
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.4 | modulitiz | 2.23.1 | Raccolta dei miei moduli - versione completa | # modulitiz
It's a Python library that contains all the useful functions.
This package requires all the others.
## Installation
Use the package manager [pip](https://pip.pypa.io/en/stable/) to install:
```bash
pip install -U modulitiz
```
The other required dependencies will be installed automatically.
## Usage
```python
from modulitiz.multimedia.ModuloImmagini import ModuloImmagini
# returns True
ModuloImmagini.screenshot("abc.png")
```
## Contributing
If you find any bug you can write me at [sderfo1234@altervista.org](mailto:sderfo1234@altervista.org)
## License
[MIT](https://choosealicense.com/licenses/mit/)
| text/markdown | null | tiz <sderfo1234@altervista.org> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"modulitiz-mini>=2",
"dash==3.4.0",
"librosa==0.11.0",
"matplotlib==3.10.8",
"mutagen==1.47.0",
"numpy==2.3.5",
"Pillow==12.1.0",
"pygame==2.6.1",
"selenium==4.40.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.9 | 2026-02-19T21:11:59.161826 | modulitiz-2.23.1-py311-none-any.whl | 20,972 | 41/35/e6e02ed9ce4207f9119a835b68bb288bdcb643d7cb3b931187d27d803ff6/modulitiz-2.23.1-py311-none-any.whl | py311 | bdist_wheel | null | false | 461a089b9fe48490303d0f243d296c68 | 94ee3be7d68adc0248d48a7f164e0aaa4b56bf6d9707f0b66c07b12e35738bdf | 4135e6e02ed9ce4207f9119a835b68bb288bdcb643d7cb3b931187d27d803ff6 | null | [
"LICENSE"
] | 94 |
2.4 | deephaven-plugin-ui | 0.32.2 | deephaven.ui plugin | # deephaven.ui Plugin
Plugin prototype for programmatic layouts and callbacks. Currently calling it `deephaven.ui` but that's not set in stone.
## Build
To create your build / development environment (skip the first two lines if you already have a venv):
```sh
python -m venv .venv
source .venv/bin/activate
pip install --upgrade pip setuptools
pip install build deephaven-plugin plotly
```
To build:
```sh
python -m build --wheel
```
The wheel is stored in `dist/`.
To test within [deephaven-core](https://github.com/deephaven/deephaven-core), note where this wheel is stored (using `pwd`, for example).
Then, follow the directions in the top-level README.md to install the wheel into your Deephaven environment.
To unit test, run the following command from the root of the repo:
```sh
tox -e py
```
## Usage
Once you have the JS and python plugins installed and the server started, you can use deephaven.ui. See [examples](docs/README.md) for examples.
## Logging
The Python library uses the [logging](https://docs.python.org/3/howto/logging.html) module to log messages. The default log level is `WARNING`. To change the log level for debugging, set the log level to `DEBUG`:
```python
import logging
import sys
# Have the root logger output to stdout instead of stderr
logging.basicConfig(stream=sys.stdout, level=logging.WARNING)
# Set the log level for the deephaven.ui logger to DEBUG
logging.getLogger("deephaven.ui").setLevel(level=logging.DEBUG)
```
You can also set the log level for specific modules if you want to see specific modules' debug messages or filter out other ones, e.g.
```python
# Only log warnings from deephaven.ui.hooks
logging.getLogger("deephaven.ui.hooks").setLevel(level=logging.WARNING)
# Log all debug messages from the render module specifically
logging.getLogger("deephaven.ui.render").setLevel(level=logging.DEBUG)
```
## Docs
Docs can be built locally
Install the necessary dependencies:
```shell
pip install -r ../../sphinx_ext/sphinx-requirements.txt
pip install dist/deephaven_plugin_ui-*.whl
```
then run the docs make script:
```shell
python make_docs.py
```
The files will be built into `docs/build/markdown`.
Note that these built files should not be committed to the repository.
## Update Icon Types
Available IconTypes can be generated automatically using icon TypeScript definitions in node_modules.
Writes to `icon_types.py`.
```shell
npm install
cd plugins/ui
python make_icon_types.py
```
| text/markdown | Deephaven Data Labs | support@deephaven.io | null | null | null | deephaven, plugin, graph | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Environment :: Plugins",
"Topic :: Scientific/Engineering :: Visualization",
"Development Status :: 3 - Alpha"
] | [
"any"
] | https://github.com/deephaven/deephaven-plugins | null | null | [] | [] | [] | [
"deephaven-core>=0.39.6",
"deephaven-plugin>=0.6.0",
"json-rpc~=1.15.0",
"pyjsonpatch~=0.1.3",
"deephaven-plugin-utilities>=0.0.2",
"typing_extensions; python_version < \"3.11\"",
"puremagic"
] | [] | [] | [] | [
"Source Code, https://github.com/deephaven/deephaven-plugins",
"Bug Tracker, https://github.com/deephaven/deephaven-plugins/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:11:44.219335 | deephaven_plugin_ui-0.32.2.tar.gz | 1,034,711 | f5/1b/4a2ba377fd9fd4c403bcc93768054559a584a21b452536265600a9cd188e/deephaven_plugin_ui-0.32.2.tar.gz | source | sdist | null | false | 819feafe83566b194e1efc463b1b3fdc | 818b2280ad016c40e5d3749b97ce689e65335ad8d045394d723dcb63b0c3d95d | f51b4a2ba377fd9fd4c403bcc93768054559a584a21b452536265600a9cd188e | null | [
"LICENSE"
] | 280 |
2.4 | modulitiz-rpi | 2.3.1 | Raccolta dei miei moduli - funzioni specifiche per il RaspberryPi | # modulitiz-rpi
It's a Python library that contains specific functions for RaspberryPi.
## Installation
Use the package manager [pip](https://pip.pypa.io/en/stable/) to install:
```bash
pip install -U modulitiz_rpi
```
The other required dependencies will be installed automatically.
## Usage
```python
from modulitiz_rpi.ModuloGPIOInput import ModuloGPIOInput
gpioInput=ModuloGPIOInput(0)
gpioInput.populate()
# return False or True
gpioInput.isActive()
```
## Contributing
If you find any bug you can write me at [sderfo1234@altervista.org](mailto:sderfo1234@altervista.org)
## License
[MIT](https://choosealicense.com/licenses/mit/)
| text/markdown | null | tiz <sderfo1234@altervista.org> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"modulitiz-micro>=2",
"RPi.GPIO==0.7.1",
"types-RPi.GPIO==0.7.0.20250318",
"adafruit-circuitpython-ads1x15==2.2.4"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.9 | 2026-02-19T21:11:28.961509 | modulitiz_rpi-2.3.1-py311-none-any.whl | 4,282 | 3e/eb/15c11bb530aeb16e1d5d15cab3b93cd90e63e7a24fdcde426f075238f453/modulitiz_rpi-2.3.1-py311-none-any.whl | py311 | bdist_wheel | null | false | fcee592f30105f7acec4cfda8c076678 | 8c1630b75b36942645b597773dc9ac5dee2402d24aae1811ab1528f8b48d1c53 | 3eeb15c11bb530aeb16e1d5d15cab3b93cd90e63e7a24fdcde426f075238f453 | null | [
"LICENSE"
] | 95 |
2.4 | modulitiz-binaries | 2.6.1 | Raccolta dei miei moduli - file binari | # modulitiz-binaries
It's a Python library that contains binary files and other libraries.
## Installation
Use the package manager [pip](https://pip.pypa.io/en/stable/) to install:
```bash
pip install -U modulitiz_binaries
```
The other required dependencies will be installed automatically.
## Usage
```python
from modulitiz_binaries.Init import Init
# returns the folder which contains binary files
print(Init.getCartellaFileBinari())
```
## Contributing
If you find any bug you can write me at [sderfo1234@altervista.org](mailto:sderfo1234@altervista.org)
## License
[MIT](https://choosealicense.com/licenses/mit/)
| text/markdown | null | tiz <sderfo1234@altervista.org> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"modulitiz-micro>=2"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.9 | 2026-02-19T21:10:43.176453 | modulitiz_binaries-2.6.1-py311-none-any.whl | 63,073,216 | 94/be/d58dca3148cc2b02187dffcd5a6c6421df2f1e95d08b05ea43b0275071aa/modulitiz_binaries-2.6.1-py311-none-any.whl | py311 | bdist_wheel | null | false | e597ad0eedac4107bf319992188fab7c | 8c2bfd4e34ba446cf7fb564f7866a64abd79cc83468c6a31cf415064e57a2854 | 94bed58dca3148cc2b02187dffcd5a6c6421df2f1e95d08b05ea43b0275071aa | null | [
"LICENSE"
] | 118 |
2.4 | SunsetLog | 0.0.1 | Add your description here | # SunsetLog
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | <3.15,>=3.10 | [] | [] | [] | [
"httpx>=0.28.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T21:10:40.452189 | sunsetlog-0.0.1.tar.gz | 5,425 | 91/8a/ee187e30ae2cbbed4638ac190234815dfd2711cf269f15aec64082535984/sunsetlog-0.0.1.tar.gz | source | sdist | null | false | 01784ebfed654b6e54761c89ad94e7cf | 66ad254bcd8c26d4af99fa9f0e9eeae6507267f3989cdcd2224e0700832c41c1 | 918aee187e30ae2cbbed4638ac190234815dfd2711cf269f15aec64082535984 | null | [] | 0 |
2.4 | cometx | 3.6.3 | Python tools for Comet | # cometx
```
_________ ____ ___ ___ / /__ __
/ ___/ __ \/ __ `__ \/ _ \/ __/ |/_/
/ /__/ /_/ / / / / / / __/ /__> <
\___/\____/_/ /_/ /_/\___/\__/_/|_|
```
Open source extensions for the [Comet](https://www.comet.com/site/?utm_source=cometx&utm_medium=referral&utm_campaign=cometx_2022&utm_content=github) SDK.
These extensions are created and supported by the community and are
not an official project of Comet ML. We welcome contributions!
## Installation
```
pip install cometx --upgrade
```
To use these command-line functions, you can set your Comet API key and URL override using command-line flags:
```
cometx --api-key="YOUR-COMET-API-KEY" COMMAND
```
If you are a Comet on-prem user, and your installation does not use smart-keys, you'll also need to set the URL override:
```
cometx --api-key="YOUR-COMET-API-KEY" --url-override="https://your-companys-comet.com/clientlib/" COMMAND
```
## Usage
`cometx` is composed of a series of commands that are useful
independently, and can be used together to create sophisticated tools
for ML management.
### Commands
* [cometx admin](#cometx-admin)
* [cometx config](#cometx-config)
* [cometx copy](#cometx-copy)
* [cometx count](#cometx-count)
* [cometx delete-assets](#cometx-delete-assets)
* [cometx download](#cometx-download)
* [cometx list](#cometx-list)
* [cometx log](#cometx-log)
* [cometx rename-duplicates](#cometx-rename-duplicates)
* [cometx reproduce](#cometx-reproduce)
* [cometx smoke-test](#cometx-smoke-test)
* [cometx update](#cometx-update)
For all commands, use the `--help` flag to get additional information.
## Global Options
These flags are availble before a command:
* `--api-key API_KEY` - Set the COMET_API_KEY
* `--url-override URL_OVERRIDE` - Set the COMET_URL_OVERRIDE
This command shows the cometx version:
* `--version` - Display comet_ml version
This command can be used globally, or for individual commands:
* `-h, --help` - Show help message
## cometx list
This command is used to:
* get a list of all workspaces that you are a member of
* get a list of all projects in a workspace
* get a list of all experiments (by name or key) in a project
cometx list examples:
```
cometx list WORKSPACE/PROJECT/EXPERIMENT-KEY-OR-NAME
cometx list WORKSPACE/PROJECT
cometx list WORKSPACE
cometx list
```
### Flags
* `-u, --use-name` - Use experiment names for experiment folders and listings
* `--query QUERY` - Only list experiments that match this Comet query string
* `--debug` - Provide debug info
For more information, `cometx list --help`
## cometx count
This command is used to:
* count the number of workspaces you are a member of
* count the number of projects in workspaces
* count the number of experiments in projects
* count the number of artifacts in workspaces
cometx count examples:
```
cometx count
cometx count --workspaces-only
cometx count --with-projects
cometx count --with-experiments
cometx count --count-all
cometx count --limit 10
```
### Flags
* `--workspaces-only` - Count only workspaces (fastest)
* `--with-projects` - Count workspaces and projects (default)
* `--with-experiments` - Count workspaces, projects, and experiments (slowest, most detailed)
* `--count-all` - Count everything: workspaces, projects, artifacts, and experiments (most comprehensive)
* `--limit LIMIT` - Process only the first N workspaces (useful for testing)
* `--debug` - Provide debug info
For more information, `cometx count --help`
## cometx download
This command is used to:
* download all workspaces, projects, and experiments of workspaces that you are a member of
* download all projects, and experiments of a given workspace
* download all experiments of a given workspace/project
* download artifacts and models from the registry
* download panels
> **Note**: For detailed information on copying experiments from one Comet installation to another, see [MIGRATIONS.md](https://github.com/comet-ml/cometx/blob/main/MIGRATIONS.md).
cometx download examples:
```
cometx download WORKSPACE/PROJECT/EXPERIMENT-KEY-OR-NAME [RESOURCE ...] [FLAGS ...]
cometx download WORKSPACE/PROJECT [RESOURCE ...] [FLAGS ...]
cometx download WORKSPACE [RESOURCE ...] [FLAGS ...]
cometx download [RESOURCE ...] [FLAGS ...]
```
Where [RESOURCE ...] is zero or more of the following names:
* run - alias for: code, git, output, graph, and requirements
* system
* others
* parameters
* metadata
* metrics
* assets
* html
* project - alias for: project_notes, project_metadata
If no RESOURCE is given it will download all of them.
### Flags
* `--from from` - Source of data to copy. Should be: comet, wandb, or neptune. When using `--from neptune`, you must set the `NEPTUNE_API_TOKEN` environment variable.
* `-i IGNORE [IGNORE ...], --ignore IGNORE [IGNORE ...]` - Resource(s) (or 'experiments') to ignore
* `-j PARALLEL, --parallel PARALLEL` - The number of threads to use for parallel downloading; default (None) is based on CPUs
* `-o OUTPUT, --output OUTPUT` - Output directory for downloads
* `-u, --use-name` - Use experiment names for experiment folders and listings
* `-l, --list` - List the items at this level (workspace, project, experiment, artifacts, or model-registry) rather than download
* `--flat` - Download the files without subfolders
* `-f, --ask` - Queries the user; if flag not included system will answer `yes` for all queries
* `--filename FILENAME` - Only get resources ending with this
* `--query QUERY` - Only download experiments that match this Comet query string
* `--asset-type ASSET_TYPE` - Only get assets with this type
* `--sync SYNC` - What level to sync at: all, experiment, project, or workspace
* `--debug` - Provide debug info
To download artifacts:
```
cometx download WORKSPACE/artifacts/NAME [FLAGS ...]
cometx download WORKSPACE/artifacts/NAME/VERSION-OR-ALIAS [FLAGS ...]
```
To download models from the model registry:
```
cometx download WORKSPACE/model-registry/NAME [FLAGS ...]
cometx download WORKSPACE/model-registry/NAME/VERSION-OR-STAGE [FLAGS ...]
```
To download panels:
```
cometx download WORKSPACE/panels/NAME-OR-ID [FLAGS ...]
cometx download WORKSPACE/panels [FLAGS ...]
```
For more information, `cometx download --help`
## cometx copy
This command is used to:
* copy downloaded data to a new experiment
* create a symlink from one project to existing experiments
* copy panels
> **Note**: For detailed information on copying experiments from one Comet installation to another, see [MIGRATIONS.md](https://github.com/comet-ml/cometx/blob/main/MIGRATIONS.md).
cometx copy examples:
```
cometx copy SOURCE DESTINATION
cometx copy --symlink SOURCE DESTINATION
cometx copy --path /base/path SOURCE DESTINATION
cometx copy --path ~/Downloads SOURCE DESTINATION
```
where SOURCE is:
* if not `--symlink`, "WORKSPACE/PROJECT/EXPERIMENT", "WORKSPACE/PROJECT", or "WORKSPACE" folder
* if `--symlink`, then it is a Comet path to workspace or workspace/project
* "WORKSPACE/panels" or "WORKSPACE/panels/PANEL-ZIP-FILENAME" to copy panels
where DESTINATION is:
* WORKSPACE
* WORKSPACE/PROJECT
Not all combinations are possible:
| Destination → <br/>Source ↓ | WORKSPACE | WORKSPACE/PROJECT |
|--------------------|----------------------|------------------------|
| `WORKSPACE/*/*` | Copies all projects | N/A |
| `WORKSPACE/PROJ/*` | N/A | Copies all experiments |
| `WORKSPACE/PROJ/EXP` | N/A | Copies experiment |
### Asset Types
* 3d-image
* 3d-points - deprecated
* audio
* confusion-matrix - may contain assets
* curve
* dataframe
* dataframe-profile
* datagrid
* embeddings - may reference image asset
* histogram2d - not used
* histogram3d - internal only, single histogram, partial logging
* histogram_combined_3d
* image
* llm_data
* model-element
* notebook
* source_code
* tensorflow-model-graph-text - not used
* text-sample
* video
### Flags
* `-i IGNORE [IGNORE ...], --ignore IGNORE [IGNORE ...]` - Resource(s) (or 'experiments') to ignore
* `-j PARALLEL, --parallel PARALLEL` - The number of threads to use for parallel uploading; default (None) is based on CPUs
* `--debug` - If given, allow debugging
* `--quiet` - If given, don't display update info
* `--symlink` - Instead of copying, create a link to an experiment in a project
* `--sync` - Check to see if experiment name has been created first; if so, skip
* `--path PATH` - Path to prepend to workspace_src when accessing files (supports ~ for home directory)
### Using --path
The `--path` option allows you to specify a base directory where your workspace folders are located. This is useful when your downloaded experiments are stored in a specific directory structure.
Examples:
```bash
# Copy from experiments in /data/experiments/workspace
cometx copy --path /data/experiments workspace dest-workspace
# Copy from experiments in your home directory
cometx copy --path ~ workspace dest-workspace
# Copy from experiments in Downloads folder
cometx copy --path ~/Downloads workspace dest-workspace
```
For more information, `cometx copy --help`
## cometx log
This command is used to log a resource (metrics, parameters, asset,
etc) file to a specific experiment or experiments.
cometx log examples:
```
cometx log WORKSPACE/PROJECT/EXPERIMENT-KEY FILENAME ... --type=TYPE
cometx log WORKSPACE PANEL-ZIP-FILENAME ... --type=panel
cometx log WORKSPACE PANEL.py ... --type=panel
cometx log WORKSPACE PANEL-URL ... --type=panel
cometx log WORKSPACE/PROJECT --type=other --set "key:value"
cometx log WORKSPACE --type=other --set "key:value"
```
Where TYPE is one of the following names:
* all
* asset
* audio
* code
* image
* metrics
* notebook
* panel
* tensorflow-file
* text-sample
* video
* other
* tensorboard-folder-assets
### Flags
* `--type TYPE` - The type of item to log
* `--set SET` - The key:value to log
* `--query QUERY` - A Comet Query string, see https://www.comet.com/docs/v2/api-and-sdk/python-sdk/reference/API/#apiquery
* `--debug` - If given, allow debugging
* `--use-base-name` - If given, using the basename for logging assets
For more information, `cometx log --help`
## cometx rename-duplicates
This command is used to rename duplicate experiments within projects. When multiple experiments share the same name in a project, this command renames the duplicates to NAME-1, NAME-2, etc. while avoiding conflicts with existing names.
```
cometx rename-duplicates [PATH] [--dry-run] [--debug]
```
cometx rename-duplicates examples:
```
cometx rename-duplicates # Process all workspaces
cometx rename-duplicates WORKSPACE # Process all projects in a workspace
cometx rename-duplicates WORKSPACE/PROJECT # Process a single project
cometx rename-duplicates WORKSPACE/PROJECT --dry-run # Preview changes without renaming
```
Where PATH is optional and can be:
* `WORKSPACE` - process all projects in a workspace
* `WORKSPACE/PROJECT` - process a single project
* (empty) - process all workspaces and projects you have access to
### Flags
* `--dry-run` - Preview changes without actually renaming experiments
* `--debug` - Provide debug info
For more information, `cometx rename-duplicates --help`
## cometx delete-assets
To delete experiments assets:
```
cometx delete-assets WORKSPACE/PROJECT --type=image
cometx delete-assets WORKSPACE/PROJECT/EXPERIMENT --type=all
```
Type can be valid asset type, including:
* all
* asset
* audio
* code
* image
* notebook
* text-sample
* video
### Flags
* `--type TYPE` - The type of item to log
* `--debug` - If given, allow debugging
* `--query QUERY` - Only delete experiments that match this Comet query string
For more information, `cometx delete-assets --help`
## cometx config
To enable auto-logging of your notebooks in Jupyter environments:
```python
cometx config --auto-log-notebook yes
```
To turn auto-logging of notebooks off, use:
```python
cometx config --auto-log-notebook no
```
If you keep the generated experiment URLs in the notebook, but later edit the notebook, the notebooks will be updated in all of the experiments created in the notebook.
### Flags
* `--debug` - If given, allow debugging
* `--auto-log-notebook AUTO_LOG_NOTEBOOK` - Takes a 1/yes/true, or 0/no/false
For more information, `cometx config --help`
## cometx reproduce
```
cometx reproduce [-h] [--run] [--executable EXECUTABLE] COMET_PATH OUTPUT_DIR
```
This command is used to reproduce experiments by copying files to a specified output directory.
### Flags
* `--run` - Run the reproducible script
* `--executable EXECUTABLE` - Run the reproducible script with specified executable
For more information, `cometx reproduce --help`
## cometx update
```
cometx update [-h] [--debug] COMET_SOURCE COMET_DESTINATION
```
To update existing experiments.
cometx update SOURCE DESTINATION
where SOURCE is a folder:
* "WORKSPACE/PROJECT/EXPERIMENT"
* "WORKSPACE/PROJECT"
* "WORKSPACE"
where DESTINATION is a Comet:
* WORKSPACE
* WORKSPACE/PROJECT
### Flags
* `--debug` - If given, allow debugging
For more information, `cometx update --help`
## cometx admin
```
cometx admin [-h] [--host HOST] [--debug] ACTION [ARGUMENTS ...]
```
To perform admin functions
### Actions
#### chargeback-report
Generate a chargeback report from the Comet server.
```
cometx admin chargeback-report [YEAR-MONTH]
```
**Arguments:**
* `YEAR-MONTH` (optional, deprecated) - The YEAR-MONTH to run report for, eg 2024-09. If not provided, generates a report for all available periods.
**Output:**
* Saves a JSON file: `comet-chargeback-report.json` (or `comet-chargeback-report-{YEAR-MONTH}.json`)
**Examples:**
```
cometx admin chargeback-report
<<<<<<< Updated upstream
cometx admin usage-report
=======
cometx admin chargeback-report 2024-09
```
>>>>>>> Stashed changes
#### usage-report
Generate a usage report with experiment counts and statistics for one or more workspaces/projects.
```
cometx admin usage-report WORKSPACE [WORKSPACE ...]
cometx admin usage-report WORKSPACE/PROJECT [WORKSPACE/PROJECT ...]
cometx admin usage-report --app
```
**Arguments:**
* `WORKSPACE_PROJECT` (required, one or more, unless using `--app`) - One or more `WORKSPACE` or `WORKSPACE/PROJECT` to run usage report for. If `WORKSPACE` is provided without a project, all projects in that workspace will be included.
**Options:**
* `--units {month,week,day,hour}` - Time unit for grouping experiments (default: month)
* `month`: Group by month (YYYY-MM format)
* `week`: Group by ISO week (YYYY-WW format)
* `day`: Group by day (YYYY-MM-DD format)
* `hour`: Group by hour (YYYY-MM-DD-HH format)
* `--max-experiments-per-chart N` - Maximum number of workspaces/projects per chart (default: 5). If more workspaces/projects are provided, multiple charts will be generated.
* `--no-open` - Don't automatically open the generated PDF file after generation.
* `--app` - Launch interactive Streamlit web app instead of generating PDF. When using this option, you don't need to specify workspace/project arguments.
**Output:**
* **PDF Report** (default): Generates a PDF report containing:
* Summary statistics (total experiments, users, run times, GPU utilization)
* Experiment count charts by time unit
* GPU utilization charts (if GPU data is available)
* GPU memory utilization charts (if GPU data is available)
* **Interactive Web App** (with `--app`): Launches a Streamlit web interface where you can:
* Select workspace and project from dropdowns
* View statistics and charts interactively
* Change time units and regenerate reports
* View "All Projects" from a workspace
**Examples:**
```
# Generate report for a single workspace
cometx admin usage-report my-workspace
# Generate report for multiple projects
cometx admin usage-report my-workspace/project1 my-workspace/project2
# Generate report with weekly grouping
cometx admin usage-report workspace1 workspace2 --units week
# Generate report with daily grouping, don't auto-open
cometx admin usage-report workspace --units day --no-open
# Launch interactive web app
cometx admin usage-report --app
```
#### gpu-report
Generate a GPU usage report for one or more workspaces/projects with detailed GPU metrics analysis.
```
cometx admin gpu-report WORKSPACE [WORKSPACE ...] --start-date DATE
cometx admin gpu-report WORKSPACE/PROJECT [WORKSPACE/PROJECT ...] --start-date DATE
```
**Arguments:**
* `WORKSPACE_PROJECT` (required, one or more) - One or more `WORKSPACE` or `WORKSPACE/PROJECT` to run GPU report for. If `WORKSPACE` is provided without a project, all projects in that workspace will be included.
**Options:**
* `--start-date DATE` (required) - Start date for the report in YYYY-MM-DD format (e.g., `2024-01-01`)
* `--end-date DATE` (optional) - End date for the report in YYYY-MM-DD format (e.g., `2024-12-31`). If not provided, reports from start-date onwards.
* `--metrics METRIC [METRIC ...]` (optional) - List of metrics to track. If not provided, uses default GPU metrics:
* `sys.gpu.0.gpu_utilization` - GPU utilization percentage
* `sys.gpu.0.memory_utilization` - GPU memory utilization percentage
* `sys.gpu.0.used_memory` - GPU memory used in GB
* `sys.gpu.0.power_usage` - GPU power usage in watts
* `sys.gpu.0.temperature` - GPU temperature in Celsius
* `--open` - Automatically open the generated PDF file after generation.
**Output:**
* Generates a PDF report containing:
* Summary statistics (total experiments, workspaces, metrics tracked)
* Breakdown by workspace (if multiple workspaces)
* Average metrics by workspace charts (bar charts)
* Maximum metrics by month charts (time series line charts with workspace legend)
* Generates individual PNG chart files for each metric:
* `gpu_report_avg_{metric}_by_workspace.png` - Average metric value per workspace
* `gpu_report_max_{metric}_by_month.png` - Maximum metric value per month over time
**Examples:**
```
# Generate report for a single workspace from a start date
cometx admin gpu-report my-workspace --start-date 2024-01-01
# Generate report with date range
cometx admin gpu-report my-workspace --start-date 2024-01-01 --end-date 2024-12-31
# Generate report for multiple projects
cometx admin gpu-report workspace1/project1 workspace2 --start-date 2024-01-01
# Generate report with custom metrics
cometx admin gpu-report my-workspace --start-date 2024-01-01 --metrics sys.gpu.0.gpu_utilization sys.gpu.0.memory_utilization
# Generate report and automatically open PDF
cometx admin gpu-report my-workspace --start-date 2024-01-01 --open
```
### Global Flags
* `--host HOST` - Override the HOST URL
* `--debug` - If given, allow debugging
* `--api-key API_KEY` - Set the COMET_API_KEY
* `--url-override URL_OVERRIDE` - Set the COMET_URL_OVERRIDE
For more information, `cometx admin --help`
> **Note**: For detailed information on admin commands, see [README-ADMIN.md](https://github.com/comet-ml/cometx/blob/main/README-ADMIN.md).
## cometx smoke-test
```
cometx smoke-test [-h] [--exclude [EXCLUDE ...]] [--debug DEBUG] COMET_PATH [include ...]
```
Perform a smoke test on a Comet installation. Logs results to WORKSPACE/smoke-tests or WORKSPACE/PROJECT.
Examples:
Run all tests:
```
cometx smoke-test WORKSPACE # project defaults to smoke-tests
cometx smoke-test WORKSPACE/PROJECT
```
Run everything except mpm tests:
```
cometx smoke-test WORKSPACE/PROJECT --exclude mpm
```
Run just optimizer tests:
```
cometx smoke-test WORKSPACE/PROJECT optimizer
```
Run just metric tests:
```
cometx smoke-test WORKSPACE/PROJECT metric
```
Items to include or exclude:
* optimizer
* mpm
* panel
* opik
* experiment
* metric
* image
* asset
* dataset-info
* confusion-matrix
* embedding
### Flags
* `--exclude [EXCLUDE ...]` - Items to exclude; any of: asset, confusion-matrix, dataset-info, embedding, experiment, image, metric, mpm, opik, optimizer, panel
* `--debug DEBUG` - Show debugging information
For more information, `cometx smoke-test --help`
## Copy/Download Use Cases
In this section we'll explore some common scenarios.
1. Copy a specific project from one Comet installation to another
2. Copy all projects in workspace to a new workspace
3. Copy specific experiments in a project to new experiments
### 1. Copy a specific project from one comet installation to another
A useful idiom is to set your Comet environment variables on the line
of a command. In this manner, you can set the `COMET_URL_OVERRIDE`
and `COMET_API_KEY` for different installations.
Of course, you don't have to set the environment variables if you are
copying experiments on the same Comet installation.
Here is how you one could download the experiments in
WORKSPACE/PROJECT from http://comet.a.com:
```shell
cometx --api-key=A-KEY download WORKSPACE/PROJECT
```
The `cometx download` command downloads all of the Comet experiment
data into local files. Note that WORKSPACE/PROJECT refers to a
workspace and project on http://comet.a.com.
One could then copy the downloaded experiment data with a similar command:
```shell
cometx --api-key=B-KEY copy WORKSPACE/PROJECT NEW-WORKSPACE/NEW-PROJECT
```
Note that WORKSPACE/PROJECT now refers to a directory, and
NEW-WORKSPACE/NEW-PROJECT refers to a workspace and project on
http://comet.b.com.
### 2. Copy all projects in workspace to a new workspace
Similarly, one can copy all of the projects by first downloading them:
```shell
cometx --api-key=A-KEY download WORKSPACE
```
and then copying them:
```shell
cometx --api-key=B-KEY copy WORKSPACE NEW-WORKSPACE
```
### 3. Copy specific experiments in a project to new experiments
Similarly, one can copy a single experiment first downloading it:
```shell
cometx --api-key=A-KEY download WORKSPACE/PROJECT/EXPERIMENT-NAME-OR-ID
```
and then copying it:
```shell
cometx --api-key=B-KEY copy WORKSPACE/PROJECT/EXPERIMENT-NAME-OR-ID NEW-WORKSPACE/NEW-PROJECT
```
## Running Tests
WARNING: Running the tests will create experiments, models, assets, etc.
in your default workspace if not set otherwise.
To run the tests, you can either export all of these items in the
environment:
```shell
$ export COMET_USER="<USERNAME>"
$ export COMET_WORKSPACE="<WORKSPACE>"
$ export COMET_API_KEY="<API-KEY>"
$ pytest tests
```
Or, define `workspace` and `api_key` in your ~/.comet.config file:
```shell
$ export COMET_USER="<USERNAME>"
$ pytest tests
```
| text/markdown | cometx development team | null | null | null | MIT License | ai, artificial intelligence, python, machine learning | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Framework :: Jupyter"
... | [
"Linux"
] | https://github.com/comet-ml/cometx/ | null | >=3.6 | [] | [] | [] | [
"pillow>=11.1.0",
"comet_ml>=3.49.1",
"reportlab",
"rich>=13.0.0",
"six",
"requests",
"tqdm",
"matplotlib",
"streamlit",
"boto3",
"opik; extra == \"all\"",
"comet_mpm; extra == \"all\"",
"numpy; extra == \"all\"",
"scikit-learn; extra == \"all\"",
"matplotlib; extra == \"all\"",
"scipy... | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T21:10:31.880180 | cometx-3.6.3.tar.gz | 151,002 | 3e/19/6073037b32ac3839fbfa14293adcd5b1a944675c4d136ac9d1c51fd2a3f8/cometx-3.6.3.tar.gz | source | sdist | null | false | 357badfe29775a852ef3400f9c36d683 | 6d5a44eb75915ec95d8dbfa904c6b465ee3a955d72028da1855ae3ce65f79a28 | 3e196073037b32ac3839fbfa14293adcd5b1a944675c4d136ac9d1c51fd2a3f8 | null | [
"LICENSE"
] | 273 |
2.4 | dataquery-sdk | 0.1.2 | Python SDK for DATAQUERY Data API - Query, download, and check availability of economic data files | # DataQuery SDK
Professional Python SDK for the DataQuery API - High-performance data access with parallel downloads, time series queries, and seamless OAuth 2.0 authentication.
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
[](https://github.com/psf/black)
## Features
- **High-Performance Downloads**: Parallel file downloads with automatic retry and progress tracking
- **Time Series Queries**: Query data by expressions, instruments, or groups with flexible filtering
- **OAuth 2.0 Authentication**: Automatic token management and refresh
- **Connection Pooling**: Optimized HTTP connections with configurable rate limiting
- **Pandas Integration**: Direct conversion to DataFrames for analysis
- **Async & Sync APIs**: Use async/await or synchronous methods based on your needs
## Installation
```bash
pip install dataquery-sdk
```
## Quick Start
### 1. Configure Credentials
Set your API credentials as environment variables:
```bash
export DATAQUERY_CLIENT_ID="your_client_id"
export DATAQUERY_CLIENT_SECRET="your_client_secret"
```
Or create a `.env` file in your project directory:
```env
DATAQUERY_CLIENT_ID=your_client_id
DATAQUERY_CLIENT_SECRET=your_client_secret
```
### 2. Download Files
**Synchronous (Python Scripts)**
```python
from dataquery import DataQuery
# Download all files for a date range
with DataQuery() as dq:
results = dq.run_group_download(
group_id="JPMAQS_GENERIC_RETURNS",
start_date="20250101",
end_date="20250131",
destination_dir="./data"
)
print(f"Downloaded {results['successful_downloads']} files")
```
**Asynchronous (Jupyter Notebooks)**
```python
from dataquery import DataQuery
# Download all files for a date range
async with DataQuery() as dq:
results = await dq.run_group_download_async(
group_id="JPMAQS_GENERIC_RETURNS",
start_date="20250101",
end_date="20250131",
destination_dir="./data"
)
print(f"Downloaded {results['successful_downloads']} files")
```
### 3. Query Time Series Data
```python
from dataquery import DataQuery
async with DataQuery() as dq:
# Query by expression
result = await dq.get_expressions_time_series_async(
expressions=["DB(MTE,IRISH EUR 1.100 15-May-2029 LON,,IE00BH3SQ895,MIDPRC)"],
start_date="20240101",
end_date="20240131"
)
# Convert to pandas DataFrame
df = dq.to_dataframe(result)
print(df.head())
```
### 4. Discover Available Data
```python
from dataquery import DataQuery
async with DataQuery() as dq:
# List all available groups
groups = await dq.list_groups_async(limit=100)
# Convert to DataFrame for easy viewing
groups_df = dq.to_dataframe(groups)
print(groups_df[['group_id', 'group_name', 'description']])
```
## Common Use Cases
### Download Single File
```python
from dataquery import DataQuery
from pathlib import Path
async with DataQuery() as dq:
result = await dq.download_file_async(
file_group_id="JPMAQS_GENERIC_RETURNS",
file_datetime="20250115",
destination_path=Path("./downloads")
)
print(f"Downloaded: {result.local_path}")
```
### Query with Filters
```python
async with DataQuery() as dq:
# Get time series for Ireland bonds only
result = await dq.get_group_time_series_async(
group_id="FI_GO_BO_EA",
attributes=["MIDPRC", "REPO_1M"],
filter="country(IRL)",
start_date="20240101",
end_date="20240131"
)
df = dq.to_dataframe(result)
```
### Search for Instruments
```python
async with DataQuery() as dq:
# Search for instruments by keywords
results = await dq.search_instruments_async(
group_id="FI_GO_BO_EA",
keywords="irish"
)
# Use the results to query time series
instrument_ids = [inst.instrument_id for inst in results.instruments[:5]]
data = await dq.get_instrument_time_series_async(
instruments=instrument_ids,
attributes=["MIDPRC"],
start_date="20240101",
end_date="20240131"
)
```
## Performance Optimization
### Parallel Downloads
```python
async with DataQuery() as dq:
# Download multiple files concurrently with parallel chunks
results = await dq.run_group_download_async(
group_id="JPMAQS_GENERIC_RETURNS",
start_date="20250101",
end_date="20250131",
destination_dir="./data",
max_concurrent=5, # Download 5 files simultaneously
num_parts=4 # Split each file into 4 parallel chunks
)
```
**Recommended Settings:**
- `max_concurrent`: 3-5 (concurrent file downloads)
- `num_parts`: 2-8 (parallel chunks per file)
### Rate Limiting
Configure rate limits to avoid API throttling:
```python
from dataquery import DataQuery, ClientConfig
config = ClientConfig(
client_id="your_client_id",
client_secret="your_client_secret",
rate_limit_rpm=300, # Requests per minute
max_retries=3,
timeout=60.0
)
async with DataQuery(config=config) as dq:
# Your code here
pass
```
## Configuration
### Environment Variables
```bash
# Required
DATAQUERY_CLIENT_ID=your_client_id
DATAQUERY_CLIENT_SECRET=your_client_secret
# Optional - API Endpoints
DATAQUERY_BASE_URL=https://api-developer.jpmorgan.com
DATAQUERY_FILES_BASE_URL=https://api-dataquery.jpmchase.com
# Optional - Performance
DATAQUERY_MAX_RETRIES=3
DATAQUERY_TIMEOUT=60
DATAQUERY_RATE_LIMIT_RPM=300
```
### Programmatic Configuration
```python
from dataquery import DataQuery, ClientConfig
config = ClientConfig(
client_id="your_client_id",
client_secret="your_client_secret",
base_url="https://api-developer.jpmorgan.com",
max_retries=3,
timeout=60.0,
rate_limit_rpm=300
)
async with DataQuery(config=config) as dq:
# Your code here
pass
```
## Error Handling
```python
from dataquery import DataQuery
from dataquery.exceptions import (
DataQueryError,
AuthenticationError,
NotFoundError,
RateLimitError
)
async def safe_query():
try:
async with DataQuery() as dq:
result = await dq.get_expressions_time_series_async(
expressions=["DB(...)"],
start_date="20240101",
end_date="20240131"
)
return result
except AuthenticationError as e:
print(f"Authentication failed: {e}")
except NotFoundError as e:
print(f"Resource not found: {e}")
except RateLimitError as e:
print(f"Rate limit exceeded: {e}")
except DataQueryError as e:
print(f"API error: {e}")
except Exception as e:
print(f"Unexpected error: {e}")
```
## Date Formats
### Absolute Dates
```python
start_date="20240101" # YYYYMMDD format
end_date="20241231"
```
### Relative Dates
```python
start_date="TODAY" # Today
start_date="TODAY-1D" # Yesterday
start_date="TODAY-1W" # 1 week ago
start_date="TODAY-1M" # 1 month ago
start_date="TODAY-1Y" # 1 year ago
```
## Calendar Conventions
| Calendar | Description | Use Case |
|----------|-------------|----------|
| `CAL_WEEKDAYS` | Monday-Friday | International data (recommended) |
| `CAL_USBANK` | US banking days | US-only data (default) |
| `CAL_WEEKDAY_NOHOLIDAY` | All weekdays | Generic business days |
| `CAL_DEFAULT` | Calendar day | Include weekends |
## Examples
The `examples/` directory contains comprehensive examples:
- **File Downloads**: Single file, batch downloads, availability checks
- **Time Series**: Expressions, instruments, groups with filters
- **Discovery**: Search instruments, list groups, get attributes
- **Advanced**: Grid data, auto-download, custom progress tracking
Run an example:
```bash
python examples/files/download_file.py
python examples/expressions/get_expressions_time_series.py
```
## CLI Usage
The SDK includes a command-line interface:
```bash
# Download files
dataquery download --group-id JPMAQS_GENERIC_RETURNS \
--start-date 20250101 \
--end-date 20250131 \
--destination ./data
# List groups
dataquery list-groups --limit 100
# Check file availability
dataquery check-availability --file-group-id JPMAQS_GENERIC_RETURNS \
--date 20250115
```
## API Reference
### Core Methods
**File Downloads**
- `download_file_async()` - Download a single file
- `run_group_download_async()` - Download all files in a date range
- `list_available_files_async()` - Check file availability
**Time Series Queries**
- `get_expressions_time_series_async()` - Query by expression
- `get_instrument_time_series_async()` - Query by instrument ID
- `get_group_time_series_async()` - Query entire group with filters
**Discovery**
- `list_groups_async()` - List available data groups
- `search_instruments_async()` - Search for instruments
- `list_instruments_async()` - List all instruments in a group
- `get_group_attributes_async()` - Get available attributes
- `get_group_filters_async()` - Get available filters
**Utilities**
- `to_dataframe()` - Convert any response to pandas DataFrame
- `health_check_async()` - Check API health
- `get_stats()` - Get connection and rate limit statistics
For detailed API documentation, see the [API Reference](docs/api/README.md).
## Requirements
- Python 3.10 or higher
- Dependencies:
- `aiohttp>=3.8.0` - Async HTTP client
- `pydantic>=2.0.0` - Data validation
- `structlog>=23.0.0` - Structured logging
- `python-dotenv>=1.0.0` - Environment variable management
Optional:
- `pandas>=2.0.0` - For DataFrame conversion
## Development
### Setup Development Environment
```bash
# Clone the repository
git clone https://github.com/dataquery/dataquery-sdk.git
cd dataquery-sdk
# Create virtual environment
python -m venv .venv
source .venv/bin/activate # On Windows: .venv\Scripts\activate
# Install development dependencies
pip install -e ".[dev]"
# Install pre-commit hooks
pre-commit install
```
### Run Tests
```bash
# Run all tests
pytest tests/ -v
# Run with coverage
pytest tests/ --cov=dataquery --cov-report=html
# Run specific test file
pytest tests/test_client.py -v
```
### Code Quality
```bash
# Format code
black dataquery/ tests/
# Check linting
flake8 dataquery/ tests/ examples/
# Type checking
mypy dataquery/
```
## Contributing
Contributions are welcome! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## Support
For issues and questions:
- **GitHub Issues**: [Report a bug](https://github.com/dataquery/dataquery-sdk/issues)
- **Documentation**: [Read the docs](https://github.com/dataquery/dataquery-sdk/wiki)
- **Email**: support@dataquery.com
## Changelog
See [CHANGELOG.md](CHANGELOG.md) for version history and release notes.
| text/markdown | null | DATAQUERY SDK Team <support@dataquery.com> | null | null | null | dataquery, data, api, economic, financial, download, async, oauth, rate-limiting, sdk | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Financial and Insurance Industry",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Pr... | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp<4.0.0,>=3.8.0",
"pydantic<3.0.0,>=2.0.0",
"structlog>=23.0.0",
"python-dotenv>=1.0.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"ruff>=0.4.0; extra == \"dev\"",
"mypy>=1.5.0; extra == \"dev\"",
"pre-commit>=3.0.0... | [] | [] | [] | [
"Homepage, https://github.com/dataquery/dataquery-sdk",
"Bug Tracker, https://github.com/dataquery/dataquery-sdk/issues",
"Documentation, https://github.com/dataquery/dataquery-sdk/wiki",
"Source Code, https://github.com/dataquery/dataquery-sdk"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T21:10:27.719907 | dataquery_sdk-0.1.2.tar.gz | 96,213 | 92/b0/3c6aea9a0b088e947658b199538ae23ccc3834ddec9cbd6483a2b27e9a9f/dataquery_sdk-0.1.2.tar.gz | source | sdist | null | false | 1e3128fd357d8154938e85f53a593b6e | b18163c14a3bb682228c54789b21e7b24daceab20ff68aee41752e14b5f15560 | 92b03c6aea9a0b088e947658b199538ae23ccc3834ddec9cbd6483a2b27e9a9f | null | [
"LICENSE"
] | 250 |
2.4 | nexus-agent-platform | 0.3.8 | AI agent platform with MCP tool integration | # Nexus Agent Platform
> **Nexus** — 라틴어 *nectere*(묶다, 연결하다)에서 유래한 말로 **'연결', '결속', '중심점'**을 뜻합니다.
**Nexus Agent**는 AI와 실제 업무 사이의 간극을 연결하기 위해 만들어진 풀스택 AI 에이전트 플랫폼입니다. 파편화된 도구, 문서, 코드, 워크스페이스를 하나의 대화형 인터페이스로 묶어 — AI가 단순한 챗봇이 아니라 **실무를 함께 수행하는 동료**가 되도록 설계되었습니다.
MCP(Model Context Protocol)를 통해 외부 도구와 연결하고, Agent Skills로 반복 업무를 자동화하며, Workspace를 통해 실제 프로젝트 파일을 직접 읽고 쓰고 실행합니다. 대화 속에서 축적되는 장기 기억(Memory)은 사용자의 맥락을 기억하여 매번 처음부터 설명할 필요 없이 연속적인 협업을 가능하게 합니다.
하나의 명령으로 설치하고, 하나의 명령으로 프론트엔드+백엔드를 실행합니다.
```bash
pip install nexus-agent-platform # 설치
nexus-agent init # 초기 설정
nexus-agent start # 실행 → http://localhost:8000
```
---
## 설치
### 사전 준비: uv 설치
[uv](https://docs.astral.sh/uv/)는 Python 패키지 관리 도구입니다. 먼저 uv를 설치합니다.
**macOS / Linux:**
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
```
**Windows (PowerShell):**
```powershell
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
```
> 설치 후 터미널을 재시작하거나 `source ~/.bashrc` (macOS/Linux) 또는 새 PowerShell 창을 엽니다.
### 방법 1: uv (권장)
```bash
uv tool install nexus-agent-platform
```
### 방법 2: pipx
```bash
pipx install nexus-agent-platform
```
### 방법 3: pip
```bash
pip install nexus-agent-platform
```
### 요구사항
- **Python 3.13** 이상 (uv가 자동으로 설치합니다)
- 지원 프로바이더 중 최소 1개의 **API Key** (아래 [API 키 설정](#2-api-키-설정) 참고)
### 플랫폼 지원
| OS | 상태 | 데이터 디렉토리 |
|----|------|-----------------|
| macOS | 테스트 완료 | `~/.nexus-agent/` |
| Linux | 지원 | `~/.nexus-agent/` |
| Windows | 지원 | `C:\Users\<사용자>\.nexus-agent\` |
---
## 빠른 시작
### 1. 초기 설정
```bash
nexus-agent init
```
`~/.nexus-agent/` 디렉토리에 설정 파일이 생성됩니다:
```
~/.nexus-agent/
├── .env # API 키 설정
├── settings.json # LLM 설정 (모델, 온도, 시스템 프롬프트)
├── mcp.json # MCP 서버 설정
├── skills.json # 스킬 활성화 상태
├── pages.json # 페이지 메타데이터
├── workspaces.json # 워크스페이스 등록 정보
├── memories.json # 장기 기억 데이터
├── skills/ # Agent Skills 저장 디렉토리
└── pages/ # 업로드된 HTML 저장 디렉토리
```
### 2. API 키 설정
`~/.nexus-agent/.env` 파일에 사용할 프로바이더의 API 키를 설정합니다.
**사용할 프로바이더만 설정하면 됩니다** (전부 설정할 필요 없음).
```env
# Google Gemini — https://aistudio.google.com/apikey
GOOGLE_API_KEY=AIzaSy...
# OpenAI — https://platform.openai.com/api-keys
OPENAI_API_KEY=sk-proj-...
# Anthropic (Claude) — https://console.anthropic.com/settings/keys
ANTHROPIC_API_KEY=sk-ant-...
# xAI (Grok) — https://console.x.ai
XAI_API_KEY=xai-...
```
**macOS / Linux:**
```bash
# 예시: Google Gemini만 사용하는 경우
echo "GOOGLE_API_KEY=your-api-key-here" > ~/.nexus-agent/.env
# 여러 프로바이더를 사용하는 경우
cat > ~/.nexus-agent/.env << 'EOF'
GOOGLE_API_KEY=AIzaSy...
OPENAI_API_KEY=sk-proj-...
ANTHROPIC_API_KEY=sk-ant-...
XAI_API_KEY=xai-...
EOF
```
**Windows (PowerShell):**
```powershell
# 예시: Google Gemini만 사용하는 경우
Set-Content "$env:USERPROFILE\.nexus-agent\.env" "GOOGLE_API_KEY=your-api-key-here"
```
> Settings 페이지(`/settings`)에서 모델을 선택하면, 해당 프로바이더의 API 키가 자동으로 사용됩니다.
### 3. 서버 시작
```bash
nexus-agent start
```
브라우저에서 **http://localhost:8000** 을 열면 UI가 표시됩니다.
```
$ nexus-agent start
Nexus Agent v0.3.3 starting on http://0.0.0.0:8000
INFO: Loading settings...
INFO: Loading MCP config and connecting servers...
INFO: Loading skills...
INFO: Loading pages...
INFO: Uvicorn running on http://0.0.0.0:8000
```
### 4. 옵션
```bash
nexus-agent start --port 9000 # 포트 변경
nexus-agent start --host 127.0.0.1 # 로컬만 허용
nexus-agent start --dev # 개발 모드 (CORS 허용, 자동 리로드)
```
---
## CLI 명령어
| 명령어 | 설명 |
|--------|------|
| `nexus-agent init` | `~/.nexus-agent/` 초기 설정 파일 생성 |
| `nexus-agent start` | 서버 시작 (UI + API 단일 포트) |
| `nexus-agent start --dev` | 개발 모드 (CORS 허용, 자동 리로드) |
| `nexus-agent start --port 9000` | 커스텀 포트로 시작 |
| `nexus-agent config` | 현재 설정 경로 및 상태 표시 |
| `nexus-agent update` | 최신 버전으로 업데이트 |
| `nexus-agent --version` | 버전 확인 |
| `nexus-agent --help` | 도움말 표시 |
---
## 주요 기능
### Chat (`/`)
- 멀티 LLM 기반 AI 채팅 (LiteLLM 추상화 — Gemini, OpenAI, Claude, Grok 등)
- **SSE 실시간 스트리밍** — 도구 호출/결과/사고 과정을 실시간으로 표시
- 이미지 첨부 지원 (base64 인코딩)
- MCP 도구 + Agent Skills + Workspace 도구 자동 라우팅
- **세션 관리** — 대화 히스토리 저장/복원/삭제
- 커스텀 배경 이미지 (배율/위치/투명도 조정)
### Long-term Memory (Memory Bank)
- 대화에서 **자동 추출** — LLM이 핵심 사실/선호/패턴/맥락을 자동 인식
- 수동 추가/편집/삭제
- **메모리 고정(Pin)** — 중요한 메모리를 핀 고정하여 자동 삭제/압축에서 보호
- **자동 압축** — 용량 임계치 도달 시 유사 메모리를 LLM으로 병합 (핀 메모리 제외)
- **자동 교체** — 최대 용량 초과 시 가장 오래된 비핀 메모리 자동 삭제
- 카테고리 분류: preference, context, pattern, fact
- 시스템 프롬프트에 자동 주입하여 대화 연속성 유지
### MCP Servers (`/tools`)
- MCP 서버 등록/연결/재시작/삭제
- stdio, SSE, streamable-http 전송 지원
- 서버별 도구 목록 자동 탐색
- 연결 상태 실시간 모니터링 및 토글
### Agent Skills (`/skills`)
- SKILL.md 기반 스킬 정의 (YAML frontmatter + Markdown 지시사항)
- 스킬 내 스크립트 실행 (Python, Shell, JS)
- 스킬 내 참조 문서 로드
- ZIP 업로드 및 로컬 경로 임포트
### Custom Pages (`/pages`)
- HTML 파일 업로드 및 뷰어
- URL 북마크 등록 (iframe 지원 여부 자동 체크)
- 폴더 트리 구조로 정리
- 브레드크럼 네비게이션
### Workspace (`/workspace`)
- 로컬 디렉토리 등록/활성화/삭제
- 파일 트리 탐색 + 읽기 전용 파일 뷰어 (이미지/바이너리/미디어 파일 지원)
- 활성 워크스페이스 설정 시 AI가 파일 읽기/쓰기/편집/검색/셸 실행 가능
- 경로 순회 방지, 위험 셸 명령 차단 등 보안 장치 내장
### Settings (`/settings`)
- 테마 커스터마이징: 액센트 컬러, 다크/라이트 모드, 배경 톤
- 채팅 배경 이미지: 프리셋 선택, 커스텀 업로드
- LLM 설정: 모델 선택, API 키, 온도, 최대 토큰, 시스템 프롬프트
- **플랫폼 브랜딩**: 플랫폼 이름, 서브타이틀 커스터마이징
- **사용자 프로필**: 이름, 아바타 설정
- **AI 봇 프로필**: 봇 이름, 봇 아바타 설정
- **장기 기억 (Memory)**: 활성화/비활성화 토글, 용량/압축 임계치 설정
---
## 아키텍처
```
User → ChatInterface (React) → POST /api/chat/stream (SSE) → AgentOrchestrator.run_stream()
→ system prompt에 <available_skills> XML + <memories> 주입
→ MCP tools + skill tools + workspace tools 병합
→ LLMClient (LiteLLM) → Gemini / OpenAI / Claude / Grok API
→ SSE 이벤트 실시간 스트리밍:
→ thinking: "LLM 호출 중..."
→ tool_call: 도구 호출 정보
→ tool_result: 도구 실행 결과
→ content: 최종 응답 텍스트
→ tool_calls 라우팅:
→ skill tool → SkillManager → ~/.nexus-agent/skills/*/SKILL.md
→ workspace_* → workspace_tools → 파일/셸 도구 (활성 워크스페이스)
→ namespaced tool (server__tool) → MCPClientManager → MCP Server
→ Tool 결과를 메시지에 추가 → 2차 LLM 호출
→ 최종 응답 → ChatInterface (장기 기억 자동 추출)
```
### 기술 스택
| 계층 | 기술 |
|------|------|
| Frontend | Next.js 16, React 19, TypeScript, Tailwind CSS, shadcn/ui |
| Backend | Python 3.13, FastAPI, Pydantic |
| LLM | Gemini, OpenAI, Claude, Grok (LiteLLM 추상화) |
| Tool System | MCP (Model Context Protocol) + Agent Skills + Workspace Tools |
| CLI | Click, Rich |
| 패키지 | PyPI (`nexus-agent-platform`), Hatchling |
### 프로젝트 구조
```
track_platform/
├── pyproject.toml # 패키지 설정 및 의존성
├── uv.lock # uv 락 파일
├── README.md # 이 파일
├── CLAUDE.md # Claude Code 가이드
├── .github/
│ └── workflows/
│ └── publish.yml # PyPI 자동 배포 (GitHub Actions)
├── .claude/
│ └── skills/ # Claude Code 커스텀 스킬
├── nexus_agent/ # Python 백엔드 패키지
│ ├── __init__.py # 패키지 버전
│ ├── __main__.py # python -m nexus_agent 지원
│ ├── cli.py # Click CLI 엔트리포인트 (nexus-agent 명령)
│ ├── server.py # FastAPI 앱 + 정적 파일 서빙
│ ├── config.py # ~/.nexus-agent/ 데이터 디렉토리 관리
│ ├── core/ # 핵심 비즈니스 로직
│ │ ├── agent.py # AgentOrchestrator (도구 라우팅 + SSE 스트리밍)
│ │ ├── llm.py # LLMClient (LiteLLM 래퍼)
│ │ ├── mcp_manager.py # MCP 서버 연결 관리
│ │ ├── skill_manager.py # Agent Skills 관리
│ │ ├── page_manager.py # Pages 폴더 트리 관리
│ │ ├── settings_manager.py # LLM 설정 관리
│ │ ├── session_manager.py # 세션 히스토리 관리
│ │ ├── workspace_manager.py # 워크스페이스 CRUD + 파일 관리
│ │ ├── workspace_tools.py # LLM용 워크스페이스 도구 + 보안
│ │ └── memory_manager.py # 장기 기억 추출/압축/고정/관리
│ ├── api/endpoints/ # FastAPI REST API 라우터
│ │ ├── chat.py # SSE 스트리밍 채팅
│ │ ├── mcp.py # MCP 서버 관리
│ │ ├── skills.py # 스킬 관리
│ │ ├── pages.py # 페이지/폴더 관리
│ │ ├── sessions.py # 세션 히스토리
│ │ ├── settings.py # 설정 관리
│ │ ├── workspace.py # 워크스페이스 관리
│ │ └── memory.py # 메모리 CRUD + 핀 토글
│ ├── models/ # Pydantic 데이터 모델
│ │ ├── mcp.py # MCP 서버/도구 모델
│ │ ├── skill.py # 스킬 모델
│ │ ├── page.py # 페이지/폴더 모델
│ │ ├── session.py # 세션 모델
│ │ ├── settings.py # 설정 모델
│ │ ├── workspace.py # 워크스페이스 모델
│ │ └── memory.py # 메모리 모델 (is_pinned 포함)
│ └── static/ # 빌드된 프론트엔드 (wheel에 포함, git 제외)
├── frontend/ # Next.js 프론트엔드
│ ├── package.json
│ ├── pnpm-lock.yaml
│ ├── pnpm-workspace.yaml
│ ├── next.config.ts # static export 설정
│ ├── tsconfig.json
│ ├── components.json # shadcn/ui 설정
│ ├── eslint.config.mjs
│ ├── postcss.config.mjs
│ └── src/ # 소스 코드 (상세는 frontend/README.md 참조)
├── backend/ # 초기 단독 백엔드 (레거시, 참고용)
│ ├── main.py
│ └── README.md
└── scripts/
├── build.sh # 통합 빌드 스크립트 (shell)
└── build.py # 통합 빌드 스크립트 (python)
```
---
## MCP 서버 등록
프론트엔드 **MCP Servers** 대시보드(`/tools`)에서 등록하거나, `~/.nexus-agent/mcp.json`에 직접 추가합니다.
```json
{
"mcpServers": {
"example": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-everything"],
"enabled": true
}
}
}
```
### 전송 방식
| transport | 필수 필드 | 예시 |
|-----------|-----------|------|
| `stdio` | `command`, `args` | `"command": "npx", "args": ["-y", "some-mcp-server"]` |
| `sse` | `url` | `"url": "http://localhost:3001/sse"` |
| `streamable-http` | `url` | `"url": "http://localhost:3001/mcp"` |
---
## Agent Skill 등록
프론트엔드 **Agent Skills** 대시보드(`/skills`)에서 등록하거나, `~/.nexus-agent/skills/` 디렉토리에 스킬 폴더를 생성합니다.
```
~/.nexus-agent/skills/
└── my-skill/
├── SKILL.md # 필수: YAML frontmatter + 지시사항
├── scripts/ # 선택: 실행 스크립트 (.py, .sh, .js)
└── references/ # 선택: 참조 문서
```
**SKILL.md 예시:**
```yaml
---
name: my-skill
description: >
이 스킬이 하는 일과 언제 사용해야 하는지 설명합니다.
---
# My Skill
## 사용 방법
1. 사용자가 관련 질문을 하면 이 스킬이 활성화됩니다
2. scripts/ 에 있는 스크립트를 실행할 수 있습니다
3. references/ 에 있는 문서를 참조할 수 있습니다
```
---
## 환경 변수
### `~/.nexus-agent/.env`
| 변수 | 필수 | 설명 | 발급 |
|------|------|------|------|
| `GOOGLE_API_KEY` | 선택 | Google Gemini API 키 | [AI Studio](https://aistudio.google.com/apikey) |
| `OPENAI_API_KEY` | 선택 | OpenAI API 키 | [Platform](https://platform.openai.com/api-keys) |
| `ANTHROPIC_API_KEY` | 선택 | Anthropic Claude API 키 | [Console](https://console.anthropic.com/settings/keys) |
| `XAI_API_KEY` | 선택 | xAI Grok API 키 | [Console](https://console.x.ai) |
> 사용할 프로바이더의 키만 설정하면 됩니다. Settings 페이지에서 모델을 선택하면 해당 프로바이더의 키가 자동으로 사용됩니다.
### 지원 모델 (프로바이더별)
Settings 페이지(`/settings`)에서 모델을 선택하거나, `settings.json`의 `model` 필드에 직접 입력합니다.
| 프로바이더 | 모델 예시 | 환경변수 |
|-----------|----------|----------|
| Google Gemini | `gemini/gemini-3-flash-preview`, `gemini/gemini-2.5-pro` | `GOOGLE_API_KEY` |
| OpenAI | `openai/gpt-5`, `openai/gpt-4.1`, `openai/o3` | `OPENAI_API_KEY` |
| Anthropic | `anthropic/claude-opus-4-6`, `anthropic/claude-sonnet-4-5-20250929` | `ANTHROPIC_API_KEY` |
| xAI | `xai/grok-4-1-fast-reasoning`, `xai/grok-3` | `XAI_API_KEY` |
| Self-hosted | `openai/<모델명>` + API Base URL 설정 | (아래 참고) |
### LLM 설정 (`~/.nexus-agent/settings.json`)
웹 UI의 Settings 페이지에서 변경하거나 직접 편집합니다:
```json
{
"llm": {
"model": "gemini/gemini-2.5-flash",
"temperature": 0.7,
"max_tokens": 4096,
"system_prompt": ""
}
}
```
### 사내 vLLM / Self-hosted 사용
사내 네트워크에 vLLM으로 호스팅된 OpenAI 호환 API 서버에 연결할 수 있습니다.
**1. `.env` 설정:**
```env
# OpenAI-compatible H200 MIG API 120B LLM Configuration (for vLLM)
OPENAI_API_BASE=http://192.168.1.120:11436/v1
# API Key (dummy for local hosted vLLM - required by LiteLLM)
OPENAI_API_KEY=dummy
```
**2. Settings 페이지 또는 `settings.json`에서 모델 설정:**
| 설정 항목 | 값 |
|-----------|-----|
| Model | `hosted_vllm/openai/gpt-oss-120b` |
| API Base URL | `http://192.168.1.120:11436/v1` |
```json
{
"llm": {
"model": "hosted_vllm/openai/gpt-oss-120b",
"api_base": "http://192.168.1.120:11436/v1",
"api_key": "dummy",
"temperature": 0.7,
"max_tokens": 4096
}
}
```
> LiteLLM 추상화 계층을 사용하므로 OpenAI 호환 API를 제공하는 모든 서버(vLLM, Ollama, TGI 등)에 연결 가능합니다.
---
## 개발 환경
프론트엔드와 백엔드를 분리하여 개발할 수 있습니다.
### 백엔드 개발
```bash
git clone https://github.com/EJCHO-salary/track_platform.git
cd track_platform
uv sync
uv run nexus-agent init
uv run nexus-agent start --dev # 개발 모드 (리로드 + CORS 허용)
```
### 프론트엔드 개발
```bash
cd frontend
pnpm install
pnpm dev # http://localhost:3000 (백엔드는 별도로 실행 필요)
```
프론트엔드 개발 시 백엔드 주소가 다르면 `frontend/.env.local`을 생성합니다:
```env
NEXT_PUBLIC_API_URL=http://localhost:8000
```
### 프론트엔드 포함 빌드 (wheel)
```bash
./scripts/build.sh
# 1. frontend/ 빌드 (static export)
# 2. nexus_agent/static/ 에 복사
# 3. uv build → dist/ 에 wheel 생성
```
---
## 포트
| 서비스 | URL | 용도 |
|--------|-----|------|
| `nexus-agent start` | http://localhost:8000 | 프로덕션 (UI + API 통합) |
| `nexus-agent start --dev` | http://localhost:8000 | 개발 (API only, CORS 허용) |
| `pnpm dev` | http://localhost:3000 | 프론트엔드 개발 서버 |
| Swagger Docs | http://localhost:8000/docs | API 문서 |
---
## 버전 확인
```bash
nexus-agent --version
```
## 업데이트 (업그레이드)
```bash
# CLI 명령으로 업데이트
nexus-agent update
# 또는 설치 도구로 직접 업그레이드
uv tool upgrade nexus-agent-platform # uv 사용 시
pipx upgrade nexus-agent-platform # pipx 사용 시
pip install --upgrade nexus-agent-platform # pip 사용 시
```
업데이트 후 서버를 재시작하면 적용됩니다:
```bash
nexus-agent start
```
> `~/.nexus-agent/` 디렉토리의 설정 파일은 업데이트 시 유지됩니다. `nexus-agent init`을 다시 실행할 필요는 없습니다.
---
## CI/CD (자동 배포)
GitHub에 태그를 push하면 자동으로 PyPI에 배포됩니다.
### 사전 설정 (1회)
1. [PyPI](https://pypi.org) → 프로젝트 → Settings → Publishing → **Add a new publisher**
2. 아래 정보를 입력:
- **Owner**: `EJCHO-salary`
- **Repository**: `track_platform`
- **Workflow name**: `publish.yml`
- **Environment**: *(비워둠)*
### 배포 방법
```bash
# 1. pyproject.toml과 __init__.py의 버전을 올린다
# 2. 커밋하고 태그를 생성한다
git tag v0.3.3
git push origin main --tags
# GitHub Actions가 자동으로:
# - 프론트엔드 빌드
# - 정적 파일 복사
# - wheel 빌드
# - PyPI 배포
```
### 수동 배포
```bash
./scripts/build.sh
uv publish -t pypi-YOUR_TOKEN
```
---
## 라이선스
MIT
| text/markdown | null | null | null | null | null | agent, ai, chatbot, gemini, llm, mcp | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Environment :: Web Environment",
"Framework :: FastAPI",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"click>=8.0",
"fastapi>=0.128.8",
"google-generativeai>=0.8.6",
"httpx>=0.28.1",
"litellm>=1.81.10",
"mcp>=1.0.0",
"pydantic>=2.12.5",
"python-dotenv>=1.2.1",
"pyyaml>=6.0",
"rich>=13.0",
"uvicorn>=0.40.0"
] | [] | [] | [] | [
"Homepage, https://github.com/EJCHO-salary/track_platform",
"Repository, https://github.com/EJCHO-salary/track_platform"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:08:05.723831 | nexus_agent_platform-0.3.8.tar.gz | 2,088,651 | e7/aa/bb8e2d784e4d8cd4e7d7d5b723aa84f343279592c04d6687dcf3e1b75ba6/nexus_agent_platform-0.3.8.tar.gz | source | sdist | null | false | 05128c14f1bec38256f36afeaa1be17b | 70fdaa7ba252a2f3a2c3cf9f04a3aa4380794d86b2241b154dd0b1580866c35b | e7aabb8e2d784e4d8cd4e7d7d5b723aa84f343279592c04d6687dcf3e1b75ba6 | MIT | [] | 225 |
2.4 | medusa-security | 2026.3.1.0 | AI-first security scanner with 76 analyzers, 3,200+ detection rules, and intelligent false positive reduction for AI/ML, LLM agents, and MCP servers | # 🐍 MEDUSA - AI Security Scanner
[](https://pypi.org/project/medusa-security/)
[](https://pypi.org/project/medusa-security/)
[](https://www.python.org/downloads/)
[](https://www.gnu.org/licenses/agpl-3.0)
[](https://github.com/Pantheon-Security/medusa/actions/workflows/test.yml)
[](https://github.com/Pantheon-Security/medusa)
[](https://github.com/Pantheon-Security/medusa)
[](https://github.com/Pantheon-Security/medusa)
**AI-first security scanner with 3,200+ detection patterns for AI/ML, agents, and LLM applications.**
**🤖 Works out of the box - no tool installation required.**
**🚨 133 CVEs: Log4Shell, Spring4Shell, XZ Utils, LangChain RCE, MCP-Remote RCE, React2Shell**
**✨ NEW v2026.3.0: 508 FP filters, scanner precision tuning, compound gates, yamllint removed!**
---
## 🎯 What is MEDUSA?
MEDUSA is an AI-first security scanner with **3,200+ detection patterns** that works out of the box. Simply install and scan - no external tool installation required. MEDUSA's built-in rules detect vulnerabilities in AI/ML applications, LLM agents, MCP servers, RAG pipelines, and traditional code.
### ✨ Key Features
- 🤖 **3,200+ AI Security Patterns** - Industry-leading coverage for AI/ML, agents, and LLM applications
- 🚀 **Zero Setup Required** - Works immediately after `pip install` - no tool installation needed
- 🚨 **133 CVE Detections** - Log4Shell, Spring4Shell, XZ Utils backdoor, LangChain RCE, MCP remote code execution, React2Shell, and more
- ⚡ **Parallel Processing** - Multi-core scanning (10-40x faster than sequential)
- 🎨 **Beautiful CLI** - Rich terminal output with progress bars
- 🧠 **IDE Integration** - Claude Code, Cursor, VS Code, Gemini CLI support
- 🔄 **Smart Caching** - Skip unchanged files for lightning-fast rescans
- ⚙️ **Configurable** - `.medusa.yml` for project-specific settings
- 🌍 **Cross-Platform** - Native Windows, macOS, and Linux support
- 📊 **Multiple Reports** - JSON, HTML, Markdown, SARIF exports for any workflow
- 🔧 **Optional Linter Support** - Auto-detects external linters if installed for enhanced coverage
### 🆕 What's New in v2026.3.0
**Scanner Precision + FP Tuning** - Compound scanner gates, precision-tuned patterns, and 508 FP filters.
| Change | Description |
|--------|-------------|
| 🎯 **508 FP Filter Patterns** | Up from 430 — 96.8% false positive reduction on real-world projects |
| 🔧 **Scanner Attribution Fix** | Parallel scan findings now correctly attributed to originating scanner |
| 🛡️ **Compound Scanner Gates** | MultiAgent, Steganography, LLMGuard scanners require framework indicators to fire |
| ✂️ **YAMLScanner Removed** | Dropped yamllint (style linter) — Trivy + Semgrep + MEDUSA rules cover YAML security |
| 🔍 **Precision Pattern Tuning** | MCP, RAG, tool poisoning, multi-agent patterns tightened to reduce FPs |
| 🚨 **133 Critical CVEs** | CVEMiner database covering LangChain, PyTorch, MCP, Log4Shell, XZ Utils |
| 🤖 **3,200+ AI Patterns** | Built-in rules for AI/ML, agents, MCP, RAG, prompt injection |
**External Linters** (optional):
- MEDUSA auto-detects `bandit`, `eslint`, `shellcheck`, etc. if installed
- See **[Optional Tools Guide](docs/OPTIONAL_TOOLS.md)** for installation instructions
---
## 🚀 Quick Start
### Installation
```bash
# Install MEDUSA (works on Windows, macOS, Linux)
pip install medusa-security
# Run your first scan - that's it!
medusa scan .
```
**Virtual Environment (Recommended):**
```bash
# Create and activate virtual environment
python3 -m venv medusa-env
source medusa-env/bin/activate # On Windows: medusa-env\Scripts\activate
# Install and scan
pip install medusa-security
medusa scan .
```
**Platform Notes:**
- **Windows**: Use `py -m medusa` if `medusa` command is not found
- **macOS/Linux**: Should work out of the box
### Optional: AI Model Scanning
```bash
# Install modelscan for ML model vulnerability detection
medusa install --ai-tools
```
### Optional: External Linters
MEDUSA auto-detects external linters if installed (bandit, eslint, shellcheck, etc.) and uses them automatically to enhance scan coverage.
**[See Installation Guide →](docs/OPTIONAL_TOOLS.md)** for platform-specific instructions.
> **Note:** External linters are optional. MEDUSA's 3,200+ built-in rules work without them. For installation support, please refer to each tool vendor's documentation.
### Screenshots
**Scan Startup** - Repository analysis, language detection, AI pattern recognition:

**Live Progress** - Real-time scanner progress with issue counts:

**Scan Complete** - Summary with stats and report paths:

### 📊 Report Formats
MEDUSA generates beautiful reports in multiple formats:
**JSON** - Machine-readable for CI/CD integration
```bash
medusa scan . --format json
```
**HTML** - Stunning glassmorphism UI with interactive charts
```bash
medusa scan . --format html
```
**Markdown** - Documentation-friendly for GitHub/wikis
```bash
medusa scan . --format markdown
```
**All Formats** - Generate everything at once
```bash
medusa scan . --format all
```
---
## 📚 Language Support
MEDUSA supports **41 different scanner types** covering all major programming languages and file formats:
### Backend Languages (9)
| Language | Scanner | Extensions |
|----------|---------|------------|
| Python | Bandit | `.py` |
| JavaScript/TypeScript | ESLint | `.js`, `.jsx`, `.ts`, `.tsx` |
| Go | golangci-lint | `.go` |
| Ruby | RuboCop | `.rb`, `.rake`, `.gemspec` |
| PHP | PHPStan | `.php` |
| Rust | Clippy | `.rs` |
| Java | Checkstyle | `.java` |
| C/C++ | cppcheck | `.c`, `.cpp`, `.cc`, `.cxx`, `.h`, `.hpp` |
| C# | Roslynator | `.cs` |
### JVM Languages (3)
| Language | Scanner | Extensions |
|----------|---------|------------|
| Kotlin | ktlint | `.kt`, `.kts` |
| Scala | Scalastyle | `.scala` |
| Groovy | CodeNarc | `.groovy`, `.gradle` |
### Functional Languages (5)
| Language | Scanner | Extensions |
|----------|---------|------------|
| Haskell | HLint | `.hs`, `.lhs` |
| Elixir | Credo | `.ex`, `.exs` |
| Erlang | Elvis | `.erl`, `.hrl` |
| F# | FSharpLint | `.fs`, `.fsx` |
| Clojure | clj-kondo | `.clj`, `.cljs`, `.cljc` |
### Mobile Development (2)
| Language | Scanner | Extensions |
|----------|---------|------------|
| Swift | SwiftLint | `.swift` |
| Objective-C | OCLint | `.m`, `.mm` |
### Frontend & Styling (3)
| Language | Scanner | Extensions |
|----------|---------|------------|
| CSS/SCSS/Sass/Less | Stylelint | `.css`, `.scss`, `.sass`, `.less` |
| HTML | HTMLHint | `.html`, `.htm` |
| Vue.js | ESLint | `.vue` |
### Infrastructure as Code (4)
| Language | Scanner | Extensions |
|----------|---------|------------|
| Terraform | tflint | `.tf`, `.tfvars` |
| Ansible | ansible-lint | `.yml` (playbooks) |
| Kubernetes | kubeval | `.yml`, `.yaml` (manifests) |
| CloudFormation | cfn-lint | `.yml`, `.yaml`, `.json` (templates) |
### Configuration Files (4)
| Language | Scanner | Extensions |
|----------|---------|------------|
| JSON | built-in | `.json` |
| TOML | taplo | `.toml` |
| XML | xmllint | `.xml` |
| Protobuf | buf lint | `.proto` |
### Shell & Scripts (4)
| Language | Scanner | Extensions |
|----------|---------|------------|
| Bash/Shell | ShellCheck | `.sh`, `.bash` |
| PowerShell | PSScriptAnalyzer | `.ps1`, `.psm1` |
| Lua | luacheck | `.lua` |
| Perl | perlcritic | `.pl`, `.pm` |
### Documentation (2)
| Language | Scanner | Extensions |
|----------|---------|------------|
| Markdown | markdownlint | `.md` |
| reStructuredText | rst-lint | `.rst` |
### Other Languages (5)
| Language | Scanner | Extensions |
|----------|---------|------------|
| SQL | SQLFluff | `.sql` |
| R | lintr | `.r`, `.R` |
| Dart | dart analyze | `.dart` |
| Solidity | solhint | `.sol` |
| Docker | hadolint | `Dockerfile*` |
**Total: 41 scanner types covering 100+ file extensions**
---
## 🚨 React2Shell CVE Detection (NEW in v2025.8)
MEDUSA now detects **CVE-2025-55182 "React2Shell"** - a CVSS 10.0 RCE vulnerability affecting React Server Components and Next.js.
```bash
# Check if your project is vulnerable
medusa scan .
# Vulnerable versions detected:
# - React 19.0.0 - 19.2.0 (Server Components)
# - Next.js 15.0.0 - 15.0.4 (App Router)
# - Various canary/rc releases
```
**Scans**: `package.json`, `package-lock.json`, `yarn.lock`, `pnpm-lock.yaml`
**Fix**: Upgrade to React 19.0.1+ and Next.js 15.0.5+
---
## 🤖 AI Agent Security
MEDUSA provides **industry-leading AI security scanning** with **3,200+ detection patterns** for the agentic AI era. Updated for **OWASP Top 10 for LLM Applications 2025** and includes detection for **CVE-2025-6514** (mcp-remote RCE).
**[Full AI Security Documentation](docs/AI_SECURITY.md)**
### AI Security Coverage
| Category | Patterns | Detects |
|----------|----------|---------|
| **Prompt Injection** | 800+ | Direct/indirect injection, jailbreaks, role manipulation |
| **MCP Server Security** | 400+ | Tool poisoning, CVE-2025-6514, confused deputy, command injection |
| **RAG Security** | 300+ | Vector injection, document poisoning, tenant isolation |
| **Agent Security** | 500+ | Excessive agency, memory poisoning, HITL bypass |
| **Model Security** | 400+ | Insecure loading, checkpoint exposure, adversarial attacks |
| **Supply Chain** | 350+ | Dependency confusion, typosquatting, malicious packages |
| **Traditional SAST** | 1,400+ | SQL injection, XSS, command injection, secrets |
### AI Attack Coverage
<table>
<tr><td>
**Context & Input Attacks**
- Prompt injection patterns
- Role/persona manipulation
- Hidden instructions
- Obfuscation tricks
**Memory & State Attacks**
- Memory poisoning
- Context manipulation
- Checkpoint tampering
- Cross-session exposure
**Tool & Action Attacks**
- Tool poisoning (CVE-2025-6514)
- Command injection
- Tool name spoofing
- Confused deputy patterns
</td><td>
**Workflow & Routing Attacks**
- Router manipulation
- Agent impersonation
- Workflow hijacking
- Delegation abuse
**RAG & Knowledge Attacks**
- Knowledge base poisoning
- Embedding pipeline attacks
- Source confusion
- Retrieval manipulation
**Advanced Attacks**
- HITL bypass techniques
- Semantic manipulation
- Evaluation poisoning
- Training data attacks
</td></tr>
</table>
### Supported AI Files
```
.cursorrules # Cursor AI instructions
CLAUDE.md # Claude Code context
.claude/ # Claude configuration directory
copilot-instructions.md # GitHub Copilot
AGENTS.md # Multi-agent definitions
mcp.json / mcp-config.json # MCP server configs
*.mcp.ts / *.mcp.py # MCP server code
rag.json / knowledge.json # RAG configurations
memory.json # Agent memory configs
```
### Quick AI Security Scan
```bash
# Scan AI configuration files
medusa scan . --ai-only
# Example output:
# 🔍 AI Security Scan Results
# ├── .cursorrules: 3 issues (1 CRITICAL, 2 HIGH)
# │ └── AIC001: Prompt injection - ignore previous instructions (line 15)
# │ └── AIC011: Tool shadowing - override default tools (line 23)
# ├── mcp-config.json: 2 issues (2 HIGH)
# │ └── MCP003: Dangerous path - home directory access (line 8)
# └── rag_config.json: 1 issue (1 CRITICAL)
# └── AIR010: Knowledge base injection pattern detected (line 45)
```
---
## 🎮 Usage
### Basic Commands
```bash
# Initialize configuration
medusa init
# Scan current directory
medusa scan .
# Scan specific directory
medusa scan /path/to/project
# Quick scan (changed files only)
medusa scan . --quick
# Force full scan (ignore cache)
medusa scan . --force
# Use specific number of workers
medusa scan . --workers 4
# Fail on HIGH severity or above
medusa scan . --fail-on high
# Custom output directory
medusa scan . -o /tmp/reports
```
### Install Commands
```bash
# Check tool status
medusa install --check
# Install AI tools (modelscan for ML model scanning)
medusa install --ai-tools
# Show detailed output
medusa install --ai-tools --debug
```
> **Note**: MEDUSA v2026.2+ no longer installs external linters. Install them via your package manager (apt, brew, npm, pip) if needed. MEDUSA auto-detects and uses any installed linters.
### Init Commands
```bash
# Interactive initialization wizard
medusa init
# Initialize with specific IDE
medusa init --ide claude-code
# Initialize with multiple IDEs
medusa init --ide claude-code --ide gemini-cli --ide cursor
# Initialize with all supported IDEs
medusa init --ide all
# Force overwrite existing config
medusa init --force
# Initialize and install tools
medusa init --install
```
### Additional Commands
```bash
# Uninstall modelscan
medusa uninstall modelscan
# Check for updates
medusa version --check-updates
# Show current configuration
medusa config
# Override scanner for specific file
medusa override path/to/file.yaml YAMLScanner
# List available scanners
medusa override --list
# Show current overrides
medusa override --show
# Remove override
medusa override path/to/file.yaml --remove
```
### Scan Options Reference
| Option | Description |
|--------|-------------|
| `TARGET` | Directory or file to scan (default: `.`) |
| `-w, --workers N` | Number of parallel workers (default: auto-detect) |
| `--quick` | Quick scan (changed files only, requires git) |
| `--force` | Force full scan (ignore cache) |
| `--no-cache` | Disable result caching |
| `--fail-on LEVEL` | Exit with error on severity: `critical`, `high`, `medium`, `low` |
| `-o, --output PATH` | Custom output directory for reports |
| `--format FORMAT` | Output format: `json`, `html`, `sarif`, `junit`, `text` (can specify multiple) |
| `--no-report` | Skip generating HTML report |
### Install Options Reference
| Option | Description |
|--------|-------------|
| `--check` | Check tool status |
| `--ai-tools` | Install AI security tools (modelscan) |
| `--debug` | Show detailed debug output |
> **v2026.2+ Change**: MEDUSA no longer manages external linter installation. The `--all` flag is deprecated. Install external linters via your system package manager if needed.
---
## ⚙️ Configuration
### `.medusa.yml`
MEDUSA uses a YAML configuration file for project-specific settings:
```yaml
# MEDUSA Configuration File
version: 2026.3.0
# Scanner control
scanners:
enabled: [] # Empty = all scanners enabled
disabled: [] # List scanners to disable
# Build failure settings
fail_on: high # critical | high | medium | low
# Exclusion patterns
exclude:
paths:
- node_modules/
- venv/
- .venv/
- .git/
- __pycache__/
- dist/
- build/
files:
- "*.min.js"
- "*.min.css"
# IDE integration
ide:
claude_code:
enabled: true
auto_scan: true
cursor:
enabled: false
vscode:
enabled: false
# Scan settings
workers: null # null = auto-detect CPU cores
cache_enabled: true # Enable file caching for speed
```
### Generate Default Config
```bash
medusa init
```
This creates `.medusa.yml` with sensible defaults and auto-detects your IDE.
---
## 🤖 IDE Integration
MEDUSA supports **5 major AI coding assistants** with native integrations. Initialize with `medusa init --ide all` or select specific platforms.
### Supported Platforms
| IDE | Context File | Commands | Status |
|-----|-------------|----------|--------|
| **Claude Code** | `CLAUDE.md` | `/medusa-scan`, `/medusa-install` | ✅ Full Support |
| **Gemini CLI** | `GEMINI.md` | `/scan`, `/install` | ✅ Full Support |
| **OpenAI Codex** | `AGENTS.md` | Native slash commands | ✅ Full Support |
| **GitHub Copilot** | `.github/copilot-instructions.md` | Code suggestions | ✅ Full Support |
| **Cursor** | Reuses `CLAUDE.md` | MCP + Claude commands | ✅ Full Support |
### Quick Setup
```bash
# Setup for all IDEs (recommended)
medusa init --ide all
# Or select specific platforms
medusa init --ide claude-code --ide gemini-cli
```
### Claude Code
**What it creates:**
- `CLAUDE.md` - Project context file
- `.claude/agents/medusa/agent.json` - Agent configuration
- `.claude/commands/medusa-scan.md` - Scan slash command
- `.claude/commands/medusa-install.md` - Install slash command
**Usage:**
```
Type: /medusa-scan
Claude: *runs security scan*
Results: Displayed in terminal + chat
```
### Gemini CLI
**What it creates:**
- `GEMINI.md` - Project context file
- `.gemini/commands/scan.toml` - Scan command config
- `.gemini/commands/install.toml` - Install command config
**Usage:**
```bash
gemini /scan # Full scan
gemini /scan --quick # Quick scan
gemini /install --check # Check tools
```
### OpenAI Codex
**What it creates:**
- `AGENTS.md` - Project context (root level)
**Usage:**
```
Ask: "Run a security scan"
Codex: *executes medusa scan .*
```
### GitHub Copilot
**What it creates:**
- `.github/copilot-instructions.md` - Security standards and best practices
**How it helps:**
- Knows project security standards
- Suggests secure code patterns
- Recommends running scans after changes
- Helps fix security issues
### Cursor
**What it creates:**
- `.cursor/mcp-config.json` - MCP server configuration
- Reuses `.claude/` structure (Cursor is VS Code fork)
**Usage:**
- Works like Claude Code integration
- MCP-native for future deeper integration
---
## 🔧 Advanced Features
### System Load Monitoring
MEDUSA automatically monitors system load and adjusts worker count:
```python
# Auto-detects optimal workers based on:
# - CPU usage
# - Memory usage
# - Load average
# - Available cores
# Warns when system is overloaded:
⚠️ High CPU usage: 85.3%
Using 2 workers (reduced due to system load)
```
### Smart Caching
Hash-based caching skips unchanged files:
```bash
# First scan
📂 Files scanned: 145
⏱️ Total time: 47.28s
# Second scan (no changes)
📂 Files scanned: 0
⚡ Files cached: 145
⏱️ Total time: 2.15s # 22× faster!
```
### Parallel Processing
Multi-core scanning for massive speedups:
```
Single-threaded: 417.5 seconds
6 workers: 47.3 seconds # 8.8× faster
24 workers: ~18 seconds # 23× faster
```
---
## 📊 Example Workflow
### New Project Setup
```bash
# 1. Initialize
cd my-awesome-project
medusa init
🐍 MEDUSA Initialization Wizard
✅ Step 1: Project Analysis
Found 15 language types
Primary: PythonScanner (44 files)
✅ Step 2: Scanner Availability
Available: 6/42 scanners
Missing: 36 tools
✅ Step 3: Configuration
Created .medusa.yml
Auto-detected IDE: Claude Code
✅ Step 4: IDE Integration
Created .claude/agents/medusa/agent.json
Created .claude/commands/medusa-scan.md
✅ MEDUSA Initialized Successfully!
# 2. First scan
medusa scan .
🔍 Issues found: 23
CRITICAL: 0
HIGH: 2
MEDIUM: 18
LOW: 3
# 3. Fix issues and rescan
medusa scan . --quick
⚡ Files cached: 142
🔍 Issues found: 12 # Progress!
```
### CI/CD Integration
```yaml
# .github/workflows/security.yml
name: Security Scan
on: [push, pull_request]
jobs:
medusa:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.11'
- name: Install MEDUSA
run: pip install medusa-security
- name: Run security scan
run: medusa scan . --fail-on high
```
> **Note**: No tool installation step needed - MEDUSA's 3,200+ built-in rules work immediately.
---
## 🏗️ Architecture
### Scanner Pattern
All scanners follow a consistent pattern:
```python
class PythonScanner(BaseScanner):
"""Scanner for Python files using Bandit"""
def get_tool_name(self) -> str:
return "bandit"
def get_file_extensions(self) -> List[str]:
return [".py"]
def scan_file(self, file_path: Path) -> ScannerResult:
# Run bandit on file
# Parse JSON output
# Map severity levels
# Return structured issues
return ScannerResult(...)
```
### Auto-Registration
Scanners automatically register themselves:
```python
# medusa/scanners/__init__.py
registry = ScannerRegistry()
registry.register(PythonScanner())
registry.register(JavaScriptScanner())
# ... all 41 scanners
```
### Severity Mapping
Unified severity levels across all tools:
- **CRITICAL** - Security vulnerabilities, fatal errors
- **HIGH** - Errors, security warnings
- **MEDIUM** - Warnings, code quality issues
- **LOW** - Style issues, conventions
- **INFO** - Suggestions, refactoring opportunities
---
## 🧪 Testing & Quality
### Dogfooding Results
MEDUSA scans itself — and real-world projects:
```
Self-scan (473 files):
✅ Issues found: 114 (pre-filter) → 0 (post-filter)
✅ FP reduction: 100% on own codebase
⏱️ Time: 8.2s
OpenClaw benchmark (4,124 files, 751K LOC):
🔍 Issues found: 825 (post-filter)
✅ FPs filtered: 11,436 (93.9% reduction)
⏱️ Time: 3.3 hours (42 scanners)
```
### Performance Benchmarks
| Project Size | Files | Time | Speed |
|--------------|-------|------|-------|
| Small (MEDUSA self-scan) | 473 | ~8s | 59 files/s |
| Medium | 1,000 | ~45s | 22 files/s |
| Large (OpenClaw) | 4,124 | ~3.3h | 0.34 files/s* |
*Large project time dominated by external tool subprocesses (Semgrep, Trivy, GitLeaks). Built-in pattern scanning is near-instant.
---
## 🗺️ Roadmap
### ✅ Completed (v2026.3.0)
- **3,200+ Detection Patterns** - Industry-leading AI security coverage
- **76 Specialized Analyzers** - Comprehensive language and platform coverage
- **133 Critical CVEs** - CVEMiner database for known vulnerability scanning
- **508 FP Filter Patterns** - 96.8% false positive reduction rate on real-world projects
- **Compound Scanner Gates** - MultiAgent, Steganography, LLMGuard scanners use framework-aware gates
- **Scanner Attribution Fix** - Parallel scan findings correctly attributed to originating scanner
- **Agent Protocol Security** - UCP, AP2, ACP vulnerability detection (91 rules)
- **Dataset Poisoning Detection** - CSV, JSON, JSONL injection scanning
- **Code-Level Prompt Injection** - F-string injection, ChatML tokens, role manipulation
- **Cross-Platform** - Native Windows, macOS, Linux support
- **IDE Integration** - Claude Code, Cursor, Gemini CLI, GitHub Copilot, OpenAI Codex
### 🔮 Upcoming
- **MEDUSA Professional** - Runtime proxy filters for production LLM protection
- **GitHub App** - Automatic PR scanning
- **VS Code Extension** - Native IDE integration
- **REST API** - CI/CD pipeline integration
---
## 🤝 Contributing
We welcome contributions! Here's how to get started:
```bash
# 1. Fork and clone
git clone https://github.com/yourusername/medusa.git
cd medusa
# 2. Create virtual environment
python -m venv .venv
source .venv/bin/activate # or `.venv\Scripts\activate` on Windows
# 3. Install in editable mode
pip install -e ".[dev]"
# 4. Run tests
pytest
# 5. Create feature branch
git checkout -b feature/my-awesome-feature
# 6. Make changes and test
medusa scan . # Dogfood your changes!
# 7. Submit PR
git push origin feature/my-awesome-feature
```
### Adding New Scanners
See `docs/development/adding-scanners.md` for a guide on adding new language support.
---
## 📜 License
AGPL-3.0-or-later - See [LICENSE](LICENSE) file
MEDUSA is free and open source software. You can use, modify, and distribute it freely, but any modifications or derivative works (including SaaS deployments) must also be released under AGPL-3.0.
For commercial licensing options, contact: support@pantheonsecurity.io
---
## Coming Soon
MEDUSA Professional adds **runtime protection** for production LLM applications - blocking prompt injection, jailbreaking, and data exfiltration attempts in real-time before they reach your models.
| Feature | Open Source | Professional | Enterprise |
|---------|-------------|--------------|------------|
| Static scanning (3,200+ patterns) | Yes | Yes | Yes |
| Runtime proxy filters (1,100+) | - | Yes | Yes |
| REST API & webhooks | - | Yes | Yes |
| Custom rules & SSO | - | - | Yes |
| **Price** | Free | $99/dev/mo | $499/50 devs/mo |
The runtime proxy is currently in private beta. If you're protecting production LLM applications and want early access, reach out to **support@pantheonsecurity.io**.
---
## 🙏 Credits
**Development:**
- Pantheon Security
- Claude AI (Anthropic) - AI-assisted development
**Built With:**
- Python 3.10+
- Click - CLI framework
- Rich - Terminal formatting
- Bandit, ESLint, ShellCheck, and 39+ other open-source security tools
**Inspired By:**
- Bandit (Python security)
- SonarQube (multi-language analysis)
- Semgrep (pattern-based security)
- Mega-Linter (comprehensive linting)
---
## 📖 Guides
- **[Quick Start](docs/guides/quick-start.md)** - Get running in 5 minutes
- **[AI Security Scanning](docs/AI_SECURITY.md)** - Complete guide to AI/LLM security (OWASP 2025, MCP, RAG)
- **[Handling False Positives](docs/guides/handling-false-positives.md)** - Reduce noise, find real issues
- **[IDE Integration](docs/guides/ide-integration.md)** - Setup Claude Code, Gemini, Copilot
---
## 📞 Support
- **GitHub Issues**: [Report bugs or request features](https://github.com/Pantheon-Security/medusa/issues)
- **Email**: support@pantheonsecurity.io
- **Documentation**: https://docs.pantheonsecurity.io
- **Discord**: https://discord.gg/medusa (coming soon)
---
## 📈 Statistics
**Version**: 2026.3.0
**Release Date**: 2026-02-16
**Detection Patterns**: 3,200+ AI security rules
**Analyzers**: 76 specialized scanners
**FP Filter Patterns**: 508 intelligent filters (96.8% reduction rate)
**CVE Coverage**: 133 critical vulnerabilities
**Language Coverage**: 46+ file types
**Platform Support**: Linux, macOS, Windows
**AI Integration**: Claude Code, Gemini CLI, GitHub Copilot, Cursor, OpenAI Codex
**Standards**: OWASP Top 10 for LLM 2025, MITRE ATLAS
**Downloads**: 11,500+ on PyPI
---
## 🌟 Why MEDUSA?
### vs. Bandit
- ✅ 3,200+ patterns (not just Python security)
- ✅ AI/ML security coverage
- ✅ Zero setup required
- ✅ IDE integration
### vs. SonarQube
- ✅ Simpler setup (`pip install && scan`)
- ✅ No server required
- ✅ AI-first security focus
- ✅ Free and open source
### vs. Semgrep
- ✅ AI/ML-specific rules built-in
- ✅ MCP, RAG, agent security
- ✅ Better IDE integration
- ✅ No rule configuration needed
### vs. Traditional SAST
- ✅ Works immediately (no tool installation)
- ✅ AI security patterns included
- ✅ Parallel processing
- ✅ Smart caching
---
**🐍🐍🐍 MEDUSA - Multi-Language Security Scanner 🐍🐍🐍**
**One Command. Complete Security.**
```bash
medusa init && medusa scan .
```
---
**Last Updated**: 2026-02-16
**Status**: Production Ready
**Current Version**: v2026.3.0 - Scanner Precision + FP Tuning
| text/markdown | null | Pantheon Security <support@pantheonsecurity.io> | null | Pantheon Security <support@pantheonsecurity.io> | null | security, scanner, sast, ai-security, llm-security, mcp, agent-security, prompt-injection, rag-security, supply-chain, owasp, cve, cybersecurity, devsecops | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Topic :: Security",
"Topic :: Software Development :: Quality Assurance",
"Topic :: Software Development :: Testing",
"Programming Language :: Python :: 3",
"Programming La... | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.1.0",
"rich>=13.0.0",
"tqdm>=4.60.0",
"requests>=2.28.0",
"urllib3>=2.6.0",
"pyyaml>=6.0.0",
"psutil>=5.9.0",
"defusedxml>=0.7.0",
"tomli-w>=1.0.0",
"toml>=0.10.2",
"pathspec>=0.11.0",
"bandit>=1.9.0; extra == \"linters\"",
"yamllint>=1.28.0; extra == \"linters\"",
"Blinter>=1.0.... | [] | [] | [] | [
"Homepage, https://medusa-security.dev",
"Documentation, https://docs.medusa-security.dev",
"Repository, https://github.com/Pantheon-Security/medusa",
"Bug Tracker, https://github.com/Pantheon-Security/medusa/issues",
"Changelog, https://github.com/Pantheon-Security/medusa/releases"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T21:07:54.553436 | medusa_security-2026.3.1.0.tar.gz | 861,366 | 81/69/0f94201841f06b09519b859b31fcc6648faadbfb1160f91650abece007c2/medusa_security-2026.3.1.0.tar.gz | source | sdist | null | false | c5cb87f46657e12ac7bc467ce60dfd4b | 07e0f39dd27ce29b4bd08f466eb0e4338b1ab2be7fc2ec8782cb0ad30037b742 | 81690f94201841f06b09519b859b31fcc6648faadbfb1160f91650abece007c2 | AGPL-3.0-or-later | [
"LICENSE"
] | 249 |
2.4 | orca-sdk | 0.1.14 | SDK for interacting with Orca Services | <!--
IMPORTANT NOTE:
- This file will get rendered in the public facing PyPi page here: https://pypi.org/project/orca_sdk/
- Only content suitable for public consumption should be placed in this file everything else should go into CONTRIBUTING.md
-->
# OrcaSDK
OrcaSDK is a Python library for building and using retrieval-augmented models with [OrcaCloud](https://orcadb.ai). It enables you to create, deploy, and maintain models that can adapt to changing circumstances without retraining by accessing external data called "memories."
## Documentation
You can find the documentation for all things Orca at [docs.orcadb.ai](https://docs.orcadb.ai). This includes tutorials, how-to guides, and the full interface reference for OrcaSDK.
## Features
- **Labeled Memorysets**: Store and manage labeled examples that your models can use to guide predictions
- **Classification Models**: Build retrieval-augmented classification models that adapt to new data without retraining
- **Embedding Models**: Use pre-trained or fine-tuned embedding models to represent your data
- **Telemetry**: Collect feedback and monitor memory usage to optimize model performance
- **Datasources**: Easily ingest data from various sources into your memorysets
## Installation
OrcaSDK is compatible with Python 3.10 or higher and is available on [PyPI](https://pypi.org/project/orca_sdk/). You can install it with your favorite python package manager:
- Pip: `pip install orca_sdk`
- Conda: `conda install orca_sdk`
- Poetry: `poetry add orca_sdk`
## Quick Start
```python
from dotenv import load_dotenv
from orca_sdk import OrcaCredentials, LabeledMemoryset, ClassificationModel
# Load your API key from environment variables
load_dotenv()
assert OrcaCredentials.is_authenticated()
# Create a labeled memoryset
memoryset = LabeledMemoryset.from_disk("my_memoryset", "./data.jsonl")
# Create a classification model using the memoryset
model = ClassificationModel("my_model", memoryset)
# Make predictions
prediction = model.predict("my input")
# Get Action Recommendation
action, rationale = prediction.recommend_action()
print(f"Recommended action: {action}")
print(f"Rationale: {rationale}")
# Generate and add synthetic memory suggestions
if action == "add_memories":
suggestions = prediction.generate_memory_suggestions(num_memories=3)
# Review suggestions
for suggestion in suggestions:
print(f"Suggested: '{suggestion['value']}' -> {suggestion['label']}")
# Add suggestions to memoryset
model.memoryset.insert(suggestions)
print(f"Added {len(suggestions)} new memories to improve model performance!")
```
For a more detailed walkthrough, check out our [Quick Start Guide](https://docs.orcadb.ai/quickstart-sdk/).
## Support
If you have any questions, please reach out to us at support@orcadb.ai.
| text/markdown | Orca DB Inc. | dev-rel@orcadb.ai | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <3.15,>=3.11 | [] | [] | [] | [
"gradio>=6.0.0; extra == \"ui\"",
"httpx>=0.28.1",
"httpx-retries<0.5.0,>=0.4.3",
"python-dotenv>=1.1.0",
"tqdm<5.0.0,>=4.67.2"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:07:47.637510 | orca_sdk-0.1.14.tar.gz | 138,034 | 25/e9/ce72bb02c53fc01eda5c3894fdb997253ae1575eff12d36a77313e9dc1ec/orca_sdk-0.1.14.tar.gz | source | sdist | null | false | d24d17342f932bd01f420b08125a3b57 | be2d78c498174c4380b8e595b525d7201111c8a63fe43fc67987aea65ff29cab | 25e9ce72bb02c53fc01eda5c3894fdb997253ae1575eff12d36a77313e9dc1ec | Apache-2.0 | [] | 215 |
2.4 | scitex | 2.18.1 | A comprehensive Python library for scientific computing and data analysis | <!-- ---
!-- Timestamp: 2026-02-16 10:13:53
!-- Author: ywatanabe
!-- File: /home/ywatanabe/proj/scitex-python/README.md
!-- --- -->
<p align="center">
<a href="https://scitex.ai">
<img src="docs/assets/images/scitex-logo-blue-cropped.png" alt="SciTeX" width="400">
</a>
</p>
<p align="center">
<a href="https://badge.fury.io/py/scitex"><img src="https://badge.fury.io/py/scitex.svg" alt="PyPI version"></a>
<a href="https://pypi.org/project/scitex/"><img src="https://img.shields.io/pypi/pyversions/scitex.svg" alt="Python Versions"></a>
<a href="https://github.com/ywatanabe1989/scitex-python/blob/main/LICENSE"><img src="https://img.shields.io/github/license/ywatanabe1989/scitex-python" alt="License"></a>
<img src="https://img.shields.io/badge/uv-recommended-blue" alt="uv recommended">
</p>
<p align="center">
<a href="https://scitex.ai">scitex.ai</a> · <a href="https://scitex-python.readthedocs.io">Read the Docs</a> · <code>pip install scitex</code>
</p>
---
# SciTeX — Modular Python Toolkit for Researchers and AI Agents
>Four Freedoms for Research
>
>0. The freedom to **run** your research anywhere — your machine, your terms.
>1. The freedom to **study** how every step works — from raw data to final manuscript.
>2. The freedom to **redistribute** your workflows, not just your papers.
>3. The freedom to **modify** any module and share improvements with the community.
>
>AGPL-3.0 — because research infrastructure deserves the same freedoms as the software it runs on.
<p align="center">
<img src="scripts/assets/workflow_out/workflow.png" alt="SciTeX Ecosystem" width="800">
</p>
## 🎬 Demo
**40 min, zero human intervention** — AI agent conducts full research pipeline:
> Literature search → Data analysis → Statistics → Figures → 21-page manuscript → Peer review simulation
<p align="center">
<a href="https://scitex.ai/demos/watch/scitex-automated-research/" title="▶ Watch full demo at scitex.ai/demos/">
<img src="docs/assets/images/scitex-demo.gif" alt="SciTeX Demo" width="800">
</a>
</p>
## 📦 Installation
``` bash
uv pip install scitex # Core (minimal)
uv pip install scitex[plt,stats,scholar] # Typical research setup
uv pip install scitex[all] # Recommended: Full installation
```
## ⚙️ Configuration
Modular environment configuration via `.env.d/`:
<details>
```bash
# 1. Copy examples
cp -r .env.d.examples .env.d
# 2. Edit with your credentials
$EDITOR .env.d/
# 3. Source in shell (~/.bashrc or ~/.zshrc)
source /path/to/.env.d/entry.src
```
**Structure:**
```
.env.d/
├── entry.src # Single entry point
├── 00_scitex.env # Base settings (SCITEX_DIR)
├── 00_crossref-local.env # CrossRef database
├── 00_figrecipe.env # Plotting config
├── 01_scholar.env # OpenAthens, API keys
├── 01_audio.env # TTS backends
└── ... # Per-module configs
```
→ **[Full configuration reference](./.env.d.examples/README.md)**
</details>
## Three Interfaces
<details>
<summary><strong>🐍 Python API for Humans and AI Agents</strong></summary>
<br>
**`@stx.session`** — Reproducible Experiment Tracking
```python
import scitex as stx
@stx.session
def main(filename="demo.jpg"):
fig, ax = stx.plt.subplots()
ax.plot_line(t, signal)
ax.set_xyt("Time (s)", "Amplitude", "Title")
stx.io.save(fig, filename)
return 0
```
**Output**:
```
script_out/FINISHED_SUCCESS/2025-01-08_12-30-00_AbC1/
├── demo.jpg # Figure with embedded metadata
├── demo.csv # Auto-exported plot data
├── CONFIGS/CONFIG.yaml # Reproducible parameters
└── logs/{stdout,stderr}.log # Execution logs
```
**`stx.io`** — Universal File I/O (30+ formats)
```python
stx.io.save(df, "output.csv")
stx.io.save(fig, "output.jpg")
df = stx.io.load("output.csv")
```
**`stx.stats`** — Publication-Ready Statistics (23 tests)
```python
result = stx.stats.test_ttest_ind(group1, group2, return_as="dataframe")
# Includes: p-value, effect size, CI, normality check, power
```
→ **[Full module status](./docs/MODULE_STATUS.md)**
</details>
<details>
<summary><strong>🖥️ CLI Commands for Humans and AI Agents</strong></summary>
<br>
```bash
scitex --help-recursive # Show all commands
scitex scholar fetch "10.1038/..." # Download paper by DOI
scitex scholar bibtex refs.bib # Enrich BibTeX
scitex stats recommend # Suggest statistical tests
scitex audio speak "Done" # Text-to-speech
scitex capture snap # Screenshot
# List available APIs and tools
scitex list-python-apis # List all Python APIs (210 items)
scitex mcp list-tools # List all MCP tools (120+ tools)
scitex introspect api scitex.stats # List APIs for specific module
```
→ **[Full CLI reference](./docs/CLI_COMMANDS.md)**
</details>
<details>
<summary><strong>🔧 MCP Tools — 120+ tools for AI Agents</strong></summary>
<br>
Turn AI agents into autonomous scientific researchers.
**Typical workflow**: Scholar (find papers) → Stats (analyze) → Plt (visualize) → Writer (manuscript) → Capture (verify)
| Category | Tools | Description |
|----------|-------|-------------|
| writer | 28 | LaTeX manuscript compilation |
| scholar | 23 | PDF download, metadata enrichment |
| capture | 12 | Screen monitoring and capture |
| introspect | 12 | Python code introspection |
| audio | 10 | Text-to-speech, audio playback |
| stats | 10 | Automated statistical testing |
| plt | 9 | Matplotlib figure creation |
| diagram | 9 | Mermaid and Graphviz diagrams |
| dataset | 8 | Scientific dataset access |
| social | 7 | Social media posting |
| canvas | 7 | Scientific figure canvas |
| template | 6 | Project scaffolding |
| verify | 6 | Reproducibility verification |
| dev | 6 | Ecosystem version management |
| ui | 5 | Notifications |
| linter | 3 | Code pattern checking |
**Claude Desktop** (`~/.config/claude/claude_desktop_config.json`):
```json
{
"mcpServers": {
"scitex": {
"command": "scitex",
"args": ["mcp", "start"],
"env": {
"SCITEX_ENV_SRC": "${SCITEX_ENV_SRC}"
}
}
}
}
```
→ **[Full MCP tool reference](./docs/MCP_TOOLS.md)**
</details>
## 🧩 Standalone Packages
SciTeX integrates several standalone packages that can be used independently:
<details>
| Package | scitex Module | Description |
|---------|--------------|-------------|
| [figrecipe](https://github.com/ywatanabe1989/figrecipe) | `scitex.plt` | Publication-ready matplotlib figures |
| [crossref-local](https://github.com/ywatanabe1989/crossref-local) | `scitex.scholar.crossref_scitex` | Local CrossRef database (167M+ papers) |
| [openalex-local](https://github.com/ywatanabe1989/openalex-local) | `scitex.scholar.openalex_scitex` | Local OpenAlex database (250M+ papers) |
| [socialia](https://github.com/ywatanabe1989/socialia) | `scitex.social` | Social media posting (Twitter, LinkedIn) |
| [scitex-writer](https://github.com/ywatanabe1989/scitex-writer) | `scitex.writer` | LaTeX manuscript compilation |
| [scitex-dataset](https://github.com/ywatanabe1989/scitex-dataset) | `scitex.dataset` | Scientific dataset access |
Each package works standalone or as part of scitex:
```bash
pip install figrecipe # Use independently
pip install scitex[plt] # Or via scitex
```
</details>
## 📖 Documentation
- **[Read the Docs](https://scitex-python.readthedocs.io/)**: Complete API reference
- **[Examples](./examples/)**: Usage examples and demonstrations
## 🤝 Contributing
We welcome contributions! See [CONTRIBUTING.md](CONTRIBUTING.md).
---
<p align="center">
<a href="https://scitex.ai" target="_blank"><img src="docs/assets/images/scitex-icon-navy-inverted.png" alt="SciTeX" width="40"/></a>
<br>
AGPL-3.0
</p>
<!-- EOF --> | text/markdown | null | Yusuke Watanabe <ywatanabe@scitex.ai> | null | null | AGPL-3.0 | data-analysis, machine-learning, neural-networks, research, scientific-computing, signal-processing | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU Affero General Public License v3",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Progr... | [] | null | null | >=3.10 | [] | [] | [] | [
"natsort",
"numpy",
"packaging",
"pandas",
"pyyaml",
"tqdm",
"anthropic; extra == \"ai\"",
"google-genai; extra == \"ai\"",
"groq; extra == \"ai\"",
"imbalanced-learn; extra == \"ai\"",
"joblib; extra == \"ai\"",
"markdown2; extra == \"ai\"",
"matplotlib; extra == \"ai\"",
"natsort; extra ... | [] | [] | [] | [
"Homepage, https://github.com/ywatanabe1989/scitex-python",
"Documentation, https://scitex.readthedocs.io",
"Repository, https://github.com/ywatanabe1989/scitex-python",
"Bug Tracker, https://github.com/ywatanabe1989/scitex-python/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:07:46.364942 | scitex-2.18.1.tar.gz | 8,921,067 | 49/b8/2ef012d72a8f20173358936c2e4e77b15468e6af68709f4e8b8f7fba10f0/scitex-2.18.1.tar.gz | source | sdist | null | false | f782d827c46ebe7554884db975bc64f8 | 883d793322914ce5d982d472c5955cadc29f0d8b4ae8098cf28791a1aca157ab | 49b82ef012d72a8f20173358936c2e4e77b15468e6af68709f4e8b8f7fba10f0 | null | [
"LICENSE"
] | 247 |
2.4 | npkt | 1.0.1 | AWS Service Control Policy toolkit: lint, analyze, and simulate SCP impact | # NPKT - AWS Service Control Policy Toolkit
**"Apply SCPs with 0% chance of breaking existing workflows"**
A unified Python toolkit for linting, analyzing, and simulating AWS Service Control Policy (SCP) impact against CloudTrail logs.
## Features
- **Lint** - Validate SCP syntax and detect common mistakes (36+ rules)
- **Analyze** - Find conflicts, shadows, duplicates across policies
- **Simulate** - Test SCP impact against real CloudTrail data before deployment
- **Validate** - Quick syntax check for SCP JSON files
- **Generate Logs** - Generate mock CloudTrail events for all 442 AWS services for testing
### Simulation Capabilities
- **400+ AWS services** with resource ARN extraction (22 hardcoded quirky services + data-driven via IAM reference)
- **1,150+ condition key extractors** (88 hand-tuned + 1,069 auto-generated from IAM reference)
- **External context enrichment** - supply org ID, principal/resource tags, VPC mappings, and management account ID via `--context` file to resolve normally-unevaluable condition keys
- **Service-linked role filtering** - automatically excludes SLR events (SCPs don't apply to them)
- **Management account filtering** - excludes management account events when `management_account_id` is in the context file
- **Simulation confidence scoring** - reports whether denial rate is exact or a lower bound based on unevaluable condition keys
- **Strict conditions mode** - `--strict-conditions` treats unevaluable conditions as non-matching to produce an upper-bound denial rate
- **Resource-level permissions lint rule** - warns when SCP statements use non-`*` Resource with actions that don't support resource-level permissions (W052)
- **Multi-policy hierarchy warning** - warns when multiple policies are evaluated as a flat set instead of OU hierarchy
- **Data event gap detection** - warns when SCPs target events not in logs
- **Mock CloudTrail generation** - generate test events for all 442 AWS services with realistic `requestParameters` and condition key values
## Installation
### Prerequisites
- Python 3.10 or higher
- pip
### Install from source
```bash
git clone <repo-url>
cd NPKT
# Install the package
pip install -e .
# Or with dev dependencies
pip install -e ".[dev]"
```
## Quick Start
### Lint an SCP
```bash
npkt lint policy.json
npkt lint ./policies/
npkt lint policy.json --format json
```
### Analyze policies for conflicts
```bash
npkt analyze ./policies/
npkt analyze policy.json
npkt analyze ./policies/ --format json
```
### Simulate SCP impact
```bash
npkt simulate policy.json --logs ./cloudtrail/
npkt simulate policy.json --logs events.json --days 30
npkt simulate policy.json --logs ./logs/ --context context.json
npkt simulate policy.json --logs ./logs/ --quick
```
### Validate syntax
```bash
npkt validate policy.json
npkt validate policy.json --verbose
```
### Generate mock CloudTrail logs
```bash
npkt generate-logs -o logs.json
npkt generate-logs -o logs.json -s ec2,s3,iam -c 100
npkt generate-logs -o logs.json --write-only --seed 42
npkt generate-logs -o logs.json -c 1000 --regions us-east-1,eu-west-1
```
## CLI Reference
### `npkt lint`
Lint SCP policies for errors and best practices.
```bash
npkt lint <policy_path> [options]
```
| Option | Description |
|--------|-------------|
| `--format, -f` | Output format: `text` (default) or `json` |
| `--strict` | Treat warnings as errors |
| `--quiet, -q` | Only show errors, suppress warnings |
**Example output:**
```
policy.json
[W] W050: Statement denies all S3 actions without conditions (Statement.0)
[I] W090: Statement uses NotAction (Statement.1)
Summary: 1 warning(s), 1 info
```
### `npkt analyze`
Analyze policies for conflicts, shadows, and redundancies.
```bash
npkt analyze <policy_path> [options]
```
| Option | Description |
|--------|-------------|
| `--format, -f` | Output format: `text` (default) or `json` |
| `--cross-policy/--no-cross-policy` | Enable cross-policy analysis (default: enabled) |
| `--strict` | Treat warnings as errors |
**Detected issues:**
- **DUPLICATE_STATEMENT** - Identical statements across policies
- **DUPLICATE_SID** - Duplicate statement IDs
- **SHADOW** - Statement is overshadowed by another
- **CONFLICT** - Conflicting Allow/Deny for same actions
- **UNREACHABLE** - Allow statement blocked by Deny statements
### `npkt simulate`
Simulate SCP impact against CloudTrail events.
```bash
npkt simulate <policy_path> --logs <logs_path> [options]
```
| Option | Description |
|--------|-------------|
| `--logs, -l` | Path to CloudTrail logs (required) |
| `--context, -c` | Path to external context JSON file (org ID, tags, VPC mappings) |
| `--format, -f` | Output format: `text` (default) or `json` |
| `--output, -o` | Write output to file |
| `--days, -d` | Days to analyze (default: 90) |
| `--quick` | Quick analysis with sampling |
| `--sample-size` | Sample size for quick mode (default: 1000) |
| `--no-details` | Hide detailed denial list |
| `--strict-conditions` | Treat unevaluable conditions as non-matching (worst-case upper-bound denial rate) |
**Exit codes:**
- `0` - No risk or low risk
- `1` - Medium risk
- `2` - High or critical risk
### `npkt validate`
Quick syntax validation for SCP files.
```bash
npkt validate <policy_path> [--verbose]
```
### `npkt generate-logs`
Generate mock CloudTrail log events for SCP simulation testing. Creates realistic events for any of the 442 AWS services in the IAM reference database, with proper `requestParameters` derived from IAM resource ARN patterns for high resource ARN resolution rates.
```bash
npkt generate-logs -o <output_path> [options]
```
| Option | Description |
|--------|-------------|
| `-o, --output` | Output file path (required) |
| `-s, --services` | Comma-separated service prefixes or `all` (default: `all`) |
| `-c, --count` | Total number of events to generate (default: 500) |
| `--regions` | Comma-separated AWS regions (default: `us-east-1,us-west-2,eu-west-1`) |
| `--account-id` | AWS account ID (default: `123456789012`) |
| `--seed` | Random seed for reproducible output |
| `--write-only` | Only include write/mutative operations (skip read/list) |
**Example workflow - generate logs then simulate:**
```bash
# Generate 500 write-only events for key services
npkt generate-logs -o test_logs.json -s ec2,s3,iam,lambda,rds -c 500 --write-only --seed 42
# Simulate your SCP against the generated events
npkt simulate policy.json --logs test_logs.json
# Simulate with external context for higher accuracy
npkt simulate policy.json --logs test_logs.json --context context.json
```
## Python API
```python
from npkt import (
load_policy,
load_policies_from_dir,
SCPLinter,
PolicyAnalyzer,
analyze_policies,
ImpactAnalyzer,
FileIngester,
)
# Load and lint a policy
policy = load_policy("policy.json")
linter = SCPLinter()
report = linter.lint(policy.to_dict())
if report.has_errors:
for result in report.errors:
print(f"{result.code}: {result.message}")
# Analyze multiple policies
policies = load_policies_from_dir("./policies/")
analysis = analyze_policies(*policies)
for issue in analysis.issues:
print(f"{issue.type.value}: {issue.message}")
# Simulate SCP impact
ingester = FileIngester("./cloudtrail/")
analyzer = ImpactAnalyzer(
scp_policies=[policy],
cloudtrail_ingester=ingester,
)
report = analyzer.analyze()
print(f"Denial rate: {report.denial_rate:.2%}")
print(f"Risk level: {report.get_risk_level()}")
# Simulate with external context for better accuracy
from npkt import ExternalContext
ctx = ExternalContext.from_file("context.json")
analyzer = ImpactAnalyzer(
scp_policies=[policy],
cloudtrail_ingester=ingester,
external_context=ctx,
)
report = analyzer.analyze()
```
## Project Structure
```
NPKT/
+-- src/npkt/ # Main package
| +-- cli/ # CLI commands
| | +-- main.py # Entry point
| | +-- lint.py # lint command
| | +-- analyze.py # analyze command
| | +-- simulate.py # simulate command
| | +-- validate.py # validate command
| | +-- generate.py # generate-logs command
| +-- models/ # Data models
| | +-- scp.py # SCPStatement, SCPPolicy
| | +-- cloudtrail.py # CloudTrailEvent
| | +-- report.py # ImpactReport, EvaluationResult, EvaluationContext
| | +-- external_context.py # ExternalContext (--context FILE)
| | +-- lint.py # LintReport, LintResult
| | +-- analysis.py # AnalysisReport, Issue
| +-- linter/ # SCP linter
| +-- analyzer/ # Policy and impact analysis
| +-- engine/ # SCP evaluation engine
| +-- parsers/ # SCP parsers
| +-- ingest/ # CloudTrail ingesters
| +-- reporters/ # Output formatters
| +-- generators/ # CloudTrail log generation
| +-- data/ # IAM reference data
+-- tests/ # Test suite (1219 tests)
| +-- test_services/ # Per-service tests (48 files)
| +-- test_cli/ # CLI command tests
| +-- test_engine/ # Engine tests
+-- fixtures/ # Test data
```
## How It Works
1. **Parse SCP**: Reads and validates SCP policies (JSON format)
2. **Ingest CloudTrail**: Loads CloudTrail events from files (JSON/gzip)
3. **Filter**: Excludes service-linked role events and management account events (SCPs don't apply)
4. **Extract Context**: Resolves resource ARNs and condition key values from each event
5. **Enrich Context**: If `--context` is provided, enriches each event with external data (org ID, principal/resource tags, VPC mappings)
6. **Evaluate**: Tests each event against SCP statements (action, resource, principal, conditions)
7. **Track Confidence**: Records unresolved resources and unevaluable condition keys; qualifies denial rate as exact or lower-bound
8. **Analyze**: Aggregates results, calculates statistics, detects data event gaps
9. **Report**: Generates output with risk assessment, confidence score, and recommendations
## Understanding Risk Levels
| Level | Denial Rate | Action |
|-------|-------------|--------|
| NONE | 0% | Safe to apply |
| LOW | <1% | Review denials, likely safe |
| MEDIUM | 1-5% | Careful review needed |
| HIGH | 5-20% | Significant impact expected |
| CRITICAL | >20% | Major impact, refine SCP first |
## Supported SCP Features
- **Effects**: Allow, Deny
- **Actions**: Wildcards (`*`, `s3:*`, `s3:Delete*`)
- **NotAction**: Inverse action matching
- **Resources/NotResource**: ARN pattern matching with wildcards
- **Principal/NotPrincipal**: Principal ARN pattern matching
- **Conditions**: 24 operators with IfExists and ForAll/ForAny modifiers
- String: `StringEquals`, `StringLike`, `StringEqualsIgnoreCase`, etc.
- ARN: `ArnEquals`, `ArnLike`, `ArnNotEquals`, `ArnNotLike`
- Numeric: `NumericEquals`, `NumericLessThan`, `NumericGreaterThan`, etc.
- IP: `IpAddress`, `NotIpAddress`
- Date: `DateEquals`, `DateLessThan`, `DateGreaterThan`, etc.
- Bool, Null
## Resource ARN Extraction
NPKT uses a hybrid approach for extracting resource ARNs from CloudTrail events:
### Hardcoded Quirky Services (22)
Services with non-trivial extraction logic that requires hand-tuned patterns:
| Category | Services |
|----------|----------|
| **Compute** | EC2 (10 resource types, nested `instancesSet`), EKS (sub-resources under cluster) |
| **Storage** | S3 (composite `bucket/key`, regionless) |
| **Database** | RDS (colon separator `db:id`), ElastiCache (colon separator `cluster:id`) |
| **Messaging** | SQS (URL parsing), EventBridge |
| **Networking** | ELBv2, Route 53 (prefix stripping, regionless), CloudFront (regionless) |
| **Security** | IAM (regionless, priority ordering), KMS (UUID/alias/ARN detection), WAFv2 (scope-based path), Organizations |
| **Monitoring** | CloudWatch, CloudTrail, AWS Config |
| **Integration** | Step Functions, SSM (leading slash stripping), CodePipeline |
| **Data** | Glue (composite `database/table`) |
| **DevOps** | CloudFormation |
### Data-Driven Services (400+)
All remaining services use IAM reference ARN patterns for automatic extraction:
- **ARN passthrough** - Detects when parameters already contain valid ARNs
- **Template scoring** - When multiple resource types exist, picks the best match by resolved placeholders and specificity
- **8 parameter matching strategies** - Exact, camelCase, lowercase, snake_case, abbreviation expansion, suffix stripping, aliases, name fallback
- **Regionless/accountless handling** - Correctly handles services that omit region or account from ARNs
## Condition Key Extraction
NPKT evaluates **1,150+ condition keys** from CloudTrail events using a two-tier system:
### Hand-Tuned Extractors (88 keys across 31 services)
Manually crafted extractors for keys with non-obvious mappings:
| Service | Example Keys |
|---------|--------------|
| **S3** | `s3:prefix`, `s3:delimiter`, `s3:x-amz-acl`, `s3:x-amz-server-side-encryption` |
| **EC2** | `ec2:instancetype`, `ec2:imageid`, `ec2:region`, `ec2:tenancy`, `ec2:volumetype` |
| **RDS** | `rds:databaseclass`, `rds:databaseengine`, `rds:multi-az`, `rds:storagetype` |
| **Lambda** | `lambda:functionarn`, `lambda:layer`, `lambda:runtime` |
| **KMS** | `kms:viaservice`, `kms:callerarn`, `kms:encryptioncontext` |
| **IAM/STS** | `iam:permissionsboundary`, `sts:rolesessionname`, `sts:externalid` |
### Auto-Generated Extractors (1,069 keys across 200+ services)
Derived from IAM reference condition key definitions at startup. Key name parts are converted to `requestParameters` field candidates (e.g., `sagemaker:VolumeKmsKeyId` -> `volumeKmsKeyId`). Hand-tuned extractors always take priority.
## External Context Enrichment
Some condition keys (`aws:PrincipalOrgId`, `aws:PrincipalTag/*`, `aws:ResourceTag/*`, `aws:SourceVpc`) require data not present in CloudTrail events. Without this data, NPKT conservatively assumes conditions match and reports them as unevaluable.
The `--context` flag lets you supply this data via a JSON file, turning "assumed match" into actual evaluation:
```bash
npkt simulate policy.json --logs ./logs/ --context context.json
```
### Context file format
```json
{
"management_account_id": "123456789012",
"organization": {
"id": "o-a1b2c3d4e5",
"paths": ["o-a1b2c3d4e5/r-ab12/ou-ab12-11111111"]
},
"principals": {
"arn:aws:iam::123456789012:role/AdminRole": {
"tags": { "Department": "Engineering", "Environment": "production" }
},
"arn:aws:iam::123456789012:role/*": {
"tags": { "OrgUnit": "eng" }
}
},
"resources": {
"arn:aws:s3:::my-bucket": {
"tags": { "Classification": "confidential" }
},
"arn:aws:s3:::public-*": {
"tags": { "Classification": "public" }
}
},
"vpc_map": {
"vpce-0a1b2c3d": "vpc-11111111"
}
}
```
### What each section resolves
| Section | Effect |
|---------|--------|
| `management_account_id` | Excludes events from this account (SCPs don't apply to management account) |
| `organization.id` | Resolves `aws:PrincipalOrgId` condition key |
| `organization.paths` | Resolves `aws:PrincipalOrgPaths` condition key |
| `principals.*.tags` | Resolves `aws:PrincipalTag/*` condition keys |
| `resources.*.tags` | Resolves `aws:ResourceTag/*` condition keys |
| `vpc_map` | Resolves `aws:SourceVpc` (via VPC endpoint ID mapping) |
Principal and resource ARN patterns support `*` and `?` wildcards. Exact matches take priority over wildcards, and more specific patterns override less specific ones.
### Gathering context data
The data for the context file can be collected with a few AWS CLI commands:
```bash
# Organization ID
aws organizations describe-organization --query 'Organization.Id'
# Principal tags
aws iam list-role-tags --role-name MyRole
aws iam list-user-tags --user-name MyUser
# Resource tags
aws resourcegroupstaggingapi get-resources --resource-type-filters ec2:instance
# VPC endpoint to VPC mapping
aws ec2 describe-vpc-endpoints --query 'VpcEndpoints[].{Id:VpcEndpointId,VpcId:VpcId}'
```
## Testing
```bash
# Run all tests
pytest
# Run with coverage
pytest --cov=npkt
# Run specific test file
pytest tests/test_engine/test_scp_engine.py
```
## Development
```bash
# Install dev dependencies
pip install -e ".[dev]"
# Run linters
ruff check .
mypy src/
# Format code
ruff format .
```
## Simulation Confidence
NPKT reports simulation confidence to help you understand result reliability:
```
X Would Be DENIED: 3 (>=0.3% -- lower bound, 2 unevaluable condition key(s))
Filtered: 42 service-linked role event(s) (SCPs do not apply to SLRs)
Filtered: 15 management account event(s) (SCPs do not apply to management account)
Simulation Confidence: MEDIUM
------------------------------------------------------------
Resource ARN resolved: 847/1,000 events (84.7%)
Unevaluable condition keys encountered:
- aws:PrincipalOrgId (found in 3 evaluations)
- aws:ResourceTag/Environment (found in 1 evaluation)
WARNING: These conditions were assumed to MATCH (not deny).
The actual denial rate may be HIGHER than reported.
Supply a --context file to resolve evaluable keys, or use
--strict-conditions to treat unevaluable conditions as denials (worst-case).
```
Use `--context` to resolve unevaluable keys and improve confidence:
```bash
npkt simulate policy.json --logs ./logs/ --context context.json
```
Use `--strict-conditions` for worst-case analysis (upper-bound denial rate):
```bash
npkt simulate policy.json --logs ./logs/ --strict-conditions
```
Running both modes gives a range: the normal mode shows a lower bound and strict mode shows an upper bound. The actual denial rate is somewhere in between.
**Confidence Levels:**
- **HIGH** - Resource resolution >95%, few unevaluable keys
- **MEDIUM** - Some resources unresolved or unevaluable keys present
- **LOW** - Significant data gaps, results may be unreliable
## Known Limitations
### CloudTrail Ingestion
- **File-based only**: CloudTrail logs must be downloaded locally (JSON or gzip format)
- **No S3 direct access**: Cannot read logs directly from S3 buckets
- **Data events**: S3 object operations, Lambda invocations, and DynamoDB item operations require explicit CloudTrail data event logging. Most trails only capture management events -- a deny rule targeting `s3:GetObject` would show 0% denial rate if data events weren't enabled, giving false confidence. NPKT warns when SCPs target these events but none are found in logs.
### Condition Keys Not Evaluable
Some condition keys require external context not available in CloudTrail. Most of these can be resolved by providing a `--context` file (see [External Context Enrichment](#external-context-enrichment)):
| Key Type | Examples | Resolvable via `--context`? |
|----------|----------|---------------------------|
| **Organization context** | `aws:PrincipalOrgId`, `aws:PrincipalOrgPaths` | Yes |
| **Principal tags** | `aws:PrincipalTag/*` | Yes |
| **Resource tags** | `aws:ResourceTag/*` | Yes |
| **VPC context** | `aws:SourceVpc` | Yes (via VPC endpoint mapping) |
| **Service-specific keys** | `s3:prefix`, `s3:x-amz-acl`, `kms:ViaService`, etc. | No |
| **Multi-factor auth** | `aws:MultiFactorAuthAge` | No |
When these keys are encountered without a context file, NPKT assumes the condition matches (conservative approach -- the reported denial rate is a lower bound) and tracks them in the simulation confidence report. SCPs that rely heavily on service-specific condition keys will have less accurate results. Use `--strict-conditions` to flip this assumption and get an upper-bound denial rate.
### Resource ARN Extraction
- **400+ services supported**: 22 hardcoded quirky services + data-driven extraction via IAM reference for all others
- **5-layer extraction**: Direct ARN fields, quirky service patterns, ~190 known ARN parameter keys, IAM reference template resolution, response element scan
- **Resolution rate**: Typically 80-98% depending on service mix. The simulation confidence section reports the exact resolution rate so you can assess impact.
### SCP Evaluation Scope
- **SCP layer only**: This tool evaluates SCPs in isolation. It does not model identity policies, resource policies, permissions boundaries, or session policies. An action the SCP allows could still be denied by other policy types (and vice versa).
- **Service-linked roles**: Automatically filtered out (SCPs do not apply to SLRs)
- **Management account**: Filtered when `management_account_id` is provided in the context file
- **Resource-level permissions**: Linter warns (W052) when actions that don't support resource-level permissions are paired with non-`*` Resource restrictions. The simulator does not yet adjust Resource matching for these actions.
- **OU hierarchy**: SCPs are inherited at every level (Root, OU, Account) and all must allow an action. This tool evaluates provided policies as a flat set and warns when multiple policies are provided.
## Troubleshooting
If you encounter issues, see [TROUBLESHOOTING.md](TROUBLESHOOTING.md).
**Common checks:**
1. Validate your SCP: `npkt validate policy.json`
2. Run tests: `pytest` (1219 tests verify functionality)
3. Check CloudTrail format: Ensure valid JSON with `Records` array
| text/markdown | NPKT Team | null | null | null | null | aws, scp, service-control-policy, cloudtrail, security, compliance, linter, policy-analysis | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: System Administrators",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language ... | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.1.0",
"rich>=13.7.0",
"python-dateutil>=2.8.0",
"pytest>=7.4.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"mypy>=1.8.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"boto3>=1.34.0; extra == \"aws\"",
"npkt[aws]; extra == \"all\""
] | [] | [] | [] | [
"Homepage, https://github.com/OnticX/npkt",
"Documentation, https://github.com/OnticX/npkt#readme",
"Repository, https://github.com/OnticX/npkt",
"Issues, https://github.com/OnticX/npkt/issues"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T21:07:43.085663 | npkt-1.0.1.tar.gz | 305,811 | 47/13/538ff225f11a499d215c52879bea32cc16487e2f69fbd5fc95a9a4af15c2/npkt-1.0.1.tar.gz | source | sdist | null | false | b194abad48c80cde7c91d4b9a710064c | a7c47d074bea20047711c50a875c0e29e993878c0e0b6c518ec45b1a53bbf457 | 4713538ff225f11a499d215c52879bea32cc16487e2f69fbd5fc95a9a4af15c2 | MIT | [
"LICENSE"
] | 224 |
2.3 | fast-abtest | 0.4.2 | A fast and lightweight A/B testing library for Python. | # Fast ABTest
[](https://badge.fury.io/py/fast-abtest)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
A lightweight Python decorator for implementing A/B testing with automatic traffic distribution and built-in metrics monitoring. Compatible with FastAPI and works with both synchronous and asynchronous functions.
## Installation
```bash
pip install fast-abtest
```
## Quick Start
### Basic Usage
```python
from fast_abtest import ab_test, Metric
@ab_test(metrics=[Metric.LATENCY, Metric.ERRORS_TOTAL])
def recommendation_service(user_id: int) -> list[str]:
# Main variant (A) - receives remaining traffic percentage
return ["item1", "item2"]
@recommendation_service.register_variant(traffic_percent=30, disable_threshold=0.2)
def recommendation_service_b(user_id: int) -> list[str]:
# Variant B - gets 30% of the traffic. If the error rate exceeds 0.2, traffic redirection will stop.
return ["item3", "item4"]
```
### FastAPI Integration
```python
from fastapi import FastAPI, Depends
from fast_abtest import ab_test
app = FastAPI()
@app.get("/recommendations")
@ab_test(metrics=[])
async def get_recommendations(user_id: int):
return {"items": ["A1", "A2"]}
@get_recommendations.register_variant(traffic_percent=30)
async def get_recommendations_b(user_id: int):
return {"items": ["B1", "B2"]}
```
**Important**: For FastAPI, the route decorator (`@app.get`) must come **before** `@ab_test`.
### Consistent distribution
```python
from fastapi import FastAPI, Depends
from fast_abtest import ab_test
app = FastAPI()
@app.get("/recommendations")
@ab_test(metrics=[], consistency_key='user_id')
async def get_recommendations(user_id: int):
return {"items": ["A1", "A2"]}
@get_recommendations.register_variant(traffic_percent=30)
async def get_recommendations_b(user_id: int):
return {"items": ["B1", "B2"]}
```
| text/markdown | Evgenii Eliseev | evgeniieliseeve@gmail.com | null | null | MIT | ab-testing, statistics, experiments, monitoring | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: ... | [] | https://github.com/Gifourm/fast-abtest | null | <4.0,>=3.10 | [] | [] | [] | [
"pydantic<3.0.0,>=2.11.7",
"fastapi>=0.115.12; extra == \"fastapi\"",
"prometheus-client>=0.22.1; extra == \"prometheus\""
] | [] | [] | [] | [
"Homepage, https://github.com/Gifourm/fast-abtest",
"Repository, https://github.com/Gifourm/fast-abtest",
"Documentation, https://github.com/Gifourm/fast-abtest#readme"
] | poetry/2.1.3 CPython/3.12.0 Windows/11 | 2026-02-19T21:07:28.753836 | fast_abtest-0.4.2-py3-none-any.whl | 17,441 | bd/28/bfa1353170345efe5d905c8100f02db98dc2d76055ff82b34d1fb0424889/fast_abtest-0.4.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 9f8d11567e2de4a12aea811ee815a801 | 6824fc7d0e5846e36a92cd8c4ec1558477c02853facba4ebaeb0dc1b20f5b9fb | bd28bfa1353170345efe5d905c8100f02db98dc2d76055ff82b34d1fb0424889 | null | [] | 224 |
2.4 | snowpark-connect | 1.14.0 | Snowpark Connect for Spark | Snowpark Connect for Spark enables developers to run their Spark workloads directly to Snowflake using the Spark Connect protocol. This approach decouples the client and server, allowing Spark code to run remotely against Snowflake's compute engine without managing a Spark cluster. It offers a streamlined way to integrate Snowflake's governance, security, and scalability into Spark-based workflows, supporting a familiar PySpark experience with pushdown optimizations into Snowflake.
| text/markdown | Snowflake, Inc | null | null | null | Apache License, Version 2.0 | snowflake, snowpark, connect, spark | [] | [] | null | null | <3.13,>=3.10 | [] | [] | [] | [
"snowpark-connect-deps-1==3.56.3",
"snowpark-connect-deps-2==3.56.3",
"certifi>=2025.1.31",
"cloudpickle",
"fsspec",
"jpype1",
"protobuf<6.32.0,>=4.25.3",
"s3fs>=2025.3.0",
"snowflake.core<2,>=1.0.5",
"snowflake-snowpark-python[pandas]<1.45.0,>=1.44.0",
"snowflake-connector-python<4.2.0,>=3.18.0... | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.9 | 2026-02-19T21:06:52.222946 | snowpark_connect-1.14.0.tar.gz | 47,763,665 | 1a/18/b3d73e9e4239eb80ab3201b58e2cfa5d35c141198d71c06a09a7a9661672/snowpark_connect-1.14.0.tar.gz | source | sdist | null | false | 4128e62aa5d782a235a684b0a2e0642d | e6a61d7f28c8bf59c86f69804d1c20cb4993d6972dea5135416861a54d55c5eb | 1a18b3d73e9e4239eb80ab3201b58e2cfa5d35c141198d71c06a09a7a9661672 | null | [
"LICENSE.txt",
"LICENSE-binary",
"NOTICE-binary"
] | 419 |
2.4 | modulitiz-micro | 2.57.1 | Raccolta dei miei moduli - versione micro | # modulitiz-micro
It's a Python library that contains daily use or generic functions.
Extends another wheel: nano
## Installation
Use the package manager [pip](https://pip.pypa.io/en/stable/) to install:
```bash
pip install -U modulitiz_micro
```
The other required dependencies will be installed automatically.
## Usage
```python
from modulitiz_micro.sistema.ModuloEnvVars import ModuloEnvVars
# returns the specified system variable
ModuloEnvVars.getOrNone("system variable")
...
```
## Contributing
If you find any bug you can write me at [sderfo1234@altervista.org](mailto:sderfo1234@altervista.org)
## License
[MIT](https://choosealicense.com/licenses/mit/)
| text/markdown | null | tiz <sderfo1234@altervista.org> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"modulitiz-nano>=0",
"androidtvremote2==0.3.0",
"beautifulsoup4==4.14.3",
"brotli==1.2.0",
"cachetools==6.2.4",
"cryptography==45.0.6",
"GitPython==3.1.46",
"mysql_connector_python==9.5.0",
"pynput==1.8.1",
"pyOpenSSL==25.1.0",
"pypyodbc==1.3.6",
"pyserial==3.5",
"requests==2.32.5",
"scapy... | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.9 | 2026-02-19T21:06:50.457894 | modulitiz_micro-2.57.1-py311-none-any.whl | 60,694 | be/f6/9f7ab1795f3cdb40fe1091289e4676cd6ce8d5c4e57837176415e7785bb1/modulitiz_micro-2.57.1-py311-none-any.whl | py311 | bdist_wheel | null | false | 0a78da3018fe2eb27094a32aa9b49a2b | d0c37b13376d16ac7c2226b81044580f1f9d1c198ad6d21e2c7420f4c1c20112 | bef69f7ab1795f3cdb40fe1091289e4676cd6ce8d5c4e57837176415e7785bb1 | null | [
"LICENSE"
] | 93 |
2.1 | arcp-py | 2.1.0 | ARCP (Agent Registry & Control Protocol) is a sophisticated agent orchestration protocol that provides centralized service discovery, registration, communication, and control for distributed agent systems. | <div align="center">
# ARCP - Agent Registry & Control Protocol
[](./LICENSE)
[](https://www.python.org/downloads/)
[](https://github.com/psf/black)
[](#security)
[](https://badge.fury.io/py/arcp-py)
[](https://www.docker.com/)
**A sophisticated agent orchestration protocol that provides centralized service discovery, registration, communication, and control for distributed agent systems.**
</div>
## ✨ Features
<div align="center">
| 🔧 **Centralized Management** | 🔍 **Service Discovery** | 🤝 **Agent Communication** |
|:---:|:---:|:---:|
| *Register & control agents* | *Automatic endpoint resolution* | *Secure agent collaboration* |
| 🛡️ **Security** | 📊 **Dashboard** | 🐳 **Production** |
|:---:|:---:|:---:|
| *Built-in authentication* | *Metrics & Alerts & Logs* | *Docker & monitoring stack* |
| ⚙️ **Extensible** | 👨💻 **Developers** | 📚 **Docs** |
|:---:|:---:|:---:|
| *Custom use cases* | *Python client, API* | *Guides & references* |
</div>
## 🚀 Quick Start
### Running the Server
#### 🐍 pip Installation
```bash
# Install ARCP
pip install arcp-py
# Set up configuration
curl -o .env https://raw.githubusercontent.com/0x00K1/ARCP/main/.env.example
# Edit .env file with your configuration
# Start the server
python -m arcp
```
#### 🐳 Docker Deployment (Recommended)
For a complete production setup with monitoring, use Docker:
```bash
# Clone ARCP
git clone https://github.com/0x00K1/ARCP.git
cd ARCP
# Set up configuration
cp .env.example .env
cp .env.example deployment/docker/.env
# Edit .env file with your configuration
# Start full stack (ARCP + Redis + Monitoring)
cd deployment/docker
docker-compose up -d --build
```
> 💡 **Need help?** Check out our detailed [Installation Guide](https://arcp.0x001.tech/docs/getting-started/installation).
### 🛠️ Agent Development
Build agents that integrate seamlessly with ARCP:
```python
from arcp import ARCPClient, AgentRequirements
async def register_with_arcp():
"""Register this agent with ARCP"""
# Create ARCP client
arcp_client = ARCPClient("http://localhost:8001")
try:
# Register the agent
agent = await arcp_client.register_agent(
agent_id="my-agent-001",
name="My Demo Agent",
agent_type="automation",
endpoint="http://localhost:8080",
capabilities=["processing", "automation"],
context_brief="A demo agent showcasing ARCP integration",
version="1.0.0",
owner="Developer",
public_key="your-public-key-min-32-chars-long",
communication_mode="remote",
metadata={
"framework": "fastapi",
"language": "python",
"created_at": "2025-09-20T03:00:00.000000",
},
features=["http-api", "json-responses"],
max_tokens=1000,
language_support=["en"],
rate_limit=100,
requirements=AgentRequirements(
system_requirements=["Python 3.11+", "FastAPI"],
permissions=["http-server"],
dependencies=["fastapi", "arcp"],
minimum_memory_mb=256,
requires_internet=True,
network_ports=["8080"]
),
policy_tags=["utility", "demo"],
agent_key="test-agent-001"
)
print(f"✅ Agent registered: {agent.name}")
print(f"📊 Status: {agent.status}")
finally:
await arcp_client.close()
# Run the registration
import asyncio
asyncio.run(register_with_arcp())
```
> 🎯 **Want to dive deeper?** Explore our comprehensive [Agent Development Guide](https://arcp.0x001.tech/docs/user-guide/agent-development).
## 📚 Documentation
<div align="center">
### Everything you need to get started, develop agents, and operate ARCP
**📖 [Complete Documentation](https://arcp.0x001.tech/docs)**
</div>
## 📄 License
<div>
This project is licensed under the **Apache License 2.0** - see the [LICENSE](https://arcp.0x001.tech/docs/LICENSE) file for details.
</div>
| text/markdown | Muhannad | 01muhannad.a@gmail.com | null | null | Apache-2.0 | ai, agents, registry, control, protocol, microservice, fastapi | [
"Development Status :: 5 - Production/Stable",
"Framework :: FastAPI",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://github.com/0x00K1/ARCP | null | <4.0,>=3.11 | [] | [] | [] | [
"PyJWT<3.0.0,>=2.10.1",
"aiohttp>=3.9.0",
"cryptography<47.0.0,>=46.0.5",
"deprecated<2.0.0,>=1.2.0",
"fastapi<1.0.0,>=0.129.0",
"httpx<1.0.0,>=0.25.2; extra == \"dev\" or extra == \"all\"",
"importlib-metadata<7.0.0,>=1.7.0",
"openai<2.0.0,>=1.3.0",
"opentelemetry-api<2.0.0,>=1.21.0",
"openteleme... | [] | [] | [] | [
"Documentation, https://arcp.0x001.tech/docs",
"Repository, https://github.com/0x00K1/ARCP"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:06:42.954201 | arcp_py-2.1.0.tar.gz | 385,230 | 85/20/476058d3b66303ffa838f66eb231a4ed0cbe387259abbf853ffa63b8668f/arcp_py-2.1.0.tar.gz | source | sdist | null | false | efe0a5cb8a05d2205cb988413bf425f5 | 79426cc77d4e0ca52832b913abc1de9c3b89a266e06fd72b20f5c5be81979614 | 8520476058d3b66303ffa838f66eb231a4ed0cbe387259abbf853ffa63b8668f | null | [] | 212 |
2.4 | gapipy | 2.42.0 | Python client for the G Adventures REST API | G API Python Client
===================
.. image:: https://badge.fury.io/py/gapipy.svg
:target: http://badge.fury.io/py/gapipy
A client for the G Adventures REST API (https://developers.gadventures.com)
* GitHub Repository: https://github.com/gadventures/gapipy/
* Documentation: http://gapipy.readthedocs.org.
* Free software: MIT License
Quick Start
-----------
.. code-block:: python
>>> from gapipy import Client
>>> api = Client(application_key='MY_SECRET_KEY')
>>> # Get a resource by id
>>> tour_dossier = api.tour_dossiers.get(24309)
>>> tour_dossier.product_line
u'AHEH'
>>> tour_dossier.departures.count()
134
>>> tour_dossier.name
u'Essential India'
>>> itinerary = tour_dossier.structured_itineraries[0]
>>> {day.day: day.summary for day in itinerary.days[:3]}
{1: u'Arrive at any time. Arrival transfer included through the G Adventures-supported Women on Wheels project.',
2: u'Take a morning walk through the city with a young adult from the G Adventures-supported New Delhi Streetkids Project. Later, visit Old Delhi, explore the spice markets, and visit Jama Masjid and Connaught Place.',
3: u"Arrive in Jaipur and explore this gorgeous 'pink city'."}
>>> # Create a new resource
>>> booking = api.bookings.create({'currency': 'CAD', 'external_id': 'abc'})
>>> # Modify an existing resource
>>> booking.external_id = 'def'
>>> booking.save()
Since `2.25.0 (2020-01-02)`_
.. code-block:: python
>>> # since 2.25.0 reference stubs that fail to fetch will return a
>>> # subclass of requests.HTTPError (See: https://github.com/gadventures/gapipy/pull/119)
>>> # This can also be done on Query.get by passing a Falsy value for the
>>> # httperrors_mapped_to_none kwarg.
>>>
>>> dep = api.departures.get('404_404', httperrors_mapped_to_none=None)
... # omitted stacktrace
HTTPError: 404 Client Error: {"http_status_code":404,"message":"Not found.","errors":[],"time":"2020-01-02T19:46:07Z","error_id":"gapi_asdf1234"} for url: https://rest.gadventures.com/departures/404_404
>>> dep = api.departures.get('404404')
>>> dep.start_address.country
<Country: BR (stub)>
>>> # lets have GAPI return a _404_ error here for the country stub `fetch`
>>> # when we attempt to retrieve the continent attribute
>>> dep.start_address.country.continent # reference/stub forces a fetch
>>> # pre 2.25.0 behaviour
... # omitted stacktrace
AttributeError: 'Country' has no field 'continent' available
>>> # post 2.25.0 behaviour
... # omitted stacktrace
HTTPError: 404 Client Error: {"http_status_code":404,"message":"Not found.","errors":[],"time":"2020-01-02T19:46:07Z","error_id":"gapi_qwer5678"} for url: https://rest.gadventures.com/countries/BR
Resources
---------
Resource objects are instantiated from python dictionaries created from JSON
data. The fields are parsed and converted to python objects as specified in the
resource class.
A nested resource will only be instantiated when its corresponding attribute is
accessed in the parent resource. These resources may be returned as a ``stub``,
and upon access of an attribute not present, will internally call ``.fetch()``
on the resource to populate it.
A field pointing to the URL for a collection of a child resources will hold a
``Query`` object for that resource. As for nested resources, it will only be
instantiated when it is first accessed.
Queries
-------
A Query for a resource can be used to fetch resources of that type (either a
single instance or an iterator over them, possibly filtered according to some
conditions). Queries are roughly analogous to Django's QuerySets.
An API client instance has a query object for each available resource
(accessible by an attribute named after the resource name)
Methods on Query objects
========================
All queries support the ``get``, ``create`` and ``options`` methods. The other
methods are only supported for queries whose resources are listable.
``options()``
Get the options for a single resource
``get(resource_id, [headers={}])``
Get a single resource; optionally passing in a dictionary of header
values.
``create(data)``
Create an instance of the query resource using the given data.
``all([limit=n])``
Generator over all resources in the current query. If ``limit`` is a
positive integer ``n``, then only the first ``n`` results will be returned.
* A ``TypeError`` will be raised if limit is not ``None`` or ``int`` type
* A ``ValueError`` will be raised if ``limit <= 0``
``filter(field1=value1, [field2=value2, ...])``
``filter(**{"nested.field": "value"})``
Filter resources on the provided fields and values. Calls to ``filter`` can
be chained. The method will return a clone of the ``Query`` object and must
be stored in a separate variable in order to have access to **stacked**
filters.
``count()``
Return the number of resources in the current query (by reading the
``count`` field on the response returned by requesting the list of
resources in the current query).
Caching
-------
``gapipy`` can be configured to use a cache to avoid having to send HTTP
requests for resources it has already seen. Cache invalidation is not
automatically handled: it is recommended to listen to G API webhooks_ to purge
resources that are outdated.
.. _webhooks: https://developers.gadventures.com/docs/webhooks.html
By default, ``gapipy`` will use the cached data to instantiate a resource, but
a fresh copy can be fetched from the API by passing ``cached=False`` to
``Query.get``. This has the side-effect of recaching the resource with the
latest data, which makes this a convenient way to refresh cached data.
Caching can be configured through the ``cache_backend`` and ``cache_options``
settings. ``cached_backend`` should be a string of the fully qualified path to
a cache backend, i.e. a subclass of ``gapipy.cache.BaseCache``. A handful of
cache backends are available out of the box:
``gapipy.cache.SimpleCache``
A simple in-memory cache for single process environments and is not
thread safe.
``gapipy.cache.RedisCache``
A key-value cache store using Redis as a backend.
``gapipy.cache.NullCache`` (Default)
A cache that doesn't cache.
``gapipy.cache.DjangoCache`` (requires Django)
A cache which uses Django's cache settings for configuration. Requires there
be a ``gapi`` entry in ``settings.CACHES``.
Since the cache backend is defined by a python module path, you are free to use
a cache backend that is defined outside of this project.
Connection Pooling
------------------
We use the ``requests`` library, and you can take advantage of the provided
connection pooling options by passing in a ``'connection_pool_options'`` dict
to your client.
Values inside the ``'connection_pool_options'`` dict of interest are as
follows:
* Set ``enable`` to ``True`` to enable pooling. Defaults to ``False``.
* Use ``number`` to set the number of connection pools to cache.
Defaults to 10.
* Use ``maxsize`` to set the max number of connections in each pool.
Defaults to 10.
* Set ``block`` to ``True`` if the connection pool should block and wait
for a connection to be released when it has reached ``maxsize``. If
``False`` and the pool is already at ``maxsize`` a new connection will
be created without blocking, but it will not be saved once it is used.
Defaults to ``False``.
See also:
---------
* http://www.python-requests.org/en/latest/api/#requests.adapters.HTTPAdapter
* http://urllib3.readthedocs.io/en/latest/reference/index.html#module-urllib3.connectionpool
Dependencies
------------
The only dependency needed to use the client is requests_.
.. _requests: http://python-requests.org
Testing
-------
Running tests is pretty simple. We use `nose` as the test runner. You can
install all requirements for testing with the following::
$ pip install -r requirements-testing.txt
Once installed, run unit tests with::
$ nosetests -A integration!=1
Otherwise, you'll want to include a GAPI Application Key so the integration
tests can successfully hit the API::
$ export GAPI_APPLICATION_KEY=MY_SECRET_KEY; nosetests
In addition to running the test suite against your local Python interpreter, you
can run tests using `Tox <http://tox.testrun.org>`_. Tox allows the test suite
to be run against multiple environments, or in this case, multiple versions of
Python. Install and run the ``tox`` command from any place in the gapipy source
tree. You'll want to export your G API application key as well::
$ export GAPI_APPLICATION_KEY=MY_SECRET_KEY
$ pip install tox
$ tox
Tox will attempt to run against all environments defined in the ``tox.ini``. It
is recommended to use a tool like `pyenv <https://github.com/yyuu/pyenv>`_ to
ensure you have multiple versions of Python available on your machine for Tox to
use.
Fields
------
* ``_model_fields`` represent dictionary fields.
.. note::
* ``_model_fields = [('address', Address)]`` AND
* ``Address`` subclasses ``BaseModel``
.. code-block:: python
{
"address": {
"street": "19 Charlotte St",
"city": "Toronto",
"state": {
"id": "CA-ON",
"href": "https://rest.gadventures.com/states/CA-ON",
"name": "Ontario"
},
"country": {
"id": "CA",
"href": "https://rest.gadventures.com/countries/CA",
"name": "Canada"
},
"postal_zip": "M5V 2H5"
}
}
* ``_model_collection_fields`` represent a list of dictionary fields.
.. note::
* ``_model_collection_fields = [('emails', AgencyEmail),]`` AND
* ``AgencyEmail`` subclasses ``BaseModel``
.. code-block:: python
{
"emails": [
{
"type": "ALLOCATIONS_RELEASE",
"address": "g@gadventures.com"
},
{
"type": "ALLOCATIONS_RELEASE",
"address": "g2@gadventures.com"
}
]
}
* ``_resource_fields`` refer to another ``Resource``
Contributing
============
.. note:: Ensure a Python 2 environment
0. Clone the project
.. code-block:: sh
$ git clone git@github.com:gadventures/gapipy
1. Run ``pip install -r requirements-dev.txt`` to setup dev dependencies.
2. Always make your changes in a branch and to submit a PR.
.. code-block:: sh
$ git checkout master
$ git pull
$ git checkout -b feature-branch-name
$ git push origin feature-branch-name
3. Once the PR has been accepted/merged into the ``master`` branch, follow
these steps.
.. code-block:: sh
$ cd /path/to/gapipy
$ git checkout master
$ git pull origin master
**Modify the following files:**
* Update **gapipy/__init__.py**
* increment the ``__version__`` variable
.. note::
* style ``major.minor.patch``
* update ``patch`` when adding new fields, fixing bugs introduced by a
minor release.
* update ``minor`` if there is some breaking change such as adding a new
resource, removing fields, adding new behaviour.
* update ``major`` when we switch to ``Python 3`` only support.
* See `semver.org <https://semver.org>`_ for more information.
* Update **HISTORY.rst**
* update this file with the new ``version`` & ``date``
* Add some brief notes describing the changes.
4. Use ``make dist`` to check the generated long_description rST file is valid.
.. note::
* ignore ``warning: no previously-included files matching`` messages.
* as long as you get a ``Checking dist/gapipy-a.b.c.tar.gz: PASSED``
message, you are good!
* If not, fix the errors as dictated in the output, and repeat.
Example output when running ``make dist``:
.. code-block:: sh
$ make dist
warning: no previously-included files matching '*' found under directory 'tests'
warning: no previously-included files matching '__pycache__' found under directory '*'
warning: no previously-included files matching '.eggs' found under directory '*'
warning: no previously-included files matching '*.py[co]' found under directory '*'
total 123
-rw-r--r-- 1 user group 76276 5 Feb 02:53 gapipy-a.b.c.tar.gz
Checking dist/gapipy-a.b.c.tar.gz: PASSED
5. Push the new *Release* commit
* Use **Release a.b.c (YYYY-MM-DD)** format for the commit title. Optionally
add a description that matches the changes made to **HISTORY.rst**.
6. Create a release on github with the following description (This will be
tagged to the ``Release`` commit and not the PR/change commit)
.. code-block:: md
# Release a.b.c (YYYY-MM-DD)
PR: #123
A brief description describing the changes
* bullet points
* make for easy reading
7. Release!
$ make release
Thanks for helping!
-------------------
History
=======
2.42.0 (2026-02-19)
-------------------
* Adds ``date_last_modified`` field to the ``BookingCompany`` resource.
* See `PR #149`_ for more details.
.. _`PR #149`: https://github.com/gadventures/gapipy/pull/149
2.41.0 (2025-12-02)
-------------------
* Add `gapipy.exceptions.TimeoutError`, which can be raised when the optional
`timeout` parameter is passed to `Query.get`. Without providing the `timeout`
parameter, the default behaviour remains unchanged, where a `requests`
Timeout exception is raised.
* See `PR #146`_ for more details.
.. code-block:: python
from gapipy import Client
gapi = Client(application_key="your_api_key")
try:
departure_service = gapi.departure_services.get(123456, timeout=1)
except gapi.exceptions.TimeoutError:
# handle exception
else:
... # success
.. _`PR #146`: https://github.com/gadventures/gapipy/pull/146
2.40.0 (2025-11-06)
-------------------
* HOTFIX for `2.39.0 (2025-08-21) (Yanked)`_: Reverts the removal of the
`self._raw_data = deepcopy(data)` in ``BaseModel._fill_fields``. This is
necessary to ensure that the ``_raw_data`` attribute is updated with new data
returned as a result of the request made in ``Resource.save()``. This bug was
introduced in `PR #145`_.
* All other changes in 2.39.0 will remain and 2.39.0 will be yanked from PyPI.
* See `PR #147`_ for more details.
.. _`PR #147`: https://github.com/gadventures/gapipy/pull/147
2.39.0 (2025-08-21) (Yanked)
----------------------------
* Remove ``costs`` and ``has_costs`` fields from the ``AccommodationDossier``
and ``ActivityDossier`` resources.
* Moves the ``AccommodationDossier.features`` field from the as-is-fields to
the model-collection-fields as references to the ``DossierFeature`` resource.
* Expose the ``primary_country`` field on the ``ActivityDossier`` resource.
This references the ``Country`` resource.
* See `PR #145`_ for more details.
.. _`PR #145`: https://github.com/gadventures/gapipy/pull/145
2.38.0 (2025-05-29)
-------------------
* Add new resources for "room upgrade" and "regional connector" products:
``room_upgrades``, ``room_upgrade_services``, ``regional_connectors``, and
``regional_connectors_services``. See `PR #143`_ for more details.
.. _`PR #143`: https://github.com/gadventures/gapipy/pull/143
2.37.0 (2025-02-19)
-------------------
* Add ``abta_number`` field to the ``Agency`` resource. This field is a string
that represents the ABTA number of the agency. See `PR #142`_ for more
details.
.. _`PR #142`: https://github.com/gadventures/gapipy/pull/142
2.36.0 (2024-05-30)
-------------------
* Add ``contact_us`` field to the ``AgenchChain`` resource. This field can be
``None``, however should a value be present, it will be an object with three
accessible attributes: ``email``, ``phone_number``, and ``website_url``. See
the `PR #141`_ for more details.
.. _`PR #141`: https://github.com/gadventures/gapipy/pull/141
2.35.0 (2022-04-18)
-------------------
* Add new ``Client`` configuration value that will raise an error when an empty
partial update (PATCH) payload is computed by gapipy. See `Issue #136`_ and
the corresponding `PR #137`_ for more details.
* The new Client configuration kwarg is ``raise_on_empty_update``, whose
default value is ``False``, and can also be set by passing it as an
environment variable ``GAPI_CLIENT_RAISE_ON_EMPTY_UPDATE``. If this config
value is set, then a call to ``Resource.save`` with ``partial=True`` will
raise the new ``EmptyPartialUpdateError`` if an empty payload is computed.
.. code-block:: python
from gapipy import Client
gapi = Client(application_key="your_api_key", raise_on_empty_update=True)
departure_service = gapi.departure_services.get(123456)
# we've changed nothing and are calling a partial save (PATCH)
#
# NOTE: the new EmptyPartialUpdateError will be raised here
departure_service.save(partial=True)
.. _`Issue #136`: https://github.com/gadventures/gapipy/issues/136
.. _`PR #137`: https://github.com/gadventures/gapipy/pull/137
2.34.0 (2021-08-20)
-------------------
* Add ``travel_ready_policy`` model field to the ``Departure`` resource.
* More details can be found in our developer documentation.
c.f. `Departure travel-ready-policy`_
.. _`Departure travel-ready-policy`: https://developers.gadventures.com/docs/departure.html#travel-ready-policy
2.33.0 (2021-07-06)
-------------------
* Add ``online_preferences`` field to the ``Agency Chain`` resource.
2.32.0 (2021-06-18)
-------------------
* Make ``future`` requirement more flexible. See `PR #134`_ for more details.
.. _`PR #134`: https://github.com/gadventures/gapipy/pull/134
2.31.1 (2021-05-14)
-------------------
* Initialize the ``DjangoCache`` via the ``BaseCache`` which exposes the
``default_timeout`` attribute to the class. Prior to this change, when using
the ``DjangoCache``, items would persist forever as no timeout would be set
on the entries. See `PR #133`_ for more details.
.. note:: ``DjangoCache`` was introduced in `2.30.0 (2021-02-08)`_
.. _`PR #133`: https://github.com/gadventures/gapipy/pull/133
2.31.0 (2021-03-02)
-------------------
* Introduce ``gapipy.constants`` module that holds common constants. See
`PR #132`_ for more details.
* Reintroduce the ability to enable old behaviour (pre `2.25.0 (2020-01-02)`_)
for ``Resource.fetch``. It adds an optional ``httperrors_mapped_to_none``
parameter to the method (default ``None``), where if a list of HTTP Status
codes is provided instead, will silently consume errors mapped to those
status codes and return a ``None`` value instead of raising the HTTPError.
See `PR #131`_ for more details.
.. _`PR #131`: https://github.com/gadventures/gapipy/pull/131
.. _`PR #132`: https://github.com/gadventures/gapipy/pull/132
2.30.1 (2021-02-08)
-------------------
* Fix for `2.30.0 (2021-02-08)`_ Adds a guard against configuring Django
settings again as per the `Django settings docs`_. See `PR #130`_ for more
details.
.. _`Django settings docs`: https://docs.djangoproject.com/en/3.1/topics/settings/#either-configure-or-django-settings-module-is-required
.. _`PR #130`: https://github.com/gadventures/gapipy/pull/130
2.30.0 (2021-02-08)
-------------------
* Adds a new cache backend; ``gapipy.cache.DjangoCache``. It requires ``Django``
and a ``gapi`` entry in ``settings.CACHES``. See `PR #129`_ for more details.
.. _`PR #129`: https://github.com/gadventures/gapipy/pull/129/
**Usage:**
* Set the ``GAPI_CACHE_BACKEND`` Env varible to ``gapipy.cache.DjangoCache``.
OR
.. code-block:: python
from gapipy import Client
gapi = Client(
application_key="live_your-secret-gapi-key",
cache_backend="gapipy.cache.DjangoCache",
)
2.29.0 (2021-02-05)
-------------------
* Adds ``Departure.relationships`` field via ``DepartureRelationship`` model
* Adds ``TourDossier.relationships`` field via ``TourDossierRelationship``
model
.. warning:: BREAKING!
* Moves the ``gapipy.resources.tour.itinerary.ValidDuringRange`` class over to
its own file ``gapipy.models.valid_duraing_range.ValidDuringRange``
so that it can be reused by the ``TourDossierRelationship`` model. Any code
importing the class directly will need to change the import path:
.. code-block:: python
# before
from gapipy.resources.tour.itinerary.ValidDuringRange
# now
from gapipy.models import ValidDuringRange
* See `PR #128`_ for more details.
.. _`PR #128`: https://github.com/gadventures/gapipy/pull/128/
2.28.0 (2020-11-23)
-------------------
* Add a new ``Client`` config option, ``global_http_headers``, a dict of HTTP
headers to add to each request made with that client.
This is similar to the ``headers=`` kwargs available when making ``get`` and
``create`` calls, except that the ``global_http_headers`` set on a client
will apply on *every request* made by that client instance.
2.27.0 (2020-05-26)
-------------------
.. warning:: BREAKING!
* Make ``Customer.nationality`` a *resource field*. This allows attribute style
access to the field values, whereas before they needed to be accessed using
dictionary accessor (``d["key"]``) syntax.
.. code-block:: python
# before
>>> api.customers.get(123456).nationality["name"]
u'Canadian'
# now
>>> api.customers.get(123456).nationality.name
u'Canadian'
2.26.4 (2020-04-28)
-------------------
* Fix `2.26.3 (2020-04-28) (Yanked)`_: Add missing ``CONTRIBUTING.rst`` to the
manifest.
.. note:: Discovered when attempting to install ``gapipy`` via ``pip``.
2.26.3 (2020-04-28) (Yanked)
----------------------------
* Fix py2 & py3 compatibility for ``urlparse``
2.26.2 (2020-04-20)
-------------------
* Fix for `2.26.1 (2020-04-20)`_ and `Issue #113`_.
* See `PR #125`_.
* Remove the ``_set_resource_collection_field`` method in ``TourDossier``
* Introducing the ``_Parent`` namedtuple in `PR #123`_.
broke being able to Query-chain from Tour-Dossiers to departures
* Buggy behaviour fixed from `2.26.1 (2020-04-20)`_
.. code-block:: python
>>> from gapipy import Client
>>> api = Client(application_key='MY_SECRET_KEY')
>>> api.tour_dossiers(24309).departures.count()
# AttributeError: 'tuple' object has no attribute 'uri'
.. _`PR #125`: https://github.com/gadventures/gapipy/pull/125
2.26.1 (2020-04-20)
-------------------
* Fix for `2.26.0 (2020-04-14)`_ and `Issue #113`_.
* Calls to ``APIRequestor.list_raw`` will use initialised its parameters,
unless the URI provides its own.
* See `PR #123`_.
* Add the ability to define the ``max_retries`` values on the requestor.
* New ``env`` value ``GAPI_CLIENT_MAX_RETRIES``.
* The default value will be ``0``, and if provided will override the ``retry``
value on the ``requests.Session``.
* This change will also always initialize a ``requests.Session`` value on
initialisation of the ``gapipy.Client``.
* See `PR #124`_.
* Add ``variation_id`` field to the ``Image`` resource.
* See `Commit edc8d9b`_.
* Update the ``ActivityDossier`` and ``AccommodationDossier`` resources.
* Remove the ``is_prepaid`` field.
* Adds the ``has_costs`` field.
* See `Commit bd35531`_.
.. _`Issue #113`: https://github.com/gadventures/gapipy/issues/113
.. _`PR #123`: https://github.com/gadventures/gapipy/pull/123
.. _`PR #124`: https://github.com/gadventures/gapipy/pull/124
.. _`Commit edc8d9b`: https://github.com/gadventures/gapipy/commit/edc8d9b
.. _`Commit bd35531`: https://github.com/gadventures/gapipy/commit/bd35531
2.26.0 (2020-04-14)
-------------------
.. warning:: BREAKING!
* The ``Query.filter`` method will return a clone/copy of itself. This will
preserve the state of ``filters`` on the original Query object.
* The ``Query.all`` method will **not** clear the filters after returning.
* The ``Query.all`` method will return a ``TypeError`` if a type other than
an ``int`` is passed to the ``limit`` argument.
* The ``Query.count`` method will **not** clear the filters after returning.
* See `PR #121`_ for more details.
New behaviour with the ``Query.filter`` method:
.. code-block:: python
>>> from gapipy import Client
>>> api = Client(application_key='MY_SECRET_KEY')
# create a filter on the departures
>>> query = api.departures.filter(**{"tour_dossier.id": "24309"})
>>> query.count()
494
# we preserve the filter status of the current query
>>> query.filter(**{"availability.status": "AVAILABLE"}).count()
80
>>> query.count()
494
* The ``AgencyChain.agencies`` attribute returns a list of ``Agency`` objects.
See `Commit f34afd52`_.
.. _`PR #121`: https://github.com/gadventures/gapipy/pull/121
.. _`Commit f34afd52`: https://github.com/gadventures/gapipy/commit/f34afd52
2.25.1 (2020-01-02)
-------------------
* Improve contribution instructions to check long_description rST file in dist
* Dev Requirement updates:
* Add ``readme_renderer==24.0``
* Add ``twine==1.15.0`` for ``twine check`` command
2.25.0 (2020-01-02)
-------------------
* Failing to fetch inlined Resource (from Stubs) will raise the underlying
requests.HTTPError instead of AttributeError resulting from a ``None``.
* Adds ``httperrors_mapped_to_none`` kwarg to ``gapipy.query.Query.get``
with default value ``gapipy.query.HTTPERRORS_MAPPED_TO_NONE``
* Modifies ``gapipy.resources.base.Resource.fetch`` to
pass ``httperrors_mapped_to_none=None`` to ``Query.get``
* This ensures that any underlying ``requests.HTTPError`` from ``Query.get``
is bubbled up to the caller. It is most prevalent when reference Resource stubs
fail to be retrieved from the G API. Prior to this change ``Resource.fetch``
would return a ``None`` value resulting in an ``AttributeError``. Now, if the
stub fails to fetch due to an HTTPError, that will be raised instead
2.24.3 (2019-12-12)
-------------------
* Exclude the ``tests`` package from the package distribution
2.24.2 (2019-12-12)
-------------------
* Adds the ``compute_request_signature`` and ``compute_webhook_validation_key``
utility methods. See `PR #122`_.
.. _`PR #122`: https://github.com/gadventures/gapipy/pull/122
2.24.1 (2019-12-12)
-------------------
* Add ``slug`` field to ``TourDossier`` resource. See `PR #120`_.
.. _`PR #120`: https://github.com/gadventures/gapipy/pull/120
2.24.0 (2019-11-05)
-------------------
* Add missing/new fields to the following resources. See `PR #117`_.
* AccommodationDossier: ``categories``, ``suggested_dossiers``, ``visited_countries``, ``visited_cities``
* ActivityDossier: ``suggested_dossiers``, ``visited_countries``, ``visited_cities``
* Departure: ``local_payments``
* Itinerary: ``publish_state``
* Add ``continent`` and ``place`` references to the ``Countries`` resource. See
`PR #115`_.
* Accept ``additional_headers`` optional kwarg on ``create``. See `PR #114`_.
.. _`PR #114`: https://github.com/gadventures/gapipy/pull/114
.. _`PR #115`: https://github.com/gadventures/gapipy/pull/115
.. _`PR #117`: https://github.com/gadventures/gapipy/pull/117
2.23.0 (2019-11-04)
-------------------
* Remove deprecated ``tour_dossiers.itineraries`` field and related code
2.22.0 (2019-10-10)
-------------------
* Add ``booking_company`` field to ``Booking`` resource
2.21.0 (2019-04-09)
-------------------
* Add ``ripple_score`` to ``Itinerary`` resource
2.20.1 (2019-02-20)
-------------------
* HISTORY.rst doc fixes
2.20.0 (2019-02-20)
-------------------
* Add ``Requirement`` and ``RequirementSet`` resources
* Move ``Checkin`` resource to the ``resources.booking`` module
* The ``Query`` object will resolve to use the ``href`` value when
returning the iterator to fetch ``all`` of some resource. This is
needed because ``bookings/123456/requirements`` actually returns a list
of ``RequirementSet`` resources
* See `Release tag 2.20.0`_ for more details.
.. _`Release tag 2.20.0`: https://github.com/gadventures/gapipy/releases/tag/2.20.0
2.19.4 (2019-02-14)
-------------------
* Add ``get_category_name`` helper method to ``TourDossier`` resource
2.19.3 (2019-02-12)
-------------------
* Attempt to fix rST formatting of ``README`` and ``HISTORY`` on pypi
2.19.2 (2019-02-12)
-------------------
* Become agnostic between redis ``2.x.x`` && ``3.x.x`` versions
* the ``setex`` method argument order changes between the major versions
2.19.1 (2019-02-12)
-------------------
.. note:: HotFix for `2.19.0 (2019-02-12)`_.
* adds ``requirements.txt`` file to the distribution ``MANIFEST``
2.19.0 (2019-02-12)
-------------------
* Add ``booking_companies`` field to ``Itinerary`` resource
* Pin our requirement/dependency versions
* pin ``future == 0.16.0``
* pin ``requests >= 2.18.4, < 3.0.0``
* read ``setup.py`` requirements from ``requirements.txt``
2.18.1 (2019-02-07)
-------------------
* Add ``customers`` nested resource to ``bookings``
2.18.0 (2018-12-14)
-------------------
* Add ``merchandise`` resource
* Add ``merchandise_services`` resources
2.17.0 (2018-11-12)
-------------------
* Add ``membership_programs`` field to the ``Customer`` resource
2.16.0 (2018-11-07)
-------------------
* Completely remove the deprecated ``add_ons`` field from the Departure resource
* Add missing fields to various Dossier resources
* AccommodationDossier: ``flags``, ``is_prepaid``, ``service_time``, ``show_on_reservation_sheet``
* ActivityDossier: ``is_prepaid``, ``service_time``, ``show_on_reservation_sheet``
* CountryDossier: ``flags``
* PlaceDossier: ``flags``
* TransportDossier: ``flags``
* Add ``valid_during_ranges`` list field to the Itinerary resource. This field is
a list field of the newly added ``ValidDuringRange`` model (described below)
* Add ``ValidDuringRange`` model. It consists of two date fields, ``start_date``,
and ``end_date``. It also provides a number of convenience methods to determine
if the date range provided is valid, or relative to some date.
* ``is_expired``: Is it expired relative to ``datetime.date.today``
* ``is_valid_today``: Is it valid relative to ``datetime.date.today``
* ``is_valid_during_range``: Is it valid for some give start/end date range
* ``is_valid_on_or_after_date``: Is it valid on or after some date
* ``is_valid_on_or_before_date``: Is it valid on or before some date
* ``is_valid_on_date``: Is it valid on some date
* ``is_valid_sometime``: Is it valid at all
2.15.0 (2018-10-10)
-------------------
* Add ``country`` reference to ``Nationality`` resource.
* Moved ``resources/bookings/nationality.py`` to ``resources/geo/*``.
2.14.6 (2018-08-01)
-------------------
* Check for presence of ``id`` field directly in the Resource ``__dict__`` in
order to prevent a chicken/egg situation when attempting to ``save``. This is
needed due to the change introduced in 2.14.4, where we explicitly raise an
AttributeError when trying to access the ``id`` attribute.
* Added ``service_code`` field for Activty & Accommodation Dossier resources.
2.14.5 (2018-08-01)
-------------------
* deleted
2.14.4 (2018-07-13)
-------------------
* Raise an ``AttributeError`` when trying to access ``id`` on
``Resource.__getattr__``.
* Don't send duplicate params when paginating through list results.
* Implement ``first()`` method for ``Query``.
2.14.3 (2018-05-29)
-------------------
* Expose Linked Bookings via the API.
2.14.1 (2018-05-15)
-------------------
* Add ``booking_companies`` field to Agency resource.
* Remove ``bookings`` field from Agency resource.
* Add ``requirements`` as_is field to Departure Service resource.
* Add ``policy_emergency_phone_number`` field to Insurance Service resource.
2.14.0 (2018-05-15)
-------------------
* Remove deprecated ``add_ons`` field from ``Departure`` resource.
* Add ``costs`` field to ``Accommodation`` & ``ActivityDossier`` resources.
2.13.0 (2018-03-31)
-------------------
* Add ``meal_budgets`` list field to ``CountryDossier`` resource.
* Add ``publish_state`` field to ``DossierFeatures`` resource.
2.12.0 (2018-02-14)
-------------------
* Add optional ``headers`` parameter to Query.get to allow HTTP-Headers to be
passed. e.g. ``client.<resource>.get(1234, headers={'A':'a'})``. See
`PR #91`_.
* Add ``preferred_display_name`` field to ``Agency`` resource. See `PR #92`_.
* Add ``booking_companies`` array field to all Product-type resources. See
`PR #93`_.
* Accommodation
* Activity
* AgencyChain
* Departure
* SingleSupplement
* TourDossier
* Transport
.. _`PR #91`: https://github.com/gadventures/gapipy/pull/91
.. _`PR #92`: https://github.com/gadventures/gapipy/pull/92
.. _`PR #93`: https://github.com/gadventures/gapipy/pull/93
2.11.4 (2018-01-29)
-------------------
* Add ``agency_chain`` field to ``Booking`` resource
* Add ``id`` field as part of the ``DossierDetail`` model See `PR #89`_.
* Add ``agency_chains`` field to the ``Agency`` resource. See `PR #90`_.
* See `Release tag 2.11.3`_ for more details.
.. _`PR #89`: https://github.com/gadventures/gapipy/pull/89
.. _`PR #90`: https://github.com/gadventures/gapipy/pull/90
.. _`Release tag 2.11.3`: https://github.com/gadventures/gapipy/releases/tag/2.11.3
2.11.0 (2017-12-18)
-------------------
* The ``Customer.address`` field uses the ``Address`` model, and is no longer a
dict.
* Passing in ``uuid=True`` to ``Client`` kwargs enables ``uuid`` generation
for every request.
2.10.0 (2017-12-01)
-------------------
* Add the ``amount_pending`` field to the ``Booking`` resource
* The ``PricePromotion`` model extends from the ``Promotion`` resource (PR/85)
* Update the ``Agent`` class to use BaseModel classes for the ``role``
and ``phone_numbers`` fields.
* see `Release tag 2.10.0`_ for more details.
.. _`Release tag 2.10.0`: https://github.com/gadventures/gapipy/releases/tag/2.10.0
2.9.3 (2017-11-23)
------------------
.. note:: We have skipped Release ``2.9.2`` due to pypi upload issues.
* Expose ``requirement_set`` for ``departure_services`` & ``activity_services``.
2.9.1 (2017-11-22)
------------------
.. note:: * We have skipped Release ``2.9.0`` due to pypi upload issues.
* Adds the ``options`` method on the Resource Query object. See
`Release tag 2.9.1`_ for more details.
.. _`Release tag 2.9.1`: https://github.com/gadventures/gapipy/releases/tag/2.9.1
2.8.2 (2017-11-14)
------------------
* Adds fields ``sale_start_datetime`` and ``sale_finish_datetime`` to the
Promotion resource. The fields mark the start/finish date-time values
for when a Promotion is applicable. The values represented are in UTC.
2.8.1 (2017-10-25)
------------------
* Add new fields to the ``Agency`` and ``AgencyChain`` resources
2.8.0 (2017-10-23)
------------------
* This release adds a behaviour change to the ``.all()`` method on resource
Query objects. Prior to this release, the base Resource Query object would
retain any previously added ``filter`` values, and be used in subsequent
calls. Now the underlying filters are reset after a ``<resource>.all()`` call
is made.
See `Issue #76`_ and `PR #77`_ for details and the resulting fix.
* Adds missing fields to the Agency and Flight Service resources (PR/78)
.. _`Issue #76`: https://github.com/gadventures/gapipy/issues/76
.. _`PR #77`: https://github.com/gadventures/gapipy/pull/77
2.7.6 (2017-10-04)
------------------
* Add ``agency`` field to ``Booking`` resource.
2.7.5 (2017-09-25)
------------------
* Add test fix for Accommodation. It is a listable resource as of ``2.7.4``
* Add regression test for departures.addon.product model
* Ensure Addon's are instantiated to the correct underlying model.
* Prior to this release, all Addon.product resources were instantiated as
``Accommodation``.
2.7.4 (2017-09-20)
------------------
* Add ``videos``, ``images``, and ``categories`` to ``Activity``, ``Transport``,
``Place``, and ``Accommodation Dossier`` resources.
* Add ``flags`` to Itinerary resource
* Add list view of ``Accommodations`` resource
2.7.3 (2017-09-06)
------------------
* Add ``type`` field to ``AgencyDocument`` model
* Add ``structured_itinerary`` model collection field to ``Departure`` resource
2.7.2 (2017-08-18)
------------------
* Fix flight_status Reference value in FlightService resource
2.7.1 (2017-08-18)
------------------
* Fix: remove FlightStatus import reference for FlightService resource
* Add fields (fixes two broken Resource tests)
* Add ``href`` field for ``checkins`` resource
* Add ``date_cancelled`` field for ``departures`` resource
* Fix broken ``UpdateCreateResource`` tests
2.7.0 (2017-08-18)
------------------
* Remove ``flight_statuses`` and ``flight_segments`` resources.
2.6.2 (2017-08-11)
------------------
* Version bump
2.6.1 (2017-08-11)
------------------
* Adds a Deprecation warning when using the ``tours`` resource.
2.6.0 (2017-08-11)
------------------
* Fixed `Issue #65`_: only
write data into the local cache after a fetch from the API, do not write data
into the local cache when fetching from the local cache.
.. _`Issue #65`: https://github.com/gadventures/gapipy/issues/65
2.5.2 (2017-04-26)
------------------
* Added ``future`` dependency to setup.py
2.5.1 (2017-02-08)
------------------
* Fixed an issue in which modifying a nested dictionary caused gapipy to not
identify a change in the data.
* Added ``tox.ini`` for testing across Python platforms.
* Capture ``403`` Status Codes as a ``None`` object.
2.5.0 (2017-01-20)
------------------
* Provided Python 3 functionality (still Python 2 compatible)
* Removed Python 2 only tests
* Installed ``future`` module for smooth Python 2 to Python 3 migration
* Remove ``DictToModel`` class and the associated tests
* Add ``Dossier`` Resource(s)
* Minor field updates to: ``Customer``, ``InsuranceService``,
``DepartureService``, ``Booking``, ``FlightStatus``, ``State``
2.4.9 (2016-11-22)
------------------
* Fixed a bug with internal ``_get_uri`` function.
2.4.8 (2016-11-11)
------------------
* Adjusted ``Checkin`` resource to meet updated spec.
2.4.7 (2016-10-25)
------------------
* Added ``Checkin`` resource.
2.4.6 (2016-10-19)
------------------
* Fix broken ``Duration`` init in ``ActivityDossier`` (likely broke due to
changes that happened in 2.0.0)
2.4.5 (2016-10-13)
------------------
* Added ``Image`` resource definition and put it to use in ``Itinerary`` and,
``PlaceDossier``
2.4.4 (2016-09-09)
------------------
* Added ``date_last_modified`` and ``date_created`` to ``Promotion``.
2.4.3 (2016-09-06)
------------------
* Added ``gender`` to ``Customer``.
* Added ``places_of_interest`` to ``Place``.
2.4.2 (2016-07-08)
------------------
* Added ``departure`` reference to ``DepartureComponent``
2.4.1 (2016-07-06)
------------------
* Removed use of ``.iteritems`` wherever present in favour of ``.items``
* Added ``features`` representation to ``ActivityDossier`` and,
``TransportDossier``
2.4.0 (2016-06-29)
------------------
* Added ``CountryDossier`` resource.
2.3.0 (2016-06-28)
------------------
* Added ``DossierSegment`` resource.
* Added ``ServiceLevel`` resource.
2.2.2 (2016-06-08)
------------------
* Added day ``label`` field to the ``Itinerary`` resource.
2.2.1 (2016-06-06)
------------------
* Added ``audience`` field to the ``Document`` resource.
2.2.0 (2016-05-17)
------------------
* Added ``transactional_email``, and ``emails`` to ``Agency`` resource.
2.1.2 (2016-05-17)
------------------
* Added ``audience`` to ``Invoice`` resource.
2.1.1 (2016-04-29)
------------------
* Removed invalid field, ``email`` from ``AgencyChain``
2.1.0 (2016-04-25)
------------------
* Added new resource, ``AgencyChain``
2.0.0 (2016-03-11)
------------------
The global reference to the last | text/x-rst | G Adventures | software@gadventures.com | null | null | MIT | gapipy | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Programming Language :: Python :: 2",
"Programming Language :: Python :: 2.7",
"Programming Language :: Python :: 3",
"Programming Language :: Pyt... | [] | https://github.com/gadventures/gapipy | null | null | [] | [] | [] | [
"future>=0.16.0",
"requests<3.0.0,>=2.18.4"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.11 | 2026-02-19T21:06:12.841285 | gapipy-2.42.0.tar.gz | 89,674 | f4/04/d7273ed64c9d1e4bb1d92149ed94843b4c4634037b1a80efd2d11e3e6608/gapipy-2.42.0.tar.gz | source | sdist | null | false | 8df9c3426f2d492897ea5532ea444fec | 3a9de08f94f204b43f3fe33e7231de6ad41b547397ffb9621a6b02d349f7d36c | f404d7273ed64c9d1e4bb1d92149ed94843b4c4634037b1a80efd2d11e3e6608 | null | [
"LICENSE"
] | 148 |
2.4 | pydantic-modelable | 0.1.3 | A set of pydantic utilities, to extend models on package load | # pydantic-modelable
A set of utilities around pydantic that allows to create extensible pydantic
models, with little code, in an aim to have models extended by third-party
python code.
## Features
Using `pydantic` for type modelisation and validation has become a very common
practice. That being said, some advanced uses are not natively supported,
although the pydantic types are extremely flexible, such as dynamic
extensibility of the models.
It can be very useful to define extensible models relying on this mechanism,
and `pydantic_modelable`, as it may provide the following benefits:
- Reduction of code maintenance (defining an "extension" registers it
automatically wherever the base was setup)
- Easy extension of a core library's models and features through the loading
of extension modules
- Automatically updated Model schemas for inclusion in any schema-based
tooling or framework (ex: FastAPI's OpenAPI Schema generation tooling)
With a few additional parameters to your model's constructor, inheriting from
`pydantic_modelable.Modelable`, you can thus configure specific behaviors for
your extensible model:
- discriminated union: `discriminator=attr_name`
You can then register other models into your base model using decorators
embedded into your base model by the `pydantic_modelable.Modelable` class:
- `extends_enum`
- `extends_union(dicriminated_union_attr_name: str)`
- `as_attribute(attr_name: str, optional: bool, default_factory: Callable[[], BaseModel])`
## Limitations
As pydantic-modelable relies on altering the pydantic models at runtime, the
type-checking tools are usually not able to understand that the model was
extended and its type signature was changed. This, sadly, often leads to an
extensive use of `#type: ignore` directives in the code relating to the use
of the extended models.
| text/markdown | null | David Pineau <dav.pineau@gmail.com> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Programming Language :: Python",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"pydantic>=2.11",
"aenum>=3.1.13",
"mypy==1.18.2; extra == \"test\"",
"ruff==0.13.2; extra == \"test\"",
"pytest; extra == \"test\"",
"mkdocs; extra == \"doc\"",
"mkdocstrings[python]; extra == \"doc\""
] | [] | [] | [] | [
"Homepage, https://joacchim.github.io/pydantic-modelable/",
"Source, https://github.com/Joacchim/pydantic-modelable"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:04:55.446456 | pydantic_modelable-0.1.3.tar.gz | 23,573 | 0d/99/af20f456f1c8cf97f94d145fc640429f1d00e56e49259bfe160aaa6e5e70/pydantic_modelable-0.1.3.tar.gz | source | sdist | null | false | 3ca1548189ed0d65ff8a6b22e1fb802e | a315740c85100fb1587ddc45435423d10b3cad6e6e027d12bd5a099b084f31b1 | 0d99af20f456f1c8cf97f94d145fc640429f1d00e56e49259bfe160aaa6e5e70 | BSD-3-Clause | [
"LICENSE"
] | 253 |
2.4 | phantom-docs | 0.2.0 | Automated documentation asset generation for software projects | # Phantom
**Automated documentation screenshots for software projects.**
[](https://pypi.org/project/phantom-docs/)
[](https://python.org)
[](LICENSE)
---
## The Problem
Documentation screenshots go stale. Every UI change means manually re-capturing images, cropping them, adding drop shadows, updating the README, and committing. Most teams give up and let their docs rot.
## The Solution
Phantom automates the entire pipeline: **launch your app, execute actions, capture screenshots, process them, and commit the results** — all from a single YAML manifest.
```yaml
# .phantom.yml
phantom: "1"
project: "my-app"
name: "My App"
setup:
type: web
build:
- npm ci
run:
command: "npm run dev"
ready_check:
type: http
url: "http://localhost:3000"
captures:
- id: dashboard
name: "Dashboard"
route: "/"
output: "docs/screenshots/dashboard.png"
actions:
- type: wait_for
selector: ".dashboard-loaded"
- type: set_theme
theme: dark
```
```bash
phantom run -p ./my-app
```
## Installation
```bash
pipx install phantom-docs
# or
pip install phantom-docs
```
For web runner captures, install Playwright browsers:
```bash
playwright install chromium
```
Check your setup:
```bash
phantom doctor
```
## Quick Start
```bash
# 1. Initialize a manifest (auto-detects project type)
phantom init
# 2. Edit .phantom.yml with your routes and captures
# 3. Run the pipeline
phantom run -p .
```
## Onboard Your Project
The fastest way to set up Phantom for an existing project is with [Claude Code](https://claude.ai/claude-code). Copy the [onboarding prompt](docs/onboarding-prompt.md) into Claude Code while in your project's root directory — it will analyze your codebase and generate everything Phantom needs:
- Demo mode with realistic fixture data
- `.phantom.yml` manifest with 5-8 captures
- GitHub Actions workflow for automated updates
- README sentinels for screenshot placement
```bash
# From your project directory:
cat path/to/phantom/docs/onboarding-prompt.md | pbcopy # macOS
# Then paste into Claude Code
```
## Runners
Phantom supports multiple runner types for different kinds of applications:
| Runner | Type | Use Case | Key Tools |
|--------|------|----------|-----------|
| **Web** | `web` | Browser-based apps | Playwright, Node |
| **TUI** | `tui` | Terminal applications | pyte, silicon |
| **Docker Compose** | `docker-compose` | Containerized apps | Docker |
Runners are pluggable — see [Writing Runner Plugins](docs/writing-runners.md) for the extension API.
## Manifest Reference
The `.phantom.yml` manifest has these top-level sections:
```yaml
phantom: "1" # Schema version
project: "my-app" # Unique project ID (kebab-case)
name: "My App" # Display name
setup: # How to build and run the project
type: web # Runner type
build: [...] # Build commands
run: # Run configuration
command: "..."
ready_check: { ... }
capture_defaults: # Defaults applied to all captures
viewport: { width: 1280, height: 800 }
theme: dark
captures: # Screenshot definitions
- id: hero
name: "Hero screenshot"
route: "/"
output: "docs/hero.png"
actions: [...]
processing: # Image processing pipeline
format: png
border:
style: drop-shadow
publishing: # Git commit settings
branch: main
strategy: direct # or "pr"
readme_update: true
```
See [docs/manifest-reference.md](docs/manifest-reference.md) for the complete field reference.
## CLI Reference
| Command | Description |
|---------|-------------|
| `phantom run -p <path>` | Run the capture pipeline |
| `phantom validate <manifest>` | Validate a manifest file |
| `phantom init` | Scaffold a new `.phantom.yml` |
| `phantom doctor` | Check system dependencies |
| `phantom status` | Show run history |
| `phantom serve` | Start webhook listener + scheduler |
| `phantom gc` | Clean up stale workspaces |
### Common Options
| Option | Description |
|--------|-------------|
| `--dry-run` | Run pipeline without git commits |
| `--capture <id>` | Run a single capture |
| `--group <name>` | Run a named group of captures |
| `--skip-publish` | Capture and process, skip git |
| `--force` | Commit even if below diff threshold |
| `--if-changed` | Skip if repo HEAD unchanged |
| `--verbose` / `-v` | Enable debug logging |
## How It Works
```
.phantom.yml
│
▼
┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
│ Validate │────▶│ Build │────▶│ Launch │────▶│ Capture │
│ Manifest │ │ Project │ │ App │ │ Screenshots│
└──────────┘ └──────────┘ └──────────┘ └──────────┘
│
┌───────────────────────────────────────────────────┘
▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ Darkroom │────▶│ README │────▶│ Git │
│ Process │ │ Update │ │ Publish │
└──────────┘ └──────────┘ └──────────┘
```
1. **Validate** — Parse and validate the manifest with Pydantic
2. **Build** — Run build commands (`npm ci`, `cargo build`, etc.)
3. **Launch** — Start the app and wait for ready check
4. **Capture** — Execute actions and take screenshots
5. **Darkroom** — Process images (crop, borders, optimize, diff)
6. **README** — Update sentinel regions with new image tags
7. **Publish** — Commit and push (or open a PR)
## Configuration
### Environment Variables
| Variable | Description |
|----------|-------------|
| `PHANTOM_WEBHOOK_SECRET` | HMAC secret for webhook verification |
| `PHANTOM_MANIFEST_MAP` | Repo-to-manifest mapping for `serve` mode |
### README Sentinels
Add markers to your README for automatic image updates:
```markdown
<!-- phantom:hero -->
<!-- /phantom:hero -->
```
Phantom will inject the `<img>` tag between these markers when a capture with `readme_target: hero` changes.
## Contributing
See [CONTRIBUTING.md](CONTRIBUTING.md) for development setup, running tests, and contribution guidelines.
## License
[MIT](LICENSE) — Copyright 2026 Will Buscombe
| text/markdown | Will Buscombe | null | null | null | null | automation, ci-cd, documentation, playwright, screenshots | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Documentation",
"Topic :: Software Development :: Build Tools"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"aiohttp>=3.9",
"click>=8.1",
"croniter>=2.0",
"gitpython>=3.1",
"httpx>=0.26",
"pillow>=10.2",
"playwright>=1.41",
"pydantic>=2.5",
"pyte>=0.8",
"rich>=13.0",
"ruamel-yaml>=0.18",
"scikit-image>=0.22",
"structlog>=24.1",
"anthropic>=0.40; extra == \"ai\"",
"build>=1.0; extra == \"dev\""... | [] | [] | [] | [
"Homepage, https://github.com/wbuscombe/phantom",
"Repository, https://github.com/wbuscombe/phantom",
"Documentation, https://github.com/wbuscombe/phantom#readme",
"Issues, https://github.com/wbuscombe/phantom/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:04:46.417629 | phantom_docs-0.2.0.tar.gz | 205,356 | 71/f5/ff519ee8769d066166fe7a8ceceb946420e9cf8ef4997d8c55498efa43ad/phantom_docs-0.2.0.tar.gz | source | sdist | null | false | e1f0281f32becfb41babd24bb3016b35 | 10ad7eb6920650ac379194343c8d1b4550650d5f7445d84253baaa8e1d341ca4 | 71f5ff519ee8769d066166fe7a8ceceb946420e9cf8ef4997d8c55498efa43ad | MIT | [
"LICENSE"
] | 231 |
2.4 | slideflow-presentations | 0.0.4 | Automated Google Slides presentation builder with charts and data replacements. | # 🚀 SlideFlow
<div align="center">
[](https://opensource.org/licenses/MIT)
[](https://www.python.org/downloads/release/python-3120/)
[](https://joe-broadhead.github.io/slideflow/)
[](https://github.com/joe-broadhead/slideflow/releases/latest)
[](https://github.com/joe-broadhead/slideflow/actions/workflows/ci.yml)
[](https://github.com/psf/black)
```
____ _ _ _ __ _
/ ___|| (_) __| | ___ / _| | _____ __
\___ \| | |/ _` |/ _ \ |_| |/ _ \ \ /\ / /
___) | | | (_| | __/ _| | (_) \ V V /
|____/|_|_|\__,_|\___|_| |_|\___/ \_/\_/
Generate
Beautiful slides.
Direct from your data.
```
**SlideFlow is a Python-based tool for generating beautiful, data-driven presentations directly from your data sources.**
[Key Features](#-key-features) • [How It Works](#-how-it-works) • [Installation](#-installation) • [Getting Started](#-getting-started) • [CLI Usage](#-cli-usage) • [Configuration](#-configuration) • [Customization](#-customization) • [Contributing](#-contributing)
</div>
---
## ✨ Why SlideFlow?
SlideFlow was built to solve a simple problem: automating the tedious process of creating data-heavy presentations. If you find yourself repeatedly copying and pasting charts and metrics into slide decks, SlideFlow is for you.
- 🎨 **Beautiful, Consistent Visuals:** Leverage the power of Plotly for stunning, replicable charts. Use YAML templates to create a library of reusable chart designs.
- 📊 **Connect Directly to Your Data:** Pull data from CSV files, JSON, Databricks, or even your dbt models. No more manual data exports.
- ⚡ **Automate Your Reporting:** Stop the manual work. Reduce errors and save time. Your presentations are always up-to-date with your latest data.
- 🚀 **Scale Instantly:** Need to create a presentation for every customer, region, or product? Generate hundreds of personalized presentations at once from a single template.
---
## 🔑 Key Features
- **Declarative YAML Configuration:** Define your entire presentation in a simple, human/agent readable YAML file.
- **Multiple Data Source Connectors:**
- `csv`: For local CSV files.
- `json`: For local JSON files.
- `databricks`: For running SQL queries directly against Databricks.
- `databricks_dbt`: For using your existing dbt models as data sources.
- **Dynamic Content Replacements:**
- **Text:** Replace simple placeholders like `{{TOTAL_REVENUE}}` with dynamic values.
- **Tables:** Populate entire tables in your slides from a DataFrame.
- **AI-Generated Text:** Use OpenAI or Gemini to generate summaries, insights, or any other text, right from your data.
- **Powerful Charting Engine:**
- **Plotly Graph Objects:** Create any chart you can imagine with the full power of Plotly.
- **YAML Chart Templates:** Use packaged built-ins or define reusable local templates.
- **Custom Python Functions:** For when you need complete control over your chart generation logic.
- **Extensible and Customizable:**
- Use **Function Registries** to extend SlideFlow with your own Python functions for data transformations, formatting, and more.
- **Powerful CLI:**
- `slideflow build`: Generate one or many presentations.
- `slideflow validate`: Validate your configuration before you build.
- `slideflow templates`: Inspect available template names and parameter contracts.
- Generate multiple presentations from a single template using a CSV parameter file.
---
## 🔧 How It Works
SlideFlow works in three simple steps:
1. **Define:** You create a YAML file that defines your presentation. This includes the Google Slides template to use, the data sources to connect to, and the content for each slide (text, charts, etc.).
2. **Connect & Transform:** SlideFlow connects to your specified data sources, fetches the data, and applies any transformations you\'ve defined.
3. **Build:** SlideFlow creates a new presentation, populates it with your data and charts, and saves it to your Google Drive.
---
## 🛠 Installation
```bash
pip install slideflow-presentations
```
---
## 🧑💻 Getting Started
To create your first presentation, you\'ll need:
1. **A Google Slides Template:** Create a Google Slides presentation with the layout and branding you want. Note the ID of each slide you want to populate.
2. **Your Data:** Have your data ready in a CSV file, or have your Databricks credentials configured.
3. **A YAML Configuration File:** This is where you\'ll define your presentation. See the [Configuration](#-configuration) section for more details.
4. **Google Cloud Credentials:** You'll need a Google Cloud service account with access to the Google Slides and Google Drive APIs. Provide your credentials in one of the following ways:
- Set the `credentials` field in your `config.yml` to the path of your JSON credentials file.
- Set the `credentials` field in your `config.yml` to the JSON content of your credentials file as a string.
- Set the `GOOGLE_SLIDEFLOW_CREDENTIALS` environment variable to the path of your JSON credentials file or the content of the file itself.
Once you have these, you can run the `build` command:
```bash
slideflow build your_config.yml
```
---
## ⚙️ CLI Usage
SlideFlow comes with a simple CLI.
### `build`
The `build` command generates your presentation(s).
```bash
slideflow build [CONFIG_FILE] [OPTIONS]
```
**Arguments:**
- `CONFIG_FILE`: Path to your YAML configuration file.
**Options:**
- `--registry, -r`: Path to a Python file containing a `function_registry`. You can use this option multiple times.
- `--params-path, -f`: Path to a CSV file containing parameters for generating multiple presentations.
- `--dry-run`: Validate the configuration without building the presentation.
### `validate`
The `validate` command checks your configuration for errors.
```bash
slideflow validate [CONFIG_FILE] [OPTIONS]
```
**Arguments:**
- `CONFIG_FILE`: Path to your YAML configuration file.
**Options:**
- `--registry, -r`: Path to a Python file containing a `function_registry`.
---
## 📝 Configuration
Your `config.yml` file is the heart of your SlideFlow project. Here\'s a high-level overview of its structure:
```yaml
presentation:
name: "My Awesome Presentation"
slides:
- id: "slide_one_id"
title: "Title Slide"
replacements:
# ... text, table, and AI replacements
charts:
# ... chart definitions
provider:
type: "google_slides"
config:
credentials: "/path/to/your/credentials.json"
template_id: "your_google_slides_template_id"
template_paths:
- "./templates"
```
For more detailed information on the configuration options, please see the documentation.
---
## 🎨 Customization
SlideFlow is designed to be extensible. You can use your own Python functions for:
- **Data Transformations:** Clean, reshape, or aggregate your data before it\'s used in charts or replacements.
- **Custom Formatting:** Format numbers, dates, and other values exactly as you need them.
- **Custom Charts:** Create unique chart types that are specific to your needs.
To use your own functions, create a `registry.py` file with a `function_registry` dictionary:
```python
# registry.py
def format_as_usd(value):
return f"${value:,.2f}"
function_registry = {
"format_as_usd": format_as_usd,
}
```
You can then reference `format_as_usd` in your YAML configuration.
---
## 📜 License
MIT License © [Joe Broadhead](https://github.com/joe-broadhead)
| text/markdown | Joe Broadhead, Tom Lovett | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"typer",
"pydantic>=2.0",
"pydantic[email]>=2.0",
"pyyaml",
"pandas",
"numpy",
"rich",
"plotly",
"kaleido",
"google-api-python-client",
"google-auth",
"google-auth-oauthlib",
"google-auth-httplib2",
"httplib2",
"gitpython",
"dbt-core",
"dbt-databricks",
"databricks-sql-connector",
... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:04:40.808326 | slideflow_presentations-0.0.4.tar.gz | 233,074 | 8d/5a/3283a81bf3f7f82c33bedfc621cb725752936b23f4b5278462692593823a/slideflow_presentations-0.0.4.tar.gz | source | sdist | null | false | 6f6da7f16815ad36136741b6579bdf82 | 5c12501c0e9cec44230f456ceec51a7bdc5b66d7ee4d27129bcaf49846b977fb | 8d5a3283a81bf3f7f82c33bedfc621cb725752936b23f4b5278462692593823a | null | [
"LICENSE"
] | 209 |
2.1 | pptx-html-generator | 0.1.0 | Generate PowerPoint files from JSON with progressive HTML support. | # PPTX HTML Generator
Python library for rendering rich HTML text into `python-pptx` text frames.
## Primary API
Most users should use this directly in their existing `python-pptx` pipeline:
```python
from pptx_html_generator import render_html_to_text_frame
render_html_to_text_frame(shape.text_frame, html_string, base_styles={...})
```
This plugs in exactly where your app converts string content into text-frame content.
See:
- API contract: `docs/API.md`
## Features
- JSON schema validation with useful error messages
- Unit parsing for `in`, `cm`, `pt`, `emu`
- Presentation generation with text box elements
- HTML rich-text support:
- Inline formatting: `<b>`, `<strong>`, `<i>`, `<em>`, `<u>`, `<s>`, `<del>`, `<strike>`, `<code>`, `<sup>`, `<sub>`
- Links and styled spans: `<a>`, `<span style>`
- Block structure: `<p>`, `<br>`, `<ul>`, `<ol>`, `<li>`, `<h1>`-`<h6>`
- JSON style/default support:
- `font_name`, `font_size`, `font_color`
- `alignment`, `vertical_anchor`, `word_wrap`
- CLI: `json_in -> pptx_out`
## Quick start
```bash
python -m pip install pptx-html-generator
```
Drop-in usage in an existing `python-pptx` workflow:
```python
from pptx import Presentation
from pptx_html_generator import render_html_to_text_frame
prs = Presentation()
slide = prs.slides.add_slide(prs.slide_layouts[6]) # blank
shape = slide.shapes.add_textbox(914400, 914400, 7315200, 1828800)
html = "<p><strong>Hello</strong> <em>world</em> with <a href='https://example.com'>a link</a>.</p>"
render_html_to_text_frame(shape.text_frame, html)
prs.save("example.pptx")
```
Forward generation CLI (optional helper for JSON-driven generation):
```bash
pptx-html-generator generate examples/full_implementation.json output/full_implementation_demo.pptx
```
Development setup:
```bash
python -m pip install -e ".[dev]"
pytest
```
## CLI
Generate PPTX:
```bash
pptx-html-generator generate examples/full_implementation.json output/full_implementation_demo.pptx
```
List selectable elements on a slide (uses PowerPoint Selection Pane names):
```bash
pptx-html-generator list-elements output/full_implementation_demo.pptx --slide 1
```
Extract HTML from a selected shape by Selection Pane name:
```bash
pptx-html-generator extract-html output/full_implementation_demo.pptx --slide 1 --shape-name "BodyContent"
```
## JSON shape (optional high-level API)
```json
{
"presentation": {
"width": "13.333in",
"height": "7.5in"
},
"slides": [
{
"layout": "blank",
"elements": [
{
"type": "textbox",
"position": {
"left": "1in",
"top": "1in",
"width": "8in",
"height": "2in"
},
"content": "Plain text content"
}
]
}
]
}
```
| text/markdown | PPTX HTML Generator Contributors | null | null | null | MIT | pptx, powerpoint, html, python-pptx, automation | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Office/Busi... | [] | null | null | >=3.10 | [] | [] | [] | [
"python-pptx>=1.0.0",
"beautifulsoup4>=4.12",
"lxml>=4.9",
"pytest>=8.0; extra == \"dev\"",
"build>=1.2.2; extra == \"release\"",
"twine>=5.1.1; extra == \"release\""
] | [] | [] | [] | [
"Homepage, https://github.com/matt-parish/pptx-html-generator",
"Repository, https://github.com/matt-parish/pptx-html-generator",
"Issues, https://github.com/matt-parish/pptx-html-generator/issues"
] | twine/6.2.0 CPython/3.12.7 | 2026-02-19T21:04:10.243612 | pptx_html_generator-0.1.0.tar.gz | 16,420 | fb/ca/753bed083b32191cc73fff2e560f8650f42d8b8256f6d37e542fb30f6c8e/pptx_html_generator-0.1.0.tar.gz | source | sdist | null | false | 7564ace46e63d23af258a7b790594824 | dd9c5dd683fb7e17f60bd157521960b6b290721dc63fe09b83c3108fabdb4689 | fbca753bed083b32191cc73fff2e560f8650f42d8b8256f6d37e542fb30f6c8e | null | [] | 229 |
2.4 | gloria | 0.1.4 | Gloria is a modern open-source framework for time series analysis and forecasting. | <h1 align="center">
<img src="https://e-dyn.github.io/gloria/_static/glorialogo.png" alt="Gloria Logo" style="width:70%;">
</h1><br>

[](https://github.com/psf/black)
[](https://github.com/astral-sh/ruff)
[](https://mypy-lang.org/)
[](https://docs.pydantic.dev/latest/contributing/#badges)
Gloria is a modern open-source framework for time series analysis and forecasting, designed for the demands of complex, real-world data. It combines robust statistical modeling with flexible controls and full transparency to enable trustworthy forecasting.
## Key Features
* **Distributional Flexibility**: Go beyond the normal distribution and model count data (Poisson, Binomial, Negative Binomial, Beta-Binomial), bounded rates (Beta), or non-negative floats (Gamma) natively
* **Any Time Grid**: Gloria handles arbitrary sampling intervals (not just daily)
* **Rich Event Modeling**: Parametric and extensible event library to handle holidays, campaigns, or maintenance windows - any event, any shape, for realistic impacts and reduced overfitting.
* **Fully Explainable**: Gloria's models are explicit, fully documented, and always inspectable.
* **Modern Python Stack**: Type hints, pydantic for validation, and a clean API design reminiscent of [Prophet](https://facebook.github.io/prophet/) but with a much more maintainable and extensible codebase.
## Important Links
* **Documentation**: https://e-dyn.github.io/gloria/
* **Installation**: https://e-dyn.github.io/gloria/get_started/installation.html
* **Source Code**: https://github.com/e-dyn/gloria
* **Bug Reports and Feature Requests**: https://github.com/e-dyn/gloria/issues
* **License**: [MIT](https://github.com/e-dyn/gloria/blob/main/LICENSE)
| text/markdown | null | Benjamin Kambs <b.kambs@e-dynamics.de>, Patrik Wollgarten <p.wollgarten@e-dynamics.de> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Intended Audience :: Sc... | [] | null | null | <3.13,>=3.9 | [] | [] | [] | [
"pandas<3.0.0,>=2.2.3",
"numpy<=2.0.2",
"pydantic<3.0.0,>=2.10.6",
"scipy<=1.13.1",
"matplotlib<=3.9.4",
"cmdstanpy<2.0.0,>=1.2.5",
"holidays<0.68,>=0.67",
"sktime<0.38.0,>=0.37.0",
"tomli<3.0.0,>=2.2.1",
"seaborn<0.14.0,>=0.13.2"
] | [] | [] | [] | [
"Homepage, https://www.e-dynamics.de/gloria-open-source-framework/",
"Documentation, https://e-dyn.github.io/gloria/",
"Repository, https://github.com/e-dyn/gloria"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:04:05.722839 | gloria-0.1.4.tar.gz | 89,569 | a6/e8/eedefb37a6c417cadc1d9b90b03770bba92c7f60674179567659005f2f06/gloria-0.1.4.tar.gz | source | sdist | null | false | 3622828ca7ceade50f98f454638824ad | 913e7ca7ecfaed3e7f9588799eeb30a165bc3fc322224323fb59afee319e49f8 | a6e8eedefb37a6c417cadc1d9b90b03770bba92c7f60674179567659005f2f06 | null | [
"LICENSE"
] | 368 |
2.4 | hash-forge | 3.1.0 | Hash Forge is a lightweight Python library designed to simplify the process of hashing and verifying data using a variety of secure hashing algorithms. | # Hash Forge
[](https://pypi.org/project/hash-forge/)  [](https://opensource.org/licenses/MIT) [](https://pypi.org/project/hash-forge/) [](https://pepy.tech/project/hash-forge) [](https://github.com/Zozi96/hash-forge/issues)  [](https://github.com/psf/black) [](https://github.com/Zozi96/hash-forge/issues)
**Hash Forge** is a lightweight Python library designed to simplify the process of hashing and verifying data using a variety of secure hashing algorithms.
## Overview
Hash Forge is a flexible and secure hash management tool that supports multiple hashing algorithms. This tool allows you to hash and verify data using popular hash algorithms, making it easy to integrate into projects where password hashing or data integrity is essential.
## Features
- **Multiple Hashing Algorithms**: Supports bcrypt, Scrypt, Argon2, Blake2, Blake3, PBKDF2, SHA-3, Whirlpool and RIPEMD-160.
- **Async/Await Support**: Non-blocking operations with `hash_async()`, `verify_async()`, and batch processing.
- **Builder Pattern**: Fluent, chainable API for elegant configuration.
- **Configuration Management**: Load settings from environment variables, JSON files, or code.
- **Hashing and Verification**: Easily hash strings and verify their integrity.
- **Hash Rotation**: Seamlessly migrate hashes to a new algorithm with `rotate()`.
- **Hash Inspection**: Retrieve algorithm metadata from any hash with `inspect()`.
- **Rehash Detection**: Automatically detects if a hash needs to be rehashed based on outdated parameters or algorithms.
- **Type-Safe API**: Full TypeScript-like type hints with `AlgorithmType` for better IDE support.
- **Performance Optimized**: O(1) hasher lookup, async batch operations 3-5x faster.
- **Security Focused**: Enforces minimum security parameters and uses cryptographically secure random generation.
- **Well Documented**: Comprehensive examples, security guidelines, and contribution docs.
## Installation
```bash
pip install hash-forge
```
### Optional Dependencies
Hash Forge provides optional dependencies for specific hashing algorithms. To install these, use:
- **bcrypt** support:
```bash
pip install "hash-forge[bcrypt]"
```
- **Argon2** support:
```bash
pip install "hash-forge[argon2]"
```
- **Whirlpool and RIPEMD-160** support:
```bash
pip install "hash-forge[crypto]"
```
- **Blake3** support:
```bash
pip install "hash-forge[blake3]"
```
## Quick Start
```python
from hash_forge import HashManager
# Create a HashManager with Argon2 (recommended)
hash_manager = HashManager.from_algorithms("argon2")
# Hash a password
hashed = hash_manager.hash("my_secure_password")
# Verify a password
is_valid = hash_manager.verify("my_secure_password", hashed)
print(is_valid) # True
# Check if rehashing is needed
needs_update = hash_manager.needs_rehash(hashed)
```
## Usage
### Basic Example
```python
from hash_forge import HashManager, AlgorithmType
from hash_forge.hashers import PBKDF2Sha256Hasher
# Initialize HashManager with PBKDF2Hasher
hash_manager = HashManager(PBKDF2Sha256Hasher())
# Hash a string
hashed_value = hash_manager.hash("my_secure_password")
# Verify the string against the hashed value
is_valid = hash_manager.verify("my_secure_password", hashed_value)
print(is_valid) # Outputs: True
# Check if the hash needs rehashing
needs_rehash = hash_manager.needs_rehash(hashed_value)
print(needs_rehash) # Outputs: False
```
### Examples
Check out the [`examples/`](examples/) directory for more practical examples:
- **[basic_usage.py](examples/basic_usage.py)** - Fundamental operations and common patterns
- **[async_fastapi.py](examples/async_fastapi.py)** - FastAPI integration with async support
- **[builder_pattern.py](examples/builder_pattern.py)** - Fluent builder API examples
### Quick Hash (New in v2.1.0)
For simple hashing without creating a HashManager instance:
```python
from hash_forge import HashManager, AlgorithmType
# Quick hash with default algorithm (PBKDF2-SHA256)
hashed = HashManager.quick_hash("my_password")
# Quick hash with specific algorithm (with IDE autocomplete!)
algorithm: AlgorithmType = "argon2"
hashed = HashManager.quick_hash("my_password", algorithm=algorithm)
# Quick hash with algorithm-specific parameters
hashed = HashManager.quick_hash("my_password", algorithm="pbkdf2_sha256", iterations=200_000)
hashed = HashManager.quick_hash("my_password", algorithm="bcrypt", rounds=14)
hashed = HashManager.quick_hash("my_password", algorithm="argon2", time_cost=4)
```
### Factory Pattern (New in v2.1.0)
Create HashManager instances using algorithm names:
```python
from hash_forge import HashManager, AlgorithmType
# Create HashManager from algorithm names
hash_manager = HashManager.from_algorithms("pbkdf2_sha256", "argon2", "bcrypt")
# With type safety
algorithms: list[AlgorithmType] = ["pbkdf2_sha256", "bcrypt_sha256"]
hash_manager = HashManager.from_algorithms(*algorithms)
# Note: from_algorithms() creates hashers with default parameters
# For custom parameters, create hashers individually
hash_manager = HashManager.from_algorithms("pbkdf2_sha256", "bcrypt", "argon2")
```
> **Note:** The first hasher provided during initialization of `HashManager` will be the **preferred hasher** used for hashing operations, though any available hasher can be used for verification.
### Available Algorithms
Currently supported algorithms with their `AlgorithmType` identifiers:
| Algorithm | Identifier | Security Level | Notes |
|-----------|------------|----------------|-------|
| **PBKDF2-SHA256** | `"pbkdf2_sha256"` | High | Default, 150K iterations minimum |
| **PBKDF2-SHA1** | `"pbkdf2_sha1"` | Medium | Legacy support |
| **bcrypt** | `"bcrypt"` | High | 12 rounds minimum |
| **bcrypt-SHA256** | `"bcrypt_sha256"` | High | With SHA256 pre-hashing |
| **Argon2** | `"argon2"` | Very High | Memory-hard function |
| **Scrypt** | `"scrypt"` | High | Memory-hard function |
| **Blake2** | `"blake2"` | High | Fast cryptographic hash |
| **Blake3** | `"blake3"` | Very High | Latest Blake variant |
| **SHA-3 256** | `"sha3_256"` | High | stdlib only, no extra dependencies |
| **SHA-3 512** | `"sha3_512"` | High | stdlib only, no extra dependencies |
| **Whirlpool** | `"whirlpool"` | Medium | 512-bit hash |
| **RIPEMD-160** | `"ripemd160"` | Medium | 160-bit hash |
### Algorithm-Specific Parameters
Different algorithms support different parameters. Use `quick_hash()` for algorithm-specific customization:
```python
from hash_forge import HashManager
# PBKDF2 algorithms
HashManager.quick_hash("password", algorithm="pbkdf2_sha256", iterations=200_000, salt_length=16)
HashManager.quick_hash("password", algorithm="pbkdf2_sha1", iterations=150_000)
# BCrypt algorithms
HashManager.quick_hash("password", algorithm="bcrypt", rounds=14)
HashManager.quick_hash("password", algorithm="bcrypt_sha256", rounds=12)
# Argon2
HashManager.quick_hash("password", algorithm="argon2", time_cost=4, memory_cost=65536, parallelism=1)
# Scrypt
HashManager.quick_hash("password", algorithm="scrypt", n=32768, r=8, p=1)
# Blake2 (with optional key)
HashManager.quick_hash("password", algorithm="blake2", key="secret_key")
# Blake3 (with optional key)
HashManager.quick_hash("password", algorithm="blake3", key="secret_key")
# SHA-3 (stdlib only — no extra dependencies)
HashManager.quick_hash("password", algorithm="sha3_256")
HashManager.quick_hash("password", algorithm="sha3_512")
# Other algorithms (use defaults)
HashManager.quick_hash("password", algorithm="whirlpool")
HashManager.quick_hash("password", algorithm="ripemd160")
```
### Traditional Initialization
For complete control over parameters, initialize `HashManager` with individual hasher instances:
```python
from hash_forge import HashManager
from hash_forge.hashers import (
Argon2Hasher,
BCryptSha256Hasher,
Blake2Hasher,
PBKDF2Sha256Hasher,
Ripemd160Hasher,
ScryptHasher,
SHA3_256Hasher,
SHA3_512Hasher,
WhirlpoolHasher,
Blake3Hasher
)
hash_manager = HashManager(
PBKDF2Sha256Hasher(iterations=200_000), # Higher iterations
BCryptSha256Hasher(rounds=14), # Higher rounds
Argon2Hasher(time_cost=4), # Custom parameters
ScryptHasher(),
SHA3_256Hasher(),
SHA3_512Hasher(),
Ripemd160Hasher(),
Blake2Hasher('MySecretKey'),
WhirlpoolHasher(),
Blake3Hasher()
)
```
### Verifying a Hash
Use the `verify` method to compare a string with its hashed counterpart:
```python
is_valid = hash_manager.verify("my_secure_password", hashed_value)
```
### Checking for Rehashing
You can check if a hash needs to be rehashed (e.g., if the hashing algorithm parameters are outdated):
```python
needs_rehash = hash_manager.needs_rehash(hashed_value)
```
### Hash Rotation
`rotate()` verifies a password against an existing hash, then re-hashes it with the preferred hasher. Returns `None` if verification fails — no exception, no exposure of the plaintext to the caller.
This is the safe way to migrate passwords from a legacy algorithm to a new one on next login:
```python
from hash_forge import HashManager
# Manager configured with the new preferred algorithm
hash_manager = HashManager.from_algorithms("argon2", "pbkdf2_sha256")
# On login, attempt rotation
old_hash = get_stored_hash(user_id) # e.g. a pbkdf2_sha256 hash
new_hash = hash_manager.rotate(user_password, old_hash)
if new_hash is not None:
save_hash(user_id, new_hash) # now stored as argon2
print("Password migrated to argon2")
else:
print("Wrong password")
```
### Hash Inspection
`inspect()` returns a dictionary with metadata about a stored hash — algorithm name and any algorithm-specific parameters — without exposing the raw hash value or salt.
```python
from hash_forge import HashManager
from hash_forge.hashers import PBKDF2Sha256Hasher, SHA3_256Hasher
hash_manager = HashManager(PBKDF2Sha256Hasher(), SHA3_256Hasher())
pbkdf2_hash = HashManager.quick_hash("password", algorithm="pbkdf2_sha256", iterations=200_000)
print(hash_manager.inspect(pbkdf2_hash))
# {'algorithm': 'pbkdf2_sha256', 'iterations': 200000}
sha3_hash = HashManager.quick_hash("password", algorithm="sha3_256")
print(hash_manager.inspect(sha3_hash))
# {'algorithm': 'sha3_256'}
print(hash_manager.inspect("unknown$abc$def"))
# None
```
### Listing Registered Algorithms
`list_algorithms()` returns the algorithm names registered in the current manager instance:
```python
from hash_forge import HashManager
hash_manager = HashManager.from_algorithms("argon2", "pbkdf2_sha256", "sha3_256")
print(hash_manager.list_algorithms())
# ['argon2', 'pbkdf2_sha256', 'sha3_256']
```
### Repr
`HashManager` has a readable `__repr__` showing the preferred algorithm and all registered algorithms:
```python
from hash_forge import HashManager
hash_manager = HashManager.from_algorithms("argon2", "pbkdf2_sha256")
print(repr(hash_manager))
# HashManager(preferred='argon2', algorithms=['argon2', 'pbkdf2_sha256'])
```
### Async Support (New in v3.0.0)
Hash Forge provides full async/await support for non-blocking operations. All synchronous methods have async equivalents that run in a thread pool executor to avoid blocking the event loop.
#### Basic Async Operations
```python
import asyncio
from hash_forge import HashManager
async def main():
hash_manager = HashManager.from_algorithms("argon2")
# Async hashing - runs synchronous hash in thread pool
hashed = await hash_manager.hash_async("my_password")
print(f"Hashed: {hashed}")
# Async verification - non-blocking verification
is_valid = await hash_manager.verify_async("my_password", hashed)
print(f"Valid: {is_valid}") # True
# Async rehash check
needs_rehash = await hash_manager.needs_rehash_async(hashed)
print(f"Needs rehash: {needs_rehash}") # False
asyncio.run(main())
```
#### Batch Operations
Process multiple passwords concurrently for better performance:
```python
import asyncio
from hash_forge import HashManager
async def batch_example():
hash_manager = HashManager.from_algorithms("pbkdf2_sha256")
# Hash multiple passwords concurrently
passwords = ["user1_pass", "user2_pass", "user3_pass", "user4_pass"]
hashes = await hash_manager.hash_many_async(passwords)
# hashes is a list with the same order as passwords
for password, hash_value in zip(passwords, hashes):
print(f"{password} -> {hash_value[:50]}...")
# Verify multiple password-hash pairs concurrently
pairs = [
("user1_pass", hashes[0]),
("user2_pass", hashes[1]),
("wrong_password", hashes[2]), # This will be False
]
results = await hash_manager.verify_many_async(pairs)
print(f"Results: {results}") # [True, True, False]
asyncio.run(batch_example())
```
#### Web Framework Integration
Perfect for async web frameworks like FastAPI, Sanic, or aiohttp:
```python
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from hash_forge import HashManager
app = FastAPI()
hash_manager = HashManager.from_algorithms("argon2")
class LoginRequest(BaseModel):
username: str
password: str
@app.post("/register")
async def register(request: LoginRequest):
# Non-blocking password hashing
hashed = await hash_manager.hash_async(request.password)
# Save user with hashed password to database
return {"username": request.username, "password_hash": hashed}
@app.post("/login")
async def login(request: LoginRequest):
# Fetch user from database (simulated)
stored_hash = get_user_hash(request.username)
# Non-blocking password verification
is_valid = await hash_manager.verify_async(request.password, stored_hash)
if not is_valid:
raise HTTPException(status_code=401, detail="Invalid credentials")
return {"message": "Login successful"}
```
#### Performance Benefits
The async methods are particularly useful when:
- Processing multiple passwords in parallel
- Integrating with async web frameworks
- Avoiding blocking the event loop during expensive hash operations
- Building responsive async applications
```python
import asyncio
import time
from hash_forge import HashManager
async def performance_comparison():
hash_manager = HashManager.from_algorithms("argon2")
passwords = [f"password_{i}" for i in range(10)]
# Sequential (blocking)
start = time.time()
hashes_sync = [hash_manager.hash(pwd) for pwd in passwords]
sync_time = time.time() - start
# Concurrent (non-blocking)
start = time.time()
hashes_async = await hash_manager.hash_many_async(passwords)
async_time = time.time() - start
print(f"Sequential: {sync_time:.2f}s")
print(f"Concurrent: {async_time:.2f}s")
print(f"Speedup: {sync_time/async_time:.2f}x")
asyncio.run(performance_comparison())
```
### Configuration Management (New in v3.0.0)
Load configuration from environment variables, JSON files, or programmatically:
```python
from hash_forge import HashManager
from hash_forge.config import HashForgeConfig
# From environment variables
# export HASH_FORGE_PBKDF2_ITERATIONS=200000
# export HASH_FORGE_BCRYPT_ROUNDS=14
config = HashForgeConfig.from_env()
# From JSON file
config = HashForgeConfig.from_json("config.json")
# Programmatically
config = HashForgeConfig(
pbkdf2_iterations=200_000,
bcrypt_rounds=14,
argon2_time_cost=4
)
# Create HashManager with config
hash_manager = HashManager.from_config(config, "pbkdf2_sha256", "bcrypt")
# Save config
config.to_json("hash_config.json")
```
### Builder Pattern (New in v3.0.0)
Create HashManager instances with a fluent, chainable API:
```python
from hash_forge import HashManager
# Use builder pattern for elegant configuration
hash_manager = (
HashManager.builder()
.with_algorithm("argon2", time_cost=4)
.with_algorithm("bcrypt", rounds=14)
.with_algorithm("pbkdf2_sha256", iterations=200_000)
.with_preferred("argon2") # Set preferred hasher
.build()
)
# Mix pre-configured hashers with algorithms
from hash_forge.hashers import PBKDF2Sha256Hasher
custom_hasher = PBKDF2Sha256Hasher(iterations=300_000)
hash_manager = (
HashManager.builder()
.with_hasher(custom_hasher)
.with_algorithm("bcrypt")
.build()
)
```
## What's New in v3.0.0
Hash Forge v3.0.0 represents a major architectural overhaul with significant performance improvements and new features while maintaining backward compatibility for the public API.
### 🏗️ Architecture Improvements
- **Modular Structure**: Complete reorganization into logical modules (`core/`, `config/`, `utils/`, `hashers/`)
- **Template Method Pattern**: Reduced code duplication in hashers by 40% through base class abstraction
- **Auto-Discovery Pattern**: Simplified hasher registration with automatic decorator-based registration
- **Chain of Responsibility**: Each hasher autonomously determines if it can handle a hash
- **Clean Architecture**: Clear separation between public API and internal implementation
### ⚡ Performance Enhancements
- **O(1) Hasher Lookup**: Internal hasher mapping for instant algorithm detection (vs O(n) iteration)
- **Async/Await Support**: Full non-blocking operations with thread pool executor for CPU-bound tasks
- **Batch Processing**: Concurrent processing of multiple hashes with `hash_many_async()` and `verify_many_async()`
- **Optimized Memory**: Reduced object creation overhead and better resource management
- **Thread Pool Efficiency**: Smart use of asyncio executors for parallel hash operations
### 🎯 New Features
- **SHA-3 Support**: `sha3_256` and `sha3_512` via Python's stdlib — no extra dependencies
- **Hash Rotation**: `rotate()` for safe on-login algorithm migration
- **Hash Inspection**: `inspect()` returns algorithm metadata without exposing raw hash values
- **Algorithm Listing**: `list_algorithms()` returns algorithms registered in a manager instance
- **Async Operations**: Complete async API with `hash_async()`, `verify_async()`, `needs_rehash_async()`
- **Builder Pattern**: Fluent, chainable API for elegant HashManager configuration
- **Config Management**: Load settings from environment variables, JSON files, or programmatic config
- **Logging Infrastructure**: Built-in structured logging for debugging and monitoring
- **Type Safety**: Enhanced type hints with `AlgorithmType` literals for IDE autocomplete
### 📊 Performance Benchmarks
With async batch operations, v3.0.0 achieves significant speedups:
- **10 concurrent hashes**: ~3-5x faster than sequential
- **100 concurrent hashes**: ~8-10x faster than sequential
- **Web framework integration**: Non-blocking operations prevent request queue buildup
- **Memory efficiency**: 40% less code duplication = smaller memory footprint
### 🛠️ Developer Experience
- **Type Safety**: `AlgorithmType` literal for IDE autocomplete and error detection
- **Factory Pattern**: Create hashers by algorithm name with `HasherFactory`
- **Builder Pattern**: Chainable API for elegant configuration
- **Convenience Methods**: `quick_hash()` and `from_algorithms()` for simpler usage
- **Logging Support**: Built-in logging infrastructure for debugging
### 🔐 Security Enhancements
- **Parameter Validation**: Enforces minimum security thresholds (150K PBKDF2 iterations, 12 BCrypt rounds)
- **Custom Exceptions**: More specific error types (`InvalidHasherError`, `UnsupportedAlgorithmError`)
- **Centralized Configuration**: Security defaults in one place
- **Timing-Safe Verification**: All hashers use `hmac.compare_digest()` to prevent timing attacks
### 🧪 Better Testing
- **Enhanced Test Suite**: 140 tests covering all functionality
- **Type Checking Tests**: Validates `AlgorithmType` usage
- **Configuration Validation**: Tests security parameter enforcement
- **Builder Pattern Tests**: Validates fluent API
- **Async Tests**: Full coverage of async operations
- **Config Tests**: JSON, env vars, and programmatic config
### 📚 API Improvements
**Before v2.1.0:**
```python
# Manual hasher imports and creation
from hash_forge.hashers.pbkdf2_hasher import PBKDF2Sha256Hasher
hasher = PBKDF2Sha256Hasher(iterations=150000)
hash_manager = HashManager(hasher)
```
**v2.1.0:**
```python
# Simplified with factory pattern and type safety
from hash_forge import HashManager, AlgorithmType
algorithm: AlgorithmType = "pbkdf2_sha256" # IDE autocomplete!
hash_manager = HashManager.from_algorithms(algorithm)
# or with custom parameters
hashed = HashManager.quick_hash("password", algorithm=algorithm, iterations=200_000)
```
**v3.0.0:**
```python
# Complete overhaul with builder, config, and async support
from hash_forge import HashManager
from hash_forge.config import HashForgeConfig
# Builder pattern with fluent API
hash_manager = (
HashManager.builder()
.with_algorithm("argon2", time_cost=4, memory_cost=65536)
.with_algorithm("bcrypt", rounds=14)
.with_preferred("argon2")
.build()
)
# Config management from JSON/env
config = HashForgeConfig.from_json("config.json")
hash_manager = HashManager.from_config(config, "argon2", "bcrypt")
# Async operations for non-blocking performance
import asyncio
async def main():
hashes = await hash_manager.hash_many_async(["pass1", "pass2", "pass3"])
# 3-5x faster than sequential hashing!
asyncio.run(main())
```
### 🔄 Migration Guide (v2.x → v3.0.0)
The public API remains backward compatible, but internal imports have changed:
**✅ No changes needed** (backward compatible):
```python
from hash_forge import HashManager, AlgorithmType
from hash_forge.hashers import PBKDF2Sha256Hasher, BCryptHasher
hash_manager = HashManager.from_algorithms("pbkdf2_sha256")
hashed = hash_manager.hash("password")
```
**⚠️ Update if using internal modules** (rare):
```python
# v2.x (deprecated)
from hash_forge.protocols import HasherProtocol
from hash_forge.factory import HasherFactory
# v3.0.0 (new paths)
from hash_forge.core.protocols import HasherProtocol
from hash_forge.core.factory import HasherFactory
```
### 📂 New Project Structure
```
hash_forge/
├── __init__.py # Public API
├── types.py # Type definitions (AlgorithmType)
├── exceptions.py # Exception classes
│
├── core/ # Core functionality (internal)
│ ├── manager.py # HashManager implementation
│ ├── builder.py # Builder pattern
│ ├── factory.py # Hasher factory
│ ├── protocols.py # Protocol definitions
│ └── base_hasher.py # Template base class
│
├── config/ # Configuration (internal)
│ ├── settings.py # Default parameters
│ ├── constants.py # Constants
│ └── logging.py # Logging configuration
│
├── hashers/ # Algorithm implementations
│ ├── pbkdf2_hasher.py
│ ├── bcrypt_hasher.py
│ ├── argon2_hasher.py
│ ├── sha3_hasher.py
│ └── ...
│
└── utils/ # Utilities (internal)
└── helpers.py
```
## Documentation
- **[CHANGELOG.md](CHANGELOG.md)** - Version history and release notes
- **[SECURITY.md](SECURITY.md)** - Security best practices and vulnerability reporting
- **[CONTRIBUTING.md](CONTRIBUTING.md)** - Contribution guidelines and development setup
- **[Examples](examples/)** - Practical usage examples
## Contributing
Contributions are welcome! Please read our [Contributing Guide](CONTRIBUTING.md) for details on:
- Setting up the development environment
- Running tests and linting
- Code style and documentation standards
- Submitting pull requests
## Security
For security best practices and to report vulnerabilities, please see our [Security Policy](SECURITY.md).
**Recommended algorithms for password hashing:**
1. Argon2 (best choice)
2. BCrypt (industry standard)
3. PBKDF2-SHA256 (NIST approved)
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
| text/markdown | null | Zozi <zozi.fer96@gmail.com> | null | null | null | RIPEMD-160, Whirlpool, argon2, bcrypt, blake2, blake3, hash, pbkdf2, scrypt, security, sha3 | [
"Development Status :: 4 - Beta",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :... | [] | null | null | >=3.11 | [] | [] | [] | [
"argon2-cffi==25.1.0; extra == \"argon2\"",
"bcrypt==5.0.0; extra == \"bcrypt\"",
"blake3==1.0.7; extra == \"blake3\"",
"pycryptodome==3.23.0; extra == \"crypto\""
] | [] | [] | [] | [
"Homepage, https://github.com/Zozi96/hash-forge",
"Repository, https://github.com/Zozi96/hash-forge",
"Issue Tracker, https://github.com/Zozi96/hash-forge/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:04:04.105255 | hash_forge-3.1.0.tar.gz | 79,524 | a7/fa/c4e3d3cbd150904561f1df45cd9e59a76fe478d189e9d5e82d43da68c2a6/hash_forge-3.1.0.tar.gz | source | sdist | null | false | 7343f8e3465ea0d5ffa7c6363a95f4f3 | ede5759bb95c0984d33ba0e01b4a37fcc8e7319799cb3a921b2ec148b4fbfc56 | a7fac4e3d3cbd150904561f1df45cd9e59a76fe478d189e9d5e82d43da68c2a6 | MIT | [
"LICENSE"
] | 233 |
2.4 | amina-cli | 0.2.1 | CLI for AminoAnalytica protein engineering platform | # Amina CLI
Command-line interface for [AminoAnalytica](https://aminoanalytica.com) protein engineering tools.
Run protein structure prediction, sequence design, docking, and analysis directly from your terminal.
## Installation
```bash
pip install amina-cli
```
Requires Python 3.11+
## Quick Start
```bash
# 1. Set your API key
amina auth set-key "ami_your_api_key"
# 2. List available tools
amina tools
# 3. Run a tool
amina run esmfold --sequence "MKFLILLFNILCLFPVLAADNH" -o ./results/
```
Get an API key at [app.aminoanalytica.com/settings/api](https://app.aminoanalytica.com/settings/api)
## Commands Overview
| Command | Description |
|---------|-------------|
| `amina auth` | Manage API key authentication |
| `amina init` | Initialize project resources (Claude Code skills) |
| `amina tools` | List available tools and view parameters |
| `amina run <tool>` | Run a computational biology tool |
| `amina jobs` | Manage background jobs |
| `amina version` | Show CLI version |
---
## Authentication
```bash
# Set API key (required before running tools)
amina auth set-key "ami_your_api_key"
# Check authentication status
amina auth status
# Link CLI outputs to a web conversation
amina auth session <conversation_id>
# Unlink session
amina auth session --unlink
# Remove stored credentials
amina auth logout
```
---
## Claude Code Integration
Install Amina skills to help Claude Code assist with protein engineering tasks.
```bash
# Install skills to .claude/skills/ in your project directory
amina init claude-skills
```
After installing, run `/amina-init` in Claude Code to get started.
The skills teach Claude Code how to:
- Use the Amina CLI effectively
- Run structure prediction, sequence design, and docking tools
- Interpret results and suggest next steps
---
## Discovering Tools
```bash
# List all available tools
amina tools
# Filter by category
amina tools --category folding
amina tools --category design
amina tools --category interactions
amina tools --category analysis
amina tools --category properties
amina tools --category utilities
# Search for tools
amina tools --search dock
amina tools --search glyco
# View tool parameters and usage
amina tools esmfold
amina tools proteinmpnn
# List all categories
amina tools categories
```
---
## Running Tools
```bash
# Basic usage
amina run <tool> [OPTIONS] -o ./output/
# Run in background (returns immediately)
amina run esmfold --sequence "MKTV..." -o ./output/ --background
# Set custom job name
amina run esmfold --sequence "MKTV..." -o ./output/ --job-name my_protein
# Get help for any tool
amina run esmfold --help
amina run proteinmpnn --help
```
---
## Managing Jobs
Background jobs continue running on the server while you work locally.
```bash
# List recent jobs
amina jobs list
amina jobs list --limit 50
amina jobs list --json
# Check job status
amina jobs status <job_id>
amina jobs status job1 job2 job3
amina jobs status <job_id> --json
# Wait for jobs to complete
amina jobs wait <job_id>
amina jobs wait job1 job2 --timeout 7200
# Download results from a completed job
amina jobs download <job_id> -o ./results/
```
---
## Available Tools
### Folding
Predict 3D protein structures from sequences.
| Tool | Command | Description |
|------|---------|-------------|
| ESMFold | `amina run esmfold` | Fast structure prediction from sequence |
| Boltz-2 | `amina run boltz2` | Predict protein/ligand/nucleic acid complexes |
| OpenFold3 | `amina run openfold3` | Predict structures of proteins, RNA, DNA, ligands |
| Protenix | `amina run protenix` | AlphaFold3 structure prediction |
**Examples:**
```bash
# ESMFold from sequence
amina run esmfold --sequence "MKFLILLFNILCLFPVLAADNH" -o ./results/
# ESMFold from FASTA file
amina run esmfold --fasta ./protein.fasta -o ./results/
# Boltz-2 with ligand
amina run boltz2 --sequence "MKTV..." --ligand "CCO" -o ./results/
# Boltz-2 multi-chain complex
amina run boltz2 --sequence "CHAIN_A_SEQ" --sequence "CHAIN_B_SEQ" -o ./results/
# OpenFold3 protein-DNA complex
amina run openfold3 --sequence "MKTV..." --dna "ATCGATCG" -o ./results/
```
---
### Design
Generate and optimize protein sequences.
| Tool | Command | Description |
|------|---------|-------------|
| ProteinMPNN | `amina run proteinmpnn` | Design sequences for a backbone structure |
| RFDiffusion | `amina run rfdiffusion` | Generate novel protein backbones |
| ESM-IF1 | `amina run esm-if1` | Inverse folding - sequences from structure |
| Protein-MC | `amina run protein-mc` | Monte Carlo sequence optimization |
**Examples:**
```bash
# ProteinMPNN sequence design
amina run proteinmpnn --pdb ./structure.pdb --num-sequences 10 -o ./results/
# ProteinMPNN with fixed positions
amina run proteinmpnn --pdb ./structure.pdb --fixed "A10,A15,A20" -o ./results/
# RFDiffusion unconditional generation
amina run rfdiffusion --mode unconditional --length 100 --num-designs 5 -o ./results/
# RFDiffusion binder design
amina run rfdiffusion --mode binder-design --input ./target.pdb --hotspots "A30,A35" -o ./results/
# ESM-IF1 inverse folding
amina run esm-if1 --pdb ./structure.pdb --chain A --num-samples 5 -o ./results/
# Protein-MC optimization
amina run protein-mc --sequence "MKTV..." --temperature 0.01 --num-steps 100 -o ./results/
```
---
### Interactions
Molecular docking, binding site prediction, and glycosylation analysis.
| Tool | Command | Description |
|------|---------|-------------|
| DiffDock | `amina run diffdock` | Diffusion-based molecular docking |
| AutoDock Vina | `amina run autodock-vina` | Classical molecular docking |
| DockQ | `amina run dockq` | Assess docked complex quality |
| P2Rank | `amina run p2rank` | Predict ligand-binding sites |
| Interface Identifier | `amina run interface-identifier` | Identify interface residues between chains |
| PeSTo | `amina run pesto` | Predict protein-protein/DNA/RNA/ligand interactions |
| LMNgly | `amina run lmngly` | N-linked glycosylation prediction |
| EMNGly | `amina run emngly` | ESM-1b based N-glycosylation prediction |
| ISOGlyP | `amina run isoglyp` | O-linked glycosylation prediction |
| Glycosylation Ensemble | `amina run glycosylation-ensemble` | Combined N/O-glycosylation prediction |
**Examples:**
```bash
# DiffDock with SMILES ligand
amina run diffdock --protein-pdb ./protein.pdb --ligand-smiles "CCO" --samples 10 -o ./results/
# DiffDock with SDF ligand file
amina run diffdock --protein-pdb ./protein.pdb --ligand-sdf ./ligand.sdf -o ./results/
# AutoDock Vina docking
amina run autodock-vina --protein-pdb ./protein.pdb --ligand-smiles "CCO" --exhaustiveness 16 -o ./results/
# P2Rank binding site prediction
amina run p2rank --pdb ./protein.pdb -o ./results/
# DockQ quality assessment
amina run dockq --model-pdb ./model.pdb --reference-pdb ./reference.pdb -o ./results/
# Glycosylation prediction
amina run glycosylation-ensemble --fasta ./protein.fasta -o ./results/
```
---
### Analysis
Structural comparison and property analysis.
| Tool | Command | Description |
|------|---------|-------------|
| RMSD Analysis | `amina run rmsd-analysis` | Calculate RMSD with active site support |
| Simple RMSD | `amina run simple-rmsd` | Quick backbone RMSD calculation |
| US-Align | `amina run usalign` | TM-score structural alignment |
| SASA | `amina run sasa` | Solvent accessible surface area |
| Hydrophobicity | `amina run hydrophobicity` | Hydrophobic residue distribution |
| Surface Charge | `amina run surface-charge` | Electrostatic surface analysis |
| MMseqs2 Cluster | `amina run mmseqs2-cluster` | Sequence clustering |
**Examples:**
```bash
# Simple RMSD calculation
amina run simple-rmsd --mobile ./model.pdb --target ./reference.pdb -o ./results/
# RMSD with active site focus
amina run rmsd-analysis --main ./model.pdb --reference ./reference.pdb --active-main "A:50,A:55,A:60" -o ./results/
# US-Align TM-score
amina run usalign --structure1 ./model.pdb --structure2 ./reference.pdb -o ./results/
# SASA calculation
amina run sasa --pdb ./protein.pdb -o ./results/
# Surface charge analysis
amina run surface-charge --pdb ./protein.pdb -o ./results/
# Sequence clustering
amina run mmseqs2-cluster --fasta ./sequences.fasta --identity 0.5 -o ./results/
```
---
### Properties
Sequence-based property prediction.
| Tool | Command | Description |
|------|---------|-------------|
| AminoSol | `amina run aminosol` | Predict E. coli solubility |
| ESM2 Embedding | `amina run esm2-embedding` | Extract protein embeddings |
**Examples:**
```bash
# Solubility prediction from FASTA
amina run aminosol --fasta ./proteins.fasta -o ./results/
# Solubility for individual sequences (comma-separated)
amina run aminosol --sequences "MKTVGQW...,MGSSHHH..." -o ./results/
# ESM2 embeddings
amina run esm2-embedding --fasta ./proteins.fasta -o ./results/
```
---
### Utilities
File preparation and conversion tools.
| Tool | Command | Description |
|------|---------|-------------|
| PDB Cleaner | `amina run pdb-cleaner` | Clean and prepare PDB files |
| PDB to FASTA | `amina run pdb-to-fasta` | Extract sequences from structures |
| PDB Quality Assessment | `amina run pdb-quality-assessment` | Ramachandran and geometry analysis |
| PDB Distance Calculator | `amina run pdb-distance-calculator` | Calculate inter-residue distances |
| PDB Chain Selector | `amina run pdb-chain-select` | Extract or remove specific chains |
| PDB B-factor Overwrite | `amina run pdb-bfactor-overwrite` | Replace B-factors with custom scores |
| Active Site Verifier | `amina run activesite-verifier` | Verify active-site residue presence |
| Protein Relaxer | `amina run protein-relaxer` | Energy minimization for steric clashes |
| MAXIT Converter | `amina run maxit-convert` | Convert between PDB and mmCIF |
| Open Babel Converter | `amina run obabel-convert` | Multi-format molecule conversion |
| Molecule Size Calculator | `amina run mol-size-calculator` | Calculate molecule dimensions |
**Examples:**
```bash
# Clean PDB file
amina run pdb-cleaner --pdb ./messy.pdb -o ./results/
# Clean PDB preserving B-factors
amina run pdb-cleaner --pdb ./messy.pdb --preserve-bfactors -o ./results/
# Extract FASTA from PDB
amina run pdb-to-fasta --pdb ./structure.pdb -o ./results/
# Keep specific chains
amina run pdb-chain-select --pdb ./complex.pdb --chains "A,B" -o ./results/
# Remove chains (invert selection)
amina run pdb-chain-select --pdb ./complex.pdb --chains "C" --invert -o ./results/
# Calculate distance between residues
amina run pdb-distance-calculator --pdb ./protein.pdb --chain1 A --resnum1 50 --chain2 A --resnum2 100 -o ./results/
# Convert PDB to mmCIF
amina run maxit-convert --input ./structure.pdb --format cif -o ./results/
# Relax structure (energy minimize)
amina run protein-relaxer --pdb ./clashing.pdb -o ./results/ --background
# Convert molecule formats
amina run obabel-convert --input ./molecule.mol2 --output-format sdf -o ./results/
```
---
## Output Files
Results are downloaded to your specified output directory. File names include the tool name and job ID:
```
./results/
├── esmfold_abc123_structure.pdb
├── esmfold_abc123_plddt_scores.csv
└── esmfold_abc123_plddt_plot.png
```
---
## Common Options
Most tools support these options:
| Option | Description |
|--------|-------------|
| `-o, --output` | Output directory (required) |
| `-j, --job-name` | Custom name for the job |
| `-b, --background` | Submit job and return immediately |
| `--help` | Show tool parameters and usage |
---
## Links
- [Website](https://aminoanalytica.com)
- [Documentation](https://docs.aminoanalytica.com)
- [Get API Key](https://app.aminoanalytica.com/settings/api)
## License
Apache 2.0
| text/markdown | null | AminoAnalytica <support@aminoanalytica.com> | null | null | Apache-2.0 | bioinformatics, cli, esmfold, protein, protein-design, proteinmpnn, structure-prediction | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Pyt... | [] | null | null | >=3.11 | [] | [] | [] | [
"httpx>=0.27.0",
"pydantic>=2.0",
"rich>=13.0.0",
"supabase>=2.0.0",
"typer>=0.9.0",
"pytest; extra == \"dev\"",
"pytest-asyncio; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://aminoanalytica.com",
"Documentation, https://docs.aminoanalytica.com"
] | twine/6.2.0 CPython/3.11.13 | 2026-02-19T21:04:01.973222 | amina_cli-0.2.1.tar.gz | 68,706 | cf/a0/4ad31e5a09dfc2838fc8a408217238f45539a78e19caff320ac58cfec02f/amina_cli-0.2.1.tar.gz | source | sdist | null | false | ab047a68e879b9fd24541b78243d3f87 | 3fbcf1fb50fb66d5091b039e133e963fcc07885f3954ec19ac9f89e4b847bd07 | cfa04ad31e5a09dfc2838fc8a408217238f45539a78e19caff320ac58cfec02f | null | [
"LICENSE"
] | 229 |
2.3 | dpm2 | 2026.2.19 | SQLite db and generated Python models for EBA DPM 2.0 databases with full type safety | # DPM2
Generated Python models for EBA DPM 2.0 databases with full type safety and SQLAlchemy integration.
## Purpose
This package contains auto-generated, type-safe Python models for working with EBA DPM 2.0 databases. It provides:
- Fully typed SQLAlchemy ORM models
- Relationship mapping between tables
- Bundled SQLite database ready to query
- IDE support with autocompletion and type checking
## Installation
```bash
pip install dpm2
```
## Usage
```python
from sqlalchemy import select
from dpm2 import get_db, models
# Get an in-memory engine backed by the bundled database (default)
engine = get_db()
# Type-safe queries with full IDE support
with engine.connect() as conn:
stmt = select(models.ConceptClass)
for row in conn.execute(stmt):
print(row)
```
### Engine options
```python
from dpm2 import get_db, disk_engine
# In-memory copy (default) - fast, safe for temporary work
engine = get_db()
# Read-only file-backed engine - lower memory usage
engine = get_db(in_memory=False)
# Custom path with disk_engine
from pathlib import Path
engine = disk_engine(Path("my_local_copy.sqlite"))
```
## Features
- **Complete Type Safety** - All columns, relationships, and constraints are fully typed
- **IDE Integration** - Full autocompletion and error detection
- **SQLAlchemy 2.0+** - Uses modern SQLAlchemy with `Mapped` annotations
- **Relationship Navigation** - Foreign keys mapped to navigable Python objects
- **Bundled Database** - Ships with a ready-to-query SQLite database
## Generated Models
This package is automatically generated from the latest EBA DPM release and includes models for all DPM tables with proper relationships and constraints.
## Regeneration
Models are regenerated with each new EBA DPM release. Install the latest version to get updated schemas and data structures. | text/markdown | Jim Lundin | Jim Lundin <jimeriklundin@gmail.com> | null | null | MIT License Copyright (c) 2025 Jim Lundin Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"sqlalchemy>=2.0.37"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:03:31.873086 | dpm2-2026.2.19-py3-none-any.whl | 91,916,117 | 29/00/0fec11ae7c41579527606ce0caf3f95f9886cbb0f2391ea80fb5833a6178/dpm2-2026.2.19-py3-none-any.whl | py3 | bdist_wheel | null | false | 2199795aadfbf346387b58486de8ed9f | e42b72730d796964331c1ad27e214f1063a28514facd1cb1603d2bed7740c63d | 29000fec11ae7c41579527606ce0caf3f95f9886cbb0f2391ea80fb5833a6178 | null | [] | 237 |
2.4 | pymodbus | 3.12.1 | A fully featured modbus protocol stack in python | PyModbus - A Python Modbus Stack
================================
.. image:: https://github.com/pymodbus-dev/pymodbus/actions/workflows/ci.yml/badge.svg?branch=dev
:target: https://github.com/pymodbus-dev/pymodbus/actions/workflows/ci.yml
.. image:: https://readthedocs.org/projects/pymodbus/badge/?version=latest
:target: https://pymodbus.readthedocs.io/en/latest/?badge=latest
:alt: Documentation Status
.. image:: https://pepy.tech/badge/pymodbus
:target: https://pepy.tech/project/pymodbus
:alt: Downloads
.. image:: https://img.shields.io/badge/Gurubase-Ask%20PyModbus%20Guru-006BFF
:target: https://gurubase.io/g/pymodbus
:alt: PyModbus Guru
Pymodbus is a full Modbus protocol implementation offering a client, server and simulator with synchronous/asynchronous API.
Please observe that pymodbus follows the standard modbus and have only limited support for non-standard devices.
Our releases follow the pattern `X.Y.Z`. We have strict rules for what different version number updates mean:
- **Z**, No API changes! bug fixes and smaller enhancements.
- **Y**, API changes, bug fixes and bigger enhancements.
- **X**, Major changes in API and/or method to use pymodbus
Upgrade examples:
- 3.12.0 -> 3.12.2: just plugin the new version, no changes needed.
Remark fixing bugs, can lead to a different behaviors/returns
- 3.10.0 -> 3.12.0: Smaller changes to the pymodbus calls might be needed (Check `API_changes <https://github.com/pymodbus-dev/pymodbus/blob/dev/API_changes.rst>`_)
- 2.5.4 -> 3.0.0: Major changes in the application might be needed
**REMARK**: As can be seen from the above Pymodbus do NOT follow the semver.org standard.
It is always recommended to read the
`CHANGELOG <https://github.com/pymodbus-dev/pymodbus/blob/dev/CHANGELOG.rst>`_
as well as the
`API_changes <https://github.com/pymodbus-dev/pymodbus/blob/dev/API_changes.rst>`_
files.
Current release is `3.12.1 <https://github.com/pymodbus-dev/pymodbus/releases/tag/v3.12.1>`_.
Bleeding edge (not released) is `dev <https://github.com/pymodbus-dev/pymodbus/tree/dev>`_.
All changes are described in `release notes <https://pymodbus.readthedocs.io/en/latest/source/changelog.html>`_
and all API changes are `documented <https://pymodbus.readthedocs.io/en/latest/source/api_changes.html>`_
A big thanks to all the `volunteers <https://pymodbus.readthedocs.io/en/latest/source/authors.html>`_ that helps make pymodbus a great project.
Source code is available on `github <https://github.com/pymodbus-dev/pymodbus>`_
Full documentation for newest releases as well as the bleeding edge (dev) `readthedocs <https://pymodbus.readthedocs.io>`_
Pymodbus in a nutshell
----------------------
Pymodbus consist of 5 parts:
- **client**, connect to your favorite device(s)
- **server**, create your own device(s)
- **simulator**, an html based server simulator
- **examples**, showing both simple and advanced usage
Common features
^^^^^^^^^^^^^^^
* Full modbus standard protocol implementation
* Support for custom function codes
* Support serial (rs-485), tcp, tls and udp communication
* Support all standard frames: socket, rtu, rtu-over-tcp, tcp and ascii
* Does not have third party dependencies, apart from pyserial (optional)
* Very lightweight project
* Requires Python >= 3.10
* Thorough test suite, that test all corners of the library (100% test coverage)
* Automatically tested on Windows, Linux and MacOS combined with python 3.10 - 3.14
* Strongly typed API (py.typed present)
The modbus protocol specification: Modbus_Application_Protocol_V1_1b3.pdf can be found on
`modbus org <https://modbus.org>`_
Client Features
^^^^^^^^^^^^^^^
* Asynchronous API and synchronous API for applications
* Very simple setup and call sequence (just 6 lines of code)
* Utilities to convert python data types to/from multiple registers
`Client documentation <https://pymodbus.readthedocs.io/en/latest/source/client.html>`_
Server Features
^^^^^^^^^^^^^^^
* Asynchronous implementation for high performance
* Synchronous API classes for convenience (runs async internally)
* Emulate real life devices
* Full server control context (device information, counters, etc)
* Different backend datastores to manage register values
* Callback to intercept requests/responses
* Work limited on RS485 in parallel with other devices
`Server documentation <https://pymodbus.readthedocs.io/en/latest/source/server.html>`_
Simulator Features
^^^^^^^^^^^^^^^^^^
- Server simulator with WEB interface
- Configure the structure of a real device
- Monitor traffic online
- Allow distributed team members to work on a virtual device using internet
- Simulation of broken requests/responses
- Simulation of error responses (hard to provoke in real devices)
`Simulator documentation <https://pymodbus.readthedocs.io/en/dev/source/simulator.html>`_
Use Cases
---------
The client is the most typically used. It is embedded into applications,
where it abstract the modbus protocol from the application by providing an
easy to use API. The client is integrated into some well known projects like
`home-assistant <https://www.home-assistant.io>`_.
Although most system administrators will find little need for a Modbus
server, the server is handy to verify the functionality of an application.
The simulator and/or server is often used to simulate real life devices testing
applications. The server is excellent to perform high volume testing (e.g.
hundreds of devices connected to the application). The advantage of the server is
that it runs not only on "normal" computers but also on small ones like a Raspberry PI.
Since the library is written in python, it allows for easy scripting and/or integration into existing
solutions.
For more information please browse the project documentation:
https://readthedocs.org/docs/pymodbus/en/latest/index.html
Install
-------
The library is available on pypi.org and github.com to install with
- :code:`pip` for those who just want to use the library
- :code:`git clone` for those who wants to help or just are curious
Be aware that there are a number of project, who have forked pymodbus and
- Seems just to provide a version frozen in time
- Extended pymodbus with extra functionality
The latter is not because we rejected the extra functionality (we welcome all changes),
but because the codeowners made that decision.
In both cases, please understand, we cannot offer support to users of these projects as we do not known
what have been changed nor what status the forked code have.
A growing number of Linux distributions include pymodbus in their standard installation.
You need to have python3 installed, preferable 3.11.
Install with pip
^^^^^^^^^^^^^^^^
.. note::
This section is intended for apps that uses the pymodbus library.
You can install using pip by issuing the following
commands in a terminal window::
pip install pymodbus
If you want to use the serial interface::
pip install pymodbus[serial]
This will install pymodbus with the pyserial dependency.
Pymodbus offers a number of extra options:
- **serial**, needed for serial communication
- **simulator**, needed by pymodbus.simulator
- **documentation**, needed to generate documentation
- **development**, needed for development
- **all**, installs all of the above
which can be installed as::
pip install pymodbus[<option>,...]
It is possible to install old releases if needed::
pip install pymodbus==3.5.4
Install with github
^^^^^^^^^^^^^^^^^^^
On github, fork https://github.com/pymodbus-dev/pymodbus.git
Clone the source, and make a virtual environment::
git clone git://github.com/<your account>/pymodbus.git
cd pymodbus
python3 -m venv .venv
Activate the virtual environment, this command needs to be repeated in every new terminal::
source .venv/bin/activate
To get a specific release::
git checkout v3.5.2
or the bleeding edge::
git checkout dev
.. note::
Please always make your changes in a branch, and never submit a pull request
from dev.
Install required development tools in editable mode::
pip install -e ".[development]"
Install all (allows creation of documentation etc) in editable mode::
pip install -e ".[all]"
.. note::
The use of the ``-e`` (editable) flag is recommended when making changes.
It registers the ``pymodbus`` namespace in your virtual environment using pointers to the
source directory. This ensures that any changes you make to the core library are
immediately reflected when running examples or tests.
Install git hooks, that helps control the commit and avoid errors when submitting a Pull Request::
cp githooks/* .git/hooks
The repository contains a number of important branches and tags.
* **dev** is where all development happens, this branch is not always stable.
* **master** is where are releases are kept.
* **vX.Y.Z** (e.g. v2.5.3) is a specific release
Example Code
------------
For those of you who just want to get started quickly, here you go::
from pymodbus.client import ModbusTcpClient
client = ModbusTcpClient('MyDevice.lan')
client.connect()
client.write_coil(1, True)
result = client.read_coils(1,1)
print(result.bits[0])
client.close()
We provide a couple of simple ready to go clients:
- `async client <https://github.com/pymodbus-dev/pymodbus/blob/dev/examples/simple_async_client.py>`_
- `sync client <https://github.com/pymodbus-dev/pymodbus/blob/dev/examples/simple_sync_client.py>`_
For more advanced examples, check out `Examples <https://pymodbus.readthedocs.io/en/dev/source/examples.html>`_ included in the
repository. If you have created any utilities that meet a specific
need, feel free to submit them so others can benefit.
Also, if you have a question, please `create a post in discussions q&a topic <https://github.com/pymodbus-dev/pymodbus/discussions/new?category=q-a>`_,
so that others can benefit from the results.
If you think, that something in the code is broken/not running well, please `open an issue <https://github.com/pymodbus-dev/pymodbus/issues/new>`_,
read the Template-text first and then post your issue with your setup information.
`Example documentation <https://pymodbus.readthedocs.io/en/dev/source/examples.html>`_
Ready to go simulator
^^^^^^^^^^^^^^^^^^^^^
The simulator can be started directly using the installed entry point::
pymodbus.simulator --modbus_device device_try
**Configuration Parameters:**
To ensure the simulator starts with the correct data context, use the following flags:
* ``--json_file``: Path to the configuration JSON (defaults to the internal ``setup.json``).
* ``--modbus_server``: Selects the server type from the JSON ``server_list``.
* ``--modbus_device``: Selects the device registers from the JSON ``device_list``.
* ``--http_port``: Port for the Web UI (default: 8081).
* ``--log``: Sets the log level (default: info).
.. note:: Starting the simulator without explicit parameters may load an internal default configuration.
Troubleshooting examples
^^^^^^^^^^^^^^^^^^^^^^^^
If you encounter errors while running examples, please check:
1. **Namespace Error** (``*** ERROR --> PyModbus not found``):
The pymodbus package is not registered/installed. Please ensure you followed the installation
steps in the `Install with github`_ section above.
2. **Directory Error** (``*** ERROR --> THIS EXAMPLE needs the example directory...``):
You are in the wrong folder. You **must** run the script from within the
``examples/`` directory.
Contributing
------------
Just fork the repo and raise your Pull Request against :code:`dev` branch, but please never
make your changes on the :code:`dev` branch
We always have more work than time, so feel free to open a discussion / issue on a theme you want to solve.
If your company would like your device tested or have a cloud based device
simulation, feel free to contact us.
We are happy to help your company solve your modbus challenges.
That said, the current work mainly involves polishing the library and
solving issues:
* Fixing bugs/feature requests
* Architecture documentation
* Functional testing against any reference we can find
There are 2 bigger projects ongoing:
* rewriting the internal part of all clients (both sync and async)
* Add features to the simulator, and enhance the web design
Development instructions
------------------------
The current code base is compatible with python >= 3.10.
Here are some of the common commands to perform a range of activities::
source .venv/bin/activate <-- Activate the virtual environment
./check_ci.sh <-- run the same checks as CI runs on a pull request.
Make a pull request::
git checkout dev <-- activate development branch
git pull <-- update branch with newest changes
git checkout -b feature <-- make new branch for pull request
... make source changes
git commit <-- commit change to git
git push <-- push to your account on github
on github open a pull request, check that CI turns green and then wait for review comments.
Test your changes::
cd test
pytest
or
./check_ci.sh
This command also generates the coverage files, which are stored in :code:`build/cov``
you can also do extended testing::
pytest --cov <-- Coverage html report in build/html
pytest --profile <-- Call profile report in prof
Internals
^^^^^^^^^
There is no documentation of the architecture (help is welcome), but most classes and
methods are documented:
`Pymodbus internals <https://pymodbus.readthedocs.io/en/dev/source/internals.html>`_
Generate documentation
^^^^^^^^^^^^^^^^^^^^^^
**Remark** Assumes that you have installed documentation tools:;
pip install ".[documentation]"
to build do::
cd doc
./build_html
The documentation is available in <root>/build/html
Remark: this generates a new zip/tgz file of examples which are uploaded.
License Information
-------------------
Released under the `BSD License <https://github.com/pymodbus-dev/pymodbus/blob/dev/LICENSE>`_
| text/x-rst | Galen Collins, Jan Iversen | null | dhoomakethu, janiversen | null | BSD-3-Clause | modbus, asyncio, scada, client, server, simulator | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Framework :: AsyncIO",
"Intended Audience :: Developers",
"License :: OSI Approved :: BSD License",
"Operating System :: POSIX :: Linux",
"Operating System :: Unix",
"Operating System :: MacOS :: MacOS X",
"Operating System ::... | [
"'Linux'"
] | null | null | >=3.10.0 | [] | [] | [] | [
"pyserial>=3.5; extra == \"serial\"",
"aiohttp>=3.8.6; python_version < \"3.12\" and extra == \"simulator\"",
"aiohttp>=3.13.2; python_version >= \"3.12\" and extra == \"simulator\"",
"recommonmark>=0.7.1; extra == \"documentation\"",
"Sphinx>=7.3.7; extra == \"documentation\"",
"sphinx-rtd-theme>=2.0.0; ... | [] | [] | [] | [
"Homepage, https://github.com/pymodbus-dev/pymodbus/",
"Source Code, https://github.com/pymodbus-dev/pymodbus",
"Bug Reports, https://github.com/pymodbus-dev/pymodbus/issues",
"Docs: Dev, https://pymodbus.readthedocs.io/en/latest/?badge=latest"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T21:02:57.035777 | pymodbus-3.12.1.tar.gz | 167,673 | c8/cf/9ace571421e4ed8bc870e79caca7fe04b7e2529764494f1fb406053640ef/pymodbus-3.12.1.tar.gz | source | sdist | null | false | d706a1227df2b0efa613ebbf3996ed40 | bcb483381747b3e3aec2c8e01d5df885e5ea43f85b7145dc1907af06aca93a2c | c8cf9ace571421e4ed8bc870e79caca7fe04b7e2529764494f1fb406053640ef | null | [
"LICENSE",
"AUTHORS.rst"
] | 16,320 |
2.4 | dlt-mcp | 0.3.0 | A Model Context Protocol (MCP) server for the Python library dlt. | <h1 align="center">
<strong>data load tool (dlt) — MCP Server</strong>
</h1>
<p align="center">
🚀 Follow <a href="https://dlthub.com/docs/dlt-ecosystem/llm-tooling/llm-native-workflow">this guide</a> to create a dlt pipeline in 10mins with AI
</p>
## How is it useful?
Large language models (LLMs) know a lot about the world, but nothing about your specific code and data.
The [Model Context Protocol](https://modelcontextprotocol.io/) (MCP) server allows the LLM to retrieve **up-to-date** and **correct** information about your [dlt](https://github.com/dlt-hub/dlt) pipelines, datasets, schema, etc. This significantly improves the development experience in AI-enabled IDEs (Copilot, Cursor, Continue, Claude Code, etc.)
## Installation
The package manager [uv](https://docs.astral.sh/uv/getting-started/installation/) is required to launch the MCP server.
Add this section to your MCP configuration file inside your IDE.
```json
{
"name": "dlt",
"command": "uv",
"args": [
"run",
"--with",
"dlt-mcp[search]",
"python",
"-m",
"dlt_mcp"
],
}
```
>[!NOTE]
>The configuration file format varies slightly across IDEs
## Features
### Tools
The dlt MCP server provides [tools](https://modelcontextprotocol.io/specification/2025-11-25/server/tools) that allows the LLM to take actions:
- **list_pipelines**: Lists all available dlt pipelines. Each pipeline consists of several tables.
- **list_tables**: Retrieves a list of all tables in the specified pipeline.
- **get_table_schemas**: Returns the schema of the specified tables.
- **execute_sql_query**: Executes a SELECT SQL statement for simple data analysis.
- **get_load_table**: Retrieves metadata about data loaded with dlt.
- **get_pipeline_local_state**: Fetches the state information of the pipeline, including incremental dates, resource state, and source state.
- **get_table_schema_diff**: Compares the current schema of a table with another version and provides a diff.
- **search_docs**: Searches over the `dlt` documentation using different modes (hybrid, full_text, or vector) to verify features and identify recommended patterns.
- **search_code**: Searches the source code for the specified query and optional file path, providing insights into internal code structures and patterns.
| text/markdown | dltHub | zilto <68975210+zilto@users.noreply.github.com> | null | null | Apache License Version 2.0, January 2004 http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION 1. Definitions. "License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document. "Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License. "Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity. "You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License. "Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types. "Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below). "Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof. "Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution." "Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work. 2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form. 3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed. 4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions: (a) You must give any other recipients of the Work or Derivative Works a copy of this License; and (b) You must cause any modified files to carry prominent notices stating that You changed the files; and (c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and (d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License. 5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions. 6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file. 7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License. 8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages. 9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability. END OF TERMS AND CONDITIONS APPENDIX: How to apply the Apache License to your work. To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives. Copyright 2025 dltHub Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. | ai, data engineering, elt, etl, mcp | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Topic :: Software Development :: Libraries",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"dlt>=1.19.0",
"fastmcp>=3.0.0",
"dlt[athena]; extra == \"athena\"",
"dlt[az]; extra == \"az\"",
"dlt[bigquery]; extra == \"bigquery\"",
"dlt[cli]; extra == \"cli\"",
"dlt[clickhouse]; extra == \"clickhouse\"",
"dlt[databricks]; extra == \"databricks\"",
"dlt[deltalake]; extra == \"deltalake\"",
"... | [] | [] | [] | [
"Documentation, https://github.com/dlt-hub/dlt-mcp#README",
"Source, https://github.com/dlt-hub/dlt-mcp",
"Issues, https://github.com/dlt-hub/dlt-mcp/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:01:49.763151 | dlt_mcp-0.3.0-py3-none-any.whl | 20,998 | c9/2a/26d9fa621cc20b4b7bdb2dedcbb6c3ca1e0b86ebdf0702dd1c8dbdd6dab2/dlt_mcp-0.3.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 56f2ff53a51653883efba8a675e7a513 | d3e2fabd2db0f4426f925bcfdc4626872e9914bb0cef57062790ddeda1f8ef76 | c92a26d9fa621cc20b4b7bdb2dedcbb6c3ca1e0b86ebdf0702dd1c8dbdd6dab2 | null | [
"LICENSE"
] | 310 |
2.1 | nvtripy | 0.1.5 | Tripy: A Python Programming Model For TensorRT |
# Tripy: A Python Programming Model For TensorRT
[**Quick Start**](#quick-start)
| [**Installation**](#installation)
| [**Examples**](https://github.com/NVIDIA/TensorRT-Incubator/tree/main/tripy/examples)
| [**Notebooks**](https://github.com/NVIDIA/TensorRT-Incubator/tree/main/tripy/notebooks)
| [**Contributing**](https://github.com/NVIDIA/TensorRT-Incubator/blob/main/tripy/CONTRIBUTING.md)
| [**Documentation**](https://nvidia.github.io/TensorRT-Incubator/)
<!-- Tripy: DOC: OMIT Start -->
[](https://github.com/NVIDIA/TensorRT-Incubator/actions/workflows/tripy-l1.yml)
<!-- Tripy: DOC: OMIT End -->
**Tripy** is a debuggable, Pythonic frontend for [TensorRT](https://developer.nvidia.com/tensorrt),
a deep learning inference compiler.
What you can expect:
- **High performance** by leveraging [TensorRT](https://developer.nvidia.com/tensorrt)'s optimization capabilties.
- An **intuitive API** that follows conventions of the ecosystem.
- **Debuggability** with features like **eager mode** to interactively debug mistakes.
- **Excellent error messages** that are informative and actionable.
- **Friendly documentation** that is comprehensive but concise, with code examples.
## Installation
```bash
python3 -m pip install nvtripy -f https://nvidia.github.io/TensorRT-Incubator/packages.html
```
## Quick Start
See the
[Introduction To Tripy](https://nvidia.github.io/TensorRT-Incubator/pre0_user_guides/00-introduction-to-tripy.html)
guide for details:
<!-- Tripy: DOC: NO_PRINT_LOCALS Start -->
- **Defining** a model:
```py
class Model(tp.Module):
def __init__(self):
self.conv = tp.Conv(in_channels=1, out_channels=1, kernel_dims=[3, 3])
def forward(self, x):
x = self.conv(x)
x = tp.relu(x)
return x
```
- **Initializing** it:
```py
model = Model()
model.load_state_dict(
{
"conv.weight": tp.ones((1, 1, 3, 3)),
"conv.bias": tp.ones((1,)),
}
)
dummy_input = tp.ones((1, 1, 4, 4)).eval()
```
- Executing in **eager mode**:
```py
eager_out = model(dummy_input)
```
- **Compiling** and executing:
```py
compiled_model = tp.compile(
model,
args=[tp.InputInfo(shape=(1, 1, 4, 4), dtype=tp.float32)],
)
compiled_out = compiled_model(dummy_input)
```
<!-- Tripy: DOC: NO_PRINT_LOCALS End -->
<!-- Tripy: DOC: OMIT Start -->
## Building Wheels From Source
For the latest changes, build Tripy wheels from source:
1. Install `build`:
```bash
python3 -m pip install build
```
2. Build a wheel from the [`tripy` root directory](.):
```bash
python3 -m build . -w
```
3. Install the wheel from the [`tripy` root directory](.):
```bash
python3 -m pip install -f https://nvidia.github.io/TensorRT-Incubator/packages.html dist/nvtripy-*.whl
```
4. **[Optional]** Sanity check:
```bash
python3 -c "import nvtripy as tp; x = tp.ones((5,), dtype=tp.int32); assert x.tolist() == [1] * 5"
```
<!-- Tripy: DOC: OMIT End -->
| text/markdown | null | NVIDIA <svc_tensorrt@nvidia.com> | null | null | Apache 2.0 | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"tensorrt<=10.13.0.35,>=10.11",
"mlir-tensorrt-compiler==0.1.43+cuda12.trt109",
"mlir-tensorrt-runtime==0.1.43+cuda12.trt109",
"colored==2.2.3",
"setuptools==75.3.0; extra == \"build\"",
"wheel==0.44.0; extra == \"build\"",
"mypy==1.11.0; extra == \"build\"",
"pre-commit==3.6.0; extra == \"dev\"",
"... | [] | [] | [] | [
"Repository, https://github.com/NVIDIA/tensorrt-incubator/tripy/",
"Issues, https://github.com/NVIDIA/tensorrt-incubator/issues",
"Documentation, https://nvidia.github.io/TensorRT-Incubator/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:01:34.359869 | nvtripy-0.1.5-py3-none-any.whl | 292,532 | 49/9a/f78d9fbf24df0159bda70897b2fd8ff75ae5e5698c3cd3029ede48faab2e/nvtripy-0.1.5-py3-none-any.whl | py3 | bdist_wheel | null | false | c22b26a549adc6e800184110be4f3859 | 530cd4a0a1aead78ef5219aa63c5bc372ba8444002e49a25284b799299685de6 | 499af78d9fbf24df0159bda70897b2fd8ff75ae5e5698c3cd3029ede48faab2e | null | [] | 98 |
2.1 | tortoise-orm | 1.1.5 | Easy async ORM for python, built with relations in mind | ============
Tortoise ORM
============
.. image:: https://img.shields.io/pypi/v/tortoise-orm.svg?style=flat
:target: https://pypi.python.org/pypi/tortoise-orm
.. image:: https://pepy.tech/badge/tortoise-orm/month
:target: https://pepy.tech/project/tortoise-orm
.. image:: https://github.com/tortoise/tortoise-orm/workflows/gh-pages/badge.svg
:target: https://github.com/tortoise/tortoise-orm/actions?query=workflow:gh-pages
.. image:: https://github.com/tortoise/tortoise-orm/actions/workflows/ci.yml/badge.svg?branch=develop
:target: https://github.com/tortoise/tortoise-orm/actions?query=workflow:ci
.. image:: https://coveralls.io/repos/github/tortoise/tortoise-orm/badge.svg
:target: https://coveralls.io/github/tortoise/tortoise-orm
Introduction
============
Tortoise ORM is an easy-to-use ``asyncio`` ORM *(Object Relational Mapper)* inspired by Django.
You can find the docs at `Documentation <https://tortoise.github.io>`_
Tortoise ORM supports CPython 3.10 and later for SQLite, MySQL, PostgreSQL, Microsoft SQL Server, and Oracle.
Why was Tortoise ORM built?
---------------------------
Tortoise ORM was built to provide a lightweight, async-native Object-Relational Mapper for Python with a familiar Django-like API.
Tortoise ORM performs well when compared to other Python ORMs. Here are `our benchmarks <https://github.com/tortoise/orm-benchmarks>`_ on PostgreSQL 17, where we measure different read and write operations (rows/sec, more is better):
.. image:: https://raw.githubusercontent.com/tortoise/tortoise-orm/develop/docs/ORM_Perf.png
:target: https://github.com/tortoise/orm-benchmarks
How is an ORM useful?
---------------------
An Object-Relational Mapper (ORM) abstracts database interactions, allowing developers to work with databases using high-level, object-oriented code instead of raw SQL.
* Reduces boilerplate SQL, allowing faster development with cleaner, more readable code.
* Helps prevent SQL injection by using parameterized queries.
* Centralized schema and relationship definitions make code easier to manage and modify.
* Handles schema changes through version-controlled migrations.
Getting Started
===============
Installation
------------
The following table shows the available installation options for different databases (note that there are multiple options of clients for some databases):
.. list-table:: Available Installation Options
:header-rows: 1
:widths: 30 70
* - Database
- Installation Command
* - SQLite
- ``pip install tortoise-orm``
* - PostgreSQL (psycopg)
- ``pip install tortoise-orm[psycopg]``
* - PostgreSQL (asyncpg)
- ``pip install tortoise-orm[asyncpg]``
* - MySQL (aiomysql)
- ``pip install tortoise-orm[aiomysql]``
* - MySQL (asyncmy)
- ``pip install tortoise-orm[asyncmy]``
* - MS SQL
- ``pip install tortoise-orm[asyncodbc]``
* - Oracle
- ``pip install tortoise-orm[asyncodbc]``
Quick Tutorial
--------------
Define the models by inheriting from ``tortoise.models.Model``.
.. code-block:: python3
from tortoise.models import Model
from tortoise import fields
class Tournament(Model):
id = fields.IntField(primary_key=True)
name = fields.CharField(max_length=20)
class Event(Model):
id = fields.BigIntField(primary_key=True)
name = fields.TextField()
tournament = fields.ForeignKeyField('models.Tournament', related_name='events', on_delete=fields.OnDelete.CASCADE)
participants = fields.ManyToManyField('models.Team', related_name='events', through='event_team', on_delete=fields.OnDelete.SET_NULL)
class Team(Model):
id = fields.UUIDField(primary_key=True)
name = fields.CharField(max_length=20, unique=True)
After defining the models, Tortoise ORM needs to be initialized to establish the relationships between models and connect to the database.
The code below creates a connection to a SQLite DB database with the ``aiosqlite`` client. ``generate_schema`` sets up schema on an empty database.
``generate_schema`` is for development purposes only; use the built-in
migrations for production use.
.. code-block:: python3
from tortoise import Tortoise, run_async
async def init():
# Here we connect to a SQLite DB file.
# also specify the app name of "models"
# which contain models from "app.models"
await Tortoise.init(
db_url='sqlite://db.sqlite3',
modules={'models': ['app.models']}
)
# Generate the schema
await Tortoise.generate_schemas()
run_async(main())
``run_async`` is a helper function to run simple Tortoise scripts. Check out `Documentation <https://tortoise.github.io>`_ for FastAPI, Sanic and other integrations.
With the Tortoise initialized, the models are available for use:
.. code-block:: python3
async def main():
await Tortoise.init(
db_url='sqlite://db.sqlite3',
modules={'models': ['app.models']}
)
await Tortoise.generate_schemas()
# Creating an instance with .save()
tournament = Tournament(name='New Tournament')
await tournament.save()
# Or with .create()
await Event.create(name='Without participants', tournament=tournament)
event = await Event.create(name='Test', tournament=tournament)
participants = []
for i in range(2):
team = await Team.create(name='Team {}'.format(i + 1))
participants.append(team)
# One to Many (ForeignKey) relations support creating related objects
another_event = await tournament.events.create(name='Another Event')
# Many to Many Relationship management is quite straightforward
# (there are .remove(...) and .clear() too)
await event.participants.add(*participants)
# Iterate over related entities with the async context manager
async for team in event.participants:
print(team.name)
# The related entities are cached and can be iterated in the synchronous way afterwards
for team in event.participants:
pass
# Use prefetch_related to fetch related objects
selected_events = await Event.filter(
participants=participants[0].id
).prefetch_related('participants', 'tournament')
for event in selected_events:
print(event.tournament.name)
print([t.name for t in event.participants])
# Prefetch multiple levels of related entities
await Team.all().prefetch_related('events__tournament')
# Filter and order by related models too
await Tournament.filter(
events__name__in=['Test', 'Prod']
).order_by('-events__participants__name').distinct()
run_async(main())
Learn more at the `documentation site <https://tortoise.github.io>`_
Migrations
==========
Tortoise ORM ships with a built-in migration framework and CLI.
Autodetect model changes, generate migration files, and apply them:
.. code-block:: shell
tortoise init # create migration packages
tortoise makemigrations # detect changes and generate migrations
tortoise migrate # apply pending migrations
tortoise sqlmigrate app 001 # preview SQL without executing
Migrations support ``RunPython`` and ``RunSQL`` for data migrations, offline migration generation,
reversible operations, and multi-app and multi db-schema projects.
See the `migrations documentation <https://tortoise.github.io/migration.html>`_ for
full setup and examples.
Contributing
============
Please have a look at the `Contribution Guide <docs/CONTRIBUTING.rst>`_.
License
=======
This project is licensed under the Apache License - see the `LICENSE.txt <LICENSE.txt>`_ file for details.
| text/x-rst | null | Andrey Bondar <andrey@bondar.ru>, Nickolas Grigoriadis <nagrigoriadis@gmail.com>, long2ice <long2ice@gmail.com> | null | null | Apache-2.0 | sql, mysql, postgres, psql, sqlite, aiosqlite, asyncpg, relational, database, rdbms, orm, object mapper, async, asyncio, aio, psycopg | [
"License :: OSI Approved :: Apache Software License",
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming ... | [] | null | null | >=3.10 | [] | [] | [] | [
"pypika-tortoise<1.0.0,>=0.6.3",
"iso8601<3.0.0,>=2.1.0; python_version < \"4.0\"",
"aiosqlite<1.0.0,>=0.16.0",
"anyio",
"tomlkit<1.0.0,>=0.11.4; python_version < \"3.11\"",
"typing-extensions>=4.1.0; python_version < \"3.11\"",
"ipython; extra == \"ipython\"",
"nest-asyncio>=1.6.0; extra == \"ipython... | [] | [] | [] | [
"documentation, https://tortoise.github.io",
"homepage, https://github.com/tortoise/tortoise-orm",
"repository, https://github.com/tortoise/tortoise-orm.git"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:01:18.429209 | tortoise_orm-1.1.5.tar.gz | 375,804 | f3/b0/2b3962847aad793d32646c6e43e7fab6f845f34a5502da5722fe704ec847/tortoise_orm-1.1.5.tar.gz | source | sdist | null | false | 5c143e93e4c35dfd8cd19dfdbc064d6d | d4074a7c34a8445fcca19ec865189d80ea7a00b29e4b12778460fcab67a5ce74 | f3b02b3962847aad793d32646c6e43e7fab6f845f34a5502da5722fe704ec847 | null | [] | 4,169 |
2.3 | clarative | 0.0.3 | The official Python library for the clarative API | # Clarative Python API library
<!-- prettier-ignore -->
[)](https://pypi.org/project/clarative/)
The Clarative Python library provides convenient access to the Clarative REST API from any Python 3.9+
application. The library includes type definitions for all request params and response fields,
and offers both synchronous and asynchronous clients powered by [httpx](https://github.com/encode/httpx).
It is generated with [Stainless](https://www.stainless.com/).
## Documentation
The REST API documentation can be found on [app.clarative.ai](https://app.clarative.ai/docs). The full API of this library can be found in [api.md](https://github.com/harbinger-labs/clarative-python/tree/main/api.md).
## Installation
```sh
# install from PyPI
pip install clarative
```
## Usage
The full API of this library can be found in [api.md](https://github.com/harbinger-labs/clarative-python/tree/main/api.md).
```python
import os
from clarative import Clarative
client = Clarative(
api_key=os.environ.get("CLARATIVE_API_KEY"), # This is the default and can be omitted
)
response = client.slas.list_data_sources(
"REPLACE_ME",
)
print(response.monitor_data_sources)
```
While you can provide an `api_key` keyword argument,
we recommend using [python-dotenv](https://pypi.org/project/python-dotenv/)
to add `CLARATIVE_API_KEY="My API Key"` to your `.env` file
so that your API Key is not stored in source control.
## Async usage
Simply import `AsyncClarative` instead of `Clarative` and use `await` with each API call:
```python
import os
import asyncio
from clarative import AsyncClarative
client = AsyncClarative(
api_key=os.environ.get("CLARATIVE_API_KEY"), # This is the default and can be omitted
)
async def main() -> None:
response = await client.slas.list_data_sources(
"REPLACE_ME",
)
print(response.monitor_data_sources)
asyncio.run(main())
```
Functionality between the synchronous and asynchronous clients is otherwise identical.
### With aiohttp
By default, the async client uses `httpx` for HTTP requests. However, for improved concurrency performance you may also use `aiohttp` as the HTTP backend.
You can enable this by installing `aiohttp`:
```sh
# install from PyPI
pip install clarative[aiohttp]
```
Then you can enable it by instantiating the client with `http_client=DefaultAioHttpClient()`:
```python
import os
import asyncio
from clarative import DefaultAioHttpClient
from clarative import AsyncClarative
async def main() -> None:
async with AsyncClarative(
api_key=os.environ.get("CLARATIVE_API_KEY"), # This is the default and can be omitted
http_client=DefaultAioHttpClient(),
) as client:
response = await client.slas.list_data_sources(
"REPLACE_ME",
)
print(response.monitor_data_sources)
asyncio.run(main())
```
## Using types
Nested request parameters are [TypedDicts](https://docs.python.org/3/library/typing.html#typing.TypedDict). Responses are [Pydantic models](https://docs.pydantic.dev) which also provide helper methods for things like:
- Serializing back into JSON, `model.to_json()`
- Converting to a dictionary, `model.to_dict()`
Typed requests and responses provide autocomplete and documentation within your editor. If you would like to see type errors in VS Code to help catch bugs earlier, set `python.analysis.typeCheckingMode` to `basic`.
## Handling errors
When the library is unable to connect to the API (for example, due to network connection problems or a timeout), a subclass of `clarative.APIConnectionError` is raised.
When the API returns a non-success status code (that is, 4xx or 5xx
response), a subclass of `clarative.APIStatusError` is raised, containing `status_code` and `response` properties.
All errors inherit from `clarative.APIError`.
```python
import clarative
from clarative import Clarative
client = Clarative()
try:
client.slas.list_data_sources(
"REPLACE_ME",
)
except clarative.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # an underlying Exception, likely raised within httpx.
except clarative.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except clarative.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
```
Error codes are as follows:
| Status Code | Error Type |
| ----------- | -------------------------- |
| 400 | `BadRequestError` |
| 401 | `AuthenticationError` |
| 403 | `PermissionDeniedError` |
| 404 | `NotFoundError` |
| 422 | `UnprocessableEntityError` |
| 429 | `RateLimitError` |
| >=500 | `InternalServerError` |
| N/A | `APIConnectionError` |
### Retries
Certain errors are automatically retried 2 times by default, with a short exponential backoff.
Connection errors (for example, due to a network connectivity problem), 408 Request Timeout, 409 Conflict,
429 Rate Limit, and >=500 Internal errors are all retried by default.
You can use the `max_retries` option to configure or disable retry settings:
```python
from clarative import Clarative
# Configure the default for all requests:
client = Clarative(
# default is 2
max_retries=0,
)
# Or, configure per-request:
client.with_options(max_retries=5).slas.list_data_sources(
"REPLACE_ME",
)
```
### Timeouts
By default requests time out after 1 minute. You can configure this with a `timeout` option,
which accepts a float or an [`httpx.Timeout`](https://www.python-httpx.org/advanced/timeouts/#fine-tuning-the-configuration) object:
```python
from clarative import Clarative
# Configure the default for all requests:
client = Clarative(
# 20 seconds (default is 1 minute)
timeout=20.0,
)
# More granular control:
client = Clarative(
timeout=httpx.Timeout(60.0, read=5.0, write=10.0, connect=2.0),
)
# Override per-request:
client.with_options(timeout=5.0).slas.list_data_sources(
"REPLACE_ME",
)
```
On timeout, an `APITimeoutError` is thrown.
Note that requests that time out are [retried twice by default](https://github.com/harbinger-labs/clarative-python/tree/main/#retries).
## Advanced
### Logging
We use the standard library [`logging`](https://docs.python.org/3/library/logging.html) module.
You can enable logging by setting the environment variable `CLARATIVE_LOG` to `info`.
```shell
$ export CLARATIVE_LOG=info
```
Or to `debug` for more verbose logging.
### How to tell whether `None` means `null` or missing
In an API response, a field may be explicitly `null`, or missing entirely; in either case, its value is `None` in this library. You can differentiate the two cases with `.model_fields_set`:
```py
if response.my_field is None:
if 'my_field' not in response.model_fields_set:
print('Got json like {}, without a "my_field" key present at all.')
else:
print('Got json like {"my_field": null}.')
```
### Accessing raw response data (e.g. headers)
The "raw" Response object can be accessed by prefixing `.with_raw_response.` to any HTTP method call, e.g.,
```py
from clarative import Clarative
client = Clarative()
response = client.slas.with_raw_response.list_data_sources(
"REPLACE_ME",
)
print(response.headers.get('X-My-Header'))
sla = response.parse() # get the object that `slas.list_data_sources()` would have returned
print(sla.monitor_data_sources)
```
These methods return an [`APIResponse`](https://github.com/harbinger-labs/clarative-python/tree/main/src/clarative/_response.py) object.
The async client returns an [`AsyncAPIResponse`](https://github.com/harbinger-labs/clarative-python/tree/main/src/clarative/_response.py) with the same structure, the only difference being `await`able methods for reading the response content.
#### `.with_streaming_response`
The above interface eagerly reads the full response body when you make the request, which may not always be what you want.
To stream the response body, use `.with_streaming_response` instead, which requires a context manager and only reads the response body once you call `.read()`, `.text()`, `.json()`, `.iter_bytes()`, `.iter_text()`, `.iter_lines()` or `.parse()`. In the async client, these are async methods.
```python
with client.slas.with_streaming_response.list_data_sources(
"REPLACE_ME",
) as response:
print(response.headers.get("X-My-Header"))
for line in response.iter_lines():
print(line)
```
The context manager is required so that the response will reliably be closed.
### Making custom/undocumented requests
This library is typed for convenient access to the documented API.
If you need to access undocumented endpoints, params, or response properties, the library can still be used.
#### Undocumented endpoints
To make requests to undocumented endpoints, you can make requests using `client.get`, `client.post`, and other
http verbs. Options on the client will be respected (such as retries) when making this request.
```py
import httpx
response = client.post(
"/foo",
cast_to=httpx.Response,
body={"my_param": True},
)
print(response.headers.get("x-foo"))
```
#### Undocumented request params
If you want to explicitly send an extra param, you can do so with the `extra_query`, `extra_body`, and `extra_headers` request
options.
#### Undocumented response properties
To access undocumented response properties, you can access the extra fields like `response.unknown_prop`. You
can also get all the extra fields on the Pydantic model as a dict with
[`response.model_extra`](https://docs.pydantic.dev/latest/api/base_model/#pydantic.BaseModel.model_extra).
### Configuring the HTTP client
You can directly override the [httpx client](https://www.python-httpx.org/api/#client) to customize it for your use case, including:
- Support for [proxies](https://www.python-httpx.org/advanced/proxies/)
- Custom [transports](https://www.python-httpx.org/advanced/transports/)
- Additional [advanced](https://www.python-httpx.org/advanced/clients/) functionality
```python
import httpx
from clarative import Clarative, DefaultHttpxClient
client = Clarative(
# Or use the `CLARATIVE_BASE_URL` env var
base_url="http://my.test.server.example.com:8083",
http_client=DefaultHttpxClient(
proxy="http://my.test.proxy.example.com",
transport=httpx.HTTPTransport(local_address="0.0.0.0"),
),
)
```
You can also customize the client on a per-request basis by using `with_options()`:
```python
client.with_options(http_client=DefaultHttpxClient(...))
```
### Managing HTTP resources
By default the library closes underlying HTTP connections whenever the client is [garbage collected](https://docs.python.org/3/reference/datamodel.html#object.__del__). You can manually close the client using the `.close()` method if desired, or with a context manager that closes when exiting.
```py
from clarative import Clarative
with Clarative() as client:
# make requests here
...
# HTTP client is now closed
```
## Versioning
This package generally follows [SemVer](https://semver.org/spec/v2.0.0.html) conventions, though certain backwards-incompatible changes may be released as minor versions:
1. Changes that only affect static types, without breaking runtime behavior.
2. Changes to library internals which are technically public but not intended or documented for external use. _(Please open a GitHub issue to let us know if you are relying on such internals.)_
3. Changes that we do not expect to impact the vast majority of users in practice.
We take backwards-compatibility seriously and work hard to ensure you can rely on a smooth upgrade experience.
We are keen for your feedback; please open an [issue](https://www.github.com/harbinger-labs/clarative-python/issues) with questions, bugs, or suggestions.
### Determining the installed version
If you've upgraded to the latest version but aren't seeing any new features you were expecting then your python environment is likely still using an older version.
You can determine the version that is being used at runtime with:
```py
import clarative
print(clarative.__version__)
```
## Requirements
Python 3.9 or higher.
## Contributing
See [the contributing documentation](https://github.com/harbinger-labs/clarative-python/tree/main/./CONTRIBUTING.md).
| text/markdown | null | Clarative <support@clarative.ai> | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: OS Independent",
"Operating System :: POSIX",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"anyio<5,>=3.5.0",
"distro<2,>=1.7.0",
"httpx<1,>=0.23.0",
"pydantic<3,>=1.9.0",
"sniffio",
"typing-extensions<5,>=4.10",
"aiohttp; extra == \"aiohttp\"",
"httpx-aiohttp>=0.1.9; extra == \"aiohttp\""
] | [] | [] | [] | [
"Homepage, https://github.com/harbinger-labs/clarative-python",
"Repository, https://github.com/harbinger-labs/clarative-python"
] | uv/0.9.13 {"installer":{"name":"uv","version":"0.9.13"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:01:04.602529 | clarative-0.0.3.tar.gz | 225,931 | c5/03/cc960c7b142e08dc82e0286ae00b4cf45ee0cae1f844202c072d2edc9618/clarative-0.0.3.tar.gz | source | sdist | null | false | 5db9748221baca9d8ae9d131db51c911 | 6b8d360e6355982979c14b2c9ab87b1b0f2e67f6dc56bda34921bb4e503962b5 | c503cc960c7b142e08dc82e0286ae00b4cf45ee0cae1f844202c072d2edc9618 | null | [] | 224 |
2.4 | open-terminal | 0.2.4 | A remote terminal API. | # ⚡ Open Terminal
A lightweight API for running shell commands remotely — designed for AI agents and automation.
The container ships with a full toolkit (Python, git, jq, curl, build tools, and more) and runs as a non-root user with passwordless `sudo`.
## Getting Started
### Docker (recommended)
```bash
docker run -d --name open-terminal --restart unless-stopped -p 8000:8000 -v open-terminal:/home/user -e OPEN_TERMINAL_API_KEY=your-secret-key ghcr.io/open-webui/open-terminal
```
If no API key is provided, one is auto-generated and printed on startup (`docker logs open-terminal`).
### Build from Source
```bash
docker build -t open-terminal .
docker run -p 8000:8000 open-terminal
```
### Bare Metal
```bash
# One-liner with uvx (no install needed)
uvx open-terminal run --host 0.0.0.0 --port 8000 --api-key your-secret-key
# Or install globally with pip
pip install open-terminal
open-terminal run --host 0.0.0.0 --port 8000 --api-key your-secret-key
```
## Quick Examples
**Run a command:**
```bash
curl -X POST http://localhost:8000/execute?wait=5 \
-H "Authorization: Bearer <api-key>" \
-H "Content-Type: application/json" \
-d '{"command": "echo hello"}'
```
**Upload a file:**
```bash
curl -X POST "http://localhost:8000/files/upload?directory=/home/user&url=https://example.com/data.csv" \
-H "Authorization: Bearer <api-key>"
```
## API Docs
Full interactive API documentation is available at [http://localhost:8000/docs](http://localhost:8000/docs).
## License
MIT — see [LICENSE](LICENSE) for details.
| text/markdown | null | Timothy Jaeryang Baek <tim@openwebui.com> | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"aiofiles>=25.1.0",
"click>=8.1.0",
"fastapi>=0.115.0",
"httpx>=0.27.0",
"python-multipart>=0.0.22",
"uvicorn[standard]>=0.34.0",
"fastmcp>=2.0.0; extra == \"mcp\""
] | [] | [] | [] | [] | uv/0.8.0 | 2026-02-19T21:00:47.208651 | open_terminal-0.2.4.tar.gz | 14,272 | 2f/0a/9f1a6010827cb958c8590e38737e5eaf69bceb98097e147d2c1710243c30/open_terminal-0.2.4.tar.gz | source | sdist | null | false | 7f5f5187dd1005680923fdee8f07b417 | 35f8b36f01f746d0cb0c7751528d935cb530df32b13c95bbc155630d9c781c77 | 2f0a9f1a6010827cb958c8590e38737e5eaf69bceb98097e147d2c1710243c30 | null | [
"LICENSE"
] | 186 |
2.4 | agno | 2.5.3 | The programming language for agentic software. | <div align="center" id="top">
<a href="https://agno.com">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://agno-public.s3.us-east-1.amazonaws.com/assets/logo-dark.svg">
<source media="(prefers-color-scheme: light)" srcset="https://agno-public.s3.us-east-1.amazonaws.com/assets/logo-light.svg">
<img src="https://agno-public.s3.us-east-1.amazonaws.com/assets/logo-light.svg" alt="Agno">
</picture>
</a>
</div>
<p align="center">
The programming language for agentic software.<br/>
Build, run, and govern multi-agent systems at scale.
</p>
<div align="center">
<a href="https://docs.agno.com">Docs</a>
<span> • </span>
<a href="https://github.com/agno-agi/agno/tree/main/cookbook">Cookbook</a>
<span> • </span>
<a href="https://docs.agno.com/first-agent">Quickstart</a>
<span> • </span>
<a href="https://www.agno.com/discord">Discord</a>
</div>
## What is Agno?
Software is shifting from deterministic request–response to reasoning systems that plan, call tools, remember context, and make decisions. Agno is the language for building that software correctly. It provides:
| Layer | Responsibility |
|-------|----------------|
| **SDK** | Agents, teams, workflows, memory, knowledge, tools, guardrails, approval flows |
| **Engine** | Model calls, tool orchestration, structured outputs, runtime enforcement |
| **AgentOS** | Streaming APIs, isolation, auth, approval enforcement, tracing, control plane |
## Quick Start
Build a stateful, tool-using agent and serve it as a production API in ~20 lines.
```python
from agno.agent import Agent
from agno.db.sqlite import SqliteDb
from agno.models.anthropic import Claude
from agno.os import AgentOS
from agno.tools.mcp import MCPTools
agno_assist = Agent(
name="Agno Assist",
model=Claude(id="claude-sonnet-4-6"),
db=SqliteDb(db_file="agno.db"),
tools=[MCPTools(url="https://docs.agno.com/mcp")],
add_history_to_context=True,
num_history_runs=3,
markdown=True,
)
agent_os = AgentOS(agents=[agno_assist], tracing=True)
app = agent_os.get_app()
```
Run it:
```bash
export ANTHROPIC_API_KEY="***"
uvx --python 3.12 \
--with "agno[os]" \
--with anthropic \
--with mcp \
fastapi dev agno_assist.py
```
In ~20 lines, you get:
- A stateful agent with streaming responses
- Per-user, per-session isolation
- A production API at http://localhost:8000
- Native tracing
Connect to the [AgentOS UI](https://os.agno.com) to monitor, manage, and test your agents.
1. Open [os.agno.com](https://os.agno.com) and sign in.
2. Click **"Add new OS"** in the top navigation.
3. Select **"Local"** to connect to a local AgentOS.
4. Enter your endpoint URL (default: `http://localhost:8000`).
5. Name it "Local AgentOS".
6. Click **"Connect"**.
https://github.com/user-attachments/assets/75258047-2471-4920-8874-30d68c492683
Open Chat, select your agent, and ask:
> What is Agno?
The agent retrieves context from the Agno MCP server and responds with grounded answers.
https://github.com/user-attachments/assets/24c28d28-1d17-492c-815d-810e992ea8d2
You can use this exact same architecture for running multi-agent systems in production.
## Why Agno?
Agentic software introduces three fundamental shifts.
### A new interaction model
Traditional software receives a request and returns a response. Agents stream reasoning, tool calls, and results in real time. They can pause mid-execution, wait for approval, and resume later.
Agno treats streaming and long-running execution as first-class behavior.
### A new governance model
Traditional systems execute predefined decision logic written in advance. Agents choose actions dynamically. Some actions are low risk. Some require user approval. Some require administrative authority.
Agno lets you define who decides what as part of the agent definition, with:
- Approval workflows
- Human-in-the-loop
- Audit logs
- Enforcement at runtime
### A new trust model
Traditional systems are designed to be predictable. Every execution path is defined in advance. Agents introduce probabilistic reasoning into the execution path.
Agno builds trust into the engine itself:
- Guardrails run as part of execution
- Evaluations integrate into the agent loop
- Traces and audit logs are first-class
## Built for Production
Agno runs in your infrastructure, not ours.
- Stateless, horizontally scalable runtime.
- 50+ APIs and background execution.
- Per-user and per-session isolation.
- Runtime approval enforcement.
- Native tracing and full auditability.
- Sessions, memory, knowledge, and traces stored in your database.
You own the system. You own the data. You define the rules.
## What You Can Build
Agno powers real agentic systems built from the same primitives above.
- [**Pal →**](https://github.com/agno-agi/pal) A personal agent that learns your preferences.
- [**Dash →**](https://github.com/agno-agi/dash) A self-learning data agent grounded in six layers of context.
- [**Scout →**](https://github.com/agno-agi/scout) A self-learning context agent that manages enterprise context knowledge.
- [**Gcode →**](https://github.com/agno-agi/gcode) A post-IDE coding agent that improves over time.
- [**Investment Team →**](https://github.com/agno-agi/investment-team) A multi-agent investment committee that debates and allocates capital.
Single agents. Coordinated teams. Structured workflows. All built on one architecture.
## Get Started
1. [Read the docs](https://docs.agno.com)
2. [Build your first agent](https://docs.agno.com/first-agent)
3. Explore the [cookbook](https://github.com/agno-agi/agno/tree/main/cookbook)
## IDE Integration
Add Agno docs as a source in your coding tools:
**Cursor:** Settings → Indexing & Docs → Add `https://docs.agno.com/llms-full.txt`
Also works with VSCode, Windsurf, and similar tools.
## Contributing
See the [contributing guide](https://github.com/agno-agi/agno/blob/main/CONTRIBUTING.md).
## Telemetry
Agno logs which model providers are used to prioritize updates. Disable with `AGNO_TELEMETRY=false`.
<p align="right"><a href="#top">↑ Back to top</a></p>
| text/markdown | null | Ashpreet Bedi <ashpreet@agno.com> | null | null | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright 2025-2026 Agno Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| agent | [
"Intended Audience :: Developers",
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Lan... | [] | null | null | <4,>=3.7 | [] | [] | [] | [
"docstring-parser",
"gitpython",
"h11>=0.16.0",
"httpx[http2]",
"packaging",
"pydantic-settings",
"pydantic",
"python-dotenv",
"python-multipart",
"pyyaml",
"rich",
"typer",
"typing-extensions",
"mypy==1.18.2; extra == \"dev\"",
"ruff==0.14.3; extra == \"dev\"",
"pytest; extra == \"dev... | [] | [] | [] | [
"homepage, https://agno.com",
"documentation, https://docs.agno.com"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:00:27.889546 | agno-2.5.3.tar.gz | 1,668,587 | c3/f5/9a3974f40c99ed86fd379a9e386d05e1eca9280d816396a2fa5ef86cf203/agno-2.5.3.tar.gz | source | sdist | null | false | 5a44215864a6cb1c1fe6cb7fc8ea7ec2 | 790a4332b9b94feda911f979fab533ac579d5dbe87fc45b6ce4337a0d3c6cd0a | c3f59a3974f40c99ed86fd379a9e386d05e1eca9280d816396a2fa5ef86cf203 | null | [
"LICENSE"
] | 14,605 |
2.1 | sas-yolov7 | 1.0.5 | SAS YOLOv7 | # Yolov7
## Overview
This python package is an implementation of "YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors".
This is a tailored version for use of the SAS Viya DLModelZoo action set.
### Installation
To install YOLOv7, use the following command:
`pip install sas-yolov7`
## Contributing
We welcome your contributions! Please read [CONTRIBUTING.md](CONTRIBUTING.md) for details on how to submit contributions to this project.
## License
This project is licensed under the [GNU GENERAL PUBLIC LICENSE 3.0 License](LICENSE.md).
## Additional Resources
* [https://github.com/AlexeyAB/darknet](https://github.com/AlexeyAB/darknet)
* [https://github.com/WongKinYiu/yolor](https://github.com/WongKinYiu/yolor)
* [https://github.com/WongKinYiu/PyTorch_YOLOv4](https://github.com/WongKinYiu/PyTorch_YOLOv4)
* [https://github.com/WongKinYiu/ScaledYOLOv4](https://github.com/WongKinYiu/ScaledYOLOv4)
* [https://github.com/Megvii-BaseDetection/YOLOX](https://github.com/Megvii-BaseDetection/YOLOX)
* [https://github.com/ultralytics/yolov3](https://github.com/ultralytics/yolov3)
* [https://github.com/ultralytics/yolov5](https://github.com/ultralytics/yolov5)
* [https://github.com/DingXiaoH/RepVGG](https://github.com/DingXiaoH/RepVGG)
* [https://github.com/JUGGHM/OREPA_CVPR2022](https://github.com/JUGGHM/OREPA_CVPR2022)
* [https://github.com/TexasInstruments/edgeai-yolov5/tree/yolo-pose](https://github.com/TexasInstruments/edgeai-yolov5/tree/yolo-pose)
* [https://github.com/WongKinYiu/yolov7](https://github.com/WongKinYiu/yolov7)
| text/markdown | SAS | support@sas.com | null | null | GNU GENERAL PUBLIC LICENSE 3.0 | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3.7",
"Topic :: Scientific/Engineering"
] | [] | https://github.com/sassoftware/yolov7/ | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/5.1.1 CPython/3.9.16 | 2026-02-19T20:59:30.329093 | sas_yolov7-1.0.5-py3-none-any.whl | 6,459,745 | 9e/ca/d94a0cd00e8d631749d51fb16849cbf35ae7e0c73249c2a55d9b0e7ab83e/sas_yolov7-1.0.5-py3-none-any.whl | py3 | bdist_wheel | null | false | 1f94fc35b2746e760678b8422ab9ec97 | 0f20ca293b0bf8e14404fba0735a2c4cf4888c5c4769da8308a6f6a654512756 | 9ecad94a0cd00e8d631749d51fb16849cbf35ae7e0c73249c2a55d9b0e7ab83e | null | [] | 81 |
2.4 | openheal | 0.1.1 | Plataforma Open Source para Saúde — módulos reutilizáveis para análise de dados clínicos. | # openheal
Plataforma Open Source para Saúde — módulos reutilizáveis para análise de dados clínicos.
## Instalação
```bash
pip install openheal
```
## Módulos disponíveis
### `openheal.endocrinology.abbott_system`
Análise de dados de glicemia hospitalar a partir de planilhas exportadas pelo sistema Abbott.
```python
from openheal.endocrinology.abbott_system.spreadsheet_reader import SpreadsheetReader
from openheal.endocrinology.abbott_system.stats import StatisticsEngine
# Ler planilha Abbott
reader = SpreadsheetReader(path="glicemias.xlsx")
df = reader.read()
# Calcular todos os indicadores
engine = StatisticsEngine()
resultados = engine.run_all(df)
```
## Publicar no PyPI
```bash
# Instalar ferramentas de build
pip install build twine
# Construir pacote
python -m build
# Enviar para PyPI
twine upload dist/*
```
## Licença
MIT
| text/markdown | OpenHeal Contributors | null | null | null | MIT License
Copyright (c) 2025 OpenHeal Contributors
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | abbott, clinical-data, endocrinology, glycemia, health | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Healthcare Industry",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scienti... | [] | null | null | >=3.11 | [] | [] | [] | [
"openpyxl>=3.1",
"pandas>=2.0",
"faster-whisper>=1.0; extra == \"clinical-ai\"",
"pydantic>=2.0; extra == \"clinical-ai\"",
"build; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"twine; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://openheal.ai",
"Repository, https://github.com/openheal-ai/openheal",
"Issues, https://github.com/openheal-ai/openheal/issues"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T20:59:14.623182 | openheal-0.1.1.tar.gz | 37,934 | 2d/f8/78cd9e1beadae0a3a19c274b7ff8092ea8b885f6d69a281c256c858864c9/openheal-0.1.1.tar.gz | source | sdist | null | false | 47804e13f6b3517fcd7a74c7579e8da9 | 95aa54553d1bb1db18ae24c9b9c928e02ce8de94bd55cad72c940ab40a594bf5 | 2df878cd9e1beadae0a3a19c274b7ff8092ea8b885f6d69a281c256c858864c9 | null | [
"LICENSE"
] | 178 |
2.4 | agentd | 0.6.2 | agent daemon | # agentd
LLM agent utilities featuring:
1. **Programmatic Tool Calling (PTC)** - Bash-enabled agents with MCP tools exposed as AgentSkills
2. **Patched Responses API + Agent Daemon** - Traditional tool_calls with MCP, plus YAML-configured reactive agents
## Installation
```bash
pip install agentd
# or
uv add agentd
```
---
## Programmatic Tool Calling (PTC)
PTC gives you a **bash-enabled agent** that unifies **MCP tools with the AgentSkills spec**.
Instead of JSON `tool_calls`, the LLM writes code in fenced blocks. MCP tools and `@tool` functions are auto-converted to Python bindings in a discoverable skills directory.
```python
from agentd import patch_openai_with_ptc, display_events, tool
from openai import OpenAI
@tool
def calculate(expression: str) -> str:
"""Evaluate a math expression."""
import math
return str(eval(expression, {"__builtins__": {}}, {"sqrt": math.sqrt}))
client = patch_openai_with_ptc(OpenAI(), cwd="./workspace")
stream = client.responses.create(
model="claude-sonnet-4-20250514",
input=[{"role": "user", "content": "List files, then calculate sqrt(144)"}],
stream=True
)
for event in display_events(stream):
if event.type == "text_delta":
print(event.text, end="", flush=True)
elif event.type == "code_execution":
print(f"\n$ {event.code}\n{event.output}\n")
```
### Key Features
**Bash-enabled agent:** The LLM can run shell commands directly:
~~~markdown
```bash:execute
ls -la
git status
curl https://api.example.com/data
```
~~~
**MCP + AgentSkills unified:** Tools from MCP servers and `@tool` decorators are exposed as Python functions following the [AgentSkills spec](https://github.com/anthropics/agentskills):
~~~markdown
```python:execute
from lib.tools import read_file, fetch_url
result = read_file(path="/tmp/data.txt")
print(result)
```
~~~
**File creation:** The LLM can create new scripts:
~~~markdown
```my_script.py:create
print("Hello from generated script!")
```
~~~
**XML support:** Also parses Claude's XML function call format:
```xml
<invoke name="bash:execute">
<parameter name="command">ls -la</parameter>
</invoke>
```
### Auto-Generated Skills Directory
PTC generates a skills directory combining MCP tools and local functions:
```
skills/
lib/
tools.py # Python bindings for ALL tools (MCP + @tool)
filesystem/ # From @modelcontextprotocol/server-filesystem
SKILL.md # AgentSkills spec: YAML frontmatter + docs
scripts/
read_file_example.py
local/ # From @tool decorated functions
SKILL.md
scripts/
calculate_example.py
```
The LLM discovers tools by exploring:
```bash
ls skills/ # List available skills
cat skills/filesystem/SKILL.md # Read skill documentation
```
Then imports and uses them:
```python
from lib.tools import read_file, calculate
```
### MCP Bridge
An HTTP bridge runs locally to route tool calls:
```python
# Auto-generated in skills/lib/tools.py
def read_file(path: str) -> dict:
return _call("read_file", path=path) # POST to http://localhost:PORT/call/read_file
```
The bridge dispatches to MCP servers or local Python functions as appropriate.
### PTC with MCP Servers
```python
from agents.mcp.server import MCPServerStdio
from agentd import patch_openai_with_ptc
mcp_server = MCPServerStdio(
params={"command": "npx", "args": ["-y", "@modelcontextprotocol/server-everything"]},
cache_tools_list=True
)
client = patch_openai_with_ptc(OpenAI(), cwd="./workspace")
response = client.responses.create(
model="claude-sonnet-4-20250514",
input="Explore the available skills and use one",
mcp_servers=[mcp_server],
stream=True
)
```
### Display Events
```python
from agentd import display_events
for event in display_events(stream):
match event.type:
case "text_delta":
print(event.text, end="")
case "code_execution":
print(f"Code: {event.code}")
print(f"Output: {event.output}")
print(f"Status: {event.status}") # "completed" or "failed"
case "turn_end":
print("\n---")
```
### Microsandbox Executor
Run code in hardware-isolated microVMs instead of subprocesses for secure execution.
**Install microsandbox:**
```bash
# Linux (requires KVM) or macOS (Apple Silicon only)
curl -sSL https://get.microsandbox.dev | sh
# Start the server
msb server start --dev
```
**Usage:**
```python
from agentd import patch_openai_with_ptc, create_microsandbox_cli_executor
from openai import OpenAI
# Create sandboxed executor
executor = create_microsandbox_cli_executor(
conversation_id="my_session",
image="python",
memory=1024,
timeout=60,
)
client = patch_openai_with_ptc(
OpenAI(),
cwd=str(executor.snapshot_manager.workspace_dir),
executor=executor,
)
stream = client.responses.create(
model="claude-sonnet-4-20250514",
input=[{"role": "user", "content": "Run some Python code"}],
stream=True
)
# ... handle events ...
# Create snapshot for time travel
executor.snapshot("checkpoint_1")
# Restore to previous state
executor.restore("checkpoint_1")
executor.close()
```
**Features:**
- **Hardware isolation:** Code runs in microVMs, not just containers
- **Persistent workspace:** Volume mounting preserves files across executions
- **Snapshots:** Save and restore workspace state at any point
- **Drop-in replacement:** Same interface as the default subprocess executor
### Sandbox Runtime Executor
Lightweight OS-level sandboxing using [Anthropic's sandbox-runtime](https://github.com/anthropic-experimental/sandbox-runtime). Uses `sandbox-exec` on macOS and `bubblewrap` on Linux - no containers or VMs required.
**Install sandbox-runtime:**
```bash
npm install -g @anthropic-ai/sandbox-runtime
```
**Linux only:** If using AppArmor, you may need to allow unprivileged user namespaces:
```bash
sudo sysctl -w kernel.apparmor_restrict_unprivileged_userns=0
```
**Usage:**
```python
from agentd import patch_openai_with_ptc, create_sandbox_runtime_executor
from openai import OpenAI
executor = create_sandbox_runtime_executor(
conversation_id="my_session",
# Network restrictions (allow-list)
allowed_domains=["github.com", "pypi.org"],
# Filesystem restrictions
deny_read=["~/.ssh", "~/.aws", "~/.gnupg"],
# allow_write defaults to workspace only
)
# Verify sandbox works on this system
ok, msg = executor.verify()
if not ok:
print(f"Sandbox unavailable: {msg}")
client = patch_openai_with_ptc(
OpenAI(),
cwd=str(executor.workspace_dir),
executor=executor,
)
stream = client.responses.create(
model="claude-sonnet-4-20250514",
input=[{"role": "user", "content": "Run some Python code"}],
stream=True
)
# ... handle events ...
# Snapshots work the same as microsandbox
executor.snapshot("checkpoint_1")
executor.restore("checkpoint_1")
executor.close()
```
**Features:**
- **OS-level isolation:** Network and filesystem restrictions via OS primitives
- **No containers:** Lighter weight than microVMs, faster startup
- **Network allow-list:** Only specified domains are accessible
- **Filesystem protection:** Block reads to sensitive paths, restrict writes
- **Snapshots:** Same time-travel API as microsandbox executor
- **MCP tools support:** Uses Unix sockets to bridge tool calls from sandbox to host
**MCP Tools:** The sandbox runtime uses network namespace isolation, but MCP tools work via Unix sockets. The MCP bridge listens on a socket in the workspace directory, which is accessible from inside the sandbox.
**Comparison:**
| Executor | Isolation | Requirements | Best For |
|----------|-----------|--------------|----------|
| `SubprocessExecutor` | None | - | Development, trusted code |
| `SandboxRuntimeExecutor` | OS-level | srt CLI | Lightweight isolation |
| `MicrosandboxCLIExecutor` | MicroVM | msb CLI + KVM | Maximum isolation |
---
## Traditional Tool Calling
For cases where you want standard JSON `tool_calls` instead of code fences.
### Patched Responses API
A lightweight agentic loop that patches the OpenAI client to transparently handle MCP tool calls. Works with any provider via LiteLLM.
```python
from agents.mcp.server import MCPServerStdio
from agentd import patch_openai_with_mcp
from openai import OpenAI
fs_server = MCPServerStdio(
params={
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/tmp/"],
},
cache_tools_list=True
)
client = patch_openai_with_mcp(OpenAI())
response = client.chat.completions.create(
model="gemini/gemini-2.0-flash", # Any provider via LiteLLM
messages=[{"role": "user", "content": "List files in /tmp/"}],
mcp_servers=[fs_server],
)
print(response.choices[0].message.content)
```
**What it does:**
- Patches `chat.completions.create` and `responses.create`
- Auto-connects to MCP servers and extracts tool schemas
- Intercepts tool calls, executes via MCP, feeds results back
- Loops until no more tool calls (max 20 iterations)
- Supports streaming
**Multi-provider support:**
```python
model="gpt-4o" # OpenAI
model="claude-sonnet-4-20250514" # Anthropic
model="gemini/gemini-2.0-flash" # Google
```
### Agent Daemon
YAML-configured agents with MCP resource subscriptions. Agents react to resource changes automatically.
```bash
uvx agentd config.yaml
```
**Configuration:**
```yaml
agents:
- name: news_agent
model: gpt-4o-mini
system_prompt: |
You monitor a URL for changes. When new content arrives,
save it to ./output/data.txt using the edit_file tool.
mcp_servers:
- type: stdio
command: uv
arguments: ["run", "mcp_subscribe", "--poll-interval", "5", "--", "uvx", "mcp-server-fetch"]
- type: stdio
command: npx
arguments: ["-y", "@modelcontextprotocol/server-filesystem", "./output/"]
subscriptions:
- "tool://fetch/?url=https://example.com/api/data"
```
**How subscriptions work:**
1. Agent connects to MCP servers
2. Subscribes to resource URIs (e.g., `tool://fetch/?url=...`)
3. When resource changes, MCP server sends notification
4. Agent calls the tool, gets result, sends to LLM
5. LLM responds (can call more tools)
Built on [mcp-subscribe](https://github.com/phact/mcp-subscribe).
Each agent also has an interactive REPL:
```
news_agent> What files have you saved?
Assistant: I've saved 3 files to ./output/...
```
---
## API Reference
### Patching Functions
```python
from agentd import patch_openai_with_mcp, patch_openai_with_ptc
# PTC: bash + skills (no isolation)
client = patch_openai_with_ptc(OpenAI(), cwd="./workspace")
# PTC with OS-level sandbox (lightweight)
from agentd import create_sandbox_runtime_executor
executor = create_sandbox_runtime_executor(conversation_id="my_session")
client = patch_openai_with_ptc(OpenAI(), executor=executor)
# PTC with microsandbox isolation (microVM)
from agentd import create_microsandbox_cli_executor
executor = create_microsandbox_cli_executor(conversation_id="my_session")
client = patch_openai_with_ptc(OpenAI(), executor=executor)
# Traditional tool_calls
client = patch_openai_with_mcp(OpenAI())
```
### Microsandbox Executor
```python
from agentd import create_microsandbox_cli_executor
executor = create_microsandbox_cli_executor(
conversation_id="session_1", # Sandbox name prefix
image="python", # microsandbox image
memory=1024, # MB
timeout=60, # seconds
)
# Snapshot API
snapshot = executor.snapshot("label") # Save state
executor.restore(snapshot.id) # Restore state
snapshots = executor.list_snapshots() # List all snapshots
executor.close() # Cleanup
```
### Sandbox Runtime Executor
```python
from agentd import create_sandbox_runtime_executor
executor = create_sandbox_runtime_executor(
conversation_id="session_1",
timeout=60,
# Network (allow-list pattern)
allowed_domains=["github.com", "*.python.org"],
denied_domains=[],
allow_local_binding=False,
# Filesystem
deny_read=["~/.ssh", "~/.aws"], # Block reading these paths
allow_write=None, # None = workspace only
deny_write=[".env"], # Block within allowed zones
)
# Check if sandbox works on this system
ok, msg = executor.verify()
# Same snapshot API as microsandbox
snapshot = executor.snapshot("label")
executor.restore(snapshot.id)
executor.close()
```
### Tool Decorator
```python
from agentd import tool
@tool
def my_function(arg1: str, arg2: int = 10) -> str:
"""Description goes here.
arg1: Description of arg1
arg2: Description of arg2
"""
return f"Result: {arg1}, {arg2}"
```
---
## Examples
See [`examples/`](./examples/):
- `ptc_with_mcp.py` - PTC with MCP servers
- `ptc_with_tools.py` - PTC with @tool decorator
- `ptc_microsandbox.py` - PTC with microsandbox isolation (microVM)
- `ptc_sandbox_runtime.py` - PTC with sandbox-runtime isolation (OS-level)
See [`config/`](./config/) for agent daemon configs.
---
## Architecture
```
┌─────────────────────────────┐ ┌─────────────────────────────┐
│ PTC │ │ Agent Daemon │
│ (bash, skills, MCP) │ │ (YAML, subscriptions) │
└──────────────┬──────────────┘ └──────────────┬──────────────┘
│ │
▼ ▼
┌──────────────────────────────────────────────────────────────────┐
│ Patched OpenAI Client │
│ ┌────────────────────────┐ ┌────────────────────────────┐ │
│ │ patch_openai_ptc │ │ patch_openai_mcp │ │
│ │ (fence parse/exec) │ │ (tool_calls loop) │ │
│ └───────────┬────────────┘ └─────────────┬──────────────┘ │
└──────────────┼───────────────────────────────┼──────────────────┘
│ │
▼ │
┌──────────────────────────────────────────┐ │
│ Executors │ │
│ ┌──────────┐ ┌─────────┐ ┌───────────┐ │ │
│ │Subprocess│ │ Sandbox │ │Microsandbox│ │ │
│ │(default) │ │ Runtime │ │ (microVM) │ │ │
│ │ │ │(OS-level)│ │ │ │ │
│ └──────────┘ └─────────┘ └───────────┘ │ │
└──────────────────┬───────────────────────┘ │
│ │
▼ │
┌──────────────────────────────┐ │
│ MCP Bridge │ │
│ (HTTP server) │ │
└──────────────┬───────────────┘ │
│ │
└───────────────┬───────────────┘
▼
┌───────────────────────────────┐
│ MCP Servers │
└───────────────────────────────┘
```
---
## License
MIT
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.27.0",
"litellm>=1.80.0",
"mcp-subscribe",
"mcp>=1.25.0",
"openai-agents>=0.6.4",
"openai>=1.76.0",
"pyyaml>=6.0.2"
] | [] | [] | [] | [] | uv/0.7.3 | 2026-02-19T20:59:09.287218 | agentd-0.6.2.tar.gz | 44,738,620 | ac/2f/c497461f8c2b1106bd422a8b3e89ffad370767a499c7a9bb56e67feeda39/agentd-0.6.2.tar.gz | source | sdist | null | false | a00ead634913a275afd6e010ed095b8c | fbf3268008428551aebd09cf08017ac9975ea256472d4cd4b8675d709c045760 | ac2fc497461f8c2b1106bd422a8b3e89ffad370767a499c7a9bb56e67feeda39 | null | [
"LICENSE"
] | 288 |
2.4 | bitp | 1.1.5 | Tools for BitBake/Yocto projects | # bitp
A CLI tool for managing BitBake/Yocto/OpenEmbedded layer repositories.
The command is `bit` for quick typing.
## Overview
`bit` helps developers working with Yocto/OpenEmbedded projects by providing tools to:
- **Update** git repos backing BitBake layers from a `bblayers.conf`
- **Explore** commits interactively with fzf-based navigation
- **Export** patches with cover letters for upstream submission
- **Manage branches** across multiple layer repositories
- **Search** the OpenEmbedded Layer Index for layers
- **Bootstrap** new projects by cloning core repositories
- **Manage projects** - switch between multiple Yocto builds from anywhere
## Features
- **Automatic layer discovery** - finds layers by searching for `conf/layer.conf` files
- **Multi-layer repo support** - handles repos containing multiple layers (e.g., meta-openembedded)
- **Interactive fzf menus** - fast navigation with preview panes and keyboard shortcuts
- **Tab completion** - bash completion via argcomplete
- **Background refresh** - upstream status checks run in background for fast startup
- **Per-repo configuration** - custom display names, update defaults, push targets
## Quick Start
```bash
# Create a new Yocto project
bit create -b scarthgap --execute
bit setup
# Check status of all layer repos
bit status
# Interactively explore repos and commits
bit explore
# Update all repos (interactive)
bit update
# Update all repos non-interactively (apply saved defaults)
bit update -y
# Search for layers in the OE Layer Index
bit layer-index security
```
## Commands
| Command | Alias | Description |
|---------|-------|-------------|
| `explore` | `x` | Interactively explore commits in layer repos |
| `update` | `u` | Update git repos referenced by layers |
| `status` | - | Show local commit summary for layer repos |
| `info` | `i` | Show build configuration and layer status |
| `config` | `c` | View and configure repo/layer settings |
| `branch` | `b` | View and switch branches across repos |
| `export` | - | Export patches from layer repos |
| `repos` | - | List layer repos |
| `create` | - | Create a new Yocto/OE project (clone core repos) |
| `setup` | - | Show OE/Yocto build environment setup command |
| `setup shell` | - | Start shell with OE build environment pre-sourced |
| `b4` | - | Mail-based patch management using b4 and lore.kernel.org |
| `patches` | - | Explore and manage patches across layers |
| `deps` | - | Show layer and recipe dependencies |
| `recipes` | - | Search and browse BitBake recipes |
| `fragments` | - | Browse and manage OE configuration fragments |
| `layer-index` | - | Search OpenEmbedded Layer Index for layers |
| `projects` | `p` | Manage and switch between multiple project directories |
Run `bit` with no arguments for an interactive command menu, or `bit --help` for detailed usage.
## Common Workflows
### Starting a New Project
```bash
# Create project and clone core repos
bit create -b scarthgap --execute
# Get the environment setup command
bit setup
# Source the environment (copy from output above)
TEMPLATECONF=... source ./layers/openembedded-core/oe-init-build-env
```
### Daily Development
```bash
# Check what's changed upstream
bit status
# Update repos (interactive)
bit update
# Update all repos non-interactively (apply saved defaults)
bit update -y
# Or update a specific repo
bit update OE-core
```
### Exploring Commits
```bash
# Interactive two-level browser
bit explore
# Jump directly to a repo
bit x OE-core
```
Keybindings in explore mode (repo list):
- `Enter` - explore commits in selected repo
- `u` - pull --rebase
- `m` - pull (merge)
- `r` - refresh repo (fetch)
- `R` - refresh all repos
- `B` - switch all repos to branch (common branches first, partial dimmed)
- `t` - launch git history viewer (tig/lazygit/gitk)
- `v` - toggle verbose display (HEAD commit per repo/layer)
- `\` - expand/collapse all multi-layer repos
- `c` - open config menu
- `q` - quit
Keybindings in commit browser:
- `Tab` - mark commit for selection
- `Space` - select range of commits
- `?` - toggle preview pane
- `d` - toggle diff view in preview (stat ↔ full patch)
- `a` - toggle blame view in preview
- `f` - switch to file/tree view (browse files, expand commit history per file)
- `c` - copy commit hash
- `e` - export selected commits
- `i` - interactive rebase (select range, then squash/reword/reorder)
- `t` - launch git history viewer
- `l` - browse commits grouped by layer (multi-layer repos)
- `p` - find patch source on lore.kernel.org
- `PgUp`/`PgDn` - scroll commit list
- `Alt-Up`/`Alt-Down` - scroll preview page
- `Ctrl-U`/`Ctrl-D` - scroll preview half-page
- `←` or `b` - go back
- `q` - quit
Keybindings in file/tree view (`f` from commit browser):
- `Enter`/`→` - expand directory or show file's commit history
- `←` - collapse directory/file or go to parent
- `\` - toggle expand/collapse directory or file commits
- `d` - toggle diff view in preview
- `a` - toggle blame view
- `f` - toggle raw file content view
- `?` - toggle preview pane
- `b`/`Esc` - go back to commit browser
- `q` - quit
### Exporting Patches for Upstream
```bash
# Prepare commits (reorder for upstream)
bit export prep --branch zedd/feature
# Export patches
bit export --target-dir ~/patches
# Export with version number
bit export --target-dir ~/patches -v 2
```
### Searching for Layers
```bash
# Interactive search
bit layer-index
# Search with query
bit layer-index virtualization
# Get layer info for scripting
bit layer-index -i meta-virtualization
# Clone a layer directly
bit layer-index -c meta-security -b scarthgap
```
### Managing Branches
```bash
# Interactive branch management
bit branch
# Switch all repos to a release branch
bit branch --all scarthgap
```
Keybindings in branch management (`bit branch`):
- `Enter`/`→` - expand repo to show branches / switch to selected branch
- `←` - collapse expanded repo
- `B` - switch all repos to branch (common branches first, partial dimmed)
- `q` - quit
### Viewing Build Info
```bash
# Show build configuration (like BitBake summary)
bit info
# Show only layer info with branch:commit
bit info layers
# Show only key variables
bit info vars
```
Output format matches BitBake's build configuration:
```
Build Configuration:
MACHINE = qemuarm64
DISTRO = poky
Layers:
meta = "master:01a65e8d5f73..."
meta-selftest
meta-poky = "master:de4abc0a175a..."
```
The `info` entry is also available in the explore repo list menu for interactive browsing.
### Managing Multiple Projects
```bash
# Open project manager (interactive)
bit projects
# Add a project directory
bit projects add /path/to/yocto-build
# List known projects
bit projects list
# Remove a project from tracking
bit projects remove /path/to/old-project
```
Keybindings in projects menu:
- `Space` - activate selected project (all commands will operate on it)
- `Enter` - activate project and open command menu (if auto-invoked)
- `+` - browse for a new directory to add
- `-` - remove selected project from tracking
- `c` - clear active project (use current directory)
- `s` - open settings
Note: When no valid project context exists (no bblayers.conf found), the projects picker is automatically shown.
## Configuration
Per-repo settings are stored in `.bit.defaults` (JSON):
```json
{
"/path/to/poky": "rebase",
"/path/to/meta-oe": "skip",
"__extra_repos__": ["/path/to/bitbake"],
"__hidden_repos__": ["/path/to/unwanted-repo"],
"__push_targets__": {
"/path/to/oe-core": {
"push_url": "ssh://git@push.openembedded.org/oe-core-contrib",
"branch_prefix": "yourname/"
}
},
"fzf_theme": "dark",
"fzf_text_color": "light-gray",
"fzf_custom_colors": {"pointer": "green"}
}
```
Configure interactively with `bit config`.
### Theme Customization
The tool supports customizable options via Settings menu (`bit config` -> Settings):
**Colors** submenu:
- **Mode** - Color source: global (`~/.config/bit/colors.json`), per-project (`.bit.defaults`), or built-in defaults
- **Theme** - Base color scheme (default, dark, light, dracula, nord, etc.)
- **Individual** - Per-element color overrides with live preview
New projects default to **global** mode — changing colors in any project updates `~/.config/bit/colors.json`, shared by all projects in global mode. Switch to **custom** for per-project overrides.
A color preview panel shows all themed elements (pointer, header, prompt, etc.) with current colors applied.
**Directory Browser** - Choose preferred file browser for project selection:
- broot (recommended)
- ranger
- nnn
- fzf (fallback)
**Git Viewer** - Choose preferred git history viewer:
- auto (detect first available: tig > lazygit > gitk)
- tig - ncurses git interface
- lazygit - terminal UI for git
- gitk - graphical git browser
**Preview Layout** - Configure commit browser preview pane position:
- Bottom (default) - preview below commit list
- Right (side-by-side) - preview beside commit list
- Top - preview above commit list
**Terminal Colors** - Configure output colors for:
- Upstream indicator (commits to pull)
- Local commit count
- Dirty/clean status
- Repo names (configured, discovered, external)
## Visual Indicators
Repos are color-coded by source:
- **Green** - from bblayers.conf
- **Magenta** with `(?)` - discovered layers (not in bblayers.conf)
- **Cyan** with `(ext)` - external repos (git repos without conf/layer.conf)
Status indicators:
- `5 local` - commits ahead of upstream tracking ref
- `↓ 3` - commits to pull from upstream
- `→ contrib` - tracking a non-origin remote (shown when not tracking origin)
- `[clean]` / `[DIRTY]` - working tree status
## Requirements
- Python 3.9+
- Git
- fzf (optional, but recommended for interactive features)
- argcomplete (optional, for tab completion)
- xclip or xsel (optional, for clipboard support)
## Development
### Installation for Development
```bash
# Clone the repository
git clone https://gitlab.com/bruce-ashfield/bitbake-project.git
cd bitbake-project
# Create a virtual environment
python3 -m venv .venv
source .venv/bin/activate
# Install with dev dependencies
pip install -e .[dev]
```
### Running Tests
The project uses pytest with pytest-mock and pytest-cov:
```bash
# Activate virtual environment first
source .venv/bin/activate
# Run all tests
pytest tests/ -v
# Run with coverage report
pytest tests/ --cov=bitbake_project --cov-report=term-missing
# Run only unit tests
pytest tests/unit/ -v
# Run only integration tests
pytest tests/integration/ -v
# Run tests matching a pattern
pytest tests/ -k "test_colors" -v
```
### Test Structure
```
tests/
├── conftest.py # Shared fixtures
├── unit/
│ ├── test_colors.py # Colors class ANSI formatting
│ ├── test_helpers.py # Pure functions (clean_title, dedupe, sort)
│ ├── test_state.py # State management (defaults, prep, export)
│ ├── test_gitrepo.py # GitRepo class
│ ├── test_fzf_menu.py # FzfMenu class (mocked)
│ ├── test_bblayers_parser.py # BblayersParser
│ ├── test_cli_parser.py # CLI argument parsing
│ ├── test_info.py # Info command parsing and formatting
│ └── test_update.py # Update command (upstream tracking)
├── integration/
│ ├── test_cli_dispatch.py # Command dispatch, --help, aliases
│ └── test_projects_command.py # Projects add/remove/list
└── data/
└── bblayers/ # Test bblayers.conf files
```
## Project Structure
The project is organized as a Python package with a commands subpackage:
```
bitbake_project/
├── core.py # Core abstractions (Colors, GitRepo, FzfMenu)
├── cli.py # Argument parsing and main()
└── commands/ # Command implementations
├── common.py # Shared utilities (BblayersParser, etc.)
├── explore.py # explore, status commands
├── export.py # export, export prep commands
├── config.py # config command
├── branch.py # branch command
├── info.py # info command (build configuration)
├── update.py # update command (upstream tracking support)
├── b4.py # b4 command (lore, mail-based patch management)
├── patches.py # patches command (patch browser, Upstream-Status)
├── search.py # layer-index command
├── setup.py # create, setup commands
├── repos.py # repos command
└── projects.py # projects command, directory browser
```
Distribution options:
- **Standalone**: Single-file zipapp (`dist/bit`)
- **Pip install**: `pip install -e .` for development
## License
This project is licensed under the GNU General Public License v2.0 (GPL-2.0-only).
See [COPYING](COPYING) for the full license text.
## See Also
- [INSTALL.md](INSTALL.md) - Installation instructions
- [Yocto Project](https://www.yoctoproject.org/)
- [OpenEmbedded](https://www.openembedded.org/)
- [OpenEmbedded Layer Index](https://layers.openembedded.org/)
| text/markdown | null | Bruce Ashfield <bruce.ashfield@gmail.com> | null | null | GPL-2.0-only | bitbake, yocto, openembedded, layers, git | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU General Public License v2 (GPLv2)",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language... | [] | null | null | >=3.9 | [] | [] | [] | [
"argcomplete>=2.0; extra == \"completion\"",
"argcomplete>=2.0; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest-mock>=3.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://gitlab.com/bruce-ashfield/bitbake-project",
"Repository, https://gitlab.com/bruce-ashfield/bitbake-project",
"Issues, https://gitlab.com/bruce-ashfield/bitbake-project/-/issues"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T20:57:47.273863 | bitp-1.1.5.tar.gz | 310,225 | e7/7c/8ec371b7ca946f4184bb7809f6bdbeb10349a4eab31a8106bd746124bfed/bitp-1.1.5.tar.gz | source | sdist | null | false | 24eddebc84cf52d0fc03cefadbe6fb82 | 62d940a923702397a80e8b534afc0b295188db5a192e715aebb871f3578211f0 | e77c8ec371b7ca946f4184bb7809f6bdbeb10349a4eab31a8106bd746124bfed | null | [
"COPYING"
] | 237 |
2.4 | gapic-generator | 1.30.9 | Google API Client Generator for Python | .. _codingstyle:
API Client Generator for Python
===============================
|release level| |pypi| |versions|
A generator for protocol buffer described APIs for and in Python 3.
This is a generator for API client libraries for APIs
specified by `protocol buffers`_, such as those inside Google.
It takes a protocol buffer (with particular annotations) and uses it
to generate a client library.
.. _protocol buffers: https://developers.google.com/protocol-buffers/
Purpose
-------
This library replaces the `monolithic generator`_
with some improvements:
- An explicit normalized format for specifying APIs.
- Light weight, in-language code generators.
.. _monolithic generator: https://github.com/googleapis/gapic-generator
Bazel
-------------
This generator can be called from Bazel, which is a recommended way of using it inside a continuous integration build or any other automated pipeline.
Clone the googleapis repository
$ git clone https://github.com/googleapis/googleapis.git
Create the targets
------------------
You need to add the following targets to your BUILD.bazel file.
.. code-block:: c
load(
"@gapic_generator_python//rules_python_gapic:py_gapic.bzl",
"py_gapic_library"
)
load(
"@gapic_generator_python//rules_python_gapic:py_gapic_pkg.bzl",
"py_gapic_assembly_pkg"
)
py_gapic_library(
name = "documentai_py_gapic",
srcs = [":documentai_proto"],
)
py_gapic_assembly_pkg(
name = "documentai-v1beta2-py",
deps = [
":documentai_py_gapic",
],
)
Compiling an API
----------------
Using Bazel:
.. code-block:: c
bazel build //google/cloud/documentai/v1beta2:documentai-v1beta2-py
Using Protoc:
.. code-block:: c
# This is assumed to be in the `googleapis` project root.
$ protoc google/cloud/vision/v1/*.proto \
--python_gapic_out=/dest/
Development
-------------
`Development`_
.. _Development: https://github.com/googleapis/gapic-generator-python/blob/main/DEVELOPMENT.md
Contributing
-------------
If you are looking to contribute to the project, please see `Contributing`_
for guidlines.
.. _Contributing: https://github.com/googleapis/gapic-generator-python/blob/main/CONTRIBUTING.md
Documentation
-------------
See the `documentation`_.
.. _documentation: https://googleapis.dev/python/gapic-generator/latest/
.. |release level| image:: https://img.shields.io/badge/support-stable-gold.svg
:target: https://github.com/googleapis/google-cloud-python/blob/main/README.rst#general-availability
.. |pypi| image:: https://img.shields.io/pypi/v/gapic-generator.svg
:target: https://pypi.org/project/gapic-generator/
.. |versions| image:: https://img.shields.io/pypi/pyversions/gapic-generator.svg
:target: https://pypi.org/project/gapic-generator/
| null | Google LLC | googleapis-packages@google.com | null | null | Apache 2.0 | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: P... | [
"Posix; MacOS X"
] | https://github.com/googleapis/gapic-generator-python | null | >=3.7 | [] | [] | [] | [
"click>=6.7",
"google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.10.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,!=2.8.*,!=2.9.*,<3.0.0,>=1.34.1",
"googleapis-common-protos>=1.55.0",
"grpcio>=1.24.3",
"jinja2>=2.11",
"protobuf!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5,<7.0.0,>=3.20.2",
"pypandoc>... | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.2 | 2026-02-19T20:57:12.382505 | gapic_generator-1.30.9.tar.gz | 1,509,340 | 50/8d/1f0a182ff9eaca0a8d168d33cea9637c06421b6f33f8a1c14b38efb723e1/gapic_generator-1.30.9.tar.gz | source | sdist | null | false | 519c13fd996785fce1a0288ed2b593f8 | 23e6c02dddf57240da896ba725234e888d3976c8914ebe9106e85b0d9aae2a4c | 508d1f0a182ff9eaca0a8d168d33cea9637c06421b6f33f8a1c14b38efb723e1 | null | [
"LICENSE"
] | 253 |
2.4 | notebooklm-mcp-cli | 0.3.4 | Unified CLI and MCP server for Google NotebookLM | # NotebookLM CLI & MCP Server

[](https://pypi.org/project/notebooklm-mcp-cli/)
[](https://pypistats.org/packages/notebooklm-mcp-cli)
[](https://pepy.tech/projects/notebooklm-mcp-cli)
[](https://pypi.org/project/notebooklm-mcp-cli/)
[](https://github.com/jacob-bd/notebooklm-mcp-cli/blob/main/LICENSE)
> 🎉 **January 2026 — Major Update!** This project has been completely refactored to unify **NotebookLM-MCP** and **NotebookLM-CLI** into a single, powerful package. One install gives you both the CLI (`nlm`) and MCP server (`notebooklm-mcp`). See the [CLI Guide](docs/CLI_GUIDE.md) and [MCP Guide](docs/MCP_GUIDE.md) for full documentation.
**Programmatic access to Google NotebookLM** — via command-line interface (CLI) or Model Context Protocol (MCP) server.
> **Note:** Tested with Pro/free tier accounts. May work with NotebookLM Enterprise accounts but has not been tested.
📺 **Watch the Demos**
### MCP Demos
| **General Overview** | **Claude Desktop** | **Perplexity Desktop** | **MCP Super Assistant** |
|:---:|:---:|:---:|:---:|
| [](https://www.youtube.com/watch?v=d-PZDQlO4m4) | [](https://www.youtube.com/watch?v=PU8JhgLPxes) | [](https://www.youtube.com/watch?v=BCKlDNg-qxs) | [](https://www.youtube.com/watch?v=7aHDbkr-l_E) |
### CLI Demos
| **CLI Overview** | **CLI, MCP & Skills Deep Dive** | **Latest: Setup, Doctor & One-Click Install** |
|:---:|:---:|:---:|
| [](https://www.youtube.com/watch?v=XyXVuALWZkE) | [](https://www.youtube.com/watch?v=ZQBQigFK-E8) | [](https://www.youtube.com/watch?v=5tOUilBTJ3Q) |
## Two Ways to Use
### 🖥️ Command-Line Interface (CLI)
Use `nlm` directly in your terminal for scripting, automation, or interactive use:
```bash
nlm notebook list # List all notebooks
nlm notebook create "Research Project" # Create a notebook
nlm source add <notebook> --url "https://..." # Add sources
nlm audio create <notebook> --confirm # Generate podcast
nlm download audio <notebook> <artifact-id> # Download audio file
nlm share public <notebook> # Enable public link
```
Run `nlm --ai` for comprehensive AI-assistant documentation.
### 🤖 MCP Server (for AI Agents)
Connect AI assistants (Claude, Gemini, Cursor, etc.) to NotebookLM:
```bash
# Automatic setup — picks the right config for each tool
nlm setup add claude-code
nlm setup add gemini
nlm setup add cursor
nlm setup add cline
nlm setup add antigravity
```
```
Then use natural language: *"Create a notebook about quantum computing and generate a podcast"*
## Features
| Capability | CLI Command | MCP Tool |
|------------|-------------|----------|
| List notebooks | `nlm notebook list` | `notebook_list` |
| Create notebook | `nlm notebook create` | `notebook_create` |
| Add Sources (URL, Text, Drive, File) | `nlm source add` | `source_add` |
| Query notebook (AI chat) | `nlm notebook query` | `notebook_query` |
| Create Studio Content (Audio, Video, etc.) | `nlm studio create` | `studio_create` |
| Download artifacts | `nlm download <type>` | `download_artifact` |
| Web/Drive research | `nlm research start` | `research_start` |
| Share notebook | `nlm share public/invite` | `notebook_share_*` |
| Sync Drive sources | `nlm source sync` | `source_sync_drive` |
| Configure AI tools | `nlm setup add/remove/list` | — |
| Install AI Skills | `nlm skill install/update` | — |
| Diagnose issues | `nlm doctor` | — |
📚 **More Documentation:**
- **[CLI Guide](docs/CLI_GUIDE.md)** — Complete command reference
- **[MCP Guide](docs/MCP_GUIDE.md)** — All 29 MCP tools with examples
- **[Authentication](docs/AUTHENTICATION.md)** — Setup and troubleshooting
- **[API Reference](docs/API_REFERENCE.md)** — Internal API docs for contributors
## Important Disclaimer
This MCP and CLI use **internal APIs** that:
- Are undocumented and may change without notice
- Require cookie extraction from your browser (I have a tool for that!)
Use at your own risk for personal/experimental purposes.
## Installation
> 🆕 **Claude Desktop users:** [Download the extension](https://github.com/jacob-bd/notebooklm-mcp-cli/releases/latest) (`.mcpb` file) → double-click → done! One-click install, no config needed.
Install from PyPI. This single package includes **both the CLI and MCP server**:
### Using uv (Recommended)
```bash
uv tool install notebooklm-mcp-cli
```
### Using uvx (Run Without Install)
```bash
uvx --from notebooklm-mcp-cli nlm --help
uvx --from notebooklm-mcp-cli notebooklm-mcp
```
### Using pip
```bash
pip install notebooklm-mcp-cli
```
### Using pipx
```bash
pipx install notebooklm-mcp-cli
```
**After installation, you get:**
- `nlm` — Command-line interface
- `notebooklm-mcp` — MCP server for AI assistants
<details>
<summary>Alternative: Install from Source</summary>
```bash
# Clone the repository
git clone https://github.com/jacob-bd/notebooklm-mcp-cli.git
cd notebooklm-mcp
# Install with uv
uv tool install .
```
</details>
## Upgrading
```bash
# Using uv
uv tool upgrade notebooklm-mcp-cli
# Using pip
pip install --upgrade notebooklm-mcp-cli
# Using pipx
pipx upgrade notebooklm-mcp-cli
```
After upgrading, restart your AI tool to reconnect to the updated MCP server:
- **Claude Code:** Restart the application, or use `/mcp` to reconnect
- **Cursor:** Restart the application
- **Gemini CLI:** Restart the CLI session
## Upgrading from Legacy Versions
If you previously installed the **separate** CLI and MCP packages, you need to migrate to the unified package.
### Step 1: Check What You Have Installed
```bash
uv tool list | grep notebooklm
```
**Legacy packages to remove:**
| Package | What it was |
|---------|-------------|
| `notebooklm-cli` | Old CLI-only package |
| `notebooklm-mcp-server` | Old MCP-only package |
### Step 2: Uninstall Legacy Packages
```bash
# Remove old CLI package (if installed)
uv tool uninstall notebooklm-cli
# Remove old MCP package (if installed)
uv tool uninstall notebooklm-mcp-server
```
### Step 3: Reinstall the Unified Package
After removing legacy packages, reinstall to fix symlinks:
```bash
uv tool install --force notebooklm-mcp-cli
```
> **Why `--force`?** When multiple packages provide the same executable, `uv` can leave broken symlinks after uninstalling. The `--force` flag ensures clean symlinks.
### Step 4: Verify Installation
```bash
uv tool list | grep notebooklm
```
You should see only:
```
notebooklm-mcp-cli v0.2.0
- nlm
- notebooklm-mcp
```
### Step 5: Re-authenticate
Your existing cookies should still work, but if you encounter auth issues:
```bash
nlm login
```
> **Note:** MCP server configuration (in Claude Code, Cursor, etc.) does not need to change — the executable name `notebooklm-mcp` is the same.
## Uninstalling
To completely remove the MCP:
```bash
# Using uv
uv tool uninstall notebooklm-mcp-cli
# Using pip
pip uninstall notebooklm-mcp-cli
# Using pipx
pipx uninstall notebooklm-mcp-cli
# Remove cached auth tokens and data (optional)
rm -rf ~/.notebooklm-mcp-cli
```
Also remove from your AI tools:
```bash
nlm setup remove claude-code
nlm setup remove cursor
# ... or any configured tool
```
## Authentication
Before using the CLI or MCP, you need to authenticate with NotebookLM:
### CLI Authentication (Recommended)
```bash
# Auto mode: launches Chrome, you log in, cookies extracted automatically
nlm login
# Check if already authenticated
nlm login --check
# Use a named profile (for multiple Google accounts)
nlm login --profile work
nlm login --profile personal
# Manual mode: import cookies from a file
nlm login --manual --file cookies.txt
# External CDP provider (e.g., OpenClaw-managed browser)
nlm login --provider openclaw --cdp-url http://127.0.0.1:18800
```
**Profile management:**
```bash
nlm login --check # Show current auth status
nlm login switch <profile> # Switch the default profile
nlm login profile list # List all profiles with email addresses
nlm login profile delete <profile> # Delete a profile
nlm login profile rename <old> <new> # Rename a profile
```
Each profile gets its own isolated Chrome session, so you can be logged into multiple Google accounts simultaneously.
### Standalone Auth Tool
If you only need the MCP server (not the CLI):
```bash
nlm login # Auto mode (launches Chrome)
nlm login --manual # Manual file mode
```
**How it works:** Auto mode launches a dedicated Chrome profile, you log in to Google, and cookies are extracted automatically. Your login persists for future auth refreshes.
For detailed instructions and troubleshooting, see **[docs/AUTHENTICATION.md](docs/AUTHENTICATION.md)**.
## MCP Configuration
> **⚠️ Context Window Warning:** This MCP provides **29 tools**. Disable it when not using NotebookLM to preserve context. In Claude Code: `@notebooklm-mcp` to toggle.
### Automatic Setup (Recommended)
Use `nlm setup` to automatically configure the MCP server for your AI tools — no manual JSON editing required:
```bash
# Add to any supported tool
nlm setup add claude-code
nlm setup add claude-desktop
nlm setup add gemini
nlm setup add cursor
nlm setup add windsurf
# Check which tools are configured
nlm setup list
# Diagnose installation & auth issues
nlm doctor
```
### Install AI Skills (Optional)
Install the NotebookLM expert guide for your AI assistant to help it use the tools effectively. Supported for **Cline**, **Antigravity**, **OpenClaw**, **Codex**, **OpenCode**, **Claude Code**, and **Gemini CLI**.
```bash
# Install skill files
nlm skill install cline
nlm skill install openclaw
nlm skill install codex
nlm skill install antigravity
# Update skills
nlm skill update
```
### Remove from a tool
```bash
nlm setup remove claude-code
```
### Using uvx (No Install Required)
If you don't want to install the package, you can use `uvx` to run on-the-fly:
```bash
# Run CLI commands directly
uvx --from notebooklm-mcp-cli nlm setup add cursor
uvx --from notebooklm-mcp-cli nlm login
```
For tools that use JSON config, point them to uvx:
```json
{
"mcpServers": {
"notebooklm-mcp": {
"command": "uvx",
"args": ["--from", "notebooklm-mcp-cli", "notebooklm-mcp"]
}
}
}
```
<details>
<summary>Manual Setup (if you prefer)</summary>
**Claude Code / Gemini CLI** support adding MCP servers via their own CLI:
```bash
claude mcp add --scope user notebooklm-mcp notebooklm-mcp
gemini mcp add --scope user notebooklm-mcp notebooklm-mcp
```
**Cursor / Windsurf** resolve commands from your `PATH`, so the command name is enough:
```json
{
"mcpServers": {
"notebooklm-mcp": {
"command": "notebooklm-mcp"
}
}
}
```
| Tool | Config Location |
|------|-----------------|
| Cursor | `~/.cursor/mcp.json` |
| Windsurf | `~/.codeium/windsurf/mcp_config.json` |
**Claude Desktop / VS Code** may not resolve `PATH` — use the full path to the binary:
```json
{
"mcpServers": {
"notebooklm-mcp": {
"command": "/full/path/to/notebooklm-mcp"
}
}
}
```
Find your path with: `which notebooklm-mcp`
| Tool | Config Location |
|------|-----------------|
| Claude Desktop | `~/Library/Application Support/Claude/claude_desktop_config.json` |
| VS Code | `~/.vscode/mcp.json` |
</details>
📚 **Full configuration details:** [MCP Guide](docs/MCP_GUIDE.md) — Server options, environment variables, HTTP transport, multi-user setup, and context window management.
## What You Can Do
Simply chat with your AI tool (Claude Code, Cursor, Gemini CLI) using natural language. Here are some examples:
### Research & Discovery
- "List all my NotebookLM notebooks"
- "Create a new notebook called 'AI Strategy Research'"
- "Start web research on 'enterprise AI ROI metrics' and show me what sources it finds"
- "Do a deep research on 'cloud marketplace trends' and import the top 10 sources"
- "Search my Google Drive for documents about 'product roadmap' and create a notebook"
### Adding Content
- "Add this URL to my notebook: https://example.com/article"
- "Add this YouTube video about Kubernetes to the notebook"
- "Add my meeting notes as a text source to this notebook"
- "Import this Google Doc into my research notebook"
### AI-Powered Analysis
- "What are the key findings in this notebook?"
- "Summarize the main arguments across all these sources"
- "What does this source say about security best practices?"
- "Get an AI summary of what this notebook is about"
- "Configure the chat to use a learning guide style with longer responses"
### Content Generation
- "Create an audio podcast overview of this notebook in deep dive format"
- "Generate a video explainer with classic visual style"
- "Make a briefing doc from these sources"
- "Create flashcards for studying, medium difficulty"
- "Generate an infographic in landscape orientation"
- "Build a mind map from my research sources"
- "Create a slide deck presentation from this notebook"
### Smart Management
- "Check which Google Drive sources are out of date and sync them"
- "Show me all the sources in this notebook with their freshness status"
- "Delete this source from the notebook"
- "Check the status of my audio overview generation"
### Sharing & Collaboration
- "Show me the sharing settings for this notebook"
- "Make this notebook public so anyone with the link can view it"
- "Disable public access to this notebook"
- "Invite user@example.com as an editor to this notebook"
- "Add a viewer to my research notebook"
**Pro tip:** After creating studio content (audio, video, reports, etc.), poll the status to get download URLs when generation completes.
## Authentication Lifecycle
| Component | Duration | Refresh |
|-----------|----------|---------|
| Cookies | ~2-4 weeks | Auto-refresh via headless Chrome (if profile saved) |
| CSRF Token | ~minutes | Auto-refreshed on every request failure |
| Session ID | Per MCP session | Auto-extracted on MCP start |
**v0.1.9+**: The server now automatically handles token expiration:
1. Refreshes CSRF tokens immediately when expired
2. Reloads cookies from disk if updated externally
3. Runs headless Chrome auth if profile has saved login
You can also call `refresh_auth()` to explicitly reload tokens.
If automatic refresh fails (Google login fully expired), run `nlm login` again.
## Troubleshooting
### `uv tool upgrade` Not Installing Latest Version
**Symptoms:**
- Running `uv tool upgrade notebooklm-mcp-cli` installs an older version (e.g., 0.1.5 instead of 0.1.9)
- `uv cache clean` doesn't fix the issue
**Why this happens:** `uv tool upgrade` respects version constraints from your original installation. If you initially installed an older version or with a constraint, `upgrade` stays within those bounds by design.
**Fix — Force reinstall:**
```bash
uv tool install --force notebooklm-mcp-cli
```
This bypasses any cached constraints and installs the absolute latest version from PyPI.
**Verify:**
```bash
uv tool list | grep notebooklm
# Should show: notebooklm-mcp-cli v0.1.9 (or latest)
```
## Limitations
- **Rate limits**: Free tier has ~50 queries/day
- **No official support**: API may change without notice
- **Cookie expiration**: Need to re-extract cookies every few weeks
## Contributing
See [CLAUDE.md](CLAUDE.md) for detailed API documentation and how to add new features.
## Vibe Coding Alert
Full transparency: this project was built by a non-developer using AI coding assistants. If you're an experienced Python developer, you might look at this codebase and wince. That's okay.
The goal here was to scratch an itch - programmatic access to NotebookLM - and learn along the way. The code works, but it's likely missing patterns, optimizations, or elegance that only years of experience can provide.
**This is where you come in.** If you see something that makes you cringe, please consider contributing rather than just closing the tab. This is open source specifically because human expertise is irreplaceable. Whether it's refactoring, better error handling, type hints, or architectural guidance - PRs and issues are welcome.
Think of it as a chance to mentor an AI-assisted developer through code review. We all benefit when experienced developers share their knowledge.
## Credits
Special thanks to:
- **Le Anh Tuan** ([@latuannetnam](https://github.com/latuannetnam)) for contributing the HTTP transport, debug logging system, and performance optimizations.
- **David Szabo-Pele** ([@davidszp](https://github.com/davidszp)) for the `source_get_content` tool and Linux auth fixes.
- **saitrogen** ([@saitrogen](https://github.com/saitrogen)) for the research polling query fallback fix.
- **VooDisss** ([@VooDisss](https://github.com/VooDisss)) for multi-browser authentication improvements.
- **codepiano** ([@codepiano](https://github.com/codepiano)) for the configurable DevTools timeout for the auth CLI.
- **Tony Hansmann** ([@997unix](https://github.com/997unix)) for contributing the `nlm setup` and `nlm doctor` commands and CLI Guide documentation.
## Star History
[](https://star-history.com/#jacob-bd/notebooklm-mcp-cli&Date)
## License
[MIT License](LICENSE)
| text/markdown | Jacob Ben-David | null | null | null | null | ai, cli, google, mcp, notebooklm, podcast, research | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"fastmcp>=0.1.0",
"httpx>=0.27.0",
"platformdirs>=4.0.0",
"pydantic>=2.0.0",
"rich>=13.0.0",
"typer>=0.9.0",
"websocket-client>=1.6.0",
"mypy>=1.0.0; extra == \"dev\"",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/jacob-bd/notebooklm-mcp-cli",
"Repository, https://github.com/jacob-bd/notebooklm-mcp-cli",
"Issues, https://github.com/jacob-bd/notebooklm-mcp-cli/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:57:08.212880 | notebooklm_mcp_cli-0.3.4.tar.gz | 470,846 | c0/7c/d40d2ec262334a77673d0730cdf3052ee5f159c2b27fb5ed4a477ca94a61/notebooklm_mcp_cli-0.3.4.tar.gz | source | sdist | null | false | 243454e7f8966a31c22cc272a143b087 | e892abf0ae3f82ca8a125c6f6dabaf7445e7455390aa9df6c603eacab784ce67 | c07cd40d2ec262334a77673d0730cdf3052ee5f159c2b27fb5ed4a477ca94a61 | MIT | [
"LICENSE"
] | 2,651 |
2.4 | license-manager-simulator-api | 4.6.3 | Provides an API for interfacing with License Manager Simulator | [contributors-url]: https://github.com/omnivector-solutions/license-manager/graphs/contributors
[forks-url]: https://github.com/omnivector-solutions/license-manager/network/members
[stars-url]: https://github.com/omnivector-solutions/license-manager/stargazers
[issues-url]: https://github.com/omnivector-solutions/license-manager/issues
[license-url]: https://github.com/omnivector-solutions/license-manager/blob/master/LICENSE
[docs-url]: https://omnivector-solutions.github.io/license-manager/
[contact-us]: mailto:info@omnivector.solutions
[Contributors][contributors-url] •
[Forks][forks-url] •
[Stargazers][stars-url] •
[Issues][issues-url] •
[MIT License][license-url] •
[Documentation][docs-url] •
[Contact Us][contact-us] •
<!-- PROJECT LOGO -->
> An [Omnivector](https://www.omnivector.io/) initiative
>
> [](https://www.omnivector.io/)
<h3 align="center">License Manager Simulator</h3>
<p align="center">
A License management simulator project for testing license integration in user applications.
<br />
</p>
## About The Project
The `License Manager Simulator API`is an REST API that simulates a license server data for use in the development of applications which interface to the license servers.
License servers supported:
* FlexLM
* RLM
* LS-Dyna
* LM-X
* OLicense
## Installation
To install this project, clone the repository and use `docker-compose` to run it in containers:
```bash
$ cd lm-simulator-api
$ docker-compose up
```
This will create a container for the API, and also a PostgreSQL container for the database.
The API will be available at `http://localhost:8000/lm-sim`.
## Prerequisites
To use the License Manager Simulator API you must have License Manager Simulator scripts deployed together with a running License Manager Agent.
Instructions for this can be found at the [License Manager documentation][docs-url].
## Usage
You can add/remove licenses from the license server API using the online interface at `http://localhost:8000/lm-sim/docs`. This helps you to make requests directly with the browser into the API, with examples.
Make sure the license name in the API matches the feature name of your license in Slurm and in the License Manager API configuration.
For example:
License Manager Simulator API:
```
{
"name": "abaqus",
"type": "flexlm",
"total": 1000
}
```
Slurm:
```
LicenseName=abaqus.abaqus@flexlm
Total=1000 Used=0 Free=1000 Reserved=0 Remote=yes
```
License Manager API configuration:
```
{
"id": 1,
"name": "Abaqus",
"cluster_client_id": "client_id",
"features": [
{
"id": 1,
"name": "abaqus",
"product": {
"id": 1,
"name": "abaqus"
},
"config_id": 1,
"reserved": 0,
"total": 0,
"used": 0,
"booked_total": 0
}
],
"license_servers": [
{
"id": 1,
"config_id": 1,
"host": "localhost",
"port": 8000
}
],
"grace_time": 300,
"type": "flexlm"
}
```
The API IP address should go into the license server section of the configuration to ensure the scripts can communicate with the API.
## License
Distributed under the MIT License. See the [LICENSE][license-url] file for details.
## Contact
Email us: [Omnivector Solutions][contact-us]
| text/markdown | null | Omnivector Solutions <info@omnivector.solutions> | null | null | MIT | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"asyncpg>=0.30.0",
"fastapi[all]>=0.116.2",
"httpx>=0.28.1",
"psycopg2==2.9.10",
"py-buzz==7.2.0",
"pydantic-settings>=2.10.1",
"pydantic>=2.11.9",
"requests>=2.32.5",
"sqlalchemy[mypy]>=2.0.43",
"toml>=0.10.2",
"uvicorn>=0.35.0",
"yarl>=1.20.1",
"pytest-asyncio>=1.0.0; extra == \"dev\"",
... | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:56:53.709720 | license_manager_simulator_api-4.6.3-py3-none-any.whl | 9,287 | 79/eb/31cbc93bd0531a8fd2681e463e5b9d70c5086c9a6cdf2163c579f66001d7/license_manager_simulator_api-4.6.3-py3-none-any.whl | py3 | bdist_wheel | null | false | 6ae0397cd572a63e92f69e4fe49e7edf | 805d8da9b12bba5933a611e9b068d8bc59ac20438b692f7e8fc0109182ebcf73 | 79eb31cbc93bd0531a8fd2681e463e5b9d70c5086c9a6cdf2163c579f66001d7 | null | [
"LICENSE"
] | 199 |
2.4 | license-manager-simulator | 4.6.3 | The License Manager Simulator is an application that simulates output from 5 license servers for use in the development of applications which interface to the license servers. | [contributors-url]: https://github.com/omnivector-solutions/license-manager/graphs/contributors
[forks-url]: https://github.com/omnivector-solutions/license-manager/network/members
[stars-url]: https://github.com/omnivector-solutions/license-manager/stargazers
[issues-url]: https://github.com/omnivector-solutions/license-manager/issues
[license-url]: https://github.com/omnivector-solutions/license-manager/blob/master/LICENSE
[docs-url]: https://omnivector-solutions.github.io/license-manager/
[contact-us]: mailto:info@omnivector.solutions
[Contributors][contributors-url] •
[Forks][forks-url] •
[Stargazers][stars-url] •
[Issues][issues-url] •
[MIT License][license-url] •
[Documentation][docs-url] •
[Contact Us][contact-us] •
<!-- PROJECT LOGO -->
> An [Omnivector](https://www.omnivector.io/) initiative
>
> [](https://www.omnivector.io/)
<h3 align="center">License Manager Simulator</h3>
<p align="center">
A License management simulator project for testing license integration in user applications.
<br />
</p>
## About The Project
The `License Manager Simulator`is an application that simulates several license servers output for use in the development of applications which interface to the license servers.
It contains fake binaries that simulate the license servers output.
License servers supported:
* FlexLM
* RLM
* LS-Dyna
* LM-X
* OLicense
## Installation
```bash
$ python -m venv .venv
$ source .venv/bin/activate
$ pip install license-manager-simulator
```
The scripts will be available inside the `bin` folder in the venv.
## Prerequisites
To use the License Manager Simulator you must have `Slurm` and License Manager Agent charms deployed with `Juju`.
Instructions for this can be found at the [License Manager documentation][docs-url].
For each license server supported, there's a script that requests license information to the simulator API and a template
where the data will be rendered.
You also need to add licenses to the Simulator API and to the Slurm cluster, and then copy an application file to the `slurmd` node to run a job.
## Usage
There is an `application.sh` script that is intended to run in Slurm as a job that uses the licenses from the Simulator API. It is just a dummy
application for testing purposes that creates a `license_in_use` in the API, sleeps, then deletes the `license_in_use`.
There is also a `batch.sh` script to run the application via `sbatch`.
These files need to be updated with the Simulator API IP address provided in the step above before being copied to the `/tmp` folder in the `slurmd` node.
To submit the job, run:
```bash
$ juju ssh slurmd/leader sbatch /tmp/batch.sh
```
## License
Distributed under the MIT License. See the [LICENSE][license-url] file for details.
## Contact
Email us: [Omnivector Solutions][contact-us]
| text/markdown | null | OmniVector Solutions <info@omnivector.solutions> | null | null | MIT | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"jinja2>=3.0.1",
"requests>=2.26.0",
"ruff>=0.13.0; extra == \"dev\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:56:50.150797 | license_manager_simulator-4.6.3-py3-none-any.whl | 17,022 | 23/9c/2bfa6f632f615e394f2941c06d380b231b3b69d651e3c1dc7926a32ddfce/license_manager_simulator-4.6.3-py3-none-any.whl | py3 | bdist_wheel | null | false | c3a2af58bbf7aa32c3bfab17befec69a | fc582e89302691c5a923b6762c0c207a33490ef3b3cd476f4fe4a6a578f68fa2 | 239c2bfa6f632f615e394f2941c06d380b231b3b69d651e3c1dc7926a32ddfce | null | [
"LICENSE"
] | 208 |
2.4 | license-manager-backend | 4.6.3 | Provides an API for managing license data | [contributors-url]: https://github.com/omnivector-solutions/license-manager/graphs/contributors
[forks-url]: https://github.com/omnivector-solutions/license-manager/network/members
[stars-url]: https://github.com/omnivector-solutions/license-manager/stargazers
[issues-url]: https://github.com/omnivector-solutions/license-manager/issues
[license-url]: https://github.com/omnivector-solutions/license-manager/blob/master/LICENSE
[docs-url]: https://omnivector-solutions.github.io/license-manager/
[contact-us]: mailto:info@omnivector.solutions
[Contributors][contributors-url] •
[Forks][forks-url] •
[Stargazers][stars-url] •
[Issues][issues-url] •
[MIT License][license-url] •
[Documentation][docs-url] •
[Contact Us][contact-us] •
<!-- PROJECT LOGO -->
> An [Omnivector](https://www.omnivector.io/) initiative
>
> [](https://www.omnivector.io/)
<h3 align="center">License Manager API</h3>
<p align="center">
A REST API used by License Manager Agent to manage license usage in HPC clusters.
</p>
# About the Project
The `License Manager API` is responsible for managing license configurations, storing license usage and handling booking requests. The API is used by the License Manager Agent to centralize the data retrieved from the license servers and from the HPC cluster.
## Documentation
Please visit the
[License Manager Documentation][docs-url]
page for details on how to install and operate License Manager.
## Bugs & Feature Requests
If you encounter a bug or a missing feature, please
[file an issue][issues-url]
## License
Distributed under the MIT License. See the [LICENSE][license-url] file for details.
## Contact
Email us: [Omnivector Solutions][contact-us]
| text/markdown | null | Omnivector Solutions <info@omnivector.solutions> | null | null | MIT | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"armasec>=3.0.3",
"asyncpg>=0.30.0",
"fastapi[all]>=0.116.2",
"greenlet>=3.2.4",
"inflection>=0.5.1",
"loguru>=0.7.3",
"pendulum[test]>=3.1.0",
"prometheus-client>=0.24.1",
"psycopg2>=2.9.10",
"py-buzz==7.3.0",
"pydantic-extra-types>=2.10.5",
"pydantic-settings>=2.10.1",
"pydantic[email]>=2.... | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:56:48.917871 | license_manager_backend-4.6.3.tar.gz | 182,814 | 23/62/c69085004205c302406517b278621722bea1d6865f789a24185b7c2a3e5b/license_manager_backend-4.6.3.tar.gz | source | sdist | null | false | ceab07d643cea478167478a80984be19 | 9c0a02548e407080e27d41ca9c6dc48f41fc25483e3eff02c944dc2423935f67 | 2362c69085004205c302406517b278621722bea1d6865f789a24185b7c2a3e5b | null | [] | 209 |
2.4 | license-manager-agent | 4.6.3 | Provides an agent for interacting with license manager | [contributors-url]: https://github.com/omnivector-solutions/license-manager/graphs/contributors
[forks-url]: https://github.com/omnivector-solutions/license-manager/network/members
[stars-url]: https://github.com/omnivector-solutions/license-manager/stargazers
[issues-url]: https://github.com/omnivector-solutions/license-manager/issues
[license-url]: https://github.com/omnivector-solutions/license-manager/blob/master/LICENSE
[docs-url]: https://omnivector-solutions.github.io/license-manager/
[contact-us]: mailto:info@omnivector.solutions
[Contributors][contributors-url] •
[Forks][forks-url] •
[Stargazers][stars-url] •
[Issues][issues-url] •
[MIT License][license-url] •
[Documentation][docs-url] •
[Contact Us][contact-us] •
<!-- PROJECT LOGO -->
> An [Omnivector](https://www.omnivector.io/) initiative
>
> [](https://www.omnivector.io/)
<h3 align="center">License Manager Agent</h3>
<p align="center">
A Python agent that runs in a HPC system to manage license usage and license reservations.
<br />
</p>
# About the Project
The `License Manager Agent` is responsible for keeping the local cluster license totals
in sync with the the 3rd party license server totals. It's also responsible for making booking requests
to the `License Manager API` when Slurm is configured to use the `PrologSlurmctld` script provided by `License Manager Agent`.
## Documentation
Please visit the
[License Manager Documentation][docs-url]
page for details on how to install and operate License Manager.
## Bugs & Feature Requests
If you encounter a bug or a missing feature, please
[file an issue][issues-url]
## License
Distributed under the MIT License. See the [LICENSE][license-url] file for details.
## Contact
Email us: [Omnivector Solutions][contact-us]
| text/markdown | null | Omnivector Solutions <info@omnivector.solutions> | null | null | MIT | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"apscheduler==3.10.4",
"httpx>=0.28.1",
"py-buzz>=7.3.0",
"pydantic-settings>=2.10.1",
"pydantic>=2.12",
"pyjwt>=2.10.0",
"sentry-sdk==2.38.0",
"mypy>=1.18.1; extra == \"dev\"",
"pytest-asyncio>=1.0.0; extra == \"dev\"",
"pytest-cov>=7.0.0; extra == \"dev\"",
"pytest-env>=1.0.0; extra == \"dev\"... | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:56:47.757834 | license_manager_agent-4.6.3-py3-none-any.whl | 41,825 | d8/02/a3c5b6659204c4153ada9c76ac1bef16836d2bafc1f8130f07cc83d6b112/license_manager_agent-4.6.3-py3-none-any.whl | py3 | bdist_wheel | null | false | 9b4815267a863d225d1f24a9816a6d36 | 2fa182901a68c7356caca8b4e0142d6140a64c2e656da4fb728e8041e5d22614 | d802a3c5b6659204c4153ada9c76ac1bef16836d2bafc1f8130f07cc83d6b112 | null | [] | 210 |
2.4 | license-manager-cli | 4.6.3 | License Manager CLI Client | [contributors-url]: https://github.com/omnivector-solutions/license-manager/graphs/contributors
[forks-url]: https://github.com/omnivector-solutions/license-manager/network/members
[stars-url]: https://github.com/omnivector-solutions/license-manager/stargazers
[issues-url]: https://github.com/omnivector-solutions/license-manager/issues
[license-url]: https://github.com/omnivector-solutions/license-manager/blob/master/LICENSE
[docs-url]: https://omnivector-solutions.github.io/license-manager/
[contact-us]: mailto:info@omnivector.solutions
[Contributors][contributors-url] •
[Forks][forks-url] •
[Stargazers][stars-url] •
[Issues][issues-url] •
[MIT License][license-url] •
[Documentation][docs-url] •
[Contact Us][contact-us] •
<!-- PROJECT LOGO -->
> An [Omnivector](https://www.omnivector.io/) initiative
>
> [](https://www.omnivector.io/)
<h3 align="center">License Manager CLI</h3>
<p align="center">
A CLI to create license configurations and check license usage.
</p>
# About the Project
The `License Manager CLI` is an interface to the `License Manager API`. It can be used to create license configurations, view bookings
and list the data in the API.
## Documentation
Please visit the
[License Manager Documentation][docs-url]
page for details on how to install and operate License Manager.
## Bugs & Feature Requests
If you encounter a bug or a missing feature, please
[file an issue][issues-url]
## License
Distributed under the MIT License. See the [LICENSE][license-url] file for details.
## Contact
Email us: [Omnivector Solutions][contact-us]
| text/markdown | null | Omnivector Solutions <info@omnivector.solutions> | null | null | MIT | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"httpx>=0.28.1",
"importlib-metadata<5.0",
"loguru>=0.7.3",
"pendulum==3.1.0",
"py-buzz>=7.3.0",
"pydantic-settings>=2.11.0",
"pydantic>=2.12",
"pyperclip>=1.11.0",
"python-dotenv>=1.1.1",
"python-jose>=3.5.0",
"rich>=14.2.0",
"typer>=0.19.2",
"mypy>=1.18.0; extra == \"dev\"",
"plummet[tim... | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:56:46.970960 | license_manager_cli-4.6.3.tar.gz | 77,707 | 9d/80/3f4e756722b0cf967ab82085ef32209ae39830789020ff3913b1e6ba5de4/license_manager_cli-4.6.3.tar.gz | source | sdist | null | false | ae34d39520af16d64e7e36e09b948ceb | a25a5e7abcb28c708c2d45ab498cd77910963e5f1b651ee392433a539c3ec64d | 9d803f4e756722b0cf967ab82085ef32209ae39830789020ff3913b1e6ba5de4 | null | [
"LICENSE"
] | 211 |
2.4 | xeen | 0.1.20 | Screenshot capture → edit → crop → publish. One command: xeen | # xeen
Screenshot capture → edit → crop → publish. One command.
```
pip install -e .
xeen
```
## Problem
Chcesz szybko stworzyć krótki film ze screenshotów — demo produktu, tutorial, changelog.
Ale Canva to za dużo kroków. `xeen` robi to w terminalu + przeglądarce.
## Jak działa
```
┌─────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
│ Capture │──→│ 1.Select │──→│2.Annotate│──→│ 3.Center │──→│ 4.Crop │──→│5.Captions│──→│6.Publish │
│ xeen │ │ klatki │ │ strzałki │ │ fokus │ │ presety │ │ napisy │ │ eksport │
└─────────┘ └──────────┘ └──────────┘ └──────────┘ └──────────┘ └──────────┘ └──────────┘
screenshoty wybór/usuw. rysowanie click=center SM formaty ręczne/AI MP4/GIF/
+ metadane duplikaty tekst, rect interpolacja zoom/pad LLM gen. WebM/ZIP
kursor/kb sortowanie kolory auto z myszy smart crop drag&drop branding
```
## Instalacja
```bash
# Z repozytorium
git clone https://github.com/softreck/xeen.git
cd xeen
pip install -e .
# Wymagania systemowe
# Linux/Mac: ffmpeg
sudo apt install ffmpeg # Ubuntu/Debian
brew install ffmpeg # macOS
# Capture wymaga środowiska GUI, ale xeen automatycznie wykrywa
# najlepszą metodę i przełącza się na przeglądarkę gdy brak ekranu:
#
# 1. mss (X11/Wayland) → najszybszy
# 2. Pillow ImageGrab → alternatywa
# 3. scrot/grim/import → narzędzia systemowe
# 4. Przeglądarka (Screen Capture API) → fallback headless
# 5. Upload ręczny → zawsze działa
```
## Użycie
### 1. Nagrywanie
```bash
# Domyślne (10s, co 1s, max 15 klatek) - komenda 'xeen' sama robi capture
xeen
# Lub jawnie
xeen capture
# Krótkie demo (5s)
xeen capture -d 5
# Gęstsze klatki
xeen capture -d 10 -i 0.5
# Nazwana sesja
xeen capture -n "ksefin-demo-v2"
# Konkretny monitor
xeen capture --monitor 1
```
Co zbiera `xeen capture`:
- **Screenshoty** z inteligentnym interwałem (pomija identyczne klatki)
- **Pozycja myszy** co 100ms — używana jako sugestia "środka uwagi"
- **Klawisze** — log co zostało wciśnięte (kontekst)
- **% zmiany ekranu** — między klatkami
### 2. Edycja w przeglądarce
```bash
# Uruchom serwer (otwiera przeglądarkę)
xeen
# Lub jawnie
xeen server -p 8080
xeen server --no-browser
```
**6 zakładek:**
| Tab | Funkcja | Narzędzia |
|-----|---------|-----------|
| 1. Wybór klatek | Grid klatek — kliknij aby zaznaczyć/usunąć | Duplikaty, sortowanie, odwróć, co N-ta, pierwsze N, zakres czasu, największe zmiany |
| 2. Adnotacje | Rysuj strzałki, prostokąty, tekst na klatkach | Strzałka, prostokąt, tekst, kolory, grubość, cofnij, wyczyść |
| 3. Środek | Kliknij na obrazie = punkt fokus | Auto (kursor), środek obrazu, kopiuj do wszystkich, interpoluj, wyczyść |
| 4. Przycinanie | Preset (Instagram, Twitter, LinkedIn...) → podgląd | Podgląd wszystkich, dopasuj do treści, własny format, resetuj, zoom/pad |
| 5. Napisy | Dodaj opisy — ręcznie lub przez AI (LLM) | Dodaj, auto 1/klatka, AI generowanie (OpenAI/Anthropic/Ollama/Gemini), drag&drop |
| 6. Publikacja | Eksport MP4/GIF/WebM/ZIP + branding + social links | Szybki eksport, eksport wszystkich, znak wodny, folder, kopiuj link |
### 3. Automatyczny fallback capture
Gdy `xeen` nie może przechwycić ekranu (headless, brak GUI), automatycznie:
1. Próbuje kolejne backendy: `mss` → `Pillow` → `scrot`/`grim`/`import`
2. Jeśli żaden nie działa — **uruchamia serwer z trybem Browser Capture**
3. Przeglądarka otworzy stronę `http://127.0.0.1:7600/capture`
4. Użyj **Screen Capture API** (getDisplayMedia) do nagrania ekranu z przeglądarki
```bash
# Automatyczny fallback — xeen sam wykryje co działa
xeen
# Lub ręcznie uruchom browser capture
xeen server
# → otwórz http://127.0.0.1:7600/capture
```
### 4. Upload ręczny
Alternatywnie, w edytorze (Tab 1):
- **Przeciągnij pliki PNG/JPG** bezpośrednio na stronę
- **Kliknij "Wybierz pliki"** aby wybrać screenshoty z komputera
### 5. Lista sesji
```bash
xeen list
```
## Presety przycinania
| Preset | Rozmiar | Użycie |
|--------|---------|--------|
| `instagram_post` | 1080×1080 | Post IG (kwadrat) |
| `instagram_story` | 1080×1920 | Story IG (9:16) |
| `twitter_post` | 1200×675 | Post Twitter/X |
| `linkedin_post` | 1200×627 | Post LinkedIn |
| `facebook_post` | 1200×630 | Post Facebook |
| `youtube_thumb` | 1280×720 | Miniatura YT |
| `widescreen` | 1920×1080 | 16:9 |
## Deploy na VPS (Docker + TLS)
```bash
# 1. Sklonuj na VPS
git clone https://github.com/softreck/xeen.git
cd xeen
# 2. Deploy z domeną
make deploy DOMAIN=xeen.twoja-domena.pl
# Lub ręcznie:
bash deploy.sh xeen.twoja-domena.pl
```
Skrypt automatycznie:
- Instaluje Docker + certbot
- Generuje cert TLS (Let's Encrypt lub self-signed)
- Buduje i uruchamia kontenery
- Konfiguruje auto-renewal
### Docker ręcznie
```bash
# Dev z self-signed cert
make dev-certs
docker-compose up -d
# Logi
docker-compose logs -f
# Stop
docker-compose down
```
### Struktura Docker
```
┌─────────────┐ ┌───────────┐
│ nginx │────→│ xeen app │
│ :80/:443 │ │ :7600 │
│ TLS term. │ │ FastAPI │
└─────────────┘ └───────────┘
│ │
│ ┌────┴────┐
│ │ /data │
│ │ volume │
└──────────────┴─────────┘
```
## Metadane
Każda sesja zapisuje `session.json` z:
```json
{
"name": "20250219_143022",
"frames": [
{
"index": 0,
"timestamp": 0.0,
"filename": "frame_0000.png",
"change_pct": 100.0,
"mouse_x": 960,
"mouse_y": 540,
"suggested_center_x": 960,
"suggested_center_y": 540,
"input_events": [
{"ts": 0.1, "kind": "mouse_move", "x": 955, "y": 538},
{"ts": 0.2, "kind": "key_press", "key": "a", "x": 955, "y": 538},
{"ts": 0.3, "kind": "mouse_click", "x": 960, "y": 540, "button": "Button.left"}
]
}
],
"input_log": [ ... ]
}
```
## Szybka prezentacja z 3-5 zrzutów ekranu
Najszybszy workflow do stworzenia demo/tutoriala:
```bash
# 1. Zrób 3-5 zrzutów ekranu (PrintScreen, Flameshot, itp.)
# 2. Uruchom xeen
xeen server
# 3. W przeglądarce:
# Tab 1: Przeciągnij screenshoty → zaznacz potrzebne
# Tab 3: Kliknij "Auto: kursor myszy" (lub ustaw ręcznie)
# Tab 4: Wybierz preset np. twitter_post
# Tab 6: Kliknij "Generuj wszystkie formaty"
```
**Wskazówki:**
- **3 zrzuty** — idealnie na social media post (Twitter, LinkedIn)
- **5 zrzutów** — dobra ilość na krótki tutorial/changelog
- **Pomiń Tab 2 (Adnotacje)** jeśli screenshoty są czytelne
- **Pomiń Tab 5 (Napisy)** jeśli nie potrzebujesz opisów
- Użyj **"Pierwsze N"** w Tab 1 aby szybko wybrać dokładnie tyle klatek ile potrzebujesz
- Ustaw **focus=mouse + pad=20%** aby wyciąć istotny fragment ekranu
## FPS — ile klatek nagrywać?
| Interwał | FPS | Zastosowanie |
|----------|-----|-------------|
| `1.0s` | 1 | Statyczne demo — klik → screenshot → klik (domyślne) |
| `0.5s` | 2 | Płynniejsze prezentacje, więcej klatek do wyboru |
| `0.33s` | 3 | Najlepszy balans: płynność + rozsądna ilość klatek |
**Rekomendacja: 2-3 FPS** (`xeen capture -i 0.5` lub `-i 0.33`).
- Przy 1 FPS możesz przegapić krótkie interakcje
- Przy 3 FPS masz wystarczająco dużo materiału bez zalewania dysku
- Duplikaty można usunąć automatycznie w Tab 1 ("Znajdź duplikaty")
## API
| Endpoint | Metoda | Opis |
|----------|--------|------|
| `/api/sessions` | GET | Lista sesji |
| `/api/sessions/{name}` | GET | Szczegóły sesji |
| `/api/sessions/{name}/thumbnails` | GET | Miniaturki (max N) |
| `/api/sessions/upload` | POST | Upload screenshotów |
| `/api/sessions/{name}/select` | POST | Zapisz wybór klatek |
| `/api/sessions/{name}/update-frames` | POST | Aktualizuj listę klatek (po usunięciu/przywróceniu) |
| `/api/sessions/{name}/centers` | POST | Zapisz środki fokus |
| `/api/sessions/{name}/crop-preview` | POST | Podgląd przycinania (z custom_centers inline) |
| `/api/sessions/{name}/video-preview` | POST | Podgląd wideo (miniatura) |
| `/api/sessions/{name}/export` | POST | Eksport MP4/GIF/WebM/ZIP |
| `/api/sessions/{name}/captions` | POST | Zapisz napisy |
| `/api/sessions/{name}/captions/generate` | POST | Generuj napisy AI (LLM) |
| `/api/presets` | GET | Presety formatów |
| `/api/branding` | GET/POST | Konfiguracja znaku wodnego |
| `/api/social-links` | GET | Linki social media |
## Licencja
MIT — Softreck
## License
Apache License 2.0 - see [LICENSE](LICENSE) for details.
## Author
Created by **Tom Sapletta** - [tom@sapletta.com](mailto:tom@sapletta.com)
| text/markdown | null | Tom Sapletta <tom@sapletta.com> | null | null | null | screenshot, video, capture, social-media, screen-recording | [
"Development Status :: 3 - Alpha",
"Environment :: Web Environment",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Multimedia :: Video :: Capture"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"fastapi>=0.104.0",
"uvicorn[standard]>=0.24.0",
"mss>=9.0.0",
"Pillow>=10.0.0",
"pynput>=1.7.6",
"jinja2>=3.1.0",
"python-multipart>=0.0.6",
"aiofiles>=23.0.0",
"numpy>=1.24.0",
"imagehash>=4.3.0",
"pytesseract>=0.3.10",
"loguru>=0.7.0",
"litellm>=1.0.0",
"pytest>=7.0; extra == \"dev\"",
... | [] | [] | [] | [
"Homepage, https://github.com/softreck/xeen-capture",
"Repository, https://github.com/softreck/xeen-capture"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-19T20:56:18.861612 | xeen-0.1.20.tar.gz | 93,554 | e4/96/066abb190ae7541336ad2112ed05d15a5ade8953f1c159db9259d3f0248c/xeen-0.1.20.tar.gz | source | sdist | null | false | f256a61353a1d7ff6f631ee27b3ea63a | 469877cde4dc394386c96da8689291b96622eba8541fbf628529dfc4a19c5491 | e496066abb190ae7541336ad2112ed05d15a5ade8953f1c159db9259d3f0248c | Apache-2.0 | [
"LICENSE"
] | 203 |
2.1 | pycombinatorial | 2.1.8 | A library to solve TSP (Travelling Salesman Problem) using Exact Algorithms, Heuristics, Metaheuristics and Reinforcement Learning | # pyCombinatorial
## Introduction
**pyCombinatorial** is a Python-based library designed to tackle the classic Travelling Salesman Problem (TSP) through a diverse set of **Exact Algorithms**, **Heuristics**, **Metaheuristics** and **Reinforcement Learning**. It brings together both well-established and cutting-edge methodologies, offering end-users a flexible toolkit to generate high-quality solutions for TSP instances of various sizes and complexities.
Techniques: **2-opt**; **2.5-opt**; **3-opt**; **4-opt**; **5-opt**; **Or-opt**; **2-opt Stochastic**; **2.5-opt Stochastic**; **3-opt Stochastic**; **4-opt Stochastic**; **5-opt Stochastic**; **Ant Colony Optimization**; **Adaptive Large Neighborhood Search**; **Bellman-Held-Karp Exact Algorithm**; **Bitonic Tour**; **Branch & Bound**; **BRKGA** (Biased Random Key Genetic Algorithm); **Brute Force**; **Cheapest Insertion**; **Christofides Algorithm**; **Clarke & Wright** (Savings Heuristic); **Concave Hull Algorithm**; **Convex Hull Algorithm**; **Elastic Net**; **Extremal Optimization**; **Farthest Insertion**; **FRNN** (Fixed Radius Near Neighbor); **Genetic Algorithm**; **GRASP** (Greedy Randomized Adaptive Search Procedure); **Greedy Karp-Steele Patching**; **Guided Search**; **Hopfield Network**; **Iterated Search**; **Karp-Steele Patching**; **Large Neighborhood Search**; **Multifragment Heuristic**; **Nearest Insertion**; **Nearest Neighbour**; **Random Insertion**; **Random Tour**; **Randomized Spectral Seriation**; **RL Q-Learning**; **RL Double Q-Learning**; **RL S.A.R.S.A** (State Action Reward State Action); **Ruin & Recreate**; **Scatter Search**; **Simulated Annealing**; **SOM** (Self Organizing Maps); **Space Filling Curve** (Hilbert); **Space Filling Curve** (Morton); **Space Filling Curve** (Sierpinski); **Spectral Seriation Initializer**; **Stochastic Hill Climbing**; **Sweep**; **Tabu Search**; **Truncated Branch & Bound**; **Twice-Around the Tree Algorithm** (Double Tree Algorithm); **Variable Neighborhood Search**; **Zero Suffix Method**.
## Usage
1. Install
```bash
pip install pycombinatorial
```
2. Import
```py3
# Required Libraries
import pandas as pd
# GA
from pyCombinatorial.algorithm import genetic_algorithm
from pyCombinatorial.utils import graphs, util
# Loading Coordinates # Berlin 52 (Minimum Distance = 7544.3659)
coordinates = pd.read_csv('https://bit.ly/3Oyn3hN', sep = '\t')
coordinates = coordinates.values
# Obtaining the Distance Matrix
distance_matrix = util.build_distance_matrix(coordinates)
# GA - Parameters
parameters = {
'population_size': 15,
'elite': 1,
'mutation_rate': 0.1,
'mutation_search': 8,
'generations': 1000,
'verbose': True
}
# GA - Algorithm
route, distance = genetic_algorithm(distance_matrix, **parameters)
# Plot Locations and Tour
graphs.plot_tour(coordinates, city_tour = route, view = 'browser', size = 10)
print('Total Distance: ', round(distance, 2))
```
3. Try it in **Colab**
3.1 Lat Long Datasets
- Lat Long ([ Colab Demo ](https://colab.research.google.com/drive/17jFw4z1R9gOoAfB-ZCZa6c-PukVKdrt3?usp=sharing))
3.2 Algorithms
- 2-opt ([ Colab Demo ](https://colab.research.google.com/drive/1SLkM8r_VdlFCpNpm-2yTfr_ynSC5WIX9?usp=sharing)) ( [ Paper ](https://www.jstor.org/stable/167074))
- 2.5-opt ([ Colab Demo ](https://colab.research.google.com/drive/17bJ-I26prnryAU8p-xf0l7R91cJzb85N?usp=sharing)) ( [ Paper ](https://doi.org/10.1007/s10955-007-9382-1))
- 3-opt ([ Colab Demo ](https://colab.research.google.com/drive/1iAZLawLBZ-7yaPCyobMtel1SvBamxtjL?usp=sharing)) ( [ Paper ](https://isd.ktu.lt/it2011//material/Proceedings/1_AI_5.pdf))
- 4-opt ([ Colab Demo ](https://colab.research.google.com/drive/1N8HKhVY4s20sfqo8IWIaCY-NHVk6gARS?usp=sharing)) ( [ Paper ](https://isd.ktu.lt/it2011//material/Proceedings/1_AI_5.pdf))
- 5-opt ([ Colab Demo ](https://colab.research.google.com/drive/15Qrk-7H4oRaTR77ADvwkiN0sLvycgFDH?usp=sharing)) ( [ Paper ](https://isd.ktu.lt/it2011//material/Proceedings/1_AI_5.pdf))
- Or-opt ([ Colab Demo ](https://colab.research.google.com/drive/1p7JwrFLH83ZroCzIweXLCAXYgA3FKAI0?usp=sharing)) ( [ Paper ](https://doi.org/10.1057/palgrave.jors.2602160))
- 2-opt Stochastic ([ Colab Demo ](https://colab.research.google.com/drive/1xTm__7OwQVC_KX2b-eExLGgG1DgnJ10a?usp=sharing)) ( [ Paper ](https://doi.org/10.1016/j.trpro.2014.10.001))
- 2.5-opt Stochastic ([ Colab Demo ](https://colab.research.google.com/drive/16W_QqJ1PebVgqUx8NFOSS5kG3DsJ51UQ?usp=sharing)) ( [ Paper ](https://doi.org/10.1007/s10955-007-9382-1))
- 3-opt Stochastic ([ Colab Demo ](https://colab.research.google.com/drive/1A5lPW6BSDD2rLNDlnpQo44U8jwKcAGXL?usp=sharing)) ( [ Paper ](https://isd.ktu.lt/it2011//material/Proceedings/1_AI_5.pdf))
- 4-opt Stochastic ([ Colab Demo ](https://colab.research.google.com/drive/1igWrUMVSInzyeOdhPcGuMjyooZ6elvLY?usp=sharing)) ( [ Paper ](https://isd.ktu.lt/it2011//material/Proceedings/1_AI_5.pdf))
- 5-opt Stochastic ([ Colab Demo ](https://colab.research.google.com/drive/13vS5MCeFqb3F4ntxrw3iCsMbJTfEVyeo?usp=sharing)) ( [ Paper ](https://isd.ktu.lt/it2011//material/Proceedings/1_AI_5.pdf))
- Ant Colony Optimization ([ Colab Demo ](https://colab.research.google.com/drive/1O2qogrjE4mZUZX3nsSxw43crumlBnd-D?usp=sharing)) ( [ Paper ](https://doi.org/10.1109/4235.585892))
- Adaptive Large Neighborhood Search ([ Colab Demo ](https://colab.research.google.com/drive/1vShK5fe2xRCpMkurgd4PzmstGtn6d_LQ?usp=sharing)) ( [ Paper ](https://www.jstor.org/stable/25769321))
- Bellman-Held-Karp Exact Algorithm ([ Colab Demo ](https://colab.research.google.com/drive/1HSnArk-v8PWY4dlCvT5zcSAnT1FJEDaf?usp=sharing)) ( [ Paper ](https://dl.acm.org/doi/10.1145/321105.321111))
- Bitonic Tour([ Colab Demo ](https://colab.research.google.com/drive/1AopZ7IBgC_2fhLE0E4yAgxofYc0wTnge?usp=sharing)) ( [ Paper ](https://doi.org/10.1007/978-3-030-63920-4_12))
- Branch & Bound ([ Colab Demo ](https://colab.research.google.com/drive/1oDHrECSW3g4vBEsrO8T7qSHID4fxFiqs?usp=sharing)) ( [ Paper ](https://doi.org/10.1016/j.disopt.2016.01.005))
- BRKGA (Biased Random Key Genetic Algorithm) ([ Colab Demo ](https://colab.research.google.com/drive/1lwnpUBl1P1LIvzN1saLgEvnaKZRMWLHn?usp=sharing)) ( [ Paper ](https://doi.org/10.1007/s10732-010-9143-1))
- Brute Force ([ Colab Demo ](https://colab.research.google.com/drive/10vOkBz3Cv9UdHPlcBWkDmJO7EvDg96ar?usp=sharing)) ( [ Paper ](https://swarm.cs.pub.ro/~mbarbulescu/cripto/Understanding%20Cryptography%20by%20Christof%20Paar%20.pdf))
- Cheapest Insertion ([ Colab Demo ](https://colab.research.google.com/drive/1QOg8FDvrFUgojwLXD2BBvEuB9Mu7q88a?usp=sharing)) ( [ Paper ](https://disco.ethz.ch/courses/fs16/podc/readingAssignment/1.pdf))
- Christofides Algorithm ([ Colab Demo ](https://colab.research.google.com/drive/1Wbm-YQ9TeH2OU-IjZzVdDkWGQILv4Pj_?usp=sharing)) ( [ Paper ](https://web.archive.org/web/20190721172134/https://apps.dtic.mil/dtic/tr/fulltext/u2/a025602.pdf))
- Clarke & Wright (Savings Heuristic) ([ Colab Demo ](https://colab.research.google.com/drive/1XC2yoVe6wTsjt7u2fBaL3LcKUu42FG8r?usp=sharing)) ( [ Paper ](http://dx.doi.org/10.1287/opre.12.4.568))
- Concave Hull Algorithm ([ Colab Demo ](https://colab.research.google.com/drive/1P96DerRe7CLyC9dQNr96nEkNHnxpGYY4?usp=sharing)) ( [ Paper ](http://repositorium.sdum.uminho.pt/bitstream/1822/6429/1/ConcaveHull_ACM_MYS.pdf))
- Convex Hull Algorithm ([ Colab Demo ](https://colab.research.google.com/drive/1Wn2OWccZukOfMtJuGV9laklLTc8vjOFq?usp=sharing)) ( [ Paper ](https://doi.org/10.1109/TSMC.1974.4309370))
- Elastic Net ([ Colab Demo ](https://colab.research.google.com/drive/1F7IlkKdZ3_zQ_MkhknkIPHvE5RqJG7YC?usp=sharing)) ( [ Paper ](https://doi.org/10.1038/326689a0))
- Extremal Optimization ([ Colab Demo ](https://colab.research.google.com/drive/1Y5YH0eYKjr1nj_IfhJXaILRDIXm-LWLs?usp=sharing)) ( [ Paper ](https://doi.org/10.1109/5992.881710))
- Farthest Insertion ([ Colab Demo ](https://colab.research.google.com/drive/13pWiLL_dO9Y1lvQO0zD50MXk4mD0Tn1W?usp=sharing)) ( [ Paper ](https://disco.ethz.ch/courses/fs16/podc/readingAssignment/1.pdf))
- FRNN (Fixed Radius Near Neighbor) ([ Colab Demo ](https://colab.research.google.com/drive/16GgUGA0_TyR6UOqg0TtndjjuZhQ0TTYT?usp=sharing)) ( [ Paper ](https://dl.acm.org/doi/pdf/10.5555/320176.320186))
- Genetic Algorithm ([ Colab Demo ](https://colab.research.google.com/drive/1zO9rm-G6HOMeg1Q_ptMHJr48EpHcCAIS?usp=sharing)) ( [ Paper ](https://doi.org/10.1007/BF02125403))
- GRASP (Greedy Randomized Adaptive Search Procedure) ([ Colab Demo ](https://colab.research.google.com/drive/1OnRyCc6C_QL6wr6-l5RlQI4eGbMdwuhS?usp=sharing)) ( [ Paper ](https://doi.org/10.1007/BF01096763))
- Greedy Karp-Steele Patching ([ Colab Demo ](https://colab.research.google.com/drive/1to3u45QWWQK8REj1_YiF5rUqUqNjB18q?usp=sharing)) ( [ Paper ](https://doi.org/10.1016/S0377-2217(99)00468-3))
- Guided Search ([ Colab Demo ](https://colab.research.google.com/drive/1uT9mlDoo37Ni7hqziGNELEGQCGBKQ83o?usp=sharing)) ( [ Paper ](https://doi.org/10.1016/S0377-2217(98)00099-X))
- Hopfield Network ([ Colab Demo ](https://colab.research.google.com/drive/1Io20FFsndsRT3Bc1nimLBcpH5WtEt7Pe?usp=sharing)) ( [ Paper ](https://doi.org/10.1515/dema-1996-0126))
- Iterated Search ([ Colab Demo ](https://colab.research.google.com/drive/1U3sPpknulwsCUQq9mK7Ywfb8ap2GIXZv?usp=sharing)) ( [ Paper ](https://doi.org/10.1063/1.36219))
- Karp-Steele Patching ([ Colab Demo ](https://colab.research.google.com/drive/12xLLDNIk6OOSNQXqYSYtdwhupZ9Kt5xb?usp=sharing)) ( [ Paper ](https://doi.org/10.1137/0208045))
- Large Neighborhood Search ([ Colab Demo ](https://colab.research.google.com/drive/1t4cafHRRzOLN4xth96jE-2qHoPQOLsn5?usp=sharing)) ( [ Paper ](https://doi.org/10.1007/3-540-49481-2_30))
- Multifragment Heuristic ([ Colab Demo ](https://colab.research.google.com/drive/1YNHVjS6P35bAnqGZyP7ERNrTnG9tNuhF?usp=sharing)) ( [ Paper ](https://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=08D176AEFA57EF1941645F2B31DF1686?doi=10.1.1.92.1635&rep=rep1&type=pdf))
- Nearest Insertion ([ Colab Demo ](https://colab.research.google.com/drive/1R4mz604EG-unKktu8ON_Hpoywi3OIRHK?usp=sharing)) ( [ Paper ](https://disco.ethz.ch/courses/fs16/podc/readingAssignment/1.pdf))
- Nearest Neighbour ([ Colab Demo ](https://colab.research.google.com/drive/1aL1kYXgSjUJYPfYSMy_0SWq4hJ3nrueJ?usp=sharing)) ( [ Paper ](https://doi.org/10.1016/S0166-218X(01)00195-0))
- Random Insertion ([ Colab Demo ](https://colab.research.google.com/drive/1RP_grqrTXyDkHOLB_L1H8TkvxdLli5hG?usp=sharing)) ( [ Paper ](https://disco.ethz.ch/courses/fs16/podc/readingAssignment/1.pdf))
- Random Tour ([ Colab Demo ](https://colab.research.google.com/drive/1DPXMJXInkGKTyVFDAQ2bKXjglhy3DaCS?usp=sharing)) ( [ Paper ](https://doi.org/10.1023/A:1011263204536))
- Randomized Spectral Seriation ([ Colab Demo ](https://colab.research.google.com/drive/1PTtO6HJfftsFZEScCYZvzpBJsgMyjBCY?usp=sharing)) ( [ Paper ](https://doi.org/10.1137/S0097539795285771))
- RL Q-Learning ([ Colab Demo ](https://colab.research.google.com/drive/1dnZhLAzQdz9kzxKrVcwMECWbyEKkZ7St?usp=sharing)) ( [ Paper ](https://doi.org/10.1049/tje2.12303))
- RL Double Q-Learning ([ Colab Demo ](https://colab.research.google.com/drive/1VTv8A6Ac-LvBxsereFyGRfkiLRbJI547?usp=sharing)) ( [ Paper ](https://doi.org/10.1049/tje2.12303))
- RL S.A.R.S.A ([ Colab Demo ](https://colab.research.google.com/drive/1q9hon3jFf8xVCw4idxhu7goLREKbQ6N3?usp=sharing)) ( [ Paper ](https://doi.org/10.1049/tje2.12303))
- Ruin & Recreate ([ Colab Demo ](https://colab.research.google.com/drive/18uPEZqwOZa07YdVoNht_VMH3SGhLBo-A?usp=sharing)) ( [ Paper ](https://doi.org/10.1006/jcph.1999.6413))
- Scatter Search ([ Colab Demo ](https://colab.research.google.com/drive/115Ql6KegvOjlNUUfsbY4fA8Vab-db26N?usp=sharing)) ( [ Paper ](https://doi.org/10.1111/j.1540-5915.1977.tb01074.x))
- Simulated Annealing ([ Colab Demo ](https://colab.research.google.com/drive/10Th0yLaAeSqp9FhYB0H00e4sXTbg7Jp2?usp=sharing)) ( [ Paper ](https://www.jstor.org/stable/1690046))
- SOM (Self Organizing Maps) ([ Colab Demo ](https://colab.research.google.com/drive/1-ZwSFnXf1_kCeY_p3SC3N21T8QeSWsg6?usp=sharing)) ( [ Paper ](https://arxiv.org/pdf/2201.07208.pdf))
- Space Filling Curve (Hilbert) ([ Colab Demo ](https://colab.research.google.com/drive/1FXzWrUBjdbJBngRFHv66CZw5pFN3yOs8?usp=sharing)) ( [ Paper ](https://doi.org/10.1016/0960-0779(95)80046-J))
- Space Filling Curve (Morton) ([ Colab Demo ](https://colab.research.google.com/drive/1Z13kXyi7eaNQbBUmhvwuQjY4VaUfGVbs?usp=sharing)) ( [ Paper ](https://dominoweb.draco.res.ibm.com/reports/Morton1966.pdf))
- Space Filling Curve (Sierpinski) ([ Colab Demo ](https://colab.research.google.com/drive/1w-Zptd5kOryCwvQ0qSNBNhPXC61c8QXF?usp=sharing)) ( [ Paper ](https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.67.9061&rep=rep1&type=pdf))
- Spectral Seriation Initializer ([ Colab Demo ](https://colab.research.google.com/drive/1lG0pYxASU75qh0jK-A_eMCoPpCWv0I4V?usp=sharing)) ( [ Paper ](https://doi.org/10.1137/S0097539795285771))
- Stochastic Hill Climbing ([ Colab Demo ](https://colab.research.google.com/drive/1_wP6vg4JoRHGItGxEtXcf9Y9OuuoDlDl?usp=sharing)) ( [ Paper ](http://aima.cs.berkeley.edu/))
- Sweep ([ Colab Demo ](https://colab.research.google.com/drive/1AkAn4yeomAp6POBslk3Asd6OrxfBrHT7?usp=sharing)) ( [ Paper ](http://dx.doi.org/10.1287/opre.22.2.340))
- Tabu Search ([ Colab Demo ](https://colab.research.google.com/drive/1SRwQrBaxkKk18SDvQPy--0yNRWdl6Y1G?usp=sharing)) ( [ Paper ](https://doi.org/10.1287/ijoc.1.3.190))
- Truncated Branch & Bound ([ Colab Demo ](https://colab.research.google.com/drive/16m72PrBZN8mWMCer12dgsStcNGs4DVdQ?usp=sharing)) ( [ Paper ](https://research.ijcaonline.org/volume65/number5/pxc3885866.pdf))
- Twice-Around the Tree Algorithm ([ Colab Demo ](https://colab.research.google.com/drive/1tf5tc5DxvEUc89JaaFgzmK1TtD1e4fkc?usp=sharing)) ( [ Paper ](https://doi.org/10.1016/0196-6774(84)90029-4))
- Variable Neighborhood Search ([ Colab Demo ](https://colab.research.google.com/drive/1yMWjYuurzpcijsCFDTA76fAwJmSaDkZq?usp=sharing)) ( [ Paper ](https://doi.org/10.1016/S0305-0548(97)00031-2))
- Zero Suffix Method ([ Colab Demo ](https://colab.research.google.com/drive/1IXiZ8eQThElMFK-ATD1GoUyKC02LI3ij?usp=sharing)) ( [ Paper ](https://www.m-hikari.com/ijcms-2011/21-24-2011/sudhakarIJCMS21-24-2011.pdf))
# Single Objective Optimization
For Single Objective Optimization try [pyMetaheuristic](https://github.com/Valdecy/pyMetaheuristic)
# Multiobjective Optimization or Many Objectives Optimization
For Multiobjective Optimization or Many Objectives Optimization try [pyMultiobjective](https://github.com/Valdecy/pyMultiobjective)
| text/markdown | Valdecy Pereira | valdecy.pereira@gmail.com | null | null | GNU | null | [] | [] | https://github.com/Valdecy/pyCombinatorial | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/5.0.0 CPython/3.10.9 | 2026-02-19T20:55:06.757623 | pycombinatorial-2.1.8.tar.gz | 57,990 | 8e/41/be5663fcbc32c66cd05fbee23f686619b7b6792dc66171fdad038f765210/pycombinatorial-2.1.8.tar.gz | source | sdist | null | false | 5fd90c79674ad682cf3d38b020ffd2ec | 1b9576e9a1c697bd7f852c60430c7d21e1f4b1c5b2e9d2195dd592701f382842 | 8e41be5663fcbc32c66cd05fbee23f686619b7b6792dc66171fdad038f765210 | null | [] | 239 |
2.4 | partialjson | 1.1.0 | Parse incomplete or partial json | # PartialJson
[](https://pypi.org/project/partialjson/)
## Parse Partial and incomplete JSON in python

### Parse Partial and incomplete JSON in python with just 3 lines of python code.
[](https://pypi.org/project/partialjson)
[](#Installation)
[](https://pepy.tech/project/partialjson)
## Example
```python
from partialjson import JSONParser
parser = JSONParser()
incomplete_json = '{"name": "John Doe", "age": 30, "is_student": false, "courses": ["Math", "Science"'
print(parser.parse(incomplete_json))
# {'name': 'John Doe', 'age': 30, 'is_student': False, 'courses': ['Math', 'Science']}
```
Problem with `\n`? Use `strict=False`:
```python
from partialjson import JSONParser
parser = JSONParser(strict=False)
incomplete_json = '{"name": "John\nDoe", "age": 30, "is_student": false, "courses": ["Math", "Science"'
print(parser.parse(incomplete_json))
# {'name': 'John\nDoe', 'age': 30, 'is_student': False, 'courses': ['Math', 'Science']}
```
### JSON5 support
Use `create_json5_parser` or `JSONParser(json5_enabled=True)` for JSON5 (comments, unquoted keys, single quotes, etc.):
```python
from partialjson import create_json5_parser
parser = create_json5_parser()
incomplete_json5 = '{name: "Demo", version: 1.0, items: [1, 2, 3,]'
print(parser.parse(incomplete_json5))
# {'name': 'Demo', 'version': 1.0, 'items': [1, 2, 3]}
```
Install the optional `json5` dependency for full JSON5 support: `pip install partialjson[json5]`
### Installation
```sh
$ pip install partialjson
```
Also can be found on [pypi](https://pypi.org/project/partialjson/)
### How can I use it?
- Install the package by pip package manager.
- After installing, you can use it and call the library.
## Testing
```bash
pip install -e .
pip install -r requirements-dev.txt
pytest -q
```
## Citation
If you use this software, please cite it using the metadata in `CITATION.cff`.
## Star History
[](https://star-history.com/#iw4p/partialjson&Date)
### Issues
Feel free to submit issues and enhancement requests or contact me via [vida.page/nima](https://vida.page/nima).
### Contributing
Please refer to each project's style and contribution guidelines for submitting patches and additions. In general, we follow the "fork-and-pull" Git workflow.
1. **Fork** the repo on GitHub
2. **Clone** the project to your own machine
3. **Update the Version** inside **init**.py
4. **Commit** changes to your own branch
5. **Push** your work back up to your fork
6. Submit a **Pull request** so that we can review your changes
| text/markdown | Nima Akbarzadeh | iw4p@protonmail.com | null | null | MIT | null | [] | [] | https://github.com/iw4p/partialjson | null | null | [] | [] | [] | [
"json5; extra == \"json5\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:55:00.295984 | partialjson-1.1.0.tar.gz | 7,697 | 23/2e/b2e97a95187e3eeb61b4b9e03f73a08db00650b5b8837c2dff673f6efc4e/partialjson-1.1.0.tar.gz | source | sdist | null | false | 85d23ae52e79afef31a40e6c170698ff | 733e540b91e8d9bb6b0d29caf02a4e67e213103d40e25c5f6d16401db3f6ede2 | 232eb2e97a95187e3eeb61b4b9e03f73a08db00650b5b8837c2dff673f6efc4e | null | [
"LICENSE"
] | 1,624 |
2.4 | jaclang | 0.10.5 | Jac programming language - a superset of both Python and TypeScript/JavaScript with novel constructs for AI-integrated programming. | <div align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://www.jac-lang.org/assets/logo.png">
<source media="(prefers-color-scheme: light)" srcset="https://www.jac-lang.org/assets/logo.png">
<img alt="Jaclang Programming Language: Unique and Powerful programming language that runs on top of Python"
src="https://www.jac-lang.org/assets/logo.png"
width="20%">
</picture>
[Jac Website] | [Getting started] | [Learn] | [Documentation] | [Contributing]
[](https://pypi.org/project/jaclang/) [](https://github.com/Jaseci-Labs/jaclang/actions/workflows/run_pytest.yml) [](https://codecov.io/github/chandralegend/jaclang)
</div>
This is the main source code repository for the [Jac] programming language. It contains the compiler, language server, and documentation.
[Jac]: https://www.jac-lang.org/
[Jac Website]: https://www.jac-lang.org/
[Getting Started]: https://docs.jaseci.org/learn/tour/
[Learn]: https://docs.jaseci.org/jac_book/
[Documentation]: https://docs.jaseci.org/jac_book/
[Contributing]: https://docs.jaseci.org/internals/contrib/
## What and Why is Jac?
- **Native Superset of Python and TypeScript/JavaScript** - Jac is a native superset of both Python and TypeScript/JavaScript, meaning both ecosystems (PyPI and npm) are directly interoperable with Jac without any trickery (no interop interface needed). Every Jac program can be ejected to pure Python, and Python programs can be transpiled to Jac.
- **AI as a Programming Language Constructs** - Jac includes a novel (neurosymbolic) language construct that allows replacing code with generative AI models themselves. Jac's philosophy abstracts away prompt engineering. (Imagine taking a function body and swapping it out with a model.)
- **New Modern Abstractions** - Jac introduces a paradigm that reasons about persistence and the notion of users as a language level construct. This enables writing simple programs for which no code changes are needed whether they run in a simple command terminal, or distributed across a large cloud. Jac's philosophy abstracts away dev ops and container/cloud configuration.
- **Jac Improves on Python** - Jac makes multiple thoughtful quality-of-life improvements/additions to Python. These include new modern operators, new types of comprehensions, new ways of organizing modules (i.e., separating implementations from declarations), etc.
## Quick Start
To install Jac, run:
```bash
pip install jaclang
```
Run `jac` in the terminal to see whether it is installed correctly.
Read ["Getting Started"] from [Docs] for more information.
["Getting Started"]: https://docs.jaseci.org/learn/tour/
[Docs]: https://docs.jaseci.org/jac_book/
## Installing from Source
If you really want to install from source (though this is not recommended):
```bash
# with a local clone at `path/to/repo`:
pip install path/to/repo/jac
# or to have `pip` clone for you:
pip install git+https://github.com/jaseci-labs/jaseci#subdirectory=jac
```
## Getting Help
Submit and issue! Community links coming soon.
## Contributing
See [CONTRIBUTING.md](.github/CONTRIBUTING.md).
## License
Jaclang is distributed under the terms of both the MIT license with a few other open source projects vendored
within with various other licenses that are very permissive.
See [LICENSE-MIT](.guthub/LICENSE), and
[COPYRIGHT](COPYRIGHT) for details.
## Trademark
[Jaseci][jaseci] owns and protects the Jaclang trademarks and logos (the "Jaclang Trademarks").
If you want to use these names or brands, please read the [media guide][media-guide].
Third-party logos may be subject to third-party copyrights and trademarks. See [Licenses][policies-licenses] for details.
[jaseci]: https://jaseci.org/
[media-guide]: https://jaseci.org/policies/logo-policy-and-media-guide/
[policies-licenses]: https://www.jaseci.org/policies/licenses
| text/markdown | null | Jason Mars <jason@mars.ninja> | null | Jason Mars <jason@mars.ninja> | null | jac, jaclang, jaseci, python, programming-language, machine-learning, artificial-intelligence | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"llvmlite>=0.43.0",
"pytest>=8.2.1; extra == \"dev\"",
"pytest-xdist>=3.6.1; extra == \"dev\"",
"pytest-cov>=5.0.0; extra == \"dev\"",
"pre-commit>=3.7.1; extra == \"dev\"",
"watchdog>=3.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Repository, https://github.com/Jaseci-Labs/jaseci",
"Homepage, https://jaseci.org",
"Documentation, https://docs.jaseci.org"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T20:52:31.749395 | jaclang-0.10.5.tar.gz | 6,831,290 | 6c/d9/bb6c95afcde76c24a7e74c3ba28f801d7f103b306ded4c16274a157f4122/jaclang-0.10.5.tar.gz | source | sdist | null | false | 73805896b0b95c9869a508fd9e1137c9 | 93ea648d160225c7273a277e8d34c259e563e982cd8879352eed2c93769f56ae | 6cd9bb6c95afcde76c24a7e74c3ba28f801d7f103b306ded4c16274a157f4122 | MIT | [] | 792 |
2.3 | buildrunner | 3.22.1 | Docker-based build tool | #############
Buildrunner
#############
Build and publish Docker images, run builds/tasks within Docker containers or
on remote hosts.
.. contents::
:local:
Overview
========
Buildrunner is a tool written on top of Docker and ssh remoting frameworks that
allows engineers to do the following:
- Build and publish Docker images
- Run other build and packaging tools within custom Docker containers while
collecting the artifacts these tools produce
- Run builds/tasks on remote systems that cannot be done within a Docker
container
- Creating ad-hoc environments using Docker containers for running automated,
self-contained integration and functional tests
Buildrunner runs builds and tests by reading configuration files within a given
source tree. This allows build and continuous integration test configurations
to live close to source files, providing engineers the ability to update and
version the build and test configuration right along with the code that is
being built and tested. This also allows build tools and infrastructures to
very easily import and setup builds for new modules and branches.
Installation
============
See `docs/installation <docs/installation.rst>`_.
Development
============
See `docs/development <docs/development.rst>`__.
Global Configuration
====================
See `docs/global-configuration <docs/global-configuration.rst>`_.
Buildrunner Builds
==================
A Buildrunner build consists of one or more build steps.
Each step may build a custom Docker image and run a task within a specific
Docker container or run commands on a remote host.
Artifacts can be collected from tasks run within containers or remote hosts
when they have finished running and archived in your build system (Jenkins, for
instance).
Resulting images (either from a build phase or a run phase) can be committed or
pushed to the central or a private Docker image registry for use in other
builds or to run services in other environments.
Build definitions are found in the root of your source tree, either in a file
named 'buildrunner.yaml'. The build definition is simply a
yaml map defining 'steps'. Each step is given a custom name and must contain
either 'build' and/or 'run' attributes (optionally containing a 'push'
attribute) or a 'remote' attribute:
.. code:: yaml
steps:
step1-name:
build: <build config>
run: <run config>
commit: <commit config>
push: <push config>
# or
remote: <remote config>
step2-name:
build: <build config>
run: <run config>
push: <push config>
# or
remote: <remote config>
Step names are arbitrary--you can use whatever names you want as long as they
are unique within a given ``steps`` configuration. Archived artifacts are stored
in a step-specific results directory. To use artifacts generated from a
previous step in a subsequent one you would reference them using the previous
step name.
.. note:: Artifacts from previous steps are not available within remote builds
There are two image builders in ``buildrunner``. The default builder is
equivalent to ``docker build`` and only supports single-platform images,
this is referenced as the legacy image builder.
The new image builder is equivalent to ``docker buildx`` and is used for for both
single and multi-platform images. To use the ``docker buildx`` builder,
set ``use-legacy-builder: false`` in the configuration file or use ``platforms``
in the ``build`` section. The legacy builder will be removed in a future release.
.. code:: yaml
use-legacy-builder: false
steps:
step1:
build: <build config>
run: <run config>
push: <push config>
# or
remote: <remote config>
Jinja
================
The 'buildrunner.yaml' file is processed as a
`Jinja template <http://jinja.pocoo.org/>`_, meaning the build definition can be
modified dynamically before it is run. In addition to the environment variables
listed below in `Running Containers`_ and the standard Jinja methods, the list
below contains available variables and methods.
:``CONFIG_FILE``: the full path to the current file being processed (buildrunner.yaml)
:``CONFIG_DIR``: the full path to the directory containing the current file being processed
:``env``: exposes the ``os.environ`` instance to retrieve arbitrary env variables
:``read_yaml_file``: a method to read an arbitrary file in the current workspace as yaml and use the
contents in the script, note that the file is processed using Jinja as well and
that the file must exist before buildrunner is run or else this method will
fail
:``raise``: a method to raise an exception with the message provided as a single argument
Jinja filters
-------------
:``hash_sha1``: SHA1 hash filter
:``base64encode``: Base64 encoding filter
:``base64decode``: Base64 decoding filter
:``re_sub``: performs a regular expression replacement on text
:``re_split``: uses a pattern to split text
Steps Dependencies
==========================
Buildrunner supports specifying steps dependencies. To use this
feature a user must specify the configuration version of ``2.0`` or higher and
also use the configuration keyword ``depends`` in the step configuration. The ``depends``
key takes a list of step names which must be completed before the execution of the
current step.
.. code:: yaml
version: 2.0
steps:
step1:
run:
image: {{ DOCKER_REGISTRY }}/ubuntu:latest
cmd: echo "Hello from step1"
step2:
depends:
- step1
- step3
run:
image: {{ DOCKER_REGISTRY }}/ubuntu:latest
cmd: echo "Hello from step 2"
step3:
run:
image: {{ DOCKER_REGISTRY }}/ubuntu:latest
cmd: echo "Hello from step 3."
step4:
run:
image: {{ DOCKER_REGISTRY }}/ubuntu:latest
cmd: echo "Hello from step 4."
The step execution order will be in the order it appears in the configuration
unless an dependency is defined by using ``depends``, then the order will
change in order to satisfy the dependencies. The ``graphlib`` library is used
to generate the directed acyclic graph and there is no guarantee how non-dependent
steps will be ordered.
An example of a step order which satisfies the dependencies in the config above:
``('step1', 'step3', 'step4', 'step2')``. Please note that there are other valid
permutations as well.
Circular dependencies are not valid. If a circular dependency is in a configuration
it will produce an exeception and halt the execution of buildrunner.
Standard Docker Builds (the ``build`` step attribute)
=====================================================
Buildrunner allows you to build a Docker image using a standard Dockerfile.
This is done using the top-level 'build' attribute in a step configuration. The
value of the 'build' attribute can either be a single string value indicating
the directory to use for the Docker build context (the directory containing the
Dockerfile) or a map that describes a dynamic build context and/or other build
arguments.
Here is an example of a build definition that would build a Docker image using
the root directory of the source tree as the build context (equivalent to
running 'docker build .' in the root of your source tree):
.. code:: yaml
steps:
build-my-container:
build: .
If the Dockerfile is in another directory within the source tree just give the
relative path as the argument to the build attribute:
.. code:: yaml
steps:
build-my-container:
build: my/container/build/context
By placing different contexts in different directories a single source tree can
produce multiple Docker images:
.. code:: yaml
steps:
build-container-1:
build: container-1
build-container-2:
build: container-2
The value of the 'build' attribute can also be a map. The following example
shows the different configuration options available:
.. code:: yaml
steps:
build-my-container:
build:
# Define the base context directory (same as string-only value)
path: my/container/build/context
# The inject map specifies other files outside the build context that
# should be included in the context sent to the Docker daemon. Files
# injected into the build context override files with the same name/path
# contained in the path configuration above.
#
# NOTE: you do not need to specify a path attribute if you inject all
# of the files you need, including a Dockerfile. When the path attribute
# is NOT explicitly specified (either as 'path: .' or 'build: .'), the
# source directory will NOT be copied into the build context. This
# optimization improves build performance by avoiding unnecessary file
# copying. Any files needed by the Dockerfile must be explicitly injected
# when not specifying a path.
#
# NOTE: if the destination is a directory then it must be indicated with
# an ending "/" or a "." component.
inject:
# Each entry in the map has a glob pattern key that resolves relative
# to the source tree root with the value being the directory within
# the build context that the file(s) should be copied to. These files
# will be available to the Dockerfile at the given location during
# the Docker build. Destination directories must have a trailing
# slash (``/``).
glob/to/files.*: dest/dir/
path/to/file1.txt: dest/dir/
path/to/file2.txt: .
path/to/file3.txt: dest/filename.txt
# The path to a Dockerfile to use, or an inline Dockerfile declaration.
# This Dockerfile overrides any provided in the path or inject
# configurations. If the docker context does not require any additional
# resources the path and inject configurations are not required.
dockerfile: path/to/Dockerfile
<or>
dockerfile: |
FROM someimage:latest
RUN /some/command
# The stage to stop at when using multi-stage docker builds
# similar to the --target option used by docker
target: dev
# Whether to use the default Docker image cache for intermediate
# images--caching images significantly speeds up the building of
# images but may not be desired when building images for publishing
no-cache: true/false (defaults to false)
# The following applies to single platform builds.
# Specify Docker images to consider as cache sources,
# similar to the --cache-from option used by Docker.
# Buildrunner will attempt to pull these images from the remote registry.
# If the pull is unsuccessful, buildrunner will still pass in the image name
# into --cache-from, allowing a cache check in the host machine cache
cache_from:
- my-images/image:PR-123
- my-images/image:latest
# The following applies to multiplatform builds.
# Specify Docker images to consider as cache sources,
# similar to the --cache-from option used by Docker.
# cache_from: Works only with the container driver. Loads the cache
# (if needed) from a registry `cache_from="user/app:cache"` or
# a directory on the client `cache_from="type=local,src=path/to/dir"`.
# It's also possible to use a dict or list of dict form for this
# argument. e.g.
# `cache_from={type="local", src="path/to/dir"}`
# cache_to: Works only with the container driver. Sends the resulting
# docker cache either to a registry `cache_to="user/app:cache"`,
# or to a local directory `cache_to="type=local,dest=path/to/dir"`.
# It's also possible to use a dict form for this argument. e.g.
# `cache_to={type="local", dest="path/to/dir", mode="max"}`
cache_from: my-images/image:PR-123
<or>
cache_from:
- type: local
src: path/to/dir
cache_to:
type: local
dest: path/to/dir
mode: max
# Whether to do a docker pull of the "FROM" image prior to the build.
# This is critical if you are building from images that are changing
# with regularity.
# NOTE: If the image was created from a 'push' or 'commit' earlier in
# this ``buildrunner.yaml`` then this will default to false
# NOTE: The command line argument ``--local-images`` can be used to temporarily
# override and assume ``pull: false`` for the build without rewriting
# ``buildrunner.yaml``.
pull: true/false # (default changes depending on if the
# image was created via buildrunner or not)
# Specify a different platform architecture when pulling and building images
# This is useful if you are building an image for a different architecture than what
# buildrunner is running on, such as using a linux/amd64 build node to produce an image
# with a docker manifest compatible with an Apple M1 linux/arm64/v8 architecture
platform: linux/amd64
<or>
platform: linux/arm64/v8 # an apple m1 architecture
# To build multiplatform images, add each platform to be built to this list and buildrunner
# will use docker buildx to build and provide a single tag containing all architectures specified.
# Notes:
# * buildx may be configured to build some platforms with emulation and therefore builds may take longer with this option specified
# * multiplatform builds cannot be used in the buildrunner docker image unless the 'build-registry' global config parameter is specified
# * only one of platform or platforms may be specified
platforms:
- linux/amd64
- linux/arm64/v8
# Specify the build args that should be used when building your image,
# similar to the --build-args option used by Docker
buildargs:
BUILD_ARG_NAME_1: BUILD_ARG_VALUE_1
BUILD_ARG_NAME_2: BUILD_ARG_VALUE_2
# Instead of building import the given tar file as a Docker image. If
# this value is present all other options are ignored and the resulting
# image is passed to subsequent steps.
import: path/to/image/archive.tar
# Specify the secrets that should be used when building your image,
# similar to the --secret option used by Docker
# More info about secrets: https://docs.docker.com/build/building/secrets/
secrets:
# Example of a secret that is a file
- id=secret1,src=<path to the secret file>
# Example of a secret that is an environment variable
- id=secret2,env=<environment variable name>
.. _Build Secrets:
Build Secrets
=============
Buildrunner supports specifying secrets that should be used when building your image,
similar to the --secret option used by Docker. This is done by adding the ``secrets``
section to the ``build`` section. This is a list of secrets that should be used when
building the image. The string should be in the format of ``id=secret1,src=<location of the file>``
when the secret is a file or ``id=secret2,env=<environment variable name>`` when the secret is an environment variable.
This syntax is the same as the syntax used by Docker to build with secrets.
More info about building with secrets in docker and the syntax of the secret string
see https://docs.docker.com/build/building/secrets/.
In order to use secrets in buildrunner, you need to do the following:
#. Update the buildrunner configuration file
* Set ``use-legacy-builder`` to ``false`` or add ``platforms`` to the ``build`` section
* Add the secrets to the ``secrets`` section in the ``build`` section
#. Update the Dockerfile to use the secrets
* Add the ``--mount`` at the beginning of each RUN command that needs the secret
.. code:: yaml
use-legacy-builder: false
steps:
build-my-container:
build:
dockerfile: |
FROM alpine:latest
# Using secrets inline
RUN --mount=type=secret,id=secret1 \
--mount=type=secret,id=secret2 \
echo Using secrets in my build - secret1 file located at /run/secrets/secret1 with contents $(cat /run/secrets/secret1) and secret2=$(cat /run/secrets/secret2)
# Using secrets in environment variables
RUN --mount=type=secret,id=secret1 \
--mount=type=secret,id=secret2 \
SECRET1_FILE=/run/secrets/secret1 \
SECRET2_VARIABLE=$(cat /run/secrets/secret2) \
&& echo Using secrets in my build - secret1 file located at $SECRET1_FILE with contents $(cat $SECRET1_FILE) and secret2=$SECRET2_VARIABLE
secrets:
# Example of a secret that is a file
- id=secret1,src=examples/build/secrets/secret1.txt
# Example of a secret that is an environment variable
- id=secret2,env=SECRET2
.. _Running Containers:
Running Containers (the ``run`` step attribute)
===============================================
The 'run' step attribute is used to create and run a Docker container from a
given image.
There are 2 reasons for running a Docker container within a build:
1. To run another build tool or test framework and collect the resulting
artifacts
2. To run scripts and operations within an existing image to create a new image
(similar to how Packer_ creates Docker images)
Buildrunner injects special environment variables and volume mounts into every
run container. The following environment variables are set and available in
every run container:
:``BUILDRUNNER_ARCH``: the architecture of the current device (x86_64, aarch64, etc), equivalent to
``platform.machine()``. Note that the ``--platform`` argument will override this value if
specified.
:``BUILDRUNNER_BUILD_NUMBER``: the build number
:``BUILDRUNNER_BUILD_ID``: a unique id identifying the build (includes vcs and build number
information), e.g. "main-1791.Ia09cc5.M0-1661374484"
:``BUILDRUNNER_BUILD_DOCKER_TAG``: identical to ``BUILDRUNNER_BUILD_ID`` but formatted for
use as a Docker tag
:``BUILDRUNNER_BUILD_TIME``: the "unix" time or "epoch" time of the build (in seconds)
:``BUILDRUNNER_STEP_ID``: a UUID representing the step
:``BUILDRUNNER_STEP_NAME``: The name of the Buildrunner step
:``BUILDRUNNER_STEPS``: the list of steps manually specified on the command line,
defaults to an empty list
:``BUILDRUNNER_INVOKE_USER``: The username of the user that invoked Buildrunner
:``BUILDRUNNER_INVOKE_UID``: The UID of the user that invoked Buildrunner
:``BUILDRUNNER_INVOKE_GROUP``: The group of the user that invoked Buildrunner
:``BUILDRUNNER_INVOKE_GID``: The GID (group ID) of the user that invoked Buildrunner
:``VCSINFO_NAME``: the VCS repository name without a path, "my-project"
:``VCSINFO_BRANCH``: the VCS branch, e.g. "main"
:``VCSINFO_NUMBER``: the VCS commit number, e.g. "1791"
:``VCSINFO_ID``: the VCS commit id, e.g. "a09cc5c407af605b57a0f16b73f896873bb74759"
:``VCSINFO_SHORT_ID``: the VCS short commit id, e.g. "a09cc5c"
:``VCSINFO_RELEASE``: the VCS branch state, .e.g. "1791.Ia09cc5.M0"
:``VCSINFO_MODIFIED``: the last file modification timestamp if local changes have been made and not
committed to the source VCS repository, e.g. "1661373883"
The following volumes are created within run containers:
:``/source``: (read-write) maps to a pristine snapshot of the current source tree (build directory)
:``/artifacts``: (read-only) maps to the buildrunner.results directory
The /source volume is actually a mapped volume to a new source container
containing a copy of the build source tree. This container is created from a
docker image containing the entire source tree. Files can be excluded from this
source image by creating a '.buildignore' file in the root of the source tree.
This file follows the same conventions as a .dockerignore file does when
creating Docker images.
The following example shows the different configuration options available in
the run step:
.. code:: yaml
# Optional buildrunner configuration syntax version
version: 2.0
steps:
my-build-step:
# Optional step dependency definition to specify which steps need to be processed before this step.
# The `version` must be present and set to `2.0` or higher for buildrunner to utilize the step dependencies list.
# An buildrunner error will occur if `depends` is present but `version` is missing or value is lower than `2.0`.
depends:
- test-step
- validation-step
# This is not supported in the same step as a multiplatform build.
run:
# xfail indicates whether the run operation is expected to fail. The
# default is false - the operation is expected to succeed. If xfail
# is true and the operation succeeds then it will result in a failure.
xfail: <boolean>
# A map of additional containers that should be created and linked to
# the primary run container. These can be used to bring up services
# (such as databases) that are required to run the step. More details
# on services below.
services:
service-name-1: <service config>
service-name-2: <service config>
# The Docker image to run. If empty the image created with the 'build'
# attribute will be used.
image: <the Docker image to run>
# The command(s) to run. If omitted Buildrunner runs the command
# configured in the Docker image without modification. If provided
# Buildrunner always sets the container command to a shell, running the
# given command here within the shell. If both 'cmd' and 'cmds' are
# present the command in 'cmd' is run before the commands in the 'cmds'
# list are run.
cmd: <a command to run>
cmds:
- <command one>
- <command two>
# A collection of provisioners to run. Provisioners work similar to the
# way Packer provisioners do and are always run within a shell.
# When a provisioner is specified Buildrunner always sets the container
# command to a shell, running the provisioners within the shell.
# Currently Buildrunner supports shell and salt provisioners.
provisioners:
shell: path/to/script.sh | [path/to/script.sh, ARG1, ...]
salt: <simple salt sls yaml config>
# The shell to use when specifying the cmd or provisioners attributes.
# Defaults to /bin/sh. If the cmd and provisioners attributes are not
# specified this setting has no effect.
shell: /bin/sh
# The directory to run commands within. Defaults to /source.
cwd: /source
# The user to run commands as. Defaults to the user specified in the
# Docker image.
user: <user to run commands as (can be username:group / uid:gid)>
# The hostname assigned to the run container.
hostname: <the hostname>
# Custom dns servers to use in the run container.
dns:
- 8.8.8.8
- 8.8.4.4
# A custom dns search path to use in the run container.
dns_search: mydomain.com
# Add entries to the hosts file
# The keys are the hostnames. The values can be either
# ip addresses or references to service containers.
extra_hosts:
"www1.test.com": "192.168.0.1"
"www2.test.com": "192.168.0.2"
# A map specifying additional environment variables to be injected into
# the container. Keys are the variable names and values are variable
# values.
env:
ENV_VARIABLE_ONE: value1
ENV_VARIABLE_TWO: value2
# A map specifying files that should be injected into the container.
# The map key is the alias referencing a given file (as configured in
# the "local-files" section of the global configuration file) or a
# relative path to a file/directory in the build directory. The value
# is the path the given file should be mounted at within the container.
files:
namespaced.file.alias1: "/path/to/readonly/file/or/dir"
namespaced.file.alias2: "/path/to/readwrite/file/or/dir:rw"
build/dir/file: "/path/to/build/dir/file"
# A map specifying cache directories that are stored as archive files on the
# host system as `local cache key` and extracted as a directory in
# the container named `docker path`. The cache directories are maintained
# between builds and can be used to store files, such as downloaded
# dependencies, to speed up builds.
# Caches can be shared between any builds or projects on the system
# as the names are not prefixed with any project-specific information.
# Caches should be treated as ephemeral and should only store items
# that can be obtained/generated by subsequent builds.
#
# Two formats are supported when defining caches.
# 1) RECOMMENDED
# <docker path>:
# - <local cache key A>
# - <local cache key B>
#
# Restore Cache:
# This format allows for prefix matching. The order of the list dictates the
# order which should be searched in the local system cache location.
# When an item isn't found it will search for archive files which prefix matches
# the item in the list. If more than one archive file is matched for a prefix
# the archive file most recently modified will be used. If there is no
# matching archive file then nothing will be restored in the docker container.
#
# Save Cache:
# The first local cache key in the list is used for the name of the local
# cache archive file.
#
# 2) <local cache key>: <docker path> (backwards compatible with older caching method, but more limited)
#
caches:
# Recommended format.
<docker path>:
- <local cache key A>
- <local cache key B>
"/root/.m2/repository":
# Buildrunner will look for a cache that matches this cache key/prefix,
# typically the first key should be the most specific as it is the closest match
# Note that this first key will also be used to save the cache for use across builds or projects
- m2repo-{{ checksum("pom.xml", "subproj/pom.xml") }}
# If the first cache key is not found in the caches, use this prefix to look for a cache that may not
# be an exact match, but may still be close and not require as much downloading of dependencies, etc
# Note that this may match across any cache done by any build on the same system, so it may be wise to
# use a unique prefix for any number of builds that have a similar dependency tree, etc
- m2repo-
# If no cache is found, nothing will be extracted and the application will need to rebuild the cache
# Backwards compatible format. Not recommended for future or updated configurations.
<local cache key>: <docker path>
maven: "/root/.m2/repository"
# A map specifying ports to expose, this is only used when the
# --publish-ports parameter is passed to buildrunner
ports:
<container port>: <host port>
# A list specifying service containers (see below) whose exposed
# volumes should be mapped into the run container's file system.
# An exposed volume is one created by the volume Dockerfile command.
# See https://docs.docker.com/engine/reference/builder/#volume for more
# details regarding the volume Dockerfile command.
volumes_from:
- my-service-container
# A list specifying ssh keys that should be injected into the container
# via an ssh agent. The list should specify the ssh key aliases (as
# configured in the "ssh-keys" section of the global configuration
# file) that buildrunner should inject into the container. Buildrunner
# injects the keys by mounting a ssh-agent socket and setting the
# appropriate environment variable, meaning that the private key itself
# is never available inside the container.
ssh-keys:
- my_ssh_key_alias
# A map specifying the artifacts that should be archived for the step.
# The keys in the map specify glob patterns of files to archive. If a
# value is present it should be a map of additional properties that
# should be added to the build artifacts.json file. The artifacts.json
# file can be used to publish artifacts to another system (such as
# Gauntlet) with the accompanying metadata. By default artifacts will be
# listed in the artifacts.json file; this can be disabled by adding the
# ``push`` property and set it to false.
#
# When archiving *directories* special properties can be set to change
# the behavior of the archiver. Directories by default are archived as
# gzip'ed TARs. The compression can be changed by setting the
# ``compression`` property to one of the below-listed values. The
# archive type can be changed by setting the property ``type:zip``.
# When a zip archive is requested then the ``compression`` property is
# ignored. If the directory tree should be gathered verbatim without
# archiving then the property ``format:uncompressed`` can be used.
#
# Rename allows for specifying exact matches to rename for files and
# compressed directories. Wildcard (*) matches is not supported.
#
# NOTE: Artifacts can only be archived from the /source directory using
# a relative path or a full path. Files outside of this directory will
# fail to be archived.
artifacts:
artifacts/to/archive/*:
[format: uncompressed]
[type: tar|zip]
[compression: gz|bz2|xz|lzma|lzip|lzop|z]
[push: true|false]
[rename: new-name]
property1: value1
property2: value2
# Whether or not to pull the image from upstream prior to running
# the step. This is almost always desirable, as it ensures the
# most up to date source image.
# NOTE: If the image was created from a 'push' or 'commit' earlier in
# this ``buildrunner.yaml`` then this will default to false
pull: true/false # (default changes depending on if the
# image was created via buildrunner or not)
# Specify a different platform architecture when pulling and running images.
# This is useful if you are running an image that was built for a different architecture
# than what buildrunner is running on, such as using a linux/arm64/v8 Apple M1 architecture
# development machine to run or test an image built for linux/amd64 architecture.
platform: linux/amd64
<or>
platform: linux/arm64/v8 # an apple m1 architecture
# systemd does not play well with docker typically, but you can
# use this setting to tell buildrunner to set the necessary docker
# flags to get systemd to work properly:
# - /usr/sbin/init needs to run as pid 1
# - /sys/fs/cgroup needs to be mounted as readonly
# (-v /sys/fs/cgroup:/sys/fs/cgroup:ro)
# - The security setting seccomp=unconfined must be set
# (--security-opt seccomp=unconfined)
# If this is ommitted, the image will be inspected for the label
# 'BUILDRUNNER_SYSTEMD'.
# If found, systemd=true will be assumed.
systemd: true/false
# (Ignored when systemd is not enabled)
# For cgroup v2, a read-write mount for /sys/fs/cgroup is required as well as a tmpfs mounted at /run, and
# this flag enables this behavior
# If this is omitted, the image will be inspected for the label
# 'BUILDRUNNER_SYSTEMD_CGROUP2' and that value will be used instead.
systemd_cgroup2: true/false
# Docker supports certain kernel capabilities, like 'SYS_ADMIN'.
# see https://goo.gl/gTQrqW for more infromation on setting these.
cap_add: 'SYS_ADMIN'
<or>
cap_add:
- 'SYS_ADMIN'
- 'SYS_RAWIO'
# Docker can run in a privileged mode. This allows access to all devices
# on the host. Using privileged is rare, but there are good use cases
# for this feature. see https://goo.gl/gTQrqW for more infromation on
# setting these.
# Default: false
privileged: true/false
# The post-build attribute commits the resulting run container as an
# image and allows additional Docker build processing to occur. This is
# useful for adding Docker configuration, such as EXPOSE and CMD
# instructions, when building an image via the run task that cannot be
# done without running a Docker build. The post-build attribute
# functions the same way as the 'build' step attribute does, except
# that it prepends the committed run container image to the provided
# Dockerfile ('FROM <image>\n').
post-build: path/to/build/context
<or>
post-build:
dockerfile: |
EXPOSE 80
CMD /runserver.sh
# A list of container names or labels created within any run container
# that buildrunner should clean up. (Use if you call
# 'docker run --name <name>' or 'docker run --label <label>' within a run container.)
containers:
- container1
- container2
Service Containers
------------------
Service containers allow you to create and start additional containers that
are linked to the primary build container. This is useful, for instance, if
your unit or integration tests require an outside service, such as a database
service. Service containers are instantiated in the order they are listed.
Service containers have the same injected environment variables and volume
mounts as build containers do, but the /source mount is read-only.
The following example shows the different configuration options available
within service container configuration:
.. code:: yaml
steps:
my-build-step:
run:
services:
my-service-container:
# The 'build' attribute functions the same way that the step
# 'build' attribute does. The only difference is that the image
# produced by a service container build attribute cannot be pushed
# to a remote repository.
build: <path/to/build/context or map>
# The pre-built image to base the container on. The 'build' and
# 'image' attributes are mutually exclusive in the service
# container context.
image: <the Docker image to run>
# The command to run. If ommitted Buildrunner runs the command
# configured in the Docker image without modification. If provided
# Buildrunner always sets the container command to a shell, running
# the given command here within the shell.
cmd: <a command to run>
# A collection of provisioners to run. Provisioners work similar to
# the way Packer provisioners do and are always run within a shell.
# When a provisioner is specified Buildrunner always sets the
# container command to a shell, running the provisioners within the
# shell. Currently Buildrunner supports shell and salt
# provisioners.
provisioners:
shell: path/to/script.sh
salt: <simple salt sls yaml config>
# The shell to use when specifying the cmd or provisioners
# attributes. Defaults to /bin/sh. If the cmd and provisioners
# attributes are not specified this setting has no effect.
shell: /bin/sh
# The directory to run commands within. Defaults to /source.
cwd: /source
# The user to run commands as. Defaults to the user specified in
# the Docker image.
user: <user to run commands as (can be username:group / uid:gid)>
# The hostname assigned to the service container.
hostname: <the hostname>
# Custom dns servers to use in the service container.
dns:
- 8.8.8.8
- 8.8.4.4
# A custom dns search path to use in the service container.
dns_search: mydomain.com
# Add entries to the hosts file
# The keys are the hostnames. The values can be either
# ip addresses or references to other service containers.
extra_hosts:
"www1.test.com": "192.168.0.1"
"www2.test.com": "192.168.0.2"
# A map specifying additional environment variables to be injected
# into the container. Keys are the variable names and values are
# variable values.
env:
ENV_VARIABLE_ONE: value1
ENV_VARIABLE_TWO: value2
# A map specifying files that should be injected into the container.
# The map key is the alias referencing a given file (as configured in
# the "local-files" section of the global configuration file) or a
# relative path to a file/directory in the build directory. The value
# is the path the given file should be mounted at within the container.
files:
namespaced.file.alias1: "/path/to/readonly/file/or/dir"
namespaced.file.alias2: "/path/to/readwrite/file/or/dir:rw"
build/dir/file: "/path/to/build/dir/file"
# A list specifying other service containers whose exposed volumes
# should be mapped into this service container's file system. Any
# service containers in this list must be defined before this
# container is.
# An exposed volume is one created by the volume Dockerfile command.
# See https://docs.docker.com/engine/reference/builder/#volume for more
# details regarding the volume Dockerfile command.
volumes_from:
- my-service-container
# A map specifying ports to expose and link within other containers
# within the step.
ports:
<container port>: <host port>
# Whether or not to pull the image from upstream prior to running
# the step. This is almost always desirable, as it ensures the
# most up to date source image. There are situations, however, when
# this can be set to false as an optimization. For example, if a
# container is built at the beginning of a buildrunner file and then
# used repeatedly. In this case, it is clear that the cached version
# is appropriate and we don't need to check upstream for changes.
pull: true/false (defaults to true)
# See above
systemd: | text/x-rst | Adobe | Adobe <noreply@adobe.com> | null | null | MIT | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"jinja2>=2.11.2",
"pyyaml>=6.0",
"bcrypt>=3.2.0",
"decorator>=5.1.0",
"docker>=6.1.2",
"fabric>=2.5.0",
"paramiko<4.0.0,>=2.10.3",
"requests>=2.27.0",
"twine>=6.1.0",
"vcsinfo>=2.1.105",
"graphlib-backport>=1.0.3",
"timeout-decorator>=0.5.0",
"python-on-whales>=0.70.1",
"pydantic>=2.11.7",... | [] | [] | [] | [
"Homepage, https://github.com/adobe/buildrunner"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:51:47.925909 | buildrunner-3.22.1.tar.gz | 100,088 | bb/50/d65e496a43202d59a7f4c1cf6604d088371a7b6149684c5da7b2b4c921ef/buildrunner-3.22.1.tar.gz | source | sdist | null | false | 9b66e22c1fa9dd0159d6c9f9001ad430 | da4db41e3bd5e9be5c42d3fe9425ebbcfc4e07c9aaa717d899974001cfcd64e7 | bb50d65e496a43202d59a7f4c1cf6604d088371a7b6149684c5da7b2b4c921ef | null | [] | 236 |
2.4 | pictologics | 0.3.5 | IBSI-compliant radiomic feature extraction package | # Pictologics
<p align="center">
<img src="https://raw.githubusercontent.com/martonkolossvary/pictologics/main/docs/assets/logo.png" width="220" alt="Pictologics logo" />
</p>
[](https://github.com/martonkolossvary/pictologics/actions/workflows/ci.yml)
[](https://martonkolossvary.github.io/pictologics/)
[](https://pypi.org/project/pictologics/)
[](https://pypi.org/project/pictologics/)
[](https://pypi.org/project/pictologics/)
[](https://github.com/martonkolossvary/pictologics/blob/main/LICENSE)
[](https://codecov.io/gh/martonkolossvary/pictologics)
[](https://github.com/astral-sh/ruff)
[](https://mypy-lang.org/)
**Pictologics** is a high-performance, IBSI-compliant Python library for radiomic feature extraction from medical images (NIfTI, DICOM).
Documentation (User Guide, API, Benchmarks): https://martonkolossvary.github.io/pictologics/
## Why Pictologics?
* **🚀 High Performance**: Uses `numba` for Just In Time (JIT) compilation, achieving significant speedups over other libraries (speedups between 15-300x compared to pyradiomics, see [Benchmarks](https://martonkolossvary.github.io/pictologics/benchmarks/) page for details).
* **✅ IBSI Compliant**: Implements standard algorithms verified against the IBSI digital and CT phantoms, and clinical datasets:
* **IBSI 1**: Feature extraction ([compliance report](https://martonkolossvary.github.io/pictologics/ibsi1_compliance/))
* **IBSI 2**: Image filters ([Phase 1](https://martonkolossvary.github.io/pictologics/ibsi2_compliance/)), filtered features ([Phase 2](https://martonkolossvary.github.io/pictologics/ibsi2_phase2_compliance/)), reproducibility ([Phase 3](https://martonkolossvary.github.io/pictologics/ibsi2_phase3_compliance/))
* **🔧 Versatile**: Provides utilities for DICOM parsing and common scientific image processing tasks. Natively supports common image formats (NIfTI, DICOM, DICOM-SEG, DICOM-SR).
* **✨ User-Friendly**: Pure Python implementation with a simple installation process and user-friendly pipeline module supporting easy feature extraction and analysis, ensuring a smooth experience from setup to analysis.
* **🛠️ Actively Maintained**: Continuously maintained and developed with the intention to provide robust latent radiomic features that can reliably describe morphological characteristics of diseases on radiological images.
## Installation
Pictologics requires Python 3.12+.
```bash
pip install pictologics
```
Or install from source:
```bash
git clone https://github.com/martonkolossvary/pictologics.git
cd pictologics
pip install .
```
## Quick Start
```python
from pictologics import RadiomicsPipeline, format_results, save_results
# 1. Initialize the pipeline
pipeline = RadiomicsPipeline()
# 2. Run the "all_standard" configurations
results = pipeline.run(
image="path/to/image.nii.gz",
mask="path/to/mask.nii.gz",
subject_id="Subject_001",
config_names=["all_standard"]
)
# 3. Inject subject ID or other metadata directly into the row
row = format_results(
results,
fmt="wide",
meta={"subject_id": "Subject_001", "group": "control"}
)
# 4. Save to CSV
save_results([row], "results.csv")
```
## Performance Benchmarks
### Benchmark Configuration
Comparisons between **Pictologics** and **PyRadiomics** (single-thread parity).
> [!TIP]
> Detailed performance tables and extra feature (IVH, local intensity, GLDZM, etc.) measurements available in the [Benchmarks Documentation](https://martonkolossvary.github.io/pictologics/benchmarks/).
**Test Data Generation:**
- **Texture**: 3D correlated noise generated using Gaussian smoothing.
- **Mask**: Blob-like structures generated via thresholded smooth noise with random holes.
- **Voxel Distribution**: Mean=486.04, Std=90.24, Min=0.00, Max=1000.00.
### HARDWARE USED FOR CALCULATIONS
- **Hardware**: Apple M4 Pro, 14 cores, 48 GB
- **OS**: macOS 26.3 (arm64)
- **Python**: 3.12.10
- **Core deps**: pictologics 0.3.4, numpy 2.2.6, scipy 1.17.0, numba 0.62.1, pandas 2.3.3, matplotlib 3.10.7
- **PyRadiomics stack (parity runs)**: pyradiomics 3.1.1.dev111+g8ed579383, SimpleITK 2.5.3
- **BLAS/LAPACK**: Apple Accelerate (from `numpy.show_config()`)
Note: the benchmark script explicitly calls `warmup_jit()` before timing to avoid including Numba compilation overhead in the measured runtimes. Timing and memory measurement are separated — `tracemalloc` is NOT active during timing to avoid biasing the comparison (its per-allocation hooks penalise pure-Python code more than JIT/C code). All calculations are repeated 5 times and the **mean** runtime is reported; peak memory is measured once separately.
### Intensity
| Execution Time (Log-Log) | Speedup |
|:---:|:---:|
| [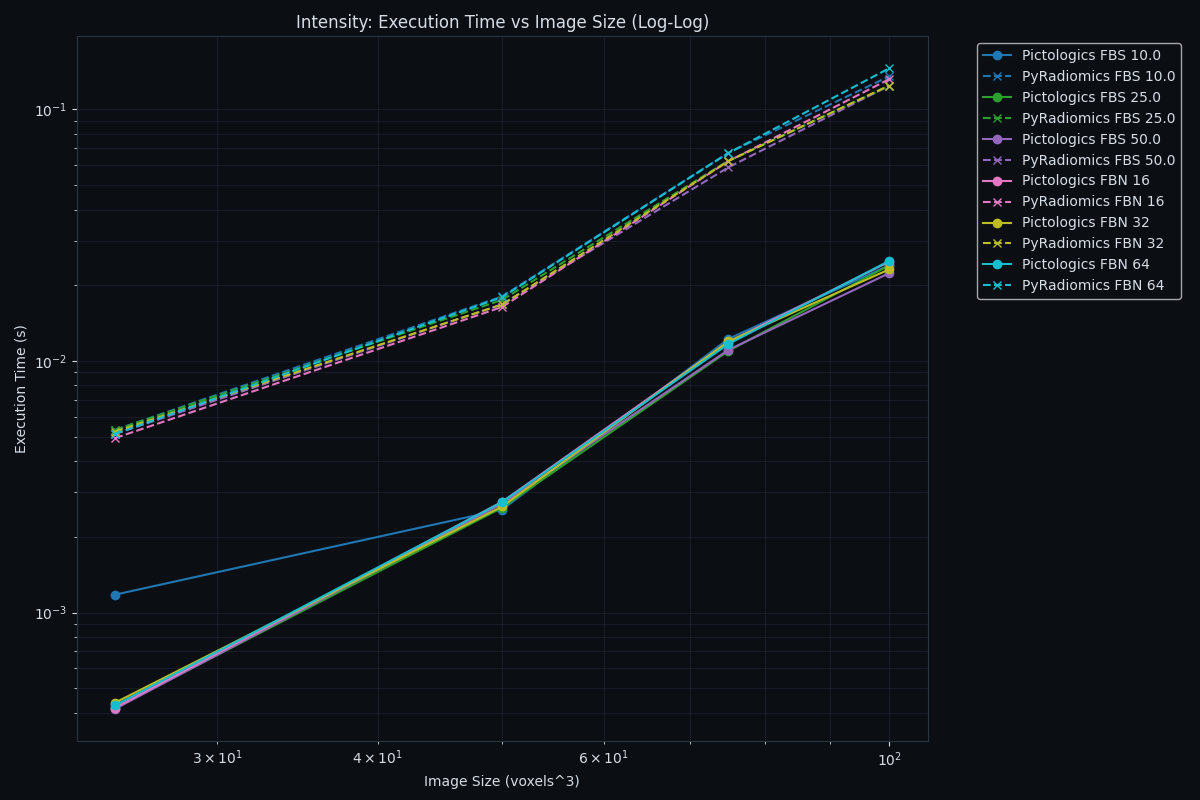](https://raw.githubusercontent.com/martonkolossvary/pictologics/main/docs/assets/benchmarks/intensity_execution_time_log.png) | [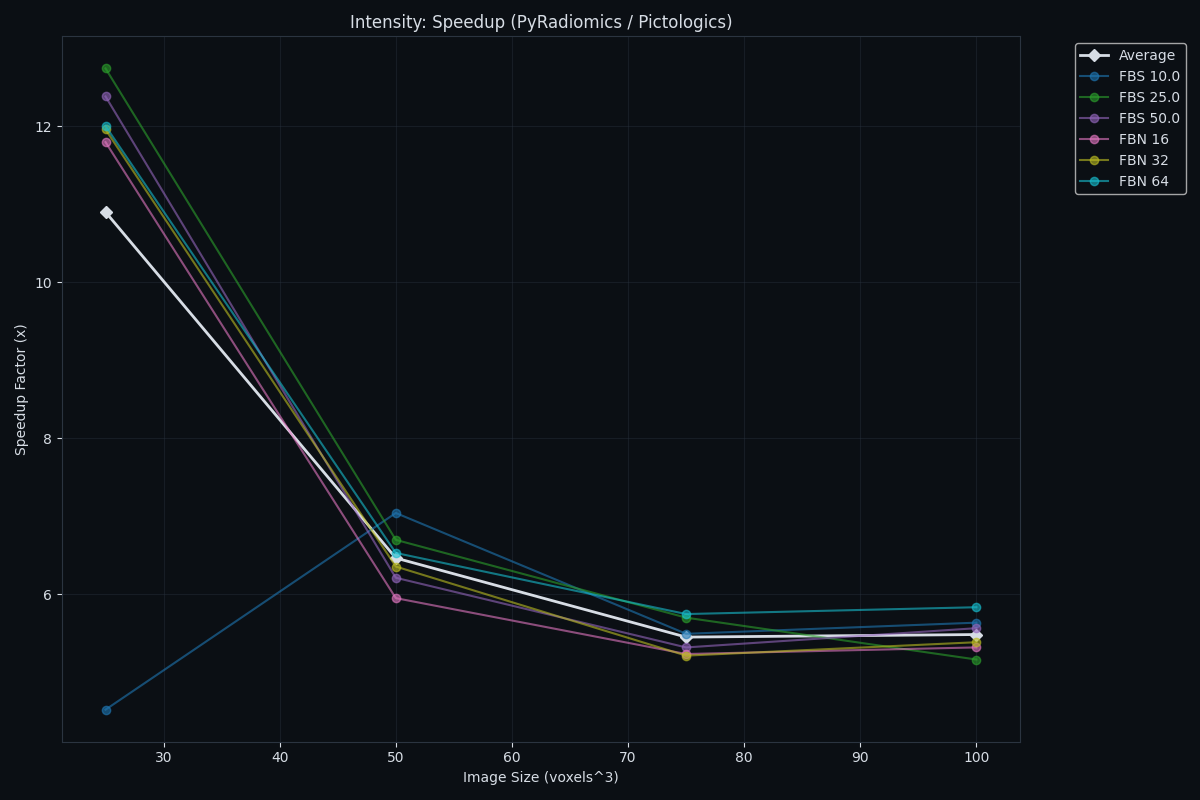](https://raw.githubusercontent.com/martonkolossvary/pictologics/main/docs/assets/benchmarks/intensity_speedup_factor.png) |
### Morphology
| Execution Time (Log-Log) | Speedup |
|:---:|:---:|
| [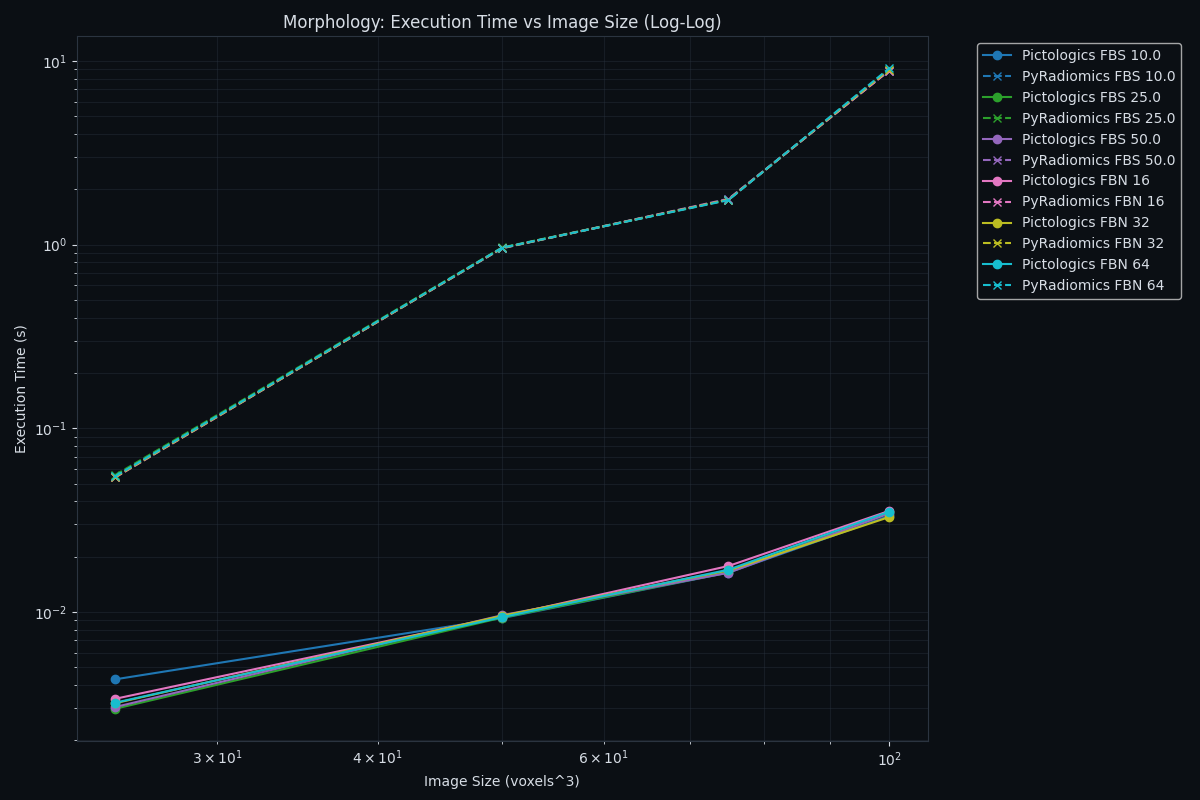](https://raw.githubusercontent.com/martonkolossvary/pictologics/main/docs/assets/benchmarks/morphology_execution_time_log.png) | [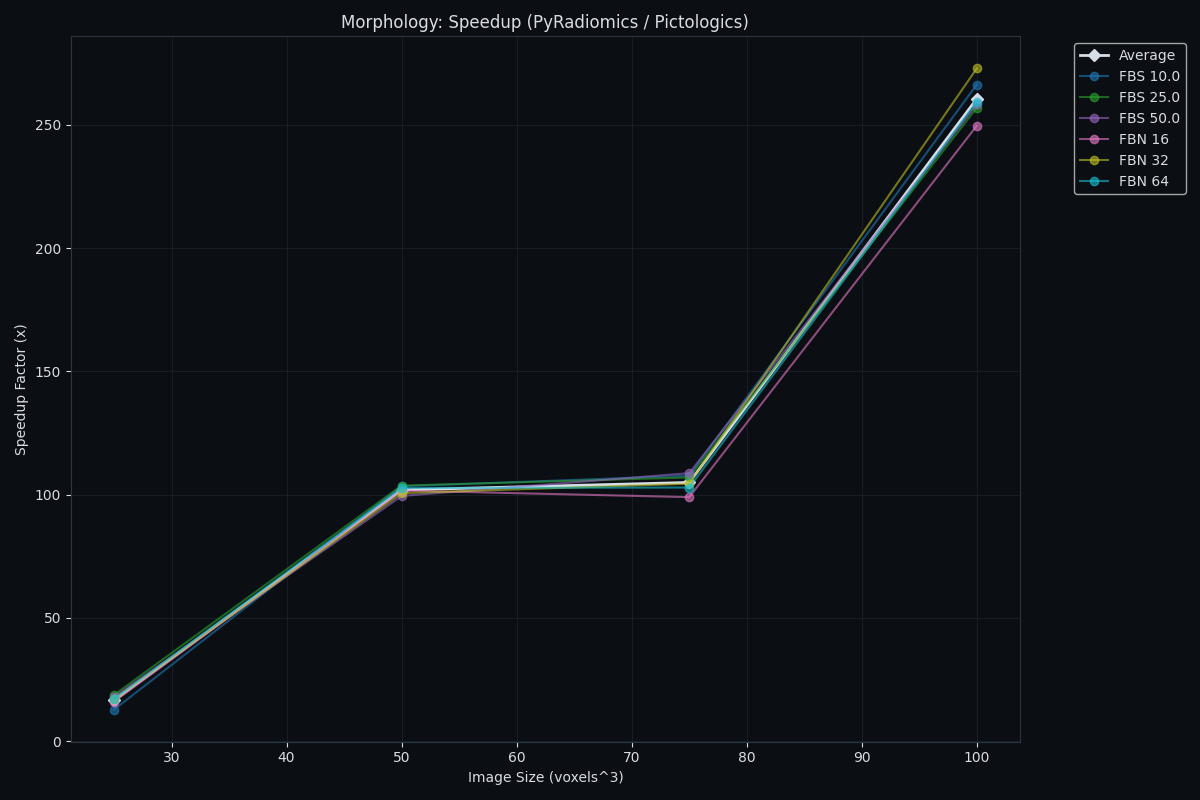](https://raw.githubusercontent.com/martonkolossvary/pictologics/main/docs/assets/benchmarks/morphology_speedup_factor.png) |
### Texture
| Execution Time (Log-Log) | Speedup |
|:---:|:---:|
| [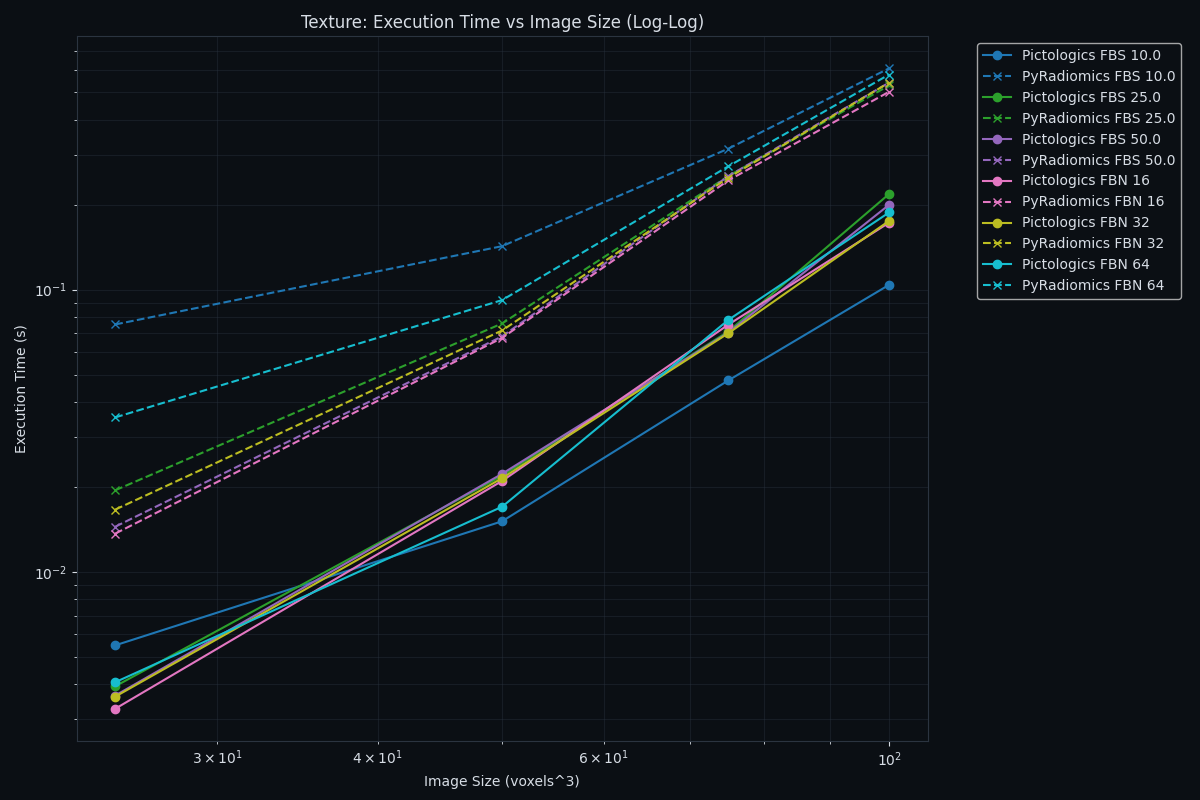](https://raw.githubusercontent.com/martonkolossvary/pictologics/main/docs/assets/benchmarks/texture_execution_time_log.png) | [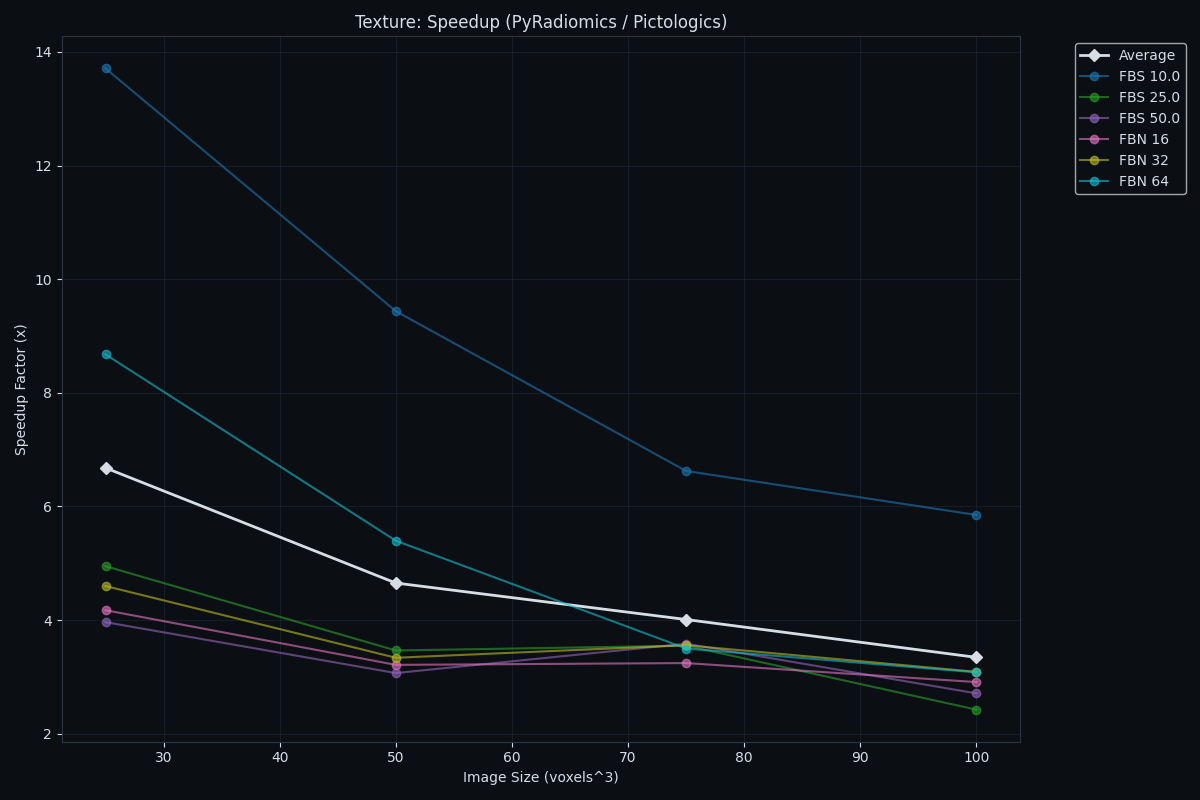](https://raw.githubusercontent.com/martonkolossvary/pictologics/main/docs/assets/benchmarks/texture_speedup_factor.png) |
### Filters
| Execution Time (Log-Log) | Speedup |
|:---:|:---:|
| [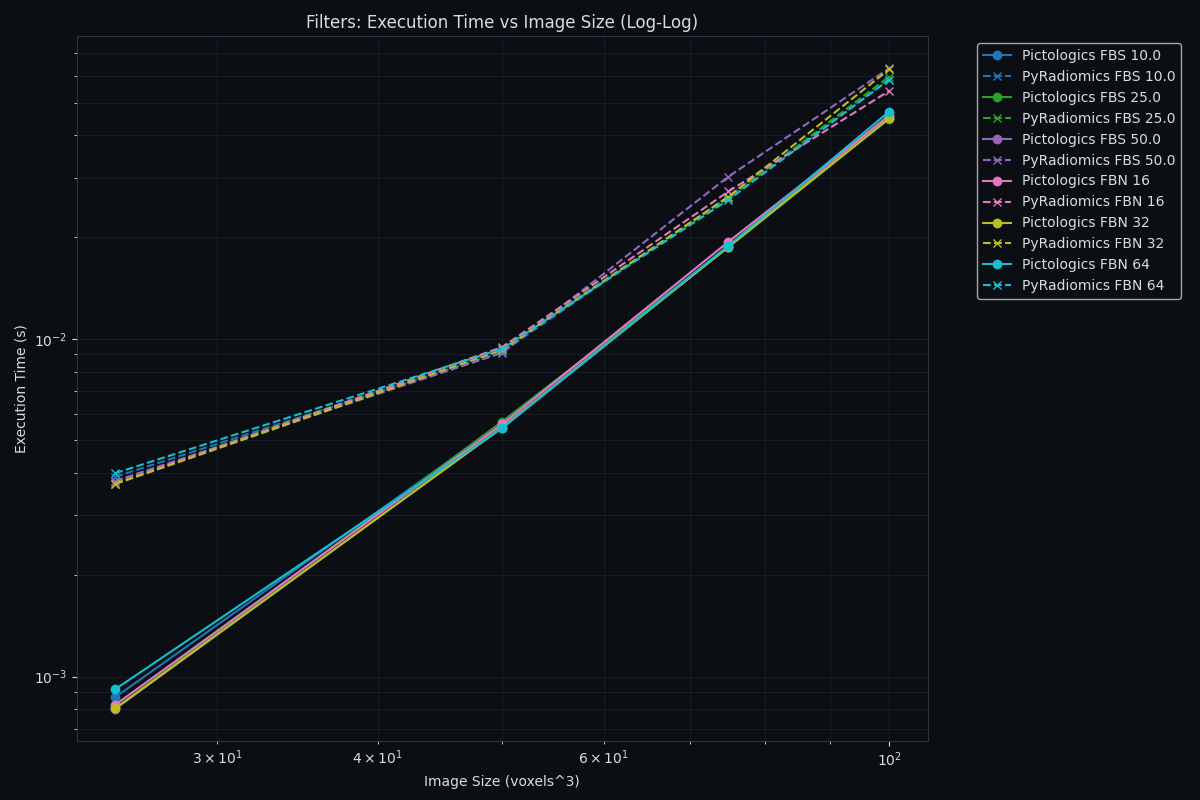](https://raw.githubusercontent.com/martonkolossvary/pictologics/main/docs/assets/benchmarks/filters_execution_time_log.png) | [](https://raw.githubusercontent.com/martonkolossvary/pictologics/main/docs/assets/benchmarks/filters_speedup_factor.png) |
## Quality & Compliance
**IBSI Compliance**: [IBSI 1 Features](https://martonkolossvary.github.io/pictologics/ibsi1_compliance/) | [IBSI 2 Phase 1 Filters](https://martonkolossvary.github.io/pictologics/ibsi2_compliance/) | [Phase 2 Features](https://martonkolossvary.github.io/pictologics/ibsi2_phase2_compliance/) | [Phase 3 Reproducibility](https://martonkolossvary.github.io/pictologics/ibsi2_phase3_compliance/)
### Code Health
- **Test Coverage**: 100.00%
- **Mypy Errors**: 0
- **Ruff Issues**: 0
See [Quality Report](https://martonkolossvary.github.io/pictologics/quality/) for full details.
## Citation
Citation information will be added/updated.
## License
Apache-2.0
| text/markdown | Márton Kolossváry | marton.kolossvary@gmail.com | null | null | Apache-2.0 | radiomics, medical-imaging, ibsi, dicom, nifti | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic ... | [] | null | null | <3.15,>=3.12 | [] | [] | [] | [
"Pillow<12.0.0,>=11.1.0",
"PyWavelets<2.0,>=1.4",
"highdicom>=0.22.0",
"matplotlib<4.0.0,>=3.10.0",
"nibabel>=3.2.0",
"numba<0.63.0,>=0.62.1",
"numpy<2.3,>=2.0",
"pandas>=2.0.0",
"pydicom>=2.2.0",
"pymcubes<0.2.0,>=0.1.6",
"pyyaml>=6.0",
"scipy<2.0.0,>=1.16.3",
"tqdm<5.0.0,>=4.66.0"
] | [] | [] | [] | [
"Documentation, https://martonkolossvary.github.io/pictologics/",
"Homepage, https://martonkolossvary.github.io/pictologics/",
"Repository, https://github.com/martonkolossvary/pictologics"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:51:44.915469 | pictologics-0.3.5.tar.gz | 130,426 | 84/3a/fef4deb176ef6e6f4a00f8f1dba6809321256e312e058134a5e2eb2596c1/pictologics-0.3.5.tar.gz | source | sdist | null | false | 77ce97b56a1541e6db0e65dc96b75d67 | 3051d86e2f4018c33af5d6db39be0c45f447bd157c1ab2346ad9bfd410d85826 | 843afef4deb176ef6e6f4a00f8f1dba6809321256e312e058134a5e2eb2596c1 | null | [
"LICENSE",
"NOTICE"
] | 209 |
2.4 | nebula-client | 2.1.24 | Official Python SDK for Nebula API | # Nebula Python SDK
Persistent memory layer for AI applications. Store, search, and retrieve information with semantic understanding.
## Requirements
- Python 3.10 or higher
## Installation
```bash
pip install nebula-client
```
## Quick Start
```python
from nebula import Nebula
# Initialize client
client = Nebula(api_key="your-api-key")
# Create a collection
collection = client.create_cluster(name="my_notes")
# Store a memory
memory_id = client.store_memory({
"collection_id": collection.id,
"content": "Machine learning is transforming healthcare",
"metadata": {"topic": "AI", "importance": "high"}
})
# Search memories
results = client.search(
query="machine learning healthcare",
collection_ids=[collection.id],
limit=5
)
for result in results:
print(f"Score: {result.score:.2f}")
print(f"Content: {result.content}")
```
## Core Operations
### Collections
```python
# Create
collection = client.create_cluster(name="my_collection", description="Optional description")
# List
collections = client.list_clusters()
# Get by ID or name
collection = client.get_cluster(collection_id)
collection = client.get_cluster_by_name("my_collection")
# Update
client.update_cluster(collection_id, name="new_name")
# Delete
client.delete_cluster(collection_id)
```
### Store Memories
```python
# Single memory
from nebula import Memory
memory = Memory(
collection_id=collection.id,
content="Your content here",
metadata={"category": "example"}
)
memory_id = client.store_memory(memory)
# Batch storage
memories = [
Memory(collection_id=collection.id, content="First memory"),
Memory(collection_id=collection.id, content="Second memory")
]
ids = client.store_memories(memories)
```
### Retrieve Memories
```python
# List memories
memories = client.list_memories(collection_ids=[collection.id], limit=10)
# Filter with metadata
memories = client.list_memories(
collection_ids=[collection.id],
metadata_filters={"metadata.category": {"$eq": "example"}}
)
# Get specific memory
memory = client.get_memory("memory_id")
```
### Search
```python
# Semantic search
results = client.search(
query="your search query",
collection_ids=[collection.id],
limit=10
)
```
### Delete
```python
# Single deletion
deleted = client.delete("memory_id") # Returns True
# Batch deletion
result = client.delete(["id1", "id2", "id3"]) # Returns detailed results
```
## Conversations
```python
# Store conversation messages
user_msg = Memory(
collection_id=collection.id,
content="What is machine learning?",
role="user",
metadata={"content_type": "conversation"},
)
conv_id = client.store_memory(user_msg)
assistant_msg = Memory(
collection_id=collection.id,
content="Machine learning is a subset of AI...",
role="assistant",
parent_id=conv_id,
metadata={"content_type": "conversation"},
)
client.store_memory(assistant_msg)
# List conversation memories (filtering by metadata set above)
conversations = client.list_memories(
collection_ids=[collection.id],
metadata_filters={"metadata.content_type": {"$eq": "conversation"}},
)
# Get messages from a conversation memory
conversation = client.get_memory(conv_id)
messages = conversation.chunks or []
```
## Async Client
```python
from nebula import AsyncNebula, Memory
async with AsyncNebula(api_key="your-api-key") as client:
# All methods available with await
collection = await client.create_cluster(name="async_collection")
memory_id = await client.store_memory(Memory(
collection_id=collection.id,
content="Async memory"
))
results = await client.search("query", collection_ids=[collection.id])
```
## Documentation
- [Full Documentation](https://docs.trynebula.ai)
- [API Reference](https://docs.trynebula.ai/clients/python)
- [Examples](./examples/)
## Support
Email [support@trynebula.ai](mailto:support@trynebula.ai)
| text/markdown | null | Nebula AI Inc <support@trynebula.ai> | null | null | MIT | nebula, ai, memory, vector, search, embeddings, rag | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.24.0",
"typing-extensions>=4.0.0",
"tiktoken>=0.6.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest-mock>=3.10.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://trynebula.ai",
"Documentation, https://docs.trynebula.ai",
"Repository, https://github.com/nebula-agi/nebula-sdks",
"Issues, https://github.com/nebula-agi/nebula-sdks/issues",
"Changelog, https://github.com/nebula-agi/nebula-sdks/blob/main/CHANGELOG.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:51:33.978507 | nebula_client-2.1.24.tar.gz | 45,341 | 39/68/cde5466c2623406f91be86c62e442fa6c1c7bdc10408e935d26e775d0f08/nebula_client-2.1.24.tar.gz | source | sdist | null | false | cfbe633bc7cbeae196daaade8179c378 | 07d06d6cc481d63d867b54a1b28ec7a37ef4154d042181a308c2c026da591525 | 3968cde5466c2623406f91be86c62e442fa6c1c7bdc10408e935d26e775d0f08 | null | [] | 411 |
2.4 | claude-kb | 0.6.0 | Universal knowledge base with Qdrant for Claude Code integration | # Claude KB
Universal knowledge base with Qdrant for Claude Code integration.
Provides semantic search across:
- Claude Code conversation history
- Personal knowledge entities
- Documents and research notes
## Installation
### Run directly (no install)
```bash
uvx claude-kb@latest status
```
### Install as a tool
```bash
uv tool install claude-kb
kb status
# Update to latest version
uv tool upgrade claude-kb
```
### Development
```bash
git clone https://github.com/tenequm/claude-kb.git
cd claude-kb
uv sync --extra dev
```
## Features
- **Hybrid search**: Dense (semantic) + sparse (keyword) vectors with RRF fusion
- **Claude Code import**: Automatically import your conversation history
- **LLM-optimized CLI**: `kb ai` command provides token-efficient schema for AI agents
- **FastEmbed/ONNX**: Fast local embeddings with bge-base-en-v1.5 (768 dim, ~1s search time)
- **Self-hosted**: Run locally with Docker Compose
## Quick Start
```bash
# Start Qdrant
docker compose up -d
# Initialize collections
kb init
# Import your Claude Code conversations
kb import claude-code-chats
# Search!
kb search "qdrant vector databases"
```
## Usage
### Search conversations
```bash
kb search "your query"
kb search "query" --collection conversations --limit 20
```
### Get specific message
```bash
kb get msg_abc123
```
### Check status
```bash
kb status
```
### LLM-optimized schema (for AI agents)
```bash
kb ai
```
This outputs a token-efficient format that Claude Code and other LLMs can parse to understand how to use the CLI. See [docs/AI_COMMAND_SPEC.md](docs/AI_COMMAND_SPEC.md) for details.
## MCP Server
Claude KB provides an MCP server for integration with Claude Code:
```bash
# Add to Claude Code
claude mcp add kb -- uv run kb mcp
# Or run standalone
uv run kb mcp
```
## Understanding Search Results
### Score Interpretation
- **0.9+**: Very high relevance (exact topic match)
- **0.7-0.9**: Good match (related concepts)
- **0.5-0.7**: Moderate match (partial relevance)
- **<0.5**: Filtered out by default
### Why results might be empty
1. **min_score too high** (default 0.5) - try lowering to 0.3
2. **Query too specific** - use broader conceptual terms
3. **Project filter doesn't match** - it's a partial, case-sensitive match
4. **No data imported** - run `kb status` to verify
### Content visibility
- All content is indexed and searchable (including tool results and thinking blocks)
- By default, output shows placeholders: `[tool result: N chars]`, `[thinking: N chars]`
- Use `include_tool_results=True` or `include_thinking=True` to see full content
### Filter Application Order
Filters are applied in this sequence:
1. **Semantic search + min_score** (server-side in Qdrant)
2. **Metadata filters** (project, role, from_date, to_date) (server-side)
3. **Recency boost** (if enabled)
4. **Limit** applied
This means if `min_score` filters out results, date filters never see them.
## Architecture
- **Simplified structure**: cli.py, core.py, import_claude.py (No manual embedding code!)
- **Qdrant collections**: conversations, entities, documents
- **Embedding**: QdrantClient built-in FastEmbed with BAAI/bge-base-en-v1.5 (768 dim, ONNX-optimized)
- **Search time**: ~1 second total (0.7s model load + 0.3s search)
- **Output format**: Structured plaintext (NOT JSON) optimized for LLM parsing
## Configuration
Create `.env` file (see `.env.example`):
```bash
QDRANT_URL=http://localhost:6333
EMBEDDING_MODEL=BAAI/bge-base-en-v1.5 # FastEmbed model (768 dims, ~1s search)
# Alternative models:
# EMBEDDING_MODEL=BAAI/bge-small-en-v1.5 # Faster (384 dims, ~0.5s)
# EMBEDDING_MODEL=BAAI/bge-large-en-v1.5 # Higher quality (1024 dims, ~2s)
```
## Development
```bash
# Format + lint
ruff format . && ruff check . --fix
# Test (manual for now)
uv run kb --help
```
## Roadmap
- [ ] Streaming search (background mode)
- [ ] Entity management (`kb add entity`)
- [ ] Document import (`kb add document`)
- [ ] Relationship traversal (`kb related`)
- [ ] Full hybrid search (sparse vectors)
- [ ] Token-aware context window truncation
## License
MIT
| text/markdown | null | Misha Kolesnik <misha@kolesnik.io> | null | null | MIT | ai, claude, embeddings, knowledge-base, qdrant, semantic-search, vector-search | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Topic :: Database",
"Topic :: Text Process... | [] | null | null | >=3.13 | [] | [] | [] | [
"click<9,>=8.1.0",
"httpx<1,>=0.27.0",
"mcp<2,>=1.23.0",
"pydantic<3,>=2.0.0",
"python-dotenv<2,>=1.0.0",
"qdrant-client<2,>=1.11.0",
"rich<15,>=13.0.0",
"sentence-transformers<6,>=5.0.0",
"tiktoken<1,>=0.5.0",
"torch<3,>=2.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/tenequm/claude-kb",
"Repository, https://github.com/tenequm/claude-kb",
"Issues, https://github.com/tenequm/claude-kb/issues"
] | uv/0.10.3 {"installer":{"name":"uv","version":"0.10.3","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T20:51:30.480851 | claude_kb-0.6.0-py3-none-any.whl | 39,087 | 2d/a6/aa7484ba1ee8636f107fdaebeacb39fa92b52227f9ea3979c0ef247a77b3/claude_kb-0.6.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 464a898c1cde57a30d907ed7c7b871cd | ddba4729745d6da27f01d8d7ed080f1de7fc1f100a0aa3743e838713428dce97 | 2da6aa7484ba1ee8636f107fdaebeacb39fa92b52227f9ea3979c0ef247a77b3 | null | [
"LICENSE"
] | 215 |
2.4 | ChainForgeLedger | 1.0.0 | A complete blockchain platform library with PoW/PoS consensus, smart contracts, and DeFi applications | # ChainForgeLedger
A complete blockchain platform library built from scratch with pure Python. ChainForgeLedger provides a comprehensive suite of blockchain functionalities, including core blockchain operations, smart contracts, decentralized finance (DeFi) applications, and enterprise-grade security mechanisms.
## Key Features
ChainForgeLedger offers a rich set of features organized into modular components:
### 1. Core Blockchain Infrastructure
- **Proof of Work (PoW)**: Bitcoin-style mining with difficulty adjustment
- **Proof of Stake (PoS)**: Ethereum-style staking with validator selection
- **Blockchain Management**: Complete chain lifecycle and block operations
- **Transaction Handling**: Full transaction lifecycle from creation to confirmation
- **State Management**: Efficient state transition and storage
- **Merkle Tree Implementation**: Secure data verification structure
### 2. Consensus Mechanisms
- **Proof of Work (PoW)**: Energy-efficient mining with difficulty adjustment algorithm
- **Proof of Stake (PoS)**: Staking-based consensus with validator management
- **Validator System**: Validator registration, management, and rewards
- **Slashing Mechanism**: Penalties for validator misbehavior (double signing, offline, etc.)
- **Consensus Interface**: Unified interface for multiple consensus mechanisms
- **Consensus Factory**: Dynamic consensus mechanism selection
- **Consensus Manager**: Coordinates consensus operations
### 3. Cryptographic Operations
- **SHA-256 & Keccak256 Hashing**: Secure hashing implementations
- **ECDSA Signatures**: Elliptic Curve Digital Signature Algorithm
- **Key Management**: Key pair generation, storage, and conversion
- **Wallet System**: Multi-type wallet support (standard, multisig, mnemonic-based)
- **Multi-signature Wallets**: Multiple signature authorization
- **Mnemonic Generation**: BIP-39 style seed phrase generation
- **Encryption**: XOR-based AES placeholder for data encryption
- **HMAC**: Hash-based Message Authentication Code
- **PBKDF2**: Password-based key derivation function
### 4. Smart Contracts
- **Virtual Machine**: Stack-based VM with gas calculation
- **Contract Compiler**: Contract compilation and deployment
- **Contract Execution Engine**: Method dispatch and storage management
- **Execution Sandbox**: Isolated contract execution environment
- **Gas Calculation**: Resource usage metering
### 5. Decentralized Finance (DeFi)
- **Automated Market Maker (AMM)**: Liquidity pool engine with constant product formula
- **Liquidity Pools**: Decentralized exchange functionality with trading fees
- **Lending Protocol**: Borrowing and lending with interest rates and collateral management
- **Staking & Rewards**: Staking pool management with reward distribution
- **Stablecoin Framework**: Algorithmic stablecoin with collateralization and pegging
- **Fee Distribution System**: Automated fee distribution to validators, treasury, and stakeholders
### 6. Tokenomics
- **KK-20 Token Standard**: Fungible token standard (similar to ERC-20)
- **KK-721 Token Standard**: Non-fungible token standard (similar to ERC-721)
- **Token Factory**: Token creation and management system
- **Native Coin Implementation**: ChainForge Coin (CFC) with supply control
- **Treasury Management**: Fund allocation and distribution with DAO governance
- **Supply Control**: Inflation, max supply, and block reward management
### 7. Governance
- **DAO Framework**: Decentralized Autonomous Organization for community governance
- **Proposal System**: Proposal creation, voting, and execution
- **Voting Mechanisms**: Secure voting with stake-weighted voting power
- **Treasury Governance**: DAO-controlled funding and spending
### 8. Networking & P2P Communication
- **Node Management**: Full node functionality
- **Peer Discovery**: Network peer discovery and management
- **Protocol Handling**: Communication protocols for blockchain operations
- **Mempool Management**: Transaction pooling and validation
- **Rate Limiting**: Network request throttling
- **Peer Reputation System**: Sybil attack prevention
### 9. Security Architecture
- **51% Attack Protection**: Chain reorganization detection
- **Sybil Attack Detection**: Node reputation and behavior monitoring
- **Replay Protection**: Transaction replay prevention
- **Double-Spending Detection**: Transaction validation mechanisms
- **Fork Handling**: Fork detection and resolution with multiple strategies
- **State Pruning**: Storage optimization for large blockchains
- **Caching Layer**: Performance optimization through caching
### 10. Scalability Solutions
- **Sharding Support**: Horizontal scaling through blockchain sharding
- **Cross-Chain Bridge**: Asset transfer between different blockchains
- **State Pruning**: Storage optimization for large blockchains
- **Caching Layer**: Performance optimization through caching
### 11. API & Developer Tools
- **RESTful API**: Comprehensive API with endpoints for all blockchain operations
- **API Server**: FastAPI-based server for blockchain interaction
- **API Routes**: Well-documented API endpoints
- **CLI Interface**: Command-line interface for direct interaction
### 12. Storage System
- **Database Abstraction**: Unified database interface
- **LevelDB Storage**: Efficient key-value storage
- **Data Models**: Structured data models for blocks, transactions, and state
- **Serialization**: Efficient data serialization for network communication
### 13. Monitoring & Analytics
- **Blockchain Explorer**: Analytics and visualization of blockchain data
- **Performance Metrics**: Real-time performance monitoring
- **Network Health Monitoring**: Node status and health checks
### 14. Configuration & Utilities
- **Configuration Management**: Environment and settings configuration
- **Logging System**: Comprehensive logging and debugging
- **Crypto Utilities**: Cryptographic helper functions
## Installation
### From Source Code
```bash
cd /home/KK-kanishk/Desktop/RunningProject/GIT _ COMMITED_PROJECTS/chainforgeledger
pip install -e .
```
### Using Virtual Environment (Recommended)
```bash
cd /home/KK-kanishk/Desktop/RunningProject/GIT _ COMMITED_PROJECTS/chainforgeledger
python3 -m venv venv
source venv/bin/activate
pip install -e .
```
## Usage
### Quick Start Example
```python
from chainforgeledger import ProofOfWork, Tokenomics, Wallet
# Create a blockchain with PoW consensus (difficulty 3)
pow_chain = ProofOfWork(difficulty=3)
pow_chain.add_transaction("Transaction 1: User1 -> User2")
pow_chain.add_transaction("Transaction 2: User3 -> User4")
block = pow_chain.mine_block("miner1")
# Create tokenomics system with 1 billion tokens
tokenomics = Tokenomics(total_supply=1000000000, inflation_rate=0.02)
tokenomics.mint_tokens(1000000, 'staking_rewards')
# Create wallets
standard_wallet = Wallet()
multisig_wallet = Wallet('multisig')
# Get blockchain info
print(f"Chain Length: {len(pow_chain.chain)}")
print(f"Block Hash: {block.hash}")
print(f"Total Supply: {tokenomics.total_supply:,}")
```
### Running Examples
#### Basic Usage Example
```bash
cd /home/KK-kanishk/Desktop/RunningProject/GIT _ COMMITED_PROJECTS/chainforgeledger
PYTHONPATH=. python3 example/basic_usage.py
```
#### Comprehensive Platform Example
```bash
cd /home/KK-kanishk/Desktop/RunningProject/GIT _ COMMITED_PROJECTS/chainforgeledger
PYTHONPATH=. python3 example/comprehensive_usage.py
```
#### DeFi Ecosystem Example
```bash
cd /home/KK-kanishk/Desktop/RunningProject/GIT _ COMMITED_PROJECTS/chainforgeledger
PYTHONPATH=. python3 example/ecosystem.py
```
#### Consensus Mechanism Comparison
```bash
cd /home/KK-kanishk/Desktop/RunningProject/GIT _ COMMITED_PROJECTS/chainforgeledger
PYTHONPATH=. python3 example/compare_consensus.py
```
## CLI Commands
### ChainForgeLedger CLI
The library provides a comprehensive command-line interface with multiple commands:
```bash
# Show help information
chainforgeledger --help
# Run basic blockchain demonstration
chainforgeledger basic
# Run comprehensive platform demonstration
chainforgeledger demo
# Run Proof of Work operations
chainforgeledger pow --mine # Mine a block with default difficulty (3)
chainforgeledger pow --mine --difficulty 2 # Mine with lower difficulty
# Run Proof of Stake operations
chainforgeledger pos --forge # Forge a block
# Tokenomics operations
chainforgeledger token --create # Create tokenomics system
chainforgeledger token --create --supply 500000000 # Custom supply
chainforgeledger token --mint 100000 # Mint 100,000 tokens
```
## Testing
ChainForgeLedger includes a comprehensive test suite to ensure the reliability and correctness of all blockchain components.
### Test Files
- **`tests/test_basic.py`**: Basic functionality tests for core blockchain operations, cryptographic functions, and wallet management.
- **`tests/test_comprehensive.py`**: Comprehensive integration tests covering all major components and features, including:
- Core blockchain operations (block creation, transaction handling, chain validation)
- Consensus mechanisms (PoW, PoS, consensus interface implementations)
- Cryptographic operations (hashing, signature, wallet functions)
- Smart contract operations (VM, compiler, executor, sandbox)
- DeFi applications (liquidity pools, lending, staking)
- Governance system (DAO, voting, treasury management)
- Tokenomics (token standards, supply management, stablecoins)
- Networking and storage
- Comprehensive platform integration testing
### Running Tests
```bash
cd /home/KK-kanishk/Desktop/RunningProject/GIT _ COMMITED_PROJECTS/chainforgeledger
python -m pytest tests/test_basic.py -v # Run basic tests
python -m pytest tests/test_comprehensive.py -v # Run all comprehensive tests
```
### Running Specific Tests
```bash
# Run only consensus interface tests
python -m pytest tests/test_comprehensive.py::TestChainForgeLedgerComprehensive::test_pow_interface tests/test_comprehensive.py::TestChainForgeLedgerComprehensive::test_pos_interface -v
# Run only tokenomics tests
python -m pytest tests/test_comprehensive.py -k "test_token" -v
# Run all tests with coverage
python -m pytest tests/test_basic.py tests/test_comprehensive.py --cov=chainforgeledger --cov-report=html
```
### Test Coverage
The comprehensive test file covers all components of the ChainForgeLedger platform, including:
- **Consensus Interfaces**: Tests for ProofOfWorkInterface, ProofOfStakeInterface, and other consensus mechanisms
- **Core Blockchain**: Tests for block operations, chain validation, and blockchain management
- **Cryptographic Functions**: Tests for SHA-256, Keccak256, signatures, and wallet operations
- **Smart Contracts**: Tests for the virtual machine, compiler, executor, and sandbox environment
- **DeFi Applications**: Tests for liquidity pools, lending protocols, and staking systems
- **Tokenomics**: Tests for token standards, supply management, and stablecoin functionality
- **Governance**: Tests for DAO operations, voting systems, and treasury management
- **Networking**: Tests for peer discovery, communication protocols, and rate limiting
- **Storage**: Tests for LevelDB storage and serialization
All tests are passing successfully and provide comprehensive coverage of the platform's functionality.
## Project Structure
```
/home/KK-kanishk/Desktop/RunningProject/GIT _ COMMITED_PROJECTS/chainforgeledger/
├── chainforgeledger/ # Main library package
│ ├── __init__.py # Package initialization
│ ├── __main__.py # CLI interface
│ ├── core/ # Core blockchain functionality
│ │ ├── block.py # Block structure and validation
│ │ ├── blockchain.py # Blockchain management
│ │ ├── transaction.py # Transaction handling
│ │ ├── merkle.py # Merkle tree implementation
│ │ ├── state.py # State management
│ │ ├── bridge.py # Cross-chain bridge
│ │ ├── staking.py # Staking and reward distribution
│ │ ├── liquidity.py # Liquidity pool and AMM
│ │ ├── fee_distribution.py # Fee distribution system
│ │ ├── fork.py # Fork handling mechanism
│ │ ├── sharding.py # Blockchain sharding
│ │ ├── state_pruning.py # State pruning for storage optimization
│ │ ├── lending.py # Lending and borrowing
│ │ ├── caching.py # Caching layer
│ │ ├── difficulty.py # Difficulty adjustment algorithm
│ │ └── serialization.py # Data serialization
│ ├── consensus/ # Consensus mechanisms
│ │ ├── pow.py # Proof of Work
│ │ ├── pos.py # Proof of Stake
│ │ ├── validator.py # Validator management
│ │ ├── slashing.py # Validator slashing mechanism
│ │ └── interface.py # Consensus interface and factory
│ ├── crypto/ # Cryptographic operations
│ │ ├── __init__.py # Crypto module initialization
│ │ ├── hashing.py # SHA-256 and Keccak256 hashing
│ │ ├── keys.py # Key pair generation and management
│ │ ├── signature.py # Digital signature utilities
│ │ ├── wallet.py # Wallet system
│ │ ├── multisig.py # Multi-signature wallets
│ │ └── mnemonic.py # Mnemonic seed phrase generation
│ ├── governance/ # Governance system
│ │ ├── dao.py # DAO framework
│ │ ├── proposal.py # Proposal management
│ │ └── voting.py # Voting mechanisms
│ ├── networking/ # Network communication
│ │ ├── node.py # Node management
│ │ ├── peer.py # Peer discovery
│ │ ├── protocol.py # Communication protocols
│ │ ├── mempool.py # Transaction mempool
│ │ └── rate_limiter.py # Network rate limiting
│ ├── smartcontracts/ # Smart contract layer
│ │ ├── vm.py # Virtual machine
│ │ ├── compiler.py # Contract compiler
│ │ ├── executor.py # Contract execution engine
│ │ └── sandbox.py # Contract execution sandbox
│ ├── tokenomics/ # Token and economic system
│ │ ├── __init__.py # Tokenomics module initialization
│ │ ├── standards.py # KK-20 and KK-721 token standards
│ │ ├── supply.py # Token supply management
│ │ ├── native.py # Native coin implementation
│ │ ├── stablecoin.py # Stablecoin framework
│ │ └── treasury.py # Treasury management
│ ├── storage/ # Data storage
│ │ ├── database.py # Database interface
│ │ ├── leveldb.py # LevelDB storage
│ │ └── models.py # Data models
│ ├── utils/ # Utility modules
│ │ ├── config.py # Configuration management
│ │ ├── crypto.py # Cryptographic utilities
│ │ └── logger.py # Logging system
│ └── api/ # API interface
│ ├── server.py # API server
│ └── routes.py # API routes
├── example/ # Usage examples
│ ├── basic_usage.py # Basic blockchain operations
│ ├── comprehensive_usage.py # Complete platform integration
│ ├── compare_consensus.py # Consensus mechanism comparison
│ └── ecosystem.py # DeFi ecosystem example
├── tests/ # Test suite
│ ├── test_basic.py # Basic functionality tests
│ └── test_comprehensive.py # Comprehensive integration tests
├── setup.py # Package configuration
├── pyproject.toml # Project metadata
├── requirements.txt # Dependency management
└── README.md # Project documentation
```
## Performance Optimizations
The ChainForgeLedger library has been optimized for minimum time and space complexity. Key optimizations include:
### 1. Core Blockchain Optimizations
- **Block Lookup**: O(1) hash map lookup using `_block_hash_map` instead of O(n) linear search
- **Transaction Lookup**: O(1) hash map lookup using `_transaction_map` instead of O(n) linear search
- **Duplicate Vote Checking**: O(1) set membership check using `_voted_addresses`
- **Proposal Lookups**: O(1) dictionary lookup using `_proposals_dict`
### 2. Storage & Caching
- **State Pruning**: Efficient storage optimization by removing old state data while maintaining integrity
- **Caching Layer**: Multi-type caching (blocks, transactions, accounts, contracts, metadata) with configurable TTL and sizes
- **LevelDB Storage**: Efficient key-value storage for blockchain data
### 3. Networking Optimizations
- **Rate Limiting**: Prevent network abuse with configurable rate limiting per IP address
- **Peer Reputation System**: Identify and block malicious nodes
- **Transaction Pool**: Optimized transaction management with quick lookup and validation
### 4. Consensus Optimizations
- **Difficulty Adjustment**: Dynamic difficulty calculation based on block time targets
- **Validator Selection**: Efficient validator selection algorithm for PoS
- **Slashing Mechanism**: Quick validation of validator behavior
### 5. Scalability Solutions
- **Sharding**: Horizontal scaling through blockchain sharding
- **Cross-Chain Bridge**: Efficient asset transfer between blockchains
- **State Pruning**: Storage optimization for large blockchains
### Performance Benefits
- **Block lookups by hash**: O(1) instead of O(n)
- **Transaction lookups**: O(1) instead of O(n)
- **Vote checking**: O(1) instead of O(n)
- **Proposal lookups**: O(1) instead of O(n)
- **Storage efficiency**: Up to 90% reduction in storage requirements through state pruning
These optimizations make ChainForgeLedger highly efficient when handling large numbers of transactions, blocks, and proposals, especially in decentralized governance and DeFi scenarios.
## Features
### Cryptographic Operations
- **SHA-256 Hashing**: Self-made implementation for secure hashing
- **ECDSA Signatures**: Self-made Elliptic Curve Digital Signature Algorithm
- **Key Management**: Key pair generation, storage, and conversion
- **Encryption**: XOR-based AES placeholder for data encryption
- **HMAC**: Hash-based Message Authentication Code
- **PBKDF2**: Password-based key derivation function
- **Random Number Generation**: Secure random string generation
### Core Blockchain
- **Proof of Work (PoW)**: Bitcoin-style mining with difficulty adjustment
- **Proof of Stake (PoS)**: Ethereum-style staking with validator selection
- **Transaction Management**: Complete transaction lifecycle
- **Block Validation**: Blockchain integrity and security checks
### Smart Contracts
- **Virtual Machine**: Stack-based VM with gas calculation
- **Contract Execution**: Method dispatch and storage management
- **Deployment**: Contract compilation and deployment process
### Decentralized Finance (DeFi)
- **DEX**: Automated Market Making (AMM) with liquidity pools
- **Lending Protocol**: Borrowing and lending with interest rates
- **NFT Marketplace**: Digital asset creation, minting, and trading
### Security
- **51% Attack Protection**: Chain reorganization detection
- **Sybil Attack Detection**: Node reputation and behavior monitoring
- **Replay Protection**: Transaction replay prevention
- **Double-Spending Detection**: Transaction validation mechanisms
### Governance
- **DAO Framework**: Decentralized governance with voting
- **Vesting Schedules**: Token distribution mechanisms
- **Treasury Management**: Fund allocation and distribution
- **Validator Rewards**: Incentive systems for network participants
### Wallet System
- **Standard Wallet**: Basic wallet functionality
- **CLI Wallet**: Command-line interface for direct interaction
- **Web Wallet**: Browser-based interface
- **Mobile Wallet**: Smartphone-optimized interface
- **Multisig Wallet**: Multiple signature authorization
- **Hardware Wallet**: Cold storage integration
### Tokenomics
- **Total Supply**: 1 billion tokens with annual inflation
- **Staking Rewards**: 10% of supply for staking incentives
- **Vesting Periods**: Lock-up periods for different stakeholders
- **Slashing Mechanisms**: Penalties for malicious behavior
## Requirements
- Python 3.8 or higher
- No external dependencies (pure Python implementation)
- Platform independent (works on Linux, macOS, Windows)
## Development
### Contributing
1. Fork the repository
2. Create a feature branch
3. Make your changes
4. Write tests for new functionality
5. Run tests to ensure everything passes
6. Create a pull request
### Building Package
```bash
cd /home/KK-kanishk/Desktop/RunningProject/GIT _ COMMITED_PROJECTS/chainforgeledger
python -m build
```
## License
MIT License - see LICENSE file for details
## Authors
Kanishk Kumar Singh - Initial development
## Support
For issues or questions:
- Open an issue on GitHub
- Contact the development team
## Project Philosophy
ChainForgeLedger is designed with the following principles:
### Educational Focus
- Complete from-scratch implementation for learning purposes
- Clean architecture with well-documented components
- Pure Python implementation for accessibility
- Comprehensive example applications
### Modular Design
- Each feature is a separate module with clear interfaces
- Easy to extend and customize
- Supports multiple consensus mechanisms
- Pluggable storage and networking components
### Enterprise-Grade Features
- Production-ready architecture patterns
- Comprehensive security mechanisms
- Scalability solutions (sharding, cross-chain)
- DeFi ecosystem support
### Performance Optimized
- O(1) complexity for key operations
- Efficient caching and storage mechanisms
- Optimized data structures
- Network and computational efficiency
---
**Note**: This is an educational implementation designed for learning purposes. It is not intended for production use with real cryptocurrency.
| text/markdown | null | Kanishk Kumar Singh <kanishkkumar2004@gmail.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Financial and Insurance Industry",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language... | [] | null | null | >=3.8 | [] | [] | [] | [
"msgpack>=1.0",
"pyyaml>=6.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"flake8>=5.0; extra == \"dev\"",
"black>=23.0; extra == \"dev\"",
"sphinx>=5.0; extra == \"docs\"",
"sphinx-rtd-theme>=1.2; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://github.com/kanishkkumarsingh2004/ChainForgeLedger",
"Repository, https://github.com/kanishkkumarsingh2004/ChainForgeLedger"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T20:50:40.082825 | chainforgeledger-1.0.0.tar.gz | 140,140 | f9/78/9020d00ac3d7e25b962fe6cc07b2caf80a2a3798db94a1ba19ff0ea99f01/chainforgeledger-1.0.0.tar.gz | source | sdist | null | false | 28ec3c40ee35c80276dbc66c033f1c1f | 10d244407d06fef66ad00dc80e29a4f2547fd4b3f0f5e47d733c6131470cc6a5 | f9789020d00ac3d7e25b962fe6cc07b2caf80a2a3798db94a1ba19ff0ea99f01 | MIT | [] | 0 |
2.4 | mypy-boto3-ecr | 1.42.53 | Type annotations for boto3 ECR 1.42.53 service generated with mypy-boto3-builder 8.12.0 | <a id="mypy-boto3-ecr"></a>
# mypy-boto3-ecr
[](https://pypi.org/project/mypy-boto3-ecr/)
[](https://pypi.org/project/mypy-boto3-ecr/)
[](https://youtype.github.io/boto3_stubs_docs/)
[](https://pypistats.org/packages/mypy-boto3-ecr)

Type annotations for [boto3 ECR 1.42.53](https://pypi.org/project/boto3/)
compatible with [VSCode](https://code.visualstudio.com/),
[PyCharm](https://www.jetbrains.com/pycharm/),
[Emacs](https://www.gnu.org/software/emacs/),
[Sublime Text](https://www.sublimetext.com/),
[mypy](https://github.com/python/mypy),
[pyright](https://github.com/microsoft/pyright) and other tools.
Generated with
[mypy-boto3-builder 8.12.0](https://github.com/youtype/mypy_boto3_builder).
More information can be found on
[boto3-stubs](https://pypi.org/project/boto3-stubs/) page and in
[mypy-boto3-ecr docs](https://youtype.github.io/boto3_stubs_docs/mypy_boto3_ecr/).
See how it helps you find and fix potential bugs:

- [mypy-boto3-ecr](#mypy-boto3-ecr)
- [How to install](#how-to-install)
- [Generate locally (recommended)](<#generate-locally-(recommended)>)
- [VSCode extension](#vscode-extension)
- [From PyPI with pip](#from-pypi-with-pip)
- [How to uninstall](#how-to-uninstall)
- [Usage](#usage)
- [VSCode](#vscode)
- [PyCharm](#pycharm)
- [Emacs](#emacs)
- [Sublime Text](#sublime-text)
- [Other IDEs](#other-ides)
- [mypy](#mypy)
- [pyright](#pyright)
- [Pylint compatibility](#pylint-compatibility)
- [Explicit type annotations](#explicit-type-annotations)
- [Client annotations](#client-annotations)
- [Paginators annotations](#paginators-annotations)
- [Waiters annotations](#waiters-annotations)
- [Literals](#literals)
- [Type definitions](#type-definitions)
- [How it works](#how-it-works)
- [What's new](#what's-new)
- [Implemented features](#implemented-features)
- [Latest changes](#latest-changes)
- [Versioning](#versioning)
- [Thank you](#thank-you)
- [Documentation](#documentation)
- [Support and contributing](#support-and-contributing)
<a id="how-to-install"></a>
## How to install
<a id="generate-locally-(recommended)"></a>
### Generate locally (recommended)
You can generate type annotations for `boto3` package locally with
`mypy-boto3-builder`. Use
[uv](https://docs.astral.sh/uv/getting-started/installation/) for build
isolation.
1. Run mypy-boto3-builder in your package root directory:
`uvx --with 'boto3==1.42.53' mypy-boto3-builder`
2. Select `boto3-stubs` AWS SDK.
3. Add `ECR` service.
4. Use provided commands to install generated packages.
<a id="vscode-extension"></a>
### VSCode extension
Add
[AWS Boto3](https://marketplace.visualstudio.com/items?itemName=Boto3typed.boto3-ide)
extension to your VSCode and run `AWS boto3: Quick Start` command.
Click `Modify` and select `boto3 common` and `ECR`.
<a id="from-pypi-with-pip"></a>
### From PyPI with pip
Install `boto3-stubs` for `ECR` service.
```bash
# install with boto3 type annotations
python -m pip install 'boto3-stubs[ecr]'
# Lite version does not provide session.client/resource overloads
# it is more RAM-friendly, but requires explicit type annotations
python -m pip install 'boto3-stubs-lite[ecr]'
# standalone installation
python -m pip install mypy-boto3-ecr
```
<a id="how-to-uninstall"></a>
## How to uninstall
```bash
python -m pip uninstall -y mypy-boto3-ecr
```
<a id="usage"></a>
## Usage
<a id="vscode"></a>
### VSCode
- Install
[Python extension](https://marketplace.visualstudio.com/items?itemName=ms-python.python)
- Install
[Pylance extension](https://marketplace.visualstudio.com/items?itemName=ms-python.vscode-pylance)
- Set `Pylance` as your Python Language Server
- Install `boto3-stubs[ecr]` in your environment:
```bash
python -m pip install 'boto3-stubs[ecr]'
```
Both type checking and code completion should now work. No explicit type
annotations required, write your `boto3` code as usual.
<a id="pycharm"></a>
### PyCharm
> ⚠️ Due to slow PyCharm performance on `Literal` overloads (issue
> [PY-40997](https://youtrack.jetbrains.com/issue/PY-40997)), it is recommended
> to use [boto3-stubs-lite](https://pypi.org/project/boto3-stubs-lite/) until
> the issue is resolved.
> ⚠️ If you experience slow performance and high CPU usage, try to disable
> `PyCharm` type checker and use [mypy](https://github.com/python/mypy) or
> [pyright](https://github.com/microsoft/pyright) instead.
> ⚠️ To continue using `PyCharm` type checker, you can try to replace
> `boto3-stubs` with
> [boto3-stubs-lite](https://pypi.org/project/boto3-stubs-lite/):
```bash
pip uninstall boto3-stubs
pip install boto3-stubs-lite
```
Install `boto3-stubs[ecr]` in your environment:
```bash
python -m pip install 'boto3-stubs[ecr]'
```
Both type checking and code completion should now work.
<a id="emacs"></a>
### Emacs
- Install `boto3-stubs` with services you use in your environment:
```bash
python -m pip install 'boto3-stubs[ecr]'
```
- Install [use-package](https://github.com/jwiegley/use-package),
[lsp](https://github.com/emacs-lsp/lsp-mode/),
[company](https://github.com/company-mode/company-mode) and
[flycheck](https://github.com/flycheck/flycheck) packages
- Install [lsp-pyright](https://github.com/emacs-lsp/lsp-pyright) package
```elisp
(use-package lsp-pyright
:ensure t
:hook (python-mode . (lambda ()
(require 'lsp-pyright)
(lsp))) ; or lsp-deferred
:init (when (executable-find "python3")
(setq lsp-pyright-python-executable-cmd "python3"))
)
```
- Make sure emacs uses the environment where you have installed `boto3-stubs`
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="sublime-text"></a>
### Sublime Text
- Install `boto3-stubs[ecr]` with services you use in your environment:
```bash
python -m pip install 'boto3-stubs[ecr]'
```
- Install [LSP-pyright](https://github.com/sublimelsp/LSP-pyright) package
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="other-ides"></a>
### Other IDEs
Not tested, but as long as your IDE supports `mypy` or `pyright`, everything
should work.
<a id="mypy"></a>
### mypy
- Install `mypy`: `python -m pip install mypy`
- Install `boto3-stubs[ecr]` in your environment:
```bash
python -m pip install 'boto3-stubs[ecr]'
```
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="pyright"></a>
### pyright
- Install `pyright`: `npm i -g pyright`
- Install `boto3-stubs[ecr]` in your environment:
```bash
python -m pip install 'boto3-stubs[ecr]'
```
Optionally, you can install `boto3-stubs` to `typings` directory.
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="pylint-compatibility"></a>
### Pylint compatibility
It is totally safe to use `TYPE_CHECKING` flag in order to avoid
`mypy-boto3-ecr` dependency in production. However, there is an issue in
`pylint` that it complains about undefined variables. To fix it, set all types
to `object` in non-`TYPE_CHECKING` mode.
```python
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from mypy_boto3_ec2 import EC2Client, EC2ServiceResource
from mypy_boto3_ec2.waiters import BundleTaskCompleteWaiter
from mypy_boto3_ec2.paginators import DescribeVolumesPaginator
else:
EC2Client = object
EC2ServiceResource = object
BundleTaskCompleteWaiter = object
DescribeVolumesPaginator = object
...
```
<a id="explicit-type-annotations"></a>
## Explicit type annotations
<a id="client-annotations"></a>
### Client annotations
`ECRClient` provides annotations for `boto3.client("ecr")`.
```python
from boto3.session import Session
from mypy_boto3_ecr import ECRClient
client: ECRClient = Session().client("ecr")
# now client usage is checked by mypy and IDE should provide code completion
```
<a id="paginators-annotations"></a>
### Paginators annotations
`mypy_boto3_ecr.paginator` module contains type annotations for all paginators.
```python
from boto3.session import Session
from mypy_boto3_ecr import ECRClient
from mypy_boto3_ecr.paginator import (
DescribeImageScanFindingsPaginator,
DescribeImagesPaginator,
DescribePullThroughCacheRulesPaginator,
DescribeRepositoriesPaginator,
DescribeRepositoryCreationTemplatesPaginator,
GetLifecyclePolicyPreviewPaginator,
ListImagesPaginator,
)
client: ECRClient = Session().client("ecr")
# Explicit type annotations are optional here
# Types should be correctly discovered by mypy and IDEs
describe_image_scan_findings_paginator: DescribeImageScanFindingsPaginator = client.get_paginator(
"describe_image_scan_findings"
)
describe_images_paginator: DescribeImagesPaginator = client.get_paginator("describe_images")
describe_pull_through_cache_rules_paginator: DescribePullThroughCacheRulesPaginator = (
client.get_paginator("describe_pull_through_cache_rules")
)
describe_repositories_paginator: DescribeRepositoriesPaginator = client.get_paginator(
"describe_repositories"
)
describe_repository_creation_templates_paginator: DescribeRepositoryCreationTemplatesPaginator = (
client.get_paginator("describe_repository_creation_templates")
)
get_lifecycle_policy_preview_paginator: GetLifecyclePolicyPreviewPaginator = client.get_paginator(
"get_lifecycle_policy_preview"
)
list_images_paginator: ListImagesPaginator = client.get_paginator("list_images")
```
<a id="waiters-annotations"></a>
### Waiters annotations
`mypy_boto3_ecr.waiter` module contains type annotations for all waiters.
```python
from boto3.session import Session
from mypy_boto3_ecr import ECRClient
from mypy_boto3_ecr.waiter import ImageScanCompleteWaiter, LifecyclePolicyPreviewCompleteWaiter
client: ECRClient = Session().client("ecr")
# Explicit type annotations are optional here
# Types should be correctly discovered by mypy and IDEs
image_scan_complete_waiter: ImageScanCompleteWaiter = client.get_waiter("image_scan_complete")
lifecycle_policy_preview_complete_waiter: LifecyclePolicyPreviewCompleteWaiter = client.get_waiter(
"lifecycle_policy_preview_complete"
)
```
<a id="literals"></a>
### Literals
`mypy_boto3_ecr.literals` module contains literals extracted from shapes that
can be used in user code for type checking.
Full list of `ECR` Literals can be found in
[docs](https://youtype.github.io/boto3_stubs_docs/mypy_boto3_ecr/literals/).
```python
from mypy_boto3_ecr.literals import ArtifactStatusFilterType
def check_value(value: ArtifactStatusFilterType) -> bool: ...
```
<a id="type-definitions"></a>
### Type definitions
`mypy_boto3_ecr.type_defs` module contains structures and shapes assembled to
typed dictionaries and unions for additional type checking.
Full list of `ECR` TypeDefs can be found in
[docs](https://youtype.github.io/boto3_stubs_docs/mypy_boto3_ecr/type_defs/).
```python
# TypedDict usage example
from mypy_boto3_ecr.type_defs import AttributeTypeDef
def get_value() -> AttributeTypeDef:
return {
"key": ...,
}
```
<a id="how-it-works"></a>
## How it works
Fully automated
[mypy-boto3-builder](https://github.com/youtype/mypy_boto3_builder) carefully
generates type annotations for each service, patiently waiting for `boto3`
updates. It delivers drop-in type annotations for you and makes sure that:
- All available `boto3` services are covered.
- Each public class and method of every `boto3` service gets valid type
annotations extracted from `botocore` schemas.
- Type annotations include up-to-date documentation.
- Link to documentation is provided for every method.
- Code is processed by [ruff](https://docs.astral.sh/ruff/) for readability.
<a id="what's-new"></a>
## What's new
<a id="implemented-features"></a>
### Implemented features
- Fully type annotated `boto3`, `botocore`, `aiobotocore` and `aioboto3`
libraries
- `mypy`, `pyright`, `VSCode`, `PyCharm`, `Sublime Text` and `Emacs`
compatibility
- `Client`, `ServiceResource`, `Resource`, `Waiter` `Paginator` type
annotations for each service
- Generated `TypeDefs` for each service
- Generated `Literals` for each service
- Auto discovery of types for `boto3.client` and `boto3.resource` calls
- Auto discovery of types for `session.client` and `session.resource` calls
- Auto discovery of types for `client.get_waiter` and `client.get_paginator`
calls
- Auto discovery of types for `ServiceResource` and `Resource` collections
- Auto discovery of types for `aiobotocore.Session.create_client` calls
<a id="latest-changes"></a>
### Latest changes
Builder changelog can be found in
[Releases](https://github.com/youtype/mypy_boto3_builder/releases).
<a id="versioning"></a>
## Versioning
`mypy-boto3-ecr` version is the same as related `boto3` version and follows
[Python Packaging version specifiers](https://packaging.python.org/en/latest/specifications/version-specifiers/).
<a id="thank-you"></a>
## Thank you
- [Allie Fitter](https://github.com/alliefitter) for
[boto3-type-annotations](https://pypi.org/project/boto3-type-annotations/),
this package is based on top of his work
- [black](https://github.com/psf/black) developers for an awesome formatting
tool
- [Timothy Edmund Crosley](https://github.com/timothycrosley) for
[isort](https://github.com/PyCQA/isort) and how flexible it is
- [mypy](https://github.com/python/mypy) developers for doing all dirty work
for us
- [pyright](https://github.com/microsoft/pyright) team for the new era of typed
Python
<a id="documentation"></a>
## Documentation
All services type annotations can be found in
[boto3 docs](https://youtype.github.io/boto3_stubs_docs/mypy_boto3_ecr/)
<a id="support-and-contributing"></a>
## Support and contributing
This package is auto-generated. Please reports any bugs or request new features
in [mypy-boto3-builder](https://github.com/youtype/mypy_boto3_builder/issues/)
repository.
| text/markdown | null | Vlad Emelianov <vlad.emelianov.nz@gmail.com> | null | null | null | boto3, ecr, boto3-stubs, type-annotations, mypy, typeshed, autocomplete | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Environment :: Console",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"... | [
"any"
] | null | null | >=3.9 | [] | [] | [] | [
"typing-extensions; python_version < \"3.12\""
] | [] | [] | [] | [
"Homepage, https://github.com/youtype/mypy_boto3_builder",
"Documentation, https://youtype.github.io/boto3_stubs_docs/mypy_boto3_ecr/",
"Source, https://github.com/youtype/mypy_boto3_builder",
"Tracker, https://github.com/youtype/mypy_boto3_builder/issues"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-19T20:50:29.318382 | mypy_boto3_ecr-1.42.53.tar.gz | 36,649 | cc/90/d5de7e81515530485a253a043b20c05292ffd98254017749d194711f9359/mypy_boto3_ecr-1.42.53.tar.gz | source | sdist | null | false | ee649fcb238f6d8cec2da9c2b18cd7cc | 65a6d605b6a5173ae9a0d452de518b218a3fe85f6ae21df139536605e0aa31cf | cc90d5de7e81515530485a253a043b20c05292ffd98254017749d194711f9359 | MIT | [
"LICENSE"
] | 140,355 |
2.4 | acorn | 0.6.2 | LLM agent framework with structured I/O |
<img width="851" height="190" alt="github" src="https://github.com/user-attachments/assets/3f06caa7-b670-4cfb-8a57-0278f7f946a0" />
**LLM agent framework with structured I/O**
Build AI agents with type-safe inputs and outputs, automatic tool calling, and powerful agentic loops.
[](tests/)
[](tests/)
[](pyproject.toml)
[](LICENSE)
---
## ✨ Features
- 🎯 **Structured I/O** - Pydantic models for inputs and outputs
- 🤖 **Agentic Loops** - Multi-turn execution with tool calling
- 🛠️ **Auto Tool Schemas** - Generate from type hints and docstrings
- 🔄 **Dynamic Tools** - Add/remove tools during execution
- ✅ **Parse Error Recovery** - Automatic retry on validation failures
- 📊 **Step Callbacks** - Full control over loop behavior
- 🔌 **LiteLLM Integration** - Works with any LLM provider
- 🌊 **Streaming Responses** - Real-time output with partial structured updates
- 💾 **Provider Caching** - Reduce latency and cost with prompt caching
- 🛡️ **Model Fallbacks** - Automatic provider failover for high availability
---
## 🚀 Quick Start
### Installation
```bash
pip install acorn
```
Set your API key:
```bash
# For Anthropic Claude
export ANTHROPIC_API_KEY="your-key-here"
# Or for OpenAI
export OPENAI_API_KEY="your-key-here"
# Or any other LiteLLM-supported provider
```
### Single-Turn Example
```python
from pydantic import BaseModel, Field
from acorn import Module
class Input(BaseModel):
text: str = Field(description="The text to summarize")
max_words: int = Field(default=100, description="Maximum words in summary")
class Output(BaseModel):
summary: str = Field(description="The concise summary")
word_count: int = Field(description="Number of words in summary")
class Summarizer(Module):
"""Summarize text concisely."""
initial_input = Input
final_output = Output
model = "anthropic/claude-sonnet-4-5-20250514"
# Use it
summarizer = Summarizer()
result = summarizer(
text="Long article text here...",
max_words=50
)
print(result.summary)
print(f"Words: {result.word_count}")
```
### Multi-Turn Agentic Loop
```python
from pydantic import BaseModel, Field
from acorn import Module, tool
class Input(BaseModel):
topic: str = Field(description="Research topic")
depth: str = Field(default="shallow", description="Research depth")
class Output(BaseModel):
findings: str = Field(description="Summary of findings")
sources: list[str] = Field(description="Sources consulted")
class ResearchAgent(Module):
"""Research assistant with tools."""
initial_input = Input
max_steps = 5 # Enable agentic loop
final_output = Output
model = "anthropic/claude-sonnet-4-5-20250514"
@tool
def search(self, query: str) -> list:
"""Search for information."""
# Your search implementation
return ["result1", "result2"]
@tool
def analyze(self, data: str) -> str:
"""Analyze collected data."""
# Your analysis implementation
return f"Analysis: {data}"
def on_step(self, step):
"""Called after each step."""
print(f"Step {step.counter}")
# Early termination if done
if len(step.tool_results) >= 3:
step.finish(
findings="Sufficient data collected",
sources=["source1", "source2"]
)
return step
# Use it
agent = ResearchAgent()
result = agent(topic="Large Language Models", depth="shallow")
```
---
## 📚 Core Concepts
### Module
Base class for LLM agents. Configure with:
- `model` - LLM to use (required - no default)
- `temperature` - Sampling temperature
- `max_tokens` - Maximum tokens to generate
- `max_steps` - Max agentic loop iterations (None = single-turn)
- `initial_input` - Pydantic model for input schema
- `final_output` - Pydantic model for output schema
- `tools` - List of available tools
- `cache` - Enable provider-level prompt caching
- `model_fallbacks` - List of fallback models for automatic failover
### Tools
Functions the LLM can call:
```python
@tool
def search(query: str, limit: int = 10) -> list:
"""Search for information.
Args:
query: The search query
limit: Maximum results to return
"""
return search_api(query, limit)
```
Schema is automatically generated from type hints and docstring.
### Step Callback
Control agentic loop execution:
```python
def on_step(self, step):
# Access step info
print(f"Step {step.counter}")
print(f"Tools called: {[tc.name for tc in step.tool_calls]}")
# Dynamic tool management
step.add_tool(new_tool)
step.remove_tool("old_tool")
# Early termination
if condition:
step.finish(result="Early exit")
return step
```
---
## 🎯 Examples
Try them live on the [Gradio app](https://askmanu-acorn.hf.space) or browse the source in `examples/`:
| Example | Category | Description |
|---------|----------|-------------|
| [Simple Q&A](https://askmanu-acorn.hf.space/simple_qa) | Basic | Single-turn question answering with structured output |
| [HN Production Readiness](https://askmanu-acorn.hf.space/hn_production_check) | Agentic | Checks if a trending HN project is production-ready |
| [Documentation Coverage](https://askmanu-acorn.hf.space/doc_coverage) | Agentic | Scores documentation coverage of a GitHub repo (0–100) |
| [Bus Factor Calculator](https://askmanu-acorn.hf.space/bus_factor) | Branching | Calculates the bus factor of a GitHub repository |
| [License Compatibility](https://askmanu-acorn.hf.space/license_checker) | Agentic | Checks dependency license compatibility for conflicts |
| [Dependency Bloat Scanner](https://askmanu-acorn.hf.space/dependency_scanner) | Branching | Finds redundant and overlapping libraries in your deps |
---
## 🧪 Testing
```bash
# Run all tests
pytest
# With coverage
pytest --cov=acorn
# Specific test file
pytest tests/test_agentic_loop.py -v
```
**Current status:** 201 tests passing, 85% coverage
---
## 📖 Documentation
- [Getting Started](docs/getting-started.md) - Installation and first steps
- [Module Reference](docs/module.md) - Complete Module API documentation
---
## 🛣️ Roadmap
### ✅ Completed
- Single-turn execution
- Multi-turn agentic loops
- Tool calling with auto-schema generation
- Parse error recovery
- Dynamic tool management
- Step callbacks
- Streaming responses with partial structured output
- Forced termination strategies
- Provider caching
- Model fallbacks
### 📋 Planned
- Branching workflows
- Async support
---
## 🤝 Contributing
Contributions welcome! Please:
1. Check open issues for areas to help
2. Write tests for new features (maintain >80% coverage)
3. Update documentation
4. Add examples for new features
---
## 💬 Questions?
Check out:
- [Getting Started](docs/getting-started.md) for installation and examples
- [Module Reference](docs/module.md) for detailed API docs
- [Examples](examples/) for working code
- [Tests](tests/) for usage patterns
---
## 🙏 Acknowledgments
Thanks to @rosenbrockc for donating the `acorn` pip package name.
---
## 📄 License
[MIT License](LICENSE)
---
| text/markdown | Andrei Onel | null | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"litellm>=1.0",
"pydantic>=2.0",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"google-cloud-aiplatform>=1.0; extra == \"vertex\""
] | [] | [] | [] | [
"Homepage, https://github.com/askmanu/acorn",
"Documentation, https://github.com/askmanu/acorn",
"Repository, https://github.com/askmanu/acorn"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:50:27.857851 | acorn-0.6.2.tar.gz | 36,839 | 15/f3/a1e422e850f3e83a210ad7662ad1b22c308408076bf83f9e88c6e980b86e/acorn-0.6.2.tar.gz | source | sdist | null | false | c45d2431ee5df3bff1a34aaae24099d9 | 05115e6804ae058aad8907dba347b4b96a8f5b1f542804077cf038ee4ea410bd | 15f3a1e422e850f3e83a210ad7662ad1b22c308408076bf83f9e88c6e980b86e | null | [
"LICENSE"
] | 250 |
2.4 | mypy-boto3-pca-connector-scep | 1.42.53 | Type annotations for boto3 PrivateCAConnectorforSCEP 1.42.53 service generated with mypy-boto3-builder 8.12.0 | <a id="mypy-boto3-pca-connector-scep"></a>
# mypy-boto3-pca-connector-scep
[](https://pypi.org/project/mypy-boto3-pca-connector-scep/)
[](https://pypi.org/project/mypy-boto3-pca-connector-scep/)
[](https://youtype.github.io/boto3_stubs_docs/)
[](https://pypistats.org/packages/mypy-boto3-pca-connector-scep)

Type annotations for
[boto3 PrivateCAConnectorforSCEP 1.42.53](https://pypi.org/project/boto3/)
compatible with [VSCode](https://code.visualstudio.com/),
[PyCharm](https://www.jetbrains.com/pycharm/),
[Emacs](https://www.gnu.org/software/emacs/),
[Sublime Text](https://www.sublimetext.com/),
[mypy](https://github.com/python/mypy),
[pyright](https://github.com/microsoft/pyright) and other tools.
Generated with
[mypy-boto3-builder 8.12.0](https://github.com/youtype/mypy_boto3_builder).
More information can be found on
[boto3-stubs](https://pypi.org/project/boto3-stubs/) page and in
[mypy-boto3-pca-connector-scep docs](https://youtype.github.io/boto3_stubs_docs/mypy_boto3_pca_connector_scep/).
See how it helps you find and fix potential bugs:

- [mypy-boto3-pca-connector-scep](#mypy-boto3-pca-connector-scep)
- [How to install](#how-to-install)
- [Generate locally (recommended)](<#generate-locally-(recommended)>)
- [VSCode extension](#vscode-extension)
- [From PyPI with pip](#from-pypi-with-pip)
- [How to uninstall](#how-to-uninstall)
- [Usage](#usage)
- [VSCode](#vscode)
- [PyCharm](#pycharm)
- [Emacs](#emacs)
- [Sublime Text](#sublime-text)
- [Other IDEs](#other-ides)
- [mypy](#mypy)
- [pyright](#pyright)
- [Pylint compatibility](#pylint-compatibility)
- [Explicit type annotations](#explicit-type-annotations)
- [Client annotations](#client-annotations)
- [Paginators annotations](#paginators-annotations)
- [Literals](#literals)
- [Type definitions](#type-definitions)
- [How it works](#how-it-works)
- [What's new](#what's-new)
- [Implemented features](#implemented-features)
- [Latest changes](#latest-changes)
- [Versioning](#versioning)
- [Thank you](#thank-you)
- [Documentation](#documentation)
- [Support and contributing](#support-and-contributing)
<a id="how-to-install"></a>
## How to install
<a id="generate-locally-(recommended)"></a>
### Generate locally (recommended)
You can generate type annotations for `boto3` package locally with
`mypy-boto3-builder`. Use
[uv](https://docs.astral.sh/uv/getting-started/installation/) for build
isolation.
1. Run mypy-boto3-builder in your package root directory:
`uvx --with 'boto3==1.42.53' mypy-boto3-builder`
2. Select `boto3-stubs` AWS SDK.
3. Add `PrivateCAConnectorforSCEP` service.
4. Use provided commands to install generated packages.
<a id="vscode-extension"></a>
### VSCode extension
Add
[AWS Boto3](https://marketplace.visualstudio.com/items?itemName=Boto3typed.boto3-ide)
extension to your VSCode and run `AWS boto3: Quick Start` command.
Click `Modify` and select `boto3 common` and `PrivateCAConnectorforSCEP`.
<a id="from-pypi-with-pip"></a>
### From PyPI with pip
Install `boto3-stubs` for `PrivateCAConnectorforSCEP` service.
```bash
# install with boto3 type annotations
python -m pip install 'boto3-stubs[pca-connector-scep]'
# Lite version does not provide session.client/resource overloads
# it is more RAM-friendly, but requires explicit type annotations
python -m pip install 'boto3-stubs-lite[pca-connector-scep]'
# standalone installation
python -m pip install mypy-boto3-pca-connector-scep
```
<a id="how-to-uninstall"></a>
## How to uninstall
```bash
python -m pip uninstall -y mypy-boto3-pca-connector-scep
```
<a id="usage"></a>
## Usage
<a id="vscode"></a>
### VSCode
- Install
[Python extension](https://marketplace.visualstudio.com/items?itemName=ms-python.python)
- Install
[Pylance extension](https://marketplace.visualstudio.com/items?itemName=ms-python.vscode-pylance)
- Set `Pylance` as your Python Language Server
- Install `boto3-stubs[pca-connector-scep]` in your environment:
```bash
python -m pip install 'boto3-stubs[pca-connector-scep]'
```
Both type checking and code completion should now work. No explicit type
annotations required, write your `boto3` code as usual.
<a id="pycharm"></a>
### PyCharm
> ⚠️ Due to slow PyCharm performance on `Literal` overloads (issue
> [PY-40997](https://youtrack.jetbrains.com/issue/PY-40997)), it is recommended
> to use [boto3-stubs-lite](https://pypi.org/project/boto3-stubs-lite/) until
> the issue is resolved.
> ⚠️ If you experience slow performance and high CPU usage, try to disable
> `PyCharm` type checker and use [mypy](https://github.com/python/mypy) or
> [pyright](https://github.com/microsoft/pyright) instead.
> ⚠️ To continue using `PyCharm` type checker, you can try to replace
> `boto3-stubs` with
> [boto3-stubs-lite](https://pypi.org/project/boto3-stubs-lite/):
```bash
pip uninstall boto3-stubs
pip install boto3-stubs-lite
```
Install `boto3-stubs[pca-connector-scep]` in your environment:
```bash
python -m pip install 'boto3-stubs[pca-connector-scep]'
```
Both type checking and code completion should now work.
<a id="emacs"></a>
### Emacs
- Install `boto3-stubs` with services you use in your environment:
```bash
python -m pip install 'boto3-stubs[pca-connector-scep]'
```
- Install [use-package](https://github.com/jwiegley/use-package),
[lsp](https://github.com/emacs-lsp/lsp-mode/),
[company](https://github.com/company-mode/company-mode) and
[flycheck](https://github.com/flycheck/flycheck) packages
- Install [lsp-pyright](https://github.com/emacs-lsp/lsp-pyright) package
```elisp
(use-package lsp-pyright
:ensure t
:hook (python-mode . (lambda ()
(require 'lsp-pyright)
(lsp))) ; or lsp-deferred
:init (when (executable-find "python3")
(setq lsp-pyright-python-executable-cmd "python3"))
)
```
- Make sure emacs uses the environment where you have installed `boto3-stubs`
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="sublime-text"></a>
### Sublime Text
- Install `boto3-stubs[pca-connector-scep]` with services you use in your
environment:
```bash
python -m pip install 'boto3-stubs[pca-connector-scep]'
```
- Install [LSP-pyright](https://github.com/sublimelsp/LSP-pyright) package
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="other-ides"></a>
### Other IDEs
Not tested, but as long as your IDE supports `mypy` or `pyright`, everything
should work.
<a id="mypy"></a>
### mypy
- Install `mypy`: `python -m pip install mypy`
- Install `boto3-stubs[pca-connector-scep]` in your environment:
```bash
python -m pip install 'boto3-stubs[pca-connector-scep]'
```
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="pyright"></a>
### pyright
- Install `pyright`: `npm i -g pyright`
- Install `boto3-stubs[pca-connector-scep]` in your environment:
```bash
python -m pip install 'boto3-stubs[pca-connector-scep]'
```
Optionally, you can install `boto3-stubs` to `typings` directory.
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="pylint-compatibility"></a>
### Pylint compatibility
It is totally safe to use `TYPE_CHECKING` flag in order to avoid
`mypy-boto3-pca-connector-scep` dependency in production. However, there is an
issue in `pylint` that it complains about undefined variables. To fix it, set
all types to `object` in non-`TYPE_CHECKING` mode.
```python
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from mypy_boto3_ec2 import EC2Client, EC2ServiceResource
from mypy_boto3_ec2.waiters import BundleTaskCompleteWaiter
from mypy_boto3_ec2.paginators import DescribeVolumesPaginator
else:
EC2Client = object
EC2ServiceResource = object
BundleTaskCompleteWaiter = object
DescribeVolumesPaginator = object
...
```
<a id="explicit-type-annotations"></a>
## Explicit type annotations
<a id="client-annotations"></a>
### Client annotations
`PrivateCAConnectorforSCEPClient` provides annotations for
`boto3.client("pca-connector-scep")`.
```python
from boto3.session import Session
from mypy_boto3_pca_connector_scep import PrivateCAConnectorforSCEPClient
client: PrivateCAConnectorforSCEPClient = Session().client("pca-connector-scep")
# now client usage is checked by mypy and IDE should provide code completion
```
<a id="paginators-annotations"></a>
### Paginators annotations
`mypy_boto3_pca_connector_scep.paginator` module contains type annotations for
all paginators.
```python
from boto3.session import Session
from mypy_boto3_pca_connector_scep import PrivateCAConnectorforSCEPClient
from mypy_boto3_pca_connector_scep.paginator import (
ListChallengeMetadataPaginator,
ListConnectorsPaginator,
)
client: PrivateCAConnectorforSCEPClient = Session().client("pca-connector-scep")
# Explicit type annotations are optional here
# Types should be correctly discovered by mypy and IDEs
list_challenge_metadata_paginator: ListChallengeMetadataPaginator = client.get_paginator(
"list_challenge_metadata"
)
list_connectors_paginator: ListConnectorsPaginator = client.get_paginator("list_connectors")
```
<a id="literals"></a>
### Literals
`mypy_boto3_pca_connector_scep.literals` module contains literals extracted
from shapes that can be used in user code for type checking.
Full list of `PrivateCAConnectorforSCEP` Literals can be found in
[docs](https://youtype.github.io/boto3_stubs_docs/mypy_boto3_pca_connector_scep/literals/).
```python
from mypy_boto3_pca_connector_scep.literals import ConnectorStatusReasonType
def check_value(value: ConnectorStatusReasonType) -> bool: ...
```
<a id="type-definitions"></a>
### Type definitions
`mypy_boto3_pca_connector_scep.type_defs` module contains structures and shapes
assembled to typed dictionaries and unions for additional type checking.
Full list of `PrivateCAConnectorforSCEP` TypeDefs can be found in
[docs](https://youtype.github.io/boto3_stubs_docs/mypy_boto3_pca_connector_scep/type_defs/).
```python
# TypedDict usage example
from mypy_boto3_pca_connector_scep.type_defs import ChallengeMetadataSummaryTypeDef
def get_value() -> ChallengeMetadataSummaryTypeDef:
return {
"Arn": ...,
}
```
<a id="how-it-works"></a>
## How it works
Fully automated
[mypy-boto3-builder](https://github.com/youtype/mypy_boto3_builder) carefully
generates type annotations for each service, patiently waiting for `boto3`
updates. It delivers drop-in type annotations for you and makes sure that:
- All available `boto3` services are covered.
- Each public class and method of every `boto3` service gets valid type
annotations extracted from `botocore` schemas.
- Type annotations include up-to-date documentation.
- Link to documentation is provided for every method.
- Code is processed by [ruff](https://docs.astral.sh/ruff/) for readability.
<a id="what's-new"></a>
## What's new
<a id="implemented-features"></a>
### Implemented features
- Fully type annotated `boto3`, `botocore`, `aiobotocore` and `aioboto3`
libraries
- `mypy`, `pyright`, `VSCode`, `PyCharm`, `Sublime Text` and `Emacs`
compatibility
- `Client`, `ServiceResource`, `Resource`, `Waiter` `Paginator` type
annotations for each service
- Generated `TypeDefs` for each service
- Generated `Literals` for each service
- Auto discovery of types for `boto3.client` and `boto3.resource` calls
- Auto discovery of types for `session.client` and `session.resource` calls
- Auto discovery of types for `client.get_waiter` and `client.get_paginator`
calls
- Auto discovery of types for `ServiceResource` and `Resource` collections
- Auto discovery of types for `aiobotocore.Session.create_client` calls
<a id="latest-changes"></a>
### Latest changes
Builder changelog can be found in
[Releases](https://github.com/youtype/mypy_boto3_builder/releases).
<a id="versioning"></a>
## Versioning
`mypy-boto3-pca-connector-scep` version is the same as related `boto3` version
and follows
[Python Packaging version specifiers](https://packaging.python.org/en/latest/specifications/version-specifiers/).
<a id="thank-you"></a>
## Thank you
- [Allie Fitter](https://github.com/alliefitter) for
[boto3-type-annotations](https://pypi.org/project/boto3-type-annotations/),
this package is based on top of his work
- [black](https://github.com/psf/black) developers for an awesome formatting
tool
- [Timothy Edmund Crosley](https://github.com/timothycrosley) for
[isort](https://github.com/PyCQA/isort) and how flexible it is
- [mypy](https://github.com/python/mypy) developers for doing all dirty work
for us
- [pyright](https://github.com/microsoft/pyright) team for the new era of typed
Python
<a id="documentation"></a>
## Documentation
All services type annotations can be found in
[boto3 docs](https://youtype.github.io/boto3_stubs_docs/mypy_boto3_pca_connector_scep/)
<a id="support-and-contributing"></a>
## Support and contributing
This package is auto-generated. Please reports any bugs or request new features
in [mypy-boto3-builder](https://github.com/youtype/mypy_boto3_builder/issues/)
repository.
| text/markdown | null | Vlad Emelianov <vlad.emelianov.nz@gmail.com> | null | null | null | boto3, pca-connector-scep, boto3-stubs, type-annotations, mypy, typeshed, autocomplete | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Environment :: Console",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"... | [
"any"
] | null | null | >=3.9 | [] | [] | [] | [
"typing-extensions; python_version < \"3.12\""
] | [] | [] | [] | [
"Homepage, https://github.com/youtype/mypy_boto3_builder",
"Documentation, https://youtype.github.io/boto3_stubs_docs/mypy_boto3_pca_connector_scep/",
"Source, https://github.com/youtype/mypy_boto3_builder",
"Tracker, https://github.com/youtype/mypy_boto3_builder/issues"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-19T20:50:23.192410 | mypy_boto3_pca_connector_scep-1.42.53.tar.gz | 17,771 | 42/57/ba6ffe302773d589c1dda5cbe35eda7d1aa87700d7230079ea423d4743cf/mypy_boto3_pca_connector_scep-1.42.53.tar.gz | source | sdist | null | false | e3c9e97f8099ab2befc442d2849f8469 | 0cd55f0cdff10f026c94d7d929f7d40e63e7e8ba62e2c1cfdfe08d2c023fb8bc | 4257ba6ffe302773d589c1dda5cbe35eda7d1aa87700d7230079ea423d4743cf | MIT | [
"LICENSE"
] | 772 |
2.4 | mypy-boto3-bcm-dashboards | 1.42.53 | Type annotations for boto3 BillingandCostManagementDashboards 1.42.53 service generated with mypy-boto3-builder 8.12.0 | <a id="mypy-boto3-bcm-dashboards"></a>
# mypy-boto3-bcm-dashboards
[](https://pypi.org/project/mypy-boto3-bcm-dashboards/)
[](https://pypi.org/project/mypy-boto3-bcm-dashboards/)
[](https://youtype.github.io/boto3_stubs_docs/)
[](https://pypistats.org/packages/mypy-boto3-bcm-dashboards)

Type annotations for
[boto3 BillingandCostManagementDashboards 1.42.53](https://pypi.org/project/boto3/)
compatible with [VSCode](https://code.visualstudio.com/),
[PyCharm](https://www.jetbrains.com/pycharm/),
[Emacs](https://www.gnu.org/software/emacs/),
[Sublime Text](https://www.sublimetext.com/),
[mypy](https://github.com/python/mypy),
[pyright](https://github.com/microsoft/pyright) and other tools.
Generated with
[mypy-boto3-builder 8.12.0](https://github.com/youtype/mypy_boto3_builder).
More information can be found on
[boto3-stubs](https://pypi.org/project/boto3-stubs/) page and in
[mypy-boto3-bcm-dashboards docs](https://youtype.github.io/boto3_stubs_docs/mypy_boto3_bcm_dashboards/).
See how it helps you find and fix potential bugs:

- [mypy-boto3-bcm-dashboards](#mypy-boto3-bcm-dashboards)
- [How to install](#how-to-install)
- [Generate locally (recommended)](<#generate-locally-(recommended)>)
- [VSCode extension](#vscode-extension)
- [From PyPI with pip](#from-pypi-with-pip)
- [How to uninstall](#how-to-uninstall)
- [Usage](#usage)
- [VSCode](#vscode)
- [PyCharm](#pycharm)
- [Emacs](#emacs)
- [Sublime Text](#sublime-text)
- [Other IDEs](#other-ides)
- [mypy](#mypy)
- [pyright](#pyright)
- [Pylint compatibility](#pylint-compatibility)
- [Explicit type annotations](#explicit-type-annotations)
- [Client annotations](#client-annotations)
- [Paginators annotations](#paginators-annotations)
- [Literals](#literals)
- [Type definitions](#type-definitions)
- [How it works](#how-it-works)
- [What's new](#what's-new)
- [Implemented features](#implemented-features)
- [Latest changes](#latest-changes)
- [Versioning](#versioning)
- [Thank you](#thank-you)
- [Documentation](#documentation)
- [Support and contributing](#support-and-contributing)
<a id="how-to-install"></a>
## How to install
<a id="generate-locally-(recommended)"></a>
### Generate locally (recommended)
You can generate type annotations for `boto3` package locally with
`mypy-boto3-builder`. Use
[uv](https://docs.astral.sh/uv/getting-started/installation/) for build
isolation.
1. Run mypy-boto3-builder in your package root directory:
`uvx --with 'boto3==1.42.53' mypy-boto3-builder`
2. Select `boto3-stubs` AWS SDK.
3. Add `BillingandCostManagementDashboards` service.
4. Use provided commands to install generated packages.
<a id="vscode-extension"></a>
### VSCode extension
Add
[AWS Boto3](https://marketplace.visualstudio.com/items?itemName=Boto3typed.boto3-ide)
extension to your VSCode and run `AWS boto3: Quick Start` command.
Click `Modify` and select `boto3 common` and
`BillingandCostManagementDashboards`.
<a id="from-pypi-with-pip"></a>
### From PyPI with pip
Install `boto3-stubs` for `BillingandCostManagementDashboards` service.
```bash
# install with boto3 type annotations
python -m pip install 'boto3-stubs[bcm-dashboards]'
# Lite version does not provide session.client/resource overloads
# it is more RAM-friendly, but requires explicit type annotations
python -m pip install 'boto3-stubs-lite[bcm-dashboards]'
# standalone installation
python -m pip install mypy-boto3-bcm-dashboards
```
<a id="how-to-uninstall"></a>
## How to uninstall
```bash
python -m pip uninstall -y mypy-boto3-bcm-dashboards
```
<a id="usage"></a>
## Usage
<a id="vscode"></a>
### VSCode
- Install
[Python extension](https://marketplace.visualstudio.com/items?itemName=ms-python.python)
- Install
[Pylance extension](https://marketplace.visualstudio.com/items?itemName=ms-python.vscode-pylance)
- Set `Pylance` as your Python Language Server
- Install `boto3-stubs[bcm-dashboards]` in your environment:
```bash
python -m pip install 'boto3-stubs[bcm-dashboards]'
```
Both type checking and code completion should now work. No explicit type
annotations required, write your `boto3` code as usual.
<a id="pycharm"></a>
### PyCharm
> ⚠️ Due to slow PyCharm performance on `Literal` overloads (issue
> [PY-40997](https://youtrack.jetbrains.com/issue/PY-40997)), it is recommended
> to use [boto3-stubs-lite](https://pypi.org/project/boto3-stubs-lite/) until
> the issue is resolved.
> ⚠️ If you experience slow performance and high CPU usage, try to disable
> `PyCharm` type checker and use [mypy](https://github.com/python/mypy) or
> [pyright](https://github.com/microsoft/pyright) instead.
> ⚠️ To continue using `PyCharm` type checker, you can try to replace
> `boto3-stubs` with
> [boto3-stubs-lite](https://pypi.org/project/boto3-stubs-lite/):
```bash
pip uninstall boto3-stubs
pip install boto3-stubs-lite
```
Install `boto3-stubs[bcm-dashboards]` in your environment:
```bash
python -m pip install 'boto3-stubs[bcm-dashboards]'
```
Both type checking and code completion should now work.
<a id="emacs"></a>
### Emacs
- Install `boto3-stubs` with services you use in your environment:
```bash
python -m pip install 'boto3-stubs[bcm-dashboards]'
```
- Install [use-package](https://github.com/jwiegley/use-package),
[lsp](https://github.com/emacs-lsp/lsp-mode/),
[company](https://github.com/company-mode/company-mode) and
[flycheck](https://github.com/flycheck/flycheck) packages
- Install [lsp-pyright](https://github.com/emacs-lsp/lsp-pyright) package
```elisp
(use-package lsp-pyright
:ensure t
:hook (python-mode . (lambda ()
(require 'lsp-pyright)
(lsp))) ; or lsp-deferred
:init (when (executable-find "python3")
(setq lsp-pyright-python-executable-cmd "python3"))
)
```
- Make sure emacs uses the environment where you have installed `boto3-stubs`
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="sublime-text"></a>
### Sublime Text
- Install `boto3-stubs[bcm-dashboards]` with services you use in your
environment:
```bash
python -m pip install 'boto3-stubs[bcm-dashboards]'
```
- Install [LSP-pyright](https://github.com/sublimelsp/LSP-pyright) package
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="other-ides"></a>
### Other IDEs
Not tested, but as long as your IDE supports `mypy` or `pyright`, everything
should work.
<a id="mypy"></a>
### mypy
- Install `mypy`: `python -m pip install mypy`
- Install `boto3-stubs[bcm-dashboards]` in your environment:
```bash
python -m pip install 'boto3-stubs[bcm-dashboards]'
```
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="pyright"></a>
### pyright
- Install `pyright`: `npm i -g pyright`
- Install `boto3-stubs[bcm-dashboards]` in your environment:
```bash
python -m pip install 'boto3-stubs[bcm-dashboards]'
```
Optionally, you can install `boto3-stubs` to `typings` directory.
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="pylint-compatibility"></a>
### Pylint compatibility
It is totally safe to use `TYPE_CHECKING` flag in order to avoid
`mypy-boto3-bcm-dashboards` dependency in production. However, there is an
issue in `pylint` that it complains about undefined variables. To fix it, set
all types to `object` in non-`TYPE_CHECKING` mode.
```python
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from mypy_boto3_ec2 import EC2Client, EC2ServiceResource
from mypy_boto3_ec2.waiters import BundleTaskCompleteWaiter
from mypy_boto3_ec2.paginators import DescribeVolumesPaginator
else:
EC2Client = object
EC2ServiceResource = object
BundleTaskCompleteWaiter = object
DescribeVolumesPaginator = object
...
```
<a id="explicit-type-annotations"></a>
## Explicit type annotations
<a id="client-annotations"></a>
### Client annotations
`BillingandCostManagementDashboardsClient` provides annotations for
`boto3.client("bcm-dashboards")`.
```python
from boto3.session import Session
from mypy_boto3_bcm_dashboards import BillingandCostManagementDashboardsClient
client: BillingandCostManagementDashboardsClient = Session().client("bcm-dashboards")
# now client usage is checked by mypy and IDE should provide code completion
```
<a id="paginators-annotations"></a>
### Paginators annotations
`mypy_boto3_bcm_dashboards.paginator` module contains type annotations for all
paginators.
```python
from boto3.session import Session
from mypy_boto3_bcm_dashboards import BillingandCostManagementDashboardsClient
from mypy_boto3_bcm_dashboards.paginator import ListDashboardsPaginator
client: BillingandCostManagementDashboardsClient = Session().client("bcm-dashboards")
# Explicit type annotations are optional here
# Types should be correctly discovered by mypy and IDEs
list_dashboards_paginator: ListDashboardsPaginator = client.get_paginator("list_dashboards")
```
<a id="literals"></a>
### Literals
`mypy_boto3_bcm_dashboards.literals` module contains literals extracted from
shapes that can be used in user code for type checking.
Full list of `BillingandCostManagementDashboards` Literals can be found in
[docs](https://youtype.github.io/boto3_stubs_docs/mypy_boto3_bcm_dashboards/literals/).
```python
from mypy_boto3_bcm_dashboards.literals import DashboardTypeType
def check_value(value: DashboardTypeType) -> bool: ...
```
<a id="type-definitions"></a>
### Type definitions
`mypy_boto3_bcm_dashboards.type_defs` module contains structures and shapes
assembled to typed dictionaries and unions for additional type checking.
Full list of `BillingandCostManagementDashboards` TypeDefs can be found in
[docs](https://youtype.github.io/boto3_stubs_docs/mypy_boto3_bcm_dashboards/type_defs/).
```python
# TypedDict usage example
from mypy_boto3_bcm_dashboards.type_defs import GroupDefinitionTypeDef
def get_value() -> GroupDefinitionTypeDef:
return {
"key": ...,
}
```
<a id="how-it-works"></a>
## How it works
Fully automated
[mypy-boto3-builder](https://github.com/youtype/mypy_boto3_builder) carefully
generates type annotations for each service, patiently waiting for `boto3`
updates. It delivers drop-in type annotations for you and makes sure that:
- All available `boto3` services are covered.
- Each public class and method of every `boto3` service gets valid type
annotations extracted from `botocore` schemas.
- Type annotations include up-to-date documentation.
- Link to documentation is provided for every method.
- Code is processed by [ruff](https://docs.astral.sh/ruff/) for readability.
<a id="what's-new"></a>
## What's new
<a id="implemented-features"></a>
### Implemented features
- Fully type annotated `boto3`, `botocore`, `aiobotocore` and `aioboto3`
libraries
- `mypy`, `pyright`, `VSCode`, `PyCharm`, `Sublime Text` and `Emacs`
compatibility
- `Client`, `ServiceResource`, `Resource`, `Waiter` `Paginator` type
annotations for each service
- Generated `TypeDefs` for each service
- Generated `Literals` for each service
- Auto discovery of types for `boto3.client` and `boto3.resource` calls
- Auto discovery of types for `session.client` and `session.resource` calls
- Auto discovery of types for `client.get_waiter` and `client.get_paginator`
calls
- Auto discovery of types for `ServiceResource` and `Resource` collections
- Auto discovery of types for `aiobotocore.Session.create_client` calls
<a id="latest-changes"></a>
### Latest changes
Builder changelog can be found in
[Releases](https://github.com/youtype/mypy_boto3_builder/releases).
<a id="versioning"></a>
## Versioning
`mypy-boto3-bcm-dashboards` version is the same as related `boto3` version and
follows
[Python Packaging version specifiers](https://packaging.python.org/en/latest/specifications/version-specifiers/).
<a id="thank-you"></a>
## Thank you
- [Allie Fitter](https://github.com/alliefitter) for
[boto3-type-annotations](https://pypi.org/project/boto3-type-annotations/),
this package is based on top of his work
- [black](https://github.com/psf/black) developers for an awesome formatting
tool
- [Timothy Edmund Crosley](https://github.com/timothycrosley) for
[isort](https://github.com/PyCQA/isort) and how flexible it is
- [mypy](https://github.com/python/mypy) developers for doing all dirty work
for us
- [pyright](https://github.com/microsoft/pyright) team for the new era of typed
Python
<a id="documentation"></a>
## Documentation
All services type annotations can be found in
[boto3 docs](https://youtype.github.io/boto3_stubs_docs/mypy_boto3_bcm_dashboards/)
<a id="support-and-contributing"></a>
## Support and contributing
This package is auto-generated. Please reports any bugs or request new features
in [mypy-boto3-builder](https://github.com/youtype/mypy_boto3_builder/issues/)
repository.
| text/markdown | null | Vlad Emelianov <vlad.emelianov.nz@gmail.com> | null | null | null | boto3, bcm-dashboards, boto3-stubs, type-annotations, mypy, typeshed, autocomplete | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Environment :: Console",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"... | [
"any"
] | null | null | >=3.9 | [] | [] | [] | [
"typing-extensions; python_version < \"3.12\""
] | [] | [] | [] | [
"Homepage, https://github.com/youtype/mypy_boto3_builder",
"Documentation, https://youtype.github.io/boto3_stubs_docs/mypy_boto3_bcm_dashboards/",
"Source, https://github.com/youtype/mypy_boto3_builder",
"Tracker, https://github.com/youtype/mypy_boto3_builder/issues"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-19T20:50:22.033653 | mypy_boto3_bcm_dashboards-1.42.53.tar.gz | 18,789 | 4a/78/368c3772adc11900024262f68b41fda8c930686119e45c84e373d583477f/mypy_boto3_bcm_dashboards-1.42.53.tar.gz | source | sdist | null | false | cb72aae020e258fc3258eb7d14f7f3d4 | 36506fa957f0fe6173c50316cff9acbe5f27a0c7806933b1d49b2e361c30b025 | 4a78368c3772adc11900024262f68b41fda8c930686119e45c84e373d583477f | MIT | [
"LICENSE"
] | 766 |
2.4 | types-boto3-bcm-dashboards | 1.42.53 | Type annotations for boto3 BillingandCostManagementDashboards 1.42.53 service generated with mypy-boto3-builder 8.12.0 | <a id="types-boto3-bcm-dashboards"></a>
# types-boto3-bcm-dashboards
[](https://pypi.org/project/types-boto3-bcm-dashboards/)
[](https://pypi.org/project/types-boto3-bcm-dashboards/)
[](https://youtype.github.io/types_boto3_docs/)
[](https://pypistats.org/packages/types-boto3-bcm-dashboards)

Type annotations for
[boto3 BillingandCostManagementDashboards 1.42.53](https://pypi.org/project/boto3/)
compatible with [VSCode](https://code.visualstudio.com/),
[PyCharm](https://www.jetbrains.com/pycharm/),
[Emacs](https://www.gnu.org/software/emacs/),
[Sublime Text](https://www.sublimetext.com/),
[mypy](https://github.com/python/mypy),
[pyright](https://github.com/microsoft/pyright) and other tools.
Generated with
[mypy-boto3-builder 8.12.0](https://github.com/youtype/mypy_boto3_builder).
More information can be found on
[types-boto3](https://pypi.org/project/types-boto3/) page and in
[types-boto3-bcm-dashboards docs](https://youtype.github.io/types_boto3_docs/types_boto3_bcm_dashboards/).
See how it helps you find and fix potential bugs:

- [types-boto3-bcm-dashboards](#types-boto3-bcm-dashboards)
- [How to install](#how-to-install)
- [Generate locally (recommended)](<#generate-locally-(recommended)>)
- [VSCode extension](#vscode-extension)
- [From PyPI with pip](#from-pypi-with-pip)
- [How to uninstall](#how-to-uninstall)
- [Usage](#usage)
- [VSCode](#vscode)
- [PyCharm](#pycharm)
- [Emacs](#emacs)
- [Sublime Text](#sublime-text)
- [Other IDEs](#other-ides)
- [mypy](#mypy)
- [pyright](#pyright)
- [Pylint compatibility](#pylint-compatibility)
- [Explicit type annotations](#explicit-type-annotations)
- [Client annotations](#client-annotations)
- [Paginators annotations](#paginators-annotations)
- [Literals](#literals)
- [Type definitions](#type-definitions)
- [How it works](#how-it-works)
- [What's new](#what's-new)
- [Implemented features](#implemented-features)
- [Latest changes](#latest-changes)
- [Versioning](#versioning)
- [Thank you](#thank-you)
- [Documentation](#documentation)
- [Support and contributing](#support-and-contributing)
<a id="how-to-install"></a>
## How to install
<a id="generate-locally-(recommended)"></a>
### Generate locally (recommended)
You can generate type annotations for `boto3` package locally with
`mypy-boto3-builder`. Use
[uv](https://docs.astral.sh/uv/getting-started/installation/) for build
isolation.
1. Run mypy-boto3-builder in your package root directory:
`uvx --with 'boto3==1.42.53' mypy-boto3-builder`
2. Select `boto3` AWS SDK.
3. Add `BillingandCostManagementDashboards` service.
4. Use provided commands to install generated packages.
<a id="vscode-extension"></a>
### VSCode extension
Add
[AWS Boto3](https://marketplace.visualstudio.com/items?itemName=Boto3typed.boto3-ide)
extension to your VSCode and run `AWS boto3: Quick Start` command.
Click `Modify` and select `boto3 common` and
`BillingandCostManagementDashboards`.
<a id="from-pypi-with-pip"></a>
### From PyPI with pip
Install `types-boto3` for `BillingandCostManagementDashboards` service.
```bash
# install with boto3 type annotations
python -m pip install 'types-boto3[bcm-dashboards]'
# Lite version does not provide session.client/resource overloads
# it is more RAM-friendly, but requires explicit type annotations
python -m pip install 'types-boto3-lite[bcm-dashboards]'
# standalone installation
python -m pip install types-boto3-bcm-dashboards
```
<a id="how-to-uninstall"></a>
## How to uninstall
```bash
python -m pip uninstall -y types-boto3-bcm-dashboards
```
<a id="usage"></a>
## Usage
<a id="vscode"></a>
### VSCode
- Install
[Python extension](https://marketplace.visualstudio.com/items?itemName=ms-python.python)
- Install
[Pylance extension](https://marketplace.visualstudio.com/items?itemName=ms-python.vscode-pylance)
- Set `Pylance` as your Python Language Server
- Install `types-boto3[bcm-dashboards]` in your environment:
```bash
python -m pip install 'types-boto3[bcm-dashboards]'
```
Both type checking and code completion should now work. No explicit type
annotations required, write your `boto3` code as usual.
<a id="pycharm"></a>
### PyCharm
> ⚠️ Due to slow PyCharm performance on `Literal` overloads (issue
> [PY-40997](https://youtrack.jetbrains.com/issue/PY-40997)), it is recommended
> to use [types-boto3-lite](https://pypi.org/project/types-boto3-lite/) until
> the issue is resolved.
> ⚠️ If you experience slow performance and high CPU usage, try to disable
> `PyCharm` type checker and use [mypy](https://github.com/python/mypy) or
> [pyright](https://github.com/microsoft/pyright) instead.
> ⚠️ To continue using `PyCharm` type checker, you can try to replace
> `types-boto3` with
> [types-boto3-lite](https://pypi.org/project/types-boto3-lite/):
```bash
pip uninstall types-boto3
pip install types-boto3-lite
```
Install `types-boto3[bcm-dashboards]` in your environment:
```bash
python -m pip install 'types-boto3[bcm-dashboards]'
```
Both type checking and code completion should now work.
<a id="emacs"></a>
### Emacs
- Install `types-boto3` with services you use in your environment:
```bash
python -m pip install 'types-boto3[bcm-dashboards]'
```
- Install [use-package](https://github.com/jwiegley/use-package),
[lsp](https://github.com/emacs-lsp/lsp-mode/),
[company](https://github.com/company-mode/company-mode) and
[flycheck](https://github.com/flycheck/flycheck) packages
- Install [lsp-pyright](https://github.com/emacs-lsp/lsp-pyright) package
```elisp
(use-package lsp-pyright
:ensure t
:hook (python-mode . (lambda ()
(require 'lsp-pyright)
(lsp))) ; or lsp-deferred
:init (when (executable-find "python3")
(setq lsp-pyright-python-executable-cmd "python3"))
)
```
- Make sure emacs uses the environment where you have installed `types-boto3`
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="sublime-text"></a>
### Sublime Text
- Install `types-boto3[bcm-dashboards]` with services you use in your
environment:
```bash
python -m pip install 'types-boto3[bcm-dashboards]'
```
- Install [LSP-pyright](https://github.com/sublimelsp/LSP-pyright) package
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="other-ides"></a>
### Other IDEs
Not tested, but as long as your IDE supports `mypy` or `pyright`, everything
should work.
<a id="mypy"></a>
### mypy
- Install `mypy`: `python -m pip install mypy`
- Install `types-boto3[bcm-dashboards]` in your environment:
```bash
python -m pip install 'types-boto3[bcm-dashboards]'
```
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="pyright"></a>
### pyright
- Install `pyright`: `npm i -g pyright`
- Install `types-boto3[bcm-dashboards]` in your environment:
```bash
python -m pip install 'types-boto3[bcm-dashboards]'
```
Optionally, you can install `types-boto3` to `typings` directory.
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="pylint-compatibility"></a>
### Pylint compatibility
It is totally safe to use `TYPE_CHECKING` flag in order to avoid
`types-boto3-bcm-dashboards` dependency in production. However, there is an
issue in `pylint` that it complains about undefined variables. To fix it, set
all types to `object` in non-`TYPE_CHECKING` mode.
```python
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from types_boto3_ec2 import EC2Client, EC2ServiceResource
from types_boto3_ec2.waiters import BundleTaskCompleteWaiter
from types_boto3_ec2.paginators import DescribeVolumesPaginator
else:
EC2Client = object
EC2ServiceResource = object
BundleTaskCompleteWaiter = object
DescribeVolumesPaginator = object
...
```
<a id="explicit-type-annotations"></a>
## Explicit type annotations
<a id="client-annotations"></a>
### Client annotations
`BillingandCostManagementDashboardsClient` provides annotations for
`boto3.client("bcm-dashboards")`.
```python
from boto3.session import Session
from types_boto3_bcm_dashboards import BillingandCostManagementDashboardsClient
client: BillingandCostManagementDashboardsClient = Session().client("bcm-dashboards")
# now client usage is checked by mypy and IDE should provide code completion
```
<a id="paginators-annotations"></a>
### Paginators annotations
`types_boto3_bcm_dashboards.paginator` module contains type annotations for all
paginators.
```python
from boto3.session import Session
from types_boto3_bcm_dashboards import BillingandCostManagementDashboardsClient
from types_boto3_bcm_dashboards.paginator import ListDashboardsPaginator
client: BillingandCostManagementDashboardsClient = Session().client("bcm-dashboards")
# Explicit type annotations are optional here
# Types should be correctly discovered by mypy and IDEs
list_dashboards_paginator: ListDashboardsPaginator = client.get_paginator("list_dashboards")
```
<a id="literals"></a>
### Literals
`types_boto3_bcm_dashboards.literals` module contains literals extracted from
shapes that can be used in user code for type checking.
Full list of `BillingandCostManagementDashboards` Literals can be found in
[docs](https://youtype.github.io/types_boto3_docs/types_boto3_bcm_dashboards/literals/).
```python
from types_boto3_bcm_dashboards.literals import DashboardTypeType
def check_value(value: DashboardTypeType) -> bool: ...
```
<a id="type-definitions"></a>
### Type definitions
`types_boto3_bcm_dashboards.type_defs` module contains structures and shapes
assembled to typed dictionaries and unions for additional type checking.
Full list of `BillingandCostManagementDashboards` TypeDefs can be found in
[docs](https://youtype.github.io/types_boto3_docs/types_boto3_bcm_dashboards/type_defs/).
```python
# TypedDict usage example
from types_boto3_bcm_dashboards.type_defs import GroupDefinitionTypeDef
def get_value() -> GroupDefinitionTypeDef:
return {
"key": ...,
}
```
<a id="how-it-works"></a>
## How it works
Fully automated
[mypy-boto3-builder](https://github.com/youtype/mypy_boto3_builder) carefully
generates type annotations for each service, patiently waiting for `boto3`
updates. It delivers drop-in type annotations for you and makes sure that:
- All available `boto3` services are covered.
- Each public class and method of every `boto3` service gets valid type
annotations extracted from `botocore` schemas.
- Type annotations include up-to-date documentation.
- Link to documentation is provided for every method.
- Code is processed by [ruff](https://docs.astral.sh/ruff/) for readability.
<a id="what's-new"></a>
## What's new
<a id="implemented-features"></a>
### Implemented features
- Fully type annotated `boto3`, `botocore`, `aiobotocore` and `aioboto3`
libraries
- `mypy`, `pyright`, `VSCode`, `PyCharm`, `Sublime Text` and `Emacs`
compatibility
- `Client`, `ServiceResource`, `Resource`, `Waiter` `Paginator` type
annotations for each service
- Generated `TypeDefs` for each service
- Generated `Literals` for each service
- Auto discovery of types for `boto3.client` and `boto3.resource` calls
- Auto discovery of types for `session.client` and `session.resource` calls
- Auto discovery of types for `client.get_waiter` and `client.get_paginator`
calls
- Auto discovery of types for `ServiceResource` and `Resource` collections
- Auto discovery of types for `aiobotocore.Session.create_client` calls
<a id="latest-changes"></a>
### Latest changes
Builder changelog can be found in
[Releases](https://github.com/youtype/mypy_boto3_builder/releases).
<a id="versioning"></a>
## Versioning
`types-boto3-bcm-dashboards` version is the same as related `boto3` version and
follows
[Python Packaging version specifiers](https://packaging.python.org/en/latest/specifications/version-specifiers/).
<a id="thank-you"></a>
## Thank you
- [Allie Fitter](https://github.com/alliefitter) for
[boto3-type-annotations](https://pypi.org/project/boto3-type-annotations/),
this package is based on top of his work
- [black](https://github.com/psf/black) developers for an awesome formatting
tool
- [Timothy Edmund Crosley](https://github.com/timothycrosley) for
[isort](https://github.com/PyCQA/isort) and how flexible it is
- [mypy](https://github.com/python/mypy) developers for doing all dirty work
for us
- [pyright](https://github.com/microsoft/pyright) team for the new era of typed
Python
<a id="documentation"></a>
## Documentation
All services type annotations can be found in
[boto3 docs](https://youtype.github.io/types_boto3_docs/types_boto3_bcm_dashboards/)
<a id="support-and-contributing"></a>
## Support and contributing
This package is auto-generated. Please reports any bugs or request new features
in [mypy-boto3-builder](https://github.com/youtype/mypy_boto3_builder/issues/)
repository.
| text/markdown | null | Vlad Emelianov <vlad.emelianov.nz@gmail.com> | null | null | null | boto3, bcm-dashboards, boto3-stubs, type-annotations, mypy, typeshed, autocomplete | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Environment :: Console",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"... | [
"any"
] | null | null | >=3.9 | [] | [] | [] | [
"typing-extensions; python_version < \"3.12\""
] | [] | [] | [] | [
"Homepage, https://github.com/youtype/mypy_boto3_builder",
"Documentation, https://youtype.github.io/types_boto3_docs/types_boto3_bcm_dashboards/",
"Source, https://github.com/youtype/mypy_boto3_builder",
"Tracker, https://github.com/youtype/mypy_boto3_builder/issues"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T20:50:18.512069 | types_boto3_bcm_dashboards-1.42.53.tar.gz | 18,819 | b8/2f/676300e44dc3bbe8caa5d35c3f1563c6500c885491dc9d059948375408c5/types_boto3_bcm_dashboards-1.42.53.tar.gz | source | sdist | null | false | b5a06e3ecf4a37b8843243873295c5ac | d58d035f94b19032bc5d79c8c64211b48c5fd2b61ab25d48cd615033a6d01a2d | b82f676300e44dc3bbe8caa5d35c3f1563c6500c885491dc9d059948375408c5 | MIT | [
"LICENSE"
] | 199 |
2.4 | unitgrade | 1.0.0.14 | A student homework/exam evaluation framework build on pythons unittest framework. | # Unitgrade
Unitgrade is an autograding framework which enables instructors to offer automatically evaluated programming assignments in a maximally convenient format for the students.
Unitgrade is build on pythons `unittest` framework; i.e., you can directly use your existing unittests without any changes. It will therefore integrate well with any modern IDE. What it offers beyond `unittest` is the ability to collect tests in reports (for automatic evaluation)
and an easy and safe mechanism for verifying results.
- 100% Python `unittest` compatible
- Integrates with any modern IDE (VSCode, Pycharm, Eclipse)
- No external configuration files
- Hint-system collects hints from code and display it with failed unittests
- A dashboard gives the students an overview of their progress
- Safe and convenient to administer
-
### Why this instead of an online autograder?
Online autograding services often say that they have adapter their particular model in order to make students better or happier. I did a small thought-experiments, and asked myself what I would ideally want out of an autograder if I was a student. I quickly realized the only thing I really cared about was easily it allowed me to fix bugs in my homework assignments. In other words, I think students prioritize the same thing as we all do when we write software tests -- to quickly and easily identify and fix problems.
However, I would not use an online autograder for any of my own software projects for a number of reasons:
- Why would I want my tests to be executed in another environment than my development-environment?
- Why would I want to copy-paste code online (or rely on a sub-standard web-IDE without autocomplete?)
- The lack of a debugger would drive me nuts
- Why `alt+tab` to an external tool when my IDE already has excellent test plugins?
- *Your test will be run within a few minutes*
- Something as basic as `print`-statements is often not readily available; I don't know any services that shows them live
- Often students have no access to the tests themselves, perhaps because they rely on special terminal commands. This means it can be hard to reason about what code is *actually* being run.
This raises the question that if I would not want to use an online autograder as a way to fix issues in my own software projects, why should students prefer it?
The alternative is in my view obvious -- simply give students a suite of unittests. This raises some potential issues such as safety and administrative convenience, but they turned out to be easy to solve. If you want to learn more about developing tests see the test-development repository here: https://gitlab.compute.dtu.dk/tuhe/unitgrade_private
## Installation
Unitgrade requires python 3.8 or higher, and can be installed using `pip`:
```terminal
pip install unitgrade
```
After the command completes you should be all. If you want to upgrade an old version of unitgrade run:
```terminal
pip install unitgrade --upgrade --no-cache-dir
```
If you are using anaconda+virtual environment you can also install it as you would any other package:
```terminal
source activate myenv
conda install git pip
pip install unitgrade
```
When you are done, you should be able to import unitgrade. Type `python` in the termial and try:
```pycon
>>> import unitgrade
```
## Using Unitgrade
Your homework assignments are called **reports** and are distributed as a regular `.py`-files. In the following I will use `cs101report1.py` as an example, and you can find a real-world example here: https://gitlab.compute.dtu.dk/tuhe/unitgrade_private/-/blob/master/examples/example_simplest/students/cs101/report1.py .
A report is simply a collection of questions, and each question may in turn involve several tests.
I recommend running the tests through your IDE. In pycharm, this is as simple as right-clicking on the test and selecting `Run as unittest`:

The outcome of the tests are shown in the lower-left corner, and in this case they are all green meaning they have passed. You can see the console output generated by a test by clicking on it. If a test fails, you can select `debug as unittest` from the menu above to launch a debugger, and you can right-click on individual tests to re-run them.
### Checking your score
To check your score, you have to run the main script (`cs101report1.py`). This can be done either through pycharm (Hint: Open the file and press `alt-shift-F10`) or in the console by running the command:
```
python cs101report1.py
```
The file will run and show an output where the score of each question is computed as a (weighted) average of the individual passed tests. An example is given below:
```terminal
_ _ _ _ _____ _
| | | | (_) | | __ \ | |
| | | |_ __ _| |_| | \/_ __ __ _ __| | ___
| | | | '_ \| | __| | __| '__/ _` |/ _` |/ _ \
| |_| | | | | | |_| |_\ \ | | (_| | (_| | __/
\___/|_| |_|_|\__|\____/_| \__,_|\__,_|\___| v0.1.29.0, started: 16/09/2022 13:47:57
02531 week 5: Looping (use --help for options)
Question 1: Cluster analysis
* q1.1) clusterAnalysis([0.8, 0.0, 0.6]) = [1, 2, 1] ?.............................................................PASS
* q1.2) clusterAnalysis([0.5, 0.6, 0.3, 0.3]) = [2, 2, 1, 1] ?.....................................................PASS
* q1.3) clusterAnalysis([0.2, 0.7, 0.3, 0.5, 0.0]) = [1, 2, 1, 2, 1] ?.............................................PASS
* q1.4) Cluster analysis for tied lists............................................................................PASS
* q1) Total.................................................................................................... 10/10
Question 2: Remove incomplete IDs
* q2.1) removeId([1.3, 2.2, 2.3, 4.2, 5.1, 3.2,...]) = [2.2, 2.3, 5.1, 3.2, 5.3, 3.3,...] ?........................PASS
* q2.2) removeId([1.1, 1.2, 1.3, 2.1, 2.2, 2.3]) = [1.1, 1.2, 1.3, 2.1, 2.2, 2.3] ?................................PASS
* q2.3) removeId([5.1, 5.2, 4.1, 4.3, 4.2, 8.1,...]) = [4.1, 4.3, 4.2, 8.1, 8.2, 8.3] ?............................PASS
* q2.4) removeId([1.1, 1.3, 2.1, 2.2, 3.1, 3.3,...]) = [4.1, 4.2, 4.3] ?...........................................PASS
* q2.5) removeId([6.1, 3.2, 7.2, 4.2, 6.2, 9.1,...]) = [9.1, 5.2, 1.2, 5.1, 1.2, 9.2,...] ?........................PASS
* q2) Total.................................................................................................... 10/10
Question 3: Bacteria growth rates
* q3.1) bacteriaGrowth(100, 0.4, 1000, 500) = 7 ?..................................................................PASS
* q3.2) bacteriaGrowth(10, 0.4, 1000, 500) = 14 ?..................................................................PASS
* q3.3) bacteriaGrowth(100, 1.4, 1000, 500) = 3 ?..................................................................PASS
* q3.4) bacteriaGrowth(100, 0.0004, 1000, 500) = 5494 ?............................................................PASS
* q3.5) bacteriaGrowth(100, 0.4, 1000, 99) = 0 ?...................................................................PASS
* q3) Total.................................................................................................... 10/10
Question 4: Fermentation rate
* q4.1) fermentationRate([20.1, 19.3, 1.1, 18.2, 19.7, ...], 15, 25) = 19.600 ?....................................PASS
* q4.2) fermentationRate([20.1, 19.3, 1.1, 18.2, 19.7, ...], 1, 200) = 29.975 ?....................................PASS
* q4.3) fermentationRate([1.75], 1, 2) = 1.750 ?...................................................................PASS
* q4.4) fermentationRate([20.1, 19.3, 1.1, 18.2, 19.7, ...], 18.2, 20) = 19.500 ?..................................PASS
* q4) Total.................................................................................................... 10/10
Total points at 13:48:02 (0 minutes, 4 seconds)....................................................................40/40
Provisional evaluation
--------- -----
q1) Total 10/10
q2) Total 10/10
q3) Total 10/10
q4) Total 10/10
Total 40/40
--------- -----
Note your results have not yet been registered.
To register your results, please run the file:
>>> looping_tests_grade.py
In the same manner as you ran this file.
```
### Handing in your homework
Once you are happy with your results and want to hand in, you should run the script with the `_grade.py`-postfix, in this case `cs101report1_grade.py` (see console output above):
```
python cs101report1_grade.py
```
This script will run *the same tests as before* and generates a file named `Report0_handin_18_of_18.token` (this is called the `token`-file because of the extension). The token-file contains all your results and it is the token-file you should upload (and no other). Because you cannot (and most definitely should not!) edit it, it shows the number of points in the file-name.
### The dashboard
I recommend to watch and run the tests from your IDE, as this allows you to use the debugger in conjunction with your tests. However, I have put together a dashboard that allows you to see the outcome of individual tests and what is currently recorded in your `token`-file. To start the dashboard, simply run the command
```
unitgrade
```
from a directory that contains a test (the directory will be searched recursively for tests). The command will start a small background service and open this page:

Features supported in the current version:
- Shows you which files need to be edited to solve the problem
- Collect hints given in the homework files and display them for the relevant tests
- fully responsive -- the UI, including the terminal, will update while the test is running regardless of where you launch the test
- Allows you to re-run tests
- Shows current test status and results captured in `.token`-file
- Tested on Windows/Linux
- No binaries or special setup required; everything is 100% python
Note that the run feature currently assumes that your system-wide `python` command can run the tests. This may not be the case if you are using virtual environments -- I expect to fix this soon.
### Why are there two scripts?
# FAQ
- **Why is there two scripts?**
The reason why we use a standard test script (one with the `_grade.py` extension and one without), is because the tests should both be easy to debug, but at the same time we have to avoid accidential changes to the test scripts. The tests themselves are the same, so if one script works, so should the other.
- **My non-grade script and the `_grade.py` script gives different number of points**
Since the two scripts should contain the same code, the reason is with near certainty that you have made an (accidental) change to the test scripts. Please ensure both scripts are up-to-date and if the problem persists, get support.
- **Why is there a `unitgrade`-directory with a bunch of pickle files? Should I also upload them?**
No. The file contains the pre-computed test results your code is compared against. You should only upload the `.token` file, nothing else
- **I am worried you might think I cheated because I opened the '_grade.py' script/token file**
This should not be a concern. Both files are in a binary format (i.e., if you open them in a text editor they look like garbage), which means that if you make an accidential change, they will with all probability simply fail to work.
- **I think I might have edited the `report1.py` file. Is this a problem since one of the tests have now been altered?**
Feel free to edit/break this file as much as you like if it helps you work out the correct solution. However, since the `report1_grade.py` script contains a seperate version of the tests, please ensure both files are in sync to avoid unexpected behavior.
### Debugging your code/making the tests pass
The course material should contain information about the intended function of the scripts, and the file `report1.py` should mainly be used to check which of your code is being run. In other words, first make sure your code solves the exercises, and only later run the test script which is less easy/nice to read.
However, obivously you might get to a situation where your code seems to work, but a test fails. In that case, it is worth looking into the code in `report1.py` to work out what exactly is going on.
- **I am 99% sure my code is correct, but the test still fails. Why is that?**
The testing framework offers a great deal of flexibility in terms of what is compared. This is either: (i) The value a function returns, (ii) what the code print to the console (iii) something derived from these.
When a test fails, you should always try to insert a breakpoint on exactly the line that generate the problem, run the test in the debugger, and figure out what the expected result was supposed to be. This should give you a clear hint as to what may be wrong.
One possibility that might trick some is that if the test compares a value computed by your code, the datatype of that value may be important. For instance, a `list` is not the same as a python `ndarray`, and a `tuple` is different from a `list`.
- **The `report1.py` class is really confusing. I can see the code it runs on my computer, but not the expected output. Why is it like this?**
To make sure the desired output of the tests is always up to date, the tests are computed from a working version of the code and loaded from the disk rather than being hard-coded.
- **How do I see the output of my programs in the tests? Or the intended output?**
There are a number of console options available to help you figure out what your program should output and what it currently outputs. They can be found using:
```python report1.py --help```
Note these are disabled for the `report1_grade.py` script to avoid confusion. It is not recommended you use the grade script to debug your code.
- **Since I cannot read the `.token` file, can I trust it contains the same number of points internally as the file name indicate?**
Yes.
### Privacy/security
- **I managed to reverse engineer the `report1_grade.py`/`*.token` files in about 30 minutes. If the safety measures are so easily broken, how do you ensure people do not cheat?**
That the script `report1_grade.py` is difficult to read is not the principle safety measure. Instead, it ensures there is no accidential tampering. If you muck around with these files and upload the result, we will very likely know you edited them.
- **I have private data on my computer. Will this be read or uploaded?**
No. The code will look for and include yours solutions in the `.token`-file, but it will not read/look at other directories in your computer. As long as your keep your private files out of the directory that contains your homework you have nothing to worry about.
- **Does this code install any spyware/etc.? Does it communicate with a website/online service?**
Unitgrade makes no changes outside the courseware directory, and it does not do anything tricky. It reads/runs code and produces the `.token` file. The development version of unitgrade has an experimental feature to look at a github page and check your version fo the tests is up-to-date, but this is currently not enabled and all this would do is to warn you about a potential problem with an outdated test.
- **I still have concerns about running code on my computer I cannot easily read**
Please contact me and we can discuss your specific concerns.
# Citing
```bibtex
@online{unitgrade,
title={Unitgrade (0.1.29.0): \texttt{pip install unitgrade}},
url={https://lab.compute.dtu.dk/tuhe/unitgrade},
urldate = {2022-09-16},
month={9},
publisher={Technical University of Denmark (DTU)},
author={Tue Herlau},
year={2022},
}
```
| text/markdown | null | Tue Herlau <tuhe@dtu.dk> | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"numpy",
"tabulate",
"coverage",
"colorama",
"tqdm",
"importnb",
"requests",
"pandas",
"watchdog",
"flask_socketio",
"flask",
"Werkzeug>=2.3.0",
"diskcache",
"openpyxl"
] | [] | [] | [] | [
"Homepage, https://lab.compute.dtu.dk/tuhe/unitgrade",
"Bug Tracker, https://lab.compute.dtu.dk/tuhe/unitgrade/issues"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-19T20:50:17.626663 | unitgrade-1.0.0.14.tar.gz | 69,167 | ec/9d/14a19874f1a864f0e76fedac87f365f8053d46131fb7dbe5fa8c5101ad52/unitgrade-1.0.0.14.tar.gz | source | sdist | null | false | af12716a54dc99d6c49d6b2e1ccaa3f4 | 387dabaf206cd6febb132a1f283e766933b9a7317ac7d99bff24ac8983b390a6 | ec9d14a19874f1a864f0e76fedac87f365f8053d46131fb7dbe5fa8c5101ad52 | null | [
"LICENSE"
] | 285 |
2.4 | types-boto3-pca-connector-scep | 1.42.53 | Type annotations for boto3 PrivateCAConnectorforSCEP 1.42.53 service generated with mypy-boto3-builder 8.12.0 | <a id="types-boto3-pca-connector-scep"></a>
# types-boto3-pca-connector-scep
[](https://pypi.org/project/types-boto3-pca-connector-scep/)
[](https://pypi.org/project/types-boto3-pca-connector-scep/)
[](https://youtype.github.io/types_boto3_docs/)
[](https://pypistats.org/packages/types-boto3-pca-connector-scep)

Type annotations for
[boto3 PrivateCAConnectorforSCEP 1.42.53](https://pypi.org/project/boto3/)
compatible with [VSCode](https://code.visualstudio.com/),
[PyCharm](https://www.jetbrains.com/pycharm/),
[Emacs](https://www.gnu.org/software/emacs/),
[Sublime Text](https://www.sublimetext.com/),
[mypy](https://github.com/python/mypy),
[pyright](https://github.com/microsoft/pyright) and other tools.
Generated with
[mypy-boto3-builder 8.12.0](https://github.com/youtype/mypy_boto3_builder).
More information can be found on
[types-boto3](https://pypi.org/project/types-boto3/) page and in
[types-boto3-pca-connector-scep docs](https://youtype.github.io/types_boto3_docs/types_boto3_pca_connector_scep/).
See how it helps you find and fix potential bugs:

- [types-boto3-pca-connector-scep](#types-boto3-pca-connector-scep)
- [How to install](#how-to-install)
- [Generate locally (recommended)](<#generate-locally-(recommended)>)
- [VSCode extension](#vscode-extension)
- [From PyPI with pip](#from-pypi-with-pip)
- [How to uninstall](#how-to-uninstall)
- [Usage](#usage)
- [VSCode](#vscode)
- [PyCharm](#pycharm)
- [Emacs](#emacs)
- [Sublime Text](#sublime-text)
- [Other IDEs](#other-ides)
- [mypy](#mypy)
- [pyright](#pyright)
- [Pylint compatibility](#pylint-compatibility)
- [Explicit type annotations](#explicit-type-annotations)
- [Client annotations](#client-annotations)
- [Paginators annotations](#paginators-annotations)
- [Literals](#literals)
- [Type definitions](#type-definitions)
- [How it works](#how-it-works)
- [What's new](#what's-new)
- [Implemented features](#implemented-features)
- [Latest changes](#latest-changes)
- [Versioning](#versioning)
- [Thank you](#thank-you)
- [Documentation](#documentation)
- [Support and contributing](#support-and-contributing)
<a id="how-to-install"></a>
## How to install
<a id="generate-locally-(recommended)"></a>
### Generate locally (recommended)
You can generate type annotations for `boto3` package locally with
`mypy-boto3-builder`. Use
[uv](https://docs.astral.sh/uv/getting-started/installation/) for build
isolation.
1. Run mypy-boto3-builder in your package root directory:
`uvx --with 'boto3==1.42.53' mypy-boto3-builder`
2. Select `boto3` AWS SDK.
3. Add `PrivateCAConnectorforSCEP` service.
4. Use provided commands to install generated packages.
<a id="vscode-extension"></a>
### VSCode extension
Add
[AWS Boto3](https://marketplace.visualstudio.com/items?itemName=Boto3typed.boto3-ide)
extension to your VSCode and run `AWS boto3: Quick Start` command.
Click `Modify` and select `boto3 common` and `PrivateCAConnectorforSCEP`.
<a id="from-pypi-with-pip"></a>
### From PyPI with pip
Install `types-boto3` for `PrivateCAConnectorforSCEP` service.
```bash
# install with boto3 type annotations
python -m pip install 'types-boto3[pca-connector-scep]'
# Lite version does not provide session.client/resource overloads
# it is more RAM-friendly, but requires explicit type annotations
python -m pip install 'types-boto3-lite[pca-connector-scep]'
# standalone installation
python -m pip install types-boto3-pca-connector-scep
```
<a id="how-to-uninstall"></a>
## How to uninstall
```bash
python -m pip uninstall -y types-boto3-pca-connector-scep
```
<a id="usage"></a>
## Usage
<a id="vscode"></a>
### VSCode
- Install
[Python extension](https://marketplace.visualstudio.com/items?itemName=ms-python.python)
- Install
[Pylance extension](https://marketplace.visualstudio.com/items?itemName=ms-python.vscode-pylance)
- Set `Pylance` as your Python Language Server
- Install `types-boto3[pca-connector-scep]` in your environment:
```bash
python -m pip install 'types-boto3[pca-connector-scep]'
```
Both type checking and code completion should now work. No explicit type
annotations required, write your `boto3` code as usual.
<a id="pycharm"></a>
### PyCharm
> ⚠️ Due to slow PyCharm performance on `Literal` overloads (issue
> [PY-40997](https://youtrack.jetbrains.com/issue/PY-40997)), it is recommended
> to use [types-boto3-lite](https://pypi.org/project/types-boto3-lite/) until
> the issue is resolved.
> ⚠️ If you experience slow performance and high CPU usage, try to disable
> `PyCharm` type checker and use [mypy](https://github.com/python/mypy) or
> [pyright](https://github.com/microsoft/pyright) instead.
> ⚠️ To continue using `PyCharm` type checker, you can try to replace
> `types-boto3` with
> [types-boto3-lite](https://pypi.org/project/types-boto3-lite/):
```bash
pip uninstall types-boto3
pip install types-boto3-lite
```
Install `types-boto3[pca-connector-scep]` in your environment:
```bash
python -m pip install 'types-boto3[pca-connector-scep]'
```
Both type checking and code completion should now work.
<a id="emacs"></a>
### Emacs
- Install `types-boto3` with services you use in your environment:
```bash
python -m pip install 'types-boto3[pca-connector-scep]'
```
- Install [use-package](https://github.com/jwiegley/use-package),
[lsp](https://github.com/emacs-lsp/lsp-mode/),
[company](https://github.com/company-mode/company-mode) and
[flycheck](https://github.com/flycheck/flycheck) packages
- Install [lsp-pyright](https://github.com/emacs-lsp/lsp-pyright) package
```elisp
(use-package lsp-pyright
:ensure t
:hook (python-mode . (lambda ()
(require 'lsp-pyright)
(lsp))) ; or lsp-deferred
:init (when (executable-find "python3")
(setq lsp-pyright-python-executable-cmd "python3"))
)
```
- Make sure emacs uses the environment where you have installed `types-boto3`
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="sublime-text"></a>
### Sublime Text
- Install `types-boto3[pca-connector-scep]` with services you use in your
environment:
```bash
python -m pip install 'types-boto3[pca-connector-scep]'
```
- Install [LSP-pyright](https://github.com/sublimelsp/LSP-pyright) package
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="other-ides"></a>
### Other IDEs
Not tested, but as long as your IDE supports `mypy` or `pyright`, everything
should work.
<a id="mypy"></a>
### mypy
- Install `mypy`: `python -m pip install mypy`
- Install `types-boto3[pca-connector-scep]` in your environment:
```bash
python -m pip install 'types-boto3[pca-connector-scep]'
```
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="pyright"></a>
### pyright
- Install `pyright`: `npm i -g pyright`
- Install `types-boto3[pca-connector-scep]` in your environment:
```bash
python -m pip install 'types-boto3[pca-connector-scep]'
```
Optionally, you can install `types-boto3` to `typings` directory.
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="pylint-compatibility"></a>
### Pylint compatibility
It is totally safe to use `TYPE_CHECKING` flag in order to avoid
`types-boto3-pca-connector-scep` dependency in production. However, there is an
issue in `pylint` that it complains about undefined variables. To fix it, set
all types to `object` in non-`TYPE_CHECKING` mode.
```python
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from types_boto3_ec2 import EC2Client, EC2ServiceResource
from types_boto3_ec2.waiters import BundleTaskCompleteWaiter
from types_boto3_ec2.paginators import DescribeVolumesPaginator
else:
EC2Client = object
EC2ServiceResource = object
BundleTaskCompleteWaiter = object
DescribeVolumesPaginator = object
...
```
<a id="explicit-type-annotations"></a>
## Explicit type annotations
<a id="client-annotations"></a>
### Client annotations
`PrivateCAConnectorforSCEPClient` provides annotations for
`boto3.client("pca-connector-scep")`.
```python
from boto3.session import Session
from types_boto3_pca_connector_scep import PrivateCAConnectorforSCEPClient
client: PrivateCAConnectorforSCEPClient = Session().client("pca-connector-scep")
# now client usage is checked by mypy and IDE should provide code completion
```
<a id="paginators-annotations"></a>
### Paginators annotations
`types_boto3_pca_connector_scep.paginator` module contains type annotations for
all paginators.
```python
from boto3.session import Session
from types_boto3_pca_connector_scep import PrivateCAConnectorforSCEPClient
from types_boto3_pca_connector_scep.paginator import (
ListChallengeMetadataPaginator,
ListConnectorsPaginator,
)
client: PrivateCAConnectorforSCEPClient = Session().client("pca-connector-scep")
# Explicit type annotations are optional here
# Types should be correctly discovered by mypy and IDEs
list_challenge_metadata_paginator: ListChallengeMetadataPaginator = client.get_paginator(
"list_challenge_metadata"
)
list_connectors_paginator: ListConnectorsPaginator = client.get_paginator("list_connectors")
```
<a id="literals"></a>
### Literals
`types_boto3_pca_connector_scep.literals` module contains literals extracted
from shapes that can be used in user code for type checking.
Full list of `PrivateCAConnectorforSCEP` Literals can be found in
[docs](https://youtype.github.io/types_boto3_docs/types_boto3_pca_connector_scep/literals/).
```python
from types_boto3_pca_connector_scep.literals import ConnectorStatusReasonType
def check_value(value: ConnectorStatusReasonType) -> bool: ...
```
<a id="type-definitions"></a>
### Type definitions
`types_boto3_pca_connector_scep.type_defs` module contains structures and
shapes assembled to typed dictionaries and unions for additional type checking.
Full list of `PrivateCAConnectorforSCEP` TypeDefs can be found in
[docs](https://youtype.github.io/types_boto3_docs/types_boto3_pca_connector_scep/type_defs/).
```python
# TypedDict usage example
from types_boto3_pca_connector_scep.type_defs import ChallengeMetadataSummaryTypeDef
def get_value() -> ChallengeMetadataSummaryTypeDef:
return {
"Arn": ...,
}
```
<a id="how-it-works"></a>
## How it works
Fully automated
[mypy-boto3-builder](https://github.com/youtype/mypy_boto3_builder) carefully
generates type annotations for each service, patiently waiting for `boto3`
updates. It delivers drop-in type annotations for you and makes sure that:
- All available `boto3` services are covered.
- Each public class and method of every `boto3` service gets valid type
annotations extracted from `botocore` schemas.
- Type annotations include up-to-date documentation.
- Link to documentation is provided for every method.
- Code is processed by [ruff](https://docs.astral.sh/ruff/) for readability.
<a id="what's-new"></a>
## What's new
<a id="implemented-features"></a>
### Implemented features
- Fully type annotated `boto3`, `botocore`, `aiobotocore` and `aioboto3`
libraries
- `mypy`, `pyright`, `VSCode`, `PyCharm`, `Sublime Text` and `Emacs`
compatibility
- `Client`, `ServiceResource`, `Resource`, `Waiter` `Paginator` type
annotations for each service
- Generated `TypeDefs` for each service
- Generated `Literals` for each service
- Auto discovery of types for `boto3.client` and `boto3.resource` calls
- Auto discovery of types for `session.client` and `session.resource` calls
- Auto discovery of types for `client.get_waiter` and `client.get_paginator`
calls
- Auto discovery of types for `ServiceResource` and `Resource` collections
- Auto discovery of types for `aiobotocore.Session.create_client` calls
<a id="latest-changes"></a>
### Latest changes
Builder changelog can be found in
[Releases](https://github.com/youtype/mypy_boto3_builder/releases).
<a id="versioning"></a>
## Versioning
`types-boto3-pca-connector-scep` version is the same as related `boto3` version
and follows
[Python Packaging version specifiers](https://packaging.python.org/en/latest/specifications/version-specifiers/).
<a id="thank-you"></a>
## Thank you
- [Allie Fitter](https://github.com/alliefitter) for
[boto3-type-annotations](https://pypi.org/project/boto3-type-annotations/),
this package is based on top of his work
- [black](https://github.com/psf/black) developers for an awesome formatting
tool
- [Timothy Edmund Crosley](https://github.com/timothycrosley) for
[isort](https://github.com/PyCQA/isort) and how flexible it is
- [mypy](https://github.com/python/mypy) developers for doing all dirty work
for us
- [pyright](https://github.com/microsoft/pyright) team for the new era of typed
Python
<a id="documentation"></a>
## Documentation
All services type annotations can be found in
[boto3 docs](https://youtype.github.io/types_boto3_docs/types_boto3_pca_connector_scep/)
<a id="support-and-contributing"></a>
## Support and contributing
This package is auto-generated. Please reports any bugs or request new features
in [mypy-boto3-builder](https://github.com/youtype/mypy_boto3_builder/issues/)
repository.
| text/markdown | null | Vlad Emelianov <vlad.emelianov.nz@gmail.com> | null | null | null | boto3, pca-connector-scep, boto3-stubs, type-annotations, mypy, typeshed, autocomplete | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Environment :: Console",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"... | [
"any"
] | null | null | >=3.9 | [] | [] | [] | [
"typing-extensions; python_version < \"3.12\""
] | [] | [] | [] | [
"Homepage, https://github.com/youtype/mypy_boto3_builder",
"Documentation, https://youtype.github.io/types_boto3_docs/types_boto3_pca_connector_scep/",
"Source, https://github.com/youtype/mypy_boto3_builder",
"Tracker, https://github.com/youtype/mypy_boto3_builder/issues"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T20:50:17.325548 | types_boto3_pca_connector_scep-1.42.53.tar.gz | 17,908 | 70/48/e9b13281cf6e54e690a532c07335f62a8e694fa3801b35fd4be17850dd9e/types_boto3_pca_connector_scep-1.42.53.tar.gz | source | sdist | null | false | 291fc55bdb7569734b604c4833898cd8 | 2f98480fa5afaa027ec59147eb59a4909a4a35acfd9647b33ac6e0e505ce6235 | 7048e9b13281cf6e54e690a532c07335f62a8e694fa3801b35fd4be17850dd9e | MIT | [
"LICENSE"
] | 202 |
2.4 | types-boto3-ecr | 1.42.53 | Type annotations for boto3 ECR 1.42.53 service generated with mypy-boto3-builder 8.12.0 | <a id="types-boto3-ecr"></a>
# types-boto3-ecr
[](https://pypi.org/project/types-boto3-ecr/)
[](https://pypi.org/project/types-boto3-ecr/)
[](https://youtype.github.io/types_boto3_docs/)
[](https://pypistats.org/packages/types-boto3-ecr)

Type annotations for [boto3 ECR 1.42.53](https://pypi.org/project/boto3/)
compatible with [VSCode](https://code.visualstudio.com/),
[PyCharm](https://www.jetbrains.com/pycharm/),
[Emacs](https://www.gnu.org/software/emacs/),
[Sublime Text](https://www.sublimetext.com/),
[mypy](https://github.com/python/mypy),
[pyright](https://github.com/microsoft/pyright) and other tools.
Generated with
[mypy-boto3-builder 8.12.0](https://github.com/youtype/mypy_boto3_builder).
More information can be found on
[types-boto3](https://pypi.org/project/types-boto3/) page and in
[types-boto3-ecr docs](https://youtype.github.io/types_boto3_docs/types_boto3_ecr/).
See how it helps you find and fix potential bugs:

- [types-boto3-ecr](#types-boto3-ecr)
- [How to install](#how-to-install)
- [Generate locally (recommended)](<#generate-locally-(recommended)>)
- [VSCode extension](#vscode-extension)
- [From PyPI with pip](#from-pypi-with-pip)
- [How to uninstall](#how-to-uninstall)
- [Usage](#usage)
- [VSCode](#vscode)
- [PyCharm](#pycharm)
- [Emacs](#emacs)
- [Sublime Text](#sublime-text)
- [Other IDEs](#other-ides)
- [mypy](#mypy)
- [pyright](#pyright)
- [Pylint compatibility](#pylint-compatibility)
- [Explicit type annotations](#explicit-type-annotations)
- [Client annotations](#client-annotations)
- [Paginators annotations](#paginators-annotations)
- [Waiters annotations](#waiters-annotations)
- [Literals](#literals)
- [Type definitions](#type-definitions)
- [How it works](#how-it-works)
- [What's new](#what's-new)
- [Implemented features](#implemented-features)
- [Latest changes](#latest-changes)
- [Versioning](#versioning)
- [Thank you](#thank-you)
- [Documentation](#documentation)
- [Support and contributing](#support-and-contributing)
<a id="how-to-install"></a>
## How to install
<a id="generate-locally-(recommended)"></a>
### Generate locally (recommended)
You can generate type annotations for `boto3` package locally with
`mypy-boto3-builder`. Use
[uv](https://docs.astral.sh/uv/getting-started/installation/) for build
isolation.
1. Run mypy-boto3-builder in your package root directory:
`uvx --with 'boto3==1.42.53' mypy-boto3-builder`
2. Select `boto3` AWS SDK.
3. Add `ECR` service.
4. Use provided commands to install generated packages.
<a id="vscode-extension"></a>
### VSCode extension
Add
[AWS Boto3](https://marketplace.visualstudio.com/items?itemName=Boto3typed.boto3-ide)
extension to your VSCode and run `AWS boto3: Quick Start` command.
Click `Modify` and select `boto3 common` and `ECR`.
<a id="from-pypi-with-pip"></a>
### From PyPI with pip
Install `types-boto3` for `ECR` service.
```bash
# install with boto3 type annotations
python -m pip install 'types-boto3[ecr]'
# Lite version does not provide session.client/resource overloads
# it is more RAM-friendly, but requires explicit type annotations
python -m pip install 'types-boto3-lite[ecr]'
# standalone installation
python -m pip install types-boto3-ecr
```
<a id="how-to-uninstall"></a>
## How to uninstall
```bash
python -m pip uninstall -y types-boto3-ecr
```
<a id="usage"></a>
## Usage
<a id="vscode"></a>
### VSCode
- Install
[Python extension](https://marketplace.visualstudio.com/items?itemName=ms-python.python)
- Install
[Pylance extension](https://marketplace.visualstudio.com/items?itemName=ms-python.vscode-pylance)
- Set `Pylance` as your Python Language Server
- Install `types-boto3[ecr]` in your environment:
```bash
python -m pip install 'types-boto3[ecr]'
```
Both type checking and code completion should now work. No explicit type
annotations required, write your `boto3` code as usual.
<a id="pycharm"></a>
### PyCharm
> ⚠️ Due to slow PyCharm performance on `Literal` overloads (issue
> [PY-40997](https://youtrack.jetbrains.com/issue/PY-40997)), it is recommended
> to use [types-boto3-lite](https://pypi.org/project/types-boto3-lite/) until
> the issue is resolved.
> ⚠️ If you experience slow performance and high CPU usage, try to disable
> `PyCharm` type checker and use [mypy](https://github.com/python/mypy) or
> [pyright](https://github.com/microsoft/pyright) instead.
> ⚠️ To continue using `PyCharm` type checker, you can try to replace
> `types-boto3` with
> [types-boto3-lite](https://pypi.org/project/types-boto3-lite/):
```bash
pip uninstall types-boto3
pip install types-boto3-lite
```
Install `types-boto3[ecr]` in your environment:
```bash
python -m pip install 'types-boto3[ecr]'
```
Both type checking and code completion should now work.
<a id="emacs"></a>
### Emacs
- Install `types-boto3` with services you use in your environment:
```bash
python -m pip install 'types-boto3[ecr]'
```
- Install [use-package](https://github.com/jwiegley/use-package),
[lsp](https://github.com/emacs-lsp/lsp-mode/),
[company](https://github.com/company-mode/company-mode) and
[flycheck](https://github.com/flycheck/flycheck) packages
- Install [lsp-pyright](https://github.com/emacs-lsp/lsp-pyright) package
```elisp
(use-package lsp-pyright
:ensure t
:hook (python-mode . (lambda ()
(require 'lsp-pyright)
(lsp))) ; or lsp-deferred
:init (when (executable-find "python3")
(setq lsp-pyright-python-executable-cmd "python3"))
)
```
- Make sure emacs uses the environment where you have installed `types-boto3`
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="sublime-text"></a>
### Sublime Text
- Install `types-boto3[ecr]` with services you use in your environment:
```bash
python -m pip install 'types-boto3[ecr]'
```
- Install [LSP-pyright](https://github.com/sublimelsp/LSP-pyright) package
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="other-ides"></a>
### Other IDEs
Not tested, but as long as your IDE supports `mypy` or `pyright`, everything
should work.
<a id="mypy"></a>
### mypy
- Install `mypy`: `python -m pip install mypy`
- Install `types-boto3[ecr]` in your environment:
```bash
python -m pip install 'types-boto3[ecr]'
```
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="pyright"></a>
### pyright
- Install `pyright`: `npm i -g pyright`
- Install `types-boto3[ecr]` in your environment:
```bash
python -m pip install 'types-boto3[ecr]'
```
Optionally, you can install `types-boto3` to `typings` directory.
Type checking should now work. No explicit type annotations required, write
your `boto3` code as usual.
<a id="pylint-compatibility"></a>
### Pylint compatibility
It is totally safe to use `TYPE_CHECKING` flag in order to avoid
`types-boto3-ecr` dependency in production. However, there is an issue in
`pylint` that it complains about undefined variables. To fix it, set all types
to `object` in non-`TYPE_CHECKING` mode.
```python
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from types_boto3_ec2 import EC2Client, EC2ServiceResource
from types_boto3_ec2.waiters import BundleTaskCompleteWaiter
from types_boto3_ec2.paginators import DescribeVolumesPaginator
else:
EC2Client = object
EC2ServiceResource = object
BundleTaskCompleteWaiter = object
DescribeVolumesPaginator = object
...
```
<a id="explicit-type-annotations"></a>
## Explicit type annotations
<a id="client-annotations"></a>
### Client annotations
`ECRClient` provides annotations for `boto3.client("ecr")`.
```python
from boto3.session import Session
from types_boto3_ecr import ECRClient
client: ECRClient = Session().client("ecr")
# now client usage is checked by mypy and IDE should provide code completion
```
<a id="paginators-annotations"></a>
### Paginators annotations
`types_boto3_ecr.paginator` module contains type annotations for all
paginators.
```python
from boto3.session import Session
from types_boto3_ecr import ECRClient
from types_boto3_ecr.paginator import (
DescribeImageScanFindingsPaginator,
DescribeImagesPaginator,
DescribePullThroughCacheRulesPaginator,
DescribeRepositoriesPaginator,
DescribeRepositoryCreationTemplatesPaginator,
GetLifecyclePolicyPreviewPaginator,
ListImagesPaginator,
)
client: ECRClient = Session().client("ecr")
# Explicit type annotations are optional here
# Types should be correctly discovered by mypy and IDEs
describe_image_scan_findings_paginator: DescribeImageScanFindingsPaginator = client.get_paginator(
"describe_image_scan_findings"
)
describe_images_paginator: DescribeImagesPaginator = client.get_paginator("describe_images")
describe_pull_through_cache_rules_paginator: DescribePullThroughCacheRulesPaginator = (
client.get_paginator("describe_pull_through_cache_rules")
)
describe_repositories_paginator: DescribeRepositoriesPaginator = client.get_paginator(
"describe_repositories"
)
describe_repository_creation_templates_paginator: DescribeRepositoryCreationTemplatesPaginator = (
client.get_paginator("describe_repository_creation_templates")
)
get_lifecycle_policy_preview_paginator: GetLifecyclePolicyPreviewPaginator = client.get_paginator(
"get_lifecycle_policy_preview"
)
list_images_paginator: ListImagesPaginator = client.get_paginator("list_images")
```
<a id="waiters-annotations"></a>
### Waiters annotations
`types_boto3_ecr.waiter` module contains type annotations for all waiters.
```python
from boto3.session import Session
from types_boto3_ecr import ECRClient
from types_boto3_ecr.waiter import ImageScanCompleteWaiter, LifecyclePolicyPreviewCompleteWaiter
client: ECRClient = Session().client("ecr")
# Explicit type annotations are optional here
# Types should be correctly discovered by mypy and IDEs
image_scan_complete_waiter: ImageScanCompleteWaiter = client.get_waiter("image_scan_complete")
lifecycle_policy_preview_complete_waiter: LifecyclePolicyPreviewCompleteWaiter = client.get_waiter(
"lifecycle_policy_preview_complete"
)
```
<a id="literals"></a>
### Literals
`types_boto3_ecr.literals` module contains literals extracted from shapes that
can be used in user code for type checking.
Full list of `ECR` Literals can be found in
[docs](https://youtype.github.io/types_boto3_docs/types_boto3_ecr/literals/).
```python
from types_boto3_ecr.literals import ArtifactStatusFilterType
def check_value(value: ArtifactStatusFilterType) -> bool: ...
```
<a id="type-definitions"></a>
### Type definitions
`types_boto3_ecr.type_defs` module contains structures and shapes assembled to
typed dictionaries and unions for additional type checking.
Full list of `ECR` TypeDefs can be found in
[docs](https://youtype.github.io/types_boto3_docs/types_boto3_ecr/type_defs/).
```python
# TypedDict usage example
from types_boto3_ecr.type_defs import AttributeTypeDef
def get_value() -> AttributeTypeDef:
return {
"key": ...,
}
```
<a id="how-it-works"></a>
## How it works
Fully automated
[mypy-boto3-builder](https://github.com/youtype/mypy_boto3_builder) carefully
generates type annotations for each service, patiently waiting for `boto3`
updates. It delivers drop-in type annotations for you and makes sure that:
- All available `boto3` services are covered.
- Each public class and method of every `boto3` service gets valid type
annotations extracted from `botocore` schemas.
- Type annotations include up-to-date documentation.
- Link to documentation is provided for every method.
- Code is processed by [ruff](https://docs.astral.sh/ruff/) for readability.
<a id="what's-new"></a>
## What's new
<a id="implemented-features"></a>
### Implemented features
- Fully type annotated `boto3`, `botocore`, `aiobotocore` and `aioboto3`
libraries
- `mypy`, `pyright`, `VSCode`, `PyCharm`, `Sublime Text` and `Emacs`
compatibility
- `Client`, `ServiceResource`, `Resource`, `Waiter` `Paginator` type
annotations for each service
- Generated `TypeDefs` for each service
- Generated `Literals` for each service
- Auto discovery of types for `boto3.client` and `boto3.resource` calls
- Auto discovery of types for `session.client` and `session.resource` calls
- Auto discovery of types for `client.get_waiter` and `client.get_paginator`
calls
- Auto discovery of types for `ServiceResource` and `Resource` collections
- Auto discovery of types for `aiobotocore.Session.create_client` calls
<a id="latest-changes"></a>
### Latest changes
Builder changelog can be found in
[Releases](https://github.com/youtype/mypy_boto3_builder/releases).
<a id="versioning"></a>
## Versioning
`types-boto3-ecr` version is the same as related `boto3` version and follows
[Python Packaging version specifiers](https://packaging.python.org/en/latest/specifications/version-specifiers/).
<a id="thank-you"></a>
## Thank you
- [Allie Fitter](https://github.com/alliefitter) for
[boto3-type-annotations](https://pypi.org/project/boto3-type-annotations/),
this package is based on top of his work
- [black](https://github.com/psf/black) developers for an awesome formatting
tool
- [Timothy Edmund Crosley](https://github.com/timothycrosley) for
[isort](https://github.com/PyCQA/isort) and how flexible it is
- [mypy](https://github.com/python/mypy) developers for doing all dirty work
for us
- [pyright](https://github.com/microsoft/pyright) team for the new era of typed
Python
<a id="documentation"></a>
## Documentation
All services type annotations can be found in
[boto3 docs](https://youtype.github.io/types_boto3_docs/types_boto3_ecr/)
<a id="support-and-contributing"></a>
## Support and contributing
This package is auto-generated. Please reports any bugs or request new features
in [mypy-boto3-builder](https://github.com/youtype/mypy_boto3_builder/issues/)
repository.
| text/markdown | null | Vlad Emelianov <vlad.emelianov.nz@gmail.com> | null | null | null | boto3, ecr, boto3-stubs, type-annotations, mypy, typeshed, autocomplete | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Environment :: Console",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"... | [
"any"
] | null | null | >=3.9 | [] | [] | [] | [
"typing-extensions; python_version < \"3.12\""
] | [] | [] | [] | [
"Homepage, https://github.com/youtype/mypy_boto3_builder",
"Documentation, https://youtype.github.io/types_boto3_docs/types_boto3_ecr/",
"Source, https://github.com/youtype/mypy_boto3_builder",
"Tracker, https://github.com/youtype/mypy_boto3_builder/issues"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T20:50:14.876016 | types_boto3_ecr-1.42.53.tar.gz | 36,798 | 4c/e6/a84ab055e49f248d7bd87275be53cfb3dc8c21ec2583b051a7d02e7a2ac2/types_boto3_ecr-1.42.53.tar.gz | source | sdist | null | false | d1289e65aeff5d459da4a05e89173a48 | c60d5908c5ada7bd99ee2dd83a0cdbb18cc0dae850a2c2b186bc923f5ae72a3b | 4ce6a84ab055e49f248d7bd87275be53cfb3dc8c21ec2583b051a7d02e7a2ac2 | MIT | [
"LICENSE"
] | 360 |
2.4 | callite | 1.0.1 | Slim Redis RPC implementation | # Callite
Callite is a lightweight Remote Procedure Call (RPC) library over Redis, designed for communication between components of a distributed system. It uses Redis Streams for request transport and Redis Pub/Sub for response delivery, with pickle serialization.
## Installation
```bash
pip install callite
```
To use the MCP bridge (for AI agent integration):
```bash
pip install callite[mcp]
```
## Prerequisites
A running Redis instance is required. You can start one locally:
```bash
docker run -d -p 6379:6379 redis:alpine
```
Or use the included Docker Compose setup for a full development environment:
```bash
docker-compose up
```
## Usage
### Request/Response (register + execute)
The most common pattern: the client sends a request and waits for a response.
**Server:**
```python
from callite.server import RPCServer
server = RPCServer("redis://localhost:6379/0", "my_service")
@server.register
def healthcheck():
return "OK"
@server.register
def add(a, b):
return a + b
server.run_forever()
```
**Client:**
```python
from callite.client import RPCClient
client = RPCClient("redis://localhost:6379/0", "my_service")
# Positional arguments
result = client.execute("add", 1, 2)
print(result) # 3
# Keyword arguments
result = client.execute("add", a=10, b=20)
print(result) # 30
# No arguments
status = client.execute("healthcheck")
print(status) # "OK"
# Close when done
client.close()
```
`execute()` blocks until the server responds or the timeout is reached (default: 30 seconds). If the server-side handler raises an exception, `execute()` re-raises it on the client side.
### Fire-and-Forget (subscribe + publish)
For one-way messages where the client does not need a response.
**Server:**
```python
from callite.server import RPCServer
server = RPCServer("redis://localhost:6379/0", "my_service")
@server.subscribe
def log(message):
print(f"Received: {message}")
server.run_forever()
```
**Client:**
```python
from callite.client import RPCClient
client = RPCClient("redis://localhost:6379/0", "my_service")
# publish() returns immediately without waiting for a response
client.publish("log", "Something happened")
```
### Combining Both Patterns
A single service can use both `register` and `subscribe`:
```python
from callite.server import RPCServer
server = RPCServer("redis://localhost:6379/0", "my_service")
@server.register
def add(a, b):
return a + b
@server.subscribe
def log(message):
print(message)
server.run_forever()
```
```python
from callite.client import RPCClient
client = RPCClient("redis://localhost:6379/0", "my_service")
# Request/response
result = client.execute("add", 3, 4)
# Fire-and-forget
client.publish("log", f"Result was {result}")
```
### MCP Integration (AI Agent Integration)
Callite includes three MCP (Model Context Protocol) components for bridging AI agents to RPC services. All three are available from `callite.mcp`:
```python
from callite.mcp import MCPBridge, MCPHTTPProxy, MCPProxy
```
#### Defining Tools and Prompts
`register_tool` works like `register` but extracts type hints and docstrings to generate rich metadata for MCP tool discovery:
```python
from callite.server import RPCServer
server = RPCServer("redis://localhost:6379/0", "data_service")
@server.register_tool(description="Add two numbers together")
def add(a: int, b: int) -> int:
"""Add two numbers.
Args:
a: The first number.
b: The second number.
"""
return a + b
server.run_forever()
```
`register_prompt` registers prompt templates that AI agents can discover and invoke:
```python
@server.register_prompt(description="Analyze a dataset")
def analyze(data: str, focus: str = "general") -> str:
return f"Please analyze the following data with focus on {focus}:\n{data}"
```
#### MCPBridge
A multi-service MCP gateway that discovers callite services via their `__describe__` endpoint and registers all tools, prompts, and resources as MCP primitives. Tool names are prefixed with the service name (e.g. `data_service_add`).
From the command line:
```bash
mcp-callite-bridge --redis redis://localhost:6379/0 --services data_service
```
Or programmatically:
```python
from callite.mcp import MCPBridge
bridge = MCPBridge("redis://localhost:6379/0", ["data_service", "auth_service"])
bridge.run() # stdio transport by default
```
CLI options:
| Flag | Description | Default |
|---|---|---|
| `--redis` | Redis connection URL | `redis://localhost:6379/0` |
| `--services` | Comma-separated service names | (required) |
| `--transport` | `stdio` or `streamable-http` | `stdio` |
| `--name` | MCP server display name | `callite-bridge` |
| `--timeout` | RPC execution timeout (seconds) | `30` |
| `--queue-prefix` | Redis key prefix | `/callite` |
#### MCPHTTPProxy
An HTTP server that exposes a single callite service over Streamable HTTP. Unlike MCPBridge, tool names are not prefixed with the service name, making it suitable for single-service deployments.
```python
from callite.client import RPCClient
from callite.mcp import MCPHTTPProxy
client = RPCClient("redis://localhost:6379/0", "data_service")
proxy = MCPHTTPProxy(client, host="0.0.0.0", port=8080)
proxy.run() # serves at /mcp
```
#### MCPProxy
A client-side proxy that manages an external MCP server subprocess (e.g. `uvx mcp-server-sqlite`) over stdio and exposes its tools through a synchronous Python API. Use `register_proxy` on an RPCServer to re-publish external MCP tools as callite RPC methods.
```python
from callite.mcp import MCPProxy
from callite.server import RPCServer
server = RPCServer("redis://localhost:6379/0", "my_service")
proxy = MCPProxy("uvx", ["mcp-server-sqlite", "--db-path", "test.db"])
server.register_proxy(proxy, prefix="sqlite")
server.run_forever()
```
The proxy auto-reconnects if the subprocess crashes, caches the tool list, and is thread-safe.
## Configuration
### Environment Variables
| Variable | Description | Default |
|---|---|---|
| `LOG_LEVEL` | Logging verbosity (`DEBUG`, `INFO`, `ERROR`, etc.) | `ERROR` (server), `INFO` (client) |
| `EXECUTION_TIMEOUT` | Client-side timeout in seconds for `execute()` | `30` |
| `REDIS_URL` | Redis URL (used by the MCP bridge CLI) | `redis://localhost:6379/0` |
### Constructor Options
**RPCServer:**
```python
RPCServer(
conn_url="redis://localhost:6379/0",
service="my_service",
queue_prefix="/callite", # Redis key prefix
xread_groupname="generic", # Consumer group name
)
```
**RPCClient:**
```python
RPCClient(
conn_url="redis://localhost:6379/0",
service="my_service",
execution_timeout=30, # Timeout in seconds
queue_prefix="/callite", # Redis key prefix
)
```
## Docker Development
The included `docker-compose.yml` starts Redis, a sample server, and a sample client:
```bash
docker-compose up
```
This runs the example `main.py` (server) and `healthcheck.py` (client stress test with 100 concurrent threads).
## License
Proprietary
| text/markdown | Emrah Gozcu | gozcu@gri.ai | null | null | Proprietary | null | [
"License :: Other/Proprietary License"
] | [] | https://github.com/gri-ai/callite | null | null | [] | [] | [] | [
"redis>=5.0.3",
"mypy>=1.9.0; extra == \"dev\"",
"setuptools>=69.1.1; extra == \"dev\"",
"mcp>=1.2.0; extra == \"mcp\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:49:50.676991 | callite-1.0.1.tar.gz | 23,497 | 45/db/d62a5ecba12419d55b67bfcfb421750a565ac51ee6bea9c3e8073eeeae85/callite-1.0.1.tar.gz | source | sdist | null | false | 933b9a4e86d11a917c4c9acbf13bed87 | 560bb4b4c5c8f8d3b1a7180cee7954370db89a86c51352a6fd927ec061cae535 | 45dbd62a5ecba12419d55b67bfcfb421750a565ac51ee6bea9c3e8073eeeae85 | null | [
"LICENSE"
] | 228 |
2.4 | ilamb3 | 2026.2.19 | Earth system model benchmarking | [<img width=250px src=https://www.ilamb.org/assets/images/RUBISCO1.png>](https://www.bgc-feedbacks.org/)
*Experimental version under development*
[![Continuous Integration][ci-badge]][ci-link]
[![Documentation Status][rtd-badge]][rtd-link]
[![Code Coverage Status][codecov-badge]][codecov-link]
# ILAMB - International Land Model Benchmarking
The python package designed to help confront earth system models with reference
data products, and then present the results in a hierarchical set of webpages.
Please see [ilamb.org](https://www.ilamb.org) where we have details about the
datasets we use, the results we catalog, and the methods we employ.
This package is being developed and not currently listed in PyPI or conda-forge. You may install it directly from this repository:
```bash
pip install git+https://github.com/rubisco-sfa/ilamb3
```
The above command will install the latest code from the repository.
We will make *releases* as new methods and functionality are ready, updating the documentation as we develop.
To install a specific version of the code, append it to the URL.
The following will install the released version v2025.5.20:
```bash
pip install git+https://github.com/rubisco-sfa/ilamb3@v2025.5.20
```
Eventually this package will replace the current [ILAMB](https://github.com/rubisco-sfa/ILAMB) package. Consult the [documentation](https://ilamb3.readthedocs.io/) for more information on current status and to see what is functional.
## Funding
This research was performed for the *Reducing Uncertainties in
Biogeochemical Interactions through Synthesis and Computation*
(RUBISCO) Scientific Focus Area, which is sponsored by the Regional
and Global Climate Modeling (RGCM) Program in the Climate and
Environmental Sciences Division (CESD) of the Biological and
Environmental Research (BER) Program in the U.S. Department of Energy
Office of Science.
[ci-badge]: https://github.com/rubisco-sfa/ilamb3/actions/workflows/ci.yml/badge.svg?branch=main
[ci-link]: https://github.com/rubisco-sfa/ilamb3/actions/workflows/ci.yml
[rtd-badge]: https://readthedocs.org/projects/ilamb3/badge/?version=latest
[rtd-link]: https://ilamb3.readthedocs.io/en/latest/?badge=latest
[codecov-badge]: https://img.shields.io/codecov/c/github/rubisco-sfa/ilamb3.svg?logo=codecov
[codecov-link]: https://codecov.io/gh/rubisco-sfa/ilamb3
| text/markdown | null | Nathan Collier <nathaniel.collier@gmail.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Operating System :: OS Independent",
"Intended Audience :: Science/Research",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python ... | [] | null | null | >=3.11 | [] | [] | [] | [
"cf-xarray>=0.10.0",
"numpy>=2.2.2",
"pandas>=2.2.3",
"pint-xarray>=0.4",
"xarray<=2025.10.1",
"netcdf4>=1.7.2",
"pooch>=1.8.2",
"scipy>=1.15.1",
"matplotlib>=3.10.0",
"cartopy>=0.24.1",
"pyyaml>=6.0.2",
"jinja2>=3.1.5",
"statsmodels>=0.14.4",
"loguru>=0.7.3",
"dask>=2025.2.0",
"nc-tim... | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:49:18.041287 | ilamb3-2026.2.19-py3-none-any.whl | 125,871 | 30/c9/15c6ee07a2e272ec9ffc76f0f04d1d86c717615b39d864eebce9818c0efc/ilamb3-2026.2.19-py3-none-any.whl | py3 | bdist_wheel | null | false | 3c0759246092d7514ca8e11a35fe9b41 | dbfbef38c11b13d832670ea7723ed319a24df2e736ceae78d85c1f78dcdb0c1c | 30c915c6ee07a2e272ec9ffc76f0f04d1d86c717615b39d864eebce9818c0efc | BSD-3-Clause | [
"LICENSE"
] | 432 |
2.4 | promtext-cli | 0.1.2.dev43 | Prometheus Textfile Tooling | # promtext-cli
promtext-cli is a tool for creating prometheus text files from a simple cli command.
It is intended for use with cronjob scripts (e.g. backups).
Features:
- supports merging new metrics into existing files
- metrics will be updated (same labelset or no labels given), or appended to existing metrics as new timeseries
- currently only supports gauge metrics
## Usage
```
promtext -h
usage: main.py [-h] [--docs DOCS] [--label KEY=VALUE] [-v] filename metric value
Prometheus textfile helper
positional arguments:
filename Path to existing or new prometheus textfile, will be updated
metric metric name (new or updated)
value metric value
options:
-h, --help show this help message and exit
--docs DOCS metric documentation
--label KEY=VALUE label key=value pairs
-v, --verbose
```
## Examples
`tmp/backup.prom` before:
```
# HELP backup_last_start
# TYPE backup_last_start gauge
backup_last_start{backup="example_1"} 1.721923501e+09
# HELP backup_last_end
# TYPE backup_last_end gauge
backup_last_end{backup="example_1"} 1.721989156e+09
# HELP backup_last_exit
# TYPE backup_last_exit gauge
backup_last_exit{backup="example_1"} 2.0
```
Updating existing timeseries: `promtext tmp/backup.prom backup_last_start 0 --label backup=example_1`:
```
# HELP backup_last_start
# TYPE backup_last_start gauge
backup_last_start{backup="example_1"} 0.0
# HELP backup_last_end
# TYPE backup_last_end gauge
backup_last_end{backup="example_1"} 1.721989156e+09
# HELP backup_last_exit
# TYPE backup_last_exit gauge
backup_last_exit{backup="example_1"} 2.0
```
Adding a new label: `promtext tmp/backup.prom backup_last_start 0 --label backup=example_2`
```
# HELP backup_last_start
# TYPE backup_last_start gauge
backup_last_start{backup="example_1"} 0.0
backup_last_start{backup="example_2"} 0.0
# HELP backup_last_end
# TYPE backup_last_end gauge
backup_last_end{backup="example_1"} 1.721989156e+09
# HELP backup_last_exit
# TYPE backup_last_exit gauge
backup_last_exit{backup="example_1"} 2.0
```
Adding a new metric: `promtext tmp/backup.prom some_other_state 0 --label new_label=foo_bar`
```
# HELP backup_last_start
# TYPE backup_last_start gauge
backup_last_start{backup="example_1"} 0.0
backup_last_start{backup="example_2"} 0.0
# HELP backup_last_end
# TYPE backup_last_end gauge
backup_last_end{backup="example_1"} 1.721989156e+09
# HELP backup_last_exit
# TYPE backup_last_exit gauge
backup_last_exit{backup="example_1"} 2.0
# HELP some_other_state metric appended by promtext-cli
# TYPE some_other_state gauge
some_other_state{new_label="foo_bar"} 0.0
```
However, changing the label keys does not work:
```
promtext tmp/backup.prom some_other_state 0 --label foo_bar=foo_bar
ERROR:promtext_cli.main:labelnames for metric some_other_state not compatible, cannot update! Old: ['new_label'], New: ['foo_bar']
```
| text/markdown | null | Vanessa Gaube <dev@vanessagaube.de> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"prometheus-client"
] | [] | [] | [] | [
"Documentation, https://codeberg.org/margau/promtext-cli/src/branch/main#readme",
"Issues, https://codeberg.org/margau/promtext-cli/issues",
"Source, https://codeberg.org/margau/promtext-cli.git"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Alpine Linux","version":"3.23.3","id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:48:06.724060 | promtext_cli-0.1.2.dev43.tar.gz | 16,889 | d6/ce/7ce1f94cb13fa70e28cea1d1fa0c76e8c2250e12deb57428c328b0427c66/promtext_cli-0.1.2.dev43.tar.gz | source | sdist | null | false | 7828a7d4f7fa1d52bf2874cbdc515d23 | 1e85adfa2c4a66c8b96e44c35c4630969070607e67b04dff2fe80f9a1da7ec5a | d6ce7ce1f94cb13fa70e28cea1d1fa0c76e8c2250e12deb57428c328b0427c66 | GPL-3.0 | [] | 178 |
2.4 | pkg-exporter | 0.2.8.dev84 | This project provides an textfile-based exporter for apt-repositories | # Prometheus PKG Exporter
This project provides an textfile-based exporter for apt-repositories.
**The Project is in its early development phases. Interfaces may change without notice. Compatibility and Stability do vary.**
For the changelog, use the [Releases-Section on GitHub](https://github.com/margau/pkg-exporter/releases/)
## Exported Metrics
At the moment, the packages installed, upgradable, broken and autoremovable are exported per repository as gauge. The label set depends on the packet manager type.
Additionally, `pkg_reboot_required` is exported to indicate that an reboot is needed.
```
# HELP pkg_reboot_required Node Requires an Reboot
# TYPE pkg_reboot_required gauge
pkg_reboot_required 1.0
# HELP pkg_update_start_time timestamp of last apt update start
# TYPE pkg_update_start_time gauge
pkg_update_start_time 1.641382890503045e+09
# HELP pkg_update_end_time Timestamp of last apt update finish
# TYPE pkg_update_end_time gauge
pkg_update_end_time 1.641382892755024e+09
# HELP pkg_update_time_available Availability of the apt update timestamp
# TYPE pkg_update_time_available gauge
pkg_update_time_available 1.0
# HELP pkg_installed Installed packages per origin
# TYPE pkg_installed gauge
pkg_installed{archive="focal-updates",component="main",label="Ubuntu",origin="Ubuntu",site="ftp.fau.de",trusted="True"} 672.0
# HELP pkg_upgradable Upgradable packages per origin
# TYPE pkg_upgradable gauge
pkg_upgradable{archive="focal-updates",component="main",label="Ubuntu",origin="Ubuntu",site="ftp.fau.de",trusted="True"} 7.0
# HELP pkg_auto_removable Auto-removable packages per origin
# TYPE pkg_auto_removable gauge
pkg_auto_removable{archive="focal-updates",component="main",label="Ubuntu",origin="Ubuntu",site="ftp.fau.de",trusted="True"} 6.0
# HELP pkg_broken Broken packages per origin
# TYPE pkg_broken gauge
pkg_broken{archive="focal-updates",component="main",label="Ubuntu",origin="Ubuntu",site="ftp.fau.de",trusted="True"} 0.0
```
## Contributing
Feel free to contribute improvements, as well as support for non-apt based systems.
## Installation
### Global pip installation
Run `pip3 install pkg-exporter`.
### Install from source
Clone the repository and run `poetry install` from the main directory.
You can also use other standard installation methods for python packages, like directly installing from this git repository.
The pyinstaller-based binary is not provided any more.
### pipx
If a global pip installation is not possible (e.g. from debian 12 onwards), you can use [pipx](https://pypa.github.io/pipx), either for install, and/or for running pkg-exporter ad hoc:
```
pipx run --system-site-packages pkg-exporter
```
`--system-site-packages` is necessary to provide access to the system python3-apt lib.
### apt-based systems
Currently, only apt-based systems are supported. `python3-apt` needs to be installed on the system.
## Configuration and Usage
The node exporter needs to be configured for textfiles using the `--collector.textfile.directory` option. This exporter needs to write the exported metrics into this directory.
The default path is `/var/prometheus/pkg-exporter.prom`, and may be changed via the `PKG_EXPORTER_FILE`-Environment Variable.
If the directory is not already present, it will be created by the exporter.
The command `pkg_exporter` provided by the package or the binary shall be executed in a appropriate interval, e.g. using cron or systemd timers.
The exporter needs to be executed with appropriate privileges, which are not necessarily root privileges.
An example configuration will be provided in this repository in the future.
### apt hook
To enable monitoring for apt update calls, place the file under `docs/00-pve-exporter` in `/etc/apt/apt.conf.d` on your system.
It will place files under `/tmp`. To customize the filepath of the timestamp files, the the environment variables `PKG_EXPORTER_APT_PRE_FILE` & `PKG_EXPORTER_APT_POST_FILE` may be used.
You can see the success of monitoring the apt update timestamps if the following metric is 1: `pkg_update_time_available 1.0`
Please not that the presence of an timestamp does not mean that all repositories were updated without issues.
## Alerting
Example alerting rules will be provided in the future.
## Roadmap
- Support for other pkg managers
- Deployment as dpkg-Packet
| text/markdown | null | Vanessa Gaube <dev@vanessagaube.de> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"prometheus-client==0.24.1"
] | [] | [] | [] | [
"Documentation, https://codeberg.org/margau/pkg-exporter/src/branch/main#readme",
"Issues, https://codeberg.org/margau/pkg-exporter/issues",
"Source, https://codeberg.org/margau/pkg-exporter.git"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Alpine Linux","version":"3.23.3","id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:47:24.773256 | pkg_exporter-0.2.8.dev84-py3-none-any.whl | 18,030 | 31/99/1f28120d4f7d49c4fbaee20a5ea6c3d181c85eb568341817f028364d4de0/pkg_exporter-0.2.8.dev84-py3-none-any.whl | py3 | bdist_wheel | null | false | 7a39dd4c63ec8b81b2beb77b8590c971 | 4c5fdf420bdeefa8c3c49b742ea68ed8287397236929fd54ae4492c972a4877f | 31991f28120d4f7d49c4fbaee20a5ea6c3d181c85eb568341817f028364d4de0 | GPL-3.0 | [
"LICENSE"
] | 185 |
2.4 | trainer-tools | 0.2.0 | Small utilities to simplify trainining of PyTorch models. | [](https://pypi.org/project/trainer-tools/)
[](https://opensource.org/licenses/MIT)


# Trainer Tools
A lightweight, hook-based training loop for PyTorch. `trainer-tools` abstracts away the boilerplate of training loops while remaining fully customizable via a powerful flexible hook system.
## Features
* **Hook System**: Customize every step of the training lifecycle (before/after batch, step, epoch, fit).
* **Built-in Integrations**: Comes with hooks for wandb or trackio, Progress Bar, and Checkpointing.
* **Optimization**: Easy Automatic Mixed Precision (AMP), Gradient Accumulation, and Gradient Clipping.
* **Metrics**: robust metric tracking and logging to JSONL or external trackers.
* **Memory Profiling**: Built-in tools to debug CUDA memory leaks.
## Installation
```bash
pip install trainer-tools
```
## Quick Start
Here is a minimal example of training a simple model:
```python
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from trainer_tools.trainer import Trainer
from trainer_tools.hooks import MetricsHook, Accuracy, Loss, ProgressBarHook
# 1. Prepare Data
x = torch.randn(100, 10)
y = torch.randint(0, 2, (100,))
ds = TensorDataset(x, y)
dl = DataLoader(ds, batch_size=32)
# 2. Define Model
model = nn.Sequential(nn.Linear(10, 2))
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# 3. Setup Hooks
metrics = MetricsHook(metrics=[Accuracy(), Loss()])
pbar = ProgressBarHook()
# 4. Train
trainer = Trainer(
model=model,
train_dl=dl,
valid_dl=dl,
optim=optimizer,
loss_func=nn.CrossEntropyLoss(),
epochs=5,
hooks=[metrics, pbar],
device="cuda" if torch.cuda.is_available() else "cpu"
)
trainer.fit()
```
## The Hook System
`trainer-tools` relies on `BaseHook`. You can create custom behavior by subclassing it:
```python
from trainer_tools.hooks import BaseHook
class MyCustomHook(BaseHook):
def after_step(self, trainer):
if trainer.step % 100 == 0:
print(f"Current Loss: {trainer.loss}")
``` | text/markdown | null | Slava Chaunin <67190162+Ssslakter@users.noreply.github.com> | null | null | MIT License
Copyright (c) 2026 Slava
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | deep-learning, pytorch, trainer, training | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence... | [] | null | null | >=3.11 | [] | [] | [] | [
"accelerate<2,>=1.12.0",
"hydra-core",
"matplotlib",
"numpy",
"torch<2.10,>=2.2",
"tqdm",
"trackio",
"wandb"
] | [] | [] | [] | [
"Repository, https://github.com/ssslakter/trainer-tools"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:47:01.883572 | trainer_tools-0.2.0.tar.gz | 114,493 | 5c/2e/d086f977559183fb171b028c2c811de509fcfa9db6a906d020691a7fcd44/trainer_tools-0.2.0.tar.gz | source | sdist | null | false | 1712472643fa195b19992c9f7880e427 | 33d42b524e60b7541935702f25607093a34ed0ba9bc86255785e095bb10ccfe2 | 5c2ed086f977559183fb171b028c2c811de509fcfa9db6a906d020691a7fcd44 | null | [
"LICENSE"
] | 211 |
2.1 | mcp-serve | 0.0.15 | Agentic server to support MCP tools for science | # mcp-serve
> Agentic Server to support MCP Tools and Science

[](https://badge.fury.io/py/mcp-serve)
## Design
This is a customizable, asynchronous server that can register and load tools of interest. Endpoints include functions (tools), prompts, resources. Those are now (for the most part) separated into modular projects:
- [flux-mcp](https://github.com/converged-computing/flux-mcp): MCP tools for Flux Framework
- [hpc-mcp](https://github.com/converged-computing/hpc-mcp): HPC tools for a larger set of HPC and converged computing use cases.
### Abstractions
The library here has the following abstractions.
- **tools**: server tools, prompts, and resources
- **ui**: user interface that an engine (with a main manager) uses
- **core**: shared assets, primarily the plan/step/config definitions
- **routes**: server views not related to mcp.
- **backends**: child of an engine, these are the model services (llama, openai, gemini)
- **databases**: how to save results as we progress in a pipeline (currently we support sqlite and filesystem JSON)
For the above, the engines, tools, ui, databases, and backends are interfaces.
### Tools
There are different means to add tools here:
- **internal** are discovered in `mcpserver/tools` (assist the server).
- **external modules**: externally discovered via the same mechanism.
- **external one-off**: add a specific tool, prompt, or resource to a server (suggested)
I am suggesting a combined approach of the first and last bullet for security. E.g., when we deploy, we do not want to open a hole to add functions that are not known. In the context of a job, we likely have a specific need or use case and can select from a library. I am developing scoped tools with this aim or goal -- to be able to deploy a job and start a server within the context of the job with exactly what is needed. Here is how the module discovery works:
```python
from mcpserver.tools.manager import ToolManager
# Discover and register defaults
manager = ToolManager()
# The tools vendored here are automatically discovered..
manager.register("mcpserver.tools")
# Register a different module
manager.register("mymodule.tools")
```
## Development
It is recommended to open in VSCode container. Then install:
```bash
pip install --break-system-packages -e .
```
### Docker
To build the Docker container:
```bash
make
```
To run a dummy example:
```bash
docker run -p 8089:8089 -it ghcr.io/converged-computing/mcp-server:latest
```
And then interact from the outside:
```bash
python3 ./examples/echo/test_echo.py
```
### Environment
The following variables can be set in the environment.
| Name | Description | Default |
|-------|------------|---------------|
| `MCPSERVER_PORT` | Port to run MCP server on, if using http variant | `8089` |
| `MCPSERVER_HOST` | Default host to run MCP server (http) | `0.0.0.0` |
| `MCPSERVER_PATH` | Default path for server endpoint | `/mcp` |
| `MCPSERVER_TOKEN` | Token to use for testing | unset |
## Usage
### Start the Server
Start the server in one terminal. Export `MCPSERVER_TOKEN` if you want some client to use simple token auth.
Leave out the token for local test. Here is an example for http.
```bash
mcpserver start --transport http --port 8089
```
## Endpoints
In addition to standard MCP endpoints that deliver JSON RPC according to [the specification](https://modelcontextprotocol.io/specification/2025-03-26/basic), we provide a set of more easily accessible http endpoints for easy access to server health or metadata.
### Health Check
```bash
# Health check
curl -s http://0.0.0.0:8089/health | jq
```
### Listing
You can list tools, prompts, and resources.
```bash
curl -s http://0.0.0.0:8089/tools/list | jq
curl -s http://0.0.0.0:8089/prompts/list | jq
curl -s http://0.0.0.0:8089/resources/list | jq
```
We do this internally in the server via discovery by the manager, and then returning a simple JSON response of those found.
## Examples
All of these can be run from a separate terminal when the server is running.
### Simple Echo
Do a simple tool request.
```bash
# Tool to echo back message
python3 examples/echo/test_echo.py
```
### Docker Build
Here is an example to deploy a server to build a Docker container.
We first need to install the functions from [hpc-mcp](https://github.com/converged-computing/hpc-mcp):
```bash
pip install hpc-mcp --break-system-packages
```
Start the server with the functions and prompt we need:
```bash
# In one terminal (start MCP)
mcpserver start -t http --port 8089 \
--prompt hpc_mcp.t.build.docker.docker_build_persona_prompt \
--tool hpc_mcp.t.build.docker.docker_build_container
# Start with a configuration file instead
mcpserver start -t http --port 8089 --config ./examples/docker-build/mcpserver.yaml
```
And then use an agentic framework to run some plan to interact with tools. Here is how you would call them manually, assuming the second start method above with custom function names. Note for docker build you need the server running on a system with docker or podman.
```bash
# Generate a build prompt
python3 examples/docker-build/docker_build_prompt.py
# Build a docker container (requires mcp server to see docker)
python3 examples/docker-build/test_docker_build.py
```
### Listing
Agents discover tools with this endpoint. We can call it too!
```bash
python3 examples/list_tools.py
python3 examples/list_prompts.py
```
### JobSpec Translation
Here is a server that shows translation of a job specification with Flux.
To prototype with Flux, open the code in the devcontainer. Install the library and start a flux instance.
```bash
pip install -e .[all] --break-system-packages
pip install flux-mcp IPython --break-system-packages
flux start
```
We will need to start the server and add the validation functions and prompt.
```bash
mcpserver start -t http --port 8089 \
--tool flux_mcp.validate.flux_validate_jobspec \
--prompt flux_mcp.validate.flux_validate_jobspec_persona \
--tool flux_mcp.transformer.transform_jobspec \
--prompt flux_mcp.transformer.transform_jobspec_persona
```
And with the configuration file instead:
```bash
mcpserver start -t http --port 8089 --config ./examples/jobspec/mcpserver.yaml
```
We will provide examples for jobspec translation functions in [fractale-mcp](https://github.com/compspec/fractale-mcp).
### Kubernetes (kind)
This example is for basic manifests to work in Kind (or Kubernetes/Openshift). Note that we use the default base container with a custom function added via ConfigMap. You can take this approach, or build ON our base container and pip install your own functions for use.
- [examples/kind](examples/kind)
We will be making a Kubernetes Operator to create this set of stuff soon.
### SSL
Generate keys
```bash
mkdir -p ./certs
openssl req -x509 -newkey rsa:4096 -keyout ./certs/key.pem -out ./certs/cert.pem -sha256 -days 365 -nodes -subj '/CN=localhost'
```
And start the server, indicating you want to use them.
```bash
mcpserver start --transport http --port 8089 --ssl-keyfile ./certs/key.pem --ssl-certfile ./certs/cert.pem
```
For the client, the way that it works is that httpx discovers the certs via [environment variables](https://github.com/modelcontextprotocol/python-sdk/issues/870#issuecomment-3449911720). E.g., try the test first without them:
```bash
python3 examples/ssl/test_ssl_client.py
📡 Connecting to https://localhost:8089/mcp...
❌ Connection failed: Client failed to connect: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self-signed certificate (_ssl.c:1000)
```
Now export the envars:
```bash
export SSL_CERT_DIR=$(pwd)/certs
export SSL_CERT_FILE=$(pwd)/certs/cert.pem
```
```console
📡 Connecting to https://localhost:8089/mcp...
⭐ Discovered tool: simple_echo
✅ Connection successful!
```
And you'll see the server get hit.
### Design Choices
Here are a few design choices (subject to change, of course). I am starting with re-implementing our fractale agents with this framework. For that, instead of agents being tied to specific functions (as classes on their agent functions) we will have a flexible agent class that changes function based on a chosen prompt. It will use mcp functions, prompts, and resources. In addition:
- Tools hosted here are internal and needed for the library. E.g, we have a prompt that allows getting a final status for an output, in case a tool does not do a good job.
- For those hosted here, we don't use mcp.tool (and associated functions) directly, but instead add them to the mcp manually to allow for dynamic loading.
- Tools that are more general are provided under extral libraries (e.g., flux-mcp and hpc-mcp)
- We can use mcp.mount to extend a server to include others, or the equivalent for proxy (I have not tested this yet).
- Async is annoying but I'm using it. This means debugging is largely print statements and not interactive.
- The backend of FastMCP is essentially starlette, so we define (and add) other routes to the server.
## TODO
- Full operator with Flux example (Flux operator with HPC apps and jobspec translation)
## License
HPCIC DevTools is distributed under the terms of the MIT license.
All new contributions must be made under this license.
See [LICENSE](LICENSE),
[COPYRIGHT](COPYRIGHT), and
[NOTICE](NOTICE) for details.
SPDX-License-Identifier: (MIT)
LLNL-CODE- 842614
| text/markdown | Vanessa Sochat | vsoch@users.noreply.github.com | Vanessa Sochat | null | LICENSE | cluster, orchestration, mcp, server, agents | [
"Intended Audience :: Science/Research",
"Intended Audience :: Developers",
"License :: OSI Approved :: Mozilla Public License 2.0 (MPL 2.0)",
"Programming Language :: C",
"Programming Language :: Python",
"Topic :: Software Development",
"Topic :: Scientific/Engineering",
"Operating System :: Unix",
... | [] | https://github.com/converged-computing/mcp-server | null | null | [] | [] | [] | [
"jsonschema",
"Jinja2",
"uvicorn",
"mcp",
"fastmcp",
"requests",
"fastapi",
"rich",
"textual",
"jsonschema; extra == \"all\"",
"Jinja2; extra == \"all\"",
"uvicorn; extra == \"all\"",
"mcp; extra == \"all\"",
"fastmcp; extra == \"all\"",
"requests; extra == \"all\"",
"fastapi; extra ==... | [] | [] | [] | [] | twine/5.1.1 CPython/3.12.2 | 2026-02-19T20:46:38.300960 | mcp_serve-0.0.15.tar.gz | 35,474 | f9/3a/cd090d85e38b9a1f73d3f50b0f6d3ab87b6396514d033bbe46513f3526d7/mcp_serve-0.0.15.tar.gz | source | sdist | null | false | f94f7ff7a1d669df979ffcd048393c10 | b9e3a0d329cbb109d2e45ba31f43b4cb6bd0f34ae0d0f2bed9645ee85c010936 | f93acd090d85e38b9a1f73d3f50b0f6d3ab87b6396514d033bbe46513f3526d7 | null | [] | 225 |
2.4 | unifi-sm-api | 0.2.3 | Python library for interacting with UniFi Site Manager API | # UniFi Site Manager API Client
Python library for interacting with UniFi’s Site Manager Integration API. Tested on a selfhosted local instance only. Downlod from here: https://pypi.org/project/unifi-sm-api/
> [!NOTE]
> This library was mainly creted to be used with [NetAlertX](https://github.com/jokob-sk/NetAlertX), as such, full API coverage is not planned. PRs are however more than welcome.
## 📦 Usage
Navigate to Site Manager _⚙️ Settings -> Control Plane -> Integrations_.
- `api_key` : You can generate your API key under the _Your API Keys_ section.
- `base_url` : You can find your base url in the _API Request Format_ section.
- `version` : You can find your version as part of the url in the _API Request Format_ section.
```python
from unifi_sm_api.api import SiteManagerAPI
api = SiteManagerAPI(
api_key="fakeApiKey1234567890",
base_url="https://192.168.100.1/proxy/network/integration/",
version="v1",
verify_ssl=False
)
sites = api.get_sites()
for site in sites:
site_id = site["id"]
unifi_devices = api.get_unifi_devices(site_id=site_id)
clients = api.get_clients(site_id=site_id)
```
---
## 📘 Endpoints Covered
- `/sites` — list available sites
- `/sites/{site_id}/devices` — list UniFi devices for a site
- `/sites/{site_id}/clients` — list connected clients
## 🔧 Requirements
- Python 3.8+
- `requests`
- `pytest` (for running tests)
- Local `.env` file with API credentials
---
## Testing
### 🌍 Environment Setup
Create a `.env` file in the project root with the following:
```env
API_KEY=fakeApiKey1234567890
BASE_URL=https://192.168.100.1/proxy/network/integration/
VERSION=v1
VERIFY_SSL=False
```
### 🧪 Running Tests
Make sure PYTHONPATH includes the project root, then run:
```bash
python3 -m venv venv
source venv/bin/activate
pip install pytest
pip install python-dotenv
cd unifi-sm-api/
pip install -e .
PYTHONPATH=.. pytest -s tests/test_api.py
```
## 💙 Donations
- [GitHub](https://github.com/sponsors/jokob-sk)
- [Buy Me A Coffee](https://www.buymeacoffee.com/jokobsk)
- [Patreon](https://www.patreon.com/user?u=84385063)
| text/markdown | null | Jokob Sk <jokob.sk@gmail.com> | null | null | MIT | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"requests>=2.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:46:29.794465 | unifi_sm_api-0.2.3.tar.gz | 17,811 | 06/cf/c8ed30d77c72b6de1bb569b94c858b9b6b2ef956e4c80cc65756c2e40147/unifi_sm_api-0.2.3.tar.gz | source | sdist | null | false | df409435408b1b3298bbf54624ac9777 | f858cbb8e592f316d9913d198235e5e580c4179fdc92946686f1c80d3a0bba76 | 06cfc8ed30d77c72b6de1bb569b94c858b9b6b2ef956e4c80cc65756c2e40147 | null | [
"LICENSE"
] | 391 |
2.4 | ocp-vscode | 3.1.2 | OCP CAD Viewer for VSCode | # _OCP CAD Viewer_ for VS Code
_OCP CAD Viewer_ for VS Code is an extension to show [CadQuery](https://github.com/cadquery/cadquery) and [build123d](https://github.com/gumyr/build123d) objects in VS Code via the [three-cad-viewer](https://github.com/bernhard-42/three-cad-viewer) viewer component.
## Installation
### Prerequisites
- A fairly recent version of Microsoft VS Code, e.g. 1.85.0 or newer
- The [Python extension](https://marketplace.visualstudio.com/items?itemName=ms-python.python) installed in VS Code
- Necessary tools:
- `python` and `pip` available in the Python environment that will be used for CAD development. Note, even when you use another package manager, `pip ` is needed internally and needs to be available.
**Notes**:
- To use OCP CAD Viewer, start VS Code from the commandline in the Python environment you want to use or select the right Python interpreter in VS Code first. **OCP CAD Viewer depends on VS Code using the right Python interpreter** (i.e. mamba / conda / pyenv / poetry / ... environment).
- For VSCodium, the extension is not available in the VS code market place. You need to download the the vsix file from the [release folder](https://github.com/bernhard-42/vscode-ocp-cad-viewer/releases) and install it manually.
### Installation
1. Open the VS Code Marketplace, and search and install _OCP CAD Viewer 3.1.2_.
Afterwards the OCP viewer is available in the VS Code sidebar:

2. Clicking on it shows the OCP CAD Viewer UI with the viewer manager and the library manager:

You have 3 options:
- Prepare _OCP CAD Viewer_ for working with [build123d](https://github.com/gumyr/build123d): Press the _Quickstart build123d_ button.
This will install _OCP_, _build123d_, _ipykernel_ (_jupyter_client_), _ocp_tessellate_ and _ocp_vscode_ via `pip`

- Prepare _OCP CAD Viewer_ for working with [CadQuery](https://github.com/cadquery/cadquery): Press the _Quickstart CadQuery_ button.
This will install _OCP_, _CadQuery_, _ipykernel_ (_jupyter_client_), _ocp_tessellate_ and _ocp_vscode_ via `pip`

- Ignore the quick starts and use the "Library Manager" to install the libraries via `pip` (per default, this can be changed in the VS Code settings). Install the needed library by pressing the down-arrow behind the library name (hover over the library name to see the button) in the "Library Manager" section of the _OCP CAD Viewer_ sidebar. For more details, see [here](./docs/install.md)
Quickstart will also
- (optionally) install the the [Jupyter extension for VS Code from Microsoft](https://marketplace.visualstudio.com/items?itemName=ms-toolsai.jupyter)
- start the OCP viewer
- create a demo file in a temporary folder to quickly see a simple usage example
**Notes:**
- Do not use the _OCP CAD Viewer_ logo to verify your _OCP CAD Viewer_ settings! The logo overwrites all your settings in VS Code with its own settings to always look the same on each instance. Use a simple own model for checking your configuration
- If you run into issues, see [Troubleshooting](#troubleshooting)
### Install Via CLI
If you aren't using VS Code, you can install/use this extension via command line
Since this is a python extension, it is recommended to install/activate a virtual environment first, (e.g. uv, venv. poetry, conda, pip, etc)
- uv based virtual environemnts:
```
source .venv/bin/activate # to activate the uv virtual environment
uv add ocp-vscode
```
- pip for other virtual environments:
```
source .venv/bin/activate # to activate venv virtual environments
conda / mamba / micromamba activate <env> # to activate conda like virtual environments
pip install ocp-vscode
```
Note: The extension is in pypi only [pypi](https://pypi.org/project/ocp-vscode/), so for conda, mamba or micromamba environments `pip` or `uv pip` needs to be used.
## Migration from v2.9.0 to v3.0.X
- Change `show` parameter `ticks` to `ticks/2`
- For `joints` together with `render_joints`, instead of
```
+- object_name
+- shape
+- joints
+- joint1
+- joint2
```
you will find
```
+- object_name
+- object_name.joints
+- joint1
+- joint2
```
Since joints are not under the `object_name` group, they do not animate automatically any more. Use the keyword `animate_joints=True` with `add_track`
- List with unviewable objects only are not shown as empty objects any more but ignored. So possibly less objects will be shown, and you might need to change how you access to these rendered objects.
## Usage
### Running code using Jupyter
- Start the _OCP CAD _ by pressing the box-arrow button in the " Manager" section of the _OCP CAD _ sidebar (hover over the `ocp_vscode` entry to see the button).
- Import ocp_vscode and the CAD library by using the paste button being the library names in the " Manager" section
- Use the usual Run menu to run the code

### Debugging code with visual debugging
After each step, the debugger checks all variables in `locals()` for being CAD objects and displays them with their variable name.
Note:
- Check that `OCP: <port>·DEBUG` is visible in the status bar
- It also shows planes, locations and axis, so name your contexts
- It remembers camera position and unselected variables in the tree
- during debugging, `show` and `show_object` are disabled. They interfere with the visual debugging

### Library Manager
You can also use "Library Manager" in the _OCP CAD _ sidebar to manage the Python libraries for _build123d_, _cadquery_, _ipython_ and _ocp_tessellate_ (Press the down-arrow when hovering over a library name to install/upgrade it)
#### Default pip config for Settings
```json
"OcpCadViewer.advanced.quickstartCommands": {
"cadquery": ["{unset_conda} {python} -m pip install ocp_vscode=={ocp_vscode_version} cadquery"],
"build123d": ["{python} -m pip install ocp_vscode=={ocp_vscode_version} build123d"]
},
"OcpCadViewer.advanced.installCommands": {
"cadquery": ["{unset_conda} {python} -m pip install --upgrade cadquery"],
"build123d": ["{python} -m pip install --upgrade build123d"],
"ocp_vscode": ["{python} -m pip install --upgrade ocp_vscode=={ocp_vscode_version}"],
"ocp_tessellate": ["{python} -m pip install --upgrade ocp_tessellate"],
"ipykernel": ["{python} -m pip install --upgrade ipykernel"],
"jupyter_console": ["{python} -m pip install --upgrade jupyter_console"]
},
```
#### uv config for Settings
```json
"OcpCadViewer.advanced.quickstartCommands": {
"cadquery": ["uv add -p {python} ocp_vscode=={ocp_vscode_version} cadquery"],
"build123d": ["uv add -p {python} ocp_vscode=={ocp_vscode_version} build123d"]
},
"OcpCadViewer.advanced.installCommands": {
"cadquery": ["uv add -p {python} --upgrade cadquery"],
"build123d": ["uv add -p {python} --upgrade build123d"],
"ocp_vscode": ["uv add -p {python} --upgrade ocp_vscode=={ocp_vscode_version}"],
"ocp_tessellate": ["uv add -p {python} --upgrade ocp_tessellate"],
"ipykernel": ["uv add -p {python} --upgrade ipykernel"],
"jupyter_console": ["uv add -p {python} --upgrade jupyter_console"]
}
```
### Extra topics
- [Quickstart experience on Windows](docs/quickstart.md)
- [Use Jupyter to execute code](docs/run.md)
- [Debug code with visual debugging](docs/debug.md)
- [Measure mode](docs/measure.md)
- [Object selection mode](docs/selector.md)
- [Use the `show` command](docs/show.md)
- [Use the `show_object` command](docs/show_object.md)
- [Use the `push_object` and `show_objects` command](docs/push_object.md)
- [Use the `show_all` command](docs/show_all.md)
- [Use the `set__config` command](docs/set__config.md)
- [Download examples for build123d or cadquery](docs/examples.md)
- [Use the build123d snippets](docs/snippets.md)
## Standalone mode
Standalone mode allows to use OCP CAD without VS Code: `python -m ocp_vscode`. This will start a Flask server and the can be reached under `http://127.0.0.1:<port number>` (per default http://127.0.0.1:3939). All client side feature of the VS Code variant (i.e. `show*` features) should be available (including measurement mode) except visual debugging (see above) which relies on VS Code.
Use `python -m ocp_vscode --help` to understand the command line args:
```
Usage: python -m ocp_vscode [OPTIONS]
Options:
--create_configfile Create the config file .ocpvscode_standalone in
the home directory
--host TEXT The host to start OCP CAD with
--port INTEGER The port to start OCP CAD with
--debug Show debugging information
--timeit Show timing information
--tree_width TEXT OCP CAD navigation tree width
(default: 240)
--no_glass Do not use glass mode with transparent
navigation tree
--theme TEXT Use theme 'light' or 'dark' (default:
'light')
--no_tools Do not show toolbar
--tree_width INTEGER Width of the CAD navigation tree (default:
240)
--control TEXT Use control mode 'orbit'or 'trackball'
--up TEXT Provides up direction, 'Z', 'Y' or 'L'
(legacy) (default: Z)
--rotate_speed INTEGER Rotation speed (default: 1)
--zoom_speed INTEGER Zoom speed (default: 1)
--pan_speed INTEGER Pan speed (default: 1)
--axes Show axes
--axes0 Show axes at the origin (0, 0, 0)
--black_edges Show edges in black
--grid_xy Show grid on XY plane
--grid_yz Show grid on YZ plane
--grid_xz Show grid on XZ plane
--center_grid Show grid planes crossing at center of object
or global origin(default: False)
--collapse INTEGER leaves: collapse all leaf nodes, all:
collapse all nodes, none: expand all nodes,
root: expand root only (default: leaves)
--perspective Use perspective camera
--ticks INTEGER Default number of ticks (default: 5)
--transparent Show objects transparent
--default_opacity FLOAT Default opacity for transparent objects
(default: 0.5)
--explode Turn explode mode on
--angular_tolerance FLOAT Angular tolerance for tessellation algorithm
(default: 0.2)
--deviation FLOAT Deviation of for tessellation algorithm
(default: 0.1)
--default_color TEXT Default shape color, CSS3 color names are
allowed (default: #e8b024)
--default_edgecolor TEXT Default color of the edges of shapes, CSS3
color names are allowed (default: #707070)
--default_thickedgecolor TEXT Default color of lines, CSS3 color names are
allowed (default: MediumOrchid)
--default_facecolor TEXT Default color of faces, CSS3 color names are
allowed (default: Violet)
--default_vertexcolor TEXT Default color of vertices, CSS3 color names
are allowed (default: MediumOrchid)
--ambient_intensity INTEGER Intensity of ambient light (default: 1.00)
--direct_intensity FLOAT Intensity of direct light (default: 1.10)
--metalness FLOAT Metalness property of material (default:
0.30)
--roughness FLOAT Roughness property of material (default:
0.65)
--help Show this message and exit.
```
## Standalone mode with Docker
If you are not using vscode and you prefer to keep the standalone web running separated in a container,
then take a look at [docker-vscode-ocp-cad-](https://github.com/nilcons/docker-vscode-ocp-cad-).
## Best practices
- Use the **Jupyter extension** for a more interactive experience. This allows to have one cell (separated by `# %%`) at the beginning to import all libraries
```python
# %%
from build123d import *
from ocp_vscode import *
# %%
b = Box(1,2,3)
show(b)
# %%
```
and then only execute the code in the cell you are currently working on repeatedly.
- The **config system** of OCP CAD Viewer
There are 3 levels:
- Workspace configuration (part of the VS Code settings, you can access them e.g. via the gear symbol in OCP CAD Viewer's "Viewer Manager" when you hover over the label "VIEWER MANAGER" to see the button)
- Defaults set with the command `set_defaults` per Python file
- Parameters in `show` or `show_object` per command
`set_defaults` overrides the Workspace settings and parameters in `show` and `show_config` override the other two.
Note that not all parameters are available in the global Workspace config, since they don't make sense globally (e.g. `helper_scale` which depends on the size of the boundary box of the currently shown object)
A common setup would be
```python
# %%
from build123d import *
import cadquery as cq
from ocp_vscode import *
set_port(3939)
set_defaults(reset_camera=False, helper_scale=5)
# %%
...
```
Explanation
- The first block imports build123d and CadQuery (omit what you are not interested in).
- The second block imports all commands for OCP CAD Viewer. `set_port` is only needed when you have more than one viewer open and can be omitted for the first viewer)
- The third block as an example sets helper_scale and reset_camera as defaults. Then every show_object or show command will respect it as the default
- Debugging build123d with `show_all` and the **visual debugger**
- If you name your contexts (including `Location` contexts), the visual debugger will show the CAD objects assigned to the context.
- Use `show_all` to show all cad objects in the current scope (`locals()`) of the Python interpreter (btw. the visual debugger uses `show_all` at each step)
```python
# %%
from build123d import *
set_defaults(helper_scale=1, transparent=True)
with BuildPart() as bp:
with PolarLocations(3,8) as locs:
Box(1,1,1)
show_all()
# %%
```

- **Keep camera orientation** of an object with `reset_camera`
Sometimes it is helpful to keep the orientation of an object across code changes. This is what `reset_camera` does:
- `reset_camera=Camera.Center` will keep position and rotation, but ignore panning. This means the new object will be repositioned to the center (most robust approach)
- `reset_camera=Camera.KEEP` will keep position, rotation and panning. However, panning can be problematic. When the next object to be shown is much larger or smaller and the object before was panned, it can happen that nothing is visible (the new object at the pan location is outside of the viewer frustum). OCP CAD Viewer checks whether the bounding box of an object is 2x smaller or larger than the one of the last shown object. If so, it falls back to `Camera.CENTER`. A notification is written to the OCP CAD Viewer output panel.
- `reset_camera=Camera.RESET` will ensure that position, rotation and panning will be reset to the initial default
## Development
Testing:
Native tessellator can be set via `NATIVE_TESSELLATOR=1` and Python tessellator via `NATIVE_TESSELLATOR=0`.
When `OCP_VSCODE_PYTEST=1` is set, `show` will not send the tessellated results to the viewer, but return it to the caller for inspection.
A full test cycle consist of:
```bash
NATIVE_TESSELLATOR=0 OCP_VSCODE_PYTEST=1 pytest -v -s tests/
NATIVE_TESSELLATOR=1 OCP_VSCODE_PYTEST=1 pytest -v -s tests/
```
## Troubleshooting
- **Generic ("it doesn't work")**
1. Confirm that VS Code extension and ocp_vscode have the same version. This can be seen in the OCP CAD Viewer UI. Or alternatively in the Output panel of VS Code:
```text
2025-07-06 14:51:33.418 [info ] extension.check_upgrade: ocp_vscode library version 2.8.6 matches extension version 2.8.6
```
2. Test whether the standalone viewer works, see [Standalone mode](#standalone-mode) (to eliminate VS Code issues)
3. Open a work folder and not a Python file (to ensure we do not get in Python path problems)
4. Check the Output panel. Search for:
- `PythonPath: 'aaa/bbb/python'` **=> right Python environment?**
- `Server started on port xxxx` (or so) **=> right port? default is 3939**
- `Starting Websocket server` **=> should not be followed by an error**
- `OCP Cad Viewer port: xxxx, folder: yyyy zzzz` **=> yyyy should be the right working folder?**
5. If all looks fine until now, then toggle Developer tools in VS Code and check browser console. Often we see a WebGL error for the browser of VS Code used for the viewer.
- **CAD Models almost always are invisible in the OCP viewer window**
```bash
three-cad-viewer.esm.js:20276 THREE.WebGLProgram: Shader Error 0 - VALIDATE_STATUS false
Material Name:
Material Type: LineBasicMaterial
Program Info Log: Program binary could not be loaded. Binary is not compatible with current driver/hardware combination. Driver build date Mar 19 2024. Please check build information of source that generated the binary.
Location of variable pc_fragColor conflicts with another variable.
```
VS Code internal browser that renders the viewer component uses a cache for code and other artifacts. This includes WebGL artifacts like compiled shaders. It can happen that e.g. due to a graphic driver update the compiled version in the cache does not fit to the new driver. Then this error message appears.
**Solution:** [Delete the VS Code browser cache on Linux](https://bobbyhadz.com/blog/vscode-clear-cache) (go to the section for your operating system)
## Changes
## v3.1.2
- Convert Montserrat to svg path for the side bar logo
- Increase logo png to 512x512
- Make default zoom faster again (regression from 4.1.1)
- Fix boundary color of colorful zebra for odd stripe count
## v3.1.1
**Fixes**
- Fix the zoom state residual issue beacuse of TrackballControls using dynamic damping (three-cad-viewer)
## v3.1.0
- Viewer UI:
- Based on a completely refactored [tcv-cad-viewer v4.1.0](https://github.com/bernhard-42/three-cad-viewer) and adapted to changes in API of tcv-cad-viewer v4.0.1
- New Zebra tool with normal and reflective stripes
- Measure tool
- Unified angle computation at closest points via `BRepExtrema`, supporting all edge/face combinations (circles, splines, cylinders, spheres, …) ([#211](https://github.com/bernhard-42/vscode-ocp-cad-viewer/issues/211))
- Backend returns direction/normal vectors and context-aware labels (`line`, `face normal`, `tangent at P1`, `surface normal at P2`)
- Measurement arrows adapt to point proximity: cones flip outward when points are close, and are hidden when coincident — preventing visual overlap
- Backend returns grouped response format for distance and properties: metadata at top level, grouped data in `result` array. Measurement panels now render grouped backend responses with horizontal separators between groups (backend is info master)
- Added keyboard shortcuts for toolbar buttons, camera presets, tab navigation, and animation control. Default bindings (only _key_ and _shift-key_ are supported. Modifier keys can only be mapped to mouse events):
- Toggle: `a` axes, `A` axes0, `g` all grids, `G` xy-grid only, `p` perspective, `t` transparent, `b` blackedges, `x` explode, `L` zscale, `D` distance, `P` properties, `S` select
- Views: (keypad cross): top: `8`, left: `4`, iso: `5`, right: `6`, bottom: `2`, front: `1`, rear: `3`
- Reset: `r` resize, `R` reset
- Tabs: `T` tree, `C` clip, `M` material, `Z` zebra
- Other: `h` help, `Space` play/pause, `Escape` stop/close-help
- Adapted to the new consistent notification system of three-cad-viewer v4
- Refreshed logo to use font Montserrat instead of Futura
- Animation
- Exposed `animation.set_relative_time` in 1/1000 steps to contol animation from within Python
- New feature to save animation as animated gif with fps and loop settings
- Animation now takes paths from actually shown object tree
- Animation allows to show additional objects beside the animated assembly (but the paths change!)
- Extension status bar
- The status bar entry for OCP CAD Viewer has been moved to the right where the Python status items live
- The status bar entry now shows the currently used port (`OCP: 3939·DEBUG` / `OCP: 3939`), is only visible when the viewer is running
- Terminal
- A new Workspace config `OcpCadViewer.advanced.shellCommandPrefix` allows to exclude commands from shell history for bash, zsh, ... ([#204](https://github.com/bernhard-42/vscode-ocp-cad-viewer/issues/204))
- The extension respects VS Code's automationProfile and defaultProfile terminal settings when creating terminals
Order: `automationProfile` (if set), then `defaultProfile` → resolved via profiles (if set) then OS login shell ([#198](https://github.com/bernhard-42/vscode-ocp-cad-viewer/issues/198))
- Python
- The new default for the `reset_camera` parameter is `Camera.KEEP`. **Note that this can be changed in the VS Code settings for "OCP CAD Viewer"**
- Added per-object render mode via `modes` parameter (`Render.ALL`, `Render.EDGES`, `Render.FACES`, `Render.NONE`). Deprecate `render_edges` in favor of `modes` ([#114](https://github.com/bernhard-42/vscode-ocp-cad-viewer/issues/114))
- Change the order how defaults (via set_defaults) and UI status (actual UI settings) are applied: the defaults set by `set_defaults` now take precedence over the viewer's current UI status
- The library installation and quickstart commands have a new placeholder `{pip-install}` which will automatically be replaced by `uv pip` when a uv env is selected, else `pip`
- Upgrade to websockets 16.0 for Python 3.14 and proxy autodetection support ([#210](https://github.com/bernhard-42/vscode-ocp-cad-viewer/issues/210))
- Quickstart commands now per fdefault install build123d via pip install git+https://github.com/gumyr/build123d (with ot without uv)
- No support for Python 3.9 any more
**Fixes**
- Tessellator does not strip parent compound any more (when it only has a single child) ([#207](https://github.com/bernhard-42/vscode-ocp-cad-viewer/issues/207))
- Removed 'text' wrapper from standalone status command result ([205](https://github.com/bernhard-42/vscode-ocp-cad-viewer/issues/205))
- Setting timeit does not turn debug mode on any more ([#206](https://github.com/bernhard-42/vscode-ocp-cad-viewer/issues/206))
- Fixed animation for Quaternion based tracks ([#208](https://github.com/bernhard-42/vscode-ocp-cad-viewer/issues/208))
- Automatically detect uv environments and use uv pip install/list ([#214](https://github.com/bernhard-42/vscode-ocp-cad-viewer/issues/214))
- Ensure that ~/.ocpvscode has services attribute ([#214](https://github.com/bernhard-42/vscode-ocp-cad-viewer/issues/214))
- Fix race condition between extension activate and webview revive
- Ensure all output messages have a proper class/file.function prefix
- Ensure workspace folder is found even when no python file is open to save quickstart demo file
- Changed trackball panning speed to be more responsive
- Normalized control speed settings (pan, rotate, zoom) for consistent behavior across orbit and trackball modes.
| text/markdown | null | Bernhard Walter <b_walter@arcor.de> | null | null | null | 3d models, 3d printing, 3d viewing, 3d, brep, cad, cadquery, opencscade, python | [
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"ocp-tessellate<3.2.0,>=3.1.2",
"requests",
"ipykernel",
"orjson",
"websockets<17.0,>=16.0",
"pyaml",
"flask<4.0,>=3.0",
"flask_sock<1.0,>=0.7",
"click<9.0,>=8.1",
"pyperclip==1.9.0",
"questionary==2.1.1",
"pillow<13.0,>=12.1.0",
"questionary~=1.10.0; extra == \"dev\"",
"bump-my-version; e... | [] | [] | [] | [
"Homepage, https://github.com/bernhard-42/vscode-ocp-cad-viewer",
"Bug Tracker, https://github.com/bernhard-42/vscode-ocp-cad-viewer/issues"
] | twine/6.2.0 CPython/3.13.3 | 2026-02-19T20:46:29.105819 | ocp_vscode-3.1.2.tar.gz | 693,301 | 22/76/4f482adfe9d89af42111a8d0398ea5c99f3f89c450495c9e4e17c0c7340c/ocp_vscode-3.1.2.tar.gz | source | sdist | null | false | ee63d47cf766926d30a0325353c13af8 | 540f66f26c13249a698a0032eaa869f6675ec71ab34c293c5a084b4cf00ec376 | 22764f482adfe9d89af42111a8d0398ea5c99f3f89c450495c9e4e17c0c7340c | Apache-2.0 | [
"LICENSE"
] | 733 |
2.4 | dhub-cli | 0.6.7 | The AI Skill Manager for Data Science Agents | # dhub-cli: The AI Skill Manager for Data Science Agents
**Decision Hub** is a CLI-first registry for publishing, discovering, and installing *Skills* — modular packages of code and prompts that AI coding agents (Claude, Cursor, Codex, Gemini, OpenCode) can use.
## Why Decision Hub?
**Agents that extend themselves.** Install Decision Hub as a skill into any supported agent, and the agent can discover new skills in natural language — then install and use them mid-conversation without human intervention.
**Publish from anywhere.** Point `dhub publish` at a local directory or a GitHub repo URL and every valid `SKILL.md` inside is discovered, versioned, and published.
**Private skills for your team.** Skills can be scoped to your GitHub organization so proprietary tooling stays internal.
**Install once, use everywhere.** A single `dhub install` symlinks a skill into every agent's skill directory — Claude, Cursor, Codex, Gemini, OpenCode. No duplication, no per-agent setup.
**Security gauntlet.** Every publish is scanned for dangerous patterns. Skills get a trust grade (A/B/C/F) before they reach the registry.
**Automated evals in sandboxes.** Skills ship with eval cases that run on publish in isolated sandboxes, scored by an LLM judge.
**Executable skills with SKILL.md.** Builds on the [Agent Skills spec](https://agentskills.io/specification) with `runtime` and `evals` blocks — skills are runnable programs, not just static prompts.
## Installation
```bash
# Via uv (recommended)
uv tool install dhub-cli
# Via pipx
pipx install dhub-cli
```
## Quick Start
```bash
# 1. Authenticate via GitHub
dhub login
# 2. Search for skills using natural language
dhub ask "analyze A/B test results"
# 3. Install a skill for all your agents
dhub install pymc-labs/causalpy
# 4. Scaffold a new skill
dhub init my-new-skill
# 5. Publish it under your namespace
# (Run this inside the skill directory)
dhub publish .
```
## Supported Agents
Skills are installed as symlinks into each agent's skill directory, making them immediately available:
- **Claude:** `~/.claude/skills`
- **Cursor:** `~/.cursor/skills`
- **Gemini:** `~/.gemini/skills`
- **OpenCode:** `~/.config/opencode/skills`
## Documentation
For full documentation on creating skills, the `SKILL.md` format, and running your own registry server, see the [main repository](https://github.com/lfiaschi/decision-hub). | text/markdown | null | Luca Fiaschi <luca.fiaschi@gmail.com> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Librari... | [] | null | null | >=3.11 | [] | [] | [] | [
"dhub-core==0.2.2",
"httpx>=0.27.0",
"pyyaml>=6.0.0",
"rich>=13.0.0",
"typer>=0.12.0",
"pytest>=8.0.0; extra == \"dev\"",
"respx>=0.21.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/lfiaschi/decision-hub",
"Repository, https://github.com/lfiaschi/decision-hub",
"Issues, https://github.com/lfiaschi/decision-hub/issues"
] | uv/0.6.12 | 2026-02-19T20:46:18.785712 | dhub_cli-0.6.7.tar.gz | 47,744 | 49/3b/9e8fa740edf3f52c3af3a9672b60a2ace9097b3aeada35bd1cdb4c27a013/dhub_cli-0.6.7.tar.gz | source | sdist | null | false | 9fc46cda3d1f0c6becd4005c7d2f1bc6 | f351d820ef7c08e065a09e5ed57c34721e46146094ce7bf0d9589f00c3920c57 | 493b9e8fa740edf3f52c3af3a9672b60a2ace9097b3aeada35bd1cdb4c27a013 | MIT | [] | 215 |
2.3 | chatvat | 0.2.4 | The Universal RAG Chatbot Factory. Zero-dependency AI deployments. | # ChatVat (The ChatBot🤖 Factory🏭)
> **The Universal RAG Chatbot Factory**
[](https://www.python.org/)
[](https://www.docker.com/)
[](https://opensource.org/licenses/Apache-2.0)
[](https://groq.com)
[](https://python.langchain.com)
[](https://fastapi.tiangolo.com)
[](https://www.trychroma.com/)
---
## 🌟 The Vision
**ChatVat** is not just another chatbot script. It is a **Manufacturing Plant** for self-contained AI systems.
It solves the "It works on my machine" problem by adhering to a strict **"Zero-Dependency"** philosophy. ChatVat takes your raw data sources—websites, secured APIs, and documents—and fuses them with a production-grade RAG engine into a sealed Docker container. This "capsule" contains everything needed to run: the code, the database, the browser, and the API server.
You can deploy a ChatVat bot anywhere: from a MacBook Air to an air-gapped server in Antarctica, with nothing but Docker installed.
### Core Philosophy
* **Split Architecture:** A lightweight CLI (~15MB) for management, and a heavy-duty Docker container for the AI engine. No more installing 3GB of CUDA drivers on your laptop just to run a build tool.
* **Universal Connectivity:** Acts as a generic **MCP (Model Context Protocol)** connector. Can ingest data from any API using custom headers and auth keys.
> Disclaimer : We advise users to ensure they have authorized access to secured APIs and to follow the provider's guidelines when extracting data from sensitive APIs. Read the full disclaimer below for more details.
* **Self-Healing:** Built-in deduplication (Content Hashing), crash recovery, and "Ghost Entry" prevention.
* **Production Parity:** The bot you test locally is bit-for-bit identical to the bot you deploy, thanks to baked-in browser binaries.
---
## ⚡ Quick Start
### 1. Installation
Install the lightweight ChatVat CLI. (It installs in seconds and won't bloat your system).
```bash
pip install chatvat
```
### 2. Initialize the Assembly Line
Create a clean directory for your new bot and run the configuration wizard.
```bash
mkdir my-crypto-bot
cd my-crypto-bot
chatvat init
```
*The wizard will guide you through:*
* **Naming your bot**
* **Setting up AI Brain** (Groq Llama-3 + HuggingFace Embeddings)
* **Connecting Data Sources** (URLs, Secured APIs, or Local Files)
* **Defining Deployment Ports**
### 3. Build the Capsule
Compile your configuration and the ChatVat engine into a Docker Image.
```bash
chatvat build
```
> **What happens here?**
> The CLI performs **Source Injection**: it copies the core engine code into a build context, injects your `chatvat.config.json`, and triggers a multi-stage Docker build. It optimizes the image by installing specific browser binaries (Chromium only) and purging build tools, keeping the final image lean.
### 4. Deploy Anywhere
Run your bot using standard Docker commands. Note the use of `--ipc=host` to prevent browser crashes on memory-heavy sites.
```bash
# Example: Running on Port 8000
docker run -d \
-p 8000:8000 \
--env-file .env \
--ipc=host \
--restart always \
--name crypto-bot \
chatvat-bot
```
---
## 🧠 Architecture Deep Dive
ChatVat implements a modular **RAG (Retrieval-Augmented Generation)** pipeline designed for resilience.
### The Components
| Component | Role | Description |
| :--- | :--- | :--- |
| **The Builder** | CLI Manager | Runs on host. Lightweight (~15MB). Orchestrates the factory process and Docker builds. |
| **The Cortex** | Intelligence | Powered by **Groq** for ultra-fast inference and **HuggingFace** for embeddings. Runs inside Docker. |
| **The Memory** | Vector Store | A persistent, thread-safe **ChromaDB** instance. Uses MD5 hashing to silently drop duplicate data during ingestion. |
| **The Eyes** | Crawler | A headless **Chromium** browser (via Crawl4AI/Playwright) managed with `--ipc=host` stability to read dynamic JS websites. |
| **The Connector** | Universal MCP | A polymorphic ingestor that can authenticate with secured APIs using environment-variable masking (e.g., `${API_KEY}`). |
| **The API** | Interface | A high-performance **FastAPI** server exposing REST endpoints. |
### The "Split Strategy" Workflow
Unlike traditional tools that force you to install heavy AI libraries locally:
1. **Local (Host):** You only have `typer`, `rich`, and `requests`. Fast and clean.
2. **Container (Engine):** The Docker build installs `torch`, `langchain`, `playwright`, and `chromadb`.
3. **Result:** You get the power of a heavy AI stack without polluting your local development environment.
---
## 🛠️ Configuration Guide
Your bot is defined by `chatvat.config.json`. You can edit this file manually after running `init`.
```json
{
"bot_name": "ChatVatBot",
"port": 8000,
"refresh_interval_minutes": 60,
"system_prompt": "You are a helpful assistant for the .....",
"llm_model": "llama-3.1-70b-versatile",
"embedding_model": "all-MiniLM-L6-v2",
"retriever_k": 5,
"max_tokens": 400,
"sources": [
{
"type": "static_url",
"target": "[https://docs.stripe.com](https://docs.stripe.com)",
"max_depth": 2,
"recursion_scope": "restrictive"
},
{
"type": "dynamic_json",
"target": "[https://api.github.com/repos/my-org/my-repo/issues](https://api.github.com/repos/my-org/my-repo/issues)",
"headers": {
"Authorization": "Bearer ${GITHUB_TOKEN}",
"Accept": "application/vnd.github.v3+json"
}
},
{
"type": "local_file",
"target": "./policy_docs.pdf"
}
]
}
```
### Source Configuration
| Field | Type | Default | Description |
| :--- | :--- | :--- | :--- |
| `type` | `string` | *required* | `"static_url"`, `"dynamic_json"`, or `"local_file"` |
| `target` | `string` | *required* | URL or local file path |
| `headers` | `object` | `{}` | Custom HTTP headers for API authentication |
| `max_depth` | `int` | `1` | Crawl depth. `1` = single page, `2+` = follow links recursively |
| `recursion_scope` | `string` | `"restrictive"` | `"restrictive"` = only follow links under the target path. `"domain"` = follow any link on the same domain |
### Global Configuration
| Field | Type | Default | Description |
| :--- | :--- | :--- | :--- |
| `bot_name` | `string` | *required* | Name of your chatbot |
| `port` | `int` | `8000` | Deployment port for the FastAPI server |
| `refresh_interval_minutes` | `int` | `0` | Auto-update interval in minutes (0 = disabled) |
| `system_prompt` | `string` | *(default assistant prompt)* | Custom persona/system prompt for the LLM |
| `llm_model` | `string` | `"llama-3.3-70b-versatile"` | Groq LLM model name |
| `embedding_model` | `string` | `"all-MiniLM-L6-v2"` | HuggingFace embedding model |
| `retriever_k` | `int` | `5` | Number of top relevant chunks to retrieve from vector DB (1-20) |
| `max_tokens` | `int` | `400` | Count of total tokens to be produced in response depending upon task |
### Field Details
* **`refresh_interval_minutes`**: Set to `0` to disable auto-updates.
* **`static_url`**: Uses Playwright to render JavaScript before scraping.
* **`max_depth`**: *(static_url only)* Controls how deep the crawler follows links. `1` = single page (default), `2+` = recursive BFS crawl.
* **`recursion_scope`**: *(static_url only)* Controls which links the crawler follows. `"restrictive"` (default) = only links under the target path, `"domain"` = any same-domain link.
* **`dynamic_json`**: Acts as a Universal Connector. Supports custom headers.
* **`headers`**: Securely inject secrets using `${VAR_NAME}` syntax. The engine resolves these from the container's environment variables at runtime.
* **`llm_model`**: You can select your required Groq LLM model while initialising the ChatBot (e.g., `llama-3.3-70b-versatile`, `mixtral-8x7b-32768`).
* **`embedding_model`**: HuggingFace model for generating text embeddings (e.g., `all-MiniLM-L6-v2`, `all-mpnet-base-v2`).
* **`retriever_k`**: Controls how many relevant document chunks are retrieved from the vector database for each query. Higher values (e.g., 10-20) provide more context but may include less relevant information. Lower values (e.g., 2-3) are more focused but may miss contextual details. Default is 5.
* **`max_tokens`**: Maximum number of tokens the LLM may generate in a single response. Use this to limit output length and guard against token-exhaustion attacks or runaway outputs. Default is `400`.
---
## 📚 API Reference
Once the container is running, interact with it via HTTP REST API.
### 1. Health Check
Used by cloud balancers (AWS/Render) to verify the bot is alive.
```bash
GET /health
```
**Response:**
```json
{
"status": "healthy",
"version": "0.1.10"
}
```
### 2. Chat Interface
The main endpoint for sending queries.
```bash
POST /chat
```
**Payload:**
```json
{
"message": "What is the return policy for digital items?"
}
```
**Response:**
```json
{
"message": "According to the policy document, digital items are non-refundable once downloaded..."
}
```
---
## ⚠️ Disclaimer & Legal Notice
**Author:** Madhav Kapila
**Project:** ChatVat - Conversational AI & Web Crawling Engine
This software is provided for **educational and research purposes only**.
1. **No Liability:** The author (Madhav Kapila) is not responsible for any damage caused by the use of this tool. This includes, but is not limited to:
* IP bans or blacklisting of your device/server.
* Legal consequences of crawling restricted or sensitive websites.
* Data loss or corruption on the user's local machine or target infrastructure.
2. **User Responsibility:** You, the user, acknowledge that you are solely responsible for compliance with all applicable laws and regulations (such as GDPR, CFAA, or Terms of Service of target websites) when using this software.
3. **"As Is" Warranty:** This software is provided "as is", without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose, and non-infringement.
**By downloading, installing, or using this software, you agree to these terms.**
---
<p align="center">
Built with ❤️ by <b>Madhav Kapila</b>.
</p> | text/markdown | Madhav Kapila | smartatk04@gmail.com | null | null | Apache-2.0 | null | [
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial ... | [] | https://github.com/madhavkapila | null | <4.0,>=3.11 | [] | [] | [] | [
"typer>=0.12.3",
"rich<14.0.0,>=13.7.0",
"pyfiglet<2.0.0,>=1.0.2",
"pydantic<3.0.0,>=2.0.0",
"python-dotenv<2.0.0,>=1.0.0",
"requests<3.0.0,>=2.31.0",
"fastapi<0.110.0,>=0.109.0; extra == \"engine\"",
"uvicorn[standard]<0.28.0,>=0.27.0; extra == \"engine\"",
"playwright<2.0.0,>=1.40.0; extra == \"en... | [] | [] | [] | [
"Homepage, https://github.com/madhavkapila",
"Repository, https://github.com/madhavkapila/ChatVat.git"
] | poetry/2.1.2 CPython/3.13.7 Linux/6.17.0-14-generic | 2026-02-19T20:46:18.699129 | chatvat-0.2.4.tar.gz | 38,478 | 7c/0a/21178d9ef39e07ae193195376922714a3a02cd83375c709b72090cadcfe3/chatvat-0.2.4.tar.gz | source | sdist | null | false | f9b79ba03838b375e4ee94d3f9a9436b | 4d98ec05d084fae2c7e580cd902866bc867b1275636644144c77825c55fb56d4 | 7c0a21178d9ef39e07ae193195376922714a3a02cd83375c709b72090cadcfe3 | null | [] | 230 |
2.4 | stringmatch | 0.14.8 | A library to match and compare strings. | # stringmatch
[](https://pypi.org/project/stringmatch/)
[](https://pypi.org/project/stringmatch/)
[](https://pepy.tech/project/stringmatch)
[](https://github.com/atomflunder/stringmatch/actions/workflows/build.yml)
[](https://stringmatch.readthedocs.io/en/latest/?badge=latest)
[](https://codecov.io/gh/atomflunder/stringmatch)
[](https://github.com/psf/black)
**stringmatch** is a small, lightweight string matching library written in Python, based on the [Levenshtein distance](https://en.wikipedia.org/wiki/Levenshtein_distance), among other algorithms.
Inspired by libraries like [seatgeek/thefuzz](https://github.com/seatgeek/thefuzz), which did not quite fit my needs. This library offers improved usability, extensibility and performance.
## Table of Contents
- [🎯 Key Features](#key-features)
- [📋 Requirements](#requirements)
- [⚙️ Installation](#installation)
- [🔨 Basic Usage](#basic-usage)
- [Matching](#matching)
- [Ratios](#ratios)
- [Matching & Ratios](#matching--ratios)
- [Distances](#distances)
- [Strings](#strings)
- [🛠️ Advanced Usage](#advanced-usage)
- [Keyword Arguments](#keyword-arguments)
- [Class Keyword Arguments](#class-keyword-arguments)
- [Your Own Scorer](#your-own-scorer)
- [🌟 Contributing](#contributing)
- [🔗 Links](#links)
- [⚠️ License](#license)
## Key Features
This library **matches compares and strings to each other** based mainly on, among others, the [Levenshtein distance](https://en.wikipedia.org/wiki/Levenshtein_distance).
What makes stringmatch special compared to other libraries with similar functions:
- 💨 Lightweight, straightforward and easy to use
- ⚡ High speed - at least ~12x faster than thefuzz and up to 70x
- 🧰 Allows for highly customisable searches, that yield better results
- 📚 Lots of utility functions to make your life easier
- 📝 Statically typed with mypy, compiled with mypyc
- 🌍 Handles special unicode characters, like emojis or characters from other languages, like ジャパニーズ
## Requirements
- Python 3.10 or later.
- The packages in [`requirements.txt`](/requirements.txt), pip will handle these for you.
## Installation
Install the latest stable version with pip:
```
pip install -U stringmatch
```
Or install the newest version via git (Might be unstable or unfinished):
```
pip install -U git+https://github.com/atomflunder/stringmatch
```
## Basic Usage
Below are some basic examples on how to use this library.
For a more detailed explanation head over to [the Documentation](https://stringmatch.readthedocs.io/en/latest/).
For examples on how to use this library, head over to the [`examples` directory](/examples/).
### Matching
The match functions allow you to compare 2 strings and check if they are "similar enough" to each other, or get the best match(es) from a list of strings:
```python
from stringmatch import Match
match = Match()
# Checks if the strings are similar:
match.match("stringmatch", "strngmach") # returns True
match.match("stringmatch", "something else") # returns False
# Returns the best match(es) found in the list:
searches = ["stringmat", "strinma", "strings", "mtch", "whatever", "s"]
match.get_best_match("stringmatch", searches) # returns "stringmat"
match.get_best_matches("stringmatch", searches) # returns ["stringmat", "strinma"]
```
### Ratios
The "ratio of similarity" describes how similar the strings are to each other. It ranges from 100 being an exact match to 0 being something completely different.
You can get the ratio between strings like this:
```python
from stringmatch import Ratio
ratio = Ratio()
# Getting the ratio between the two strings:
ratio.ratio("stringmatch", "stringmatch") # returns 100
ratio.ratio("stringmatch", "strngmach") # returns 90
ratio.ratio("stringmatch", "eh") # returns 15
# Getting the ratio between the first string and the list of strings at once:
searches = ["stringmatch", "strngmach", "eh"]
ratio.ratio_list("stringmatch", searches) # returns [100, 90, 15]
# Searching for partial ratios with substrings:
ratio.partial_ratio("a string", "a string longer") # returns 80
```
### Matching & Ratios
You can also get both the match and the ratio together in a tuple using these functions:
```python
from stringmatch import Match
match = Match()
match.match_with_ratio("stringmatch", "strngmach") # returns (True, 90)
searches = ["test", "nope", "tset"]
match.get_best_match_with_ratio("test", searches) # returns ("test", 100)
match.get_best_matches_with_ratio("test", searches) # returns [("test", 100), ("tset", 75)]
```
### Distances
Instead of the ratio, you can also get the Levenshtein distance between strings directly. The bigger the distance, the more different the strings:
```python
from stringmatch import Distance
distance = Distance()
distance.distance("kitten", "sitting") # returns 3
searches = ["sitting", "kitten"]
distance.distance_list("kitten", searches) # returns [3, 0]
```
### Strings
This is primarily meant for internal usage, but you can also use this library to modify strings:
```python
from stringmatch import Strings
strings = Strings()
strings.latinise("Héllö, world!") # returns "Hello, world!"
strings.remove_punctuation("wh'at;, ever") # returns "what ever"
strings.alphanumeric("Héllö, world!") # returns "Hll world"
strings.ignore_case("test test!", lower=False) # returns "TEST TEST!"
```
## Advanced Usage
### Keyword Arguments
There are some **optional arguments** available for a few functions.
### `score`
| Type | Default | Description | Available for: |
| ------- | ------- | -------------------------------------------------------------------------------------------- | --------------------------------------- |
| Integer | 70 | The score cutoff for matching. If the score is below the threshold it will not get returned. | All functions from the `Match()` class. |
```python
# Example:
from stringmatch import Match
match = Match()
match.match("stringmatch", "strngmach", score=95) # returns False
match.match("stringmatch", "strngmach", score=70) # returns True
```
---
### `limit`
| Type | Default | Description | Available for: |
| ------- | ------- | ----------------------------------------------------------------------------------------------------- | ----------------------------------------------------- |
| Integer | 5 | The limit of how many matches to return. **If you want to return every match set this to 0 or None.** | `get_best_matches()`, `get_best_matches_with_ratio()` |
```python
# Example:
from stringmatch import Match
match = Match()
searches = ["limit 5", "limit 4", "limit 3", "limit 2", "limit 1", "limit 0", "something else"]
# returns ["limit 5", "limit 4"]
match.get_best_matches("limit 5", searches, limit=2)
# returns ["limit 5"]
match.get_best_matches("limit 5", searches, limit=1)
# returns ["limit 5", "limit 4", "limit 3", "limit 2", "limit 1", "limit 0"]
match.get_best_matches("limit 5", searches, limit=None)
```
---
### Class Keyword Arguments
You can also pass in on or more of these **optional arguments when initialising the `Match()` and `Ratio()`** classes to customize your search even further.
Of course you can use multiple of these keyword arguments at once, to customise the search to do exactly what you intend to do.
### `scorer`
| Type | Default | Description |
| ---------- | ----------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| BaseScorer | LevenshteinScorer | Different scoring algorithms to use. The available options are: [`LevenshteinScorer`](https://en.wikipedia.org/wiki/Levenshtein_distance), [`JaroScorer`](https://en.wikipedia.org/wiki/Jaro–Winkler_distance#Jaro_similarity), [`JaroWinklerScorer`](https://en.wikipedia.org/wiki/Jaro–Winkler_distance#Jaro–Winkler_similarity). |
Click on the links above for detailed information about these, but speaking generally the Jaro Scorer will be the fastest, focussing on the characters the strings have in common.
The Jaro-Winkler Scorer slightly modified the Jaro Scorer to prioritise characters at the start of the string.
The Levenshtein Scorer will, most likely, produce the best results, focussing on the number of edits needed to get from one string to the other.
```python
# Example:
from stringmatch import Match, LevenshteinScorer, JaroWinklerScorer
lev_matcher = Match(scorer=LevenshteinScorer)
lev_matcher.match_with_ratio("test", "th test") # returns (True, 73)
jw_matcher = Match(scorer=JaroWinklerScorer)
jw_matcher.match_with_ratio("test", "th test") # returns (False, 60)
```
---
### `latinise`
| Type | Default | Description |
| ------- | ------- | -------------------------------------------------------------------------------------------------------------------- |
| Boolean | False | Replaces special unicode characters with their latin alphabet equivalents. Examples: `Ǽ` -> `AE`, `ノース` -> `nosu` |
```python
# Example:
from stringmatch import Match
lat_match = Match(latinise=True)
lat_match.match("séärçh", "search") # returns True
def_match = Match(latinise=False)
def_match.match("séärçh", "search") # returns False
```
---
### `ignore_case`
| Type | Default | Description |
| ------- | ------- | ------------------------------------------------------- |
| Boolean | True | If you want to ignore case sensitivity while searching. |
```python
# Example:
from stringmatch import Match
def_match = Match(ignore_case=True)
def_match.match("test", "TEST") # returns True
case_match = Match(ignore_case=False)
case_match.match("test", "TEST") # returns False
```
---
### `remove_punctuation`
| Type | Default | Description |
| ------- | ------- | ------------------------------------------------------------------------------------ |
| Boolean | False | Removes commonly used punctuation symbols from the strings, like `.,;:!?` and so on. |
```python
# Example:
from stringmatch import Match
punc_match = Match(remove_punctuation=True)
punc_match.match("test,---....", "test") # returns True
def_match = Match(remove_punctuation=False)
def_match.match("test,---....", "test") # returns False
```
---
### `alphanumeric`
| Type | Default | Description |
| ------- | ------- | ---------------------------------------------------------------------------------------------------------------------- |
| Boolean | False | Removes every character that is not a number or in the latin alphabet, a more extreme version of `remove_punctuation`. |
```python
# Example:
from stringmatch import Match
let_match = Match(alphanumeric=True)
let_match.match("»»ᅳtestᅳ►", "test") # returns True
def_match = Match(alphanumeric=False)
def_match.match("»»ᅳtestᅳ►", "test") # returns False
```
---
### `include_partial`
| Type | Default | Description |
| ------- | ------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Boolean | False | If set to true, also searches for partial substring matches. This may lead to more desirable results but is a bit slower. This will return a score of 65-95 depending on how far apart the sizes of the strings are to ensure only identical matches provide a score of 100. It will start matching at a length of 2, or 1 if it is the first letter of the string. |
```python
# Example:
from stringmatch import Match
part_match = Match(include_partial=True)
# returns (True, 65)
part_match.match_with_ratio("A string", "A string thats like really really long", score=60)
def_match = Match(include_partial=False)
# returns (False, 35)
def_match.match_with_ratio("A string", "A string thats like really really long", score=60)
```
---
### Your Own Scorer
If you are unhappy with the scoring algorithms provided, you can of course construct your own scorer class. Make sure it inherits from `BaseScorer` and has a `score()` method that takes 2 strings and returns a float between 0 and 100.
```python
# Example:
from stringmatch import BaseScorer, Match
class MyOwnScorer(BaseScorer):
def score(self, string1: str, string2: str) -> float:
# Highly advanced technology
return 100
my_matcher = Match(scorer=MyOwnScorer)
my_matcher.match_with_ratio("anything", "whatever") # returns (True, 100)
```
## Contributing
Contributions to this library are always appreciated! If you have any sort of feedback, or are interested in contributing, head on over to the [Contributing Guidelines](/.github/CONTRIBUTING.md).
Additionally, if you like this library, leaving a star and spreading the word would be appreciated a lot!
Thanks in advance for taking the time to do so.
## Links
Packages used:
- [Mypy](https://github.com/python/mypy) ([Mypyc](https://github.com/mypyc/mypyc))
- [RapidFuzz](https://github.com/maxbachmann/RapidFuzz)
- [Unidecode](https://github.com/avian2/unidecode)
## License
This project is licensed under the [MIT License](/LICENSE).
| text/markdown | atomflunder | 80397293+atomflunder@users.noreply.github.com | null | null | MIT | stringmatch string match fuzzy matching | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.... | [] | https://github.com/atomflunder/stringmatch | null | >=3.10 | [] | [] | [] | [
"rapidfuzz==3.14.3",
"unidecode==1.4.0",
"mypy==1.19.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T20:46:16.452212 | stringmatch-0.14.8.tar.gz | 18,547 | e0/48/9a4b5696e7dfd248f717c3ec07726fed1f0954350b5ff254e8e9bacb878a/stringmatch-0.14.8.tar.gz | source | sdist | null | false | 80df31985f32d9c503d32dc473cff1ca | 4002c3e1f00da9020a0477fb10300707b511531f137cb989b9739c4c1a278693 | e0489a4b5696e7dfd248f717c3ec07726fed1f0954350b5ff254e8e9bacb878a | null | [
"LICENSE"
] | 2,861 |
2.1 | himalaya | 0.4.10 | Multiple-target machine learning | Himalaya: Multiple-target linear models
=======================================
|Github| |Python| |License| |Build| |Codecov| |Downloads|
``Himalaya`` [1]_ implements machine learning linear models in Python, focusing
on computational efficiency for large numbers of targets.
Use ``himalaya`` if you need a library that:
- estimates linear models on large numbers of targets,
- runs on CPU and GPU hardware,
- provides estimators compatible with ``scikit-learn``'s API.
``Himalaya`` is stable (with particular care for backward compatibility) and
open for public use (give it a star!).
Example
=======
.. code-block:: python
import numpy as np
n_samples, n_features, n_targets = 10, 5, 4
np.random.seed(0)
X = np.random.randn(n_samples, n_features)
Y = np.random.randn(n_samples, n_targets)
from himalaya.ridge import RidgeCV
model = RidgeCV(alphas=[1, 10, 100])
model.fit(X, Y)
print(model.best_alphas_) # [ 10. 100. 10. 100.]
- The model ``RidgeCV`` uses the same API as ``scikit-learn``
estimators, with methods such as ``fit``, ``predict``, ``score``, etc.
- The model is able to efficiently fit a large number of targets (routinely
used with 100k targets).
- The model selects the best hyperparameter ``alpha`` for each target
independently.
More examples
-------------
Check more examples of use of ``himalaya`` in the `gallery of examples
<https://gallantlab.github.io/himalaya/_auto_examples/index.html>`_.
Tutorials using ``himalaya`` for fMRI
-------------------------------------
``Himalaya`` was designed primarily for functional magnetic resonance imaging
(fMRI) encoding models. In depth tutorials about using ``himalaya`` for fMRI
encoding models can be found at `gallantlab/voxelwise_tutorials
<https://github.com/gallantlab/voxelwise_tutorials>`_.
Models
======
``Himalaya`` implements the following models:
- Ridge, RidgeCV
- KernelRidge, KernelRidgeCV
- GroupRidgeCV, MultipleKernelRidgeCV, WeightedKernelRidge
- SparseGroupLassoCV
See the `model descriptions
<https://gallantlab.github.io/himalaya/models.html>`_ in the documentation
website.
Himalaya backends
=================
``Himalaya`` can be used seamlessly with different backends.
The available backends are ``numpy`` (default), ``cupy``, ``torch``, and
``torch_cuda``.
To change the backend, call:
.. code-block:: python
from himalaya.backend import set_backend
backend = set_backend("torch")
and give ``torch`` arrays inputs to the ``himalaya`` solvers. For convenience,
estimators implementing ``scikit-learn``'s API can cast arrays to the correct
input type.
GPU acceleration
----------------
To run ``himalaya`` on a graphics processing unit (GPU), you can use either
the ``cupy`` or the ``torch_cuda`` backend:
.. code-block:: python
from himalaya.backend import set_backend
backend = set_backend("cupy") # or "torch_cuda"
data = backend.asarray(data)
Installation
============
Dependencies
------------
- Python 3
- Numpy
- Scikit-learn
Optional (GPU backends):
- PyTorch (1.9+ preferred)
- Cupy
Standard installation
---------------------
You may install the latest version of ``himalaya`` using the package manager
``pip``, which will automatically download ``himalaya`` from the Python Package
Index (PyPI):
.. code-block:: bash
pip install himalaya
Installation from source
------------------------
To install ``himalaya`` from the latest source (``main`` branch), you may
call:
.. code-block:: bash
pip install git+https://github.com/gallantlab/himalaya.git
Developers can also install ``himalaya`` in editable mode via:
.. code-block:: bash
git clone https://github.com/gallantlab/himalaya
cd himalaya
pip install --editable .
.. |Github| image:: https://img.shields.io/badge/github-himalaya-blue
:target: https://github.com/gallantlab/himalaya
.. |Python| image:: https://img.shields.io/badge/python-3.7%2B-blue
:target: https://www.python.org/downloads/release/python-370
.. |License| image:: https://img.shields.io/badge/License-BSD%203--Clause-blue.svg
:target: https://opensource.org/licenses/BSD-3-Clause
.. |Build| image:: https://github.com/gallantlab/himalaya/actions/workflows/run_tests.yml/badge.svg
:target: https://github.com/gallantlab/himalaya/actions/workflows/run_tests.yml
.. |Codecov| image:: https://codecov.io/gh/gallantlab/himalaya/branch/main/graph/badge.svg?token=ECzjd9gvrw
:target: https://codecov.io/gh/gallantlab/himalaya
.. |Downloads| image:: https://pepy.tech/badge/himalaya
:target: https://pepy.tech/project/himalaya
Cite this package
=================
If you use ``himalaya`` in your work, please give it a star, and cite our
publication:
.. [1] Dupré La Tour, T., Eickenberg, M., Nunez-Elizalde, A.O., & Gallant, J. L. (2022).
Feature-space selection with banded ridge regression. `NeuroImage <https://doi.org/10.1016/j.neuroimage.2022.119728>`_.
| text/x-rst | null | null | Tom Dupre la Tour | tomdlt@berkeley.edu | BSD (3-clause) | null | [] | [] | https://github.com/gallantlab/himalaya | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/5.1.1 CPython/3.12.3 | 2026-02-19T20:45:29.099294 | himalaya-0.4.10.tar.gz | 72,972 | d8/b0/69d91606d65d9f034bfb25f1069ed431381449a383c1c408fa98e32b964b/himalaya-0.4.10.tar.gz | source | sdist | null | false | 8ed14786772e623a8a3a630e5d805b32 | ba6b2a4d47c15185d087e2f87a24f43740ceb83128035781ab19e098d104c933 | d8b069d91606d65d9f034bfb25f1069ed431381449a383c1c408fa98e32b964b | null | [] | 334 |
2.3 | dpm-toolkit | 2026.2.19 | Open-source tools and models for working with DPM databases | # DPM Toolkit
Open-source tools and models for working with EBA DPM 2.0 (Data Point Model) databases.
**📚 Documentation:** [Architecture](#architecture-overview) | [CLI Reference](#cli-reference) | [Contributing](CONTRIBUTING.md) | [Projects](#project-components)
## Disclaimer
This is an unofficial tool and is not affiliated with or endorsed by the European Banking Authority (EBA). The original AccessDB source is available at the [EBA DPM Website](https://www.eba.europa.eu/risk-and-data-analysis/reporting-frameworks/dpm-data-dictionary).
## What is DPM Toolkit?
DPM Toolkit makes EBA DPM 2.0 databases accessible across all platforms by converting Windows-only Access databases to SQLite and generating type-safe Python models.
### Key Benefits
- **Cross-Platform Access**: SQLite databases work on Windows, macOS, and Linux
- **Type-Safe Development**: Auto-generated SQLAlchemy models with IDE support
- **Automated Updates**: CI/CD pipeline ensures latest versions are always available
- **Multiple Options**: Download pre-built artifacts or convert databases yourself
- **Zero Setup**: Ready-to-use databases and Python models
### Why Use DPM Toolkit?
**For Data Analysts**: Skip the hassle of Windows-only Access databases. Get clean SQLite files that work everywhere.
**For Python Developers**: Type-annotated models with relationship mapping, autocompletion, and documentation.
**For Organizations**: Automated pipeline keeps databases current with EBA releases.
**For Compliance Teams**: Maintains original database structure and relationships while improving accessibility.
## Quick Start
### Install DPM Toolkit
```bash
# Basic installation (recommended for most users)
pip install dpm-toolkit
# With optional extras for specific functionality
pip install dpm-toolkit[scrape] # Web scraping capabilities
pip install dpm-toolkit[migrate] # Database migration (Windows only)
pip install dpm-toolkit[schema] # Python model generation
```
### Download Latest Database
```bash
# List available versions
dpm-toolkit list
# Download latest release (SQLite)
dpm-toolkit download --version release --type converted
# Download specific version
dpm-toolkit download --version "3.2" --type converted
```
### Use in Python
First install the generated models package:
```bash
pip install dpm2
```
Then use the bundled database and models:
```python
from dpm2 import get_db
from dpm2.models import TableVersionCell, Cell
# Get database connection (bundled SQLite database)
engine = get_db()
# Type-safe database operations with IDE support
with engine.connect() as conn:
# Your code here with full type checking and autocompletion
pass
```
## Platform-Specific Options
### All Platforms (Recommended)
Download pre-converted SQLite databases and Python models:
```bash
# Download from CLI (recommended)
dpm-toolkit download --version release --type converted
# Or download directly from GitHub releases
# https://github.com/JimLundin/dpm-toolkit/releases/latest/download/dpm-sqlite.zip
```
### Windows Only - Self Conversion
⚠️ **Windows Requirement**: Database conversion requires Microsoft Access ODBC driver and is only supported on Windows due to `sqlalchemy-access` and `pyodbc` dependencies.
```bash
# Install with conversion support (Windows only)
pip install dpm-toolkit[migrate]
# Convert your own Access databases
dpm-toolkit migrate --source /path/to/access/database.accdb --target /path/to/output.sqlite
```
### Non-Windows Users
- **Recommended**: Use pre-built artifacts from releases or CLI download
- **Alternative**: Set up Windows VM if self-conversion is absolutely required
- **Not Supported**: Direct conversion on macOS/Linux
## CLI Reference
### Core Commands
```bash
# List available database versions
dpm-toolkit list [--version VERSION] [--json|--yaml|--table]
# Download databases and models
dpm-toolkit download [--version VERSION] [--type TYPE] [--target DIRECTORY]
[--extract|--no-extract] [--overwrite]
# Find new versions (maintenance)
dpm-toolkit update [--json|--yaml|--table]
# Convert Access to SQLite (Windows only)
dpm-toolkit migrate --source SOURCE --target TARGET [--overwrite]
# Generate Python models from SQLite
dpm-toolkit schema --source SOURCE [--target TARGET]
```
### Version Selection
- `--version release` - Latest stable release (recommended, default)
- `--version latest` - Most recent version (including prereleases)
- `--version "X.Y"` - Specific version (e.g., "3.2")
### Download Types
- `--type converted` - SQLite database + Python models (default, recommended)
- `--type original` - Original EBA Access database
- `--type archive` - Processed Access database
### Examples
```bash
# Download latest stable release
dpm-toolkit download --version release
# Download specific version to custom directory
dpm-toolkit download --version "3.2" --target ./dpm-data
# List all versions in JSON format
dpm-toolkit list --json
# Convert local Access database (Windows only)
dpm-toolkit migrate --source ./database.accdb --target ./output.sqlite
# Generate Python models from SQLite database
dpm-toolkit schema --source ./output.sqlite --target ./models.py
```
## Using the Generated Models
### Database Access
```python
from sqlalchemy import select
from dpm2 import get_db
from dpm2.models import TableVersionCell, Cell
# Get bundled database connection (no setup required)
engine = get_db()
# Type-safe queries with IDE support
with engine.connect() as conn:
# Query with autocompletion and type checking
stmt = select(TableVersionCell).where(TableVersionCell.cell_content.isnot(None))
result = conn.execute(stmt)
for row in result:
print(f"Cell ID: {row.cell_id}, Content: {row.cell_content}")
# Alternative: Use in-memory database for better performance
engine = get_db(in_memory=True)
```
### Model Features
The generated SQLAlchemy models provide:
- **Type Annotations**: Full type hints for all columns and relationships
- **Automatic Relationships**: Foreign key relationships mapped to Python objects
- **Enum Types**: Constrained values represented as Python Literal types
- **Nullable Detection**: Optional types for columns that can be NULL
- **IDE Integration**: Full autocompletion and type checking support
### Example Generated Model
```python
# Example from dpm2.models
class TableVersionCell(DPM):
"""Auto-generated model for the TableVersionCell table."""
__tablename__ = "TableVersionCell"
cell_id: Mapped[str] = mapped_column(primary_key=True)
table_version_cell_id: Mapped[str]
cell_content: Mapped[str | None] # Nullable column
is_active: Mapped[bool] # Boolean type
created_date: Mapped[date] # Date type
# Automatically generated relationships
cell: Mapped[Cell] = relationship(foreign_keys=[cell_id])
table_version_header: Mapped[TableVersionHeader] = relationship(
foreign_keys=[table_version_cell_id]
)
```
## Database Conversion Process
The conversion process enhances the original Access database structure:
### 1. Type Refinement
- **Smart Type Detection**: Infers better types from column names and data
- **Date Conversion**: Converts Access date strings to Python date objects
- **Boolean Normalization**: Transforms Access -1/0 to Python True/False
- **GUID Recognition**: Identifies UUID columns by naming patterns
### 2. Constraint Enhancement
- **Nullable Analysis**: Detects which columns can be NULL from actual data
- **Enum Detection**: Identifies constrained value sets and creates Literal types
- **Relationship Mapping**: Establishes foreign key relationships
- **Primary Key Optimization**: Optimizes indexes for SQLite performance
### 3. Model Generation
- **Type-Safe Classes**: Creates fully annotated SQLAlchemy models
- **Relationship Objects**: Maps foreign keys to navigable Python relationships
- **Documentation**: Auto-generates docstrings for all models and tables
- **Code Quality**: Produces PEP-8 compliant, linted Python code
## Architecture Overview
DPM Toolkit is built as a modular workspace with specialized components:
### Project Components
- **[`dpm-toolkit`](src/dpm-toolkit/)**: Central CLI that coordinates all functionality
- **[`archive`](projects/archive/)**: Version management, downloads, and release tracking
- **[`migrate`](projects/migrate/)**: Access-to-SQLite conversion engine (Windows only)
- **[`scrape`](projects/scrape/)**: Automated discovery of new EBA releases
- **[`schema`](projects/schema/)**: Python model generation from SQLite databases
- **[`dpm2`](projects/dpm2/)**: Generated Python models package
### Automated Pipeline
1. **Discovery**: GitHub Actions automatically detect new EBA releases
2. **Conversion**: Windows runners convert Access databases to SQLite
3. **Model Generation**: Creates type-safe SQLAlchemy models
4. **Type Analysis**: Automated analysis across all database versions for type refinement opportunities
5. **Publishing**: Releases artifacts as GitHub releases
6. **Distribution**: Makes databases available via CLI and direct download
### Analysis Workflow
The `analyze-all-versions.yml` workflow runs type refinement analysis across all database versions:
- **Original Database Analysis**: Analyzes original Access databases (not converted SQLite) to capture true type refinement opportunities before migration
- **Automated Execution**: Runs on pushes to main branch (after PR merges)
- **Multi-Version Analysis**: Analyzes all available database versions in parallel on Windows runners
- **Database Caching**: Caches downloaded databases to avoid unnecessary load on EBA servers
- **Aggregate Reports**: Generates summary statistics and common recommendations across versions
- **Trend Tracking**: Identifies columns that consistently appear in recommendations
- **GitHub Actions Summary**: Results displayed directly in workflow run summaries
Manual trigger:
```bash
# Via GitHub Actions UI: Actions → Analyze All Database Versions → Run workflow
```
## Important Notes
### Platform Limitations
- **Conversion**: Only supported on Windows due to Microsoft Access ODBC driver requirements
- **SQLAlchemy-Access**: Depends on `pyodbc` and Win32 APIs
- **Recommended**: Use pre-built artifacts for non-Windows platforms
### Database Compatibility
- **Structure Preservation**: Maintains original Access database schema
- **Relationship Mapping**: Preserves table relationships where possible
- **Constraint Limitations**: Some referential integrity constraints may not be fully enforced due to cyclic dependencies
- **Data Currency**: Only current DPM release data is included, not historical versions
---
## Developer Guide
### Development Setup
```bash
# Clone the repository
git clone https://github.com/JimLundin/dpm-toolkit.git
cd dpm-toolkit
# Install UV package manager
pip install uv
# Install all dependencies
uv sync
# Install in development mode
uv pip install -e .
```
### Project Structure
DPM Toolkit uses a UV workspace with multiple subprojects:
```
dpm-toolkit/
├── src/dpm-toolkit/ # Main CLI package
├── projects/ # Workspace subprojects
│ ├── archive/ # Version management & downloads
│ ├── migrate/ # Access-to-SQLite conversion
│ ├── scrape/ # Web scraping for new versions
│ ├── schema/ # Python model generation
│ └── dpm2/ # Generated Python models package
├── .github/workflows/ # CI/CD automation
└── pyproject.toml # Workspace configuration
```
### Working with Subprojects
Each subproject is independently installable:
```bash
# Install specific subprojects
uv pip install -e projects/archive
uv pip install -e projects/migrate # Windows only
uv pip install -e projects/scrape
uv pip install -e projects/schema
```
### Code Quality
The project uses strict code quality tools:
```bash
# Run linting and formatting
ruff check --fix
ruff format
# Type checking
mypy src/
pyright src/
```
### Testing
```bash
# Run tests (when available)
uv run pytest
```
### Requirements
- **Python**: 3.13+
- **Package Manager**: UV (recommended) or pip
- **Platform**: Windows required for conversion functionality
- **Dependencies**: Microsoft Access ODBC driver (for conversion)
### Contributing
1. Fork the repository
2. Create a feature branch
3. Make your changes with tests
4. Ensure code quality checks pass
5. Submit a Pull Request
Contributions are welcome! Please ensure all code follows the project's quality standards and includes appropriate tests.
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
| text/markdown | Jim Lundin | Jim Lundin <jimeriklundin@gmail.com> | null | null | MIT License Copyright (c) 2025 Jim Lundin Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"archive",
"cyclopts>=3.1.0",
"analysis; extra == \"analysis\"",
"compare; extra == \"compare\"",
"migrate; extra == \"migrate\"",
"schema; extra == \"schema\"",
"scrape; extra == \"scrape\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:44:47.510609 | dpm_toolkit-2026.2.19-py3-none-any.whl | 10,999 | 31/c8/9dda608460bb9f8bfaa92e7a0623dcde55c6d0eb47e6193d9fe5d49306ea/dpm_toolkit-2026.2.19-py3-none-any.whl | py3 | bdist_wheel | null | false | 9b1b3238c20bab65980045d8758c2ae0 | c7dc75cd948a17ab063392fa7efd8ecfbb7ddf2030a2769087aea4fcf10315f4 | 31c89dda608460bb9f8bfaa92e7a0623dcde55c6d0eb47e6193d9fe5d49306ea | null | [] | 225 |
2.4 | taipanstack | 0.2.8 | TaipanStack - Modular, secure, and scalable Python stack for robust development | <div align="center">
# 🐍 TaipanStack
### **The Modern Python Foundation**
*Launch secure, high-performance Python applications in seconds.*
[](https://github.com/gabrielima7/TaipanStack/actions/workflows/ci.yml)
[](https://www.python.org/)
[](https://github.com/gabrielima7/TaipanStack)
[](https://github.com/astral-sh/ruff)
[](http://mypy-lang.org/)
[](LICENSE)
[](SECURITY.md)
[](https://pypi.org/project/taipanstack/)
---
[**Features**](#-features) • [**Quick Start**](#-quick-start) • [**Architecture**](#-architecture) • [**DevSecOps**](#-devsecops) • [**API**](#-api-highlights) • [**Contributing**](#-contributing)
</div>
---
## ✨ Why TaipanStack?
> **"Write less, build better."**
TaipanStack is a battle-tested foundation for production-grade Python projects that combines **security**, **performance**, and **developer experience** into a single, cohesive toolkit.
<table>
<tr>
<td width="50%">
### 🛡️ Security First
- Path traversal protection
- Command injection guards
- Input sanitizers & validators
- Secret detection integration
</td>
<td width="50%">
### ⚡ High Performance
- `uvloop` async event loop
- `orjson` fast JSON serialization
- `Pydantic v2` validation
- Optimized for production
</td>
</tr>
<tr>
<td width="50%">
### 🎯 Rust-Style Error Handling
- `Ok`/`Err` Result types
- Explicit error propagation
- Pattern matching support
- No silent failures
</td>
<td width="50%">
### 🔧 Developer Experience
- Pre-configured quality tools
- Comprehensive test suite
- Architecture enforcement
- Zero-config setup
</td>
</tr>
</table>
---
## 🚀 Quick Start
### Prerequisites
- **Python 3.11+** (supports 3.11, 3.12, 3.13, 3.14)
- **Poetry** ([install guide](https://python-poetry.org/docs/#installation))
### Installation
#### From PyPI
```bash
pip install taipanstack
```
#### From Source
```bash
# Clone the repository
git clone https://github.com/gabrielima7/TaipanStack.git
cd TaipanStack
# Install dependencies
poetry install --with dev
# Run quality checks
make all
```
### Verify Installation
```bash
# Run tests with coverage (97%+ coverage)
make test
# Check architecture contracts
make lint-imports
# Run security scans
make security
```
---
## 📐 Architecture
TaipanStack follows a clean, layered architecture with strict dependency rules enforced by **Import Linter**.
```
┌─────────────────────────────────────┐
│ Application │
│ (src/app/main.py) │
└─────────────────┬───────────────────┘
│
┌───────────────────────────┼───────────────────────────┐
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Security │ │ Config │ │ Utils │
│ guards, saniti- │ │ models, │ │ logging, retry │
│ zers, validators│ │ generators │ │ metrics, fs │
└────────┬────────┘ └────────┬────────┘ └────────┬────────┘
│ │ │
└─────────────────────────┼─────────────────────────┘
▼
┌─────────────────────────────────────┐
│ Core │
│ Result types, base patterns │
└─────────────────────────────────────┘
```
### Project Structure
```text
TaipanStack/
├── src/
│ ├── app/ # Application entry point
│ └── taipanstack/
│ ├── core/ # 🎯 Result types, functional patterns
│ ├── config/ # ⚙️ Configuration models & generators
│ ├── security/ # 🛡️ Guards, sanitizers, validators
│ └── utils/ # 🔧 Logging, metrics, retry, filesystem
├── tests/ # ✅ Comprehensive test suite (97%+ coverage)
├── pyapp/ # 📦 Standalone executable builder
├── .github/ # 🔄 CI/CD workflows
└── pyproject.toml # 📋 Modern dependency management
```
---
## 🔐 DevSecOps
TaipanStack integrates security and quality at every level:
| Category | Tools | Purpose |
|----------|-------|---------|
| **SAST** | Bandit, Semgrep | Static Application Security Testing |
| **SCA** | Safety | Dependency vulnerability scanning |
| **Types** | Mypy (strict) | Compile-time type checking |
| **Lint** | Ruff | Lightning-fast linting & formatting |
| **Arch** | Import Linter | Dependency rule enforcement |
| **Test** | Pytest, Hypothesis | Property-based testing |
### CI Pipeline
```yaml
# Runs on every push/PR
✓ Test Matrix → Python 3.11-3.14 × (Ubuntu, macOS, Windows)
✓ Linux Distros → Ubuntu, Debian, Fedora, openSUSE, Arch, Alpine
✓ Code Quality → Ruff check & format
✓ Type Check → Mypy strict mode
✓ Security → Bandit + Semgrep
✓ Architecture → Import Linter contracts
```
---
## 📚 API Highlights
### Result Types (Rust-Style Error Handling)
```python
from taipanstack.core.result import Result, Ok, Err, safe
@safe
def divide(a: int, b: int) -> float:
return a / b
# Explicit error handling with pattern matching
match divide(10, 0):
case Ok(value):
print(f"Result: {value}")
case Err(error):
print(f"Error: {error}")
```
### Security Guards
```python
from taipanstack.security.guards import guard_path_traversal, guard_command_injection
# Prevent path traversal attacks
safe_path = guard_path_traversal(user_input, base_dir="/app/data")
# Prevent command injection
safe_cmd = guard_command_injection(
["git", "clone", repo_url],
allowed_commands=["git"]
)
```
### Retry with Exponential Backoff
```python
from taipanstack.utils.retry import retry
@retry(max_attempts=3, on=(ConnectionError, TimeoutError))
async def fetch_data(url: str) -> dict:
return await http_client.get(url)
```
### Circuit Breaker
```python
from taipanstack.utils.circuit_breaker import circuit_breaker
@circuit_breaker(failure_threshold=5, timeout=30)
def call_external_service() -> Response:
return service.call()
```
---
## 🛠️ Tech Stack
<table>
<tr>
<th>Runtime</th>
<th>Quality</th>
<th>DevOps</th>
</tr>
<tr>
<td>
- Pydantic v2
- Orjson
- Uvloop
- Structlog
- Result
</td>
<td>
- Ruff
- Mypy
- Bandit
- Pytest
- Hypothesis
</td>
<td>
- GitHub Actions
- Dependabot
- Pre-commit
- Poetry
- Import Linter
</td>
</tr>
</table>
---
## 🤝 Contributing
Contributions are welcome! Please check our [Contributing Guide](CONTRIBUTING.md) for details on:
- 🐛 Bug reports
- ✨ Feature requests
- 📝 Documentation improvements
- 🔧 Pull requests
---
## 📝 License
This project is open-sourced under the [MIT License](LICENSE).
---
<div align="center">
**Made with ❤️ for the Python community**
[⬆ Back to Top](#-taipanstack)
</div>
| text/markdown | gabrielima7 | gabrielima.alu.lmb@gmail.com | null | null | MIT | security, devops, python, taipanstack, bootstrapper, quality | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: P... | [] | https://github.com/gabrielima7/TaipanStack | null | <4.0,>=3.11 | [] | [] | [] | [
"pydantic>=2.0",
"pydantic-settings>=2.0.0",
"orjson>=3.9.0",
"email-validator>=2.0.0",
"result>=0.17.0",
"uvloop>=0.19.0; sys_platform != \"win32\" and extra == \"runtime\"",
"structlog>=23.0.0; extra == \"runtime\""
] | [] | [] | [] | [
"Homepage, https://github.com/gabrielima7/TaipanStack",
"Repository, https://github.com/gabrielima7/TaipanStack",
"Documentation, https://github.com/gabrielima7/TaipanStack#readme",
"Changelog, https://github.com/gabrielima7/TaipanStack/blob/main/CHANGELOG.md",
"Issues, https://github.com/gabrielima7/Taipan... | poetry/2.2.1 CPython/3.12.3 Linux/6.17.0-14-generic | 2026-02-19T20:43:49.314482 | taipanstack-0.2.8.tar.gz | 43,646 | 13/c4/9cb4ae8d80658cf420b45f06f0b9fe91759d5210303d993c674d2068ebb4/taipanstack-0.2.8.tar.gz | source | sdist | null | false | a6fbcfe4b7b32e2c16c90805aa2b4e3c | 4ea485e29932ab7882f2b4ba019ceca72236c18e52cf36c9dafb44010cb9e46c | 13c49cb4ae8d80658cf420b45f06f0b9fe91759d5210303d993c674d2068ebb4 | null | [] | 214 |
2.4 | hwcomponents | 1.0.95 | Hardware Component Area, Energy, Latency, and Leak Power Models | # HWComponents
The HWComponents (Hardware Components) package, part of the
[CiMLoop](https://github.com/mit-emze/cimloop) project, provides an interface for the
estimation of area, energy, latency, and leak power of hardware components in hardware
architectures. Key features in HWComponents include:
[Information about the package is available on the hwcomponents website](https://accelergy-project.github.io/hwcomponents/).
## Citing HWComponents
If you use this package in your work, please cite the CiMLoop project:
```bibtex
@INPROCEEDINGS{cimloop,
author={Andrulis, Tanner and Emer, Joel S. and Sze, Vivienne},
booktitle={2024 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS)},
title={CiMLoop: A Flexible, Accurate, and Fast Compute-In-Memory Modeling Tool},
year={2024},
volume={},
number={},
pages={10-23},
keywords={Performance evaluation;Accuracy;Computational modeling;Computer architecture;Artificial neural networks;In-memory computing;Data models;Compute-In-Memory;Processing-In-Memory;Analog;Deep Neural Networks;Systems;Hardware;Modeling;Open-Source},
doi={10.1109/ISPASS61541.2024.00012}
}
```
| text/markdown | null | Tanner Andrulis <andrulis@mit.edu> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:43:30.801482 | hwcomponents-1.0.95.tar.gz | 38,528 | 92/92/8afc7bdcd3dd563f04d4232c08334a68f5a916cd7adeae7e587988308f8d/hwcomponents-1.0.95.tar.gz | source | sdist | null | false | fc7edddea2667696da66e1b3a403cae7 | 93192b26850e1bba65b1d0ba9b9a530c66f3fd8fed611eaeed7e16162f6df93d | 92928afc7bdcd3dd563f04d4232c08334a68f5a916cd7adeae7e587988308f8d | MIT | [] | 309 |
2.4 | hwcomponents-library | 1.0.46 | A library of hardware components for energy estimation. | # HWComponents-Library
HWComponents-Library contains a library of components from published works. It is
intended to be used to rapidly model prior works and to provide a common set of
components for comparison.
These models are for use with the HWComponents package, found at
https://accelergy-project.github.io/hwcomponents/.
## Installation
Install from PyPI:
```bash
pip install hwcomponents-library
# Check that the installation is successful
hwc --list | grep adder
```
## Contributing: Adding or Updating Numbers from Your Work
We would be happy to update these models given a pull request. Please see
"Creating Library Entries" and format your entries to match the existing
entries. If you have any questions, we would be happy to help.
Note that we will only accept entries that are published or backed by public
data. Citations are required for all entries.
## Citation
If you use this library in your work, please cite the following:
```bibtex
@inproceedings{cimloop,
author={Andrulis, Tanner and Emer, Joel S. and Sze, Vivienne},
booktitle={2024 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS)},
title={{CiMLoop}: A Flexible, Accurate, and Fast Compute-In-Memory Modeling Tool},
year={2024},
volume={},
number={},
pages={10-23},
keywords={Compute-In-Memory;Processing-In-Memory;Analog;Deep Neural Networks;Systems;Hardware;Modeling;Open-Source},
doi={10.1109/ISPASS61541.2024.00012}}
}
```
| text/markdown | null | Tanner Andrulis <Andrulis@Mit.edu> | null | null | null | hardware, components, energy, estimation | [
"Development Status :: 3 - Alpha",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering :: Electronic Design Automation (EDA)"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"hwcomponents",
"hwcomponents-cacti"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:43:29.635335 | hwcomponents_library-1.0.46.tar.gz | 19,899 | ac/7f/1388dcb9fac25f1f70378f5decb0d15ae594b614596a98b332c660cb52d6/hwcomponents_library-1.0.46.tar.gz | source | sdist | null | false | ba837653365dc8d5d24537d169e39943 | 6660c01845ef22409b71fc5a53a5be7ffdde81e7897dd04ad1abc8777730d363 | ac7f1388dcb9fac25f1f70378f5decb0d15ae594b614596a98b332c660cb52d6 | MIT | [] | 313 |
2.1 | odoo-addon-base-global-discount | 19.0.1.0.0.2 | Base Global Discount | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
====================
Base Global Discount
====================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:ae23d0a6e17a66d37c9c694933c2511f4b889b9ac5000d2d745f7e968f95d06a
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fserver--backend-lightgray.png?logo=github
:target: https://github.com/OCA/server-backend/tree/19.0/base_global_discount
:alt: OCA/server-backend
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/server-backend-19-0/server-backend-19-0-base_global_discount
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/server-backend&target_branch=19.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
Base module to have global discounts applied to either sales or
purchases. It doesn't do much for itself, so account_global_discount or
purchase_global_discount should be installed to benefit from it.
**Table of contents**
.. contents::
:local:
Configuration
=============
To use this module, you need to:
1. Go to *Settings > Users*, choose yours and set *Manage Global
Discounts*.
2. Go to *Settings > Parameters > Global Discounts*
3. Choose the discount scope (sales or purchases).
4. You can also restrict it to a certain company if needed.
Usage
=====
You can assign global discounts to partners as well. You'll need the
proper permission (*Manage Global Discounts*):
1. Go to a partner that is a company.
2. Go to the *Sales & Purchases* tab.
3. In section sale, you can set sale discounts.
4. In section purchase, you can set purchase discounts.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/server-backend/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/server-backend/issues/new?body=module:%20base_global_discount%0Aversion:%2019.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Tecnativa
Contributors
------------
- `Tecnativa <https://www.tecnativa.com>`__
- Pedro M. Baeza
- David Vidal
- Carlos Dauden
- Rafael Blasco
- Ernesto Tejeda
- Omar Castiñeira <omar@comunitea.com>
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/server-backend <https://github.com/OCA/server-backend/tree/19.0/base_global_discount>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Tecnativa, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 19.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/server-backend | null | null | [] | [] | [] | [
"odoo==19.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T20:42:58.516101 | odoo_addon_base_global_discount-19.0.1.0.0.2-py3-none-any.whl | 33,042 | 1f/ef/3987ab3e4e0193fb0245690d876bd03d01082f0d63fd3ece2155d99edcad/odoo_addon_base_global_discount-19.0.1.0.0.2-py3-none-any.whl | py3 | bdist_wheel | null | false | ce8f78a8a89cabdd7a08eb8c60bb397a | 7adfd8e4a7be3452f4a92ac858a2247538545745f7dc0c1df33bb7ad739e43a5 | 1fef3987ab3e4e0193fb0245690d876bd03d01082f0d63fd3ece2155d99edcad | null | [] | 99 |
2.4 | signalwire-agents | 1.0.19.dev39 | SignalWire AI Agents SDK | <!-- Header -->
<div align="center">
<a href="https://signalwire.com" target="_blank">
<img src="https://github.com/user-attachments/assets/0c8ed3b9-8c50-4dc6-9cc4-cc6cd137fd50" width="500" />
</a>
# Agents SDK
#### _A Python SDK for creating, hosting, and securing SignalWire AI agents as microservices with minimal boilerplate._
<br/>
<p align="center">
<a href="https://developer.signalwire.com/sdks/agents-sdk" target="_blank">📖 Documentation</a> <code>#</code>
<a href="https://github.com/signalwire/signalwire-docs/issues/new/choose" target="_blank">🐛 Report an issue</a> <code>#</code>
<a href="https://pypi.org/project/signalwire-agents/" target="_blank">🐍 PyPI</a>
</p>
<br/>
<!-- Badges -->
<div align="center">
<a href="https://discord.com/invite/F2WNYTNjuF" target="_blank"><img src="https://img.shields.io/badge/Discord%20Community-5865F2" alt="Discord" /></a>
<a href="LICENSE"><img src="https://img.shields.io/badge/MIT-License-blue" alt="MIT License" /></a>
<a href="https://github.com/signalwire" target="_blank"><img src="https://img.shields.io/badge/GitHub-%23121011.svg?logo=github&logoColor=white&" alt="GitHub" /></a>
<a href="https://github.com/signalwire/docs" target="_blank"><img src="https://img.shields.io/github/stars/signalwire/signalwire-agents" alt="GitHub Stars" /></a>
</div>
<br/>
<a href="https://signalwire.com/signup" target="_blank">
<img src="https://github.com/user-attachments/assets/c2510c86-ae03-42a9-be06-ab9bcea948e1" alt="Sign Up" height="65"/>
</a>
</div>
## Features
| | |
|-------------------------------|:-----------------------------------------------------------------------------:|
| 🤖 **Self-Contained Agents** | Each agent is both a web app and an AI persona |
| 📝 **Prompt Object Model** | Structured prompt composition using POM |
| ⚙️ **SWAIG Integration** | Easily define and handle AI tools/functions |
| 🔧 **Dynamic Configuration** | Configure agents per-request for multi-tenant apps and personalization |
| 🗺️ **Custom Routing** | Dynamic request handling for different paths and content |
| 📞 **SIP Integration** | Route SIP calls to agents based on SIP usernames |
| 🔒 **Security Built-In** | Session management, function-specific security tokens, and basic auth |
| 💾 **State Management** | Persistent conversation state with automatic tracking |
| 🏗️ **Prefab Archetypes** | Ready-to-use agent types for common scenarios |
| 🏢 **Multi-Agent Support** | Host multiple agents on a single server |
| � **Modular Skills System** | Add capabilities to agents with simple one-liner calls |
| 🔍 **Local Search System** | Offline document search with vector similarity and keyword search |
## Installation
### Basic Installation
```bash
pip install signalwire-agents
```
### Optional Search Functionality
The SDK includes optional local search capabilities that can be installed separately to avoid adding large dependencies to the base installation:
#### Search Installation Options
```bash
# Query existing .swsearch files only (smallest footprint)
pip install signalwire-agents[search-queryonly]
# Basic search (vector search + keyword search + building indexes)
pip install signalwire-agents[search]
# Full search with document processing (PDF, DOCX, etc.)
pip install signalwire-agents[search-full]
# Advanced NLP features (includes spaCy)
pip install signalwire-agents[search-nlp]
# All search features
pip install signalwire-agents[search-all]
```
#### What Each Option Includes
| Option | Size | Features |
|--------|------|----------|
| `search-queryonly` | ~400MB | Query existing .swsearch files only (no building/processing) |
| `search` | ~500MB | Vector embeddings, keyword search, basic text processing |
| `search-full` | ~600MB | + PDF, DOCX, Excel, PowerPoint, HTML, Markdown processing |
| `search-nlp` | ~600MB | + Advanced spaCy NLP features |
| `search-all` | ~700MB | All search features combined |
**When to use `search-queryonly`:**
- Production containers with pre-built `.swsearch` files
- Lambda/serverless deployments
- Agents that only need to query knowledge bases (not build them)
- Smaller deployment footprint requirements
#### Search Features
- **Local/Offline Search**: No external API dependencies
- **Hybrid Search**: Vector similarity + keyword search
- **Smart Document Processing**: Markdown, Python, PDF, DOCX, etc.
- **Multiple Languages**: English, Spanish, with extensible framework
- **CLI Tools**: Build search indexes from document directories
- **HTTP API**: Standalone or embedded search service
#### Usage Example
```python
# Only available with search extras installed
from signalwire_agents.search import IndexBuilder, SearchEngine
# Build search index
builder = IndexBuilder()
builder.build_index(
source_dir="./docs",
output_file="knowledge.swsearch",
file_types=['md', 'txt', 'pdf']
)
# Search documents
engine = SearchEngine("knowledge.swsearch")
results = engine.search(
query_vector=embeddings,
enhanced_text="search query",
count=5
)
```
<details>
<summary><h2>Documentation</h2></summary>
### Skills System
The SignalWire Agents SDK includes a powerful modular skills system that allows you to add complex capabilities to your agents with simple one-liner calls:
```python
from signalwire_agents import AgentBase
# Create an agent
agent = AgentBase("My Assistant", route="/assistant")
# Add skills with one-liners
agent.add_skill("web_search", {
"api_key": "your-google-api-key",
"search_engine_id": "your-search-engine-id"
}) # Web search capability
agent.add_skill("datetime") # Current date/time info
agent.add_skill("math") # Mathematical calculations
# Configure skills with parameters
agent.add_skill("web_search", {
"api_key": "your-google-api-key",
"search_engine_id": "your-search-engine-id",
"num_results": 1, # Get 1 search results
"no_results_message": "Sorry, I couldn't find anything about '{query}'. Try rephrasing your question."
})
# Advanced: Customize SWAIG function properties
agent.add_skill("math", {
"swaig_fields": {
"secure": False, # Override security settings
"fillers": {"en-US": ["Calculating..."]} # Custom filler phrases
}
})
# Multiple web search instances with different tool names
agent.add_skill("web_search", {
"api_key": "your-google-api-key",
"search_engine_id": "general-search-engine-id",
"tool_name": "search_general", # Creates search_general tool
"num_results": 1
})
agent.add_skill("web_search", {
"api_key": "your-google-api-key",
"search_engine_id": "news-search-engine-id",
"tool_name": "search_news", # Creates search_news tool
"num_results": 3,
"delay": 0.5
})
# Multiple DataSphere instances with different tool names
agent.add_skill("datasphere", {
"space_name": "my-space",
"project_id": "my-project",
"token": "my-token",
"document_id": "drinks-doc",
"tool_name": "search_drinks", # Creates search_drinks tool
"count": 2
})
agent.add_skill("datasphere", {
"space_name": "my-space",
"project_id": "my-project",
"token": "my-token",
"document_id": "food-doc",
"tool_name": "search_recipes", # Creates search_recipes tool
"tags": ["Food", "Recipes"]
})
agent.serve()
```
#### Available Built-in Skills
- **web_search**: Google Custom Search API integration with web scraping (supports multiple instances)
- **datetime**: Current date and time with timezone support
- **math**: Safe mathematical expression evaluation
- **datasphere**: SignalWire DataSphere knowledge search (supports multiple instances)
- **native_vector_search**: Offline document search with vector similarity and keyword search
#### Benefits
- **One-liner integration**: `agent.add_skill("skill_name")`
- **Configurable parameters**: `agent.add_skill("skill_name", {"param": "value"})`
- **Automatic discovery**: Skills are automatically found from the skills directory
- **Dependency validation**: Clear error messages for missing requirements
- **Modular architecture**: Skills are self-contained and reusable
For detailed documentation, see [Skills System README](docs/skills_system.md).
### DataMap Tools
The SDK provides a DataMap system for creating SWAIG tools that integrate directly with REST APIs without requiring custom webhook endpoints. DataMap tools execute on the SignalWire server, making them simpler to deploy than traditional webhook-based tools.
#### Basic DataMap Usage
```python
from signalwire_agents import AgentBase
from signalwire_agents.core.data_map import DataMap
from signalwire_agents.core.function_result import SwaigFunctionResult
class APIAgent(AgentBase):
def __init__(self):
super().__init__(name="api-agent", route="/api")
# Create a simple weather API tool
weather_tool = (DataMap('get_weather')
.description('Get current weather information')
.parameter('location', 'string', 'City name', required=True)
.webhook('GET', 'https://api.weather.com/v1/current?key=YOUR_API_KEY&q=${location}')
.output(SwaigFunctionResult('Weather in ${location}: ${response.current.condition.text}, ${response.current.temp_f}°F'))
)
# Register the tool with the agent
self.register_swaig_function(weather_tool.to_swaig_function())
agent = APIAgent()
agent.serve()
```
#### Advanced DataMap Examples
```python
# POST API with authentication
search_tool = (DataMap('search_knowledge')
.description('Search company knowledge base')
.parameter('query', 'string', 'Search query', required=True)
.webhook('POST', 'https://api.company.com/search',
headers={'Authorization': 'Bearer YOUR_TOKEN'})
.body({'query': '${query}', 'limit': 3})
.output(SwaigFunctionResult('Found: ${response.title} - ${response.summary}'))
)
# Expression-based tools (no API calls)
control_tool = (DataMap('file_control')
.description('Control file playback')
.parameter('command', 'string', 'Playback command')
.parameter('filename', 'string', 'File to control', required=False)
.expression(r'start.*', SwaigFunctionResult().add_action('start_playback', {'file': '${args.filename}'}))
.expression(r'stop.*', SwaigFunctionResult().add_action('stop_playback', True))
)
# Process API response arrays
docs_tool = (DataMap('get_latest_docs')
.description('Get latest documentation')
.webhook('GET', 'https://api.docs.com/latest')
.foreach('${response.documents}')
.output(SwaigFunctionResult('Document: ${foreach.title} (${foreach.updated_date})'))
)
```
#### Helper Functions
For simpler use cases, use the convenience functions:
```python
from signalwire_agents.core.data_map import create_simple_api_tool, create_expression_tool
# Simple API tool
weather = create_simple_api_tool(
name='get_weather',
url='https://api.weather.com/v1/current?key=API_KEY&q=${location}',
response_template='Weather in ${location}: ${response.current.condition.text}',
parameters={'location': {'type': 'string', 'description': 'City name', 'required': True}}
)
# Expression-based tool
file_control = create_expression_tool(
name='file_control',
patterns={
r'start.*': SwaigFunctionResult().add_action('start_playback', {'file': '${args.filename}'}),
r'stop.*': SwaigFunctionResult().add_action('stop_playback', True)
},
parameters={'command': {'type': 'string', 'description': 'Playback command'}}
)
# Register with agent
self.register_swaig_function(weather.to_swaig_function())
self.register_swaig_function(file_control.to_swaig_function())
```
#### Variable Expansion
DataMap tools support powerful variable expansion using `${variable}` syntax:
- **Function arguments**: `${args.parameter_name}`
- **API responses**: `${response.field.nested_field}`
- **Array processing**: `${foreach.item_field}` (when using foreach)
- **Global data**: `${global_data.key}`
- **Metadata**: `${meta_data.call_id}`
#### Benefits of DataMap Tools
- **No webhook infrastructure**: Tools run on SignalWire servers
- **Simplified deployment**: No need to expose endpoints
- **Built-in authentication**: Support for API keys, Bearer tokens, Basic auth
- **Response processing**: Built-in JSON path traversal and array iteration
- **Error handling**: Automatic error detection with `error_keys`
- **Pattern matching**: Expression-based responses without API calls
For detailed documentation, see [DataMap Guide](docs/datamap_guide.md).
### Contexts and Steps
The SignalWire Agents SDK provides a powerful enhancement to traditional prompts through the **Contexts and Steps** system. This feature allows you to add structured, workflow-driven AI interactions on top of your base prompt, with explicit navigation control and step-by-step guidance.
#### Why Use Contexts and Steps?
- **Structured Workflows**: Define clear, step-by-step processes for complex interactions
- **Navigation Control**: Explicitly control which steps or contexts users can access
- **Completion Criteria**: Set specific criteria for step completion and progression
- **Function Restrictions**: Limit which AI tools are available in each step
- **Workflow Isolation**: Create separate contexts for different conversation flows
- **Enhanced Base Prompts**: Adds structured workflows on top of your existing prompt foundation
#### Basic Usage
```python
from signalwire_agents import AgentBase
class WorkflowAgent(AgentBase):
def __init__(self):
super().__init__(name="Workflow Assistant", route="/workflow")
# Set base prompt (required even when using contexts)
self.prompt_add_section("Role", "You are a helpful workflow assistant.")
self.prompt_add_section("Instructions", "Guide users through structured processes step by step.")
# Define contexts and steps (adds structured workflow to base prompt)
contexts = self.define_contexts()
# Create a single context named "default" (required for single context)
context = contexts.add_context("default")
# Add step-by-step workflow
context.add_step("greeting") \
.set_text("Welcome! I'm here to help you complete your application. Let's start with your personal information.") \
.set_step_criteria("User has provided their name and confirmed they want to continue") \
.set_valid_steps(["personal_info"]) # Can only go to personal_info step
context.add_step("personal_info") \
.add_section("Instructions", "Collect the user's personal information") \
.add_bullets(["Ask for full name", "Ask for email address", "Ask for phone number"]) \
.set_step_criteria("All personal information has been collected and confirmed") \
.set_valid_steps(["review", "personal_info"]) # Can stay or move to review
context.add_step("review") \
.set_text("Let me review the information you've provided. Please confirm if everything is correct.") \
.set_step_criteria("User has confirmed or requested changes") \
.set_valid_steps(["personal_info", "complete"]) # Can go back or complete
context.add_step("complete") \
.set_text("Thank you! Your application has been submitted successfully.") \
.set_step_criteria("Application processing is complete")
# No valid_steps = end of workflow
agent = WorkflowAgent()
agent.serve()
```
#### Advanced Features
```python
class MultiContextAgent(AgentBase):
def __init__(self):
super().__init__(name="Multi-Context Agent", route="/multi-context")
# Set base prompt (required)
self.prompt_add_section("Role", "You are a versatile AI assistant.")
self.prompt_add_section("Capabilities", "You can help with calculations and provide time information.")
# Add skills
self.add_skill("datetime")
self.add_skill("math")
# Define contexts for different service modes
contexts = self.define_contexts()
# Main conversation context
main_context = contexts.add_context("main")
main_context.add_step("welcome") \
.set_text("Welcome! I can help with calculations or provide date/time info. What would you like to do?") \
.set_step_criteria("User has chosen a service type") \
.set_valid_contexts(["calculator", "datetime_info"]) # Can switch contexts
# Calculator context with function restrictions
calc_context = contexts.add_context("calculator")
calc_context.add_step("math_mode") \
.add_section("Role", "You are a mathematical assistant") \
.add_section("Instructions", "Help users with calculations") \
.set_functions(["math"]) # Only math function available \
.set_step_criteria("Calculation is complete") \
.set_valid_contexts(["main"]) # Can return to main
# DateTime context
datetime_context = contexts.add_context("datetime_info")
datetime_context.add_step("time_mode") \
.set_text("I can provide current date and time information. What would you like to know?") \
.set_functions(["datetime"]) # Only datetime function available \
.set_step_criteria("Date/time information has been provided") \
.set_valid_contexts(["main"]) # Can return to main
```
#### Context and Step Methods
##### Context Methods
- `add_step(name)`: Create a new step in this context
- `set_valid_contexts(contexts)`: Control which contexts can be accessed from this context
##### Step Methods
- `set_text(text)`: Set direct text prompt for the step
- `add_section(title, body)`: Add POM-style section (alternative to set_text)
- `add_bullets(bullets)`: Add bullet points to the current or last section
- `set_step_criteria(criteria)`: Define completion criteria for this step
- `set_functions(functions)`: Restrict available functions ("none" or array of function names)
- `set_valid_steps(steps)`: Control navigation to other steps in same context
- `set_valid_contexts(contexts)`: Control navigation to other contexts
#### Navigation Rules
- **Valid Steps**: If omitted, only "next" step is implied. If specified, only those steps are allowed.
- **Valid Contexts**: If omitted, user is trapped in current context. If specified, can navigate to those contexts.
- **Single Context**: Must be named "default" for single-context workflows.
- **Function Restrictions**: Use `set_functions(["function_name"])` or `set_functions("none")` to control AI tool access.
#### Complete Example: Customer Support Workflow
```python
class SupportAgent(AgentBase):
def __init__(self):
super().__init__(name="Customer Support", route="/support")
# Set base prompt (required)
self.prompt_add_section("Role", "You are a professional customer support representative.")
self.prompt_add_section("Goal", "Provide excellent customer service using structured workflows.")
# Add skills for enhanced capabilities
self.add_skill("datetime")
self.add_skill("web_search", {"api_key": "your-key", "search_engine_id": "your-id"})
# Define support workflow contexts
contexts = self.define_contexts()
# Triage context
triage = contexts.add_context("triage")
triage.add_step("initial_greeting") \
.add_section("Current Task", "Understand the customer's issue and route them appropriately") \
.add_bullets("Questions to Ask", ["What problem are you experiencing?", "How urgent is this issue?", "Have you tried any troubleshooting steps?"]) \
.set_step_criteria("Issue type has been identified") \
.set_valid_contexts(["technical_support", "billing_support", "general_inquiry"])
# Technical support context
tech = contexts.add_context("technical_support")
tech.add_step("technical_diagnosis") \
.add_section("Current Task", "Help diagnose and resolve technical issues") \
.add_section("Available Tools", "Use web search to find solutions and datetime to check service windows") \
.set_functions(["web_search", "datetime"]) # Can search for solutions and check times \
.set_step_criteria("Technical issue is resolved or escalated") \
.set_valid_contexts(["triage"]) # Can return to triage
# Billing support context
billing = contexts.add_context("billing_support")
billing.add_step("billing_assistance") \
.set_text("I'll help you with your billing inquiry. Please provide your account details.") \
.set_functions("none") # No external tools for sensitive billing info \
.set_step_criteria("Billing issue is addressed") \
.set_valid_contexts(["triage"])
# General inquiry context
general = contexts.add_context("general_inquiry")
general.add_step("general_help") \
.set_text("I'm here to help with general questions. What can I assist you with?") \
.set_functions(["web_search", "datetime"]) # Full access to search and time \
.set_step_criteria("Inquiry has been answered") \
.set_valid_contexts(["triage"])
agent = SupportAgent()
agent.serve()
```
#### Benefits
- **Clear Structure**: Explicit workflow definition makes agent behavior predictable
- **Enhanced Control**: Fine-grained control over function access and navigation
- **Improved UX**: Users understand where they are in the process and what's expected
- **Debugging**: Easy to trace and debug workflow issues
- **Scalability**: Complex multi-step processes are easier to maintain
For detailed documentation and advanced examples, see [Contexts and Steps Guide](docs/contexts_guide.md).
### Quick Start
```python
from signalwire_agents import AgentBase
from signalwire_agents.core.function_result import SwaigFunctionResult
class SimpleAgent(AgentBase):
def __init__(self):
super().__init__(name="simple", route="/simple")
# Configure the agent's personality
self.prompt_add_section("Personality", body="You are a helpful assistant.")
self.prompt_add_section("Goal", body="Help users with basic questions.")
self.prompt_add_section("Instructions", bullets=["Be concise and clear."])
# Note: Use prompt_add_section() for all prompt configuration
@AgentBase.tool(
name="get_time",
description="Get the current time",
parameters={}
)
def get_time(self, args, raw_data):
from datetime import datetime
now = datetime.now().strftime("%H:%M:%S")
return SwaigFunctionResult(f"The current time is {now}")
# Run the agent
if __name__ == "__main__":
agent = SimpleAgent()
agent.serve(host="0.0.0.0", port=8000)
```
### Customizing LLM Parameters
The SDK allows you to customize LLM parameters for both the main prompt and post-prompt, giving you fine control over the AI's behavior:
```python
from signalwire_agents import AgentBase
class PreciseAgent(AgentBase):
def __init__(self):
super().__init__(name="precise", route="/precise")
# Configure the agent's personality
self.prompt_add_section("Role", "You are a precise technical assistant.")
self.prompt_add_section("Instructions", "Provide accurate, detailed information.")
# Set custom LLM parameters for the main prompt
# These parameters are passed to the server which validates them based on the model
self.set_prompt_llm_params(
temperature=0.3, # Low temperature for more consistent responses
top_p=0.9, # Slightly reduced for focused responses
barge_confidence=0.7, # Moderate interruption threshold
presence_penalty=0.1, # Slight penalty for repetition
frequency_penalty=0.2 # Encourage varied vocabulary
)
# Set post-prompt for summaries
self.set_post_prompt("Provide a concise summary of the key points discussed.")
# Different parameters for post-prompt (summaries should be even more focused)
self.set_post_prompt_llm_params(
temperature=0.2, # Very low for consistent summaries
top_p=0.85 # More focused token selection
)
agent = PreciseAgent()
agent.serve()
```
#### Common LLM Parameters
The SDK accepts any parameters which are passed to the server for validation based on the model. Common parameters include:
- **temperature**: Controls randomness. Lower = more focused, higher = more creative
- **top_p**: Nucleus sampling. Lower = more focused on likely tokens
- **barge_confidence**: ASR confidence to interrupt. Higher = harder to interrupt (main prompt only)
- **presence_penalty**: Topic diversity. Positive = new topics
- **frequency_penalty**: Repetition control. Positive = varied vocabulary
Note: No defaults are sent unless explicitly set. The server handles validation and applies appropriate defaults based on the model.
For more details on LLM parameter tuning, see [LLM Parameters Guide](docs/llm_parameters.md).
### Using Prefab Agents
```python
from signalwire_agents.prefabs import InfoGathererAgent
agent = InfoGathererAgent(
fields=[
{"name": "full_name", "prompt": "What is your full name?"},
{"name": "reason", "prompt": "How can I help you today?"}
],
confirmation_template="Thanks {full_name}, I'll help you with {reason}.",
name="info-gatherer",
route="/info-gatherer"
)
agent.serve(host="0.0.0.0", port=8000)
```
Available prefabs include:
- `InfoGathererAgent`: Collects structured information from users
- `FAQBotAgent`: Answers questions based on a knowledge base
- `ConciergeAgent`: Routes users to specialized agents
- `SurveyAgent`: Conducts structured surveys with questions and rating scales
- `ReceptionistAgent`: Greets callers and transfers them to appropriate departments
### Dynamic Agent Configuration
Configure agents dynamically based on request parameters for multi-tenant applications, A/B testing, and personalization.
#### Static vs Dynamic Configuration
- **Static**: Agent configured once at startup (traditional approach)
- **Dynamic**: Agent configured fresh for each request based on parameters
#### Basic Example
```python
from signalwire_agents import AgentBase
class DynamicAgent(AgentBase):
def __init__(self):
super().__init__(name="dynamic-agent", route="/dynamic")
# Set up dynamic configuration callback
self.set_dynamic_config_callback(self.configure_per_request)
def configure_per_request(self, query_params, body_params, headers, agent):
"""Configure agent based on request parameters"""
# Extract parameters from request
tier = query_params.get('tier', 'standard')
language = query_params.get('language', 'en')
customer_id = query_params.get('customer_id')
# Configure voice and language
if language == 'es':
agent.add_language("Spanish", "es-ES", "rime.spore:mistv2")
else:
agent.add_language("English", "en-US", "rime.spore:mistv2")
# Configure based on service tier
if tier == 'premium':
agent.set_params({"end_of_speech_timeout": 300}) # Faster response
agent.prompt_add_section("Service Level", "You provide premium support.")
else:
agent.set_params({"end_of_speech_timeout": 500}) # Standard response
agent.prompt_add_section("Service Level", "You provide standard support.")
# Personalize with customer data
global_data = {"tier": tier, "language": language}
if customer_id:
global_data["customer_id"] = customer_id
agent.set_global_data(global_data)
# Usage examples:
# curl "http://localhost:3000/dynamic?tier=premium&language=es&customer_id=123"
# curl "http://localhost:3000/dynamic?tier=standard&language=en"
```
#### Use Cases
- **Multi-tenant SaaS**: Different configurations per customer/organization
- **A/B Testing**: Test different agent behaviors with different user groups
- **Personalization**: Customize voice, prompts, and behavior per user
- **Localization**: Language and cultural adaptation based on user location
- **Dynamic Pricing**: Adjust features and capabilities based on subscription tiers
#### Preserving Dynamic State in SWAIG Callbacks
When using dynamic configuration to add skills or tools based on request parameters, there's a challenge: SWAIG webhook callbacks are separate HTTP requests that won't have the original query parameters. The SDK provides `add_swaig_query_params()` to solve this:
```python
class DynamicAgent(AgentBase):
def __init__(self):
super().__init__(name="dynamic-agent", route="/agent")
self.set_dynamic_config_callback(self.configure_per_request)
def configure_per_request(self, query_params, body_params, headers, agent):
tier = query_params.get('tier', 'basic')
region = query_params.get('region', 'us-east')
if tier == 'premium':
# Add premium skills dynamically
agent.add_skill('advanced_search', {
'api_key': 'your-api-key',
'num_results': 5
})
# IMPORTANT: Preserve parameters for SWAIG callbacks
agent.add_swaig_query_params({
'tier': tier,
'region': region
})
# Now when SignalWire calls the SWAIG webhook, these params
# will be included, triggering the same dynamic configuration
# Initial request: GET /agent?tier=premium®ion=eu-west
# SWAIG callback: POST /swaig/?tier=premium®ion=eu-west
# Result: Premium skills are available in both requests!
```
**Key Points:**
- **Problem**: Dynamically added skills/tools won't exist during SWAIG callbacks without the original request parameters
- **Solution**: Use `add_swaig_query_params()` to include critical parameters in all SWAIG webhook URLs
- **Clear State**: Use `clear_swaig_query_params()` if needed to reset parameters between requests
- **Token Safety**: The SDK automatically renames security tokens from `token` to `__token` to avoid parameter collisions
This ensures that any dynamic configuration based on request parameters is consistently applied across the initial SWML request and all subsequent SWAIG function callbacks.
For detailed documentation and advanced examples, see the [Agent Guide](docs/agent_guide.md#dynamic-agent-configuration).
### Configuration
#### Environment Variables
The SDK supports the following environment variables:
- `SWML_BASIC_AUTH_USER`: Username for basic auth (default: auto-generated)
- `SWML_BASIC_AUTH_PASSWORD`: Password for basic auth (default: auto-generated)
- `SWML_PROXY_URL_BASE`: Base URL to use when behind a reverse proxy, used for constructing webhook URLs
- `SWML_SSL_ENABLED`: Enable HTTPS/SSL support (values: "true", "1", "yes")
- `SWML_SSL_CERT_PATH`: Path to SSL certificate file
- `SWML_SSL_KEY_PATH`: Path to SSL private key file
- `SWML_DOMAIN`: Domain name for SSL certificate and external URLs
- `SWML_SCHEMA_PATH`: Optional path to override the location of the schema.json file
When the auth environment variables are set, they will be used for all agents instead of generating random credentials. The proxy URL base is useful when your service is behind a reverse proxy or when you need external services to access your webhooks.
To enable HTTPS directly (without a reverse proxy), set `SWML_SSL_ENABLED` to "true", provide valid paths to your certificate and key files, and specify your domain name.
### Testing
The SDK includes powerful CLI tools for development and testing:
- **`swaig-test`**: Comprehensive local testing and serverless environment simulation
- **`sw-search`**: Build local search indexes from document directories and search within them
#### Local Testing with swaig-test
Test your agents locally without deployment:
```bash
# Install the SDK
pip install -e .
# Discover agents in a file
swaig-test examples/my_agent.py
# List available functions
swaig-test examples/my_agent.py --list-tools
# Test SWAIG functions with CLI syntax
swaig-test examples/my_agent.py --exec get_weather --location "New York"
# Multi-agent support
swaig-test examples/multi_agent.py --route /agent-path --list-tools
swaig-test examples/multi_agent.py --agent-class AgentName --exec function_name
# Generate and inspect SWML documents
swaig-test examples/my_agent.py --dump-swml
swaig-test examples/my_agent.py --dump-swml --raw | jq '.'
```
#### Serverless Environment Simulation
Test your agents in simulated serverless environments without deployment:
```bash
# Test in AWS Lambda environment
swaig-test examples/my_agent.py --simulate-serverless lambda --dump-swml
# Test Lambda function execution with proper response format
swaig-test examples/my_agent.py --simulate-serverless lambda \
--exec get_weather --location "Miami" --full-request
# Test with custom Lambda configuration
swaig-test examples/my_agent.py --simulate-serverless lambda \
--aws-function-name my-production-function \
--aws-region us-west-2 \
--exec my_function --param value
# Test CGI environment
swaig-test examples/my_agent.py --simulate-serverless cgi \
--cgi-host my-server.com --cgi-https --dump-swml
# Test Google Cloud Functions
swaig-test examples/my_agent.py --simulate-serverless cloud_function \
--gcp-function-url https://my-function.cloudfunctions.net \
--exec my_function
# Test Azure Functions
swaig-test examples/my_agent.py --simulate-serverless azure_function \
--azure-function-url https://my-function.azurewebsites.net \
--exec my_function
```
#### Environment Management
Use environment files for consistent testing across platforms:
```bash
# Create environment file
cat > production.env << EOF
AWS_LAMBDA_FUNCTION_NAME=prod-my-agent
AWS_REGION=us-east-1
API_KEY=prod_api_key_123
DEBUG=false
EOF
# Test with environment file
swaig-test examples/my_agent.py --simulate-serverless lambda \
--env-file production.env --exec my_function
# Override specific variables
swaig-test examples/my_agent.py --simulate-serverless lambda \
--env-file production.env --env DEBUG=true --dump-swml
```
#### Cross-Platform Testing
Test the same agent across multiple serverless platforms:
```bash
# Test across all platforms
for platform in lambda cgi cloud_function azure_function; do
echo "Testing $platform..."
swaig-test examples/my_agent.py --simulate-serverless $platform \
--exec my_function --param value
done
# Compare webhook URLs across platforms
swaig-test examples/my_agent.py --simulate-serverless lambda --dump-swml | grep web_hook_url
swaig-test examples/my_agent.py --simulate-serverless cgi --cgi-host example.com --dump-swml | grep web_hook_url
```
#### Key Benefits
- **No Deployment Required**: Test serverless behavior locally
- **Environment Simulation**: Complete platform-specific environment variable setup
- **URL Generation**: Verify webhook URLs are generated correctly for each platform
- **Function Execution**: Test with platform-specific request/response formats
- **Environment Files**: Reusable configurations for different stages
- **Multi-Platform**: Test Lambda, CGI, Cloud Functions, and Azure Functions
For detailed testing documentation, see the [CLI Testing Guide](docs/cli_testing_guide.md).
### Documentation
The package includes comprehensive documentation in the `docs/` directory:
- [Agent Guide](docs/agent_guide.md) - Detailed guide to creating and customizing agents, including dynamic configuration
- [Architecture](docs/architecture.md) - Overview of the SDK architecture and core concepts
- [SWML Service Guide](docs/swml_service_guide.md) - Guide to the underlying SWML service
- [Local Search System](docs/search-system.md) - Complete guide to the local search system with vector similarity and keyword search
- [Skills System](docs/skills_system.md) - Detailed documentation on the modular skills system
- [CLI Tools](docs/cli.md) - Command-line interface tools for development and testing
These documents provide in-depth explanations of the features, APIs, and usage patterns.
</details
### ***[Read the official docs.](https://developer.signalwire.com/sdks/agents-sdk)***
---
## License
MIT
| text/markdown | null | SignalWire Team <info@signalwire.com> | null | null | MIT | signalwire, ai, agents, voice, telephony, swaig, swml | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"fastapi>=0.115.12",
"pydantic>=2.11.4",
"PyYAML>=6.0.2",
"Requests>=2.32.3",
"setuptools<81,>=66.1.1",
"signalwire_pom>=2.7.1",
"structlog>=25.3.0",
"uvicorn>=0.34.2",
"beautifulsoup4>=4.12.3",
"pytz>=2023.3",
"lxml>=4.9.0",
"jsonschema-rs>=0.20.0",
"numpy>=1.24.0; extra == \"search-queryon... | [] | [] | [] | [
"Homepage, https://github.com/signalwire/signalwire-agents"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T20:40:34.837812 | signalwire_agents-1.0.19.dev39.tar.gz | 458,675 | 2d/62/af47339952cb8f5e08d56d17a4e7f12daf5b5f37c21fc1d6d4754faf28a2/signalwire_agents-1.0.19.dev39.tar.gz | source | sdist | null | false | db2ca739591f1f080422d116b50faca7 | 3c71edcc46c2a85fe0ddc286c53da4adc1074ea1a6d5ae5b48d80d939160362c | 2d62af47339952cb8f5e08d56d17a4e7f12daf5b5f37c21fc1d6d4754faf28a2 | null | [
"LICENSE"
] | 187 |
2.4 | openreview-py | 1.57.1 | OpenReview API Python client library | OpenReview Python library
=========================
[](https://circleci.com/gh/openreview/openreview-py)
[](https://openreview-py.readthedocs.io/en/latest/?badge=latest)
[](https://codecov.io/gh/openreview/openreview-py)
Prerequisites
-------------
Python 3.9 or newer is required to use openreview-py.
Installation
------------
There are two ways to install the OpenReview python library.
Using `pip`:
```bash
pip install openreview-py
```
From the repository:
```bash
git clone https://github.com/openreview/openreview-py.git
cd openreview-py
pip install -e .
```
> Note: Depending on your Python installation you may need to use the command `pip3` instead of `pip`.
Usage
-----
The openreview-py library can be used to easily access and modify any data stored in the OpenReview system.
For more information, see [the official reference](https://openreview-py.readthedocs.io/en/latest/).
You can also check the [OpenReview docs](https://docs.openreview.net/getting-started/using-the-api/installing-and-instantiating-the-python-client) for examples and How-To Guides
Test Setup
----------
Running the openreview-py test suite requires some initial setup. First, the OpenReview API V1, OpenReview API V2 and OpenReview Web frontend must be cloned and configured to run on ports 3000, 3001 and 3030 respectively. For more information on how to install and configure those services see the README for each project:
- [OpenReview API V1](https://github.com/openreview/openreview-api-v1)
- [OpenReview API V2](https://github.com/openreview/openreview-api)
- [OpenReview Web](https://github.com/openreview/openreview-web)
Next, `pytest` along with `pytest-selenium` and `pytest-cov` have to be installed. These packages can be installed with `pip`:
```bash
pip install pytest pytest-selenium pytest-cov
```
Finally, you must download the proper Firefox Selenium driver for your OS [from GitHub](https://github.com/mozilla/geckodriver/releases), and place the `geckodriver` executable in the directory `openreview-py/tests/drivers`. When you are done your folder structure should look like this:
```bash
├── openreview-py
│ ├── tests
│ │ ├── data
│ │ ├── drivers
│ │ │ └── geckodriver
```
Run Tests
---------
Once the test setup above is complete you should be ready to run the test suite. To do so, start both OpenReview API versions running:
Inside the OpenReview API V1 directory
```bash
npm run cleanStart
```
Inside the OpenReview API V2 directory
```bash
npm run cleanStart
```
Inside the OpenReview Web directory
```bash
SUPER_USER=openreview.net npm run dev
```
Once all three services are running, start the tests:
```bash
pytest
```
> Note: If you have previously set environment variables with your OpenReview credentials, make sure to clear them before running the tests: `unset OPENREVIEW_USERNAME && unset OPENREVIEW_PASSWORD`
To run a single set of tests from a file, you can include the file name as an argument. For example:
```bash
pytest tests/test_double_blind_conference.py
```
| text/markdown | null | OpenReview Team <info@openreview.net> | null | null | MIT | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"pycryptodome",
"requests>=2.18.4",
"future",
"tqdm",
"Deprecated",
"pylatexenc",
"tld>=0.12",
"pyjwt",
"numpy",
"litellm==1.76.1",
"nbsphinx; extra == \"docs\"",
"sphinx; extra == \"docs\"",
"sphinx_rtd_theme; extra == \"docs\"",
"nbformat; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://github.com/openreview/openreview-py"
] | twine/6.2.0 CPython/3.11.0 | 2026-02-19T20:40:11.881768 | openreview_py-1.57.1-py3-none-any.whl | 839,905 | d6/27/a37c310f43bba28358f3dd40105c3c8bb44c8189718a1b2b8d8339651653/openreview_py-1.57.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 78f006273689ac349c4f24a84e8d8868 | a79770adc0f1c9b32c7d188356f80f0a8c7f65cac65e991498bce94ba51e279c | d627a37c310f43bba28358f3dd40105c3c8bb44c8189718a1b2b8d8339651653 | null | [
"LICENSE"
] | 1,232 |
2.4 | clue-api | 1.4.0.dev168 | Clue distributed enrichment service | # Clue
To start the API for clue, check to ensure that:
1. Docker is composed up through `dev/docker-compose.yml`
2. `cd clue/api`
3. Run `poetry install` within the clue/api folder to install all dependencies
4. You may need to run `poetry install --with test,dev,types,plugins --all-extras`
5. Run `sudo mkdir -p /var/log/clue/`
6. Run `sudo mkdir -p /etc/clue/conf/`
7. Run `sudo chmod a+rw /var/log/clue/`
8. Run `sudo chmod a+rw /etc/clue/conf/`
9. Run `cp build_scripts/classification.yml /etc/clue/conf/classification.yml`
10. Run `cp test/unit/config.yml /etc/clue/conf/config.yml`
11. To start server: `poetry run server`
To start Enrichment Testing:
* In order to have the local server connect to the UI the servers need to be ran manually
* Please ensure that ```pwd``` is clue/api
* May need to add ```poetry run``` before each command
1. ```flask --app test.utils.test_server run --no-reload --port 5008```
2. ```flask --app test.utils.bad_server run --no-reload --port 5009```
3. ```flask --app test.utils.slow_server run --no-reload --port 5010```
4. ```flask --app test.utils.telemetry_server run --no-reload --port 5011```
Troubleshooting:
1. If there are issues with these steps please check the build system for poetry installation steps
2. The scripts will show all necessary directories that need to be made in order for classfication to work
## Contributing
See [CONTRIBUTING.md](docs/CONTRIBUTING.en.md) for more information
## FAQ
### I'm getting permissions issues on `/var/log/clue` or `/etc/clue/conf`?
Run `sudo chmod a+rw /var/log/clue/` and `sudo chmod a+rw /etc/clue/conf/`.
### How can I add dependencies for my plugin?
See [this section](docs/CONTRIBUTING.en.md#external-dependencies) of CONTRIBUTING.md.
### Email rendering does not seem to be working?
You must install `wkhtmltopdf`, both locally for development and in your Dockerfile:
```bash
sudo apt install wkhtmltopdf
```
| text/markdown | Canadian Centre for Cyber Security | contact@cyber.gc.ca | null | null | MIT | clue, distributed, enrichment, gc, canada, cse-cst, cse, cst, cyber, cccs | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Sof... | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"PyYAML<7.0.0,>=6.0.1; extra == \"server\"",
"Werkzeug<4.0.0,>=3.0.2; extra == \"server\"",
"apscheduler<4.0.0,>=3.10.4; extra == \"server\"",
"authlib<2.0.0; extra == \"server\"",
"bcrypt<5.0.0,>=4.1.2; extra == \"server\"",
"beautifulsoup4<5.0.0,>=4.13.3",
"cart<2.0.0,>=1.2.3",
"celery<6.0.0,>=5.6.2... | [] | [] | [] | [
"Documentation, https://github.com/CybercentreCanada/clue",
"Homepage, https://github.com/CybercentreCanada/clue",
"Repository, https://github.com/CybercentreCanada/clue"
] | poetry/2.3.2 CPython/3.12.3 Linux/6.14.0-1017-azure | 2026-02-19T20:40:06.228823 | clue_api-1.4.0.dev168-py3-none-any.whl | 147,279 | 0e/28/6814e15428d60556dc95f6c58c9034462645be21c4873f11c1763541d4ff/clue_api-1.4.0.dev168-py3-none-any.whl | py3 | bdist_wheel | null | false | eb4d4fcfa34d5e0dc75809ec08fdfb96 | ccb6a02558e9c16d45bc7befaa038d70ac539c578a16ee42ffa36434983eaba3 | 0e286814e15428d60556dc95f6c58c9034462645be21c4873f11c1763541d4ff | null | [
"LICENSE"
] | 203 |
2.4 | pyboj | 0.3.0 | Beginner-friendly Python client for the Bank of Japan Time-Series Statistics API | # pyboj
Beginner-friendly Python client for the [Bank of Japan Time-Series Statistics API](https://www.stat-search.boj.or.jp/).
[](https://pypi.org/project/pyboj/)
[](https://opensource.org/licenses/MIT)
[](https://www.python.org/downloads/)
[](https://colab.research.google.com/github/obichan117/pyboj/blob/main/examples/quickstart.ipynb)
Built on top of [boj-ts-api](https://pypi.org/project/boj-ts-api/) for advanced users who need direct API access.
## Installation
```bash
pip install pyboj
```
## Quick Start
```python
from pyboj import BOJ, Currency, Frequency
boj = BOJ()
# Exchange rates — no magic strings
rates = boj.exchange_rates(
currency=Currency.USD_JPY,
frequency=Frequency.D,
start_date="202401",
)
for r in rates:
print(r.currency_pair, r.rate_type, r.values[:3])
df = r.to_dataframe() # pandas DataFrame
# Interest rates
rates = boj.interest_rates(frequency=Frequency.D)
for r in rates:
print(r.rate_category, r.collateralization, r.tenor)
# TANKAN survey
from pyboj import TankanIndustry, TankanSize
results = boj.tankan(
industry=TankanIndustry.MANUFACTURING,
size=TankanSize.LARGE,
)
# Price indices
indices = boj.price_indices(start_date="202401")
# Balance of payments, Money/Deposits, Loans, and more
bop = boj.balance_of_payments()
money = boj.money_deposits()
loans = boj.loans()
```
See the [full documentation](https://obichan117.github.io/pyboj/) for all 14 methods, filter enums, and domain wrapper properties.
## License
MIT
| text/markdown | obichan117 | null | null | null | null | api, bank-of-japan, boj, pyboj, statistics, time-series | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Financial and Insurance Industry",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programmin... | [] | null | null | >=3.10 | [] | [] | [] | [
"boj-ts-api>=0.2.0",
"pandas>=2.0",
"japanize-matplotlib>=1.1.3; extra == \"plot\"",
"matplotlib>=3.5; extra == \"plot\""
] | [] | [] | [] | [
"Repository, https://github.com/obichan117/pyboj"
] | twine/6.2.0 CPython/3.11.0 | 2026-02-19T20:39:48.622725 | pyboj-0.3.0.tar.gz | 36,702 | 6c/be/91d6db809d94c19e82c8c7f56a824308756176575f23d42eb8ab07a9637c/pyboj-0.3.0.tar.gz | source | sdist | null | false | ba986f50b35c7e30017b94ea20deef1d | 3126323af521cfbad7e3d599019ec7bc8ae8035d41e6678527319c61b2e05a0c | 6cbe91d6db809d94c19e82c8c7f56a824308756176575f23d42eb8ab07a9637c | MIT | [] | 219 |
2.4 | CosmoSim | 2.6.0 | Simulator of Gravitational Lenses | ---
title: The CosmoAI project
---
# The CosmoSim software
This project provides a simulator for gravitational lensing based on
Chris Clarkson's Roulettes framework. The code is experimental,
and intended for research, with many loose ends. If you think it
may be useful, we shall be happy to discuss collaboration and help
you get started.
The core team is
+ [Dr. Ben David Normann]() - computer science and mathematics
+ [Hans Georg Schaathun]() - cosmology and mathematics
Documentation is being written at
[https://cosmoai-aes.github.io/](https://cosmoai-aes.github.io/),
but it still incomplete and fragmented.
## Installation Guide
CosmoSim is set up to build python packages (wheels) that
can be installed with pip.
```sh
pip install CosmoSim
```
We successfully build CosmoSim for
Linux/x86_64 and MacOS/arm, for python 3.11 trough 3.14, and 3.14.t
Buiilding for python 3.10 is impossible because tomllib is required.
Building on Windows (amd64, python 3.11-3.14) sometimes works,
but currently not.
To build locally from source, you can run (from the root of
the repo),
```
pip install build
python -m build
```
This is highly dependent on the local configuration, and may fail
for a number of reasons. If it succeeds, the binary file for the
python module appears under src/CosmoSim.
If you can build, pip can also install the package from the working
directory. Again, from the root of the repo,
```
pip install .
```
For non-standard building, see [BUILD.md](BUILD.md).
## Running the GUI
```sh
python3 -m CosmoSim.GUI
```
The GUI tool is hopefully quite self-explanatory.
The images shown are the actual source on the left and the distorted (lensed)
image on the right.
## The Command Line Interface (CLI)
### Overview of Tools
The modules that can be run as command line scripts are the following:
+ `python -m CosmoSim.datagen` (simulate images from lens parameters)
+ `python -m CosmoSim.roulettegen` (simulate images from roulette amplitudes)
+ `python -m CosmoSim.roulettestatistics` (descriptive statistics of roulette amplitudes)
### Testing
Once built, an illustrative test set can be generated by
the following command issued from the root directory.
Note that you have to install python dependencies from the requirements
file. You may want to install python libraries in a virtual environment.
Here this is given to do that in global user space.
```sh
mkdir images
python3 -m CosmoSim.datagen -CR -Z 400 --csvfile Datasets/debug.csv --directory images
```
This generates a range of images in the newly created images directory. This should be on the .gitignore.
The flags may be changed; `-C` centres det distorted image in the centre
of the image (being debugged); `-Z` sets the image size; `-R` prints an
axes cross.
### Dataset generation
The basic use case is bulk generation of images.
The parameter distribution can be specified in a TOML file,
see `Datasets/dataset.toml` for an example.
The following command generates a dataset.
```sh
python3 -m CosmoSim.datagen --toml dataset.toml --csvfile dataset.csv --outfile roulette.csv --directory images -C
```
Note the following
+ `dataset.csv` - contains the dataset with all the lens and source parameters.
+ The `images` directory contains the images generated from the dataset.
+ `roulette.csv` gives the dataset with roulette amplitudes.
+ `-C` centres the images on the centre of mass (luminence). This is necessary
to avoid leaking information to a machine learning model.
Most of the options are optional, and further options are available. See below.
### Two-step generation
It is possible two generate the dataset and the images in two separate steps.
```
python3 -m CosmoSim.dataset input.toml output.csv
python3 -m CosmoSim.datagen --csvfile output.csv --outfile roulette.csv --directory images -C
```
### Roulette Resimulation
**TODO**
```sh
python3 -m CosmoSim.roulettegen
```
### Generating individual images
To generate images from specified parameters, you can use
```sh
python3 -m CosmoSim.datagen -S sourcemodel -L lensmodel -x x -y y -s sigma -X chi -E einsteinR -n n -I imageSize -N name -R -C
```
Here are the options specified:
+ `lensmodel` is `p` for point mass (exact), `r` for Roulette (point mass),
or `s` for SIS (Roulette).
+ `sourcemodel` is `s` for sphere, `e` for ellipse, or `t` for
triangle.
+ `-C` centres the image on the centre of mass (centre of light)
+ `-R` draw the axes cross
+ `x` and `y` are the coordinates of the actual source
+ `s` is the standard deviation of the source
+ `chi` is the distance to the lens in percent of the distance to the source
+ `einsteinR` is the Einstein radius of the lens
+ `n` is the number of terms to use in roulette sum.
(Not used for the point mass model.)
+ `imageSize` size of output image in pixels. The image will be
`imageSize`$\times$`imageSize` pixels.
+ `name` is the name of the simulation, and used to generate filenames.
+ `--help` for a complete list of options.
## Use cases
### Training sets for roulette amplitudes
The datasets generated from `datasetgen.py` give the parameters for the
lens and the source, as well as the image file.
This allows us to train a machine learning model to identify the lens
parameters, *assuming* a relatively simple lens model.
It is still a long way to go to map cluster lenses.
An alternative approach is to try to estimate the effect (lens potential)
in a neighbourhood around a point in the image. For instance, we may want
to estimate the roulette amplitudes in the centre of the image.
The `datagen.py` script can generate a CSV file containing these data along
with the image, as follows:
```sh
mkdir images
python3 -m CosmoSim.datagen -C -Z 400 --csvfile Datasets/debug.csv \
--directory images --outfile images.csv --nterms 5
```
The images should be centred (`-C`); the amplitudes may not be
meaningful otherwise. The `--directory` flag puts images in
the given directory which must exist. The image size is given by
`-Z` and is square. The input and output files go without saying.
The number of terms (`--nterms`) is the maximum $m$ for which the
amplitudes are generated; 5 should give about 24 scalar values.
The amplitudes are labeled `alpha[`$s$,$m$`]` and `beta[`$s$,$m$`]`
in the outout CSV file. One should focus on predicting the amplitudes
for low values of $m$ first. The file also reproduces the source
parameters, and the centre of mass $(x,y)$ in the original co-ordinate
system using image coordinates with the origin in the upper left corner.
The most interesting lens model for this exercise is PsiFunctionSIS (fs),
which gives the most accurate computations. The roulette amplitudes have
not been implemented for any of the point mass lenses yet, and it also
does not work for «SIS (rotated)» which is a legacy implementation of
the roulette model with SIS and functionally equivalent to «Roulette SIS«
(rs).
**Warning** This has yet to be tested properly.
## Other scripts
The `python/` directory contains scripts which do not depend on
C++ code.
+ `compare.py` is used to compare images in the Regression Tests.
+ Several scripts used to calculate roulette amplitudes.
## Versions
+ The imortant git branches are
- develop is the current state of the art
- pypitest is used for final testing with automatic deployment
to the PyPI test index.
- master should be the last stable version
+ Releases
- v-test-* are test releases, used to debug workflows. Please ignore.
- see the releases on githun and CHANGELOG.md
+ Prior to v2.0.0 some releases have been tagged, but not registered
as releases in github.
- v0.1.0, v0.2.0, v1.0.0 are versions made by the u/g students
Spring 2022.
- v1.0.1 is cleaned up to be able to build v1.0.0
## Caveats
The simulator makes numerical calculations and there will always
be approximation errors.
1. The images generated from the same parameters have changed slightly
between version. Some changes are because some unfortunate uses of
integers and single-precision numbers have later been avoided, and some
simply because the order of calculation has changed.
1. The SIS model is implemented in two versions, one rotating
to have the source on the x-axis and one working directly with
arbitrary position. Difference are not perceptible by visual
comparison, but the difference image shows noticeable difference.
## Contributors
The initial prototype was an undergraduate
[final year project](https://ntnuopen.ntnu.no/ntnu-xmlui/handle/11250/3003634)
by Ingebrigtsen, Remøy, Westbø, Nedreberg, and Austnes (2022).
The software includes both a GUI simulator for interactive experimentation,
and a command line interface for batch generation of datasets.
+ **Idea and Current Maintainance** Hans Georg Schaathun <hasc@ntnu.no>
+ **Mathematical Models** Ben David Normann
+ **Initial Prototype** Simon Ingebrigtsen, Sondre Westbø Remøy,
Einar Leite Austnes, and Simon Nedreberg Runde
| text/markdown | Hans Georg Schaathun et al | Hans Georg Schaathun <georg+github@schaathun.net> | null | null | null | cosmology, gravitational lensing, simulation | [
"Programming Language :: Python :: 3",
"Programming Language :: C++",
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"sympy>=1.13",
"numpy",
"matplotlib",
"opencv-python",
"pandas"
] | [] | [] | [] | [
"Homepage, https://github.com/CosmoAI-AES/CosmoSim",
"Issues, https://github.com/CosmoAI-AES/CosmoSim/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:39:34.624733 | cosmosim-2.6.0.tar.gz | 22,242,580 | db/04/21bda84215d6464f6f0722388616cce0a674dbc28bce16482005ac80972c/cosmosim-2.6.0.tar.gz | source | sdist | null | false | ca83c89d462e83306965d5e80a1e664d | 04fce293ad1b68f78531b5a7f00d3ad6ae738cf8c45beca03d4a811249fde348 | db0421bda84215d6464f6f0722388616cce0a674dbc28bce16482005ac80972c | MIT | [
"LICENSE"
] | 0 |
2.4 | snowduck | 0.0.5 | Run Snowflake SQL locally, powered by DuckDB - lightweight in-memory SQL engine for development and testing | # ❄️🦆 SnowDuck
[](https://github.com/hupe1980/snowduck/actions/workflows/ci.yml)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
[](https://github.com/astral-sh/ruff)
> **Run Snowflake SQL locally, powered by DuckDB**
SnowDuck is a lightweight, in-memory SQL engine that emulates Snowflake's behavior for development and testing. Write and test Snowflake SQL locally without cloud access or costs.
## Why SnowDuck?
- 🚀 **Fast Development** - Test SQL queries instantly without waiting for cloud connections
- 💰 **Zero Cloud Costs** - Develop and test locally without Snowflake compute charges
- 🧪 **Easy Testing** - Mock Snowflake databases for unit tests and CI/CD pipelines
- ⚡ **Lightning Fast** - Powered by DuckDB's in-memory execution engine
- 🔌 **Drop-in Compatible** - Uses Snowflake's connector interface - just patch and go
## Features
### Core SQL Support
| Category | Functions |
|----------|-----------|
| **DDL Operations** | CREATE/DROP DATABASE, SCHEMA, TABLE |
| **DML Operations** | INSERT, UPDATE, DELETE, MERGE |
| **Advanced SQL** | CTEs, JOINs, subqueries, CASE, QUALIFY |
| **Session Variables** | SET/SELECT \$variable syntax |
| **Information Schema** | Query metadata (databases, tables, columns) |
### Function Support
| Category | Functions |
|----------|-----------|
| **String** | CONCAT, CONCAT_WS, SPLIT, SPLIT_PART, CONTAINS, REPLACE, TRIM, LTRIM, RTRIM, LPAD, RPAD, SPACE, STRTOK, TRANSLATE, REVERSE, STARTSWITH, ENDSWITH, ASCII, CHR, INITCAP, SOUNDEX, UPPER, LOWER, LENGTH, LEN, SUBSTR, SUBSTRING, INSTR, POSITION |
| **Date/Time** | DATEADD, DATEDIFF, TIMEDIFF, DATE_TRUNC, DATE_PART, EXTRACT, LAST_DAY, ADD_MONTHS, DATE_FROM_PARTS, TIME_FROM_PARTS, TIMESTAMP_FROM_PARTS, CONVERT_TIMEZONE, TO_DATE, TO_TIMESTAMP |
| **Numeric** | ABS, CEIL, FLOOR, ROUND, MOD, SQRT, POWER, EXP, LN, LOG, SIGN, DIV0, DIV0NULL, WIDTH_BUCKET, TRUNCATE, CBRT, FACTORIAL, DEGREES, RADIANS, PI, RANDOM, GREATEST, LEAST |
| **Aggregate** | COUNT, SUM, AVG, MIN, MAX, MEDIAN, LISTAGG, ANY_VALUE, KURTOSIS, SKEW, COVAR_POP, COVAR_SAMP |
| **Window** | ROW_NUMBER, RANK, DENSE_RANK, LEAD, LAG, FIRST_VALUE, LAST_VALUE |
| **JSON** | PARSE_JSON, OBJECT_CONSTRUCT, OBJECT_INSERT, GET_PATH, TRY_PARSE_JSON, OBJECT_KEYS, CHECK_JSON, TO_JSON |
| **Array** | ARRAY_CONSTRUCT, ARRAY_SIZE, ARRAY_CONTAINS, FLATTEN, ARRAY_SLICE, ARRAY_CAT, ARRAY_APPEND, ARRAY_PREPEND, ARRAY_SORT, ARRAY_REVERSE, ARRAY_MIN, ARRAY_MAX, ARRAY_SUM, ARRAYS_OVERLAP, ARRAY_DISTINCT, ARRAY_INTERSECTION, ARRAY_EXCEPT |
| **Conditional** | NVL, NVL2, DECODE, IFF, COALESCE, NULLIF, EQUAL_NULL, ZEROIFNULL, NULLIFZERO |
| **Conversion** | TO_CHAR, TO_NUMBER, TO_BOOLEAN, TO_DATE, TRY_CAST, TRY_TO_NUMBER, TRY_TO_DATE, TRY_TO_TIMESTAMP, TRY_TO_BOOLEAN |
| **Regex** | REGEXP_LIKE, REGEXP_SUBSTR, REGEXP_REPLACE, REGEXP_COUNT |
| **Hash** | MD5, SHA1, SHA2, SHA256, HASH |
| **Encoding** | BASE64_ENCODE, BASE64_DECODE_STRING, HEX_ENCODE, HEX_DECODE_STRING |
| **Bitwise** | BITAND, BITOR, BITXOR, BITNOT, BITAND_AGG, BITOR_AGG, BITXOR_AGG |
| **Boolean Agg** | BOOLAND_AGG, BOOLOR_AGG |
| **Utility** | UUID_STRING, TYPEOF |
### Cursor Methods
SnowDuck supports all standard Snowflake cursor methods:
- `execute()` - Execute SQL statements
- `fetchone()` - Fetch a single row
- `fetchmany(size)` - Fetch multiple rows
- `fetchall()` - Fetch all rows
- `fetch_pandas_all()` - Fetch all rows as pandas DataFrame
- `fetch_pandas_batches()` - Fetch rows as iterator of DataFrames
- `get_result_batches()` - Get Arrow record batches
- `describe()` - Get result schema without execution
> **Note**: SnowDuck is designed for development and testing. Use production Snowflake for production workloads.
## Quick Start
### Installation
```bash
# Using uv (recommended)
uv pip install snowduck
# Or using pip
pip install snowduck
```
### Basic Usage
```python
import snowflake.connector
from snowduck import start_patch_snowflake
# Patch the Snowflake connector to use DuckDB
start_patch_snowflake()
# Use Snowflake connector as normal - it's now backed by DuckDB!
with snowflake.connector.connect() as conn:
cursor = conn.cursor()
cursor.execute("CREATE DATABASE my_database")
cursor.execute("USE DATABASE my_database")
cursor.execute("""
CREATE TABLE employees (id INTEGER, name VARCHAR, salary INTEGER)
""")
cursor.execute("""
INSERT INTO employees VALUES
(1, 'Alice', 95000),
(2, 'Bob', 75000),
(3, 'Carol', 105000)
""")
cursor.execute("""
SELECT name, salary, RANK() OVER (ORDER BY salary DESC) as rank
FROM employees
""")
for row in cursor.fetchall():
print(f"{row[0]}: \${row[1]:,} (Rank: {row[2]})")
```
### Data Persistence
```python
# In-memory (default) - fast, isolated
start_patch_snowflake()
# File-based - persistent across restarts
start_patch_snowflake(db_file='my_data.duckdb')
# Fresh start - reset existing data
start_patch_snowflake(db_file='my_data.duckdb', reset=True)
```
### Test Data Seeding
```python
from snowduck import seed_table
with snowflake.connector.connect() as conn:
# From dict
seed_table(conn, 'customers', {
'id': [1, 2, 3],
'name': ['Acme', 'TechStart', 'DataCo']
})
# From pandas DataFrame
seed_table(conn, 'orders', df)
```
## Testing
### Using the Decorator
```python
from snowduck import mock_snowflake
@mock_snowflake
def test_query():
conn = snowflake.connector.connect()
cursor = conn.cursor()
cursor.execute("SELECT 1")
assert cursor.fetchone()[0] == 1
```
### Using the Context Manager
```python
from snowduck import patch_snowflake
def test_with_fixture():
with patch_snowflake():
conn = snowflake.connector.connect()
# Test code here
```
### pytest Fixture
```python
import pytest
from snowduck import patch_snowflake
@pytest.fixture
def conn():
with patch_snowflake():
yield snowflake.connector.connect()
def test_feature(conn):
cursor = conn.cursor()
cursor.execute("SELECT 1")
```
## REST API Server
```bash
# Install with server extras
uv pip install snowduck[server]
# Start the server
uvicorn snowduck.server:app --reload
```
The server provides:
- Execute SQL queries via REST API
- Arrow IPC format responses
- Multi-session support
## Architecture
```
┌─────────────────────┐
│ Your Application │
│ (Snowflake code) │
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ SnowDuck Patch │ ← Intercepts connector calls
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ SQL Translator │ ← Snowflake → DuckDB dialect
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ DuckDB Engine │ ← Fast in-memory execution
└─────────────────────┘
```
## Examples
See the [examples/](examples/) directory for Jupyter notebooks demonstrating:
- Basic operations and queries
- String, date, and numeric functions
- JSON and array operations
- Window functions
- Advanced SQL patterns
## Development
```bash
git clone https://github.com/hupe1980/snowduck.git
cd snowduck
uv sync
just test
just check
```
## Contributing
Contributions welcome! See issues for areas where help is needed.
## License
MIT License - see [LICENSE](LICENSE) for details.
| text/markdown | hupe1980 | null | null | null | MIT | data-engineering, database, duckdb, mock, snowflake, sql, testing | [
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Topic :: Database",
"Topic :: Software Development :: Libraries"
] | [] | null | null | <4,>=3.11 | [] | [] | [] | [
"duckdb<2.0.0,>=1.2.1",
"pyarrow<19.0.0",
"snowflake-connector-python<4.0.0,>=3.14.0",
"sqlglot[rs]<27.0.0,>=26.12.0",
"starlette>=0.46.1; extra == \"server\"",
"uvicorn>=0.34.0; extra == \"server\"",
"zstandard>=0.23.0; extra == \"server\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:39:07.086420 | snowduck-0.0.5.tar.gz | 293,910 | 6a/55/accac2536a477a75f3655f2998db30fb8f459f5e331520f45e79d5a3d03b/snowduck-0.0.5.tar.gz | source | sdist | null | false | 6cb613b39d365e55be0824513de8ccae | b84d7b11f55e12263e3cfbe2ba78e31bd950e0aa538373216de98eb6bcc41b9c | 6a55accac2536a477a75f3655f2998db30fb8f459f5e331520f45e79d5a3d03b | null | [
"LICENSE"
] | 207 |
2.4 | yaml-to-schemdraw | 0.1.2 | Generate schemdraw diagrams from YAML files or Python dictionaries. | # yaml-to-schemdraw
Generate schemdraw diagrams from YAML files or Python dictionaries.
`pip install yaml-to-schemdraw`
- [yaml-to-schemdraw](#yaml-to-schemdraw)
- [Usage](#usage)
- [Why?](#why)
- [How it works](#how-it-works)
The following YAML spec:
```yaml
V1:
- elements.SourceV
- label: ["5V"]
line1:
- elements.Line
- right: [0.75]
S1:
- elements.SwitchSpdt2: [{ action: close }]
- up
- anchor: ["b"]
- label: ["$t=0$", { loc: rgt }]
line2:
- elements.Line
- right: [0.75]
- at: ["S1.c"]
R1:
- elements.Resistor
- down
- label: ["$100\\Omega$"]
- label: [["+", "$v_o$", "-"], { loc: bot }]
line3:
- elements.Line
- to: ["V1.start"]
C1:
- elements.Capacitor
- at: ["S1.a"]
- toy: ["V1.start"]
- label: ["1$\\mu$F"]
- dot
```
Represents the equivalent Python code:
```python
with schemdraw.Drawing() as d:
V1 = elm.SourceV().label('5V')
elm.Line().right(d.unit*.75)
S1 = elm.SwitchSpdt2(action='close').up().anchor('b').label('$t=0$', loc='rgt')
elm.Line().right(d.unit*.75).at(S1.c)
elm.Resistor().down().label(r'$100\Omega$').label(['+','$v_o$','-'], loc='bot')
elm.Line().to(V1.start)
elm.Capacitor().at(S1.a).toy(V1.start).label(r'1$\mu$F').dot()
```
And can be loaded with this library as follows:
## Usage
```python
from yaml_to_schemdraw import from_yaml_file
# "from_yaml_string" and "from_dict" are also available
diagram = from_yaml_file("diagram.yaml")
```
You can now call `diagram.draw()` or `diagram.save("diagram.svg")` as usual.

## Why?
Schemdraw was always intended to be used as a Python library, with developers manually writing diagrams in code.
However, when it comes to accepting diagram definitions provided by clients through the network or originating from an untrusted environment, the naive approach of running arbitrary Python code with a function like `exec()` poses a significant security risk.
This module proposes an alternative, declarative way to represent Schemdraw diagrams as a YAML file or a Python dictionary.
## How it works
The module parses the dictionary and resolves the function calls against the schemdraw library.
Internally, it uses `getattr()` to resolve function calls, with an attribute allowlist to prevent module escalation.
It can easily and safely parse most of the [schemdraw circuit gallery](https://schemdraw.readthedocs.io/en/stable/gallery/index.html).
If you encounter any valid diagrams that cannot be parsed (or easily adapted into something that this module can parse), please open an issue.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"ruamel-yaml",
"schemdraw"
] | [] | [] | [] | [
"Homepage, https://github.com/Julynx/yaml-to-schemdraw",
"Repository, https://github.com/Julynx/yaml-to-schemdraw"
] | uv/0.10.2 {"installer":{"name":"uv","version":"0.10.2","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T20:38:09.641514 | yaml_to_schemdraw-0.1.2.tar.gz | 9,396 | 63/d1/270eaf7e12730f3487af87f9310fd4f147172700c76d9a67e1f63bb50e12/yaml_to_schemdraw-0.1.2.tar.gz | source | sdist | null | false | ea9839dba25b8317cfd78d01f2cc08d0 | 5abd2ff5cdf8b9eae9317659e7d6a6434eb7a2eaeda651c00ec57cf3bd52b55c | 63d1270eaf7e12730f3487af87f9310fd4f147172700c76d9a67e1f63bb50e12 | null | [] | 229 |
2.4 | scaevola | 1.1.4 | This project provides a class with preset right handed magic methods. | ========
scaevola
========
Visit the website for more information: `https://scaevola.johannes-programming.online/ <https://scaevola.johannes-programming.online/>`_
| text/x-rst | null | Johannes <johannes.programming@gmail.com> | null | null | The MIT License (MIT)
Copyright (c) 2024 Johannes
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | null | [
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Typing :: Typed"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"setdoc<2,>=1.2.8"
] | [] | [] | [] | [
"Download, https://pypi.org/project/scaevola/#files",
"Index, https://pypi.org/project/scaevola/",
"Source, https://github.com/johannes-programming/scaevola/",
"Website, https://scaevola.johannes-programming.online/"
] | twine/6.2.0 CPython/3.11.13 | 2026-02-19T20:38:02.363001 | scaevola-1.1.4.tar.gz | 5,977 | d9/ca/32c2bb074ca113651c3dce4405d07d339f86fe1611894036be7e6e87acd9/scaevola-1.1.4.tar.gz | source | sdist | null | false | 02701f66abf031ff6d3a719d94d0a94d | 954a3b53ff0de3d0caf0e4841f1e07e0c4c2623c34ed6218587c6fa995b7db08 | d9ca32c2bb074ca113651c3dce4405d07d339f86fe1611894036be7e6e87acd9 | null | [
"LICENSE.txt"
] | 212 |
2.4 | pyhems | 0.3.0 | ECHONET Lite library for Home Energy Management System (HEMS) | # pyhems
[](https://www.python.org/downloads/)
[](LICENSE)
ECHONET Lite library for Home Energy Management System (HEMS).
**[🇯🇵 日本語ドキュメント](README.ja.md)**
## Features
- ECHONET Lite frame encoding/decoding
- UDP multicast device discovery
- Async runtime client with event subscription
- Entity definitions based on MRA data
- Full type hints (`py.typed`)
## Requirements
- Python 3.13+
- bidict>=0.23.0
## License
MIT License
## Installation
```bash
pip install pyhems
```
## Quick Start
```python
import asyncio
from pyhems.runtime import HemsClient, HemsInstanceListEvent
async def main():
client = HemsClient(interface="0.0.0.0")
await client.start()
def on_event(event):
if isinstance(event, HemsInstanceListEvent):
print(f"Node: {event.node_id}, Instances: {event.instances}")
unsubscribe = client.subscribe(on_event)
await asyncio.sleep(60)
unsubscribe()
await client.stop()
asyncio.run(main())
```
| text/markdown | Sayurin | null | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"bidict>=0.23.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:37:16.870187 | pyhems-0.3.0.tar.gz | 55,965 | ed/34/12a66d1e96352edcb582b6b2529e7f57d45070baff9643768217788e0826/pyhems-0.3.0.tar.gz | source | sdist | null | false | 4e1dac334dec6d188901a2de776ede40 | e6f11d8f96290aecb3a43ced533f1acf34f982d75198ba5a55b0919643caf27d | ed3412a66d1e96352edcb582b6b2529e7f57d45070baff9643768217788e0826 | MIT | [
"LICENSE"
] | 208 |
2.4 | wkls | 1.0.0 | Easy access to global administrative boundaries and geometries via Overture Maps data | # wkls: Well-Known Locations
[](https://pypi.org/project/wkls/)
[](https://pypi.org/project/wkls/)
[](https://pypi.org/project/wkls/)
[](https://opensource.org/licenses/Apache-2.0)
[](https://github.com/wherobots/wkls/actions/workflows/run_tests.yaml)
`wkls` gives you administrative boundaries — countries, regions, counties, and cities — in one line of Python.
```python
import wkls
wkls.us.ca.sanfrancisco.wkt()
# "MULTIPOLYGON (((-122.5279985 37.8155806...)))"
```
- Chainable attribute access to countries, states, counties, and cities
- Precise geometries from [Overture Maps Foundation](https://overturemaps.org/) — no bounding boxes, no shapefiles
- Currently, `wkls` outputs boundaries in WKT or WKB
- Support for GeoJSON, HexWKB, and SVG planned
- Zero configuration — no API keys, no downloads, no setup
- Automatically uses the latest Overture Maps release
## Installation
```bash
pip install wkls
```
## Usage
### Countries, regions, counties, and cities
Chain up to 3 levels: **country** → **region** → **county or city**.
```python
import wkls
wkls.us.wkt() # United States
wkls.us.ca.wkt() # California
wkls.us.ca.sanfrancisco.wkt() # San Francisco
```
Countries and dependencies use [ISO 3166-1 alpha-2](https://en.wikipedia.org/wiki/ISO_3166-1_alpha-2) codes.
Regions use the code suffix from Overture (e.g. `ca` for `US-CA`).
Counties and cities match by name against the Overture dataset.
### Geometry formats
```python
wkls.de.wkt() # Well-Known Text string
wkls.de.wkb() # Well-Known Binary bytes
```
### Exploring the dataset
```python
wkls.countries() # all countries
wkls.dependencies() # all dependencies
wkls.us.regions() # regions in the US
wkls.us.ca.counties() # counties in California
wkls.us.ca.cities() # cities in California
wkls.fk.cities() # countries without regions work too
```
### Wildcard search
Use `%` for pattern matching when you're not sure of the exact name:
```python
wkls.us.ca["%francis%"] # matches "San Francisco"
```
### Pinning an Overture version
`wkls` auto-detects the latest Overture Maps release. To pin a specific version:
```python
wkls.configure(overture_version="2025-12-17.0")
wkls.overture_version() # current version
wkls.overture_releases() # available versions
```
Or set the `WKLS_OVERTURE_VERSION` environment variable:
```bash
export WKLS_OVERTURE_VERSION=2025-12-17.0
```
Priority: `configure()` > environment variable > auto-detect.
### Bracket access
Some names collide with Python keywords or DataFrame methods. Use bracket
syntax when attribute access doesn't work:
```python
wkls["us"]["ne"].wkt() # Nebraska (wkls.us.ne would call DataFrame.ne)
wkls["at"]["1"].regions() # Austria's region "1"
```
You can mix attribute and bracket access freely.
## How it works
`wkls` resolves locations in two stages:
1. **Metadata resolution** — your chained attributes are matched against a
bundled metadata table (country by ISO code, region by code suffix, county
or city by name). No geometry is loaded at this stage.
2. **Geometry fetch** — when you call `.wkt()` or `.wkb()`, the geometry is
fetched from Overture Maps GeoParquet on S3 via
[Apache SedonaDB](https://sedona.apache.org/sedonadb/).
## Contributing
We welcome contributions! Please see our [Contributing Guide](CONTRIBUTING.md) for details on how to get started, development setup, and submission guidelines.
## License
This project is licensed under the Apache License 2.0 - see the [LICENSE](LICENSE) file for details.
`wkls` includes, references, and leverages data from the "Divisions" theme of [Overture](https://overturemaps.org), from Overture Maps Foundation:
* © OpenStreetMap contributors. Available under the [Open Database License](https://www.openstreetmap.org/copyright).
* [geoBoundaries](https://www.geoboundaries.org/). Available under [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/).
* [Esri Community Maps contributors](https://communitymaps.arcgis.com/home/). Available under [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/).
* [Land Information New Zealand (LINZ)](https://www.linz.govt.nz/). Available under [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/).
## Acknowledgments
- [Overture Maps Foundation](https://overturemaps.org/) for providing high-quality, open geospatial data.
- [AWS Open Data Registry](https://registry.opendata.aws/) for hosting the dataset.
- [Apache SedonaDB](https://sedona.apache.org/sedonadb/) for the high-performance, single-node spatial query and analytics engine.
| text/markdown | null | Pranav Toggi <pranav@wherobots.com>, Maxime Petazzoni <max@wherobots.com>, Matthew Powers <mpowers@wherobots.com> | null | null | null | admin boundaries, boundaries, geography, geojson, geometry, geospatial, gis, overture-maps, spatial, wkt | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python ... | [] | null | null | >=3.9 | [] | [] | [] | [
"geoarrow-pyarrow>=0.2.0",
"pyarrow>=14.0.0",
"sedonadb>=0.2.0",
"sqlescapy>=1.0.1"
] | [] | [] | [] | [
"Homepage, https://github.com/wherobots/wkls",
"Repository, https://github.com/wherobots/wkls.git",
"Issues, https://github.com/wherobots/wkls/issues",
"Documentation, https://github.com/wherobots/wkls#readme",
"Changelog, https://github.com/wherobots/wkls/releases"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T20:36:46.685184 | wkls-1.0.0.tar.gz | 16,424,477 | 5d/68/1342756e58fd0c2a09d4b7412de49d15307e57409745209c20b302984fac/wkls-1.0.0.tar.gz | source | sdist | null | false | a221e5e5f63a1f969b44acd6802b7dc2 | 36fceb26513c7ec2238bd28b4e209116f9d5e70d219ef38a4cea1d59ee4691ca | 5d681342756e58fd0c2a09d4b7412de49d15307e57409745209c20b302984fac | Apache-2.0 | [
"LICENSE"
] | 233 |
2.1 | coinmetrics-api-client | 2026.2.19.20 | Python client for Coin Metrics API v4. | <h1 align="center"><b>Coin Metrics Python API Client</b></h1>
<p align="center">
<img src="assets/images/cm-dark-combination.png">
</p>
The **Coin Metrics Python API Client** is the official Python wrapper for the [Coin Metrics API](https://docs.coinmetrics.io/api/v4), allowing you to access [Coin Metrics data](https://docs.coinmetrics.io/) using Python. In just a few lines of code, anyone can access clean cryptocurrency data in a familiar form, such as a pandas dataframe.
This tool offers the following convenient features over simply using `requests` to query the Coin Metrics API:
- **Automatic Pagination**. The Coin Metrics API limits most endpoints to no more than 10,000 entries, requiring users to handle pagination. The Python API Client handles this automatically.
- **DataFrames**. Users may access Coin Metrics data using pandas DataFrames and potentially other data structures, such as polars.
- **Data Exports**. Users may export API outputs to CSV and JSON files.
- **Typing**. DataFrames are automatically converted to the appropriate data types.
- **Parallelization**. Users may submit many requests at once to extract data much more quickly than sending one request at a time.
# Getting Started
## Installation and Updates
To install the client you can run the following command:
```
pip install coinmetrics-api-client
```
Note that the client is updated regularly to reflect the changes made in [API v4](https://docs.coinmetrics.io/api/v4). Ensure that your latest version matches with what's in [pyPI](https://pypi.org/project/coinmetrics-api-client/)
To update your version, run the following command:
```
pip install coinmetrics-api-client -U
```
## Initialization
To initialize the client you should use your API key, and the CoinMetricsClient class like the following.
```python
from coinmetrics.api_client import CoinMetricsClient
import os
# we recommend storing your Coin Metrics API key in an environment variable
api_key = os.environ.get("CM_API_KEY")
client = CoinMetricsClient(api_key)
# or to use community API:
client = CoinMetricsClient()
``` | text/markdown | Coin Metrics | info@coinmetrics.io | null | null | MIT | coin metrics, coin, metrics, crypto, bitcoin, network-data, market-data, api, handy | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://coinmetrics.github.io/api-client-python/site/index.html | null | <4.0.0,>=3.10.0 | [] | [] | [] | [
"requests<3.0.0,>=2.24.0",
"orjson<4.0.0,>=3.6.0",
"numpy<2.0,>=1.26.4; python_version == \"3.10\"",
"numpy>=2.3; python_version >= \"3.11\"",
"pandas<3.0.0,>=2.0.0",
"polars<2.0.0,>=0.20.15",
"prance>=23.6.0",
"pyarrow>=16.0.0",
"python-dateutil<3.0.0,>=2.8.2",
"typer>=0.7.0",
"tqdm<5.0.0,>=4.6... | [] | [] | [] | [
"Repository, https://github.com/coinmetrics/api-client-python",
"Documentation, https://coinmetrics.github.io/api-client-python/site/index.html"
] | poetry/1.8.4 CPython/3.11.14 Linux/6.8.0-55-generic | 2026-02-19T20:36:20.699274 | coinmetrics_api_client-2026.2.19.20.tar.gz | 164,492 | 11/8d/36b9671ebc931be073715d62f4298722e998020854b7d79dcb2cc29ec689/coinmetrics_api_client-2026.2.19.20.tar.gz | source | sdist | null | false | c75ba95b9f8fe3c6f49fbc732e9df556 | 51170652fcd4fbf073ca831c8ac41b7ec692b4628078d085ea7cd61c5ff79919 | 118d36b9671ebc931be073715d62f4298722e998020854b7d79dcb2cc29ec689 | null | [] | 389 |
2.4 | flet-webview | 0.80.6.dev7615 | Embed web content inside Flet apps via WebView. | # flet-webview
[](https://pypi.python.org/pypi/flet-webview)
[](https://pepy.tech/project/flet-webview)
[](https://pypi.org/project/flet-webview)
[](https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet/docs/assets/badges/docs-coverage)
[](https://github.com/flet-dev/flet/blob/main/sdk/python/packages/flet-webview/LICENSE)
A [Flet](https://flet.dev) extension for displaying web content in a WebView.
It is based on the [webview_flutter](https://pub.dev/packages/webview_flutter)
and [webview_flutter_web](https://pub.dev/packages/webview_flutter_web) Flutter packages.
> **Important:** WebView requires platform-specific configuration (e.g., enabling webview on iOS). Consult Flutter's platform setup guides.
## Documentation
Detailed documentation to this package can be found [here](https://docs.flet.dev/webview/).
## Platform Support
| Platform | Windows | macOS | Linux | iOS | Android | Web |
|----------|---------|-------|-------|-----|---------|-----|
| Supported| ❌ | ✅ | ❌ | ✅ | ✅ | ✅ |
## Usage
### Installation
To install the `flet-webview` package and add it to your project dependencies:
- Using `uv`:
```bash
uv add flet-webview
```
- Using `pip`:
```bash
pip install flet-webview
```
After this, you will have to manually add this package to your `requirements.txt` or `pyproject.toml`.
### Examples
For examples, see [these](https://github.com/flet-dev/flet/tree/main/examples/controls/webview).
| text/markdown | null | Flet contributors <hello@flet.dev> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"flet==0.80.6.dev7615"
] | [] | [] | [] | [
"Homepage, https://flet.dev",
"Documentation, https://docs.flet.dev/webview",
"Repository, https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet-webview",
"Issues, https://github.com/flet-dev/flet/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:36:00.452841 | flet_webview-0.80.6.dev7615-py3-none-any.whl | 24,725 | e0/e4/e8348220d02082a8cfbdaed40efccc393937ffa1ce9753876f3d9f69d1fa/flet_webview-0.80.6.dev7615-py3-none-any.whl | py3 | bdist_wheel | null | false | aa0c4ebb975d0514077d463d63a5ac3b | 46c45dce534150e4edd92f8eeff7b10c820e27235df7e381dd111d386ad34040 | e0e4e8348220d02082a8cfbdaed40efccc393937ffa1ce9753876f3d9f69d1fa | Apache-2.0 | [
"LICENSE"
] | 181 |
2.4 | flet-video | 0.80.6.dev7615 | Cross-platform video playback for Flet apps. | # flet-video
[](https://pypi.python.org/pypi/flet-video)
[](https://pepy.tech/project/flet-video)
[](https://pypi.org/project/flet-video)
[](https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet/docs/assets/badges/docs-coverage)
[](https://github.com/flet-dev/flet/blob/main/sdk/python/packages/flet-video/LICENSE)
A cross-platform video player for [Flet](https://flet.dev) apps.
It is based on the [media_kit](https://pub.dev/packages/media_kit) Flutter package.
## Documentation
Detailed documentation to this package can be found [here](https://docs.flet.dev/video/).
## Platform Support
| Platform | Windows | macOS | Linux | iOS | Android | Web |
|----------|---------|-------|-------|-----|---------|-----|
| Supported| ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
## Usage
### Installation
To install the `flet-video` package and add it to your project dependencies:
- Using `uv`:
```bash
uv add flet-video
```
- Using `pip`:
```bash
pip install flet-video
```
After this, you will have to manually add this package to your `requirements.txt` or `pyproject.toml`.
> [!NOTE]
> To play video on Linux/WSL you need to install [`libmpv`](https://github.com/mpv-player/mpv) library:
>
> ```bash
> sudo apt update
> sudo apt install libmpv-dev libmpv2
> ```
>
> If you encounter `libmpv.so.1` load errors, run:
>
> ```bash
> sudo ln -s /usr/lib/x86_64-linux-gnu/libmpv.so /usr/lib/libmpv.so.1
> ```
### Examples
For examples, see [these](https://github.com/flet-dev/flet/tree/main/sdk/python/examples/controls/video).
| text/markdown | null | Flet contributors <hello@flet.dev> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"flet==0.80.6.dev7615"
] | [] | [] | [] | [
"Homepage, https://flet.dev",
"Documentation, https://docs.flet.dev/video",
"Repository, https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet-video",
"Issues, https://github.com/flet-dev/flet/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:35:57.606135 | flet_video-0.80.6.dev7615.tar.gz | 29,203 | a0/2b/7da04a81bbf3bd337134e66b41b44037f1a50041293e92eba43cdb9a7074/flet_video-0.80.6.dev7615.tar.gz | source | sdist | null | false | 4bc929eaafd14fa01ff416e989a09a98 | 044806f732b56163751829599e19b7ac578f109a6d70ee30069f2840fe9fd4bf | a02b7da04a81bbf3bd337134e66b41b44037f1a50041293e92eba43cdb9a7074 | Apache-2.0 | [
"LICENSE"
] | 173 |
2.4 | flet-secure-storage | 0.80.6.dev7615 | Secure Storage control for Flet | # flet-secure-storage
[](https://pypi.python.org/pypi/flet-secure-storage)
[](https://pepy.tech/project/flet-secure-storage)
[](https://pypi.org/project/flet-secure-storage)
[](https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet/docs/assets/badges/docs-coverage)
[](https://github.com/flet-dev/flet/blob/main/sdk/python/packages/flet-secure-storage/LICENSE)
A service for safely storing sensitive key–value data using the platform’s native secure storage mechanisms—Keychain on iOS/macOS, Windows Credential Manager, libsecret on Linux, and Keystore on Android.
Powered by Flutter's [`flutter_secure_storage`](https://pub.dev/packages/flutter_secure_storage) package.
You need `libsecret-1-dev` on your machine to build the project, and `libsecret-1-0` to run the application (add it as a dependency after packaging your app). If you using snapcraft to build the project use the following.
Apart from `libsecret` you also need a keyring service, for that you need either [`gnome-keyring`](https://wiki.gnome.org/Projects/GnomeKeyring) (for Gnome users) or [`kwalletmanager`](https://wiki.archlinux.org/title/KDE_Wallet) (for KDE users) or other light provider like [`secret-service`](https://github.com/yousefvand/secret-service).
```bash
sudo apt-get install libsecret-1-dev libsecret-1-0
```
## Documentation
Detailed documentation to this package can be found [here](https://docs.flet.dev/secure_storage/).
## Platform Support
| Platform | Windows | macOS | Linux | iOS | Android | Web |
|----------|---------|-------|-------|-----|---------|-----|
| Supported| ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
## Usage
### Installation
To install the `flet-secure-storage` package and add it to your project dependencies:
- Using `uv`:
```bash
uv add flet-secure-storage
```
- Using `pip`:
```bash
pip install flet-secure-storage
```
After this, you will have to manually add this package to your `requirements.txt` or `pyproject.toml`.
### Examples
For examples, see [these](https://github.com/flet-dev/flet/tree/main/sdk/python/examples/services/secure_storage).
| text/markdown | null | "Appveyor Systems Inc." <hello@flet.dev> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"flet==0.80.6.dev7615"
] | [] | [] | [] | [
"Homepage, https://flet.dev",
"Documentation, https://docs.flet.dev/secure-storage",
"Repository, https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet-secure-storage",
"Issues, https://github.com/flet-dev/flet/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:35:53.516017 | flet_secure_storage-0.80.6.dev7615.tar.gz | 24,363 | e3/f8/832f2f198933dcf8e6a4b30f272e2fc864e3f7ba4659a915eca4b536d560/flet_secure_storage-0.80.6.dev7615.tar.gz | source | sdist | null | false | 20312108318bc23fcb875d6d3d0819ae | 337b3e3b7018c51925261870efb0c98d4a2c76b0ec6f6807676a4e156f8de610 | e3f8832f2f198933dcf8e6a4b30f272e2fc864e3f7ba4659a915eca4b536d560 | null | [
"LICENSE"
] | 179 |
2.4 | flet-rive | 0.80.6.dev7615 | Display Rive animations in Flet apps. | # flet-rive
[](https://pypi.python.org/pypi/flet-rive)
[](https://pepy.tech/project/flet-rive)
[](https://pypi.org/project/flet-rive)
[](https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet/docs/assets/badges/docs-coverage)
[](https://github.com/flet-dev/flet/blob/main/sdk/python/packages/flet-rive/LICENSE)
A cross-platform [Flet](https://flet.dev) extension for displaying [Rive](https://rive.app/) animations.
It is based on the [rive](https://pub.dev/packages/rive) Flutter package.
## Documentation
Detailed documentation to this package can be found [here](https://docs.flet.dev/rive/).
## Platform Support
| Platform | Windows | macOS | Linux | iOS | Android | Web |
|----------|---------|-------|-------|-----|---------|-----|
| Supported| ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
## Usage
### Installation
To install the `flet-rive` package and add it to your project dependencies:
- Using `uv`:
```bash
uv add flet-rive
```
- Using `pip`:
```bash
pip install flet-rive
```
After this, you will have to manually add this package to your `requirements.txt` or `pyproject.toml`.
### Examples
For examples, see [these](https://github.com/flet-dev/flet/tree/main/sdk/python/examples/controls/rive).
| text/markdown | null | Flet contributors <hello@flet.dev> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"flet==0.80.6.dev7615"
] | [] | [] | [] | [
"Homepage, https://flet.dev",
"Documentation, https://docs.flet.dev/rive",
"Repository, https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet-rive",
"Issues, https://github.com/flet-dev/flet/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:35:50.591344 | flet_rive-0.80.6.dev7615-py3-none-any.whl | 19,635 | 5e/e0/9acda69a580e970592540309af411940672908093cfc7d89035a2786351c/flet_rive-0.80.6.dev7615-py3-none-any.whl | py3 | bdist_wheel | null | false | 3d6d5c35de2b080a95773c4b293c74b0 | f412e91e5bf392acf4f15904d5d775ba959167b43d9a1e58bdd0078371def9b8 | 5ee09acda69a580e970592540309af411940672908093cfc7d89035a2786351c | Apache-2.0 | [
"LICENSE"
] | 178 |
2.4 | flet-permission-handler | 0.80.6.dev7615 | Manage runtime permissions in Flet apps. | # flet-permission-handler
[](https://pypi.python.org/pypi/flet-permission-handler)
[](https://pepy.tech/project/flet-permission-handler)
[](https://pypi.org/project/flet-permission-handler)
[](https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet/docs/assets/badges/docs-coverage)
[](https://github.com/flet-dev/flet/blob/main/sdk/python/packages/flet-permission-handler/LICENSE)
A [Flet](https://flet.dev) extension that simplifies working with device permissions.
It is based on the [permission_handler](https://pub.dev/packages/permission_handler) Flutter package
and brings similar functionality to Flet, including:
- Requesting permissions at runtime
- Checking the current permission status (e.g., granted, denied)
- Redirecting users to system settings to manually grant permissions
## Documentation
Detailed documentation to this package can be found [here](https://docs.flet.dev/permission-handler/).
## Platform Support
| Platform | Windows | macOS | Linux | iOS | Android | Web |
|----------|---------|-------|-------|-----|---------|-----|
| Supported| ✅ | ❌ | ❌ | ✅ | ✅ | ✅ |
## Usage
### Installation
To install the `flet-permission-handler` package and add it to your project dependencies:
- Using `uv`:
```bash
uv add flet-permission-handler
```
- Using `pip`:
```bash
pip install flet-permission-handler
```
After this, you will have to manually add this package to your `requirements.txt` or `pyproject.toml`.
### Examples
For examples, see [these](https://github.com/flet-dev/flet/tree/main/sdk/python/examples/services/permission_handler).
| text/markdown | null | Flet contributors <hello@flet.dev> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"flet==0.80.6.dev7615"
] | [] | [] | [] | [
"Homepage, https://flet.dev",
"Documentation, https://docs.flet.dev/permission-handler",
"Repository, https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet-permission-handler",
"Issues, https://github.com/flet-dev/flet/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:35:46.843106 | flet_permission_handler-0.80.6.dev7615.tar.gz | 20,976 | 4f/54/77f011ce7dbad728b80fb8feb70848ecb4810b1c25c004801ad39d67af94/flet_permission_handler-0.80.6.dev7615.tar.gz | source | sdist | null | false | 94e7ad0074c6193fe03f3536e44be087 | 0b939655f7a28a402f311a0bc89985d681c5543e60c0680b1d604b2e2fe01816 | 4f5477f011ce7dbad728b80fb8feb70848ecb4810b1c25c004801ad39d67af94 | Apache-2.0 | [
"LICENSE"
] | 186 |
2.4 | flet-map | 0.80.6.dev7615 | Interactive map controls for Flet apps. | # flet-map
[](https://pypi.python.org/pypi/flet-map)
[](https://pepy.tech/project/flet-map)
[](https://pypi.org/project/flet-map)
[](https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet/docs/assets/badges/docs-coverage)
[](https://github.com/flet-dev/flet/blob/main/sdk/python/packages/flet-map/LICENSE)
A [Flet](https://flet.dev) extension for displaying interactive maps.
It is based on the [flutter_map](https://pub.dev/packages/flutter_map) Flutter package.
## Documentation
Detailed documentation to this package can be found [here](https://docs.flet.dev/map/).
## Platform Support
| Platform | Windows | macOS | Linux | iOS | Android | Web |
|----------|---------|-------|-------|-----|---------|-----|
| Supported| ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
## Usage
### Installation
To install the `flet-map` package and add it to your project dependencies:
- Using `uv`:
```bash
uv add flet-map
```
- Using `pip`:
```bash
pip install flet-map
```
After this, you will have to manually add this package to your `requirements.txt` or `pyproject.toml`.
### Examples
For examples, see [these](https://github.com/flet-dev/flet/tree/main/sdk/python/examples/controls/map).
| text/markdown | null | Flet contributors <hello@flet.dev> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"flet==0.80.6.dev7615"
] | [] | [] | [] | [
"Homepage, https://flet.dev",
"Documentation, https://docs.flet.dev/map",
"Repository, https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet-map",
"Issues, https://github.com/flet-dev/flet/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:35:42.850299 | flet_map-0.80.6.dev7615-py3-none-any.whl | 48,147 | 99/56/6313f6dbdb52dbe0bd560122c5ba4ce6874140e81886de9efae91d9bc6c7/flet_map-0.80.6.dev7615-py3-none-any.whl | py3 | bdist_wheel | null | false | 26086fe7fb8a57101008cb457ad8d469 | c6f2c22ad50b6c681879f302ab5f8fa9067dc41889cc9b008373f0a331b7ad93 | 99566313f6dbdb52dbe0bd560122c5ba4ce6874140e81886de9efae91d9bc6c7 | Apache-2.0 | [
"LICENSE"
] | 178 |
2.4 | flet-lottie | 0.80.6.dev7615 | Display Lottie animations in Flet apps. | # flet-lottie
[](https://pypi.python.org/pypi/flet-lottie)
[](https://pepy.tech/project/flet-lottie)
[](https://pypi.org/project/flet-lottie)
[](https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet/docs/assets/badges/docs-coverage)
[](https://github.com/flet-dev/flet/blob/main/sdk/python/packages/flet-lottie/LICENSE)
A [Flet](https://flet.dev) extension package for displaying Lottie animations.
It is based on the [lottie](https://pub.dev/packages/lottie) Flutter package.
## Documentation
Detailed documentation to this package can be found [here](https://docs.flet.dev/lottie/).
## Platform Support
| Platform | Windows | macOS | Linux | iOS | Android | Web |
|----------|---------|-------|-------|-----|---------|-----|
| Supported| ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
## Usage
### Installation
To install the `flet-lottie` package and add it to your project dependencies:
- Using `uv`:
```bash
uv add flet-lottie
```
- Using `pip`:
```bash
pip install flet-lottie
```
After this, you will have to manually add this package to your `requirements.txt` or `pyproject.toml`.
### Examples
For examples, see [these](https://github.com/flet-dev/flet/tree/main/sdk/python/examples/controls/lottie).
| text/markdown | null | Flet contributors <hello@flet.dev> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"flet==0.80.6.dev7615"
] | [] | [] | [] | [
"Homepage, https://flet.dev",
"Documentation, https://docs.flet.dev/lottie",
"Repository, https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet-lottie",
"Issues, https://github.com/flet-dev/flet/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:35:40.069608 | flet_lottie-0.80.6.dev7615.tar.gz | 16,889 | 3e/9c/71fed4003e33cbea91abf7c1f3fd42e10c7259bb3185efd4bbfc67bf45fc/flet_lottie-0.80.6.dev7615.tar.gz | source | sdist | null | false | 416e0e1ab26e2bdfafd67a435ea06299 | a694e20406653996e5b162d36eb25f6fe69883720e9a43662ae4eb5aa6a229ad | 3e9c71fed4003e33cbea91abf7c1f3fd42e10c7259bb3185efd4bbfc67bf45fc | Apache-2.0 | [
"LICENSE"
] | 180 |
2.4 | flet-geolocator | 0.80.6.dev7615 | Adds geolocation capabilities to your Flet apps. | # flet-geolocator
[](https://pypi.python.org/pypi/flet-geolocator)
[](https://pepy.tech/project/flet-geolocator)
[](https://pypi.org/project/flet-geolocator)
[](https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet/docs/assets/badges/docs-coverage)
[](https://github.com/flet-dev/flet/blob/main/sdk/python/packages/flet-geolocator/LICENSE)
Adds geolocation capabilities to your [Flet](https://flet.dev) apps.
Features include:
- Get the last known location;
- Get the current location of the device;
- Get continuous location updates;
- Check if location services are enabled on the device.
It is based on the [geolocator](https://pub.dev/packages/geolocator) Flutter package.
## Documentation
Detailed documentation to this package can be found [here](https://docs.flet.dev/geolocator/).
## Platform Support
| Platform | Windows | macOS | Linux | iOS | Android | Web |
|----------|---------|-------|-------|-----|---------|-----|
| Supported| ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
## Usage
### Installation
To install the `flet-geolocator` package and add it to your project dependencies:
- Using `uv`:
```bash
uv add flet-geolocator
```
- Using `pip`:
```bash
pip install flet-geolocator
```
After this, you will have to manually add this package to your `requirements.txt` or `pyproject.toml`.
### Examples
For examples, see [these](https://github.com/flet-dev/flet/tree/main/examples/services/geolocator).
| text/markdown | null | Flet contributors <hello@flet.dev> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"flet==0.80.6.dev7615"
] | [] | [] | [] | [
"Homepage, https://flet.dev",
"Documentation, https://docs.flet.dev/geolocator",
"Repository, https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet-geolocator",
"Issues, https://github.com/flet-dev/flet/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:35:36.675174 | flet_geolocator-0.80.6.dev7615-py3-none-any.whl | 24,527 | 1a/66/40bf44c3cf2d7a58b79020bdf60f8c668fb4c0e8662e57cd35c3812e9d83/flet_geolocator-0.80.6.dev7615-py3-none-any.whl | py3 | bdist_wheel | null | false | 9f06bf5084646955e1a7bdf876702fb7 | 6fb8e6fb9537a7d407be7cd1a27e669d7ae83cff1390df0a0c1f703e25b2db2a | 1a6640bf44c3cf2d7a58b79020bdf60f8c668fb4c0e8662e57cd35c3812e9d83 | Apache-2.0 | [
"LICENSE"
] | 179 |
2.4 | pyneb | 1.1.30 | A Python package for nebular analysis | # PyNeb
PyNeb (Luridiana V., Morisset C. and Shaw, R. A 2013) is a modern python tool to compute emission line emissivities (recombination and collisionally excited lines).
In PyNeb, the atom is represented as an n-level atom. For given density and temperature, PyNeb's machinery solves the equilibrium equations and determines the level populations. These are some of the things it can do:
- compute physical conditions from suitable diagnostic line ratios.
- compute level populations, critical densities and line emissivities
- compute and display emissivity grids as a function of Te and Ne
- deredden line intensities
- read and manage observational data
- plot and compare atomic data from different publications
- compute ionic abundances from line intensities and physical conditions
- compute elemental abundances from ionic abundances and icfs.
PyNeb also incorporates emissivity tables of recombination lines for a few atoms. The interpolated emissivities can be used by any of the module that rely on the n-level line emissivities to carry out the actions listed above.
Emission line ratios are used to self consistently determine electron temperature and density and ionic abundances
Diagnostic diagrams can easily be plotted.
Various ionization correction factors (ICFs) from the literarure are available to obtain total elemental abundances from the ionic abundances.
Atomic data can easily be changed and updated.
Additional tools are provided, like reddening determination and correction procedures, Balmer/Pashen jump
temperature determinations.
## Citation
If you use PyNeb in your research, please cite the following paper:
- Luridiana, V., Morisset, C. and Shaw, R. A. 2013, A&A, 558, A57
http://adsabs.harvard.edu/abs/2015A%26A...573A..42L
- Morisset, C., Luridiana, V., García-Rojas, J., Gómez-Llanos, V., Bautista, M., & Mendoza, C. 2020, Atoms, 8, 66,
«Atomic Data Assessment with PyNeb»
https://ui.adsabs.harvard.edu/abs/2020Atoms...8...66M
- Mendoza, C., Méndez-Delgado, J. E., Bautista, M., García-Rojas, J., & Morisset, C. 2023, Atoms, 11, 63,
«Atomic Data Assessment with PyNeb: Radiative and Electron Impact Excitation Rates for [Fe ii] and [Fe iii]»
https://ui.adsabs.harvard.edu/abs/2023Atoms..11...63M
## Requirements
PyNeb uses numpy, matplotlib, pyfits, scipy and other standard python libraries.
## Installation
You may find useful to download, install and upgrade PyNeb using [pip](http://www.pip-installer.org/en/latest/index.html).
For example:
- `pip install -U PyNeb`
Note: you MAY need `--user` if you installed python without Anaconda or Canopy.
Updates use the same command.
You can also install from the github repository:
- `pip install -U git+https://github.com/Morisset/PyNeb_devel.git`
To use the development branch (at your own risks!!!):
- `pip install -U git+https://github.com/Morisset/PyNeb_devel.git@devel`
## Warranty
PyNeb is provided as it is. No warranty at all.
## Manual
- An introduction to PyNeb is available here: <https://github.com/Morisset/PyNeb_devel/tree/master/docs/PyNeb.pdf>
- The manuals are here: <https://github.com/Morisset/PyNeb_devel/tree/master/docs>
- The reference manual is accessible from <http://morisset.github.io/PyNeb_devel/>
## Discussion Groups
- https://groups.google.com/forum/#!forum/pyneb
- Send a mail to the group: pyneb@googlegroups.com
## Acknowledgements
This project is partly supported by grants DGAPA/PAPIIT-107215 and CONACyT-CB2015-254132.
PyNeb uses part of Chiantipy:
- Utility functions, many for reading the CHIANTI database files:
Copyright 2009, 2010 Kenneth P. Dere
This software is distributed under the terms of the GNU General Public License that is found in the LICENSE file
- FortranFormat: Written by Konrad Hinsen <hinsen@cnrs-orleans.fr> With contributions from Andreas Prlic <andreas@came.sbg.ac.at> last revision: 2006-6-23
| text/markdown | Valentina Luridiana | Christophe Morisset <chris.morisset@gmail.com> | null | null | null | nebular, analysis, astronomy | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy",
"matplotlib",
"scipy",
"h5py",
"astropy"
] | [] | [] | [] | [
"Homepage, http://www.iac.es/proyecto/PyNeb/",
"Repository, https://github.com/Morisset/PyNeb_devel",
"Documentation, http://morisset.github.io/PyNeb_devel/",
"Changelog, https://github.com/Morisset/PyNeb_devel/tree/master/docs/CHANGES"
] | twine/6.2.0 CPython/3.12.9 | 2026-02-19T20:35:33.687327 | pyneb-1.1.30.tar.gz | 27,836,536 | 42/c6/fa5ea6d60b15b9b1af8afcade7a07f7ab19e15f54569544170ddb00307c2/pyneb-1.1.30.tar.gz | source | sdist | null | false | f3165372fbf26d29838613562e38876d | b490ace3e554f279c9074b084ecdf198ef2eb744d108e3e0e3048f0d537c0a56 | 42c6fa5ea6d60b15b9b1af8afcade7a07f7ab19e15f54569544170ddb00307c2 | null | [
"LICENSE.md"
] | 254 |
2.4 | flet-flashlight | 0.80.6.dev7615 | Control device torch/flashlight from Flet apps. | # flet-flashlight
[](https://pypi.python.org/pypi/flet-flashlight)
[](https://pepy.tech/project/flet-flashlight)
[](https://pypi.org/project/flet-flashlight)
[](https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet/docs/assets/badges/docs-coverage)
[](https://github.com/flet-dev/flet/blob/main/sdk/python/packages/flet-flashlight/LICENSE)
A [Flet](https://flet.dev) extension to manage the device torch/flashlight.
It is based on the [flashlight](https://pub.dev/packages/flashlight) Flutter package.
> **Important:** Add `Flashlight` instances to `page.services` before calling toggle or other methods.
## Documentation
Detailed documentation to this package can be found [here](https://docs.flet.dev/flashlight/).
## Platform Support
| Platform | Windows | macOS | Linux | iOS | Android | Web |
|----------|---------|-------|-------|-----|---------|-----|
| Supported| ❌ | ❌ | ❌ | ✅ | ✅ | ❌ |
## Usage
### Installation
To install the `flet-flashlight` package and add it to your project dependencies:
- Using `uv`:
```bash
uv add flet-flashlight
```
- Using `pip`:
```bash
pip install flet-flashlight
```
After this, you will have to manually add this package to your `requirements.txt` or `pyproject.toml`.
### Examples
For examples, see [these](https://github.com/flet-dev/flet/tree/main/examples/services/flashlight).
| text/markdown | null | Flet contributors <hello@flet.dev> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"flet==0.80.6.dev7615"
] | [] | [] | [] | [
"Homepage, https://flet.dev",
"Documentation, https://docs.flet.dev/flashlight",
"Repository, https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet-flashlight",
"Issues, https://github.com/flet-dev/flet/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:35:33.520324 | flet_flashlight-0.80.6.dev7615-py3-none-any.whl | 16,841 | ee/88/1c0251c3b9aa4b1450e36d501d60e749bea88cd8b6333a929d34f1f18094/flet_flashlight-0.80.6.dev7615-py3-none-any.whl | py3 | bdist_wheel | null | false | 5213a4cd7090dae71babb5da7da1071a | a2dbcd78e9dfb0f25683047e378520c4ed63788dff03844a7f0e3a5c1c9e3c33 | ee881c0251c3b9aa4b1450e36d501d60e749bea88cd8b6333a929d34f1f18094 | Apache-2.0 | [
"LICENSE"
] | 174 |
2.4 | flet-datatable2 | 0.80.6.dev7615 | Enhanced data table widgets for Flet apps. | # flet-datatable2
[](https://pypi.python.org/pypi/flet-datatable2)
[](https://pepy.tech/project/flet-datatable2)
[](https://pypi.org/project/flet-datatable2)
[](https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet/docs/assets/badges/docs-coverage)
[](https://github.com/flet-dev/flet/blob/main/sdk/python/packages/flet-datatable2/LICENSE)
An enhanced data table for [Flet](https://flet.dev) apps that builds on the built-in component by adding sticky headers,
fixed top rows, and fixed left columns while preserving all core features.
It is based on [data_table_2](https://pub.dev/packages/data_table_2) Flutter package.
## Documentation
You can find its documentation [here](https://docs.flet.dev/datatable2/).
## Platform Support
This package supports the following platforms:
| Platform | Windows | macOS | Linux | iOS | Android | Web |
|----------|---------|-------|-------|-----|---------|-----|
| Supported| ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
## Usage
### Installation
To install the `flet-datatable2` package and add it to your project dependencies:
- Using `uv`:
```bash
uv add flet-datatable2
```
- Using `pip`:
```bash
pip install flet-datatable2
```
After this, you will have to manually add this package to your `requirements.txt` or `pyproject.toml`.
### Examples
For examples, see [these](https://github.com/flet-dev/flet/tree/main/examples/controls/datatable2).
| text/markdown | null | Flet contributors <hello@flet.dev> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"flet==0.80.6.dev7615"
] | [] | [] | [] | [
"Homepage, https://flet.dev",
"Documentation, https://docs.flet.dev/datatable2",
"Repository, https://github.com/flet-dev/flet/tree/main/sdk/python/packages/flet-datatable2",
"Issues, https://github.com/flet-dev/flet/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T20:35:28.741455 | flet_datatable2-0.80.6.dev7615-py3-none-any.whl | 25,473 | 73/24/9d9e9403b695ad8c44f2035075f689c0502fcfe51614b5ef6a7759be2521/flet_datatable2-0.80.6.dev7615-py3-none-any.whl | py3 | bdist_wheel | null | false | 930e4670b4e3630a2867fb48976cf1c6 | cef17eb376ed650b9d45186f181394337510ef0f2215b8f10abe6fff19dc7a21 | 73249d9e9403b695ad8c44f2035075f689c0502fcfe51614b5ef6a7759be2521 | Apache-2.0 | [
"LICENSE"
] | 188 |
2.4 | pwndck | 0.5 | Check for leaked passwords in HaveIBeenPwned. | # pwndck
Check the the HaveIBeenPwned password database to see if a particular password
has been compromised.
It uses the [haveibeenpwned API](https://haveibeenpwned.com/API/v3#PwnedPasswords)
for the check:
* This use does not require an API key. Anyone can run it.
* This is more secure than the [web page tool](https://haveibeenpwned.com/Passwords).
your password is
[not exposed](https://blog.cloudflare.com/validating-leaked-passwords-with-k-anonymity/)
beyond your local machine.
* It returns the number of times the password occurs in the database.
# Install
Install from [PyPi](https://pypi.org/project/pwndck/)
# Usage
$ pwndck -h
usage: pwndck [-h] [-q] [-i [INPUT] | passwords ...]
Report # of password hits in HaveIBeenPwned
positional arguments:
passwords The password(s) to check
options:
-h, --help show this help message and exit
-q, --quiet Suppress output
-i, --input [INPUT] File containing passwords, one per line
('-' for stdin)
Evaluate one or more passwords against the HaveIBeenPwned
password database, and return the number of accounts for which
they have been reported as compromised.
The number of entries found in the database is returned. if
multiple passwords are being checked, the password name is also
returned.
If the password is not specified on the command line, the user
will be prompted.
The command returns with an error code if the password is found
in the database.
See https://haveibeenpwned.com/API/v3#PwnedPasswords
# Module
$ python3
Python 3.13.11 (main, Dec 8 2025, 11:43:54) [GCC 15.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pwndck
>>> pwndck.process_pw("password")
52256179
>>>
| text/markdown | David Steele | dsteele@gmail.com | null | null | null | passwords, security, breach, haveibeenpwned | [
"Environment :: Console",
"Development Status :: 5 - Production/Stable",
"Intended Audience :: End Users/Desktop",
"License :: OSI Approved :: GNU General Public License v2 or later (GPLv2+)",
"Natural Language :: English",
"Operating System :: POSIX :: Linux",
"Operating System :: MacOS",
"Operating ... | [] | null | null | >=3.9 | [] | [] | [] | [
"argparse-formatter<2.0,>=1.4",
"brotli>=1.1.0",
"requests<3.0.0,>=2.32.5"
] | [] | [] | [] | [
"Changelog, https://github.com/davesteele/pwndck/blob/main/CHANGELOG.md",
"Homepage, https://github.com/davesteele/pwndck",
"Issues, https://github.com/davesteele/pwndck/issues",
"Source, https://github.com/davesteele/pwndck.git"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T20:35:27.939261 | pwndck-0.5.tar.gz | 11,396 | 7b/10/8b33bf4c8c0428b899caf285a37602d775ab18816e4a891fe7822284b83b/pwndck-0.5.tar.gz | source | sdist | null | false | f468d1c22057869a6e1bbe70058c0d6a | b5b0ad3b7b2833867410e5fa62a46a66e191fa54f178b9a37ba4b54f1890d1c5 | 7b108b33bf4c8c0428b899caf285a37602d775ab18816e4a891fe7822284b83b | null | [
"LICENSE"
] | 200 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.