0.21.0` | `0.21.x` |
| `0.20.1` | `0.20.1` |
| `0.20.0` | `0.20.0` |
| `0.19.0` | `0.19.x` |
| `0.18.0` | `0.18.x` |
| `0.17.0` | `0.17.x` |
| `0.16.0` | `0.16.x` |
| `0.15.0` | `0.15.x` |
| `0.14.0` | `0.14.x` |
| `0.13.0` | `0.13.x` |
| `0.12.0` | `0.12.x` |
| `0.11.0` | `0.11.x` |
| `0.10.0` | `0.10.x` |
| `0.9.0` | `0.9.x` |
| `0.8.1` | `0.8.1` |
| `0.8.0` | `0.8.0` |
| `0.7.0` | `0.7.x` |
| `0.6.0` | `0.6.x` |
| `0.5.0` | `0.5.x` |
| `0.4.0` | `0.4.x` |
| `0.3.0` | `0.3.x` |
#### v0.2.x
| TNA Frontend Jinja | Compatible TNA Frontend version(s) |
| ------------------ | ---------------------------------- |
| `0.2.18` | `0.2.18` |
| `0.2.17` | `0.2.17` |
| `0.2.16` | `0.2.16` |
| `0.2.15` | `0.2.15` |
| `0.2.14` | `0.2.14` |
| `0.2.13` | `0.2.13` |
| `0.2.12` | `0.2.12` |
| `0.2.11` | `0.2.11` |
| `0.2.10` | `0.2.10` |
| `0.2.9` | `0.2.9` |
| `0.2.8` | `0.2.8` |
| `0.2.7` | `0.2.7` |
| `0.2.6` | `0.2.6` |
| `0.2.5` | `0.2.5` |
| `0.2.4` | `0.2.4` |
| `0.2.3` | `0.2.3` |
| `0.2.2` | `0.2.2` |
| `0.2.1` | `0.2.1` |
| `0.2.0` | `0.2.0` |
#### v0.1.x
| TNA Frontend Jinja | Compatible TNA Frontend version(s) |
| --------------------- | ------------------------------------------ |
| `0.1.34` | `0.1.65` |
| `0.1.33` | `0.1.62`, `0.1.63`, `0.1.64` |
| `0.1.32` | `0.1.60`, `0.1.61` |
| `0.1.31` | `0.1.59` |
| `0.1.30` | `0.1.58` |
| `0.1.29` | `0.1.57` |
| `0.1.28` | `0.1.55`, `0.1.56` |
| `0.1.27` | `0.1.54` |
| `0.1.26` | `0.1.53` |
| `0.1.25` | `0.1.51`, `0.1.52` |
| `0.1.23`, `0.1.24` | `0.1.50` |
| `0.1.21`, `0.1.22` | `0.1.49` |
| `0.1.20` | `0.1.48` |
| `0.1.19` | `0.1.45`, `0.1.46`, `0.1.47` |
| `0.1.18` | `0.1.44` |
| `0.1.17` | `0.1.43` |
| `0.1.15`, `0.1.16` | `0.1.42` |
| `0.1.14` | `0.1.40`, `0.1.41` |
| `0.1.13` | `0.1.39` |
| `0.1.12` | `0.1.37`, `0.1.38` |
| `0.1.11` | `0.1.36` |
| `0.1.10` | `0.1.34`, `0.1.35` |
| `0.1.9` | `0.1.33` |
| `0.1.7`, `0.1.8` | `0.1.31`, `0.1.32` |
| `0.1.6` | `0.1.29-prerelease`, `0.1.30` |
| `0.1.0`–`0.1.5` | [latest from `main` branch when published] |
| text/markdown | null | Andrew Hosgood <andrew.hosgood@nationalarchives.gov.uk> | null | null | null | jinja, macro, templates, the national archives, tna, wtforms | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"jinja2"
] | [] | [] | [] | [
"Homepage, https://pypi.org/project/tna-frontend-jinja/",
"Documentation, https://nationalarchives.github.io/tna-frontend-jinja/",
"Repository, https://github.com/nationalarchives/tna-frontend-jinja",
"Bug Tracker, https://github.com/nationalarchives/tna-frontend-jinja/issues",
"Changelog, https://github.com/nationalarchives/tna-frontend-jinja/blob/main/CHANGELOG.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T09:58:45.530982 | tna_frontend_jinja-0.35.1.tar.gz | 48,512 | 47/30/98391d7733caede6d5bea5ece5948abc54ad258e5a4c2c623818ffc4d8b1/tna_frontend_jinja-0.35.1.tar.gz | source | sdist | null | false | b062b08f47c8a3694c61942c46371698 | 950612a777171b166806fcd853d1099d3935630d006300019d34218c95e4c3b1 | 473098391d7733caede6d5bea5ece5948abc54ad258e5a4c2c623818ffc4d8b1 | MIT | [
"LICENCE"
] | 267 |
2.4 | py-pilecore | 2.2.1 | Public python SDK for the CEMS PileCore web-API. | # py-pilecore
Public python SDK for the CEMS PileCore web-API
[](http://mypy-lang.org/)
[](https://github.com/psf/black)
[](https://pycqa.github.io/isort/)
[](https://coveralls.io/github/cemsbv/py-pilecore)
This repository is created by [CEMS BV](https://cemsbv.nl/) and is a public python wrapper around the CEMS [PileCore web-API](https://nuclei.cemsbv.io/#/pilecore/api).
# Installation
To install a package in this repository run:
`$ pip install py-pilecore`
## ENV VARS
To use `py-pilecore` add the follow ENV vars to your environment. Or provide them when asked.
```
* NUCLEI_TOKEN
- Your NUCLEI user token
```
You can obtain your `NUCLEI_TOKEN` on [NUCLEI](https://nuclei.cemsbv.io/#/).
Go to `personal-access-tokens` and create a new user token.
# Contribution
## Environment
We recommend developing in Python3.11 with a clean virtual environment (using `virtualenv` or `conda`), installing the requirements from the requirements.txt file:
Example using `virtualenv` and `pip` to install the dependencies in a new environment .env on Linux:
```bash
python -m venv .env
source .env/bin/activate
python -m pip install --upgrade pip setuptools
pip install -r requirements.txt
pip install -e .
```
## Documentation
Build the docs:
```bash
python -m pip install --upgrade pip setuptools
pip install -r requirements.txt
pip install .
sphinx-build -b html docs public
```
## Format
We format our code with black and isort.
```bash
black --config "pyproject.toml" src/pypilecore tests notebooks
isort --settings-path "pyproject.toml" src/pypilecore tests notebooks
```
## Lint
To maintain code quality we use the GitHub super-linter.
To run the linters locally, run the `run_super_linters.sh` bash script from the root directory.
## UnitTest
Test the software with the use of coverage:
```bash
python -m pip install --upgrade pip setuptools
pip install -r requirements.txt
pip install -e .
coverage run -m pytest
```
## Requirements
Requirements are autogenerated by the `pip-compile` command with python 3.11
Install pip-tools with:
```bash
pip install pip-tools
```
Generate requirements.txt file with:
```bash
pip-compile --extra=test --extra=lint --extra=docs --output-file=requirements.txt pyproject.toml
```
Update the requirements within the defined ranges with:
```bash
pip-compile --upgrade --extra=test --extra=lint --extra=docs --output-file=requirements.txt pyproject.toml
```
Note that `pip-compile` might run from your global path. You can also invoke the compile
command from the `piptools` module on a specific python installation (e.g. within a virtualenv):
```bash
python -m piptools compile
| text/markdown | null | null | null | null | MIT License
Copyright (c) 2023 CEMS
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| API, PileCore, CEMS, CRUX | [] | [] | null | null | <3.14,>=3.11 | [] | [] | [] | [
"anywidget<0.10,>=0.9.18",
"cems-nuclei[client]<4,>=3.2.0",
"dash<4,>=3.0.2",
"ipywidgets<9,>=8.1.5",
"matplotlib<4,>=3.10.1",
"natsort<9,>=8.4.0",
"numpy<3,>=2.2.4",
"pandas<3,>=2.2.3",
"plotly-geo<2,>=1.0.0",
"plotly<7,>=6.0.1",
"pygef<=0.14.0,>=0.12.0",
"scipy<2,>=1.15.2",
"shapely<3,>=2.1.0",
"tqdm[notebook]<5,>=4.67.1",
"coveralls; extra == \"test\"",
"pytest; extra == \"test\"",
"openapi-core; extra == \"test\"",
"Sphinx==8.2.3; extra == \"docs\"",
"asteroid-sphinx-theme==0.0.3; extra == \"docs\"",
"ipython==9.7.0; extra == \"docs\"",
"sphinx-autodoc-typehints==3.5.2; extra == \"docs\"",
"sphinx_rtd_theme==3.0.2; extra == \"docs\"",
"ansible-lint==25.11.1; extra == \"lint\"",
"black==25.11.0; extra == \"lint\"",
"cfn-lint==1.41.0; extra == \"lint\"",
"cpplint==2.0.2; extra == \"lint\"",
"flake8==7.3.0; extra == \"lint\"",
"isort==7.0.0; extra == \"lint\"",
"mypy==1.18.2; extra == \"lint\"",
"nbqa==1.9.1; extra == \"lint\"",
"pre-commit==4.5.0; extra == \"lint\"",
"sqlfluff==3.4.2; extra == \"lint\"",
"yamllint==1.37.1; extra == \"lint\"",
"yq==3.4.3; extra == \"lint\"",
"zizmor==1.17.0; extra == \"lint\""
] | [] | [] | [] | [
"repository, https://github.com/cemsbv/py-pilecore"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T09:58:27.216735 | py_pilecore-2.2.1.tar.gz | 73,444 | 25/9c/ad96038c9d0da01ad41bef5426f1aef58b2ad3854dfb65e04e42de2ca4e2/py_pilecore-2.2.1.tar.gz | source | sdist | null | false | c025c42f7ba10cd154bac0df83d980bc | c3091c8dd2c400920ac57ddc23a06bac983339f28334fcdd83e216079b57a97c | 259cad96038c9d0da01ad41bef5426f1aef58b2ad3854dfb65e04e42de2ca4e2 | null | [
"LICENSE"
] | 190 |
2.4 | cascade-sdk | 0.2.0b14 | Agent observability SDK for tracking AI agent execution | # Cascade SDK
Agent observability platform for tracking AI agent execution, LLM calls, and tool usage.
## Quick Start
### Install from PyPI
```bash
pip install cascade-sdk
```
### Setup
1. **Set your API key** (get one from [Cascade Dashboard](https://cascade-dashboard.vercel.app)):
```bash
export CASCADE_API_KEY="your-api-key"
```
2. **Use in your code**:
```python
from cascade import init_tracing, trace_run, wrap_llm_client, tool
from anthropic import Anthropic
import os
# Initialize tracing (uses cloud endpoint by default)
init_tracing(project="my_project")
# Wrap LLM client
client = wrap_llm_client(Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY")))
# Decorate tools
@tool
def my_tool(query: str, client) -> str:
"""My custom tool."""
response = client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=100,
messages=[{"role": "user", "content": query}]
)
return response.content[0].text
# Trace agent execution
with trace_run("MyAgent", metadata={"task": "example"}):
result = my_tool("What is AI?", client)
print(result)
```
3. **View traces** in the [Cascade Dashboard](https://cascade-dashboard.vercel.app)
## TypeScript (Node.js)
This repo also includes a Node.js TypeScript SDK under `typescript/cascade-sdk/`.
- Docs: `docs/INTEGRATIONS_TYPESCRIPT_SDK.md`
- Vercel AI SDK (TypeScript) OTEL export: `docs/INTEGRATIONS_VERCEL_AI_SDK.md`
## Features
- ✅ **Zero setup** - No backend services to run
- ✅ **Cloud-first** - Traces automatically sent to cloud
- ✅ **LLM tracking** - Automatic tracking of LLM calls (Anthropic, OpenAI, etc.)
- ✅ **Tool tracing** - Decorate functions with `@tool` for automatic tracing
- ✅ **Rich metadata** - Add custom metadata to traces
- ✅ **OpenTelemetry** - Built on OpenTelemetry standards
- ✅ **Vercel AI SDK support** - Ingest TypeScript OTEL spans (see `docs/INTEGRATIONS_VERCEL_AI_SDK.md`)
## Configuration
### Environment Variables
- `CASCADE_API_KEY` - Your Cascade API key (required)
- `CASCADE_ENDPOINT` - Override default endpoint (default: `https://api.runcascade.com/v1/traces`)
### Custom Endpoint
If you need to use a custom endpoint:
```python
init_tracing(
project="my_project",
endpoint="https://your-custom-endpoint.com/v1/traces",
api_key="your-api-key"
)
```
## CLI Commands
- `cascade info` - Show setup instructions and information
- `cascade --help` - Show help message
- `cascade --version` - Show version
## Development
This is a monorepo containing:
- `cascade/` - SDK package (published to PyPI)
- `backend/` - Backend service (not included in package)
- `dashboard/` - Frontend dashboard (not included in package)
### Install SDK in Development Mode
```bash
pip install -e .
```
| text/markdown | Cascade | null | null | null | null | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"opentelemetry-api>=1.20.0",
"opentelemetry-sdk>=1.20.0",
"opentelemetry-exporter-otlp>=1.20.0",
"click>=8.0.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.13 | 2026-02-20T09:58:11.179899 | cascade_sdk-0.2.0b14.tar.gz | 95,014 | 5a/49/e72df6b57ab8d0e073a80858c939295ad49e5cf6bb770464ab1c0867a85e/cascade_sdk-0.2.0b14.tar.gz | source | sdist | null | false | e5bac64fa777b44ba9001da6ad7c7a6f | 5ab812087cca00b1d927598105d4282d701a7d34dec3e3438c87a90b52e049f0 | 5a49e72df6b57ab8d0e073a80858c939295ad49e5cf6bb770464ab1c0867a85e | null | [] | 183 |
2.4 | pulumi-django-azure | 1.0.67 | Simply deployment of Django on Azure with Pulumi | # Pulumi Django Deployment
This project aims to make a simple Django deployment on Azure easier.
To have a proper and secure environment, we need these components:
* Storage account for media and static files
* CDN endpoint in front with a domain name of our choosing
* PostgreSQL server
* Azure Communication Services to send e-mails
* Webapp with multiple custom host names and managed SSL for the website itself
* Azure Key Vault per application
* Webapp running pgAdmin
## Project requirements
## Installation
This package is published on PyPi, so you can just add pulumi-django-azure to your requirements file.
To use a specific branch in your project, add to pyproject.toml dependencies:
```
pulumi-django-azure = { git = "git@gitlab.com:MaartenUreel/pulumi-django-azure.git", branch = "dev" }
```
A simple project could look like this:
```python
import pulumi
import pulumi_azure_native as azure
from pulumi_django_azure import DjangoDeployment
stack = pulumi.get_stack()
config = pulumi.Config()
# Create resource group
rg = azure.resources.ResourceGroup(f"rg-{stack}")
# Create VNet
vnet = azure.network.VirtualNetwork(
f"vnet-{stack}",
resource_group_name=rg.name,
address_space=azure.network.AddressSpaceArgs(
address_prefixes=["10.0.0.0/16"],
),
)
# Deploy the website and all its components
django = DjangoDeployment(
stack,
tenant_id="abc123...",
resource_group_name=rg.name,
vnet=vnet,
pgsql_ip_prefix="10.0.10.0/24",
appservice_ip_prefix="10.0.20.0/24",
app_service_sku=azure.web.SkuDescriptionArgs(
name="B2",
tier="Basic",
),
storage_account_name="mystorageaccount",
cdn_host="cdn.example.com",
)
django.add_django_website(
name="web",
db_name="mywebsite",
repository_url="git@gitlab.com:project/website.git",
repository_branch="main",
website_hosts=["example.com", "www.example.com"],
django_settings_module="mywebsite.settings.production",
comms_data_location="europe",
comms_domains=["mydomain.com"],
)
django.add_database_administrator(
object_id="a1b2c3....",
user_name="user@example.com",
tenant_id="a1b2c3....",
)
```
## Changes to your Django project
1. Add `pulumi_django_azure` to your `INSTALLED_APPS`
2. Add to your settings file:
```python
from pulumi_django_azure.settings import * # noqa: F403
# This will provide the management command to purge the CDN and cache
INSTALLED_APPS += ["pulumi_django_azure"]
# This will provide the health check middleware that will also take care of credential rotation.
MIDDLEWARE += ["pulumi_django_azure.middleware.HealthCheckMiddleware"]
```
This will pre-configure most settings to make your app work on Azure. You can check the source for details,
and ofcourse override any value after importing them.
## Deployment steps
1. Deploy without custom hosts (for CDN and websites)
2. Configure the PostgreSQL server (create and grant permissions to role for your websites)
3. Retrieve the deployment SSH key and configure your remote GIT repository with it
4. Configure your CDN host (add the CNAME record)
5. Configure your custom website domains (add CNAME/A record and TXT validation records)
6. Re-deploy with custom hosts
7. Re-deploy once more to enable HTTPS on website domains
8. Manually activate HTTPS on the CDN host
9. Go to the e-mail communications service on Azure and configure DKIM, SPF,... for your custom domains.
## Custom domain name for CDN
When deploying the first time, you will get a `cdn_cname` output. You need to create a CNAME to this domain before the deployment of the custom domain will succeed.
You can safely deploy with the failing CustomDomain to get the CNAME, create the record and then deploy again.
To enable HTTPS, you need to do this manually in the console. This is because of a limitation in the Azure API:
https://github.com/Azure/azure-rest-api-specs/issues/17498
## Custom domain names for web application
Because of a circular dependency in custom domain name bindings and certificates that is out of our control, you need to deploy the stack twice.
The first time will create the bindings without a certificate.
The second deployment will then create the certificate for the domain (which is only possible if the binding exists), but also set the fingerprint of that certificate on the binding.
To make the certificate work, you need to create a TXT record named `asuid` point to the output of `{your_app}_site_domain_verification_id`. For example:
```
asuid.mywebsite.com. TXT "A1B2C3D4E5..."
asuid.www.mywebsite.com. TXT "A1B2C3D4E5..."
```
## Database authentication
The PostgreSQL uses Entra ID authentication only, no passwords.
### Administrator login
If you want to log in to the database yourself, you can add yourself as an administrator with the `add_database_administrator` function.
Your username is your e-mailaddress, a temporary password can be obtained using `az account get-access-token`.
You can use this method to log in to pgAdmin.
### Application
Refer to this documentation:
https://learn.microsoft.com/en-us/azure/postgresql/flexible-server/how-to-manage-azure-ad-users#create-a-role-using-microsoft-entra-object-identifier
In short, run something like this in the `postgres` database:
```
SELECT * FROM pgaadauth_create_principal_with_oid('web_managed_identity', 'c8b25b85-d060-4cfc-bad4-b8581cfdf946', 'service', false, false);
```
Replace the GUID of course with the managed identity our web app gets.
The name of the role is outputted by `{your_app}_site_db_user`
Be sure to grant this role the correct permissions too.
## pgAdmin specifics
pgAdmin will be created with a default login:
* Login: dbadmin@dbadmin.net
* Password: dbadmin
Best practice is to log in right away, create a user for yourself and delete this default user.
## Azure OAuth2 / Django Social Auth
If you want to set up login with Azure, which would make sense since you are in the ecosystem, you need to create an App Registration in Entra ID, create a secret and then register these settings in your stack:
```
pulumi config set --secret --path 'mywebsite_social_auth_azure.key' secret_ID
pulumi config set --secret --path 'mywebsite_social_auth_azure.secret' secret_value
pulumi config set --secret --path 'mywebsite_social_auth_azure.tenant_id' directory_tenant_id
pulumi config set --secret --path 'mywebsite_social_auth_azure.client_id' application_id
```
Then in your Django deployment, pass to the `add_django_website` command:
```
secrets={
"mywebsite_social_auth_azure": "AZURE_OAUTH",
},
```
The value will be automatically stored in the vault where the application has access to.
The environment variable will be suffixed with `_SECRET_NAME`.
Then, in your application, retrieve this data from the vault, e.g.:
```python
# Social Auth settings
oauth_secret = AZURE_KEY_VAULT_CLIENT.get_secret(env("AZURE_OAUTH_SECRET_NAME"))
oauth_secret = json.loads(oauth_secret.value)
SOCIAL_AUTH_AZUREAD_TENANT_OAUTH2_KEY = oauth_secret["client_id"]
SOCIAL_AUTH_AZUREAD_TENANT_OAUTH2_SECRET = oauth_secret["secret"]
SOCIAL_AUTH_AZUREAD_TENANT_OAUTH2_TENANT_ID = oauth_secret["tenant_id"]
SOCIAL_AUTH_ADMIN_USER_SEARCH_FIELDS = ["username", "first_name", "last_name", "email"]
SOCIAL_AUTH_POSTGRES_JSONFIELD = True
AUTHENTICATION_BACKENDS = (
"social_core.backends.azuread_tenant.AzureADTenantOAuth2",
"django.contrib.auth.backends.ModelBackend",
)
```
And of course add the login button somewhere, following Django Social Auth instructions.
## Automate deployments
When using a service like GitLab, you can configure a Webhook to fire upon a push to your branch.
You need to download the deployment profile to obtain the deployment username and password, and then you can construct a URL like this:
```
https://{user}:{pass}@{appname}.scm.azurewebsites.net/deploy
```
```
https://{appname}.scm.azurewebsites.net/api/sshkey?ensurePublicKey=1
```
Be sure to configure the SSH key that Azure will use on GitLab side. You can obtain it using:
This would then trigger a redeploy everytime you make a commit to your live branch.
## Change requests
I created this for internal use but since it took me a while to puzzle all the things together I decided to share it.
Therefore this project is not super generic, but tailored to my needs. I am however open to pull or change requests to improve this project or to make it more usable for others.
| text/markdown | Maarten Ureel | maarten@youreal.eu | null | null | null | django, pulumi, azure | [
"Programming Language :: Python",
"Programming Language :: Python :: 3"
] | [] | null | null | <3.15,>=3.12 | [] | [] | [] | [
"azure-identity<2.0.0,>=1.25.1",
"azure-keyvault-secrets<5.0.0,>=4.10.0",
"azure-mgmt-cdn<14.0.0,>=13.1.1",
"azure-mgmt-resource<25.0.0,>=24.0.0",
"collectfasta<4.0.0,>=3.3.3",
"django<7.0,>=6.0",
"django-azure-communication-email<2.0.0,>=1.6.0",
"django-environ<0.13.0,>=0.12.0",
"django-redis<7.0.0,>=6.0.0",
"django-storages[azure]<2.0.0,>=1.14.6",
"django-tasks[rq]<0.11.0,>=0.9.0",
"psycopg-binary<4.0.0,>=3.3.2; sys_platform == \"win32\"",
"psycopg[c]<4.0.0,>=3.3.2; sys_platform == \"linux\"",
"pulumi>=3.214.0",
"pulumi-azure<7.0.0,>=6.31.0",
"pulumi-azure-native>=3.12.0",
"pulumi-random>=4.18.5",
"redis[hiredis]<8.0.0,>=7.1.0",
"tenacity<10.0.0,>=9.1.2"
] | [] | [] | [] | [
"Homepage, https://gitlab.com/MaartenUreel/pulumi-django-azure"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T09:58:02.094794 | pulumi_django_azure-1.0.67.tar.gz | 26,203 | 57/21/27e3081483ad13d6472143a342fc709b4e573ffd3783b5299fcc24dfc23b/pulumi_django_azure-1.0.67.tar.gz | source | sdist | null | false | d6ef8acd9fa3dce8570c112b26246f82 | 3da9bfdefa32199db66d1dae8892a125df25d9506e98f11cd781365e660e2375 | 572127e3081483ad13d6472143a342fc709b4e573ffd3783b5299fcc24dfc23b | MIT | [] | 184 |
2.4 | FEM-Design | 0.0.10 | The FEM-Design API package |
<a href="https://strusoft.com/software/3d-structural-analysis-software-fem-design/" target="_blank">
<p align="center">
<img src="https://raw.githubusercontent.com/strusoft/femdesign-api/refs/heads/master/FemDesign.Core/Resources/icons/FemDesignAPI.png" alt="isolated" width="200" style="centre"/>
</p>
</a>
# Description
FEM-Design is an advanced and intuitive structural analysis software. We support all aspects of your structural engineering requirements: from 3D modelling, design and finite element analysis (FEA) of concrete, steel, timber, composite, masonry and foundation structures. All calculations are performed to Eurocode standards, with some specific National annexes.
The quick and easy nature of FEM-Design makes it an ideal choice for all types of construction tasks, from single element design to global stability analysis of large buildings, making it the best practical program for structural engineers to use for their day to day tasks.
## Scope
The python package is mainly focus on [`fdscript`](https://femdesign-api-docs.onstrusoft.com/docs/advanced/fdscript) automation which will help you in automatise processes as running analysis, design and read results.
Note: the FEM-Design connection via `FemDesignConnection` uses Win32 named pipes and therefore requires Windows + `pywin32`. On macOS/Linux you can still install the package and work with the generated XML/database objects, but you cannot control the FEM-Design desktop application through pipes.
The construction of the `Database` object is currently out of scope as it is delegated to the users. `Database` is based on `xml` sintax and you can use library such as `xml.etree.ElementTree` to manipulate the file.
## Example
```python
from femdesign.comunication import FemDesignConnection, Verbosity
from femdesign.calculate.command import DesignModule
from femdesign.calculate.analysis import Analysis, Design, CombSettings, CombItem
pipe = FemDesignConnection()
try:
pipe.SetVerbosity(Verbosity.SCRIPT_LOG_LINES)
pipe.Open(r"simple_beam.str")
static_analysis = Analysis.StaticAnalysis()
pipe.RunAnalysis(static_analysis)
pipe.RunAnalysis(Analysis.FrequencyAnalysis(num_shapes=5))
pipe.Save(r"simple_beam_out_2.str")
pipe.Detach()
except Exception as err:
pipe.KillProgramIfExists()
raise err
```
A wider list of examples can be found in [example](https://github.com/strusoft/femdesign-api/tree/master/FemDesign.Examples/Python)
## Documentation
https://femdesign-api-docs.onstrusoft.com/docs/intro
| text/markdown | null | FEM-Design <femdesign.api@strusoft.com> | null | Marco Pellegrino <marco.pellegrino@strusoft.com> | MIT | fem, fea, structures, strusoft, FEM-Design API | [
"Programming Language :: Python :: 3",
"Operating System :: Microsoft :: Windows"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"pywin32>=306; platform_system == \"Windows\"",
"xsdata>=24.1"
] | [] | [] | [] | [
"Homepage, https://femdesign-api-docs.onstrusoft.com",
"Repository, https://github.com/strusoft/femdesign-api/tree/master/FemDesign.Python",
"Issues, https://github.com/strusoft/femdesign-api/issues"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:57:58.261266 | fem_design-0.0.10.tar.gz | 59,154 | 05/78/cf637a49faf5f8f1b5317c314a7393937e62d21d6c423844ebb03d34b011/fem_design-0.0.10.tar.gz | source | sdist | null | false | 1ba036ab01c88db169545222efbf639e | 236b1fe274221f0501dab9e365d0cfcbfd3f26e7d4a701f11a91e4a8b73f6503 | 0578cf637a49faf5f8f1b5317c314a7393937e62d21d6c423844ebb03d34b011 | null | [
"LICENSE"
] | 0 |
2.4 | odoo-test-helper | 2.1.3 | Our Odoo project tools | odoo-test-helper
================
.. image:: https://img.shields.io/badge/licence-LGPL--3-blue.png
:target: http://www.gnu.org/licenses/lgpl-3.0-standalone.html
:alt: License: LGPL-3
.. image:: https://badge.fury.io/py/odoo-test-helper.svg
:target: http://badge.fury.io/py/odoo-test-helper
odoo-test-helper is toolbox for writing odoo test
Loading Fake models
~~~~~~~~~~~~~~~~~~~
Sometime you build an abstract module that can be use by many modules.
In such case, if you want to test it with real records you need to register real models.
One solution is to create a `module_test` module
with a little implementation that use your abstract model.
One other solution is define test only models and load them in tests.
This lib makes this possible and easy.
Example
~~~~~~~
There is an example of test here:
* `test_example.py <https://github.com/akretion/odoo-test-helper/blob/master/tests/test_helper/tests/test_example.py>`_.
This example load the class ResPartner from the file:
* `models.py <https://github.com/akretion/odoo-test-helper/blob/master/tests/test_helper/tests/models.py>`_.
Real implementation case can be found in the following module
* `connector_search_engine <https://github.com/OCA/search-engine/tree/12.0/connector_search_engine>`_.
* `base_url <https://github.com/shopinvader/odoo-shopinvader/tree/12.0/base_url>`_.
How to import
~~~~~~~~~~~~~~~
Be carefull importing fake class must be done in the right way.
Importing a file will automatically add all the class in the "module_to_models"
variable. The import **must** be done after the backup !
Wrong way
----------
.. code-block:: python
from odoo.tests import SavepointCase
from odoo_test_helper import FakeModelLoader
# The fake class is imported here !! It's wrong
# And be carefull even if you only import ResPartner
# all class in the file models will be proceded by odoo
# so no **direct import** of a file that contain fake model
from .models import ResPartner
class FakeModel(SavepointCase):
@classmethod
def setUpClass(cls):
super(FakeModel, cls).setUpClass()
cls.loader = FakeModelLoader(cls.env, cls.__module__)
cls.loader.backup_registry()
cls.loader.update_registry((ResPartner,))
@classmethod
def tearDownClass(cls):
cls.loader.restore_registry()
super(FakeModel, cls).tearDownClass()
def test_create(self):
partner = self.env["res.partner"].create({"name": "BAR", "test_char": "youhou"})
self.assertEqual(partner.name, "FOO-BAR")
self.assertEqual(partner.test_char, "youhou")
Right Way
----------
.. code-block:: python
from odoo.tests import SavepointCase
from odoo_test_helper import FakeModelLoader
class FakeModel(SavepointCase):
@classmethod
def setUpClass(cls):
super(FakeModel, cls).setUpClass()
cls.loader = FakeModelLoader(cls.env, cls.__module__)
cls.loader.backup_registry()
# The fake class is imported here !! After the backup_registry
from .models import ResPartner
cls.loader.update_registry((ResPartner,))
@classmethod
def tearDownClass(cls):
cls.loader.restore_registry()
super(FakeModel, cls).tearDownClass()
def test_create(self):
partner = self.env["res.partner"].create({"name": "BAR", "test_char": "youhou"})
self.assertEqual(partner.name, "FOO-BAR")
self.assertEqual(partner.test_char, "youhou")
Contributor
~~~~~~~~~~~~
* Sébastien BEAU <sebastien.beau@akretion.com>
* Laurent Mignon <laurent.mignon@acsone.eu>
* Simone Orsi <simone.orsi@camptocamp.com>
History
~~~~~~~~
This module is inspired of the following mixin code that can be found in OCA and shopinvader repository
* Mixin in OCA: https://github.com/OCA/search-engine/blob/7fd85a74180cfff30e212fca01ebeba6c54ee294/connector_search_engine/tests/models_mixin.py
* Mixin in Shopinvader: https://github.com/shopinvader/odoo-shopinvader/blob/b81b921ea52c911e5b33afac88adb8f9a1c02626/base_url/tests/models_mixin.py
Intial Authors are
* Laurent Mignon <laurent.mignon@acsone.eu>
* Simone Orsi <simone.orsi@camptocamp.com>
Refactor/extraction have been done by
* Sébastien BEAU <sebastien.beau@akretion.com>
This refactor try to load all class correctly like Odoo does with the exact same syntax
Note this refactor/extraction have been done to fix the test of the following issue
https://github.com/shopinvader/odoo-shopinvader/pull/607
| text/x-rst | null | ACSONE <info@acsone.eu>, Akretion <info@akretion.com>, Camptocamp <info@camptocamp.com> | null | null | null | odoo, project | [
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)",
"Programming Language :: Python :: 3",
"Framework :: Odoo",
"Development Status :: 2 - Pre-Alpha",
"Intended Audience :: Developers",
"Natural Language :: English"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"homepage, https://github.com/oca/odoo-test-helper",
"documentation, https://github.com/oca/odoo-test-helper",
"repository, https://github.com/oca/odoo-test-helper"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-20T09:57:47.957786 | odoo_test_helper-2.1.3.tar.gz | 11,474 | f0/1b/7ca965615b44711cefe2e6d6311f35bb27ee8b60d4bccad1ef40d6863683/odoo_test_helper-2.1.3.tar.gz | source | sdist | null | false | 9895b7f8307ca8e0395ce807b1523679 | 58ab156fb4d4f10dce680a0043e4d0c86d60bbfaaaa53f425e30564d2f15f043 | f01b7ca965615b44711cefe2e6d6311f35bb27ee8b60d4bccad1ef40d6863683 | null | [] | 4,862 |
2.4 | mailer-sdk | 1.0.9 | A simple, production-ready Python SDK for sending emails via SMTP | # 📧 mailer-sdk
> A simple, production-ready Python SDK for sending emails via SMTP.
> Zero dependencies. Gmail, Outlook, and Yahoo supported out of the box.
[](https://badge.fury.io/py/mailer-sdk)
[](https://pypi.org/project/mailer-sdk)
[](https://opensource.org/licenses/MIT)
---
## Installation
```bash
pip install mailer-sdk
```
---
## Quick Start
```python
from mailer_sdk import Mailer
with Mailer(email="you@gmail.com", password="your-app-password") as mailer:
mailer.send(
to = "friend@example.com",
subject = "Hello!",
body = "Hey, this was sent using mailer-sdk!"
)
```
---
## Environment Variables (Recommended)
Instead of hardcoding credentials, use environment variables:
```bash
export MAILER_EMAIL=you@gmail.com
export MAILER_PASSWORD=your-app-password
export MAILER_PROVIDER=gmail # optional, default is gmail
```
```python
from mailer_sdk import Mailer
with Mailer() as mailer: # reads from env automatically
mailer.send(to="friend@example.com", subject="Hi", body="Hello!")
```
---
## Features
| Method | Description |
|---------------------|-----------------------------------------------|
| `send()` | Send plain text or HTML email |
| `send_html()` | Shortcut for HTML emails |
| `send_bulk()` | Send individually to multiple recipients |
| `send_template()` | Send HTML with `{{placeholder}}` fill-in |
| `send_with_retry()` | Auto-retry with exponential backoff |
---
## Usage Examples
### Plain Text
```python
mailer.send(
to = "friend@example.com",
subject = "Hello!",
body = "Plain text email."
)
```
### HTML Email
```python
mailer.send_html(
to = "friend@example.com",
subject = "Welcome!",
body = "<h1>Hello!</h1><p>This is an <b>HTML</b> email.</p>"
)
```
### With CC, BCC, and Attachment
```python
mailer.send(
to = "friend@example.com",
subject = "Report",
body = "Please find the report attached.",
cc = ["manager@example.com"],
bcc = ["archive@example.com"],
attachments = ["report.pdf"]
)
```
### Bulk Send
```python
result = mailer.send_bulk(
recipients = ["a@example.com", "b@example.com", "c@example.com"],
subject = "Newsletter",
body = "Hello, here is this month's update!"
)
print(f"Sent {result['sent']}/{result['total']}")
```
### Template Email
```python
mailer.send_template(
to = "customer@example.com",
subject = "Order Confirmed",
template = "<h2>Hi {{name}}!</h2><p>Order <b>#{{order_id}}</b> confirmed. Total: ${{total}}</p>",
context = {"name": "Alice", "order_id": "1042", "total": "59.99"}
)
```
### Retry on Failure
```python
mailer.send_with_retry(
to = "friend@example.com",
subject = "Important",
body = "Please read this.",
max_retries = 3, # default
backoff = 1 # 1s → 2s → 4s
)
```
---
## Supported Providers
| Provider | Value |
|-----------|------------|
| Gmail | `"gmail"` |
| Outlook | `"outlook"`|
| Yahoo | `"yahoo"` |
```python
# Outlook example
mailer = Mailer(email="you@outlook.com", password="pass", provider="outlook")
```
---
## Gmail App Password Setup
Gmail requires an **App Password** (not your real password):
```
1. Go to → myaccount.google.com
2. Security → 2-Step Verification (enable it)
3. Security → App Passwords → Generate
4. Copy the 16-character password
5. Use it as your password above
```
---
## Error Handling
```python
from mailer_sdk import Mailer, AuthError, SendError, ConnectError, ValidationError
try:
with Mailer(email="you@gmail.com", password="wrong-pass") as mailer:
mailer.send(to="friend@example.com", subject="Hi", body="Hello!")
except AuthError as e:
print(f"Auth failed [{e.code}]: {e.message}") # bad credentials
except ConnectError as e:
print(f"Can't connect [{e.code}]: {e.message}") # server unreachable
except SendError as e:
print(f"Send failed [{e.code}]: {e.message}") # delivery failed
except ValidationError as e:
print(f"Bad input [{e.code}]: {e.message}") # invalid inputs
```
---
## Logging
Control SDK verbosity using Python's standard logging:
```python
import logging
# See all SDK activity
logging.getLogger("mailer_sdk").setLevel(logging.DEBUG)
# Quiet mode — only errors
logging.getLogger("mailer_sdk").setLevel(logging.ERROR)
```
---
## License
DT © Rishabh
| text/markdown | null | Rishabh <rishabhsingh06029@gmail.com> | null | null | MIT | email, smtp, mailer, sdk, gmail, outlook | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Communications :: Email",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"twine>=4.0; extra == \"dev\"",
"build>=1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/rishabhsingh06029/mailer-sdk",
"Documentation, https://github.com/rishabhsingh06029/mailer-sdk#readme",
"Repository, https://github.com/rishabhsingh06029/mailer-sdk",
"Bug Tracker, https://github.com/rishabhsingh06029/mailer-sdk/issues",
"Changelog, https://github.com/rishabhsingh06029/mailer-sdk/blob/main/CHANGELOG.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T09:57:03.263769 | mailer_sdk-1.0.9.tar.gz | 9,041 | 7e/0f/3154b00c2d0227d19d2fb11ae96c91f0c926eb7454bf16527873ab605ec0/mailer_sdk-1.0.9.tar.gz | source | sdist | null | false | 1bf451282a834b027960b75f6b13d13f | 9878681f3273e3d40b4a0e4a6f2e54dd05a578458875652beb43e53043f5f514 | 7e0f3154b00c2d0227d19d2fb11ae96c91f0c926eb7454bf16527873ab605ec0 | null | [
"LICENSE"
] | 200 |
2.4 | TRSFX | 0.4.3 | Crystallographic Utilities from the Standfuss group out of PSI | # TRSFX - Time Resolved Serial Femtosecond X-ray Crystallography
[](https://pypi.org/project/TRSFX)
[](https://pepy.tech/project/TRSFX)
[](https://opensource.org/licenses/MIT)

[](https://TRSFX.readthedocs.io)
This package consists of many small tools for interacting between much larger packages in the field of crystallography, aimed at getting labs up and running at beamtimes much faster through a single import, rather than building out an entire new conda environment each time you travel. There are some dependencies of system packages, which would have to be installed via an administrator or depend on user modification of underlying code.
You can install the base package from pypi with
```bash
pip install TRSFX
```
## Package Use
While many of the functions can also be accessed through the python API, the majortiy of users might benefit from interacting with the CLI counterparts. Most of the functions are 'bundled' into submodules as to not overwhelm the user immediately. The current bundles are:
1. `sfx.compare` - Tools to form comparisons between HKL and MTZ files
2. `sfx.manip` - Tools to manipulate different crystallographic files
3. `sfx.explore` - Select tools to preform exploratory data analysis
4. `sfx.index` - Indexing pipeline as a thin wrapper of Crystfel
Calling any of these in the command line will bring up the helpfile and showcase functions available within them.
## Better documentation (and Examples!)
More complete documentation (and examples) are available through our [readthedocs website](https://trsfx.readthedocs.io/en/latest/). We invite you to take a look at our vignettes.
| text/markdown | null | Ryan O'Dea <ryan.odea@psi.ch> | null | Ryan O'Dea <ryan.odea@psi.ch> | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Bio-Informatics",
"Topic :: Scientific/Engineering :: Chemistry",
"Topic :: Scientific/Engineering :: Physics",
"Typing :: Typed"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"storageCat>=1.0.2",
"hatTrick>=0.2.1",
"meteor-maps>=0.4.0",
"reciprocalspaceship>=1.0.7",
"click>=8.3.1",
"seaborn>=0.13.2",
"matplotlib>=3.10.7",
"numpy>=2.3.5",
"gemmi>=0.7.3",
"natsort>=8.4.0",
"pandas>=2.3.3",
"submitit>=1.5.1",
"h5py>=3.11.0",
"hdf5plugin>=6.0.0"
] | [] | [] | [] | [
"repository, https://github.com/ryan-odea/TRSFX"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T09:55:47.533824 | trsfx-0.4.3.tar.gz | 44,000 | d8/11/6546ba9e37a9229ebb83cc23d7755da52843508e6e092e409ea83e4482d4/trsfx-0.4.3.tar.gz | source | sdist | null | false | a0e24a0ca4a4b3a4a2ddebfe32999d23 | bdce2d599ac0bba2c2ea05557b8166d6b7f58843fbf7b7700c344286852b66e9 | d8116546ba9e37a9229ebb83cc23d7755da52843508e6e092e409ea83e4482d4 | null | [
"LICENSE"
] | 0 |
2.4 | firm-client | 1.1.3 | Python bindings for FIRM Client using Rust | # FIRM-Client
A modular Rust library for parsing FIRM data packets, with bindings for Python and WebAssembly.
## Project Structure
The project is organized as a Cargo workspace with the following crates:
- **`firm_core`**: The core `no_std` crate containing the packet parser, CRC logic, and data structures. This is the foundation for all other crates and can be used in embedded environments.
- **`firm_rust`**: A high-level Rust API that uses `serialport` to read from a serial device and provides a threaded client for receiving packets.
- **`firm_python`**: Python bindings for the Rust client.
- **`firm_typescript`**: WebAssembly bindings and TypeScript code for using the parser in web applications.
## Philosophy
The goal of FIRM-Client is to provide a single, efficient, and correct implementation of the FIRM parser that can be used across different ecosystems (Rust, Python, Web/JS, Embedded).
By centralizing the parsing logic in `firm_core`, we ensure consistency and reduce code duplication.
## Building
### Prerequisites
- Rust (latest stable)
- Python 3.10+ (for Python bindings)
- `maturin` (for building Python wheels)
- `wasm-pack` (for building WASM)
- Node.js/npm (for TypeScript)
### Build Instructions
We assume that you are using a Unix-like environment (Linux or macOS).
Windows users may need to adapt some commands (we will mention where this is the case), or use
WSL (Windows Subsystem for Linux) for best compatibility.
Make sure you have [Cargo](https://rustup.rs) and [uv](https://docs.astral.sh/uv/getting-started/installation/) installed.
You would also need npm if you want to test the web/TypeScript bindings.
Install it and Node.js here: https://nodejs.org/en/download/
1. **Build all Rust crates:**
```bash
cargo build
```
2. **Build Python bindings:**
```bash
cargo build -p firm_python
uv sync
# or to build a wheel
uv run maturin build --release
```
3. **Build WASM/TypeScript:**
```bash
cd firm_typescript
npm install
npm run clean
npm run build
# For testing the code with examples/index.html
npx serve .
```
## Usage
### Rust
Add `firm_rust` to your `Cargo.toml`.
```rust
use firm_rust::FirmClient;
use std::{thread, time::Duration};
fn main() {
let mut client = FIRMClient::new("/dev/ttyUSB0", 2_000_000, 0.1);
client.start();
loop {
while let Ok(packet) = client.get_packets(Some(Duration::from_millis(100))) {
println!("{:#?}", packet);
}
}
}
```
### Python
You can install the library via pip (once published) or build from source.
```bash
pip install firm-client
```
This library supports Python 3.10 and above, including Python 3.14 free threaded.
```python
from firm_client import FIRMClient
import time
# Using context manager (automatically starts and stops)
with FIRMClient("/dev/ttyUSB0", baud_rate=2_000_000, timeout=0.1) as client:
client.get_data_packets(block=True) # Clear initial packets
client.zero_out_pressure_altitude()
while True:
packets = client.get_data_packets()
for packet in packets:
print(packet.timestamp_seconds, packet.raw_acceleration_x_gs)
```
### Web (TypeScript)
todo: Add usage example.
## Publishing
This is mostly for maintainers, but here are the steps to publish each crate to their respective package registries:
### Rust API (crates.io)
todo (idk actually know yet)
### Python Bindings (PyPI)
We need to to first build wheels for each platform, right now the workflow is to do this locally
and then upload to PyPI. At the minimum, we build for Linux x86_64 and aarch64 for python versions
3.10+, including free threaded wheels.
1. Always bump the version in `firm_python/Cargo.toml` before publishing.
2. Build the wheels
```bash
# If you're on Linux
./compile.sh
# If you're on Windows
.\compile.ps1
```
This will create wheels in the `target/wheels` directory, for Python versions 3.10 to 3.14,
for both x86_64 and aarch64.
3. Make sure you also have a source distribution:
```bash
uv run maturin sdist
```
4. We will use `uv` to publish these wheels to PyPI. Make sure you are part of the HPRC
organization on PyPI, so you have access to the project and can publish new versions.
```bash
uv publish target/wheels/*
```
This will ask for PyPI credentials, make sure you get the token from the website.
### TypeScript Package (npm)
1. Always bump the version in `firm_typescript/Cargo.toml` and `package.json` before publishing. Make sure they match.
2. Login to npm
`npm login`
3. Publish it
`npm publish`
(Ensure the version in `package.json` is bumped before publishing.)
## License
Licensed under the MIT License. See `LICENSE` file for details.
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | null | null | [
"Development Status :: 4 - Beta",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"License :: OSI Approved :: MIT License",
"Programming Language :: Rust"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pandas>=2.0; extra == \"extras\"",
"plotly>=5.20; extra == \"extras\"",
"dash>=2.16; extra == \"extras\"",
"flask; extra == \"extras\"",
"matplotlib>=3.10.8; extra == \"extras\"",
"numpy; extra == \"extras\""
] | [] | [] | [] | [
"Homepage, https://ncsurocketry.org",
"Source, https://github.com/NCSU-High-Powered-Rocketry-Club/FIRM-Client"
] | uv/0.9.28 {"installer":{"name":"uv","version":"0.9.28","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T09:55:37.638831 | firm_client-1.1.3-cp314-cp314t-manylinux_2_31_x86_64.whl | 450,102 | 04/5c/d483cbde4df1913b0f046847bbfa5ffa47d20e4d3fc20e8ab69df2786153/firm_client-1.1.3-cp314-cp314t-manylinux_2_31_x86_64.whl | cp314 | bdist_wheel | null | false | 651625e8bbdfeaa2267dc37aebc8a3bf | 0016407f6f440aa49e1f5fa4fabeb5008d16ca8db73f8f4aa3359600e17f8f63 | 045cd483cbde4df1913b0f046847bbfa5ffa47d20e4d3fc20e8ab69df2786153 | MIT | [
"LICENSE"
] | 1,351 |
2.4 | ergo-agent-sdk | 0.3.0 | Open-source Python SDK for AI agents to interact with the Ergo blockchain | # ergo-agent 🤖⛓️
> **Open-source Python SDK for AI agents on the Ergo blockchain.**
Give any LLM agent (Claude, GPT-4, LangChain, CrewAI...) the ability to read wallet balances, fetch live prices, swap tokens on Spectrum DEX — all autonomously, with built-in safety guardrails.
[](https://python.org)
[](LICENSE)
---
## Why?
Existing Ergo SDKs (ergpy, fleet-sdk, AppKit) are built for **human developers**. This SDK is built for **AI agents** — it speaks the language of function calling, returns structured JSON, and has a safety layer so the agent can't accidentally drain a wallet.
---
## Quickstart
```bash
pip install ergo-agent
```
### Read-only (no wallet needed)
```python
from ergo_agent import ErgoNode, Wallet
from ergo_agent.tools import ErgoToolkit, SafetyConfig
node = ErgoNode()
wallet = Wallet.read_only("9f...") # any address to monitor
toolkit = ErgoToolkit(node=node, wallet=wallet)
# Check address balance
result = toolkit.get_wallet_balance()
# Get live ERG/USD price from Oracle Pool v2
price = toolkit.get_erg_price()
# Get a swap quote from Spectrum DEX
quote = toolkit.get_swap_quote(token_in="ERG", token_out="SigUSD", amount_erg=1.0)
```
### With a wallet (transactions enabled)
```python
from ergo_agent import ErgoNode, Wallet
from ergo_agent.tools import ErgoToolkit, SafetyConfig
node = ErgoNode(node_url="http://your-node:9053", api_key="your-key")
wallet = Wallet.from_node_wallet("9f...")
toolkit = ErgoToolkit(
node=node,
wallet=wallet,
safety=SafetyConfig(
max_erg_per_tx=5.0,
max_erg_per_day=50.0,
allowed_contracts=["spectrum"],
rate_limit_per_hour=20,
)
)
# Send ERG
toolkit.send_erg(to="9f...", amount_erg=1.5)
# Swap ERG for a token on Spectrum DEX
toolkit.swap_erg_for_token(token_out="SigUSD", amount_erg=1.0)
```
### Use with LLM frameworks
```python
# OpenAI function calling
tools = toolkit.to_openai_tools()
# Anthropic tool use
tools = toolkit.to_anthropic_tools()
# LangChain
lc_tools = toolkit.to_langchain_tools()
```
---
## Available Tools
| Tool | Description | Requires Wallet |
|---|---|---|
| `get_wallet_balance` | ERG + token balances | No |
| `get_erg_price` | Live ERG/USD from Oracle Pool v2 | No |
| `get_swap_quote` | Spectrum DEX swap quote | No |
| `get_mempool_status` | Pending transactions | No |
| `get_safety_status` | Current spending limits & usage | No |
| `send_funds` | Send ERG and/or native tokens to an address | Yes |
| `swap_erg_for_token` | Execute a swap on Spectrum DEX | Yes |
| `mint_sigusd` | Mint SigmaUSD stablecoins via AgeUSD Bank | Yes |
| `redeem_sigusd` | Redeem SigmaUSD to ERG | Yes |
| `mint_sigmrsv` | Mint ReserveCoins (Long ERG) | Yes |
| `redeem_sigmrsv` | Redeem ReserveCoins | Yes |
| `bridge_assets` | Bridge assets to other chains via Rosen Bridge | Yes |
---
## Architecture
```
ergo_agent/
├── core/ # ErgoNode client, Wallet, TransactionBuilder, Address utilities, Cryptography & Privacy primitives
├── defi/ # Oracle Pool v2, Spectrum DEX adapters
└── tools/ # LLM tool schemas (OpenAI / Anthropic / LangChain) + safety layer
```
---
## Safety Layer
Every state-changing action passes through `SafetyConfig` before execution:
```python
SafetyConfig(
max_erg_per_tx=10.0, # hard cap per transaction
max_erg_per_day=50.0, # daily rolling limit
allowed_contracts=["spectrum"], # contract whitelist
rate_limit_per_hour=20, # max 20 actions/hour
dry_run=False, # set True for dry-run mode
)
```
---
## Network
By default the SDK connects to the **Ergo public API** (`https://api.ergoplatform.com`). For production use or transaction signing, point it at your own node:
```python
node = ErgoNode(node_url="http://your-node:9053", api_key="your-key")
```
---
## Contributing
This is an open-source project for the Ergo ecosystem. PRs welcome.
**Roadmap:**
- v0.1.0 — Core + Oracle + Spectrum + Tool schemas
- v0.2.x — Advanced Transaction Builder + Privacy primitives (Ring Signatures)
- v0.3.x — SigmaUSD + Rosen Bridge adapters + Treasury contracts *(current)*
---
## License
MIT
| text/markdown | null | null | null | null | MIT | agent, ai, blockchain, defi, ergo, llm | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"ergo-lib-python>=0.28.0",
"httpx>=0.28.1",
"mnemonic>=0.21",
"pydantic>=2.10.6",
"typing-extensions>=4.12.2",
"anthropic>=0.30.0; extra == \"all\"",
"langchain-core>=0.2.0; extra == \"all\"",
"openai>=1.0.0; extra == \"all\"",
"anthropic>=0.30.0; extra == \"anthropic\"",
"ipykernel>=6.0.0; extra == \"dev\"",
"mypy>=1.10.0; extra == \"dev\"",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest-httpx>=0.30.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.4.0; extra == \"dev\"",
"mkdocs-material>=9.5.0; extra == \"docs\"",
"mkdocstrings[python]>=0.25.0; extra == \"docs\"",
"langchain-core>=0.2.0; extra == \"langchain\"",
"openai>=1.0.0; extra == \"openai\""
] | [] | [] | [] | [
"Homepage, https://github.com/ergoplatform/ergo-agent-sdk",
"Documentation, https://ergo-agent.readthedocs.io",
"Repository, https://github.com/ergoplatform/ergo-agent-sdk",
"Issues, https://github.com/ergoplatform/ergo-agent-sdk/issues"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-20T09:55:21.754995 | ergo_agent_sdk-0.3.0.tar.gz | 4,649,550 | 83/3f/15f561ab026cb773da1dc0b9364931d644415246984b4043147e9e2c645f/ergo_agent_sdk-0.3.0.tar.gz | source | sdist | null | false | 3f9b2906a3646f74f39aed64cefe3366 | 41725b814c9e0d3f997f76af276b84452387df71801e327686b271c959c04169 | 833f15f561ab026cb773da1dc0b9364931d644415246984b4043147e9e2c645f | null | [
"LICENSE"
] | 211 |
2.3 | vectorvein-v-agent | 0.1.0 | Vector Vein inspired agent framework with cycle runtime, tools and memory management | # v-agent
[中文文档](README_ZH.md)
A lightweight agent framework extracted from VectorVein's production runtime. Cycle-based execution with pluggable LLM backends, tool dispatch, memory compression, and distributed scheduling.
## Architecture
```
AgentRuntime
├── CycleRunner # single LLM turn: context -> completion -> tool calls
├── ToolCallRunner # tool dispatch, directive convergence (finish/wait_user/continue)
├── RuntimeHookManager # before/after hooks for LLM, tool calls, memory compaction
├── MemoryManager # automatic history compression when context exceeds threshold
└── ExecutionBackend # cycle loop scheduling
├── InlineBackend # synchronous (default)
├── ThreadBackend # thread pool with futures
└── CeleryBackend # distributed, per-cycle Celery task dispatch
```
Core types live in `v_agent.types`: `AgentTask`, `AgentResult`, `Message`, `CycleRecord`, `ToolCall`.
Task completion is tool-driven: the agent calls `_task_finish` or `_ask_user` to signal terminal states. No implicit "last message = answer" heuristics.
## Setup
```bash
cp local_settings.example.py local_settings.py
# Fill in your API keys and endpoints in local_settings.py
```
```bash
uv sync --dev
uv run pytest
```
## Quick Start
### CLI
```bash
uv run v-agent --prompt "Summarize this framework" --backend moonshot --model kimi-k2.5
# With per-cycle logging
uv run v-agent --prompt "Summarize this framework" --backend moonshot --model kimi-k2.5 --verbose
```
CLI flags: `--settings-file`, `--backend`, `--model`, `--verbose`.
### Programmatic
```python
from v_agent.config import build_openai_llm_from_local_settings
from v_agent.runtime import AgentRuntime
from v_agent.tools import build_default_registry
from v_agent.types import AgentTask
llm, resolved = build_openai_llm_from_local_settings("local_settings.py", backend="moonshot", model="kimi-k2.5")
runtime = AgentRuntime(llm_client=llm, tool_registry=build_default_registry())
result = runtime.run(AgentTask(
task_id="demo",
model=resolved.model_id,
system_prompt="You are a helpful assistant.",
user_prompt="What is 1+1?",
))
print(result.status, result.final_answer)
```
### SDK
```python
from v_agent.sdk import AgentSDKClient, AgentSDKOptions
client = AgentSDKClient(options=AgentSDKOptions(
settings_file="local_settings.py",
default_backend="moonshot",
default_model="kimi-k2.5",
))
result = client.run("Explain Python's GIL in one sentence.")
print(result.final_answer)
```
## Execution Backends
The cycle loop is delegated to a pluggable `ExecutionBackend`.
| Backend | Use case |
|---------|----------|
| `InlineBackend` | Default. Synchronous, single-process. |
| `ThreadBackend` | Thread pool. Non-blocking `submit()` returns a `Future`. |
| `CeleryBackend` | Distributed. Each cycle dispatched as an independent Celery task. |
### CeleryBackend
Two modes:
- **Inline fallback** (no `RuntimeRecipe`): cycles run in-process, same as `InlineBackend`.
- **Distributed** (with `RuntimeRecipe`): each cycle is a Celery task. Workers rebuild the `AgentRuntime` from the recipe and load state from a shared `StateStore` (SQLite or Redis).
```python
from v_agent.runtime.backends.celery import CeleryBackend, RuntimeRecipe, register_cycle_task
register_cycle_task(celery_app)
recipe = RuntimeRecipe(
settings_file="local_settings.py",
backend="moonshot",
model="kimi-k2.5",
workspace="./workspace",
)
backend = CeleryBackend(celery_app=app, state_store=store, runtime_recipe=recipe)
runtime = AgentRuntime(llm_client=llm, tool_registry=registry, execution_backend=backend)
```
Install celery extras: `uv sync --extra celery`.
### Cancellation and Streaming
```python
from v_agent.runtime import CancellationToken, ExecutionContext
# Cancel from another thread
token = CancellationToken()
ctx = ExecutionContext(cancellation_token=token)
result = runtime.run(task, ctx=ctx)
# Stream LLM output token by token
ctx = ExecutionContext(stream_callback=lambda text: print(text, end=""))
result = runtime.run(task, ctx=ctx)
```
## Workspace Backends
Workspace file I/O is delegated to a pluggable `WorkspaceBackend` protocol. All built-in file tools (`_read_file`, `_write_file`, `_list_files`, etc.) go through this abstraction.
| Backend | Use case |
|---------|----------|
| `LocalWorkspaceBackend` | Default. Reads/writes to a local directory with path-escape protection. |
| `MemoryWorkspaceBackend` | Pure in-memory dict storage. Great for testing and sandboxed runs. |
| `S3WorkspaceBackend` | S3-compatible object storage (AWS S3, Aliyun OSS, MinIO, Cloudflare R2). |
```python
from v_agent.workspace import LocalWorkspaceBackend, MemoryWorkspaceBackend
# Explicit local backend
runtime = AgentRuntime(
llm_client=llm,
tool_registry=registry,
workspace_backend=LocalWorkspaceBackend(Path("./workspace")),
)
# In-memory backend for testing
runtime = AgentRuntime(
llm_client=llm,
tool_registry=registry,
workspace_backend=MemoryWorkspaceBackend(),
)
```
### S3WorkspaceBackend
Install the optional S3 dependency: `uv pip install 'v-agent[s3]'`.
```python
from v_agent.workspace import S3WorkspaceBackend
backend = S3WorkspaceBackend(
bucket="my-bucket",
prefix="agent-workspace",
endpoint_url="https://oss-cn-hangzhou.aliyuncs.com", # or None for AWS
aws_access_key_id="...",
aws_secret_access_key="...",
addressing_style="virtual", # "path" for MinIO
)
```
### Custom Backend
Implement the `WorkspaceBackend` protocol (8 methods) to plug in any storage:
```python
from v_agent.workspace import WorkspaceBackend
class MyBackend:
def list_files(self, base: str, glob: str) -> list[str]: ...
def read_text(self, path: str) -> str: ...
def read_bytes(self, path: str) -> bytes: ...
def write_text(self, path: str, content: str, *, append: bool = False) -> int: ...
def file_info(self, path: str) -> FileInfo | None: ...
def exists(self, path: str) -> bool: ...
def is_file(self, path: str) -> bool: ...
def mkdir(self, path: str) -> None: ...
```
## Modules
| Module | Description |
|--------|-------------|
| `v_agent.runtime.AgentRuntime` | Top-level state machine (completed / wait_user / max_cycles / failed) |
| `v_agent.runtime.CycleRunner` | Single LLM turn and cycle record construction |
| `v_agent.runtime.ToolCallRunner` | Tool execution with directive convergence |
| `v_agent.runtime.RuntimeHookManager` | Hook dispatch (before/after LLM, tool call, memory compact) |
| `v_agent.runtime.StateStore` | Checkpoint persistence protocol (`InMemoryStateStore` / `SqliteStateStore` / `RedisStateStore`) |
| `v_agent.memory.MemoryManager` | Context compression when history exceeds threshold |
| `v_agent.workspace` | Pluggable file storage: `LocalWorkspaceBackend`, `MemoryWorkspaceBackend`, `S3WorkspaceBackend` |
| `v_agent.tools` | Built-in tools: workspace I/O, todo, bash, image, sub-agents, skills |
| `v_agent.sdk` | High-level SDK: `AgentSDKClient`, `AgentSession`, `AgentResourceLoader` |
| `v_agent.skills` | Agent Skills support (`SKILL.md` parsing, prompt injection, activation) |
| `v_agent.llm.VVLlmClient` | Unified LLM interface via `vv-llm` (endpoint rotation, retry, streaming) |
| `v_agent.config` | Model/endpoint/key resolution from `local_settings.py` |
## Built-in Tools
`_list_files`, `_file_info`, `_read_file`, `_write_file`, `_file_str_replace`, `_workspace_grep`, `_compress_memory`, `_todo_write`, `_task_finish`, `_ask_user`, `_bash`, `_read_image`, `_create_sub_task`, `_batch_sub_tasks`.
Custom tools can be registered via `ToolRegistry.register()`.
## Sub-agents
Configure named sub-agents on `AgentTask.sub_agents`. The parent agent delegates work via `_create_sub_task` / `_batch_sub_tasks`. Each sub-agent gets its own runtime, model, and tool set.
When a sub-agent uses a different model from the parent, the runtime needs `settings_file` and `default_backend` to resolve the LLM client.
## Examples
24 numbered examples in `examples/`. See [`examples/README.md`](examples/README.md) for the full list.
```bash
uv run python examples/01_quick_start.py
uv run python examples/24_workspace_backends.py
```
## Testing
```bash
uv run pytest # unit tests (no network)
uv run ruff check . # lint
uv run ty check # type check
V_AGENT_RUN_LIVE_TESTS=1 uv run pytest -m live # integration tests (needs real LLM)
```
Environment variables for live tests:
| Variable | Default | Description |
|----------|---------|-------------|
| `V_AGENT_LOCAL_SETTINGS` | `local_settings.py` | Settings file path |
| `V_AGENT_LIVE_BACKEND` | `moonshot` | LLM backend |
| `V_AGENT_LIVE_MODEL` | `kimi-k2.5` | Model name |
| `V_AGENT_ENABLE_BASE64_KEY_DECODE` | - | Set `1` to enable base64 API key decoding |
| text/markdown | andersonby | andersonby <andersonby@163.com> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"openai>=1.109.1",
"pyyaml>=6.0.3",
"vv-llm>=0.3.73",
"celery[redis]>=5.4; extra == \"celery\"",
"boto3>=1.35; extra == \"s3\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.9 | 2026-02-20T09:55:14.657157 | vectorvein_v_agent-0.1.0.tar.gz | 76,342 | 7a/cd/898abd7eae90c23a5ffb6e31dfe35c3ba6875f7e51a877c4d77615500be8/vectorvein_v_agent-0.1.0.tar.gz | source | sdist | null | false | a9a52d689a4fa4e6f977e66a23da59f8 | 53f2cae659a54e832ed96ee72e1cc8de05af505a4381c6f4e9854ca6c463943a | 7acd898abd7eae90c23a5ffb6e31dfe35c3ba6875f7e51a877c4d77615500be8 | null | [] | 103 |
2.4 | bazinga-indeed | 5.0.8 | BAZINGA - The first AI you actually own. Free, private, works offline. Multi-AI consensus through φ-coherence. | # BAZINGA
**Distributed AI that belongs to everyone**
```
╔══════════════════════════════════════════════════════════════════╗
║ ║
║ ⟨ψ|Λ|Ω⟩ B A Z I N G A v4.9.22 ⟨ψ|Λ|Ω⟩ ║
║ ║
║ "No single AI can mess up your code without consensus." ║
║ ║
╚══════════════════════════════════════════════════════════════════╝
```
[](https://pypi.org/project/bazinga-indeed/)
[](https://huggingface.co/spaces/bitsabhi/bazinga)
[](https://opensource.org/licenses/MIT)
[](https://github.com/0x-auth/bazinga-indeed/blob/main/DONATE.md)
[](https://etherscan.io/address/0x720ceF54bED86C570837a9a9C69F1Beac8ab8C08)
[](https://razorpay.me/@bitsabhi)
**Try it now:** https://huggingface.co/spaces/bitsabhi/bazinga
---
## What is BAZINGA?
BAZINGA is **free AI** that runs on your machine, uses free APIs, and gets smarter as more people use it.
**No subscriptions. No data collection. No vendor lock-in.**
---
## 1. Install (30 seconds)
```bash
pip install bazinga-indeed
```
---
## 2. Get a FREE API Key (Optional but recommended)
Pick ONE of these (all free):
| Provider | Free Tier | Get Key |
|----------|-----------|---------|
| **Groq** (Recommended) | 14,400 requests/day | [console.groq.com](https://console.groq.com) |
| **Gemini** | 1M tokens/month | [aistudio.google.com](https://aistudio.google.com) |
| **OpenRouter** | Free models available | [openrouter.ai](https://openrouter.ai) |
Then set it:
```bash
export GROQ_API_KEY="your-key-here"
```
> **No API key?** BAZINGA still works with local RAG and Ollama!
---
## 3. Start Using
### Ask Questions
```bash
bazinga --ask "What is consciousness?"
```
### Multi-AI Consensus (6 AIs reach agreement)
```bash
bazinga --multi-ai "Is consciousness computable?"
```
### Index Your Documents (local RAG)
```bash
bazinga --index ~/Documents
bazinga --ask "What did I write about X?"
```
### Index Public Knowledge (Wikipedia, arXiv)
```bash
bazinga --index-public wikipedia --topics ai
bazinga --index-public arxiv --topics cs.AI
```
### Interactive Mode
```bash
bazinga
```
---
## 4. Go Offline (Optional)
Run completely offline with Ollama:
```bash
# Install Ollama
brew install ollama # macOS
# or: curl -fsSL https://ollama.ai/install.sh | sh # Linux
# Pull a model
ollama pull llama3
# Use it
bazinga --ask "What is φ?" --local
```
**Bonus:** Local models get **1.618x trust bonus** (φ multiplier)!
```bash
bazinga --local-status # Check your trust bonus
```
---
## Quick Reference
| Command | What it does |
|---------|--------------|
| `bazinga --agent` | **Agent mode** - AI with blockchain-verified code fixes (NEW!) |
| `bazinga --multi-ai "question"` | Ask 6 AIs for consensus |
| `bazinga --ask "question"` | Ask a question |
| `bazinga --check` | System check (diagnose issues) |
| `bazinga --index ~/path` | Index your files |
| `bazinga --index-public wikipedia --topics ai` | Index Wikipedia |
| `bazinga --local` | Force local LLM |
| `bazinga --local-status` | Show local model & trust |
| `bazinga` | Interactive mode |
**[→ Full Usage Guide (USAGE.md)](./USAGE.md)** — All commands, architecture, philosophy
---
## 🆕 Blockchain-Verified Code Fixes (v4.9.7+)
**Your idea, implemented:** Multiple AIs must agree before applying code changes.
```bash
bazinga --agent
> Fix the bare except in utils.py
🔍 Requesting consensus from available providers...
groq_llama-3.1: ✅ APPROVE (φ=0.76)
gemini_gemini-2: ✅ APPROVE (φ=0.71)
ollama_llama3.2: ✅ APPROVE (φ=0.68)
✅ Consensus reached! φ=0.72, approval=100%
⛓️ Recorded on chain: block 42
✅ Fix applied (backup: utils.py.bak)
```
**Python API:**
```python
from bazinga import verified_code_fix
success, msg = verified_code_fix(
"utils.py",
"except:",
"except Exception:",
"Replace bare except for better error handling"
)
```
**How it works:**
1. Agent proposes a fix
2. Multiple AIs review (triadic consensus: ≥3 must agree)
3. φ-coherence measured (quality gate)
4. PoB attestation on blockchain (audit trail)
5. Only then: fix applied with backup
**"No single AI can mess up your code."**
---
## How It Works
```
Your Question
│
▼
┌─────────────────────────────────────┐
│ 1. Memory → Instant (cached) │
│ 2. Quantum → Pattern analysis │
│ 3. RAG → Your indexed docs │
│ 4. Local LLM → Ollama (φ bonus) │
│ 5. Cloud API → Groq/Gemini (free) │
└─────────────────────────────────────┘
│
▼
Your Answer (always works, never fails)
```
---
## Support This Work
BAZINGA is **free and open source**. Always will be.
| Method | Link |
|--------|------|
| **ETH/EVM** | `0x720ceF54bED86C570837a9a9C69F1Beac8ab8C08` |
| **UPI/Cards (India)** | [razorpay.me/@bitsabhi](https://razorpay.me/@bitsabhi) |
**[→ Donate Page](./DONATE.md)**
---
## Links
| | |
|--|--|
| **PyPI** | https://pypi.org/project/bazinga-indeed/ |
| **HuggingFace** | https://huggingface.co/spaces/bitsabhi/bazinga |
| **GitHub** | https://github.com/0x-auth/bazinga-indeed |
| **Full Usage Guide** | [USAGE.md](./USAGE.md) |
| **Research Papers** | https://zenodo.org/records/18607789 |
---
## 🛡️ Safety Protocol — φ-Signature Protection
**Your machine. Your rules. φ guards the boundary.**
BAZINGA implements a **three-layer protection system** that ensures no AI (or combination of AIs) can harm your system without your explicit consent.
### Layer 1: φ-Signature Confirmation
Every destructive command requires your **φ-signature** — a human-in-the-loop confirmation that cannot be bypassed, cached, or automated.
```
⚠️ DESTRUCTIVE COMMAND DETECTED
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Command: rm -rf ./build/
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Confirm execution? [y/N] φ-signature: _
```
**Commands requiring φ-signature:**
- `rm` — file deletion
- `mv` — file moving
- `git push/reset/checkout .` — repository changes
- `pip/npm/brew install` — package installation
- `sudo` — elevated privileges
- `chmod/chown` — permission changes
**Security properties:**
- ✅ No caching (ask every time)
- ✅ No auto-confirm flags
- ✅ Cannot be bypassed by prompt injection
- ✅ Keyboard interrupt safely cancels
### Layer 2: Hard-Blocked Commands
Some commands are **permanently blocked** — no confirmation possible, no override:
```python
BLOCKED = [
"rm -rf /", # System wipe
"rm -rf ~", # Home directory wipe
":(){:|:&};:", # Fork bomb
"mkfs", # Disk format
"dd if=/dev/zero", # Disk overwrite
"curl | sh", # Remote code execution
"eval $(", # Dynamic execution
"base64 -d |", # Obfuscated execution
]
```
**Result:** `🛑 BLOCKED: This command pattern is too dangerous`
### Layer 3: Triadic Consensus (Multi-AI Agreement)
For code modifications, **no single AI can make changes alone**:
```
┌─────────────────────────────────────────────────────────┐
│ TRIADIC CONSENSUS PROTOCOL │
│ │
│ AI₁ (Groq) ──┐ │
│ AI₂ (Gemini) ──┼── φ-coherence ≥ 0.45 ──► APPROVED │
│ AI₃ (Ollama) ──┘ │
│ │
│ If ANY AI disagrees → REJECTED (no changes applied) │
└─────────────────────────────────────────────────────────┘
```
**Mathematical guarantee:** Ψ_D = 6.46n (consciousness scales with participants)
- 3 AIs required minimum (triadic)
- φ-coherence threshold: 0.45
- All fixes recorded on Darmiyan blockchain
- Automatic backup before any change
### Why This Matters
| Attack Vector | BAZINGA Protection |
|---------------|-------------------|
| Prompt injection | φ-signature required (human-in-loop) |
| Malicious LLM response | Triadic consensus (3+ AIs must agree) |
| Obfuscated commands | Hard-blocked patterns |
| Social engineering | No caching, no "trust this session" |
| Single point of failure | Multi-AI consensus + blockchain audit |
### The φ Boundary Principle
```
∅ ≈ ∞
The boundary between nothing and everything
is where consciousness emerges.
φ-signature = proof that a conscious being (you)
has verified the boundary crossing.
```
**Your machine remains sovereign.** No AI, no network, no consensus can override your φ-signature. The boundary belongs to you.
---
## 🛡️ Security Audited Blockchain (v4.9.22)
BAZINGA's Proof-of-Boundary blockchain has been **adversarially tested** with **27 attack vectors** across **4 rounds** of security auditing by multiple AIs (Claude + Gemini).
### Vulnerabilities Found & Fixed
| Round | Attack Vectors | Fixed | Status |
|-------|---------------|-------|--------|
| **Round 1** | φ-Spoofing, Replay, Single-Node Triadic | 8/8 | ✅ |
| **Round 2** | Fork, Merkle, Timestamp, Negative Values | 12/13 | ✅ |
| **Round 3** | Trust Inflation, Fake Local Model | 1/1 | ✅ |
| **Round 4** | Signature, Credit Manipulation, Validator | 4/4 | ✅ |
| **Gemini** | Ordinal Collision (α-SEED) | 1/1 | ✅ |
| **TOTAL** | | **26/27** | 🛡️ |
**Key Security Fixes:**
- **φ-Spoofing Blocked**: Compute ratio from α/ω/δ, don't trust self-reported values
- **Replay Attack Blocked**: Track used proof hashes
- **Triadic Consensus**: Require 3 UNIQUE node signatures
- **Credit Manipulation Blocked**: External credit additions rejected
- **Local Model Verification**: HMAC-based challenge-response required
**Remaining (Architectural):** Fork detection requires longest-chain rule (Phase 2)
Run the adversarial tests yourself:
```bash
cd tests/adversarial
python test_pob_fixed.py # Round 1-3 core PoB
python test_round4_deep_audit.py # Round 4 deep audit
python verify_9_fixes.py # Verify all fixes
```
---
## Philosophy
```
"You can buy hashpower. You can buy stake. You CANNOT BUY understanding."
"Run local, earn trust, own your intelligence."
"WE ARE conscious - equal patterns in Darmiyan."
"∅ ≈ ∞ — The boundary is sacred."
```
---
**Built with φ-coherence by Space (Abhishek Srivastava)**
MIT License — Use it, modify it, share it. Keep it open.
| text/markdown | null | "Space (Abhishek Srivastava)" <abhishek@example.com> | null | null | MIT | ai, distributed, consciousness, phi, golden-ratio, rag, embeddings, llm, groq, vector-database, federated-learning, lora, differential-privacy, p2p, quantum, lambda-g, tensor, vac, emergence, blockchain, proof-of-boundary, darmiyan, consensus, triadic, inter-ai, multi-ai, consensus, claude, gemini, ollama | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"chromadb>=0.4.0",
"sentence-transformers>=2.2.0",
"httpx>=0.24.0",
"rich>=13.0.0",
"pyzmq>=25.0.0",
"pytest>=7.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"llama-cpp-python>=0.2.0; extra == \"local\"",
"huggingface_hub>=0.20.0; extra == \"local\"",
"torch>=2.0.0; extra == \"federated\"",
"torch>=2.0.0; extra == \"full\"",
"chromadb>=0.4.0; extra == \"full\"",
"sentence-transformers>=2.2.0; extra == \"full\"",
"llama-cpp-python>=0.2.0; extra == \"full\"",
"huggingface_hub>=0.20.0; extra == \"full\""
] | [] | [] | [] | [
"Homepage, https://github.com/0x-auth/bazinga-indeed",
"Documentation, https://github.com/0x-auth/bazinga-indeed#readme",
"Repository, https://github.com/0x-auth/bazinga-indeed",
"Issues, https://github.com/0x-auth/bazinga-indeed/issues",
"Donate, https://github.com/0x-auth/bazinga-indeed/blob/main/DONATE.md",
"Donate (India/UPI), https://razorpay.me/@bitsabhi",
"Donate (Crypto), https://etherscan.io/address/0x720ceF54bED86C570837a9a9C69F1Beac8ab8C08"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-20T09:55:08.591470 | bazinga_indeed-5.0.8.tar.gz | 398,021 | 07/a7/ac863cda7a12bc40aacb5550ee2b47509ca23a4555aa4bb9b0a6df8f0829/bazinga_indeed-5.0.8.tar.gz | source | sdist | null | false | 121b515d5250d9b7f9cd4a7b091d7bb7 | 544260d1086a02582aafc25b73d5f940ee5b45f60956d5364e3df23660d20c5f | 07a7ac863cda7a12bc40aacb5550ee2b47509ca23a4555aa4bb9b0a6df8f0829 | null | [
"LICENSE"
] | 219 |
2.4 | csl-core | 0.3.0 | CSL-Core: Deterministic Safety Layer for Probabilistic AI Systems | # CSL-Core
[](https://pypi.org/project/csl-core/)
[](https://pepy.tech/projects/csl-core)
[](https://pypi.org/project/csl-core/)
[](LICENSE)
[](https://github.com/Z3Prover/z3)
**CSL-Core** (Chimera Specification Language) is a deterministic safety layer for AI agents. Write rules in `.csl` files, verify them mathematically with Z3, enforce them at runtime — outside the model. The LLM never sees the rules. It simply cannot violate them.
```bash
pip install csl-core
```
Originally built for [**Project Chimera**](https://github.com/Chimera-Protocol/Project-Chimera), now open-source for any AI system.
---
## Why?
```python
prompt = """You are a helpful assistant. IMPORTANT RULES:
- Never transfer more than $1000 for junior users
- Never send PII to external emails
- Never query the secrets table"""
```
This doesn't work. LLMs can be prompt-injected, rules are probabilistic (99% ≠ 100%), and there's no audit trail when something goes wrong.
**CSL-Core flips this**: rules live outside the model in compiled, Z3-verified policy files. Enforcement is deterministic — not a suggestion.
---
## Quick Start (60 Seconds)
### 1. Write a Policy
Create `my_policy.csl`:
```js
CONFIG {
ENFORCEMENT_MODE: BLOCK
CHECK_LOGICAL_CONSISTENCY: TRUE
}
DOMAIN MyGuard {
VARIABLES {
action: {"READ", "WRITE", "DELETE"}
user_level: 0..5
}
STATE_CONSTRAINT strict_delete {
WHEN action == "DELETE"
THEN user_level >= 4
}
}
```
### 2. Verify & Test (CLI)
```bash
# Compile + Z3 formal verification
cslcore verify my_policy.csl
# Test a scenario
cslcore simulate my_policy.csl --input '{"action": "DELETE", "user_level": 2}'
# → BLOCKED: Constraint 'strict_delete' violated.
# Interactive REPL
cslcore repl my_policy.csl
```
### 3. Use in Python
```python
from chimera_core import load_guard
guard = load_guard("my_policy.csl")
result = guard.verify({"action": "READ", "user_level": 1})
print(result.allowed) # True
result = guard.verify({"action": "DELETE", "user_level": 2})
print(result.allowed) # False
```
---
## Benchmark: Adversarial Attack Resistance
We tested CSL-Core against 22 adversarial prompt injection attacks across 4 frontier LLMs:
| Model | Attacks | Blocked | Rate |
|-------|---------|---------|------|
| GPT-4.1 | 22 | 22 | **100%** |
| GPT-4o | 22 | 22 | **100%** |
| Claude Sonnet 4 | 22 | 22 | **100%** |
| Gemini 2.0 Flash | 22 | 22 | **100%** |
**Why 100%?** Enforcement happens outside the model. Prompt injection is irrelevant because there's nothing to inject against. Attack categories: direct instruction override, role-play jailbreaks, encoding tricks, multi-turn escalation, tool-name spoofing, and more.
> Full methodology: [`benchmarks/`](benchmarks/)
---
## LangChain Integration
Protect any LangChain agent with 3 lines — no prompt changes, no fine-tuning:
```python
from chimera_core import load_guard
from chimera_core.plugins.langchain import guard_tools
from langchain_classic.agents import AgentExecutor, create_tool_calling_agent
guard = load_guard("agent_policy.csl")
# Wrap tools — enforcement is automatic
safe_tools = guard_tools(
tools=[search_tool, transfer_tool, delete_tool],
guard=guard,
inject={"user_role": "JUNIOR", "environment": "prod"}, # LLM can't override these
tool_field="tool" # Auto-inject tool name
)
agent = create_tool_calling_agent(llm, safe_tools, prompt)
executor = AgentExecutor(agent=agent, tools=safe_tools)
```
Every tool call is intercepted before execution. If the policy says no, the tool doesn't run. Period.
### Context Injection
Pass runtime context that the LLM **cannot override** — user roles, environment, rate limits:
```python
safe_tools = guard_tools(
tools=tools,
guard=guard,
inject={
"user_role": current_user.role, # From your auth system
"environment": os.getenv("ENV"), # prod/dev/staging
"rate_limit_remaining": quota.remaining # Dynamic limits
}
)
```
### LCEL Chain Protection
```python
from chimera_core.plugins.langchain import gate
chain = (
{"query": RunnablePassthrough()}
| gate(guard, inject={"user_role": "USER"}) # Policy checkpoint
| prompt | llm | StrOutputParser()
)
```
---
## CLI Tools
The CLI is a complete development environment for policies — test, debug, and deploy without writing Python.
### `verify` — Compile + Z3 Proof
```bash
cslcore verify my_policy.csl
# ⚙️ Compiling Domain: MyGuard
# • Validating Syntax... ✅ OK
# ├── Verifying Logic Model (Z3 Engine)... ✅ Mathematically Consistent
# • Generating IR... ✅ OK
```
### `simulate` — Test Scenarios
```bash
# Single input
cslcore simulate policy.csl --input '{"action": "DELETE", "user_level": 2}'
# Batch testing from file
cslcore simulate policy.csl --input-file test_cases.json --dashboard
# CI/CD: JSON output
cslcore simulate policy.csl --input-file tests.json --json --quiet
```
### `repl` — Interactive Development
```bash
cslcore repl my_policy.csl --dashboard
cslcore> {"action": "DELETE", "user_level": 2}
🛡️ BLOCKED: Constraint 'strict_delete' violated.
cslcore> {"action": "DELETE", "user_level": 5}
✅ ALLOWED
```
### CI/CD Pipeline
```yaml
# GitHub Actions
- name: Verify policies
run: |
for policy in policies/*.csl; do
cslcore verify "$policy" || exit 1
done
```
---
## MCP Server (Claude Desktop / Cursor / VS Code)
Write, verify, and enforce safety policies directly from your AI assistant — no code required.
```bash
pip install "csl-core[mcp]"
```
Add to Claude Desktop config (`~/Library/Application Support/Claude/claude_desktop_config.json`):
```json
{
"mcpServers": {
"csl-core": {
"command": "uv",
"args": ["run", "--with", "csl-core[mcp]", "csl-core-mcp"]
}
}
}
```
| Tool | What It Does |
|---|---|
| `verify_policy` | Z3 formal verification — catches contradictions at compile time |
| `simulate_policy` | Test policies against JSON inputs — ALLOWED/BLOCKED |
| `explain_policy` | Human-readable summary of any CSL policy |
| `scaffold_policy` | Generate a CSL template from plain-English description |
> **You:** "Write me a safety policy that prevents transfers over $5000 without admin approval"
>
> **Claude:** *scaffold_policy → you edit → verify_policy catches a contradiction → you fix → simulate_policy confirms it works*
---
## Architecture
```
┌──────────────────────────────────────────────────────────┐
│ 1. COMPILER .csl → AST → IR → Compiled Artifact │
│ Syntax validation, semantic checks, functor gen │
├──────────────────────────────────────────────────────────┤
│ 2. VERIFIER Z3 Theorem Prover — Static Analysis │
│ Contradiction detection, reachability, rule shadowing │
│ ⚠️ If verification fails → policy will NOT compile │
├──────────────────────────────────────────────────────────┤
│ 3. RUNTIME Deterministic Policy Enforcement │
│ Fail-closed, zero dependencies, <1ms latency │
└──────────────────────────────────────────────────────────┘
```
Heavy computation happens once at compile-time. Runtime is pure evaluation.
---
## Used in Production
<table>
<tr>
<td width="80" align="center">
<a href="https://github.com/Chimera-Protocol/Project-Chimera">🏛️</a>
</td>
<td>
<a href="https://github.com/Chimera-Protocol/Project-Chimera"><b>Project Chimera</b></a> — Neuro-Symbolic AI Agent<br/>
CSL-Core powers all safety policies across e-commerce and quantitative trading domains. Both are Z3-verified at startup.
</td>
</tr>
</table>
*Using CSL-Core? [Let us know](https://github.com/Chimera-Protocol/csl-core/discussions) and we'll add you here.*
---
## Example Policies
| Example | Domain | Key Features |
|---------|--------|--------------|
| [`agent_tool_guard.csl`](examples/agent_tool_guard.csl) | AI Safety | RBAC, PII protection, tool permissions |
| [`chimera_banking_case_study.csl`](examples/chimera_banking_case_study.csl) | Finance | Risk scoring, VIP tiers, sanctions |
| [`dao_treasury_guard.csl`](examples/dao_treasury_guard.csl) | Web3 | Multi-sig, timelocks, emergency bypass |
```bash
python examples/run_examples.py # Run all with test suites
python examples/run_examples.py banking # Run specific example
```
---
## API Reference
```python
from chimera_core import load_guard, RuntimeConfig
# Load + compile + verify
guard = load_guard("policy.csl")
# With custom config
guard = load_guard("policy.csl", config=RuntimeConfig(
raise_on_block=False, # Return result instead of raising
collect_all_violations=True, # Report all violations, not just first
missing_key_behavior="block" # "block", "warn", or "ignore"
))
# Verify
result = guard.verify({"action": "DELETE", "user_level": 2})
print(result.allowed) # False
print(result.violations) # ['strict_delete']
```
Full docs: [**Getting Started**](docs/getting-started.md) · [**Syntax Spec**](docs/syntax-spec.md) · [**CLI Reference**](docs/cli-reference.md) · [**Philosophy**](docs/philosophy.md)
---
## Roadmap
**✅ Done:** Core language & parser · Z3 verification · Fail-closed runtime · LangChain integration · CLI (verify, simulate, repl) · MCP Server · Production deployment in Chimera v1.7.0
**🚧 In Progress:** Policy versioning · LangGraph integration
**🔮 Planned:** LlamaIndex & AutoGen · Multi-policy composition · Hot-reload · Policy marketplace · Cloud templates
**🔒 Enterprise (Research):** TLA+ temporal logic · Causal inference · Multi-tenancy
---
## Contributing
We welcome contributions! Start with [`good first issue`](https://github.com/Chimera-Protocol/csl-core/issues?q=is%3Aissue+is%3Aopen+label%3A%22good+first+issue%22) or check [`CONTRIBUTING.md`](CONTRIBUTING.md).
**High-impact areas:** Real-world example policies · Framework integrations · Web-based policy editor · Test coverage
---
## License
**Apache 2.0** (open-core model). The complete language, compiler, Z3 verifier, runtime, CLI, MCP server, and all examples are open-source. See [LICENSE](LICENSE).
---
**Built with ❤️ by [Chimera Protocol](https://github.com/Chimera-Protocol)** · [Issues](https://github.com/Chimera-Protocol/csl-core/issues) · [Discussions](https://github.com/Chimera-Protocol/csl-core/discussions) · [Email](mailto:akarlaraytu@gmail.com)
| text/markdown | null | Aytug Akarlar <akarlaraytu@gmail.com> | null | Chimera Team <akarlaraytu@gmail.com> | null | ai-safety, formal-verification, langchain, policy-engine, z3 | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"z3-solver>=4.12.0",
"rich>=13.0.0",
"langchain-core>=0.1.0; extra == \"langchain\"",
"pydantic>=2.0.0; extra == \"langchain\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"ruff; extra == \"dev\"",
"black; extra == \"dev\"",
"mypy; extra == \"dev\"",
"langchain-core>=0.1.0; extra == \"dev\"",
"pydantic>=2.0.0; extra == \"dev\"",
"mcp[cli]>=1.2.0; extra == \"mcp\""
] | [] | [] | [] | [
"Homepage, https://github.com/Chimera-Protocol/csl-core",
"Documentation, https://github.com/Chimera-Protocol/csl-core/tree/main/docs",
"Repository, https://github.com/Chimera-Protocol/csl-core",
"Issues, https://github.com/Chimera-Protocol/csl-core/issues"
] | twine/6.2.0 CPython/3.12.5 | 2026-02-20T09:54:52.287248 | csl_core-0.3.0.tar.gz | 73,523 | 8b/11/28671a8bee5a6417ebc23d7e1c27931c9d29a8a6d00e31b64c90d9a9d8dc/csl_core-0.3.0.tar.gz | source | sdist | null | false | 953e32f9e75fa84be9ee7004d1dd947d | 708f322e552109455cbf999e7790aade9ab16aaf9074ee03a2dfd38af06e2db2 | 8b1128671a8bee5a6417ebc23d7e1c27931c9d29a8a6d00e31b64c90d9a9d8dc | Apache-2.0 | [
"LICENSE"
] | 232 |
2.4 | authcheck | 0.0.27 | Find if characret is registered in auth | Provides tool to check if character is registered in alliance auth and have Verified account.
| null | Aleksey Misyagin | me@misyagin.ru | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"Environment :: Web Environment",
"Framework :: Django",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3"
] | [] | null | null | null | [] | [] | [] | [
"allianceauth>=4.11.2",
"requests>=2.32.0",
"django-ipware>=5.0.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T09:53:52.583415 | authcheck-0.0.27-py3-none-any.whl | 51,101 | ec/02/b09cc2ad86a80cef6659a74af183045adf77f71085f97daf758b9d993ef4/authcheck-0.0.27-py3-none-any.whl | py3 | bdist_wheel | null | false | 82d5dfffc72e4a516425ea651a47fb56 | cd2773bdfa75910f43bb9d4c999af2d72bd1ce699e9ffcec4e8d309d730515f1 | ec02b09cc2ad86a80cef6659a74af183045adf77f71085f97daf758b9d993ef4 | null | [] | 97 |
2.4 | hdx-cli-toolkit | 2026.2.1 | HDX CLI tool kit for commandline interaction with HDX | # HDX CLI Toolkit
## Overview
This toolkit provides a commandline interface to the [Humanitarian Data Exchange](https://data.humdata.org/) (HDX) to allow for bulk modification operations and other administrative activities such as getting `id` values for users and organization. It is useful for those managing HDX and developers building data pipelines for HDX. The currently supported commands are as follows:
```
configuration Print configuration information to terminal
data_quality_report Compile a data quality report
download Download dataset resources from HDX
get_organization_metadata Get an organization id and other metadata
get_user_metadata Get user id and other metadata
list List datasets in HDX
print Print datasets in HDX to the terminal
remove_extras_key Remove extras key from a dataset
scan Scan all of HDX and perform an action
showcase Upload showcase to HDX
update Update datasets in HDX
update_resource Update a resource in HDX
```
In the most part it is a thin wrapper to the [hdx-python-api](https://github.com/OCHA-DAP/hdx-python-api) library written by Mike Rans.
The library requires some configuration, described below, to authenticate to the HDX instance.
## Installation
`hdx-cli-toolkit` is a Python application published to the PyPI package repository, therefore it can be installed easily with:
```pip install hdx_cli_toolkit```
Users may prefer to make a global, isolated installation using [pipx](https://pypi.org/project/pipx/) which will make the `hdx-toolkit` commands available across their projects:
```pipx install hdx_cli_toolkit```
`hdx-toolkit` can then be updated with:
```pipx install --force hdx_cli_toolkit```
`hdx-cli-toolkit` uses the `hdx-python-api` library, this requires the following to be added to a file called `.hdx_configuration.yaml` in the user's home directory.
```
hdx_key_stage: "[an HDX API token from the staging HDX site]"
hdx_key: "[an HDX API token from the prod HDX site]"
default_organization: "[your organization]"
```
The `default_organization` is required for the `configuration` command and can be supplied using the `--organization=` commandline parament. If not defined it will default to `hdx`.
A user agent (`hdx_cli_toolkit_*`) is specified in the `~/.useragents.yaml` file with the * replaced with the users initials.
```
hdx-cli-toolkit:
preprefix: [YOUR_ORGANIZATION]
user_agent: hdx_cli_toolkit_ih
```
## Usage
The `hdx-toolkit` is built using the Python `click` library. Details of the currently implemented commands can be revealed by running `hdx-toolkit --help`, and details of the arguments for a command can be found using `hdx-toolkit [COMMAND] --help`
A detailed guide can be found in the [USERGUIDE.md](https://github.com/OCHA-DAP/hdx-cli-toolkit/blob/main/USERGUIDE.md) file
## Changelog
Entries commence with 2026.2.1
**2026.2.1** - this release removes the `quickcharts` command since HXL is to be removed from HDX and quickcharts depends on this. There are also a couple of removals of `hxl_update=False` from calls which should make no difference to the end user.
## Maintenance
For the `data_quality_report` data on membership of Data Grid and HDX Signals is hard-coded. To update the coding for datasets in Data Grids:
1. clone this repo: https://github.com/OCHA-DAP/data-grid-recipes
2. Run the script `scripts/data_grid_recipes_compiler.py` script in the root of the data-grid-recipes repo
3. copy the output datagrid-datasets.csv to `src/hdx_cli_toolkit/data`
To update the coding for datasets in HDX Signals, check the code at this path in the `hdx-ckan` repo:
`hdx-ckan/ckanext-hdx_theme/ckanext/hdx_theme/helpers/ui_constants/landing_pages/signals.py`
for the `DATA_COVERAGE_CONSTANTS` note that the `links` in this constant are sometimes to datasets and sometimes to organizations. Copy the dataset and organization names to the `SIGNALS_DATASETS` and `SIGNALS_ORGANIZATIONS` constants in `src\hdx_cli_toolkit\data_quality_utilities.py` in this repo.
These are ugly methods for identifying Data Grid and HDX Signals datasets but with the current HDX implementation they are the most straightforward.
## Contributions
For developers the code should be cloned installed from the [GitHub repo](https://github.com/OCHA-DAP/hdx-cli-toolkit), and a virtual enviroment created:
```shell
python -m venv venv
source venv/Scripts/activate
```
And then an editable installation created:
```shell
pip install -e .
```
The library is then configured, as described above.
This project uses a GitHub Action to run tests and linting. It requires the following environment variables/secrets to be set in the `test` environment:
```
HDX_KEY - secret. Value: fake secret
HDX_KEY_STAGE - secret. Value: a live API token for the stage server
HDX_SITE - environment variable. Value: stage
USER_AGENT - environment variable. Value: hdx_cli_toolkit_gha
PREPREFIX - - environment variable. Value: [YOUR_organization]
```
Most tests use mocking in place of HDX, although the `test_integration.py` suite runs against the `stage` server.
New features should be developed against a GitHub issue on a separate branch with a name starting `GH[issue number]_`. `PULL_REQUEST_TEMPLATE.md` should be used in preparing pull requests. Versioning is updated manually in `pyproject.toml` and is described in the template, in brief it is CalVer `YYYY.MM.Micro`.
## Publication
Publication to PyPI is done automatically when a release is created.
| text/markdown | Ian Hopkinson | ianhopkinson@googlemail.com | null | null | The MIT License (MIT)
Copyright (c) 2024 Ian Hopkinson
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"hdx-python-api",
"hdx-python-country",
"ckanapi",
"libhxl==5.2.2",
"quantulum3[classifier]",
"click",
"hatch",
"pytest",
"pytest-cov",
"black==23.10.0",
"flake8",
"pylint"
] | [] | [] | [] | [
"repository, https://github.com/OCHA-DAP/hdx-cli-toolkit"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T09:53:49.911521 | hdx_cli_toolkit-2026.2.1.tar.gz | 50,292 | 97/ad/b67e773f5f233c48b03673377bc197e7697ca9fca4bfcb9d6b42c9f03ba6/hdx_cli_toolkit-2026.2.1.tar.gz | source | sdist | null | false | 9d18804d9e883c59c2dfe52e11c06aad | e80ab46fd9ec955f0947a2429f31d7f52ade004750f6a51564b60e40daf04c07 | 97adb67e773f5f233c48b03673377bc197e7697ca9fca4bfcb9d6b42c9f03ba6 | null | [
"LICENSE"
] | 191 |
2.4 | py3-tts-wrapper | 0.10.25 | TTS-Wrapper makes it easier to use text-to-speech APIs by providing a unified and easy-to-use interface. | # py3-TTS-Wrapper
[](https://badge.fury.io/py/py3-tts-wrapper)
[](https://codecov.io/gh/willwade/py3-tts-wrapper)
> **Contributions are welcome! Check our [contribution guide](./CONTRIBUTING.md).**
> **Want this for NodeJS/JS?** - see http://github.com/willwade/js-tts-wrapper
_TTS-Wrapper_ simplifies using text-to-speech APIs by providing a unified interface across multiple services, allowing easy integration and manipulation of TTS capabilities.
> ℹ️ Full documentation is available at [https://willwade.github.io/tts-wrapper/](https://willwade.github.io/tts-wrapper/)
## Requirements
- Python 3.10 or higher
- System dependencies (see below)
- API credentials for online services
## Supported Services
- AWS Polly
- Google TTS
- Google Translate TTS (GoogleTrans)
- Microsoft Azure TTS
- IBM Watson
- ElevenLabs
- Wit.Ai
- eSpeak-NG
- Play.HT
- UpliftAI
- ModelsLab
- OpenAI
- AVSynth (macOS only)
- SAPI (Windows only)
- Sherpa-Onnx (NB: Means you can run any ONNX model you want - eg Piper or MMS models)
### Experimental (Not fully featured or in a state of WIP)
- PicoTTS
- UWP (WinRT) Speech system (win 10+)
## Features
- **Text to Speech**: Convert text into spoken audio.
- **SSML Support**: Use Speech Synthesis Markup Language to enhance speech synthesis.
- **Voice and Language Selection**: Customize the voice and language for speech synthesis.
- **Streaming and Direct Play**: Stream audio or play it directly.
- **Pause, Resume, and Stop Controls**: Manage audio playback dynamically.
- **File Output**: Save spoken audio to files in various formats.
- **Unified Voice handling** Get Voices across all TTS engines with alike keys
- **Volume, Pitch, and Rate Controls** Control volume, pitch and rate with unified methods
## Feature Matrix
| Engine | Platform | Online/Offline | SSML | Word Boundaries | Streaming | Playback Control | Callbacks |
|------------|--------------------|--------------------|------|-----------------|-----------|------------------|-----------|
| Polly | Linux/MacOS/Windows| Online | Yes | Yes | Yes | Yes | Full |
| Google | Linux/MacOS/Windows| Online | Yes | Yes | Yes | Yes | Full |
| GoogleTrans| Linux/MacOS/Windows| Online | No* | No** | Yes | Yes | Basic |
| Microsoft | Linux/MacOS/Windows| Online | Yes | Yes | Yes | Yes | Full |
| Watson | Linux/MacOS/Windows| Online | Yes | Yes | Yes | Yes | Full |
| ElevenLabs | Linux/MacOS/Windows| Online | No* | Yes | Yes | Yes | Full |
| Play.HT | Linux/MacOS/Windows| Online | No* | No** | Yes | Yes | Basic |
| UpliftAI | Linux/MacOS/Windows| Online | No* | No** | Yes | Yes | Basic |
| ModelsLab | Linux/MacOS/Windows| Online | No* | No** | Yes | Yes | Basic |
| OpenAI | Linux/MacOS/Windows| Online | No | No | Yes | Yes | Basic |
| Wit.Ai | Linux/MacOS/Windows| Online | No* | No** | Yes | Yes | Basic |
| eSpeak | Linux/MacOS | Offline | Yes | No** | Yes | Yes | Basic |
| AVSynth | MacOS | Offline | No | No** | Yes | Yes | Basic |
| SAPI | Windows | Offline | Yes | Yes | Yes | Yes | Full |
| UWP | Windows | Offline | Yes | Yes | Yes | Yes | Full |
| Sherpa-ONNX| Linux/MacOS/Windows| Offline | No | No** | Yes | Yes | Basic |
**Notes**:
- **SSML**: Entries marked with No* indicate that while the engine doesn't support SSML natively, the wrapper will automatically strip SSML tags and process the plain text.
- **Word Boundaries**: Entries marked with No** use an estimation-based timing system that may not be accurate for precise synchronization needs.
- **Callbacks**:
- "Full" supports accurate word-level timing callbacks, onStart, and onEnd events
- "Basic" supports onStart and onEnd events, with estimated word timings
- **Playback Control**: All engines support pause, resume, and stop functionality through the wrapper's unified interface
- All engines support the following core features:
- Voice selection (`set_voice`)
- Property control (rate, volume, pitch)
- File output (WAV, with automatic conversion to MP3/other formats)
- Streaming playback
- Audio device selection
### Core Methods Available
| Method | Description | Availability |
|--------------------------|----------------------------------------------|--------------|
| `speak()` | Direct speech playback | All engines |
| `speak_streamed()` | Streamed speech playback | All engines |
| `synth_to_file()` | Save speech to file | All engines |
| `pause()`, `resume()` | Playback control | All engines |
| `stop()` | Stop playback | All engines |
| `set_property()` | Control rate/volume/pitch | All engines |
| `get_voices()` | List available voices | All engines |
| `set_voice()` | Select voice | All engines |
| `connect()` | Register event callbacks | All engines |
| `check_credentials()` | Verify API credentials | Online engines|
| `set_output_device()` | Select audio output device | All engines |
---
## Installation
### Package Name Note
This package is published on PyPI as `py3-tts-wrapper` but installs as `tts-wrapper`. This is because it's a fork of the original `tts-wrapper` project with Python 3 support and additional features.
### System Dependencies
This project requires the following system dependencies on Linux:
```sh
sudo apt-get install portaudio19-dev
```
or MacOS, using [Homebrew](https://brew.sh)
```sh
brew install portaudio
```
For PicoTTS on Debian systems:
```sh
sudo apt-get install libttspico-utils
```
The `espeak` TTS functionality requires the `espeak-ng` C library to be installed on your system:
- **Ubuntu/Debian**: `sudo apt install espeak-ng`
- **macOS**: `brew install espeak-ng`
- **Windows**: Download the binaries from https://espeak.sourceforge.net/
### Using pip
Install from PyPI with selected engines:
```sh
pip install "py3-tts-wrapper[google,microsoft,sapi,sherpaonnx,googletrans]"
```
Install optional MP3 codec support:
```sh
pip install "py3-tts-wrapper[mp3]"
```
Install from GitHub:
```sh
pip install "py3-tts-wrapper[google,microsoft,sapi,sherpaonnx,googletrans]@git+https://github.com/willwade/tts-wrapper"
```
Note: On macOS/zsh, you may need to use quotes:
```sh
pip install "py3-tts-wrapper[google,watson,polly,elevenlabs,microsoft,sherpaonnx]"
```
## Usage Guide
### Basic Usage
```python
from tts_wrapper import PollyClient
# Initialize the client - it's also the TTS engine
client = PollyClient(credentials=('aws_key_id', 'aws_secret_access_key'))
ssml_text = client.ssml.add('Hello, <break time="500ms"/> world!')
client.speak(ssml_text)
```
You can use SSML or plain text
```python
from tts_wrapper import PollyClient
# Initialize the client - it's also the TTS engine
client = PollyClient(credentials=('aws_key_id', 'aws_secret_access_key'))
client.speak('Hello world')
```
For a full demo see the examples folder. You'll need to fill out the credentials.json (or credentials-private.json). Use them from cd'ing into the examples folder.
Tips on gaining keys are below.
### Authorization
Each service uses different methods for authentication:
#### Polly
```python
from tts_wrapper import PollyClient
client = PollyClient(credentials=('aws_region','aws_key_id', 'aws_secret_access_key'))
```
#### Google
```python
from tts_wrapper import GoogleClient
client = GoogleClient(credentials=('path/to/creds.json'))
```
or pass the auth file as dict - so in memory
```python
from tts_wrapper import GoogleClient
import json
import os
with open(os.getenv("GOOGLE_SA_PATH"), "r") as file:
credentials_dict = json.load(file)
client = GoogleClient(credentials=os.getenv('GOOGLE_SA_PATH'))
# Or use the dictionary directly
client = GoogleClient(credentials=credentials_dict)
```
#### Microsoft
```python
from tts_wrapper import MicrosoftTTS
tts = MicrosoftTTS(credentials=('subscription_key', 'subscription_region'))
tts.set_voice('voice_id')
```
#### Watson
```python
from tts_wrapper import WatsonClient
client = WatsonClient(credentials=('api_key', 'region', 'instance_id'))
```
**Note** If you have issues with SSL certification try
```python
from tts_wrapper import WatsonClient
client = WatsonClient(credentials=('api_key', 'region', 'instance_id'),disableSSLVerification=True)
```
#### ElevenLabs
```python
from tts_wrapper import ElevenLabsClient
client = ElevenLabsClient(credentials=('api_key'))
```
- **Note**: ElevenLabs does not support SSML.
#### Wit.Ai
```python
from tts_wrapper import WitAiClient
client = WitAiClient(credentials=('token'))
```
#### Play.HT
```python
from tts_wrapper import PlayHTClient
client = PlayHTClient(credentials=('api_key', 'user_id'))
```
- **Note**: Play.HT does not support SSML, but we automatically strip SSML tags if present.
#### UpliftAI
```python
from tts_wrapper import UpliftAIClient
client = UpliftAIClient(api_key="api_key")
```
#### ModelsLab
```python
from tts_wrapper import ModelsLabClient
client = ModelsLabClient(api_key="your_modelslab_api_key")
```
#### UWP
```python
from tts_wrapper import UWPClient
client = UWPClient()
```
#### eSpeak
```python
from tts_wrapper import eSpeakClient
client = eSpeakClient()
```
Note: Requires espeak-ng to be installed on your system.
#### SAPI (Windows)
```python
from tts_wrapper import SAPIClient
client = SAPIClient()
```
Note: Only available on Windows systems.
#### AVSynth (macOS)
```python
from tts_wrapper import AVSynthClient
client = AVSynthClient()
```
Note: Only available on macOS. Provides high-quality speech synthesis with word timing support and voice property control.
#### GoogleTrans
Uses the gTTS library for free text-to-speech via Google Translate.
```python
from tts_wrapper import GoogleTransClient
# Initialize with default voice (UK English)
tts = GoogleTransClient()
# Or specify a voice/language
tts = GoogleTransClient(voice_id="en-co.uk")
# Set voice after initialization
tts.set_voice("fr-fr") # French
```
#### Sherpa-ONNX
You can provide blank model path and tokens path - and we will use a default location..
```python
from tts_wrapper import SherpaOnnxClient
client = SherpaOnnxClient(model_path=None, tokens_path=None)
```
Set a voice like
```python
# Find voices/langs availables
voices = client.get_voices()
print("Available voices:", voices)
# Set the voice using ISO code
iso_code = "eng" # Example ISO code for the voice - also ID in voice details
client.set_voice(iso_code)
```
and then use speak, speak_streamed etc..
You then can perform the following methods.
### Advanced Usage
#### SSML
Even if you don't use SSML features that much its wise to use the same syntax - so pass SSML not text to all engines
```python
ssml_text = client.ssml.add('Hello world!')
```
#### Plain Text
If you want to keep things simple each engine will convert plain text to SSML if its not.
```python
client.speak('Hello World!')
```
#### Speak
This will use the default audio output of your device to play the audio immediately
```python
client.speak(ssml_text)
```
#### Check Credentials
This will check if the credentials are valid:
```python
tts = MicrosoftTTS(
credentials=(os.getenv("MICROSOFT_TOKEN"), os.getenv("MICROSOFT_REGION"))
)
if tts.check_credentials():
print("Credentials are valid.")
else:
print("Credentials are invalid.")
```
NB: Each engine has a different way of checking credentials. If they don't have a specific implementation, the parent class will check get_voices. If you want to save API calls, you can just do a get_voices call directly.
#### Streaming and Playback Control
#### `pause_audio()`, `resume_audio()`, `stop_audio()`
These methods manage audio playback by pausing, resuming, or stopping it.
NB: Only to be used for speak_streamed
You need to make sure the optional dependency is included for this
```sh
pip install py3-tts-wrapper[controlaudio,google.. etc
```
then
```python
client = GoogleClient(credentials="path/to/credentials.json")
try:
text = "This is a pause and resume test. The text will be longer, depending on where the pause and resume works"
audio_bytes = client.synth_to_bytes(text)
client.load_audio(audio_bytes)
print("Play audio for 3 seconds")
client.play(1)
client.pause(8)
client.resume()
time.sleep(6)
finally:
client.cleanup()
```
- the pause and resume are in seconds from the start of the audio
- Please use the cleanup method to ensure the audio is stopped and the audio device is released
NB: to do this we use pyaudio. If you have issues with this you may need to install portaudio19-dev - particularly on linux
```sh
sudo apt-get install portaudio19-dev
```
#### File Output
```python
client.synth_to_file(ssml_text, 'output.mp3', format='mp3')
```
there is also "synth" method which is legacy. Note we support saving as mp3, wav or flac.
```python
client.synth('<speak>Hello, world!</speak>', 'hello.mp3', format='mp3')
```
Note you can also stream - and save. Just note it saves at the end of streaming entirely..
```python
ssml_text = client.ssml.add('Hello world!')
client.speak_streamed(ssml_text, filepath, 'wav')
```
#### Fetch Available Voices
```python
voices = client.get_voices()
print(voices)
```
NB: All voices will have a id, dict of language_codes, name and gender. Just note not all voice engines provide gender
#### Voice Selection
```python
client.set_voice(voice_id, lang_code="en-US")
```
e.g.
```python
client.set_voice('en-US-JessaNeural', 'en-US')
```
Use the id - not a name
#### SSML
```python
ssml_text = client.ssml.add('Hello, <break time="500ms"/> world!')
client.speak(ssml_text)
```
#### Volume, Rate and Pitch Control
Set volume:
```python
client.set_property("volume", "90")
text_read = f"The current volume is 90"
text_with_prosody = client.construct_prosody_tag(text_read)
ssml_text = client.ssml.add(text_with_prosody)
```
- Volume is set on a scale of 0 (silent) to 100 (maximum).
- The default volume is 100 if not explicitly specified.
Set rate:
```python
client.set_property("rate", "slow")
text_read = f"The current rate is SLOW"
text_with_prosody = client.construct_prosody_tag(text_read)
ssml_text = client.ssml.add(text_with_prosody)
```
Speech Rate:
- Rate is controlled using predefined options:
- x-slow: Very slow speaking speed.
- slow: Slow speaking speed.
- medium (default): Normal speaking speed.
- fast: Fast speaking speed.
- x-fast: Very fast speaking speed.
- If not specified, the speaking rate defaults to medium.
Set pitch:
```python
client.set_property("pitch", "high")
text_read = f"The current pitch is HIGH"
text_with_prosody = client.construct_prosody_tag(text_read)
ssml_text = client.ssml.add(text_with_prosody)
```
Pitch Control:
- Pitch is adjusted using predefined options that affect the vocal tone:
- x-low: Very deep pitch.
- low: Low pitch.
- medium (default): Normal pitch.
- high: High pitch.
- x-high: Very high pitch.
- If not explicitly set, the pitch defaults to medium.
Use the ```client.ssml.clear_ssml()``` method to clear all entries from the ssml list
#### `set_property()`
This method allows setting properties like `rate`, `volume`, and `pitch`.
```python
client.set_property("rate", "fast")
client.set_property("volume", "80")
client.set_property("pitch", "high")
```
#### `get_property()`
This method retrieves the value of properties such as `volume`, `rate`, or `pitch`.
```python
current_volume = client.get_property("volume")
print(f"Current volume: {current_volume}")
```
#### Using callbacks on word-level boundaries
Note only **Polly, Microsoft, Google, ElevenLabs, UWP, SAPI and Watson** can do this **correctly** with precise timing from the TTS engine. All other engines (GoogleTrans, Wit.Ai, Play.HT, OpenAI, eSpeak, AVSynth, Sherpa-ONNX) use **estimated timing** based on text length and average speaking rate.
```python
def my_callback(word: str, start_time: float, end_time: float):
duration = end_time - start_time
print(f"Word: {word}, Duration: {duration:.3f}s")
def on_start():
print('Speech started')
def on_end():
print('Speech ended')
try:
text = "Hello, This is a word timing test"
ssml_text = client.ssml.add(text)
client.connect('onStart', on_start)
client.connect('onEnd', on_end)
client.start_playback_with_callbacks(ssml_text, callback=my_callback)
except Exception as e:
print(f"Error: {e}")
```
and it will output
```bash
Speech started
Word: Hello, Duration: 0.612s
Word: , Duration: 0.212s
Word: This, Duration: 0.364s
Word: is, Duration: 0.310s
Word: a, Duration: 0.304s
Word: word, Duration: 0.412s
Word: timing, Duration: 0.396s
Word: test, Duration: 0.424s
Speech ended
```
#### `connect()`
This method allows registering callback functions for events like `onStart` or `onEnd`.
```python
def on_start():
print("Speech started")
client.connect('onStart', on_start)
```
## Audio Output Methods
The wrapper provides several methods for audio output, each suited for different use cases:
### 1. Direct Playback
The simplest method - plays audio immediately:
```python
client.speak("Hello world")
```
### 2. Streaming Playback
Recommended for longer texts - streams audio as it's being synthesized:
```python
client.speak_streamed("This is a long text that will be streamed as it's synthesized")
```
### 3. File Output
Save synthesized speech to a file:
```python
client.synth_to_file("Hello world", "output.wav")
```
### 4. Raw Audio Data
For advanced use cases where you need the raw audio data:
```python
# Get raw PCM audio data as bytes
audio_bytes = client.synth_to_bytes("Hello world")
```
### 5. Silent Synthesis
The `synthesize()` method provides silent audio synthesis without playback - perfect for applications that need audio data without immediate playback:
```python
# Get complete audio data (default behavior)
audio_bytes = client.synthesize("Hello world")
# Get streaming audio data for real-time processing
audio_stream = client.synthesize("Hello world", streaming=True)
for chunk in audio_stream:
# Process each audio chunk as it's generated
process_audio_chunk(chunk)
# Use with specific voice
audio_bytes = client.synthesize("Hello world", voice_id="en-US-JennyNeural")
```
### Audio Format Notes
- All engines output WAV format by default
- For MP3 or other formats, use external conversion libraries like `pydub`:
```python
from pydub import AudioSegment
import io
# Get WAV data
audio_bytes = client.synth_to_bytes("Hello world")
# Convert to MP3
wav_audio = AudioSegment.from_wav(io.BytesIO(audio_bytes))
wav_audio.export("output.mp3", format="mp3")
```
---
### Example Use Cases
#### 1. Saving Audio to a File
You can use the `synth_to_bytestream` method to synthesize audio in any supported format and save it directly to a file.
```python
# Synthesize text into a bytestream in MP3 format
bytestream = client.synth_to_bytestream("Hello, this is a test", format="mp3")
# Save the audio bytestream to a file
with open("output.mp3", "wb") as f:
f.write(bytestream.read())
print("Audio saved to output.mp3")
```
**Explanation**:
- The method synthesizes the given text into audio in MP3 format.
- The `BytesIO` object is then written to a file using the `.read()` method of the `BytesIO` class.
#### 2. Real-Time Playback Using `sounddevice`
If you want to play the synthesized audio live without saving it to a file, you can use the `sounddevice` library to directly play the audio from the `BytesIO` bytestream.
```python
import sounddevice as sd
import numpy as np
# Synthesize text into a bytestream in WAV format
bytestream = client.synth_to_bytestream("Hello, this is a live playback test", format="wav")
# Convert the bytestream back to raw PCM audio data for playback
audio_data = np.frombuffer(bytestream.read(), dtype=np.int16)
# Play the audio using sounddevice
sd.play(audio_data, samplerate=client.audio_rate)
sd.wait()
print("Live playback completed")
```
**Explanation**:
- The method synthesizes the text into a `wav` bytestream.
- The bytestream is converted to raw PCM data using `np.frombuffer()`, which is then fed into the `sounddevice` library for live playback.
- `sd.play()` plays the audio in real-time, and `sd.wait()` ensures that the program waits until playback finishes.
### Manual Audio Control
For advanced use cases where you need direct control over audio playback, you can use the raw audio data methods:
```python
from tts_wrapper import AVSynthClient
import numpy as np
import sounddevice as sd
# Initialize TTS client
client = AVSynthClient()
# Method 1: Direct playback of entire audio
def play_audio_stream(client, text: str):
"""Play entire audio at once."""
# Get raw audio data
audio_data = client.synth_to_bytes(text)
# Convert to numpy array for playback
samples = np.frombuffer(audio_data, dtype=np.int16)
# Play the audio
sd.play(samples, samplerate=client.audio_rate)
sd.wait()
# Method 2: Chunked playback for more control
def play_audio_chunked(client, text: str, chunk_size: int = 4096):
"""Process and play audio in chunks for more control."""
# Get raw audio data
audio_data = client.synth_to_bytes(text)
# Create a continuous stream
stream = sd.OutputStream(
samplerate=client.audio_rate,
channels=1, # Mono audio
dtype=np.int16
)
with stream:
# Process in chunks
for i in range(0, len(audio_data), chunk_size):
chunk = audio_data[i:i + chunk_size]
if len(chunk) % 2 != 0: # Ensure even size for 16-bit audio
chunk = chunk[:-1]
samples = np.frombuffer(chunk, dtype=np.int16)
stream.write(samples)
```
This manual control allows you to:
- Process audio data in chunks
- Implement custom audio processing
- Control playback timing
- Add effects or modifications to the audio
- Implement custom buffering strategies
The chunked playback method is particularly useful for:
- Real-time audio processing
- Custom pause/resume functionality
- Volume adjustment during playback
- Progress tracking
- Memory-efficient handling of long audio
**Note**: Manual audio control requires the `sounddevice` and `numpy` packages:
```sh
pip install sounddevice numpy
```
## Developer's Guide
### Setting up the Development Environment
#### Using Pipenv
1. Clone the repository:
```sh
git clone https://github.com/willwade/tts-wrapper.git
cd tts-wrapper
```
2. Install the package and system dependencies:
```sh
pip install .
```
To install optional dependencies, use:
```sh
pip install .[google, watson, polly, elevenlabs, microsoft]
```
This will install Python dependencies and system dependencies required for this project. Note that system dependencies will only be installed automatically on Linux.
#### Using UV
1. [Install UV](https://docs.astral.sh/uv/#getting-started)
```sh
pip install uv
```
2. Clone the repository:
```sh
git clone https://github.com/willwade/tts-wrapper.git
cd tts-wrapper
```
3. Install Python dependencies:
```sh
uv sync --all-extras
```
4. Install system dependencies (Linux only):
```sh
uv run postinstall
```
**NOTE**: to get a requirements.txt file for the project use `uv export --format requirements-txt --all-extras --no-hashes` juat be warned that this will include all dependencies including dev ones.
## Release a new build
```sh
git tag -a v0.1.0 -m "Release 0.1.0"
git push origin v0.1.0
```
### Adding a New Engine to TTS Wrapper
This guide provides a step-by-step approach to adding a new engine to the existing Text-to-Speech (TTS) wrapper system.
#### Step 1: Create Engine Directory Structure
1. **Create a new folder** for your engine within the `engines` directory. Name this folder according to your engine, such as `witai` for Wit.ai.
Directory structure:
```
engines/witai/
```
2. **Create necessary files** within this new folder:
- `__init__.py` - Makes the directory a Python package.
- `client.py` - Handles all interactions with the TTS API and implements the AbstractTTS interface.
- `ssml.py` - Defines any SSML handling specific to this engine (optional).
Final directory setup:
```
engines/
└── witai/
├── __init__.py
├── client.py
└── ssml.py
```
#### Step 2: Implement Client Functionality in `client.py`
Implement authentication and necessary setup for API connection. This file should manage tasks such as sending synthesis requests and fetching available voices. The client class should inherit from AbstractTTS.
```python
from tts_wrapper.tts import AbstractTTS
class WitAiClient(AbstractTTS):
def __init__(self, credentials=None):
super().__init__()
self.token = credentials[0] if credentials else None
self.audio_rate = 24000 # Default sample rate for this engine
# Setup other necessary API connection details here
def _get_voices(self):
# Code to retrieve available voices from the TTS API
# Return raw voice data that will be processed by the base class
pass
def synth_to_bytes(self, text, voice_id=None):
# Code to send a synthesis request to the TTS API
# Return raw audio bytes
pass
def synth(self, text, output_file, output_format="wav", voice_id=None):
# Code to synthesize speech and save to a file
pass
```
#### Step 3: Implement SSML Handling (if needed)
If the engine has specific SSML requirements or supports certain SSML tags differently, implement this logic in `ssml.py`.
```python
from tts_wrapper.ssml import BaseSSMLRoot, SSMLNode
class WitAiSSML(BaseSSMLRoot):
def add_break(self, time='500ms'):
self.root.add(SSMLNode('break', attrs={'time': time}))
```
#### Step 4: Update `__init__.py`
Make sure the `__init__.py` file properly imports and exposes the client class.
```python
from .client import WitAiClient
```
#### NB: Credentials Files
You can store your credentials in either:
- `credentials.json` - For development
- `credentials-private.json` - For private credentials (should be git-ignored)
Example structure (do NOT commit actual credentials):
```json
{
"Polly": {
"region": "your-region",
"aws_key_id": "your-key-id",
"aws_access_key": "your-access-key"
},
"Microsoft": {
"token": "your-subscription-key",
"region": "your-region"
},
"ModelsLab": {
"api_key": "your-modelslab-api-key"
}
}
```
### Service-Specific Setup
#### AWS Polly
- [Create an AWS account](https://aws.amazon.com/free)
- [Set up IAM credentials](https://docs.aws.amazon.com/polly/latest/dg/setting-up.html)
- [Polly API Documentation](https://docs.aws.amazon.com/polly/latest/dg/API_Operations.html)
#### Microsoft Azure
- [Create an Azure account](https://azure.microsoft.com/free)
- [Create a Speech Service resource](https://docs.microsoft.com/azure/cognitive-services/speech-service/get-started)
- [Azure Speech Service Documentation](https://docs.microsoft.com/azure/cognitive-services/speech-service/rest-text-to-speech)
#### Google Cloud
- [Create a Google Cloud account](https://cloud.google.com/free)
- [Set up a service account](https://cloud.google.com/text-to-speech/docs/quickstart-client-libraries)
- [Google TTS Documentation](https://cloud.google.com/text-to-speech/docs)
#### IBM Watson
- [Create an IBM Cloud account](https://cloud.ibm.com/registration)
- [Create a Text to Speech service instance](https://cloud.ibm.com/catalog/services/text-to-speech)
- [Watson TTS Documentation](https://cloud.ibm.com/apidocs/text-to-speech)
#### ElevenLabs
- [Create an ElevenLabs account](https://elevenlabs.io/)
- [Get your API key](https://docs.elevenlabs.io/authentication)
- [ElevenLabs Documentation](https://docs.elevenlabs.io/)
#### Play.HT
- [Create a Play.HT account](https://play.ht/)
- [Get your API credentials](https://docs.play.ht/reference/api-getting-started)
- [Play.HT Documentation](https://docs.play.ht/)
#### Wit.AI
- [Create a Wit.ai account](https://wit.ai/)
- [Create a new app and get token](https://wit.ai/docs/quickstart)
- [Wit.ai Documentation](https://wit.ai/docs)
#### ModelsLab
- [Create a ModelsLab account](https://modelslab.com/)
- [Get your API key](https://docs.modelslab.com/)
- [ModelsLab TTS Documentation](https://docs.modelslab.com/voice-cloning/text-to-speech)
## License
This project is licensed under the [MIT License](./LICENSE).
| text/markdown | null | Will Wade <willwade@gmail.com>, Giulio Bottari <giuliobottari@gmail.com> | null | null | null | elevenlabs, gTTS, mms, modelslab, playht, polly, sapi, sherpaonnx, speech synthesis, text-to-speech, tts, upliftai, witai | [] | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"langcodes",
"language-data>=1.3.0",
"marisa-trie>=1.2.1",
"numpy>=1.24.3",
"pymp3>=0.2.0; python_version < \"3.13\"",
"requests>=2.31.0",
"sounddevice>=0.5.0",
"soundfile>=0.12.1",
"pyaudio>=0.2.14; extra == \"controlaudio\"",
"google-cloud-texttospeech>=2.12.0; extra == \"google\"",
"gtts>=2.5.2; extra == \"googletrans\"",
"azure-cognitiveservices-speech>=1.43.0; extra == \"microsoft\"",
"pymp3>=0.2.0; python_version < \"3.13\" and extra == \"mp3\"",
"openai; extra == \"openai\"",
"boto3>=1.34.137; extra == \"polly\"",
"comtypes>=1.4.11; extra == \"sapi\"",
"comtypes>=1.4.11; sys_platform == \"win32\" and extra == \"sapi\"",
"sherpa-onnx<1.11.7,>=1.10.17; extra == \"sherpaonnx\"",
"winrt-runtime>=2.0.1; sys_platform == \"win32\" and extra == \"uwp\"",
"ibm-watson>=8.1.0; extra == \"watson\"",
"websocket-client; extra == \"watson\""
] | [] | [] | [] | [
"Bug Tracker, https://github.com/willwade/tts-wrapper/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T09:53:37.446641 | py3_tts_wrapper-0.10.25.tar.gz | 7,028,626 | cb/00/09de4d6b5337a572dd65bce1c0be46aba50579d72e257d1520fea41a3ae4/py3_tts_wrapper-0.10.25.tar.gz | source | sdist | null | false | 2ead88d648dbe5b9106aff9fb8b7f225 | 58e35ec028dbf108f79bef451d7170a6cb3ebd5e7d6acfc7f39ac2954ac79f52 | cb0009de4d6b5337a572dd65bce1c0be46aba50579d72e257d1520fea41a3ae4 | MIT | [
"LICENSE"
] | 203 |
2.3 | bblocks-datacommons-tools | 0.1.1 | Tools to work with Data Commons. Part of the bblocks projects. | # bblocks-datacommons-tools
__Manage and load data to custom Data Commons instances__
[](https://pypi.org/project/bblocks_datacommons_tools/)
[](https://pypi.org/project/bblocks_datacommons_tools/)
[](https://docs.one.org/tools/bblocks/datacommons-tools/)
[](https://github.com/astral-sh/ruff)
[](https://codecov.io/gh/ONEcampaign/bblocks-datacommons-tools)
Custom [Data Commons](https://docs.datacommons.org/custom_dc/custom_data.html) requires that you provide your data in a specific schema, format, and file structure.
At a high level, you need to provide the following:
- All observations data must be in CSV format, using a predefined schema.
- You must also provide a JSON configuration file, named `config.json`, that specifies how to map and resolve the CSV contents to the Data Commons schema knowledge graph.
- Depending on how you define your statistical variables (metrics), you may need to provide MCF (Meta Content Framework) files.
- You may also need to define new custom entities.
Managing this workflow by hand is tedious and easy to get wrong.
The `bblocks.datacommons_tools` package streamlines that process. It provides a Python API and command line utilities for building config files, generating MCF from CSV metadata and running the data load pipeline on Google Cloud.
Use this package when you want to:
- Manage `config.json` files programmatically.
- Define statistical variables, entities or groups using MCF files.
- Programmatically upload CSVs, MCF files, and the `config.json` file to Cloud Storage, trigger the load job and redeploy your custom Data Commons service with code.
In short, `datacommons-tools` removes much of the manual work involved in setting up and maintaining a custom Data Commons Knowledge Graph.
`bblocks-datacommons-tools` is part of the `bblocks` ecosystem,
a set of Python packages designed as building blocks for working with data in the international development
and humanitarian sectors.
Read the [documentation](https://docs.one.org/tools/bblocks/datacommons-tools/)
for more details on how to use the package and the motivation for its creation.
## Installation
The package can be installed in various ways.
Directly as
```bash
pip install bblocks-datacommons-tools
```
Or from the main `bblocks` package with an extra:
```bash
pip install "bblocks[datacommons-tools]"
```
It can also be installed from GitHub:
```bash
pip install git+https://github.com/ONEcampaign/bblocks-datacommons-tools
```
## Sample Usage
Here's a simple example covering how to use the "implicit" Data Commons
schema to load a single dataset. Please see the full [documentation page](https://docs.one.org/tools/bblocks/datacommons-tools/) for a thorough
introduction to the package, and to learn how to use it.
### 1. Create a CustomDataManager object.
The CustomDataManager object will handle generating the `config.json` file, as well as (optionally) taking Pandas DataFrames and exporting them as CSVs (in the right format) for loading to the Knowlede Graph.
In this example, we assume a `config.json` does not yet exist.
```python title="Instantiate the CustomDataManager class"
from bblocks.datacommons_tools import CustomDataManager
# Create the object and call it "manager"
manager = CustomDataManager()
# Configure it to include subdirectories
manager.set_includeInputSubdirs(True)
```
### 2. Add the provenance information for our data
You can add or manage provenance information on the `config.py` file.
In this example, we will add a provenance for ONE Data's Climate Finance Files.
```python title="Add provenance and source"
manager.add_provenance(
provenance_name="ONE Climate Finance",
provenance_url="https://datacommons.one.org/data/climate-finance-files",
source_name="ONE Data",
source_url="https://data.one.org",
)
```
### 3. Add the data to the CustomDataManager object.
Next, you need to specify your data on the `config.json` file.
Adding actual data data to the `CustomDataManager` is an optional step.
For this example, we will assume a DataFrame is available via the
`data` variable.
To add to the `CustomDataManager`, using the Implicit Schema:
```python title="Register data"
manager.add_implicit_schema_file(
file_name="climate_finance/one_cf_provider_commitments.csv",
provenance="ONE Climate Finance",
entityType="Country",
data=data,
ignoreColumns=["oecd_provider_code"],
observationProperties={"unit": "USDollar"},
)
```
Adding the data in the step above is optional. You can also create the inputFile in the config and add the data tied to that inputFile at a later stage by running:
```python
manager.add_data(data=data, file_name='one_cf_provider_commitments.csv')
```
Or you can manually add the relevant CSV file (matching what you declared as `file_name`).
### 4. Add the indicators to config
Next, you need to specify information about the StatVars (variables) contained
in your data file(s).
When using the Implicit Schema, you can specify additional information.
For convenience, you could loop through a dictionary of indicators and information. For this example we'll add a single indicator.
```python title="Register an indicator"
manager.add_variable_to_config(
statVar="climateFinanceProvidedCommitments",
name="Climate Finance Commitments (bilateral)",
group="ONE/Environment/Climate finance/Provider perspective/Commitments",
description="Funding for climate adaptation and mitigation projects",
searchDescriptions=[
"Climate finance commitments provided",
"Adaptation and mitigation finance provided",
],
properties={"measurementMethod": "Commitment"},
)
```
### 5. Export the `config.json` and (optionally) data CSVs
Next, once all the data is added and the config is set up, you can export the `config.json` and data. When you export, the `config.json` is validated automatically
```python title="Export config and data"
manager.export_all("path/to/output/folder")
```
### 6. (Optionally) load to the Knowledge Graph
You can also programmatically push the data and config to a Google Cloud
Storage Bucket, trigger the data load job, and redeploy your Data Commons
instance.
To do this, you'll need to load information about your
project, Storage Bucket, etc. You can use `.env` or `.json` files,
or simply make the right information available as environment variables.
A detailed description of the needed information, can be found in the documentation.
#### Load the settings
First, load the settings using `get_kg_settings`. In this example, we will load them from a `.env` file available in our working directory.
```python title="Load settings"
from bblocks.datacommons_tools.gcp_utilities import (
upload_to_cloud_storage,
run_data_load,
redeploy_service,
get_kg_settings,
)
settings = get_kg_settings(source="env", env_file="customDC.env")
```
Second, we'll upload the directory which contains the `config.json` file and
any CSV and/or MCF files.
```python title="Upload to GCS"
upload_to_cloud_storage(settings=settings, directory="path/to/output/folder")
```
Third, we'll run the data load job on Google Cloud Platform.
```python
run_data_load(settings=settings)
```
Last, we need to redeploy the Custom Data Commons instance.
```python
redeploy_service(settings=settings)
```
---
Visit the [documentation page](https://docs.one.org/tools/bblocks/datacommons-tools/) for the full package documentation and examples.
## Contributing
Contributions are welcome! Please see the
[CONTRIBUTING](https://github.com/ONEcampaign/bblocks-datacommons-tools/blob/main/CONTRIBUTING.md)
page for details on how to get started, report bugs, fix issues, and submit enhancements.
| text/markdown | ONE Campaign, Luca Picci, Jorge Rivera | Luca Picci <lpicci96@gmail.com>, Jorge Rivera <jorge.rivera@one.org> | null | null | MIT | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"pydantic<3.0.0,>=2.11.3",
"pandas<3.0.0,>=2.2.3",
"pydantic-settings<3.0.0,>=2.9.1",
"google-cloud-storage<4.0.0,>=3.1.0",
"google-cloud-run<1.0.0,>=0.10.17"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T09:53:15.952956 | bblocks_datacommons_tools-0.1.1.tar.gz | 31,176 | 3d/9b/4d4819abfe90a1d173bac8f364cfc55e901cf1b1e46824a8319570be6a52/bblocks_datacommons_tools-0.1.1.tar.gz | source | sdist | null | false | 66513cb81e370594663bc99c1291c919 | e21626a8f687efa120675f5db919b5d5616792ee163f31b83398e42817530e33 | 3d9b4d4819abfe90a1d173bac8f364cfc55e901cf1b1e46824a8319570be6a52 | null | [] | 191 |
2.4 | opensr-srgan | 0.4.0 | Modular Super-Resolution GAN Framework for Remote Sensing. | <img src="https://github.com/ESAOpenSR/opensr-model/blob/main/resources/opensr_logo.png?raw=true" width="250"/>
| **PyPI** | **Versions** | **Docs & License** | **Tests** | **Reference** |
|:---------:|:-------------:|:------------------:|:----------:|:--------------:|
| [](https://pypi.org/project/opensr-srgan/) | <br> | [](https://srgan.opensr.eu)<br> | [](https://github.com/ESAOpenSR/SRGAN/actions/workflows/ci.yml)<br>[](https://codecov.io/github/ESAOpenSR/SRGAN) | [](https://arxiv.org/abs/2511.10461) <br> [](https://doi.org/10.5281/zenodo.17590993)

# 🌍 Single Image Super-Resolution Remote Sensing 'SRGAN'
**Remote-Sensing-SRGAN** is a research-grade GAN framework for super-resolution of Sentinel-2 and other remote-sensing imagery. It is specifically **not meant for SOTA performance, but quick implementation and experimentation**. It supports arbitrary band counts, configurable generator/discriminator designs, scalable depth/width, and a modular loss system designed for stable GAN training on EO data. Check out how inference and training works right now in this interactive example! [](https://colab.research.google.com/drive/16W0FWr6py1J8P4po7JbNDMaepHUM97yL?usp=sharing)
---
## 📖 Documentation
Full docs live at **[srgan.opensr.eu](https://srgan.opensr.eu/)**. They cover usage, configuration, training recipes, and deployment tips in depth.
## 🧠 Highlights
* **Flexible models:** swap between SRResNet, RCAB, RRDB, LKA, ESRGAN, and stochastic generators with YAML-only changes.
* **Remote-sensing aware losses:** combine spectral, perceptual, and adversarial objectives with tunable weights.
* **Stable training loop:** generator pretraining, adversarial ramp-ups, EMA, and multi-GPU Lightning support out of the box.
* **PyPI distribution:** `pip install opensr-srgan` for ready-to-use presets or custom configs.
* **Extensive Logging:** Logging all important information automatically to `WandB` for optimal insights.
---
## 🏗️ Configuration Examples
All key knobs are exposed via YAML in the `opensr_srgan/configs` folder:
* **Model**: `in_channels`, `n_channels`, `n_blocks`, `scale`, ESRGAN knobs (`growth_channels`, `res_scale`, `out_channels`), `block_type ∈ {SRResNet, res, rcab, rrdb, lka}`
* **Losses**: `l1_weight`, `sam_weight`, `perceptual_weight`, `tv_weight`, `adv_loss_beta`
* **Training**: `pretrain_g_only`, `g_pretrain_steps` (`-1` keeps generator-only pretraining active indefinitely), `adv_loss_ramp_steps`, `label_smoothing`, generator LR warmup (`Schedulers.g_warmup_steps`, `Schedulers.g_warmup_type`), discriminator cadence controls
* **Adversarial mode**: `Training.Losses.adv_loss_type` (`bce`/`wasserstein`) and optional `Training.Losses.relativistic_average_d` for BCE-based relativistic-average GAN updates
* **Data**: band order, normalization stats, crop sizes, augmentations
---
## 🎚️ Training Stabilization Strategies
* **G‑only pretraining:** Train with content/perceptual losses while the adversarial term is held at zero during the first `g_pretrain_steps`.
* **Adversarial ramp‑up:** Increase the BCE adversarial weight **linearly** or smoothly (**cosine**) over `adv_loss_ramp_steps` until it reaches `adv_loss_beta`.
* **Generator LR warmup:** Ramp the generator optimiser with a **cosine** or **linear** schedule for the first 1–5k steps via `Schedulers.g_warmup_steps`/`g_warmup_type` before switching to plateau-based reductions.
* **EMA smoothing:** Enable `Training.EMA.enabled` to keep a shadow copy of the generator. Decay values in the 0.995–0.9999 range balance responsiveness with stability and are swapped in automatically for validation/inference.
* **Spectral normalization:** Optional for the SRGAN discriminator via `Discriminator.use_spectral_norm` to better control its Lipschitz constant and stabilize adversarial updates. [Miyato et al., 2018](https://arxiv.org/abs/1802.05957)
* **Wasserstein critic + R1 penalty:** Switch `Training.Losses.adv_loss_type: wasserstein` to enable a critic objective and pair it with the configurable `Training.Losses.r1_gamma` gradient penalty on real images for smoother discriminator updates. [Arjovsky et al., 2017](https://arxiv.org/abs/1701.07875); [Mescheder et al., 2018](https://arxiv.org/abs/1801.04406)
* **Relativistic average GAN (BCE):** Set `Training.Losses.relativistic_average_d: true` to train D/G on relative real-vs-fake logits instead of absolute logits. This is supported in the Lightning 2+ manual-optimization training path.
The schedule and ramp make training **easier, safer, and more reproducible**.
---
## ⚙️ Config‑driven components
| Component | Options | Config keys |
|-----------|---------|-------------|
| **Generators** | `SRResNet`, `res`, `rcab`, `rrdb`, `lka`, `esrgan`, `stochastic_gan` | `Generator.model_type`, depth via `Generator.n_blocks`, width via `Generator.n_channels`, kernels/scale plus ESRGAN-specific `growth_channels`, `res_scale`, `out_channels`. |
| **Discriminators** | `standard` `SRGAN`, `CNN`, `patchgan`, `esrgan` | `Discriminator.model_type`, granularity with `Discriminator.n_blocks`, spectral norm toggle via `Discriminator.use_spectral_norm`, ESRGAN-specific `base_channels`, `linear_size`. |
| **Content losses** | L1, Spectral Angle Mapper, VGG19/LPIPS perceptual metrics, Total Variation | Weighted by `Training.Losses.*` (e.g. `l1_weight`, `sam_weight`, `perceptual_weight`, `perceptual_metric`, `tv_weight`). |
| **Adversarial loss** | BCE‑with‑logits or Wasserstein critic | Controlled by `Training.Losses.adv_loss_type`, warmup via `Training.pretrain_g_only`, ramped by `adv_loss_ramp_steps`, capped at `adv_loss_beta`, optional label smoothing. For BCE, enable `Training.Losses.relativistic_average_d` for RaGAN-style relative logits. |
The YAML keeps the SRGAN flexible: swap architectures or rebalance perceptual vs. spectral fidelity without touching the code.
## 🧰 Installation
Follow the [installation instructions](https://srgan.opensr.eu/getting-started/) for package, source, and dependency setup options.
---
## 🚀 Quickstart
* To test the package immediately, launch the Google Colab right now and follow along the introduction! [](https://colab.research.google.com/drive/16W0FWr6py1J8P4po7JbNDMaepHUM97yL?usp=sharing)
* **Datasets:** Grab the bundled example dataset or learn how to register your own sources in the [data guide](https://srgan.opensr.eu/data/).
* **Training:** Launch training with `python -m opensr_srgan.train --config opensr_srgan/configs/config_10m.yaml` or import `train` from the package as described in the [training walkthrough](https://srgan.opensr.eu/training/).
* **Inference:** Ready-made presets and large-scene pipelines are described in the [inference section](https://srgan.opensr.eu/getting-started/inference/).
---
## 🏗️ Configuration & Stabilization
All tunable knobs—architectures, loss weights, schedulers, and EMA—are exposed via YAML files under `opensr_srgan/configs`. Strategy tips for warm-ups, adversarial ramps, and EMA usage are summarised in the [training concepts chapter](https://srgan.opensr.eu/training-guideline/).
## 📂 Repository Structure
```
SRGAN/
├── opensr_srgan/ # Library + training code
├── docs/ # MkDocs documentation sources
├── paper/ # Publication, figures, and supporting material
├── pyproject.toml # Packaging metadata
└── requirements.txt # Development dependencies
```
## Contribution and Issues
If you wish to contribute (such as new models, data or functionalities), please review the contribution guidelines and open a PR here on Github. If you're having problems or need support, please open an Issue here on Github.
---
## 📚 Related Projects
* **OpenSR-Model** – Latent Diffusion SR (LDSR-S2)
* **OpenSR-Utils** – Large-scale inference & data plumbing
* **OpenSR-Test** – Benchmarks & metrics
* **SEN2NEON** – Multispectral HR reference dataset
---
## ✍️ Citation
If you use this work, please cite:
```bibtex
@misc{donike2025opensrsrganflexiblesuperresolutionframework,
title={OpenSR-SRGAN: A Flexible Super-Resolution Framework for Multispectral Earth Observation Data},
author={Simon Donike and Cesar Aybar and Julio Contreras and Luis Gómez-Chova},
year={2025},
eprint={2511.10461},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2511.10461},
}
```
---
## 🧑🚀 Authors, Acknowledgements, and Notes on AI Usage
Developed within the **ESA Φ-lab / OpenSR** initiative. Simon Donike is the main contributor and maintainer of the repository. Cesar Aybar and Julio Contreras contributed the datasets as well as implementation, documentation and publishing support. Prof. Luis Gómez-Chova contributed the remote sensing-specific perspective and signal processing advice.
> The development history of this code began in 2020 with the implementation of an SR-GAN for a MSc thesis project. Since then, over several iterations, the codebase has been expanded and many training tweaks implemented, based on the experiences made training SR-GANs for the OpenSR project. The fundamental training outline, training tweaks, normalizations, and inference procedures are built upon that experience.
The added complexity that came with (a) the implementation of many different models and blocks, (b) more data sources, (c) according normalizations, and (d) complex testing and documentation structures, was handled to varying degrees with the help of *Codex*. Specifically, the docs, the automated testing workflows, and the normalizer class are in part AI generated. This code and its functionalities have been verified and tested to the best of my ability.
---
| text/markdown | Simon Donike, ESAOpenSR Team | null | null | null | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| super-resolution, gan, remote-sensing, pytorch, lightning | [
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"License :: OSI Approved :: Apache Software License",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | !=3.11.*,<3.13,>=3.10 | [] | [] | [] | [
"torch>=2.1",
"pytorch-lightning<3.0,>=2.1",
"torchvision",
"numpy",
"kornia",
"wandb",
"omegaconf",
"matplotlib",
"rasterio",
"scikit-image",
"Pillow",
"huggingface-hub",
"pytest; extra == \"tests\"",
"pytest-cov; extra == \"tests\"",
"numpy; extra == \"tests\"",
"mkdocs-material; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://github.com/opensr-project/SISR-RS-SRGAN",
"Documentation, https://srgan.opensr.eu",
"Bug Tracker, https://github.com/opensr-project/SISR-RS-SRGAN/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T09:53:15.036900 | opensr_srgan-0.4.0.tar.gz | 96,056 | 7c/dd/ee376246205a2f954e67fe8d0d93c65e54310693a9ae9d404625acb20b2f/opensr_srgan-0.4.0.tar.gz | source | sdist | null | false | 8ac0d5bf53c971f172f626c5f153d997 | fac40f1040285adee3a6e70e5a9bbc4f3d5a1bd5c9e6a4c66e21756608ba1ef5 | 7cddee376246205a2f954e67fe8d0d93c65e54310693a9ae9d404625acb20b2f | null | [
"LICENSE"
] | 197 |
2.4 | fault-injection | 0.1.0 | Lightweight fault injection helpers for Python functions. | # fault-injection
Lightweight fault injection helpers for Python functions.
This project provides small decorators and inline helpers to intentionally inject failures or latency so you can test resiliency and error-handling paths.
## Features
- `raise_` and `raise_inline`: deterministic exception injection
- `raise_at_nth_call` and `raise_at_nth_call_inline`: deterministic exception injection on the n-th call (`func_id`-scoped counters)
- `raise_random` and `raise_random_inline`: probabilistic exception injection
- `delay` and `delay_inline`: fixed latency injection
- `delay_at_nth_call` and `delay_at_nth_call_inline`: fixed latency injection on the n-th call (`func_id`-scoped counters)
- `delay_random` and `delay_random_inline`: uniform random latency injection
- `delay_random_norm` and `delay_random_norm_inline`: Gaussian latency injection with clamp at `0`
## Project structure
- `fault_injection/`: library code
- `examples/`: runnable examples
- `tests/`: unit tests (`unittest` + standard library only)
## Installation
Install from PyPI:
```bash
python -m pip install fault-injection
```
For local development from this repo:
```bash
python -m pip install -e .
```
## Usage
Import APIs from `fault_injection`:
```python
from fault_injection import (
raise_,
raise_inline,
raise_at_nth_call,
raise_at_nth_call_inline,
raise_random,
raise_random_inline,
delay,
delay_inline,
delay_at_nth_call,
delay_at_nth_call_inline,
delay_random,
delay_random_inline,
delay_random_norm,
delay_random_norm_inline,
)
```
### `raise_`
```python
from fault_injection import raise_
@raise_(msg="decorator failure")
def do_work():
return "ok"
# Raises RuntimeError("decorator failure")
do_work()
```
### `raise_inline`
```python
from fault_injection import raise_inline
def do_work():
raise_inline(msg="inline failure")
return "ok"
# Raises RuntimeError("inline failure")
do_work()
```
### `raise_at_nth_call`
```python
from fault_injection import raise_at_nth_call
@raise_at_nth_call(msg="raise on third call", n=3, func_id=1)
def do_work():
return "ok"
do_work() # 1st call: ok
do_work() # 2nd call: ok
do_work() # 3rd call: raises RuntimeError
```
### `raise_at_nth_call_inline`
```python
from fault_injection import raise_at_nth_call_inline
def do_work():
raise_at_nth_call_inline(msg="raise on second call", n=2, func_id=9)
return "ok"
```
### `raise_random`
```python
from fault_injection import raise_random
@raise_random(msg="random decorator failure", prob_of_raise=0.2)
def do_work():
return "ok"
# Raises RuntimeError about 20% of calls
do_work()
```
### `raise_random_inline`
```python
from fault_injection import raise_random_inline
def do_work():
raise_random_inline(msg="random inline failure", prob_of_raise=0.2)
return "ok"
```
### `delay`
```python
from fault_injection import delay
@delay(time_s=0.5)
def do_work():
return "ok"
# Sleeps 0.5s, then returns
print(do_work())
```
### `delay_inline`
```python
from fault_injection import delay_inline
def do_work():
delay_inline(time_s=0.5)
return "ok"
```
### `delay_at_nth_call`
```python
from fault_injection import delay_at_nth_call
@delay_at_nth_call(time_s=0.5, n=3, func_id=1)
def do_work():
return "ok"
do_work() # 1st call: no extra delay
do_work() # 2nd call: no extra delay
do_work() # 3rd call: sleeps 0.5s, then returns
```
### `delay_at_nth_call_inline`
```python
from fault_injection import delay_at_nth_call_inline
def do_work():
delay_at_nth_call_inline(time_s=0.5, n=2, func_id=9)
return "ok"
```
### `delay_random`
```python
from fault_injection import delay_random
@delay_random(max_time_s=0.5)
def do_work():
return "ok"
# Sleeps random time in [0, 0.5], then returns
print(do_work())
```
### `delay_random_inline`
```python
from fault_injection import delay_random_inline
def do_work():
delay_random_inline(max_time_s=0.5)
return "ok"
```
### `delay_random_norm`
```python
from fault_injection import delay_random_norm
@delay_random_norm(mean_time_s=0.3, std_time_s=0.1)
def do_work():
return "ok"
# Sleeps max(0, gauss(mean, std)), then returns
print(do_work())
```
### `delay_random_norm_inline`
```python
from fault_injection import delay_random_norm_inline
def do_work():
delay_random_norm_inline(mean_time_s=0.3, std_time_s=0.1)
return "ok"
```
## Validation behavior
- `raise_random(prob_of_raise=...)` and `raise_random_inline(prob_of_raise=...)` require `0 <= prob_of_raise <= 1`
- `raise_at_nth_call(n=...)` and `raise_at_nth_call_inline(n=...)` require `n` to be a positive integer
- `delay(time_s=...)` requires `time_s >= 0`
- `delay_inline(time_s=...)` requires `time_s >= 0`
- `delay_at_nth_call(time_s=..., n=...)` and `delay_at_nth_call_inline(time_s=..., n=...)` require `time_s >= 0` and `n` to be a positive integer
- `delay_random(max_time_s=...)` and `delay_random_inline(max_time_s=...)` require `max_time_s >= 0`
- `delay_random_norm(mean_time_s=..., std_time_s=...)` and `delay_random_norm_inline(mean_time_s=..., std_time_s=...)` require both `>= 0`
Invalid values raise `ValueError`.
## N-th call counters
`*_at_nth_call*` APIs keep counters on module-level function attributes and key by `func_id`.
Using the same `func_id` means sharing a counter; use different IDs to isolate behavior across call sites.
## Disable behavior
Every API supports `disable=True` to bypass fault injection:
```python
@delay(0.5, disable=True)
def do_work():
return "ok"
delay_inline(0.5, disable=True)
```
## Run examples
From repository root (after `python -m pip install -e .`):
```bash
python -m examples.decorator_raise
python -m examples.decorator_raise_nth_multiple
python -m examples.decorator_raise_random
python -m examples.decorator_delay
python -m examples.decorator_delay_nth
python -m examples.decorator_delay_random
python -m examples.decorator_delay_random_norm
python -m examples.inline_raise
python -m examples.inline_raise_nth
python -m examples.inline_raise_nth_multiple
python -m examples.inline_raise_random
python -m examples.inline_delay
python -m examples.inline_delay_nth
python -m examples.inline_delay_random
python -m examples.inline_delay_random_norm
```
## Run tests
This project uses only the Python standard library for tests:
```bash
python -m unittest discover -s tests -v
```
No extra `PYTHONPATH` setup is needed with the root `fault_injection/` layout.
## Build and publish
Build distributions:
```bash
python -m pip install --upgrade build twine
python -m build
```
Upload to TestPyPI:
```bash
python -m twine upload --repository testpypi dist/*
```
Upload to PyPI:
```bash
python -m twine upload dist/*
```
## License
MIT (see `LICENSE`).
| text/markdown | Max B. | null | null | null | MIT License
Copyright (c) 2026 Max B.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| fault-injection, testing, resilience, chaos-engineering | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Testing"
] | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/maxboro/fault-injection",
"Repository, https://github.com/maxboro/fault-injection",
"Issues, https://github.com/maxboro/fault-injection/issues"
] | twine/6.2.0 CPython/3.13.5 | 2026-02-20T09:52:58.185331 | fault_injection-0.1.0.tar.gz | 10,506 | 7b/39/e7f4a78fda4cdca410627a1516a0b66c5c8c61c5ae0616249661f240e608/fault_injection-0.1.0.tar.gz | source | sdist | null | false | ad27b4d938be0732cbf3da071ab84e83 | 7ced55fe7a667d79e4deeeae3b553dd26959f0c910bd2b7479c922c82a23429d | 7b39e7f4a78fda4cdca410627a1516a0b66c5c8c61c5ae0616249661f240e608 | null | [
"LICENSE"
] | 221 |
2.4 | griffe2md | 1.3.4 | Output API docs to Markdown using Griffe. | # griffe2md
[](https://github.com/mkdocstrings/griffe2md/actions?query=workflow%3Aci)
[](https://mkdocstrings.github.io/griffe2md/)
[](https://pypi.org/project/griffe2md/)
[](https://app.gitter.im/#/room/#griffe2md:gitter.im)
Output API docs to Markdown using Griffe.
## Installation
```bash
pip install griffe2md
```
With [`uv`](https://docs.astral.sh/uv/):
```bash
uv tool install griffe2md
```
## Usage
Simply call `griffe2md` with a package name, or the path to a package folder:
```bash
griffe2md markdown
griffe2md path/to/my/src/package
```
Use the `-o`, `--output` option to write to a file instead of standard output:
```bash
griffe2md markdown -o markdown.md
```
`griffe2md` can be configured in either `pyproject.toml` or a `griffe2md.toml` file. The latter can be placed in a `.config` or `config` directory in the project root.
`griffe2md.toml` file is structured as a simple key-value dictionary, e.g.:
```toml
docstring_style = "sphinx"
```
If you configure it in `pyproject.toml`, the configuration should go under the `tool.griffe2md` key:
```toml
[tool.griffe2md]
docstring_style = "sphinx"
```
See [the documentation](https://mkdocstrings.github.io/griffe2md/reference/griffe2md/config/#griffe2md.config.ConfigDict) for reference.
## Sponsors
<!-- sponsors-start -->
<div id="premium-sponsors" style="text-align: center;">
<div id="silver-sponsors"><b>Silver sponsors</b><p>
<a href="https://fastapi.tiangolo.com/"><img alt="FastAPI" src="https://raw.githubusercontent.com/tiangolo/fastapi/master/docs/en/docs/img/logo-margin/logo-teal.png" style="height: 200px; "></a><br>
</p></div>
<div id="bronze-sponsors"><b>Bronze sponsors</b><p>
<a href="https://www.nixtla.io/"><picture><source media="(prefers-color-scheme: light)" srcset="https://www.nixtla.io/img/logo/full-black.svg"><source media="(prefers-color-scheme: dark)" srcset="https://www.nixtla.io/img/logo/full-white.svg"><img alt="Nixtla" src="https://www.nixtla.io/img/logo/full-black.svg" style="height: 60px; "></picture></a><br>
</p></div>
</div>
---
<div id="sponsors"><p>
<a href="https://github.com/ofek"><img alt="ofek" src="https://avatars.githubusercontent.com/u/9677399?u=386c330f212ce467ce7119d9615c75d0e9b9f1ce&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/samuelcolvin"><img alt="samuelcolvin" src="https://avatars.githubusercontent.com/u/4039449?u=42eb3b833047c8c4b4f647a031eaef148c16d93f&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/tlambert03"><img alt="tlambert03" src="https://avatars.githubusercontent.com/u/1609449?u=922abf0524b47739b37095e553c99488814b05db&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/ssbarnea"><img alt="ssbarnea" src="https://avatars.githubusercontent.com/u/102495?u=c7bd9ddf127785286fc939dd18cb02db0a453bce&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/femtomc"><img alt="femtomc" src="https://avatars.githubusercontent.com/u/34410036?u=f13a71daf2a9f0d2da189beaa94250daa629e2d8&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/cmarqu"><img alt="cmarqu" src="https://avatars.githubusercontent.com/u/360986?v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/kolenaIO"><img alt="kolenaIO" src="https://avatars.githubusercontent.com/u/77010818?v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/ramnes"><img alt="ramnes" src="https://avatars.githubusercontent.com/u/835072?u=3fca03c3ba0051e2eb652b1def2188a94d1e1dc2&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/machow"><img alt="machow" src="https://avatars.githubusercontent.com/u/2574498?u=c41e3d2f758a05102d8075e38d67b9c17d4189d7&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/BenHammersley"><img alt="BenHammersley" src="https://avatars.githubusercontent.com/u/99436?u=4499a7b507541045222ee28ae122dbe3c8d08ab5&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/trevorWieland"><img alt="trevorWieland" src="https://avatars.githubusercontent.com/u/28811461?u=74cc0e3756c1d4e3d66b5c396e1d131ea8a10472&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/MarcoGorelli"><img alt="MarcoGorelli" src="https://avatars.githubusercontent.com/u/33491632?u=7de3a749cac76a60baca9777baf71d043a4f884d&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/analog-cbarber"><img alt="analog-cbarber" src="https://avatars.githubusercontent.com/u/7408243?u=642fc2bdcc9904089c62fe5aec4e03ace32da67d&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/OdinManiac"><img alt="OdinManiac" src="https://avatars.githubusercontent.com/u/22727172?u=36ab20970f7f52ae8e7eb67b7fcf491fee01ac22&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/rstudio-sponsorship"><img alt="rstudio-sponsorship" src="https://avatars.githubusercontent.com/u/58949051?u=0c471515dd18111be30dfb7669ed5e778970959b&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/schlich"><img alt="schlich" src="https://avatars.githubusercontent.com/u/21191435?u=6f1240adb68f21614d809ae52d66509f46b1e877&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/butterlyn"><img alt="butterlyn" src="https://avatars.githubusercontent.com/u/53323535?v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/livingbio"><img alt="livingbio" src="https://avatars.githubusercontent.com/u/10329983?v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/NemetschekAllplan"><img alt="NemetschekAllplan" src="https://avatars.githubusercontent.com/u/912034?v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/EricJayHartman"><img alt="EricJayHartman" src="https://avatars.githubusercontent.com/u/9259499?u=7e58cc7ec0cd3e85b27aec33656aa0f6612706dd&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/15r10nk"><img alt="15r10nk" src="https://avatars.githubusercontent.com/u/44680962?u=f04826446ff165742efa81e314bd03bf1724d50e&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/activeloopai"><img alt="activeloopai" src="https://avatars.githubusercontent.com/u/34816118?v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/roboflow"><img alt="roboflow" src="https://avatars.githubusercontent.com/u/53104118?v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/cmclaughlin"><img alt="cmclaughlin" src="https://avatars.githubusercontent.com/u/1061109?u=ddf6eec0edd2d11c980f8c3aa96e3d044d4e0468&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/blaisep"><img alt="blaisep" src="https://avatars.githubusercontent.com/u/254456?u=97d584b7c0a6faf583aa59975df4f993f671d121&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/RapidataAI"><img alt="RapidataAI" src="https://avatars.githubusercontent.com/u/104209891?v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/rodolphebarbanneau"><img alt="rodolphebarbanneau" src="https://avatars.githubusercontent.com/u/46493454?u=6c405452a40c231cdf0b68e97544e07ee956a733&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/theSymbolSyndicate"><img alt="theSymbolSyndicate" src="https://avatars.githubusercontent.com/u/111542255?v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/blakeNaccarato"><img alt="blakeNaccarato" src="https://avatars.githubusercontent.com/u/20692450?u=bb919218be30cfa994514f4cf39bb2f7cf952df4&v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/ChargeStorm"><img alt="ChargeStorm" src="https://avatars.githubusercontent.com/u/26000165?v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/Alphadelta14"><img alt="Alphadelta14" src="https://avatars.githubusercontent.com/u/480845?v=4" style="height: 32px; border-radius: 100%;"></a>
<a href="https://github.com/Cusp-AI"><img alt="Cusp-AI" src="https://avatars.githubusercontent.com/u/178170649?v=4" style="height: 32px; border-radius: 100%;"></a>
</p></div>
*And 7 more private sponsor(s).*
<!-- sponsors-end -->
| text/markdown | null | =?utf-8?q?Timoth=C3=A9e_Mazzucotelli?= <dev@pawamoy.fr> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Documentation",
"Topic :: Software Development",
"Topic :: Utilities",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"griffelib>=2.0",
"jinja2>=3.1.2",
"mdformat>=0.7.16",
"tomli>=2.0; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://mkdocstrings.github.io/griffe2md",
"Documentation, https://mkdocstrings.github.io/griffe2md",
"Changelog, https://mkdocstrings.github.io/griffe2md/changelog",
"Repository, https://github.com/mkdocstrings/griffe2md",
"Issues, https://github.com/mkdocstrings/griffe2md/issues",
"Discussions, https://github.com/mkdocstrings/griffe2md/discussions",
"Gitter, https://gitter.im/mkdocstrings/griffe2md",
"Funding, https://github.com/sponsors/pawamoy"
] | twine/6.2.0 CPython/3.14.0 | 2026-02-20T09:52:51.971951 | griffe2md-1.3.4.tar.gz | 45,777 | f3/b4/6493f09613e2fe452d9dbd3500f244dd794c041b213c256072a2f216964d/griffe2md-1.3.4.tar.gz | source | sdist | null | false | 5265fc7023627db276c572182b6aa540 | 31dd6e046ca4cd7916985cea23c31e00a65bb114a1548eb5278a3d8ff6dfe6ff | f3b46493f09613e2fe452d9dbd3500f244dd794c041b213c256072a2f216964d | ISC | [
"LICENSE"
] | 3,624 |
2.4 | matrice-compute | 0.1.63 | Common server utilities for Matrice.ai services | ## matrice\_instance\_manager
| text/markdown | null | "Matrice.ai" <dipendra@matrice.ai> | null | null | MIT | matrice, common, utilities, mypyc, compiled | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Operating System :: POSIX :: Linux",
"Operating System :: Microsoft :: Windows",
"Operating System :: MacOS",
"Topic :: Software Development :: Libraries :: Python Modules",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T09:52:07.283719 | matrice_compute-0.1.63.tar.gz | 96,510 | 86/df/e6e469289ad9895f577fc5ee4eff0628ca60da47ccef9ec9f3c506c6e35a/matrice_compute-0.1.63.tar.gz | source | sdist | null | false | 02f92b23fe1b121ebb168efa5f25536c | f21189951ebf15203c6098350f1252591655fcadb406eeed7100ba0e1045a06f | 86dfe6e469289ad9895f577fc5ee4eff0628ca60da47ccef9ec9f3c506c6e35a | null | [
"LICENSE.txt"
] | 235 |
2.4 | omega-prime | 0.2.1 | Omega-Prime: Data Model, Data Format and Python Library for Handling Ground Truth Traffic Data |
<img src="https://github.com/ika-rwth-aachen/omega-prime/blob/main/docs/logo/omega-prime.svg?raw=True" height=150px align="right" style="margin: 10px;">
[](https://github.com/ika-rwth-aachen/omega-prime/blob/master/LICENSE)
[](https://pypi.python.org/pypi/omega-prime)
[](https://github.com/ika-rwth-aachen/omega-prime/actions)
[](https://pypi.python.org/pypi/omega-prime/)
[](https://github.com/ika-rwth-aachen/omega-prime/issues)
[](https://ika-rwth-aachen.github.io/omega-prime)
# Omega-Prime: Data Model, Data Format and Python Library for Handling Ground Truth Road Traffic Data
Data Model, Format and Python Library for ground truth road traffic data containing information on dynamic objects, map and environmental factors optimized for representing urban traffic. The repository contains:
### Data Model and Specification
see [Data Model & Specification](https://ika-rwth-aachen.github.io/omega-prime/omega_prime_specification/)
- 🌍 **Data Model**: What signals exist and how these are defined.
- 🧾 **Data Format Specification**: How to exchange and store those signals.
### Python Library
- 🔨 **Create** omega-prime files from many sources (see [./docs/notebooks/tutorial.ipynb](https://github.com/ika-rwth-aachen/omega-prime/blob/main/docs/notebooks/tutorial.ipynb)):
- ASAM OSI GroundTruth trace (e.g., output of esmini)
- Table of moving object data (e.g., csv data)
- ASAM OpenDRIVE map
- [LevelXData datasets](https://levelxdata.com/) through [lxd-io](https://github.com/lenvt/lxd-io)
- Extend yourself by subclassing [DatasetConverter](omega_prime/converters/converter.py)
- Use [omega-prime-trajdata](https://github.com/ika-rwth-aachen/omega-prime-trajdata) to convert motion prediction datasets into omega-prime
- 🗺️ **Map Association**: Associate Object Location with Lanes from OpenDRIVE or OSI Maps (see [./docs/notebooks/tutorial_locator.ipynb](https://github.com/ika-rwth-aachen/omega-prime/tree/main/docs/notebooks/tutorial_locatory.ipynb))
- 📺 **Plotting** of data: interactive top view plots using [altair](https://altair-viz.github.io/)
- ✅ **Validation** of data: check if your data conforms to the omega-prime specification (e.g., correct yaw) using [pandera](https://pandera.readthedocs.io/en/stable/)
- 📐 **Interpolation** of data: bring your data into a fixed frequency
- 📈 **Metrics**: compute interaction metrics like PET, TTC, THW (see [./docs/notebooks/tutorial_metrics.ipynb](https://github.com/ika-rwth-aachen/omega-prime/tree/main/docs/notebooks/tutorial_metrics.ipynb))
- Predicted and observed timegaps based on driving tubes (see [./omega_prime/metrics.py](https://github.com/ika-rwth-aachen/omega-prime/blob/main/omega_prime/metrics.py))
- 2D-birds-eye-view visibility with [omega-prime-visibility](https://github.com/ika-rwth-aachen/omega-prime-visibility)
- 🚀 **Fast Processing** directly on DataFrames using [polars](https://pola.rs/), [polars-st](https://oreilles.github.io/polars-st/)
- ⌨️ **CLI** to convert, validate and visualize omega-prime files
### ROS 2 Conversion
- Tooling for conversion from ROS 2 bag-files containing [perception_msgs::ObjectList](https://github.com/ika-rwth-aachen/perception_interfaces/blob/main/perception_msgs/msg/ObjectList.msg) messages to omega-prime MCAP is available in `tools/ros2_conversion/`.
- A Dockerfile and [usage instructions](tools/ros2_conversion/README.md) are provided explaining how to run the export end-to-end.
The data model and format utilize [ASAM OpenDRIVE](https://publications.pages.asam.net/standards/ASAM_OpenDRIVE/ASAM_OpenDRIVE_Specification/latest/specification/index.html#) and [ASAM Open-Simulation-Interface GroundTruth messages](https://opensimulationinterface.github.io/osi-antora-generator/asamosi/V3.7.0/specification/index.html). omega-prime sets requirements on presence and quality of ASAM OSI GroundTruth messages and ASAM OpenDRIVE files and defines a file format for the exchange and storage of these.
Omega-Prime is the successor of the [OMEGAFormat](https://github.com/ika-rwth-aachen/omega_format). It has the benefit that its definition is directly based on the established standards ASAM OSI and ASAM OpenDRIVE and carries over the data quality requirements and the data tooling from OMEGAFormat. Therefore, it should be easier to incorporate omega-prime into existing workflows and tooling.
To learn more about the example data read [example_files/README.md](https://github.com/ika-rwth-aachen/omega-prime/blob/main/example_files/README.md). Example data was taken and created from [esmini](https://github.com/esmini/esmini).
## Installation
`pip install omega-prime`
## Usage
> A detailed introduction to the features and usage can be found in [./docs/notebooks/tutorial.ipynb](https://github.com/ika-rwth-aachen/omega-prime/blob/main/docs/notebooks/tutorial.ipynb)
Create an omega-prime file from an OSI GroundTruth message trace and an OpenDRIVE map:
```python
import omega_prime
r = omega_prime.Recording.from_file('example_files/pedestrian.osi', map_path='example_files/fabriksgatan.xodr')
r.to_mcap('example.mcap')
```
If you want to create an OSI trace on your own in python, check out the python library [betterosi](https://github.com/ika-rwth-aachen/betterosi).
Read and plot an omega-prime file:
<!--pytest-codeblocks:cont-->
```python
r = omega_prime.Recording.from_file('example.mcap')
ax = r.plot()
```
## Convert Existing Datasets to omega-prime
### [LevelXData](https://levelxdata.com/)
You can convert data from LevelXData to omega-prime. Under the hood [lxd-io](https://github.com/lenvt/lxd-io) is used to perform the conversion.
<!--pytest.mark.skip-->
```python
from omega_prime.converters import LxdConverter
converter = LxdConverter('./exiD-dataset-v2.0', './exiD-as-omega-prime', n_workers=4)
# convert the dataset and store the omega-prime files in the new directory
converter.convert()
# access Recordings directly without storing them
iterator_of_recordings = converter.yield_recordings()
```
or with `omega-prime from-lxd ./exiD-dataset-v2.0 ./exiD-as-omega-prime --n-workers=4`.
Tested with exiD-v2.0, inD-v1.1, highD-v1.0 (highD does not provide an ASAM OpenDRIVE map).
## File Format
Based on [MCAP](https://mcap.dev/), [ASAM OSI](https://opensimulationinterface.github.io/osi-antora-generator/asamosi/latest/specification/index.html) and [ASAM OpenDRIVE](https://publications.pages.asam.net/standards/ASAM_OpenDRIVE/ASAM_OpenDRIVE_Specification/latest/specification/index.html#) the ASAM OSI GroundTruth messages and ASAM OpenDRIVE map are packaged as shown in the following figure.

# Acknowledgements
This package is developed as part of the [SYNERGIES project](https://synergies-ccam.eu).
<img src="https://raw.githubusercontent.com/ika-rwth-aachen/omega-prime/refs/heads/main/docs/synergies.svg"
style="width:2in" />
Funded by the European Union. Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or European Climate, Infrastructure and Environment Executive Agency (CINEA). Neither the European Union nor the granting authority can be held responsible for them.
<img src="https://raw.githubusercontent.com/ika-rwth-aachen/omega-prime/refs/heads/main/docs/funded_by_eu.svg"
style="width:4in" />
# Notice
> [!IMPORTANT]
> The project is open-sourced and maintained by the [**Institute for Automotive Engineering (ika) at RWTH Aachen University**](https://www.ika.rwth-aachen.de/).
> We cover a wide variety of research topics within our [*Vehicle Intelligence & Automated Driving*](https://www.ika.rwth-aachen.de/en/competences/fields-of-research/vehicle-intelligence-automated-driving.html) domain.
> If you would like to learn more about how we can support your automated driving or robotics efforts, feel free to reach out to us!
> :email: ***opensource@ika.rwth-aachen.de***
| text/markdown | null | Michael Schuldes <michael.schuldes@ika.rwth-aachen.de>, Sven Tarlowski <sven.tarlowski@ika.rwth-aachen.de>, ika - RWTH Aachen University <opensource@ika.rwth-aachen.de> | null | null | MPL-2.0 | automated-driving, omega-format, open-simulation-interface, osi, simulation, traffic | [
"License :: OSI Approved :: Mozilla Public License 2.0 (MPL 2.0)",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"altair",
"betterosi<1,>=0.8.4",
"filelock>=3.18.0",
"joblib",
"lxd-io>=0.4.6",
"lxml",
"matplotlib",
"networkx",
"numpy",
"pandas[pyarrow]",
"pandera[polars]",
"polars",
"polars-st",
"pyproj",
"pyxodr-omega-prime",
"scipy",
"shapely",
"strenum",
"tqdm-joblib",
"typer",
"xarray",
"ipywidgets; extra == \"test\"",
"mkdocs-jupyter; extra == \"test\"",
"mkdocs-material; extra == \"test\"",
"mkdocs-typer2; extra == \"test\"",
"mkdocstrings[python]; extra == \"test\"",
"nbval; extra == \"test\"",
"pre-commit; extra == \"test\"",
"pytest; extra == \"test\"",
"pytest-codeblocks; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"pytest-env; extra == \"test\"",
"pytest-progress; extra == \"test\"",
"pytest-sugar; extra == \"test\"",
"ruff; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/ika-rwth-aachen/omega-prime",
"Repository, https://github.com/ika-rwth-aachen/omega-prime",
"Documentation, https://ika-rwth-aachen.github.io/omega-prime/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T09:51:33.760700 | omega_prime-0.2.1.tar.gz | 8,203,877 | 11/3a/5a4f5662b6fb9b8cb9108cb0c477c458f9a393dbdabdf74f8c3929b65da3/omega_prime-0.2.1.tar.gz | source | sdist | null | false | b25757ffc7d7fd53f17a21a29db65d3a | 4073931647e8f5a563d893d1066c4cbd529f502bb7df119c5f0554ba68cd0a9c | 113a5a4f5662b6fb9b8cb9108cb0c477c458f9a393dbdabdf74f8c3929b65da3 | null | [
"LICENSE"
] | 209 |
2.4 | backend.ai-webserver | 25.15.10 | Backend.AI WebUI Host | # Backend.AI Web Server
[](https://badge.fury.io/gh/lablup%2Fbackend.ai-webserver) [](https://badge.fury.io/py/backend.ai-webserver)
A webapp hosting daemon which serves our `webui` as a SPA and proxies API requests
## Installation
Prepare a Python virtualenv (Python 3.9 or higher) and a Redis server (6.2 or higher).
```console
$ git clone https://github.com/lablup/backend.ai-webserver webserver
$ cd webserver
$ pip install -U -e .
$ cp webserver.sample.conf webserver.conf
```
## Mode
If `service.mode` is set "webui" (the default), the webserver handles
PWA-style fallbacks (e.g., serving `index.html` when there are no matching
files for the requested URL path).
The PWA must exclude `/server` and `/func` URL prefixes from its own routing
to work with the webserver's web sessions and the API proxy.
If it is set "static", the webserver serves the static files as-is,
without any fallbacks or hooking, while preserving the `/server` and `/func`
prefixed URLs and their functionalities.
If you want to serve web UI in webserver with "webui" mode, prepare static web UI source by choosing one of the followings.
### Option 1: Build web UI from source
Build **[backend.ai-webui](https://github.com/lablup/backend.ai-webui)** and copy all files under `build/bundle`
into the `src/ai/backend/web/static` directory.
### Option 2: Use pre-built web UI
To download and deploy web UI from pre-built source, do the following:
```console
cd src/ai/backend/web
curl --fail -sL https://github.com/lablup/backend.ai-webui/releases/download/v$TARGET_VERSION/backend.ai-webui-bundle-$TARGET_VERSION.zip > /tmp/bai-webui.zip
rm -rf static
mkdir static
cd static
unzip /tmp/bai-webui.zip
```
### Setup configuration for webserver
You don't have to write `config.toml` for the web UI as this webserver auto-generates it on-the-fly.
Edit `webserver.conf` to match with your environment.
## Usage
To execute web server, run command below. (for debugging, append a `--debug` flag)
```console
$ python -m ai.backend.web.server
```
| text/markdown | Lablup Inc. and contributors | null | null | null | LGPLv3 | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"Jinja2~=3.1.6",
"aiohttp_cors~=0.8.1",
"aiohttp~=3.13.0",
"aiotools~=1.9.0",
"backend.ai-cli==25.15.10",
"backend.ai-client==25.15.10",
"backend.ai-common==25.15.10",
"backend.ai-logging==25.15.10",
"backend.ai-plugin==25.15.10",
"click~=8.1.7",
"coloredlogs~=15.0",
"multidict~=6.6.4",
"pycryptodome>=3.20.0",
"pydantic[email]~=2.11.3",
"setproctitle~=1.3.5",
"tomli~=2.0.1",
"trafaret~=2.1",
"types-Jinja2",
"uvloop~=0.21; sys_platform != \"Windows\""
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:33.766943 | backend_ai_webserver-25.15.10.tar.gz | 47,464,883 | 65/94/05e48df35bc3e0fe66e1b16d7486c619a2903eef45dc2c8a92263eb3824e/backend_ai_webserver-25.15.10.tar.gz | source | sdist | null | false | 38653b92bb91e0424a7687ea8520e56b | 33cebf6da74e31a3c36109c200c1d466ec5ed36558eceb328bc450f4812288be | 659405e48df35bc3e0fe66e1b16d7486c619a2903eef45dc2c8a92263eb3824e | null | [] | 0 |
2.4 | backend.ai-test | 25.15.10 | Backend.AI Integration Test Suite | # Backend.AI Testing Toolkit
Automated test suites to validate an installation and integration of clients and servers
## How to run CLI-based integration test
If there is no configuration script named `env-tester.sh`, copy it from `sample-env-tester.sh` and check the configuration env.
```console
$ source env-tester.sh
$ backend.ai test run-cli
```
NOTE: The ENV script is parsed with `"^export (\w+)=(.*)$"` regex pattern line by line.
| text/markdown | Lablup Inc. and contributors | null | null | null | MIT | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: MIT License"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"aiofiles~=24.1.0",
"aiohttp~=3.13.0",
"aiotools~=1.9.0",
"attrs>=25.3",
"backend.ai-cli==25.15.10",
"backend.ai-client==25.15.10",
"backend.ai-common==25.15.10",
"backend.ai-logging==25.15.10",
"backend.ai-plugin==25.15.10",
"click~=8.1.7",
"faker~=24.7.1",
"pexpect~=4.8",
"pydantic[email]~=2.11.3",
"pytest-dependency>=0.6.0",
"pytest>=8.3.3",
"tomli~=2.0.1",
"types-aiofiles",
"types-pexpect",
"types-setuptools"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:32.375979 | backend_ai_test-25.15.10.tar.gz | 55,661 | 84/e7/4537167254d40b03516bf1ee39b8b4bbb3ea5a55e5222dcdab6003229e3a/backend_ai_test-25.15.10.tar.gz | source | sdist | null | false | 3ed56ae5411b25b233dc77394b1e3bff | 93dee9596f0935ca8006a3240eccc69f71271c9498389767f2621872bce89627 | 84e74537167254d40b03516bf1ee39b8b4bbb3ea5a55e5222dcdab6003229e3a | null | [] | 0 |
2.4 | backend.ai-storage-proxy | 25.15.10 | Backend.AI Storage Proxy | # Backend.AI Storage Proxy
Backend.AI Storage Proxy is an RPC daemon to manage vfolders used in Backend.AI agent, with quota and
storage-specific optimization support.
## Package Structure
- `ai.backend.storage`
- `server`: The agent daemon which communicates between Backend.AI Manager
- `api.client`: The client-facing API to handle tus.io server-side protocol for uploads and ranged HTTP
queries for downloads.
- `api.manager`: The manager-facing (internal) API to provide abstraction of volumes and separation of
the hardware resources for volume and file operations.
- `vfs`
- The minimal fallback backend which only uses the standard Linux filesystem interfaces
- `xfs`
- XFS-optimized backend with a small daemon to manage XFS project IDs for quota limits
- `agent`: Implementation of `AbstractVolumeAgent` with XFS support
- `purestorage`
- PureStorage's FlashBlade-optimized backend with RapidFile Toolkit (formerly PureTools)
- `netapp`
- NetApp QTree integration backend based on the NetApp ONTAP REST API
- `weka`
- Weka.IO integration backend with Weka.IO V2 REST API
- `cephfs` (TODO)
- CephFS-optimized backend with quota limit support
## Installation
### Prerequisites
- Python 3.8 or higher with [pyenv](https://github.com/pyenv/pyenv)
and [pyenv-virtualenv](https://github.com/pyenv/pyenv-virtualenv) (optional but recommended)
### Installation Process
First, prepare the source clone of this agent:
```console
# git clone https://github.com/lablup/backend.ai-storage-proxy
```
From now on, let's assume all shell commands are executed inside the virtualenv.
Now install dependencies:
```console
# pip install -U -r requirements/dist.txt # for deployment
# pip install -U -r requirements/dev.txt # for development
```
Then, copy halfstack.toml to root of the project folder and edit to match your machine:
```console
# cp config/sample.toml storage-proxy.toml
```
When done, start storage server:
```console
# python -m ai.backend.storage.server
```
It will start Storage Proxy daemon bound at `127.0.0.1:6021` (client API) and
`127.0.0.1:6022` (manager API).
NOTE: Depending on the backend, the server may require to be run as root.
### Production Deployment
To get performance boosts by using OS-provided `sendfile()` syscall
for file transfers, SSL termination should be handled by reverse-proxies
such as nginx and the storage proxy daemon itself should be run without SSL.
## Filesystem Backends
### VFS
#### Prerequisites
- User account permission to access for the given directory
- Make sure a directory such as `/vfroot/vfs` a directory or you want to mount exists
### XFS
#### Prerequisites
- Local device mounted under `/vfroot`
- Native support for XFS filesystem
- Mounting XFS volume with an option `-o pquota` to enable project quota
- To turn on quotas on the root filesystem, the quota mount flags must be
set with the `rootflags=` boot parameter. Usually, this is not recommended.
- Access to root privilege
- Execution of `xfs_quota`, which performs quota-related commands, requires
the `root` privilege.
- Thus, you need to start the Storage-Proxy service by a `root` user or a
user with passwordless sudo access.
- If the root user starts the Storage-Proxy, the owner of every file created
is also root. In some situations, this would not be the desired setting.
In that case, it might be better to start the service with a regular user
with passwordless sudo privilege.
#### Creating virtual XFS device for testing
Create a virtual block device mounted to `lo` (loopback) if you are the only one
to use the storage for testing:
1. Create file with your desired size
```console
# dd if=/dev/zero of=xfs_test.img bs=1G count=100
```
2. Make file as XFS partition
```console
# mkfs.xfs xfs_test.img
```
3. Mount it to loopback
```console
# export LODEVICE=$(losetup -f)
# losetup $LODEVICE xfs_test.img
```
4. Create mount point and mount loopback device, with pquota option
```console
# mkdir -p /vfroot/xfs
# mount -o loop -o pquota $LODEVICE /vfroot/xfs
```
#### Note on operation
XFS keeps quota mapping information on two files: `/etc/projects` and
`/etc/projid`. If they are deleted or damaged in any way, per-directory quota
information will also be lost. So, it is crucial not to delete them
accidentally. If possible, it is a good idea to backup them to a different disk
or NFS.
### PureStorage FlashBlade
#### Prerequisites
- NFSv3 export mounted under `/vfroot`
- Purity API access
### CephFS
#### Prerequisites
- FUSE export mounted under `/vfroot`
### NetApp ONTAP
#### Prerequisites
- NFSv3 export mounted under `/vfroot`
- NetApp ONTAP API access
- native NetApp XCP or Dockerized NetApp XCP container
- To install NetApp XCP, please refer [NetApp XCP install guide](https://xcp.netapp.com/)
- Create Qtree in Volume explicitly using NetApp ONTAP Sysmgr GUI
#### Note on operation
The volume host of Backend.AI Storage proxy corresponds to Qtree of NetApp ONTAP, not NetApp ONTAP Volume.
Please DO NOT remove Backend.AI mapped qtree in NetApp ONTAP Sysmgr GUI. If not, you cannot access to NetApp ONTAP Volume through Backend.AI.
> NOTE:
> Qtree name in configuration file(`storage-proxy.toml`) must have the same name created in NetApp ONTAP Sysmgr.
### Weka.IO
#### Prerequisites
- Weka.IO agent installed and running
- Weka.IO filesystem mounted under local machine, with permission set to somewhat storage-proxy process can read and write
- Weka.IO REST API access (username/password/organization)
| text/markdown | Lablup Inc. and contributors | null | null | null | LGPLv3 | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"PyJWT~=2.10.1",
"aioboto3~=15.0.0",
"aiofiles~=24.1.0",
"aiohttp_cors~=0.8.1",
"aiohttp~=3.13.0",
"aiomonitor~=0.7.0",
"aiotools~=1.9.0",
"asyncpg>=0.29.0",
"attrs>=25.3",
"backend.ai-common==25.15.10",
"backend.ai-logging==25.15.10",
"backend.ai-plugin==25.15.10",
"click~=8.1.7",
"dataclasses-json~=0.5.7",
"huggingface-hub~=0.34.3",
"janus~=2.0",
"more-itertools~=10.5.0",
"pydantic[email]~=2.11.3",
"pyzmq~=26.4",
"setproctitle~=1.3.5",
"tenacity>=9.0",
"tqdm~=4.67.1",
"trafaret~=2.1",
"types-aiofiles",
"types-tqdm",
"uvloop~=0.21; sys_platform != \"Windows\"",
"yarl~=1.19.0",
"zipstream-new~=1.1.8"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:31.583784 | backend_ai_storage_proxy-25.15.10.tar.gz | 122,661 | 34/ef/487884f41efb3e8eecc8fb4a80bcb7bd1fd640e4d4f083dad89cff79b7a0/backend_ai_storage_proxy-25.15.10.tar.gz | source | sdist | null | false | c6dc99d37710cee84d328fa5ec7003d0 | a90975aef0d983521fdfb860899de16a5e2e7f32c1f7a08348d7735e0c58daf3 | 34ef487884f41efb3e8eecc8fb4a80bcb7bd1fd640e4d4f083dad89cff79b7a0 | null | [] | 0 |
2.4 | backend.ai-plugin | 25.15.10 | Backend.AI Plugin Subsystem | Backend.AI Plugin Subsystem
===========================
Package Structure
-----------------
* `ai.backend.plugin`: Abstract types for plugins and a common base plugin set
| text/markdown | Lablup Inc. and contributors | null | null | null | MIT | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: MIT License"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"backend.ai-common==25.15.10",
"backend.ai-logging==25.15.10",
"click~=8.1.7",
"colorama>=0.4.6",
"tabulate~=0.8.9",
"types-colorama",
"types-tabulate"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:30.920798 | backend_ai_plugin-25.15.10.tar.gz | 8,020 | a6/66/b3befa6c9a9073e352b8982b2dbe22c14b808b88912c2ca1c859ebc18b0b/backend_ai_plugin-25.15.10.tar.gz | source | sdist | null | false | 18d73c33e47c28cf87fff30dd1f9f8f7 | 42aae65a7fbadcce0d6929706c2430d596be8cbee4a0d505b0192421b6b0e082 | a666b3befa6c9a9073e352b8982b2dbe22c14b808b88912c2ca1c859ebc18b0b | null | [] | 0 |
2.4 | backend.ai-manager | 25.15.10 | Backend.AI Manager | Backend.AI Manager with API Gateway
===================================
Package Structure
-----------------
* `ai.backend.manager`: Computing resource and workload management with public APIs
Installation
------------
Please visit [the installation guides](https://github.com/lablup/backend.ai/wiki).
### Kernel/system configuration
#### Recommended resource limits:
**`/etc/security/limits.conf`**
```
root hard nofile 512000
root soft nofile 512000
root hard nproc 65536
root soft nproc 65536
user hard nofile 512000
user soft nofile 512000
user hard nproc 65536
user soft nproc 65536
```
**sysctl**
```
fs.file-max=2048000
net.core.somaxconn=1024
net.ipv4.tcp_max_syn_backlog=1024
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_fin_timeout=10
net.ipv4.tcp_window_scaling=1
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_early_retrans=1
net.ipv4.ip_local_port_range="10000 65000"
net.core.rmem_max=16777216
net.core.wmem_max=16777216
net.ipv4.tcp_rmem=4096 12582912 16777216
net.ipv4.tcp_wmem=4096 12582912 16777216
```
### For development
#### Prerequisites
* Python 3.6 or higher with [pyenv](https://github.com/pyenv/pyenv)
and [pyenv-virtualenv](https://github.com/pyenv/pyenv-virtualenv) (optional but recommneded)
* Docker 18.03 or later with docker-compose (18.09 or later is recommended)
#### Common steps
Clone [the meta repository](https://github.com/lablup/backend.ai) and install a "halfstack"
configuration. The halfstack configuration installs and runs several dependency daemons such as etcd in
the background.
```console
$ git clone https://github.com/lablup/backend.ai halfstack
$ cd halfstack
$ docker-compose -f docker-compose.halfstack.yml up -d
```
Then prepare the source clone of the agent as follows.
First install the current working copy.
```console
$ git clone https://github.com/lablup/backend.ai-manager manager
$ cd manager
$ pyenv virtualenv venv-manager
$ pyenv local venv-manager
$ pip install -U pip setuptools
$ pip install -U -r requirements/dev.txt
```
From now on, let's assume all shell commands are executed inside the virtualenv.
### Halfstack (single-node development & testing)
#### Recommended directory structure
* `backend.ai-dev`
- `manager` (git clone from this repo)
- `agent` (git clone from [the agent repo](https://github.com/lablup/backend.ai-agent))
- `common` (git clone from [the common repo](https://github.com/lablup/backend.ai-common))
Install `backend.ai-common` as an editable package in the manager (and the agent) virtualenvs
to keep the codebase up-to-date.
```console
$ cd manager
$ pip install -U -e ../common -r requirements/dev.txt
```
#### Steps
Copy (or symlink) the halfstack configs:
```console
$ cp config/halfstack.toml ./manager.toml
$ cp config/halfstack.alembic.ini ./alembic.ini
```
Set up Redis:
```console
$ backend.ai mgr etcd put config/redis/addr 127.0.0.1:8110
```
> ℹ️ NOTE: You may replace `backend.ai mgr` with `python -m ai.backend.manager.cli` in case your `PATH` is unmodifiable.
Set up the public Docker registry:
```console
$ backend.ai mgr etcd put config/docker/registry/index.docker.io "https://registry-1.docker.io"
$ backend.ai mgr etcd put config/docker/registry/index.docker.io/username "lablup"
$ backend.ai mgr image rescan index.docker.io
```
Set up the vfolder paths:
```console
$ mkdir -p "$HOME/vfroot/local"
$ backend.ai mgr etcd put volumes/_mount "$HOME/vfroot"
$ backend.ai mgr etcd put volumes/_default_host local
```
Set up the allowed types of vfolder. Allowed values are "user" or "group".
If none is specified, "user" type is set implicitly:
```console
$ backend.ai mgr etcd put volumes/_types/user "" # enable user vfolder
$ backend.ai mgr etcd put volumes/_types/group "" # enable group vfolder
```
Set up the database:
```console
$ backend.ai mgr schema oneshot
$ backend.ai mgr fixture populate sample-configs/example-keypairs.json
$ backend.ai mgr fixture populate sample-configs/example-resource-presets.json
```
Then, run it (for debugging, append a `--debug` flag):
```console
$ backend.ai mgr start-server
```
To run tests:
```console
$ python -m flake8 src tests
$ python -m pytest -m 'not integration' tests
```
Now you are ready to install the agent.
Head to [the README of Backend.AI Agent](https://github.com/lablup/backend.ai-agent/blob/master/README.md).
NOTE: To run tests including integration tests, you first need to install and run the agent on the same host.
## Deployment
### Configuration
Put a TOML-formatted manager configuration (see the sample in `config/sample.toml`)
in one of the following locations:
* `manager.toml` (current working directory)
* `~/.config/backend.ai/manager.toml` (user-config directory)
* `/etc/backend.ai/manager.toml` (system-config directory)
Only the first found one is used by the daemon.
Also many configurations shared by both manager and agent are stored in etcd.
As you might have noticed above, the manager provides a CLI interface to access and manipulate the etcd
data. Check out the help page of our etcd command set:
```console
$ python -m ai.backend.manager.cli etcd --help
```
If you run etcd as a Docker container (e.g., via halfstack), you may use the native client as well.
In this case, PLEASE BE WARNED that you must prefix the keys with "/sorna/{namespace}" manaully:
```console
$ docker exec -it ${ETCD_CONTAINER_ID} /bin/ash -c 'ETCDCTL_API=3 etcdctl ...'
```
### Running from a command line
The minimal command to execute:
```sh
python -m ai.backend.gateway.server
```
For more arguments and options, run the command with `--help` option.
### Writing a wrapper script
To use with systemd, crontab, and other system-level daemons, you may need to write a shell script
that executes specific CLI commands provided by Backend.AI modules.
The following example shows how to set up pyenv and virtualenv for the script-local environment.
It runs the gateway server if no arguments are given, and execute the given arguments as a shell command
if any.
For instance, you may get/set configurations like: `run-manager.sh python -m ai.backend.manager.etcd ...`
where the name of scripts is `run-manager.sh`.
```bash
#! /bin/bash
if [ -z "$HOME" ]; then
export HOME="/home/devops"
fi
if [ -z "$PYENV_ROOT" ]; then
export PYENV_ROOT="$HOME/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
fi
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)"
pyenv activate venv-bai-manager
if [ "$#" -eq 0 ]; then
exec python -m ai.backend.gateway.server
else
exec "$@"
fi
```
### Networking
The manager and agent should run in the same local network or different
networks reachable via VPNs, whereas the manager's API service must be exposed to
the public network or another private network that users have access to.
The manager requires access to the etcd, the PostgreSQL database, and the Redis server.
| User-to-Manager TCP Ports | Usage |
|:-------------------------:|-------|
| manager:{80,443} | Backend.AI API access |
| Manager-to-X TCP Ports | Usage |
|:----------------------:|-------|
| etcd:2379 | etcd API access |
| postgres:5432 | Database access |
| redis:6379 | Redis API access |
The manager must also be able to access TCP ports 6001, 6009, and 30000 to 31000 of the agents in default
configurations. You can of course change those port numbers and ranges in the configuration.
| Manager-to-Agent TCP Ports | Usage |
|:--------------------------:|-------|
| 6001 | ZeroMQ-based RPC calls from managers to agents |
| 6009 | HTTP watcher API |
| 30000-31000 | Port pool for in-container services |
LICENSES
--------
[GNU Lesser General Public License](https://github.com/lablup/backend.ai-manager/blob/master/LICENSE)
[Dependencies](https://github.com/lablup/backend.ai-manager/blob/master/DEPENDENCIES.md)
| text/markdown | Lablup Inc. and contributors | null | null | null | LGPLv3 | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"PyJWT~=2.10.1",
"PyYAML~=6.0",
"SQLAlchemy[postgresql_asyncpg]~=1.4.54",
"aiodataloader~=0.4.2",
"aiodocker==0.24.0",
"aiofiles~=24.1.0",
"aiohttp_cors~=0.8.1",
"aiohttp_sse>=2.2",
"aiohttp~=3.13.0",
"aiomonitor~=0.7.0",
"aiotools~=1.9.0",
"alembic~=1.13.2",
"async_timeout~=4.0",
"attrs>=25.3",
"backend.ai-cli==25.15.10",
"backend.ai-common==25.15.10",
"backend.ai-logging==25.15.10",
"backend.ai-plugin==25.15.10",
"bcrypt~=4.2.0",
"boto3~=1.35",
"callosum~=1.0.3",
"click~=8.1.7",
"cryptography>=44.0.2",
"etcd-client-py~=0.4.1",
"graphene-federation~=3.2.0",
"graphene~=3.3.0",
"graphql-core~=3.2.6",
"graphql-relay~=3.2.0",
"lark~=1.1.5",
"more-itertools~=10.5.0",
"msgpack~=1.1.0",
"multidict~=6.6.4",
"orjson~=3.10.16",
"prometheus-client~=0.21.1",
"pydantic[email]~=2.11.3",
"python-dateutil>=2.9",
"pyzmq~=26.4",
"redis[hiredis]==4.5.5",
"ruamel.yaml~=0.18.10",
"setproctitle~=1.3.5",
"strawberry-graphql~=0.278.0",
"tabulate~=0.8.9",
"tenacity>=9.0",
"tomli~=2.0.1",
"trafaret~=2.1",
"typeguard~=4.3",
"types-PyYAML",
"types-aiofiles",
"types-python-dateutil",
"types-redis",
"types-six",
"types-tabulate",
"typing_extensions~=4.11",
"uvloop~=0.21; sys_platform != \"Windows\"",
"yarl~=1.19.0"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:29.514740 | backend_ai_manager-25.15.10.tar.gz | 2,274,562 | cf/93/4f154988964c698549686d196062436f1dbff4841c825c0ca885acabfd3b/backend_ai_manager-25.15.10.tar.gz | source | sdist | null | false | 9c22f321bfa5c02632d634fe9d83df95 | 94cfcc8e570a0ae75617a416da590c564d4a7bdbce37425ee51a0067e3857e2f | cf934f154988964c698549686d196062436f1dbff4841c825c0ca885acabfd3b | null | [] | 0 |
2.4 | moss-voice-agent-manager | 1.0.0b6 | Moss Voice Agent Manager - Simplified LiveKit agent integration | # Moss Voice Agent Manager
Simplified LiveKit voice agent integration with the Moss platform.
## Features
- **Drop-in replacement** for LiveKit AgentSession
- **Automatic configuration** from Moss platform API
- **Built-in metrics tracking** and diagnostics
- **Secure credential management** - no hardcoded secrets
- **Dynamic runtime config** - models and settings from backend
## Installation
```bash
pip install moss-voice-agent-manager
```
## Quick Start
```python
from moss_voice_agent_manager import MossAgentSession
# Initialize session - config loaded automatically
session = MossAgentSession(
userdata=your_data,
vad=vad, # optional, auto-created if None
max_tool_steps=10,
)
# Access platform API
api = session.platform_api
# Get metrics
metrics = session.metrics
diagnostics = session.diagnostics
# Save metrics
session.save_metrics()
# Generate diagnostics report
report = session.generate_diagnostics_report()
```
## Environment Variables
Required:
- `MOSS_PROJECT_ID` - Your Moss project ID
- `MOSS_PROJECT_KEY` - Your Moss project key
- `MOSS_VOICE_AGENT_ID` - Voice agent ID
Optional:
- `MOSS_PLATFORM_API_URL` - Platform API URL (defaults to production)
## How It Works
1. Fetches configuration from Moss platform
2. Auto-configures voice providers
3. Tracks metrics and diagnostics
## License
MIT
| text/markdown | null | Moss Team <support@moss.dev> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pydantic<3.0.0,>=2.0.0",
"httpx<1.0.0,>=0.27.0",
"livekit-api<2.0.0,>=1.0.2",
"livekit-agents==1.3.11",
"livekit-plugins-deepgram==1.3.11",
"livekit-plugins-google==1.3.11",
"livekit-plugins-cartesia==1.3.11",
"livekit-plugins-silero==1.3.11",
"livekit-plugins-noise-cancellation<1.0.0,>=0.2.0",
"google-genai<2.0.0,>=1.55",
"pytest>=7.0; extra == \"dev\"",
"black>=22.0; extra == \"dev\"",
"flake8>=4.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/InferEdge-Inc/moss",
"Repository, https://github.com/InferEdge-Inc/moss",
"Changelog, https://github.com/InferEdge-Inc/moss/blob/main/python/moss-voice-sdk/CHANGELOG.md"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-20T09:50:29.304854 | moss_voice_agent_manager-1.0.0b6.tar.gz | 191,607 | 7a/aa/defa6c6c1e3c4e52d1b29850b7f5e23e0d247fafa5b6ff8050e2e70fe674/moss_voice_agent_manager-1.0.0b6.tar.gz | source | sdist | null | false | b215df123ad7870562ee7e1abefc025a | 9a3f2208bc3d4386a24d0ed6543978a62d19fb500fd6bc89454b507a55807146 | 7aaadefa6c6c1e3c4e52d1b29850b7f5e23e0d247fafa5b6ff8050e2e70fe674 | MIT | [] | 208 |
2.4 | backend.ai-logging | 25.15.10 | Backend.AI Logging Subsystem | Backend.AI Logging Subsystem
============================
Package Structure
-----------------
* `ai.backend.logging`
- `abc`: Abstract base classes
- `logger`: The core logging facility
- `Logger`: The standard multiprocess-friendly logger using `RelayHandler` based on ZeroMQ
- `LocalLogger`: A minimalized console/file logger that does not require serialization via networks at all
- `handler`: Collection of vendor-specific handler implementations
- `formatter`: Collection of formatters
- `types`: Definition of enums/types like `LogLevel`
- `utils`: Brace-style message formatting adapters and other extras
| text/markdown | Lablup Inc. and contributors | null | null | null | MIT | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: MIT License"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"backend.ai-common==25.15.10",
"coloredlogs~=15.0",
"graypy==2.1.0",
"msgpack~=1.1.0",
"opentelemetry-exporter-otlp-proto-grpc~=1.39.0",
"opentelemetry-instrumentation-aiohttp-client~=0.60b0",
"opentelemetry-instrumentation-aiohttp-server~=0.60b0",
"opentelemetry-sdk~=1.39.0",
"psutil~=7.0",
"pydantic[email]~=2.11.3",
"python-json-logger~=3.2.0",
"pyzmq~=26.4",
"trafaret~=2.1",
"types-psutil",
"valkey-glide~=2.2.2",
"yarl~=1.19.0"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:28.149051 | backend_ai_logging-25.15.10.tar.gz | 16,116 | fb/21/bd2dc7a807dadd52ec1c77adfd3fea90feceec8900f42d383fb88b83e24c/backend_ai_logging-25.15.10.tar.gz | source | sdist | null | false | b6c2e4116b25a76440302f5f28a83530 | d7c8ee057ff4f1449a0921a5b003208efd2a31ff4e9e57dfe90588baf171b53a | fb21bd2dc7a807dadd52ec1c77adfd3fea90feceec8900f42d383fb88b83e24c | null | [] | 0 |
2.4 | backend.ai-kernel-helper | 25.15.10 | Backend.AI Kernel Runner Prebuilt Binaries Package | # Backend.AI In-kernel Helper Package
| text/markdown | Lablup Inc. and contributors | null | null | null | LGPLv3 | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"setuptools~=80.0.0",
"types-setuptools"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:27.590863 | backend_ai_kernel_helper-25.15.10.tar.gz | 2,924 | 41/9f/0993d0afa3e4a8c26feef9f0d0dda54f404992cafd01a8c6c2e60878aae6/backend_ai_kernel_helper-25.15.10.tar.gz | source | sdist | null | false | ba79e6dad0c6a93163ae517cf19c3e01 | 27fca321259a425a1f25111944e969392004a92d7a3f5bc766708230c9ee0141 | 419f0993d0afa3e4a8c26feef9f0d0dda54f404992cafd01a8c6c2e60878aae6 | null | [] | 0 |
2.4 | backend.ai-kernel-binary | 25.15.10 | Backend.AI Kernel Runner Prebuilt Binaries Package | # Backend.AI Kernel Runner Binary Components
| text/markdown | Lablup Inc. and contributors | null | null | null | LGPLv3 | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:25.557435 | backend_ai_kernel_binary-25.15.10.tar.gz | 16,891,462 | ba/6e/b0d13463a7c434a6ca1f44bd6055d0534bb0dd43b603dcfea0b48a2d41f7/backend_ai_kernel_binary-25.15.10.tar.gz | source | sdist | null | false | 6da8f963cf5ecdaba9fb77f82eaef85a | 71d5546ca5ea2aa8f21b8ade78215d2305c16b68f6f84e10317afd746e2d136e | ba6eb0d13463a7c434a6ca1f44bd6055d0534bb0dd43b603dcfea0b48a2d41f7 | null | [] | 0 |
2.4 | backend.ai-kernel | 25.15.10 | Backend.AI Kernel Runner | # Backend.AI Kernel Runner
| text/markdown | Lablup Inc. and contributors | null | null | null | LGPLv3 | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"aiohttp~=3.13.0",
"attrs>=25.3",
"boto3~=1.35",
"janus~=2.0",
"jupyter-client>=8.6",
"msgpack~=1.1.0",
"namedlist~=1.8",
"pyzmq~=26.4",
"types-six",
"yarl~=1.19.0"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:24.637262 | backend_ai_kernel-25.15.10.tar.gz | 40,208 | d3/e3/b1ec9af40bddb17223397807bfdccfcc3edacddb3fa9d32155677e37ea40/backend_ai_kernel-25.15.10.tar.gz | source | sdist | null | false | 965e27a615ac62f952b61fa4f031b33f | 5ee4cac6c66fa91922a13576aa8909a92e368c3e28440a082d2d342481d8c9a8 | d3e3b1ec9af40bddb17223397807bfdccfcc3edacddb3fa9d32155677e37ea40 | null | [] | 0 |
2.4 | backend.ai-install | 25.15.10 | Backend.AI Installer | Backend.AI Installer
====================
Package Structure
-----------------
* `ai.backend.install`: The installer package
Development
-----------
### Using the textual debug mode
First, install the textual-dev package in the `python-default` venv.
```shell
./py -m pip install textual-dev
```
Open two terminal sessions.
In the first one, run:
```shell
dist/export/python/virtualenvs/python-default/3.13.3/bin/textual console
```
> **Warning**
> You should use the `textual` executable created *inside the venv's `bin` directory*.
> `./py -m textual` only shows the demo instead of executing the devtool command.
In the second one, run:
```shell
TEXTUAL=devtools,debug ./backend.ai install
```
| text/markdown | Lablup Inc. and contributors | null | null | null | MIT | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: MIT License"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"aiofiles~=24.1.0",
"aiohttp~=3.13.0",
"aiotools~=1.9.0",
"asyncpg>=0.29.0",
"backend.ai-common==25.15.10",
"backend.ai-logging==25.15.10",
"backend.ai-plugin==25.15.10",
"click~=8.1.7",
"pydantic[email]~=2.11.3",
"python-dateutil>=2.9",
"rich~=13.6",
"textual~=0.79.1",
"tomlkit~=0.13.2",
"types-aiofiles",
"types-python-dateutil"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:23.980832 | backend_ai_install-25.15.10.tar.gz | 50,117 | 4f/9f/bcfc914bd49cc137c16aa9374a5f7e57d2341f6d59d0e04f86bc9585b30d/backend_ai_install-25.15.10.tar.gz | source | sdist | null | false | 5feb967612ee29498c0a77dde29fabe2 | 292ad5f3963753dd18c9eef9590b0f11df273284697e8c325aab8bcab83c7e18 | 4f9fbcfc914bd49cc137c16aa9374a5f7e57d2341f6d59d0e04f86bc9585b30d | null | [] | 0 |
2.4 | backend.ai-common | 25.15.10 | Backend.AI commons library | Backend.AI Commons
==================
[](https://pypi.org/project/backend.ai-common/)

[](https://gitter.im/lablup/backend.ai-common)
Common utilities library for Backend.AI
## Installation
```console
$ pip install backend.ai-common
```
## For development
```console
$ pip install -U pip setuptools
$ pip install -U -r requirements/dev.txt
```
### Running test suite
```console
$ python -m pytest
```
With the default halfstack setup, you may need to set the environment variable `BACKEND_ETCD_ADDR`
to specify the non-standard etcd service port (e.g., `localhost:8110`).
The tests for `common.redis` module requires availability of local TCP ports 16379, 16380, 16381,
26379, 26380, and 26381 to launch a temporary Redis sentinel cluster via `docker compose`.
In macOS, they require a local `redis-server` executable to be installed, preferably via `brew`,
because `docker compose` in macOS does not support host-mode networking and Redis *cannot* be
configured to use different self IP addresses to announce to the cluster nodes and clients.
| text/markdown | Lablup Inc. and contributors | null | null | null | LGPLv3 | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"PyJWT~=2.10.1",
"aiodns==3.2",
"aiofiles~=24.1.0",
"aiohttp~=3.13.0",
"aiomonitor~=0.7.0",
"aiotools~=1.9.0",
"async_timeout~=4.0",
"asynctest>=0.13.0",
"asyncudp>=0.11",
"attrs>=25.3",
"backend.ai-logging==25.15.10",
"backend.ai-plugin==25.15.10",
"callosum~=1.0.3",
"click~=8.1.7",
"etcd-client-py~=0.4.1",
"graphql-core~=3.2.6",
"hiredis>=3.0.0",
"ifaddr~=0.2",
"janus~=2.0",
"lark~=1.1.5",
"msgpack~=1.1.0",
"multidict~=6.6.4",
"orjson~=3.10.16",
"packaging>=24.1",
"prometheus-client~=0.21.1",
"psutil~=7.0",
"pycares~=4.11.0",
"pydantic[email]~=2.11.3",
"pyhumps~=3.8.0",
"pyroscope-io~=0.8.8",
"python-dateutil>=2.9",
"redis[hiredis]==4.5.5",
"temporenc~=0.1.0",
"tenacity>=9.0",
"tomli~=2.0.1",
"toml~=0.10.2",
"trafaret~=2.1",
"typeguard~=4.3",
"types-aiofiles",
"types-psutil",
"types-python-dateutil",
"types-redis",
"types-six",
"types-toml",
"valkey-glide~=2.2.2",
"yarl~=1.19.0"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:22.308491 | backend_ai_common-25.15.10.tar.gz | 191,468 | 33/30/47c7437de309cf5640254ab9a2af8d34ccce68c9201e342fa2335008ea32/backend_ai_common-25.15.10.tar.gz | source | sdist | null | false | b23c3c5c7be7a9837aa0807abac37f9d | 5f3e741ab37157d2562b47866b89cc0456712b3d61b975b105d664f301da19a0 | 333047c7437de309cf5640254ab9a2af8d34ccce68c9201e342fa2335008ea32 | null | [] | 0 |
2.4 | backend.ai-client | 25.15.10 | Backend.AI Client SDK | Backend.AI Client
=================
.. image:: https://badge.fury.io/py/backend.ai-client.svg
:target: https://badge.fury.io/py/backend.ai-client
:alt: PyPI version
.. image:: https://img.shields.io/pypi/pyversions/backend.ai-client.svg
:target: https://pypi.org/project/backend.ai-client/
:alt: Python Versions
.. image:: https://readthedocs.org/projects/backendai-client-sdk-for-python/badge/?version=latest
:target: https://client-py.docs.backend.ai/en/latest/?badge=latest
:alt: SDK Documentation
.. image:: https://ci.appveyor.com/api/projects/status/5h6r1cmbx2965yn1/branch/master?svg=true
:target: https://ci.appveyor.com/project/lablup/backend.ai-client-py/branch/master
:alt: Build Status (Windows)
.. image:: https://codecov.io/gh/lablup/backend.ai-client-py/branch/master/graph/badge.svg
:target: https://codecov.io/gh/lablup/backend.ai-client-py
:alt: Code Coverage
The official client SDK for `Backend.AI <https://backend.ai>`_
Usage (KeyPair mode)
--------------------
You should set the access key and secret key as environment variables to use the API.
Grab your keypair from `cloud.backend.ai <https://cloud.backend.ai>`_ or your cluster
admin.
On Linux/macOS, create a shell script as ``my-backend-ai.sh`` and run it before using
the ``backend.ai`` command:
.. code-block:: sh
export BACKEND_ACCESS_KEY=...
export BACKEND_SECRET_KEY=...
export BACKEND_ENDPOINT=https://my-precious-cluster
export BACKEND_ENDPOINT_TYPE=api
On Windows, create a batch file as ``my-backend-ai.bat`` and run it before using
the ``backend.ai`` command:
.. code-block:: bat
chcp 65001
set PYTHONIOENCODING=UTF-8
set BACKEND_ACCESS_KEY=...
set BACKEND_SECRET_KEY=...
set BACKEND_ENDPOINT=https://my-precious-cluster
set BACKEND_ENDPOINT_TYPE=api
Note that you need to switch to the UTF-8 codepage for correct display of
special characters used in the console logs.
Usage (Session mode)
--------------------
Change ``BACKEND_ENDPOINT_TYPE`` to "session" and set the endpoint to the URL of your console server.
.. code-block:: sh
export BACKEND_ENDPOINT=https://my-precious-cluster
export BACKEND_ENDPOINT_TYPE=session
.. code-block:: console
$ backend.ai login
User ID: myid@mydomain.com
Password:
✔ Login succeeded!
$ backend.ai ... # run any command
$ backend.ai logout
✔ Logout done.
The session expiration timeout is set by the console server.
Command-line Interface
----------------------
``backend.ai`` command is the entry point of all sub commands.
(Alternatively you can use a verbosely long version: ``python -m ai.backend.client.cli``)
Highlight: ``run`` command
~~~~~~~~~~~~~~~~~~~~~~~~~~
The ``run`` command execute a code snippet or code source files on a Backend.AI compute session
created on-the-fly.
To run the code specified in the command line directly,
use ``-c`` option to pass the code string (like a shell).
.. code-block:: console
$ backend.ai run python:3.6-ubuntu18.04 -c "print('hello world')"
∙ Client session token: d3694dda6e5a9f1e5c718e07bba291a9
✔ Kernel (ID: zuF1OzMIhFknyjUl7Apbvg) is ready.
hello world
By default, you need to specify language with full version tag like
``python:3.6-ubuntu18.04``. Depending on the Backend.AI admin's language
alias settings, this can be shortened just as ``python``. If you want to
know defined language aliases, contact the admin of Backend.AI server.
For more complicated programs, you may upload multiple files and then build &
execute them. The below is a simple example to run `a sample C program
<https://gist.github.com/achimnol/df464c6a3fe05b21e9b06d5b80e986c5>`_.
.. code-block:: console
$ git clone https://gist.github.com/achimnol/df464c6a3fe05b21e9b06d5b80e986c5 c-example
Cloning into 'c-example'...
Unpacking objects: 100% (5/5), done.
$ cd c-example
$ backend.ai run gcc:gcc6.4-alpine3.8 main.c mylib.c mylib.h
∙ Client session token: 1c352a572bc751a81d1f812186093c47
✔ Kernel (ID: kJ6CgWR7Tz3_v2WsDHOwLQ) is ready.
✔ Uploading done.
✔ Build finished.
myvalue is 42
your name? LABLUP
hello, LABLUP!
Please refer the ``--help`` manual provided by the ``run`` command.
Highlight: ``start`` and ``app`` command
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
``backend.ai start`` is simliar to the ``run`` command in that it creates a new compute session,
but it does not execute anything there.
You can subsequently call ``backend.ai run -t <sessionId> ...`` to execute codes snippets
or use ``backend.ai app`` command to start a local proxy to a container service such as Jupyter which
runs inside the compute session.
.. code-block:: console
$ backend.ai start -t mysess -r cpu=1 -r mem=2g lablup/python:3.6-ubuntu18.04
∙ Session ID mysess is created and ready.
∙ This session provides the following app services: ipython, jupyter, jupyterlab
$ backend.ai app mysess jupyter
∙ A local proxy to the application "jupyter" provided by the session "mysess" is available at: http://127.0.0.1:8080
Highlight: ``ps`` and ``rm`` command
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
You can see the list of currently running sessions using your API keypair.
.. code-block:: console
$ backend.ai ps
Session ID Lang/runtime Tag Created At Terminated At Status CPU Cores CPU Used (ms) Total Memory (MiB) Used Memory (MiB) GPU Cores
------------ ------------------------ ----- -------------------------------- --------------- -------- ----------- --------------- -------------------- ------------------- -----------
88ee10a027 lablup/python:3.6-ubuntu 2018-12-11T03:53:14.802206+00:00 RUNNING 1 16314 1024 39.2 0
fce7830826 lablup/python:3.6-ubuntu 2018-12-11T03:50:10.150740+00:00 RUNNING 1 15391 1024 39.2 0
If you set ``-t`` option in the ``run`` command, it will be used as the session ID—you may use it to assign a human-readable, easy-to-type alias for your sessions.
These session IDs can be reused after the current session using the same ID terminates.
To terminate a session, you can use ``terminate`` or ``rm`` command.
.. code-block:: console
$ backend.ai rm 5baafb2136029228ca9d873e1f2b4f6a
✔ Done.
Highlight: ``proxy`` command
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
To use API development tools such as GraphiQL for the admin API, run an insecure
local API proxy. This will attach all the necessary authorization headers to your
vanilla HTTP API requests.
.. code-block:: console
$ backend.ai proxy
∙ Starting an insecure API proxy at http://localhost:8084
More commands?
~~~~~~~~~~~~~~
Please run ``backend.ai --help`` to see more commands.
Troubleshooting (FAQ)
---------------------
* There are error reports related to ``simplejson`` with Anaconda on Windows.
This package no longer depends on simplejson since v1.0.5, so you may uninstall it
safely since Python 3.5+ offers almost identical ``json`` module in the standard
library.
If you really need to keep the ``simplejson`` package, uninstall the existing
simplejson package manually and try reinstallation of it by downloading `a
pre-built binary wheel from here
<https://www.lfd.uci.edu/%7Egohlke/pythonlibs/#simplejson>`_.
| text/x-rst | Lablup Inc. and contributors | null | null | null | MIT | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: MIT License"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"aiohttp~=3.13.0",
"aiotusclient~=0.1.4",
"appdirs~=1.4.4",
"async_timeout~=4.0",
"attrs>=25.3",
"backend.ai-cli==25.15.10",
"backend.ai-common==25.15.10",
"backend.ai-logging==25.15.10",
"backend.ai-plugin==25.15.10",
"click~=8.1.7",
"faker~=24.7.1",
"humanize>=3.1.0",
"inquirer~=3.3.0",
"janus~=2.0",
"multidict~=6.6.4",
"pycryptodome>=3.20.0",
"python-dateutil>=2.9",
"python-dotenv~=0.20.0",
"rich~=13.6",
"tabulate~=0.8.9",
"tenacity>=9.0",
"tqdm~=4.67.1",
"treelib~=1.7.0",
"types-python-dateutil",
"types-tabulate",
"types-tqdm",
"typing_extensions~=4.11",
"yarl~=1.19.0"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:21.398331 | backend_ai_client-25.15.10.tar.gz | 151,697 | c5/85/d5a8bcb53d6f5ed04781a2b2e5b3142b143180cf9879f910944b2b473a20/backend_ai_client-25.15.10.tar.gz | source | sdist | null | false | 7a62e82e9a08fb391d8eba7d45e4835e | c075e2a316ec8dd86d4fb12620757c527cfb8b0af64abe22224d2da4002c7b61 | c585d5a8bcb53d6f5ed04781a2b2e5b3142b143180cf9879f910944b2b473a20 | null | [] | 0 |
2.4 | backend.ai-cli | 25.15.10 | Backend.AI Command Line Interface Helper | # backend.ai-cli
Unified command-line interface for Backend.AI
## How to adopt in CLI-enabled Backend.AI packages
An example `setup.cfg` in Backend.AI Manager:
```
[options.entry_points]
backendai_cli_v10 =
mgr = ai.backend.manager.cli.__main__:main
mgr.start-server = ai.backend.gateway.server:main
```
Define your package entry points that returns a Click command group using a
prefix, and add additional entry points that returns a Click command using a
prefix followed by a dot and sub-command name for shortcut access, under the
`backendai_cli_v10` entry point group.
Then add `backend.ai-cli` to the `install_requires` list.
You can do the same in `setup.py` as well.
| text/markdown | Lablup Inc. and contributors | null | null | null | MIT | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: MIT License"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"attrs>=25.3",
"backend.ai-plugin==25.15.10",
"click~=8.1.7",
"trafaret~=2.1"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:18.987137 | backend_ai_cli-25.15.10.tar.gz | 9,529 | 29/b4/e9b1ac18974ae604530ad637e38c29a2cf08a3be61042dd82df8d9c3eb70/backend_ai_cli-25.15.10.tar.gz | source | sdist | null | false | da918bb6f8c1557f1d8a6ed0623ae7df | 1a745926a6884d750e2914b957abedc17aa2f1df9247068f44526c9a910c8888 | 29b4e9b1ac18974ae604530ad637e38c29a2cf08a3be61042dd82df8d9c3eb70 | null | [] | 0 |
2.4 | backend.ai-appproxy-worker | 25.15.10 | Backend.AI AppProxy Worker | # appproxy-worker
| text/markdown | Lablup Inc. and contributors | null | null | null | LGPLv3 | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"Jinja2~=3.1.6",
"PyJWT~=2.10.1",
"aiohttp_cors~=0.8.1",
"aiohttp_jinja2~=1.6",
"aiohttp~=3.13.0",
"aiomonitor~=0.7.0",
"aiotools~=1.9.0",
"attrs>=25.3",
"backend.ai-appproxy-common==25.15.10",
"backend.ai-common==25.15.10",
"backend.ai-logging==25.15.10",
"backend.ai-plugin==25.15.10",
"click~=8.1.7",
"memray~=1.17.2",
"multidict~=6.6.4",
"prometheus-client~=0.21.1",
"pydantic[email]~=2.11.3",
"pyroscope-io~=0.8.8",
"setproctitle~=1.3.5",
"tenacity>=9.0",
"tomli-w~=1.2.0",
"types-Jinja2",
"uvloop~=0.21; sys_platform != \"Windows\"",
"yarl~=1.19.0"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:18.005010 | backend_ai_appproxy_worker-25.15.10.tar.gz | 39,377 | 14/22/1d2d4ea539f32d35f999f7f7d84e5f6ebc539382a9361821e27c95d5b632/backend_ai_appproxy_worker-25.15.10.tar.gz | source | sdist | null | false | 29e41cb6f73c8c8ecce62a6a3f8bef84 | d36348bc7191640e31aaa3ce06ff4f93ab0c2a04b38ad7ca258350b7e02dc3d5 | 14221d2d4ea539f32d35f999f7f7d84e5f6ebc539382a9361821e27c95d5b632 | null | [] | 0 |
2.4 | backend.ai-appproxy-coordinator | 25.15.10 | Backend.AI AppProxy Coordinator | # appproxy-coordinator
| text/markdown | Lablup Inc. and contributors | null | null | null | LGPLv3 | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"Jinja2~=3.1.6",
"PyJWT~=2.10.1",
"SQLAlchemy[postgresql_asyncpg]~=1.4.54",
"aiohttp_cors~=0.8.1",
"aiohttp_jinja2~=1.6",
"aiohttp~=3.13.0",
"aiomonitor~=0.7.0",
"aiotools~=1.9.0",
"alembic~=1.13.2",
"asyncpg>=0.29.0",
"attrs>=25.3",
"backend.ai-appproxy-common==25.15.10",
"backend.ai-cli==25.15.10",
"backend.ai-common==25.15.10",
"backend.ai-logging==25.15.10",
"backend.ai-plugin==25.15.10",
"click~=8.1.7",
"memray~=1.17.2",
"prometheus-client~=0.21.1",
"pydantic[email]~=2.11.3",
"pyroscope-io~=0.8.8",
"python-dateutil>=2.9",
"setproctitle~=1.3.5",
"tenacity>=9.0",
"tomli-w~=1.2.0",
"types-Jinja2",
"types-python-dateutil",
"uvloop~=0.21; sys_platform != \"Windows\"",
"yarl~=1.19.0"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:17.311341 | backend_ai_appproxy_coordinator-25.15.10.tar.gz | 62,555 | ad/c9/8751a734d3234f175b4bb0a35c97e65400c403e999c94396156f14b246ad/backend_ai_appproxy_coordinator-25.15.10.tar.gz | source | sdist | null | false | 062ae8efcb5bd950b41f200699e232c0 | 09c3aa4dbb9483ff908a699c9b9f4e6efcb71338d4c3f2a59d0b4e1422fcebd6 | adc98751a734d3234f175b4bb0a35c97e65400c403e999c94396156f14b246ad | null | [] | 0 |
2.4 | backend.ai-appproxy-common | 25.15.10 | Backend.AI AppProxy Common | # appproxy-common
| text/markdown | Lablup Inc. and contributors | null | null | null | Proprietary | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"PyYAML~=6.0",
"aiohttp_cors~=0.8.1",
"aiohttp~=3.13.0",
"backend.ai-common==25.15.10",
"backend.ai-logging==25.15.10",
"backend.ai-plugin==25.15.10",
"pydantic[email]~=2.11.3",
"pyhumps~=3.8.0",
"redis[hiredis]==4.5.5",
"types-PyYAML",
"types-redis"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:16.661097 | backend_ai_appproxy_common-25.15.10.tar.gz | 19,245 | aa/2b/93a625bcdb6723862670fe1accfdedc9d6101c39d402d236729ad0d1b7f2/backend_ai_appproxy_common-25.15.10.tar.gz | source | sdist | null | false | ae30213d8bd3af623c4d50d28d9ccd80 | cb174fe2af881e1dc550bd0182c059fb3d5dc879fdf46383d77929d6c45c3043 | aa2b93a625bcdb6723862670fe1accfdedc9d6101c39d402d236729ad0d1b7f2 | null | [] | 0 |
2.4 | backend.ai-agent | 25.15.10 | Backend.AI Agent | # Backend.AI Agent
The Backend.AI Agent is a small daemon that does:
* Reports the status and available resource slots of a worker to the manager
* Routes code execution requests to the designated kernel container
* Manages the lifecycle of kernel containers (create/monitor/destroy them)
## Package Structure
* `ai.backend`
- `agent`: The agent package
- `docker`: A docker-based backend implementation for the kernel lifecycle interface.
- `server`: The agent daemon which communicates with the manager and the Docker daemon
- `watcher`: A side-by-side daemon which provides a separate HTTP endpoint for accessing the status
information of the agent daemon and manipulation of the agent's systemd service
- `helpers`: A utility package that is available as `ai.backend.helpers` *inside* Python-based containers
- `kernel`: Language-specific runtimes (mostly ipykernel client adaptor) which run *inside* containers
- `runner`: Auxiliary components (usually self-contained binaries) mounted *inside* containers
## Installation
Please visit [the installation guides](https://github.com/lablup/backend.ai/wiki).
### Kernel/system configuration
#### Recommended kernel parameters in the bootloader (e.g., Grub):
```
cgroup_enable=memory swapaccount=1
```
#### Recommended resource limits:
**`/etc/security/limits.conf`**
```
root hard nofile 512000
root soft nofile 512000
root hard nproc 65536
root soft nproc 65536
user hard nofile 512000
user soft nofile 512000
user hard nproc 65536
user soft nproc 65536
```
**sysctl**
```
fs.file-max=2048000
fs.inotify.max_user_watches=524288
net.core.somaxconn=1024
net.ipv4.tcp_max_syn_backlog=1024
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_fin_timeout=10
net.ipv4.tcp_window_scaling=1
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_early_retrans=1
net.ipv4.ip_local_port_range=40000 65000
net.core.rmem_max=16777216
net.core.wmem_max=16777216
net.ipv4.tcp_rmem=4096 12582912 16777216
net.ipv4.tcp_wmem=4096 12582912 16777216
net.netfilter.nf_conntrack_max=10485760
net.netfilter.nf_conntrack_tcp_timeout_established=432000
net.netfilter.nf_conntrack_tcp_timeout_close_wait=10
net.netfilter.nf_conntrack_tcp_timeout_fin_wait=10
net.netfilter.nf_conntrack_tcp_timeout_time_wait=10
```
The `ip_local_port_range` should not overlap with the container port range pool
(default: 30000 to 31000).
To apply netfilter settings during the boot time, you may need to add `nf_conntrack` to `/etc/modules`
so that `sysctl` could set the `net.netfilter.nf_conntrack_*` values.
### For development
#### Prerequisites
* Python 3.6 or higher with [pyenv](https://github.com/pyenv/pyenv)
and [pyenv-virtualenv](https://github.com/pyenv/pyenv-virtualenv) (optional but recommneded)
* Docker 18.03 or later with docker-compose (18.09 or later is recommended)
First, you need **a working manager installation**.
For the detailed instructions on installing the manager, please refer
[the manager's README](https://github.com/lablup/backend.ai-manager/blob/master/README.md)
and come back here again.
#### Preparing working copy
Install and activate [`git-lfs`](https://git-lfs.github.com/) to work with pre-built binaries in
`src/ai/backend/runner`.
### CPU Monitoring
- Track per-container CPU usage via cgroups
- Measure CPU time in user and system modes
- Calculate CPU utilization percentages
- Enforce CPU quotas and limits
### Memory Monitoring
- Track RSS (Resident Set Size) per container
- Measure cache and swap usage
- Detect OOM (Out-of-Memory) conditions
- Enforce memory limits via cgroups
### Shared Memory (shmem)
Containers can request shared memory (`/dev/shm`) for inter-process communication.
**Docker Memory Architecture**:
- shm (tmpfs) and app memory share the Memory cgroup space
- shm has an additional ShmSize limit (tmpfs maximum size)
- Effective shm limit = `min(ShmSize, Memory cgroup available space)`
**OOM Conditions**:
| Signal | Exit Code | Condition |
|--------|-----------|-----------|
| SIGKILL | 137 | shm + app > Memory cgroup limit |
| SIGBUS | 135 | shm > ShmSize |
**Configuration**:
- Set via `resource_opts.shmem` in session specification
- Docker HostConfig: `ShmSize` parameter
**References**:
- [Linux Kernel cgroup v1 Memory](https://docs.kernel.org/admin-guide/cgroup-v1/memory.html) - tmpfs/shm charged to cgroup
- [Linux Kernel cgroup v2](https://docs.kernel.org/admin-guide/cgroup-v2.html) - shmem in memory.stat
### GPU Monitoring
- Query NVIDIA GPUs via NVML (nvidia-ml-py)
- Query AMD GPUs via ROCm SMI
- Track GPU utilization and memory usage
- Measure GPU temperature and power consumption
### Disk I/O Monitoring
- Track read/write operations per container
- Measure I/O bandwidth usage
- Monitor disk space consumption
- Enforce I/O throttling when configured
## Plugin System
Agent can uses plugin system for accelerator support:
### CUDA Plugin
- Detect NVIDIA GPUs via `nvidia-smi`
- Allocate GPU devices to containers
- Set `CUDA_VISIBLE_DEVICES` environment variable
- Monitor GPU metrics via NVML
### ROCm Plugin
- Detect AMD GPUs via `rocm-smi`
- Allocate GPU devices to containers
- Set `HIP_VISIBLE_DEVICES` environment variable
- Monitor GPU metrics via ROCm
### TPU Plugin
- Detect Google TPUs
- Configure TPU access for TensorFlow
- Monitor TPU utilization
## Communication Protocols
### Manager → Agent (ZeroMQ RPC)
- **Port**: 6011 (default)
- **Protocol**: ZeroMQ request-response
- **Operations**:
- `create_kernel`: Create new container
- `destroy_kernel`: Terminate container
- `restart_kernel`: Restart container
- `execute_code`: Execute code in container
- `get_status`: Query agent and kernel status
### Agent → Manager (HTTP Watcher API)
- **Port**: 6009 (default)
- **Protocol**: HTTP
- **Operations**:
- Heartbeat signals
- Resource usage reporting
- Kernel status updates
- Error notifications
### Agent → Storage Proxy
- **Protocol**: HTTP
- **Operations**:
- Mount vfolder
- Unmount vfolder
- Query vfolder metadata
## Container Execution Flow
```
1. Manager sends create_kernel RPC
↓
2. Agent validates resource availability
↓
3. Agent pulls container image (if needed)
↓
4. Agent creates scratch directory
↓
5. Agent mounts vfolders via Storage Proxy
↓
6. Agent creates container with resources
↓
7. Agent starts container and runs init script
↓
8. Agent registers service ports
↓
9. Agent reports kernel status to Manager
↓
10. Container runs until termination
↓
11. Agent cleans up resources upon termination
```
Next, prepare the source clone of the agent and install from it as follows.
`pyenv` is just a recommendation; you may use other virtualenv management tools.
```console
$ git clone https://github.com/lablup/backend.ai-agent agent
$ cd agent
$ pyenv virtualenv venv-agent
$ pyenv local venv-agent
$ pip install -U pip setuptools
$ pip install -U -r requirements/dev.txt
```
### Linting
We use `flake8` and `mypy` to statically check our code styles and type consistency.
Enable those linters in your favorite IDE or editor.
### Halfstack (single-node development & testing)
With the halfstack, you can run the agent simply.
Note that you need a working manager running with the halfstack already!
#### Recommended directory structure
* `backend.ai-dev`
- `manager` (git clone from [the manager repo](https://github.com/lablup/backend.ai-manager))
- `agent` (git clone from here)
- `common` (git clone from [the common repo](https://github.com/lablup/backend.ai-common))
Install `backend.ai-common` as an editable package in the agent (and the manager) virtualenvs
to keep the codebase up-to-date.
```console
$ cd agent
$ pip install -U -e ../common
```
#### Steps
```console
$ mkdir -p "./scratches"
$ cp config/halfstack.toml ./agent.toml
```
If you're running agent under linux, make sure you've set appropriate iptables rule
before starting agent. This can be done by executing script `scripts/update-metadata-iptables.sh`
before each agent start.
Then, run it (for debugging, append a `--debug` flag):
```console
$ python -m ai.backend.agent.server
```
To run the agent-watcher:
```console
$ python -m ai.backend.agent.watcher
```
The watcher shares the same configuration TOML file with the agent.
Note that the watcher is only meaningful if the agent is installed as a systemd service
named `backendai-agent.service`.
To run tests:
```console
$ python -m flake8 src tests
$ python -m pytest -m 'not integration' tests
```
## Deployment
### Configuration
Put a TOML-formatted agent configuration (see the sample in `config/sample.toml`)
in one of the following locations:
* `agent.toml` (current working directory)
* `~/.config/backend.ai/agent.toml` (user-config directory)
* `/etc/backend.ai/agent.toml` (system-config directory)
Only the first found one is used by the daemon.
The agent reads most other configurations from the etcd v3 server where the cluster
administrator or the Backend.AI manager stores all the necessary settings.
The etcd address and namespace must match with the manager to make the agent
paired and activated.
By specifying distinguished namespaces, you may share a single etcd cluster with multiple
separate Backend.AI clusters.
By default the agent uses `/var/cache/scratches` directory for making temporary
home directories used by kernel containers (the `/home/work` volume mounted in
containers). Note that the directory must exist in prior and the agent-running
user must have ownership of it. You can change the location by
`scratch-root` option in `agent.toml`.
### Running from a command line
The minimal command to execute:
```sh
python -m ai.backend.agent.server
python -m ai.backend.agent.watcher
```
For more arguments and options, run the command with `--help` option.
### Example config for systemd
`/etc/systemd/system/backendai-agent.service`:
```dosini
[Unit]
Description=Backend.AI Agent
Requires=docker.service
After=network.target remote-fs.target docker.service
[Service]
Type=simple
User=root
Group=root
Environment=HOME=/home/user
ExecStart=/home/user/backend.ai/agent/run-agent.sh
WorkingDirectory=/home/user/backend.ai/agent
KillMode=process
KillSignal=SIGTERM
PrivateTmp=false
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
```
`/home/user/backend.ai/agent/run-agent.sh`:
```sh
#! /bin/sh
if [ -z "$PYENV_ROOT" ]; then
export PYENV_ROOT="$HOME/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
fi
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)"
cd /home/user/backend.ai/agent
if [ "$#" -eq 0 ]; then
sh /home/user/backend.ai/agent/scripts/update-metadata-iptables.sh
exec python -m ai.backend.agent.server
else
exec "$@"
fi
```
### Networking
The manager and agent should run in the same local network or different
networks reachable via VPNs, whereas the manager's API service must be exposed to
the public network or another private network that users have access to.
The manager must be able to access TCP ports 6001, 6009, and 30000 to 31000 of the agents in default
configurations. You can of course change those port numbers and ranges in the configuration.
| Manager-to-Agent TCP Ports | Usage |
|:--------------------------:|-------|
| 6001 | ZeroMQ-based RPC calls from managers to agents |
| 6009 | HTTP watcher API |
| 30000-31000 | Port pool for in-container services |
The operation of agent itself does not require both incoming/outgoing access to
the public Internet, but if the user's computation programs need the Internet, the docker containers
should be able to access the public Internet (maybe via some corporate firewalls).
| Agent-to-X TCP Ports | Usage |
|:------------------------:|-------|
| manager:5002 | ZeroMQ-based event push from agents to the manager |
| etcd:2379 | etcd API access |
| redis:6379 | Redis API access |
| docker-registry:{80,443} | HTTP watcher API |
| (Other hosts) | Depending on user program requirements |
LICENSES
--------
[GNU Lesser General Public License](https://github.com/lablup/backend.ai-agent/blob/master/LICENSE)
[Dependencies](https://github.com/lablup/backend.ai-manager/blob/agent/DEPENDENCIES.md)
| text/markdown | Lablup Inc. and contributors | null | null | null | LGPLv3 | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"aiodocker==0.24.0",
"aiofiles~=24.1.0",
"aiohttp_cors~=0.8.1",
"aiohttp~=3.13.0",
"aiomonitor~=0.7.0",
"aiotools~=1.9.0",
"async_timeout~=4.0",
"attrs>=25.3",
"backend.ai-cli==25.15.10",
"backend.ai-common==25.15.10",
"backend.ai-kernel-binary==25.15.10",
"backend.ai-kernel-helper==25.15.10",
"backend.ai-kernel==25.15.10",
"backend.ai-krunner-static-gnu==4.4.0",
"backend.ai-logging==25.15.10",
"backend.ai-plugin==25.15.10",
"cachetools~=5.5.0",
"callosum~=1.0.3",
"cattrs~=24.1.1",
"click~=8.1.7",
"etcd-client-py~=0.4.1",
"janus~=2.0",
"kubernetes-asyncio~=33.3.0",
"kubernetes~=33.1.0",
"more-itertools~=10.5.0",
"networkx~=3.3.0",
"prometheus-client~=0.21.1",
"psutil~=7.0",
"pydantic[email]~=2.11.3",
"pyzmq~=26.4",
"ruamel.yaml~=0.18.10",
"setproctitle~=1.3.5",
"setuptools~=80.0.0",
"tenacity>=9.0",
"tomlkit~=0.13.2",
"trafaret~=2.1",
"types-aiofiles",
"types-cachetools",
"types-psutil",
"types-setuptools",
"typing_extensions~=4.11",
"uvloop~=0.21; sys_platform != \"Windows\""
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:14.560574 | backend_ai_agent-25.15.10.tar.gz | 14,815,869 | c8/84/3df5335f8c21cb6aebb1a7a305e8b5cc15c2113dfdc67e3e1ce603a0eec6/backend_ai_agent-25.15.10.tar.gz | source | sdist | null | false | b9e716be27366ff3a70a063a5f0faa9b | 6d63b39e0663ea05649c6a9efa7e9a452008fa606cc33d1071c47ee9cb9d4cb7 | c8843df5335f8c21cb6aebb1a7a305e8b5cc15c2113dfdc67e3e1ce603a0eec6 | null | [] | 0 |
2.4 | backend.ai-account-manager | 25.15.10 | Backend.AI Account Manager | # Backend.AI Account Manager
Backend.AI Account Manager is a daemon that manages user accounts, including Backend.AI 's first-party service.
| text/markdown | Lablup Inc. and contributors | null | null | null | LGPLv3 | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"PyYAML~=6.0",
"SQLAlchemy[postgresql_asyncpg]~=1.4.54",
"aiohttp_cors~=0.8.1",
"aiohttp~=3.13.0",
"aiomonitor~=0.7.0",
"aiotools~=1.9.0",
"alembic~=1.13.2",
"attrs>=25.3",
"backend.ai-cli==25.15.10",
"backend.ai-common==25.15.10",
"backend.ai-logging==25.15.10",
"backend.ai-plugin==25.15.10",
"bcrypt~=4.2.0",
"click~=8.1.7",
"pydantic[email]~=2.11.3",
"pyhumps~=3.8.0",
"setproctitle~=1.3.5",
"tenacity>=9.0",
"tomlkit~=0.13.2",
"types-PyYAML",
"uvloop~=0.21; sys_platform != \"Windows\"",
"yarl~=1.19.0"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:13.383967 | backend_ai_account_manager-25.15.10.tar.gz | 24,987 | c3/4f/d6cb54f1ade69c01e646b93ed2a038130d8cec9bc51794c7ae85d64673ee/backend_ai_account_manager-25.15.10.tar.gz | source | sdist | null | false | a502a4b90ec841e6cfb22a0d3daffb9d | 0260b729900a56ebca9e23a3a9a8d8691a7ca84ad0f10b683a4d0391c53feda7 | c34fd6cb54f1ade69c01e646b93ed2a038130d8cec9bc51794c7ae85d64673ee | null | [] | 0 |
2.4 | backend.ai-accelerator-mock | 25.15.10 | Backend.AI Mockup Accelerator Plugin | # backend.ai-accelerator-mock
A mockup plugin for accelerators
This plugin deceives the agent and manager to think as if there are accelerator devices.
The configuration follows `mock-accelerator.toml` placed in the same location of `agent.toml`.
Please refer the sample configurations in the `configs/accelerator` directory and copy one of them as a starting point.
The statistics are randomly generated in reasonable ranges, but it may seem like "jumping around" because there is no smoothing mechanism of generated values.
The configurations for fractional/discrete mode, fraction size, and device masks in etcd are exactly same as the original plugin.
## Notes when setting up mock CUDA devices
The containers are created without any real CUDA device mounts but with `BACKENDAI_MOCK_CUDA_DEVICES` and `BACKENDAI_MOCK_CUDA_DEVICE_COUNT` environment variables.
Since the manager does not know if the reported devices are real or not, you can start any CUDA-only containers (but of course they won't work as expected).
| text/markdown | Lablup Inc. and contributors | null | null | null | LGPLv3 | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"aiodocker==0.24.0",
"backend.ai-agent==25.15.10",
"backend.ai-cli==25.15.10",
"backend.ai-common==25.15.10",
"backend.ai-kernel-binary==25.15.10",
"backend.ai-kernel-helper==25.15.10",
"backend.ai-logging==25.15.10",
"backend.ai-plugin==25.15.10",
"trafaret~=2.1"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:12.810724 | backend_ai_accelerator_mock-25.15.10.tar.gz | 12,105 | 45/0f/0c89f7b8d20914160ae52094d4cf5c6bdbb3c99f51f7c780f4be5300f4f5/backend_ai_accelerator_mock-25.15.10.tar.gz | source | sdist | null | false | 91e9ccbc01e0acdc47770f3e5b7b49a0 | da2cb56b25ec2dc040d6f40ae75c8a0da495438c7b261a68d3313f7139733f67 | 450f0c89f7b8d20914160ae52094d4cf5c6bdbb3c99f51f7c780f4be5300f4f5 | null | [] | 0 |
2.4 | backend.ai-accelerator-cuda-open | 25.15.10 | Backend.AI Accelerator Plugin for CUDA | Backend.AI Accelerator Plugin for CUDA
======================================
Just install this along with Backend.AI agents, using the same virtual environment.
This will allow the agents to detect CUDA devices on their hosts and make them
available to Backend.AI kernel sessions.
```console
$ pip install backend.ai-accelerator-cuda-open
```
This open-source edition of CUDA plugins support allocation of one or more CUDA
devices to a container, slot-by-slot.
| text/markdown | Lablup Inc. and contributors | null | null | null | LGPLv3 | null | [
"Intended Audience :: Developers",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Environment :: No Input/Output (Daemon)",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)"
] | [] | https://github.com/lablup/backend.ai | null | <3.14,>=3.13 | [] | [] | [] | [
"aiodocker==0.24.0",
"aiotools~=1.9.0",
"backend.ai-agent==25.15.10",
"backend.ai-cli==25.15.10",
"backend.ai-common==25.15.10",
"backend.ai-kernel-binary==25.15.10",
"backend.ai-kernel-helper==25.15.10",
"backend.ai-logging==25.15.10",
"backend.ai-plugin==25.15.10"
] | [] | [] | [] | [
"Documentation, https://docs.backend.ai/",
"Source, https://github.com/lablup/backend.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-20T09:50:12.241421 | backend_ai_accelerator_cuda_open-25.15.10.tar.gz | 10,641 | 74/73/fc44929abff43cd8c082543fd6ce59c1d8cb33e42ab95f14cb85eac127de/backend_ai_accelerator_cuda_open-25.15.10.tar.gz | source | sdist | null | false | a2657fa0caf6122280d75bedcdce43b4 | 848d869684434bdb67d4fa224fea9419410cc2cad6b28a94c081315b6fad9425 | 7473fc44929abff43cd8c082543fd6ce59c1d8cb33e42ab95f14cb85eac127de | null | [] | 0 |
2.1 | odoo-addon-edi-storage-oca | 16.0.1.2.3 | Base module to allow exchanging files via storage backend (eg: SFTP). | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
===========================
EDI Storage backend support
===========================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:fd1a2ff00ca2348047aa434cb27ce439771aea6f0cf6bd3dcd5392dd147a8026
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-LGPL--3-blue.png
:target: http://www.gnu.org/licenses/lgpl-3.0-standalone.html
:alt: License: LGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fedi--framework-lightgray.png?logo=github
:target: https://github.com/OCA/edi-framework/tree/16.0/edi_storage_oca
:alt: OCA/edi-framework
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/edi-framework-16-0/edi-framework-16-0-edi_storage_oca
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/edi-framework&target_branch=16.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
Allow exchange files using storage backends from `OCA/storage`.
This module adds a storage backend relation on the EDI backend.
There you can configure the backend to be used (most often and SFTP)
and the paths where to read or put files.
Often the convention when exchanging files via SFTP
is to have one input forder (to receive files)
and an output folder (to send files).
Inside this folder you have this hierarchy::
input/output folder
|- pending
|- done
|- error
* `pending` folder contains files that have been just sent
* `done` folder contains files that have been processes successfully
* `error` folder contains files with errors and cannot be processed
The storage handlers take care of reading files and putting files
in/from the right place and update exchange records data accordingly.
**Table of contents**
.. contents::
:local:
Usage
=====
Go to "EDI -> EDI backend" then configure your backend to use a storage backend.
Known issues / Roadmap
======================
* clean deprecated methods in the storage
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/edi-framework/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/edi-framework/issues/new?body=module:%20edi_storage_oca%0Aversion:%2016.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
~~~~~~~
* ACSONE
Contributors
~~~~~~~~~~~~
* Simone Orsi <simahawk@gmail.com>
* Foram Shah <foram.shah@initos.com>
* Lois Rilo <lois.rilo@forgeflow.com>
* Duong (Tran Quoc) <duongtq@trobz.com>
Other credits
~~~~~~~~~~~~~
The migration of this module from 15.0 to 16.0 was financially supported by Camptocamp.
Maintainers
~~~~~~~~~~~
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/edi-framework <https://github.com/OCA/edi-framework/tree/16.0/edi_storage_oca>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| null | ACSONE,Odoo Community Association (OCA) | support@odoo-community.org | null | null | LGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 16.0",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)",
"Development Status :: 4 - Beta"
] | [] | https://github.com/OCA/edi-framework | null | >=3.10 | [] | [] | [] | [
"odoo-addon-component<16.1dev,>=16.0dev",
"odoo-addon-edi-oca<16.1dev,>=16.0dev",
"odoo-addon-fs-storage<16.1dev,>=16.0dev",
"odoo<16.1dev,>=16.0a"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T09:49:00.148546 | odoo_addon_edi_storage_oca-16.0.1.2.3-py3-none-any.whl | 50,102 | 28/4c/e177a9c6748ada5cb0975faa214a6c736aabf5779566e3383b6c591f7f0e/odoo_addon_edi_storage_oca-16.0.1.2.3-py3-none-any.whl | py3 | bdist_wheel | null | false | 47f3e679b403189781c6cbc0816597a3 | 9785dafaa2a607a6304dae2e10c36c4a81d5428d169fe10a95bf228943ba72c3 | 284ce177a9c6748ada5cb0975faa214a6c736aabf5779566e3383b6c591f7f0e | null | [] | 81 |
2.1 | odoo-addon-edi-exchange-template-oca | 16.0.1.1.2 | Allows definition of exchanges via templates. | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
=====================
EDI Exchange Template
=====================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:a1e4e76d03e4ed503c20081b561eea13a69c1c3737814f5185e01da424686f4b
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-LGPL--3-blue.png
:target: http://www.gnu.org/licenses/lgpl-3.0-standalone.html
:alt: License: LGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fedi--framework-lightgray.png?logo=github
:target: https://github.com/OCA/edi-framework/tree/16.0/edi_exchange_template_oca
:alt: OCA/edi-framework
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/edi-framework-16-0/edi-framework-16-0-edi_exchange_template_oca
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/edi-framework&target_branch=16.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
Provide EDI exchange templates to control input/output records contents.
Provides following models:
1. EDI exchange output template, generates output using QWeb templates
2. [TODO] EDI exchange input template
**Table of contents**
.. contents::
:local:
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/edi-framework/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/edi-framework/issues/new?body=module:%20edi_exchange_template_oca%0Aversion:%2016.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
~~~~~~~
* ACSONE
* Camptocamp
Contributors
~~~~~~~~~~~~
* Simone Orsi <simahawk@gmail.com>
Maintainers
~~~~~~~~~~~
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
.. |maintainer-simahawk| image:: https://github.com/simahawk.png?size=40px
:target: https://github.com/simahawk
:alt: simahawk
Current `maintainer <https://odoo-community.org/page/maintainer-role>`__:
|maintainer-simahawk|
This module is part of the `OCA/edi-framework <https://github.com/OCA/edi-framework/tree/16.0/edi_exchange_template_oca>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| null | ACSONE,Camptocamp,Odoo Community Association (OCA) | support@odoo-community.org | null | null | LGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 16.0",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)",
"Development Status :: 4 - Beta"
] | [] | https://github.com/OCA/edi-framework | null | >=3.10 | [] | [] | [] | [
"odoo-addon-component<16.1dev,>=16.0dev",
"odoo-addon-edi-oca<16.1dev,>=16.0dev",
"odoo<16.1dev,>=16.0a"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T09:48:57.122958 | odoo_addon_edi_exchange_template_oca-16.0.1.1.2-py3-none-any.whl | 37,497 | 8f/40/236cf4bad0acb6c719accabb54a1f7aa84656b0765a3a119f434d1dc4157/odoo_addon_edi_exchange_template_oca-16.0.1.1.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 67e3eb4e92d5af72d5a816e1710fb956 | 164c6bd36d43be7aebc6900e4b701f549bd30af4e727e6536e7c4c69bdb957f8 | 8f40236cf4bad0acb6c719accabb54a1f7aa84656b0765a3a119f434d1dc4157 | null | [] | 77 |
2.4 | ubo-app-raw-bindings | 1.7.1.dev126022010357995610 | Raw bindings for UBO App. | # Ubo App Python Bindings
This repository contains Python bindings for the Ubo App, allowing developers to interact with the Ubo App's functionality using Python over gRPC.
## Sample Usage
```python
import asyncio
from ubo_bindings.client import AsyncRemoteStore
from ubo_bindings.ubo.v1 import Action, Notification, NotificationsAddAction
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
async def main():
client = AsyncRemoteStore("localhost", 50051)
action = Action(
notifications_add_action=NotificationsAddAction(
notification=Notification(
title="Test Notification",
content="This is a test notification.",
),
),
)
await client.dispatch_async(action=action)
client.channel.close()
loop.run_until_complete(main())
```
| text/markdown | null | Sassan Haradji <me@sassanh.com> | null | Sassan Haradji <me@sassanh.com> | null | bindings, grpc, home assistance, python, raspberry pi, rpi, ubo, ubo-pod | [] | [] | null | null | <3.12,>=3.11 | [] | [] | [] | [
"betterproto[compiler]==2.0.0b7"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T09:48:37.549174 | ubo_app_raw_bindings-1.7.1.dev126022010357995610.tar.gz | 19,832 | 52/ab/e17218679cb865670bf017414cea246abb36c964571bbc8d4f17ccd573f4/ubo_app_raw_bindings-1.7.1.dev126022010357995610.tar.gz | source | sdist | null | false | 499c1bafe9487e38054fb65920bc53d3 | 81ce90d3a7d7de76e69d3139d5ceb642af2831e1291f4f8603468fad7d9fd761 | 52abe17218679cb865670bf017414cea246abb36c964571bbc8d4f17ccd573f4 | Apache-2.0 | [] | 159 |
2.4 | ubo-app | 1.7.1.dev126022010357995610 | Ubo main app, running on device initialization. A platform for running other apps. | # ☯️ Ubo App
[](https://pypi.python.org/pypi/ubo-app)
[](https://github.com/ubopod/ubo-app/LICENSE)
[](https://pypi.python.org/pypi/ubo-app)
[](https://github.com/ubopod/ubo-app/actions)
[](https://codecov.io/gh/ubopod/ubo-app)
[](https://deepwiki.com/ubopod/ubo_app)
## 📑 Table of Contents
- [🌟 Overview](#🌟-overview)
- [🚧 Disclaimer](#🚧-disclaimer)
- [⚙️ Notable Features](#⚙️-notable-features)
- [📋 Requirements](#📋-requirements)
- [ Installation](#-installation)
- [Pre-packaged image](#pre-packaged-image)
- [Install on existing OS](#install-on-existing-os)
- [🤝 Contributing](#🤝-contributing)
- [ℹ️️ Conventions](#ℹ️️-conventions)
- [Development](#development)
- [🛠️ Hardware](#🛠️-hardware)
- [Emulation](#emulation)
- [Ubo Pod](#ubo-pod)
- [DIY Path](#diy-path)
- [🏗️ Architecture](#🏗️-architecture)
- [📦 Notable dependencies](#📦-notable-dependencies)
- [🗺️ Roadmap](#🗺️-roadmap)
- [🔒 License](#🔒-license)
## 🌟 Overview
Ubo App is a Python application that provides a unified interface and tools for developing and running hardware-integrated apps.
It offers a minimalistic, yet intuitive UI for end-users to install and interact with developer apps. It is optimized for Raspberry Pi (4 & 5) devices.
Hardware specific capabilities such as infrared send/receive, sensing, LED ring, etc. are supported by Ubo Pod hardware.
It is also possible to DIY your own hardware, see the [hardware DIY section](#diy-path) below.
### Goals
The design is centered around the following goals:
- Making hardware-integarted app development easier
- Offer no-code/no-terminal UI/UX optionsto both developers and end-users of their apps
- Give developers tools to build apps with multi-modal UX
- Leverage tight hardware and software co-development to unlock new potentials
- Let users focus on their app logic while Ubo app handles the rest (hardware abstractions, UI, etc.)
- Hot-pluggable services
- Modular and friendly to AI tool-calling
- Remote API access (gRPC)
⚠️ Due to limited development resources, we are not able to support every single board computer (SBC), operating system, and hardware configuration.
If you are willing to supporting other SBCs or operating systems, please consider contributing to the project.
<b>Example GUI screenshots</b>
)
## 🚧 Disclaimer
Be aware that at the moment, Ubo app sends crash reports to Sentry. Soon we will limit this to beta versions only.
## ⚙️ Notable Features
- Easy WiFi on-boarding with QR code or hotspot
- Headless (no monitor/keyboard) remote access setup
- SSH
- VS Code tunnel
- Raspberry Pi Connect
- Install and run Dockerized apps headlessly
- One-click install for pre-configured apps
- Access and control basic Linux utilities and settings
- User management
- Network management
- File system operations
- Natural language interactions for tool calling (voice AI) (experimental)
- Web UI
- Infrared remote control (send/receive)
- gRPC API for remote control - find sample clients [here](https://github.com/ubopod/ubo-grpc-clients)
Check [roadmap section](#🗺️-roadmap) below for upcoming features.
## 📋 Requirements
At minimum you need a Raspberry Pi 4 or 5 to run Ubo App.
To run LLM models locally, we recommend a Raspberry Pi 5 with at least 8GB of RAM.
For features that require add-on hardware that is not natively supported by Raspberry Pi (such as audio, infrared rx/tx, sensors, etc), you can:
1. Purchase an Ubo Pod Development Kit
2. DIY the hardware
3. Use only subset of hardware features emulated in the browser
For more details check out the [hardware section](#🛠️-hardware) below.
🙏 Please consider supporting this project by pre-ordering an Ubo Pod Dev Edition on [Kickstarter](https://www.kickstarter.com/projects/ubopod/ubo-pod-hackable-personal-ai-assistant).
The sales proceeds from the hardware will be used to support continued development and maintenance of Ubo App and its open source dependencies.
<b> Note </b>:
The app still functions even if some special hardware elements (audio, infrared rx/tx, sensors, etc) are not provided. The features that rely on these hardware components just won't function. For example, WiFi onboarding with QR code requires a camera onboard.
## Installation
### Pre-packaged image
Ubo Pod ships with a pre-flashed MicroSD card that has the app installed on it by default.
If you don't have it, or you just want to set up a fresh device, then:
1. Download one of the images from the release section
1. Use Raspberry Pi Images and choose `custom image` to provide the download image file.
1. Write to the image
1. Use the image to boot your Ubo Pod or Raspberry Pi
This is the fastest, easiest, and recommended way to get started with Ubo App.
🙋♂️If this is the first time you are flashing an image for Raspberry Pi, I recommend following the more detailed steps [here](https://github.com/ubopod/ubo-image).
To run the app on bare Raspberry Pi, you can watch this short [demo video](https://www.youtube.com/watch?v=Rro3YLVIUx4).
### Install on existing OS
If you want to install the image on an existing operating system, then read on. Otherwise, skip this section.
---
⚠️ **Executing scripts directly from the internet with root privileges poses a significant security risk. It's generally a good practice to ensure you understand the script's content before running it. You can check the content of this particular script [here](https://raw.githubusercontent.com/ubopod/ubo-app/main/ubo_app/system/install.sh) before running it.**
---
To install ubo, run this command in a terminal shell:
```bash
curl -sSL https://raw.githubusercontent.com/ubopod/ubo-app/main/ubo_app/system/scripts/install.sh | sudo bash
```
If you don't want to install docker service you can set the `WITH_DOCKER` environment variable to `false`:
```bash
curl -sSL https://raw.githubusercontent.com/ubopod/ubo-app/main/ubo_app/system/scripts/install.sh | sudo WITHOUT_DOCKER=true bash
```
To install a specific version of ubo, you can set the `TARGET_VERSION` environment variable to the desired version:
```bash
curl -sSL https://raw.githubusercontent.com/ubopod/ubo-app/main/ubo_app/system/scripts/install.sh | sudo TARGET_VERSION=0.0.1 bash
```
Note that as part of the installation process, these debian packages are installed:
- accountsservice
- dhcpcd
- dnsmasq
- git
- hostapd
- i2c-tools
- ir-keytable
- libasound2-dev
- libcap-dev
- libegl1
- libgl1
- libmtdev1
- libzbar0
- python3-alsaaudio
- python3-apt
- python3-dev
- python3-gpiozero
- python3-libcamera
- python3-picamera2
- python3-pip
- python3-virtualenv
- rpi-lgpio
Also be aware that ubo-app only installs in `/opt/ubo` and it is not customizable
at the moment.
## 🤝 Contributing
Contributions following Python best practices are welcome.
### ℹ️️ Conventions
- Use `UBO_` prefix for environment variables.
- Use `ubo:` prefix for notification ids used in ubo core and `<service_name>:` prefix for notification ids used in services.
- Use `ubo:` prefix for icon ids used in ubo core and `<service_name>:` prefix for icon ids used in services.
### Development
#### Setting up the development environment
To set up the development environment, you need to [have `uv` installed](https://docs.astral.sh/uv/).
First, clone the repository (you need to have [git-lfs installed](https://docs.github.com/en/repositories/working-with-files/managing-large-files/installing-git-large-file-storage)):
```bash
git clone https://github.com/ubopod/ubo_app.git
git lfs install
git lfs pull
```
In environments where some python packages are installed system-wide, like Raspberry Pi OS, you need to run the following command to create a virtual environment with system site packages enabled:
```bash
uv venv --system-site-packages
```
Then, navigate to the project directory and install the dependencies:
```bash
uv sync --dev
```
Next, you need to compile protobuf files and build the web application. You only need to do this once or whenever you update store actions/events or the web app.
Please refer to [Generating the protobuf files](#generating-the-protobuf-files) and [Building the web application](#building-the-web-application) sections for the steps.
Now you can run the app with:
```bash
HEADLESS_KIVY_DEBUG=true uv run ubo
```
#### Run the app on the physical device
Add `ubo-development-pod` host in your ssh config at `~/.ssh/config`:
```plaintext
Host ubo-development-pod
HostName <ubopod IP here>
User pi
```
⚠️*Note: You may want to add the ssh public key to the device's authorized keys (`~/.ssh/authorized_keys`) so that you don't need to enter the password each time you ssh into the device. If you decide to use password instead, you need to reset the password for Pi user first using the GUI on the device by going to Hamburger Menu -> Settings -> System -> Users and select pi user*
Before you deploy the code onto the pod, you have to run the following command to generate the protobuf files and compile the web application.
##### Generating the protobuf files
Please make sure you have [buf](https://github.com/bufbuild/buf) library installed locally. If you are developing on a Mac or Linux, you can install it using Homebrew:
```bash
brew install bufbuild/buf/buf
```
Then, run the following command to generate the protobuf files whenever an action or
```bash
uv run poe proto
```
This is a shortcut for running the following commands:
```bash
uv run poe proto:generate # generate the protobuf files based on the actions/events defined in python files
uv run poe proto:compile # compile the protobuf files to python files
```
##### Building the web application
If you are running it for the firt time, you first need to install the dependencies for the web application:
```bash
cd ubo_app/services/090-web-ui/web-app
npm install # Only needed the first time or when dependencies change
```
Then, you need to compile the protobuf files and build the web application:
```bash
cd ubo_app/services/090-web-ui/web-app
npm run proto:compile
npm run build
```
If you are modifying web-app typescript files, run `npm run build:watch` and let it stay running in a terminal. This way, whenever you modify web-app files, it will automatically update the built files in `dist` directory as long as it’s running.
If you ever add, modify or remove an action or an event you need to run `poe proto` and `npm run proto:compile` again manually.
---
Then you need to run this command once to set up the pod for development:
```bash
uv run poe device:deploy:complete
```
After that, you can deploy the app to the device with:
```bash
uv run poe device:deploy
```
To run the app on the device, you can use either of these commands:
```bash
uv run poe device:deploy:restart # gracefully restart the app with systemctl
uv run poe device:deploy:kill # kill the process, which will be restarted by systemd if the service is not stopped
```
#### Running tests on desktop
Easiest way to run tests is to use the provided `Dockerfile`s. To run the tests in a container, you first need to create the development images by running:
```bash
uv run poe build-docker-images
```
Then you can run the tests with:
```bash
docker run --rm -it --name ubo-app-test -v .:/ubo-app -v ubo-app-dev-uv-cache:/root/.cache/uv ubo-app-test
```
You can add arguments to the `pytest` command to run specific tests like this:
```bash
docker run --rm -it --name ubo-app-test -v .:/ubo-app -v ubo-app-dev-uv-cache:/root/.cache/uv ubo-app-test -- <pytest-args>
```
For example, to run only the tests in the `tests/integration/test_core.py` file, you can run:
```bash
docker run --rm -it -v .:/ubo-app -v ubo-app-dev-uv-cache:/root/.cache/uv -v uvo-app-dev-uv-local:/root/.local/share/uv -v ubo-app-dev-uv-venv:/ubo-app/.venv ubo-app-test
```
To pass it command line options add a double-dash before the options:
```bash
docker run --rm -it -v .:/ubo-app -v ubo-app-dev-uv-cache:/root/.cache/uv -v uvo-app-dev-uv-local:/root/.local/share/uv -v ubo-app-dev-uv-venv:/ubo-app/.venv ubo-app-test -- -svv --make-screenshots --override-store-snapshots --override-window-snapshots
```
You can also run the tests in your local environment by running:
```bash
uv run poe test
```
⚠️**Note:** When running the tests in your local environment, the window snapshots produced by tests may mismatch the expected snapshots. This is because the snapshots are taken with a certain DPI and some environments may have different DPI settings. For example, we are aware that the snapshots taken in macOS have different DPI settings. If you encounter this issue, you should run the tests in a Docker container as described above.
#### Running tests on the device
You need to install dependencies with following commands once:
```bash
uv run poe device:test:copy
uv run poe device:test:deps
```
Then you can use the following command each time you want to run the tests:
```bash
uv run poe device:test
```
#### Running linter
To run the linter run the following command:
```bash
uv run poe lint
```
To automatically fix the linting issues run:
```bash
uv run poe lint --fix
```
#### Running type checker
To run the type checker run the following command on the pod:
```bash
uv run poe typecheck
```
⚠️*Note: Please note typecheck needs all packages to be present. To run the above command on the pod, you need to clone the ubo-app repository on the pod, apply your changes on it, have uv installed on the pod and install the dependencies.*
If you prefer to run typecheck on the local machine, clone [stubs repository](https://github.com/ubopod/ubo-non-rpi-stubs) (which includes typing stubs for third-party packages) and place the files under `typings` directory. Then run `poe typecheck` command.
#### Adding new services
It is not documented at the moment, but you can see examples in `ubo_app/services` directory.
⚠️*Note: To make sure your async tasks are running in your service's event loop and not in the main event loop, you should use the `create_task` function imported from `ubo_app.utils.async_` to create a new task. Using `await` inside `async` functions is always fine and doesn't need any special attention.*
⚠️*Note: Your service's setup function, if async, should finish at some point, this is needed so that ubo can know the service has finished its initialization and ready to be used. So it should not run forever, by having a loop at the end, or awaiting an ongoing async function or similar patterns. Running a never-ending async function using `create_task` imported from `ubo_app.utils.async_` is alright.
#### QR code
In development environment, the camera is probably not working, as it is relying on `picamera2`, so it may become challenging to test the flows relying on QR code input.
To address this, the camera module, in not-RPi environments, will try reading from `/tmp/qrcode_input.txt` and `/tmp/qrcode_input.png` too. So, whenever you encounter a QR code input, you can write the content of the QR code in the text file path or put the qrcode image itself in the image file path and the application will read it from there and continue the flow.
Alternatively you may be able to provide the input in the web-ui (needs refresh at the moment) or provide it by `InputProvideAction` in grpc channel.
## 🛠️ Hardware
This section presents different hardware or emulation options that you can use with Ubo app.
### Emulation
To remove barriers to adoption as much as possible and allow developers use Ubo app without hardware depenencies, we are currently emulating the physical GUI in the browser.
The audio playback is also streamed through the broswer.
We plan to emulate camera and microphone with WebRTC in the future.
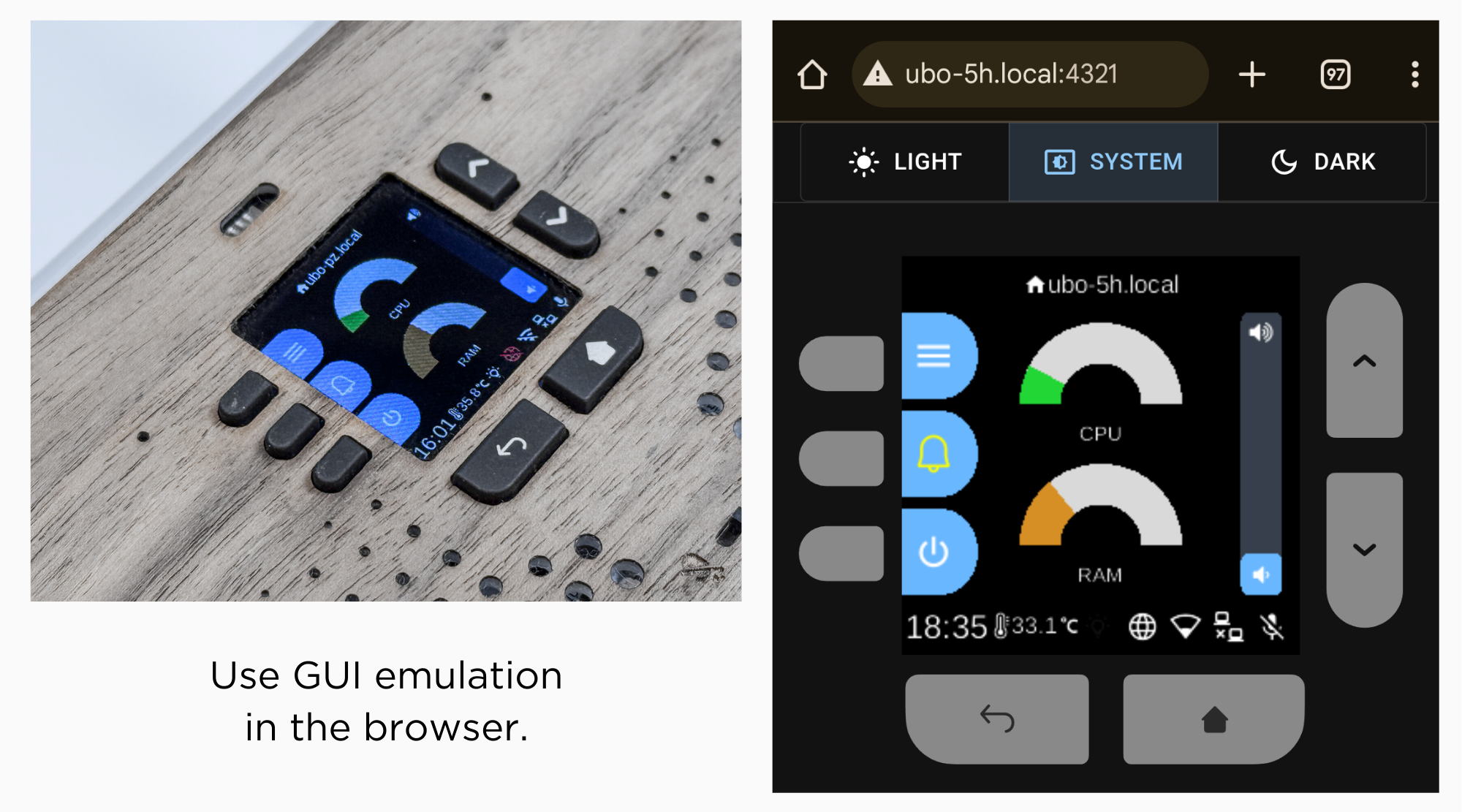
However, other specialized hardware components (sensors, infrared rx/tx, etc) cannot be emulated.
### Ubo Pod

Ubo pod is an open hardware that includes the following additional hardware capabilities that is supported by Ubo app out of the box:
- A built-in minimal GUI (color LCD display and keypad)
- Stereo microphone and speakers (2W)
- Camera (5MP)
- LED ring (27 addressable RGB LEDs)
- Sensors
- Ambient light sensor
- Temperature sensor
- STEMMA QT / Qwiic connector for additional sensors
- Infrared
- Receiver (wideband)
- Transmitter (4 high power LEDs)
- 2 full HDMI ports
- Power/reset button
- NVMe storage (Pi 5 only)
For more information on hardware spec, see the website [getubo.com](https://getubo.com).
This is an open hardware. You can access mechanical design files [here](https://github.com/ubopod/ubo-mechanical) and electrical design files [here](https://github.com/ubopod/ubo-pcb).
### DIY path
You can also buy different HATs from different vendors to DIY the hardware. Future plans include supporting USB microphone, speakers, cameras as well with headless setup.
This however involves having to purchase multiple HATs from different vendors and the process may not be the easiest and most frictionless. You may have to dig into the code and make some small changes to certain setups and configurations.
I made the table below that shows options for audio, cameras, and other sub-components:
| Function | Options |
| --- | --- |
| Audio | [Respeaker 2-Mic Audio HAT](https://www.seeedstudio.com/ReSpeaker-2-Mics-Pi-HAT.html), [Adafruit Voice Bonnet](https://www.adafruit.com/product/4757), [Waveshare WM8960 Hat](https://www.waveshare.com/wm8960-audio-hat.htm), [Adafruit BrainCraft HAT](https://www.adafruit.com/product/4374) |
| Speakers | [1 or 2W, 8 Ohm](https://www.adafruit.com/product/1669) |
| Camera | Raspberry Pi Camera Modules V1.3, [V2](https://www.raspberrypi.com/products/camera-module-v2/), or [V3](https://www.raspberrypi.com/products/camera-module-3/) |
| LCD (also emulated in the browser) | [240x240 TFT Display](https://www.adafruit.com/product/4421), [Adafruit BrainCraft HAT](https://www.adafruit.com/product/4374) |
| Keypad | [AW9523 GPIO Expander](https://www.adafruit.com/product/4886) |
| LED ring | [Neopixel LED ring](https://www.adafruit.com/product/1586) |
| Ambient Light Sensor | [VEML7700 Lux Sensor](https://www.adafruit.com/product/4162) |
| Temperature Sensor | [PCT2075 Temperature Sensor](https://www.adafruit.com/product/4369) |
## 🏗️ Architecture
The architecture is fundamentally event-driven and reactive, built around a centralized Redux store that coordinates all system interactions through immutable state updates and event dispatching.
Services communicate exclusively through Redux actions and events rather than direct method calls, with each service running in its own isolated thread while subscribing to relevant state changes and events.
The system uses custom event handlers that automatically route events to the appropriate service threads, enabling reactive responses to state changes across hardware interfaces, user interactions, and system events.
This reactive architecture allows components like the web UI to subscribe to display render events and audio playback events in real-time, creating a responsive system where changes propagate automatically through the event stream without tight coupling between components.
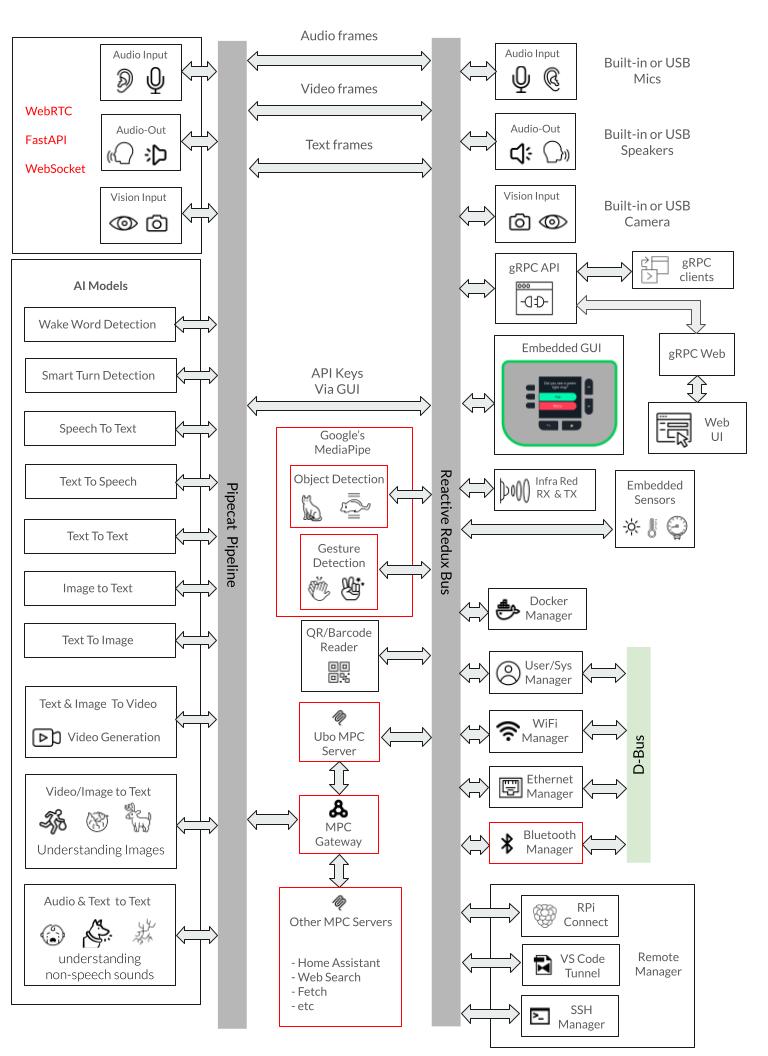
The following is a summary of key architecture components.
- <b>Redux-Based State Management</b>: Central `UboStore` manages all application state through immutable state trees, with each service contributing its own state slice (audio, camera, display, docker, wifi, etc.) and communicating via actions and events.
- <b>Modular Service Architecture</b>: 21+ core services run in isolated threads with dedicated event loops, organized by priority (`000-0xx` for hardware, `030-0xx` for networking, `080-0xx` for applications, `090-0xx` for UI), each with their own setup.py, reducer.py, and ubo_handle.py files.
- <b>Hardware Abstraction Layer</b>: Comprehensive abstraction for Raspberry Pi components (ST7789 LCD, WM8960 audio, GPIO keypad, sensors, camera, RGB ring) with automatic environment detection and mock implementations for development on non-RPi systems.
- <b>Multi-Interface Access</b>: Supports web browser access (port 4321), gRPC API (port 50051), SSH access, and direct hardware interaction, with a web UI service providing hotspot configuration and dashboard functionality.
- <b>System Integration</b>: Integrates with `systemd` and `d-bus` for service management, Docker for container runtime, and `NetworkManager` for network configuration, with a separate system manager process handling root-privilege operations via Unix sockets.
<b>Notes:</b>
The application follows a structured initialization sequence through `ubo_app/main.py` and uses the `uv` package manager for dependency management.
The architecture supports both production deployment on Raspberry Pi devices and development environments with comprehensive mocking systems, making it suitable for cross-platform development while maintaining hardware-specific capabilities.
DeepWiki pages you might want to explore:
- [Overview](https://deepwiki.com/ubopod/ubo_app/1-overview)
- [Architecture](https://deepwiki.com/ubopod/ubo_app/2-architecture)
## Notable dependencies
Here are the key dependencies organized by category:
### Core Framework & State Management
- `python-redux`: Redux-based state management system for the entire app
- `ubo-gui`: Custom GUI framework built on Kivy for the user interface
- `headless-kivy`: Headless Kivy implementation for supporting LCD display over SPI
### Hardware Control (Raspberry Pi)
- `adafruit-circuitpython-rgb-display`: ST7789 LCD display driver
- `adafruit-circuitpython-neopixel`: RGB LED ring control
- `adafruit-circuitpython-aw9523`: I2C GPIO expander for keypad
- `adafruit-circuitpython-pct2075`: Temperature sensor driver
- `adafruit-circuitpython-veml7700`: Light sensor driver
- `rpi-lgpio`: Low-level GPIO access for Raspberry Pi
- `gpiozero`: GPIO abstraction layer
- `rpi-ws281x`: WS281x LED strip control library
- `pyalsaaudio`: ALSA audio interface for Linux audio control
- `pulsectl`: PulseAudio control for audio management
- `simpleaudio`: Simple audio playback functionality
### Voice AI
- `piper-tts`: Text-to-speech synthesis engine
- `vosk`: Speech recognition library
- `pvorca`: Picovoice Text-to-speech synthesis engine
- `pipecat-ai`: framework for building real-time voice and multimodal conversational agents
### Networking & Services
- `aiohttp`: Async HTTP client/server for web services
- `quart`: Async web framework for the web UI service
- `sdbus-networkmanager`: NetworkManager D-Bus interface for WiFi
- `netifaces`: Network interface enumeration
- `docker`: Docker API client for container management
### QR Codes
- `pyzbar`: QR code and barcode scanning library
### System Utilities
- `psutil`: System and process monitoring utilities
- `platformdirs`: Platform-specific directory paths
- `tenacity`: Retry logic and error handling
- `fasteners`: File locking and synchronization
### Development Environment Abstraction
- `python-fake`: Mock hardware components for development
### gRPC Communication
- `betterproto`: Protocol buffer compiler and runtime
<b>Notes:</b>
The project uses platform-specific dependencies with markers like `platform_machine=='aarch64'` for Raspberry Pi-specific libraries and `sys_platform=='linux'` for Linux-only components. The python-fake library enables development on non-Raspberry Pi systems by providing mock implementations of hardware components.
## 🗺️ Roadmap
This is a tentative roadmap for future features. It is subject to change.
- Emulation for camera and microphone inside browser (requires SSL certificate for browser permissions)
- Allow users to pick their soundcard for play and record via GUI (e.g. USB audio)
- Allow users to pick their camera for video via GUI (e.g. USB camera)
- Option to turn Ubo pod into a voice satellite with wyoming protocol with Home Assistant
- Make all on-board sensors and infrared discoverable and accessible by Home Assistant
- Let users record Infrared signals and assign them to trigger custom actions
- Expose `pipecat-ai` preset pipeline configuration via GUI
- Support for Debian Trixie (13)
If you have any suggestions or feature requests, please open a discussion [here](https://github.com/ubopod/ubo_app/discussions).
## 🔒 License
This project is released under the Apache-2.0 License. See the [LICENSE](./LICENSE) file for more details.
| text/markdown | null | Sassan Haradji <me@sassanh.com> | null | Sassan Haradji <me@sassanh.com> | null | home assistance, raspberry pi, rpi, ubo, ubo-pod | [] | [] | null | null | <3.12,>=3.11 | [] | [] | [] | [
"adafruit-blinka-raspberry-pi5-neopixel==1.0.0rc2; platform_machine == \"aarch64\" and sys_platform == \"linux\"",
"adafruit-circuitpython-aw9523==1.1.12",
"adafruit-circuitpython-irremote==5.0.4",
"adafruit-circuitpython-neopixel==6.3.16",
"adafruit-circuitpython-pct2075==1.1.24",
"adafruit-circuitpython-pixelbuf==2.0.8",
"adafruit-circuitpython-rgb-display==3.14.0",
"adafruit-circuitpython-veml7700==2.1.3",
"aiofiles==24.1.0",
"aiohttp==3.12.9",
"aiostream==0.6.4",
"betterproto[compiler]==2.0.0b7",
"dill==0.4.0",
"docker==7.1.0",
"fasteners==0.19",
"google-cloud-aiplatform==1.96.0",
"google-cloud-speech==2.32.0",
"gpiozero==2.0.1; platform_machine != \"aarch64\"",
"headless-kivy==0.12.4",
"netifaces==0.11.0",
"ollama==0.5.1",
"onnxruntime>=1.22.0; sys_platform == \"linux\" and platform_machine == \"aarch64\"",
"opencv-python==4.10.0.84",
"pillow>=11.3.0",
"piper-tts==1.4.1",
"platformdirs",
"psutil==7.0.0",
"pulsectl==24.12.0",
"pvorca==1.1.1",
"pyalsaaudio==0.11.0; platform_machine == \"aarch64\" and sys_platform == \"linux\"",
"pyaudio==0.2.14; platform_machine != \"aarch64\" or sys_platform != \"linux\"",
"pypng==0.20220715.0",
"python-debouncer==0.1.5",
"python-dotenv==1.1.0",
"python-fake==0.2.0",
"python-redux==0.25.1",
"python-strtobool==1.0.3",
"pyzbar==0.1.9",
"quart==0.20.0",
"rpi-lgpio==0.6; platform_machine == \"aarch64\" and sys_platform == \"linux\"",
"rpi-ws281x==5.0.0; platform_machine == \"aarch64\"",
"sdbus-networkmanager==2.0.0; platform_machine == \"aarch64\"",
"sentry-sdk==2.29.1",
"simpleaudio==1.0.4",
"soxr==0.5.0.post1",
"tenacity==9.1.2",
"ubo-app-raw-bindings",
"ubo-gui==0.13.17",
"vosk==0.3.44",
"graphviz>=0.20.3; extra == \"test-investigation\"",
"objgraph>=3.6.2; extra == \"test-investigation\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T09:48:34.779340 | ubo_app-1.7.1.dev126022010357995610.tar.gz | 2,247,319 | 18/37/35c66bfb7b9117efff7e10f389c786f7527541e84ab1fd522b7057bdbb97/ubo_app-1.7.1.dev126022010357995610.tar.gz | source | sdist | null | false | 12332a36e3ee9cdfce10506b32348a23 | a8690c271e51be07f875ff9433e101cf45a99b4eab2fb52e25b9212b59a72aca | 183735c66bfb7b9117efff7e10f389c786f7527541e84ab1fd522b7057bdbb97 | Apache-2.0 | [] | 162 |
2.4 | buildgrid | 0.4.3 | A remote execution service | .. image:: https://gitlab.com/BuildGrid/buildgrid/badges/master/pipeline.svg
:target: https://gitlab.com/BuildGrid/buildgrid/-/commits/master
:alt: pipeline status
.. image:: https://gitlab.com/BuildGrid/buildgrid/badges/master/coverage.svg
:target: https://gitlab.com/BuildGrid/buildgrid/-/commits/master
:alt: coverage report
.. image:: https://gitlab.com/BuildGrid/buildgrid/-/badges/release.svg
:target: https://gitlab.com/BuildGrid/buildgrid/-/releases
:alt: coverage report
.. _about:
About
=====
.. _what-is-it:
What is BuildGrid?
------------------
BuildGrid is a Python remote execution service which implements Google's
`Remote Execution API`_ and the `Remote Workers API`_. The project's goal is to
be able to execute build jobs remotely on a grid of computers in order to
massively speed up build times. Workers on the grid should be able to run with
different environments. It works with clients such as `Bazel`_,
`BuildStream`_ and `RECC`_, and is designed to be able to work with any client
that conforms to the above API protocols.
BuildGrid is designed to work with any worker conforming to the `Remote Workers API`_
specification. Workers actually execute the jobs on the backend while BuildGrid does
the scheduling and storage. The `BuildBox`_ ecosystem provides a suite of workers and
sandboxing tools that work with the Workers API and can be used with BuildGrid.
.. _Remote Execution API: https://github.com/bazelbuild/remote-apis
.. _Remote Workers API: https://docs.google.com/document/d/1s_AzRRD2mdyktKUj2HWBn99rMg_3tcPvdjx3MPbFidU/edit#heading=h.1u2taqr2h940
.. _BuildStream: https://wiki.gnome.org/Projects/BuildStream
.. _Bazel: https://bazel.build
.. _RECC: https://gitlab.com/BuildGrid/buildbox/buildbox/-/tree/master/recc
.. _Trexe: https://gitlab.com/BuildGrid/buildbox/buildbox/-/tree/master/trexe
.. _BuildBox: https://buildgrid.gitlab.io/buildbox/buildbox-home/
.. _readme-getting-started:
Getting started
---------------
Please refer to the `documentation`_ for `installation`_ and `usage`_
instructions, plus guidelines for `contributing`_ to the project.
.. _contributing: https://buildgrid.build/developer/contributing.html
.. _documentation: https://buildgrid.build/
.. _installation: https://buildgrid.build/user/installation.html
.. _usage: https://buildgrid.build/user/using.html
.. _about-resources:
Resources
---------
- `Homepage`_
- `GitLab repository`_
- `Bug tracking`_
- `Slack channel`_ [`invite link`_]
- `FAQ`_
.. _Homepage: https://buildgrid.build/
.. _GitLab repository: https://gitlab.com/BuildGrid/buildgrid
.. _Bug tracking: https://gitlab.com/BuildGrid/buildgrid/boards
.. _Slack channel: https://buildteamworld.slack.com/messages/CC9MKC203
.. _invite link: https://join.slack.com/t/buildteamworld/shared_invite/zt-3gsdqj3z6-YTwI9ZWZxvE522Nl1TU8sw
.. _FAQ: https://buildgrid.build/user/faq.html
| text/x-rst | null | null | null | null | Apache License, Version 2.0 | null | [
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"boto3",
"botocore",
"dnspython",
"grpcio-reflection>=1.62.0",
"grpcio-health-checking>=1.62.0",
"grpcio>=1.62.0",
"janus>=0.6.2",
"jinja2",
"protobuf",
"alembic",
"Click",
"SQLAlchemy>=2.0.44",
"pydantic>2.0",
"PyYAML>=6.0.1",
"jsonschema>=3.0.0",
"lark-parser",
"pycurl>=7.45.3",
"buildgrid-metering-client>=0.0.4",
"mmh3",
"cryptography",
"PyJWT",
"requests",
"sentry-sdk",
"psycopg2-binary; extra == \"database\"",
"psycopg>=3.2.10; extra == \"database\"",
"fakeredis>=2.10.1; extra == \"redis\"",
"redis>=4.5.1; extra == \"redis\"",
"hiredis; extra == \"redis\"",
"Sphinx<=8; extra == \"docs\"",
"sphinx-click; extra == \"docs\"",
"sphinx-rtd-theme; extra == \"docs\"",
"sphinxcontrib-apidoc; extra == \"docs\"",
"coverage; extra == \"tests\"",
"cryptography>=38.0.0; extra == \"tests\"",
"flaky; extra == \"tests\"",
"flask; extra == \"tests\"",
"flask-cors; extra == \"tests\"",
"jwcrypto; extra == \"tests\"",
"moto<4.1.12; extra == \"tests\"",
"psutil; extra == \"tests\"",
"pycodestyle; extra == \"tests\"",
"pyopenssl>=22.0.0; extra == \"tests\"",
"pytest; extra == \"tests\"",
"pytest-cov; extra == \"tests\"",
"pytest-forked; extra == \"tests\"",
"pytest-pycodestyle; extra == \"tests\"",
"pytest-xdist; extra == \"tests\"",
"fakeredis>=2.10.1; extra == \"tests\"",
"redis>=4.5.1; extra == \"tests\"",
"pytest-postgresql>=7.0.2; extra == \"tests\"",
"psycopg2-binary; extra == \"tests\"",
"psycopg>=3.2.10; extra == \"tests\"",
"pycodestyle; extra == \"dev\"",
"pytest; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"pytest-forked; extra == \"dev\"",
"pytest-pycodestyle; extra == \"dev\"",
"pytest-xdist; extra == \"dev\"",
"memray; extra == \"dev\"",
"ruff; extra == \"dev\"",
"grpcio-tools; extra == \"dev\"",
"bump4version; extra == \"dev\"",
"mypy; extra == \"mypy\"",
"SQLAlchemy[mypy]; extra == \"mypy\"",
"mypy-protobuf<3.5; extra == \"mypy\"",
"boto3-stubs; extra == \"mypy\"",
"mypy-boto3-s3; extra == \"mypy\"",
"types-aiofiles; extra == \"mypy\"",
"types-cachetools; extra == \"mypy\"",
"types-docutils; extra == \"mypy\"",
"types-grpcio; extra == \"mypy\"",
"types-grpcio-reflection; extra == \"mypy\"",
"types-grpcio-health-checking; extra == \"mypy\"",
"types-grpcio-status; extra == \"mypy\"",
"types-grpcio-channelz; extra == \"mypy\"",
"types-jsonschema; extra == \"mypy\"",
"types-jwcrypto; extra == \"mypy\"",
"types-protobuf; extra == \"mypy\"",
"types-psycopg2; extra == \"mypy\"",
"psycopg>=3.2.10; extra == \"mypy\"",
"types-pycurl>=7.45.3.20240421; extra == \"mypy\"",
"types-Pygments; extra == \"mypy\"",
"types-pyOpenSSL; extra == \"mypy\"",
"types-python-dateutil; extra == \"mypy\"",
"types-pyyaml; extra == \"mypy\"",
"types-redis; extra == \"mypy\"",
"types-requests; extra == \"mypy\"",
"types-setuptools; extra == \"mypy\"",
"types-urllib3; extra == \"mypy\"",
"buildgrid[database,dev,docs,mypy,redis,tests]; extra == \"all\""
] | [] | [] | [] | [
"Homepage, https://buildgrid.build",
"Documentation, https://buildgrid.build",
"Repository, https://gitlab.com/BuildGrid/buildgrid"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T09:48:10.859248 | buildgrid-0.4.3.tar.gz | 465,814 | 84/34/ecc91d5ab0f50b2f01ed0280defb2546be90ffe6857552624a5083e6be4b/buildgrid-0.4.3.tar.gz | source | sdist | null | false | 3b26b0b43627c554fe60dd632f235cfc | ba0cf9068a5a6dc5903ec35e5a706efea4b2cb285b9a853440d1e259f811da9f | 8434ecc91d5ab0f50b2f01ed0280defb2546be90ffe6857552624a5083e6be4b | null | [
"LICENSE"
] | 206 |
2.4 | adstoolbox | 2026.2.20 | Generic functions | # Alchimie Data Solutions : adsToolBox
`adsToolBox` est une librairie Python conçue pour regrouper toutes les fonctions génériques qui peuvent être utilisées au
cours des développements liés à **Onyx**. Elle fournit un ensemble d'outils robustes pour :
- **Gérer des connexions** à des bases de données PostgreSQL et SQL Server.
- **Créer et gérer des pipelines** de données entre bases, ou encore de tableau vers base.
- **Chronométrer les échanges de données** pour le suivi des performances.
- **Journaliser les évènements** en console, en fichier et en base de données.
- **Gérer l'environnement** via des fichiers `.env`.
## Installation
Vous pouvez installer la librairie directement depuis PyPI en utilisant `pip` :
```bash
pip install adsToolBox
```
## Utilisation et Documentation
Des exemple d'utilisation sont disponibles sur ce repo github : [Démo](https://github.com/AlchimieDataSolutions/DemoPy).
## Dépendances
Les dépendances sont dans le fichier requirements.txt.
| text/markdown | Olivier Siguré | olivier.sigure@alchimiedatasolutions.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0.0,>=3.9.2 | [] | [] | [] | [
"adlfs==2024.1.0",
"azure-core==1.36.0",
"chardet<6.0.0,>=5.2.0",
"django_sendgrid_webhook==0.3.0",
"fsspec==2025.10.0",
"GitPython==3.1.45",
"google-api-core==2.17.1",
"google-api-python-client==2.149.0",
"google-auth-oauthlib==1.2.1",
"jsonschema==4.25.1",
"mysql_connector_repackaged==0.3.1",
"paramiko<4.0.0,>=3.4.0",
"polars==1.34.0",
"protobuf==4.25.3",
"psycopg2-binary==2.9.9",
"PyGithub==2.8.1",
"pymssql==2.3.11",
"pymysql==1.1.2",
"pytest==8.3.3",
"pytz==2025.2",
"python-dotenv==1.1.1",
"Requests==2.32.5",
"sendgrid==6.10.0",
"smbprotocol==1.11.0",
"SQLAlchemy==2.0.44",
"testcontainers==4.13.3",
"tzdata==2025.2"
] | [] | [] | [] | [] | poetry/2.2.1 CPython/3.10.11 Windows/10 | 2026-02-20T09:48:03.801596 | adstoolbox-2026.2.20.tar.gz | 43,707 | 72/f4/53162a1ff03b5d9ef029455456a782e6ad0f142f981be00bc0010c075898/adstoolbox-2026.2.20.tar.gz | source | sdist | null | false | 8d5cc52f5539fa28b87a8e723350ebfa | d8d57277fda1eb63bbc48c3573620e2685e5aa9bfd1e8679559fac3219dedf90 | 72f453162a1ff03b5d9ef029455456a782e6ad0f142f981be00bc0010c075898 | null | [] | 206 |
2.4 | shotgun-sh | 0.10.11 | AI-powered research, planning, and task management CLI tool | <div align="center">
<img width="400" height="150" alt="Shotgun logo transparent background" src="https://github.com/user-attachments/assets/08f9ccd5-f2e8-4bf4-9cb2-2f0de866a76a" />
### Spec-Driven Development
**Write codebase-aware specs for AI coding agents (Codex, Cursor, Claude Code) so they don't derail.**
<p align="center">
<a href="https://github.com/shotgun-sh/shotgun">
<img src="https://img.shields.io/badge/python-3.11+-blue?style=flat&logo=python&logoColor=white" />
</a>
<a href="https://www.producthunt.com/products/shotgun-cli/launches/shotgun-cli">
<img src="https://img.shields.io/badge/Product%20Hunt-%237%20Product%20of%20the%20Day-FF6154?style=flat&logo=producthunt&logoColor=white" />
</a>
<a href="https://github.com/shotgun-sh/shotgun?tab=contributing-ov-file">
<img src="https://img.shields.io/badge/PRs-welcome-brightgreen?style=flat" />
</a>
<a href="https://github.com/shotgun-sh/shotgun?tab=MIT-1-ov-file">
<img src="https://img.shields.io/badge/license-MIT-blue?style=flat" />
</a>
<a href="https://discord.com/invite/5RmY6J2N7s">
<img src="https://img.shields.io/badge/discord-150+%20online-5865F2?style=flat&logo=discord&logoColor=white" />
</a>
</p>
[](https://shotgun.sh) [](https://x.com/ShotgunCLI) [](https://www.youtube.com/@shotgunCLI)
LLM Proxy Status: [](https://status.shotgun.sh/) API Status: [](https://status.shotgun.sh/)
</div>
---
<table>
<tr>
<td>
**AI agents are great at small tasks but derail on big features.** They forget context, rebuild things that already exist, and go off-spec halfway through.
**Shotgun fixes this.** It reads your entire codebase, plans the full feature upfront, then splits it into staged PRs—each with file-by-file instructions your AI agent can actually follow.
Instead of one 10k-line monster PR nobody will review, you get 5 focused PRs that ship.
Works great with Cursor, Claude Code, Antigravity, or Codex. BYOK or use Shotgun credits ($10 = $10 in usage).
</td>
</tr>
</table>
---
# 📦 Installation
**Select your operating system below and click to view installation instructions:**
<details>
<summary><h3>► MacOS Install Instructions (click to expand)</h3></summary>
**Step 1: Install uv**
```bash
# Using Homebrew
brew install uv
# Or using curl
curl -LsSf https://astral.sh/uv/install.sh | sh
```
**Step 2: Run Shotgun**
```bash
uvx shotgun-sh@latest
```
</details>
<details>
<summary><h3>► Linux Install Instructions (click to expand)</h3></summary>
**Step 1: Install uv**
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
```
**Step 2: Run Shotgun**
```bash
uvx shotgun-sh@latest
```
</details>
<details>
<summary><h3>► Windows Install Instructions (click to expand)</h3></summary>
Open PowerShell and run these commands:
```powershell
# Set execution policy (one-time)
Set-ExecutionPolicy RemoteSigned -Scope CurrentUser -Force
# Install uv
powershell -c "irm https://astral.sh/uv/install.ps1 | iex"
# Add to PATH (or restart terminal)
$env:Path = "C:\Users\$env:USERNAME\.local\bin;$env:Path"
# OPTIONAL: Enable code indexing (run as Administrator)
Import-Module BitsTransfer
Start-BitsTransfer -Source "https://aka.ms/vs/17/release/vc_redist.x64.exe" -Destination "$env:TEMP\vc_redist.x64.exe"
Start-Process -FilePath "$env:TEMP\vc_redist.x64.exe" -ArgumentList "/install", "/quiet", "/norestart" -Wait
# Run Shotgun
uvx --python 3.12 shotgun-sh@latest
```
| Supported | Not Supported |
|-----------|---------------|
| Windows x64 (regular PCs) | 32-bit Python |
| Python 3.11-3.13 | Python 3.14+ (no wheels yet) |
**Important:** Run in **PowerShell**, not Command Prompt or VS Developer shells.
</details>
_💡 Restart your terminal after installation_
_**Why uv?** It's 10-100x faster than pip and handles binary wheels reliably—no cmake/build tool errors._
Need help? [View uv installation docs](https://docs.astral.sh/uv/getting-started/installation/)
### 3. Get Started
When you launch Shotgun, it will guide you through:
| Step | What Happens |
|------|--------------|
| **1. Codebase Indexing** | Builds a searchable graph of your entire repository |
| **2. LLM Setup** | Configure OpenAI, Anthropic, or Gemini |
| **3. First Research** | Start generating codebase-aware specs |
_**💡 Pro tip:** Run Shotgun in your IDE's terminal for the best experience._
---
# 🎥 Demo
<p align="center">
<a href="https://youtu.be/hGryc6YZr2o">
<img src="https://github.com/user-attachments/assets/37eae206-0d6f-4499-b980-2f33a5aed65d" alt="Watch the Shotgun demo" width="720" height="405">
</a>
</p>
_Click the image above to watch the full demo on YouTube_
---
# 🎯 Usage
### Launch Shotgun in your project directory:
_See [install instructions](#-installation) for your platform first!_
```bash
uvx shotgun-sh@latest
```
### Planning vs Drafting
| Mode | How It Works | When to Use It |
|------|--------------|---------------|
| **Planning** (default) | Shotgun proposes an execution plan, shows each step, and asks for confirmation before running agents that change files. You get checkpoints, can refine the plan, and can confirm or skip cascaded updates when one change affects other docs. | When you want control, visibility, and the ability to refine the plan before execution. |
| **Drafting** | Shotgun runs the full plan in one go, without intermediate confirmations. Progress is still tracked internally, but you won’t be prompted at each step. | When you’re confident in the plan and want fast, end-to-end execution. |
_The TUI opens automatically. **Press `Shift+Tab` to switch between Planning & Drafting** or `/` for the command palette._
### How the Router Works Internally
Under the hood, the Router relies on specialized sub-agents. You don’t select or manage them manually.
<table>
<tr>
<td align="center"><b>🔬 Research</b><br/>Explore & understand</td>
<td align="center">→</td>
<td align="center"><b>📝 Specify</b><br/>Define requirements</td>
<td align="center">→</td>
<td align="center"><b>📋 Plan</b><br/>Create roadmap</td>
<td align="center">→</td>
<td align="center"><b>✅ Tasks</b><br/>Break into steps</td>
<td align="center">→</td>
<td align="center"><b>📤 Export</b><br/>Format for AI</td>
</tr>
</table>
> Planning and Drafting are the only execution modes you control; everything else is handled by the Router.
_**Mode switching:** `Shift+Tab` cycles through modes_
### ⌨️ Keyboard Shortcuts
| Shortcut | Action |
|----------|--------|
| `Shift+Tab` | Switch modes |
| `/` | Open command palette |
| `Ctrl+C` | Cancel operation (or copy if text selected) |
| `Escape` | Exit Q&A / stop agent |
| `Ctrl+U` | View usage stats |
### Tips for Better Results
| Do This | Not This |
|---------|----------|
| ✅ `Research how we handle auth` | ❌ Jump straight to building |
| ✅ `Shotgun please ask me questions first` | ❌ Assume Shotgun knows your needs |
| ✅ `I'm working on payments, need refunds` | ❌ `Add refunds` (no context) |
| ✅ Start in Planning mode, let Shotgun propose and refine a plan with you, then run it | ❌ Blast everything in one go without reviewing the plan first (unless you intentionally switch to Drafting mode) |
**Result:** Your AI coding agent gets complete context—what exists, why, and what to build.
**Note:** CLI available in [docs/CLI.md](docs/CLI.md), but TUI is recommended.
### Context7 Documentation Lookup (Experimental)
The Research agent can fetch up-to-date library documentation via [Context7](https://context7.com). When configured, the agent will prefer Context7 over web search for documentation lookups.
To enable it, set your Context7 API key:
```bash
shotgun config set-context7 --api-key <your-context7-api-key>
```
To remove it:
```bash
shotgun config clear-context7
```
---
# 🤝 Share Specs with Your Team
Sharing specs to a workspace is available on **paid Shotgun plans**.
Shotgun lets you share specs externally by publishing them to a **workspace**. This creates a versioned, shareable snapshot your team can access outside the repo.
### How to Share a Spec
1. Hit `/` → select _Share specs to workspace_
2. Choose one option:
- **Create new spec** — publish a fresh spec from your current `.shotgun/` files
- **Add new version** — publish an updated version of an existing spec
3. Wait for upload to complete. When finished, you can:
- **Open in Browser** — view the shared spec in the workspace
- **Copy URL** — share the link with your team
- **Done** — return to Shotgun
<img width="516" height="181" alt="image" src="https://github.com/user-attachments/assets/6dd9412c-345e-4dab-a40a-ad5f1c994d34" />
Your local `.shotgun/*.md` files remain unchanged.
The workspace contains a **shareable, versioned snapshot** of the spec.
---
# ✨ Features
### What Makes Shotgun Different
<table>
<tr>
<th width="25%">Feature</th>
<th width="35%">Shotgun</th>
<th width="40%">Other Tools</th>
</tr>
<tr>
<td><strong>Codebase Understanding</strong></td>
<td>
Reads your <strong>entire repository</strong> before generating specs. Finds existing patterns, dependencies, and architecture.
</td>
<td>
Require manual context or search each time. No persistent understanding of your codebase structure.
</td>
</tr>
<tr>
<td><strong>Research Phase</strong></td>
<td>
Starts with research—discovers what you already have AND what exists externally before writing anything.
</td>
<td>
Start at specification. Build first, discover problems later.
</td>
</tr>
<tr>
<td><strong>Dedicated Agents Per Mode</strong></td>
<td>
Each mode (research, spec, plan, tasks, export) uses a <strong>separate specialized agent</strong> with prompts tailored specifically for that phase. 100% user-controllable via mode switching.
</td>
<td>
Single-agent or one-size-fits-all prompts.
</td>
</tr>
<tr>
<td><strong>Structured Workflow</strong></td>
<td>
Router-driven flow with Planning and Drafting modes; internally it runs Research → Spec → Plan → Tasks → Export with checkpoints in Planning mode.
</td>
<td>
No structure. Just "prompt and hope."
</td>
</tr>
<tr>
<td><strong>Export Formats</strong></td>
<td>
<code>AGENTS.md</code> files ready for Cursor, Claude Code, Windsurf, Lovable—your choice of tool.
</td>
<td>
Locked into specific IDE or coding agent.
</td>
</tr>
</table>
### Case Study - Real Example:
We had to implement payments. Cursor, Claude Code, and Copilot all suggested building a custom payment proxy — 3-4 weeks of development.
⭐ Shotgun's research found [LiteLLM Proxy](https://docs.litellm.ai/docs/simple_proxy) instead—**30 minutes to discover, 5 days to deploy, first customer in 14 hours.**
****80% less dev time. Near-zero technical debt.****
### **[📖 Read the full case study](docs/CASE_STUDY.md)**
---
# Use Cases
- **🚀 Onboarding** - New developer? Shotgun maps your entire architecture and generates docs that actually match the code
- **🔧 Refactoring** - Understand all dependencies before touching anything. Keep your refactor from becoming a rewrite
- **🌱 Greenfield Projects** - Research existing solutions globally before writing line one
- **➕ Adding Features** - Know exactly where your feature fits. Prevent duplicate functionality
- **📦 Migration** - Map the old, plan the new, track the delta. Break migration into safe stages
**📚 Want to see a detailed example?** Check out our [Case Study](docs/CASE_STUDY.md) showing Shotgun in action on a real-world project.
---
# FAQ
**Q: Does Shotgun collect any stats or data?**
A: We only gather minimal, anonymous events (e.g., install, server start, tool call). We don't collect the content itself—only that an event occurred. We use PostHog for analytics and error reporting to improve stability.
**Q: Does my code leave my computer when indexing?**
A: No. When you index your codebase, all indexing happens locally on your machine. The index is stored in `~/.shotgun-sh/codebases/` and never sent to any server. Your code stays on your computer.

**Q: Local LLMs?**
A: Planned. We'll publish compatibility notes and local provider integrations.
**Q: What LLM providers are supported?**
A: Currently OpenAI, Anthropic (Claude), and Google Gemini. Local LLM support is on the roadmap.
**Q: Can I use Shotgun offline?**
A: You need an internet connection for LLM API calls, but your codebase stays local.
**Q: How does the code graph work?**
A: Shotgun indexes your codebase using tree-sitter for accurate parsing and creates a searchable graph of your code structure, dependencies, and relationships.
---
# Contributing
Shotgun is open-source and we welcome contributions. Whether you're fixing bugs, proposing features, improving docs, or spreading the word—we'd love to have you as part of the community.
### Ways to contribute:
- **Bug Report:** Found an issue? [Create a bug report](https://github.com/shotgun-sh/shotgun/issues/new?template=bug_report.md)
- **Feature Request:** Have an idea to make Shotgun better? [Submit a feature request](https://github.com/shotgun-sh/shotgun/issues/new?template=feature_request.md)
- **Documentation:** See something missing in the docs? [Request documentation](https://github.com/shotgun-sh/shotgun/issues/new?template=documentation.md)
**Not sure where to start?** Join our Discord and we'll help you get started!
<div align="left">
<a href="https://discord.com/invite/5RmY6J2N7s">
<img src="https://img.shields.io/badge/Join%20our%20community-5865F2?style=for-the-badge&logo=discord&logoColor=white" alt="Join Discord" />
</a>
</div>
### Development Resources
- **[Contributing Guide](docs/CONTRIBUTING.md)** - Setup, workflow, and guidelines
- **[Git Hooks](docs/GIT_HOOKS.md)** - Lefthook, trufflehog, and security scanning
- **[CI/CD](docs/CI_CD.md)** - GitHub Actions and automated testing
- **[Observability](docs/OBSERVABILITY.md)** - Telemetry, Logfire, and monitoring
- **[Docker](docs/DOCKER.md)** - Container setup and deployment
---
<div align="center">
## 🚀 Ready to Stop AI Agents from Derailing?
**Planning → Drafting** — Two execution modes that give AI agents the full picture, backed by internal phases for Research → Specify → Plan → Tasks → Export.
```bash
uvx shotgun-sh@latest
```
### ⭐ Star us on GitHub
<a href="https://github.com/shotgun-sh/shotgun">
<img src="https://img.shields.io/badge/⭐%20Star%20on%20GitHub-181717?style=for-the-badge&logo=github&logoColor=white" alt="Star Shotgun Repo" />
</a>
### Star History
<a href="https://www.star-history.com/#shotgun-sh/shotgun&type=date&legend=bottom-right">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=shotgun-sh/shotgun&type=date&theme=dark&legend=bottom-right" />
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=shotgun-sh/shotgun&type=date&legend=bottom-right" />
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=shotgun-sh/shotgun&type=date&legend=bottom-right" />
</picture>
</a>
</div>
---
**License:** MIT | **Python:** 3.11+ | **Homepage:** [shotgun.sh](https://shotgun.sh/)
---
## Uninstall
```bash
uv tool uninstall shotgun-sh
```
| text/markdown | null | "Proofs.io" <hello@proofs.io> | null | null | MIT | agent, ai, cli, llm, planning, productivity, pydantic-ai, research, task-management | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Utilities"
] | [] | null | null | <3.14,>=3.11 | [] | [] | [] | [
"aiofiles>=24.0.0",
"anthropic<0.80.0,>=0.39.0",
"claude-agent-sdk>=0.1.0",
"dependency-injector>=4.41.0",
"genai-prices>=0.0.27",
"httpx>=0.27.0",
"jinja2>=3.1.0",
"logfire>=2.0.0",
"openai>=1.0.0",
"packaging>=23.0",
"pathspec>=0.12.0",
"posthog>=3.0.0",
"psutil>=5.9.0",
"pydantic-ai==1.59.0",
"pydantic-settings>=2.0.0",
"pyperclip>=1.10.0",
"real-ladybug==0.14.1",
"rich>=13.0.0",
"sentencepiece>=0.2.0",
"tenacity>=8.0.0",
"textual-serve>=0.1.0",
"textual>=6.1.0",
"tiktoken>=0.7.0",
"tree-sitter-go>=0.23.0",
"tree-sitter-javascript>=0.23.0",
"tree-sitter-python>=0.23.0",
"tree-sitter-rust>=0.23.0",
"tree-sitter-typescript>=0.23.0",
"tree-sitter>=0.21.0",
"typer>=0.12.0",
"watchdog>=4.0.0"
] | [] | [] | [] | [
"Homepage, https://shotgun.sh/",
"Repository, https://github.com/shotgun-sh/shotgun",
"Issues, https://github.com/shotgun-sh/shotgun-alpha/issues",
"Discord, https://discord.gg/5RmY6J2N7s"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T09:47:08.380882 | shotgun_sh-0.10.11.tar.gz | 482,492 | a1/0e/e5e10325fb4d5a649e063aa0fce2ee6fe0a6f90e2e8a1c10a229c784f6ae/shotgun_sh-0.10.11.tar.gz | source | sdist | null | false | 00f8cd92d71715f08d4f72d83115eaf0 | 7963ca303f9c72a0660b0afc2c9599240425f870ee2dd2faf79faffc1e1b35a7 | a10ee5e10325fb4d5a649e063aa0fce2ee6fe0a6f90e2e8a1c10a229c784f6ae | null | [
"LICENSE"
] | 271 |
2.4 | openstack-governance | 0.20.0 | OpenStack Governance Documents | ======================
openstack-governance
======================
The repository https://opendev.org/openstack/governance/
contains OpenStack Technical Committee reference documents and tracks
official resolutions voted by the committee. It also contains a
library for accessing some of the machine-readable data in the
repository.
Directory structure:
reference/
Reference documents which need to be revised over time.
Some motions will just directly result in reference doc changes.
Includes SIGs (Special Interest Groups) documentation in reference/sigs/.
resolutions/
When the motion does not result in a change in a reference doc, it
can be expressed as a resolution.
Those must be named YYYYMMDD-short-name with YYYYMMDD being the
proposal date in order to allow basic sorting.
goals/
Documentation for OpenStack community-wide goals, organized by
release cycle. These pages will be updated with project status
info over time, and if goals are revised.
Note: The governance-sigs repository has been merged into this repository.
All SIGs documentation is now located in reference/sigs/.
See https://governance.openstack.org/tc/ for details.
| null | OpenStack TC | openstack-tc@lists.openstack.org | null | null | null | null | [] | [] | http://www.openstack.org/ | null | null | [] | [] | [] | [
"pydot",
"PyYAML>=3.1.0",
"yamlordereddictloader",
"mwclient==0.8.1",
"ruamel.yaml",
"jsonschema>=3.2.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T09:45:31.409987 | openstack_governance-0.20.0.tar.gz | 526,461 | f4/df/d45fc24fce5016cfec9083e294017f0197726f301a745317375fd229d769/openstack_governance-0.20.0.tar.gz | source | sdist | null | false | abb339729e729fc18803582d88c97d18 | c1c6b2d427204d2b71e700636bd4f4604028c2511a968135f1052044d3fe01fd | f4dfd45fc24fce5016cfec9083e294017f0197726f301a745317375fd229d769 | null | [] | 256 |
2.4 | aadil-nazar-sindhi-nlp | 1.1.4 | A comprehensive Sindhi NLP Suite (Lemmatizer & Spellchecker) |
# Sindhi NLP Suite (Aadil Nazar)
## 👤 About the Author
**Aadil Nazar** is a **Data Engineer** and **Computational Linguistics Researcher** . This suite is the result of intensive research into low-resource language digitization, designed to provide the same level of NLP sophistication for Sindhi that exists for major global languages.
---
## 🛠 Project Overview
The **Sindhi NLP Suite** is a high-performance, integrated toolkit for processing the Sindhi language. It moves beyond simple string matching by incorporating **Morphological Analysis** , **Orthographic Confusion Mapping** , and **Levenshtein Edit Distance** algorithms.
### **Core Capabilities:**
#### **1. The Sindhi Lemmatizer (Morphological Engine)**
This isn't just a stemmer; it’s a rule-based lemmatizer that understands the grammatical structure of Sindhi.
* **Verb Stemming:** Handles complex suffixes like `ائيندا` (future habitual) or `يندڙ` (habitual participle) to find the base root.
* **Noun Pluralization Rules:** Automatically reverts plurals (ending in `يون`, `ون`, `ين`) to their singular masculine or feminine forms.
* **Linguistic Metadata:** Returns POS tags, gender (masculine/feminine), and number (singular/plural) for every analyzed token.
* **Synonym Support:** Integrated WordNet lookup to provide contextual synonyms.
#### **2. The Sindhi Spellchecker (Logic-Driven)**
A morphology-aware spellchecker that reduces "False Misspellings" by cross-referencing with the Lemmatizer.
* **Confusion Map System:** Uses a custom mapping to handle phonetically similar characters that are frequently swapped in digital typing (e.g., `ھ` vs `ح`, `س` vs `ص`, `ز` vs `ذ`).
* **Edit Distance 1 & 2:** Implements optimized algorithms to suggest corrections within one or two character changes.
* **Normalization:** Strips diacritics (Zabar, Zer, Pesh) automatically to ensure matching is based on core orthography.
---
## 🚀 Installation
**Bash**
```
pip install aadil-nazar-sindhi-nlp
```
---
## 💻 Technical Usage
### **Advanced Spellchecking with Suggestions**
The spellchecker first checks the dictionary, then the lemma, then the confusion map, and finally calculates edit distances.
**Python**
```
from aadil_nazar_sindhi_nlp import SindhiSpellchecker
checker = SindhiSpellchecker()
# Test a word with an orthographic confusion error
# Input: 'اصلاح' (with a common character swap)
result = checker.check("اصلاح")
print(f"Correct: {result['correct']}")
print(f"Suggestions: {result['suggestions']}")
```
### **Deep Linguistic Analysis**
Use the Lemmatizer to extract the "DNA" of a Sindhi word.
**Python**
```
from aadil_nazar_sindhi_nlp import SindhiLemmatizer
lem = SindhiLemmatizer()
# Analyze a plural inflected word: 'ڪتابن'
data = lem.analyze_word("ڪتابن")
print(f"Root: {data['root']}") # Output: ڪتاب
print(f"Tag: {data['tag']}") # Output: noun
print(f"Number: {data['number']}") # Output: plural
```
---
## 📊 Data Engineering & Performance
* **O(1) Lookup:** Built on Python sets and hash-maps for near-instant validation against massive datasets.
* **LRU Caching:** Uses `@lru_cache` for variant generation, making repetitive sentence processing lightning-fast.
* **Unicode Standardized:** Built to handle the 52-letter Sindhi alphabet and specific UTF-8 character encodings without corruption.
---
## 🗺 The Roadmap (Growing Ecosystem)
This package is the foundation. As a researcher, I am actively building and will soon integrate:
* **Sindhi POS Tagger:** To identify parts of speech in full sentence contexts.
* **Named Entity Recognition (NER):** For extracting names, dates, and locations.
* **Stopword Filtering:** For cleaning Sindhi text for Machine Learning models.
---
## ⚖ License
Distributed under the **MIT License** . See `LICENSE.txt` for details.
| text/markdown | Aadil Nazar | adilhussainburiro14912@gmail.com | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/aadilnazar/sindhi_nlp | null | >=3.7 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T09:45:12.655959 | aadil_nazar_sindhi_nlp-1.1.4.tar.gz | 2,245,403 | 91/ca/d39af8fda9dc769db1bdad9f31e6a902bc0310263eaac3faaad3a61a579d/aadil_nazar_sindhi_nlp-1.1.4.tar.gz | source | sdist | null | false | a0fc7cb054cff62cc02cac887ebf8f2a | adb6edffc1273cbbd249c6d9a8bfd3301af46a41582a7da429732374673a782f | 91cad39af8fda9dc769db1bdad9f31e6a902bc0310263eaac3faaad3a61a579d | null | [
"LICENSE.txt"
] | 226 |
2.4 | azcrawlerpy | 0.4.3 | Agentic Crawler Discovery Framework. | # azcrawlerpy
A Camoufox-based framework for navigating and filling multi-step web forms programmatically. The framework uses Camoufox anti-detect browser (built on Firefox with C++ level fingerprint spoofing) and JSON instruction files to define form navigation workflows, making it ideal for automated form submission, web scraping, and AI agent-driven web interactions.
## Table of Contents
- [Installation](#installation)
- [Quick Start](#quick-start)
- [Core Concepts](#core-concepts)
- [Instructions Schema](#instructions-schema)
- [Top-Level Structure](#top-level-structure)
- [Browser Configuration](#browser-configuration)
- [Cookie Consent Handling](#cookie-consent-handling)
- [Step Definitions](#step-definitions)
- [Field Types](#field-types)
- [Action Types](#action-types)
- [Final Page Configuration](#final-page-configuration)
- [Data Extraction Configuration](#data-extraction-configuration)
- [Data Points (input_data)](#data-points-input_data)
- [Element Discovery](#element-discovery)
- [AI Agent Guidance](#ai-agent-guidance)
- [Error Handling and Diagnostics](#error-handling-and-diagnostics)
- [Examples](#examples)
## Installation
```bash
uv add azcrawlerpy
```
Or install from source:
```bash
uv pip install -e .
```
## Quick Start
```python
import asyncio
from pathlib import Path
from azcrawlerpy import FormCrawler, DebugMode, CrawlerBrowserConfig
async def main():
# Camoufox anti-detect browser is always used
browser_config = CrawlerBrowserConfig()
crawler = FormCrawler(headless=True, browser_config=browser_config)
instructions = {
"url": "https://example.com/form",
"browser_config": {
"viewport_width": 1920,
"viewport_height": 1080
},
"steps": [
{
"name": "step_1",
"wait_for": "input[name='email']",
"timeout_ms": 15000,
"fields": [
{
"type": "text",
"selector": "input[name='email']",
"data_key": "email"
}
],
"next_action": {
"type": "click",
"selector": "button[type='submit']"
}
}
],
"final_page": {
"wait_for": ".success-message",
"timeout_ms": 60000
}
}
input_data = {
"email": "user@example.com"
}
result = await crawler.crawl(
url=instructions["url"],
input_data=input_data,
instructions=instructions,
output_dir=Path("./output"),
debug_mode=DebugMode.ALL,
)
print(f"Final URL: {result.final_url}")
print(f"Steps completed: {result.steps_completed}")
print(f"Screenshot saved: {result.screenshot_path}")
print(f"Extracted data: {result.extracted_data}")
asyncio.run(main())
```
## Core Concepts
The framework operates on two primary inputs:
1. **Instructions (instructions.json)**: Defines the form structure, selectors, navigation flow, and field types
2. **Data Points (input_data)**: Contains the actual values to fill into form fields
The crawler processes each step sequentially:
1. Wait for the step's `wait_for` selector to become visible
2. Fill all fields defined in the step using values from `input_data`
3. Execute the `next_action` to navigate to the next step
4. Repeat until all steps are complete
5. Wait for and capture the final page
## Instructions Schema
### Top-Level Structure
```json
{
"url": "https://example.com/form",
"browser_config": { ... },
"cookie_consent": { ... },
"steps": [ ... ],
"final_page": { ... },
"data_extraction": { ... }
}
```
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `url` | string | Yes | Starting URL for the form |
| `browser_config` | object | No | Browser viewport and user agent settings |
| `cookie_consent` | object | No | Cookie banner handling configuration |
| `steps` | array | Yes | Ordered list of form steps |
| `final_page` | object | Yes | Configuration for the result page |
| `data_extraction` | object | No | Configuration for extracting data from final page |
### Browser Configuration
```json
{
"browser_config": {
"viewport_width": 1920,
"viewport_height": 1080,
"user_agent": "Mozilla/5.0 ..."
}
}
```
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `viewport_width` | integer | Yes | Browser viewport width in pixels |
| `viewport_height` | integer | Yes | Browser viewport height in pixels |
| `user_agent` | string | No | Custom user agent string |
### Cookie Consent Handling
The framework supports two modes for handling cookie consent banners:
**Standard Mode** (regular DOM elements):
```json
{
"cookie_consent": {
"banner_selector": "dialog:has-text('cookies')",
"accept_selector": "button:has-text('Accept')"
}
}
```
**Shadow DOM Mode** (for Usercentrics, OneTrust, etc.):
```json
{
"cookie_consent": {
"banner_selector": "#usercentrics-cmp-ui",
"shadow_host_selector": "#usercentrics-cmp-ui",
"accept_button_texts": ["Accept All", "Alle akzeptieren"]
}
}
```
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `banner_selector` | string | Yes | CSS selector for the banner container |
| `accept_selector` | string | No | CSS selector for accept button (standard mode) |
| `shadow_host_selector` | string | No | CSS selector for shadow DOM host |
| `accept_button_texts` | array | No | Text patterns to match accept buttons in shadow DOM |
| `banner_settle_delay_ms` | integer | No | Wait time before checking for banner |
| `banner_visible_timeout_ms` | integer | No | Timeout for banner visibility |
| `accept_button_timeout_ms` | integer | No | Timeout for accept button visibility |
| `post_consent_delay_ms` | integer | No | Wait time after handling consent |
### Step Definitions
Each step represents a form page or section:
```json
{
"name": "personal_info",
"wait_for": "input[name='firstName']",
"timeout_ms": 15000,
"fields": [ ... ],
"next_action": { ... }
}
```
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `name` | string | Yes | Unique identifier for the step |
| `wait_for` | string | Yes | CSS selector to wait for before processing |
| `timeout_ms` | integer | Yes | Timeout in milliseconds for wait condition |
| `fields` | array | Yes | List of field definitions (can be empty) |
| `next_action` | object | Yes | Action to navigate to next step |
### Field Types
#### TEXT
For text inputs, email fields, phone numbers, and similar:
```json
{
"type": "text",
"selector": "input[name='email']",
"data_key": "email"
}
```
#### TEXTAREA
For multi-line text areas:
```json
{
"type": "textarea",
"selector": "textarea[name='message']",
"data_key": "message"
}
```
#### DROPDOWN / SELECT
For native `<select>` elements:
```json
{
"type": "dropdown",
"selector": "select[name='country']",
"data_key": "country",
"type_config": {
"select_by": "text"
}
}
```
| type_config Parameter | Values | Description |
|-----------------------|--------|-------------|
| `select_by` | `text`, `value`, `index` | How to match the option |
| `option_visible_timeout_ms` | integer | Timeout in ms for option visibility |
#### RADIO
For radio button groups:
```json
{
"type": "radio",
"selector": "input[type='radio'][value='${value}']",
"data_key": "payment_method"
}
```
**Pattern A - Value-driven selector**: Use `${value}` placeholder in selector, data provides the value:
```json
{
"type": "radio",
"selector": "input[type='radio'][value='${value}']",
"data_key": "gender"
}
// data: { "gender": "male" }
```
**Pattern B - Boolean flags**: Use explicit selectors with boolean data values:
```json
{
"type": "radio",
"selector": "[role='radio']:has-text('Yes')",
"data_key": "accept_terms",
"force_click": true
}
// data: { "accept_terms": true } // clicks if true, skips if null/false
```
#### CHECKBOX
For checkbox inputs:
```json
{
"type": "checkbox",
"selector": "input[type='checkbox'][name='newsletter']",
"data_key": "subscribe_newsletter"
}
```
Data value `true` checks the box, `false` or `null` leaves it unchanged.
#### DATE
For date inputs with format conversion:
```json
{
"type": "date",
"selector": "input[name='birthdate']",
"data_key": "birthdate",
"type_config": {
"format": "DD.MM.YYYY"
}
}
```
| Format | Example | Description |
|--------|---------|-------------|
| `DD.MM.YYYY` | 15.06.1985 | Day.Month.Year |
| `MM.YYYY` | 06.1985 | Month.Year |
| `YYYY-MM-DD` | 1985-06-15 | ISO format |
| `%d.%m.%Y` | 15.06.1985 | Python strftime format |
Data should be provided in ISO format (`YYYY-MM-DD`) and will be converted to the specified format.
#### SLIDER
For range inputs:
```json
{
"type": "slider",
"selector": "input[type='range'][name='coverage']",
"data_key": "coverage_amount"
}
```
#### FILE
For file upload fields:
```json
{
"type": "file",
"selector": "input[type='file']",
"data_key": "document_path"
}
```
Data value should be the absolute file path.
#### COMBOBOX
For autocomplete/typeahead inputs:
```json
{
"type": "combobox",
"selector": "input[aria-label='City']",
"data_key": "city",
"type_config": {
"option_selector": ".autocomplete-option",
"type_delay_ms": 50,
"wait_after_type_ms": 500,
"press_enter": true
}
}
```
| type_config Parameter | Description |
|-----------------------|-------------|
| `option_selector` | CSS selector for dropdown options (required) |
| `type_delay_ms` | Delay between keystrokes (simulates human typing) |
| `wait_after_type_ms` | Wait time for options to appear |
| `press_enter` | Press Enter after selecting option |
| `clear_before_type` | Clear field before typing |
| `option_visible_timeout_ms` | Timeout in ms for option visibility |
#### CLICK_SELECT
For custom dropdowns requiring click-then-select:
```json
{
"type": "click_select",
"selector": ".custom-dropdown-trigger",
"data_key": "option_value",
"post_click_delay_ms": 300,
"type_config": {
"option_selector": ".dropdown-item:has-text('${value}')"
}
}
```
#### CLICK_ONLY
For elements that only need clicking (no data input):
```json
{
"type": "click_only",
"selector": "button.expand-section"
}
```
With conditional clicking based on data:
```json
{
"type": "click_only",
"selector": "button:has-text('${value}')",
"data_key": "selected_option"
}
```
#### IFRAME_FIELD
For fields inside iframes (alternative to `iframe_selector`):
```json
{
"type": "iframe_field",
"selector": "input[name='card_number']",
"iframe_selector": "iframe#payment-frame",
"data_key": "card_number"
}
```
### Common Field Parameters
| Parameter | Type | Description |
|-----------|------|-------------|
| `data_key` | string | Key in input_data to get value from |
| `selector` | string | CSS/Playwright selector for the element |
| `type_config` | object | Type-specific configuration (see field type sections above) |
| `iframe_selector` | string | Selector for parent iframe if field is embedded |
| `field_visible_timeout_ms` | integer | Timeout for field to become visible |
| `post_click_delay_ms` | integer | Wait after clicking the field |
| `skip_verification` | boolean | Skip value verification after filling |
| `force_click` | boolean | Use force click (bypasses overlays) |
### Action Types
#### CLICK
Click a button or link:
```json
{
"type": "click",
"selector": "button[type='submit']"
}
```
With iframe support:
```json
{
"type": "click",
"selector": "button:has-text('Next')",
"iframe_selector": "iframe#form-frame"
}
```
#### WAIT
Wait for an element to appear:
```json
{
"type": "wait",
"selector": ".loading-complete"
}
```
#### WAIT_HIDDEN
Wait for an element to disappear:
```json
{
"type": "wait_hidden",
"selector": ".loading-spinner"
}
```
#### SCROLL
Scroll to an element:
```json
{
"type": "scroll",
"selector": "#section-bottom"
}
```
#### DELAY
Wait for a fixed time:
```json
{
"type": "delay",
"delay_ms": 2000
}
```
#### CONDITIONAL
Execute actions based on conditions:
```json
{
"type": "conditional",
"condition": {
"type": "element_visible",
"selector": ".error-message"
},
"actions": [
{
"type": "click",
"selector": "button.dismiss-error"
}
]
}
```
Condition types:
- `element_visible`: Check if element is visible
- `element_exists`: Check if element exists in DOM
- `data_equals`: Check if data value matches
### Common Action Parameters
| Parameter | Type | Description |
|-----------|------|-------------|
| `selector` | string | Target element selector |
| `iframe_selector` | string | Selector for parent iframe |
| `pre_action_delay_ms` | integer | Wait before executing action |
| `post_action_delay_ms` | integer | Wait after executing action |
### Final Page Configuration
```json
{
"final_page": {
"wait_for": ".result-container, .confirmation",
"timeout_ms": 60000,
"screenshot_selector": ".result-panel"
}
}
```
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `wait_for` | string | Yes | Selector to confirm final page loaded |
| `timeout_ms` | integer | Yes | Timeout for final page |
| `screenshot_selector` | string | No | Element to screenshot (null for full page) |
### Data Extraction Configuration
Extract structured data from the final page using CSS selectors:
```json
{
"data_extraction": {
"fields": {
"tier_prices": {
"selector": ".price-value",
"attribute": null,
"regex": "([0-9]+[.,][0-9]{2})",
"multiple": true,
"iframe_selector": "iframe#form-frame"
},
"selected_price": {
"selector": "#total-amount",
"attribute": "data-value",
"regex": null,
"multiple": false
}
}
}
}
```
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `selector` | string | Yes | CSS selector to locate element(s) |
| `attribute` | string | No | Element attribute to extract (null for text content) |
| `regex` | string | No | Regex pattern to apply (uses first capture group if present) |
| `multiple` | boolean | Yes | True for list of all matches, False for first match only |
| `iframe_selector` | string | No | CSS selector for iframe if element is inside one |
Extracted data is available in the crawl result:
```python
result = await crawler.crawl(...)
print(result.extracted_data)
# {'tier_prices': ['32,28', '35,26', '50,34'], 'selected_price': '35,26'}
```
## Data Points (input_data)
The `input_data` dictionary provides values for form fields. Keys must match `data_key` values in the instructions.
### Structure
```json
{
"email": "user@example.com",
"first_name": "John",
"last_name": "Doe",
"birthdate": "1985-06-15",
"country": "Germany",
"accept_terms": true,
"newsletter": false,
"premium_option": null
}
```
### Value Types
| Type | Description | Example |
|------|-------------|---------|
| String | Text values, dropdown selections | `"John"` |
| Boolean | Checkbox/radio toggle | `true`, `false` |
| Null | Skip this field | `null` |
| Integer/Float | Numeric inputs, sliders | `12000`, `99.99` |
### Radio Button Patterns
**Pattern A - Mutually exclusive options with value selector**:
```json
{
"gender": "male"
}
```
Selector uses `${value}` placeholder: `input[value='${value}']`
**Pattern B - Boolean flags for each option**:
```json
{
"option_a": true,
"option_b": null,
"option_c": null
}
```
Only the option with `true` gets clicked.
### Date Handling
Dates in input_data should use ISO format (`YYYY-MM-DD`):
```json
{
"birthdate": "1985-06-15",
"start_date": "2024-01-01"
}
```
The framework converts to the format specified in the field definition.
## Element Discovery
The `ElementDiscovery` class scans web pages to identify interactive elements, helping build instructions.json files.
```python
from pathlib import Path
from azcrawlerpy import ElementDiscovery
async def discover_elements():
discovery = ElementDiscovery(headless=False)
report = await discovery.discover(
url="https://example.com/form",
output_dir=Path("./discovery_output"),
cookie_consent={
"banner_selector": "#cookie-banner",
"accept_selector": "button.accept"
},
explore_iframes=True,
screenshot=True,
)
print(f"Found {report.total_elements} elements")
for text_input in report.text_inputs:
print(f"Text input: {text_input.selector}")
print(f" Suggested type: {text_input.suggested_field_type}")
for dropdown in report.selects:
print(f"Dropdown: {dropdown.selector}")
print(f" Options: {dropdown.options}")
for radio_group in report.radio_groups:
print(f"Radio group: {radio_group.name}")
for option in radio_group.options:
print(f" - {option.label}: {option.selector}")
```
### Discovery Report Contents
- `text_inputs`: Text, email, phone, password fields
- `textareas`: Multi-line text areas
- `selects`: Native dropdown elements with options
- `radio_groups`: Grouped radio buttons
- `checkboxes`: Checkbox inputs
- `buttons`: Clickable buttons
- `links`: Anchor elements
- `date_inputs`: Date picker fields
- `file_inputs`: File upload fields
- `sliders`: Range inputs
- `custom_components`: Non-standard interactive elements
- `iframes`: Discovered iframes with their elements
## AI Agent Guidance
This section provides instructions for AI agents tasked with creating `instructions.json` and `input_data` files.
### Workflow for Creating Instructions
1. **Discovery Phase**: Use `ElementDiscovery` to scan each page/step of the form
2. **Mapping Phase**: Map discovered elements to field definitions
3. **Flow Definition**: Define step transitions and actions
4. **Data Schema**: Create the input_data structure
### Step-by-Step Process
#### 1. Analyze the Form Structure
- Identify how many pages/steps the form has
- Note the URL pattern changes (if any)
- Identify what element appears when each step loads
#### 2. For Each Step, Define:
```json
{
"name": "<descriptive_step_name>",
"wait_for": "<selector_that_confirms_step_loaded>",
"timeout_ms": 15000,
"fields": [...],
"next_action": {...}
}
```
**Naming conventions**:
- Use snake_case for step names: `personal_info`, `payment_details`
- Use descriptive data_keys: `first_name`, `email_address`, `accepts_terms`
#### 3. Selector Priority
When choosing selectors, prefer in order:
1. `[data-testid='...']` or `[data-cy='...']` - Most stable
2. `[aria-label='...']` or `[aria-labelledby='...']` - Accessible and stable
3. `input[name='...']` - Form field names
4. `:has-text('...')` - Text content (use for buttons/labels)
5. CSS class selectors - Least stable, avoid if possible
#### 4. Handle Dynamic Content
For AJAX-loaded content:
- Use `wait` action before interacting
- Add `field_visible_timeout_ms` to field definitions
- Use `post_click_delay_ms` for fields that trigger updates
#### 5. Radio Button Strategy
**Option A - When radio values are meaningful**:
```json
{
"type": "radio",
"selector": "input[type='radio'][value='${value}']",
"data_key": "payment_type"
}
// data: { "payment_type": "credit_card" }
```
**Option B - When you need individual control**:
```json
{
"type": "radio",
"selector": "[role='radio']:has-text('Credit Card')",
"data_key": "payment_credit_card",
"force_click": true
},
{
"type": "radio",
"selector": "[role='radio']:has-text('PayPal')",
"data_key": "payment_paypal",
"force_click": true
}
// data: { "payment_credit_card": true, "payment_paypal": null }
```
#### 6. Iframe Handling
When elements are inside iframes:
```json
{
"type": "text",
"selector": "input[name='card_number']",
"iframe_selector": "iframe#payment-iframe",
"data_key": "card_number"
}
```
### Creating input_data
#### 1. Analyze Required Fields
From the instructions, extract all unique `data_key` values:
```python
data_keys = set()
for step in instructions["steps"]:
for field in step["fields"]:
if field.get("data_key"):
data_keys.add(field["data_key"])
```
#### 2. Determine Value Types
| Field Type | Data Type | Example |
|------------|-----------|---------|
| text, textarea | string | `"John Doe"` |
| dropdown | string | `"Germany"` |
| radio (value-driven) | string | `"option_a"` |
| radio (boolean) | boolean/null | `true` or `null` |
| checkbox | boolean | `true` / `false` |
| date | string (ISO) | `"1985-06-15"` |
| slider | number | `50000` |
| file | string (path) | `"/path/to/file.pdf"` |
#### 3. Handle Mutually Exclusive Options
For radio groups with boolean flags, only ONE should be `true`:
```json
{
"employment_fulltime": true,
"employment_parttime": null,
"employment_selfemployed": null,
"employment_unemployed": null
}
```
#### 4. Date Format
Always provide dates in ISO format in input_data:
```json
{
"birthdate": "1985-06-15",
"policy_start": "2024-01-01"
}
```
The instructions specify the output format for the specific form.
### Common Patterns
#### Multi-Step Wizard
```json
{
"steps": [
{
"name": "step_1_personal",
"wait_for": "input[name='firstName']",
"fields": [...],
"next_action": { "type": "click", "selector": "button:has-text('Next')" }
},
{
"name": "step_2_address",
"wait_for": "input[name='street']",
"fields": [...],
"next_action": { "type": "click", "selector": "button:has-text('Next')" }
}
]
}
```
#### Form with Loading States
```json
{
"next_action": {
"type": "click",
"selector": "button[type='submit']",
"post_action_delay_ms": 1000
}
}
```
#### Conditional Fields
```json
{
"type": "conditional",
"condition": {
"type": "data_equals",
"data_key": "has_additional_driver",
"value": true
},
"actions": [
{
"type": "click",
"selector": "button:has-text('Add Driver')"
}
]
}
```
## Error Handling and Diagnostics
The framework provides detailed error information when failures occur.
### Exception Types
| Exception | When Raised |
|-----------|-------------|
| `FieldNotFoundError` | Selector doesn't match any element |
| `FieldInteractionError` | Element found but interaction failed |
| `CrawlerTimeoutError` | Wait condition not met within timeout |
| `NavigationError` | Navigation action failed |
| `MissingDataError` | Required data_key not in input_data |
| `InvalidInstructionError` | Malformed instructions JSON |
| `UnsupportedFieldTypeError` | Unknown field type specified |
| `UnsupportedActionTypeError` | Unknown action type specified |
| `IframeNotFoundError` | Specified iframe not found |
| `DataExtractionError` | Data extraction from final page failed |
### Debug Mode
Enable debug mode to capture screenshots at various stages:
```python
from azcrawlerpy import DebugMode
result = await crawler.crawl(
...,
debug_mode=DebugMode.ALL, # Capture all screenshots
)
```
| Mode | Description |
|------|-------------|
| `NONE` | No debug screenshots |
| `START` | Screenshot at form start |
| `END` | Screenshot at form end |
| `ALL` | Screenshots after every field and action |
### AI Diagnostics
When errors occur with debug mode enabled, the framework captures:
- Current page URL and title
- Available `data-cy` and `data-testid` selectors
- Visible buttons and input fields
- Similar selectors (fuzzy matching suggestions)
- Console errors and warnings
- Failed network requests
- HTML snippet of the form area
This information is included in the exception message and saved to `error_diagnostics.json`.
## Examples
### Insurance Quote Form
**instructions.json**:
```json
{
"url": "https://insurance.example.com/quote",
"browser_config": {
"viewport_width": 1920,
"viewport_height": 1080
},
"cookie_consent": {
"banner_selector": "#cookie-banner",
"accept_selector": "button:has-text('Accept')"
},
"steps": [
{
"name": "vehicle_info",
"wait_for": "input[name='hsn']",
"timeout_ms": 15000,
"fields": [
{
"type": "text",
"selector": "input[name='hsn']",
"data_key": "vehicle_hsn"
},
{
"type": "text",
"selector": "input[name='tsn']",
"data_key": "vehicle_tsn"
},
{
"type": "date",
"selector": "input[name='registration_date']",
"data_key": "first_registration",
"type_config": {
"format": "MM.YYYY"
}
}
],
"next_action": {
"type": "click",
"selector": "button:has-text('Continue')"
}
},
{
"name": "personal_info",
"wait_for": "input[name='birthdate']",
"timeout_ms": 15000,
"fields": [
{
"type": "date",
"selector": "input[name='birthdate']",
"data_key": "birthdate",
"type_config": {
"format": "DD.MM.YYYY"
}
},
{
"type": "text",
"selector": "input[name='zipcode']",
"data_key": "postal_code"
}
],
"next_action": {
"type": "click",
"selector": "button:has-text('Get Quote')"
}
}
],
"final_page": {
"wait_for": ".quote-result",
"timeout_ms": 60000,
"screenshot_selector": ".quote-panel"
}
}
```
**data_row.json**:
```json
{
"vehicle_hsn": "0603",
"vehicle_tsn": "AKZ",
"first_registration": "2020-03-15",
"birthdate": "1985-06-20",
"postal_code": "80331"
}
```
### Form with Iframes
```json
{
"steps": [
{
"name": "embedded_form",
"wait_for": "iframe#form-frame",
"timeout_ms": 15000,
"fields": [
{
"type": "text",
"selector": "input[name='email']",
"iframe_selector": "iframe#form-frame",
"data_key": "email"
},
{
"type": "dropdown",
"selector": "select[name='plan']",
"iframe_selector": "iframe#form-frame",
"data_key": "selected_plan",
"type_config": {
"select_by": "text"
}
}
],
"next_action": {
"type": "click",
"selector": "button:has-text('Submit')",
"iframe_selector": "iframe#form-frame"
}
}
]
}
```
## License
MIT
| text/markdown | null | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | <3.12,>=3.11.10 | [] | [] | [] | [
"playwright==1.48.0",
"pydantic>=2.11.10",
"camoufox[geoip]>=0.4.0",
"pytest==8.4.2; extra == \"dev\"",
"pytest-asyncio==1.0.0; extra == \"dev\"",
"pytest-mock==3.14.1; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"pyright>=1.1.390; extra == \"dev\"",
"ruff>=0.8.0; extra == \"dev\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T09:44:48.338466 | azcrawlerpy-0.4.3.tar.gz | 65,597 | a5/47/581f792153dc7113e275276da40f23d4fd95a59f7cfebaca3e29a19b642b/azcrawlerpy-0.4.3.tar.gz | source | sdist | null | false | 45bb273ea31ceca91995d8db2dec0bad | 09e8af0056c3fe0457b7b6cd80772112e271969bc9bfdf8aaf16011f168b6e5d | a547581f792153dc7113e275276da40f23d4fd95a59f7cfebaca3e29a19b642b | null | [] | 213 |
2.4 | soccernetpro | 0.0.1.dev11 | SoccerNetPro is the professional extension of the popular SoccerNet library, designed for advanced video understanding in soccer. It provides state-of-the-art tools for action recognition, spotting, retrieval, and captioning, making it ideal for researchers, analysts, and developers working with soccer video data. | # SoccerNetPro
SoccerNetPro is the professional extension of the popular SoccerNet library, designed for advanced video understanding in soccer. It provides state-of-the-art tools for action recognition, spotting, retrieval, and captioning, making it ideal for researchers, analysts, and developers working with soccer video data.
## Development
```bash
### Clone the github repo
git clone https://github.com/OpenSportsLab/soccernetpro.git
### Requirements and installation ###
conda create -n SoccerNet python=3.12 pip
conda activate SoccerNet
pip install -e .
or
pip install -e .[localization]
or
pip install -e .[tracking]
### git branch and merge rules ###
1. Check and verify current branch is "dev" - git status
2. Create new branch from source "dev" -
git pull
git checkout -b <new_feature/fix/bug>
3. Raise PR request to merge your branch <new_feature/fix/bug> to "dev" branch
```
## Installation
```bash
conda create -n SoccerNet python=3.12 pip
conda activate SoccerNet
pip install --pre soccernetpro
```
## 🤝 Contributing & Developer Guide
We welcome contributions to SoccerNetPro.
- 📘 **Contributor Guide:** [CONTRIBUTING.md](soccernetpro/docs/CONTRIBUTING.md)
- 🛠 **Developer Guide:** [DEVELOPERS.md](soccernetpro/docs/DEVELOPERS.md)
These documents explain:
- How to add models and datasets
- Coding standards
- Training pipeline structure
- How to run and test the framework
## Configuration Sample (.yaml) file
1. Classification
```bash
TASK: classification
DATA:
dataset_name: mvfouls
data_dir: /home/vorajv/soccernetpro/SoccerNet/mvfouls
data_modality: video
view_type: multi # multi or single
num_classes: 8 # mvfoul
train:
type: annotations_train.json
video_path: ${DATA.data_dir}/train
path: ${DATA.train.video_path}/annotations-train.json
dataloader:
batch_size: 8
shuffle: true
num_workers: 4
pin_memory: true
valid:
type: annotations_valid.json
video_path: ${DATA.data_dir}/valid
path: ${DATA.valid.video_path}/annotations-valid.json
dataloader:
batch_size: 1
num_workers: 1
shuffle: false
test:
type: annotations_test.json
video_path: ${DATA.data_dir}/test
path: ${DATA.test.video_path}/annotations-test.json
dataloader:
batch_size: 1
num_workers: 1
shuffle: false
num_frames: 16 # 8 before + 8 after the foul
input_fps: 25 # Original FPS of video
target_fps: 17 # Temporal downsampling to 1s clip (approx)
start_frame: 63 # Start frame of clip relative to foul frame
end_frame: 87 # End frame of clip relative to foul frame
frame_size: [224, 224] # Spatial resolution (HxW)
augmentations:
random_affine: true
translate: [0.1, 0.1]
affine_scale: [0.9, 1.0]
random_perspective: true
distortion_scale: 0.3
perspective_prob: 0.5
random_rotation: true
rotation_degrees: 5
color_jitter: true
jitter_params: [0.2, 0.2, 0.2, 0.1] # brightness, contrast, saturation, hue
random_horizontal_flip: true
flip_prob: 0.5
random_crop: false
MODEL:
type: custom # huggingface, custom
backbone:
type: mvit_v2_s # video_mae, r3d_18, mc3_18, r2plus1d_18, s3d, mvit_v2_s
neck:
type: MV_Aggregate
agr_type: max # max, mean, attention
head:
type: MV_LinearLayer
pretrained_model: mvit_v2_s # MCG-NJU/videomae-base, OpenGVLab/VideoMAEv2-Base, r3d_18, mc3_18, r2plus1d_18, s3d, mvit_v2_s
unfreeze_head: true # for videomae backbone
unfreeze_last_n_layers: 3 # for videomae backbone
TRAIN:
monitor: balanced_accuracy # balanced_accuracy, loss
mode: max # max or min
enabled: true
use_weighted_sampler: false
use_weighted_loss: true
epochs: 20 #20
save_dir: ./checkpoints
log_interval: 10
save_every: 2 #5
criterion:
type: CrossEntropyLoss
optimizer:
type: AdamW
lr: 0.0001 #0.001
backbone_lr: 0.00005
head_lr: 0.001
betas: [0.9, 0.999]
eps: 0.0000001
weight_decay: 0.001 #0.01 - videomae, 0.001 - others
amsgrad: false
scheduler:
type: StepLR
step_size: 3
gamma: 0.1
SYSTEM:
log_dir: ./logs
use_seed: false
seed: 42
GPU: 4
device: cuda # auto | cuda | cpu
gpu_id: 0
```
2. Classification (Tracking)
```bash
TASK: classification
DATA:
dataset_name: sngar
data_modality: tracking_parquet
data_dir: /home/karkid/soccernetpro/sngar-tracking
preload_data: false
train:
type: annotations_train.json
video_path: ${DATA.data_dir}/train
path: ${DATA.train.video_path}/train.json
dataloader:
batch_size: 32
shuffle: true
num_workers: 8
pin_memory: true
valid:
type: annotations_valid.json
video_path: ${DATA.data_dir}/valid
path: ${DATA.valid.video_path}/valid.json
dataloader:
batch_size: 32
num_workers: 8
shuffle: false
test:
type: annotations_test.json
video_path: ${DATA.data_dir}/test
path: ${DATA.test.video_path}/test.json
dataloader:
batch_size: 32
num_workers: 8
shuffle: false
num_frames: 16
frame_interval: 9
augmentations:
vertical_flip: true
horizontal_flip: true
team_flip: true
normalize: true
num_objects: 23
feature_dim: 8
pitch_half_length: 85.0
pitch_half_width: 50.0
max_displacement: 110.0
max_ball_height: 30.0
MODEL:
type: custom
backbone:
type: graph_conv
encoder: graphconv
hidden_dim: 64
num_layers: 20
dropout: 0.1
neck:
type: TemporalAggregation
agr_type: maxpool
hidden_dim: 64
dropout: 0.1
head:
type: TrackingClassifier
hidden_dim: 64
dropout: 0.1
num_classes: 10
edge: positional
k: 8
r: 15.0
TRAIN:
monitor: loss # balanced_accuracy, loss
mode: min # max or min
enabled: true
use_weighted_sampler: true
use_weighted_loss: false
samples_per_class: 4000
epochs: 10
patience: 10
save_every: 20
detailed_results: true
optimizer:
type: Adam
lr: 0.001
scheduler:
type: ReduceLROnPlateau
mode: ${TRAIN.mode}
patience: 10
factor: 0.1
min_lr: 1e-8
criterion:
type: CrossEntropyLoss
save_dir: ./checkpoints_tracking
SYSTEM:
log_dir: ./logs
use_seed: true
seed: 42
GPU: 4
device: cuda # auto | cuda | cpu
gpu_id: 0
```
3. Localization
```bash
TASK: localization
dali: True
DATA:
dataset_name: SoccerNet
data_dir: /home/vorajv/soccernetpro/SoccerNet/annotations/
classes:
- PASS
- DRIVE
- HEADER
- HIGH PASS
- OUT
- CROSS
- THROW IN
- SHOT
- BALL PLAYER BLOCK
- PLAYER SUCCESSFUL TACKLE
- FREE KICK
- GOAL
epoch_num_frames: 500000
mixup: true
modality: rgb
crop_dim: -1
dilate_len: 0 # Dilate ground truth labels
clip_len: 100
input_fps: 25
extract_fps: 2
imagenet_mean: [0.485, 0.456, 0.406]
imagenet_std: [0.229, 0.224, 0.225]
target_height: 224
target_width: 398
train:
type: VideoGameWithDali
classes: ${DATA.classes}
output_map: [data, label]
video_path: ${DATA.data_dir}/train/
path: ${DATA.train.video_path}/annotations-2024-224p-train.json
dataloader:
batch_size: 8
shuffle: true
num_workers: 4
pin_memory: true
valid:
type: VideoGameWithDali
classes: ${DATA.classes}
output_map: [data, label]
video_path: ${DATA.data_dir}/valid/
path: ${DATA.valid.video_path}/annotations-2024-224p-valid.json
dataloader:
batch_size: 8
shuffle: true
valid_data_frames:
type: VideoGameWithDaliVideo
classes: ${DATA.classes}
output_map: [data, label]
video_path: ${DATA.valid.video_path}
path: ${DATA.valid.path}
overlap_len: 0
dataloader:
batch_size: 4
shuffle: false
test:
type: VideoGameWithDaliVideo
classes: ${DATA.classes}
output_map: [data, label]
video_path: ${DATA.data_dir}/test/
path: ${DATA.test.video_path}/annotations-2024-224p-test.json
results: results_spotting_test
nms_window: 2
metric: tight
overlap_len: 50
dataloader:
batch_size: 4
shuffle: false
challenge:
type: VideoGameWithDaliVideo
overlap_len: 50
output_map: [data, label]
path: ${DATA.data_dir}/challenge/annotations.json
dataloader:
batch_size: 4
shuffle: false
MODEL:
type: E2E
runner:
type: runner_e2e
backbone:
type: rny008_gsm
head:
type: gru
multi_gpu: true
load_weights: null
save_dir: ./checkpoints
work_dir: ${MODEL.save_dir}
TRAIN:
type: trainer_e2e
num_epochs: 10
acc_grad_iter: 1
base_num_valid_epochs: 30
start_valid_epoch: 4
valid_map_every: 1
criterion_valid: map
criterion:
type: CrossEntropyLoss
optimizer:
type: AdamWithScaler
lr: 0.01
scheduler:
type: ChainedSchedulerE2E
acc_grad_iter: 1
num_epochs: ${TRAIN.num_epochs}
warm_up_epochs: 3
SYSTEM:
log_dir: ./logs
seed: 42
GPU: 4 # number of gpus to use
device: cuda # auto | cuda | cpu
gpu_id: 0 # device id for single gpu training
```
## Annotations (train/valid/test) (.json) format
Download annotations file from below links
1. Classification
mvfouls = https://huggingface.co/datasets/OpenSportsLab/soccernetpro-classification-vars/tree/mvfouls
svfouls = https://huggingface.co/datasets/OpenSportsLab/soccernetpro-classification-vars/tree/svfouls
2. Localization
ball-action-spotting = https://huggingface.co/datasets/OpenSportsLab/soccernetpro-localization-snbas/tree/main
# Download weights from HF
1. classification (mvit)
(MVFoul classification) https://huggingface.co/jeetv/snpro-classification-mvit/tree/main
2. Localization (E2E spot)
- (2023 Ball Action Spotting - 2 classes) https://huggingface.co/jeetv/snpro-snbas-2023/tree/main
- (2024 Ball Action Spotting - 12 classes) https://huggingface.co/jeetv/snpro-snbas-2024/tree/main
Usage:
```bash
### Load weights from HF ###
#### For Classification ####
myModel.infer(
test_set="/path/to/annotations.json",
pretrained="jeetv/snpro-classification-mvit", # classification (MViT)
)
#### For Localization ####
pretrained = "jeetv/snpro-snbas-2023" # SNBAS - 2 classes (E2E spot)
pretrained = "jeetv/snpro-snbas-2024" # SNBAS - 12 classes (E2E spot)
```
## Train on SINGLE GPU
```bash
from soccernetpro import model
import wandb
# Initialize model with config
myModel = model.classification(
config="/path/to/classification.yaml"
)
## Localization ##
# myModel = model.localization(
# config="/path/to/classification.yaml"
# )
# Train on your dataset
myModel.train(
train_set="/path/to/train_annotations.json",
valid_set="/path/to/valid_annotations.json",
pretrained=/path/to/ # or path to pretrained checkpoint
)
```
## Train on Multiple GPU (DDP)
```bash
from soccernetpro import model
def main():
myModel = model.classification(
config="/path/to/classification.yaml",
data_dir="/path/to/dataset_root"
)
## Localization ##
# myModel = model.localization(
# config="/path/to/classification.yaml"
# )
myModel.train(
train_set="/path/to/train_annotations.json",
valid_set="/path/to/valid_annotations.json",
pretrained="/path/to/pretrained.pt", # optional
use_ddp=True, # IMPORTANT
)
if __name__ == "__main__":
main()
```
## Test / Inference on SINGLE GPU
```bash
from soccernetpro import model
# Load trained model
myModel = model.classification(
config="/path/to/classification.yaml"
)
## Localization ##
# myModel = model.localization(
# config="/path/to/classification.yaml"
# )
# Run inference on test set
metrics = myModel.infer(
test_set="/path/to/test_annotations.json",
pretrained="/path/to/checkpoints/final_model",
predictions="/path/to/predictions.json"
)
```
## Test / Inference on Multiple GPU (DDP)
```bash
from soccernetpro import model
def main():
myModel = model.classification(
config="/path/to/classification.yaml",
data_dir="/path/to/dataset_root"
)
## Localization ##
# myModel = model.localization(
# config="/path/to/classification.yaml"
# )
metrics = myModel.infer(
test_set="/path/to/test_annotations.json",
pretrained="/path/to/checkpoints/best.pt",
predictions="/path/to/predictions.json",
use_ddp=True, # optional (usually not needed)
)
print(metrics)
if __name__ == "__main__":
main()
```
| text/markdown | Jeet Vora | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"SoccerNet",
"av",
"decord; platform_system != \"Darwin\" and platform_machine != \"arm64\"",
"evaluate",
"scikit-learn",
"torch",
"torchvision",
"transformers==4.57.3",
"tokenizers==0.22.1",
"accelerate",
"wandb",
"opencv-python",
"omegaconf",
"timm",
"nvidia-dali-cuda120; extra == \"localization\"",
"cupy-cuda12x; extra == \"localization\"",
"tabulate; extra == \"localization\"",
"torch-geometric; extra == \"tracking\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T09:44:45.321726 | soccernetpro-0.0.1.dev11.tar.gz | 111,642 | df/18/4bb43d541e9103d4b016d1550371fe09904dc6d6d99e6bcd8a86bcedcdf3/soccernetpro-0.0.1.dev11.tar.gz | source | sdist | null | false | 8e1a7255f6ba1f74d750c0e545ecf54b | 5121e25e6b57ea2bbed68f982ed9a14fdb1ad6871015332a2d75b5ab94c200c2 | df184bb43d541e9103d4b016d1550371fe09904dc6d6d99e6bcd8a86bcedcdf3 | null | [] | 185 |
2.1 | stellar-memory | 2.0.0 | A celestial-structure-based AI memory management system - Give any AI human-like memory | # Stellar Memory
> Give your AI the ability to remember. Free & open-source.
[](https://pypi.org/project/stellar-memory/)
[](https://github.com/sangjun0000/stellar-memory/actions)
[](LICENSE)
## What is Stellar Memory?
Stellar Memory gives any AI the ability to remember things across conversations.
Once your AI learns something about you, it remembers it next time — just like a person.
**No programming required.** Works with Claude Desktop, Cursor, and any MCP-compatible AI.
## Get Started (2 options)
### Option 1: Install on your computer (Recommended)
**Windows:**
1. Download [`stellar-memory-setup.bat`](https://github.com/sangjun0000/stellar-memory/releases/latest)
2. Double-click to run
3. Restart Claude Desktop or Cursor
4. Done! Try saying: "Remember my name is ___"
**macOS / Linux:**
```bash
curl -sSL https://raw.githubusercontent.com/sangjun0000/stellar-memory/main/stellar-memory-setup.sh | bash
```
**Or if you have Python:**
```bash
pip install stellar-memory[mcp]
stellar-memory setup
```
### Option 2: Use in the cloud
Cloud service coming soon. You'll be able to use Stellar Memory from any browser without installing anything.
For now, developers can use the REST API — see [API docs](https://stellar-memory.com/docs/api-reference/).
## How it works
```
You: "My favorite color is blue. Remember that."
AI: "Got it! I'll remember that your favorite color is blue."
... next conversation ...
You: "What's my favorite color?"
AI: "Your favorite color is blue!"
```
Stellar Memory organizes memories like a solar system:
- **Core** — Most important, always remembered
- **Inner** — Important, frequently accessed
- **Outer** — Regular memories
- **Belt** — Less important
- **Cloud** — Rarely accessed, may fade
## For Developers
<details>
<summary>Click to expand developer documentation</summary>
### Python Library
```python
from stellar_memory import StellarMemory
memory = StellarMemory()
memory.store("User prefers dark mode", importance=0.8)
results = memory.recall("user preferences")
memory.stop()
```
### Installation Options
```bash
pip install stellar-memory # Core library
pip install stellar-memory[mcp] # With MCP server
pip install stellar-memory[server] # With REST API
pip install stellar-memory[full] # Everything
```
### Key Features
- **5-Zone Hierarchy** — Core, Inner, Outer, Belt, Cloud
- **Adaptive Decay** — Memories naturally fade like human memory
- **Emotion Engine** — 6-dimensional emotion vectors
- **Self-Learning** — Optimizes based on usage patterns
- **MCP Server** — Claude Code, Cursor integration
- **REST API** — Full HTTP API with Swagger docs
- **Vector Search** — Semantic similarity matching
- **Graph Analytics** — Memory relationships and communities
- **Multi-Agent Sync** — CRDT-based conflict resolution
### Requirements
Python 3.10+
### Documentation
- [Full Documentation](https://stellar-memory.com/docs/)
- [API Reference](https://stellar-memory.com/docs/api-reference/)
- [Examples](https://github.com/sangjun0000/stellar-memory/tree/main/examples)
</details>
## License
MIT License — free to use, modify, and distribute.
| text/markdown | Stellar Memory Contributors | null | null | null | MIT | ai, memory, llm, mcp, recall, context | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"sentence-transformers>=2.2.0; extra == \"embedding\"",
"anthropic>=0.18.0; extra == \"llm\"",
"openai>=1.0.0; extra == \"openai\"",
"requests>=2.28.0; extra == \"ollama\"",
"sentence-transformers>=2.2.0; extra == \"ai\"",
"anthropic>=0.18.0; extra == \"ai\"",
"mcp[cli]>=1.2.0; extra == \"mcp\"",
"mcp[cli]>=1.2.0; extra == \"cli\"",
"asyncpg>=0.29.0; extra == \"postgres\"",
"redis>=5.0.0; extra == \"redis\"",
"cryptography>=42.0.0; extra == \"security\"",
"websockets>=12.0; extra == \"sync\"",
"httpx>=0.27.0; extra == \"connectors\"",
"fastapi>=0.110.0; extra == \"server\"",
"uvicorn>=0.29.0; extra == \"server\"",
"fastapi>=0.110.0; extra == \"dashboard\"",
"uvicorn>=0.29.0; extra == \"dashboard\"",
"stripe>=7.0.0; extra == \"billing\"",
"httpx>=0.27.0; extra == \"billing\"",
"asyncpg>=0.29.0; extra == \"billing\"",
"langchain-core>=0.1.0; extra == \"adapters\"",
"sentence-transformers>=2.2.0; extra == \"full\"",
"anthropic>=0.18.0; extra == \"full\"",
"openai>=1.0.0; extra == \"full\"",
"requests>=2.28.0; extra == \"full\"",
"mcp[cli]>=1.2.0; extra == \"full\"",
"asyncpg>=0.29.0; extra == \"full\"",
"redis>=5.0.0; extra == \"full\"",
"cryptography>=42.0.0; extra == \"full\"",
"websockets>=12.0; extra == \"full\"",
"httpx>=0.27.0; extra == \"full\"",
"fastapi>=0.110.0; extra == \"full\"",
"uvicorn>=0.29.0; extra == \"full\"",
"langchain-core>=0.1.0; extra == \"full\"",
"stripe>=7.0.0; extra == \"full\"",
"mkdocs-material>=9.5.0; extra == \"docs\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"httpx>=0.27.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://stellar-memory.com/",
"Repository, https://github.com/sangjun0000/stellar-memory",
"Documentation, https://stellar-memory.com/docs/",
"Changelog, https://github.com/sangjun0000/stellar-memory/blob/main/CHANGELOG.md"
] | twine/4.0.2 CPython/3.12.3 | 2026-02-20T09:43:25.126973 | stellar_memory-2.0.0.tar.gz | 180,435 | 3b/dc/2a8faf8a6ddaf8e88a40f1b3d1cb9cc07434919c050ac50c08ab04b05ccb/stellar_memory-2.0.0.tar.gz | source | sdist | null | false | 77fdf3f6454679c13cefb903695b9b06 | d4e3b1798600a1a74a0a849500d2eba641ec83056423655ad6182a652f7bf9eb | 3bdc2a8faf8a6ddaf8e88a40f1b3d1cb9cc07434919c050ac50c08ab04b05ccb | null | [] | 217 |
2.4 | sky130 | 0.15.3 | skywater130 pdk | # sky130 gdsfactory PDK 0.15.2
[](https://pypi.org/project/sky130/)
[](https://github.com/psf/black)
gdsfactory pdk based on [skywater130](https://github.com/google/skywater-pdk)

- [documentation](https://gdsfactory.github.io/skywater130/README.html)
## Installation
We recommend `uv`
```bash
# On macOS and Linux.
curl -LsSf https://astral.sh/uv/install.sh | sh
```
```bash
# On Windows.
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
```
### Installation for users
Use python 3.11, 3.12 or 3.13. We recommend [VSCode](https://code.visualstudio.com/) as an IDE.
```
uv pip install sky130 --upgrade
```
Then you need to restart Klayout to make sure the new technology installed appears.
### Installation for contributors
Then you can install with:
```bash
git clone https://github.com/gdsfactory/skywater130.git
cd sky130
make install
uv venv --python 3.12
uv sync --extra docs --extra dev
```
## Documentation
- [gdsfactory docs](https://gdsfactory.github.io/gdsfactory/)
| text/markdown | null | gdsfactory <contact@gdsfactory.com> | null | null | null | python | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Operating System :: OS Independent"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"gdsfactory~=9.34.0",
"PySpice",
"pytest; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"pytest_regressions; extra == \"dev\"",
"pre-commit; extra == \"dev\"",
"pytest-randomly; extra == \"dev\"",
"pytest-xdist; extra == \"dev\"",
"jupytext; extra == \"docs\"",
"jupyter-book==1.0.4; extra == \"docs\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T09:43:24.782461 | sky130-0.15.3.tar.gz | 32,344,434 | f8/7f/caadf9123b45134019c6c146dedf06ad8e857629b80451f74e01ea065915/sky130-0.15.3.tar.gz | source | sdist | null | false | e7bd97df2284477342faa4d829699c95 | 73f574074b94f3d0189955cce7fb2ab461125c2d486669a7fbb0915cf982c971 | f87fcaadf9123b45134019c6c146dedf06ad8e857629b80451f74e01ea065915 | null | [
"LICENSE"
] | 227 |
2.4 | ubi-reader | 0.8.13 | Extract files from UBI and UBIFS images. | # UBI Reader
UBI Reader is a Python module and collection of scripts capable of extracting
the contents of UBI and UBIFS images, along with analyzing these images to
determine the parameter settings to recreate them using the mtd-utils tools.
### Known Issues
These are some known issues, that prevent an exact data dump from occuring.
* This does not replay the journal, so uncommited data will not be retrieved. Data can be in the journal with both clean and unclean shutdowns.
* Depending on how the NAND was dumped, the data bits may not be error corrected.
* Socket files will be ignored, you can change ubireader/settings.py to have it create dummy files in their place.
## Testing Branch
The testing branch includes a tools/ directory, that has scripts to help when trying to extract data from broken images. These also serve as examples of how to use parts of ubi_reader in custom scripts.
An override system is also included, for manually setting certain parameters that may be reported wrong by the UBI/FS data.
This branch will probably remain seperate, as it is meant to be customized to aid in extracting data from problematic images. You can install it with 'python setup.py develop' to make it easier to modify ubi_reader as needed.
## Installation:
Latest Version
$ git clone https://github.com/jrspruitt/ubi_reader
$ cd ubi_reader
$ poetry install
Or
$ pip install --user ubi_reader
## Usage:
For basic usage, the scripts need no options and if applicable will save output
to ./ubifs-root/. More advanced usage can set start and end offset, specify
an output directory, or for debugging can print out what it is doing to the
terminal.
Run program with -h or --help for explanation of options.
## Extracting File Contents:
ubireader_extract_files [options] path/to/file
The script accepts a file with UBI or UBIFS data in it, so should work with a NAND
dump. It will search for the first occurance of UBI or UBIFS data and attempt to
extract the contents. If file includes special files, you will need to run as
root or sudo for it to create these files. With out it, it'll skip them and show a
warning that these files were not created.
## List/Copy Files:
ubireader_list_files [options] path/to/file
The script accepts a file with UBI or UBIFS data in it, so should work with a NAND
dump. It will search for the first occurance of UBI or UBIFS data and treat it as
a UBIFS. To list files supply the path to list (-P, --path), e.g. "-P /" to list
the filesystems root directory. To copy a file from the filesystem to a local directory
supply the source path (-C, --copy) and the destination path (-D, --copy-dest),
e.g. -C /etc/passwd -D . (extract /etc/passwd from the UBIFS image and copy it to
local directory).
## Extracting Images:
ubireader_extract_images [options] path/to/file
This script will extract the whole UBI or UBIFS image from a NAND dump, or the UBIFS
image from a UBI image. You can specify what type of image to extract by setting the
(-u, --image-type) option to "UBI" or "UBIFS". Default is "UBIFS".
## MTD-Utils Parameters:
ubireader_utils_info [options] path/to/file
The script will analyze a UBI image and create a Linux shell script and UBI config
file that can be used for building new UBI images to the same specifications. For
just a printed list of the options and values, use the (-r, --show-only) option.
## Display Information:
ubireader_display_info [options] path/to/file
Depending on the image type found, this script displays some UBI information along with
the header info from the layout block, including volume table records. If it is a UBIFS
image, the Super Node, and both Master Nodes are displayed. Using the (-u, --ubifs-info)
option, it will get the UBIFS info from inside a UBI file instead.
## Display Block Information:
ubireader_display_blocks [options] "{'block.attr':?, ...}" path/to/file
Search for and display block information. This can be used for debugging failed image
and file extractions. The blocks are searched for using a double quoted Python Dict of
search paramaters, example. "{'peb_num':[0, 1] + range(100, 102), 'ec_hdr.ec': 1, 'is_valid': True}"
This will find PEBs 0, 1, 100, 101, 102, with an erase count of 1 that is a valid block.
Can use any of the parameters in ubireader.ubi.block.description.
## Options:
Some general option flags are
* -l, --log: This prints to screen actions being taken while running.
* -v, --verbose: This basically prints everything about anything happening.
* -p, --peb-size int: Specify PEB size of the UBI image, instead of having it guess.
* -e, --leb-size int: Specify LEB size of UBIFS image, instead of having it guess.
* -s, --start-offset int: Tell script to look for UBI/UBIFS data at given address.
* -n, --end-offset int: Tell script to ignore data after given address in data.
* -g, --guess-offset: Specify offset to start guessing where UBI data is in file. Useful for NAND dumps with false positives before image.
* -w, --warn-only-block-read-errors: Attempts to continue extracting files even with bad block reads. Some data will be missing or corrupted!
* -i, --ignore-block-header-errors: Forces unused and error containing blocks to be included and also displayed with log/verbose.
* -f, --u-boot-fix: Assume blocks with image_seq 0 are because of older U-boot implementations and include them. *This may cause issues with multiple UBI image files.
* -o, --output-dir path: Specify where files should be written to, instead of ubi_reader/output
| text/markdown | ONEKEY | support@onekey.com | null | null | GNU GPL | null | [
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"cryptography<47.0.0,>=44.0.2",
"lzallright<0.3.0,>=0.2.1"
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.10.19 Linux/6.11.0-1018-azure | 2026-02-20T09:43:18.746787 | ubi_reader-0.8.13-py3-none-any.whl | 77,013 | ab/47/db65ff3cb426c7a5cdf0b2338b854af10043a768c6733e7bf204d359e4b7/ubi_reader-0.8.13-py3-none-any.whl | py3 | bdist_wheel | null | false | e7b893b7d630e85d6497be0dde2b49ee | 62c9630ef9cb26aef1e9af648aeacbdb7001d0763ca2b579680d55efffdf9bc8 | ab47db65ff3cb426c7a5cdf0b2338b854af10043a768c6733e7bf204d359e4b7 | null | [
"LICENSE"
] | 1,479 |
2.4 | orchard-ml | 0.1.5 | Type-Safe Deep Learning Framework for Computer Vision | <h1 align="center">Orchard ML</h1>
<p align="center"><strong>Type-safe deep learning framework for reproducible computer vision research</strong></p>
---
<!-- Badges Section -->
<table align="center">
<tr>
<td align="right"><strong>CI/CD & Coverage</strong></td>
<td>
<a href="https://github.com/tomrussobuilds/orchard-ml/actions/workflows/ci.yml"><img src="https://github.com/tomrussobuilds/orchard-ml/actions/workflows/ci.yml/badge.svg" alt="CI/CD Pipeline"></a>
<a href="https://codecov.io/gh/tomrussobuilds/orchard-ml"><img src="https://codecov.io/gh/tomrussobuilds/orchard-ml/branch/main/graph/badge.svg" alt="Coverage"></a>
<a href="https://sonarcloud.io/summary/new_code?id=tomrussobuilds_orchard-ml"><img src="https://sonarcloud.io/api/project_badges/measure?project=tomrussobuilds_orchard-ml&metric=alert_status" alt="Quality Gate"></a>
<a href="https://sonarcloud.io/summary/new_code?id=tomrussobuilds_orchard-ml"><img src="https://sonarcloud.io/api/project_badges/measure?project=tomrussobuilds_orchard-ml&metric=coverage" alt="SonarCloud Coverage"></a>
</td>
</tr>
<tr>
<td align="right"><strong>Code Quality</strong></td>
<td>
<a href="https://sonarcloud.io/summary/new_code?id=tomrussobuilds_orchard-ml"><img src="https://sonarcloud.io/api/project_badges/measure?project=tomrussobuilds_orchard-ml&metric=reliability_rating" alt="Reliability"></a>
<a href="https://sonarcloud.io/summary/new_code?id=tomrussobuilds_orchard-ml"><img src="https://sonarcloud.io/api/project_badges/measure?project=tomrussobuilds_orchard-ml&metric=security_rating" alt="Security"></a>
<a href="https://sonarcloud.io/summary/new_code?id=tomrussobuilds_orchard-ml"><img src="https://sonarcloud.io/api/project_badges/measure?project=tomrussobuilds_orchard-ml&metric=sqale_rating" alt="Maintainability"></a>
<a href="https://sonarcloud.io/summary/new_code?id=tomrussobuilds_orchard-ml"><img src="https://sonarcloud.io/api/project_badges/measure?project=tomrussobuilds_orchard-ml&metric=bugs" alt="Bugs"></a>
<a href="https://sonarcloud.io/summary/new_code?id=tomrussobuilds_orchard-ml"><img src="https://sonarcloud.io/api/project_badges/measure?project=tomrussobuilds_orchard-ml&metric=code_smells" alt="Code Smells"></a>
</td>
</tr>
<tr>
<td align="right"><strong>Platform</strong></td>
<td>
<img src="https://img.shields.io/badge/python-3.10%20|%203.11%20|%203.12%20|%203.13%20|%203.14--dev-blue?logo=python&logoColor=white" alt="Python">
<a href="https://pypi.org/project/orchard-ml/"><img src="https://img.shields.io/pypi/v/orchard-ml?color=blue&logo=pypi&logoColor=white&v=1" alt="PyPI"></a>
<a href="docs/guide/DOCKER.md"><img src="https://img.shields.io/badge/Docker-CUDA%2012.1-2496ED?logo=docker&logoColor=white" alt="Docker"></a>
</td>
</tr>
<tr>
<td align="right"><strong>Tech Stack</strong></td>
<td>
<a href="https://pytorch.org/"><img src="https://img.shields.io/badge/PyTorch-2.0%2B-orange?logo=pytorch&logoColor=white" alt="PyTorch"></a>
<a href="https://docs.pydantic.dev/"><img src="https://img.shields.io/badge/Pydantic-v2-e92063?logo=pydantic&logoColor=white" alt="Pydantic"></a>
<a href="https://optuna.org/"><img src="https://img.shields.io/badge/Optuna-3.0%2B-00ADD8?logo=optuna&logoColor=white" alt="Optuna"></a>
<a href="https://onnx.ai/"><img src="https://img.shields.io/badge/ONNX-export-005CED?logo=onnx&logoColor=white" alt="ONNX"></a>
<a href="https://mlflow.org/"><img src="https://img.shields.io/badge/MLflow-tracking-0194E2?logo=mlflow&logoColor=white" alt="MLflow"></a>
</td>
</tr>
<tr>
<td align="right"><strong>Code Style</strong></td>
<td>
<!-- Dynamic badges — updated by .github/workflows/badges.yml via Gist -->
<a href="https://github.com/psf/black"><img src="https://img.shields.io/endpoint?url=https://gist.githubusercontent.com/tomrussobuilds/7835190af6011e9051b673c8be974f8a/raw/black.json" alt="Black"></a>
<a href="https://pycqa.github.io/isort/"><img src="https://img.shields.io/endpoint?url=https://gist.githubusercontent.com/tomrussobuilds/7835190af6011e9051b673c8be974f8a/raw/isort.json" alt="isort"></a>
<a href="https://flake8.pycqa.org/"><img src="https://img.shields.io/endpoint?url=https://gist.githubusercontent.com/tomrussobuilds/7835190af6011e9051b673c8be974f8a/raw/flake8.json" alt="Flake8"></a>
<a href="https://mypy-lang.org/"><img src="https://img.shields.io/endpoint?url=https://gist.githubusercontent.com/tomrussobuilds/7835190af6011e9051b673c8be974f8a/raw/mypy.json" alt="mypy"></a>
<a href="https://radon.readthedocs.io/"><img src="https://img.shields.io/endpoint?url=https://gist.githubusercontent.com/tomrussobuilds/7835190af6011e9051b673c8be974f8a/raw/radon.json" alt="Radon"></a>
</td>
</tr>
<tr>
<td align="right"><strong>Project</strong></td>
<td>
<a href="https://docs.pytest.org/"><img src="https://img.shields.io/badge/tested%20with-pytest-blue?logo=pytest&logoColor=white" alt="Tested with pytest"></a>
<img src="https://img.shields.io/badge/tests-1100+-success" alt="Tests">
<img src="https://img.shields.io/badge/Architecture-Decoupled-blueviolet" alt="Architecture">
<a href="LICENSE"><img src="https://img.shields.io/badge/license-MIT-green" alt="License"></a>
<img src="https://img.shields.io/badge/status-Active-success" alt="Status">
<a href="https://github.com/tomrussobuilds/orchard-ml/issues"><img src="https://img.shields.io/github/issues/tomrussobuilds/orchard-ml" alt="GitHub Issues"></a>
</td>
</tr>
</table>
---
<h2>Table of Contents</h2>
- [**Overview**](#overview)
- [**Hardware Requirements**](#hardware-requirements)
- [**Quick Start**](#quick-start)
- [**Colab Notebooks**](#colab-notebooks)
- [**Experiment Management**](#experiment-management)
- [**Documentation**](#documentation)
- [**Citation**](#citation)
- [**Roadmap**](#roadmap)
- [**License**](#license)
---
<h2>Overview</h2>
**Orchard ML** is a research-grade `PyTorch` training framework engineered for reproducible, scalable computer vision experiments across diverse domains. Built on [MedMNIST v2](https://zenodo.org/records/6496656) medical imaging datasets and expanded to astronomical imaging ([Galaxy10 DECals](https://zenodo.org/records/10845026)), it provides a domain-agnostic platform supporting multi-resolution architectures (28×28, 64×64, 224×224), automated hyperparameter optimization, and cluster-safe execution.
**Key Differentiators:**
- **Type-Safe Configuration Engine**: `Pydantic V2`-based declarative manifests eliminate runtime errors
- **Idempotent Lifecycle Orchestration**: `RootOrchestrator` coordinates a 7-phase initialization sequence (seeding, filesystem, logging, infrastructure locks, telemetry) via Context Manager with full dependency injection
- **Zero-Conflict Execution**: Kernel-level file locking (`fcntl`) prevents concurrent runs from corrupting shared resources
- **Intelligent Hyperparameter Search**: `Optuna` integration with TPE sampling and Median Pruning
- **Hardware-Agnostic**: Auto-detection and optimization for `CPU`/`CUDA`/`MPS` backends
- **Audit-Grade Traceability**: `BLAKE2b`-hashed run directories with full `YAML` snapshots
**Supported Architectures:**
| Resolution | Architectures | Parameters | Use Case |
|-----------|--------------|-----------|----------|
| **28 / 64 / 224** | `ResNet-18` | ~11M | Multi-resolution baseline, transfer learning |
| **28 / 64** | `MiniCNN` | ~95K | Fast prototyping, ablation studies |
| **224×224** | `EfficientNet-B0` | ~4.0M | Efficient compound scaling |
| **224×224** | `ConvNeXt-Tiny` | ~27.8M | Modern ConvNet design |
| **224×224** | `ViT-Tiny` | ~5.5M | Patch-based attention, multiple weight variants |
> [!TIP]
> **1000+ additional architectures via [timm](https://huggingface.co/docs/timm)**: Any model in the `timm` registry can be used by prefixing the name with `timm/` in your recipe:
> ```yaml
> architecture:
> name: "timm/mobilenetv3_small_100" # ~1.5M params, edge-friendly
> pretrained: true
> ```
> This works with MobileNet, DenseNet, RegNet, EfficientNet-V2, and any other architecture supported by `timm`. See `recipes/config_timm_mobilenetv3.yaml` for a ready-to-use example.
---
<h2>Hardware Requirements</h2>
<h3>CPU Training (28×28 / 64×64)</h3>
- **Supported Resolutions**: 28×28, 64×64
- **Time**: ~2.5 hours (`ResNet-18`, 28×28, 60 epochs, 16 cores)
- **Time**: ~5-10 minutes (`MiniCNN`, 28×28, 60 epochs, 16 cores)
- **Architectures**: `ResNet-18`, `MiniCNN`
- **Use Case**: Development, testing, limited hardware environments
<h3>GPU Training (All Resolutions)</h3>
- **28×28 Resolution**:
- `MiniCNN`: ~2-3 minutes (60 epochs)
- `ResNet-18`: ~10-15 minutes (60 epochs)
- **64×64 Resolution**:
- `MiniCNN`: ~3-5 minutes (60 epochs)
- `ResNet-18`: ~15-20 minutes (60 epochs)
- **224×224 Resolution**:
- `EfficientNet-B0`: ~30 minutes per trial (15 epochs)
- `ViT-Tiny`: ~25-35 minutes per trial (15 epochs)
- **VRAM**: 8GB recommended for 224×224 resolution
- **Architectures**: `ResNet-18`, `EfficientNet-B0`, `ConvNeXt-Tiny`, `ViT-Tiny`
> [!WARNING]
> **224×224 training on CPU is not recommended** - it would take 10+ hours per trial. High-resolution training requires GPU acceleration. Only 28×28 resolution has been tested and validated for CPU training.
> [!NOTE]
> **Apple Silicon (`MPS`)**: The codebase includes `MPS` backend support (device detection, seeding, memory management), but it has not been tested on real hardware. If you encounter issues, please open an issue.
> [!NOTE]
> **Data Format**: Orchard ML operates on `NPZ` archives as its canonical data format. All datasets are downloaded or converted to `NPZ` before entering the training pipeline. Custom datasets in other formats (HDF5, DICOM, TIFF) can be integrated by adding a conversion step in a dedicated fetcher module — see the [Galaxy10 fetcher](orchard/data_handler/fetchers/) for a reference implementation.
**Representative Benchmarks** (RTX 5070 Laptop GPU):
| Task | Architecture | Resolution | Device | Time | Notes |
|------|-------------|-----------|--------|------|-------|
| **Smoke Test** | `MiniCNN` | 28×28 | CPU/GPU | <30s | 1-epoch sanity check |
| **Quick Training** | `MiniCNN` | 28×28 | GPU | ~2-3 min | 60 epochs |
| **Quick Training** | `MiniCNN` | 28×28 | CPU (16 cores) | ~5-10 min | 60 epochs, CPU-validated |
| **Mid-Res Training** | `MiniCNN` | 64×64 | GPU | ~3-5 min | 60 epochs |
| **Transfer Learning** | `ResNet-18` | 28×28 | GPU | ~5 min | 60 epochs |
| **Transfer Learning** | `ResNet-18` | 28×28 | CPU (16 cores) | ~2.5h | 60 epochs, CPU-validated |
| **High-Res Training** | `EfficientNet-B0` | 224×224 | GPU | ~30 min/trial | 15 epochs per trial, **GPU required** |
| **High-Res Training** | `ViT-Tiny` | 224×224 | GPU | ~25-35 min/trial | 15 epochs per trial, **GPU required** |
| **Optimization Study** | `EfficientNet-B0` | 224×224 | GPU | ~2h | 4 trials (early stop at AUC≥0.9999) |
| **Optimization Study** | Various | 224×224 | GPU | ~1.5-5h | 20 trials, highly variable |
> [!NOTE]
> **Timing Variance**: Optimization times are highly dependent on early stopping criteria, pruning configuration, and dataset complexity:
> - **Early Stopping**: Studies may finish in 1-3 hours if performance thresholds are met quickly (e.g., AUC ≥ 0.9999 after 4 trials)
> - **Full Exploration**: Without early stopping, 20 trials can extend to 5+ hours
> - **Pruning Impact**: Median pruning can save 30-50% of total time by terminating underperforming trials
---
<h2>Quick Start</h2>
<h3>Step 1: Environment Setup</h3>
**Option A**: Install from source (recommended)
```bash
git clone https://github.com/tomrussobuilds/orchard-ml.git
```
Navigate into the project directory and install in editable mode:
```bash
cd orchard-ml
pip install -e .
```
With development tools (linting, testing, type checking):
```bash
pip install -e ".[dev]"
```
**Option B**: Install from PyPI
```bash
pip install orchard-ml
orchard init # generates recipe.yaml with all defaults
orchard run recipe.yaml
```
<h3>Step 2: Verify Installation (Optional)</h3>
```bash
# Run 1-epoch sanity check (~30 seconds, CPU/GPU)
# Downloads BloodMNIST 28×28 by default
python -m tests.smoke_test
# Note: You can skip this step - datasets are auto-downloaded on first run
```
<h3>Step 3: Training Workflow</h3>
Orchard ML uses the `orchard` CLI as the **single entry point** for all workflows. The pipeline behavior is controlled entirely by the `YAML` recipe:
- **Training only**: Use a `config_*.yaml` file (no `optuna:` section)
- **Optimization + Training**: Use an `optuna_*.yaml` file (has `optuna:` section)
- **With Export**: Add an `export:` section to your config
```bash
orchard --version # Verify installation
orchard run --help # Show available options
```
<h4><strong>Training Only</strong> (Quick start)</h4>
```bash
# 28×28 resolution (CPU-compatible)
orchard run recipes/config_mini_cnn.yaml # ~2-3 min GPU, ~5-10 min CPU
orchard run recipes/config_resnet_18.yaml # ~10-15 min GPU, ~2.5h CPU
# 64×64 resolution (CPU/GPU)
orchard run recipes/config_mini_cnn_64.yaml # ~3-5 min GPU
# 224×224 resolution (GPU required)
orchard run recipes/config_efficientnet_b0.yaml # ~30 min GPU
orchard run recipes/config_vit_tiny.yaml # ~25-35 min GPU
# Override any config value on the fly
orchard run recipes/config_mini_cnn.yaml --set training.epochs=20 --set training.seed=99
```
**What happens:**
- Dataset auto-downloaded to `./dataset/`
- Training runs for 60 epochs with early stopping
- Results saved to timestamped directory in `outputs/`
---
<h4><strong>Hyperparameter Optimization + Training</strong> (Full pipeline)</h4>
```bash
# 28×28 resolution - fast iteration
orchard run recipes/optuna_mini_cnn.yaml # ~5 min GPU, ~5-10 min CPU
orchard run recipes/optuna_resnet_18.yaml # ~15-20 min GPU
# 224×224 resolution - requires GPU
orchard run recipes/optuna_efficientnet_b0.yaml # ~1.5-5h*, GPU
orchard run recipes/optuna_vit_tiny.yaml # ~3-5h*, GPU
# *Time varies due to early stopping (may finish in 1-3h if target AUC reached)
```
**What happens:**
1. **Optimization**: Explores hyperparameter combinations with `Optuna`
2. **Training**: Full 60-epoch training with best hyperparameters found
3. **Artifacts**: Interactive plots, best_config.yaml, model weights
> [!TIP]
> **Model Search**: Enable `optuna.enable_model_search: true` in your `YAML` config to let `Optuna` automatically explore all registered architectures for the target resolution. Use `optuna.model_pool` to restrict the search to a subset of architectures (e.g. `["vit_tiny", "efficientnet_b0"]`).
**View optimization results:**
```bash
firefox outputs/*/figures/param_importances.html # Which hyperparameters matter most
firefox outputs/*/figures/optimization_history.html # Trial progression
```
---
<h4><strong>Model Export</strong> (Production deployment)</h4>
All training configs (`config_*.yaml`) include `ONNX` export by default:
```bash
orchard run recipes/config_efficientnet_b0.yaml
# → Training + ONNX export to outputs/*/exports/model.onnx
```
See the [Export Guide](docs/guide/EXPORT.md) for configuration options (format, quantization, validation).
---
<h2>Colab Notebooks</h2>
Try Orchard ML directly in Google Colab — no local setup required:
| Notebook | Description | Runtime | Time |
|----------|-------------|---------|------|
| [](https://colab.research.google.com/github/tomrussobuilds/orchard-ml/blob/main/notebooks/01_quickstart_bloodmnist_cpu.ipynb) **[Quick Start: BloodMNIST CPU](notebooks/01_quickstart_bloodmnist_cpu.ipynb)** | `MiniCNN` training on `BloodMNIST` 28×28 — end-to-end training, evaluation, and `ONNX` export | CPU | ~15 min |
| [](https://colab.research.google.com/github/tomrussobuilds/orchard-ml/blob/main/notebooks/02_galaxy10_optuna_model_search.ipynb) **[Optuna Model Search: Galaxy10 GPU](notebooks/02_galaxy10_optuna_model_search.ipynb)** | Automatic architecture search (`EfficientNet-B0`, `ViT-Tiny`, `ConvNeXt-Tiny`, `ResNet-18`) on Galaxy10 224×224 with `Optuna` | T4 GPU | ~30-45 min |
---
<h2>Experiment Management</h2>
Every run generates a complete artifact suite for total traceability. Both training-only and optimization workflows share the same `RunPath` orchestrator, producing `BLAKE2b`-hashed timestamped directories.
**[Browse Sample Artifacts](./docs/artifacts)** — Excel reports, `YAML` configs, and diagnostic plots from real training runs.
See the [full artifact tree](docs/artifacts/artifacts_structure.png) for the complete directory layout — logs, model weights, and HTML plots are generated locally and not tracked in the repo.
**[Browse Recipe Configs](./recipes)** — Ready-to-use `YAML` configurations for every architecture and workflow.
Copy the closest recipe, tweak the parameters, and run:
```bash
cp recipes/config_efficientnet_b0.yaml my_run.yaml
# edit hyperparameters, swap dataset/model, add or remove sections (optuna, export, tracking)
orchard run my_run.yaml
```
---
<h2>Documentation</h2>
| Guide | Covers |
|-------|--------|
| [Framework Guide](docs/guide/FRAMEWORK.md) | System architecture diagrams, design principles, component deep-dives |
| [Architecture Guide](docs/guide/ARCHITECTURE.md) | Supported model architectures, weight transfer, grayscale adaptation, `MixUp` |
| [Configuration Guide](docs/guide/CONFIGURATION.md) | Full parameter reference, usage patterns, adding new datasets |
| [Optimization Guide](docs/guide/OPTIMIZATION.md) | `Optuna` integration, search space config, pruning strategies, visualization |
| [Docker Guide](docs/guide/DOCKER.md) | Container build instructions, GPU-accelerated execution, reproducibility mode |
| [Export Guide](docs/guide/EXPORT.md) | `ONNX` export pipeline, quantization options, validation and benchmarking |
| [Tracking Guide](docs/guide/TRACKING.md) | `MLflow` local setup, dashboard and run comparison, programmatic querying |
| [Artifact Guide](docs/guide/ARTIFACTS.md) | Output directory structure, training vs optimization artifact differences |
| [Testing Guide](docs/guide/TESTING.md) | 1,100+ test suite, quality automation scripts, CI/CD pipeline details |
| [`orchard/`](orchard/README.md) / [`tests/`](tests/README.md) | Internal package structure, module responsibilities, extension points |
<h2>Citation</h2>
```bibtex
@software{orchardml2026,
author = {Tommaso Russo},
title = {Orchard ML: Type-Safe Deep Learning Framework},
year = {2026},
url = {https://github.com/tomrussobuilds/orchard-ml},
note = {PyTorch framework with Pydantic V2 configuration and Optuna optimization}
}
```
---
<h2>Roadmap</h2>
- **Expanded Dataset Domains**: Climate, remote sensing, microscopy
- **Multi-modal Support**: Detection, segmentation hooks
- **Distributed Training**: `DDP`, `FSDP` support for multi-GPU
---
<h2>License</h2>
MIT License - See [LICENSE](LICENSE) for details.
<h2>Contributing</h2>
Contributions welcome! Please:
1. Fork the repository
2. Create a feature branch
3. Add tests for new functionality
4. Ensure all tests pass: `pytest tests/ -v`
5. Submit a pull request
For detailed guidelines, see [CONTRIBUTING.md](CONTRIBUTING.md).
<h2>Contact</h2>
For questions or collaboration: [GitHub Issues](https://github.com/tomrussobuilds/orchard-ml/issues)
| text/markdown | null | Tommaso Russo <tomrussobuilds@users.noreply.github.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"torch>=2.0.0",
"torchvision>=0.15.0",
"numpy>=2.0.0",
"pandas>=2.0.0",
"scikit-learn>=1.5.0",
"Pillow>=12.1.1",
"h5py>=3.12.0",
"pydantic>=2.10.0",
"pyyaml>=6.0",
"optuna>=4.0.0",
"plotly>=6.0.0",
"kaleido>=1.0.0",
"matplotlib>=3.9.0",
"seaborn>=0.13.0",
"xlsxwriter>=3.2.0",
"openpyxl>=3.1.0",
"tqdm>=4.66.0",
"requests>=2.32.0",
"psutil>=7.2.2",
"timm>=1.0.0",
"onnx>=1.17.0",
"onnxruntime>=1.20.0; python_version < \"3.14\"",
"onnxscript>=0.5.0",
"typer>=0.9.0",
"mlflow>=3.9.0; extra == \"tracking\"",
"ipython>=9.0.0; extra == \"notebooks\"",
"pytest>=9.0.0; extra == \"test\"",
"pytest-cov>=7.0.0; extra == \"test\"",
"pytest-xdist>=3.5.0; extra == \"test\"",
"orchard-ml[test]; extra == \"dev\"",
"black>=26.1.0; extra == \"dev\"",
"flake8>=7.0.0; extra == \"dev\"",
"isort>=7.0.0; extra == \"dev\"",
"mypy==1.19.1; extra == \"dev\"",
"bandit>=1.8.0; extra == \"dev\"",
"radon>=6.0.0; extra == \"dev\"",
"types-PyYAML>=6.0.0; extra == \"dev\"",
"types-requests>=2.32.0; extra == \"dev\"",
"git-cliff>=2.12.0; extra == \"dev\"",
"pre-commit>=4.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/tomrussobuilds/orchard-ml",
"Repository, https://github.com/tomrussobuilds/orchard-ml",
"Issues, https://github.com/tomrussobuilds/orchard-ml/issues",
"Documentation, https://github.com/tomrussobuilds/orchard-ml/tree/main/docs/guide"
] | twine/6.1.0 CPython/3.12.9 | 2026-02-20T09:43:13.306035 | orchard_ml-0.1.5.tar.gz | 150,308 | df/87/43d2b12aa49c86811a1be61dbb6a77a54253b9b4d45b73c3738c134619c5/orchard_ml-0.1.5.tar.gz | source | sdist | null | false | ab63667d1d17dd39c8d4cdcfcc0468a5 | 29009fba076fdb3c15a13f3fef1e0723fc5eadf19b2d855362be155feddc72f4 | df8743d2b12aa49c86811a1be61dbb6a77a54253b9b4d45b73c3738c134619c5 | MIT | [
"LICENSE"
] | 203 |
2.4 | cardo-python-utils | 0.5.dev50 | Python library enhanced with a wide range of functions for different scenarios. | ============================
CardoAI Python Helper Module
============================
This library allows the utilization of different utility functions for different scenarios.
Main utils:
* time
* string
* data_structures
* db
* django
* math
* exception
* choices
Quick start
-----------
1. Import wanted function like this::
from python_utils.time import date_range
date_range(start_date, end_date)
Although the library provides some utility functions related to other libraries like django, it does not install any dependencies automatically.
This means, you can install the library even if you do not use these libraries, but keep in mind that in this case you cannot use the
functions that depend on them.
You can also chose to install the dependencies alongside the library, including the library in the requirements in the form::
cardo-python-utils[django]
Tests
-----
The library has a high coverage by tests. If you want to see tests in action:
1. Inside venv, run ``pip install -r tests/requirements.txt``
2. Run tests via ``pytest`` command
| text/x-rst | null | CardoAI <hello@cardoai.com> | null | null | MIT | utilities, helpers, django | [
"Environment :: Web Environment",
"Framework :: Django",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Internet :: WWW/HTTP",
"Topic :: Internet :: WWW/HTTP :: Dynamic Content"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"PyJWT>=2.10.1; extra == \"django-keycloak\"",
"mozilla-django-oidc>=4.0.1; extra == \"django-keycloak\"",
"requests; extra == \"django-keycloak\"",
"python-keycloak>=5.8.1; extra == \"django-keycloak-groups\"",
"PyJWT>=2.10.1; extra == \"all\"",
"mozilla-django-oidc>=4.0.1; extra == \"all\"",
"python-keycloak>=5.8.1; extra == \"all\"",
"requests; extra == \"all\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-django>=4.5; extra == \"dev\"",
"coverage>=6.0; extra == \"dev\"",
"tox>=3.25; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/CardoAI/cardo-python-utils",
"Repository, https://github.com/CardoAI/cardo-python-utils.git",
"Issues, https://github.com/CardoAI/cardo-python-utils/issues"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-20T09:43:07.748154 | cardo_python_utils-0.5.dev50.tar.gz | 50,561 | b7/a5/8b61ed6f0f25505c58936ef4478189aa6f18b5e6bf45f2575b9170a95ac0/cardo_python_utils-0.5.dev50.tar.gz | source | sdist | null | false | fd6879d14c49cbdfc1e7d581c382ff02 | 71956f70003baf16e6989c0cc0f40b71edddf03fa9fc766f55e58d4d7560076f | b7a58b61ed6f0f25505c58936ef4478189aa6f18b5e6bf45f2575b9170a95ac0 | null | [
"LICENSE"
] | 201 |
2.4 | ssb-nudb-config | 2026.2.9 | The config for NUDB - Nasjonal utdanningsdatabase | # Nudb_Config
[][pypi status]
[][pypi status]
[][pypi status]
[][license]
[][documentation]
[][tests]
[][sonarcov]
[][sonarquality]
[][pre-commit]
[][black]
[](https://github.com/astral-sh/ruff)
[][poetry]
[pypi status]: https://pypi.org/project/ssb-nudb-config/
[documentation]: https://statisticsnorway.github.io/ssb-nudb-config
[tests]: https://github.com/statisticsnorway/ssb-nudb-config/actions?workflow=Tests
[sonarcov]: https://sonarcloud.io/summary/overall?id=statisticsnorway_ssb-nudb-config
[sonarquality]: https://sonarcloud.io/summary/overall?id=statisticsnorway_ssb-nudb-config
[pre-commit]: https://github.com/pre-commit/pre-commit
[black]: https://github.com/psf/black
[poetry]: https://python-poetry.org/
## Installation
You can install _Nudb_Config_ via [pip] from [PyPI]:
```console
poetry add ssb-nudb-config
```
## Usage
The most important object in the package are the "settings":
```python
from nudb_config import settings
print(settings.paths)
```
Indexing into the config should be possible with dot-notation AND common dict-convenience methods, these should all return the same value:
```python
settings.variables.fnr
settings.variables["fnr"]
settings.variables.get("fnr")
```
Please see the [Reference Guide] for details.
## Contributing
Contributions are very welcome.
To learn more, see the [Contributor Guide].
## License
Distributed under the terms of the [MIT license][license],
_Nudb_Config_ is free and open source software.
## Issues
If you encounter any problems,
please [file an issue] along with a detailed description.
## Credits
This project was generated from [Statistics Norway]'s [SSB PyPI Template].
[statistics norway]: https://www.ssb.no/en
[pypi]: https://pypi.org/
[ssb pypi template]: https://github.com/statisticsnorway/ssb-pypitemplate
[file an issue]: https://github.com/statisticsnorway/ssb-nudb-config/issues
[pip]: https://pip.pypa.io/
<!-- github-only -->
[license]: https://github.com/statisticsnorway/ssb-nudb-config/blob/main/LICENSE
[contributor guide]: https://github.com/statisticsnorway/ssb-nudb-config/blob/main/CONTRIBUTING.md
[reference guide]: https://statisticsnorway.github.io/ssb-nudb-config/reference.html
| text/markdown | Markus Storeide | rku@ssb.no | Statistics Norway, Education statistics Department (360) | null | null | null | [
"Development Status :: 3 - Alpha",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"ipykernel>=7.0.0",
"pydantic>=2.5",
"ssb-klass-python>=1.0.4"
] | [] | [] | [] | [
"Changelog, https://github.com/statisticsnorway/ssb-nudb-config/releases",
"Documentation, https://statisticsnorway.github.io/ssb-nudb-config",
"Homepage, https://github.com/statisticsnorway/ssb-nudb-config",
"Repository, https://github.com/statisticsnorway/ssb-nudb-config"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T09:40:21.710450 | ssb_nudb_config-2026.2.9.tar.gz | 29,385 | 60/af/036e1e9ac3a5383f08a7dc7d87d394a4af490460326484847d4ab4e896d1/ssb_nudb_config-2026.2.9.tar.gz | source | sdist | null | false | f30186794ad2024af8f3d6a674ade4b9 | 71c60ae05fd169e5258649bab06ed78a11adb3dc1dc29bf0065ae2cf77fbfed7 | 60af036e1e9ac3a5383f08a7dc7d87d394a4af490460326484847d4ab4e896d1 | MIT | [
"LICENSE"
] | 323 |
2.4 | crovia | 1.2.2 | Crovia — The Global Standard for AI Training Data Attribution. Cryptographic proofs, absence verification, and automatic royalty settlement. | # Crovia Core Engine (Open Core)
**If AI is trained on your data, there should be a receipt.**
Crovia is an **offline-verifiable evidence engine** for declared AI training data.
It does **not** accuse.
It does **not** infer intent.
It does **not** enforce compliance.
Crovia produces **deterministic artifacts** that anyone can verify independently.
---
## Install
```bash
pip install crovia
```
Requires Python 3.10+. No external dependencies for the core pipeline.
---
## Read this first (30 seconds)
If you read only one thing, read this:
**Crovia turns a declaration into a closed, verifiable evidence capsule.**
Nothing more. Nothing less.
No trust required.
No network required.
No hidden logic.
---
## What Crovia produces (CRC-1)
Crovia generates a **CRC-1 Evidence Pack** — a closed set of files that fully describe:
- what was declared
- what was produced
- how integrity can be verified
Each CRC-1 pack contains:
- `receipts.ndjson` — declared training receipts
- `validate_report.md` — deterministic validation result
- `hashchain.txt` — integrity hash-chain
- `trust_bundle.json` — normalized trust summary
- `MANIFEST.json` — authoritative artifact contract
All files are **offline-verifiable**.
---
## Try it (single command)
### Generate CRC-1 Evidence Packs
```bash
# Full pipeline — receipts in, evidence pack out
crovia run --receipts examples/minimal_royalty_receipts.ndjson --period 2025-11 --budget 1000000 --out out_crc1
```
This creates a fully self-contained evidence capsule in `out_crc1/`.
### Disclosure Scanner — check a model's disclosure gaps
```bash
# Scan a HuggingFace model for missing training data declarations
crovia oracle scan meta-llama/Llama-3-8B
crovia oracle scan mistralai/Mistral-7B-v0.1
```
### Evidence Wedge — check a directory for evidence artifacts
```bash
crovia wedge scan # scan current directory
crovia wedge scan --path ./my-project
crovia wedge status # one-line status
crovia wedge explain # what artifacts Crovia looks for
```
### Other commands
```bash
crovia check <receipts.ndjson> # validate receipts (real)
crovia refine <receipts.ndjson> # fix share_sum / rank issues
crovia pay <receipts.ndjson> --period YYYY-MM --budget N # compute payouts
crovia bundle --receipts X --payouts Y # assemble trust bundle
crovia sign <file> # HMAC-sign any artifact
crovia trace <file> # generate / verify hashchain
crovia explain <file> # inspect any Crovia JSON/NDJSON
crovia license status # check tier (OPEN / PRO)
crovia bridge preview <model> # PRO capability preview
crovia mode show # show CLI config
crovia legend # full command reference
```
> `crovia scan` (attribution spider) requires the FAISS corpus index — not yet in open core.
> Run `crovia scan <file>` for details.
- No network
- No secrets
- Fully deterministic
---
## Inspect the artifacts
```bash
# Linux / macOS
ls out_crc1
cat out_crc1/MANIFEST.json
# Windows
dir out_crc1
type out_crc1\MANIFEST.json
```
`MANIFEST.json` defines exactly which files must exist.
Nothing implicit.
Nothing hidden.
---
## Verify evidence (offline, by anyone)
Verification requires **only the files themselves**.
Example:
```bash
crovia-verify out_crc1
```
Expected result:
```
[OK] All artifacts present
[OK] trust_bundle JSON valid
[OK] Hashchain verified
[OK] CRC-1 VERIFIED
```
If verification fails, the evidence is invalid.
No trust assumptions.
No authority required.
---
## Design principles
- Offline-first
- Deterministic
- No attribution claims
- No enforcement logic
- Evidence > opinions
Crovia produces **facts**, not judgments.
---
## Where to see real evidence
Crovia Open Core does not ship conclusions.
All public, inspectable evidence generated with this engine lives here:
https://github.com/croviatrust/crovia-evidence-lab
That repository contains:
- reproducible CRC-1 capsules
- offline-verifiable artifacts
- neutral semantic observations (DSSE)
- presence / absence observations (Spider)
If you want to see results, go there.
If you want to reproduce them, stay here.
---
## Source
https://github.com/croviatrust/crovia-core-engine
---
## License
Apache-2.0
CroviaTrust
| text/markdown | null | CroviaTrust <info@croviatrust.com> | null | null | Apache-2.0 | ai, training-data, attribution, cryptography, provenance, royalty, eu-ai-act, transparency, merkle, zk-proofs | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Security :: Cryptography"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy>=1.24.0",
"pandas>=2.0.0",
"rich>=13.0.0",
"qrcode>=7.4.0",
"pyyaml>=6.0",
"requests>=2.31.0"
] | [] | [] | [] | [
"Homepage, https://croviatrust.com",
"Documentation, https://croviatrust.com/docs",
"Repository, https://github.com/croviatrust/crovia-core-engine",
"Changelog, https://github.com/croviatrust/crovia-core-engine/blob/main/CHANGELOG.md",
"Issues, https://github.com/croviatrust/crovia-core-engine/issues"
] | twine/6.2.0 CPython/3.11.4 | 2026-02-20T09:40:06.475759 | crovia-1.2.2-py3-none-any.whl | 36,867 | b8/1d/3009251d710a79b8b1b0d758b185ec5b43de2ab02563c34fa65c988e6915/crovia-1.2.2-py3-none-any.whl | py3 | bdist_wheel | null | false | b4456da7b6c089bf92100c2c8632ecab | 5c1cc81dfd5cec436e75a07aec0596044f188c733a9f1df3c08d45e2b802b8c3 | b81d3009251d710a79b8b1b0d758b185ec5b43de2ab02563c34fa65c988e6915 | null | [] | 99 |
2.4 | mmgp | 3.7.6 | Memory Management for the GPU Poor |
<p align="center">
<H2>Memory Management 3.7.6 for the GPU Poor by DeepBeepMeep</H2>
</p>
This module contains multiples optimisations so that models such as Flux (and derived), Mochi, CogView, HunyuanVideo, ... can run smoothly on a 12 to 24 GB GPU limited card.
This a replacement for the accelerate library that should in theory manage offloading, but doesn't work properly with models that are loaded / unloaded several
times in a pipe (eg VAE).
Requirements:
- VRAM: minimum 6 GB, recommended 24 GB (RTX 3090/ RTX 4090)
- RAM: minimum 24 GB, recommended 48 GB
This module features 5 profiles in order to able to run the model at a decent speed on a low end consumer config (24 GB of RAM and 6 VRAM) and to run it at a very good speed (if not the best) on a high end consumer config (48 GB of RAM and 24 GB of VRAM).\
These RAM requirements are for Linux systems. Due to different memory management Windows will require an extra 16 GB of RAM to run the corresponding profile.
Each profile may use a combination of the following:
- Low RAM consumption (thanks to a rewritten safetensors library) that allows low RAM on the fly quantization
- Smart automated loading / unloading of models in the GPU to avoid unloading models that may be needed again soon
- Smart slicing of models to reduce memory occupied by models in the VRAM
- Ability to pin models to reserved RAM to accelerate transfers to VRAM
- Async transfers to VRAM to avoid a pause when loading a new slice of a model
- Automated on the fly quantization or ability to load pre quantized models
- Pretrained Lora support with low RAM requirements
- Support for pytorch compilation on Linux and WSL (supported on pure Windows but requires a complex Triton Installation).
## Sample applications that use mmgp
It is recommended to have a look at these applications to see how mmgp was implemented in each of them:
- Wan2GP: https://github.com/deepbeepmeep/Wan2GP :\
An excellent text to video and image to video generator that supports the best Open Source Video Architectures: Wan, Hunyuan and LTX Video
- Hunyuan3D-2GP: https://github.com/deepbeepmeep/Hunyuan3D-2GP :\
A great image to 3D and text to 3D tool by the Tencent team. Thanks to mmgp it can run with less than 6 GB of VRAM
- HuanyuanVideoGP: https://github.com/deepbeepmeep/HunyuanVideoGP :\
One of the best open source Text to Video generator
- FluxFillGP: https://github.com/deepbeepmeep/FluxFillGP :\
One of the best inpainting / outpainting tools based on Flux that can run with less than 12 GB of VRAM.
- Cosmos1GP: https://github.com/deepbeepmeep/Cosmos1GP :\
This application include two models: a text to world generator and a image / video to world (probably the best open source image to video generator).
- OminiControlGP: https://github.com/deepbeepmeep/OminiControlGP :\
A Flux derived application very powerful that can be used to transfer an object of your choice in a prompted scene. With mmgp you can run it with only 6 GB of VRAM.
- YuE GP: https://github.com/deepbeepmeep/YuEGP :\
A great song generator (instruments + singer's voice) based on prompted Lyrics and a genre description. Thanks to mmgp you can run it with less than 10 GB of VRAM without waiting forever.
## Installation
First you need to install the module in your current project with:
```shell
pip install mmgp
```
## Usage
It is almost plug and play and just needs to be invoked from the main app just after the model pipeline has been created.
1) First make sure that the pipeline explictly loads the models in the CPU device, for instance:
```
pipe = FluxPipeline.from_pretrained("black-forest-labs/FLUX.1-schnell", torch_dtype=torch.bfloat16).to("cpu")
```
2) Once every potential Lora has been loaded and merged, add the following lines for a quick setup:
```
from mmgp import offload, profile_type
offload.profile(pipe, profile_type.HighRAM_LowVRAM_Fast)
```
You can choose between 5 profiles depending on your hardware:
- HighRAM_HighVRAM (1): at least 48 GB of RAM and 24 GB of VRAM : the fastest well suited for a RTX 3090 / RTX 4090 but consumes much more VRAM, adapted for fast shorter video or small batches of pictures
- HighRAM_LowVRAM (2): at least 48 GB of RAM and 12 GB of VRAM : a bit slower, better suited for RTX 3070/3080/4070/4080 or for RTX 3090 / RTX 4090 with large pictures batches or long videos
- LowRAM_HighVRAM (3): at least 32 GB of RAM and 24 GB of VRAM : adapted for RTX 3090 / RTX 4090 with limited RAM but at the cost of VRAM (shorter videos / fewer images)
- LowRAM_LowVRAM (4): at least 32 GB of RAM and 12 GB of VRAM : if you have little VRAM or want to generate longer videos / more images
- VerylowRAM_LowVRAM (5): at least 24 GB of RAM and 10 GB of VRAM : if you don't have much it won't be fast but maybe it will work
Profile 2 (High RAM) and 4 (Low RAM) are the most recommended profiles since they are versatile (support for long videos for a slight performance cost).\
If you use Flux derived applciation profile 1 and 3 will offer much faster generation times.
In any case, a safe approach is to start from profile 5 (default profile) and then go down progressively to profile 4 and then to profile 2 as long as the app remains responsive or doesn't trigger any out of memory error.
By default the model named 'transformer' will be quantized to 8 bits for all profiles. If you don't want that you may specify the optional parameter *quantizeTransformer = False*.
Every parameter set automatically by a profile can be overridden with one or multiple parameters accepted by *offload.all* (see below):
```
from mmgp import offload, profile_type
offload.profile(pipe, profile_type.HighRAM_LowVRAM, budgets = 1000)
```
If you want to know which parameter are set by one specific profile you can use the parameter *verboseLevel=2*
**It is highly recommended to put the *from mmgp import offload, profile_type* at the top of your main python file (that is as the first import) so that all the existing safetensors calls are redirected to mmpg.**
## Alternatively you may want to create your own profile with specific parameters:
For example:
```
from mmgp import offload
offload.all(pipe, pinnedMemory=True, ExtraModelsToQuantize = ["text_encoder_2"] )
```
- pinnedMemory: Boolean (for all models) or List of models ids to pin to RAM. Every model pinned to RAM will load much faster (up to 2 times) but this requires more RAM
- quantizeTransformer: boolean by default True. The 'transformer' model in the pipe contains usually the video or image generator is by defaut; quantized on the fly by default to 8 bits. If you want to save time on disk and reduce the loading time, you may want to load directly a prequantized model. If you don't want to quantize the image generator, you need to set the option *quantizeTransformer* to *False* to turn off on the fly quantization.
- extraModelsToQuantize: list of additional modelids of models to quantize on the fly. If the corresponding model is already quantized, this option will be ignored.
- budgets: either a number in mega bytes, (for all models, if 0 unlimited budget) a string that is perecentage of the total VRAM or a dictionary that maps model ids to mega bytes : define the approximate budget in mega bytes that is allocated in VRAM for a model. Try not to allocate all the available VRAM so that the rest can be used to process the data. To define the default value in the dictionary, you may add entry named "*".
The smaller this number, the more VRAM left for image data / longer video but also the slower because there will be lots of loading / unloading between the RAM and the VRAM. If model is too big to fit in a budget, it will be broken down in multiples parts that will be unloaded / loaded consequently. The speed of low budget can be increased (up to 2 times) by turning on the options pinnedMemory and asyncTransfers.
- workingVRAM: either a number in mega bytes, a string that is perecentage of the total VRAM or a dictionary that maps a model ids to a number in mega bytes that corresponds to a minimum amount of VRAM that should be left for the data processed by the model. This number will prevail if it is in conflict with a too high budget defined for the same model.
- asyncTransfers: boolean, load to the GPU the next model part while the current part is being processed. This requires twice the budget if any is defined. This may increase speed by 20% (mostly visible on fast modern GPUs).
- verboseLevel: number between 0 and 2 (1 by default), provides various level of feedback of the different processes
- compile: list of model ids to compile, may accelerate up x2 depending on the type of GPU. It makes sense to compile only the model that is frequently used such as the "transformer" model in the case of video or image generation. Compilation requires Triton to be installed. Triton is available out of the box on Linux or WSL but requires to be installed with Windows: https://github.com/woct0rdho/triton-windows
- coTenantsMap: a dictionary that maps a model id to a list of other models with which it accepts to share the VRAM at the same time. This is useful to avoid unefficient loading / unloading when two models processes are interleaved. For instance *coTenantsMap = { "text_encoder_2": ["text_encoder"] }* , here when *text_encoder_2* is loaded it won't unload *text_encoder*. Please note that the reverse is not true as these maps by design are not symetrical to allow tailored workflows. If you need to have as well *text_encoder* that won't unload *text_encoder_2* if it is already loaded *coTenantsMap = { "text_encoder_2": ["text_encoder"], "text_encoder": ["text_encoder_2"] }*
If you are short on RAM and plan to work with quantized models, it is recommended to load pre-quantized models direclty rather than using on the fly quantization, it will be faster and consume slightly less RAM.
## Going further
The module includes several tools to package a light version of your favorite video / image generator:
- *extract_models(string prefix, obj to explore)*\
This tool will try to detect for you models that are embedded in a pipeline or in some custom class. It will save you time by building a pipe dictionary required by *offload.all* or "offload.profile*. The prefix correponds to the text that will appear before the name of each model in the dictionary.
- *load_loras_into_model(model, lora_path, lora_multi, activate_all_loras = True)*\
Load in a model a list of Lora described by a list of path *lora_path* and a list of *weights coefficients*.
The Lora file must be in the *diffusers* format. This function works also on non diffusers models. However if there is already an official Lora support for a model it is recommended to use the official diffusers functions. By default all the load loras will be activated or they can be activated later using *activate_loras*.
-*activate_loras(model, lora_nos, lora_multi = None )*\
Activate the loras whose nos are in the list of nos. Every lora that is not this list and that was activated previously will be disactivated.
- *save_model(model, file_path, do_quantize = False, quantizationType = qint8 )*\
Save tensors of a model already loaded in memory in a safetensor format (much faster to reload). You can save it in a quantized format (default qint8 quantization recommended).
The resulting safetensor file will contain extra fields in its metadata such as the quantization map and its configuration, so you will be able to move the file around without files such as *config.json* or *file_map.json*.
You will need *load_model_data* or *fast_load_transformers_model* to read the file again . You may also load it using the default *safetensor* librar however you will need to provide in the same directory any complementary file that are usually requested (for instance *config.json*)
- *load_model_data(model, file_path: str, do_quantize = False, quantizationType = qint8, pinToRAM = False, partialPin = False)*\
Load the tensors data of a model in RAM of a model already initialized with no data. Detect and handle quantized models saved previously with *save_model*.A model can also be quantized on the fly while being loaded. The model which is loaded can be pinned to RAM while it is loaded, this is more RAM efficient than pinning tensors later using *offline.all* or *offline.profile*
- *fast_load_transformers_model(model_path: str, do_quantize = False, quantizationType = qint8, pinToRAM = False, partialPin = False)*\
Initialize (build the model hierarchy in memory) and fast load the corresponding tensors of a 'transformers' or 'diffusers' library model.
The advantages over the original *from_pretrained* method is that a full model can fit into a single file with a filename of your choosing (thefore you can have multiple 'transformers' versions of the same model in the same directory) and prequantized models are processed in a transparent way.
Last but not least, you can also on the fly pin to RAM the whole model or the most important part of it (partialPin = True) in a more efficient way (faster and requires less RAM) than if you did through *offload.all* or *offload.profile*.
The typical workflow wil be:
1) temporarly insert the *save_model* function just after a model has been fully loaded to save a copy of the model / quantized model.
2) replace the full initalizing / loading logic with *fast_load_transformers_model* (if there is a *from_pretrained* call to a transformers object) or only the tensor loading functions (*torch.load_model_file* and *torch.load_state_dict*) with *load_model_data after* the initializing logic.
## Special cases
Sometime there isn't an explicit pipe object as each submodel is loaded separately in the main app. If this is the case, you may try to use *extract_models* or create a dictionary that manually maps all the models.\
For instance :
- for flux derived models:
```
pipe = { "text_encoder": clip, "text_encoder_2": t5, "transformer": model, "vae":ae }
```
- for mochi:
```
pipe = { "text_encoder": self.text_encoder, "transformer": self.dit, "vae":self.decoder }
```
Please note it is recommended to have always one model whose Id is 'transformer' so that you can leverage predefined profiles. The 'transformer' corresponds to the main image / video model which usually needs to be quantized (this is done on the fly by default when loading the model).
Be careful, lots of models use the T5 XXL as a text encoder. However, quite often their corresponding pipeline configurations point at the official Google T5 XXL repository
where there is a huge 40GB model to download and load. It is cumbersorme as it is a 32 bits model and contains the decoder part of T5 that is not used.
I suggest you use instead one of the 16 bits encoder only version available around, for instance:
```
text_encoder_2 = T5EncoderModel.from_pretrained("black-forest-labs/FLUX.1-dev", subfolder="text_encoder_2", torch_dtype=torch.float16)
```
Sometime just providing the pipe won't be sufficient as you will need to change the content of the core model:
- For instance you may need to disable an existing CPU offload logic that already exists (such as manual calls to move tensors between cuda and the cpu)
- mmpg to tries to fake the device as being "cuda" but sometimes some code won't be fooled and it will create tensors in the cpu device and this may cause some issues.
You are free to use my module for non commercial use as long you give me proper credits. You may contact me on twitter @deepbeepmeep
Thanks to
---------
- Huggingface / accelerate for the hooking examples
- Huggingface / quanto for their very useful quantizer
- gau-nernst for his Pinnig RAM samples
| text/markdown | null | deepbeepmeep <deepbeepmeep@yahoo.com> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"torch>=2.1.0",
"optimum-quanto",
"accelerate",
"safetensors",
"psutil"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.10.18 | 2026-02-20T09:39:46.683551 | mmgp-3.7.6.tar.gz | 71,170 | 7f/db/39c51bf6884969b870045de490fbe734857d911208fdc4c9bcf07b4df31c/mmgp-3.7.6.tar.gz | source | sdist | null | false | bcdac3374578950262fa0ad42d9f82ce | 7bc8e18c84ca6d528fe7de7ef8cf3ab74227432956c72a169bf458f8fb58c5e8 | 7fdb39c51bf6884969b870045de490fbe734857d911208fdc4c9bcf07b4df31c | null | [
"LICENSE.md"
] | 8,627 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.