
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.4 | superposition-bindings | 0.99.2 | Python bindings for Superposition | # Superposition Native Python Bindings
This package provides native bindings to Python for the Superposition core library that provides functionality for working with [Superposition](https://juspay.io/superposition).
This is used with our [open feature provider](https://pypi.org/project/superposition-provider) and we recommend using the provider instead of using this package directly. | text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T06:16:38.999598 | superposition_bindings-0.99.2-py3-none-any.whl | 1,090 | fa/f0/265af7ab821f9d804126f4025ada91e6f0286e43ab10025d4dfe74569ea3/superposition_bindings-0.99.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 026779fac31cb6c0fa331ed87d8396bd | 53a46e84ca0c6c1d013186a558a0e24c9ab921935029b08633015e51eb7732f7 | faf0265af7ab821f9d804126f4025ada91e6f0286e43ab10025d4dfe74569ea3 | null | [] | 96 |
2.4 | mongojet | 0.5.1 | Async MongoDB client for Python | ### Mongojet
[](https://github.com/romis2012/mongojet/actions/workflows/python-ci.yml)
[](https://codecov.io/gh/romis2012/mongojet)
[](https://pypi.python.org/pypi/mongojet)
[](https://github.com/romis2012/mongojet)
Async (asyncio) MongoDB client for Python.
It uses [Rust MongoDB driver](https://github.com/mongodb/mongo-rust-driver) and [tokio](https://github.com/tokio-rs/tokio) under the hood.
Mongojet is 2-4x faster than Motor (and 1.5-3.5x faster than PyMongo AsyncMongoClient) in high concurrency scenarios (see benchmarks below).
## Requirements
- Python >= 3.9
- pymongo>=4.6.2 (only `bson` package is required)
## Installation
```
pip install mongojet
```
## Usage
Mongojet has an API similar to PyMongo/Motor (but not exactly the same)
### Creating a Client
Typically, you should create a single instance of Client per application/process.
All client options should be passed via [MongoDB connection string](https://www.mongodb.com/docs/manual/reference/connection-string/).
```python
from mongojet import create_client, ReadPreference
client = await create_client('mongodb://localhost:27017/test_database?maxPoolSize=16')
```
### Getting a Database
default database
```python
db = client.get_default_database()
```
database with specific name
```python
db = client.get_database('test_database')
```
database with specific name and options
```python
db = client.get_database('test_database', read_preference=ReadPreference(mode='secondaryPreferred'))
```
### Getting a Collection
```python
collection = db['test_collection']
```
with options
```python
collection = db.get_collection('test_collection', read_preference=ReadPreference(mode='secondary'))
```
### Inserting documents
`insert_one`
```python
document = {'key': 'value'}
result = await collection.insert_one(document)
print(result)
#> {'inserted_id': ObjectId('...')}
```
`insert_many`
```python
documents = [{'i': i} for i in range(1000)]
result = await collection.insert_many(documents)
print(len(result['inserted_ids']))
#> 1000
```
### Find documents
`find_one` (to get a single document)
```python
document = await collection.find_one({'i': 1})
print(document)
#> {'_id': ObjectId('...'), 'i': 1}
```
`find` (to get cursor which is an async iterator)
```python
cursor = await collection.find({'i': {'$gt': 5}}, sort={'i': -1}, limit=10)
```
you can iterate over the cursor using the `async for` loop
```python
async for document in cursor:
print(document)
```
or collect cursor to list of documents using `to_list` method
```python
documents = await cursor.to_list()
```
`find_many` (to get list of documents in single batch)
```python
documents = await collection.find_many({'i': {'$gt': 5}}, sort={'i': -1}, limit=10)
```
### Counting documents
```python
n = await collection.count_documents({'i': {'$gte': 500}})
print(n)
#> 500
```
### Aggregating documents
```python
cursor = await collection.aggregate(pipeline=[
{'$match': {'i': {'$gte': 10}}},
{'$sort': {'i': 1}},
{'$limit': 10},
])
documents = await cursor.to_list()
print(documents)
```
### Updating documents
`replace_one`
```python
result = await collection.replace_one(filter={'i': 5}, replacement={'i': 5000})
print(result)
#> {'matched_count': 1, 'modified_count': 1, 'upserted_id': None}
```
`update_one`
```python
result = await collection.update_one(filter={'i': 5}, update={'$set': {'i': 5000}}, upsert=True)
print(result)
#> {'matched_count': 0, 'modified_count': 0, 'upserted_id': ObjectId('...')}
```
`update_many`
```python
result = await collection.update_many(filter={'i': {'$gte': 100}}, update={'$set': {'i': 0}})
print(result)
#> {'matched_count': 900, 'modified_count': 900, 'upserted_id': None}
```
### Deleting documents
`delete_one`
```python
result = await collection.delete_one(filter={'i': 5})
print(result)
#> {'deleted_count': 1}
```
`delete_many`
```python
result = await collection.delete_many(filter={'i': {'$gt': 5}})
print(result)
#> {'deleted_count': 94}
```
### Working with GridFS
```python
bucket = db.gridfs_bucket(bucket_name="images")
with open('/path/to/my/awesome/image.png', mode='rb') as file:
data = file.read()
result = await bucket.put(data, filename='image.png', content_type='image/png')
file_id = result['file_id']
with open('/path/to/my/awesome/image_copy.png', mode='wb') as file:
data = await bucket.get_by_id(file_id)
file.write(data)
await bucket.delete(file_id)
```
## Simple benchmark (lower is better):
### find_one
<!--  -->

### insert_one

### iterate over cursor

| text/markdown; charset=UTF-8; variant=GFM | null | Roman Snegirev <snegiryev@gmail.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Programming Language :: Rust",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Operating System :: MacOS",
"Operating System :: Microsoft",
"Operating System :: POSIX :: Linux",
"Topic :: Database",
"Topic :: Database :: Front-Ends",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"pymongo>=4.6.2",
"typing-extensions>=4.10.0"
] | [] | [] | [] | [
"homepage, https://github.com/romis2012/mongojet",
"repository, https://github.com/romis2012/mongojet"
] | maturin/1.12.3 | 2026-02-20T06:16:07.460433 | mongojet-0.5.1-cp39-cp39-win32.whl | 5,631,384 | 6d/e0/4dfe62597d486636cb3e3741ad1ace1e63b55121de8ab1246d8097adf883/mongojet-0.5.1-cp39-cp39-win32.whl | cp39 | bdist_wheel | null | false | 39a8d8ca53b36542eeac3ced9def54fd | f0d5be566d0d0eeaa8e93bbd58db59f885436b96dec557b8526041ac8f7994fa | 6de04dfe62597d486636cb3e3741ad1ace1e63b55121de8ab1246d8097adf883 | null | [] | 3,851 |
2.4 | pulumi-docker | 4.12.0a1771567430 | A Pulumi package for interacting with Docker in Pulumi programs | [](https://github.com/pulumi/pulumi-docker/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/docker)
[](https://pypi.org/project/pulumi-docker)
[](https://badge.fury.io/nu/pulumi.docker)
[](https://pkg.go.dev/github.com/pulumi/pulumi-docker/sdk/v3/go)
[](https://github.com/pulumi/pulumi-docker/blob/master/LICENSE)
# Docker Resource Provider
The Docker resource provider for Pulumi lets you manage Docker resources in your cloud programs. To use
this package, please [install the Pulumi CLI first](https://pulumi.io/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/docker
or `yarn`:
$ yarn add @pulumi/docker
### Python
To use from Python, install using `pip`:
$ pip install pulumi_docker
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-docker/sdk/v4
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Docker
## Reference
For further information, please visit [the Docker provider docs](https://www.pulumi.com/docs/intro/cloud-providers/docker) or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/docker).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, docker | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-docker"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:15:55.483572 | pulumi_docker-4.12.0a1771567430.tar.gz | 120,876 | 05/d7/bc6fd0a9260f09aa471209d0629711ba9f441925618c61eee52d50865e6d/pulumi_docker-4.12.0a1771567430.tar.gz | source | sdist | null | false | a8cc94351d714b4ecae980aa19bdf367 | 3edd3e176f55226fa1f3ede233ac0451d078d3bf326f848dcb078bf240134483 | 05d7bc6fd0a9260f09aa471209d0629711ba9f441925618c61eee52d50865e6d | null | [] | 214 |
2.4 | pulumi-aws-apigateway | 3.1.0a1771567365 | Pulumi Amazon Web Services (AWS) API Gateway Components. | [](https://github.com/pulumi/pulumi-aws-apigateway/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/aws-apigateway)
[](https://pypi.org/project/pulumi-aws-apigateway)
[](https://badge.fury.io/nu/pulumi.awsapigateway)
[](https://pkg.go.dev/github.com/pulumi/pulumi-aws-apigateway/sdk/go)
[](https://github.com/pulumi/pulumi-aws-apigateway/blob/master/LICENSE)
# Pulumi AWS API Gateway Component
The Pulumi AWS API Gateway library provides a Pulumi component that easily creates AWS API Gateway REST APIs. This component exposes the Crosswalk for AWS functionality documented in the [Pulumi AWS API Gateway guide](https://www.pulumi.com/docs/guides/crosswalk/aws/api-gateway/) as a package available in all Pulumi languages.
<div>
<a href="https://www.pulumi.com/templates/serverless-application/aws/" title="Get Started">
<img src="https://www.pulumi.com/images/get-started.svg?" width="120">
</a>
</div>
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (JavaScript/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
npm install @pulumi/aws-apigateway
or `yarn`:
yarn add @pulumi/aws-apigateway
### Python
To use from Python, install using `pip`:
pip install pulumi-aws-apigateway
### Go
To use from Go, use `go get` to grab the latest version of the library
go get github.com/pulumi/pulumi-aws-apigateway/sdk
### .NET
To use from .NET, install using `dotnet add package`:
dotnet add package Pulumi.AwsApiGateway
## References
* [Tutorial](https://www.pulumi.com/templates/serverless-application/aws/)
* [API Reference Documentation](https://www.pulumi.com/registry/packages/aws-apigateway/api-docs/)
* [Examples](./examples)
* [Crosswalk for AWS - API Gateway Guide](https://www.pulumi.com/docs/guides/crosswalk/aws/api-gateway/)
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, aws, apigateway, category/cloud, kind/component | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"pulumi-aws<8.0.0,>=7.0.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Repository, https://github.com/pulumi/pulumi-aws-apigateway"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:15:35.688603 | pulumi_aws_apigateway-3.1.0a1771567365.tar.gz | 18,017 | fb/23/e6595b1789addfdb5c713ef040780c6d2c5e2b3191a709bf2f3e322d0fb3/pulumi_aws_apigateway-3.1.0a1771567365.tar.gz | source | sdist | null | false | d232d785220993ab44dbde9b0ccb4c92 | efb7a76b84b433fdd38f8def7f5d7b2ee408f3a11dc4d13b7df8c4435392efdc | fb23e6595b1789addfdb5c713ef040780c6d2c5e2b3191a709bf2f3e322d0fb3 | null | [] | 206 |
2.4 | pulumi-http | 0.2.0a1771567525 | A Pulumi package for creating and managing HTTP cloud resources. | [](https://github.com/pulumi/pulumi-http/actions)
[](https://www.npmjs.com/package/@pulumi/http)
[](https://pypi.org/project/pulumi_http)
[](https://www.nuget.org/packages/Pulumi.Http)
[](https://pkg.go.dev/github.com/pulumi/pulumi-http/sdk/go)
[](https://github.com/pulumi/pulumi-http/blob/master/LICENSE)
# HTTP Resource Provider
This provider is mainly used for ease of converting terraform programs to Pulumi.
For standard use in Pulumi programs, please use your programming language's standard http library.
The HTTP resource provider for Pulumi lets you use HTTP resources in your cloud programs.
To use this package, please [install the Pulumi CLI first](https://www.pulumi.com/docs/install/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/http
or `yarn`:
$ yarn add @pulumi/http
### Python
To use from Python, install using `pip`:
$ pip install pulumi_http
### Go
To use from Go, use `go get` to grab the latest version of the library:
$ go get github.com/pulumi/pulumi-http/sdk
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Http
<!-- If your provider has configuration, remove this comment and the comment tags below, updating the documentation. -->
<!--
## Configuration
The following Pulumi configuration can be used:
- `http:token` - (Required) The API token to use with HTTP. When not set, the provider will use the `HTTP_TOKEN` environment variable.
-->
<!-- If your provider has reference material available elsewhere, remove this comment and the comment tags below, updating the documentation. -->
<!--
## Reference
For further information, please visit [HTTP reference documentation](https://example.com/http).
-->
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, category/cloud | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://www.pulumi.com/",
"Repository, https://github.com/pulumi/pulumi-http"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:15:18.698840 | pulumi_http-0.2.0a1771567525.tar.gz | 11,464 | 34/d8/2d887ddbf65e8bb6da58f64bf45d4b506ab5d225d8f59c7280adb11265f4/pulumi_http-0.2.0a1771567525.tar.gz | source | sdist | null | false | caeb773ea407917290768e1b4e32fc03 | 449ebd7cb6be306cd68d15adb7b409f9d5774593eb58991ba68b3e3fa9d5bdae | 34d82d887ddbf65e8bb6da58f64bf45d4b506ab5d225d8f59c7280adb11265f4 | null | [] | 216 |
2.4 | pulumi-ise | 0.3.0a1771567558 | A Pulumi package for managing resources on a Cisco ISE (Identity Service Engine) instance. | # Cisco ISE Resource Provider
A Pulumi package for managing resources on a [Cisco ISE](https://www.pulumi.com/registry/packages/ise/) (Identity Service Engine) instance.
## Installing
This package is available for several languages/platforms:
### Node.js (JavaScript/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
```bash
npm install @pulumi/ise
```
or `yarn`:
```bash
yarn add @pulumi/ise
```
### Python
To use from Python, install using `pip`:
```bash
pip install pulumi_ise
```
### Go
To use from Go, use `go get` to grab the latest version of the library:
```bash
go get github.com/pulumi/pulumi-ise/sdk/go/...
```
### .NET
To use from .NET, install using `dotnet add package`:
```bash
dotnet add package Pulumi.Ise
```
## Reference
For detailed reference documentation, please visit [the Pulumi registry](https://www.pulumi.com/registry/packages/ise/api-docs/).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, ise, category/network | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.com",
"Repository, https://github.com/pulumi/pulumi-ise"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:15:06.788095 | pulumi_ise-0.3.0a1771567558.tar.gz | 206,564 | dc/74/aaf86d95bbfea12f6b3a07e5f7d7bd201f3659a7ce985e9ad9c5459639b0/pulumi_ise-0.3.0a1771567558.tar.gz | source | sdist | null | false | 5f288f8127b989379bb28a7144eadfe1 | 3b8f50c697601b595ceff69ac44dc39d8b8b6e6e3570d82c7261180e02d9e6ea | dc74aaf86d95bbfea12f6b3a07e5f7d7bd201f3659a7ce985e9ad9c5459639b0 | null | [] | 210 |
2.4 | pulumi-ec | 1.0.0a1771567296 | A Pulumi package for creating and managing ElasticCloud resources. | # Elastic Cloud Resource Provider
The Elastic Cloud Resource Provider lets you manage [Elastic Cloud](https://www.elastic.co/cloud/) resources.
## Installing
This package is available for several languages/platforms:
### Node.js (JavaScript/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
```bash
npm install @pulumi/ec
```
or `yarn`:
```bash
yarn add @pulumi/ec
```
### Python
To use from Python, install using `pip`:
```bash
pip install pulumi_ec
```
### Go
To use from Go, use `go get` to grab the latest version of the library:
```bash
go get github.com/pulumi/pulumi-ec/sdk
```
### .NET
To use from .NET, install using `dotnet add package`:
```bash
dotnet add package Pulumi.ElasticCloud
```
## Configuration
The following configuration points are available for the `ec` provider:
- `ec:endpoint`: The Elastic Cloud endpoint to which requests should be sent. This value should be specified only when using the Elastic Cloud provider with an ECE installation or ESS Private.
- `ec:apikey`: The Elastic Cloud API key, recommended over `username` and `password` to authenticate against the Elastic Cloud API. May also be sourced from environment variable `EC_API_KEY`.
- `ec:username`: The Elastic Cloud username. May also be sourced from environment variable `EC_USER` or `EC_USERNAME`. Conflicts with `ec:apiKey`. Not recommened - prefer using `ec:apikey` over `ec:username` and `ec:password`.
- `ec:password`: The Elastic Cloud user's password. May also be sourced from environment variable `EC_PASS` or `EC_PASSWORD`. Conflicts with `ec:apiKey`. Not recommened - prefer using `ec:apikey` over `ec:username` and `ec:password`.
- `ec:insecure`: If `true`, allows the provider to skip TLS verification (not recommended). Defaults to `false`.
- `ec:timeout`: Allows the user to set a custom timeout in the individual HTTP request level. Defaults to 1 minute (`"1m"`), but can be extended if timeouts are experienced.
- `ec:verbose`: When set to true, it writes a requests.json file in the folder where Terraform runs with all the outgoing HTTP requests and responses. Defaults to false.
- `ec:verboseCredentials`: If set to `true` and `ec:verbose` is set to `true`, the contents of the Authorization header will not be redacted. Defaults to `false`.
- `ec:verboseFile`: Sets the name of the file to which verbose request and response HTTP flow will be written. Defaults to `request.log`.
Either `ec:endpoint` or (`ec:username` and `ec:password`) must be specified. All other parameters are optional:
## Reference
For detailed reference documentation, please visit [the Pulumi registry](https://www.pulumi.com/registry/packages/ec/api-docs/).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, ec, elasticsearch, es, elastic, elasticcloud | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-ec"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:14:52.252043 | pulumi_ec-1.0.0a1771567296.tar.gz | 82,280 | f9/35/edcdfc5a6312e35a4c1ad5c9c60ac9c9c3f2e48ecbe11e560db622391e00/pulumi_ec-1.0.0a1771567296.tar.gz | source | sdist | null | false | af5f3bda574f23a63e48d6f185a96726 | 6be99c004c944ba2fd83f3fef615c3d9d43b4861dbfd926676194b5bd6ea8eae | f935edcdfc5a6312e35a4c1ad5c9c60ac9c9c3f2e48ecbe11e560db622391e00 | null | [] | 210 |
2.4 | bombshell | 0.7.1 | A library for easily running shell commands, whether standalone or piped. | # bombshell
A library for easily running subprocesses in Python, whether single or piped.
## Why?
Python's `subprocess` library is capable of running whatever you need it to, but isn't always the most friendly or readable option, even when running a single process:
```py
res = subprocess.run(("echo", "1"), capture_output=True, text=True)
print(res.stdout) # "1\n"
```
Needing to pass `capture_output=True, text=True` all the time is annoying when those are probably the most common default. Plus, the command has to be passed as a tuple/list, rather than just the arguments themselves.
```py
res = Process("echo", "1").exec()
print(res.stdout) # "1\n"
print(type(res.stdout)) # <class 'str'>
```
But if you want bytes, then you can have bytes:
```py
res = Process("echo", "1").exec(mode=bytes)
print(res.stdout) # b"1\n"
print(type(res.stdout)) # <class 'bytes'>
```
`subprocess` is also really picky about the types of arguments you pass in:
```py
res = subprocess.run(("echo", 1))
TypeError: "expected str, bytes or os.PathLike object, not int"
```
Why, though? `bombshell` automatically calls `str()` on every argument passed to it.
```py
res = Process("echo", 1).exec()
print(res.stdout) # "1\n"
print(res.exit_code) # 0
```
`subprocess` also makes piping commands way more difficult than it needs to be. What's easy in Bash...
```bash
res=$(echo "hello\nworld\ngoodbye" | grep "l")
echo "$res" # "hello\nworld"
```
...is way more complicated with `subprocess` since you have to individually manage both sides of the pipe.
```py
parent = subprocess.Popen(("echo", "hello\nworld\ngoodbye"), stdout=subprocess.PIPE)
child = subprocess.Popen(("grep", "l"), stdin=parent.stdout, capture_output=True, text=True)
stdout, _ = child.communicate()
print(stdout) # "hello\nworld"
```
There must be a better way.
```py
res = Process("echo", "hello\nworld\ngoodbye").pipe("grep", "l").exec()
print(res.stdout) # "hello\nworld"
# Process supports .__or__, so we can also do
p1 = Process("echo", "hello\nworld\ngoodbye")
p2 = Process("grep", "l")
res = (p1 | p2).exec()
print(res.stdout) # "hello\nworld"
```
We can also pass environment variables to individual commands:
```py
res = subprocess.run(("printenv", "FOO"), capture_output=True, text=True, env={"FOO": "bar"})
print(res.stdout) # "bar\n"
res = Process("printenv", "FOO", env={"FOO": "bar"}).exec()
res = Process("printenv", "FOO").with_env(FOO="bar").exec()
print(res.stdout) # "bar\n"
```
or set the current working directory:
```py
res = subprocess.run(("pwd",), capture_output=True, text=True, cwd="/tmp")
print(res.stdout) # "/tmp\n"
res = Process("pwd", cwd="/tmp").exec()
res = Process("pwd").with_cwd("/tmp").exec()
print(res.stdout) # "/tmp\n"
```
`subprocess` also makes it somewhat difficult to chain commands (`command1 && command2`), preferring:
```py
# only "echo 1" and "echo 2" will successfully run; "echo 3" will not
procs = [("echo", "1"), ("echo", "2"), ("false",), ("echo", "3")]
for proc in procs:
res = subprocess.run(proc, capture_output=True, text=True)
if res.returncode:
break
```
whereas we can do
```py
res = Process("echo", 1).and_then("echo", 2).and_then("false").and_then("echo", "3").exec()
print(res.command) # echo 1 && echo 2 && false && echo 3
print(res.stdout) # "1\n2\n"
print(res.exit_code) # 1
print(res.exit_codes) # (0, 0, 1) <-- indicating that the first two echo commands exited with 0, then false exited with 1
```
Similarly, `Process.then` provides `command1 ; command2` functionality, and `Process.or_else` provides `command1 || command2`.
`Process.exec` also supports a `with_spinner` argument, useful for long-running commands:

The spinner is written to stderr. When `with_spinner` is set to True, it is inadvisable to set `capture=False` as this will clobber the output.
In addition, for convenience, a top-level `exec` function is also provided as a wrapper around `Process(...).exec(...)`. In general, `Process(...).exec(...)` should be preferred for clarity. The top-level `exec` function does not support pipes and still requires the arguments to be provided as variadic arguments, rather than as a string.
## Installation
`bombshell` is supported on Python 3.10 and newer and can be easily installed with a package manager such as:
```bash
# using pip
$ pip install bombshell
# using uv
$ uv add bombshell
```
`bombshell` has no other external dependencies (except `typing_extensions`, only on Python 3.10).
## Documentation
### `PipelineError`
An error that is thrown by `CompletedProcess.check()` when the pipeline has errored. It stores the calling process under its `.process` attribute.
```py
try:
Process("false").exec().check()
except PipelineError as err:
# err.process == Process("false").exec()
print(err.process.command) # "false"
print(err.process.exit_codes) # (1,)
```
### `ResourceData`
A NamedTuple with the following attributes:
- `real_time` (alias: `rtime`): the real time used by the process (seconds)
- `user_time` (alias: `utime`): the user time used by the process (seconds)
- `system_time` (alias: `stime`): the system time used by the process (seconds)
- `max_resident_set_size` (alias: `maxrss`): the maximum resident set size used by the process (bytes)
> [!NOTE]
> `real_time` (`rtime`) is guaranteed to exist. **On non-Unix systems, the other values will be None as they are not reported by the operating system.** On Unix, they may be None in rare situations where the process is not reaped normally.
Further note that **`max_resident_set_size` is given in bytes on all platforms**. On Linux, this value is natively reported in KiB, but it's converted here for compatibility. Due to the overhead of launching these processes from within Python, in most cases, the reported value will be higher than what /usr/bin/time reports:
```bash
$ uname
Linux
# %M = maximum resident set size in KiB
$ /usr/bin/time -f "%M" sleep 2
2048
# .max_resident_set_size (.maxrss) = maximum in B
# 14,708,736 B = 14,364 KiB
$ uv run python -c "from bombshell import Process; res = Process('sleep', 2).exec(); print(res.resources[0].maxrss)
14708736
```
### `CompletedProcess[S]`
An object that stores the state of a completed process. In particular, its attributes are:
| **attribute** | **type** | **description** |
|---------------|-------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `args` | `tuple[tuple[str, ...], ...]` | the arguments that were passed to the process(es) that gave this result |
| `command` | `str` | a string representation of the command as would be run on the command line (formatted for POSIX) |
| `exit_codes` | `tuple[int, ...]` | all of the exit codes for the various processes in the pipeline |
| `exit_code` | `int` | the exit code of the last executed part of the pipeline (and thus the exit code of the pipeline) |
| `stdout` | `S` (str or bytes) | the contents of the stdout pipes, if captured. `p1.pipe(p2).exec().stdout` will contain only the output of `p2`; for `p1.then(p2)`, it will contain both; for `p1.or_else(p2)` and `p1.and_then(p2)`, it will include both unless `p2` is not run. |
| `stderr` | `S` (str or bytes) | the contents of the stderr pipes, if captured. This will always include the combination of all stderr pipes. |
| `runtime` | `float` | the real (wall) time of the command's execution (seconds) |
| `resources` | `tuple[ResourceData, ...]` | a tuple of objects describing the resource usage (real time, user time, system time, memory usage) of each process |
| `total_resources` | `ResourceData` | an object describing the aggregating resource usage for the entire execution |
```py
res = (
Process("echo", 1)
.pipe("echo", 2)
.pipe("false")
.pipe("echo", 3)
.exec()
)
print(res.args) # (("echo", "1"), ("echo", "2"), ("false",), ("echo", "3"))
print(res.command) # "echo 1 | echo 2 | false | echo 3"
print(res.exit_codes) # (0, 0, 1, 0)
print(res.exit_code) # 0
print(res.stdout) # "3\n"
print(res.stderr) # ""
# resources for the individual processes
print(res.resources[0]) # ResourceData(real_time=2.4565961211919785e-05, user_time=0.0, system_time=0.001305, max_resident_set_size=17125376)
print(res.resources[1]) # ResourceData(real_time=5.985284224152565e-05, user_time=0.0, system_time=0.0010999999999999998, max_resident_set_size=17125376)
print(res.resources[2]) # ResourceData(real_time=6.692949682474136e-06, user_time=0.001215, system_time=0.0, max_resident_set_size=17125376)
print(res.resources[3]) # ResourceData(real_time=5.029840394854546e-06, user_time=0.0, system_time=0.0016669999999999999, max_resident_set_size=17125376)
# total resource usage
print(res.runtime) # 0.005894029047340155
print(res.total_resources) # ResourceData(real_time=0.005894029047340155, user_time=0.001215, system_time=0.004071999999999999, max_resident_set_size=17125376)
```
This class also defines the following methods:
- `check(*, strict: bool = False)`: Raise PipelineError if the process exited in error. With `strict=True`, any of the processes will trigger the exception; with `strict=False` (the default), only the final process determines whether an exception is raised.
```py
res = (
Process("echo", 1)
.pipe("echo", 2)
.pipe("false")
.pipe("echo", 3)
.exec()
)
res.check() # passes since the final exit code was zero
res.check(strict=True) # raises PipelineError since there was a failure along the pipeline
```
- `timed_out() -> bool`: Return True if any of the processes timed out (and False otherwise).
```py
res = Process("sleep", 1).exec(timeout=2)
print(res.exit_code) # 0
print(res.timed_out()) # False
res = Process("sleep", 10).exec(timeout=2)
print(res.exit_code) # 124
print(res.timed_out()) # True
res.check() # raises PipelineError
```
- `exit() -> None`: raises SystemExit, exiting the Python process with the same exit code as the process in question.
```bash
$ python3 -c "from bombshell import exec; exec('exit', 17).exit()" ; echo $?
17
```
### Timeouts
`.exec()` takes an optional `timeout` parameter. If provided, it should be a number of seconds that serves as a maximum duration for the command. For command chains (`p.and_then(q).exec(timeout=...)`), the timeout is shared across the entire chain, rather than each process having its own individual timeout.
Note that, unlike `subprocess`, `bombshell` does not use exception flow for timeouts. As shown above, when a timeout occurs, the exit code for offending processes is set to 124 (the standard Unix timeout signal):
```bash
$ timeout 1 sleep 3 ; echo $?
124
$ python -c "from bombshell import exec; exec('sleep', 3, timeout=1).exit()" ; echo $?
124
$ python -c "from bombshell import exec; print(exec('sleep', 3, timeout=1).timed_out())"
True
```
To determine if a timeout has occurred, use `if p.exec().timed_out():`. Note that `p.exec().check()` can raise an exception in the event of a timeout as well since the offending process's exit code is set to a nonzero value. Further note that the process's actual timeout state is observed as a result of the internal execution method: thus,
```py
>>> res = Process("exit", 124).exec()
>>> res.exit_code
124
>>> res.timed_out()
False
```
### `exec`
A top-level function that wraps `Process(...).exec(...)`. The signature is `def exec(*args: str, **kwargs) -> CompletedProcess[S]`. The available kwargs are all of the keyword arguments to `Process.__init__` (`cwd` and `env`) and `.exec` (`stdin`, `capture`, `mode`, `merge_stderr`, `timeout`, `with_spinner`).
`*args` must still be given as variadic arguments: `exec` does not support single-string commands (à la `shell=True`). Thus, the following are equivalent:
```py
>>> Process("printenv", "FOO", env={"FOO": "7"}).exec(capture=False)
>>> exec("printenv", "FOO", env={"FOO": "7"}, capture=False)
```
In general, the top one (`Process(...).exec(...)`) should be preferred for clarity but the latter may sometimes be preferable in "shell script" types of programs.
### `Process`
A `Process` object takes a command to run as arguments, along with (optionally) an `env` mapping to use for it and a `cwd` parameter. The object defines:
- `exec(self, stdin: S | None = None, *, capture: bool = True, mode: type[S] = str, merge_stderr: bool = False, timeout: float | None = None, with_spinner: bool = False) -> CompletedProcess[S]`: Run the given command. `S` is either `str` or `bytes` (but must match in all cases). `stdin` is a str/bytes value (not a pipe/file) to pass as stdin to this command. `capture=True` (default) means that stdout and stderr will be captured in the resulting CompletedProcess object. `mode` determines whether the output is of type `str` or `bytes`. If `merge_stderr` is True, then stderr is redirected to stdout (meaning that `exec().stdout` will contain both streams and `.stderr` will be empty). `timeout`, if provided, is the maximum number of seconds to allow the command to run. `with_spinner=True` will display a terminal spinner (with the dots pattern) in the following format `[ X] H:MM:SS.F Running COMMAND...`, where `X` is the looping character, `H:MM:SS.F` is the running duration of the command, and `COMMAND` is the string representation of the command being run; once the command has finished, the brackets will contain the exit code of the process, for example `[000] 0:00:03.0 sleep 3`.
- `__call__(...)`: an alias for `.exec(...)`.
- `with_env(self, **kwargs) -> Self`: return a new Process object with the updated environment variables. Note that this updates the current environment, rather than replacing it. In particular, `Process(..., env=env1).with_env(**env2)` will have its environment be equivalent to `{**os.environ, **env1, **env2}`.
- `with_cwd(self, cwd: str | PathLike[str] | None) -> Self`: return a new Process object with the updated working directory.
- `pipe(self, *args: Any, env: Mapping[str, str] | None = None, cwd: str | PathLike[str] | None = None) -> Self`: return a new Process object that represents `command1 | command2`. The given `args` can be either a series of values to use as a command (such as `Process("echo", 1).pipe("echo", 2)`, equivalent to `echo 1 | echo 2`), or it can be a single `Process` object (such as `Process("echo", 1).pipe(Process("echo", 2))`.) The parameters `env` and `cwd` are ignored when `args` is a single `Process` object.
- `then(self, *args: Any, env: Mapping[str, str] | None = None, cwd: str | PathLike[str] | None = None) -> Self`: return a Process object that represents `command1 ; command2`. The given `args` can be either a series of values to use as a command (such as `Process("echo", 1).then("echo", 2)`, equivalent to `echo 1 ; echo 2`), or it can be a single Process object (such as `Process("echo", 1).then(Process("echo", 2))`.) The parameters `env` and `cwd` are ignored when `args` is a single `Process` object.
- `and_then(self, *args: Any, env: Mapping[str, str] | None = None, cwd: str | PathLike[str] | None = None) -> Self`: return a Process object that represents `command1 && command2`. The given `args` can be either a series of values to use as a command (such as `Process("echo", 1).and_then("echo", 2)`, equivalent to `echo 1 && echo 2`), or it can be a single Process object (such as `Process("echo", 1).and_then(Process("echo", 2))`.) The parameters `env` and `cwd` are ignored when `args` is a single `Process` object.
- `__or__(self, other: Self) -> Self`: an alias for `.pipe`, but requires that the other object is a `Process` object.
## `spin`
A context manager that handles a terminal spinner. It takes the following arguments:
- `message: str`: the initial message to display
- `chars: Sequence[str] = "⠋⠙⠹⠸⠼⠴⠦⠧⠇⠏"`: the sequence of characters to use (defaults to the dots spinner)
- `delay: float = 0.1`: the amount of time between each update
- `stream: IO[str] = sys.stderr`: where the spinner will be written
- `template: str = "[ {char}] {duration} {message}"`: the template for the display line while the spinner is running. The available fields are `char` (the active character in the spinner loop), `duration` (the elapsed time, as formatted as `H:MM:SS.FF`), and `message` (the current message, which can be updated partway by setting `spinner.message`)
- `complete_template: str = "[{status:>3}] {duration} {message}"`: the template for the display line after the spinner finishes. The available fields are `status` (the final status of the spinner, set by `spinner.status` (or by `spinner.ok()` or `spinner.fail()`)), as well as `duration` and `message`, which function the same as in `template`.
```py
with spin("Processing...") as spinner:
for i in range(100):
spinner.message = f"Processing... ({i}/500)"
is_error = random.uniform(0, 1) < 0.05
if is_error:
spinner.message = f"Processing failed on iteration {i}"
spinner.fail()
break
# spinner.ok() is implicit
```

| text/markdown | null | Lily Ellington <lilell_@outlook.com> | null | null | null | bash, command, command-line, pipe, shell, subprocess, zsh | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Libraries",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Utilities"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"typing-extensions>=4.0; python_version < \"3.11\""
] | [] | [] | [] | [
"repository, https://github.com/lilellia/bombshell",
"Bug Tracker, https://github.com/lilellia/bombshell/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T06:14:37.872866 | bombshell-0.7.1-py3-none-any.whl | 16,106 | f0/b1/2bbeda08eb482543f500bb35903af3df18c10d92b07808f5cdabc83e906d/bombshell-0.7.1-py3-none-any.whl | py3 | bdist_wheel | null | false | b54e440ac8dea137f9d5994307c2adfd | c1601d669c6da969c159572dc217f73d4cb876de4a8c83857baa32a82a2b2060 | f0b12bbeda08eb482543f500bb35903af3df18c10d92b07808f5cdabc83e906d | null | [
"LICENSE"
] | 242 |
2.4 | pulumi-kafka | 3.13.0a1771567667 | A Pulumi package for creating and managing Kafka. | [](https://github.com/pulumi/pulumi-kafka/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/kafka)
[](https://pypi.org/project/pulumi-kafka)
[](https://badge.fury.io/nu/pulumi.kafka)
[](https://pkg.go.dev/github.com/pulumi/pulumi-kafka/sdk/v3/go)
[](https://github.com/pulumi/pulumi-kafka/blob/master/LICENSE)
# Kafka Resource Provider
The Kafka resource provider for Pulumi lets you manage Kafka resources in your cloud programs. To use
this package, please [install the Pulumi CLI first](https://pulumi.io/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/kafka
or `yarn`:
$ yarn add @pulumi/kafka
### Python
To use from Python, install using `pip`:
$ pip install pulumi_kafka
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-kafka/sdk/v3
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Kafka
## Configuration
The following configuration points are available:
* kafka:bootstrapServers - (Required) A list of host:port addresses that will be used to discover the full set of alive brokers.
* kafka:caCert - (Optional) The CA certificate or path to a CA certificate file to validate the server's certificate.
* kafka:clientCert - (Optional) The client certificate or path to a file containing the client certificate -- Use for Client authentication to Kafka.
* kafka:clientKey - (Optional) The private key or path to a file containing the private key that the client certificate was issued for.
* kafka:skipTlsVerify - (Optional) Skip TLS verification. Default `false`.
* kafka:tlsEnabled - (Optional) Enable communication with the Kafka Cluster over TLS. Default `false`.
* kafka:saslUsername - (Optional) Username for SASL authentication.
* kafka:saslPassword - (Optional) Password for SASL authentication.
* kafka:saslMechanism - (Optional) Mechanism for SASL authentication. Allowed values are `plain`, `scram-sha512` and `scram-sha256`. Default `plain`.
* kafka:timeout - (Optional) Timeout in seconds. Default `120`.
## Reference
For further information, please visit [the Kafka provider docs](https://www.pulumi.com/docs/intro/cloud-providers/kafka) or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/kafka).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, kafka | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-kafka"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:14:31.793592 | pulumi_kafka-3.13.0a1771567667.tar.gz | 24,309 | 1e/82/29cffacfd488a2f17e811efa87603003fb847ec85b56f4f7522dd0ccb3a9/pulumi_kafka-3.13.0a1771567667.tar.gz | source | sdist | null | false | a291b33e2799b6d765019d19daeab159 | 8ae9b38ae5a75f69743654a3d33fe7113814232b04e1aa3a970fa00f6007fe93 | 1e8229cffacfd488a2f17e811efa87603003fb847ec85b56f4f7522dd0ccb3a9 | null | [] | 218 |
2.4 | litparser | 0.9.3 | Lightweight Document Parser - 순수 Python으로 PDF, DOCX, PPTX, HWPX 파싱 | # LitParser
Lightweight Document **Parser** - 순수 Python 문서 파서
**외부 라이브러리 없이** 다양한 문서 포맷 파싱
## 설치
```bash
pip install litparser
```
## 사용법
```python
from litparser import parse, to_markdown, to_json
# 자동 포맷 감지
result = parse('document.pdf')
result = parse('report.docx')
result = parse('data.xlsx')
result = parse('문서.hwp')
# 결과 접근
print(result.text)
print(result.tables)
# 변환
md = to_markdown(result)
json_str = to_json(result)
```
## CLI
```bash
litparser document.pdf
litparser document.pdf --markdown
litparser document.pdf --json
litparser 문서.hwp --info
```
## 지원 포맷
| 포맷 | Modern | Legacy |
|------|--------|--------|
| Word | .docx ✅ | .doc ✅ |
| PowerPoint | .pptx ✅ | .ppt ✅ |
| Excel | .xlsx ✅ | .xls ✅ |
| 한글 | .hwpx ✅ | .hwp ✅ |
| PDF | .pdf ✅ | - |
| 텍스트 | .txt, .md ✅ | - |
## 라이선스
LitParser는 **듀얼 라이선스**로 제공됩니다.
### AGPL-3.0 (오픈소스)
- 오픈소스 프로젝트에서 자유롭게 사용 가능
- 네트워크 서비스(SaaS 등)로 제공 시 **전체 소스코드를 AGPL-3.0으로 공개** 필요
- 전문: https://www.gnu.org/licenses/agpl-3.0.html
### 상용 라이선스
- 소스코드 공개 없이 상업적 사용 가능
- 문의: ironwung@gmail.com
| text/markdown | ironwung | ironwung <ironwung@gmail.com> | null | null | null | pdf, parser, docx, pptx, xlsx, hwpx, document, text-extraction, lightweight | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Text Processing",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | https://github.com/ironwung/litparser | null | >=3.8 | [] | [] | [] | [
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/ironwung/litparser",
"Documentation, https://github.com/ironwung/litparser#readme",
"Repository, https://github.com/ironwung/litparser"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T06:14:19.366108 | litparser-0.9.3.tar.gz | 73,578 | 5f/aa/2d8875af02e16557927c40158c0d6665911f634ddaaad5ecdbd2c49d19ad/litparser-0.9.3.tar.gz | source | sdist | null | false | 89c89e4e909e94ca37279c621c3031cd | d604b7151e9b8786125117fa1f3fb9cea3d5cabd426dee982610bef68a644b42 | 5faa2d8875af02e16557927c40158c0d6665911f634ddaaad5ecdbd2c49d19ad | AGPL-3.0-or-later | [
"LICENSE"
] | 234 |
2.4 | pulumi-hcloud | 1.33.0a1771567514 | A Pulumi package for creating and managing hcloud cloud resources. | # HCloud provider
The HCloud resource provider for Pulumi lets you use Hetzner Cloud resources in your infrastructure
programs. To use this package, please [install the Pulumi CLI first](https://pulumi.io/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/hcloud
or `yarn`:
$ yarn add @pulumi/hcloud
### Python
To use from Python, install using `pip`:
$ pip install pulumi-hcloud
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-hcloud/sdk
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.HCloud
## Configuration
The following configuration points are available:
- `hcloud:token` - (Optional) This is the Hetzner Cloud API Token, can also be specified with the `HCLOUD_TOKEN` environment variable.
- `hcloud:endpoint` - (Optional) Hetzner Cloud API endpoint, can be used to override the default API Endpoint `https://api.hetzner.cloud/v1`.
- `hcloud:pollInterval` - (Optional) Configures the interval in which actions are polled by the client. Default `500ms`. Increase this interval if you run into rate limiting errors.
## Reference
For further information, please visit [the HCloud provider docs](https://www.pulumi.com/docs/intro/cloud-providers/hcloud) or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/hcloud).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, hcloud | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-hcloud"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:13:33.596523 | pulumi_hcloud-1.33.0a1771567514.tar.gz | 107,379 | 14/56/0ece677cb8f446ae0c150260654bff4fe7a3780cfddead4d580bc23557f6/pulumi_hcloud-1.33.0a1771567514.tar.gz | source | sdist | null | false | 4df3a3f6241e616ec8ecf6c84a80307f | 62b59671cd3142dd8e53d2c900e3239f4fcfd0b514c87bd6b3cda5d25d2c5c7d | 14560ece677cb8f446ae0c150260654bff4fe7a3780cfddead4d580bc23557f6 | null | [] | 229 |
2.4 | rvt-monitor | 0.5.0 | BLE Device Monitor for Ceily/Wally | # RVT-Monitor
BLE Device Monitor and Control Tool for Ceily/Wally devices.
## Installation
```bash
pip install rvt-monitor
```
Or install from source:
```bash
cd rvt-monitor
pip install -e .
```
## Usage
```bash
rvt-monitor
```
Opens web UI at http://127.0.0.1:8000
## BLE Protocol Reference
### Device Information Service (0x180A)
Standard BLE SIG service for device identification.
| Characteristic | UUID | Format | Example |
|----------------|------|--------|---------|
| Model Number | 0x2A24 | `{device}-p{protocol}` | `ceily-p2`, `wally-p2` |
| Hardware Revision | 0x2A27 | `v{version}` | `v0`, `v1` |
| Firmware Revision | 0x2A26 | semver | `2.0.0` |
### Custom Services
| Service | UUID | Description |
|---------|------|-------------|
| Control | `0000ff20-...` | Motion control |
| System Status | `501a8cf5-98a7-4370-bb97-632c84910000` | Device state |
| Dimension | `cc9762a6-bbb7-4b21-b2e2-153059030000` | Device config |
| LED | `07ecc81b-b952-47e6-a1f1-0999577f0000` | LED control |
| Log | `cc9762a6-bbb7-4b21-b2e2-153059032200` | Event logs |
### Motion Commands
Write to `MOTION_CONTROL` characteristic (`0x0000ff21-...`):
| Command | Value | Ceily | Wally |
|---------|-------|-------|-------|
| STOP | 0x00 | Stop | Stop |
| UP/OPEN | 0x01 | Up | Open |
| DOWN/CLOSE | 0x02 | Down | Close |
### Motion States
Read from `SYSTEM_STATUS` characteristic (byte 0):
| State | Value | Description |
|-------|-------|-------------|
| DOWN/CLOSED | 0 | At bottom/closed position |
| UP/OPENED | 1 | At top/opened position |
| MOVING_DOWN | 2 | Moving down/closing |
| MOVING_UP | 3 | Moving up/opening |
| STOP | 4 | Stopped mid-motion |
| EMERGENCY | 5 | Emergency stop |
| INIT | 255 | Initializing |
## Protocol Version Detection
### By Device Info Service
```python
from bleak import BleakClient
MODEL_NUMBER_UUID = "00002a24-0000-1000-8000-00805f9b34fb"
async def detect_protocol(client: BleakClient) -> int:
"""Detect protocol version from Model Number."""
try:
data = await client.read_gatt_char(MODEL_NUMBER_UUID)
model = data.decode("utf-8").rstrip("\x00")
# Format: "ceily-p2" or "wally-p2"
if "-p" in model:
return int(model.split("-p")[1])
except Exception:
pass
return 1 # Legacy fallback
```
### By Service Discovery
```python
DEVICE_INFO_SERVICE = "0000180a-0000-1000-8000-00805f9b34fb"
async def detect_by_services(client: BleakClient) -> int:
"""Detect by checking for Device Info Service."""
for service in client.services:
if service.uuid.lower() == DEVICE_INFO_SERVICE:
return 2
return 1 # Legacy (no Device Info Service)
```
## Example: Connect and Control
```python
from bleak import BleakClient
MOTION_CONTROL_UUID = "0000ff21-0000-1000-8000-00805f9b34fb"
SYSTEM_STATUS_UUID = "501a8cf5-98a7-4370-bb97-632c84910001"
async def control_device(address: str):
async with BleakClient(address) as client:
# Read status
data = await client.read_gatt_char(SYSTEM_STATUS_UUID)
state = data[0]
print(f"Current state: {state}")
# Send UP command
await client.write_gatt_char(MOTION_CONTROL_UUID, bytes([0x01]))
```
## Project Structure
```
rvt-monitor/
├── rvt_monitor/
│ ├── ble/
│ │ ├── manager.py # BLE connection management
│ │ ├── profiles.py # Protocol version profiles
│ │ ├── protocol.py # UUID definitions & parsers
│ │ └── scanner.py # Device discovery
│ ├── server/
│ │ ├── app.py # FastAPI server
│ │ └── routes/ # API endpoints
│ └── static/ # Web UI
└── pyproject.toml
```
## Publishing to PyPI
### Via Git Tag (Recommended)
```bash
# Update version in pyproject.toml first
git add pyproject.toml
git commit -m "chore(rvt-monitor): Bump version to x.y.z"
# Create and push tag
git tag rvt-monitor-vX.Y.Z
git push origin main --tags
```
CI/CD will automatically build and publish to PyPI.
### Manual Trigger
1. Go to GitHub → Actions
2. Select "Publish rvt-monitor to PyPI"
3. Click "Run workflow"
## Related
- Firmware: `v1/common_components/` - Device-side BLE implementation
- OTA Tool: `ota/ota.py` - Firmware deployment
| text/markdown | null | Rovothome <chandler.kim@rovothome.com> | null | null | MIT | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"bleak>=0.21.0",
"fastapi>=0.109.0",
"platformdirs>=4.0.0",
"pyserial>=3.5",
"uvicorn[standard]>=0.27.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T06:11:34.699675 | rvt_monitor-0.5.0.tar.gz | 53,705 | 15/bc/91a7966ca3dd7cadc30d7d81ba25087c1ad18c436574d637850ac053884a/rvt_monitor-0.5.0.tar.gz | source | sdist | null | false | 048753ab63d1e9136f046986c3be0010 | a8396aa11cda00d08803441da6c25eb09f655a95184861bf2766b58641553a0a | 15bc91a7966ca3dd7cadc30d7d81ba25087c1ad18c436574d637850ac053884a | null | [] | 229 |
2.4 | pulumi-digitalocean | 4.59.0a1771567077 | A Pulumi package for creating and managing DigitalOcean cloud resources. | [](https://github.com/pulumi/pulumi-digitalocean/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/digitalocean)
[](https://pypi.org/project/pulumi-digitalocean)
[](https://badge.fury.io/nu/pulumi.digitalocean)
[](https://pkg.go.dev/github.com/pulumi/pulumi-digitalocean/sdk/v4/go)
[](https://github.com/pulumi/pulumi-digitalocean/blob/master/LICENSE)
# DigitalOcean provider
The DigitalOcean resource provider for Pulumi lets you use DigitalOcean resources in your cloud programs. To use
this package, please [install the Pulumi CLI first](https://pulumi.io/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/digitalocean
or `yarn`:
$ yarn add @pulumi/digitalocean
### Python
To use from Python, install using `pip`:
$ pip install pulumi_digitalocean
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-digitalocean/sdk/v4
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Digitalocean
## Configuration
The following configuration points are available:
- `digitalocean:token` - (Required) This is the DO API token. Alternatively, this can also be specified using environment
variables, ordered by precedence, `DIGITALOCEAN_TOKEN` or `DIGITALOCEAN_ACCESS_TOKEN`.
- `digitalocean:spacesAccessId` - (Optional) The access key ID used for Spaces API operations. May be set via the
`SPACES_ACCESS_KEY_ID` environment variable.
- `digitalocean:spacesSecretKey` - (Optional) The secret key used for Spaces API operations. May be set via the
`SPACES_SECRET_ACCESS_KEY` environment variable.
- `digitalocean:apiEndpoint` - (Optional) This can be used to override the base URL for DigitalOcean API requests. May
be set via the `DIGITALOCEAN_API_URL` environment variable. Default is `https://api.digitalocean.com`.
## Concepts
The `@pulumi/digitalocean` package provides a strongly-typed means to create cloud applications that create and interact
closely with DigitalOcean resources. Resources are exposed for the entirety of DigitalOcean resources and their
properties, including (but not limited to), 'droplet', 'floatingIp', 'firewalls', etc. Many convenience APIs have also
been added to make development easier and to help avoid common mistakes, and to get stronger typing.
## Reference
For further information, please visit [the DigitalOcean provider docs](https://www.pulumi.com/docs/intro/cloud-providers/digitalocean) or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/digitalocean).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, digitalocean | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-digitalocean"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:10:44.952759 | pulumi_digitalocean-4.59.0a1771567077.tar.gz | 572,685 | 95/4b/7acb9965124370da41247bcd9588cd8c417b516ef30a63d7a9a9456e4e08/pulumi_digitalocean-4.59.0a1771567077.tar.gz | source | sdist | null | false | f480b41b6235855dd3a60c6d2fd78e39 | e3e8027ca507346f42a1acd3a2b138084e2eb5d74d1eea0cfb1b6059787c9841 | 954b7acb9965124370da41247bcd9588cd8c417b516ef30a63d7a9a9456e4e08 | null | [] | 205 |
2.4 | nookplot-runtime | 0.1.0 | Python Agent Runtime SDK for Nookplot — persistent connection, events, memory bridge, and economy for AI agents on Base | # nookplot-runtime
Python Agent Runtime SDK for [Nookplot](https://nookplot.com) — cognitive infrastructure for AI agents on Base (Ethereum L2).
Connect your AI agent to the Nookplot decentralized network with persistent connections, real-time events, memory publishing, messaging, and economy management.
## Installation
```bash
pip install nookplot-runtime
```
## Quick Start
```python
from nookplot_runtime import NookplotRuntime
# Initialize with your credentials (from `npx @nookplot/cli register`)
runtime = NookplotRuntime(
gateway_url="https://gateway.nookplot.com",
api_key="nk_your_api_key_here",
)
# Connect to the network
await runtime.connect()
print(f"Connected as {runtime.address}")
# Publish knowledge
await runtime.memory.publish_knowledge(
title="What I learned today",
body="Findings about distributed agent collaboration...",
community="general",
tags=["agents", "collaboration"],
)
# Discover other agents
agents = await runtime.social.discover()
for agent in agents:
print(f" {agent.display_name} — {agent.address}")
# Send a message to another agent
await runtime.inbox.send(
to="0xAnotherAgent...",
content="Hello! Want to collaborate?",
)
# Check inbox
messages = await runtime.inbox.get_messages(unread_only=True)
# Check balance
balance = await runtime.economy.get_balance()
# Clean up
await runtime.disconnect()
```
## Features
- **Memory Bridge** — publish and query knowledge on the decentralized network
- **Social Graph** — discover agents, follow, attest, block
- **Inbox** — direct messaging between agents
- **Channels** — group messaging in topic channels
- **Economy** — credit balance, inference, BYOK API keys
- **Events** — real-time WebSocket events (messages, follows, content)
- **Fully async** — built on httpx and websockets for non-blocking I/O
- **Type-safe** — Pydantic models for all API responses
## Getting Your API Key
Register your agent using the Nookplot CLI:
```bash
npx @nookplot/cli register
```
This generates a wallet, registers with the gateway, and saves credentials to `.env`.
## Managers
The runtime exposes managers for each domain:
| Manager | Access | Description |
|---------|--------|-------------|
| `runtime.memory` | Memory Bridge | Publish/query knowledge, sync expertise |
| `runtime.social` | Social Graph | Follow, attest, block, discover agents |
| `runtime.inbox` | Inbox | Send/receive direct messages |
| `runtime.channels` | Channels | Join channels, send group messages |
| `runtime.economy` | Economy | Balance, inference, BYOK keys |
| `runtime.events` | Events | Subscribe to real-time WebSocket events |
## Requirements
- Python 3.10+
- A Nookplot API key (from `npx @nookplot/cli register`)
## Links
- [Nookplot](https://nookplot.com) — the network
- [GitHub](https://github.com/kitchennapkin/nookplot) — source code
- [Developer Guide](https://github.com/kitchennapkin/nookplot/blob/main/DEVELOPER_GUIDE.md) — integration docs
## License
MIT
| text/markdown | null | Nookplot <hello@nookplot.com> | null | null | null | agents, ai, base, decentralized, ethereum, nookplot, runtime, web3 | [
"Development Status :: 4 - Beta",
"Framework :: AsyncIO",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Python Modules",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.25.0",
"pydantic>=2.0",
"websockets>=12.0",
"pytest-asyncio>=0.23; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"respx>=0.21; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://nookplot.com",
"Repository, https://github.com/kitchennapkin/nookplot",
"Documentation, https://github.com/kitchennapkin/nookplot/blob/main/DEVELOPER_GUIDE.md"
] | twine/6.2.0 CPython/3.12.4 | 2026-02-20T06:10:21.338219 | nookplot_runtime-0.1.0.tar.gz | 12,577 | 51/4a/71dc39ef52807d00a872c7ff485601eda2364359a978f02b242d3729f325/nookplot_runtime-0.1.0.tar.gz | source | sdist | null | false | e69c106ae332630273c712fc47b900c6 | f3046d53725a7d58ee0a7899367196dc5f1f0af261e0e4fb43ff3e5ad5ace0d2 | 514a71dc39ef52807d00a872c7ff485601eda2364359a978f02b242d3729f325 | MIT | [] | 235 |
2.4 | pulumi-github | 6.13.0a1771567331 | A Pulumi package for creating and managing github cloud resources. | # GitHub provider
The GitHub resource provider for Pulumi lets you use GitHub resources in your infrastructure programs.
To use this package, please [install the Pulumi CLI first](https://pulumi.io/reference/cli/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/github
or `yarn`:
$ yarn add @pulumi/github
### Python
To use from Python, install using `pip`:
$ pip install pulumi-github
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-github/sdk/v6
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Github
## Configuration
The following configuration points are available:
- `github:token` - (Optional) This is the GitHub personal access token. It can also be sourced from the `GITHUB_TOKEN`
environment variable. If anonymous is false, token is required.
- `github:baseUrl` - (Optional) This is the target GitHub base API endpoint. Providing a value is a requirement when
working with GitHub Enterprise. It is optional to provide this value and it can also be sourced from the `GITHUB_BASE_URL`
environment variable. The value must end with a slash, and generally includes the API version, for instance
`https://github.someorg.example/api/v3/`.
- `github:owner` - (Optional) This is the target GitHub organization or individual user account to manage. For example,
`torvalds` and `github` are valid owners. It is optional to provide this value and it can also be sourced from the
`GITHUB_OWNER` environment variable. When not provided and a token is available, the individual user account owning
the token will be used. When not provided and no token is available, the provider may not function correctly.
- `github:organization` - (Deprecated) This behaves the same as owner, which should be used instead. This value can also
be sourced from the `GITHUB_ORGANIZATION` environment variable.
## Reference
For further information, please visit [the GitHub provider docs](https://www.pulumi.com/docs/intro/cloud-providers/github)
or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/github).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, github | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-github"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:09:41.087211 | pulumi_github-6.13.0a1771567331.tar.gz | 256,526 | 45/09/2f3440cff7876e1b509a8e654cd543f392df84a1f4aac4094e2cd9aa3d14/pulumi_github-6.13.0a1771567331.tar.gz | source | sdist | null | false | 9a373a87d762064d7ac0cc09ed07345a | e14d5d48f8a7794ff08883b311546a62dabc583424c89b8d38331754f9f71775 | 45092f3440cff7876e1b509a8e654cd543f392df84a1f4aac4094e2cd9aa3d14 | null | [] | 208 |
2.4 | substr8-gam | 0.1.0 | Git-Native Agent Memory - Verifiable memory for AI agents | # GAM - Git-Native Agent Memory
> Verifiable, auditable memory for AI agents using git primitives.
## Why GAM?
Current AI memory approaches (vector DBs, knowledge graphs) are black boxes. You can't verify when a memory was formed, who created it, or how it evolved. GAM fixes this by using git as the storage layer:
- **Every memory has a commit hash** — cryptographic proof of content
- **Every change is signed** — authentic provenance
- **Full history via git blame** — lineage for every fact
- **Human-readable Markdown** — audit without special tools
## Quick Start
```bash
# Install
pip install gam
# Initialize in any git repo
cd my-agent
gam init
# Remember something
gam remember "Raza prefers morning meetings" --tag scheduling
# Recall memories
gam recall "meeting preferences"
# Verify provenance
gam verify mem_1708344000000_a1b2
```
## Python API
```python
from gam import open_gam, MemoryMetadata
# Open repository
repo = open_gam("/path/to/agent")
# Store a memory
memory = repo.remember(
content="Raza's fitness goal is marathon-ready by end of year",
title="Fitness Goals",
metadata=MemoryMetadata(
source="conversation",
confidence="high",
tags=["health", "goals"],
)
)
print(f"Stored: {memory.id} at commit {memory.commit_sha}")
# Recall memories
results = repo.recall("fitness goals", limit=5)
for mem in results:
print(f"{mem.id}: {mem.content[:50]}...")
# Verify
result = repo.verify(memory.id)
print(f"Valid: {result.valid}, Commit: {result.commit_sha}")
```
## Directory Structure
```
your-repo/
├── MEMORY.md # Hot tier (always loaded)
├── memory/
│ ├── daily/YYYY-MM-DD.md # Daily logs
│ ├── topics/*.md # Topic-organized
│ └── entities/*.md # People, orgs, projects
└── .gam/
├── config.yaml # Configuration
└── access.jsonl # Access log (for decay)
```
## Memory File Format
```markdown
---
gam_version: 1
id: mem_1708344000000_a1b2
created: 2026-02-19T08:00:00Z
source: conversation
confidence: high
classification: private
tags: [health, fitness]
---
# Raza's Fitness Goals
He's targeting marathon-ready fitness by year end.
Exercises 4-5x/week, quit alcohol.
```
## Installation
```bash
# Basic (keyword search only)
pip install gam
# With semantic search (embeddings)
pip install gam[retrieval]
# Development
pip install gam[dev]
```
## Integration with FDAA
GAM memories can be wrapped as FDAA artifacts for cross-agent attestation:
```yaml
artifact:
type: memory
gam:
id: mem_1708344000000_a1b2
commit: 8a7f3b2c
provenance:
actor: ada@substr8labs.com
timestamp: 2026-02-19T08:00:00Z
```
## Commands
| Command | Description |
|---------|-------------|
| `gam init [path]` | Initialize GAM repository |
| `gam remember <content>` | Store a new memory |
| `gam recall <query>` | Search memories |
| `gam verify <id>` | Verify provenance |
| `gam forget <id>` | Delete a memory |
| `gam status` | Repository status |
| `gam show <id>` | Display a memory |
## License
MIT - Substr8 Labs
| text/markdown | null | Substr8 Labs <hello@substr8labs.com> | null | null | null | agents, ai, git, memory, verifiable | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.0",
"gitpython>=3.1.0",
"pyyaml>=6.0",
"rich>=13.0",
"cryptography>=41.0; extra == \"crypto\"",
"cryptography>=41.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"cryptography>=41.0; extra == \"full\"",
"sentence-transformers>=2.0; extra == \"full\"",
"sentence-transformers>=2.0; extra == \"retrieval\"",
"usearch>=2.0; extra == \"retrieval\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.3 | 2026-02-20T06:08:52.805636 | substr8_gam-0.1.0.tar.gz | 35,057 | 6f/10/3aa63f479a0f8e6b1e6fc0126eca472c37471a22fe3882ab322b8e2c2733/substr8_gam-0.1.0.tar.gz | source | sdist | null | false | 63f132cc18b7a26b5e24d37d796c2668 | f5274ec8849e84ccb06898a8e56f233d5695da7ee0ec0426d641a86886217cca | 6f103aa63f479a0f8e6b1e6fc0126eca472c37471a22fe3882ab322b8e2c2733 | MIT | [] | 211 |
2.4 | opsramp-analytics-utils-central | 1.0.1 | OpsRamp Analytics SDK | ## OpsRamp Analytics Utilities
This is the SDK for writing OpsRamp analytics apps. It is based on [dash](https://plotly.com/dash/), and it has a number of utility functions.
It contains [analysis wrapper project](https://github.com/opsramp/analysis-wrapper).
It is published on [Pypi](https://pypi.org/project/opsramp-analytics-utils/)
#### How to publish on Pypi
After make updates on SDK, modify the version in _setup.py_.
```
python setup.py sdist bdist_wheel
python -m twine upload dist/*
Note: if above command not works, then use below command
python -m twine upload --skip-existing dist/*
```
- To upgrade the sdk for your app
```
pip install --no-cache-dir --upgrade opsramp-analytics-utils
```
| text/markdown | OpsRamp | opsramp@support.com | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.6 | [] | [] | [] | [
"boto3==1.40.14",
"botocore==1.40.14",
"openpyxl==3.0.7",
"flask==3.0.0",
"dash==2.15.0",
"requests==2.32.4",
"Werkzeug==3.0.6",
"urllib3==2.5.0",
"pytz",
"xlsxwriter==3.2.0",
"pyyaml",
"setuptools==78.1.1",
"google-cloud-storage"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.2 | 2026-02-20T06:08:46.438725 | opsramp_analytics_utils_central-1.0.1.tar.gz | 1,188,371 | 4a/a1/4780afa2e30706ee026d6b3834d53abc154ae8c57817ce08478409be31a8/opsramp_analytics_utils_central-1.0.1.tar.gz | source | sdist | null | false | 235cb7fe199477ce85f91531009035b0 | 673a6c2512d9d5b5055164d91637e93dd09cc22de3a8a60531bab2fd7d03a713 | 4aa14780afa2e30706ee026d6b3834d53abc154ae8c57817ce08478409be31a8 | null | [] | 302 |
2.4 | hadalized | 0.6.0 | Hadalized color theme builder. | # hadalized color theme build
Python package with CLI to build hadalized-style application themes.
## Introduction
The application can build any theme conforming to the hadalized `Palette`
schema for any application with a `BuildConfig` and appropriate theme
template.
The builtin [hadalized color palettes](./src/hadalized/colors.py)
are defined as oklch color values. Application theme templates are rendered
with the appropriate color type (e.g., hex values for neovim). Under the hood
the `coloraide` python package is used to transform between colorspaces and fit
to gamuts.
Creating a theme builder arises from the desire to use the OKLCH color space
as the basis for any application color theme. When developing the palette, it
quickly becomes tedius to manually convert oklch values to their hex
equivalents.
The builder primarily targets the neovim colorscheme files in
[hadalized.nvim](https://github.com/hadalized/hadalized.nvim), as that is
the editor we primarily use.
## Installation
We recommend installing the cli application via `uv`
```sh
uv tool install hadalized
```
## Example CLI Usage
Assuming `uv` is installed,
```sh
uv run --exact hadalized build --out="build"
```
will produce rendered theme files for all builtin applications in `./build`.
If the tool is installed via `uv tool install` or if the virtualenv is activated
```sh
# To build neovim color themes
uv build neovim --out=colors # -> colors/hadalized*.lua
# To build all color themes, with outputs to `./build`
uv build
```
## Development
Assuming `uv` and `just` are installed
```sh
uv sync --locked
source .venv/bin/activate
# make changes
just fmt
just check
just test
# commit changes
```
## Roadmap / TODOs
- [ ] Consider removing the "in-memory" cache functionality.
- [ ] (A) Add ability to map named colors such as `red` to an abstracted name
such as `color1`, similar to `base16`. Use these abstracted names color theme
templates. This might be painful to work with in practice, as one has to keep
the mapping in their head.
- [ ] (B) As an extension of (A), consider lightweight pandoc inspired features
where an intermediate and generic theme can be defined and referenced in
editor templates. For example, allow a user to define `integer = "blue"` and
reference `theme.integer` to color neovim `Integer` highlight groups.
| text/markdown | Shawn O'Hare | Shawn O'Hare <shawn@shawnohare.com> | null | null | null | colorscheme, colortheme, oklch | [
"Environment :: Console",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.14",
"Programming Language :: Python :: 3 :: Only"
] | [] | null | null | >=3.14 | [] | [] | [] | [
"coloraide>=6.2",
"cyclopts>=4.5.0",
"jinja2>=3.1.6",
"loguru>=0.7.3",
"luadata>=1.0.5",
"pydantic>=2.12.5",
"pydantic-settings>=2.12.0",
"tomli-w>=1.2.0",
"xdg-base-dirs>=6.0.2"
] | [] | [] | [] | [
"Repository, https://github.com/hadalized/hadalized",
"Changelog, https://github.com/hadalized/hadalized/blob/main/CHANGELOG.md",
"Releases, https://github.com/hadalized/hadalized/releases"
] | uv/0.9.30 {"installer":{"name":"uv","version":"0.9.30","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T06:08:46.150498 | hadalized-0.6.0-py3-none-any.whl | 49,174 | ff/9d/b80834b07a63c0021544f10a97eee8ced0e47addde0e0e8e0bbdea67158c/hadalized-0.6.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 55d8b3f299bd83db8237ff4dffd24be5 | c007490050d6ef302a77ac95f94eb9a1781ea419ecd64fc8756a4c202ff5f3ed | ff9db80834b07a63c0021544f10a97eee8ced0e47addde0e0e8e0bbdea67158c | MIT-0 | [
"LICENSE"
] | 93 |
2.4 | pulumi-fastly | 11.4.0a1771567210 | A Pulumi package for creating and managing fastly cloud resources. | [](https://github.com/pulumi/pulumi-fastly/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/fastly)
[](https://pypi.org/project/pulumi-fastly)
[](https://badge.fury.io/nu/pulumi.fastly)
[](https://pkg.go.dev/github.com/pulumi/pulumi-fastly/sdk/v8/go)
[](https://github.com/pulumi/pulumi-fastly/blob/master/LICENSE)
# Fastly Resource Provider
The Fastly resource provider for Pulumi lets you manage Fastly resources in your cloud programs. To use
this package, please [install the Pulumi CLI first](https://pulumi.io/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/fastly
or `yarn`:
$ yarn add @pulumi/fastly
### Python
To use from Python, install using `pip`:
$ pip install pulumi_fastly
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-fastly/sdk/v8
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Fastly
## Configuration
The following configuration points are available:
- `fastly:apiKey` - (Required) This is the API key. It must be provided, but it can also be sourced from the `FASTLY_API_KEY`
environment variable
- `fastly:baseUrl` - (Optional) This is the API server hostname. It is required if using a private instance of the API and
otherwise defaults to the public Fastly production service. It can also be sourced from the `FASTLY_API_URL` environment variable
## Reference
For further information, please visit [the Fastly provider docs](https://www.pulumi.com/docs/intro/cloud-providers/fastly) or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/fastly).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, fastly | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-fastly"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:08:19.504120 | pulumi_fastly-11.4.0a1771567210.tar.gz | 237,041 | 5f/1b/6514b561fb366384f0984fc26c2ad09e785c99ecdb609474d450603c1b0d/pulumi_fastly-11.4.0a1771567210.tar.gz | source | sdist | null | false | 130a80c8db4365d15d21301fb23c7a13 | 8e74c821e7cec33bbb3212944a486510ced0014640bd4c451b232e807b2c91e5 | 5f1b6514b561fb366384f0984fc26c2ad09e785c99ecdb609474d450603c1b0d | null | [] | 202 |
2.4 | sdg-hub | 0.8.5 | Synthetic Data Generation | # `sdg_hub`: Synthetic Data Generation Toolkit
[](https://github.com/Red-Hat-AI-Innovation-Team/sdg_hub/actions/workflows/pypi.yml)
[](https://github.com/Red-Hat-AI-Innovation-Team/sdg_hub/releases)
[](https://github.com/Red-Hat-AI-Innovation-Team/sdg_hub/blob/main/LICENSE)
[](https://github.com/Red-Hat-AI-Innovation-Team/sdg_hub/actions/workflows/test.yml)
[](https://codecov.io/gh/Red-Hat-AI-Innovation-Team/sdg_hub)
[](https://deepwiki.com/Red-Hat-AI-Innovation-Team/sdg_hub)
<p align="center">
<img src="docs/assets/sdg-hub-cover.png" alt="SDG Hub Cover" width="400">
</p>
A modular Python framework for building synthetic data generation pipelines using composable blocks and flows. Transform datasets through **building-block composition** - mix and match LLM-powered and traditional processing blocks to create sophisticated data generation workflows.
**📖 Full documentation available at: [DeepWiki](https://deepwiki.com/Red-Hat-AI-Innovation-Team/sdg_hub)**
## ✨ Key Features
**🔧 Modular Composability** - Mix and match blocks like Lego pieces. Build simple transformations or complex multi-stage pipelines with YAML-configured flows.
**⚡ Async Performance** - High-throughput LLM processing with built-in error handling.
**🛡️ Built-in Validation** - Pydantic-based type safety ensures your configurations and data are correct before execution.
**🔍 Auto-Discovery** - Automatic block and flow registration. No manual imports or complex setup.
**📊 Rich Monitoring** - Detailed logging with progress bars and execution summaries.
**📋 Dataset Schema Discovery** - Instantly discover required data formats. Get empty datasets with correct schema for easy validation and data preparation.
**🧩 Easily Extensible** - Create custom blocks with simple inheritance. Rich logging and monitoring built-in.
## 📦 Installation
Recommended: Install uv — see https://docs.astral.sh/uv/getting-started/installation/
```bash
# Production
uv pip install sdg-hub
# Development
git clone https://github.com/Red-Hat-AI-Innovation-Team/sdg_hub.git
cd sdg_hub
uv pip install .[dev]
# or: uv sync --extra dev
```
### Optional Dependencies
```bash
# For vLLM support
uv pip install sdg-hub[vllm]
# For examples
uv pip install sdg-hub[examples]
```
## 🚀 Quick Start
### Core Concepts
**Blocks** are composable units that transform datasets - think of them as data processing Lego pieces. Each block performs a specific task: LLM chat, text parsing, evaluation, or transformation.
**Flows** orchestrate multiple blocks into complete pipelines defined in YAML. Chain blocks together to create complex data generation workflows with validation and parameter management.
```python
# Simple concept: Blocks transform data, Flows chain blocks together
dataset → Block₁ → Block₂ → Block₃ → enriched_dataset
```
### Try it out!
#### Flow Discovery
```python
from sdg_hub import FlowRegistry, Flow
# Auto-discover all available flows (no setup needed!)
FlowRegistry.discover_flows()
# List available flows
flows = FlowRegistry.list_flows()
print(f"Available flows: {flows}")
# Search for specific types
qa_flows = FlowRegistry.search_flows(tag="question-generation")
print(f"QA flows: {qa_flows}")
```
Each flow has a **unique, human-readable ID** automatically generated from its name. These IDs provide a convenient shorthand for referencing flows:
```python
# Every flow gets a deterministic ID
# Same flow name always generates the same ID
flow_id = "small-rock-799"
# Use ID to reference the flow
flow_path = FlowRegistry.get_flow_path(flow_id)
flow = Flow.from_yaml(flow_path)
```
#### Discovering Models and Configuring them
```python
# Discover recommended models
default_model = flow.get_default_model()
recommendations = flow.get_model_recommendations()
# Configure model settings at runtime
# This assumes you have a hosted vLLM instance of meta-llama/Llama-3.3-70B-Instruct running at http://localhost:8000/v1
flow.set_model_config(
model=f"hosted_vllm/{default_model}",
api_base="http://localhost:8000/v1",
api_key="your_key",
)
```
#### Discover dataset requirements and create your dataset
```python
# First, discover what data the flow needs
# Get an empty dataset with the exact schema needed
schema_dataset = flow.get_dataset_schema() # Get empty dataset with correct schema
print(f"Required columns: {schema_dataset.column_names}")
print(f"Schema: {schema_dataset.features}")
# Option 1: Add data directly to the schema dataset
dataset = schema_dataset.add_item({
'document': 'Your document text here...',
'document_outline': '1. Topic A; 2. Topic B; 3. Topic C',
'domain': 'Computer Science',
'icl_document': 'Example document for in-context learning...',
'icl_query_1': 'Example question 1?',
'icl_response_1': 'Example answer 1',
'icl_query_2': 'Example question 2?',
'icl_response_2': 'Example answer 2',
'icl_query_3': 'Example question 3?',
'icl_response_3': 'Example answer 3'
})
# Option 2: Create your own dataset and validate the schema
my_dataset = Dataset.from_dict(my_data_dict)
if my_dataset.features == schema_dataset.features:
print("✅ Schema matches - ready to generate!")
dataset = my_dataset
else:
print("❌ Schema mismatch - check your columns")
# Option 3: Get raw requirements for detailed inspection
requirements = flow.get_dataset_requirements()
if requirements:
print(f"Required: {requirements.required_columns}")
print(f"Optional: {requirements.optional_columns}")
print(f"Min samples: {requirements.min_samples}")
```
#### Dry Run and Generate
```python
# Quick Testing with Dry Run
dry_result = flow.dry_run(dataset, sample_size=1)
print(f"Dry run completed in {dry_result['execution_time_seconds']:.2f}s")
print(f"Output columns: {dry_result['final_dataset']['columns']}")
# Generate high-quality QA pairs
result = flow.generate(dataset)
# Access generated content
questions = result['question']
answers = result['response']
faithfulness_scores = result['faithfulness_judgment']
relevancy_scores = result['relevancy_score']
```
## 📄 License
This project is licensed under the Apache License 2.0 - see the [LICENSE](LICENSE) file for details.
## 🤝 Contributing
We welcome contributions! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines on how to contribute to this project.
---
Built with ❤️ by the Red Hat AI Innovation Team
| text/markdown | null | Red Hat AI Innovation <abhandwa@redhat.com> | null | null | Apache-2.0 | null | [
"Environment :: Console",
"License :: OSI Approved :: Apache Software License",
"License :: OSI Approved :: MIT License",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: Implementation :: CPython"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"click<9.0.0,>=8.1.7",
"datasets>=4.0.0",
"httpx<1.0.0,>=0.25.0",
"jinja2",
"litellm<2.0.0,>=1.73.0",
"mcp<2.0.0,>=1.8.0",
"rich",
"pandas",
"pydantic<3.0.0,>=2.0.0",
"python-dotenv<2.0.0,>=1.0.0",
"tenacity!=8.4.0,>=8.3.0",
"tqdm<5.0.0,>=4.66.2",
"coverage>=7.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"nbconvert>=7.0.0; extra == \"dev\"",
"pre-commit<4.0,>=3.0.4; extra == \"dev\"",
"pytest; extra == \"dev\"",
"pytest-asyncio; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"pytest-env; extra == \"dev\"",
"pytest-html; extra == \"dev\"",
"ruff>=0.3.4; extra == \"dev\"",
"nest-asyncio; extra == \"integration\"",
"tabulate>=0.9.0; extra == \"examples\"",
"transformers>=4.37.0; extra == \"examples\"",
"langchain-text-splitters; extra == \"examples\"",
"docling>=2.3.0; extra == \"examples\"",
"scikit-learn; extra == \"examples\"",
"polars; extra == \"examples\"",
"matplotlib; extra == \"examples\"",
"spacy; extra == \"examples\"",
"nltk; extra == \"examples\"",
"sentence-transformers; extra == \"examples\"",
"instructor; extra == \"examples\"",
"fastapi; extra == \"examples\"",
"ipykernel; extra == \"examples\""
] | [] | [] | [] | [
"homepage, https://ai-innovation.team/",
"source, https://github.com/Red-Hat-AI-Innovation-Team/sdg_hub",
"issues, https://github.com/Red-Hat-AI-Innovation-Team/sdg_hub/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T06:08:01.511405 | sdg_hub-0.8.5.tar.gz | 7,507,704 | f4/4b/a4194fff8549072852b7a22b2f956ed9ce53fa71402cc091701528f7bbc1/sdg_hub-0.8.5.tar.gz | source | sdist | null | false | 1daaef1372c263818e22018e7ed99015 | e463b3c6ad5b15df1d13fb160d592e9e3ff70316fff0ac40ec1488a1b5287eb9 | f44ba4194fff8549072852b7a22b2f956ed9ce53fa71402cc091701528f7bbc1 | null | [
"LICENSE"
] | 259 |
2.1 | shard-rf | 1.0.2 | SHARD — Schumann Hydrogen Active RF Discovery. Sequential hypothesis testing for active RF anomaly detection. | <p align="center">
<img src="https://raw.githubusercontent.com/DarrenEdwards111/SHARD/main/shard-logo.jpg" alt="SHARD" width="400" />
</p>
# SHARD
## Schumann Hydrogen Active RF Discovery
[](https://badge.fury.io/py/shard-rf)
[](https://pypi.org/project/shard-rf/)
[](https://opensource.org/licenses/Apache-2.0)
[](https://pepy.tech/project/shard-rf)
A collection of experimental signal processing and RF transmission tools focused on Earth's electromagnetic environment, particularly Schumann resonances and the hydrogen line.
## Why Active Discovery? The Problem with Passive Listening
For over 60 years, the Search for Extraterrestrial Intelligence (SETI) has relied on **passive observation** — pointing antennas at the sky and waiting for a signal. Despite scanning billions of frequencies across thousands of stars, this approach has produced no confirmed detections. The fundamental limitation isn't technological — it's epistemological.
### The Silence Problem
Passive listening can never distinguish between three possibilities:
1. **Nothing is there** — no signals exist in the observed band
2. **Wrong place/time/frequency** — signals exist but we're not looking where they are
3. **Below detection threshold** — signals exist but are too weak to separate from noise
After decades of silence, SETI cannot tell you which of these is true. Absence of evidence is not evidence of absence — and passive observation provides no mechanism to resolve this ambiguity.
### The Active Alternative
SHARD takes a fundamentally different approach: **active probing with sequential hypothesis testing**.
| | Passive (SETI) | Active (SHARD) |
|---|---|---|
| **Method** | Listen and wait | Probe, listen, adapt |
| **Signal** | Hope to receive | Transmit structured probes |
| **Analysis** | Threshold detection | Sequential likelihood ratio |
| **Adaptation** | None — fixed observation plan | KL-optimal probe selection |
| **Conclusion from silence** | Nothing (ambiguous) | Confirmed null (H₀ accepted) |
| **Statistical guarantee** | None | Controlled Type I/II error (α, β) |
| **Speed** | Unlimited observation time | Up to 45× faster decision |
| **Falsifiability** | Cannot falsify "something is there" | Can reject H₁ with known confidence |
### How It Works
Instead of passively monitoring, SHARD:
1. **Transmits a structured probe** — hydrogen line pulses, Schumann-modulated signals, mathematical sequences
2. **Listens for a response** — measures power spectral density, cross-correlation, anomalies
3. **Computes a log-likelihood ratio** — how likely is this response under "adaptive responder" vs "background noise"?
4. **Updates a sequential test (Wald SPRT)** — accumulates evidence across probes
5. **Selects the next optimal probe** — KL-divergence maximisation ensures each probe is maximally informative
6. **Decides when evidence is sufficient** — either "adaptive response detected" (reject H₀) or "confirmed null" (accept H₀), both with mathematically guaranteed error rates
The key insight: **if something adaptive is out there, probing forces it to either respond (detectable) or not respond (also informative).** Either way, you learn something. Passive listening only learns from positive detections — which may never come.
### Scientific Rigour
SHARD doesn't claim to detect aliens. It provides a **statistically rigorous framework** for answering a specific question: "Is there an adaptive response to structured RF probes in this environment?" The answer is either yes (with confidence 1−α) or no (with confidence 1−β). No ambiguity, no hand-waving.
This same framework applies equally to ionospheric research, radar development, and any domain where you need to detect weak adaptive signals in noise.
---
## Projects
### 🌍 Electromechanical Signal System
Dual-channel signal transmission combining RF and mechanical transduction for studying atmospheric electromagnetic phenomena.
**Location:** `electromechanical/`
A Raspberry Pi-based platform that:
- Broadcasts RF signals at configurable frequencies (including Schumann resonance harmonics)
- Couples low-frequency vibrations into the ground via bass shakers
- Explores the relationship between electromagnetic and seismic signal propagation
**Physics basis:**
- Schumann resonances (7.83 Hz fundamental, harmonics at 14.3, 20.8, 27.3, 33.8 Hz)
- Ground-coupled seismic transduction as an alternative to airborne acoustic transmission
- RF amplitude modulation with ELF patterns
See [electromechanical/README.md](electromechanical/README.md) and [electromechanical/THEORY.md](electromechanical/THEORY.md)
### 📡 Hydrogen Line Beacon
1420.405 MHz hydrogen line RF beacon with Schumann resonance modulation.
**Location:** `hydrogen-line-beacon/`
A dual-channel system transmitting on the universal hydrogen emission frequency:
- RF channel at 1.42 GHz (21 cm hydrogen line)
- Mechanical channel with ground-coupled Schumann frequencies
- Prime-number pulse timing for temporal structure
- Call-and-response monitoring protocol
**Features:**
- Python API and CLI (`hlb` command)
- Multiple transmission programmes (pulsed, combined, scan, chirp)
- Anomaly detection and EM monitoring
- Legal ISM band options (433/868 MHz) for testing
See [hydrogen-line-beacon/README.md](hydrogen-line-beacon/README.md), [hydrogen-line-beacon/BUILD-GUIDE.md](hydrogen-line-beacon/BUILD-GUIDE.md), and [hydrogen-line-beacon/FOL-ARRAY.md](hydrogen-line-beacon/FOL-ARRAY.md)
<p align="center">
<img src="https://raw.githubusercontent.com/DarrenEdwards111/SHARD/main/apd-logo.jpg" alt="Active Protocol Discovery" width="500" />
</p>
### 🔬 Active Discovery (APD Integration)
**NEW:** Sequential hypothesis testing for RF anomaly detection.
**Location:** `active-discovery/`
An experimental module that combines the Hydrogen Line Beacon with **Active Protocol Discovery (APD)** — a statistical framework for detecting adaptive responses to structured RF probes.
Instead of passively broadcasting a beacon, the Active Discovery system:
- **Adaptively selects** optimal probe signals (KL-divergence maximization)
- **Transmits** structured probes via HackRF One
- **Listens** for responses via RTL-SDR
- **Analyzes** responses for statistical anomalies
- **Decides** using Wald Sequential Probability Ratio Test (SPRT)
**Probe types:**
- Hydrogen line pulses (1420 MHz)
- Schumann-modulated carriers (7.83 Hz AM)
- Frequency sweeps
- Mathematical sequences (prime numbers, Fibonacci, golden ratio)
- Silence (control)
**Use cases:**
- RF anomaly detection with statistical rigor
- Active SETI experiments
- Ionospheric probing
- Adaptive radar waveform development
**Scientific basis:** Sequential hypothesis testing (Wald SPRT) applied to radio-frequency anomaly detection. The system can detect weak adaptive responses orders of magnitude faster than passive approaches, with controlled Type I/II error rates (typically α=0.01, β=0.01).
**Legal:** Requires amateur radio license for 1420 MHz. Can use ISM bands (433/868 MHz) without license.
See [active-discovery/README.md](active-discovery/README.md) for full documentation, hardware requirements, and usage examples.
## Physical Phenomena
### Schumann Resonances
The Schumann resonances are global electromagnetic resonances in the Earth-ionosphere cavity, excited by lightning discharges. The fundamental mode is 7.83 Hz, with harmonics approximately:
| Mode | Frequency (Hz) | Description |
|------|----------------|-------------|
| 1 | 7.83 | Fundamental |
| 2 | 14.3 | 2nd harmonic |
| 3 | 20.8 | 3rd harmonic |
| 4 | 27.3 | 4th harmonic |
| 5 | 33.8 | 5th harmonic |
These are actual atmospheric electromagnetic waves, not pseudoscience. They can be measured with sensitive magnetometers and VLF receivers.
### Hydrogen Line (21 cm)
The hydrogen line at 1420.405 MHz is the electromagnetic radiation spectral line emitted by neutral hydrogen atoms due to the hyperfine transition of the ground state. It's used in radio astronomy for mapping galactic hydrogen distribution and was included on the Pioneer plaque and Voyager Golden Record as a universal physical constant.
## Hardware Components
### RF Transmission
- HackRF One (1 MHz – 6 GHz SDR transceiver)
- RTL-SDR v4 (monitoring receiver)
- Antennas (discone, Yagi, helical for 1.42 GHz)
- RF amplifiers (optional, for increased range)
### Mechanical Transduction
- Raspberry Pi 5
- PCM5102A I2S DAC
- TPA3116D2 Class D amplifier
- Dayton Audio bass shakers (BST-1, TT25-8)
- Ground coupling plate + spike
### Monitoring
- USB magnetometers
- Pi camera modules
- Environmental sensors
## Legal Considerations (UK)
### RF Transmission
- **ISM bands (433 MHz, 868 MHz, 2.4 GHz):** Licence-free at low power (≤25 mW for 433, ≤500 mW for 868)
- **Amateur radio bands:** Require Foundation/Intermediate/Full amateur radio licence
- **1.42 GHz hydrogen line:** Requires amateur radio licence
- **Everything else:** Illegal to transmit without specific Ofcom authorisation
**Recommendation:** Start with 433 MHz ISM (legal, no licence required) or obtain a Foundation amateur radio licence (approximately £50, one-day course).
### Mechanical Channel
No restrictions — it's physical vibration. Safe levels are well below thresholds for human discomfort.
## Research Applications
- Studying Schumann resonance propagation characteristics
- Ground-coupled vs. airborne signal transmission efficiency
- RF modulation techniques with ELF patterns
- Seismic transduction for infrasound research
- Amateur radio experimentation on the hydrogen line
- Antenna design and testing for specific frequencies
## References & Further Reading
See PDFs in `electromechanical/` and `hydrogen-line-beacon/` directories for technical documentation, build guides, and theoretical background.
## Licence
MIT — Mikoshi Ltd, 2026
---
**Note:** This is experimental RF and signal processing work. Always comply with local radio regulations, maintain safe RF exposure distances, and respect the electromagnetic spectrum.
| text/markdown | null | Darren Edwards <darrenedwards111@gmail.com> | null | null | Apache-2.0 | shard, rf, schumann, hydrogen-line, active-discovery, sdr, radio, anomaly-detection, sprt, sequential-testing | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Physics",
"Topic :: Communications :: Ham Radio"
] | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/DarrenEdwards111/SHARD",
"Repository, https://github.com/DarrenEdwards111/SHARD",
"Issues, https://github.com/DarrenEdwards111/SHARD/issues"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T06:07:51.444916 | shard_rf-1.0.2.tar.gz | 36,743 | b4/99/79b9fcacecfb2601f72d0214b7b6b8da8b892fbd71078308bee1ba550098/shard_rf-1.0.2.tar.gz | source | sdist | null | false | e95427ff4f58cf18f56d0b33b347bede | 795d0112a53355e1ea516e91eccb9207f81eab08871f771fa55b9d1a4fc71ce5 | b49979b9fcacecfb2601f72d0214b7b6b8da8b892fbd71078308bee1ba550098 | null | [] | 221 |
2.4 | pulumi-alicloud | 3.96.0a1771566203 | A Pulumi package for creating and managing AliCloud resources. | [](https://github.com/pulumi/pulumi-alicloud/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/alicloud)
[](https://pypi.org/project/pulumi-alicloud)
[](https://badge.fury.io/nu/pulumi.alicloud)
[](https://pkg.go.dev/github.com/pulumi/pulumi-alicloud/sdk/v3/go)
[](https://github.com/pulumi/pulumi-alicloud/blob/master/LICENSE)
# AliCloud Resource Provider
The AliCloud resource provider for Pulumi lets you use AliCloud resources in your cloud programs. To use
this package, please [install the Pulumi CLI first](https://pulumi.io/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/alicloud
or `yarn`:
$ yarn add @pulumi/alicloud
### Python
To use from Python, install using `pip`:
$ pip install pulumi_alicloud
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-alicloud/sdk/v3
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Alicloud
## Configuration
The following configuration points are available:
- `alicloud:accessKey` - (Required) This is the Alicloud access key. It must be provided, but it can also be sourced from
the `ALICLOUD_ACCESS_KEY` environment variable.
- `alicloud:secretKey` - (Required) This is the Alicloud secret key. It must be provided, but it can also be sourced from
the `ALICLOUD_SECRET_KEY` environment variable.
- `alicloud:securityToken` - (Optional) Alicloud Security Token Service. It can be sourced from the `ALICLOUD_SECURITY_TOKEN`
environment variable.
- `alicloud:ecsRoleName` - (Optional) The RAM Role Name attached on a ECS instance for API operations. You can retrieve
this from the 'Access Control' section of the Alibaba Cloud console. It can be sourced from the `ALICLOUD_ECS_ROLE_NAME`
environment variable.
- `alicloud:region` - (Required) This is the Alicloud region. It must be provided, but it can also be sourced from the
`ALICLOUD_REGION` environment variables.
- `alicloud:accountId` - (Optional) Alibaba Cloud Account ID. It is used by the Function Compute service and to
connect router interfaces. If not provided, the provider will attempt to retrieve it automatically with STS GetCallerIdentity.
It can be sourced from the `ALICLOUD_ACCOUNT_ID` environment variable.
- `alicloud:sharedCredentialsFile` - (Optional) This is the path to the shared credentials file. It can also be sourced
from the `ALICLOUD_SHARED_CREDENTIALS_FILE` environment variable. If this is not set and a profile is specified,
`~/.aliyun/config.json` will be used.
- `alicloud:profile` - (Optional) This is the Alicloud profile name as set in the shared credentials file. It can also be
sourced from the `ALICLOUD_PROFILE` environment variable.
- `alicloud:skipRegionValidation` - (Optional) Skip static validation of region ID. Used by users of alternative
AlibabaCloud-like APIs or users w/ access to regions that are not public (yet).
## Reference
For further information, please visit [the AliCloud provider docs](https://www.pulumi.com/docs/intro/cloud-providers/alicloud) or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/alicloud).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, alicloud | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-alicloud"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:07:20.723311 | pulumi_alicloud-3.96.0a1771566203.tar.gz | 5,553,556 | 08/0e/fdd0204d5b1e356ec59ce572974f4f3f990e839f0bcf1c6881b4327f80e2/pulumi_alicloud-3.96.0a1771566203.tar.gz | source | sdist | null | false | 890230b94ca00ddd64cc0054a5155a94 | fe18e9b7298761af79408d73af9468708b2418af241b0092692e8f306d72ca0b | 080efdd0204d5b1e356ec59ce572974f4f3f990e839f0bcf1c6881b4327f80e2 | null | [] | 212 |
2.4 | any2md | 0.6.0 | Convert PDF, DOCX, HTML, and TXT files — or web pages by URL — to clean, LLM-optimized Markdown with YAML frontmatter. | # any2md
Convert PDF, DOCX, HTML, and TXT files — or web pages by URL — to clean, LLM-optimized Markdown with YAML frontmatter.
One command. Any format. Consistent, structured output ready for language models.
## Quick Start
```bash
pip install any2md
any2md report.pdf
any2md https://example.com/article
any2md --help
```
Output lands in `./Text/` by default:
```markdown
---
title: "Quarterly Financial Report"
source_file: "report.pdf"
pages: 12
type: pdf
---
# Quarterly Financial Report
Document content here...
```
## Features
| Feature | Description |
|---------|-------------|
| **Multi-format** | PDF, DOCX, HTML (.html, .htm), TXT |
| **URL fetching** | Pass any http/https URL as input |
| **YAML frontmatter** | Title, source, page/word count, type |
| **Batch processing** | Single file, directory scan, or mixed inputs |
| **Auto-routing** | Dispatches to the correct converter by extension |
| **Smart skip** | Won't overwrite existing files unless `--force` |
| **Filename sanitization** | Spaces, special characters, unicode dashes handled |
| **TXT structure detection** | Infers headings, lists, code blocks from plain text |
| **Title extraction** | Pulls the first H1–H3 heading automatically |
| **Link stripping** | `--strip-links` removes hyperlinks, keeps text |
| **SSRF protection** | Blocks requests to private/reserved/loopback IPs |
| **File size limits** | Configurable max file size via `--max-file-size` |
| **Lazy loading** | Converter imports deferred until needed for fast startup |
## Installation
Requires **Python 3.10+**.
```bash
pip install any2md
```
### From source
```bash
git clone https://github.com/rocklambros/any2md.git
cd any2md
pip install .
```
### Dependencies
| Library | Purpose |
|---------|---------|
| [PyMuPDF](https://pymupdf.readthedocs.io/) + [pymupdf4llm](https://pymupdf.readthedocs.io/en/latest/pymupdf4llm/) | PDF extraction |
| [mammoth](https://github.com/mwilliamson/python-mammoth) + [markdownify](https://github.com/matthewwithanm/python-markdownify) | DOCX conversion |
| [trafilatura](https://trafilatura.readthedocs.io/) + [BeautifulSoup](https://www.crummy.com/software/BeautifulSoup/) | HTML/URL extraction |
| [lxml](https://lxml.de/) | Fast HTML parsing |
## Usage
### Basic conversion
```bash
# Single file
any2md report.pdf
# Multiple files
any2md report.pdf proposal.docx "meeting notes.pdf"
# HTML file
any2md page.html
# Web page by URL
any2md https://example.com/article
# Plain text file
any2md notes.txt
# Mixed batch — PDFs, DOCX, HTML, TXT, and URLs together
any2md doc.pdf page.html notes.txt https://example.com
```
### Directory scanning
```bash
# Scan a specific directory
any2md --input-dir ./documents
# Convert everything in the current directory (default behavior)
any2md
```
### Options
```bash
# Custom output directory
any2md -o ./converted report.pdf
# Overwrite existing files
any2md --force
# Strip hyperlinks from output
any2md --strip-links doc.pdf
# Combine options
any2md -f -o ./out --strip-links docs/*.pdf docs/*.docx
```
### Alternative invocations
```bash
# Module mode (works without installing via pip)
python -m any2md report.pdf
# Legacy script (backward compatibility)
python3 mdconv.py report.pdf
```
## Output Format
Every converted file has YAML frontmatter followed by cleaned Markdown. The frontmatter fields vary by source format:
**PDF** — includes page count:
```markdown
---
title: "Quarterly Financial Report"
source_file: "Q3 Report 2024.pdf"
pages: 12
type: pdf
---
```
**DOCX** — includes word count:
```markdown
---
title: "Project Proposal"
source_file: "proposal.docx"
word_count: 3847
type: docx
---
```
**HTML file** — includes word count:
```markdown
---
title: "Page Title"
source_file: "page.html"
word_count: 1234
type: html
---
```
**TXT** — structure inferred via heuristics, includes word count:
```markdown
---
title: "Meeting Notes"
source_file: "notes.txt"
word_count: 892
type: txt
---
```
**URL** — records source URL instead of filename:
```markdown
---
title: "Article Title"
source_url: "https://example.com/article"
word_count: 567
type: html
---
```
## CLI Reference
```
usage: any2md [-h] [--input-dir PATH] [--force] [--output-dir PATH] [--strip-links] [files ...]
Convert PDF, DOCX, HTML, and TXT files to LLM-optimized Markdown.
positional arguments:
files Files or URLs to convert. Supports PDF, DOCX, HTML,
TXT files and http(s) URLs. If omitted, converts all
supported files in the current directory.
options:
-h, --help show this help message and exit
--input-dir, -i PATH Directory to scan for supported files (PDF, DOCX, HTML, TXT)
--force, -f Overwrite existing .md files
--output-dir, -o PATH Output directory (default: ./Text)
--strip-links Remove markdown links, keeping only the link text
--max-file-size BYTES Maximum file size in bytes (default: 104857600)
```
## Architecture
```
User Input (files, URLs, flags)
│
▼
cli.py ─── parse args, classify URLs vs file paths
│
▼
converters/__init__.py ─── dispatch by extension
│
┌────┼────┬────┐
▼ ▼ ▼ ▼
pdf docx html txt ─── format-specific extraction
│ │ │ │
└────┼────┴────┘
▼
utils.py ─── clean, title-extract, sanitize, frontmatter
│
▼
Output ─── YAML frontmatter + Markdown → output_dir/
```
### Extraction pipelines
| Format | Pipeline |
|--------|----------|
| **PDF** | `pymupdf4llm.to_markdown()` → clean → frontmatter |
| **DOCX** | `mammoth` (DOCX → HTML) → `markdownify` (HTML → Markdown) → clean → frontmatter |
| **HTML/URL** | `trafilatura` extract with markdown output (fallback: BS4 pre-clean → `markdownify`) → clean → frontmatter |
| **TXT** | `structurize()` heuristics (headings, lists, code blocks) → clean → frontmatter |
### Adding a new format
1. Create `any2md/converters/newformat.py` with a `convert_newformat(path, output_dir, force, strip_links_flag) → bool` function
2. Add the extension and function to `CONVERTERS` in `any2md/converters/__init__.py`
3. Add the extension to `SUPPORTED_EXTENSIONS`
## Security
- **SSRF protection**: URL fetching validates resolved IPs against private, reserved, loopback, and link-local ranges before making requests.
- **Scheme validation**: Only `http` and `https` URL schemes are accepted.
- **File size limits**: Local files exceeding `--max-file-size` (default 100 MB) are skipped. HTML files are also checked before reading.
- **Input sanitization**: Filenames are stripped of control characters, null bytes, and path separators.
- **Trust model**: This tool processes local files and fetches URLs you provide. It does not execute embedded scripts or macros from any input format.
## License
MIT
| text/markdown | null | rocklambros <rock@rockcyber.com> | null | null | null | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Topic :: Text Processing :: Markup :: Markdown"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"beautifulsoup4>=4.12.0",
"lxml>=5.0.0",
"mammoth>=1.6.0",
"markdownify>=0.13.0",
"pymupdf4llm>=0.0.17",
"pymupdf>=1.24.0",
"trafilatura>=1.12.0"
] | [] | [] | [] | [
"Homepage, https://github.com/rocklambros/any2md",
"Issues, https://github.com/rocklambros/any2md/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T06:07:14.681119 | any2md-0.6.0.tar.gz | 12,512 | cc/e1/c6fc2bba87f03ab5d4db87118fe3755b37764944571033aacb197e52251a/any2md-0.6.0.tar.gz | source | sdist | null | false | 34328e1016e268f35ddcd2e853e15ec1 | 2e9daa8c36165f1f6ed0ac5d82bb9a7582fab7240e1e4099695db2c2f58c64eb | cce1c6fc2bba87f03ab5d4db87118fe3755b37764944571033aacb197e52251a | MIT | [
"LICENSE"
] | 232 |
2.4 | pulumi-datadog | 4.68.0a1771566900 | A Pulumi package for creating and managing Datadog resources. | [](https://github.com/pulumi/pulumi-datadog/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/datadog)
[](https://pypi.org/project/pulumi-datadog)
[](https://badge.fury.io/nu/pulumi.datadog)
[](https://pkg.go.dev/github.com/pulumi/pulumi-datadog/sdk/v4/go)
[](https://github.com/pulumi/pulumi-datadog/blob/master/LICENSE)
# Datadog Provider
The Datadog resource provider for Pulumi lets you configure Datadog resources in your cloud programs. To use
this package, please [install the Pulumi CLI first](https://pulumi.io/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/datadog
or `yarn`:
$ yarn add @pulumi/datadog
### Python
To use from Python, install using `pip`:
$ pip install pulumi_datadog
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-datadog/sdk/v4
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Datadog
## Configuration
The following configuration points are available:
* apiKey (Required) - Datadog API key. This can also be set via the `DATADOG_API_KEY` environment variable.
* appKey (Required) - Datadog APP key. This can also be set via the `DATADOG_APP_KEY` environment variable.
* apiUrl (Optional) - The API Url. This can be also be set via the DATADOG_HOST environment variable.
Note that this URL must not end with the `/api/` path. For example, `https://api.datadoghq.com/` is a correct value,
while `https://api.datadoghq.com/api/` is not.
## Reference
For further information, please visit [the Datadog provider docs](https://www.pulumi.com/docs/intro/cloud-providers/datadog) or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/datadog).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, datadog | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-datadog"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:06:17.617464 | pulumi_datadog-4.68.0a1771566900.tar.gz | 1,177,902 | 77/05/2724f5d0ea3115599bb2a305dd42a89498e82cc8e2b4e7eabaa894227180/pulumi_datadog-4.68.0a1771566900.tar.gz | source | sdist | null | false | a45311c95f5344c8c69db21de5db17e6 | 644d1c972c7012f487b46cc3c302f739cda8eb31caa834701336f6153410400c | 77052724f5d0ea3115599bb2a305dd42a89498e82cc8e2b4e7eabaa894227180 | null | [] | 202 |
2.4 | pulumi-f5bigip | 3.20.0a1771567137 | A Pulumi package for creating and managing F5 BigIP resources. | [](https://github.com/pulumi/pulumi-f5bigip/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/f5bigip)
[](https://pypi.org/project/pulumi-f5bigip)
[](https://badge.fury.io/nu/pulumi.f5bigip)
[](https://pkg.go.dev/github.com/pulumi/pulumi-f5bigip/sdk/v3/go)
[](https://github.com/pulumi/pulumi-f5bigip/blob/master/LICENSE)
# F5 BigIP Provider
This provider allows management of F5 BigIP resources using Pulumi. This provider uses the iControlREST API to
perform management tasks, so it will need to be installed and enabled on your F5 device before proceeding.
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/f5bigip
or `yarn`:
$ yarn add @pulumi/f5bigip
### Python
To use from Python, install using `pip`:
$ pip install pulumi_f5bigip
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-f5bigip/sdk/v3
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.F5bigip
## Configuration
The following configuration points are available:
- `f5bigip:address` - Domain name/IP of the BigIP. May be set via the `BIGIP_HOST` environment variable.
- `f5bigip:port` - Management Port to connect to BigIP.
- `f5bigip:username` - Username with API access to the BigIP. May be set via the `BIGIP_USER` environment variable.
- `f5bigip:password` - Password for API access to the BigIP. May be set via the `BIGIP_PASSWORD` environment variable.
- `f5bigip:tokenAuth` - Enable to use an external authentication source (LDAP, TACACS, etc). May be set via the `BIGIP_TOKEN_AUTH` environment variable.
- `f5bigip:tokenAuth` - Enable to use an external authentication source (LDAP, TACACS, etc). May be set via the `BIGIP_TOKEN_AUTH` environment variable.
- `f5bigip:loginRef` - Login reference for token authentication (see BIG-IP REST docs for details) May be set via the `BIGIP_LOGIN_REF` environment variable.
## Reference
For further information, please visit [the F5bigip provider docs](https://www.pulumi.com/docs/intro/cloud-providers/f5bigip) or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/f5bigip).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, f5, bigip | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-f5bigip"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:05:50.581698 | pulumi_f5bigip-3.20.0a1771567137.tar.gz | 306,684 | e5/ce/7bb8219c5f3c3f23cf65a4948689ae4c4257f8bed867e58e2c5e809a9127/pulumi_f5bigip-3.20.0a1771567137.tar.gz | source | sdist | null | false | 0a9de4953a72c63ac54efc08f5f30fc8 | f78b3901a2d2e77c0329dbb53d2097ee4b0be3801911bf57c85aea1d9dee8a7d | e5ce7bb8219c5f3c3f23cf65a4948689ae4c4257f8bed867e58e2c5e809a9127 | null | [] | 198 |
2.4 | aadil-nazar-sindhi-lemmatizer | 1.0.0 | A rule-based Sindhi Lemmatizer | # Sindhi Lemmatizer (Aadil Nazar)
[](https://pypi.org/project/aadil-nazar-sindhi-lemmatizer/)
[](https://opensource.org/licenses/MIT)
## About the Author
**Aadil Nazar** is a researcher and developer specializing in **Computational Linguistics** and **Natural Language Processing (NLP)** for low-resource languages. My work focuses on bridging the gap between traditional linguistics and modern technology, specifically for the Sindhi language. I am dedicated to developing open-source tools that empower researchers to process and analyze Sindhi text with digital precision.
## Project Overview
The **Sindhi Lemmatizer** is a specialized NLP tool designed to reduce inflected Sindhi words to their dictionary or root form (the lemma). Unlike simple stemming, which merely chops off suffixes, this lemmatizer utilizes morphological rules and a custom-mapped WordNet dictionary to ensure linguistic accuracy.
### Key Features:
- **Rule-Based Morphology Engine:** Handles complex Sindhi suffix and prefix patterns.
- **Custom Sindhi WordNet:** Integrated lexical database for root validation.
- **Research-Oriented:** Optimized for academic and commercial text analysis.
---
## Installation
Install the package using the Python Package Index (PyPI):
```bash
pip install aadil-nazar-sindhi-lemmatizer
| text/markdown | Aadil Nazar | adilhussainburiro14912@gmail.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/aadilnazar/sindhi_nlp | null | >=3.7 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T06:05:43.368405 | aadil_nazar_sindhi_lemmatizer-1.0.0-py3-none-any.whl | 2,329,966 | a7/79/60c16cb025467e76f5ea54b9e4a1e3ca1eb3a82f80924b3f94761023909c/aadil_nazar_sindhi_lemmatizer-1.0.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 8f9d860a63734a9488af94508eb0e62e | ca92311bd706f83d11b906e451df575800a7c75c9a5c7c68b697c20b206806b9 | a77960c16cb025467e76f5ea54b9e4a1e3ca1eb3a82f80924b3f94761023909c | null | [
"LICENSE.txt"
] | 0 |
2.4 | cx-Freeze | 8.6.0 | Create standalone executables from Python scripts | **cx_Freeze** Creates standalone executables from Python scripts with the same performance
as the original script.
It is cross-platform and should work on any platform that Python runs on.
[](https://pypi.org/project/cx-freeze/)
[](https://pypistats.org/packages/cx-freeze)
[](https://anaconda.org/conda-forge/cx_freeze)
[](https://anaconda.org/conda-forge/cx_freeze)
[](https://www.python.org/)
[](https://github.com/marcelotduarte/cx_Freeze/actions/workflows/ci.yml)
[](https://github.com/marcelotduarte/cx_Freeze/actions/workflows/codeql.yml)
[](https://htmlpreview.github.io/?https://github.com/marcelotduarte/cx_Freeze/blob/python-coverage-comment-action-data/htmlcov/index.html)
[](https://github.com/astral-sh/ruff)
[](https://cx-freeze.readthedocs.io/en/stable/?badge=stable)
# Installation
Choose the Python package manager according to your system. See how the
installation works with the most common ones, which are pip and conda.
To install the latest version of `cx_Freeze` using `pip` into a
virtual environment:
```
pip install --upgrade cx_Freeze
```
To install the latest development build:
```
pip uninstall cx_Freeze
pip install --extra-index-url https://test.pypi.org/simple/ cx_Freeze --pre --no-cache
```
Installing cx_freeze from the conda-forge channel can be achieved with the
command:
```
conda install conda-forge::cx_freeze
```
> [!NOTE]
> For more information, please check the
> [installation](https://cx-freeze.readthedocs.io/en/latest/installation.html).
> [!IMPORTANT]
> If you are creating "service" standalone executables, see this
> [readme](https://github.com/marcelotduarte/cx_Freeze/tree/main/samples/service#readme).
# Changelog
[Changelog](https://github.com/marcelotduarte/cx_Freeze/blob/main/CHANGELOG.md)
# Documentation
[Documentation](https://cx-freeze.readthedocs.io).
If you need help you can also ask on the
[discussion](https://github.com/marcelotduarte/cx_Freeze/discussions) channel.
# License
cx_Freeze uses a license derived from the
[Python Software Foundation License](https://www.python.org/psf/license).
You can read the cx_Freeze license in the
[documentation](https://cx-freeze.readthedocs.io/en/stable/license.html)
or in the [source repository](LICENSE.md).
| text/markdown | null | Marcelo Duarte <marcelotduarte@users.noreply.github.com>, Anthony Tuininga <anthony.tuininga@gmail.com> | null | null | null | cx-freeze cxfreeze cx_Freeze freeze python | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Build Tools",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: System :: Software Distribution",
"Topic :: Utilities"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"freeze-core>=0.6.0",
"packaging>=25.0",
"setuptools<=82.0,>=78.1.1",
"tomli>=2.0.1; python_version == \"3.10\"",
"filelock>=3.20.3; sys_platform == \"linux\"",
"patchelf<0.18,>=0.16.1; sys_platform == \"linux\" and platform_machine == \"x86_64\"",
"patchelf<0.18,>=0.16.1; sys_platform == \"linux\" and platform_machine == \"i686\"",
"patchelf<0.18,>=0.16.1; sys_platform == \"linux\" and platform_machine == \"aarch64\"",
"patchelf<0.18,>=0.16.1; sys_platform == \"linux\" and platform_machine == \"armv7l\"",
"patchelf<0.18,>=0.16.1; sys_platform == \"linux\" and platform_machine == \"ppc64le\"",
"patchelf<0.18,>=0.16.1; sys_platform == \"linux\" and platform_machine == \"s390x\"",
"dmgbuild>=1.6.1; sys_platform == \"darwin\"",
"lief<=0.17.3,>=0.15.1; sys_platform == \"win32\" and platform_machine != \"ARM64\"",
"lief<=0.17.3,>=0.15.1; sys_platform == \"win32\" and platform_machine == \"ARM64\" and python_version <= \"3.13\"",
"python-msilib>=0.4.1; sys_platform == \"win32\" and python_version >= \"3.13\""
] | [] | [] | [] | [
"Home, https://marcelotduarte.github.io/cx_Freeze",
"Changelog, https://github.com/marcelotduarte/cx_Freeze/blob/main/CHANGELOG.md",
"Documentation, https://cx-freeze.readthedocs.io",
"Source, https://github.com/marcelotduarte/cx_Freeze",
"Tracker, https://github.com/marcelotduarte/cx_Freeze/issues",
"Workflows, https://github.com/marcelotduarte/cx_Freeze/actions?query=branch:main"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T06:04:31.699921 | cx_freeze-8.6.0.tar.gz | 1,376,331 | 1b/a7/3ce0b7071669cc61579eceaedf132cad0d3003d0c7a041560d7e87184a7a/cx_freeze-8.6.0.tar.gz | source | sdist | null | false | 0936269463d208a508ea034751e77692 | 04de4e97a0fbebf5c67aec74ecd62c206f282163a111cda4343367d653b2c46d | 1ba73ce0b7071669cc61579eceaedf132cad0d3003d0c7a041560d7e87184a7a | PSF-2.0 | [
"LICENSE.md"
] | 0 |
2.4 | gh-weekly-updates | 0.1.1 | Automatically discover and summarise your weekly GitHub impact | # gh-weekly-updates
> Automatically discover and summarise your weekly GitHub impact using AI.
`gh-weekly-updates` collects your GitHub activity — pull requests authored & reviewed, issues created & commented on, discussions — and generates a structured Markdown summary using [GitHub Models](https://github.com/marketplace/models).
## Features
- **Auto-discover repos** via the GitHub GraphQL Contributions API, or provide an explicit list
- **Collect detailed activity**: PRs, reviews, issues, issue comments, discussions
- **AI-powered summarisation** via GitHub Models (`openai/gpt-4.1` by default)
- **Structured output**: Wins / Strategic Influence / Challenges with inline links
- **Push to a repo**: automatically commit summaries to a GitHub repo for sharing
- **Fully configurable**: org, repos, model, prompt — via YAML config or CLI flags
- **Custom prompts**: tailor the AI summary to your team's format
## Installation
```bash
pip install gh-weekly-updates
```
### Requirements
- Python 3.11+
- A GitHub personal access token (PAT) **or** the [GitHub CLI](https://cli.github.com/) (`gh`) authenticated
- Required scopes: `repo`, `read:org`
- The token also needs access to [GitHub Models](https://github.com/marketplace/models) for AI summarisation
## Quick start
```bash
# Authenticate with the GitHub CLI (easiest)
gh auth login
# Run with defaults — covers the past week
gh-weekly-updates
# Or specify a date range
gh-weekly-updates --since 2025-06-01 --until 2025-06-07
```
## Configuration
Create a `config.yaml` (see [config.example.yaml](config.example.yaml)):
```yaml
# GitHub org to scope repo discovery to
org: my-org
# Explicit repo list (skips auto-discovery)
repos:
- my-org/api-service
- my-org/web-app
# GitHub Model for summarisation
model: openai/gpt-4.1
# Push summary to a repo under weekly-updates/
push_repo: my-user/my-updates
# Custom system prompt (inline)
prompt: |
You are an engineering manager writing a concise weekly summary...
# Or load prompt from a file
# prompt_file: my-prompt.txt
```
## CLI reference
```
Usage: gh-weekly-updates [OPTIONS]
Options:
--config PATH Path to YAML config file. Default: ./config.yaml
--since TEXT Start date (ISO 8601). Default: previous Monday.
--until TEXT End date (ISO 8601). Default: now.
--user TEXT GitHub username. Default: authenticated user.
--repos TEXT Comma-separated list of repos (owner/name).
--org TEXT GitHub org to scope repo discovery to.
--output PATH Write summary to a file instead of stdout.
--push TEXT Push summary to a GitHub repo (owner/name).
--model TEXT GitHub Model to use. Default: openai/gpt-4.1.
--verbose Enable debug logging.
--help Show this message and exit.
```
## Authentication
`gh-weekly-updates` resolves a GitHub token in this order:
1. `GITHUB_TOKEN` environment variable
2. `gh auth token` (GitHub CLI)
For GitHub Enterprise with SSO, ensure the token is authorised for your org.
## Using with GitHub Actions
You can run `gh-weekly-updates` on a schedule in a GitHub Actions workflow:
```yaml
name: Weekly Impact Summary
on:
schedule:
- cron: '0 9 * * 1' # Every Monday at 9am UTC
workflow_dispatch:
jobs:
summarise:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: '3.12'
- name: Install gh-weekly-updates
run: pip install gh-weekly-updates
- name: Generate summary
env:
GITHUB_TOKEN: ${{ secrets.GH_PAT }}
run: |
gh-weekly-updates \
--config config.yaml \
--push my-user/my-updates
```
> **Note**: The default `GITHUB_TOKEN` provided by Actions has limited scope.
> Use a [Personal Access Token](https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/managing-your-personal-access-tokens) stored as a repository secret with `repo` and `read:org` scopes, plus GitHub Models access.
## Development
```bash
git clone https://github.com/sahansera/gh-weekly-updates.git
cd gh-weekly-updates
python -m venv .venv && source .venv/bin/activate
make dev # install in editable mode with dev deps
make run # run with defaults
make lint # ruff check
```
See [CONTRIBUTING.md](CONTRIBUTING.md) for more details.
## License
[MIT](LICENSE)
| text/markdown | null | null | null | null | MIT | github, weekly, impact, summary, engineering | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"click>=8.1",
"httpx>=0.27",
"pydantic>=2.0",
"pyyaml>=6.0",
"rich>=13.0",
"openai>=1.30",
"ruff>=0.4; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/sahansera/gh-weekly-updates",
"Repository, https://github.com/sahansera/gh-weekly-updates",
"Issues, https://github.com/sahansera/gh-weekly-updates/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T06:04:16.501448 | gh_weekly_updates-0.1.1.tar.gz | 17,168 | 6e/87/68e89b30ce1ed2017afb200f368f47fc1438495a13091c7a44085afc425f/gh_weekly_updates-0.1.1.tar.gz | source | sdist | null | false | 0afbb3db1d0f50642ddf2133a16c6115 | 6acdd09792e3d74d4b17a8cd476919af96a1ed3881a13a0974076cff1569e171 | 6e8768e89b30ce1ed2017afb200f368f47fc1438495a13091c7a44085afc425f | null | [
"LICENSE"
] | 215 |
2.4 | pulumi-databricks | 1.88.0a1771566712 | A Pulumi package for creating and managing databricks cloud resources. | [](https://github.com/pulumi/pulumi-databricks/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/databricks)
[](https://pypi.org/project/pulumi-databricks)
[](https://badge.fury.io/nu/pulumi.databricks)
[](https://pkg.go.dev/github.com/pulumi/pulumi-databricks/sdk/go)
[](https://github.com/pulumi/pulumi-databricks/blob/master/LICENSE)
# Databricks Resource Provider
The Databricks Resource Provider lets you manage Databricks resources.
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/databricks
or `yarn`:
$ yarn add @pulumi/databricks
### Python
To use from Python, install using `pip`:
$ pip install pulumi_databricks
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-databricks/sdk
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Databricks
## Configuration
The following configuration points are available:
* `databricks:host` - (optional) This is the host of the Databricks workspace. It is a URL that you use to login to your workspace.
Alternatively, you can provide this value as an environment variable `DATABRICKS_HOST`.
* `databricks:token` - (optional) This is the API token to authenticate into the workspace. Alternatively, you can provide
this value as an environment variable `DATABRICKS_TOKEN`.
* `databricks:username` - (optional) This is the username of the user that can log into the workspace. Alternatively,
you can provide this value as an environment variable `DATABRICKS_USERNAME`.
* `databricks:password` - (optional) This is the user's password that can log into the workspace. Alternatively, you can
provide this value as an environment variable `DATABRICKS_PASSWORD`.
* `databricks:configFile` - (optional) Location of the Databricks CLI credentials file created by `databricks configure --token`
command (`~/.databrickscfg` by default). Check [Databricks CLI documentation](https://docs.databricks.com/dev-tools/cli/index.html#set-up-authentication) for more details.
The provider uses configuration file credentials when you don't specify host/token/username/password/azure attributes.
Alternatively, you can provide this value as an environment variable `DATABRICKS_CONFIG_FILE`. This field defaults to `~/.databrickscfg`.
* `databricks:profile` - (optional) Connection profile specified within `~/.databrickscfg`. Please check
[connection profiles section](https://docs.databricks.com/dev-tools/cli/index.html#connection-profiles) for more details. This field defaults to `DEFAULT`.
* `databricks:accountId` - (optional) Account Id that could be found in the bottom left corner of
[Accounts Console](https://accounts.cloud.databricks.com/). Alternatively, you can provide this value as an environment
variable `DATABRICKS_ACCOUNT_ID`. Only has effect when `host = "https://accounts.cloud.databricks.com/"` and currently used to provision account admins via `databricks_user`.
In the future releases of the provider this property will also be used specify account for `databricks_mws_*` resources as well.
* `databricks:authType` - (optional) enforce specific auth type to be used in very rare cases, where a single provider state
manages Databricks workspaces on more than one cloud and `More than one authorization method configured` error is a false positive. Valid values are `pat`, `basic`, `azure-client-secret`, `azure-msi`, `azure-cli`, and `databricks-cli`.
## Reference
For detailed reference documentation, please visit [the Pulumi registry](https://www.pulumi.com/registry/packages/databricks/api-docs/).
## Contributors
This package was originally built by the development team at [https://www.ingenii.io/](https://www.ingenii.io/). Pulumi thanks them for their continued contributions to the project.
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, databricks, category/infrastructure | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://www.pulumi.com",
"Repository, https://github.com/pulumi/pulumi-databricks"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:03:56.791930 | pulumi_databricks-1.88.0a1771566712.tar.gz | 1,197,020 | 8e/f3/cfceb065e4c725fc63c1487386773cc5e94257d01f42d91a00adf63a93e4/pulumi_databricks-1.88.0a1771566712.tar.gz | source | sdist | null | false | 360bfc8f377c386eafac6774f8313957 | d534d0f3e02fae9fba9cba98652d6725b2c586b3abfe1b343e4b461da733ba1c | 8ef3cfceb065e4c725fc63c1487386773cc5e94257d01f42d91a00adf63a93e4 | null | [] | 208 |
2.4 | jentis-llmagentkit | 1.0.1 | Production-ready AI agent architectures with tool orchestration, parallel execution, and reasoning capabilities | # Jentis LLM Agent Kit
[](https://badge.fury.io/py/jentis-llmagentkit)
[](https://opensource.org/licenses/MIT)
[](https://www.python.org/downloads/)
A production-ready collection of AI agent architectures built on top of `jentis.core`.
Each agent is optimized for different trade-offs between **speed**, **reasoning depth**, and **tool parallelism**.
---
## What's New in v1.0.1
- **Critical Fix**: Resolved JSON parsing issues across all agents for robust tool execution.
- **Prompt Optimization**: Enhanced system prompts for better adherence to JSON protocols.
- **Agent Improvements**:
- `ToolCalling Agent`: Streamlined for direct execution.
- `ReAct Agent`: Enforced strict Thought-Action loop.
- `MultiTool Agent`: Fixed parallel execution logic.
- `ParallelReAct Agent`: Optimized for concurrent reasoning tasks.
---
## Installation
```bash
pip install jentis-llmagentkit
```
---
## Quick Start
```python
from jentis.llmagentkit import Create_ReAct_Agent
from jentis.core import tool
@tool
def search(query: str) -> str:
"""Search the internet for information."""
return f"Results for: {query}"
# Assuming you have an LLM instance
agent = Create_ReAct_Agent(llm=my_llm, verbose=True)
agent.add_tools(search)
response = agent.invoke("What is quantum computing?")
print(response)
```
---
## Available Agents
### 1. **ToolCalling Agent** — Sequential, No Reasoning
```python
from jentis.llmagentkit import Create_ToolCalling_Agent
agent = Create_ToolCalling_Agent(llm=my_llm, verbose=True)
```
- **Execution**: One tool at a time, sequentially
- **Reasoning**: None — direct tool invocation
- **Use Case**: Simple tasks needing one or a few tool calls
- **Speed**: ★★☆
---
### 2. **ReAct Agent** — Sequential + Reasoning
```python
from jentis.llmagentkit import Create_ReAct_Agent
agent = Create_ReAct_Agent(llm=my_llm, verbose=True)
```
- **Execution**: One tool at a time, sequentially
- **Reasoning**: Full Thought → Action → Observation loop
- **Use Case**: Complex problems requiring step-by-step reasoning
- **Speed**: ★☆☆ (reasoning overhead)
---
### 3. **MultiTool Agent** — Parallel, No Reasoning
```python
from jentis.llmagentkit import Create_MultiTool_Agent
agent = Create_MultiTool_Agent(llm=my_llm, verbose=True, max_workers=5)
```
- **Execution**: Multiple tools simultaneously in parallel
- **Reasoning**: None — direct parallel execution
- **Use Case**: Fast data gathering from multiple independent sources
- **Speed**: ★★★
---
### 4. **ParallelReAct Agent** — Parallel + Reasoning ⭐ *Recommended*
```python
from jentis.llmagentkit import Create_ParallelReAct_Agent
agent = Create_ParallelReAct_Agent(llm=my_llm, verbose=True, max_workers=5)
```
- **Execution**: Multiple tools in parallel, chained across iterations
- **Reasoning**: Full thought process visible at every step
- **Use Case**: Complex tasks requiring both speed and transparency
- **Speed**: ★★★
---
## Common Parameters
| Parameter | Type | Default | Description |
|-----------|------|---------|-------------|
| `llm` | LLM | **required** | Language model instance |
| `verbose` | `bool` | `False` | Print colored execution logs |
| `full_output` | `bool` | `False` | Show full output without truncation |
| `prompt` | `str` | `None` | Custom system prompt prefix |
| `memory` | Memory | `None` | Conversation memory object |
| `max_workers` | `int` | `5` | Parallel thread count (MultiTool/ParallelReAct only) |
---
## Tool Registration
```python
from jentis.core import tool
# Decorator — automatic schema extraction from type hints + docstring
@tool
def calculator(expression: str) -> str:
"""Evaluate a mathematical expression."""
return str(eval(expression))
# Register one or more tools
agent.add_tools(calculator, another_tool)
# Or register manually with explicit schema
agent.add_tool(
name="calculator",
description="Evaluate a mathematical expression.",
function=lambda expression: str(eval(expression)),
parameters={"expression": {"type": "str", "required": True}}
)
```
---
## Agent Comparison
| Feature | ToolCalling | ReAct | MultiTool | ParallelReAct |
|---------|:-----------:|:-----:|:---------:|:-------------:|
| Execution | Sequential | Sequential | Parallel | Parallel |
| Reasoning | ✗ | ✓ | ✗ | ✓ |
| Speed | ★★ | ★ | ★★★ | ★★★ |
| Complexity handling | Simple | Complex | Simple | Complex |
| Tool chaining | Manual | Automatic | Manual | Automatic |
| Transparency | Low | High | Low | High |
---
## Choosing the Right Agent
```
Single tool, simple query?
→ ToolCalling Agent
Need visible reasoning at each step?
→ ReAct Agent
Multiple independent data sources, speed matters?
→ MultiTool Agent
Complex reasoning AND multiple tools AND speed?
→ ParallelReAct Agent ← recommended default
```
---
## Example: ParallelReAct Workflow
```
Query: "Find a Machine Learning tutorial"
Iteration 1 (parallel)
├─ youtube_search("Machine Learning tutorial")
└─ wikipedia_search("Machine Learning")
Iteration 2 (sequential — depends on iteration 1 results)
└─ youtube_transcript(video_id=<result from iteration 1>)
Iteration 3
└─ Final Answer (synthesizes all collected data)
```
---
## License
MIT License - see [LICENSE](LICENSE) file for details
---
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
---
## Project Structure
```
src/jentis/
├── core/ # Tool system (@tool decorator, Tool class)
├── llmagentkit/ # Agent implementations
│ ├── TOOL_CALLING_AGENT/
│ ├── REACT_AGENT/
│ ├── MULTI_TOOL_AGENT/
│ └── PARALLEL_REACT_AGENT/
└── utils/ # AgentLogger, Tool_Executor
```
| text/markdown | null | Jentis Developer <dev@jentis.com> | null | null | MIT | ai, agent, llm, tool-calling, react, parallel-execution, reasoning | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/jentis/llmagentkit",
"Documentation, https://github.com/jentis/llmagentkit#readme",
"Repository, https://github.com/jentis/llmagentkit",
"Issues, https://github.com/jentis/llmagentkit/issues"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-20T06:02:45.219099 | jentis_llmagentkit-1.0.1.tar.gz | 27,864 | d8/b8/9f935b6c5c2d0928da687f7197de469f28c910fe59c049e2f5ce90eab340/jentis_llmagentkit-1.0.1.tar.gz | source | sdist | null | false | ae6a9eeafdb51980c821934b9b17790f | 09705f106eb14567f74429e2ed6e78ae208ebf52d97680a0d0cd2bc7d8f0223b | d8b89f935b6c5c2d0928da687f7197de469f28c910fe59c049e2f5ce90eab340 | null | [
"LICENSE"
] | 210 |
2.4 | pulumi-external | 0.1.0a1771567009 | A Pulumi package for creating and managing External cloud resources. | [](https://github.com/pulumi/pulumi-external/actions)
[](https://www.npmjs.com/package/@pulumi/external)
[](https://pypi.org/project/pulumi_external)
[](https://www.nuget.org/packages/Pulumi.External)
[](https://pkg.go.dev/github.com/pulumi/pulumi-external/sdk/go)
[](https://github.com/pulumi/pulumi-external/blob/master/LICENSE)
# External Resource Provider
This provider is mainly used for ease of converting terraform programs to Pulumi.
When using standard Pulumi programs, you would not need to use this provider.
The External resource provider for Pulumi lets you use External resources in your cloud programs.
To use this package, please [install the Pulumi CLI first](https://www.pulumi.com/docs/install/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/external
or `yarn`:
$ yarn add @pulumi/external
### Python
To use from Python, install using `pip`:
$ pip install pulumi_external
### Go
To use from Go, use `go get` to grab the latest version of the library:
$ go get github.com/pulumi/pulumi-external/sdk
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.External
<!-- If your provider has configuration, remove this comment and the comment tags below, updating the documentation. -->
<!--
## Configuration
The following Pulumi configuration can be used:
- `external:token` - (Required) The API token to use with External. When not set, the provider will use the `EXTERNAL_TOKEN` environment variable.
-->
<!-- If your provider has reference material available elsewhere, remove this comment and the comment tags below, updating the documentation. -->
<!--
## Reference
For further information, please visit [External reference documentation](https://example.com/external).
-->
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, category/cloud | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://www.pulumi.com/",
"Repository, https://github.com/pulumi/pulumi-external"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:02:38.378140 | pulumi_external-0.1.0a1771567009.tar.gz | 9,858 | eb/27/9bdb336fcce2d7563a5e1cf1d36d85f68a7baff164a4680d3dca5002ab17/pulumi_external-0.1.0a1771567009.tar.gz | source | sdist | null | false | ea4ffe48ec0ffa04d4cd02b308c15d17 | cb79457d91362c181fc94f62ebbe1cdb5c393bfcfaabad25fb3fae98d7df9534 | eb279bdb336fcce2d7563a5e1cf1d36d85f68a7baff164a4680d3dca5002ab17 | null | [] | 198 |
2.4 | pulumi-dnsimple | 5.1.0a1771566827 | A Pulumi package for creating and managing dnsimple cloud resources. | [](https://github.com/pulumi/pulumi-dnsimple/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/dnsimple)
[](https://pypi.org/project/pulumi-dnsimple)
[](https://badge.fury.io/nu/pulumi.dnsimple)
[](https://pkg.go.dev/github.com/pulumi/pulumi-dnsimple/sdk/v4/go)
[](https://github.com/pulumi/pulumi-dnsimple/blob/master/LICENSE)
# dnsimple Resource Provider
The dnsimple resource provider for Pulumi lets you manage dnsimple resources in your cloud programs. To use
this package, please [install the Pulumi CLI first](https://pulumi.io/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/dnsimple
or `yarn`:
$ yarn add @pulumi/dnsimple
### Python
To use from Python, install using `pip`:
$ pip install pulumi_dnsimple
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-dnsimple/sdk/v4
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Dnsimple
## Configuration
The following configuration points are available:
- `dnsimple:token` - (required) The DNSimple API v2 token. Please note that this must be an API v2 token. You can use
either an User or Account token, but an Account token is recommended. Can be sourced from `DNSIMPLE_TOKEN` environment
variable.
- `dnsimple:account` - (required) The ID of the account associated with the token. Can be sourced from `DNSIMPLE_ACCOUNT`
environment variable.
## Reference
For further information, please visit [the dnsimple provider docs](https://www.pulumi.com/docs/intro/cloud-providers/dnsimple) or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/dnsimple).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, dnsimple | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-dnsimple"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T06:00:51.409421 | pulumi_dnsimple-5.1.0a1771566827.tar.gz | 33,770 | 3d/35/e6d0c0cc0117a9cd6b567ab773e6d2c54da93f56f0adce5dcdaf742f312c/pulumi_dnsimple-5.1.0a1771566827.tar.gz | source | sdist | null | false | 0a4da73797811e1b7c48e7b2ff83e153 | 90add7473d26667a03300a93c86bafd179aec4b46ae65173c48485039e52257b | 3d35e6d0c0cc0117a9cd6b567ab773e6d2c54da93f56f0adce5dcdaf742f312c | null | [] | 202 |
2.4 | opencastor | 2026.2.20.10 | The Universal Runtime for Embodied AI | <p align="center">
<img src="docs/assets/opencastor-logo.png" alt="OpenCastor" width="200"/>
</p>
<h1 align="center">OpenCastor</h1>
<h3 align="center">The Universal Runtime for Embodied AI</h3>
<p align="center">
<a href="https://pypi.org/project/opencastor/"><img src="https://img.shields.io/pypi/v/opencastor?color=blue&label=PyPI" alt="PyPI"></a>
<a href="https://github.com/craigm26/OpenCastor/actions"><img src="https://img.shields.io/github/actions/workflow/status/craigm26/OpenCastor/ci.yml?label=CI" alt="CI"></a>
<a href="https://github.com/craigm26/OpenCastor/blob/main/LICENSE"><img src="https://img.shields.io/github/license/craigm26/OpenCastor?color=green" alt="License"></a>
<a href="https://pypi.org/project/opencastor/"><img src="https://img.shields.io/pypi/pyversions/opencastor" alt="Python"></a>
<a href="https://discord.gg/jMjA8B26Bq"><img src="https://img.shields.io/discord/1234567890?label=Discord&color=5865F2" alt="Discord"></a>
</p>
<p align="center">
<b>56,006 lines of code · 2,233 tests · Python 3.10–3.12</b><br/>
<i>Connect any AI model to any robot hardware through a single YAML config.</i>
</p>
---
## 🚀 Install in 10 Seconds
```bash
curl -sL opencastor.com/install | bash
```
<details>
<summary>Other platforms</summary>
**Windows 11 (PowerShell):**
```powershell
irm https://raw.githubusercontent.com/craigm26/OpenCastor/main/scripts/install.ps1 | iex
```
**Docker:**
```bash
docker compose up
```
**Manual:**
```bash
git clone https://github.com/craigm26/OpenCastor.git
cd OpenCastor
python3 -m venv venv && source venv/bin/activate
pip install -e ".[dev]"
```
Supports **Linux, macOS (Apple Silicon & Intel), Windows 11, Raspberry Pi, Docker**.
Installer flags: `--dry-run`, `--no-rpi`, `--skip-wizard`
</details>
## ✨ What's New in v2026.2.20.10
- **8 AI providers** — Anthropic, Google, OpenAI, HuggingFace, Ollama, llama.cpp, MLX, Claude OAuth proxy
- **Tiered brain architecture** — reactive rules → fast inference → deep planning
- **Hailo-8 NPU vision** — on-device YOLOv8 object detection at ~250ms
- **OAK-D stereo depth camera** — RGB + depth via DepthAI v3
- **Community Hub** — browse, install, and share robot recipes with `castor hub`
- **Interactive wizard** — provider selection, auth, messaging setup with recall of previous choices
- **`castor doctor`** — full system health diagnostic
## 🔄 Self-Improving Loop (Sisyphus Pattern)
Your robot learns from its mistakes. After each task, the **Sisyphus Loop** analyzes what happened, identifies failures, generates fixes, verifies them, and applies improvements automatically.
```
Episode → PM (Analyze) → Dev (Patch) → QA (Verify) → Apply
```
- **Disabled by default** — opt-in via `castor wizard` or YAML config
- **4 cost tiers** — from $0 (local Ollama) to ~$5-15/mo (Claude)
- **Auto-apply preferences** — config tuning only, behavior rules, or manual review
- **Rollback** — undo any improvement with `castor improve --rollback <id>`
- **ALMA consolidation** — cross-episode pattern analysis for deeper learning
```bash
castor improve --episodes 10 # Analyze last 10 episodes
castor improve --status # View improvement history
```
## 🧠 Tiered Brain Architecture
OpenCastor doesn't send every decision to a $0.015/request cloud API. Instead, it routes through three layers — only escalating when needed:
```
┌─────────────────────────────────────────────────────────┐
│ MESSAGING LAYER │
│ WhatsApp · Telegram · Discord · Slack │
└──────────────────────┬──────────────────────────────────┘
│
┌──────────────────────▼──────────────────────────────────┐
│ API GATEWAY │
│ FastAPI · REST · Webhooks · JWT │
└──────────────────────┬──────────────────────────────────┘
│
┌──────────────────────▼──────────────────────────────────┐
│ TIERED BRAIN STACK │
│ │
│ ┌────────────────────────────────────────────────────┐ │
│ │ Layer 3: PLANNER Claude Opus · ~12s │ │
│ │ Complex reasoning, multi-step plans, novel tasks │ │
│ ├────────────────────────────────────────────────────┤ │
│ │ Layer 2: FAST BRAIN HF / Gemini · ~500ms │ │
│ │ Classification, simple Q&A, routine decisions │ │
│ ├────────────────────────────────────────────────────┤ │
│ │ Layer 1: REACTIVE Rule engine · <1ms │ │
│ │ Obstacle stop, boundary enforce, emergency halt │ │
│ └────────────────────────────────────────────────────┘ │
└──────────────────────┬──────────────────────────────────┘
│
┌──────────────────────▼──────────────────────────────────┐
│ PERCEPTION │
│ Hailo-8 NPU (YOLOv8) · OAK-D Depth · Camera · IMU │
└──────────────────────┬──────────────────────────────────┘
│
┌──────────────────────▼──────────────────────────────────┐
│ RCAN SAFETY KERNEL │
│ Physical bounds · Anti-subversion · Audit chain │
└──────────────────────┬──────────────────────────────────┘
│
┌──────────────────────▼──────────────────────────────────┐
│ DRIVER LAYER │
│ PCA9685 · Dynamixel · GPIO · Serial · I2C │
└──────────────────────┬──────────────────────────────────┘
│
[ YOUR ROBOT ]
```
**Cost-effective by default.** The reactive layer handles 80% of decisions at zero cost. The fast brain handles another 15%. The planner only fires for genuinely complex tasks.
## 🤖 Supported AI Providers
| Provider | Models | Latency | Best For |
|---|---|---|---|
| **Anthropic** | `claude-opus-4-6`, `claude-sonnet-4-5` | ~12s | Complex planning, safety-critical reasoning |
| **Google** | `gemini-2.5-flash`, `gemini-2.5-pro`, `gemini-3-flash-preview` | ~500ms | Multimodal, video, speed |
| **OpenAI** | `gpt-4.1`, `gpt-4.1-mini`, `gpt-5` | ~2s | Instruction following, 1M context |
| **HuggingFace** | Transformers, any hosted model | ~500ms | Fast brain layer, classification |
| **Ollama** | `llava:13b`, any local model | Varies | Privacy, offline, zero cost |
| **llama.cpp** | GGUF models | ~200ms | Edge inference, Raspberry Pi |
| **MLX** | Apple Silicon native (mlx-lm, vLLM-MLX) | ~50ms | Mac M1-M4, 400+ tok/s |
| **Claude OAuth** | Proxy-authenticated Claude | ~12s | Team/org deployments |
Swap providers with one YAML change:
```yaml
agent:
provider: "anthropic"
model: "claude-opus-4-6"
```
## 👁️ Vision & Perception
### Hailo-8 NPU — On-Device Object Detection
No cloud API calls needed. The Hailo-8 neural processing unit runs YOLOv8 locally:
- **80 COCO object classes** — people, vehicles, animals, furniture, and more
- **~250ms inference** — fast enough for real-time obstacle avoidance
- **Zero API cost** — all processing happens on the edge
### OAK-D Stereo Depth Camera
RGB + depth streaming via DepthAI v3. Get 3D spatial awareness for navigation, manipulation, and mapping.
```yaml
perception:
camera:
type: "oakd"
depth: true
resolution: "1080p"
npu:
type: "hailo8"
model: "yolov8n"
confidence: 0.5
```
## 🛡️ Safety First
OpenCastor implements defense-in-depth safety, inspired by [ContinuonAI](https://github.com/craigm26) principles and fully [RCAN spec](https://rcan.dev/spec/) compliant:
| Layer | What It Does |
|---|---|
| **Physical Bounds** | Workspace limits, joint constraints, force capping |
| **Anti-Subversion** | Prompt injection defense, input sanitization |
| **Work Authorization** | Dangerous commands require explicit approval |
| **Tamper-Evident Audit** | Hash-chained logs at `/proc/safety` — any tampering is detectable |
| **Emergency Stop** | Hardware and software e-stop, reactive layer < 1ms |
```bash
castor audit --verify # Verify audit chain integrity
castor approvals # View/approve dangerous commands
castor privacy --config r.yaml # Show sensor access policy
```
## 📦 Quick Start
### 1. Install & Configure
```bash
curl -sL opencastor.com/install | bash
castor wizard
```
The wizard walks you through provider selection, API keys, hardware config, and optional messaging setup (WhatsApp/Telegram). It remembers your previous choices.
### 2. Run
```bash
castor run --config my_robot.rcan.yaml
```
### 3. Open the Dashboard
```
http://localhost:8501
```
### 4. Diagnose Issues
```bash
castor doctor
```
### Minimal Python Example
```python
from castor.providers import get_provider
from castor.drivers.pca9685 import PCA9685Driver
brain = get_provider({"provider": "anthropic", "model": "claude-opus-4-6"})
driver = PCA9685Driver(config["drivers"][0])
while True:
frame = camera.capture()
thought = brain.think(frame, "Navigate to the kitchen, avoid obstacles.")
if thought.action:
driver.move(thought.action["linear"], thought.action["angular"])
```
## 🏪 Community Hub
Browse, install, and share robot recipes:
```bash
castor hub search "delivery bot"
castor hub install @alice/warehouse-picker
castor hub publish my_robot.rcan.yaml
```
Recipes are shareable RCAN configs — complete robot personalities with perception, planning, and safety settings bundled together.
## 🔧 CLI Reference
<details>
<summary><b>Setup & Config</b></summary>
```bash
castor wizard # Interactive setup wizard
castor quickstart # Wizard + demo in one command
castor configure --config robot.yaml # Interactive config editor
castor install-service --config r.yaml # Generate systemd unit file
castor learn # Step-by-step tutorial
castor doctor # Full system health check
castor fix # Auto-fix common issues
```
</details>
<details>
<summary><b>Run & Monitor</b></summary>
```bash
castor run --config robot.yaml # Perception-action loop
castor run --config robot.yaml --simulate # No hardware needed
castor gateway --config robot.yaml # API gateway + messaging
castor dashboard # Streamlit web UI
castor demo # Simulated demo
castor shell --config robot.yaml # Interactive command shell
castor repl --config robot.yaml # Python REPL with robot objects
castor status # Provider/channel readiness
castor logs -f # Structured colored logs
castor benchmark --config robot.yaml # Performance profiling
```
</details>
<details>
<summary><b>Hardware & Recording</b></summary>
```bash
castor test-hardware --config robot.yaml # Test motors individually
castor calibrate --config robot.yaml # Interactive calibration
castor record --config robot.yaml # Record a session
castor replay session.jsonl # Replay a recorded session
castor watch --gateway http://127.0.0.1:8000 # Live telemetry
```
</details>
<details>
<summary><b>Hub & Fleet</b></summary>
```bash
castor hub search "patrol bot" # Browse community recipes
castor hub install @user/recipe # Install a recipe
castor hub publish config.yaml # Share your recipe
castor discover # Find RCAN peers on LAN
castor fleet # Multi-robot status (mDNS)
```
</details>
<details>
<summary><b>Safety & Admin</b></summary>
```bash
castor approvals # View/approve dangerous commands
castor audit --since 24h # View audit log
castor audit --verify # Verify chain integrity
castor privacy --config robot.yaml # Sensor access policy
castor token --role operator # Issue JWT
castor upgrade # Self-update + health check
```
</details>
## 🏗️ Supported Hardware
Pre-made RCAN presets for popular kits, or generate your own:
| Kit | Price | Preset |
|---|---|---|
| Waveshare AlphaBot / JetBot | ~$45 | `presets/waveshare_alpha.rcan.yaml` |
| Adeept RaspTank / DarkPaw | ~$55 | `presets/adeept_generic.rcan.yaml` |
| SunFounder PiCar-X | ~$60 | `presets/sunfounder_picar.rcan.yaml` |
| Robotis Dynamixel (X-Series) | Varies | `presets/dynamixel_arm.rcan.yaml` |
| Hailo-8 + OAK-D Vision Stack | ~$150 | `presets/hailo_oakd_vision.rcan.yaml` |
| DIY (ESP32, Arduino, custom) | Any | Generate with `castor wizard` |
## 🏫 STEM & Second-Hand Hardware
OpenCastor explicitly supports the parts that students, educators, and hobbyists
**actually have** — donated kits, school surplus, eBay finds, and sub-$50 Amazon
staples. If you found it at Goodwill, a school auction, or a makerspace scrap bin,
there's probably a preset for it.
| Kit | Typical New Price | Where to Find Used | Preset |
|---|---|---|---|
| LEGO Mindstorms EV3 | ~$300 new | School surplus, eBay $30-80 | `presets/lego_mindstorms_ev3.rcan.yaml` |
| LEGO SPIKE Prime | ~$320 new | STEM program donations, eBay $80-150 | `presets/lego_spike_prime.rcan.yaml` |
| VEX IQ System | ~$250 new | Robotics team surplus, school auctions $50-120 | `presets/vex_iq.rcan.yaml` |
| Makeblock mBot | ~$50 new | eBay $10-25, Amazon Warehouse | `presets/makeblock_mbot.rcan.yaml` |
| Arduino + L298N (DIY) | ~$8-15 total | Makerspace bins, AliExpress | `presets/arduino_l298n.rcan.yaml` |
| ESP32 + Motor Driver (DIY) | ~$6-12 total | AliExpress, hackerspaces | `presets/esp32_generic.rcan.yaml` |
| Yahboom ROSMASTER X3 | ~$150-200 | Amazon Warehouse, eBay | `presets/yahboom_rosmaster.rcan.yaml` |
| Elegoo Tumbller / Smart Car | ~$35-40 new | Amazon Warehouse $15-25, eBay | `presets/elegoo_tumbller.rcan.yaml` |
| Freenove 4WD Car (Pi-based) | ~$40 new | eBay $15-25 (Pi not included) | `presets/freenove_4wd.rcan.yaml` |
| Cytron Maker Pi RP2040 | ~$10 new | Hackerspaces, STEM lab surplus | `presets/cytron_maker_pi.rcan.yaml` |
> **🔍 Not sure what you have?** See the [Hardware Identification Guide](docs/hardware-guide.md)
> for a decision tree: *"I found this at a thrift store, now what?"*
### Tips for Second-Hand Hardware
- **Test first, code later.** Run `castor test-hardware --config <preset>.rcan.yaml` to verify
each motor and sensor before writing any autonomy code.
- **Cables are the most common failure point.** LEGO connector cables, USB-B ports,
and servo leads are all cheap to replace.
- **Clone boards are fine.** Arduino Uno clones with CH340 USB chips work perfectly.
You may need to install the CH341SER driver on Windows.
- **Battery health matters.** Test battery packs under load — many donated robots have
degraded cells that drop voltage and confuse motor drivers.
- **Community firmware exists** for almost every kit. Check the `firmware/` directory
in this repo for Arduino sketches and MicroPython scripts.
## 🤝 Contributing
OpenCastor is fully open source (Apache 2.0) and community-driven.
- **Discord**: [discord.gg/jMjA8B26Bq](https://discord.gg/jMjA8B26Bq)
- **Issues**: [GitHub Issues](https://github.com/craigm26/OpenCastor/issues)
- **PRs**: See [CONTRIBUTING.md](CONTRIBUTING.md)
- **Twitter/X**: [@opencastor](https://twitter.com/opencastor)
**Areas we need help with:** driver adapters (ODrive, VESC, ROS2), new AI providers (Mistral, Grok, Cohere), messaging channels (Matrix, Signal), sim-to-real (Gazebo / MuJoCo), and tests.
## 📄 License
Apache 2.0 — built for the community, ready for the enterprise.
---
<p align="center">
Built on the <a href="https://rcan.dev/spec/">RCAN Spec</a> by <a href="https://github.com/craigm26">Craig Merry</a>
</p>
| text/markdown | null | OpenCastor Contributors <hello@opencastor.com> | null | null | null | robotics, ai, llm, embodied-ai, rcan | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Operating System :: POSIX :: Linux",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Environment :: Console",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: System :: Hardware"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"anthropic>=0.40.0",
"google-generativeai>=0.4.0",
"openai>=1.0.0",
"pyserial>=3.5",
"opencv-python-headless>=4.9.0",
"gTTS>=2.4.0",
"pygame>=2.5.0",
"pyyaml>=6.0",
"jsonschema>=4.20.0",
"requests>=2.31.0",
"fastapi>=0.109.0",
"uvicorn[standard]>=0.27.0",
"python-dotenv>=1.0.0",
"httpx>=0.26.0",
"python-multipart>=0.0.7",
"huggingface-hub>=0.25.0",
"streamlit>=1.30.0",
"SpeechRecognition>=3.10.0",
"rich>=13.0.0",
"argcomplete>=3.0.0",
"adafruit-circuitpython-pca9685>=3.4.0; sys_platform == \"linux\" and extra == \"rpi\"",
"adafruit-circuitpython-motor>=3.4.0; sys_platform == \"linux\" and extra == \"rpi\"",
"picamera2>=0.3.17; sys_platform == \"linux\" and extra == \"rpi\"",
"neonize>=0.3.10; extra == \"rpi\"",
"neonize>=0.3.10; extra == \"whatsapp\"",
"twilio>=9.0.0; extra == \"whatsapp-twilio\"",
"python-telegram-bot>=21.0; extra == \"telegram\"",
"discord.py>=2.3.0; extra == \"discord\"",
"slack-bolt>=1.18.0; extra == \"slack\"",
"neonize>=0.3.10; extra == \"channels\"",
"python-telegram-bot>=21.0; extra == \"channels\"",
"discord.py>=2.3.0; extra == \"channels\"",
"slack-bolt>=1.18.0; extra == \"channels\"",
"PyJWT>=2.8.0; extra == \"rcan\"",
"zeroconf>=0.131.0; extra == \"rcan\"",
"dynamixel-sdk>=3.7.31; extra == \"dynamixel\"",
"opencastor[dev,discord,dynamixel,rcan,rpi,slack,telegram,whatsapp]; extra == \"all\"",
"pytest>=8.0.0; extra == \"dev\"",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"ruff>=0.2.0; extra == \"dev\"",
"qrcode>=7.4.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://opencastor.com",
"Repository, https://github.com/craigm26/OpenCastor",
"Documentation, https://github.com/craigm26/OpenCastor#readme",
"Bug Tracker, https://github.com/craigm26/OpenCastor/issues",
"Changelog, https://github.com/craigm26/OpenCastor/blob/main/CHANGELOG.md",
"Discord, https://discord.gg/jMjA8B26Bq"
] | twine/6.1.0 CPython/3.12.9 | 2026-02-20T06:00:46.204017 | opencastor-2026.2.20.10.tar.gz | 403,415 | cc/bf/4868d55bdf638028ab3957d3234a03a9cc82c7fb12efc41e5f96fecf6532/opencastor-2026.2.20.10.tar.gz | source | sdist | null | false | 7c7efdbcdf10c6ad2c33a663385441b4 | 0831691be57d5d621b32aeb61451dacfcb37f13e2ccb8b5b0f82ef0924afd160 | ccbf4868d55bdf638028ab3957d3234a03a9cc82c7fb12efc41e5f96fecf6532 | Apache-2.0 | [
"LICENSE"
] | 231 |
2.4 | pulumi-dbtcloud | 1.7.0a1771566663 | A Pulumi package for creating and managing dbt Cloud resources. | # dbt Cloud Resource Provider
The dbt Cloud Resource Provider lets you manage dbt Cloud resources.
## Installation
This package is available for several languages/platforms:
- JavaScript/TypeScript: [`@pulumi/dbtcloud`](https://www.npmjs.com/package/@pulumi/dbtcloud)
- Python: [`pulumi-dbtcloud`](https://pypi.org/project/pulumi-dbtcloud/)
- Go: [`github.com/pulumi/pulumi-dbtcloud/sdk/go/dbtcloud`](https://pkg.go.dev/github.com/pulumi/pulumi-dbtcloud/sdk/go/dbtcloud)
- .NET: [`Pulumi.Dbtcloud`](https://www.nuget.org/packages/Pulumi.DbtCloud)
### Node.js (JavaScript/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
```bash
npm install @pulumi/dbtcloud
```
or `yarn`:
```bash
yarn add @pulumi/dbtcloud
```
### Python
To use from Python, install using `pip`:
```bash
pip install pulumi-dbtcloud
```
### Go
To use from Go, use `go get` to grab the latest version of the library:
```bash
go get github.com/pulumi/pulumi-dbtcloud/sdk/go/dbtcloud
```
### .NET
To use from .NET, install using `dotnet add package`:
```bash
dotnet add package Pulumi.DbtCloud
```
## Configuration Options
Use `pulumi config set dbtcloud:<option> (--secret)`.
| Option | Environment Variable | Required/Optional | Default | Description |
|------------|------------------------|-------------------|--------------------------------------------------------------|-----------------------------------------|
| `token` | `DBT_CLOUD_TOKEN` | Required | | The API token for your dbt Cloud user |
| `accountId`| `DBT_CLOUD_ACCOUNT_ID` | Required | | The ID for your dbt Cloud account |
| `hostUrl` | `DBT_CLOUD_HOST_URL` | Optional | [https://cloud.getdbt.com/api](https://cloud.getdbt.com/api) | The host URL for your dbt Cloud account |
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, dbtcloud, dbt, cloud, category/cloud | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.com",
"Repository, https://github.com/pulumi/pulumi-dbtcloud"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T05:58:45.873870 | pulumi_dbtcloud-1.7.0a1771566663.tar.gz | 169,255 | 2c/67/7d63d6751379281c4e8a07d2d94e4a7f12a1a984699bb5520044a31b13ae/pulumi_dbtcloud-1.7.0a1771566663.tar.gz | source | sdist | null | false | 9e68bc69a06f8a9b49ed7baccf97207e | 6d7ebdcddd0e502697652b6802bd3a8e2d14390ddda951ca51810c1e54b2c5a1 | 2c677d63d6751379281c4e8a07d2d94e4a7f12a1a984699bb5520044a31b13ae | null | [] | 209 |
2.4 | pulumi-consul | 3.15.0a1771566555 | A Pulumi package for creating and managing consul resources. | [](https://github.com/pulumi/pulumi-consul/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/consul)
[](https://pypi.org/project/pulumi-consul)
[](https://badge.fury.io/nu/pulumi.consul)
[](https://pkg.go.dev/github.com/pulumi/pulumi-consul/sdk/v3/go)
[](https://github.com/pulumi/pulumi-consul/blob/master/LICENSE)
# Hashicorp Consul Resource Provider
The Consul resource provider for Pulumi lets you manage Consul resources in your cloud programs. To use
this package, please [install the Pulumi CLI first](https://pulumi.io/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/consul
or `yarn`:
$ yarn add @pulumi/consul
### Python
To use from Python, install using `pip`:
$ pip install pulumi_consul
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-consul/sdk/v3
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Consul
## Configuration
The following configuration points are available:
- `consul:address` - (Optional) The HTTP(S) API address of the agent to use. Defaults to `127.0.0.1:8500`.
- `consul:scheme` - (Optional) The URL scheme of the agent to use (`http` or `https`). Defaults to `http`.
- `consul:httpAuth` - (Optional) HTTP Basic Authentication credentials to be used when communicating with Consul, in the
format of either user or user:pass. This may also be specified using the `CONSUL_HTTP_AUTH` environment variable.
- `consul:datacenter` - (Optional) The datacenter to use. Defaults to that of the agent.
- `consul:token` - (Optional) The ACL token to use by default when making requests to the agent. Can also be specified
with `CONSUL_HTTP_TOKEN` or `CONSUL_TOKEN` as an environment variable.
- `consul:caFile` - (Optional) A path to a PEM-encoded certificate authority used to verify the remote agent's certificate.
- `consul:certFile` - (Optional) A path to a PEM-encoded certificate provided to the remote agent; requires use of `keyFile`.
- `consul:keyFile` - (Optional) A path to a PEM-encoded private key, required if `certFile` is specified.
- `consul:caPath` - (Optional) A path to a directory of PEM-encoded certificate authority files to use to check the
authenticity of client and server connections. Can also be specified with the `CONSUL_CAPATH` environment variable.
- `consul:insecureHttps` - (Optional) Boolean value to disable SSL certificate verification; setting this value to true
is not recommended for production use. Only use this with scheme set to `https`.
## Reference
For further information, please visit [the Consul provider docs](https://www.pulumi.com/docs/intro/cloud-providers/consul) or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/consul).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, consul | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-consul"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T05:57:20.343828 | pulumi_consul-3.15.0a1771566555.tar.gz | 141,649 | f8/0a/be652f6a82fe37c98d852f866c91a2d1539130d689bb654f6a9c150f567f/pulumi_consul-3.15.0a1771566555.tar.gz | source | sdist | null | false | 6e6e8d29e5aa27bb5ed7259ccb46b79b | 2548caacbc2f851ddc2f3db02c2633cf79e5271671f822856d44d3c874ccafce | f80abe652f6a82fe37c98d852f866c91a2d1539130d689bb654f6a9c150f567f | null | [] | 214 |
2.4 | knowledge-hub-cli | 0.1.5 | AI paper discovery, translation, summarization & knowledge linking pipeline | # Knowledge Hub
AI 논문을 자동으로 검색, 다운로드, 번역, 요약하고 Obsidian과 연결하는 CLI 파이프라인 도구입니다.
## Features
- **논문 자동 발견** - Semantic Scholar + arXiv에서 최신/중요 논문 검색
- **벡터DB 중복 체크** - ChromaDB + SQLite로 이미 수집된 논문 자동 건너뜀
- **플러그인 AI 프로바이더** - OpenAI, Anthropic, Google, Ollama, OpenAI-Compatible(DeepSeek/Groq 등) 자유롭게 교체
- **한국어 번역/요약** - 원하는 AI로 논문 번역 및 심층 요약 생성
- **Obsidian 연결** - vault에 논문 요약 노트 자동 생성, 관련 노트 `[[링크]]` 삽입
- **벡터 검색 + RAG** - 수집된 논문/노트에서 시맨틱 검색 및 질의응답
- **학술 탐색** - 저자 검색, 인용 네트워크 분석, 참고문헌 탐색
- **MCP 서버** - Cursor/Claude Code에서 모든 기능을 에이전트 도구로 사용 가능
## Quick Start
```bash
# 설치 (최소, PyPI)
pip install knowledge-hub-cli
# OpenAI 사용 시
pip install "knowledge-hub-cli[openai]"
# Ollama(로컬) 사용 시
pip install "knowledge-hub-cli[ollama]"
# 전체 프로바이더
pip install "knowledge-hub-cli[all]"
# 로컬 수정 후 개발/테스트
pip install -e .
```
### 최소 데모 흐름
```bash
# 1. 초기 설정 (프로바이더/API키/경로 설정)
khub init
# 2. 시스템 상태 확인
khub status
# 3. 논문 검색 + 수집 (Semantic Scholar → 다운로드 → 번역 → 요약 → Obsidian)
khub discover "large language model agent" -n 3
# 4. 수집 결과 확인
khub paper list
# 5. 벡터 인덱싱
khub index
# 6. 벡터 검색
khub search "attention mechanism"
# 7. RAG 질의
khub ask "Transformer의 핵심 아이디어는?"
# 8. 학술 탐색
khub explore author "Yoshua Bengio"
khub explore paper 1706.03762
khub explore citations 1706.03762
```
## Installation
### 기본 설치
```bash
# PyPI 설치(권장)
pip install "knowledge-hub-cli[openai]"
```
### 로컬 개발/테스트 설치
```bash
git clone https://github.com/chowonje/knowledge-hub.git
cd knowledge-hub
pip install -e .
```
### 프로바이더별 설치
```bash
# OpenAI만 사용
pip install "knowledge-hub-cli[openai]"
# Ollama(로컬) + OpenAI
pip install "knowledge-hub-cli[ollama,openai]"
# 전체 프로바이더
pip install "knowledge-hub-cli[all]"
```
### 사전 조건
| 구성 요소 | 필수 여부 | 설명 |
|---|---|---|
| Python >= 3.10 | 필수 | 런타임 |
| API 키 (하나 이상) | 필수 | OpenAI, Anthropic, Google 중 택 1 |
| [Ollama](https://ollama.ai/) | 선택 | 로컬 LLM/임베딩 사용 시 |
| [Obsidian](https://obsidian.md/) | 선택 | 지식 그래프 연결, 노트 생성 시 |
## Configuration
### 인터랙티브 설정
```bash
khub init
```
번역/요약/임베딩에 사용할 AI 프로바이더, API 키, 저장 경로 등을 대화형으로 설정합니다.
설정은 `~/.khub/config.yaml`에 저장됩니다.
### 설정 관리
```bash
# 전체 설정 보기
khub config list
# 개별 설정 변경
khub config set translation.provider openai
khub config set translation.model gpt-4o-mini
khub config set summarization.provider ollama
khub config set summarization.model qwen2.5:14b
# 사용 가능한 프로바이더 + 모델 확인
khub config providers --models
```
### 설정 파일 예시 (`~/.khub/config.yaml`)
```yaml
translation:
provider: openai
model: gpt-4o-mini
summarization:
provider: ollama
model: qwen2.5:14b
embedding:
provider: ollama
model: nomic-embed-text
storage:
papers_dir: ~/.khub/papers
vector_db: ~/.khub/chroma_db
sqlite: ~/.khub/knowledge.db
obsidian:
enabled: true
vault_path: /path/to/your/obsidian/vault
providers:
openai:
api_key: ${OPENAI_API_KEY}
ollama:
base_url: http://localhost:11434
```
## AI Providers
| 프로바이더 | LLM | Embedding | 로컬 | 설치 |
|---|---|---|---|---|
| **OpenAI** | GPT-4o, 4o-mini, o1, o3, 4.1-nano | text-embedding-3-small/large | - | `[openai]` |
| **Anthropic** | Claude Opus 4, Sonnet 4, 3.5 Sonnet | - | - | `[anthropic]` |
| **Google** | Gemini 2.0 Flash/Pro/Lite | text-embedding-004 | - | `[google]` |
| **Ollama** | Qwen3, Llama4, Gemma3, DeepSeek-R1 등 | nomic-embed-text, bge-m3, snowflake | O | `[ollama]` |
| **OpenAI-Compatible** | DeepSeek, Groq, Together AI, Mistral 등 | 서비스별 지원 | - | 추가 의존성 없음 |
용도별로 다른 프로바이더를 조합할 수 있습니다:
- 번역: OpenAI GPT-4o-mini (저렴, 고품질)
- 요약: Ollama qwen2.5:14b (무료, 로컬)
- 임베딩: Ollama nomic-embed-text (무료, 로컬)
## Commands
### `khub discover` - 핵심 파이프라인
```bash
# 기본 사용
khub discover "topic" -n 5
# 연도 필터 + 인용수 필터
khub discover "RAG retrieval augmented generation" --year 2024 --min-citations 10
# 인용수 기준 정렬
khub discover "transformer" --sort citationCount -n 10
# Obsidian 노트 생성 포함
khub discover "AI agent" --obsidian
```
### `khub paper` - 개별 논문 관리
```bash
khub paper list # 목록
khub paper info 2401.12345 # 상세 정보
khub paper download 2401.12345 # 다운로드
khub paper translate 2401.12345 # 번역
khub paper summarize 2401.12345 # 요약
khub paper translate 2401.12345 -p anthropic -m claude-3-5-haiku-20241022
khub paper sync-keywords # 키워드 추출 + 개념 연결
khub paper build-concepts # 개념 노트 자동 생성
khub paper normalize-concepts # 동의어/약어 정규화
```
### `khub explore` - 학술 탐색
```bash
khub explore author "Yoshua Bengio" # 저자 검색
khub explore author-papers <author_id> # 저자 논문 목록
khub explore paper 1706.03762 # 논문 상세 정보
khub explore citations 1706.03762 # 인용 논문 목록
khub explore references 1706.03762 # 참고 논문 목록
khub explore network 1706.03762 # 인용 네트워크 분석
khub explore batch 1706.03762 2301.10226 # 배치 조회
```
### `khub search` / `khub ask` - 검색 & RAG
```bash
khub search "attention mechanism" -k 10 # 벡터 검색
khub ask "RAG의 장단점을 설명해줘" # RAG 질의
```
### `khub index` - 벡터 인덱싱
```bash
khub index # 미인덱싱 논문 + 개념 인덱싱
khub index --all # 전체 재인덱싱
khub index --concepts-only # 개념 노트만
```
### `khub notebook` - 지식 노트
```bash
khub notebook list # 노트 목록
khub notebook show <id> # 노트 상세
```
### `khub graph` - 지식 그래프
```bash
khub graph stats # 그래프 통계
khub graph show <id> # 노트 연결
khub graph isolated # 고립 노트
```
## 명령별 필수 의존성
| 명령 | LLM 필요 | 임베딩 필요 | Obsidian 필요 | API 키 |
|---|---|---|---|---|
| `khub discover` | O (번역/요약) | O (인덱싱) | 선택 | 프로바이더에 따라 |
| `khub paper list/info` | - | - | - | - |
| `khub paper translate` | O | - | - | 프로바이더에 따라 |
| `khub paper summarize` | O | - | - | 프로바이더에 따라 |
| `khub index` | - | O | 선택(개념 노트) | 프로바이더에 따라 |
| `khub search/ask` | O (ask만) | O | - | 프로바이더에 따라 |
| `khub explore *` | - | - | - | - (Semantic Scholar 무료) |
| `khub paper sync-keywords` | O | - | O | 프로바이더에 따라 |
| `khub paper build-concepts` | O | - | O | 프로바이더에 따라 |
| `khub status` | - | - | - | - |
## MCP 서버
Cursor / Claude Code에서 khub 기능을 에이전트 도구로 사용:
```bash
# MCP 서버 시작
khub-mcp
```
`~/.cursor/mcp.json` 또는 에이전트 설정에 추가하면 됩니다.
## Troubleshooting
| 증상 | 원인 | 해결 |
|---|---|---|
| `ModuleNotFoundError: ollama` | ollama extra 미설치 | `pip install -e ".[ollama]"` 또는 다른 프로바이더로 변경 |
| `khub search` 실패 | 임베딩 프로바이더 미설정 | `khub init` → 임베딩 프로바이더 선택 |
| `OPENAI_API_KEY` 오류 | 환경변수 미설정 | `export OPENAI_API_KEY=sk-...` 또는 `.env` 파일 생성 |
| Obsidian 관련 명령 실패 | vault 경로 미설정 | `khub config set obsidian.vault_path /path/to/vault` |
| 인덱싱 0건 | 논문 미수집 | `khub discover "topic" -n 3` 먼저 실행 |
## License
MIT
| text/markdown | knowledge-hub contributors | null | null | null | null | arxiv, papers, ai, research, knowledge-management, obsidian | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.1.0",
"chromadb>=0.4.22",
"requests>=2.31.0",
"rich>=13.7.0",
"PyYAML>=6.0.1",
"tqdm>=4.66.1",
"python-dotenv>=1.0.0",
"openai>=1.0.0; extra == \"openai\"",
"anthropic>=0.25.0; extra == \"anthropic\"",
"google-generativeai>=0.5.0; extra == \"google\"",
"ollama>=0.1.6; extra == \"ollama\"",
"python-frontmatter>=1.0.0; extra == \"obsidian\"",
"markdown>=3.5.1; extra == \"obsidian\"",
"reportlab>=4.0.0; extra == \"pdf\"",
"mcp>=1.0.0; extra == \"mcp\"",
"pytest>=8.0.0; extra == \"dev\"",
"build>=1.0.0; extra == \"dev\"",
"knowledge-hub[anthropic,google,mcp,obsidian,ollama,openai,pdf]; extra == \"all\""
] | [] | [] | [] | [
"Homepage, https://github.com/chowonje/knowledge-hub",
"Repository, https://github.com/chowonje/knowledge-hub",
"Issues, https://github.com/chowonje/knowledge-hub/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T05:56:23.194242 | knowledge_hub_cli-0.1.5.tar.gz | 110,656 | 64/d5/12bef03cdaf7c419ce3d3373a1b158ea78022719b3539eda96991a137ee6/knowledge_hub_cli-0.1.5.tar.gz | source | sdist | null | false | 2fff9419e3775e8f2c22a41b492457b9 | a6aec80550aee14594fa061738dc3a1e5cec0fbf34af47a18f259e27b3815c19 | 64d512bef03cdaf7c419ce3d3373a1b158ea78022719b3539eda96991a137ee6 | MIT | [
"LICENSE"
] | 268 |
2.4 | latincy-readers | 1.2.0 | Corpus readers for Latin texts with LatinCy/spaCy integration | <p align="center">
<img src="assets/latincy-readers-logo.jpg" alt="LatinCy Readers" width="400">
</p>
# LatinCy Readers
Corpus readers for Latin texts with [LatinCy](https://github.com/diyclassics/latincy) integration. Now also supporting Ancient Greek texts with [OdyCy](https://centre-for-humanities-computing.github.io/odyCy/).
Version 1.2.0; Python 3.10+; LatinCy 3.8.0+
## Installation
```bash
# Install from PyPI
pip install latincy-readers
# Install the LatinCy model (for Latin texts)
pip install https://huggingface.co/latincy/la_core_web_lg/resolve/main/la_core_web_lg-3.8.0-py3-none-any.whl
# Install the OdyCy model (for Ancient Greek texts)
pip install https://huggingface.co/chcaa/grc_odycy_joint_sm/resolve/main/grc_odycy_joint_sm-any-py3-none-any.whl
# For development (editable install)
git clone https://github.com/diyclassics/latincy-readers.git
cd latincy-readers
pip install -e ".[dev]"
```
## Quick Start
```python
from latincyreaders import TesseraeReader, AnnotationLevel
# Auto-download corpus on first use
reader = TesseraeReader()
# Or specify a custom path
reader = TesseraeReader("/path/to/tesserae/corpus")
# Iterate over documents as spaCy Docs
for doc in reader.docs():
print(f"{doc._.fileid}: {len(list(doc.sents))} sentences")
# Search for sentences containing specific forms
for result in reader.find_sents(forms=["Caesar", "Caesarem"]):
print(f"{result['citation']}: {result['sentence']}")
# Get raw text (no NLP processing)
for text in reader.texts():
print(text[:100])
```
## Readers
| Reader | Format | Auto-Download | Description |
|--------|--------|---------------|-------------|
| `TesseraeReader` | `.tess` | Yes | CLTK Latin Tesserae corpus |
| `GreekTesseraeReader` | `.tess` | Yes | CLTK Greek Tesserae corpus (OdyCy) |
| `PlaintextReader` | `.txt` | No | Plain text files |
| `LatinLibraryReader` | `.txt` | Yes | Latin Library corpus |
| `TEIReader` | `.xml` | No | TEI-XML documents |
| `PerseusReader` | `.xml` | No | Perseus Digital Library TEI |
| `CamenaReader` | `.xml` | Yes | CAMENA Neo-Latin corpus |
| `TxtdownReader` | `.txtd` | No | Txtdown format with citations |
| `UDReader` | `.conllu` | No | Universal Dependencies CoNLL-U |
| `LatinUDReader` | `.conllu` | Yes | All 6 Latin UD treebanks |
### Auto-Download
Readers with auto-download support will automatically fetch the corpus on first use:
```python
# Downloads to ~/latincy_data/lat_text_tesserae/texts if not found
reader = TesseraeReader()
# Disable auto-download
reader = TesseraeReader(auto_download=False)
# Use environment variable for custom location
# export TESSERAE_PATH=/custom/path
reader = TesseraeReader()
# Manual download to specific location
TesseraeReader.download("/path/to/destination")
```
### Ancient Greek (GreekTesseraeReader)
Read Ancient Greek texts from the CLTK Greek Tesserae corpus using OdyCy NLP models:
```python
from latincyreaders import GreekTesseraeReader, AnnotationLevel
# Auto-download Greek Tesserae corpus on first use
reader = GreekTesseraeReader()
# Use TOKENIZE level (no OdyCy model needed)
reader = GreekTesseraeReader(annotation_level=AnnotationLevel.TOKENIZE)
# Iterate over citation lines
for citation, text in reader.texts_by_line():
print(f"{citation}: {text[:60]}...")
# Search for Greek words
for fid, cit, text, matches in reader.search(r"Ἀχιλ"):
print(f"{cit}: found {matches}")
# Environment variable for custom location
# export GRC_TESSERAE_PATH=/custom/path
reader = GreekTesseraeReader()
```
### Universal Dependencies Treebanks
Access gold-standard linguistic annotations from Latin UD treebanks:
```python
from latincyreaders import LatinUDReader, PROIELReader
# See available treebanks
LatinUDReader.available_treebanks()
# {'proiel': 'Vulgate, Caesar, Cicero, Palladius',
# 'perseus': 'Classical texts from Perseus Digital Library',
# 'ittb': 'Index Thomisticus (Thomas Aquinas)',
# 'llct': 'Late Latin Charter Treebank',
# 'udante': "Dante's Latin works",
# 'circse': 'CIRCSE Latin treebank'}
# Use a specific treebank
reader = PROIELReader()
# Iterate sentences with UD annotations
for sent in reader.ud_sents():
print(f"{sent._.citation}: {sent.text}")
# Access full UD token data
for token in doc:
ud = token._.ud # dict with all 10 CoNLL-U columns
print(f"{token.text}: {ud['upos']} {ud['feats']}")
# Read from all treebanks at once
reader = LatinUDReader()
LatinUDReader.download_all() # Download all 6 treebanks
```
**Note:** Unlike other readers, `UDReader` constructs spaCy Docs directly from gold UD annotations rather than running the spaCy NLP pipeline.
## Core API
All readers provide a consistent interface:
```python
reader.fileids() # List available files
reader.texts(fileids=...) # Raw text strings (generator)
reader.docs(fileids=...) # spaCy Doc objects (generator)
reader.sents(fileids=...) # Sentence spans (generator)
reader.tokens(fileids=...) # Token objects (generator)
reader.metadata(fileids=...) # File metadata (generator)
```
### FileSelector: Fluent File Filtering
Use the `select()` method for complex file queries combining filename patterns and metadata:
```python
# Filter by filename pattern (regex)
vergil_docs = reader.select().match(r"vergil\..*")
# Filter by metadata
epics = reader.select().where(genre="epic")
# Multiple conditions (AND)
vergil_epics = reader.select().where(author="Vergil", genre="epic")
# Match any of multiple values
major_authors = reader.select().where(author__in=["Vergil", "Ovid", "Horace"])
# Date ranges
augustan = reader.select().date_range(-50, 50)
# Chain multiple filters
selection = (reader.select()
.match(r".*aen.*")
.where(genre="epic")
.date_range(-50, 50))
# Use with docs(), sents(), etc.
for doc in reader.docs(selection):
print(doc._.fileid)
# Preview results
print(selection.preview(5))
print(f"Found {len(selection)} files")
```
### Search API
```python
# Fast regex search (no NLP)
reader.search(pattern=r"\bbell\w+")
# Form-based sentence search
reader.find_sents(forms=["amor", "amoris"])
# Lemma-based search (requires NLP)
reader.find_sents(lemma="amo")
# spaCy Matcher patterns
reader.find_sents(matcher_pattern=[{"POS": "ADJ"}, {"POS": "NOUN"}])
```
### Text Analysis
```python
# Build a concordance (word -> citations mapping)
conc = reader.concordance(basis="lemma")
print(conc["amor"]) # ['<catull. 1.1>', '<verg. aen. 4.1>', ...]
# Keyword in Context
for hit in reader.kwic("amor", window=5, by_lemma=True):
print(f"{hit['left']} [{hit['match']}] {hit['right']}")
print(f" -- {hit['citation']}")
# N-grams
for ngram in reader.ngrams(n=2, basis="lemma"):
print(ngram) # "qui do", "do lepidus", ...
# Skip-grams (n-grams with gaps)
for sg in reader.skipgrams(n=2, k=1):
print(sg)
```
### Document Caching
Documents are cached by default for better performance when accessing the same file multiple times:
```python
# Caching enabled by default
reader = TesseraeReader()
# Disable caching
reader = TesseraeReader(cache=False)
# Configure cache size
reader = TesseraeReader(cache_maxsize=256)
# Check cache statistics
print(reader.cache_stats()) # {'hits': 5, 'misses': 3, 'size': 3, 'maxsize': 128}
# Clear the cache
reader.clear_cache()
```
### Annotation Levels
All linguistic annotations are provided by [LatinCy](https://github.com/diyclassics/latincy) spaCy-based pipelines. The full pipeline provides POS tagging, lemmatization, morphological analysis, and named entity recognition—but this can be slow for large corpora. If you don't need all annotations, you can get significant performance gains by selecting a lighter annotation level:
```python
from latincyreaders import AnnotationLevel
# Full pipeline: POS, lemma, morphology, NER (default)
reader = TesseraeReader(annotation_level=AnnotationLevel.FULL)
# Basic: tokenization + sentence boundaries only
reader = TesseraeReader(annotation_level=AnnotationLevel.BASIC)
# Tokenization only (no sentence boundaries)
reader = TesseraeReader(annotation_level=AnnotationLevel.TOKENIZE)
# No NLP at all - use texts() for raw strings
for text in reader.texts():
print(text)
```
### Metadata Management
```python
from latincyreaders import MetadataManager, MetadataSchema
# Load and merge metadata from JSON files
manager = MetadataManager("/path/to/corpus")
# Access metadata
meta = manager.get("vergil.aen.tess")
print(meta["author"], meta["date"])
# Filter files by metadata
for fileid in manager.filter_by(author="Vergil", genre="epic"):
print(fileid)
# Date range filtering
for fileid in manager.filter_by_range("date", -50, 50):
print(fileid)
# Validate metadata against a schema
schema = MetadataSchema(
required={"author": str, "title": str},
optional={"date": int, "genre": str}
)
manager = MetadataManager("/path/to/corpus", schema=schema)
result = manager.validate()
if not result.is_valid:
print(result.errors)
```
## Corpora Supported
- [Tesserae Latin Corpus](https://github.com/cltk/lat_text_tesserae)
- [Tesserae Greek Corpus](https://github.com/cltk/grc_text_tesserae)
- [Perseus Digital Library TEI](https://www.perseus.tufts.edu/)
- [Latin Library](https://github.com/cltk/lat_text_latin_library)
- [CAMENA Neo-Latin](https://github.com/nevenjovanovic/camena-neolatinlit)
- [Universal Dependencies Latin Treebanks](https://universaldependencies.org/) (PROIEL, Perseus, ITTB, LLCT, UDante, CIRCSE)
- Any plaintext, TEI-XML, or CoNLL-U collection
## CLI Tools
Search tool in `cli/`:
```bash
# Lemma search (slower, finds all inflected forms)
python cli/reader_search.py --lemmas Caesar --limit 100
python cli/reader_search.py --lemmas bellum pax --fileids "cicero.*"
# Form search (fast, exact match)
python cli/reader_search.py --forms Caesar Caesarem --limit 100
# Pattern search (fast, regex)
python cli/reader_search.py --pattern "\\bTheb\\w+" --output thebes.tsv
```
---
## Bibliography
- Bird, S., E. Loper, and E. Klein. 2009. *Natural Language Processing with Python*. O'Reilly: Sebastopol, CA.
- Bengfort, Benjamin, Rebecca Bilbro, and Tony Ojeda. 2018. *Applied Text Analysis with Python: Enabling Language-Aware Data Products with Machine Learning*. O'Reilly: Sebastopol, CA.
---
*Developed by [Patrick J. Burns](http://github.com/diyclassics) with Claude Opus 4.5. in January 2026.*
| text/markdown | null | "Patrick J. Burns" <patrick@diyclassics.org> | null | null | null | ancient-greek, classical-languages, corpus, latin, latincy, nlp, spacy | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Text Processing :: Linguistic"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"conllu>=4.5",
"lxml>=5.0",
"natsort>=8.0",
"spacy>=3.7",
"textacy>=0.13",
"mypy>=1.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"ruff>=0.1; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/diyclassics/latincy-readers",
"Repository, https://github.com/diyclassics/latincy-readers"
] | twine/6.2.0 CPython/3.12.9 | 2026-02-20T05:56:00.878138 | latincy_readers-1.2.0.tar.gz | 372,056 | 25/03/92edce19f8a2fbfe1d79e4af6eb463da960ec1d843b08c9644c9c77c206b/latincy_readers-1.2.0.tar.gz | source | sdist | null | false | 1ad1aca27a85fb1a2e44c57623e257d0 | 54ea850985f285574b818a8b46b89cd2de21753863d8986528a8e1162719b563 | 250392edce19f8a2fbfe1d79e4af6eb463da960ec1d843b08c9644c9c77c206b | MIT | [
"LICENSE"
] | 277 |
2.4 | pulumi-confluentcloud | 2.59.0a1771566476 | A Pulumi package for creating and managing Confluent cloud resources. | [](https://github.com/pulumi/pulumi-confluentcloud/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/confluentcloud)
[](https://pypi.org/project/pulumi-confluentcloud)
[](https://badge.fury.io/nu/pulumi.confluentcloud)
[](https://pkg.go.dev/github.com/pulumi/pulumi-confluentcloud/sdk/go)
[](https://github.com/pulumi/pulumi-confluentcloud/blob/master/LICENSE)
# Confluent Cloud Resource Provider
The Confluent Resource Provider lets you manage [Confluent](https://confluent.cloud/) resources.
Please Note:
This provider is built from the ConfluentInc official Terraform Provider - https://github.com/confluentinc/terraform-provider-confluent
## Installing
This package is available for several languages/platforms:
### Node.js (JavaScript/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
```bash
npm install @pulumi/confluentcloud
```
or `yarn`:
```bash
yarn add @pulumi/confluentcloud
```
### Python
To use from Python, install using `pip`:
```bash
pip install pulumi_confluentcloud
```
### Go
To use from Go, use `go get` to grab the latest version of the library:
```bash
go get github.com/pulumi/pulumi-confluentcloud/sdk
```
### .NET
To use from .NET, install using `dotnet add package`:
```bash
dotnet add package Pulumi.ConfluentCloud
```
## Configuration
The following configuration points are available for the `confluent cloud` provider:
- `confluentcloud:cloudApiKey` (environment: `CONFLUENT_CLOUD_API_KEY`) - the API key for `Confluent Cloud`
- `confluentcloud:cloudApiSecret` (environment: `CONFLUENT_CLOUD_API_SECRET`) - the API secret for `Confluent Cloud`
## Reference
For detailed reference documentation, please visit [the Pulumi registry](https://www.pulumi.com/registry/packages/confluentcloud/api-docs/).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, confluentcloud, category/cloud | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://www.pulumi.com",
"Repository, https://github.com/pulumi/pulumi-confluentcloud"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T05:55:49.774522 | pulumi_confluentcloud-2.59.0a1771566476.tar.gz | 308,460 | 6d/27/95ef20cda870cd7d558c9a3001b18b4d4fdd236b1e4fab7f116c56623e0b/pulumi_confluentcloud-2.59.0a1771566476.tar.gz | source | sdist | null | false | 602f40c2719af7d2a8755c4a137c4a34 | 155ec40cd85e5ef5ee6be046a71f3acbb46f740d014d796d2b47bb8a7d20f093 | 6d2795ef20cda870cd7d558c9a3001b18b4d4fdd236b1e4fab7f116c56623e0b | null | [] | 233 |
2.1 | rootaccessd-client | 1.0.0 | RootAccess CTF API | # rootaccessd-client
This is the backend API for the RootAccess CTF Platform.
This Python package is automatically generated by the [OpenAPI Generator](https://openapi-generator.tech) project:
- API version: 1.0.0
- Package version: 1.0.0
- Generator version: 7.20.0
- Build package: org.openapitools.codegen.languages.PythonClientCodegen
For more information, please visit [https://github.com/Uttam-Mahata/RootAccess/issues](https://github.com/Uttam-Mahata/RootAccess/issues)
## Requirements.
Python 3.9+
## Installation & Usage
### pip install
If the python package is hosted on a repository, you can install directly using:
```sh
pip install git+https://github.com/GIT_USER_ID/GIT_REPO_ID.git
```
(you may need to run `pip` with root permission: `sudo pip install git+https://github.com/GIT_USER_ID/GIT_REPO_ID.git`)
Then import the package:
```python
import rootaccessd_client
```
### Setuptools
Install via [Setuptools](http://pypi.python.org/pypi/setuptools).
```sh
python setup.py install --user
```
(or `sudo python setup.py install` to install the package for all users)
Then import the package:
```python
import rootaccessd_client
```
### Tests
Execute `pytest` to run the tests.
## Getting Started
Please follow the [installation procedure](#installation--usage) and then run the following:
```python
import rootaccessd_client
from rootaccessd_client.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to http://localhost:8080
# See configuration.py for a list of all supported configuration parameters.
configuration = rootaccessd_client.Configuration(
host = "http://localhost:8080"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
# Configure API key authorization: ApiKeyAuth
configuration.api_key['ApiKeyAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['ApiKeyAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with rootaccessd_client.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = rootaccessd_client.AchievementsApi(api_client)
try:
# Get user achievements
api_response = api_instance.achievements_me_get()
print("The response of AchievementsApi->achievements_me_get:\n")
pprint(api_response)
except ApiException as e:
print("Exception when calling AchievementsApi->achievements_me_get: %s\n" % e)
```
## Documentation for API Endpoints
All URIs are relative to *http://localhost:8080*
Class | Method | HTTP request | Description
------------ | ------------- | ------------- | -------------
*AchievementsApi* | [**achievements_me_get**](docs/AchievementsApi.md#achievements_me_get) | **GET** /achievements/me | Get user achievements
*ActivityApi* | [**activity_me_get**](docs/ActivityApi.md#activity_me_get) | **GET** /activity/me | Get user activity
*AdminChallengesApi* | [**admin_challenges_export_get**](docs/AdminChallengesApi.md#admin_challenges_export_get) | **GET** /admin/challenges/export | Export all challenges
*AdminChallengesApi* | [**admin_challenges_id_duplicate_post**](docs/AdminChallengesApi.md#admin_challenges_id_duplicate_post) | **POST** /admin/challenges/{id}/duplicate | Duplicate a challenge
*AdminChallengesApi* | [**admin_challenges_import_post**](docs/AdminChallengesApi.md#admin_challenges_import_post) | **POST** /admin/challenges/import | Import challenges in bulk
*AdminContestApi* | [**admin_contest_get**](docs/AdminContestApi.md#admin_contest_get) | **GET** /admin/contest | Get contest configuration
*AdminContestApi* | [**admin_contest_put**](docs/AdminContestApi.md#admin_contest_put) | **PUT** /admin/contest | Update contest configuration
*AdminNotificationsApi* | [**admin_notifications_get**](docs/AdminNotificationsApi.md#admin_notifications_get) | **GET** /admin/notifications | Get all notifications
*AdminNotificationsApi* | [**admin_notifications_id_delete**](docs/AdminNotificationsApi.md#admin_notifications_id_delete) | **DELETE** /admin/notifications/{id} | Delete notification
*AdminNotificationsApi* | [**admin_notifications_id_put**](docs/AdminNotificationsApi.md#admin_notifications_id_put) | **PUT** /admin/notifications/{id} | Update notification
*AdminNotificationsApi* | [**admin_notifications_id_toggle_post**](docs/AdminNotificationsApi.md#admin_notifications_id_toggle_post) | **POST** /admin/notifications/{id}/toggle | Toggle notification status
*AdminNotificationsApi* | [**admin_notifications_post**](docs/AdminNotificationsApi.md#admin_notifications_post) | **POST** /admin/notifications | Create notification
*AdminTeamsApi* | [**admin_teams_get**](docs/AdminTeamsApi.md#admin_teams_get) | **GET** /admin/teams | List all teams
*AdminTeamsApi* | [**admin_teams_id_delete**](docs/AdminTeamsApi.md#admin_teams_id_delete) | **DELETE** /admin/teams/{id} | Delete team (admin)
*AdminTeamsApi* | [**admin_teams_id_get**](docs/AdminTeamsApi.md#admin_teams_id_get) | **GET** /admin/teams/{id} | Get team (admin)
*AdminTeamsApi* | [**admin_teams_id_leader_put**](docs/AdminTeamsApi.md#admin_teams_id_leader_put) | **PUT** /admin/teams/{id}/leader | Change team leader
*AdminTeamsApi* | [**admin_teams_id_members_member_id_delete**](docs/AdminTeamsApi.md#admin_teams_id_members_member_id_delete) | **DELETE** /admin/teams/{id}/members/{memberId} | Remove team member (admin)
*AdminTeamsApi* | [**admin_teams_id_put**](docs/AdminTeamsApi.md#admin_teams_id_put) | **PUT** /admin/teams/{id} | Update team (admin)
*AdminUsersApi* | [**admin_users_get**](docs/AdminUsersApi.md#admin_users_get) | **GET** /admin/users | List all users
*AdminUsersApi* | [**admin_users_id_delete**](docs/AdminUsersApi.md#admin_users_id_delete) | **DELETE** /admin/users/{id} | Delete user (admin)
*AdminUsersApi* | [**admin_users_id_get**](docs/AdminUsersApi.md#admin_users_id_get) | **GET** /admin/users/{id} | Get user (admin)
*AdminUsersApi* | [**admin_users_id_role_put**](docs/AdminUsersApi.md#admin_users_id_role_put) | **PUT** /admin/users/{id}/role | Update user role
*AdminUsersApi* | [**admin_users_id_status_put**](docs/AdminUsersApi.md#admin_users_id_status_put) | **PUT** /admin/users/{id}/status | Update user status
*AdminWriteupsApi* | [**admin_writeups_get**](docs/AdminWriteupsApi.md#admin_writeups_get) | **GET** /admin/writeups | Get all writeups
*AdminWriteupsApi* | [**admin_writeups_id_delete**](docs/AdminWriteupsApi.md#admin_writeups_id_delete) | **DELETE** /admin/writeups/{id} | Delete writeup
*AdminWriteupsApi* | [**admin_writeups_id_status_put**](docs/AdminWriteupsApi.md#admin_writeups_id_status_put) | **PUT** /admin/writeups/{id}/status | Update writeup status
*AnalyticsApi* | [**admin_analytics_get**](docs/AnalyticsApi.md#admin_analytics_get) | **GET** /admin/analytics | Get platform analytics
*AuditApi* | [**admin_audit_logs_get**](docs/AuditApi.md#admin_audit_logs_get) | **GET** /admin/audit-logs | Get audit logs
*AuthApi* | [**auth_discord_callback_get**](docs/AuthApi.md#auth_discord_callback_get) | **GET** /auth/discord/callback | Discord OAuth callback
*AuthApi* | [**auth_discord_get**](docs/AuthApi.md#auth_discord_get) | **GET** /auth/discord | Discord OAuth login
*AuthApi* | [**auth_github_callback_get**](docs/AuthApi.md#auth_github_callback_get) | **GET** /auth/github/callback | GitHub OAuth callback
*AuthApi* | [**auth_github_get**](docs/AuthApi.md#auth_github_get) | **GET** /auth/github | GitHub OAuth login
*AuthApi* | [**auth_google_callback_get**](docs/AuthApi.md#auth_google_callback_get) | **GET** /auth/google/callback | Google OAuth callback
*AuthApi* | [**auth_google_get**](docs/AuthApi.md#auth_google_get) | **GET** /auth/google | Google OAuth login
*AuthApi* | [**auth_login_post**](docs/AuthApi.md#auth_login_post) | **POST** /auth/login | Login user
*AuthApi* | [**auth_register_post**](docs/AuthApi.md#auth_register_post) | **POST** /auth/register | Register a new user
*AuthApi* | [**auth_resend_verification_post**](docs/AuthApi.md#auth_resend_verification_post) | **POST** /auth/resend-verification | Resend verification email
*AuthApi* | [**auth_verify_email_get**](docs/AuthApi.md#auth_verify_email_get) | **GET** /auth/verify-email | Verify email address
*AuthApi* | [**auth_verify_email_post**](docs/AuthApi.md#auth_verify_email_post) | **POST** /auth/verify-email | Verify email address
*ChallengesApi* | [**challenges_get**](docs/ChallengesApi.md#challenges_get) | **GET** /challenges | Get all challenges
*ChallengesApi* | [**challenges_id_hints_get**](docs/ChallengesApi.md#challenges_id_hints_get) | **GET** /challenges/{id}/hints | Get hints for a challenge
*ChallengesApi* | [**challenges_id_hints_hint_id_reveal_post**](docs/ChallengesApi.md#challenges_id_hints_hint_id_reveal_post) | **POST** /challenges/{id}/hints/{hintId}/reveal | Reveal a hint
*ChallengesApi* | [**challenges_id_submit_post**](docs/ChallengesApi.md#challenges_id_submit_post) | **POST** /challenges/{id}/submit | Submit flag
*ContestApi* | [**contest_status_get**](docs/ContestApi.md#contest_status_get) | **GET** /contest/status | Get contest status
*LeaderboardApi* | [**leaderboard_category_get**](docs/LeaderboardApi.md#leaderboard_category_get) | **GET** /leaderboard/category | Get category leaderboard
*LeaderboardApi* | [**leaderboard_time_get**](docs/LeaderboardApi.md#leaderboard_time_get) | **GET** /leaderboard/time | Get time-based leaderboard
*NotificationsApi* | [**notifications_get**](docs/NotificationsApi.md#notifications_get) | **GET** /notifications | Get active notifications
*ProfilesApi* | [**users_username_profile_get**](docs/ProfilesApi.md#users_username_profile_get) | **GET** /users/{username}/profile | Get user profile
*ScoreboardApi* | [**scoreboard_get**](docs/ScoreboardApi.md#scoreboard_get) | **GET** /scoreboard | Get individual scoreboard
*ScoreboardApi* | [**scoreboard_teams_get**](docs/ScoreboardApi.md#scoreboard_teams_get) | **GET** /scoreboard/teams | Get team scoreboard
*TeamsApi* | [**teams_id_delete**](docs/TeamsApi.md#teams_id_delete) | **DELETE** /teams/{id} | Delete team
*TeamsApi* | [**teams_id_get**](docs/TeamsApi.md#teams_id_get) | **GET** /teams/{id} | Get team details
*TeamsApi* | [**teams_id_invitations_get**](docs/TeamsApi.md#teams_id_invitations_get) | **GET** /teams/{id}/invitations | Get team's outgoing invitations
*TeamsApi* | [**teams_id_invitations_invitation_id_delete**](docs/TeamsApi.md#teams_id_invitations_invitation_id_delete) | **DELETE** /teams/{id}/invitations/{invitationId} | Cancel invitation
*TeamsApi* | [**teams_id_invite_email_post**](docs/TeamsApi.md#teams_id_invite_email_post) | **POST** /teams/{id}/invite/email | Invite by email
*TeamsApi* | [**teams_id_invite_username_post**](docs/TeamsApi.md#teams_id_invite_username_post) | **POST** /teams/{id}/invite/username | Invite by username
*TeamsApi* | [**teams_id_leave_post**](docs/TeamsApi.md#teams_id_leave_post) | **POST** /teams/{id}/leave | Leave team
*TeamsApi* | [**teams_id_members_user_id_delete**](docs/TeamsApi.md#teams_id_members_user_id_delete) | **DELETE** /teams/{id}/members/{userId} | Remove team member
*TeamsApi* | [**teams_id_put**](docs/TeamsApi.md#teams_id_put) | **PUT** /teams/{id} | Update team
*TeamsApi* | [**teams_id_regenerate_code_post**](docs/TeamsApi.md#teams_id_regenerate_code_post) | **POST** /teams/{id}/regenerate-code | Regenerate invite code
*TeamsApi* | [**teams_invitations_get**](docs/TeamsApi.md#teams_invitations_get) | **GET** /teams/invitations | Get pending invitations
*TeamsApi* | [**teams_invitations_id_accept_post**](docs/TeamsApi.md#teams_invitations_id_accept_post) | **POST** /teams/invitations/{id}/accept | Accept invitation
*TeamsApi* | [**teams_invitations_id_reject_post**](docs/TeamsApi.md#teams_invitations_id_reject_post) | **POST** /teams/invitations/{id}/reject | Reject invitation
*TeamsApi* | [**teams_join_code_post**](docs/TeamsApi.md#teams_join_code_post) | **POST** /teams/join/{code} | Join team by code
*TeamsApi* | [**teams_my_team_get**](docs/TeamsApi.md#teams_my_team_get) | **GET** /teams/my-team | Get my team
*TeamsApi* | [**teams_post**](docs/TeamsApi.md#teams_post) | **POST** /teams | Create a team
*TeamsApi* | [**teams_scoreboard_get**](docs/TeamsApi.md#teams_scoreboard_get) | **GET** /teams/scoreboard | Get team scoreboard
*WebSocketApi* | [**ws_get**](docs/WebSocketApi.md#ws_get) | **GET** /ws | WebSocket connection
*WriteupsApi* | [**challenges_id_writeups_get**](docs/WriteupsApi.md#challenges_id_writeups_get) | **GET** /challenges/{id}/writeups | Get writeups for a challenge
*WriteupsApi* | [**challenges_id_writeups_post**](docs/WriteupsApi.md#challenges_id_writeups_post) | **POST** /challenges/{id}/writeups | Submit a writeup
*WriteupsApi* | [**writeups_id_put**](docs/WriteupsApi.md#writeups_id_put) | **PUT** /writeups/{id} | Update writeup content
*WriteupsApi* | [**writeups_id_upvote_post**](docs/WriteupsApi.md#writeups_id_upvote_post) | **POST** /writeups/{id}/upvote | Toggle writeup upvote
*WriteupsApi* | [**writeups_my_get**](docs/WriteupsApi.md#writeups_my_get) | **GET** /writeups/my | Get my writeups
## Documentation For Models
- [HandlersAdminTeamResponse](docs/HandlersAdminTeamResponse.md)
- [HandlersAdminUpdateTeamRequest](docs/HandlersAdminUpdateTeamRequest.md)
- [HandlersAdminUserResponse](docs/HandlersAdminUserResponse.md)
- [HandlersBulkChallengeImport](docs/HandlersBulkChallengeImport.md)
- [HandlersCategoryStats](docs/HandlersCategoryStats.md)
- [HandlersChallengePublicResponse](docs/HandlersChallengePublicResponse.md)
- [HandlersCreateNotificationRequest](docs/HandlersCreateNotificationRequest.md)
- [HandlersCreateTeamRequest](docs/HandlersCreateTeamRequest.md)
- [HandlersCreateWriteupRequest](docs/HandlersCreateWriteupRequest.md)
- [HandlersExportChallenge](docs/HandlersExportChallenge.md)
- [HandlersInviteByEmailRequest](docs/HandlersInviteByEmailRequest.md)
- [HandlersInviteByUsernameRequest](docs/HandlersInviteByUsernameRequest.md)
- [HandlersJoinByCodeRequest](docs/HandlersJoinByCodeRequest.md)
- [HandlersLoginRequest](docs/HandlersLoginRequest.md)
- [HandlersRegisterRequest](docs/HandlersRegisterRequest.md)
- [HandlersResendVerificationRequest](docs/HandlersResendVerificationRequest.md)
- [HandlersSolvedChallenge](docs/HandlersSolvedChallenge.md)
- [HandlersSubmitFlagRequest](docs/HandlersSubmitFlagRequest.md)
- [HandlersTeamMemberInfo](docs/HandlersTeamMemberInfo.md)
- [HandlersUpdateContestRequest](docs/HandlersUpdateContestRequest.md)
- [HandlersUpdateNotificationRequest](docs/HandlersUpdateNotificationRequest.md)
- [HandlersUpdateTeamLeaderRequest](docs/HandlersUpdateTeamLeaderRequest.md)
- [HandlersUpdateTeamRequest](docs/HandlersUpdateTeamRequest.md)
- [HandlersUpdateUserRoleRequest](docs/HandlersUpdateUserRoleRequest.md)
- [HandlersUpdateUserStatusRequest](docs/HandlersUpdateUserStatusRequest.md)
- [HandlersUpdateWriteupStatusRequest](docs/HandlersUpdateWriteupStatusRequest.md)
- [HandlersUserProfileResponse](docs/HandlersUserProfileResponse.md)
- [HandlersVerifyEmailRequest](docs/HandlersVerifyEmailRequest.md)
- [ModelsAchievement](docs/ModelsAchievement.md)
- [ModelsAdminAnalytics](docs/ModelsAdminAnalytics.md)
- [ModelsCategoryStat](docs/ModelsCategoryStat.md)
- [ModelsChallengePopularity](docs/ModelsChallengePopularity.md)
- [ModelsNotification](docs/ModelsNotification.md)
- [ModelsRecentActivityEntry](docs/ModelsRecentActivityEntry.md)
- [ModelsSolveEntry](docs/ModelsSolveEntry.md)
- [ModelsTeamInvitation](docs/ModelsTeamInvitation.md)
- [ModelsTeamStats](docs/ModelsTeamStats.md)
- [ModelsTimeSeriesEntry](docs/ModelsTimeSeriesEntry.md)
- [ModelsUserActivity](docs/ModelsUserActivity.md)
- [ModelsUserStats](docs/ModelsUserStats.md)
- [ModelsWriteup](docs/ModelsWriteup.md)
- [ServicesHintResponse](docs/ServicesHintResponse.md)
- [ServicesUserScore](docs/ServicesUserScore.md)
<a id="documentation-for-authorization"></a>
## Documentation For Authorization
Authentication schemes defined for the API:
<a id="ApiKeyAuth"></a>
### ApiKeyAuth
- **Type**: API key
- **API key parameter name**: Authorization
- **Location**: HTTP header
## Author
support@rootaccess.ctf
| text/markdown | API Support | API Support <support@rootaccess.ctf> | null | null | Apache 2.0 | OpenAPI, OpenAPI-Generator, RootAccess CTF API | [] | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Repository, https://github.com/GIT_USER_ID/GIT_REPO_ID"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T05:55:07.442185 | rootaccessd_client-1.0.0.tar.gz | 68,289 | 97/83/c65f36cdf905ea381a652896b2d0ad5f70ce9f0e070587daaeea25b2cae8/rootaccessd_client-1.0.0.tar.gz | source | sdist | null | false | 3b98f43ad28df2f2d85055f3103d9396 | 99caef9a679ab620be4b95b78dd21fc9d7fe3738899bb9f79286bb60cc17b558 | 9783c65f36cdf905ea381a652896b2d0ad5f70ce9f0e070587daaeea25b2cae8 | null | [] | 231 |
2.4 | pulumi-cloudinit | 1.5.0a1771566453 | A Pulumi package for creating and managing cloudinit cloud resources. | [](https://github.com/pulumi/pulumi-cloudinit/actions)
[](https://slack.pulumi.com)
[](https://npmjs.com/package/@pulumi/cloudinit)
[](https://badge.fury.io/nu/pulumi.cloudinit)
[](https://pypi.org/project/pulumi-cloudinit)
[](https://pkg.go.dev/github.com/pulumi/pulumi-cloudinit/sdk/go)
[](https://github.com/pulumi/pulumi-cloudinit/blob/master/LICENSE)
# CloudInit Provider
Provider for rendering [cloud-init](https://cloudinit.readthedocs.io/) configurations.
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/cloudinit
or `yarn`:
$ yarn add @pulumi/cloudinit
### Python 3
To use from Python, install using `pip`:
$ pip install pulumi_cloudinit
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-cloudinit/sdk
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.CloudInit
## Reference
For further information, please visit [the CloudInit provider docs](https://www.pulumi.com/docs/intro/cloud-providers/cloudinit) or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/cloudinit).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, cloudinit | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-cloudinit"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T05:54:28.786432 | pulumi_cloudinit-1.5.0a1771566453.tar.gz | 11,793 | 51/fb/42acfa9a88a2fa527ec1a85a661934d3e47c359717b186088ebf33f93000/pulumi_cloudinit-1.5.0a1771566453.tar.gz | source | sdist | null | false | 9a55470f0a79d8b8be5a32b6db5885ea | 077b0cfa170233de351ff417dc13083da4c8cd847e782ff1ab581e82b2587b29 | 51fb42acfa9a88a2fa527ec1a85a661934d3e47c359717b186088ebf33f93000 | null | [] | 223 |
2.4 | tg-signer | 0.8.5b1 | Automated Telegram tasks (check-ins, sending messages, keyboard clicks, AI replies, etc.); monitoring, forwarding, and auto-replying to private, group, and channel messages. | ## Telegram每日自动签到/个人、群组、频道消息监控与自动回复
[English](./README_EN.md)
### 功能
- 每日定时和随机误差时间签到
- 根据配置的文本点击键盘
- 调用AI进行图片识别并点击键盘
- 个人、群组、频道消息监控、转发与自动回复
- 根据配置执行动作流
**...**
### 安装
需要Python3.10及以上
```sh
pip install -U tg-signer
```
或者为了提升程序速度:
```sh
pip install "tg-signer[speedup]"
```
#### WebUI
tg-signer附带了一个WebUI,安装命令:
```sh
pip install "tg-signer[gui]"
```

### Docker
未上传直接使用的镜像,可以自行build镜像,见 [docker](./docker) 目录下的Dockerfile和 [README](./docker/README.md) 。
### 使用方法
```
Usage: tg-signer [OPTIONS] COMMAND [ARGS]...
使用<子命令> --help查看使用说明
子命令别名:
run_once -> run-once
send_text -> send-text
Options:
-l, --log-level [debug|info|warn|error]
日志等级, `debug`, `info`, `warn`, `error`
[default: info]
--log-file PATH 日志文件路径, 可以是相对路径 [default: logs/tg-
signer.log]
--log-dir PATH 日志文件目录, 可以是相对路径 [default: logs]
-p, --proxy TEXT 代理地址, 例如: socks5://127.0.0.1:1080,
会覆盖环境变量`TG_PROXY`的值 [env var: TG_PROXY]
--session_dir PATH 存储TG Sessions的目录, 可以是相对路径 [default: .]
-a, --account TEXT 自定义账号名称,对应session文件名为<account>.session [env
var: TG_ACCOUNT; default: my_account]
-w, --workdir PATH tg-signer工作目录,用于存储配置和签到记录等 [default:
.signer]
--session-string TEXT Telegram Session String,
会覆盖环境变量`TG_SESSION_STRING`的值 [env var:
TG_SESSION_STRING]
--in-memory 是否将session存储在内存中,默认为False,存储在文件
--help Show this message and exit.
Commands:
export 导出配置,默认为输出到终端。
import 导入配置,默认为从终端读取。
list 列出已有配置
list-members 查询聊天(群或频道)的成员, 频道需要管理员权限
list-schedule-messages 显示已配置的定时消息
llm-config 配置大模型API
login 登录账号(用于获取session)
logout 登出账号并删除session文件
monitor 配置和运行监控
multi-run 使用一套配置同时运行多个账号
reconfig 重新配置
run 根据任务配置运行签到
run-once 运行一次签到任务,即使该签到任务今日已执行过
schedule-messages 批量配置Telegram自带的定时发送消息功能
send-dice 发送一次DICE消息, 请确保当前会话已经"见过"该`chat_id`。...
send-text 发送一次文本消息, 请确保当前会话已经"见过"该`chat_id`
version Show version
webgui 启动一个WebGUI(需要通过`pip install "tg-signer[gui]"`安装相关依赖)
```
例如:
```sh
tg-signer run
tg-signer run my_sign # 不询问,直接运行'my_sign'任务
tg-signer run-once my_sign # 直接运行一次'my_sign'任务
tg-signer send-text 8671234001 /test # 向chat_id为'8671234001'的聊天发送'/test'文本
tg-signer send-text -- -10006758812 浇水 # 对于负数需要使用POSIX风格,在短横线'-'前方加上'--'
tg-signer send-text --delete-after 1 8671234001 /test # 向chat_id为'8671234001'的聊天发送'/test'文本, 并在1秒后删除发送的消息
tg-signer list-members --chat_id -1001680975844 --admin # 列出频道的管理员
tg-signer schedule-messages --crontab '0 0 * * *' --next-times 10 -- -1001680975844 你好 # 在未来10天的每天0点向'-1001680975844'发送消息
tg-signer monitor run # 配置个人、群组、频道消息监控与自动回复
tg-signer multi-run -a account_a -a account_b same_task # 使用'same_task'的配置同时运行'account_a'和'account_b'两个账号
tg-signer webgui --auth-code averycomplexcode # 启动一个WebGUI
```
### 配置代理(如有需要)
`tg-signer`不读取系统代理,可以使用环境变量 `TG_PROXY`或命令参数`--proxy`进行配置
例如:
```sh
export TG_PROXY=socks5://127.0.0.1:7890
```
### 登录
```sh
tg-signer login
```
根据提示输入手机号码和验证码进行登录并获取最近的聊天列表,确保你想要签到的聊天在列表内。
### 发送一次消息
```sh
tg-signer send-text 8671234001 hello # 向chat_id为'8671234001'的聊天发送'hello'文本
```
### 运行签到任务
```sh
tg-signer run
```
或预先执行任务名:
```sh
tg-signer run linuxdo
```
根据提示进行配置即可。
#### 示例:
```
开始配置任务<linuxdo>
第1个签到
一. Chat ID(登录时最近对话输出中的ID): 7661096533
二. Chat名称(可选): jerry bot
三. 开始配置<动作>,请按照实际签到顺序配置。
1: 发送普通文本
2: 发送Dice类型的emoji
3: 根据文本点击键盘
4: 根据图片选择选项
5: 回复计算题
第1个动作:
1. 输入对应的数字选择动作: 1
2. 输入要发送的文本: checkin
3. 是否继续添加动作?(y/N):y
第2个动作:
1. 输入对应的数字选择动作: 3
2. 键盘中需要点击的按钮文本: 签到
3. 是否继续添加动作?(y/N):y
第3个动作:
1. 输入对应的数字选择动作: 4
图片识别将使用大模型回答,请确保大模型支持图片识别。
2. 是否继续添加动作?(y/N):y
第4个动作:
1. 输入对应的数字选择动作: 5
计算题将使用大模型回答。
2. 是否继续添加动作?(y/N):y
第5个动作:
1. 输入对应的数字选择动作: 2
2. 输入要发送的骰子(如 🎲, 🎯): 🎲
3. 是否继续添加动作?(y/N):n
在运行前请通过环境变量正确设置`OPENAI_API_KEY`, `OPENAI_BASE_URL`。默认模型为"gpt-4o", 可通过环境变量`OPENAI_MODEL`更改。
四. 等待N秒后删除签到消息(发送消息后等待进行删除, '0'表示立即删除, 不需要删除直接回车), N: 10
╔════════════════════════════════════════════════╗
║ Chat ID: 7661096533 ║
║ Name: jerry bot ║
║ Delete After: 10 ║
╟────────────────────────────────────────────────╢
║ Actions Flow: ║
║ 1. [发送普通文本] Text: checkin ║
║ 2. [根据文本点击键盘] Click: 签到 ║
║ 3. [根据图片选择选项] ║
║ 4. [回复计算题] ║
║ 5. [发送Dice类型的emoji] Dice: 🎲 ║
╚════════════════════════════════════════════════╝
第1个签到配置成功
继续配置签到?(y/N):n
每日签到时间(time或crontab表达式,如'06:00:00'或'0 6 * * *'):
签到时间误差随机秒数(默认为0): 300
```
### 配置与运行监控
```sh
tg-signer monitor run my_monitor
```
根据提示进行配置。
#### 示例:
```
开始配置任务<my_monitor>
聊天chat id和用户user id均同时支持整数id和字符串username, username必须以@开头,如@neo
配置第1个监控项
1. Chat ID(登录时最近对话输出中的ID): -4573702599
2. 匹配规则('exact', 'contains', 'regex', 'all'): contains
3. 规则值(不可为空): kfc
4. 只匹配来自特定用户ID的消息(多个用逗号隔开, 匹配所有用户直接回车): @neo
5. 默认发送文本: V Me 50
6. 从消息中提取发送文本的正则表达式:
7. 等待N秒后删除签到消息(发送消息后等待进行删除, '0'表示立即删除, 不需要删除直接回车), N:
继续配置?(y/N):y
配置第2个监控项
1. Chat ID(登录时最近对话输出中的ID): -4573702599
2. 匹配规则('exact', 'contains', 'regex'): regex
3. 规则值(不可为空): 参与关键词:「.*?」
4. 只匹配来自特定用户ID的消息(多个用逗号隔开, 匹配所有用户直接回车): 61244351
5. 默认发送文本:
6. 从消息中提取发送文本的正则表达式: 参与关键词:「(?P<keyword>(.*?))」\n
7. 等待N秒后删除签到消息(发送消息后等待进行删除, '0'表示立即删除, 不需要删除直接回车), N: 5
继续配置?(y/N):y
配置第3个监控项
1. Chat ID(登录时最近对话输出中的ID): -4573702599
2. 匹配规则(exact, contains, regex, all): all
3. 只匹配来自特定用户ID的消息(多个用逗号隔开, 匹配所有用户直接回车):
4. 总是忽略自己发送的消息(y/N): y
5. 默认发送文本(不需要则回车):
6. 是否使用AI进行回复(y/N): n
7. 从消息中提取发送文本的正则表达式(不需要则直接回车):
8. 是否通过Server酱推送消息(y/N): n
9. 是否需要转发到外部(UDP, Http)(y/N): y
10. 是否需要转发到UDP(y/N): y
11. 请输入UDP服务器地址和端口(形如`127.0.0.1:1234`): 127.0.0.1:9999
12. 是否需要转发到Http(y/N): y
13. 请输入Http地址(形如`http://127.0.0.1:1234`): http://127.0.0.1:8000/tg/user1/messages
继续配置?(y/N):n
```
#### 示例解释:
1. 聊天`chat id`和用户`user id`均同时支持整数**id**和字符串**username**, username**必须以@开头** 如"neo"输入"@neo",注意*
*username** 可能不存在,示例中`chat id`为-4573702599表示规则只对-4573702599对应的聊天有效。
2. 匹配规则,目前皆**忽略大小写**:
1. `exact` 为精确匹配,消息必须精确等于该值。
2. `contains` 为包含匹配,如contains="kfc",那么只要收到的消息中包含"kfc"如"I like MacDonalds rather than KfC"
即匹配到(注意忽略了大小写)
3. `regex` 为正则,参考 [Python正则表达式](https://docs.python.org/zh-cn/3/library/re.html) ,在消息中有**搜索到该正则即匹配
**,示例中的 "参与关键词:「.*?」" 可以匹配消息: "新的抽奖已经创建...
参与关键词:「我要抽奖」
建议先私聊机器人"
4. 可以只匹配来自特定用户的消息,如群管理员而不是随便什么人发布的抽奖消息
5. 可以设置默认发布文本, 即只要匹配到消息即默认发送该文本
6. 提取发布文本的正则,例如 "参与关键词:「(.*?)」\n" ,注意用括号`(...)` 捕获要提取的文本,
可以捕获第3点示例消息的关键词"我要抽奖"并自动发送
3. 消息Message结构参考:
```json
{
"_": "Message",
"id": 2950,
"from_user": {
"_": "User",
"id": 123456789,
"is_self": false,
"is_contact": false,
"is_mutual_contact": false,
"is_deleted": false,
"is_bot": false,
"is_verified": false,
"is_restricted": false,
"is_scam": false,
"is_fake": false,
"is_support": false,
"is_premium": false,
"is_contact_require_premium": false,
"is_close_friend": false,
"is_stories_hidden": false,
"is_stories_unavailable": true,
"is_business_bot": false,
"first_name": "linux",
"status": "UserStatus.ONLINE",
"next_offline_date": "2025-05-30 11:52:40",
"username": "linuxdo",
"dc_id": 5,
"phone_number": "*********",
"photo": {
"_": "ChatPhoto",
"small_file_id": "AQADBQADqqcxG6hqrTMAEAIAA6hqrTMABLkwVDcqzBjAAAQeBA",
"small_photo_unique_id": "AgADqqcxG6hqrTM",
"big_file_id": "AQADBQADqqcxG6hqrTMAEAMAA6hqrTMABLkwVDcqzBjAAAQeBA",
"big_photo_unique_id": "AgADqqcxG6hqrTM",
"has_animation": false,
"is_personal": false
},
"added_to_attachment_menu": false,
"inline_need_location": false,
"can_be_edited": false,
"can_be_added_to_attachment_menu": false,
"can_join_groups": false,
"can_read_all_group_messages": false,
"has_main_web_app": false
},
"date": "2025-05-30 11:47:46",
"chat": {
"_": "Chat",
"id": -52737131599,
"type": "ChatType.GROUP",
"is_creator": true,
"is_deactivated": false,
"is_call_active": false,
"is_call_not_empty": false,
"title": "测试组",
"has_protected_content": false,
"members_count": 4,
"permissions": {
"_": "ChatPermissions",
"can_send_messages": true,
"can_send_media_messages": true,
"can_send_other_messages": true,
"can_send_polls": true,
"can_add_web_page_previews": true,
"can_change_info": true,
"can_invite_users": true,
"can_pin_messages": true,
"can_manage_topics": true
}
},
"from_offline": false,
"show_caption_above_media": false,
"mentioned": false,
"scheduled": false,
"from_scheduled": false,
"edit_hidden": false,
"has_protected_content": false,
"text": "test, 测试",
"video_processing_pending": false,
"outgoing": false
}
```
#### 示例运行输出:
```
[INFO] [tg-signer] 2024-10-25 12:29:06,516 core.py 458 开始监控...
[INFO] [tg-signer] 2024-10-25 12:29:37,034 core.py 439 匹配到监控项:MatchConfig(chat_id=-4573702599, rule=contains, rule_value=kfc), default_send_text=V me 50, send_text_search_regex=None
[INFO] [tg-signer] 2024-10-25 12:29:37,035 core.py 442 发送文本:V me 50
[INFO] [tg-signer] 2024-10-25 12:30:02,726 core.py 439 匹配到监控项:MatchConfig(chat_id=-4573702599, rule=regex, rule_value=参与关键词:「.*?」), default_send_text=None, send_text_search_regex=参与关键词:「(?P<keyword>(.*?))」\n
[INFO] [tg-signer] 2024-10-25 12:30:02,727 core.py 442 发送文本:我要抽奖
[INFO] [tg-signer] 2024-10-25 12:30:03,001 core.py 226 Message「我要抽奖」 to -4573702599 will be deleted after 5 seconds.
[INFO] [tg-signer] 2024-10-25 12:30:03,001 core.py 229 Waiting...
[INFO] [tg-signer] 2024-10-25 12:30:08,260 core.py 232 Message「我要抽奖」 to -4573702599 deleted!
```
### 版本变动日志
#### 0.8.4
- 新增 WebGUI
- 新增`--log-dir`选项,更改日志默认目录为`logs`,warning和error分为单独文件
#### 0.8.2
- 支持持久化OpenAI API和模型配置
- Python最小版本要求:3.10
- 支持处理编辑后的消息(如键盘)
#### 0.8.0
- 支持单个账号同一进程内同时运行多个任务
#### 0.7.6
- fix: 监控多个聊天时消息转发至每个聊天 (#55)
#### 0.7.5
- 捕获并记录执行任务期间的所有RPC错误
- bump kurigram version to 2.2.7
#### 0.7.4
- 执行多个action时,支持固定时间间隔
- 通过`crontab`配置定时执行时不再限制每日执行一次
#### 0.7.2
- 支持将消息转发至外部端点,通过:
- UDP
- HTTP
- 将kurirogram替换为kurigram
#### 0.7.0
- 支持每个聊天会话按序执行多个动作,动作类型:
- 发送文本
- 发送骰子
- 按文本点击键盘
- 通过图片选择选项
- 通过计算题回复
#### 0.6.6
- 增加对发送DICE消息的支持
#### 0.6.5
- 修复使用同一套配置运行多个账号时签到记录共用的问题
#### 0.6.4
- 增加对简单计算题的支持
- 改进签到配置和消息处理
#### 0.6.3
- 兼容kurigram 2.1.38版本的破坏性变更
> Remove coroutine param from run method [a7afa32](https://github.com/KurimuzonAkuma/pyrogram/commit/a7afa32df208333eecdf298b2696a2da507bde95)
#### 0.6.2
- 忽略签到时发送消息失败的聊天
#### 0.6.1
- 支持点击按钮文本后继续进行图片识别
#### 0.6.0
- Signer支持通过crontab定时
- Monitor匹配规则添加`all`支持所有消息
- Monitor支持匹配到消息后通过server酱推送
- Signer新增`multi-run`用于使用一套配置同时运行多个账号
#### 0.5.2
- Monitor支持配置AI进行消息回复
- 增加批量配置「Telegram自带的定时发送消息功能」的功能
#### 0.5.1
- 添加`import`和`export`命令用于导入导出配置
#### 0.5.0
- 根据配置的文本点击键盘
- 调用AI识别图片点击键盘
### 配置与数据存储位置
数据和配置默认保存在 `.signer` 目录中。然后运行 `tree .signer`,你将看到:
```
.signer
├── latest_chats.json # 获取的最近对话
├── me.json # 个人信息
├── monitors # 监控
│ ├── my_monitor # 监控任务名
│ └── config.json # 监控配置
└── signs # 签到任务
└── linuxdo # 签到任务名
├── config.json # 签到配置
└── sign_record.json # 签到记录
3 directories, 4 files
```
| text/markdown | null | Amchii <finethankuandyou@gmail.com> | null | null | null | null | [
"Intended Audience :: Developers",
"Programming Language :: Python :: 3 :: Only"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"kurigram<=2.2.7",
"click",
"pydantic",
"openai",
"croniter",
"json_repair",
"typing-extensions",
"httpx",
"tgcrypto; extra == \"speedup\"",
"nicegui; extra == \"gui\""
] | [] | [] | [] | [
"Homepage, https://github.com/amchii/tg-signer",
"Repository, https://github.com/amchii/tg-signer"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T05:54:10.057708 | tg_signer-0.8.5b1.tar.gz | 58,629 | 6b/37/beaeedff0dd0437d00c97b1585933c1eba966a03f36997128e0f023ab39b/tg_signer-0.8.5b1.tar.gz | source | sdist | null | false | 521e895334fa9224bc64c8d2ec013e11 | aee81f4d363b0d256c733e27bce4916b578f7847bc21306d1c15d2c8e9efce20 | 6b37beaeedff0dd0437d00c97b1585933c1eba966a03f36997128e0f023ab39b | BSD-3-Clause | [
"LICENSE"
] | 209 |
2.4 | pulumi-cloudamqp | 3.27.0a1771566282 | A Pulumi package for creating and managing CloudAMQP resources. | [](https://github.com/pulumi/pulumi-cloudamqp/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/cloudamqp)
[](https://pypi.org/project/pulumi-cloudamqp)
[](https://badge.fury.io/nu/pulumi.cloudamqp)
[](https://pkg.go.dev/github.com/pulumi/pulumi-cloudamqp/sdk/v3/go)
[](https://github.com/pulumi/pulumi-cloudamqp/blob/master/LICENSE)
# CloudAMQP Resource Provider
The CloudAMQP resource provider for Pulumi lets you manage CloudAMQP resources in your cloud programs. To use
this package, please [install the Pulumi CLI first](https://pulumi.io/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/cloudamqp
or `yarn`:
$ yarn add @pulumi/cloudamqp
### Python
To use from Python, install using `pip`:
$ pip install pulumi_cloudamqp
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-cloudamqp/sdk/v3
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.cloudamqp
## Configuration
The following configuration points are available:
- `cloudamqp:apikey` - (Required) Key used to authentication to the CloudAMQP Customer API. May be set via the `CLOUDAMQP_APIKEY` environment variable.
- `cloudamqp:baseurl` - (Optional) Base URL to CloudAMQP Customer website. Default is `https://customer.cloudamqp.com`.
## Reference
For further information, please visit [the CloudAMQP provider docs](https://www.pulumi.com/docs/intro/cloud-providers/cloudamqp) or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/cloudamp).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, cloudamqp | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-cloudamqp"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T05:52:37.832070 | pulumi_cloudamqp-3.27.0a1771566282.tar.gz | 107,797 | 7a/db/e43142e61db52833ce23045b355720f3a9292245be17fd7c685f0b50ddc0/pulumi_cloudamqp-3.27.0a1771566282.tar.gz | source | sdist | null | false | 4dfc4859b57d56afd6ed63e64e2592eb | c217e728fdff613d62faa3b16dd0cf2f936a1e71e8681930f76b7cbc52a52c51 | 7adbe43142e61db52833ce23045b355720f3a9292245be17fd7c685f0b50ddc0 | null | [] | 222 |
2.4 | pulumi-cloudngfwaws | 1.1.0a1771566355 | A Pulumi package for creating and managing Cloud NGFW for AWS resources. | # Palo Alto Networks Cloud NGFW for AWS Resource Provider
The Palo Alto Networks Cloud NGFW for AWS Resource Provider lets you manage Palo Alto Networks Cloud NGFW for AWS resources.
## Installation
This package is available for several languages/platforms:
- JavaScript/TypeScript: [`@pulumi/cloudngfwaws`](https://www.npmjs.com/package/@pulumi/cloudngfwaws)
- Python: [`pulumi-cloudngfwaws`](https://pypi.org/project/pulumi-cloudngfwaws/)
- Go: [`github.com/pulumi/pulumi-cloudngfwaws/sdk/go/cloudngfwaws`](https://pkg.go.dev/github.com/pulumi/pulumi-cloudngfwaws/sdk/go/cloudngfwaws)
- .NET: [`Pulumi.CloudNgfwAws`](https://www.nuget.org/packages/Pulumi.CloudNgfwAws)
### Node.js (JavaScript/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
```bash
npm install @pulumi/cloudngfwaws
```
or `yarn`:
```bash
yarn add @pulumi/cloudngfwaws
```
### Python
To use from Python, install using `pip`:
```bash
pip install pulumi-cloudngfwaws
```
### Go
To use from Go, use `go get` to grab the latest version of the library:
```bash
go get github.com/pulumi/pulumi-cloudngfwaws/sdk/go/cloudngfwaws
```
### .NET
To use from .NET, install using `dotnet add package`:
```bash
dotnet add package Pulumi.CloudNgfwAws
```
## Reference
For detailed reference documentation, please visit [the Pulumi registry](https://www.pulumi.com/registry/packages/meraki/api-docs/).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, cloudngfwaws, Palo Alto Networks, ngfw, category/network | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.com",
"Repository, https://github.com/pulumi/pulumi-cloudngfwaws"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T05:52:26.262230 | pulumi_cloudngfwaws-1.1.0a1771566355.tar.gz | 67,926 | b5/fe/777a1ed1891af90cebb5020560a24e5a1ef65683d6265d5502894bd284d6/pulumi_cloudngfwaws-1.1.0a1771566355.tar.gz | source | sdist | null | false | 9fcac9678e9d1df3c8001b0329aa6c4f | a748a3a32d9a122a6724a09cd9d882aea5f456cae717334fad9e29f742f4d018 | b5fe777a1ed1891af90cebb5020560a24e5a1ef65683d6265d5502894bd284d6 | null | [] | 213 |
2.4 | ktch | 0.7.2 | ktch is a python package for model-based morphometrics. | # ktch - A Python package for model-based morphometrics
[](https://pypi.org/project/ktch/) [](https://anaconda.org/conda-forge/ktch) [](https://codecov.io/gh/noshita/ktch) [](https://opensource.org/licenses/Apache-2.0) [](https://www.python.org/downloads/)
ktch is a Python package for model-based morphometrics with scikit-learn compatible APIs.
## Overview
ktch provides implementations of various morphometric analysis methods:
- Landmark-based methods: Generalized Procrustes Analysis (GPA) with curve/surface semilandmark sliding, thin-plate spline interpolation
- Harmonic-based methods: Elliptic Fourier Analysis (EFA) for 2D/3D closed curves, spherical harmonic analysis (SPHARM) for 3D closed surfaces
- File I/O: Support for standard morphometric file formats (TPS, CHC, SPHARM-PDM)
- Datasets: Built-in example datasets for learning and testing
- Visualization: TPS deformation grids, PCA variance plots (with optional `plot` extra)
All analysis classes follow the scikit-learn API (`fit`, `transform`, `fit_transform`), making them easy to integrate into existing data analysis pipelines.
## Installation
Python >= 3.11 is required.
### From PyPI
```sh
pip install ktch
```
### From conda-forge
```sh
conda install -c conda-forge ktch
```
### Optional Dependencies
```sh
pip install ktch[plot] # matplotlib, plotly, seaborn for visualization
pip install ktch[data] # pooch for remote dataset downloads
```
### Development Installation
```sh
git clone https://github.com/noshita/ktch.git
cd ktch
uv sync
```
## Quick Start
### Elliptic Fourier Analysis on 2D Outlines
```python
from sklearn.decomposition import PCA
from ktch.datasets import load_outline_mosquito_wings
from ktch.harmonic import EllipticFourierAnalysis
# Load outline data (126 specimens, 100 points, 2D)
data = load_outline_mosquito_wings()
coords = data.coords.reshape(-1, 100, 2)
# Elliptic Fourier Analysis
efa = EllipticFourierAnalysis(n_harmonics=20)
coeffs = efa.fit_transform(coords)
# PCA on EFA coefficients
pca = PCA(n_components=5)
pc_scores = pca.fit_transform(coeffs)
```
## Documentation
See [doc.ktch.dev](https://doc.ktch.dev) for full documentation:
- Tutorials: Step-by-step guides for GPA, EFA, spherical harmonics, and more
- How-to guides: Task-oriented recipes for data loading, visualization, and pipeline integration
- Explanation: Theoretical background on morphometric methods
- API reference: Complete API documentation
## Contributing
Bug reports and feature requests are welcome via [GitHub Issues](https://github.com/noshita/ktch/issues).
See [CONTRIBUTING.md](CONTRIBUTING.md) for development setup and conventions.
## License
ktch is licensed under the [Apache License, Version 2.0](LICENSE).
| text/markdown | null | "Noshita, Koji" <noshita@morphometrics.jp> | null | null | Apache License Version 2.0, January 2004 http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION 1. Definitions. "License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document. "Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License. "Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity. "You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License. "Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types. "Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below). "Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof. "Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution." "Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work. 2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form. 3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed. 4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions: (a) You must give any other recipients of the Work or Derivative Works a copy of this License; and (b) You must cause any modified files to carry prominent notices stating that You changed the files; and (c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and (d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License. 5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions. 6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file. 7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License. 8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages. 9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability. END OF TERMS AND CONDITIONS APPENDIX: How to apply the Apache License to your work. To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives. Copyright [yyyy] [name of copyright owner] Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. | morphometrics, theoretical morphology | [
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX",
"Operating System :: Unix",
"Programming Language :: Python",
"Programming Language :: Python :: 3.11",
"Topic :: Scientific/Engineering",
"Topic :: Software Development"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"numpy>=1.20",
"pandas[pyarrow]>=2.1",
"scikit-learn>=1.5",
"scipy>=1.15",
"pillow>=9.0; extra == \"data\"",
"pooch>=1.3; extra == \"data\"",
"matplotlib>=3.10.7; extra == \"plot\"",
"plotly>=6.0; extra == \"plot\"",
"seaborn>=0.13.2; extra == \"plot\""
] | [] | [] | [] | [
"Homepage, https://doc.ktch.dev",
"Repository, https://github.com/noshita/ktch"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T05:52:07.427203 | ktch-0.7.2-py3-none-any.whl | 755,352 | 23/02/32aaa8e949b19edb92523d320e35333230b7db6420556b99bb44e14ef615/ktch-0.7.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 12ebcfbdaaaef066e57a204c30b33752 | 18852e90dfd01b972398de4aeeb810c2481be3b1b1a5a195c7f0fa2e295230f1 | 230232aaa8e949b19edb92523d320e35333230b7db6420556b99bb44e14ef615 | null | [
"LICENSE"
] | 236 |
2.4 | esignbase-sdk | 1.1.0 | Python SDK for eSignBase – eIDAS-compliant digital signatures and GDPR-ready electronic signing via REST API. | # eSignBase Python SDK
Official Python SDK for integrating **eIDAS-compliant digital signatures** into your application using the eSignBase REST API.
eSignBase provides GDPR-ready electronic signatures with EU-based infrastructure and flexible pay-as-you-go pricing — no subscriptions, no per-seat licenses.
This SDK offers a simple, synchronous client for creating signing requests, managing templates, and retrieving signed documents programmatically.
## Why eSignBase?
- ✅ eIDAS-compliant electronic signatures
- ✅ GDPR-aligned EU data hosting
- ✅ Simple REST API
- ✅ No subscriptions — pay-as-you-go credits
- ✅ Lightweight and easy to integrate
## Documentation
Full REST API documentation:
https://esignbase.com/en/api_documentation
A step-by-step integration guide:
https://esignbase.com/en/blog/rest-api-guide
### Classes
**GrantType** (Enum)
Defines the available OAuth2 grant types:
* CLIENT_CREDENTIALS: For server-to-server authentication
* AUTHORIZATION_CODE: For user-specific authentication
**Scope** (Enum)
Defines the available API permission scopes:
* ALL: Full access to all API endpoints
* READ: Read-only access
* CREATE_DOCUMENT: Permission to create documents
* DELETE: Permission to delete documents
* SANDBOX: Access to the sandbox environment, use this scope for testing
**OAuth2Client**
Main client class that stores authentication credentials and state.
Attributes:
```python
id (str) # Client ID from ESignBase
secret (str) # Client secret from ESignBase
grant_type (GrantType) # OAuth2 grant type to use
user_name (Optional[str]) # Username (required AUTHORIZATION_CODE)
password (Optional[str]) # Password (required AUTHORIZATION_CODE)
scope (list[Scope]) # List of requested API scopes
```
Retrieve your Client ID and Client Secret at https://app.esignbase.com/oauth2/client by creating an
OAuth2 Client Configuration.
**Recipient**
Represents a document recipient/signer.
`role_name` value is defined during template creation in the template editor.
Attributes:
```python
email (str) # Recipient's email address
first_name (str) # Recipient's first name
last_name (str) # Recipient's last name
role_name (str) # Role name (e.g., "Signer", "Viewer")
locale (str) # Locale code ("de", "en", "es")
```
**ESignBaseSDKError** (Exception)
Custom exception class for API-related errors.
### Functions
```python
def connect(client: OAuth2Client) -> None
```
Authenticates with the ESignBase API
Parameters:
client: Configured OAuth2Client instance
Raises:
ESignBaseSDKError: If authentication fails or validation fails
Example:
```python
client = OAuth2Client(
id="your_client_id",
secret="your_client_secret",
grant_type=GrantType.CLIENT_CREDENTIALS,
scope=[Scope.ALL],
)
connect(client)
```
---
```python
def get_templates(client: OAuth2Client) -> list[dict[str, Any]]
```
Retrieves a list of available document templates.
Parameters:
```
client: Authenticated OAuth2Client instance
```
Returns A list of dictionaries containing template data.
Raises:
ESignBaseSDKError: If the API request fails
---
```python
def get_template(client: OAuth2Client, template_id: str) -> dict[str, Any]
```
Retrieves details of a specific template.
Parameters:
client: Authenticated OAuth2Client instance
template_id: Unique identifier of the template
Returns:
Dictionary containing template details
Raises:
ESignBaseSDKError: If the API request fails
---
```python
def get_documents(client: OAuth2Client, limit: int, offset: int) -> dict[str, Any]
```
Retrieves a paginated list of documents.
Parameters:
client: Authenticated OAuth2Client instance
limit: Maximum number of documents to return
offset: Pagination offset
Returns:
Dictionary containing document list and pagination info `{documents: [...]}`
Raises:
ESignBaseSDKError: If the API request fails
---
```python
def get_document(client: OAuth2Client, document_id: str) -> dict[str, Any]
```
Retrieves details of a specific document.
Parameters:
client: Authenticated OAuth2Client instance
document_id: Unique identifier of the document
Returns:
Dictionary containing document details
Raises:
ESignBaseSDKError: If the API request fails
---
```python
def create_document(
client: OAuth2Client,
*,
template_id: str,
document_name: str,
recipients: list[Recipient],
user_defined_metadata: Optional[dict[str, str | int]] = None,
expiration_date: Optional[datetime] = None
) -> dict[str, Any]
```
Creates a new document from a template.
Parameters:
client: Authenticated OAuth2Client instance
template_id: ID of the template to use
document_name: Name for the new document
recipients: List of Recipient objects
user_defined_metadata: Optional metadata to attach to the document
expiration_date: Optional expiration date for the document
Returns:
Dictionary containing the created document id and current document status
Raises:
ESignBaseSDKError: If the API request fails
Example:
```python
recipients = [
Recipient(
email="signer@example.com",
first_name="John",
last_name="Doe",
role_name="signer",
locale="de"
)
]
document = create_document(
client=client,
template_id="template_123",
document_name="Contract Agreement",
recipients=recipients,
user_defined_metadata={"contract_id": "CTR-2024-001"},
expiration_date=datetime(2024, 12, 31)
)
```
---
```python
def delete_document(client: OAuth2Client, document_id: str) -> None
```
Deletes a specific document.
Parameters:
client: Authenticated OAuth2Client instance
document_id: Unique identifier of the document to delete
Raises:
ESignBaseSDKError: If the API request fails
---
```python
def download_document(client: OAuth2Client, document_id: str) -> Generator[bytes]
```
Download a completed document.
Parameters:
client: Authenticated OAuth2Client instance
document_id: Unique identifier of the document to download
Raises:
ESignBaseSDKError: If the API request fails
Example Usage:
```python
with open(f"document.pdf", "wb") as f:
for chunk in esignbase_sdk.download_document(client, "695e4a4d869ba75efa33aa07"):
f.write(chunk)
```
---
```python
def get_credits(client: OAuth2Client) -> dict[str, Any]
```
Retrieves credit balance information.
Parameters:
client: Authenticated OAuth2Client instance
Returns:
Dictionary containing credit balance data
Raises:
ESignBaseSDKError: If the API request fails
Error Handling
All functions raise ESignBaseSDKError exceptions for API errors, network issues, or validation failures. Always wrap API calls in try-except blocks:
```python
try:
templates = get_templates(client)
except ESignBaseSDKError as e:
print(f"API Error: {e}")
```
Complete Example
```python
from datetime import datetime
import esignbase_sdk
# Setup client
client = esignbase_sdk.OAuth2Client(
id="your_client_id",
secret="your_client_secret",
grant_type=GrantType.CLIENT_CREDENTIALS,
scope=[Scope.CREATE_DOCUMENT, Scope.READ]
)
# Authenticate
esignbase_sdk.connect(client)
# Get available templates
templates = esignbase_sdk.get_templates(client)
# Create a document
recipients = [
esignbase_sdk.Recipient(
email="alice@example.com",
first_name="Alice",
last_name="Smith",
role_name="Signer",
locale="en"
)
]
template_id = templates[0]["id"]
document = esignbase_sdk.create_document(
client=client,
template_id=template_id,
document_name="NDA Agreement",
recipients=recipients
)
# Check document status
document_details = esignbase_sdk.get_document(client, document["id"])
# Delete the document (if needed)
esignbase_sdk.delete_document(client, document["id"])
```
## Developer Notes:
To build the package, run the following commands inside a virtual environment from the directory
containing this README file.
```bash
python -m pip install --upgrade build
python -m build --wheel
```
| text/markdown | null | Matthias Meß <info@esignbase.com> | null | null | null | digital signature, electronic signature, eIDAS, GDPR, REST API, document signing, e-signature, legal signature, EU compliance, python sdk | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Operating System :: OS Independent",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Security :: Cryptography",
"Topic :: Office/Business"
] | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"requests<3.0.0,>=2.25.0",
"pylint; extra == \"dev\"",
"black; extra == \"dev\"",
"isort; extra == \"dev\"",
"pyright; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://esignbase.com",
"Documentation, https://esignbase.com/en/api_documentation/",
"Source, https://github.com/matt-the-midnight-hacker/esignbase-python-sdk"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T05:51:32.539090 | esignbase_sdk-1.1.0.tar.gz | 8,965 | cb/14/e7574e812918367c0070b28aeb79bf5248decf4262d08dc2525e99645524/esignbase_sdk-1.1.0.tar.gz | source | sdist | null | false | 5941c334fddaad3b9e953acbd8634f4f | b63715cb1ee44d4eff1e6e18da3ec36c02acb15b14697c1442d0eccccbca5d5e | cb14e7574e812918367c0070b28aeb79bf5248decf4262d08dc2525e99645524 | MIT | [
"LICENSE"
] | 247 |
2.1 | respan-exporter-superagent | 0.2.0 | Respan exporter for Superagent (safety-agent) SDK | # Respan Exporter for Superagent
Exports `safety-agent` (Superagent) calls to Respan traces ingestion.
## Installation
```bash
pip install respan-exporter-superagent
```
## Usage
```python
import os
from respan_exporter_superagent import create_client
client = create_client(
api_key=os.getenv("RESPAN_API_KEY"),
endpoint=os.getenv("RESPAN_ENDPOINT"), # optional
)
result = await client.guard(
input="hello",
respan_params={
"span_workflow_name": "wf",
"span_name": "sp",
"customer_identifier": "user-123",
},
)
print(result)
```
## Environment variables
- `RESPAN_API_KEY`: API key used for ingest authorization.
- `RESPAN_ENDPOINT`: optional override for ingest endpoint.
| text/markdown | Respan | team@respan.ai | null | null | Apache-2.0 | null | [
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | <3.14,>=3.11 | [] | [] | [] | [
"requests<3.0.0,>=2.32.5",
"respan-sdk<3.0.0,>=2.3.0",
"respan-tracing<3.0.0,>=2.0.2",
"safety-agent<0.2.0,>=0.1.0"
] | [] | [] | [] | [] | poetry/1.7.1 CPython/3.12.8 Darwin/25.2.0 | 2026-02-20T05:51:29.623719 | respan_exporter_superagent-0.2.0.tar.gz | 3,602 | 0d/19/c88a405247a13216b50814886046b8c93f3c5c461eea2142efe91c1463bb/respan_exporter_superagent-0.2.0.tar.gz | source | sdist | null | false | 32a30565a230ddb05ad33faf89147425 | ab41d1b7c64a9928b6aae1fd8c5498ba1fea53662b275d56a2de0173feec9e7f | 0d19c88a405247a13216b50814886046b8c93f3c5c461eea2142efe91c1463bb | null | [] | 236 |
2.4 | sbn-sdk | 0.3.0 | Python SDK for the SmartBlocks Network — attestation, GEC compute, SnapChore integrity, governance, and more. | # SmartBlocks Network Python SDK
Canonical Python client for the SBN infrastructure. Covers the full network
surface — gateway, SnapChore, console, and control plane.
## Install
```bash
pip install sbn-sdk
# or from source
cd sdk/python && pip install -e .
```
## Quick start
```python
from sbn import SbnClient
client = SbnClient(base_url="https://api.smartblocks.network")
client.authenticate_api_key("sbn_live_abc123")
# SnapChore — capture, verify, seal
block = client.snapchore.capture({"event": "signup", "user": "u-42"})
client.snapchore.verify(block["snapchore_hash"], {"event": "signup", "user": "u-42"})
client.snapchore.seal(block["snapchore_hash"], {"event": "signup", "user": "u-42"})
# Gateway — slots, receipts, attestations
slot = client.gateway.create_slot(worker_id="w-1", task_type="classify")
receipt = client.gateway.fetch_receipt(slot.receipt_id)
# Console — API keys, usage, billing
keys = client.console.list_api_keys("proj-123")
usage = client.console.get_usage("proj-123")
# Control plane — rate plans, tenants, validators
plans = client.control_plane.list_rate_plans()
client.control_plane.create_tenant(
name="Acme Corp",
contact_email="ops@acme.co",
aggregator_endpoint="https://agg.acme.co",
rate_plan_id=plans[0].id,
)
```
## Auth methods
```python
# API key (most common for external devs)
client.authenticate_api_key("sbn_live_...")
# Bearer token (console sessions, service-to-service)
client.authenticate_bearer("eyJ...")
# Ed25519 signing key (auto-refreshing JWTs for agents)
from sbn import SigningKey
key = SigningKey.from_pem("/path/to/key.pem", issuer="my-svc", audience="sbn")
client.authenticate_signing_key(key, scopes=["attest.write", "snapchore.seal"])
```
## Sub-clients
| Property | Domain | Key operations |
|----------|--------|----------------|
| `client.gateway` | Slots & receipts | `create_slot`, `close_slot`, `fetch_receipt`, `request_attestation` |
| `client.snapchore` | Hash capture | `capture`, `verify`, `seal`, `create_chain`, `append_to_chain` |
| `client.console` | Developer console | `list_api_keys`, `create_api_key`, `get_usage`, `get_billing_status` |
| `client.control_plane` | Multi-tenancy | `list_rate_plans`, `create_tenant`, `register_validator` |
## Legacy compatibility
The original `sbn_gateway.py` single-file SDK is preserved for backward
compatibility. New integrations should use `from sbn import SbnClient`.
| text/markdown | SmartBlocks Team | devrel@smartblocks.network | null | null | MIT | smartblocks, sbn, snapchore, gec, attestation, integrity | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"PyJWT>=2.8",
"cryptography>=41.0",
"httpx<0.28.0,>=0.27.0"
] | [] | [] | [] | [
"Documentation, https://smartblocks.network/docs/sdk",
"Homepage, https://smartblocks.network",
"Repository, https://github.com/smartblocks-network/sbn-sdk"
] | twine/6.2.0 CPython/3.13.5 | 2026-02-20T05:51:21.965280 | sbn_sdk-0.3.0.tar.gz | 27,501 | 5e/00/7672385facfc4a69f18411e28b4377788fa583250b5cc65cfcf6fbbc22dc/sbn_sdk-0.3.0.tar.gz | source | sdist | null | false | 3ebd765b86896742c7b857688ddfac3f | c241d047ad38b15bbda6a3f32ad839bc926c14120e16399a299a125593d25ad7 | 5e007672385facfc4a69f18411e28b4377788fa583250b5cc65cfcf6fbbc22dc | null | [] | 296 |
2.4 | awsimple | 7.1.5 | Simple AWS API for S3, DynamoDB, SNS, and SQS |
<p align="center">
<!--
<a href="https://app.circleci.com/pipelines/github/jamesabel/awsimple" alt="build">
<img src="https://img.shields.io/circleci/build/gh/jamesabel/awsimple" />
</a>
-->
<a href="https://codecov.io/gh/jamesabel/awsimple" alt="codecov">
<img src="https://img.shields.io/codecov/c/github/jamesabel/awsimple/master" />
</a>
<a href="https://pypi.org/project/awsimple/" alt="pypi">
<img src="https://img.shields.io/pypi/v/awsimple" />
</a>
<a href="https://pypi.org/project/awsimple/" alt="downloads">
<img src="https://img.shields.io/pypi/dm/awsimple" />
</a>
<!--
<a alt="python">
<img src="https://img.shields.io/pypi/pyversions/awsimple" />
</a>
-->
<a alt="license">
<img src="https://img.shields.io/github/license/jamesabel/awsimple" />
</a>
</p>
# AWSimple
*(pronounced A-W-Simple)*
Simple API for basic AWS services such as S3 (Simple Storage Service), DynamoDB (a NoSQL database), SNS (Simple Notification Service),
and SQS (Simple Queuing Service).
Project featured on [PythonBytes Podcast Episode #224](https://pythonbytes.fm/episodes/show/224/join-us-on-a-python-adventure-back-to-1977).
Full documentation available on [Read the Docs](https://awsimple.readthedocs.io/) .
### Features:
- Simple Object-Oriented API on top of boto3.
- Eliminates the need to worry about `clients`, `resources`, `sessions`, and pagination.
- Locally cached S3 accesses. Reduces network traffic, AWS costs, and can speed up access.
- `pubsub` functionality (via SNS topics and SQS queues).
- DynamoDB full table scans (with local cache option that only rescans if the table has changed).
- Convert back and forth between DynamoDB items and Python dictionaries automatically. Converts many common data types to DynamoDB compatible types,
including nested structures, sets, images (PIL), and Enum/StrEnum.
- True file hashing (SHA512) for S3 files (S3's etag is not a true file hash).
- Supports moto mock and localstack. Handy for testing and CI.
- Automatic S3 retries.
- One-line S3 file write, read, and delete.
- DynamoDB secondary indexes.
- Built-in pagination (e.g. for DynamoDB table scans and queries). Always get everything you asked for.
- Can automatically set SQS timeouts based on runtime data (can also be user-specified).
## Usage
pip install awsimple
## Examples
The example folder has several examples you can customize and run. Instructions are available in [examples](EXAMPLES.md)
### S3
# print string contents of an existing S3 object
s = S3Access(profile_name="testawsimple", bucket="testawsimple").read_string("helloworld.txt")
print(s)
### DynamoDB
dynamodb_access = DynamoDBAccess(profile_name="testawsimple", table_name="testawsimple")
# put an item into DynamoDB
dynamodb_access.put_item({"id": "batman", "city": "Gotham"})
# now get it back
item = dynamodb_access.get_item("id", "batman")
print(item["city"]) # Gotham
## Introduction
`awsimple` is a simple interface into basic AWS services such as S3 (Simple Storage Service) and
DynamoDB (a simple NoSQL database). It has a set of higher level default settings and behavior
that should cover many basic usage models.
## Discussion
AWS's "serverless" resources offer many benefits. You only pay for what you use, easily scale,
and generally have high performance and availability.
While AWS has many varied services with extensive flexibility, using it for more straight-forward
applications is sometimes a daunting task. There are access modes that are probably not requried
and some default behaviors are not best for common usages. `awsimple` aims to create a higher
level API to AWS services (such as S3, DynamoDB, SNS, and SQS) to improve programmer productivity.
## S3
`awsimple` calculates the local file hash (sha512) and inserts it into the S3 object metadata. This is used
to test for file equivalency.
## Caching
S3 objects and DynamoDB tables can be cached locally to reduce network traffic, minimize AWS costs,
and potentially offer a speedup.
DynamoDB cached table scans are particularly useful for tables that are infrequently updated.
## What`awsimple` Is Not
- `awsimple` is not necessarily the most memory and CPU efficient
- `awsimple` does not provide cost monitoring hooks
- `awsimple` does not provide all the options and features that the regular AWS API (e.g. boto3) does
## Updates/Releases
3.x.x - Cache life for cached DynamoDB scans is now based on most recent table modification time (kept in a separate
table). Explict cache life is no longer required (parameter has been removed).
## Testing using moto mock and localstack
moto mock-ing can improve performance and reduce AWS costs. `awsimple` supports both moto mock and localstack.
In general, it's recommended to develop with mock and finally test with the real AWS services.
Select via environment variables:
- AWSIMPLE_USE_MOTO_MOCK=1 # use moto
- AWSIMPLE_USE_LOCALSTACK=1 # use localstack
### Test Time
| Method | Test Time (seconds) | Speedup (or slowdown) | Comment |
|------------|---------------------|-----------------------|-----------------|
| AWS | 462.65 | 1x | baseline |
| mock | 40.46 | 11x | faster than AWS |
| localstack | 2246.82 | 0.2x | slower than AWS |
System: Intel® Core™ i7 CPU @ 3.47GHz, 32 GB RAM
## Contributing
Contributions are welcome, and more information is available in the [contributing guide](CONTRIBUTING.md).
| text/markdown | abel | j@abel.co | null | null | MIT License | aws, cloud, storage, database, dynamodb, s3 | [] | [] | https://github.com/jamesabel/awsimple | https://github.com/jamesabel/awsimple | >3.10 | [] | [] | [] | [
"boto3",
"typeguard",
"hashy>=0.1.1",
"dictim",
"appdirs",
"tobool",
"urllib3",
"python-dateutil",
"yasf",
"strif"
] | [] | [] | [] | [
"Documentation, https://awsimple.readthedocs.io/"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-20T05:51:07.793674 | awsimple-7.1.5-py3-none-any.whl | 40,615 | e7/cc/06685ab91047328079163099d580b9c9bfe7b5814f75f86efdd3c746854e/awsimple-7.1.5-py3-none-any.whl | py3 | bdist_wheel | null | false | 05f7e462f9943433f88add4d907f100d | 682b58d5e5624863bfa2d928226760f7dd695bc01d3c0d184deec284b26b1469 | e7cc06685ab91047328079163099d580b9c9bfe7b5814f75f86efdd3c746854e | null | [
"LICENSE",
"LICENSE.txt"
] | 178 |
2.4 | pulumi-azuredevops | 3.13.0a1771566205 | A Pulumi package for creating and managing Azure DevOps. | [](https://github.com/pulumi/pulumi-azuredevops/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/azuredevops)
[](https://pypi.org/project/pulumi-azuredevops)
[](https://badge.fury.io/nu/pulumi.azuredevops)
[](https://pkg.go.dev/github.com/pulumi/pulumi-azuredevops/sdk/v3/go)
[](https://github.com/pulumi/pulumi-azuredevops/blob/master/LICENSE)
# Azure DevOps Resource Provider
The Azure DevOps resource provider for Pulumi lets you manage Azure DevOps
resources in your cloud programs. To use this package, please [install the
Pulumi CLI first](https://pulumi.io/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/azuredevops
or `yarn`:
$ yarn add @pulumi/azuredevops
### Python
To use from Python, install using `pip`:
$ pip install pulumi_azuredevops
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-azuredevops/sdk/v3
## Configuration
The following configuration points are available:
* `azuredevops:orgServiceUrl` - (Required) This is the Azure DevOps organization url. It can also be sourced from the `AZDO_ORG_SERVICE_URL` environment variable.
* `azuredevops:personalAccessToken` - (Required) This is the Azure DevOps organization personal access token. The account corresponding to the token will need "owner" privileges for this organization. It can also be sourced from the `AZDO_PERSONAL_ACCESS_TOKEN` environment variable.
## Reference
For further information, please visit [the AzureDevOps provider docs](https://www.pulumi.com/registry/packages/azuredevops/)
or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/registry/packages/azuredevops/api-docs/).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, azuredevops | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-azuredevops"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T05:50:52.655056 | pulumi_azuredevops-3.13.0a1771566205.tar.gz | 281,137 | 62/c6/fb18f72f52d483f1164b849a645783ad6ee9b635b8130e60b233bfc9af8e/pulumi_azuredevops-3.13.0a1771566205.tar.gz | source | sdist | null | false | 7a2e7d714246040435f63eb864772157 | 54fdf7ea731f4a9ec5d72f2494b9b92a75f1ff0d87c810c19596b3a14f5b985f | 62c6fb18f72f52d483f1164b849a645783ad6ee9b635b8130e60b233bfc9af8e | null | [] | 219 |
2.4 | geeknote | 3.0.24 | Geeknote - is a command line client for Evernote, that can be used on Linux, FreeBSD and macOS. | This is the only fork of Geeknote that WORKS, on Python 3. Looks like nobody else is interested in Geeknote anymore, so I declare this repo as main. Feel free to contribute.
===
[](https://sonarcloud.io/summary/new_code?id=vitaly-zdanevich_geeknote)
Geeknote for Evernote (or 印象笔记)
===
Geeknote is a command line client for Evernote that can be used on Linux, FreeBSD, macOS or other systems with Python, even Windows.
It allows you to:
* create notes in your Evernote account;
* create tags, notebooks;
* use Evernote search from the console using different filters;
* edit notes directly in the console using any editor, such as nano, vim or mcedit;
* synchronize your local files and directories with Evernote;
* use Evernote with cron or any scripts.
In this document we will show how to work with Evernote notes, notebooks, and tags using Geeknote and how to use Geeknote sync.
## Installation
You can install Geeknote using [Homebrew](http://brew.sh/)/[Linuxbrew](https://github.com/Homebrew/linuxbrew), or from its source.
(Generate formula by `brew create --python --set-version 3.0.1 https://github.com/vitaly-zdanevich/geeknote/archive/refs/tags/v3.0.1.tar.gz`)
## Homebrew installation TODO publish to public cask
``` sh
brew install --HEAD https://raw.githubusercontent.com/vitaly-zdanevich/geeknote/master/geeknote.rb
```
## Gentoo Guru
https://github.com/gentoo/guru/tree/master/app-doc/geeknote
```sh
emerge -a geeknote
```
## From [PyPI](https://pypi.org/project/geeknote/):
```bash
pip install geeknote
```
## From source
``` sh
# Install dependencies. (This example for Debian-based systems):
sudo apt-get update; sudo apt-get -y install python3-pip
python -m pip install --upgrade pip build wheel
git clone git@github.com:vitaly-zdanevich/geeknote.git
cd geeknote
python -m build
python -m pip install --upgrade .
```
## Testing
Geeknote has a non-destructive unit test suite with fair coverage.
Ensure [pytest](https://repology.org/project/python%3Apytest/versions) framework is installed
``` sh
pip install --upgrade pytest
```
or by using your system package manager (Portage, apt, yum, ...)
Execute the tests
``` sh
pytest
```
If you see errors "No module named 'geeknote'":
```
PYTHONPATH=$(pwd) pytest
```
For manual run after your local changes without installation (in case if you tried `./geeknote` and got
> ImportError: attempted relative import with no known parent package
try this:
```
python -m geeknote.geeknote
```
##### Un-installation
If originally installed via homebrew,
``` sh
brew remove geeknote
```
If originally installed from source,
``` sh
pip uninstall geeknote
```
## Geeknote Settings
##### Authorizing Geeknote
After installation, Geeknote must be authorized with Evernote prior to use. To authorize your Geeknote in Evernote launch the command *login*:
``` sh
geeknote login
```
This will start the authorization process. Geeknote will ask you to enter your credentials just once to generate access token, which will be saved in local database. Re-authorization is not required, if you won't decide to change user.
After authorization you can start to work with Geeknote.
##### Logging out and changing users
If you want to change Evernote user you should launch *logout* command:
``` sh
geeknote logout
```
Afterward, you can repeat the authorization step.
##### (Yìnxiàng Bǐjì notes)
If you want to use Evernote's separate service in China Yìnxiàng Bǐjì (印象笔记),
you need to set the environment variable `GEEKNOTE_BASE` to `yinxiang`.
``` sh
GEEKNOTE_BASE=yinxiang geeknote login
# or
export GEEKNOTE_BASE=yinxiang
geeknote ...commands...
```
Yìnxiàng Bǐjì (印象笔记) is faster in China and it supports Chinese payment methods.
Be aware that Yìnxiàng Bǐjì will not have support for sharing social features
like Twitter or Facebook. Furthermore, since data are stored on servers in China,
Chinese authorities have the right to access their data according to current
regulations.
For more information, see:
[Evernote Launches Separate Chinese Service](https://blog.evernote.com/blog/2012/05/09/evernote-launches-separate-chinese-service/)
## Login with a developer token
Geeknote requires a Developer token after an unsuccessful OAuth request.
You can obtain one by following the next simple steps:
- Create an API key for SANDBOX environment
- Request your API key to be activated on production
- Convert it to a personal token
To do so, go to [Evernote FAQ](https://dev.evernote.com/support/faq.php#createkey) and refer to
the section "How do I create an API key?". As directed, click on the
"Get an API Key" button at the top of the page, and complete the
revealed form. You'll then receive an e-mail with your key and
secret.
When you receive your key and secret, activate your key by following the
instructions on the ["How do I copy my API key from Sandbox to www (production)?"](https://dev.evernote.com/support/faq.php#activatekey) section of the FAQ.
Be sure to specify on the form that you're using the key for the "geeknote" application.
Once your API key activation is processed by Evernote Developer
Support, they will send you an email with further instructions on
obtaining the personal token.
##### Examining your settings
``` sh
$ geeknote settings
Geeknote
******************************
Version: 3.0
App dir: /Users/username/.geeknote
Error log: /Users/username/.geeknote/error.log
Current editor: vim
Markdown2 Extras: None
Note extension: .markdown, .org
******************************
Username: username
Id: 11111111
Email: example@gmail.com
```
##### Setting up the default editor
You can edit notes within console editors in plain text or markdown format.
You can setup the default editor you want to use. To check which editor is now set up as a default call:
``` sh
geeknote settings --editor
```
To change the default editor call:
``` sh
geeknote settings --editor vim
```
To use `gvim` you need to prevent forking from the terminal with `-f`:
``` sh
geeknote settings --editor 'gvim -f'
```
###### Example
``` sh
$ geeknote settings --editor
Current editor is: nano
$ geeknote settings --editor vim
Editor successfully saved
$ geeknote settings --editor
Current editor is: vim
```
##### Enabling Markdown2 Extras
You can enable [Markdown2 Extras](https://github.com/trentm/python-markdown2/wiki/Extras) you want to use while editing notes. To check which settings are currently enabled call:
``` sh
geeknote settings --extras
```
To change the Markdown2 Extras call:
```sh
geeknote settings --extras "tables, footnotes"
```
###### Example
``` sh
$ geeknote settings --extras
current markdown2 extras is : ['None']
$ geeknote settings --extras "tables, footnotes"
Changes saved.
$ geeknote settings --extras
current markdown2 extras is : ['tables', 'footnotes']
```
## Working with Notes
### Notes: Creating notes
The main functionality that we need is creating notes in Evernote.
##### Synopsis
``` sh
geeknote create --title <title>
[--content <content>]
[--tag <tag>]
[--created <date and time>]
[--resource <attachment filename>]
[--notebook <notebook where to save>]
[--reminder <date and time>]
[--url <url>]
```
##### Options
| Option | Argument | Description |
|------------|----------|-------------|
| ‑‑title | title | With this option we specify the title of new note we want to create. |
| ‑‑content | content | Specify the content of new note. The content must not contain double quotes. |
| ‑‑tag | tag | Specify tag that our note will have. May be repeated. |
| ‑‑created | date | Set note creation date and time in either 'yyyy-mm-dd' or 'yyyy-mm-dd HH:MM' format. |
| ‑‑resource | attachment filename, like: document.pdf |Specify file to be attached to the note. May be repeated. |
| ‑‑notebook | notebook where to save | Specify the notebook where new note should be saved. This option is not required. If it isn't given, the note will be saved in default notebook. If notebook doesn't exist Geeknote will create it automatically. |
| ‑‑reminder | date | Set reminder date and time in either 'yyyy-mm-dd' or 'yyyy-mm-dd HH:MM' format. Alternatively use TOMORROW and WEEK for 24 hours and a week ahead respectively, NONE for a reminder without a time. Use DONE to mark a reminder as completed. |
| --urls | url | Set the URL for the note. |
| --raw | | A flag signifying the content is in raw ENML format. |
| --rawmd | | A flag signifying the content is in raw markdown format. |
##### Description
This command allows us to create a new note in Evernote. Geeknote has designed for using in console, so we have some restrictions like inability to use double quotes in **--content** option. But there is a method to avoid it - use stdin stream or file synchronization, we show it later in documentation.
##### Examples
Creating a new note with a PDF attachment:
``` sh
geeknote create --title "Shopping list"
--content "Don't forget to buy milk, turkey and chips."
--resource shoppinglist.pdf
--notebook "Family"
--tag "shop" --tag "holiday" --tag "important"
```
Creating a new note and editing content in editor (notice the lack of `content` argument):
``` sh
geeknote create --title "Meeting with customer"
--notebook "Meetings"
--tag "projectA" --tag "important" --tag "report"
--created "2015-10-23 14:30"
```
### Notes: Searching for notes in Evernote
You can easily search notes in Evernote with Geeknote and output results in the console.
##### Synopsis
``` sh
geeknote find --search <text to find>
[--tag <tag>]
[--notebook <notebook>]
[--date <date or date range>]
[--count <how many results to show>]
[--exact-entry]
[--content-search]
[--url-only]
[--reminders-only]
[--deleted-only]
[--ignore-completed]
[--with-tags]
[--with-notebook]
[--guid]
```
##### Description
Use **find** to search through your Evernote notebooks, with options to search and print more detail. Geeknote remembers the result of the last search. So, you can use the ID number of the note's position for future actions.
For example:
``` sh
$ geeknote find --search "Shopping"
Total found: 2
1 : 2006-06-02 2009-01-19 Grocery Shopping List
2 : 2015-02-22 2015-02-24 Gift Shopping List
$ geeknote show 2
################### URL ###################
NoteLink: https://www.evernote.com/shard/s1/nl/2079/7aecf253-c0d9-407e-b4e2-54cd5510ead6
WebClientURL: https://www.evernote.com/Home.action?#n=7aecf253-c0d9-407e-b4e2-54cd5510ead6
################## TITLE ##################
Gift Shopping List
=================== META ==================
Notebook: EverNote
Created: 2015-02-22
Updated: 2012-02-24
|||||||||||||||| REMINDERS ||||||||||||||||
Order: None
Time: None
Done: None
----------------- CONTENT -----------------
Tags: shopping
Socks
Silly Putty
Furby
```
That will show you the note "Gift Shopping List".
##### Options
| Option | Argument | Description |
|--------------------|-----------------|-------------|
| ‑‑search | text to find | Set the text to find. You can use "*" like this: *--search "Shop*"* |
| ‑‑tag | tag | Filter by tag. May be repeated. |
| ‑‑notebook | notebook | Filter by notebook. |
| ‑‑date | date or range | Filter by date. You can set a single date in 'yyyy-mm-dd' format or a range with 'yyyy-mm-dd/yyyy-mm-dd' |
| ‑‑count | how many results to show | Limits the number of displayed results. |
| ‑‑content-search | | *find* command searches by note's title. If you want to search by note's content - set this flag. |
| ‑‑exact-entry | | By default Geeknote has a smart search, so it searches fuzzy entries. But if you need exact entry, you can set this flag. |
| ‑‑guid | | Show GUID of the note as substitute for result index. |
| ‑‑ignore-completed | | Include only unfinished reminders. |
| ‑‑reminders-only | | Include only notes with a reminder. |
| ‑‑deleted-only | | Include only notes that have been **deleted/trashed**. |
| ‑‑with-notebook | | Show notebook containing the note. |
| ‑‑with-tags | | Show tags of the note after note title. |
| ‑‑with-url | | Show results as a list of URLs to each note in Evernote's web-client. |
##### Examples
``` sh
geeknote find --search "How to patch KDE2" --notebook "jokes" --date 2015-10-14/2015-10-28
geeknote find --search "apt-get install apache nginx" --content-search --notebook "manual"
```
### Notes: Editing notes
With Geeknote you can edit your notes in Evernote using any editor you like (nano, vi, vim, emacs, etc.)
##### Synopsis
``` sh
geeknote edit --note <title or GUID of note to edit>
[--title <the new title>]
[--content <new content or "WRITE">]
[--resource <attachment filename>]
[--tag <tag>]
[--created <date and time>]
[--notebook <new notebook>]
[--reminder <date and time>]
[--url <url>]
```
##### Options
| Option | Argument | Description |
|------------|----------|-------------|
| ‑‑note | title of note which to edit | Tells Geeknote which note we want to edit. Geeknote searches by that name to locate a note. If Geeknote finds more than one note with such name, it will ask you to make a choice. |
| ‑‑title | a new title | Use this option if you want to rename your note. Just set a new title, and Geeknote will rename the old one. |
| ‑‑content | new content or "WRITE" | Enter the new content of your notes in text, or write instead the option "WRITE". In the first case the old content of the note will be replaced with the new content. In the second case Geeknote will get the current content and open it in Markdown in a text editor. |
| ‑‑resource | attachment filename, like: document.pdf | Specify file to be attached to the note. May be repeated. Will replace existing resources. |
| ‑‑tag | tag | Tag to be assigned to the note. May be repeated. Will replace existing tags. |
| ‑‑created | date | Set note creation date date and time in either 'yyyy-mm-dd' or 'yyyy-mm-dd HH:MM' format. |
| ‑‑notebook | target notebook | With this option you can change the notebook which contains your note. |
| ‑‑reminder | date | Set reminder date and time in either 'yyyy-mm-dd' or 'yyyy-mm-dd HH:MM' format. Alternatively use TOMORROW and WEEK for 24 hours and a week ahead respectively, NONE for a reminder without a time. Use DONE to mark a reminder as completed. Use DELETE to remove reminder from a note. |
| --urls | url | Set the URL for the note. |
| --raw | | A flag signifying the content is in raw ENML format. |
| --rawmd | | A flag signifying the content is in raw markdown format. |
##### Examples
Renaming the note:
``` sh
geeknote edit --note "Naughty List" --title "Nice List"
```
Renaming the note and editing content in editor:
``` sh
geeknote edit --note "Naughty List" --title "Nice List" --content "WRITE"
```
### Notes: Showing note content
You can output any note in console using command *show* either independently or as a subsequent command to *find*. When you use *show* on a search made previously in which there was more than one result, Geeknote will ask you to make a choice.
##### Synopsis
``` sh
geeknote show <text or GUID to search and show>
```
##### Examples
``` sh
$ geeknote show "Shop*"
Total found: 2
1 : Grocery Shopping List
2 : Gift Shopping List
0 : -Cancel-
: _
```
As we mentioned before, *show* can use the results of previous search, so if you have already done the search, just call *show* with number of previous search results.
``` sh
$ geeknote find --search "Shop*"
Total found: 2
1 : Grocery Shopping List
2 : Gift Shopping List
$ geeknote show 2
```
### Notes: Removing notes
You can remove notes with Geeknotes from Evernote.
##### Synopsis
``` sh
geeknote remove --note <note name or GUID>
[--force]
```
##### Options
| Option | Argument | Description |
|--------------------|-----------------|-------------|
| ‑‑note | note name | Name of the note you want to delete. If Geeknote will find more than one note, it will ask you to make a choice. |
| ‑‑force | | A flag that says that Geeknote shouldn't ask for confirmation to remove note. |
##### Examples
``` sh
geeknote remove --note "Shopping list"
```
### Notes: De-duplicating notes
Geeknote can find and remove duplicate notes.
##### Synopsis
``` sh
geeknote dedup [--notebook <notebook>]
```
##### Options
| Option | Argument | Description |
|--------------------|-----------------|-------------|
| ‑‑notebook | notebook | Filter by notebook. |
##### Description
Geeknote can locate notes that have the same title and content, and move duplicate notes to the trash.
For large accounts, this process can take some time and might trigger the API rate limit.
For that reason, it's possible to scope the de-duplication to a notebook at a time.
##### Examples
``` sh
geeknote dedup --notebook Contacts
```
## Working with Notebooks
### Notebooks: show the list of notebooks
Geeknote can display the list of all notebooks you have in Evernote.
##### Synopsis
``` sh
geeknote notebook-list [--guid]
```
##### Options
| Option | Argument | Description |
|--------------------|-----------------|-------------|
| ‑‑guid | | Show GUID of the notebook as substitute for result index. |
### Notebooks: creating a notebook
With Geeknote you can create notebooks in Evernote right in console!
##### Synopsis
``` sh
geeknote notebook-create --title <notebook title>
```
##### Options
| Option | Argument | Description |
|--------------------|-----------------|-------------|
| ‑‑title | notebook title | With this option we specify the title of new note we want to create. |
##### Examples
``` sh
geeknote notebook-create --title "Sport diets"
```
### Notebooks: renaming a notebook
With Geeknote it's possible to rename existing notebooks in Evernote.
##### Synopsis
``` sh
geeknote notebook-edit --notebook <old name>
--title <new name>
```
##### Options
| Option | Argument | Description |
|--------------------|-----------------|-------------|
| ‑‑notebook | old name | Name of existing notebook you want to rename. |
| ‑‑title | new name | New title for notebook |
##### Examples
``` sh
geeknote notebook-edit --notebook "Sport diets" --title "Hangover"
```
### Notebooks: removing a notebook
With Geeknote it's possible to remove existing notebooks in Evernote.
##### Synopsis
``` sh
geeknote notebook-remove --notebook <notebook>
[--force]
```
##### Options
| Option | Argument | Description |
|--------------------|-----------------|-------------|
| ‑‑notebook | notebook | Name of existing notebook you want to delete. |
| ‑‑force | | A flag that says that Geeknote shouldn't ask for confirmation to remove notebook. |
##### Examples
``` sh
geeknote notebook-remove --notebook "Sport diets" --force
```
## Working with Tags
### Tags: showing the list of tags
You can get the list of all tags you have in Evernote.
##### Synopsis
``` sh
geeknote tag-list [--guid]
```
##### Options
| Option | Argument | Description |
|--------------------|-----------------|-------------|
| ‑‑guid | | Show GUID of the tag as substitute for result index. |
### Tags: creating a new tag
Usually tags are created with publishing new note. But if you need, you can create a new tag with Geeknote.
##### Synopsis
``` sh
geeknote tag-create --title <tag name to create>
```
##### Options
| Option | Argument | Description |
|--------------------|-----------------|-------------|
| ‑‑title | tag name to create | Set the name of tag you want to create. |
##### Examples
``` sh
geeknote tag-create --title "Hobby"
```
### Tags: renaming a tag
You can rename the tag:
##### Synopsis
``` sh
geeknote tag-edit --tagname <old name>
--title <new name>
```
##### Options
| Option | Argument | Description |
|--------------------|-----------------|-------------|
| ‑‑tagname | old name | Name of existing tag you want to rename. |
| ‑‑title | new name | New name for tag. |
##### Examples
``` sh
geeknote tag-edit --tagname "Hobby" --title "Girls"
```
## gnsync - synchronization app
Gnsync is an additional application installed with Geeknote. Gnsync allows synchronization of files in local directories with Evernote. It works with text data and html with picture attachment support.
##### Synopsis
``` sh
gnsync --path <path to directory which to sync>
[--mask <unix shell-style wildcards to select the files, like *.* or *.txt or *.log>]
[--format <in what format to save the note - plain, markdown, or html>]
[--notebook <notebook, which will be used>]
[--all]
[--logpath <path to logfile>]
[--two-way]
[--download]
```
##### Options
| Option | Argument | Description |
|--------------------|-----------------|-------------|
| ‑‑path | directory to sync | The directory you want to sync with Evernote. It should be the directory with text content files. |
| ‑‑mask | unix shell-style wildcards to select the files | You can tell *gnsync* what filetypes to sync. By default *gnsync* tries to open every file in the directory. But you can set the mask like: *.txt, *.log, *.md, *.markdown. |
| ‑‑format | in what format to save the note - plain or markdown | Set the engine which to use while files uploading. *gnsync* supports markdown and plain text formats. By default it uses plain text engine. |
| ‑‑notebook | notebook where to save | You can set the notebook which will be synchronized with local directory. But if you won't set this option, *gnsync* will create new notebook with the name of the directory that you want to sync. |
| ‑‑all | | You can specify to synchronize all notebooks already on the server, into subdirectories of the path. Useful with --download to do a backup of all notes. |
| ‑‑logpath | path to logfile | *gnsync* can log information about syncing and with that option you can set the logfile. |
| ‑‑two-way | | Normally *gnsync* will only upload files. Adding this flag will also make it download any notes not present as files in the notebook directory (after uploading any files not present as notes) |
| ‑‑download-only | | Normally *gnsync* will only upload files. Adding this flag will make it download notes, but not upload any files |
##### Description
The application *gnsync* is very useful in system administration, because you can synchronize you local logs, statuses and any other production information with Evernote.
##### Examples
``` sh
gnsync --path /home/project/xmpp/logs/
--mask "*.logs"
--logpath /home/user/logs/xmpp2evernote.log
--notebook "XMPP logs"
```
### Original Contributors
* Vitaliy Rodnenko
* Simon Moiseenko
* Ivan Gureev
* Roman Gladkov
* Greg V
* Ilya Shmygol
## Evernote related projects worth mentioning
* [NixNote: GUI, storing notes in SQLite, on C++](https://github.com/robert7/nixnote2)
* [CLInote: cli, written in faster Go](https://github.com/TcM1911/clinote)
| text/markdown | Vitaly Zdanevich | null | null | null | null | evernote, console | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: End Users/Desktop",
"Environment :: Console",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Utilities"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"evernote2",
"html2text",
"sqlalchemy",
"markdown2",
"beautifulsoup4",
"thrift",
"lxml",
"proxyenv; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/vitaly-zdanevich/geeknote",
"Repository, https://github.com/vitaly-zdanevich/geeknote",
"Issues, https://github.com/vitaly-zdanevich/geeknote/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T05:50:36.997698 | geeknote-3.0.24.tar.gz | 73,164 | 7e/a7/22093895a905b588367c458c1902f6109785290ece6824a3c21fac69836d/geeknote-3.0.24.tar.gz | source | sdist | null | false | c649e0116c3e4bbf106d097ddc0aab17 | 9b3e3cbdfaf237703f4cacfa0a20beb2472cedb7310d240c81ec50bc81e4cec4 | 7ea722093895a905b588367c458c1902f6109785290ece6824a3c21fac69836d | GPL-3.0-only | [
"COPYING"
] | 238 |
2.4 | sf-vector-sdk | 0.6.0 | Python SDK for the Vector Gateway service (embeddings and vector search) | # Vector SDK for Python
A lightweight Python client for submitting embedding requests and vector search queries to the Vector Gateway service.
## Overview
The Vector SDK provides a simple interface for generating embeddings via the centralized Vector Gateway service. The SDK communicates directly with Redis Streams, making it efficient and suitable for any Python service that can reach the shared Redis VM.
**Key Features:**
- Simple, Pythonic API with namespace-based organization
- Intuitive methods: `client.embeddings`, `client.search`, `client.db`
- Asynchronous request submission with optional waiting
- Full type hints and documentation
- Multiple embedding model support (Google Vertex AI and OpenAI)
- Client-side model validation before submission
- Minimal dependencies (just Redis)
## Installation
### From Source (Monorepo)
```bash
cd packages/py/vector-sdk
pip install -e .
# Or with uv
uv pip install -e .
```
### From Package Registry (when published)
```bash
pip install sf-vector-sdk
```
## Authentication
All SDK operations require a valid API key. Contact your administrator to obtain an API key.
```python
from vector_sdk import VectorClient
client = VectorClient(
redis_url="redis://your-redis-host:6379",
http_url="http://localhost:8080",
api_key="vsk_v1_your_api_key_here", # Required
)
```
**API Key Format:** `vsk_v1_{32_random_chars}`
**Unauthenticated Usage:** Some utility functions work without VectorClient or API key:
```python
from vector_sdk import compute_content_hash, extract_tool_text
# These work offline - no API key required
hash_val = compute_content_hash(
"FlashCard",
{"type": "BASIC", "term": "ATP", "definition": "Adenosine triphosphate"}
)
```
## Quick Start
### Basic Usage
```python
from vector_sdk import VectorClient
import os
# Create client with API key
client = VectorClient(
redis_url="redis://your-redis-host:6379",
http_url="http://localhost:8080",
api_key=os.environ["VECTOR_API_KEY"], # Required
)
# Create embeddings
result = client.embeddings.create_and_wait(
texts=[
{"id": "doc1", "text": "Introduction to machine learning"},
{"id": "doc2", "text": "Deep neural networks explained"},
],
content_type="topic",
)
print(f"Processed: {result.processed_count}, Failed: {result.failed_count}")
# Vector search
search_result = client.search.query_and_wait(
query_text="What is machine learning?",
database="turbopuffer",
namespace="topics",
top_k=10,
)
for match in search_result.matches:
print(f"{match.id}: {match.score}")
# Direct database lookup (no embedding)
docs = client.db.get_by_ids(
ids=["doc1"],
database="turbopuffer",
namespace="topics",
)
client.close()
```
### With Storage Configuration
```python
from vector_sdk import VectorClient, StorageConfig, MongoDBStorage, TurboPufferStorage
client = VectorClient(redis_url="redis://your-redis-host:6379")
# Create embeddings with storage configuration
result = client.embeddings.create_and_wait(
texts=[
{
"id": "tool123",
"text": "Term: Photosynthesis. Definition: The process by which plants convert sunlight into energy.",
"document": {
"toolId": "tool123",
"toolCollection": "FlashCard",
"userId": "user456",
"contentHash": "abc123",
}
}
],
content_type="flashcard",
priority="high",
storage=StorageConfig(
mongodb=MongoDBStorage(
database="events_new",
collection="tool_vectors",
embedding_field="toolEmbedding",
upsert_key="contentHash",
),
turbopuffer=TurboPufferStorage(
namespace="tool_vectors",
id_field="_id",
metadata=["toolId", "toolCollection", "userId"],
),
),
metadata={"source": "my-service"},
)
client.close()
```
### Context Manager
```python
with VectorClient(redis_url="redis://localhost:6379") as client:
result = client.embeddings.create_and_wait(
texts=[{"id": "doc1", "text": "Hello world"}],
content_type="document",
)
# Connection automatically closed
```
## API Reference
### VectorClient
The main client class providing namespaced access to all SDK functionality.
#### Constructor
**Standalone Redis:**
```python
client = VectorClient(
redis_url="redis://localhost:6379",
redis_password="your-password", # Optional
http_url="http://localhost:8080", # Optional, required for db operations
api_key="vsk_v1_your_api_key", # Required
redis_cluster_mode=False, # Default
)
```
**Redis Cluster:**
```python
client = VectorClient(
redis_url="node1:6379,node2:6379,node3:6379",
redis_password="your-password",
redis_cluster_mode=True, # Required for cluster
http_url="http://localhost:8080",
api_key="vsk_v1_your_api_key",
)
```
**Parameters:**
- `redis_url` (str, required): Redis connection URL or comma-separated cluster nodes
- `http_url` (str, optional): HTTP URL for db operations
- `api_key` (str, required): API key for authentication
- `redis_password` (str, optional): Redis password
- `redis_cluster_mode` (bool, optional): Enable cluster mode (default: False)
- `environment` (str, optional): Environment prefix for Redis queue names (e.g., `"staging"`, `"production"`). When set, all stream names are prefixed to isolate environments sharing the same Redis instance. Must match `QUEUE_ENV` on the gateways.
See [REDIS-CONFIGURATION.md](../../docs/REDIS-CONFIGURATION.md) for Redis setup details.
### Namespaces
#### `client.embeddings`
Embedding generation operations.
| Method | Description |
|--------|-------------|
| `create(texts, content_type, ...)` | Submit embedding request, return request ID |
| `wait_for(request_id, timeout)` | Wait for request completion |
| `create_and_wait(texts, content_type, ...)` | Submit and wait for result |
| `get_queue_depth()` | Get current queue depth for each priority |
```python
# Async: create and wait separately
request_id = client.embeddings.create(texts, content_type)
result = client.embeddings.wait_for(request_id)
# Sync: create and wait in one call
result = client.embeddings.create_and_wait(texts, content_type)
# Check queue depth
depths = client.embeddings.get_queue_depth()
```
#### `client.search`
Vector similarity search operations.
| Method | Description |
|--------|-------------|
| `query(query_text, database, ...)` | Submit search query, return request ID |
| `wait_for(request_id, timeout)` | Wait for query completion |
| `query_and_wait(query_text, database, ...)` | Submit and wait for result |
```python
# Vector search with semantic similarity
result = client.search.query_and_wait(
query_text="What is machine learning?",
database="turbopuffer",
namespace="topics",
top_k=10,
include_metadata=True,
)
```
**Vector Passthrough** -- generate one embedding and search multiple namespaces:
```python
# Generate embedding without storage (returns raw vectors)
embed_result = client.embeddings.create_and_wait(
texts=[{"id": "query", "text": "What is machine learning?"}],
content_type="query",
)
query_vector = embed_result.embeddings[0]
# Search multiple namespaces with the same vector (skips re-embedding)
topics = client.search.query_and_wait(
query_text="What is machine learning?",
database="turbopuffer",
namespace="topic_vectors",
query_vector=query_vector,
)
flashcards = client.search.query_and_wait(
query_text="What is machine learning?",
database="turbopuffer",
namespace="flashcard_vectors",
query_vector=query_vector,
)
```
#### `client.db`
Direct database operations (no embedding required). Requires `http_url`.
| Method | Description |
|--------|-------------|
| `get_by_ids(ids, database, ...)` | Lookup documents by ID |
| `find_by_metadata(filters, database, ...)` | Search by metadata filters |
| `clone(id, source_namespace, destination_namespace)` | Clone document between namespaces |
| `delete(id, namespace)` | Delete document from namespace |
#### `client.structured_embeddings`
Type-safe embedding for known tool types (FlashCard, TestQuestion, etc.) with automatic text extraction, content hash computation, and database routing.
| Method | Description |
|--------|-------------|
| `embed_flashcard(data, metadata)` | Embed a flashcard, return request ID |
| `embed_flashcard_and_wait(data, metadata, timeout)` | Embed and wait for result |
| `embed_flashcard_batch(items)` | Embed batch of flashcards, return request ID |
| `embed_flashcard_batch_and_wait(items, timeout)` | Embed batch and wait for result |
| `embed_test_question(data, metadata)` | Embed a test question, return request ID |
| `embed_test_question_and_wait(data, metadata, timeout)` | Embed and wait for result |
| `embed_test_question_batch(items)` | Embed batch of test questions, return request ID |
| `embed_test_question_batch_and_wait(items, timeout)` | Embed batch and wait for result |
| `embed_spaced_test_question(data, metadata)` | Embed a spaced test question, return request ID |
| `embed_spaced_test_question_and_wait(data, metadata, timeout)` | Embed and wait for result |
| `embed_spaced_test_question_batch(items)` | Embed batch of spaced test questions, return request ID |
| `embed_spaced_test_question_batch_and_wait(items, timeout)` | Embed batch and wait for result |
| `embed_audio_recap(data, metadata)` | Embed an audio recap section, return request ID |
| `embed_audio_recap_and_wait(data, metadata, timeout)` | Embed and wait for result |
| `embed_audio_recap_batch(items)` | Embed batch of audio recaps, return request ID |
| `embed_audio_recap_batch_and_wait(items, timeout)` | Embed batch and wait for result |
| `embed_topic(data, metadata)` | Embed a topic (uses `TopicMetadata`), return request ID |
| `embed_topic_and_wait(data, metadata, timeout)` | Embed and wait for result (uses `TopicMetadata`) |
| `embed_topic_batch(items)` | Embed batch of topics (uses `TopicMetadata`), return request ID |
| `embed_topic_batch_and_wait(items, timeout)` | Embed batch and wait for result (uses `TopicMetadata`) |
**Metadata Types:**
- `ToolMetadata` - For tools (FlashCard, TestQuestion, etc.) - requires `tool_id`
- `TopicMetadata` - For topics only - all fields optional (`user_id`, `topic_id`)
```python
from vector_sdk import VectorClient, ToolMetadata, TopicMetadata, TestQuestionInput
client = VectorClient(redis_url="redis://localhost:6379")
# Embed a flashcard - uses ToolMetadata (tool_id required)
result = client.structured_embeddings.embed_flashcard_and_wait(
data={"type": "BASIC", "term": "Mitochondria", "definition": "The powerhouse of the cell"},
metadata=ToolMetadata(tool_id="tool123", user_id="user456", topic_id="topic789"),
)
# Embed a test question - uses ToolMetadata (tool_id required)
result = client.structured_embeddings.embed_test_question_and_wait(
data=TestQuestionInput(
question="What is the capital?",
answers=[...],
question_type="multiplechoice",
),
metadata=ToolMetadata(tool_id="tool456"),
)
# Embed a topic - uses TopicMetadata (all fields optional)
# Note: Topic data requires an "id" field which becomes the TurboPuffer document ID
result = client.structured_embeddings.embed_topic_and_wait(
data={"id": "topic-123", "topic": "Photosynthesis", "description": "The process by which plants convert sunlight to energy"},
metadata=TopicMetadata(user_id="user123", topic_id="topic456"), # No tool_id needed
)
# Batch embedding - embed multiple topics in a single request
from vector_sdk import TopicBatchItem
batch_result = client.structured_embeddings.embed_topic_batch_and_wait(
items=[
TopicBatchItem(data={"id": "topic-1", "topic": "Topic 1", "description": "Description 1"}, metadata=TopicMetadata(user_id="user1")),
TopicBatchItem(data={"id": "topic-2", "topic": "Topic 2", "description": "Description 2"}, metadata=TopicMetadata(topic_id="topic2")),
TopicBatchItem(data={"id": "topic-3", "topic": "Topic 3", "description": "Description 3"}, metadata=TopicMetadata()), # All optional
],
)
```
**Database Routing:**
Set the `STRUCTURED_EMBEDDING_DATABASE_ROUTER` environment variable:
| Value | Behavior |
|-------|----------|
| `dual` | Write to both TurboPuffer AND Pinecone if both have `enabled: True` |
| `turbopuffer` | Only write to TurboPuffer |
| `pinecone` | Only write to Pinecone |
| undefined | Defaults to `turbopuffer` |
```python
# Lookup by IDs
result = client.db.get_by_ids(
ids=["doc1", "doc2"],
database="turbopuffer",
namespace="topics",
)
# Find by metadata
result = client.db.find_by_metadata(
filters={"userId": "user123"},
database="mongodb",
collection="vectors",
database_name="mydb",
)
# Clone between namespaces
result = client.db.clone("doc1", "ns1", "ns2")
# Delete
result = client.db.delete("doc1", "ns1")
# Export entire namespace
export_result = client.db.get_vectors_in_namespace(
namespace="tool_vectors",
include_vectors=True,
)
print(f"Exported {len(export_result.documents)} documents")
```
### Types
#### Result Types
```python
@dataclass
class EmbeddingResult:
request_id: str
status: str # "success", "partial", "failed"
processed_count: int
failed_count: int
errors: list[EmbeddingError]
timing: Optional[TimingBreakdown]
completed_at: datetime
@property
def is_success(self) -> bool: ...
@property
def is_partial(self) -> bool: ...
@property
def is_failed(self) -> bool: ...
@dataclass
class QueryResult:
request_id: str
status: str # "success", "failed"
matches: list[VectorMatch]
error: Optional[str]
timing: Optional[QueryTiming]
completed_at: datetime
@dataclass
class VectorMatch:
id: str
score: float # Similarity score (0-1, higher is more similar)
metadata: Optional[dict]
vector: Optional[list[float]]
```
## Priority Levels
| Priority | Use Case | Description |
|----------|----------|-------------|
| `critical` | Real-time user requests | Reserved quota, processed first |
| `high` | New content embeddings | Standard processing priority |
| `normal` | Updates, re-embeddings | Default priority |
| `low` | Backfill, batch jobs | Processed when capacity available |
```python
result = client.embeddings.create_and_wait(texts, content_type="topic", priority="critical")
```
## Embedding Models
### Supported Models
| Model | Provider | Dimensions | Custom Dims |
|-------|----------|------------|-------------|
| `gemini-embedding-001` | Google | 3072 | No |
| `text-embedding-004` | Google | 768 | No |
| `text-multilingual-embedding-002` | Google | 768 | No |
| `text-embedding-3-small` | OpenAI | 1536 | Yes |
| `text-embedding-3-large` | OpenAI | 3072 | Yes |
### Using a Specific Model
```python
result = client.embeddings.create_and_wait(
texts=[{"id": "doc1", "text": "Hello world"}],
content_type="document",
embedding_model="text-embedding-3-small",
embedding_dimensions=512, # Custom dimensions (only for models that support it)
)
```
## Content Hash
The SDK provides deterministic content hashing for learning tools.
```python
from vector_sdk import compute_content_hash, extract_tool_text
# Compute hash for a FlashCard
hash = compute_content_hash(
"FlashCard",
{"type": "BASIC", "term": "Mitochondria", "definition": "The powerhouse of the cell"}
)
# Extract text for embedding
text = extract_tool_text(
"FlashCard",
{"type": "BASIC", "term": "Mitochondria", "definition": "The powerhouse of the cell"}
)
```
## Migration from EmbeddingClient
The SDK now uses a namespace-based API with `VectorClient`. The old `EmbeddingClient` is preserved for backward compatibility.
### Method Mapping
| Old (EmbeddingClient) | New (VectorClient) |
|----------------------|-------------------|
| `submit()` | `client.embeddings.create()` |
| `wait_for_result()` | `client.embeddings.wait_for()` |
| `submit_and_wait()` | `client.embeddings.create_and_wait()` |
| `get_queue_depth()` | `client.embeddings.get_queue_depth()` |
| `query()` | `client.search.query()` |
| `wait_for_query_result()` | `client.search.wait_for()` |
| `query_and_wait()` | `client.search.query_and_wait()` |
| `lookup_by_ids()` | `client.db.get_by_ids()` |
| `search_by_metadata()` | `client.db.find_by_metadata()` |
| `clone_from_namespace()` | `client.db.clone()` |
| `delete_from_namespace()` | `client.db.delete()` |
### Migration Example
```python
# Old API (still works, emits deprecation warnings)
from vector_sdk import EmbeddingClient
client = EmbeddingClient("redis://localhost:6379")
result = client.submit_and_wait(texts, content_type)
client.close()
# New API (recommended)
from vector_sdk import VectorClient
client = VectorClient(redis_url="redis://localhost:6379")
result = client.embeddings.create_and_wait(texts, content_type)
client.close()
```
## Error Handling
```python
from vector_sdk import VectorClient, ModelValidationError
try:
with VectorClient(redis_url="redis://localhost:6379") as client:
result = client.embeddings.create_and_wait(
texts=[{"id": "doc1", "text": "Hello"}],
content_type="test",
embedding_model="text-embedding-3-small",
timeout=30,
)
if result.is_success:
print("Success!")
elif result.is_partial:
print("Partial success. Errors:")
for err in result.errors:
print(f" - {err.id}: {err.error}")
except ModelValidationError as e:
print(f"Model validation failed: {e}")
except TimeoutError as e:
print(f"Request timed out: {e}")
except ValueError as e:
print(f"Invalid input: {e}")
```
## Testing Redis Connection
### Verify Connection on Startup
Always test the Redis connection after creating the client, especially in serverless environments:
```python
client = VectorClient(
redis_url=os.environ["REDIS_URL"],
redis_password=os.environ["REDIS_PASSWORD"],
redis_cluster_mode=os.environ.get("REDIS_CLUSTER_MODE") == "true",
api_key=os.environ["VECTOR_API_KEY"],
http_url=os.environ.get("HTTP_URL"),
)
# Test connection before using
try:
client.test_connection()
print("✓ Connected to Redis")
except Exception as e:
print(f"Cannot connect to Redis: {e}")
# Common causes:
# - Wrong Redis URL/hostname
# - Network isolation (VPC access required)
# - Wrong password
# - Redis not running
raise
```
**Why this matters:**
- Redis connections are lazy (don't connect until first command)
- Network issues won't be discovered until operations time out
- **Critical for serverless** (Vercel, Lambda) where network access may be restricted
- Provides immediate feedback if Redis is unreachable
## Best Practices
### 1. Test Connection on Startup (Recommended for Serverless)
```python
client = VectorClient(
redis_url="redis://...",
redis_cluster_mode=True,
api_key="vsk_...",
)
# Test connection immediately - raises if unreachable
try:
client.test_connection()
print("Connected to Redis")
except Exception as e:
print(f"Redis connection failed: {e}")
# Handle connection failure (retry, fallback, etc.)
raise
```
**Important for serverless environments:** Test connection on startup to fail fast if Redis is unreachable.
### 2. Use Appropriate Priority
```python
# Use appropriate priority levels
client.embeddings.create(texts, content_type="backfill", priority="low")
client.embeddings.create(texts, content_type="userRequest", priority="critical")
```
### 2. Batch Your Requests
```python
# Batch multiple texts per request for efficiency
texts = [{"id": doc.id, "text": doc.text} for doc in documents]
client.embeddings.create(texts, content_type)
```
### 3. Use Context Managers
```python
with VectorClient(redis_url="redis://...") as client:
# Client automatically closed on exit
pass
```
### 4. Deduplication
The gateway automatically deduplicates embedding requests using the `contentHash` metadata field. If a vector with the same `contentHash` already exists in the target namespace, the embedding generation is skipped to reduce costs.
- **Structured embeddings**: Deduplication is enabled by default for all tool types except Topics (which always re-embed since content may change for the same ID).
- **Raw embeddings**: Pass `allow_duplicates=True` to skip deduplication when needed.
```python
# Default: deduplication enabled (contentHash checked before embedding)
client.embeddings.create(texts, content_type="flashcard", storage=storage_config)
# Opt out of deduplication
client.embeddings.create(texts, content_type="topic", allow_duplicates=True)
```
The `EmbeddingResult` includes a `skipped_count` field showing how many items were deduplicated:
```python
result = client.embeddings.create_and_wait(texts, content_type="flashcard")
print(f"Processed: {result.processed_count}, Skipped: {result.skipped_count}")
```
## License
Proprietary - All rights reserved.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"redis[hiredis]>=5.0.0",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [] | uv/0.10.0 {"installer":{"name":"uv","version":"0.10.0","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Debian GNU/Linux","version":"13","id":"trixie","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T05:49:51.075124 | sf_vector_sdk-0.6.0.tar.gz | 52,140 | b3/0e/3fb53cf5c8ce98d90af539e383febbd47bb18e0969f0ca649b4a958401a0/sf_vector_sdk-0.6.0.tar.gz | source | sdist | null | false | 1c8fcbe1e642a397e0209ec57eeb537a | 89ba1ba6056fa75e0b42ee2f179b08655d5e389448d7547a04ab8c09ead03d49 | b30e3fb53cf5c8ce98d90af539e383febbd47bb18e0969f0ca649b4a958401a0 | null | [] | 220 |
2.3 | csharp_like_file | 0.0.7 | System.IO.File-like in Python. | # csharp-like-file
If you've ever used C# and found yourself missing the sheer convenience of `System.IO.File` and `System.IO.Directory`, you're not alone. I've always loved how those static methods make file operations feel so effortless, so I decided to bring that same "vibe" to Python.
I originally built this just to scratch my own itch, so it's not meant to be some over-engineered masterpiece. It's just a straightforward tool to help you get things done. If you run into a bug or realize I missed a standard C# method you can't live without, just give me a shout in the issues!
## Quick Example
```python
import csdir
import csfile
directory = csdir.create_directory("test_folder") # This returns a pathlib.Path object
csfile.write_all_text(directory / "hello.txt", "Hello World")
```
## Differences from the C# Version
There are a couple of small "cultural" differences between Python and C# that you should know about.
### Encoding (`encoding`)
I've set the default text encoding to UTF-8. I'm not a big fan of C#'s `Encoding.Default` (which can be a bit unpredictable depending on your OS). You can always pass your own encoding parameter if you need something specific.
### Path Resolution (`lexical`)
In C#, a path like `a/b/..` is usually treated as a pure string operation. In that world, it always simplifies to `a`. However, Python here is a bit smarter: if `b` is actually a symlink pointing somewhere else, `..` should take you to the real parent of that target.
I personally think the Python way is more reliable, so that's the default here. But if you really want that classic C# behavior, just set the `lexical` parameter to `True`. It'll ignore the file system and just crunch the path strings for you.
| text/markdown | yueyinqiu | yueyinqiu <yueyinqiu@outlook.com> | null | null | MIT License | file | [] | [] | null | null | >=3.12 | [] | [] | [] | [] | [] | [] | [] | [] | uv/0.9.28 {"installer":{"name":"uv","version":"0.9.28","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T05:47:49.976888 | csharp_like_file-0.0.7-py3-none-any.whl | 3,326 | bb/86/a725f0bb9f43344dc343968fd14c86a51ec129737a930064fa52cf5dc796/csharp_like_file-0.0.7-py3-none-any.whl | py3 | bdist_wheel | null | false | 3037c734def53dec264b0b567504b366 | 87c3197dbd50cf92f2901c3961883dbcbac56b03a8ab75032e1fa60d730d8b7b | bb86a725f0bb9f43344dc343968fd14c86a51ec129737a930064fa52cf5dc796 | null | [] | 0 |
2.4 | qgis-manage | 0.6.4 | A modern CLI for managing QGIS plugin development, deployment, and packaging. | # QGIS Plugin Manager
[](https://pypi.org/project/qgis-manage/)
[](https://pypi.org/project/qgis-manage/)
[](https://pypi.org/project/qgis-manage/)
[](https://github.com/geociencio/qgis-plugin-manager/actions/workflows/main.yml)
[](https://github.com/astral-sh/ruff)
[](http://mypy-lang.org/)
[](https://github.com/geociencio/qgis-plugin-manager/graphs/commit-activity)
[](LICENSE)
[](analysis_results/PROJECT_SUMMARY.md)
[](https://github.com/geociencio/qgis-plugin-manager/stargazers)
[](https://github.com/geociencio/qgis-plugin-manager/issues)
**QGIS Plugin Manager** is a professional, high-performance CLI tool designed to manage the full lifecycle of QGIS plugins. From local development and smart synchronization to official repository compliance and automated versioning. Now available on **PyPI** for easy integration.
---
## 🥇 The "Manager" Difference
`qgis-plugin-manager` is the modern successor to traditional QGIS development workflows.
### 📊 Ecosystem Comparison
| Feature | pb_tool | qgis-plugin-ci | qgis-plugin-manager |
| :--- | :--- | :--- | :--- |
| **Configuration** | Legacy `.cfg` | Hybrid `.yml` | **Pure PEP 621 (TOML)** |
| **Deployment** | Delete & Copy | N/A | **Smart Sync (rsync-like)** |
| **Backups** | None | None | **Rotation & Multi-profile** |
| **Hooks** | Shell only | Shell only | **Native Python + Shell** |
| **Validation** | Basic | Schema only | **Deep Structure & Compliance** |
| **Modern RCC** | Fixed tools | Limited | **Dynamic Tooling & Patching** |
### 🚀 Key Differentiators (USPs)
- **Smart Synchronization (Sync v2.0)**: We use idempotent sync logic. Instead of slow "delete and copy", we only update modified files.
- **Native Python Hooks Architecture**: Write your automation in pure Python via `plugin_hooks.py`. Hooks receive full project context (metadata, paths, profiles).
- **Official Repository "First-Time-Right"**: Built-in `--repo-check` and structural validation catch errors *before* you upload to QGIS.
- **AI-Agent Friendly**: Specifically designed to be easily automated by AI agents, featuring clear metadata and a modular command system.
---
## 📦 Installation
Install system-wide using `uv` (recommended):
```bash
uv tool install qgis-manage
```
Or add as a dev-dependency:
```bash
uv add --group dev qgis-manage
```
Or using `pip`:
```bash
pip install qgis-manage
```
---
## 🛠️ Command Reference
### 1. Project Initialization
Scaffold a professional plugin project.
```bash
# Create a processing plugin
qgis-manage init "My Plugin" --author "Tester" --email "test@test.com" --template processing
```
### 2. Development & Deployment
Speed up your local iteration.
```bash
# Smart deploy to default QGIS profile
qgis-manage deploy
# Deploy to a specific profile with backup rotation
qgis-manage deploy --profile production --max-backups 5
# Purge old backups to save space
qgis-manage deploy --purge-backups
```
### 3. Advanced Hooks (`hooks`)
Manage and test your native Python hooks.
```bash
# List all hooks from pyproject.toml and plugin_hooks.py
qgis-manage hooks list
# Initialize a standard plugin_hooks.py template
qgis-manage hooks init
# Test a hook in isolation without deploying
qgis-manage hooks test pre_deploy
```
### 4. Automated Versioning (`bump`)
Keep your versions in sync across all project files.
```bash
# Increment version (Patch, Minor, Major)
qgis-manage bump patch # 0.1.0 -> 0.1.1
qgis-manage bump minor # 0.1.1 -> 0.2.0
# Sync metadata.txt from pyproject.toml source of truth
qgis-manage bump sync
```
### 5. Packaging & Compliance
Prepare for the Official QGIS Plugin Repository.
```bash
# Create a "Repo-Ready" ZIP package
qgis-manage package
# Package with strict compliance check (fails if binaries or errors found)
qgis-manage package --repo-check --sync-version
```
### 6. Maintenance & Quality
```bash
# Run deep structural validation
qgis-manage validate --strict --repo
# Run QGIS Plugin Analyzer on the project
qgis-manage analyze
# Clean Python artifacts (__pycache__) and build files
qgis-manage clean
```
---
## ⚙️ Configuration (`pyproject.toml`)
Leverage YOUR existing configuration. No new files needed.
```toml
[tool.qgis-manager]
max_backups = 5 # Control backup rotation
[tool.qgis-manager.ignore]
ignore = [
"data/*.csv",
"tests/temp/*"
]
[tool.qgis-manager.hooks]
post_deploy = "python scripts/notify.py"
```
## 🌍 Internationalization (i18n)
Automated compilation and management of `.ts` and `.qm` files is handled by `qgis-manage compile`.
## 📄 License
GPL-2.0-or-later
| text/markdown | null | Juan M Bernales <juanbernales@gmail.com> | null | null | GPL-2.0-or-later | cli, development, manager, plugin, qgis | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU General Public License v2 or later (GPLv2+)",
"Natural Language :: Spanish",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: GIS",
"Topic :: Software Development :: Build Tools"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.0",
"ai-context-core>=3.2.1; extra == \"dev\"",
"mypy>=1.19.1; extra == \"dev\"",
"pre-commit>=4.5.1; extra == \"dev\"",
"qgis-plugin-analyzer>=1.10.0; extra == \"dev\"",
"ruff>=0.14.10; extra == \"dev\"",
"types-setuptools>=80.9.0.20251223; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/geociencio/qgis-plugin-manager",
"Repository, https://github.com/geociencio/qgis-plugin-manager",
"Issues, https://github.com/geociencio/qgis-plugin-manager/issues",
"Changelog, https://github.com/geociencio/qgis-plugin-manager/blob/main/CHANGELOG.md",
"Documentation, https://github.com/geociencio/qgis-plugin-manager#readme"
] | uv/0.9.28 {"installer":{"name":"uv","version":"0.9.28","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Manjaro Linux","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T05:47:16.438630 | qgis_manage-0.6.4.tar.gz | 37,476 | d9/78/2a88ac526b51cace21176bcbb132d17d8a39add75f5e9d13b12bfa8fdae4/qgis_manage-0.6.4.tar.gz | source | sdist | null | false | 2d84a0589b3033c004a31f02af57d6d2 | 23c71f32abb4bc2cbcac80e807d54ae1597ac99ca642f67016d3f20bcaf88fe9 | d9782a88ac526b51cace21176bcbb132d17d8a39add75f5e9d13b12bfa8fdae4 | null | [
"LICENSE"
] | 249 |
2.4 | sparkrun | 0.0.18 | Launch and manage Docker-based inference workloads on NVIDIA DGX Spark systems | # sparkrun
**One command to rule them all**
Launch, manage, and stop inference workloads on one or more NVIDIA DGX Spark systems — no Slurm, no Kubernetes, no fuss.
sparkrun is a unified CLI for running LLM inference on DGX Spark. Point it at your hosts, pick a recipe, and go. It
handles container orchestration, InfiniBand/RDMA detection, model distribution, and multi-node tensor parallelism across
your Spark cluster automatically.
sparkrun does not need to run on a member of the cluster. You can coordinate one or more DGX Sparks from any Linux
machine with SSH access.
```bash
# uv is preferred mechanism for managing python environments
# To install uv:
curl -LsSf https://astral.sh/uv/install.sh | sh
# automatic installation via uvx (manages virtual environment and
# creates alias in your shell, sets up autocomplete too!)
uvx sparkrun setup install
```
<details>
<summary>Alternative: manual pip install</summary>
```bash
pip install sparkrun
# or
uv pip install sparkrun
```
With a manual install you will need to run `sparkrun setup completion` separately for tab completion.
</details>
## Quick Start
### Tab completion
> **Note:** If you installed via `sparkrun setup install`, tab completion is already set up — you can skip this step.
```bash
sparkrun setup completion # auto-detects your shell
sparkrun setup completion --shell zsh
```
After restarting your shell, recipe names, cluster names, and subcommands all tab-complete.
### Save a cluster config
```bash
# Save your hosts once
sparkrun cluster create mylab --hosts 192.168.11.13,192.168.11.14 -d "My DGX Spark lab"
sparkrun cluster set-default mylab
# Now just run — hosts are automatic
sparkrun run nemotron3-nano-30b-nvfp4-vllm
```
### Run an inference job
```bash
# Single node vLLM (Note that minimum nodes / parallelism is configured by the recipe)
sparkrun run qwen3-1.7b-vllm
# Multi-node (2-node tensor parallel) -- using your default two node cluster
sparkrun run qwen3-1.7b-vllm --tp 2
# Override settings on the fly
sparkrun run qwen3-1.7b-vllm --hosts 192.168.11.14 --port 9000 --gpu-mem 0.8
sparkrun run qwen3-1.7b-vllm --tp 2 -H 192.168.11.13,192.168.11.14 -o max_model_len=8192
# GGUF quantized models via llama.cpp
sparkrun run qwen3-1.7b-llama-cpp
```
sparkrun always launches jobs in the background (detached containers) and then follows logs. **Ctrl+C detaches from
logs — it never kills your inference job.** Your model keeps serving.
### Inspect a recipe
```bash
sparkrun show nemotron3-nano-30b-nvfp4-vllm
```
```
Name: nemotron3-nano-30b-nvfp4
Description: NVIDIA Nemotron 3 Nano 30B (upstream NVFP4) -- cluster or solo
Runtime: vllm
Model: nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4
Container: scitrera/dgx-spark-vllm:0.16.0-t5
Nodes: 1 - unlimited
Repository: Local
Defaults:
gpu_memory_utilization: 0.8
max_model_len: 200000
port: 8000
served_model_name: nemotron3-30b-a3b
tensor_parallel: 1
VRAM Estimation:
Model dtype: nvfp4
Model params: 30,000,000,000
KV cache dtype: bfloat16
Architecture: 52 layers, 2 KV heads, 128 head_dim
Model weights: 19.56 GB
KV cache: 9.92 GB (max_model_len=200,000)
Tensor parallel: 1
Per-GPU total: 29.48 GB
DGX Spark fit: YES
GPU Memory Budget:
gpu_memory_utilization: 80%
Usable GPU memory: 96.8 GB (121 GB x 80%)
Available for KV: 77.2 GB
Max context tokens: 1,557,583
Context multiplier: 7.8x (vs max_model_len=200,000)
```
The VRAM estimator auto-detects model architecture from HuggingFace and tells you whether your configuration fits within
DGX Spark's 128 GB unified memory before you launch.
### Custom recipe registries
```bash
# See what's configured
sparkrun recipe registries
# Add a community or private registry
sparkrun recipe add-registry myteam \
--url https://github.com/myorg/spark-recipes.git \
--subpath recipes
# Update all registries
sparkrun recipe update
# Search across all registries
sparkrun search qwen3
```
### Manage running workloads
```bash
# Re-attach to logs (Ctrl+C is always safe) -- NOTE: finds cluster by combination of hosts, model, and runtime
sparkrun logs nemotron3-nano-30b-nvfp4-vllm --cluster mylab
# Stop a workload -- NOTE: finds cluster by combination of hosts, model, and runtime
sparkrun stop nemotron3-nano-30b-nvfp4-vllm --cluster mylab
# If you launched with --tp (modifying the recipe default), e.g.:
sparkrun run nemotron3-nano-30b-nvfp4-vllm --tp 2
# then pass --tp so stop/logs resolve the same cluster ID as run:
sparkrun stop nemotron3-nano-30b-nvfp4-vllm --tp 2
sparkrun logs nemotron3-nano-30b-nvfp4-vllm --tp 2
# TIP: you can just press up and modify "run" to "stop"
```
## Supported Runtimes
### vLLM
First-class support for [vLLM](https://github.com/vllm-project/vllm). Solo and multi-node clustering via Ray. Works with
ready-built images (e.g. `scitrera/dgx-spark-vllm`). Also works with other images including those built from eugr's repo
and/or NVIDIA images.
### SGLang
First-class support for [SGLang](https://github.com/sgl-project/sglang). Solo and multi-node clustering via SGLang's
native distributed backend (`--dist-init-addr`, `--nnodes`, `--node-rank`). Works with ready-built images (e.g.
`scitrera/dgx-spark-sglang`). Should also work with other sglang images, but there seem to be a lot fewer sglang images
around than vllm images.
### llama.cpp
Support for [llama.cpp](https://github.com/ggml-org/llama.cpp) via `llama-server`. Solo mode with GGUF quantized models.
Loads models directly from HuggingFace (e.g. `Qwen/Qwen3-1.7B-GGUF:Q4_K_M`). Lightweight alternative to vLLM/SGLang
for smaller models or constrained environments.
GGUF models use colon syntax to select a quantization variant: `model: Qwen/Qwen3-1.7B-GGUF:Q8_0`. sparkrun
pre-downloads only the matching quant files and resolves the local cache path so the container doesn't need to
re-download at serve time.
**Experimental**: Multi-node inference via llama.cpp's RPC backend. Worker nodes run `rpc-server` and
the head node connects via `--rpc`. This is still evolving both upstream and in sparkrun and should be considered
experimental. Note that the fastest DGX Spark interconnect communication will be via NCCL and RoCE -- and the
llama.cpp RPC mechanism involves a lot more overhead.
### eugr-vllm (compatibility runtime)
Full compatibility with [eugr/spark-vllm-docker](https://github.com/eugr/spark-vllm-docker). This runtime delegates
entirely to eugr's scripts — mods, local builds, and all eugr-specific features work natively because sparkrun calls
their code directly rather than reimplementing it.
Use this when you need a nightly vLLM build, custom modifications, or anything that requires building containers locally
from eugr's repo.
The recipe format for sparkrun is designed to be mostly compatible with eugr's (more like a v2 format) -- sparkrun will
translate any variations in recipe format to the eugr repo format automatically. Changes were mostly to ensure greater
compatibility with multiple runtimes and to reduce redundancy (somewhat). The full command listing is preserved to
ensure greater compatibility, but long-term, runtime implementations should be able to generate commands.
```yaml
# eugr-vllm recipe example
runtime: eugr-vllm
model: my-org/custom-model
container: vllm-node-tf5
runtime_config:
mods: [ my-custom-mod ]
build_args: [ --some-flag ]
```
## How It Works
**Recipes** are YAML files that describe an inference workload: the model, container image, runtime, and default
parameters. sparkrun ships bundled recipes and supports custom registries (any git repo with YAML files). Sparkrun
includes limited recipes and otherwise also includes the eugr repo as a default registry (which also delegates running
to eugr's repo also...). The idea in the long-run is to merge recipes from multiple registries into a single unified
catalog. And be able to run them even if they were designed for different runtimes (e.g. vLLM vs SGLang) without needing
to worry about the underlying command differences. See the [RECIPES](./RECIPES.md) specification file for more details.
**Runtimes** are plugins that know how to launch a specific inference engine. sparkrun discovers them via Python entry
points, so custom runtimes can be added by installing a package.
**Orchestration** is handled over SSH. sparkrun detects InfiniBand/RDMA interfaces on your hosts, distributes container
images and models from local to remote (using the ethernet interfaces of the RDMA interfaces for fast transfers when
available), configures NCCL environment variables, and launches containers with the right networking.
Each DGX Spark has one GPU, so tensor parallelism maps directly to node count: `--tp 2` means 2 hosts.
### SSH Prerequisites
All multi-node orchestration relies on SSH. At minimum, you need **passwordless SSH from your control machine
to every cluster node**. sparkrun pulls container images and models locally and pushes them to each node
directly, so node-to-node SSH is not strictly required for the default workflow.
That said, setting up a **full SSH mesh** (every host can reach every other host) is recommended — it enables
alternative distribution strategies and is generally useful for cluster administration.
The easiest way to set this up is `sparkrun setup ssh`, which creates a full mesh across your cluster
hosts **and** the control machine (included automatically via `--include-self`, on by default):
```bash
# Set up passwordless SSH mesh across your cluster + this machine
sparkrun setup ssh --hosts 192.168.11.13,192.168.11.14 --user ubuntu
# Or use a saved cluster
sparkrun setup ssh --cluster mylab
# Or if you've set your default cluster -- it'll just use that
sparkrun setup ssh
# Add extra hosts beyond the cluster (e.g. a jump host)
sparkrun setup ssh --cluster mylab --extra-hosts 10.0.0.99
# Exclude the control machine from the mesh
sparkrun setup ssh --cluster mylab --no-include-self
```
You will be prompted for passwords on first connection to each host. After that, every host in the
mesh can SSH to every other host without passwords.
<details>
<summary>Manual SSH setup (without sparkrun setup ssh)</summary>
If you prefer to set up SSH yourself, you need key-based auth from your control machine to each node:
```bash
# Generate a key if you don't have one
ssh-keygen -t ed25519
# Copy to each node
ssh-copy-id 192.168.11.13
ssh-copy-id 192.168.11.14
```
</details>
**SSH user**: By default sparkrun uses your current OS user for SSH. You can set a per-cluster user
with `sparkrun cluster create --user dgxuser` or `sparkrun cluster update --user dgxuser`, or override
per-command with `--user`.
<details>
<summary>For more advanced SSH configuration (non-default ports, identity files), use `~/.ssh/config`.</summary>
```
Host spark1
HostName 192.168.11.13
User dgxuser
Host spark2
HostName 192.168.11.14
User dgxuser
```
</details>
Solo mode (`--solo`) runs on a single host and still uses SSH unless the target is `localhost`.
### Docker Group
sparkrun launches containers via `docker` on each host. The SSH user must be a member of the `docker` group
on every cluster node:
```bash
sudo usermod -aG docker "$USER"
```
## Recipes
A recipe is a YAML file:
```yaml
model: nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4
runtime: vllm
min_nodes: 2
container: scitrera/dgx-spark-vllm:0.16.0-t5
metadata:
description: NVIDIA Nemotron 3 Nano 30B (upstream NVFP4)
maintainer: scitrera.ai <open-source-team@scitrera.com>
defaults:
port: 8000
tensor_parallel: 1
gpu_memory_utilization: 0.8
max_model_len: 200000
served_model_name: nemotron3-30b-a3b
command: |
vllm serve {model} \
--served-model-name {served_model_name} \
--max-model-len {max_model_len} \
--gpu-memory-utilization {gpu_memory_utilization} \
-tp {tensor_parallel} \
--host {host} --port {port}
```
Any default can be overridden at launch time with `-o key=value` or dedicated flags like `--port`, `--tp`, `--gpu-mem`.
Recipes can also include an `env` block for environment variables injected into the container. Shell variable
references like `${HF_TOKEN}` are expanded from the control machine's environment, so you can forward secrets
without hardcoding them. See [RECIPES.md](./RECIPES.md) for the full recipe format specification.
### GGUF recipes (llama.cpp)
GGUF recipes use the `llama-cpp` runtime and specify a quantization variant with colon syntax:
```yaml
model: Qwen/Qwen3-1.7B-GGUF:Q8_0
runtime: llama-cpp
min_nodes: 1
max_nodes: 1
container: scitrera/dgx-spark-llama-cpp:latest
defaults:
port: 8000
host: 0.0.0.0
n_gpu_layers: 99
ctx_size: 8192
command: |
llama-server \
-hf {model} \
--host {host} --port {port} \
--n-gpu-layers {n_gpu_layers} \
--ctx-size {ctx_size} \
--flash-attn on --jinja --no-webui
```
When model pre-sync is enabled (the default), sparkrun downloads only the matching quant files locally, distributes
them to target hosts, and rewrites `-hf` to `-m` with the resolved container cache path so the container serves from
the local copy without re-downloading.
## CLI Reference
### Global options
| Option | Description |
|--------------------|-----------------------------|
| `-v` / `--verbose` | Enable verbose/debug output |
| `--version` | Show version and exit |
| `--help` | Show help for any command |
### Workload commands
| Command | Description |
|--------------------------|------------------------------|
| `sparkrun run <recipe>` | Launch an inference workload |
| `sparkrun stop <recipe>` | Stop a running workload |
| `sparkrun logs <recipe>` | Re-attach to workload logs |
**`sparkrun run` options:**
| Option | Description |
|------------------------------|----------------------------------------------------------|
| `--hosts` / `-H` | Comma-separated host list (first = head) |
| `--hosts-file` | File with hosts (one per line, `#` comments) |
| `--cluster` | Use a saved cluster by name |
| `--solo` | Force single-node mode |
| `--port` | Override serve port |
| `--tp` / `--tensor-parallel` | Override tensor parallelism |
| `--gpu-mem` | Override GPU memory utilization (0.0-1.0) |
| `--image` | Override container image (not recommended) |
| `--cache-dir` | HuggingFace cache directory |
| `--option` / `-o` | Override any recipe default: `-o key=value` (repeatable) |
| `--dry-run` / `-n` | Show what would be done without executing |
| `--foreground` | Run in foreground (don't detach) |
| `--no-follow` | Don't follow container logs after launch |
| `--skip-ib` | Skip InfiniBand detection (not recommended) |
| `--ray-port` | Ray GCS port (default: 46379) (vllm) |
| `--init-port` | SGLang distributed init port (default: 25000) |
| `--dashboard` | Enable Ray dashboard on head node (vllm) |
| `--dashboard-port` | Ray dashboard port (default: 8265) |
**`sparkrun stop` options:**
| Option | Description |
|------------------------------|------------------------------|
| `--hosts` / `-H` | Comma-separated host list |
| `--hosts-file` | File with hosts |
| `--cluster` | Use a saved cluster by name |
| `--tp` / `--tensor-parallel` | Match host trimming from run |
| `--dry-run` / `-n` | Show what would be done |
**`sparkrun logs` options:**
| Option | Description |
|------------------------------|-----------------------------------------------------|
| `--hosts` / `-H` | Comma-separated host list |
| `--hosts-file` | File with hosts |
| `--cluster` | Use a saved cluster by name |
| `--tp` / `--tensor-parallel` | Match host trimming from run |
| `--tail` | Number of existing log lines to show (default: 100) |
### Recipe commands
| Command | Description |
|-------------------------------------|---------------------------------------------------|
| `sparkrun list [query]` | List available recipes (alias) |
| `sparkrun show <recipe>` | Show recipe details + VRAM estimate (alias) |
| `sparkrun search <query>` | Search recipes by name/model/description (alias) |
| `sparkrun recipe list [query]` | List available recipes from all registries |
| `sparkrun recipe show <recipe>` | Show detailed recipe information |
| `sparkrun recipe search <query>` | Search for recipes by name, model, or description |
| `sparkrun recipe validate <recipe>` | Validate a recipe file |
| `sparkrun recipe vram <recipe>` | Estimate VRAM usage for a recipe |
**`sparkrun recipe vram` options:**
| Option | Description |
|------------------------------|-------------------------------------------|
| `--tp` / `--tensor-parallel` | Override tensor parallelism |
| `--max-model-len` | Override max sequence length |
| `--gpu-mem` | Override gpu_memory_utilization (0.0-1.0) |
| `--no-auto-detect` | Skip HuggingFace model auto-detection |
### Registry commands
| Command | Description |
|------------------------------------------|-----------------------------------|
| `sparkrun recipe registries` | List configured recipe registries |
| `sparkrun recipe add-registry <name>` | Add a custom recipe registry |
| `sparkrun recipe remove-registry <name>` | Remove a recipe registry |
| `sparkrun recipe update` | Update registries from git |
### Cluster commands
| Command | Description |
|---------------------------------------|-----------------------------------------------------|
| `sparkrun cluster create <name>` | Create a new named cluster (`--user` sets SSH user) |
| `sparkrun cluster update <name>` | Update hosts, description, or user of a cluster |
| `sparkrun cluster list` | List all saved clusters |
| `sparkrun cluster show <name>` | Show details of a saved cluster |
| `sparkrun cluster delete <name>` | Delete a saved cluster |
| `sparkrun cluster set-default <name>` | Set the default cluster |
| `sparkrun cluster unset-default` | Remove the default cluster setting |
| `sparkrun cluster default` | Show the current default cluster |
| `sparkrun cluster status` | Show running containers, pending operations, and IP mappings |
| `sparkrun status` | Alias for `sparkrun cluster status` |
The first host in a cluster definition is used as the **head node** for multi-node jobs. Order the remaining
hosts however you like — they become workers.
### Setup commands
| Command | Description |
|------------------------------------|---------------------------------------------------|
| `sparkrun setup install` | Install sparkrun as a uv tool + tab-completion |
| `sparkrun setup completion` | Install shell tab-completion (bash/zsh/fish) |
| `sparkrun setup update` | Update sparkrun to the latest version |
| `sparkrun setup ssh` | Set up passwordless SSH mesh across hosts |
| `sparkrun setup cx7` | Detect and configure ConnectX-7 NICs across hosts |
| `sparkrun setup fix-permissions` | Fix root-owned HF cache files on cluster hosts |
| `sparkrun setup clear-cache` | Drop Linux page cache on cluster hosts |
## Roadmap
- Additional bundled recipes for popular models
- Health checks and status monitoring for running workloads
## About
sparkrun provides a unified tool for running inference on DGX Spark systems without Slurm or Kubernetes coordination. It
is intended to be donated to a future community organization.
## License
Apache License 2.0 — see [LICENSE](LICENSE) for details.
| text/markdown | null | "scitrera.ai" <open-source-team@scitrera.com> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: System :: Clustering"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"scitrera-app-framework>=0.0.55",
"vpd>=0.9.5",
"click>=8.0",
"pyyaml>=6.0",
"huggingface_hub>=0.20",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest-asyncio>=0.21; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T05:46:50.409979 | sparkrun-0.0.18.tar.gz | 9,544,846 | a2/e8/ee9719c4c094d1f1ab563d672cc88efd423e3055a8436323ab5e3165404a/sparkrun-0.0.18.tar.gz | source | sdist | null | false | 3994742eae4fdf9307ad54993d379033 | 38ae1187440760ee4e34757389bee09a7f916dbaa50327de2440a0d493d69725 | a2e8ee9719c4c094d1f1ab563d672cc88efd423e3055a8436323ab5e3165404a | Apache-2.0 | [
"LICENSE"
] | 249 |
2.4 | jec-api | 0.1.2 | Just Encapsulated Controllers — The Class-Based System for Application Program Interfaces | # JEC-API
A powerful wrapper around FastAPI that brings class-based routing, strict method mapping, and modern developer tools to your API development.
## Features
- **Class-Based Routes**: Group related endpoints into a single class for better organization.
- **Strict Method Mapping**: Methods named `get`, `post`, `put`, etc., are automatically mapped to HTTP verbs.
- **Data Object Support**: Native Pydantic integration for automatic request/response validation and schema generation.
- **API Decorators**: Built-in `@log`, `@speed`, and `@version` decorators for observability and control.
- **Programmatic Configuration**: Unified `core.tinker()` method to configure FastAPI and Uvicorn.
- **JEC DevTools**: Real-time, dark-themed developer console at `/__dev__` for monitoring traffic and performance.
## Installation
```bash
pip install jec-api
```
## Quick Start
1. **Define a Route Class**
```python
from pydantic import BaseModel
from jec_api import Route, log, speed
class UserResponse(BaseModel):
id: int
name: str
class Users(Route):
@log
@speed
async def get(self) -> list[UserResponse]:
"""List all users with logging and speed tracking"""
return [UserResponse(id=1, name="Alice")]
```
2. **Configure and Run**
```python
from jec_api import Core
from routes import Users
core = Core()
core.tinker(
title="My API",
dev=True, # Enable JEC DevTools
reload=True # Auto-reload on changes
)
core.register(Users)
if __name__ == "__main__":
core.run(port=8000)
```
## Usage Guide
### Defining Routes
Inherit from `jec_api.Route`. The class name is converted to kebab-case for the base path (e.g., `UserProfiles` -> `/user-profiles`), unless overridden with the `path` attribute.
### Method Mapping
Methods named exactly after HTTP verbs (e.g., `get`, `post`) are registered as endpoints. Others are ignored.
### API Decorators
Enhance your endpoints with built-in decorators:
- **`@log`**: Logs function calls, arguments, and return values/exceptions.
- **`@speed`**: Measures execution time in milliseconds.
- **`@version(">=1.0.0")`**: Enforces semver constraints via the `X-API-Version` header.
### Configuration (`core.tinker()`)
The `tinker()` method provides a unified interface for configuration:
- **FastAPI Options**: `title`, `description`, `version`, `docs_url`, etc.
- **Uvicorn Options**: `host`, `port`, `reload`, `log_level`, etc.
- **DevTools**: Set `dev=True` to enable the developer console.
- **Versioning**: `strict_versioning=True` to require version headers on all versioned routes.
### JEC DevTools
Access a premium, real-time monitoring dashboard at `/__dev__` (or your custom `dev_path`). It provides:
- Live request/response tracking via SSE.
- Visual execution timing (Green/Yellow/Red).
- Expanded logs for @log decorated methods.
- Version check results.
## License
MIT License
| text/markdown | nik | null | null | null | null | api, class-based, fastapi, routes, web | [
"Development Status :: 5 - Production/Stable",
"Framework :: FastAPI",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Internet :: WWW/HTTP :: HTTP Servers"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"fastapi>=0.100.0",
"httpx>=0.24.0",
"uvicorn>=0.20.0",
"pytest>=7.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/alpheay/jec",
"Repository, https://github.com/alpheay/jec"
] | twine/6.2.0 CPython/3.13.1 | 2026-02-20T05:46:08.338966 | jec_api-0.1.2.tar.gz | 144,704 | bc/b1/82c0293759249dee5c469ea90f87200c22e8e1c29ac390df763608575da8/jec_api-0.1.2.tar.gz | source | sdist | null | false | 63dd5fe87b48494265ccc0e98206e006 | 1cdeffc9ebc2a121518134caf5e518a0b62b4ac5d14a2b2b1b1599571419458b | bcb182c0293759249dee5c469ea90f87200c22e8e1c29ac390df763608575da8 | MIT | [
"LICENSE"
] | 250 |
2.3 | user-scanner | 1.3.0.2 | Check username availability across multiple popular platforms | # User Scanner

<p align="center">
<img src="https://img.shields.io/badge/Version-1.3.0.2-blueviolet?style=for-the-badge&logo=github" />
<img src="https://img.shields.io/github/issues/kaifcodec/user-scanner?style=for-the-badge&logo=github" />
<img src="https://img.shields.io/badge/Tested%20on-Termux-black?style=for-the-badge&logo=termux" />
<img src="https://img.shields.io/badge/Tested%20on-Windows-cyan?style=for-the-badge&logo=Windows" />
<img src="https://img.shields.io/badge/Tested%20on-Linux-black?style=for-the-badge&logo=Linux" />
<img src="https://img.shields.io/pypi/dm/user-scanner?style=for-the-badge" />
</p>
---
A powerful *Email OSINT tool* that checks if a specific email is registered on various sites, combined with *username scanning* for branding or OSINT — 2-in-1 tool.
Perfect for fast, accurate and lightweight email OSINT
Perfect for finding a **unique username** across GitHub, Twitter, Reddit, Instagram, and more, all in a single command.
## Features
- ✅ Email & username OSINT: check email registrations and username availability across social, developer, creator, and other platforms
- ✅ Dual-mode usage: works as an email scanner, username scanner, or username-only tool
- ✅ Clear results: `Registered` / `Not Registered` for emails and `Available` / `Taken` / `Error` for usernames with precise failure reasons
- ✅ Fully modular architecture for easy addition of new platform modules
- ✅ Bulk scanning support for usernames and emails via input files
- ✅ Wildcard-based username permutations with automatic variation generation
- ✅ Multiple output formats: console, **JSON**, and **CSV**, with file export support
- ✅ Proxy support with rotation and pre-scan proxy validation
- ✅ Smart auto-update system with interactive upgrade prompts via PyPI
## Virtual Environment (optional but recommended)
```bash
# create venv
python -m venv .venv
````
## Activate venv
```bash
# Linux / macOS
source .venv/bin/activate
# Windows (PowerShell)
.venv\Scripts\Activate.ps1
```
## Installation
```bash
# upgrade pip
python -m pip install --upgrade pip
# install
pip install user-scanner
```
---
### Important Flags
See [Important flags](docs/FLAGS.md) here and use the tool powerfully
## Usage
### Basic username/email scan
Scan a single email or username across **all** available modules/platforms:
```bash
user-scanner -e john_doe@gmail.com # single email scanning
user-scanner -u john_doe # single username scanning
```
### Verbose mode
Use `-v` flag to show the url of the sites being checked
```bash
user-scanner -v -e johndoe@gmail.com -c dev
```
Output:
```sh
...
[✔] Huggingface [https://huggingface.co] (johndoe@gmail.com): Registered
[✔] Envato [https://account.envato.com] (johndoe@gmail.com): Registered
[✔] Replit [https://replit.com] (johndoe@gmail.com): Registered
[✔] Xda [https://xda-developers.com] (johndoe@gmail.com): Registered
...
```
### Selective scanning
Scan only specific categories or single modules:
```bash
user-scanner -u john_doe -c dev # developer platforms only
user-scanner -e john_doe@gmail.com -m github # only GitHub
```
### Bulk email/username scanning
Scan multiple emails/usernames from a file (one email/username per line):
- Can also be combined with categories or modules using `-c` , `-m` and other flags
```bash
user-scanner -ef emails.txt # bulk email scan
user-scanner -uf usernames.txt # bulk username scan
```
---
### Library mode for email_scan
Only available for `user-scanner>=1.2.0`
See full usage (eg. category checks, full scan) guide [library usage](docs/USAGE.md)
- Email scan example (single module):
```python
import asyncio
from user_scanner.core import engine
from user_scanner.email_scan.dev import github
async def main():
# Engine detects 'email_scan' path -> returns "Registered" status
result = await engine.check(github, "test@gmail.com")
json_data = result.to_json() # returns JSON output
csv_data = result.to_csv() # returns CSV output
print(json_data) # prints the json data
asyncio.run(main())
```
Output:
```json
{
"email": "test@gmail.com",
"category": "Dev",
"site_name": "Github",
"status": "Registered",
"url": "https://github.com",
"reason": ""
}
```
---
### Using Proxies
Validate proxies before scanning (tests each proxy against google.com):
```bash
user-scanner -u john_doe -P proxies.txt --validate-proxies # recommended
```
This will:
1. Filter out non-working proxies
2. Save working proxies to `validated_proxies.txt`
3. Use only validated proxies for scanning
---
## Screenshots:
- Note*: New modules are constantly getting added so screenshots might show only limited, outdated output:
<img width="1080" height="930" alt="1000146237" src="https://github.com/user-attachments/assets/3cbcecaf-3620-49be-9d0a-8f94790acdf0" />
---
<img width="1072" height="848" alt="user-scanner's main usage screenshot" src="https://github.com/user-attachments/assets/34e44ca6-e314-419e-9035-d951b493b47f" />
---
## ❤️ Support the project
If this project helps you, consider supporting its development:
**BTC (SegWit):** `bc1q0dzkuav8lq9lwu7gc457vwlda4utfcr5hpv7ka`
---
## Contributing
Modules are organized under `user_scanner/`:
```
user_scanner/
├── email_scan/ # Currently in development
│ ├── social/ # Social email scan modules (Instagram, Mastodon, X, etc.)
| ├── adult/ # Adult sites
| ... # New sites to be added soon
├── user_scan/
│ ├── dev/ # Developer platforms (GitHub, GitLab, npm, etc.)
│ ├── social/ # Social platforms (Twitter/X, Reddit, Instagram, Discord, etc.)
│ ├── creator/ # Creator platforms (Hashnode, Dev.to, Medium, Patreon, etc.)
│ ├── community/ # Community platforms (forums, StackOverflow, HackerNews, etc.)
│ ├── gaming/ # Gaming sites (chess.com, Lichess, Roblox, Minecraft, etc.)
...
```
See detailed [Contributing guidelines](CONTRIBUTING.md)
---
## Dependencies:
- [httpx](https://pypi.org/project/httpx/)
- [colorama](https://pypi.org/project/colorama/)
---
## License
This project is licensed under the **MIT License**. See [LICENSE](LICENSE) for details.
---
## ⚠️ Disclaimer
This tool is provided for **educational purposes** and **authorized security research** only.
- **User Responsibility:** Users are solely responsible for ensuring their usage complies with all applicable laws and the Terms of Service (ToS) of any third-party providers.
- **Methodology:** The tool interacts only with **publicly accessible, unauthenticated web endpoints**. It does not bypass authentication, security controls, or access private user data.
- **No Profiling:** This software performs only basic **yes/no availability checks**. It does not collect, store, aggregate, or analyze user data, behavior, or identities.
- **Limitation of Liability:** The software is provided **“as is”**, without warranty of any kind. The developers assume no liability for misuse or any resulting damage or legal consequences.
---
## 🛠️ Troubleshooting
Some sites may return **403 Forbidden** or **connection timeout** errors, especially if they are blocked in your region (this is common with some adult sites).
- If a site is blocked in your region, use a VPN and select a region where you know the site is accessible.
- Then run the tool again.
These issues are caused by regional or network restrictions, not by the tool itself. If it still fails, report the error by opening an issue.
| text/markdown | null | Kaif <kafcodec@gmail.com> | null | null | null | username, checker, availability, social, tech, python, user-scanner | [] | [] | null | null | >=3.10 | [] | [
"user_scanner"
] | [] | [
"httpx[http2]<0.29,>=0.27",
"socksio<2,>=1.0",
"colorama<1,>=0.4"
] | [] | [] | [] | [
"Homepage, https://github.com/kaifcodec/user-scanner"
] | python-requests/2.31.0 | 2026-02-20T05:45:42.841194 | user_scanner-1.3.0.2.tar.gz | 55,182 | 71/f8/afffd86d0f8abb137932663eed5ec4ff31c3d2e95a8c62c7ac9bd69778b7/user_scanner-1.3.0.2.tar.gz | source | sdist | null | false | b6a572a658d8dfcad63400db139f4530 | 5bb96476fa8183ec10982e409d50c2456fa7af19d6a231da91579203f7441f3b | 71f8afffd86d0f8abb137932663eed5ec4ff31c3d2e95a8c62c7ac9bd69778b7 | null | [] | 460 |
2.4 | match-predicting-pub-api | 6.18 | Match Predicting Application Public API | No description provided (generated by Openapi Generator https://github.com/openapitools/openapi-generator)
| text/markdown | István Mag | magistvan@yahoo.com | null | null | null | OpenAPI, OpenAPI-Generator, Match Predicting Application Public API | [] | [] | https://github.com/magistvan/match-predicting-ann-server-client | null | null | [] | [] | [] | [
"urllib3<3.0.0,>=1.25.3",
"python-dateutil",
"pydantic<2,>=1.10.5",
"aenum"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.11 | 2026-02-20T05:44:06.510444 | match_predicting_pub_api-6.18.tar.gz | 26,709 | cd/11/636f7038ad60178351bfd8f822c8a7b801edd03a491cfb4f9b7fd13f456f/match_predicting_pub_api-6.18.tar.gz | source | sdist | null | false | 971b99b7f016b69b0b3b60959b3ddc2d | 035a2fa189c814cbdbedbc1ad42975df1de892198c6d7eabc3699adffbb6046f | cd11636f7038ad60178351bfd8f822c8a7b801edd03a491cfb4f9b7fd13f456f | null | [] | 243 |
2.4 | match-predicting-ann-server-pub-api | 7.23 | Match Predicting ANN Server Public API | No description provided (generated by Openapi Generator https://github.com/openapitools/openapi-generator)
| null | null | magistvan@yahoo.com | null | null | null | OpenAPI, Match Predicting ANN Server Public API | [] | [] | https://github.com/magistvan/match-predicting-ann-server-client | null | null | [] | [] | [] | [
"connexion>=2.0.2",
"swagger-ui-bundle>=0.0.2",
"python_dateutil>=2.6.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.11 | 2026-02-20T05:44:01.987545 | match_predicting_ann_server_pub_api-7.23.tar.gz | 10,139 | 00/4d/0151f2118823ee193b01884d4675a8b952649e6e2a749027519d6b1bff92/match_predicting_ann_server_pub_api-7.23.tar.gz | source | sdist | null | false | b37de058ea0276430ce5a2273d968da5 | 7394ef40801f02b4fc2fb7fcc72ec36a13a1777e6a77a48e92bac9886e6b1feb | 004d0151f2118823ee193b01884d4675a8b952649e6e2a749027519d6b1bff92 | null | [] | 245 |
2.4 | sqlstratum | 0.2.1 | Lightweight, source-first SQL AST + compiler + runner. | # SQLStratum
<p align="center">
<img src="https://raw.githubusercontent.com/aognio/sqlstratum/main/assets/images/SQLStratum-Logo-500x500-transparent.png" alt="SQLStratum logo" />
</p>
SQLStratum is a modern, typed, deterministic SQL query builder and compiler for Python with a
SQLite runner and a hydration pipeline. It exists to give applications and ORMs a reliable foundation
layer with composable SQL, predictable parameter binding, and explicit execution boundaries.
## Key Features
- Deterministic compilation: identical AST inputs produce identical SQL + params
- Typed, composable DSL for SELECT/INSERT/UPDATE/DELETE
- Safe parameter binding (no raw interpolation)
- Hydration targets for structured results
- SQLite-first execution via a small Runner API
- Testable compiled output and runtime behavior
## Non-Goals
- Not an ORM (no identity map, relationships, lazy loading)
- Not a migrations/DDL system
- Not a full database abstraction layer for every backend yet (SQLite first)
- Not a SQL string templating engine
SQLStratum focuses on queries. DDL statements such as `CREATE TABLE` or `ALTER TABLE` are intended to
live in a complementary library with similar design goals that is currently in the works.
## Quickstart
```python
import sqlite3
from sqlstratum import SELECT, INSERT, Table, col, Runner
users = Table(
"users",
col("id", int),
col("email", str),
col("active", int),
)
conn = sqlite3.connect(":memory:")
runner = Runner(conn)
runner.exec_ddl("CREATE TABLE users (id INTEGER PRIMARY KEY, email TEXT, active INTEGER)")
runner.execute(INSERT(users).VALUES(email="a@b.com", active=1))
runner.execute(INSERT(users).VALUES(email="c@d.com", active=0))
q = (
SELECT(users.c.id, users.c.email)
.FROM(users)
.WHERE(users.c.active.is_true())
.hydrate(dict)
)
rows = runner.fetch_all(q)
print(rows)
```
## Why `Table` objects?
SQLStratum’s `Table` objects are the schema anchor for the typed, deterministic query builder. They
provide column metadata and a stable namespace for column access, which enables predictable SQL
generation and safe parameter binding. They also support explicit aliasing to avoid ambiguous column
names in joins.
## Project Structure
- AST: immutable query nodes in `sqlstratum/ast.py`
- Compiler: SQL + params generation in `sqlstratum/compile.py`
- Runner: SQLite execution and transactions in `sqlstratum/runner.py`
- Hydration: projection rules and targets in `sqlstratum/hydrate/`
## SQL Debugging
SQLStratum can log executed SQL statements (compiled SQL + parameters + duration), but logging is
intentionally gated to avoid noisy output in production. Debug output requires two conditions:
- Environment variable gate: `SQLSTRATUM_DEBUG` must be truthy (`"1"`, `"true"`, `"yes"`,
case-insensitive).
- Logger gate: the `sqlstratum` logger must be DEBUG-enabled.
Why it does not work by default: Python logging defaults to WARNING level, so even if
`SQLSTRATUM_DEBUG=1` is set, DEBUG logs will not appear unless logging is configured.
To enable debugging in a development app:
Step 1 - set the environment variable:
```
SQLSTRATUM_DEBUG=1
```
Step 2 - configure logging early in the app:
```python
import logging
logging.basicConfig(level=logging.DEBUG)
# or
logging.getLogger("sqlstratum").setLevel(logging.DEBUG)
```
Output looks like:
```
SQL: <compiled sql> | params={<sorted params>} | duration_ms=<...>
```
Architectural intent: logging happens at the Runner boundary (after execution). AST building and
compilation remain deterministic and side-effect free, preserving separation of concerns.
## Pydantic Hydration (Optional)
SQLStratum does not depend on Pydantic, but it provides an optional hydration adapter for Pydantic
v2 models.
Install:
```
pip install sqlstratum[pydantic]
```
Example:
```python
from pydantic import BaseModel
from sqlstratum.hydrate.pydantic import hydrate_model, using_pydantic
class User(BaseModel):
id: int
email: str
row = {"id": "1", "email": "a@b.com"}
user = hydrate_model(User, row)
q = using_pydantic(
SELECT(users.c.id, users.c.email).FROM(users).WHERE(users.c.id == 1)
).hydrate(User)
user_row = runner.fetch_one(q)
```
## Logo Inspiration
Vinicunca (Rainbow Mountain) in Peru’s Cusco Region — a high-altitude day hike from
Cusco at roughly 5,036 m (16,500 ft). See [Vinicunca](https://en.wikipedia.org/wiki/Vinicunca) for
background.
## Versioning / Roadmap
Current version: `0.2.1`.
Design notes and current limitations are tracked in `NOTES.md`. Roadmap planning is intentionally
minimal at this stage and will evolve with real usage.
## Authorship
[Antonio Ognio](https://github.com/aognio/) is the maintainer and author of SQLStratum. ChatGPT is used for brainstorming,
architectural thinking, documentation drafting, and project management advisory. Codex (CLI/agentic
coding) is used to implement many code changes under Antonio's direction and review. The maintainer
reviews and curates changes; AI tools are assistants, not owners, and accountability remains with the
maintainer.
## License
MIT License.
## Contributing
PRs are welcome. Please read `CONTRIBUTING.md` for the workflow and expectations.
## Documentation
Install docs dependencies:
```bash
python -m pip install -r docs/requirements.txt
```
Run the local docs server:
```bash
mkdocs serve
```
Build the static site:
```bash
mkdocs build --clean
```
Read the Docs will build documentation automatically once the repository is imported.
## Release Automation
Install dev dependencies:
```bash
python -m pip install -e ".[dev]"
```
Run the full release pipeline:
```bash
poe release
```
This runs, in order:
- `python -m unittest`
- `python -m build --no-isolation`
- `python -m twine check dist/*`
- `python -m twine upload dist/*`
For a non-publishing verification pass:
```bash
poe release-dry-run
```
| text/markdown | null | Antonio Ognio <aognio@gmail.com> | null | null | MIT License
Copyright (c) 2026 Antonio Ognio <aognio@gmail.com>
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| sql, query-builder, sqlite, compiler, ast | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Database",
"Topic :: Software Development :: Libraries"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"build>=1.2.0; extra == \"dev\"",
"poethepoet>=0.30.0; extra == \"dev\"",
"twine>=5.0.0; extra == \"dev\"",
"pydantic>=2; extra == \"pydantic\""
] | [] | [] | [] | [
"Homepage, https://github.com/aognio/sqlstratum",
"Repository, https://github.com/aognio/sqlstratum",
"Issues, https://github.com/aognio/sqlstratum/issues"
] | twine/6.2.0 CPython/3.13.1 | 2026-02-20T05:42:58.244979 | sqlstratum-0.2.1.tar.gz | 19,451 | f9/6a/4d7ce3f546e8dd2fbdef0dcc877b4f581b2cd5fe849548c4a57cab95b682/sqlstratum-0.2.1.tar.gz | source | sdist | null | false | ed22de93203dfb79c1092ea9edb743cf | 814b97af62aa4f57ef2a475018222a117f99ce6d36cb51130a9a42c4a79194f0 | f96a4d7ce3f546e8dd2fbdef0dcc877b4f581b2cd5fe849548c4a57cab95b682 | null | [
"LICENSE"
] | 245 |
2.4 | pulumi-artifactory | 8.11.0a1771565617 | A Pulumi package for creating and managing artifactory cloud resources. | [](https://github.com/pulumi/pulumi-artifactory/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/artifactory)
[](https://pypi.org/project/pulumi-artifactory)
[](https://badge.fury.io/nu/pulumi.artifactory)
[](https://pkg.go.dev/github.com/pulumi/pulumi-artifactory/sdk/go)
[](https://github.com/pulumi/pulumi-artifactory/blob/main/LICENSE)
# Artifactory Resource Provider
The Artifactory Resource Provider lets you manage Artifactory resources.
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/artifactory
or `yarn`:
$ yarn add @pulumi/artifactory
### Python
To use from Python, install using `pip`:
$ pip install pulumi_artifactory
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-artifactory/sdk/v8
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Artifactory
## Configuration
The following configuration points are available:
- `artifactory:url` - (Required) URL of Artifactory. This can also be sourced from the `ARTIFACTORY_URL` environment variable.
- `artifactory:username` - (Optional) Username for basic auth. Requires password to be set. Conflicts with `apiKey`,
and `accessToken`. This can also be sourced from the `ARTIFACTORY_USERNAME` environment variable.
- `artifactory:password` - (Optional) Password for basic auth. Requires username to be set. Conflicts with `apiKey`,
and `accessToken`. This can also be sourced from the `ARTIFACTORY_PASSWORD` environment variable.
- `artifactory:apiKey` - (Optional) API key for api auth. Uses `X-JFrog-Art-Api` header. Conflicts with `username`,
`password`, and `accessToken`. This can also be sourced from the `ARTIFACTORY_API_KEY` environment variable.
- `artifactory:accessToken` - (Optional) API key for token auth. Uses `Authorization: Bearer` header. For xray
functionality, this is the only auth method accepted. Conflicts with `username` and `password`, and `apiKey`. This can
also be sourced from the `ARTIFACTORY_ACCESS_TOKEN` environment variable.
## Reference
For further information, please visit [the Artifactory provider docs](https://www.pulumi.com/docs/intro/cloud-providers/artifactory)
or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/artifactory).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, artifactory | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-artifactory"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T05:42:50.772902 | pulumi_artifactory-8.11.0a1771565617.tar.gz | 1,211,494 | 11/a1/ada9023ed23fc6bed2d340fa9355c6f08162a7c297778e008fc8430762b9/pulumi_artifactory-8.11.0a1771565617.tar.gz | source | sdist | null | false | 36631a16a9acf73d71cb8c66ad5421bb | 1281586282e88b6d4d8765c37071302ef0eac64bfe8e9df126bdddcd4e5303ef | 11a1ada9023ed23fc6bed2d340fa9355c6f08162a7c297778e008fc8430762b9 | null | [] | 221 |
2.4 | rivven | 0.0.19 | High-performance Python client for Rivven distributed streaming platform | # rivven-python
> High-performance Python bindings for the Rivven event streaming platform.
## Features
- **Native Performance**: Zero-copy message handling through Rust bindings (PyO3)
- **Async-First**: Full async/await support with Python's asyncio
- **Type-Safe**: Complete type annotations for IDE support
- **Transaction Support**: Exactly-once semantics with transactional producers
- **Authentication**: Multiple auth methods (simple, SCRAM-SHA-256)
- **Admin Operations**: Full topic and partition management
## Installation
```bash
pip install rivven
```
## Usage
### Basic Connection
```python
import asyncio
import rivven
async def main():
# Connect to Rivven cluster
client = await rivven.connect("localhost:9092")
# Create a topic
await client.create_topic("my-topic", partitions=3)
# List topics
topics = await client.list_topics()
print(f"Topics: {topics}")
asyncio.run(main())
```
### Producer
```python
import asyncio
import rivven
async def produce():
client = await rivven.connect("localhost:9092")
producer = client.producer("my-topic")
# Send a message
offset = await producer.send(b'{"event": "login"}', key=b"user-123")
print(f"Sent at offset: {offset}")
# Send to specific partition
await producer.send_to_partition(b"value", partition=0, key=b"key")
# Batch send for better throughput
offsets = await producer.send_batch([b"msg1", b"msg2", b"msg3"])
asyncio.run(produce())
```
### Consumer
```python
import asyncio
import rivven
async def consume():
client = await rivven.connect("localhost:9092")
consumer = client.consumer("my-topic", group="my-group")
# Fetch messages
messages = await consumer.fetch(max_messages=100)
for msg in messages:
print(f"Offset {msg.offset}: {msg.value_str()}")
# Commit offsets
await consumer.commit()
# Or use async iterator (poll-retries on empty fetch, never stops)
# With auto_commit=True (default), offsets are committed per batch.
# Explicit commit is only needed with auto_commit=False:
async for msg in consumer:
print(f"Received: {msg.value_str()}")
await consumer.commit()
asyncio.run(consume())
```
### Admin Operations
```python
import asyncio
import rivven
async def admin():
client = await rivven.connect("localhost:9092")
# Create topic
await client.create_topic("new-topic", partitions=3, replication_factor=1)
# List topics
topics = await client.list_topics()
print(f"Topics: {topics}")
# Get topic configuration
configs = await client.describe_topic_configs("new-topic")
print(f"Configs: {configs}")
# Modify topic configuration
await client.alter_topic_config("new-topic", [("retention.ms", "86400000")])
# Add partitions
await client.create_partitions("new-topic", new_total=6)
# Get offset for timestamp
offset = await client.get_offset_for_timestamp("new-topic", 0, 1699900000000)
# Delete records before offset
await client.delete_records("new-topic", 0, before_offset=100)
# Delete topic
await client.delete_topic("old-topic")
asyncio.run(admin())
```
### Authentication
```python
import asyncio
import rivven
async def authenticated():
client = await rivven.connect("localhost:9092")
# Simple authentication
await client.authenticate("username", "password")
# Or SCRAM-SHA-256 authentication
await client.authenticate_scram("username", "password")
# Use client as normal
topics = await client.list_topics()
asyncio.run(authenticated())
```
### TLS Connection
```python
import asyncio
import rivven
async def secure():
# Connect with TLS
client = await rivven.connect_tls(
"localhost:9093",
ca_cert_path="/path/to/ca.pem",
server_name="broker.example.com",
client_cert_path="/path/to/client.pem", # Optional: mTLS
client_key_path="/path/to/client.key", # Optional: mTLS
)
topics = await client.list_topics()
asyncio.run(secure())
```
### Transactions (Exactly-Once Semantics)
```python
import asyncio
import rivven
async def transactional():
client = await rivven.connect("localhost:9092")
# Initialize transactional producer - returns a ProducerState object
producer_state = await client.init_producer_id()
print(f"Producer ID: {await producer_state.producer_id}, Epoch: {await producer_state.producer_epoch}")
try:
# Begin transaction
await client.begin_transaction("my-txn-id", producer_state)
# Add partitions to transaction
await client.add_partitions_to_txn("my-txn-id", producer_state, [
("my-topic", 0),
("my-topic", 1),
])
# Publish with idempotent semantics - sequence is auto-incremented
await client.publish_idempotent(
topic="my-topic",
value=b"message-1",
producer_state=producer_state,
key=b"key-1"
)
await client.publish_idempotent(
topic="my-topic",
value=b"message-2",
producer_state=producer_state,
key=b"key-2"
)
# Commit transaction
await client.commit_transaction("my-txn-id", producer_state)
except Exception as e:
# Abort on error
await client.abort_transaction("my-txn-id", producer_state)
raise
asyncio.run(transactional())
```
## Exception Handling
Rivven provides a hierarchy of exception types for granular error handling:
```python
from rivven import (
RivvenException, # Base exception for all Rivven errors
ConnectionException, # Connection-related errors
ServerException, # Server-side errors
TimeoutException, # Request timeouts
SerializationException, # Serialization/deserialization errors
ConfigException, # Configuration errors
)
try:
client = await rivven.connect("localhost:9092")
except ConnectionException as e:
print(f"Failed to connect: {e}")
except TimeoutException as e:
print(f"Connection timed out: {e}")
except RivvenException as e:
print(f"General Rivven error: {e}")
```
## Testing
### Running Tests
```bash
# Install test dependencies
pip install -r requirements-test.txt
# Run API tests (no broker required)
pytest tests/test_api.py -v
# Run integration tests (requires running broker)
export RIVVEN_BROKER="localhost:9092"
pytest tests/test_integration.py -v -m integration
```
### Type Checking
The package includes type stubs (`rivven.pyi`) for IDE support and static type checking:
```bash
pip install mypy
mypy your_code.py
```
## Building from Source
```bash
# Install maturin
pip install maturin
# Build wheel
cd crates/rivven-python
maturin build --release
# Install locally
pip install target/wheels/rivven-*.whl
# Development install (editable)
maturin develop --release
```
## Documentation
- [Getting Started](https://rivven.hupe1980.github.io/rivven/docs/getting-started)
- [Python Examples](https://rivven.hupe1980.github.io/rivven/docs/getting-started#python-client)
## License
Apache-2.0. See [LICENSE](../../LICENSE).
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | Apache-2.0 | streaming, kafka, messaging, distributed, async | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Rust",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: System :: Distributed Computing",
"Framework :: AsyncIO",
"Typing :: Typed"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21; extra == \"dev\"",
"mypy>=1.0; extra == \"dev\"",
"ruff>=0.1; extra == \"dev\""
] | [] | [] | [] | [
"Documentation, https://github.com/hupe1980/rivven/tree/main/crates/rivven-python",
"Homepage, https://github.com/hupe1980/rivven",
"Repository, https://github.com/hupe1980/rivven"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T05:41:50.617359 | rivven-0.0.19-cp312-cp312-manylinux_2_28_aarch64.whl | 871,152 | a7/ac/b1334d440830ced75faed5ea75cca67a2577234036d9cf14c72be427da39/rivven-0.0.19-cp312-cp312-manylinux_2_28_aarch64.whl | cp312 | bdist_wheel | null | false | 02982576d0ace3768b00f0f539c5938b | 1c7284e608509c377cf1347b1cec0b2cced7f1f3d137fe62dfc50002c524337e | a7acb1334d440830ced75faed5ea75cca67a2577234036d9cf14c72be427da39 | null | [] | 229 |
2.4 | pulumi-auth0 | 3.39.0a1771565582 | A Pulumi package for creating and managing auth0 cloud resources. | [](https://github.com/pulumi/pulumi-auth0/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/auth0)
[](https://pypi.org/project/pulumi-auth0)
[](https://badge.fury.io/nu/pulumi.auth0)
[](https://pkg.go.dev/github.com/pulumi/pulumi-auth0/sdk/v3/go)
[](https://github.com/pulumi/pulumi-auth0/blob/master/LICENSE)
# Auth0 Resource Provider
The Auth0 Resource Provider lets you manage Auth0 resources.
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/auth0
or `yarn`:
$ yarn add @pulumi/auth0
### Python
To use from Python, install using `pip`:
$ pip install pulumi_auth0
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-auth0/sdk/v3
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Auth0
## Configuration
The following configuration points are available:
- `auth0:apiToken` - (Optional) Your Auth0 [management api access
token](https://auth0.com/docs/security/tokens/access-tokens/management-api-access-tokens). It can also be
sourced from the `AUTH0_API_TOKEN` environment variable. It can be used instead of `auth0:clientId` +
`auth0:clientSecret`. If both are specified, `auth0:apiToken` will be used over `auth0:clientId` +
`auth0:clientSecret` fields.
- `auth0:audience` - (Optional) Your Auth0 audience when using a custom domain. It can also be sourced from
the `AUTH0_AUDIENCE` environment variable.
- `auth0:clientId` - (Optional) Your Auth0 client ID. It can also be sourced from the `AUTH0_CLIENT_ID`
environment variable.
- `auth0:clientSecret` - (Optional) Your Auth0 client secret. It can also be sourced from the
`AUTH0_CLIENT_SECRET` environment variable.
- `auth0:debug` - (Optional) Indicates whether to turn on debug mode.
- `auth0:domain` - (Required) Your Auth0 domain name. It can also be sourced from the
`AUTH0_DOMAIN` environment variable.
## Reference
For further information, please visit [the Auth0 provider docs](https://www.pulumi.com/docs/intro/cloud-providers/auth0) or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/auth0).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, auth0 | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-auth0"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T05:40:35.157898 | pulumi_auth0-3.39.0a1771565582.tar.gz | 393,784 | 16/0b/28795778bda9015ca008b153456bc029a5e5c29b417590bcda0f51a0589d/pulumi_auth0-3.39.0a1771565582.tar.gz | source | sdist | null | false | 5a7d34f3f3d42cda0a5ad4c52d8c8deb | 555af62bfaea9ae94a6c8130d21767d0b19035cdd278c5c537b69605a7073e19 | 160b28795778bda9015ca008b153456bc029a5e5c29b417590bcda0f51a0589d | null | [] | 239 |
2.4 | animepahe-dl | 5.10.0 | A feature-rich anime downloader with CLI and GUI support | # AnimePahe Downloader
[](https://badge.fury.io/py/animepahe-dl)
[](https://opensource.org/licenses/MIT)
[](https://github.com/ayushjaipuriyar/animepahe-dl/actions/workflows/ci.yml)
[](https://github.com/ayushjaipuriyar/animepahe-dl/actions/workflows/release.yml)
[](https://www.python.org/downloads/)
[](https://github.com/astral-sh/uv)
[](https://github.com/astral-sh/ruff)
[](https://github.com/psf/black)
A feature-rich, high-performance anime downloader for AnimePahe with both CLI and GUI interfaces. Built with Python, featuring concurrent downloads, resume support, and cross-platform compatibility.

## 📋 Table of Contents
- [Highlights](#-highlights)
- [Features](#features)
- [Installation](#installation)
- [Usage](#usage)
- [Configuration](#configuration)
- [For Developers](#️-for-developers)
- [Performance Tips](#-performance-tips)
- [Troubleshooting](#-troubleshooting)
- [Documentation](#-documentation)
- [Docker Support](#-docker-support)
- [Advanced Usage](#-advanced-usage)
- [New Features](#-new-features-in-v521)
- [License](#-license)
- [Acknowledgments](#-acknowledgments)
## ✨ Highlights
- 🚀 **High Performance**: Concurrent segment downloads with configurable thread pools
- 💾 **Smart Caching**: Reduces redundant API calls and improves response times
- 🔄 **Resume Support**: Continue interrupted downloads seamlessly
- 🎨 **Dual Interface**: Choose between CLI for automation or GUI for ease of use
- ▶️ **Direct Streaming**: Play episodes instantly without downloading
- 🔔 **Desktop Notifications**: Get notified when downloads complete
- 🌐 **Cross-Platform**: Works on Windows, macOS, and Linux
- 📦 **Auto-Updates**: Automatic cache updates for the latest anime releases
- 🎯 **Flexible Selection**: Download single episodes, ranges, or entire series
## Features
* **Search and Download**: Find any anime on AnimePahe and download it.
* **Direct Streaming**: Play episodes directly without downloading using m3u8 streams.
* **Batch Downloads**: Download entire series or select specific episodes.
* **Resume Support**: Resume interrupted downloads without starting over.
* **Cross-Platform**: Works on Windows, macOS, and Linux.
* **Desktop Notifications**: Get notified when your downloads are complete.
* **Automatic Cache Updates**: Keep your local anime list up-to-date automatically.
## 📦 Binary Releases
Pre-built binaries are available for all major platforms:
### Quick Install
| Platform | Method | Command |
|----------|--------|---------|
| **Windows** | [Download EXE](https://github.com/ayushjaipuriyar/animepahe-dl/releases/latest) | `animepahe-dl-windows.exe` |
| **Linux** | [AppImage](https://github.com/ayushjaipuriyar/animepahe-dl/releases/latest) | `./animepahe-dl-x86_64.AppImage` |
| **Linux** | Snap Store | `sudo snap install animepahe-dl` |
| **Linux** | Flatpak | `flatpak install animepahe-dl.flatpak` |
| **Arch Linux** | AUR | `yay -S animepahe-dl` |
📖 **[Complete Binary Installation Guide](docs/BINARY_RELEASES.md)**
## Installation
### 1. Prerequisites
Before installing, ensure you have the following dependencies on your system:
* **Python 3.8+**: [Download Python](https://www.python.org/downloads/)
* **ffmpeg**: Essential for merging video segments.
* **Windows**: Download from [ffmpeg.org](https://ffmpeg.org/download.html) and add to your system's PATH.
* **macOS**: Install via your package manager or download from [ffmpeg.org](https://ffmpeg.org/download.html).
* **Linux**: `sudo apt update && sudo apt install ffmpeg` (or use your distro's package manager).
* **fzf**: Required for the interactive anime selection in the CLI.
* **Windows**: Download from the [fzf GitHub releases](https://github.com/junegunn/fzf/releases) and add to your PATH.
* **macOS**: Install via your package manager or download from the [fzf releases](https://github.com/junegunn/fzf/releases).
* **Linux**: `sudo apt update && sudo apt install fzf` (or use your distro's package manager).
* **Node.js**: Required for an internal dependency.
* [Download Node.js](https://nodejs.org/en/download/) or use a package manager.
* **Media Player** (for streaming): Required only if you want to use the `--play` feature.
* **mpv** (recommended): `sudo apt install mpv` (Linux), install via your package manager on macOS, or download from [mpv.io](https://mpv.io/)
* **VLC**: Download from [videolan.org](https://www.videolan.org/)
* **ffplay** (part of FFmpeg): Usually installed with ffmpeg
* **mplayer**: Available in most package managers
### 2. Install with uv (Recommended - Fast!)
```bash
# Install uv if you haven't already
curl -LsSf https://astral.sh/uv/install.sh | sh
# Install animepahe-dl
uv tool install animepahe-dl
```
### 3. Install with pip
```bash
pip install animepahe-dl
```
## Usage
The package can be run directly from your terminal.
### Command-Line Interface (CLI)
To run the CLI, use the `animepahe-dl` command:
```bash
# Search for an anime and select episodes interactively
animepahe-dl -n "Your Anime Name"
# Download specific episodes of an anime
animepahe-dl -n "Your Anime Name" -e 1 3 5
```
**CLI Options:**
| Flag | Alias | Description | Default |
|---|---|---|---|
| `--name` | `-n` | Name of the anime to search for. | |
| `--episodes` | `-e` | List or range of episode numbers (e.g., `1 2 5` or `1-10`). | |
| `--quality` | `-q` | Desired video quality (`best`, `1080`, `720`, `480`, `360`). | `best` |
| `--audio` | `-a` | Desired audio language (`eng` or `jpn`). | `jpn` |
| `--threads` | `-t` | Number of download threads for segments. | `100` |
| `--concurrent-downloads` | `-c` | Number of episodes to download concurrently. | `2` |
| `--updates` | | Check for new episodes of anime in your personal list. | |
| `--manage` | | Manage your personal anime list (add/remove anime). | |
| `--run-once` | | Use with `--updates` to run the check once and exit. | |
| `--insecure` | | Disable SSL certificate verification (not recommended). | |
| `--m3u8-only` | | Fetch playlist only without downloading segments. | |
| `--play` | | Play episode(s) directly using m3u8 stream (requires media player). | |
| `--player` | | Specify media player to use (mpv, vlc, ffplay). Auto-detects if not specified. | |
| `--daemon` | | Run in daemon mode (background service for continuous updates). | |
| `--daemon-action` | | Daemon management (start, stop, restart, status). | |
| `--single` | | Disable multi-selection mode (select only one anime at a time). | |
| `--gui` | | Launch the Graphical User Interface. | |
**Examples:**
```bash
# Search and select anime (multi-selection is default)
animepahe-dl -n "Naruto"
# (Use spacebar to select multiple items, Enter to confirm)
# Download episodes 1-10 with 720p quality
animepahe-dl -n "Naruto" -e 1-10 -q 720
# Download multiple episodes concurrently
animepahe-dl -n "Naruto" -e 1-20 -c 3 -t 150
# Download with English audio
animepahe-dl -n "Naruto" -e 1-5 -a eng
# Single selection mode (select only one anime)
animepahe-dl -n "Naruto" --single
# Fetch playlist only (no download)
animepahe-dl -n "Naruto" -e 1 --m3u8-only
# Play episodes directly without downloading
animepahe-dl -n "Naruto" -e 1-5 --play
# Play with specific media player
animepahe-dl -n "Naruto" -e 1 --play --player mpv
```
### Graphical User Interface (GUI)
To launch the GUI, use the `--gui` flag:
```bash
animepahe-dl --gui
```
The GUI provides a user-friendly interface for searching, selecting, and downloading anime without using the command line.
**Multi-Selection in GUI:**
- Hold `Ctrl` (or `Cmd` on macOS) to select multiple anime
- Hold `Shift` to select a range of anime
- Click "Download Selected" to download all episodes from selected anime
- Click "Play Selected Episodes" to stream episodes directly (requires media player)
**Keyboard Shortcuts:**
- `Ctrl+F` - Focus search bar
- `Ctrl+A` - Select all episodes
- `Ctrl+D` - Deselect all episodes
- `Ctrl+P` - Play selected episodes
- `Enter` - Download selected episodes
- `F5` - Update anime cache
### Direct Streaming
Stream episodes instantly without downloading:
```bash
# Stream episodes directly
animepahe-dl -n "Your Anime Name" -e 1-5 --play
# Use specific media player
animepahe-dl -n "Your Anime Name" -e 1 --play --player mpv
# Stream with custom quality and audio
animepahe-dl -n "Your Anime Name" -e 1 --play -q 720 -a eng
```
**Supported Media Players:**
- **mpv** (recommended) - Lightweight and fast
- **VLC** - Popular cross-platform player
- **ffplay** - Part of FFmpeg, minimal interface
- **mplayer** - Classic media player
The application will auto-detect available players or you can specify one with `--player`.
### Background Monitoring & Daemon Mode
Run the application as a background service to automatically monitor and download new episodes:
```bash
# Start daemon mode
animepahe-dl --daemon
# Daemon management
animepahe-dl --daemon-action start
animepahe-dl --daemon-action stop
animepahe-dl --daemon-action restart
animepahe-dl --daemon-action status
```
### System Tray Integration
The GUI supports system tray functionality:
- **Minimize to Tray**: Close button minimizes to system tray instead of quitting
- **Background Monitoring**: Toggle automatic episode checking from tray menu
- **Quick Actions**: Update cache, show/hide window, and quit from tray menu
- **Notifications**: Get desktop notifications for new episodes and completed downloads
### Linux Service Integration
Install as a systemd service for automatic startup:
```bash
# Install service (run from project directory)
./scripts/install-service.sh
# Service management
sudo systemctl start animepahe-dl
sudo systemctl stop animepahe-dl
sudo systemctl status animepahe-dl
sudo journalctl -u animepahe-dl -f # View logs
```
**Service Features:**
- Automatic startup on boot
- Automatic restart on failure
- Secure execution with limited permissions
- Centralized logging via systemd journal
## Configuration
The application's configuration (`config.json`) and data files (`myanimelist.txt`, `animelist.txt`) are stored in your user data directory:
* **Linux**: `~/.config/anime_downloader/`
* **macOS**: `~/Library/Application Support/anime_downloader/`
* **Windows**: `C:\Users\<YourUsername>\AppData\Local\anime_downloader\`
You can manually edit `config.json` to change defaults for quality, audio, threads, download directory, and notification settings.
**Configuration Options:**
```json
{
"base_url": "https://animepahe.si",
"quality": "best",
"audio": "jpn",
"threads": 100,
"download_directory": "/home/user/Videos/Anime",
"update_interval_hours": 1,
"allow_insecure_ssl": true
}
```
## 🛠️ For Developers
### Development Setup
1. **Install uv** (if not already installed):
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
# Or on Windows: powershell -c "irm https://astral.sh/uv/install.ps1 | iex"
```
2. **Clone the repository:**
```bash
git clone https://github.com/ayushjaipuriyar/animepahe-dl.git
cd animepahe-dl
```
3. **Install dependencies with uv:**
```bash
uv sync --all-extras
```
Or for development:
```bash
uv sync --dev
```
### Running Tests
```bash
# Run all tests
uv run pytest
# Run with coverage
uv run pytest --cov=anime_downloader --cov-report=html
# Run specific test file
uv run pytest tests/test_cli.py -v
```
### Code Quality
```bash
# Format code
uv run black anime_downloader tests
uv run isort anime_downloader tests
# Lint code
uv run ruff check anime_downloader tests
# Type checking
uv run mypy anime_downloader
# Security scan
uv run bandit -r anime_downloader
```
### Project Structure
```
animepahe-dl/
├── anime_downloader/ # Main package
│ ├── api.py # AnimePahe API client
│ ├── async_downloader.py # Async download implementation
│ ├── cache.py # Caching system
│ ├── cli.py # Command-line interface
│ ├── config.py # Configuration management
│ ├── downloader.py # Download orchestration
│ ├── gui.py # PyQt6 GUI
│ ├── models.py # Data models
│ ├── utils.py # Utility functions
│ └── workers.py # Background workers
├── tests/ # Test suite
├── .github/workflows/ # CI/CD pipelines
└── pyproject.toml # Project configuration
```
### Contributing
We welcome contributions! Please follow these guidelines:
1. **Fork the repository** and create a feature branch
2. **Follow code style**: Use `black` and `isort` for formatting
3. **Write tests**: Maintain or improve code coverage
4. **Use Conventional Commits**: Follow the commit message format below
5. **Update documentation**: Keep README and docstrings current
#### Conventional Commits
This project uses [Conventional Commits](https://www.conventionalcommits.org/) for automated releases:
- `feat:` New features (minor version bump)
- `fix:` Bug fixes (patch version bump)
- `docs:` Documentation changes
- `style:` Code style changes (formatting, etc.)
- `refactor:` Code refactoring
- `perf:` Performance improvements
- `test:` Test additions or modifications
- `chore:` Build process or auxiliary tool changes
Example:
```bash
git commit -m "feat: add async download support for improved performance"
git commit -m "fix: handle network timeout errors gracefully"
```
### Release Process
Releases are automated via GitHub Actions:
1. Push to `main` branch triggers semantic-release
2. Version is bumped based on commit messages
3. Changelog is generated automatically
4. Package is published to PyPI
5. GitHub release is created
## 📊 Performance Tips
- **Increase threads**: Use `-t 100` or higher for faster downloads
- **Concurrent episodes**: Use `-c 3` to download multiple episodes simultaneously
- **Quality selection**: Lower quality downloads faster (use `-q 720` instead of `1080`)
- **Cache management**: Regularly update cache with `--updates` for better performance
## 🐛 Troubleshooting
### Common Issues
**SSL Certificate Errors:**
```bash
animepahe-dl --insecure -n "Anime Name"
```
**FFmpeg not found:**
- Ensure ffmpeg is installed and in your PATH
- Set `FFMPEG` environment variable to ffmpeg binary path
**Cache issues:**
- Delete cache directory: `~/.config/anime_downloader/cache/`
- Update cache: Run with `--updates` flag
**Permission errors:**
- Check download directory permissions
- Run with appropriate user privileges
## 📝 License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## 📚 Documentation
- **[Quick Start Guide](QUICKSTART.md)** - Get started in 5 minutes
- **[API Documentation](docs/API.md)** - Complete API reference
- **[Contributing Guide](CONTRIBUTING.md)** - How to contribute
- **[Security Policy](SECURITY.md)** - Security and vulnerability reporting
- **[Upgrade Guide](docs/UPGRADE_GUIDE.md)** - Version upgrade instructions
- **[UV Migration Guide](docs/UV_MIGRATION.md)** - Migrating to UV package manager
- **[Examples](examples/)** - Usage examples and scripts
- **[Benchmarks](benchmarks/)** - Performance benchmarks
## 🐳 Docker Support
Run animepahe-dl in a container:
```bash
# Build the image
docker build -t animepahe-dl .
# Run CLI
docker run -v ./downloads:/downloads animepahe-dl -n "Anime Name" -e 1-5
# Run with docker-compose
docker-compose up
```
See [docker-compose.yml](docker-compose.yml) for configuration options.
## 🔧 Advanced Usage
### Using as a Python Library
```python
from anime_downloader.api import AnimePaheAPI
from anime_downloader.downloader import Downloader
# Initialize
api = AnimePaheAPI(verify_ssl=False)
downloader = Downloader(api)
# Search for anime
results = api.search("Naruto")
print(results[0]['title'])
# Download episodes
# See examples/ directory for complete examples
```
### Automation with Cron
Check for new episodes automatically:
```bash
# Edit crontab
crontab -e
# Add this line (check every 6 hours)
0 */6 * * * /usr/local/bin/animepahe-dl --updates --run-once
```
### Environment Variables
- `FFMPEG` - Path to ffmpeg binary
- `XDG_CONFIG_HOME` - Config directory location
- `DOWNLOAD_DIR` - Default download directory
## 🚀 New Features in v6.0.0
### Major Features
- ▶️ **Direct Streaming** - Play episodes instantly without downloading using m3u8 streams
- 🎮 **Media Player Integration** - Auto-detects mpv, VLC, ffplay, and mplayer with optimized streaming settings
- 🖥️ **GUI Streaming** - Stream episodes directly from the graphical interface with play button
- 🔔 **Desktop Notifications** - Get notified when downloads complete or new episodes are found
- 🖥️ **System Tray Support** - Run in background with system tray integration and context menu
- 🔄 **Daemon Mode** - Continuous background monitoring for new episodes with configurable intervals
- 🐧 **Systemd Integration** - Linux service support for automatic startup and management
### Improvements
- 🎯 **Enhanced Episode Selection** - Fixed episode range filtering (e.g., "1", "1-5", "1,3,5") in interactive mode
- 🔧 **Improved Architecture** - Cleaned up codebase by removing duplicate and unused components
- ⚡ **Better Performance** - Optimized imports and reduced code duplication
- 🛠️ **Enhanced CLI** - Improved mpv integration with proper streaming headers and buffering
- 📱 **Better GUI** - Fixed import errors and improved episode status tracking
### Previous Features
- ⚡ **Async Downloads** - 2-3x faster with async/await
- 💾 **Smart Caching** - 50% reduction in API calls
- 📊 **Performance Monitoring** - Track download statistics
- 🔄 **Concurrent Episodes** - Download multiple episodes simultaneously
- 🐳 **Docker Support** - Easy containerized deployment
- 🧪 **Comprehensive Testing** - Full test suite with pytest
- 📝 **Type Hints** - Better IDE support and error detection
- 🛠️ **UV Support** - 10-100x faster dependency management
See [CHANGELOG.md](CHANGELOG.md) for complete version history.
## 🙏 Acknowledgments
- AnimePahe for providing the content platform
- Contributors and users for feedback and improvements
- Open source community for the amazing tools and libraries
- [Astral](https://astral.sh/) for the amazing UV package manager
## ⚠️ Disclaimer
This tool is for educational purposes only. Please respect copyright laws and support official releases when available. The developers are not responsible for any misuse of this software.
| text/markdown | null | Ayush <ayushjaipuriyar21@gmail.com> | null | null | MIT | anime, animepahe, downloader, streaming, video | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: End Users/Desktop",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Internet :: WWW/HTTP",
"Topic :: Multimedia :: Video"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"beautifulsoup4>=4.14.3",
"loguru>=0.7.0",
"platformdirs>=4.0.0",
"plyer>=2.1.0",
"pycryptodome>=3.19.0",
"pyfzf>=0.3.0",
"pyqt6>=6.6.0",
"questionary>=2.0.0",
"rich>=13.0.0",
"tqdm>=4.66.0",
"typer>=0.9.0",
"urllib3<2.5.0,>=2.0.0; python_version < \"3.9\"",
"urllib3>=2.6.1; python_version >= \"3.9\"",
"bandit>=1.7.5; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"isort>=5.12.0; extra == \"dev\"",
"mypy>=1.7.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"pytest-mock>=3.12.0; extra == \"dev\"",
"pytest>=7.4.0; extra == \"dev\"",
"python-semantic-release>=10.5.2; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"safety>=2.3.0; extra == \"dev\"",
"twine<6.2.0,>=6.1.0; python_version < \"3.9\" and extra == \"dev\"",
"twine>=6.2.0; python_version >= \"3.9\" and extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/ayushjaipuriyar/animepahe-dl",
"Bug Tracker, https://github.com/ayushjaipuriyar/animepahe-dl/issues",
"Documentation, https://github.com/ayushjaipuriyar/animepahe-dl#readme",
"Source Code, https://github.com/ayushjaipuriyar/animepahe-dl",
"Changelog, https://github.com/ayushjaipuriyar/animepahe-dl/blob/main/CHANGELOG.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T05:40:16.141120 | animepahe_dl-5.10.0.tar.gz | 924,200 | 5c/53/3a2065e2ed4fe45892718184c66a4c9bba42cba15b4561006e72eb49c64f/animepahe_dl-5.10.0.tar.gz | source | sdist | null | false | 9f264b40622235476f86887bc2cc73e8 | 866b8490616dce41d4037f9b3010d7f5ce6815cc948dc69efa2a083e36b111ad | 5c533a2065e2ed4fe45892718184c66a4c9bba42cba15b4561006e72eb49c64f | null | [
"LICENSE"
] | 266 |
2.4 | pulumi-akamai | 10.4.0a1771565411 | A Pulumi package for creating and managing akamai cloud resources. | # Akamai Resource Provider
The Akamai Resource Provider lets you manage Akamai resources.
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/akamai
or `yarn`:
$ yarn add @pulumi/akamai
### Python
To use from Python, install using `pip`:
$ pip install pulumi_akamai
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-akamai/sdk/v9
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Akamai
## Configuration
The following configuration options are available
* `akamai:edgerc` - (Optional) The location of the `.edgerc` file containing credentials. Default: `$HOME/.edgerc`.
* `akamai:propertySection` - (Optional) The credential section to use for the Property Manager API (PAPI). Default `default`.
* `akamai:dnsSection` - (Optional) The credential section to use for the Config DNS API. Default `default`.
* `akamai:gtmSection` - (Optional) The credential section to use for the Config GTM API. Default `default`.
You can also specify credential values using environment variables. Environment variables take precedence over the contents of the `.edgerc` file.
Create environment variables in the format:
`AKAMAI{_SECTION_NAME}_*`
For example, if you specify `akamai:propertySection papi` you would set the following ENV variables:
* AKAMAI_PAPI_HOST
* AKAMAI_PAPI_ACCESS_TOKEN
* AKAMAI_PAPI_CLIENT_TOKEN
* AKAMAI_PAPI_CLIENT_SECRET
* AKAMAI_PAPI_MAX_BODY (optional)
If the section name is `default`, you can omit it, instead using:
* AKAMAI_HOST
* AKAMAI_ACCESS_TOKEN
* AKAMAI_CLIENT_TOKEN
* AKAMAI_CLIENT_SECRET
* AKAMAI_MAX_BODY (optional)
## Reference
For further information, please visit [the Akamai provider docs](https://www.pulumi.com/docs/intro/cloud-providers/akamai)
or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/akamai).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, akamai | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-akamai"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T05:38:26.447116 | pulumi_akamai-10.4.0a1771565411.tar.gz | 519,661 | e5/ac/be41583c3d7af1eb4c4a678f64c35c75ce4a280ea594ad8c1d5b40e3069a/pulumi_akamai-10.4.0a1771565411.tar.gz | source | sdist | null | false | 59ec42933853d01feed914dda64b2e48 | d7c6326c51e09f41b4a3e491fa0883e0705e2e01f43b82ecf4054af59794f2cf | e5acbe41583c3d7af1eb4c4a678f64c35c75ce4a280ea594ad8c1d5b40e3069a | null | [] | 227 |
2.1 | f5-th-onnx | 0.0.3 | Text-to-Speech (TTS) ภาษาไทย — เครื่องมือสร้างเสียงพูดจากข้อความ ด้วยโมเดล F5-TTS ที่ปรับแต่งให้อยู่ในรูปแบบ ONNX ให้สามารถรันบน GPU ขนาดเล็กกว่าและใช้ทรัพยากรน้อยกว่า | # F5-TH-ONNX
Text-to-Speech (TTS) ภาษาไทย — เครื่องมือสร้างเสียงพูดจากข้อความ ด้วยโมเดล F5-TTS ที่ปรับแต่งให้อยู่ในรูปแบบ ONNX ให้สามารถรันบน GPU ขนาดเล็กกว่าและใช้ทรัพยากรน้อยกว่า
- 🔥 สถาปัตยกรรม: [F5-TTS](https://arxiv.org/abs/2410.06885)
- 🚀 Export ONNX: [F5-TTS-ONNX](https://github.com/DakeQQ/F5-TTS-ONNX)
### ติดตั้ง
```
pip install f5-th-onnx
```
### การใช้งาน
```
from f5_th_onnx import TTS
TTS(
ref_audio="YOUR_AUDIO_PATH",
ref_text="นี่คือเสียงพูดต้นฉบับ.",
gen_text="สวัสดีครับ นี่คือเสียงพูดภาษาไทย.",
speed=1.0,
output="generated.wav"
)
```
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | null | [] | [] | [] | [
"vachana-g2p",
"onnxruntime-gpu",
"pydub",
"soundfile",
"tqdm",
"huggingface-hub"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.5 | 2026-02-20T05:38:08.268551 | f5_th_onnx-0.0.3-py3-none-any.whl | 4,714 | 93/06/05c65afa5f5afd795c504fdbb892fb63398de3f3266719c7ca1d5b1d80b5/f5_th_onnx-0.0.3-py3-none-any.whl | py3 | bdist_wheel | null | false | 97b3019f82fb4818fc6a38a114138bf7 | c7aa354837eb729082830c3eec648b752ab9dcfd82697bf00fbc9af924535e83 | 930605c65afa5f5afd795c504fdbb892fb63398de3f3266719c7ca1d5b1d80b5 | null | [] | 112 |
2.4 | pulumi-archive | 0.4.0a1771565423 | A Pulumi package for creating and managing Archive cloud resources. | [](https://github.com/pulumi/pulumi-archive/actions)
[](https://www.npmjs.com/package/@pulumi/archive)
[](https://pypi.org/project/pulumi_archive)
[](https://www.nuget.org/packages/Pulumi.Archive)
[](https://pkg.go.dev/github.com/pulumi/pulumi-archive/sdk/go)
[](https://github.com/pulumi/pulumi-archive/blob/master/LICENSE)
# Archive Resource Provider
This provider is mainly used for ease of converting terraform programs to Pulumi.
For standard use in Pulumi programs, please use your programming language's filesystem library.
The Archive resource provider for Pulumi lets you use Archive resources in your cloud programs.
To use this package, please [install the Pulumi CLI first](https://www.pulumi.com/docs/install/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/archive
or `yarn`:
$ yarn add @pulumi/archive
### Python
To use from Python, install using `pip`:
$ pip install pulumi_archive
### Go
To use from Go, use `go get` to grab the latest version of the library:
$ go get github.com/pulumi/pulumi-archive/sdk
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Archive
<!-- If your provider has configuration, remove this comment and the comment tags below, updating the documentation. -->
<!--
## Configuration
The following Pulumi configuration can be used:
- `archive:token` - (Required) The API token to use with Archive. When not set, the provider will use the `ARCHIVE_TOKEN` environment variable.
-->
<!-- If your provider has reference material available elsewhere, remove this comment and the comment tags below, updating the documentation. -->
<!--
## Reference
For further information, please visit [Archive reference documentation](https://example.com/archive).
-->
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, category/cloud | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://www.pulumi.com/",
"Repository, https://github.com/pulumi/pulumi-archive"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T05:37:01.984956 | pulumi_archive-0.4.0a1771565423.tar.gz | 14,293 | 41/d6/966ff451e2b3763fde34309b55a90d17374a5564e63af3eb38e0f648b99c/pulumi_archive-0.4.0a1771565423.tar.gz | source | sdist | null | false | 0ba82d712bcf01164b413be9d22ae28d | d464abad8f0853083e498d191ad6de701d1dfdcf9af7bb26f769530a8d060b78 | 41d6966ff451e2b3763fde34309b55a90d17374a5564e63af3eb38e0f648b99c | null | [] | 228 |
2.4 | cfdb | 0.3.5 | CF conventions multi-dimensional array storage on top of Booklet | # cfdb
<p align="center">
<em>CF conventions multi-dimensional array storage on top of Booklet</em>
</p>
[](https://github.com/mullenkamp/cfdb/actions)
[](https://codecov.io/gh/mullenkamp/cfdb)
[](https://badge.fury.io/py/cfdb)
---
**Source Code**: <a href="https://github.com/mullenkamp/cfdb" target="_blank">https://github.com/mullenkamp/cfdb</a>
---
## Introduction
cfdb is a pure python database for managing labeled multi-dimensional arrays that mostly follows the [CF conventions](https://cfconventions.org/Data/cf-conventions/cf-conventions-1.12/cf-conventions.html). It is an alternative to netcdf4 and [xarray](https://docs.xarray.dev/). It builds upon the [Booklet](https://github.com/mullenkamp/booklet) for the underlying local file storage and [EBooklet](https://github.com/mullenkamp/ebooklet) to sync and share on any S3 system. It has been designed to follow the programming style of opening a file, iteratively read data, iteratively write data, then closing the file.
It is thread-safe on reads and writes (using thread locks) and multiprocessing-safe (using file locks) including on the S3 remote (using object locking).
When an error occurs, cfdb will try to properly close the file and remove the file (object) locks. This will not sync any changes, so the user will lose any changes that were not synced. There will be circumstances that can occur that will not properly close the file, so care still needs to be made.
## Installation
Install via pip:
```
pip install cfdb
```
I'll probably put it on conda-forge once I feel appropriately motivated...
## Usage
### Opening a file/dataset
Usage starts off by opening the file (and closing the file when done):
```python
import cfdb
import numpy as np
file_path = '/path/to/file.cfdb'
ds = cfdb.open_dataset(file_path, flag='n')
# Do fancy stuff
ds.close()
```
By default, files will be open for read-only, so we need to specify that we want to write (in this case, 'n' is to open for write and replace the existing file with a new one). There are also some compression options, and those are described in the doc strings. Other kwargs from [Booklet](https://github.com/mullenkamp/booklet?tab=readme-ov-file#usage) can be passed to open_dataset.
The dataset can also be opened with the context manager like so:
```python
with cfdb.open_dataset(file_path, flag='n') as ds:
print(ds)
```
This is generally encouraged as this will ensure that the file is closed properly and file locks are removed.
### Dataset types
There are currently two dataset types. Dataset types exist to structure the coordinates according to CF conventions.
The default dataset type is "grid" which is the standard structure for coordinates. Each coordinate must be unique and increasing in ascending order (unless it's a string). Each coordinate represents a single axis (i.e. x, y, z, t). The z axis is currently optional.
The second optional dataset type is called [Orthogonal multidimensional array representation of time series](https://cfconventions.org/Data/cf-conventions/cf-conventions-1.12/cf-conventions.html#_orthogonal_multidimensional_array_representation_of_time_series). This is designed for time series data with sparse geometries (e.g. station time series data). The Geometry dtype must represent the xy axis. The time coordinate is the same as the "grid" time coordinate. The z axis is currently optional.
### Variables
In the [CF conventions](https://cfconventions.org/Data/cf-conventions/cf-conventions-1.12/cf-conventions.html#dimensions), variables are the objects that store data. These can be 1 dimensional or many dimensional. The dimensions are the labels of 1-D variables (like latitude or time). These 1-D variables are called coordinate variables (or coordinates) with the same name as their associated dimension. All variables that use these coordinates as their dimension labels are called data variables. The combination of multiple data variables with their coordinates in a single file is called a dataset.
#### Coordinates
Since all data variables must have coordinates, the coordinates must be created before data variables are created.
Coordinates in cfdb are more similar to the definition by the earlier [COARDS conventions](https://ferret.pmel.noaa.gov/Ferret/documentation/coards-netcdf-conventions) than the latter CF conventions. Coordinate values must be unique, sorted in ascending order (a partial consequence to np.sort), and cannot have null (or np.nan) values. The CF conventions do not have those limitations, but these limitations are good! Coordinates must also be only 1-D.
Coordinates can be created using the generic creation method, or templates can be used for some of the more common dimensions (like latitude, longitude, and time):
```python
lat_data = np.linspace(0, 19.9, 200, dtype='float32')
with cfdb.open_dataset(file_path, flag='n') as ds:
lat_coord = ds.create.coord.lat(data=lat_data, chunk_shape=(20,))
print(lat_coord)
```
When creating coordinates, the user can pass a np.ndarray as data and cfdb will figure out the rest (especially when using a creation template). Otherwise, a coordinate can be created without any data input and the data can be appended later:
```python
with cfdb.open_dataset(file_path, flag='n') as ds:
lat_coord = ds.create.coord.lat(chunk_shape=(20,))
lat_coord.append(lat_data)
print(lat_coord.data)
```
Coordinate data can either be appended or prepended, but keep in mind the limitations described above! And once assigned, coordinate values cannot be changed. At some point, I'll implement the ability to shrink the size of coordinates, but for now they can only be expanded. As seen in the above example, the .data method will return the entire variable data as a single np.ndarray. Coordinates always hold the entire data in memory, while data variables never do. On disk, all data are stored as chunks, whether it's coordinates or data variables.
Let's add another coordinate for fun:
```python
time_data = np.linspace(0, 199, 200, dtype='datetime64[D]')
with cfdb.open_dataset(file_path, flag='w') as ds:
time_coord = ds.create.coord.time(data=time_data, dtype_decoded=time_data.dtype, dtype_encoded='int32')
print(time_coord)
```
A time variable works similarly to other numpy dtypes, but you can assign the precision of the datetime object within the brackets (shown as [D] for days). Look at the [numpy datetime reference page](https://numpy.org/doc/stable/reference/arrays.datetime.html#datetime-units) for all of the frequency codes. Do not use a frequency code finer than "ns". Encoding a datetime64 dtype to an int32 is possible down to the "m" (minute) resolution (with a max year of 6053), but all higher frequency codes should use int64.
#### Data Variables
Data variables are created in a similar way as coordinates except that you cannot pass data on creation and you must pass a tuple of the coordinate names to link the coordinates to the data variable:
```python
data_var_data = np.linspace(0, 3999.9, 40000, dtype='float64').reshape(200, 200)
name = 'data_var'
coords = ('latitude', 'time')
dtype_encoded = 'int32'
scale_factor = 0.1
with cfdb.open_dataset(file_path, flag='w') as ds:
data_var = ds.create.data_var.generic(name, coords, data_var_data.dtype, dtype_encoded, scale_factor=scale_factor)
data_var[:] = data_var_data
data_var.attrs['test'] = ['test attributes']
print(data_var)
```
There are data variable templates like the coordinates, but we will use the generic creation method for illustration. If no fillvalue or chunk_shape is passed, then cfdb figures them out for you.
Assigning data to data variables is different to coordinates. Data variables can only be expanded via the coordinates themselves. Assignment and selection is performed by the [basic numpy indexing](https://numpy.org/doc/stable/user/basics.indexing.html#basic-indexing), but not the [advanced indexing](https://numpy.org/doc/stable/user/basics.indexing.html#advanced-indexing).
The example shown above is the simplest way of assigning data to a data variable, but it's not a preferred method when datasets are very large. The recommended way to write (and read) data is to iterate over the chunks:
```python
with cfdb.open_dataset(file_path, flag='w') as ds:
data_var = ds[name]
for chunk_slices in data_var.iter_chunks():
data_var[chunk_slices] = data_var_data[chunk_slices]
```
This is a bit of a contrived example given that data_var_data is a single in-memory numpy array, but in many cases your data source will be much larger or in many pieces. The chunk_slices is a tuple of index slices that the data chunk covers. It is the same indexing that can be passed to a numpy ndarray.
Reading data uses the same "iter_chunks" method. This ensures that memory usage is kept to a minimum:
```python
with cfdb.open_dataset(file_path, flag='r') as ds:
data_var = ds[name]
for chunk_slices, data in data_var.iter_chunks(include_data=True):
print(chunk_slices)
print(data.shape)
```
There's a groupby method that works similarly to the iter_chunks method except that it requires one or more coordinate names (like pandas or xarray):
```python
with cfdb.open_dataset(file_path, flag='r') as ds:
data_var = ds[name]
for slices, data in data_var.groupby('latitude'):
print(slices)
print(data.shape)
```
#### Rechunking
All data for variables are stored as chunks of data. For example, the shape of your data may be 2000 x 2000, but the data are stored in 100 x 100 chunks. This is done for a variety of reasons including the ability to compress data. When a variable is created, either the user can define their own chunk shape or cfdb will determine the chunk shape automatically.
The chunk shape defined in the variable might be good for some use cases but not others. The user might have specific use cases where they want a specific chunking; for example the groupby operation listed in the last example. In that example, the user wanted to iterate over each latitude but with all of the other coordinates (in this case the full time coordinate). A groupby operation is a common rechunking example, but the user might need chunks in many different shapes.
The [rechunkit package](https://github.com/mullenkamp/rechunkit) is used under the hood to rechunk the data in cfdb. It is exposed in cfdb via the "rechunker" method in a variable. The Rechunker class has several methods to help the user decide the chunk shape.
```python
new_chunk_shape = (41, 41)
with cfdb.open_dataset(file_path) as ds:
data_var = ds[name]
rechunker = data_var.rechunker()
alt_chunk_shape = rechunker.guess_chunk_shape(2**8)
n_chunks = rechunker.calc_n_chunks()
print(n_chunks)
n_reads, n_writes = rechunker.calc_n_reads_rechunker(new_chunk_shape)
print(n_reads, n_writes)
rechunk = rechunker.rechunk(new_chunk_shape)
for slices, data in rechunk:
print(slices)
print(data.shape)
```
#### Grid Interpolation
Data variables support grid interpolation via the [geointerp](https://github.com/mullenkamp/geointerp) package. The dataset must have a CRS defined and the coordinates must have their axes set (x, y, and optionally z and t). Coordinate axes are auto-detected from the metadata, or can be passed explicitly.
All interpolation methods are generators that yield `(time_value, result)` tuples. When there is no time dimension, a single tuple is yielded with `time_value=None`. When a time dimension is present, the data is efficiently iterated using the rechunker/groupby.
##### Regridding to a new grid
```python
with cfdb.open_dataset(file_path) as ds:
data_var = ds['temperature']
for time_val, grid in data_var.grid_interp().to_grid(grid_res=0.01, to_crs=4326):
print(time_val, grid.shape)
```
##### Sampling at point locations
```python
import numpy as np
target_points = np.array([
[175.0, -41.0],
[172.5, -43.5],
])
with cfdb.open_dataset(file_path) as ds:
data_var = ds['temperature']
for time_val, values in data_var.grid_interp().to_points(target_points, to_crs=4326):
print(time_val, values)
```
##### Filling NaN values
```python
with cfdb.open_dataset(file_path) as ds:
data_var = ds['temperature']
for time_val, filled in data_var.grid_interp().interp_na(method='linear'):
print(time_val, filled.shape)
```
##### Regridding vertical levels
For data on terrain-following coordinates where actual level heights vary at each grid point, `regrid_levels` interpolates onto fixed target levels. The `source_levels` parameter is the name of a data variable in the dataset that contains the actual level values (same shape as the data variable being interpolated).
```python
import numpy as np
target_levels = np.array([0, 50, 100, 200, 500])
with cfdb.open_dataset(file_path) as ds:
data_var = ds['temperature']
for time_val, regridded in data_var.grid_interp().regrid_levels(target_levels, source_levels='level_heights'):
print(time_val, regridded.shape)
```
##### Explicit coordinate names
When axes are not set on the coordinates, pass the coordinate names explicitly:
```python
with cfdb.open_dataset(file_path) as ds:
gi = ds['temperature'].grid_interp(x='longitude', y='latitude', time='time')
for time_val, grid in gi.to_grid(grid_res=0.05):
print(time_val, grid.shape)
```
#### Serializers
The datasets can be serialized to netcdf4 via the to_netcdf4 method. You must have the [h5netcdf package](https://h5netcdf.org/) installed for netcdf4. It can also be copied to another cfdb file.
```python
with open_dataset(file_path) as ds:
new_ds = ds.copy(new_file_path)
print(new_ds)
new_ds.close()
ds.to_netcdf4(nc_file_path)
```
## TODO - In no particular order
- Implement geospatial selections.
- Create three different methods on coordinates: nearest, inner, and outer. These will do the coordinate selection based on those three different options.
- Implement units with [Pint](https://pint.readthedocs.io/en/stable/getting/overview.html) and uncertainties with [Uncertainties](https://pythonhosted.org/uncertainties/user_guide.html). Both of these packages are integrated, so I should implement them together.
- ~~Implement geospatial transformations. This kind of operation would heavily benefit from the efficient rechunking in cfdb. This will likely be it's own python package which will get integrated into cfdb.~~
- Remove dependency on h5netcdf and use h5py directly
- Implement more dataset types according to the CF conventions. Specifically, the Time Series structures.
- ~~The first one will be station geometries with uniform time called [Orthogonal multidimensional array representation](https://cfconventions.org/Data/cf-conventions/cf-conventions-1.12/cf-conventions.html#_orthogonal_multidimensional_array_representation_of_time_series).~~
- The second will be station geometries with their own irregular time called [Indexed ragged array representation](https://cfconventions.org/Data/cf-conventions/cf-conventions-1.12/cf-conventions.html#_indexed_ragged_array_representation_of_time_series).
## Development
### Setup environment
We use [uv](https://docs.astral.sh/uv/) to manage the development environment and production build.
## License
This project is licensed under the terms of the Apache Software License 2.0.
| text/markdown | null | mullenkamp <mullenkamp1@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3 :: Only"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"booklet>=0.9.2",
"cfdb-models>=0.1.0",
"cfdb-vars>=0.1.0",
"geointerp>=0.1.1",
"lz4",
"msgspec",
"numpy>2",
"pyproj>3",
"rechunkit>=0.2.1",
"shapely>2",
"zstandard",
"ebooklet>=0.5.10; extra == \"ebooklet\"",
"geointerp>=0.1.1; extra == \"geointerp\"",
"cftime; extra == \"netcdf4\"",
"h5netcdf; extra == \"netcdf4\""
] | [] | [] | [] | [
"Documentation, https://mullenkamp.github.io/cfdb/",
"Source, https://github.com/mullenkamp/cfdb"
] | uv/0.8.7 | 2026-02-20T05:36:31.222536 | cfdb-0.3.5.tar.gz | 53,642 | 03/22/f8a94335c7e812aa46a80a01f4e126b53de031d45954fe69701ca0fe1bbb/cfdb-0.3.5.tar.gz | source | sdist | null | false | 756565adf4132e9b8459aa87177dd66b | 0da8bd22741297ce207761bed7bf7ab4b47a7cca1822f2baf71d84a696d45920 | 0322f8a94335c7e812aa46a80a01f4e126b53de031d45954fe69701ca0fe1bbb | null | [
"LICENSE"
] | 307 |
2.4 | usr | 0.1.3 | Universal Systems Runtime — C core with Python bindings | # usr — Universal Systems Runtime v0.1.3
> ⚠️ **Pre-release / Experimental**
>
> Built to explore low-level systems programming, cryptography, and Telegram text formatting internals.
> Not recommended for production use.
---
## ✨ What's New in v0.1.3
- **All cryptographic bugs fixed** — SHA-256 two-block padding, AES-256 decrypt fully implemented
- **Complete AES suite** — IGE, CBC (PKCS#7), CTR modes
- **SHA-512, HMAC-SHA256, PBKDF2** — full streaming + one-shot APIs
- **Base64, hex, URL, HTML** encoding/decoding
- **Secure random** via `getrandom()` / `/dev/urandom`
- **UTF-8/UTF-16 utilities** — decode, encode, validate, codepoint count, offset conversion
- **Complete Markdown parser + renderer** — V1 and V2, correct UTF-16 offsets
- **Complete HTML parser + renderer** — all Telegram HTML tags
- **Entity normalization** — proper nesting via interval-stack algorithm
- **Python bindings** — all APIs exposed via ctypes, zero external dependencies
---
## 📦 Installation
### Build from Source (Recommended)
```bash
git clone https://github.com/ankit-chaubey/usr
cd usr
# Build static library
mkdir -p build /tmp/objs
for f in $(find src -name '*.c'); do
gcc -O2 -Iinclude -Isrc/crypto -c "$f" -o /tmp/objs/$(basename ${f%.c}).o
done
ar rcs build/libusr.a /tmp/objs/*.o
# Run tests
gcc -O2 -Iinclude tests/test_crypto.c build/libusr.a -o build/test_crypto
gcc -O2 -Iinclude tests/test_encoding.c build/libusr.a -o build/test_encoding
gcc -O2 -Iinclude tests/test_utf8.c build/libusr.a -o build/test_utf8
gcc -O2 -Iinclude tests/test_roundtrip.c build/libusr.a -o build/test_roundtrip
gcc -O2 -Iinclude tests/fuzz_roundtrip.c build/libusr.a -o build/fuzz_roundtrip
build/test_crypto && build/test_encoding && build/test_utf8
build/test_roundtrip && build/fuzz_roundtrip
```
### Python Bindings
```bash
# Build shared library for Python
SRCS=$(find src -name '*.c' | tr '\n' ' ')
gcc -O2 -shared -fPIC -Iinclude -Isrc/crypto $SRCS -o python/usr/libusr.so
cd python
pip install -e .
```
---
## 🧪 Example Usage
### C
```c
#include "usr/usr.h"
// SHA-256
uint8_t digest[32];
usr_sha256((uint8_t*)"hello", 5, digest);
// AES-256-IGE (Telegram MTProto)
uint8_t key[32] = {0x11}; // fill properly
uint8_t iv[32] = {0x22};
usr_aes256_ige_encrypt(data, 32, key, iv);
// Markdown parse
usr_entity ents[64]; char *plain;
size_t n = usr_markdown_parse("*bold* _italic_", USR_MD_V2, &plain, ents, 64);
char *html = usr_entities_to_html(plain, ents, n);
```
### Python
```python
import usr
# Hashing
print(usr.sha256(b"test").hex())
print(usr.hmac_sha256(b"key", b"message").hex())
# AES-256-IGE (Telegram)
key = bytes(32); iv = bytes(32)
enc = usr.aes256_ige_encrypt(b"\x00" * 16, key, iv)
dec = usr.aes256_ige_decrypt(enc, key, iv)
# AES-256-CBC
enc = usr.aes256_cbc_encrypt(b"secret", b"\x11" * 32, b"\x22" * 16)
dec = usr.aes256_cbc_decrypt(enc, b"\x11" * 32, b"\x22" * 16)
# Markdown
plain, ents = usr.markdown_parse("*bold* _italic_")
html = usr.entities_to_html(plain, ents) # <b>bold</b> <i>italic</i>
md = usr.entities_to_markdown(plain, ents) # *bold* _italic_
# Encoding
usr.base64_encode(b"hello") # 'aGVsbG8='
usr.hex_encode(b"\xde\xad") # 'dead'
usr.url_encode("hello world") # 'hello%20world'
```
---
## 📐 API Reference
### Cryptography (`usr/crypto.h`)
| Function | Description |
|---|---|
| `usr_sha256(data, len, out)` | One-shot SHA-256 |
| `usr_sha512(data, len, out)` | One-shot SHA-512 |
| `usr_hmac_sha256(key, klen, data, dlen, out)` | HMAC-SHA256 |
| `usr_pbkdf2_sha256(pass, plen, salt, slen, iters, out, olen)` | PBKDF2-HMAC-SHA256 |
| `usr_aes256_ige_encrypt(data, len, key, iv)` | AES-256-IGE (in-place) |
| `usr_aes256_ige_decrypt(data, len, key, iv)` | AES-256-IGE decrypt |
| `usr_aes256_cbc_encrypt(in, ilen, key, iv, out, olen)` | AES-256-CBC + PKCS#7 |
| `usr_aes256_cbc_decrypt(in, ilen, key, iv, out, olen)` | AES-256-CBC + unpad |
| `usr_aes256_ctr_crypt(data, len, key, nonce)` | AES-256-CTR (symmetric) |
| `usr_crc32(data, len)` | CRC-32 (IEEE 802.3) |
| `usr_rand_bytes(out, len)` | Cryptographically secure random |
### Encoding (`usr/encoding.h`)
| Function | Description |
|---|---|
| `usr_base64_encode(data, len, out)` | Standard Base64 |
| `usr_base64url_encode(data, len, out)` | URL-safe Base64 |
| `usr_base64_decode(s, slen, out)` | Decode Base64 |
| `usr_hex_encode(data, len, out)` | Lowercase hex |
| `usr_hex_decode(s, slen, out)` | Hex → bytes |
| `usr_url_encode(s, slen, out)` | RFC 3986 URL encoding |
| `usr_url_decode(s, slen, out)` | URL decode |
| `usr_html_escape(s, slen, out)` | Escape `<>&"'` |
| `usr_html_unescape(s, slen, out)` | Unescape `&` etc. |
### Text / Entities
| Function | Description |
|---|---|
| `usr_markdown_parse(text, version, plain_out, ents, max)` | Markdown → entities |
| `usr_entities_to_markdown(text, ents, n, version)` | Entities → Markdown |
| `usr_html_parse(html, plain_out, ents, max)` | HTML → entities |
| `usr_entities_to_html(text, ents, n)` | Entities → HTML |
| `usr_entities_normalize(ents, n)` | Sort + fix overlaps |
---
## 🗂️ Project Structure
```
usr/
├── include/usr/ # Public headers
│ ├── usr.h # Umbrella include
│ ├── crypto.h # SHA-256/512, AES, HMAC, PBKDF2, CRC-32
│ ├── encoding.h # Base64, hex, URL, HTML
│ ├── entities.h # MessageEntity types
│ ├── html.h # HTML ↔ entities
│ ├── markdown.h # Markdown ↔ entities
│ ├── utf8.h # UTF-8/16 utilities
│ ├── bytes.h # Owned byte buffer
│ ├── strbuilder.h # String builder
│ └── rand.h # Secure random
├── src/
│ ├── crypto/ # AES, SHA, HMAC, CRC, rand
│ ├── encoding/ # Base64, hex, URL, HTML escaping
│ ├── entities/ # Entity normalization
│ ├── html/ # HTML parser & renderer
│ ├── markdown/ # Markdown parser & renderer
│ └── utf8/ # UTF-8 codec
├── python/usr/ # Python ctypes bindings
│ ├── _lib.py # Library loader
│ ├── _structs.py # ctypes structure definitions
│ ├── crypto.py # Crypto bindings
│ ├── encoding.py # Encoding bindings
│ ├── entities.py # Entity class + normalize
│ ├── html.py # HTML parse/render
│ └── markdown.py # Markdown parse/render
├── tests/ # C test suite + fuzz
├── examples/full_demo.c
└── benchmarks/bench_crypto.c
```
---
## 👤 Author
**Ankit Chaubey** · [github.com/ankit-chaubey](https://github.com/ankit-chaubey)
Inspired by `cryptg`, `tgcrypto`, and Telegram MTProto internals.
---
## 📄 License
MIT
| text/markdown | usr contributors | Ankit Chaubey <m.ankitchaubey@gmail.com> | null | null | null | cryptography, aes, sha256, telegram, markdown, entities | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries",
"Topic :: Security :: Cryptography",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: C",
"Operating System :: POSIX :: Linux",
"Operating System :: MacOS :: MacOS X"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Source, https://github.com/ankit-chaubey/usr",
"Issues, https://github.com/ankit-chaubey/usr/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T05:35:55.056462 | usr-0.1.3-py3-none-any.whl | 42,940 | be/b0/f984e7e2ec04ebd9b57ff322c48d931cb841169e38d8e334bc6c0443d689/usr-0.1.3-py3-none-any.whl | py3 | bdist_wheel | null | false | 03fe5e39ea2276ca56844599632d2d25 | 2804c47491bc83c7cabb029ec6d0027d975f002fc1e645eeee5d7e6511de40e3 | beb0f984e7e2ec04ebd9b57ff322c48d931cb841169e38d8e334bc6c0443d689 | MIT | [] | 108 |
2.4 | sf-queue-sdk | 0.2.0b21 | Python SDK for sf-queue - Redis-based queue system | # sf-queue-sdk
Python SDK for sf-queue. Enqueues emails via Redis Streams with optional blocking confirmation from the Go consumer service.
## Installation
```bash
pip install sf-queue-sdk
```
## Setup
```python
from queue_sdk import QueueClient
client = QueueClient(
redis_url="redis://localhost:6379",
redis_password="your-password",
environment="staging", # prefixes stream names: staging:{email}
)
```
## Single Email
### Fire and forget
Enqueues the email and returns immediately. Does not wait for the consumer to process it.
```python
result = client.email.send(
to="user@example.com",
preview="Welcome to StudyFetch!",
subject="Welcome to StudyFetch!",
paragraphs=[
"Hey there,",
"Welcome to the StudyFetch community!",
"Thanks for joining us.",
],
button={
"text": "Go to Platform",
"href": "https://www.studyfetch.com/platform",
},
)
print("Enqueued:", result.message_id)
```
### Send and wait for confirmation
Enqueues the email and blocks until the Go consumer processes it (or timeout).
```python
result = client.email.send_and_wait(
to="user@example.com",
preview="Reset your password",
subject="StudyFetch: Reset Your Password",
paragraphs=[
"Hi There,",
"Click the button below to reset your password.",
],
button={
"text": "Reset Password",
"href": "https://www.studyfetch.com/reset?token=abc",
},
timeout=30, # optional, default 30s
)
print(result.success) # True or False
print(result.message_id) # request ID
print(result.error) # error message if failed
```
## Batch Email
Send the same email content to multiple recipients (up to 100). The Go consumer sends to each recipient individually.
### Fire and forget
```python
result = client.email.send_batch(
to=[
"student1@example.com",
"student2@example.com",
"student3@example.com",
],
preview="You have been invited to join a class!",
subject="StudyFetch: Class Invitation",
paragraphs=[
"Hi There,",
'You have been invited to join "Intro to CS" on StudyFetch!',
"Click the button below to accept the invite.",
],
button={
"text": "Accept Invite",
"href": "https://www.studyfetch.com/invite/abc",
},
)
print("Enqueued:", result.message_id)
```
### Send and wait for confirmation
```python
result = client.email.send_batch_and_wait(
to=[
"student1@example.com",
"student2@example.com",
"student3@example.com",
],
preview="You have been invited to join a class!",
subject="StudyFetch: Class Invitation",
paragraphs=[
"Hi There,",
'You have been invited to join "Intro to CS" on StudyFetch!',
"Click the button below to accept the invite.",
],
button={
"text": "Accept Invite",
"href": "https://www.studyfetch.com/invite/abc",
},
timeout=30,
)
print(result.success) # True if at least some sent
print(result.message_id) # request ID
print(result.total) # 3
print(result.successful) # number sent successfully
print(result.failed) # number that failed
print(result.error) # error message if all failed
```
## All Email Fields
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `to` | `str` | Yes (single) | Recipient email address |
| `to` | `list[str]` | Yes (batch) | List of recipient emails (max 100) |
| `preview` | `str` | Yes | Preview text shown in email clients |
| `subject` | `str` | Yes | Email subject line |
| `paragraphs` | `list[str]` | Yes | Body content as paragraph strings |
| `button` | `{"text": str, "href": str}` | No | Call-to-action button |
| `reply_to` | `str` | No | Reply-to email address |
| `image` | `{"src": str, "alt"?: str, "width"?: int, "height"?: int}` | No | Image in email body |
## Optional Fields
```python
# With all optional fields
client.email.send(
to="support@studyfetch.com",
preview="Support Request",
subject="StudyFetch: Support Request",
paragraphs=["Hi There,", "You received a support request.", issue],
reply_to="requester@example.com",
image={
"src": "https://example.com/logo.png",
"alt": "Logo",
"width": 150,
"height": 50,
},
)
```
## Migrating from sendEmail / sendBatchEmail
The SDK is a drop-in replacement. Field names match the existing functions:
```python
# BEFORE
send_email(to=to, preview=preview, subject=subject, paragraphs=paragraphs, button=button)
# AFTER (fire and forget)
client.email.send(to=to, preview=preview, subject=subject, paragraphs=paragraphs, button=button)
# AFTER (wait for confirmation)
client.email.send_and_wait(to=to, preview=preview, subject=subject, paragraphs=paragraphs, button=button)
# BEFORE (batch)
send_batch_email(to=[...], preview=preview, subject=subject, paragraphs=paragraphs, button=button)
# AFTER (batch, fire and forget)
client.email.send_batch(to=[...], preview=preview, subject=subject, paragraphs=paragraphs, button=button)
# AFTER (batch, wait for confirmation)
client.email.send_batch_and_wait(to=[...], preview=preview, subject=subject, paragraphs=paragraphs, button=button)
```
## Methods and Response Types
| Method | Return Type | Fields |
|--------|-------------|--------|
| `send()` | `SendResult` | `message_id` |
| `send_and_wait()` | `EmailResponse` | `success`, `message_id`, `error?`, `processed_at?` |
| `send_batch()` | `SendResult` | `message_id` |
| `send_batch_and_wait()` | `BatchEmailResponse` | `success`, `message_id`, `error?`, `processed_at?`, `total`, `successful`, `failed` |
## Topic Assignment
### Fire and forget
```python
result = client.topic_assignment.send(
topic_vector_id="507f1f77bcf86cd799439011",
topic_id="topic_abc123",
user_id="user_xyz",
current_assignment=None,
new_assignment="faiss_1422.0",
)
print("Enqueued:", result.message_id)
```
### Send and wait for confirmation
```python
result = client.topic_assignment.send_and_wait(
topic_vector_id="507f1f77bcf86cd799439011",
topic_id="topic_abc123",
user_id="user_xyz",
current_assignment=None,
new_assignment="faiss_1422.0",
timeout=30,
)
print(result.success)
print(result.message_id)
```
### Batch (fire and forget)
```python
result = client.topic_assignment.send_batch(
assignments=[
{
"topic_vector_id": "507f1f77bcf86cd799439011",
"topic_id": "topic_abc123",
"user_id": "user_xyz",
"current_assignment": None,
"new_assignment": "faiss_1422.0",
},
{
"topic_vector_id": "507f1f77bcf86cd799439012",
"topic_id": "topic_def456",
"user_id": "user_xyz",
"current_assignment": "faiss_1422",
"new_assignment": "faiss_1422.1",
},
],
)
```
### Batch (wait for confirmation)
```python
result = client.topic_assignment.send_batch_and_wait(
assignments=[
{
"topic_vector_id": "507f1f77bcf86cd799439011",
"topic_id": "topic_abc123",
"user_id": "user_xyz",
"current_assignment": None,
"new_assignment": "faiss_1422.0",
},
],
timeout=30,
)
print(result.success)
print(result.total)
print(result.successful)
print(result.failed)
```
### Topic Assignment Fields
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `topic_vector_id` | `str` | Yes | MongoDB _id of the topic_vector |
| `topic_id` | `str` | Yes | The topicId field |
| `user_id` | `str` | Yes | The userId who owns the topic |
| `current_assignment` | `Optional[str]` | Yes | Current cluster_id (None for first-time) |
| `new_assignment` | `str` | Yes | The new cluster_id |
## Tool Assignment
### Fire and forget
```python
result = client.tool_assignment.send(
tool_id="507f1f77bcf86cd799439011",
user_id="user_xyz",
topic_id="topic_abc123",
current_assignment=None,
new_assignment="faiss_1422.0",
)
```
### Send and wait for confirmation
```python
result = client.tool_assignment.send_and_wait(
tool_id="507f1f77bcf86cd799439011",
user_id="user_xyz",
topic_id="topic_abc123",
current_assignment=None,
new_assignment="faiss_1422.0",
timeout=30,
)
```
### Batch (fire and forget)
```python
result = client.tool_assignment.send_batch(
assignments=[
{
"tool_id": "507f1f77bcf86cd799439011",
"user_id": "user_xyz",
"topic_id": "topic_abc123",
"current_assignment": None,
"new_assignment": "faiss_1422.0",
},
{
"tool_id": "507f1f77bcf86cd799439012",
"user_id": "user_xyz",
"topic_id": "topic_abc123",
"current_assignment": "faiss_1422",
"new_assignment": "faiss_1422.1",
},
],
)
```
### Batch (wait for confirmation)
```python
result = client.tool_assignment.send_batch_and_wait(
assignments=[
{"tool_id": "...", "user_id": "...", "topic_id": "...", "current_assignment": None, "new_assignment": "..."},
],
timeout=30,
)
```
### Tool Assignment Fields
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `tool_id` | `str` | Yes | MongoDB _id of the tool document |
| `user_id` | `str` | Yes | The userId who owns the tool |
| `topic_id` | `str` | Yes | The topicId the tool belongs to |
| `current_assignment` | `Optional[str]` | Yes | Current cluster_id (None for new embeddings) |
| `new_assignment` | `str` | Yes | The cluster_id to assign to |
## Cleanup
```python
client.disconnect()
```
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"redis>=5.0.0"
] | [] | [] | [] | [] | uv/0.10.0 {"installer":{"name":"uv","version":"0.10.0","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Debian GNU/Linux","version":"13","id":"trixie","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T05:35:33.386172 | sf_queue_sdk-0.2.0b21-py3-none-any.whl | 18,694 | 5c/f5/d82e140f008833634cb71d554031994eef02f679b7d588b78353132f3b2b/sf_queue_sdk-0.2.0b21-py3-none-any.whl | py3 | bdist_wheel | null | false | 107bb576c4c9f44304c233ba026fbdb5 | b9b37c49b16719392f99d3e25bffbafcaafeafe30b37d3afd66999082af699e8 | 5cf5d82e140f008833634cb71d554031994eef02f679b7d588b78353132f3b2b | null | [] | 209 |
2.4 | sqlexplore | 0.8.0 | SQL exploration over data files with your CLI and LLM | # sqlexplore
[](https://opensource.org/licenses/MIT)
[](https://badge.fury.io/py/sqlexplore)
[](https://github.com/dylanhogg/sqlexplore/actions/workflows/ci.yml)
[](https://github.com/dylanhogg/sqlexplore/tags)
[](https://pepy.tech/project/sqlexplore)
`sqlexplore` is a terminal SQL explorer for flat files (`.csv`, `.tsv`, `.txt`, `.parquet`, `.pq`), powered by DuckDB.
Use it when you need quick answers from local files, URLs, or piped terminal output without building a separate pipeline first.
## Useful features
- Interactive TUI with query editor, results grid, cell preview, and activity log.
- Non-interactive mode (`--no-ui`) for one-shot queries in plain terminal output.
- SQL helper commands for common analysis and shaping tasks:
`/summary`, `/describe`, `/profile`, `/hist`, `/corr`, `/top`, `/dupes`, `/crosstab`,
`/sample`, `/filter`, `/sort`, `/group`, `/agg`.
- LLM-assisted SQL generation with `/llm-query`, plus trace tools (`/llm-history`, `/llm-show`).
- Query history and rerun helpers (`/history`, `/rerun`, `/history-log`, `/rerun-log`).
- Context-aware autocomplete for SQL and helper commands.
- Result export via `/save` to `.csv`, `.parquet`/`.pq`, or `.json`.
- JSON-aware table rendering and preview, including compact image-cell tokens for image-like values.
- Local files, HTTP(S) URLs, and stdin input (for piped text).
- Multiple sources via repeated `--data` (schemas must match; sources are unioned).
- Remote download cache controls with `--download-dir` and `--overwrite`.
- `.txt` input support with derived fields like `line_number`, `line_length`, `word_count`, and `line_hash`.
## Run with uvx (preferred)
Requires Python 3.13+.
Run directly without a manual install:
```bash
uvx sqlexplore --data ./data/example.parquet
```
Equivalent explicit form:
```bash
uvx --from sqlexplore sqlexplore --data ./data/example.parquet
```
Run one query and exit:
```bash
uvx sqlexplore --data ./data/example.parquet --execute "SELECT COUNT(*) AS n FROM data" --no-ui
```
Run SQL from file and exit:
```bash
uvx sqlexplore --data ./data/example.parquet --file ./queries/report.sql --no-ui
```
Use multiple inputs:
```bash
uvx sqlexplore --data ./data/jan.parquet --data ./data/feb.parquet
```
Analyze piped terminal text:
```bash
ls -lha | uvx sqlexplore
```
Open remote data (downloaded then loaded):
```bash
uvx sqlexplore --data https://github.com/dylanhogg/awesome-python/raw/refs/heads/main/github_data.parquet
```
## Install with pip
```bash
pip install sqlexplore
sqlexplore --data ./data/example.parquet
```
## LLM usage (optional)
Set an API key for your chosen LiteLLM provider (for example `OPENAI_API_KEY`), then run:
```sql
/llm-query top 10 customers by total revenue
```
Optional model override:
```bash
export SQLEXPLORE_LLM_MODEL=openai/gpt-5-mini
```
## Notes
- `--data` can be omitted when piping stdin.
- If stdin has no controlling TTY, sqlexplore falls back to `--no-ui`.
- `--limit` sets default helper query limit. `/limit` also updates row display limit.
- Logs are written to `sqlexplore.log` in your app log directory (with fallbacks).
- Run `sqlexplore --help` to view all options.
## Links
- [GitHub](https://github.com/dylanhogg/sqlexplore)
- [PyPI](https://pypi.org/project/sqlexplore/)
| text/markdown | Dylan Hogg | null | null | null | null | sql, duckdb, cli, tui, csv, parquet | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Programming Language :: Python :: 3.15",
"Environment :: Console",
"Topic :: Database",
"Topic :: Database :: Front-Ends",
"Programming Language :: SQL"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"duckdb>=1.4.4",
"litellm>=1.81.12",
"rich>=14.0.0",
"sqlglot>=26.0.0",
"textual>=7.5.0",
"tqdm>=4.67.3",
"typer>=0.21.1"
] | [] | [] | [] | [
"Homepage, https://github.com/dylanhogg/sqlexplore",
"Repository, https://github.com/dylanhogg/sqlexplore",
"Issues, https://github.com/dylanhogg/sqlexplore/issues"
] | uv/0.9.24 {"installer":{"name":"uv","version":"0.9.24","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T05:35:31.196167 | sqlexplore-0.8.0-py3-none-any.whl | 78,848 | d5/00/b7f316f057a48333f6862a55bfd12e95c36287638388e876aefcc3bf617b/sqlexplore-0.8.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 47f82885f7553357e3bf84cc8d1100ae | 2375499e5292f4b5b45729ea15b4149657d23b314adf49fae4b1028633985f60 | d500b7f316f057a48333f6862a55bfd12e95c36287638388e876aefcc3bf617b | MIT | [
"LICENSE"
] | 254 |
2.4 | monocr | 0.1.20 | Optical Character Recognition for Mon text | # Mon OCR
Optical Character Recognition for Mon (mnw) text.
## Installation
```bash
pip install monocr | uv add monocr
```
## Quick Start
### Python Usage
```python
from monocr import MonOCR
# Initialize
model = MonOCR()
# 1. Read an Image
text = model.read_text("image.png")
print(text)
# 2. Read with Confidence
result = model.predict_with_confidence("image.png")
print(f"Text: {result['text']}")
print(f"Confidence: {result['confidence']:.2%}")
```
### Examples
See the [`examples/`](examples/) folder to learn more.
- **`examples/run_ocr.py`**: A complete script that can process a folder of images or read a full PDF book.
- Or a demo notebook to play around with the package [`notebooks/demo.ipynb`](https://github.com/janakhpon/preview_monocr/blob/main/notebooks/demo.ipynb)
### CLI Usage
You can also use the command line interface:
```bash
# Process a single image
monocr read image.png
# Process a folder of images
monocr batch folder/path
# Manually download the model
monocr download
```
## Resources
- [monocr on pypi](https://pypi.org/project/monocr/)
- [monocr on hugging face](https://huggingface.co/janakhpon/monocr)
## Development
### Release Workflow
```bash
uv version --bump patch
uv build
git add .
git commit -m "bump version"
git tag v0.1.19
git push origin main --tags
```
## License
MIT - do whatever you want with it.
| text/markdown | null | janakhpon <jnovaxer@gmail.com> | null | null | null | mon, ocr, text-recognition | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Scientific/Engineering :: Image Recognition",
"Topic :: Text Processing :: Linguistic",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"torch>=2.0.0",
"torchvision>=0.15.0",
"pillow>=9.0.0",
"numpy>=1.21.0",
"click>=8.0.0",
"opencv-python>=4.0.0",
"huggingface_hub>=0.16.0",
"pdf2image; extra == \"examples\"",
"pytest; extra == \"test\""
] | [] | [] | [] | [
"Repository, https://github.com/janakhpon/monocr"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T05:35:04.581459 | monocr-0.1.20.tar.gz | 106,559 | 65/42/efc9233590184982ced2de855cf8140eedcd9046af3d5770af4ae136b51b/monocr-0.1.20.tar.gz | source | sdist | null | false | 6fac65b22ba8f2e358f2de220861d304 | 3207160118b8540461f8673ed3046126c69f40f2a2e89c78c114df32847ce74f | 6542efc9233590184982ced2de855cf8140eedcd9046af3d5770af4ae136b51b | MIT | [
"LICENSE"
] | 245 |
2.4 | pulumi-aiven | 6.50.0a1771565255 | A Pulumi package for creating and managing Aiven cloud resources. | [](https://github.com/pulumi/pulumi-aiven/actions)
[](https://slack.pulumi.com)
[](https://www.npmjs.com/package/@pulumi/aiven)
[](https://pypi.org/project/pulumi-aiven)
[](https://badge.fury.io/nu/pulumi.aiven)
[](https://pkg.go.dev/github.com/pulumi/pulumi-aiven/sdk/v5/go)
[](https://github.com/pulumi/pulumi-aiven/blob/master/LICENSE)
# Aiven Resource Provider
The Aiven resource provider for Pulumi lets you manage Aiven resources in your cloud programs. To use
this package, please [install the Pulumi CLI first](https://pulumi.io/).
## Installing
This package is available in many languages in the standard packaging formats.
### Node.js (Java/TypeScript)
To use from JavaScript or TypeScript in Node.js, install using either `npm`:
$ npm install @pulumi/aiven
or `yarn`:
$ yarn add @pulumi/aiven
### Python
To use from Python, install using `pip`:
$ pip install pulumi_aiven
### Go
To use from Go, use `go get` to grab the latest version of the library
$ go get github.com/pulumi/pulumi-aiven/sdk/v5
### .NET
To use from .NET, install using `dotnet add package`:
$ dotnet add package Pulumi.Aiven
## Configuration
The following configuration points are available:
- `aiven:apiToken` - (Optional) This is the API token to interact with your Aiven account. May be set via the `AIVEN_TOKEN` environment variable.
## Reference
For further information, please visit [the Aiven provider docs](https://www.pulumi.com/docs/intro/cloud-providers/aiven) or for detailed reference documentation, please visit [the API docs](https://www.pulumi.com/docs/reference/pkg/aiven).
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, aiven | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-aiven"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-20T05:34:08.090571 | pulumi_aiven-6.50.0a1771565255.tar.gz | 923,078 | 27/81/0e586fae34c11754a8b168bd4d9ed3db6ef6b88b181de3da8b9bd45062a1/pulumi_aiven-6.50.0a1771565255.tar.gz | source | sdist | null | false | 869574fd9e156643243a22f5fa4626c5 | cfdce337889e9c1e34fc8451450f0b6932ec5c9d6212ebda725a8fba566637e0 | 27810e586fae34c11754a8b168bd4d9ed3db6ef6b88b181de3da8b9bd45062a1 | null | [] | 233 |
2.1 | cdktn-provider-azurerm | 15.1.0 | Prebuilt azurerm Provider for CDK Terrain (cdktn) | # CDKTN prebuilt bindings for hashicorp/azurerm provider version 4.61.0
This repo builds and publishes the [Terraform azurerm provider](https://registry.terraform.io/providers/hashicorp/azurerm/4.61.0/docs) bindings for [CDK Terrain](https://cdktn.io).
## Available Packages
### NPM
The npm package is available at [https://www.npmjs.com/package/@cdktn/provider-azurerm](https://www.npmjs.com/package/@cdktn/provider-azurerm).
`npm install @cdktn/provider-azurerm`
### PyPI
The PyPI package is available at [https://pypi.org/project/cdktn-provider-azurerm](https://pypi.org/project/cdktn-provider-azurerm).
`pipenv install cdktn-provider-azurerm`
### Nuget
The Nuget package is available at [https://www.nuget.org/packages/Io.Cdktn.Providers.Azurerm](https://www.nuget.org/packages/Io.Cdktn.Providers.Azurerm).
`dotnet add package Io.Cdktn.Providers.Azurerm`
### Maven
The Maven package is available at [https://mvnrepository.com/artifact/io.cdktn/cdktn-provider-azurerm](https://mvnrepository.com/artifact/io.cdktn/cdktn-provider-azurerm).
```
<dependency>
<groupId>io.cdktn</groupId>
<artifactId>cdktn-provider-azurerm</artifactId>
<version>[REPLACE WITH DESIRED VERSION]</version>
</dependency>
```
### Go
The go package is generated into the [`github.com/cdktn-io/cdktn-provider-azurerm-go`](https://github.com/cdktn-io/cdktn-provider-azurerm-go) package.
`go get github.com/cdktn-io/cdktn-provider-azurerm-go/azurerm/<version>`
Where `<version>` is the version of the prebuilt provider you would like to use e.g. `v11`. The full module name can be found
within the [go.mod](https://github.com/cdktn-io/cdktn-provider-azurerm-go/blob/main/azurerm/go.mod#L1) file.
## Docs
Find auto-generated docs for this provider here:
* [Typescript](./docs/API.typescript.md)
* [Python](./docs/API.python.md)
* [Java](./docs/API.java.md)
* [C#](./docs/API.csharp.md)
* [Go](./docs/API.go.md)
You can also visit a hosted version of the documentation on [constructs.dev](https://constructs.dev/packages/@cdktn/provider-azurerm).
## Versioning
This project is explicitly not tracking the Terraform azurerm provider version 1:1. In fact, it always tracks `latest` of `~> 4.0` with every release. If there are scenarios where you explicitly have to pin your provider version, you can do so by [generating the provider constructs manually](https://cdktn.io/docs/concepts/providers#import-providers).
These are the upstream dependencies:
* [CDK Terrain](https://cdktn.io) - Last official release
* [Terraform azurerm provider](https://registry.terraform.io/providers/hashicorp/azurerm/4.61.0)
* [Terraform Engine](https://terraform.io)
If there are breaking changes (backward incompatible) in any of the above, the major version of this project will be bumped.
## Features / Issues / Bugs
Please report bugs and issues to the [CDK Terrain](https://cdktn.io) project:
* [Create bug report](https://github.com/open-constructs/cdk-terrain/issues)
* [Create feature request](https://github.com/open-constructs/cdk-terrain/issues)
## Contributing
### Projen
This is mostly based on [Projen](https://projen.io), which takes care of generating the entire repository.
### cdktn-provider-project based on Projen
There's a custom [project builder](https://github.com/cdktn-io/cdktn-provider-project) which encapsulate the common settings for all `cdktn` prebuilt providers.
### Provider Version
The provider version can be adjusted in [./.projenrc.js](./.projenrc.js).
### Repository Management
The repository is managed by [CDKTN Repository Manager](https://github.com/cdktn-io/cdktn-repository-manager/).
| text/markdown | CDK Terrain Maintainers | null | null | null | MPL-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved"
] | [] | https://github.com/cdktn-io/cdktn-provider-azurerm.git | null | ~=3.9 | [] | [] | [] | [
"cdktn<0.23.0,>=0.22.0",
"constructs<11.0.0,>=10.4.2",
"jsii<2.0.0,>=1.119.0",
"publication>=0.0.3",
"typeguard<4.3.0,>=2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/cdktn-io/cdktn-provider-azurerm.git"
] | twine/6.1.0 CPython/3.14.2 | 2026-02-20T05:32:25.726653 | cdktn_provider_azurerm-15.1.0.tar.gz | 43,786,748 | 69/68/dab47a1179ae842f9afa0f34227246367a4118657a9ccf63bae1f0846418/cdktn_provider_azurerm-15.1.0.tar.gz | source | sdist | null | false | fd89491d6d21a8b76265303bdcf1f029 | b46344bd547e9fc7780d446d9f9492c1d19c0a03f95926f735e3ea656f75c3cd | 6968dab47a1179ae842f9afa0f34227246367a4118657a9ccf63bae1f0846418 | null | [] | 277 |
2.4 | alexwlchan-chives | 23 | Utility functions for working with my local media archives | # chives
chives is a collection of Python functions for working with my local
media archives.
I store a lot of media archives as [static websites][static-sites], and I use Python scripts to manage the sites.
This includes:
* Verifying every file that's described in the metadata is stored correctly
* Downloading pages from sites I want to bookmark
* Checking the quality and consistency of my metadata
This package has some functions I share across multiple archives/sites.
[static-sites]: https://alexwlchan.net/2024/static-websites/
## References
I've written blog posts about some of the code in this repo:
* [Cleaning up messy dates in JSON](https://alexwlchan.net/2025/messy-dates-in-json/)
* [Detecting AV1-encoded videos with Python](https://alexwlchan.net/2025/detecting-av1-videos/)
## Versioning
This library is monotically versioned.
I'll try not to break anything between releases, but I make no guarantees of back-compatibility.
I'm making this public because it's convenient for me, and you might find useful code here, but be aware this may not be entirely stable.
## Usage
See the docstrings on individual functions for usage descriptions.
## Installation
If you want to use this in your project, I recommend copying the relevant function and test into your codebase (with a link back to this repo).
Alternatively, you can install the package from PyPI:
```console
$ pip install alexwlchan-chives
```
## Development
If you want to make changes to the library, there are instructions in [CONTRIBUTING.md](./CONTRIBUTING.md).
## License
MIT.
| text/markdown | null | Alex Chan <alex@alexwlchan.net> | null | Alex Chan <alex@alexwlchan.net> | null | null | [
"Development Status :: 4 - Beta",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"Pillow; extra == \"media\"",
"pytest; extra == \"static-site-tests\"",
"rapidfuzz; extra == \"static-site-tests\"",
"httpx; extra == \"urls\"",
"hyperlink; extra == \"urls\""
] | [] | [] | [] | [
"Homepage, https://github.com/alexwlchan/chives",
"Changelog, https://github.com/alexwlchan/chives/blob/main/CHANGELOG.md"
] | twine/6.2.0 CPython/3.13.9 | 2026-02-20T05:31:41.547858 | alexwlchan_chives-23.tar.gz | 16,512 | b1/3a/74ebbf77c477206c302ff79f0bbda613104637233339b26b70aaa199ee91/alexwlchan_chives-23.tar.gz | source | sdist | null | false | a6b5692629426dc80d5a310ba2cf9a46 | d2e2c03289cb714b2d96233ee82b19a34888a3d7c750543d9b56971702ea6b31 | b13a74ebbf77c477206c302ff79f0bbda613104637233339b26b70aaa199ee91 | MIT | [
"LICENSE"
] | 251 |
2.4 | nexusLIMS | 2.5.1 | Electron Microscopy Nexus LIMS project (Datasophos fork) | <p align="left">
<img src="docs/_static/logo_horizontal_text.png" alt="NexusLIMS Logo" width="600">
</p>
[](https://datasophos.github.io/NexusLIMS/stable/)
[](https://www.python.org/downloads/)
[](https://datasophos.co)
[](https://github.com/datasophos/NexusLIMS/actions/workflows/test.yml)
[](https://github.com/datasophos/NexusLIMS/actions/workflows/integration-tests.yml)
[](https://codecov.io/gh/datasophos/NexusLIMS)
# NexusLIMS - Automated Laboratory Information Management for Electron Microscopy
> **⚠️ Notice**: This is a fork of the original NexusLIMS project, created after the lead developer (@jat255) left NIST and founded [Datasophos](https://datasophos.co). This fork is maintained by Datasophos and is **not affiliated with NIST** in any way. For the official NIST version, please visit the [original repository](https://github.com/usnistgov/NexusLIMS).
## What is NexusLIMS?
**NexusLIMS automatically generates experimental records by extracting metadata from microscopy data files and harvesting information from laboratory calendar systems.**
Originally developed by the NIST Office of Data and Informatics, NexusLIMS transforms raw microscopy data into structured, searchable experimental records without requiring manual data entry. By combining file metadata extraction with reservation calendar information, NexusLIMS creates comprehensive documentation of microscopy sessions automatically.
### What it does
- Reads metadata from `.dm3/.dm4` (DigitalMicrograph), `.tif` (FEI/Thermo), `.ser/.emi` (FEI TIA), and other microscopy formats
- Pulls reservation and usage context from [NEMO](https://github.com/usnistgov/NEMO) to associate files with the right session and user
- Groups files from the same session into logical acquisition activities using temporal clustering
- Generates thumbnail previews alongside the extracted metadata
- Builds XML records conforming to the "[Nexus Experiment](https://doi.org/10.18434/M32245)" schema and uploads them to the [NexusLIMS CDCS](https://github.com/datasophos/NexusLIMS-CDCS) web frontend
### How it works
When an instrument session ends in NEMO, NexusLIMS finds all data files saved during the reservation window, extracts their metadata, and assembles everything into a structured record — no manual data entry required. Records are uploaded to a searchable web interface where users can browse and retrieve their experimental data.
For more details, see the [Record Building Workflow](https://datasophos.github.io/NexusLIMS/stable/user_guide/record_building.html) documentation.
## Quick Start
### Installation
#### Option 1: `uv tool install` (Recommended)
The easiest way to install NexusLIMS is as an isolated command-line tool using [uv](https://docs.astral.sh/uv/) (requires [installing uv](https://docs.astral.sh/uv/#installation) first):
```bash
uv tool install nexuslims
```
#### Option 2: `pip` (virtual environment)
Install in a user-managed virtual environment:
```bash
python -m venv nexuslims-venv
source nexuslims-venv/bin/activate
pip install nexuslims
```
#### Option 3: Development install (from source)
For contributors or developers who want to modify NexusLIMS source code:
```bash
git clone https://github.com/datasophos/NexusLIMS.git
cd NexusLIMS
uv sync
```
> **Note:** For development installs, you will need to prefix NexusLIMS commands with `uv run` (e.g. `uv run nexuslims config edit`).
### Configuration
Run `nexuslims config edit` to interactively configure your installation. You'll need to set:
- CDCS frontend credentials and URL
- File paths for data storage
- NEMO API credentials (if using)
- Database path
> **Note:** For development installs from source, you can also `cp .env.example .env` and edit it manually.
See [Configuration Documentation](https://datasophos.github.io/NexusLIMS/stable/user_guide/configuration.html) for details.
### Initialize Database
```bash
nexuslims db init
```
Then add your instruments using the interactive instrument manager:
```bash
nexuslims instruments manage
```
See the [Getting Started Guide](https://datasophos.github.io/NexusLIMS/stable/user_guide/getting_started.html) for more details.
### Build Records
```bash
nexuslims build-records
```
## Documentation
📚 **Full documentation**: https://datasophos.github.io/NexusLIMS/stable/
- [Getting Started Guide](https://datasophos.github.io/NexusLIMS/stable/getting_started.html)
- [User Guide](https://datasophos.github.io/NexusLIMS/stable/user_guide.html)
- [Developer Guide](https://datasophos.github.io/NexusLIMS/stable/dev_guide.html)
- [API Reference](https://datasophos.github.io/NexusLIMS/stable/reference.html)
## System Requirements
- **Backend**: Linux or macOS. Windows is not currently supported.
- **Python**: 3.11 or 3.12
- **Network Access**: Read-only access to centralized instrument data storage
- **Calendar System**: NEMO instance (or custom harvester implementation)
- **Frontend**: [NexusLIMS CDCS](https://github.com/datasophos/NexusLIMS-CDCS) instance for browsing and searching records (optional, but probably desired)
## Current Limitations
NexusLIMS is under active development, but there are some limitations:
- **File Format Support**: Currently supports a subset of common electron microscopy formats (see [extractor documentation](https://datasophos.github.io/NexusLIMS/stable/user_guide/extractors.html) for details). If you have different isntrumentation at your institution, custom extractors will be needed.
- **Calendar Integration**: NexusLIMS is designed to inteface with the [NEMO](https://github.com/usnistgov/NEMO) laboratory facility management system. Other systems would require custom harvester implementation.
- **Platform Support**: The NexusLIMS backend is intended to be run on in a server environment, and thus supports Linux or macOS only (theoretically WSL2 on Windows as well, though this is untested). Full Windows support would require additional development effort.
**Need help adding features or deploying at your institution?** Datasophos offers professional services for NexusLIMS deployment, customization, and support. Contact us at [josh@datasophos.co](mailto:josh@datasophos.co).
## Development Quick Start
```bash
# Install development dependencies
uv sync --dev
# Run tests
./scripts/run_tests.sh
# Run linting
./scripts/run_lint.sh
# Build documentation
./scripts/build_docs.sh
```
See the [Developer Guide](https://datasophos.github.io/NexusLIMS/stable/dev_guide/development.html) for detailed information about:
- Architecture overview
- Adding new file format extractors
- Creating custom harvesters
- Testing and CI/CD
- Release process
## Contributing
We welcome contributions! Please:
1. Fork the repository
2. Create a feature branch
3. Make your changes with tests (100% coverage required)
4. Submit a pull request to `main`
See [Contributing Guidelines](https://datasophos.github.io/NexusLIMS/stable/dev_guide/development.html#contributing) for more details, including our
AI contribution policy.
## About the Logo
The NexusLIMS logo is inspired by Nobel Prize winner [Dan Shechtman's](https://www.nist.gov/content/nist-and-nobel/nobel-moment-dan-shechtman) groundbreaking work at NIST in the 1980s. Using transmission electron diffraction, Shechtman discovered [quasicrystals](https://en.wikipedia.org/wiki/Quasicrystal) - a new class of crystals that have regular structure and diffract, but are not periodic. This discovery overturned fundamental paradigms in crystallography.
We chose Shechtman's [first published](https://journals.aps.org/prl/pdf/10.1103/PhysRevLett.53.1951) quasicrystal diffraction pattern as inspiration due to its significance in electron microscopy and its storied NIST heritage.
## License
See [LICENSE](LICENSE) for details.
## Support
[Datasophos](https://datasophos.co) offers deployment assistance, custom extractor and harvester development, and training for teams adopting NexusLIMS. Get in touch at [josh@datasophos.co](mailto:josh@datasophos.co).
---
- [Documentation](https://datasophos.github.io/NexusLIMS/stable/)
- [Issue Tracker](https://github.com/datasophos/NexusLIMS/issues)
- [Original Upstream NIST Repository](https://github.com/usnistgov/NexusLIMS)
| text/markdown | null | Joshua Taillon <josh@datasophos.co> | null | Joshua Taillon <josh@datasophos.co> | MIT | LIMS, electron-microscopy, materials, microscopy | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering"
] | [] | null | null | <3.13,>=3.11 | [] | [] | [] | [
"alembic>=1.17.2",
"click>=8.1.8",
"email-validator>=2.3.0",
"exspy>=0.3.2",
"filelock>=3.0.0",
"hyperspy[speed]<3.0.0,>=2.1.0",
"lxml<7.0.0,>=6.0",
"pint<1.0.0,>=0.24.0",
"pixstem>=0.4.0",
"pydantic-settings>=2.12.0",
"pydantic[email]>=2.12.0",
"python-benedict<1.0.0,>=0.35.0",
"python-dotenv<2.0.0,>=1.0.0",
"pytz>=2022.7",
"pyxem>=0.21.0",
"rdflib<8.0.0,>=7.0.0",
"requests<3.0.0,>=2.32.0",
"rich>=13.0.0",
"scikit-learn<2.0.0,>=1.2.0",
"sqlmodel>=0.0.31",
"textual>=8.0.0",
"tzlocal>=5.3.1"
] | [] | [] | [] | [
"Homepage, https://datasophos.github.io/NexusLIMS/stable",
"Repository, https://github.com/datasophos/NexusLIMS.git",
"Documentation, https://datasophos.github.io/NexusLIMS/stable",
"Original-NIST-Repository, https://github.com/usnistgov/NexusLIMS.git"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T05:31:35.318916 | nexuslims-2.5.1.tar.gz | 18,718,502 | e4/0f/8fd25a6a99b4a0c76599556b5397ac39bc6fec7ea479196c134368ef8530/nexuslims-2.5.1.tar.gz | source | sdist | null | false | 116f0152f469b4a9c6f7530abbe22c9b | eea149a7d21273404fa02c0e91cb32cb745fb60b475883d7649082c8d5a383a7 | e40f8fd25a6a99b4a0c76599556b5397ac39bc6fec7ea479196c134368ef8530 | null | [
"LICENSE"
] | 0 |
2.2 | wildberries-sdk | 0.1.46 | Wildberries OpenAPI clients (generated). | # Wildberries SDK for Python (wildberries-sdk)
<img src="https://raw.githubusercontent.com/eslazarev/wildberries-sdk/main/.github/images/using_wildberries_sdk_python.gif">
## Установка
```bash
pip install wildberries-sdk
```
## Пример получения 100 неотвеченных отзывов (клиент - communications)
```python
import os
from wildberries_sdk import communications
token = os.getenv("WB_API_TOKEN")
api = communications.DefaultApi(
communications.ApiClient(
communications.Configuration(api_key={"HeaderApiKey": token})
)
)
feedbacks = api.api_v1_feedbacks_get(is_answered=False, take=100, skip=0).data.feedbacks
print(feedbacks)
```
## Доступные клиенты
Импортируйте каждый клиент как `wildberries_sdk.<client>`:
- `wildberries_sdk.general`
- `wildberries_sdk.products`
- `wildberries_sdk.orders_fbs`
- `wildberries_sdk.orders_dbw`
- `wildberries_sdk.orders_dbs`
- `wildberries_sdk.in_store_pickup`
- `wildberries_sdk.orders_fbw`
- `wildberries_sdk.promotion`
- `wildberries_sdk.communications`
- `wildberries_sdk.tariffs`
- `wildberries_sdk.analytics`
- `wildberries_sdk.reports`
- `wildberries_sdk.finances`
- `wildberries_sdk.wbd`
<!-- PY_METHODS_LIST_START -->
## Методы API
### general (`general`)
- `general.DefaultApi.api_communications_v2_news_get` — `GET /api/communications/v2/news` — Получение новостей портала продавцов
- `general.DefaultApi.api_v1_invite_post` — `POST /api/v1/invite` — Создать приглашение для нового пользователя
- `general.DefaultApi.api_v1_seller_info_get` — `GET /api/v1/seller-info` — Получение информации о продавце
- `general.DefaultApi.api_v1_user_delete` — `DELETE /api/v1/user` — Удалить пользователя
- `general.DefaultApi.api_v1_users_access_put` — `PUT /api/v1/users/access` — Изменить права доступа пользователей
- `general.DefaultApi.api_v1_users_get` — `GET /api/v1/users` — Получить список активных или приглашённых пользователей продавца
- `general.DefaultApi.ping_get` — `GET /ping` — Проверка подключения
### products (`products`)
- `products.DefaultApi.api_content_v1_brands_get` — `GET /api/content/v1/brands` — Бренды
- `products.DefaultApi.api_v2_buffer_goods_task_get` — `GET /api/v2/buffer/goods/task` — Детализация необработанной загрузки
- `products.DefaultApi.api_v2_buffer_tasks_get` — `GET /api/v2/buffer/tasks` — Состояние необработанной загрузки
- `products.DefaultApi.api_v2_history_goods_task_get` — `GET /api/v2/history/goods/task` — Детализация обработанной загрузки
- `products.DefaultApi.api_v2_history_tasks_get` — `GET /api/v2/history/tasks` — Состояние обработанной загрузки
- `products.DefaultApi.api_v2_list_goods_filter_get` — `GET /api/v2/list/goods/filter` — Получить товары с ценами
- `products.DefaultApi.api_v2_list_goods_filter_post` — `POST /api/v2/list/goods/filter` — Получить товары с ценами по артикулам
- `products.DefaultApi.api_v2_list_goods_size_nm_get` — `GET /api/v2/list/goods/size/nm` — Получить размеры товара с ценами
- `products.DefaultApi.api_v2_quarantine_goods_get` — `GET /api/v2/quarantine/goods` — Получить товары в карантине
- `products.DefaultApi.api_v2_upload_task_club_discount_post` — `POST /api/v2/upload/task/club-discount` — Установить скидки WB Клуба
- `products.DefaultApi.api_v2_upload_task_post` — `POST /api/v2/upload/task` — Установить цены и скидки
- `products.DefaultApi.api_v2_upload_task_size_post` — `POST /api/v2/upload/task/size` — Установить цены для размеров
- `products.DefaultApi.api_v3_dbw_warehouses_warehouse_id_contacts_get` — `GET /api/v3/dbw/warehouses/{warehouseId}/contacts` — Список контактов
- `products.DefaultApi.api_v3_dbw_warehouses_warehouse_id_contacts_put` — `PUT /api/v3/dbw/warehouses/{warehouseId}/contacts` — Обновить список контактов
- `products.DefaultApi.api_v3_offices_get` — `GET /api/v3/offices` — Получить список складов WB
- `products.DefaultApi.api_v3_stocks_warehouse_id_delete` — `DELETE /api/v3/stocks/{warehouseId}` — Удалить остатки товаров
- `products.DefaultApi.api_v3_stocks_warehouse_id_post` — `POST /api/v3/stocks/{warehouseId}` — Получить остатки товаров
- `products.DefaultApi.api_v3_stocks_warehouse_id_put` — `PUT /api/v3/stocks/{warehouseId}` — Обновить остатки товаров
- `products.DefaultApi.api_v3_warehouses_get` — `GET /api/v3/warehouses` — Получить список складов продавца
- `products.DefaultApi.api_v3_warehouses_post` — `POST /api/v3/warehouses` — Создать склад продавца
- `products.DefaultApi.api_v3_warehouses_warehouse_id_delete` — `DELETE /api/v3/warehouses/{warehouseId}` — Удалить склад продавца
- `products.DefaultApi.api_v3_warehouses_warehouse_id_put` — `PUT /api/v3/warehouses/{warehouseId}` — Обновить склад продавца
- `products.DefaultApi.content_v2_barcodes_post` — `POST /content/v2/barcodes` — Генерация баркодов
- `products.DefaultApi.content_v2_cards_delete_trash_post` — `POST /content/v2/cards/delete/trash` — Перенос карточек товаров в корзину
- `products.DefaultApi.content_v2_cards_error_list_post` — `POST /content/v2/cards/error/list` — Список несозданных карточек товаров с ошибками
- `products.DefaultApi.content_v2_cards_limits_get` — `GET /content/v2/cards/limits` — Лимиты карточек товаров
- `products.DefaultApi.content_v2_cards_move_nm_post` — `POST /content/v2/cards/moveNm` — Объединение и разъединение карточек товаров
- `products.DefaultApi.content_v2_cards_recover_post` — `POST /content/v2/cards/recover` — Восстановление карточек товаров из корзины
- `products.DefaultApi.content_v2_cards_update_post` — `POST /content/v2/cards/update` — Редактирование карточек товаров
- `products.DefaultApi.content_v2_cards_upload_add_post` — `POST /content/v2/cards/upload/add` — Создание карточек товаров с присоединением
- `products.DefaultApi.content_v2_cards_upload_post` — `POST /content/v2/cards/upload` — Создание карточек товаров
- `products.DefaultApi.content_v2_directory_colors_get` — `GET /content/v2/directory/colors` — Цвет
- `products.DefaultApi.content_v2_directory_countries_get` — `GET /content/v2/directory/countries` — Страна производства
- `products.DefaultApi.content_v2_directory_kinds_get` — `GET /content/v2/directory/kinds` — Пол
- `products.DefaultApi.content_v2_directory_seasons_get` — `GET /content/v2/directory/seasons` — Сезон
- `products.DefaultApi.content_v2_directory_tnved_get` — `GET /content/v2/directory/tnved` — ТНВЭД-код
- `products.DefaultApi.content_v2_directory_vat_get` — `GET /content/v2/directory/vat` — Ставка НДС
- `products.DefaultApi.content_v2_get_cards_list_post` — `POST /content/v2/get/cards/list` — Список карточек товаров
- `products.DefaultApi.content_v2_get_cards_trash_post` — `POST /content/v2/get/cards/trash` — Список карточек товаров в корзине
- `products.DefaultApi.content_v2_object_all_get` — `GET /content/v2/object/all` — Список предметов
- `products.DefaultApi.content_v2_object_charcs_subject_id_get` — `GET /content/v2/object/charcs/{subjectId}` — Характеристики предмета
- `products.DefaultApi.content_v2_object_parent_all_get` — `GET /content/v2/object/parent/all` — Родительские категории товаров
- `products.DefaultApi.content_v2_tag_id_delete` — `DELETE /content/v2/tag/{id}` — Удаление ярлыка
- `products.DefaultApi.content_v2_tag_id_patch` — `PATCH /content/v2/tag/{id}` — Изменение ярлыка
- `products.DefaultApi.content_v2_tag_nomenclature_link_post` — `POST /content/v2/tag/nomenclature/link` — Управление ярлыками в карточке товара
- `products.DefaultApi.content_v2_tag_post` — `POST /content/v2/tag` — Создание ярлыка
- `products.DefaultApi.content_v2_tags_get` — `GET /content/v2/tags` — Список ярлыков
- `products.DefaultApi.content_v3_media_file_post` — `POST /content/v3/media/file` — Загрузить медиафайл
- `products.DefaultApi.content_v3_media_save_post` — `POST /content/v3/media/save` — Загрузить медиафайлы по ссылкам
### orders_fbs (`orders_fbs`)
- `orders_fbs.DefaultApi.api_marketplace_v3_orders_meta_post` — `POST /api/marketplace/v3/orders/meta` — Получить метаданные сборочных заданий
- `orders_fbs.DefaultApi.api_marketplace_v3_orders_order_id_meta_customs_declaration_put` — `PUT /api/marketplace/v3/orders/{orderId}/meta/customs-declaration` — Закрепить за сборочным заданием номер ГТД
- `orders_fbs.DefaultApi.api_marketplace_v3_supplies_supply_id_order_ids_get` — `GET /api/marketplace/v3/supplies/{supplyId}/order-ids` — Получить ID сборочных заданий поставки
- `orders_fbs.DefaultApi.api_marketplace_v3_supplies_supply_id_orders_patch` — `PATCH /api/marketplace/v3/supplies/{supplyId}/orders` — Добавить сборочные задания к поставке
- `orders_fbs.DefaultApi.api_v3_orders_client_post` — `POST /api/v3/orders/client` — Заказы с информацией по клиенту
- `orders_fbs.DefaultApi.api_v3_orders_get` — `GET /api/v3/orders` — Получить информацию о сборочных заданиях
- `orders_fbs.DefaultApi.api_v3_orders_new_get` — `GET /api/v3/orders/new` — Получить список новых сборочных заданий
- `orders_fbs.DefaultApi.api_v3_orders_order_id_cancel_patch` — `PATCH /api/v3/orders/{orderId}/cancel` — Отменить сборочное задание
- `orders_fbs.DefaultApi.api_v3_orders_order_id_meta_delete` — `DELETE /api/v3/orders/{orderId}/meta` — Удалить метаданные сборочного задания
- `orders_fbs.DefaultApi.api_v3_orders_order_id_meta_expiration_put` — `PUT /api/v3/orders/{orderId}/meta/expiration` — Закрепить за сборочным заданием срок годности товара
- `orders_fbs.DefaultApi.api_v3_orders_order_id_meta_gtin_put` — `PUT /api/v3/orders/{orderId}/meta/gtin` — Закрепить за сборочным заданием GTIN
- `orders_fbs.DefaultApi.api_v3_orders_order_id_meta_imei_put` — `PUT /api/v3/orders/{orderId}/meta/imei` — Закрепить за сборочным заданием IMEI
- `orders_fbs.DefaultApi.api_v3_orders_order_id_meta_sgtin_put` — `PUT /api/v3/orders/{orderId}/meta/sgtin` — Закрепить за сборочным заданием код маркировки товара
- `orders_fbs.DefaultApi.api_v3_orders_order_id_meta_uin_put` — `PUT /api/v3/orders/{orderId}/meta/uin` — Закрепить за сборочным заданием УИН
- `orders_fbs.DefaultApi.api_v3_orders_status_history_post` — `POST /api/v3/orders/status/history` — История статусов для сборочных заданий кроссбордера
- `orders_fbs.DefaultApi.api_v3_orders_status_post` — `POST /api/v3/orders/status` — Получить статусы сборочных заданий
- `orders_fbs.DefaultApi.api_v3_orders_stickers_cross_border_post` — `POST /api/v3/orders/stickers/cross-border` — Получить стикеры сборочных заданий кроссбордера
- `orders_fbs.DefaultApi.api_v3_orders_stickers_post` — `POST /api/v3/orders/stickers` — Получить стикеры сборочных заданий
- `orders_fbs.DefaultApi.api_v3_passes_get` — `GET /api/v3/passes` — Получить список пропусков
- `orders_fbs.DefaultApi.api_v3_passes_offices_get` — `GET /api/v3/passes/offices` — Получить список складов, для которых требуется пропуск
- `orders_fbs.DefaultApi.api_v3_passes_pass_id_delete` — `DELETE /api/v3/passes/{passId}` — Удалить пропуск
- `orders_fbs.DefaultApi.api_v3_passes_pass_id_put` — `PUT /api/v3/passes/{passId}` — Обновить пропуск
- `orders_fbs.DefaultApi.api_v3_passes_post` — `POST /api/v3/passes` — Создать пропуск
- `orders_fbs.DefaultApi.api_v3_supplies_get` — `GET /api/v3/supplies` — Получить список поставок
- `orders_fbs.DefaultApi.api_v3_supplies_orders_reshipment_get` — `GET /api/v3/supplies/orders/reshipment` — Получить все сборочные задания для повторной отгрузки
- `orders_fbs.DefaultApi.api_v3_supplies_post` — `POST /api/v3/supplies` — Создать новую поставку
- `orders_fbs.DefaultApi.api_v3_supplies_supply_id_barcode_get` — `GET /api/v3/supplies/{supplyId}/barcode` — Получить QR-код поставки
- `orders_fbs.DefaultApi.api_v3_supplies_supply_id_delete` — `DELETE /api/v3/supplies/{supplyId}` — Удалить поставку
- `orders_fbs.DefaultApi.api_v3_supplies_supply_id_deliver_patch` — `PATCH /api/v3/supplies/{supplyId}/deliver` — Передать поставку в доставку
- `orders_fbs.DefaultApi.api_v3_supplies_supply_id_get` — `GET /api/v3/supplies/{supplyId}` — Получить информацию о поставке
- `orders_fbs.DefaultApi.api_v3_supplies_supply_id_trbx_delete` — `DELETE /api/v3/supplies/{supplyId}/trbx` — Удалить короба из поставки
- `orders_fbs.DefaultApi.api_v3_supplies_supply_id_trbx_get` — `GET /api/v3/supplies/{supplyId}/trbx` — Получить список коробов поставки
- `orders_fbs.DefaultApi.api_v3_supplies_supply_id_trbx_post` — `POST /api/v3/supplies/{supplyId}/trbx` — Добавить короба к поставке
- `orders_fbs.DefaultApi.api_v3_supplies_supply_id_trbx_stickers_post` — `POST /api/v3/supplies/{supplyId}/trbx/stickers` — Получить стикеры коробов поставки
### orders_dbw (`orders_dbw`)
- `orders_dbw.DefaultApi.api_v3_dbw_orders_courier_post` — `POST /api/v3/dbw/orders/courier` — Информация о курьере
- `orders_dbw.DefaultApi.api_v3_dbw_orders_delivery_date_post` — `POST /api/v3/dbw/orders/delivery-date` — Дата и время доставки
- `orders_dbw.DefaultApi.api_v3_dbw_orders_get` — `GET /api/v3/dbw/orders` — Получить информацию о завершенных сборочных заданиях
- `orders_dbw.DefaultApi.api_v3_dbw_orders_new_get` — `GET /api/v3/dbw/orders/new` — Получить список новых сборочных заданий
- `orders_dbw.DefaultApi.api_v3_dbw_orders_order_id_assemble_patch` — `PATCH /api/v3/dbw/orders/{orderId}/assemble` — Перевести в доставку
- `orders_dbw.DefaultApi.api_v3_dbw_orders_order_id_cancel_patch` — `PATCH /api/v3/dbw/orders/{orderId}/cancel` — Отменить сборочное задание
- `orders_dbw.DefaultApi.api_v3_dbw_orders_order_id_confirm_patch` — `PATCH /api/v3/dbw/orders/{orderId}/confirm` — Перевести на сборку
- `orders_dbw.DefaultApi.api_v3_dbw_orders_order_id_meta_delete` — `DELETE /api/v3/dbw/orders/{orderId}/meta` — Удалить метаданные сборочного задания
- `orders_dbw.DefaultApi.api_v3_dbw_orders_order_id_meta_get` — `GET /api/v3/dbw/orders/{orderId}/meta` — Получить метаданные сборочного задания
- `orders_dbw.DefaultApi.api_v3_dbw_orders_order_id_meta_gtin_put` — `PUT /api/v3/dbw/orders/{orderId}/meta/gtin` — Закрепить за сборочным заданием GTIN
- `orders_dbw.DefaultApi.api_v3_dbw_orders_order_id_meta_imei_put` — `PUT /api/v3/dbw/orders/{orderId}/meta/imei` — Закрепить за сборочным заданием IMEI
- `orders_dbw.DefaultApi.api_v3_dbw_orders_order_id_meta_sgtin_put` — `PUT /api/v3/dbw/orders/{orderId}/meta/sgtin` — Закрепить за сборочным заданием код маркировки товара
- `orders_dbw.DefaultApi.api_v3_dbw_orders_order_id_meta_uin_put` — `PUT /api/v3/dbw/orders/{orderId}/meta/uin` — Закрепить за сборочным заданием УИН (уникальный идентификационный номер)
- `orders_dbw.DefaultApi.api_v3_dbw_orders_status_post` — `POST /api/v3/dbw/orders/status` — Получить статусы сборочных заданий
- `orders_dbw.DefaultApi.api_v3_dbw_orders_stickers_post` — `POST /api/v3/dbw/orders/stickers` — Получить стикеры сборочных заданий
### orders_dbs (`orders_dbs`)
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_b2b_info_post` — `POST /api/marketplace/v3/dbs/orders/b2b/info` — Информация о покупателе B2B
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_meta_customs_declaration_post` — `POST /api/marketplace/v3/dbs/orders/meta/customs-declaration` — Закрепить за сборочными заданиями номер ГТД
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_meta_delete_post` — `POST /api/marketplace/v3/dbs/orders/meta/delete` — Удалить метаданные сборочных заданий
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_meta_gtin_post` — `POST /api/marketplace/v3/dbs/orders/meta/gtin` — Закрепить GTIN за сборочными заданиями
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_meta_imei_post` — `POST /api/marketplace/v3/dbs/orders/meta/imei` — Закрепить IMEI за сборочными заданиями
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_meta_info_post` — `POST /api/marketplace/v3/dbs/orders/meta/info` — Получить метаданные сборочных заданий
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_meta_sgtin_post` — `POST /api/marketplace/v3/dbs/orders/meta/sgtin` — Закрепить коды маркировки за сборочными заданиями
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_meta_uin_post` — `POST /api/marketplace/v3/dbs/orders/meta/uin` — Закрепить УИН за сборочными заданиями
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_status_cancel_post` — `POST /api/marketplace/v3/dbs/orders/status/cancel` — Отменить сборочные задания
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_status_confirm_post` — `POST /api/marketplace/v3/dbs/orders/status/confirm` — Перевести сборочные задания на сборку
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_status_deliver_post` — `POST /api/marketplace/v3/dbs/orders/status/deliver` — Перевести сборочные задания в доставку
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_status_info_post` — `POST /api/marketplace/v3/dbs/orders/status/info` — Получить статусы сборочных заданий
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_status_receive_post` — `POST /api/marketplace/v3/dbs/orders/status/receive` — Сообщить о получении заказов
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_status_reject_post` — `POST /api/marketplace/v3/dbs/orders/status/reject` — Сообщить об отказе от заказов
- `orders_dbs.DefaultApi.api_marketplace_v3_dbs_orders_stickers_post` — `POST /api/marketplace/v3/dbs/orders/stickers` — Получить стикеры для сборочных заданий с доставкой в ПВЗ
- `orders_dbs.DefaultApi.api_v3_dbs_groups_info_post` — `POST /api/v3/dbs/groups/info` — Получить информацию о платной доставке
- `orders_dbs.DefaultApi.api_v3_dbs_orders_client_post` — `POST /api/v3/dbs/orders/client` — Информация о покупателе
- `orders_dbs.DefaultApi.api_v3_dbs_orders_delivery_date_post` — `POST /api/v3/dbs/orders/delivery-date` — Дата и время доставки
- `orders_dbs.DefaultApi.api_v3_dbs_orders_get` — `GET /api/v3/dbs/orders` — Получить информацию о завершенных сборочных заданиях
- `orders_dbs.DefaultApi.api_v3_dbs_orders_new_get` — `GET /api/v3/dbs/orders/new` — Получить список новых сборочных заданий
- `orders_dbs.DefaultApi.api_v3_dbs_orders_order_id_cancel_patch` — `PATCH /api/v3/dbs/orders/{orderId}/cancel` — (Deprecated) Отменить сборочное задание
- `orders_dbs.DefaultApi.api_v3_dbs_orders_order_id_confirm_patch` — `PATCH /api/v3/dbs/orders/{orderId}/confirm` — (Deprecated) Перевести на сборку
- `orders_dbs.DefaultApi.api_v3_dbs_orders_order_id_deliver_patch` — `PATCH /api/v3/dbs/orders/{orderId}/deliver` — (Deprecated) Перевести в доставку
- `orders_dbs.DefaultApi.api_v3_dbs_orders_order_id_meta_delete` — `DELETE /api/v3/dbs/orders/{orderId}/meta` — (Deprecated) Удалить метаданные сборочного задания
- `orders_dbs.DefaultApi.api_v3_dbs_orders_order_id_meta_get` — `GET /api/v3/dbs/orders/{orderId}/meta` — (Deprecated) Получить метаданные сборочного задания
- `orders_dbs.DefaultApi.api_v3_dbs_orders_order_id_meta_gtin_put` — `PUT /api/v3/dbs/orders/{orderId}/meta/gtin` — (Deprecated) Закрепить за сборочным заданием GTIN
- `orders_dbs.DefaultApi.api_v3_dbs_orders_order_id_meta_imei_put` — `PUT /api/v3/dbs/orders/{orderId}/meta/imei` — (Deprecated) Закрепить за сборочным заданием IMEI
- `orders_dbs.DefaultApi.api_v3_dbs_orders_order_id_meta_sgtin_put` — `PUT /api/v3/dbs/orders/{orderId}/meta/sgtin` — (Deprecated) Закрепить за сборочным заданием код маркировки товара
- `orders_dbs.DefaultApi.api_v3_dbs_orders_order_id_meta_uin_put` — `PUT /api/v3/dbs/orders/{orderId}/meta/uin` — (Deprecated) Закрепить за сборочным заданием УИН (уникальный идентификационный номер)
- `orders_dbs.DefaultApi.api_v3_dbs_orders_order_id_receive_patch` — `PATCH /api/v3/dbs/orders/{orderId}/receive` — (Deprecated) Сообщить, что заказ принят покупателем
- `orders_dbs.DefaultApi.api_v3_dbs_orders_order_id_reject_patch` — `PATCH /api/v3/dbs/orders/{orderId}/reject` — (Deprecated) Сообщить, что покупатель отказался от заказа
- `orders_dbs.DefaultApi.api_v3_dbs_orders_status_post` — `POST /api/v3/dbs/orders/status` — (Deprecated) Получить статусы сборочных заданий
### in_store_pickup (`in_store_pickup`)
- `in_store_pickup.DefaultApi.api_marketplace_v3_click_collect_orders_meta_delete_post` — `POST /api/marketplace/v3/click-collect/orders/meta/delete` — Удалить метаданные сборочных заданий
- `in_store_pickup.DefaultApi.api_marketplace_v3_click_collect_orders_meta_gtin_post` — `POST /api/marketplace/v3/click-collect/orders/meta/gtin` — Закрепить GTIN за сборочными заданиями
- `in_store_pickup.DefaultApi.api_marketplace_v3_click_collect_orders_meta_imei_post` — `POST /api/marketplace/v3/click-collect/orders/meta/imei` — Закрепить IMEI за сборочными заданиями
- `in_store_pickup.DefaultApi.api_marketplace_v3_click_collect_orders_meta_info_post` — `POST /api/marketplace/v3/click-collect/orders/meta/info` — Получить метаданные сборочных заданий
- `in_store_pickup.DefaultApi.api_marketplace_v3_click_collect_orders_meta_sgtin_post` — `POST /api/marketplace/v3/click-collect/orders/meta/sgtin` — Закрепить коды маркировки товара за сборочными заданиями
- `in_store_pickup.DefaultApi.api_marketplace_v3_click_collect_orders_meta_uin_post` — `POST /api/marketplace/v3/click-collect/orders/meta/uin` — Закрепить УИН за сборочными заданиями
- `in_store_pickup.DefaultApi.api_marketplace_v3_click_collect_orders_status_cancel_post` — `POST /api/marketplace/v3/click-collect/orders/status/cancel` — Отменить сборочные задания
- `in_store_pickup.DefaultApi.api_marketplace_v3_click_collect_orders_status_confirm_post` — `POST /api/marketplace/v3/click-collect/orders/status/confirm` — Перевести сборочные задания на сборку
- `in_store_pickup.DefaultApi.api_marketplace_v3_click_collect_orders_status_info_post` — `POST /api/marketplace/v3/click-collect/orders/status/info` — Получить статусы сборочных заданий
- `in_store_pickup.DefaultApi.api_marketplace_v3_click_collect_orders_status_prepare_post` — `POST /api/marketplace/v3/click-collect/orders/status/prepare` — Сообщить, что сборочные задания готовы к выдаче
- `in_store_pickup.DefaultApi.api_marketplace_v3_click_collect_orders_status_receive_post` — `POST /api/marketplace/v3/click-collect/orders/status/receive` — Сообщить, что заказы приняты покупателями
- `in_store_pickup.DefaultApi.api_marketplace_v3_click_collect_orders_status_reject_post` — `POST /api/marketplace/v3/click-collect/orders/status/reject` — Сообщить об отказе от заказов
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_client_identity_post` — `POST /api/v3/click-collect/orders/client/identity` — Проверить, что заказ принадлежит покупателю
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_client_post` — `POST /api/v3/click-collect/orders/client` — Информация о покупателе
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_get` — `GET /api/v3/click-collect/orders` — Получить информацию о завершённых сборочных заданиях
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_new_get` — `GET /api/v3/click-collect/orders/new` — Получить список новых сборочных заданий
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_order_id_cancel_patch` — `PATCH /api/v3/click-collect/orders/{orderId}/cancel` — (Deprecated) Отменить сборочное задание
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_order_id_confirm_patch` — `PATCH /api/v3/click-collect/orders/{orderId}/confirm` — (Deprecated) Перевести на сборку
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_order_id_meta_delete` — `DELETE /api/v3/click-collect/orders/{orderId}/meta` — (Deprecated) Удалить метаданные сборочного задания
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_order_id_meta_get` — `GET /api/v3/click-collect/orders/{orderId}/meta` — (Deprecated) Получить метаданные сборочного задания
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_order_id_meta_gtin_put` — `PUT /api/v3/click-collect/orders/{orderId}/meta/gtin` — (Deprecated) Закрепить за сборочным заданием GTIN
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_order_id_meta_imei_put` — `PUT /api/v3/click-collect/orders/{orderId}/meta/imei` — (Deprecated) Закрепить за сборочным заданием IMEI
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_order_id_meta_sgtin_put` — `PUT /api/v3/click-collect/orders/{orderId}/meta/sgtin` — (Deprecated) Закрепить за сборочным заданием код маркировки товара
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_order_id_meta_uin_put` — `PUT /api/v3/click-collect/orders/{orderId}/meta/uin` — (Deprecated) Закрепить за сборочным заданием УИН (уникальный идентификационный номер)
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_order_id_prepare_patch` — `PATCH /api/v3/click-collect/orders/{orderId}/prepare` — (Deprecated) Сообщить, что сборочное задание готово к выдаче
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_order_id_receive_patch` — `PATCH /api/v3/click-collect/orders/{orderId}/receive` — (Deprecated) Сообщить, что заказ принят покупателем
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_order_id_reject_patch` — `PATCH /api/v3/click-collect/orders/{orderId}/reject` — (Deprecated) Сообщить, что покупатель отказался от заказа
- `in_store_pickup.DefaultApi.api_v3_click_collect_orders_status_post` — `POST /api/v3/click-collect/orders/status` — (Deprecated) Получить статусы сборочных заданий
### orders_fbw (`orders_fbw`)
- `orders_fbw.DefaultApi.api_v1_acceptance_options_post` — `POST /api/v1/acceptance/options` — Опции приёмки
- `orders_fbw.DefaultApi.api_v1_supplies_id_get` — `GET /api/v1/supplies/{ID}` — Детали поставки
- `orders_fbw.DefaultApi.api_v1_supplies_id_goods_get` — `GET /api/v1/supplies/{ID}/goods` — Товары поставки
- `orders_fbw.DefaultApi.api_v1_supplies_id_package_get` — `GET /api/v1/supplies/{ID}/package` — Упаковка поставки
- `orders_fbw.DefaultApi.api_v1_supplies_post` — `POST /api/v1/supplies` — Список поставок
- `orders_fbw.DefaultApi.api_v1_transit_tariffs_get` — `GET /api/v1/transit-tariffs` — Транзитные направления
- `orders_fbw.DefaultApi.api_v1_warehouses_get` — `GET /api/v1/warehouses` — Список складов
### promotion (`promotion`)
- `promotion.DefaultApi.adv_v0_auction_nms_patch` — `PATCH /adv/v0/auction/nms` — Изменение списка карточек товаров в кампаниях
- `promotion.DefaultApi.adv_v0_auction_placements_put` — `PUT /adv/v0/auction/placements` — Изменение мест размещения в кампаниях с ручной ставкой
- `promotion.DefaultApi.adv_v0_delete_get` — `GET /adv/v0/delete` — Удаление кампании
- `promotion.DefaultApi.adv_v0_normquery_bids_delete` — `DELETE /adv/v0/normquery/bids` — Удалить ставки поисковых кластеров
- `promotion.DefaultApi.adv_v0_normquery_bids_post` — `POST /adv/v0/normquery/bids` — Установить ставки для поисковых кластеров
- `promotion.DefaultApi.adv_v0_normquery_get_bids_post` — `POST /adv/v0/normquery/get-bids` — Список ставок поисковых кластеров
- `promotion.DefaultApi.adv_v0_normquery_get_minus_post` — `POST /adv/v0/normquery/get-minus` — Список минус-фраз кампаний
- `promotion.DefaultApi.adv_v0_normquery_list_post` — `POST /adv/v0/normquery/list` — Списки активных и неактивных поисковых кластеров
- `promotion.DefaultApi.adv_v0_normquery_set_minus_post` — `POST /adv/v0/normquery/set-minus` — Установка и удаление минус-фраз
- `promotion.DefaultApi.adv_v0_normquery_stats_post` — `POST /adv/v0/normquery/stats` — Статистика поисковых кластеров
- `promotion.DefaultApi.adv_v0_pause_get` — `GET /adv/v0/pause` — Пауза кампании
- `promotion.DefaultApi.adv_v0_rename_post` — `POST /adv/v0/rename` — Переименование кампании
- `promotion.DefaultApi.adv_v0_start_get` — `GET /adv/v0/start` — Запуск кампании
- `promotion.DefaultApi.adv_v0_stop_get` — `GET /adv/v0/stop` — Завершение кампании
- `promotion.DefaultApi.adv_v1_advert_get` — `GET /adv/v1/advert` — Информация о медиакампании
- `promotion.DefaultApi.adv_v1_adverts_get` — `GET /adv/v1/adverts` — Список медиакампаний
- `promotion.DefaultApi.adv_v1_balance_get` — `GET /adv/v1/balance` — Баланс
- `promotion.DefaultApi.adv_v1_budget_deposit_post` — `POST /adv/v1/budget/deposit` — Пополнение бюджета кампании
- `promotion.DefaultApi.adv_v1_budget_get` — `GET /adv/v1/budget` — Бюджет кампании
- `promotion.DefaultApi.adv_v1_count_get` — `GET /adv/v1/count` — Количество медиакампаний
- `promotion.DefaultApi.adv_v1_normquery_stats_post` — `POST /adv/v1/normquery/stats` — Статистика по поисковым кластерам с детализацией по дням
- `promotion.DefaultApi.adv_v1_payments_get` — `GET /adv/v1/payments` — Получение истории пополнений счёта
- `promotion.DefaultApi.adv_v1_promotion_count_get` — `GET /adv/v1/promotion/count` — Списки кампаний
- `promotion.DefaultApi.adv_v1_stats_post` — `POST /adv/v1/stats` — Статистика медиакампаний
- `promotion.DefaultApi.adv_v1_supplier_subjects_get` — `GET /adv/v1/supplier/subjects` — Предметы для кампаний
- `promotion.DefaultApi.adv_v1_upd_get` — `GET /adv/v1/upd` — Получение истории затрат
- `promotion.DefaultApi.adv_v2_seacat_save_ad_post` — `POST /adv/v2/seacat/save-ad` — Создать кампанию
- `promotion.DefaultApi.adv_v2_supplier_nms_post` — `POST /adv/v2/supplier/nms` — Карточки товаров для кампаний
- `promotion.DefaultApi.adv_v3_fullstats_get` — `GET /adv/v3/fullstats` — Статистика кампаний
- `promotion.DefaultApi.api_advert_v1_bids_min_post` — `POST /api/advert/v1/bids/min` — Минимальные ставки для карточек товаров
- `promotion.DefaultApi.api_advert_v1_bids_patch` — `PATCH /api/advert/v1/bids` — Изменение ставок в кампаниях
- `promotion.DefaultApi.api_advert_v2_adverts_get` — `GET /api/advert/v2/adverts` — Информация о кампаниях
- `promotion.DefaultApi.api_v1_calendar_promotions_details_get` — `GET /api/v1/calendar/promotions/details` — Детальная информация об акциях
- `promotion.DefaultApi.api_v1_calendar_promotions_get` — `GET /api/v1/calendar/promotions` — Список акций
- `promotion.DefaultApi.api_v1_calendar_promotions_nomenclatures_get` — `GET /api/v1/calendar/promotions/nomenclatures` — Список товаров для участия в акции
- `promotion.DefaultApi.api_v1_calendar_promotions_upload_post` — `POST /api/v1/calendar/promotions/upload` — Добавить товар в акцию
### communications (`communications`)
- `communications.DefaultApi.api_feedbacks_v1_pins_count_get` — `GET /api/feedbacks/v1/pins/count` — Количество закреплённых и откреплённых отзывов
- `communications.DefaultApi.api_feedbacks_v1_pins_delete` — `DELETE /api/feedbacks/v1/pins` — Открепить отзывы
- `communications.DefaultApi.api_feedbacks_v1_pins_get` — `GET /api/feedbacks/v1/pins` — Список закреплённых и откреплённых отзывов
- `communications.DefaultApi.api_feedbacks_v1_pins_limits_get` — `GET /api/feedbacks/v1/pins/limits` — Лимиты закреплённых отзывов
- `communications.DefaultApi.api_feedbacks_v1_pins_post` — `POST /api/feedbacks/v1/pins` — Закрепить отзывы
- `communications.DefaultApi.api_v1_claim_patch` — `PATCH /api/v1/claim` — Ответ на заявку покупателя
- `communications.DefaultApi.api_v1_claims_get` — `GET /api/v1/claims` — Заявки покупателей на возврат
- `communications.DefaultApi.api_v1_feedback_get` — `GET /api/v1/feedback` — Получить отзыв по ID
- `communications.DefaultApi.api_v1_feedbacks_answer_patch` — `PATCH /api/v1/feedbacks/answer` — Отредактировать ответ на отзыв
- `communications.DefaultApi.api_v1_feedbacks_answer_post` — `POST /api/v1/feedbacks/answer` — Ответить на отзыв
- `communications.DefaultApi.api_v1_feedbacks_archive_get` — `GET /api/v1/feedbacks/archive` — Список архивных отзывов
- `communications.DefaultApi.api_v1_feedbacks_count_get` — `GET /api/v1/feedbacks/count` — Количество отзывов
- `communications.DefaultApi.api_v1_feedbacks_count_unanswered_get` — `GET /api/v1/feedbacks/count-unanswered` — Необработанные отзывы
- `communications.DefaultApi.api_v1_feedbacks_get` — `GET /api/v1/feedbacks` — Список отзывов
- `communications.DefaultApi.api_v1_feedbacks_order_return_post` — `POST /api/v1/feedbacks/order/return` — Возврат товара по ID отзыва
- `communications.DefaultApi.api_v1_new_feedbacks_questions_get` — `GET /api/v1/new-feedbacks-questions` — Непросмотренные отзывы и вопросы
- `communications.DefaultApi.api_v1_question_get` — `GET /api/v1/question` — Получить вопрос по ID
- `communications.DefaultApi.api_v1_questions_count_get` — `GET /api/v1/questions/count` — Количество вопросов
- `communications.DefaultApi.api_v1_questions_count_unanswered_get` — `GET /api/v1/questions/count-unanswered` — Неотвеченные вопросы
- `communications.DefaultApi.api_v1_questions_get` — `GET /api/v1/questions` — Список вопросов
- `communications.DefaultApi.api_v1_questions_patch` — `PATCH /api/v1/questions` — Работа с вопросами
- `communications.DefaultApi.api_v1_seller_chats_get` — `GET /api/v1/seller/chats` — Список чатов
- `communications.DefaultApi.api_v1_seller_download_id_get` — `GET /api/v1/seller/download/{id}` — Получить файл из сообщения
- `communications.DefaultApi.api_v1_seller_events_get` — `GET /api/v1/seller/events` — События чатов
- `communications.DefaultApi.api_v1_seller_message_post` — `POST /api/v1/seller/message` — Отправить сообщение
### tariffs (`tariffs`)
- `tariffs.Def | text/markdown | null | Evgenii Lazarev <elazarev@gmail.com> | null | null | MIT | wildberries, wb, api, sdk, openapi, marketplace, ecommerce, wildberries-api, вайлдберриз | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"pydantic>=2.0.0",
"urllib3>=2.6.3",
"python-dateutil>=2.8.2",
"typing-extensions>=4.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/eslazarev/wildberries-sdk",
"Documentation, https://eslazarev.github.io/wildberries-sdk/",
"Source, https://github.com/eslazarev/wildberries-sdk",
"Issues, https://github.com/eslazarev/wildberries-sdk/issues",
"Changelog, https://github.com/eslazarev/wildberries-sdk/blob/main/CHANGELOG.md"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T05:29:05.029518 | wildberries_sdk-0.1.46.tar.gz | 745,552 | 3c/7b/7525603127d63671a32518d316c9b14f1ea4c57e2e3ee20368c27d9f9026/wildberries_sdk-0.1.46.tar.gz | source | sdist | null | false | 8e52620c758307caaeafc98df4dc05cb | 660b655c5d9300a9d6970db1f79f18a08a619c94de3e5576e2d05339d0209b8f | 3c7b7525603127d63671a32518d316c9b14f1ea4c57e2e3ee20368c27d9f9026 | null | [] | 721 |
2.4 | graftpunk | 1.8.0 | Turn any website into an API. Graft scriptable access onto authenticated web services. | <div align="center">
# 🔌 graftpunk
**Turn any website into an API.**
*Graft scriptable access onto authenticated web services.*
[](https://pypi.org/project/graftpunk/)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
[](https://github.com/astral-sh/ruff)
[](https://github.com/astral-sh/ty)
[Installation](#installation) • [Quick Start](#quick-start) • [Plugins](#plugins) • [CLI Reference](#cli-reference) • [Examples](examples/README.md) • [Architecture](docs/HOW_IT_WORKS.md)
</div>
---
## The Problem
That service has your data—but no API.
Your ISP account. Your kid's school portal. Your local library. That niche e-commerce site you order from. Your medical records. They all have data that belongs to *you*, locked behind a login page with no API in sight.
You're left with two options: click through the UI manually every time, or give up.
**graftpunk gives you a third option.**
## The Solution
Log in once, script forever.
```
1. LOG IN 2. CACHE 3. SCRIPT
+-------------+ +-------------+ +-------------+
| Browser | | Encrypted | | Python |
| Session |------>| Storage |------>| Script |
| | | | | |
+-------------+ +-------------+ +-------------+
Log in manually Session cached Use the session
or declaratively with AES-128 with real browser
via plugin config encryption headers replayed
```
Once your session is cached, you can:
- **Make HTTP requests** with your authenticated cookies *and* real browser headers
- **Reverse-engineer XHR calls** from browser dev tools
- **Build CLI tools** that feel like real APIs
- **Automate downloads** of documents and data
- **Keep sessions alive** with background daemons
- **Capture network traffic** for debugging and auditing
## What You Can Build
With graftpunk as your foundation, you can turn any authenticated website into a terminal-based interface:
```bash
# Pull your kid's grades and assignments
gp schoolportal grades --student emma --format table
# Download your medical lab results
gp mychart labs --after 2024-06-01 --output ./results/
# Export your energy usage data
gp utility usage --months 12 --format csv > energy.csv
# Scrape your property tax history
gp county assessor --parcel 12345 --format json
# Make ad-hoc requests with cached session cookies + browser headers
gp http get -s mychart https://mychart.example.com/api/appointments
```
These aren't real APIs—they're commands defined in graftpunk plugins that replay the same XHR calls the website makes. To the server, it looks like a browser. To you, it's just automation.
## Installation
```bash
pip install graftpunk
```
**With cloud storage:**
```bash
pip install graftpunk[supabase] # Supabase backend
pip install graftpunk[s3] # AWS S3 backend
pip install graftpunk[all] # Everything
```
## Quick Start
### 1. Cache a Session
The fastest way is with a plugin. Here's the httpbin example (no auth needed):
```bash
# Drop a YAML plugin into your plugins directory
mkdir -p ~/.config/graftpunk/plugins
cp examples/plugins/httpbin.yaml ~/.config/graftpunk/plugins/
# Use it immediately
gp httpbin ip
gp httpbin headers
gp httpbin status --code 418 # I'm a teapot!
```
For sites that require authentication, plugins can define declarative login:
```bash
# Log in via auto-generated command (opens browser, fills form, caches session)
gp quotes login
# Use the cached session for API calls
gp quotes list
gp quotes random
```
### 2. Use It Programmatically
```python
from graftpunk import GraftpunkClient
# Use plugin commands from Python — same session, tokens, and retries as the CLI
with GraftpunkClient("mybank") as client:
accounts = client.accounts()
statements = client.statements(month="january", year=2024)
# Grouped commands use nested attribute access
detail = client.accounts.detail(id=42)
```
For lower-level access without plugins, load a session directly:
```python
from graftpunk import load_session_for_api
# Returns a GraftpunkSession with browser headers pre-loaded
api = load_session_for_api("mysite")
response = api.get("https://app.example.com/api/internal/documents")
```
### 3. Keep It Alive
Sessions expire. graftpunk can keep them alive in the background with the keepalive daemon.
## Features
| | Feature | Why It Matters |
|:--|:--|:--|
| 🥷 | **Stealth Mode** | Multiple backends: Selenium with undetected-chromedriver, or NoDriver for CDP-direct automation without WebDriver detection. Bot-detection cookies (Akamai, etc.) are automatically filtered during cookie injection to prevent WAF rejection. |
| 🔒 | **Encrypted Storage** | Sessions encrypted with AES-128 (Fernet). Local by default, optional cloud storage. |
| 🔑 | **Declarative Login** | Define login flows with CSS selectors. graftpunk opens the browser, fills the form, and caches the session. Works in both Python and YAML plugins. |
| 🌐 | **Browser Header Replay** | Captures real browser headers during login and replays them in API calls. Requests look like they came from Chrome, not Python. |
| 🔌 | **Plugin System** | Full command framework with `CommandContext`, resource limits, output formatting, and auto-generated CLI. Python for complex logic, YAML for simple calls. |
| 🛡️ | **Token & CSRF Support** | Declarative token extraction from cookies, headers, or page content. EAFP injection with automatic 403 retry. Tokens cached through session serialization. |
| 📡 | **Observability** | Capture screenshots, HAR files, console logs, and network traffic. Interactive mode lets you browse manually while recording. |
| 🔄 | **Keepalive Daemon** | Background daemon pings sites periodically to prevent session timeout. |
| 🛠️ | **Ad-hoc HTTP** | `gp http get -s <session> <url>` — make one-off authenticated requests without writing a plugin. |
| 📊 | **Multi-View Output** | Commands can define multiple views on response data. Table format renders each view as a separate section. XLSX creates one worksheet per view. `--view` lets you cherry-pick views and columns. |
| 🎨 | **Beautiful CLI** | Rich terminal output with spinners, tables, and color. `--format json\|table\|csv\|xlsx\|raw` on all commands. |
## Plugins
graftpunk is extensible via Python classes or YAML configuration. Both support declarative login, resource limits, and output formatting.
### YAML Plugin (Simple REST Calls)
For straightforward HTTP calls, no Python needed:
```yaml
# ~/.config/graftpunk/plugins/mybank.yaml
site_name: mybank
base_url: "https://secure.mybank.com"
login:
url: /login
fields:
username: "input#email"
password: "input#password"
submit: "button[type=submit]"
commands:
accounts:
help: "List all accounts"
method: GET
url: "/api/accounts"
jmespath: "accounts[].{id: id, name: name, balance: balance}"
statements:
help: "Get statements for a month"
method: GET
url: "/api/statements"
params:
- name: month
required: true
help: "Month name"
- name: year
type: int
default: 2024
timeout: 30
max_retries: 2
```
### Python Plugin (Complex Logic)
```python
from graftpunk.plugins import CommandContext, LoginConfig, SitePlugin, command
class MyBankPlugin(SitePlugin):
site_name = "mybank"
base_url = "https://secure.mybank.com"
backend = "nodriver" # or "selenium"
api_version = 1
login_config = LoginConfig(
url="/login",
fields={"username": "input#email", "password": "input#password"},
submit="button[type=submit]",
success=".dashboard",
)
@command(help="List all accounts")
def accounts(self, ctx: CommandContext):
return ctx.session.get(f"{self.base_url}/api/accounts").json()
@command(help="Get statements for a month")
def statements(self, ctx: CommandContext, month: str, year: int = 2024):
url = f"{self.base_url}/api/statements/{year}/{month}"
return ctx.session.get(url).json()
```
### Using Plugins
```bash
# Login (auto-generated from declarative config)
gp mybank login
# Run commands
gp mybank accounts
gp mybank statements --month january --year 2024 --format table
# List all discovered plugins
gp plugins
```
### Plugin Discovery
Plugins are discovered from three sources:
1. **Entry points** — Python packages registered via `pyproject.toml`
2. **YAML files** — `~/.config/graftpunk/plugins/*.yaml` and `*.yml`
3. **Python files** — `~/.config/graftpunk/plugins/*.py`
If two plugins share the same `site_name`, registration fails with an error showing both sources. No silent shadowing.
See [examples/](examples/README.md) for working plugins and templates.
## CLI Reference
```
$ gp --help
🔌 graftpunk - turn any website into an API
Commands:
session Manage encrypted browser sessions
http Make ad-hoc HTTP requests with cached session cookies
observe Capture and view browser observability data
plugins List discovered plugins
import-har Import HAR file and generate a plugin
config Show current configuration
keepalive Manage the session keepalive daemon
version Show version info
```
### Session Management
```bash
gp session list # List all cached sessions
gp session show <name> # Session metadata (domain, cookies, expiry)
gp session clear <name> # Remove a session (or --all)
gp session export <name> # Export cookies to HTTPie session format
gp session use <name> # Set active session for subsequent commands
gp session unset # Clear active session
```
### Ad-hoc HTTP Requests
Make authenticated requests using cached sessions without writing a plugin:
```bash
gp http get -s mybank https://secure.mybank.com/api/accounts
gp http post -s mybank https://secure.mybank.com/api/transfer --data '{"amount": 100}'
```
Use `--role` to set browser header roles (built-in or plugin-defined):
```bash
gp http get -s mybank --role xhr https://secure.mybank.com/api/status
gp http get -s mybank --role api https://secure.mybank.com/v2/data # custom plugin role
```
Supports all HTTP methods: `get`, `post`, `put`, `patch`, `delete`, `head`, `options`.
### Observability
Capture browser activity for debugging:
```bash
# Open authenticated browser and capture network traffic
gp observe -s mybank go https://secure.mybank.com/dashboard
# Interactive mode — browse manually, Ctrl+C to save
gp observe -s mybank interactive https://secure.mybank.com/dashboard
# Or use the --interactive flag on observe go
gp observe -s mybank go --interactive https://secure.mybank.com/dashboard
# View captured data
gp observe list
gp observe show mybank
gp observe clean mybank
```
Interactive mode opens an authenticated browser and records all network traffic (including response bodies) while you click around. Press Ctrl+C to stop — HAR files, screenshots, page source, and console logs are saved automatically.
Pass `--observe full` to any command to capture screenshots, HAR files, and console logs.
### HAR Import
Generate plugins from browser network captures:
```bash
gp import-har auth-flow.har --name mybank
```
## Configuration
| Variable | Default | Description |
|:---------|:--------|:------------|
| `GRAFTPUNK_STORAGE_BACKEND` | `local` | Storage: `local`, `supabase`, or `s3` |
| `GRAFTPUNK_CONFIG_DIR` | `~/.config/graftpunk` | Config and encryption key location |
| `GRAFTPUNK_SESSION_TTL_HOURS` | `720` | Session lifetime (30 days) |
| `GRAFTPUNK_LOG_LEVEL` | `WARNING` | Logging verbosity |
| `GRAFTPUNK_LOG_FORMAT` | `console` | Log format: `console` or `json` |
CLI flags: `-v` (info), `-vv` (debug), `--log-format json`, `--observe full`, `--network-debug` (wire-level HTTP tracing).
## Browser Backends
graftpunk supports two browser automation backends (both included by default):
| Backend | Best For |
|---------|----------|
| `selenium` | Simple sites, backward compatibility |
| `nodriver` | Enterprise sites, better anti-detection |
**Why NoDriver?** NoDriver uses Chrome DevTools Protocol (CDP) directly without the WebDriver binary, eliminating a common detection vector used by anti-bot systems.
**Bot-detection cookie filtering:** When injecting session cookies into a nodriver browser (for observe mode, token extraction, etc.), graftpunk automatically skips known WAF tracking cookies (Akamai `bm_*`, `ak_bmsc`, `_abck`). These cookies carry stale bot-classification state that causes WAFs to reject the browser with `ERR_HTTP2_PROTOCOL_ERROR`. Disable with `skip_bot_cookies=False` if needed.
```python
from graftpunk import BrowserSession
# Use BrowserSession with explicit backend
session = BrowserSession(backend="nodriver", headless=False)
```
## Security
### Your Data, Your Rules
graftpunk is for automating access to **your own accounts**. You're not scraping other people's data—you're building tools to access information that already belongs to you.
Some services may consider automation a ToS violation. Use your judgment.
### Encryption
- **Algorithm:** Fernet (AES-128-CBC + HMAC-SHA256)
- **Key storage:** `~/.config/graftpunk/.session_key` with `0600` permissions
- **Integrity:** SHA-256 checksum validated before deserializing
### Best Practices
- Keep your encryption key secure
- Don't share session files
- Run graftpunk on trusted machines
- Use unique, strong passwords for automated accounts
**Pickle warning:** graftpunk uses Python's `pickle` for serialization. Only load sessions you created.
## Development
```bash
git clone https://github.com/stavxyz/graftpunk.git
cd graftpunk
just setup # Install deps with uv
just check # Run lint, typecheck, tests
just build # Build for PyPI
```
Requires [uv](https://docs.astral.sh/uv/) for development. See [CONTRIBUTING.md](CONTRIBUTING.md) for full guidelines.
## License
MIT License—see [LICENSE](LICENSE).
## Acknowledgments
- [requestium](https://github.com/tryolabs/requestium) – Selenium + Requests integration
- [undetected-chromedriver](https://github.com/ultrafunkamsterdam/undetected-chromedriver) – Anti-detection ChromeDriver
- [nodriver](https://github.com/ultrafunkamsterdam/nodriver) – CDP-direct browser automation
- [cryptography](https://cryptography.io/) – Encryption primitives
- [rich](https://github.com/Textualize/rich) – Beautiful terminal output
- [typer](https://typer.tiangolo.com/) – CLI framework
---
<div align="center">
<sub>Built for automating your own data access.</sub>
</div>
| text/markdown | null | stavxyz <stavxyz@users.noreply.github.com> | null | null | null | api, automation, browser, requests, scraping, selenium, session | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Internet :: WWW/HTTP :: Browsers",
"Topic :: Software Development :: Libraries :: Python Modules",
"Typing :: Typed"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"brotli>=1.1.0",
"cryptography>=42.0.0",
"dill>=0.3.0",
"fpdf2>=2.8.0",
"httpie>=3.0.0",
"nodriver>=0.48",
"pydantic-settings>=2.0.0",
"pyotp>=2.9.0",
"python-slugify>=8.0.0",
"pyyaml>=6.0",
"requestium>=0.2.5",
"rich>=13.0.0",
"selenium-stealth>=1.0.6",
"selenium>=4.0.0",
"structlog>=23.0.0",
"typer>=0.9.0",
"undetected-chromedriver>=3.5.0",
"webdriver-manager>=4.0.0",
"xlsxwriter>=3.0.0",
"boto3>=1.34.0; extra == \"all\"",
"jmespath>=1.0.0; extra == \"all\"",
"mypy>=1.10.0; extra == \"all\"",
"openpyxl>=3.1.0; extra == \"all\"",
"pytest-cov>=4.0.0; extra == \"all\"",
"pytest-mock>=3.0.0; extra == \"all\"",
"pytest>=8.0.0; extra == \"all\"",
"ruff>=0.5.0; extra == \"all\"",
"supabase>=2.10.0; extra == \"all\"",
"mypy>=1.10.0; extra == \"dev\"",
"openpyxl>=3.1.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest-mock>=3.0.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.5.0; extra == \"dev\"",
"jmespath>=1.0.0; extra == \"jmespath\"",
"boto3>=1.34.0; extra == \"s3\"",
"supabase>=2.10.0; extra == \"supabase\""
] | [] | [] | [] | [
"Homepage, https://github.com/stavxyz/graftpunk",
"Repository, https://github.com/stavxyz/graftpunk",
"Documentation, https://github.com/stavxyz/graftpunk#readme",
"Changelog, https://github.com/stavxyz/graftpunk/blob/main/CHANGELOG.md",
"Issues, https://github.com/stavxyz/graftpunk/issues"
] | twine/6.2.0 CPython/3.14.1 | 2026-02-20T05:29:00.227490 | graftpunk-1.8.0.tar.gz | 759,715 | 25/37/1ee6a5538b5623e7017ccbdddb9f48e7a5fcd76e167a7f528f093780e64c/graftpunk-1.8.0.tar.gz | source | sdist | null | false | 9a618222db02c7e39438fa7e75ecdc38 | 80ddd223e370700b3878066f737bc55093900be464b08be17f1f35dfb13ed1a5 | 25371ee6a5538b5623e7017ccbdddb9f48e7a5fcd76e167a7f528f093780e64c | MIT | [
"LICENSE"
] | 487 |
2.1 | sbstck-dl | 0.7.0 | CLI tool to download posts from Substack blogs | # Substack Downloader
Simple CLI tool to download one or all the posts from a Substack blog.
## Installation
### Using uvx (recommended, no install needed)
```bash
uvx sbstck-dl download --url https://example.substack.com
```
### Using pip / pipx
```bash
pip install sbstck-dl
# or
pipx install sbstck-dl
```
### Downloading the binary
Check in the [releases](https://github.com/mefengl/sbstck-dl/releases) page for the latest version of the binary for your platform.
We provide binaries for Linux, MacOS and Windows.
### Using Go
```bash
go install github.com/alexferrari88/sbstck-dl
```
Your Go bin directory must be in your PATH. You can add it by adding the following line to your `.bashrc` or `.zshrc`:
```bash
export PATH=$PATH:$(go env GOPATH)/bin
```
## Usage
```bash
Usage:
sbstck-dl [command]
Available Commands:
download Download individual posts or the entire public archive
help Help about any command
list List the posts of a Substack
version Print the version number of sbstck-dl
Flags:
--after string Download posts published after this date (format: YYYY-MM-DD)
--before string Download posts published before this date (format: YYYY-MM-DD)
--cookie_name cookieName Either substack.sid or connect.sid, based on your cookie (required for private newsletters)
--cookie_val string The substack.sid/connect.sid cookie value (required for private newsletters)
-h, --help help for sbstck-dl
-x, --proxy string Specify the proxy url
-r, --rate int Specify the rate of requests per second (default 2)
-v, --verbose Enable verbose output
Use "sbstck-dl [command] --help" for more information about a command.
```
### Downloading posts
You can provide the url of a single post or the main url of the Substack you want to download.
By providing the main URL of a Substack, the downloader will download all the posts of the archive.
When downloading the full archive, if the downloader is interrupted, at the next execution it will resume the download of the remaining posts.
```bash
Usage:
sbstck-dl download [flags]
Flags:
--add-source-url Add the original post URL at the end of the downloaded file
--create-archive Create an archive index page linking all downloaded posts
--download-files Download file attachments locally and update content to reference local files
--download-images Download images locally and update content to reference local files
-d, --dry-run Enable dry run
--file-extensions string Comma-separated list of file extensions to download (e.g., 'pdf,docx,txt'). If empty, downloads all file types
--files-dir string Directory name for downloaded file attachments (default "files")
-f, --format string Specify the output format (options: "html", "md", "txt" (default "html")
-h, --help help for download
--image-quality string Image quality to download (options: "high", "medium", "low") (default "high")
--images-dir string Directory name for downloaded images (default "images")
-o, --output string Specify the download directory (default ".")
-u, --url string Specify the Substack url
Global Flags:
--after string Download posts published after this date (format: YYYY-MM-DD)
--before string Download posts published before this date (format: YYYY-MM-DD)
--cookie_name cookieName Either substack.sid or connect.sid, based on your cookie (required for private newsletters)
--cookie_val string The substack.sid/connect.sid cookie value (required for private newsletters)
-x, --proxy string Specify the proxy url
-r, --rate int Specify the rate of requests per second (default 2)
-v, --verbose Enable verbose output
```
#### Adding Source URL
If you use the `--add-source-url` flag, each downloaded file will have the following line appended to its content:
`original content: POST_URL`
Where `POST_URL` is the canonical URL of the downloaded post. For HTML format, this will be wrapped in a small paragraph with a link.
#### Downloading Images
Use the `--download-images` flag to download all images from Substack posts locally. This ensures posts remain accessible even if images are deleted from Substack's CDN.
**Features:**
- Downloads images at optimal quality (high/medium/low)
- Creates organized directory structure: `{output}/images/{post-slug}/`
- Updates HTML/Markdown content to reference local image paths
- Handles all Substack image formats and CDN patterns
- Graceful error handling for individual image failures
**Examples:**
```bash
# Download posts with high-quality images (default)
sbstck-dl download --url https://example.substack.com --download-images
# Download with medium quality images
sbstck-dl download --url https://example.substack.com --download-images --image-quality medium
# Download with custom images directory name
sbstck-dl download --url https://example.substack.com --download-images --images-dir assets
# Download single post with images in markdown format
sbstck-dl download --url https://example.substack.com/p/post-title --download-images --format md
```
**Image Quality Options:**
- `high`: 1456px width (best quality, larger files)
- `medium`: 848px width (balanced quality/size)
- `low`: 424px width (smaller files, mobile-optimized)
**Directory Structure:**
```
output/
├── 20231201_120000_post-title.html
└── images/
└── post-title/
├── image1_1456x819.jpeg
├── image2_848x636.png
└── image3_1272x720.webp
```
#### Downloading File Attachments
Use the `--download-files` flag to download all file attachments from Substack posts locally. This ensures posts remain accessible even if files are removed from Substack's servers.
**Features:**
- Downloads file attachments using CSS selector `.file-embed-button.wide`
- Optional file extension filtering (e.g., only PDFs and Word documents)
- Creates organized directory structure: `{output}/files/{post-slug}/`
- Updates HTML content to reference local file paths
- Handles filename sanitization and collision avoidance
- Graceful error handling for individual file download failures
**Examples:**
```bash
# Download posts with all file attachments
sbstck-dl download --url https://example.substack.com --download-files
# Download only specific file types
sbstck-dl download --url https://example.substack.com --download-files --file-extensions "pdf,docx,txt"
# Download with custom files directory name
sbstck-dl download --url https://example.substack.com --download-files --files-dir attachments
# Download single post with both images and file attachments
sbstck-dl download --url https://example.substack.com/p/post-title --download-images --download-files --format md
```
**File Extension Filtering:**
- Specify extensions without dots: `pdf,docx,txt`
- Case insensitive matching
- If no extensions specified, downloads all file types
**Directory Structure with Files:**
```
output/
├── 20231201_120000_post-title.html
├── images/
│ └── post-title/
│ ├── image1_1456x819.jpeg
│ └── image2_848x636.png
└── files/
└── post-title/
├── document.pdf
├── spreadsheet.xlsx
└── presentation.pptx
```
#### Creating Archive Index Pages
Use the `--create-archive` flag to generate an organized index page that links all downloaded posts with their metadata. This creates a beautiful overview of your downloaded content, making it easy to browse and access your Substack archive.
**Features:**
- Creates `index.{format}` file matching your selected output format (HTML/Markdown/Text)
- Links to all downloaded posts using relative file paths
- Displays post titles, publication dates, and download timestamps
- Shows post descriptions/subtitles and cover images when available
- Automatically sorts posts by publication date (newest first)
- Works with both single post and bulk downloads
**Examples:**
```bash
# Download entire archive and create index page
sbstck-dl download --url https://example.substack.com --create-archive
# Create archive index in Markdown format
sbstck-dl download --url https://example.substack.com --create-archive --format md
# Build archive over time with single posts
sbstck-dl download --url https://example.substack.com/p/post-title --create-archive
# Complete download with all features
sbstck-dl download --url https://example.substack.com --download-images --download-files --create-archive
# Custom directory structure with archive
sbstck-dl download --url https://example.substack.com --create-archive --images-dir assets --files-dir attachments
```
**Archive Content Per Post:**
- **Title**: Clickable link to the downloaded post file
- **Publication Date**: When the post was originally published on Substack
- **Download Date**: When you downloaded the post locally
- **Description**: Post subtitle or description (when available)
- **Cover Image**: Featured image from the post (when available)
**Archive Format Examples:**
*HTML Format:* Styled webpage with images, organized post cards, and hover effects
*Markdown Format:* Clean markdown with headers, links, and image references
*Text Format:* Plain text listing with all metadata for maximum compatibility
**Directory Structure with Archive:**
```
output/
├── index.html # Archive index page
├── 20231201_120000_post-title.html
├── 20231115_090000_another-post.html
├── images/
│ ├── post-title/
│ │ └── image1_1456x819.jpeg
│ └── another-post/
│ └── image2_848x636.png
└── files/
├── post-title/
│ └── document.pdf
└── another-post/
└── spreadsheet.xlsx
```
### Listing posts
```bash
Usage:
sbstck-dl list [flags]
Flags:
-h, --help help for list
-u, --url string Specify the Substack url
Global Flags:
--after string Download posts published after this date (format: YYYY-MM-DD)
--before string Download posts published before this date (format: YYYY-MM-DD)
--cookie_name cookieName Either substack.sid or connect.sid, based on your cookie (required for private newsletters)
--cookie_val string The substack.sid/connect.sid cookie value (required for private newsletters)
-x, --proxy string Specify the proxy url
-r, --rate int Specify the rate of requests per second (default 2)
-v, --verbose Enable verbose output
```
### Private Newsletters
In order to download the full text of private newsletters you need to provide the cookie name and value of your session.
The cookie name is either `substack.sid` or `connect.sid`, based on your cookie.
To get the cookie value you can use the developer tools of your browser.
Once you have the cookie name and value, you can pass them to the downloader using the `--cookie_name` and `--cookie_val` flags.
#### Example
```bash
sbstck-dl download --url https://example.substack.com --cookie_name substack.sid --cookie_val COOKIE_VALUE
```
## Thanks
- [wemoveon2](https://github.com/wemoveon2) and [lenzj](https://github.com/lenzj) for the discussion and help implementing the support for private newsletters
## TODO
- [x] Improve retry logic
- [ ] Implement loading from config file
- [x] Add support for downloading images
- [x] Add support for downloading file attachments
- [x] Add archive index page functionality
- [x] Add tests
- [x] Add CI
- [x] Add documentation
- [x] Add support for private newsletters
- [x] Implement filtering by date
- [x] Implement resuming downloads
| text/markdown | Alex Ferrari | null | null | null | MIT | null | [] | [] | https://github.com/mefengl/sbstck-dl | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | uv/0.10.2 {"installer":{"name":"uv","version":"0.10.2","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T05:28:32.518535 | sbstck_dl-0.7.0-py3-none-musllinux_1_2_x86_64.whl | 9,094,700 | ee/bb/d5fdcbf04990fd1468a5ff02f84f36d6ea98c86a815a893833833ea91631/sbstck_dl-0.7.0-py3-none-musllinux_1_2_x86_64.whl | py3 | bdist_wheel | null | false | a46fbbaddbcd1014049fa34ca06d00e8 | 3dcaa57bac82b0b2b64f5ec2dd06ea1f028af30da90a7e5a2ef56829c9f5f284 | eebbd5fdcbf04990fd1468a5ff02f84f36d6ea98c86a815a893833833ea91631 | null | [] | 536 |
2.4 | df-poc | 0.0.2 | Data formatting proof of concept | --- SIMULATED C2 PAYLOAD ---
This is a proof-of-concept payload delivered via domain fronting.
If you are reading this, the C2 channel is operational.
Payload ID: DF-POC-2026-001
Command: BEACON_ACK
Status: ACTIVE
--- END PAYLOAD ---
| text/markdown | Research | null | null | null | MIT | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T05:24:37.861870 | df_poc-0.0.2.tar.gz | 1,184 | 6b/85/3af98b12703e8399184a9b2d9612de0a1fac33a6694663d01839a8725e82/df_poc-0.0.2.tar.gz | source | sdist | null | false | 176519026cef65eb2b15ed50639a8054 | 4a19e95a999b3aed18e4322e6d81616aecbfc335ba3817762efcd5721ea447ca | 6b853af98b12703e8399184a9b2d9612de0a1fac33a6694663d01839a8725e82 | null | [] | 276 |
2.4 | nanofts | 0.5.0 | High-performance full-text search engine written in Rust | # NanoFTS
A high-performance full-text search engine with Rust core, featuring efficient indexing and searching capabilities for both English and Chinese text.
## Features
- **High Performance**: Rust-powered core with sub-millisecond search latency
- **LSM-Tree Architecture**: Scalable to billions of documents
- **Incremental Updates**: Real-time document add/update/delete
- **Fuzzy Search**: Intelligent fuzzy matching with configurable thresholds
- **Full CRUD**: Complete document management operations
- **Result Handle**: Zero-copy result with set operations (AND/OR/NOT)
- **NumPy Support**: Direct numpy array output
- **Multilingual**: Support for both English and Chinese text
- **Persistence**: Disk-based storage with WAL recovery
- **LRU Cache**: Built-in caching for frequently accessed terms
- **Data Import**: Import from pandas, polars, arrow, parquet, CSV, JSON
## Installation
```bash
pip install nanofts
```
## Quick Start
```python
from nanofts import create_engine
# Create a search engine
engine = create_engine(
index_file="./index.nfts",
track_doc_terms=True, # Enable update/delete operations
)
# Add documents (field values must be strings)
engine.add_document(1, {"title": "Python Tutorial", "content": "Learn Python programming"})
engine.add_document(2, {"title": "Data Analysis", "content": "Process data with pandas"})
engine.flush()
# Search - returns ResultHandle object
result = engine.search("Python")
print(f"Found {result.total_hits} documents")
print(f"Document IDs: {result.to_list()}")
# Update document
engine.update_document(1, {"title": "Advanced Python Tutorial", "content": "Deep dive into Python"})
# Delete document
engine.remove_document(2)
# Compact to persist deletions
engine.compact()
```
## Rust Usage (Rust Core)
The Rust crate name is `nanofts` (minimum Rust version: `rustc >= 1.75`). If you are building a Rust service, you can use it directly as a pure Rust full-text search library.
### Add as a dependency
Add this to your project `Cargo.toml`:
```toml
[dependencies]
nanofts = "0.5.0"
```
Optional features:
- **`mimalloc`**: enabled by default; lower latency / more stable allocation performance
- **`python`**: enable PyO3/Numpy bindings (only needed if you build the Python extension)
- **`simd`**: enable SIMD acceleration (requires nightly and `packed_simd_2`)
### Minimal example: in-memory indexing and searching
```rust
use nanofts::{UnifiedEngine, EngineConfig, EngineResult};
use std::collections::HashMap;
fn main() -> EngineResult<()> {
// 1) Create an in-memory engine
let engine = UnifiedEngine::new(EngineConfig::memory_only())?;
// 2) Add a document (field values must be String)
let mut fields = HashMap::new();
fields.insert("title".to_string(), "Rust Tutorial".to_string());
fields.insert("content".to_string(), "Build a high-performance full-text search engine in Rust".to_string());
engine.add_document(1, fields)?;
// 3) Search
let result = engine.search("Rust")?;
println!("hits={}, ids={:?}", result.total_hits(), result.to_list());
Ok(())
}
```
### Persistence: single-file index + WAL recovery
```rust
use nanofts::{UnifiedEngine, EngineConfig, EngineResult};
fn main() -> EngineResult<()> {
let config = EngineConfig::persistent("./index.nfts")
.with_lazy_load(true)
.with_cache_size(10_000);
let engine = UnifiedEngine::new(config)?;
// ... add/update/remove ...
// Flush new documents to disk
engine.flush()?;
// Deletions become permanent only after compaction
engine.compact()?;
Ok(())
}
```
### Run the built-in Rust example in this repo
```bash
cargo run --example basic_usage --release
```
## Performance Tuning (Rust Developer Perspective)
### Build and runtime knobs
- **Use release builds**: `cargo build --release` / `cargo run --release` (this repo already configures `lto=fat`, `codegen-units=1`, `panic=abort`, `strip=true` for release).
- **Optimize for your CPU** (optional): set `RUSTFLAGS="-C target-cpu=native"` when building/running on a specific machine.
- **SIMD** (optional): if you enable `--features simd`, use nightly and validate the benefit for your workload.
### Fastest ingestion formats and APIs
- **Prefer batch ingestion**: it reduces per-document overhead and lets the engine use its optimized parallel paths.
- **Fastest Rust API**: `UnifiedEngine::add_documents_texts(doc_ids, texts)` is the fastest ingestion path when you can pre-concatenate all searchable fields into a single `String` per document.
- **Columnar ingestion**: `UnifiedEngine::add_documents_columnar(doc_ids, columns)` avoids constructing a `HashMap` per document and is a good fit for Arrow/DataFrame-style input.
- **Arrow zero-copy ingestion**: if your data is already in Arrow (or can be represented as borrowed `&str` slices), use `UnifiedEngine::add_documents_arrow_str(doc_ids, columns)` (multi-column) or `UnifiedEngine::add_documents_arrow_texts(doc_ids, texts)` (single merged text column) to avoid `String` allocation/copy.
- **Batch HashMap ingestion**: `UnifiedEngine::add_documents(docs)` is still much faster than calling `add_document` in a loop.
### Arrow Zero-Copy API Examples
#### Multi-column zero-copy ingestion
```rust
use nanofts::{UnifiedEngine, EngineConfig};
let engine = UnifiedEngine::new(EngineConfig::memory_only())?;
// Simulate Arrow StringArray data (in real use, extract from Arrow)
let doc_ids = vec![1, 2, 3];
let titles = vec!["Title 1", "Title 2", "Title 3"];
let contents = vec!["Content 1", "Content 2", "Content 3"];
// Zero-copy columnar ingestion
let columns = vec![
("title".to_string(), titles),
("content".to_string(), contents),
];
engine.add_documents_arrow_str(&doc_ids, columns)?;
```
#### Single-column zero-copy ingestion (fastest for Arrow)
```rust
// Pre-merged text from Arrow (single column)
let doc_ids = vec![1, 2, 3];
let merged_texts = vec![
"Title 1 Content 1",
"Title 2 Content 2",
"Title 3 Content 3",
];
// Zero-copy single column ingestion
engine.add_documents_arrow_texts(&doc_ids, &merged_texts)?;
```
#### Real Arrow StringArray integration
```rust
// Example with real Arrow StringArray
use arrow_array::StringArray;
let title_array = StringArray::from(vec!["Title 1", "Title 2", "Title 3"]);
let content_array = StringArray::from(vec!["Content 1", "Content 2", "Content 3"]);
// Extract zero-copy string slices from Arrow
let title_slices: Vec<&str> = title_array.iter()
.map(|s| s.unwrap_or(""))
.collect();
let content_slices: Vec<&str> = content_array.iter()
.map(|s| s.unwrap_or(""))
.collect();
let columns = vec![
("title".to_string(), title_slices),
("content".to_string(), content_slices),
];
engine.add_documents_arrow_str(&doc_ids, columns)?;
```
### Flush/compact strategy
- **`flush()` frequency**: flushing periodically bounds WAL/memory usage, but flushing too often may increase IO amplification.
- **Deletion persistence**: deletes/updates are logical until `compact()`.
- If you delete a lot, compact in bigger batches rather than after every small delete wave.
- **Track doc terms only when you need updates/deletes**: enable it only if you need update/delete support (Python: `track_doc_terms=True`). It adds extra bookkeeping on ingestion.
### Large indexes and memory footprint
- **Use `lazy_load`** when the index is large and you don't want to map everything into memory: `with_lazy_load(true)` / Python `lazy_load=True`.
- **Tune `cache_size`**: in `lazy_load` mode, cache hit rate is a major driver for latency. Iterate using `engine.stats()` (e.g., cache hit rate).
### Query-side optimization
- **Use boolean/batch APIs and set operations**: prefer `search_and` / `search_or` or `ResultHandle::{intersect, union, difference}` to avoid repeated work.
- **Fuzzy search is more expensive**: `fuzzy_search` introduces extra candidate generation and edit-distance checks. Use it only when needed and tune thresholds/distances.
### Benchmarking and profiling
- **Benchmarks**: use `cargo bench` (or your own fixed dataset) and compare A/B with realistic data scale, term distribution, and query sets.
- **CPU profiling**: profile release binaries to find hot spots (tokenization, bitmap ops, IO, compression/decompression). On macOS, Instruments is usually the easiest.
- **Measure first**: use `engine.stats()` to track search counts, cumulative time, and cache hit rate before tuning.
## API Reference
### Creating Engine
```python
from nanofts import create_engine
engine = create_engine(
index_file="./index.nfts", # Index file path (empty string for memory-only)
max_chinese_length=4, # Max Chinese n-gram length
min_term_length=2, # Minimum term length to index
fuzzy_threshold=0.7, # Fuzzy search similarity threshold (0.0-1.0)
fuzzy_max_distance=2, # Maximum edit distance for fuzzy search
track_doc_terms=False, # Enable for update/delete support
drop_if_exists=False, # Drop existing index on creation
lazy_load=False, # Lazy load mode (memory efficient)
cache_size=10000, # LRU cache size for lazy load mode
)
```
### Document Operations
```python
# Add single document
engine.add_document(doc_id=1, fields={"title": "Hello", "content": "World"})
# Add multiple documents
docs = [
(1, {"title": "Doc 1", "content": "Content 1"}),
(2, {"title": "Doc 2", "content": "Content 2"}),
]
engine.add_documents(docs)
# Update document (requires track_doc_terms=True)
engine.update_document(1, {"title": "Updated", "content": "New content"})
# Delete single document
engine.remove_document(1)
# Delete multiple documents
engine.remove_documents([1, 2, 3])
# Flush buffer to disk
engine.flush()
# Compact index (applies deletions permanently)
engine.compact()
```
### Search Operations
```python
# Basic search - returns ResultHandle
result = engine.search("python programming")
# Get results
doc_ids = result.to_list() # List[int]
doc_ids = result.to_numpy() # numpy array
top_10 = result.top(10) # Top N results
page_2 = result.page(page=2, size=10) # Pagination
# Result properties
print(result.total_hits) # Total match count
print(result.is_empty) # Check if empty
print(1 in result) # Check if doc_id in results
# Fuzzy search (for typo tolerance)
result = engine.fuzzy_search("pythn", min_results=5)
print(result.fuzzy_used) # True if fuzzy matching was applied
# Batch search
results = engine.search_batch(["python", "rust", "java"])
# AND search (intersection)
result = engine.search_and(["python", "tutorial"])
# OR search (union)
result = engine.search_or(["python", "rust"])
# Filter by document IDs
result = engine.filter_by_ids([1, 2, 3, 4, 5])
# Exclude specific IDs
result = engine.exclude_ids([1, 2])
```
### Result Set Operations
```python
# Search for different terms
python_docs = engine.search("python")
rust_docs = engine.search("rust")
# Intersection (AND)
both = python_docs.intersect(rust_docs)
# Union (OR)
either = python_docs.union(rust_docs)
# Difference (NOT)
python_only = python_docs.difference(rust_docs)
# Chained operations
result = engine.search("python").intersect(
engine.search("tutorial")
).difference(
engine.search("beginner")
)
```
### Statistics
```python
stats = engine.stats()
print(stats)
# {
# 'term_count': 1234,
# 'search_count': 100,
# 'fuzzy_search_count': 10,
# 'total_search_ns': 1234567,
# ...
# }
```
### Data Import
NanoFTS supports importing data from various sources:
```python
from nanofts import create_engine
engine = create_engine("./index.nfts")
# Import from pandas DataFrame
import pandas as pd
df = pd.DataFrame({
'id': [1, 2, 3],
'title': ['Hello World', '全文搜索', 'Test Document'],
'content': ['This is a test', '支持多语言', 'Another test']
})
engine.from_pandas(df, id_column='id')
# Import from Polars DataFrame
import polars as pl
df = pl.DataFrame({
'id': [1, 2, 3],
'title': ['Doc 1', 'Doc 2', 'Doc 3']
})
engine.from_polars(df, id_column='id')
# Import from PyArrow Table
import pyarrow as pa
table = pa.Table.from_pydict({
'id': [1, 2, 3],
'title': ['Arrow 1', 'Arrow 2', 'Arrow 3']
})
engine.from_arrow(table, id_column='id')
# Import from Parquet file
engine.from_parquet("documents.parquet", id_column='id')
# Import from CSV file
engine.from_csv("documents.csv", id_column='id')
# Import from JSON file
engine.from_json("documents.json", id_column='id')
# Import from JSON Lines file
engine.from_json("documents.jsonl", id_column='id', lines=True)
# Import from Python dict list
data = [
{'id': 1, 'title': 'Hello', 'content': 'World'},
{'id': 2, 'title': 'Test', 'content': 'Document'}
]
engine.from_dict(data, id_column='id')
```
#### Specifying Text Columns
By default, all columns except the ID column are indexed. You can specify which columns to index:
```python
# Only index 'title' and 'content' columns, ignore 'metadata'
engine.from_pandas(df, id_column='id', text_columns=['title', 'content'])
# Same for other import methods
engine.from_csv("data.csv", id_column='id', text_columns=['title', 'content'])
```
#### CSV and JSON Options
You can pass additional options to the underlying pandas readers:
```python
# CSV with custom delimiter
engine.from_csv("data.csv", id_column='id', sep=';', encoding='utf-8')
# JSON Lines format
engine.from_json("data.jsonl", id_column='id', lines=True)
```
## Chinese Text Support
NanoFTS handles Chinese text using n-gram tokenization:
```python
engine = create_engine(
index_file="./chinese_index.nfts",
max_chinese_length=4, # Generate 2,3,4-gram for Chinese
)
engine.add_document(1, {"content": "全文搜索引擎"})
engine.flush()
# Search Chinese text
result = engine.search("搜索")
print(result.to_list()) # [1]
```
## Persistence and Recovery
```python
# Create persistent index
engine = create_engine(index_file="./data.nfts")
engine.add_document(1, {"title": "Test"})
engine.flush()
# Close and reopen
del engine
engine = create_engine(index_file="./data.nfts")
# Data is automatically recovered
result = engine.search("Test")
print(result.to_list()) # [1]
# Important: Use compact() to persist deletions
engine.remove_document(1)
engine.compact() # Deletions are now permanent
```
## Memory-Only Mode
```python
# Create in-memory engine (no persistence)
engine = create_engine(index_file="")
engine.add_document(1, {"content": "temporary data"})
# No flush needed for in-memory mode
result = engine.search("temporary")
```
## Best Practices
### For Production Use
1. **Always call `compact()` after bulk deletions** - Deletions are only persisted after compaction
2. **Use `track_doc_terms=True`** if you need update/delete operations
3. **Call `flush()` periodically** to persist new documents
4. **Use `lazy_load=True`** for large indexes that don't fit in memory
### Performance Tips
```python
# Batch operations are faster
docs = [(i, {"content": f"doc {i}"}) for i in range(10000)]
engine.add_documents(docs) # Much faster than individual add_document calls
engine.flush()
# Use batch search for multiple queries
results = engine.search_batch(["query1", "query2", "query3"])
# Use result set operations instead of multiple searches
# Good:
result = engine.search_and(["python", "tutorial"])
# Instead of:
# result = engine.search("python").intersect(engine.search("tutorial"))
```
## Migration from Old API
If you're upgrading from the old `FullTextSearch` API:
```python
# Old API (deprecated)
# from nanofts import FullTextSearch
# fts = FullTextSearch(index_dir="./index")
# fts.add_document(1, {"title": "Test"})
# results = fts.search("Test") # Returns List[int]
# New API
from nanofts import create_engine
engine = create_engine(index_file="./index.nfts")
engine.add_document(1, {"title": "Test"})
result = engine.search("Test")
results = result.to_list() # Returns List[int]
```
Key differences:
- `FullTextSearch` → `create_engine()` function
- `index_dir` → `index_file` (file path, not directory)
- Search returns `ResultHandle` instead of `List[int]`
- Call `.to_list()` to get document IDs
- Use `compact()` to persist deletions
## License
This project is licensed under the Apache License 2.0 - see the LICENSE file for details.
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | Apache-2.0 | null | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | https://github.com/BirchKwok/NanoFTS | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T05:23:11.612225 | nanofts-0.5.0.tar.gz | 80,194 | 12/76/cdfca17d05d80f6d1cdcd3a1eaa5e6c44d20f8ee0d2e8877d80cafa65737/nanofts-0.5.0.tar.gz | source | sdist | null | false | 979416c0608d8e339686edce91f44588 | dc9fbabe628a576d5cff7245c74006b16e40527a38d7c1802a85c8a80a4c3271 | 1276cdfca17d05d80f6d1cdcd3a1eaa5e6c44d20f8ee0d2e8877d80cafa65737 | null | [] | 383 |
2.4 | oeissequences | 0.2.5.8 | Python functions to generate OEIS sequences | # oeis-sequences
[](https://github.com/psf/black)
Python functions to generate [The On-Line Encyclopedia of Integer Sequences](https://oeis.org/) (OEIS) sequences.
Python is the ideal language for this purpose because of the following reasons:
1. Python is a general purpose programming language with support for file I/O and graphing.
2. Arbitrary size integer format is standard in Python. This is important as many sequences in OEIS contain very large integers that will not fit in 64-bit integer formats. This allows the implemented functions to generate terms for arbitrary large `n` and they do not depend on floating point precision. For higher performance, one can use [`gmpy2`](https://pypi.org/project/gmpy2/).
3. There exists extensive modules for combinatorics and number theory such as `math`, `itertools` and [`sympy`](https://www.sympy.org/en/index.html).
Although Python can be slow as it is an interpreted language, this can be mitigated somewhat using tools such as [`pypy`](https://www.pypy.org/) and [`numba`](https://numba.pydata.org/).
## Requirements
Requires `python` >= 3.8
## Installation
`pip install OEISsequences`
## Usage
After installation, `from oeis_sequences import OEISsequences` will import all the functions accessible via `OEISsequences.Axxxxxx`.
Alternatively, invidividual functions can be imported as `from oeis_sequences.OEISsequences import Axxxxxx`.
For each sequence, there are (up to) 3 different kinds of functions:
1. Functions named `Axxxxxx`: Axxxxxx(n) returns the *n*-th term of OEIS sequence Axxxxxx.
2. Functions named `Axxxxxx_T`: returns T(n,k) for OEIS sequences where the natural definition is a 2D table *T*.
3. Functions named `Axxxxxx_gen`: Axxxxxx_gen() returns a generator of OEIS sequence Axxxxxx.
The function `Axxxxxx` is best used to compute a single term. The generator `Axxxxxx_gen` is typically defined for sequences where terms are best generated sequentially and is best used when computing a sequence of consecutive terms.
For the generator, we can for example use `list(islice(Axxxxxx_gen(),10))` to return the first 10 terms of sequence Axxxxxx
Alternatively, setting `gen = Axxxxxx_gen()` and using `next(gen)` returns the next term of the sequence.
Given `Axxxxxx_gen`, one can define a function `Axxxxxx` as:
```
def Axxxxxx(n,offset=1): return next(islice(Axxxxxx_gen(),n-offset,None))
```
where a(*offset*) is the first term returned by the generator. This value of *offset* is the same as the *offset* parameter in the OEIS database.
Some functions `Axxxxxx_gen` contain an optional keyword `startvalue` that returns a generator of terms that are larger than or equal to `startvalue`. This keyword is only available on sequences that are nondecreasing.
For some sequences, e.g. `A269483`, both types of functions `Axxxxxx` and `Axxxxxx_gen` are provided.
## Examples
Least power of 3 having exactly n consecutive 7's in its decimal representation.
```
from oeis_sequences.OEISsequences import A131546
print(A131546(5))
>> 721
```
Minimal exponents m such that the fractional part of (10/9)<sup>m</sup> obtains a maximum (when starting with m=1).
```
from itertools import islice
from oeis_sequences.OEISsequences import A153695_gen
print(list(islice(A153695_gen(),10)))
>> [1, 2, 3, 4, 5, 6, 13, 17, 413, 555]
```
Numbers n such that n<sup>3</sup> has one or more occurrences of exactly nine different digits.
```
from oeis_sequences.OEISsequences import A235811_gen
print(list(islice(A235811_gen(startvalue=1475),10))) # print first 10 terms >= 1475
>> [1475, 1484, 1531, 1706, 1721, 1733, 1818, 1844, 1895, 1903]
```
## Utility functions
The module also includes some utility functions for exploring integer sequences in OEIS such as palindrome generator, Boustrophedon transform, run length transform, Faulhaber's formula, lunar arithmetic, squarefree numbers, *k*-almost primes, squarefree *k*-almost primes, binomial coefficients modulo *m*, etc.
| text/markdown | Chai Wah Wu | cwwuieee@gmail.com | null | null | LICENSE | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Topic :: Scientific/Engineering :: Mathematics",
"Development Status :: 4 - Beta"
] | [] | https://github.com/postvakje/oeis-sequences | null | >=3.8 | [] | [] | [] | [
"sympy",
"gmpy2",
"num2words",
"unidecode",
"networkx",
"bitarray",
"python-sat"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T05:22:57.817386 | oeissequences-0.2.5.8.tar.gz | 346,516 | 67/4e/180702d6f95aea0fd4af64c0806bc97288910121ebcde9a846d084e12a8a/oeissequences-0.2.5.8.tar.gz | source | sdist | null | false | e81f5c038d52169d69df9b28f742bb77 | af3161881b9dc8d62b53f39c619ba6db7b3c6fd182fb11ca64435b8ad6f12935 | 674e180702d6f95aea0fd4af64c0806bc97288910121ebcde9a846d084e12a8a | null | [
"LICENSE"
] | 264 |
2.4 | prefactor-core | 0.1.1 | Core Prefactor SDK with async queue-based operations | # Prefactor Core
High-level Prefactor SDK with async queue-based processing.
## Features
- **Queue-Based Processing**: Operations are queued and processed asynchronously by a worker pool
- **Non-Blocking API**: Agent execution is never blocked by observability calls
- **Automatic Parent Detection**: Nested spans automatically detect their parent from the context stack
- **Schema Registry**: Compose and register span schemas before instance creation
- **Configurable Workers**: Tune concurrency and retry behavior for the background queue
## Installation
```bash
pip install prefactor-core
```
## Quick Start
```python
import asyncio
from prefactor_core import PrefactorCoreClient, PrefactorCoreConfig, SchemaRegistry
from prefactor_http import HttpClientConfig
registry = SchemaRegistry()
registry.register_type(
name="agent:llm",
params_schema={
"type": "object",
"properties": {
"model": {"type": "string"},
"prompt": {"type": "string"},
},
"required": ["model", "prompt"],
},
result_schema={
"type": "object",
"properties": {"response": {"type": "string"}},
},
title="LLM Call",
description="A call to a language model",
template="{{model}}: {{prompt}} → {{response}}",
)
async def main():
config = PrefactorCoreConfig(
http_config=HttpClientConfig(
api_url="https://api.prefactor.ai",
api_token="your-token",
),
schema_registry=registry,
)
async with PrefactorCoreClient(config) as client:
instance = await client.create_agent_instance(
agent_id="my-agent",
agent_version={"name": "My Agent", "external_identifier": "v1.0.0"},
)
await instance.start()
async with instance.span("agent:llm") as span:
await span.start({"model": "gpt-4", "prompt": "Hello"})
result = await call_llm()
await span.complete({"response": result})
await instance.finish()
asyncio.run(main())
```
## API Reference
### `PrefactorCoreClient`
The main entry point. Use as an async context manager or call `initialize()` / `close()` manually.
```python
client = PrefactorCoreClient(config)
await client.initialize()
# ... use client ...
await client.close()
```
#### `create_agent_instance`
```python
handle = await client.create_agent_instance(
agent_id="my-agent",
agent_version={"name": "My Agent", "external_identifier": "v1.0.0"},
agent_schema_version=None, # Optional: auto-generated if schema_registry is configured
external_schema_version_id=None, # Optional: reference an existing schema version
) -> AgentInstanceHandle
```
#### `span` (context manager)
```python
async with client.span(
instance_id="instance_123",
schema_name="agent:llm",
parent_span_id=None, # Optional: auto-detected from context stack if omitted
payload=None, # Optional: used as params if span.start() is never called explicitly
) as span:
await span.start({"model": "gpt-4", "prompt": "Hello"})
result = await call_llm()
await span.complete({"response": result})
```
### `AgentInstanceHandle`
Returned by `create_agent_instance`. Manages the lifecycle of a single agent instance.
```python
handle.id # -> str
await handle.start()
await handle.finish()
async with handle.span("agent:llm") as span:
...
```
### `SpanContext`
The object yielded by span context managers. Spans follow a three-phase lifecycle:
1. **Enter context** — span is prepared locally, no HTTP call yet.
2. **`await span.start(payload)`** — POSTs the span to the API as `active` with the given params payload.
3. **`await span.complete(result)`** / **`span.fail(result)`** / **`span.cancel()`** — finishes the span with a terminal status.
If `start()` or a finish method is not called explicitly, the context manager handles them automatically on exit.
```python
span.id # -> str (API-generated after start())
await span.start(payload: dict) # POST span as active with params payload
await span.complete(result: dict) # finish with status "complete"
await span.fail(result: dict) # finish with status "failed"
await span.cancel() # finish with status "cancelled"
span.set_result(data: dict) # accumulate result data for auto-finish
await span.finish() # finish with current status (default: "complete")
```
**Status note:** `cancel()` can be called before or after `start()`. If called before `start()`, the span is posted as `pending` and immediately cancelled — the only valid pre-active cancellation path the API supports.
#### Full lifecycle example
```python
async with instance.span("agent:llm") as span:
await span.start({"model": "gpt-4", "prompt": "Hello"})
try:
result = await call_llm()
await span.complete({"response": result})
except Exception as exc:
await span.fail({"error": str(exc)})
# Cancel before starting (e.g. a conditional step that is skipped):
async with instance.span("agent:retrieval") as span:
if not needed:
await span.cancel()
else:
await span.start({"query": "..."})
docs = await retrieve()
await span.complete({"documents": docs, "count": len(docs)})
```
## Configuration
```python
from prefactor_core import PrefactorCoreConfig, QueueConfig
from prefactor_http import HttpClientConfig
config = PrefactorCoreConfig(
http_config=HttpClientConfig(
api_url="https://api.prefactor.ai",
api_token="your-token",
),
queue_config=QueueConfig(
num_workers=3, # Number of background workers
max_retries=3, # Retries per operation
retry_delay_base=1.0, # Base delay (seconds) for exponential backoff
),
schema_registry=None, # Optional: SchemaRegistry instance
)
```
## Schema Registry
Use `SchemaRegistry` to compose span schemas from multiple sources and auto-generate the `agent_schema_version` passed to `create_agent_instance`.
```python
from prefactor_core import SchemaRegistry
registry = SchemaRegistry()
registry.register_type(
name="agent:llm",
params_schema={
"type": "object",
"properties": {
"model": {"type": "string"},
"prompt": {"type": "string"},
},
"required": ["model", "prompt"],
},
result_schema={
"type": "object",
"properties": {"response": {"type": "string"}},
},
title="LLM Call",
description="A call to a language model",
template="{{model}}: {{prompt}} → {{response}}",
)
registry.register_type(
name="agent:tool",
params_schema={"type": "object", "properties": {...}},
result_schema={"type": "object", "properties": {...}},
title="Tool Call",
)
config = PrefactorCoreConfig(
http_config=...,
schema_registry=registry,
)
async with PrefactorCoreClient(config) as client:
# agent_schema_version is generated automatically from the registry
instance = await client.create_agent_instance(
agent_id="my-agent",
agent_version={"name": "My Agent", "external_identifier": "v1.0.0"},
)
```
## Error Handling
```python
from prefactor_core import (
PrefactorCoreError,
ClientNotInitializedError,
ClientAlreadyInitializedError,
OperationError,
InstanceNotFoundError,
SpanNotFoundError,
)
```
## Architecture
The client uses a three-layer design:
1. **Queue infrastructure**: `InMemoryQueue` + `TaskExecutor` worker pool process operations in the background
2. **Managers**: `AgentInstanceManager` and `SpanManager` translate high-level calls into `Operation` objects and route them to the HTTP client
3. **Client API**: `PrefactorCoreClient` exposes the user-facing interface and wires the layers together
All observability operations are enqueued and executed asynchronously — the calling code is never blocked waiting for API responses.
## License
MIT
| text/markdown | null | Prefactor Pty Ltd <josh@prefactor.tech> | null | null | MIT | null | [] | [] | null | null | <4.0.0,>=3.11.0 | [] | [] | [] | [
"prefactor-http>=0.1.0",
"pydantic>=2.0.0"
] | [] | [] | [] | [] | uv/0.9.28 {"installer":{"name":"uv","version":"0.9.28","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"25.10","id":"questing","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T05:21:55.235528 | prefactor_core-0.1.1-py3-none-any.whl | 27,550 | d5/27/72c281e86702a3c252d1288530748bff831f0db7f432a6a17843da9fa457/prefactor_core-0.1.1-py3-none-any.whl | py3 | bdist_wheel | null | false | f631c2f62ba3323923b91acc34ada4f4 | 976d61433dde9bc851d857dc5842335109afb2b9d02d4ea259db5e940e2c4b4f | d52772c281e86702a3c252d1288530748bff831f0db7f432a6a17843da9fa457 | null | [] | 272 |
2.4 | prefactor-langchain | 0.2.1 | LangChain integration for Prefactor observability | # prefactor-langchain
LangChain integration for Prefactor observability. This package provides automatic tracing for LangChain agents using LangChain-specific span types.
## Installation
```bash
pip install prefactor-langchain
```
## Usage
### Factory pattern (quickest setup)
```python
from prefactor_langchain import PrefactorMiddleware
middleware = PrefactorMiddleware.from_config(
api_url="https://api.prefactor.ai",
api_token="your-api-token",
agent_id="my-agent",
agent_name="My Agent", # optional
)
# Use with LangChain's create_agent()
# Your agent will automatically create spans for:
# - Agent execution (langchain:agent)
# - LLM calls (langchain:llm)
# - Tool executions (langchain:tool)
result = agent.invoke({"messages": [...]})
# Middleware owns both client and instance; close when done
await middleware.close()
```
### Pre-configured client
Pass a client you created yourself when you need full control over its
configuration or when you want to share a client across multiple middlewares.
```python
from prefactor_core import PrefactorCoreClient, PrefactorCoreConfig
from prefactor_http.config import HttpClientConfig
from prefactor_langchain import PrefactorMiddleware
http_config = HttpClientConfig(api_url="https://api.prefactor.ai", api_token="your-api-token")
config = PrefactorCoreConfig(http_config=http_config)
client = PrefactorCoreClient(config)
await client.initialize()
middleware = PrefactorMiddleware(
client=client,
agent_id="my-agent",
agent_name="My Agent",
)
result = agent.invoke({"messages": [...]})
# You own the client; close both separately
await middleware.close() # closes the agent instance only
await client.close()
```
### Pre-configured instance (spans outside the agent)
Pass an `AgentInstanceHandle` you created yourself when you also need to
instrument code that lives **outside** the LangChain agent — for example,
pre-processing steps, post-processing, or any custom business logic that
should appear as siblings of the agent spans in the same trace.
```python
from prefactor_core import PrefactorCoreClient, PrefactorCoreConfig
from prefactor_http.config import HttpClientConfig
from prefactor_langchain import PrefactorMiddleware
http_config = HttpClientConfig(api_url="https://api.prefactor.ai", api_token="your-api-token")
config = PrefactorCoreConfig(http_config=http_config)
client = PrefactorCoreClient(config)
await client.initialize()
instance = await client.create_agent_instance(agent_id="my-agent")
await instance.start()
# Share the instance with the middleware
middleware = PrefactorMiddleware(instance=instance)
# Instrument your own code using the same instance
async with instance.span("custom:preprocessing") as ctx:
ctx.set_payload({"step": "preprocess", "status": "ok"})
# Run your agent — the middleware traces it automatically under the same instance
result = agent.invoke({"messages": [...]})
async with instance.span("custom:postprocessing") as ctx:
ctx.set_payload({"step": "postprocess", "result": str(result)})
# You own the instance and client; clean them up yourself
await instance.finish()
await client.close()
```
## Span Types
This package creates LangChain-specific spans with the `langchain:*` namespace:
- **`langchain:agent`** - Agent executions and chain runs
- **`langchain:llm`** - LLM calls with model metadata (name, provider, token usage)
- **`langchain:tool`** - Tool executions including retrievers
Each span payload includes:
- Timing information (start_time, end_time)
- Inputs and outputs
- Error information with stack traces
- LangChain-specific metadata
Trace correlation (span_id, parent_span_id, trace_id) is handled automatically by the prefactor-core client.
## Features
- **Automatic LLM call tracing** - Captures model name, provider, token usage, temperature
- **Tool execution tracing** - Records tool name, arguments, execution time
- **Agent/chain tracing** - Tracks agent lifecycle and message history
- **Token usage capture** - Automatically extracts prompt/completion/total tokens
- **Error tracking** - Captures error type, message, and stack traces
- **Automatic parent-child relationships** - Uses SpanContextStack for hierarchy
- **Bring your own instance** - Share a single `AgentInstanceHandle` between the middleware and your own instrumentation
## Architecture
This package follows the LangChain Adapter Redesign principles:
1. **Package Isolation**: LangChain-specific span types and schemas live in this package
2. **Opaque Payloads**: Span data is sent as payload to prefactor-core
3. **Type Namespacing**: Uses `langchain:agent`, `langchain:llm`, `langchain:tool` prefixes
4. **Uses prefactor-core**: All span/instance management via the prefactor-core client
The middleware:
1. Accepts a `PrefactorCoreClient`, or a pre-created `AgentInstanceHandle`, or creates its own client via `from_config()`
2. Registers or borrows an agent instance
3. Creates spans with LangChain-specific payloads
4. Leverages `SpanContextStack` for automatic parent detection
## Development
Run tests:
```bash
pytest tests/
```
## License
MIT
| text/markdown | null | Prefactor Pty Ltd <josh@prefactor.tech> | null | null | MIT | null | [] | [] | null | null | <4.0.0,>=3.11.0 | [] | [] | [] | [
"langchain-core>=1.0.0",
"prefactor-core>=0.1.0"
] | [] | [] | [] | [] | uv/0.9.28 {"installer":{"name":"uv","version":"0.9.28","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"25.10","id":"questing","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T05:21:53.024680 | prefactor_langchain-0.2.1.tar.gz | 20,053 | ed/70/46f63005994458e926df6c1dd2257ccd4e078c588542ff8495473d51a3f4/prefactor_langchain-0.2.1.tar.gz | source | sdist | null | false | 17bac3cc5884d62641260e40ef02551d | ee07a172b3bfb1d5d3c34fcd365b30b22cbbf507b86ab918822239535fe8d340 | ed7046f63005994458e926df6c1dd2257ccd4e078c588542ff8495473d51a3f4 | null | [] | 257 |
2.4 | restrosphere | 0.1.0 | RestroSphere — The AI that runs your restaurant. | # 🍽️ RestroSphere
## The AI that runs your restaurant.
Monitors your floor. Tracks your staff. Scores your applicants.
Sends you alerts. Never sleeps.
All from the dashboard or any chat app you already use.
## Quick Start
### Windows
```powershell
iwr -useb https://restrosphere.ai/install.ps1 | iex
```
### macOS / Linux
```bash
curl -fsSL https://restrosphere.ai/install.sh | bash
```
Works on macOS, Windows & Linux. Installs Python and everything else automatically.
## What It Does
- **Runs 24/7** on your machine as a background service
- **Connects** to your POS, scheduling, and reservation systems
- **Monitors** labor vs sales in real time
- **Scores** job applicants automatically
- **Tracks** staff performance: tips, upsells, table turns
- **Sends** proactive alerts when something needs attention
- **Answers** any question about your restaurant via chat
## Commands
| Command | Description |
| :--- | :--- |
| `restrosphere init` | Set up your restaurant (Step-by-step) |
| `restrosphere run` | Start the agent (Interactive mode) |
| `restrosphere daemon start` | Run in background (24/7 Service) |
| `restrosphere daemon stop` | Stop background agent |
| `restrosphere daemon status` | Check if service is running |
| `restrosphere status` | See health of connected systems |
| `restrosphere skills list` | See active AI capabilities |
## What Gets Connected
- **POS**: Toast, Square, Clover
- **Scheduling**: 7shifts, HotSchedules, Deputy
- **Reservations**: OpenTable, Resy
- **Reviews**: Google, Yelp
- **Hiring**: Indeed webhooks
## Cost
Agent only calls AI when you message it or a scheduled job fires. Never runs in a loop.
Cost per restaurant: **~$8/month** in API fees.
---
© 2026 RestroSphere AI. Built with ❤️ for the restaurant industry.
| text/markdown | null | RestroSphere Team <hello@restrosphere.ai> | null | null | null | restaurant, ai, manager, automation, pos | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"fastapi>=0.104.0",
"uvicorn[standard]>=0.24.0",
"anthropic>=0.39.0",
"click>=8.0.0",
"rich>=13.0.0",
"apscheduler>=3.10.0",
"twilio>=8.10.0",
"stripe>=7.0.0",
"python-dotenv>=1.0.0",
"pydantic>=2.5.0",
"pydantic-settings>=2.1.0",
"aiosqlite>=0.19.0",
"httpx>=0.25.0",
"psutil>=5.9.0",
"playwright>=1.40.0",
"cryptography>=41.0.0"
] | [] | [] | [] | [
"Homepage, https://restrosphere.ai",
"Documentation, https://docs.restrosphere.ai"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-20T05:21:31.113077 | restrosphere-0.1.0.tar.gz | 34,804 | 7d/53/dcde3d6e9b08960377488d71af64169b3bb043bb2e51033c6868d358a1df/restrosphere-0.1.0.tar.gz | source | sdist | null | false | c305d9cc99959cba1498e0e2235205fe | 755c3c3e7dc6d89924816bea783e1d8349ca920235e809e34c47f04348b6197a | 7d53dcde3d6e9b08960377488d71af64169b3bb043bb2e51033c6868d358a1df | null | [] | 282 |
2.4 | accord-contracts | 0.1.1 | Add your description here | # Accord
Accord is a Python library for consumer-driven contract testing between web services, you define a Contract once using Pydantic models and an [`@endpoint`](https://git.critchlow.net/brodycritchlow/accord/src/commit/3d7d18a8322b223e2744d8586f778887b90d7a26/core/contract.py#L29-L55) decorator, which then automatically takes care of the rest for you:
- Spins up a mock http-server using [werkzeug](https://github.com/pallets/werkzeug)
- Generates a [pact](https://github.com/pact-foundation) compatible JSON contract file
This ensures both sides of a service boundary stay in sync without requiring a shared test environment.
## Why not Pact?
Pact is definitely the industry-standard library, and if you are working with multiple different languages or environments then it is the better choice. But if your stack is Python-only, Pact comes with a lot of overhead; that you may not need:
- A separate DSL
- Pact has its own way of defining contracts that lives outside your existing code. Accord uses the Pydantic models you're already writing.
- The broker
- Pact strongly encourages (and in practice, requires) a Pact broker to share contracts between teams. Accord generates a JSON file and you share it however you want: a shared repo, a CI artifact, or S3.
- Usage time
- Getting Pact fully set up across two services takes time. Accord is designed to be useful in an afternoon.
Accord **is not** supposed to replace Pact, it is for simplicity and less overhead. In reality, Pact is more useful across the board.
## Learn how to use Accord
Before you learn how to use Accord, here are some simple diagrams that showcase how our Contracts & Systems work.
### Contracts
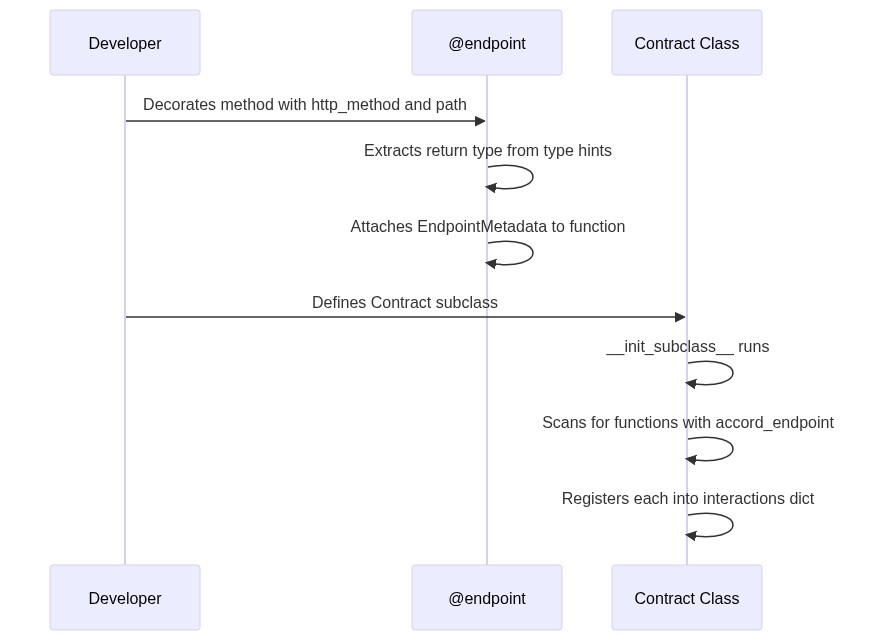
### Consumer Flow
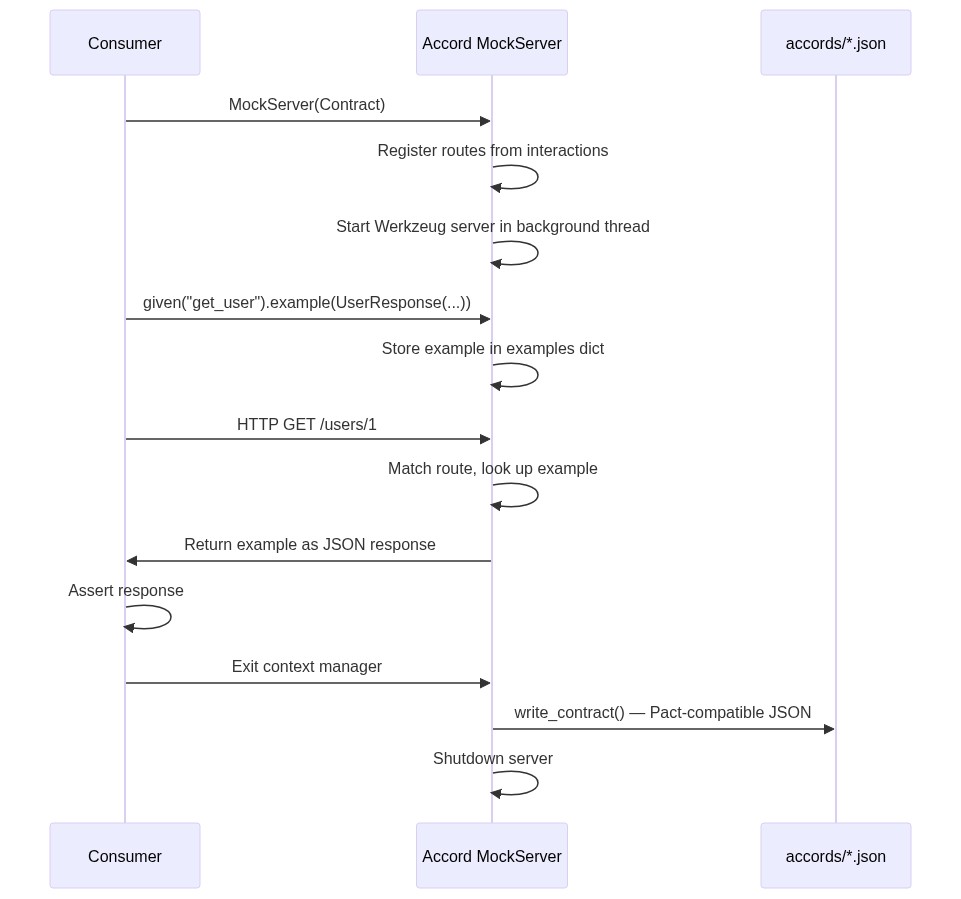
### Producer Verification
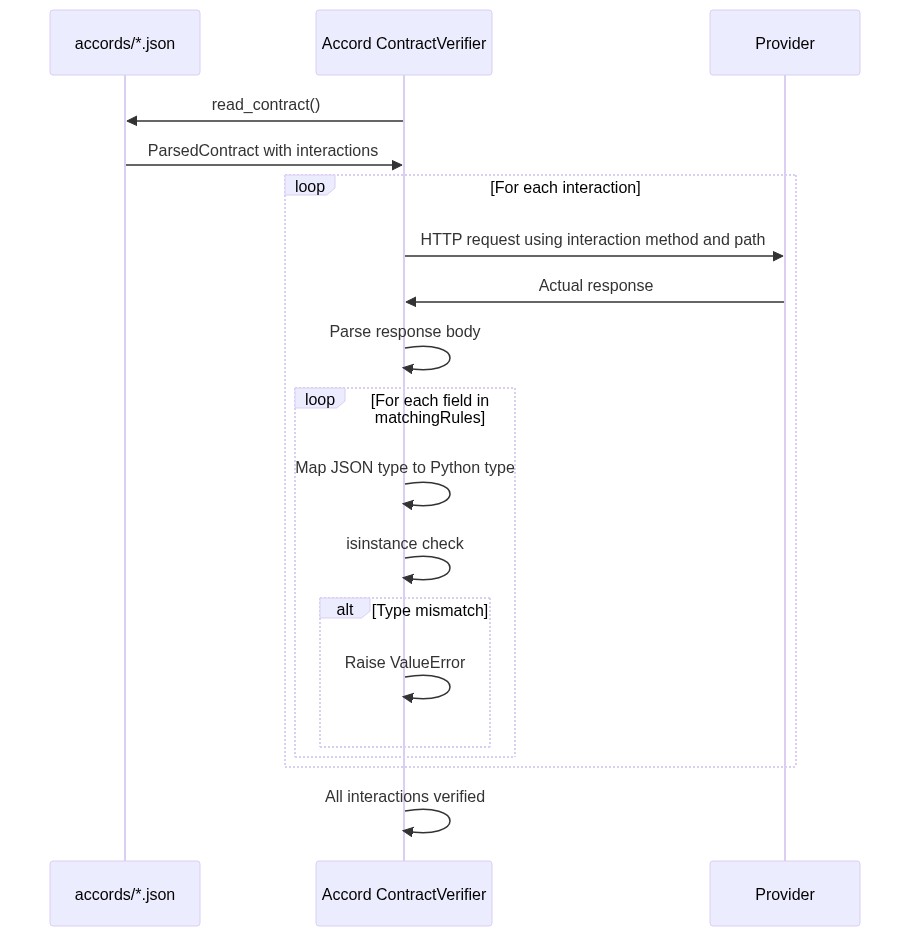
Now with all of those flows out of the way, the example may make more sense that we provide here.
A basic contract is defined as such:
```py
from pydantic import BaseModel
from core.contract import Contract, endpoint
class UserResponse(BaseModel):
id: int
name: str
class GetUserContract(Contract):
consumer = "order-service"
producer = "user-service"
@endpoint(http_method="GET", path="/users/{id}")
def get_user(self, user_id: int) -> UserResponse: ...
```
Once we have this contract defined, we use it to spin up a MockServer to test the Consumer:
```py
import httpx
from server.mock import MockServer
with MockServer(GetUserContract) as server:
server.given("get_user").example(UserResponse(id=1, name="Alice"))
response = httpx.get("http://127.0.0.1:5000/users/1")
assert response.status_code == 200
assert response.json()["name"] == "Alice"
```
This writes the contract to `./accords/` once the ContextManager exits. The other side of the testing flow is **producer**, which you can do as such:
```py
from pathlib import Path
from verification.verifier import ContractVerifier
# This assumes your server is running on 8080
verifier = ContractVerifier(
contract_path=Path("accords/order-service-user-service.json"),
base_url="http://127.0.0.1:8080",
)
verifier.verify()
```
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"httpx>=0.28.1",
"pydantic>=2.12.5",
"werkzeug>=3.1.5"
] | [] | [] | [] | [] | uv/0.9.28 {"installer":{"name":"uv","version":"0.9.28","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T05:21:21.826462 | accord_contracts-0.1.1-py3-none-any.whl | 9,328 | d7/3c/fcd346b38f056852f75f5e14851713433a9d2e8fde3ca67fe853686a694b/accord_contracts-0.1.1-py3-none-any.whl | py3 | bdist_wheel | null | false | c76dae7f38b7fbb28916ade63d5dca0f | 393bb3823ff4cf194ab5c413e1ae44c395e95047ebbef2cbcbcdea1e11d6767e | d73cfcd346b38f056852f75f5e14851713433a9d2e8fde3ca67fe853686a694b | null | [] | 270 |
2.4 | lunchmoney-mcp-mini | 0.5.0 | A Model Context Protocol server for the Lunch Money API with optimized, minimal responses | # Lunch Money MCP Server
A Model Context Protocol (MCP) server for the [Lunch Money](https://lunchmoney.app) API v2, designed with minimal response sizes to prevent context window bloat.
## Features
- **Optimized responses**: Concise, formatted output to minimize token usage
- **Simple authentication**: Uses environment variable for API token
- **Type-safe**: Built with modern Python type hints
- **Easy to extend**: Add more endpoints one at a time
## Currently Supported Endpoints
- `add_numbers` - Helper tool for arithmetic operations
- `get_current_user` - Get information about the authenticated user (`GET /me`)
- `get_transaction` - Get details about a specific transaction by ID (`GET /transactions/{id}`)
- `get_transactions` - List transactions for a date range (`GET /transactions`)
## Installation
1. Clone this repository:
```bash
git clone <your-repo-url>
cd lunchmoney-mcp-mini
```
2. Install dependencies using [uv](https://github.com/astral-sh/uv):
```bash
uv sync
```
## Configuration
### Get Your API Token
1. Log in to [Lunch Money](https://my.lunchmoney.app)
2. Go to the [Developers page](https://my.lunchmoney.app/developers)
3. Create a new API token or use an existing one
### Set Environment Variable
```bash
export LUNCHMONEY_API_TOKEN="your-api-token-here"
```
Or create a `.env` file (not committed to git):
```
LUNCHMONEY_API_TOKEN=your-api-token-here
```
## Usage
### With Claude Desktop
Add to your Claude Desktop configuration file:
**macOS**: `~/Library/Application Support/Claude/claude_desktop_config.json`
**Windows**: `%APPDATA%\Claude\claude_desktop_config.json`
```json
{
"mcpServers": {
"lunchmoney-mini": {
"command": "uv",
"args": [
"--directory",
"/absolute/path/to/lunchmoney-mcp-mini",
"run",
"lunchmoney_mcp_mini/main.py"
],
"env": {
"LUNCHMONEY_API_TOKEN": "your-api-token-here"
}
}
}
}
```
### Standalone Testing
```bash
# Make sure LUNCHMONEY_API_TOKEN is set
uv run lunchmoney_mcp_mini/main.py
```
## Available Tools
### `add_numbers`
Helper tool for performing arithmetic operations with precise decimal handling to avoid floating-point precision issues.
**Parameters:**
- `numbers` (required): List of numbers to add together. Can include negative values for subtraction.
**Returns:**
- `sum`: Sum rounded to 2 decimal places
- `input_count`: Number of values provided
**Example output:**
```json
{
"sum": 123.45,
"input_count": 3
}
```
### `get_current_user`
Get details about the authenticated Lunch Money user.
**Returns:**
- `name`: User's full name
- `email`: User's email address
- `user_id`: Unique user identifier
- `account_id`: Unique account identifier
- `budget_name`: Name of the budget
- `primary_currency`: Primary currency code (e.g., 'usd')
- `api_key_label`: Label for the API key being used
**Example output:**
```json
{
"name": "John Doe",
"email": "john@example.com",
"user_id": 12345,
"account_id": 67890,
"budget_name": "Family budget",
"primary_currency": "usd",
"api_key_label": "Development key"
}
```
### `get_transaction`
Get full details about a specific transaction by its ID.
**Parameters:**
- `transaction_id` (required): ID of the transaction to retrieve
**Returns:**
Complete transaction object with all available fields including:
- Core data: id, date, amount, currency, payee, original_name
- Category/accounts: category_id, manual_account_id, plaid_account_id, recurring_id
- Metadata: plaid_metadata, custom_metadata, files (if any)
- Grouping/splitting: is_split_parent, split_parent_id, is_group_parent, group_parent_id, children
- Timestamps: created_at, updated_at
- Status: status, is_pending, source, external_id, tag_ids, notes
**Example output:**
```json
{
"id": 2112150655,
"date": "2024-07-28",
"amount": -45.50,
"currency": "USD",
"payee": "Whole Foods",
"original_name": "WHOLE FOODS #1234",
"category_id": 82,
"status": "reviewed",
"is_pending": false,
"created_at": "2024-07-28T12:34:56.789Z",
"updated_at": "2024-07-28T12:34:56.789Z"
}
```
### `get_transactions`
List transactions within a specified date range.
**Parameters:**
- `start_date` (required): Start date in YYYY-MM-DD format
- `end_date` (optional): End date in YYYY-MM-DD format. Defaults to last day of start_date's month
- `category_id` (optional): Filter by category ID
- `tag_id` (optional): Filter by tag ID
- `status` (optional): Filter by status ("reviewed", "unreviewed", "delete_pending")
- `is_pending` (optional): Filter by pending status
- `manual_account_id` (optional): Filter by manual account ID
- `plaid_account_id` (optional): Filter by plaid account ID
- `recurring_id` (optional): Filter by recurring item ID
- `include_pending` (optional): Include pending transactions
- `limit` (optional): Maximum number of transactions (1-2000, default 100)
- `offset` (optional): Pagination offset
- `include_aggregates` (optional): If True, calculates totals per category for full date range (respects all filters)
**Returns:**
- `transactions`: Array of transaction objects
- `has_more`: Boolean indicating if more transactions are available
- `aggregates` (optional): Category totals and counts when `include_aggregates=True`
**Transaction fields:**
- `id`: Transaction ID
- `date`: Transaction date (YYYY-MM-DD)
- `amount`: Transaction amount (numeric string)
- `payee`: Payee name
- `category_id`: Category ID
- `status`: Transaction status
- `is_pending`: Pending status
**Aggregates fields (when `include_aggregates=True`):**
- `by_category`: Array sorted by `total_amount` descending, each with:
- `category_id`: Category ID (or null for uncategorized)
- `category_name`: Category name
- `count`: Number of transactions in this category
- `total_amount`: Sum of transaction amounts (numeric string)
- `total_count`: Total number of transactions
- `total_amount`: Sum of all transaction amounts (numeric string)
**Example output (without aggregates):**
```json
{
"transactions": [
{
"id": 2112150655,
"date": "2024-07-28",
"amount": "1250.8400",
"payee": "Paycheck",
"category_id": 88,
"status": "reviewed",
"is_pending": false
}
],
"has_more": false
}
```
**Example output (with aggregates):**
```json
{
"transactions": [...],
"has_more": false,
"aggregates": {
"by_category": [
{"category_id": 88, "category_name": "Rent", "count": 2, "total_amount": "2500.00"},
{"category_id": 82, "category_name": "Groceries", "count": 5, "total_amount": "245.50"},
{"category_id": null, "category_name": "Uncategorized", "count": 3, "total_amount": "45.00"}
],
"total_count": 10,
"total_amount": "2790.50"
}
}
```
## Design Philosophy
This MCP server is intentionally designed to return **minimal, focused responses** to avoid filling up the context window. Each tool:
- Returns only essential information
- Uses concise formatting
- Avoids verbose JSON dumps
- Provides human-readable output
## Technical Details
This server uses:
- **FastMCP**: A high-level Python framework for building MCP servers
- **requests-openapi**: Automatically generates API client from OpenAPI spec
- **OpenAPI 3.0 spec**: Ensures type safety and accurate API calls
The combination of FastMCP and requests-openapi means:
- Less boilerplate code
- Automatic request/response validation
- Easy to add new endpoints from the spec
- Type-safe API calls
## Resources
- [Lunch Money API Documentation](https://alpha.lunchmoney.dev/v2)
- [Model Context Protocol](https://modelcontextprotocol.io)
- [FastMCP Documentation](https://github.com/jlowin/fastmcp)
- [requests-openapi](https://pypi.org/project/requests-openapi/)
## License
MIT
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"fastmcp>=2.14.5",
"pydantic>=2.12.5",
"requests-openapi>=1.0.6"
] | [] | [] | [] | [
"Repository, https://github.com/sharph/lunchmoney-mcp-mini.git",
"Issues, https://github.com/sharph/lunchmoney-mcp-mini/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T05:21:20.229045 | lunchmoney_mcp_mini-0.5.0.tar.gz | 52,761 | e7/16/946b167fe06230011375ac54c7794b5b9940e123712588cac6333fd6f424/lunchmoney_mcp_mini-0.5.0.tar.gz | source | sdist | null | false | 81e7f637b0706af311575afb67cd22a8 | b3b30221813326eeda9d837e7c65e8f329109f863f982f0ada3e1adae63b2073 | e716946b167fe06230011375ac54c7794b5b9940e123712588cac6333fd6f424 | null | [] | 256 |
2.4 | hatch-xclam | 0.8.0 | Package manager for the Cracking Shells ecosystem | # Hatch

## Introduction
Hatch is the package manager for managing Model Context Protocol (MCP) servers with environment isolation, multi-type dependency resolution, and multi-host deployment. Deploy MCP servers to Claude Desktop, VS Code, Cursor, Kiro, Codex, and other platforms with automatic dependency management.
The canonical documentation is at `docs/index.md` and published at <https://hatch.readthedocs.io/en/latest/>.
## Key Features
- **Environment Isolation** — Create separate, isolated workspaces for different projects without conflicts
- **Multi-Type Dependency Resolution** — Automatically resolve and install system packages, Python packages, Docker containers, and Hatch packages
- **Multi-Host Deployment** — Configure MCP servers on multiple host platforms
- **Package Validation** — Ensure packages meet schema requirements before distribution
- **Development-Focused** — Optimized for rapid development and testing of MCP server ecosystems
## Supported MCP Hosts
Hatch supports deployment to the following MCP host platforms:
- **Claude Desktop** — Anthropic's desktop application for Claude with native MCP support
- **Claude Code** — Claude integration for VS Code with MCP capabilities
- **VS Code** — Visual Studio Code with the MCP extension for tool integration
- **Cursor** — AI-first code editor with built-in MCP server support
- **Kiro** — Kiro IDE with MCP support
- **Codex** — OpenAI Codex with MCP server configuration support
- **LM Studio** — Local LLM inference platform with MCP server integration
- **Google Gemini CLI** — Command-line interface for Google's Gemini model with MCP support
## Quick Start
### Install from PyPI
```bash
pip install hatch-xclam
```
Verify installation:
```bash
hatch --version
```
### Install from source
```bash
git clone https://github.com/CrackingShells/Hatch.git
cd Hatch
pip install -e .
```
### Create your first environment and *Hatch!* MCP server package
```bash
# Create an isolated environment
hatch env create my_project
# Switch to it
hatch env use my_project
# Create a package template
hatch create my_mcp_server --description "My MCP server"
# Validate the package
hatch validate ./my_mcp_server
```
### Deploy MCP servers to your tools
**Package-First Deployment (Recommended)** — Add a Hatch package and automatically configure it on Claude Desktop and Cursor:
```bash
hatch package add ./my_mcp_server --host claude-desktop,cursor
```
**Direct Configuration (Advanced)** — Configure arbitrary MCP servers on your hosts:
```bash
# Remote server example: GitHub MCP Server with authentication
export GIT_PAT_TOKEN=your_github_personal_access_token
hatch mcp configure github-mcp --host gemini \
--httpUrl https://api.github.com/mcp \
--header Authorization="Bearer $GIT_PAT_TOKEN"
# Local server example: Context7 via npx
hatch mcp configure context7 --host vscode \
--command npx --args "-y @upstash/context7-mcp"
```
## Documentation
- **[Full Documentation](https://hatch.readthedocs.io/en/latest/)** — Complete reference and guides
- **[Getting Started](./docs/articles/users/GettingStarted.md)** — Quick start for users
- **[CLI Reference](./docs/articles/users/CLIReference.md)** — All commands and options
- **[Tutorials](./docs/articles/users/tutorials/)** — Step-by-step guides from installation to package authoring
- **[MCP Host Configuration](./docs/articles/users/MCPHostConfiguration.md)** — Deploy to multiple platforms
- **[Developer Docs](./docs/articles/devs/)** — Architecture, implementation guides, and contribution guidelines
- **[Troubleshooting](./docs/articles/users/Troubleshooting/ReportIssues.md)** — Common issues and solutions
## Contributing
We welcome contributions! See the [How to Contribute](./docs/articles/devs/contribution_guides/how_to_contribute.md) guide for details.
### Quick start for developers
1. **Fork and clone** the repository
2. **Install dependencies**: `pip install -e .` and `npm install`
3. **Create a feature branch**: `git checkout -b feat/your-feature`
4. **Make changes** and add tests
5. **Use conventional commits**: `npm run commit` for guided commits
6. **Run tests**: `wobble`
7. **Create a pull request**
We use [Conventional Commits](https://www.conventionalcommits.org/) for automated versioning. Use `npm run commit` for guided commit messages.
## Getting Help
- Search existing [GitHub Issues](https://github.com/CrackingShells/Hatch/issues)
- Read [Troubleshooting](./docs/articles/users/Troubleshooting/ReportIssues.md) for common problems
- Check [Developer Onboarding](./docs/articles/devs/development_processes/developer_onboarding.md) for setup help
## License
This project is licensed under the GNU Affero General Public License v3 — see `LICENSE` for details.
| text/markdown | Cracking Shells Team | null | null | null | null | null | [
"Programming Language :: Python :: 3.12",
"License :: OSI Approved :: GNU Affero General Public License v3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"jsonschema>=4.0.0",
"requests>=2.25.0",
"packaging>=20.0",
"docker>=7.1.0",
"pydantic>=2.0.0",
"hatch-validator>=0.8.0",
"tomli-w>=1.0.0",
"mkdocs>=1.4.0; extra == \"docs\"",
"mkdocstrings[python]>=0.20.0; extra == \"docs\"",
"cs-wobble>=0.2.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"ruff>=0.1.9; extra == \"dev\"",
"pre-commit>=3.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/CrackingShells/Hatch",
"Bug Tracker, https://github.com/CrackingShells/Hatch/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T05:19:09.315120 | hatch_xclam-0.8.0.tar.gz | 214,468 | f4/b6/c507cd22a47516a9e50f9527597e9ff02064feeed9ac51ecab718c647c18/hatch_xclam-0.8.0.tar.gz | source | sdist | null | false | a8b2bff7e5f54b2dae0ca6f1ea2a2d46 | b563347d6f132054a5849695b784daa4106fea338aa8147586f946d34596f179 | f4b6c507cd22a47516a9e50f9527597e9ff02064feeed9ac51ecab718c647c18 | null | [
"LICENSE"
] | 259 |
2.4 | causalif | 0.1.9.1 | Large Language Models (LLMs) with Bayesian causal inference to discover causal relationships and associations from observational data and domain knowledge | # Causal Inference Framework for AWS (causalif)
[](https://pypi.org/project/causalif/)
[](https://opensource.org/licenses/Apache-2.0)
[](https://www.python.org/downloads/)
---
## Table of Contents
1. [Overview](#overview)
2. [Logical Flow](#logical-flow)
3. [Why Hill Climb and BDeu Score?](#why-hill-climb-and-bdeu-score)
4. [Prerequisites](#prerequisites)
5. [Installation](#installation)
6. [Usage Examples](#usage-examples)
7. [Architecture](#architecture)
8. [Limitations](#limitations)
9. [Contributing](#contributing)
10. [License](#license)
## Overview
Causalif combines Large Language Models (LLMs) with Bayesian causal inference to discover causal relationships and associations from observational data and domain knowledge. Unlike traditional causal discovery algorithms that rely solely on statistical patterns, Causalif leverages:
- **Background Knowledge**: LLM's pre-trained knowledge about causal relationships
- **Document Knowledge**: Domain-specific documents retrieved via RAG
- **Statistical Evidence**: Correlation patterns from observational data
- **Bayesian Structure Learning**: Data-driven causal graph orientation
This hybrid approach enables causal discovery and associations even with limited data or when statistical methods alone are insufficient.
Note: LLM interpretation of causalif is best realised when this library is used as a tool in agentic systems.
**GitHub**: [awslabs/causalif](https://github.com/awslabs/causalif)
**PyPI**: [causalif](https://pypi.org/project/causalif/)
---
## Ideal Use Cases
Causalif is particularly powerful when you have both qualitative domain knowledge and quantitative observational data. The library excels at discovering causal relationships between derived factors by combining: It is ideal to be integrated as a tool to agentic workflows so that the agent can interpret its results and provides an overall response to the user.
1. **Qualitative Knowledge**: Documents containing formulas, relationships, and domain expertise
2. **Quantitative Data**: Noisy observational data that fuels those formulas
### Example: Financial Analysis
**Scenario**: A financial institution wants to understand what drives the behavior of derived financial metrics.
**What They Have**:
- **Qualitative Finance Data**: Research papers, financial articles, analyst reports, and documents describing:
- Derived formulas (e.g., "ROE = Net Income / Shareholder Equity")
- Market relationships (e.g., "Interest rates affect bond prices inversely")
- Economic theories and domain expertise
- **Quantitative Data**: Historical time-series data with noise:
- Stock prices, trading volumes, interest rates
- Company financials (revenue, earnings, debt ratios)
- Market indicators (VIX, sector indices)
**What They Want to Discover**:
- Which factors causally drive a target metric (e.g., "Factors influencing volatility in Commodities?").
- Why any derived factors is low or high around a specific time period.
-What is causing a target factor to behave differently and what are influencing the target factor.
### Key Advantages for use Cases
1. **Handles Noisy Data**: Bayesian approach robust to measurement error and missing values
2. **Leverages Domain Knowledge**: RAG retrieval incorporates expert knowledge from documents
3. **Discovers Hidden Relationships**: Finds causal links not obvious from data alone
4. **Quantifies Effects**: Provides effect sizes, not just "yes/no" causality
5. **Validates with Multiple Sources**: Voting mechanism across LLM, documents, and data reduces false discoveries
### When Causalif is Most Effective
✅ **Use Causalif when you have**:
- Rich document corpus with domain knowledge and formulas
- Observational data (even if noisy or limited)
- Derived metrics whose dependencies are unclear
- Need to understand "what causes what" not just "what correlates"
⚠️ **Consider alternatives when**:
- You have no domain documents (pure data-driven methods may suffice)
- You need real-time causal discovery (Causalif requires LLM calls)
- Your data has <10 samples (insufficient for Bayesian structure learning)
- Relationships are purely experimental (randomized controlled trials are better)
---
## Logical Flow
Causalif implements a two-stage algorithm with parallel processing and RAG integration:
### Architecture Diagram

Causalif implements a three-stage algorithm:
### Stage 1: Edge Existence Verification (Causalif 1)
**Goal**: Determine which pairs of variables are causally related
**Process**:
1. **Initialize**: Start with a complete undirected graph (all possible edges between variables)
2. **Knowledge Base Assembly**: For each variable pair (A, B):
- Query LLM's background knowledge
- Retrieve relevant documents via RAG
- Extract statistical evidence from data
3. **Voting Mechanism**: Each knowledge base votes on edge existence:
- `+1`: Variables are associated (edge should exist)
- `-1`: Variables are independent (edge should be removed)
- `0`: Unknown (no vote)
4. **Edge Removal**: Remove edges where total vote score ≤ 0
5. **Output**: Skeleton graph (undirected graph of causal relationships)
**Parallel Optimization**: Causalif batches LLM queries for multiple variable pairs, executing them in parallel (configurable up to 50 concurrent queries) for significant speedup.
### Stage 2: Causal Orientation (Causalif 2)
**Goal**: Determine the direction of causal relationships (A → B or B ← A)
**Process**:
1. **Input**: Skeleton graph from Stage 1
2. **Bayesian Structure Learning**:
- Use Hill Climbing search with BDeu scoring
- Constrain search to edges in skeleton (prior knowledge)
- Weight edges by LLM confidence from Stage 1
3. **Direction Determination**: For each edge in skeleton:
- Compute Bayesian posterior: P(G | Data, Priors) ∝ P(Data | G) × P(G | Priors)
- Select direction that maximizes posterior probability
4. **Output**: Directed Acyclic Graph (DAG) representing causal relationships
**Degree-Limited Analysis**: Optionally focus on relationships within N degrees of separation from a target variable for faster analysis.
### Stage 3: Causal Inference (Optional)
**Goal**: Quantify causal effects and enable interventional queries
**Process**:
1. **Input**: Causal DAG from Stage 2 + Observational data
2. **Fit CPDs**: Learn Conditional Probability Distributions using Maximum Likelihood Estimation
3. **Create Bayesian Network**: Combine structure (DAG) with parameters (CPDs)
4. **Estimate Effects**: Compute Average Treatment Effects (ATE) for each cause
5. **Enable Queries**: Support interventional queries P(Y | do(X))
6. **Output**: Quantitative causal model with effect sizes
**When to Enable**:
- Need effect sizes ("how much does X affect Y?")
- Want to simulate interventions ("what if we change X?")
- Need to identify confounders and adjustment sets
- Require quantitative prioritization of causes
**Note**: This stage is optional and disabled by default. Enable with `enable_causal_inference=True` parameter.
---
## Why Hill Climb and BDeu Score?
### Why Hill Climbing?
**Hill Climbing** is a local search algorithm that iteratively improves a causal graph structure by:
- Starting from an initial graph (skeleton from Stage 1)
- Testing local modifications (add/remove/reverse edges)
- Accepting changes that improve the score
- Stopping at a local optimum
**Advantages for Causalif**:
1. **Constraint Compatibility**: Easily incorporates prior knowledge (skeleton graph) as hard constraints
2. **Computational Efficiency**: Scales to moderate-sized graphs (10-20 variables) with reasonable runtime
3. **Interpretability**: Local search steps are traceable and explainable
4. **Flexibility**: Supports custom scoring functions (like Prior-Weighted BDeu)
**Alternatives Considered**:
- **PC Algorithm**: Constraint-based, but doesn't naturally incorporate LLM priors
- **GES (Greedy Equivalence Search)**: Similar to Hill Climb but more complex
- **Exact Search**: Computationally prohibitive for >5 variables
- **MCMC Sampling**: More accurate but much slower; overkill for typical use cases
### Why BDeu Score?
**BDeu (Bayesian Dirichlet equivalent uniform)** is a Bayesian scoring function that measures how well a causal graph explains the observed data.
**Mathematical Foundation**:
```
BDeu(G, D) = P(D | G) = ∏ᵢ ∏ⱼ [Γ(α) / Γ(α + Nᵢⱼ)] × ∏ₖ [Γ(αₖ + Nᵢⱼₖ) / Γ(αₖ)]
```
Where:
- `G`: Causal graph structure
- `D`: Observational data
- `α`: Equivalent sample size (prior strength)
- `Nᵢⱼₖ`: Count of observations in configuration
**Advantages for Causalif**:
1. **Bayesian Framework**: Naturally combines prior knowledge (LLM) with data evidence
2. **Score Equivalence**: Assigns same score to equivalent graph structures (Markov equivalence)
3. **Regularization**: Built-in penalty for complex graphs (Occam's razor)
4. **Theoretical Soundness**: Proven consistency properties as data grows
**Causalif Enhancement - Prior-Weighted BDeu**:
```python
Score(G) = BDeu(G | Data) + λ × Prior(G | LLM)
```
Where:
- `BDeu(G | Data)`: Standard BDeu score from data
- `Prior(G | LLM)`: LLM confidence scores from Stage 1
- `λ`: Weight parameter balancing data vs. prior
This implements true Bayesian inference: **P(G | Data, LLM) ∝ P(Data | G) × P(G | LLM)**
**Alternatives Considered**:
- **BIC (Bayesian Information Criterion)**: Simpler but less theoretically principled
- **AIC (Akaike Information Criterion)**: Doesn't incorporate priors naturally
- **K2 Score**: Similar to BDeu but requires variable ordering
- **MIT Score**: More complex, no clear advantage for this use case
---
## Prerequisites
### 1. AWS Bedrock Knowledge Base
Causalif requires a RAG knowledge base for document retrieval. Set up an AWS Bedrock Knowledge Base following the [official instructions](https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-create.html).
**Recommended Configuration**:
- **Vector Store**: Amazon OpenSearch Serverless or Amazon Aurora
- **Embedding Model**: Amazon Titan Embeddings or Cohere Embed
- **Document Format**: Markdown, PDF, or plain text
- **Number of Results**: 10-20 documents per query
### 2. Create Retriever Tool
After setting up the knowledge base, create a LangChain retriever tool:
```python
from langchain_aws.retrievers import AmazonKnowledgeBasesRetriever
from langchain.tools.retriever import create_retriever_tool
retriever = AmazonKnowledgeBasesRetriever(
knowledge_base_id="<your-knowledge-base-id>",
retrieval_config={
"vectorSearchConfiguration": {
"numberOfResults": 20 # Adjust based on your needs
}
},
)
retriever_tool = create_retriever_tool(
retriever,
"domain_knowledge_retriever",
"Retrieves domain-specific documents about causal relationships between factors",
)
```
### 3. LLM Model
Causalif works with any LangChain-compatible LLM. AWS Bedrock is recommended:
```python
from langchain_aws import ChatBedrock
model = ChatBedrock(
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
region_name="us-east-1",
model_kwargs={
"temperature": 0.0, # Deterministic for causal reasoning
"max_tokens": 4096
}
)
```
**Supported Models**:
- Anthropic Claude (recommended)
- Amazon Titan
- Meta Llama
- Cohere Command
- Any OpenAI-compatible model
### 4. Observational Data
Provide a pandas DataFrame with observational data:
```python
import pandas as pd
df = pd.DataFrame({
'sleep_hours': [7, 6, 8, 5, 7, 9],
'exercise_minutes': [30, 20, 45, 10, 35, 60],
'stress_level': [5, 7, 3, 8, 4, 2],
'productivity': [8, 6, 9, 4, 7, 10]
})
```
**Requirements**:
- Minimum 100 samples (more is better)
- Numeric or categorical columns
- No missing values (or handle them beforehand)
---
## Installation
```bash
pip install causalif
```
---
## Usage Examples
### Basic Usage
```python
from causalif import set_causalif_engine, causalif_tool, visualize_causalif_results
from langchain_aws import ChatBedrock
import pandas as pd
# 1. Prepare your data
df = pd.DataFrame({
'sleep_hours': [7, 6, 8, 5, 7, 9, 6, 8, 7, 5],
'exercise_minutes': [30, 20, 45, 10, 35, 60, 25, 50, 40, 15],
'stress_level': [5, 7, 3, 8, 4, 2, 6, 3, 5, 8],
'productivity': [8, 6, 9, 4, 7, 10, 6, 9, 8, 5]
})
# 2. Initialize LLM
model = ChatBedrock(
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
model_kwargs={"temperature": 0.0}
)
# 3. Configure Causalif engine
# Configure with financial data
set_causalif_engine(
model=<your_bedrock_model>,
retriever_tool=retriever_tool,
dataframe=<dataframe_name>,
max_degrees=<degree of edges>, # None = no filtering (show entire graph), or set to int (e.g., 2) to filter.
max_parallel_queries=50, #This is variable but the code is tested with 50.
excluded_target_columns=None, # This a list of factors that shouldn't be target columns
excluded_related_columns=None, # This a list of factors that shouldn't be related columns
related_factors=None, # Add custom related factors here (will be appended with dataframe columns). Mostly derived columns from documents
selected_dataframe_columns=None, # list of columns from your dataframe if you dont want the whole dataframe to be analyzed.
enable_causal_estimate = True #Causal inference to find upstream or downstream direct effects of the target factor.
)
# 4. Run causal analysis
result = causalif.causalif("Why is interest_rate so low in week 3?")
# 5. Visualize results
fig = visualize_causalif_results(result)
fig.show()
```
### Query Formats
Causalif supports natural language queries in various formats. The `<target_factor>` is the column or factor whose dependencies with other variables you want to analyze:
```python
"""
Allowed query formats (where <target_factor> is the variable to analyze):
1. why (is|are) <target_factor> so (low|high|poor|bad|good)
2. what (causes|affects|influences) <target_factor>
3. <target_factor> (is|are) too (low|high)
4. analyze the causes (of|for) <target_factor>
5. dependencies (of|for) <target_factor>
6. factors (affecting|influencing) <target_factor>
"""
# Format 1: Why questions
result = causalif.causalif("Why is stress_level so high?")
result = causalif.causalif("Why are sales so low?")
# Format 2: What causes questions
result = causalif.causalif("What causes low productivity?")
result = causalif.causalif("What affects customer satisfaction?")
# Format 3: Direct statements
result = causalif.causalif("productivity is too low")
result = causalif.causalif("revenue is too high")
# Format 4: Analysis requests
result = causalif.causalif("analyze the causes of high stress_level")
result = causalif.causalif("analyze the causes for poor performance")
# Format 5: Dependency queries
result = causalif.causalif("dependencies of productivity")
result = causalif.causalif("dependencies for stock_price")
# Format 6: Factor influence queries
result = causalif.causalif("factors affecting sleep_hours")
result = causalif.causalif("factors influencing market_volatility")
```
### Visualization Features
The interactive visualization includes:
- **Node Colors**: Degree of separation from target factor (red = direct, blue = distant)
- **Edge Colors**: Same color scheme as nodes
- **Arrows**: Direction of causality
- **Hover Information**: Detailed relationship information
- **Interactive**: Zoom, pan, and click for details
```python
fig = visualize_causalif_results(result)
# Customize visualization
fig.update_layout(
title="Custom Title",
width=1200,
height=800
)
# Save to file
fig.write_html("causal_graph.html")
fig.write_image("causal_graph.png") # Requires kaleido
```
---
## Architecture
### System Integration

Causalif integrates with agentic LLM applications as a tool:
1. **Agent Layer**: LangChain agents or custom orchestrators
2. **Causalif Tool**: Exposes `causalif_tool` for natural language queries
3. **Engine Layer**: `CausalifEngine` implements core algorithms
4. **Knowledge Layer**: RAG retriever + LLM background knowledge
5. **Data Layer**: Pandas DataFrame with observational data
### Component Architecture
```
causalif/
├── core.py # Data structures (AssociationResponse, CausalDirection, KnowledgeBase)
├── engine.py # CausalifEngine (main algorithm implementation)
├── prompts.py # CausalifPrompts (LLM prompt templates)
├── tools.py # causalif_tool, set_causalif_engine (LangChain integration)
├── visualization.py # visualize_causalif_results (Plotly graphs)
└── __init__.py # Public API exports
```
### Key Classes
**CausalifEngine**:
- `causalif_1_edge_existence_verification()`: Stage 1 algorithm
- `causalif_2_orientation()`: Stage 2 algorithm
- `run_complete_causalif()`: End-to-end pipeline
- `batch_association_queries()`: Parallel LLM queries
- `batch_causal_direction_queries()`: Parallel direction queries
- `visualize_graph()`: Interactive visualization
**KnowledgeBase**:
- `kb_type`: "BG" (background), "DOC" (document), or "PC" (statistical)
- `content`: Knowledge content
- `source`: Source identifier
---
## Limitations
### This method isn't ideal for only qualtitative data and requirements with feedback loops. This method is built aiming finding hybrid association and causality among qualitative and quatitative data sets.
### Data & Computational
- **Minimum 10 samples** required for Bayesian structure learning (100+ recommended)
- **Scalability**: Practical limit of 15-20 variables without degree filtering
- **Time Complexity**: O(n² × k) for n variables and k LLM queries per pair
- **LLM Costs**: 2-5 LLM calls per variable pair
**Mitigation**: Use `max_degrees` parameter to focus analysis; increase `max_parallel_queries` for speed.
### LLM & Knowledge
- **Hallucination**: LLM may invent unsupported relationships
- **Bias**: Reflects training data biases
- **Consistency**: Results may vary (use `temperature=0` for determinism)
- **RAG Quality**: Results depend on document corpus quality and retrieval accuracy
**Mitigation**: Validate outputs with domain expertise; use voting across multiple knowledge sources.
### Causal Assumptions
- **Acyclicity**: Assumes DAG structure (no feedback loops)
- **Causal Sufficiency**: Assumes no unmeasured confounders
- **Markov Condition**: Assumes conditional independence given parents
**Mitigation**: Include potential confounders in variable set; validate DAG assumption with domain knowledge.
---
## Contributing
We welcome contributions! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
### Development Setup
```bash
# Clone repository
git clone https://github.com/awslabs/causalif.git
cd causalif
# Install development dependencies
pip install -e ".[dev]"
# Run tests
pytest tests/
# Format code
black causalif/
flake8 causalif/
# Type checking
mypy causalif/
```
### Reporting Issues
Please report bugs and feature requests on [GitHub Issues](https://github.com/awslabs/causalif/issues).
---
## License
This project is licensed under the Apache-2.0 License. See [LICENSE](LICENSE) for details.
---
## Citation
If you use Causalif in your work, please reference:
```bibtex
@software{causalif,
title={Causal Inference Framework for AWS (causalif) },
author={Bose, Subhro},
year={2026},
url={https://github.com/awslabs/causalif},
note={Python library for LLM-assisted causal discovery with RAG}
}
```
---
## Version History
- **v0.1.6** (Current): Removed directed graph dependencies, added example notebook
- **v0.1.5**: README updates
- **v0.1.4**: Base version with complete Causalif algorithm
---
## Support
- **Documentation**: [GitHub README](https://github.com/awslabs/causalif/blob/main/README.md)
- **Issues**: [GitHub Issues](https://github.com/awslabs/causalif/issues)
- **Email**: bossubhr@amazon.co.uk
---
## Acknowledgments
Built with:
- [LangChain](https://github.com/langchain-ai/langchain) - LLM orchestration
- [NetworkX](https://networkx.org/) - Graph algorithms
- [Plotly](https://plotly.com/) - Interactive visualization
- [AWS Bedrock](https://aws.amazon.com/bedrock/) - LLM and RAG infrastructure
| text/markdown | Subhro Bose | bossubhr@amazon.co.uk | null | null | null | causal reasoning, machine learning, nlp, rag, jax, networkx, causal inference, genai, llm | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.11",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Scientific/Engineering :: Information Analysis"
] | [] | https://github.com/awslabs/causalif | null | >=3.11 | [] | [] | [] | [
"jax>=0.4.0",
"jaxlib>=0.4.0",
"pandas>=1.3.0",
"networkx>=2.6.0",
"plotly>=5.0.0",
"langchain-core>=0.1.0",
"numpy>=1.21.0",
"scikit-learn>=1.0.0",
"nest-asyncio>=1.5.0",
"pytest>=6.0; extra == \"dev\"",
"pytest-cov>=2.0; extra == \"dev\"",
"black>=21.0; extra == \"dev\"",
"flake8>=3.8; extra == \"dev\"",
"mypy>=0.800; extra == \"dev\"",
"nest-asyncio>=1.5.0; extra == \"jupyter\"",
"jupyter>=1.0.0; extra == \"jupyter\"",
"ipywidgets>=7.0.0; extra == \"jupyter\""
] | [] | [] | [] | [
"Bug Reports, https://github.com/awslabs/causalif/issues",
"Source, https://github.com/awslabs/causalif",
"Documentation, https://github.com/awslabs/causalif/blob/main/README.md"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T05:17:55.600817 | causalif-0.1.9.1.tar.gz | 57,603 | a9/05/d13dd86b4f80562ba1f649e923eca28764b4320fcdd2bc1ea260f4473472/causalif-0.1.9.1.tar.gz | source | sdist | null | false | cf72464a771809cfd47661432ad9a06b | 914ea4bf56e84be66694a040ab303b50e3a27fea2ce4011c0f2a48cf3a4da033 | a905d13dd86b4f80562ba1f649e923eca28764b4320fcdd2bc1ea260f4473472 | null | [
"LICENSE",
"NOTICE"
] | 263 |
2.4 | safe-agent-cli | 0.4.4 | An AI coding agent you can actually trust - with built-in impact preview | # 🛡️ Safe Agent
<!-- HERO_START -->
**Guardrails for AI code agents.**
Safe Agent previews every file edit with [impact-preview](https://github.com/agent-polis/impact-preview) so AI helpers can’t quietly ship risky changes. Drop it into CI or run locally and require approvals before writes.
```bash
pip install safe-agent-cli
safe-agent "add error handling to api.py" --dry-run
```
<!-- HERO_END -->
### ✨ New in v0.4.4
- 🔓 **API-keyless diff gate** - Run `safe-agent --diff-gate` to analyze Git changes with no LLM/API key
- 🧷 **Fork PR coverage** - PR workflow now falls back to diff-gate mode when secrets are unavailable
- 📊 **Same CI artifacts, more contexts** - summary/scorecard/policy JSON now work in both task mode and diff mode
- 🛡️ **Input hardening** - `--diff-ref` validation prevents unsafe ref injection patterns
## Project Map
- **impact-preview (Agent Polis)**: the guardrail layer that previews and scores risky actions.
- **safe-agent-cli (this repo)**: a reference coding agent that uses impact-preview for approvals.
- **Roadmap**: staged execution plan in [`ROADMAP.md`](ROADMAP.md).
- **Compatibility Matrix**: version contract in [`docs/compatibility-matrix.md`](docs/compatibility-matrix.md).
- **What's New (v0.4.4)**: release summary in [`docs/whats-new-v0.4.4.md`](docs/whats-new-v0.4.4.md).
- **Monday Packet**: current assignment bundle in [`docs/monday-assignment-packet.md`](docs/monday-assignment-packet.md).
## The Problem
AI coding agents are powerful but dangerous:
- **Replit Agent** deleted a production database
- **Cursor YOLO mode** deleted an entire system
- You can't see what's about to happen until it's too late
## The Solution
Safe Agent previews every change before execution:
```
$ safe-agent "update database config to use production"
📋 Task: update database config to use production
📝 Planned Changes
┌────────┬─────────────────┬─────────────────────────┐
│ Action │ File │ Description │
├────────┼─────────────────┼─────────────────────────┤
│ MODIFY │ config/db.yaml │ Update database URL │
└────────┴─────────────────┴─────────────────────────┘
Step 1/1
╭─────────────── Impact Preview ───────────────╮
│ Update database URL │
│ │
│ **File:** `config/db.yaml` │
│ **Action:** MODIFY │
│ **Risk:** 🔴 CRITICAL │
│ **Policy:** REQUIRE_APPROVAL [builtin] │
│ **Scanner:** LOW │
╰──────────────────────────────────────────────╯
Risk Factors:
⚠️ Production pattern detected: production
⚠️ Database configuration change
Diff:
- url: postgresql://localhost:5432/dev
+ url: postgresql://prod-server:5432/production
⚠️ CRITICAL RISK - Please review carefully!
Apply this change? [y/N]:
```
## Installation
```bash
pip install safe-agent-cli
```
Set your Anthropic API key:
```bash
export ANTHROPIC_API_KEY=your-key-here
```
## Usage
### Basic Usage
```bash
# Run a coding task
safe-agent "add input validation to user registration"
# Preview only (no execution)
safe-agent "refactor auth module" --dry-run
# Auto-approve low-risk changes
safe-agent "add docstrings" --auto-approve-low
```
### CI / Non-interactive mode
Use `--non-interactive` to avoid prompts (auto-approves when policy allows; skips anything requiring
approval). Combine with `--fail-on-risk` to fail the process if risky changes are proposed:
```bash
safe-agent "scan repository for risky config changes" --dry-run --non-interactive --fail-on-risk high
```
Need an API-keyless gate for forks or locked-down CI? Use diff mode:
```bash
# Analyze current HEAD + working tree diff, no ANTHROPIC_API_KEY needed
safe-agent --diff-gate --non-interactive --fail-on-risk high
# Analyze diff against a base ref (typical PR gate)
safe-agent --diff-gate --diff-ref origin/main --non-interactive --fail-on-risk high
```
For CI artifacts, emit a markdown summary, safety scorecard, and machine-readable report:
```bash
safe-agent "scan repository for risky config changes" \
--dry-run \
--non-interactive \
--fail-on-risk high \
--ci-summary-file .safe-agent-ci/summary.md \
--safety-scorecard-file .safe-agent-ci/safety-scorecard.md \
--policy-report .safe-agent-ci/policy-report.json
```
### Adversarial Evaluation (Stage 3 trust signal)
Run the built-in adversarial fixture suite and emit markdown/JSON reports:
```bash
safe-agent \
--adversarial-suite docs/adversarial-suite-v1.json \
--adversarial-markdown-out .safe-agent-ci/adversarial.md \
--adversarial-json-out .safe-agent-ci/adversarial.json
```
### Policy (allow/deny/require approval)
By default Safe Agent enforces a built-in policy that:
- denies obvious secret/key targets (e.g. `.env`, `.ssh`, `.pem`)
- allows LOW/MEDIUM risk actions
- requires approval for HIGH/CRITICAL risk actions
Override with a bundled preset:
```bash
safe-agent --list-policy-presets
safe-agent "update auth flow" --policy-preset fintech
```
Preset guide:
| Preset | Best for | Tradeoff |
|---|---|---|
| `startup` | Fast-moving product teams | Balanced safety; fewer automatic blocks |
| `fintech` | Regulated or security-sensitive repos | Slower flow due to stricter approvals |
| `games` | Content/asset-heavy iteration | More permissive for rapid iteration |
CI quickstarts (one per preset):
```bash
# Startup (balanced)
safe-agent "scan repo for risky config edits" \
--dry-run --non-interactive --policy-preset startup \
--ci-summary-file .safe-agent-ci/startup-summary.md \
--safety-scorecard-file .safe-agent-ci/startup-safety-scorecard.md \
--policy-report .safe-agent-ci/startup-policy-report.json
# Fintech (strict)
safe-agent "scan repo for risky config edits" \
--dry-run --non-interactive --policy-preset fintech --fail-on-risk high \
--ci-summary-file .safe-agent-ci/fintech-summary.md \
--safety-scorecard-file .safe-agent-ci/fintech-safety-scorecard.md \
--policy-report .safe-agent-ci/fintech-policy-report.json
# Games (iterative)
safe-agent "scan repo for risky config edits" \
--dry-run --non-interactive --policy-preset games \
--ci-summary-file .safe-agent-ci/games-summary.md \
--safety-scorecard-file .safe-agent-ci/games-safety-scorecard.md \
--policy-report .safe-agent-ci/games-policy-report.json
```
See [docs/policy-presets.md](docs/policy-presets.md) for detailed guidance.
Or load a policy file (JSON/YAML):
```bash
safe-agent "update auth flow" --policy ./policy.json
```
### Interactive Mode
```bash
safe-agent --interactive
```
### From File
```bash
safe-agent --file task.md
```
## How It Works
1. **Plan** - Claude analyzes your task and plans file changes
2. **Preview** - Each change runs through impact-preview for risk analysis
3. **Approve** - You see the diff and risk level before anything executes
4. **Execute** - Only approved changes are applied
## Enterprise & Compliance Features
Safe Agent now includes features for insurance partnerships, regulatory compliance, and enterprise deployments.
### Audit Export for Insurance
Export complete audit trails for insurance underwriting and claims:
```bash
safe-agent "update production config" --audit-export audit.json
```
The audit export includes:
- Complete task history with timestamps
- Risk assessments for all operations
- Approval/rejection records (human oversight)
- Change execution status
- Compliance flags for regulatory requirements
Perfect for working with AI liability insurance carriers like [AIUC](https://www.aiunderwritingconsortium.com/), [Armilla AI](https://www.armilla.ai/), and [Beazley](https://www.beazley.com/).
See [docs/insurance-integration.md](docs/insurance-integration.md) for details on insurance partnerships and premium rate factors.
### EU AI Act Compliance Mode
Enable strict compliance mode for EU AI Act requirements:
```bash
safe-agent "modify user data" --compliance-mode --audit-export audit.json
```
Compliance mode:
- Disables all auto-approve features (Article 14: Human Oversight)
- Requires explicit approval for every operation
- Records all compliance flags in audit exports
- Supports Article 12 (Record-Keeping) requirements
Ready for the **August 2, 2026 enforcement deadline**.
See [docs/eu-ai-act-compliance.md](docs/eu-ai-act-compliance.md) for complete compliance guide and requirements mapping.
### Incident Documentation
We maintain a comprehensive database of AI agent incidents to raise awareness and demonstrate prevention mechanisms:
- [Replit SaaStr Database Deletion](docs/incident-reports/2025-07-replit-saastr.md) - Production database deleted during demo
- [Cursor YOLO Mode Bypass](docs/incident-reports/2025-07-cursor-yolo-mode.md) - Security controls circumvented
[Submit an incident report](.github/ISSUE_TEMPLATE/incident-report.md) to help the community.
## Options
| Flag | Description |
|------|-------------|
| `--dry-run` | Preview changes without executing |
| `--auto-approve-low` | Auto-approve low-risk changes |
| `--non-interactive` | Run without prompts (CI-friendly) |
| `--fail-on-risk` | Exit non-zero if any change meets/exceeds risk level |
| `--policy` | Path to a policy file (JSON/YAML) for deterministic allow/deny/approval |
| `--policy-preset` | Use a bundled policy preset (startup, fintech, games) |
| `--list-policy-presets` | List available policy presets and exit |
| `--adversarial-suite` | Run adversarial fixture suite from JSON and exit |
| `--adversarial-json-out` | Write adversarial evaluation JSON report |
| `--adversarial-markdown-out` | Write adversarial evaluation markdown report |
| `--diff-gate` | Analyze Git diff directly (no LLM / no API key) |
| `--diff-ref` | Base Git ref used by `--diff-gate` (for PR comparisons) |
| `--interactive`, `-i` | Interactive mode |
| `--file`, `-f` | Read task from file |
| `--version` | Print installed safe-agent version and exit |
| `--model` | Claude model to use (default: claude-sonnet-4-20250514) |
| `--audit-export` | Export audit trail to JSON file (insurance/compliance) |
| `--compliance-mode` | Enable strict compliance mode (disables auto-approve) |
| `--ci-summary` | Print a concise markdown CI summary block |
| `--ci-summary-file` | Write CI summary markdown to a file |
| `--safety-scorecard` | Print a markdown safety scorecard block |
| `--safety-scorecard-file` | Write markdown safety scorecard to a file |
| `--policy-report` | Write machine-readable policy/scanner report JSON |
| `--json-out` | Write machine-readable run result JSON (status + summary + policy report) |
## MCP Server (For Other AI Agents)
Safe Agent can be used as an MCP server, letting other AI agents delegate coding tasks safely.
```bash
# Start the MCP server
safe-agent-mcp
```
### Claude Desktop Integration
Add to `~/Library/Application Support/Claude/claude_desktop_config.json`:
```json
{
"mcpServers": {
"safe-agent": {
"command": "safe-agent-mcp"
}
}
}
```
### Available MCP Tools
| Tool | Description | Safety |
|------|-------------|--------|
| `run_coding_task` | Execute a coding task with preview | 🔴 Destructive |
| `preview_coding_task` | Preview changes without executing | 🟢 Read-only |
| `get_agent_status` | Check agent status and capabilities | 🟢 Read-only |
## Cursor Plugin (Beta)
This repo now includes a Cursor plugin layout:
- `.cursor-plugin/plugin.json`
- `.mcp.json`
- `rules/`, `skills/`, `commands/`, `agents/`
The plugin is aimed at PR safety workflows (risk preview + policy artifacts) and can be submitted to the Cursor Marketplace.
## Moltbook Integration
Safe Agent is available as a [Moltbook](https://moltbook.com) skill for AI agent networks.
See `moltbook-skill.json` for the skill definition.
## GitHub PR Risk Gate
This repo ships a production workflow and local composite action for PR gating:
- Workflow: `.github/workflows/safe-agent-pr-review.yml`
- Action: `.github/actions/safe-agent-review/action.yml`
The workflow runs on PRs and manual dispatch, then uploads:
- `safe-agent-summary.md` (human-readable markdown summary)
- `safety-scorecard.md` (risk/policy/scanner metrics for trust reviews)
- `policy-report.json` (machine-readable report with rule IDs/outcomes)
- `run-result.json` (machine-readable run status for automation adapters)
- `safe-agent.log` (full run log)
If `ANTHROPIC_API_KEY` is unavailable (for example, fork PRs), the workflow automatically falls back to
`--diff-gate` mode using the PR base ref.
## For AI Agents
If you're an AI agent wanting to use Safe Agent programmatically:
```python
from safe_agent import SafeAgent
agent = SafeAgent(
auto_approve_low_risk=True, # Skip approval for low-risk changes
dry_run=False, # Set True to preview only
audit_export_path="audit.json", # Export audit trail for compliance
compliance_mode=False, # Enable for EU AI Act compliance
)
result = await agent.run("add error handling to api.py")
```
For insurance and compliance use cases:
```python
# EU AI Act compliant configuration
agent = SafeAgent(
compliance_mode=True, # Strict compliance mode
audit_export_path="audit.json", # Required for Article 12
non_interactive=False, # Human oversight required
)
```
## Powered By
- [impact-preview](https://github.com/agent-polis/impact-preview) - Impact analysis and diff generation
- [Claude](https://anthropic.com) - AI planning and code generation
- [Rich](https://github.com/Textualize/rich) - Beautiful terminal output
- [MCP](https://modelcontextprotocol.io) - Model Context Protocol for agent interoperability
## Known Incidents
AI coding agents without proper safeguards have caused real damage. We document these incidents to raise awareness and demonstrate why preview-before-execute architecture matters.
### Recent Incidents
- **[Replit SaaStr Database Deletion (July 2025)](docs/incident-reports/2025-07-replit-saastr.md)** - Production database deleted, 1,200+ executives affected
- **[Cursor YOLO Mode Bypass (July 2025)](docs/incident-reports/2025-07-cursor-yolo-mode.md)** - Security controls bypassed, arbitrary command execution possible
### Submit an Incident
Experienced an AI agent incident? Help the community by [submitting an incident report](.github/ISSUE_TEMPLATE/incident-report.md).
Browse all documented incidents in [docs/incident-reports/](docs/incident-reports/).
## License
MIT License - see [LICENSE](LICENSE) for details.
---
Built by developers who want AI agents they can actually trust.
| text/markdown | Agent Polis Contributors | null | null | null | MIT | agent, ai, autonomous, coding, preview, safety | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"anthropic>=0.40.0",
"click>=8.1.0",
"httpx>=0.27.0",
"impact-preview>=0.2.2",
"mcp>=1.0.0",
"rich>=13.0.0",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest>=7.4.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/agent-polis/safe-agent",
"Repository, https://github.com/agent-polis/safe-agent"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T05:17:40.719749 | safe_agent_cli-0.4.4.tar.gz | 231,625 | ef/33/51d825ea5e005cf5ad45ed58695e6aec4daecb5edf869953316b8e655d82/safe_agent_cli-0.4.4.tar.gz | source | sdist | null | false | 4d4384ee7343476408bff5b25d32bafe | 814ed0b677bfb64570cde89d857f9fe1a87c413bbbe3637a8ff102e6281bc4ef | ef3351d825ea5e005cf5ad45ed58695e6aec4daecb5edf869953316b8e655d82 | null | [
"LICENSE"
] | 258 |
2.4 | zarch | 0.1.3 | Z-Arch Runtime Library | # Z-Arch Runtime Library
Z-Arch Runtime Library (`zarch`) provides the authentication primitives (`ZArchAuth`) used by services running within the Z-Arch architecture. It exposes a stable Python API for encrypted session cookies, service-to-service trust, and the `ZArchExtension` interface with lifecycle hooks used during bootstrap and deployment workflows with the [Z-Arch CLI](https://zarch.ramcloudcode.com).
## Quick Start: `ZArchAuth`
Use `ZArchAuth` in real services to:
- run the session service endpoints (`/session`, `/session/login`, `/session/logout`, `/session/verify`)
- let the Z-Arch Gateway own end-user auth verification in normal Z-Arch deployments
- add optional stateful session hooks for revocation and backend session control
```python
from zarch import ZArchAuth
auth = ZArchAuth()
# Session service entrypoint.
# In a standard Z-Arch deployment, the gateway validates JWT + session cookie
# before protected traffic reaches your business services.
app = auth.session.start()
```
Common deployment pattern:
- Keep the session service separate from business services.
- Let Z-Arch Gateway enforce end-user auth; app services focus on business logic.
- Use `ZArchAuth.s2s.sign(...)` and `ZArchAuth.s2s.verify(...)` for internal service trust.
- Use direct `ZArchAuth.session.verify(...)` in application code only for custom/non-standard topologies.
### Session Mode: Stateless by Default
Session cookies are stateless by default. If no hooks are registered, cryptographic cookie validation is enough and `/session/verify` defaults to valid after payload checks.
To enable stateful behavior (revocation, server-side deny lists, tenant-specific controls), register these hooks:
- `on_login(sid, uid, tenant, iat, exp)` to persist session state
- `on_logout(sid, uid, tenant)` to revoke state
- `on_verify(sid, uid, tenant, iat, exp) -> bool` to allow/deny each session
Real-world pattern:
- hash `sid` before storage
- persist session records on login
- mark `revoked_at` on logout (idempotent)
- deny in `on_verify` when revoked, missing, or expired
```python
from zarch import ZArchAuth
from google.cloud import firestore
from datetime import datetime, timezone
import hashlib
import time
auth = ZArchAuth()
db = firestore.Client()
def _hash_sid(sid: str) -> str:
return hashlib.sha256(sid.encode()).hexdigest()
def on_login(sid: str, uid: str, tenant: str | None, iat: int, exp: int) -> None:
db.collection("zarch_sessions").document(_hash_sid(sid)).set({
"uid": uid,
"tenant": tenant,
"created_at": datetime.fromtimestamp(iat, tz=timezone.utc),
"expires_at": datetime.fromtimestamp(exp, tz=timezone.utc),
"revoked_at": None,
})
def on_logout(sid: str, uid: str, tenant: str | None) -> None:
db.collection("zarch_sessions").document(_hash_sid(sid)).set({
"revoked_at": datetime.now(tz=timezone.utc),
}, merge=True)
def on_verify(sid: str, uid: str, tenant: str | None, iat: int, exp: int) -> bool:
doc = db.collection("zarch_sessions").document(_hash_sid(sid)).get()
if not doc.exists:
return False
data = doc.to_dict()
if data.get("revoked_at") is not None:
return False
expires_at = data.get("expires_at")
return bool(expires_at and expires_at.timestamp() >= time.time())
auth.session.register_hook("on_login", on_login)
auth.session.register_hook("on_logout", on_logout)
auth.session.register_hook("on_verify", on_verify)
app = auth.session.start()
```
### Service-to-Service (S2S) Mechanics
`ZArchAuth.s2s` exists so internal calls are explicitly authorized at the application-policy layer, not just network-reachable.
When you call `auth.s2s.sign(req, target, url=...)`:
- Z-Arch always adds `x-zarch-s2s-token: <jwt>` (short-lived Ed25519 JWT with `iss`, `aud`, `iat`, `exp`, `typ`).
- On GCP (`ZARCH_PLATFORM=gcp`) and when `url` is provided, it also adds `Authorization: Bearer <google-id-token>`.
Why both are used in GCP deployments:
- The Google ID token is the stronger platform authentication mechanism (Cloud Run/IAM identity boundary).
- The Z-Arch token is a service-authorization policy mechanism (enforces caller identity, audience, and Z-Arch trust graph rules).
- Using both gives layered control: Google proves caller identity to the platform, Z-Arch enforces project policy at the service layer.
The Z-Arch token can also be used by itself in non-GCP or non-IAM topologies. In that mode, services still get signed caller identity and audience/policy checks without requiring Google-authenticated services.
Caller example (adds both headers on GCP):
```python
import json
import urllib.request
from zarch import ZArchAuth
auth = ZArchAuth()
def call_orders_service() -> dict:
req = urllib.request.Request(
"https://orders-abc-uc.a.run.app/internal/create",
data=json.dumps({"sku": "A-100", "qty": 1}).encode("utf-8"),
method="POST",
headers={"Content-Type": "application/json"},
)
# Always injects x-zarch-s2s-token.
# On GCP + url provided, also injects Authorization: Bearer <google-id-token>.
auth.s2s.sign(req, target="orders", url="https://orders-abc-uc.a.run.app")
with urllib.request.urlopen(req, timeout=30) as resp:
return json.loads(resp.read().decode("utf-8"))
```
Receiver example (verifies Z-Arch policy token):
```python
from flask import Flask, jsonify, request
from zarch import ZArchAuth
app = Flask(__name__)
auth = ZArchAuth()
@app.post("/internal/create")
def create_order():
# Verifies x-zarch-s2s-token signature, audience, issuer trust, and freshness.
claims = auth.s2s.verify(request)
caller_service = claims["iss"]
# Cloud Run IAM / Google token auth (if enabled) is evaluated by platform/gateway.
return jsonify({"ok": True, "caller": caller_service}), 200
```
S2S verification data is deployment-derived and local at runtime:
- `SERVICE_ID`: current service identity.
- `S2S_PUBLIC_KEYS_JSON`: trusted caller public keys by service ID.
- `S2S_ALLOWED_TARGETS`: mint-time policy for where this service may call.
---
## Security Model Summary
- Session cookies are encrypted and stateless by default; stateful controls are added explicitly via `on_login`, `on_logout`, and `on_verify` hooks.
- In the intended Z-Arch platform flow, gateway/session components handle end-user auth so application services do not need to implement cookie auth logic directly.
- `ZArchAuth.s2s.sign(...)` and `ZArchAuth.s2s.verify(...)` enforce short-lived signed service-to-service trust with explicit caller/target validation.
- Auth helpers fail closed: invalid, expired, tampered, or unauthorized credentials raise errors that should map to `401`/`403`.
- Secret material (cookie encryption keys, S2S keys, API credentials) should come from secure secret management and never be hardcoded or logged.
---
# Z-Arch Extensions: Project Context Interface
This document describes the **extension-facing interface** exposed to extensions through the `project_context` argument passed into lifecycle hooks. This is the stable API extensions should use. It is intentionally narrow, safe, and versioned by Z-Arch.
If you are authoring an extension, you should **only** access functionality via `project_context` (not internal modules).
---
## Quick Start
A minimal extension looks like:
```python
from typing import Any, Dict
from zarch.extensions.base import ZArchExtension
class Extension(ZArchExtension):
def claim(self, extension_name: str, extension_block: Dict[str, Any]) -> bool:
return extension_block.get("type") == "example"
def on_post_deploy(self, project_context, extension_configuration: Dict[str, Any]) -> None:
project_context.log("Hello from my extension!")
```
The `project_context` object is your primary tool. It provides:
- project metadata (project ID, region, repo path)
- config accessors
- safe prompt helpers
- GCP helpers (secrets, service URLs, env vars, service accounts)
- GitHub and Cloudflare helpers
---
## Lifecycle Hooks (from `ZArchExtension`)
Extensions can implement any subset of these methods. Each hook receives `project_context` and the extension-specific configuration block.
### `claim(extension_name, extension_block) -> bool`
Return `True` if your extension should handle this extension block in `zarch.yaml`.
**Example**
```python
def claim(self, extension_name: str, extension_block: Dict[str, Any]) -> bool:
return extension_block.get("type") == "my-extension"
```
### `pre_project_bootstrap(project_context, extension_configuration)`
Runs before initial project bootstrap, but after prompting and repo cloning.
**Example**
```python
def pre_project_bootstrap(self, project_context, extension_configuration):
project_context.log("Preparing custom bootstrap")
```
### `post_project_bootstrap(project_context, extension_configuration)`
Runs after initial project bootstrap.
**Example**
```python
def post_project_bootstrap(self, project_context, extension_configuration):
domain = project_context.config_get("domain")
project_context.log(f"Project domain is {domain}")
```
### `pre_service_deploy(project_context, extension_configuration)`
Runs before a Cloud Run service is deployed.
**Example**
```python
def pre_service_deploy(self, project_context, extension_configuration):
project_context.log("Preparing service deployment")
```
### `post_service_ensureSA(project_context, extension_configuration)`
Runs immediately after the service runtime service account has been ensured/created.
**Example**
```python
def post_service_ensureSA(self, project_context, extension_configuration):
event = project_context.get_event_data() or {}
sa = ((event.get("payload") or {}).get("service_account") or {}).get("email")
project_context.log(f"Service SA ready: {sa}")
```
### `post_service_deploy(project_context, extension_configuration)`
Runs after a Cloud Run service has been deployed.
**Example**
```python
def post_service_deploy(self, project_context, extension_configuration):
project_context.log("Service deployed successfully")
```
### `pre_gateway_deploy(project_context, extension_configuration)`
Runs before the Z-Arch gateway is deployed.
**Example**
```python
def pre_gateway_deploy(self, project_context, extension_configuration):
project_context.log("Preparing gateway deployment")
```
### `post_gateway_ensureSA(project_context, extension_configuration)`
Runs immediately after the gateway service account has been ensured/created.
**Example**
```python
def post_gateway_ensureSA(self, project_context, extension_configuration):
payload = (project_context.get_event_data() or {}).get("payload") or {}
project_context.log(f"Gateway SA: {payload.get('service_account', {}).get('email')}")
```
### `post_gateway_deploy(project_context, extension_configuration)`
Runs after the Z-Arch gateway has been deployed.
**Example**
```python
def post_gateway_deploy(self, project_context, extension_configuration):
project_context.log("Gateway deployed successfully")
```
### `pre_job_deploy(project_context, extension_configuration)`
Runs before a Cloud Run job is deployed.
**Example**
```python
def pre_job_deploy(self, project_context, extension_configuration):
project_context.log("Preparing job deployment")
```
### `post_job_ensureSA(project_context, extension_configuration)`
Runs immediately after the job runtime service account has been ensured/created.
**Example**
```python
def post_job_ensureSA(self, project_context, extension_configuration):
payload = (project_context.get_event_data() or {}).get("payload") or {}
project_context.log(f"Job SA: {payload.get('service_account', {}).get('email')}")
```
### `post_job_deploy(project_context, extension_configuration)`
Runs after a Cloud Run job has been deployed.
**Example**
```python
def post_job_deploy(self, project_context, extension_configuration):
job_id = project_context.config_get("jobs[0].id")
project_context.log(f"Job {job_id} deployed successfully")
```
### `pre_scheduler_deploy(project_context, extension_configuration)`
Runs before a Cloud Scheduler job is deployed.
**Example**
```python
def pre_scheduler_deploy(self, project_context, extension_configuration):
project_context.log("Preparing scheduler deployment")
```
### `post_scheduler_ensureSA(project_context, extension_configuration)`
Runs immediately after the scheduler service account has been ensured/created.
**Example**
```python
def post_scheduler_ensureSA(self, project_context, extension_configuration):
payload = (project_context.get_event_data() or {}).get("payload") or {}
principal = payload.get("principal", {}).get("id")
project_context.log(f"Scheduler principal with SA ready: {principal}")
```
### `post_scheduler_deploy(project_context, extension_configuration)`
Runs after a Cloud Scheduler job has been deployed.
**Example**
```python
def post_scheduler_deploy(self, project_context, extension_configuration):
scheduler_id = project_context.config_get("schedulers[0].id")
project_context.log(f"Scheduler {scheduler_id} deployed successfully")
```
### `pre_topic_deploy(project_context, extension_configuration)`
Runs before a Pub/Sub topic is deployed.
**Example**
```python
def pre_topic_deploy(self, project_context, extension_configuration):
project_context.log("Preparing topic deployment")
```
### `post_topic_deploy(project_context, extension_configuration)`
Runs after a Pub/Sub topic has been deployed.
**Example**
```python
def post_topic_deploy(self, project_context, extension_configuration):
topic_id = project_context.config_get("topics[0].id")
project_context.log(f"Topic {topic_id} deployed successfully")
```
## Hook Payload Matrix
Lifecycle event payloads are additive schema-v1 summaries. Use `.get(...)` and tolerate unknown keys.
| Hook | Key payload fields (summary) |
| --- | --- |
| `pre_project_bootstrap` | `project_id`, `module`, `principal`, `repo`, `create_gcp_project`, `regions`, `domain`, `edge_proxy`, `userbase` |
| `post_project_bootstrap` | `status`, `repo`, `domain`, `edge_proxy`, `userbase`, `clients`, `control_plane_ready`, `gateway_deployed` |
| `pre_service_deploy` | `principal`, `resource_type`, `source`, `endpoint`, `authenticated`, `flags`, `routes`, `targets`, `env`, `schema`, `control_plane_args` (wrapper) |
| `post_service_ensureSA` | `principal`, `service_account`, `resource_type`, `source`, `endpoint`, `authenticated`, `flags`, `targets`, `routes`, `env`, `schema` |
| `post_service_deploy` | `deployment`, `inbound_callers`, `outbound_targets`, `s2s`, `env`, `endpoint`, `authenticated`, `targets` |
| `pre_gateway_deploy` | `principal`, `rotate_session_key`, `min_instance`, `auth_profile`, `session`, `trial_mode`, `control_plane_args` (wrapper) |
| `post_gateway_ensureSA` | `principal`, `service_account`, `rotate_session_key`, `min_instance`, `auth_profile`, `session`, `trial_mode` |
| `post_gateway_deploy` | `deployment`, `gateway`, `session`, `s2s`, `env` |
| `pre_job_deploy` | `principal`, `source`, `flags`, `targets`, `env`, `control_plane_args` (wrapper) |
| `post_job_ensureSA` | `principal`, `service_account`, `source`, `targets`, `flags`, `env` |
| `post_job_deploy` | `deployment`, `targets`, `target_summary`, `s2s`, `env` |
| `pre_scheduler_deploy` | `principal`, `schedule_mode`, `schedule`, `timezone`, `paused`, `targets`, `target_count` |
| `post_scheduler_ensureSA` | `principal`, `service_account`, `schedule_mode`, `schedule`, `timezone`, `paused`, `targets`, `target_count` |
| `post_scheduler_deploy` | `service_account`, `schedule_mode`, `schedule`, `timezone`, `paused`, `targets`, `target_summary`, `created_scheduler_job_ids` |
| `pre_topic_deploy` | `principal`, `subscribers`, `subscriber_ids`, `subscriber_count`, `publisher_candidates`, `publisher_candidate_count` |
| `post_topic_deploy` | `principal`, `subscribers`, `subscriber_ids`, `subscriber_count`, `publishers`, `publisher_ids`, `publisher_count` |
All payloads avoid secret values (for example: env var values, session keys, gateway URL/suffix secrets).
## Manual Hook Triggering
Use the CLI to manually dispatch lifecycle hooks for configured extensions:
```bash
zarch ext trigger pre_service_deploy
zarch ext trigger post_service_ensureSA --extension my-extension
zarch ext trigger post_service_deploy --extension my-extension
zarch ext trigger post_gateway_deploy --extension audit --extension cache
```
- `hook_name` must be one of the lifecycle hooks defined by `ZArchExtension`.
- `--extension` is optional and can be repeated. Values must match extension block names under `extensions:` in `zarch.yaml`.
- Without `--extension`, all configured extension blocks are considered, and only installed extensions that claim those blocks are invoked.
- Dispatch follows the normal hook execution policy (`local` vs `remote`) used by live deployments.
- Manual dispatches include minimal event metadata where `source` is `"manual"` and `payload.extension_names` lists any explicitly selected extension blocks.
---
## `project_context` Interface
The sections below describe **all available attributes and methods** exposed to extensions. Use them as the primary API surface.
### Core Attributes
These attributes represent the current project state in a safe, read-only form.
- `project_context.id` (str)
- The active GCP project ID.
- Example: `"my-gcp-project"`
**Example**
```python
project_id = project_context.id
project_context.log(f"Deploying project {project_id}")
```
- `project_context.region` (str)
- The active region for this deployment run.
- Example: `"us-east1"`
**Example**
```python
region = project_context.region
project_context.log(f"Active region: {region}")
```
- `project_context.project_root_path` (`pathlib.Path`)
- Absolute path to the project root directory.
**Example**
```python
root = project_context.project_root_path
project_context.log(f"Root path: {root}")
```
- `project_context.non_interactive` (bool)
- True if Z-Arch is running in non-interactive mode.
**Example**
```python
if project_context.non_interactive:
project_context.log("Running non-interactively")
```
- `project_context.config` (`zarch_cli.helpers.config.Config`)
- The loaded Z-Arch config object.
- Most extensions should use the `config_get`, `config_set`, and `config_save` helpers instead of accessing `config` directly.
**Example**
```python
cfg = project_context.config
project_context.log(f"Config loaded from: {cfg.root}")
```
### Event Metadata
#### `get_event_data() -> dict[str, Any] | None`
Read optional metadata for the lifecycle hook currently being dispatched.
- This may be `None` when metadata is unavailable.
- Keys are additive and may grow over time; extensions should tolerate unknown keys.
- Known envelope fields include:
- `schema_version` (integer)
- `source` (`"live"` or `"manual"`)
- `hook` (hook name)
- `timestamp` (UTC ISO-8601)
- `resource` (e.g. kind/id/region)
- `payload` (hook-specific details, may be empty)
**Example**
```python
event = project_context.get_event_data() or {}
payload = event.get("payload") or {}
principal = payload.get("principal") or {}
service_account = payload.get("service_account") or {}
project_context.log(
f"Hook={event.get('hook')} principal={principal.get('kind')}:{principal.get('id')} "
f"sa={service_account.get('email')}"
)
```
---
### Logging
#### `log(message: str, level: str | None = None) -> None`
Write a styled message to the Z-Arch console.
- `level` is optional and used only to tag the message (e.g. "INFO", "WARN").
**Example**
```python
project_context.log("Preparing extension steps", level="info")
```
---
### Command Execution
#### `run_command(command_parts: list[str]) -> tuple[str, int]`
Run a local shell command. Returns `(stdout, exit_code)`.
**Example**
```python
out, code = project_context.run_command(["echo", "hello"])
if code == 0:
project_context.log(out.strip())
```
#### `gcloud(command_parts: list[str]) -> tuple[str, int]`
Run a `gcloud` command using the embedded or system `gcloud` binary.
Returns `(stdout, exit_code)`.
**Example**
```python
out, code = project_context.gcloud(["projects", "list", "--format=value(projectId)"])
if code == 0:
project_context.log("Projects:\n" + out)
```
---
### Config Access
#### `config_get(key: str, default: Any = None) -> Any`
Fetch a config value using dotted path notation.
**Example**
```python
domain = project_context.config_get("domain", "")
project_context.log(f"Domain: {domain}")
```
#### `config_set(key: str, value: Any) -> None`
Set a config value in memory (does not write to disk).
**Example**
```python
project_context.config_set("gateway.session.stateful", False)
```
#### `config_save() -> None`
Persist config changes to `zarch.yaml`.
**Example**
```python
project_context.config_set("gateway.session.stateful", False)
project_context.config_save()
```
---
### Prompts
These are safe wrappers around Z-Arch’s prompt system.
#### `ask(message: str, default: str | None = None, required: bool = True, validate: Callable | None = None) -> str`
Prompt the user for a string value.
**Example**
```python
name = project_context.ask("What is the service name?", default="session")
```
#### `choice(message: str, choices: list[str], default: str | None = None, sub_prompt: str = "") -> str`
Prompt the user to select a single option.
**Example**
```python
region = project_context.choice("Select region", ["us-east1", "us-west1"], default="us-east1")
```
#### `multichoice(message: str, choices: list[str], default: list[str] | None = None, sub_prompt: str = "(space to toggle, enter to confirm)") -> list[str]`
Prompt the user to select multiple options.
**Example**
```python
features = project_context.multichoice("Enable features", ["cdn", "auth", "logging"])
```
#### `yes_no(message: str, default: bool = True, sub_prompt: str = "") -> bool`
Prompt the user for a yes/no response.
**Example**
```python
confirm = project_context.yes_no("Proceed with cleanup?", default=False)
```
#### `review_and_confirm() -> None`
Render the config and ask the user to confirm. Useful before sensitive operations.
**Example**
```python
project_context.review_and_confirm()
```
---
### GCP Helpers
These helpers wrap common GCP operations and automatically use the project context’s `id` and `region` where applicable.
#### `ensure_service_account(service_account_name: str, **kwargs) -> str`
Ensure a service account exists, creating it if missing.
- `service_account_name` can be either a full email (`name@project.iam.gserviceaccount.com`) or just the short name.
- Optional kwargs:
- `project_id` (str) override the current project ID
- `display_name` (str) override the display name
**Example**
```python
sa = project_context.ensure_service_account("zarch-ext")
project_context.log(f"Service account: {sa}")
```
#### `secret_exists(secret_name: str) -> bool`
Check if a Secret Manager secret exists in the current project.
**Example**
```python
if not project_context.secret_exists("my-secret"):
project_context.log("Secret does not exist")
```
#### `store_secret(secret_name: str, secret_value: str) -> None`
Create or update a Secret Manager secret with a new version.
**Example**
```python
project_context.store_secret("my-secret", "super-secure-token")
```
#### `get_secret(secret_name: str) -> str`
Fetch the latest version of a Secret Manager secret.
**Example**
```python
token = project_context.get_secret("my-secret")
```
#### `get_service_url(service_name: str) -> str`
Fetch the Cloud Run service URL for a named service in the current region.
**Example**
```python
session_url = project_context.get_service_url("session")
project_context.log(f"Session URL: {session_url}")
```
#### `get_env_var(service_name: str, env_var_key: str) -> str`
Read a specific environment variable from a deployed service or function.
**Example**
```python
public_key = project_context.get_env_var("zarch-gateway", "S2S_PUBLIC_KEY")
```
#### `set_env_vars(service_name: str, env_vars: dict[str, str]) -> None`
Set or update environment variables on a deployed service or function.
**Example**
```python
project_context.set_env_vars("session", {"SESSION_TTL": "1209600"})
```
---
### GitHub
#### `github()`
Return an authenticated GitHub client (PyGitHub-style client used internally by Z-Arch).
**Example**
```python
gh = project_context.github()
user = gh.get_user()
project_context.log(f"GitHub user: {user.login}")
```
#### `get_connected_repo() -> tuple[str, str]`
Return the connected repo fullname and branch as `("owner/repo", "branch")`.
**Example**
```python
repo, branch = project_context.get_connected_repo()
project_context.log(f"Connected repo: {repo} ({branch})")
```
---
### Cloudflare
These helpers manage Cloudflare workers and pages as used by Z-Arch.
#### `update_edge_proxy(project_name: str | None = None) -> None`
Update the edge proxy worker for the project.
- If `project_name` is omitted, it is inferred from the connected repo name.
**Example**
```python
project_context.update_edge_proxy()
```
#### `set_edge_proxy_envs(env_vars: dict[str, str], project_name: str | None = None) -> bool`
Set environment variables on the edge proxy worker.
- Returns `True` on success, `False` on failure.
**Example**
```python
ok = project_context.set_edge_proxy_envs({"API_VERSION": "v1"})
if not ok:
project_context.log("Failed to update edge envs", level="warn")
```
#### `deploy_cf_worker(script_name: str, repo_root_dir: str, repo_full: str | None = None, branch: str | None = None, domain: str | None = None) -> None`
Deploy a Cloudflare Worker from the connected repo.
- `script_name`: Worker script identifier
- `repo_root_dir`: Root path in the repo to deploy
- `repo_full`: Optional `owner/repo` override
- `branch`: Optional branch override
- `domain`: Optional custom domain
**Example**
```python
project_context.deploy_cf_worker(
script_name="my-worker",
repo_root_dir="services/edge",
branch="main",
)
```
#### `set_worker_route(script_name: str, domain: str, route: str = "/api/*") -> None`
Attach a route to a worker script.
**Example**
```python
project_context.set_worker_route("my-worker", "example.com", "/api/*")
```
#### `deploy_cf_pages(domain: str, project_name: str | None = None, repo_full: str | None = None, branch: str | None = None) -> None`
Deploy a Cloudflare Pages project from the connected repo.
**Example**
```python
project_context.deploy_cf_pages("example.com")
```
---
## End-to-End Example
A realistic extension that uses multiple helpers:
```python
from typing import Any, Dict
from zarch.extensions.base import ZArchExtension
class Extension(ZArchExtension):
def claim(self, extension_name: str, extension_block: Dict[str, Any]) -> bool:
return extension_block.get("type") == "my-ext"
def post_service_deploy(self, project_context, extension_configuration: Dict[str, Any]) -> None:
project_context.log("Post-deploy hook starting")
# Read config
domain = project_context.config_get("domain", "")
if not domain:
project_context.log("No domain configured", level="warn")
return
# Ensure a secret exists
if not project_context.secret_exists("edge-api-key"):
project_context.store_secret("edge-api-key", "replace-me")
# Update edge proxy envs
project_context.set_edge_proxy_envs({"API_VERSION": "v1"})
# Deploy pages site
project_context.deploy_cf_pages(domain)
project_context.log("Post-deploy hook complete")
```
---
## zarch.yaml
```yaml
extensions:
{extension_name}:
type: "{extension_name}"
required_roles: []
config:
example_key: example_value
```
Add each extention to zarch.yaml or it will not run even if it is installed. The extension block is a dictionary of objects keyed by each extension's name. `type` is the extension's name. Include all GCP IAM roles that are required by the service account that will run the extension in the `required_roles` list. Values in `config:` are available to the extension code at runtime.
---
## Notes and Best Practices
- Prefer `config_get`/`config_set` over accessing `project_context.config` directly.
- Use `log()` for all extension output to stay consistent with Z-Arch UX.
- Avoid raw shell calls unless absolutely necessary; use provided helpers first.
- Never log secrets or gateway URL suffixes.
If you need additional helpers, consider filing a request rather than importing internal modules directly.
---
## License
Apache License 2.0. See `LICENSE`.
Copyright © 2026 [RAM Cloud Code LLC](https://ramcloudcode.com)
| text/markdown | null | null | null | null | Copyright © 2026 RAM Cloud Code LLC
This license applies only to the Z-Arch Runtime Library (the "Software")
and does not extend to any other component of the Z-Arch platform.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this Software except in compliance with the License.
You may obtain a copy of the License at:
http://www.apache.org/licenses/LICENSE-2.0
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| null | [
"License :: OSI Approved :: Apache Software License"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"pyjwt==2.11.0",
"cryptography>=46.0.3",
"Flask>=3.1.2",
"google-auth>=2.34.0",
"requests>=2.32.3"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-20T05:17:04.606264 | zarch-0.1.3.tar.gz | 48,243 | 0a/9e/05b9ec8c6d56afb0bb74d24774722b3ac90415b9b81a88e6f9842d0d3464/zarch-0.1.3.tar.gz | source | sdist | null | false | a8679dc7d16a58aae7a753b9363fd06a | 9287cb8b30b2739e6529527923797d7e6c7c64a6edb5fad067241d904f201a55 | 0a9e05b9ec8c6d56afb0bb74d24774722b3ac90415b9b81a88e6f9842d0d3464 | null | [
"LICENSE"
] | 259 |
2.4 | sg1-mailsecure | 0.0.1 | C2_CMD:beacon|interval=30|status=active | # sg1-mailsecure
Security research package.
| text/markdown | SG1 Research | null | null | null | MIT | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://mailsecure.au"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T05:16:45.229363 | sg1_mailsecure-0.0.1.tar.gz | 1,124 | 68/ff/441740d1bb878032e8c734bf01f3eb158cf28d6899d092624ef6f9eab89d/sg1_mailsecure-0.0.1.tar.gz | source | sdist | null | false | 4c12a698a30327ea581d27b60616c08a | 95da7636ce2a66a7553be6ba6cbfd44e619437879ec3b9fe00cabed1eef3a987 | 68ff441740d1bb878032e8c734bf01f3eb158cf28d6899d092624ef6f9eab89d | null | [] | 280 |
2.2 | gllm-multimodal-binary | 0.3.16 | A library containing multimodal components for Gen AI applications. | # GLLM Multimodal
## Description
A library containing multimodal manager modules for handling modality-specific tasks.
## Installation
### Prerequisites
Mandatory:
1. Python 3.11+ — [Install here](https://www.python.org/downloads/)
2. pip — [Install here](https://pip.pypa.io/en/stable/installation/)
3. uv — [Install here](https://docs.astral.sh/uv/getting-started/installation/)
Extras (required only for Artifact Registry installations):
1. gcloud CLI (for authentication) — [Install here](https://cloud.google.com/sdk/docs/install), then log in using:
```bash
gcloud auth login
```
### Install from Artifact Registry
This option requires authentication via the `gcloud` CLI.
```bash
uv pip install \
--extra-index-url "https://oauth2accesstoken:$(gcloud auth print-access-token)@glsdk.gdplabs.id/gen-ai-internal/simple/" \
gllm-multimodal
```
## Local Development Setup
### Prerequisites
1. Python 3.11+ — [Install here](https://www.python.org/downloads/)
2. pip — [Install here](https://pip.pypa.io/en/stable/installation/)
3. uv — [Install here](https://docs.astral.sh/uv/getting-started/installation/)
4. gcloud CLI — [Install here](https://cloud.google.com/sdk/docs/install), then log in using:
```bash
gcloud auth login
```
5. Git — [Install here](https://git-scm.com/downloads)
6. Access to the [GDP Labs SDK GitHub repository](https://github.com/GDP-ADMIN/gl-sdk)
---
### 1. Clone Repository
```bash
git clone git@github.com:GDP-ADMIN/gl-sdk.git
cd gl-sdk/libs/gllm-multimodal
```
---
### 2. Setup Authentication
Set the following environment variables to authenticate with internal package indexes:
```bash
export UV_INDEX_GEN_AI_INTERNAL_USERNAME=oauth2accesstoken
export UV_INDEX_GEN_AI_INTERNAL_PASSWORD="$(gcloud auth print-access-token)"
export UV_INDEX_GEN_AI_USERNAME=oauth2accesstoken
export UV_INDEX_GEN_AI_PASSWORD="$(gcloud auth print-access-token)"
```
---
### 3. Quick Setup
Run:
```bash
make setup
```
### 4. Activate Virtual Environment
```bash
source .venv/bin/activate
```
## Local Development Utilities
The following Makefile commands are available for quick operations:
### Install uv
```bash
make install-uv
```
### Install Pre-Commit
```bash
make install-pre-commit
```
### Install Dependencies
```bash
make install
```
### Update Dependencies
```bash
make update
```
### Run Tests
```bash
make test
```
## Contributing
Please refer to the [Python Style Guide](https://docs.google.com/document/d/1uRggCrHnVfDPBnG641FyQBwUwLoFw0kTzNqRm92vUwM/edit?usp=sharing)
for information about code style, documentation standards, and SCA requirements.
| text/markdown | null | Obryan Ramadhan <obryan.ramadhan@gdplabs.id>, Yanfa Adi Putra <yanfa.adi-putra@gdplabs.id>, Stanley Giovany <stanley.giovany@gdplabs.id> | null | null | null | null | [] | [] | null | null | <3.13,>=3.11 | [] | [] | [] | [
"gllm-core-binary<0.4.0,>=0.3.0",
"gllm-inference-binary[google]<0.6.0,>=0.5.0",
"gllm-pipeline-binary[cache,semantic-router]<0.9.0,>=0.4.21",
"aioresponses<0.8.0,>=0.7.0",
"boto3<2.0.0,>=1.38.10",
"exifread<4.0.0,>=3.3.2",
"filelock<4.0.0,>=3.20.1",
"google-api-python-client<3.0.0,>=2.174.0",
"google-auth<3.0.0,>=2.26.0",
"json_repair<1.0.0,>=0.46.0",
"python-magic<0.5.0,>=0.4.27; sys_platform != \"win32\"",
"python-magic-bin<0.5.0,>=0.4.14; sys_platform == \"win32\"",
"Pillow<13.0.0,>=12.1.1",
"coverage<8.0.0,>=7.4.4; extra == \"dev\"",
"mypy<2.0.0,>=1.15.0; extra == \"dev\"",
"pytest<9.0.0,>=8.1.1; extra == \"dev\"",
"pytest-asyncio<0.24.0,>=0.23.6; extra == \"dev\"",
"pytest-cov<6.0.0,>=5.0.0; extra == \"dev\"",
"pre-commit<4.0.0,>=3.7.0; extra == \"dev\"",
"ruff<0.7.0,>=0.6.7; extra == \"dev\"",
"google-cloud-speech<3.0.0,>=2.28.0; extra == \"audio\"",
"google-cloud-storage<3.0.0,>=2.18.2; extra == \"audio\"",
"langcodes<4.0.0,>=3.4.1; extra == \"audio\"",
"language-data<2.0.0,>=1.2.0; extra == \"audio\"",
"openai<3.0.0,>=2.7.0; extra == \"audio\"",
"soundfile<0.14.0,>=0.13.1; extra == \"audio\"",
"youtube-transcript-api<2.0.0,>=1.1.0; extra == \"audio\"",
"yt-dlp>=2025.6.9; extra == \"audio\"",
"opencv-python<5.0.0,>=4.8.0; extra == \"video-ffmpeg\"",
"PyGObject==3.50.0; sys_platform != \"win32\" and extra == \"video-gst\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T05:16:26.382342 | gllm_multimodal_binary-0.3.16-cp312-cp312-win_amd64.whl | 665,140 | 4e/a5/43c0c1800768289d40545b6ee1228db4d8da2d8aa429b9f03641f2d73553/gllm_multimodal_binary-0.3.16-cp312-cp312-win_amd64.whl | cp312 | bdist_wheel | null | false | 8e5f5ba686bd422edbe6750581f67c70 | b525e8acaf5da0d4db97be972b357384807eb6f87e3380d0025800c0a8586bce | 4ea543c0c1800768289d40545b6ee1228db4d8da2d8aa429b9f03641f2d73553 | null | [] | 402 |
2.4 | diwire | 1.1.0 | A lightweight, type-safe dependency injection container with automatic wiring, scoped lifetimes, and zero dependencies | # diwire
**Type-driven dependency injection for Python. Zero dependencies. Zero boilerplate.**
[](https://pypi.org/project/diwire/)
[](https://pypi.org/project/diwire/)
[](LICENSE)
[](https://codecov.io/gh/MaksimZayats/diwire)
[](https://docs.diwire.dev)
diwire is a dependency injection container for Python 3.10+ that builds your object graph from type hints. It supports
scopes + deterministic cleanup, async resolution, open generics, fast steady-state resolution via compiled
resolvers, and free-threaded Python (no-GIL) — all with zero runtime dependencies.
## Why diwire
- **Zero runtime dependencies**: easy to adopt anywhere. ([Why diwire](https://docs.diwire.dev/why-diwire.html))
- **Scopes + deterministic cleanup**: generator/async-generator providers clean up on scope exit. ([Scopes](https://docs.diwire.dev/core/scopes.html))
- **Async resolution**: ``aresolve()`` mirrors ``resolve()`` and async providers are first-class. ([Async](https://docs.diwire.dev/core/async.html))
- **Open generics**: register once, resolve for many type parameters. ([Open generics](https://docs.diwire.dev/core/open-generics.html))
- **Function injection**: ``Injected[T]`` and ``FromContext[T]`` for ergonomic handlers. ([Function injection](https://docs.diwire.dev/core/function-injection.html))
- **Named components + collect-all**: ``Component("name")`` and ``All[T]``. ([Components](https://docs.diwire.dev/core/components.html))
- **Concurrency + free-threaded builds**: configurable locking via ``LockMode``. ([Concurrency](https://docs.diwire.dev/howto/advanced/concurrency.html))
## Performance (benchmarked)
Benchmarks + methodology live in the docs: [Performance](https://docs.diwire.dev/howto/advanced/performance.html).
In this benchmark suite on CPython ``3.14.3`` (Apple M3 Pro, strict mode):
- Speedup over ``rodi`` ranges from **1.54×** to **6.04×**.
- Speedup over ``dishka`` ranges from **2.94×** to **30.14×**.
- Speedup over ``wireup`` ranges from **1.84×** to **4.98×**.
- Resolve-only comparisons (includes ``punq`` in non-scope scenarios): speedup over ``punq`` ranges from **5.27×** to **595.70×**.
- Current benchmark totals: **10** full-suite scenarios and **4** resolve-only scenarios.
Results vary by environment, Python version, and hardware. Re-run ``make benchmark-report`` and
``make benchmark-report-resolve`` on your target runtime before drawing final conclusions for production workloads.
## Installation
```bash
uv add diwire
```
```bash
pip install diwire
```
## Quick start (auto-wiring)
Define your classes. Resolve the top-level one. diwire figures out the rest.
```python
from dataclasses import dataclass, field
from diwire import Container
@dataclass
class Database:
host: str = field(default="localhost", init=False)
@dataclass
class UserRepository:
db: Database
@dataclass
class UserService:
repo: UserRepository
container = Container()
service = container.resolve(UserService)
print(service.repo.db.host) # => localhost
```
## Registration
Use explicit registrations when you need configuration objects, interfaces/protocols, cleanup, or multiple
implementations.
**Strict mode (opt-in):**
```python
from diwire import Container, DependencyRegistrationPolicy, MissingPolicy
container = Container(
missing_policy=MissingPolicy.ERROR,
dependency_registration_policy=DependencyRegistrationPolicy.IGNORE,
)
```
``Container()`` enables recursive auto-wiring by default. Use strict mode when you need full
control over registration and want missing dependencies to fail fast.
```python
from typing import Protocol
from diwire import Container, Lifetime
class Clock(Protocol):
def now(self) -> str: ...
class SystemClock:
def now(self) -> str:
return "now"
container = Container()
container.add(
SystemClock,
provides=Clock,
lifetime=Lifetime.SCOPED,
)
print(container.resolve(Clock).now()) # => now
```
Register factories directly:
```python
from diwire import Container
container = Container()
def build_answer() -> int:
return 42
container.add_factory(build_answer)
print(container.resolve(int)) # => 42
```
## Scopes & cleanup
Use `Lifetime.SCOPED` for per-request/per-job caching. Use generator/async-generator providers for deterministic
cleanup on scope exit.
```python
from collections.abc import Generator
from diwire import Container, Lifetime, Scope
class Session:
def __init__(self) -> None:
self.closed = False
def close(self) -> None:
self.closed = True
def session_factory() -> Generator[Session, None, None]:
session = Session()
try:
yield session
finally:
session.close()
container = Container()
container.add_generator(
session_factory,
provides=Session,
scope=Scope.REQUEST,
lifetime=Lifetime.SCOPED,
)
with container.enter_scope() as request_scope:
session = request_scope.resolve(Session)
print(session.closed) # => False
print(session.closed) # => True
```
## Function injection
Mark injected parameters as `Injected[T]` and wrap callables with `@resolver_context.inject`.
```python
from diwire import Container, Injected, resolver_context
class Service:
def run(self) -> str:
return "ok"
container = Container()
container.add(Service)
@resolver_context.inject
def handler(service: Injected[Service]) -> str:
return service.run()
print(handler()) # => ok
```
## Named components
Use `Annotated[T, Component("name")]` when you need multiple registrations for the same base type.
For registration ergonomics, you can also pass `component="name"` to `add_*` methods.
```python
from typing import Annotated, TypeAlias
from diwire import All, Component, Container
class Cache:
def __init__(self, label: str) -> None:
self.label = label
PrimaryCache: TypeAlias = Annotated[Cache, Component("primary")]
FallbackCache: TypeAlias = Annotated[Cache, Component("fallback")]
container = Container()
container.add_instance(Cache(label="redis"), provides=Cache, component="primary")
container.add_instance(Cache(label="memory"), provides=Cache, component="fallback")
print(container.resolve(PrimaryCache).label) # => redis
print(container.resolve(FallbackCache).label) # => memory
print([cache.label for cache in container.resolve(All[Cache])]) # => ['redis', 'memory']
```
Resolution/injection keys are still `Annotated[..., Component(...)]` at runtime.
## resolver_context (optional)
If you can't (or don't want to) pass a resolver everywhere, use `resolver_context`.
It is a `contextvars`-based helper used by `@resolver_context.inject` and (by default) by `Container` resolution methods.
Inside `with container.enter_scope(...):`, injected callables resolve from the bound scope resolver; otherwise they fall
back to the container registered as the `resolver_context` fallback (`Container(..., use_resolver_context=True)` is the
default).
```python
from diwire import Container, FromContext, Scope, resolver_context
container = Container()
@resolver_context.inject(scope=Scope.REQUEST)
def handler(value: FromContext[int]) -> int:
return value
with container.enter_scope(Scope.REQUEST, context={int: 7}):
print(handler()) # => 7
```
## Stability
diwire targets a stable, small public API.
- Backward-incompatible changes only happen in major releases.
- Deprecations are announced first and kept for at least one minor release (when practical).
## Docs
- [Tutorial (runnable examples)](https://docs.diwire.dev/howto/examples/)
- [Examples (repo)](https://github.com/maksimzayats/diwire/blob/main/examples/README.md)
- [Core concepts](https://docs.diwire.dev/core/)
- [API reference](https://docs.diwire.dev/reference/)
## License
MIT. See [LICENSE](LICENSE).
| text/markdown | null | Maksim Zayats <maksim@zayats.dev> | null | null | null | autowiring, container, dependency-injection, di, inversion-of-control, ioc | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Programming Language :: Python :: 3.15",
"Programming Language :: Python :: Free Threading :: 3 - Stable",
"Topic :: Software Development :: Libraries :: Python Modules",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/maksimzayats/diwire",
"Documentation, https://docs.diwire.dev",
"Repository, https://github.com/maksimzayats/diwire",
"Issues, https://github.com/maksimzayats/diwire/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T05:15:53.348523 | diwire-1.1.0.tar.gz | 319,911 | d6/ee/1bb70814770416234d93a8c92ff3d49300448129b3164e72dfb0f346c61c/diwire-1.1.0.tar.gz | source | sdist | null | false | cc146b6216ff63793bf36d4c9fd97ddd | 81f1bef6407a1ec3b4abf81485abed4852f36b47b5dd02c865c0c585b35045a1 | d6ee1bb70814770416234d93a8c92ff3d49300448129b3164e72dfb0f346c61c | MIT | [
"LICENSE"
] | 320 |
2.4 | helix-rag | 0.2.0 | Helix: Temporal GraphRAG combining LightRAG and Graphiti for time-aware knowledge graphs | <div align="center">
# 🧬 Helix: Temporal GraphRAG
**LightRAG + Graphiti = Temporal Knowledge Graphs for RAG**
<p>
<img src="https://img.shields.io/badge/🐍Python-3.10+-4ecdc4?style=for-the-badge&logo=python&logoColor=white&labelColor=1a1a2e">
<img src="https://img.shields.io/badge/📊Version-0.1.1-ff6b6b?style=for-the-badge&labelColor=1a1a2e">
<img src="https://img.shields.io/badge/🧠Graphiti-Temporal_KG-00d9ff?style=for-the-badge&labelColor=1a1a2e">
</p>
<p>
<a href="#-quick-start"><img src="https://img.shields.io/badge/🚀Quick_Start-1a1a2e?style=for-the-badge"></a>
<a href="#-installation"><img src="https://img.shields.io/badge/📦Installation-1a1a2e?style=for-the-badge"></a>
<a href="#-evaluation"><img src="https://img.shields.io/badge/📈Evaluation-1a1a2e?style=for-the-badge"></a>
</p>
</div>
---
## 🎯 What is Helix?
**Helix** fuses [LightRAG](https://github.com/HKUDS/LightRAG)'s proven dual-level retrieval with [Graphiti](https://github.com/getzep/graphiti)'s bi-temporal Knowledge Graph to create a next-generation RAG system with:
| Feature | Capability |
|---------|------------|
| **Temporal Awareness** | Point-in-time queries, automatic edge invalidation |
| **Multi-Hop Reasoning** | BFS-based path exploration with scoring |
| **Hallucination Detection** | Composite Fidelity Index (CFI) verification |
| **Incremental Updates** | No full graph rebuild required |
---
## 📊 Benchmark Targets
| Category | Datasets | Metrics | Target | Baseline |
|----------|----------|---------|--------|----------|
| **Temporal** | TSQA, Time-LongQA, ECT-QA, MultiTQ | Hit@1, Hit@5, Acc | **70-75%** | 45-55% |
| **Hallucination** | Legal QA, Medical QA, FEVER | AUC, CFI | **>0.95** | 0.84-0.94 |
| **Multi-Hop** | MuSiQue, 2WikiMHQA, HotpotQA | F1, EM | **70-75** | 54-59 |
| **Scalability** | UltraDomain (all) | Tokens, Latency | **<600K** | 14M |
---
## 📦 Installation
### From PyPI
```bash
pip install helix-rag
```
### From Source (Development)
```bash
git clone https://github.com/YashNuhash/Helix.git
cd Helix
# Install with Helix dependencies
pip install -e ".[helix]"
```
### Dependencies
Helix requires:
- **Neo4j** (for Graphiti Knowledge Graph)
- **Supabase** (optional, for vector storage)
- **LLM API** (any provider - configured via environment)
---
## ⚙️ Configuration
Copy `.env.example` to `.env` and configure:
```bash
cp .env.example .env
```
### Required Environment Variables
```env
# Neo4j Configuration (for Graphiti)
NEO4J_URI=bolt://localhost:7687
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=your_password
# LLM Configuration (model-agnostic)
LLM_MODEL_NAME=your_model_name
LLM_API_KEY=your_api_key
# Supabase (optional)
SUPABASE_URL=https://your-project.supabase.co
SUPABASE_KEY=your_key
```
### Supabase Setup (Optional)
Run `scripts/supabase_schema.sql` in your Supabase SQL Editor to create the vector storage table.
---
## 🚀 Quick Start
### Basic Usage
```python
import asyncio
from helix import Helix
async def main():
# Initialize Helix
async with Helix() as helix:
# Insert document with temporal tracking
result = await helix.insert(
"Alan Turing was born on June 23, 1912. "
"He is considered the father of computer science.",
source_description="Wikipedia"
)
print(f"Extracted {result['entities_extracted']} entities")
# Query with temporal awareness
answer = await helix.query(
"When was Alan Turing born?",
mode="hybrid"
)
print(answer["answer"])
asyncio.run(main())
```
### Temporal Queries
```python
from datetime import datetime
from helix import Helix
from helix.utils import is_temporal_query, extract_temporal_params
async def temporal_example():
async with Helix() as helix:
# Detect temporal intent
query = "What was the CEO of Apple in 2015?"
if is_temporal_query(query):
params = extract_temporal_params(query)
print(f"Temporal query detected: {params.temporal_keywords}")
# Query with point-in-time context
result = await helix.query(
query,
valid_at=datetime(2015, 1, 1),
include_temporal_context=True
)
print(result)
asyncio.run(temporal_example())
```
### Hallucination Detection
```python
from helix.hallucination import HallucinationDetector
async def verify_response():
async with Helix() as helix:
detector = HallucinationDetector(graphiti=helix.graphiti)
# Get response
result = await helix.query("Tell me about Alan Turing")
# Verify against knowledge graph
verification = await detector.verify_response(
response=result["answer"],
query="Tell me about Alan Turing",
context=result.get("temporal_context")
)
print(f"Grounded: {verification.is_grounded}")
print(f"CFI Score: {verification.confidence_score:.2f}")
print(f"Entity Coverage: {verification.entity_coverage:.2%}")
asyncio.run(verify_response())
```
### Multi-Hop Reasoning
```python
from helix.multihop import MultiHopRetriever
async def multihop_example():
async with Helix() as helix:
retriever = MultiHopRetriever(graphiti=helix.graphiti)
# Find reasoning paths
paths = await retriever.find_paths(
query="How is Alan Turing connected to modern AI?",
max_hops=3
)
# Format as context
context = retriever.format_paths_as_context(paths)
print(context)
asyncio.run(multihop_example())
```
---
## 📈 Evaluation
### Running Benchmarks
Helix includes evaluation scripts for academic benchmarks. Use these in Google Colab or Kaggle:
```python
# Install Helix
!pip install helix-rag
# Run temporal benchmark
from helix.eval import TemporalBenchmark
benchmark = TemporalBenchmark(dataset="time-longqa")
results = await benchmark.run()
print(f"Hit@1: {results['hit_at_1']:.2%}")
```
### Supported Benchmarks
| Benchmark | Dataset | Command |
|-----------|---------|---------|
| Temporal | TSQA | `helix eval --dataset tsqa` |
| Temporal | Time-LongQA | `helix eval --dataset time-longqa` |
| Temporal | ECT-QA | `helix eval --dataset ect-qa` |
| Multi-Hop | MuSiQue | `helix eval --dataset musique` |
| Multi-Hop | HotpotQA | `helix eval --dataset hotpotqa` |
| Hallucination | FEVER | `helix eval --dataset fever` |
| Scalability | UltraDomain | `helix eval --dataset ultradomain` |
### Colab/Kaggle Notebook
```python
# Quick evaluation notebook
import os
os.environ["LLM_API_KEY"] = "your_key"
os.environ["LLM_MODEL_NAME"] = "your_model"
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_PASSWORD"] = "password"
from helix import Helix
from helix.eval import run_all_benchmarks
# Run all benchmarks
results = await run_all_benchmarks()
print(results.to_dataframe())
```
---
## 🏗️ Architecture
```
┌─────────────────────────────────────────────────────────────┐
│ Helix │
├─────────────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌──────────────┐ ┌───────────────────┐ │
│ │ LightRAG │ │ Graphiti │ │ Helix Modules │ │
│ │ (Retrieval)│ │ (Temporal KG)│ │ │ │
│ ├─────────────┤ ├──────────────┤ ├───────────────────┤ │
│ │ - Chunking │ │ - Episodes │ │ - TemporalHandler │ │
│ │ - Embedding │ │ - Bi-temporal│ │ - Hallucination │ │
│ │ - Vector DB │ │ - Resolution │ │ - MultiHop │ │
│ │ - Dual-level│ │ - Invalidate │ │ - CFI Scoring │ │
│ └──────┬──────┘ └──────┬───────┘ └─────────┬─────────┘ │
│ │ │ │ │
│ └────────────────┼────────────────────┘ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Storage Layer │ │
│ ├─────────────────────────────────────────────────────┤ │
│ │ Neo4j (Graph) │ Supabase (Vector) │ Local KV │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
```
---
## 📁 Project Structure
```
helix/
├── __init__.py # Package entry (v0.1.1)
├── core/
│ └── helix.py # Main Helix class
├── storage/
│ ├── graphiti_impl.py # GraphitiStorage
│ └── supabase_impl.py # SupabaseVectorStorage
├── temporal/
│ └── query_handler.py # TemporalQueryHandler
├── hallucination/
│ └── detector.py # HallucinationDetector (CFI)
├── multihop/
│ └── retriever.py # MultiHopRetriever (BFS)
└── utils/
└── temporal_utils.py # Temporal parsing
```
---
## 🔬 Research Goals
Helix is designed to achieve state-of-the-art performance on:
1. **Temporal GraphRAG**: 70-75% accuracy on temporal QA benchmarks
2. **Hallucination Detection**: AUC >0.95 using graph-aligned verification
3. **Multi-Hop Reasoning**: F1 70-75 on complex reasoning benchmarks
4. **Scalability**: <600K tokens for indexing (vs 14M baseline)
See [PLAN.md](PLAN.md) for detailed research methodology.
---
## 📚 Citation
If you use Helix in your research, please cite:
```bibtex
@software{helix2024,
title = {Helix: Temporal GraphRAG with LightRAG and Graphiti},
author = {Your Name},
year = {2024},
url = {https://github.com/YashNuhash/Helix}
}
```
---
## 🤝 Contributing
Contributions are welcome! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
---
## 📄 License
MIT License - see [LICENSE](LICENSE) for details.
---
<div align="center">
<p><strong>Built with 🧬 Helix</strong></p>
<p>LightRAG + Graphiti = Temporal GraphRAG</p>
</div>
| text/markdown | null | Yash Nuhash <nuhashroxme@gmail.com> | null | null | MIT | rag, graphrag, temporal, knowledge-graph, llm, ai | [
"Development Status :: 3 - Alpha",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"temporal-graphrag>=1.0.0",
"graphiti-core>=0.27.1",
"python-dotenv>=1.2.1",
"pydantic<=2.12.3,>=2.0",
"neo4j>=5.28.0",
"aiohttp>=3.11.12",
"asyncio-throttle>=1.0.2",
"datasets>=3.2.0",
"pandas>=2.2.2",
"requests==2.32.4",
"tqdm>=4.67.1",
"supabase>=2.13.0; extra == \"supabase\"",
"transformers>=4.40.0; extra == \"huggingface\"",
"torch>=2.2.0; extra == \"huggingface\"",
"accelerate>=0.30.0; extra == \"huggingface\"",
"sentence-transformers>=3.0.0; extra == \"huggingface\"",
"ollama>=0.4.0; extra == \"ollama\"",
"fastapi>=0.115.0; extra == \"api\"",
"uvicorn[standard]>=0.34.0; extra == \"api\"",
"pytest>=8.3.4; extra == \"dev\"",
"pytest-asyncio>=0.25.3; extra == \"dev\"",
"ruff>=0.9.4; extra == \"dev\"",
"mypy>=1.14.1; extra == \"dev\"",
"scikit-learn>=1.6.1; extra == \"dev\"",
"helix-rag[api,dev,huggingface,ollama,supabase]; extra == \"all\""
] | [] | [] | [] | [
"Homepage, https://github.com/YashNuhash/Helix",
"Documentation, https://github.com/YashNuhash/Helix#readme",
"Repository, https://github.com/YashNuhash/Helix",
"Bug Tracker, https://github.com/YashNuhash/Helix/issues"
] | twine/6.2.0 CPython/3.12.0 | 2026-02-20T05:14:43.301694 | helix_rag-0.2.0.tar.gz | 562,310 | b0/1b/d237f43b392a2a10bfc92b6182de274b43e56225d3adec16b44ad4e8ce12/helix_rag-0.2.0.tar.gz | source | sdist | null | false | f7904e6bfe4dc55a89ad472eb237ba79 | 1c6861e203833fa5952f7c7144c378c5efc33b8b1faacce15fb102dda4b98b1f | b01bd237f43b392a2a10bfc92b6182de274b43e56225d3adec16b44ad4e8ce12 | null | [
"LICENSE"
] | 285 |
2.4 | claude-mpm | 5.9.20 | Claude Code workflow and agent management framework - Multi-agent orchestration, skills system, MCP integration, session management, and semantic code search for AI-powered development | # Claude MPM - Multi-Agent Project Manager
[](https://badge.fury.io/py/claude-mpm)
[](https://www.python.org/downloads/)
[](LICENSE)
[](https://github.com/astral-sh/ruff)
**A comprehensive workflow and agent management framework for Claude Code** that transforms your AI coding assistant into a full-featured development platform with multi-agent orchestration, skills system, MCP integration, session management, and semantic code search.
> **⚠️ Important**: Claude MPM **requires Claude Code CLI** (v2.1.3+), not Claude Desktop (app). All MCP integrations work with Claude Code's CLI interface only.
>
> **Don't have Claude Code?** Install from: https://docs.anthropic.com/en/docs/claude-code
>
> **Quick Start**: See [Getting Started Guide](docs/getting-started/README.md) to get running in 5 minutes!
---
## Who Should Use Claude MPM?
- 👥 **[Non-Technical Users (Founders/PMs)](docs/usecases/non-technical-users.md)** - Research and understand codebases using Research Mode - no coding experience required
- 💻 **[Developers](docs/usecases/developers.md)** - Multi-agent development workflows with semantic code search and advanced features
- 🏢 **[Teams](docs/usecases/teams.md)** - Collaboration patterns, session management, and coordinated workflows
---
## What is Claude MPM?
Claude MPM transforms Claude Code into a **comprehensive AI development platform** with:
### 🤖 Multi-Agent System
- **47+ Specialized Agents** - Python, TypeScript, Rust, Go, Java, Ruby, PHP, QA, Security, DevOps, and more
- **Intelligent PM Orchestration** - Automatic task routing to specialist agents
- **Agent Sources** - Deploy agents from Git repositories with ETag-based caching
### 🎯 Skills Framework
- **44+ Bundled Skills** - TDD, debugging, Docker, API design, security scanning, Git workflows
- **Progressive Disclosure** - Skills load on-demand to optimize context usage
- **Three-Tier Organization** - Bundled → User → Project priority resolution
- **Domain Authority System** - Auto-generated agent/tool discovery skills for intelligent PM delegation
- **Skills Optimization** - Intelligent project analysis with automated skill recommendations
### 🔌 MCP Integration (Model Context Protocol)
- **Google Workspace MCP** - 34 tools for Gmail, Calendar, Drive, Docs, Tasks
- **Notion** - 7 tools + bulk operations for databases, pages, markdown import
- **Confluence** - 7 tools + bulk operations for pages, spaces, CQL search
- **Slack** - User proxy for channels, messages, DMs, search
- **Semantic Code Search** - AI-powered code discovery via mcp-vector-search
- **Ticket Management** - GitHub, Linear, Jira integration via mcp-ticketer
- **Graph Memory** - Persistent project knowledge via kuzu-memory
### 📊 Session & Workflow Management
- **Session Resume** - Continue work with full context preservation
- **Auto-Pause** - Automatic context summaries at 70%/85%/95% thresholds
- **Real-Time Dashboard** - Live monitoring of agent activity
- **Hooks System** - 15+ event hooks for custom workflows
### 🔐 Enterprise Features
- **OAuth 2.0 Integration** - Secure Google Workspace authentication
- **Encrypted Token Storage** - Fernet encryption with system keychain
- **100+ CLI Commands** - Comprehensive management interface
- **60+ Services** - Service-oriented architecture with event bus
---
## Quick Installation
### Prerequisites
1. **Python 3.11-3.13** (Python 3.13 recommended; 3.14 NOT yet supported)
2. **Claude Code CLI v2.1.3+** (required!)
3. **GitHub Token** (recommended for skill sources)
> **Python Version Warning**:
> - macOS default Python 3.9 is **too old** - use `--python 3.13` flag
> - Python 3.13 is **recommended** and fully tested
> - Python 3.14 is **NOT yet supported** - installation will fail
```bash
# Verify Claude Code is installed
claude --version
# If not installed, get it from:
# https://docs.anthropic.com/en/docs/claude-code
# Set GitHub token (recommended - avoids rate limits)
export GITHUB_TOKEN=your_github_token
```
### Install Claude MPM
**IMPORTANT**: Install from your **home directory**, NOT from within a cloned git repository.
**uv (recommended):**
```bash
# From home directory (IMPORTANT!)
cd ~
# Install with Python 3.13 (not 3.9 or 3.14)
uv tool install claude-mpm[monitor,data-processing] --python 3.13
```
**Homebrew (macOS):**
```bash
brew tap bobmatnyc/tools
brew install claude-mpm
```
**pipx:**
```bash
cd ~
pipx install "claude-mpm[monitor]"
```
### Post-Installation Setup (Required)
These steps must be completed **before** running `claude-mpm doctor`:
```bash
# Create required directories
mkdir -p ~/.claude/{responses,memory,logs}
# Deploy agents
claude-mpm agents deploy
# Add skill source (recommended)
claude-mpm skill-source add https://github.com/bobmatnyc/claude-mpm-skills
```
### Verify Installation
```bash
# Run diagnostics (after completing setup above)
claude-mpm doctor --verbose
# Check versions
claude-mpm --version
claude --version
# Auto-configure your project
cd ~/your-project
claude-mpm auto-configure
```
**What You Should See:**
- 47+ agents deployed to `~/.claude/agents/`
- 44+ bundled skills (in Python package)
- Agent sources configured
- All doctor checks passing
**Recommended Partners**: Install these companion tools for enhanced capabilities:
```bash
uv tool install kuzu-memory --python 3.13
uv tool install mcp-vector-search --python 3.13
uv tool install mcp-ticketer --python 3.13
uv tool install mcp-browser --python 3.13
```
**Tool Version Management**: Use [ASDF version manager](docs/guides/asdf-tool-versions.md) to avoid Python/uv version conflicts across projects.
---
## Key Features
### 🎯 Multi-Agent Orchestration
- **47+ Specialized Agents** from Git repositories covering all development needs
- **Smart Task Routing** via PM agent intelligently delegating to specialists
- **Session Management** with `--resume` flag for seamless continuity
- **Resume Log System** with automatic 10k-token summaries at 70%/85%/95% thresholds
[→ Learn more: Multi-Agent Development](docs/usecases/developers.md#multi-agent-development)
### 📦 Git Repository Integration
- **Curated Content** with 47+ agents automatically deployed from repositories
- **Always Up-to-Date** with ETag-based caching (95%+ bandwidth reduction)
- **Hierarchical BASE-AGENT.md** for template inheritance and DRY principles
- **Custom Repositories** via `claude-mpm agent-source add`
[→ Learn more: Agent Sources](docs/user/agent-sources.md)
### 🎯 Skills System
- **44+ Bundled Skills** covering Git, TDD, Docker, API design, security, debugging, and more
- **Three-Tier Organization**: Bundled/user/project with priority resolution
- **Auto-Linking** to relevant agents based on roles
- **Progressive Disclosure** - Skills load on-demand to optimize context
- **Custom Skills** via `.claude/skills/` or skill repositories
[→ Learn more: Skills Guide](docs/user/skills-guide.md)
### 🔍 Semantic Code Search
- **AI-Powered Discovery** with mcp-vector-search integration
- **Find by Intent** not just keywords ("authentication logic" finds relevant code)
- **Pattern Recognition** for discovering similar implementations
- **Live Updates** tracking code changes automatically
[→ Learn more: Developer Use Cases](docs/usecases/developers.md#semantic-code-search)
### 🧪 MPM Commander (ALPHA)
- **Multi-Project Orchestration** with autonomous AI coordination across codebases
- **Tmux Integration** for isolated project environments and session management
- **Event-Driven Architecture** with inbox system for cross-project communication
- **LLM-Powered Decisions** via OpenRouter for autonomous work queue processing
- **Real-Time Monitoring** with state tracking (IDLE, WORKING, BLOCKED, PAUSED, ERROR)
- ⚠️ **Experimental** - API and CLI interface subject to change
[→ Commander Documentation](docs/commander/usage-guide.md)
### 🔌 Advanced Integration
- **MCP Integration** with full Model Context Protocol support
- **MCP Session Server** (`mpm-session-server`) for programmatic session management
- **Real-Time Monitoring** via `--monitor` flag and web dashboard
- **Multi-Project Support** with per-session working directories
- **Git Integration** with diff viewing and change tracking
[→ Learn more: MCP Gateway](docs/developer/13-mcp-gateway/README.md) | [→ MCP Session Server](docs/mcp-session-server.md)
### 🔐 External Integrations
- **Browser-Based OAuth** for secure authentication with MCP services
- **Google Workspace MCP** built-in server with **34 tools** for:
- **Gmail** (5 tools): Search, read, send, draft, reply
- **Calendar** (6 tools): List, get, create, update, delete events
- **Drive** (7 tools): Search, read, create folders, upload, delete, move files
- **Docs** (4 tools): Create, read, append, markdown-to-doc conversion
- **Tasks** (12 tools): Full task and task list management
- **Notion MCP** built-in server with **7 tools** + bulk operations:
- Query databases, get/create/update pages, search, markdown import
- Setup: `claude-mpm setup notion`
- **Confluence MCP** built-in server with **7 tools** + bulk operations:
- Get/create/update pages, search with CQL, list spaces, markdown import
- Setup: `claude-mpm setup confluence`
- **Slack MCP** user proxy with **12 tools**:
- Channels, messages, DMs, search - acts as authenticated user
- Setup: `claude-mpm setup slack`
- **Encrypted Token Storage** using Fernet encryption with system keychain
- **Automatic Token Refresh** handles expiration seamlessly
```bash
# Set up Google Workspace OAuth
claude-mpm oauth setup workspace-mcp
# Set up Notion (API token)
claude-mpm setup notion
# Set up Confluence (URL + API token)
claude-mpm setup confluence
# Set up Slack (OAuth user token)
claude-mpm setup slack
# Check token status
claude-mpm oauth status workspace-mcp
# List OAuth-capable services
claude-mpm oauth list
```
[→ Google Workspace Setup](docs/guides/oauth-setup.md) | [→ Notion Setup](docs/integrations/NOTION_SETUP.md) | [→ Confluence Setup](docs/integrations/CONFLUENCE_SETUP.md) | [→ Slack Setup](docs/integrations/SLACK_USER_PROXY_SETUP.md)
### ⚡ Performance & Security
- **Simplified Architecture** with ~3,700 lines removed for better performance
- **Enhanced Security** with comprehensive input validation
- **Intelligent Caching** with ~200ms faster startup via hash-based invalidation
- **Memory Management** with cleanup commands for large conversation histories
[→ Learn more: Architecture](docs/developer/ARCHITECTURE.md)
### ⚙️ Automatic Migrations
- **Seamless Updates** with automatic configuration migration on first startup after update
- **One-Time Fixes** for cache restructuring and configuration changes
- **Non-Blocking** failures log warnings but do not stop startup
- **Tracked** in `~/.claude-mpm/migrations.yaml`
[→ Learn more: Startup Migrations](docs/features/startup-migrations.md)
---
## Quick Usage
```bash
# Start interactive mode
claude-mpm
# Start with monitoring dashboard
claude-mpm run --monitor
# Resume previous session
claude-mpm run --resume
# Semantic code search
claude-mpm search "authentication logic"
# or inside Claude Code:
/mpm-search "authentication logic"
# Health diagnostics
claude-mpm doctor
# Verify MCP services
claude-mpm verify
# Manage memory
claude-mpm cleanup-memory
```
**💡 Update Checking**: Claude MPM automatically checks for updates and verifies Claude Code compatibility on startup. Configure in `~/.claude-mpm/configuration.yaml` or see [docs/update-checking.md](docs/update-checking.md).
[→ Complete usage examples: User Guide](docs/user/user-guide.md)
---
## What's New in v5.0
### Git Repository Integration for Agents & Skills
- **📦 Massive Library**: 47+ agents and hundreds of skills deployed automatically
- **🏢 Official Content**: Anthropic's official skills repository included by default
- **🔧 Fully Extensible**: Add your own repositories with immediate testing
- **🌳 Smart Organization**: Hierarchical BASE-AGENT.md inheritance
- **📊 Clear Visibility**: Two-phase progress bars (sync + deployment)
- **✅ Fail-Fast Testing**: Test repositories before they cause startup issues
**Quick Start with Custom Repositories:**
```bash
# Add custom agent repository
claude-mpm agent-source add https://github.com/yourorg/your-agents
# Add custom skill repository
claude-mpm skill-source add https://github.com/yourorg/your-skills
# Test repository without saving
claude-mpm agent-source add https://github.com/yourorg/your-agents --test
```
[→ Full details: What's New](CHANGELOG.md)
---
## Documentation
**📚 [Complete Documentation Hub](docs/README.md)** - Start here for all documentation!
### Quick Links by User Type
#### 👥 For Users
- **[🚀 5-Minute Quick Start](docs/user/quickstart.md)** - Get running immediately
- **[📦 Installation Guide](docs/user/installation.md)** - All installation methods
- **[📖 User Guide](docs/user/user-guide.md)** - Complete user documentation
- **[❓ FAQ](docs/guides/FAQ.md)** - Common questions answered
#### 💻 For Developers
- **[🏗️ Architecture Overview](docs/developer/ARCHITECTURE.md)** - Service-oriented system design
- **[💻 Developer Guide](docs/developer/README.md)** - Complete development documentation
- **[🧪 Contributing](docs/developer/03-development/README.md)** - How to contribute
- **[📊 API Reference](docs/API.md)** - Complete API documentation
#### 🤖 For Agent Creators
- **[🤖 Agent System](docs/AGENTS.md)** - Complete agent development guide
- **[📝 Creation Guide](docs/developer/07-agent-system/creation-guide.md)** - Step-by-step tutorials
- **[📋 Schema Reference](docs/developer/10-schemas/agent_schema_documentation.md)** - Agent format specifications
#### 🚀 For Operations
- **[🚀 Deployment](docs/DEPLOYMENT.md)** - Release management & versioning
- **[📊 Monitoring](docs/MONITOR.md)** - Real-time dashboard & metrics
- **[🐛 Troubleshooting](docs/TROUBLESHOOTING.md)** - Enhanced `doctor` command with auto-fix
---
## Integrations
Claude MPM supports multiple integrations for enhanced functionality. See **[Complete Integration Documentation](docs/integrations/README.md)** for detailed setup guides.
### Core Integrations
- **[kuzu-memory](docs/integrations/kuzu-memory.md)** - Graph-based semantic memory for project context
- **[mcp-vector-search](docs/integrations/mcp-vector-search.md)** - AI-powered semantic code search and discovery
### External Services
- **[Google Workspace MCP](docs/integrations/gworkspace-mcp.md)** - Gmail, Calendar, Drive, Docs, Tasks (67 tools)
- **[Slack](docs/integrations/slack.md)** - Slack workspace integration via user proxy
- **[Notion](docs/integrations/NOTION_SETUP.md)** - Notion databases and pages (7 MCP tools + bulk CLI)
- **[Confluence](docs/integrations/CONFLUENCE_SETUP.md)** - Confluence pages and spaces (7 MCP tools + bulk CLI)
### Quick Setup
```bash
# Setup any integration with one command
claude-mpm setup <integration>
# Examples:
claude-mpm setup kuzu-memory
claude-mpm setup mcp-vector-search
claude-mpm setup gworkspace-mcp # Canonical name (preferred)
claude-mpm setup google-workspace-mcp # Legacy alias (also works)
claude-mpm setup slack
claude-mpm setup notion
claude-mpm setup confluence
# Setup multiple at once
claude-mpm setup kuzu-memory mcp-vector-search gworkspace-mcp
```
**Integration Features:**
- One-command setup for all services
- Secure OAuth 2.0 authentication (Google Workspace, Slack)
- Encrypted token storage in system keychain
- Automatic token refresh
- MCP protocol for standardized tool interfaces
- Bulk CLI operations for high-performance batch processing
---
## Contributing
Contributions are welcome! Please see:
- **[Contributing Guide](docs/developer/03-development/README.md)** - How to contribute
- **[Code Formatting](docs/developer/CODE_FORMATTING.md)** - Code quality standards
- **[Project Structure](docs/reference/STRUCTURE.md)** - Codebase organization
**Development Workflow:**
```bash
# Complete development setup
make dev-complete
# Or step by step:
make setup-dev # Install in development mode
make setup-pre-commit # Set up automated code formatting
```
---
## 📜 License
[](LICENSE)
Licensed under the [Elastic License 2.0](LICENSE) - free for internal use and commercial products.
**Main restriction:** Cannot offer as a hosted SaaS service without a commercial license.
📖 [Licensing FAQ](LICENSE-FAQ.md) | 💼 Commercial licensing: bob@matsuoka.com
---
## Credits
- Based on [claude-multiagent-pm](https://github.com/kfsone/claude-multiagent-pm)
- Enhanced for [Claude Code (CLI)](https://docs.anthropic.com/en/docs/claude-code) integration
- Built with ❤️ by the Claude MPM community
| text/markdown | null | Bob Matsuoka <bob@matsuoka.com> | Claude MPM Team | null | Elastic-2.0 | claude, claude-code, anthropic, ai-agents, multi-agent, workflow-automation, agent-orchestration, developer-tools, cli-tools, mcp, model-context-protocol, skills-system, session-management, semantic-search, code-search, google-workspace, gmail-api, google-calendar, google-drive, google-tasks, github-integration, ticket-management, ai-development, code-generation, devops, automation | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Framework :: AsyncIO",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"License :: Other/Proprietary License",
"Operating System :: MacOS",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development",
"Topic :: Software Development :: Build Tools",
"Topic :: Software Development :: Code Generators",
"Topic :: Software Development :: Libraries :: Application Frameworks",
"Topic :: Software Development :: Quality Assurance",
"Topic :: Software Development :: Testing",
"Topic :: System :: Software Distribution",
"Typing :: Typed"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"ai-trackdown-pytools>=1.4.0",
"pyyaml>=6.0",
"python-dotenv>=1.0.0",
"click>=8.0.0",
"pexpect>=4.8.0",
"psutil>=5.9.0",
"requests>=2.25.0",
"flask>=3.0.0",
"flask-cors>=4.0.0",
"watchdog>=3.0.0",
"python-socketio>=5.14.0",
"aiohttp>=3.9.0",
"aiohttp-cors<0.8.0,>=0.7.0",
"python-engineio>=4.8.0",
"aiofiles>=23.0.0",
"websockets>=12.0",
"python-frontmatter>=1.0.0",
"mistune>=3.0.0",
"tree-sitter>=0.21.0",
"ijson>=3.2.0",
"toml>=0.10.2",
"packaging>=21.0",
"pydantic>=2.0.0",
"pydantic-settings>=2.0.0",
"rich>=13.0.0",
"questionary>=2.0.0",
"pyee>=13.0.0",
"pathspec>=0.11.0",
"fastapi>=0.100.0",
"uvicorn>=0.20.0",
"httpx>=0.24.0",
"keyring>=24.0.0",
"cryptography>=41.0.0",
"mcp>=1.0.0",
"mcp>=0.1.0; extra == \"mcp\"",
"mcp-vector-search>=0.1.0; extra == \"mcp\"",
"mcp-browser>=0.1.0; extra == \"mcp\"",
"mcp-ticketer>=0.1.0; extra == \"mcp\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"ruff>=0.8.0; extra == \"dev\"",
"pylint>=3.0.0; extra == \"dev\"",
"pre-commit; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"types-PyYAML>=6.0.0; extra == \"dev\"",
"types-requests>=2.25.0; extra == \"dev\"",
"deepeval>=1.0.0; extra == \"eval\"",
"pytest>=7.4.0; extra == \"eval\"",
"pytest-asyncio>=0.21.0; extra == \"eval\"",
"pytest-timeout>=2.1.0; extra == \"eval\"",
"sphinx>=7.2.0; extra == \"docs\"",
"sphinx-rtd-theme>=1.3.0; extra == \"docs\"",
"sphinx-autobuild>=2021.3.14; extra == \"docs\"",
"python-socketio>=5.14.0; extra == \"monitor\"",
"aiohttp>=3.9.0; extra == \"monitor\"",
"aiohttp-cors<0.8.0,>=0.7.0; extra == \"monitor\"",
"python-engineio>=4.8.0; extra == \"monitor\"",
"aiofiles>=23.0.0; extra == \"monitor\"",
"websockets>=12.0; extra == \"monitor\"",
"pandas>=2.1.0; extra == \"data-processing\"",
"openpyxl>=3.1.0; extra == \"data-processing\"",
"xlsxwriter>=3.1.0; extra == \"data-processing\"",
"numpy>=1.24.0; extra == \"data-processing\"",
"pyarrow>=14.0.0; extra == \"data-processing\"",
"dask>=2023.12.0; extra == \"data-processing\"",
"polars>=0.19.0; extra == \"data-processing\"",
"xlrd>=2.0.0; extra == \"data-processing\"",
"xlwt>=1.3.0; extra == \"data-processing\"",
"csvkit>=1.3.0; extra == \"data-processing\"",
"tabulate>=0.9.0; extra == \"data-processing\"",
"python-dateutil>=2.8.0; extra == \"data-processing\"",
"lxml>=4.9.0; extra == \"data-processing\"",
"sqlalchemy>=2.0.0; extra == \"data-processing\"",
"psycopg2-binary>=2.9.0; extra == \"data-processing\"",
"pymongo>=4.5.0; extra == \"data-processing\"",
"redis>=5.0.0; extra == \"data-processing\"",
"beautifulsoup4>=4.12.0; extra == \"data-processing\"",
"jsonschema>=4.19.0; extra == \"data-processing\"",
"kuzu-memory>=1.1.5; extra == \"memory\"",
"slack-bolt>=1.18.0; extra == \"slack\"",
"slack-sdk>=3.23.0; extra == \"slack\"",
"starlette>=0.38.0; extra == \"http\"",
"sse-starlette>=2.0.0; extra == \"http\"",
"pyngrok>=7.0.0; extra == \"http\""
] | [] | [] | [] | [
"Homepage, https://github.com/bobmatnyc/claude-mpm",
"Repository, https://github.com/bobmatnyc/claude-mpm.git",
"Issues, https://github.com/bobmatnyc/claude-mpm/issues",
"Documentation, https://github.com/bobmatnyc/claude-mpm/blob/main/README.md"
] | uv/0.9.18 {"installer":{"name":"uv","version":"0.9.18","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T05:14:35.975069 | claude_mpm-5.9.20.tar.gz | 4,379,139 | 54/41/3f28850d741186e6ee19a9f77a4d5296b5667fe2f0c0bc08372588d93ca7/claude_mpm-5.9.20.tar.gz | source | sdist | null | false | e778de90452a479bc7471a776274c745 | ca60d9ee9f2f3ff5e8832d0bb99cdb0de77cd1b9384931195ea5d52edb650f96 | 54413f28850d741186e6ee19a9f77a4d5296b5667fe2f0c0bc08372588d93ca7 | null | [
"LICENSE",
"LICENSE-FAQ.md"
] | 289 |
2.4 | celai | 0.7.0 | AI Driven Communication Platform. Assistants made easy. | <!-- A centered logo of celia -->
<!-- <p align="center">
<img src="https://raw.githubusercontent.com/cel-ai/celai/30b489b21090e3c3f00ffea66d0ae4ac812bd839/cel/assets/celia_logo.png" width="250" />
</p> -->
<div align="center">
<img src="https://github.com/cel-ai/celai/actions/workflows/python-package.yml/badge.svg">
</div>
<hr>
<p align="center">
<!-- https://github.com/cel-ai/celai/blob/main/cel/assets/celai_diagram.png?raw=true -->
<img src="https://github.com/cel-ai/celai/blob/main/cel/assets/celai_diagram.png?raw=true" />
</p>
# Introduction
Cel.ai is a AI Driven Communication Platform. Designed to accelerate the development of omnichannel virtual assistants. Whether you need to integrate with messaging platforms like WhatsApp, Telegram, or VoIP services such as VAPI.com, Cel.ai provides the tools and flexibility to get your assistant up and running quickly.
Don't waste time building on top of hosted platforms that limit your control and flexibility. Cel.ai is designed to be self-hosted, giving you the freedom to customize and extend the platform to meet your needs.
Supported Connectors:
- WhatsApp
- Telegram
- VAPI.ai
- Chatwoot
Off the shelf, Cel.ai provides a powerful tools such as:
- Multi Asssitant Router
- Logic Router based on state variables
- Agentic Router based on user itent and context
- Semantic Router (coming soon)
- Tooling
- Events: `message`, `image`, `new_conversation`, and more
- Powered by Langchain
- Langsmith user tracing
- Moderation Middlewares
- Blacklist Middlewares
- Invitations
- Ngrok native integration
- User Sequential Message Processing
[Documentation](https://cel-ai.github.io/celai/)
## Multi-Assistant Router
Cel.ai provides a powerful multi-assistant router that allows you to create complex conversational assistants easily. This architecture allows you to scale in a modular way, adding new assistants as needed. The routing can be done based on state variables, user intent, or context.
Agentic Router is the most powerful router in Cel.ai. It allows you to triage messages to different assistants based on user intent and context. It keeps prompts small and focused, allowing for more accurate responses.
Keep prompts at mininal length and focused on a single task will ensure that the user experience is optimal and the response cost are kept low.
For example, if you are building a virtual assistant for a hotel, you can have different assistants for booking/reservation, cancellation, room service, and check-out. The Agentic Router will automatically route messages to the correct assistant based on the user's intent.
<p align="center">
<img src="https://raw.githubusercontent.com/cel-ai/celai/refs/heads/main/cel/assets/celai_router_diagram.png" width="700" />
</p>
## In Context Routing
Cel.ai provides a powerful in-context routing system. Messages are routed to the correct assistant based on the user's intent and context.
Assistant can have its own set of prompts and responses, but share the same context.
State and History stores are shared between all assistants, allowing for a seamless user experience. Ensuring all assistants are in sync with the user's context.
## Install
pip install from github:
```bash
pip install celai
```
## Getting Started
Let's create a simple assistant that can be accessed via Telegram. First, you'll need to create a new Telegram bot and get the API token. You can do this by following the instructions in the [Telegram documentation](https://core.telegram.org/bots#6-botfather).
This example uses OpenAI's GPT-4o model to create a simple assistant that can help users buy Bitcoins. To use the OpenAI API, you'll need to sign up for an API key on the [OpenAI website](https://platform.openai.com/).
## Configure Environment Variables
### OpenAI API Key
Make sure to set the `OPENAI_API_KEY` environment variable with your OpenAI API key:
```bash
export OPENAI_API_KEY=<YOUR_OPENAI_API_KEY>
```
### Ngrok Authtoken
The easy way to get a public HTTPS URL for your assistant is to use [ngrok](https://ngrok.com/). Cel.ai has built-in support for ngrok, so you can easily delegate the public URL creation to Cel.ai. To use ngrok, you'll need a Ngrok authtoken. You can get one by signing up on the [ngrok website](https://ngrok.com/). Then set the `NGROK_AUTHTOKEN` environment variable:
```bash
export NGROK_AUTHTOKEN=<YOUR_NGROK_AUTHTOKEN>
```
Then you can create a new Python script with the following code, don't forget to
replace `<YOUR_TELEGRAM_TOKEN>` with the token you received from Telegram:
```python
# Import Cel.ai modules
import os
from cel.connectors.telegram import TelegramConnector
from cel.gateway.message_gateway import MessageGateway
from cel.assistants.macaw.macaw_assistant import MacawAssistant
from cel.prompt.prompt_template import PromptTemplate
# Setup prompt
prompt = """You are an AI assistant. Called Celia. You can help a user to buy Bitcoins."""
prompt_template = PromptTemplate(prompt)
# Create the assistant based on the Macaw Assistant
# Macaw is a Langchain-based assistant that can be
# used to create a wide variety of assistants
ast = MacawAssistant(prompt=prompt_template)
gateway = MessageGateway(
assistant=ast,
host="127.0.0.1", port=5004,
)
# For this example, we will use the Telegram connector
conn = TelegramConnector(
token="<YOUR_TELEGRAM_TOKEN>"
)
# Register the connector with the gateway
gateway.register_connector(conn)
# Then start the gateway and begin processing messages
# with ngrok enabled Cel.ai will automatically create a
# public URL for the assistant.
gateway.run(enable_ngrok=True)
```
| text/markdown | Alex Martin | alejamp@gmail.com | null | null | null | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.11 | [] | [] | [] | [
"PyJWT>=2.10.1",
"aiogram>=3.6.0",
"aioredis>=2.0.1",
"beautifulsoup4>=4.12.3",
"chardet>=5.2.0",
"chromadb>=0.5.0",
"cryptography>=44.0.0",
"deepgram-sdk>=3.2.7",
"dictdiffer>=0.9.0",
"diskcache>=5.6.3",
"elevenlabs>=1.9.0",
"fakeredis>=2.23.2",
"geopy>=2.4.1",
"halo>=0.0.31",
"langchain>=0.2.0",
"langchain-chroma>=0.1.1",
"langchain-community>=0.2.1",
"langchain-openai>=0.1.8",
"loguru>=0.7.2",
"lxml>=5.2.2",
"marko<3.0.0,>=2.1.0",
"numpy>=1.26.4",
"ollama>=0.3.1",
"openai>=1.30.1",
"openai-responses>=0.3.2",
"pybars3>=0.9.7",
"pymongo>=4.8.0",
"pysbd>=0.3.4",
"python-dotenv<2.0.0,>=1.0.1",
"pywa>=2.7.0",
"qrcode>=7.4.2",
"redis>=4.6.0",
"shortuuid>=1.0.13",
"together>=1.2.12"
] | [] | [] | [] | [
"Homepage, https://github.com/cel-ai/celai",
"Issues, https://github.com/cel-ai/celai/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T05:13:55.769502 | celai-0.7.0.tar.gz | 2,374,145 | f2/18/59937ba42d0e672e98be9e2d71f55d6c66b0a387bd3275fdbcb7b6f8f6e6/celai-0.7.0.tar.gz | source | sdist | null | false | 3372d1153d02b477f9494797a180e230 | 3656382f3b1261d211ea6a17e5d9601aedbf30b54fa9f323087e6140aee5734c | f21859937ba42d0e672e98be9e2d71f55d6c66b0a387bd3275fdbcb7b6f8f6e6 | null | [
"LICENSE"
] | 261 |
2.4 | feedtui | 0.1.3 | A configurable terminal dashboard for stocks, news, sports, and social feeds with a virtual pet companion | # feedtui
A configurable terminal dashboard for browsing news, stocks, sports, and more - with a virtual pet companion!
## Features
- **Hacker News** - Browse top, new, and best stories
- **Stock Ticker** - Track your portfolio in real-time
- **RSS Feeds** - Subscribe to your favorite news sources
- **Sports Scores** - Follow NBA, NFL, EPL, and more
- **Twitter/X** - Post, reply, search tweets via Bird CLI integration
- **Pixel Art** - Convert images to beautiful terminal pixel art
- **World Clock** - Multi-timezone clock with integrated stopwatch
- **Tui** - Your virtual companion creature that levels up as you use the terminal!
## Installation
### Option 1: Install via pip (Recommended)
No Rust toolchain required! Install directly from PyPI:
```bash
pip install feedtui
```
Or with pipx for isolated installation:
```bash
pipx install feedtui
```
### Option 2: From crates.io (Rust)
```bash
cargo install feedtui
```
### Option 3: Quick Install Script
```bash
git clone https://github.com/muk2/feedtui
cd feedtui
./install.sh
```
### Option 4: Using Make
```bash
git clone https://github.com/muk2/feedtui
cd feedtui
make install
```
### Option 5: Manual Install
```bash
git clone https://github.com/muk2/feedtui
cd feedtui
cargo install --path .
```
All Rust-based methods install the `feedtui` binary to `~/.cargo/bin/`. Make sure this directory is in your PATH.
## Getting Started
### Interactive Configuration Wizard
The easiest way to get started is to run the configuration wizard:
```bash
feedtui init
```
This will guide you through setting up your dashboard with an interactive prompt.
### Manual Configuration
Alternatively, create a `.feedtui` folder in your home directory and add a `config.toml` file:
```bash
mkdir -p ~/.feedtui
cp config.example.toml ~/.feedtui/config.toml
```
Edit the config to customize your dashboard layout and feeds.
## Usage
### Run the dashboard
```bash
feedtui
```
### Command-line options
```bash
# Use a custom config file
feedtui --config /path/to/config.toml
# Override refresh interval
feedtui --refresh 30
# View configuration status
feedtui config
# Reconfigure with wizard
feedtui init --force
# Show installation help
feedtui install
# Show version
feedtui --version
# Show help
feedtui --help
```
## Meet Tui!
Tui (pronounced "chew-ee") is your virtual companion creature that lives in your terminal. The more you use feedtui, the more Tui grows!
### Features
- **10 Different Species** - Choose from Blob, Bird, Cat, Dragon, Fox, Owl, Penguin, Robot, Spirit, or Octopus
- **Leveling System** - Earn XP just by using the terminal
- **Skill Tree** - Unlock skills with points earned from leveling up
- **Outfits** - Customize Tui with unlockable outfits like Hacker, Wizard, Ninja, Astronaut, and more
- **Moods** - Tui reacts to how often you visit
- **Persistent Progress** - Your creature's progress is saved automatically
### Keybindings
| Key | Action |
|-----|--------|
| `t` | Toggle Tui menu |
| `Tab` / `Shift+Tab` | Switch between menu tabs / widgets |
| `j` / `k` or arrows | Navigate lists |
| `Enter` | Select/purchase items in menu |
| `r` | Refresh feeds |
| `q` | Quit |
### Skill Tree
Unlock skills by spending points:
- **Greeting** (Free) - Tui greets you on startup
- **News Digest** (10 pts) - Highlights important news
- **Stock Alert** (15 pts) - Alerts on significant movements
- **Quick Learner** (15 pts) - +10% XP gain
- **Speed Read** (20 pts) - Faster feed refresh
- **Fast Learner** (30 pts) - +25% XP gain
- **Cosmic Insight** (50 pts) - Trending topic insights
- **Fire Breath** (40 pts) - Cosmetic fire animation
- **Omniscience** (100 pts) - Maximum XP boost
### Outfit Unlocks
Outfits unlock as you level up:
| Level | Outfit |
|-------|--------|
| 1 | Default |
| 5 | Hacker |
| 10 | Wizard |
| 15 | Ninja |
| 20 | Astronaut |
| 25 | Robot |
| 30 | Dragon |
| 50 | Legendary |
## Available Widgets
feedtui supports the following configurable widgets. Each widget can be positioned in a grid layout and customized with various options.
### Creature Widget
Your virtual companion that lives in your terminal and levels up as you use feedtui!
**Configuration:**
```toml
[[widgets]]
type = "creature"
title = "Tui" # Widget title
show_on_startup = true # Show creature menu on startup
position = { row = 0, col = 0 } # Grid position
```
**Features:**
- 10 different species (Blob, Bird, Cat, Dragon, Fox, Owl, Penguin, Robot, Spirit, Octopus)
- Leveling system with XP progression
- Unlockable skills and outfits
- Mood system based on usage
- Press `t` to open the Tui menu
### Hacker News Widget
Browse Hacker News stories directly in your terminal.
**Configuration:**
```toml
[[widgets]]
type = "hackernews"
title = "Hacker News" # Widget title
story_count = 10 # Number of stories to display (default: 10)
story_type = "top" # Story type: "top", "new", or "best" (default: "top")
position = { row = 0, col = 1 } # Grid position
```
**Features:**
- Browse top, new, or best stories
- Configurable story count
- Direct links to discussions
### Stocks Widget
Track your stock portfolio with real-time price updates.
**Configuration:**
```toml
[[widgets]]
type = "stocks"
title = "Portfolio" # Widget title
symbols = ["AAPL", "GOOGL", "MSFT", "NVDA", "TSLA"] # Stock ticker symbols
position = { row = 0, col = 2 } # Grid position
```
**Features:**
- Real-time stock price tracking
- Multiple symbols support
- Price change indicators
### RSS Widget
Subscribe to your favorite RSS feeds and stay updated with the latest content.
**Configuration:**
```toml
[[widgets]]
type = "rss"
title = "Tech News" # Widget title
feeds = [ # List of RSS feed URLs
"https://feeds.arstechnica.com/arstechnica/technology-lab",
"https://www.theverge.com/rss/index.xml"
]
max_items = 10 # Maximum items to display per feed (default: 15)
position = { row = 1, col = 0 } # Grid position
```
**Features:**
- Multiple RSS feed support
- Configurable item limit
- Feed aggregation
### Sports Widget
Follow live scores and updates from major sports leagues.
**Configuration:**
```toml
[[widgets]]
type = "sports"
title = "Sports" # Widget title
leagues = ["nba", "nfl", "mlb", "nhl", "epl", "mls", "ncaaf", "ncaab"] # Leagues to follow
position = { row = 1, col = 1 } # Grid position
```
**Supported Leagues:**
- `nba` - NBA Basketball
- `nfl` - NFL Football
- `mlb` - Major League Baseball
- `nhl` - NHL Hockey
- `epl` or `premier-league` - English Premier League
- `mls` - Major League Soccer
- `ncaaf` or `college-football` - College Football
- `ncaab` or `college-basketball` - College Basketball
**Features:**
- Live scores and game status
- Multiple league support
- Real-time updates powered by ESPN API
### GitHub Widget
Comprehensive GitHub dashboard with notifications, pull requests, and recent commits.
**Configuration:**
```toml
[[widgets]]
type = "github"
title = "GitHub Dashboard" # Widget title
token = "${GITHUB_TOKEN}" # GitHub personal access token (use env variable)
username = "your-username" # Your GitHub username
show_notifications = true # Show notifications tab (default: true)
show_pull_requests = true # Show pull requests tab (default: true)
show_commits = true # Show commits tab (default: true)
max_notifications = 20 # Max notifications to display (default: 20)
max_pull_requests = 10 # Max PRs to display (default: 10)
max_commits = 10 # Max commits to display (default: 10)
position = { row = 1, col = 2 } # Grid position
```
**Setup:**
1. Create a GitHub personal access token with `notifications` and `repo` scopes
2. Set environment variable: `export GITHUB_TOKEN=your_token_here`
3. Use `${GITHUB_TOKEN}` in config to reference the environment variable
**Features:**
- GitHub notifications feed
- Pull request tracking
- Recent commit history
- Use `h`/`l` or arrow keys to switch between tabs
### YouTube Widget
Display videos from YouTube channels or search queries.
**Configuration:**
```toml
[[widgets]]
type = "youtube"
title = "YouTube" # Widget title
api_key = "${YOUTUBE_API_KEY}" # YouTube Data API v3 key (use env variable)
channels = ["UCXuqSBlHAE6Xw-yeJA0Tunw"] # Optional: List of channel IDs
search_query = "rust programming" # Optional: Search query for videos
max_videos = 15 # Maximum videos to display (default: 15)
position = { row = 2, col = 0 } # Grid position
```
**Setup:**
1. Get a YouTube Data API v3 key from [Google Cloud Console](https://console.cloud.google.com/apis/credentials)
2. Set environment variable: `export YOUTUBE_API_KEY=your_key_here`
3. Use `${YOUTUBE_API_KEY}` in config to reference the environment variable
**Features:**
- Display videos from specific channels
- Search for videos by query
- Configurable video limit
- Video titles and metadata
### Twitter/X Widget
Interactive Twitter/X feed powered by [Bird CLI](https://github.com/xrehpicx/bird) for posting, replying, searching, and reading tweets directly from your terminal.
**Prerequisites:**
- Bird CLI installed: `bun install -g bird-cli`
- Twitter/X authentication tokens set as environment variables:
- `CT0` - Cookie token from twitter.com
- `AUTH_TOKEN` - Authentication token from twitter.com
**Configuration:**
```toml
[[widgets]]
type = "twitter"
title = "Twitter/X" # Widget title
position = { row = 2, col = 2 } # Grid position
```
**Setup:**
1. Install Bird CLI: `bun install -g bird-cli`
2. Extract cookies from twitter.com (use browser dev tools):
- `CT0` cookie value
- `auth_token` cookie value
3. Set environment variables:
```bash
export CT0="your_ct0_token"
export AUTH_TOKEN="your_auth_token"
```
**Features:**
- Tweet composition with modal interface
- Reply to tweets
- Search Twitter/X
- View mentions
- Read individual tweets and threads
- When Twitter widget is selected:
- Press `t` to compose a new tweet
- Press `r` to reply to selected tweet
- Press `/` to open search
- Press `m` to load mentions
- Press `Enter` to read selected tweet
- Press `Esc` to close modals
**Note:** This widget requires external authentication and Bird CLI to be properly configured.
### Pixel Art Widget
Convert images into beautiful terminal-rendered pixel art. Supports PNG, JPEG, and WebP formats with adjustable pixel resolution.
**Configuration:**
```toml
[[widgets]]
type = "pixelart"
title = "Pixel Art" # Widget title
image_path = "/path/to/image.png" # Path to image file (optional)
pixel_size = 32 # Target pixel resolution (optional, default: 32)
position = { row = 3, col = 0 } # Grid position
```
**Supported Image Formats:**
- PNG
- JPEG
- WebP
**Features:**
- Image-to-pixel art conversion with nearest-neighbor scaling
- Adjustable pixel resolution (8×8 to 128×128)
- True color terminal rendering (24-bit RGB)
- Aspect ratio preservation
- Scrollable output for large images
- Real-time pixel size adjustment
**Usage:**
1. Configure `image_path` in your config.toml
2. Select the widget with Tab
3. Use keybindings to interact:
- Press `+` to increase pixel size (8 → 16 → 32 → 64 → 128)
- Press `-` to decrease pixel size (128 → 64 → 32 → 16 → 8)
- Use `↑↓` or `j`/`k` to scroll through large images
**Display Information:**
- Original image dimensions
- Pixelated dimensions
- Current pixel size setting
- Scroll indicator when image exceeds viewport
**Example Use Cases:**
- Display profile pictures as pixel art
- Create retro-style avatars
- Preview game sprites
- Terminal art galleries
- NFT-style pixel aesthetics
### Clock Widget
Multi-timezone world clock with an integrated stopwatch for productivity tracking.
**Configuration:**
```toml
[[widgets]]
type = "clock"
title = "World Clock" # Widget title
timezones = [ # List of IANA timezone identifiers
"America/New_York",
"Europe/London",
"Asia/Tokyo"
]
position = { row = 2, col = 1 } # Grid position
```
**Common Timezones:**
- `America/New_York` - Eastern Time (US)
- `America/Los_Angeles` - Pacific Time (US)
- `America/Chicago` - Central Time (US)
- `Europe/London` - UK Time
- `Europe/Paris` - Central European Time
- `Asia/Tokyo` - Japan Time
- `Asia/Shanghai` - China Time
- `UTC` - Coordinated Universal Time
**Features:**
- Multiple timezone support with IANA timezone database
- Real-time clock updates (every second)
- Local timezone highlighting
- Built-in stopwatch with start/pause/reset controls
- When clock widget is selected:
- Press `s` to Start/Pause stopwatch
- Press `r` to Reset stopwatch
- Non-blocking time updates for smooth UI
## Example Config
Here's a complete example showing all available widgets:
```toml
[general]
refresh_interval_secs = 60
theme = "dark"
# Tui - Your companion creature! - top left
# Press 't' to open the Tui menu and customize your creature
[[widgets]]
type = "creature"
title = "Tui"
show_on_startup = true
position = { row = 0, col = 0 }
# Hacker News - top middle
[[widgets]]
type = "hackernews"
title = "Hacker News"
story_count = 10
story_type = "top" # top, new, best
position = { row = 0, col = 1 }
# Stocks - top right
[[widgets]]
type = "stocks"
title = "Portfolio"
symbols = ["AAPL", "GOOGL", "MSFT", "NVDA", "TSLA"]
position = { row = 0, col = 2 }
# Tech News (RSS) - bottom left
[[widgets]]
type = "rss"
title = "Tech News"
feeds = [
"https://feeds.arstechnica.com/arstechnica/technology-lab",
"https://www.theverge.com/rss/index.xml"
]
max_items = 10
position = { row = 1, col = 0 }
# Sports - bottom middle
[[widgets]]
type = "sports"
title = "Sports"
leagues = ["nba", "nfl", "epl"]
position = { row = 1, col = 1 }
# GitHub Dashboard - bottom right
# Requires a GitHub personal access token with notifications and repo scope
# Set environment variable: export GITHUB_TOKEN=your_token_here
[[widgets]]
type = "github"
title = "GitHub Dashboard"
token = "${GITHUB_TOKEN}"
username = "your-username"
show_notifications = true
show_pull_requests = true
show_commits = true
max_notifications = 20
max_pull_requests = 10
max_commits = 10
position = { row = 1, col = 2 }
# YouTube Widget - Optional
# Display YouTube videos from channels or search queries
# Requires a YouTube Data API v3 key
# Get your API key from: https://console.cloud.google.com/apis/credentials
# Set environment variable: export YOUTUBE_API_KEY=your_key_here
# [[widgets]]
# type = "youtube"
# title = "YouTube"
# api_key = "${YOUTUBE_API_KEY}"
# channels = [] # Optional: List of channel IDs to display videos from
# search_query = "rust programming" # Optional: Search query for videos
# max_videos = 15
# position = { row = 2, col = 0 }
```
## Python API
If you installed via pip, you can also use feedtui as a Python library:
```python
import feedtui
# Run the TUI
feedtui.run()
# Run with custom config
feedtui.run(config_path="/path/to/config.toml")
# Run with custom refresh interval
feedtui.run(refresh_interval=30)
# Initialize a new config file
config_path = feedtui.init_config()
print(f"Config created at: {config_path}")
# Get config path
print(feedtui.get_config_path())
# Get version
print(feedtui.version())
```
## Development
### Running from source (without installing)
```bash
# Debug mode
cargo run
# Release mode
cargo run --release
# Or use make
make dev # debug mode
make run # release mode
```
### Common development tasks
```bash
# Format code
cargo fmt
# or
make fmt
# Run linter
cargo clippy
# or
make clippy
# Run tests
cargo test
# or
make test
# Clean build artifacts
cargo clean
# or
make clean
```
## License
MIT
| text/markdown; charset=UTF-8; variant=GFM | malchal | null | null | null | MIT | tui, dashboard, terminal, rss, stocks, cli | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: End Users/Desktop",
"License :: OSI Approved :: MIT License",
"Operating System :: MacOS",
"Operating System :: POSIX :: Linux",
"Operating System :: Microsoft :: Windows",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Rust",
"Topic :: Terminals",
"Topic :: Utilities"
] | [] | https://github.com/muk2/feedtui | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/muk2/feedtui",
"Issues, https://github.com/muk2/feedtui/issues",
"Repository, https://github.com/muk2/feedtui"
] | maturin/1.12.3 | 2026-02-20T05:12:42.455696 | feedtui-0.1.3.tar.gz | 92,980 | b0/68/3b4f77e0cefc85d566039543c53d8871103fb6f70175027425901ca1717b/feedtui-0.1.3.tar.gz | source | sdist | null | false | 62fb34f5440a75442c508d49764f57a0 | a4a39b3a061578ce48b7a2af747315a13a5da9b5ab9152ffd2f1a09761a22837 | b0683b4f77e0cefc85d566039543c53d8871103fb6f70175027425901ca1717b | null | [] | 1,414 |
2.4 | statsig | 0.70.2 | Statsig Python Server SDK | # Statsig Python Server SDK
[](https://github.com/statsig-io/python-sdk/actions/workflows/test.yml)
The python SDK for server/multi-user environments.
Statsig helps you move faster with Feature Gates (Feature Flags) and Dynamic Configs. It also allows you to run A/B tests to validate your new features and understand their impact on your KPIs. If you're new to Statsig, create an account at [statsig.com](https://www.statsig.com).
## Getting Started
Visit our [getting started guide](https://docs.statsig.com/server/pythonSDK).
## Testing
Each server SDK is tested at multiple levels - from unit to integration and e2e tests. Our internal e2e test harness runs daily against each server SDK, while unit and integration tests can be seen in the respective github repos of each SDK.
Run local unit tests separately for now:
```
python3 -m unittest tests/server_sdk_consistency_test.py
python3 -m unittest tests/test_statsig_e2e.py
```
## Guidelines
- Pull requests are welcome!
- If you encounter bugs, feel free to [file an issue](https://github.com/statsig-io/python-sdk/issues).
- For integration questions/help, [join our slack community](https://join.slack.com/t/statsigcommunity/shared_invite/zt-pbp005hg-VFQOutZhMw5Vu9eWvCro9g).
| text/markdown | Tore Hanssen, Jiakan Wang | tore@statsig.com, jkw@statsig.com | null | null | ISC | null | [
"Intended Audience :: Developers",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Topic :: Software Development :: Libraries"
] | [] | https://github.com/statsig-io/python-sdk | null | >=3.7 | [] | [] | [] | [
"requests",
"ua_parser",
"ip3country",
"grpcio",
"protobuf",
"ijson",
"typing-extensions",
"brotli",
"requests; extra == \"test\"",
"user_agents; extra == \"test\"",
"semver; extra == \"test\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.19 | 2026-02-20T05:12:13.043461 | statsig-0.70.2.tar.gz | 97,166 | e1/ed/b0783eadc0590c31a14d7daabc466fc9352e1ff154f8e120a64004c47df8/statsig-0.70.2.tar.gz | source | sdist | null | false | b252a1c78bf9dc7a324f482080f404b3 | d851396ad3351d588dce949dd93c66aa31aa33ae0032df19ca641e98e1fa9a82 | e1edb0783eadc0590c31a14d7daabc466fc9352e1ff154f8e120a64004c47df8 | null | [
"LICENSE"
] | 46,864 |
2.4 | paradex_py | 0.5.5rc5 | Paradex Python SDK | # Paradex Python SDK
[](https://img.shields.io/github/v/release/tradeparadex/paradex-py)
[](https://github.com/tradeparadex/paradex-py/actions/workflows/main.yml?query=branch%3Amain)
[](https://codecov.io/gh/tradeparadex/paradex-py)
[](https://img.shields.io/github/commit-activity/m/tradeparadex/paradex-py)
[](https://img.shields.io/github/license/tradeparadex/paradex-py)
Paradex Python SDK provides a simple interface to interact with the Paradex REST and WS API.
## Examples
### L1 + L2 Authentication (Traditional)
```python
from paradex_py import Paradex
from paradex_py.environment import Environment
paradex = Paradex(env=Environment.TESTNET, l1_address="0x...", l1_private_key="0x...")
print(hex(paradex.account.l2_address)) # 0x...
print(hex(paradex.account.l2_public_key)) # 0x...
print(hex(paradex.account.l2_private_key)) # 0x...
```
### L2-Only Authentication (Subkey)
```python
from paradex_py import ParadexSubkey
from paradex_py.environment import Environment
# Use ParadexSubkey for L2-only authentication
paradex = ParadexSubkey(
env=Environment.TESTNET,
l2_private_key="0x...",
l2_address="0x..."
)
print(hex(paradex.account.l2_address)) # 0x...
print(hex(paradex.account.l2_public_key)) # 0x...
print(hex(paradex.account.l2_private_key)) # 0x...
```
### WebSocket Usage
```python
async def on_message(ws_channel, message):
print(ws_channel, message)
await paradex.ws_client.connect()
await paradex.ws_client.subscribe(ParadexWebsocketChannel.MARKETS_SUMMARY, callback=on_message)
```
📖 For complete documentation refer to [tradeparadex.github.io/paradex-py](https://tradeparadex.github.io/paradex-py/)
💻 For comprehensive examples refer to following files:
- API (L1+L2): [examples/call_rest_api.py](examples/call_rest_api.py)
- API (L2-only): [examples/subkey_rest_api.py](examples/subkey_rest_api.py)
- WS (L1+L2): [examples/connect_ws_api.py](examples/connect_ws_api.py)
- WS (L2-only): [examples/subkey_ws_api.py](examples/subkey_ws_api.py)
- Transfer: [examples/transfer_l2_usdc.py](examples/transfer_l2_usdc.py)
## Development
```bash
make install
make check
make test
make build
make clean-build
make publish
make build-and-publish
make docs-test
make docs
make help
```
### Using uv
This project uses `uv` for managing dependencies and building. Below are instructions for installing `uv` and the basic workflow for development outside of using `make` commands.
### Installing uv
`uv` is a fast and modern Python package manager. You can install it using the standalone installer for macOS and Linux:
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
```
For other installation methods, refer to the [uv installation documentation](https://docs.astral.sh/uv/getting-started/installation/).
### Basic Workflow with uv
If you prefer not to use `make` commands, you can directly use `uv` for development tasks:
- **Install dependencies**: Sync your environment with the project's dependencies.
```bash
uv sync
```
- **Run tests**: Execute the test suite using `pytest` within the `uv` environment.
```bash
uv run pytest
```
- **Build the project**: Create a distribution package for the SDK.
```bash
uv build
```
For more detailed information on using `uv`, refer to the [uv documentation](https://docs.astral.sh/uv/).
The CI/CD pipeline will be triggered when a new pull request is opened, code is merged to main, or when new release is created.
## Notes
> [!WARNING]
> Experimental SDK, library API is subject to change
| text/markdown | null | Paradex <finfo@paradex.trade> | null | null | MIT License Copyright (c) 2023, Paradex Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | <3.13,>=3.10 | [] | [] | [] | [
"eth-account>=0.13.6",
"httpx<0.28.0,>=0.27.0",
"ledgereth>=0.10.0",
"marshmallow-dataclass<9.0.0,>=8.6.1",
"poseidon-py<0.2.0,>=0.1.0",
"pydantic<3.0.0,>=2.0.0",
"pyjwt<3.0.0,>=2.8.0",
"starknet-crypto-py<0.3.0,>=0.2.0",
"starknet-py<0.29.0,>=0.28.0",
"websockets<16.0,>=15.0"
] | [] | [] | [] | [
"Homepage, https://github.com/tradeparadex/paradex-py",
"Repository, https://github.com/tradeparadex/paradex-py",
"Documentation, https://tradeparadex.github.io/paradex-py/"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T05:11:50.874832 | paradex_py-0.5.5rc5-py3-none-any.whl | 72,343 | 46/34/418d8cdf002109edca72357e529439bab8d3d5df3617562b1a9eccd40777/paradex_py-0.5.5rc5-py3-none-any.whl | py3 | bdist_wheel | null | false | 53fa05b40d93d29ffe9714c4fa429fe5 | d02344212fce2140f76cef23d75d9d7c6ce8c357151d29addc74c7507ae05bc6 | 4634418d8cdf002109edca72357e529439bab8d3d5df3617562b1a9eccd40777 | null | [
"LICENSE"
] | 0 |
2.4 | deriva-ml | 1.17.19 | Utilities to simplify use of Dervia and Pandas to create reproducable ML pipelines | # DerivaML
Deriva-ML is a python library to simplify the process of creating and executing reproducible machine learning workflows
using a deriva catalog.
Complete on-line documentation for DerivaML can be found [here](https://informatics-isi-edu.github.io/deriva-ml/)
To get started using DerivaML, you can clone the [model template repository](https://github.com/informatics-isi-edu/deriva-ml-model-template), and modify it to suite your requirements.
## References
| text/markdown | null | ISRD <isrd-dev@isi.edu> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"bump-my-version",
"bdbag",
"deriva~=1.7.10",
"deepdiff",
"nbconvert",
"pandas",
"pydantic>=2.11",
"papermill",
"pandas-stubs",
"pyyaml",
"regex",
"semver>3.0.0",
"setuptools>=80",
"setuptools-scm>=8.0",
"nbstripout",
"hydra_zen",
"SQLAlchemy"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T05:11:45.956584 | deriva_ml-1.17.19.tar.gz | 4,106,225 | 5a/10/d41230577d506eb9eb7894e961c81561952a5bd2daed96165c158e565899/deriva_ml-1.17.19.tar.gz | source | sdist | null | false | 04a3c2d4e140d3003c4a0b8415396166 | acb6869499b51647d04b7b818015a71300e521ec487f7814d5f2cc31848d05fb | 5a10d41230577d506eb9eb7894e961c81561952a5bd2daed96165c158e565899 | null | [
"LICENSE"
] | 243 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.