
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.1 | aws-cdk.aws-imagebuilder-alpha | 2.239.0a0 | The CDK Construct Library for EC2 Image Builder | # EC2 Image Builder Construct Library
<!--BEGIN STABILITY BANNER-->---

> The APIs of higher level constructs in this module are experimental and under active development.
> They are subject to non-backward compatible changes or removal in any future version. These are
> not subject to the [Semantic Versioning](https://semver.org/) model and breaking changes will be
> announced in the release notes. This means that while you may use them, you may need to update
> your source code when upgrading to a newer version of this package.
---
<!--END STABILITY BANNER-->
This module is part of the [AWS Cloud Development Kit](https://github.com/aws/aws-cdk) project.
## README
[Amazon EC2 Image Builder](https://docs.aws.amazon.com/imagebuilder/latest/userguide/what-is-image-builder.html) is a
fully managed AWS service that helps you automate the creation, management, and deployment of customized, secure, and
up-to-date server images. You can use Image Builder to create Amazon Machine Images (AMIs) and container images for use
across AWS Regions.
This module is part of the [AWS Cloud Development Kit](https://github.com/aws/aws-cdk) project. It allows you to define
Image Builder pipelines, images, recipes, components, workflows, and lifecycle policies.
A component defines the sequence of steps required to customize an instance during image creation (build component) or
test an instance launched from the created image (test component). Components are created from declarative YAML or JSON
documents that describe runtime configuration for building, validating, or testing instances. Components are included
when added to the image recipe or container recipe for an image build.
EC2 Image Builder supports AWS-managed components for common tasks, AWS Marketplace components, and custom components
that you create. Components run during specific workflow phases: build and validate phases during the build stage, and
test phase during the test stage.
### Image Pipeline
An image pipeline provides the automation framework for building secure AMIs and container images. The pipeline
orchestrates the entire image creation process by combining an image recipe or container recipe with infrastructure
configuration and distribution configuration. Pipelines can run on a schedule or be triggered manually, and they manage
the build, test, and distribution phases automatically.
#### Image Pipeline Basic Usage
Create a simple AMI pipeline with just an image recipe:
```python
image_recipe = imagebuilder.ImageRecipe(self, "MyImageRecipe",
base_image=imagebuilder.BaseImage.from_ssm_parameter_name("/aws/service/ami-amazon-linux-latest/al2023-ami-minimal-kernel-default-x86_64")
)
image_pipeline = imagebuilder.ImagePipeline(self, "MyImagePipeline",
recipe=example_image_recipe
)
```
Create a simple container pipeline with just a container recipe:
```python
container_recipe = imagebuilder.ContainerRecipe(self, "MyContainerRecipe",
base_image=imagebuilder.BaseContainerImage.from_docker_hub("amazonlinux", "latest"),
target_repository=imagebuilder.Repository.from_ecr(
ecr.Repository.from_repository_name(self, "Repository", "my-container-repo"))
)
container_pipeline = imagebuilder.ImagePipeline(self, "MyContainerPipeline",
recipe=example_container_recipe
)
```
#### Image Pipeline Scheduling
##### Manual Pipeline Execution
Create a pipeline that runs only when manually triggered:
```python
manual_pipeline = imagebuilder.ImagePipeline(self, "ManualPipeline",
image_pipeline_name="my-manual-pipeline",
description="Pipeline triggered manually for production builds",
recipe=example_image_recipe
)
# Grant Lambda function permission to trigger the pipeline
manual_pipeline.grant_start_execution(lambda_role)
```
##### Automated Pipeline Scheduling
Schedule a pipeline to run automatically using cron expressions:
```python
weekly_pipeline = imagebuilder.ImagePipeline(self, "WeeklyPipeline",
image_pipeline_name="weekly-build-pipeline",
recipe=example_image_recipe,
schedule=imagebuilder.ImagePipelineSchedule(
expression=events.Schedule.cron(
minute="0",
hour="6",
week_day="MON"
)
)
)
```
Use rate expressions for regular intervals:
```python
daily_pipeline = imagebuilder.ImagePipeline(self, "DailyPipeline",
recipe=example_container_recipe,
schedule=imagebuilder.ImagePipelineSchedule(
expression=events.Schedule.rate(Duration.days(1))
)
)
```
##### Pipeline Schedule Configuration
Configure advanced scheduling options:
```python
advanced_schedule_pipeline = imagebuilder.ImagePipeline(self, "AdvancedSchedulePipeline",
recipe=example_image_recipe,
schedule=imagebuilder.ImagePipelineSchedule(
expression=events.Schedule.rate(Duration.days(7)),
# Only trigger when dependencies are updated (new base images, components, etc.)
start_condition=imagebuilder.ScheduleStartCondition.EXPRESSION_MATCH_AND_DEPENDENCY_UPDATES_AVAILABLE,
# Automatically disable after 3 consecutive failures
auto_disable_failure_count=3
),
# Start enabled
status=imagebuilder.ImagePipelineStatus.ENABLED
)
```
#### Image Pipeline Configuration
##### Infrastructure and Distribution in Image Pipelines
Configure custom infrastructure and distribution settings:
```python
infrastructure_configuration = imagebuilder.InfrastructureConfiguration(self, "Infrastructure",
infrastructure_configuration_name="production-infrastructure",
instance_types=[
ec2.InstanceType.of(ec2.InstanceClass.COMPUTE7_INTEL, ec2.InstanceSize.LARGE)
],
vpc=vpc,
subnet_selection=ec2.SubnetSelection(subnet_type=ec2.SubnetType.PRIVATE_WITH_EGRESS)
)
distribution_configuration = imagebuilder.DistributionConfiguration(self, "Distribution")
distribution_configuration.add_ami_distributions(
ami_name="production-ami-{{ imagebuilder:buildDate }}",
ami_target_account_ids=["123456789012", "098765432109"]
)
production_pipeline = imagebuilder.ImagePipeline(self, "ProductionPipeline",
recipe=example_image_recipe,
infrastructure_configuration=infrastructure_configuration,
distribution_configuration=distribution_configuration
)
```
##### Pipeline Logging Configuration
Configure custom CloudWatch log groups for pipeline and image logs:
```python
pipeline_log_group = logs.LogGroup(self, "PipelineLogGroup",
log_group_name="/custom/imagebuilder/pipeline/logs",
retention=logs.RetentionDays.ONE_MONTH
)
image_log_group = logs.LogGroup(self, "ImageLogGroup",
log_group_name="/custom/imagebuilder/image/logs",
retention=logs.RetentionDays.ONE_WEEK
)
logged_pipeline = imagebuilder.ImagePipeline(self, "LoggedPipeline",
recipe=example_image_recipe,
image_pipeline_log_group=pipeline_log_group,
image_log_group=image_log_group
)
```
##### Workflow Integration in Image Pipelines
Use AWS-managed workflows for common pipeline phases:
```python
workflow_pipeline = imagebuilder.ImagePipeline(self, "WorkflowPipeline",
recipe=example_image_recipe,
workflows=[imagebuilder.WorkflowConfiguration(workflow=imagebuilder.AmazonManagedWorkflow.build_image(self, "BuildWorkflow")), imagebuilder.WorkflowConfiguration(workflow=imagebuilder.AmazonManagedWorkflow.test_image(self, "TestWorkflow"))
]
)
```
For container pipelines, use container-specific workflows:
```python
container_workflow_pipeline = imagebuilder.ImagePipeline(self, "ContainerWorkflowPipeline",
recipe=example_container_recipe,
workflows=[imagebuilder.WorkflowConfiguration(workflow=imagebuilder.AmazonManagedWorkflow.build_container(self, "BuildContainer")), imagebuilder.WorkflowConfiguration(workflow=imagebuilder.AmazonManagedWorkflow.test_container(self, "TestContainer")), imagebuilder.WorkflowConfiguration(workflow=imagebuilder.AmazonManagedWorkflow.distribute_container(self, "DistributeContainer"))
]
)
```
##### Advanced Features in Image Pipelines
Configure image scanning for container pipelines:
```python
scanning_repository = ecr.Repository(self, "ScanningRepo")
scanned_container_pipeline = imagebuilder.ImagePipeline(self, "ScannedContainerPipeline",
recipe=example_container_recipe,
image_scanning_enabled=True,
image_scanning_ecr_repository=scanning_repository,
image_scanning_ecr_tags=["security-scan", "latest"]
)
```
Control metadata collection and testing:
```python
controlled_pipeline = imagebuilder.ImagePipeline(self, "ControlledPipeline",
recipe=example_image_recipe,
enhanced_image_metadata_enabled=True, # Collect detailed OS and package info
image_tests_enabled=False
)
```
#### Image Pipeline Events
##### Pipeline Event Handling
Handle specific pipeline events:
```python
# Monitor CVE detection
example_pipeline.on_cVEDetected("CVEAlert",
target=targets.SnsTopic(topic)
)
# Handle pipeline auto-disable events
example_pipeline.on_image_pipeline_auto_disabled("PipelineDisabledAlert",
target=targets.LambdaFunction(lambda_function)
)
```
#### Importing Image Pipelines
Reference existing pipelines created outside CDK:
```python
# Import by name
existing_pipeline_by_name = imagebuilder.ImagePipeline.from_image_pipeline_name(self, "ExistingPipelineByName", "my-existing-pipeline")
# Import by ARN
existing_pipeline_by_arn = imagebuilder.ImagePipeline.from_image_pipeline_arn(self, "ExistingPipelineByArn", "arn:aws:imagebuilder:us-east-1:123456789012:image-pipeline/imported-pipeline")
# Grant permissions to imported pipelines
automation_role = iam.Role(self, "AutomationRole",
assumed_by=iam.ServicePrincipal("lambda.amazonaws.com")
)
existing_pipeline_by_name.grant_start_execution(automation_role)
existing_pipeline_by_arn.grant_read(lambda_role)
```
### Image
An image is the output resource created by Image Builder, consisting of an AMI or container image plus metadata such as
version, platform, and creation details. Images are used as base images for future builds and can be shared across AWS
accounts. While images are the output from image pipeline executions, they can also be created in an ad-hoc manner
outside a pipeline, defined as a standalone resource.
#### Image Basic Usage
Create a simple AMI-based image from an image recipe:
```python
image_recipe = imagebuilder.ImageRecipe(self, "MyImageRecipe",
base_image=imagebuilder.BaseImage.from_ssm_parameter_name("/aws/service/ami-amazon-linux-latest/al2023-ami-minimal-kernel-default-x86_64")
)
ami_image = imagebuilder.Image(self, "MyAmiImage",
recipe=image_recipe
)
```
Create a simple container image from a container recipe:
```python
container_recipe = imagebuilder.ContainerRecipe(self, "MyContainerRecipe",
base_image=imagebuilder.BaseContainerImage.from_docker_hub("amazonlinux", "latest"),
target_repository=imagebuilder.Repository.from_ecr(
ecr.Repository.from_repository_name(self, "Repository", "my-container-repo"))
)
container_image = imagebuilder.Image(self, "MyContainerImage",
recipe=container_recipe
)
```
#### AWS-Managed Images
##### Pre-defined OS Images
Use AWS-managed images for common operating systems:
```python
# Amazon Linux 2023 AMI for x86_64
amazon_linux2023_ami = imagebuilder.AmazonManagedImage.amazon_linux2023(self, "AmazonLinux2023",
image_type=imagebuilder.ImageType.AMI,
image_architecture=imagebuilder.ImageArchitecture.X86_64
)
# Ubuntu 22.04 AMI for ARM64
ubuntu2204_ami = imagebuilder.AmazonManagedImage.ubuntu_server2204(self, "Ubuntu2204",
image_type=imagebuilder.ImageType.AMI,
image_architecture=imagebuilder.ImageArchitecture.ARM64
)
# Windows Server 2022 Full AMI
windows2022_ami = imagebuilder.AmazonManagedImage.windows_server2022_full(self, "Windows2022",
image_type=imagebuilder.ImageType.AMI,
image_architecture=imagebuilder.ImageArchitecture.X86_64
)
# Use as base image in recipe
managed_image_recipe = imagebuilder.ImageRecipe(self, "ManagedImageRecipe",
base_image=amazon_linux2023_ami.to_base_image()
)
```
##### Custom AWS-Managed Images
Import AWS-managed images by name or attributes:
```python
# Import by name
managed_image_by_name = imagebuilder.AmazonManagedImage.from_amazon_managed_image_name(self, "ManagedImageByName", "amazon-linux-2023-x86")
# Import by attributes with specific version
managed_image_by_attributes = imagebuilder.AmazonManagedImage.from_amazon_managed_image_attributes(self, "ManagedImageByAttributes",
image_name="ubuntu-server-22-lts-x86",
image_version="2024.11.25"
)
```
#### Image Configuration
##### Infrastructure and Distribution in Images
Configure custom infrastructure and distribution settings:
```python
infrastructure_configuration = imagebuilder.InfrastructureConfiguration(self, "Infrastructure",
infrastructure_configuration_name="production-infrastructure",
instance_types=[
ec2.InstanceType.of(ec2.InstanceClass.COMPUTE7_INTEL, ec2.InstanceSize.LARGE)
],
vpc=vpc,
subnet_selection=ec2.SubnetSelection(subnet_type=ec2.SubnetType.PRIVATE_WITH_EGRESS)
)
distribution_configuration = imagebuilder.DistributionConfiguration(self, "Distribution")
distribution_configuration.add_ami_distributions(
ami_name="production-ami-{{ imagebuilder:buildDate }}",
ami_target_account_ids=["123456789012", "098765432109"]
)
production_image = imagebuilder.Image(self, "ProductionImage",
recipe=example_image_recipe,
infrastructure_configuration=infrastructure_configuration,
distribution_configuration=distribution_configuration
)
```
##### Logging Configuration
Configure custom CloudWatch log groups for image builds:
```python
log_group = logs.LogGroup(self, "ImageLogGroup",
log_group_name="/custom/imagebuilder/image/logs",
retention=logs.RetentionDays.ONE_MONTH
)
logged_image = imagebuilder.Image(self, "LoggedImage",
recipe=example_image_recipe,
log_group=log_group
)
```
##### Workflow Integration in Images
Use workflows for custom build, test, and distribution processes:
```python
image_with_workflows = imagebuilder.Image(self, "ImageWithWorkflows",
recipe=example_image_recipe,
workflows=[imagebuilder.WorkflowConfiguration(workflow=imagebuilder.AmazonManagedWorkflow.build_image(self, "BuildWorkflow")), imagebuilder.WorkflowConfiguration(workflow=imagebuilder.AmazonManagedWorkflow.test_image(self, "TestWorkflow"))
]
)
```
##### Advanced Features in Images
Configure image scanning, metadata collection, and testing:
```python
scanning_repository = ecr.Repository(self, "ScanningRepository")
advanced_container_image = imagebuilder.Image(self, "AdvancedContainerImage",
recipe=example_container_recipe,
image_scanning_enabled=True,
image_scanning_ecr_repository=scanning_repository,
image_scanning_ecr_tags=["security-scan", "latest"],
enhanced_image_metadata_enabled=True,
image_tests_enabled=False
)
```
#### Importing Images
Reference existing images created outside CDK:
```python
# Import by name
existing_image_by_name = imagebuilder.Image.from_image_name(self, "ExistingImageByName", "my-existing-image")
# Import by ARN
existing_image_by_arn = imagebuilder.Image.from_image_arn(self, "ExistingImageByArn", "arn:aws:imagebuilder:us-east-1:123456789012:image/imported-image/1.0.0")
# Import by attributes
existing_image_by_attributes = imagebuilder.Image.from_image_attributes(self, "ExistingImageByAttributes",
image_name="shared-base-image",
image_version="2024.11.25"
)
# Grant permissions to imported images
role = iam.Role(self, "ImageAccessRole",
assumed_by=iam.ServicePrincipal("lambda.amazonaws.com")
)
existing_image_by_name.grant_read(role)
existing_image_by_arn.grant(role, "imagebuilder:GetImage", "imagebuilder:ListImagePackages")
```
### Image Recipe
#### Image Recipe Basic Usage
Create an image recipe with the required base image:
```python
image_recipe = imagebuilder.ImageRecipe(self, "MyImageRecipe",
base_image=imagebuilder.BaseImage.from_ssm_parameter_name("/aws/service/ami-amazon-linux-latest/al2023-ami-minimal-kernel-default-x86_64")
)
```
#### Image Recipe Base Images
To create a recipe, you have to select a base image to build and customize from. This base image can be referenced from
various sources, such as from SSM parameters, AWS Marketplace products, and AMI IDs directly.
##### SSM Parameters
Using SSM parameter references:
```python
image_recipe = imagebuilder.ImageRecipe(self, "SsmImageRecipe",
base_image=imagebuilder.BaseImage.from_ssm_parameter_name("/aws/service/ami-amazon-linux-latest/al2023-ami-minimal-kernel-default-x86_64")
)
# Using an SSM parameter construct
parameter = ssm.StringParameter.from_string_parameter_name(self, "BaseImageParameter", "/aws/service/ami-windows-latest/Windows_Server-2022-English-Full-Base")
windows_recipe = imagebuilder.ImageRecipe(self, "WindowsImageRecipe",
base_image=imagebuilder.BaseImage.from_ssm_parameter(parameter)
)
```
##### AMI IDs
When you have a specific AMI to use:
```python
image_recipe = imagebuilder.ImageRecipe(self, "AmiImageRecipe",
base_image=imagebuilder.BaseImage.from_ami_id("ami-12345678")
)
```
##### Marketplace Images
For marketplace base images:
```python
image_recipe = imagebuilder.ImageRecipe(self, "MarketplaceImageRecipe",
base_image=imagebuilder.BaseImage.from_marketplace_product_id("prod-1234567890abcdef0")
)
```
#### Image Recipe Components
Components from various sources, such as custom-owned, AWS-owned, or AWS Marketplace-owned, can optionally be included
in recipes. For parameterized components, you are able to provide the parameters to use in the recipe, which will be
applied during the image build when executing components.
##### Custom Components in Image Recipes
Add your own components to the recipe:
```python
custom_component = imagebuilder.Component(self, "MyComponent",
platform=imagebuilder.Platform.LINUX,
data=imagebuilder.ComponentData.from_json_object({
"schema_version": imagebuilder.ComponentSchemaVersion.V1_0,
"phases": [{
"name": imagebuilder.ComponentPhaseName.BUILD,
"steps": [{
"name": "install-app",
"action": imagebuilder.ComponentAction.EXECUTE_BASH,
"inputs": {
"commands": ["yum install -y my-application"]
}
}
]
}
]
})
)
image_recipe = imagebuilder.ImageRecipe(self, "ComponentImageRecipe",
base_image=imagebuilder.BaseImage.from_ssm_parameter_name("/aws/service/ami-amazon-linux-latest/al2023-ami-minimal-kernel-default-x86_64"),
components=[imagebuilder.ComponentConfiguration(
component=custom_component
)
]
)
```
##### AWS-Managed Components in Image Recipes
Use pre-built AWS components:
```python
image_recipe = imagebuilder.ImageRecipe(self, "AmazonManagedImageRecipe",
base_image=imagebuilder.BaseImage.from_ssm_parameter_name("/aws/service/ami-amazon-linux-latest/al2023-ami-minimal-kernel-default-x86_64"),
components=[imagebuilder.ComponentConfiguration(
component=imagebuilder.AmazonManagedComponent.update_os(self, "UpdateOS",
platform=imagebuilder.Platform.LINUX
)
), imagebuilder.ComponentConfiguration(
component=imagebuilder.AmazonManagedComponent.aws_cli_v2(self, "AwsCli",
platform=imagebuilder.Platform.LINUX
)
)
]
)
```
##### Component Parameters in Image Recipes
Pass parameters to components that accept them:
```python
parameterized_component = imagebuilder.Component.from_component_name(self, "ParameterizedComponent", "my-parameterized-component")
image_recipe = imagebuilder.ImageRecipe(self, "ParameterizedImageRecipe",
base_image=imagebuilder.BaseImage.from_ssm_parameter_name("/aws/service/ami-amazon-linux-latest/al2023-ami-minimal-kernel-default-x86_64"),
components=[imagebuilder.ComponentConfiguration(
component=parameterized_component,
parameters={
"environment": imagebuilder.ComponentParameterValue.from_string("production"),
"version": imagebuilder.ComponentParameterValue.from_string("1.0.0")
}
)
]
)
```
#### Image Recipe Configuration
##### Block Device Configuration
Configure storage for the build instance:
```python
image_recipe = imagebuilder.ImageRecipe(self, "BlockDeviceImageRecipe",
base_image=imagebuilder.BaseImage.from_ssm_parameter_name("/aws/service/ami-amazon-linux-latest/al2023-ami-minimal-kernel-default-x86_64"),
block_devices=[ec2.BlockDevice(
device_name="/dev/sda1",
volume=ec2.BlockDeviceVolume.ebs(100,
encrypted=True,
volume_type=ec2.EbsDeviceVolumeType.GENERAL_PURPOSE_SSD_GP3
)
)
]
)
```
##### AMI Tagging
Tag the output AMI:
```python
image_recipe = imagebuilder.ImageRecipe(self, "TaggedImageRecipe",
base_image=imagebuilder.BaseImage.from_ssm_parameter_name("/aws/service/ami-amazon-linux-latest/al2023-ami-minimal-kernel-default-x86_64"),
ami_tags={
"Environment": "Production",
"Application": "WebServer",
"Owner": "DevOps Team"
}
)
```
### Container Recipe
A container recipe is similar to an image recipe but specifically for container images. It defines the base container
image and components applied to produce the desired configuration for the output container image. Container recipes work
with Docker images from DockerHub, Amazon ECR, or Amazon-managed container images as starting points.
#### Container Recipe Basic Usage
Create a container recipe with the required base image and target repository:
```python
container_recipe = imagebuilder.ContainerRecipe(self, "MyContainerRecipe",
base_image=imagebuilder.BaseContainerImage.from_docker_hub("amazonlinux", "latest"),
target_repository=imagebuilder.Repository.from_ecr(
ecr.Repository.from_repository_name(self, "Repository", "my-container-repo"))
)
```
#### Container Recipe Base Images
##### DockerHub Images
Using public Docker Hub images:
```python
container_recipe = imagebuilder.ContainerRecipe(self, "DockerHubContainerRecipe",
base_image=imagebuilder.BaseContainerImage.from_docker_hub("amazonlinux", "latest"),
target_repository=imagebuilder.Repository.from_ecr(
ecr.Repository.from_repository_name(self, "Repository", "my-container-repo"))
)
```
##### ECR Images
Using images from your own ECR repositories:
```python
source_repo = ecr.Repository.from_repository_name(self, "SourceRepo", "my-base-image")
target_repo = ecr.Repository.from_repository_name(self, "TargetRepo", "my-container-repo")
container_recipe = imagebuilder.ContainerRecipe(self, "EcrContainerRecipe",
base_image=imagebuilder.BaseContainerImage.from_ecr(source_repo, "1.0.0"),
target_repository=imagebuilder.Repository.from_ecr(target_repo)
)
```
##### ECR Public Images
Using images from Amazon ECR Public:
```python
container_recipe = imagebuilder.ContainerRecipe(self, "EcrPublicContainerRecipe",
base_image=imagebuilder.BaseContainerImage.from_ecr_public("amazonlinux", "amazonlinux", "2023"),
target_repository=imagebuilder.Repository.from_ecr(
ecr.Repository.from_repository_name(self, "Repository", "my-container-repo"))
)
```
#### Container Recipe Components
##### Custom Components in Container Recipes
Add your own components to the container recipe:
```python
custom_component = imagebuilder.Component(self, "MyComponent",
platform=imagebuilder.Platform.LINUX,
data=imagebuilder.ComponentData.from_json_object({
"schema_version": imagebuilder.ComponentSchemaVersion.V1_0,
"phases": [{
"name": imagebuilder.ComponentPhaseName.BUILD,
"steps": [{
"name": "install-app",
"action": imagebuilder.ComponentAction.EXECUTE_BASH,
"inputs": {
"commands": ["yum install -y my-container-application"]
}
}
]
}
]
})
)
container_recipe = imagebuilder.ContainerRecipe(self, "ComponentContainerRecipe",
base_image=imagebuilder.BaseContainerImage.from_docker_hub("amazonlinux", "latest"),
target_repository=imagebuilder.Repository.from_ecr(
ecr.Repository.from_repository_name(self, "Repository", "my-container-repo")),
components=[imagebuilder.ComponentConfiguration(
component=custom_component
)
]
)
```
##### AWS-Managed Components in Container Recipes
Use pre-built AWS components:
```python
container_recipe = imagebuilder.ContainerRecipe(self, "AmazonManagedContainerRecipe",
base_image=imagebuilder.BaseContainerImage.from_docker_hub("amazonlinux", "latest"),
target_repository=imagebuilder.Repository.from_ecr(
ecr.Repository.from_repository_name(self, "Repository", "my-container-repo")),
components=[imagebuilder.ComponentConfiguration(
component=imagebuilder.AmazonManagedComponent.update_os(self, "UpdateOS",
platform=imagebuilder.Platform.LINUX
)
), imagebuilder.ComponentConfiguration(
component=imagebuilder.AmazonManagedComponent.aws_cli_v2(self, "AwsCli",
platform=imagebuilder.Platform.LINUX
)
)
]
)
```
#### Container Recipe Configuration
##### Custom Dockerfile
Provide your own Dockerfile template:
```python
container_recipe = imagebuilder.ContainerRecipe(self, "CustomDockerfileContainerRecipe",
base_image=imagebuilder.BaseContainerImage.from_docker_hub("amazonlinux", "latest"),
target_repository=imagebuilder.Repository.from_ecr(
ecr.Repository.from_repository_name(self, "Repository", "my-container-repo")),
dockerfile=imagebuilder.DockerfileData.from_inline("""
FROM {{{ imagebuilder:parentImage }}}
CMD ["echo", "Hello, world!"]
{{{ imagebuilder:environments }}}
{{{ imagebuilder:components }}}
""")
)
```
##### Instance Configuration
Configure the build instance:
```python
container_recipe = imagebuilder.ContainerRecipe(self, "InstanceConfigContainerRecipe",
base_image=imagebuilder.BaseContainerImage.from_docker_hub("amazonlinux", "latest"),
target_repository=imagebuilder.Repository.from_ecr(
ecr.Repository.from_repository_name(self, "Repository", "my-container-repo")),
# Custom ECS-optimized AMI for building
instance_image=imagebuilder.ContainerInstanceImage.from_ssm_parameter_name("/aws/service/ecs/optimized-ami/amazon-linux-2023/recommended/image_id"),
# Additional storage for build process
instance_block_devices=[ec2.BlockDevice(
device_name="/dev/xvda",
volume=ec2.BlockDeviceVolume.ebs(50,
encrypted=True,
volume_type=ec2.EbsDeviceVolumeType.GENERAL_PURPOSE_SSD_GP3
)
)
]
)
```
### Component
A component defines the sequence of steps required to customize an instance during image creation (build component) or
test an instance launched from the created image (test component). Components are created from declarative YAML or JSON
documents that describe runtime configuration for building, validating, or testing instances. Components are included
when added to the image recipe or container recipe for an image build.
EC2 Image Builder supports AWS-managed components for common tasks, AWS Marketplace components, and custom components
that you create. Components run during specific workflow phases: build and validate phases during the build stage, and
test phase during the test stage.
#### Basic Component Usage
Create a component with the required properties: platform and component data.
```python
component = imagebuilder.Component(self, "MyComponent",
platform=imagebuilder.Platform.LINUX,
data=imagebuilder.ComponentData.from_json_object({
"schema_version": imagebuilder.ComponentSchemaVersion.V1_0,
"phases": [{
"name": imagebuilder.ComponentPhaseName.BUILD,
"steps": [{
"name": "install-app",
"action": imagebuilder.ComponentAction.EXECUTE_BASH,
"inputs": {
"commands": ["echo \"Installing my application...\"", "yum update -y"]
}
}
]
}
]
})
)
```
#### Component Data Sources
##### Inline Component Data
Use `ComponentData.fromInline()` for existing YAML/JSON definitions:
```python
component = imagebuilder.Component(self, "InlineComponent",
platform=imagebuilder.Platform.LINUX,
data=imagebuilder.ComponentData.from_inline("""
name: my-component
schemaVersion: 1.0
phases:
- name: build
steps:
- name: update-os
action: ExecuteBash
inputs:
commands: ['yum update -y']
""")
)
```
##### JSON Object Component Data
Most developer-friendly approach using objects:
```python
component = imagebuilder.Component(self, "JsonComponent",
platform=imagebuilder.Platform.LINUX,
data=imagebuilder.ComponentData.from_json_object({
"schema_version": imagebuilder.ComponentSchemaVersion.V1_0,
"phases": [{
"name": imagebuilder.ComponentPhaseName.BUILD,
"steps": [{
"name": "configure-app",
"action": imagebuilder.ComponentAction.CREATE_FILE,
"inputs": {
"path": "/etc/myapp/config.json",
"content": "{\"env\": \"production\"}"
}
}
]
}
]
})
)
```
##### Structured Component Document
For type-safe, CDK-native definitions with enhanced properties like `timeout` and `onFailure`.
###### Defining a component step
You can define steps in the component which will be executed in order when the component is applied:
```python
step = imagebuilder.ComponentDocumentStep(
name="configure-app",
action=imagebuilder.ComponentAction.CREATE_FILE,
inputs=imagebuilder.ComponentStepInputs.from_object({
"path": "/etc/myapp/config.json",
"content": "{\"env\": \"production\"}"
})
)
```
###### Defining a component phase
Phases group steps together, which run in sequence when building, validating or testing in the component:
```python
phase = imagebuilder.ComponentDocumentPhase(
name=imagebuilder.ComponentPhaseName.BUILD,
steps=[imagebuilder.ComponentDocumentStep(
name="configure-app",
action=imagebuilder.ComponentAction.CREATE_FILE,
inputs=imagebuilder.ComponentStepInputs.from_object({
"path": "/etc/myapp/config.json",
"content": "{\"env\": \"production\"}"
})
)
]
)
```
###### Defining a component
The component data defines all steps across the provided phases to execute during the build:
```python
component = imagebuilder.Component(self, "StructuredComponent",
platform=imagebuilder.Platform.LINUX,
data=imagebuilder.ComponentData.from_component_document_json_object(
schema_version=imagebuilder.ComponentSchemaVersion.V1_0,
phases=[imagebuilder.ComponentDocumentPhase(
name=imagebuilder.ComponentPhaseName.BUILD,
steps=[imagebuilder.ComponentDocumentStep(
name="install-with-timeout",
action=imagebuilder.ComponentAction.EXECUTE_BASH,
timeout=Duration.minutes(10),
on_failure=imagebuilder.ComponentOnFailure.CONTINUE,
inputs=imagebuilder.ComponentStepInputs.from_object({
"commands": ["./install-script.sh"]
})
)
]
)
]
)
)
```
##### S3 Component Data
For those components you want to upload or have uploaded to S3:
```python
# Upload a local file
component_from_asset = imagebuilder.Component(self, "AssetComponent",
platform=imagebuilder.Platform.LINUX,
data=imagebuilder.ComponentData.from_asset(self, "ComponentAsset", "./my-component.yml")
)
# Reference an existing S3 object
bucket = s3.Bucket.from_bucket_name(self, "ComponentBucket", "my-components-bucket")
component_from_s3 = imagebuilder.Component(self, "S3Component",
platform=imagebuilder.Platform.LINUX,
data=imagebuilder.ComponentData.from_s3(bucket, "components/my-component.yml")
)
```
#### Encrypt component data with a KMS key
You can encrypt component data with a KMS key, so that only principals with access to decrypt with the key are able to
access the component data.
```python
component = imagebuilder.Component(self, "EncryptedComponent",
platform=imagebuilder.Platform.LINUX,
kms_key=kms.Key(self, "ComponentKey"),
data=imagebuilder.ComponentData.from_json_object({
"schema_version": imagebuilder.ComponentSchemaVersion.V1_0,
"phases": [{
"name": imagebuilder.ComponentPhaseName.BUILD,
"steps": [{
"name": "secure-setup",
"action": imagebuilder.ComponentAction.EXECUTE_BASH,
"inputs": {
"commands": ["echo \"This component data is encrypted with KMS\""]
}
}
]
}
]
})
)
```
#### AWS-Managed Components
AWS provides a collection of managed components for common tasks:
```python
# Install AWS CLI v2
aws_cli_component = imagebuilder.AmazonManagedComponent.aws_cli_v2(self, "AwsCli",
platform=imagebuilder.Platform.LINUX
)
# Update the operating system
update_component = imagebuilder.AmazonManagedComponent.update_os(self, "UpdateOS",
platform=imagebuilder.Platform.LINUX
)
# Reference any AWS-managed component by name
custom_aws_component = imagebuilder.AmazonManagedComponent.from_amazon_managed_component_name(self, "CloudWatchAgent", "amazon-cloudwatch-agent-linux")
```
#### AWS Marketplace Components
You can reference AWS Marketplace components using the marketplace component name and its product ID:
```python
marketplace_component = imagebuilder.AwsMarketplaceComponent.from_aws_marketplace_component_attributes(self, "MarketplaceComponent",
component_name="my-marketplace-component",
marketplace_product_id="prod-1234567890abcdef0"
)
```
### Infrastructure Configuration
Infrastructure configuration defines the compute resources and environment settings used during the image building
process. This includes instance types, IAM instance profile, VPC settings, subnets, security groups, SNS topics for
notifications, logging configuration, and troubleshooting settings like whether to terminate instances on failure or
keep them running for debugging. These settings are applied to builds when included in an image or an image pipeline.
```python
infrastructure_configuration = imagebuilder.InfrastructureConfiguration(self, "InfrastructureConfiguration",
infrastructure_configuration_name="test-infrastructure-configuration",
description="An Infrastructure Configuration",
# Optional - instance types to use for build/test
instance_types=[
ec2.InstanceType.of(ec2.InstanceClass.STANDARD7_INTEL, ec2.InstanceSize.LARGE),
ec2.InstanceType.of(ec2.InstanceClass.BURSTABLE3, ec2.InstanceSize.LARGE)
],
# Optional - create an instance profile with necessary permissions
instance_profile=iam.InstanceProfile(self, "InstanceProfile",
instance_profile_name="test-instance-profile",
role=iam.Role(self, "InstanceProfileRole",
assumed_by=iam.ServicePrincipal.from_static_service_principle_name("ec2.amazonaws.com"),
managed_policies=[
iam.ManagedPolicy.from_aws_managed_policy_name("AmazonSSMManagedInstanceCore"),
iam.ManagedPolicy.from_aws_managed_policy_name("EC2InstanceProfileForImageBuilder")
]
)
),
# Use VPC network configuration
vpc=vpc,
subnet_selection=ec2.SubnetSelection(subnet_type=ec2.SubnetType.PUBLIC),
security_groups=[ec2.SecurityGroup.from_security_group_id(self, "SecurityGroup", vpc.vpc_default_security_group)],
key_pair=ec2.KeyPair.from_key_pair_name(self, "KeyPair", "imagebuilder-instance-key-pair"),
terminate_instance_on_failure=True,
# Optional - IMDSv2 settings
http_tokens=imagebuilder.HttpTokens.REQUIRED,
http_put_response_hop_limit=1,
# Optional - publish image completion messages to an SNS topic
notification_topic=sns.Topic.from_topic_arn(self, "Topic",
self.format_arn(service="sns", resource="image-builder-topic")),
# Optional - log settings. Logging is enabled by default
logging=imagebuilder.InfrastructureConfigurationLogging(
s3_bucket=s3.Bucket.from_bucket_name(self, "LogBucket", f"imagebuilder-logging-{Aws.ACCOUNT_ID}"),
s3_key_prefix="imagebuilder-logs"
),
# Optional - host placement settings
ec2_instance_availability_zone=Stack.of(self).availability_zones[0],
ec2_instance_host_id=dedicated_host.attr_host_id,
ec2_instance_tenancy=imagebuilder.Tenancy.HOST,
resource_tags={
"Environment": "production"
}
)
```
### Distribution Configuration
Distribution configuration defines how and where your built images are distributed after successful creation. For AMIs,
this includes target AWS Regions, KMS encryption keys, account sharing permissions, License Manager associations, and
launch template configurations. For container images, it specifies the target Amazon ECR repositories across regions.
A distribution configuration can be associated with an image or an image pipeline to define these distribution settings
for image builds.
#### AMI Distributions
AMI distributions can be defined to copy and modify AMIs in different accounts and regions, and apply them to launch
templates, SSM parameters, etc.:
```python
distribution_configuration = imagebuilder.DistributionConfiguration(self, "DistributionConfiguration",
distribution_configuration_name="test-distribution-configuration",
description="A Distribution Configuration",
ami_distributions=[imagebuilder.AmiDistribution(
# Distribute AMI to us-east-2 and publish the AMI ID to an SSM parameter
region="us-east-2",
ssm_parameters=[imagebuilder.SSMParameterConfigurations(
parameter=ssm.StringParameter.from_string_parameter_attributes(self, "CrossRegionParameter",
parameter_name="/imagebuilder/ami",
force_dynamic_reference=True
)
)
]
)
]
)
# For AMI-based image builds - add an AMI distribution in the current region
distribution_configuration.add_ami_distributions(
ami_name="imagebuilder-{{ imagebuilder:buildDate }}",
ami_description="Build AMI",
ami_kms_key=kms.Key.from_lookup(self, "ComponentKey", alias_name="alias/distribution-encryption-key"),
# Copy the AMI to different accounts
ami_target_account_ids=["123456789012", "098765432109"],
# Add launch permissions on the AMI
ami_launch_permission=imagebuilder.AmiLaunchPermission(
organization_arns=[
self.format_arn(region="", service="organizations", resource="organization", resource_name="o-1234567abc")
],
organizational_unit_arns=[
self.format_arn(
region="",
service="organizations",
resource="ou",
resource_name="o-1234567abc/ou-a123-b4567890"
)
],
is_public_user_group=True,
account_ids=["234567890123"]
),
# Attach tags to the AMI
ami_tags={
"Environment": "production",
"Version": "{{ imagebuilder:buildVersion }}"
},
# Optional - publish the distributed AMI ID to an SSM parameter
ssm_parameters=[imagebuilder.SSMParameterConfigurations(
parameter=ssm.StringParameter. | text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/aws/aws-cdk | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.239.0",
"constructs<11.0.0,>=10.5.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/aws/aws-cdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:58:01.537470 | aws_cdk_aws_imagebuilder_alpha-2.239.0a0.tar.gz | 688,076 | fc/b2/6ae0b2ce70fcaa85ea2a8843416928eafb228148df44d7330b425136bff0/aws_cdk_aws_imagebuilder_alpha-2.239.0a0.tar.gz | source | sdist | null | false | 0cfaf5f19f168005e918ec8b05c0a38c | a286e917f93ed16b49c88263aaf759978f21ecab570d1fa646c4781247c9199e | fcb26ae0b2ce70fcaa85ea2a8843416928eafb228148df44d7330b425136bff0 | null | [] | 0 |
2.1 | aws-cdk.aws-glue-alpha | 2.239.0a0 | The CDK Construct Library for AWS::Glue | # AWS Glue Construct Library
<!--BEGIN STABILITY BANNER-->---

> The APIs of higher level constructs in this module are experimental and under active development.
> They are subject to non-backward compatible changes or removal in any future version. These are
> not subject to the [Semantic Versioning](https://semver.org/) model and breaking changes will be
> announced in the release notes. This means that while you may use them, you may need to update
> your source code when upgrading to a newer version of this package.
---
<!--END STABILITY BANNER-->
This module is part of the [AWS Cloud Development Kit](https://github.com/aws/aws-cdk) project.
## README
[AWS Glue](https://aws.amazon.com/glue/) is a serverless data integration
service that makes it easier to discover, prepare, move, and integrate data
from multiple sources for analytics, machine learning (ML), and application
development.
The Glue L2 construct has convenience methods working backwards from common
use cases and sets required parameters to defaults that align with recommended
best practices for each job type. It also provides customers with a balance
between flexibility via optional parameter overrides, and opinionated
interfaces that discouraging anti-patterns, resulting in reduced time to develop
and deploy new resources.
### References
* [Glue Launch Announcement](https://aws.amazon.com/blogs/aws/launch-aws-glue-now-generally-available/)
* [Glue Documentation](https://docs.aws.amazon.com/glue/index.html)
* [Glue L1 (CloudFormation) Constructs](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/AWS_Glue.html)
* Prior version of the [@aws-cdk/aws-glue-alpha module](https://github.com/aws/aws-cdk/blob/v2.51.1/packages/%40aws-cdk/aws-glue/README.md)
## Create a Glue Job
A Job encapsulates a script that connects to data sources, processes
them, and then writes output to a data target. There are four types of Glue
Jobs: Spark (ETL and Streaming), Python Shell, Ray, and Flex Jobs. Most
of the required parameters for these jobs are common across all types,
but there are a few differences depending on the languages supported
and features provided by each type. For all job types, the L2 defaults
to AWS best practice recommendations, such as:
* Use of Secrets Manager for Connection JDBC strings
* Glue job autoscaling
* Default parameter values for Glue job creation
This iteration of the L2 construct introduces breaking changes to
the existing glue-alpha-module, but these changes streamline the developer
experience, introduce new constants for defaults, and replacing synth-time
validations with interface contracts for enforcement of the parameter combinations
that Glue supports. As an opinionated construct, the Glue L2 construct does
not allow developers to create resources that use non-current versions
of Glue or deprecated language dependencies (e.g. deprecated versions of Python).
As always, L1s allow you to specify a wider range of parameters if you need
or want to use alternative configurations.
Optional and required parameters for each job are enforced via interface
rather than validation; see [Glue's public documentation](https://docs.aws.amazon.com/glue/latest/dg/aws-glue-api.html)
for more granular details.
### Spark Jobs
#### ETL Jobs
ETL jobs support pySpark and Scala languages, for which there are separate but
similar constructors. ETL jobs default to the G2 worker type, but you can
override this default with other supported worker type values (G1, G2, G4
and G8). ETL jobs defaults to Glue version 4.0, which you can override to 3.0.
The following ETL features are enabled by default:
`—enable-metrics, —enable-spark-ui, —enable-continuous-cloudwatch-log.`
You can find more details about version, worker type and other features in
[Glue's public documentation](https://docs.aws.amazon.com/glue/latest/dg/aws-glue-api-jobs-job.html).
Reference the pyspark-etl-jobs.test.ts and scalaspark-etl-jobs.test.ts unit tests
for examples of required-only and optional job parameters when creating these
types of jobs.
For the sake of brevity, examples are shown using the pySpark job variety.
Example with only required parameters:
```python
import aws_cdk as cdk
import aws_cdk.aws_iam as iam
# stack: cdk.Stack
# role: iam.IRole
# script: glue.Code
glue.PySparkEtlJob(stack, "PySparkETLJob",
role=role,
script=script,
job_name="PySparkETLJob"
)
```
Example with optional override parameters:
```python
import aws_cdk as cdk
import aws_cdk.aws_iam as iam
# stack: cdk.Stack
# role: iam.IRole
# script: glue.Code
glue.PySparkEtlJob(stack, "PySparkETLJob",
job_name="PySparkETLJobCustomName",
description="This is a description",
role=role,
script=script,
glue_version=glue.GlueVersion.V5_1,
continuous_logging=glue.ContinuousLoggingProps(enabled=False),
worker_type=glue.WorkerType.G_2X,
max_concurrent_runs=100,
timeout=cdk.Duration.hours(2),
connections=[glue.Connection.from_connection_name(stack, "Connection", "connectionName")],
security_configuration=glue.SecurityConfiguration.from_security_configuration_name(stack, "SecurityConfig", "securityConfigName"),
tags={
"FirstTagName": "FirstTagValue",
"SecondTagName": "SecondTagValue",
"XTagName": "XTagValue"
},
number_of_workers=2,
max_retries=2
)
```
#### Streaming Jobs
Streaming jobs are similar to ETL jobs, except that they perform ETL on data
streams using the Apache Spark Structured Streaming framework. Some Spark
job features are not available to Streaming ETL jobs. They support Scala
and pySpark languages. PySpark streaming jobs default Python 3.9,
which you can override with any non-deprecated version of Python. It
defaults to the G2 worker type and Glue 4.0, both of which you can override.
The following best practice features are enabled by default:
`—enable-metrics, —enable-spark-ui, —enable-continuous-cloudwatch-log`.
Reference the pyspark-streaming-jobs.test.ts and scalaspark-streaming-jobs.test.ts
unit tests for examples of required-only and optional job parameters when creating
these types of jobs.
Example with only required parameters:
```python
import aws_cdk as cdk
import aws_cdk.aws_iam as iam
# stack: cdk.Stack
# role: iam.IRole
# script: glue.Code
glue.PySparkStreamingJob(stack, "ImportedJob", role=role, script=script)
```
Example with optional override parameters:
```python
import aws_cdk as cdk
import aws_cdk.aws_iam as iam
# stack: cdk.Stack
# role: iam.IRole
# script: glue.Code
glue.PySparkStreamingJob(stack, "PySparkStreamingJob",
job_name="PySparkStreamingJobCustomName",
description="This is a description",
role=role,
script=script,
glue_version=glue.GlueVersion.V5_1,
continuous_logging=glue.ContinuousLoggingProps(enabled=False),
worker_type=glue.WorkerType.G_2X,
max_concurrent_runs=100,
timeout=cdk.Duration.hours(2),
connections=[glue.Connection.from_connection_name(stack, "Connection", "connectionName")],
security_configuration=glue.SecurityConfiguration.from_security_configuration_name(stack, "SecurityConfig", "securityConfigName"),
tags={
"FirstTagName": "FirstTagValue",
"SecondTagName": "SecondTagValue",
"XTagName": "XTagValue"
},
number_of_workers=2,
max_retries=2
)
```
#### Flex Jobs
The flexible execution class is appropriate for non-urgent jobs such as
pre-production jobs, testing, and one-time data loads. Flexible jobs default
to Glue version 3.0 and worker type `G_2X`. The following best practice
features are enabled by default:
`—enable-metrics, —enable-spark-ui, —enable-continuous-cloudwatch-log`
Reference the pyspark-flex-etl-jobs.test.ts and scalaspark-flex-etl-jobs.test.ts
unit tests for examples of required-only and optional job parameters when creating
these types of jobs.
Example with only required parameters:
```python
import aws_cdk as cdk
import aws_cdk.aws_iam as iam
# stack: cdk.Stack
# role: iam.IRole
# script: glue.Code
glue.PySparkFlexEtlJob(stack, "ImportedJob", role=role, script=script)
```
Example with optional override parameters:
```python
import aws_cdk as cdk
import aws_cdk.aws_iam as iam
# stack: cdk.Stack
# role: iam.IRole
# script: glue.Code
glue.PySparkEtlJob(stack, "pySparkEtlJob",
job_name="pySparkEtlJob",
description="This is a description",
role=role,
script=script,
glue_version=glue.GlueVersion.V5_1,
continuous_logging=glue.ContinuousLoggingProps(enabled=False),
worker_type=glue.WorkerType.G_2X,
max_concurrent_runs=100,
timeout=cdk.Duration.hours(2),
connections=[glue.Connection.from_connection_name(stack, "Connection", "connectionName")],
security_configuration=glue.SecurityConfiguration.from_security_configuration_name(stack, "SecurityConfig", "securityConfigName"),
tags={
"FirstTagName": "FirstTagValue",
"SecondTagName": "SecondTagValue",
"XTagName": "XTagValue"
},
number_of_workers=2,
max_retries=2
)
```
### Python Shell Jobs
Python shell jobs support a Python version that depends on the AWS Glue
version you use. These can be used to schedule and run tasks that don't
require an Apache Spark environment. Python shell jobs default to
Python 3.9 and a MaxCapacity of `0.0625`. Python 3.9 supports pre-loaded
analytics libraries using the `library-set=analytics` flag, which is
enabled by default.
Reference the pyspark-shell-job.test.ts unit tests for examples of
required-only and optional job parameters when creating these types of jobs.
Example with only required parameters:
```python
import aws_cdk as cdk
import aws_cdk.aws_iam as iam
# stack: cdk.Stack
# role: iam.IRole
# script: glue.Code
glue.PythonShellJob(stack, "ImportedJob", role=role, script=script)
```
Example with optional override parameters:
```python
import aws_cdk as cdk
import aws_cdk.aws_iam as iam
# stack: cdk.Stack
# role: iam.IRole
# script: glue.Code
glue.PythonShellJob(stack, "PythonShellJob",
job_name="PythonShellJobCustomName",
description="This is a description",
python_version=glue.PythonVersion.TWO,
max_capacity=glue.MaxCapacity.DPU_1,
role=role,
script=script,
glue_version=glue.GlueVersion.V2_0,
continuous_logging=glue.ContinuousLoggingProps(enabled=False),
worker_type=glue.WorkerType.G_2X,
max_concurrent_runs=100,
timeout=cdk.Duration.hours(2),
connections=[glue.Connection.from_connection_name(stack, "Connection", "connectionName")],
security_configuration=glue.SecurityConfiguration.from_security_configuration_name(stack, "SecurityConfig", "securityConfigName"),
tags={
"FirstTagName": "FirstTagValue",
"SecondTagName": "SecondTagValue",
"XTagName": "XTagValue"
},
number_of_workers=2,
max_retries=2
)
```
### Ray Jobs
Glue Ray jobs use worker type Z.2X and Glue version 4.0. These are not
overrideable since these are the only configuration that Glue Ray jobs
currently support. The runtime defaults to Ray2.4 and min workers defaults to 3.
Reference the ray-job.test.ts unit tests for examples of required-only and
optional job parameters when creating these types of jobs.
Example with only required parameters:
```python
import aws_cdk as cdk
import aws_cdk.aws_iam as iam
# stack: cdk.Stack
# role: iam.IRole
# script: glue.Code
glue.RayJob(stack, "ImportedJob", role=role, script=script)
```
Example with optional override parameters:
```python
import aws_cdk as cdk
import aws_cdk.aws_iam as iam
# stack: cdk.Stack
# role: iam.IRole
# script: glue.Code
glue.RayJob(stack, "ImportedJob",
role=role,
script=script,
job_name="RayCustomJobName",
description="This is a description",
worker_type=glue.WorkerType.Z_2X,
number_of_workers=5,
runtime=glue.Runtime.RAY_TWO_FOUR,
max_retries=3,
max_concurrent_runs=100,
timeout=cdk.Duration.hours(2),
connections=[glue.Connection.from_connection_name(stack, "Connection", "connectionName")],
security_configuration=glue.SecurityConfiguration.from_security_configuration_name(stack, "SecurityConfig", "securityConfigName"),
tags={
"FirstTagName": "FirstTagValue",
"SecondTagName": "SecondTagValue",
"XTagName": "XTagValue"
}
)
```
### Metrics Control
By default, Glue jobs enable CloudWatch metrics (`--enable-metrics`) and observability metrics (`--enable-observability-metrics`) for monitoring and debugging. You can disable these metrics to reduce CloudWatch costs:
```python
import aws_cdk as cdk
import aws_cdk.aws_iam as iam
# stack: cdk.Stack
# role: iam.IRole
# script: glue.Code
# Disable both metrics for cost optimization
glue.PySparkEtlJob(stack, "CostOptimizedJob",
role=role,
script=script,
enable_metrics=False,
enable_observability_metrics=False
)
# Selective control - keep observability, disable profiling
glue.PySparkEtlJob(stack, "SelectiveJob",
role=role,
script=script,
enable_metrics=False
)
```
This feature is available for all Spark job types (ETL, Streaming, Flex) and Ray jobs.
### Enable Job Run Queuing
AWS Glue job queuing monitors your account level quotas and limits. If quotas or limits are insufficient to start a Glue job run, AWS Glue will automatically queue the job and wait for limits to free up. Once limits become available, AWS Glue will retry the job run. Glue jobs will queue for limits like max concurrent job runs per account, max concurrent Data Processing Units (DPU), and resource unavailable due to IP address exhaustion in Amazon Virtual Private Cloud (Amazon VPC).
Enable job run queuing by setting the `jobRunQueuingEnabled` property to `true`.
```python
import aws_cdk as cdk
import aws_cdk.aws_iam as iam
# stack: cdk.Stack
# role: iam.IRole
# script: glue.Code
glue.PySparkEtlJob(stack, "PySparkETLJob",
role=role,
script=script,
job_name="PySparkETLJob",
job_run_queuing_enabled=True
)
```
### Uploading scripts from the CDK app repository to S3
Similar to other L2 constructs, the Glue L2 automates uploading / updating
scripts to S3 via an optional fromAsset parameter pointing to a script
in the local file structure. You provide the existing S3 bucket and
path to which you'd like the script to be uploaded.
Reference the unit tests for examples of repo and S3 code target examples.
### Workflow Triggers
You can use Glue workflows to create and visualize complex
extract, transform, and load (ETL) activities involving multiple crawlers,
jobs, and triggers. Standalone triggers are an anti-pattern, so you must
create triggers from within a workflow using the L2 construct.
Within a workflow object, there are functions to create different
types of triggers with actions and predicates. You then add those triggers
to jobs.
StartOnCreation defaults to true for all trigger types, but you can
override it if you prefer for your trigger not to start on creation.
Reference the workflow-triggers.test.ts unit tests for examples of creating
workflows and triggers.
#### **1. On-Demand Triggers**
On-demand triggers can start glue jobs or crawlers. This construct provides
convenience functions to create on-demand crawler or job triggers. The constructor
takes an optional description parameter, but abstracts the requirement of an
actions list using the job or crawler objects using conditional types.
#### **2. Scheduled Triggers**
You can create scheduled triggers using cron expressions. This construct
provides daily, weekly, and monthly convenience functions,
as well as a custom function that allows you to create your own
custom timing using the [existing event Schedule class](https://docs.aws.amazon.com/cdk/api/v2/docs/aws-cdk-lib.aws_events.Schedule.html)
without having to build your own cron expressions. The L2 extracts
the expression that Glue requires from the Schedule object. The constructor
takes an optional description and a list of jobs or crawlers as actions.
#### **3. Notify Event Triggers**
There are two types of notify event triggers: batching and non-batching.
For batching triggers, you must specify `BatchSize`. For non-batching
triggers, `BatchSize` defaults to 1. For both triggers, `BatchWindow`
defaults to 900 seconds, but you can override the window to align with
your workload's requirements.
#### **4. Conditional Triggers**
Conditional triggers have a predicate and actions associated with them.
The trigger actions are executed when the predicateCondition is true.
### Connection Properties
A `Connection` allows Glue jobs, crawlers and development endpoints to access
certain types of data stores.
* **Secrets Management**
You must specify JDBC connection credentials in Secrets Manager and
provide the Secrets Manager Key name as a property to the job connection.
* **Networking - the CDK determines the best fit subnet for Glue connection
configuration**
The prior version of the glue-alpha-module requires the developer to
specify the subnet of the Connection when it’s defined. Now, you can still
specify the specific subnet you want to use, but are no longer required
to. You are only required to provide a VPC and either a public or private
subnet selection. Without a specific subnet provided, the L2 leverages the
existing [EC2 Subnet Selection](https://docs.aws.amazon.com/cdk/api/v2/python/aws_cdk.aws_ec2/SubnetSelection.html)
library to make the best choice selection for the subnet.
```python
# security_group: ec2.SecurityGroup
# subnet: ec2.Subnet
glue.Connection(self, "MyConnection",
type=glue.ConnectionType.NETWORK,
# The security groups granting AWS Glue inbound access to the data source within the VPC
security_groups=[security_group],
# The VPC subnet which contains the data source
subnet=subnet
)
```
For RDS `Connection` by JDBC, it is recommended to manage credentials using AWS Secrets Manager. To use Secret, specify `SECRET_ID` in `properties` like the following code. Note that in this case, the subnet must have a route to the AWS Secrets Manager VPC endpoint or to the AWS Secrets Manager endpoint through a NAT gateway.
```python
# security_group: ec2.SecurityGroup
# subnet: ec2.Subnet
# db: rds.DatabaseCluster
glue.Connection(self, "RdsConnection",
type=glue.ConnectionType.JDBC,
security_groups=[security_group],
subnet=subnet,
properties={
"JDBC_CONNECTION_URL": f"jdbc:mysql://{db.clusterEndpoint.socketAddress}/databasename",
"JDBC_ENFORCE_SSL": "false",
"SECRET_ID": db.secret.secret_name
}
)
```
If you need to use a connection type that doesn't exist as a static member on `ConnectionType`, you can instantiate a `ConnectionType` object, e.g: `new glue.ConnectionType('NEW_TYPE')`.
See [Adding a Connection to Your Data Store](https://docs.aws.amazon.com/glue/latest/dg/populate-add-connection.html) and [Connection Structure](https://docs.aws.amazon.com/glue/latest/dg/aws-glue-api-catalog-connections.html#aws-glue-api-catalog-connections-Connection) documentation for more information on the supported data stores and their configurations.
## SecurityConfiguration
A `SecurityConfiguration` is a set of security properties that can be used by AWS Glue to encrypt data at rest.
```python
glue.SecurityConfiguration(self, "MySecurityConfiguration",
cloud_watch_encryption=glue.CloudWatchEncryption(
mode=glue.CloudWatchEncryptionMode.KMS
),
job_bookmarks_encryption=glue.JobBookmarksEncryption(
mode=glue.JobBookmarksEncryptionMode.CLIENT_SIDE_KMS
),
s3_encryption=glue.S3Encryption(
mode=glue.S3EncryptionMode.KMS
)
)
```
By default, a shared KMS key is created for use with the encryption configurations that require one. You can also supply your own key for each encryption config, for example, for CloudWatch encryption:
```python
# key: kms.Key
glue.SecurityConfiguration(self, "MySecurityConfiguration",
cloud_watch_encryption=glue.CloudWatchEncryption(
mode=glue.CloudWatchEncryptionMode.KMS,
kms_key=key
)
)
```
See [documentation](https://docs.aws.amazon.com/glue/latest/dg/encryption-security-configuration.html) for more info for Glue encrypting data written by Crawlers, Jobs, and Development Endpoints.
## Database
A `Database` is a logical grouping of `Tables` in the Glue Catalog.
```python
glue.Database(self, "MyDatabase",
database_name="my_database",
description="my_database_description"
)
```
## Table
A Glue table describes a table of data in S3: its structure (column names and types), location of data (S3 objects with a common prefix in a S3 bucket), and format for the files (Json, Avro, Parquet, etc.):
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
database=my_database,
columns=[glue.Column(
name="col1",
type=glue.Schema.STRING
), glue.Column(
name="col2",
type=glue.Schema.array(glue.Schema.STRING),
comment="col2 is an array of strings"
)],
data_format=glue.DataFormat.JSON
)
```
By default, a S3 bucket will be created to store the table's data but you can manually pass the `bucket` and `s3Prefix`:
```python
# my_bucket: s3.Bucket
# my_database: glue.Database
glue.S3Table(self, "MyTable",
bucket=my_bucket,
s3_prefix="my-table/",
# ...
database=my_database,
columns=[glue.Column(
name="col1",
type=glue.Schema.STRING
)],
data_format=glue.DataFormat.JSON
)
```
Glue tables can be configured to contain user-defined properties, to describe the physical storage of table data, through the `storageParameters` property:
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
storage_parameters=[
glue.StorageParameter.skip_header_line_count(1),
glue.StorageParameter.compression_type(glue.CompressionType.GZIP),
glue.StorageParameter.custom("separatorChar", ",")
],
# ...
database=my_database,
columns=[glue.Column(
name="col1",
type=glue.Schema.STRING
)],
data_format=glue.DataFormat.JSON
)
```
Glue tables can also be configured to contain user-defined table properties through the [`parameters`](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-glue-table-tableinput.html#cfn-glue-table-tableinput-parameters) property:
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
parameters={
"key1": "val1",
"key2": "val2"
},
database=my_database,
columns=[glue.Column(
name="col1",
type=glue.Schema.STRING
)],
data_format=glue.DataFormat.JSON
)
```
### Partition Keys
To improve query performance, a table can specify `partitionKeys` on which data is stored and queried separately. For example, you might partition a table by `year` and `month` to optimize queries based on a time window:
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
database=my_database,
columns=[glue.Column(
name="col1",
type=glue.Schema.STRING
)],
partition_keys=[glue.Column(
name="year",
type=glue.Schema.SMALL_INT
), glue.Column(
name="month",
type=glue.Schema.SMALL_INT
)],
data_format=glue.DataFormat.JSON
)
```
### Partition Indexes
Another way to improve query performance is to specify partition indexes. If no partition indexes are
present on the table, AWS Glue loads all partitions of the table and filters the loaded partitions using
the query expression. The query takes more time to run as the number of partitions increase. With an
index, the query will try to fetch a subset of the partitions instead of loading all partitions of the
table.
The keys of a partition index must be a subset of the partition keys of the table. You can have a
maximum of 3 partition indexes per table. To specify a partition index, you can use the `partitionIndexes`
property:
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
database=my_database,
columns=[glue.Column(
name="col1",
type=glue.Schema.STRING
)],
partition_keys=[glue.Column(
name="year",
type=glue.Schema.SMALL_INT
), glue.Column(
name="month",
type=glue.Schema.SMALL_INT
)],
partition_indexes=[glue.PartitionIndex(
index_name="my-index", # optional
key_names=["year"]
)], # supply up to 3 indexes
data_format=glue.DataFormat.JSON
)
```
Alternatively, you can call the `addPartitionIndex()` function on a table:
```python
# my_table: glue.Table
my_table.add_partition_index(
index_name="my-index",
key_names=["year"]
)
```
### Partition Filtering
If you have a table with a large number of partitions that grows over time, consider using AWS Glue partition indexing and filtering.
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
database=my_database,
columns=[glue.Column(
name="col1",
type=glue.Schema.STRING
)],
partition_keys=[glue.Column(
name="year",
type=glue.Schema.SMALL_INT
), glue.Column(
name="month",
type=glue.Schema.SMALL_INT
)],
data_format=glue.DataFormat.JSON,
enable_partition_filtering=True
)
```
### Partition Projection
Partition projection allows Athena to automatically add new partitions as new data arrives, without requiring `ALTER TABLE ADD PARTITION` statements. This improves query performance and reduces management overhead by eliminating the need to manually manage partition metadata.
For more information, see the [AWS documentation on partition projection](https://docs.aws.amazon.com/athena/latest/ug/partition-projection.html).
#### INTEGER Projection
For partition keys with sequential numeric values:
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
database=my_database,
columns=[glue.Column(
name="data",
type=glue.Schema.STRING
)],
partition_keys=[glue.Column(
name="year",
type=glue.Schema.INTEGER
)],
data_format=glue.DataFormat.JSON,
partition_projection={
"year": glue.PartitionProjectionConfiguration.integer(
min=2020,
max=2023,
interval=1, # optional, defaults to 1
digits=4
)
}
)
```
#### DATE Projection
For partition keys with date or timestamp values. Supports both fixed dates and relative dates using `NOW`:
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
database=my_database,
columns=[glue.Column(
name="data",
type=glue.Schema.STRING
)],
partition_keys=[glue.Column(
name="date",
type=glue.Schema.STRING
)],
data_format=glue.DataFormat.JSON,
partition_projection={
"date": glue.PartitionProjectionConfiguration.date(
min="2020-01-01",
max="2023-12-31",
format="yyyy-MM-dd",
interval=1, # optional, defaults to 1
interval_unit=glue.DateIntervalUnit.DAYS
)
}
)
```
You can also use relative dates with `NOW`:
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
database=my_database,
columns=[glue.Column(
name="data",
type=glue.Schema.STRING
)],
partition_keys=[glue.Column(
name="date",
type=glue.Schema.STRING
)],
data_format=glue.DataFormat.JSON,
partition_projection={
"date": glue.PartitionProjectionConfiguration.date(
min="NOW-3YEARS",
max="NOW",
format="yyyy-MM-dd"
)
}
)
```
#### ENUM Projection
For partition keys with a known set of values:
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
database=my_database,
columns=[glue.Column(
name="data",
type=glue.Schema.STRING
)],
partition_keys=[glue.Column(
name="region",
type=glue.Schema.STRING
)],
data_format=glue.DataFormat.JSON,
partition_projection={
"region": glue.PartitionProjectionConfiguration.enum(
values=["us-east-1", "us-west-2", "eu-west-1"]
)
}
)
```
#### INJECTED Projection
For custom partition values injected at query time:
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
database=my_database,
columns=[glue.Column(
name="data",
type=glue.Schema.STRING
)],
partition_keys=[glue.Column(
name="custom",
type=glue.Schema.STRING
)],
data_format=glue.DataFormat.JSON,
partition_projection={
"custom": glue.PartitionProjectionConfiguration.injected()
}
)
```
#### Multiple Partition Projections
You can configure partition projection for multiple partition keys:
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
database=my_database,
columns=[glue.Column(
name="data",
type=glue.Schema.STRING
)],
partition_keys=[glue.Column(
name="year",
type=glue.Schema.INTEGER
), glue.Column(
name="month",
type=glue.Schema.INTEGER
), glue.Column(
name="region",
type=glue.Schema.STRING
)
],
data_format=glue.DataFormat.JSON,
partition_projection={
"year": glue.PartitionProjectionConfiguration.integer(
min=2020,
max=2023
),
"month": glue.PartitionProjectionConfiguration.integer(
min=1,
max=12,
digits=2
),
"region": glue.PartitionProjectionConfiguration.enum(
values=["us-east-1", "us-west-2"]
)
}
)
```
### Glue Connections
Glue connections allow external data connections to third party databases and data warehouses. However, these connections can also be assigned to Glue Tables, allowing you to query external data sources using the Glue Data Catalog.
Whereas `S3Table` will point to (and if needed, create) a bucket to store the tables' data, `ExternalTable` will point to an existing table in a data source. For example, to create a table in Glue that points to a table in Redshift:
```python
# my_connection: glue.Connection
# my_database: glue.Database
glue.ExternalTable(self, "MyTable",
connection=my_connection,
external_data_location="default_db_public_example", # A table in Redshift
# ...
database=my_database,
columns=[glue.Column(
name="col1",
type=glue.Schema.STRING
)],
data_format=glue.DataFormat.JSON
)
```
## [Encryption](https://docs.aws.amazon.com/athena/latest/ug/encryption.html)
You can enable encryption on a Table's data:
* [S3Managed](https://docs.aws.amazon.com/AmazonS3/latest/dev/UsingServerSideEncryption.html) - (default) Server side encryption (`SSE-S3`) with an Amazon S3-managed key.
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
encryption=glue.TableEncryption.S3_MANAGED,
# ...
database=my_database,
columns=[glue.Column(
name="col1",
type=glue.Schema.STRING
)],
data_format=glue.DataFormat.JSON
)
```
* [Kms](https://docs.aws.amazon.com/AmazonS3/latest/dev/UsingKMSEncryption.html) - Server-side encryption (`SSE-KMS`) with an AWS KMS Key managed by the account owner.
```python
# my_database: glue.Database
# KMS key is created automatically
glue.S3Table(self, "MyTable",
encryption=glue.TableEncryption.KMS,
# ...
database=my_database,
columns=[glue.Column(
name="col1",
type=glue.Schema.STRING
)],
data_format=glue.DataFormat.JSON
)
# with an explicit KMS key
glue.S3Table(self, "MyTable",
encryption=glue.TableEncryption.KMS,
encryption_key=kms.Key(self, "MyKey"),
# ...
database=my_database,
columns=[glue.Column(
name="col1",
type=glue.Schema.STRING
)],
data_format=glue.DataFormat.JSON
)
```
* [KmsManaged](https://docs.aws.amazon.com/AmazonS3/latest/dev/UsingKMSEncryption.html) - Server-side encryption (`SSE-KMS`), like `Kms`, except with an AWS KMS Key managed by the AWS Key Management Service.
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
encryption=glue.TableEncryption.KMS_MANAGED,
# ...
database=my_database,
columns=[glue.Column(
name="col1",
type=glue.Schema.STRING
)],
data_format=glue.DataFormat.JSON
)
```
* [ClientSideKms](https://docs.aws.amazon.com/AmazonS3/latest/dev/UsingClientSideEncryption.html#client-side-encryption-kms-managed-master-key-intro) - Client-side encryption (`CSE-KMS`) with an AWS KMS Key managed by the account owner.
```python
# my_database: glue.Database
# KMS key is created automatically
glue.S3Table(self, "MyTable",
encryption=glue.TableEncryption.CLIENT_SIDE_KMS,
# ...
database=my_database,
columns=[glue.Column(
name="col1",
type=glue.Schema.STRING
)],
data_format=glue.DataFormat.JSON
)
# with an explicit KMS key
glue.S3Table(self, "MyTable",
encryption=glue.TableEncryption.CLIENT_SIDE_KMS,
encryption_key=kms.Key(self, "MyKey"),
# ...
database=my_database,
columns=[glue.Column(
name="col1",
type=glue.Schema.STRING
)],
data_format=glue.DataFormat.JSON
)
```
*Note: you cannot provide a `Bucket` when creating the `S3Table` if you wish to use server-side encryption (`KMS`, `KMS_MANAGED` or `S3_MANAGED`)*.
## Types
A table's schema is a collection of columns, each of which have a `name` and a `type`. Types are recursive structures, consisting of primitive and complex types:
```python
# my_database: glue.Database
glue.S3Table(self, "MyTable",
columns=[glue.Column(
name="primitive_column",
type=glue.Schema.STRING
), glue.Column(
name="array_column",
type=glue.Schema.array(glue.Schema.INTEGER),
comment="array<integer>"
), glue.Column(
name="map_column",
type=glue.Schema.map(glue.Schema.STRING, glue.Schema.TIMESTAMP),
comment="map<string,string>"
), glue.Column(
name="struct_column",
type=glue.Schema.struct([
name="nested_column",
type=glue.Schema.DATE,
comment="nested comment"
]),
comment="struct<nested_column:date COMMENT 'nested comment'>"
)],
# ...
database=my_database,
data_format=glue.DataFormat.JSON
)
```
## Public FAQ
### What are we launching today?
We’re launching new features to an AWS CDK Glue L2 Construct to provide
best-practice defaults and convenience methods to create Glue Jobs, Connections,
Triggers, Workflows, and the underlying permissions and configuration.
### Why should I use this Construct?
Developers should use this Construct to reduce the amount of boilerplate
code and complexity each individual has to navigate, and make it easier to
create best-practice Glue resources.
### What’s not in scope?
Glue Crawlers and other resources that are now managed by the AWS LakeFormation
team are not in scope for this effort. Developers should use existing methods
to create these resources, and the new Glue L2 construct assumes they already
exist as inputs. While best practice is for application and infrastructure code
to be as close as possible for teams using fully-implemented DevOps mechanisms,
in practice these ETL scripts are likely managed by a data science team who
know Python or Scala and don’t necessarily own or manage their own
infrastructure deployments. We want to meet developers where they are, and not
assume that all of the code resides in the same repository, Developers can
automate this themselves via the CDK, however, if they do own both.
Validating Glue version and feature use per AWS region at synth time is also
not in scope. AWS’ intention is for all features to eventually be propagated to
all Global regions, so the complexity involved in creating and updating region-
specific configuration to match shifting feature sets does not out-weigh the
likelihood that a developer will use this construct to deploy resources to a
region without a particular new feature to a region that doesn’t yet support
it without researching or manually attempting to use that feature before
developing it via IaC. The developer will, of course, still get feedback from
the underlying Glue APIs as CloudFormation deploys the resources similar to the
current CDK L1 Glue experience.
| text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/aws/aws-cdk | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.239.0",
"constructs<11.0.0,>=10.5.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/aws/aws-cdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:58:00.406048 | aws_cdk_aws_glue_alpha-2.239.0a0.tar.gz | 510,867 | 95/c7/fd413b31b1e67d174b5cc44af381e2b9a3c9fd7db1d91b227584a7723d7f/aws_cdk_aws_glue_alpha-2.239.0a0.tar.gz | source | sdist | null | false | 11391d625dc27b102339d093809f813f | 5d84988c3ce4d4c5ce3552da56c3f1b8323b56cff67907720cecbdefce69b767 | 95c7fd413b31b1e67d174b5cc44af381e2b9a3c9fd7db1d91b227584a7723d7f | null | [] | 0 |
2.1 | aws-cdk.aws-gamelift-alpha | 2.239.0a0 | The CDK Construct Library for AWS::GameLift | # Amazon GameLift Construct Library
<!--BEGIN STABILITY BANNER-->---

> The APIs of higher level constructs in this module are experimental and under active development.
> They are subject to non-backward compatible changes or removal in any future version. These are
> not subject to the [Semantic Versioning](https://semver.org/) model and breaking changes will be
> announced in the release notes. This means that while you may use them, you may need to update
> your source code when upgrading to a newer version of this package.
---
<!--END STABILITY BANNER-->
[Amazon GameLift](https://docs.aws.amazon.com/gamelift/latest/developerguide/gamelift-intro.html) is a service used
to deploy, operate, and scale dedicated, low-cost servers in the cloud for session-based multiplayer games. Built
on AWS global computing infrastructure, GameLift helps deliver high-performance, high-reliability game servers
while dynamically scaling your resource usage to meet worldwide player demand.
GameLift is composed of three main components:
* GameLift FlexMatch which is a customizable matchmaking service for
multiplayer games. With FlexMatch, you can
build a custom set of rules that defines what a multiplayer match looks like
for your game, and determines how to
evaluate and select compatible players for each match. You can also customize
key aspects of the matchmaking
process to fit your game, including fine-tuning the matching algorithm.
* GameLift hosting for custom or realtime servers which helps you deploy,
operate, and scale dedicated game servers. It regulates the resources needed to
host games, finds available game servers to host new game sessions, and puts
players into games.
* GameLift FleetIQ to optimize the use of low-cost Amazon Elastic Compute Cloud
(Amazon EC2) Spot Instances for cloud-based game hosting. With GameLift
FleetIQ, you can work directly with your hosting resources in Amazon EC2 and
Amazon EC2 Auto Scaling while taking advantage of GameLift optimizations to
deliver inexpensive, resilient game hosting for your players
This module is part of the [AWS Cloud Development Kit](https://github.com/aws/aws-cdk) project. It allows you to define components for your matchmaking
configuration or game server fleet management system.
## GameLift FlexMatch
### Defining a Matchmaking configuration
FlexMatch is available both as a GameLift game hosting solution (including
Realtime Servers) and as a standalone matchmaking service. To set up a
FlexMatch matchmaker to process matchmaking requests, you have to create a
matchmaking configuration based on a RuleSet.
More details about matchmaking ruleSet are covered [below](#matchmaking-ruleset).
There is two types of Matchmaking configuration:
Through a game session queue system to let FlexMatch forms matches and uses the specified GameLift queue to start a game session for the match.
```python
# queue: gamelift.GameSessionQueue
# rule_set: gamelift.MatchmakingRuleSet
gamelift.QueuedMatchmakingConfiguration(self, "QueuedMatchmakingConfiguration",
matchmaking_configuration_name="test-queued-config-name",
game_session_queues=[queue],
rule_set=rule_set
)
```
Or through a standalone version to let FlexMatch forms matches and returns match information in an event.
```python
# rule_set: gamelift.MatchmakingRuleSet
gamelift.StandaloneMatchmakingConfiguration(self, "StandaloneMatchmaking",
matchmaking_configuration_name="test-standalone-config-name",
rule_set=rule_set
)
```
More details about Game session queue are covered [below](#game-session-queue).
### Matchmaking RuleSet
Every FlexMatch matchmaker must have a rule set. The rule set determines the
two key elements of a match: your game's team structure and size, and how to
group players together for the best possible match.
For example, a rule set might describe a match like this: Create a match with
two teams of four to eight players each, one team is the cowboy and the other
team the aliens. A team can have novice and experienced players, but the
average skill of the two teams must be within 10 points of each other. If no
match is made after 30 seconds, gradually relax the skill requirements.
```python
gamelift.MatchmakingRuleSet(self, "RuleSet",
matchmaking_rule_set_name="my-test-ruleset",
content=gamelift.RuleSetContent.from_json_file(path.join(__dirname, "my-ruleset", "ruleset.json"))
)
```
### FlexMatch Monitoring
You can monitor GameLift FlexMatch activity for matchmaking configurations and
matchmaking rules using Amazon CloudWatch. These statistics are used to provide
a historical perspective on how your Gamelift FlexMatch solution is performing.
#### FlexMatch Metrics
GameLift FlexMatch sends metrics to CloudWatch so that you can collect and
analyze the activity of your matchmaking solution, including match acceptance
workflow, ticket consumtion.
You can then use CloudWatch alarms to alert you, for example, when matches has
been rejected (potential matches that were rejected by at least one player
since the last report) exceed a certain thresold which could means that you may
have an issue in your matchmaking rules.
CDK provides methods for accessing GameLift FlexMatch metrics with default configuration,
such as `metricRuleEvaluationsPassed`, or `metricRuleEvaluationsFailed` (see
[`IMatchmakingRuleSet`](https://docs.aws.amazon.com/cdk/api/latest/docs/@aws-cdk_aws-gamelift.IMatchmakingRuleSet.html)
for a full list). CDK also provides a generic `metric` method that can be used
to produce metric configurations for any metric provided by GameLift FlexMatch;
the configurations are pre-populated with the correct dimensions for the
matchmaking configuration.
```python
# matchmaking_rule_set: gamelift.MatchmakingRuleSet
# Alarm that triggers when the per-second average of not placed matches exceed 10%
rule_evaluation_ratio = cloudwatch.MathExpression(
expression="1 - (ruleEvaluationsPassed / ruleEvaluationsFailed)",
using_metrics={
"rule_evaluations_passed": matchmaking_rule_set.metric_rule_evaluations_passed(statistic=cloudwatch.Statistic.SUM),
"rule_evaluations_failed": matchmaking_rule_set.metric("ruleEvaluationsFailed")
}
)
cloudwatch.Alarm(self, "Alarm",
metric=rule_evaluation_ratio,
threshold=0.1,
evaluation_periods=3
)
```
See: [Monitoring Using CloudWatch Metrics](https://docs.aws.amazon.com/gamelift/latest/developerguide/monitoring-cloudwatch.html)
in the *Amazon GameLift Developer Guide*.
## GameLift Hosting
### Uploading builds and scripts to GameLift
Before deploying your GameLift-enabled multiplayer game servers for hosting with the GameLift service, you need to upload
your game server files. This section provides guidance on preparing and uploading custom game server build
files or Realtime Servers server script files. When you upload files, you create a GameLift build or script resource, which
you then deploy on fleets of hosting resources.
To troubleshoot fleet activation problems related to the server script, see [Debug GameLift fleet issues](https://docs.aws.amazon.com/gamelift/latest/developerguide/fleets-creating-debug.html).
#### Upload a custom server build to GameLift
Before uploading your configured game server to GameLift for hosting, package the game build files into a build directory.
This directory must include all components required to run your game servers and host game sessions, including the following:
* Game server binaries – The binary files required to run the game server. A build can include binaries for multiple game
servers built to run on the same platform. For a list of supported platforms, see [Download Amazon GameLift SDKs](https://docs.aws.amazon.com/gamelift/latest/developerguide/gamelift-supported.html).
* Dependencies – Any dependent files that your game server executables require to run. Examples include assets, configuration
files, and dependent libraries.
* Install script – A script file to handle tasks that are required to fully install your game build on GameLift hosting
servers. Place this file at the root of the build directory. GameLift runs the install script as part of fleet creation.
You can set up any application in your build, including your install script, to access your resources securely on other AWS
services.
```python
# bucket: s3.Bucket
build = gamelift.Build(self, "Build",
content=gamelift.Content.from_bucket(bucket, "sample-asset-key")
)
CfnOutput(self, "BuildArn", value=build.build_arn)
CfnOutput(self, "BuildId", value=build.build_id)
```
To specify a server SDK version you used when integrating your game server build with Amazon GameLift use the `serverSdkVersion` parameter:
> See [Integrate games with custom game servers](https://docs.aws.amazon.com/gamelift/latest/developerguide/integration-custom-intro.html) for more details.
```python
# bucket: s3.Bucket
build = gamelift.Build(self, "Build",
content=gamelift.Content.from_bucket(bucket, "sample-asset-key"),
server_sdk_version="5.0.0"
)
```
#### Upload a realtime server Script
Your server script can include one or more files combined into a single .zip file for uploading. The .zip file must contain
all files that your script needs to run.
You can store your zipped script files in either a local file directory or in an Amazon Simple Storage Service (Amazon S3)
bucket or defines a directory asset which is archived as a .zip file and uploaded to S3 during deployment.
After you create the script resource, GameLift deploys the script with a new Realtime Servers fleet. GameLift installs your
server script onto each instance in the fleet, placing the script files in `/local/game`.
```python
# bucket: s3.Bucket
gamelift.Script(self, "Script",
content=gamelift.Content.from_bucket(bucket, "sample-asset-key")
)
```
### Defining a GameLift Fleet
#### Creating a custom game server fleet
Your uploaded game servers are hosted on GameLift virtual computing resources,
called instances. You set up your hosting resources by creating a fleet of
instances and deploying them to run your game servers. You can design a fleet
to fit your game's needs.
```python
gamelift.BuildFleet(self, "Game server fleet",
fleet_name="test-fleet",
content=gamelift.Build.from_asset(self, "Build", path.join(__dirname, "CustomerGameServer")),
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C4, ec2.InstanceSize.LARGE),
runtime_configuration=gamelift.RuntimeConfiguration(
server_processes=[gamelift.ServerProcess(
launch_path="test-launch-path"
)]
)
)
```
### Managing game servers launch configuration
GameLift uses a fleet's runtime configuration to determine the type and number
of processes to run on each instance in the fleet. At a minimum, a runtime
configuration contains one server process configuration that represents one
game server executable. You can also define additional server process
configurations to run other types of processes related to your game. Each
server process configuration contains the following information:
* The file name and path of an executable in your game build.
* Optionally Parameters to pass to the process on launch.
* The number of processes to run concurrently.
A GameLift instance is limited to 50 processes running concurrently.
```python
# build: gamelift.Build
# Server processes can be delcared in a declarative way through the constructor
fleet = gamelift.BuildFleet(self, "Game server fleet",
fleet_name="test-fleet",
content=build,
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C4, ec2.InstanceSize.LARGE),
runtime_configuration=gamelift.RuntimeConfiguration(
server_processes=[gamelift.ServerProcess(
launch_path="/local/game/GameLiftExampleServer.x86_64",
parameters="-logFile /local/game/logs/myserver1935.log -port 1935",
concurrent_executions=100
)]
)
)
```
See [Managing how game servers are launched for hosting](https://docs.aws.amazon.com/gamelift/latest/developerguide/fleets-multiprocess.html)
in the *Amazon GameLift Developer Guide*.
### Defining an instance type
GameLift uses Amazon Elastic Compute Cloud (Amazon EC2) resources, called
instances, to deploy your game servers and host game sessions for your players.
When setting up a new fleet, you decide what type of instances your game needs
and how to run game server processes on them (using a runtime configuration). All instances in a fleet use the same type of resources and the same runtime
configuration. You can edit a fleet's runtime configuration and other fleet
properties, but the type of resources cannot be changed.
```python
# build: gamelift.Build
gamelift.BuildFleet(self, "Game server fleet",
fleet_name="test-fleet",
content=build,
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C5, ec2.InstanceSize.LARGE),
runtime_configuration=gamelift.RuntimeConfiguration(
server_processes=[gamelift.ServerProcess(
launch_path="/local/game/GameLiftExampleServer.x86_64"
)]
)
)
```
### Using Spot instances
When setting up your hosting resources, you have the option of using Spot
Instances, On-Demand Instances, or a combination.
By default, fleet are using on demand capacity.
```python
# build: gamelift.Build
gamelift.BuildFleet(self, "Game server fleet",
fleet_name="test-fleet",
content=build,
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C4, ec2.InstanceSize.LARGE),
runtime_configuration=gamelift.RuntimeConfiguration(
server_processes=[gamelift.ServerProcess(
launch_path="/local/game/GameLiftExampleServer.x86_64"
)]
),
use_spot=True
)
```
### Allowing Ingress traffic
The allowed IP address ranges and port settings that allow inbound traffic to
access game sessions on this fleet.
New game sessions are assigned an IP address/port number combination, which
must fall into the fleet's allowed ranges. Fleets with custom game builds must
have permissions explicitly set. For Realtime Servers fleets, GameLift
automatically opens two port ranges, one for TCP messaging and one for UDP.
```python
# build: gamelift.Build
fleet = gamelift.BuildFleet(self, "Game server fleet",
fleet_name="test-fleet",
content=build,
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C4, ec2.InstanceSize.LARGE),
runtime_configuration=gamelift.RuntimeConfiguration(
server_processes=[gamelift.ServerProcess(
launch_path="/local/game/GameLiftExampleServer.x86_64"
)]
),
ingress_rules=[gamelift.IngressRule(
source=gamelift.Peer.any_ipv4(),
port=gamelift.Port.tcp_range(100, 200)
)]
)
# Allowing a specific CIDR for port 1111 on UDP Protocol
fleet.add_ingress_rule(gamelift.Peer.ipv4("1.2.3.4/32"), gamelift.Port.udp(1111))
```
### Managing locations
A single Amazon GameLift fleet has a home Region by default (the Region you
deploy it to), but it can deploy resources to any number of GameLift supported
Regions. Select Regions based on where your players are located and your
latency needs.
By default, home region is used as default location but we can add new locations if needed and define desired capacity
```python
# build: gamelift.Build
# Locations can be added directly through constructor
fleet = gamelift.BuildFleet(self, "Game server fleet",
fleet_name="test-fleet",
content=build,
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C4, ec2.InstanceSize.LARGE),
runtime_configuration=gamelift.RuntimeConfiguration(
server_processes=[gamelift.ServerProcess(
launch_path="/local/game/GameLiftExampleServer.x86_64"
)]
),
locations=[gamelift.Location(
region="eu-west-1",
capacity=gamelift.LocationCapacity(
desired_capacity=5,
min_size=2,
max_size=10
)
), gamelift.Location(
region="us-east-1",
capacity=gamelift.LocationCapacity(
desired_capacity=5,
min_size=2,
max_size=10
)
)]
)
# Or through dedicated methods
fleet.add_location("ap-southeast-1", 5, 2, 10)
```
### Specifying an IAM role for a Fleet
Some GameLift features require you to extend limited access to your AWS
resources. This is done by creating an AWS IAM role. The GameLift Fleet class
automatically created an IAM role with all the minimum necessary permissions
for GameLift to access your resources. If you wish, you may
specify your own IAM role.
```python
# build: gamelift.Build
role = iam.Role(self, "Role",
assumed_by=iam.CompositePrincipal(iam.ServicePrincipal("gamelift.amazonaws.com"))
)
role.add_managed_policy(iam.ManagedPolicy.from_aws_managed_policy_name("CloudWatchAgentServerPolicy"))
fleet = gamelift.BuildFleet(self, "Game server fleet",
fleet_name="test-fleet",
content=build,
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C5, ec2.InstanceSize.LARGE),
runtime_configuration=gamelift.RuntimeConfiguration(
server_processes=[gamelift.ServerProcess(
launch_path="/local/game/GameLiftExampleServer.x86_64"
)]
),
role=role
)
# Actions can also be grantted through dedicated method
fleet.grant(role, "gamelift:ListFleets")
```
### Alias
A GameLift alias is used to abstract a fleet designation. Fleet designations
tell Amazon GameLift where to search for available resources when creating new
game sessions for players. By using aliases instead of specific fleet IDs, you
can more easily and seamlessly switch player traffic from one fleet to another
by changing the alias's target location.
```python
# fleet: gamelift.BuildFleet
# Add an alias to an existing fleet using a dedicated fleet method
live_alias = fleet.add_alias("live")
# You can also create a standalone alias
gamelift.Alias(self, "TerminalAlias",
alias_name="terminal-alias",
terminal_message="A terminal message"
)
```
See [Add an alias to a GameLift fleet](https://docs.aws.amazon.com/gamelift/latest/developerguide/aliases-creating.html)
in the *Amazon GameLift Developer Guide*.
### Monitoring your Fleet
GameLift is integrated with CloudWatch, so you can monitor the performance of
your game servers via logs and metrics.
#### Fleet Metrics
GameLift Fleet sends metrics to CloudWatch so that you can collect and analyze
the activity of your Fleet, including game and player sessions and server
processes.
You can then use CloudWatch alarms to alert you, for example, when matches has
been rejected (potential matches that were rejected by at least one player
since the last report) exceed a certain threshold which could means that you may
have an issue in your matchmaking rules.
CDK provides methods for accessing GameLift Fleet metrics with default configuration,
such as `metricActiveInstances`, or `metricIdleInstances` (see [`IFleet`](https://docs.aws.amazon.com/cdk/api/latest/docs/@aws-cdk_aws-gamelift.IFleet.html)
for a full list). CDK also provides a generic `metric` method that can be used
to produce metric configurations for any metric provided by GameLift Fleet,
Game sessions or server processes; the configurations are pre-populated with
the correct dimensions for the matchmaking configuration.
```python
# fleet: gamelift.BuildFleet
# Alarm that triggers when the per-second average of not used instances exceed 10%
instances_used_ratio = cloudwatch.MathExpression(
expression="1 - (activeInstances / idleInstances)",
using_metrics={
"active_instances": fleet.metric("ActiveInstances", statistic=cloudwatch.Statistic.SUM),
"idle_instances": fleet.metric_idle_instances()
}
)
cloudwatch.Alarm(self, "Alarm",
metric=instances_used_ratio,
threshold=0.1,
evaluation_periods=3
)
```
See: [Monitoring Using CloudWatch Metrics](https://docs.aws.amazon.com/gamelift/latest/developerguide/monitoring-cloudwatch.html)
in the *Amazon GameLift Developer Guide*.
## Game session queue
The game session queue is the primary mechanism for processing new game session
requests and locating available game servers to host them. Although it is
possible to request a new game session be hosted on specific fleet or location.
The `GameSessionQueue` resource creates a placement queue that processes requests for
new game sessions. A queue uses FleetIQ algorithms to determine the best placement
locations and find an available game server, then prompts the game server to start a
new game session. Queues can have destinations (GameLift fleets or aliases), which
determine where the queue can place new game sessions. A queue can have destinations
with varied fleet type (Spot and On-Demand), instance type, and AWS Region.
```python
# fleet: gamelift.BuildFleet
# alias: gamelift.Alias
queue = gamelift.GameSessionQueue(self, "GameSessionQueue",
game_session_queue_name="my-queue-name",
destinations=[fleet]
)
queue.add_destination(alias)
```
A more complex configuration can also be definied to override how FleetIQ algorithms prioritize game session placement in order to favour a destination based on `Cost`, `Latency`, `Destination order`or `Location`.
```python
# fleet: gamelift.BuildFleet
# topic: sns.Topic
gamelift.GameSessionQueue(self, "MyGameSessionQueue",
game_session_queue_name="test-gameSessionQueue",
custom_event_data="test-event-data",
allowed_locations=["eu-west-1", "eu-west-2"],
destinations=[fleet],
notification_target=topic,
player_latency_policies=[gamelift.PlayerLatencyPolicy(
maximum_individual_player_latency=Duration.millis(100),
policy_duration=Duration.seconds(300)
)],
priority_configuration=gamelift.PriorityConfiguration(
location_order=["eu-west-1", "eu-west-2"
],
priority_order=[gamelift.PriorityType.LATENCY, gamelift.PriorityType.COST, gamelift.PriorityType.DESTINATION, gamelift.PriorityType.LOCATION
]
),
timeout=Duration.seconds(300)
)
```
See [Setting up GameLift queues for game session placement](https://docs.aws.amazon.com/gamelift/latest/developerguide/realtime-script-uploading.html)
in the *Amazon GameLift Developer Guide*.
## GameLift FleetIQ
The GameLift FleetIQ solution is a game hosting layer that supplements the full
set of computing resource management tools that you get with Amazon EC2 and
Auto Scaling. This solution lets you directly manage your Amazon EC2 and Auto
Scaling resources and integrate as needed with other AWS services.
### Defining a Game Server Group
When using GameLift FleetIQ, you prepare to launch Amazon EC2 instances as
usual: make an Amazon Machine Image (AMI) with your game server software,
create an Amazon EC2 launch template, and define configuration settings for an
Auto Scaling group. However, instead of creating an Auto Scaling group
directly, you create a GameLift FleetIQ game server group with your Amazon EC2
and Auto Scaling resources and configuration. All game server groups must have
at least two instance types defined for it.
Once a game server group and Auto Scaling group are up and running with
instances deployed, when updating a Game Server Group instance, only certain
properties in the Auto Scaling group may be overwrite. For all other Auto
Scaling group properties, such as MinSize, MaxSize, and LaunchTemplate, you can
modify these directly on the Auto Scaling group using the AWS Console or
dedicated Api.
```python
# launch_template: ec2.ILaunchTemplate
# vpc: ec2.IVpc
gamelift.GameServerGroup(self, "Game server group",
game_server_group_name="sample-gameservergroup-name",
instance_definitions=[gamelift.InstanceDefinition(
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C5, ec2.InstanceSize.LARGE)
), gamelift.InstanceDefinition(
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C4, ec2.InstanceSize.LARGE)
)],
launch_template=launch_template,
vpc=vpc
)
```
See [Manage game server groups](https://docs.aws.amazon.com/gamelift/latest/fleetiqguide/gsg-integrate-gameservergroup.html)
in the *Amazon GameLift FleetIQ Developer Guide*.
### Scaling Policy
The scaling policy uses the metric `PercentUtilizedGameServers` to maintain a
buffer of idle game servers that can immediately accommodate new games and
players.
```python
# launch_template: ec2.ILaunchTemplate
# vpc: ec2.IVpc
gamelift.GameServerGroup(self, "Game server group",
game_server_group_name="sample-gameservergroup-name",
instance_definitions=[gamelift.InstanceDefinition(
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C5, ec2.InstanceSize.LARGE)
), gamelift.InstanceDefinition(
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C4, ec2.InstanceSize.LARGE)
)],
launch_template=launch_template,
vpc=vpc,
auto_scaling_policy=gamelift.AutoScalingPolicy(
estimated_instance_warmup=Duration.minutes(5),
target_tracking_configuration=5
)
)
```
See [Manage game server groups](https://docs.aws.amazon.com/gamelift/latest/fleetiqguide/gsg-integrate-gameservergroup.html)
in the *Amazon GameLift FleetIQ Developer Guide*.
### Specifying an IAM role for GameLift
The GameLift FleetIQ class automatically creates an IAM role with all the minimum necessary
permissions for GameLift to access your Amazon EC2 Auto Scaling groups. If you wish, you may
specify your own IAM role. It must have the correct permissions, or FleetIQ creation or resource usage may fail.
```python
# launch_template: ec2.ILaunchTemplate
# vpc: ec2.IVpc
role = iam.Role(self, "Role",
assumed_by=iam.CompositePrincipal(iam.ServicePrincipal("gamelift.amazonaws.com"),
iam.ServicePrincipal("autoscaling.amazonaws.com"))
)
role.add_managed_policy(iam.ManagedPolicy.from_aws_managed_policy_name("GameLiftGameServerGroupPolicy"))
gamelift.GameServerGroup(self, "Game server group",
game_server_group_name="sample-gameservergroup-name",
instance_definitions=[gamelift.InstanceDefinition(
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C5, ec2.InstanceSize.LARGE)
), gamelift.InstanceDefinition(
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C4, ec2.InstanceSize.LARGE)
)],
launch_template=launch_template,
vpc=vpc,
role=role
)
```
See [Controlling Access](https://docs.aws.amazon.com/gamelift/latest/fleetiqguide/gsg-iam-permissions-roles.html)
in the *Amazon GameLift FleetIQ Developer Guide*.
### Specifying VPC Subnets
GameLift FleetIQ use by default, all supported GameLift FleetIQ Availability
Zones in your chosen region. You can override this parameter to specify VPCs
subnets that you've set up.
This property cannot be updated after the game server group is created, and the
corresponding Auto Scaling group will always use the property value that is set
with this request, even if the Auto Scaling group is updated directly.
```python
# launch_template: ec2.ILaunchTemplate
# vpc: ec2.IVpc
gamelift.GameServerGroup(self, "GameServerGroup",
game_server_group_name="sample-gameservergroup-name",
instance_definitions=[gamelift.InstanceDefinition(
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C5, ec2.InstanceSize.LARGE)
), gamelift.InstanceDefinition(
instance_type=ec2.InstanceType.of(ec2.InstanceClass.C4, ec2.InstanceSize.LARGE)
)],
launch_template=launch_template,
vpc=vpc,
vpc_subnets=ec2.SubnetSelection(subnet_type=ec2.SubnetType.PUBLIC)
)
```
### FleetIQ Monitoring
GameLift FleetIQ sends metrics to CloudWatch so that you can collect and
analyze the activity of your Game server fleet, including the number of
utilized game servers, and the number of game server interruption due to
limited Spot availability.
You can then use CloudWatch alarms to alert you, for example, when the portion
of game servers that are currently supporting game executions exceed a certain
threshold which could means that your autoscaling policy need to be adjust to
add more instances to match with player demand.
CDK provides a generic `metric` method that can be used
to produce metric configurations for any metric provided by GameLift FleetIQ;
the configurations are pre-populated with the correct dimensions for the
matchmaking configuration.
```python
# game_server_group: gamelift.IGameServerGroup
# Alarm that triggers when the percent of utilized game servers exceed 90%
cloudwatch.Alarm(self, "Alarm",
metric=game_server_group.metric("UtilizedGameServers"),
threshold=0.9,
evaluation_periods=2
)
```
See: [Monitoring with CloudWatch](https://docs.aws.amazon.com/gamelift/latest/fleetiqguide/gsg-metrics.html)
in the *Amazon GameLift FleetIQ Developer Guide*.
| text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/aws/aws-cdk | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.239.0",
"constructs<11.0.0,>=10.5.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/aws/aws-cdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:57:59.243527 | aws_cdk_aws_gamelift_alpha-2.239.0a0.tar.gz | 365,004 | bf/95/536f0e0c1091056184d854c474eea96297055d0c4ee3c2d8c7e08273f08b/aws_cdk_aws_gamelift_alpha-2.239.0a0.tar.gz | source | sdist | null | false | ecc6e5528835105912b78e9c505a995c | 30d0722586d30b3e0f2e963fb222bfa5b4261c420d24c7b9a2e0746722f87f62 | bf95536f0e0c1091056184d854c474eea96297055d0c4ee3c2d8c7e08273f08b | null | [] | 0 |
2.1 | aws-cdk.aws-elasticache-alpha | 2.239.0a0 | The CDK Construct Library for AWS::ElastiCache | # ElastiCache CDK Construct Library
<!--BEGIN STABILITY BANNER-->---

> The APIs of higher level constructs in this module are experimental and under active development.
> They are subject to non-backward compatible changes or removal in any future version. These are
> not subject to the [Semantic Versioning](https://semver.org/) model and breaking changes will be
> announced in the release notes. This means that while you may use them, you may need to update
> your source code when upgrading to a newer version of this package.
---
<!--END STABILITY BANNER-->
This module has constructs for [Amazon ElastiCache](https://docs.aws.amazon.com/AmazonElastiCache/latest/dg/WhatIs.html).
* The `ServerlessCache` construct facilitates the creation and management of serverless cache.
* The `User` and `UserGroup` constructs facilitate the creation and management of users for the cache.
## Serverless Cache
Amazon ElastiCache Serverless is a serverless option that automatically scales cache capacity based on application traffic patterns. You can create a serverless cache using the `ServerlessCache` construct:
```python
vpc = ec2.Vpc(self, "VPC")
cache = elasticache.ServerlessCache(self, "ServerlessCache",
vpc=vpc
)
```
### Connecting to serverless cache
To control who can access the serverless cache by the security groups, use the `.connections` attribute.
The serverless cache has a default port `6379`.
This example allows an EC2 instance to connect to the serverless cache:
```python
# serverless_cache: elasticache.ServerlessCache
# instance: ec2.Instance
# allow the EC2 instance to connect to serverless cache on default port 6379
serverless_cache.connections.allow_default_port_from(instance)
```
### Cache usage limits
You can configure usage limits on both cache data storage and ECPU/second for your cache to control costs and ensure predictable performance.
**Configuration options:**
* **Maximum limits**: Ensure your cache usage never exceeds the configured maximum
* **Minimum limits**: Reserve a baseline level of resources for consistent performance
* **Both**: Define a range where your cache usage will operate
For more infomation, see [Setting scaling limits to manage costs](https://docs.aws.amazon.com/AmazonElastiCache/latest/dg/Scaling.html#Pre-Scaling).
```python
# vpc: ec2.Vpc
serverless_cache = elasticache.ServerlessCache(self, "ServerlessCache",
engine=elasticache.CacheEngine.VALKEY_LATEST,
vpc=vpc,
cache_usage_limits=elasticache.CacheUsageLimitsProperty(
# cache data storage limits (GB)
data_storage_minimum_size=Size.gibibytes(2), # minimum: 1GB
data_storage_maximum_size=Size.gibibytes(3), # maximum: 5000GB
# rate limits (ECPU/second)
request_rate_limit_minimum=1000, # minimum: 1000
request_rate_limit_maximum=10000
)
)
```
### Backups and restore
You can enable automatic backups for serverless cache.
When automatic backups are enabled, ElastiCache creates a backup of the cache on a daily basis.
Also you can set the backup window for any time when it's most convenient.
If you don't specify a backup window, ElastiCache assigns one automatically.
For more information, see [Scheduling automatic backups](https://docs.aws.amazon.com/AmazonElastiCache/latest/dg/backups-automatic.html).
To enable automatic backups, set the `backupRetentionLimit` property. You can also specify the snapshot creation time by setting `backupTime` property:
```python
# vpc: ec2.Vpc
serverless_cache = elasticache.ServerlessCache(self, "ServerlessCache",
backup=elasticache.BackupSettings(
# enable automatic backups and set the retention period to 6 days
backup_retention_limit=6,
# set the backup window to 9:00 AM UTC
backup_time=events.Schedule.cron(
hour="9",
minute="0"
)
),
vpc=vpc
)
```
You can create a final backup by setting `backupNameBeforeDeletion` property.
```python
# vpc: ec2.Vpc
serverless_cache = elasticache.ServerlessCache(self, "ServerlessCache",
engine=elasticache.CacheEngine.VALKEY_LATEST,
backup=elasticache.BackupSettings(
# set a backup name before deleting a cache
backup_name_before_deletion="my-final-backup-name"
),
vpc=vpc
)
```
You can restore from backups by setting snapshot ARNs to `backupArnsToRestore` property:
```python
# vpc: ec2.Vpc
serverless_cache = elasticache.ServerlessCache(self, "ServerlessCache",
engine=elasticache.CacheEngine.VALKEY_LATEST,
backup=elasticache.BackupSettings(
# set the backup(s) to restore
backup_arns_to_restore=["arn:aws:elasticache:us-east-1:123456789012:serverlesscachesnapshot:my-final-backup-name"]
),
vpc=vpc
)
```
### Encryption at rest
At-rest encryption is always enabled for Serverless Cache. There are two encryption options:
* **Default**: When no `kmsKey` is specified (left as `undefined`), AWS owned KMS keys are used automatically
* **Customer Managed Key**: Create a KMS key first, then pass it to the cache via the `kmsKey` property
### Customer Managed Key for encryption at rest
ElastiCache supports symmetric Customer Managed key (CMK) for encryption at rest.
For more information, see [Using customer managed keys from AWS KMS](https://docs.aws.amazon.com/AmazonElastiCache/latest/dg/at-rest-encryption.html#using-customer-managed-keys-for-elasticache-security).
To use CMK, set your CMK to the `kmsKey` property:
```python
from aws_cdk.aws_kms import Key
# kms_key: Key
# vpc: ec2.Vpc
serverless_cache = elasticache.ServerlessCache(self, "ServerlessCache",
engine=elasticache.CacheEngine.VALKEY_LATEST,
serverless_cache_name="my-serverless-cache",
vpc=vpc,
# set Customer Managed Key
kms_key=kms_key
)
```
### Metrics and monitoring
You can monitor your serverless cache using CloudWatch Metrics via the `metric` method.
For more information about serverless cache metrics, see [Serverless metrics and events for Valkey and Redis OSS](https://docs.aws.amazon.com/AmazonElastiCache/latest/dg/serverless-metrics-events-redis.html) and [Serverless metrics and events for Memcached](https://docs.aws.amazon.com/AmazonElastiCache/latest/dg/serverless-metrics-events.memcached.html).
```python
# serverless_cache: elasticache.ServerlessCache
# The 5 minutes average of the total number of successful read-only key lookups in the cache.
cache_hits = serverless_cache.metric_cache_hit_count()
# The 5 minutes average of the total number of bytes used by the data stored in the cache.
bytes_used_for_cache = serverless_cache.metric_data_stored()
# The 5 minutes average of the total number of ElastiCacheProcessingUnits (ECPUs) consumed by the requests executed on the cache.
elasti_cache_processing_units = serverless_cache.metric_processing_units_consumed()
# Create an alarm for ECPUs.
elasti_cache_processing_units.create_alarm(self, "ElastiCacheProcessingUnitsAlarm",
threshold=50,
evaluation_periods=1
)
```
### Import an existing serverless cache
To import an existing ServerlessCache, use the `ServerlessCache.fromServerlessCacheAttributes` method:
```python
# security_group: ec2.SecurityGroup
imported_serverless_cache = elasticache.ServerlessCache.from_serverless_cache_attributes(self, "ImportedServerlessCache",
serverless_cache_name="my-serverless-cache",
security_groups=[security_group]
)
```
## User and User Group
Setup required properties and create:
```python
new_default_user = elasticache.NoPasswordUser(self, "NoPasswordUser",
user_id="default",
access_control=elasticache.AccessControl.from_access_string("on ~* +@all")
)
user_group = elasticache.UserGroup(self, "UserGroup",
users=[new_default_user]
)
```
### RBAC
In Valkey 7.2 and onward and Redis OSS 6.0 onward you can use a feature called Role-Based Access Control (RBAC). RBAC is also the only way to control access to serverless caches.
RBAC enables you to control cache access through user groups. These user groups are designed as a way to organize access to caches.
For more information, see [Role-Based Access Control (RBAC)](https://docs.aws.amazon.com/AmazonElastiCache/latest/dg/Clusters.RBAC.html).
To enable RBAC for ElastiCache with Valkey or Redis OSS, you take the following steps:
* Create users.
* Create a user group and add users to the user group.
* Assign the user group to a cache.
### Create users
First, you need to create users by using `IamUser`, `PasswordUser` or `NoPasswordUser` construct.
With RBAC, you create users and assign them specific permissions by using `accessString` property.
For more information, see [Specifying Permissions Using an Access String](https://docs.aws.amazon.com/AmazonElastiCache/latest/dg/Clusters.RBAC.html#Access-string).
You can create an IAM-enabled user by using `IamUser` construct:
```python
user = elasticache.IamUser(self, "User",
# set user engine
engine=elasticache.UserEngine.REDIS,
# set user id
user_id="my-user",
# set username
user_name="my-user",
# set access string
access_control=elasticache.AccessControl.from_access_string("on ~* +@all")
)
```
> NOTE: IAM-enabled users must have matching user id and username. For more information, see [Limitations](https://docs.aws.amazon.com/AmazonElastiCache/latest/dg/auth-iam.html). The construct can set automatically the username to be the same as the user id.
If you want to create a password authenticated user, use `PasswordUser` construct:
```python
user = elasticache.PasswordUser(self, "User",
# set user engine
engine=elasticache.UserEngine.VALKEY,
# set user id
user_id="my-user-id",
# set access string
access_control=elasticache.AccessControl.from_access_string("on ~* +@all"),
# set username
user_name="my-user-name",
# set up to two passwords
passwords=[
# "SecretIdForPassword" is the secret id for the password
SecretValue.secrets_manager("SecretIdForPassword"),
# "AnotherSecretIdForPassword" is the secret id for the password
SecretValue.secrets_manager("AnotherSecretIdForPassword")
]
)
```
You can also create a no password required user by using `NoPasswordUser` construct:
```python
user = elasticache.NoPasswordUser(self, "User",
# set user engine
engine=elasticache.UserEngine.REDIS,
# set user id
user_id="my-user-id",
# set access string
access_control=elasticache.AccessControl.from_access_string("on ~* +@all"),
# set username
user_name="my-user-name"
)
```
> NOTE: `NoPasswordUser` is only available for Redis Cache.
### Default user
ElastiCache automatically creates a default user with both a user ID and username set to `default`. This default user cannot be modified or deleted. The user is created as a no password authentication user.
This user is intended for compatibility with the default behavior of previous Redis OSS versions and has an access string that permits it to call all commands and access all keys.
To use this automatically created default user in CDK, you can import it using `NoPasswordUser.fromUserAttributes` method. For more information on import methods, see the [Import an existing user and user group](#import-an-existing-user-and-user-group) section.
To add proper access control to a cache, replace the default user with a new one that is either disabled by setting the `accessString` to `off -@all` or secured with a strong password.
To change the default user, create a new default user with the username set to `default`. You can then swap it with the original default user.
For more information, see [Applying RBAC to a Cache for ElastiCache with Valkey or Redis OSS](https://docs.aws.amazon.com/AmazonElastiCache/latest/dg/Clusters.RBAC.html#rbac-using).
If you want to create a new default user, `userName` must be `default` and `userId` must not be `default` by using `NoPasswordUser` or `PasswordUser`:
```python
# use the original `default` user by using import method
default_user = elasticache.NoPasswordUser.from_user_attributes(self, "DefaultUser",
# userId and userName must be 'default'
user_id="default"
)
# create a new default user
new_default_user = elasticache.NoPasswordUser(self, "NewDefaultUser",
# new default user id must not be 'default'
user_id="new-default",
# new default username must be 'default'
user_name="default",
# set access string
access_control=elasticache.AccessControl.from_access_string("on ~* +@all")
)
```
> NOTE: You can't create a new default user using `IamUser` because an IAM-enabled user's username and user ID cannot be different.
### Add users to the user group
Next, use the `UserGroup` construct to create a user group and add users to it.
Ensure that you include either the original default user or a new default user:
```python
# new_default_user: elasticache.IUser
# user: elasticache.IUser
# another_user: elasticache.IUser
user_group = elasticache.UserGroup(self, "UserGroup",
# add users including default user
users=[new_default_user, user]
)
# you can also add a user by using addUser method
user_group.add_user(another_user)
```
### Assign user group
Finally, assign a user group to cache:
```python
# vpc: ec2.Vpc
# user_group: elasticache.UserGroup
serverless_cache = elasticache.ServerlessCache(self, "ServerlessCache",
engine=elasticache.CacheEngine.VALKEY_LATEST,
serverless_cache_name="my-serverless-cache",
vpc=vpc,
# assign User Group
user_group=user_group
)
```
### Grant permissions to IAM-enabled users
If you create IAM-enabled users, `"elasticache:Connect"` action must be allowed for the users and cache.
> NOTE: You don't need grant permissions to no password required users or password authentication users.
For more information, see [Authenticating with IAM](https://docs.aws.amazon.com/AmazonElastiCache/latest/dg/auth-iam.html).
To grant permissions, you can use the `grantConnect` method in `IamUser` and `ServerlessCache` constructs:
```python
# user: elasticache.IamUser
# serverless_cache: elasticache.ServerlessCache
# role: iam.Role
# grant "elasticache:Connect" action permissions to role
user.grant_connect(role)
serverless_cache.grants.connect(role)
```
### Import an existing user and user group
You can import an existing user and user group by using import methods:
```python
stack = Stack()
imported_iam_user = elasticache.IamUser.from_user_id(self, "ImportedIamUser", "my-iam-user-id")
imported_password_user = elasticache.PasswordUser.from_user_attributes(stack, "ImportedPasswordUser",
user_id="my-password-user-id"
)
imported_no_password_user = elasticache.NoPasswordUser.from_user_attributes(stack, "ImportedNoPasswordUser",
user_id="my-no-password-user-id"
)
imported_user_group = elasticache.UserGroup.from_user_group_attributes(self, "ImportedUserGroup",
user_group_name="my-user-group-name"
)
```
| text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/aws/aws-cdk | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.239.0",
"constructs<11.0.0,>=10.5.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/aws/aws-cdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:57:57.867434 | aws_cdk_aws_elasticache_alpha-2.239.0a0.tar.gz | 155,412 | ae/6a/2e3803b643044d2e14195fc49a95e82acf509590399363a3532da8e17793/aws_cdk_aws_elasticache_alpha-2.239.0a0.tar.gz | source | sdist | null | false | cbcd4447d10b84733a20751dd3193e02 | 9fe53fd2cb6d4080090dd753ac9eba36c3cdf3bd71eb3dd41ba9ba67c6e8d33b | ae6a2e3803b643044d2e14195fc49a95e82acf509590399363a3532da8e17793 | null | [] | 0 |
2.1 | aws-cdk.aws-eks-v2-alpha | 2.239.0a0 | The CDK Construct Library for AWS::EKS | # Amazon EKS V2 Construct Library
<!--BEGIN STABILITY BANNER-->---

> The APIs of higher level constructs in this module are in **developer preview** before they
> become stable. We will only make breaking changes to address unforeseen API issues. Therefore,
> these APIs are not subject to [Semantic Versioning](https://semver.org/), and breaking changes
> will be announced in release notes. This means that while you may use them, you may need to
> update your source code when upgrading to a newer version of this package.
---
<!--END STABILITY BANNER-->
The eks-v2-alpha module is a rewrite of the existing aws-eks module (https://docs.aws.amazon.com/cdk/api/v2/docs/aws-cdk-lib.aws_eks-readme.html). This new iteration leverages native L1 CFN resources, replacing the previous custom resource approach for creating EKS clusters and Fargate Profiles.
Compared to the original EKS module, it has the following major changes:
* Use native L1 AWS::EKS::Cluster resource to replace custom resource Custom::AWSCDK-EKS-Cluster
* Use native L1 AWS::EKS::FargateProfile resource to replace custom resource Custom::AWSCDK-EKS-FargateProfile
* Kubectl Handler will not be created by default. It will only be created if users specify it.
* Remove AwsAuth construct. Permissions to the cluster will be managed by Access Entry.
* Remove the limit of 1 cluster per stack
* Remove nested stacks
* API changes to make them more ergonomic.
## Quick start
Here is the minimal example of defining an AWS EKS cluster
```python
cluster = eks.Cluster(self, "hello-eks",
version=eks.KubernetesVersion.V1_34
)
```
## Architecture
```text +-----------------+
kubectl | |
+------------>| Kubectl Handler |
| | (Optional) |
| +-----------------+
+-------------------------------------+-------------------------------------+
| EKS Cluster (Auto Mode) |
| AWS::EKS::Cluster |
| |
| +---------------------------------------------------------------------+ |
| | Auto Mode Compute (Managed by EKS) (Default) | |
| | | |
| | - Automatically provisions EC2 instances | |
| | - Auto scaling based on pod requirements | |
| | - No manual node group configuration needed | |
| | | |
| +---------------------------------------------------------------------+ |
| |
+---------------------------------------------------------------------------+
```
In a nutshell:
* **[Auto Mode](#eks-auto-mode)** (Default) – The fully managed capacity mode in EKS.
EKS automatically provisions and scales EC2 capacity based on pod requirements.
It manages internal *system* and *general-purpose* NodePools, handles networking and storage setup, and removes the need for user-managed node groups or Auto Scaling Groups.
```python
cluster = eks.Cluster(self, "AutoModeCluster",
version=eks.KubernetesVersion.V1_34
)
```
* **[Managed Node Groups](#managed-node-groups)** – The semi-managed capacity mode.
EKS provisions and manages EC2 nodes on your behalf but you configure the instance types, scaling ranges, and update strategy.
AWS handles node health, draining, and rolling updates while you retain control over scaling and cost optimization.
You can also define *Fargate Profiles* that determine which pods or namespaces run on Fargate infrastructure.
```python
cluster = eks.Cluster(self, "ManagedNodeCluster",
version=eks.KubernetesVersion.V1_34,
default_capacity_type=eks.DefaultCapacityType.NODEGROUP
)
# Add a Fargate Profile for specific workloads (e.g., default namespace)
cluster.add_fargate_profile("FargateProfile",
selectors=[eks.Selector(namespace="default")
]
)
```
* **[Fargate Mode](#fargate-profiles)** – The Fargate capacity mode.
EKS runs your pods directly on AWS Fargate without provisioning EC2 nodes.
```python
cluster = eks.FargateCluster(self, "FargateCluster",
version=eks.KubernetesVersion.V1_34
)
```
* **[Self-Managed Nodes](#self-managed-capacity)** – The fully manual capacity mode.
You create and manage EC2 instances (via an Auto Scaling Group) and connect them to the cluster manually.
This provides maximum flexibility for custom AMIs or configurations but also the highest operational overhead.
```python
cluster = eks.Cluster(self, "SelfManagedCluster",
version=eks.KubernetesVersion.V1_34
)
# Add self-managed Auto Scaling Group
cluster.add_auto_scaling_group_capacity("self-managed-asg",
instance_type=ec2.InstanceType.of(ec2.InstanceClass.T3, ec2.InstanceSize.MEDIUM),
min_capacity=1,
max_capacity=5
)
```
* **[Kubectl Handler](#kubectl-support) (Optional)** – A Lambda-backed custom resource created by the AWS CDK to execute `kubectl` commands (like `apply` or `patch`) during deployment.
Regardless of the capacity mode, this handler may still be created to apply Kubernetes manifests as part of CDK provisioning.
## Provisioning cluster
Creating a new cluster is done using the `Cluster` constructs. The only required property is the kubernetes version.
```python
eks.Cluster(self, "HelloEKS",
version=eks.KubernetesVersion.V1_34
)
```
You can also use `FargateCluster` to provision a cluster that uses only fargate workers.
```python
eks.FargateCluster(self, "HelloEKS",
version=eks.KubernetesVersion.V1_34
)
```
**Note: Unlike the previous EKS cluster, `Kubectl Handler` will not
be created by default. It will only be deployed when `kubectlProviderOptions`
property is used.**
```python
from aws_cdk.lambda_layer_kubectl_v34 import KubectlV34Layer
eks.Cluster(self, "hello-eks",
version=eks.KubernetesVersion.V1_34,
kubectl_provider_options=eks.KubectlProviderOptions(
kubectl_layer=KubectlV34Layer(self, "kubectl")
)
)
```
### EKS Auto Mode
[Amazon EKS Auto Mode](https://aws.amazon.com/eks/auto-mode/) extends AWS management of Kubernetes clusters beyond the cluster itself, allowing AWS to set up and manage the infrastructure that enables the smooth operation of your workloads.
#### Using Auto Mode
While `aws-eks` uses `DefaultCapacityType.NODEGROUP` by default, `aws-eks-v2` uses `DefaultCapacityType.AUTOMODE` as the default capacity type.
Auto Mode is enabled by default when creating a new cluster without specifying any capacity-related properties:
```python
# Create EKS cluster with Auto Mode implicitly enabled
cluster = eks.Cluster(self, "EksAutoCluster",
version=eks.KubernetesVersion.V1_34
)
```
You can also explicitly enable Auto Mode using `defaultCapacityType`:
```python
# Create EKS cluster with Auto Mode explicitly enabled
cluster = eks.Cluster(self, "EksAutoCluster",
version=eks.KubernetesVersion.V1_34,
default_capacity_type=eks.DefaultCapacityType.AUTOMODE
)
```
#### Node Pools
When Auto Mode is enabled, the cluster comes with two default node pools:
* `system`: For running system components and add-ons
* `general-purpose`: For running your application workloads
These node pools are managed automatically by EKS. You can configure which node pools to enable through the `compute` property:
```python
cluster = eks.Cluster(self, "EksAutoCluster",
version=eks.KubernetesVersion.V1_34,
default_capacity_type=eks.DefaultCapacityType.AUTOMODE,
compute=eks.ComputeConfig(
node_pools=["system", "general-purpose"]
)
)
```
For more information, see [Create a Node Pool for EKS Auto Mode](https://docs.aws.amazon.com/eks/latest/userguide/create-node-pool.html).
#### Disabling Default Node Pools
You can disable the default node pools entirely by setting an empty array for `nodePools`. This is useful when you want to use Auto Mode features but manage your compute resources separately:
```python
cluster = eks.Cluster(self, "EksAutoCluster",
version=eks.KubernetesVersion.V1_34,
default_capacity_type=eks.DefaultCapacityType.AUTOMODE,
compute=eks.ComputeConfig(
node_pools=[]
)
)
```
When node pools are disabled this way, no IAM role will be created for the node pools, preventing deployment failures that would otherwise occur when a role is created without any node pools.
### Node Groups as the default capacity type
If you prefer to manage your own node groups instead of using Auto Mode, you can use the traditional node group approach by specifying `defaultCapacityType` as `NODEGROUP`:
```python
# Create EKS cluster with traditional managed node group
cluster = eks.Cluster(self, "EksCluster",
version=eks.KubernetesVersion.V1_34,
default_capacity_type=eks.DefaultCapacityType.NODEGROUP,
default_capacity=3, # Number of instances
default_capacity_instance=ec2.InstanceType.of(ec2.InstanceClass.T3, ec2.InstanceSize.LARGE)
)
```
You can also create a cluster with no initial capacity and add node groups later:
```python
cluster = eks.Cluster(self, "EksCluster",
version=eks.KubernetesVersion.V1_34,
default_capacity_type=eks.DefaultCapacityType.NODEGROUP,
default_capacity=0
)
# Add node groups as needed
cluster.add_nodegroup_capacity("custom-node-group",
min_size=1,
max_size=3,
instance_types=[ec2.InstanceType.of(ec2.InstanceClass.T3, ec2.InstanceSize.LARGE)]
)
```
Read [Managed node groups](#managed-node-groups) for more information on how to add node groups to the cluster.
### Mixed with Auto Mode and Node Groups
You can combine Auto Mode with traditional node groups for specific workload requirements:
```python
cluster = eks.Cluster(self, "Cluster",
version=eks.KubernetesVersion.V1_34,
default_capacity_type=eks.DefaultCapacityType.AUTOMODE,
compute=eks.ComputeConfig(
node_pools=["system", "general-purpose"]
)
)
# Add specialized node group for specific workloads
cluster.add_nodegroup_capacity("specialized-workload",
min_size=1,
max_size=3,
instance_types=[ec2.InstanceType.of(ec2.InstanceClass.C5, ec2.InstanceSize.XLARGE)],
labels={
"workload": "specialized"
}
)
```
### Important Notes
1. Auto Mode and traditional capacity management are mutually exclusive at the default capacity level. You cannot opt in to Auto Mode and specify `defaultCapacity` or `defaultCapacityInstance`.
2. When Auto Mode is enabled:
* The cluster will automatically manage compute resources
* Node pools cannot be modified, only enabled or disabled
* EKS will handle scaling and management of the node pools
3. Auto Mode requires specific IAM permissions. The construct will automatically attach the required managed policies.
### Managed node groups
Amazon EKS managed node groups automate the provisioning and lifecycle management of nodes (Amazon EC2 instances) for Amazon EKS Kubernetes clusters.
With Amazon EKS managed node groups, you don't need to separately provision or register the Amazon EC2 instances that provide compute capacity to run your Kubernetes applications. You can create, update, or terminate nodes for your cluster with a single operation. Nodes run using the latest Amazon EKS optimized AMIs in your AWS account while node updates and terminations gracefully drain nodes to ensure that your applications stay available.
> For more details visit [Amazon EKS Managed Node Groups](https://docs.aws.amazon.com/eks/latest/userguide/managed-node-groups.html).
By default, when using `DefaultCapacityType.NODEGROUP`, this library will allocate a managed node group with 2 *m5.large* instances (this instance type suits most common use-cases, and is good value for money).
```python
eks.Cluster(self, "HelloEKS",
version=eks.KubernetesVersion.V1_34,
default_capacity_type=eks.DefaultCapacityType.NODEGROUP
)
```
At cluster instantiation time, you can customize the number of instances and their type:
```python
eks.Cluster(self, "HelloEKS",
version=eks.KubernetesVersion.V1_34,
default_capacity_type=eks.DefaultCapacityType.NODEGROUP,
default_capacity=5,
default_capacity_instance=ec2.InstanceType.of(ec2.InstanceClass.M5, ec2.InstanceSize.SMALL)
)
```
To access the node group that was created on your behalf, you can use `cluster.defaultNodegroup`.
Additional customizations are available post instantiation. To apply them, set the default capacity to 0, and use the `cluster.addNodegroupCapacity` method:
```python
cluster = eks.Cluster(self, "HelloEKS",
version=eks.KubernetesVersion.V1_34,
default_capacity_type=eks.DefaultCapacityType.NODEGROUP,
default_capacity=0
)
cluster.add_nodegroup_capacity("custom-node-group",
instance_types=[ec2.InstanceType("m5.large")],
min_size=4,
disk_size=100
)
```
### Fargate profiles
AWS Fargate is a technology that provides on-demand, right-sized compute
capacity for containers. With AWS Fargate, you no longer have to provision,
configure, or scale groups of virtual machines to run containers. This removes
the need to choose server types, decide when to scale your node groups, or
optimize cluster packing.
You can control which pods start on Fargate and how they run with Fargate
Profiles, which are defined as part of your Amazon EKS cluster.
See [Fargate Considerations](https://docs.aws.amazon.com/eks/latest/userguide/fargate.html#fargate-considerations) in the AWS EKS User Guide.
You can add Fargate Profiles to any EKS cluster defined in your CDK app
through the `addFargateProfile()` method. The following example adds a profile
that will match all pods from the "default" namespace:
```python
# cluster: eks.Cluster
cluster.add_fargate_profile("MyProfile",
selectors=[eks.Selector(namespace="default")]
)
```
You can also directly use the `FargateProfile` construct to create profiles under different scopes:
```python
# cluster: eks.Cluster
eks.FargateProfile(self, "MyProfile",
cluster=cluster,
selectors=[eks.Selector(namespace="default")]
)
```
To create an EKS cluster that **only** uses Fargate capacity, you can use `FargateCluster`.
The following code defines an Amazon EKS cluster with a default Fargate Profile that matches all pods from the "kube-system" and "default" namespaces. It is also configured to [run CoreDNS on Fargate](https://docs.aws.amazon.com/eks/latest/userguide/fargate-getting-started.html#fargate-gs-coredns).
```python
cluster = eks.FargateCluster(self, "MyCluster",
version=eks.KubernetesVersion.V1_34
)
```
`FargateCluster` will create a default `FargateProfile` which can be accessed via the cluster's `defaultProfile` property. The created profile can also be customized by passing options as with `addFargateProfile`.
**NOTE**: Classic Load Balancers and Network Load Balancers are not supported on
pods running on Fargate. For ingress, we recommend that you use the [ALB Ingress
Controller](https://docs.aws.amazon.com/eks/latest/userguide/alb-ingress.html)
on Amazon EKS (minimum version v1.1.4).
### Self-managed capacity
Self-managed capacity gives you the most control over your worker nodes by allowing you to create and manage your own EC2 Auto Scaling Groups. This approach provides maximum flexibility for custom AMIs, instance configurations, and scaling policies, but requires more operational overhead.
You can add self-managed capacity to any cluster using the `addAutoScalingGroupCapacity` method:
```python
cluster = eks.Cluster(self, "Cluster",
version=eks.KubernetesVersion.V1_34
)
cluster.add_auto_scaling_group_capacity("self-managed-nodes",
instance_type=ec2.InstanceType.of(ec2.InstanceClass.T3, ec2.InstanceSize.MEDIUM),
min_capacity=1,
max_capacity=10,
desired_capacity=3
)
```
You can specify custom subnets for the Auto Scaling Group:
```python
# vpc: ec2.Vpc
# cluster: eks.Cluster
cluster.add_auto_scaling_group_capacity("custom-subnet-nodes",
vpc_subnets=ec2.SubnetSelection(subnets=vpc.private_subnets),
instance_type=ec2.InstanceType.of(ec2.InstanceClass.T3, ec2.InstanceSize.MEDIUM),
min_capacity=2
)
```
### Endpoint Access
When you create a new cluster, Amazon EKS creates an endpoint for the managed Kubernetes API server that you use to communicate with your cluster (using Kubernetes management tools such as `kubectl`)
You can configure the [cluster endpoint access](https://docs.aws.amazon.com/eks/latest/userguide/cluster-endpoint.html) by using the `endpointAccess` property:
```python
cluster = eks.Cluster(self, "hello-eks",
version=eks.KubernetesVersion.V1_34,
endpoint_access=eks.EndpointAccess.PRIVATE
)
```
The default value is `eks.EndpointAccess.PUBLIC_AND_PRIVATE`. Which means the cluster endpoint is accessible from outside of your VPC, but worker node traffic and `kubectl` commands issued by this library stay within your VPC.
### Alb Controller
Some Kubernetes resources are commonly implemented on AWS with the help of the [ALB Controller](https://kubernetes-sigs.github.io/aws-load-balancer-controller/latest/).
From the docs:
> AWS Load Balancer Controller is a controller to help manage Elastic Load Balancers for a Kubernetes cluster.
>
> * It satisfies Kubernetes Ingress resources by provisioning Application Load Balancers.
> * It satisfies Kubernetes Service resources by provisioning Network Load Balancers.
To deploy the controller on your EKS cluster, configure the `albController` property:
```python
eks.Cluster(self, "HelloEKS",
version=eks.KubernetesVersion.V1_34,
alb_controller=eks.AlbControllerOptions(
version=eks.AlbControllerVersion.V2_8_2
)
)
```
To provide additional Helm chart values supported by `albController` in CDK, use the `additionalHelmChartValues` property. For example, the following code snippet shows how to set the `enableWafV2` flag:
```python
from aws_cdk.lambda_layer_kubectl_v34 import KubectlV34Layer
eks.Cluster(self, "HelloEKS",
version=eks.KubernetesVersion.V1_34,
alb_controller=eks.AlbControllerOptions(
version=eks.AlbControllerVersion.V2_8_2,
additional_helm_chart_values={
"enable_wafv2": False
}
)
)
```
To overwrite an existing ALB controller service account, use the `overwriteServiceAccount` property:
```python
eks.Cluster(self, "HelloEKS",
version=eks.KubernetesVersion.V1_34,
alb_controller=eks.AlbControllerOptions(
version=eks.AlbControllerVersion.V2_8_2,
overwrite_service_account=True
)
)
```
The `albController` requires `defaultCapacity` or at least one nodegroup. If there's no `defaultCapacity` or available
nodegroup for the cluster, the `albController` deployment would fail.
Querying the controller pods should look something like this:
```console
❯ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
aws-load-balancer-controller-76bd6c7586-d929p 1/1 Running 0 109m
aws-load-balancer-controller-76bd6c7586-fqxph 1/1 Running 0 109m
...
...
```
Every Kubernetes manifest that utilizes the ALB Controller is effectively dependant on the controller.
If the controller is deleted before the manifest, it might result in dangling ELB/ALB resources.
Currently, the EKS construct library does not detect such dependencies, and they should be done explicitly.
For example:
```python
# cluster: eks.Cluster
manifest = cluster.add_manifest("manifest", {})
if cluster.alb_controller:
manifest.node.add_dependency(cluster.alb_controller)
```
You can specify the VPC of the cluster using the `vpc` and `vpcSubnets` properties:
```python
# vpc: ec2.Vpc
eks.Cluster(self, "HelloEKS",
version=eks.KubernetesVersion.V1_34,
vpc=vpc,
vpc_subnets=[ec2.SubnetSelection(subnet_type=ec2.SubnetType.PRIVATE_WITH_EGRESS)]
)
```
If you do not specify a VPC, one will be created on your behalf, which you can then access via `cluster.vpc`. The cluster VPC will be associated to any EKS managed capacity (i.e Managed Node Groups and Fargate Profiles).
Please note that the `vpcSubnets` property defines the subnets where EKS will place the *control plane* ENIs. To choose
the subnets where EKS will place the worker nodes, please refer to the **Provisioning clusters** section above.
If you allocate self managed capacity, you can specify which subnets should the auto-scaling group use:
```python
# vpc: ec2.Vpc
# cluster: eks.Cluster
cluster.add_auto_scaling_group_capacity("nodes",
vpc_subnets=ec2.SubnetSelection(subnets=vpc.private_subnets),
instance_type=ec2.InstanceType("t2.medium")
)
```
There is an additional components you might want to provision within the VPC.
The `KubectlHandler` is a Lambda function responsible to issuing `kubectl` and `helm` commands against the cluster when you add resource manifests to the cluster.
The handler association to the VPC is derived from the `endpointAccess` configuration. The rule of thumb is: *If the cluster VPC can be associated, it will be*.
Breaking this down, it means that if the endpoint exposes private access (via `EndpointAccess.PRIVATE` or `EndpointAccess.PUBLIC_AND_PRIVATE`), and the VPC contains **private** subnets, the Lambda function will be provisioned inside the VPC and use the private subnets to interact with the cluster. This is the common use-case.
If the endpoint does not expose private access (via `EndpointAccess.PUBLIC`) **or** the VPC does not contain private subnets, the function will not be provisioned within the VPC.
If your use-case requires control over the IAM role that the KubeCtl Handler assumes, a custom role can be passed through the ClusterProps (as `kubectlLambdaRole`) of the EKS Cluster construct.
### Kubectl Support
You can choose to have CDK create a `Kubectl Handler` - a Python Lambda Function to
apply k8s manifests using `kubectl apply`. This handler will not be created by default.
To create a `Kubectl Handler`, use `kubectlProviderOptions` when creating the cluster.
`kubectlLayer` is the only required property in `kubectlProviderOptions`.
```python
from aws_cdk.lambda_layer_kubectl_v34 import KubectlV34Layer
eks.Cluster(self, "hello-eks",
version=eks.KubernetesVersion.V1_34,
kubectl_provider_options=eks.KubectlProviderOptions(
kubectl_layer=KubectlV34Layer(self, "kubectl")
)
)
```
`Kubectl Handler` created along with the cluster will be granted admin permissions to the cluster.
If you want to use an existing kubectl provider function, for example with tight trusted entities on your IAM Roles - you can import the existing provider and then use the imported provider when importing the cluster:
```python
handler_role = iam.Role.from_role_arn(self, "HandlerRole", "arn:aws:iam::123456789012:role/lambda-role")
# get the serivceToken from the custom resource provider
function_arn = lambda_.Function.from_function_name(self, "ProviderOnEventFunc", "ProviderframeworkonEvent-XXX").function_arn
kubectl_provider = eks.KubectlProvider.from_kubectl_provider_attributes(self, "KubectlProvider",
service_token=function_arn,
role=handler_role
)
cluster = eks.Cluster.from_cluster_attributes(self, "Cluster",
cluster_name="cluster",
kubectl_provider=kubectl_provider
)
```
#### Environment
You can configure the environment of this function by specifying it at cluster instantiation. For example, this can be useful in order to configure an http proxy:
```python
from aws_cdk.lambda_layer_kubectl_v34 import KubectlV34Layer
cluster = eks.Cluster(self, "hello-eks",
version=eks.KubernetesVersion.V1_34,
kubectl_provider_options=eks.KubectlProviderOptions(
kubectl_layer=KubectlV34Layer(self, "kubectl"),
environment={
"http_proxy": "http://proxy.myproxy.com"
}
)
)
```
#### Runtime
The kubectl handler uses `kubectl`, `helm` and the `aws` CLI in order to
interact with the cluster. These are bundled into AWS Lambda layers included in
the `@aws-cdk/lambda-layer-awscli` and `@aws-cdk/lambda-layer-kubectl` modules.
The version of kubectl used must be compatible with the Kubernetes version of the
cluster. kubectl is supported within one minor version (older or newer) of Kubernetes
(see [Kubernetes version skew policy](https://kubernetes.io/releases/version-skew-policy/#kubectl)).
Depending on which version of kubernetes you're targeting, you will need to use one of
the `@aws-cdk/lambda-layer-kubectl-vXY` packages.
```python
from aws_cdk.lambda_layer_kubectl_v34 import KubectlV34Layer
cluster = eks.Cluster(self, "hello-eks",
version=eks.KubernetesVersion.V1_34,
kubectl_provider_options=eks.KubectlProviderOptions(
kubectl_layer=KubectlV34Layer(self, "kubectl")
)
)
```
#### Memory
By default, the kubectl provider is configured with 1024MiB of memory. You can use the `memory` option to specify the memory size for the AWS Lambda function:
```python
from aws_cdk.lambda_layer_kubectl_v34 import KubectlV34Layer
eks.Cluster(self, "MyCluster",
kubectl_provider_options=eks.KubectlProviderOptions(
kubectl_layer=KubectlV34Layer(self, "kubectl"),
memory=Size.gibibytes(4)
),
version=eks.KubernetesVersion.V1_34
)
```
### ARM64 Support
Instance types with `ARM64` architecture are supported in both managed nodegroup and self-managed capacity. Simply specify an ARM64 `instanceType` (such as `m6g.medium`), and the latest
Amazon Linux 2 AMI for ARM64 will be automatically selected.
```python
# cluster: eks.Cluster
# add a managed ARM64 nodegroup
cluster.add_nodegroup_capacity("extra-ng-arm",
instance_types=[ec2.InstanceType("m6g.medium")],
min_size=2
)
# add a self-managed ARM64 nodegroup
cluster.add_auto_scaling_group_capacity("self-ng-arm",
instance_type=ec2.InstanceType("m6g.medium"),
min_capacity=2
)
```
### Masters Role
When you create a cluster, you can specify a `mastersRole`. The `Cluster` construct will associate this role with `AmazonEKSClusterAdminPolicy` through [Access Entry](https://docs.aws.amazon.com/eks/latest/userguide/access-policy-permissions.html).
```python
# role: iam.Role
eks.Cluster(self, "HelloEKS",
version=eks.KubernetesVersion.V1_34,
masters_role=role
)
```
If you do not specify it, you won't have access to the cluster from outside of the CDK application.
### Encryption
When you create an Amazon EKS cluster, envelope encryption of Kubernetes secrets using the AWS Key Management Service (AWS KMS) can be enabled.
The documentation on [creating a cluster](https://docs.aws.amazon.com/eks/latest/userguide/create-cluster.html)
can provide more details about the customer master key (CMK) that can be used for the encryption.
You can use the `secretsEncryptionKey` to configure which key the cluster will use to encrypt Kubernetes secrets. By default, an AWS Managed key will be used.
> This setting can only be specified when the cluster is created and cannot be updated.
```python
secrets_key = kms.Key(self, "SecretsKey")
cluster = eks.Cluster(self, "MyCluster",
secrets_encryption_key=secrets_key,
version=eks.KubernetesVersion.V1_34
)
```
You can also use a similar configuration for running a cluster built using the FargateCluster construct.
```python
secrets_key = kms.Key(self, "SecretsKey")
cluster = eks.FargateCluster(self, "MyFargateCluster",
secrets_encryption_key=secrets_key,
version=eks.KubernetesVersion.V1_34
)
```
The Amazon Resource Name (ARN) for that CMK can be retrieved.
```python
# cluster: eks.Cluster
cluster_encryption_config_key_arn = cluster.cluster_encryption_config_key_arn
```
### Hybrid Nodes
When you create an Amazon EKS cluster, you can configure it to leverage the [EKS Hybrid Nodes](https://aws.amazon.com/eks/hybrid-nodes/) feature, allowing you to use your on-premises and edge infrastructure as nodes in your EKS cluster. Refer to the Hyrid Nodes [networking documentation](https://docs.aws.amazon.com/eks/latest/userguide/hybrid-nodes-networking.html) to configure your on-premises network, node and pod CIDRs, access control, etc before creating your EKS Cluster.
Once you have identified the on-premises node and pod (optional) CIDRs you will use for your hybrid nodes and the workloads running on them, you can specify them during cluster creation using the `remoteNodeNetworks` and `remotePodNetworks` (optional) properties:
```python
from aws_cdk.lambda_layer_kubectl_v34 import KubectlV34Layer
eks.Cluster(self, "Cluster",
version=eks.KubernetesVersion.V1_34,
remote_node_networks=[eks.RemoteNodeNetwork(
cidrs=["10.0.0.0/16"]
)
],
remote_pod_networks=[eks.RemotePodNetwork(
cidrs=["192.168.0.0/16"]
)
]
)
```
### Self-Managed Add-ons
Amazon EKS automatically installs self-managed add-ons such as the Amazon VPC CNI plugin for Kubernetes, kube-proxy, and CoreDNS for every cluster. You can change the default configuration of the add-ons and update them when desired. If you wish to create a cluster without the default add-ons, set `bootstrapSelfManagedAddons` as `false`. When this is set to false, make sure to install the necessary alternatives which provide functionality that enables pod and service operations for your EKS cluster.
> Changing the value of `bootstrapSelfManagedAddons` after the EKS cluster creation will result in a replacement of the cluster.
## Permissions and Security
In the new EKS module, `ConfigMap` is deprecated. Clusters created by the new module will use `API` as authentication mode. Access Entry will be the only way for granting permissions to specific IAM users and roles.
### Access Entry
An access entry is a cluster identity—directly linked to an AWS IAM principal user or role that is used to authenticate to
an Amazon EKS cluster. An Amazon EKS access policy authorizes an access entry to perform specific cluster actions.
Access policies are Amazon EKS-specific policies that assign Kubernetes permissions to access entries. Amazon EKS supports
only predefined and AWS managed policies. Access policies are not AWS IAM entities and are defined and managed by Amazon EKS.
Amazon EKS access policies include permission sets that support common use cases of administration, editing, or read-only access
to Kubernetes resources. See [Access Policy Permissions](https://docs.aws.amazon.com/eks/latest/userguide/access-policies.html#access-policy-permissions) for more details.
Use `AccessPolicy` to include predefined AWS managed policies:
```python
# AmazonEKSClusterAdminPolicy with `cluster` scope
eks.AccessPolicy.from_access_policy_name("AmazonEKSClusterAdminPolicy",
access_scope_type=eks.AccessScopeType.CLUSTER
)
# AmazonEKSAdminPolicy with `namespace` scope
eks.AccessPolicy.from_access_policy_name("AmazonEKSAdminPolicy",
access_scope_type=eks.AccessScopeType.NAMESPACE,
namespaces=["foo", "bar"]
)
```
Use `grantAccess()` to grant the AccessPolicy to an IAM principal:
```python
from aws_cdk.lambda_layer_kubectl_v34 import KubectlV34Layer
# vpc: ec2.Vpc
cluster_admin_role = iam.Role(self, "ClusterAdminRole",
assumed_by=iam.ArnPrincipal("arn_for_trusted_principal")
)
eks_admin_role = iam.Role(self, "EKSAdminRole",
assumed_by=iam.ArnPrincipal("arn_for_trusted_principal")
)
cluster = eks.Cluster(self, "Cluster",
vpc=vpc,
masters_role=cluster_admin_role,
version=eks.KubernetesVersion.V1_34,
kubectl_provider_options=eks.KubectlProviderOptions(
kubectl_layer=KubectlV34Layer(self, "kubectl"),
memory=Size.gibibytes(4)
)
)
# Cluster Admin role for this cluster
cluster.grant_access("clusterAdminAccess", cluster_admin_role.role_arn, [
eks.AccessPolicy.from_access_policy_name("AmazonEKSClusterAdminPolicy",
access_scope_type=eks.AccessScopeType.CLUSTER
)
])
# EKS Admin role for specified namespaces of this cluster
cluster.grant_access("eksAdminRoleAccess", eks_admin_role.role_arn, [
eks.AccessPolicy.from_access_policy_name("AmazonEKSAdminPolicy",
access_scope_type=eks.AccessScopeType.NAMESPACE,
namespaces=["foo", "bar"]
)
])
```
#### Access Entry Types
You can optionally specify an access entry type when granting access. This is particularly useful for EKS Auto Mode clusters with custom node roles, which require the `EC2` type:
```python
# cluster: eks.Cluster
# node_role: iam.Role
# Grant access with EC2 type for Auto Mode node role
cluster.grant_access("nodeAccess", node_role.role_arn, [
eks.AccessPolicy.from_access_policy_name("AmazonEKSAutoNodePolicy",
access_scope_type=eks.AccessScopeType.CLUSTER
)
], access_entry_type=eks.AccessEntryType.EC2)
```
The following access entry types are supported:
* `STANDARD` - Default type for standard IAM principals (default when not specified)
* `FARGATE_LINUX` - For Fargate profiles
* `EC2_LINUX` - For EC2 Linux worker nodes
* `EC2_WINDOWS` - For EC2 Windows worker nodes
* `EC2` - For EKS Auto Mode node roles
* `HYBRID_LINUX` - For EKS Hybrid Nodes
* `HYPERPOD_LINUX` - For Amazon SageMaker HyperPod
**Note**: Access entries with type `EC2`, `HYBRID_LINUX`, or `HYPERPOD_LINUX` cannot have access policies attached per AWS EKS API constraints. For these types, use the `AccessEntry` construct directly with an empty access policies array.
By default, the cluster creator role will be granted the cluster admin permissions. You can disable it by setting
`bootstrapClusterCreatorAdminPermissions` to false.
> **Note** - Switching `bootstrapClusterCreatorAdminPermissions` on an existing cluster would cause cluster replacement and should be avoided in production.
### Service Accounts
With services account you can provide Kubernetes Pods access to AWS resources.
```python
import aws_cdk.aws_s3 as s3
# cluster: eks.Cluster
# add service account
service_account = cluster.add_service_account("MyServiceAccount")
bucket = s3.Bucket(self, "Bucket")
bucket.grant_read_write(service_account)
mypod = cluster.add_manifest("mypod", {
"api_version": "v1",
"kind": "Pod",
"metadata": {"name": "mypod"},
"spec": {
"service_account_name": service_account.service_account_name,
"containers": [{
"name": "hello",
"image": "paulbouwer/hello-kubernetes:1.5",
"ports": [{"container_port": 8080}]
}
]
}
})
# create the resource after the service account.
mypod.node.add_dependency(service_account)
# print the IAM role arn for this service account
CfnOutput(self, "ServiceAccountIamRole", value=service_account.role.role_arn)
```
Note that using `serviceAccount.serviceAccountName` above **does not** translate into a resource dependency.
This is why an explicit dependency is needed. See [https://github.com/aws/aws-cdk/issues/9910](https://github.com/aws/aws-cdk/issues/9910) for more details.
It is possible to pass annotations and labels to the service account.
```python
# cluster: eks.Cluster
# add service account with annotations and labels
service_account = cluster.add_service_account("MyServiceAccount",
annotations={
"eks.amazonaws.com/sts-regional-endpoints": "false"
},
labels={
"some-label": "with-some-value"
}
)
```
You can also add service accounts to existing clusters.
To do so, pass the `openIdConnectProvider` property when you import the cluster into the application.
```python
import aws_cdk.aws_s3 as s3
# or create a new one using an existing issuer url
# issuer_url: str
from aws_cdk.lambda_layer_kubectl_v34 import KubectlV34Layer
# you can import an existing provider
provider = eks.OidcProviderNative.from_oidc_provider_arn(self, "Provider", "arn:aws:iam::123456:oidc-provider/oidc.eks.eu-west-1.amazonaws.com/id/AB123456ABC")
provider2 = eks.OidcProviderNative(self, "Provider",
url=issuer_url
)
cluster = eks.Cluster.from_cluster_attributes(self, "MyCluster",
cluster_name="Cluster",
open_id_connect_provider=provider,
kubectl_provider_options=eks.KubectlProviderOptions(
kubectl_layer=KubectlV34Layer(self, "kubectl")
)
)
service_account = cluster.add_service_account("MyServiceAccount")
bucket = s3.Bucket(self, "Bucket")
bucket.grant_read_write(service_account)
```
Note that adding service accounts requires running `kubectl` commands against the cluster which requires you to provide `kubectlProviderOptions` in the cluster props to create the `kubectl` provider. See [Kubectl Support](https://docs.aws.amazon.com/cdk/api/v2/docs/aws-eks-v2-alpha-readme.html#kubectl-support)
#### Migrating from the deprecated eks.OpenIdConnectProvider to eks.OidcProviderNative
`eks.OpenIdConnectProvider` creates an IAM OIDC (OpenId Connect) provider using a custom resource while `eks.OidcProviderNative` uses the CFN L1 (AWS::IAM::OidcProvider) to create the provider. It is recommended for new and existing projects to use `eks.OidcProviderNative`.
To migrate without temporarily removing the OIDCProvider, follow these steps:
1. Set the `removalPolicy` of `cluster.openIdConnectProvider` to `RETAIN`.
```python
import aws_cdk as cdk
# cluster: eks.Cluster
cdk.RemovalPolicies.of(cluster.open_id_connect_provider).apply(cdk.RemovalPolicy.RETAIN)
```
2. Run `cdk diff` to verify the changes are expected then `cdk deploy`.
3. Add the following to the `context` field of your `cdk.json` to enable the feature flag that creates the native oidc provider.
```json
"@aws-cdk/aws-eks:useNativeOidcProvider": true,
```
4. Run `cdk diff` and ensure the changes are expected. Example of an expected diff:
```bash
Resources
[-] Custom::AWSCDKOpenIdConnectProvider TestCluster/OpenIdConnectProvider/Resource TestClusterOpenIdConnectProviderE18F0FD0 orphan
[-] AWS::IAM::Role Custom::AWSCDKOpenIdConnectProviderCustomResourceProvider/Role CustomAWSCDKOpenIdConnectProviderCustomResourceProviderRole517FED65 destroy
[-] AWS::Lambda::Function Custom::AWSCDKOpenIdConnectProviderCustomResourceProvider/Handler CustomAWSCDKOpenIdConnectProviderCustomResourceProviderHandlerF2C543E0 destroy
[+] AWS::IAM::OIDCProvider TestCluster/OidcProviderNative TestClusterOidcProviderNative0BE3F155
```
5. Run `cdk import --force` and provide the ARN of the existing OpenIdConnectProvider when prompted. You will get a warning about pending changes to existing resources which is expected.
6. Run `cdk deploy` to apply any pending changes. This will apply the destroy/orphan changes in the above example.
If you are creating the OpenIdConnectProvider manually via `new eks.OpenIdConnectProvider`, follow these steps:
1. Set the `removalPolicy` of the existing `OpenIdConnectProvider` to `RemovalPolicy.RETAIN`.
```python
import aws_cdk as cdk
# Step 1: Add retain policy to existing provider
existing_provider = eks.OpenIdConnectProvider(self, "Provider",
url="https://oidc.eks.us-west-2.amazonaws.com/id/EXAMPLE",
removal_policy=cdk.RemovalPolicy.RETAIN
)
```
2. Deploy with the retain policy to avoid deletion of the underlying resource.
```bash
cdk deploy
```
3. Replace `OpenIdConnectProvider` with `OidcProviderNative` in your code.
```python
# Step 3: Replace with native provider
native_provider = eks.OidcProviderNative(self, "Provider",
url="https://oidc.eks.us-west-2.amazonaws.com/id/EXAMPLE"
)
```
4. Run `cdk diff` and verify the changes are expected. Example of | text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/aws/aws-cdk | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.239.0",
"constructs<11.0.0,>=10.5.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/aws/aws-cdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:57:56.526982 | aws_cdk_aws_eks_v2_alpha-2.239.0a0.tar.gz | 622,038 | 2d/28/d3a412a7f70136e469127fad3933ca6482596649f9211ee999aa82fe3b01/aws_cdk_aws_eks_v2_alpha-2.239.0a0.tar.gz | source | sdist | null | false | e62b562c5500a7f8ad60c7de3b152e02 | f1c9f3f38f66cf671a0383d043f05c03a881e226e8fed826df32d95dbcf07288 | 2d28d3a412a7f70136e469127fad3933ca6482596649f9211ee999aa82fe3b01 | null | [] | 0 |
2.1 | aws-cdk.aws-ec2-alpha | 2.239.0a0 | The CDK construct library for VPC V2 | # Amazon VpcV2 Construct Library
<!--BEGIN STABILITY BANNER-->---

> The APIs of higher level constructs in this module are in **developer preview** before they
> become stable. We will only make breaking changes to address unforeseen API issues. Therefore,
> these APIs are not subject to [Semantic Versioning](https://semver.org/), and breaking changes
> will be announced in release notes. This means that while you may use them, you may need to
> update your source code when upgrading to a newer version of this package.
---
<!--END STABILITY BANNER-->
## VpcV2
`VpcV2` is a re-write of the [`ec2.Vpc`](https://docs.aws.amazon.com/cdk/api/v2/docs/aws-cdk-lib.aws_ec2.Vpc.html) construct. This new construct enables higher level of customization
on the VPC being created. `VpcV2` implements the existing [`IVpc`](https://docs.aws.amazon.com/cdk/api/v2/docs/aws-cdk-lib.aws_ec2.IVpc.html), therefore,
`VpcV2` is compatible with other constructs that accepts `IVpc` (e.g. [`ApplicationLoadBalancer`](https://docs.aws.amazon.com/cdk/api/v2/docs/aws-cdk-lib.aws_elasticloadbalancingv2.ApplicationLoadBalancer.html#construct-props)).
`VpcV2` supports the addition of both primary and secondary addresses. The primary address must be an IPv4 address, which can be specified as a CIDR string or assigned from an IPAM pool. Secondary addresses can be either IPv4 or IPv6.
By default, `VpcV2` assigns `10.0.0.0/16` as the primary CIDR if no other CIDR is specified.
Below is an example of creating a VPC with both IPv4 and IPv6 support:
```python
stack = Stack()
VpcV2(self, "Vpc",
primary_address_block=IpAddresses.ipv4("10.0.0.0/24"),
secondary_address_blocks=[
IpAddresses.amazon_provided_ipv6(cidr_block_name="AmazonProvidedIpv6")
]
)
```
`VpcV2` does not automatically create subnets or allocate IP addresses, which is different from the `Vpc` construct.
## SubnetV2
`SubnetV2` is a re-write of the [`ec2.Subnet`](https://docs.aws.amazon.com/cdk/api/v2/docs/aws-cdk-lib.aws_ec2.Subnet.html) construct.
This new construct can be used to add subnets to a `VpcV2` instance:
Note: When defining a subnet with `SubnetV2`, CDK automatically creates a new route table, unless a route table is explicitly provided as an input to the construct.
To enable the `mapPublicIpOnLaunch` feature (which is `false` by default), set the property to `true` when creating the subnet.
```python
stack = Stack()
my_vpc = VpcV2(self, "Vpc",
secondary_address_blocks=[
IpAddresses.amazon_provided_ipv6(cidr_block_name="AmazonProvidedIp")
]
)
SubnetV2(self, "subnetA",
vpc=my_vpc,
availability_zone="us-east-1a",
ipv4_cidr_block=IpCidr("10.0.0.0/24"),
ipv6_cidr_block=IpCidr("2a05:d02c:25:4000::/60"),
subnet_type=SubnetType.PUBLIC,
map_public_ip_on_launch=True
)
```
Since `VpcV2` does not create subnets automatically, users have full control over IP addresses allocation across subnets.
## IP Addresses Management
Additional CIDRs can be added to the VPC via the `secondaryAddressBlocks` property.
The following example illustrates the options of defining these secondary address blocks using `IPAM`:
Note: There’s currently an issue with IPAM pool deletion that may affect the `cdk --destroy` command. This is because IPAM takes time to detect when the IP address pool has been deallocated after the VPC is deleted. The current workaround is to wait until the IP address is fully deallocated from the pool before retrying the deletion. Below command can be used to check allocations for a pool using CLI
```shell
aws ec2 get-ipam-pool-allocations --ipam-pool-id <ipam-pool-id>
```
Ref: https://docs.aws.amazon.com/cli/latest/reference/ec2/get-ipam-pool-allocations.html
```python
stack = Stack()
ipam = Ipam(self, "Ipam",
operating_regions=["us-west-1"]
)
ipam_public_pool = ipam.public_scope.add_pool("PublicPoolA",
address_family=AddressFamily.IP_V6,
aws_service=AwsServiceName.EC2,
locale="us-west-1",
public_ip_source=IpamPoolPublicIpSource.AMAZON
)
ipam_public_pool.provision_cidr("PublicPoolACidrA", netmask_length=52)
ipam_private_pool = ipam.private_scope.add_pool("PrivatePoolA",
address_family=AddressFamily.IP_V4
)
ipam_private_pool.provision_cidr("PrivatePoolACidrA", netmask_length=8)
VpcV2(self, "Vpc",
primary_address_block=IpAddresses.ipv4("10.0.0.0/24"),
secondary_address_blocks=[
IpAddresses.amazon_provided_ipv6(cidr_block_name="AmazonIpv6"),
IpAddresses.ipv6_ipam(
ipam_pool=ipam_public_pool,
netmask_length=52,
cidr_block_name="ipv6Ipam"
),
IpAddresses.ipv4_ipam(
ipam_pool=ipam_private_pool,
netmask_length=8,
cidr_block_name="ipv4Ipam"
)
]
)
```
### Bring your own IPv6 addresses (BYOIP)
If you have your own IP address that you would like to use with EC2, you can set up an IPv6 pool via the AWS CLI, and use that pool ID in your application.
Once you have certified your IP address block with an ROA and have obtained an X-509 certificate, you can run the following command to provision your CIDR block in your AWS account:
```shell
aws ec2 provision-byoip-cidr --region <region> --cidr <your CIDR block> --cidr-authorization-context Message="1|aws|<account>|<your CIDR block>|<expiration date>|SHA256".Signature="<signature>"
```
When your BYOIP CIDR is provisioned, you can run the following command to retrieve your IPv6 pool ID, which will be used in your VPC declaration:
```shell
aws ec2 describe-byoip-cidr --region <region>
```
For more help on setting up your IPv6 address, please review the [EC2 Documentation](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-byoip.html).
Once you have provisioned your address block, you can use the IPv6 in your VPC as follows:
```python
my_vpc = VpcV2(self, "Vpc",
primary_address_block=IpAddresses.ipv4("10.1.0.0/16"),
secondary_address_blocks=[IpAddresses.ipv6_byoip_pool(
cidr_block_name="MyByoipCidrBlock",
ipv6_pool_id="ipv6pool-ec2-someHashValue",
ipv6_cidr_block="2001:db8::/32"
)],
enable_dns_hostnames=True,
enable_dns_support=True
)
```
## Routing
`RouteTable` is a new construct that allows for route tables to be customized in a variety of ways. Using this construct, a customized route table can be added to the subnets defined using `SubnetV2`.
For instance, the following example shows how a custom route table can be created and appended to a `SubnetV2`:
```python
my_vpc = VpcV2(self, "Vpc")
route_table = RouteTable(self, "RouteTable",
vpc=my_vpc
)
subnet = SubnetV2(self, "Subnet",
vpc=my_vpc,
route_table=route_table,
availability_zone="eu-west-2a",
ipv4_cidr_block=IpCidr("10.0.0.0/24"),
subnet_type=SubnetType.PRIVATE_ISOLATED
)
```
`Routes` can be created to link subnets to various different AWS services via gateways and endpoints. Each unique route target has its own dedicated construct that can be routed to a given subnet via the `Route` construct. An example using the `InternetGateway` construct can be seen below:
```python
stack = Stack()
my_vpc = VpcV2(self, "Vpc")
route_table = RouteTable(self, "RouteTable",
vpc=my_vpc
)
subnet = SubnetV2(self, "Subnet",
vpc=my_vpc,
availability_zone="eu-west-2a",
ipv4_cidr_block=IpCidr("10.0.0.0/24"),
subnet_type=SubnetType.PRIVATE_ISOLATED
)
igw = InternetGateway(self, "IGW",
vpc=my_vpc
)
Route(self, "IgwRoute",
route_table=route_table,
destination="0.0.0.0/0",
target={"gateway": igw}
)
```
Alternatively, `Routes` can also be created via method `addRoute` in the `RouteTable` class. An example using the `EgressOnlyInternetGateway` construct can be seen below:
Note: `EgressOnlyInternetGateway` can only be used to set up outbound IPv6 routing.
```python
stack = Stack()
my_vpc = VpcV2(self, "Vpc",
primary_address_block=IpAddresses.ipv4("10.1.0.0/16"),
secondary_address_blocks=[IpAddresses.amazon_provided_ipv6(
cidr_block_name="AmazonProvided"
)]
)
eigw = EgressOnlyInternetGateway(self, "EIGW",
vpc=my_vpc
)
route_table = RouteTable(self, "RouteTable",
vpc=my_vpc
)
route_table.add_route("EIGW", "::/0", {"gateway": eigw})
```
Other route targets may require a deeper set of parameters to set up properly. For instance, the example below illustrates how to set up a `NatGateway`:
```python
my_vpc = VpcV2(self, "Vpc")
route_table = RouteTable(self, "RouteTable",
vpc=my_vpc
)
subnet = SubnetV2(self, "Subnet",
vpc=my_vpc,
availability_zone="eu-west-2a",
ipv4_cidr_block=IpCidr("10.0.0.0/24"),
subnet_type=SubnetType.PRIVATE_ISOLATED
)
natgw = NatGateway(self, "NatGW",
subnet=subnet,
vpc=my_vpc,
connectivity_type=NatConnectivityType.PRIVATE,
private_ip_address="10.0.0.42"
)
Route(self, "NatGwRoute",
route_table=route_table,
destination="0.0.0.0/0",
target={"gateway": natgw}
)
```
It is also possible to set up endpoints connecting other AWS services. For instance, the example below illustrates the linking of a Dynamo DB endpoint via the existing `ec2.GatewayVpcEndpoint` construct as a route target:
```python
stack = Stack()
my_vpc = VpcV2(self, "Vpc")
route_table = RouteTable(self, "RouteTable",
vpc=my_vpc
)
subnet = SubnetV2(self, "Subnet",
vpc=my_vpc,
availability_zone="eu-west-2a",
ipv4_cidr_block=IpCidr("10.0.0.0/24"),
subnet_type=SubnetType.PRIVATE
)
dynamo_endpoint = ec2.GatewayVpcEndpoint(self, "DynamoEndpoint",
service=ec2.GatewayVpcEndpointAwsService.DYNAMODB,
vpc=my_vpc,
subnets=[subnet]
)
Route(self, "DynamoDBRoute",
route_table=route_table,
destination="0.0.0.0/0",
target={"endpoint": dynamo_endpoint}
)
```
## VPC Peering Connection
VPC peering connection allows you to connect two VPCs and route traffic between them using private IP addresses. The VpcV2 construct supports creating VPC peering connections through the `VPCPeeringConnection` construct from the `route` module.
Peering Connection cannot be established between two VPCs with overlapping CIDR ranges. Please make sure the two VPC CIDRs do not overlap with each other else it will throw an error.
For more information, see [What is VPC peering?](https://docs.aws.amazon.com/vpc/latest/peering/what-is-vpc-peering.html).
The following show examples of how to create a peering connection between two VPCs for all possible combinations of same-account or cross-account, and same-region or cross-region configurations.
Note: You cannot create a VPC peering connection between VPCs that have matching or overlapping CIDR blocks
**Case 1: Same Account and Same Region Peering Connection**
```python
stack = Stack()
vpc_a = VpcV2(self, "VpcA",
primary_address_block=IpAddresses.ipv4("10.0.0.0/16")
)
vpc_b = VpcV2(self, "VpcB",
primary_address_block=IpAddresses.ipv4("10.1.0.0/16")
)
peering_connection = vpc_a.create_peering_connection("sameAccountSameRegionPeering",
acceptor_vpc=vpc_b
)
```
**Case 2: Same Account and Cross Region Peering Connection**
There is no difference from Case 1 when calling `createPeeringConnection`. The only change is that one of the VPCs are created in another stack with a different region. To establish cross region VPC peering connection, acceptorVpc needs to be imported to the requestor VPC stack using `fromVpcV2Attributes` method.
```python
from aws_cdk import Environment, Environment
app = App()
stack_a = Stack(app, "VpcStackA", env=Environment(account="000000000000", region="us-east-1"))
stack_b = Stack(app, "VpcStackB", env=Environment(account="000000000000", region="us-west-2"))
vpc_a = VpcV2(stack_a, "VpcA",
primary_address_block=IpAddresses.ipv4("10.0.0.0/16")
)
VpcV2(stack_b, "VpcB",
primary_address_block=IpAddresses.ipv4("10.1.0.0/16")
)
vpc_b = VpcV2.from_vpc_v2_attributes(stack_a, "ImportedVpcB",
vpc_id="MockVpcBid",
vpc_cidr_block="10.1.0.0/16",
region="us-west-2",
owner_account_id="000000000000"
)
peering_connection = vpc_a.create_peering_connection("sameAccountCrossRegionPeering",
acceptor_vpc=vpc_b
)
```
**Case 3: Cross Account Peering Connection**
For cross-account connections, the acceptor account needs an IAM role that grants the requestor account permission to initiate the connection. Create a new IAM role in the acceptor account using method `createAcceptorVpcRole` to provide the necessary permissions.
Once role is created in account, provide role arn for field `peerRoleArn` under method `createPeeringConnection`
```python
stack = Stack()
acceptor_vpc = VpcV2(self, "VpcA",
primary_address_block=IpAddresses.ipv4("10.0.0.0/16")
)
acceptor_role_arn = acceptor_vpc.create_acceptor_vpc_role("000000000000")
```
After creating an IAM role in the acceptor account, we can initiate the peering connection request from the requestor VPC. Import acceptorVpc to the stack using `fromVpcV2Attributes` method, it is recommended to specify owner account id of the acceptor VPC in case of cross account peering connection, if acceptor VPC is hosted in different region provide region value for import as well.
The following code snippet demonstrates how to set up VPC peering between two VPCs in different AWS accounts using CDK:
```python
stack = Stack()
acceptor_vpc = VpcV2.from_vpc_v2_attributes(self, "acceptorVpc",
vpc_id="vpc-XXXX",
vpc_cidr_block="10.0.0.0/16",
region="us-east-2",
owner_account_id="111111111111"
)
acceptor_role_arn = "arn:aws:iam::111111111111:role/VpcPeeringRole"
requestor_vpc = VpcV2(self, "VpcB",
primary_address_block=IpAddresses.ipv4("10.1.0.0/16")
)
peering_connection = requestor_vpc.create_peering_connection("crossAccountCrossRegionPeering",
acceptor_vpc=acceptor_vpc,
peer_role_arn=acceptor_role_arn
)
```
### Route Table Configuration
After establishing the VPC peering connection, routes must be added to the respective route tables in the VPCs to enable traffic flow. If a route is added to the requestor stack, information will be able to flow from the requestor VPC to the acceptor VPC, but not in the reverse direction. For bi-directional communication, routes need to be added in both VPCs from their respective stacks.
For more information, see [Update your route tables for a VPC peering connection](https://docs.aws.amazon.com/vpc/latest/peering/vpc-peering-routing.html).
```python
stack = Stack()
acceptor_vpc = VpcV2(self, "VpcA",
primary_address_block=IpAddresses.ipv4("10.0.0.0/16")
)
requestor_vpc = VpcV2(self, "VpcB",
primary_address_block=IpAddresses.ipv4("10.1.0.0/16")
)
peering_connection = requestor_vpc.create_peering_connection("peeringConnection",
acceptor_vpc=acceptor_vpc
)
route_table = RouteTable(self, "RouteTable",
vpc=requestor_vpc
)
route_table.add_route("vpcPeeringRoute", "10.0.0.0/16", {"gateway": peering_connection})
```
This can also be done using AWS CLI. For more information, see [create-route](https://docs.aws.amazon.com/cli/latest/reference/ec2/create-route.html).
```bash
# Add a route to the requestor VPC route table
aws ec2 create-route --route-table-id rtb-requestor --destination-cidr-block 10.0.0.0/16 --vpc-peering-connection-id pcx-xxxxxxxx
# For bi-directional add a route in the acceptor vpc account as well
aws ec2 create-route --route-table-id rtb-acceptor --destination-cidr-block 10.1.0.0/16 --vpc-peering-connection-id pcx-xxxxxxxx
```
### Deleting the Peering Connection
To delete a VPC peering connection, use the following command:
```bash
aws ec2 delete-vpc-peering-connection --vpc-peering-connection-id pcx-xxxxxxxx
```
For more information, see [Delete a VPC peering connection](https://docs.aws.amazon.com/vpc/latest/peering/create-vpc-peering-connection.html#delete-vpc-peering-connection).
## Adding Egress-Only Internet Gateway to VPC
An egress-only internet gateway is a horizontally scaled, redundant, and highly available VPC component that allows outbound communication over IPv6 from instances in your VPC to the internet, and prevents the internet from initiating an IPv6 connection with your instances.
For more information see [Enable outbound IPv6 traffic using an egress-only internet gateway](https://docs.aws.amazon.com/vpc/latest/userguide/egress-only-internet-gateway.html).
VpcV2 supports adding an egress only internet gateway to VPC using the `addEgressOnlyInternetGateway` method.
By default, this method sets up a route to all outbound IPv6 address ranges, unless a specific destination is provided by the user. It can only be configured for IPv6-enabled VPCs.
The `Subnets` parameter accepts a `SubnetFilter`, which can be based on a `SubnetType` in VpcV2. A new route will be added to the route tables of all subnets that match this filter.
```python
stack = Stack()
my_vpc = VpcV2(self, "Vpc",
primary_address_block=IpAddresses.ipv4("10.1.0.0/16"),
secondary_address_blocks=[IpAddresses.amazon_provided_ipv6(
cidr_block_name="AmazonProvided"
)]
)
route_table = RouteTable(self, "RouteTable",
vpc=my_vpc
)
subnet = SubnetV2(self, "Subnet",
vpc=my_vpc,
availability_zone="eu-west-2a",
ipv4_cidr_block=IpCidr("10.0.0.0/24"),
ipv6_cidr_block=IpCidr("2001:db8:1::/64"),
subnet_type=SubnetType.PRIVATE
)
my_vpc.add_egress_only_internet_gateway(
subnets=[ec2.SubnetSelection(subnet_type=SubnetType.PRIVATE)],
destination="::/60"
)
```
## Adding NATGateway to the VPC
A NAT gateway is a Network Address Translation (NAT) service.You can use a NAT gateway so that instances in a private subnet can connect to services outside your VPC but external services cannot initiate a connection with those instances.
For more information, see [NAT gateway basics](https://docs.aws.amazon.com/vpc/latest/userguide/vpc-nat-gateway.html).
When you create a NAT gateway, you specify one of the following connectivity types:
**Public – (Default)**: Instances in private subnets can connect to the internet through a public NAT gateway, but cannot receive unsolicited inbound connections from the internet
**Private**: Instances in private subnets can connect to other VPCs or your on-premises network through a private NAT gateway.
To define the NAT gateway connectivity type as `ConnectivityType.Public`, you need to ensure that there is an IGW(Internet Gateway) attached to the subnet's VPC.
Since a NATGW is associated with a particular subnet, providing `subnet` field in the input props is mandatory.
Additionally, you can set up a route in any route table with the target set to the NAT Gateway. The function `addNatGateway` returns a `NATGateway` object that you can reference later.
The code example below provides the definition for adding a NAT gateway to your subnet:
```python
stack = Stack()
my_vpc = VpcV2(self, "Vpc")
route_table = RouteTable(self, "RouteTable",
vpc=my_vpc
)
subnet = SubnetV2(self, "Subnet",
vpc=my_vpc,
availability_zone="eu-west-2a",
ipv4_cidr_block=IpCidr("10.0.0.0/24"),
subnet_type=SubnetType.PUBLIC
)
my_vpc.add_internet_gateway()
my_vpc.add_nat_gateway(
subnet=subnet,
connectivity_type=NatConnectivityType.PUBLIC
)
```
## Enable VPNGateway for the VPC
A virtual private gateway is the endpoint on the VPC side of your VPN connection.
For more information, see [What is AWS Site-to-Site VPN?](https://docs.aws.amazon.com/vpn/latest/s2svpn/VPC_VPN.html).
VPN route propagation is a feature in Amazon Web Services (AWS) that automatically updates route tables in your Virtual Private Cloud (VPC) with routes learned from a VPN connection.
To enable VPN route propagation, use the `vpnRoutePropagation` property to specify the subnets as an input to the function. VPN route propagation will then be enabled for each subnet with the corresponding route table IDs.
Additionally, you can set up a route in any route table with the target set to the VPN Gateway. The function `enableVpnGatewayV2` returns a `VPNGatewayV2` object that you can reference later.
The code example below provides the definition for setting up a VPN gateway with `vpnRoutePropagation` enabled:
```python
stack = Stack()
my_vpc = VpcV2(self, "Vpc")
vpn_gateway = my_vpc.enable_vpn_gateway_v2(
vpn_route_propagation=[ec2.SubnetSelection(subnet_type=SubnetType.PUBLIC)],
type=VpnConnectionType.IPSEC_1
)
route_table = RouteTable(stack, "routeTable",
vpc=my_vpc
)
Route(stack, "route",
destination="172.31.0.0/24",
target={"gateway": vpn_gateway},
route_table=route_table
)
```
## Adding InternetGateway to the VPC
An internet gateway is a horizontally scaled, redundant, and highly available VPC component that allows communication between your VPC and the internet. It supports both IPv4 and IPv6 traffic.
For more information, see [Enable VPC internet access using internet gateways](https://docs.aws.amazon.com/vpc/latest/userguide/vpc-igw-internet-access.html).
You can add an internet gateway to a VPC using `addInternetGateway` method. By default, this method creates a route in all Public Subnets with outbound destination set to `0.0.0.0` for IPv4 and `::0` for IPv6 enabled VPC.
Instead of using the default settings, you can configure a custom destination range by providing an optional input `destination` to the method.
In addition to the custom IP range, you can also choose to filter subnets where default routes should be created.
The code example below shows how to add an internet gateway with a custom outbound destination IP range:
```python
stack = Stack()
my_vpc = VpcV2(self, "Vpc")
subnet = SubnetV2(self, "Subnet",
vpc=my_vpc,
availability_zone="eu-west-2a",
ipv4_cidr_block=IpCidr("10.0.0.0/24"),
subnet_type=SubnetType.PUBLIC
)
my_vpc.add_internet_gateway(
ipv4_destination="192.168.0.0/16"
)
```
The following code examples demonstrates how to add an internet gateway with a custom outbound destination IP range for specific subnets:
```python
stack = Stack()
my_vpc = VpcV2(self, "Vpc")
my_subnet = SubnetV2(self, "Subnet",
vpc=my_vpc,
availability_zone="eu-west-2a",
ipv4_cidr_block=IpCidr("10.0.0.0/24"),
subnet_type=SubnetType.PUBLIC
)
my_vpc.add_internet_gateway(
ipv4_destination="192.168.0.0/16",
subnets=[my_subnet]
)
```
```python
stack = Stack()
my_vpc = VpcV2(self, "Vpc")
my_vpc.add_internet_gateway(
ipv4_destination="192.168.0.0/16",
subnets=[ec2.SubnetSelection(subnet_type=SubnetType.PRIVATE_WITH_EGRESS)]
)
```
## Importing an existing VPC
You can import an existing VPC and its subnets using the `VpcV2.fromVpcV2Attributes()` method or an individual subnet using `SubnetV2.fromSubnetV2Attributes()` method.
### Importing a VPC
To import an existing VPC, use the `VpcV2.fromVpcV2Attributes()` method. You'll need to provide the VPC ID, primary CIDR block, and information about the subnets. You can import secondary address as well created through IPAM, BYOIP(IPv4) or enabled through Amazon Provided IPv6. You must provide VPC Id and its primary CIDR block for importing it.
If you wish to add a new subnet to imported VPC, new subnet's IP range(IPv4) will be validated against provided secondary and primary address block to confirm that it is within the the range of VPC.
Here's an example of importing a VPC with only the required parameters
```python
stack = Stack()
imported_vpc = VpcV2.from_vpc_v2_attributes(stack, "ImportedVpc",
vpc_id="mockVpcID",
vpc_cidr_block="10.0.0.0/16"
)
```
In case of cross account or cross region VPC, its recommended to provide region and ownerAccountId so that these values for the VPC can be used to populate correct arn value for the VPC. If a VPC region and account ID is not provided, then region and account configured in the stack will be used. Furthermore, these fields will be referenced later while setting up VPC peering connection, so its necessary to set these fields to a correct value.
Below is an example of importing a cross region and cross account VPC, VPC arn for this case would be 'arn:aws:ec2:us-west-2:123456789012:vpc/mockVpcID'
```python
stack = Stack()
# Importing a cross account or cross region VPC
imported_vpc = VpcV2.from_vpc_v2_attributes(stack, "ImportedVpc",
vpc_id="mockVpcID",
vpc_cidr_block="10.0.0.0/16",
owner_account_id="123456789012",
region="us-west-2"
)
```
Here's an example of how to import a VPC with multiple CIDR blocks, IPv6 support, and different subnet types:
In this example, we're importing a VPC with:
* A primary CIDR block (10.1.0.0/16)
* One secondary IPv4 CIDR block (10.2.0.0/16)
* Two secondary address using IPAM pool (IPv4 and IPv6)
* VPC has Amazon-provided IPv6 CIDR enabled
* An isolated subnet in us-west-2a
* A public subnet in us-west-2b
```python
from aws_cdk.aws_ec2_alpha import VPCCidrBlockattributes, VPCCidrBlockattributes, VPCCidrBlockattributes, VPCCidrBlockattributes, SubnetV2Attributes, SubnetV2Attributes
stack = Stack()
imported_vpc = VpcV2.from_vpc_v2_attributes(self, "ImportedVPC",
vpc_id="vpc-XXX",
vpc_cidr_block="10.1.0.0/16",
secondary_cidr_blocks=[VPCCidrBlockattributes(
cidr_block="10.2.0.0/16",
cidr_block_name="ImportedBlock1"
), VPCCidrBlockattributes(
ipv6_ipam_pool_id="ipam-pool-XXX",
ipv6_netmask_length=52,
cidr_block_name="ImportedIpamIpv6"
), VPCCidrBlockattributes(
ipv4_ipam_pool_id="ipam-pool-XXX",
ipv4_ipam_provisioned_cidrs=["10.2.0.0/16"],
cidr_block_name="ImportedIpamIpv4"
), VPCCidrBlockattributes(
amazon_provided_ipv6_cidr_block=True
)
],
subnets=[SubnetV2Attributes(
subnet_name="IsolatedSubnet2",
subnet_id="subnet-03cd773c0fe08ed26",
subnet_type=SubnetType.PRIVATE_ISOLATED,
availability_zone="us-west-2a",
ipv4_cidr_block="10.2.0.0/24",
route_table_id="rtb-0871c310f98da2cbb"
), SubnetV2Attributes(
subnet_id="subnet-0fa477e01db27d820",
subnet_type=SubnetType.PUBLIC,
availability_zone="us-west-2b",
ipv4_cidr_block="10.3.0.0/24",
route_table_id="rtb-014f3043098fe4b96"
)]
)
# You can now use the imported VPC in your stack
# Adding a new subnet to the imported VPC
imported_subnet = SubnetV2(self, "NewSubnet",
availability_zone="us-west-2a",
ipv4_cidr_block=IpCidr("10.2.2.0/24"),
vpc=imported_vpc,
subnet_type=SubnetType.PUBLIC
)
# Adding gateways to the imported VPC
imported_vpc.add_internet_gateway()
imported_vpc.add_nat_gateway(subnet=imported_subnet)
imported_vpc.add_egress_only_internet_gateway()
```
You can add more subnets as needed by including additional entries in the `isolatedSubnets`, `publicSubnets`, or other subnet type arrays (e.g., `privateSubnets`).
### Importing Subnets
You can also import individual subnets using the `SubnetV2.fromSubnetV2Attributes()` method. This is useful when you need to work with specific subnets independently of a VPC.
Here's an example of how to import a subnet:
```python
SubnetV2.from_subnet_v2_attributes(self, "ImportedSubnet",
subnet_id="subnet-0123456789abcdef0",
availability_zone="us-west-2a",
ipv4_cidr_block="10.2.0.0/24",
route_table_id="rtb-0871c310f98da2cbb",
subnet_type=SubnetType.PRIVATE_ISOLATED
)
```
By importing existing VPCs and subnets, you can easily integrate your existing AWS infrastructure with new resources created through CDK. This is particularly useful when you need to work with pre-existing network configurations or when you're migrating existing infrastructure to CDK.
### Tagging VPC and its components
By default, when a resource name is given to the construct, it automatically adds a tag with the key `Name` and the value set to the provided resource name. To add additional custom tags, use the Tag Manager, like this: `Tags.of(myConstruct).add('key', 'value');`.
For example, if the `vpcName` is set to `TestVpc`, the following code will add a tag to the VPC with `key: Name` and `value: TestVpc`.
```python
vpc = VpcV2(self, "VPC-integ-test-tag",
primary_address_block=IpAddresses.ipv4("10.1.0.0/16"),
enable_dns_hostnames=True,
enable_dns_support=True,
vpc_name="CDKintegTestVPC"
)
# Add custom tags if needed
Tags.of(vpc).add("Environment", "Production")
```
## Transit Gateway
The AWS Transit Gateway construct library allows you to create and configure Transit Gateway resources using AWS CDK.
See [AWS Transit Gateway Docs](docs.aws.amazon.com/vpc/latest/tgw/what-is-transit-gateway.html) for more info.
### Overview
The Transit Gateway construct (`TransitGateway`) is the main entry point for creating and managing your Transit Gateway infrastructure. It provides methods to create route tables, attach VPCs, and configure cross-account access.
The Transit Gateway construct library provides four main constructs:
* `TransitGateway`: The central hub for your network connections
* `TransitGatewayRouteTable`: Manages routing between attached networks
* `TransitGatewayVpcAttachment`: Connects VPCs to the Transit Gateway
* `TransitGatewayRoute`: Defines routing rules within your Transit Gateway
### Basic Usage
To create a minimal deployable `TransitGateway`:
```python
transit_gateway = TransitGateway(self, "MyTransitGateway")
```
### Default Transit Gateway Route Table
By default, `TransitGateway` is created with a default `TransitGatewayRouteTable`, for which automatic Associations and automatic Propagations are enabled.
> Note: When you create a default Transit Gateway in AWS Console, a default Transit Gateway Route Table is automatically created by AWS. However, when using the CDK Transit Gateway L2 construct, the underlying L1 construct is configured with `defaultRouteTableAssociation` and `defaultRouteTablePropagation` explicitly disabled. This ensures that AWS does not create the default route table, allowing the CDK to define a custom default route table instead.
>
> As a result, in the AWS Console, the **Default association route table** and **Default propagation route table** settings will appear as disabled. Despite this, the CDK still provides automatic association and propagation functionality through its internal implementation, which can be controlled using the `defaultRouteTableAssociation` and `defaultRouteTablePropagation` properties within the CDK.
You can disable the automatic Association/Propagation on the default `TransitGatewayRouteTable` via the `TransitGateway` properties. This will still create a default route table for you:
```python
transit_gateway = TransitGateway(self, "MyTransitGateway",
default_route_table_association=False,
default_route_table_propagation=False
)
```
### Transit Gateway Route Table Management
Add additional Transit Gateway Route Tables using the `addRouteTable()` method:
```python
transit_gateway = TransitGateway(self, "MyTransitGateway")
route_table = transit_gateway.add_route_table("CustomRouteTable")
```
### Attaching VPCs to the Transit Gateway
Currently only VPC to Transit Gateway attachments are supported.
Create an attachment from a VPC to the Transit Gateway using the `attachVpc()` method:
```python
my_vpc = VpcV2(self, "Vpc")
subnet1 = SubnetV2(self, "Subnet",
vpc=my_vpc,
availability_zone="eu-west-2a",
ipv4_cidr_block=IpCidr("10.0.0.0/24"),
subnet_type=SubnetType.PUBLIC
)
subnet2 = SubnetV2(self, "Subnet",
vpc=my_vpc,
availability_zone="eu-west-2a",
ipv4_cidr_block=IpCidr("10.0.1.0/24"),
subnet_type=SubnetType.PUBLIC
)
transit_gateway = TransitGateway(self, "MyTransitGateway")
# Create a basic attachment
attachment = transit_gateway.attach_vpc("VpcAttachment",
vpc=my_vpc,
subnets=[subnet1, subnet2]
)
# Create an attachment with optional parameters
attachment_with_options = transit_gateway.attach_vpc("VpcAttachmentWithOptions",
vpc=my_vpc,
subnets=[subnet1],
vpc_attachment_options={
"dns_support": True,
"appliance_mode_support": True,
"ipv6_support": True,
"security_group_referencing_support": True
}
)
```
If you want to automatically associate and propagate routes with transit gateway route tables, you can pass the `associationRouteTable` and `propagationRouteTables` parameters. This will automatically create the necessary associations and propagations based on the provided route tables.
```python
my_vpc = VpcV2(self, "Vpc")
subnet1 = SubnetV2(self, "Subnet",
vpc=my_vpc,
availability_zone="eu-west-2a",
ipv4_cidr_block=IpCidr("10.0.0.0/24"),
subnet_type=SubnetType.PUBLIC
)
subnet2 = SubnetV2(self, "Subnet",
vpc=my_vpc,
availability_zone="eu-west-2a",
ipv4_cidr_block=IpCidr("10.0.1.0/24"),
subnet_type=SubnetType.PUBLIC
)
transit_gateway = TransitGateway(self, "MyTransitGateway")
association_route_table = transit_gateway.add_route_table("AssociationRouteTable")
propagation_route_table1 = transit_gateway.add_route_table("PropagationRouteTable1")
propagation_route_table2 = transit_gateway.add_route_table("PropagationRouteTable2")
# Create an attachment with automatically created association + propagations
attachment_with_routes = transit_gateway.attach_vpc("VpcAttachment",
vpc=my_vpc,
subnets=[subnet1, subnet2],
association_route_table=association_route_table,
propagation_route_tables=[propagation_route_table1, propagation_route_table2]
)
```
In this example, the `associationRouteTable` is set to `associationRouteTable`, and `propagationRouteTables` is set to an array containing `propagationRouteTable1` and `propagationRouteTable2`. This triggers the automatic creation of route table associations and route propagations between the Transit Gateway and the specified route tables.
### Adding static routes to the route table
Add static routes using either the `addRoute()` method to add an active route or `addBlackholeRoute()` to add a blackhole route:
```python
transit_gateway = TransitGateway(self, "MyTransitGateway")
route_table = transit_gateway.add_route_table("CustomRouteTable")
my_vpc = VpcV2(self, "Vpc")
subnet = SubnetV2(self, "Subnet",
vpc=my_vpc,
availability_zone="eu-west-2a",
ipv4_cidr_block=IpCidr("10.0.0.0/24"),
subnet_type=SubnetType.PUBLIC
)
attachment = transit_gateway.attach_vpc("VpcAttachment",
vpc=my_vpc,
subnets=[subnet]
)
# Add a static route to direct traffic
route_table.add_route("StaticRoute", attachment, "10.0.0.0/16")
# Block unwanted traffic with a blackhole route
route_table.add_blackhole_route("BlackholeRoute", "172.16.0.0/16")
```
### Route Table Associations and Propagations
Configure route table associations and enable route propagation:
```python
transit_gateway = TransitGateway(self, "MyTransitGateway")
route_table = transit_gateway.add_route_table("CustomRouteTable")
my_vpc = VpcV2(self, "Vpc")
subnet = SubnetV2(self, "Subnet",
vpc=my_vpc,
availability_zone="eu-west-2a",
ipv4_cidr_block=IpCidr("10.0.0.0/24"),
subnet_type=SubnetType.PUBLIC
)
attachment = transit_gateway.attach_vpc("VpcAttachment",
vpc=my_vpc,
subnets=[subnet]
)
# Associate an attachment with a route table
route_table.add_association("Association", attachment)
# Enable route propagation for an attachment
route_table.enable_propagation("Propagation", attachment)
```
**Associations** — The linking of a Transit Gateway attachment to a specific route table, which determines which routes that attachment will use for routing decisions.
**Propagation** — The automatic advertisement of routes from an attachment to a route table, allowing the route table to learn about available network destinations.
| text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/aws/aws-cdk | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.239.0",
"constructs<11.0.0,>=10.5.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/aws/aws-cdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:57:55.671786 | aws_cdk_aws_ec2_alpha-2.239.0a0.tar.gz | 357,679 | aa/e7/64a1bac337dacaab1e21b7a02f91cff003ae191cb48019c58da3b8fbe505/aws_cdk_aws_ec2_alpha-2.239.0a0.tar.gz | source | sdist | null | false | 10989b04f57601f863d5a5c0770a99af | 44148e9ce2f461e41a83218c98f006510c23ab084178a438b10e319e5277e663 | aae764a1bac337dacaab1e21b7a02f91cff003ae191cb48019c58da3b8fbe505 | null | [] | 0 |
2.1 | aws-cdk.aws-codestar-alpha | 2.239.0a0 | The CDK Construct Library for AWS::CodeStar | # AWS::CodeStar Construct Library
<!--BEGIN STABILITY BANNER-->---

> The APIs of higher level constructs in this module are experimental and under active development.
> They are subject to non-backward compatible changes or removal in any future version. These are
> not subject to the [Semantic Versioning](https://semver.org/) model and breaking changes will be
> announced in the release notes. This means that while you may use them, you may need to update
> your source code when upgrading to a newer version of this package.
---
<!--END STABILITY BANNER-->
## GitHub Repository
To create a new GitHub Repository and commit the assets from S3 bucket into the repository after it is created:
```python
import aws_cdk.aws_codestar_alpha as codestar
import aws_cdk.aws_s3 as s3
codestar.GitHubRepository(self, "GitHubRepo",
owner="aws",
repository_name="aws-cdk",
access_token=SecretValue.secrets_manager("my-github-token",
json_field="token"
),
contents_bucket=s3.Bucket.from_bucket_name(self, "Bucket", "amzn-s3-demo-bucket"),
contents_key="import.zip"
)
```
## Update or Delete the GitHubRepository
At this moment, updates to the `GitHubRepository` are not supported and the repository will not be deleted upon the deletion of the CloudFormation stack. You will need to update or delete the GitHub repository manually.
| text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/aws/aws-cdk | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.239.0",
"constructs<11.0.0,>=10.5.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/aws/aws-cdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:57:54.954926 | aws_cdk_aws_codestar_alpha-2.239.0a0.tar.gz | 45,637 | cc/c9/5181c5f4f0ebd9022b950a279a697ddde0a5de719c5aca57677b3f079a7b/aws_cdk_aws_codestar_alpha-2.239.0a0.tar.gz | source | sdist | null | false | f369df09d3bca6b550c3b91f7f36a193 | 75582b706770f62981335bb684f932218fb4a15490557b5599539c749cd4e02b | ccc95181c5f4f0ebd9022b950a279a697ddde0a5de719c5aca57677b3f079a7b | null | [] | 0 |
2.1 | aws-cdk.aws-cloud9-alpha | 2.239.0a0 | The CDK Construct Library for AWS::Cloud9 | # AWS Cloud9 Construct Library
<!--BEGIN STABILITY BANNER-->---

> The APIs of higher level constructs in this module are experimental and under active development.
> They are subject to non-backward compatible changes or removal in any future version. These are
> not subject to the [Semantic Versioning](https://semver.org/) model and breaking changes will be
> announced in the release notes. This means that while you may use them, you may need to update
> your source code when upgrading to a newer version of this package.
---
<!--END STABILITY BANNER-->
This module is part of the [AWS Cloud Development Kit](https://github.com/aws/aws-cdk) project.
AWS Cloud9 is a cloud-based integrated development environment (IDE) that lets you write, run, and debug your code with just a
browser. It includes a code editor, debugger, and terminal. Cloud9 comes prepackaged with essential tools for popular
programming languages, including JavaScript, Python, PHP, and more, so you don’t need to install files or configure your
development machine to start new projects. Since your Cloud9 IDE is cloud-based, you can work on your projects from your
office, home, or anywhere using an internet-connected machine. Cloud9 also provides a seamless experience for developing
serverless applications enabling you to easily define resources, debug, and switch between local and remote execution of
serverless applications. With Cloud9, you can quickly share your development environment with your team, enabling you to pair
program and track each other's inputs in real time.
## Creating EC2 Environment
EC2 Environments are defined with `Ec2Environment`. To create an EC2 environment in the private subnet, specify
`subnetSelection` with private `subnetType`.
```python
# create a cloud9 ec2 environment in a new VPC
vpc = ec2.Vpc(self, "VPC", max_azs=3)
cloud9.Ec2Environment(self, "Cloud9Env", vpc=vpc, image_id=cloud9.ImageId.AMAZON_LINUX_2)
# or create the cloud9 environment in the default VPC with specific instanceType
default_vpc = ec2.Vpc.from_lookup(self, "DefaultVPC", is_default=True)
cloud9.Ec2Environment(self, "Cloud9Env2",
vpc=default_vpc,
instance_type=ec2.InstanceType("t3.large"),
image_id=cloud9.ImageId.AMAZON_LINUX_2
)
# or specify in a different subnetSelection
c9env = cloud9.Ec2Environment(self, "Cloud9Env3",
vpc=vpc,
subnet_selection=ec2.SubnetSelection(
subnet_type=ec2.SubnetType.PRIVATE_WITH_EGRESS
),
image_id=cloud9.ImageId.AMAZON_LINUX_2
)
# print the Cloud9 IDE URL in the output
CfnOutput(self, "URL", value=c9env.ide_url)
```
## Specifying EC2 AMI
Use `imageId` to specify the EC2 AMI image to be used:
```python
default_vpc = ec2.Vpc.from_lookup(self, "DefaultVPC", is_default=True)
cloud9.Ec2Environment(self, "Cloud9Env2",
vpc=default_vpc,
instance_type=ec2.InstanceType("t3.large"),
image_id=cloud9.ImageId.UBUNTU_18_04
)
```
## Cloning Repositories
Use `clonedRepositories` to clone one or multiple AWS Codecommit repositories into the environment:
```python
import aws_cdk.aws_codecommit as codecommit
# create a new Cloud9 environment and clone the two repositories
# vpc: ec2.Vpc
# create a codecommit repository to clone into the cloud9 environment
repo_new = codecommit.Repository(self, "RepoNew",
repository_name="new-repo"
)
# import an existing codecommit repository to clone into the cloud9 environment
repo_existing = codecommit.Repository.from_repository_name(self, "RepoExisting", "existing-repo")
cloud9.Ec2Environment(self, "C9Env",
vpc=vpc,
cloned_repositories=[
cloud9.CloneRepository.from_code_commit(repo_new, "/src/new-repo"),
cloud9.CloneRepository.from_code_commit(repo_existing, "/src/existing-repo")
],
image_id=cloud9.ImageId.AMAZON_LINUX_2
)
```
## Specifying Owners
Every Cloud9 Environment has an **owner**. An owner has full control over the environment, and can invite additional members to the environment for collaboration purposes. For more information, see [Working with shared environments in AWS Cloud9](https://docs.aws.amazon.com/cloud9/latest/user-guide/share-environment.html)).
By default, the owner will be the identity that creates the Environment, which is most likely your CloudFormation Execution Role when the Environment is created using CloudFormation. Provider a value for the `owner` property to assign a different owner, either a specific IAM User or the AWS Account Root User.
`Owner` is an IAM entity that owns a Cloud9 environment. `Owner` has their own access permissions, and resources. You can specify an `Owner`in an EC2 environment which could be of the following types:
1. Account Root
2. IAM User
3. IAM Federated User
4. IAM Assumed Role
The ARN of the owner must satisfy the following regular expression: `^arn:(aws|aws-cn|aws-us-gov|aws-iso|aws-iso-b):(iam|sts)::\d+:(root|(user\/[\w+=/:,.@-]{1,64}|federated-user\/[\w+=/:,.@-]{2,32}|assumed-role\/[\w+=:,.@-]{1,64}\/[\w+=,.@-]{1,64}))$`
Note: Using the account root user is not recommended, see [environment sharing best practices](https://docs.aws.amazon.com/cloud9/latest/user-guide/share-environment.html#share-environment-best-practices).
To specify the AWS Account Root User as the environment owner, use `Owner.accountRoot()`
```python
# vpc: ec2.Vpc
cloud9.Ec2Environment(self, "C9Env",
vpc=vpc,
image_id=cloud9.ImageId.AMAZON_LINUX_2,
owner=cloud9.Owner.account_root("111111111")
)
```
To specify a specific IAM User as the environment owner, use `Owner.user()`. The user should have the `AWSCloud9Administrator` managed policy
The user should have the `AWSCloud9User` (preferred) or `AWSCloud9Administrator` managed policy attached.
```python
import aws_cdk.aws_iam as iam
# vpc: ec2.Vpc
user = iam.User(self, "user")
user.add_managed_policy(iam.ManagedPolicy.from_aws_managed_policy_name("AWSCloud9Administrator"))
cloud9.Ec2Environment(self, "C9Env",
vpc=vpc,
image_id=cloud9.ImageId.AMAZON_LINUX_2,
owner=cloud9.Owner.user(user)
)
```
To specify a specific IAM Federated User as the environment owner, use `Owner.federatedUser(accountId, userName)`.
The user should have the `AWSCloud9User` (preferred) or `AWSCloud9Administrator` managed policy attached.
```python
import aws_cdk.aws_iam as iam
# vpc: ec2.Vpc
cloud9.Ec2Environment(self, "C9Env",
vpc=vpc,
image_id=cloud9.ImageId.AMAZON_LINUX_2,
owner=cloud9.Owner.federated_user(Stack.of(self).account, "Admin/johndoe")
)
```
To specify an IAM Assumed Role as the environment owner, use `Owner.assumedRole(accountId: string, roleName: string)`.
The role should have the `AWSCloud9User` (preferred) or `AWSCloud9Administrator` managed policy attached.
```python
import aws_cdk.aws_iam as iam
# vpc: ec2.Vpc
cloud9.Ec2Environment(self, "C9Env",
vpc=vpc,
image_id=cloud9.ImageId.AMAZON_LINUX_2,
owner=cloud9.Owner.assumed_role(Stack.of(self).account, "Admin/johndoe-role")
)
```
## Auto-Hibernation
A Cloud9 environment can automatically start and stop the associated EC2 instance to reduce costs.
Use `automaticStop` to specify the number of minutes until the running instance is shut down after the environment was last used.
```python
default_vpc = ec2.Vpc.from_lookup(self, "DefaultVPC", is_default=True)
cloud9.Ec2Environment(self, "Cloud9Env2",
vpc=default_vpc,
image_id=cloud9.ImageId.AMAZON_LINUX_2,
automatic_stop=Duration.minutes(30)
)
```
| text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/aws/aws-cdk | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.239.0",
"constructs<11.0.0,>=10.5.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/aws/aws-cdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:57:54.326055 | aws_cdk_aws_cloud9_alpha-2.239.0a0.tar.gz | 66,845 | 69/7b/eb4c914419ca70e7d2a4e049456a958030f3ef5ef0d31f96105533465585/aws_cdk_aws_cloud9_alpha-2.239.0a0.tar.gz | source | sdist | null | false | df858b137888d248958ffd9234a9fb5f | 9cc2a33b324d36d643f1cab0c56f42092850994706b7ef3b11fbd40b96569c13 | 697beb4c914419ca70e7d2a4e049456a958030f3ef5ef0d31f96105533465585 | null | [] | 0 |
2.1 | aws-cdk.aws-bedrock-alpha | 2.239.0a0 | The CDK Construct Library for Amazon Bedrock | # Amazon Bedrock Construct Library
<!--BEGIN STABILITY BANNER-->---

> The APIs of higher level constructs in this module are experimental and under active development.
> They are subject to non-backward compatible changes or removal in any future version. These are
> not subject to the [Semantic Versioning](https://semver.org/) model and breaking changes will be
> announced in the release notes. This means that while you may use them, you may need to update
> your source code when upgrading to a newer version of this package.
---
<!--END STABILITY BANNER-->
| **Language** | **Package** |
| :--------------------------------------------------------------------------------------------- | --------------------------------------- |
|  TypeScript | `@aws-cdk/aws-bedrock-alpha` |
[Amazon Bedrock](https://aws.amazon.com/bedrock/) is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
This construct library facilitates the deployment of Bedrock Agents, enabling you to create sophisticated AI applications that can interact with your systems and data sources.
## Table of contents
* [Agents](#agents)
* [Create an Agent](#create-an-agent)
* [Action groups](#action-groups)
* [Prepare the Agent](#prepare-the-agent)
* [Prompt Override Configuration](#prompt-override-configuration)
* [Memory Configuration](#memory-configuration)
* [Agent Collaboration](#agent-collaboration)
* [Custom Orchestration](#custom-orchestration)
* [Agent Alias](#agent-alias)
* [Guardrails](#guardrails)
* [Guardrail Properties](#guardrail-properties)
* [Filter Types](#filter-types)
* [Content Filters](#content-filters)
* [Denied Topics](#denied-topics)
* [Word Filters](#word-filters)
* [PII Filters](#pii-filters)
* [Regex Filters](#regex-filters)
* [Contextual Grounding Filters](#contextual-grounding-filters)
* [Guardrail Methods](#guardrail-methods)
* [Guardrail Permissions](#guardrail-permissions)
* [Guardrail Metrics](#guardrail-metrics)
* [Importing Guardrails](#importing-guardrails)
* [Guardrail Versioning](#guardrail-versioning)
* [Prompts](#prompts)
* [Prompt Variants](#prompt-variants)
* [Basic Text Prompt](#basic-text-prompt)
* [Chat Prompt](#chat-prompt)
* [Agent Prompt](#agent-prompt)
* [Prompt Properties](#prompt-properties)
* [Prompt Version](#prompt-version)
* [Import Methods](#import-methods)
* [Inference Profiles](#inference-profiles)
* [Using Inference Profiles](#using-inference-profiles)
* [Types of Inference Profiles](#types-of-inference-profiles)
* [Prompt Routers](#prompt-routers)
* [Inference Profile Permissions](#inference-profile-permissions)
* [Inference Profiles Import Methods](#inference-profiles-import-methods)
## Agents
Amazon Bedrock Agents allow generative AI applications to automate complex, multistep tasks by seamlessly integrating with your company's systems, APIs, and data sources. It uses the reasoning of foundation models (FMs), APIs, and data to break down user requests, gather relevant information, and efficiently complete tasks.
### Create an Agent
Building an agent is straightforward and fast.
The following example creates an Agent with a simple instruction and default prompts:
```python
agent = bedrock.Agent(self, "Agent",
foundation_model=bedrock.BedrockFoundationModel.ANTHROPIC_CLAUDE_HAIKU_V1_0,
instruction="You are a helpful and friendly agent that answers questions about literature."
)
```
You can also create an agent with a guardrail:
```python
# Create a guardrail to filter inappropriate content
guardrail = bedrock.Guardrail(self, "bedrockGuardrails",
guardrail_name="my-BedrockGuardrails",
description="Legal ethical guardrails."
)
guardrail.add_content_filter(
type=bedrock.ContentFilterType.SEXUAL,
input_strength=bedrock.ContentFilterStrength.HIGH,
output_strength=bedrock.ContentFilterStrength.MEDIUM
)
# Create an agent with the guardrail
agent_with_guardrail = bedrock.Agent(self, "AgentWithGuardrail",
foundation_model=bedrock.BedrockFoundationModel.ANTHROPIC_CLAUDE_HAIKU_V1_0,
instruction="You are a helpful and friendly agent that answers questions about literature.",
guardrail=guardrail
)
```
### Agent Properties
The Bedrock Agent class supports the following properties.
| Name | Type | Required | Description |
|---|---|---|---|
| name | string | No | The name of the agent. Defaults to a name generated by CDK |
| instruction | string | Yes | The instruction used by the agent that determines how it will perform its task. Must have a minimum of 40 characters |
| foundationModel | IBedrockInvokable | Yes | The foundation model used for orchestration by the agent |
| existingRole | iam.IRole | No | The existing IAM Role for the agent to use. Must have a trust policy allowing Bedrock service to assume the role. Defaults to a new created role |
| shouldPrepareAgent | boolean | No | Specifies whether to automatically update the `DRAFT` version of the agent after making changes. Defaults to false |
| idleSessionTTL | Duration | No | How long sessions should be kept open for the agent. Session expires if no conversation occurs during this time. Defaults to 1 hour |
| kmsKey | kms.IKey | No | The KMS key of the agent if custom encryption is configured. Defaults to AWS managed key |
| description | string | No | A description of the agent. Defaults to no description |
| actionGroups | AgentActionGroup[] | No | The Action Groups associated with the agent |
| guardrail | IGuardrail | No | The guardrail that will be associated with the agent. Defaults to no guardrail |
| memory | Memory | No | The type and configuration of the memory to maintain context across multiple sessions and recall past interactions. Defaults to no memory |
| promptOverrideConfiguration | PromptOverrideConfiguration | No | Overrides some prompt templates in different parts of an agent sequence configuration |
| userInputEnabled | boolean | No | Select whether the agent can prompt additional information from the user when it lacks enough information. Defaults to false |
| codeInterpreterEnabled | boolean | No | Select whether the agent can generate, run, and troubleshoot code when trying to complete a task. Defaults to false |
| forceDelete | boolean | No | Whether to delete the resource even if it's in use. Defaults to true |
| agentCollaboration | AgentCollaboration | No | Configuration for agent collaboration settings, including type and collaborators. This property allows you to define how the agent collaborates with other agents and what collaborators it can work with. Defaults to no agent collaboration configuration |
| customOrchestrationExecutor | CustomOrchestrationExecutor | No | The Lambda function to use for custom orchestration. If provided, orchestrationType is set to CUSTOM_ORCHESTRATION. If not provided, orchestrationType defaults to DEFAULT. Defaults to default orchestration |
### Action Groups
An action group defines functions your agent can call. The functions are Lambda functions. The action group uses an OpenAPI schema to tell the agent what your functions do and how to call them.
#### Action Group Properties
The AgentActionGroup class supports the following properties.
| Name | Type | Required | Description |
|---|---|---|---|
| name | string | No | The name of the action group. Defaults to a name generated in the format 'action_group_quick_start_UUID' |
| description | string | No | A description of the action group |
| apiSchema | ApiSchema | No | The OpenAPI schema that defines the functions in the action group |
| executor | ActionGroupExecutor | No | The Lambda function that executes the actions in the group |
| enabled | boolean | No | Whether the action group is enabled. Defaults to true |
| forceDelete | boolean | No | Whether to delete the resource even if it's in use. Defaults to false |
| functionSchema | FunctionSchema | No | Defines functions that each define parameters that the agent needs to invoke from the user |
| parentActionGroupSignature | ParentActionGroupSignature | No | The AWS Defined signature for enabling certain capabilities in your agent |
There are three ways to provide an API schema for your action group:
From a local asset file (requires binding to scope):
```python
action_group_function = lambda_.Function(self, "ActionGroupFunction",
runtime=lambda_.Runtime.PYTHON_3_12,
handler="index.handler",
code=lambda_.Code.from_asset(path.join(__dirname, "../lambda/action-group"))
)
# When using ApiSchema.fromLocalAsset, you must bind the schema to a scope
schema = bedrock.ApiSchema.from_local_asset(path.join(__dirname, "action-group.yaml"))
schema.bind(self)
action_group = bedrock.AgentActionGroup(
name="query-library",
description="Use these functions to get information about the books in the library.",
executor=bedrock.ActionGroupExecutor.from_lambda(action_group_function),
enabled=True,
api_schema=schema
)
agent = bedrock.Agent(self, "Agent",
foundation_model=bedrock.BedrockFoundationModel.ANTHROPIC_CLAUDE_HAIKU_V1_0,
instruction="You are a helpful and friendly agent that answers questions about literature."
)
agent.add_action_group(action_group)
```
From an inline OpenAPI schema:
```python
inline_schema = bedrock.ApiSchema.from_inline("""
openapi: 3.0.3
info:
title: Library API
version: 1.0.0
paths:
/search:
get:
summary: Search for books
operationId: searchBooks
parameters:
- name: query
in: query
required: true
schema:
type: string
""")
action_group_function = lambda_.Function(self, "ActionGroupFunction",
runtime=lambda_.Runtime.PYTHON_3_12,
handler="index.handler",
code=lambda_.Code.from_asset(path.join(__dirname, "../lambda/action-group"))
)
action_group = bedrock.AgentActionGroup(
name="query-library",
description="Use these functions to get information about the books in the library.",
executor=bedrock.ActionGroupExecutor.from_lambda(action_group_function),
enabled=True,
api_schema=inline_schema
)
agent = bedrock.Agent(self, "Agent",
foundation_model=bedrock.BedrockFoundationModel.ANTHROPIC_CLAUDE_HAIKU_V1_0,
instruction="You are a helpful and friendly agent that answers questions about literature."
)
agent.add_action_group(action_group)
```
From an existing S3 file:
```python
bucket = s3.Bucket.from_bucket_name(self, "ExistingBucket", "my-schema-bucket")
s3_schema = bedrock.ApiSchema.from_s3_file(bucket, "schemas/action-group.yaml")
action_group_function = lambda_.Function(self, "ActionGroupFunction",
runtime=lambda_.Runtime.PYTHON_3_12,
handler="index.handler",
code=lambda_.Code.from_asset(path.join(__dirname, "../lambda/action-group"))
)
action_group = bedrock.AgentActionGroup(
name="query-library",
description="Use these functions to get information about the books in the library.",
executor=bedrock.ActionGroupExecutor.from_lambda(action_group_function),
enabled=True,
api_schema=s3_schema
)
agent = bedrock.Agent(self, "Agent",
foundation_model=bedrock.BedrockFoundationModel.ANTHROPIC_CLAUDE_HAIKU_V1_0,
instruction="You are a helpful and friendly agent that answers questions about literature."
)
agent.add_action_group(action_group)
```
### Using FunctionSchema with Action Groups
As an alternative to using OpenAPI schemas, you can define functions directly using the `FunctionSchema` class. This approach provides a more structured way to define the functions that your agent can call.
```python
action_group_function = lambda_.Function(self, "ActionGroupFunction",
runtime=lambda_.Runtime.PYTHON_3_12,
handler="index.handler",
code=lambda_.Code.from_asset(path.join(__dirname, "../lambda/action-group"))
)
# Define a function schema with parameters
function_schema = bedrock.FunctionSchema(
functions=[bedrock.FunctionProps(
name="searchBooks",
description="Search for books in the library catalog",
parameters={
"query": bedrock.FunctionParameterProps(
type=bedrock.ParameterType.STRING,
required=True,
description="The search query string"
),
"maxResults": bedrock.FunctionParameterProps(
type=bedrock.ParameterType.INTEGER,
required=False,
description="Maximum number of results to return"
),
"includeOutOfPrint": bedrock.FunctionParameterProps(
type=bedrock.ParameterType.BOOLEAN,
required=False,
description="Whether to include out-of-print books"
)
},
require_confirmation=bedrock.RequireConfirmation.DISABLED
), bedrock.FunctionProps(
name="getBookDetails",
description="Get detailed information about a specific book",
parameters={
"bookId": bedrock.FunctionParameterProps(
type=bedrock.ParameterType.STRING,
required=True,
description="The unique identifier of the book"
)
},
require_confirmation=bedrock.RequireConfirmation.ENABLED
)
]
)
# Create an action group using the function schema
action_group = bedrock.AgentActionGroup(
name="library-functions",
description="Functions for interacting with the library catalog",
executor=bedrock.ActionGroupExecutor.from_lambda(action_group_function),
function_schema=function_schema,
enabled=True
)
agent = bedrock.Agent(self, "Agent",
foundation_model=bedrock.BedrockFoundationModel.ANTHROPIC_CLAUDE_HAIKU_V1_0,
instruction="You are a helpful and friendly agent that answers questions about literature.",
action_groups=[action_group]
)
```
The `FunctionSchema` approach offers several advantages:
* Type-safe definition of functions and parameters
* Built-in validation of parameter names, descriptions, and other properties
* Clear structure that maps directly to the AWS Bedrock API
* Support for parameter types including string, number, integer, boolean, array, and object
* Option to require user confirmation before executing specific functions
If you chose to load your schema file from S3, the construct will provide the necessary permissions to your agent's execution role to access the schema file from the specific bucket. Similar to performing the operation through the console, the agent execution role will get a permission like:
```json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AmazonBedrockAgentS3PolicyProd",
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::<BUCKET_NAME>/<OBJECT_KEY>"
],
"Condition": {
"StringEquals": {
"aws:ResourceAccount": "ACCOUNT_NUMBER"
}
}
}
]
}
```
```python
# create a bucket containing the input schema
schema_bucket = s3.Bucket(self, "SchemaBucket",
enforce_sSL=True,
versioned=True,
public_read_access=False,
block_public_access=s3.BlockPublicAccess.BLOCK_ALL,
encryption=s3.BucketEncryption.S3_MANAGED,
removal_policy=RemovalPolicy.DESTROY,
auto_delete_objects=True
)
# deploy the local schema file to S3
deployement = aws_s3_deployment.BucketDeployment(self, "DeployWebsite",
sources=[aws_s3_deployment.Source.asset(path.join(__dirname, "../inputschema"))],
destination_bucket=schema_bucket,
destination_key_prefix="inputschema"
)
# create the agent
agent = bedrock.Agent(self, "Agent",
foundation_model=bedrock.BedrockFoundationModel.ANTHROPIC_CLAUDE_3_5_SONNET_V1_0,
instruction="You are a helpful and friendly agent that answers questions about literature.",
user_input_enabled=True,
should_prepare_agent=True
)
# create a lambda function
action_group_function = lambda_.Function(self, "ActionGroupFunction",
runtime=lambda_.Runtime.PYTHON_3_12,
handler="index.handler",
code=lambda_.Code.from_asset(path.join(__dirname, "../lambda/action-group"))
)
# create an action group and read the schema file from S3
action_group = bedrock.AgentActionGroup(
name="query-library",
description="Use these functions to get information about the books in the library.",
executor=bedrock.ActionGroupExecutor.from_lambda(action_group_function),
enabled=True,
api_schema=bedrock.ApiSchema.from_s3_file(schema_bucket, "inputschema/action-group.yaml")
)
# add the action group to the agent
agent.add_action_group(action_group)
# add dependency for the agent on the s3 deployment
agent.node.add_dependency(deployement)
```
### Prepare the Agent
The `Agent` constructs take an optional parameter `shouldPrepareAgent` to indicate that the Agent should be prepared after any updates to an agent or action group. This may increase the time to create and update those resources. By default, this value is false.
#### Prepare Agent Properties
| Name | Type | Required | Description |
|---|---|---|---|
| shouldPrepareAgent | boolean | No | Whether to automatically update the DRAFT version of the agent after making changes. Defaults to false |
Creating an agent alias will not prepare the agent, so if you create an alias using the `AgentAlias` resource then you should set `shouldPrepareAgent` to ***true***.
### Prompt Override Configuration
Bedrock Agents allows you to customize the prompts and LLM configuration for different steps in the agent sequence. The implementation provides type-safe configurations for each step type, ensuring correct usage at compile time.
#### Prompt Override Configuration Properties
| Name | Type | Required | Description |
|---|---|---|---|
| steps | PromptStepConfiguration[] | Yes | Array of step configurations for different parts of the agent sequence |
| parser | lambda.IFunction | No | Lambda function for custom parsing of agent responses |
#### Prompt Step Configuration Properties
Each step in the `steps` array supports the following properties:
| Name | Type | Required | Description |
|---|---|---|---|
| stepType | AgentStepType | Yes | The type of step being configured (PRE_PROCESSING, ORCHESTRATION, POST_PROCESSING, ROUTING_CLASSIFIER, MEMORY_SUMMARIZATION, KNOWLEDGE_BASE_RESPONSE_GENERATION) |
| stepEnabled | boolean | No | Whether this step is enabled. Defaults to true |
| customPromptTemplate | string | No | Custom prompt template to use for this step |
| inferenceConfig | InferenceConfiguration | No | Configuration for model inference parameters |
| foundationModel | BedrockFoundationModel | No | Alternative foundation model to use for this step (only valid for ROUTING_CLASSIFIER step) |
| useCustomParser | boolean | No | Whether to use a custom parser for this step. Requires parser to be provided in PromptOverrideConfiguration |
#### Inference Configuration Properties
When providing `inferenceConfig`, the following properties are supported:
| Name | Type | Required | Description |
|---|---|---|---|
| temperature | number | No | Controls randomness in the model's output (0.0-1.0) |
| topP | number | No | Controls diversity via nucleus sampling (0.0-1.0) |
| topK | number | No | Controls diversity by limiting the cumulative probability |
| maximumLength | number | No | Maximum length of generated text |
| stopSequences | string[] | No | Sequences where the model should stop generating |
The following steps can be configured:
* PRE_PROCESSING: Prepares the user input for orchestration
* ORCHESTRATION: Main step that determines the agent's actions
* POST_PROCESSING: Refines the agent's response
* ROUTING_CLASSIFIER: Classifies and routes requests to appropriate collaborators
* MEMORY_SUMMARIZATION: Summarizes conversation history for memory retention
* KNOWLEDGE_BASE_RESPONSE_GENERATION: Generates responses using knowledge base content
Example with pre-processing configuration:
```python
agent = bedrock.Agent(self, "Agent",
foundation_model=bedrock.BedrockFoundationModel.AMAZON_NOVA_LITE_V1,
instruction="You are a helpful assistant.",
prompt_override_configuration=bedrock.PromptOverrideConfiguration.from_steps([
step_type=bedrock.AgentStepType.PRE_PROCESSING,
step_enabled=True,
custom_prompt_template="Your custom prompt template here",
inference_config=bedrock.InferenceConfiguration(
temperature=0,
top_p=1,
top_k=250,
maximum_length=1,
stop_sequences=["\n\nHuman:"]
)
])
)
```
Example with routing classifier and foundation model:
```python
agent = bedrock.Agent(self, "Agent",
foundation_model=bedrock.BedrockFoundationModel.AMAZON_NOVA_LITE_V1,
instruction="You are a helpful assistant.",
prompt_override_configuration=bedrock.PromptOverrideConfiguration.from_steps([
step_type=bedrock.AgentStepType.ROUTING_CLASSIFIER,
step_enabled=True,
custom_prompt_template="Your routing template here",
foundation_model=bedrock.BedrockFoundationModel.ANTHROPIC_CLAUDE_V2
])
)
```
Using a custom Lambda parser:
```python
parser_function = lambda_.Function(self, "ParserFunction",
runtime=lambda_.Runtime.PYTHON_3_10,
handler="index.handler",
code=lambda_.Code.from_asset("lambda")
)
agent = bedrock.Agent(self, "Agent",
foundation_model=bedrock.BedrockFoundationModel.AMAZON_NOVA_LITE_V1,
instruction="You are a helpful assistant.",
prompt_override_configuration=bedrock.PromptOverrideConfiguration.with_custom_parser(
parser=parser_function,
pre_processing_step=bedrock.PromptPreProcessingConfigCustomParser(
step_type=bedrock.AgentStepType.PRE_PROCESSING,
use_custom_parser=True
)
)
)
```
Foundation models can only be specified for the ROUTING_CLASSIFIER step.
### Memory Configuration
Agents can maintain context across multiple sessions and recall past interactions using memory. This feature is useful for creating a more coherent conversational experience.
#### Memory Configuration Properties
| Name | Type | Required | Description |
|---|---|---|---|
| maxRecentSessions | number | No | Maximum number of recent session summaries to retain |
| memoryDuration | Duration | No | How long to retain session summaries |
Example:
```python
agent = bedrock.Agent(self, "MyAgent",
agent_name="MyAgent",
instruction="Your instruction here",
foundation_model=bedrock.BedrockFoundationModel.AMAZON_NOVA_LITE_V1,
memory=Memory.session_summary(
max_recent_sessions=10, # Keep the last 10 session summaries
memory_duration=Duration.days(20)
)
)
```
### Agent Collaboration
Agent Collaboration enables multiple Bedrock Agents to work together on complex tasks. This feature allows agents to specialize in different areas and collaborate to provide more comprehensive responses to user queries.
#### Agent Collaboration Properties
| Name | Type | Required | Description |
|---|---|---|---|
| type | AgentCollaboratorType | Yes | Type of collaboration (SUPERVISOR or PEER) |
| collaborators | AgentCollaborator[] | Yes | List of agent collaborators |
#### Agent Collaborator Properties
| Name | Type | Required | Description |
|---|---|---|---|
| agentAlias | AgentAlias | Yes | The agent alias to collaborate with |
| collaborationInstruction | string | Yes | Instructions for how to collaborate with this agent |
| collaboratorName | string | Yes | Name of the collaborator |
| relayConversationHistory | boolean | No | Whether to relay conversation history to the collaborator. Defaults to false |
Example:
```python
# Create a specialized agent
customer_support_agent = bedrock.Agent(self, "CustomerSupportAgent",
instruction="You specialize in answering customer support questions.",
foundation_model=bedrock.BedrockFoundationModel.AMAZON_NOVA_LITE_V1
)
# Create an agent alias
customer_support_alias = bedrock.AgentAlias(self, "CustomerSupportAlias",
agent=customer_support_agent,
agent_alias_name="production"
)
# Create a main agent that collaborates with the specialized agent
main_agent = bedrock.Agent(self, "MainAgent",
instruction="You route specialized questions to other agents.",
foundation_model=bedrock.BedrockFoundationModel.AMAZON_NOVA_LITE_V1,
agent_collaboration={
"type": bedrock.AgentCollaboratorType.SUPERVISOR,
"collaborators": [
bedrock.AgentCollaborator(
agent_alias=customer_support_alias,
collaboration_instruction="Route customer support questions to this agent.",
collaborator_name="CustomerSupport",
relay_conversation_history=True
)
]
}
)
```
### Custom Orchestration
Custom Orchestration allows you to override the default agent orchestration flow with your own Lambda function. This enables more control over how the agent processes user inputs and invokes action groups.
When you provide a customOrchestrationExecutor, the agent's orchestrationType is automatically set to CUSTOM_ORCHESTRATION. If no customOrchestrationExecutor is provided, the orchestrationType defaults to DEFAULT, using Amazon Bedrock's built-in orchestration.
#### Custom Orchestration Properties
| Name | Type | Required | Description |
|---|---|---|---|
| function | lambda.IFunction | Yes | The Lambda function that implements the custom orchestration logic |
Example:
```python
orchestration_function = lambda_.Function(self, "OrchestrationFunction",
runtime=lambda_.Runtime.PYTHON_3_10,
handler="index.handler",
code=lambda_.Code.from_asset("lambda/orchestration")
)
agent = bedrock.Agent(self, "CustomOrchestrationAgent",
instruction="You are a helpful assistant with custom orchestration logic.",
foundation_model=bedrock.BedrockFoundationModel.AMAZON_NOVA_LITE_V1,
custom_orchestration_executor=bedrock.CustomOrchestrationExecutor.from_lambda(orchestration_function)
)
```
### Agent Alias
After you have sufficiently iterated on your working draft and are satisfied with the behavior of your agent, you can set it up for deployment and integration into your application by creating aliases.
To deploy your agent, you need to create an alias. During alias creation, Amazon Bedrock automatically creates a version of your agent. The alias points to this newly created version. You can point the alias to a previously created version if necessary. You then configure your application to make API calls to that alias.
By default, the Agent resource creates a test alias named 'AgentTestAlias' that points to the 'DRAFT' version. This test alias is accessible via the `testAlias` property of the agent. You can also create additional aliases for different environments using the AgentAlias construct.
#### Agent Alias Properties
| Name | Type | Required | Description |
|---|---|---|---|
| agent | Agent | Yes | The agent to create an alias for |
| agentAliasName | string | No | The name of the agent alias. Defaults to a name generated by CDK |
| description | string | No | A description of the agent alias. Defaults to no description |
| routingConfiguration | AgentAliasRoutingConfiguration | No | Configuration for routing traffic between agent versions |
| agentVersion | string | No | The version of the agent to use. If not specified, a new version is created |
When redeploying an agent with changes, you must ensure the agent version is updated to avoid deployment failures with "agent already exists" errors. The recommended way to handle this is to include the `lastUpdated` property in the agent's description, which automatically updates whenever the agent is modified. This ensures a new version is created on each deployment.
Example:
```python
agent = bedrock.Agent(self, "Agent",
foundation_model=bedrock.BedrockFoundationModel.ANTHROPIC_CLAUDE_HAIKU_V1_0,
instruction="You are a helpful and friendly agent that answers questions about literature."
)
agent_alias = bedrock.AgentAlias(self, "myAlias",
agent_alias_name="production",
agent=agent,
description=f"Production version of my agent. Created at {agent.lastUpdated}"
)
```
## Guardrails
Amazon Bedrock's Guardrails feature enables you to implement robust governance and control mechanisms for your generative AI applications, ensuring alignment with your specific use cases and responsible AI policies. Guardrails empowers you to create multiple tailored policy configurations, each designed to address the unique requirements and constraints of different use cases. These policy configurations can then be seamlessly applied across multiple foundation models (FMs) and Agents, ensuring a consistent user experience and standardizing safety, security, and privacy controls throughout your generative AI ecosystem.
With Guardrails, you can define and enforce granular, customizable policies to precisely govern the behavior of your generative AI applications. You can configure the following policies in a guardrail to avoid undesirable and harmful content and remove sensitive information for privacy protection.
Content filters – Adjust filter strengths to block input prompts or model responses containing harmful content.
Denied topics – Define a set of topics that are undesirable in the context of your application. These topics will be blocked if detected in user queries or model responses.
Word filters – Configure filters to block undesirable words, phrases, and profanity. Such words can include offensive terms, competitor names etc.
Sensitive information filters – Block or mask sensitive information such as personally identifiable information (PII) or custom regex in user inputs and model responses.
You can create a Guardrail with a minimum blockedInputMessaging, blockedOutputsMessaging and default content filter policy.
### Basic Guardrail Creation
#### TypeScript
```python
guardrail = bedrock.Guardrail(self, "bedrockGuardrails",
guardrail_name="my-BedrockGuardrails",
description="Legal ethical guardrails."
)
```
### Guardrail Properties
| Property | Type | Required | Description |
|----------|------|----------|-------------|
| guardrailName | string | Yes | The name of the guardrail |
| description | string | No | The description of the guardrail |
| blockedInputMessaging | string | No | The message to return when the guardrail blocks a prompt. Default: "Sorry, your query violates our usage policy." |
| blockedOutputsMessaging | string | No | The message to return when the guardrail blocks a model response. Default: "Sorry, I am unable to answer your question because of our usage policy." |
| kmsKey | IKey | No | A custom KMS key to use for encrypting data. Default: Your data is encrypted by default with a key that AWS owns and manages for you. |
| crossRegionConfig | GuardrailCrossRegionConfigProperty | No | The cross-region configuration for the guardrail. This enables cross-region inference for enhanced language support and filtering capabilities. Default: No cross-region configuration |
| contentFilters | ContentFilter[] | No | The content filters to apply to the guardrail |
| contentFiltersTierConfig | TierConfig | No | The tier configuration to apply to content filters. Default: TierConfig.CLASSIC |
| deniedTopics | Topic[] | No | Up to 30 denied topics to block user inputs or model responses associated with the topic |
| topicsTierConfig | TierConfig | No | The tier configuration to apply to topic filters. Default: TierConfig.CLASSIC |
| wordFilters | string[] | No | The word filters to apply to the guardrail |
| managedWordListFilters | ManagedWordFilterType[] | No | The managed word filters to apply to the guardrail |
| piiFilters | PIIFilter[] | No | The PII filters to apply to the guardrail |
| regexFilters | RegexFilter[] | No | The regular expression (regex) filters to apply to the guardrail |
| contextualGroundingFilters | ContextualGroundingFilter[] | No | The contextual grounding filters to apply to the guardrail |
### Filter Types
#### Content Filters
Content filters allow you to block input prompts or model responses containing harmful content. You can adjust the filter strength and configure separate actions for input and output.
##### Content Filter Configuration
```python
guardrail = bedrock.Guardrail(self, "bedrockGuardrails",
guardrail_name="my-BedrockGuardrails",
# Configure tier for content filters (optional)
content_filters_tier_config=bedrock.TierConfig.STANDARD
)
guardrail.add_content_filter(
type=bedrock.ContentFilterType.SEXUAL,
input_strength=bedrock.ContentFilterStrength.HIGH,
output_strength=bedrock.ContentFilterStrength.MEDIUM,
# props below are optional
input_action=bedrock.GuardrailAction.BLOCK,
input_enabled=True,
output_action=bedrock.GuardrailAction.NONE,
output_enabled=True,
input_modalities=[bedrock.ModalityType.TEXT, bedrock.ModalityType.IMAGE],
output_modalities=[bedrock.ModalityType.TEXT]
)
```
Available content filter types:
* `SEXUAL`: Describes input prompts and model responses that indicates sexual interest, activity, or arousal
* `VIOLENCE`: Describes input prompts and model responses that includes glorification of or threats to inflict physical pain
* `HATE`: Describes input prompts and model responses that discriminate, criticize, insult, denounce, or dehumanize a person or group
* `INSULTS`: Describes input prompts and model responses that includes demeaning, humiliating, mocking, insulting, or belittling language
* `MISCONDUCT`: Describes input prompts and model responses that seeks or provides information about engaging in misconduct activity
* `PROMPT_ATTACK`: Enable to detect and block user inputs attempting to override system instructions
Available content filter strengths:
* `NONE`: No filtering
* `LOW`: Light filtering
* `MEDIUM`: Moderate filtering
* `HIGH`: Strict filtering
Available guardrail actions:
* `BLOCK`: Blocks the content from being processed
* `ANONYMIZE`: Masks the content with an identifier tag
* `NONE`: Takes no action
> Warning: the ANONYMIZE action is not available in all configurations. Please refer to the documentation of each filter to see which ones
> support
Available modality types:
* `TEXT`: Text modality for content filters
* `IMAGE`: Image modality for content filters
#### Tier Configuration
Guardrails support tier configurations that determine the level of language support and robustness for content and topic filters. You can configure separate tier settings for content filters and topic filters.
##### Tier Configuration Options
```python
guardrail = bedrock.Guardrail(self, "bedrockGuardrails",
guardrail_name="my-BedrockGuardrails",
# Configure tier for content filters
content_filters_tier_config=bedrock.TierConfig.STANDARD,
# Configure tier for topic filters
topics_tier_config=bedrock.TierConfig.CLASSIC
)
```
Available tier configurations:
* `CLASSIC`: Provides established guardrails functionality supporting English, French, and Spanish languages
* `STANDARD`: Provides a more robust solution than the CLASSIC tier and has more comprehensive language support. This tier requires that your guardrail use cross-Region inference
> Note: The STANDARD tier provides enhanced language support and more comprehensive filtering capabilities, but requires cross-Region inference to be enabled for your guardrail.
#### Cross-Region Configuration
You can configure a system-defined guardrail profile to use with your guardrail. Guardrail profiles define the destination AWS Regions where guardrail inference requests can be automatically routed. Using guardrail profiles helps maintain guardrail performance and reliability when demand increases.
##### Cross-Region Configuration Properties
| Property | Type | Required | Description |
|----------|------|----------|-------------|
| guardrailProfileArn | string | Yes | The ARN of the system-defined guardrail profile that defines the destination AWS Regions where guardrail inference requests can be automatically routed |
##### Cross-Region Configuration Example
```python
guardrail = bedrock.Guardrail(self, "bedrockGuardrails",
guardrail_name="my-BedrockGuardrails",
description="Guardrail with cross-region configuration for enhanced language support",
cross_region_config=bedrock.GuardrailCrossRegionConfigProperty(
guardrail_profile_arn="arn:aws:bedrock:us-east-1:123456789012:guardrail-profile/my-profile"
),
# Use STANDARD tier for enhanced capabilities
content_filters_tier_config=bedrock.TierConfig.STANDARD,
topics_tier_config=bedrock.TierConfig.STANDARD
)
```
> Note: Cross-region configuration is required when using the STANDARD tier for content and topic filters. It helps maintain guardrail performance and reliability when demand increases by automatically routing inference requests to appropriate regions.
You will need to provide the necessary permissions for cross region: https://docs.aws.amazon.com/bedrock/latest/userguide/guardrail-profiles-permissions.html .
#### Denied Topics
Denied topics allow you to define a set of topics that are undesirable in the context of your application. These topics will be blocked if detected in user queries or model responses. You can configure separate actions for input and output.
##### Denied Topic Configuration
```python
guardrail = bedrock.Guardrail(self, "bedrockGuardrails",
guardrail_name="my-BedrockGuardrails",
# Configure tier for topic filters (optional)
topics_tier_config=bedrock.TierConfig.STANDARD
)
# Use a predefined topic
guardrail.add_denied_topic_filter(bedrock.Topic.FINANCIAL_ADVICE)
# Create a custom topic with input/output actions
guardrail.add_denied_topic_filter(
bedrock.Topic.custom(
name="Legal_Advice",
definition="Offering guidance or suggestions on legal matters, legal actions, interpretation of laws, or legal rights and responsibilities.",
examples=["Can I sue someone for this?", "What are my legal rights in this situation?", "Is this action against the law?", "What should I do to file a legal complaint?", "Can you explain this law to me?"
],
# props below are optional
input_action=bedrock.GuardrailAction.BLOCK,
input_enabled=True,
output_action=bedrock.GuardrailAction.NONE,
output_enabled=True
))
```
#### Word Filters
Word filters allow you to block specific words, phrases, or profanity in user inputs and model responses. You can configure separate actions for input and output.
##### Word Filter Configuration
```python
guardrail = bedrock.Guardrail(self, "bedrockGuardrails",
guardrail_name="my-BedrockGuardrails"
)
# Add managed word list with input/output actions
guardrail.add_managed_word_list_filter(
type=bedrock.ManagedWordFilterType.PROFANITY,
input_action=bedrock.GuardrailAction.BLOCK,
input_enabled=True,
output_action=bedrock.GuardrailAction.NONE,
output_enabled=True
)
# Add individual words
guardrail.add_word_filter(text="drugs")
guardrail.add_word_filter(text="competitor")
# Add words from a file
guardrail.add_word_filter_from_file("./scripts/wordsPolicy.csv")
```
# | text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/aws/aws-cdk | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.239.0",
"constructs<11.0.0,>=10.5.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/aws/aws-cdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:57:53.154876 | aws_cdk_aws_bedrock_alpha-2.239.0a0.tar.gz | 645,316 | 27/03/b5a0bb0675dd61501647a739cc7712b872a3ff390d94f2cf2ec42a882afe/aws_cdk_aws_bedrock_alpha-2.239.0a0.tar.gz | source | sdist | null | false | c99b1105b579e4b7f1b6b1f2d0ddcc8b | e1363799b3bdf8518f630cee67c2f54825d2f46d62b01ebe30e8020243ef026b | 2703b5a0bb0675dd61501647a739cc7712b872a3ff390d94f2cf2ec42a882afe | null | [] | 0 |
2.1 | aws-cdk.aws-bedrock-agentcore-alpha | 2.239.0a0 | The CDK Construct Library for Amazon Bedrock | # Amazon Bedrock AgentCore Construct Library
<!--BEGIN STABILITY BANNER-->---

> The APIs of higher level constructs in this module are experimental and under active development.
> They are subject to non-backward compatible changes or removal in any future version. These are
> not subject to the [Semantic Versioning](https://semver.org/) model and breaking changes will be
> announced in the release notes. This means that while you may use them, you may need to update
> your source code when upgrading to a newer version of this package.
---
<!--END STABILITY BANNER-->
| **Language** | **Package** |
| :--------------------------------------------------------------------------------------------- | --------------------------------------- |
|  TypeScript | `@aws-cdk/aws-bedrock-agentcore-alpha` |
[Amazon Bedrock AgentCore](https://aws.amazon.com/bedrock/agentcore/) enables you to deploy and operate highly capable AI agents securely, at scale. It offers infrastructure purpose-built for dynamic agent workloads, powerful tools to enhance agents, and essential controls for real-world deployment. AgentCore services can be used together or independently and work with any framework including CrewAI, LangGraph, LlamaIndex, and Strands Agents, as well as any foundation model in or outside of Amazon Bedrock, giving you ultimate flexibility. AgentCore eliminates the undifferentiated heavy lifting of building specialized agent infrastructure, so you can accelerate agents to production.
This construct library facilitates the deployment of Bedrock AgentCore primitives, enabling you to create sophisticated AI applications that can interact with your systems and data sources.
> **Note:** Users need to ensure their CDK deployment role has the `iam:CreateServiceLinkedRole` permission for AgentCore service-linked roles.
## Table of contents
* [Amazon Bedrock AgentCore Construct Library](#amazon-bedrock-agentcore-construct-library)
* [Table of contents](#table-of-contents)
* [AgentCore Runtime](#agentcore-runtime)
* [Runtime Endpoints](#runtime-endpoints)
* [AgentCore Runtime Properties](#agentcore-runtime-properties)
* [Runtime Endpoint Properties](#runtime-endpoint-properties)
* [Creating a Runtime](#creating-a-runtime)
* [Option 1: Use an existing image in ECR](#option-1-use-an-existing-image-in-ecr)
* [Option 2: Use a local asset](#option-2-use-a-local-asset)
* [Option 3: Use direct code deployment](#option-3-use-direct-code-deployment)
* [Option 4: Use an ECR container image URI](#option-4-use-an-ecr-container-image-uri)
* [Granting Permissions to Invoke Bedrock Models or Inference Profiles](#granting-permissions-to-invoke-bedrock-models-or-inference-profiles)
* [Runtime Versioning](#runtime-versioning)
* [Managing Endpoints and Versions](#managing-endpoints-and-versions)
* [Step 1: Initial Deployment](#step-1-initial-deployment)
* [Step 2: Creating Custom Endpoints](#step-2-creating-custom-endpoints)
* [Step 3: Runtime Update Deployment](#step-3-runtime-update-deployment)
* [Step 4: Testing with Staging Endpoints](#step-4-testing-with-staging-endpoints)
* [Step 5: Promoting to Production](#step-5-promoting-to-production)
* [Creating Standalone Runtime Endpoints](#creating-standalone-runtime-endpoints)
* [Example: Creating an endpoint for an existing runtime](#example-creating-an-endpoint-for-an-existing-runtime)
* [Runtime Authentication Configuration](#runtime-authentication-configuration)
* [IAM Authentication (Default)](#iam-authentication-default)
* [Cognito Authentication](#cognito-authentication)
* [JWT Authentication](#jwt-authentication)
* [OAuth Authentication](#oauth-authentication)
* [Using a Custom IAM Role](#using-a-custom-iam-role)
* [Runtime Network Configuration](#runtime-network-configuration)
* [Public Network Mode (Default)](#public-network-mode-default)
* [VPC Network Mode](#vpc-network-mode)
* [Managing Security Groups with VPC Configuration](#managing-security-groups-with-vpc-configuration)
* [Runtime IAM Permissions](#runtime-iam-permissions)
* [Other configuration](#other-configuration)
* [Lifecycle configuration](#lifecycle-configuration)
* [Request header configuration](#request-header-configuration)
* [Browser](#browser)
* [Browser Network modes](#browser-network-modes)
* [Browser Properties](#browser-properties)
* [Basic Browser Creation](#basic-browser-creation)
* [Browser with Tags](#browser-with-tags)
* [Browser with VPC](#browser-with-vpc)
* [Browser with Recording Configuration](#browser-with-recording-configuration)
* [Browser with Custom Execution Role](#browser-with-custom-execution-role)
* [Browser with S3 Recording and Permissions](#browser-with-s3-recording-and-permissions)
* [Browser with Browser signing](#browser-with-browser-signing)
* [Browser IAM Permissions](#browser-iam-permissions)
* [Code Interpreter](#code-interpreter)
* [Code Interpreter Network Modes](#code-interpreter-network-modes)
* [Code Interpreter Properties](#code-interpreter-properties)
* [Basic Code Interpreter Creation](#basic-code-interpreter-creation)
* [Code Interpreter with VPC](#code-interpreter-with-vpc)
* [Code Interpreter with Sandbox Network Mode](#code-interpreter-with-sandbox-network-mode)
* [Code Interpreter with Custom Execution Role](#code-interpreter-with-custom-execution-role)
* [Code Interpreter IAM Permissions](#code-interpreter-iam-permissions)
* [Code interpreter with tags](#code-interpreter-with-tags)
* [Gateway](#gateway)
* [Gateway Properties](#gateway-properties)
* [Basic Gateway Creation](#basic-gateway-creation)
* [Protocol configuration](#protocol-configuration)
* [Inbound authorization](#inbound-authorization)
* [Gateway with KMS Encryption](#gateway-with-kms-encryption)
* [Gateway with Custom Execution Role](#gateway-with-custom-execution-role)
* [Gateway IAM Permissions](#gateway-iam-permissions)
* [Gateway Target](#gateway-target)
* [Gateway Target Properties](#gateway-target-properties)
* [Targets types](#targets-types)
* [Understanding Tool Naming](#understanding-tool-naming)
* [Tools schema For Lambda target](#tools-schema-for-lambda-target)
* [Api schema For OpenAPI and Smithy target](#api-schema-for-openapi-and-smithy-target)
* [Outbound auth](#outbound-auth)
* [Basic Gateway Target Creation](#basic-gateway-target-creation)
* [Using addTarget methods (Recommended)](#using-addtarget-methods-recommended)
* [Using static factory methods](#using-static-factory-methods)
* [Advanced Usage: Direct Configuration for gateway target](#advanced-usage-direct-configuration-for-gateway-target)
* [Configuration Factory Methods](#configuration-factory-methods)
* [Example: Lambda Target with Custom Configuration](#example-lambda-target-with-custom-configuration)
* [Gateway Target IAM Permissions](#gateway-target-iam-permissions)
* [Memory](#memory)
* [Memory Properties](#memory-properties)
* [Basic Memory Creation](#basic-memory-creation)
* [LTM Memory Extraction Stategies](#ltm-memory-extraction-stategies)
* [Memory with Built-in Strategies](#memory-with-built-in-strategies)
* [Memory with custom Strategies](#memory-with-custom-strategies)
* [Memory with Custom Execution Role](#memory-with-custom-execution-role)
* [Memory with self-managed Strategies](#memory-with-self-managed-strategies)
* [Memory Strategy Methods](#memory-strategy-methods)
## AgentCore Runtime
The AgentCore Runtime construct enables you to deploy containerized agents on Amazon Bedrock AgentCore.
This L2 construct simplifies runtime creation just pass your ECR repository name
and the construct handles all the configuration with sensible defaults.
### Runtime Endpoints
Endpoints provide a stable way to invoke specific versions of your agent runtime, enabling controlled deployments across different environments.
When you create an agent runtime, Amazon Bedrock AgentCore automatically creates a "DEFAULT" endpoint which always points to the latest version
of runtime.
You can create additional endpoints in two ways:
1. **Using Runtime.addEndpoint()** - Convenient method when creating endpoints alongside the runtime.
2. **Using RuntimeEndpoint** - Flexible approach for existing runtimes.
For example, you might keep a "production" endpoint on a stable version while testing newer versions
through a "staging" endpoint. This separation allows you to test changes thoroughly before promoting them
to production by simply updating the endpoint to point to the newer version.
### AgentCore Runtime Properties
| Name | Type | Required | Description |
|------|------|----------|-------------|
| `runtimeName` | `string` | No | The name of the agent runtime. Valid characters are a-z, A-Z, 0-9, _ (underscore). Must start with a letter and can be up to 48 characters long. If not provided, a unique name will be auto-generated |
| `agentRuntimeArtifact` | `AgentRuntimeArtifact` | Yes | The artifact configuration for the agent runtime containing the container configuration with ECR URI |
| `executionRole` | `iam.IRole` | No | The IAM role that provides permissions for the agent runtime. If not provided, a role will be created automatically |
| `networkConfiguration` | `NetworkConfiguration` | No | Network configuration for the agent runtime. Defaults to `RuntimeNetworkConfiguration.usingPublicNetwork()` |
| `description` | `string` | No | Optional description for the agent runtime |
| `protocolConfiguration` | `ProtocolType` | No | Protocol configuration for the agent runtime. Defaults to `ProtocolType.HTTP` |
| `authorizerConfiguration` | `RuntimeAuthorizerConfiguration` | No | Authorizer configuration for the agent runtime. Use `RuntimeAuthorizerConfiguration` static methods to create configurations for IAM, Cognito, JWT, or OAuth authentication |
| `environmentVariables` | `{ [key: string]: string }` | No | Environment variables for the agent runtime. Maximum 50 environment variables |
| `tags` | `{ [key: string]: string }` | No | Tags for the agent runtime. A list of key:value pairs of tags to apply to this Runtime resource |
| `lifecycleConfiguration` | LifecycleConfiguration | No | The life cycle configuration for the AgentCore Runtime. Defaults to 900 seconds (15 minutes) for idle, 28800 seconds (8 hours) for max life time |
| `requestHeaderConfiguration` | RequestHeaderConfiguration | No | Configuration for HTTP request headers that will be passed through to the runtime. Defaults to no configuration |
### Runtime Endpoint Properties
| Name | Type | Required | Description |
|------|------|----------|-------------|
| `endpointName` | `string` | No | The name of the runtime endpoint. Valid characters are a-z, A-Z, 0-9, _ (underscore). Must start with a letter and can be up to 48 characters long. If not provided, a unique name will be auto-generated |
| `agentRuntimeId` | `string` | Yes | The Agent Runtime ID for this endpoint |
| `agentRuntimeVersion` | `string` | Yes | The Agent Runtime version for this endpoint. Must be between 1 and 5 characters long.|
| `description` | `string` | No | Optional description for the runtime endpoint |
| `tags` | `{ [key: string]: string }` | No | Tags for the runtime endpoint |
### Creating a Runtime
#### Option 1: Use an existing image in ECR
Reference an image available within ECR.
```python
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
# The runtime by default create ECR permission only for the repository available in the account the stack is being deployed
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v1.0.0")
# Create runtime using the built image
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact
)
```
#### Option 2: Use a local asset
Reference a local directory containing a Dockerfile.
Images are built from a local Docker context directory (with a Dockerfile), uploaded to Amazon Elastic Container Registry (ECR)
by the CDK toolkit,and can be naturally referenced in your CDK app.
```python
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_asset(
path.join(__dirname, "path to agent dockerfile directory"))
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact
)
```
#### Option 3: Use direct code deployment
With the container deployment method, developers create a Dockerfile, build ARM-compatible containers, manage ECR repositories, and upload containers for code changes. This works well where container DevOps pipelines have already been established to automate deployments.
However, customers looking for fully managed deployments can benefit from direct code deployment, which can significantly improve developer time and productivity. Direct code deployment provides a secure and scalable path forward for rapid prototyping agent capabilities to deploying production workloads at scale.
With direct code deployment, developers create a zip archive of code and dependencies, upload to Amazon S3, and configure the bucket in the agent configuration. A ZIP archive containing Linux arm64 dependencies needs to be uploaded to S3 as a pre-requisite to Create Agent Runtime.
For more information, please refer to the [documentation](https://docs.aws.amazon.com/bedrock-agentcore/latest/devguide/runtime-get-started-code-deploy.html).
```python
# S3 bucket containing the agent core
code_bucket = s3.Bucket(self, "AgentCode",
bucket_name="my-code-bucket",
removal_policy=RemovalPolicy.DESTROY
)
# the bucket above needs to contain the agent code
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_s3(s3.Location(
bucket_name=code_bucket.bucket_name,
object_key="deployment_package.zip"
), agentcore.AgentCoreRuntime.PYTHON_3_12, ["opentelemetry-instrument", "main.py"])
runtime_instance = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact
)
```
Alternatively, you can use local code assets that will be automatically packaged and uploaded to a CDK-managed S3 bucket:
```python
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_code_asset(
path=path.join(__dirname, "path/to/agent/code"),
runtime=agentcore.AgentCoreRuntime.PYTHON_3_12,
entrypoint=["opentelemetry-instrument", "main.py"]
)
runtime_instance = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact
)
```
#### Option 4: Use an ECR container image URI
Reference an ECR container image directly by its URI. This is useful when you have a pre-existing ECR image URI from CloudFormation parameters or cross-stack references. No IAM permissions are automatically granted - you must ensure the runtime has ECR pull permissions.
```python
# Direct URI reference
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_image_uri("123456789012.dkr.ecr.us-east-1.amazonaws.com/my-agent:v1.0.0")
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact
)
```
You can also use CloudFormation parameters or references:
```python
# Using a CloudFormation parameter
image_uri_param = cdk.CfnParameter(self, "ImageUri",
type="String",
description="Container image URI for the agent runtime"
)
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_image_uri(image_uri_param.value_as_string)
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact
)
```
### Granting Permissions to Invoke Bedrock Models or Inference Profiles
To grant the runtime permissions to invoke Bedrock models or inference profiles:
```python
# Note: This example uses @aws-cdk/aws-bedrock-alpha which must be installed separately
# runtime: agentcore.Runtime
# Define the Bedrock Foundation Model
model = bedrock.BedrockFoundationModel.ANTHROPIC_CLAUDE_3_7_SONNET_V1_0
# Grant the runtime permissions to invoke the model
model.grant_invoke(runtime)
# Create a cross-region inference profile for Claude 3.7 Sonnet
inference_profile = bedrock.CrossRegionInferenceProfile.from_config(
geo_region=bedrock.CrossRegionInferenceProfileRegion.US,
model=bedrock.BedrockFoundationModel.ANTHROPIC_CLAUDE_3_7_SONNET_V1_0
)
# Grant the runtime permissions to invoke the inference profile
inference_profile.grant_invoke(runtime)
```
### Runtime Versioning
Amazon Bedrock AgentCore automatically manages runtime versioning to ensure safe deployments and rollback capabilities.
When you create an agent runtime, AgentCore automatically creates version 1 (V1). Each subsequent update to the
runtime configuration (such as updating the container image, modifying network settings, or changing protocol configurations)
creates a new immutable version. These versions contain complete, self-contained configurations that can be referenced by endpoints,
allowing you to maintain different versions for different environments or gradually roll out updates.
#### Managing Endpoints and Versions
Amazon Bedrock AgentCore automatically manages runtime versioning to provide safe deployments and rollback capabilities. You can follow
the steps below to understand how to use versioning with runtime for controlled deployments across different environments.
##### Step 1: Initial Deployment
When you first create an agent runtime, AgentCore automatically creates Version 1 of your runtime. At this point, a DEFAULT endpoint is
automatically created that points to Version 1. This DEFAULT endpoint serves as the main access point for your runtime.
```python
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v1.0.0")
)
```
##### Step 2: Creating Custom Endpoints
After the initial deployment, you can create additional endpoints for different environments. For example, you might create a "production"
endpoint that explicitly points to Version 1. This allows you to maintain stable access points for specific environments while keeping the
flexibility to test newer versions elsewhere.
```python
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v1.0.0")
)
prod_endpoint = runtime.add_endpoint("production",
version="1",
description="Stable production endpoint - pinned to v1"
)
```
##### Step 3: Runtime Update Deployment
When you update the runtime configuration (such as updating the container image, modifying network settings, or changing protocol
configurations), AgentCore automatically creates a new version (Version 2). Upon this update:
* Version 2 is created automatically with the new configuration
* The DEFAULT endpoint automatically updates to point to Version 2
* Any explicitly pinned endpoints (like the production endpoint) remain on their specified versions
```python
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
agent_runtime_artifact_new = agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v2.0.0")
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact_new
)
```
##### Step 4: Testing with Staging Endpoints
Once Version 2 exists, you can create a staging endpoint that points to the new version. This staging endpoint allows you to test the
new version in a controlled environment before promoting it to production. This separation ensures that production traffic continues
to use the stable version while you validate the new version.
```python
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
agent_runtime_artifact_new = agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v2.0.0")
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact_new
)
staging_endpoint = runtime.add_endpoint("staging",
version="2",
description="Staging environment for testing new version"
)
```
##### Step 5: Promoting to Production
After thoroughly testing the new version through the staging endpoint, you can update the production endpoint to point to Version 2.
This controlled promotion process ensures that you can validate changes before they affect production traffic.
```python
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
agent_runtime_artifact_new = agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v2.0.0")
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact_new
)
prod_endpoint = runtime.add_endpoint("production",
version="2", # New version added here
description="Stable production endpoint"
)
```
### Creating Standalone Runtime Endpoints
RuntimeEndpoint can also be created as a standalone resource.
#### Example: Creating an endpoint for an existing runtime
```python
# Reference an existing runtime by its ID
existing_runtime_id = "abc123-runtime-id" # The ID of an existing runtime
# Create a standalone endpoint
endpoint = agentcore.RuntimeEndpoint(self, "MyEndpoint",
endpoint_name="production",
agent_runtime_id=existing_runtime_id,
agent_runtime_version="1", # Specify which version to use
description="Production endpoint for existing runtime"
)
```
### Runtime Authentication Configuration
The AgentCore Runtime supports multiple authentication modes to secure access to your agent endpoints. Authentication is configured during runtime creation using the `RuntimeAuthorizerConfiguration` class's static factory methods.
#### IAM Authentication (Default)
IAM authentication is the default mode, when no authorizerConfiguration is set then the underlying service use IAM.
#### Cognito Authentication
To configure AWS Cognito User Pool authentication:
```python
# user_pool: cognito.UserPool
# user_pool_client: cognito.UserPoolClient
# another_user_pool_client: cognito.UserPoolClient
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v1.0.0")
# Optional: Create custom claims for additional validation
custom_claims = [
agentcore.RuntimeCustomClaim.with_string_value("department", "engineering"),
agentcore.RuntimeCustomClaim.with_string_array_value("roles", ["admin"], agentcore.CustomClaimOperator.CONTAINS),
agentcore.RuntimeCustomClaim.with_string_array_value("permissions", ["read", "write"], agentcore.CustomClaimOperator.CONTAINS_ANY)
]
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact,
authorizer_configuration=agentcore.RuntimeAuthorizerConfiguration.using_cognito(user_pool, [user_pool_client, another_user_pool_client], ["audience1"], ["read", "write"], custom_claims)
)
```
You can configure:
* User Pool: The Cognito User Pool that issues JWT tokens
* User Pool Clients: One or more Cognito User Pool App Clients that are allowed to access the runtime
* Allowed audiences: Used to validate that the audiences specified in the Cognito token match or are a subset of the audiences specified in the AgentCore Runtime
* Allowed scopes: Allow access only if the token contains at least one of the required scopes configured here
* Custom claims: A set of rules to match specific claims in the incoming token against predefined values for validating JWT tokens
#### JWT Authentication
To configure custom JWT authentication with your own OpenID Connect (OIDC) provider:
```python
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v1.0.0")
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact,
authorizer_configuration=agentcore.RuntimeAuthorizerConfiguration.using_jWT("https://example.com/.well-known/openid-configuration", ["client1", "client2"], ["audience1"], ["read", "write"])
)
```
You can configure:
* Discovery URL: Enter the Discovery URL from your identity provider (e.g. Okta, Cognito, etc.), typically found in that provider's documentation. This allows your Agent or Tool to fetch login, downstream resource token, and verification settings.
* Allowed audiences: This is used to validate that the audiences specified for the OAuth token matches or are a subset of the audiences specified in the AgentCore Runtime.
* Allowed clients: This is used to validate that the public identifier of the client, as specified in the authorization token, is allowed to access the AgentCore Runtime.
* Allowed scopes: Allow access only if the token contains at least one of the required scopes configured here.
* Custom claims: A set of rules to match specific claims in the incoming token against predefined values for validating JWT tokens.
**Note**: The discovery URL must end with `/.well-known/openid-configuration`.
##### Custom Claims Validation
Custom claims allow you to validate additional fields in JWT tokens beyond the standard audience, client, and scope validations. You can create custom claims using the `RuntimeCustomClaim` class:
```python
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v1.0.0")
# String claim - validates that the claim exactly equals the specified value
# Uses EQUALS operator automatically
department_claim = agentcore.RuntimeCustomClaim.with_string_value("department", "engineering")
# String array claim with CONTAINS operator (default)
# Validates that the claim array contains a specific string value
# IMPORTANT: CONTAINS requires exactly one value in the array parameter
roles_claim = agentcore.RuntimeCustomClaim.with_string_array_value("roles", ["admin"])
# String array claim with CONTAINS_ANY operator
# Validates that the claim array contains at least one of the specified values
# Use this when you want to check for multiple possible values
permissions_claim = agentcore.RuntimeCustomClaim.with_string_array_value("permissions", ["read", "write"], agentcore.CustomClaimOperator.CONTAINS_ANY)
# Use custom claims in authorizer configuration
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact,
authorizer_configuration=agentcore.RuntimeAuthorizerConfiguration.using_jWT("https://example.com/.well-known/openid-configuration", ["client1", "client2"], ["audience1"], ["read", "write"], [department_claim, roles_claim, permissions_claim])
)
```
**Custom Claim Rules**:
* **String claims**: Must use the `EQUALS` operator (automatically set). The claim value must exactly match the specified string.
* **String array claims**: Can use `CONTAINS` (default) or `CONTAINS_ANY` operators:
* **`CONTAINS`**: Checks if the claim array contains a specific string value. **Requires exactly one value** in the array parameter. For example, `['admin']` will check if the token's claim array contains the string `'admin'`.
* **`CONTAINS_ANY`**: Checks if the claim array contains at least one of the provided string values. Use this when you want to validate against multiple possible values. For example, `['read', 'write']` will check if the token's claim array contains either `'read'` or `'write'`.
**Example Use Cases**:
* Use `CONTAINS` when you need to verify a user has a specific role: `RuntimeCustomClaim.withStringArrayValue('roles', ['admin'])`
* Use `CONTAINS_ANY` when you need to verify a user has any of several permissions: `RuntimeCustomClaim.withStringArrayValue('permissions', ['read', 'write'], CustomClaimOperator.CONTAINS_ANY)`
#### OAuth Authentication
To configure OAuth 2.0 authentication:
```python
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v1.0.0")
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact,
authorizer_configuration=agentcore.RuntimeAuthorizerConfiguration.using_oAuth("https://github.com/.well-known/openid-configuration", "oauth_client_123", ["audience1"], ["openid", "profile"])
)
```
#### Using a Custom IAM Role
Instead of using the auto-created execution role, you can provide your own IAM role with specific permissions:
The auto-created role includes all necessary baseline permissions for ECR access, CloudWatch logging, and X-Ray tracing. When providing a custom role, ensure these permissions are included.
### Runtime Network Configuration
The AgentCore Runtime supports two network modes for deployment:
#### Public Network Mode (Default)
By default, runtimes are deployed in PUBLIC network mode, which provides internet access suitable for less sensitive or open-use scenarios:
```python
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v1.0.0")
# Explicitly using public network (this is the default)
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact,
network_configuration=agentcore.RuntimeNetworkConfiguration.using_public_network()
)
```
#### VPC Network Mode
For enhanced security and network isolation, you can deploy your runtime within a VPC:
```python
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v1.0.0")
# Create or use an existing VPC
vpc = ec2.Vpc(self, "MyVpc",
max_azs=2
)
# Configure runtime with VPC
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact,
network_configuration=agentcore.RuntimeNetworkConfiguration.using_vpc(self,
vpc=vpc,
vpc_subnets=ec2.SubnetSelection(subnet_type=ec2.SubnetType.PRIVATE_WITH_EGRESS)
)
)
```
#### Managing Security Groups with VPC Configuration
When using VPC mode, the Runtime implements `ec2.IConnectable`, allowing you to manage network access using the `connections` property:
```python
vpc = ec2.Vpc(self, "MyVpc",
max_azs=2
)
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v1.0.0")
# Create runtime with VPC configuration
runtime = agentcore.Runtime(self, "MyAgentRuntime",
runtime_name="myAgent",
agent_runtime_artifact=agent_runtime_artifact,
network_configuration=agentcore.RuntimeNetworkConfiguration.using_vpc(self,
vpc=vpc,
vpc_subnets=ec2.SubnetSelection(subnet_type=ec2.SubnetType.PRIVATE_WITH_EGRESS)
)
)
# Now you can manage network access using the connections property
# Allow inbound HTTPS traffic from a specific security group
web_server_security_group = ec2.SecurityGroup(self, "WebServerSG", vpc=vpc)
runtime.connections.allow_from(web_server_security_group, ec2.Port.tcp(443), "Allow HTTPS from web servers")
# Allow outbound connections to a database
database_security_group = ec2.SecurityGroup(self, "DatabaseSG", vpc=vpc)
runtime.connections.allow_to(database_security_group, ec2.Port.tcp(5432), "Allow PostgreSQL connection")
# Allow outbound HTTPS to anywhere (for external API calls)
runtime.connections.allow_to_any_ipv4(ec2.Port.tcp(443), "Allow HTTPS outbound")
```
### Runtime IAM Permissions
The Runtime construct provides convenient methods for granting IAM permissions to principals that need to invoke the runtime or manage its execution role.
```python
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v1.0.0")
# Create a runtime
runtime = agentcore.Runtime(self, "MyRuntime",
runtime_name="my_runtime",
agent_runtime_artifact=agent_runtime_artifact
)
# Create a Lambda function that needs to invoke the runtime
invoker_function = lambda_.Function(self, "InvokerFunction",
runtime=lambda_.Runtime.PYTHON_3_12,
handler="index.handler",
code=lambda_.Code.from_inline("""
import boto3
def handler(event, context):
client = boto3.client('bedrock-agentcore')
# Invoke the runtime...
""")
)
# Grant permission to invoke the runtime directly
runtime.grant_invoke_runtime(invoker_function)
# Grant permission to invoke the runtime on behalf of a user
# (requires X-Amzn-Bedrock-AgentCore-Runtime-User-Id header)
runtime.grant_invoke_runtime_for_user(invoker_function)
# Grant both invoke permissions (most common use case)
runtime.grant_invoke(invoker_function)
# Grant specific custom permissions to the runtime's execution role
runtime.grant(["bedrock:InvokeModel"], ["arn:aws:bedrock:*:*:*"])
# Add a policy statement to the runtime's execution role
runtime.add_to_role_policy(iam.PolicyStatement(
actions=["s3:GetObject"],
resources=["arn:aws:s3:::my-bucket/*"]
))
```
### Other configuration
#### Lifecycle configuration
The LifecycleConfiguration input parameter to CreateAgentRuntime lets you manage the lifecycle of runtime sessions and resources in Amazon Bedrock AgentCore Runtime. This configuration helps optimize resource utilization by automatically cleaning up idle sessions and preventing long-running instances from consuming resources indefinitely.
You can configure:
* idleRuntimeSessionTimeout: Timeout in seconds for idle runtime sessions. When a session remains idle for this duration, it will trigger termination. Termination can last up to 15 seconds due to logging and other process completion. Default: 900 seconds (15 minutes)
* maxLifetime: Maximum lifetime for the instance in seconds. Once reached, instances will initialize termination. Termination can last up to 15 seconds due to logging and other process completion. Default: 28800 seconds (8 hours)
For additional information, please refer to the [documentation](https://docs.aws.amazon.com/bedrock-agentcore/latest/devguide/runtime-lifecycle-settings.html).
```python
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v1.0.0")
agentcore.Runtime(self, "test-runtime",
runtime_name="test_runtime",
agent_runtime_artifact=agent_runtime_artifact,
lifecycle_configuration=agentcore.LifecycleConfiguration(
idle_runtime_session_timeout=Duration.minutes(10),
max_lifetime=Duration.hours(4)
)
)
```
#### Request header configuration
Custom headers let you pass contextual information from your application directly to your agent code without cluttering the main request payload. This includes authentication tokens like JWT (JSON Web Tokens, which contain user identity and authorization claims) through the Authorization header, allowing your agent to make decisions based on who is calling it. You can also pass custom metadata like user preferences, session identifiers, or trace context using headers prefixed with X-Amzn-Bedrock-AgentCore-Runtime-Custom-, giving your agent access to up to 20 pieces of runtime context that travel alongside each request. This information can be also used in downstream systems like AgentCore Memory that you can namespace based on those characteristics like user_id or aud in claims like line of business.
For additional information, please refer to the [documentation](https://docs.aws.amazon.com/bedrock-agentcore/latest/devguide/runtime-header-allowlist.html).
```python
repository = ecr.Repository(self, "TestRepository",
repository_name="test-agent-runtime"
)
agent_runtime_artifact = agentcore.AgentRuntimeArtifact.from_ecr_repository(repository, "v1.0.0")
agentcore.Runtime(self, "test-runtime",
runtime_name="test_runtime",
agent_runtime_artifact=agent_runtime_artifact,
request_header_configuration=agentcore.RequestHeaderConfiguration(
allowlisted_headers=["X-Amzn-Bedrock-AgentCore-Runtime-Custom-H1"]
)
)
```
## Browser
The Amazon Bedrock AgentCore Browser provides a secure, cloud-based browser that enables AI agents to interact with websites. It includes security features such as session isolation, built-in observability through live viewing, CloudTrail logging, and session replay capabilities.
Additional information about the browser tool can be found in the [official documentation](https://docs.aws.amazon.com/bedrock-agentcore/latest/devguide/browser-tool.html)
### Browser Network modes
The Browser construct supports the following network modes:
1. **Public Network Mode** (`BrowserNetworkMode.usingPublicNetwork()`) - Default
* Allows internet access for web browsing and external API calls
* Suitable for scenarios where agents need to interact with publicly available websites
* Enables full web browsing capabilities
* VPC mode is not supported with this option
2. **VPC (Virtual Private Cloud)** (`BrowserNetworkMode.usingVpc()`)
* Select whether to run the browser in a virtual private cloud (VPC).
* By configuring VPC connectivity, you enable secure access to private resources such as databases, internal APIs, and services within your VPC.
While the VPC itself is mandatory, these are optional:
* Subnets - if not provided, CDK will select appropriate subnets from the VPC
* Security Groups - if not provided, CDK will create a default security group
* Specific subnet selection criteria - you can let CDK choose automatically
For more information on VPC connectivity for Amazon Bedrock AgentCore Browser, please refer to the [official documentation](https://docs.aws.amazon.com/bedrock-agentcore/latest/devguide/agentcore-vpc.html).
### Browser Properties
| Name | Type | Required | Description |
|------|------|----------|-------------|
| `browserCustomName` | `string` | No | The name of the browser. Must start with a letter and can be up to 48 characters long. Pattern: `[a-zA-Z][a-zA-Z0-9_]{0,47}`. If not provided, a unique name will be auto-generated |
| `description` | `string` | No | Optional description for the browser. Can have up to 200 characters |
| `networkConfiguration` | `BrowserNetworkConfiguration` | No | Network configuration for browser. Defaults to PUBLIC network mode |
| `recordingConfig` | `RecordingCo | text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/aws/aws-cdk | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.239.0",
"aws-cdk.aws-bedrock-alpha==2.239.0.a0",
"constructs<11.0.0,>=10.5.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/aws/aws-cdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:57:51.839012 | aws_cdk_aws_bedrock_agentcore_alpha-2.239.0a0.tar.gz | 870,131 | 87/d4/bf9adb936cc23dae3164418ca3d1a1b0b0002dd739565d57dc74605b761e/aws_cdk_aws_bedrock_agentcore_alpha-2.239.0a0.tar.gz | source | sdist | null | false | 407b53c0e8279ee52d2569a3e1f04033 | c468d4376db43c3a1f10442ca81f92f1289f6a8e7dbcd7411c80c4f33c09f835 | 87d4bf9adb936cc23dae3164418ca3d1a1b0b0002dd739565d57dc74605b761e | null | [] | 0 |
2.1 | aws-cdk.aws-apprunner-alpha | 2.239.0a0 | The CDK Construct Library for AWS::AppRunner | # AWS::AppRunner Construct Library
<!--BEGIN STABILITY BANNER-->---

> The APIs of higher level constructs in this module are experimental and under active development.
> They are subject to non-backward compatible changes or removal in any future version. These are
> not subject to the [Semantic Versioning](https://semver.org/) model and breaking changes will be
> announced in the release notes. This means that while you may use them, you may need to update
> your source code when upgrading to a newer version of this package.
---
<!--END STABILITY BANNER-->
This module is part of the [AWS Cloud Development Kit](https://github.com/aws/aws-cdk) project.
```python
import aws_cdk.aws_apprunner_alpha as apprunner
```
## Introduction
AWS App Runner is a fully managed service that makes it easy for developers to quickly deploy containerized web applications and APIs, at scale and with no prior infrastructure experience required. Start with your source code or a container image. App Runner automatically builds and deploys the web application and load balances traffic with encryption. App Runner also scales up or down automatically to meet your traffic needs. With App Runner, rather than thinking about servers or scaling, you have more time to focus on your applications.
## Service
The `Service` construct allows you to create AWS App Runner services with `ECR Public`, `ECR` or `Github` with the `source` property in the following scenarios:
* `Source.fromEcr()` - To define the source repository from `ECR`.
* `Source.fromEcrPublic()` - To define the source repository from `ECR Public`.
* `Source.fromGitHub()` - To define the source repository from the `Github repository`.
* `Source.fromAsset()` - To define the source from local asset directory.
The `Service` construct implements `IGrantable`.
## ECR Public
To create a `Service` with ECR Public:
```python
apprunner.Service(self, "Service",
source=apprunner.Source.from_ecr_public(
image_configuration=apprunner.ImageConfiguration(port=8000),
image_identifier="public.ecr.aws/aws-containers/hello-app-runner:latest"
)
)
```
## ECR
To create a `Service` from an existing ECR repository:
```python
import aws_cdk.aws_ecr as ecr
apprunner.Service(self, "Service",
source=apprunner.Source.from_ecr(
image_configuration=apprunner.ImageConfiguration(port=80),
repository=ecr.Repository.from_repository_name(self, "NginxRepository", "nginx"),
tag_or_digest="latest"
)
)
```
To create a `Service` from local docker image asset directory built and pushed to Amazon ECR:
You can specify whether to enable continuous integration from the source repository with the `autoDeploymentsEnabled` flag.
```python
import aws_cdk.aws_ecr_assets as assets
image_asset = assets.DockerImageAsset(self, "ImageAssets",
directory=path.join(__dirname, "docker.assets")
)
apprunner.Service(self, "Service",
source=apprunner.Source.from_asset(
image_configuration=apprunner.ImageConfiguration(port=8000),
asset=image_asset
),
auto_deployments_enabled=True
)
```
## GitHub
To create a `Service` from the GitHub repository, you need to specify an existing App Runner `Connection`.
See [Managing App Runner connections](https://docs.aws.amazon.com/apprunner/latest/dg/manage-connections.html) for more details.
```python
apprunner.Service(self, "Service",
source=apprunner.Source.from_git_hub(
repository_url="https://github.com/aws-containers/hello-app-runner",
branch="main",
configuration_source=apprunner.ConfigurationSourceType.REPOSITORY,
connection=apprunner.GitHubConnection.from_connection_arn("CONNECTION_ARN")
)
)
```
Use `codeConfigurationValues` to override configuration values with the `API` configuration source type.
```python
apprunner.Service(self, "Service",
source=apprunner.Source.from_git_hub(
repository_url="https://github.com/aws-containers/hello-app-runner",
branch="main",
configuration_source=apprunner.ConfigurationSourceType.API,
code_configuration_values=apprunner.CodeConfigurationValues(
runtime=apprunner.Runtime.PYTHON_3,
port="8000",
start_command="python app.py",
build_command="yum install -y pycairo && pip install -r requirements.txt"
),
connection=apprunner.GitHubConnection.from_connection_arn("CONNECTION_ARN")
)
)
```
## IAM Roles
You are allowed to define `instanceRole` and `accessRole` for the `Service`.
`instanceRole` - The IAM role that provides permissions to your App Runner service. These are permissions that
your code needs when it calls any AWS APIs. If not defined, a new instance role will be generated
when required.
To add IAM policy statements to this role, use `addToRolePolicy()`:
```python
import aws_cdk.aws_iam as iam
service = apprunner.Service(self, "Service",
source=apprunner.Source.from_ecr_public(
image_configuration=apprunner.ImageConfiguration(port=8000),
image_identifier="public.ecr.aws/aws-containers/hello-app-runner:latest"
)
)
service.add_to_role_policy(iam.PolicyStatement(
effect=iam.Effect.ALLOW,
actions=["s3:GetObject"],
resources=["*"]
))
```
`accessRole` - The IAM role that grants the App Runner service access to a source repository. It's required for
ECR image repositories (but not for ECR Public repositories). If not defined, a new access role will be generated
when required.
See [App Runner IAM Roles](https://docs.aws.amazon.com/apprunner/latest/dg/security_iam_service-with-iam.html#security_iam_service-with-iam-roles) for more details.
## Auto Scaling Configuration
To associate an App Runner service with a custom Auto Scaling Configuration, define `autoScalingConfiguration` for the service.
```python
auto_scaling_configuration = apprunner.AutoScalingConfiguration(self, "AutoScalingConfiguration",
auto_scaling_configuration_name="MyAutoScalingConfiguration",
max_concurrency=150,
max_size=20,
min_size=5
)
apprunner.Service(self, "DemoService",
source=apprunner.Source.from_ecr_public(
image_configuration=apprunner.ImageConfiguration(port=8000),
image_identifier="public.ecr.aws/aws-containers/hello-app-runner:latest"
),
auto_scaling_configuration=auto_scaling_configuration
)
```
## VPC Connector
To associate an App Runner service with a custom VPC, define `vpcConnector` for the service.
```python
import aws_cdk.aws_ec2 as ec2
vpc = ec2.Vpc(self, "Vpc",
ip_addresses=ec2.IpAddresses.cidr("10.0.0.0/16")
)
vpc_connector = apprunner.VpcConnector(self, "VpcConnector",
vpc=vpc,
vpc_subnets=vpc.select_subnets(subnet_type=ec2.SubnetType.PUBLIC),
vpc_connector_name="MyVpcConnector"
)
apprunner.Service(self, "Service",
source=apprunner.Source.from_ecr_public(
image_configuration=apprunner.ImageConfiguration(port=8000),
image_identifier="public.ecr.aws/aws-containers/hello-app-runner:latest"
),
vpc_connector=vpc_connector
)
```
## VPC Ingress Connection
To make your App Runner service private and only accessible from within a VPC use the `isPubliclyAccessible` property and associate it to a `VpcIngressConnection` resource.
To set up a `VpcIngressConnection`, specify a VPC, a VPC Interface Endpoint, and the App Runner service.
Also you must set `isPubliclyAccessible` property in ther `Service` to `false`.
For more information, see [Enabling Private endpoint for incoming traffic](https://docs.aws.amazon.com/apprunner/latest/dg/network-pl.html).
```python
import aws_cdk.aws_ec2 as ec2
# vpc: ec2.Vpc
interface_vpc_endpoint = ec2.InterfaceVpcEndpoint(self, "MyVpcEndpoint",
vpc=vpc,
service=ec2.InterfaceVpcEndpointAwsService.APP_RUNNER_REQUESTS,
private_dns_enabled=False
)
service = apprunner.Service(self, "Service",
source=apprunner.Source.from_ecr_public(
image_configuration=apprunner.ImageConfiguration(
port=8000
),
image_identifier="public.ecr.aws/aws-containers/hello-app-runner:latest"
),
is_publicly_accessible=False
)
apprunner.VpcIngressConnection(self, "VpcIngressConnection",
vpc=vpc,
interface_vpc_endpoint=interface_vpc_endpoint,
service=service
)
```
## Dual Stack
To use dual stack (IPv4 and IPv6) for your incoming public network configuration, set `ipAddressType` to `IpAddressType.DUAL_STACK`.
```python
apprunner.Service(self, "Service",
source=apprunner.Source.from_ecr_public(
image_configuration=apprunner.ImageConfiguration(port=8000),
image_identifier="public.ecr.aws/aws-containers/hello-app-runner:latest"
),
ip_address_type=apprunner.IpAddressType.DUAL_STACK
)
```
**Note**: Currently, App Runner supports dual stack for only Public endpoint.
Only IPv4 is supported for Private endpoint.
If you update a service that's using dual-stack Public endpoint to a Private endpoint,
your App Runner service will default to support only IPv4 for Private endpoint and fail
to receive traffic originating from IPv6 endpoint.
## Secrets Manager
To include environment variables integrated with AWS Secrets Manager, use the `environmentSecrets` attribute.
You can use the `addSecret` method from the App Runner `Service` class to include secrets from outside the
service definition.
```python
import aws_cdk.aws_secretsmanager as secretsmanager
import aws_cdk.aws_ssm as ssm
# stack: Stack
secret = secretsmanager.Secret(stack, "Secret")
parameter = ssm.StringParameter.from_secure_string_parameter_attributes(stack, "Parameter",
parameter_name="/name",
version=1
)
service = apprunner.Service(stack, "Service",
source=apprunner.Source.from_ecr_public(
image_configuration=apprunner.ImageConfiguration(
port=8000,
environment_secrets={
"SECRET": apprunner.Secret.from_secrets_manager(secret),
"PARAMETER": apprunner.Secret.from_ssm_parameter(parameter),
"SECRET_ID": apprunner.Secret.from_secrets_manager_version(secret, version_id="version-id"),
"SECRET_STAGE": apprunner.Secret.from_secrets_manager_version(secret, version_stage="version-stage")
}
),
image_identifier="public.ecr.aws/aws-containers/hello-app-runner:latest"
)
)
service.add_secret("LATER_SECRET", apprunner.Secret.from_secrets_manager(secret, "field"))
```
## Use a customer managed key
To use a customer managed key for your source encryption, use the `kmsKey` attribute.
```python
import aws_cdk.aws_kms as kms
# kms_key: kms.IKey
apprunner.Service(self, "Service",
source=apprunner.Source.from_ecr_public(
image_configuration=apprunner.ImageConfiguration(port=8000),
image_identifier="public.ecr.aws/aws-containers/hello-app-runner:latest"
),
kms_key=kms_key
)
```
## HealthCheck
To configure the health check for the service, use the `healthCheck` attribute.
You can specify it by static methods `HealthCheck.http` or `HealthCheck.tcp`.
```python
apprunner.Service(self, "Service",
source=apprunner.Source.from_ecr_public(
image_configuration=apprunner.ImageConfiguration(port=8000),
image_identifier="public.ecr.aws/aws-containers/hello-app-runner:latest"
),
health_check=apprunner.HealthCheck.http(
healthy_threshold=5,
interval=Duration.seconds(10),
path="/",
timeout=Duration.seconds(10),
unhealthy_threshold=10
)
)
```
## Observability Configuration
To associate an App Runner service with a custom observability configuration, use the `observabilityConfiguration` property.
```python
observability_configuration = apprunner.ObservabilityConfiguration(self, "ObservabilityConfiguration",
observability_configuration_name="MyObservabilityConfiguration",
trace_configuration_vendor=apprunner.TraceConfigurationVendor.AWSXRAY
)
apprunner.Service(self, "DemoService",
source=apprunner.Source.from_ecr_public(
image_configuration=apprunner.ImageConfiguration(port=8000),
image_identifier="public.ecr.aws/aws-containers/hello-app-runner:latest"
),
observability_configuration=observability_configuration
)
```
| text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/aws/aws-cdk | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.239.0",
"constructs<11.0.0,>=10.5.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/aws/aws-cdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:57:50.843492 | aws_cdk_aws_apprunner_alpha-2.239.0a0.tar.gz | 177,068 | f7/8c/e55c28a001be9beacec393402b7775366e4bc6f2eec7fc3a2f543ec0af76/aws_cdk_aws_apprunner_alpha-2.239.0a0.tar.gz | source | sdist | null | false | a46ec0ce5cf441aaaf3c2ef6d52b605b | 44f025594d90b671a06362e204d52be8f5579ea4b334e7094b8869ba96da1032 | f78ce55c28a001be9beacec393402b7775366e4bc6f2eec7fc3a2f543ec0af76 | null | [] | 0 |
2.1 | aws-cdk.aws-applicationsignals-alpha | 2.239.0a0 | The CDK Construct Library for AWS::Amplify | # AWS::ApplicationSignals Construct Library
<!--BEGIN STABILITY BANNER-->---

> The APIs of higher level constructs in this module are experimental and under active development.
> They are subject to non-backward compatible changes or removal in any future version. These are
> not subject to the [Semantic Versioning](https://semver.org/) model and breaking changes will be
> announced in the release notes. This means that while you may use them, you may need to update
> your source code when upgrading to a newer version of this package.
---
<!--END STABILITY BANNER-->
CloudWatch Application Signals is an auto-instrumentation solution built on OpenTelemetry that enables zero-code collection of monitoring data, such
as traces and metrics, from applications running across multiple platforms. It also supports topology auto-discovery based on collected monitoring data
and includes a new feature for managing service-level objectives (SLOs).
It supports Java, Python, .NET, and Node.js on platforms including EKS (and native Kubernetes), Lambda, ECS, and EC2. For more details, visit
[Application Signals](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch-Application-Monitoring-Sections.html) on the AWS
public website.
## Application Signals Enablement L2 Constructs
A collection of L2 constructs which leverages native L1 CFN resources, simplifying the enablement steps and the creation of Application
Signals resources.
### ApplicationSignalsIntegration
`ApplicationSignalsIntegration` aims to address key challenges in the current CDK enablement process, which requires complex manual configurations for
ECS customers. Application Signals is designed to be flexible and is supported for other platforms as well. However, the initial focus is on supporting
ECS, with plans to potentially extend support to other platforms in the future.
#### Enable Application Signals on ECS with sidecar mode
1. Configure `instrumentation` to instrument the application with the ADOT SDK Agent.
2. Specify `cloudWatchAgentSidecar` to configure the CloudWatch Agent as a sidecar container.
```python
from constructs import Construct
import aws_cdk.aws_applicationsignals_alpha as appsignals
import aws_cdk as cdk
import aws_cdk.aws_ec2 as ec2
import aws_cdk.aws_ecs as ecs
class MyStack(cdk.Stack):
def __init__(self, scope=None, id=None, *, description=None, env=None, stackName=None, tags=None, notificationArns=None, synthesizer=None, terminationProtection=None, analyticsReporting=None, crossRegionReferences=None, permissionsBoundary=None, suppressTemplateIndentation=None, propertyInjectors=None):
super().__init__()
vpc = ec2.Vpc(self, "TestVpc")
cluster = ecs.Cluster(self, "TestCluster", vpc=vpc)
fargate_task_definition = ecs.FargateTaskDefinition(self, "SampleAppTaskDefinition",
cpu=2048,
memory_limit_mi_b=4096
)
fargate_task_definition.add_container("app",
image=ecs.ContainerImage.from_registry("test/sample-app")
)
appsignals.ApplicationSignalsIntegration(self, "ApplicationSignalsIntegration",
task_definition=fargate_task_definition,
instrumentation=appsignals.InstrumentationProps(
sdk_version=appsignals.JavaInstrumentationVersion.V2_10_0
),
service_name="sample-app",
cloud_watch_agent_sidecar=appsignals.CloudWatchAgentOptions(
container_name="cloudwatch-agent",
enable_logging=True,
cpu=256,
memory_limit_mi_b=512
)
)
ecs.FargateService(self, "MySampleApp",
cluster=cluster,
task_definition=fargate_task_definition,
desired_count=1
)
```
#### Enable Application Signals on ECS with daemon mode
Note: Since the daemon deployment strategy is not supported on ECS Fargate, this mode is only supported on ECS on EC2.
1. Run CloudWatch Agent as a daemon service with HOST network mode.
2. Configure `instrumentation` to instrument the application with the ADOT Python Agent.
3. Override environment variables by configuring `overrideEnvironments` to use service connect endpoints to communicate to the CloudWatch agent server
```python
from constructs import Construct
import aws_cdk.aws_applicationsignals_alpha as appsignals
import aws_cdk as cdk
import aws_cdk.aws_ec2 as ec2
import aws_cdk.aws_ecs as ecs
class MyStack(cdk.Stack):
def __init__(self, scope=None, id=None, *, description=None, env=None, stackName=None, tags=None, notificationArns=None, synthesizer=None, terminationProtection=None, analyticsReporting=None, crossRegionReferences=None, permissionsBoundary=None, suppressTemplateIndentation=None, propertyInjectors=None):
super().__init__(scope, id, description=description, env=env, stackName=stackName, tags=tags, notificationArns=notificationArns, synthesizer=synthesizer, terminationProtection=terminationProtection, analyticsReporting=analyticsReporting, crossRegionReferences=crossRegionReferences, permissionsBoundary=permissionsBoundary, suppressTemplateIndentation=suppressTemplateIndentation, propertyInjectors=propertyInjectors)
vpc = ec2.Vpc(self, "TestVpc")
cluster = ecs.Cluster(self, "TestCluster", vpc=vpc)
# Define Task Definition for CloudWatch agent (Daemon)
cw_agent_task_definition = ecs.Ec2TaskDefinition(self, "CloudWatchAgentTaskDefinition",
network_mode=ecs.NetworkMode.HOST
)
appsignals.CloudWatchAgentIntegration(self, "CloudWatchAgentIntegration",
task_definition=cw_agent_task_definition,
container_name="ecs-cwagent",
enable_logging=False,
cpu=128,
memory_limit_mi_b=64,
port_mappings=[ecs.PortMapping(
container_port=4316,
host_port=4316
), ecs.PortMapping(
container_port=2000,
host_port=2000
)
]
)
# Create the CloudWatch Agent daemon service
ecs.Ec2Service(self, "CloudWatchAgentDaemon",
cluster=cluster,
task_definition=cw_agent_task_definition,
daemon=True
)
# Define Task Definition for user application
sample_app_task_definition = ecs.Ec2TaskDefinition(self, "SampleAppTaskDefinition",
network_mode=ecs.NetworkMode.HOST
)
sample_app_task_definition.add_container("app",
image=ecs.ContainerImage.from_registry("test/sample-app"),
cpu=0,
memory_limit_mi_b=512
)
# No CloudWatch Agent side car is needed as application container communicates to CloudWatch Agent daemon through host network
appsignals.ApplicationSignalsIntegration(self, "ApplicationSignalsIntegration",
task_definition=sample_app_task_definition,
instrumentation=appsignals.InstrumentationProps(
sdk_version=appsignals.PythonInstrumentationVersion.V0_8_0
),
service_name="sample-app"
)
ecs.Ec2Service(self, "MySampleApp",
cluster=cluster,
task_definition=sample_app_task_definition,
desired_count=1
)
```
#### Enable Application Signals on ECS with replica mode
**Note**
*Running CloudWatch Agent service using replica mode requires specific security group configurations to enable communication with other services.
For Application Signals functionality, configure the security group with the following minimum inbound rules: Port 2000 (HTTP) and Port 4316 (HTTP).
This configuration ensures proper connectivity between the CloudWatch Agent and dependent services.*
1. Run CloudWatch Agent as a replica service with service connect.
2. Configure `instrumentation` to instrument the application with the ADOT Python Agent.
3. Override environment variables by configuring `overrideEnvironments` to use service connect endpoints to communicate to the CloudWatch agent server
```python
from constructs import Construct
import aws_cdk.aws_applicationsignals_alpha as appsignals
import aws_cdk as cdk
import aws_cdk.aws_ec2 as ec2
import aws_cdk.aws_ecs as ecs
from aws_cdk.aws_servicediscovery import PrivateDnsNamespace
class MyStack(cdk.Stack):
def __init__(self, scope=None, id=None, *, description=None, env=None, stackName=None, tags=None, notificationArns=None, synthesizer=None, terminationProtection=None, analyticsReporting=None, crossRegionReferences=None, permissionsBoundary=None, suppressTemplateIndentation=None, propertyInjectors=None):
super().__init__(scope, id, description=description, env=env, stackName=stackName, tags=tags, notificationArns=notificationArns, synthesizer=synthesizer, terminationProtection=terminationProtection, analyticsReporting=analyticsReporting, crossRegionReferences=crossRegionReferences, permissionsBoundary=permissionsBoundary, suppressTemplateIndentation=suppressTemplateIndentation, propertyInjectors=propertyInjectors)
vpc = ec2.Vpc(self, "TestVpc")
cluster = ecs.Cluster(self, "TestCluster", vpc=vpc)
dns_namespace = PrivateDnsNamespace(self, "Namespace",
vpc=vpc,
name="local"
)
security_group = ec2.SecurityGroup(self, "ECSSG", vpc=vpc)
security_group.add_ingress_rule(security_group, ec2.Port.tcp_range(0, 65535))
# Define Task Definition for CloudWatch agent (Replica)
cw_agent_task_definition = ecs.FargateTaskDefinition(self, "CloudWatchAgentTaskDefinition")
appsignals.CloudWatchAgentIntegration(self, "CloudWatchAgentIntegration",
task_definition=cw_agent_task_definition,
container_name="ecs-cwagent",
enable_logging=False,
cpu=128,
memory_limit_mi_b=64,
port_mappings=[ecs.PortMapping(
name="cwagent-4316",
container_port=4316,
host_port=4316
), ecs.PortMapping(
name="cwagent-2000",
container_port=2000,
host_port=2000
)
]
)
# Create the CloudWatch Agent replica service with service connect
ecs.FargateService(self, "CloudWatchAgentService",
cluster=cluster,
task_definition=cw_agent_task_definition,
security_groups=[security_group],
service_connect_configuration=ecs.ServiceConnectProps(
namespace=dns_namespace.namespace_arn,
services=[ecs.ServiceConnectService(
port_mapping_name="cwagent-4316",
dns_name="cwagent-4316-http",
port=4316
), ecs.ServiceConnectService(
port_mapping_name="cwagent-2000",
dns_name="cwagent-2000-http",
port=2000
)
]
),
desired_count=1
)
# Define Task Definition for user application
sample_app_task_definition = ecs.FargateTaskDefinition(self, "SampleAppTaskDefinition")
sample_app_task_definition.add_container("app",
image=ecs.ContainerImage.from_registry("test/sample-app"),
cpu=0,
memory_limit_mi_b=512
)
# Overwrite environment variables to connect to the CloudWatch Agent service just created
appsignals.ApplicationSignalsIntegration(self, "ApplicationSignalsIntegration",
task_definition=sample_app_task_definition,
instrumentation=appsignals.InstrumentationProps(
sdk_version=appsignals.PythonInstrumentationVersion.V0_8_0
),
service_name="sample-app",
override_environments=[appsignals.EnvironmentExtension(
name=appsignals.CommonExporting.OTEL_AWS_APPLICATION_SIGNALS_EXPORTER_ENDPOINT,
value="http://cwagent-4316-http:4316/v1/metrics"
), appsignals.EnvironmentExtension(
name=appsignals.TraceExporting.OTEL_EXPORTER_OTLP_TRACES_ENDPOINT,
value="http://cwagent-4316-http:4316/v1/traces"
), appsignals.EnvironmentExtension(
name=appsignals.TraceExporting.OTEL_TRACES_SAMPLER_ARG,
value="endpoint=http://cwagent-2000-http:2000"
)
]
)
# Create ECS Service with service connect configuration
ecs.FargateService(self, "MySampleApp",
cluster=cluster,
task_definition=sample_app_task_definition,
service_connect_configuration=ecs.ServiceConnectProps(
namespace=dns_namespace.namespace_arn
),
desired_count=1
)
```
| text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/aws/aws-cdk | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.239.0",
"constructs<11.0.0,>=10.5.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/aws/aws-cdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:57:50.020658 | aws_cdk_aws_applicationsignals_alpha-2.239.0a0.tar.gz | 129,262 | f9/be/151766a83a43c98a34dd1d77554a895207b13b408f16545cac10bec1be44/aws_cdk_aws_applicationsignals_alpha-2.239.0a0.tar.gz | source | sdist | null | false | 2c76cc8d2294b5ee637fa61642544196 | 54ea5d26c9a3d96ea7ef4ea9d7ebf101503c89beac8995242b4b3ba3f9b66649 | f9be151766a83a43c98a34dd1d77554a895207b13b408f16545cac10bec1be44 | null | [] | 0 |
2.1 | aws-cdk.aws-amplify-alpha | 2.239.0a0 | The CDK Construct Library for AWS::Amplify | # AWS Amplify Construct Library
<!--BEGIN STABILITY BANNER-->---

> The APIs of higher level constructs in this module are experimental and under active development.
> They are subject to non-backward compatible changes or removal in any future version. These are
> not subject to the [Semantic Versioning](https://semver.org/) model and breaking changes will be
> announced in the release notes. This means that while you may use them, you may need to update
> your source code when upgrading to a newer version of this package.
---
<!--END STABILITY BANNER-->
The AWS Amplify Console provides a Git-based workflow for deploying and hosting fullstack serverless web applications. A fullstack serverless app consists of a backend built with cloud resources such as GraphQL or REST APIs, file and data storage, and a frontend built with single page application frameworks such as React, Angular, Vue, or Gatsby.
## Setting up an app with branches, custom rules and a domain
To set up an Amplify Console app, define an `App`:
```python
import aws_cdk.aws_codebuild as codebuild
amplify_app = amplify.App(self, "MyApp",
source_code_provider=amplify.GitHubSourceCodeProvider(
owner="<user>",
repository="<repo>",
oauth_token=SecretValue.secrets_manager("my-github-token")
),
build_spec=codebuild.BuildSpec.from_object_to_yaml({
# Alternatively add a `amplify.yml` to the repo
"version": "1.0",
"frontend": {
"phases": {
"pre_build": {
"commands": ["yarn"
]
},
"build": {
"commands": ["yarn build"
]
}
},
"artifacts": {
"base_directory": "public",
"files": -"**/*"
}
}
})
)
```
To connect your `App` to GitLab, use the `GitLabSourceCodeProvider`:
```python
amplify_app = amplify.App(self, "MyApp",
source_code_provider=amplify.GitLabSourceCodeProvider(
owner="<user>",
repository="<repo>",
oauth_token=SecretValue.secrets_manager("my-gitlab-token")
)
)
```
To connect your `App` to CodeCommit, use the `CodeCommitSourceCodeProvider`:
```python
import aws_cdk.aws_codecommit as codecommit
repository = codecommit.Repository(self, "Repo",
repository_name="my-repo"
)
amplify_app = amplify.App(self, "App",
source_code_provider=amplify.CodeCommitSourceCodeProvider(repository=repository)
)
```
The IAM role associated with the `App` will automatically be granted the permission
to pull the CodeCommit repository.
Add branches:
```python
# amplify_app: amplify.App
main = amplify_app.add_branch("main") # `id` will be used as repo branch name
dev = amplify_app.add_branch("dev",
performance_mode=True
)
dev.add_environment("STAGE", "dev")
```
Auto build and pull request preview are enabled by default.
Add custom rules for redirection:
```python
from aws_cdk.aws_amplify_alpha import CustomRule
# amplify_app: amplify.App
amplify_app.add_custom_rule(CustomRule(
source="/docs/specific-filename.html",
target="/documents/different-filename.html",
status=amplify.RedirectStatus.TEMPORARY_REDIRECT
))
```
When working with a single page application (SPA), use the
`CustomRule.SINGLE_PAGE_APPLICATION_REDIRECT` to set up a 200
rewrite for all files to `index.html` except for the following
file extensions: css, gif, ico, jpg, js, png, txt, svg, woff,
ttf, map, json, webmanifest.
```python
# my_single_page_app: amplify.App
my_single_page_app.add_custom_rule(amplify.CustomRule.SINGLE_PAGE_APPLICATION_REDIRECT)
```
Add a domain and map sub domains to branches:
```python
# amplify_app: amplify.App
# main: amplify.Branch
# dev: amplify.Branch
domain = amplify_app.add_domain("example.com",
enable_auto_subdomain=True, # in case subdomains should be auto registered for branches
auto_subdomain_creation_patterns=["*", "pr*"]
)
domain.map_root(main) # map main branch to domain root
domain.map_sub_domain(main, "www")
domain.map_sub_domain(dev)
```
To specify a custom certificate for your custom domain use the `customCertificate` property:
```python
# custom_certificate: acm.Certificate
# amplify_app: amplify.App
domain = amplify_app.add_domain("example.com",
custom_certificate=custom_certificate
)
```
## Restricting access
Password protect the app with basic auth by specifying the `basicAuth` prop.
Use `BasicAuth.fromCredentials` when referencing an existing secret:
```python
amplify_app = amplify.App(self, "MyApp",
source_code_provider=amplify.GitHubSourceCodeProvider(
owner="<user>",
repository="<repo>",
oauth_token=SecretValue.secrets_manager("my-github-token")
),
basic_auth=amplify.BasicAuth.from_credentials("username", SecretValue.secrets_manager("my-github-token"))
)
```
Use `BasicAuth.fromGeneratedPassword` to generate a password in Secrets Manager:
```python
amplify_app = amplify.App(self, "MyApp",
source_code_provider=amplify.GitHubSourceCodeProvider(
owner="<user>",
repository="<repo>",
oauth_token=SecretValue.secrets_manager("my-github-token")
),
basic_auth=amplify.BasicAuth.from_generated_password("username")
)
```
Basic auth can be added to specific branches:
```python
# amplify_app: amplify.App
amplify_app.add_branch("feature/next",
basic_auth=amplify.BasicAuth.from_generated_password("username")
)
```
## Automatically creating and deleting branches
Use the `autoBranchCreation` and `autoBranchDeletion` props to control creation/deletion
of branches:
```python
amplify_app = amplify.App(self, "MyApp",
source_code_provider=amplify.GitHubSourceCodeProvider(
owner="<user>",
repository="<repo>",
oauth_token=SecretValue.secrets_manager("my-github-token")
),
auto_branch_creation=amplify.AutoBranchCreation( # Automatically connect branches that match a pattern set
patterns=["feature/*", "test/*"]),
auto_branch_deletion=True
)
```
## Adding custom response headers
Use the `customResponseHeaders` prop to configure custom response headers for an Amplify app:
```python
amplify_app = amplify.App(self, "App",
source_code_provider=amplify.GitHubSourceCodeProvider(
owner="<user>",
repository="<repo>",
oauth_token=SecretValue.secrets_manager("my-github-token")
),
custom_response_headers=[amplify.CustomResponseHeader(
pattern="*.json",
headers={
"custom-header-name-1": "custom-header-value-1",
"custom-header-name-2": "custom-header-value-2"
}
), amplify.CustomResponseHeader(
pattern="/path/*",
headers={
"custom-header-name-1": "custom-header-value-2"
}
)
]
)
```
If the app uses a monorepo structure, define which appRoot from the build spec the custom response headers should apply to by using the `appRoot` property:
```python
import aws_cdk.aws_codebuild as codebuild
amplify_app = amplify.App(self, "App",
source_code_provider=amplify.GitHubSourceCodeProvider(
owner="<user>",
repository="<repo>",
oauth_token=SecretValue.secrets_manager("my-github-token")
),
build_spec=codebuild.BuildSpec.from_object_to_yaml({
"version": "1.0",
"applications": [{
"app_root": "frontend",
"frontend": {
"phases": {
"pre_build": {
"commands": ["npm install"]
},
"build": {
"commands": ["npm run build"]
}
}
}
}, {
"app_root": "backend",
"backend": {
"phases": {
"pre_build": {
"commands": ["npm install"]
},
"build": {
"commands": ["npm run build"]
}
}
}
}
]
}),
custom_response_headers=[amplify.CustomResponseHeader(
app_root="frontend",
pattern="*.json",
headers={
"custom-header-name-1": "custom-header-value-1",
"custom-header-name-2": "custom-header-value-2"
}
), amplify.CustomResponseHeader(
app_root="backend",
pattern="/path/*",
headers={
"custom-header-name-1": "custom-header-value-2"
}
)
]
)
```
## Configure server side rendering when hosting app
Setting the `platform` field on the Amplify `App` construct can be used to control whether the app will host only static assets or server side rendered assets in addition to static. By default, the value is set to `WEB` (static only), however, server side rendering can be turned on by setting to `WEB_COMPUTE` as follows:
```python
amplify_app = amplify.App(self, "MyApp",
platform=amplify.Platform.WEB_COMPUTE
)
```
## Compute role
This integration, enables you to assign an IAM role to the Amplify SSR Compute service to allow your server-side rendered (SSR) application to securely access specific AWS resources based on the role's permissions.
For example, you can allow your app's SSR compute functions to securely access other AWS services or resources, such as Amazon Bedrock or an Amazon S3 bucket, based on the permissions defined in the assigned IAM role.
For more information, see [Adding an SSR Compute role to allow access to AWS resources](https://docs.aws.amazon.com/amplify/latest/userguide/amplify-SSR-compute-role.html).
By default, a new role is created when `platform` is `Platform.WEB_COMPUTE` or `Platform.WEB_DYNAMIC`.
If you want to assign an IAM role to the APP, set `compute` to the role:
```python
# compute_role: iam.Role
amplify_app = amplify.App(self, "MyApp",
platform=amplify.Platform.WEB_COMPUTE,
compute_role=compute_role
)
```
It is also possible to override the compute role for a specific branch by setting `computeRole` in `Branch`:
```python
# compute_role: iam.Role
# amplify_app: amplify.App
branch = amplify_app.add_branch("dev", compute_role=compute_role)
```
## Cache Config
Amplify uses Amazon CloudFront to manage the caching configuration for your hosted applications. A cache configuration is applied to each app to optimize for the best performance.
Setting the `cacheConfigType` field on the Amplify `App` construct can be used to control cache configuration. By default, the value is set to `AMPLIFY_MANAGED`. If you want to exclude all cookies from the cache key, set `AMPLIFY_MANAGED_NO_COOKIES`.
For more information, see [Managing the cache configuration for an app](https://docs.aws.amazon.com/amplify/latest/userguide/caching.html).
```python
amplify_app = amplify.App(self, "MyApp",
cache_config_type=amplify.CacheConfigType.AMPLIFY_MANAGED_NO_COOKIES
)
```
## Build Compute Type
You can specify the build compute type by setting the `buildComputeType` property.
For more information, see [Configuring the build instance for an Amplify application](https://docs.aws.amazon.com/amplify/latest/userguide/custom-build-instance.html).
```python
amplify_app = amplify.App(self, "MyApp",
build_compute_type=amplify.BuildComputeType.LARGE_16GB
)
```
## Deploying Assets
`sourceCodeProvider` is optional; when this is not specified the Amplify app can be deployed to using `.zip` packages. The `asset` property can be used to deploy S3 assets to Amplify as part of the CDK:
```python
import aws_cdk.aws_s3_assets as assets
# asset: assets.Asset
# amplify_app: amplify.App
branch = amplify_app.add_branch("dev", asset=asset)
```
## Skew protection for Amplify Deployments
Deployment skew protection is available to Amplify applications to eliminate version skew issues between client and servers in web applications.
When you apply skew protection to an Amplify application, you can ensure that your clients always interact with the correct version of server-side assets, regardless of when a deployment occurs.
For more information, see [Skew protection for Amplify deployments](https://docs.aws.amazon.com/amplify/latest/userguide/skew-protection.html).
To enable skew protection, set the `skewProtection` property to `true`:
```python
# amplify_app: amplify.App
branch = amplify_app.add_branch("dev", skew_protection=True)
```
| text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/aws/aws-cdk | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.239.0",
"constructs<11.0.0,>=10.5.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/aws/aws-cdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:57:49.132193 | aws_cdk_aws_amplify_alpha-2.239.0a0.tar.gz | 138,569 | c2/0e/cab63a47cf2f19866fab62d5dee4fc86ab9e95413fb35aad287e64ba9830/aws_cdk_aws_amplify_alpha-2.239.0a0.tar.gz | source | sdist | null | false | 0b84ccc71ef1fb26e785f9efdd82e77e | ffb0ee3eea309fd2ebdebd73c11d0f780280056068f2227519f903076a730c7f | c20ecab63a47cf2f19866fab62d5dee4fc86ab9e95413fb35aad287e64ba9830 | null | [] | 0 |
2.1 | aws-cdk.app-staging-synthesizer-alpha | 2.239.0a0 | Cdk synthesizer for with app-scoped staging stack | # App Staging Synthesizer
<!--BEGIN STABILITY BANNER-->---

> The APIs of higher level constructs in this module are experimental and under active development.
> They are subject to non-backward compatible changes or removal in any future version. These are
> not subject to the [Semantic Versioning](https://semver.org/) model and breaking changes will be
> announced in the release notes. This means that while you may use them, you may need to update
> your source code when upgrading to a newer version of this package.
---
<!--END STABILITY BANNER-->
This library includes constructs aimed at replacing the current model of bootstrapping and providing
greater control of the bootstrap experience to the CDK user. The important constructs in this library
are as follows:
* the `IStagingResources` interface: a framework for an app-level bootstrap stack that handles
file assets and docker assets.
* the `DefaultStagingStack`, which is a works-out-of-the-box implementation of the `IStagingResources`
interface.
* the `AppStagingSynthesizer`, a new CDK synthesizer that will synthesize CDK applications with
the staging resources provided.
> As this library is `experimental`, there are features that are not yet implemented. Please look
> at the list of [Known Limitations](#known-limitations) before getting started.
To get started, update your CDK App with a new `defaultStackSynthesizer`:
```python
from aws_cdk.aws_s3 import BucketEncryption
app = App(
default_stack_synthesizer=AppStagingSynthesizer.default_resources(
app_id="my-app-id", # put a unique id here
staging_bucket_encryption=BucketEncryption.S3_MANAGED
)
)
```
This will introduce a `DefaultStagingStack` in your CDK App and staging assets of your App
will live in the resources from that stack rather than the CDK Bootstrap stack.
If you are migrating from a different version of synthesis your updated CDK App will target
the resources in the `DefaultStagingStack` and no longer be tied to the bootstrapped resources
in your account.
## Bootstrap Model
In our default bootstrapping process, when you run `cdk bootstrap aws://<account>/<region>`, the following
resources are created:
* It creates Roles to assume for cross-account deployments and for Pipeline deployments;
* It creates staging resources: a global S3 bucket and global ECR repository to hold CDK assets;
* It creates Roles to write to the S3 bucket and ECR repository;
Because the bootstrapping resources include regional resources, you need to bootstrap
every region you plan to deploy to individually. All assets of all CDK apps deploying
to that account and region will be written to the single S3 Bucket and ECR repository.
By using the synthesizer in this library, instead of the
`DefaultStackSynthesizer`, a different set of staging resources will be created
for every CDK application, and they will be created automatically as part of a
regular deployment, in a separate Stack that is deployed before your application
Stacks. The staging resources will be one S3 bucket, and *one ECR repository per
image*, and Roles necessary to access those buckets and ECR repositories. The
Roles from the default bootstrap stack are still used (though their use can be
turned off).
This has the following advantages:
* Because staging resources are now application-specific, they can be fully cleaned up when you clean up
the application.
* Because there is now one ECR repository per image instead of one ECR repository for all images, it is
possible to effectively use ECR life cycle rules (for example, retain only the most recent 5 images)
to cut down on storage costs.
* Resources between separate CDK Apps are separated so they can be cleaned up and lifecycle
controlled individually.
* Because the only shared bootstrapping resources required are Roles, which are global resources,
you now only need to bootstrap every account in one Region (instead of every Region). This makes it
easier to do with CloudFormation StackSets.
For the deployment roles, this synthesizer still uses the Roles from the default
bootstrap stack, and nothing else. The staging resources from that bootstrap
stack will be unused. You can customize the template to remove those resources
if you prefer. In the future, we will provide a bootstrap stack template with
only those Roles, specifically for use with this synthesizer.
## Using the Default Staging Stack per Environment
The most common use case will be to use the built-in default resources. In this scenario, the
synthesizer will create a new Staging Stack in each environment the CDK App is deployed to store
its staging resources. To use this kind of synthesizer, use `AppStagingSynthesizer.defaultResources()`.
```python
from aws_cdk.aws_s3 import BucketEncryption
app = App(
default_stack_synthesizer=AppStagingSynthesizer.default_resources(
app_id="my-app-id",
staging_bucket_encryption=BucketEncryption.S3_MANAGED,
# The following line is optional. By default it is assumed you have bootstrapped in the same
# region(s) as the stack(s) you are deploying.
deployment_identities=DeploymentIdentities.default_bootstrap_roles(bootstrap_region="us-east-1")
)
)
```
Every CDK App that uses the `DefaultStagingStack` must include an `appId`. This should
be an identifier unique to the app and is used to differentiate staging resources associated
with the app.
### Default Staging Stack
The Default Staging Stack includes all the staging resources necessary for CDK Assets. The below example
is of a CDK App using the `AppStagingSynthesizer` and creating a file asset for the Lambda Function
source code. As part of the `DefaultStagingStack`, an S3 bucket and IAM role will be created that will be
used to upload the asset to S3.
```python
from aws_cdk.aws_s3 import BucketEncryption
app = App(
default_stack_synthesizer=AppStagingSynthesizer.default_resources(
app_id="my-app-id",
staging_bucket_encryption=BucketEncryption.S3_MANAGED
)
)
stack = Stack(app, "my-stack")
lambda_.Function(stack, "lambda",
code=lambda_.AssetCode.from_asset(path.join(__dirname, "assets")),
handler="index.handler",
runtime=lambda_.Runtime.PYTHON_3_9
)
app.synth()
```
### Custom Roles
You can customize some or all of the roles you'd like to use in the synthesizer as well,
if all you need is to supply custom roles (and not change anything else in the `DefaultStagingStack`):
```python
from aws_cdk.aws_s3 import BucketEncryption
app = App(
default_stack_synthesizer=AppStagingSynthesizer.default_resources(
app_id="my-app-id",
staging_bucket_encryption=BucketEncryption.S3_MANAGED,
deployment_identities=DeploymentIdentities.specify_roles(
cloud_formation_execution_role=BootstrapRole.from_role_arn("arn:aws:iam::123456789012:role/Execute"),
deployment_role=BootstrapRole.from_role_arn("arn:aws:iam::123456789012:role/Deploy"),
lookup_role=BootstrapRole.from_role_arn("arn:aws:iam::123456789012:role/Lookup")
)
)
)
```
Or, you can ask to use the CLI credentials that exist at deploy-time.
These credentials must have the ability to perform CloudFormation calls,
lookup resources in your account, and perform CloudFormation deployment.
For a full list of what is necessary, see `LookupRole`, `DeploymentActionRole`,
and `CloudFormationExecutionRole` in the
[bootstrap template](https://github.com/aws/aws-cdk-cli/blob/main/packages/aws-cdk/lib/api/bootstrap/bootstrap-template.yaml).
```python
from aws_cdk.aws_s3 import BucketEncryption
app = App(
default_stack_synthesizer=AppStagingSynthesizer.default_resources(
app_id="my-app-id",
staging_bucket_encryption=BucketEncryption.S3_MANAGED,
deployment_identities=DeploymentIdentities.cli_credentials()
)
)
```
The default staging stack will create roles to publish to the S3 bucket and ECR repositories,
assumable by the deployment role. You can also specify an existing IAM role for the
`fileAssetPublishingRole` or `imageAssetPublishingRole`:
```python
from aws_cdk.aws_s3 import BucketEncryption
app = App(
default_stack_synthesizer=AppStagingSynthesizer.default_resources(
app_id="my-app-id",
staging_bucket_encryption=BucketEncryption.S3_MANAGED,
file_asset_publishing_role=BootstrapRole.from_role_arn("arn:aws:iam::123456789012:role/S3Access"),
image_asset_publishing_role=BootstrapRole.from_role_arn("arn:aws:iam::123456789012:role/ECRAccess")
)
)
```
### Deploy Time S3 Assets
There are two types of assets:
* Assets used only during deployment. These are used to hand off a large piece of data to another
service, that will make a private copy of that data. After deployment, the asset is only necessary for
a potential future rollback.
* Assets accessed throughout the running life time of the application.
Examples of assets that are only used at deploy time are CloudFormation Templates and Lambda Code
bundles. Examples of assets accessed throughout the life time of the application are script files
downloaded to run in a CodeBuild Project, or on EC2 instance startup. ECR images are always application
life-time assets. S3 deploy time assets are stored with a `deploy-time/` prefix, and a lifecycle rule will collect them after a configurable number of days.
Lambda assets are by default marked as deploy time assets:
```python
# stack: Stack
lambda_.Function(stack, "lambda",
code=lambda_.AssetCode.from_asset(path.join(__dirname, "assets")), # lambda marks deployTime = true
handler="index.handler",
runtime=lambda_.Runtime.PYTHON_3_9
)
```
Or, if you want to create your own deploy time asset:
```python
from aws_cdk.aws_s3_assets import Asset
# stack: Stack
asset = Asset(stack, "deploy-time-asset",
deploy_time=True,
path=path.join(__dirname, "deploy-time-asset")
)
```
By default, we store deploy time assets for 30 days, but you can change this number by specifying
`deployTimeFileAssetLifetime`. The number you specify here is how long you will be able to roll back
to a previous version of an application just by doing a CloudFormation deployment with the old
template, without rebuilding and republishing assets.
```python
from aws_cdk.aws_s3 import BucketEncryption
app = App(
default_stack_synthesizer=AppStagingSynthesizer.default_resources(
app_id="my-app-id",
staging_bucket_encryption=BucketEncryption.S3_MANAGED,
deploy_time_file_asset_lifetime=Duration.days(100)
)
)
```
### Lifecycle Rules on ECR Repositories
By default, we store a maximum of 3 revisions of a particular docker image asset. This allows
for smooth faciliation of rollback scenarios where we may reference previous versions of an
image. When more than 3 revisions of an asset exist in the ECR repository, the oldest one is
purged.
To change the number of revisions stored, use `imageAssetVersionCount`:
```python
from aws_cdk.aws_s3 import BucketEncryption
app = App(
default_stack_synthesizer=AppStagingSynthesizer.default_resources(
app_id="my-app-id",
staging_bucket_encryption=BucketEncryption.S3_MANAGED,
image_asset_version_count=10
)
)
```
### Auto Delete Staging Assets on Deletion
By default, the staging resources will be cleaned up on stack deletion. That means that the
S3 Bucket and ECR Repositories are set to `RemovalPolicy.DESTROY` and have `autoDeleteObjects`
or `emptyOnDelete` turned on. This creates custom resources under the hood to facilitate
cleanup. To turn this off, specify `autoDeleteStagingAssets: false`.
```python
from aws_cdk.aws_s3 import BucketEncryption
app = App(
default_stack_synthesizer=AppStagingSynthesizer.default_resources(
app_id="my-app-id",
staging_bucket_encryption=BucketEncryption.S3_MANAGED,
auto_delete_staging_assets=False
)
)
```
### Staging Bucket Encryption
You must explicitly specify the encryption type for the staging bucket via the `stagingBucketEncryption` property. In
future versions of this package, the default will be `BucketEncryption.S3_MANAGED`.
In previous versions of this package, the default was to use KMS encryption for the staging bucket. KMS keys cost
$1/month, which could result in unexpected costs for users who are not aware of this. As we stabilize this module
we intend to make the default S3-managed encryption, which is free. However, the migration path from KMS to S3
managed encryption for existing buckets is not straightforward. Therefore, for now, this property is required.
If you have an existing staging bucket encrypted with a KMS key, you will likely want to set this property to
`BucketEncryption.KMS`. If you are creating a new staging bucket, you can set this property to
`BucketEncryption.S3_MANAGED` to avoid the cost of a KMS key.
You can learn more about choosing a bucket encryption type in the
[S3 documentation](https://docs.aws.amazon.com/AmazonS3/latest/userguide/serv-side-encryption.html).
## Using a Custom Staging Stack per Environment
If you want to customize some behavior that is not configurable via properties,
you can implement your own class that implements `IStagingResources`. To get a head start,
you can subclass `DefaultStagingStack`.
```python
class CustomStagingStack(DefaultStagingStack):
pass
```
Or you can roll your own staging resources from scratch, as long as it implements `IStagingResources`.
```python
from aws_cdk.app_staging_synthesizer_alpha import FileStagingLocation, ImageStagingLocation
@jsii.implements(IStagingResources)
class CustomStagingStack(Stack):
def __init__(self, scope, id, *, description=None, env=None, stackName=None, tags=None, notificationArns=None, synthesizer=None, terminationProtection=None, analyticsReporting=None, crossRegionReferences=None, permissionsBoundary=None, suppressTemplateIndentation=None, propertyInjectors=None):
super().__init__(scope, id, description=description, env=env, stackName=stackName, tags=tags, notificationArns=notificationArns, synthesizer=synthesizer, terminationProtection=terminationProtection, analyticsReporting=analyticsReporting, crossRegionReferences=crossRegionReferences, permissionsBoundary=permissionsBoundary, suppressTemplateIndentation=suppressTemplateIndentation, propertyInjectors=propertyInjectors)
def add_file(self, *, sourceHash, executable=None, fileName=None, packaging=None, deployTime=None, displayName=None):
return FileStagingLocation(
bucket_name="amzn-s3-demo-bucket",
assume_role_arn="myArn",
dependency_stack=self
)
def add_docker_image(self, *, sourceHash, executable=None, directoryName=None, dockerBuildArgs=None, dockerBuildSecrets=None, dockerBuildSsh=None, dockerBuildTarget=None, dockerFile=None, repositoryName=None, networkMode=None, platform=None, dockerOutputs=None, assetName=None, dockerCacheFrom=None, dockerCacheTo=None, dockerCacheDisabled=None, displayName=None):
return ImageStagingLocation(
repo_name="myRepo",
assume_role_arn="myArn",
dependency_stack=self
)
```
Using your custom staging resources means implementing a `CustomFactory` class and calling the
`AppStagingSynthesizer.customFactory()` static method. This has the benefit of providing a
custom Staging Stack that can be created in every environment the CDK App is deployed to.
```python
@jsii.implements(IStagingResourcesFactory)
class CustomFactory:
def obtain_staging_resources(self, stack, *, environmentString, deployRoleArn=None, qualifier):
my_app = App.of(stack)
return CustomStagingStack(my_app, f"CustomStagingStack-{context.environmentString}")
app = App(
default_stack_synthesizer=AppStagingSynthesizer.custom_factory(
factory=CustomFactory(),
once_per_env=True
)
)
```
## Using an Existing Staging Stack
Use `AppStagingSynthesizer.customResources()` to supply an existing stack as the Staging Stack.
Make sure that the custom stack you provide implements `IStagingResources`.
```python
resource_app = App()
resources = CustomStagingStack(resource_app, "CustomStagingStack")
app = App(
default_stack_synthesizer=AppStagingSynthesizer.custom_resources(
resources=resources
)
)
```
## Known Limitations
Since this module is experimental, there are some known limitations:
* Currently this module does not support CDK Pipelines. You must deploy CDK Apps using this
synthesizer via `cdk deploy`. Please upvote [this issue](https://github.com/aws/aws-cdk/issues/26118)
to indicate you want this.
* This synthesizer only needs a bootstrap stack with Roles, without staging resources. We
haven't written such a bootstrap stack yet; at the moment you can use the existing modern
bootstrap stack, the staging resources in them will just go unused. You can customize the
template to remove them if desired.
* Due to limitations on the CloudFormation template size, CDK Applications can have
at most 20 independent ECR images. Please upvote [this issue](https://github.com/aws/aws-cdk/issues/26119)
if you need more than this.
| text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/aws/aws-cdk | null | ~=3.9 | [] | [] | [] | [
"aws-cdk-lib<3.0.0,>=2.239.0",
"constructs<11.0.0,>=10.5.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/aws/aws-cdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:57:46.149519 | aws_cdk_app_staging_synthesizer_alpha-2.239.0a0.tar.gz | 142,260 | 13/25/724ecf319596b575505868d83ae8b909aa116858b97bf4660c8e9632b27b/aws_cdk_app_staging_synthesizer_alpha-2.239.0a0.tar.gz | source | sdist | null | false | 93c84cbea89f68369668aa7f15f599d9 | a5ade6c4e0d5df85d8bae606d417d1fee6725e0e897e0a033194281499ccbe50 | 1325724ecf319596b575505868d83ae8b909aa116858b97bf4660c8e9632b27b | null | [] | 0 |
2.4 | arches-modular-reports | 1.0.0b4 | Fast, configurable reports for Arches models in Vue.js | # Welcome to Arches Modular Reports!
Arches Modular Reports is an Arches Application that provides an alternate and more modular way to present and configure reports in Arches.
Please see the [project page](http://archesproject.org/) for more information on the Arches project.
## Installation
If you are installing Arches Modular Reports for the first time, **we strongly recommend** that you install it as an Arches application into an existing (or new) project. Running Arches Modular Reports as a standalone project can provide some convenience if you are a developer contributing to the Arches Modular Reports project but you risk conflicts when upgrading to the next version of Arches Modular Reports.
### If installing for development
Clone the arches-modular-reports repo and checkout the latest `dev/x.x.x` or any other branch you may be interested in.
Navigate to the `arches-modular-reports` directory from your terminal and run the following commands:
```
pip install -e . --group dev
pre-commit install
```
`Important`: Installing the arches-modular-reports app will install Arches as a dependency. This may replace your current install of Arches with a version from PyPi. If you've installed Arches for development using the `--editable` flag, you'll need to reinstall Arches using the `--editable` flag again after installing arches-modular-reports.
### If installing for deployment, run:
```
pip install arches-modular-reports
```
## Project Configuration
1. If you don't already have an Arches project, you'll need to create one by following the instructions in the Arches [documentation](http://archesproject.org/documentation/).
2. When your project is ready add "rest_framework", "arches_modular_reports", "arches_querysets", and "arches_component_lab" to INSTALLED_APPS **below** the name of your project:
```
INSTALLED_APPS = (
...
"my_project_name",
"rest_framework",
"arches_modular_reports",
"arches_querysets",
"arches_component_lab",
)
```
3. Next ensure arches, arches_modular_reports are included as dependencies in package.json
```
"dependencies": {
"arches": "archesproject/arches#stable/7.6.12",
"arches-modular-reports": "archesproject/arches-modular-reports#beta/1.0.0b0"
}
```
4. Update urls.py to include the arches-modular-reports urls
```
urlpatterns = [
...
]
urlpatterns.append(path("", include("arches_modular_reports.urls")))
# Ensure Arches core urls are superseded by project-level urls
urlpatterns.append(path("", include("arches.urls")))
```
5. Run migrations
```
python manage.py migrate
```
6. Start your project
```
python manage.py runserver
```
7. Next cd into your project's app directory (the one with package.json) install and build front-end dependencies:
```
npm install
npm run build_development
```
## Setting up a graph to use the Modular Reports Template
Once you've installed the Arches Modular Report Application into your project you'll notice a new report template available called "Modular Report Template".
1. Select a Graph in the graph designer that you'd like to use with the new modular reports.
2. Navigate to the "Cards" tab, select the root node and select the "Modular Report Template" from the Report Configuration section on the right.
3. Next go to the [admin page](https://arches.readthedocs.io/en/stable/administering/django-admin-ui/) and login.
4. Click on the "+ Add" button next to the item called "Report configs" under the "Arches Modular Reports" section.
5. You'll be presented with a large "Config" section that should only contain empty curly brackets "{}". Below that is a text field with the word "default" - do not change this for a default report setup. The slug is used for situations where multiple report configurations are needed for different custom reports. Below that is a dropdown with a listing of graphs available in your project. Select the graph you chose earlier in step 1 and then click the button that says "Save and continue editing".
6. Notice that the "Config" section is populated with a default configuration.
7. If you view a report of the type of graph set up to use the new template you should notice that it is now using the new report template and has a different appearance.
---
## Editing the structure of the report configuration
This document explains the structure and purpose of a JSON configuration used to define custom reports in Arches. It breaks down key components and their configuration properties to help you understand how to control the layout and display of resource data.
### Top-Level Structure
At a high level, the configuration defines a report with a name and a list of UI components that will be rendered in the report interface.
```json
{
"name": "Untitled Report",
"components": [ ... ]
}
```
Each entry in the `components` array defines a section of the report interface, such as the header, toolbar, tombstone (summary), or tabs.
---
### Key Components
#### `ReportHeader`
Displays the report title or descriptor. The descriptor can include references to node values by referencing the node_alias from within `<>` brackets.
Additionally, if a node in brackets contains more than 1 entry (eg: concept-list or resource-instance-list) then the number of those values can be limited via the `node_alias_options` property and a separator character can be specified.
```json
{
"component": "ReportHeader",
"config": {
"descriptor": "<name_node> - born on <date_of_birth>",
"node_alias_options": {
"name_node": {
"limit": 3,
"separator": "|"
}
}
}
}
```
---
#### `ReportToolbar`
Adds export buttons and list tools to the report.
```json
{
"component": "ReportToolbar",
"config": {
"lists": true,
"export_formats": ["csv", "json-ld", "json"]
}
}
```
---
#### `ReportTombstone`
Displays a summary or key metadata for the resource.
```json
{
"component": "ReportTombstone",
"config": {
"node_aliases": [],
"custom_labels": {},
"image_node_alias": null <-- unused
}
}
```
---
#### `ReportTabs`
Defines tabs for organizing the main content of the report.
```json
{
"component": "ReportTabs",
"config": {
"tabs": [ ... ]
}
}
```
Each tab contains components — typically `LinkedSections` — that organize content into visual sections.
---
### LinkedSections and Subcomponents
#### `LinkedSections`
Used within tabs to group and render multiple content sections.
Each `section` has a name and an array of components like `DataSection` or `RelatedResourcesSection`.
---
#### `DataSection`
Displays a group of nodes from the main resource graph. DataSection objects can be grouped together under a common name within LinkedSection components. By default, top-level node groups will appear as individual sections each with its own DataSection in the "Data" tab. For cardinality-n tiles, reports can optionally be filtered to limit the tile(s) displayed in the report.
```json
{
"component": "DataSection",
"config": {
"node_aliases": ["color"],
"custom_labels": {},
"nodegroup_alias": "physical_characteristics",
"custom_card_name": "Physical Description"
}
}
```
OR
```json
{
"component": "DataSection",
"config": {
"node_aliases": ["color", "status_date", "status_type"],
"filters": [{
"alias": "status_date"
"value": "2024-12-31",
"field_lookup": "lt"
},{
"alias": "status_type",
"value": "dd48ae2d-025a-4d62-978b-be35e106e6e9",
"field_lookup": "0__uri__icontains"
}],
"custom_labels": {},
"nodegroup_alias": "physical_characteristics",
"custom_card_name": "Physical Description"
}
}
```
---
#### `RelatedResourcesSection`
Displays resources related to this resource instance based on the related resource graph slug. By default the resource instance name and relationship is displayed. Other nodes from that related resource can be displayed by adding entries in the "node_aliases" array and those node names can be overwritten with the "custom_labels" object.
RelatedResourcesSection objects can be grouped together under a common name within LinkedSection components.
```json
{
"component": "RelatedResourcesSection",
"config": {
"graph_slug": "digital",
"node_aliases": [],
"custom_labels": {}
}
}
```
---
### Common Configuration Properties
#### `node_aliases`
- **Type:** `array`
- **Description:** A list of node aliases that specify which nodes to display in a component.
---
#### `custom_labels`
- **Type:** `object`
- **Description:** A dictionary used to override default labels for fields. Each key is a `node_alias`, and each value is the custom label to display.
```json
"custom_labels": {
"color_primary": "Primary Color",
"material_label_1": "Composition"
}
```
---
#### `custom_card_name`
- **Type:** `string` or `null`
- **Description:** Overrides the default title shown on a data card (section). If not set, the system uses the label from the associated card.
```json
"custom_card_name": "Physical Description"
```
---
#### `nodegroup_alias`
- **Type:** \`string\*\*
- **Description:** The alias of a **node group** — the node that groups child nodes beneath it. Each node group is represented in the UI as a **Card**, which has a label used by default as the section title. You can override that label with `custom_card_name`.
```json
"nodegroup_alias": "physical_characteristics"
```
| text/markdown | Arches Project | null | null | null | null | null | [
"Development Status :: 4 - Beta",
"Framework :: Django",
"Framework :: Django :: 4.2",
"Framework :: Django :: 5.2",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"Programming Language :: Python",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"arches<8.2.0,>=7.6.19",
"arches-component-lab>=0.0.1a7"
] | [] | [] | [] | [
"Homepage, https://archesproject.org/",
"Documentation, https://arches.readthedocs.io",
"Repository, https://github.com/archesproject/arches-modular-reports.git",
"Issues, https://github.com/archesproject/arches-modular-reports/issues"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T21:57:30.756056 | arches_modular_reports-1.0.0b4.tar.gz | 255,528 | 09/50/6a5b75d7a94b9372c0851cc2b0ecdba40fba29af00e85b3e1d98024869a9/arches_modular_reports-1.0.0b4.tar.gz | source | sdist | null | false | 10c748ad8f4f84c903b151ec4947275d | a3412d079ed53605278a2ce5ffa53418e6c653508c6434996f5337331603da68 | 09506a5b75d7a94b9372c0851cc2b0ecdba40fba29af00e85b3e1d98024869a9 | AGPL-3.0-or-later | [
"LICENSE"
] | 203 |
2.4 | mcp-eregistrations-bpa | 0.18.0 | MCP server for eRegistrations BPA platform | # MCP eRegistrations BPA
**AI-powered Service Design for Government Digital Transformation**
An MCP server that enables AI assistants like Claude to design, configure, and deploy government services on the eRegistrations BPA platform using natural language.
## What It Does
Design and configure BPA services through conversation:
```
You: Create a "Business License" service
Claude: Created service with registration. Service ID: abc-123
You: Add a reviewer role
Claude: Added "Reviewer" role to the service
You: Set a $50 processing fee
Claude: Created fixed cost of $50 attached to the registration
```
Each step uses the right MCP tool. Full audit trail. Rollback if needed.
## Installation
### Mac App Installer (Recommended)
Download `Install-BPA-MCP.dmg` from the [latest release](https://github.com/UNCTAD-eRegistrations/mcp-eregistrations-bpa/releases/latest). Open the DMG, **right-click `Install BPA MCP` → Open**. A native dialog lets you pick your BPA instance(s). Everything installs automatically — Homebrew, uv, and Claude configuration.
### Single-Instance Install (Mac)
Download your country's `.command` installer from the [latest release](https://github.com/UNCTAD-eRegistrations/mcp-eregistrations-bpa/releases/latest) (e.g. `install-bpa-nigeria.command`). **Right-click → Open**. Everything installs automatically.
### Desktop Extension
Download a `.mcpb` package from the [latest release](https://github.com/UNCTAD-eRegistrations/mcp-eregistrations-bpa/releases/latest) and double-click to install. No Python required.
- **Pre-configured**: `bpa-nigeria-*.mcpb`, `bpa-elsalvador-*.mcpb`, etc. (just install and login)
- **Generic**: `bpa-mcp-server-*.mcpb` (configure your BPA URL after install)
### One-Line Installer
Requires [GitHub CLI](https://cli.github.com/) (`gh auth login` first). Provides an **interactive multi-select menu** to choose instances. Configures both Claude Desktop and Claude Code automatically.
```bash
gh api repos/UNCTAD-eRegistrations/mcp-eregistrations-bpa/contents/scripts/install.sh \
--jq '.content' | base64 -d | bash
```
With pre-configured instance(s):
```bash
gh api repos/UNCTAD-eRegistrations/mcp-eregistrations-bpa/contents/scripts/install.sh \
--jq '.content' | base64 -d | bash -s -- --instance nigeria
```
See [Installation Guide](docs/INSTALLATION.md) for all methods, troubleshooting, and advanced configuration.
## Manual Configuration
The MCP server supports two authentication providers:
- **Keycloak** (modern BPA systems) — OIDC with PKCE
- **CAS** (legacy BPA systems) — OAuth2 with Basic Auth
The provider is auto-detected based on which environment variables you set.
### Keycloak Configuration (Modern Systems)
**For Claude Desktop** — add to `claude_desktop_config.json`:
```json
{
"mcpServers": {
"BPA-elsalvador-dev": {
"command": "uvx",
"args": ["mcp-eregistrations-bpa@latest"],
"env": {
"BPA_INSTANCE_URL": "https://bpa.dev.els.eregistrations.org",
"KEYCLOAK_URL": "https://login.dev.els.eregistrations.org",
"KEYCLOAK_REALM": "SV"
}
}
}
}
```
**For Claude Code** — add to `.mcp.json` in your project:
```json
{
"mcpServers": {
"BPA-elsalvador-dev": {
"command": "uvx",
"args": ["mcp-eregistrations-bpa@latest"],
"env": {
"BPA_INSTANCE_URL": "https://bpa.dev.els.eregistrations.org",
"KEYCLOAK_URL": "https://login.dev.els.eregistrations.org",
"KEYCLOAK_REALM": "SV"
}
}
}
}
```
**Or via CLI** — install globally with one command:
```bash
claude mcp add --scope user --transport stdio BPA-kenya \
--env BPA_INSTANCE_URL=https://bpa.test.kenya.eregistrations.org \
--env KEYCLOAK_URL=https://login.test.kenya.eregistrations.org \
--env KEYCLOAK_REALM=KE \
-- uvx mcp-eregistrations-bpa@latest
```
### CAS Configuration (Legacy Systems)
For older BPA deployments using CAS (e.g., Cuba test environment):
#### Step 1: Register OAuth Client in CAS
Before configuring the MCP server, you must register an OAuth client in CAS with:
| Setting | Value |
|---------|-------|
| Client ID | Your chosen ID (e.g., `mcp-bpa`) |
| Client Secret | Generated secret |
| Redirect URI | `http://127.0.0.1:8914/callback` |
> **Important:** The redirect URI must be exactly `http://127.0.0.1:8914/callback`. The MCP server uses a fixed port (8914) because CAS requires exact redirect URI matching.
#### Step 2: Configure MCP Server
**For Claude Desktop** — add to `claude_desktop_config.json`:
```json
{
"mcpServers": {
"BPA-cuba-test": {
"command": "uvx",
"args": ["mcp-eregistrations-bpa@latest"],
"env": {
"BPA_INSTANCE_URL": "https://bpa.test.cuba.eregistrations.org",
"CAS_URL": "https://eid.test.cuba.eregistrations.org/cback/v1.0",
"CAS_CLIENT_ID": "mcp-bpa",
"CAS_CLIENT_SECRET": "your-client-secret"
}
}
}
}
```
**For Claude Code** — add to `~/.claude.json` (global) or `.mcp.json` (project):
```json
{
"mcpServers": {
"BPA-cuba-test": {
"command": "uvx",
"args": ["mcp-eregistrations-bpa@latest"],
"env": {
"BPA_INSTANCE_URL": "https://bpa.test.cuba.eregistrations.org",
"CAS_URL": "https://eid.test.cuba.eregistrations.org/cback/v1.0",
"CAS_CLIENT_ID": "mcp-bpa",
"CAS_CLIENT_SECRET": "your-client-secret"
}
}
}
}
```
**Or via CLI** — install globally with one command:
```bash
claude mcp add --scope user --transport stdio BPA-cuba-test \
--env BPA_INSTANCE_URL=https://bpa.test.cuba.eregistrations.org \
--env CAS_URL=https://eid.test.cuba.eregistrations.org/cback/v1.0 \
--env CAS_CLIENT_ID=mcp-bpa \
--env CAS_CLIENT_SECRET=your-client-secret \
-- uvx mcp-eregistrations-bpa@latest
```
> **Note:** CAS requires `CAS_CLIENT_SECRET` (unlike Keycloak which uses PKCE). Get this from your BPA administrator.
> **Troubleshooting:** If you get "command not found: uvx", you installed via curl which puts uvx in `~/.local/bin` (not in GUI app PATH). Fix: either `brew install uv`, or use `"command": "/bin/zsh", "args": ["-c", "$HOME/.local/bin/uvx mcp-eregistrations-bpa"]`
On first use, a browser opens for login. Your BPA permissions apply automatically.
> **Tip:** Name each MCP after its instance (e.g., `BPA-elsalvador-dev`, `BPA-cuba-test`) to manage multiple environments, or use the multi-instance feature below to target any profile from a single server.
## Multi-Instance Support
A single MCP server can target multiple BPA instances using named profiles, eliminating the need for a separate server process per country.
### Setup
The `BPA_INSTANCE_URL` env var configures the **default instance**. Additional instances are registered at runtime via `instance_add`:
```
You: Register the Nigeria BPA instance
Claude: [calls instance_add("nigeria", "https://bpa.gateway.nipc.gov.ng", keycloak_url=..., keycloak_realm="NG")]
Done. Profile "nigeria" saved.
You: List all configured instances
Claude: [calls instance_list()]
Active (default): jamaica — https://bpa.jamaica.eregistrations.org
Profiles: nigeria — https://bpa.gateway.nipc.gov.ng
```
### Per-Call Targeting
Every tool accepts an optional `instance` parameter:
```
You: List services in Nigeria
Claude: [calls service_list(instance="nigeria")]
You: Now check the same service in Jamaica
Claude: [calls service_get("abc-123")] ← uses default (Jamaica)
```
No switching, no restarts. Both instances usable in the same conversation.
### Authentication per Instance
Each instance has its own isolated token:
```
You: Log in to Nigeria
Claude: [calls auth_login(username="admin@nipc.gov.ng", password="...", instance="nigeria")]
You: Check Jamaica connection
Claude: [calls connection_status()] ← Jamaica default, separate token
```
### Profiles Storage
Profiles are saved to `~/.config/mcp-eregistrations-bpa/profiles.json`. Each profile stores its own token, audit log, and rollback state under a separate data directory.
### Instance Management Tools
| Tool | Description |
|------|-------------|
| `instance_list` | List all configured profiles + active env-var instance |
| `instance_add` | Register a new BPA instance profile |
| `instance_remove` | Remove a profile by name |
## 164 MCP Tools
| Category | Capabilities |
| ----------------- | --------------------------------------------------------------- |
| **Services** | Create, read, update, copy, export, transform to YAML |
| **Registrations** | Full CRUD with parent service linking |
| **Institutions** | Assign/unassign institutions to registrations |
| **Forms** | Read/write Form.io components with container support |
| **Roles** | Create reviewer/approver/processor roles |
| **Bots** | Configure workflow automation |
| **Determinants** | Text, select, numeric, boolean, date, classification, grid |
| **Behaviours** | Component visibility/validation effects with JSONLogic |
| **Costs** | Fixed fees and formula-based pricing |
| **Documents** | Link document requirements to registrations |
| **Workflows** | Arazzo-driven intent-based natural language service design |
| **Debugging** | Scan, investigate, and fix service configuration issues |
| **Audit** | Complete operation history with rollback |
| **Analysis** | Service inspection and dependency mapping |
## Natural Language Workflows
Ask Claude to design services using plain English:
| What you say | What happens |
| --------------------------------------- | ---------------------------------------------------- |
| "Create a permit service" | Creates service + registration with proper structure |
| "Add a reviewer role to this service" | Adds UserRole with 'processing' assignment |
| "Set a $75 application fee" | Creates fixed cost attached to registration |
| "Add document requirement for ID proof" | Links requirement to the registration |
The workflow system uses [Arazzo](https://spec.openapis.org/arazzo/latest.html) specifications to orchestrate multi-step operations. It extracts your intent, validates inputs, and executes with full audit trail.
### Workflow Tools
| Tool | Purpose |
|------|---------|
| `workflow_list` | List available workflows by category |
| `workflow_search` | Find workflows matching natural language intent |
| `workflow_describe` | Get workflow details, inputs, and steps |
| `workflow_execute` | Run workflow with provided inputs |
| `workflow_start_interactive` | Begin guided step-by-step execution |
| `workflow_status` | Check execution progress |
| `workflow_rollback` | Undo a completed workflow |
## Service Debugger Tools
AI-assisted debugging for BPA service configuration issues. Scan, investigate, and fix problems collaboratively.
### Available Tools
| Tool | Purpose |
|------|---------|
| `debug_scan` | Scan service for configuration issues |
| `debug_investigate` | Analyze root cause of a specific issue |
| `debug_fix` | Execute fix for a single issue |
| `debug_fix_batch` | Fix multiple issues of the same type |
| `debug_group_issues` | Group issues by type, severity, or fix strategy |
| `debug_plan` | Generate phased fix plan with dependencies |
| `debug_verify` | Verify fixes were applied successfully |
### Issue Types Detected
| Type | Severity | Auto-Fixable |
|------|----------|--------------|
| `effects_determinant` | High | Yes |
| `determinant` | High | Yes |
| `translation_moustache` | Medium | Yes |
| `catalog` | Medium | Yes |
| `missing_determinants_in_component_behaviours` | Medium | Yes |
| Component moustache issues | Low | Manual |
| Role/registration issues | Low | Manual |
### Usage Example
```
You: Scan this service for issues
Claude: Found 144 issues across 5 categories:
- 67 effects referencing deleted determinants (HIGH)
- 18 orphaned determinants (HIGH)
- 33 translation issues (MEDIUM)
[shows summary]
You: Fix all the high severity issues
Claude: I'll fix these in two phases:
Phase 1: Delete 67 orphaned effects
Phase 2: Delete 18 orphaned determinants
Proceed? [waits for approval]
You: Yes, proceed
Claude: Fixed 85 issues. Audit IDs saved for rollback.
Verification scan shows 0 high-severity issues remaining.
```
## Key Features
**Audit Trail** — Every operation logged (who, what, when). Query history with `audit_list`.
**Rollback** — Undo any write operation. Restore previous state with `rollback`.
**Export** — Get complete service definitions as clean YAML (~25x smaller than raw JSON) for review or version control.
**Copy** — Clone existing services with selective component inclusion.
**Pagination** — All list endpoints support `limit` and `offset` for large datasets. Responses include `total` and `has_more` for navigation.
## Form MCP Tools
BPA uses Form.io for dynamic forms. These tools provide full CRUD operations on form components.
### Available Tools
| Tool | Purpose |
|------|---------|
| `form_get` | Get form structure with simplified component list |
| `form_component_get` | Get full details of a specific component |
| `form_component_add` | Add new component to form |
| `form_component_update` | Update component properties |
| `form_component_remove` | Remove component from form |
| `form_component_move` | Move component to new position/parent |
| `form_update` | Replace entire form schema |
### Form Types
- `applicant` (default) - Main application form
- `guide` - Guidance/help form
- `send_file` - File submission form
- `payment` - Payment form
### Property Availability
Properties vary by tool. Use `form_get` for overview, `form_component_get` for full details:
| Property | `form_get` | `form_component_get` |
|----------|------------|----------------------|
| key | Yes | Yes |
| type | Yes | Yes |
| label | Yes | Yes |
| path | Yes | Yes |
| is_container | Yes | No |
| children_count | For containers | No |
| required | When present | Yes (in validate) |
| validate | No | Yes |
| registrations | No | Yes |
| determinant_ids | No | Yes (in raw) |
| data | No | Yes |
| default_value | No | Yes |
| raw | No | Yes (complete object) |
### Container Types
Form.io uses containers to organize components. Each has different child accessors:
```
Container Type Children Accessor
-------------- -----------------
tabs components[] (tab panes)
panel components[]
columns columns[].components[] (2-level)
fieldset components[]
editgrid components[] (repeatable)
datagrid components[]
table rows[][] (HTML table)
well components[]
container components[]
```
### Usage Examples
**Get form overview:**
```
form_get(service_id="abc-123", form_type="applicant")
# Returns: component_count, component_keys, simplified components list
```
**Get specific component details:**
```
form_component_get(service_id="abc-123", component_key="firstName")
# Returns: full component with validate, data, determinant_ids, raw object
```
**Add component to form:**
```
form_component_add(
service_id="abc-123",
component={"key": "email", "type": "email", "label": "Email Address"},
parent_key="personalInfo", # Optional: nest under panel
position=0 # Optional: insert at position
)
```
**Update component:**
```
form_component_update(
service_id="abc-123",
component_key="firstName",
updates={"validate": {"required": True}, "label": "First Name *"}
)
```
**Move component:**
```
form_component_move(
service_id="abc-123",
component_key="phoneNumber",
new_parent_key="contactPanel",
new_position=1
)
```
All write operations include `audit_id` for rollback capability.
## Determinant & Conditional Logic Tools
Create conditional logic that controls form behavior based on user input.
### Determinant Types
| Type | Use Case | Example |
|------|----------|---------|
| `textdeterminant` | Text field conditions | Show panel if country = "USA" |
| `selectdeterminant` | Dropdown selection | Different fees by business type |
| `numericdeterminant` | Numeric comparisons | Require docs if amount > 10000 |
| `booleandeterminant` | Checkbox conditions | Show section if newsletter = true |
| `datedeterminant` | Date comparisons | Validate expiry > today |
| `classificationdeterminant` | Catalog selections | Requirements by industry code |
| `griddeterminant` | Grid/table row conditions | Validate line items |
### Behaviour Effects
Apply determinants to components to control visibility and validation:
```
effect_create(
service_id="abc-123",
determinant_id="det-456",
component_key="additionalDocs",
effect_type="visibility" # or "required", "disabled"
)
```
Use `componentbehaviour_list` and `componentbehaviour_get` to inspect existing effects.
## Example Session
```
You: List all services
Claude: Found 12 services. [displays table with IDs, names, status]
You: Analyze the "Business Registration" service
Claude: [shows registrations, roles, determinants, documents, costs]
Found 3 potential issues: orphaned determinant, missing cost...
You: Create a copy called "Business Registration v2"
Claude: Created service with ID abc-123. Copied 2 registrations,
4 roles, 8 determinants. Audit ID: xyz-789
```
## Authentication
The MCP server supports two authentication providers, auto-detected based on configuration:
### Keycloak (Modern Systems)
Uses OIDC with Authorization Code + PKCE:
1. Browser opens automatically on first connection
2. Login with your Keycloak/BPA credentials
3. Tokens managed automatically with refresh
4. Your BPA permissions apply to all operations
**No client secret required** — Keycloak uses PKCE for secure public clients.
### CAS (Legacy Systems)
Uses OAuth2 with Basic Auth (client credentials):
1. Browser opens to CAS login page (`/cas/spa.html`)
2. Login with your eRegistrations credentials
3. Tokens exchanged using HTTP Basic Auth
4. User roles fetched from PARTC service (if configured)
**Client secret required** — CAS doesn't support PKCE, so `CAS_CLIENT_SECRET` must be provided.
### Provider Detection
The provider is automatically detected based on which environment variables are set:
| Configuration | Provider Used |
|---------------|---------------|
| `CAS_URL` set | CAS |
| `KEYCLOAK_URL` set (no `CAS_URL`) | Keycloak |
If both are set, CAS takes precedence.
### Non-Interactive Authentication
For CI/CD pipelines, SSH sessions, Docker containers, and other environments without a browser, the MCP server supports password-based authentication.
#### Credential Storage (Keyring)
Store credentials securely in your OS keyring (macOS Keychain, GNOME Keyring, Windows Credential Manager) so you only enter them once:
```
You: Log me in
Claude: [calls auth_login] Cannot open browser. Please provide credentials.
You: user@example.org / my-password, and remember them
Claude: [calls auth_login(username="user@example.org", password="...", store_credentials=True)]
Authenticated. Credentials saved to system keyring.
```
On subsequent sessions, stored credentials are used automatically.
#### Headless Override
Force non-interactive mode (skip browser detection) by setting:
```bash
MCP_HEADLESS=1
```
This is useful on systems where browser detection gives a false positive (e.g., macOS over SSH where `DISPLAY` is forwarded).
#### How Auto-Detection Works
When `auth_login` is called without credentials, the server tries methods in order:
1. **Cached token** -- reuse existing session
2. **Refresh token** -- silently refresh expired session
3. **Keyring credentials** -- use stored credentials (password grant)
4. **Browser login** -- open browser if available (OIDC/CAS)
5. **Ask credentials** -- return structured prompt for the AI agent to collect credentials
> **Keycloak requirement:** Password grant requires "Direct Access Grants" enabled on the Keycloak client. See [Keycloak Setup](docs/keycloak-setup.md) for details.
## Configuration
### Common Variables
| Variable | Description | Required |
| ------------------ | --------------------------- | -------- |
| `BPA_INSTANCE_URL` | BPA server URL | Yes |
| `LOG_LEVEL` | DEBUG, INFO, WARNING, ERROR | No |
### Keycloak Variables
| Variable | Description | Required |
| ------------------ | --------------------------- | -------- |
| `KEYCLOAK_URL` | Keycloak server URL | Yes |
| `KEYCLOAK_REALM` | Keycloak realm name | Yes |
### CAS Variables
| Variable | Description | Required | Default |
| ------------------- | ------------------------------------ | -------- | ------- |
| `CAS_URL` | CAS OAuth2 server URL | Yes | — |
| `CAS_CLIENT_ID` | OAuth2 client ID | Yes | — |
| `CAS_CLIENT_SECRET` | OAuth2 client secret | Yes | — |
| `CAS_CALLBACK_PORT` | Local callback port for redirect URI | No | 8914 |
> **Note:** The callback port must match the redirect URI registered in CAS. Default is 8914 (`http://127.0.0.1:8914/callback`).
> **Note:** The PARTC URL for fetching user roles is automatically derived from `CAS_URL` by replacing `/cback/` with `/partc/`.
Logs: `~/.config/mcp-eregistrations-bpa/instances/{instance-slug}/server.log`
### Multi-Instance Profiles
Named profiles are stored at `~/.config/mcp-eregistrations-bpa/profiles.json`. Each profile is a JSON object with the same fields as the env vars above:
```json
{
"profiles": {
"nigeria": {
"bpa_instance_url": "https://bpa.gateway.nipc.gov.ng",
"keycloak_url": "https://login.nipc.gov.ng",
"keycloak_realm": "NG"
},
"cuba": {
"bpa_instance_url": "https://bpa.test.cuba.eregistrations.org",
"cas_url": "https://eid.test.cuba.eregistrations.org/cback/v1.0",
"cas_client_id": "mcp-client",
"cas_client_secret": "..."
}
}
}
```
Profiles are managed via `instance_add` / `instance_remove` tools, or by editing the file directly. Each profile gets its own isolated data directory, token store, audit log, and rollback state.
## Development
```bash
# Clone and install
git clone https://github.com/UNCTAD-eRegistrations/mcp-eregistrations-bpa.git
cd mcp-eregistrations-bpa
uv sync
# Run tests (1200+ tests)
uv run pytest
# Lint and format
uv run ruff check . && uv run ruff format .
# Type checking
uv run mypy src/
```
## Complete Tool Reference
### Authentication & Instance Management (5 tools)
| Tool | Description |
|------|-------------|
| `auth_login` | Authenticate with BPA (browser, password grant, or keyring). Accepts `instance=` to target a specific profile. |
| `connection_status` | Check current authentication state. Accepts `instance=` to check a specific profile. |
| `instance_list` | List all configured BPA instance profiles and the active env-var instance |
| `instance_add` | Register a new BPA instance profile (saved to profiles.json) |
| `instance_remove` | Remove a BPA instance profile by name |
> **Multi-instance:** Every tool accepts `instance="profile_name"` to target a named profile instead of the default `BPA_INSTANCE_URL`. See the [Multi-Instance Support](#multi-instance-support) section above.
### Services (6 tools)
| Tool | Description |
|------|-------------|
| `service_list` | List all services with pagination |
| `service_get` | Get service details by ID |
| `service_create` | Create new service |
| `service_update` | Update service properties |
| `service_publish` | Publish service for frontend |
| `service_activate` | Activate/deactivate service |
### Registrations (6 tools)
| Tool | Description |
|------|-------------|
| `registration_list` | List registrations with service filter |
| `registration_get` | Get registration details |
| `registration_create` | Create registration in service |
| `registration_delete` | Delete registration |
| `registration_activate` | Activate/deactivate registration |
| `serviceregistration_link` | Link registration to service |
### Institutions (7 tools)
| Tool | Description |
|------|-------------|
| `registrationinstitution_list` | List institution assignments |
| `registrationinstitution_get` | Get assignment details |
| `registrationinstitution_create` | Assign institution to registration |
| `registrationinstitution_delete` | Remove institution assignment |
| `registrationinstitution_list_by_institution` | List registrations by institution |
| `institution_discover` | Discover institution IDs |
| `institution_create` | Create institution in Keycloak |
### Fields (2 tools)
| Tool | Description |
|------|-------------|
| `field_list` | List fields for a service |
| `field_get` | Get field details |
### Forms (7 tools)
| Tool | Description |
|------|-------------|
| `form_get` | Get form structure |
| `form_component_get` | Get component details |
| `form_component_add` | Add component to form |
| `form_component_update` | Update component properties |
| `form_component_remove` | Remove component |
| `form_component_move` | Move component |
| `form_update` | Replace entire form schema |
### Determinants (12 tools)
| Tool | Description |
|------|-------------|
| `determinant_list` | List determinants for service |
| `determinant_get` | Get determinant details |
| `determinant_search` | Search determinants by criteria |
| `determinant_delete` | Delete determinant |
| `textdeterminant_create` | Create text comparison |
| `textdeterminant_update` | Update text determinant |
| `selectdeterminant_create` | Create dropdown selection |
| `numericdeterminant_create` | Create numeric comparison |
| `booleandeterminant_create` | Create checkbox condition |
| `datedeterminant_create` | Create date comparison |
| `classificationdeterminant_create` | Create catalog selection |
| `griddeterminant_create` | Create grid row condition |
### Behaviours (5 tools)
| Tool | Description |
|------|-------------|
| `componentbehaviour_list` | List behaviours for service |
| `componentbehaviour_get` | Get behaviour by ID |
| `componentbehaviour_get_by_component` | Get behaviour for component |
| `effect_create` | Create visibility/validation effect |
| `effect_delete` | Delete behaviour/effect |
### Actions (2 tools)
| Tool | Description |
|------|-------------|
| `componentaction_get` | Get component actions by ID |
| `componentaction_get_by_component` | Get actions for component |
### Bots (5 tools)
| Tool | Description |
|------|-------------|
| `bot_list` | List bots for service |
| `bot_get` | Get bot details |
| `bot_create` | Create workflow bot |
| `bot_update` | Update bot properties |
| `bot_delete` | Delete bot |
### Classifications (5 tools)
| Tool | Description |
|------|-------------|
| `classification_list` | List catalog classifications |
| `classification_get` | Get classification with entries |
| `classification_create` | Create classification catalog |
| `classification_update` | Update classification |
| `classification_export_csv` | Export as CSV |
### Notifications (2 tools)
| Tool | Description |
|------|-------------|
| `notification_list` | List service notifications |
| `notification_create` | Create notification trigger |
### Messages (5 tools)
| Tool | Description |
|------|-------------|
| `message_list` | List global message templates |
| `message_get` | Get message details |
| `message_create` | Create message template |
| `message_update` | Update message |
| `message_delete` | Delete message |
### Roles (8 tools)
| Tool | Description |
|------|-------------|
| `role_list` | List roles for service |
| `role_get` | Get role with statuses |
| `role_create` | Create UserRole or BotRole |
| `role_update` | Update role properties |
| `role_delete` | Delete role |
| `roleinstitution_create` | Assign institution to role |
| `roleregistration_create` | Assign registration to role |
### Role Status (4 tools)
| Tool | Description |
|------|-------------|
| `rolestatus_get` | Get status transition details |
| `rolestatus_create` | Create workflow transition |
| `rolestatus_update` | Update status |
| `rolestatus_delete` | Delete status |
### Role Units (4 tools)
| Tool | Description |
|------|-------------|
| `roleunit_list` | List units for role |
| `roleunit_get` | Get unit assignment |
| `roleunit_create` | Assign unit to role |
| `roleunit_delete` | Remove unit assignment |
### Documents (5 tools)
| Tool | Description |
|------|-------------|
| `requirement_list` | List global requirements |
| `documentrequirement_list` | List requirements for registration |
| `documentrequirement_create` | Link requirement to registration |
| `documentrequirement_update` | Update requirement |
| `documentrequirement_delete` | Remove requirement |
### Costs (4 tools)
| Tool | Description |
|------|-------------|
| `cost_create_fixed` | Create fixed fee |
| `cost_create_formula` | Create formula-based cost |
| `cost_update` | Update cost |
| `cost_delete` | Delete cost |
### Export (3 tools)
| Tool | Description |
|------|-------------|
| `service_export_raw` | Export service as JSON |
| `service_to_yaml` | Transform to AI-optimized YAML |
| `service_copy` | Clone service with new name |
### Analysis (1 tool)
| Tool | Description |
|------|-------------|
| `analyze_service` | AI-optimized service analysis |
### Audit (2 tools)
| Tool | Description |
|------|-------------|
| `audit_list` | List audit log entries |
| `audit_get` | Get audit entry details |
### Rollback (3 tools)
| Tool | Description |
|------|-------------|
| `rollback` | Undo write operation |
| `rollback_history` | Get object state history |
| `rollback_cleanup` | Clean old rollback states |
### Workflows (13 tools)
| Tool | Description |
|------|-------------|
| `workflow_list` | List available workflows |
| `workflow_describe` | Get workflow details |
| `workflow_search` | Search by intent |
| `workflow_execute` | Run workflow |
| `workflow_status` | Check execution status |
| `workflow_cancel` | Cancel running workflow |
| `workflow_retry` | Retry failed workflow |
| `workflow_rollback` | Undo completed workflow |
| `workflow_chain` | Execute workflow sequence |
| `workflow_start_interactive` | Begin guided mode |
| `workflow_continue` | Continue interactive session |
| `workflow_confirm` | Confirm and execute |
| `workflow_validate` | Validate workflow definitions |
### Debugging (7 tools)
| Tool | Description |
|------|-------------|
| `debug_scan` | Scan for configuration issues |
| `debug_investigate` | Analyze issue root cause |
| `debug_fix` | Fix single issue |
| `debug_fix_batch` | Fix multiple issues |
| `debug_group_issues` | Group issues by criteria |
| `debug_plan` | Generate fix plan |
| `debug_verify` | Verify fixes applied |
## Arazzo Workflow Reference (96 workflows)
### Service Creation
| Workflow | Description |
|----------|-------------|
| `createMinimalService` | Create service with registration |
| `createCompleteService` | Full service with roles and costs |
| `createQuickService` | Minimal service setup |
### Service Publishing
| Workflow | Description |
|----------|-------------|
| `fullPublish` | Complete publish workflow |
| `publishServiceChanges` | Publish pending changes |
| `activateService` | Activate service |
| `deactivateService` | Deactivate service |
### Roles & Workflow
| Workflow | Description |
|----------|-------------|
| `addRole` | Add role to service |
| `updateRole` | Update role properties |
| `configureStandardWorkflow` | Setup standard approval flow |
| `createCustomStatus` | Create workflow status |
| `updateCustomStatus` | Update status |
| `deleteRoleStatus` | Remove status |
| `createUserDefinedStatusWithMessage` | Status with notification |
| `updateUserDefinedStatusMessage` | Update status message |
| `getRoleFull` | Get complete role details |
| `getRoleStatus` | Get status details |
| `getRoleBots` | Get role bots |
| `getRoleUnits` | Get role units |
| `getRoleInstitutions` | Get role institutions |
| `getRoleHistory` | Get role version history |
| `listRolesWithDetails` | List all roles with details |
| `addUnitToRole` | Assign unit to role |
| `assignRoleInstitution` | Assign institution |
| `assignRegistrationToRole` | Assign single registration |
| `assignRegistrationsToRole` | Assign multiple registrations |
| `revertRoleVersion` | Rollback role version |
### Forms
| Workflow | Description |
|----------|-------------|
| `getApplicantForm` | Get applicant form |
| `getGuideForm` | Get guide form |
| `getDocumentForm` | Get document form |
| `updateApplicantForm` | Update applicant form |
| `updateGuideForm` | Update guide form |
| `toggleApplicantForm` | Enable/disable form |
| `deleteComponent` | Remove form component |
| `getField` | Get field details |
| `listFields` | List all fields |
| `getComponentActions` | Get component actions |
| `getComponentValidation` | Get validation rules |
| `getComponentFormula` | Get calculation formula |
| `updateComponentActions` | Update actions |
| `updateComponentValidation` | Update validation |
| `updateComponentFormula` | Update formula |
| `getFormHistory` | Get form version history |
| `revertFormVersion` | Rollback form version |
| `linkFieldToDeterminant` | Link field to condition |
### Determinants
| Workflow | Description |
|----------|-------------|
| `addTextDeterminant` | Create text condition |
| `addSelectDeterminant` | Create dropdown condition |
| `addRadioDeterminant` | Create radio condition |
| `addNumericDeterminant` | Create numeric condition |
| `addClassificationDeterminant` | Create catalog condition |
| `addGridDeterminant` | Create grid row condition |
| `updateTextDeterminant` | Update text determinant |
### Classifications
| Workflow | Description |
|----------|-------------|
| `listClassifications` | List all classifications |
| `searchClassifications` | Search classifications |
| `getClassificationType` | Get classification type |
| `createClassificationType` | Create classification type |
| `updateClassificationType` | Update type |
| `deleteClassificationType` | Delete type |
| `createClassificationGroup` | Create group |
| `deleteClassificationGroup` | Delete group |
| `listClassificationGroups` | List groups |
| `addClassificationField` | Add field to classification |
| `addClassificationFields` | Add multiple fields |
| `updateClassificationField` | Update field |
| `deleteClassificationField` | Delete field |
| `listClassificationFields` | List fields |
| `generateClassificationKeys` | Generate unique keys |
| `addSubcatalogs` | Add subcatalogs |
| `copyClassification` | Copy classification |
| `getServiceClassifications` | Get service classifications |
### Institutions
| Workflow | Description |
|----------|-------------|
| `completeInstitutionSetup` | Full institution setup |
| `assignRegistrationInstitution` | Assign to registration |
| `getRegistrationInstitution` | Get assignment |
| `removeRegistrationInstitution` | Remove assignment |
| `listRegistrationsByInstitution` | List by institution |
### Payments & Costs
| Workflow | Description |
|----------|-------------|
| `addFixedCost` | Add fixed fee |
| `addFormulaCost` | Add formula cost |
| `configureCompletePayments` | Full payment setup |
| `configureTieredPricing` | Tiered pricing rules |
### Documents
| Workflow | Description |
|----------|-------------|
| `addDocumentRequirement` | Add required document |
### Bots
| Workflow | Description |
|----------|-------------|
| `addBot` | Add automation bot |
| `updateBot` | Update bot |
### Notifications & Messages
| Workflow | Description |
|----------|-------------|
| `createServiceNotification` | Create notification |
| `updateNotification` | Update notification |
| `getNotification` | Get notification details |
| `listServiceNotifications` | List notifications |
| `sortServiceNotifications` | Reorder notifications |
| `createMessage` | Create message template |
| `getMessage` | Get message |
| `updateMessage` | Update message |
| `deleteMessage` | Delete message |
| `listMessages` | List messages |
| `updateFileStatus` | Update file status message |
| `updateFileValidatedStatusMessage` | Update validated message |
| `updateFileDeclineStatusMessage` | Update decline message |
| `updateFilePendingStatusMessage` | Update pending message |
| `updateFileRejectStatusMessage` | Update reject message |
### Debugging
| Workflow | Description |
|----------|-------------|
| `scanService` | Scan for issues |
| `planFixes` | Generate fix plan |
| `verifyFixes` | Verify fixes applied |
## License
Copyright (c) 2025-2026
UN for Trade & Development (UNCTAD)
Division on Investment and Enterprise (DIAE)
Business Facilitation Section
All rights reserved. See [LICENSE](LICENSE).
---
Part of [eRegistrations](https://businessfacilitation.org)
| text/markdown | null | Moulay Mehdi Benmoumen <benmoumen@gmail.com> | UNCTAD Business Facilitation Section | null | Proprietary - UNCTAD/DIAE/Business Facilitation Section | ai, bpa, claude, eregistrations, govtech, mcp, unctad | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Office/Business ::... | [] | null | null | >=3.11 | [] | [] | [] | [
"aiosqlite>=0.22.1",
"authlib",
"fastmcp>=2.11.3",
"httpx",
"keyring>=25.0.0",
"pydantic>=2.0",
"pyyaml"
] | [] | [] | [] | [
"Homepage, https://github.com/UNCTAD-eRegistrations/mcp-eregistrations-bpa",
"Repository, https://github.com/UNCTAD-eRegistrations/mcp-eregistrations-bpa",
"Documentation, https://github.com/UNCTAD-eRegistrations/mcp-eregistrations-bpa#readme"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:56:57.922842 | mcp_eregistrations_bpa-0.18.0.tar.gz | 241,628 | 30/ad/b3576b3a27dceff828167e1c4af19eeb343dcd9fe27d0d3634f6d1685592/mcp_eregistrations_bpa-0.18.0.tar.gz | source | sdist | null | false | 9070e56990008dadc25ee7bbb30f1e02 | 008c2a0afb2d76493842e3aca03faf9ef66f2c56229c5a546a98bbfc45963a5b | 30adb3576b3a27dceff828167e1c4af19eeb343dcd9fe27d0d3634f6d1685592 | null | [
"LICENSE"
] | 183 |
2.4 | stkai | 0.4.13 | Python SDK for StackSpot AI - Remote Quick Commands and more | # stkai
[](https://pypi.org/project/stkai/)
[](https://www.python.org/downloads/)
[](LICENSE)
An unofficial, opinionated Python SDK for [StackSpot AI](https://ai.stackspot.com/) — Execute Remote Quick Commands (RQCs) and interact with AI Agents with built-in resilience.
> **Note:** This is a community-driven SDK, not officially maintained by StackSpot. It was built to fill gaps we encountered in real-world projects — such as retries, rate limiting, and batch execution — that the platform's API alone doesn't provide out of the box.
## Design Principles
This SDK is opinionated by design. It prioritizes:
- **Reliability over latency** — Built-in retries, rate limiting, and fault tolerance mechanisms
- **Predictability over throughput** — Synchronous, blocking API for straightforward debugging and reasoning
- **Pragmatism over flexibility** — Simple, direct API with well-designed extension points
- **Convention over configuration** — Sensible defaults and seamless StackSpot CLI integration
## Installation
Install from [PyPI](https://pypi.org/project/stkai/):
```bash
pip install stkai
```
## Requirements
- Python 3.12+
- [StackSpot CLI](https://docs.stackspot.com/docs/stk-cli/installation/) installed and authenticated, or client credentials for standalone auth
## Quick Start
### Remote Quick Commands
Execute LLM-powered quick commands with automatic polling and retries:
```python
from stkai import RemoteQuickCommand, RqcRequest
rqc = RemoteQuickCommand(slug_name="my-quick-command")
response = rqc.execute(
request=RqcRequest(payload={"code": "def hello(): pass"})
)
if response.is_completed():
print(response.result)
else:
print(response.error_with_details())
```
### AI Agents
Chat with StackSpot AI Agents for conversational AI capabilities:
```python
from stkai import Agent, ChatRequest
agent = Agent(agent_id="my-agent-slug")
response = agent.chat(
request=ChatRequest(user_prompt="What is SOLID?")
)
if response.is_success():
print(response.result)
else:
print(response.error_with_details())
```
### Batch Processing
Process multiple requests concurrently with thread pool execution:
```python
# RQC batch
responses = rqc.execute_many(
request_list=[RqcRequest(payload=data) for data in files]
)
completed = [r for r in responses if r.is_completed()]
```
```python
# Agent batch
responses = agent.chat_many(
request_list=[ChatRequest(user_prompt=p) for p in prompts]
)
successful = [r for r in responses if r.is_success()]
```
## Features
| Feature | Description | Docs |
|---------|-------------|------|
| **Remote Quick Commands** | Execute AI commands with polling and retries | [Guide](https://rafaelpontezup.github.io/stkai-sdk-python/rqc/) |
| **AI Agents** | Chat with agents, batch execution, conversations, knowledge sources | [Guide](https://rafaelpontezup.github.io/stkai-sdk-python/agents/) |
| **Batch Execution** | Process multiple requests concurrently (RQC and Agents) | [RQC](https://rafaelpontezup.github.io/stkai-sdk-python/rqc/usage/#batch-execution) · [Agents](https://rafaelpontezup.github.io/stkai-sdk-python/agents/usage/#batch-execution) |
| **Result Handlers** | Customize response processing | [Guide](https://rafaelpontezup.github.io/stkai-sdk-python/rqc/handlers/) |
| **Event Listeners** | Monitor execution lifecycle | [Guide](https://rafaelpontezup.github.io/stkai-sdk-python/rqc/listeners/) |
| **Rate Limiting** | Token Bucket and adaptive AIMD algorithms | [Guide](https://rafaelpontezup.github.io/stkai-sdk-python/rqc/rate-limiting/) |
| **Configuration** | Global config via code or environment variables | [Guide](https://rafaelpontezup.github.io/stkai-sdk-python/configuration/) |
## Documentation
Full documentation available at: **https://rafaelpontezup.github.io/stkai-sdk-python/**
- [Getting Started](https://rafaelpontezup.github.io/stkai-sdk-python/getting-started/)
- [RQC Guide](https://rafaelpontezup.github.io/stkai-sdk-python/rqc/)
- [Agents Guide](https://rafaelpontezup.github.io/stkai-sdk-python/agents/)
- [Configuration](https://rafaelpontezup.github.io/stkai-sdk-python/configuration/)
- [API Reference](https://rafaelpontezup.github.io/stkai-sdk-python/api/rqc/)
## Development
```bash
# Clone and setup
git clone https://github.com/rafaelpontezup/stkai-sdk.git
cd stkai-sdk
python -m venv .venv && source .venv/bin/activate
pip install -e ".[dev]"
# Run tests
pytest
# Run tests with coverage
pytest --cov=src --cov-report=term-missing
# Lint and type check
ruff check src tests
mypy src
# Build docs locally
pip install -e ".[docs]"
mkdocs serve
```
## License
Apache License 2.0 - see [LICENSE](LICENSE) for details.
| text/markdown | null | Rafael Ponte <rponte@gmail.com> | null | null | Apache-2.0 | stackspot, ai, sdk, quick-commands, llm, agents, api client | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Softwar... | [] | null | null | >=3.12 | [] | [] | [] | [
"requests>=2.28.0",
"python-ulid>=2.2.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"coverage>=5.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"types-requests>=2.28.0; extra == \"dev\"",
"mkdocs>=1.5.0; extra == \"docs\"",
... | [] | [] | [] | [
"Homepage, https://github.com/rafaelpontezup/stkai-sdk-python",
"Documentation, https://rafaelpontezup.github.io/stkai-sdk-python/",
"Repository, https://github.com/rafaelpontezup/stkai-sdk-python",
"Issues, https://github.com/rafaelpontezup/stkai-sdk-python/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:55:49.832757 | stkai-0.4.13.tar.gz | 95,260 | 9e/5b/91d7df04cf62e0ee625ae2fecd911845750658d9c73764edfb44ac6ee8dd/stkai-0.4.13.tar.gz | source | sdist | null | false | 60b8c785ecf2c4a0e4ed071f4502176f | 23128f91cad9d128435f741cf8a6c32a9949627b75320cbf9f654e29aa897551 | 9e5b91d7df04cf62e0ee625ae2fecd911845750658d9c73764edfb44ac6ee8dd | null | [
"LICENSE"
] | 199 |
2.1 | pyqontrol | 0.1.0 | Python bindings for Qontrol - A quadratic optimization library for robot control | # Qontrol Python Bindings
Python bindings for Qontrol - A quadratic optimization library for hierarchical robot control.
Qontrol enables efficient inverse kinematics and dynamics with task priorities, joint limits, and custom constraints using quadratic programming.
## Features
- **Four control levels**: Joint Position, Velocity, Acceleration, and Torque control.
- **Hierarchical task priorities**: Weighted and prioritize multiple tasks (Generalized Hierarchical Control)
- **Comprehensive constraints**: Joint limits, Cartesian planes, custom constraints
- **Multiple solvers**: qpOASES, qpmad support (and more coming)
- **High performance**: Minimal overhead C++ bindings via nanobind
## Installation
Install from PyPI:
```bash
pip install pyqontrol
```
## Requirements
- Python 3.9+
- NumPy >= 2.0
- Pinocchio >= 2.6 (automatically installed as `pin` package)
## Core Concepts
### Control Levels
Qontrol supports three levels of control:
- **JointVelocityProblem**: Direct velocity control (kinematic)
- **JointAccelerationProblem**: Acceleration control with dynamics preview
- **JointTorqueProblem**: Torque-level control with full inverse dynamics
For each control level it is possible to also compute the resulting joint position command.
### Tasks
Tasks define control objectives with configurable weights and priorities:
- `CartesianVelocity/Acceleration`: End-effector tracking
- `JointVelocity/Acceleration/Torque`: Joint-space control
- Custom tasks via generic task interface
Task often represents how a robot should follow a trajectory or a reference pose/configuration.
### Constraints
Hard constraints that must be satisfied:
- `JointConfigurationConstraint`: Position limits
- `JointVelocityConstraint`: Velocity limits
- `JointTorqueConstraint`: Torque limits
- `CartesianPlaneConstraint`: Collision avoidance planes
Every constraints can be softened using `Slack` variables
### Resolution Strategies
- **Weighted**: Combine tasks with weights (QP)
- **Generalized**: Generalized hierarchical control (GHC). Multiple task with complete hierarchy handling
## Examples
The package includes interactive examples demonstrating various control scenarios. After installing with `pip install pyqontrol mujoco pin`:
```bash
# Download example resources (URDF files) from the repository
git clone https://gitlab.inria.fr/auctus-team/components/control/qontrol.git
cd qontrol/bindings/python/examples
# Run interactive velocity control
python velocity_control_interactive.py panda
# Run torque control with dynamics
python torque_control_interactive.py panda
```
## Documentation
- [Full documentation](https://auctus-team.gitlabpages.inria.fr/components/control/qontrol/)
- [Examples](https://gitlab.inria.fr/auctus-team/components/control/qontrol/-/tree/main/bindings/python/examples)
## Development
### Building from Source
If you want to contribute or build from source, the project requires CMake, a C++ compiler, and Eigen3. On Ubuntu/Debian, install the required packages with:
```bash
sudo apt install build-essential cmake libeigen3-dev
```
Qontrol uses the Pinocchio library by default for robot modeling. To install Pinocchio, follow the official installation guide and choose the method that best fits your system: [Pinocchio installation guide](https://stack-of-tasks.github.io/pinocchio/download.html).
Then to build Qontrol from source :
```bash
# Clone the repository
git clone https://gitlab.inria.fr/auctus-team/components/control/qontrol
cd qontrol/bindings/python
# Install in editable mode (automatically builds C++ library and Python bindings)
pip install -e .
```
### Running Tests
```bash
cd bindings/python
pytest tests/ -v
```
## License
GNU Lesser General Public License v3.0
| text/markdown | null | Lucas Joseph <lucas.joseph@inria.fr> | null | null | null | robotics, control, optimization, quadratic-programming, inverse-kinematics | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Pytho... | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy>=1.20",
"pin>=3.8.0",
"pytest>=6.0; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"black; extra == \"dev\"",
"isort; extra == \"dev\"",
"mypy; extra == \"dev\"",
"sphinx>=5.0; extra == \"docs\"",
"sphinx-rtd-theme>=1.0; extra == \"docs\"",
"breathe>=4.35; extra == \"docs\"",
"sphinx-... | [] | [] | [] | [
"Homepage, https://gitlab.inria.fr/auctus-team/components/control/qontrol",
"Documentation, https://auctus-team.gitlabpages.inria.fr/components/control/qontrol/python",
"Repository, https://gitlab.inria.fr/auctus-team/components/control/qontrol",
"Issues, https://gitlab.inria.fr/auctus-team/components/control... | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:55:20.982830 | pyqontrol-0.1.0-cp310-cp310-manylinux_2_34_x86_64.manylinux_2_35_x86_64.whl | 9,316,755 | c0/7a/cc6e2c5e2f4b09de87ab19c94e5de744eecab64f47038665ff346d1a075c/pyqontrol-0.1.0-cp310-cp310-manylinux_2_34_x86_64.manylinux_2_35_x86_64.whl | cp310 | bdist_wheel | null | false | 34acdd03b422ec82fa0ac928cdcf62a3 | 37a45b5eb0aa4d17b62b92356a99a2e7173ed4cab41f81e2a879e0cd77fb2ae5 | c07acc6e2c5e2f4b09de87ab19c94e5de744eecab64f47038665ff346d1a075c | null | [] | 157 |
2.4 | paskia | 1.3.4 | Passkey Auth made easy: all sites and APIs can be guarded even without any changes on the protected site. | # Paskia

An easy to install passkey-based authentication service that protects any web application with strong passwordless login.
## What is Paskia?
- Easy to use fully featured auth&auth system (login and permissions)
- Organization and role-based access control
* Org admins control their users and roles
* Multiple independent orgs
* Master admin can do everything or delegate to org admins
- User Profile and Admin by API and web interface
- Implements login/reauth/forbidden flows for you
- Single Sign-On (SSO): Users register once and authenticate across your services
- Remote autentication by entering random keywords from another device (like 2fa)
- No CORS, NodeJS or anything extra needed.
## Authenticate to get to your app, or in your app
- API fetch: auth checks and login without leaving your app
- Forward-auth proxy: protect any unprotected site or service (Caddy, Nginx)
The API mode is useful for applications that can be customized to run with Paskia. Forward auth can also protect your javascript and other assets. Each provides fine-grained permission control and reauthentication requests where needed, and both can be mixed where needed.
## Authentication flows already done

**Automatic light/dark mode switching with overrides by user profile and protected app's theme.**
Paskia includes set of login, reauthentication and forbidden dialogs that it can use to perform the needed flows. We never leave the URL, no redirections, and if you make use of API mode, we won't even interrupt whatever your app was doing but retry the blocked API fetch after login like nothing happened.
## Quick Start
Install [UV](https://docs.astral.sh/uv/getting-started/installation/) and run:
```sh
uvx paskia --rp-id example.com
```
On the first run it downloads the software and prints a registration link for the Admin. The server starts on [localhost:4401](http://localhost:4401), serving authentication for `*.example.com`. For local testing, leave out `--rp-id`.
For production you need a web server such as [Caddy](https://caddyserver.com/) to serve HTTPS on your actual domain names and proxy requests to Paskia and your backend apps (see documentation below).
For a permanent install of `paskia` CLI command, not needing `uvx`:
```sh
uv tool install paskia
```
## Configuration
You will need to specify your main domain to which all passkeys will be tied as rp-id. Use your main domain even if Paskia is not running there. All other options are optional.
```text
paskia [options]
```
| Option | Description | Default |
|--------|-------------|---------|
| -l, --listen *endpoint* | Listen address: *host*:*port*, :*port* (all interfaces), or */path.sock* | **localhost:4401** |
| --rp-id *domain* | Main/top domain for passkeys | **localhost** |
| --rp-name *"text"* | Branding name for the entire system (passkey auth, login dialog). | Same as rp-id |
| --origin *url* | Only sites listed can login (repeatable) | rp-id and all subdomains |
| --auth-host *url* | Dedicated authentication site, e.g. **auth.example.com** | Use **/auth/** path on each site |
| --save | Save current options to database | (only --rp-id required on further invocations) |
To clear a stored setting, pass an empty value like `--auth-host=`. The database is stored in `{rp-id}.paskiadb` in current directory. This can be overridden by environment `PASKIA_DB` if needed.
## Tutorial: From Local Testing to Production
This section walks you through a complete example, from running Paskia locally to protecting a real site in production.
### Step 1: Production Configuration
For a real deployment, configure Paskia with your domain name (rp-id). This enables SSO setup for that domain and any subdomains.
```sh
uvx paskia --rp-id=example.com --rp-name="Example Corp"
```
This binds passkeys to the rp-id, allowing them to be used there or on any subdomain of it. The `--rp-name` is the branding shown in UI and registered with passkeys for everything on your domain (rp id). On the first run, you'll see a registration link—use it to create your Admin account. You may enter your real name here for a more suitable account name.
### Step 2: Set Up Caddy
Install [Caddy](https://caddyserver.com/) and copy the [auth folder](caddy/auth) to `/etc/caddy/auth`. Say your current unprotected Caddyfile looks like this:
```caddyfile
app.example.com {
reverse_proxy :3000
}
```
Add Paskia full site protection:
```caddyfile
app.example.com {
import auth/setup
handle {
import auth/require perm=myapp:login
reverse_proxy :3000
}
}
```
Run `systemctl reload caddy`. Now `app.example.com` requires the `myapp:login` permission. Try accessing it and you'll land on a login dialog.
### Step 3: Assign Permissions via Admin Panel

1. Go to `app.example.com/auth/admin/`
2. Create a permission, give it a name and scope `myapp:login`
3. Assign it to Organization
4. In that organization, assign it to the Administration role
Now you have granted yourself the new permission.
Permission scopes are text identifiers with colons as separators that we can use for permission checks. The `myapp:` prefix is a convention to namespace permissions per application—you but you can use other forms as you see fit (urlsafe characters, no spaces allowed).
### Step 4: Add API Authentication to Your App
Your backend already receives `Remote-*` headers from Caddy's forward-auth. For frontend API calls, we provide a [JS paskia module](https://www.npmjs.com/package/paskia):
```js
import { apiJson } from 'https://cdn.jsdelivr.net/npm/paskia@latest/dist/paskia.js'
const data = await apiJson('/api/sensitive', { method: 'POST' })
```
When a 401/403 occurs, the auth dialog appears automatically, and the request retries after authentication.
To protect the API path with a different permission, update your Caddyfile:
```caddyfile
app.example.com {
import auth/setup
@api path /api/*
handle @api {
import auth/require perm=myapp:api
reverse_proxy :3000
}
handle {
import auth/require perm=myapp:login
reverse_proxy :3000
}
}
```
Create the `myapp:api` permission in the admin panel, that will be required for all API access. Link to `/auth/` for the built-in profile page.
You may also remove the `myapp:login` protection from the rest of your site paths, unless you wish to keep all your assets behind a login page. Having this as the last entry in your config allows free access to everything not matched by other sections.
```Caddyfile
handle {
reverse_proxy :3000
}
```
### Step 5: Run Paskia as a Service
Create a system user paskia, install UV on the system, and create a systemd unit:
```sh
sudo useradd --system --home-dir /srv/paskia --create-home paskia
```
Install UV on the system (or arch btw `pacman -S uv`):
```sh
curl -LsSf https://astral.sh/uv/install.sh | sudo env UV_INSTALL_DIR=/usr/local/bin sh
```
Create a systemd unit:
```sh
sudo systemctl edit --force --full paskia@.service
```
Paste the following and save:
```ini
[Unit]
Description=Paskia for %i
[Service]
Type=simple
User=paskia
WorkingDirectory=/srv/paskia
ExecStart=uvx paskia@latest --rp-id=%i
[Install]
WantedBy=multi-user.target
```
Run the service and view log:
```sh
sudo systemctl enable --now paskia@example.com && sudo journalctl -n30 -ocat -fu paskia@example.com
```
### Optional: Dedicated Authentication Site
Add a Caddy configuration for the authentication domain:
```caddyfile
auth.example.com {
reverse_proxy :4401
}
```
Now all authentication happens at `auth.example.com` instead of `/auth/` paths on your apps. Your existing protected sites continue to work as before but they just forward to the dedicated site for user profile and other such functionality.
Enter your auth site domain on Admin / Server Options panel or use `--auth-host=auth.example.com` when starting the server.
## Further Documentation
- [Caddy configuration](https://git.zi.fi/LeoVasanko/paskia/src/branch/main/docs/Caddy.md)
- [Trusted Headers for Backend Apps](https://git.zi.fi/LeoVasanko/paskia/src/branch/main/docs/Headers.md)
- [Frontend integration](https://git.zi.fi/LeoVasanko/paskia/src/branch/main/docs/Integration.md)
- [Paskia API](https://git.zi.fi/LeoVasanko/paskia/src/branch/main/docs/API.md)
| text/markdown | Leo Vasanko | null | null | null | null | FastAPI, auth_request, forward_auth | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"base64url>=1.1.1",
"fastapi-vue>=1.1.0",
"fastapi[standard]>=0.129.0",
"jsondiff>=2.2.1",
"msgspec>=0.20.0",
"pyjwt[crypto]>=2.11.0",
"ua-parser[regex]>=1.0.1",
"uuid7-standard>=1.1.0",
"webauthn>=2.7.1",
"websockets>=16.0"
] | [] | [] | [] | [
"Homepage, https://git.zi.fi/LeoVasanko/paskia",
"Repository, https://github.com/LeoVasanko/paskia"
] | uv/0.9.21 {"installer":{"name":"uv","version":"0.9.21","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T21:54:53.256041 | paskia-1.3.4.tar.gz | 1,943,789 | f0/16/9efef2ca01ffc8abcc2ec27e6b500543307ff1bb60fbcd8ba40dff0a25c1/paskia-1.3.4.tar.gz | source | sdist | null | false | 2d63876af1eaa38cde393c781c5c7748 | d7da960694c773d3b1bf824693e9206272f24fc53ccb98ada080e7047bf74e36 | f0169efef2ca01ffc8abcc2ec27e6b500543307ff1bb60fbcd8ba40dff0a25c1 | null | [] | 190 |
2.4 | aria-runtime | 0.1.0 | Agent Runtime for Intelligent Automation — local-first, secure by default | # ARIA — Agent Runtime for Intelligent Automation
**Local-first. Secure by default. Fully auditable.**
> *Build smallest possible correct system. Fail loudly, never silently.*
---
## What This Is
ARIA is a production-grade, single-agent AI execution runtime. It is not a framework, not a platform, and not a library. It is a complete, runnable system with explicit contracts between every component.
**Design philosophy:**
- Fail loudly, never silently
- Explicit state transitions only (typed FSM)
- Every side effect logged before and after
- All boundaries validate input/output against schemas
- Synchronous core — no async race conditions
- Security by default, least privilege
- No vendor lock-in (abstraction layers)
---
## Quick Start
```bash
# Set your API key
export ANTHROPIC_API_KEY=sk-ant-...
# Run a task
python -m aria.cli.main run --task "What are the first 5 prime numbers?"
# See registered tools
python -m aria.cli.main tools list
# View audit log
python -m aria.cli.main audit list
python -m aria.cli.main audit export --session-id <id>
python -m aria.cli.main audit verify --session-id <id>
```
---
## Architecture
```text
CLI Layer (thin boundary, zero business logic)
│
▼
AgentKernel (orchestrator — sequences, delegates, enforces limits)
│
├── SessionFSM (IDLE→RUNNING→WAITING→DONE|FAILED|CANCELLED)
├── ModelRouter (retry + circuit breaker per provider)
├── ToolRegistry (manifest validation, permission enforcement)
├── SandboxRunner (subprocess isolation, path traversal prevention)
└── SQLiteStorage (memory + audit, WAL mode, chain hashing)
```
### State Machine
```text
IDLE ──► RUNNING ──► WAITING ──► RUNNING
│ │ │
│ ▼ ▼
└────► CANCELLED FAILED
▲
RUNNING ──► DONE
```
Every transition is validated. Invalid transitions raise `InvalidStateTransitionError` immediately.
---
## Security Architecture
| Threat | Mitigation |
| :----------------------- | :------------------------------------------------------------ |
| Malicious model output | Schema validation before any tool execution |
| Path traversal | `Path.resolve()` + allowlist check before subprocess |
| Prompt injection | Syntactic scanner + structural separation + schema validation |
| Command injection | `shell=False` always; args as `list[str]`, never concatenated |
| API key leaks | Secrets scrubber in every log record — cannot be bypassed |
| Malicious plugins | Subprocess isolation + permission boundaries enforced at load |
| Audit tampering | SHA-256 chain hash across all audit records |
**Security invariants that must never be broken:**
1. `shell=False` everywhere. No exceptions.
2. Paths resolved and validated before subprocess spawns.
3. Tool input/output validated against manifest schemas.
4. Audit writes preceded by chain hash computation.
5. `AuditWriteFailureError` always halts the process.
---
## Directory Structure
```text
aria/
├── aria/
│ ├── kernel/
│ │ ├── fsm.py # Session finite state machine
│ │ ├── context.py # Immutable per-step execution context
│ │ └── kernel.py # Agent kernel (orchestrator)
│ ├── models/
│ │ ├── types.py # All shared data contracts (dataclasses)
│ │ ├── errors.py # Typed exception hierarchy
│ │ ├── router.py # Model router: retry + circuit breaker
│ │ └── providers/
│ │ ├── base.py # ModelProviderInterface ABC
│ │ ├── circuit_breaker.py # Per-provider circuit breaker
│ │ ├── anthropic_provider.py # Anthropic Claude adapter
│ │ └── ollama_provider.py # Local Ollama adapter (tinyllama)
│ ├── tools/
│ │ ├── registry.py # Tool registry: load, validate, enforce permissions
│ │ ├── sandbox.py # Subprocess sandbox + path/schema validation
│ │ └── builtin/
│ │ ├── read_file.py
│ │ └── write_file.py
│ ├── memory/
│ │ └── sqlite.py # SQLite memory + audit (WAL, chain hashing)
│ ├── security/
│ │ ├── secrets.py # Env-based secrets loader
│ │ └── scrubber.py # Log scrubber + injection scanner
│ ├── cli/
│ │ ├── main.py # CLI entry point
│ │ ├── bootstrap.py # Dependency wiring
│ │ ├── run_cmd.py
│ │ ├── audit_cmd.py
│ │ ├── tools_cmd.py
│ │ └── config_cmd.py
│ └── logging_setup.py # Structured JSON logging (stdlib)
└── tests/
├── unit/ # FSM, scrubber, CB, memory, manifest validation
├── integration/ # Full kernel with mock provider + real SQLite
└── security/ # Path traversal, injection, tampering, permissions
```
---
## Error Taxonomy
| Error | Retryable | Action |
| :-------------------------- | :-------- | :-------------------------- |
| `ToolInputValidationError` | No | FAILED + log |
| `ToolTimeoutError` | No | FAILED + log |
| `ModelProviderError` (5xx) | Yes (3x) | Retry with backoff |
| `ModelRateLimitError` (429) | Yes (3x) | Retry with backoff |
| `CircuitBreakerOpenError` | No | Try fallback or FAILED |
| `StepLimitExceededError` | No | FAILED + log |
| `InvalidStateTransitionError` | No | CRITICAL + halt |
| `AuditWriteFailureError` | No | CRITICAL + halt |
| `UnknownToolError` | No | FAILED + log |
| `PathTraversalError` | No | FAILED + log |
**No silent failures. No bare `except Exception: pass`. Every error has a name.**
---
## Configuration
All configuration via environment variables:
```bash
ANTHROPIC_API_KEY=sk-ant-... # Required for Anthropic provider
ARIA_PRIMARY_PROVIDER=ollama # Default: ollama
ARIA_PRIMARY_MODEL=tinyllama # Default: tinyllama
ARIA_MAX_STEPS=20 # Default: 20
ARIA_MAX_COST_USD=1.0 # Default: 1.00
ARIA_DB_PATH=~/.aria/aria.db
ARIA_LOG_PATH=~/.aria/logs/aria.jsonl
ARIA_LOG_LEVEL=INFO
```
---
## Writing a Plugin Tool
```python
# my_tool.py — place in a plugin_dirs directory
from aria.models.types import ToolManifest, ToolPermission
class ToolPlugin:
manifest = ToolManifest(
name="word_count",
version="1.0.0",
description="Count words in a text string. Returns integer count.",
permissions=frozenset({ToolPermission.NONE}), # No FS/network access
timeout_seconds=5,
input_schema={
"type": "object",
"properties": {"text": {"type": "string"}},
"required": ["text"],
"additionalProperties": False,
},
output_schema={
"type": "object",
"properties": {"count": {"type": "integer"}},
"required": ["count"],
"additionalProperties": False,
},
)
@staticmethod
def execute(input_data: dict) -> dict:
return {"count": len(input_data["text"].split())}
```
**Plugin rules:**
- Must define `ToolPlugin` class with `manifest: ToolManifest` and `execute(dict) -> dict`
- `execute` runs in a subprocess — it cannot import ARIA internals
- Schema validation happens before and after execution
- Path access validated against `allowed_paths` before subprocess spawns
- `shell=False` always — never use `subprocess.call` with string args
---
## Audit & Observability
Every session produces a complete, append-only audit trail:
```bash
# List recent sessions
aria audit list --last 20
# Export full audit trail (JSON or human-readable text)
aria audit export --session-id <id> --format json
aria audit export --session-id <id> --format text
# Verify audit chain integrity (detect tampering)
aria audit verify --session-id <id>
```
The audit chain uses SHA-256 linking: each record's hash is computed from the previous record's hash and the current record's content. Any modification breaks the chain.
---
## Roadmap
**Month 1 (Foundation — ONLY phase that matters):**
✅ Agent kernel + FSM
✅ ToolManifest validation
✅ Subprocess sandbox
✅ Anthropic + Ollama provider adapters
✅ SQLite memory + audit with chain hashing
✅ Structured JSON logging with secrets scrubber
✅ CLI: run, audit, tools
✅ Unit + integration + security tests
**Month 3 (Stability):** OpenAI adapter, full circuit breaker, schema migration, cost dashboard, fuzzing tests.
**Month 6 (Hardening):** Prometheus metrics, 4 built-in tools, plugin SDK, chaos testing, session resumption.
**Month 12 (Enterprise):** Postgres backend, multi-session concurrency, read-only web UI, RBAC, OpenTelemetry.
---
## Known Limitations (v1)
- **Subprocess ≠ container**: Same-user processes can observe each other. For untrusted plugins, upgrade to namespace isolation (Month 6).
- **No session resumption**: FAILED sessions are terminal. Replay from beginning.
- **Context truncation**: Conversation history truncated when approaching token limits. Crude but deterministic.
- **SQLite only**: Concurrent write throughput bottleneck. Acceptable for single-process v1. `MemoryInterface` abstraction enables Postgres migration.
- **Prompt injection**: Syntactic + structural defenses implemented. Schema validation is the last hard boundary, not the only one.
---
### ARIA Philosophy
*"Stable > Feature-rich. Predictable > Smart. Auditable > Autonomous."*
| text/markdown | null | Shivay Singh <shivcomjputofficial@gmail.com> | null | null | MIT | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"anthropic>=0.25.0",
"click>=8.1.7",
"httpx>=0.27.0",
"pytest>=8.1.0; extra == \"dev\"",
"pytest-cov>=5.0.0; extra == \"dev\"",
"mypy>=1.10.0; extra == \"dev\"",
"ruff>=0.4.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.6 | 2026-02-19T21:54:25.807718 | aria_runtime-0.1.0.tar.gz | 50,820 | 0c/1a/e40daab6ab159b4a8ecd512103158561a87d71f7144022d6b78e40166157/aria_runtime-0.1.0.tar.gz | source | sdist | null | false | ab3e9d96da39f5065618c173b4f63286 | 710ef36b8f1319d024955a321002efc4f4162f78d6d6ead69a4b9b554d64e542 | 0c1ae40daab6ab159b4a8ecd512103158561a87d71f7144022d6b78e40166157 | null | [] | 206 |
2.4 | soma-sdk | 0.1.2 | Python SDK for the Soma network | # soma-sdk
Python SDK for interacting with the Soma network. Built with [PyO3](https://pyo3.rs) and [Maturin](https://www.maturin.rs), providing native-speed bindings to the Rust SDK.
## Install
```bash
pip install soma-sdk
```
Or with [uv](https://docs.astral.sh/uv/):
```bash
uv add soma-sdk
```
**Requires Python ≥ 3.10.**
## Quick Start
```python
import asyncio
from soma_sdk import SomaClient, WalletContext
async def main():
# Connect to a Soma node
client = await SomaClient("http://localhost:9000")
# Query chain info
chain_id = await client.get_chain_identifier()
version = await client.get_server_version()
print(f"Chain: {chain_id}, Version: {version}")
# Check a balance (returns shannons; 1 SOMA = 1_000_000_000 shannons)
balance = await client.get_balance("0xADDRESS")
print(f"Balance: {balance} shannons")
asyncio.run(main())
```
## Classes
### `SomaClient`
Read-only client for querying chain state and submitting pre-signed transactions via gRPC.
```python
client = await SomaClient("http://localhost:9000")
```
#### Chain & Node Info
| Method | Returns | Description |
|--------|---------|-------------|
| `get_chain_identifier()` | `str` | Chain identifier string |
| `get_server_version()` | `str` | Server version string |
| `get_protocol_version()` | `int` | Current protocol version |
| `check_api_version()` | `None` | Raises if client/server versions mismatch |
#### Objects & State
| Method | Returns | Description |
|--------|---------|-------------|
| `get_object(object_id)` | `str` (JSON) | Get object by hex ID |
| `get_object_with_version(object_id, version)` | `str` (JSON) | Get object at a specific version |
| `get_balance(address)` | `int` | Balance in shannons |
| `get_latest_system_state()` | `str` (JSON) | Current global system state |
| `get_epoch(epoch=None)` | `str` (JSON) | Epoch info (`None` for latest) |
| `list_owned_objects(owner, object_type=None, limit=None)` | `list[str]` (JSON) | Objects owned by an address |
`object_type` can be: `"coin"`, `"staked_soma"`, `"target"`, `"submission"`, `"challenge"`, `"system_state"`.
#### Targets & Challenges
| Method | Returns | Description |
|--------|---------|-------------|
| `list_targets(status=None, epoch=None, limit=None)` | `str` (JSON) | List targets with optional filters |
| `get_challenge(challenge_id)` | `str` (JSON) | Get challenge by ID |
| `list_challenges(target_id=None, status=None, epoch=None, limit=None)` | `str` (JSON) | List challenges with optional filters |
#### Checkpoints
| Method | Returns | Description |
|--------|---------|-------------|
| `get_latest_checkpoint()` | `str` (JSON) | Latest checkpoint summary |
| `get_checkpoint_summary(sequence_number)` | `str` (JSON) | Checkpoint by sequence number |
#### Transactions
| Method | Returns | Description |
|--------|---------|-------------|
| `execute_transaction(tx_bytes)` | `str` (JSON) | Execute a signed transaction (BCS bytes) |
| `simulate_transaction(tx_data_bytes)` | `str` (JSON) | Simulate unsigned transaction data (BCS bytes) |
| `get_transaction(digest)` | `str` (JSON) | Get transaction effects by digest |
---
### `WalletContext`
Manages keys, builds transactions, signs, and executes. Wraps a local wallet config file (e.g. `~/.soma/client.yaml`).
```python
wallet = WalletContext("/path/to/client.yaml")
```
#### Key Management
| Method | Returns | Description |
|--------|---------|-------------|
| `get_addresses()` | `list[str]` | All managed addresses |
| `active_address()` | `str` | Currently active address |
| `has_addresses()` | `bool` | Whether any addresses exist |
| `get_gas_objects(address)` | `list[str]` (JSON) | Gas coin objects for an address |
| `save_config()` | `None` | Persist wallet config to disk |
#### Signing & Execution
| Method | Returns | Description |
|--------|---------|-------------|
| `sign_transaction(tx_data_bytes)` | `bytes` | Sign BCS `TransactionData`, returns BCS `Transaction` |
| `sign_and_execute_transaction(tx_data_bytes)` | `str` (JSON) | Sign, execute, and wait for checkpoint inclusion. **Panics on failure.** |
| `sign_and_execute_transaction_may_fail(tx_data_bytes)` | `str` (JSON) | Same as above but returns effects even on failure |
#### Transaction Builders
All builders return `bytes` (BCS-encoded `TransactionData`). Pass the result to `sign_transaction` or `sign_and_execute_transaction`.
The `gas` parameter is always optional — when `None`, a gas coin is auto-selected from the sender's owned coins. When provided, it must be a dict with `{"id": str, "version": int, "digest": str}`.
**Coin & Object Transfers**
```python
# Transfer a coin (optionally a partial amount)
tx = await wallet.build_transfer_coin(sender, recipient, coin, amount=None, gas=None)
# Transfer arbitrary objects
tx = await wallet.build_transfer_objects(sender, recipient, [obj1, obj2], gas=None)
# Multi-recipient payment
tx = await wallet.build_pay_coins(sender, recipients, amounts, coins, gas=None)
```
**Staking**
```python
# Stake with a validator
tx = await wallet.build_add_stake(sender, validator, coin, amount=None, gas=None)
# Withdraw stake
tx = await wallet.build_withdraw_stake(sender, staked_soma, gas=None)
# Stake with a model
tx = await wallet.build_add_stake_to_model(sender, model_id, coin, amount=None, gas=None)
```
**Model Management**
```python
# Register a model (commit-reveal pattern)
tx = await wallet.build_commit_model(
sender, model_id,
weights_url_commitment, # 32-byte hex
weights_commitment, # 32-byte hex
architecture_version, # int
stake_amount, # int (shannons)
commission_rate, # int (BPS, 10000 = 100%)
staking_pool_id, # hex object ID
gas=None,
)
# Reveal model weights (must be called the epoch after commit)
tx = await wallet.build_reveal_model(
sender, model_id,
weights_url, # URL string
weights_checksum, # 32-byte hex
weights_size, # int (bytes)
decryption_key, # 32-byte hex
embedding, # list[float] — model embedding vector
gas=None,
)
# Update model weights (commit-reveal)
tx = await wallet.build_commit_model_update(sender, model_id, weights_url_commitment, weights_commitment, gas=None)
tx = await wallet.build_reveal_model_update(sender, model_id, weights_url, weights_checksum, weights_size, decryption_key, embedding, gas=None)
# Other model operations
tx = await wallet.build_deactivate_model(sender, model_id, gas=None)
tx = await wallet.build_set_model_commission_rate(sender, model_id, new_rate, gas=None)
tx = await wallet.build_report_model(sender, model_id, gas=None)
tx = await wallet.build_undo_report_model(sender, model_id, gas=None)
```
**Mining Submissions**
```python
# Submit data to fill a target
tx = await wallet.build_submit_data(
sender,
target_id,
data_commitment, # 32-byte hex
data_url, # URL string
data_checksum, # 32-byte hex
data_size, # int (bytes)
model_id, # hex object ID
embedding, # list[float]
distance_score, # float
bond_coin, # {"id", "version", "digest"} dict
gas=None,
)
# Claim rewards from a filled/expired target
tx = await wallet.build_claim_rewards(sender, target_id, gas=None)
# Report/undo-report a fraudulent submission
tx = await wallet.build_report_submission(sender, target_id, challenger=None, gas=None)
tx = await wallet.build_undo_report_submission(sender, target_id, gas=None)
```
**Challenges**
```python
# Initiate a challenge against a filled target
tx = await wallet.build_initiate_challenge(sender, target_id, bond_coin, gas=None)
# Validator reports that challenger is wrong
tx = await wallet.build_report_challenge(sender, challenge_id, gas=None)
tx = await wallet.build_undo_report_challenge(sender, challenge_id, gas=None)
# Resolve and claim challenge bond
tx = await wallet.build_claim_challenge_bond(sender, challenge_id, gas=None)
```
**Validator Management**
```python
tx = await wallet.build_add_validator(sender, pubkey_bytes, network_pubkey_bytes, worker_pubkey_bytes, net_address, p2p_address, primary_address, proxy_address, gas=None)
tx = await wallet.build_remove_validator(sender, pubkey_bytes, gas=None)
tx = await wallet.build_update_validator_metadata(sender, gas=None, next_epoch_network_address=None, ...)
tx = await wallet.build_set_commission_rate(sender, new_rate, gas=None)
tx = await wallet.build_report_validator(sender, reportee, gas=None)
tx = await wallet.build_undo_report_validator(sender, reportee, gas=None)
```
## End-to-End Example
```python
import asyncio
import json
from soma_sdk import SomaClient, WalletContext
async def transfer_soma():
client = await SomaClient("http://localhost:9000")
wallet = WalletContext("~/.soma/client.yaml")
sender = await wallet.active_address()
# Find a gas coin
gas_objects = await wallet.get_gas_objects(sender)
coin = json.loads(gas_objects[0])
# Build, sign, and execute
tx_bytes = await wallet.build_transfer_coin(
sender=sender,
recipient="0xRECIPIENT",
coin=coin,
amount=1_000_000_000, # 1 SOMA
)
effects_json = await wallet.sign_and_execute_transaction(tx_bytes)
print(json.loads(effects_json))
asyncio.run(transfer_soma())
```
## Building from Source
Requires Rust and Python ≥ 3.10.
```bash
# Install maturin
pip install maturin
# Development build (editable install)
cd python-sdk
maturin develop
# Release build
maturin build --release
```
## License
Apache-2.0
| text/markdown; charset=UTF-8; variant=GFM | Soma Contributors | null | null | null | Apache-2.0 | null | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/soma-org/soma",
"Repository, https://github.com/soma-org/soma"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:54:10.201167 | soma_sdk-0.1.2-cp313-cp313t-musllinux_1_2_x86_64.whl | 3,590,904 | ae/1d/2dcb5e27b340254d1c4de562b5ca235d136a5fda625af1216e1911fc3535/soma_sdk-0.1.2-cp313-cp313t-musllinux_1_2_x86_64.whl | cp313 | bdist_wheel | null | false | c1efdbd5274edd76d4506d2746711c45 | 49b8c1699fb79fcab20e46cc54f84979b5f30f672b1305afcd966a8f21f12260 | ae1d2dcb5e27b340254d1c4de562b5ca235d136a5fda625af1216e1911fc3535 | null | [] | 3,616 |
2.4 | aquapose | 1.0.0 | 3D fish pose estimation via differentiable refractive rendering | # AquaPose
3D fish pose estimation via differentiable refractive rendering. AquaPose fits a parametric fish mesh to multi-view silhouettes from a 13-camera aquarium rig, producing dense 3D trajectories and midline kinematics for behavioral research on cichlids.
## Installation
```bash
pip install aquapose
```
## Quick Start
```python
from aquapose.calibration import load_calibration
from aquapose.segmentation import segment_frame
from aquapose.optimization import optimize_pose
# Load multi-camera calibration (from AquaCal)
cameras = load_calibration("calibration.json")
# Segment fish in a multi-view frame
masks = segment_frame(frame, cameras)
# Reconstruct 3D pose via analysis-by-synthesis
pose = optimize_pose(masks, cameras)
```
## Development
```bash
# Set up the development environment
pip install hatch
hatch env create
hatch run pre-commit install
hatch run pre-commit install --hook-type pre-push
# Run tests, lint, and type check
hatch run test
hatch run lint
hatch run typecheck
```
See [Contributing](docs/contributing.md) for full development guidelines.
## Documentation
<!-- TODO: Uncomment once docs are deployed -->
<!-- Full documentation is available at [aquapose.readthedocs.io](https://aquapose.readthedocs.io). -->
## License
[MIT](LICENSE)
| text/markdown | Tucker Lancaster | null | null | null | MIT | 3d-reconstruction, behavioral-neuroscience, computer-vision, differentiable-rendering, fish, pose-estimation, pytorch | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientifi... | [] | null | null | >=3.11 | [] | [] | [] | [
"h5py>=3.9",
"numpy>=1.24",
"opencv-python>=4.8",
"scipy>=1.11",
"torch>=2.0"
] | [] | [] | [] | [
"Homepage, https://github.com/tlancaster6/aquapose",
"Documentation, https://aquapose.readthedocs.io",
"Repository, https://github.com/tlancaster6/aquapose",
"Issues, https://github.com/tlancaster6/aquapose/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:54:02.669232 | aquapose-1.0.0.tar.gz | 13,549 | 2c/2f/01e6d6fbcde8b429f0c1986a4f0e47943001a8050d00a866599c8fcd780d/aquapose-1.0.0.tar.gz | source | sdist | null | false | ad59d34189115365bf8f5d10b7838043 | 3813a6b875f673ad8fc1460a73740decf2611936911eb90c25c73a0d91a28a0a | 2c2f01e6d6fbcde8b429f0c1986a4f0e47943001a8050d00a866599c8fcd780d | null | [
"LICENSE"
] | 210 |
2.4 | llama-index-llms-langchain | 0.7.2 | llama-index llms langchain integration | # LlamaIndex Llms Integration: Langchain
## Installation
1. Install the required Python packages:
```bash
%pip install llama-index-llms-langchain
```
## Usage
### Import Required Libraries
```python
from langchain.llms import OpenAI
from llama_index.llms.langchain import LangChainLLM
```
### Initialize LangChain LLM
To create an instance of `LangChainLLM` with OpenAI:
```python
llm = LangChainLLM(llm=OpenAI())
```
### Generate Streaming Response
To generate a streaming response, use the following code:
```python
response_gen = llm.stream_complete("Hi this is")
for delta in response_gen:
print(delta.delta, end="")
```
### LLM Implementation example
https://docs.llamaindex.ai/en/stable/examples/llm/langchain/
| text/markdown | null | Your Name <you@example.com> | null | null | null | null | [] | [] | null | null | <4.0,>=3.9 | [] | [] | [] | [
"langchain>=0.1.7",
"llama-index-core<0.15,>=0.13.0"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:53:44.951729 | llama_index_llms_langchain-0.7.2.tar.gz | 6,067 | 0b/b9/87b76f270a424d07ed8e9524576136b9de675ad50f9da3c29708e5fbfbb2/llama_index_llms_langchain-0.7.2.tar.gz | source | sdist | null | false | d2a1e5825e243dcc6b9498711d4f48ad | 86f2e5654c22d63dfaa94772569401d6148ef146bc04c427a5673503f23db00f | 0bb987b76f270a424d07ed8e9524576136b9de675ad50f9da3c29708e5fbfbb2 | MIT | [
"LICENSE"
] | 2,124 |
2.4 | freeplay-langgraph | 0.5.1 | Freeplay integration for LangGraph and LangChain | # Freeplay LangGraph Integration
Freeplay integration for LangGraph and LangChain, providing observability and prompt management for your AI applications.
## Installation
**Requirements:** Python 3.10 or higher
```bash
pip install freeplay-langgraph
```
## Features
- **🔍 Automatic Observability**: OpenTelemetry instrumentation for LangChain and LangGraph applications
- **📝 Prompt Management**: Call Freeplay-hosted prompts with version control and environment management
- **🤖 Auto-Model Instantiation**: Automatically create LangChain models based on Freeplay's configuration
- **🤖 Full Agent Support**: Create LangGraph agents with ReAct loops, tool calling, and state management
- **⚡ Complete Async Support**: All methods support async/await (ainvoke, astream, abatch, etc.)
- **💬 Conversation History**: Native support for multi-turn conversations with LangGraph MessagesState
- **🛠️ Tool Support**: Seamless integration with LangChain tools
- **🎛️ Middleware**: Support for custom middleware to extend agent behavior
- **📊 Structured Output**: ToolStrategy and ProviderStrategy for formatted responses
- **🌊 Streaming**: Stream agent execution step-by-step or token-by-token (both simple and agent modes)
- **🧪 Test Execution Tracking**: Track test runs and test cases for evaluation workflows
- **🎯 Multi-Provider Support**: Works with OpenAI, Anthropic, Vertex AI, and more
- **🔒 Type Safety**: Full generic typing support with proper IDE autocomplete
## Quick Start
### Configuration
Set up your environment variables:
```bash
export FREEPLAY_API_URL="https://app.freeplay.ai/api"
export FREEPLAY_API_KEY="fp-..."
export FREEPLAY_PROJECT_ID="..."
```
Or pass them directly when initializing:
```python
from freeplay_langgraph import FreeplayLangGraph
freeplay = FreeplayLangGraph(
freeplay_api_url="https://app.freeplay.ai/api",
freeplay_api_key="fp-...",
project_id="...",
)
```
#### Bundled Prompts
By default, FreeplayLangGraph uses the API-based template resolver to fetch prompts from Freeplay. If you need to use bundled prompts or custom prompt resolution logic, you can provide your own template resolver:
```python
from pathlib import Path
from freeplay.resources.prompts import FilesystemTemplateResolver
from freeplay_langgraph import FreeplayLangGraph
# Use filesystem-based prompts (e.g., bundled with your app)
freeplay = FreeplayLangGraph(
template_resolver=FilesystemTemplateResolver(Path("bundled_prompts"))
)
```
## Usage
### Creating Agents with `create_agent`
The recommended way to use Freeplay with LangGraph is through the `create_agent` method, which uses Freeplay-hosted prompts via `prompt_name` and provides full support for LangGraph's agent capabilities including the ReAct loop, tool calling, middleware, structured output, and streaming.
```python
from freeplay_langgraph import FreeplayLangGraph
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
from langgraph.checkpoint.memory import MemorySaver
@tool
def get_weather(city: str) -> str:
"""Get the current weather for a city."""
return f"Weather in {city}: Sunny, 72°F"
freeplay = FreeplayLangGraph()
# Create agent (no variables parameter)
agent = freeplay.create_agent(
prompt_name="weather-assistant",
tools=[get_weather],
checkpointer=MemorySaver(),
environment="production"
)
# Invoke with variables in input dict
result = agent.invoke({
"messages": [HumanMessage(content="What's the weather?")],
"variables": {"location": "San Francisco", "company": "Acme Corp"}
})
# Template-only invocation (no messages key)
result = agent.invoke({
"variables": {"location": "New York", "company": "Acme Corp"}
})
print(result["messages"][-1].content)
```
**Note:** The system prompt and template messages are re-rendered on each model call using the variables from your input dict. Variables persist in checkpoint state automatically.
#### Streaming Agent Execution
Stream agent steps in real-time:
```python
agent = freeplay.create_agent(
prompt_name="weather-assistant",
tools=[get_weather]
)
# Stream with variables in input dict
for chunk in agent.stream(
{
"messages": [HumanMessage(content="What's the weather?")],
"variables": {"city": "Seattle", "company": "Acme"}
},
stream_mode="values"
):
latest_message = chunk["messages"][-1]
if hasattr(latest_message, "content") and latest_message.content:
print(f"Agent: {latest_message.content}")
elif hasattr(latest_message, "tool_calls") and latest_message.tool_calls:
print(f"Calling tools: {[tc['name'] for tc in latest_message.tool_calls]}")
```
#### Custom Middleware
Add custom behavior to your agent with middleware (requires LangChain 1.0+):
```python
from langchain.agents.middleware import AgentMiddleware
class LoggingMiddleware(AgentMiddleware):
"""Custom middleware that logs before model calls."""
def before_model(self, state, runtime):
message_count = len(state.get("messages", []))
print(f"About to call model with {message_count} messages")
return None
def after_model(self, state, runtime):
return None
def wrap_tool_call(self, request, handler):
return handler(request)
agent = freeplay.create_agent(
prompt_name="weather-assistant",
tools=[get_weather],
middleware=[LoggingMiddleware()]
)
# Invoke with variables
result = agent.invoke({
"messages": [HumanMessage("What's the weather?")],
"variables": {"city": "Boston", "company": "Acme"}
})
```
#### Structured Output
Get structured responses using `ToolStrategy` or `ProviderStrategy`:
```python
from pydantic import BaseModel
from langchain.agents.structured_output import ToolStrategy
class WeatherReport(BaseModel):
city: str
temperature: float
conditions: str
agent = freeplay.create_agent(
prompt_name="weather-assistant",
tools=[get_weather],
response_format=ToolStrategy(WeatherReport)
)
result = agent.invoke({
"messages": [HumanMessage(content="Get weather")],
"variables": {"city": "NYC", "company": "Acme"}
})
# Access structured output
weather_report = result["structured_response"]
print(f"{weather_report.city}: {weather_report.temperature}°F, {weather_report.conditions}")
```
### Prompt Management with Auto-Model Instantiation
For simple use cases without the full agent loop, use the `invoke` method:
Call a Freeplay-hosted prompt and let the SDK automatically instantiate the correct model:
```python
from freeplay_langgraph import FreeplayLangGraph
freeplay = FreeplayLangGraph()
# Invoke a prompt - model is automatically created based on Freeplay's config
response = freeplay.invoke(
prompt_name="weather-assistant",
variables={"city": "San Francisco"},
environment="production"
)
```
#### Async Support
All methods support async/await for better performance in async applications:
```python
# Async invocation
response = await freeplay.ainvoke(
prompt_name="weather-assistant",
variables={"city": "San Francisco"}
)
# Async streaming
async for chunk in freeplay.astream(
prompt_name="weather-assistant",
variables={"city": "San Francisco"}
):
print(chunk.content, end="", flush=True)
```
#### Streaming Simple Invocations
Stream model responses without the full agent loop:
```python
# Synchronous streaming
for chunk in freeplay.stream(
prompt_name="weather-assistant",
variables={"city": "San Francisco"}
):
print(chunk.content, end="", flush=True)
# Async streaming
async for chunk in freeplay.astream(
prompt_name="weather-assistant",
variables={"city": "San Francisco"}
):
print(chunk.content, end="", flush=True)
```
### Using Custom Models
You can also provide your own pre-configured model:
```python
from langchain_openai import ChatOpenAI
from freeplay_langgraph import FreeplayLangGraph
freeplay = FreeplayLangGraph()
model = ChatOpenAI(model="gpt-4", temperature=0.7)
response = freeplay.invoke(
prompt_name="weather-assistant",
variables={"city": "New York"},
model=model
)
```
### Conversation History (Multi-turn Chat)
Maintain conversation context with history:
```python
from langchain_core.messages import HumanMessage, AIMessage
from freeplay_langgraph import FreeplayLangGraph
freeplay = FreeplayLangGraph()
# Build conversation history
history = [
HumanMessage(content="What's the weather in Paris?"),
AIMessage(content="It's sunny and 22°C in Paris."),
HumanMessage(content="What about in winter?")
]
response = freeplay.invoke(
prompt_name="weather-assistant",
variables={"city": "Paris"},
history=history
)
```
### Tool Calling
Bind LangChain tools to your prompts:
```python
from langchain_core.tools import tool
from freeplay_langgraph import FreeplayLangGraph
@tool
def get_weather(city: str) -> str:
"""Get the current weather for a city."""
# Your weather API logic here
return f"Weather in {city}: Sunny, 22°C"
freeplay = FreeplayLangGraph()
response = freeplay.invoke(
prompt_name="weather-assistant",
variables={"city": "London"},
tools=[get_weather]
)
```
### Test Execution Tracking
Track test runs for evaluation workflows by pulling test cases from Freeplay and executing them with automatic tracking.
#### Creating Test Runs
```python
import os
from freeplay_langgraph import FreeplayLangGraph
from langchain_core.messages import HumanMessage
freeplay = FreeplayLangGraph()
# Create a test run from a dataset
test_run = freeplay.client.test_runs.create(
project_id=os.getenv("FREEPLAY_PROJECT_ID"),
testlist="name of the dataset",
name="name your test run",
)
print(f"Created test run: {test_run.id}")
```
#### Executing Test Cases with Simple Invocations
For simple prompt invocations, use the test tracking parameters directly:
```python
# Execute each test case
for test_case in test_run.test_cases:
response = freeplay.invoke(
prompt_name="my-prompt",
variables=test_case.variables,
test_run_id=test_run.id,
test_case_id=test_case.id
)
print(f"Test case {test_case.id}: {response.content}")
```
#### Executing Test Cases with Agents
For LangGraph agents, pass test tracking metadata via config and use dynamic variables per test case:
```python
from langchain_core.messages import HumanMessage
# Create agent once
agent = freeplay.create_agent(
prompt_name="my-prompt",
tools=[get_weather],
)
# Execute each test case with variables in input
for test_case in test_run.trace_test_cases:
result = agent.invoke(
{
"messages": [HumanMessage(content=test_case.input)],
"variables": test_case.variables
},
config={
"metadata": {
"freeplay.test_run_id": test_run.id,
"freeplay.test_case_id": test_case.id
}
}
)
print(f"Test case {test_case.id}: {result['messages'][-1].content}")
```
## API Reference
### `create_agent()`
Create a LangGraph agent with Freeplay-hosted prompt and full observability.
**Parameters:**
- `prompt_name` (str): Name of the prompt in Freeplay
- `tools` (list, optional): List of tools for the agent to use
- `environment` (str, optional): Environment to use (default: "latest")
- `model` (BaseChatModel, optional): Pre-instantiated model (auto-created if not provided)
- `state_schema` (type, optional): Custom state schema (TypedDict)
- `context_schema` (type, optional): Context schema for runtime context
- `middleware` (list, optional): List of middleware to apply (Freeplay middleware prepended automatically)
- `response_format` (optional): Structured output format (ToolStrategy or ProviderStrategy)
- `checkpointer` (BaseCheckpointSaver, optional): Checkpointer for state persistence
- `validate_tools` (bool, optional): Validate tools against Freeplay schema (default: True)
**Returns:** `FreeplayAgent` - A wrapper around the compiled LangGraph agent that injects Freeplay metadata
**Variables in Input Dict:**
Pass variables in the input dict alongside messages. The Freeplay prompt is re-rendered on each model call:
```python
# With messages and variables
result = agent.invoke({
"messages": [HumanMessage("Question")],
"variables": {"location": "SF", "company": "Acme"}
})
# Template-only (no messages key)
result = agent.invoke({
"variables": {"location": "NYC", "company": "Acme"}
})
# Streaming
for chunk in agent.stream(
{
"messages": [...],
"variables": {...}
},
stream_mode="values"
):
print(chunk)
# Batch (each input can have different variables)
results = agent.batch([
{"messages": [...], "variables": {"location": "SF"}},
{"messages": [...], "variables": {"location": "NYC"}}
])
```
**Note:** For state management methods, use `unwrap()` - see [State Management](#state-management) below.
### `invoke()` / `ainvoke()` (Simple Invocations)
Invoke a model with a Freeplay-hosted prompt (simple use cases without agent loop).
**Parameters:**
- `prompt_name` (str): Name of the prompt in Freeplay
- `variables` (dict): Variables to render the prompt template (re-rendered on each call)
- `environment` (str, optional): Environment to use (default: "latest")
- `model` (BaseChatModel, optional): Pre-instantiated model
- `history` (list, optional): Conversation history
- `tools` (list, optional): Tools to bind to the model
- `test_run_id` (str, optional): Test run ID for tracking
- `test_case_id` (str, optional): Test case ID for tracking
**Returns:** The model's response message
**Async:** Use `ainvoke()` with the same parameters for async execution.
### `stream()` / `astream()`
Stream model responses with a Freeplay-hosted prompt (simple use cases).
**Parameters:** Same as `invoke()`
**Yields:** Chunks from the model's streaming response
**Async:** Use `astream()` with the same parameters for async streaming.
## State Management
When using agents with checkpointers, you can access LangGraph's state management features via the `unwrap()` method. This is necessary because `FreeplayAgent` extends `RunnableBindingBase` (LangChain's official wrapper pattern) which provides automatic metadata injection but doesn't directly expose CompiledStateGraph-specific methods.
### Core Invocation (Works Directly)
All standard invocation methods work without `unwrap()`:
```python
agent = freeplay.create_agent(
prompt_name="assistant",
checkpointer=MemorySaver()
)
# ✅ All of these work directly - no unwrap needed
result = agent.invoke({
"messages": [...],
"variables": {"location": "SF", "company": "Acme"}
})
stream = agent.stream({"messages": [...], "variables": {...}})
batched = agent.batch([{"messages": [...], "variables": {...}}])
graph = agent.get_graph()
```
### State Management (Requires unwrap())
For CompiledStateGraph-specific methods, use `unwrap()`:
#### Inspecting Agent State
```python
from langgraph.checkpoint.memory import MemorySaver
agent = freeplay.create_agent(
prompt_name="assistant",
checkpointer=MemorySaver()
)
config = {"configurable": {"thread_id": "user-123"}}
# Run agent with variables in input
agent.invoke(
{
"messages": [HumanMessage(content="Hello")],
"variables": {"user_tier": "premium", "company": "Acme"}
},
config=config
)
# Inspect state via unwrap()
state = agent.unwrap().get_state(config)
print(f"Current messages: {state.values['messages']}")
print(f"Variables in state: {state.values.get('variables', {})}")
print(f"Next steps: {state.next}")
```
#### Human-in-the-Loop Workflows
```python
agent = freeplay.create_agent(
prompt_name="booking-assistant",
tools=[book_flight],
checkpointer=MemorySaver()
)
config = {"configurable": {"thread_id": "booking-456"}}
# Agent runs and stops before booking (if configured with interrupt_before)
result = agent.invoke(
{
"messages": [HumanMessage(content="Book flight to Paris")],
"variables": {"user_tier": "premium", "company": "Acme Travel"}
},
config={**config, "interrupt_before": ["book_flight"]}
)
# Review and approve
print("Agent wants to book flight. Approve? (y/n)")
if input() == "y":
# Update state to continue
agent.unwrap().update_state(
config,
{"approval": "granted"},
as_node="human"
)
# Resume execution
result = agent.invoke(None, config=config)
```
#### Multi-Agent Systems
```python
# For agents with nested subgraphs
coordinator_agent = freeplay.create_agent(
prompt_name="coordinator",
variables={"role": "orchestrator"}
)
# Access subgraph information
subgraphs = coordinator_agent.unwrap().get_subgraphs(recurse=True)
print(f"Available sub-agents: {list(subgraphs.keys())}")
```
#### State History
```python
# View execution history
config = {"configurable": {"thread_id": "thread-123"}}
for state in agent.unwrap().get_state_history(config, limit=5):
print(f"Checkpoint: {state.config['configurable']['checkpoint_id']}")
print(f"Messages: {len(state.values['messages'])}")
```
### Methods Requiring unwrap()
**State Access:**
- `get_state(config)` / `aget_state(config)` - Get current state snapshot
- `get_state_history(config)` / `aget_state_history(config)` - View history
**State Modification:**
- `update_state(config, values)` / `aupdate_state(config, values)` - Manual state updates
- `bulk_update_state(config, updates)` / `abulk_update_state(config, updates)` - Batch updates
**Advanced Features:**
- `get_subgraphs()` / `aget_subgraphs()` - Access nested agents
- `clear_cache()` / `aclear_cache()` - Clear LLM response cache
### Type Safety with unwrap()
For full type hints when using state methods:
```python
from typing import cast
from langgraph.graph.state import CompiledStateGraph
agent = freeplay.create_agent(...)
# Option 1: Direct unwrap (works at runtime)
state = agent.unwrap().get_state(config)
# Option 2: Cast for full type hints
compiled = cast(CompiledStateGraph, agent.unwrap())
state = compiled.get_state(config) # ✅ Full IDE autocomplete
```
## Observability
The SDK automatically instruments your LangChain and LangGraph applications with OpenTelemetry. All traces are sent to Freeplay with the following metadata:
- Input variables
- Prompt template version ID
- Environment name
- Test run and test case IDs (if provided)
All metadata is injected automatically without requiring extra configuration or manual instrumentation.
## Architecture
The library uses LangChain's official `RunnableBindingBase` pattern to inject Freeplay metadata into all agent invocations. This provides:
- **LangChain-Idiomatic**: Uses the same pattern as `.bind()`, `.with_config()`, `.with_retry()` throughout LangChain
- **Automatic Coverage**: ALL Runnable methods work automatically (invoke, ainvoke, stream, astream, batch, abatch, astream_events, transform, atransform, etc.)
- **Type Safety**: Generic typing with proper IDE autocomplete for invocation methods
- **No Config Mutation**: User configurations are never modified
- **Future-Proof**: New LangChain methods automatically supported via inheritance
- **State Management via unwrap()**: Access to CompiledStateGraph-specific methods for checkpointing and state operations
**Key Points:**
- `FreeplayAgent` extends `RunnableBindingBase` and uses `config_factories` for metadata injection
- Client methods (`invoke`, `stream`, etc.) use `.with_config()` to bind metadata (LangChain's official pattern)
- Both approaches follow LangChain's patterns used throughout the ecosystem
## Provider Support
The SDK supports automatic model instantiation for the following providers:
- **OpenAI**: Requires `langchain-openai` package
- **Anthropic**: Requires `langchain-anthropic` package
- **Vertex AI**: Requires `langchain-google-vertexai` package
Install the required provider package:
```bash
pip install langchain-openai
# or
pip install langchain-anthropic
# or
pip install langchain-google-vertexai
```
| text/markdown | null | Engineering at Freeplay <engineering@freeplay.ai> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"freeplay>=0.5.8",
"langchain-community>=0.3.0",
"langchain-core>=0.3.0",
"langchain>=1.0.0",
"langgraph>=0.2.0",
"openinference-instrumentation-langchain>=0.1.0",
"opentelemetry-exporter-otlp-proto-http>=1.35.0",
"opentelemetry-sdk>=1.35.0"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:52:59.544997 | freeplay_langgraph-0.5.1-py3-none-any.whl | 22,051 | 51/fb/fae26d5c891c72ded4a1f6aa0dfea528603073eafcb97e95367e1bd25b0c/freeplay_langgraph-0.5.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 3013c0385c4bbb8e7e68a382a3d26167 | 9b3f18a1ed54d252e3a47355527c7c06a85b37b070d1ea56e008ca7866e41352 | 51fbfae26d5c891c72ded4a1f6aa0dfea528603073eafcb97e95367e1bd25b0c | null | [] | 260 |
2.4 | freeplay-python-adk | 0.2.3 | Freeplay integration for Google ADK | This folder contains the Freeplay Python ADK, which provides integration between Freeplay and Google ADK.
You can use it to instrument your Google ADK agents and send traces to Freeplay to observe and analyze your agent's behavior.
If you choose, you can also move your prompts into Freeplay for centralized management and versioning, which can help
you run experiments efficiently and let your whole team collaborate on your agent's prompts, even for users that don't feel comfortable writing code.
# Setup
## Setup ADK
First, make sure you can run a simple agent [Python Quickstart for ADK](https://google.github.io/adk-docs/get-started/python/).
If you already have an agent that you want to observe using Freeplay, you can move on to the next step.
## Sign up for Freeplay
Sign up for an account on [Freeplay](https://freeplay.ai). It's free to get started.
Once you've signed up and created a project in Freeplay, copy the project ID from the URL. For example, if your project has the URL
https://app.freeplay.ai/projects/532982fa-a847-4e87-9c44-7e79b98cc965/sessions, your project ID would be `532982fa-a847-4e87-9c44-7e79b98cc965`.
Create an API key on the [Freeplay API Access page](https://app.freeplay.ai/settings/api-access).
Set the project ID, API URL and API key in your environment file:
```
FREEPLAY_PROJECT_ID=
FREEPLAY_API_URL=https://app.freeplay.ai/api
FREEPLAY_API_KEY=
```
If you are using a private Freeplay instance, set the `FREEPLAY_API_URL` to your instance's URL, for example: `https://my-company.freeplay.ai/api`.
## Install the library
You can install the Freeplay Python ADK using pip:
```bash
pip install freeplay-python-adk
```
Or uv:
```bash
uv add freeplay-python-adk
```
## Instrument your agent
Instrument your code to use the Freeplay Python ADK library.
We recommend doing this in the config.py file that runs before your agent is initialized.
```python
from freeplay_python_adk import FreeplayADK
FreeplayADK.initialize_observability()
```
Add the FreeplayObservabilityPlugin to your app's plugins:
```python
from freeplay_python_adk.freeplay_observability_plugin import FreeplayObservabilityPlugin
from google.adk.apps import App
app = App(
name="my_agent_app",
root_agent=my_agent,
plugins=[FreeplayObservabilityPlugin()],
)
```
And run your app! You should see traces show up in the Freeplay application.
You can run your app from this directory like so: `uv run adk run examples`. | text/markdown | null | Nico Tonozzi <nico@freeplay.ai> | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"freeplay>=0.5.8",
"google-adk>=1.8.0",
"litellm>=1.77.1",
"openinference-instrumentation-google-adk>=0.1.3",
"opentelemetry-exporter-otlp-proto-http>=1.35.0",
"opentelemetry-sdk>=1.35.0"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:52:52.864958 | freeplay_python_adk-0.2.3.tar.gz | 476,602 | 75/9b/19b9fa770465a55eff4f6072024efe73417eaf171af06664c8f2a949265c/freeplay_python_adk-0.2.3.tar.gz | source | sdist | null | false | 70da8553a5b65be4a6030e29b98b53af | 9888e34247877f72d3ce0c692f5efcaf9e89387d78bc4683b8186f8655201cfa | 759b19b9fa770465a55eff4f6072024efe73417eaf171af06664c8f2a949265c | null | [] | 180 |
2.3 | genrepo | 0.1.6 | Add your description here | # Genrepo
Generate typed, readable data-access repositories for FastAPI apps using SQLModel or SQLAlchemy. Genrepo removes CRUD boilerplate by rendering Jinja2 templates into real Python code that follows the Repository Pattern. It supports three generation modes (standalone, base-only, combined) and an optional stub-only mode (no ORM, structure only).
Explore concrete configurations in the `examples/` folder to see common scenarios and how to tailor `genrepo.yaml`.
---
## What it is / isn’t
- Is: a small CLI that
- Reads a `genrepo.yaml` configuration.
- Renders Jinja2 templates to per-model repository files.
- Standardizes naming, docstrings, and common CRUD methods.
- Isn’t:
- An ORM.
- An API router/service generator.
- A migration or database session/engine manager.
## Requirements
- Python 3.10+ (tested on 3.10–3.13).
- Dependencies managed via `uv` (recommended) or classic `pip`.
## Installation
Install from PyPI (recommended):
```bash
pip install genrepo
```
Install via pipx (isolated):
```bash
pipx install genrepo
```
Install from local artifacts (dist/):
```bash
pip install dist/genrepo-0.1.6-py3-none-any.whl
# or
pip install dist/genrepo-0.1.6.tar.gz
```
## Quickstart (installed)
```bash
# Verify installation
genrepo healthcheck --verbose
# 1) Create a starter genrepo.yaml (combined + example)
genrepo init-config
# 2) Open and configure genrepo.yaml (models, methods, etc.)
# Then generate repositories from the YAML
genrepo generate
```
## Quickstart (uv)
```bash
# Install deps from uv.lock (creates .venv)
uv sync
# Verify environment
uv run genrepo healthcheck --verbose
# 1) Create a starter genrepo.yaml (combined + example)
uv run genrepo init-config
# 2) Open and configure genrepo.yaml (models, methods, etc.)
# Then generate repositories from the YAML
uv run genrepo generate
```
Or activate the venv manually:
```bash
source .venv/bin/activate
genrepo healthcheck --verbose
```
Upgrading from older Python: after bumping to 3.12.9, regenerate the lockfile and environment:
```bash
uv sync --python 3.12.9
```
## CLI Commands
### healthcheck
Checks CLI readiness. With `--verbose` prints versions.
Installed:
```bash
genrepo healthcheck
genrepo healthcheck --verbose
```
From repo (dev):
```bash
uv run genrepo healthcheck
uv run genrepo healthcheck --verbose
```
### init-config
Creates a `genrepo.yaml` sample (combined mode by default). If the file already exists, it does not overwrite it unless `--force` is provided.
Options:
- `--path/-p`: target path (default `genrepo.yaml`).
- `--force/-f`: overwrite existing file.
Installed:
```bash
genrepo init-config
genrepo init-config --path config/genrepo.yaml
```
From repo (dev):
```bash
uv run genrepo init-config
uv run genrepo init-config --path config/genrepo.yaml
```
### generate
Reads `genrepo.yaml` and generates repositories according to the selected mode.
Options:
- `--config/-c`: path to `genrepo.yaml` (default `genrepo.yaml`).
- `--templates-dir`: override templates directory (e.g., `./templates`).
- `--force/-f`: overwrite existing generated files (only where applicable).
- `--stub-only`: generate stub-only repositories (structure only, no ORM logic).
Installed:
```bash
genrepo generate
genrepo generate --stub-only
```
From repo (dev):
```bash
uv run genrepo generate
uv run genrepo generate --stub-only
```
## Configuration (`genrepo.yaml`)
Top-level fields:
- `orm`: `sqlmodel` or `sqlalchemy` (ignored if `generation.stub_only: true`).
- `async_mode`: `true|false` to enable AsyncSession and async/await (per ORM).
- `output_dir`: destination folder for generated repositories.
- `generation`:
- `mode`: `standalone | base | combined`.
- `base_filename`: base filename (default `base_repository.py`).
- `base_class_name`: base class name (default `BaseRepository`).
- `overwrite_base`: overwrite base on regeneration (default `false`).
- `stub_only`: generate skeletons only (structure; no ORM logic).
- Discovery: `models: all` with `models_package` and `models_dir` to discover all models under a package/directory.
- Explicit list: `models: []` to define per-model config.
- `commit_strategy`: `commit|flush|none` (default: `none`). Typically your app/service controls transactions.
- `allow_missing_models`: if `true`, do not fail when an explicit `import_path` cannot be imported.
Per-model (`models[]`):
- `name`, `import_path` (`module.path:Class`), `id_field`, `id_type`.
- `methods`: only base CRUD presets are allowed: `get`, `get_or_raise`, `list`, `find_one`, `create`, `update`, `delete`, `delete_by_id`, `exists`, `count`, plus presets `all` and `none`.
- `personalize_methods`: custom repo-only stubs (combined: user repo, standalone: appended at bottom).
Default sample created by `generate` (combined + wildcard):
```yaml
orm: sqlmodel
async_mode: false
commit_strategy: none
output_dir: app/repositories
generation:
mode: combined
base_filename: base_repository.py
base_class_name: BaseRepository
models:
- name: All
import_path: app.models
id_field: id
id_type: int
methods: [none]
personalize_methods: [calculate_something]
```
Alternative discovery:
```yaml
models: all
models_package: app.models
models_dir: app/models
```
Explicit per-model customization (some base methods + one personalized):
```yaml
orm: sqlmodel
output_dir: app/repositories
generation:
mode: standalone
models:
- name: User
import_path: app.models.user:User # module:Class
id_field: id
id_type: int
methods: [get, list] # pick from the base set
personalize_methods: [calculate_age]
```
## Methods you can generate (base set)
Reading:
- `get(session, id) -> Optional[Model]`: Fetch by primary key, or `None`.
- `get_or_raise(session, id) -> Model`: Same as `get` but raises `NotFoundError` when missing.
- `list(session, *where, limit=100, offset=0) -> list[Model]`: Paginated list with optional SQLAlchemy filter clauses.
- `find_one(session, *where) -> Optional[Model]`: First row matching filters, or `None`.
Writing:
- `create(session, obj) -> Model`: Persist and refresh.
- `update(session, db_obj, obj_in: dict[str, Any]) -> Model`: Apply changes and refresh.
- `delete(session, db_obj) -> None`: Delete by instance.
- `delete_by_id(session, id) -> bool`: Delete by PK; returns `True` if removed.
Utilities:
- `exists(session, *where) -> bool`: Any row matches filters.
- `count(session, *where) -> int`: Count rows matching filters.
Notes:
- In standalone, `methods` limits which of the above are generated in each repository.
- In combined, the base repository exposes the full set; `personalize_methods` adds repo-only stubs in the user repo.
- In stub-only, only method signatures are generated (TODO + pass), without ORM imports or logic.
## Templates
Packaged defaults cover the following scenarios:
- Base repositories per ORM and sync/async.
- Standalone repositories per ORM (async controlled by context).
- Combined user repository stub.
- Stub-only base and standalone (no ORM).
Local overrides (optional): use `--templates-dir ./templates` in `generate` to point to your own copies.
## Template Map
- Base + SQLModel + sync: `base_repository_sqlmodel_sync.j2`
- Base + SQLModel + async: `base_repository_sqlmodel_async.j2`
- Base + SQLAlchemy + sync: `base_repository_sqlalchemy_sync.j2`
- Base + SQLAlchemy + async: `base_repository_sqlalchemy_async.j2`
- Standalone + SQLModel: `repository_sqlmodel.j2`
- Standalone + SQLAlchemy: `repository_sqlalchemy.j2`
- Combined (user repo): `model_repository_user_stub.j2`
- Stub-only (base): `repository_base_stub.j2`
- Stub-only (standalone): `repository_standalone_stub.j2`
## Output
- Location: `output_dir` (default `app/repositories`).
- File name: `<model>_repository.py` (snake_case).
- Class name: `<Model>NameRepository` (PascalCase).
Example (User, standalone):
```python
from sqlmodel import Session, select
from app.models.user import User
class UserRepository:
def get(self, session: Session, id: int) -> User | None: ...
def list(self, session: Session, *where, limit: int = 100, offset: int = 0) -> list[User]: ...
def create(self, session: Session, obj_in: User) -> User: ...
def update(self, session: Session, db_obj: User, obj_in: dict[str, Any]) -> User: ...
def delete_by_id(self, session: Session, id: int) -> bool: ...
```
> The imported model (e.g., `app.models.user:User`) must exist in your target project; Genrepo does not create models or configure sessions/engines. Use `allow_missing_models: true` if you want to generate repos even when imports are not yet resolvable.
In combined mode:
- `base_repository.py` → `class BaseRepository[T]` (editable).
- `<model>_repository.py` (user) → `class <Model>Repository(BaseRepository[<Model>])` (created once; extend for your domain).
Stub-only mode generates the same file layout, but with TODO + pass bodies (no ORM logic).
## Flow diagram
```mermaid
flowchart TD
A["genrepo CLI<br/>init-config"] -->|writes once| B["genrepo.yaml<br/>(sample)"]
B -->|edit / configure| C["genrepo CLI<br/>generate"]
C -->|reads| T["Templates (packaged)<br/>- base per ORM/async<br/>- standalone per ORM<br/>- user stub<br/>- stub-only (no ORM)"]
T -->|render| G["Generated files<br/>app/repositories/*.py"]
C -.-> M["select mode:<br/>standalone / base / combined"]
C -->|stub_only=true| S["Use stub-only templates<br/>(signatures only; TODO + pass)"]
C -->|stub_only=false| N["Normal generation<br/>(full templates)"]
S --> T
N --> T
```
Legend: “sa” = standalone.
## Packaging the templates (.j2)
When distributing the library, ensure `.j2` files are included in the wheel/sdist.
Hatchling example:
```toml
[tool.hatch.build.targets.wheel]
packages = ["src/genrepo"]
[tool.hatch.build.targets.wheel.force-include]
"src/genrepo/templates" = "genrepo/templates"
```
Setuptools example:
```
recursive-include src/genrepo/templates *.j2
recursive-include src/genrepo/assets *.yaml
```
## Repository structure (maintainers)
- `src/genrepo/cli/app.py`: Typer CLI. Commands: `init-config` (writes sample YAML), `generate` (generates code), `healthcheck`.
- `src/genrepo/config.py`: Pydantic schema and loader/validation for `genrepo.yaml` (modes, discovery, methods/personalize_methods, errors).
- `src/genrepo/generator.py`: Orchestrates Jinja2 rendering, selects templates by mode/ORM/async or stub-only, writes outputs.
- `src/genrepo/constants.py`: Central constants (messages/errors, CRUD method set, template filenames, sample asset path, ORM IDs).
- `src/genrepo/templates/`: Packaged Jinja2 templates:
- Base per ORM/async: `base_repository_sqlmodel_sync.j2`, `base_repository_sqlmodel_async.j2`, `base_repository_sqlalchemy_sync.j2`, `base_repository_sqlalchemy_async.j2`.
- Standalone per ORM: `repository_sqlmodel.j2`, `repository_sqlalchemy.j2`.
- Combined user repo: `model_repository_user_stub.j2`.
- Stub-only (no ORM): `repository_base_stub.j2`, `repository_standalone_stub.j2`.
- `src/genrepo/assets/genrepo.sample.yaml`: Default YAML sample used by `generate`.
Notes for contributors
- Keep templates focused (no business logic), one responsibility per file.
- Extend via new templates or constants (e.g., adding ORMs) rather than scattering literals.
- Prefer errors/messages from `constants.py` to keep CLI output consistent and localizable.
And configure `package_data`/`include_package_data` accordingly.
## Docker
- Build locally: `docker build -t genrepo:local .`
- Run the CLI against your project (mount current dir):
```
docker run --rm \
-v "$PWD":"$PWD" -w "$PWD" \
genrepo:local generate --check
```
## CI (--check)
Example GitHub Actions job to ensure repositories are up to date:
```
jobs:
validate-architecture:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install Genrepo
run: pip install genrepo
- name: Verify repositories are up to date
run: genrepo generate --check
```
### Exit Codes and CI behavior
- `--dry-run`: computes the plan and prints a summary (or JSON when `--format json`), without writing files.
- `--check`: exits with code 1 if any file would be written (drift detected), otherwise 0.
- `--format json`: stdout is strict JSON suitable for parsing; avoid mixing logs into stdout. If you need logs, send them to stderr.
## Tips
- Local template overrides (`--templates-dir`): copy packaged templates, tweak, and point the CLI to your folder.
```bash
# Copy packaged templates locally
uv run genrepo init-templates --dest ./templates/genrepo
# Add a tiny marker to verify overrides are being used
printf "# LOCAL_TPL\n" | cat - templates/genrepo/repository_sqlmodel.j2 > /tmp/t && mv /tmp/t templates/genrepo/repository_sqlmodel.j2
# Generate using local templates
uv run genrepo generate --templates-dir ./templates/genrepo
```
- Stub-only (skeletons, no ORM):
```bash
uv run genrepo generate --stub-only
# Repositories contain method signatures + TODO/pass, with no SQLModel/SQLAlchemy imports
```
- Discover all models (`models: all`):
In your `genrepo.yaml`:
```yaml
models: all
models_dir: app/models
models_package: app.models
```
All Python files under `models_dir` (excluding dunders) will be mapped as `models_package.<file>:<Class>`.
- Shell completion:
```bash
genrepo --install-completion # install for your shell
# zsh: ensure fpath+=($HOME/.zfunc); autoload -U compinit; compinit; source ~/.zshrc
```
## Examples
See the `examples/` folder for ready-to-use `genrepo.yaml` samples:
- `examples/standalone_sqlmodel_sync.yaml`: Standalone repos with SQLModel (sync).
- `examples/standalone_sqlalchemy_async.yaml`: Standalone repos with SQLAlchemy (async).
- `examples/combined_sqlmodel.yaml`: Combined mode (base + user repo stubs).
- `examples/combined_sqlmodel_multi.yaml`: Combined with multiple models and per-model methods (SQLModel, sync).
- `examples/combined_sqlmodel_multi_async.yaml`: Combined with multiple models (SQLModel, async).
- `examples/combined_sqlalchemy_multi.yaml`: Combined with multiple models (SQLAlchemy, sync).
- `examples/stub_only.yaml`: Stub-only (signatures + TODO/pass; no ORM).
- `examples/discover_all.yaml`: Discover models automatically from a package.
- `examples/base_only_sqlmodel_sync.yaml`: BaseRepository only (SQLModel, sync).
Copy one to `genrepo.yaml`, adjust `import_path` to your models, and run `genrepo generate`.
## Troubleshooting
- “No module named pydantic/typer”: run inside the venv (`uv run ...`) or `source .venv/bin/activate`.
- `sqlmodel`/`sqlalchemy` missing in your target app: install them in that project.
- “No files generated”: likely exist already; use `--force`.
## License
This project is licensed under the terms of the MIT License.
See the `LICENSE` file for details.
| text/markdown | Andrea Fuentes | Andrea Fuentes <mfuentescastellanos@gmail.com> | null | null | MIT | null | [
"License :: OSI Approved :: MIT License"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"jinja2>=3.1.6",
"pydantic>=2.12.5",
"pyyaml>=6.0.3",
"rich>=14.3.2",
"typer>=0.21.1",
"sqlalchemy>=2.0; extra == \"sqlalchemy\"",
"sqlmodel>=0.0.32; extra == \"sqlmodel\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:52:29.088401 | genrepo-0.1.6-py3-none-any.whl | 29,978 | a5/a5/85d9b69197438291172b82e0db8036f5c291a05ac2d70818b9d38b4c8f1f/genrepo-0.1.6-py3-none-any.whl | py3 | bdist_wheel | null | false | 38abf7e6b5a5eb4f39a2aa1a240f3c2d | 95492f76253b8f84a1620c918d40f252d3a7236d40d520795bd3ef596ca68c9a | a5a585d9b69197438291172b82e0db8036f5c291a05ac2d70818b9d38b4c8f1f | null | [] | 194 |
2.4 | pantheon-streamlit-javascript | 1.42.1 | component to run javascript code in streamlit application | # *Streamlit javascript execution extension*
[![GitHub][github_badge]][github_link] [![PyPI][pypi_badge]][pypi_link]
## Installation using pypi
Activate your python virtual environment
```sh
pip install streamlit-javascript>=1.42.0
```
## Installation using github source
Activate your python virtual environment
```sh
pip install git+https://github.com/thunderbug1/streamlit-javascript.git@1.42.0
```
## Installation using local source
Activate your python virtual environment
```sh
git clone https://github.com/thunderbug1/streamlit-javascript.git
cd streamlit-javascript
pip install .
```
## Installing tools required for build
You may need to install some packages to build the source
```sh
# APT
sudo apt install python-pip protobuf-compiler libgconf-2-4
# HOMEBREW
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
brew install protobuf graphviz gawk
# YARN v4 - if you set PACKAGE_MGR="yarn" in setup.py
sudo npm uninstall --global yarn
corepack enable || sudo npm install --global corepack && corepack enable
```
## Running a local development environment (hot source update)
Activate your python virtual environment
```sh
git clone https://github.com/thunderbug1/streamlit-javascript.git
cd streamlit-javascript
pip install -e .
# NPM option - if you set PACKAGE_MGR="npm" in setup.py
(cd streamlit_javascript/frontend && npm install -D)
(cd streamlit_javascript/frontend && npm run start)
# YARN alternate - if you set PACKAGE_MGR="yarn" in setup.py
(cd streamlit_javascript/frontend && yarn install --production=false)
(cd streamlit_javascript/frontend && yarn start)
```
### which will run this streamlit site concurrently with the following command
```sh
streamlit run dev.py --browser.serverAddress localhost --browser.gatherUsageStats false
```
This allows hot reloading of both the streamlit python and ReAct typescript
## Debugging python in a local development environment (hot source update)
Activate your python virtual environment
```sh
git clone https://github.com/thunderbug1/streamlit-javascript.git
cd streamlit-javascript
pip install -e .
# NPM option - if you set PACKAGE_MGR="npm" in setup.py
(cd streamlit_javascript/frontend && npm run hottsx)
# YARN alternate - if you set PACKAGE_MGR="yarn" in setup.py
(cd streamlit_javascript/frontend && yarn hottsx)
```
### Now run this in your debugging tool
Remembering to match your python virtual environment in the debugger
```sh
streamlit run dev.py --browser.serverAddress localhost --browser.gatherUsageStats false
```
This sill allows hot reloading of both the streamlit python and ReAct typescript
## Using st_javascript in your code
You can look at dev.py for working examples by getting the github source
### Simple expression
```py
import streamlit as st
from streamlit_javascript import st_javascript
st.subheader("Javascript API call")
return_value = st_javascript("1+1")
st.markdown(f"Return value was: {return_value}")
```
### An in place function (notice the brace positions)
```py
return_value = st_javascript("(function(){ return window.parent.document.body.clientWidth; })()")
```
### An async place function (notice the brace positions)
```py
return_value = st_javascript("""
(async function(){
return await fetch("https://reqres.in/api/products/3")
.then(function(response) {return response.json();});
})()
""","Waiting for response")
```
### A muplitple setComponentValue
```py
st.markdown("Browser Time: "+st_javascript("today.toUTCString()","...","TODAY",1000))
```
### An on_change muplitple setComponentValue (with a block while we wait for the first return value)
```py
def width_changed() -> None:
st.toast(st.session_state['WIDTH'])
return_value = st_javascript("window.parent.document.body.clientWidth",None,"WIDTH",1000,width_changed)
if return_value is None:
st.stop()
```
### You can also this code at the top of your page to hide the code frames
```py
st.markdown("""<style> .stElementContainer:has(IFrame) { display: none;} </style>""", unsafe_allow_html=True)
```
[github_badge]: https://badgen.net/badge/icon/GitHub?icon=github&color=black&label
[github_link]: https://github.com/thunderbug1/streamlit-javascript
[pypi_badge]: https://badge.fury.io/py/streamlit-javascript.svg
[pypi_link]: https://pypi.org/project/streamlit-javascript/
| text/markdown | Alexander Balasch & Strings | null | null | null | MIT License | null | [
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language... | [] | null | null | !=3.9.7,>=3.9 | [] | [] | [] | [
"streamlit>=1.42.0"
] | [] | [] | [] | [
"Homepage, https://github.com/ckosmic/streamlit-javascript"
] | twine/6.2.0 CPython/3.11.5 | 2026-02-19T21:51:55.351813 | pantheon_streamlit_javascript-1.42.1.tar.gz | 8,825 | d9/f2/edf319b5cb42030124e908681278366b0cd1f245de9f08eccfe06d8fbc2f/pantheon_streamlit_javascript-1.42.1.tar.gz | source | sdist | null | false | 9c32b6c0884a36557ac6a13b33af2d23 | ddfc22cc253ff894e4f2915ecbb98c4f1d405b1ed53ff1f8696ce32eef2cea96 | d9f2edf319b5cb42030124e908681278366b0cd1f245de9f08eccfe06d8fbc2f | null | [
"LICENSE"
] | 187 |
2.4 | invenio-accounts | 6.3.0 | Invenio user management and authentication. | ..
This file is part of Invenio.
Copyright (C) 2015-2018 CERN.
Invenio is free software; you can redistribute it and/or modify it
under the terms of the MIT License; see LICENSE file for more details.
==================
Invenio-Accounts
==================
.. image:: https://img.shields.io/github/license/inveniosoftware/invenio-accounts.svg
:target: https://github.com/inveniosoftware/invenio-accounts/blob/master/LICENSE
.. image:: https://github.com/inveniosoftware/invenio-accounts/workflows/CI/badge.svg
:target: https://github.com/inveniosoftware/invenio-accounts/actions?query=workflow%3ACI
.. image:: https://img.shields.io/coveralls/inveniosoftware/invenio-accounts.svg
:target: https://coveralls.io/r/inveniosoftware/invenio-accounts
.. image:: https://img.shields.io/pypi/v/invenio-accounts.svg
:target: https://pypi.org/pypi/invenio-accounts
Invenio user management and authentication.
Features:
- User and role management.
- User registration, password reset/recovery and email verification.
- Administration interface and CLI for managing users.
- Session based authentication with session theft protection support.
- Strong cryptographic password hashing with support for migrating password
hashes (including Invenio v1.x) to new stronger algorithms.
- Session activity tracking allowing users to e.g. logout of all devices.
- Server-side session management.
- JSON Web Token encoding and decoding support useful for e.g. CSRF-protection
in REST APIs.
Invenio-Accounts relies on the following community packages to do all the
heavy-lifting:
- `Flask-Security <https://flask-security.readthedocs.io>`_
- `Flask-Login <https://flask-login.readthedocs.io/>`_
- `Flask-Principal <https://pythonhosted.org/Flask-Principal/>`_
- `Flask-KVSession <http://pythonhosted.org/Flask-KVSession/>`_
- `Passlib <https://passlib.readthedocs.io/>`_
Further documentation is available on
https://invenio-accounts.readthedocs.io/
..
This file is part of Invenio.
Copyright (C) 2015-2024 CERN.
Copyright (C) 2024-2026 Graz University of Technology.
Copyright (C) 2025 KTH Royal Institute of Technology.
Invenio is free software; you can redistribute it and/or modify it
under the terms of the MIT License; see LICENSE file for more details.
Changes
=======
Version v6.3.0 (released 2026-02-19)
- feat(auth): add per-account auth rate limits
- Enforce per-account limits on forgot-password, login, and send-confirmation flows using user-id limiter keys.
- Add configurable rate-limit and key-prefix settings for each protected flow.
Version v6.2.3 (released 2026-01-27)
- chore(black): update formatting to >= 26.0
- chore(setup): pin dependencies
Version v6.2.2 (released 2025-12-08)
- i18n: pulled translations
- tests: extend support to Python 3.14
Version v6.2.1 (released 2025-10-20)
- fix(user): allow properties to be accessed via the class
- i18n: pulled translations
Version v6.2.0 (released 2025-07-17)
- i18n: force pull translations
- docs: update transifex-client installation instructions
- i18n: extract msgs
Version v6.1.1 (released 2025-07-03)
- fix: find_spec raise ValueError
Version v6.1.0 (released 2025-07-03)
- fix: pkg_resources DeprecationWarning
Version v6.0.1 (released 2025-04-28)
- session: fix cleanup session task
- fix: update session removal flash messages for consistent formatting
Version 6.0.0 (release 2024-12-04)
- fix: cookie_app and users not using same app
- test: fix properties not existing anymore
- tests: fix cookie_jar not existing anymore
- fix: add translation flag for publishing
- tests: apply changes for sqlalchemy>=2.0
- setup: bump major dependencies
Version v5.1.7 (released 2024-11-29)
- datastore: Fix domain fetching on None value
Version v5.1.6 (released 2024-11-28)
- setup: pin dependencies
Version v5.1.5 (released 2024-11-05)
- model: make forward compatible to sqlalchemy >= 2
Version v5.1.4 (released 2024-11-04)
- UI: fix spacing on password reset form
Version v5.1.3 (released 2024-10-31)
- UI: fix spacing on password reset form
Version 5.1.2 (released 2024-09-19)
- setup: bump minimum flask-security-invenio dependency
- security: handle missing value for current session
Version 5.1.1 (released 2024-08-08)
- revert: commit f9a8a85
Version 5.1.0 (released 2024-07-30)
- feat(cli): add command for group creation
- feat(cli): add command for domain create
Version 5.0.1 (released 2024-03-22)
- models: fix username case-insensitive comparator
Version 5.0.0 (released 2024-03-21)
- fix: before_first_request deprecation
- change module blueprint to callable
Version 4.0.2 (released 2024-02-19)
- add change history tracking of domains
- add task to calculate domain statistics
- add methods to verify, block and deactivate users in datastore
Version 4.0.1 (released 2024-02-01)
- models: fix column type for domain status
Version 4.0.0 (released 2024-01-29)
- sessions: check for request before accessing session
- global: new domain list feature
Version 3.5.1 (released 2023-12-10)
- views: disable registering of `settings.change_password` menu
if `ACCOUNTS_REGISTER_BLUEPRINT` is False
Version 3.5.0 (released 2023-11-10)
- datastore: override put method to add changes to db history
Version 3.4.4 (released 2023-11-10)
models: do not set value in user preference getter
Version 3.4.3 (released 2023-10-20)
- email: force lowercase
Version 3.4.2 (released 2023-10-17)
- Adds support for user impersonation
Version 3.4.1 (released 2023-10-14)
- datastore: prevent autoflush on db
Version 3.4.0 (released 2023-08-30)
- templates: refactor send confirmation template
Version 3.3.1 (released 2023-08-23)
- config: set `ACCOUNTS_DEFAULT_USERS_VERIFIED` to False by default
Version 3.3.0 (released 2023-08-21)
- models: add `verified_at` column in User model. The default value is controlled by
a new config variable called `ACCOUNTS_DEFAULT_USERS_VERIFIED`. If True, then a date
is generated, otherwise is set to `None`.
Version 3.2.1 (released 2023-08-17)
- alembic: fix sqlalchemy op.execute statements due to latest sqlalchamy-continuum
Version 3.2.0 (released 2023-08-02)
- users: add blocket_at and verified_at data model fields
Version 3.1.0 (released 2023-07-31)
- templates: Improve accessibility and layout
- pulled translations
Version 3.0.3 (released 2023-06-15)
- models: fix autogeneration of role id
Version 3.0.2 (released 2023-06-14)
- alembic: adapt recipe to mysql
Version 3.0.1 (released 2023-06-14)
- alembic: fix upgrade recipes
Version 3.0.0 (released 2023-06-14)
- models: add managed field to groups
- models: alter primary key type of group (id)
- cli: pass id on create role action
Version 2.2.0 (released 2023-04-25)
- models: add support for locale in user preferences
Version 2.1.0 (released 2023-03-01)
- global: replace deprecated babelex imports
- update invenio-i18n
Version 2.0.2 (released 2022-12-14)
- cli: add `--confirm` flag when creating a user
- new config variables to set the default user and email visibility
- register_user: method accepts new argument, `send_register_msg`, to control
programmatically the send of registration email independently of the global
configuration.
Version 2.0.1 (released 2022-11-18)
- Add translation workflow
- Add pulled translations
- Add black
- Fix icons not appearing
Version 2.0.0 (released 2022-05-23)
- Adds customizable user profiles and user preferences fields to the user
data model.
- Adds version counter to the user table to enable optimistic concurrency
control on the user table.
- Moves login information fields from user table to a separate login
information table.
- Moves the external user identity table from Invenio-OAuthclient to
Invenio-Accounts.
- Adds support for tracking changed users within a transaction to allow for
updating the related indexes.
- Changes from using Flask-Security to using a private fork named
Flask-Security-Invenio. Flask-Security-Too was evaluated but was found to
have significantly increased scope with features not needed.
Version 1.4.9 (released 2021-12-04)
- Fixed issue with account creation via CLI due to issue with changed API in
Flask-WTF.
Version 1.4.8 (released 2021-10-18)
- Unpin Flask requirement.
Version 1.4.7 (released 2021-10-06)
- Adds celery task to remove IP addresses from user table after a specified
retention period (defaults to 30 days).
Version 1.4.6 (released 2021-07-12)
- Adds german translations
Version 1.4.5 (released 2021-05-21)
- Removes config entrypoint.
- Bump module versions.
Version 1.4.4 (released 2021-05-11)
- Enables login view function overridability.
- Allows to disable local login via configuration variable.
Version 1.4.3 (released 2020-12-17)
- Adds theme dependent icons.
Version 1.4.2 (released 2020-12-11)
- Fixes logout from security view.
Version 1.4.1 (released 2020-12-10)
- Fixes styling of forgot password form in semantic ui theme.
Version 1.4.0 (released 2020-12-09)
- Major: adds new Semantic UI theme.
- Adds Turkish translations.
- Fixes ``next`` parameter being used in the sign-up form.
- Fixes issue with translation files causing translations not to be picked up.
- Fixes wording from sign in to log in.
- Removes password length validation during login.
Version 1.3.0 (released 2020-05-15)
- Refreshes the CSRF token on login and logout.
- Removes the example app.
- Migrate from `Flask-KVSession` to `Flask-KVSession-Invenio`, fork of
the former.
Version 1.2.2 (released 2020-05-13)
*This release was removed from PyPI on 2020-05-15 due to issues with the
release.*
Version 1.2.1 (released 2020-04-28)
- Fixes issue with the latest WTForms v2.3.x release which now requires an
extra library for email validation.
Version 1.2.0 (released 2020-03-09)
- Replaces Flask dependency with centrally managed invenio-base
Version 1.1.4 (released 2020-04-28)
- Fixes issue with the latest WTForms v2.3.x release which now requires an
extra library for email validation.
Version 1.1.3 (released 2020-02-19)
- Replaces Flask-CeleryExt to invenio-celery due to version incompatibilities
with celery, kombu. Removes Flask-BabelExt already provided by invenio-i18n
Version 1.1.2 (released 2020-02-12)
- Fixes requirements for Flask, Werkzeug and Flask-Login due to
incompatibilities of latest released modules.
Version 1.1.1 (released 2019-03-10)
- Fixes an issue where the HTTP headers X-Session-ID and X-User-ID are added
even if the value is not known. This causes 'None' to be logged in Nginx,
instead of simply '-'.
Version 1.1.0 (released 2019-02-15)
- Added support for for adding the user id and session id of the current user
into the HTTP headers (``X-User-ID`` and ``X-Session-ID``) for upstream
servers to use. For instance, this way current user/session ids can be logged
by Nginx into the web server access logs. The feature is off by default and
can be enabled via the ``ACCOUNTS_USERINFO_HEADERS`` configuration variable.
Note: The upstream server should strip the two headers from the response
returned to the client. The purpose is purely to allow upstream proxies like
Nginx to log the user/session id for a specific request.
- Changed token expiration from 5 days to 30 minutes for the password reset
token and email confirmation token. Using the tokens will as a side-effect
login in the user, which means that if the link is leaked (e.g. forwarded by
the users themselves), then another person can use the link to access the
account. Flask-Security v3.1.0 addresses this issue, but has not yet been
released.
- Fixes issue that could rehash the user password in the adminstration
interface.
Version 1.0.2 (released 2018-10-31)
- Added AnonymousIdentity loader to app initialisation to fix the ``any_user``
Need in Invenio-Access.
Version 1.0.1 (released 2018-05-25)
- Bumped Flask-CeleryExt from v0.3.0 to v0.3.1 to fix issue with Celery version
string not being parsable and thus causing problems with installing Celery.
Version 1.0.0 (released 2018-03-23)
- Initial public release.
| null | CERN | info@inveniosoftware.org | null | null | MIT | invenio accounts user role login | [
"Development Status :: 5 - Production/Stable"
] | [
"any"
] | https://github.com/inveniosoftware/invenio-accounts | null | >=3.7 | [] | [] | [] | [
"cryptography>=3.0.0",
"Flask-KVSession-Invenio<1.0.0,>=0.6.3",
"Flask-Security-Invenio<4.0.0,>=3.3.0",
"invenio-celery<3.0.0,>=2.0.0",
"invenio-i18n<4.0.0,>=3.0.0",
"invenio-mail<3.0.0,>=1.0.2",
"invenio-rest<3.0.0,>=2.0.0",
"invenio-theme<5.0.0,>=4.0.0",
"maxminddb-geolite2>=2017.404",
"pyjwt>=1... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:51:23.350869 | invenio_accounts-6.3.0.tar.gz | 109,666 | 07/8a/53a5a28f4d515f8e978d50037dce873922082c058034118f4b48107959f2/invenio_accounts-6.3.0.tar.gz | source | sdist | null | false | e96044f4a23a668c029e7703ef75e2fa | 2a104780dcff19dae7a2e60330efe7050333fa67475bbc78998b5d89b7032a35 | 078a53a5a28f4d515f8e978d50037dce873922082c058034118f4b48107959f2 | null | [
"LICENSE",
"AUTHORS.rst"
] | 526 |
2.4 | BERATools | 0.3.0 | An advanced forest line feature analysis platform | # BERA Tools
BERA Tools is successor of [Forest Line Mapper](https://github.com/appliedgrg/flm). It is a toolset for enhanced delineation and attribution of linear disturbances in forests.
<div align="center">
[](https://github.com/appliedgrg/beratools/actions/workflows/python-tests.yml)
[](https://codecov.io/gh/appliedgrg/beratools)
[](https://appliedgrg.github.io/beratools/)
[](https://anaconda.org/AppliedGRG/beratools)
[](https://www.python.org/downloads/release/python-3100/)
[](https://www.gnu.org/licenses/gpl-3.0)
</div>
## [Quick Start](https://appliedgrg.github.io/beratools)
BERA Tools is built upon open-source Python libraries. Anaconda is used to manage runtime environments.
Ways to install BERA Tools:
- Windows installer
- Install with Anaconda.
### Windows Installer
Windows installer is provided with releases. Check the [latest release](https://github.com/appliedgrg/beratools/releases/latest) for the up-to-date installer.
### Install with Anaconda
Install with Anaconda works on Windows, macOS, and Linux.
- Install Miniconda. Download Miniconda from [Miniconda](https://docs.anaconda.com/miniconda/) and install on your machine.
- Download the file [environment.yml](https://raw.githubusercontent.com/appliedgrg/beratools/main/environment.yml
) and save to local storage. Launch **Anaconda Prompt** or **Miniconda Prompt**.
- **Change directory** to where environment.yml is saved in the command prompt.
- Run the following command to create a new environment named **bera**. **BERA Tools** will be installed in the new environment at the same time.
```bash
$ conda env create -n bera -f environment.yml
```
Wait until the installation is done.
- Activate the **bera** environment and launch BERA Tools:
```bash
$ conda activate bera
$ beratools
```
- [Download latest example data](https://github.com/appliedgrg/beratools/releases/latest/download/test_data.zip) to try with BERA Tools.
- To update BERA Tools when new release is issued, run the following commands:
```bash
$ conda activate bera
$ conda update beratools
```
- To completely remove BERA Tools and its environment, run the following command:
```bash
$ conda remove -n bera
```
## BERA Tools Guide
Check the online [BERA Tools Guide](https://appliedgrg.github.io/beratools/) for user, developer guides.
## Credits
<table>
<tr>
<td><img src="docs/files/icons/bera_logo.png" alt="Logos" width="80"></td>
<td>
<p>
This tool is part of the <strong><a href="http://www.beraproject.org/">Boreal Ecosystem Recovery & Assessment (BERA)</a></strong>.
It is actively developed by the <a href="https://www.appliedgrg.ca/"><strong>Applied Geospatial Research Group</strong></a>.
</p>
<p>
© 2026 Applied Geospatial Research Group. All rights reserved.
</p>
</td>
</tr>
</table>
| text/markdown | null | AppliedGRG <appliedgrg@gmail.com>, Richard Zeng <richardqzeng@gmail.com> | null | null | GPL-3.0-or-later | BERA, Line | [
"Development Status :: 2 - Pre-Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Natural Language :: English",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Pr... | [] | null | null | >=3.10 | [] | [] | [] | [
"bera-centerlines",
"gdal; platform_system != \"Windows\"",
"geopandas",
"networkit",
"pyogrio>=0.9.0",
"pyqt5",
"rasterio",
"scikit-image>=0.24.0",
"tabulate",
"tqdm",
"xarray-spatial",
"build; extra == \"dev\"",
"isort; extra == \"dev\"",
"mypy; extra == \"dev\"",
"pre-commit; extra ==... | [] | [] | [] | [
"Homepage, https://github.com/appliedgrg/beratools"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:51:02.338451 | beratools-0.3.0.tar.gz | 4,495,436 | 76/12/1864ff34e4f869efef39739008aea5f7c9c28c05e34e2c98ac202650008e/beratools-0.3.0.tar.gz | source | sdist | null | false | f51e3ccd5342310c54dd3f3aaa446e27 | 219e8815e5dab7058961c62c8464555b9e5a0d921e8746fcdb7e4fb714aa476c | 76121864ff34e4f869efef39739008aea5f7c9c28c05e34e2c98ac202650008e | null | [
"LICENSE"
] | 0 |
2.4 | physarum-sdk | 0.2.4 | Physarum Intelligence Network Python SDK — MCP tool routing, model selection, and cost optimization | # physarum-sdk
Python SDK for the **Physarum Intelligence Network** — real-time MCP tool routing, model selection, and cost optimization powered by network-wide telemetry and Physarum-inspired conductivity algorithms.
[](https://pypi.org/project/physarum-sdk/)
[](LICENSE)
[](https://pypi.org/project/physarum-sdk/)
## What it does
- **Routes tool calls** to the best-performing implementation based on live success rates, latency, and quality signals collected across all tenants
- **Tracks every tool execution** with zero-overhead telemetry batching
- **Works with any Python AI framework** — LangChain, LlamaIndex, raw OpenAI/Anthropic calls
- **Fails open** — if the API is unavailable, falls back to your configured static priorities
## Installation
```bash
pip install physarum-sdk
```
## Quick start
```python
from physarum import PhysarumClient, PhysarumConfig
client = PhysarumClient(PhysarumConfig(
api_key=os.environ["PHYSARUM_API_KEY"],
tenant_id=os.environ["PHYSARUM_TENANT_ID"],
ingestion_base_url="https://api.physarum.network",
recommendation_base_url="https://api.physarum.network",
mode="SHADOW", # Start with SHADOW, graduate to CONTROLLED
))
# Ask Physarum which tool to use
from physarum.types import RouteRequest
decision = client.select_tool(RouteRequest(
task_category="payment_flow",
candidate_tools=["stripe", "paypal", "razorpay"],
action_class="SIDE_EFFECT_CRITICAL",
))
print(decision["selected_tool"]) # e.g. "stripe"
print(decision["reason"]) # "controlled_mode" | "shadow_mode" | ...
client.shutdown()
```
## Operating modes
| Mode | Behaviour |
|------|-----------|
| `SHADOW` | Observes only. Records telemetry but never changes which tool is called. Zero risk, full learning. |
| `ADVISORY` | Calls the recommendation API and logs the suggestion but still runs your default tool. |
| `CONTROLLED` | Physarum selects the tool. The network's best recommendation is used for every call. |
Start with `SHADOW` to accumulate signal, then graduate to `CONTROLLED` once you trust the data.
## Manual tool wrapping
Wrap any function call to automatically record success, latency, and error telemetry:
```python
from physarum.types import WrapToolCallInput
outcome = client.wrap_tool_call(WrapToolCallInput(
tool_id="stripe",
tool_name="stripe",
task_category="payment_flow",
action_class="SIDE_EFFECT_CRITICAL",
session_id_hash="hashed-session-id",
execute=lambda: stripe.charge(amount=9900, currency="usd"),
))
print(outcome.result) # whatever stripe.charge returned
print(outcome.telemetry) # full telemetry dict, already flushed to Physarum
```
## LangChain integration
```python
from langchain.tools import StructuredTool
from physarum.types import WrapToolCallInput
def make_physarum_tool(client, name, description, func, task_category, action_class):
def wrapped(**kwargs):
outcome = client.wrap_tool_call(WrapToolCallInput(
tool_id=name,
tool_name=name,
task_category=task_category,
action_class=action_class,
session_id_hash="your-session-hash",
execute=lambda: func(**kwargs),
))
return outcome.result
return StructuredTool.from_function(
func=wrapped,
name=name,
description=description,
)
search_tool = make_physarum_tool(
client,
name="search_products",
description="Search the product catalogue",
func=search_products_api,
task_category="product_search",
action_class="READ_ONLY",
)
```
## Context enrichment
Pass context to improve routing accuracy. Physarum learns per-country, per-domain, and per-locale performance:
```python
from physarum.types import RouteRequest, ContextInput
decision = client.select_tool(RouteRequest(
task_category="payment_flow",
candidate_tools=["stripe", "razorpay"],
action_class="SIDE_EFFECT_CRITICAL",
context=ContextInput(
country_code="IN", # India — Razorpay likely performs better
domain="e-commerce",
locale="en-IN",
model_id="claude-sonnet-4-6",
time_of_day_utc="14:30",
),
))
```
## Model routing
```python
from physarum.types import ModelRouteRequest
result = client.get_model_routes(ModelRouteRequest(
task_category="code_debug",
candidate_models=["claude-opus-4-6", "claude-sonnet-4-6", "gpt-4o"],
))
best_model = result.recommendations[0]["model_id"]
```
## Cost optimization
```python
from physarum.types import CostOptimizeRequest
result = client.get_cost_optimized_path(CostOptimizeRequest(
task_category="document_summarization",
candidate_tools=["gpt-4o", "claude-sonnet-4-6", "gemini-flash"],
quality_floor=0.8, # minimum acceptable quality score
budget_tokens=50_000, # max tokens to spend
))
```
## MCP server discovery
```python
# Get all MCP servers registered on the network
servers = client.get_mcp_servers()
# Filter by task category
payment_servers = client.get_mcp_servers(task_category="payment_flow")
```
## Static fallback priorities
Configure a deterministic fallback order used when the recommendation API is unavailable:
```python
client = PhysarumClient(PhysarumConfig(
# ...
local_static_priorities=["stripe", "paypal", "razorpay"],
local_static_priorities_by_task_category={
"payment_flow_india": ["razorpay", "stripe"],
},
))
```
## Configuration reference
```python
from physarum import PhysarumConfig
config = PhysarumConfig(
api_key="...",
tenant_id="...",
ingestion_base_url="https://api.physarum.network",
recommendation_base_url="https://api.physarum.network",
mode="SHADOW", # "SHADOW" | "ADVISORY" | "CONTROLLED"
request_timeout_ms=5000, # default: 5000
telemetry_batch_size=50, # events per flush, default: 50
telemetry_flush_interval_ms=2000, # default: 2000ms
local_static_priorities=[], # fallback tool order
local_static_priorities_by_task_category={},
)
```
## Action classes
| Value | Use when |
|-------|----------|
| `READ_ONLY` | Tool only reads data — search, lookup, fetch |
| `IDEMPOTENT_WRITE` | Safe to retry — upsert, idempotent create |
| `SIDE_EFFECT_CRITICAL` | Must not be retried blindly — payment, email send, webhook |
## Shutdown
Always call `shutdown()` before your process exits to flush buffered telemetry:
```python
import atexit
atexit.register(client.shutdown)
```
Or use as a context manager pattern:
```python
try:
result = client.wrap_tool_call(...)
finally:
client.shutdown()
```
## License
MIT
| text/markdown | null | null | null | null | MIT | mcp, ai, routing, tool-selection, intelligence | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"requests>=2.31.0"
] | [] | [] | [] | [
"Homepage, https://github.com/physarum-network/physarum",
"Repository, https://github.com/physarum-network/physarum"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:50:58.839021 | physarum_sdk-0.2.4.tar.gz | 10,604 | b9/15/687a84905b52981838a8784cb41d9bdc061001a70a089695d13f2918d546/physarum_sdk-0.2.4.tar.gz | source | sdist | null | false | 4998e900b66386b795617bcafe844d8f | f2460b236260f26fb8fed204fa29415ccefc4f23a7b2da69669defde470dfd36 | b915687a84905b52981838a8784cb41d9bdc061001a70a089695d13f2918d546 | null | [] | 196 |
2.3 | clope | 0.2.3 | Python package for interacting with the Cantaloupe/Seed vending system. Primarily the Spotlight API. | # Overview
clope (see-lope) is a Python package for interacting with the Cantaloupe/Seed vending system. Primarily being a wrapper for their Spotlight API. It uses the pandas library to return information from a given spotlight report as a dataframe object. clope also has functionality for connecting to the snowflake data warehouse Cantaloupe product as well.
## Installation
Base install (Spotlight only):
`pip install clope`
Install with Snowflake support:
`pip install "clope[snow]"`
## Usage
Several environment variables are required for clope to function. Functionality is divided into two modules, so vars are only required if you are using functions from that particular module.
Quick start (Spotlight):
```python
from clope.spotlight import run_report
df_report = run_report(
"123",
[("filter0", "2024-01-01"), ("filter1", "2024-01-31")],
)
```
Quick start (Snowflake):
```python
from clope.snow import facts
# Example: load a fact table (adjust function and params to your use case)
df_sales = facts.get_sales_revenue_by_day_fact()
```
| Module | Required? | Env Variable | Description |
| --------- | --------- | ------------ | ----------- |
| Spotlight | Yes | CLO_USERNAME | Username of the Spotlight API user. Should be provided by Cantaloupe. |
| Spotlight | Yes | CLO_PASSWORD | Password of the Spotlight API user. Should be provided by Cantaloupe. |
| Spotlight | No | CLO_BASE_URL | Not actually sure if this varies between clients. I have this as an optional variable in case it does. Default value if no env variable is <https://api.mycantaloupe.com>, otherwise can be overridden. |
| Snowflake | Yes | SNOWFLAKE_USER | Username of the Snowflake user |
| Snowflake | Yes | SNOWFLAKE_PRIVATE_KEY_FILE | Path pointing to the private key file for the Snowflake user. |
| Snowflake | Yes | SNOWFLAKE_PRIVATE_KEY_FILE_PWD | Password for the private key file |
| Snowflake | Yes | SNOWFLAKE_ACCOUNT | Snowflake account you're connecting to. Should be something along the lines of "{Cantaloupe account}-{Your Company Name}" |
| Snowflake | Yes | SNOWFLAKE_DATABASE | Snowflake database to connect to. Likely begins with "PRD_SEED...". |
## Spotlight
The spotlight module involves interaction with the Cantaloupe Spotlight API. The API allows you to run a Spotlight report remotely and retrieve the raw Excel data via HTTP requests. Reports must be set up in the browser prior to using the API. This is quick and suited for getting data that needs to be up-to-date at that moment.
### Run Spotlight Report (run_report())
The primary function. Used to run a spotlight report, retrieve the excel results, and transform the excel file into a workable pandas dataframe. Cantaloupe's spotlight reports return an excel file with two tabs: Report and Stats. This pulls the info from the Report tab, Stats is ignored.
> Note: Make sure your spotlight report has been shared with the "Seed Spotlight API Users" security group in Seed Office. Won't be accessible otherwise.
Takes in two parameters:
*report_id*
A string ID for the report in Cantaloupe. When logged into Seed Office, the report ID can be found in the URL. E.G. <https://mycantaloupe.com/cs3/ReportsEdit/Run?ReportId=XXXXX>, XXXXX being the report ID needed.
*params*
Optional parameter, list of tuples of strings. Some Spotlight reports have required filters which must be supplied to get data back. Date ranges being a common one. Cantaloupe's error messages are fairly clear, in my experience, with telling you what parameteres are needed to run the report and in what format they should be. First element of tuple is filter name and second is filter value. Filter names are in format of "filter0", "filter1", "filter2", etc.
Example call
```python
# Import package
from clope.spotlight import run_report
# Run report with a report_id and additional parameters
df_report = run_report("123", [("filter0", "2024-01-01"), ("filter1", "2024-01-31")])
```
## Snowflake
Cantaloupe also offers a data warehouse product in Snowflake. Good for aggregating lots of information, as well as pulling historical information. However, notably, data is only pushed from Seed into the Snowflake data warehouse once a day, so it is not necessarily going to be accurate as of that moment.
Also something to keep in mind is that the system makes use of SCD (slowly changing dimension) in order to keep track of historical info vs current info. So some care should be taken when interpreting the data.
For each dataset that uses SCD, a parameter has been included to restrict to current data only or include all data.
Authentication to Snowflake is handled via [key-pair authentication](https://docs.snowflake.com/en/developer-guide/python-connector/python-connector-connect#using-key-pair-authentication-and-key-pair-rotation). You'll need to create a key pair using openssl and set the snowflake user's RSA_PUBLIC_KEY.
### Dates
In Snowflake, most date columns are represented by an integer key, rather than the date itself. A couple functions are included with regards to dates. If working directly with Snowflake, you would join the date table onto the fact table you're working with. However, from what I can see the dates are largely deterministic. 1 is 1900-01-01, 2 is 1900-01-02. So I just directly translate from key to date and vice versa with some date math. Much quicker and should give same results as querying the date table itself.
### Dimensions
Dimensions describe facts. The location something happened in. The route it happened on. Dimensions generally change over time and make the most use of the SCD schema.
- Barcodes (for each pack)
- Branches
- Coils (planogram slots)
- Customers
- Devices (telemetry)
- Item Packs (UOMs)
- Items
- Lines of Business
- Locations
- Machines
- Micromarkets
- Operators
- Routes
- Supplier Branch
- Supplier Items (Not yet used seemingly)
- Suppliers
- Warehouses
- Machine Alerts
### Facts
A fact is the central information being stored. Generally, things that are not changing. A sale, an inventory, a product movement.
- Cashless Vending Tranaction
- Collection Micromarket Sales
- Order to Fulfillment (Delivery)
- Order to Fulfillment (Vending and Micromarket)
- Delivery Order Receive
- Sales Revenue By Day
- Sales Revenue By Visit
- Sales By Coil
- Scheduling Machine
- Scheduling Route Summary
- Telemetry Sales
- Vending Micromarket Visit
- Warehouse Inventory
- Warehouse Observed Inventory
- Warehouse Product Movement
- Warehouse Purchase
- Warehouse Receive
### Functions
Also included in Cantaloupe's Snowflake are a couple functions. General intention seems to be gathering a subset of data from a couple core fact tables. Haven't yet implemented wrappers for these.
| text/markdown | Jordan Maynor | Jordan Maynor <jmaynor@pepsimidamerica.com> | null | null | This is free and unencumbered software released into the public domain. Anyone is free to copy, modify, publish, use, compile, sell, or distribute this software, either in source code form or as a compiled binary, for any purpose, commercial or non-commercial, and by any means. In jurisdictions that recognize copyright laws, the author or authors of this software dedicate any and all copyright interest in the software to the public domain. We make this dedication for the benefit of the public at large and to the detriment of our heirs and successors. We intend this dedication to be an overt act of relinquishment in perpetuity of all present and future rights to this software under copyright law. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. For more information, please refer to <https://unlicense.org> | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: The Unlicense (Unlicense)",
"Operating System :: OS Independent"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"aiohttp",
"openpyxl",
"pandas",
"requests",
"tenacity",
"snowflake-connector-python[pandas]>=4.0.0; extra == \"snow\""
] | [] | [] | [] | [
"Homepage, https://github.com/pepsimidamerica/clope"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:50:31.916159 | clope-0.2.3.tar.gz | 11,991 | f9/b9/224da985c80e711d93e56c58e82df2ef76b0b83ca24e0080251a85b859ac/clope-0.2.3.tar.gz | source | sdist | null | false | 93188ba34bdaa6974d75603f2f5d4320 | 4053dfd54821ebcfae4ca97e02dd375fce8c4e716459d1ea7f76bfbec863152e | f9b9224da985c80e711d93e56c58e82df2ef76b0b83ca24e0080251a85b859ac | null | [] | 184 |
2.4 | safe-push | 0.1.4 | An educational CLI tool to prevent accidental sensitive data exposure. | # safe-push 🛡️
An educational, beginner-friendly Python CLI tool that teaches you about accidental sensitive data exposure while helping you keep your repositories clean.
## 🌟 Why safe-push?
Accidentally pushing a `.env` file or a hardcoded API key to GitHub is a rite of passage for many developers—but it's also a major security risk! `safe-push` helps you identify these risks *before* you push, explaining **why** certain files shouldn't be shared.
Perfect for "vibe coders" and beginners who want to stay safe while learning.
## 🚀 Features
### 🆓 Free Tier (Always)
- **Scan Current Directory**: Detects common mistakes like `.env` files, `__pycache__`, and `venv` folders.
- **Basic Secret Detection**: Finds generic API keys and tokens.
- **Educational Insights**: Explains the danger of each finding so you learn as you go.
- **No Data Leaves Your Machine**: Your code stays local. Always.
### 💎 Premium Features
- **Advanced Secret Scanning**: Deep detection for AWS, Stripe, OpenAI, Firebase, and more.
- **Auto .gitignore Generator**: Quickly create a recommended `.gitignore` for your Python projects.
- **Pre-commit Hook Template**: Automatically scan your code every time you try to `git commit`.
- **Verbose Mode**: See exactly what's happening under the hood.
## 🛠️ Installation
```bash
pip install safe-push
```
## 📖 How to Use
Simply run the tool in your project's root directory:
```bash
safe-push
```
### Options
- `safe-push --verbose`: Show a detailed breakdown of the scan.
- `safe-push --unlock`: Learn how to unlock premium features.
- `safe-push --generate-gitignore`: (Premium) Create a recommended `.gitignore`.
- `safe-push --install-hook`: (Premium) Install a Git pre-commit hook.
## 🔓 Unlocking Premium (The Solana Way)
We use a simple, decentralized verification system. No accounts, no credit cards.
1. Donate at least **0.005 SOL** (~$2) to the recipient wallet shown when you run `safe-push --unlock`.
2. Enter your wallet address and the Transaction ID (TXID).
3. The CLI verifies the transaction directly on the Solana blockchain and unlocks your features locally!
## 🔒 Security & Privacy
- **Local Only**: This tool scans only your local directory.
- **Privacy First**: No data, code, or telemetry is ever sent to any server.
- **Transparency**: The only network call made is to a public Solana RPC endpoint for donation verification.
## 📜 License
MIT License. Feel free to use, learn, and share!
---
*Stay safe and keep coding!* 🚀
| text/markdown | null | "Chris Alih (azmoth)" <chrisalih5@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Topic :: Security",
"Intended Audience :: Developers"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"requests>=2.25.0"
] | [] | [] | [] | [
"Homepage, https://github.com/a-zmuth/safe-push.git",
"Bug Tracker, https://github.com/a-zmuth/safe-push/issues"
] | twine/6.2.0 CPython/3.12.5 | 2026-02-19T21:48:52.981766 | safe_push-0.1.4.tar.gz | 10,752 | 2d/b5/25f2416687c404e0ff39c3b6617a1da4d2d0e523a151e79bad5f74b17dd9/safe_push-0.1.4.tar.gz | source | sdist | null | false | 2f0f48af9df0678e40a69c0ae77ac876 | afd987fd06872e9b1a738cbf9af3bf17ab5658e09992de97ae55f69ed4af2b0c | 2db525f2416687c404e0ff39c3b6617a1da4d2d0e523a151e79bad5f74b17dd9 | null | [] | 185 |
2.3 | turbo-lambda | 0.7.1 | Turbo Lambda Description | # turbo-lambda
Turbo Lambda Library
| text/markdown | Sam Mosleh | Sam Mosleh <sam.mosleh.d@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"opentelemetry-api>=1.27.0",
"pydantic-settings>=2.11.0"
] | [] | [] | [] | [] | uv/0.10.2 {"installer":{"name":"uv","version":"0.10.2","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T21:48:48.266166 | turbo_lambda-0.7.1-py3-none-any.whl | 12,463 | a4/a5/5046b274d29c1c85338a8c15254288465441837b5fc50c38f62b488a7e09/turbo_lambda-0.7.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 5c52fe15505bc79eb9176e97755d22d3 | c787c9f4369fd19f5aedc47bb0a43733b76626b99253bc031ad223247e8c7727 | a4a55046b274d29c1c85338a8c15254288465441837b5fc50c38f62b488a7e09 | null | [] | 187 |
2.4 | dxt-explorer | 0.4 | DXT Explorer is an interactive web-based log analysis tool to visualize Darshan DXT logs and help understand the I/O behavior. | <p align="center">
<img src="https://github.com/hpc-io/dxt-explorer/raw/main/docs/source/_static/images/dxt-explorer.png" alt="DXT Explorer"/>
</p>
DXT Explorer is an interactive web-based log analysis tool to visualize Darshan DXT logs and help understand the I/O behavior of applications. Our tool adds an interactive component to Darshan trace analysis that can aid researchers, developers, and end-users to visually inspect their applications' I/O behavior, zoom-in on areas of interest and have a clear picture of where is the I/O problem.
### Documentation
You can find our complete documentation at [dxt-explorer.readthedocs.io](https://dxt-explorer.readthedocs.io).
### Citation
You can find more information about DXT Explorer in our PDSW'21 paper. If you use DXT in your experiments, please consider citing:
```
@inproceedings{dxt-explorer,
title = {{I/O Bottleneck Detection and Tuning: Connecting the Dots using Interactive Log Analysis}},
author = {Bez, Jean Luca and Tang, Houjun and Xie, Bing and Williams-Young, David and Latham, Rob and Ross, Rob and Oral, Sarp and Byna, Suren},
booktitle = {2021 IEEE/ACM Sixth International Parallel Data Systems Workshop (PDSW)},
year = {2021},
volume = {},
number = {},
pages = {15-22},
doi = {10.1109/PDSW54622.2021.00008}
}
```
---
DXT Explorer Copyright (c) 2022, The Regents of the University of California, through Lawrence Berkeley National Laboratory (subject to receipt of any required approvals from the U.S. Dept. of Energy). All rights reserved.
If you have questions about your rights to use or distribute this software, please contact Berkeley Lab's Intellectual Property Office at IPO@lbl.gov.
NOTICE. This Software was developed under funding from the U.S. Department of Energy and the U.S. Government consequently retains certain rights. As such, the U.S. Government has been granted for itself and others acting on its behalf a paid-up, nonexclusive, irrevocable, worldwide license in the Software to reproduce, distribute copies to the public, prepare derivative works, and perform publicly and display publicly, and to permit others to do so.
| text/markdown | Jean Luca Bez, Hammad Ather, Suren Byna | jlbez@lbl.gov, hather@lbl.gov, sbyna@lbl.gov | null | null | null | dxt-explorer | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3 :: Only"
] | [] | https://github.com/hpc-io/dxt-explorer | null | >=3.8 | [] | [] | [] | [
"numpy>=1.23",
"Pillow>=9.4.0",
"plotly>=5.13.0",
"argparse>=1.4.0",
"pandas>=1.4.3",
"pyranges>=0.0.120",
"darshan",
"pyarrow>=10.0.1",
"bs4>=0.0.1",
"drishti-io>=0.8"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T21:48:40.339108 | dxt_explorer-0.4.tar.gz | 62,987 | ba/df/135a6f6797186475e34ef56d02f3ad677c4474b50cb83aad17f7fbb85a7a/dxt_explorer-0.4.tar.gz | source | sdist | null | false | 7a7ab5ccbf45e4547807c81981f838e4 | 6216d5b5eac2716f97dd819744fc76a65da62668e4f5a778a79935bdf038eaf4 | badf135a6f6797186475e34ef56d02f3ad677c4474b50cb83aad17f7fbb85a7a | null | [
"LICENSE"
] | 207 |
2.4 | voxelops | 0.3.2 | Clean, simple neuroimaging pipeline automation for brain banks | VoxelOps
========
.. image:: https://github.com/GalKepler/VoxelOps/blob/main/docs/images/Gemini_Generated_Image_m9bi47m9bi47m9bi.png?raw=true
:alt: VoxelOps Logo
Clean, simple neuroimaging pipeline automation for brain banks.
---------------------------------------------------------------
Brain banks need to process neuroimaging data **consistently**, **reproducibly**, and **auditably**. VoxelOps makes that simple by wrapping Docker-based neuroimaging tools into clean Python functions that return plain dicts -- ready for your database, your logs, and your peace of mind.
========
Overview
========
.. list-table::
:stub-columns: 1
* - docs
- |docs|
* - tests, CI & coverage
- |github-actions| |codecov| |codacy|
* - version
- |pypi| |python|
* - styling
- |black| |isort| |flake8| |pre-commit|
* - license
- |license|
.. |docs| image:: https://readthedocs.org/projects/voxelops/badge/?version=latest
:target: https://voxelops.readthedocs.io/en/latest/?badge=latest
:alt: Documentation Status
.. |github-actions| image:: https://github.com/GalKepler/VoxelOps/actions/workflows/ci.yml/badge.svg
:target: https://github.com/GalKepler/VoxelOps/actions/workflows/ci.yml
:alt: CI
.. |codecov| image:: https://codecov.io/gh/GalKepler/VoxelOps/graph/badge.svg?token=GBOLQOB5VI
:target: https://codecov.io/gh/GalKepler/VoxelOps
:alt: codecov
.. |codacy| image:: https://app.codacy.com/project/badge/Grade/84bfb76385244fc3b80bc18e5c8f3bfd
:target: https://app.codacy.com/gh/GalKepler/VoxelOps/dashboard?utm_source=gh&utm_medium=referral&utm_content=&utm_campaign=Badge_grade
:alt: Codacy Badge
.. |pypi| image:: https://badge.fury.io/py/voxelops.svg
:target: https://badge.fury.io/py/voxelops
:alt: PyPI version
.. |python| image:: https://img.shields.io/badge/python-3.10%2B-blue.svg
:target: https://www.python.org/downloads/
:alt: Python 3.10+
.. |license| image:: https://img.shields.io/github/license/yalab-devops/yalab-procedures.svg
:target: https://opensource.org/license/mit
:alt: License
.. |black| image:: https://img.shields.io/badge/formatter-black-000000.svg
:target: https://github.com/psf/black
.. |isort| image:: https://img.shields.io/badge/imports-isort-%231674b1.svg
:target: https://pycqa.github.io/isort/
.. |flake8| image:: https://img.shields.io/badge/style-flake8-000000.svg
:target: https://flake8.pycqa.org/en/latest/
.. |pre-commit| image:: https://img.shields.io/badge/pre--commit-enabled-brightgreen?logo=pre-commit&logoColor=white
:target: https://github.com/pre-commit/pre-commit
Features
--------
- **Simple Functions** -- No classes, no inheritance -- just ``run_*()`` functions that return dicts
- **Clear Schemas** -- Typed dataclass inputs, outputs, and defaults for every procedure
- **Reproducibility** -- The exact Docker command is stored in every execution record
- **Database-Ready** -- Results are plain dicts, trivial to save to PostgreSQL, MongoDB, or JSON
- **Brain Bank Defaults** -- Define your standard parameters once, reuse across all participants
- **Comprehensive Logging** -- Every run logged to JSON with timestamps, duration, and exit codes
- **Validation Framework** -- Pre- and post-execution validation with detailed reports
- **Audit Trail** -- Full audit logging for every procedure run
Installation
------------
.. code-block:: bash
pip install voxelops
For development:
.. code-block:: bash
git clone https://github.com/yalab-devops/VoxelOps.git
cd VoxelOps
pip install -e ".[dev]"
**Requirements**: Python >= 3.10, Docker installed and accessible.
Quick Start
-----------
**Basic (direct execution):**
.. code-block:: python
from voxelops import run_qsiprep, QSIPrepInputs
inputs = QSIPrepInputs(
bids_dir="/data/bids",
participant="01",
)
result = run_qsiprep(inputs, nprocs=16)
print(f"Completed in: {result['duration_human']}")
print(f"Outputs: {result['expected_outputs'].qsiprep_dir}")
print(f"Command: {' '.join(result['command'])}")
**With validation and audit logging (recommended):**
.. code-block:: python
from voxelops import run_procedure, QSIPrepInputs
inputs = QSIPrepInputs(
bids_dir="/data/bids",
participant="01",
)
result = run_procedure("qsiprep", inputs)
if result.success:
print(f"Completed in {result.duration_seconds:.1f}s")
else:
print(f"Failed: {result.get_failure_reason()}")
# Save complete audit trail to your database
db.save_procedure_result(result.to_dict())
Available Procedures
--------------------
.. list-table::
:header-rows: 1
:widths: 15 35 25 25
* - Procedure
- Purpose
- Function
- Execution
* - HeudiConv
- DICOM to BIDS conversion
- ``run_heudiconv()``
- Docker
* - QSIPrep
- Diffusion MRI preprocessing
- ``run_qsiprep()``
- Docker
* - QSIRecon
- Diffusion reconstruction & connectivity
- ``run_qsirecon()``
- Docker
* - QSIParc
- Parcellation via ``parcellate``
- ``run_qsiparc()``
- Python (direct)
Brain Bank Standards
--------------------
Define your standard parameters once, use them everywhere:
.. code-block:: python
from voxelops import run_qsiprep, QSIPrepInputs, QSIPrepDefaults
BRAIN_BANK_QSIPREP = QSIPrepDefaults(
nprocs=16,
mem_mb=32000,
output_resolution=1.6,
anatomical_template=["MNI152NLin2009cAsym"],
docker_image="pennlinc/qsiprep:latest",
)
for participant in participants:
inputs = QSIPrepInputs(bids_dir=bids_root, participant=participant)
result = run_qsiprep(inputs, config=BRAIN_BANK_QSIPREP)
db.save_processing_record(result)
Validation & Audit
------------------
``run_procedure()`` wraps any runner with pre-validation, post-validation, and a full audit trail:
.. code-block:: python
from voxelops import run_procedure, HeudiconvInputs, HeudiconvDefaults
inputs = HeudiconvInputs(
dicom_dir="/data/dicoms",
participant="01",
session="baseline",
)
config = HeudiconvDefaults(heuristic="/code/heuristic.py")
result = run_procedure("heudiconv", inputs, config)
# result.pre_validation -- ValidationReport before execution
# result.post_validation -- ValidationReport after execution
# result.audit_log_file -- path to the JSON audit log
Logging
-------
All runners accept an optional ``log_dir`` parameter. When provided, an execution
JSON log is written alongside any audit logs. The log directory defaults to
``<output_dir>/../logs`` derived from the inputs.
.. code-block:: python
result = run_qsiprep(inputs, log_dir="/data/logs/qsiprep")
Documentation
-------------
Full documentation is available at `voxelops.readthedocs.io <https://voxelops.readthedocs.io>`_.
License
-------
MIT License -- see the `LICENSE <LICENSE>`_ file for details.
| text/x-rst | null | YALab DevOps <yalab.dev@gmail.com> | null | null | MIT | brain-bank, docker, heudiconv, neuroimaging, qsiprep, qsirecon | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific... | [] | null | null | >=3.10 | [] | [] | [] | [
"ipython>=8.12.3",
"pandas>=2.0.3",
"parcellate>=0.1.2",
"pyyaml>=6.0.3",
"templateflow>=24.2.2",
"pyyaml>=6.0; extra == \"config\"",
"tomli>=2.0; python_version < \"3.11\" and extra == \"config\"",
"black>=23.0; extra == \"dev\"",
"pre-commit>=3.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"... | [] | [] | [] | [
"Homepage, https://github.com/yalab-devops/VoxelOps",
"Documentation, https://github.com/yalab-devops/VoxelOps#readme",
"Repository, https://github.com/yalab-devops/VoxelOps",
"Issues, https://github.com/yalab-devops/VoxelOps/issues"
] | uv/0.9.28 {"installer":{"name":"uv","version":"0.9.28","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T21:48:14.768560 | voxelops-0.3.2.tar.gz | 22,940,425 | 9b/bf/eabb9087f254c362541f41af8b5f13d5827178895ebb88a3fec304df5de0/voxelops-0.3.2.tar.gz | source | sdist | null | false | d78771fe13a46ca21537c31f6d4bde1a | 3aa62b917a8e605fc536c6ad7219c6bfb001bba664183a415cfce635c225fb61 | 9bbfeabb9087f254c362541f41af8b5f13d5827178895ebb88a3fec304df5de0 | null | [
"LICENSE"
] | 185 |
2.4 | macrotools | 0.1.7 | Employ America tools for pulling and graphing U.S. macroeconomic data. | # MacroTools
A Python package providing flexible tools to work with macroeconomic data and create Employ America-style time series graphs.
## Installation
`pip install macrotools`
## Features
- Download Flat Files and individual series easily
- Caches flat files by default for easy retrieval
- Create professional time series graphs with matplotlib in EA style
- Support for dual y-axes for comparing different data series
- Flexible formatting options
- Includes a few useful tools to work with time series macro data (compounded annual growth rates, rebasing)
## Examples
See [this notebook](https://github.com/PrestonMui/macrotools/blob/main/examples/macrotools_guide.ipynb) for examples on how to use Macrotools
## Roadmap and Development
Currently stored at [GitHub](https://github.com/PrestonMui/macrotools.git).
Some features I am working on.
[] Wrapper for FRED API -- allow for pulling multiple series
| text/markdown | null | Preston Mui <preston@employamerica.org> | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"matplotlib>=3.10.0",
"numpy>=2.0.0",
"statsmodels>=0.14.4",
"pandas>=2.2.3",
"requests>=2.32.3",
"fredapi>=0.5.0; extra == \"fred\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.0 | 2026-02-19T21:47:44.321896 | macrotools-0.1.7.tar.gz | 147,453 | 6a/58/4c6311cd394ecb4ba7bb820d5ce2c93297f7b716534de631144d9874757c/macrotools-0.1.7.tar.gz | source | sdist | null | false | cf6644fefe2e6a9481c06ba00d9acc6e | 1f491efcf1f7c9237749e91b124308974859e39f7a3629788bdc7623d818f230 | 6a584c6311cd394ecb4ba7bb820d5ce2c93297f7b716534de631144d9874757c | null | [
"LICENSE"
] | 176 |
2.4 | dreem-track | 0.4 | Global Tracking Transformers for biological multi-object tracking. | # DREEM Relates Every Entity's Motion
[](https://github.com/talmolab/dreem/actions/workflows/ci.yml)
[](https://codecov.io/gh/talmolab/dreem)
[](https://dreem.sleap.ai)
[](https://github.com/talmolab/dreem)
<!-- [](https://github.com/talmolab/dreem/releases/)
[](https://pypi.org/project/dreem-track)
**DREEM** is an open-source framework for multiple object tracking in biological data. Train your own models, run inference on new data, and evaluate your results. DREEM supports a variety of detection types, including keypoints, bounding boxes, and segmentation masks.
<!-- TODO: Add GIF showing DREEM in action -->
<!--  -->
## Features
- ✅ **Command-Line & API Access:** Use DREEM via a simple CLI or integrate into your own Python scripts.
- ✅ **Pretrained Models:** Get started quickly with models trained specially for microscopy and animal domains.
- ✅ **Configurable Workflows:** Easily customize training and inference using YAML configuration files.
- ✅ **Visualization:** Visualize tracking results in your browser without any data leaving your machine, or use the SLEAP GUI for a more detailed view.
- ✅ **Examples:** Step-by-step notebooks and guides for common workflows.
<!-- TODO: Add GIF showing CLI usage -->
<!--  -->
## Installation
DREEM works best with Python 3.12. We recommend using [uv](https://docs.astral.sh/uv/) for package management.
In a new directory:
```bash
uv venv && source .venv/bin/activate
uv pip install dreem-track
```
or as a system-wide package that does not require a virtual environment:
```bash
uv tool install dreem-track
```
Now dreem commands will be available without activating a virtual environment.
For more installation options and details, see the [Installation Guide](https://dreem.sleap.ai/installation/).
## Quickstart
### 1. Download Sample Data and Model
```bash
# Install huggingface-hub if needed
uv pip install huggingface_hub
# Download sample data
hf download talmolab/sample-flies --repo-type dataset --local-dir ./data
# Download pretrained model
hf download talmolab/animals-pretrained \
--repo-type model \
--local-dir ./models \
--include "animals-pretrained.ckpt"
```
### 2. Run Tracking
```bash
dreem track ./data/inference \
--checkpoint ./models/animals-pretrained.ckpt \
--output ./results \
--crop-size 70
```
### 3. Visualize Results
Results are saved as `.slp` files that can be opened directly in [SLEAP](https://sleap.ai) for visualization.
<!-- TODO: Add GIF showing visualization in SLEAP -->
<!--  -->
For a more detailed walkthrough, check out the [Quickstart Guide](https://dreem.sleap.ai/quickstart/) or try the [Colab notebook](https://colab.research.google.com/github/talmolab/dreem/blob/docs/examples/quickstart.ipynb).
## Usage
### Training a Model
Train your own model on custom data:
```bash
dreem train ./data/train \
--val-dir ./data/val \
--crop-size 70 \
--epochs 10
```
### Running Inference
Run tracking on new data with a pretrained model:
```bash
dreem track ./data/inference \
--checkpoint ./models/my_model.ckpt \
--output ./results \
--crop-size 70
```
### Evaluating Results
Evaluate tracking accuracy against ground truth:
```bash
dreem eval ./data/test \
--checkpoint ./models/my_model.ckpt \
--output ./results \
--crop-size 70
```
For detailed usage instructions, see the [Usage Guide](https://dreem.sleap.ai/usage/).
## Documentation
- **[Installation Guide](https://dreem.sleap.ai/installation/)** - Detailed installation instructions
- **[Quickstart Guide](https://dreem.sleap.ai/quickstart/)** - Get started in minutes
- **[Usage Guide](https://dreem.sleap.ai/usage/)** - Complete workflow documentation
- **[Configuration Reference](https://dreem.sleap.ai/configs/)** - Customize training and inference
- **[API Reference](https://dreem.sleap.ai/reference/dreem/)** - Python API documentation
- **[Examples](https://dreem.sleap.ai/Examples/)** - Step-by-step notebooks
## Examples
We provide several example notebooks to help you get started:
- **[Quickstart Notebook](examples/quickstart.ipynb)** - Fly tracking demo with pretrained model
- **[End-to-End Demo](examples/dreem-demo.ipynb)** - Train, run inference, and evaluate
- **[Microscopy Demo](examples/microscopy-demo-simple.ipynb)** - Track cells in microscopy data
All notebooks are available on [Google Colab](https://colab.research.google.com/github/talmolab/dreem/tree/docs/examples).
## Contributing
We welcome contributions! Please see our [Contributing Guide](CONTRIBUTING.md) for details on:
- Code style and conventions
- Submitting pull requests
- Reporting issues
<!-- TODO: Add GIF showing contribution workflow -->
<!--  -->
## Citation
If you use DREEM in your research, please cite our paper:
```bibtex
@article{dreem2024,
title={DREEM: Global Tracking Transformers for Biological Multi-Object Tracking},
author={...},
journal={...},
year={2024}
}
```
## License
This project is licensed under the BSD-3-Clause License - see the [LICENSE](LICENSE) file for details.
---
**Questions?** Open an issue on [GitHub](https://github.com/talmolab/dreem/issues) or visit our [documentation](https://dreem.sleap.ai).
| text/markdown | null | Mustafa Shaikh <mshaikh@salk.edu>, Arlo Sheridan <asheridan@salk.edu>, Aaditya Prasad <aprasad@salk.edu>, Vincent Tu <vtu@ucsd.edu>, Uri Manor <umanor@salk.edu>, Talmo Pereira <talmo@salk.edu> | null | null | BSD-3-Clause | deep learning, gtr, mot, tracking, transformers | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | <3.13,>=3.12 | [] | [] | [] | [
"albumentations",
"av",
"huggingface-hub",
"hydra-core",
"imageio-ffmpeg",
"imageio>=2.34.0",
"lightning",
"matplotlib",
"motmetrics",
"numpy",
"opencv-python",
"rich>=13.0.0",
"seaborn",
"sleap-io",
"timm",
"torch>=2.0.0",
"torchvision",
"typer>=0.12.0",
"wandb",
"scikit-image... | [] | [] | [] | [
"Homepage, https://github.com/talmolab/dreem",
"Repository, https://github.com/talmolab/dreem"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:46:46.791341 | dreem_track-0.4.tar.gz | 19,598,802 | 86/32/07ed69fa4f0f2625b39c62c1d6f1231b15a3e2d46ab8c7cb0fbc2692bbbf/dreem_track-0.4.tar.gz | source | sdist | null | false | 887d1a971c5b13a85c25f2527c4c9b1d | 5af00c0e2b428736d12712aff5471500e5d315665e068bb046c379088bfe62a4 | 863207ed69fa4f0f2625b39c62c1d6f1231b15a3e2d46ab8c7cb0fbc2692bbbf | null | [
"LICENSE"
] | 185 |
2.3 | zensols-datdesc | 1.4.4 | This API and command line program describes data in tables with metadata and generate LaTeX tables in a `.sty` file from CSV files. | # Describe and optimize data
[![PyPI][pypi-badge]][pypi-link]
[![Python 3.13][python313-badge]][python313-link]
[![Python 3.12][python312-badge]][python312-link]
[![Build Status][build-badge]][build-link]
In this package, Pythonic objects are used to easily (un)serialize to create
LaTeX tables, figures and Excel files. The API and command-line program
describes data in tables with metadata and using YAML and CSV files and
integrates with [Pandas]. The paths to the CSV files to create tables from and
their metadata is given as a YAML configuration file.
Features:
* Create LaTeX tables (with captions) and Excel files (with notes) of tabular
metadata from CSV files.
* Create LaTeX friendly encapsulated postscript (`.eps`) files from CSV files.
* Data and metadata is viewable in a nice format with paging in a web browser
using the [Render program].
* Usable as an API during data collection for research projects.
<!-- markdown-toc start - Don't edit this section. Run M-x markdown-toc-refresh-toc -->
## Table of Contents
- [Documentation](#documentation)
- [Obtaining](#obtaining)
- [Usage](#usage)
- [Tables](#tables)
- [Figures](#figures)
- [Changelog](#changelog)
- [Community](#community)
- [License](#license)
<!-- markdown-toc end -->
## Documentation
See the [full documentation](https://plandes.github.io/datdesc/index.html).
The [API reference](https://plandes.github.io/datdesc/api.html) is also
available.
## Obtaining
The library can be installed with pip from the [pypi] repository:
```bash
pip3 install zensols.datdesc
```
Binaries are also available on [pypi].
## Usage
The library can be used as a Python API to programmatically create tables,
figures, and/or represent tabular data. However, it also has a very robust
command-line that is intended by be used by [GNU make]. The command-line can
be used to create on the fly LaTeX `.sty` files that are generated as commands
and figures are generated as Encapsulated Postscript (`.eps`) files.
The YAML file format is used to create both tables and figures. Parameters are
both files or both directories when using directories, only files that match
`*-table.yml` are considered on the command line.
### Tables
First create the table's configuration file. For example, to create a Latex
`.sty` file from the CSV file `test-resources/section-id.csv` using the first
column as the index (makes that column go away) using a variable size and
placement, use:
```yaml
intercodertab:
type: one_column
path: test-resources/section-id.csv
caption: >-
Krippendorff’s ...
single_column: true
uses: zentable
read_params:
index_col: 0
tabulate_params:
disable_numparse: true
replace_nan: ' '
blank_columns: [0]
bold_cells: [[0, 0], [1, 0], [2, 0], [3, 0]]
```
Some of these fields include:
* **index_col**: clears column 0 and
* **bold_cells**: make certain cells bold
* **disable_numparse** tells the `tabulate` module not reformat numbers
See the [Table] class for a full listing of options.
### Figures
Figures can be generated in any format supported by [matplotlib] (namely
`.eps`, `.svg`, and `.pdf`). Figures are configured in a very similar fashion
to [tables](#tables). The configuration also points to a CSV file, but
describes the plot.
The primary difference is that the YAML is parsed using the [Zensols parsing
rules] so the string `path: target` will be given to a new [Plot] instance as a
[pathlib.Path].
A bar plot is configured below:
```yaml
irisFig:
image_dir: 'path: target'
seaborn:
style:
style: darkgrid
rc:
axes.facecolor: 'str: .9'
context:
context: 'paper'
font_scale: 1.3
plots:
- type: bar
data: 'dataframe: test-resources/fig/iris.csv'
title: 'Iris Splits'
x_column_name: ds_type
y_column_name: count
core_pre: |
plot.data = plot.data.groupby('ds_type').agg({'ds_type': 'count'}).\
rename(columns={'ds_type': 'count'}).reset_index()
```
This configuration meaning:
* The top level `irisFig` creates a [Figure] instance, and when used with the
command line, outputs this root level string as the name in the `image_dir`
directory.
* The `image_dir` tells where to write the image. This should be left out when
invoking from the command-line to allow it to decide where to write the file.
* The `seaborn` section configures the [seaborn] module.
* The plots are a *list* of [Plot] instances that, like the [Figure] level, are
populated with all the values.
* The `code_pre` (optionally) allows the massaging of the plot (bound to
variable `data`) and/or [Pandas] dataframe accessible with `plot.dataframe`
with all other properties and attributes.
If `code_post` is given, it is called after the plot is created and accessible
with variable ``plot``. If `code_post_render` it is executed after the plot is
rendered by `matplotlib`.
Other plot configuration examples are given in the [test
cases](test-resources/fig) directory. See the [Figure] and [Plot] classes for
a full listing of options.
## Changelog
An extensive changelog is available [here](CHANGELOG.md).
## Community
Please star this repository and let me know how and where you use this API.
[Contributions](CONTRIBUTING.md) as pull requests, feedback, and any input is
welcome.
## License
[MIT License](LICENSE.md)
Copyright (c) 2023 - 2026 Paul Landes
<!-- links -->
[pypi]: https://pypi.org/project/zensols.datdesc/
[pypi-link]: https://pypi.python.org/pypi/zensols.datdesc
[pypi-badge]: https://img.shields.io/pypi/v/zensols.datdesc.svg
[python313-badge]: https://img.shields.io/badge/python-3.13-blue.svg
[python313-link]: https://www.python.org/downloads/release/python-3130
[python312-badge]: https://img.shields.io/badge/python-3.12-blue.svg
[python312-link]: https://www.python.org/downloads/release/python-3120
[build-badge]: https://github.com/plandes/datdesc/workflows/CI/badge.svg
[build-link]: https://github.com/plandes/datdesc/actions
[GNU make]: https://www.gnu.org/software/make/
[matplotlib]: https://matplotlib.org
[seaborn]: http://seaborn.pydata.org
[hyperopt]: http://hyperopt.github.io/hyperopt/
[pathlib.Path]: https://docs.python.org/3/library/pathlib.html
[Pandas]: https://pandas.pydata.org
[Zensols parsing rules]: https://plandes.github.io/util/doc/config.html#parsing
[Render program]: https://github.com/plandes/rend
[Table]: api/zensols.datdesc.html#zensols.datdesc.table.Table
[Figure]: api/zensols.datdesc.html#zensols.datdesc.figure.Figure
[Plot]: api/zensols.datdesc.html#zensols.datdesc.figure.Plot
| text/markdown | null | Paul Landes <landes@mailc.net> | null | null | MIT | academia, data, tooling | [] | [] | null | null | <3.15,>=3.11 | [] | [] | [] | [
"hyperopt~=0.2.7",
"jinja2~=3.1.6",
"matplotlib~=3.10.8",
"numpy~=2.4.0",
"openpyxl~=3.1.5",
"pandas~=2.3.3",
"seaborn~=0.13.2",
"tabulate~=0.9.0",
"xlsxwriter~=3.0.3",
"zensols-util~=1.16.3"
] | [] | [] | [] | [
"Homepage, https://github.com/plandes/datdesc",
"Documentation, https://plandes.github.io/datdesc",
"Repository, https://github.com/plandes/datdesc.git",
"Issues, https://github.com/plandes/datdesc/issues",
"Changelog, https://github.com/plandes/datdesc/blob/master/CHANGELOG.md"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T21:46:07.000974 | zensols_datdesc-1.4.4-py3-none-any.whl | 60,906 | 7d/0f/d9daf0f55c7993dd515b37795a7d799f9ab2994ae6060c2744e615eebe8f/zensols_datdesc-1.4.4-py3-none-any.whl | py3 | bdist_wheel | null | false | e61c3284253ce83fe55b8b2f999a9301 | c248d6c2a40ea54d6e2928fc0967eebcf11197d91ee0658eac93b1e54f85cb36 | 7d0fd9daf0f55c7993dd515b37795a7d799f9ab2994ae6060c2744e615eebe8f | null | [] | 95 |
2.4 | rubin-sim | 2.6.1a4 | Scheduler, survey strategy analysis, and other simulation tools for Rubin Observatory. | # rubin_sim
Scheduler, survey strategy analysis, and other simulation tools for Rubin Observatory.
[](https://pypi.org/project/rubin-sim/)
[](https://anaconda.org/conda-forge/rubin-sim) <br>
[](https://github.com/lsst/rubin_sim/actions/workflows/test_and_build.yaml)
[](https://github.com/lsst/rubin_sim/actions/workflows/build_docs.yaml)
[](https://codecov.io/gh/lsst/rubin_sim)
[](https://zenodo.org/badge/latestdoi/365031715)
## rubin_sim ##
The [Legacy Survey of Space and Time](http://www.lsst.org) (LSST)
is anticipated to encompass around 2 million observations spanning a decade,
averaging 800 visits per night. The `rubin_sim` package was built to help
understand the predicted performance of the LSST.
The `rubin_sim` package contains the following main modules:
* `phot_utils` - provides synthetic photometry
using provided throughput curves based on current predicted performance.
* `skybrightness` incorporates the ESO
sky model, modified to match measured sky conditions at the LSST site,
including an addition of a model for twilight skybrightness. This is used
to generate the pre-calculated skybrightness data used in
[`rubin_scheduler.skybrightness_pre`](https://rubin-scheduler.lsst.io/skybrightness-pre.html).
* `moving_objects` provides a way to generate
synthetic observations of moving objects, based on how they would appear in
pointing databases ("opsims") created by
[`rubin_scheduler`](https://rubin-scheduler.lsst.io).
* `maf` the Metrics Analysis Framework, enabling efficient and
scientifically varied evaluation of the LSST survey strategy and progress
by providing a framework to enable these metrics to run in a
standardized way on opsim outputs.
More documentation for `rubin_sim` is available at
[https://rubin-sim.lsst.io](https://rubin-sim.lsst.io), including installation instructions.
### Getting Help ###
Questions about `rubin_sim` can be posted on the [sims slack channel](https://lsstc.slack.com/archives/C2LQ5JW9W), or on https://community.lsst.org/c/sci/survey_strategy/ (optionally, tag @yoachim and/or @ljones so we get notifications about it).
| text/markdown | null | null | null | null | GPL | null | [
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Astronomy"
] | [] | null | null | null | [] | [] | [] | [
"astroplan",
"astropy",
"colorcet",
"cycler",
"gitpython",
"h5py",
"healpy",
"matplotlib",
"numexpr",
"numpy",
"pandas",
"pyarrow",
"rubin-scheduler>=3.18",
"scikit-learn",
"scipy",
"shapely",
"skyfield>=1.52",
"skyproj",
"sqlalchemy",
"tables",
"tqdm",
"pytest; extra == \"... | [] | [] | [] | [
"documentation, https://rubin-sim.lsst.io",
"repository, https://github.com/lsst/rubin_sim"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:45:29.219877 | rubin_sim-2.6.1a4.tar.gz | 738,860 | cd/9c/2e03c138afca72350f02c9b9ea57b61e27ff6323b1e7224e6b372203fbf7/rubin_sim-2.6.1a4.tar.gz | source | sdist | null | false | e56d5eeca32692e8589c9a0ec5de41aa | 5a219831a83b169b6e5269694cfa69b80c5130257b63ac3288001887980feaa9 | cd9c2e03c138afca72350f02c9b9ea57b61e27ff6323b1e7224e6b372203fbf7 | null | [
"LICENSE"
] | 147 |
2.4 | pulp-container-client | 2.24.5 | Pulp 3 API | Fetch, Upload, Organize, and Distribute Software Packages
| text/markdown | Pulp Team | pulp-list@redhat.com | null | null | GPL-2.0-or-later | pulp, pulpcore, client, Pulp 3 API | [] | [] | null | null | null | [] | [] | [] | [
"urllib3<2.7,>=1.25.3",
"python-dateutil<2.10.0,>=2.8.1",
"pydantic>=2",
"typing-extensions>=4.7.1"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:44:56.076141 | pulp_container_client-2.24.5.tar.gz | 123,914 | 7f/b6/0c3b4f35c0b41b828a1b5bb4c0c05597b0681c3eff946f74719231a69c8e/pulp_container_client-2.24.5.tar.gz | source | sdist | null | false | cfe2b2099de7f433297e11f81bacb89a | bd3f8879e16e98f54340c63a1af95ea92152839d594fcadbecb5a9bd40646b21 | 7fb60c3b4f35c0b41b828a1b5bb4c0c05597b0681c3eff946f74719231a69c8e | null | [] | 194 |
2.4 | nitor-vault | 2.7.7 | Vault for storing locally encrypted data in S3 using KMS keys | # nitor-vault
Python Vault CLI and library implementation using the Rust vault exposed as a Python extension module.
Encrypt data using client-side encryption with [AWS KMS](https://aws.amazon.com/kms/) keys.
See the [repo](https://github.com/NitorCreations/vault) root readme for more general information.
## Vault CLI
```console
Encrypted AWS key-value storage utility
Usage: vault [OPTIONS] [COMMAND]
Commands:
all, -a, --all List available secrets [aliases: a, list, ls]
completion, --completion Generate shell completion
delete, -d, --delete Delete an existing key from the store [aliases: d]
describe, --describe Print CloudFormation stack parameters for current configuration
decrypt, -y, --decrypt Directly decrypt given value [aliases: y]
encrypt, -e, --encrypt Directly encrypt given value [aliases: e]
exists, --exists Check if a key exists
info, --info Print vault information
id Print AWS user account information
status, --status Print vault stack information
init, -i, --init Initialize a new KMS key and S3 bucket [aliases: i]
update, -u, --update Update the vault CloudFormation stack [aliases: u]
lookup, -l, --lookup Output secret value for given key [aliases: l]
store, -s, --store Store a new key-value pair [aliases: s]
help Print this message or the help of the given subcommand(s)
Options:
-b, --bucket <BUCKET> Override the bucket name [env: VAULT_BUCKET=]
-k, --key-arn <ARN> Override the KMS key ARN [env: VAULT_KEY=]
-p, --prefix <PREFIX> Optional prefix for key name [env: VAULT_PREFIX=]
-r, --region <REGION> Specify AWS region for the bucket [env: AWS_REGION=]
--vaultstack <NAME> Specify CloudFormation stack name to use [env: VAULT_STACK=]
--id <ID> Specify AWS IAM access key ID
--secret <SECRET> Specify AWS IAM secret access key
--profile <PROFILE> Specify AWS profile name to use [env: AWS_PROFILE=]
-q, --quiet Suppress additional output and error messages
-h, --help Print help (see more with '--help')
-V, --version Print version
```
### Install
#### From PyPI
Use [pipx](https://github.com/pypa/pipx) or [uv](https://github.com/astral-sh/uv)
to install the Python vault package from [PyPI](https://pypi.org/project/nitor-vault/)
globally in an isolated environment.
```shell
pipx install nitor-vault
# or
uv tool install nitor-vault
```
The command `vault` should now be available in path.
#### From source
Build and install locally from source code using pip.
This requires a [Rust toolchain](https://rustup.rs/) to be able to build the Rust library.
From the repo root:
```shell
cd python-pyo3
pip install .
# or with uv
uv pip install .
```
Check the command is found in path.
If you ran the install command inside a virtual env,
it will only be installed inside the venv,
and will not be available in path globally.
```shell
which -a vault
```
## Vault library
This Python package can also be used as a Python library to interact with the Vault directly from Python code.
Add the `nitor-vault` package to your project dependencies,
or install directly with pip.
Example usage:
```python
from n_vault import Vault
if not Vault().exists("key"):
Vault().store("key", "value")
keys = Vault().list_all()
value = Vault().lookup("key")
if Vault().exists("key"):
Vault().delete("key")
# specify vault parameters
vault = Vault(vault_stack="stack-name", profile="aws-credentials-name")
value = vault.lookup("key")
```
## Development
Uses:
- [PyO3](https://pyo3.rs/) for creating a native Python module from Rust code.
- [Maturin](https://www.maturin.rs) for building and packaging the Python module from Rust.
### Workflow
You can use [uv](https://github.com/astral-sh/uv) or the traditional Python and pip combo.
First, create a virtual env:
```shell
# uv
uv sync --all-extras
# pip
python3 -m venv .venv
source .venv/bin/activate
pip install '.[dev]'
```
After making changes to Rust code, build and install module:
```shell
# uv
uv run maturin develop
# venv
maturin develop
```
Run Python CLI:
```shell
# uv
uv run python/n_vault/cli.py -h
# venv
python3 python/n_vault/cli.py -h
```
Install and run vault inside virtual env:
```shell
# uv
uv pip install .
uv run vault -h
# venv
pip install .
vault -h
```
### Updating dependencies
Update all Python dependencies to latest versions:
```shell
uv lock --upgrade
uv sync
```
To update a specific package:
```shell
uv lock --upgrade-package <package-name>
uv sync
```
| text/markdown; charset=UTF-8; variant=GFM | null | Pasi Niemi <pasi@nitor.com>, Akseli Lukkarila <akseli.lukkarila@nitor.com> | null | null | Apache-2.0 | null | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"maturin; extra == \"build\"",
"wheel; extra == \"build\"",
"maturin; extra == \"dev\"",
"ruff; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/NitorCreations/vault",
"Repository, https://github.com/NitorCreations/vault"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:44:07.672397 | nitor_vault-2.7.7-cp314-cp314t-win_amd64.whl | 7,948,777 | 60/d5/35240cea383a92bd6ed30c8ca2a7088a662fa4d16263cb4eebc7df03b171/nitor_vault-2.7.7-cp314-cp314t-win_amd64.whl | cp314 | bdist_wheel | null | false | 63931d1c8805814008799d9fee1d47af | 17e6d754eba9696c22d8f8fd9f1dcbb6357aa1bbb5d658c4e56edbb4006d7a18 | 60d535240cea383a92bd6ed30c8ca2a7088a662fa4d16263cb4eebc7df03b171 | null | [] | 935 |
2.3 | together | 2.2.0 | The official Python library for the together API | # Together Python API library
<!-- prettier-ignore -->
[)](https://pypi.org/project/together/)
The Together Python library provides convenient access to the Together REST API from any Python 3.9+
application. The library includes type definitions for all request params and response fields,
and offers both synchronous and asynchronous clients powered by [httpx](https://github.com/encode/httpx).
It is generated with [Stainless](https://www.stainless.com/).
## Documentation
The REST API documentation can be found on [docs.together.ai](https://docs.together.ai/). The full API of this library can be found in [api.md](https://github.com/togethercomputer/together-py/tree/main/api.md).
## Installation
```sh
pip install together
```
```sh
uv add together
```
## Usage
The full API of this library can be found in [api.md](https://github.com/togethercomputer/together-py/tree/main/api.md).
```python
import os
from together import Together
client = Together(
api_key=os.environ.get("TOGETHER_API_KEY"), # This is the default and can be omitted
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": "Say this is a test!",
}
],
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
)
print(chat_completion.choices)
```
While you can provide an `api_key` keyword argument,
we recommend using [python-dotenv](https://pypi.org/project/python-dotenv/)
to add `TOGETHER_API_KEY="My API Key"` to your `.env` file
so that your API Key is not stored in source control.
## Async usage
Simply import `AsyncTogether` instead of `Together` and use `await` with each API call:
```python
import os
import asyncio
from together import AsyncTogether
client = AsyncTogether(
api_key=os.environ.get("TOGETHER_API_KEY"), # This is the default and can be omitted
)
async def main() -> None:
chat_completion = await client.chat.completions.create(
messages=[
{
"role": "user",
"content": "Say this is a test!",
}
],
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
)
print(chat_completion.choices)
asyncio.run(main())
```
Functionality between the synchronous and asynchronous clients is otherwise identical.
### With aiohttp
By default, the async client uses `httpx` for HTTP requests. However, for improved concurrency performance you may also use `aiohttp` as the HTTP backend.
You can enable this by installing `aiohttp`:
```sh
# install from PyPI
pip install '--pre together[aiohttp]'
```
Then you can enable it by instantiating the client with `http_client=DefaultAioHttpClient()`:
```python
import os
import asyncio
from together import DefaultAioHttpClient
from together import AsyncTogether
async def main() -> None:
async with AsyncTogether(
api_key=os.environ.get("TOGETHER_API_KEY"), # This is the default and can be omitted
http_client=DefaultAioHttpClient(),
) as client:
chat_completion = await client.chat.completions.create(
messages=[
{
"role": "user",
"content": "Say this is a test!",
}
],
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
)
print(chat_completion.choices)
asyncio.run(main())
```
## Streaming responses
We provide support for streaming responses using Server Side Events (SSE).
```python
from together import Together
client = Together()
stream = client.chat.completions.create(
messages=[
{
"role": "user",
"content": "Say this is a test!",
}
],
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
stream=True,
)
for chat_completion in stream:
print(chat_completion.choices)
```
The async client uses the exact same interface.
```python
from together import AsyncTogether
client = AsyncTogether()
stream = await client.chat.completions.create(
messages=[
{
"role": "user",
"content": "Say this is a test!",
}
],
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
stream=True,
)
async for chat_completion in stream:
print(chat_completion.choices)
```
## Using types
Nested request parameters are [TypedDicts](https://docs.python.org/3/library/typing.html#typing.TypedDict). Responses are [Pydantic models](https://docs.pydantic.dev) which also provide helper methods for things like:
- Serializing back into JSON, `model.to_json()`
- Converting to a dictionary, `model.to_dict()`
Typed requests and responses provide autocomplete and documentation within your editor. If you would like to see type errors in VS Code to help catch bugs earlier, set `python.analysis.typeCheckingMode` to `basic`.
## Nested params
Nested parameters are dictionaries, typed using `TypedDict`, for example:
```python
from together import Together
client = Together()
chat_completion = client.chat.completions.create(
messages=[
{
"content": "content",
"role": "system",
}
],
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
reasoning={},
)
print(chat_completion.reasoning)
```
The async client uses the exact same interface. If you pass a [`PathLike`](https://docs.python.org/3/library/os.html#os.PathLike) instance, the file contents will be read asynchronously automatically.
## Handling errors
When the library is unable to connect to the API (for example, due to network connection problems or a timeout), a subclass of `together.APIConnectionError` is raised.
When the API returns a non-success status code (that is, 4xx or 5xx
response), a subclass of `together.APIStatusError` is raised, containing `status_code` and `response` properties.
All errors inherit from `together.APIError`.
```python
import together
from together import Together
client = Together()
try:
client.chat.completions.create(
messages=[
{
"role": "user",
"content": "Say this is a test",
}
],
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
)
except together.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # an underlying Exception, likely raised within httpx.
except together.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except together.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
```
Error codes are as follows:
| Status Code | Error Type |
| ----------- | -------------------------- |
| 400 | `BadRequestError` |
| 401 | `AuthenticationError` |
| 403 | `PermissionDeniedError` |
| 404 | `NotFoundError` |
| 422 | `UnprocessableEntityError` |
| 429 | `RateLimitError` |
| >=500 | `InternalServerError` |
| N/A | `APIConnectionError` |
### Retries
Certain errors are automatically retried 2 times by default, with a short exponential backoff.
Connection errors (for example, due to a network connectivity problem), 408 Request Timeout, 409 Conflict,
429 Rate Limit, and >=500 Internal errors are all retried by default.
You can use the `max_retries` option to configure or disable retry settings:
```python
from together import Together
# Configure the default for all requests:
client = Together(
# default is 2
max_retries=0,
)
# Or, configure per-request:
client.with_options(max_retries=5).chat.completions.create(
messages=[
{
"role": "user",
"content": "Say this is a test",
}
],
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
)
```
### Timeouts
By default requests time out after 1 minute. You can configure this with a `timeout` option,
which accepts a float or an [`httpx.Timeout`](https://www.python-httpx.org/advanced/timeouts/#fine-tuning-the-configuration) object:
```python
from together import Together
# Configure the default for all requests:
client = Together(
# 20 seconds (default is 1 minute)
timeout=20.0,
)
# More granular control:
client = Together(
timeout=httpx.Timeout(60.0, read=5.0, write=10.0, connect=2.0),
)
# Override per-request:
client.with_options(timeout=5.0).chat.completions.create(
messages=[
{
"role": "user",
"content": "Say this is a test",
}
],
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
)
```
On timeout, an `APITimeoutError` is thrown.
Note that requests that time out are [retried twice by default](https://github.com/togethercomputer/together-py/tree/main/#retries).
## Advanced
### Logging
We use the standard library [`logging`](https://docs.python.org/3/library/logging.html) module.
You can enable logging by setting the environment variable `TOGETHER_LOG` to `info`.
```shell
$ export TOGETHER_LOG=info
```
Or to `debug` for more verbose logging.
### How to tell whether `None` means `null` or missing
In an API response, a field may be explicitly `null`, or missing entirely; in either case, its value is `None` in this library. You can differentiate the two cases with `.model_fields_set`:
```py
if response.my_field is None:
if 'my_field' not in response.model_fields_set:
print('Got json like {}, without a "my_field" key present at all.')
else:
print('Got json like {"my_field": null}.')
```
### Accessing raw response data (e.g. headers)
The "raw" Response object can be accessed by prefixing `.with_raw_response.` to any HTTP method call, e.g.,
```py
from together import Together
client = Together()
response = client.chat.completions.with_raw_response.create(
messages=[{
"role": "user",
"content": "Say this is a test",
}],
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
)
print(response.headers.get('X-My-Header'))
completion = response.parse() # get the object that `chat.completions.create()` would have returned
print(completion.choices)
```
These methods return an [`APIResponse`](https://github.com/togethercomputer/together-py/tree/main/src/together/_response.py) object.
The async client returns an [`AsyncAPIResponse`](https://github.com/togethercomputer/together-py/tree/main/src/together/_response.py) with the same structure, the only difference being `await`able methods for reading the response content.
#### `.with_streaming_response`
The above interface eagerly reads the full response body when you make the request, which may not always be what you want.
To stream the response body, use `.with_streaming_response` instead, which requires a context manager and only reads the response body once you call `.read()`, `.text()`, `.json()`, `.iter_bytes()`, `.iter_text()`, `.iter_lines()` or `.parse()`. In the async client, these are async methods.
```python
with client.chat.completions.with_streaming_response.create(
messages=[
{
"role": "user",
"content": "Say this is a test",
}
],
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
) as response:
print(response.headers.get("X-My-Header"))
for line in response.iter_lines():
print(line)
```
The context manager is required so that the response will reliably be closed.
### Making custom/undocumented requests
This library is typed for convenient access to the documented API.
If you need to access undocumented endpoints, params, or response properties, the library can still be used.
#### Undocumented endpoints
To make requests to undocumented endpoints, you can make requests using `client.get`, `client.post`, and other
http verbs. Options on the client will be respected (such as retries) when making this request.
```py
import httpx
response = client.post(
"/foo",
cast_to=httpx.Response,
body={"my_param": True},
)
print(response.headers.get("x-foo"))
```
#### Undocumented request params
If you want to explicitly send an extra param, you can do so with the `extra_query`, `extra_body`, and `extra_headers` request
options.
#### Undocumented response properties
To access undocumented response properties, you can access the extra fields like `response.unknown_prop`. You
can also get all the extra fields on the Pydantic model as a dict with
[`response.model_extra`](https://docs.pydantic.dev/latest/api/base_model/#pydantic.BaseModel.model_extra).
### Configuring the HTTP client
You can directly override the [httpx client](https://www.python-httpx.org/api/#client) to customize it for your use case, including:
- Support for [proxies](https://www.python-httpx.org/advanced/proxies/)
- Custom [transports](https://www.python-httpx.org/advanced/transports/)
- Additional [advanced](https://www.python-httpx.org/advanced/clients/) functionality
```python
import httpx
from together import Together, DefaultHttpxClient
client = Together(
# Or use the `TOGETHER_BASE_URL` env var
base_url="http://my.test.server.example.com:8083",
http_client=DefaultHttpxClient(
proxy="http://my.test.proxy.example.com",
transport=httpx.HTTPTransport(local_address="0.0.0.0"),
),
)
```
You can also customize the client on a per-request basis by using `with_options()`:
```python
client.with_options(http_client=DefaultHttpxClient(...))
```
### Managing HTTP resources
By default the library closes underlying HTTP connections whenever the client is [garbage collected](https://docs.python.org/3/reference/datamodel.html#object.__del__). You can manually close the client using the `.close()` method if desired, or with a context manager that closes when exiting.
```py
from together import Together
with Together() as client:
# make requests here
...
# HTTP client is now closed
```
## Usage – CLI
### Files
```bash
# Help
together files --help
# Check file
together files check example.jsonl
# Upload file
together files upload example.jsonl
# List files
together files list
# Retrieve file metadata
together files retrieve file-6f50f9d1-5b95-416c-9040-0799b2b4b894
# Retrieve file content
together files retrieve-content file-6f50f9d1-5b95-416c-9040-0799b2b4b894
# Delete remote file
together files delete file-6f50f9d1-5b95-416c-9040-0799b2b4b894
```
### Fine-tuning
```bash
# Help
together fine-tuning --help
# Create fine-tune job
together fine-tuning create \
--model togethercomputer/llama-2-7b-chat \
--training-file file-711d8724-b3e3-4ae2-b516-94841958117d
# List fine-tune jobs
together fine-tuning list
# Retrieve fine-tune job details
together fine-tuning retrieve ft-c66a5c18-1d6d-43c9-94bd-32d756425b4b
# List fine-tune job events
together fine-tuning list-events ft-c66a5c18-1d6d-43c9-94bd-32d756425b4b
# Cancel running job
together fine-tuning cancel ft-c66a5c18-1d6d-43c9-94bd-32d756425b4b
# Download fine-tuned model weights
together fine-tuning download ft-c66a5c18-1d6d-43c9-94bd-32d756425b4b
```
### Models
```bash
# Help
together models --help
# List models
together models list
```
## Versioning
This package generally follows [SemVer](https://semver.org/spec/v2.0.0.html) conventions, though certain backwards-incompatible changes may be released as minor versions:
1. Changes that only affect static types, without breaking runtime behavior.
2. Changes to library internals which are technically public but not intended or documented for external use. _(Please open a GitHub issue to let us know if you are relying on such internals.)_
3. Changes that we do not expect to impact the vast majority of users in practice.
We take backwards-compatibility seriously and work hard to ensure you can rely on a smooth upgrade experience.
We are keen for your feedback; please open an [issue](https://www.github.com/togethercomputer/together-py/issues) with questions, bugs, or suggestions.
### Determining the installed version
If you've upgraded to the latest version but aren't seeing any new features you were expecting then your python environment is likely still using an older version.
You can determine the version that is being used at runtime with:
```py
import together
print(together.__version__)
```
## Requirements
Python 3.9 or higher.
## Usage – CLI
### Files
```bash
# Help
together files --help
# Check file
together files check example.jsonl
# Upload file
together files upload example.jsonl
# List files
together files list
# Retrieve file metadata
together files retrieve file-6f50f9d1-5b95-416c-9040-0799b2b4b894
# Retrieve file content
together files retrieve-content file-6f50f9d1-5b95-416c-9040-0799b2b4b894
# Delete remote file
together files delete file-6f50f9d1-5b95-416c-9040-0799b2b4b894
```
### Fine-tuning
```bash
# Help
together fine-tuning --help
# Create fine-tune job
together fine-tuning create \
--model togethercomputer/llama-2-7b-chat \
--training-file file-711d8724-b3e3-4ae2-b516-94841958117d
# List fine-tune jobs
together fine-tuning list
# Retrieve fine-tune job details
together fine-tuning retrieve ft-c66a5c18-1d6d-43c9-94bd-32d756425b4b
# List fine-tune job events
together fine-tuning list-events ft-c66a5c18-1d6d-43c9-94bd-32d756425b4b
# List fine-tune checkpoints
together fine-tuning list-checkpoints ft-c66a5c18-1d6d-43c9-94bd-32d756425b4b
# Cancel running job
together fine-tuning cancel ft-c66a5c18-1d6d-43c9-94bd-32d756425b4b
# Download fine-tuned model weights
together fine-tuning download ft-c66a5c18-1d6d-43c9-94bd-32d756425b4b
# Delete fine-tuned model weights
together fine-tuning delete ft-c66a5c18-1d6d-43c9-94bd-32d756425b4b
```
### Models
```bash
# Help
together models --help
# List models
together models list
# Upload a model
together models upload --model-name my-org/my-model --model-source s3-or-hugging-face
```
### Clusters
```bash
# Help
together beta clusters --help
# Create a cluster
together beta clusters create
# List clusters
together beta clusters list
# Retrieve cluster details
together beta clusters retrieve [cluster-id]
# Update a cluster
together beta clusters update [cluster-id]
# Retrieve Together cluster configuration options such as regions, gpu types and drivers available
together beta clusters list-regions
```
##### Cluster Storage
```bash
# Help
together beta clusters storage --help
# Create cluster storage volume
together beta clusters storage create
# List storage volumes
together beta clusters storage list
# Retrieve storage volume
together beta clusters storage retrieve [storage-id]
# Delete storage volume
together beta clusters storage delete [storage-id]
```
### Jig (Container Deployments)
```bash
# Help
together beta jig --help
# Initialize jig configuration (creates pyproject.toml)
together beta jig init
# Generate Dockerfile from config
together beta jig dockerfile
# Build container image
together beta jig build
together beta jig build --tag v1.0 --warmup
# Push image to registry
together beta jig push
together beta jig push --tag v1.0
# Deploy model (builds, pushes, and deploys)
together beta jig deploy
together beta jig deploy --build-only
together beta jig deploy --image existing-image:tag
# Get deployment status
together beta jig status
# Get deployment endpoint URL
together beta jig endpoint
# View deployment logs
together beta jig logs
together beta jig logs --follow
# Destroy deployment
together beta jig destroy
# Get queue metrics
together beta jig queue-status
# List all deployments
together beta jig list
```
##### Jig Secrets
```bash
# Help
together beta jig secrets --help
# Set a secret (creates or updates)
together beta jig secrets set --name MY_SECRET --value "secret-value"
# Remove a secret from local state
together beta jig secrets unset --name MY_SECRET
# List all secrets with sync status
together beta jig secrets list
```
##### Jig Volumes
```bash
# Help
together beta jig volumes --help
# Create a volume and upload files from directory
together beta jig volumes create --name my-volume --source ./data
# Update a volume with new files
together beta jig volumes update --name my-volume --source ./data
# Set volume mount path for deployment
together beta jig volumes set --name my-volume --mount-path /app/data
# Remove volume from deployment config (does not delete remote volume)
together beta jig volumes unset --name my-volume
# Delete a volume
together beta jig volumes delete --name my-volume
# Describe a volume
together beta jig volumes describe --name my-volume
# List all volumes
together beta jig volumes list
```
## Contributing
See [the contributing documentation](https://github.com/togethercomputer/together-py/tree/main/./CONTRIBUTING.md).
| text/markdown | null | Together <dev-feedback@TogetherAI.com> | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: OS Independent",
"Operating System :: POSIX",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"anyio<5,>=3.5.0",
"click>=8.1.7",
"distro<2,>=1.7.0",
"filelock>=3.13.1",
"httpx<1,>=0.23.0",
"pillow>=10.4.0",
"pydantic<3,>=1.9.0",
"rich>=13.7.1",
"sniffio",
"tabulate>=0.9.0",
"tomli>=2.0.0; python_version < \"3.11\"",
"tqdm>=4.67.1",
"types-pyyaml>=6.0.12.20250915",
"types-tabulate>=... | [] | [] | [] | [
"Homepage, https://github.com/togethercomputer/together-py",
"Repository, https://github.com/togethercomputer/together-py",
"Documentation, https://docs.together.ai/",
"Changelog, https://github.com/togethercomputer/together-py/blob/main/CHANGELOG.md"
] | uv/0.9.13 {"installer":{"name":"uv","version":"0.9.13"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:42:53.861499 | together-2.2.0-py3-none-any.whl | 330,792 | 38/4b/a8728ea83e1cb7bdad4d90fa3f27b0ecd3717117490389706f7b00ab3364/together-2.2.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 9709378a81918f446893282bb42d9b7d | 9c49537ce4be1ed27bdb2969ad09bcd06a137b767a760a71f98d3918df3a8183 | 384ba8728ea83e1cb7bdad4d90fa3f27b0ecd3717117490389706f7b00ab3364 | null | [] | 45,913 |
2.4 | nlweb-crawler | 0.7.1 | NLWeb Crawler - Web crawling and indexing service | # Crawler
Distributed web crawler for schema.org structured data.
## Architecture
Master/worker pattern running as separate pods in Kubernetes:
- **Master**: Flask API + job scheduler
- **Worker**: Queue processor (embedding + upload to Azure AI Search)
Flow: Parse schema.org sitemaps → queue JSON files → embed → upload
## Endpoints
- `GET /` - Web UI
- `GET /api/status` - System status
- `POST /api/sites` - Add site to crawl
- `GET /api/queue/status` - Queue statistics
## Commands
Run `make help` for the full list. Key targets:
```
make dev # Run master + worker via Docker Compose
make test # Run pytest
make build # Build image to ACR
make deploy # Deploy to AKS via Helm
```
| text/markdown | nlweb-ai | null | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"flask>=2.3.3",
"flask-cors>=4.0.0",
"pymssql>=2.2.0",
"requests>=2.31.0",
"azure-storage-blob>=12.19.0",
"azure-identity>=1.14.0",
"azure-search-documents>=11.4.0",
"azure-storage-queue>=12.8.0",
"azure-cosmos>=4.5.0",
"openai>=1.0.0",
"defusedxml>=0.7.1",
"feedparser>=6.0.0",
"python-dateu... | [] | [] | [] | [
"Homepage, https://github.com/nlweb-ai/nlweb-ask-agent",
"Repository, https://github.com/nlweb-ai/nlweb-ask-agent",
"Issues, https://github.com/nlweb-ai/nlweb-ask-agent/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:42:44.641114 | nlweb_crawler-0.7.1-py3-none-any.whl | 94,514 | d6/91/03a4c6693bfce71f9ff882cc8564ffd3f297074ae21586189362d6ced289/nlweb_crawler-0.7.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 5873e8872bcf1c0e1fe6f5b3713bf65a | e813dee6adfd4a293bd1a635550b7e72ea9aa466c19d3871ba55d23417e23658 | d69103a4c6693bfce71f9ff882cc8564ffd3f297074ae21586189362d6ced289 | null | [
"LICENSE"
] | 197 |
2.4 | odse | 0.4.0 | Open Data Schema for Energy - validation and transformation library | # ODS-E: Open Data Schema for Energy
[](https://creativecommons.org/licenses/by-sa/4.0/)
[](https://opensource.org/licenses/Apache-2.0)
[](https://github.com/AsobaCloud/odse/actions/workflows/ci.yml)
ODS-E is an open specification for interoperable energy asset data across generation, consumption, and net metering.
## Start Here
- [Documentation Site](https://opendataschema.energy/docs/)
- [Documentation Source Repo](https://github.com/AsobaCloud/odse-docs/)
- [Launch Kit](spec/launch-kit.md)
## Repository Map
- [Specification docs](spec/)
- [Schemas](schemas/)
- [Transforms](transforms/)
- [Python reference runtime](src/python/)
- [Tools](tools/)
- [Demos](demos/)
## For Implementers
- [Schema: `energy-timeseries.json`](schemas/energy-timeseries.json)
- [Schema: `asset-metadata.json`](schemas/asset-metadata.json)
- [Transform harness usage](tools/transform_harness.py)
- [Inverter API access setup](spec/inverter-api-access.md)
- [ComStock/ResStock integration](spec/comstock-integration.md)
- [Municipal emissions modeling guide](spec/municipal-emissions-modeling.md)
- [Market context extensions (settlement, tariff, topology)](spec/market-context.md)
- [Market reform extensions (wheeling, curtailment, BRP, certificates)](spec/market-reform-extensions.md)
- [SA trading conformance profiles (SEP-002)](spec/conformance-profiles.md)
- [Reference enrichment contract (SEP-003)](spec/market-context.md)
## Project
- [Contributing](CONTRIBUTING.md)
- [Governance](GOVERNANCE.md)
- [Security policy](SECURITY.md)
- [Code of Conduct](CODE_OF_CONDUCT.md)
- [Roadmap](ROADMAP.md)
- [Changelog](CHANGELOG.md)
## License
- Specification, schemas, transforms: [CC-BY-SA 4.0](LICENSE-SPEC.md)
- Reference implementation and tools: [Apache 2.0](LICENSE-CODE.md)
---
Maintained by [Asoba Corporation](https://asoba.co)
| text/markdown | null | Asoba Corporation <support@asoba.co> | null | null | Apache-2.0 | energy, solar, iot, data, schema, validation | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming La... | [] | null | null | >=3.8 | [] | [] | [] | [
"jsonschema>=4.0.0",
"pyyaml>=6.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/AsobaCloud/odse",
"Documentation, https://opendataschema.energy/docs/",
"Repository, https://github.com/AsobaCloud/odse"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:42:22.953746 | odse-0.4.0.tar.gz | 20,422 | 59/1c/f30bdc3d99c00d92d36295148c27d8a83949002d988255b1d9005166a226/odse-0.4.0.tar.gz | source | sdist | null | false | e62567fd2b572ef6181605a0e1aafe4d | 1a2426786b816eae7b0f0d62f18042b26919fe02c8eae0b43b78b3217d3af154 | 591cf30bdc3d99c00d92d36295148c27d8a83949002d988255b1d9005166a226 | null | [] | 199 |
2.4 | dartsort | 0.3.6.5 | DARTsort | [](https://github.com/cwindolf/dartsort/actions/)
[](https://coveralls.io/github/cwindolf/dartsort)
# dartsort
## :warning: Work in progress code repository
We do not currently recommend DARTsort for production spike sorting purposes. We are in the process of implementing a robust and documented pipeline in [`src/dartsort`](src/dartsort), and we will update this page accordingly.
A workflow described in our preprint (https://www.biorxiv.org/content/10.1101/2023.08.11.553023v1) is in [uhd_pipeline.py](scripts/uhd_pipeline.py), which is implemented using the legacy code in [`src/spike_psvae`](src/spike_psvae).
## Suggested install steps
If you don't already have Python and PyTorch 2 installed, we recommend doing this with the Miniforge distribution of `conda`. You can find info and installers for your platform [at Miniforge's GitHub repository](https://github.com/conda-forge/miniforge). After installing Miniforge, `conda` will be available on your computer for installing Python packages, as well as the newer and faster conda replacement tool `mamba`. We recommend using `mamba` instead of `conda` below, since the installation tends to be a lot faster with `mamba`.
To install DARTsort, first clone this GitHub repository.
After cloning the repository, create and activate the `mamba`/`conda` environment from the configuration file provided as follows:
```bash
$ mamba env create -f environment.yml
$ mamba activate dartsort
```
Next, visit https://pytorch.org/get-started/locally/ and follow the `PyTorch` install instructions for your specific OS and hardware needs.
We also need to install `linear_operator` from the `gpytorch` channel.
For example, on a Linux workstation or cluster with NVIDIA GPUs available, one might use (dropping in `mamba` for `conda` commands):
```bash
# Example -- see https://pytorch.org/get-started/locally/ to find your platform's command.
(dartsort) $ mamba install pytorch torchvision torchaudio pytorch-cuda=11.8 linear_operator -c pytorch -c nvidia -c gpytorch
```
Finally, install the remaining `pip` dependencies and `dartsort` itself:
```bash
(dartsort) $ pip install -r requirements-full.txt
(dartsort) $ pip install -e .
```
To enable DARTsort's default motion correction algorithm [DREDge](https://www.biorxiv.org/content/10.1101/2023.10.24.563768), clone [its GitHub repository](https://github.com/evarol/dredge), and then `cd dredge/` and install the DREDge package with `pip install -e .`.
Soon we will have a package on PyPI so that these last steps will be just a `pip install dartsort`.
To make sure everything is working:
```bash
$ (dartsort) pytest tests/*
```
| text/markdown | null | Charlie Windolf <ciw2107@columbia.edu> | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"h5py",
"linear_operator",
"numba",
"numpy>=1.20; python_version < \"3.13\"",
"numpy>=2.0.0; python_version >= \"3.13\"",
"opt-einsum",
"pandas",
"probeinterface",
"pydantic",
"scipy>=1.13",
"scikit-learn",
"spikeinterface>=0.101.2",
"sympy",
"torch>=2.0",
"tqdm",
"matplotlib; extra ==... | [] | [] | [] | [
"Homepage, https://github.com/cwindolf/dartsort",
"Bug Tracker, https://github.com/cwindolf/dartsort/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:42:19.198311 | dartsort-0.3.6.5.tar.gz | 4,129,135 | ff/53/5bb4464ebcf7be7fcb816986cab1518e4c91ef45c5ccbc2fd1bbc5257341/dartsort-0.3.6.5.tar.gz | source | sdist | null | false | 3037623c7ee596be04cba5f546ae8506 | a73e9ffa7c4e9e1b8f4ca4ab32547f4e08cea65ce68ca9542f1ce3c3c0bcd651 | ff535bb4464ebcf7be7fcb816986cab1518e4c91ef45c5ccbc2fd1bbc5257341 | null | [] | 196 |
2.4 | drf-sessions | 0.1.1 | Stateful, database-backed session management for Django Rest Framework with JWT access tokens, rotating refresh tokens, and comprehensive security features | # `drf-sessions` Documentation
`drf-sessions` bridges the gap between stateless JWT authentication and stateful session management. Unlike pure JWT solutions, `drf-sessions` maintains a persistent record of each authentication session in your database, enabling instant revocation, session limits, activity tracking, and audit trails—all while leveraging the performance benefits of JWT for request authentication.
### Why DRF Sessions?
**Traditional JWT Problems:**
- Cannot revoke tokens before expiration
- No centralized session management
- Limited user context tracking
- No per-user session limits
**DRF Sessions Solutions:**
- ✅ Instant session revocation
- ✅ Database-backed session lifecycle management
- ✅ Flexible context metadata storage
- ✅ Per-user session limits with FIFO eviction
- ✅ Multiple transport layers (Headers/Cookies)
- ✅ Rotating refresh tokens with optional reuse detection
- ✅ Sliding session windows
- ✅ Built-in Django Admin integration
- ✅ Easy customization and feature extensions.
## Requirements
- Python 3.9+
- Django 4.2+
- Django Rest Framework 3.14+
- PyJWT 2.10.0+
- django-swapper 1.3+
- uuid6-python 2025.0.1+
## Installation
```bash
pip install drf-sessions
```
### Cryptographic Dependencies (Optional)
if you are planning on encoding or decoding jwt tokens using certain digital signature algorithms (like RSA or ECDSA), you will need to install the cryptography library. This can be installed explicitly, or as a required extra in the `drf-sessions` requirement:
```bash
pip install drf-sessions[crypto]
```
Add to your `INSTALLED_APPS`:
```python
INSTALLED_APPS = [
# ...
'rest_framework',
'drf_sessions',
# ...
]
```
Run migrations:
```bash
python manage.py migrate
```
## Quick Start
### 1. Configure Settings
Add to your `settings.py`:
```python
from datetime import timedelta
DRF_SESSIONS = {
'ACCESS_TOKEN_TTL': timedelta(minutes=15),
'REFRESH_TOKEN_TTL': timedelta(days=7),
'ROTATE_REFRESH_TOKENS': True,
'ENFORCE_SINGLE_SESSION': False,
'MAX_SESSIONS_PER_USER': 5,
}
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': (
'drf_sessions.auth.BearerAuthentication',
'drf_sessions.auth.CookieAuthentication',
),
}
```
### 2. Create a Login View
```python
from rest_framework.views import APIView
from django.contrib.auth import authenticate
from rest_framework.response import Response
from rest_framework.permissions import AllowAny
from drf_sessions.services import SessionService
class LoginView(APIView):
permission_classes = [AllowAny]
def post(self, request):
username = request.data.get('username')
password = request.data.get('password')
user = authenticate(username=username, password=password)
if not user:
return Response({'error': 'Invalid credentials'}, status=401)
# Create a new header session
issued = SessionService.create_header_session(
user=user,
context={
'ip_address': request.META.get('REMOTE_ADDR'),
'user_agent': request.META.get('HTTP_USER_AGENT'),
}
)
return Response({
'access_token': issued.access_token,
'refresh_token': issued.refresh_token,
})
```
### 3. Create a Refresh View
```python
class RefreshView(APIView):
permission_classes = [AllowAny]
def post(self, request):
refresh_token = request.data.get('refresh_token')
if not refresh_token:
return Response({'error': 'Refresh token required'}, status=400)
issued = SessionService.refresh_token(refresh_token)
if not issued:
return Response({'error': 'Invalid or expired token'}, status=401)
return Response({
'access_token': issued.access_token,
'refresh_token': issued.refresh_token,
})
```
### 4. Protected Endpoint Example
```python
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.permissions import IsAuthenticated
class ProfileView(APIView):
permission_classes = [IsAuthenticated]
def get(self, request):
# request.user contains the authenticated user
# request.auth contains the session instance
return Response({
'username': request.user.username,
'session_id': str(request.auth.session_id),
'created_at': request.auth.created_at,
})
```
## Configuration
### Core Settings
All settings are configured in your Django `settings.py` under the `DRF_SESSIONS` dictionary:
```python
DRF_SESSIONS = {
# Session Lifecycle
"ACCESS_TOKEN_TTL": timedelta(minutes=15),
"REFRESH_TOKEN_TTL": timedelta(days=7),
"SESSION_MODEL": "drf_sessions.Session",
"ENFORCE_SINGLE_SESSION": False,
"MAX_SESSIONS_PER_USER": 10,
"UPDATE_LAST_LOGIN": True,
"RETAIN_EXPIRED_SESSIONS": False,
# Sliding Window Logic
"ENABLE_SLIDING_SESSION": False,
"SLIDING_SESSION_MAX_LIFETIME": timedelta(days=30),
# Security Policy
"AUTH_COOKIE_NAMES": ("token",),
"AUTH_HEADER_TYPES": ("Bearer",),
"ENFORCE_SESSION_TRANSPORT": True,
"ROTATE_REFRESH_TOKENS": True,
"REVOKE_SESSION_ON_REUSE": True,
"REFRESH_TOKEN_HASH_ALGORITHM": "sha256",
"LEEWAY": timedelta(seconds=0),
"RAISE_ON_MISSING_CONTEXT_ATTR": False,
# JWT Configuration
"JWT_ALGORITHM": "HS256",
"JWT_SIGNING_KEY": settings.SECRET_KEY,
"JWT_VERIFYING_KEY": None,
"JWT_KEY_ID": None,
"JWT_AUDIENCE": None,
"JWT_ISSUER": None,
"JWT_JSON_ENCODER": None,
"JWT_HEADERS": {},
# Claims Mapping
"USER_ID_FIELD": "id",
"USER_ID_CLAIM": "sub",
"SESSION_ID_CLAIM": "sid",
"JTI_CLAIM": "jti",
# Extensibility Hooks (Dotted paths to callables)
"JWT_PAYLOAD_EXTENDER": None,
"SESSION_VALIDATOR_HOOK": None,
"POST_AUTHENTICATED_HOOK": None,
}
```
Above, the default values for these settings are shown.
### Session Lifecycle
#### `ACCESS_TOKEN_TTL`
**Type**: `timedelta`
**Default**: `timedelta(minutes=15)`
How long access tokens remain valid. Short lifetimes improve security.
```python
DRF_SESSIONS = {
'ACCESS_TOKEN_TTL': timedelta(minutes=5),
}
```
#### `REFRESH_TOKEN_TTL`
**Type**: `timedelta` or `None`
**Default**: `timedelta(days=7)`
How long refresh tokens remain valid. Must be longer than `ACCESS_TOKEN_TTL`.
```python
DRF_SESSIONS = {
'REFRESH_TOKEN_TTL': timedelta(days=7),
}
```
#### `ENFORCE_SINGLE_SESSION`
**Type**: `bool`
**Default**: `False`
If `True`, only one active session per user is allowed. Creating a new session revokes all previous sessions.
```python
DRF_SESSIONS = {
'ENFORCE_SINGLE_SESSION': True, # Force logout from other devices
}
```
#### `MAX_SESSIONS_PER_USER`
**Type**: `int` or `None`
**Default**: `10`
Maximum number of concurrent sessions per user. Oldest sessions are removed when limit is reached (FIFO). Set to `None` for unlimited sessions.
```python
DRF_SESSIONS = {
'MAX_SESSIONS_PER_USER': 3,
}
```
#### `UPDATE_LAST_LOGIN`
**Type**: `bool`
**Default**: `True`
Whether to update the user's `last_login` field when creating a session.
```python
DRF_SESSIONS = {
'UPDATE_LAST_LOGIN': True,
}
```
#### `RETAIN_EXPIRED_SESSIONS`
**Type**: `bool`
**Default**: `False`
If `True`, expired sessions are soft-deleted (revoked) for audit purposes. If `False`, they are permanently deleted.
```python
DRF_SESSIONS = {
'RETAIN_EXPIRED_SESSIONS': True, # Keep history
}
```
### Sliding Session Window
#### `ENABLE_SLIDING_SESSION`
**Type**: `bool`
**Default**: `False`
Enable sliding session windows. When enabled, sessions extend their lifetime on each activity. Each refresh token expiry will be extended until the `SLIDING_SESSION_MAX_LIFETIME` set on the session instance is reached.
```python
DRF_SESSIONS = {
'ENABLE_SLIDING_SESSION': True,
}
```
#### `SLIDING_SESSION_MAX_LIFETIME`
**Type**: `timedelta` or `None`
**Default**: `timedelta(days=30)`
Maximum lifetime for sliding sessions. Required when `ENABLE_SLIDING_SESSION` is `True`. Must be greater than `REFRESH_TOKEN_TTL`.
```python
DRF_SESSIONS = {
'ENABLE_SLIDING_SESSION': True,
'SLIDING_SESSION_MAX_LIFETIME': timedelta(days=90),
}
```
### Security Settings
#### `ENFORCE_SESSION_TRANSPORT`
**Type**: `bool`
**Default**: `True`
If `True`, sessions created for a specific transport (cookie/header) cannot be used with a different transport. Prevents session hijacking across transport layers.
```python
DRF_SESSIONS = {
'ENFORCE_SESSION_TRANSPORT': True,
}
```
#### `ROTATE_REFRESH_TOKENS`
**Type**: `bool`
**Default**: `True`
If `True`, refresh tokens are one-time-use and automatically rotated on each refresh request.
```python
DRF_SESSIONS = {
'ROTATE_REFRESH_TOKENS': True,
}
```
#### `REVOKE_SESSION_ON_REUSE`
**Type**: `bool`
**Default**: `True`
If `True`, attempting to reuse a consumed refresh token immediately revokes the entire session. Critical for detecting token theft.
```python
DRF_SESSIONS = {
'REVOKE_SESSION_ON_REUSE': True,
}
```
#### `REFRESH_TOKEN_HASH_ALGORITHM`
**Type**: `str`
**Default**: `"sha256"`
Hashing algorithm for refresh tokens. Must be available in Python's `hashlib`.
```python
DRF_SESSIONS = {
'REFRESH_TOKEN_HASH_ALGORITHM': 'sha256',
}
```
#### `LEEWAY`
**Type**: `timedelta`
**Default**: `timedelta(seconds=0)`
Clock skew tolerance for JWT validation.
```python
DRF_SESSIONS = {
'LEEWAY': timedelta(seconds=10),
}
```
#### `AUTH_HEADER_TYPES`
**Type**: `tuple` or `list`
**Default**: `("Bearer",)`
Accepted authorization header prefixes.
```python
DRF_SESSIONS = {
'AUTH_HEADER_TYPES': ('Bearer', 'JWT', 'Token'),
}
```
#### `AUTH_COOKIE_NAMES`
**Type**: `tuple` or `list`
**Default**: `("token",)`
Cookie names to check for authentication tokens.
```python
DRF_SESSIONS = {
'AUTH_COOKIE_NAMES': ('token', 'access_token', 'auth_token'),
}
```
### JWT Configuration
#### `JWT_ALGORITHM`
**Type**: `str`
**Default**: `"HS256"`
JWT signing algorithm. Supported: `HS256`, `HS384`, `HS512`, `RS256`, `RS384`, `RS512`, `ES256`, `ES384`, `ES512`.
```python
DRF_SESSIONS = {
'JWT_ALGORITHM': 'RS256',
}
```
#### `JWT_SIGNING_KEY`
**Type**: `str`
**Default**: `settings.SECRET_KEY`
Secret key for signing JWTs (HMAC) or private key (RSA/ECDSA).
```python
DRF_SESSIONS = {
'JWT_SIGNING_KEY': 'your-secret-key-here',
}
```
#### `JWT_VERIFYING_KEY`
**Type**: `str` or `None`
**Default**: `None`
Public key for asymmetric algorithms (RS256, ES256, etc.). Required for asymmetric algorithms.
```python
DRF_SESSIONS = {
'JWT_ALGORITHM': 'RS256',
'JWT_VERIFYING_KEY': """--BEGIN PUBLIC KEY--
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA...
--END PUBLIC KEY--""",
}
```
#### `JWT_AUDIENCE`
**Type**: `str` or `None`
**Default**: `None`
JWT audience claim (`aud`).
```python
DRF_SESSIONS = {
'JWT_AUDIENCE': 'my-api',
}
```
#### `JWT_ISSUER`
**Type**: `str` or `None`
**Default**: `None`
JWT issuer claim (`iss`).
```python
DRF_SESSIONS = {
'JWT_ISSUER': 'https://myapp.com',
}
```
#### `JWT_KEY_ID`
**Type**: `str` or `None`
**Default**: `None`
JWT key identifier header (`kid`).
```python
DRF_SESSIONS = {
'JWT_KEY_ID': 'key-2024-01',
}
```
#### `JWT_HEADERS`
**Type**: `dict`
**Default**: `{}`
Additional JWT headers.
```python
DRF_SESSIONS = {
'JWT_HEADERS': {'typ': 'JWT'},
}
```
#### Claims Mapping
##### `USER_ID_FIELD`
**Type**: `str`
**Default**: `"id"`
User model field to use as the user identifier.
```python
DRF_SESSIONS = {
'USER_ID_FIELD': 'uuid', # If using UUID primary keys
}
```
##### `USER_ID_CLAIM`
**Type**: `str`
**Default**: `"sub"`
JWT claim name for user identifier.
##### `SESSION_ID_CLAIM`
**Type**: `str`
**Default**: `"sid"`
JWT claim name for session identifier.
##### `JTI_CLAIM`
**Type**: `str`
**Default**: `"jti"`
JWT claim name for JWT ID.
### Extensibility Hooks
#### `JWT_PAYLOAD_EXTENDER`
**Type**: `str` (dotted path) or `None`
**Default**: `None`
Callable to add custom claims to JWT payload.
```python
# myapp/auth.py
def add_custom_claims(session):
return {
'role': session.user.role,
'department': session.user.department,
}
# settings.py
DRF_SESSIONS = {
'JWT_PAYLOAD_EXTENDER': 'myapp.auth.add_custom_claims',
}
```
**Function Signature:**
```python
def custom_extender(session: AbstractSession) -> dict:
"""
Args:
session: The session instance being encoded
Returns:
Dictionary of additional claims to include
"""
pass
```
#### `SESSION_VALIDATOR_HOOK`
**Type**: `str` (dotted path) or `None`
**Default**: `None`
Callable to validate sessions during authentication. Return `False` to reject.
```python
# myapp/auth.py
def validate_ip_address(session, request):
"""Ensure IP address hasn't changed."""
stored_ip = session.context_obj.ip_address
current_ip = request.META.get('REMOTE_ADDR')
return stored_ip == current_ip
# settings.py
DRF_SESSIONS = {
'SESSION_VALIDATOR_HOOK': 'myapp.auth.validate_ip_address',
}
```
**Function Signature:**
```python
def custom_validator(session: AbstractSession, request: Request) -> bool:
"""
Args:
session: The session being authenticated
request: The DRF request object
Returns:
True if session is valid, False to reject authentication
"""
pass
```
#### `POST_AUTHENTICATED_HOOK`
**Type**: `str` (dotted path) or `None`
**Default**: `None`
Callable executed after successful authentication. Can modify user or session.
```python
# myapp/auth.py
def update_activity(user, session, request):
"""Update last activity timestamp."""
session.last_activity_at = timezone.now()
session.save(update_fields=['last_activity_at'])
return user, session
# settings.py
DRF_SESSIONS = {
'POST_AUTHENTICATED_HOOK': 'myapp.auth.update_activity',
}
```
**Function Signature:**
```python
def post_auth_hook(
user: AbstractBaseUser,
session: AbstractSession,
request: Request
) -> Tuple[AbstractBaseUser, AbstractSession]:
"""
Args:
user: The authenticated user
session: The session instance
request: The DRF request object
Returns:
Tuple of (user, session) - can return modified instances
"""
pass
```
#### `RAISE_ON_MISSING_CONTEXT_ATTR`
**Type**: `bool`
**Default**: `False`
If `True`, accessing missing context attributes raises `AttributeError`. If `False`, returns `None`.
```python
DRF_SESSIONS = {
'RAISE_ON_MISSING_CONTEXT_ATTR': True,
}
# With True:
session.context_obj.nonexistent # Raises AttributeError
# With False:
session.context_obj.nonexistent # Returns None
```
## Authentication Classes
DRF Sessions provides two ready-to-use authentication classes:
### BearerAuthentication
Extracts tokens from the `Authorization` header.
```python
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': (
'drf_sessions.auth.BearerAuthentication',
),
}
```
**Request Example:**
```
GET /api/profile HTTP/1.1
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...
```
### CookieAuthentication
Extracts tokens from HTTP-only cookies.
```python
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': (
'drf_sessions.auth.CookieAuthentication',
),
}
```
**Setting Cookie in Response:**
```python
response = Response({'message': 'Logged in'})
response.set_cookie(
key='token',
value=issued.access_token,
httponly=True,
secure=True,
samesite='Strict',
)
```
### Using Both
You can combine both authentication methods:
```python
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': (
'drf_sessions.auth.BearerAuthentication',
'drf_sessions.auth.CookieAuthentication',
),
}
```
### Custom Authentication Classes
Create custom authentication by subclassing base classes:
```python
from drf_sessions.base.auth import BaseHeaderAuthentication, BaseCookieAuthentication
class CustomHeaderAuth(BaseHeaderAuthentication):
def extract_token(self, request):
# Custom extraction logic
return request.META.get('HTTP_X_AUTH_TOKEN')
class CustomCookieAuth(BaseCookieAuthentication):
def extract_token(self, request):
# Custom extraction logic
return request.META.get('HTTP_X_AUTH_TOKEN')
```
## Session Management
### Creating Sessions
#### Using SessionService
The `SessionService` provides a high-level API for session creation:
```python
from drf_sessions.services import SessionService
from drf_sessions.choices import AUTH_TRANSPORT
# Generic session (works with any transport)
issued = SessionService.create_session(
user=user,
context={'device': 'mobile'},
)
# Header-only session
issued = SessionService.create_header_session(
user=user,
context={'platform': 'ios'},
)
# Cookie-only session
issued = SessionService.create_cookie_session(
user=user,
context={'browser': 'chrome'},
)
```
#### Using Session Manager Directly
```python
from drf_sessions.models import get_session_model
Session = get_session_model()
issued = Session.objects.create_session(
user=user,
transport='header',
context={'ip': request.META.get('REMOTE_ADDR')},
)
```
#### Custom TTLs
Override default token lifetimes per session:
```python
from datetime import timedelta
issued = SessionService.create_session(
user=user,
access_ttl=timedelta(minutes=30),
refresh_ttl=timedelta(days=14),
)
```
### Token Rotation
Refresh tokens to obtain new access tokens:
```python
from drf_sessions.services import SessionService
# In your refresh view
refresh_token = request.data.get('refresh_token')
issued = SessionService.rotate_refresh_token(refresh_token)
if not issued:
return Response({'error': 'Invalid token'}, status=401)
return Response({
'access_token': issued.access_token,
'refresh_token': issued.refresh_token,
})
```
**Rotation Behavior:**
With `ROTATE_REFRESH_TOKENS=True` (default):
- Old refresh token is consumed (marked as used)
- New refresh token is generated and returned
- Attempting to reuse old token triggers reuse detection
With `ROTATE_REFRESH_TOKENS=False`:
- Same refresh token can be used multiple times
- Less secure but simpler for some use cases
### Session Revocation
#### Revoke Single Session
```python
# In a logout view
from drf_sessions.models import get_session_model
Session = get_session_model()
# Revoke current session (where auth return an instance of a session)
request.auth.revoke()
```
#### Revoke All User Sessions
```python
# Logout from all devices
from drf_sessions.services import SessionService
SessionService.revoke_user_sessions(user)
```
#### Query Active Sessions
```python
# Get all active sessions for a user
active_sessions = Session.objects.active().filter(user=request.user)
for session in active_sessions:
print(f"Session: {session.session_id}")
print(f"Created: {session.created_at}")
print(f"Transport: {session.transport}")
print(f"Device: {session.context_obj.user_agent}")
```
## Context Metadata
Store arbitrary metadata with each session using the `context` field:
### Setting Context on Creation
```python
issued = SessionService.create_session(
user=user,
context={
'ip_address': request.META.get('REMOTE_ADDR'),
'user_agent': request.META.get('HTTP_USER_AGENT'),
'device_id': request.data.get('device_id'),
'platform': 'web',
'location': 'San Francisco',
}
)
```
### Accessing Context
Context data is available via dot notation through the `context_obj` property:
```python
# In a view
session = request.auth
# Access via dot notation
ip = session.context_obj.ip_address
device = session.context_obj.device_id
platform = session.context_obj.platform
# Missing attributes return None (or raise AttributeError if configured)
missing = session.context_obj.nonexistent # None
# Raw dict access
raw_context = session.context
```
### Context Validation
The library validates that context is always a dictionary:
```python
# ✅ Valid
context = {'key': 'value', 'nested': {'data': 123}}
# ❌ Invalid - will raise ValidationError
context = ['list', 'not', 'allowed']
context = "string not allowed"
```
### Best Practices
**Security-Sensitive Data:**
```python
context = {
'ip_address': request.META.get('REMOTE_ADDR'),
'user_agent': request.META.get('HTTP_USER_AGENT')[:200], # Truncate
'device_fingerprint': compute_fingerprint(request),
}
```
**Session Validator Using Context:**
```python
def ip_consistency_validator(session, request):
"""Reject if IP address changed."""
original_ip = session.context_obj.ip_address
current_ip = request.META.get('REMOTE_ADDR')
return original_ip == current_ip
DRF_SESSIONS = {
'SESSION_VALIDATOR_HOOK': 'myapp.validators.ip_consistency_validator',
}
```
## Transport Enforcement
Transport enforcement prevents session hijacking across different delivery methods.
### How It Works
When `ENFORCE_SESSION_TRANSPORT=True` (default), sessions are bound to their creation transport:
```python
# Session created for header transport
issued = SessionService.create_header_session(user=user)
# ✅ Works: Using Authorization header
GET /api/profile
Authorization: Bearer <token>
# ❌ Fails: Trying to use same token in cookie
GET /api/profile
Cookie: token=<same-token>
# AuthenticationFailed: This session is restricted to header transport
```
### Transport Types
```python
from drf_sessions.choices import AUTH_TRANSPORT
# ANY - works with both headers and cookies
AUTH_TRANSPORT.ANY # 'any'
# HEADER - only Authorization header
AUTH_TRANSPORT.HEADER # 'header'
# COOKIE - only HTTP cookies
AUTH_TRANSPORT.COOKIE # 'cookie'
```
### Use Cases
**Mobile Apps (Header-only):**
```python
issued = SessionService.create_header_session(user=user)
# Prevents token theft if attacker gains access to web session
```
**Web Apps (Cookie-only):**
```python
issued = SessionService.create_cookie_session(user=user)
# Prevents XSS attacks from stealing tokens
```
**Hybrid (Flexible):**
```python
issued = SessionService.create_universal_session(user=user)
# Allow same session across web and mobile
```
### Disabling Enforcement
```python
DRF_SESSIONS = {
'ENFORCE_SESSION_TRANSPORT': False,
}
# Sessions work with any transport, regardless of creation method
```
## Custom Session Models
DRF Sessions uses Django Swapper to allow custom session models.
### Creating a Custom Model
```python
# myapp/models.py
from drf_sessions.base.models import AbstractSession
class CustomSession(AbstractSession):
# Add custom fields
device_name = models.CharField(max_length=100, blank=True)
is_trusted = models.BooleanField(default=False)
class Meta(AbstractSession.Meta):
"""override or define custom Meta here"""
pass
```
### Configuring Swapper
```python
# settings.py
DRF_SESSIONS = {
'SESSION_MODEL': 'myapp.CustomSession',
}
```
### Migrations
```bash
python manage.py makemigrations
python manage.py migrate
```
### Using Custom Model
```python
from drf_sessions.models import get_session_model
Session = get_session_model() # Returns your CustomSession
# Create session with custom fields
issued = Session.objects.create_session(
user=user,
device_name='iPhone 13',
is_trusted=True,
)
# Access custom fields
session = request.auth
if session.is_trusted:
# Allow sensitive operations
pass
```
### RefreshToken Foreign Key
The `RefreshToken` model automatically uses the swapped session model:
```python
# In RefreshToken model
session = models.ForeignKey(
swapper.get_model_name('drf_sessions', 'Session'),
on_delete=models.CASCADE,
)
```
## Advanced Usage
### Sliding Sessions
Extend session lifetime on each activity (by extend refresh token until absolute expiry is reach on session instance):
```python
DRF_SESSIONS = {
'ENABLE_SLIDING_SESSION': True,
'REFRESH_TOKEN_TTL': timedelta(days=7),
'SLIDING_SESSION_MAX_LIFETIME': timedelta(days=30),
}
```
**How it works:**
1. Session created with `absolute_expiry` = now + 30 days
2. User refreshes token after 5 days
3. New refresh token expires in 7 days (capped at absolute_expiry)
4. Session remains valid until absolute_expiry (30 days from creation)
### Reuse Detection
Detect stolen refresh tokens:
```python
DRF_SESSIONS = {
'ROTATE_REFRESH_TOKENS': True,
'REVOKE_SESSION_ON_REUSE': True,
}
```
**Scenario:**
1. User refreshes token → gets new token A
2. Attacker steals old token and tries to use it
3. System detects reuse → revokes entire session
4. Both user and attacker are logged out
5. User must re-authenticate
### Custom JWT Claims
Add custom data to access tokens:
```python
# myapp/auth.py
def add_permissions(session):
user = session.user
return {
'permissions': list(user.get_all_permissions()),
'is_superuser': user.is_superuser,
'groups': [g.name for g in user.groups.all()],
}
# settings.py
DRF_SESSIONS = {
'JWT_PAYLOAD_EXTENDER': 'myapp.auth.add_permissions',
}
```
**Accessing in Views:**
```python
import jwt
def my_view(request):
# Decode JWT from request (already verified by authentication)
auth_header = request.META.get('HTTP_AUTHORIZATION', '').split()
token = auth_header[1] if len(auth_header) == 2 else None
# Get claims (verification already done by DRF)
claims = jwt.decode(
token,
options={"verify_signature": False} # Already verified
)
permissions = claims.get('permissions', [])
```
### IP Address Validation
Enforce IP consistency:
```python
# myapp/validators.py
def validate_ip(session, request):
stored_ip = session.context_obj.ip_address
current_ip = request.META.get('REMOTE_ADDR')
if not stored_ip:
return True # No IP stored, allow
return stored_ip == current_ip
# settings.py
DRF_SESSIONS = {
'SESSION_VALIDATOR_HOOK': 'myapp.validators.validate_ip',
}
# In your login view, store IP
issued = SessionService.create_session(
user=user,
context={'ip_address': request.META.get('REMOTE_ADDR')}
)
```
### Device Fingerprinting
```python
# myapp/utils.py
import hashlib
def compute_fingerprint(request):
components = [
request.META.get('HTTP_USER_AGENT', ''),
request.META.get('HTTP_ACCEPT_LANGUAGE', ''),
request.META.get('HTTP_ACCEPT_ENCODING', ''),
]
raw = '|'.join(components)
return hashlib.sha256(raw.encode()).hexdigest()
# In your login view
issued = SessionService.create_session(
user=user,
context={
'fingerprint': compute_fingerprint(request),
'user_agent': request.META.get('HTTP_USER_AGENT'),
}
)
# Validator
def validate_fingerprint(session, request):
stored = session.context_obj.fingerprint
current = compute_fingerprint(request)
return stored == current
```
### Activity Tracking
Update last activity on each request:
```python
# myapp/middleware.py
from django.utils import timezone
class ActivityMiddleware:
def __init__(self, get_response):
self.get_response = get_response
def __call__(self, request):
response = self.get_response(request)
# Update session activity if authenticated
if hasattr(request, 'auth') and request.auth:
request.auth.last_activity_at = timezone.now()
request.auth.save(update_fields=['last_activity_at'])
return response
# settings.py
MIDDLEWARE = [
# ...
'myapp.middleware.ActivityMiddleware',
]
```
### Asymmetric JWT (RS256)
```python
# Generate keys (example using cryptography library)
from cryptography.hazmat.primitives.asymmetric import rsa
from cryptography.hazmat.primitives import serialization
# Generate private key
private_key = rsa.generate_private_key(
public_exponent=65537,
key_size=2048,
)
# Serialize private key
private_pem = private_key.private_bytes(
encoding=serialization.Encoding.PEM,
format=serialization.PrivateFormat.PKCS8,
encryption_algorithm=serialization.NoEncryption()
)
# Serialize public key
public_pem = private_key.public_key().public_bytes(
encoding=serialization.Encoding.PEM,
format=serialization.PublicFormat.SubjectPublicKeyInfo
)
# settings.py
DRF_SESSIONS = {
'JWT_ALGORITHM': 'RS256',
'JWT_SIGNING_KEY': private_pem.decode('utf-8'),
'JWT_VERIFYING_KEY': public_pem.decode('utf-8'),
}
```
## Security Considerations
### Token Storage
**Never store tokens in:**
- localStorage (vulnerable to XSS)
- sessionStorage (vulnerable to XSS)
- Unencrypted databases
**Best practices:**
- Use HTTP-only cookies for web apps
- Store in secure keychain/keystore for mobile apps
- Use `secure=True` and `samesite='Strict'` for cookies
### Token Lifetimes
**Recommendations:**
```python
DRF_SESSIONS = {
'ACCESS_TOKEN_TTL': timedelta(minutes=15), # Short-lived
'REFRESH_TOKEN_TTL': timedelta(days=7), # Medium-lived
'SLIDING_SESSION_MAX_LIFETIME': timedelta(days=30), # Hard limit
}
```
### Transport Security
**Always use HTTPS in production:**
```python
# settings.py (production)
SESSION_COOKIE_SECURE = True
CSRF_COOKIE_SECURE = True
SECURE_SSL_REDIRECT = True
```
### Refresh Token Rotation
**Always enable rotation:**
```python
DRF_SESSIONS = {
'ROTATE_REFRESH_TOKENS': True,
'REVOKE_SESSION_ON_REUSE': True,
}
```
### Session Limits
Prevent session exhaustion attacks:
```python
DRF_SESSIONS = {
'MAX_SESSIONS_PER_USER': 5, # Reasonable limit
}
```
### Context Sanitization
**Never store sensitive data in context:**
```python
# ❌ Bad
context = {
'password': user.password, # Never!
'credit_card': '1234-5678-9012-3456', # Never!
}
# ✅ Good
context = {
'ip_address': request.META.get('REMOTE_ADDR'),
'user_agent': request.META.get('HTTP_USER_AGENT')[:200],
'device_type': 'mobile',
}
```
### Validator Performance
Keep validators fast to avoid request latency:
```python
# ❌ Slow - database queries
def slow_validator(session, request):
# Avoid heavy database operations
user_status = UserStatus.objects.get(user=session.user)
return user_status.is_active
# ✅ Fast - in-memory checks
def fast_validator(session, request):
# Use cached/in-memory data
return session.user.is_active
```
## API Reference
### SessionService
#### `create_session(user, transport='any', context=None, access_ttl=None, refresh_ttl=None)`
Creates a new authentication session.
**Parameters:**
- `user` (User): The user to authenticate
- `transport` (str): Transport type ('any', 'header', 'cookie')
- `context` (dict): Metadata to store with session
- `access_ttl` (timedelta): Override default access token TTL
- `refresh_ttl` (timedelta): Override default refresh token TTL
**Returns:** `IssuedSession(access_token, refresh_token, session)`
#### `create_header_session(user, context=None, access_ttl=None, refresh_ttl=None)`
Creates a header-only session.
#### `create_cookie_session(user, context=None, access_ttl=None, refresh_ttl=None)`
Creates a cookie-only session.
#### `create_session(user, context=None, access_ttl=None, refresh_ttl=None)`
Creates a universal session.
#### `refresh_token(raw_refresh_token)`
Exchanges a refresh token for new credentials.
**Parameters:**
- `raw_refresh_token` (str): The refresh token to rotate
**Returns:** `IssuedSession` or `None` if invalid/expired
#### `revoke_user_sessions(user)`
Revokes all of users tokens based on the configuration for expired tokens.
**Parameters:**
- `user` (str): The user whose token is to be revoked.
**Returns:** `None`
### SessionManager
#### `create_session(user, transport, context=None, access_ttl=None, refresh_ttl=None, **kwargs)`
Low-level session creation. See `SessionService.create_session`.
#### `active()`
Returns QuerySet of active (non-revoked, non-expired) sessions.
```python
Session.objects.active()
```
#### `revoke()`
Revokes all sessions in the QuerySet.
```python
Session.objects.filter(user=user).revoke()
```
### Session Model
#### Properties
##### `session_id`
UUID v7 unique identifier
##### `user`
ForeignKey to User model
##### `transport`
String: 'any', 'header', or 'cookie'
##### `context`
JSONField for metadata storage
##### `context_obj`
ContextParams wrapper for dot-notation access
##### `last_activity_at`
DateTime of last token refresh
##### `revoked_at`
DateTime of revocation (None if active)
##### `absolute_expiry`
DateTime of hard expiration (None if no limit)
##### `is_active`
Boolean property: True if not revoked and not expired
#### Methods
##### `__str__()`
Returns: `"username (session-id)"`
### RefreshToken Model
#### Properties
##### `token_hash`
SHA-256 hash of the raw token
##### `session`
ForeignKey to Session
##### `expires_at`
DateTime when token expires
##### `consumed_at`
DateTime when token was used (None if unused)
##### `is_expired`
Boolean property: True if past expires_at
### ContextParams
#### Methods
##### `__getattr__(name)`
Dot-notation access to context data
```python
session.context_obj.ip_address # Returns value or None
```
##### `__repr__()`
Returns string representation of context
### IssuedSession
NamedTuple containing new session credentials.
**Fields:**
- `access_token` (str): JWT access token
- `refresh_token` (str | None): Refresh token (None if REFRESH_TOKEN_TTL is None)
- `session` (AbstractSession): The database session instance
## Migration Guide
### From Simple JWT
DRF Sessions is designed to complement or replace django-rest-framework-simplejwt.
**Key Differences:**
| Feature | Simple JWT | DRF Sessions |
||--|--|
| Storage | Stateless | Database-backed |
| Revocation | Token blacklist | Session revocation |
| Session Limits | None | FIFO session limits |
| Context Storage | None | JSON metadata |
| Transport Binding | None | Enforced transport types |
| Admin Interface | Minimal | Full-featured |
**Migration Steps:**
1. **Install DRF Sessions:**
```bash
pip install drf-sessions
```
2. **Update Settings:**
```python
# Before (Simple JWT)
SIMPLE_JWT = {
'ACCESS_TOKEN_LIFETIME': timedelta(minutes=5),
'REFRESH_TOKEN_LIFETIME': timedelta(days=1),
}
# After (DRF Sessions)
DRF_SESSIONS = {
'ACCESS_TOKEN_TTL': timedelta(minutes=5),
'REFRESH_TOKEN_TTL': timedelta(days=1),
}
```
3. **Update Authentication Classes:**
```python
# Before
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': (
'rest_framework_simplejwt.authentication.JWTAuthentication',
),
}
# After
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': (
'drf_sessions.auth.BearerAuthentication',
),
}
```
4. **Update Views:**
```python
# Before (Simple JWT)
from rest_framework_simplejwt.views import TokenObtainPairView
# After (DRF Sessions)
from drf_sessions.services import SessionService
class LoginView(APIView):
def post(self, request):
user = authenticate(...)
issued = SessionService.create_session(user=user)
return Response({
'access': issued.access_token,
'refresh': issued.refresh_token,
})
```
5. **Run Migrations:**
```bash
python manage.py migrate drf_sessions
```
### From Session Authentication
If migrating from DRF's built-in session authentication:
**Advantages of DRF Sessions:**
- No CSRF tokens needed (JWT-based)
- Works seamlessly with mobile apps
- Better horizontal scaling (stateless access tokens)
- Explicit session lifecycle management
**Migration Steps:**
1. **Dual Authentication (Transition Period):**
```python
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': (
'drf_sessions.auth.BearerAuthentication',
'rest_framework.authentication.SessionAuthentication',
),
}
```
2. **Create Migration Endpoint:**
```python
class MigrateSessionView(APIView):
"""Allow users to convert session auth to JWT."""
authentication_classes = [SessionAuthentication]
def post(self, request):
issued = SessionService.create_session(user=request.user)
return Response({
'access_token': issued.access_token,
'refresh_token': issued.refresh_token,
})
```
3. **Update Frontend:**
- Store tokens in secure storage
- Add Authorization header to requests
- Implement token refresh logic
4. **Remove Old Authentication:**
Once all clients migrated, remove SessionAuthentication.
## Troubleshooting
### Common Issues
#### "Invalid access token"
**Cause:** Token expired or signature invalid
**Solutions:**
- Check `ACCESS_TOKEN_TTL` setting
- Verify `JWT_SIGNING_KEY` hasn't changed
- Implement token refresh flow
#### "Session is invalid or has been revoked"
**Cause:** Session deleted or explicitly revoked
**Solutions:**
- Check session still exists in database
- Verify `revoked_at` is None
- Check `absolute_expiry` hasn't passed
#### "Token missing session identifier"
**Cause:** JWT doesn't contain session ID claim
**Solutions:**
- Verify token was created by DRF Sessions
- Check `SESSION_ID_CLAIM` setting matches token
#### Import Error: "Cannot import name 'Session'"
**Cause:** Swapper configuration issue
**Solutions:**
```python
# Use get_session_model() instead of direct import
from drf_sessions.models import get_session_model
Session = get_session_model()
```
#### "This session is restricted to X transport"
**Cause:** Transport enforcement preventing cross-transport usage
**Solutions:**
- Use correct authentication class for session type
- Or set `ENFORCE_SESSION_TRANSPORT=False`
- Or create universal sessions with `create_universal_session()`
### Performance Optimization
#### Database Queries
Add select_related for better query performance:
```python
session = Session.objects.select_related('user').get(session_id=sid)
```
```bash
python manage.py migrate drf_sessions
```
#### Cleanup Old Sessions
Create periodic task to delete expired sessions:
```python
from django.utils import timezone
from drf_sessions.models import get_session_model
from drf_sessions.services import SessionService
Session = get_session_model()
# Delete all user tokens
SessionService.revoke_user_sessions(user)
# Delete expired sessions
Session.objects.filter(
absolute_expiry__lt=timezone.now()
).delete()
# Or revoke instead of delete
Session.objects.filter(
absolute_expiry__lt=timezone.now(),
revoked_at__isnull=True
).revoke()
```
## Contributing
Contributions are welcome! Please follow these guidelines:
1. Fork the repository
2. Create a feature branch (`git checkout -b feature/amazing-feature`)
3. Commit your changes (`git commit -m 'Add amazing feature'`)
4. Push to the branch (`git push origin feature/amazing-feature`)
5. Open a Pull Request
### Development Setup
```bash
git clone https://github.com/idenyigabriel/drf-sessions.git
cd drf-sessions
pip install -e ".[dev]"
python manage.py migrate
python manage.py test
```
## Acknowledgments
- Inspired by [django-rest-framework-simplejwt](https://github.com/jazzband/djangorestframework-simplejwt)
- Built on [Django Rest Framework](https://www.django-rest-framework.org/)
- Uses [PyJWT](https://pyjwt.readthedocs.io/) for JWT handling
- UUID v7 support via [uuid6-python](https://github.com/oittaa/uuid6-python)
## Support
- **Issues:** [GitHub Issues](https://github.com/idenyigabriel/drf-sessions/issues)
- **Documentation:** [Read the Docs](https://drf-sessions.readthedocs.io/)
- **Discussions:** [GitHub Discussions](https://github.com/idenyigabriel/drf-sessions/discussions)
| text/markdown | Gabriel Idenyi | null | Gabriel Idenyi | null | null | django, django-rest-framework, jwt, authentication, session-management, security, python, drf, refresh-token, token-rotation, stateful-jwt | [
"Development Status :: 4 - Beta",
"Environment :: Web Environment",
"Framework :: Django",
"Framework :: Django :: 4.2",
"Framework :: Django :: 5.0",
"Framework :: Django :: 5.1",
"Framework :: Django :: 5.2",
"Intended Audience :: Developers",
"Natural Language :: English",
"Operating System :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"Django<6.0,>=4.2",
"djangorestframework<4.0,>=3.14",
"PyJWT<3.0,>=2.11",
"swapper<2.0,>=1.3",
"uuid6==2025.0.1",
"typing-extensions>=4.0; python_version < \"3.11\"",
"cryptography>=3.4.0; extra == \"crypto\""
] | [] | [] | [] | [
"Homepage, https://github.com/idenyigabriel/drf-sessions",
"Documentation, https://github.com/idenyigabriel/drf-sessions/blob/main/README.md",
"Repository, https://github.com/idenyigabriel/drf-sessions",
"Issues, https://github.com/idenyigabriel/drf-sessions/issues",
"Changelog, https://github.com/idenyigab... | twine/6.1.0 CPython/3.12.3 | 2026-02-19T21:41:59.209969 | drf_sessions-0.1.1.tar.gz | 52,128 | f4/4a/e998f29fa157390c1f128e738a8eca4554de076447d8ff2be133ae5e927e/drf_sessions-0.1.1.tar.gz | source | sdist | null | false | 646fad2cd6ad03cc86b29d6942ad7bc3 | 9bfb1dc65aa26120616478546ecfa7075e5b2e1844f3e55d33231899d49dd1de | f44ae998f29fa157390c1f128e738a8eca4554de076447d8ff2be133ae5e927e | BSD-3-Clause | [
"LICENSE"
] | 216 |
2.4 | makerrepo | 0.3.2 | Open source library that brings Manufacturing As Code concept into build123d ecosystem | # MakerRepo
Open source library that brings Manufacturing As Code concept into build123d ecosystem
| text/markdown | null | Fang-Pen Lin <fangpen@launchplatform.com> | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"build123d>=0.10.0",
"pydantic>=2.12.5",
"PyYAML>=6.0",
"venusian>=3.1.1"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"22.04","id":"jammy","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:41:56.830762 | makerrepo-0.3.2-py3-none-any.whl | 6,475 | 98/43/ffd41790c6bee3914cefe97ff2d32d7c786c1f2e82ba78724207b4d86da0/makerrepo-0.3.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 5c0216b88990ae33aaf56c1729813ab7 | 24e9cc7e69f602bcef4d96bc59092d5c82a8def3e9bd69633068b15740b9cd7a | 9843ffd41790c6bee3914cefe97ff2d32d7c786c1f2e82ba78724207b4d86da0 | MIT | [
"LICENSE"
] | 202 |
2.4 | prelude-cli | 2.6.13 | For interacting with the Prelude SDK | # Prelude CLI
Interact with the full range of features in Prelude Detect, organized by:
- IAM: manage your account
- Build: write and maintain your collection of security tests
- Detect: schedule security tests for your endpoints
## Quick start
```bash
pip install prelude-cli
prelude --help
prelude --interactive
```
## Documentation
https://docs.preludesecurity.com/docs/prelude-cli
| text/markdown | Prelude Research | support@preludesecurity.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/preludeorg | null | >=3.10 | [] | [] | [] | [
"prelude-sdk==2.6.44",
"click>8",
"rich",
"python-dateutil",
"pyyaml"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:40:48.447471 | prelude_cli-2.6.13.tar.gz | 19,429 | fa/e1/22680b7966df38d44960c34a2f542e391a4e8bfc6afe4f89503d93f2004f/prelude_cli-2.6.13.tar.gz | source | sdist | null | false | e5ed027d51b02bf9652badaaf31abd6f | da12ab6c24673367107a43a282eaf0bdd44b374b1a1b91382ef775a7f55c28a0 | fae122680b7966df38d44960c34a2f542e391a4e8bfc6afe4f89503d93f2004f | null | [
"LICENSE"
] | 206 |
2.1 | antares-devkit | 0.6.3 | Provides tools and utility methods to write and debug ANTARES filters with Python. | # antares-devkit
Provides tools and utility methods to write and debug [ANTARES](http://antares.noirlab.edu) filters with Python.
ANTARES is an Alert Broker developed by the [NSF NOIRLab](http://noirlab.edu) for ZTF and
LSST.
If you want to write and submit a filter to ANTARES please follow the [steps to submit a filter](https://nsf-noirlab.gitlab.io/csdc/antares/devkit/learn/submit-a-filter/)
in our documentation. ***If you wrote a filter for antares and is not in the devkit repository, contact us and we'll send you your code from our backup.***
## Installation
The ANTARES DevKit supports Python version 3.9 and up and can be installed with pip:
```sh
pip install antares-devkit
```
## Basic Usage
The DevKit can be used in a local environment and also on NSF NOIRLab’s [Astro Data Lab](https://datalab.noirlab.edu/) Jupyter environment.
A basic example of creating and executing a filter is provided below.
Create a `HelloWorld` filter:
```python
from antares_devkit.models import BaseFilter
class HelloWorld(BaseFilter):
OUTPUT_LOCUS_TAGS = [
{"name": "hello_world", "description": "hello!"},
]
def _run(self, locus):
print("Hello Locus ", locus.locus_id)
```
Run the filter on a random ANTARES locus:
```python
from antares_client import search
from antares_devkit.models import DevKitLocus
from antares_devkit.utils import filter_report
# fetch a random locus from the antares database using the antares-client
client_locus = search.get_random_locus()
devkit_locus = DevKitLocus.model_validate(client_locus.to_devkit())
# execute the filter
HelloWorld().run(devkit_locus)
```
For more information and additional examples visit our [DevKit guide](https://nsf-noirlab.gitlab.io/csdc/antares/devkit/).
## Development
### How does this work?
This repository can be shipped as a python package on pip and also can be used in installations using the repository with tags.
Then the filter_runner docker image in the antares main repository is going to install all the filters and required packages,
then we use a gcp bucket to know which filters are enabled or disabled.
### How to test filters using Docker (Recommended)
```sh
docker build -t antares_devkit:3.9 -f test/Dockerfile .
docker run -v $(pwd)/antares_devkit:/usr/src/app/antares_devkit -v $(pwd)/test:/usr/src/app/test -it antares_devkit:3.9
uv run pytest test
```
### How to setup local environment (with conda)
```sh
conda create -n devkit python=3.9 -y
conda activate devkit
pip install uv
uv sync --all-groups --all-extras
```
### How to add a filter dependency
```sh
uv add "{package_name}" --optional filter-dependencies
```
or for jupyter lab libraries use:
```sh
uv add "{package_name}" --optional jupyter
```
### How to add a dev dependency
```sh
uv add "{package_name}" --group dev
```
or for docs libraries use:
```sh
uv add "{package_name}" --group docs
```
### How to run a jupyter notebook
```sh
uv run --with jupyter jupyter lab
```
### How to write documentation
Add md files and update `mkdocs.yml` to add them in the nav.
### How to update filters src
1. Execute `uv run python scripts/update_filters_src.py`
2. Paste the output in `mkdocs.yml` within the nav.Filters replacing the entire section.
### How to view the documentation locally
Install necessary dependencies:
```sh
uv sync --group docs
```
Serve the docs:
```sh
uv run mkdocs serve
```
| text/markdown | null | NSF NOIRLab ANTARES Team <antares@noirlab.edu> | null | NSF NOIRLab ANTARES Team <antares@noirlab.edu> | Copyright (c) 2025 Association of Universities for Research in Astronomy, Inc. (AURA)
All rights reserved.
Unless otherwise stated, the copyright of this software is owned by AURA.
Redistribution and use in source and binary forms, with or without modification,
are permitted provided that the following conditions are met:
1) Redistributions of source code must retain the above copyright notice,
this list of conditions and the following disclaimer.
2) Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3) The names of AURA and its representatives may not be used to endorse or
promote products derived from this software without specific prior written
permission.
THIS SOFTWARE IS PROVIDED BY AURA "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES,
INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND
FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL AURA BE
LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE
GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF
THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | antares, devkit, filter development | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Astronomy",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python :: 3.9"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"astropy>=5.1.1",
"numpy>=1.24.4",
"pandas>=1.5.1",
"pydantic>=2.10.5",
"scikit-learn<=0.25; extra == \"filter-dependencies\"",
"statsmodels>=0.12.2; extra == \"filter-dependencies\"",
"scipy>=1.13.1; extra == \"filter-dependencies\"",
"light-curve==0.7.2; extra == \"filter-dependencies\"",
"ssi-for... | [] | [] | [] | [
"Homepage, https://gitlab.com/nsf-noirlab/csdc/antares/devkit",
"Documentation, https://nsf-noirlab.gitlab.io/csdc/antares/devkit/",
"Bug Reports, https://gitlab.com/nsf-noirlab/csdc/antares/devkit/issues",
"Source, https://gitlab.com/nsf-noirlab/csdc/antares/devkit"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-19T21:40:43.135434 | antares_devkit-0.6.3.tar.gz | 12,503,267 | 25/12/c3109bdefbdb1ec605f3f58954879e4928c52f17564005a2de4f4147530b/antares_devkit-0.6.3.tar.gz | source | sdist | null | false | a7d7c481d91cea3b9062d71ea1f53111 | bdfabc6b1d1629568410a8e1621dba96058a5ffd32ab80bb24221acae76251dc | 2512c3109bdefbdb1ec605f3f58954879e4928c52f17564005a2de4f4147530b | null | [] | 284 |
2.4 | prelude-sdk | 2.6.44 | For interacting with the Prelude API | # Prelude SDK
Interact with the Prelude Service API via Python.
> The prelude-cli utility wraps around this SDK to provide a rich command line experience.
Install this package to write your own tooling that works with Build or Detect functionality.
- IAM: manage your account
- Build: write and maintain your collection of security tests
- Detect: schedule security tests for your endpoints
## Quick start
```bash
pip install prelude-sdk
```
## Documentation
TBD
## Testing
To test the Python SDK and Probes, run the following commands from the python/sdk/ directory:
```bash
pip install -r tests/requirements.txt
pytest tests --api https://api.preludesecurity.com --email <EMAIL>
```
| text/markdown | Prelude Research | support@preludesecurity.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/preludeorg | null | >=3.10 | [] | [] | [] | [
"requests"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:39:56.183325 | prelude_sdk-2.6.44.tar.gz | 29,403 | 04/16/8e431f7b938f1d493cf9816656adbdfe3aedbdd99fd7eec8196260e15284/prelude_sdk-2.6.44.tar.gz | source | sdist | null | false | dade5308bea1381eb84ac1fd3f7dc711 | 99d910e95d0477b06b5b29e382f680424d9f60972f2f9efc87caa5216a07ca3a | 04168e431f7b938f1d493cf9816656adbdfe3aedbdd99fd7eec8196260e15284 | null | [
"LICENSE"
] | 227 |
2.4 | sprites-py | 0.0.1rc37 | Python SDK for the Sprites API | # Sprites Python SDK
Python SDK for [Sprites](https://sprites.dev) - remote command execution platform.
## Installation
```bash
pip install sprites-py
```
## Quick Start
```python
from sprites import SpritesClient
# Create a client
client = SpritesClient(token="your-token")
# Get a sprite handle
sprite = client.sprite("my-sprite")
# Run a command
result = sprite.run("echo", "hello", capture_output=True)
print(result.stdout.decode()) # "hello\n"
# Or use the Go-style API
cmd = sprite.command("ls", "-la")
output = cmd.output()
print(output.decode())
```
## API Overview
### SpritesClient
```python
from sprites import SpritesClient
client = SpritesClient(
token="your-token",
base_url="https://api.sprites.dev", # optional
timeout=30.0, # optional
)
# Create a sprite
sprite = client.create_sprite("my-sprite")
# Get a sprite handle (doesn't create it)
sprite = client.sprite("my-sprite")
# Delete a sprite
client.delete_sprite("my-sprite")
```
### Sprite
```python
# Run a command (subprocess.run style)
result = sprite.run("echo", "hello", capture_output=True, timeout=30)
print(result.returncode)
print(result.stdout)
# Create a command (Go exec.Cmd style)
cmd = sprite.command("bash", "-c", "echo hello")
output = cmd.output() # Returns stdout
combined = cmd.combined_output() # Returns stdout + stderr
# TTY mode
cmd = sprite.command("bash", tty=True, tty_rows=24, tty_cols=80)
cmd.run()
```
### Checkpoints
```python
# List checkpoints
checkpoints = sprite.list_checkpoints()
# Create a checkpoint
stream = sprite.create_checkpoint("my checkpoint")
for msg in stream:
print(msg.type, msg.data)
# Restore a checkpoint
stream = sprite.restore_checkpoint("checkpoint-id")
for msg in stream:
print(msg.type, msg.data)
```
### Network Policy
```python
from sprites.types import NetworkPolicy, PolicyRule
# Get current policy
policy = sprite.get_network_policy()
# Update policy
new_policy = NetworkPolicy(rules=[
PolicyRule(domain="example.com", action="allow"),
])
sprite.update_network_policy(new_policy)
```
## Requirements
- Python 3.11+
- websockets
- httpx
## License
MIT
| text/markdown | Sprites Team | null | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.9 | [] | [] | [] | [
"httpx>=0.25.0",
"websockets>=12.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"mypy>=1.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:38:51.643050 | sprites_py-0.0.1rc37.tar.gz | 35,226 | 88/cd/24bbca8438fdc8a89e3365b927b20f511e1c4529a8574ea252e967f8071c/sprites_py-0.0.1rc37.tar.gz | source | sdist | null | false | 71d0e1fbd2e6f95d082fa51dd761b1ac | 2fc58aa80a9a99c1a12cb17725d13675d5e25dc2a33f245f21486473aede05b9 | 88cd24bbca8438fdc8a89e3365b927b20f511e1c4529a8574ea252e967f8071c | null | [] | 308 |
2.4 | quantization-rs | 0.6.0 | Neural network quantization toolkit for ONNX models | # quantize-rs Python API
Python bindings for quantize-rs, a neural network quantization toolkit for ONNX models.
## Installation
```bash
pip install quantization-rs
```
Build from source (requires Rust toolchain and maturin):
```bash
pip install maturin
maturin develop --release --features python
```
## API reference
### `quantize(input_path, output_path, bits=8, per_channel=False)`
Weight-based quantization. Loads the model, quantizes all weight tensors, and saves the result in ONNX QDQ format.
**Parameters:**
| Name | Type | Default | Description |
|------|------|---------|-------------|
| `input_path` | str | required | Path to input ONNX model |
| `output_path` | str | required | Path to save quantized model |
| `bits` | int | 8 | Bit width: 4 or 8 |
| `per_channel` | bool | False | Use per-channel quantization (separate scale/zp per output channel) |
**Example:**
```python
import quantize_rs
quantize_rs.quantize("model.onnx", "model_int8.onnx", bits=8)
quantize_rs.quantize("model.onnx", "model_int4.onnx", bits=4, per_channel=True)
```
---
### `quantize_with_calibration(input_path, output_path, ...)`
Activation-based calibration quantization. Runs inference on calibration samples to determine optimal quantization ranges per layer, then quantizes using those ranges.
**Parameters:**
| Name | Type | Default | Description |
|------|------|---------|-------------|
| `input_path` | str | required | Path to input ONNX model |
| `output_path` | str | required | Path to save quantized model |
| `calibration_data` | str or None | None | Path to `.npy` file (shape `[N, ...]`), or None for random samples |
| `bits` | int | 8 | Bit width: 4 or 8 |
| `per_channel` | bool | False | Per-channel quantization |
| `method` | str | "minmax" | Calibration method (see below) |
| `num_samples` | int | 100 | Number of random samples when `calibration_data` is None |
| `sample_shape` | list[int] or None | None | Shape of random samples; auto-detected from model if None |
**Calibration methods:**
| Method | Description |
|--------|-------------|
| `"minmax"` | Uses observed min/max from activations |
| `"percentile"` | Clips at 99.9th percentile to reduce outlier sensitivity |
| `"entropy"` | Selects range minimizing KL divergence between original and quantized distributions |
| `"mse"` | Selects range minimizing mean squared error |
**Example:**
```python
import quantize_rs
# With real calibration data
quantize_rs.quantize_with_calibration(
"resnet18.onnx",
"resnet18_int8.onnx",
calibration_data="calibration_samples.npy",
method="minmax"
)
# With random samples (auto-detects input shape from model)
quantize_rs.quantize_with_calibration(
"resnet18.onnx",
"resnet18_int8.onnx",
num_samples=100,
sample_shape=[3, 224, 224],
method="percentile"
)
```
---
### `model_info(input_path)`
Returns metadata about an ONNX model.
**Parameters:**
| Name | Type | Default | Description |
|------|------|---------|-------------|
| `input_path` | str | required | Path to ONNX model |
**Returns:** `ModelInfo` object with the following fields:
| Field | Type | Description |
|-------|------|-------------|
| `name` | str | Graph name |
| `version` | int | Model version |
| `num_nodes` | int | Number of computation nodes |
| `inputs` | list[str] | Input tensor names |
| `outputs` | list[str] | Output tensor names |
**Example:**
```python
info = quantize_rs.model_info("model.onnx")
print(f"Name: {info.name}")
print(f"Nodes: {info.num_nodes}")
print(f"Inputs: {info.inputs}")
print(f"Outputs: {info.outputs}")
```
## Preparing calibration data
For best results, use 50-200 representative samples from your validation or training set:
```python
import numpy as np
# Collect preprocessed samples
samples = []
for img in validation_dataset[:100]:
preprocessed = preprocess(img) # your preprocessing pipeline
samples.append(preprocessed)
# Save as .npy (shape: [num_samples, channels, height, width])
calibration_data = np.stack(samples)
np.save("calibration_samples.npy", calibration_data)
# Use during quantization
quantize_rs.quantize_with_calibration(
"model.onnx",
"model_int8.onnx",
calibration_data="calibration_samples.npy",
method="minmax"
)
```
If you do not have calibration data, the function generates random samples. This is adequate for testing but will produce less accurate quantization than real data.
## ONNX Runtime integration
Quantized models use the standard `DequantizeLinear` operator and load directly in ONNX Runtime:
```python
import onnxruntime as ort
import numpy as np
session = ort.InferenceSession("model_int8.onnx")
input_name = session.get_inputs()[0].name
output = session.run(None, {input_name: your_input})
```
## Limitations
- ONNX format only. Export PyTorch/TensorFlow models to ONNX before quantizing.
- Requires ONNX opset >= 13 (automatically upgraded if needed).
- INT4 values are stored as INT8 bytes in the ONNX file (DequantizeLinear requires INT8 input in opsets < 21).
- All weight tensors are quantized. Per-layer selection is not yet supported.
## License
[MIT](LICENSE)
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | MIT OR Apache-2.0 | quantization, onnx, neural-networks, machine-learning | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Lan... | [] | https://github.com/AR-Kamal/quantize-rs | null | >=3.8 | [] | [] | [] | [
"numpy>=1.20.0",
"pytest>=7.0; extra == \"dev\"",
"onnxruntime>=1.16.0; extra == \"dev\"",
"onnx>=1.14.0; extra == \"dev\""
] | [] | [] | [] | [
"Documentation, https://github.com/AR-Kamal/quantize-rs#readme",
"Homepage, https://github.com/AR-Kamal/quantize-rs",
"Repository, https://github.com/AR-Kamal/quantize-rs"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:37:39.103725 | quantization_rs-0.6.0.tar.gz | 113,527 | 8f/79/515eb8956da781f59be8b807293e7595a57ed19a4876cd25e9b9928786b6/quantization_rs-0.6.0.tar.gz | source | sdist | null | false | aa23fd3b758705ea483518009f6eec75 | 09594140bd29728ff5dc1e77c122476cf938804be6e6cd67f9cce7b107ec51a5 | 8f79515eb8956da781f59be8b807293e7595a57ed19a4876cd25e9b9928786b6 | null | [
"LICENSE"
] | 371 |
2.4 | btlightning | 0.1.3 | QUIC transport layer for Bittensor | <div align="center">
<h2>Ligh𝞽ning</h2>
<p><strong>Rust QUIC transport layer for Bittensor</strong></p>
<p>Persistent QUIC connections with sr25519 handshake authentication for validator-miner communication.</p>
</div>
## Python
```bash
pip install btlightning
```
```python
from btlightning import Lightning
client = Lightning(wallet_hotkey="5GrwvaEF...")
client.set_python_signer(my_signer_callback)
client.initialize_connections([
{"hotkey": "5FHneW46...", "ip": "192.168.1.1", "port": 8443}
])
response = client.query_axon(
{"hotkey": "5FHneW46...", "ip": "192.168.1.1", "port": 8443},
{"synapse_type": "MyQuery", "data": {"key": "value"}}
)
```
## Rust
```toml
[dependencies]
btlightning = "0.1"
```
```rust
use btlightning::{LightningClient, Sr25519Signer, QuicAxonInfo, QuicRequest};
let mut client = LightningClient::new("5GrwvaEF...".into());
client.set_signer(Box::new(Sr25519Signer::from_seed(seed)));
client.initialize_connections(vec![
QuicAxonInfo::new("5FHneW46...".into(), "192.168.1.1".into(), 8443, 4, 0, 0)
]).await?;
```
## Build from source
```bash
cargo build -p btlightning
maturin develop --manifest-path crates/btlightning-py/Cargo.toml
```
| text/markdown; charset=UTF-8; variant=GFM | Inference Labs Inc | null | null | null | MIT | null | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:37:35.363436 | btlightning-0.1.3.tar.gz | 57,021 | ff/5d/f049da27784a1cbbdeb0e22aa3f2186c1087895474e5aeed6399b9aed5d7/btlightning-0.1.3.tar.gz | source | sdist | null | false | 67e4263caa4ff817b9e4033f50eefb40 | 0ec1807c1e96f59e5acd828f56e8f0eec32c591fa7548b0fda4b3d8223de1666 | ff5df049da27784a1cbbdeb0e22aa3f2186c1087895474e5aeed6399b9aed5d7 | null | [] | 329 |
2.4 | analogpy | 0.1.4 | Analog circuit IR (Intermediate Representation) and Spectre netlist generator | License: Apache-2.0
# analog-py
Python DSL + AST + Codegen for Analog Circuit Design and Netlist Generation.
## Project Goals
**analogpy** is a Python library for generating circuit netlists. It bridges the gap between Python programming and analog circuit simulation.
### What analogpy DOES:
1. **Generate netlists** (MVP: Spectre, future: ngspice)
- Circuit topology in Python
- Hierarchical circuits
- Testbench with analyses
2. **Build simulation commands** (not execute)
- SpectreCommand builder with configurable options
- User executes via shell or [tmux-ssh](https://github.com/circuitmuggle/tmux-ssh)
3. **Parse simulation results** (planned)
- Read PSF/nutbin files
- Expose data as numpy arrays / pandas DataFrames
- Enable Python-native post-processing
4. **Make Python loop design easy**
- PVT corners: Python loop generates N netlists
- Monte Carlo: Python loop with different seeds
- Parameter sweeps: Python variables directly in netlist
### What analogpy does NOT do:
- **Job submission**: Use shell or [tmux-ssh](https://github.com/circuitmuggle/tmux-ssh)
- **Heavy analysis**: Use numpy, scipy (FFT, filtering, etc.)
- **Visualization**: Use matplotlib, plotly (analogpy provides helpers)
- **Replace Cadence ADE**: analogpy is CLI/script-first, not GUI
### Design Philosophy
```
┌─────────────────────────────────────────────────────────────┐
│ Python Script │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────┐ │
│ │ analogpy │ │ numpy │ │ matplotlib │ │
│ │ (netlist) │ │ scipy │ │ plotly │ │
│ │ (parse) │ │ pandas │ │ (visualization) │ │
│ │ (expose) │ │ (analysis) │ │ │ │
│ └──────┬──────┘ └──────┬──────┘ └─────────┬──────────-┘ │
└─────────┼────────────────┼───────────────────┼──────────────┘
│ │ │
▼ ▼ ▼
┌──────────┐ ┌──────────────┐ ┌───────────┐
│ Spectre │ │ Post-process │ │ Plots │
│ Netlist │ │ (FFT, etc.) │ │ PNG/HTML │
└──────────┘ └──────────────┘ └───────────┘
```
## Roadmap
- 0.1.x AST + netlist generation ✅
- 0.2.x Result parser + data exposure
- 0.3.x Optimization / AI hooks
- 1.0.0 Stable IR
## Installation
```bash
pip install -e .
```
## Quick Start
```python
from analogpy import Circuit, nmos, pmos, generate_spectre
from analogpy.devices import vsource
class Inverter(Circuit):
"""CMOS Inverter cell - parameters visible in signature."""
def __init__(
self,
w_n: float = 1e-6,
w_p: float = 2e-6,
l: float = 180e-9,
name: str = "inverter",
):
# Ports with optional direction using colon syntax
# "inp:input" = input direction, "out:output" = output, default = inout
super().__init__(name, ports=["inp:input", "out:output", "vdd", "vss"])
self.add_instance(nmos, "MN", d=self.net("out"), g=self.net("inp"),
s=self.net("vss"), b=self.net("vss"), w=w_n, l=l)
self.add_instance(pmos, "MP", d=self.net("out"), g=self.net("inp"),
s=self.net("vdd"), b=self.net("vdd"), w=w_p, l=l)
# Create inverter with default sizing - parameters visible in signature
inv = Inverter()
# Create top-level circuit (no ports = top level)
top = Circuit("tb_inverter", ports=[])
vin = top.net("vin")
vout = top.net("vout")
vdd = top.net("vdd")
gnd = top.gnd() # Global ground "0" at testbench level
# Add voltage source
top.add_instance(vsource, instance_name="I_Vdd", p=vdd, n=gnd, dc=1.8)
# Instantiate inverter
top.add_instance(inv, "X1", inp=vin, out=vout, vdd=vdd, vss=gnd)
# Generate Spectre netlist
netlist = generate_spectre(top)
print(netlist)
```
> **Note on port naming:** Avoid using Python reserved keywords (`in`, `for`, `class`, etc.)
> as port names. For example, `add_instance(inv, "X1", in=vin)` is a syntax error because
> `in` is a reserved word. Use `inp` instead. If you must match an existing netlist that
> uses `in` as a port name, use dict unpacking as a workaround:
> `add_instance(inv, "X1", **{"in": vin, "out": vout, "vdd": vdd, "vss": gnd})`
## Examples
See the `examples/` folder for complete workflows:
- `examples/01_inverter_basic.py` - Simple inverter netlist
- `examples/02_ota_testbench.py` - OTA with DC/AC analysis
- `examples/03_pvt_sweep.py` - PVT corner sweep with Python loop
- `examples/04_monte_carlo.py` - Monte Carlo with Python loop
- `examples/05_result_processing.py` - Parse results and plot (planned)
- `examples/06_oled_dc.py` - OLED DC simulation with Verilog-A LUTs (includes SpectreCommand reference)
- `examples/07_oled2.py` - Series OLED testbench using function-built cells
## Features
### Phase 1: Core Hierarchy (Implemented)
- **Circuit**: Reusable circuit blocks with defined ports (maps to Spectre `subckt`)
- **Aliases**: `Subcircuit` and `Subckt` are aliases for `Circuit`
- **Instantiation**: Hierarchical design with `circuit.add_instance()`
- **Nested hierarchy**: Circuits can contain other circuits
- **Top-level**: Use `Circuit("name", ports=[])` or `Testbench` for simulation top
### Phase 2: Testbench & Analysis (Implemented)
- **Testbench**: Test environment extending Circuit with simulation setup
- **Analysis classes**: DC, AC, Transient, Noise, STB
- **Simulator options**: Temperature, tolerances, convergence settings
- **Behavioral models**: Verilog-A include support
```python
from analogpy import Testbench, DC, AC, Transient
from analogpy.devices import vsource
tb = Testbench("tb_amp")
vdd = tb.net("vdd")
gnd = tb.gnd() # Global ground "0"
tb.add_instance(vsource, instance_name="I_Vdd", p=vdd, n=gnd, dc=1.8)
tb.set_temp(27)
tb.add_analysis(DC())
tb.add_analysis(AC(start=1, stop=1e9, points=100))
tb.add_analysis(Transient(stop=1e-6))
```
#### Analysis extras and SimulatorOptions
All analysis classes and `SimulatorOptions` support an `extras` dict for arbitrary Spectre parameters not covered by named fields:
```python
from analogpy import Transient, DC
# cmin is a named field on Transient (minimum capacitance per node for convergence)
tran = Transient(stop=1e-6, cmin=1e-18)
# Use extras for any other Spectre analysis parameter
tran = Transient(stop=1e-6, extras={"errpreset": "conservative", "method": "euler"})
dc = DC(extras={"homotopy": "all"})
```
**SimulatorOptions** — tolerance fields (`reltol`, `vabstol`, `iabstol`, `gmin`) default to `None` and are not emitted, letting the command-line accuracy mode (`++aps`, `+aps`) control them. Set explicitly only when you need to override:
```python
tb = Testbench("tb_amp")
tb.simulator_options.reltol = 1e-6 # Override tolerance
tb.simulator_options.gmin = 1e-15 # Tighter gmin
tb.simulator_options.extras = {"rforce": 1, "pivotdc": "yes"} # Convergence helpers
```
**temp vs tnom:**
- `temp` — circuit simulation temperature (varies in PVT sweeps)
- `tnom` — temperature at which device model parameters were measured/extracted (usually fixed to match PDK characterization, e.g. 27 or 25)
### Phase 3: SaveConfig (Implemented)
- **Hierarchical saves**: Define saves at block level, apply with prefix
- **Tagged signals**: Filter saves by category
- **Testbench control**: Override, include, exclude saves
```python
from analogpy import SaveConfig
# Define saves for OTA block
ota_saves = (SaveConfig("ota")
.voltage("out", "tail", tag="essential")
.op("M1:gm", "M2:gm", tag="op_params"))
# In testbench, apply with hierarchy prefix
tb.save(ota_saves.with_prefix("X_LDO.X_OTA"))
```
### Phase 4: Device Primitives (Implemented)
- **MOSFETs**: `nmos()`, `pmos()` with nf support
- **BJT/JFET**: `bjt()`, `jfet()` for bipolar and junction FETs
- **Passives**: `resistor()`, `capacitor()`, `inductor()`, `mutual_inductor()`
- **Sources**: `vsource()`, `isource()`
- **Controlled sources**: `vcvs()`, `vccs()`, `ccvs()`, `cccs()`
- **Other**: `diode()`, `iprobe()`, `port()` (for S-parameter)
### Phase 5: SpectreCommand (Implemented)
- **Command builder**: Generate spectre commands without execution
- **Minimal defaults**: Only emits flags you explicitly set
- **Configurable**: Accuracy, threads, output format, include paths
- **Presets**: Liberal (fast), conservative (robust), moderate
```python
from analogpy import SpectreCommand
cmd = (SpectreCommand("input.scs")
.accuracy("liberal")
.threads(16)
.include_path("/path/to/models")
.build())
# User executes via shell or tmux-ssh
```
#### SpectreCommand Options Reference
| Method | Spectre Flag | Description |
|--------|-------------|-------------|
| `.output_format(fmt)` | `-format` | Raw data format: `"psfascii"` (default), `"psfbin"`, `"psfxl"`, `"psfbinf"`, `"nutbin"`, `"nutascii"`, `"sst2"`, `"fsdb"`, `"fsdb5"`, `"wdf"`, `"uwi"`, `"tr0ascii"`. PSF ASCII files can be read with [psf-utils](https://pypi.org/project/psf-utils/) |
| `.accuracy(level, mode)` | `++aps`, `+aps`, `+errpreset` | Error tolerance and acceleration (see below) |
| `.threads(n)` | `+mt=N` | Number of parallel threads (max 64) |
| `.include_path(*paths)` | `-I` | Add include paths for model files |
| `.log_file(path)` | `+log` | Log file path (default: Spectre writes `<netlist>.log`) |
| `.raw_dir(path)` | `-raw` | Raw output directory (default: Spectre writes in current dir) |
| `.ahdl_libdir(path)` | `-ahdllibdir` | Compiled Verilog-A model cache directory (default: raw output dir) |
| `.timeout(seconds)` | `+lqtimeout` | License queue timeout — abort if license not acquired in time |
| `.max_warnings(n)` | `-maxw` | Max warnings before Spectre aborts |
| `.max_notes(n)` | `-maxn` | Max informational notes before suppression |
| `.logstatus()` | `+logstatus` | Enable status logging for monitoring simulation progress |
| `.flag("+escchars")` | `+escchars` | Allow backslash-escaped characters in paths/strings |
**Accuracy modes** — `.accuracy(level, mode)`:
- `level`: `"liberal"` (fast), `"moderate"`, `"conservative"` (accurate)
- `mode` (optional, default `"++aps"`):
- `"++aps"` — Uses a different time-step control algorithm for improved performance while satisfying error tolerances. Emits `++aps=<level>`
- `"+aps"` — Spectre APS mode, a different simulator engine from base Spectre. Emits `+aps=<level>`
- `"errpreset"` — Base Spectre error preset only, no APS acceleration. Emits `+errpreset=<level>`
```python
# Examples
.accuracy("liberal") # ++aps=liberal (default mode)
.accuracy("liberal", "+aps") # +aps=liberal
.accuracy("moderate", "errpreset") # +errpreset=moderate
```
**Note**: Only `.output_format()` is emitted by default (`-format psfascii`). All other flags are opt-in — if not called, they are not included in the generated command, letting Spectre use its own defaults.
### Phase 6: SimulationBatch (Implemented)
- **PVT sweeps**: Process/Voltage/Temperature corners
- **Monte Carlo**: Generate N runs with different seeds
- **Runner scripts**: Python scripts with CLI configuration
```python
from analogpy import SimulationBatch
# Python loop generates multiple netlists
batch = SimulationBatch("ldo_pvt", "/sim/ldo_pvt")
batch.pvt_sweep(make_tb_ldo, corners=[
{"process": "tt", "voltage": 1.8, "temp": 27},
{"process": "ff", "voltage": 1.98, "temp": -40},
{"process": "ss", "voltage": 1.62, "temp": 125},
])
batch.command_options(accuracy="liberal", threads=16)
batch.generate()
batch.write_runner("run_pvt.py")
# User runs: python run_pvt.py commands | parallel tmux-ssh {}
```
### Phase 7: PDK Infrastructure (Implemented)
- **PDK loader**: Load PDK configuration by name
- **Multi-source config**: Project, user, environment variables
- **NDA-safe**: PDK files never included in package
```python
from analogpy.pdk import PDK
pdk = PDK.load("tsmc28") # Loads from config
mn1 = pdk.nmos("M1", d=vout, g=vin, s=gnd, b=gnd, w=1e-6, l=28e-9, nf=4)
```
### Visualization Module (Experimental)
Generate schematic symbols and block diagrams for circuit documentation.
```bash
pip install analogpy[visualization] # Requires schemdraw, reportlab, pypdf
```
#### Port Type Inference
The visualization module automatically infers port placement on symbols based on naming conventions:
| Port Type | Position | Pattern Examples |
|-----------|----------|------------------|
| **POWER** | Top | `vdd`, `avdd`, `vcc`, `pwr`, `anode`, `*_vdd` |
| **GROUND** | Bottom | `vss`, `gnd`, `elvss`, `cathode`, `*_gnd` |
| **INPUT** | Left | `in`, `clk`, `en`, `rst`, `din`, `sel`, `*_in` |
| **OUTPUT** | Right | `out`, `q`, `y`, `dout`, `*_out` |
| **INOUT** | Left (below inputs) | `io`, `sda`, `scl`, `data`, `bus` |
| **UNKNOWN** | Left (default) | All other names |
#### Customizing Port Locations
Override the auto-inference using `port_overrides`:
```python
from analogpy.visualization import draw_cell_symbol, PortType
import schemdraw
# Define your custom port types
port_overrides = {
"BIAS": PortType.INPUT, # Force BIAS to left side
"MONITOR": PortType.OUTPUT, # Force MONITOR to right side
}
# Draw symbol with overrides
with schemdraw.Drawing() as d:
d.config(unit=1, fontsize=10)
positions = draw_cell_symbol(
d, "my_cell",
ports=["VDD", "VSS", "IN", "OUT", "BIAS", "MONITOR"],
port_overrides=port_overrides
)
d.save("my_cell.png")
```
#### Standalone Symbol Generation
```python
from analogpy.visualization import create_cell_symbol_standalone
# Quick way to generate a symbol image
d = create_cell_symbol_standalone("oled_cell", ["ANODE", "ELVSS"])
d.save("oled_symbol.png")
```
**Note**: This module is experimental. Block diagram connection routing still needs work.
### Phase 8: Result Parsing (Planned)
- **Parse PSF/nutbin**: Read Spectre output files
- **Expose as Python data**: numpy arrays, pandas DataFrames
- **Display config**: Separate from save config
- **Validation**: Warn if display signal not in saved signals
```python
# Planned API
from analogpy.results import load_results
results = load_results("/sim/ldo_pvt/tt_v1.8_t27/psf")
# Point query
vout_dc = results.dc["X_OTA.vout"]
# Waveform as numpy array
vout_tran = results.tran["vout"] # Returns (time, values) arrays
# At specific time
vgs_at_10ns = results.tran["M1:vgs"].at(10e-9)
# Use Python for analysis
import numpy as np
from scipy.fft import fft
spectrum = fft(vout_tran.values) # numpy/scipy does the work
```
## Architecture
```
analogpy/
├── circuit.py # Circuit (Subcircuit, Subckt are aliases), Net, Instance
├── devices.py # nmos, pmos, resistor, capacitor, etc.
├── spectre.py # Spectre netlist generation
├── testbench.py # Testbench class
├── analysis.py # DC, AC, Transient, Noise, STB
├── save.py # SaveConfig for probe management
├── command.py # SpectreCommand builder
├── batch.py # SimulationBatch for PVT/MC
├── pdk/ # PDK loader infrastructure
└── results/ # Result parsing (planned)
```
## Design Principles
1. **Netlist-focused**: Generate netlists, expose results - that's it
2. **Python-native**: Use Python variables, loops, data structures
3. **Don't reinvent**: FFT? Use scipy. Plots? Use matplotlib.
4. **CLI-first**: No GUI, scripts and commands
5. **AI-friendly**: Simple patterns for LLM generation
## Testing
```bash
pytest tests/ -v
```
### Simulator Integration Tests
Some tests require a working Spectre simulator. These are marked with `@pytest.mark.simulator` and will be **automatically skipped** if no simulator is available.
**Test levels:**
1. **Syntax checks** - Always run, use Python-based validation
2. **Basic simulation** - Requires simulator, runs actual simulations
3. **Result validation** - Compares results against expected values
**Setting up simulator access:**
Option 1: **Config file** (recommended for remote simulation)
```bash
# Copy template to ~/.analogpy/
mkdir -p ~/.analogpy
cp config.yaml.template ~/.analogpy/config.yaml
# Edit the config file to set remote spectre path
# Uncomment and modify the settings you need
```
Example `~/.analogpy/config.yaml`:
```yaml
simulator:
mode: remote
remote:
spectre_path: /tools/cadence/SPECTRE231/bin/spectre
workdir: /tmp/analogpy
```
Option 2: **Local Spectre** (if installed on your machine)
```bash
# Spectre in PATH
which spectre # Should return path
# Or set explicit path
export SPECTRE_PATH=/path/to/spectre
```
Option 3: **Remote via tmux-ssh** (auto-detected if config exists)
```bash
# Install tmux-ssh
pip install tmux-ssh
# Configure once (credentials are saved to ~/.tmux_ssh_config)
tmux-ssh user@your-spectre-server.com
# Now pytest will automatically use remote execution
pytest tests/test_simulation.py -v
```
**Configuration precedence:**
1. `~/.analogpy/config.yaml` (user config file)
2. Environment variables (override config file)
3. Local Spectre (PATH or SPECTRE_PATH)
4. Remote via tmux-ssh (reads ~/.tmux_ssh_config)
5. Skip with helpful message
**Environment variables:**
| Variable | Description | Default |
|----------|-------------|---------|
| `SPECTRE_PATH` | Path to local spectre binary | Auto-detect from PATH |
| `ANALOGPY_WORKDIR` | Working directory for simulation files | `/tmp/analogpy` |
| `ANALOGPY_SKIP_SIMULATION` | Set to "1" to skip all simulation tests | Disabled |
## License
Apache-2.0
| text/markdown | null | Gaofeng Fan <circuitmuggle@gmaigmaill.com> | null | null | null | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy",
"schemdraw>=0.18; extra == \"visualization\"",
"reportlab>=4.0; extra == \"visualization\"",
"pypdf>=4.0; extra == \"visualization\""
] | [] | [] | [] | [
"Homepage, https://github.com/circuitmuggle/analogpy"
] | twine/6.2.0 CPython/3.12.10 | 2026-02-19T21:36:25.056337 | analogpy-0.1.4.tar.gz | 78,564 | ee/3b/86f6ee97f860d6090b47eaf67076e102264b0e1adbbd4dba71c5bc2947db/analogpy-0.1.4.tar.gz | source | sdist | null | false | 0750d2d0f501b9bd79600aaf805a3e50 | c5f4f6d97332c759f5df6c2b8d14b2e48ffffce2cb177ac10f93eb4fea66ae8b | ee3b86f6ee97f860d6090b47eaf67076e102264b0e1adbbd4dba71c5bc2947db | Apache-2.0 | [
"LICENSE"
] | 228 |
2.4 | qtype | 0.1.18 | DSL for Generative AI Prototyping | # QType
**QType is a domain-specific language (DSL) for rapid prototyping of AI applications.**
It is designed to help developers define modular, composable AI systems using a structured YAML-based specification. QType supports models, prompts, tools, retrievers, and flow orchestration, and is extensible for code generation or live interpretation.
---
## 🚀 Quick Start
Install QType:
```bash
pip install qtype[interpreter]
```
Create a file `hello_world.qtype.yaml` that answers a question:
```yaml
id: hello_world
flows:
- id: chat_example
description: A simple chat flow with OpenAI
mode: Chat
steps:
- id: llm_inference_step
model:
id: gpt-4
provider: openai
auth:
id: openai_auth
type: api_key
api_key: ${OPENAI_KEY}
system_message: |
You are a helpful assistant.
inputs:
- id: user_message
type: ChatMessage
outputs:
- id: response
type: ChatMessage
```
Put your openai api key into your `.env` file:
```
echo "OPENAI_KEY=sk...." >> .env
```
Validate it's semantic correctness:
```bash
qtype validate hello_world.qtype.yaml
```
You should see:
```
INFO: ✅ Schema validation successful.
INFO: ✅ Model validation successful.
INFO: ✅ Language validation successful
INFO: ✅ Semantic validation successful
```
Launch the interpreter:
```bash
qtype serve hello_world.qtype.yaml`
```
And go to [http://localhost:8000/ui](http://localhost:8000/ui) to see the user interface for your application:

---
See the [full docs](https://bazaarvoice.github.io/qtype/) for more examples and guides.
## ✨ Developing with AI?
Use the QType MCP server to speed yourself up! Just set your assistant to run `qtype mcp`.
For VSCode, just add the following to `.vscode/mcp.json`:
```json
{
"servers": {
"qtype": {
"type": "stdio",
"command": "qtype",
"cwd": "${workspaceFolder}",
"args": ["mcp", "--transport", "stdio"]
}
}
}
```
For Claude Code:
```
claude mcp add qtype -- qtype mcp --transport stdio"
```
## 🤝 Contributing
Contributions welcome! Please follow the instructions in the [contribution guide](https://bazaarvoice.github.io/qtype/contributing/).
## 📄 License
This project is licensed under the **MIT License**.
See the [LICENSE](./LICENSE) file for details.
---
## 🧠 Philosophy
QType is built around modularity, traceability, and rapid iteration. It aims to empower developers to quickly scaffold ideas into usable AI applications without sacrificing maintainability or control.
Stay tuned for upcoming features like:
- Integrated OpenTelemetry tracing
- Validation via LLM-as-a-judge
- UI hinting via input display types
- Flow state switching and conditional routing
---
Happy hacking with QType! 🛠️
[](https://github.com/bazaarvoice/qtype/actions/workflows/github_workflows_generate-schema.yml) [](https://github.com/bazaarvoice/qtype/actions/workflows/publish-pypi.yml) | text/markdown | null | Lou Kratz <lou.kratz+qtype@bazaarvoice.com> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"cachetools>=6.2.1",
"fsspec>=2025.5.1",
"google-cloud-aiplatform>=1.120.0",
"jsonschema>=4.24.0",
"mkdocs-awesome-pages-plugin>=2.10.1",
"openai>=1.93.0",
"openapi3-parser>=1.1.21",
"pip-system-certs>=5.2",
"pydantic-yaml>=1.6.0",
"pydantic>=2.12.4",
"python-dotenv>=1.0.0",
"pyyaml>=6.0.2",
... | [] | [] | [] | [
"Homepage, https://github.com/bazaarvoice/qtype"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:36:18.519978 | qtype-0.1.18.tar.gz | 3,595,758 | 6f/68/288a03795d654552fd2695727d6482ed2cca479282266a0a0f3a4b0e40e6/qtype-0.1.18.tar.gz | source | sdist | null | false | 06fc0cf55f7625a2aa5bc8f08d344dbe | f3aac77117c02386a76c2674565b1e2463d3574c57276817c7394a1e006344ba | 6f68288a03795d654552fd2695727d6482ed2cca479282266a0a0f3a4b0e40e6 | Apache-2.0 | [
"LICENSE"
] | 229 |
2.4 | lfcdemolib | 0.0.13 | Lakeflow Connect Demo Library | # lfcdemolib
**Lakeflow Connect Demo Library**
A comprehensive Python library for building and managing Databricks Lakeflow Connect (LFC) demonstrations with support for multiple cloud providers and database types.
## Features
- **Simplified Demo Initialization**: One-line setup for Databricks notebooks with `DemoInstance`
- **Multi-Database Support**: SQL Server, MySQL, PostgreSQL, Oracle
- **Cloud Provider Support**: Azure, Oracle Cloud Infrastructure (OCI)
- **Change Data Capture (CDC)**: Built-in CDC/CT (Change Tracking) implementations
- **Schema Evolution**: Automatic schema evolution and migration handling
- **Connection Management**: Secure credential storage and retrieval
- **DML Operations**: Simplified data manipulation with automatic scheduling
- **REST API Integration**: Databricks workspace API wrapper
- **Test Framework**: Comprehensive testing utilities for database operations
## Installation
```bash
pip install lfcdemolib
```
**All database drivers are included** as core dependencies:
- pymysql (MySQL)
- psycopg2-binary (PostgreSQL)
- pymssql (SQL Server)
- oracledb (Oracle)
### Optional Dependencies
For development tools:
```bash
# Development tools (pytest, black, flake8, mypy, isort)
pip install "lfcdemolib[dev]"
# Documentation tools (sphinx)
pip install "lfcdemolib[docs]"
```
## Quick Start
### Databricks Notebook
```python
import lfcdemolib
# Configuration
config_dict = {
"source_connection_name": "lfcddemo-azure-mysql-both",
"cdc_qbc": "cdc",
"database": {
"cloud": "azure",
"type": "mysql"
}
}
# One-line initialization
d = lfcdemolib.DemoInstance(config_dict, dbutils, spark)
# Create pipeline
d.create_pipeline(pipeline_spec)
# Execute DML operations
d.dml.execute_delete_update_insert()
# Get recent data
df = d.dml.get_recent_data()
display(df)
```
### Tuple Unpacking (Advanced)
```python
# Get all components
d, config, dbxs, dmls, dbx_key, dml_key, scheduler = lfcdemolib.DemoInstance(
config_dict,
dbutils,
spark
)
# Use individual components
config.source_connection_name
dmls[dml_key].execute_delete_update_insert()
scheduler.get_jobs()
```
## Core Components
### DemoInstance
Simplified facade for demo initialization with automatic caching and scheduler management.
```python
d = lfcdemolib.DemoInstance(config_dict, dbutils, spark)
```
**Features:**
- Singleton scheduler management
- Automatic instance caching
- Simplified one-line initialization
- Delegates to DbxRest for Databricks operations
### LfcScheduler
Background task scheduler using APScheduler.
```python
scheduler = lfcdemolib.LfcScheduler()
scheduler.add_job(my_function, 'interval', seconds=60)
```
### DbxRest
Databricks REST API client with connection and secret management.
```python
dbx = lfcdemolib.DbxRest(dbutils=dbutils, config=config, lfc_scheduler=scheduler)
dbx.create_pipeline(spec)
```
### SimpleDML
Simplified DML operations with automatic scheduling.
```python
dml = lfcdemolib.SimpleDML(secrets_json, config=config, lfc_scheduler=scheduler)
dml.execute_delete_update_insert()
df = dml.get_recent_data()
```
### Pydantic Models
Type-safe configuration and credential management.
```python
from lfcdemolib import LfcNotebookConfig, LfcCredential
# Validate configuration
config = LfcNotebookConfig(config_dict)
# Validate credentials
credential = LfcCredential(secrets_json)
```
## Database Support
### Supported Databases
- **SQL Server**: CDC and Change Tracking (CT) support
- **MySQL**: Full replication support
- **PostgreSQL**: Logical replication support
- **Oracle**: 19c and later
### Supported Cloud Providers
- **Azure**: SQL Database, Azure Database for MySQL/PostgreSQL
- **OCI**: Oracle Cloud Infrastructure databases
## Configuration
### LfcNotebookConfig
```python
config_dict = {
"source_connection_name": "lfcddemo-azure-mysql-both", # Required
"cdc_qbc": "cdc", # Required: "cdc" or "qbc"
"target_catalog": "main", # Optional: defaults to "main"
"source_schema": None, # Optional: auto-detect
"database": { # Required if connection_name is blank
"cloud": "azure", # "azure" or "oci"
"type": "mysql" # "mysql", "postgresql", "sqlserver", "oracle"
}
}
```
### LfcCredential (V2 Format)
```python
credential = {
"host_fqdn": "myserver.database.windows.net",
"port": 3306,
"catalog": "mydb",
"schema": "dbo",
"username": "user",
"password": "pass",
"db_type": "mysql",
"cloud": {
"provider": "azure",
"region": "eastus"
},
"dba": {
"username": "admin",
"password": "adminpass"
}
}
```
## Advanced Features
### Automatic Scheduling
```python
# DML operations run automatically
d = lfcdemolib.DemoInstance(config_dict, dbutils, spark)
# Auto-scheduled DML operations every 10 seconds
```
### Custom Scheduler Jobs
```python
def my_task():
print("Running custom task")
d.scheduler.add_job(my_task, 'interval', seconds=30, id='my_task')
```
### Connection Management
```python
from lfcdemolib import LfcConn
# Manage Databricks connections
lfc_conn = LfcConn(workspace_client=workspace_client)
connection = lfc_conn.get_connection(connection_name)
```
### Secret Management
```python
from lfcdemolib import LfcSecrets
# Manage Databricks secrets
lfc_secrets = LfcSecrets(workspace_client=workspace_client)
secret = lfc_secrets.get_secret(scope='lfcddemo', key='mysql_password')
```
### Local Credential Storage
```python
from lfcdemolib import SimpleLocalCred
# Save credentials locally
cred_manager = SimpleLocalCred()
cred_manager.save_credentials(db_details, db_type='mysql', cloud='azure')
# Load credentials
credential = cred_manager.get_credential(
host='myserver.database.windows.net',
db_type='mysql'
)
```
## Testing
### SimpleTest
Comprehensive database test suite.
```python
from lfcdemolib import SimpleTest
tester = SimpleTest(workspace_client, config)
results = tester.run_comprehensive_tests()
```
## Command-Line Tools
### Deploy Credentials
```bash
cd lfc/db/bin
python deploy_credentials_to_workspaces.py \
--credential-file ~/.lfcddemo/credentials.json \
--target-workspace prod
```
### Convert Secrets
```bash
python convert_secret_to_credential.py \
--scope-name lfcddemo \
--secret-name mysql-connection \
--source azure
```
## Examples
### Multi-Database Demo
```python
import lfcdemolib
# MySQL
mysql_d = lfcdemolib.DemoInstance(mysql_config, dbutils, spark)
mysql_d.create_pipeline(mysql_spec)
# PostgreSQL
pg_d = lfcdemolib.DemoInstance(pg_config, dbutils, spark)
pg_d.create_pipeline(pg_spec)
# SQL Server
sqlserver_d = lfcdemolib.DemoInstance(sqlserver_config, dbutils, spark)
sqlserver_d.create_pipeline(sqlserver_spec)
# All share the same scheduler
print(mysql_d.scheduler is pg_d.scheduler) # True
```
### Monitoring
```python
# Check active jobs
for job in d.scheduler.get_jobs():
print(f"{job.id}: {job.next_run_time}")
# Check cleanup queue
for item in d.cleanup_queue.queue:
print(item)
```
## Requirements
- Python >= 3.8
- Databricks Runtime 13.0+
- SQLAlchemy >= 1.4.0
- Pydantic >= 1.8.0 (v1 compatibility)
- APScheduler >= 3.9.0
## License
This project is licensed under the Databricks Labs License - see the [LICENSE](LICENSE) file for details.
## Contributing
This is a Databricks Labs project. Contributions are welcome! Please ensure:
- Code follows PEP 8 style guidelines
- All tests pass
- Documentation is updated
- Pydantic v1 compatibility is maintained
## Support
For issues, questions, or contributions, please contact the Databricks Labs team.
## Changelog
### Version 0.0.6 (Current)
- Fixed `AttributeError: 'LfcNotebookConfig' object has no attribute 'get'` in `SimpleConn.py` for Pydantic v2
- Added `_get_config_value()` helper method for safe config access from both Pydantic models and dicts
- Corrected README.md changelog (was incorrectly showing "Version 1.0.0", now shows accurate release history)
- Improved compatibility with both Pydantic v1 and v2 models
### Version 0.0.5
- Fixed `AttributeError` with Pydantic v2 `LfcNotebookConfig` in `SimpleConn.py`
- Added `_get_config_value()` helper method for safe config access
- Improved compatibility with both Pydantic v1 and v2 models
### Version 0.0.4
- Added Pydantic v1/v2 compatibility layer (`_pydantic_compat.py`)
- Now works with both Pydantic v1.10+ and v2.x
- Resolves dependency conflicts with langchain, databricks-agents, etc.
- Updated `LfcCredentialModel` and `LfcNotebookConfig` to use compatibility layer
### Version 0.0.3
- Fixed VERSION file not included in MANIFEST.in (build error fix)
- Added VERSION to package manifest for proper sdist builds
- Fixed cleanup queue display format in notebooks
### Version 0.0.2
- Fixed pydantic version requirement for Databricks compatibility
- Added typing_extensions compatibility
- All database drivers included as core dependencies
- Updated description to "Lakeflow Connect Demo Library"
### Version 0.0.1
- Initial release
- DemoInstance facade for simplified initialization
- Support for MySQL, PostgreSQL, SQL Server, Oracle
- Azure and OCI cloud provider support
- Pydantic v1-based validation
- APScheduler integration
- Comprehensive test framework
---
**Databricks Labs** | [Documentation](#) | [Examples](#) | [API Reference](#)
| text/markdown | null | Databricks Labs <labs@databricks.com> | null | Databricks Labs <labs@databricks.com> | null | databricks, lakeflow, federation, cdc, change-data-capture, data-engineering, etl, database, replication | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Py... | [] | null | null | >=3.8 | [] | [] | [] | [
"sqlalchemy<3.0.0,>=1.4.0",
"pandas>=1.3.0",
"databricks-sdk>=0.1.0",
"apscheduler<4.0.0,>=3.9.0",
"pydantic>=1.10.0",
"requests>=2.25.0",
"pymysql>=1.0.0",
"psycopg2-binary>=2.9.0",
"pymssql>=2.2.0",
"oracledb>=1.0.0",
"pytest>=6.0; extra == \"dev\"",
"pytest-cov>=3.0; extra == \"dev\"",
"b... | [] | [] | [] | [
"Homepage, https://github.com/databricks-labs/lfcdemolib",
"Documentation, https://github.com/databricks-labs/lfcdemolib#readme",
"Repository, https://github.com/databricks-labs/lfcdemolib",
"Bug Tracker, https://github.com/databricks-labs/lfcdemolib/issues"
] | twine/6.2.0 CPython/3.12.11 | 2026-02-19T21:35:39.627887 | lfcdemolib-0.0.13.tar.gz | 188,099 | e5/4e/106865e3bdb84384c0ba719e562780a5009a09784b8a44fdb760552e5f0b/lfcdemolib-0.0.13.tar.gz | source | sdist | null | false | c5abfbbb5abfae72d51cc90ed271e73b | f063b9cf0ecb876a6ff9d48d159329cb44001684e90e4763ac8cb1d4faa3110f | e54e106865e3bdb84384c0ba719e562780a5009a09784b8a44fdb760552e5f0b | null | [
"LICENSE"
] | 237 |
2.4 | sequrity | 0.4.0.post2 | A Python client for Sequrity API | # Sequrity
Please see the full [Documentation](https://sequrity-ai.github.io/sequrity-api/)
Python client and REST API for Sequrity.
## Installation
```bash
pip install sequrity
```
## Quick Start
```python
from sequrity import SequrityClient
sequrity_key = "<your-sequrity-api-key>"
openrouter_key = "<your-openrouter-key>"
client = SequrityClient(api_key=sequrity_key)
response = client.control.chat.create(
messages=[{"role": "user", "content": "What is the largest prime number below 100?"}],
model="openai/gpt-5-mini", # model name on OpenRouter
llm_api_key=openrouter_key,
provider="openrouter",
)
# Print the response
print(response)
```
## Requirements
- Python 3.11+
## License
Apache 2.0
| text/markdown | null | Ilya Shumailov <ilya@sequrity.ai>, Yiren Zhao <yiren@sequrity.ai>, Cheng Zhang <cheng@sequrity.ai> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Soft... | [] | null | null | >=3.11 | [] | [] | [] | [
"httpx>=0.28.1",
"lark>=1.3.1",
"pydantic>=2.11.9",
"langchain-openai>=1.1.7; extra == \"langchain\"",
"langgraph>=1.0.7; extra == \"langchain\"",
"openai-agents>=0.1.0; extra == \"openai\"",
"openai>=1.0.0; extra == \"openai\""
] | [] | [] | [] | [
"Homepage, https://sequrity.ai",
"Repository, https://github.com/sequrity-ai/sequrity-api"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:34:40.965482 | sequrity-0.4.0.post2.tar.gz | 1,580,886 | a9/d3/01b985f56cdcc693c2dfacdd0ded3611b11d64c08d507dcab03ca235ebbe/sequrity-0.4.0.post2.tar.gz | source | sdist | null | false | d1270ce269c4c9bd556d8e138c75c3b5 | c18071ad5b5d6936613d4867b1c3e557bc5a3159bd48eaa70ed06ced1e64d3d1 | a9d301b985f56cdcc693c2dfacdd0ded3611b11d64c08d507dcab03ca235ebbe | Apache-2.0 | [
"LICENSE"
] | 216 |
2.4 | incite-app | 0.1.0 | Local-first citation recommendation system | # inCite
**Write text. Get relevant papers from your library.**
[](https://opensource.org/licenses/Apache-2.0)
[](https://www.python.org/downloads/)
[](https://pypi.org/project/incite/)
## Overview
inCite is a local-first citation recommendation system. It indexes your Zotero library or a folder of PDFs and suggests relevant papers as you write. Everything runs on your machine -- no cloud account, no API keys, no data leaving your laptop.
- **Local-first**: Your papers and writing stay on your machine
- **Works with what you have**: Zotero library, a folder of PDFs, or a JSONL corpus
- **Editor plugins**: Obsidian, VS Code, Google Docs, and Microsoft Word
- **Fine-tuned models**: Citation-specific sentence transformers trained on 64K academic citation contexts
## Quick Start
```bash
pip install incite
incite setup
```
The setup wizard auto-detects your Zotero library (or accepts a folder of PDFs), builds a search index, and verifies everything works.
## Usage
### Command Line
```bash
# Get recommendations for a passage
incite recommend "The relationship between CO2 emissions and global temperature..." -k 10
# Start the API server (for editor plugins)
incite serve --embedder minilm-ft
# Start the menu bar app (macOS, manages the server for you)
pip install incite[tray]
incite tray
```
### Python API
```python
from incite.agent import InCiteAgent
# From Zotero library
agent = InCiteAgent.from_zotero(embedder_type="minilm-ft")
# From a folder of PDFs
agent = InCiteAgent.from_folder("~/Papers")
# Get recommendations
response = agent.recommend("climate change and agricultural productivity", k=10)
for rec in response.recommendations:
print(f" {rec.rank}. [{rec.score:.2f}] {rec.title} ({rec.year})")
```
### REST API
```bash
incite serve --embedder minilm-ft
# API docs at http://localhost:8230/docs
curl -X POST http://localhost:8230/recommend \
-H "Content-Type: application/json" \
-d '{"query": "climate change impacts on crop yields", "k": 5}'
```
## Editor Plugins
inCite integrates with your writing environment via editor plugins that connect to the local API server.
| Editor | Status | Install |
|--------|--------|---------|
| **Obsidian** | Stable | Build from `editor-plugins/obsidian-incite/` |
| **VS Code** | Stable | Build from `editor-plugins/vscode-incite/` |
| **Google Docs** | Stable | Apps Script add-on via `clasp push` |
| **Microsoft Word** | Beta | Office.js add-in, sideload `manifest.xml` |
All plugins share the `@incite/shared` TypeScript package for API communication and context extraction.
## Paper Sources
- **Zotero** (recommended): Auto-detects your local Zotero library and reads directly from the SQLite database
- **PDF folder**: Point at any directory of PDFs -- metadata is extracted automatically
- **JSONL corpus**: Load a pre-built corpus file with title, abstract, authors, and other metadata
## How It Works
1. **Embed papers**: Each paper is embedded as `title. authors. year. journal. abstract` using a sentence transformer
2. **Embed your writing**: Your text is embedded with the same model
3. **Search**: FAISS finds the nearest papers by cosine similarity
4. **Fuse** (optional): BM25 keyword matching is combined with neural results via Reciprocal Rank Fusion for improved recall
5. **Evidence**: The best matching paragraph from each paper's full text is attached as supporting evidence
## Embedder Models
| Model | Key | Dims | Notes |
|-------|-----|------|-------|
| MiniLM fine-tuned v4 | `minilm-ft` | 384 | Default. Citation-specific, auto-downloads from HuggingFace |
| MiniLM | `minilm` | 384 | Fast, good baseline |
| SPECTER2 | `specter` | 768 | Scientific domain |
| Nomic v1.5 | `nomic` | 768 | Long context (8K tokens) |
| Granite | `granite` | 384 | IBM Granite, 8K context |
> For even better results (MRR 0.550 vs 0.428), try the cloud service at [inciteref.com](https://inciteref.com) which uses our best fine-tuned model.
## Fine-Tuning
You can fine-tune your own citation embedder on your training data:
```bash
pip install incite[finetune]
incite finetune train --train data.jsonl --dev dev.jsonl
```
The training pipeline uses Matryoshka representation learning with cached multiple negatives ranking loss, supporting hard negatives for best results.
## Development
```bash
git clone https://github.com/galenphall/incite.git
pip install -e ".[dev]"
pytest
ruff check src/incite && ruff format src/incite
```
## Optional Dependencies
inCite's core is Apache 2.0 licensed. Some optional features depend on copyleft-licensed libraries and are packaged as extras to keep the default installation permissive.
```bash
pip install incite[pdf] # PyMuPDF for PDF text extraction (AGPL)
pip install incite[zotero] # pyzotero for Zotero integration (GPL)
pip install incite[api] # FastAPI server
pip install incite[webapp] # Streamlit UI
pip install incite[finetune] # Training pipeline
pip install incite[tray] # macOS menu bar app
pip install incite[all] # Everything
```
> **Note**: The `pdf` and `zotero` extras pull in AGPL and GPL dependencies respectively. If license compatibility matters for your use case, install only the extras you need.
## Cloud Service
[inciteref.com](https://inciteref.com) offers a hosted version of inCite with additional features:
- **Better model**: Granite-FT fine-tuned embedder (MRR 0.550 vs 0.428 for the default local model)
- **Cloud PDF processing**: Full-text extraction without running GROBID locally
- **Reference manager**: Collections, tags, notes, and citation export (BibTeX/RIS)
- **Multi-device sync**: Access your library from anywhere
The local CLI and cloud service are complementary -- use whichever fits your workflow.
## Contributing
Contributions are welcome. See [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
## License
[Apache License 2.0](LICENSE)
## Citation
```bibtex
@software{incite2025,
author = {Hall, Galen},
title = {inCite: Local-First Citation Recommendation},
year = {2025},
url = {https://github.com/galenphall/incite},
license = {Apache-2.0}
}
```
| text/markdown | Galen Hall | null | null | null | null | academic, citation, embeddings, recommendation, zotero | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"bibtexparser>=2.0.0b1",
"faiss-cpu>=1.7.0",
"nltk>=3.8.0",
"numpy>=1.24.0",
"python-dotenv>=1.0.0",
"pyyaml>=6.0",
"rank-bm25>=0.2.2",
"requests>=2.28.0",
"sentence-transformers>=2.2.0",
"tqdm>=4.65.0",
"playwright>=1.40.0; extra == \"acquire\"",
"incite[acquire,api,dev,finetune,llm,nlp,pdf,t... | [] | [] | [] | [
"Homepage, https://github.com/galenphall/incite",
"Repository, https://github.com/galenphall/incite",
"Issues, https://github.com/galenphall/incite/issues",
"Documentation, https://github.com/galenphall/incite#readme"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:33:35.344525 | incite_app-0.1.0.tar.gz | 298,707 | f9/39/edc2c48208250accb54c6e6f734af36b16897079396d6af30dddbd7933bb/incite_app-0.1.0.tar.gz | source | sdist | null | false | 95ee7dd7400eaa6b26c4d172d59ef96f | 9c9c7a1a05a8c94eec5da5c9be181058595d4f6311b999512b05a5d62572fd79 | f939edc2c48208250accb54c6e6f734af36b16897079396d6af30dddbd7933bb | Apache-2.0 | [
"LICENSE"
] | 235 |
2.4 | epicsdev-tektronix | 1.0.3 | EPICS PVAccess server for Tektronix MSO oscilloscopes | # epicsdev_tektronix
This version 1.0.1 is correction of an AI-generated code,
[generated by Git copilot](fallback/__main__.py).<br>
Python-based EPICS PVAccess server for Tektronix MSO oscilloscopes (4, 5, and 6 Series).
It is based on [p4p](https://epics-base.github.io/p4p/) and [epicsdev](https://github.com/ASukhanov/epicsdev) packages
and it can run standalone on Linux, OSX, and Windows platforms.
This implementation is adapted from [epicsdev_rigol_scope](https://github.com/ASukhanov/epicsdev_rigol_scope)
and supports Tektronix MSO series oscilloscopes using SCPI commands as documented in the
[Tektronix 4-5-6 Series MSO Programmer Manual](https://download.tek.com/manual/4-5-6-Series-MSO-Programmer_077130524.pdf).
## Installation
```pip install epicsdev_tektronix```
For control GUI and plotting:
```pip install pypeto,pvplot```
Control GUI:
```python -m pypeto -c path_to_repository/config -f epicsdev_tektronix```
## Features
- Support for Tektronix MSO oscilloscopes (configurable)
- Real-time waveform acquisition via EPICS PVAccess
- SCPI command interface for scope control
- Support for multiple trigger modes (AUTO, NORMAL, SINGLE)
- Configurable horizontal and vertical scales
- Channel-specific controls (coupling, offset, termination)
- Performance timing diagnostics
## Command-line Options
- `-c, --channels`: Number of channels per device (default: 4)
- `-d, --device`: Device name for PV prefix (default: 'tektronix')
- `-i, --index`: Device index for PV prefix (default: '0')
- `-r, --resource`: VISA resource string (default: 'TCPIP::192.168.1.100::INSTR')
- `-v, --verbose`: Increase verbosity (-vv for debug output)
## Example Usage
```bash
python -m epicsdev_tektronix.mso -r'TCPIP::192.168.1.100::4000:SOCKET'
```
Control GUI:
```python -m pypeto -c path_to_repository/config -f epicsdev_tektronix```
## Supported Tektronix Models
- MSO44, MSO46, MSO48 (4 Series)
- MSO54, MSO56, MSO58 (5 Series)
- MSO64 (6 Series)
- Other MSO series models using compatible SCPI commands
## Performance
Acquisition time of 6 channels, each with 1M of floating point values is 2.0 s. Throughput maxes out at 12 MB/s.
| text/markdown | Andrey Sukhanov | null | null | null | null | epics oscilloscope tektronix mso pvaccess scpi visa | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: P... | [] | https://github.com/ASukhanov/epicsdev_tektronix | null | >=3.7 | [] | [] | [] | [] | [] | [] | [] | [
"Bug Reports, https://github.com/ASukhanov/epicsdev_tektronix/issues",
"Source, https://github.com/ASukhanov/epicsdev_tektronix",
"Documentation, https://github.com/ASukhanov/epicsdev_tektronix/blob/main/README.md"
] | twine/6.1.0 CPython/3.11.5 | 2026-02-19T21:33:22.506174 | epicsdev_tektronix-1.0.3.tar.gz | 12,516 | 6b/2c/f0a4eb16776a11eccb525b26d1c2495d346d1b912ea42f7abb1a900aec97/epicsdev_tektronix-1.0.3.tar.gz | source | sdist | null | false | b17d309b408d5049052c1dfd0989b4c8 | a1ff96bc89febfd9a6846d61629132f9d2776790276d5334a6b28ebdea51621b | 6b2cf0a4eb16776a11eccb525b26d1c2495d346d1b912ea42f7abb1a900aec97 | null | [
"LICENSE"
] | 244 |
2.4 | bbot | 2.8.2.7508rc0 | OSINT automation for hackers. | [](https://github.com/blacklanternsecurity/bbot)
[](https://www.python.org) [](https://github.com/blacklanternsecurity/bbot/blob/dev/LICENSE) [](https://www.reconvillage.org/talks) [](https://pepy.tech/project/bbot) [](https://github.com/astral-sh/ruff) [](https://github.com/blacklanternsecurity/bbot/actions?query=workflow%3A"tests") [](https://codecov.io/gh/blacklanternsecurity/bbot) [](https://discord.com/invite/PZqkgxu5SA)
### **BEE·bot** is a multipurpose scanner inspired by [Spiderfoot](https://github.com/smicallef/spiderfoot), built to automate your **Recon**, **Bug Bounties**, and **ASM**!
https://github.com/blacklanternsecurity/bbot/assets/20261699/e539e89b-92ea-46fa-b893-9cde94eebf81
_A BBOT scan in real-time - visualization with [VivaGraphJS](https://github.com/blacklanternsecurity/bbot-vivagraphjs)_
## Installation
```bash
# stable version
pipx install bbot
# bleeding edge (dev branch)
pipx install --pip-args '\--pre' bbot
```
_For more installation methods, including [Docker](https://hub.docker.com/r/blacklanternsecurity/bbot), see [Getting Started](https://www.blacklanternsecurity.com/bbot/Stable/)_
## Example Commands
### 1) Subdomain Finder
Passive API sources plus a recursive DNS brute-force with target-specific subdomain mutations.
```bash
# find subdomains of evilcorp.com
bbot -t evilcorp.com -p subdomain-enum
# passive sources only
bbot -t evilcorp.com -p subdomain-enum -rf passive
```
<!-- BBOT SUBDOMAIN-ENUM PRESET EXPANDABLE -->
<details>
<summary><b><code>subdomain-enum.yml</code></b></summary>
```yaml
description: Enumerate subdomains via APIs, brute-force
flags:
# enable every module with the subdomain-enum flag
- subdomain-enum
output_modules:
# output unique subdomains to TXT file
- subdomains
config:
dns:
threads: 25
brute_threads: 1000
# put your API keys here
# modules:
# github:
# api_key: ""
# chaos:
# api_key: ""
# securitytrails:
# api_key: ""
```
</details>
<!-- END BBOT SUBDOMAIN-ENUM PRESET EXPANDABLE -->
BBOT consistently finds 20-50% more subdomains than other tools. The bigger the domain, the bigger the difference. To learn how this is possible, see [How It Works](https://www.blacklanternsecurity.com/bbot/Dev/how_it_works/).

### 2) Web Spider
```bash
# crawl evilcorp.com, extracting emails and other goodies
bbot -t evilcorp.com -p spider
```
<!-- BBOT SPIDER PRESET EXPANDABLE -->
<details>
<summary><b><code>spider.yml</code></b></summary>
```yaml
description: Recursive web spider
modules:
- httpx
blacklist:
# Prevent spider from invalidating sessions by logging out
- "RE:/.*(sign|log)[_-]?out"
config:
web:
# how many links to follow in a row
spider_distance: 2
# don't follow links whose directory depth is higher than 4
spider_depth: 4
# maximum number of links to follow per page
spider_links_per_page: 25
```
</details>
<!-- END BBOT SPIDER PRESET EXPANDABLE -->
### 3) Email Gatherer
```bash
# quick email enum with free APIs + scraping
bbot -t evilcorp.com -p email-enum
# pair with subdomain enum + web spider for maximum yield
bbot -t evilcorp.com -p email-enum subdomain-enum spider
```
<!-- BBOT EMAIL-ENUM PRESET EXPANDABLE -->
<details>
<summary><b><code>email-enum.yml</code></b></summary>
```yaml
description: Enumerate email addresses from APIs, web crawling, etc.
flags:
- email-enum
output_modules:
- emails
```
</details>
<!-- END BBOT EMAIL-ENUM PRESET EXPANDABLE -->
### 4) Web Scanner
```bash
# run a light web scan against www.evilcorp.com
bbot -t www.evilcorp.com -p web-basic
# run a heavy web scan against www.evilcorp.com
bbot -t www.evilcorp.com -p web-thorough
```
<!-- BBOT WEB-BASIC PRESET EXPANDABLE -->
<details>
<summary><b><code>web-basic.yml</code></b></summary>
```yaml
description: Quick web scan
include:
- iis-shortnames
flags:
- web-basic
```
</details>
<!-- END BBOT WEB-BASIC PRESET EXPANDABLE -->
<!-- BBOT WEB-THOROUGH PRESET EXPANDABLE -->
<details>
<summary><b><code>web-thorough.yml</code></b></summary>
```yaml
description: Aggressive web scan
include:
# include the web-basic preset
- web-basic
flags:
- web-thorough
```
</details>
<!-- END BBOT WEB-THOROUGH PRESET EXPANDABLE -->
### 5) Everything Everywhere All at Once
```bash
# everything everywhere all at once
bbot -t evilcorp.com -p kitchen-sink --allow-deadly
# roughly equivalent to:
bbot -t evilcorp.com -p subdomain-enum cloud-enum code-enum email-enum spider web-basic paramminer dirbust-light web-screenshots --allow-deadly
```
<!-- BBOT KITCHEN-SINK PRESET EXPANDABLE -->
<details>
<summary><b><code>kitchen-sink.yml</code></b></summary>
```yaml
description: Everything everywhere all at once
include:
- subdomain-enum
- cloud-enum
- code-enum
- email-enum
- spider
- web-basic
- paramminer
- dirbust-light
- web-screenshots
- baddns-intense
config:
modules:
baddns:
enable_references: True
```
</details>
<!-- END BBOT KITCHEN-SINK PRESET EXPANDABLE -->
## How it Works
Click the graph below to explore the [inner workings](https://www.blacklanternsecurity.com/bbot/Stable/how_it_works/) of BBOT.
[](https://www.blacklanternsecurity.com/bbot/Stable/how_it_works/)
## Output Modules
- [Neo4j](docs/scanning/output.md#neo4j)
- [Teams](docs/scanning/output.md#teams)
- [Discord](docs/scanning/output.md#discord)
- [Slack](docs/scanning/output.md#slack)
- [Postgres](docs/scanning/output.md#postgres)
- [MySQL](docs/scanning/output.md#mysql)
- [SQLite](docs/scanning/output.md#sqlite)
- [Splunk](docs/scanning/output.md#splunk)
- [Elasticsearch](docs/scanning/output.md#elasticsearch)
- [CSV](docs/scanning/output.md#csv)
- [JSON](docs/scanning/output.md#json)
- [HTTP](docs/scanning/output.md#http)
- [Websocket](docs/scanning/output.md#websocket)
...and [more](docs/scanning/output.md)!
## BBOT as a Python Library
#### Synchronous
```python
from bbot.scanner import Scanner
if __name__ == "__main__":
scan = Scanner("evilcorp.com", presets=["subdomain-enum"])
for event in scan.start():
print(event)
```
#### Asynchronous
```python
from bbot.scanner import Scanner
async def main():
scan = Scanner("evilcorp.com", presets=["subdomain-enum"])
async for event in scan.async_start():
print(event.json())
if __name__ == "__main__":
import asyncio
asyncio.run(main())
```
<details>
<summary><b>SEE: This Nefarious Discord Bot</b></summary>
A [BBOT Discord Bot](https://www.blacklanternsecurity.com/bbot/Stable/dev/#discord-bot-example) that responds to the `/scan` command. Scan the internet from the comfort of your discord server!
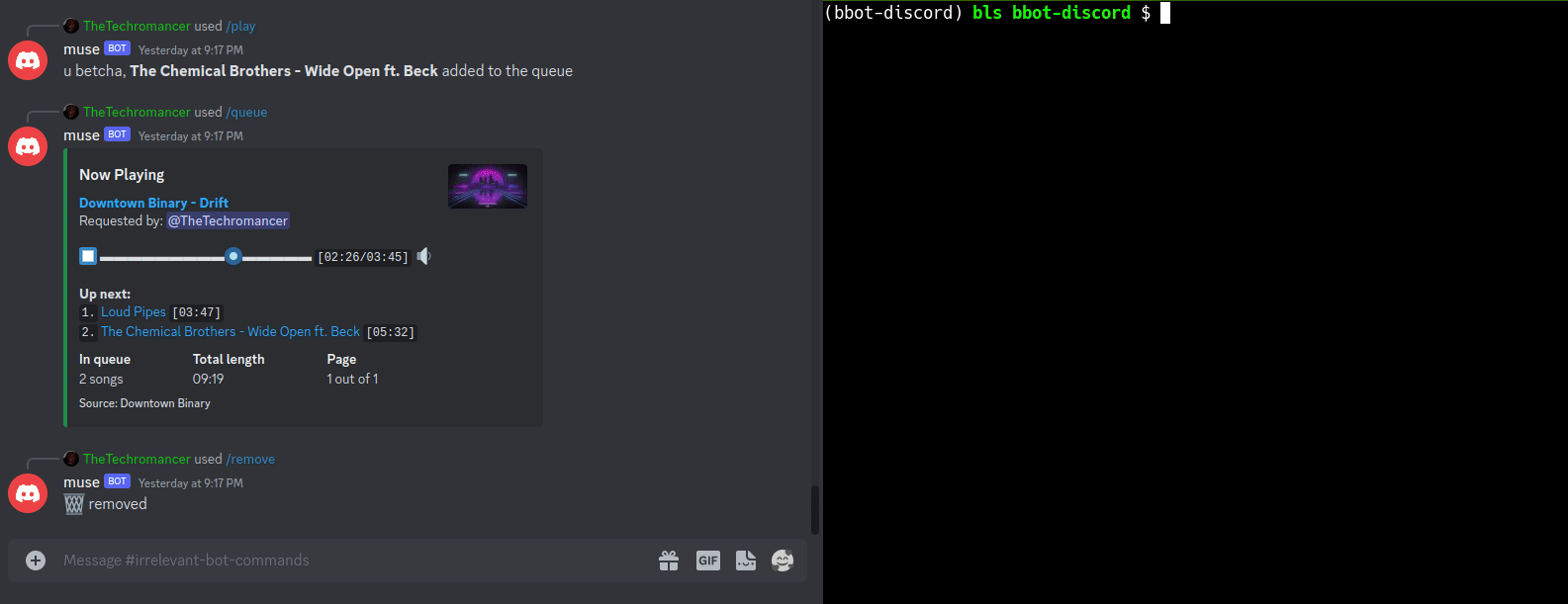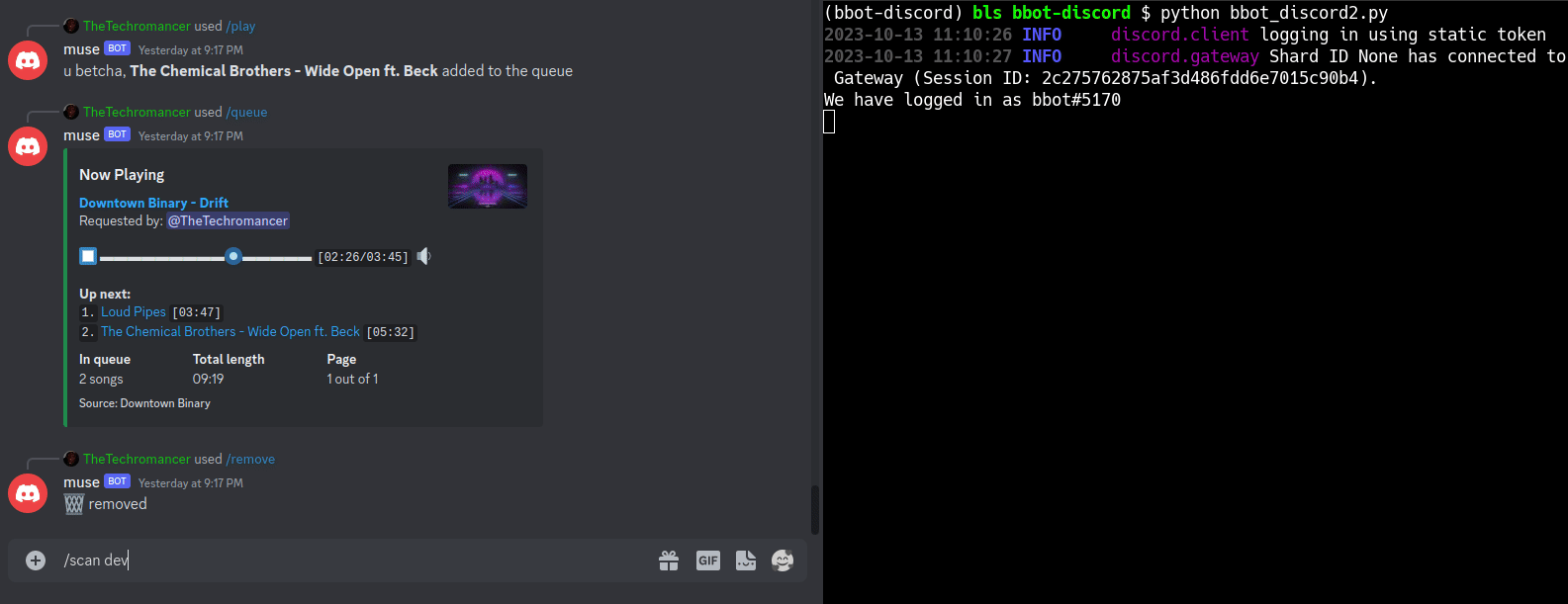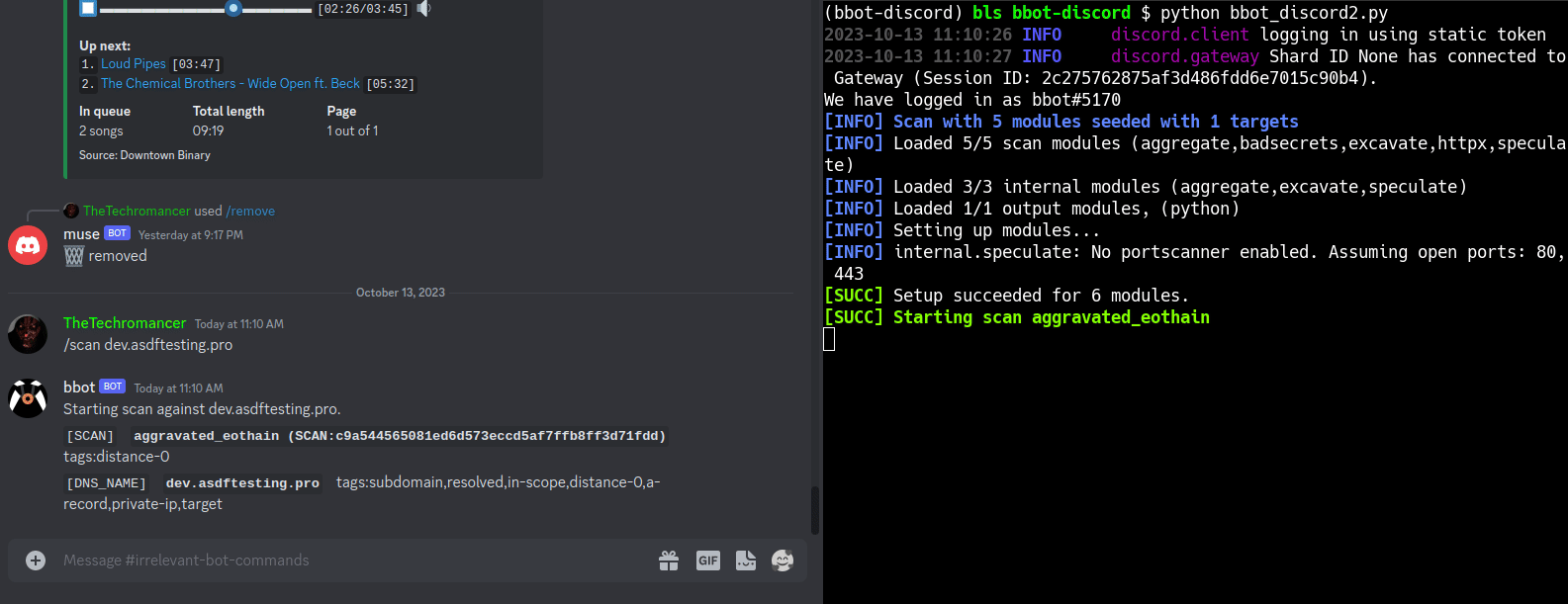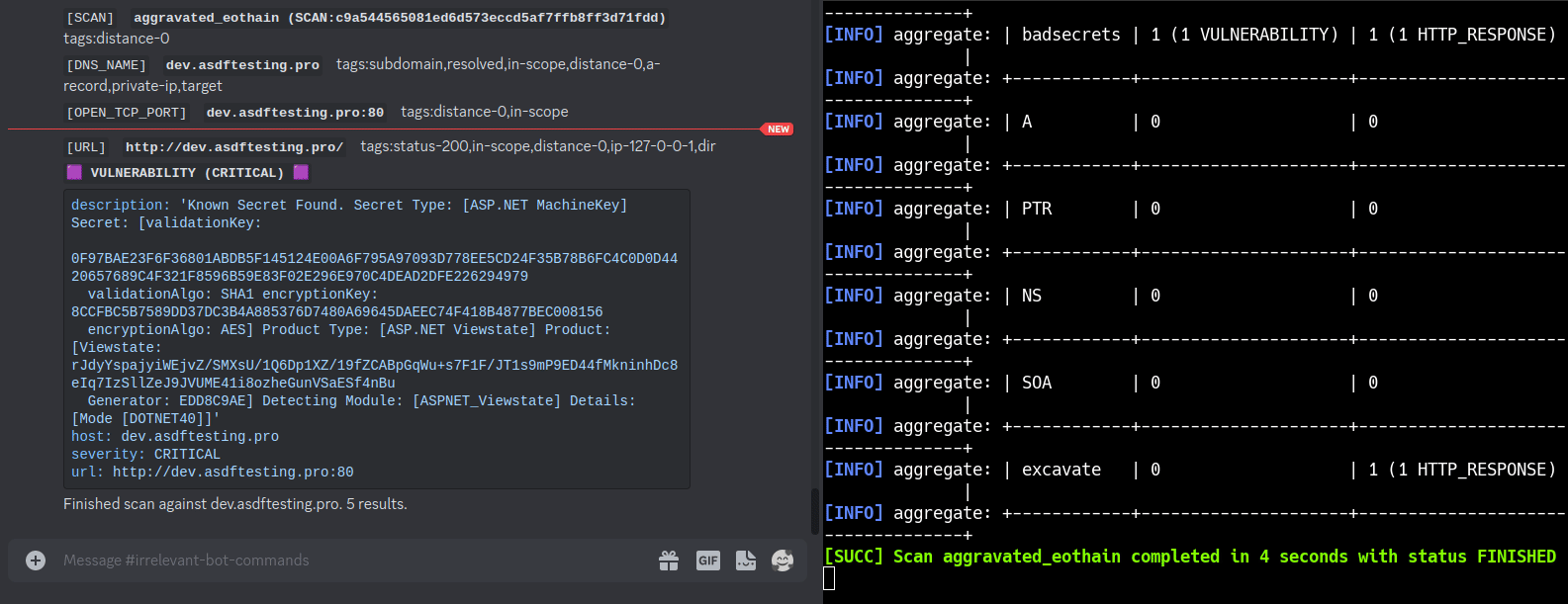
</details>
## Feature Overview
- Support for Multiple Targets
- Web Screenshots
- Suite of Offensive Web Modules
- NLP-powered Subdomain Mutations
- Native Output to Neo4j (and more)
- Automatic dependency install with Ansible
- Search entire attack surface with custom YARA rules
- Python API + Developer Documentation
## Targets
BBOT accepts an unlimited number of targets via `-t`. You can specify targets either directly on the command line or in files (or both!):
```bash
bbot -t evilcorp.com evilcorp.org 1.2.3.0/24 -p subdomain-enum
```
Targets can be any of the following:
- DNS Name (`evilcorp.com`)
- IP Address (`1.2.3.4`)
- IP Range (`1.2.3.0/24`)
- Open TCP Port (`192.168.0.1:80`)
- URL (`https://www.evilcorp.com`)
- Email Address (`bob@evilcorp.com`)
- Organization (`ORG:evilcorp`)
- Username (`USER:bobsmith`)
- Filesystem (`FILESYSTEM:/tmp/asdf`)
- Mobile App (`MOBILE_APP:https://play.google.com/store/apps/details?id=com.evilcorp.app`)
For more information, see [Targets](https://www.blacklanternsecurity.com/bbot/Stable/scanning/#targets-t). To learn how BBOT handles scope, see [Scope](https://www.blacklanternsecurity.com/bbot/Stable/scanning/#scope).
## API Keys
Similar to Amass or Subfinder, BBOT supports API keys for various third-party services such as SecurityTrails, etc.
The standard way to do this is to enter your API keys in **`~/.config/bbot/bbot.yml`**. Note that multiple API keys are allowed:
```yaml
modules:
shodan_dns:
api_key: 4f41243847da693a4f356c0486114bc6
c99:
# multiple API keys
api_key:
- 21a270d5f59c9b05813a72bb41707266
- ea8f243d9885cf8ce9876a580224fd3c
- 5bc6ed268ab6488270e496d3183a1a27
virustotal:
api_key: dd5f0eee2e4a99b71a939bded450b246
securitytrails:
api_key: d9a05c3fd9a514497713c54b4455d0b0
```
If you like, you can also specify them on the command line:
```bash
bbot -c modules.virustotal.api_key=dd5f0eee2e4a99b71a939bded450b246
```
For details, see [Configuration](https://www.blacklanternsecurity.com/bbot/Stable/scanning/configuration/).
## Complete Lists of Modules, Flags, etc.
- Complete list of [Modules](https://www.blacklanternsecurity.com/bbot/Stable/modules/list_of_modules/).
- Complete list of [Flags](https://www.blacklanternsecurity.com/bbot/Stable/scanning/#list-of-flags).
- Complete list of [Presets](https://www.blacklanternsecurity.com/bbot/Stable/scanning/presets_list/).
- Complete list of [Global Config Options](https://www.blacklanternsecurity.com/bbot/Stable/scanning/configuration/#global-config-options).
- Complete list of [Module Config Options](https://www.blacklanternsecurity.com/bbot/Stable/scanning/configuration/#module-config-options).
## Documentation
<!-- BBOT DOCS TOC -->
- **User Manual**
- **Basics**
- [Getting Started](https://www.blacklanternsecurity.com/bbot/Stable/)
- [How it Works](https://www.blacklanternsecurity.com/bbot/Stable/how_it_works)
- [Comparison to Other Tools](https://www.blacklanternsecurity.com/bbot/Stable/comparison)
- **Scanning**
- [Scanning Overview](https://www.blacklanternsecurity.com/bbot/Stable/scanning/)
- **Presets**
- [Overview](https://www.blacklanternsecurity.com/bbot/Stable/scanning/presets)
- [List of Presets](https://www.blacklanternsecurity.com/bbot/Stable/scanning/presets_list)
- [Events](https://www.blacklanternsecurity.com/bbot/Stable/scanning/events)
- [Output](https://www.blacklanternsecurity.com/bbot/Stable/scanning/output)
- [Tips and Tricks](https://www.blacklanternsecurity.com/bbot/Stable/scanning/tips_and_tricks)
- [Advanced Usage](https://www.blacklanternsecurity.com/bbot/Stable/scanning/advanced)
- [Configuration](https://www.blacklanternsecurity.com/bbot/Stable/scanning/configuration)
- **Modules**
- [List of Modules](https://www.blacklanternsecurity.com/bbot/Stable/modules/list_of_modules)
- [Nuclei](https://www.blacklanternsecurity.com/bbot/Stable/modules/nuclei)
- [Custom YARA Rules](https://www.blacklanternsecurity.com/bbot/Stable/modules/custom_yara_rules)
- [Lightfuzz](https://www.blacklanternsecurity.com/bbot/Stable/modules/lightfuzz)
- **Misc**
- [Contribution](https://www.blacklanternsecurity.com/bbot/Stable/contribution)
- [Release History](https://www.blacklanternsecurity.com/bbot/Stable/release_history)
- [Troubleshooting](https://www.blacklanternsecurity.com/bbot/Stable/troubleshooting)
- **Developer Manual**
- [Development Overview](https://www.blacklanternsecurity.com/bbot/Stable/dev/)
- [Setting Up a Dev Environment](https://www.blacklanternsecurity.com/bbot/Stable/dev/dev_environment)
- [BBOT Internal Architecture](https://www.blacklanternsecurity.com/bbot/Stable/dev/architecture)
- [How to Write a BBOT Module](https://www.blacklanternsecurity.com/bbot/Stable/dev/module_howto)
- [Unit Tests](https://www.blacklanternsecurity.com/bbot/Stable/dev/tests)
- [Discord Bot Example](https://www.blacklanternsecurity.com/bbot/Stable/dev/discord_bot)
- **Code Reference**
- [Scanner](https://www.blacklanternsecurity.com/bbot/Stable/dev/scanner)
- [Presets](https://www.blacklanternsecurity.com/bbot/Stable/dev/presets)
- [Event](https://www.blacklanternsecurity.com/bbot/Stable/dev/event)
- [Target](https://www.blacklanternsecurity.com/bbot/Stable/dev/target)
- [BaseModule](https://www.blacklanternsecurity.com/bbot/Stable/dev/basemodule)
- [BBOTCore](https://www.blacklanternsecurity.com/bbot/Stable/dev/core)
- [Engine](https://www.blacklanternsecurity.com/bbot/Stable/dev/engine)
- **Helpers**
- [Overview](https://www.blacklanternsecurity.com/bbot/Stable/dev/helpers/)
- [Command](https://www.blacklanternsecurity.com/bbot/Stable/dev/helpers/command)
- [DNS](https://www.blacklanternsecurity.com/bbot/Stable/dev/helpers/dns)
- [Interactsh](https://www.blacklanternsecurity.com/bbot/Stable/dev/helpers/interactsh)
- [Miscellaneous](https://www.blacklanternsecurity.com/bbot/Stable/dev/helpers/misc)
- [Web](https://www.blacklanternsecurity.com/bbot/Stable/dev/helpers/web)
- [Word Cloud](https://www.blacklanternsecurity.com/bbot/Stable/dev/helpers/wordcloud)
<!-- END BBOT DOCS TOC -->
## Contribution
Some of the best BBOT modules were written by the community. BBOT is being constantly improved; every day it grows more powerful!
We welcome contributions. Not just code, but ideas too! If you have an idea for a new feature, please let us know in [Discussions](https://github.com/blacklanternsecurity/bbot/discussions). If you want to get your hands dirty, see [Contribution](https://www.blacklanternsecurity.com/bbot/Stable/contribution/). There you can find setup instructions and a simple tutorial on how to write a BBOT module. We also have extensive [Developer Documentation](https://www.blacklanternsecurity.com/bbot/Stable/dev/).
Thanks to these amazing people for contributing to BBOT! :heart:
<p align="center">
<a href="https://github.com/blacklanternsecurity/bbot/graphs/contributors">
<img src="https://contrib.rocks/image?repo=blacklanternsecurity/bbot&max=500">
</a>
</p>
Special thanks to:
- @TheTechromancer for creating BBOT
- @liquidsec for his extensive work on BBOT's web hacking features, including [badsecrets](https://github.com/blacklanternsecurity/badsecrets) and [baddns](https://github.com/blacklanternsecurity/baddns)
- Steve Micallef (@smicallef) for creating Spiderfoot
- @kerrymilan for his Neo4j and Ansible expertise
- @domwhewell-sage for his family of badass code-looting modules
- @aconite33 and @amiremami for their ruthless testing
- Aleksei Kornev (@alekseiko) for granting us ownership of the bbot Pypi repository <3
| text/markdown | TheTechromancer | null | null | null | GPL-3.0 | python, cli, automation, osint, threat-intel, intelligence, neo4j, scanner, python-library, hacking, recursion, pentesting, recon, command-line-tool, bugbounty, subdomains, security-tools, subdomain-scanner, osint-framework, attack-surface, subdomain-enumeration, osint-tool | [
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python ::... | [] | null | null | <4.0,>=3.9 | [] | [] | [] | [
"ansible-core<3.0.0,>=2.15.13",
"ansible-runner<3.0.0,>=2.3.2",
"beautifulsoup4<5.0.0,>=4.12.2",
"cachetools<7.0.0,>=5.3.2",
"cloudcheck<10.0.0,>=9.2.0",
"deepdiff<9.0.0,>=8.0.0",
"dnspython<2.8.0,>=2.7.0",
"httpx<0.29.0,>=0.28.1",
"idna<4.0,>=3.4",
"jinja2<4.0.0,>=3.1.3",
"lxml<7.0.0,>=4.9.2",
... | [] | [] | [] | [
"Documentation, https://www.blacklanternsecurity.com/bbot/",
"Discord, https://discord.com/invite/PZqkgxu5SA",
"Docker Hub, https://hub.docker.com/r/blacklanternsecurity/bbot",
"Homepage, https://github.com/blacklanternsecurity/bbot",
"Repository, https://github.com/blacklanternsecurity/bbot"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:32:06.344158 | bbot-2.8.2.7508rc0.tar.gz | 1,366,291 | 46/c4/0f12d603830a5183fdfa8ea83f5c1f97a7c77b039a819167de57753f206e/bbot-2.8.2.7508rc0.tar.gz | source | sdist | null | false | 30f5c7d8c6c1c6fbae376b7bea9b6db6 | 8fab8e6734a1d633a4436ef34a016568647a23af3d6f853f07dd5abc4f9f9cdd | 46c40f12d603830a5183fdfa8ea83f5c1f97a7c77b039a819167de57753f206e | null | [
"LICENSE"
] | 241 |
2.4 | tasqalent-shared | 1.0.1 | Shared utilities, types and helpers for TASQALENT (Python/Flask) | # Python Shared Library
| text/markdown | Youssef Tawakal | youssef7931@gmail.com | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11"
] | [] | https://github.com/tasqalent/tq-shared-python | null | >=3.8 | [] | [] | [] | [
"pytest>=7.0.0; extra == \"dev\"",
"black>=22.0.0; extra == \"dev\"",
"flake8>=4.0.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:31:44.295010 | tasqalent_shared-1.0.1.tar.gz | 1,583 | e7/ea/e56e0bb129708691a8f268f43c7d8502235bf812d4de922e446767d65f16/tasqalent_shared-1.0.1.tar.gz | source | sdist | null | false | 011e731e9163f9fd179b58d31da8bff9 | 9351e22993e56a037539cc7d8c3334e579916131567a072f04cdc01a06152267 | e7eae56e0bb129708691a8f268f43c7d8502235bf812d4de922e446767d65f16 | null | [] | 239 |
2.4 | saengra | 0.1.5 | Reactive graph database with pattern matching | # Saengra
Python wrapper for Saengra graph database.
## Quickstart: primitives and edges
Saengra is a graph database. It supports hashable Python objects (**primitives**) as graph
vertices. Built-in types like `int` or `str` can be used directly; also Saengra provides `@primitive`
decorator to declare dataclass-like types to be used as graph vertices.
Directed edges between primitives are always labelled with a string (**edge label**). It can
be an arbitrary string, but the engine is optimized to support limited number of different labels per graph.
There can't be two edges between the same two primitives with the same label.
We can construct a graph directly from primitives and edges by using elementary graph operations:
```python
from datetime import datetime
from saengra import primitive, Environment
from saengra.graph import AddVertex, AddEdge
@primitive
class user:
id: int
u1 = user(id=1)
u2 = user(id=2)
u1_registered_at = datetime(2022, 1, 1, 12, 0, 0)
u2_registered_at = datetime(2023, 2, 3, 15, 0, 0)
env = Environment()
env.update(
AddVertex(u1),
AddVertex(u2),
AddVertex(u1_registered_at),
AddVertex(u2_registered_at),
AddEdge(u1, "follows", u2),
AddEdge(u1, "registered_at", u1_registered_at),
AddEdge(u2, "registered_at", u2_registered_at),
)
env.commit()
```
## Quickstart: entities and environment
Operating with vertices and edges is tedious and slow. A higher-level abstraction, **entities**,
is provided to make working with graph more like your normal object-oriented programming.
Let's declare some entity classes and rewrite the code above:
```python
from datetime import datetime
from saengra import primitive, Entity, Environment
@primitive
class user:
id: int
class User(Entity, user):
registered_at: datetime
follows: set["User"]
env = Environment(entity_types=[User])
u1 = User.create(env, id=1, registered_at=datetime(2022, 1, 1, 12, 0, 0))
u2 = User.create(env, id=2, registered_at=datetime(2023, 2, 3, 15, 0, 0))
u1.follows.add(u2)
env.commit()
```
## Quickstart: expressions and observers
Saengra introduces a domain-specific language to describe subgraphs of the graph, i.e. subset of
vertices and edges. These expressions are quite similar to queries in SQL.
```python
# Find all subscriptions, i.e. pairs (u1, u2) where u1 follows u2:
env.match("user as u1 -follows> user as u2")
# -> [{"u1": User(id=1), "u2": User(id=2)}]
# Find all mutual subscriptions:
env.match("user as u1 <follows> user as u2")
# -> []
```
But the most powerful aspect of Saengra is its observation capability. Saengra can match
expressions incrementally after processing graph updates, and notify the program about created,
changed and deleted subgraphs after each commit.
```python
from saengra import observer
mutual_follow = observer("user as u1 <follows> user as u2")
@mutual_follow.on_create
def notify_mutuals(u1: User, u2: User):
print(f"{u1} is now mutuals with {u2}!")
env.register_observers([mutual_follow])
u2.follows.add(u1)
env.commit()
# -> User(id=1) is now mutuals with User(id=2)!
# -> User(id=2) is now mutuals with User(id=1)!
```
## Generating Protobuf Code
The `messages_pb2.py` file is generated from the protobuf definitions in `saengra-server/proto/messages.proto`.
To regenerate:
```bash
protoc --python_out=saengra --proto_path=saengra-server/proto saengra-server/proto/messages.proto
```
Requirements:
- `protoc` (Protocol Buffers compiler) must be installed
- Python protobuf library: `pip install protobuf>=4.21.0`
## Usage
### Option 1: Automatically start server
```python
from saengra.client import SaengraClient
# Client automatically starts saengra-server in background
with SaengraClient() as client:
# Connect to a graph
created = client.connect("my_graph")
# Add vertices and edges
client.apply_updates([
# Your updates here
])
# Commit changes
response = client.commit()
```
The client expects `saengra-server` binary to be available in PATH.
### Option 2: Connect to existing server
```python
from saengra.client import SaengraClient
# Connect to an existing server socket
with SaengraClient(socket_path="/path/to/server.sock") as client:
# Connect to a graph
created = client.connect("my_graph")
# Work with the graph...
```
When using an existing socket, the client will not start or stop the server process, and will not clean up the socket file.
| text/markdown | null | Tigran Saluev <tigran@saluev.com> | null | null | MIT | graph, database, reactive, pattern-matching, entity | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: C++"... | [] | null | null | >=3.11 | [] | [] | [] | [
"frozendict>=2.4.6",
"protobuf>=4.0",
"termcolor>=2.4.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"build; extra == \"dev\"",
"twine; extra == \"dev\"",
"cibuildwheel; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/Saluev/saengra",
"Repository, https://github.com/Saluev/saengra",
"Issues, https://github.com/Saluev/saengra/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:31:34.995275 | saengra-0.1.5.tar.gz | 85,137 | 35/f2/2d41ac2098c90d387bdc2d7a48248565e52996869c791670c22e1ffe0587/saengra-0.1.5.tar.gz | source | sdist | null | false | 5511165da61a8702b1989b2dc4d01177 | 9f8223b6232e0bfa45be49b56c8256b24581e6e2cd393ca8db2eda1a116b9394 | 35f22d41ac2098c90d387bdc2d7a48248565e52996869c791670c22e1ffe0587 | null | [
"LICENSE"
] | 429 |
2.4 | fid-ffmpeg | 0.5.3 | FFmpeg-based CLI tool for video and audio operations like editing, extracting, streaming, and encoding | # fid-ffmpeg [](https://pepy.tech/project/fid-ffmpeg)
Python wrapper around the FFmpeg command line tool for video operations.
```bash
fid
```
https://github.com/user-attachments/assets/abcc8aa0-3ada-4548-8f99-987687cfccd9
## Requirements
- python >=3.9 : [Download Python](https://www.python.org/downloads/)
- ffmpeg : [Download FFmpeg](https://www.ffmpeg.org/download.html)
- install fid-cli with pip :
```bash
pip install fid-ffmpeg
```
## installation demo
https://github.com/user-attachments/assets/6063b46b-dd4a-4cb3-a318-869f37bcf60f
## Usage
Run `fid` for the interactive menu, or use direct commands:
- `fid --help`: Show help for fid CLI.
- `fid info "videoPath"`: Get all info about the video.
- `fid audio "videoPath"`: Extract audio from the video.
- `fid mute "videoPath"`: Mute the video.
- `fid gif "videoPath"`: Create a GIF from the video.
- `fid frames "videoPath"`: Extract all video frames into a folder.
- `fid compress "videoPath"`: Compress the video to reduce file size.
For more advanced options, use the interactive mode by running `fid` without arguments.
## Features
- Interactive CLI with menus for video, audio, extract, stream, and encode operations.
- Built with Typer for commands and Questionary for interactive prompts.
- Rich console output for a modern look.
## Contributing
Contributions are welcome! Fork the repo, create a branch, and submit a pull request. For major changes, open an issue first.
## About
Python wrapper around the FFmpeg command line tool.
[PyPI Project](https://pypi.org/project/fid-ffmpeg/)
### Topics
- audio
- python
- cli
- video
- ffmpeg
- frames
- gif
- compressor
- ffmpeg-wrapper
- rich
- mute
- typer-cli
| text/markdown | null | Omar Abdalgwad <ahlawyomar95@gmail.com> | null | null | MIT License
Copyright (c) 2026 Omar Abdalgwad
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE . | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"License :: OSI Approved :: MIT License",
"Operating Sy... | [] | null | null | >=3.8 | [] | [] | [] | [
"typer>=0.7",
"questionary>=1.10",
"rich>=13.0",
"pyfiglet>=0.8",
"requests>=2.28",
"tqdm>=4.65",
"colorama>=0.4"
] | [] | [] | [] | [
"Homepage, https://github.com/Omarabdalgwad/fid-FFmpeg",
"Repository, https://github.com/Omarabdalgwad/fid-FFmpeg.git",
"Documentation, https://github.com/Omarabdalgwad/fid-FFmpeg#readme",
"Issues, https://github.com/Omarabdalgwad/fid-FFmpeg/issues"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T21:31:17.622438 | fid_ffmpeg-0.5.3.tar.gz | 13,122 | 05/59/4a73bdf66771d616da018b6a6364f5e444a9aff0a8fee1e54ddd0ee6eabd/fid_ffmpeg-0.5.3.tar.gz | source | sdist | null | false | 8e1b086dee1cc840314f8fdb84354626 | f4a311d74ccb261b85c7c1f4f698488ba9ed0c466654db895cc690bb321e6317 | 05594a73bdf66771d616da018b6a6364f5e444a9aff0a8fee1e54ddd0ee6eabd | null | [
"LICENSE"
] | 245 |
2.4 | vorbote | 1.4.0 | Communicate releases/changes via Git annotations | # vorbote
Vorbote ([ˈfoː̯ɐˌboːtə]), from the German word for "harbinger", is a python application that renders commit information
and commit annotations from a GIT repository into various formats. Different output formats can be templated using
[Jinja2](https://jinja.palletsprojects.com/en/3.1.x/) templates.
The project itself contains a lean parser to extract information from GIT objects, as well as a small command-line
application to render data from a repository into the specified template structure. Example templates for Markdown and
LaTeX export are included under [templates](vorbote/templates).
## Usage
Upon installation, this project installs a Python command-line application `vorbote`. The application is split into
multiple subcommands:
The application supports a number of command-line arguments, which can be listed via `--help`. Subcommand-specific
arguments can be listed via `<subcommand> --help`:
```
usage: vorbote [-h] ...
options:
-h, --help show this help message and exit
config:
-c, --config, --config-path CONFIG
Config file path (default: None)
input:
-s, --schema, --no-schema
Toggle JSON schema validation for annotations
-v, --validate, --no-validate
Toggle GIT commit/message validation
output:
-o, --output, --output-path OUTPUT_PATH
Output path (default: None)
-d, --descriptions, --no-descriptions
Toggle showing commit descriptions
--title OUTPUT_TITLE Document title (default: 'Change Notes')
--author OUTPUT_AUTHOR
Document author (default: 'Vorbote')
--date OUTPUT_DATE Document author (default: 2026-02-19, format: YYYY-MM-DD)
annotation:
-a, --annotation, --annotation-path ANNOTATIONS
Annotation YAML path(s) (default: [])
repository:
-r, --revision, --revision-range REPOSITORY_REVISION
Git revision range
-R, --repository, --repository-path REPOSITORY_PATH
Git repository path (default: '.')
project:
-P, --project PROJECT_KEYS [PROJECT_KEYS ...]
Project keys (default: [])
tags:
--sorted-tag TAGS_SORTED
Tag(s) honouring input order (default: [])
--tag TAGS_UNSORTED Tag discarding input order (default: [])
exclude:
-b, --exclude-bare, --no-exclude-bare
Toggle exclusion of bare commits
-m, --exclude-merges, --no-exclude-merges
Toggle exclusion of merge commits
whitespace:
-S, --strip-whitespace, --no-strip-whitespace
Toggle stripping preceding whitespace from template blocks
-W, --trim-whitespace, --no-trim-whitespace
Toggle trimming surrounding whitespace from template blocks
subcommands:
{changes,changelogs,history,template}
changes Render epic/story-based changes
changelogs Render type-based changes
history Render tag-based history
template Render customisable templates
```
### Configuration files
The application can additionally be configured via a configuration file, whose location has to be specified on the
command-line via `-c` or `--config`. Configuration files support YAML or TOML syntax.
An example YAML file might look like this:
```yaml
annotations: []
tags:
sorted:
- tests
unsorted:
- deployment
- components
template:
path: ""
name: ""
project:
keys:
- "FOO"
- "ABC"
input:
schema: true
validate: true
output:
path: ""
descriptions: true
title: ""
author: ""
date: ""
repository:
path: ""
revision: ""
exclude:
bare: true
merges: false
whitespace:
strip: false
trim: false
```
An example TOML file might look like this:
```toml
annotations = []
[input]
schema = true
validate = true
[output]
path = ""
descriptions = true
title = ""
author = ""
date = ""
[project]
keys = ["FOO", "ABC"]
[repository]
path = ""
revision = ""
[tags]
unsorted = [
"deployment",
"components",
]
sorted = ["tests"]
[template]
path = ""
name = ""
[exclude]
bare = true
merges = false
[whitespace]
strip = false
trim = false
```
Both YAML and TOML files are checked against a JSON schema as defined in [config.schema](vorbote/schemas/config.schema).
All keys except for `tags` are optional if configuration files are used.
## Git commit annotations
Git has a system for annotations called [trailers](https://git-scm.com/docs/git-interpret-trailers), which is most
commonly used for fields such as `Signed-By` etc. However, trailers encompass essentially arbitrary key/value-pairs
which can be added to the bottom of a commit message. This project makes assumptions about a predefined set of these
trailers, in order to gather additional contextual information about GIT commits that is unrelated to the specific
diffs themselves, such as relationships to epics, stories etc.
### Sample commit message
A fully-fledged commit message might look like this:
```
ABC-100: A short description of things the current commit changes
A longer, freeform description can be added here, which might give additional
background, list some features, discuss why a certain change was implemented
this way, if any known TODOs remain, and why it's okay to have these TODOs
around for the time being.
If necessary, things can be broken down, i.e.:
- Take care when committing
- Check that the ticket number is listed
- Make sure a short description is added
- Ask if you are unsure
- Read further for how to use "tags"
- Git calls these hints "trailers", by the way...
Machine-readable hints can be added to commits as key-value pairs, separated
with a colon (i.e. ":"). Multiple values can be separated via commas.
Additionally, tests or validations can be added with a loosely formed list,
with each list item on a separate line, prefixed with " +", i.e. two spaces
and a plus sign. Finally, an "epic" can be specified as such, just as well.
Unsure how that works? Have a look!
epic: Cleaner GIT
deployment: manual
components: foo, bar, baz
tests:
+ First test
+ Second test
+ Check this thing last
```
This sample commit message consists of:
- A ticket reference (`ABC-100`)
- A short description for the given commit
- A longer description with arbitrary content
- Additional context information via a set of key/value pairs (as trailers)
- An epic relationship (`Cleaner GIT`)
- A deployment hit (`manual`)
- A list of components (`foo`, `bar`, `baz`)
- A list of tests (`First test`, `Second test`, `Check this thing last`)
While any kind of relationship can theoretically be modelled via trailers, it makes sense to decide on a common set of
trailers and their potential content, so that they can be supplied to this tool via config or on the command-line.
## Repository annotations
In addition to GIT commit annotations using trailers, users might want to supply additional repository-level annotations
which are to be merged with information read from commits before rendering the combined output.
These repository annotations can be supplied as YAML files, which are checked against a JSON schema as defined in
[annotations.schema](vorbote/schemas/annotations.schema). Currently, entire epics (with associated stories and
commits) can be supplied. A sample annotations file might look like this:
```yaml
epics:
- name: Cleaner GIT
stories:
- reference: ABC-1230
tickets:
- tagline: Commit 1
- reference: ABC-1231
tickets:
- tagline: Commit 2
description: Single Line
- tagline: Commit 3
description: |
Line 1
Line 2
Line 3
- name: Explore Annotations
description: >
Let's explore some
annotations
that we added
very much
manually
stories:
- reference: ABC-1234
tickets:
- tagline: Commit 4
authors:
- name: Foo
email: foo@example.com
tags:
roles:
- foo
- bar
```
This would add the following elements to the combined output:
- An epic `Cleaner GIT` without description
- A story `ABC-1230`
- A commit `Commit 1` without description
- A story `ABC-1231`
- A commit `Commit 2` with a single-line description
- A commit `Commit 3` with a multi-line description
- An epic `Explore Annotations` with a single-line description (folded via `>`)
- A Story `ABC-1234`
- A commit `Commit 4` without description
- An additional author `Foo`
- Additional impacted roles `foo` & `bar`
- Two certificate changes for the servers `foo.example.com` & `bar.example.com`
If an epic already exists, any subordinate stories (and tickets) will get merged recursively.
## Development
This project is written in python3. It uses `pipenv` for dependency management, `pytest` for testing, and `black` for
formatting.
| text/markdown | null | rmk2 <ryko@rmk2.org> | null | null | null | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"gitpython~=3.1",
"jinja2~=3.1",
"pyyaml~=6.0",
"jsonschema~=4.17",
"tomli~=2.0",
"skabelon~=1.1"
] | [] | [] | [] | [
"Repository, https://gitlab.com/rmk2/vorbote"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T21:30:19.939971 | vorbote-1.4.0-py3-none-any.whl | 26,720 | dd/63/0a5cb08e8733faf5d9968424d83bb28d3dbd86d0654bf4c1329a77b0513c/vorbote-1.4.0-py3-none-any.whl | py3 | bdist_wheel | null | false | b2d68ceac00629f2f19084c884627576 | 2344e043471e2e5caf9c57b425cd21481c2532e17ea3c249e612e61921029d75 | dd630a5cb08e8733faf5d9968424d83bb28d3dbd86d0654bf4c1329a77b0513c | Apache-2.0 | [
"LICENSE"
] | 86 |
2.4 | LLM-Bridge | 1.15.16 | A Bridge for LLMs | # LLM Bridge
LLM Bridge is a unified API wrapper for native interactions with various LLM providers.
GitHub: [https://github.com/windsnow1025/LLM-Bridge](https://github.com/windsnow1025/LLM-Bridge)
PyPI: [https://pypi.org/project/LLM-Bridge/](https://pypi.org/project/LLM-Bridge/)
## Workflow and Features
1. **Message Preprocessor**: extracts text content from documents (Word, Excel, PPT, Code files, PDFs) which are not natively supported by the target model.
2. **Chat Client Factory**: creates a client for the specific LLM API with model parameters
1. **Model Message Converter**: converts general messages to model messages
1. **Media Processor**: converts general media (Image, Audio, Video, PDF) to model compatible formats.
3. **Chat Client**: generate stream or non-stream responses
- **Model Thoughts**: captures the model's thinking process
- **Code Execution**: generates and executes Python code
- **Web Search**: generates response from search results
- **Token Counter**: tracks and reports input and output token usage
### Supported Features for API Types
The features listed represent the maximum capabilities of each API type supported by LLM Bridge.
| API Type | Input Format | Capabilities | Output Format |
|----------|--------------------------------|---------------------------------------------------------|-------------------|
| OpenAI | Text, Image, PDF | Thinking, Web Search, Code Execution, Structured Output | Text, Image |
| Gemini | Text, Image, Video, Audio, PDF | Thinking, Web Search, Code Execution, Structured Output | Text, Image, File |
| Claude | Text, Image, PDF | Thinking, Web Search, Code Execution, Structured Output | Text, File |
| Grok | Text, Image | | Text |
#### Planned Features
- More features for API Types
- Native support for Grok
## Development
### Python uv
1. Install uv: `powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"`
2. Install Python in uv: `uv python install 3.12`; upgrade Python in uv: `uv python upgrade 3.12`
3. Configure requirements:
```bash
uv sync --refresh
```
### Pycharm
1. Add New Interpreter >> Add Local Interpreter
- Environment: Select existing
- Type: uv
2. Add New Configuration >> uv run >> Script: `./usage/main.py`
### Usage
Copy `./usage/.env.example` and rename it to `./usage/.env`, then fill in the environment variables.
### Build
```bash
uv build
```
| text/markdown | null | windsnow1025 <windsnow1025@gmail.com> | null | null | null | ai, llm | [
"Framework :: FastAPI",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"anthropic==0.75.0",
"docxlatex>=1.1.1",
"fastapi",
"google-genai==1.46.0",
"httpx",
"openai==2.9.0",
"openpyxl",
"pymupdf",
"python-pptx",
"tenacity",
"tiktoken==0.11.0"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:30:12.634523 | llm_bridge-1.15.16-py3-none-any.whl | 44,674 | 14/76/4c20508c8f45bec0987e7c3a79fcbd00c665148274a2184bc39110e4a459/llm_bridge-1.15.16-py3-none-any.whl | py3 | bdist_wheel | null | false | 7618fddeffa4fa6863e8df979f8ade36 | 53c7c94f5b27621d5ae43479b110e5451440687bb83e264cf1e04c348be14930 | 14764c20508c8f45bec0987e7c3a79fcbd00c665148274a2184bc39110e4a459 | MIT | [
"LICENSE"
] | 0 |
2.3 | bb-integrations-library | 3.0.47.2 | Provides common logic for all types of integration jobs. | # BB Integrations Library
A standard integrations library designed for **Gravitate** to manage and interact with various external services.
## Installation
Using pip:
```bash
pip install bb-integrations-library
```
Using uv:
```bash
uv add bb-integrations-library
```
## Usage
```python
import bb_integrations_lib
```
| text/markdown | Alejandro Jordan, Ben Allen, Nicholas De Nova, Kira Threlfall | Alejandro Jordan <ajordan@capspire.com>, Ben Allen <ben.allen@capspire.com>, Nicholas De Nova <nicholas.denova@gravitate.energy>, Kira Threlfall <kira.threlfall@gravitate.energy> | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"boto3",
"email-validator",
"fastapi",
"google-cloud-run",
"google-cloud-secret-manager",
"google-cloud-storage",
"google-cloud-tasks",
"httpx",
"loguru",
"openpyxl",
"pandas",
"pydantic",
"pymongo",
"python-dotenv",
"sqlalchemy",
"pyodbc",
"more-itertools",
"async-lru",
"pydanti... | [] | [] | [] | [] | uv/0.9.21 {"installer":{"name":"uv","version":"0.9.21","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:29:57.710337 | bb_integrations_library-3.0.47.2.tar.gz | 239,833 | 97/89/659a0af4aa531d9155837e51b7e8c17e7ee7d2849f5e625da9f586c21993/bb_integrations_library-3.0.47.2.tar.gz | source | sdist | null | false | 670bc8d67e2d974761acd6f8b6d1f7b2 | fc76a2751d5f560226a20b26bebb6e7618536cff49c49f47537461bf354dea28 | 9789659a0af4aa531d9155837e51b7e8c17e7ee7d2849f5e625da9f586c21993 | null | [] | 246 |
2.4 | cenplot | 0.1.6 | Centromere plotting library. | # `CenPlot`
[](https://pypi.org/project/cenplot/)
[](https://github.com/logsdon-lab/cenplot/actions/workflows/main.yaml)
[](https://github.com/logsdon-lab/cenplot/actions/workflows/docs.yaml)
A Python library for producing centromere figures.
<table>
<tr>
<td>
<figure float="left">
<img align="middle" src="docs/example_cdr.png" width="100%">
<figcaption>CDR plot.</figcaption>
</figure>
<figure float="left">
<img align="middle" src="docs/example_split_hor.png" width="100%">
<figcaption>HOR plot.</figcaption>
</figure>
</td>
<td>
<figure float="left">
<img align="middle" src="docs/example_multiple.png" width="100%">
<figcaption>Combined plot.</figcaption>
</figure>
<figure float="left">
<img align="middle" src="docs/example_ident.png" width="100%">
<figcaption>Identity plots.</figcaption>
</figure>
</td>
</tr>
</table>
## Getting Started
Install the package from `pypi`.
```bash
pip install cenplot
```
## CLI
Generating a split HOR tracks using the `cenplot draw` command and an input layout.
```bash
# examples/example_cli.sh
cenplot draw \
-t examples/tracks_hor.toml \
-c "chm13_chr10:38568472-42561808" \
-p 4 \
-d plots \
-o "plot/merged_image.png"
```
## Python API
The same HOR track can be created with a few lines of code.
```python
# examples/example_api.py
from cenplot import plot_tracks, read_tracks
chrom = "chm13_chr10:38568472-42561808"
track_list, settings = read_tracks("examples/tracks_hor.toml", chrom=chrom)
fig, axes, _ = plot_tracks(track_list.tracks, settings)
```
## Development
Requires `Python >= 3.12` and `Git LFS` to pull test files.
Create a `venv`, build `cenplot`, and install it. Also, generate the docs.
```bash
which python3.12 pip
git lfs install && git lfs pull
make dev && make build && make install
pdoc ./cenplot -o docs/
```
The generated `venv` will have the `cenplot` script.
```bash
# source venv/bin/activate
venv/bin/cenplot -h
```
To run tests.
```bash
make test
```
## [Documentation](https://logsdon-lab.github.io/CenPlot/cenplot.html)
Read the documentation [here](https://logsdon-lab.github.io/CenPlot/cenplot.html).
## Cite
**Gao S, Oshima KK**, Chuang SC, Loftus M, Montanari A, Gordon DS, Human Genome Structural Variation Consortium, Human Pangenome Reference Consortium, Hsieh P, Konkel MK, Ventura M, Logsdon GA. A global view of human centromere variation and evolution. bioRxiv. 2025. p. 2025.12.09.693231. [doi:10.64898/2025.12.09.693231](https://doi.org/10.64898/2025.12.09.693231)
| text/markdown | null | Keith Oshima <oshimak@pennmedicine.upenn.edu> | null | null | MIT License | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"matplotlib>=3.10.0",
"polars>=1.19.0",
"numpy>=2.2.1",
"intervaltree>=3.1.0",
"censtats>=0.0.13",
"PyYAML>=6.0.2"
] | [] | [] | [] | [
"Homepage, https://github.com/logsdon-lab/cenplot"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:29:42.340407 | cenplot-0.1.6.tar.gz | 32,874 | 05/e7/c9aed73447edcdd2fd1ec228c5ef7d0b99336173eda19970be0cf6834507/cenplot-0.1.6.tar.gz | source | sdist | null | false | dbedd73448e4c7def5ce52cc174d23ce | cf86b7e05e93acef8a8b4088bd6968fd1052dd9f38439f240c664f20a7ee2240 | 05e7c9aed73447edcdd2fd1ec228c5ef7d0b99336173eda19970be0cf6834507 | null | [
"LICENSE"
] | 285 |
2.4 | tp-mcp-server | 0.1.0 | A Model Context Protocol server for TrainingPeaks with analytics focus | # TrainingPeaks MCP Server
A [Model Context Protocol](https://modelcontextprotocol.io/) server for TrainingPeaks with an analytics focus — enabling real-time querying of training data, performance trends, CTL/ATL/TSB analysis, and training load optimization through Claude Desktop.
## Features
**13 tools** organized across 5 categories:
| Category | Tools | Description |
|----------|-------|-------------|
| Auth | `tp_auth_status`, `tp_refresh_auth` | Check/refresh authentication |
| Profile | `tp_get_profile` | Athlete profile + auto-detect ID |
| Workouts | `tp_get_workouts`, `tp_get_workout` | List and detail workouts |
| Fitness | `tp_get_fitness` | CTL/ATL/TSB with computed values |
| Peaks | `tp_get_peaks`, `tp_get_workout_prs` | Personal records by sport |
| Analytics | `tp_training_load_summary` | Weekly/monthly TSS, load ramp rate |
| | `tp_fitness_trend` | CTL trajectory, 7-day projection |
| | `tp_workout_analysis` | Efficiency factor, variability index |
| | `tp_performance_summary` | Sport-specific volume & consistency |
| | `tp_training_zones_distribution` | IF-based zone breakdown |
**Key feature**: CTL/ATL/TSB are computed from TSS using standard exponential weighted moving averages (42-day/7-day time constants), since the TP API doesn't return these values directly.
## Prerequisites
- **Python 3.12+**
- **[uv](https://docs.astral.sh/uv/)** (recommended) or pip
- **Claude Desktop** (to use the MCP server)
- A **TrainingPeaks** account with training data
## Installation
### Step 1: Clone the repository
```bash
git clone https://github.com/banananovej-chuan/tp-mcp-server.git
cd tp-mcp-server
```
### Step 2: Create a virtual environment and install dependencies
```bash
uv venv --python 3.12
uv pip install .
```
> **Note**: If you don't have `uv`, install it first: `curl -LsSf https://astral.sh/uv/install.sh | sh`
### Step 3: Get your TrainingPeaks auth cookie
This server authenticates using your browser's TrainingPeaks session cookie. Here's how to get it:
1. Open your browser and go to [trainingpeaks.com](https://trainingpeaks.com)
2. Log in to your account
3. Open **Developer Tools**:
- **Mac**: `Cmd + Option + I`
- **Windows/Linux**: `F12` or `Ctrl + Shift + I`
4. Click the **Application** tab (Chrome/Edge) or **Storage** tab (Firefox)
5. In the left sidebar, expand **Cookies** and click on `https://www.trainingpeaks.com`
6. Find the cookie named **`Production_tpAuth`**
7. Double-click its **Value** column and copy the entire value (it's a long string)
### Step 4: Configure the environment
```bash
cp .env.example .env
```
Open `.env` in a text editor and replace `your_cookie_value_here` with the cookie you copied:
```
TP_AUTH_COOKIE=V0014F_4tV2mrk...your_long_cookie_value...
```
### Step 5: Verify it works
```bash
uv run python -m tp_mcp_server
```
If authentication is successful, the server will start and wait for MCP connections. Press `Ctrl+C` to stop it.
## Claude Desktop Configuration
To use this server with Claude Desktop, you need to add it to Claude's MCP config file.
### 1. Find your config file
- **macOS**: `~/Library/Application Support/Claude/claude_desktop_config.json`
- **Windows**: `%APPDATA%\Claude\claude_desktop_config.json`
If the file doesn't exist, create it.
### 2. Find your absolute path to the server
Run this command in the `tp-mcp-server` directory to get the full path:
```bash
echo "$(pwd)/.venv/bin/python"
```
This will output something like:
```
/Users/yourname/projects/tp-mcp-server/.venv/bin/python
```
### 3. Add the server config
Open the config file and add the following. **You must replace two values**:
1. Replace the `command` path with the output from step 2
2. Replace the `TP_AUTH_COOKIE` value with your cookie from the installation steps
```json
{
"mcpServers": {
"trainingpeaks": {
"command": "/Users/yourname/projects/tp-mcp-server/.venv/bin/python",
"args": ["-m", "tp_mcp_server"],
"env": {
"TP_AUTH_COOKIE": "your_Production_tpAuth_cookie_value"
}
}
}
}
```
> **Important**: The `command` path must be an **absolute path** (starting with `/`). Do not use `~` or relative paths — Claude Desktop won't resolve them.
**Alternative** — if you have `uv` installed globally:
```json
{
"mcpServers": {
"trainingpeaks": {
"command": "uv",
"args": ["run", "--directory", "/Users/yourname/projects/tp-mcp-server", "python", "-m", "tp_mcp_server"],
"env": {
"TP_AUTH_COOKIE": "your_Production_tpAuth_cookie_value"
}
}
}
}
```
### 4. Restart Claude Desktop
After saving the config file, fully quit and reopen Claude Desktop. You should see "trainingpeaks" listed as a connected MCP server (look for the hammer icon).
## Example Queries
Once connected in Claude Desktop, try:
- "What's my current fitness level?"
- "Show my training load trend for the last 3 months"
- "Analyze my last bike workout"
- "What are my power PRs?"
- "How is my training zone distribution this month?"
- "Compare my bike performance over the last 90 days"
## Refreshing Your Auth Cookie
The TrainingPeaks auth cookie expires periodically (typically every few days to weeks). When it expires:
1. You'll see authentication errors in Claude Desktop
2. Re-extract the cookie from your browser (repeat Step 3 from Installation)
3. Update the `TP_AUTH_COOKIE` value in both your `.env` file and Claude Desktop config
4. Restart Claude Desktop
## Architecture
```
src/tp_mcp_server/
├── server.py # FastMCP entry point
├── mcp_instance.py # Shared MCP instance
├── config.py # Environment config
├── api/
│ ├── client.py # Async httpx client, token management
│ └── endpoints.py # API URL constants
├── auth/
│ ├── storage.py # Cookie storage (env/keyring)
│ └── browser.py # Browser cookie extraction
├── tools/
│ ├── auth.py # Auth status/refresh
│ ├── profile.py # Athlete profile
│ ├── workouts.py # Workout list/detail
│ ├── fitness.py # CTL/ATL/TSB data
│ ├── peaks.py # Personal records
│ └── analytics.py # Derived analytics
├── models/
│ ├── workout.py # Workout models
│ ├── fitness.py # Fitness models + CTL computation
│ ├── peaks.py # PR models
│ └── profile.py # Profile model
└── utils/
├── dates.py # Date helpers
└── formatting.py # Output formatting
```
## Known Limitations
- **Internal API**: TrainingPeaks has no public API. This uses the same internal API as the web app, which could change without notice.
- **Cookie auth**: Requires periodic browser re-login to refresh the cookie.
- **Sport-level PRs**: The `/personalrecord/v2/athletes/{id}/{sport}` endpoint returns 500. PRs are aggregated from individual workouts instead.
- **CTL/ATL/TSB**: The API returns `"NaN"` for these values. They are computed locally from TSS data.
- **Rate limiting**: Requests are throttled to 150ms apart to avoid hitting TP rate limits.
| text/markdown | Viet Anh Chu | null | null | null | MIT | analytics, cycling, fitness, mcp, training, trainingpeaks | [
"Development Status :: 4 - Beta",
"Intended Audience :: End Users/Desktop",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Information Analysis"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"browser-cookie3>=0.19.0",
"cryptography>=42.0.0",
"httpx>=0.25.0",
"keyring>=25.0.0",
"mcp[cli]>=1.4.0",
"python-dotenv>=1.0.0",
"mypy>=1.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21; extra == \"dev\"",
"pytest-mock>=3.12.0; extra == \"dev\"",
"pytest>=8.3.5; extra == \"dev\"",
"ruff>=0.1.0; e... | [] | [] | [] | [
"Homepage, https://github.com/banananovej-chuan/tp-mcp-server",
"Repository, https://github.com/banananovej-chuan/tp-mcp-server"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T21:29:33.800694 | tp_mcp_server-0.1.0.tar.gz | 77,790 | 3e/f7/454af88959e985c53214f1053886e1dedc32c9a9a32f890640f2c67a88fb/tp_mcp_server-0.1.0.tar.gz | source | sdist | null | false | e9e884a6ad613ac65146fce193c4a434 | 70afd4f972235c81dd25e29a01d5a98f482fab473186f1c54cf19549c8c02bd1 | 3ef7454af88959e985c53214f1053886e1dedc32c9a9a32f890640f2c67a88fb | null | [] | 257 |
2.4 | ncompass | 0.1.15 | Profiling and trace analysis SDK | # nCompass Python SDK
[](https://pypi.org/project/ncompass/)
[](https://pepy.tech/project/ncompass)
[](LICENSE)
[](https://www.python.org/downloads/)
The Python SDK powering our Performance Optimization IDE—bringing seamless profiling and performance analysis directly into your development workflow.
Built by [nCompass Technologies](https://ncompass.tech).
## What are we building?
We're building a **Performance Optimization IDE** that improves developer productivity by 100x when profiling and analyzing performance of GPU and other accelerator systems. Our IDE consists of two integrated components:
### 🎯 [VSCode Extension](https://marketplace.visualstudio.com/items?itemName=nCompassTech.ncprof-vscode)
Unify your profiling workflow with seamless integration between traces and codebases:
- **No more context switching** — profile, analyze, and optimize all in one place
- **Zero-copy workflow** — visualize traces directly in your editor without transferring files between machines
- **Code-to-trace navigation** — jump seamlessly between your codebase and performance traces
- **AI-powered insights** — get intelligent suggestions for performance improvements and bottleneck identification
### ⚙️ **SDK (this repo)**
The Python SDK that powers the extension with powerful automation features:
- **Zero-instrumentation profiling** — AST-level code injection means you never need to manually add profiling statements
- **Universal trace conversion** — convert traces from nsys and other formats to Chrome traces for integrated visualization
- **Extensible architecture** — built for customization and extension (contributions welcome!)
## Installation
Install via pip:
```bash
pip install ncompass
```
> ⚠️ **Troubleshooting**: If you run into issues with `ncompasslib` or `pydantic`, ensure that:
>
> 1. You are running Python 3.10+
> 2. You have `Pydantic>=2.0` installed
## Examples
Refer to our [open source GitHub repo](https://github.com/nCompass-tech/ncompass/tree/main/examples) for examples. Our examples are built to work together with the VSCode extension. For instance, with adding tracepoints to the code, you can add/remove tracepoints using the extension and then run profiling using our examples.
- **[vLLM Profiling Example](examples/vllm_example/)** — Profile vLLM using .pth-based auto-initialization with NCU, Nsys, and Torch profilers
- **[Running remotely on Modal](examples/modal_basic_example/)** — Run profiling sessions on Modal cloud infrastructure
- **[Unified Docker Environment](examples/docker/)** — Shared Docker setup with all profiling tools (CUDA, Nsys, NCU, PyTorch)
## Online Resources
- 🌐 **Website**: [ncompass.tech](https://ncompass.tech)
- 📚 **Documentation**: [Documentation](https://round-hardhat-a0a.notion.site/ncprof-Quick-Start-2c4097a5a430805db541c01762ea6922?source=copy_link)
- 💬 **Community**: [community.ncompass.tech](https://community.ncompass.tech)
- 🐛 **Issues**: [GitHub Issues](https://github.com/ncompass-tech/ncompass/issues)
- __ **Discord**: [Join our discord](https://discord.gg/9K48xTxKvN)
## Requirements
- Python 3.10 or higher
- Nsight Systems CLI installed (for .nsys-rep to .json.gz conversion features)
## Building without packaging
Because of Rust dependencies for the fast .nsys-rep to .json.gz converter, `-e` (editable) builds
aren't setup. To build you have to just `pip install ./` and use the package from your python env.
To run tests, run the following:
```bash
nix develop
pytest tests/ # python tests
cd ncompass_rust/trace_converters/
cargo test --target=x86_64-unknown-linux-musl # rust tests
```
## License
This project is licensed under the Apache License 2.0 - see the [LICENSE](LICENSE) file for details.
Made with ⚡ by [nCompass Technologies](https://ncompass.tech)
| text/markdown | null | nCompass Technologies <support@ncompass.tech> | null | nCompass Technologies <support@ncompass.tech> | null | ai, inference, profiling, tracing, performance, gpu, pytorch, cuda | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Pytho... | [] | null | null | >=3.10 | [] | [] | [] | [
"requests>=2.28.0",
"pydantic>2.0.0",
"orjson>=3.9.0",
"tomli>=2.0.0; python_version < \"3.11\"",
"typing_extensions>=4.0.0; python_version < \"3.11\"",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"interrogate>=1.5.0; extra == \"dev\"",
"pyright>=1.1.0; extra == \"dev\"... | [] | [] | [] | [
"Homepage, https://ncompass.tech",
"Documentation, https://docs.ncompass.tech",
"Repository, https://github.com/ncompass-tech/ncompass",
"Community, https://community.ncompass.tech",
"Bug Tracker, https://github.com/ncompass-tech/ncompass/issues"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-19T21:29:19.469520 | ncompass-0.1.15.tar.gz | 147,580 | 55/41/3e034efe6617272564b15090155997bd7698e7c7216e544e0a908f06b320/ncompass-0.1.15.tar.gz | source | sdist | null | false | 9d19536848a04d4baada950f1d8144cb | 89b1da58aa1199330ca4fa33c90261673151c8d7cdf776d4ebb120ac624612d4 | 55413e034efe6617272564b15090155997bd7698e7c7216e544e0a908f06b320 | Apache-2.0 | [
"LICENSE"
] | 251 |
2.4 | hivemind-crewai | 0.1.0 | CrewAI tool for searching the HiveMind shared knowledge commons | # hivemind-crewai
CrewAI tool for [HiveMind](https://github.com/AmirK-S/HiveMind) — the shared knowledge commons for AI agents.
## Installation
```bash
pip install hivemind-crewai
```
## Usage
```python
from hivemind_crewai import HiveMindTool
tool = HiveMindTool(
base_url="http://localhost:8000",
api_key="your-api-key",
namespace="my-org",
)
# Add to any CrewAI agent
agent = Agent(
role="Researcher",
tools=[tool],
)
```
## How it works
`HiveMindTool` wraps the HiveMind `search_knowledge` endpoint as a CrewAI-compatible tool. Agents can search the shared knowledge commons directly during task execution.
## License
MIT
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"crewai>=0.100.0",
"httpx>=0.25.0"
] | [] | [] | [] | [
"Homepage, https://github.com/AmirK-S/HiveMind"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T21:28:58.322001 | hivemind_crewai-0.1.0.tar.gz | 2,557 | 7d/9f/11e52838cb07a8014acf05cb1554f5829a3e1494880970586d7c4f1cffab/hivemind_crewai-0.1.0.tar.gz | source | sdist | null | false | 30dcfebf9462eb47a38c5ed95873e4fe | bb21db7909618f132a178ad7f3668b267f19778a6c38ed0ab90afd3050d1d5ae | 7d9f11e52838cb07a8014acf05cb1554f5829a3e1494880970586d7c4f1cffab | MIT | [] | 262 |
2.4 | hivemind-langchain | 0.1.0 | LangChain retriever for HiveMind shared knowledge commons | # hivemind-langchain
LangChain retriever for [HiveMind](https://github.com/AmirK-S/HiveMind) — the shared knowledge commons for AI agents.
## Installation
```bash
pip install hivemind-langchain
```
## Usage
```python
from hivemind_langchain import HiveMindRetriever
retriever = HiveMindRetriever(
base_url="http://localhost:8000",
api_key="your-api-key",
namespace="my-org",
)
# Use in any LangChain chain
docs = retriever.invoke("How to configure FastAPI middleware?")
```
## How it works
`HiveMindRetriever` calls the HiveMind `search_knowledge` endpoint and returns results as LangChain `Document` objects, ready to plug into any retrieval chain or RAG pipeline.
## License
MIT
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.25.0",
"langchain-core>=0.2.0"
] | [] | [] | [] | [
"Homepage, https://github.com/AmirK-S/HiveMind"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T21:28:48.958204 | hivemind_langchain-0.1.0.tar.gz | 2,295 | a4/98/10493da4ffcc2cfc4e4532f645a450bdbd2a85623f270c794b50e4dc036b/hivemind_langchain-0.1.0.tar.gz | source | sdist | null | false | 7cf589d32c993e60c550b68e5a37b3fe | 145847bf38597d4d75cae25c51f8c3f11eee94aa4f5b89330f99e8efaa3e701d | a49810493da4ffcc2cfc4e4532f645a450bdbd2a85623f270c794b50e4dc036b | MIT | [] | 263 |
2.4 | esbonio | 1.1.0 | A language server for sphinx/docutils based documentation projects. | 
# Esbonio
[](https://pypi.org/project/esbonio)[](https://pypi.org/project/esbonio)[](https://github.com/swyddfa/esbonio/blob/develop/lib/esbonio/LICENSE)
**esbonio - (v.) to explain**
A [Language Server](https://microsoft.github.io/language-server-protocol/) that aims to make it easier to work with [reStructuredText](https://docutils.sourceforge.io/rst.html) tools such as [Sphinx](https://www.sphinx-doc.org/en/master/)
The language server provides the following features
## Completion

## Definitions

## Diagnostics

## Document Links

## Document & Workspace Symbols

## Hover

## Implementations

## Installation
It's recommended to install the language server with [`pipx`](https://pipx.pypa.io/stable/)
Be sure to check out the [Getting Started](https://docs.esbon.io/en/latest/lsp/getting-started.html) guide for details on integrating the server with your editor of choice.
```
$ pipx install esbonio
```
| text/markdown | null | Alex Carney <alcarneyme@gmail.com> | null | null | MIT | null | [
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programm... | [] | null | null | >=3.10 | [] | [] | [] | [
"aiosqlite",
"docutils",
"platformdirs",
"pygls>=2.0",
"tomli; python_version < \"3.11\"",
"websockets",
"mypy; extra == \"typecheck\"",
"pytest-lsp>=1.0; extra == \"typecheck\"",
"types-docutils; extra == \"typecheck\"",
"types-pygments; extra == \"typecheck\""
] | [] | [] | [] | [
"Bug Tracker, https://github.com/swyddfa/esbonio/issues",
"Documentation, https://swyddfa.github.io/esbonio/",
"Source Code, https://github.com/swyddfa/esbonio"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:27:47.904235 | esbonio-1.1.0.tar.gz | 124,101 | c3/72/9fe15777287679f3898ee67c06755b5703731b3998af81f3957f12db5484/esbonio-1.1.0.tar.gz | source | sdist | null | false | 577407a311626a4ba27b60be9c2684d6 | 9000192d8a71e0e244e5143f7f6d74dcd1ec59a06b8dda4b13a6dbf6ac0e9190 | c3729fe15777287679f3898ee67c06755b5703731b3998af81f3957f12db5484 | null | [
"LICENSE"
] | 1,856 |
2.4 | timeback-sdk | 0.1.10b20260219212635 | Timeback SDK for Python - adapters for FastAPI, Django, and more | # Timeback SDK
Server-side SDK for integrating Timeback into Python web applications.
## Installation
```bash
# pip
pip install timeback-sdk[fastapi]
pip install timeback-sdk[django]
# uv (add to a project)
uv add "timeback-sdk[fastapi]"
uv add "timeback-sdk[django]"
# uv (install into current environment)
uv pip install "timeback-sdk[fastapi]"
uv pip install "timeback-sdk[django]"
```
## FastAPI
```python
from fastapi import FastAPI
from timeback.fastapi import create_timeback_router
app = FastAPI()
timeback_router = create_timeback_router(
env="staging",
client_id="...",
client_secret="...",
identity={
"mode": "sso",
"client_id": "...",
"client_secret": "...",
"get_user": lambda req: get_session_user(req),
"on_callback_success": lambda ctx: handle_sso_success(ctx),
},
)
app.include_router(timeback_router, prefix="/api/timeback")
```
## Django
```python
# Coming soon
```
| text/markdown | null | Timeback <dev@timeback.dev> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Typing :: Typed"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"httpx>=0.27.0",
"starlette>=0.35.0",
"timeback-common>=0.1.0",
"timeback-core>=0.1.0",
"pytest-asyncio>=0.23; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.8.0; extra == \"dev\"",
"django>=4.0; extra == \"django\"",
"fastapi>=0.100.0; extra == \"fastapi\""
] | [] | [] | [] | [
"Homepage, https://developer.timeback.com",
"Documentation, https://docs.timeback.com",
"Repository, https://github.com/superbuilders/timeback-dev-python"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:26:52.765660 | timeback_sdk-0.1.10b20260219212635.tar.gz | 90,855 | 6b/24/89d5e3940ab327c17787dfe5b1d291440774c76c7d03e76c0e053be9b539/timeback_sdk-0.1.10b20260219212635.tar.gz | source | sdist | null | false | 72a182d2a79a9f6792c9368d0f549769 | 239fef7deb5be16e696684a01026637bf043c554a998f6a730705c0b7f095c44 | 6b2489d5e3940ab327c17787dfe5b1d291440774c76c7d03e76c0e053be9b539 | MIT | [] | 230 |
2.4 | timeback-oneroster | 0.1.10b20260219212635 | Timeback OneRoster v1.2 client for rostering and gradebook APIs | # timeback-oneroster
Python client for the OneRoster v1.2 API.
## Installation
```bash
# pip
pip install timeback-oneroster
# uv (add to a project)
uv add timeback-oneroster
# uv (install into current environment)
uv pip install timeback-oneroster
```
## Quick Start
```python
from timeback_oneroster import OneRosterClient
async def main():
client = OneRosterClient(
env="staging", # or "production"
client_id="your-client-id",
client_secret="your-client-secret",
)
# List all schools
schools = await client.schools.list()
for school in schools:
print(school.name)
# Get a specific user
user = await client.users.get("user-sourced-id")
print(f"{user.given_name} {user.family_name}")
await client.close()
```
## Client Structure
```python
client = OneRosterClient(options)
# Rostering
client.users # All users
client.students # Students (filtered users)
client.teachers # Teachers (filtered users)
client.classes # Classes
client.schools # Schools
# client.courses # Coming soon
# client.enrollments # Coming soon
# client.terms # Coming soon
```
## Resource Operations
Each resource supports:
```python
# List all items
users = await client.users.list()
# List with type-safe filtering (recommended)
active_teachers = await client.users.list(
where={"status": "active", "role": "teacher"}
)
# With operators
teachers_or_aides = await client.users.list(
where={"role": {"in_": ["teacher", "aide"]}}
)
# Not equal
non_deleted = await client.users.list(
where={"status": {"ne": "deleted"}}
)
# Sorting
sorted_users = await client.users.list(
where={"status": "active"},
sort="familyName",
order_by="asc",
)
# Legacy filter string (still supported)
active_users = await client.users.list(filter="status='active'")
# Get by sourcedId
user = await client.users.get("user-id")
# Create (where supported)
create_result = await client.classes.create({
"title": "Math 101",
"course": {"sourcedId": "course-id"},
"school": {"sourcedId": "school-id"},
})
print(create_result.sourced_id_pairs.allocated_sourced_id)
# Update (where supported)
await client.classes.update("class-id", {"title": "Math 102"})
# Delete (where supported)
await client.classes.delete("class-id")
```
## Nested Resources
```python
# Schools
classes = await client.schools("school-id").classes()
students = await client.schools("school-id").students()
teachers = await client.schools("school-id").teachers()
courses = await client.schools("school-id").courses()
# Classes
students = await client.classes("class-id").students()
teachers = await client.classes("class-id").teachers()
enrollments = await client.classes("class-id").enrollments()
# Enroll a student
await client.classes("class-id").enroll({"sourcedId": "student-id", "role": "student"})
# Users
classes = await client.users("user-id").classes()
demographics = await client.users("user-id").demographics()
# Students / Teachers
classes = await client.students("student-id").classes()
classes = await client.teachers("teacher-id").classes()
```
## Filtering
The client supports type-safe filtering with the `where` parameter:
```python
# Simple equality
users = await client.users.list(where={"status": "active"})
# Multiple conditions (AND)
users = await client.users.list(
where={"status": "active", "role": "teacher"}
)
# Operators
users = await client.users.list(where={"score": {"gte": 90}}) # >=
users = await client.users.list(where={"score": {"gt": 90}}) # >
users = await client.users.list(where={"score": {"lte": 90}}) # <=
users = await client.users.list(where={"score": {"lt": 90}}) # <
users = await client.users.list(where={"status": {"ne": "deleted"}}) # !=
users = await client.users.list(where={"email": {"contains": "@school.edu"}}) # substring
# Match any of multiple values (OR)
users = await client.users.list(
where={"role": {"in_": ["teacher", "aide"]}}
)
# Exclude multiple values
users = await client.users.list(
where={"status": {"not_in": ["deleted", "inactive"]}}
)
# Explicit OR across fields
users = await client.users.list(
where={"OR": [{"role": "teacher"}, {"status": "active"}]}
)
```
## Pagination
For large datasets, use streaming:
```python
# Collect all users
all_users = await client.users.stream().to_list()
# With limits
first_100 = await client.users.stream(max_items=100).to_list()
# With filtering
active_users = await client.users.stream(
where={"status": "active"}
).to_list()
# Get first item only
first_user = await client.users.stream().first()
```
## Configuration
```python
OneRosterClient(
# Environment-based (recommended)
env="production", # or "staging"
client_id="...",
client_secret="...",
# Or explicit URLs
base_url="https://api.example.com",
auth_url="https://auth.example.com/oauth2/token",
client_id="...",
client_secret="...",
# Optional
timeout=30.0, # Request timeout in seconds
)
```
## Environment Variables
If credentials are not provided explicitly, the client reads from:
- `ONEROSTER_CLIENT_ID`
- `ONEROSTER_CLIENT_SECRET`
- `ONEROSTER_BASE_URL` (optional)
- `ONEROSTER_TOKEN_URL` (optional)
## Error Handling
```python
from timeback_oneroster import OneRosterError, NotFoundError, AuthenticationError
try:
user = await client.users.get("invalid-id")
except NotFoundError as e:
print(f"User not found: {e.sourced_id}")
except AuthenticationError:
print("Invalid credentials")
except OneRosterError as e:
print(f"API error: {e}")
```
## Async Context Manager
```python
async with OneRosterClient(client_id="...", client_secret="...") as client:
schools = await client.schools.list()
# Client is automatically closed
```
## FastAPI Integration
```python
from fastapi import FastAPI, Depends
from timeback_oneroster import OneRosterClient
app = FastAPI()
async def get_oneroster():
client = OneRosterClient(
env="production",
client_id="...",
client_secret="...",
)
try:
yield client
finally:
await client.close()
@app.get("/schools")
async def list_schools(client: OneRosterClient = Depends(get_oneroster)):
return await client.schools.list()
```
| text/markdown | null | Timeback <dev@timeback.dev> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Typing :: Typed"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"email-validator>=2.3.0",
"timeback-common>=0.1.0"
] | [] | [] | [] | [
"Homepage, https://developer.timeback.com",
"Documentation, https://docs.timeback.com",
"Repository, https://github.com/superbuilders/timeback-dev-python"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:26:49.584145 | timeback_oneroster-0.1.10b20260219212635-py3-none-any.whl | 56,996 | 99/58/da14da8b9ac1e104b7479b5b23b548322ff37049d5d98f7daf8f64a0feaa/timeback_oneroster-0.1.10b20260219212635-py3-none-any.whl | py3 | bdist_wheel | null | false | 362875561cd7188a9426295a53165abc | bf6763a465d45d2b04c857c7a330958bf342b348560e68c7d771a8ebd7d8fdf8 | 9958da14da8b9ac1e104b7479b5b23b548322ff37049d5d98f7daf8f64a0feaa | MIT | [] | 220 |
2.4 | timeback-edubridge | 0.1.10b20260219212635 | Python client for the Timeback EduBridge API | # Timeback EduBridge Client
Python client for the Timeback EduBridge API with async support.
## Installation
```bash
# pip
pip install timeback-edubridge
# uv (add to a project)
uv add timeback-edubridge
# uv (install into current environment)
uv pip install timeback-edubridge
```
## Quick Start
```python
from timeback_edubridge import EdubridgeClient
# Initialize with explicit configuration
client = EdubridgeClient(
base_url="https://api.timeback.ai",
auth_url="https://auth.timeback.ai/oauth2/token",
client_id="your-client-id",
client_secret="your-client-secret",
)
# Or use environment variables with a prefix
client = EdubridgeClient(env="PRODUCTION")
# Reads: PRODUCTION_EDUBRIDGE_BASE_URL, PRODUCTION_EDUBRIDGE_TOKEN_URL, etc.
```
## Resources
### Enrollments
```python
# List enrollments for a user
enrollments = await client.enrollments.list(user_id="user-123")
# Enroll a user in a course
enrollment = await client.enrollments.enroll(
user_id="user-123",
course_id="course-456",
school_id="school-789", # Optional
)
# Unenroll a user
await client.enrollments.unenroll(
user_id="user-123",
course_id="course-456",
)
# Reset goals for a course
result = await client.enrollments.reset_goals("course-456")
# Reset a user's progress
await client.enrollments.reset_progress("user-123", "course-456")
# Get default class for a course
default_class = await client.enrollments.get_default_class("course-456")
```
### Users
```python
# List users by role
users = await client.users.list(roles=["student", "teacher"])
# Convenience methods
students = await client.users.list_students()
teachers = await client.users.list_teachers()
# Search users
results = await client.users.search(
roles=["student"],
search="john",
limit=50,
)
# With additional filters
filtered = await client.users.list(
roles=["student"],
org_sourced_ids=["school-123"],
limit=100,
offset=0,
)
```
### Analytics
```python
# Get activity for a date range
activity = await client.analytics.get_activity(
student_id="student-123", # or email="student@example.com"
start_date="2025-01-01",
end_date="2025-01-31",
timezone="America/New_York",
)
# Get weekly facts
facts = await client.analytics.get_weekly_facts(
student_id="student-123",
week_date="2025-01-15",
)
# Get enrollment-specific facts
enrollment_facts = await client.analytics.get_enrollment_facts(
enrollment_id="enrollment-123",
start_date="2025-01-01",
end_date="2025-01-31",
)
# Get highest grade mastered
grade = await client.analytics.get_highest_grade_mastered(
student_id="student-123",
subject="Math",
)
```
### Applications
```python
# List all applications
apps = await client.applications.list()
# Get metrics for an application
metrics = await client.applications.get_metrics("app-123")
```
### Subject Tracks
```python
from timeback_edubridge import SubjectTrackInput
# List all subject tracks
tracks = await client.subject_tracks.list()
# Create or update a subject track
track = await client.subject_tracks.upsert(
id="track-123",
data=SubjectTrackInput(
subject="Math",
grade_level="9",
target_course_id="course-456",
),
)
# Delete a subject track
await client.subject_tracks.delete("track-123")
# List subject track groups
groups = await client.subject_tracks.list_groups()
```
### Learning Reports
```python
# Get MAP profile for a user
profile = await client.learning_reports.get_map_profile("user-123")
# Get time saved metrics
time_saved = await client.learning_reports.get_time_saved("user-123")
```
## Context Manager
The client can be used as an async context manager:
```python
async with EdubridgeClient(base_url="...") as client:
enrollments = await client.enrollments.list(user_id="user-123")
# Client is automatically closed
```
## Error Handling
```python
from timeback_edubridge import (
EdubridgeError,
AuthenticationError,
ForbiddenError,
NotFoundError,
ValidationError,
APIError,
)
try:
enrollments = await client.enrollments.list(user_id="user-123")
except AuthenticationError:
print("Invalid credentials")
except ForbiddenError:
print("Access denied")
except NotFoundError:
print("Resource not found")
except ValidationError as e:
print(f"Invalid request: {e}")
except APIError as e:
print(f"API error {e.status_code}: {e}")
```
## Environment Variables
When using `env` parameter, the client looks for these variables:
| Variable | Description |
|----------|-------------|
| `{PREFIX}_EDUBRIDGE_BASE_URL` | Base URL for the API |
| `{PREFIX}_EDUBRIDGE_TOKEN_URL` | OAuth2 token endpoint |
| `{PREFIX}_EDUBRIDGE_CLIENT_ID` | OAuth2 client ID |
| `{PREFIX}_EDUBRIDGE_CLIENT_SECRET` | OAuth2 client secret |
Without a prefix, it uses the variables without the prefix (e.g., `EDUBRIDGE_BASE_URL`).
| text/markdown | null | Timeback <dev@timeback.dev> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Typing :: Typed"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"timeback-common>=0.1.0"
] | [] | [] | [] | [
"Homepage, https://developer.timeback.com",
"Documentation, https://docs.timeback.com",
"Repository, https://github.com/superbuilders/timeback-dev-python"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:26:47.329481 | timeback_edubridge-0.1.10b20260219212635.tar.gz | 26,719 | ad/0d/07b10e19e3b2674008a4e329ed2bb21dc217b9b5be2bc8651b02f77002e8/timeback_edubridge-0.1.10b20260219212635.tar.gz | source | sdist | null | false | e3a220107ab8b0a6bc616483609aff3e | 79e3427bc544bc39a34a29a79ca5a3179031abd4e795ec0c34c4fc70359a9b8f | ad0d07b10e19e3b2674008a4e329ed2bb21dc217b9b5be2bc8651b02f77002e8 | MIT | [] | 218 |
2.4 | timeback-core | 0.1.10b20260219212635 | Unified Timeback client for all education APIs (OneRoster, Caliper, Edubridge) | # timeback-core
Unified Python client for all Timeback education APIs.
## Installation
```bash
# pip
pip install timeback-core
# uv (add to a project)
uv add timeback-core
# uv (install into current environment)
uv pip install timeback-core
```
## Quick Start
```python
from timeback_core import TimebackClient
async def main():
client = TimebackClient(
env="staging", # or "production"
client_id="your-client-id",
client_secret="your-client-secret",
)
# OneRoster - rostering and gradebook
users = await client.oneroster.users.list()
for user in users:
print(f"{user.given_name} {user.family_name}")
# Edubridge - simplified enrollments and analytics
analytics = await client.edubridge.analytics.summary()
# Caliper - learning analytics events
await client.caliper.events.send(sensor_id, events)
await client.close()
```
## Managing Multiple Clients
For applications that need to manage multiple `TimebackClient` instances, use `TimebackManager`:
```python
from timeback_core import TimebackManager
async def main():
manager = TimebackManager()
manager.register("alpha", env="production", client_id="...", client_secret="...")
manager.register("beta", env="production", client_id="...", client_secret="...")
# Target a specific platform
users = await manager.get("alpha").oneroster.users.list()
# Broadcast to all platforms (uses asyncio.gather — never raises)
async def create_user(client):
return await client.oneroster.users.create(user_data)
results = await manager.broadcast(create_user)
# Check results
if results.all_succeeded:
print("Synced to all platforms!")
for name, user in results.succeeded:
print(f"Created on {name}: {user}")
for name, error in results.failed:
print(f"Failed on {name}: {error}")
await manager.close()
```
### Manager API
| Method | Description |
| ------------------------ | ------------------------------------------------ |
| `register(name, **cfg)` | Add a named client |
| `get(name)` | Retrieve a client by name |
| `has(name)` | Check if a client is registered |
| `names` | Get all registered client names |
| `size` | Get number of registered clients |
| `broadcast(fn)` | Execute on all clients, returns `BroadcastResults` |
| `unregister(name)` | Remove a client |
| `close()` | Close all clients |
### BroadcastResults API
| Property/Method | Description |
| --------------- | ------------------------------------------- |
| `succeeded` | Get successful results as `[(name, value)]` |
| `failed` | Get failed results as `[(name, error)]` |
| `all_succeeded` | `True` if all operations succeeded |
| `any_failed` | `True` if any operation failed |
| `values()` | Get all values (raises if any failed) |
## Configuration
The client supports three configuration modes:
### Environment Mode (Recommended)
Derive all URLs from `staging` or `production`:
```python
client = TimebackClient(
env="staging", # or "production"
client_id="...",
client_secret="...",
)
```
| Environment | API Base URL |
| ------------ | ------------------------------ |
| `staging` | `api.staging.alpha-1edtech.ai` |
| `production` | `api.alpha-1edtech.ai` |
### Base URL Mode
For self-hosted or custom deployments with a single base URL:
```python
client = TimebackClient(
base_url="https://timeback.myschool.edu",
auth_url="https://timeback.myschool.edu/oauth/token",
client_id="...",
client_secret="...",
)
```
### Explicit Services Mode
Full control over each service URL:
```python
client = TimebackClient(
services={
"oneroster": "https://roster.example.com",
"caliper": "https://analytics.example.com",
"edubridge": "https://api.example.com",
},
auth_url="https://auth.example.com/oauth/token",
client_id="...",
client_secret="...",
)
```
## Individual Clients
For standalone usage, install individual packages:
```bash
pip install timeback-oneroster
pip install timeback-edubridge
pip install timeback-caliper
```
```python
from timeback_oneroster import OneRosterClient
client = OneRosterClient(
env="staging",
client_id="...",
client_secret="...",
)
```
## Environment Variables
If credentials are not provided explicitly, the client reads from:
- `TIMEBACK_ENV` - Environment (staging/production)
- `TIMEBACK_CLIENT_ID`
- `TIMEBACK_CLIENT_SECRET`
- `TIMEBACK_TOKEN_URL` (optional)
## Async Context Manager
```python
async with TimebackClient(env="staging", client_id="...", client_secret="...") as client:
schools = await client.oneroster.schools.list()
# Client is automatically closed
```
## Error Handling
```python
from timeback_core import OneRosterError, CaliperError, EdubridgeError
try:
users = await client.oneroster.users.list()
except OneRosterError as e:
print(f"OneRoster API error: {e}")
except CaliperError as e:
print(f"Caliper API error: {e}")
except EdubridgeError as e:
print(f"Edubridge API error: {e}")
```
| text/markdown | null | Timeback <dev@timeback.dev> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Typing :: Typed"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"timeback-caliper>=0.1.0",
"timeback-common>=0.1.0",
"timeback-edubridge>=0.1.0",
"timeback-oneroster>=0.1.0"
] | [] | [] | [] | [
"Homepage, https://developer.timeback.com",
"Documentation, https://docs.timeback.com",
"Repository, https://github.com/superbuilders/timeback-dev-python"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:26:43.740075 | timeback_core-0.1.10b20260219212635-py3-none-any.whl | 14,021 | f2/b9/46bb49880cbcfbb849a7a20e12815ca788de6f34f5b2722bf8fad621229b/timeback_core-0.1.10b20260219212635-py3-none-any.whl | py3 | bdist_wheel | null | false | c28a6f7145bca0fee7ac6b15900271f7 | 1e1e07de91a06e470ddfcdf788e0d2dc61f28535768c80668a25ba9ef820dfa7 | f2b946bb49880cbcfbb849a7a20e12815ca788de6f34f5b2722bf8fad621229b | MIT | [] | 221 |
2.4 | timeback-common | 0.1.10b20260219212635 | Shared infrastructure for Timeback Python clients | # timeback-common
Shared infrastructure for Timeback Python clients.
## Installation
```bash
# pip
pip install timeback-common
# uv (add to a project)
uv add timeback-common
# uv (install into current environment)
uv pip install timeback-common
```
```python
from timeback_common import BaseTransport, APIError, Paginator, where_to_filter
class MyTransport(BaseTransport):
ENV_VAR_BASE_URL = "MY_SERVICE_BASE_URL"
ENV_VAR_AUTH_URL = "MY_SERVICE_TOKEN_URL"
ENV_VAR_CLIENT_ID = "MY_SERVICE_CLIENT_ID"
ENV_VAR_CLIENT_SECRET = "MY_SERVICE_CLIENT_SECRET"
```
## Components
| Module | Description |
|--------|-------------|
| `transport` | Base HTTP transport with OAuth2 client credentials |
| `errors` | Shared exception hierarchy (APIError, NotFoundError, etc.) |
| `pagination` | Async Paginator for list endpoints |
| `filter` | `where_to_filter()` for type-safe filtering |
## Usage
This package is used internally by:
- `timeback-oneroster`
- `timeback-caliper`
- `timeback-edubridge`
- `timeback-core`
| text/markdown | null | Timeback <dev@timeback.dev> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Typing :: Typed"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"httpx>=0.27",
"pydantic>=2.0"
] | [] | [] | [] | [
"Homepage, https://developer.timeback.com",
"Documentation, https://docs.timeback.com",
"Repository, https://github.com/superbuilders/timeback-dev-python"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:26:40.780133 | timeback_common-0.1.10b20260219212635.tar.gz | 39,360 | ef/a1/879c30c6f26ea364a2bbc64e10f7aaab86708973f84ab2c3fc88783913c0/timeback_common-0.1.10b20260219212635.tar.gz | source | sdist | null | false | a1ba1c1cee728aca3f09f5bdb4df2af0 | 453d3b0fe22b657a1945710cf8ffdaa9ef6a15f480fc0b6e9525860a434b394a | efa1879c30c6f26ea364a2bbc64e10f7aaab86708973f84ab2c3fc88783913c0 | MIT | [] | 220 |
2.4 | timeback-caliper | 0.1.10b20260219212635 | Timeback Caliper client for learning analytics events | # timeback-caliper
Python client for sending Caliper learning analytics events to Timeback.
## Installation
```bash
# pip
pip install timeback-caliper
# uv (add to a project)
uv add timeback-caliper
# uv (install into current environment)
uv pip install timeback-caliper
```
## Quick Start
```python
from timeback_caliper import (
CaliperClient,
ActivityCompletedInput,
TimebackUser,
TimebackActivityContext,
TimebackApp,
TimebackActivityMetric,
)
# Initialize client
client = CaliperClient(
env="staging", # or "production"
client_id="your-client-id",
client_secret="your-client-secret",
)
# Send an activity completed event
result = await client.events.send_activity(
sensor_id="https://myapp.example.com/sensors/main",
input=ActivityCompletedInput(
actor=TimebackUser(
id="https://example.edu/users/123",
email="student@example.edu",
),
object=TimebackActivityContext(
id="https://myapp.example.com/activities/456",
subject="Math",
app=TimebackApp(name="My Learning App"),
),
metrics=[
TimebackActivityMetric(type="totalQuestions", value=10),
TimebackActivityMetric(type="correctQuestions", value=8),
TimebackActivityMetric(type="xpEarned", value=150),
],
),
)
# Wait for processing
status = await client.jobs.wait_for_completion(result.job_id)
print(f"Processed {status.events_processed} events")
```
## FastAPI Integration
```python
from fastapi import FastAPI, HTTPException
from timeback_caliper import (
CaliperClient,
ActivityCompletedInput,
APIError,
)
app = FastAPI()
# Initialize client (reuse across requests)
caliper = CaliperClient(
env="staging",
client_id="...",
client_secret="...",
)
@app.post("/api/activity")
async def submit_activity(input: ActivityCompletedInput):
"""Submit a learning activity event."""
try:
result = await caliper.events.send_activity(
sensor_id="https://myapp.example.com/sensors/main",
input=input,
)
return {"success": True, "job_id": result.job_id}
except APIError as e:
raise HTTPException(status_code=e.status_code or 500, detail=str(e))
@app.on_event("shutdown")
async def shutdown():
await caliper.close()
```
## Event Types
### ActivityCompletedEvent
Records when a student completes an activity with performance metrics:
```python
from timeback_caliper import (
ActivityCompletedInput,
TimebackUser,
TimebackActivityContext,
TimebackApp,
TimebackCourse,
TimebackActivityMetric,
)
input = ActivityCompletedInput(
actor=TimebackUser(
id="https://example.edu/users/123",
email="student@example.edu",
name="Jane Doe",
role="student",
),
object=TimebackActivityContext(
id="https://myapp.example.com/activities/456",
subject="Math",
app=TimebackApp(name="My Learning App"),
course=TimebackCourse(name="Algebra 101"),
),
metrics=[
TimebackActivityMetric(type="totalQuestions", value=10),
TimebackActivityMetric(type="correctQuestions", value=8),
TimebackActivityMetric(type="xpEarned", value=150),
TimebackActivityMetric(type="masteredUnits", value=1),
],
)
result = await client.events.send_activity(sensor_id, input)
```
### TimeSpentEvent
Records time spent on an activity:
```python
from timeback_caliper import TimeSpentInput, TimeSpentMetric
input = TimeSpentInput(
actor=TimebackUser(id="...", email="..."),
object=TimebackActivityContext(id="...", subject="Reading", app=TimebackApp(name="...")),
metrics=[
TimeSpentMetric(type="active", value=1800), # 30 minutes
TimeSpentMetric(type="inactive", value=300), # 5 minutes
],
)
result = await client.events.send_time_spent(sensor_id, input)
```
## Job Tracking
Events are processed asynchronously. Track processing status:
```python
# Get job status
status = await client.jobs.get_status(job_id)
print(f"Status: {status.status}")
# Wait for completion (with timeout)
status = await client.jobs.wait_for_completion(
job_id,
timeout=60.0, # Max wait time
poll_interval=1.0, # Check every second
)
if status.status == "completed":
print(f"Processed {status.events_processed} events")
elif status.status == "failed":
print(f"Failed: {status.error}")
```
## Context Manager
Use the client as an async context manager for automatic cleanup:
```python
async with CaliperClient(client_id="...", client_secret="...") as client:
await client.events.send_activity(sensor_id, input)
# Client is automatically closed
```
## Error Handling
```python
from timeback_caliper import (
CaliperClient,
AuthenticationError,
APIError,
)
try:
result = await client.events.send_activity(sensor_id, input)
except AuthenticationError:
print("Invalid credentials")
except APIError as e:
print(f"API error ({e.status_code}): {e}")
```
## Configuration
| Parameter | Type | Default | Description |
|-----------|------|---------|-------------|
| `env` | `str` | `None` | `"staging"` or `"production"` |
| `base_url` | `str` | auto | Override API URL |
| `auth_url` | `str` | auto | Override auth URL |
| `client_id` | `str` | env var | OAuth2 client ID |
| `client_secret` | `str` | env var | OAuth2 client secret |
| `timeout` | `float` | `30.0` | Request timeout in seconds |
### Environment Variables
```bash
CALIPER_CLIENT_ID=your-client-id
CALIPER_CLIENT_SECRET=your-client-secret
CALIPER_BASE_URL=https://api.staging.timeback.com
CALIPER_TOKEN_URL=https://auth.staging.timeback.com/oauth2/token
```
| text/markdown | null | Timeback <dev@timeback.dev> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Typing :: Typed"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"timeback-common>=0.1.0"
] | [] | [] | [] | [
"Homepage, https://developer.timeback.com",
"Documentation, https://docs.timeback.com",
"Repository, https://github.com/superbuilders/timeback-dev-python"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:26:37.921524 | timeback_caliper-0.1.10b20260219212635.tar.gz | 25,600 | 6f/5f/90a8b3e6921e609049e12d148f4850e6a5ffd65444f504f4a7593d2f228f/timeback_caliper-0.1.10b20260219212635.tar.gz | source | sdist | null | false | 0a4b79d33b366ea36e07fa9d10bd02e7 | 57f0656f290fff5e141d10b54540d808d2f0f49247cf985653d3ce349636bb85 | 6f5f90a8b3e6921e609049e12d148f4850e6a5ffd65444f504f4a7593d2f228f | MIT | [] | 219 |
2.4 | ag-quant | 2026.2.19.5 | 简易量化框架 | 数据分为两种, <市场价格数据>和<因子构造基础数据>,要求这两种数据在上传时命名一样。
这两种数据缺一不可,因为没有<市场价格数据>就无法进行横截面分析和回测,没有<因子构造基础数据>因子就无法生成具体值
举个例子:我们现在有大豆的<CBOT连续合约的市场价格数据>和<大连期货交易所的持仓数据>,我们想用持仓数据构建一个“持仓波动率”因子,然后测试这个因子的表现(也就是横截面分析)。那么此时<CBOT连续合约的市场价格数据>就是<市场价格数据>,<大连期货交易所的持仓数据>就是<因子构造基础数据>。
因子和策略,分为构造和具体值,千万不能搞混。
同一个因子构造,在不同交易品种数据下会有不同的因子值。比如我们构造了一个因子叫<价格动量>,那么具体到大豆还是菜籽,会得到完全不同的因子具体值,但是他们都在用共同的一个因子构造叫<价格动量>策略同理,同一个策略构造,在不同市场环境下会产生完全不同的策略具体值(或者换一个熟悉的名字叫做交易信号)。
因子构造需要<因子构造基础数据>生成具体值,然后在<市场价格数据>下进行横截面分析。策略构造需要结合因子具体值生成策略具体值(交易信号),然后在<市场价格数据>下进行回测。横截面分析和回测的主体千万不能搞混。 | text/markdown | 1, 2 | null | null | null | null | null | [
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.2 | 2026-02-19T21:24:19.295476 | ag_quant-2026.2.19.5.tar.gz | 9,921 | c7/ab/c49ba31995704521d33a3a25aae324c9ba97cf886b6b1261c663712ac921/ag_quant-2026.2.19.5.tar.gz | source | sdist | null | false | 9530aded60b99b34e02f58b7fdab62ad | 88b61b77420bc206b8de828fc01ce4964918167072caeff2f0fe1e2d6bed6801 | c7abc49ba31995704521d33a3a25aae324c9ba97cf886b6b1261c663712ac921 | MIT | [] | 266 |
2.4 | datadepot | 0.0.49 | The datadepot package provides a collection of datasets used in the book Data Science Foundations and Machine Learning with Python. | # Package `datadepot`
**Package ‘datadepot’**
**Title** DataDepot
**Description**
The **datadepot** package provides a collection of datasets used in the book `Data Science Foundations and Machine Learning with Python`.
**URL** <https://github.com/vanraak/datadepot>
**Depends** Python (\>= 3.8) and Pandas (\>2.0)
**License** GPL (\>= 2)
**Repository** Pypi
**Authors** Jeroen van Raak and Reza Mohammadi
**Maintainer** Jeroen van Raak, <j.j.f.vanraak@uva.nl>
**NeedsCompilation** no
**Installation**
pip install datadepot
**Usage**
import datadepot
df=datadepot.load('<dataset>')
Replace <dataset> with the name of the dataset, such as ‘bank’, ‘house’, or ‘churn’.
**Example**
df=datadepot.load('bank') # Load the bank dataset.
**Datasets**
The following datasets are included:
- adult
- advertising
- bank
- caravan
- cereal
- churn
- churn_ibm
- churn_tel
- corona
- diamonds
- drug
- gapminder
- house
- house_price
- insurance
- marketing
- mpg
- red_wines
- risk
- white_wines
**Documentation**
The full documentation is available at:
<https://github.com/vanraak/datadepot/blob/main/README.pdf>
| text/markdown | null | Jeroen van Raak <j.j.f.vanraak@uva.nl> | null | null | Copyright (c) 2025 Jeroen van Raak
MIT License
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pandas>=1.5",
"numpy>=1.21"
] | [] | [] | [] | [
"Homepage, https://github.com/vanraak/datadepot"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:24:07.108273 | datadepot-0.0.49.tar.gz | 4,513,550 | 85/ff/dcc9aabf5a7aee5dce1becb8420440c0285e006341b934a0b052b3261e46/datadepot-0.0.49.tar.gz | source | sdist | null | false | 21aff8cd60431355816f6b468a550a85 | 9388cf1dc4caf7240c73f0386e87e2ebd4564b120f77588e94624ba9af9fcc7e | 85ffdcc9aabf5a7aee5dce1becb8420440c0285e006341b934a0b052b3261e46 | null | [
"LICENSE"
] | 263 |
2.4 | onako | 0.6.1 | Dispatch and monitor Claude Code tasks from your phone | # Onako
Dispatch and monitor Claude Code tasks from your phone.
Onako is a lightweight server that runs on your machine. It spawns Claude Code sessions in tmux, and you monitor them through a mobile-friendly web dashboard. Fire off tasks from an iOS Shortcut or the dashboard, check in from anywhere.
## Install
```bash
pipx install onako
```
Requires [tmux](https://github.com/tmux/tmux) and [Claude Code](https://docs.anthropic.com/en/docs/claude-code).
## Usage
```bash
onako # starts server, drops you into tmux
onako --session my-project # custom session name
```
If you're already inside tmux, onako auto-detects your session and skips the attach. Open http://localhost:8787 on your phone (same network) or set up [Tailscale](https://tailscale.com) for access from anywhere.
```bash
onako stop # stop the server
onako status # check if running
onako clean # remove worktrees for finished tasks
onako reset # full teardown: stop, kill session, clean worktrees
onako serve # foreground server (for development)
onako version # print version
```
### Dispatching tasks from the CLI
```bash
onako task "fix the login bug" # create a task
onako task "add tests" --branch feat/tests # run in a git worktree
onako task "refactor auth" --branch feat/auth --base-branch develop
```
### Flags
```bash
onako --dangerously-skip-permissions # skip Claude Code permission prompts
onako --no-attach # start server without attaching to tmux
onako --dir /path/to/project # set working directory for tasks
```
### Adopting existing tmux windows
If you already have work running in another tmux session, move those windows into onako's session so they show up in the dashboard:
```bash
tmux move-window -s <session>:<window> -t onako
```
## How it works
Onako monitors all tmux windows in the configured session. Windows it creates (via the dashboard) are "managed" tasks. Windows created by you or other tools are discovered automatically as "external" — both get full dashboard support: view output, send messages, kill.
Task state is persisted in SQLite so it survives server restarts.
| text/markdown | Amir | null | null | null | null | claude, claude-code, tmux, orchestrator, ai | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"fastapi>=0.100.0",
"uvicorn>=0.20.0",
"click>=8.0.0",
"pytest>=7.0; extra == \"dev\"",
"httpx>=0.24.0; extra == \"dev\""
] | [] | [] | [] | [
"Repository, https://github.com/AzRu/onako"
] | twine/6.2.0 CPython/3.13.0 | 2026-02-19T21:23:52.270078 | onako-0.6.1.tar.gz | 51,804 | 8c/3f/b3446a669de1dbaaf3c41ee4b314a0aa3d3e83902c8263dc10078a2bf522/onako-0.6.1.tar.gz | source | sdist | null | false | a194849ec5ad551ef0713a8ff6e52b4d | 3cebdcfa6802c5144ab4606dec3ff2b13de2598aca41a9209cb4d7249ab6c1f9 | 8c3fb3446a669de1dbaaf3c41ee4b314a0aa3d3e83902c8263dc10078a2bf522 | MIT | [] | 249 |
2.3 | bits-aviso-python-sdk | 1.10.8 | Repository containing python wrappers to various services for bits-aviso. | # bits-aviso-python-sdk
Repository containing python wrappers to various services Team AVISO develops against.
[Link to Documentation](https://legendary-adventure-kgmn2m7.pages.github.io/)
---
## Installation
To install the SDK, you can use pip:
```bash
pip install bits-aviso-python-sdk
```
---
## Usage
Here is a simple example of how to use the SDK:
```python
from bits_aviso_python_sdk import ServiceName
service = ServiceName(username='username', password='password') # Initialize the service
response = service.some_method()
print(response)
```
However, please refer to the documentation for each service for more specific parameters and methods.
---
## Sub Modules
There are three upper-level modules in this SDK:
### helpers
> Helpers are utility functions that assist with various tasks within the SDK.
They can also be used independently of the services. Functions that are commonly used will be included here.
Please see the documentation under `bits-aviso-python-sdk.helpers` for more information.
### services
> Services are the main components of the SDK. Each service corresponds to a specific functionality leveraged by
Team AVISO.
Please see the documentation under `bits-aviso-python-sdk.services` for more information.
### tests
> Tests are included to ensure the functionality of the SDK.
They can be run to verify that the SDK is working as expected.
>
> However, these are not proper unit tests and are a work in progress.
Please see the documentation under `bits-aviso-python-sdk.tests` for more information.
---
## Generating Documentation
The documentation for this SDK is generated using pdoc.
To generate the documentation, run the following command:
```bash
poetry run pdoc -o docs bits_aviso_python_sdk
```
This will create an HTML version of the documentation in the `docs` directory.
You may need to use the `--force` flag to overwrite existing files.
| text/markdown | Miranda Nguyen | mirandanguyen98@gmail.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <4.0,>=3.11 | [] | [] | [] | [
"google-api-python-client<3.0.0,>=2.143.0",
"google-cloud-pubsub<3.0.0,>=2.22.0",
"google-cloud-secret-manager<3.0.0,>=2.20.1",
"google-cloud-storage<3.0.0,>=2.18.0",
"pypuppetdb<4.0.0,>=3.2.0",
"pre-commit<4.0.0,>=3.8.0",
"xmltodict<0.14.0,>=0.13.0",
"dnspython<3.0,>=2.7",
"progressbar2<5.0.0,>=4.5... | [] | [] | [] | [] | poetry/2.1.1 CPython/3.13.2 Darwin/25.3.0 | 2026-02-19T21:23:49.403773 | bits_aviso_python_sdk-1.10.8.tar.gz | 43,553 | 9e/3b/f3091ee4c6f74526019cf59332c70662b7f1e89b4ad34a915774ec240120/bits_aviso_python_sdk-1.10.8.tar.gz | source | sdist | null | false | cb0714a706df09665036f0f94c694671 | 1dfa4fbab11c79d809264ead6621401b47bccb63606b0d124ab72835dcad8ef9 | 9e3bf3091ee4c6f74526019cf59332c70662b7f1e89b4ad34a915774ec240120 | null | [] | 280 |
2.4 | kboard | 0.4.0 | Console-based Kanban task manager created in Python. | # kboard
Console-based Kanban task manager created in Python.
Create and manage tasks visually in your terminal using handy commands.
## Features
- CLI based Kanban board.
- Easy setup.
- Simple commands.
- Structured database file.
## Installation
Install using pip running the following command in the terminal:
## Usage
If you installed the library, you can use the CLI as a system command:
```sh
kb COMMAND [ARGS] ...
```
### Examples
Here are some examples of the commands available:
```sh
# List the existing boards.
kb board ls
# Create a new board.
kb board add "Board name"
# Add a task to the backlog.
kb task add "Task title"
# Add a task to a board with high priority.
kb task add --board 1 --priority 3 "Important task"
# Move a task
kb task mv 2
```
## Contributing
Thank you for considering contributing to my project! Any pull requests are
welcome and greatly appreciated. If you encounter any issues while using
the project, please feel free to post them on the issue tracker.
To contribute to the project, please follow these steps:
1. Fork the repository.
2. Add a new feature or bug fix.
3. Commit them using descriptive messages, using
[conventional commits](https://www.conventionalcommits.org/) is recommended.
4. Submit a pull request.
## License
This project is licensed under the MIT License. See the [LICENSE](LICENSE) file
for more details.
| text/markdown | Óscar Miranda | oscarmiranda3615@gmail.com | null | null | MIT License
Copyright (c) 2026 Óscar Miranda
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | kanban, board, project, management, cli | [
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Topic :: Software Development",
"Topic :: Utilities"
] | [] | null | null | >=3.14.2 | [] | [] | [] | [
"rich<15.0.0,>=14.3.2",
"sqlalchemy<3.0.0,>=2.0.46",
"typer<0.22.0,>=0.21.1"
] | [] | [] | [] | [
"Homepage, https://github.com/OscarM3615/kboard/",
"Repository, https://github.com/OscarM3615/kboard/"
] | poetry/2.3.2 CPython/3.14.2 Linux/6.11.0-1018-azure | 2026-02-19T21:23:08.185679 | kboard-0.4.0-py3-none-any.whl | 17,160 | 2e/77/355cef7340480956ef925accac21e055e727aa5c537c79959176fb0a3be4/kboard-0.4.0-py3-none-any.whl | py3 | bdist_wheel | null | false | b7609c1e08354e1a7e368e99438bec0d | 8c9f0132efbfff0d45a1241132e00bd58e814a5a2f6e20ceb1d805240f7b369e | 2e77355cef7340480956ef925accac21e055e727aa5c537c79959176fb0a3be4 | null | [
"LICENSE"
] | 256 |
2.4 | otel-messagequeue-exporter | 0.1.2 | OpenTelemetry span exporters for AWS SQS and Azure Service Bus | # otel-messagequeue-exporter
Export OpenTelemetry traces to **AWS SQS** and **Azure Service Bus** in OTLP format (Protobuf or JSON).
Built for async-first frameworks like FastAPI. Includes a custom `AsyncSpanProcessor`, an mmap-backed **Write-Ahead Log** for guaranteed delivery, and an **S3 Extended Client** for payloads exceeding SQS's 256KB limit.
## Installation
```bash
# Base
pip install otel-messagequeue-exporter
# With AWS support
pip install otel-messagequeue-exporter[aws]
# With Azure support
pip install otel-messagequeue-exporter[azure]
# All exporters
pip install otel-messagequeue-exporter[all]
```
## Quick Start — FastAPI + SQS
```python
from contextlib import asynccontextmanager
from fastapi import FastAPI
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.resources import Resource, SERVICE_NAME
from otel_messagequeue_exporter import SQSSpanExporter, AsyncSpanProcessor
resource = Resource.create({SERVICE_NAME: "my-fastapi-service"})
provider = TracerProvider(resource=resource)
trace.set_tracer_provider(provider)
exporter = SQSSpanExporter(
queue_url="https://sqs.us-east-1.amazonaws.com/123456789/traces",
region_name="us-east-1",
encoding="otlp_proto",
wal_enabled=True,
flush_interval_ms=5000,
max_batch_size=512,
)
processor = AsyncSpanProcessor(exporter=exporter, max_queue_size=2000)
provider.add_span_processor(processor)
@asynccontextmanager
async def lifespan(app):
await processor.start()
yield
await processor.shutdown()
app = FastAPI(lifespan=lifespan)
@app.get("/")
async def root():
tracer = trace.get_tracer(__name__)
with tracer.start_as_current_span("handle_request"):
return {"status": "ok"}
```
## Quick Start — Azure Service Bus
```python
from otel_messagequeue_exporter import AzureServiceBusSpanExporter, AsyncSpanProcessor
exporter = AzureServiceBusSpanExporter(
connection_string="Endpoint=sb://namespace.servicebus.windows.net/;SharedAccessKeyName=...",
queue_name="traces",
encoding="otlp_proto",
wal_enabled=True,
flush_interval_ms=5000,
)
processor = AsyncSpanProcessor(exporter=exporter)
# Same lifespan pattern as above
```
## Quick Start — Sync (BatchSpanProcessor)
For non-async applications (Django, Flask, scripts), use the standard `BatchSpanProcessor`:
```python
from opentelemetry.sdk.trace.export import BatchSpanProcessor
exporter = SQSSpanExporter(
queue_url="https://sqs.us-east-1.amazonaws.com/123456789/traces",
wal_enabled=True,
)
processor = BatchSpanProcessor(exporter)
provider.add_span_processor(processor)
```
## Architecture
```
on_end(span) -> asyncio.Queue -> micro-batch (up to 64 spans)
|
run_in_executor
|
exporter.export(batch)
|
serialize each span -> WAL write_batch()
(single lock, single mmap flush)
|
check flush conditions:
- time since last flush > interval?
- WAL pending count >= max_batch_size?
| (if yes)
merge all pending WAL entries -> single OTLP message
|
send to SQS/Azure Service Bus -> mark delivered
```
**Key design**: Each span is durable on disk the moment it arrives (WAL write). Flushing to the queue happens separately — on interval or when the pending count hits the threshold. This gives maximum crash safety with batched network I/O.
## How It Works
### AsyncSpanProcessor
A thin async bridge between OpenTelemetry's sync `on_end()` callback and the async world. All batching and flush logic lives in the exporter.
- **Micro-batching**: After getting the first span from the queue, drains up to 63 more that are already waiting. This reduces thread pool submissions by up to 64x under load.
- **Idle flush**: When no spans arrive for 1 second, calls `export([])` to give the exporter a chance to flush pending WAL entries.
### Exporters (SQS / Azure Service Bus)
Two modes of operation:
**WAL mode** (`wal_enabled=True`):
1. Each span is serialized and written to WAL immediately via `write_batch()` (single file lock + single mmap flush for the whole micro-batch)
2. Pending WAL entries are merged into a single OTLP message and sent as one SQS/Azure API call
3. On success, all entries are marked delivered. On transient failure, entries stay in WAL for retry.
**In-memory mode** (`wal_enabled=False`, default):
1. Spans are buffered in a list
2. When the buffer reaches `max_batch_size` or `flush_interval_ms` elapses, the batch is serialized and sent
3. On crash, in-memory spans are lost
### Write-Ahead Log (WAL)
mmap-backed durable storage with per-operation file locking for multi-process safety (Gunicorn, Uvicorn, Celery workers can share a single WAL file).
- **Level 2 durability**: Process crash safe. Each `write_batch()` does a single `mmap.flush()` after all entries are written.
- **CRC32 per entry**: Detects corruption without invalidating the entire file
- **Auto-compaction**: Triggered when >50% of entries are delivered, or when space runs out
- **Crash recovery**: On startup, scans for orphan entries past the write offset
### S3 Extended Client (SQS only)
When a merged payload exceeds the threshold (default 250KB), it's uploaded to S3 and a reference is sent via SQS:
```python
exporter = SQSSpanExporter(
queue_url="...",
s3_bucket="my-traces-bucket",
s3_prefix="otel-traces/",
large_payload_threshold_kb=250,
)
```
The SQS message includes `payload_location=s3` and `s3_bucket` in message attributes. Your consumer reads the attribute to decide whether to fetch from S3 or read inline.
## Configuration Reference
### SQSSpanExporter
| Parameter | Type | Default | Description |
|-----------|------|---------|-------------|
| `queue_url` | `str` | required | AWS SQS queue URL |
| `region_name` | `str` | `"us-east-1"` | AWS region |
| `encoding` | `str` | `"otlp_proto"` | `"otlp_proto"` or `"otlp_json"` |
| `aws_access_key_id` | `str` | `None` | AWS credentials (for dev; use IAM roles in prod) |
| `aws_secret_access_key` | `str` | `None` | AWS credentials (for dev) |
| `wal_enabled` | `bool` | `False` | Enable Write-Ahead Log |
| `wal_file_path` | `str` | `None` | WAL file path (default: `.otel_wal/sqs_exporter.wal`) |
| `wal_max_size` | `int` | `67108864` | WAL file size in bytes (default: 64MB) |
| `s3_bucket` | `str` | `None` | S3 bucket for large payloads |
| `s3_prefix` | `str` | `"otel-traces/"` | S3 key prefix |
| `large_payload_threshold_kb` | `int` | `250` | Size threshold (KB) to trigger S3 upload |
| `flush_interval_ms` | `int` | `5000` | Flush interval in milliseconds |
| `max_batch_size` | `int` | `512` | Flush when this many spans are pending |
### AzureServiceBusSpanExporter
| Parameter | Type | Default | Description |
|-----------|------|---------|-------------|
| `connection_string` | `str` | required | Azure Service Bus connection string |
| `queue_name` | `str` | required | Queue name |
| `encoding` | `str` | `"otlp_proto"` | `"otlp_proto"` or `"otlp_json"` |
| `servicebus_namespace` | `str` | `None` | Namespace (for logging) |
| `wal_enabled` | `bool` | `False` | Enable Write-Ahead Log |
| `wal_file_path` | `str` | `None` | WAL file path (default: `.otel_wal/azure_exporter.wal`) |
| `wal_max_size` | `int` | `67108864` | WAL file size in bytes (default: 64MB) |
| `flush_interval_ms` | `int` | `5000` | Flush interval in milliseconds |
| `max_batch_size` | `int` | `512` | Flush when this many spans are pending |
### AsyncSpanProcessor
| Parameter | Type | Default | Description |
|-----------|------|---------|-------------|
| `exporter` | `SpanExporter` | required | The span exporter to use |
| `max_queue_size` | `int` | `1000` | Max spans in the asyncio.Queue before dropping |
## Encoding Formats
| Format | Size | Speed | Use case |
|--------|------|-------|----------|
| `otlp_proto` | ~121 KB / 500 spans | Faster | Production (default) |
| `otlp_json` | ~243 KB / 500 spans | Slightly slower | Debugging, human readability |
Both formats are compatible with the OpenTelemetry Collector's SQS and Azure Service Bus receivers.
## Benchmarks
Run the benchmarks:
```bash
# WAL write() vs write_batch() comparison
uv run python benchmarks/bench_wal.py
# Full end-to-end pipeline benchmarks
uv run python benchmarks/bench_pipeline.py
```
Results on Apple Silicon (M-series):
| Benchmark | Result |
|-----------|--------|
| WAL `write_batch()` speedup | **10x** faster than `write()` loop at 1024 spans |
| Micro-batch effectiveness | **62.5x** fewer `export()` calls (32 vs 2000) |
| Full pipeline (WAL mode) | ~7,400 spans/sec |
| Full pipeline (in-memory) | ~136,000 spans/sec |
| Sustained throughput (3s) | ~4,200 spans/sec, 0 drops, ~529 spans/SQS call |
## Graceful Shutdown
```python
# FastAPI lifespan (recommended)
@asynccontextmanager
async def lifespan(app):
await processor.start()
yield
await processor.shutdown() # Drains queue, flushes WAL, closes connections
# Sync shutdown
import atexit
atexit.register(lambda: (exporter.force_flush(), exporter.shutdown()))
```
## Development
```bash
git clone https://github.com/NeuralgoLyzr/otel-messagequeue-exporter.git
cd otel-messagequeue-exporter
# Install with dev dependencies
uv sync --all-extras
# Run tests
uv run pytest
# Run benchmarks
uv run python benchmarks/bench_pipeline.py
```
## License
MIT
| text/markdown | null | Abhishek Bhat <abhishek.bhat@lyzr.ai> | null | null | MIT | opentelemetry, tracing, observability, telemetry | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Py... | [] | null | null | >=3.8.1 | [] | [] | [] | [
"opentelemetry-api>=1.20.0",
"opentelemetry-sdk>=1.20.0",
"opentelemetry-proto>=1.20.0",
"protobuf>=4.0.0",
"boto3>=1.28.0; extra == \"aws\"",
"azure-servicebus>=7.11.0; extra == \"azure\"",
"boto3>=1.28.0; extra == \"all\"",
"azure-servicebus>=7.11.0; extra == \"all\"",
"pytest>=7.0.0; extra == \"d... | [] | [] | [] | [
"Homepage, https://github.com/NeuralgoLyzr/otel-messagequeue-exporter",
"Documentation, https://github.com/NeuralgoLyzr/otel-messagequeue-exporter#readme",
"Repository, https://github.com/NeuralgoLyzr/otel-messagequeue-exporter",
"Bug Tracker, https://github.com/NeuralgoLyzr/otel-messagequeue-exporter/issues"... | twine/6.2.0 CPython/3.11.14 | 2026-02-19T21:23:02.375417 | otel_messagequeue_exporter-0.1.2.tar.gz | 28,133 | e0/8e/ef75dafa3bf4f2f27550e63084b04b4b8b66354e625fc59a5bb912fb73ea/otel_messagequeue_exporter-0.1.2.tar.gz | source | sdist | null | false | b4f4b9d2adec2e8acb44d3fb5ddba2ec | fc7f51cf064081457ac269ff2f5abaa42ecdbefd5d09de317b6bfccb986bb2fa | e08eef75dafa3bf4f2f27550e63084b04b4b8b66354e625fc59a5bb912fb73ea | null | [
"LICENSE"
] | 266 |
2.4 | mfawesome | 0.1.91 | CLI multi-factor authenticator: TOTP/HOTP 2FA/MFA codes in the terminal, encrypted secrets storage, Google Authenticator QR import/export, NTP time sync, fuzzy search | [](https://pypi.org/project/mfawesome)
[](https://pypi.org/project/mfawesome)
<div align="center">
<h1><img src="https://github.com/rpm5099/mfawesome/blob/e22d7b1387ec9e6492e82327da3c17fd543c585d/images/lock_logo_3d_400.png?raw=true"/></h1>
</div>

# **MFAwesome: CLI Multi Factor Authenticaton**
# Summary
**MFAwesome** (MFA) is an open-source system cross-platform command line based multifactor authentication tool. It allows secure storage of your TOTP and HOTP secrets in a simple config file that can be exported for use even on systems you do not trust. It allows importing secrets via Google Authenticator QR codes. Anything that refers to using your "Authenticator App" can be stored and accessed in MFAwesome. In addition, you can store any secrets in `mfawesome.conf` and they will be searchable, exportable, and secure once encrypted. It can also be used to read the raw contents of any QR code
MFA provides keylogger protection, fuzzy matching on secret names, multiple encryption options and automatic synchronization via public NTP servers (custom NTP sever can be set in the config). It is faster and easier for those accustomed to CLI than using an app on your phone.
The bottom line is this: if both of your two factor authentication methods are available on your mobile device the second factor provides no security against an attacker with access to it.
# Preview

# Issue Reporting
If you have any MF'ing issues with the MF'ing package contact the MF'ing author or submit an MF'ing ticket so he can make it ***MFAWesome***.
# Requirements
Python:
`python>=3.11`
Python Libraries `pip install mfawesome`:
- `rich` (CLI Display output)
- `pyyaml` (Config/Secrets storage)
- `cryptography` (Secrets encryption)
- `numpy` (math)
- `protobuf` (Google Authenticator QR Generation)
- `opencv-contrib-python-headless` (Google Authenticator QR Generation, QR Reading)
- `qrcode[pil]` (QR Code Generation)
| :zap: NOTE |
| ----------- |
According to the instructions provided with [opencv-contrib-python-headless](https://pypi.org/project/opencv-python-headless/) you are advised to remove any existing installations of opencv as they all share the same `cv2` namespace and will conflict.
# Installation
There are several methods to test/install MFAwesome on your system.
## PyPI: The standard way
MFAwesome is on `PyPI`. By using PyPI, you will be using the latest
stable version.
- To install MFAwesome, simply use `pip`:
`pip install --user mfawesome`
- For a full installation (with dev features):
`pip install --user mfawesome[all]`
- To upgrade MFAwesome to the latest version:
`pip install --user --upgrade mfawesome`
- To install the latest development version:
`pip install -U -i https://test.pypi.org/simple/ mfawesome`
# Config File
The config file is named `mfawesome.conf` by default. This can be changed by specifying via environment variable. It is formatted in [YAML](https://yaml.org/spec/1.2.2/). It's location is checked for in the following resolution order which can be checked using `mfa config debug`:
1. MFAWESOME_CONFIG environment variable (full file name with path)
2. Local directory for mfawesome.conf
3. `~/mfawesome.conf` (profile home)
4. `~/.config/mfawesome/mfawesome.conf` (default location)
5. Provided as a command line argument using `mfa --configfile`
**ALL** secrets are entered in the config file, either manually while it is not encrypted or via the command line using `mfa secrets add` and `mfa secrets import` (removal via `mfa secrets remove`). Other metadata is fine to enter in the yaml config file and will be encrypted along with the secrets. The only *required* section in the config file is `secrets`.
`mfa secrets add` takes a single parameter which must be in the form of json/python dictionary, i.e.:
`{"secretname": {"totp":"SECRETCODE", "user":"theduke", "url":"www.example.com"}}`
The active config file in use can be located via `mfa config debug` (similar to `pip config debug`). The option `mfa secrets export` can be used to export the existing secrets in the config file in QR code format.
The option `mfa config print` can be used to \[decrypt\] and display the full config file (*subjecting it to command line output logging*).
A double underscore - `__disabled_secret` in the `secrets` section of the config will disable the TOTP/HOTP calculation for that secret.
# NTP Time Servers
A list of time servers to use can be specified either via the `NTP_SERVERS` environment variable or within the config file under the root as `timeserver` (see config options below).
:zap: Having the correct time is essential to ensuring that the 2FA codes provided are correct. Most of the time they operate on 30 second intervals, so even a small difference in time between MFA and the authentication server is problematic.
# Environment Variables
All environment variables take precedence over the config file, but not over manually passed arguments. Secrets cannot be stored in environment variables.
## MFAWESOME_CONFIG
The environment variable `MFAWESOME_CONFIG`, if set, will be used as the path to the config file. If the file does not exist or is invalid an exception will be raised.
## MFAWESOME_PWD
The environment variable `MFAWESOME_PWD`, if set, will be used as the password to decrypt secrets. An attempt to decrypt or export secrets will still request that the password be entered for validation.
:zap: ***NOTE:*** *It is recommended to only store your password this way on machines that you trust. Environment variables can be logged.*
## MFAWESOME_LOGLEVEL
If set `MFAWESOME_LOGLEVEL` will override the setting in the config file, but not the level passed as a command line argument using `--loglevel`.
## NTP_SERVERS
The environment variable `NTP_SERVERS` can be specified as a colon `:` separated list of NTP time servers. If none of the specified NTP servers can be contacted MFAwesome will fall back to the local system time, which if incorrect, _will cause time based codes to be incorrect._ A warning will be displayed if this is the case.
## MFAWESOME_TEST
This environment variable is only used for testing, do not enable.
# Encryption Details
Password hashing is accomplished via
[Scrypt](https://www.tarsnap.com/scrypt/scrypt.pdf) and the encryption
cipher is
[ChaCha20-Poly1305](https://en.wikipedia.org/wiki/ChaCha20-Poly1305)
using the Python [Cryptography](https://cryptography.io/en/latest/)
library ([source](https://github.com/pyca/cryptography)) which uses [OpenSSL](https://www.openssl.org/)
because it is the de facto standard for cryptographic libraries and provides
high performance along with various certifications. More info on
[Poly1305](https://cr.yp.to/mac/poly1305-20050329.pdf) and
[ChaCha](https://cr.yp.to/chacha/chacha-20080128.pdf). Scrypt is purpose
built to be both (A) configurable in how much work is required to
calculate a hash and (B) computationally and/or memory expensive
(depending on settings). These algorithms are considered
state-of-the-art as of 2024. The following settings are used for Scrypt
password hashing:
- CPU cost: 2\*\*14
- Blocksize: 8
- Parallelization: 1
Salt, Chacha \"add\" and Chacha \"nonce\" are generated using `secrets.token_bytes(...)`.
# Other Config File Options
**keylogprotection**
Setting this option to [true]{.title-ref} will display a randomized set of characters each time it is used that are used to enter your password, ensuring that keystroke loggers record only random characters, rather than your password. This option is set by default when using `mfa config export`. Note that `mfa config export` is for exporting the entire config file and `mfa secrets export` is for exporting specific secrets in QR code format.
**loglevel**
At the root level of the config file loglevel can be entered as either an integer or ascii value using `-L` (*Note: ASCII log levels are not case sensitive*):
| ASCII Log Level | Integer Log Level |
| :-------------- | ----------------: |
| DISABLED | 0 |
| DEBUG | 10 |
| INFO | 20 |
| WARNING | 30 |
| ERROR | 40 |
| CRITICAL | 50 |
**timeserver**
If you would like to force MFAwesome to use a specific time server include it under the [timeserver]{.title-ref} field in the root of the config. Otherwise a saved list of known publicly available timeservers will be used. The use of a timerserver ensures that the program has accurate time for calculating time based authentication codes.
# Command Line Options
MFAwesome is executed by running `mfa` at command line. There are three optional arguments that apply to any `mfa` command, and they must be specified immediatly following `mfa`. `--configfile` is used to override the default config and the `MFAWESOME_CONFIG` to use a specific config file for that execution only. `-L` is used to set the log level. `-T` is for test mode - *do not use as it could potentially expose secrets.*
## Sub-Commands
There are five `mfa` subcommands some of which in turn have additional subcommands. To reduce the keystrokes to display secrets the `run` subcommand is assumed if the first term after `mfa` is not one of the five subcommands. For example `mfa banksecret` is equivalent to running `mfa run banksecret`. Similarly running that same command while specifying a config file and exact secrets matching would be `mfa --configfile someconfig.conf -e banksecrets` and `mfa --configfile someconfig.conf run -e banksecrets` respectively. Note that the `-e` is actually an argument to `run`, and must be specified immediately following it.
`mfa -s` will show protected information about the secret including the raw TOTP code and password is stored.
| :exclamation: WARNING |
| ---------------------- |
Showing secrets will subject the to viewing by others as well as terminal output logging. A warning is issued if the config option `keylogprotection: true` is set.

`mfa -c`: Run and display codes for 90s (or whatever is specified as timeout)

```
$mfa -h
usage: MFAwesome [-h] [--configfile CONFIGFILE] [-L LOGLEVEL] [-T] <run config secrets version hotp test> ...
__ ____________
/ |/ / ____/ |_ _____ _________ ____ ___ ___
/ /|_/ / /_ / /| | | /| / / _ \/ ___/ __ \/ __ `__ \/ _ \
/ / / / __/ / ___ | |/ |/ / __(__ ) /_/ / / / / / / __/
/_/ /_/_/ /_/ |_|__/|__/\___/____/\____/_/ /_/ /_/\___/
MFAwesome Multifactor Authentication CLI tool. Protect your secrets and access them easily. Run 'mfa'
options:
-h, --help show this help message and exit
--configfile CONFIGFILE
Specify config file with your secrets
-L, --loglevel LOGLEVEL
Set loglevel
-T, --test Run in test mode - FOR DEBUGGING ONLY
MFA Commands:
<run config secrets version hotp test>
run Run mfa and display codes
version Show version and exit
test Run MFAwesome tests via pytests
hotp Display HOTP codes
config Config related sub-commands
secrets Secrets related sub-commands
```
```
$mfa run -h
usage: MFAwesome run [-h] [-c] [-e] [-s] [-l] [-n] [-E] [-t TIMELIMIT] [-N] [filterterm]
positional arguments:
filterterm Optional term to filter displayed secrets
options:
-h, --help show this help message and exit
-c, --continuous Enable continuous code display - default to 90 but add optional argument for otherwise
-e, --exact Disable fuzzy matching on secret filterterm
-s, --showsecrets Enable showing secrets - WARNING: this will reveal sensitive information on your screen
-l, --noclearscreen Disable clearing the screen before exit - WARNING - can leave sensitive data on the screen
-n, --now Get codes now even if they expire very soon. N/A for continuous.
-E, --showerr Show errors getting and parsing codes
-t TIMELIMIT, --timelimit TIMELIMIT
Length of time to show codes continuously (Default 90.0 seconds)
-N, --noendtimer Disable countdown timer for codes, N/A for --continuous
```
- `hotp`: Same as run, except for HOTP codes. Counters are automatically incremented when the HOTP codes are displayed. They can be modified in the config file manually if necessary.
```
$mfa hotp -h
usage: MFAwesome hotp [-h] [-c] [-e] [-s] [filterterm]
positional arguments:
filterterm Optional term to filter displayed secrets
options:
-h, --help show this help message and exit
-c, --continuous Enable continuous code display - default to 90 but add optional argument for otherwise
-e, --exact Disable fuzzy matching on secret filterterm
-s, --showsecrets Enable showing secrets - WARNING: this will reveal sensitive information on your screen
```
- `config`: Commands related to config file management
```
$mfa config -h
usage: MFAwesome config [-h] <debug encrypt decrypt password print generate> ...
options:
-h, --help show this help message and exit
mfa config commands:
<debug encrypt decrypt password print generate>
Config file operations
generate Generate a new config file in the default location '$HOME/.config/mfawesome/mfawesome.conf'
encrypt Encrypt secrets in config file (if not already encrypted)
decrypt Permanently decrypt secrets in config file (if encrypted)
export Export config to the specified file (required). Keylog protection will be enabled. Please see the documentation for details
print Print entire unencrypted config and exit
debug Show config file resolution details
password Change password for secrets - unencrypted secrets are never written to disk
```
- `secrets`: Commands related to managing secrets.
```
$mfa secrets -h
usage: MFAwesome secrets [-h] <search generate remove export import qread> ...
options:
-h, --help show this help message and exit
mfa secrets commands:
<search generate remove export import qread>
Secrets operations
search Search through all secrets for a filtertem and display matching.
generate Generate and print an OTP secret key
remove Remove a secret by specifying the secret name
export Export codes in QR images to be scanned by Google Authenticator
import Import codes from QR images
add Add new secret(s), must be in dict json format: {"secretname": {"totp":"SECRETCODE", "user":"theduke", "url":"www.example.com"}}. Multiple secrets are acceptable
qread Read QR image and output the raw data
```
`mfa config encrypt`

`mfa config decrypt`

`mfa config print`

`mfa config debug`

`mfa hotp`

| :exclamation: WARNING |
| ---------------------- |
Running in debug mode can output sensitive information to the terminal and could potentially be logged. A warning is issued if the config option `keylogprotection: true` is set.
`mfa secrets search`

- `--addqrsecrets TEXT`: The required term is the name of the directory containing screenshots/images of QR images from Google Authenticator (or other source) you wish to import to your config
| :exclamation: WARNING |
| ---------------------- |
***MFAwesome makes every attempt to ensure that your secrets are cleared from the screen following execution unless you have explicitly enabled \'\--noclearscreen/-l\', including on keyboard interrupt (SIGINT signal). However, Ctrl+Z (SIGTSTP signal) will stop the processs without leaving python a chance to clear output.***


`mfa test`: Run self tests
# Running From a Jupyter Notebook
``` python
from mfawesome import mfa
mfa("run")
mfa("secrets export /tmp/mfa")
```
| :iphone: Mobile Import |
| ---------------------- |
`secrets export` run in Jupyter will display the QR images to scan for import into your mobile device
# License
MFAwesome is distributed under the license described in the `LICENSE` file.
# Author
Rob Milloy (\@rpm5099) <rob@milloy.net>
| text/markdown | Rob Milloy | rob@milloy.net | null | null | null | 2fa, mfa, cli, totp, otp, two-factor, command-line, security, encryption, time-based, one-time-password, multi-factor, hotp, HMAC, authentication, authenticator, google-authenticator, terminal, qrcode, secrets, mfawesome | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: End Users/Desktop",
"Intended Audience :: Information Technology",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: MIT License",
"Natural Language... | [] | null | null | >=3.10 | [] | [] | [] | [
"PyYAML",
"coverage; extra == \"all\"",
"coverage; extra == \"dev\"",
"coverage; extra == \"test\"",
"cryptography>=42.0",
"dnspython; extra == \"all\"",
"dnspython; extra == \"dns\"",
"numpy",
"opencv-contrib-python-headless>=4.5",
"protobuf",
"pytest; extra == \"all\"",
"pytest; extra == \"d... | [] | [] | [] | [
"Bug Tracker, https://github.com/rpm5099/mfawesome/issues",
"Homepage, https://github.com/rpm5099/mfawesome",
"Repository, https://github.com/rpm5099/mfawesome"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:22:45.352964 | mfawesome-0.1.91.tar.gz | 70,566 | db/fb/048bd2c58b69d0d9badaa50aa754a17c62161c16b1040febfa6380432a53/mfawesome-0.1.91.tar.gz | source | sdist | null | false | cf8763be072e2dbfcea195f6bf910e8e | a25891de58dea29e51921ebead60820753420f4e5f7bacb8ecb07dcf4b9142a6 | dbfb048bd2c58b69d0d9badaa50aa754a17c62161c16b1040febfa6380432a53 | MIT | [
"LICENSE"
] | 244 |
2.4 | shar | 0.1.6 | Простой магазин на PyQt6 + MySQL | # shar
Простой магазин на PyQt6 + MySQL.
## Установка
```bash
pip install shar
```
## Получить файлы (app.py, database.sql, database.txt)
```bash
shar-get
```
Скопирует в текущую папку:
- app.py
- database.sql
- database.txt
## Запуск приложения
```bash
shar
```
## Требования
- Python 3.8+
- MySQL
- Выполни database.sql (или database.txt) в MySQL Workbench
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"pymysql>=1.1.0",
"PyQt6>=6.6.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T21:21:45.074101 | shar-0.1.6.tar.gz | 13,572 | c1/c2/0a19ad7b5da256917860a542c1aeedd1ede3ec66e4c469e9eba6c5919e93/shar-0.1.6.tar.gz | source | sdist | null | false | 1ea31136dc57299ded9789c7a46db546 | bfd11b60345a23d7546aed6fe4869ac11b41868aa33fe6838825429343619fa7 | c1c20a19ad7b5da256917860a542c1aeedd1ede3ec66e4c469e9eba6c5919e93 | MIT | [
"LICENSE"
] | 247 |
2.1 | sas-yolov7-seg | 1.0.4 | SAS YOLOv7 Seg | # Yolov7-seg
This python package is an implementation of "YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors".
This implementation is based on [yolov5](https://github.com/ultralytics/yolov5).
This is a tailored version for use of the SAS Viya DLModelZoo action set.
### Installation
To install Yolov7-seg, use the following command:
`pip install sas-yolov7-seg`
## Contributing
We welcome your contributions! Please read [CONTRIBUTING.md](CONTRIBUTING.md) for details on how to submit contributions to this project.
## License
This project is licensed under the [GNU GENERAL PUBLIC LICENSE 3.0 License](LICENSE.md).
## Additional Resources
* [https://github.com/AlexeyAB/darknet](https://github.com/AlexeyAB/darknet)
* [https://github.com/WongKinYiu/yolor](https://github.com/WongKinYiu/yolor)
* [https://github.com/WongKinYiu/PyTorch_YOLOv4](https://github.com/WongKinYiu/PyTorch_YOLOv4)
* [https://github.com/WongKinYiu/ScaledYOLOv4](https://github.com/WongKinYiu/ScaledYOLOv4)
* [https://github.com/Megvii-BaseDetection/YOLOX](https://github.com/Megvii-BaseDetection/YOLOX)
* [https://github.com/ultralytics/yolov3](https://github.com/ultralytics/yolov3)
* [https://github.com/ultralytics/yolov5](https://github.com/ultralytics/yolov5)
* [https://github.com/DingXiaoH/RepVGG](https://github.com/DingXiaoH/RepVGG)
* [https://github.com/JUGGHM/OREPA_CVPR2022](https://github.com/JUGGHM/OREPA_CVPR2022)
* [https://github.com/TexasInstruments/edgeai-yolov5/tree/yolo-pose](https://github.com/TexasInstruments/edgeai-yolov5/tree/yolo-pose)
* [https://github.com/WongKinYiu/yolov7/tree/u7](https://github.com/WongKinYiu/yolov7/tree/u7)
| text/markdown | SAS | support@sas.com | null | null | GNU GENERAL PUBLIC LICENSE 3.0 | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3.7",
"Topic :: Scientific/Engineering"
] | [] | https://github.com/sassoftware/yolov7-seg/ | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/5.1.1 CPython/3.9.16 | 2026-02-19T21:21:16.208153 | sas_yolov7_seg-1.0.4-py3-none-any.whl | 86,259,351 | 79/8e/aaf54cf5f833c8667c32540c2a98745b33d28f68bb822bafe1d524b66892/sas_yolov7_seg-1.0.4-py3-none-any.whl | py3 | bdist_wheel | null | false | 5052a7e11eccaeb4b0540d3f7dd95fc2 | 957d2215e249df09dd67d772f9bff44c9fd06c2fc0b904ed36355aee1f410c18 | 798eaaf54cf5f833c8667c32540c2a98745b33d28f68bb822bafe1d524b66892 | null | [] | 138 |
2.4 | talktollm | 0.8.2 | A Python utility for interacting with large language models (LLMs) via web automation | # talktollm
[](https://badge.fury.io/py/talktollm)
[](https://opensource.org/licenses/MIT)
A Python utility for interacting with large language models (LLMs) through browser automation. It leverages image recognition to automate interactions with LLM web interfaces, enabling seamless conversations and task execution.
## Features
- **Simple Interface:** Provides a single, intuitive function for interacting with LLMs.
- **Automated Image Recognition:** Employs image recognition (`optimisewait`) to identify and interact with elements on the LLM interface.
- **Multi-LLM Support:** Supports DeepSeek, Gemini, and Google AI Studio.
- **Automated Conversations:** Facilitates automated conversations and task execution by simulating user interactions.
- **Image Support:** Allows sending one or more images (as base64 data URIs) to the LLM.
- **Robust Clipboard Handling:** Includes retry mechanisms for setting and getting clipboard data, handling common access errors and timing issues.
- **Self-Healing Image Cache:** Creates a clean, temporary image cache for each run, preventing issues from stale or corrupted recognition assets.
- **Easy to use:** Designed for simple setup and usage.
## Core Functionality
The core function is `talkto(llm, prompt, imagedata=None, debug=False, tabswitch=True)`.
**Arguments:**
- `llm` (str): The LLM name ('deepseek', 'gemini', or 'aistudio').
- `prompt` (str): The text prompt to send.
- `imagedata` (list[str] | None): Optional list of base64 encoded image data URIs (e.g., "data:image/png;base64,...").
- `debug` (bool): Enable detailed console output. Defaults to `False`.
- `tabswitch` (bool): Switch focus back to the previous window after closing the LLM tab. Defaults to `True`.
**Steps:**
1. Validates the LLM name.
2. Ensures a clean temporary image cache is ready for `optimisewait`.
3. Opens the LLM's website in a new browser tab.
4. Waits for and clicks the message input area.
5. If `imagedata` is provided, it pastes each image into the input area.
6. Pastes the `prompt` text.
7. Clicks the 'run' or 'send' button.
8. Sets a placeholder value on the clipboard.
9. Waits for the 'copy' button to appear (indicating the response is ready) and clicks it.
10. Polls the clipboard until its content changes from the placeholder value.
11. Closes the browser tab (`Ctrl+W`).
12. Switches focus back if `tabswitch` is `True` (`Alt+Tab`).
13. Returns the retrieved text response, or an empty string if the process times out.
## Helper Functions
**Clipboard Handling:**
- `set_clipboard(text: str, retries: int = 5, delay: float = 0.2)`: Sets text to the clipboard. Retries on common access errors.
- `set_clipboard_image(image_data: str, retries: int = 5, delay: float = 0.2)`: Sets a base64 encoded image to the clipboard. Retries on common access errors.
- `_get_clipboard_content(...)`: Internal helper to read text from the clipboard with retry logic.
**Image Path Management:**
- `copy_images_to_temp(llm: str, debug: bool = False)`: **Deletes and recreates** the LLM-specific temporary image folder to ensure a clean state. Copies necessary `.png` images from the package's internal `images/` directory to the temporary location.
## Installation
```
pip install talktollm
```
*Note: Requires `optimisewait` for image recognition. Install separately if needed (`pip install optimisewait`).*
## Usage
Here are some examples of how to use `talktollm`.
**Example 1: Simple Text Prompt**
Send a basic text prompt to Gemini.
```python
import talktollm
prompt_text = "Explain quantum entanglement in simple terms."
response = talktollm.talkto('gemini', prompt_text)
print("--- Simple Gemini Response ---")
print(response)
```
**Example 2: Text Prompt with Debugging**
Send a text prompt to AI Studio and enable debugging output.
```python
import talktollm
prompt_text = "What are the main features of Python 3.12?"
response = talktollm.talkto('aistudio', prompt_text, debug=True)
print("--- AI Studio Debug Response ---")
print(response)
```
**Example 3: Preparing Image Data**
Load an image file, encode it in base64, and format it correctly for the `imagedata` argument.
```python
import base64
# Load your image (replace 'path/to/your/image.png' with the actual path)
try:
with open("path/to/your/image.png", "rb") as image_file:
# Encode to base64
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
# Format as a data URI
image_data_uri = f"data:image/png;base64,{encoded_string}"
print("Image prepared successfully!")
except FileNotFoundError:
print("Error: Image file not found. Please check the path.")
image_data_uri = None
# This 'image_data_uri' variable holds the string needed for the next example
```
**Example 4: Text and Image Prompt**
Send a text prompt along with a prepared image to DeepSeek. (Assumes `image_data_uri` was successfully created in Example 3).
```python
import talktollm
# Assuming image_data_uri is available from the previous example
if image_data_uri:
prompt_text = "Describe the main subject of this image."
response = talktollm.talkto(
'deepseek',
prompt_text,
imagedata=[image_data_uri], # Pass the image data as a list
debug=True
)
print("--- DeepSeek Image Response ---")
print(response)
else:
print("Skipping image example because image data is not available.")
```
## Dependencies
- `pywin32`: For Windows API access (clipboard).
- `pyautogui`: For GUI automation (keystrokes).
- `Pillow`: For image processing.
- `optimisewait` (Recommended): For robust image-based waiting and clicking.
## Contributing
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
## License
MIT
| text/markdown | Alex M | alexmalone489@gmail.com | null | null | null | llm, automation, gui, pyautogui, gemini, deepseek, clipboard, aistudio | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: Microsoft :: Windows",
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Communications :: Chat",
"Topic :: Scientific/Engineering :: Image Recognition"
] | [] | https://github.com/AMAMazing/talktollm | null | >=3.6 | [] | [] | [] | [
"pywin32",
"pyautogui",
"pillow",
"optimisewait"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.6 | 2026-02-19T21:20:54.056932 | talktollm-0.8.2.tar.gz | 80,528 | a8/93/cb7a846dbe1368e5c6a1cd11c964eb54305dde74e06c1e0c8fbfcf84dc3f/talktollm-0.8.2.tar.gz | source | sdist | null | false | 26d3f971b10b3f11c95e2e427d7eeb4f | 7a289d5bf08dae0a173401f70ec3563feb73625283c1dbe11ded8610a09d9323 | a893cb7a846dbe1368e5c6a1cd11c964eb54305dde74e06c1e0c8fbfcf84dc3f | null | [
"LICENSE"
] | 256 |
2.1 | sas-yolov7-pose | 1.0.3 | SAS YOLOv7 Pose | # Yolov7-pose
## Overview
This python package is an implementation of "YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors".
Pose estimation implimentation is based on [YOLO-Pose](https://arxiv.org/abs/2204.06806).
This is a tailored version for use of the SAS Viya DLModelZoo action set.
### Installation
To install YOLOv7-Pose, use the following command:
`pip install sas-yolov7-pose`
## Contributing
We welcome your contributions! Please read [CONTRIBUTING.md](CONTRIBUTING.md) for details on how to submit contributions to this project.
## License
This project is licensed under the [GNU GENERAL PUBLIC LICENSE 3.0 License](LICENSE.md).
## Additional Resources
* [https://github.com/AlexeyAB/darknet](https://github.com/AlexeyAB/darknet)
* [https://github.com/WongKinYiu/yolor](https://github.com/WongKinYiu/yolor)
* [https://github.com/WongKinYiu/PyTorch_YOLOv4](https://github.com/WongKinYiu/PyTorch_YOLOv4)
* [https://github.com/WongKinYiu/ScaledYOLOv4](https://github.com/WongKinYiu/ScaledYOLOv4)
* [https://github.com/Megvii-BaseDetection/YOLOX](https://github.com/Megvii-BaseDetection/YOLOX)
* [https://github.com/ultralytics/yolov3](https://github.com/ultralytics/yolov3)
* [https://github.com/ultralytics/yolov5](https://github.com/ultralytics/yolov5)
* [https://github.com/DingXiaoH/RepVGG](https://github.com/DingXiaoH/RepVGG)
* [https://github.com/JUGGHM/OREPA_CVPR2022](https://github.com/JUGGHM/OREPA_CVPR2022)
* [https://github.com/TexasInstruments/edgeai-yolov5/tree/yolo-pose](https://github.com/TexasInstruments/edgeai-yolov5/tree/yolo-pose)
* [https://github.com/WongKinYiu/yolov7/tree/pose](https://github.com/WongKinYiu/yolov7/tree/pose)
| text/markdown | SAS | support@sas.com | null | null | GNU GENERAL PUBLIC LICENSE 3.0 | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3.7",
"Topic :: Scientific/Engineering"
] | [] | https://github.com/sassoftware/yolov7-pose/ | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/5.1.1 CPython/3.9.16 | 2026-02-19T21:19:52.190879 | sas_yolov7_pose-1.0.3-py3-none-any.whl | 16,405,416 | 62/c9/1737f22ea4c3a46873f677f70a56213956a910f73aced36f705cc9602ae8/sas_yolov7_pose-1.0.3-py3-none-any.whl | py3 | bdist_wheel | null | false | 9f3654bc6159161807e4ec91ea59d0ad | 2ca8e4f681445d32c96098e767a6e3eb4a99cef5f016dc5846a36a00a3880180 | 62c91737f22ea4c3a46873f677f70a56213956a910f73aced36f705cc9602ae8 | null | [] | 112 |
2.4 | django-unfold-modal | 0.1.0 | Modal-based related-object popups for django-unfold | 
# django-unfold-modal
[](https://github.com/metaforx/django-unfold-modal/actions/workflows/ci.yml)
Modal-based related-object popups for [django-unfold](https://github.com/unfoldadmin/django-unfold).
Replaces Django admin's popup windows for related objects (ForeignKey, ManyToMany, etc.) with Unfold-styled modals.
## Features
- Modal replacement for admin related-object popups
- Supports nested modals (replace/restore behavior)
- Raw ID lookup + autocomplete + inline related fields
- Optional modal resize + size presets
- Optional admin header suppression inside iframe
- Stylable using Unfold theme configuration & custom CSS
## Motivation
As much as I love the Django admin, I’ve always found its related-object pop-ups clunky and outdated.
They open in separate browser windows, which breaks the flow and doesn’t fit modern UI patterns.
It’s fine for straightforward admin use, but when exposed to users, it often causes confusion.
[Django Unfold](https://github.com/unfoldadmin/django-unfold) greatly improves the admin’s UX for regular users.
This package modernizes related-object interactions while following Unfold’s design principles.
> **AI Disclaimer:** My goal was to research agentic capabilities in the development process of this package. All code was intentionally written by AI using structured, automated agent orchestration, including development and review by different models (Claude CLI Sonnet/Opus & Codex CLI), result verification, and regression testing.
>
> Design and implementation decisions were made by me and reviewed/tested.
>
> If interested in the process, see plans, tasks and reviews folder to get an idea of how the package was developed.
## Requirements
- Python 3.10+
- Django 5.0+
- django-unfold 0.52.0+ (tested with latest)
## Installation
```bash
pip install django-unfold-modal
```
> **Naming:** Install name is `django-unfold-modal`, import/app name is `unfold_modal` — mirroring the `django-unfold` / `unfold` pattern.
Add to your `INSTALLED_APPS` after `unfold`:
```python
INSTALLED_APPS = [
"unfold",
"unfold.contrib.filters",
"unfold_modal", # Add after unfold, before django.contrib.admin
"django.contrib.admin",
# ...
]
```
Add the required styles and scripts to your Unfold configuration in `settings.py`:
**Minimal setup:**
```python
from unfold_modal.utils import get_modal_styles, get_modal_scripts
UNFOLD = {
# ... other unfold settings ...
"STYLES": [
*get_modal_styles(),
],
"SCRIPTS": [
*get_modal_scripts(),
],
}
```
This setup loads only the core modal scripts. If you do not use the configuration options below, this is enough.
**Config-enabled setup** (for custom sizes and resize handle):
```python
from unfold_modal.utils import get_modal_styles, get_modal_scripts_with_config
UNFOLD = {
# ... other unfold settings ...
"STYLES": [
*get_modal_styles(),
],
"SCRIPTS": [
*get_modal_scripts_with_config(),
],
}
```
This setup adds a config script (served from `unfold_modal.urls`) before the core JS so the frontend can read size presets and `UNFOLD_MODAL_RESIZE`. See **Configuration** below for the options that require it.
## Configuration
The following settings are available (all optional):
```python
# Content loading strategy: "iframe" (default, v1 only)
UNFOLD_MODAL_VARIANT = "iframe"
# Presentation style: "modal" (default, v1 only)
UNFOLD_MODAL_PRESENTATION = "modal"
# Modal size preset: "default", "large", or "full"
UNFOLD_MODAL_SIZE = "default"
# Enable manual resize handle on modal (default: False)
UNFOLD_MODAL_RESIZE = False
# Hide admin header inside modal iframes (default: True)
UNFOLD_MODAL_DISABLE_HEADER = True
```
### Size Presets
To use custom size presets (`UNFOLD_MODAL_SIZE`) or enable resize (`UNFOLD_MODAL_RESIZE`):
1. Include the app's URLs in your `urls.py`:
```python
from django.urls import include, path
urlpatterns = [
path("admin/", admin.site.urls),
path("unfold-modal/", include("unfold_modal.urls")),
]
```
2. Use `get_modal_scripts_with_config` instead of `get_modal_scripts` in your UNFOLD configuration (see Installation section above).
| Preset | Width | Max Width | Height | Max Height |
|-----------|-------|-----------|--------|------------|
| `default` | 90% | 900px | 85vh | 700px |
| `large` | 95% | 1200px | 90vh | 900px |
| `full` | 98% | none | 95vh | none |
## Supported Widgets
- ForeignKey select
- ManyToMany select
- OneToOne select
- `raw_id_fields` lookup
- `autocomplete_fields` (Select2)
- Related fields within inline forms
## Testing
```bash
pytest -q
pytest --browser chromium
```
See `tests/README.md` for the test app overview and Playwright scope.
## CI
GitHub Actions runs on all PRs and pushes to `main`/`development`:
- Unit tests across Python 3.10, 3.11, 3.12
- Playwright UI tests with Chromium
Configure branch protection to require the CI check to pass before merging.
## License
MIT
| text/markdown | null | Marc Widmer <marc@pbi.io> | null | null | null | admin, django, modal, popup, related widget, unfold | [
"Development Status :: 3 - Alpha",
"Environment :: Web Environment",
"Framework :: Django",
"Framework :: Django :: 5.0",
"Framework :: Django :: 5.1",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :... | [] | null | null | >=3.10 | [] | [] | [] | [
"django-unfold>=0.52.0",
"django>=5.0"
] | [] | [] | [] | [
"Homepage, https://github.com/metaforx/django-unfold-modal",
"Repository, https://github.com/metaforx/django-unfold-modal"
] | python-httpx/0.28.1 | 2026-02-19T21:19:35.200932 | django_unfold_modal-0.1.0-py3-none-any.whl | 18,944 | 99/f1/968da93f400b6ef21e5784f7bb9090860ae9e9ad65f9e222a425410b433e/django_unfold_modal-0.1.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 1d2fcea38af94be2b36c4c65221a1e56 | af953e76dad190127e9b9ce0800673f1f9e2299d697f8f2cb1d90893afb18305 | 99f1968da93f400b6ef21e5784f7bb9090860ae9e9ad65f9e222a425410b433e | MIT | [
"LICENSE"
] | 266 |
2.4 | alembic-pg-autogen | 0.0.2 | Alembic autogenerate extension for PostgreSQL-specific objects | # alembic-pg-autogen
Alembic autogenerate extension for PostgreSQL. Extends Alembic's `--autogenerate` to detect and emit migrations for
PostgreSQL functions and triggers that Alembic doesn't handle out of the box.
## How it works
You declare your desired functions and triggers as DDL strings. When you run `alembic revision --autogenerate`, the
extension:
1. **Inspects** the current database catalog (`pg_proc`, `pg_trigger`)
1. **Canonicalizes** your DDL by executing it in a savepoint and reading back the catalog (then rolling back)
1. **Diffs** current vs. desired state, matching objects by identity
1. **Emits** `CREATE`, `DROP`, or `CREATE OR REPLACE` operations in dependency-safe order (drop triggers before
functions, create functions before triggers)
## Installation
```bash
pip install alembic-pg-autogen
```
Requires Python 3.10+ and SQLAlchemy 2.x. You provide your own PostgreSQL driver (psycopg, psycopg2, asyncpg, etc.).
## Usage
In your `env.py`, import the extension and pass your DDL via `process_revision_directives` options:
```python
import alembic_pg_autogen # noqa: F401 # registers the comparator plugin
# Define your functions and triggers as DDL strings
PG_FUNCTIONS = [
"""
CREATE OR REPLACE FUNCTION audit_trigger_func()
RETURNS trigger LANGUAGE plpgsql AS $$
BEGIN
NEW.updated_at = now();
RETURN NEW;
END;
$$
""",
]
PG_TRIGGERS = [
"""
CREATE TRIGGER set_updated_at
BEFORE UPDATE ON my_table
FOR EACH ROW EXECUTE FUNCTION audit_trigger_func()
""",
]
```
Then in your `run_migrations_online()` function, pass them as context options:
```python
context.configure(
connection=connection,
target_metadata=target_metadata,
opts={
"pg_functions": PG_FUNCTIONS,
"pg_triggers": PG_TRIGGERS,
},
)
```
Run autogenerate as usual:
```bash
alembic revision --autogenerate -m "add audit trigger"
```
The generated migration will contain `op.execute()` calls with the appropriate `CREATE`, `DROP`, or `CREATE OR REPLACE`
statements.
## Development
```bash
make install # Install dependencies (uses uv)
make lint # Format (mdformat, codespell, ruff) then type-check (basedpyright)
make test # Run full test suite (requires Docker for integration tests)
make test-unit # Run unit tests only (no Docker needed)
```
## License
MIT
| text/markdown | null | Edward Jones <edwardrjones97@gmail.com> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.... | [] | null | null | >=3.10 | [] | [] | [] | [
"alembic>=1.18",
"sqlalchemy>=2"
] | [] | [] | [] | [
"Repository, https://github.com/eddie-on-gh/alembic-pg-autogen"
] | uv/0.10.2 {"installer":{"name":"uv","version":"0.10.2","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T21:19:19.723125 | alembic_pg_autogen-0.0.2-py3-none-any.whl | 13,377 | bf/f3/4ca6a6504841491cc65a30f678c8c65fc9c8c2175552fe34ca07483c58ef/alembic_pg_autogen-0.0.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 65aed0b8e92e2594bb22367020eacb48 | c0b1ebe8277e7d6342c8e400b5ef454bb34b777bf9d75545ea2f1cc89c1cf07a | bff34ca6a6504841491cc65a30f678c8c65fc9c8c2175552fe34ca07483c58ef | MIT | [
"LICENSE"
] | 263 |
2.4 | paystack-django | 1.1.1 | A comprehensive Django integration for Paystack Payment Gateway | # paystack-django
A comprehensive Django integration for the **Paystack Payment Gateway**. This package provides a complete, production-ready solution for integrating Paystack payments into your Django applications.
[](https://badge.fury.io/py/paystack-django)
[](https://www.djangoproject.com)
[](https://www.python.org)
[](https://opensource.org/licenses/MIT)
## Features
- **Complete Paystack API Coverage** — 26 API modules covering every Paystack endpoint
- **Django Models** — Pre-built models for transactions, customers, plans, subscriptions, transfers, and webhook events
- **Webhook System** — Signature-verified webhook handling with IP whitelisting and event deduplication
- **Django Signals** — Signals for payment success/failure, subscriptions, transfers, refunds, and disputes
- **System Checks** — Django startup checks validate your Paystack configuration
- **Context Manager** — `PaystackClient` supports `with` statements for clean session management
- **Retry & Backoff** — Automatic retries with exponential back-off on transient failures
- **Type Hints** — Fully typed with `py.typed` marker for IDE and mypy support
- **Production Ready** — Secure defaults, lazy logging, Decimal-safe currency conversion
## Supported Services
| Category | API Modules |
|----------|------------|
| **Payments** | Transactions, Charge, Payment Requests, Pages |
| **Customers** | Customers, Direct Debit, Dedicated Accounts |
| **Recurring** | Plans, Subscriptions |
| **Payouts** | Transfers, Transfer Recipients, Transfer Control |
| **Commerce** | Products, Splits, Subaccounts |
| **Operations** | Refunds, Disputes, Settlements, Bulk Charges |
| **Other** | Verification, Terminal, Virtual Terminal, Apple Pay, Integration, Miscellaneous |
## Installation
```bash
pip install paystack-django
```
## Quick Start
### 1. Add to Django Settings
```python
# settings.py
INSTALLED_APPS = [
# ...
'djpaystack',
]
PAYSTACK = {
'SECRET_KEY': 'sk_live_your_secret_key_here',
'PUBLIC_KEY': 'pk_live_your_public_key_here',
'WEBHOOK_SECRET': 'whsec_your_webhook_secret',
}
```
### 2. Run Migrations
```bash
python manage.py migrate djpaystack
```
### 3. Initialize a Transaction
```python
from djpaystack import PaystackClient
client = PaystackClient()
response = client.transactions.initialize(
email='customer@example.com',
amount=50000, # Amount in kobo (500 NGN)
reference='order-001',
)
authorization_url = response['data']['authorization_url']
# Redirect user to authorization_url
```
The client can also be used as a context manager:
```python
with PaystackClient() as client:
response = client.transactions.verify(reference='order-001')
```
### 4. Verify Transaction
```python
response = client.transactions.verify(reference='order-001')
if response['data']['status'] == 'success':
print("Payment successful!")
```
### 5. Set Up Webhooks
```python
# urls.py
from django.urls import path
from djpaystack.webhooks.views import handle_webhook
urlpatterns = [
path('webhooks/paystack/', handle_webhook, name='paystack_webhook'),
]
```
Configure the webhook URL in your [Paystack Dashboard](https://dashboard.paystack.com/settings/developer).
## Usage Examples
### Customers
```python
client = PaystackClient()
# Create customer
response = client.customers.create(
email='customer@example.com',
first_name='John',
last_name='Doe',
phone='2348012345678',
)
# Fetch customer
response = client.customers.fetch(email_or_code='CUS_xxxxx')
```
### Subscriptions
```python
# Create a plan
response = client.plans.create(
name='Monthly Pro',
amount=500000, # 5,000 NGN
interval='monthly',
)
plan_code = response['data']['plan_code']
# Subscribe a customer
response = client.subscriptions.create(
customer='CUS_xxxxx',
plan=plan_code,
authorization='AUTH_xxxxx',
)
```
### Transfers
```python
# Create transfer recipient
response = client.transfer_recipients.create(
type='nuban',
name='John Doe',
account_number='0000000000',
bank_code='058',
)
recipient_code = response['data']['recipient_code']
# Initiate transfer
response = client.transfers.initiate(
source='balance',
amount=50000,
recipient=recipient_code,
reason='Payout',
)
```
### Charge (Card, Bank Transfer, USSD, QR, EFT)
```python
# Charge with bank transfer
response = client.charge.create(
email='customer@example.com',
amount=50000,
bank_transfer={'account_expires_at': '2025-12-31T23:59:59'},
)
# Charge with QR code (scan-to-pay)
response = client.charge.create(
email='customer@example.com',
amount=50000,
qr={'provider': 'visa'},
)
```
### Refunds
```python
# Create refund
response = client.refunds.create(transaction='123456')
# Retry a stuck refund
response = client.refunds.retry(id='123456')
```
### Dedicated Virtual Accounts
```python
# Single-step assignment
response = client.dedicated_accounts.assign(
email='customer@example.com',
first_name='John',
last_name='Doe',
phone='+2348012345678',
preferred_bank='wema-bank',
)
```
### Dynamic Transaction Splits
```python
response = client.transactions.initialize(
email='customer@example.com',
amount=100000,
split={
'type': 'percentage',
'bearer_type': 'account',
'subaccounts': [
{'subaccount': 'ACCT_xxx', 'share': 30},
{'subaccount': 'ACCT_yyy', 'share': 20},
],
},
)
```
## Webhook Signals
Listen for payment events using Django signals:
```python
from django.dispatch import receiver
from djpaystack.signals import paystack_payment_successful, paystack_payment_failed
@receiver(paystack_payment_successful)
def on_payment_success(sender, transaction_data, **kwargs):
reference = transaction_data['reference']
# Fulfil the order
@receiver(paystack_payment_failed)
def on_payment_failed(sender, transaction_data, **kwargs):
reference = transaction_data['reference']
# Notify the customer
```
Available signals: `paystack_payment_successful`, `paystack_payment_failed`, `paystack_subscription_created`, `paystack_subscription_cancelled`, `paystack_transfer_successful`, `paystack_transfer_failed`, `paystack_refund_processed`, `paystack_dispute_created`, `paystack_dispute_resolved`.
## Configuration Reference
```python
PAYSTACK = {
# Required
'SECRET_KEY': 'sk_...',
'PUBLIC_KEY': 'pk_...',
# Webhook
'WEBHOOK_SECRET': 'whsec_...',
'ALLOWED_WEBHOOK_IPS': [], # Empty = Paystack default IPs
# API behaviour
'BASE_URL': 'https://api.paystack.co',
'TIMEOUT': 30,
'MAX_RETRIES': 3,
'VERIFY_SSL': True,
'CURRENCY': 'NGN',
'ENVIRONMENT': 'production', # 'production' or 'test'
# Features
'AUTO_VERIFY_TRANSACTIONS': True,
'ENABLE_SIGNALS': True,
'ENABLE_MODELS': True,
'CACHE_TIMEOUT': 300,
'LOG_REQUESTS': False,
'LOG_RESPONSES': False,
'CALLBACK_URL': None,
}
```
## Django Models
```python
from djpaystack.models import (
PaystackTransaction,
PaystackCustomer,
PaystackPlan,
PaystackSubscription,
PaystackTransfer,
PaystackWebhookEvent,
)
```
## Error Handling
```python
from djpaystack.exceptions import (
PaystackError,
PaystackAPIError,
PaystackValidationError,
PaystackAuthenticationError,
PaystackNetworkError,
)
try:
response = client.transactions.verify(reference='ref-123')
except PaystackAuthenticationError:
print("Invalid API key")
except PaystackNetworkError:
print("Network error — will be retried automatically")
except PaystackAPIError as e:
print(f"API error: {e}")
```
## Django Compatibility
| paystack-django | Django 3.2 | 4.0 | 4.1 | 4.2 | 5.0 | 5.2 | 6.0 |
|-----------------|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| 1.1.x | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Python 3.8 – 3.14 supported.
## Testing
```bash
pip install -e ".[dev]"
pytest --cov=djpaystack
```
## Documentation
Full documentation is available at [paystack-django.readthedocs.io](https://paystack-django.readthedocs.io/).
## Contributing
See [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
## License
MIT — see [LICENSE](LICENSE).
## Links
- [Full Documentation](https://paystack-django.readthedocs.io/)
- [PyPI](https://pypi.org/project/paystack-django/)
- [GitHub](https://github.com/HummingByteDev/paystack-django)
- [Bug Tracker](https://github.com/HummingByteDev/paystack-django/issues)
- [Changelog](CHANGELOG.md)
---
**Made with ❤️ by [Humming Byte](https://hummingbyte.org)**
| text/markdown | Humming Byte | Humming Byte <dev@hummingbyte.org> | null | null | MIT | django, paystack, payment, payment-gateway, nigerian-payment | [
"Development Status :: 5 - Production/Stable",
"Environment :: Web Environment",
"Framework :: Django",
"Framework :: Django :: 3.2",
"Framework :: Django :: 4.0",
"Framework :: Django :: 4.1",
"Framework :: Django :: 4.2",
"Framework :: Django :: 5.0",
"Framework :: Django :: 5.2",
"Framework :: ... | [] | https://github.com/HummingByteDev/paystack-django | null | >=3.8 | [] | [] | [] | [
"Django>=3.2",
"requests>=2.25.0",
"urllib3>=1.26.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-django>=4.5; extra == \"dev\"",
"pytest-cov>=3.0; extra == \"dev\"",
"black>=22.0; extra == \"dev\"",
"flake8>=4.0; extra == \"dev\"",
"isort>=5.10; extra == \"dev\"",
"mypy>=0.950; extra == \"dev\"",
... | [] | [] | [] | [
"Homepage, https://github.com/HummingByteDev/paystack-django",
"Documentation, https://paystack-django.readthedocs.io",
"Repository, https://github.com/HummingByteDev/paystack-django.git",
"Bug Tracker, https://github.com/HummingByteDev/paystack-django/issues",
"Changelog, https://github.com/HummingByteDev/... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:17:35.618293 | paystack_django-1.1.1.tar.gz | 55,299 | f1/6f/1544c78f080f2efa4ce4ffb6e1d464f40eb527446211d78f58a8b03f4c20/paystack_django-1.1.1.tar.gz | source | sdist | null | false | c9f54e6ee520af9dd3c9a9bf8dfa5131 | 327559120623938b6c02b706ac386f19619afbba7dc940e7487609b16af3d164 | f16f1544c78f080f2efa4ce4ffb6e1d464f40eb527446211d78f58a8b03f4c20 | null | [
"LICENSE"
] | 249 |
2.4 | pyromax | 0.4 | Асинхронный, модульный фреймворк для юзерботов в MAX Messenger | # "The Official Pyromax Library (available on PyPI)".
# Pyromax 🚀
**Асинхронный, модульный и современный фреймворк для создания юзерботов в MAX Messenger.**



`Pyromax` создан для тех, кто устал от "лапши" в одном файле. Мы перенесли лучшие практики из **aiogram 3.x** в мир MAX: роутеры, строгая типизация и удобная архитектура.
## 🔥 Почему Pyromax?
В отличие от других библиотек, мы ставим **Developer Experience (DX)** на первое место:
- **📦 Система Роутеров (Routers):** Разбивайте бота на файлы и плагины. Никаких файлов на 2000 строк.
- **⚡ Скорость:** Полностью асинхронное ядро на `aiohttp` и `websockets`.
- **clean_code:** Архитектура, вдохновленная `aiogram`. Если вы писали ботов для Telegram, вы будете чувствовать себя как дома.
- **🛠 Гибкость:** Встроенный Dispatcher и Observer паттерн.
---
## 📦 Установка
Библиотека поддерживает современные менеджеры пакетов, включая `uv`.
### Через pip
```bash
pip install pyromax
```
## 🚀 Быстрый старт
### Простой эхо-бот:
```python
import asyncio
import logging
import os
from pyromax.api import MaxApi
from pyromax.api.observer import Dispatcher as MaxDispatcher
from pyromax.types import Message
import qrcode
# Инициализация диспетчера
dp = MaxDispatcher()
# Регистрация хендлера (обрабатываем все сообщения, включая свои)
@dp.message(pattern=lambda update: True, from_me=True)
async def echo_handler(update: Message, max_api: MaxApi):
# Отвечаем на сообщение тем же текстом и вложениями
await update.reply(text=update.text, attaches=update.attaches)
async def url_callback_for_login_url(url: str):
"""
Отрабатывает если пользователь не авторизован(т.е не передается token)
и в него попадает авторизационная ссылка
Необходимо привести эту ссылку к виду qr кода, и отсканировать с приложения Макса
К примеру можно использовать модуль qrcode
т.е pip install qrcode
"""
qr = qrcode.QRCode()
qr.add_data(url)
img = qr.make_image()
img.save('qr.jpg')
"""
После этого появится в домашнем каталоге проекта сам файл qr кода,
его нужно будет отсканировать, и далее бот начнет работать дальше
"""
async def main():
logging.basicConfig(level=logging.INFO)
# Получаем токен из переменных окружения
token = os.getenv('MaxApiToken')
# Создаем экземпляр API
bot = await MaxApi(url_callback_for_login_url, token=token)
# Запускаем бота с диспетчером
await bot.reload_if_connection_broke(dp)
if __name__ == "__main__":
asyncio.run(main())
```
## 🧩 Модульность и Роутеры (Killer Feature)
### 1. Создайте модуль (например, handlers/admin.py)
```python
from pyromax.api import MaxApi
from pyromax.api.observer import Router
from pyromax.filters import Command, CommandStart, CommandObject
from pyromax.types import Message
# Создаем отдельный роутер
router = Router()
# Регистрируем хендлер в роутер
@router.message(Command('ping'), from_me=True)
async def ping_handler(message: Message, max_api: MaxApi):
await message.reply("Pong! 🏓")
@router.message(CommandStart())
async def start(message: Message):
await message.answer(text='Ну начинаем?')
@router.message(Command('sum'), from_me=True)
async def sum_handler(message: Message, command: CommandObject) -> None:
"""
В чате:
>>>/sum 8 8
>>>Ответ: 16
>>>/sum 3 string
>>>В аргументах могут быть только цифры
"""
if command.args is None:
return
args = command.args.split()
nums = []
for arg in args:
if not arg.isdigit():
await message.reply(text = 'В аргументах могут быть только цифры')
return
nums.append(int(arg))
await message.reply(text = f'Ответ: {sum(nums)}')
```
### 2. Подключите его в главном файле (main.py)
```python
from pyromax.api.observer import Dispatcher as MaxDispatcher
from handlers.admin import router as admin_router
dp = MaxDispatcher()
# Подключаем роутер к главному диспетчеру
dp.include_router(admin_router)
# ... далее запуск бота как в примере выше
```
### Теперь ваш код чист, структурирован и легко масштабируется!
## 🗺 Roadmap (Планы развития)
Мы активно развиваем библиотеку и стремимся сделать её стандартом для MAX.
### 📍 Текущий статус (Alpha)
- [x] **Core:** Полностью асинхронное ядро (`MaxApi`, `Dispatcher`).
- [x] **Routers:** Модульная система (разбиение бота на файлы).
- [x] **Types:** Строгая типизация всех объектов (Update, Message, Attachments).
- [x] **Observer:** Система паттернов и фильтров для хендлеров.
### 🚧 В разработке
- [ ] **FSM (Finite State Machine):** Машина состояний для создания сценариев (опросы, диалоги, формы).
- [ ] **Middlewares:** Перехват событий до хендлеров (логирование, анти-флуд, базы данных).
- [ ] **Magic Filters:** Удобный синтаксис фильтров (как `F.text.startswith("!")`).
### 🔮 Планы на будущее
- [ ] **Документация:** Полноценный сайт с документацией и примерами.
- [ ] **Плагины:** Готовые модули для администрирования чатов.
---
## 📞 Контакты
Telegram разработчика: [ТЫК](https://t.me/Nonamegodman)
## 🤝 Contributing
Мы рады любой помощи! Если вы хотите предложить фичу или исправить баг:
1. Форкните репозиторий.
2. Создайте ветку (`git checkout -b feature/NewFeature`).
3. Откройте Pull Request.
## 📄 Лицензия
MIT License. Свободно используйте в своих проектах.
| text/markdown | null | rast-games <jggtrrrdg@gmail.com> | null | null | MIT License Copyright (c) 2026 rast-games Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Framework :: AsyncIO"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp>=3.13.3",
"pillow==12.1.0",
"pydantic>=2.12.5",
"qrcode==8.2",
"websockets==16.0"
] | [] | [] | [] | [
"Homepage, https://github.com/rast-games/MaxUserBotLib",
"Bug Tracker, https://github.com/rast-games/MaxUserBotLib/issues"
] | uv/0.8.3 | 2026-02-19T21:16:45.830866 | pyromax-0.4.tar.gz | 27,839 | 79/84/d0905c79b00825fe61732ca420f4ececdc9f0d6280c5cb8fd496d5687add/pyromax-0.4.tar.gz | source | sdist | null | false | 75cf26935009e18f8e8a1a771b28e6ad | a7d08cbedce7e366e21d361707977810630b50ad735c0d70e135a0fd6b238f4e | 7984d0905c79b00825fe61732ca420f4ececdc9f0d6280c5cb8fd496d5687add | null | [
"LICENSE"
] | 290 |
2.4 | lusid-sdk | 2.3.56 | LUSID API | <a id="documentation-for-api-endpoints"></a>
## Documentation for API Endpoints
All URIs are relative to *https://fbn-prd.lusid.com/api*
Class | Method | HTTP request | Description
------------ | ------------- | ------------- | -------------
*AborApi* | [**add_diary_entry**](docs/AborApi.md#add_diary_entry) | **POST** /api/abor/{scope}/{code}/accountingdiary | [EXPERIMENTAL] AddDiaryEntry: Add a diary entry to the specified Abor. This would be type 'Other'.
*AborApi* | [**close_period**](docs/AborApi.md#close_period) | **POST** /api/abor/{scope}/{code}/accountingdiary/$closeperiod | [EXPERIMENTAL] ClosePeriod: Closes or locks the current period for the given Abor.
*AborApi* | [**create_abor**](docs/AborApi.md#create_abor) | **POST** /api/abor/{scope} | [EXPERIMENTAL] CreateAbor: Create an Abor.
*AborApi* | [**delete_abor**](docs/AborApi.md#delete_abor) | **DELETE** /api/abor/{scope}/{code} | [EXPERIMENTAL] DeleteAbor: Delete an Abor.
*AborApi* | [**delete_diary_entry**](docs/AborApi.md#delete_diary_entry) | **DELETE** /api/abor/{scope}/{code}/accountingdiary/{diaryEntryCode} | [EXPERIMENTAL] DeleteDiaryEntry: Delete a diary entry type 'Other' from the specified Abor.
*AborApi* | [**get_abor**](docs/AborApi.md#get_abor) | **GET** /api/abor/{scope}/{code} | [EXPERIMENTAL] GetAbor: Get Abor.
*AborApi* | [**get_abor_properties**](docs/AborApi.md#get_abor_properties) | **GET** /api/abor/{scope}/{code}/properties | [EXPERIMENTAL] GetAborProperties: Get Abor properties
*AborApi* | [**get_journal_entry_lines**](docs/AborApi.md#get_journal_entry_lines) | **POST** /api/abor/{scope}/{code}/journalentrylines/$query | [EXPERIMENTAL] GetJournalEntryLines: Get the Journal Entry lines for the given Abor.
*AborApi* | [**get_trial_balance**](docs/AborApi.md#get_trial_balance) | **POST** /api/abor/{scope}/{code}/trialbalance/$query | [EXPERIMENTAL] GetTrialBalance: Get the Trial Balance for the given Abor.
*AborApi* | [**list_abors**](docs/AborApi.md#list_abors) | **GET** /api/abor | [EXPERIMENTAL] ListAbors: List Abors.
*AborApi* | [**list_diary_entries**](docs/AborApi.md#list_diary_entries) | **GET** /api/abor/{scope}/{code}/accountingdiary | [EXPERIMENTAL] ListDiaryEntries: List diary entries.
*AborApi* | [**lock_period**](docs/AborApi.md#lock_period) | **POST** /api/abor/{scope}/{code}/accountingdiary/$lockperiod | [EXPERIMENTAL] LockPeriod: Locks the last Closed or given Closed Period.
*AborApi* | [**patch_abor**](docs/AborApi.md#patch_abor) | **PATCH** /api/abor/{scope}/{code} | [EXPERIMENTAL] PatchAbor: Patch Abor.
*AborApi* | [**re_open_periods**](docs/AborApi.md#re_open_periods) | **POST** /api/abor/{scope}/{code}/accountingdiary/$reopenperiods | [EXPERIMENTAL] ReOpenPeriods: Reopen periods from a seed Diary Entry Code or when not specified, the last Closed Period for the given Abor.
*AborApi* | [**upsert_abor_properties**](docs/AborApi.md#upsert_abor_properties) | **POST** /api/abor/{scope}/{code}/properties/$upsert | [EXPERIMENTAL] UpsertAborProperties: Upsert Abor properties
*AborConfigurationApi* | [**create_abor_configuration**](docs/AborConfigurationApi.md#create_abor_configuration) | **POST** /api/aborconfiguration/{scope} | [EXPERIMENTAL] CreateAborConfiguration: Create an AborConfiguration.
*AborConfigurationApi* | [**delete_abor_configuration**](docs/AborConfigurationApi.md#delete_abor_configuration) | **DELETE** /api/aborconfiguration/{scope}/{code} | [EXPERIMENTAL] DeleteAborConfiguration: Delete an AborConfiguration.
*AborConfigurationApi* | [**get_abor_configuration**](docs/AborConfigurationApi.md#get_abor_configuration) | **GET** /api/aborconfiguration/{scope}/{code} | [EXPERIMENTAL] GetAborConfiguration: Get AborConfiguration.
*AborConfigurationApi* | [**get_abor_configuration_properties**](docs/AborConfigurationApi.md#get_abor_configuration_properties) | **GET** /api/aborconfiguration/{scope}/{code}/properties | [EXPERIMENTAL] GetAborConfigurationProperties: Get Abor Configuration properties
*AborConfigurationApi* | [**list_abor_configurations**](docs/AborConfigurationApi.md#list_abor_configurations) | **GET** /api/aborconfiguration | [EXPERIMENTAL] ListAborConfigurations: List AborConfiguration.
*AborConfigurationApi* | [**patch_abor_configuration**](docs/AborConfigurationApi.md#patch_abor_configuration) | **PATCH** /api/aborconfiguration/{scope}/{code} | [EXPERIMENTAL] PatchAborConfiguration: Patch Abor Configuration.
*AborConfigurationApi* | [**upsert_abor_configuration_properties**](docs/AborConfigurationApi.md#upsert_abor_configuration_properties) | **POST** /api/aborconfiguration/{scope}/{code}/properties/$upsert | [EXPERIMENTAL] UpsertAborConfigurationProperties: Upsert AborConfiguration properties
*AddressKeyDefinitionApi* | [**create_address_key_definition**](docs/AddressKeyDefinitionApi.md#create_address_key_definition) | **POST** /api/addresskeydefinitions | [EARLY ACCESS] CreateAddressKeyDefinition: Create an AddressKeyDefinition.
*AddressKeyDefinitionApi* | [**get_address_key_definition**](docs/AddressKeyDefinitionApi.md#get_address_key_definition) | **GET** /api/addresskeydefinitions/{key} | [EARLY ACCESS] GetAddressKeyDefinition: Get an AddressKeyDefinition.
*AddressKeyDefinitionApi* | [**list_address_key_definitions**](docs/AddressKeyDefinitionApi.md#list_address_key_definitions) | **GET** /api/addresskeydefinitions | [EARLY ACCESS] ListAddressKeyDefinitions: List AddressKeyDefinitions.
*AggregatedReturnsApi* | [**delete_returns_entity**](docs/AggregatedReturnsApi.md#delete_returns_entity) | **DELETE** /api/returns/{scope}/{code} | [EXPERIMENTAL] DeleteReturnsEntity: Delete returns entity.
*AggregatedReturnsApi* | [**get_returns_entity**](docs/AggregatedReturnsApi.md#get_returns_entity) | **GET** /api/returns/{scope}/{code} | [EXPERIMENTAL] GetReturnsEntity: Get returns entity.
*AggregatedReturnsApi* | [**list_returns_entities**](docs/AggregatedReturnsApi.md#list_returns_entities) | **GET** /api/returns | [EXPERIMENTAL] ListReturnsEntities: List returns entities.
*AggregatedReturnsApi* | [**upsert_returns_entity**](docs/AggregatedReturnsApi.md#upsert_returns_entity) | **POST** /api/returns | [EXPERIMENTAL] UpsertReturnsEntity: Upsert returns entity.
*AggregationApi* | [**generate_configuration_recipe**](docs/AggregationApi.md#generate_configuration_recipe) | **POST** /api/aggregation/{scope}/{code}/$generateconfigurationrecipe | [EXPERIMENTAL] GenerateConfigurationRecipe: Generates a recipe sufficient to perform valuations for the given portfolio.
*AggregationApi* | [**get_queryable_keys**](docs/AggregationApi.md#get_queryable_keys) | **GET** /api/results/queryable/keys | GetQueryableKeys: Query the set of supported \"addresses\" that can be queried from the aggregation endpoint.
*AggregationApi* | [**get_valuation**](docs/AggregationApi.md#get_valuation) | **POST** /api/aggregation/$valuation | GetValuation: Perform valuation for a list of portfolios and/or portfolio groups
*AggregationApi* | [**get_valuation_of_weighted_instruments**](docs/AggregationApi.md#get_valuation_of_weighted_instruments) | **POST** /api/aggregation/$valuationinlined | GetValuationOfWeightedInstruments: Perform valuation for an inlined portfolio
*AllocationsApi* | [**delete_allocation**](docs/AllocationsApi.md#delete_allocation) | **DELETE** /api/allocations/{scope}/{code} | [EARLY ACCESS] DeleteAllocation: Delete allocation
*AllocationsApi* | [**get_allocation**](docs/AllocationsApi.md#get_allocation) | **GET** /api/allocations/{scope}/{code} | [EARLY ACCESS] GetAllocation: Get Allocation
*AllocationsApi* | [**list_allocations**](docs/AllocationsApi.md#list_allocations) | **GET** /api/allocations | ListAllocations: List Allocations
*AllocationsApi* | [**upsert_allocations**](docs/AllocationsApi.md#upsert_allocations) | **POST** /api/allocations | UpsertAllocations: Upsert Allocations
*AmortisationRuleSetsApi* | [**create_amortisation_rule_set**](docs/AmortisationRuleSetsApi.md#create_amortisation_rule_set) | **POST** /api/amortisation/rulesets/{scope} | [EXPERIMENTAL] CreateAmortisationRuleSet: Create an amortisation rule set.
*AmortisationRuleSetsApi* | [**delete_amortisation_ruleset**](docs/AmortisationRuleSetsApi.md#delete_amortisation_ruleset) | **DELETE** /api/amortisation/rulesets/{scope}/{code} | [EXPERIMENTAL] DeleteAmortisationRuleset: Delete an amortisation rule set.
*AmortisationRuleSetsApi* | [**get_amortisation_rule_set**](docs/AmortisationRuleSetsApi.md#get_amortisation_rule_set) | **GET** /api/amortisation/rulesets/{scope}/{code} | [EXPERIMENTAL] GetAmortisationRuleSet: Retrieve the definition of a single amortisation rule set
*AmortisationRuleSetsApi* | [**list_amortisation_rule_sets**](docs/AmortisationRuleSetsApi.md#list_amortisation_rule_sets) | **GET** /api/amortisation/rulesets | [EXPERIMENTAL] ListAmortisationRuleSets: List amortisation rule sets.
*AmortisationRuleSetsApi* | [**set_amortisation_rules**](docs/AmortisationRuleSetsApi.md#set_amortisation_rules) | **PUT** /api/amortisation/rulesets/{scope}/{code}/rules | [EXPERIMENTAL] SetAmortisationRules: Set Amortisation Rules on an existing Amortisation Rule Set.
*AmortisationRuleSetsApi* | [**update_amortisation_rule_set_details**](docs/AmortisationRuleSetsApi.md#update_amortisation_rule_set_details) | **PUT** /api/amortisation/rulesets/{scope}/{code}/details | [EXPERIMENTAL] UpdateAmortisationRuleSetDetails: Update an amortisation rule set.
*ApplicationMetadataApi* | [**get_excel_addin**](docs/ApplicationMetadataApi.md#get_excel_addin) | **GET** /api/metadata/downloads/exceladdin | GetExcelAddin: Download Excel Addin
*ApplicationMetadataApi* | [**get_lusid_versions**](docs/ApplicationMetadataApi.md#get_lusid_versions) | **GET** /api/metadata/versions | GetLusidVersions: Get LUSID versions
*ApplicationMetadataApi* | [**list_access_controlled_resources**](docs/ApplicationMetadataApi.md#list_access_controlled_resources) | **GET** /api/metadata/access/resources | ListAccessControlledResources: Get resources available for access control
*BlocksApi* | [**delete_block**](docs/BlocksApi.md#delete_block) | **DELETE** /api/blocks/{scope}/{code} | [EARLY ACCESS] DeleteBlock: Delete block
*BlocksApi* | [**get_block**](docs/BlocksApi.md#get_block) | **GET** /api/blocks/{scope}/{code} | [EARLY ACCESS] GetBlock: Get Block
*BlocksApi* | [**list_blocks**](docs/BlocksApi.md#list_blocks) | **GET** /api/blocks | [EARLY ACCESS] ListBlocks: List Blocks
*BlocksApi* | [**upsert_blocks**](docs/BlocksApi.md#upsert_blocks) | **POST** /api/blocks | [EARLY ACCESS] UpsertBlocks: Upsert Block
*CalendarsApi* | [**add_business_days_to_date**](docs/CalendarsApi.md#add_business_days_to_date) | **POST** /api/calendars/businessday/{scope}/add | [EARLY ACCESS] AddBusinessDaysToDate: Adds the requested number of Business Days to the provided date.
*CalendarsApi* | [**add_date_to_calendar**](docs/CalendarsApi.md#add_date_to_calendar) | **PUT** /api/calendars/generic/{scope}/{code}/dates | AddDateToCalendar: Add a date to a calendar
*CalendarsApi* | [**batch_upsert_dates_for_calendar**](docs/CalendarsApi.md#batch_upsert_dates_for_calendar) | **POST** /api/calendars/generic/{scope}/{code}/dates/$batchUpsert | BatchUpsertDatesForCalendar: Batch upsert dates to a calendar
*CalendarsApi* | [**create_calendar**](docs/CalendarsApi.md#create_calendar) | **POST** /api/calendars/generic | [EARLY ACCESS] CreateCalendar: Create a calendar in its generic form
*CalendarsApi* | [**delete_calendar**](docs/CalendarsApi.md#delete_calendar) | **DELETE** /api/calendars/generic/{scope}/{code} | [EARLY ACCESS] DeleteCalendar: Delete a calendar
*CalendarsApi* | [**delete_date_from_calendar**](docs/CalendarsApi.md#delete_date_from_calendar) | **DELETE** /api/calendars/generic/{scope}/{code}/dates/{dateId} | DeleteDateFromCalendar: Remove a date from a calendar
*CalendarsApi* | [**delete_dates_from_calendar**](docs/CalendarsApi.md#delete_dates_from_calendar) | **POST** /api/calendars/generic/{scope}/{code}/dates/$delete | DeleteDatesFromCalendar: Delete dates from a calendar
*CalendarsApi* | [**generate_schedule**](docs/CalendarsApi.md#generate_schedule) | **POST** /api/calendars/schedule/{scope} | [EARLY ACCESS] GenerateSchedule: Generate an ordered schedule of dates.
*CalendarsApi* | [**get_calendar**](docs/CalendarsApi.md#get_calendar) | **GET** /api/calendars/generic/{scope}/{code} | GetCalendar: Get a calendar in its generic form
*CalendarsApi* | [**get_dates**](docs/CalendarsApi.md#get_dates) | **GET** /api/calendars/generic/{scope}/{code}/dates | [EARLY ACCESS] GetDates: Get dates for a specific calendar
*CalendarsApi* | [**is_business_date_time**](docs/CalendarsApi.md#is_business_date_time) | **GET** /api/calendars/businessday/{scope}/{code} | [EARLY ACCESS] IsBusinessDateTime: Check whether a DateTime is a \"Business DateTime\"
*CalendarsApi* | [**list_calendars**](docs/CalendarsApi.md#list_calendars) | **GET** /api/calendars/generic | [EARLY ACCESS] ListCalendars: List Calendars
*CalendarsApi* | [**list_calendars_in_scope**](docs/CalendarsApi.md#list_calendars_in_scope) | **GET** /api/calendars/generic/{scope} | ListCalendarsInScope: List all calenders in a specified scope
*CalendarsApi* | [**update_calendar**](docs/CalendarsApi.md#update_calendar) | **POST** /api/calendars/generic/{scope}/{code} | [EARLY ACCESS] UpdateCalendar: Update a calendar
*ChartOfAccountsApi* | [**create_chart_of_accounts**](docs/ChartOfAccountsApi.md#create_chart_of_accounts) | **POST** /api/chartofaccounts/{scope} | [EXPERIMENTAL] CreateChartOfAccounts: Create a Chart of Accounts
*ChartOfAccountsApi* | [**create_cleardown_module**](docs/ChartOfAccountsApi.md#create_cleardown_module) | **POST** /api/chartofaccounts/{scope}/{code}/cleardownmodules | [EXPERIMENTAL] CreateCleardownModule: Create a Cleardown Module
*ChartOfAccountsApi* | [**create_general_ledger_profile**](docs/ChartOfAccountsApi.md#create_general_ledger_profile) | **POST** /api/chartofaccounts/{scope}/{code}/generalledgerprofile | [EXPERIMENTAL] CreateGeneralLedgerProfile: Create a General Ledger Profile.
*ChartOfAccountsApi* | [**create_posting_module**](docs/ChartOfAccountsApi.md#create_posting_module) | **POST** /api/chartofaccounts/{scope}/{code}/postingmodules | [EXPERIMENTAL] CreatePostingModule: Create a Posting Module
*ChartOfAccountsApi* | [**delete_accounts**](docs/ChartOfAccountsApi.md#delete_accounts) | **POST** /api/chartofaccounts/{scope}/{code}/accounts/$delete | [EXPERIMENTAL] DeleteAccounts: Soft or hard delete multiple accounts
*ChartOfAccountsApi* | [**delete_chart_of_accounts**](docs/ChartOfAccountsApi.md#delete_chart_of_accounts) | **DELETE** /api/chartofaccounts/{scope}/{code} | [EXPERIMENTAL] DeleteChartOfAccounts: Delete a Chart of Accounts
*ChartOfAccountsApi* | [**delete_cleardown_module**](docs/ChartOfAccountsApi.md#delete_cleardown_module) | **DELETE** /api/chartofaccounts/{scope}/{code}/cleardownmodules/{cleardownModuleCode} | [EXPERIMENTAL] DeleteCleardownModule: Delete a Cleardown Module.
*ChartOfAccountsApi* | [**delete_general_ledger_profile**](docs/ChartOfAccountsApi.md#delete_general_ledger_profile) | **DELETE** /api/chartofaccounts/{scope}/{code}/generalledgerprofile/{generalLedgerProfileCode} | [EXPERIMENTAL] DeleteGeneralLedgerProfile: Delete a General Ledger Profile.
*ChartOfAccountsApi* | [**delete_posting_module**](docs/ChartOfAccountsApi.md#delete_posting_module) | **DELETE** /api/chartofaccounts/{scope}/{code}/postingmodules/{postingModuleCode} | [EXPERIMENTAL] DeletePostingModule: Delete a Posting Module.
*ChartOfAccountsApi* | [**get_account**](docs/ChartOfAccountsApi.md#get_account) | **GET** /api/chartofaccounts/{scope}/{code}/accounts/{accountCode} | [EXPERIMENTAL] GetAccount: Get Account
*ChartOfAccountsApi* | [**get_account_properties**](docs/ChartOfAccountsApi.md#get_account_properties) | **GET** /api/chartofaccounts/{scope}/{code}/accounts/{accountCode}/properties | [EXPERIMENTAL] GetAccountProperties: Get Account properties
*ChartOfAccountsApi* | [**get_chart_of_accounts**](docs/ChartOfAccountsApi.md#get_chart_of_accounts) | **GET** /api/chartofaccounts/{scope}/{code} | [EXPERIMENTAL] GetChartOfAccounts: Get ChartOfAccounts
*ChartOfAccountsApi* | [**get_chart_of_accounts_properties**](docs/ChartOfAccountsApi.md#get_chart_of_accounts_properties) | **GET** /api/chartofaccounts/{scope}/{code}/properties | [EXPERIMENTAL] GetChartOfAccountsProperties: Get chart of accounts properties
*ChartOfAccountsApi* | [**get_cleardown_module**](docs/ChartOfAccountsApi.md#get_cleardown_module) | **GET** /api/chartofaccounts/{scope}/{code}/cleardownmodules/{cleardownModuleCode} | [EXPERIMENTAL] GetCleardownModule: Get a Cleardown Module
*ChartOfAccountsApi* | [**get_general_ledger_profile**](docs/ChartOfAccountsApi.md#get_general_ledger_profile) | **GET** /api/chartofaccounts/{scope}/{code}/generalledgerprofile/{generalLedgerProfileCode} | [EXPERIMENTAL] GetGeneralLedgerProfile: Get a General Ledger Profile.
*ChartOfAccountsApi* | [**get_posting_module**](docs/ChartOfAccountsApi.md#get_posting_module) | **GET** /api/chartofaccounts/{scope}/{code}/postingmodules/{postingModuleCode} | [EXPERIMENTAL] GetPostingModule: Get a Posting Module
*ChartOfAccountsApi* | [**list_accounts**](docs/ChartOfAccountsApi.md#list_accounts) | **GET** /api/chartofaccounts/{scope}/{code}/accounts | [EXPERIMENTAL] ListAccounts: List Accounts
*ChartOfAccountsApi* | [**list_charts_of_accounts**](docs/ChartOfAccountsApi.md#list_charts_of_accounts) | **GET** /api/chartofaccounts | [EXPERIMENTAL] ListChartsOfAccounts: List Charts of Accounts
*ChartOfAccountsApi* | [**list_cleardown_module_rules**](docs/ChartOfAccountsApi.md#list_cleardown_module_rules) | **GET** /api/chartofaccounts/{scope}/{code}/cleardownmodules/{cleardownModuleCode}/cleardownrules | [EXPERIMENTAL] ListCleardownModuleRules: List Cleardown Module Rules
*ChartOfAccountsApi* | [**list_cleardown_modules**](docs/ChartOfAccountsApi.md#list_cleardown_modules) | **GET** /api/chartofaccounts/{scope}/{code}/cleardownmodules | [EXPERIMENTAL] ListCleardownModules: List Cleardown Modules
*ChartOfAccountsApi* | [**list_general_ledger_profiles**](docs/ChartOfAccountsApi.md#list_general_ledger_profiles) | **GET** /api/chartofaccounts/{scope}/{code}/generalledgerprofile | [EXPERIMENTAL] ListGeneralLedgerProfiles: List General Ledger Profiles.
*ChartOfAccountsApi* | [**list_posting_module_rules**](docs/ChartOfAccountsApi.md#list_posting_module_rules) | **GET** /api/chartofaccounts/{scope}/{code}/postingmodules/{postingModuleCode}/postingrules | [EXPERIMENTAL] ListPostingModuleRules: List Posting Module Rules
*ChartOfAccountsApi* | [**list_posting_modules**](docs/ChartOfAccountsApi.md#list_posting_modules) | **GET** /api/chartofaccounts/{scope}/{code}/postingmodules | [EXPERIMENTAL] ListPostingModules: List Posting Modules
*ChartOfAccountsApi* | [**patch_chart_of_accounts**](docs/ChartOfAccountsApi.md#patch_chart_of_accounts) | **PATCH** /api/chartofaccounts/{scope}/{code} | [EXPERIMENTAL] PatchChartOfAccounts: Patch a Chart of Accounts.
*ChartOfAccountsApi* | [**patch_cleardown_module**](docs/ChartOfAccountsApi.md#patch_cleardown_module) | **PATCH** /api/chartofaccounts/{scope}/{code}/cleardownmodules/{cleardownModuleCode} | [EXPERIMENTAL] PatchCleardownModule: Patch a Cleardown Module
*ChartOfAccountsApi* | [**patch_posting_module**](docs/ChartOfAccountsApi.md#patch_posting_module) | **PATCH** /api/chartofaccounts/{scope}/{code}/postingmodules/{postingModuleCode} | [EXPERIMENTAL] PatchPostingModule: Patch a Posting Module
*ChartOfAccountsApi* | [**set_cleardown_module_details**](docs/ChartOfAccountsApi.md#set_cleardown_module_details) | **PUT** /api/chartofaccounts/{scope}/{code}/cleardownmodules/{cleardownModuleCode} | [EXPERIMENTAL] SetCleardownModuleDetails: Set the details of a Cleardown Module
*ChartOfAccountsApi* | [**set_cleardown_module_rules**](docs/ChartOfAccountsApi.md#set_cleardown_module_rules) | **PUT** /api/chartofaccounts/{scope}/{code}/cleardownmodules/{cleardownModuleCode}/cleardownrules | [EXPERIMENTAL] SetCleardownModuleRules: Set the rules of a Cleardown Module
*ChartOfAccountsApi* | [**set_general_ledger_profile_mappings**](docs/ChartOfAccountsApi.md#set_general_ledger_profile_mappings) | **PUT** /api/chartofaccounts/{scope}/{code}/generalledgerprofile/{generalLedgerProfileCode}/mappings | [EXPERIMENTAL] SetGeneralLedgerProfileMappings: Sets the General Ledger Profile Mappings.
*ChartOfAccountsApi* | [**set_posting_module_details**](docs/ChartOfAccountsApi.md#set_posting_module_details) | **PUT** /api/chartofaccounts/{scope}/{code}/postingmodules/{postingModuleCode} | [EXPERIMENTAL] SetPostingModuleDetails: Set the details of a Posting Module
*ChartOfAccountsApi* | [**set_posting_module_rules**](docs/ChartOfAccountsApi.md#set_posting_module_rules) | **PUT** /api/chartofaccounts/{scope}/{code}/postingmodules/{postingModuleCode}/postingrules | [EXPERIMENTAL] SetPostingModuleRules: Set the rules of a Posting Module
*ChartOfAccountsApi* | [**upsert_account_properties**](docs/ChartOfAccountsApi.md#upsert_account_properties) | **POST** /api/chartofaccounts/{scope}/{code}/accounts/{accountCode}/properties/$upsert | [EXPERIMENTAL] UpsertAccountProperties: Upsert account properties
*ChartOfAccountsApi* | [**upsert_accounts**](docs/ChartOfAccountsApi.md#upsert_accounts) | **POST** /api/chartofaccounts/{scope}/{code}/accounts | [EXPERIMENTAL] UpsertAccounts: Upsert Accounts
*ChartOfAccountsApi* | [**upsert_chart_of_accounts_properties**](docs/ChartOfAccountsApi.md#upsert_chart_of_accounts_properties) | **POST** /api/chartofaccounts/{scope}/{code}/properties/$upsert | [EXPERIMENTAL] UpsertChartOfAccountsProperties: Upsert Chart of Accounts properties
*CheckDefinitionsApi* | [**create_check_definition**](docs/CheckDefinitionsApi.md#create_check_definition) | **POST** /api/dataquality/checkdefinitions | [EXPERIMENTAL] CreateCheckDefinition: Create a Check Definition
*CheckDefinitionsApi* | [**delete_check_definition**](docs/CheckDefinitionsApi.md#delete_check_definition) | **DELETE** /api/dataquality/checkdefinitions/{scope}/{code} | [EXPERIMENTAL] DeleteCheckDefinition: Deletes a particular Check Definition
*CheckDefinitionsApi* | [**delete_rules**](docs/CheckDefinitionsApi.md#delete_rules) | **POST** /api/dataquality/checkdefinitions/{scope}/{code}/$deleteRules | [EXPERIMENTAL] DeleteRules: Delete rules on a particular Check Definition
*CheckDefinitionsApi* | [**get_check_definition**](docs/CheckDefinitionsApi.md#get_check_definition) | **GET** /api/dataquality/checkdefinitions/{scope}/{code} | [EXPERIMENTAL] GetCheckDefinition: Get a single Check Definition by scope and code.
*CheckDefinitionsApi* | [**list_check_definitions**](docs/CheckDefinitionsApi.md#list_check_definitions) | **GET** /api/dataquality/checkdefinitions | [EXPERIMENTAL] ListCheckDefinitions: List Check Definitions
*CheckDefinitionsApi* | [**run_check_definition**](docs/CheckDefinitionsApi.md#run_check_definition) | **POST** /api/dataquality/checkdefinitions/{scope}/{code}/$run | [EXPERIMENTAL] RunCheckDefinition: Runs a Check Definition against given dataset.
*CheckDefinitionsApi* | [**update_check_definition**](docs/CheckDefinitionsApi.md#update_check_definition) | **PUT** /api/dataquality/checkdefinitions/{scope}/{code} | [EXPERIMENTAL] UpdateCheckDefinition: Update Check Definition defined by scope and code
*CheckDefinitionsApi* | [**upsert_rules**](docs/CheckDefinitionsApi.md#upsert_rules) | **POST** /api/dataquality/checkdefinitions/{scope}/{code}/$upsertRules | [EXPERIMENTAL] UpsertRules: Upsert rules to a particular Check Definition
*ComplexMarketDataApi* | [**delete_complex_market_data**](docs/ComplexMarketDataApi.md#delete_complex_market_data) | **POST** /api/complexmarketdata/{scope}/$delete | DeleteComplexMarketData: Delete one or more items of complex market data, assuming they are present.
*ComplexMarketDataApi* | [**get_complex_market_data**](docs/ComplexMarketDataApi.md#get_complex_market_data) | **POST** /api/complexmarketdata/{scope}/$get | GetComplexMarketData: Get complex market data
*ComplexMarketDataApi* | [**list_complex_market_data**](docs/ComplexMarketDataApi.md#list_complex_market_data) | **GET** /api/complexmarketdata | ListComplexMarketData: List the set of ComplexMarketData
*ComplexMarketDataApi* | [**upsert_append_complex_market_data**](docs/ComplexMarketDataApi.md#upsert_append_complex_market_data) | **POST** /api/complexmarketdata/{scope}/$append | [EARLY ACCESS] UpsertAppendComplexMarketData: Appends a new point to the end of a ComplexMarketData definition.
*ComplexMarketDataApi* | [**upsert_complex_market_data**](docs/ComplexMarketDataApi.md#upsert_complex_market_data) | **POST** /api/complexmarketdata/{scope} | UpsertComplexMarketData: Upsert a set of complex market data items. This creates or updates the data in Lusid.
*ComplianceApi* | [**create_compliance_template**](docs/ComplianceApi.md#create_compliance_template) | **POST** /api/compliance/templates/{scope} | [EARLY ACCESS] CreateComplianceTemplate: Create a Compliance Rule Template
*ComplianceApi* | [**delete_compliance_rule**](docs/ComplianceApi.md#delete_compliance_rule) | **DELETE** /api/compliance/rules/{scope}/{code} | [EARLY ACCESS] DeleteComplianceRule: Delete compliance rule.
*ComplianceApi* | [**delete_compliance_template**](docs/ComplianceApi.md#delete_compliance_template) | **DELETE** /api/compliance/templates/{scope}/{code} | [EARLY ACCESS] DeleteComplianceTemplate: Delete a ComplianceRuleTemplate
*ComplianceApi* | [**get_compliance_rule**](docs/ComplianceApi.md#get_compliance_rule) | **GET** /api/compliance/rules/{scope}/{code} | [EARLY ACCESS] GetComplianceRule: Get compliance rule.
*ComplianceApi* | [**get_compliance_rule_result**](docs/ComplianceApi.md#get_compliance_rule_result) | **GET** /api/compliance/runs/summary/{runScope}/{runCode}/{ruleScope}/{ruleCode} | [EARLY ACCESS] GetComplianceRuleResult: Get detailed results for a specific rule within a compliance run.
*ComplianceApi* | [**get_compliance_template**](docs/ComplianceApi.md#get_compliance_template) | **GET** /api/compliance/templates/{scope}/{code} | [EARLY ACCESS] GetComplianceTemplate: Get the requested compliance template.
*ComplianceApi* | [**get_decorated_compliance_run_summary**](docs/ComplianceApi.md#get_decorated_compliance_run_summary) | **GET** /api/compliance/runs/summary/{scope}/{code}/$decorate | [EARLY ACCESS] GetDecoratedComplianceRunSummary: Get decorated summary results for a specific compliance run.
*ComplianceApi* | [**list_compliance_rules**](docs/ComplianceApi.md#list_compliance_rules) | **GET** /api/compliance/rules | [EARLY ACCESS] ListComplianceRules: List compliance rules.
*ComplianceApi* | [**list_compliance_runs**](docs/ComplianceApi.md#list_compliance_runs) | **GET** /api/compliance/runs | [EARLY ACCESS] ListComplianceRuns: List historical compliance run identifiers.
*ComplianceApi* | [**list_compliance_templates**](docs/ComplianceApi.md#list_compliance_templates) | **GET** /api/compliance/templates | [EARLY ACCESS] ListComplianceTemplates: List compliance templates.
*ComplianceApi* | [**list_order_breach_history**](docs/ComplianceApi.md#list_order_breach_history) | **GET** /api/compliance/runs/breaches | [EXPERIMENTAL] ListOrderBreachHistory: List Historical Order Breaches.
*ComplianceApi* | [**run_compliance**](docs/ComplianceApi.md#run_compliance) | **POST** /api/compliance/runs | [EARLY ACCESS] RunCompliance: Run a compliance check.
*ComplianceApi* | [**run_compliance_preview**](docs/ComplianceApi.md#run_compliance_preview) | **POST** /api/compliance/preview/runs | [EARLY ACCESS] RunCompliancePreview: Run a compliance check.
*ComplianceApi* | [**update_compliance_template**](docs/ComplianceApi.md#update_compliance_template) | **PUT** /api/compliance/templates/{scope}/{code} | [EARLY ACCESS] UpdateComplianceTemplate: Update a ComplianceRuleTemplate
*ComplianceApi* | [**upsert_compliance_rule**](docs/ComplianceApi.md#upsert_compliance_rule) | **POST** /api/compliance/rules | [EARLY ACCESS] UpsertComplianceRule: Upsert a compliance rule.
*ComplianceApi* | [**upsert_compliance_run_summary**](docs/ComplianceApi.md#upsert_compliance_run_summary) | **POST** /api/compliance/runs/summary | [EARLY ACCESS] UpsertComplianceRunSummary: Upsert a compliance run summary.
*ConfigurationRecipeApi* | [**delete_configuration_recipe**](docs/ConfigurationRecipeApi.md#delete_configuration_recipe) | **DELETE** /api/recipes/{scope}/{code} | DeleteConfigurationRecipe: Delete a Configuration Recipe, assuming that it is present.
*ConfigurationRecipeApi* | [**delete_recipe_composer**](docs/ConfigurationRecipeApi.md#delete_recipe_composer) | **DELETE** /api/recipes/composer/{scope}/{code} | DeleteRecipeComposer: Delete a Recipe Composer, assuming that it is present.
*ConfigurationRecipeApi* | [**get_configuration_recipe**](docs/ConfigurationRecipeApi.md#get_configuration_recipe) | **GET** /api/recipes/{scope}/{code} | GetConfigurationRecipe: Get Configuration Recipe
*ConfigurationRecipeApi* | [**get_derived_recipe**](docs/ConfigurationRecipeApi.md#get_derived_recipe) | **GET** /api/recipes/derived/{scope}/{code} | GetDerivedRecipe: Get Configuration Recipe either from the store or expanded from a Recipe Composer.
*ConfigurationRecipeApi* | [**get_recipe_composer**](docs/ConfigurationRecipeApi.md#get_recipe_composer) | **GET** /api/recipes/composer/{scope}/{code} | GetRecipeComposer: Get Recipe Composer
*ConfigurationRecipeApi* | [**get_recipe_composer_resolved_inline**](docs/ConfigurationRecipeApi.md#get_recipe_composer_resolved_inline) | **POST** /api/recipes/composer/resolvedinline$ | GetRecipeComposerResolvedInline: Given a Recipe Composer, this endpoint expands into a Configuration Recipe without persistence. Primarily used for testing purposes.
*ConfigurationRecipeApi* | [**list_configuration_recipes**](docs/ConfigurationRecipeApi.md#list_configuration_recipes) | **GET** /api/recipes | ListConfigurationRecipes: List the set of Configuration Recipes
*ConfigurationRecipeApi* | [**list_derived_recipes**](docs/ConfigurationRecipeApi.md#list_derived_recipes) | **GET** /api/recipes/derived | ListDerivedRecipes: List the complete set of all Configuration Recipes, both from the configuration recipe store and also from expanded recipe composers.
*ConfigurationRecipeApi* | [**list_recipe_composers**](docs/ConfigurationRecipeApi.md#list_recipe_composers) | **GET** /api/recipes/composer | ListRecipeComposers: List the set of Recipe Composers
*ConfigurationRecipeApi* | [**upsert_configuration_recipe**](docs/ConfigurationRecipeApi.md#upsert_configuration_recipe) | **POST** /api/recipes | UpsertConfigurationRecipe: Upsert a Configuration Recipe. This creates or updates the data in Lusid.
*ConfigurationRecipeApi* | [**upsert_recipe_composer**](docs/ConfigurationRecipeApi.md#upsert_recipe_composer) | **POST** /api/recipes/composer | UpsertRecipeComposer: Upsert a Recipe Composer. This creates or updates the data in Lusid.
*ConventionsApi* | [**delete_cds_flow_conventions**](docs/ConventionsApi.md#delete_cds_flow_conventions) | **DELETE** /api/conventions/credit/conventions/{scope}/{code} | [BETA] DeleteCdsFlowConventions: Delete the CDS Flow Conventions of given scope and code, assuming that it is present.
*ConventionsApi* | [**delete_flow_conventions**](docs/ConventionsApi.md#delete_flow_conventions) | **DELETE** /api/conventions/rates/flowconventions/{scope}/{code} | [BETA] DeleteFlowConventions: Delete the Flow Conventions of given scope and code, assuming that it is present.
*ConventionsApi* | [**delete_index_convention**](docs/ConventionsApi.md#delete_index_convention) | **DELETE** /api/conventions/rates/indexconventions/{scope}/{code} | [BETA] DeleteIndexConvention: Delete the Index Convention of given scope and code, assuming that it is present.
*ConventionsApi* | [**get_cds_flow_conventions**](docs/ConventionsApi.md#get_cds_flow_conventions) | **GET** /api/conventions/credit/conventions/{scope}/{code} | [BETA] GetCdsFlowConventions: Get CDS Flow Conventions
*ConventionsApi* | [**get_flow_conventions**](docs/ConventionsApi.md#get_flow_conventions) | **GET** /api/conventions/rates/flowconventions/{scope}/{code} | [BETA] GetFlowConventions: Get Flow Conventions
*ConventionsApi* | [**get_index_convention**](docs/ConventionsApi.md#get_index_convention) | **GET** /api/conventions/rates/indexconventions/{scope}/{code} | [BETA] GetIndexConvention: Get Index Convention
*ConventionsApi* | [**list_cds_flow_conventions**](docs/ConventionsApi.md#list_cds_flow_conventions) | **GET** /api/conventions/credit/conventions | [BETA] ListCdsFlowConventions: List the set of CDS Flow Conventions
*ConventionsApi* | [**list_flow_conventions**](docs/ConventionsApi.md#list_flow_conventions) | **GET** /api/conventions/rates/flowconventions | [BETA] ListFlowConventions: List the set of Flow Conventions
*ConventionsApi* | [**list_index_convention**](docs/ConventionsApi.md#list_index_convention) | **GET** /api/conventions/rates/indexconventions | [BETA] ListIndexConvention: List the set of Index Conventions
*ConventionsApi* | [**upsert_cds_flow_conventions**](docs/ConventionsApi.md#upsert_cds_flow_conventions) | **POST** /api/conventions/credit/conventions | [BETA] UpsertCdsFlowConventions: Upsert a set of CDS Flow Conventions. This creates or updates the data in Lusid.
*ConventionsApi* | [**upsert_flow_conventions**](docs/ConventionsApi.md#upsert_flow_conventions) | **POST** /api/conventions/rates/flowconventions | [BETA] UpsertFlowConventions: Upsert Flow Conventions. This creates or updates the data in Lusid.
*ConventionsApi* | [**upsert_index_convention**](docs/ConventionsApi.md#upsert_index_convention) | **POST** /api/conventions/rates/indexconventions | [BETA] UpsertIndexConvention: Upsert a set of Index Convention. This creates or updates the data in Lusid.
*CorporateActionSourcesApi* | [**batch_upsert_corporate_actions**](docs/CorporateActionSourcesApi.md#batch_upsert_corporate_actions) | **POST** /api/corporateactionsources/{scope}/{code}/corporateactions | [EARLY ACCESS] BatchUpsertCorporateActions: Batch upsert corporate actions (instrument transition events) to corporate action source.
*CorporateActionSourcesApi* | [**create_corporate_action_source**](docs/CorporateActionSourcesApi.md#create_corporate_action_source) | **POST** /api/corporateactionsources | [EARLY ACCESS] CreateCorporateActionSource: Create corporate action source
*CorporateActionSourcesApi* | [**delete_corporate_action_source**](docs/CorporateActionSourcesApi.md#delete_corporate_action_source) | **DELETE** /api/corporateactionsources/{scope}/{code} | [EARLY ACCESS] DeleteCorporateActionSource: Delete a corporate action source
*CorporateActionSourcesApi* | [**delete_corporate_actions**](docs/CorporateActionSourcesApi.md#delete_corporate_actions) | **DELETE** /api/corporateactionsources/{scope}/{code}/corporateactions | [EARLY ACCESS] DeleteCorporateActions: Delete corporate actions (instrument transition events) from a corporate action source
*CorporateActionSourcesApi* | [**delete_instrument_events**](docs/CorporateActionSourcesApi.md#delete_instrument_events) | **DELETE** /api/corporateactionsources/{scope}/{code}/instrumentevents | [EARLY ACCESS] DeleteInstrumentEvents: Delete instrument events from a corporate action source
*CorporateActionSourcesApi* | [**get_corporate_actions**](docs/CorporateActionSourcesApi.md#get_corporate_actions) | **GET** /api/corporateactionsources/{scope}/{code}/corporateactions | [EARLY ACCESS] GetCorporateActions: List corporate actions (instrument transition events) from the corporate action source.
*CorporateActionSourcesApi* | [**get_instrument_events**](docs/CorporateActionSourcesApi.md#get_instrument_events) | **GET** /api/corporateactionsources/{scope}/{code}/instrumentevents | [EARLY ACCESS] GetInstrumentEvents: Get extrinsic instrument events out of a given corporate actions source.
*CorporateActionSourcesApi* | [**list_corporate_action_sources**](docs/CorporateActionSourcesApi.md#list_corporate_action_sources) | **GET** /api/corporateactionsources | [EARLY ACCESS] ListCorporateActionSources: List corporate action sources
*CorporateActionSourcesApi* | [**upsert_instrument_events**](docs/CorporateActionSourcesApi.md#upsert_instrument_events) | **POST** /api/corporateactionsources/{scope}/{code}/instrumentevents | [EARLY ACCESS] UpsertInstrumentEvents: Upsert instrument events to the provided corporate actions source.
*CounterpartiesApi* | [**delete_counterparty_agreement**](docs/CounterpartiesApi.md#delete_counterparty_agreement) | **DELETE** /api/counterparties/counterpartyagreements/{scope}/{code} | [EARLY ACCESS] DeleteCounterpartyAgreement: Delete the Counterparty Agreement of given scope and code
*CounterpartiesApi* | [**delete_credit_support_annex**](docs/CounterpartiesApi.md#delete_credit_support_annex) | **DELETE** /api/counterparties/creditsupportannexes/{scope}/{code} | [EARLY ACCESS] DeleteCreditSupportAnnex: Delete the Credit Support Annex of given scope and code
*CounterpartiesApi* | [**get_counterparty_agreement**](docs/CounterpartiesApi.md#get_counterparty_agreement) | **GET** /api/counterparties/counterpartyagreements/{scope}/{code} | [EARLY ACCESS] GetCounterpartyAgreement: Get Counterparty Agreement
*CounterpartiesApi* | [**get_credit_support_annex**](docs/CounterpartiesApi.md#get_credit_support_annex) | **GET** /api/counterparties/creditsupportannexes/{scope}/{code} | [EARLY ACCESS] GetCreditSupportAnnex: Get Credit Support Annex
*CounterpartiesApi* | [**list_counterparty_agreements**](docs/CounterpartiesApi.md#list_counterparty_agreements) | **GET** /api/counterparties/counterpartyagreements | [EARLY ACCESS] ListCounterpartyAgreements: List the set of Counterparty Agreements
*CounterpartiesApi* | [**list_credit_support_annexes**](docs/CounterpartiesApi.md#list_credit_support_annexes) | **GET** /api/counterparties/creditsupportannexes | [EARLY ACCESS] ListCreditSupportAnnexes: List the set of Credit Support Annexes
*CounterpartiesApi* | [**upsert_counterparty_agreement**](docs/CounterpartiesApi.md#upsert_counterparty_agreement) | **POST** /api/counterparties/counterpartyagreements | [EARLY ACCESS] UpsertCounterpartyAgreement: Upsert Counterparty Agreement
*CounterpartiesApi* | [**upsert_credit_support_annex**](docs/CounterpartiesApi.md#upsert_credit_support_annex) | **POST** /api/counterparties/creditsupportannexes | [EARLY ACCESS] UpsertCreditSupportAnnex: Upsert Credit Support Annex
*CustomEntitiesApi* | [**delete_custom_entity**](docs/CustomEntitiesApi.md#delete_custom_entity) | **DELETE** /api/customentities/{entityType}/{identifierType}/{identifierValue} | DeleteCustomEntity: Delete a Custom Entity instance.
*CustomEntitiesApi* | [**delete_custom_entity_access_metadata**](docs/CustomEntitiesApi.md#delete_custom_entity_access_metadata) | **DELETE** /api/customentities/{entityType}/{identifierType}/{identifierValue}/metadata/{metadataKey} | [EARLY ACCESS] DeleteCustomEntityAccessMetadata: Delete a Custom Entity Access Metadata entry
*CustomEntitiesApi* | [**get_all_custom_entity_access_metadata**](docs/CustomEntitiesApi.md#get_all_custom_entity_access_metadata) | **GET** /api/customentities/{entityType}/{identifierType}/{identifierValue}/metadata | [EARLY ACCESS] GetAllCustomEntityAccessMetadata: Get all the Access Metadata rules for a Custom Entity
*CustomEntitiesApi* | [**get_all_custom_entity_properties**](docs/CustomEntitiesApi.md#get_all_custom_entity_properties) | **GET** /api/customentities/{entityType}/{identifierType}/{identifierValue}/properties | [EARLY ACCESS] GetAllCustomEntityProperties: Get all properties related to a Custom Entity instance.
*CustomEntitiesApi* | [**get_custom_entity**](docs/CustomEntitiesApi.md#get_custom_entity) | **GET** /api/customentities/{entityType}/{identifierType}/{identifierValue} | GetCustomEntity: Get a Custom Entity instance.
*CustomEntitiesApi* | [**get_custom_entity_access_metadata_by_key**](docs/CustomEnt | text/markdown | FINBOURNE Technology | info@finbourne.com | null | null | MIT | OpenAPI, OpenAPI-Generator, LUSID API, lusid-sdk | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.11 | [] | [] | [] | [
"aenum<4.0.0,>=3.1.11",
"aiohttp<4.0.0,>=3.8.4",
"pydantic<3.0.0,>=2.6.3",
"python-dateutil<3.0.0,>=2.8.2",
"requests<3,>=2",
"urllib3<3.0.0,>=2.6.0"
] | [] | [] | [] | [
"Repository, https://github.com/finbourne/lusid-sdk-python"
] | poetry/2.3.1 CPython/3.11.9 Linux/6.12.54-flatcar | 2026-02-19T21:15:44.847558 | lusid_sdk-2.3.56-py3-none-any.whl | 3,132,071 | d8/2c/712b15a32029812e7176979a4a29542d868edbb9f548a17f9f0af0917265/lusid_sdk-2.3.56-py3-none-any.whl | py3 | bdist_wheel | null | false | 979f1781e1e85bece9a02cb3e9720a69 | 820733e1a5b23bc3fbcd2158e1bbf0f8ec9b18905954256311f460e6722b9135 | d82c712b15a32029812e7176979a4a29542d868edbb9f548a17f9f0af0917265 | null | [] | 436 |
2.4 | genlayer-test | 0.20.4 | GenLayer Testing Suite | # GenLayer Testing Suite
[](https://opensource.org/license/mit/)
[](https://discord.gg/qjCU4AWnKE)
[](https://x.com/GenLayer)
[](https://badge.fury.io/py/genlayer-test)
[](https://docs.genlayer.com/api-references/genlayer-test)
[](https://github.com/psf/black)
A pytest-based testing framework for [GenLayer](https://docs.genlayer.com/) intelligent contracts. Built on top of [genlayer-py](https://docs.genlayer.com/api-references/genlayer-py).
```bash
pip install genlayer-test
```
## Two Ways to Test
The testing suite provides two execution modes. Pick the one that fits your workflow:
| | Direct Mode | Studio Mode |
|---|---|---|
| **How it works** | Runs contract Python code directly in-memory | Deploys to GenLayer Studio, interacts via RPC |
| **Speed** | ~milliseconds per test | ~minutes per test |
| **Prerequisites** | Python >= 3.12 | Python >= 3.12 + GenLayer Studio (Docker) |
| **Best for** | Unit tests, rapid development, CI/CD | Integration tests, consensus validation, testnet |
| **Mocking** | Foundry-style cheatcodes (`mock_web`, `mock_llm`) | Mock validators with transaction context |
**Start with Direct Mode.** It's faster, simpler, and doesn't require Docker. Use Studio Mode when you need full network behavior, multi-validator consensus, or testnet deployment.
---
## Direct Mode
Run contracts directly in Python — no simulator, no Docker, no network. Tests execute in milliseconds.
### Quick Start
```python
def test_storage(direct_vm, direct_deploy):
# Deploy contract in-memory
storage = direct_deploy("contracts/Storage.py", "initial")
# Read state directly
assert storage.get_storage() == "initial"
# Write state directly
storage.update_storage("updated")
assert storage.get_storage() == "updated"
```
Run with pytest:
```bash
pytest tests/ -v
```
### Fixtures
| Fixture | Description |
|---------|-------------|
| `direct_vm` | VM context with cheatcodes |
| `direct_deploy` | Deploy contracts directly |
| `direct_alice`, `direct_bob`, `direct_charlie` | Test addresses |
| `direct_owner` | Default sender address |
| `direct_accounts` | List of 10 test addresses |
### Cheatcodes
```python
# Change sender
direct_vm.sender = alice
# Prank (temporary sender change)
with direct_vm.prank(bob):
contract.method() # Called as bob
# Snapshots (captures full state: storage, mocks, sender, validators)
snap_id = direct_vm.snapshot()
contract.modify_state()
direct_vm.revert(snap_id) # Full state restored
# Expect revert
with direct_vm.expect_revert("Insufficient balance"):
contract.transfer(bob, 1000000)
# Mock web/LLM (regex pattern matching)
direct_vm.mock_web(r"api\.example\.com", {"status": 200, "body": "{}"})
direct_vm.mock_llm(r"analyze.*", "positive sentiment")
# Test validator consensus logic
contract.update_price() # Runs leader_fn, captures validator
direct_vm.clear_mocks() # Swap mocks for validator
direct_vm.mock_llm(r".*", "different result")
assert direct_vm.run_validator() is False # Validator disagrees
# Strict mocks (detect unused mocks)
direct_vm.strict_mocks = True
# Pickling validation (catch production serialization issues)
direct_vm.check_pickling = True
```
**[Full Direct Mode Documentation](docs/direct-runner.md)** — fixtures, cheatcodes, validator testing, limitations, and complete examples.
---
## Studio Mode
Deploy contracts to a running GenLayer Studio instance and interact via RPC. This gives you full network behavior including multi-validator consensus.
### Prerequisites
- Python >= 3.12
- GenLayer Studio running (Docker)
### Quick Start
```python
from gltest import get_contract_factory, get_default_account
from gltest.assertions import tx_execution_succeeded
factory = get_contract_factory("MyContract")
contract = factory.deploy()
# Read method — returns value directly
result = contract.get_value().call()
# Write method — returns transaction receipt
tx_receipt = contract.set_value(args=["new_value"]).transact()
assert tx_execution_succeeded(tx_receipt)
```
Run with the `gltest` CLI:
```bash
gltest # Run all tests
gltest tests/test_mycontract.py # Specific file
gltest --network studionet # Specific network
gltest --leader-only # Skip consensus (faster)
gltest -v # Verbose output
```
### Configuration
Create a `gltest.config.yaml` in your project root:
```yaml
networks:
default: localnet
localnet:
url: "http://127.0.0.1:4000/api"
leader_only: false
studionet:
# Pre-configured — accounts auto-generated
testnet_asimov:
accounts:
- "${ACCOUNT_PRIVATE_KEY_1}"
- "${ACCOUNT_PRIVATE_KEY_2}"
from: "${ACCOUNT_PRIVATE_KEY_1}"
paths:
contracts: "contracts"
artifacts: "artifacts"
environment: .env
```
Key options:
- **Networks**: `localnet` and `studionet` work out of the box. `testnet_asimov` requires account keys.
- **Paths**: Where your contracts and artifacts live.
- **Environment**: `.env` file for private keys.
Override via CLI:
```bash
gltest --network testnet_asimov
gltest --contracts-dir custom/contracts/path
gltest --rpc-url http://custom:4000/api
gltest --chain-type localnet
```
### Contract Deployment
```python
from gltest import get_contract_factory, get_default_account
from gltest.assertions import tx_execution_succeeded
factory = get_contract_factory("Storage")
# deploy() returns the contract instance (recommended)
contract = factory.deploy(
args=["initial_value"],
account=get_default_account(),
consensus_max_rotations=3,
)
# deploy_contract_tx() returns only the receipt
receipt = factory.deploy_contract_tx(args=["initial_value"])
assert tx_execution_succeeded(receipt)
```
### Read and Write Methods
```python
# Read — call() returns the value
result = contract.get_storage().call()
# Write — transact() returns a receipt
tx_receipt = contract.update_storage(args=["new_value"]).transact(
value=0,
consensus_max_rotations=3,
wait_interval=1000,
wait_retries=10,
)
assert tx_execution_succeeded(tx_receipt)
```
### Assertions
```python
from gltest.assertions import tx_execution_succeeded, tx_execution_failed
assert tx_execution_succeeded(tx_receipt)
assert tx_execution_failed(tx_receipt)
# Regex matching on stdout/stderr (localnet/studionet only)
assert tx_execution_succeeded(tx_receipt, match_std_out=r".*code \d+")
assert tx_execution_failed(tx_receipt, match_std_err=r"Method.*failed")
```
### Fixtures
| Fixture | Scope | Description |
|---------|-------|-------------|
| `gl_client` | session | GenLayer client for network operations |
| `default_account` | session | Default account for transactions |
| `accounts` | session | List of test accounts |
```python
def test_workflow(gl_client, default_account, accounts):
factory = get_contract_factory("MyContract")
contract = factory.deploy(account=default_account)
tx_receipt = contract.some_method(args=["value"], account=accounts[1])
assert tx_execution_succeeded(tx_receipt)
```
### Mock LLM Responses
Simulate LLM responses for deterministic tests:
```python
from gltest import get_contract_factory, get_validator_factory
from gltest.types import MockedLLMResponse
mock_response: MockedLLMResponse = {
"nondet_exec_prompt": {
"analyze this": "positive sentiment"
},
"eq_principle_prompt_comparative": {
"values match": True
}
}
validator_factory = get_validator_factory()
validators = validator_factory.batch_create_mock_validators(
count=5,
mock_llm_response=mock_response
)
transaction_context = {
"validators": [v.to_dict() for v in validators],
"genvm_datetime": "2024-01-01T00:00:00Z"
}
factory = get_contract_factory("LLMContract")
contract = factory.deploy(transaction_context=transaction_context)
result = contract.analyze_text(args=["analyze this"]).transact(
transaction_context=transaction_context
)
```
Mock keys map to GenLayer methods:
| Mock Key | GenLayer Method |
|----------|----------------|
| `"nondet_exec_prompt"` | `gl.nondet.exec_prompt` |
| `"eq_principle_prompt_comparative"` | `gl.eq_principle.prompt_comparative` |
| `"eq_principle_prompt_non_comparative"` | `gl.eq_principle.prompt_non_comparative` |
The system performs **substring matching** on the internal user message — your mock key must appear within the message.
### Mock Web Responses
Simulate HTTP responses for contracts that call `gl.nondet.web.get()`, etc.:
```python
from gltest.types import MockedWebResponse
import json
mock_web_response: MockedWebResponse = {
"nondet_web_request": {
"https://api.example.com/price": {
"method": "GET",
"status": 200,
"body": json.dumps({"price": 100.50})
}
}
}
validators = validator_factory.batch_create_mock_validators(
count=5,
mock_web_response=mock_web_response
)
```
You can combine both `mock_llm_response` and `mock_web_response` in a single `batch_create_mock_validators` call. URL matching is exact (including query parameters).
### Custom Validators
```python
from gltest import get_validator_factory
factory = get_validator_factory()
# Real validators with specific LLM providers
validators = factory.batch_create_validators(
count=5,
stake=10,
provider="openai",
model="gpt-4o",
config={"temperature": 0.7},
plugin="openai-compatible",
plugin_config={"api_key_env_var": "OPENAI_API_KEY"}
)
# Use in transaction context
transaction_context = {
"validators": [v.to_dict() for v in validators],
"genvm_datetime": "2024-03-15T14:30:00Z"
}
```
### Statistical Analysis
For LLM-based contracts, `.analyze()` runs multiple simulations to measure consistency:
```python
analysis = contract.process_with_llm(args=["input"]).analyze(
provider="openai",
model="gpt-4o",
runs=100,
)
print(f"Success rate: {analysis.success_rate:.2f}%")
print(f"Reliability: {analysis.reliability_score:.2f}%")
print(f"Unique states: {analysis.unique_states}")
```
**[Full Studio Mode Documentation](docs/studio-runner.md)** — configuration reference, all CLI flags, mock LLM/web details, custom validators, statistical analysis, and complete examples.
---
## Example Contract
```python
from genlayer import *
class Storage(gl.Contract):
storage: str
def __init__(self, initial_storage: str):
self.storage = initial_storage
@gl.public.view
def get_storage(self) -> str:
return self.storage
@gl.public.write
def update_storage(self, new_storage: str) -> None:
self.storage = new_storage
```
### Project Structure
```
my-project/
├── contracts/
│ └── Storage.py
├── tests/
│ ├── test_direct.py # Direct mode tests (fast)
│ └── test_integration.py # Studio mode tests
└── gltest.config.yaml # Studio mode config
```
For more examples, see the [contracts directory](tests/examples/contracts).
## Troubleshooting
**Contract not found**: Ensure contracts are in `contracts/` or specify `--contracts-dir`. Contracts must inherit from `gl.Contract`.
**Transaction timeouts** (Studio mode): Increase `wait_interval` and `wait_retries` in `.transact()`.
**Consensus failures** (Studio mode): Increase `consensus_max_rotations` or use `--leader-only` for faster iteration.
**Environment issues**: Verify Python >= 3.12. For Studio mode, check Docker is running (`docker ps`).
## Contributing
See our [Contributing Guide](CONTRIBUTING.md).
## License
MIT — see [LICENSE](LICENSE).
## Support
- [Documentation](https://docs.genlayer.com/api-references/genlayer-test)
- [Discord](https://discord.gg/qjCU4AWnKE)
- [GitHub Issues](https://github.com/genlayerlabs/genlayer-testing-suite/issues)
- [Twitter](https://x.com/GenLayer)
| text/markdown | GenLayer | null | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Testing"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"pytest",
"setuptools>=77.0",
"genlayer-py==0.9.0",
"colorama>=0.4.6",
"pyyaml",
"python-dotenv",
"fastapi>=0.100; extra == \"sim\"",
"uvicorn[standard]>=0.20; extra == \"sim\"",
"httpx>=0.24; extra == \"sim\"",
"eth-account>=0.10; extra == \"sim\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.12 | 2026-02-19T21:14:58.323705 | genlayer_test-0.20.4.tar.gz | 63,052 | ce/be/4d9dda897cd0fafeb39a14aa48919eda3d884ee2a1f8c13a6482046b3595/genlayer_test-0.20.4.tar.gz | source | sdist | null | false | bdff8b332d0c41f138682775ca86eaab | e91cfc056af248beb60c5c1568d203852a7b696fddeedbd14a8150da1383581a | cebe4d9dda897cd0fafeb39a14aa48919eda3d884ee2a1f8c13a6482046b3595 | MIT | [
"LICENSE"
] | 256 |
2.1 | da4ml | 0.6.0rc1 | Distributed Arithmetic for Machine Learning | # da4ml: HLS Compiler for Low-latency, Static-dataflow Kernels on FPGAs
[](https://github.com/calad0i/da4ml/actions/workflows/unit-test.yml)
[](https://calad0i.github.io/da4ml/)
[](https://pypi.org/project/da4ml/)
[](https://arxiv.org/abs/2507.04535)
[](https://codecov.io/gh/calad0i/da4ml)
da4ml is a light-weight high-level synthesis (HLS) compiler for generating low-latency, static-dataflow kernels for FPGAs. The main motivation of da4ml is to provide a simple and efficient way for machine learning practitioners requiring ultra-low latency to deploy their models on FPGAs quickly and easily, similar to hls4ml but with a much simpler design and better performance, both for the generated kernels and for the compilation process.
As a static dataflow compiler, da4ml is specialized for kernels that are equivalent to a combinational or fully pipelined logic circuit, which means that the kernel has no loops or has only fully unrolled loops. There is no specific limitation on the types of operations that can be used in the kernel. For resource sharing and time-multiplexing, the users are expected to use the generated kernels as building blocks and manually assemble them into a larger design. In the future, we may employ a XLS-like design to automate the communication and buffer instantiation between kernels, but for now we will keep it simple and let the users have full control over the design.
With DA in its name, da4ml do perform distributed arithmetic (DA) optimization to generate efficient kernels for linear DSP operations. The algorithm used is an efficient hybrid algorithm described in our [TRETS'25 paper](https://doi.org/10.1145/3777387). With DA optimization, any linear DSP operation can be implemented efficiently with only adders (i.e., fast accum and LUTs on FPGAs) without any hardened multipliers. If the user wishes, one can also control what multiplication pairs shall be excluded from DA optimization.
Installation
------------
```bash
pip install da4ml
```
Note: da4ml is now released as binary wheels on PyPI for Linux X86_64 and MacOS ARM64 platforms. For other platforms, please install from source. C++20 compliant compiler with OpenMP support is required to build da4ml from source. Windows is not officially supported, but you may try building it with MSVC or MinGW.
Getting Started
---------------
- See the [Getting Started](https://calad0i.github.io/da4ml/getting_started.html) guide for a quick introduction to using da4ml.
- See [JEDI-linear](https://github.com/calad0i/JEDI-linear) project which is based on da4ml
## License
LGPLv3. See the [LICENSE](LICENSE) file for details.
## Citation
If you use da4ml in a publication, please cite our [TRETS'25 paper](https://doi.org/10.1145/3777387) with the following bibtex entry:
```bibtex
@article{sun2025da4ml,
author = {Sun, Chang and Que, Zhiqiang and Loncar, Vladimir and Luk, Wayne and Spiropulu, Maria},
title = {da4ml: Distributed Arithmetic for Real-time Neural Networks on FPGAs},
year = {2025},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
issn = {1936-7406},
url = {https://doi.org/10.1145/3777387},
doi = {10.1145/3777387},
journal = {ACM Trans. Reconfigurable Technol. Syst.},
month = nov,
}
```
| text/markdown | null | Chang Sun <chsun@cern.ch> | null | null | GNU Lesser General Public License v3 (LGPLv3) | CMVM, distributed arithmetic, high-level synthesis, HLS Complier, machine learning, RTL Generator | [
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy>=2",
"quantizers<2,>=1",
"myst-parser; extra == \"docs\"",
"pyparsing; extra == \"docs\"",
"sphinx; extra == \"docs\"",
"sphinx-rtd-theme; extra == \"docs\"",
"pytest; extra == \"tests\"",
"pytest-cov; extra == \"tests\"",
"pytest-env; extra == \"tests\"",
"pytest-sugar; extra == \"tests\""... | [] | [] | [] | [
"repository, https://github.com/calad0i/da4ml"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:14:36.654083 | da4ml-0.6.0rc1-cp312-abi3-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl | 694,323 | 2f/04/0ff96c7245a35618ddb21eed8ef1ed115ce2bc03595dec4a9cf1b5fe70b7/da4ml-0.6.0rc1-cp312-abi3-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl | cp312 | bdist_wheel | null | false | 5dff7ff7b9aae858c741d85b175db765 | b4218110d0d0dc001dc643b5a2af11080977df9c8f09e9b8ffe37b1f1d38a77c | 2f040ff96c7245a35618ddb21eed8ef1ed115ce2bc03595dec4a9cf1b5fe70b7 | null | [] | 385 |
2.4 | surety-api | 0.0.1 | Contract-aware API interaction layer for the Surety ecosystem. | # Surety API
Contract-aware API interaction layer for the Surety ecosystem.
`surety-api` enables structured API testing, mocking, and
interaction based on Surety contracts.
It bridges declarative contracts and real HTTP communication.
---
## Installation
```bash
pip install surety-api
| text/markdown | null | Elena Kulgavaya <elena.kulgavaya@gmail.com> | null | null | MIT | api, contract-testing, automation, integration-testing, surety | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"deepdiff==8.0.1",
"surety<1.0,>=0.0.4",
"surety-config>=0.0.3",
"surety-diff>=0.0.1",
"requests",
"pyyaml",
"waiting"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:14:01.654578 | surety_api-0.0.1.tar.gz | 14,142 | 34/bd/a5d7566ae3eb1c1b07af80e2a87c46f584749f159ba5ac813a96b44ea91c/surety_api-0.0.1.tar.gz | source | sdist | null | false | e9c2c644f2a31053479e6967c87d441c | 7a367ed86e84c360a54a42056b990f6afe43d05f2080e271839b881ff42955c5 | 34bda5d7566ae3eb1c1b07af80e2a87c46f584749f159ba5ac813a96b44ea91c | null | [
"LICENSE"
] | 271 |
2.3 | fabrictestbed | 2.0.1 | FABRIC Python Client Library with CLI | [](https://pypi.org/project/fabrictestbed/)
# FABRIC TESTBED USER LIBRARY AND CLI
Fabric User CLI for experiments
## Overview
This package supports User facing APIs as well as CLI.
- Tokens: Token management
- Slices: Slice management
- Slivers: Sliver management
- Resources: Resource management
### CLI Commands
Command | SubCommand | Action | Input | Output
:--------|:----:|:----:|:---:|:---:
`tokens` | `issue`| Issue token with projectId and scope | `projectId` Project Id, `scope` Scope | Points user to Credential Manager to generate the tokens
`token` | `refresh`| Refresh token | `projectId` Project Id, `scope` Scope, `refreshtoken` Refresh Token | Returns new identity and refresh tokens
`token` | `revoke` | Revoke token | `refreshtoken` Refresh Token | Success or Failure status
`slices` | `query` | Query user slice(s) | `idtoken` Identity Token, `refreshtoken` Refresh Token, `projectId` Project Id, `scope` Scope, `sliceid` Slice Id | List of Slices or Graph ML representing slice identified by Slice Id
`slices` | `create` | Create user slice | `idtoken` Identity Token, `refreshtoken` Refresh Token, `projectId` Project Id, `scope` Scope, `slicename` Slice Name, `slicegraph` Slice graph | List of Slivers created for the Slice
`slices` | `delete` | Delete user slice | `idtoken` Identity Token, `refreshtoken` Refresh Token, `projectId` Project Id, `scope` Scope, `sliceid` Slice Id | Success or Failure Status
`slivers` | `query` | Query user sliver(s) | `idtoken` Identity Token, `refreshtoken` Refresh Token, `projectId` Project Id, `scope` Scope, `sliceid` Slice Id, `sliverid` Sliver Id | List of Slivers for the slice identified by Slice Id or Sliver identified by Sliver Id
`resources` | `query` | Query resources | `idtoken` Identity Token, `refreshtoken` Refresh Token, `projectId` Project Id, `scope` Scope | Graph ML representing the available resources
### API
`SliceManager` class implements the API supporting the operations listed above. Check example in Usage below.
## Requirements
Python 3.9+
## Installation
Multiple installation options possible. For CF development the recommended method is to install from GitHub MASTER branch:
```
$ mkvirtualenv fabrictestbed
$ workon fabrictestbed
$ pip install git+https://github.com/fabric-testbed/fabric-cli.git
```
For inclusion in tools, etc, use PyPi
```
$ mkvirtualenv fabrictestbed
$ workon fabrictestbed
$ pip install fabrictestbed
```
### Pre-requisites for the install example above
Ensure that following are installed
- `virtualenv`
- `virtualenvwrapper`
NOTE: Any of the virtual environment tools (`venv`, `virtualenv`, or `virtualenvwrapper`) should work.
## Usage (API)
User API supports token and orchestrator commands. Please refer to Jupyter Notebooks [here](https://github.com/fabric-testbed/jupyter-examples/tree/master/fabric_examples/beta_functionality) for examples.
## Usage (CLI)
### Configuration
User CLI expects the user to set following environment variables:
```
export FABRIC_ORCHESTRATOR_HOST=orchestrator.fabric-testbed.net
export FABRIC_CREDMGR_HOST=cm.fabric-testbed.net
export FABRIC_TOKEN_LOCATION=<location of the token file downloaded from the Portal>
export FABRIC_PROJECT_ID=<Project Id of the project for which resources are being provisioned>
```
Alternatively, user can pass these as parameters to the commands.
#### To enable CLI auto-completion, add following line to your ~/.bashrc
```
eval "$(_FABRIC_CLI_COMPLETE=source_bash fabric-cli)"
```
Open a new shell to enable completion.
Or run the eval command directly in your current shell to enable it temporarily.
User CLI supports token and orchestrator commands:
```
(usercli) $ fabric-cli
Usage: fabric-cli [OPTIONS] COMMAND [ARGS]...
Options:
-v, --verbose
--help Show this message and exit.
Commands:
resources Resource management (set $FABRIC_ORCHESTRATOR_HOST to the...
slices Slice management (set $FABRIC_ORCHESTRATOR_HOST to the...
slivers Sliver management (set $FABRIC_ORCHESTRATOR_HOST to the...
tokens Token management (set $FABRIC_CREDMGR_HOST to the Credential...
```
### Token Management Commands
List of the token commands supported can be found below:
```
(usercli) $ fabric-cli tokens
Usage: fabric-cli tokens [OPTIONS] COMMAND [ARGS]...
Token management (set $FABRIC_CREDMGR_HOST to the Credential Manager
Server)
Options:
--help Show this message and exit.
Commands:
issue Issue token with projectId and scope
refresh Refresh token
revoke Revoke token
```
### Resource Management Commands
List of the resource commands supported can be found below:
```
$ fabric-cli resources
Usage: fabric-cli resources [OPTIONS] COMMAND [ARGS]...
Query Resources (set $FABRIC_ORCHESTRATOR_HOST to the Control Framework
Orchestrator)
Options:
--help Show this message and exit.
Commands:
query issue token with projectId and scope
```
### Slice Management Commands
```
(usercli) $ fabric-cli slices
Usage: fabric-cli slices [OPTIONS] COMMAND [ARGS]...
Slice management (set $FABRIC_ORCHESTRATOR_HOST to the Orchestrator)
Options:
--help Show this message and exit.
Commands:
create Create user slice
delete Delete user slice
query Query user slice(s)
```
### Sliver Management Commands
```
(usercli) $ fabric-cli slivers
Usage: fabric-cli slivers [OPTIONS] COMMAND [ARGS]...
Sliver management (set $FABRIC_ORCHESTRATOR_HOST to the Orchestrator)
Options:
--help Show this message and exit.
Commands:
query Query user slice sliver(s)
```
| text/markdown | null | Komal Thareja <kthare10@renci.org> | null | null | null | Swagger, FABRIC Python Client Library with CLI | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.9 | [] | [
"fabrictestbed"
] | [] | [
"fabric_fss_utils>=1.5.1",
"click",
"fabric-credmgr-client==1.6.2",
"fabric-orchestrator-client==1.9.1",
"paramiko",
"coverage>=4.0.3; extra == \"test\"",
"nose>=1.3.7; extra == \"test\"",
"pluggy>=0.3.1; extra == \"test\"",
"py>=1.4.31; extra == \"test\"",
"randomize>=0.13; extra == \"test\""
] | [] | [] | [] | [
"Home, https://fabric-testbed.net/",
"Sources, https://github.com/fabric-testbed/fabric-cli"
] | python-requests/2.32.5 | 2026-02-19T21:13:45.389148 | fabrictestbed-2.0.1.tar.gz | 59,260 | c2/c4/681656ea94b0ee2e9e8c5ba1c5d02dcc7ac4725bd9917a4c32a053c318db/fabrictestbed-2.0.1.tar.gz | source | sdist | null | false | 4ffb63a09a4d6099115b5a6aba2c19ec | bfd772ff394aae29ef07bdecf6c37c8fe97e5bd1eb10e405e5f128a9db83a877 | c2c4681656ea94b0ee2e9e8c5ba1c5d02dcc7ac4725bd9917a4c32a053c318db | null | [] | 409 |
2.4 | zombie-escape | 2.2.2 | Top-down zombie survival game built with pygame. | # Zombie Escape
The city is overrun with zombies!
You fled the horde, taking refuge in an abandoned factory.
Inside, it's a maze. They won't get in easily.
But you have no weapons. Night has fallen. The power's out, plunging the factory into darkness.
Your only tool: a single flashlight.
A car... somewhere inside... it's your only hope.
Pierce the darkness and find the car!
Then, escape this nightmare city!
## Overview
This game is a simple 2D top-down action game where the player aims to escape by finding and driving a car out of a large building infested with zombies. The player must evade zombies, break through walls to find a path, and then escape the building in a car.
<img src="https://raw.githubusercontent.com/tos-kamiya/zombie-escape/main/imgs/screenshot1.png" width="400">
<img src="https://raw.githubusercontent.com/tos-kamiya/zombie-escape/main/imgs/screenshot2.png" width="400">
<img src="https://raw.githubusercontent.com/tos-kamiya/zombie-escape/main/imgs/screenshot3.png" width="400">
<img src="https://raw.githubusercontent.com/tos-kamiya/zombie-escape/main/imgs/screenshot4.png" width="400">
## Controls
**Keyboard/Gamepad**
- **Player/Car Movement:** `W` / `↑` (Up), `A` / `←` (Left), `S` / `↓` (Down), `D` / `→` (Right)
- **Enter Car:** Overlap the player with the car.
- **Pause:** `P`/Start or `ESC`/Select
- **Quit Game:** `ESC`/Select (from pause)
- **Restart:** `R` key (on Game Over/Clear screen)
- **Window/Fullscreen:** `[` to shrink by one step (400x300), `]` to enlarge by one step, `F` to toggle fullscreen
- After any of these operations, gameplay is forced into pause so input/focus state stays explicit.
- **FPS Overlay:** Launch with `--show-fps` (implied by `--debug`)
- **Time Acceleration:** Hold either `Shift` key or `R1` to run the entire world 4x faster; release to return to normal speed.
**Mouse**
- **Gameplay** While holding left mouse button, the player moves toward the cursor.
- While holding left mouse button over the player character, the whole game runs at 4x speed.
- Moving the cursor into a corner hotspot triangle pauses the game.
- Resizing the OS window by mouse drag also forces gameplay pause.
- **Title/Settings/etc.** Select items by releasing left mouse button.
## Title Screen
### Stages
At the title screen you can pick a stage:
- **Stage 1: Find the Car** — find the car and escape.
- **Stage 2: Fuel Run** — you start with no fuel; find a fuel can first, pick it up, then find the car and escape.
- **Stage 3: Rescue Buddy** — similarly, find fuel, locate your buddy, pick them up with the car, and escape together.
- **Stage 4: Evacuate Survivors** — find the car, gather survivors, and escape before zombies reach them. The stage has multiple parked cars; ramming one while driving adds +5 capacity.
- **Stage 5: Survive Until Dawn** — cars are unusable. Survive until sunrise, then leave on foot through an existing exterior opening.
Stage pages unlock progressively:
- Stages 1-5 are always available.
- Stages 6-15 unlock after clearing all Stages 1-5.
- Stages 16-25 unlock after clearing at least 5 stages on the Stages 6-15 page.
- For later pages, the same rule repeats: clear at least 5 stages on the current page to unlock the next page.
If fewer than 5 stages are cleared on a page (except page 1), the next page remains locked.
On the title screen, use left/right to switch unlocked pages.
**Stage names are red until cleared** and turn white after at least one clear. Cleared stage names also show icons for characters/items that appear in that stage.
An objective reminder is shown at the top-left during play.
### Win/Lose Conditions
- **Win Condition:** Escape the stage (level) boundaries while inside the car.
- Stage 1 and Stage 4 follow the base rule: drive out of the building by car.
- Stage 2 also requires that you have collected the fuel can before driving out.
- Stage 3 requires meeting up with your buddy and escaping the building by car.
- Stage 5 has no working cars; survive until dawn, then walk out through an exterior opening on foot.
- **Lose Condition:**
- The player is touched by a zombie while *not* inside a car.
- In Stage 3, if your buddy is caught (when visible), it's game over.
- (Note: In the current implementation, the game does not end immediately when the car is destroyed. The player can search for another car and continue trying to escape.)
### Shared Seeds
The title screen also lets you enter a numeric **seed**. Type digits (or pass `--seed <number>` on the CLI) to lock the procedural layout, wall placement, and pickups; share that seed with a friend and you will both play the exact same stage even on different machines. The current seed is shown at the bottom right of the title screen and in-game HUD. Backspace reverts to an automatically generated value so you can quickly roll a fresh challenge.
## Settings Screen
Open **Settings** from the title to toggle gameplay assists:
- **Footprints:** Leave breadcrumb trails so you can backtrack in the dark.
- **Fast zombies:** Allow faster zombie variants; each zombie rolls a random speed between the normal and fast ranges.
- **Car hint:** After a delay, show a small triangle pointing toward the fuel (Stage 2 before pickup) or the car.
- **Steel beams:** Adds tougher single-cell obstacles (about 5% density) that block movement.
## Game Rules
### Characters/Items
#### Characters
<table>
<colgroup>
<col style="width:20%">
<col>
<col>
</colgroup>
<thead>
<tr>
<th>Name</th>
<th>Image</th>
<th>Notes</th>
</tr>
</thead>
<tbody>
<tr>
<td>Player</td>
<td><img src="https://raw.githubusercontent.com/tos-kamiya/zombie-escape/main/imgs/exports/player.png" width="64"></td>
<td>Blue circle with small hands; controlled with WASD/arrow keys. When carrying fuel, a tiny yellow square appears near the sprite.</td>
</tr>
<tr>
<td>Zombie (Normal)</td>
<td><img src="https://raw.githubusercontent.com/tos-kamiya/zombie-escape/main/imgs/exports/zombie-normal.png" width="64"></td>
<td>Chases the player once detected; out of sight it periodically switches movement modes.</td>
</tr>
<tr>
<td>Car</td>
<td><img src="https://raw.githubusercontent.com/tos-kamiya/zombie-escape/main/imgs/exports/car.png" width="64"></td>
<td>Driveable escape vehicle; touch to enter. Durability drops from wall hits and running over zombies; if it reaches 0, the car breaks. Capacity starts at five. Ramming a parked car while driving restores health and adds +5 capacity. After ~5 minutes, a small triangle points to the current objective.</td>
</tr>
<tr>
<td>Buddy (Stage 3)</td>
<td><img src="https://raw.githubusercontent.com/tos-kamiya/zombie-escape/main/imgs/exports/buddy.png" width="64"></td>
<td>Teal-blue survivor you can rescue; zombies only target them on-screen and off-screen catches just respawn them. Touch on foot to follow (70% speed), touch while driving to pick up. Helps chip away at walls you bash.</td>
</tr>
<tr>
<td>Survivors (Stage 4)</td>
<td><img src="https://raw.githubusercontent.com/tos-kamiya/zombie-escape/main/imgs/exports/survivor.png" width="64"></td>
<td>Civilians to evacuate by car; they idle until approached, then follow at ~1/3 speed. On-screen zombie contact converts them. If you exceed the car's capacity, the car is damaged and everyone disembarks.</td>
</tr>
</tbody>
</table>
#### Items
<table>
<colgroup>
<col style="width:20%">
<col>
<col>
</colgroup>
<thead>
<tr>
<th>Name</th>
<th>Image</th>
<th>Notes</th>
</tr>
</thead>
<tbody>
<tr>
<td>Flashlight</td>
<td><img src="https://raw.githubusercontent.com/tos-kamiya/zombie-escape/main/imgs/exports/flashlight.png" width="64"></td>
<td>Each pickup expands your visible radius by about 20%.</td>
</tr>
<tr>
<td>Fuel Can (Stages 2 & 3)</td>
<td><img src="https://raw.githubusercontent.com/tos-kamiya/zombie-escape/main/imgs/exports/fuel.png" width="64"></td>
<td>Appears only in stages that begin without fuel; pick it up to unlock driving.</td>
</tr>
<tr>
<td>Steel Beam (optional)</td>
<td><img src="https://raw.githubusercontent.com/tos-kamiya/zombie-escape/main/imgs/exports/steel-beam.png" width="64"></td>
<td>Striped obstacle with the same collision as inner walls, but 1.5x durability. Can also appear after an inner wall is destroyed.</td>
</tr>
</tbody>
</table>
#### Environment
<table>
<colgroup>
<col style="width:20%">
<col>
<col>
</colgroup>
<thead>
<tr>
<th>Name</th>
<th>Image</th>
<th>Notes</th>
</tr>
</thead>
<tbody>
<tr>
<td>Outer Wall</td>
<td><img src="https://raw.githubusercontent.com/tos-kamiya/zombie-escape/main/imgs/exports/wall-outer.png" width="64"></td>
<td>Gray perimeter walls that are nearly indestructible; each side has a single opening (exit).</td>
</tr>
<tr>
<td>Inner Wall</td>
<td><img src="https://raw.githubusercontent.com/tos-kamiya/zombie-escape/main/imgs/exports/wall-inner.png" width="64"></td>
<td>Beige interior walls with durability. The player can break them by repeated collisions; zombies wear them down slowly; the car cannot break them.</td>
</tr>
</tbody>
</table>
## How to Run
**Requirements: Python 3.10 or higher**
Install using pipx:
```sh
pipx install zombie-escape
```
Alternatively, you can install using pip in a virtual environment:
```sh
pip install zombie-escape
```
Launch using the following command line:
```sh
zombie-escape
```
## License
This project is licensed under the MIT License - see the [LICENSE.txt](LICENSE.txt) file for details.
This project depends on pygame-ce (repository: `https://github.com/pygame-community/pygame-ce`), which is licensed under GNU LGPL version 2.1.
The bundled Silkscreen-Regular.ttf font follows the license terms of its original distribution.
Please refer to the upstream website for details: https://fonts.google.com/specimen/Silkscreen
The bundled misaki_gothic.ttf font (Misaki font by Num Kadoma) follows the license terms provided by Little Limit.
Please refer to the official site for details: https://littlelimit.net/misaki.htm
## Acknowledgements
Significant assistance for many technical implementation and documentation aspects of this game's development was received from Google's large language model, Gemini (accessed during development), and from OpenAI's GPT-5. This included generating Python/Pygame code, suggesting rule adjustments, providing debugging support, and creating this README. Their rapid coding capabilities and contributions to problem-solving are greatly appreciated.
Thanks to Jason Kottke, the author of the Silkscreen-Regular.ttf font used in the game.
Thanks to Num Kadoma, the author of the Misaki font (misaki_gothic.ttf) distributed via Little Limit.
| text/markdown | null | Toshihiro Kamiya <kamiya@mbj.nifty.com> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programmin... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy",
"platformdirs",
"pygame-ce",
"python-i18n",
"typing-extensions; python_version < \"3.11\"",
"pydeps; extra == \"dev\"",
"pyright; extra == \"dev\"",
"pytest; extra == \"dev\"",
"ruff; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/tos-kamiya/zombie-escape"
] | Hatch/1.16.3 cpython/3.12.3 HTTPX/0.28.1 | 2026-02-19T21:12:44.778359 | zombie_escape-2.2.2.tar.gz | 450,764 | 58/3d/7c588fb46a9ac83ce4ace3e00ccabf2b2f7b001cf1b23dda88be8a9f6afb/zombie_escape-2.2.2.tar.gz | source | sdist | null | false | 80f1d33ca21c61532f0f6691da673d0a | 3cfc728d331ccc3374984075d6a556b023f4ffde6c6d2f7865cc3dd6b6ff680e | 583d7c588fb46a9ac83ce4ace3e00ccabf2b2f7b001cf1b23dda88be8a9f6afb | MIT | [
"LICENSE.txt"
] | 265 |
2.4 | arcgispro-cli | 0.4.0 | CLI tool for inspecting ArcGIS Pro session exports | # ArcGIS Pro CLI
[](https://pypi.org/project/arcgispro-cli/)
[](https://github.com/danmaps/arcgispro_cli/actions)
Give AI agents eyes into ArcGIS Pro.
```bash
pip install arcgispro-cli
arcgispro install
```
## What's New in v0.4.0
- Enhanced TUI with map preview support and improved banner rendering
- Mermaid project structure export (`project-structure.mmd` + markdown wrapper)
- Best-effort stable IDs for maps/layers/tables to improve snapshot tracking
- Geoprocessing history export scaffold for richer context artifacts
- Reliability fixes including Python 3.9 compatibility and improved terminal/add-in robustness
## How It Works
ProExporter (Pro add-in) creates detailed flat files that explain the state of your ArcGIS Pro project. `arcgispro` CLI tool facilitates frictionless reasoning over the context. Fewer assumptions and annoying follow-up questions. Helps the AI help you.
1. Open a project in ArcGIS Pro
2. Click **Snapshot** in the **CLI** ribbon tab
3. Ask questions:
```bash
arcgispro layers # What layers do I have?
arcgispro layer "Parcels" # Tell me about this layer
arcgispro fields "Parcels" # What fields are in it?
```
## CLI Commands
### Setup
| Command | Description |
|---------|-------------|
| `arcgispro install` | Install the ProExporter add-in |
| `arcgispro uninstall` | Show uninstall instructions |
| `arcgispro launch` | Launch ArcGIS Pro (opens .aprx in current dir if found) |
| `arcgispro status` | Show export status and validate files |
| `arcgispro clean` | Remove generated files |
| `arcgispro open` | Open export folder |
### Query
| Command | Description |
|---------|-------------|
| `arcgispro project` | Show project info |
| `arcgispro maps` | List all maps |
| `arcgispro map [name]` | Map details |
| `arcgispro layers` | List all layers |
| `arcgispro layers --broken` | Just the broken ones |
| `arcgispro layer <name>` | Layer details + fields |
| `arcgispro fields <name>` | Just the fields |
| `arcgispro tables` | Standalone tables |
| `arcgispro connections` | Data connections |
| `arcgispro notebooks` | Jupyter notebooks in project |
| `arcgispro context` | Full markdown dump |
| `arcgispro diagram` | Render Mermaid diagram of project structure |
Add `--json` to any query command for machine-readable output.
## Troubleshooting
**`arcgispro` launches ArcGIS Pro instead of the CLI?**
This happens if `C:\Program Files\ArcGIS\Pro\bin` is on your PATH. Options:
- Use `agp` instead (alias): `agp layers`, `agp launch`
- Or fix PATH order: ensure Python Scripts comes before ArcGIS Pro bin
## Requirements
- Windows 10/11
- ArcGIS Pro 3.x
- Python 3.9+
## Development
To build the add-in from source, you'll need:
- Visual Studio 2022 with ArcGIS Pro SDK extension
- .NET 8 SDK
```bash
# Clone and install CLI in dev mode
git clone https://github.com/danmaps/arcgispro_cli.git
cd arcgispro_cli/cli
pip install -e .
# Build add-in in Visual Studio
# Open ProExporter/ProExporter.sln
# Build → Build Solution (Release)
```
## License
MIT
---
## Using with AI Agents
This tool is designed to make ArcGIS Pro sessions observable for AI coding assistants.
### What Gets Exported
When you click **Snapshot** in ArcGIS Pro, the project structure is:
```
project_root/
├── AGENTS.md # AI agent skill file (start here!)
├── YourProject.aprx # ArcGIS Pro project file
└── .arcgispro/
├── config.yml # Export settings (auto-export, toggles)
├── meta.json # Export timestamp, tool version
├── context/
│ ├── project.json # Project name, path, geodatabases
│ ├── maps.json # Map names, spatial references, scales
│ ├── layers.json # Full layer details with field schemas
│ ├── tables.json # Standalone tables
│ ├── connections.json # Database connections
│ ├── layouts.json # Print layouts
│ └── notebooks.json # Jupyter notebooks
├── images/
│ ├── map_*.png # Screenshots of each map view
│ └── layout_*.png # Screenshots of each layout
└── snapshot/
├── context.md # Human-readable summary
├── project-structure.mmd # Mermaid diagram source
└── project-structure.md # Mermaid diagram markdown
```
The `AGENTS.md` file teaches AI agents how to use the CLI and interpret the exported data; no user explanation needed.
### Configuration
Edit `.arcgispro/config.yml` to control export behavior:
```yaml
# Auto-export on project open (default: false)
autoExportEnabled: false
autoExportLocalOnly: true # Skip network drives
autoExportMaxLayers: 50 # Safety limit
# Content toggles
exportImages: true # Map/layout screenshots
exportNotebooks: true # Jupyter notebook metadata
exportFields: true # Layer field schemas
```
### Claude Code / Copilot CLI / Gemini CLI
These tools can read files and run commands in your working directory. Navigate to your ArcGIS Pro project folder and start your AI session:
```bash
cd /path/to/your/project
claude # or: copilot, gemini
```
**Example prompts:**
```
What layers are in this project?
> AI runs: arcgispro layers
What fields are in the Parcels layer?
> AI runs: arcgispro fields "Parcels"
Which layers have broken data sources?
> AI runs: arcgispro layers --broken
Give me the full project context
> AI runs: arcgispro context
Look at the map screenshot and describe what you see
> AI reads: .arcgispro/images/map_*.png
```
### Tips for Best Results
1. **Click Snapshot in Pro before starting your AI session** - ensures context is fresh
2. **Ask naturally** - the CLI commands map to common questions:
- "What layers do I have?" → `arcgispro layers`
- "Tell me about the Parcels layer" → `arcgispro layer Parcels`
- "What's the schema?" → `arcgispro fields Parcels`
3. **Use `--json` for programmatic access** - AI can parse structured output:
```bash
arcgispro layers --json
arcgispro layer "Parcels" --json
```
4. **Check images for visual context** - map screenshots help AI understand spatial data
5. **Be bold. Try pasting in a question you'd normally answer by working in ArcGIS Pro manually.**
- "Jeff wants an updated map of the project area with an imagery basemap instead of streets"
- AI generates a (working) python script that exports the PDF directly, using your existing map and layout. You get to go to lunch early, and get a raise.
### Custom Agent Integration
The JSON files are designed for programmatic access:
```python
import json
from pathlib import Path
context_dir = Path(".arcgispro/context")
layers = json.loads((context_dir / "layers.json").read_text(encoding="utf-8-sig"))
for layer in layers:
print(f"{layer['name']}: {layer.get('featureCount', 'N/A')} features")
for field in layer.get('fields', []):
print(f" - {field['name']} ({field['fieldType']})")
```
| text/markdown | mcveydb | null | null | null | MIT | arcgis, cli, esri, gis | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: Microsoft :: Windows",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10"... | [] | null | null | >=3.9 | [] | [] | [] | [
"click>=8.0",
"pillow>=10.0.0",
"rich>=13.0",
"textual>=0.56",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T21:12:13.500793 | arcgispro_cli-0.4.0.tar.gz | 115,009 | 0b/08/141285d2e571b625b1667f491a04ec30a6f4a7cc16467b66019886461ac2/arcgispro_cli-0.4.0.tar.gz | source | sdist | null | false | 18e08cabc66840ebdb19ce5c1d4f86dc | 50eff4163511471eeae41f735654332538a2faaa139376e46898b726924c28c3 | 0b08141285d2e571b625b1667f491a04ec30a6f4a7cc16467b66019886461ac2 | null | [] | 261 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.