
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.3 | gumnut-sdk | 0.53.0 | The official Python library for the Gumnut API | # Gumnut Python API library
<!-- prettier-ignore -->
[)](https://pypi.org/project/gumnut-sdk/)
The Gumnut Python library provides convenient access to the Gumnut REST API from any Python 3.9+
application. The library includes type definitions for all request params and response fields,
and offers both synchronous and asynchronous clients powered by [httpx](https://github.com/encode/httpx).
It is generated with [Stainless](https://www.stainless.com/).
## Documentation
The REST API documentation can be found on [api.gumnut.ai](https://api.gumnut.ai/redoc). The full API of this library can be found in [api.md](https://github.com/gumnut-ai/photos-sdk-python/tree/main/api.md).
## Installation
```sh
# install from PyPI
pip install gumnut-sdk
```
## Usage
The full API of this library can be found in [api.md](https://github.com/gumnut-ai/photos-sdk-python/tree/main/api.md).
```python
import os
from gumnut import Gumnut
client = Gumnut(
api_key=os.environ.get("GUMNUT_API_KEY"), # This is the default and can be omitted
)
album_response = client.albums.create()
print(album_response.id)
```
While you can provide an `api_key` keyword argument,
we recommend using [python-dotenv](https://pypi.org/project/python-dotenv/)
to add `GUMNUT_API_KEY="My API Key"` to your `.env` file
so that your API Key is not stored in source control.
## Async usage
Simply import `AsyncGumnut` instead of `Gumnut` and use `await` with each API call:
```python
import os
import asyncio
from gumnut import AsyncGumnut
client = AsyncGumnut(
api_key=os.environ.get("GUMNUT_API_KEY"), # This is the default and can be omitted
)
async def main() -> None:
album_response = await client.albums.create()
print(album_response.id)
asyncio.run(main())
```
Functionality between the synchronous and asynchronous clients is otherwise identical.
### With aiohttp
By default, the async client uses `httpx` for HTTP requests. However, for improved concurrency performance you may also use `aiohttp` as the HTTP backend.
You can enable this by installing `aiohttp`:
```sh
# install from PyPI
pip install gumnut-sdk[aiohttp]
```
Then you can enable it by instantiating the client with `http_client=DefaultAioHttpClient()`:
```python
import os
import asyncio
from gumnut import DefaultAioHttpClient
from gumnut import AsyncGumnut
async def main() -> None:
async with AsyncGumnut(
api_key=os.environ.get("GUMNUT_API_KEY"), # This is the default and can be omitted
http_client=DefaultAioHttpClient(),
) as client:
album_response = await client.albums.create()
print(album_response.id)
asyncio.run(main())
```
## Using types
Nested request parameters are [TypedDicts](https://docs.python.org/3/library/typing.html#typing.TypedDict). Responses are [Pydantic models](https://docs.pydantic.dev) which also provide helper methods for things like:
- Serializing back into JSON, `model.to_json()`
- Converting to a dictionary, `model.to_dict()`
Typed requests and responses provide autocomplete and documentation within your editor. If you would like to see type errors in VS Code to help catch bugs earlier, set `python.analysis.typeCheckingMode` to `basic`.
## Pagination
List methods in the Gumnut API are paginated.
This library provides auto-paginating iterators with each list response, so you do not have to request successive pages manually:
```python
from gumnut import Gumnut
client = Gumnut()
all_assets = []
# Automatically fetches more pages as needed.
for asset in client.assets.list(
starting_after_id="asset_abc123",
):
# Do something with asset here
all_assets.append(asset)
print(all_assets)
```
Or, asynchronously:
```python
import asyncio
from gumnut import AsyncGumnut
client = AsyncGumnut()
async def main() -> None:
all_assets = []
# Iterate through items across all pages, issuing requests as needed.
async for asset in client.assets.list(
starting_after_id="asset_abc123",
):
all_assets.append(asset)
print(all_assets)
asyncio.run(main())
```
Alternatively, you can use the `.has_next_page()`, `.next_page_info()`, or `.get_next_page()` methods for more granular control working with pages:
```python
first_page = await client.assets.list(
starting_after_id="asset_abc123",
)
if first_page.has_next_page():
print(f"will fetch next page using these details: {first_page.next_page_info()}")
next_page = await first_page.get_next_page()
print(f"number of items we just fetched: {len(next_page.data)}")
# Remove `await` for non-async usage.
```
Or just work directly with the returned data:
```python
first_page = await client.assets.list(
starting_after_id="asset_abc123",
)
print(f"next page cursor: {first_page.starting_after_id}") # => "next page cursor: ..."
for asset in first_page.data:
print(asset.id)
# Remove `await` for non-async usage.
```
from datetime import datetime
## File uploads
Request parameters that correspond to file uploads can be passed as `bytes`, or a [`PathLike`](https://docs.python.org/3/library/os.html#os.PathLike) instance or a tuple of `(filename, contents, media type)`.
```python
from pathlib import Path
from gumnut import Gumnut
client = Gumnut()
client.assets.create(
asset_data=Path("/path/to/file"),
device_asset_id="device_asset_id",
device_id="device_id",
file_created_at=datetime.fromisoformat("2019-12-27T18:11:19.117"),
file_modified_at=datetime.fromisoformat("2019-12-27T18:11:19.117"),
)
```
The async client uses the exact same interface. If you pass a [`PathLike`](https://docs.python.org/3/library/os.html#os.PathLike) instance, the file contents will be read asynchronously automatically.
## Handling errors
When the library is unable to connect to the API (for example, due to network connection problems or a timeout), a subclass of `gumnut.APIConnectionError` is raised.
When the API returns a non-success status code (that is, 4xx or 5xx
response), a subclass of `gumnut.APIStatusError` is raised, containing `status_code` and `response` properties.
All errors inherit from `gumnut.APIError`.
```python
import gumnut
from gumnut import Gumnut
client = Gumnut()
try:
client.albums.create()
except gumnut.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # an underlying Exception, likely raised within httpx.
except gumnut.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except gumnut.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
```
Error codes are as follows:
| Status Code | Error Type |
| ----------- | -------------------------- |
| 400 | `BadRequestError` |
| 401 | `AuthenticationError` |
| 403 | `PermissionDeniedError` |
| 404 | `NotFoundError` |
| 422 | `UnprocessableEntityError` |
| 429 | `RateLimitError` |
| >=500 | `InternalServerError` |
| N/A | `APIConnectionError` |
### Retries
Certain errors are automatically retried 2 times by default, with a short exponential backoff.
Connection errors (for example, due to a network connectivity problem), 408 Request Timeout, 409 Conflict,
429 Rate Limit, and >=500 Internal errors are all retried by default.
You can use the `max_retries` option to configure or disable retry settings:
```python
from gumnut import Gumnut
# Configure the default for all requests:
client = Gumnut(
# default is 2
max_retries=0,
)
# Or, configure per-request:
client.with_options(max_retries=5).albums.create()
```
### Timeouts
By default requests time out after 1 minute. You can configure this with a `timeout` option,
which accepts a float or an [`httpx.Timeout`](https://www.python-httpx.org/advanced/timeouts/#fine-tuning-the-configuration) object:
```python
from gumnut import Gumnut
# Configure the default for all requests:
client = Gumnut(
# 20 seconds (default is 1 minute)
timeout=20.0,
)
# More granular control:
client = Gumnut(
timeout=httpx.Timeout(60.0, read=5.0, write=10.0, connect=2.0),
)
# Override per-request:
client.with_options(timeout=5.0).albums.create()
```
On timeout, an `APITimeoutError` is thrown.
Note that requests that time out are [retried twice by default](https://github.com/gumnut-ai/photos-sdk-python/tree/main/#retries).
## Advanced
### Logging
We use the standard library [`logging`](https://docs.python.org/3/library/logging.html) module.
You can enable logging by setting the environment variable `GUMNUT_LOG` to `info`.
```shell
$ export GUMNUT_LOG=info
```
Or to `debug` for more verbose logging.
### How to tell whether `None` means `null` or missing
In an API response, a field may be explicitly `null`, or missing entirely; in either case, its value is `None` in this library. You can differentiate the two cases with `.model_fields_set`:
```py
if response.my_field is None:
if 'my_field' not in response.model_fields_set:
print('Got json like {}, without a "my_field" key present at all.')
else:
print('Got json like {"my_field": null}.')
```
### Accessing raw response data (e.g. headers)
The "raw" Response object can be accessed by prefixing `.with_raw_response.` to any HTTP method call, e.g.,
```py
from gumnut import Gumnut
client = Gumnut()
response = client.albums.with_raw_response.create()
print(response.headers.get('X-My-Header'))
album = response.parse() # get the object that `albums.create()` would have returned
print(album.id)
```
These methods return an [`APIResponse`](https://github.com/gumnut-ai/photos-sdk-python/tree/main/src/gumnut/_response.py) object.
The async client returns an [`AsyncAPIResponse`](https://github.com/gumnut-ai/photos-sdk-python/tree/main/src/gumnut/_response.py) with the same structure, the only difference being `await`able methods for reading the response content.
#### `.with_streaming_response`
The above interface eagerly reads the full response body when you make the request, which may not always be what you want.
To stream the response body, use `.with_streaming_response` instead, which requires a context manager and only reads the response body once you call `.read()`, `.text()`, `.json()`, `.iter_bytes()`, `.iter_text()`, `.iter_lines()` or `.parse()`. In the async client, these are async methods.
```python
with client.albums.with_streaming_response.create() as response:
print(response.headers.get("X-My-Header"))
for line in response.iter_lines():
print(line)
```
The context manager is required so that the response will reliably be closed.
### Making custom/undocumented requests
This library is typed for convenient access to the documented API.
If you need to access undocumented endpoints, params, or response properties, the library can still be used.
#### Undocumented endpoints
To make requests to undocumented endpoints, you can make requests using `client.get`, `client.post`, and other
http verbs. Options on the client will be respected (such as retries) when making this request.
```py
import httpx
response = client.post(
"/foo",
cast_to=httpx.Response,
body={"my_param": True},
)
print(response.headers.get("x-foo"))
```
#### Undocumented request params
If you want to explicitly send an extra param, you can do so with the `extra_query`, `extra_body`, and `extra_headers` request
options.
#### Undocumented response properties
To access undocumented response properties, you can access the extra fields like `response.unknown_prop`. You
can also get all the extra fields on the Pydantic model as a dict with
[`response.model_extra`](https://docs.pydantic.dev/latest/api/base_model/#pydantic.BaseModel.model_extra).
### Configuring the HTTP client
You can directly override the [httpx client](https://www.python-httpx.org/api/#client) to customize it for your use case, including:
- Support for [proxies](https://www.python-httpx.org/advanced/proxies/)
- Custom [transports](https://www.python-httpx.org/advanced/transports/)
- Additional [advanced](https://www.python-httpx.org/advanced/clients/) functionality
```python
import httpx
from gumnut import Gumnut, DefaultHttpxClient
client = Gumnut(
# Or use the `GUMNUT_BASE_URL` env var
base_url="http://my.test.server.example.com:8083",
http_client=DefaultHttpxClient(
proxy="http://my.test.proxy.example.com",
transport=httpx.HTTPTransport(local_address="0.0.0.0"),
),
)
```
You can also customize the client on a per-request basis by using `with_options()`:
```python
client.with_options(http_client=DefaultHttpxClient(...))
```
### Managing HTTP resources
By default the library closes underlying HTTP connections whenever the client is [garbage collected](https://docs.python.org/3/reference/datamodel.html#object.__del__). You can manually close the client using the `.close()` method if desired, or with a context manager that closes when exiting.
```py
from gumnut import Gumnut
with Gumnut() as client:
# make requests here
...
# HTTP client is now closed
```
## Versioning
This package generally follows [SemVer](https://semver.org/spec/v2.0.0.html) conventions, though certain backwards-incompatible changes may be released as minor versions:
1. Changes that only affect static types, without breaking runtime behavior.
2. Changes to library internals which are technically public but not intended or documented for external use. _(Please open a GitHub issue to let us know if you are relying on such internals.)_
3. Changes that we do not expect to impact the vast majority of users in practice.
We take backwards-compatibility seriously and work hard to ensure you can rely on a smooth upgrade experience.
We are keen for your feedback; please open an [issue](https://www.github.com/gumnut-ai/photos-sdk-python/issues) with questions, bugs, or suggestions.
### Determining the installed version
If you've upgraded to the latest version but aren't seeing any new features you were expecting then your python environment is likely still using an older version.
You can determine the version that is being used at runtime with:
```py
import gumnut
print(gumnut.__version__)
```
## Requirements
Python 3.9 or higher.
## Contributing
See [the contributing documentation](https://github.com/gumnut-ai/photos-sdk-python/tree/main/./CONTRIBUTING.md).
| text/markdown | null | Gumnut <tedmao@gmail.com> | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: OS Independent",
"Operating System :: POSIX",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"anyio<5,>=3.5.0",
"distro<2,>=1.7.0",
"httpx<1,>=0.23.0",
"pydantic<3,>=1.9.0",
"sniffio",
"typing-extensions<5,>=4.10",
"aiohttp; extra == \"aiohttp\"",
"httpx-aiohttp>=0.1.9; extra == \"aiohttp\""
] | [] | [] | [] | [
"Homepage, https://github.com/gumnut-ai/photos-sdk-python",
"Repository, https://github.com/gumnut-ai/photos-sdk-python"
] | uv/0.9.13 {"installer":{"name":"uv","version":"0.9.13"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T19:12:05.508214 | gumnut_sdk-0.53.0-py3-none-any.whl | 131,834 | 16/59/9e533cd5605c3131dd696bcd1cd5269b0216118d1297b4222cad0fbaa54a/gumnut_sdk-0.53.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 8dc0fdaa52b86669ee745caa55cf91a3 | b1df64c040833fdc1a2a71805043248e4e346d74cd417b7071ca1c7d36e15763 | 16599e533cd5605c3131dd696bcd1cd5269b0216118d1297b4222cad0fbaa54a | null | [] | 247 |
2.4 | hailtheking-reader-realpython | 1.1.0 | A easy and quick way to get help from realpythons latest articles onto your terminal | Real Python Feed Reader
The Real Python Feed Reader is a basic web feed reader that can download the latest Real Python tutorials from the Real Python feed,allowing the convience of have the latest advice right at your fingertips while working.
For more information see the tutorial How to Publish an Open-Source Python Package to PyPI on Real Python.
Installation
You can install the Real Python Feed Reader from PyPI:
python -m pip install realpython-reader
The reader is supported on Python 3.7 and above. Older versions of Python, including Python 2.7, are supported by version 1.0.0 of the reader.
How to use
The Real Python Feed Reader is a command line application, named realpython. To see a list of the latest Real Python tutorials, call the program without any arguments:
$ realpython
The latest tutorials from Real Python (https://realpython.com/)
0 How to Publish an Open-Source Python Package to PyPI
1 Python "while" Loops (Indefinite Iteration)
2 Writing Comments in Python (Guide)
3 Setting Up Python for Machine Learning on Windows
4 Python Community Interview With Michael Kennedy
5 Practical Text Classification With Python and Keras
6 Getting Started With Testing in Python
7 Python, Boto3, and AWS S3: Demystified
8 Python's range() Function (Guide)
9 Python Community Interview With Mike Grouchy
10 How to Round Numbers in Python
11 Building and Documenting Python REST APIs With Flask and Connexion – Part 2
12 Splitting, Concatenating, and Joining Strings in Python
13 Image Segmentation Using Color Spaces in OpenCV + Python
14 Python Community Interview With Mahdi Yusuf
15 Absolute vs Relative Imports in Python
16 Top 10 Must-Watch PyCon Talks
17 Logging in Python
18 The Best Python Books
19 Conditional Statements in Python
To read one particular tutorial, call the program with the numerical ID of the tutorial as a parameter:
$ realpython 0
# How to Publish an Open-Source Python Package to PyPI
Python is famous for coming with batteries included. Sophisticated
capabilities are available in the standard library. You can find modules for
working with sockets, parsing CSV, JSON, and XML files, and working with
files and file paths.
However great the packages included with Python are, there are many
fantastic projects available outside the standard library. These are most
often hosted at the Python Packaging Index (PyPI), historically known as the
Cheese Shop. At PyPI, you can find everything from Hello World to advanced
deep learning libraries.
[... The full text of the article ...]
You can also call the Real Python Feed Reader in your own Python code, by importing from the reader package:
>>> from reader import feed
>>> feed.get_titles()
['How to Publish an Open-Source Python Package to PyPI', ...]
| text/markdown | Abhinav B | bijishabhinav@gmail.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7"
] | [] | https://github.com/HailtheKing2024/Python/tree/main/pythonreader | null | null | [] | [] | [] | [
"feedparser",
"html2text"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T19:12:03.987672 | hailtheking_reader_realpython-1.1.0.tar.gz | 3,989 | 13/47/d143c23152e0cb3dadb09c12ca6e18377b6799a06de33a84d90f1ce6f26f/hailtheking_reader_realpython-1.1.0.tar.gz | source | sdist | null | false | 1b35c36d0f9f98280b8b58b22c11c8a6 | c340c2951960db73badc6007155ecaad67d2940a04fd6619fdf23141a223c565 | 1347d143c23152e0cb3dadb09c12ca6e18377b6799a06de33a84d90f1ce6f26f | null | [] | 262 |
2.4 | debrief | 0.8.4 | Dynamically generated BRIEF.md summaries for your Python projects, to make them accessible to new contributors or coding agents. | # debrief: Project Summarizer
`debrief` generates a comprehensive `BRIEF.md` file designed to provide new contributors or coding agents with a high-density overview of a Python project.
## Installation
```bash
pip install debrief
```
## Usage
```bash
debrief [run|lint] [path] [--output BRIEF.md]
```
### Arguments
| Argument | Description | Default |
| :--------------------- | :------------------------------------------------- | :------------------ |
| `mode` | `run` generates BRIEF.md, `lint` only runs checks. | `run` |
| `path` | Project root path. | `.` |
| `-o`, `--output` | Output filename. | `BRIEF.md` |
| `--tree-budget` | Max lines for Directory Tree (auto-depth). | `60` |
| `--max-tree-siblings` | Max items at same level in tree. | `tree_budget/3` |
| `--max-readme` | Max lines to include from README. | `20` |
| `--max-deps` | Max lines for dependencies list. | `15` |
| `--max-imports` | Max lines for Import Tree. | `50` |
| `--max-definitions` | Max lines for Module Definitions. | `200` |
| `--max-class-methods` | Max public methods shown per class. | `max_definitions/3` |
| `--max-module-defs` | Max top-level defs shown per module. | `max_definitions/3` |
| `--include-docstrings` | Include docstrings in the output. | `False` |
| `--exclude` | Additional patterns to exclude. | None |
### Lint Mode
```bash
debrief lint [path]
```
Runs all quality checks without generating `BRIEF.md`:
| Check | Threshold | Condition |
| :--------------------- | :---------------- | :------------------------------- |
| README non-empty lines | ≥ 2 | Always |
| Description length | ≥ 16 non-ws chars | Always |
| Docstring length | ≥ 16 non-ws chars | Only with `--include-docstrings` |
## Features
- **Project Metadata**: Extracts description and dependencies from `pyproject.toml` (with `requirements.txt` fallback).
- **Directory Tree**: Adaptive depth tree that fits within a line budget, respecting `.gitignore`.
- **Import Analysis**: Generates an import dependency tree to visualize project structure.
- **Code Definitions**: Extracts class and function signatures with docstrings for all Python files.
- **Optimized Output**:
- **Truncation**: Automatically truncates long lines (>300 chars) and large sections.
- **"Read more"**: Links to local files for truncated content.
- **Markdown**: Formatted for optimal readability.
## Example Output (`BRIEF.md`)
The [BRIEF.md](BRIEF.md) file in this repository serves as a real example of the output of `debrief`.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [] | [] | [] | [] | [
"Repository, https://github.com/Julynx/debrief",
"Homepage, https://github.com/Julynx/debrief"
] | uv/0.10.2 {"installer":{"name":"uv","version":"0.10.2","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T19:11:52.834727 | debrief-0.8.4-py3-none-any.whl | 13,656 | 5e/a1/08a247a424f28ed72a746e5c9ba90231b926899a4aa68c8348f32453b02e/debrief-0.8.4-py3-none-any.whl | py3 | bdist_wheel | null | false | dd1d5d34996bb535dde1bdceea6e3730 | ca96d4d72cb7401390c49012ac31b7bf6434d6cf51c30484d9249658f757a47d | 5ea108a247a424f28ed72a746e5c9ba90231b926899a4aa68c8348f32453b02e | null | [] | 248 |
2.4 | sunwaee-gen | 0.1.15 | All LLMs, one response format. | # SUNWÆE-GEN
All LLMs, one response format, two dependencies (aiohttp, pydantic).
[](https://python.org)
[](tests/)
[](tests/)
[](LICENSE)
## OVERVIEW
All LLMs, one response format - available through SDK or self-hosted API. Includes usage, cost and performance metrics like reasoning duration and throughput (see [response format](#response)).
> GEN doesn't use provider-specific libraries (e.g. openai, anthropic, google...) and parses the raw HTTP responses (including server-sent event streams) directly from the providers using provider-specific logic called `adapters`.
What GEN does under the hood:
1. validates messages according to the openai format (see [MODELS](#models))
2. validates tools according to the openai format (see [MODELS](#models))
3. use provider-specific logic (`adapters`) to build provider-specific payload.
4. use provider-specific logic (`adapters`) to parse provider-specific response.
5. compute additional metrics related to performance, cost, usage... and return a [block](#response)
> Reasoning tokens are not available for certain agents despite supporting reasoning (e.g. `openai/gpt-5`, `xai/grok-4-1-fast-reasoning`...). When that's the case, a block with `reasoning="reasoning started, but reasoning tokens are not available for this model..."` will be returned, indicating reasoning has started.
## INSTALLATION
1. For regular usage:
```bash
pip install sunwaee-gen
```
2. For self-hosting usage:
```bash
pip install sunwaee-gen[api]
```
3. For dev usage (contributors):
```bash
pip install "sunwaee-gen[dev]"
```
### USAGE
1. SDK
```python
import asyncio
import sunwaee_gen as gen
# list available resources
print(gen.Agents.names())
print(gen.Models.names())
print(gen.Providers.names())
# NOTE you need to pass back reasoning as reasoning_content
# and thought signature as "reasoning_signature"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What's the latest news about AI?"},
]
tools = [
{
"type": "function",
"function": {
"name": "search_web",
"description": "Search the web for information",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "Search query"}
},
"required": ["query"],
},
},
}
]
async def main():
# NOTE we use `async for` for both the regular and streaming completion
async for block in gen.async_completion(
"openai/gpt-5-mini", # or gen.Agents.GPT_5_MINI
messages=messages,
tools=tools,
streaming=False,
mock=False, # NOTE mock=True will return a mocked response (no cost)
):
if block["reasoning"]:
print(f"🤔 Reasoning: {block['reasoning']}")
if block["content"]:
print(f"💬 Content: {block['content']}")
if block["tool_calls"]:
print(f"🔧 Tool calls: {block['tool_calls']}")
asyncio.run(main())
```
2. API
```sh
# serve
uvicorn sunwaee_gen.api:api
curl -X 'POST' \
'http://localhost:8000/completion' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <api_key>' \
-H 'Content-Type: application/json' \
-d '{
"agent": "openai/gpt-5-nano",
"messages": [{"role": "user", "content": "hi"}],
"tools": [],
"streaming": false,
"mock": false
}'
```
### MODELS
#### MESSAGES
```python
[
{
"role": "system|user|assistant|tool",
"reasoning_content": "some reasoning", # str
"reasoning_signature": "some signature", # str
"content": "Here's a response.", # str
"tool_call_id": "tc_123", # str
"tool_calls": [
{
"id": "tc_123", # str
"type": "function",
"function": {
"name": "get_weather", # str
"arguments": "{\"city\": \"Paris\"}" # str
}
}
]
}
]
```
> **`tool` messages must contain `tool_call_id`.**
#### TOOLS
```python
[
{
"type": "function", # str
"function": {
"name": "get_weather", # str
"description": "Get a weather in a given city.", # str
"parameters": {
"type": "object", # str
"properties": {
"city": {
"type": "string", # str
"description": "The city (e.g. Paris, London...)" # str
}
},
"required": ["city"] # list[str]
}
}
}
]
```
#### RESPONSE
```python
{
"model": {
"name": "string",
"display_name": "string",
"origin": "string",
"version": "string"
},
"provider": {
"name": "string",
"url": "string"
},
"error": {
"status_code": 0
"message": "string",
},
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
},
"cost": {
"prompt_cost": 0,
"completion_cost": 0,
"total_cost": 0
},
"performance": {
"latency": 0,
"reasoning_duration": 0,
"content_duration": 0,
"total_duration": 0,
"throughput": 0
},
"reasoning": "string",
"reasoning_signature": "string",
"content": "string",
"tool_calls": [], # list[dict]
"raw": "string",
"streaming": False
}
```
| text/markdown | David NAISSE | null | David NAISSE | null | MIT License
Copyright (c) 2025 DvdNss
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp",
"pydantic",
"fastapi[standard]; extra == \"api\"",
"uvicorn[standard]; extra == \"api\"",
"python-dotenv; extra == \"dev\"",
"fastapi[standard]; extra == \"dev\"",
"uvicorn[standard]; extra == \"dev\"",
"pytest; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"pytest-asyncio; extra =... | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T19:11:40.766967 | sunwaee_gen-0.1.15.tar.gz | 143,369 | 43/2b/cd79fa5f930231458f54e12418441d6696077ae6c849640a989da78e3b55/sunwaee_gen-0.1.15.tar.gz | source | sdist | null | false | a847488a3d18dc821f1de6acb4ff61d6 | 7ffb8421987d4df83b056809ee59c6ed7a0a656fa731e24aa2ae5c4290843d12 | 432bcd79fa5f930231458f54e12418441d6696077ae6c849640a989da78e3b55 | null | [
"LICENSE"
] | 238 |
2.4 | newsflash | 0.2.4 | Add your description here | # NewsFlash
Documentation coming soon... | text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"fastapi[standard]>=0.122.0",
"fonttools>=4.60.1",
"polars>=1.35.2"
] | [] | [] | [] | [] | uv/0.8.22 | 2026-02-19T19:10:54.473899 | newsflash-0.2.4.tar.gz | 177,976 | f0/28/4d246da8466a66383bdf63d9647c6aa03afc0a5fe41a8f0d6166d4acdb42/newsflash-0.2.4.tar.gz | source | sdist | null | false | 763a36df30557a3b662a24bcc57cae47 | 963b7c1fce490d4d9367f4a33e0a7fd49a5d208dc14f2e594cc2729c564b3296 | f0284d246da8466a66383bdf63d9647c6aa03afc0a5fe41a8f0d6166d4acdb42 | null | [
"LICENSE"
] | 229 |
2.4 | headroom-ai | 0.3.7 | The Context Optimization Layer for LLM Applications - Cut costs by 50-90% | <p align="center">
<h1 align="center">Headroom</h1>
<p align="center">
<strong>The Context Optimization Layer for LLM Applications</strong>
</p>
<p align="center">
Tool outputs are 70-95% redundant boilerplate. Headroom compresses that away.
</p>
</p>
<p align="center">
<a href="https://github.com/chopratejas/headroom/actions/workflows/ci.yml">
<img src="https://github.com/chopratejas/headroom/actions/workflows/ci.yml/badge.svg" alt="CI">
</a>
<a href="https://pypi.org/project/headroom-ai/">
<img src="https://img.shields.io/pypi/v/headroom-ai.svg" alt="PyPI">
</a>
<a href="https://pypi.org/project/headroom-ai/">
<img src="https://img.shields.io/pypi/pyversions/headroom-ai.svg" alt="Python">
</a>
<a href="https://pypistats.org/packages/headroom-ai">
<img src="https://img.shields.io/pypi/dm/headroom-ai.svg" alt="Downloads">
</a>
<a href="https://github.com/chopratejas/headroom/blob/main/LICENSE">
<img src="https://img.shields.io/badge/license-Apache%202.0-blue.svg" alt="License">
</a>
<a href="https://chopratejas.github.io/headroom/">
<img src="https://img.shields.io/badge/docs-GitHub%20Pages-blue.svg" alt="Documentation">
</a>
</p>
---
## Demo
<p align="center">
<img src="Headroom-2.gif" alt="Headroom Demo" width="800">
</p>
---
## Quick Start
```bash
pip install "headroom-ai[all]"
```
### Simplest: Proxy (zero code changes)
```bash
headroom proxy --port 8787
```
```bash
# Claude Code — just set the base URL
ANTHROPIC_BASE_URL=http://localhost:8787 claude
# Cursor, Continue, any OpenAI-compatible tool
OPENAI_BASE_URL=http://localhost:8787/v1 cursor
```
Works with any language, any tool, any framework. One env var. **[Proxy docs](docs/proxy.md)**
### Python: One function
```python
from headroom import compress
result = compress(messages, model="claude-sonnet-4-5-20250929")
response = client.messages.create(model="claude-sonnet-4-5-20250929", messages=result.messages)
print(f"Saved {result.tokens_saved} tokens ({result.compression_ratio:.0%})")
```
Works with any Python LLM client — Anthropic, OpenAI, LiteLLM, httpx, anything.
### Already have a proxy or gateway?
You don't need to replace it. Drop Headroom into your existing stack:
| Your setup | Add Headroom | One-liner |
|------------|-------------|-----------|
| **LiteLLM** | Callback | `litellm.callbacks = [HeadroomCallback()]` |
| **Any Python proxy** | ASGI Middleware | `app.add_middleware(CompressionMiddleware)` |
| **Any Python app** | `compress()` | `result = compress(messages, model="gpt-4o")` |
| **Agno agents** | Wrap model | `HeadroomAgnoModel(your_model)` |
| **LangChain** | Wrap model | `HeadroomChatModel(your_llm)` *(experimental)* |
**[Full Integration Guide](docs/integration-guide.md)** — detailed setup for LiteLLM, ASGI middleware, compress(), and every framework.
---
## Does It Actually Work?
**100 production log entries. One critical error buried at position 67.**
| | Baseline | Headroom |
|--|----------|----------|
| Input tokens | 10,144 | 1,260 |
| Correct answers | **4/4** | **4/4** |
Both responses: *"payment-gateway, error PG-5523, fix: Increase max_connections to 500, 1,847 transactions affected."*
**87.6% fewer tokens. Same answer.** Run it: `python examples/needle_in_haystack_test.py`
<details>
<summary><b>What Headroom kept</b></summary>
From 100 log entries, SmartCrusher kept 6: first 3 (boundary), the FATAL error at position 67 (anomaly detection), and last 2 (recency). The error was automatically preserved — not by keyword matching, but by statistical analysis of field variance.
</details>
### Accuracy Benchmarks
| Benchmark | Metric | Result | Compression |
|-----------|--------|--------|------------|
| [Scrapinghub Extraction](https://huggingface.co/datasets/allenai/scrapinghub-article-extraction-benchmark) | Recall | **98.2%** | 94.9% |
| Multi-Tool Agent (4 tools) | Accuracy | **100%** | 76.3% |
| SmartCrusher (JSON) | Accuracy | **100%** | 87.6% |
Full methodology: [Benchmarks](docs/benchmarks.md) | Run yourself: `python -m headroom.evals quick`
---
## How It Works
```mermaid
flowchart LR
App["Your App"] --> H["Headroom"] --> LLM["LLM Provider"]
LLM --> Resp["Response"]
```
### Inside Headroom
```mermaid
flowchart TB
subgraph Pipeline["Transform Pipeline"]
CA["1. CacheAligner\nStabilizes prefix for KV cache"]
CR["2. ContentRouter\nDetects content type, picks compressor"]
IC["3. IntelligentContext\nScore-based token fitting"]
QE["4. Query Echo\nRe-injects user question"]
CA --> CR --> IC --> QE
end
subgraph Compressors["ContentRouter dispatches to"]
SC["SmartCrusher\nJSON arrays"]
CC["CodeCompressor\nAST-aware code"]
LL["LLMLingua\nML-based text"]
end
subgraph CCR["CCR: Compress-Cache-Retrieve"]
Store[("Compressed\nStore")]
Tool["headroom_retrieve"]
Tool <--> Store
end
CR --> Compressors
SC -. "stores originals +\nsummary of what's omitted" .-> Store
QE --> LLM["LLM Provider"]
LLM -. "retrieves when\nit needs more" .-> Tool
```
> Headroom never throws data away. It compresses aggressively and retrieves precisely.
> When it compresses 500 items to 20, it tells the LLM *what was omitted*
> ("87 passed, 2 failed, 1 error") so the LLM knows when to ask for more.
### Verified on Real Workloads
| Scenario | Before | After | Savings |
|----------|--------|-------|---------|
| Code search (100 results) | 17,765 | 1,408 | **92%** |
| SRE incident debugging | 65,694 | 5,118 | **92%** |
| Codebase exploration | 78,502 | 41,254 | **47%** |
| GitHub issue triage | 54,174 | 14,761 | **73%** |
**Overhead**: 1-5ms compression latency.
---
## Integrations
| Integration | Status | Docs |
|-------------|--------|------|
| `compress()` — one function | **Stable** | [Integration Guide](docs/integration-guide.md) |
| LiteLLM callback | **Stable** | [Integration Guide](docs/integration-guide.md#litellm) |
| ASGI middleware | **Stable** | [Integration Guide](docs/integration-guide.md#asgi-middleware) |
| Proxy server | **Stable** | [Proxy Docs](docs/proxy.md) |
| Agno | **Stable** | [Agno Guide](docs/agno.md) |
| MCP (Claude Code) | **Stable** | [MCP Guide](docs/mcp.md) |
| Strands | **Stable** | [Strands Guide](docs/strands.md) |
| LangChain | **Experimental** | [LangChain Guide](docs/langchain.md) |
---
## Features
| Feature | What it does |
|---------|-------------|
| **Content Router** | Auto-detects content type, routes to optimal compressor |
| **SmartCrusher** | Statistically compresses JSON arrays — preserves errors, anomalies, boundaries |
| **CodeCompressor** | AST-aware compression for Python, JS, Go, Rust, Java, C++ |
| **LLMLingua-2** | ML-based 20x text compression |
| **CCR** | Reversible compression — LLM retrieves originals when needed |
| **Compression Summaries** | Tells the LLM what was omitted ("3 errors, 12 failures") |
| **Query Echo** | Re-injects user question after compressed data for better attention |
| **CacheAligner** | Stabilizes prefixes for provider KV cache hits |
| **IntelligentContext** | Score-based context management with learned importance |
| **Image Compression** | 40-90% token reduction via trained ML router |
| **Memory** | Persistent memory across conversations |
| **Compression Hooks** | Customize compression with pre/post hooks |
| **Query Echo** | Re-injects user question after compressed data for better attention |
---
## Cloud Providers
```bash
headroom proxy --backend bedrock --region us-east-1 # AWS Bedrock
headroom proxy --backend vertex_ai --region us-central1 # Google Vertex
headroom proxy --backend azure # Azure OpenAI
headroom proxy --backend openrouter # OpenRouter (400+ models)
```
---
## Installation
```bash
pip install headroom-ai # Core library
pip install "headroom-ai[all]" # Everything (recommended)
pip install "headroom-ai[proxy]" # Proxy server
pip install "headroom-ai[mcp]" # MCP for Claude Code
pip install "headroom-ai[agno]" # Agno integration
pip install "headroom-ai[langchain]" # LangChain (experimental)
pip install "headroom-ai[evals]" # Evaluation framework
```
Python 3.10+
---
## Documentation
| | |
|---|---|
| [Integration Guide](docs/integration-guide.md) | LiteLLM, ASGI, compress(), proxy |
| [Proxy Docs](docs/proxy.md) | Proxy server configuration |
| [Architecture](docs/ARCHITECTURE.md) | How the pipeline works |
| [CCR Guide](docs/ccr.md) | Reversible compression |
| [Benchmarks](docs/benchmarks.md) | Accuracy validation |
| [Evals Framework](headroom/evals/README.md) | Prove compression preserves accuracy |
| [Memory](docs/memory.md) | Persistent memory |
| [Agno](docs/agno.md) | Agno agent framework |
| [MCP](docs/mcp.md) | Claude Code subscriptions |
| [Configuration](docs/configuration.md) | All options |
---
## Contributing
```bash
git clone https://github.com/chopratejas/headroom.git && cd headroom
pip install -e ".[dev]" && pytest
```
---
## License
Apache License 2.0 — see [LICENSE](LICENSE).
| text/markdown | Headroom Contributors | null | Headroom Contributors | null | null | ai, anthropic, caching, claude, compression, context, gpt, llm, machine-learning, openai, optimization, proxy, token | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Langu... | [] | null | null | >=3.10 | [] | [] | [] | [
"accelerate>=1.12.0",
"click>=8.1.0",
"datasets>=4.5.0",
"hnswlib>=0.8.0",
"litellm>=1.0.0",
"openai>=2.14.0",
"pillow>=10.0.0",
"protobuf>=6.33.4",
"pydantic>=2.0.0",
"rich>=13.0.0",
"semantic-router>=0.1.12",
"sentence-transformers>=5.2.0",
"sentencepiece>=0.2.1",
"tiktoken>=0.5.0",
"a... | [] | [] | [] | [
"Homepage, https://github.com/chopratejas/headroom",
"Documentation, https://github.com/chopratejas/headroom#readme",
"Repository, https://github.com/chopratejas/headroom",
"Issues, https://github.com/chopratejas/headroom/issues",
"Changelog, https://github.com/chopratejas/headroom/blob/main/CHANGELOG.md"
] | twine/6.2.0 CPython/3.11.3 | 2026-02-19T19:10:46.591067 | headroom_ai-0.3.7.tar.gz | 1,094,736 | 74/4f/9f0f44990cc1fec8f722b7f2312edefc97c4d3f70d426c26ccaba93b40cd/headroom_ai-0.3.7.tar.gz | source | sdist | null | false | 473c4b663efd416c539c22a4797257e6 | 3ff02b66f5a6b08a1e53a38409aa3c21ff4e97a30cb9180b285b2cdf7386562b | 744f9f0f44990cc1fec8f722b7f2312edefc97c4d3f70d426c26ccaba93b40cd | Apache-2.0 | [
"LICENSE",
"NOTICE"
] | 270 |
2.4 | xgift | 0.3.8 | Python библиотека для работы с xGift API | # xgift
[](https://badge.fury.io/py/xgift)
[](https://pypi.org/project/xgift/)
[](https://opensource.org/licenses/MIT)
**xgift** — это простая и асинхронная Python библиотека для взаимодействия с API платформы [xGift](https://xgift.tg/). Она позволяет легко получать информацию о коллекционных NFT-гифтах, их ценах, элементах и многом другом.
Библиотека предоставляет как высокоуровневый интерфейс (`Gift`) для удобного доступа к данным, так и низкоуровневый клиент (`GiftRaw`) для прямых запросов к API.
---
## Особенности
* **Асинхронность**: Полностью асинхронная работа на базе `asyncio` и `curl_cffi`.
* **Простота**: Интуитивно понятный API для быстрого старта.
* **Гибкость**: Поддержка одиночных и пакетных запросов к нескольким гифтам/коллекциям одновременно.
* **Низкоуровневый доступ**: Возможность использовать "сырые" ответы от API через класс `GiftRaw`.
* **Эмуляция браузера**: Использование `curl_cffi` для имитации реального браузера и обхода простых блокировок.
* **Утилиты**: Встроенные функции для получения курса TON, списка NFT и Lottie-анимаций.
---
## Установка
Установить библиотеку можно с помощью `pip`:
```bash
pip install xgift
```
---
## Быстрый старт
### Получение минимальной цены (Floor Price) гифта
```python
import asyncio
from xgift import Gift
async def main():
# 1. Создаем клиент
client = Gift()
# 2. Получаем цену для одного гифта (по его названию)
price = await client.floorPrice("PlushPepe")
print(f"PlushPepe floor price: {price} TON")
# 3. Всегда закрываем клиент после использования
await client.close()
asyncio.run(main())
```
### Получение информации для нескольких гифтов
```python
import asyncio
from xgift import Gift
async def main():
client = Gift()
gifts = ["PlushPepe", "AstralShard", "FreshSocks"]
prices = await client.floorPrice(gifts)
for gift, price in zip(gifts, prices):
print(f"{gift}: {price} TON")
await client.close()
asyncio.run(main())
```
---
## Подробное руководство
### 1. Класс `Gift` (Высокоуровневый)
Это основной класс для взаимодействия с API. Он использует `GiftRaw` внутри себя и предоставляет удобные методы.
#### Инициализация
```python
from xgift import Gift
client = Gift(
proxy="http://user:pass@host:port", # Опционально: прокси-сервер
batch_size=5, # Опционально: кол-во запросов в пачке (для списков)
delay=0.5, # Опционально: задержка между пачками (в секундах)
impersonate="chrome_120" # Опционально: браузер для эмуляции
)
```
* `proxy`: Адрес прокси-сервера (поддерживается http/https).
* `batch_size`: При передаче списка названий, запросы будут выполняться пачками по `batch_size` штук для оптимизации.
* `delay`: Задержка между отправкой пачек.
* `impersonate`: Указывает, какой браузер имитировать. По умолчанию `safari_ios`. Список поддерживаемых значений можно найти в [документации curl_cffi](https://github.com/yifeikong/curl_cffi).
#### Основные методы `Gift`
* **`async floorPrice(name: Union[str, List[str]])`**
* Возвращает текущую минимальную цену (`floorPrice`) для одного или нескольких **названий коллекций**.
* Если передан `str`, возвращает `float` или `False` в случае ошибки.
* Если передан `List[str]`, возвращает `List[float | bool]`.
* **Пример:** `await client.floorPrice("PlushPepe")`
* **`async simpleEstimation(slug: Union[str, List[str]])`**
* Возвращает упрощенную оценочную цену (`simpleEstimation.price`) для одного или нескольких **конкретных гифтов (slug)**.
* `slug` — это уникальный идентификатор гифта, например `"plushpepe-1"`.
* **Пример:** `await client.simpleEstimation("plushpepe-1")`
* **`async estimatedPrice(slug: Union[str, List[str]], asset: Literal["Ton", "Usd"]="Ton")`**
* Возвращает оценочную цену (`estimatedPriceTon` или `estimatedPriceUsd`) для гифта(ов).
* **Пример:** `await client.estimatedPrice("plushpepe-1", asset="Usd")`
* **`async models_floor(name: Union[str, List[str]])`**
* Возвращает словарь, где ключи — это названия **моделей (модификаторов)** гифта из коллекции `name`, а значения — их минимальные цены (`floorPriceTon`).
* **Пример:** `await client.models_floor("PlushPepe")` вернет `{'Amalgam': 9999.0, 'Aqua Plush': 9999.0, 'Barcelona': 10500.0, ...}`
* **`async backdrops_floor(name: Union[str, List[str]])`** (Аналогично `models_floor`, но для фонов)
* **`async symbols_floor(name: Union[str, List[str]])`** (Аналогично `models_floor`, но для символов)
* **`async getFloorGraph(slug: Union[str, List[str]])`**
* Возвращает данные для построения графика цены (`floor`) для гифта(ов). Обычно это список исторических значений.
* **`async isMonochrome(slug: Union[str, List[str]])`**
* Проверяет, является ли гифт монохромным.
* **`async close()`**
* **Важно!** Этот метод закрывает HTTP-сессию. Всегда вызывайте его после завершения работы с клиентом, чтобы освободить ресурсы.
---
### 2. Класс `GiftRaw` (Низкоуровневый)
Предоставляет "сырые" методы, которые напрямую соответствуют эндпоинтам API xGift и возвращают необработанные `dict` с ответом от сервера.
#### Методы `GiftRaw`
* **`async GiftInfo(slug: Union[str, List[str]])`**
* Получает детальную информацию о конкретном гифте по его `slug`.
* **Эндпоинт:** `https://app-api.xgift.tg/gifts/{slug}`
* **`async CollectionInfo(name: Union[str, List[str]])`**
* Получает информацию о коллекции по её названию (например, "PlushPepe").
* **Эндпоинт:** `https://app-api.xgift.tg/collections/{name}`
* **`async CollectionGifts(name: Union[str, List[str]])`**
* Получает список всех гифтов в коллекции, включая их модели, бэкдропы и символы.
* **Эндпоинт:** `https://app-api.xgift.tg/gifts/filters/{name}`
* **`async close()`**
* Закрывает HTTP-сессию.
```python
import asyncio
from xgift import GiftRaw
async def main():
raw_client = GiftRaw()
# Получаем "сырые" данные
data = await raw_client.GiftInfo("plushpepe-1")
print(data) # Выведет полный JSON-ответ от API
await raw_client.close()
asyncio.run(main())
```
---
### 3. Утилиты (`xgift.utils`)
Набор полезных функций для быстрого доступа к дополнительным данным.
* **`async tonRate()`**
* Возвращает текущий курс TON к фиатным валютам (обычно USD).
* **Пример:** `rate = await tonRate()`
* **`async nfts(type: Literal["names", "ids", "all"]="all")`**
* Возвращает список всех доступных NFT-гифтов.
* `type="names"` — вернет список названий.
* `type="ids"` — вернет список ID.
* `type="all"` — вернет словарь `{name: id}`.
* **Пример:** `all_nfts_dict = await nfts()`
* **`async lottie(slug: str)`**
* Возвращает JSON с Lottie-анимацией для указанного гифта.
* **Пример:** `anim = await lottie("plushpepe-1")`
* **`async emoji(collection_id="all")`**
* Загружает данные из локального файла `gift_data.json`, который содержит маппинг ID коллекций, названий и их моделей. Полезно для получения официальных emojiID телеграм подарков.
* **Пример:** `data = await emoji("6005564615793050414")` (Вернет данные для коллекции Instant Ramen)
* **`async graph(collection_id)`**
* Возвращает URL до PNG-изображения графика цены для указанной коллекции.
* **Пример:** `graph_url = await graph("6005564615793050414")`
---
## Лицензия
Этот проект распространяется под лицензией MIT. Подробности смотрите в файле `LICENSE`.
| text/markdown | aiofake | null | null | null | MIT License
Copyright (c) 2026 aiofake
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Operating System :: OS Independent"
] | [] | null | null | null | [] | [] | [] | [
"curl_cffi"
] | [] | [] | [] | [
"Homepage, https://github.com/aiofake/xgift",
"Bug Tracker, https://github.com/aiofake/xgift/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:10:35.854032 | xgift-0.3.8.tar.gz | 131,898 | 8e/c4/3afc96f69a81a0f9315f70206138e2af3cd28c43a95c3d3987807a6630a2/xgift-0.3.8.tar.gz | source | sdist | null | false | ee1d9bf3e5c1e08fbad0a52bfeee17be | 52c56e38a766d337b0b22ac1b6c47583d48f823b348466d4a98b197d9e5f9caa | 8ec43afc96f69a81a0f9315f70206138e2af3cd28c43a95c3d3987807a6630a2 | null | [
"LICENSE"
] | 227 |
2.4 | svgsubfig | 0.1.0 | Compose raster and vector images to publication-ready figures for scientific journals | # svgsubfig
A python package for swift arrangement of raster images and vector graphics into a single figure based on SVG.
This package is focussed on the preparation of high quality figures that consist of several subimages, both vector and raster graphics, for publication in scientific journals. A label is inserted below each subimage, e.g. ``(a)``, ``(b)``, ...
Font family, size and gaps can be adjusted based on a JSON configuration. An example figure created with ``svgsubfig`` could look like this:

## Basic usage
### Configuration
Create a JSON configuration file with the following structure, use relative filenames for the individual (sub-)images (the directory of the config file acts as base directory).
```json
{
"gap-between": 5,
"gap-label": 3,
"width": 150,
"font-size": 9,
"font-family": "Arial, Helvetica, sans-serif",
"images": [
"img/dog.jpeg",
"img/population.svg"
]
}
```
Following keys are available for the config file:
- ``font-family``: Typeface used in the SVG file for text.
- ``font-size``: Size of the labeling of the images in **pt**.
- ``gab-between``: Spacing between the subimages in **mm**.
- ``gap-label``: Spacing between labels and lower boundary of the images in **mm**.
- ``images``: Array of file paths of the images to include into the figure.
- ``index-offset``: Offset of the first subimage index, e.g. if ``index-offset = 3``, the first label will be ``(d)``
- ``width``: Width of the figure in **mm**.
To use automatic conversion of the created SVG figure file into PDF and PNG file formats, [Inkscape](https://inkscape.org/) needs to be installed and accessible on PATH.
### Figure composition
To create the final figure using the JSON configuration, a small ``svgsubfig`` command line utility can be used, but also scripting is possible.
#### Command line utility
To use the ``svgsubfig`` module to create the final figure file, use following command in your terminal:
```terminal
python -m svgsubfig [--noconvert] CONFIG_PATH
```
Replace ``CONFIG_PATH`` with the path of the JSON config file. Option ``--noconvert`` prevents conversion of the created SVG into PDF and PNG with Inkscape, which is useful in case Inkscape is not installed, or manual edits on the created SVG file are necessary.
#### Script
```python
import svgsubfig.utility as util
from svgsubfig import SVGSubFigure
from pathlib import Path
pth_config = Path("figure.json")
pth_svg = pth_config.with_suffix(".svg")
fig = SVGSubFigure.from_json(pth_config)
fig.save(pth_svg)
util.convert_svg(pth_svg)
```
| text/markdown | Felix Faber | felix.faber@ovgu.de | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"lxml<7.0.0,>=6.0.2",
"pillow<13.0.0,>=12.1.1"
] | [] | [] | [] | [
"Repository, https://github.com/fefafe/svgsubfig"
] | poetry/2.3.2 CPython/3.14.0 Windows/11 | 2026-02-19T19:10:12.673380 | svgsubfig-0.1.0-py3-none-any.whl | 6,334 | 25/f1/73642840841b17218024527bb39a16b4405243787ee2b4d5b5f2b05bcfcd/svgsubfig-0.1.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 757ef476375d67e6b40ff19fcecc67e9 | 1fc4bfe0d9d68a4b4ce8c3f01fbea0650a9f83d8b38aacac563b3ae7695600cc | 25f173642840841b17218024527bb39a16b4405243787ee2b4d5b5f2b05bcfcd | MIT | [
"LICENSE.txt"
] | 238 |
2.4 | django-blueprint | 1.0.0b2 | Blueprint is a modular CMS for Django. | # Django Blueprint
[](https://badge.fury.io/py/django-blueprint)
[](https://pypi.org/project/django-blueprint/)
[](https://www.djangoproject.com/)
[](LICENSE)
Common models and fields for adding CMS-like functionality to your Django application.
## 🚀 Quick Start
### Installation
☝️ Django Headless depends on Django.
```bash
pip install django-blueprint
```
### Add to Django Settings
```python
# settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'blueprint', # Add this
# ... your apps
]
```
## 🛠️ Requirements
- Python 3.12+
- Django 5.0+
## 🤝 Contributing
We welcome contributions! Here's how to get started:
1. Fork the repository
2. Create a feature branch (`git checkout -b feature/amazing-feature`)
3. Make your changes
4. Commit your changes (`git commit -m 'Add amazing feature'`)
5. Push to the branch (`git push origin feature/amazing-feature`)
6. Open a Pull Request
## 📚 Documentation
For detailed documentation, visit [djangoheadless.org](https://djangoheadless.org)
## 🐛 Issues & Support
- 🐛 **Bug Reports**: [GitHub Issues](https://github.com/BitsOfAbstraction/django-blueprint/issues)
- 💬 **Discussions**: [GitHub Discussions](https://github.com/BitsOfAbstraction/django-blueprint/discussions)
- 📧 **Email**: leon@devtastic.io
## 📄 License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## 🙏 Acknowledgments
- Inspired by the headless CMS and Jamstack movement
- Thanks to all contributors and the Django community
## 🔗 Links
- [PyPI Package](https://pypi.org/project/django-blueprint/)
- [Documentation](https:/djangoheadless.org)
- [GitHub Repository](https://github.com/BitsOfAbstraction/django-blueprint)
- [Changelog](CHANGELOG.md)
---
Made in Europe 🇪🇺 with 💚 for Django
| text/markdown | Leon van der Grient | leon@devtastic.io | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"jsonschema<5.0.0,>=4.26.0"
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.13.12 Darwin/25.2.0 | 2026-02-19T19:09:56.205461 | django_blueprint-1.0.0b2-py3-none-any.whl | 11,769 | d5/99/7a738985e6531bcab8c8eaf118b2c29eecd9f6e83cd5d44306ed41756364/django_blueprint-1.0.0b2-py3-none-any.whl | py3 | bdist_wheel | null | false | dc403d8f09f360c882f4adb05bde1a3d | 7ddbceb4d5b8cbc082b83e655c0dce8e4728df521df0115a3e2001ae28d0dcc9 | d5997a738985e6531bcab8c8eaf118b2c29eecd9f6e83cd5d44306ed41756364 | null | [
"LICENSE"
] | 215 |
2.4 | rustmap3d | 0.3.0 | Python geodetic coordinate conversions written in rust | # rustmap3d
[](https://github.com/lskyweiler/rustmap3d#license)

[](https://pypi.org/project/rustmap3d/)
[](https://crates.io/crates/map3d)
[](https://github.com/astral-sh/ruff)
<p align="center"><img src="docs/rustmap3d.logo.svg" width="300px" height="300px"/></p>
**Simple, fast, and ergonomic geodetic coordinate conversions**
---
### Installation
```bash
# add to an existing project
uv add rustmap3d
# pip install it directly
uv pip install rustmap3d
# pip install without uv
pip install rustmap3d
```
---
### Examples
Low-level transforms api similar to [pymap3d](https://github.com/geospace-code/pymap3d) and [matlab](https://www.mathworks.com/matlabcentral/fileexchange/15285-geodetic-toolbox)
```python
import rustmap3d
# wgs84 geodetic conversions
lla = rustmap3d.ecef2lla(x, y, z)
ecef = rustmap3d.lla2ecef(lat, lon, alt)
...
# local conversions
ecef_uvw = rustmap3d.enu2ecef_uvw(e, n, u, lat_ref, lon_ref)
ecef = rustmap3d.enu2ecef(e, n, u, lat_ref, lon_ref)
ecef_uvw = rustmap3d.ned2ecef_uvw(n, e, d, lat_ref, lon_ref)
ecef = rustmap3d.ned2ecef(n, e, d, lat_ref, lon_ref)
# enu, ned, aer
...
# local rotations
enu_quat = rustmap3d.enu2ecef_quat(lat, lon)
enu_dcm = rustmap3d.enu2ecef_dcm(lat, lon)
# enu, ned
# Conversions
dd = rustmap3d.dms2dd("25:22:44.738N") #> 25.37909389
dms = rustmap3d.dd2dms(25.37909389, is_lat=true) #> "25:22:44.738N"
lat, lon = rustmap3d.ll2dms(25.37909389, -138.7895679) #> "25:22:44.738N", "138:47:22.444W"
...
# distance functions
lat, lon = rustmap3d.vincenty_direct(lat_deg, lon_deg, range_m, bearing_deg)
range_m, bearing_ab, bearing_ba = rustmap3d.vincenty_inverse(lat_a, lon_a, lat_b, lon_b)
```
High-level GeoObject API
```python
import rustmap3d
import math
# Construct a GeoPosition from either global or local coordinates
reference = rustmap3d.GeoPosition.from_lla((0.0, 0.0, 0.0))
rustmap3d.GeoPosition.from_enu(rustmap3d.DVec3(100.0, 0.0, 0.0), reference)
rustmap3d.GeoPosition.from_ned(rustmap3d.DVec3(100.0, 0.0, 0.0), reference)
pos = rustmap3d.GeoPosition.from_aer(
rustmap3d.DVec3(90.0, 0.0, 100.0), (0.0, 0.0, 0.0)
) # all reference locations accept LLA tuples or GeoPositions for reference locations
# Conversions
reference.aer_to(pos)
reference.ned_to(pos)
reference.enu_to(pos)
# Operations
vec = pos - reference #> GeoVector
new_pos = reference + vec #> GeoPosition
vel = rustmap3d.GeoVelocity.from_dir_speed(rustmap3d.DVec3(1.0, 0.0, 0.0), 100.0)
dt = 1.0
pos = reference + vel * dt #> GeoPosition
rotation = rustmap3d.GeoOrientation.from_ecef_euler(rustmap3d.DVec3(0.0, math.pi, 0.0))
vec = rustmap3d.GeoVector.from_ecef(rustmap3d.DVec3(100.0, 0, 0.0), reference)
vec = rotation * vec
# Orientations
rot = rustmap3d.GeoOrientation.from_axis_angle(rustmap3d.DVec3(0., 0., 1), math.pi)
rot.forward() #> ecef x axis
rot.left() #> ecef y axis
rot.up() #> ecef y axis
```
## Comparison with similar packages
- 🚀🚀 Blazingly fast - written in rust (see [benchmarks](#benchmarks))
- Zero dependencies
- Dead simple api modeled after [pymap3d](https://github.com/geospace-code/pymap3d) and [matlab](https://www.mathworks.com/matlabcentral/fileexchange/15285-geodetic-toolbox)
- Exposes rotations (both quaternions and 3x3 matrices)
## Benchmarks
Compared to [pymap3d](https://github.com/geospace-code/pymap3d)
> Note: This is comparing calls with python scalars. Vectorized batched conversions will be implemented in the future
- *~50x* faster for lla2ecef
- *~400x* faster for ecef2lla
<p align="center"><img src="docs/benchmarks.svg"></p>
```bash
# Run benchmarks
uv run pytest --benchmark-histogram="./docs/benchmarks" bench/
```
## Build From Source
Uses standard [maturin](https://github.com/PyO3/maturin) build process
```bash
uv run maturin build -r # build a whl
uv run maturin dev -r # build a dev package similar to -e
```
| text/markdown; charset=UTF-8; variant=GFM | null | weiler <lucas.l.weiler@leidos.com>, molnar <andrew.b.molnar@leidos.com> | null | null | null | null | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy"
] | [] | https://github.com/lskyweiler/rustmap3d | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/lskyweiler/rustmap3d"
] | uv/0.9.5 | 2026-02-19T19:09:41.789362 | rustmap3d-0.3.0-cp314-cp314-manylinux_2_31_x86_64.whl | 463,761 | dc/dd/272ed83d1317cdbf54abebbc72c755f1e7394808bc4be6d7adf6229b1c19/rustmap3d-0.3.0-cp314-cp314-manylinux_2_31_x86_64.whl | cp314 | bdist_wheel | null | false | 6f96776308fbaba5161c7ea32af357d2 | 2e9037768fa54281d26b8b6f000c6dedca5cbb68d765b10bc44c4c9d8de14b1f | dcdd272ed83d1317cdbf54abebbc72c755f1e7394808bc4be6d7adf6229b1c19 | null | [
"LICENSE"
] | 2,003 |
2.3 | openregister-sdk | 2.4.1 | The official Python library for the openregister API | # Openregister Python API library
<!-- prettier-ignore -->
[)](https://pypi.org/project/openregister-sdk/)
The Openregister Python library provides convenient access to the Openregister REST API from any Python 3.9+
application. The library includes type definitions for all request params and response fields,
and offers both synchronous and asynchronous clients powered by [httpx](https://github.com/encode/httpx).
It is generated with [Stainless](https://www.stainless.com/).
## MCP Server
Use the Openregister MCP Server to enable AI assistants to interact with this API, allowing them to explore endpoints, make test requests, and use documentation to help integrate this SDK into your application.
[](https://cursor.com/en-US/install-mcp?name=openregister-mcp&config=eyJjb21tYW5kIjoibnB4IiwiYXJncyI6WyIteSIsIm9wZW5yZWdpc3Rlci1tY3AiXSwiZW52Ijp7Ik9QRU5SRUdJU1RFUl9BUElfS0VZIjoiTXkgQVBJIEtleSJ9fQ)
[](https://vscode.stainless.com/mcp/%7B%22name%22%3A%22openregister-mcp%22%2C%22command%22%3A%22npx%22%2C%22args%22%3A%5B%22-y%22%2C%22openregister-mcp%22%5D%2C%22env%22%3A%7B%22OPENREGISTER_API_KEY%22%3A%22My%20API%20Key%22%7D%7D)
> Note: You may need to set environment variables in your MCP client.
## Documentation
The full API of this library can be found in [api.md](https://github.com/oregister/openregister-python/tree/main/api.md).
## Installation
```sh
# install from PyPI
pip install openregister-sdk
```
## Usage
The full API of this library can be found in [api.md](https://github.com/oregister/openregister-python/tree/main/api.md).
```python
import os
from openregister import Openregister
client = Openregister(
api_key=os.environ.get("OPENREGISTER_API_KEY"), # This is the default and can be omitted
)
response = client.company.get_details_v1(
company_id="DE-HRB-F1103-267645",
)
print(response.id)
```
While you can provide an `api_key` keyword argument,
we recommend using [python-dotenv](https://pypi.org/project/python-dotenv/)
to add `OPENREGISTER_API_KEY="My API Key"` to your `.env` file
so that your API Key is not stored in source control.
## Async usage
Simply import `AsyncOpenregister` instead of `Openregister` and use `await` with each API call:
```python
import os
import asyncio
from openregister import AsyncOpenregister
client = AsyncOpenregister(
api_key=os.environ.get("OPENREGISTER_API_KEY"), # This is the default and can be omitted
)
async def main() -> None:
response = await client.company.get_details_v1(
company_id="DE-HRB-F1103-267645",
)
print(response.id)
asyncio.run(main())
```
Functionality between the synchronous and asynchronous clients is otherwise identical.
### With aiohttp
By default, the async client uses `httpx` for HTTP requests. However, for improved concurrency performance you may also use `aiohttp` as the HTTP backend.
You can enable this by installing `aiohttp`:
```sh
# install from PyPI
pip install openregister-sdk[aiohttp]
```
Then you can enable it by instantiating the client with `http_client=DefaultAioHttpClient()`:
```python
import os
import asyncio
from openregister import DefaultAioHttpClient
from openregister import AsyncOpenregister
async def main() -> None:
async with AsyncOpenregister(
api_key=os.environ.get("OPENREGISTER_API_KEY"), # This is the default and can be omitted
http_client=DefaultAioHttpClient(),
) as client:
response = await client.company.get_details_v1(
company_id="DE-HRB-F1103-267645",
)
print(response.id)
asyncio.run(main())
```
## Using types
Nested request parameters are [TypedDicts](https://docs.python.org/3/library/typing.html#typing.TypedDict). Responses are [Pydantic models](https://docs.pydantic.dev) which also provide helper methods for things like:
- Serializing back into JSON, `model.to_json()`
- Converting to a dictionary, `model.to_dict()`
Typed requests and responses provide autocomplete and documentation within your editor. If you would like to see type errors in VS Code to help catch bugs earlier, set `python.analysis.typeCheckingMode` to `basic`.
## Nested params
Nested parameters are dictionaries, typed using `TypedDict`, for example:
```python
from openregister import Openregister
client = Openregister()
company_search = client.search.find_companies_v1(
location={
"latitude": 0,
"longitude": 0,
},
)
print(company_search.location)
```
## Handling errors
When the library is unable to connect to the API (for example, due to network connection problems or a timeout), a subclass of `openregister.APIConnectionError` is raised.
When the API returns a non-success status code (that is, 4xx or 5xx
response), a subclass of `openregister.APIStatusError` is raised, containing `status_code` and `response` properties.
All errors inherit from `openregister.APIError`.
```python
import openregister
from openregister import Openregister
client = Openregister()
try:
client.company.get_details_v1(
company_id="DE-HRB-F1103-267645",
)
except openregister.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # an underlying Exception, likely raised within httpx.
except openregister.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except openregister.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
```
Error codes are as follows:
| Status Code | Error Type |
| ----------- | -------------------------- |
| 400 | `BadRequestError` |
| 401 | `AuthenticationError` |
| 403 | `PermissionDeniedError` |
| 404 | `NotFoundError` |
| 422 | `UnprocessableEntityError` |
| 429 | `RateLimitError` |
| >=500 | `InternalServerError` |
| N/A | `APIConnectionError` |
### Retries
Certain errors are automatically retried 2 times by default, with a short exponential backoff.
Connection errors (for example, due to a network connectivity problem), 408 Request Timeout, 409 Conflict,
429 Rate Limit, and >=500 Internal errors are all retried by default.
You can use the `max_retries` option to configure or disable retry settings:
```python
from openregister import Openregister
# Configure the default for all requests:
client = Openregister(
# default is 2
max_retries=0,
)
# Or, configure per-request:
client.with_options(max_retries=5).company.get_details_v1(
company_id="DE-HRB-F1103-267645",
)
```
### Timeouts
By default requests time out after 1 minute. You can configure this with a `timeout` option,
which accepts a float or an [`httpx.Timeout`](https://www.python-httpx.org/advanced/timeouts/#fine-tuning-the-configuration) object:
```python
from openregister import Openregister
# Configure the default for all requests:
client = Openregister(
# 20 seconds (default is 1 minute)
timeout=20.0,
)
# More granular control:
client = Openregister(
timeout=httpx.Timeout(60.0, read=5.0, write=10.0, connect=2.0),
)
# Override per-request:
client.with_options(timeout=5.0).company.get_details_v1(
company_id="DE-HRB-F1103-267645",
)
```
On timeout, an `APITimeoutError` is thrown.
Note that requests that time out are [retried twice by default](https://github.com/oregister/openregister-python/tree/main/#retries).
## Advanced
### Logging
We use the standard library [`logging`](https://docs.python.org/3/library/logging.html) module.
You can enable logging by setting the environment variable `OPENREGISTER_LOG` to `info`.
```shell
$ export OPENREGISTER_LOG=info
```
Or to `debug` for more verbose logging.
### How to tell whether `None` means `null` or missing
In an API response, a field may be explicitly `null`, or missing entirely; in either case, its value is `None` in this library. You can differentiate the two cases with `.model_fields_set`:
```py
if response.my_field is None:
if 'my_field' not in response.model_fields_set:
print('Got json like {}, without a "my_field" key present at all.')
else:
print('Got json like {"my_field": null}.')
```
### Accessing raw response data (e.g. headers)
The "raw" Response object can be accessed by prefixing `.with_raw_response.` to any HTTP method call, e.g.,
```py
from openregister import Openregister
client = Openregister()
response = client.company.with_raw_response.get_details_v1(
company_id="DE-HRB-F1103-267645",
)
print(response.headers.get('X-My-Header'))
company = response.parse() # get the object that `company.get_details_v1()` would have returned
print(company.id)
```
These methods return an [`APIResponse`](https://github.com/oregister/openregister-python/tree/main/src/openregister/_response.py) object.
The async client returns an [`AsyncAPIResponse`](https://github.com/oregister/openregister-python/tree/main/src/openregister/_response.py) with the same structure, the only difference being `await`able methods for reading the response content.
#### `.with_streaming_response`
The above interface eagerly reads the full response body when you make the request, which may not always be what you want.
To stream the response body, use `.with_streaming_response` instead, which requires a context manager and only reads the response body once you call `.read()`, `.text()`, `.json()`, `.iter_bytes()`, `.iter_text()`, `.iter_lines()` or `.parse()`. In the async client, these are async methods.
```python
with client.company.with_streaming_response.get_details_v1(
company_id="DE-HRB-F1103-267645",
) as response:
print(response.headers.get("X-My-Header"))
for line in response.iter_lines():
print(line)
```
The context manager is required so that the response will reliably be closed.
### Making custom/undocumented requests
This library is typed for convenient access to the documented API.
If you need to access undocumented endpoints, params, or response properties, the library can still be used.
#### Undocumented endpoints
To make requests to undocumented endpoints, you can make requests using `client.get`, `client.post`, and other
http verbs. Options on the client will be respected (such as retries) when making this request.
```py
import httpx
response = client.post(
"/foo",
cast_to=httpx.Response,
body={"my_param": True},
)
print(response.headers.get("x-foo"))
```
#### Undocumented request params
If you want to explicitly send an extra param, you can do so with the `extra_query`, `extra_body`, and `extra_headers` request
options.
#### Undocumented response properties
To access undocumented response properties, you can access the extra fields like `response.unknown_prop`. You
can also get all the extra fields on the Pydantic model as a dict with
[`response.model_extra`](https://docs.pydantic.dev/latest/api/base_model/#pydantic.BaseModel.model_extra).
### Configuring the HTTP client
You can directly override the [httpx client](https://www.python-httpx.org/api/#client) to customize it for your use case, including:
- Support for [proxies](https://www.python-httpx.org/advanced/proxies/)
- Custom [transports](https://www.python-httpx.org/advanced/transports/)
- Additional [advanced](https://www.python-httpx.org/advanced/clients/) functionality
```python
import httpx
from openregister import Openregister, DefaultHttpxClient
client = Openregister(
# Or use the `OPENREGISTER_BASE_URL` env var
base_url="http://my.test.server.example.com:8083",
http_client=DefaultHttpxClient(
proxy="http://my.test.proxy.example.com",
transport=httpx.HTTPTransport(local_address="0.0.0.0"),
),
)
```
You can also customize the client on a per-request basis by using `with_options()`:
```python
client.with_options(http_client=DefaultHttpxClient(...))
```
### Managing HTTP resources
By default the library closes underlying HTTP connections whenever the client is [garbage collected](https://docs.python.org/3/reference/datamodel.html#object.__del__). You can manually close the client using the `.close()` method if desired, or with a context manager that closes when exiting.
```py
from openregister import Openregister
with Openregister() as client:
# make requests here
...
# HTTP client is now closed
```
## Versioning
This package generally follows [SemVer](https://semver.org/spec/v2.0.0.html) conventions, though certain backwards-incompatible changes may be released as minor versions:
1. Changes that only affect static types, without breaking runtime behavior.
2. Changes to library internals which are technically public but not intended or documented for external use. _(Please open a GitHub issue to let us know if you are relying on such internals.)_
3. Changes that we do not expect to impact the vast majority of users in practice.
We take backwards-compatibility seriously and work hard to ensure you can rely on a smooth upgrade experience.
We are keen for your feedback; please open an [issue](https://www.github.com/oregister/openregister-python/issues) with questions, bugs, or suggestions.
### Determining the installed version
If you've upgraded to the latest version but aren't seeing any new features you were expecting then your python environment is likely still using an older version.
You can determine the version that is being used at runtime with:
```py
import openregister
print(openregister.__version__)
```
## Requirements
Python 3.9 or higher.
## Contributing
See [the contributing documentation](https://github.com/oregister/openregister-python/tree/main/./CONTRIBUTING.md).
| text/markdown | null | Openregister <founders@openregister.de> | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: OS Independent",
"Operating System :: POSIX",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"anyio<5,>=3.5.0",
"distro<2,>=1.7.0",
"httpx<1,>=0.23.0",
"pydantic<3,>=1.9.0",
"sniffio",
"typing-extensions<5,>=4.10",
"aiohttp; extra == \"aiohttp\"",
"httpx-aiohttp>=0.1.9; extra == \"aiohttp\""
] | [] | [] | [] | [
"Homepage, https://github.com/oregister/openregister-python",
"Repository, https://github.com/oregister/openregister-python"
] | twine/5.1.1 CPython/3.12.9 | 2026-02-19T19:09:09.566277 | openregister_sdk-2.4.1.tar.gz | 122,814 | c0/49/112d92655cbcbc86fe0c2694260a5d814cd3d0404d0721f00de9b20f3a8a/openregister_sdk-2.4.1.tar.gz | source | sdist | null | false | 29e1e385be7c9895bfd220eb9f046858 | c61be3d4e4cd1942a10368cea0aef73cbcc8bd9527618743042a6646ea49d772 | c049112d92655cbcbc86fe0c2694260a5d814cd3d0404d0721f00de9b20f3a8a | null | [] | 270 |
2.4 | alphagenome-ft | 0.1.2 | Finetuning utilities for AlphaGenome with custom heads and parameter freezing | # AlphaGenome Finetuning (`alphagenome-ft`)
A lightweight Python package for finetuning [Google DeepMind's AlphaGenome](https://github.com/google-deepmind/alphagenome_research/) model with custom prediction heads and parameter freezing capabilities, **without modifying the original codebase**.
**Project leads - [Alan Murphy](https://al-murphy.github.io/), [Masayuki (Moon) Nagai](https://masayukinagai.github.io/), [Alejandro Buendia](https://abuendia.github.io/)**
## Use cases
- If you want to apply AlphaGenome to your MPRA (or other perturbation) data of interest, see [Encoder-only / short sequences (MPRA)](#workflow-1-encoder-only--short-sequences-mpra).
- If you want to apply AlphaGenome to your own genome-wide assay, start with [Heads-only finetuning (frozen backbone)](#workflow-2-heads-only-finetuning-frozen-backbone); then [LoRA-style adapters](#workflow-3-lora-style-adapters) or [Full-model finetuning](#workflow-4-full-model-finetuning) if needed.
## Contents
- **Overview**
- [Features](#features)
- [Installation](#installation)
- [Quick Start](#quick-start)
- **Workflows**
1. [Encoder-only / short sequences (MPRA)](#workflow-1-encoder-only--short-sequences-mpra) — finetune on short sequences (< 1 kb)
2. [Heads-only finetuning (frozen backbone)](#workflow-2-heads-only-finetuning-frozen-backbone) — train a new head on top of a frozen model
3. [LoRA-style adapters](#workflow-3-lora-style-adapters) — low-rank adapter layers
4. [Full-model finetuning](#workflow-4-full-model-finetuning) — unfreeze the backbone (e.g. progressive unfreezing)
5. [Attribution analysis](#after-training-attribution-analysis) — interpret predictions after training
- **Reference**
- [AlphaGenome Architecture](#alphagenome-architecture)
- [Head types and embeddings](#custom-head-types-guide)
- [Add head / custom head from scratch](#add-head-to-existing-model-keep-standard-heads)
- [API Reference](#api-reference)
- [Saving and loading checkpoints](#saving-and-loading-checkpoints)
- [Attribution analysis (full detail)](#attribution-analysis)
- **Other**
- [Testing](#testing)
- [Contributing](#contributing)
**How to use this README:** Sections are ordered by how you typically run things. Start with adapting to MPRA or heads-only finetuning; then add full-model workflows if needed. Run attribution and interpretation **after** you have a trained model. Step-by-step tutorials live in [`docs/`](docs/).
## Features
- **Custom Prediction Heads**: Define and register your own task-specific prediction heads
- **Parameter Freezing**: Flexible parameter management (freeze backbone, heads, or specific layers)
- **Easy Integration**: Works seamlessly with pretrained AlphaGenome models (simple wrapper classes)
- **Parameter Inspection**: Utilities to explore and count model parameters
- **Attribution Analysis**: Utilities to calculate attributions based on gradients or _in silico_ mutagenesis (ISM)
- **JAX/Haiku Native**: Built on the same framework as AlphaGenome
## Installation
This package depends on the AlphaGenome stack (`alphagenome` and `alphagenome_research`), which are not on PyPI and must be installed from GitHub. Use the following order.
### Step 1: Install alphagenome-ft
**From PyPI (recommended):**
```bash
pip install alphagenome-ft
```
**From source (development):**
```bash
git clone https://github.com/genomicsxai/alphagenome_ft.git
cd alphagenome_ft
pip install -e .
```
This installs `alphagenome-ft` and its PyPI dependencies (JAX, Haiku, optax, etc.). It does **not** install the AlphaGenome model code.
### Step 2: Install AlphaGenome and AlphaGenome Research
`alphagenome_ft` wraps [AlphaGenome](https://github.com/google-deepmind/alphagenome/) and [AlphaGenome Research](https://github.com/google-deepmind/alphagenome_research/). Install both from GitHub:
```bash
pip install git+https://github.com/google-deepmind/alphagenome.git
pip install git+https://github.com/google-deepmind/alphagenome_research.git
```
### Requirements
- Python ≥ 3.11
- All other runtime dependencies (JAX, Haiku, optax, orbax-checkpoint, etc.) are installed automatically with `alphagenome-ft`. See `pyproject.toml` for versions.
- AlphaGenome and AlphaGenome Research must be installed separately as above; they are not on PyPI.
## Quick Start
There are three options to add new heads to AlphaGenome.
### Option A: Use a Predefined AlphaGenome Head
You can reuse the predefined head kinds from `alphagenome_research` without importing
`HeadName` by passing the string value. Supported strings are:
`atac`, `dnase`, `procap`, `cage`, `rna_seq`, `chip_tf`, `chip_histone`, `contact_maps`,
`splice_sites_classification`, `splice_sites_usage`, `splice_sites_junction`. For the details of each head, refer to [alphagenome_research](https://github.com/google-deepmind/alphagenome_research/blob/main/src/alphagenome_research/model/heads.py).
```python
from alphagenome_ft import (
get_predefined_head_config,
register_predefined_head,
create_model_with_heads,
)
# 1. Build a predefined head config (num_tracks must match the number of your target tracks)
rna_config = get_predefined_head_config(
"rna_seq",
num_tracks=4,
)
# 2. Register it under an instance name you will train
register_predefined_head("K562_rna_seq", rna_config)
# 3. Create a model that uses the registered instance
model = create_model_with_heads("all_folds", heads=["K562_rna_seq"])
model.freeze_except_head("K562_rna_seq")
```
Note if you have a local AlphaGenome weights version you want to use instead of getting the weights from Kaggle use:
```python
model = create_model_with_heads(
'all_folds',
heads=['my_head'],
checkpoint_path="full/path/to/weights",
)
```
### Option B: Use Template Heads
We provide ready-to-use template heads for common scenarios, see `./alphagenome_ft/templates.py`:
```python
from alphagenome.models import dna_output
from alphagenome_research.model import dna_model
from alphagenome_ft import (
templates,
CustomHeadConfig,
CustomHeadType,
register_custom_head,
create_model_with_heads,
)
# 1. Register a template head (modify class for your task)
register_custom_head(
'my_head',
templates.StandardHead, # Choose template: StandardHead, TransformerHead, EncoderOnlyHead
CustomHeadConfig(
type=CustomHeadType.GENOME_TRACKS,
output_type=dna_output.OutputType.RNA_SEQ,
num_tracks=1,
)
)
# 2. Create model with custom head
model = create_model_with_heads(
'all_folds',
heads=['my_head'],
)
# 3. Freeze backbone for finetuning
model.freeze_except_head('my_head')
```
**Available Templates:**
- `templates.StandardHead` - Uses 1bp embeddings (decoder output: local + global features)
- `templates.TransformerHead` - Uses 128bp embeddings (transformer output: pure attention)
- `templates.EncoderOnlyHead` - Uses encoder output (CNN only, for short sequences < 1kb)
All templates use simple architecture: **Linear → ReLU → Linear**
The key difference is **which embeddings** they access. See [`alphagenome_ft/templates.py`](alphagenome_ft/templates.py) for code.
### Option C: Define Custom Head from Scratch
Define your own head when you need specific head architectures and/or loss:
```python
import jax
import jax.numpy as jnp
import haiku as hk
from alphagenome_ft import CustomHead
class MyCustomHead(CustomHead):
"""Your custom prediction head."""
def predict(self, embeddings, organism_index, **kwargs):
# Get embeddings at desired resolution
x = embeddings.get_sequence_embeddings(resolution=1) # or 128
# Add your prediction layers
x = hk.Linear(256, name='hidden')(x)
x = jax.nn.relu(x)
predictions = hk.Linear(self._num_tracks, name='output')(x)
return predictions
def loss(self, predictions, batch):
targets = batch.get('targets')
if targets is None:
return {'loss': jnp.array(0.0)}
mse = jnp.mean((predictions - targets) ** 2)
return {'loss': mse, 'mse': mse}
# Register and use in the same way as Option B
```
### Note: Add Custom Head to Existing Model (Keep pre-trained Heads)
The three approaches above create models that include only the heads you explicitly provide. If you want to **keep AlphaGenome's pre-trained heads** (ATAC, RNA-seq, etc.) alongside your custom head:
```python
from alphagenome.models import dna_output
from alphagenome_research.model import dna_model
from alphagenome_ft import (
templates,
CustomHeadConfig,
CustomHeadType,
register_custom_head,
add_heads_to_model,
)
# 1. Load pretrained model (includes standard heads)
base_model = dna_model.create_from_kaggle('all_folds')
# 2. Register custom or predefined head
register_custom_head(
'my_head',
templates.StandardHead,
CustomHeadConfig(
type=CustomHeadType.GENOME_TRACKS,
output_type=dna_output.OutputType.RNA_SEQ,
num_tracks=1,
)
)
# 3. Add custom head to model (keeps ALL standard heads)
model = add_heads_to_model(base_model, heads=['my_head'])
# 4. Freeze backbone + standard heads, train only custom head
model.freeze_except_head('my_head')
# 5. Create loss function for training (see "Training with Custom Heads" section)
loss_fn = model.create_loss_fn_for_head('my_head')
```
**When to use each approach:**
- `create_model_with_heads()` - Heads **only** (faster, smaller)
- `add_heads_to_model()` - Added heads **+ pre-trained heads** (useful when referring to the original tracks)
## Workflows
### Workflow 1: Encoder-only / short sequences (MPRA)
**When to use:** Short sequences (< ~1 kb): MPRA, promoters, enhancers. Uses encoder (CNN) only.
**Tutorial:** [Encoder-only finetuning](docs/encoder_only_perturbation.md). Use `templates.EncoderOnlyHead` and **`use_encoder_output=True`** in `create_model_with_heads(...)`. Run zero-shot after training; see [MPRA repo](https://github.com/genomicsxai/alphagenome_FT_MPRA).
---
### Workflow 2: Heads-only finetuning (frozen backbone)
**When to use:** New task (ChIP-seq, gene expression, etc.) on standard-length sequences; train only a new head, backbone frozen.
**Tutorial:** [Frozen backbone, new head](docs/frozen_backbone_new_head.md).
---
### Workflow 3: LoRA-style adapters
**When to use:** Low-rank adapters on the backbone. **Tutorial:** [LoRA-style adapters](docs/lora_adapters.md).
---
### Workflow 4: Full-model finetuning
**When to use:** Adapt the backbone (e.g. after heads-only or for a different distribution).
**Tutorial:** [Full-model finetuning (unfreezing the backbone)](docs/full_model_finetuning.md). Unfreeze via `unfreeze_parameters(unfreeze_prefixes=[...])` or `freeze_backbone(freeze_prefixes=[...])`; save with `save_checkpoint(..., save_full_model=True)`.
---
### After training: Attribution analysis
Compute attributions after training to see which sequence features drive predictions.
**Methods:** DeepSHAP*, Gradient × Input, Gradient, ISM.
Load a checkpoint, then use `compute_deepshap_attributions`, `compute_input_gradients`, or `compute_ism_attributions`; visualize with `plot_attribution_map` and `plot_sequence_logo`.
Full API, examples (basic, visualization, single-sequence pipeline), method comparison, and multi-track `output_index`: **[Attribution analysis](docs/attribution.md)**.
**NOTE**: DeepSHAP* - The implementation is DeepSHAP-like in that it uses a reference sequence but is note a faithful reimplmenntation.
---
## References
### AlphaGenome Architecture
Understanding the architecture helps design custom heads:
```
DNA Sequence (B, S, 4)
↓
┌─────────────────────────────────────┐
│ BACKBONE (can be frozen) │
│ ├─ SequenceEncoder ←────────────┐ │
│ ├─ TransformerTower (9 blocks) │ │
│ └─ SequenceDecoder │ │
└──────────────────────────────────┼──┘
↓ │
┌──────────────────────────────────┼─────────────┐
│ EMBEDDINGS (multi-resolution) │ │
│ ├─ embeddings_1bp: (B, S, 1536) │
│ ├─ embeddings_128bp: (B, S/128, 3072) │
│ ├─ embeddings_pair: (B, S/2048, S/2048, 128) │
│ └─ encoder_output: (B, S/128, D) │
└────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ HEADS (task-specific) │
│ ├─ Standard: ATAC, RNA-seq, etc. │
│ └─ Custom: YOUR_HEAD_HERE ← Add! │
└─────────────────────────────────────┘
```
### Available Embedding Resolutions
```python
# In your custom head's predict() method:
# 1bp resolution (highest detail, local + global features)
x_1bp = embeddings.get_sequence_embeddings(resolution=1)
# Shape: (batch, sequence_length, 1536)
# 128bp resolution (global attention features)
x_128bp = embeddings.get_sequence_embeddings(resolution=128)
# Shape: (batch, sequence_length//128, 3072)
# Encoder output (CNN features only, requires use_encoder_output=True)
x_encoder = embeddings.encoder_output
# Shape: (batch, sequence_length//128, D)
```
### Parameter Management
```python
# Freeze/unfreeze by path or prefix
model.freeze_parameters(freeze_paths=['alphagenome/encoder/...'])
model.unfreeze_parameters(unfreeze_prefixes=['alphagenome/head/'])
# Convenient presets
model.freeze_backbone() # Freeze all backbone components (default)
model.freeze_backbone(freeze_prefixes=['sequence_encoder']) # Freeze only encoder
model.freeze_backbone(freeze_prefixes=['transformer_tower']) # Freeze only transformer
model.freeze_backbone(freeze_prefixes=['sequence_decoder']) # Freeze only decoder
model.freeze_backbone(freeze_prefixes=['sequence_encoder', 'transformer_tower']) # Freeze encoder + transformer
model.freeze_all_heads(except_heads=['my_head']) # Freeze all heads except one
model.freeze_except_head('my_head') # Freeze everything except one head
# Inspection
paths = model.get_parameter_paths() # All parameter paths
head_paths = model.get_head_parameter_paths() # Just head parameters
backbone_paths = model.get_backbone_parameter_paths() # Just backbone
count = model.count_parameters() # Total parameter count
```
### Modular Backbone Freezing
The `freeze_backbone()` method now supports modular freezing of backbone components. This allows you to selectively freeze only specific parts of the backbone (encoder, transformer, or decoder) while keeping others trainable. This is useful for progressive finetuning strategies:
```python
# Example: Progressive finetuning strategy
# 1. Start with only head trainable
model.freeze_backbone() # Freeze all backbone
# 2. Unfreeze decoder for fine-grained adaptation
model.unfreeze_parameters(unfreeze_prefixes=['sequence_decoder'])
# 3. Later, unfreeze transformer for global context adaptation
model.unfreeze_parameters(unfreeze_prefixes=['transformer_tower'])
# 4. Finally, unfreeze encoder for full finetuning
model.unfreeze_parameters(unfreeze_prefixes=['sequence_encoder'])
# Or use freeze_backbone with specific prefixes from the start:
model.freeze_backbone(freeze_prefixes=['sequence_encoder', 'transformer_tower']) # Only decoder trainable
```
### Saving a Checkpoint
- `save_full_model=False` (default): Only saves custom head parameters (~MBs)
- **Recommended for finetuning** - much smaller checkpoints
- Requires loading the base model when restoring
- `save_full_model=True`: Saves entire model including backbone (~GBs)
- Self-contained checkpoint
- Larger file size but no need for base model
- Use if unfreezing the base model
### Loading a Checkpoint
```python
from alphagenome_ft import load_checkpoint
# Load a heads-only checkpoint (requires base model)
model = load_checkpoint(
'checkpoints/my_model',
base_model_version='all_folds' # Which base model to use
)
# Now use for inference or continue training
predictions = model.predict(...)
```
**Important:** Before loading, you must register the custom head classes:
```python
# Import and register your custom head class
from your_module import MyCustomHead
from alphagenome_ft import register_custom_head
register_custom_head('my_head', MyCustomHead, config)
# Now load checkpoint
model = load_checkpoint('checkpoints/my_model')
```
## Testing
The package includes a comprehensive test suite using pytest.
### Run Tests
```bash
# Install test dependencies
pip install -e ".[test]"
# Run all tests
pytest
# Run with coverage
pytest --cov=alphagenome_ft --cov-report=html
# Run specific test file
pytest tests/test_custom_heads.py
pytest tests/test_checkpoint.py
```
See [`tests/README.md`](tests/README.md) for detailed testing documentation.
## Contributing
Contributions welcome! Please:
1. Fork the repository
2. Create a feature branch
3. **Add tests for new functionality** (see [`tests/README.md`](tests/README.md))
4. Ensure tests pass: `pytest`
5. Submit a pull request
## Publishing (maintainers)
Releases are published to PyPI via GitHub Actions using [Trusted Publishing](https://docs.pypi.org/trusted-publishers/) (no API token stored in the repo).
### One-time setup on PyPI
1. Open [PyPI → alphagenome-ft → Publishing](https://pypi.org/manage/project/alphagenome-ft/settings/publishing/).
2. Add a trusted publisher:
- **Owner:** your GitHub user or org (e.g. `genomicsxai`)
- **Repository:** `alphagenome_ft`
- **Workflow name:** `publish.yml`
- **Environment (optional):** `pypi` if you create that environment in the repo
If you use the `pypi` environment, create it in the repo under Settings → Environments so the workflow can run.
### Releasing a new version
1. Bump `version` in `pyproject.toml` (e.g. `0.1.2`).
2. Commit and push.
3. Create and push a tag matching the version:
`git tag v0.1.2 && git push origin v0.1.2`
4. The [Publish to PyPI](.github/workflows/publish.yml) workflow runs and uploads to PyPI.
## License
MIT License - see [LICENSE](LICENSE) file for details.
This project extends [AlphaGenome](https://github.com/google-deepmind/alphagenome_research/), which has its own license terms.
| text/markdown | null | Alan Murphy <amurphy@cshl.edu>, Masayuki Nagai <nagai@cshl.edu> | null | null | MIT | alphagenome, genomics, deep-learning, finetuning, jax | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientifi... | [] | null | null | >=3.11 | [] | [] | [] | [
"aiohttp>=3.0.0",
"dm-haiku>=0.0.10",
"jaxtyping>=0.2.0",
"optax>=0.2.7",
"orbax-checkpoint>=0.4.0",
"pandas>=2.0.0",
"requests>=2.0.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"pytest>=7.0.0;... | [] | [] | [] | [
"Homepage, https://github.com/genomicsxai/alphagenome_ft",
"Repository, https://github.com/genomicsxai/alphagenome_ft",
"Issues, https://github.com/genomicsxai/alphagenome_ft/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:08:42.339658 | alphagenome_ft-0.1.2.tar.gz | 70,675 | 74/96/577eee7c45f8feb8830562c8f87c28f75422093e593a0d5470f65dcbc7b7/alphagenome_ft-0.1.2.tar.gz | source | sdist | null | false | 9db62f4c292b2ce2a25143c7096b8efb | 43dfdf24b093d25cfb29349720fc7db678aedceef684fa0e2725be85abf95e1b | 7496577eee7c45f8feb8830562c8f87c28f75422093e593a0d5470f65dcbc7b7 | null | [
"LICENSE"
] | 239 |
2.4 | bingo-nasa | 0.5.7 | A package for genetic optimization and symbolic regression. | 
master: [](https://github.com/nasa/bingo/actions?query=branch%3Adevelop)
[](https://coveralls.io/github/nasa/bingo?branch=develop)
develop:
[](https://github.com/nasa/bingo/actions?query=branch%3Adevelop)
[](https://coveralls.io/github/nasa/bingo?branch=develop)
## Description
Bingo is an open source package for performing symbolic regression, though it
can be used as a general purpose evolutionary optimization package.
## Key Features
* Integrated local optimization strategies
* Parallel island evolution strategy implemented with mpi4py
* Coevolution of fitness predictors
# Quick Start
## Documentation
[Full Documentation Here](https://nasa.github.io/bingo/)
## Installation
```sh
pip install bingo-nasa
```
## Usage Example
A no-fuss way of using Bingo is by using the scikit-learn wrapper:
`SymbolicRegressor`. Let's setup a test case to show how it works.
### Setting Up the Regressor
There are many options that can be set in `SymbolicRegressor`. Here we set some basic ones including
`population_size` (the number of equations in a population), `stack_size` (the max number of nodes per equation), and `use_simplification`
(whether to use simplification to speed up equation evaluation and for easier reading). You can see all of `SymbolicRegressor`'s
options [here](https://nasa.github.io/bingo/_apidocs/bingo.symbolic_regression.html#module-bingo.symbolic_regression.symbolic_regressor).
```python
from bingo.symbolic_regression.symbolic_regressor import SymbolicRegressor
regressor = SymbolicRegressor(population_size=100, stack_size=16,
use_simplification=True)
```
/home/gbomarit/Projects/Genetic_Programming/bingo/bingo/symbolic_regression/__init__.py:31: UserWarning: Could not load C++ modules No module named 'bingocpp.build.bingocpp'
warnings.warn(f"Could not load C++ modules {import_err}")
### Training Data
Here we're just creating some dummy training data from the equation $5.0 X_0^2 + 3.5 X_0$. More on training data can be found
in the [data formatting guide](https://nasa.github.io/bingo/_high_level/data_formatting.html).
```python
import numpy as np
X_0 = np.linspace(-10, 10, num=30).reshape((-1, 1))
X = np.array(X_0)
y = 5.0 * X_0 ** 2 + 3.5 * X_0
```
```python
import matplotlib.pyplot as plt
plt.scatter(X, y)
plt.xlabel("X_0")
plt.ylabel("y")
plt.title("Training Data")
plt.show()
```

### Fitting the Regressor
Fitting is as simple as calling the `.fit()` method.
```python
regressor.fit(X, y)
```
using 1 processes
Generating a diverse population took 274 iterations.
archipelago: <class 'bingo.evolutionary_optimizers.island.Island'>
done with opt, best_ind: X_0 + (5.0)((0.49999999999999967)(X_0) + (X_0)(X_0)), fitness: 5.4391466376923e-28
reran CLO, best_ind: X_0 + (5.0)((0.4999999999999999)(X_0) + (X_0)(X_0)), fitness: 5.352980018399097e-28
### Getting the Best Individual
```python
best_individual = regressor.get_best_individual()
print("best individual is:", best_individual)
```
best individual is: X_0 + (5.0)((0.4999999999999999)(X_0) + (X_0)(X_0))
### Predicting Data with the Best Individual
You can use the regressor's `.predict(X)` or
the best_individual's `.evaluate_equation_at(X)` to get
its predictions for `X`.
```python
pred_y = regressor.predict(X)
pred_y = best_individual.evaluate_equation_at(X)
plt.scatter(X, y)
plt.plot(X, pred_y, 'r')
plt.xlabel("X_0")
plt.ylabel("y")
plt.legend(["Actual", "Predicted"])
plt.show()
```

# Source
## Installation from Source
For those looking to develop their own features in Bingo.
First clone the repo and move into the directory:
```sh
git clone --recurse-submodules https://github.com/nasa/bingo.git
cd bingo
```
Then make sure you have the requirements necessary to use Bingo:
```sh
conda env create -f conda_environment.yml
```
or
```sh
pip install -r requirements.txt
```
(Optional) Then build the c++ performance library BingoCpp:
```sh
./.build_bingocpp.sh
```
Now you should be good to go! You can run Bingo's test suite to make sure that
the installation process worked properly:
```sh
pytest tests
```
Add Bingo to your Python path to begin using it from other directories.
```sh
export PYTHONPATH="$PYTHONPATH:/path/to/bingo/"
```
and test it with:
```sh
python -c 'import bingo; import bingocpp'
```
## Contributing
1. Fork it (<https://github.com/nasa/bingo/fork>)
2. Create your feature branch (`git checkout -b feature/fooBar`)
3. Commit your changes (`git commit -am 'Add some fooBar'`)
4. Push to the branch (`git push origin feature/fooBar`)
5. Create a new Pull Request
# Citing Bingo
Please consider citing the following reference when using bingo in your works.
### MLA:
Randall, David L., et al. "Bingo: a customizable framework for symbolic regression with genetic programming." Proceedings of the Genetic and Evolutionary Computation Conference Companion. 2022.
### Bibtex:
```latex
@inproceedings{randall2022bingo,
title={Bingo: a customizable framework for symbolic regression with genetic programming},
author={Randall, David L and Townsend, Tyler S and Hochhalter, Jacob D and Bomarito, Geoffrey F},
booktitle={Proceedings of the Genetic and Evolutionary Computation Conference Companion},
pages={2282--2288},
year={2022}
}
```
# Versioning
We use [SemVer](http://semver.org/) for versioning. For the versions available,
see the [tags on this repository](https://github.com/nasa/bingo/tags).
# Authors
* Geoffrey Bomarito
* Tyler Townsend
* Jacob Hochhalter
* David Randall
* Ethan Adams
* Kathryn Esham
* Diana Vera
# License
Copyright 2018 United States Government as represented by the Administrator of
the National Aeronautics and Space Administration. No copyright is claimed in
the United States under Title 17, U.S. Code. All Other Rights Reserved.
The Bingo Mini-app framework is licensed under the Apache License, Version 2.0
(the "License"); you may not use this application except in compliance with the
License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0 .
Unless required by applicable law or agreed to in writing, software distributed
under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
| text/markdown | null | Geoffrey Bomarito <geoffrey.f.bomarito@nasa.gov> | null | null | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| symbolic regression | [
"License :: OSI Approved :: Apache Software License",
"Development Status :: 3 - Alpha",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"mpi4py>=4.0",
"numpy",
"scipy",
"dill",
"sympy",
"scikit-learn",
"smcpy",
"pybind11[global]",
"onnx; extra == \"onnx\"",
"pytest; extra == \"tests\"",
"pytest-mock; extra == \"tests\"",
"pytest-timeout; extra == \"tests\"",
"pytest-cov; extra == \"tests\"",
"coverage; extra == \"tests\"",... | [] | [] | [] | [
"Documentation, https://nasa.github.io/bingo/",
"Repository, https://github.com/nasa/bingo"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:08:22.514434 | bingo_nasa-0.5.7.tar.gz | 2,486,859 | b8/45/794d0e71c1b5d694fcf8772f2de6cf1227206fc8a16bf21b38c1d44a72d3/bingo_nasa-0.5.7.tar.gz | source | sdist | null | false | 87cf699bfd715a92ad554010cadac2f8 | 8c70f3345650bc351717bc978cc84c3b81870cd1c49f2ebc35374babd6fad5f1 | b845794d0e71c1b5d694fcf8772f2de6cf1227206fc8a16bf21b38c1d44a72d3 | null | [
"LICENSE.txt"
] | 913 |
2.4 | csu-radartools | 1.5.0 | Python tools for polarimetric radar retrievals. |
Python tools for polarimetric radar retrievals.
To access, use the following in your analysis code:
from csu_radartools import (
csu_fhc, csu_kdp, csu_dsd, csu_liquid_ice_mass, csu_misc,
csu_blended_rain, fundamentals)
Works on Windows, but you'll need to install a C++ compiler (e.g. MSVC >=2015).
| text/plain | Brenda Dolan, Brody Fuchs, Timothy Lang | bdolan@colostate.edu | null | null | GPLv2 | radar precipitation meteorology weather | [
"Development Status :: 4 - Beta",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU General Public License v2 (GPLv2)",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Operating System :: Unix",
"Programming Langua... | [] | https://radarmet.atmos.colostate.edu | https://github.com/CSU-Radarmet/CSU_RadarTools/releases | >=3.8 | [] | [] | [] | [
"numpy>=1.18",
"scipy",
"matplotlib",
"pandas",
"cython",
"netCDF4"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.10 | 2026-02-19T19:08:16.901625 | csu_radartools-1.5.0.tar.gz | 6,564,308 | 40/71/9cdf6aa7e50519661e93924f7ffdd39dbb4e382736a7aec14e7eb0345e32/csu_radartools-1.5.0.tar.gz | source | sdist | null | false | 62ac57dffbc47d1fe94f7a98a6a599e5 | 863cc2842d9a98d10109fd9ff801393b03a915386f66f1b2894d82bf0de42d3d | 40719cdf6aa7e50519661e93924f7ffdd39dbb4e382736a7aec14e7eb0345e32 | null | [
"LICENSE.txt"
] | 233 |
2.1 | mally-cli | 0.7.11 | Autonomous coding agent powered by Otonomy | # Mally
**Autonomous coding agent powered by Claude Opus 4.5**
Zero-config AI assistant that helps you write, debug, and understand code. Just install and run - no API keys needed!
## Quick Start
**macOS/Linux:**
```bash
curl -fsSL https://mally-api.otonomy.ai/install.sh | bash
```
**Windows (PowerShell):**
```powershell
irm https://mally-api.otonomy.ai/install.ps1 | iex
```
**Or with pip:**
```bash
pip install mally
```
Then just run:
```bash
mally
```
That's it! Start chatting with your AI coding assistant.
## Features
- **Zero Config** - Works out of the box, no API keys required
- **Claude Opus 4.5** - Powered by Anthropic's most capable model
- **Full Coding Support** - Read, write, edit files, run commands
- **Web Search** - Search the web and extract content
- **Multi-turn Chat** - Natural conversation with context
- **Session History** - Resume previous conversations
## Usage
```bash
# Start interactive mode
mally
# Start with a task
mally "help me build a REST API"
# Resume last session
mally --continue
```
## Commands
Inside Mally, you can:
- Type your request naturally
- Press `Enter` twice to send (or `Esc` then `Enter`)
- Type `done` or press `Ctrl+C` to exit
- Use `--help` for more options
## Examples
```
You: Create a Python function to calculate fibonacci numbers
You: Find all TODO comments in this project
You: Explain how the authentication works in this codebase
You: Write tests for the user service
```
## Requirements
- Python 3.9+
- macOS, Linux, or Windows
## Optional Features
```bash
# Browser automation
pip install mally-cli[browser]
# Desktop control (screenshots, clicks)
pip install mally-cli[desktop]
# Everything
pip install mally-cli[all]
```
## Advanced: Using Your Own Keys
By default, Mally uses the Otonomy proxy. For your own API keys:
```bash
export USE_DIRECT_API=true
export ANTHROPIC_API_KEY=sk-ant-...
export KIMI_API_KEY=sk-...
mally
```
## Links
- [Documentation](https://docs.otonomy.dev)
- [GitHub](https://github.com/otonomy/mally)
- [Get API Key](https://otonomy.dev)
## License
MIT
| text/markdown | null | Otonomy <hello@otonomy.dev> | null | null | MIT | ai, coding, agent, autonomous, llm, assistant, otonomy | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12"
] | [] | https://otonomy.dev | null | >=3.9 | [] | [] | [] | [
"openai>=1.0.0",
"anthropic>=0.70.0",
"tiktoken>=0.5.0",
"prompt_toolkit>=3.0.0",
"simple-term-menu>=1.6.0; sys_platform != \"win32\"",
"rich>=13.0.0",
"requests>=2.28.0",
"httpx>=0.24.0",
"tavily-python>=0.3.0",
"nest_asyncio>=1.5.0",
"websocket-client>=1.6.0",
"playwright>=1.40.0",
"fpdf2>... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:07:51.506444 | mally_cli-0.7.11-cp312-cp312-win_amd64.whl | 1,336,064 | 64/a6/e94993f93d204ddeaaab21cefa441355975446968c5a7a1426fd6656e3aa/mally_cli-0.7.11-cp312-cp312-win_amd64.whl | cp312 | bdist_wheel | null | false | 08f843530629c80d6e6278183b3c4716 | 2d3c0a241c27667818eab233d1bfa168801d14c7775acedd5c418e81285a4d65 | 64a6e94993f93d204ddeaaab21cefa441355975446968c5a7a1426fd6656e3aa | null | [] | 241 |
2.4 | youtube-connector-mcp | 0.3.1 | YouTube MCP Server for Claude Code | # YouTube MCP Server (youtube-connector-mcp)
[](https://lobehub.com/mcp/shellydeng08-youtube-connector-mcp)
`youtube-connector-mcp` is a **YouTube MCP Server / Connector** that allows AI assistants like **Claude, Cursor, Cline, Windsurf, Continue.dev, Grapes AI** to interact with the **YouTube Data API v3** via the **Model Context Protocol (MCP)**.
🌐 Project Website: https://youtube-connector-mcp-website.vercel.app/
📦 PyPI Package: https://pypi.org/project/youtube-connector-mcp/
---
## Quick Start
```bash
# 1. Get your YouTube API Key from Google Cloud Console
# https://console.cloud.google.com/apis/credentials
# 2. Set your API key as environment variable
export YOUTUBE_API_KEY="your_api_key_here"
# 3. Install pipx first (if not installed)
brew install pipx # macOS
# or: apt install pipx # Ubuntu/Debian
# 4. Install the package
pipx install youtube-connector-mcp
# 5. Add the MCP server
claude mcp add youtube-connector-mcp youtube-connector-mcp -s user -e YOUTUBE_API_KEY="${YOUTUBE_API_KEY}"
# 6. Restart Claude Code and start using!
```
---
## Prerequisites
| Requirement | How to Get |
| ------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| **Python 3.10+** | [Download Python](https://www.python.org/downloads/) or `brew install python3` |
| **YouTube API Key** | Get it free from [Google Cloud Console](https://console.cloud.google.com/apis/credentials) |
| **MCP Client** | Any MCP-compatible AI: [Claude](https://claude.com/code), [Cursor](https://cursor.sh), [Cline](https://cline.so), [Windsurf](https://codeium.com/windsurf), [Continue.dev](https://continue.dev), etc. |
---
## Installation
### Install from PyPI (Recommended)
```bash
# Install pipx first (if not installed)
brew install pipx # macOS
# or: apt install pipx # Ubuntu/Debian
# Then install the package
pipx install youtube-connector-mcp
# Or with pip in a virtual environment
python3 -m venv .venv
source .venv/bin/activate
pip install youtube-connector-mcp
```
### Install from Source
```bash
git clone https://github.com/ShellyDeng08/youtube-connector-mcp.git
cd youtube-connector-mcp
python3 -m venv .venv
source .venv/bin/activate
pip install -e .
```
### Verify Installation
```bash
youtube-connector-mcp --help
claude mcp list # Check if server is registered
```
---
## Configuration
### Popular AI Coding Tools
| Tool | Platform | Config |
| ------------------ | ----------------- | ---------------------------- |
| **Claude Code** | CLI | `claude mcp add` |
| **Claude Desktop** | macOS/Windows | `claude_desktop_config.json` |
| **Cursor IDE** | Desktop | Settings UI |
| **Cline** | VS Code Extension | `.cline/config.yaml` |
> **Note:** Any MCP-compatible AI tool works! Just use the standard JSON config format below.
---
### Option 1: Using `claude mcp add` (Claude Code - Easiest)
```bash
# Install for current project only
claude mcp add youtube-connector-mcp youtube-connector-mcp -s local -e YOUTUBE_API_KEY="${YOUTUBE_API_KEY}"
# Install for all your projects (recommended)
claude mcp add youtube-connector-mcp youtube-connector-mcp -s user -e YOUTUBE_API_KEY="${YOUTUBE_API_KEY}"
# Install to project's .mcp.json
claude mcp add youtube-connector-mcp youtube-connector-mcp -s project -e YOUTUBE_API_KEY="${YOUTUBE_API_KEY}"
```
> **Don't have an API key?** See [Creating a YouTube API Key](#creating-a-youtube-api-key) below - it's free and takes just a few minutes.
---
### Option 2: Standard JSON Configuration
**适用于任何 MCP 兼容的 AI 工具**
```json
{
"mcpServers": {
"youtube-connector-mcp": {
"command": "youtube-connector-mcp",
"env": {
"YOUTUBE_API_KEY": "your_api_key_here"
}
}
}
}
```
**各工具配置文件位置:**
| Tool | Config File Path |
| --------------- | ------------------------------------------------------------------------- |
| Claude Code | `~/.claude/mcp_config.json` |
| Claude Desktop | `~/Library/Application Support/Claude/claude_desktop_config.json` (macOS) |
| Cursor IDE | Settings → MCP Servers (UI) |
| Cline (VS Code) | `.cline/config.yaml` |
---
### Option 3: Claude Desktop
1. Open Claude Desktop
2. Go to Settings → Developer → Edit Config
3. Or edit the config file directly:
**macOS:** `~/Library/Application Support/Claude/claude_desktop_config.json`
**Windows:** `%APPDATA%\Claude\claude_desktop_config.json`
```json
{
"mcpServers": {
"youtube-connector-mcp": {
"command": "youtube-connector-mcp",
"env": {
"YOUTUBE_API_KEY": "your_api_key_here"
}
}
}
}
```
### Option 4: Cursor IDE
1. Open Cursor Settings (Cmd/Ctrl + ,)
2. Go to **MCP Servers** section
3. Add a new server using the JSON format above
### Option 5: Cline (VS Code Extension)
Add to your `.cline/config.yaml`:
```yaml
mcpServers:
youtube-connector-mcp:
command: youtube-connector-mcp
env:
YOUTUBE_API_KEY: "your_api_key_here"
```
---
### API Key Setup
**Set as Environment Variable (Recommended):**
```bash
# Linux/Mac - Add to ~/.bashrc, ~/.zshrc, or ~/.profile
export YOUTUBE_API_KEY="your_api_key_here"
source ~/.zshrc
```
```powershell
# Windows PowerShell - Add to $PROFILE
$env:YOUTUBE_API_KEY="your_api_key_here"
# Or set permanently
[System.Environment]::SetEnvironmentVariable('YOUTUBE_API_KEY', 'your_api_key_here', 'User')
```
```cmd
# Windows CMD
setx YOUTUBE_API_KEY "your_api_key_here"
```
**Or Put Directly in MCP Config:**
```json
{
"mcpServers": {
"youtube-connector-mcp": {
"command": "youtube-connector-mcp",
"env": {
"YOUTUBE_API_KEY": "AIzaSyC-Your-Actual-API-Key-Here"
}
}
}
}
```
> **Security Note:** Using environment variables is safer as it keeps your key out of version control.
---
### Creating a YouTube API Key
1. Go to [Google Cloud Console](https://console.cloud.google.com/)
2. Create a new project or select an existing one
3. Enable [YouTube Data API v3](https://console.cloud.google.com/apis/library)
4. Go to [Credentials](https://console.cloud.google.com/apis/credentials) and create an API key
5. (Optional) Restrict the key to YouTube Data API v3 for better security
### Environment Variables
| Variable | Required | Default | Description |
| -------------------- | -------- | ------- | ----------------------- |
| `YOUTUBE_API_KEY` | Yes | - | YouTube Data API v3 key |
| `YOUTUBE_RATE_LIMIT` | No | 100 | Max requests per second |
---
## Features
### Core Capabilities
| Tool | Description |
| ------------------------ | ----------------------------------------------------------------------------- |
| `youtube_search` | Search videos, channels, playlists with filters (duration, date, type, order) |
| `youtube_get_video` | Get detailed video metadata, statistics, thumbnails, and content details |
| `youtube_get_channel` | Get channel info, subscriber count, upload playlists, statistics |
| `youtube_get_transcript` | Retrieve actual video transcript text with timestamps |
| `youtube_get_comments` | Fetch video comments with pagination support |
| `youtube_get_playlist` | Get playlist details and complete video list |
| `youtube_list_playlists` | List all playlists for a specific channel |
### Use Cases
- **Research**: Search and analyze YouTube content programmatically
- **Content Analysis**: Extract transcripts and comments for AI processing
- **Channel Monitoring**: Track channel statistics and new uploads
- **Data Mining**: Gather YouTube data for your projects
- **Automated Workflows**: Integrate YouTube data into AI-assisted workflows
---
## Usage Examples
| Category | Example Prompts |
| ------------ | --------------------------------------------------------------------------------------------------------- |
| **Search** | "Search for Python tutorials" / "Find recent AI videos" / "Channels about cooking with 100k+ subscribers" |
| **Video** | "Get details for this video: URL" / "What's the view count?" / "Get the transcript" |
| **Channel** | "How many subscribers does @MKBHD have?" / "Recent uploads from this channel" / "Channel statistics" |
| **Playlist** | "List all playlists for this channel" / "Get videos in this playlist" |
---
## Troubleshooting
### MCP Server Not Found
**Error:** `No MCP servers configured`
**Solutions:**
1. Verify `~/.claude/mcp_config.json` exists
2. Check JSON syntax is valid
3. Run `claude mcp list` to see registered servers
4. Restart Claude Code after updating config
### Python Not Found
**Error:** `command not found: python`
**Solutions:**
1. Use `python3` instead of `python`
2. Provide full path: `which python3` (Mac/Linux) or `where python` (Windows)
### Module Not Found
**Error:** `ModuleNotFoundError: No module named 'mcp'`
**Solutions:**
- **If using pipx**: `pipx reinstall youtube-connector-mcp`
- **If using pip in venv**: Activate virtual environment first `source .venv/bin/activate`
### API Quota Exceeded
**Error:** `403 Forbidden - quota exceeded`
**Solutions:**
1. Check [Google Cloud Console quota](https://console.cloud.google.com/apis/api/youtube.googleapis.com/quotas)
2. Default: 10,000 units/day
3. Consider upgrading for higher limits
### Transcript Not Available
**Error:** "No transcript available" or "Transcripts are disabled"
**Solutions:**
1. Video may not have captions enabled
2. Auto-generated captions may take 24+ hours after upload
3. Try a video known to have captions
### Transcript Request Blocked
**Error:** "YouTube is blocking requests from your IP"
**Solutions:**
See [youtube-transcript-api documentation](https://github.com/jdepoix/youtube-transcript-api?tab=readme-ov-file#working-around-ip-bans-requestblocked-or-ipblocked-exception) for proxy options.
---
## Development
### Setup
```bash
git clone https://github.com/ShellyDeng08/youtube-connector-mcp.git
cd youtube-connector-mcp
poetry install --with dev
```
### Run Tests
```bash
poetry run pytest
```
### Publishing to PyPI
```bash
# Bump version (PyPI doesn't allow re-uploading the same version)
poetry version patch # 0.3.0 → 0.3.1
poetry version minor # 0.3.0 → 0.4.0
poetry version major # 0.3.0 → 1.0.0
# Build and publish
poetry build
poetry publish
```
---
## License
MIT License - see [LICENSE](LICENSE) for details.
---
## Links
- [Official Website](https://youtube-connector-mcp-website.vercel.app/)
- [GitHub Repository](https://github.com/ShellyDeng08/youtube-connector-mcp)
- [PyPI Package](https://pypi.org/project/youtube-connector-mcp/)
- [YouTube Data API v3 Docs](https://developers.google.com/youtube/v3)
- [Claude Code](https://claude.com/code)
## SEO Keywords
YouTube MCP Server, YouTube MCP Connector, MCP YouTube API, Claude MCP YouTube, Cursor MCP YouTube, AI YouTube API, Model Context Protocol YouTube
| text/markdown | ShellyDeng08 | ShellyDeng08@users.noreply.github.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"google-api-python-client>=2.140.0",
"mcp>=1.0.0",
"pydantic>=2.0.0",
"youtube-transcript-api>=0.6.0"
] | [] | [] | [] | [
"Documentation, https://github.com/ShellyDeng08/youtube-connector-mcp/blob/main/README.md",
"Homepage, https://github.com/ShellyDeng08/youtube-connector-mcp",
"Repository, https://github.com/ShellyDeng08/youtube-connector-mcp",
"Website, https://youtube-connector-mcp-website.vercel.app/"
] | poetry/2.3.1 CPython/3.13.2 Darwin/24.6.0 | 2026-02-19T19:07:29.925807 | youtube_connector_mcp-0.3.1-py3-none-any.whl | 17,884 | 8a/9b/77c599676d8028c8e20715ec0663013ba4cd4d562ac80f9fa38d432172c0/youtube_connector_mcp-0.3.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 48d07c350f4ce347fdcdd4997a75edab | 443930825eca67787c41f70c1f2e6d112ababb5a854bdd695a814fc74e10bc2c | 8a9b77c599676d8028c8e20715ec0663013ba4cd4d562ac80f9fa38d432172c0 | null | [] | 227 |
2.4 | kagent-crewai | 0.7.17 | CrewAI integration for KAgent with A2A server support | # KAgent CrewAI Integration
This package provides CrewAI integration for KAgent with A2A (Agent-to-Agent) server support and session-aware memory storage.
## Features
- **A2A Server Integration**: Compatible with KAgent's Agent-to-Agent protocol
- **Event Streaming**: Real-time streaming of crew execution events
- **FastAPI Integration**: Ready-to-deploy web server for agent execution
- **Session-aware Memory**: Store and retrieve agent memories scoped by session ID
- **Flow State Persistence**: Save and restore CrewAI Flow states to KAgent backend
## Quick Start
This package supports both CrewAI Crews and Flows. To get started, define your CrewAI crew or flow as you normally would, then replace the `kickoff` command with the `KAgentApp` which will handle A2A requests and execution.
```python
from kagent.crewai import KAgentApp
# This is the crew or flow you defined
from research_crew.crew import ResearchCrew
app = KAgentApp(crew=ResearchCrew().crew(), agent_card={
"name": "my-crewai-agent",
"description": "A CrewAI agent with KAgent integration",
"version": "0.1.0",
"capabilities": {"streaming": True},
"defaultInputModes": ["text"],
"defaultOutputModes": ["text"]
})
fastapi_app = app.build()
uvicorn.run(fastapi_app, host="0.0.0.0", port=8080)
```
## User Guide
### Creating Tasks
For this version, tasks should either accept a single `input` parameter (string) or no parameters at all. Future versions will allow JSON / structured input where you can replace multiple values in your task to make it more flexible.
For example, you can create a task like follow with yaml (see CrewAI docs) and when triggered from the A2A client, the `input` field will be populated with the input text if provided.
```yaml
research_task:
description: >
Research topics on {input} and provide a summary.
```
This is equivalent of `crew.kickoff(inputs={"input": "your input text"})` when triggering agents manually.
### Session-aware Memory
#### CrewAI Crews
Session scoped memory is implemented using the `LongTermMemory` interface in CrewAI. If you wish to share memories between agents, you must interact with them in the same session to share long term memory so they can search and access the previous conversation history (because agent ID is volatile, we must use session ID). You can enable this by setting `memory=True` when creating your CrewAI crew. Note that this memory is also scoped by user ID so different users will not see each other's memories.
Our KAgent backend is designed to handle long term memory saving and retrieval with the identical logic as `LTMSQLiteStorage` which is used by default for `LongTermMemory` in CrewAI, with the addition of session and user scoping. It will search the LTM items based on the task description and return the most relevant items (sorted and limited).
> Note that when you set `memory=True`, you are responsible to ensure that short term and entity memory are configured properly (e.g. with `OPENAI_API_KEY` or set your own providers). The KAgent CrewAI integration only handles long term memory.
#### CrewAI Flows
In flow mode, we implement memory similar to checkpointing in LangGraph so that the flow state is persisted to the KAgent backend after each method finishes execution. We consider each session to be a single flow execution, so you can reuse state within the same session by enabling `@persist()` for flow or methods. We do not manage `LongTermMemory` for crews inside a flow since flow is designed to be very customizable. You are responsible for implementing your own memory management for all the crew you use in the flow.
### Tracing
To enable tracing, follow [this guide](https://kagent.dev/docs/kagent/getting-started/tracing#installing-kagent) on Kagent docs. Once you have Jaeger (or any OTLP-compatible backend) running and the kagent settings updated, your CrewAI agent will automatically send traces to the configured backend.
## Architecture
The package mirrors the structure of `kagent-adk` and `kagent-langgraph` but uses CrewAI for multi-agent orchestration:
- **CrewAIAgentExecutor**: Executes CrewAI workflows within A2A protocol
- **KAgentApp**: FastAPI application builder with A2A integration
- **Event Converters**: Translates CrewAI events into A2A events for streaming.
- **Session-aware Memory**: Custom persistence backend scoped by session ID and user ID, works with Crew and Flow mode by leveraging memory and state persistence.
## Deployment
The uses the same deployment approach as other KAgent A2A applications (ADK / LangGraph). You can refer to `samples/crewai/` for examples.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"a2a-sdk[http-server]>=0.3.23",
"crewai[tools]>=1.2.0",
"fastapi>=0.100.0",
"google-genai>=1.21.1",
"httpx>=0.25.0",
"kagent-core",
"opentelemetry-instrumentation-crewai>=0.47.3",
"pydantic>=2.0.0",
"typing-extensions>=4.0.0",
"uvicorn>=0.20.0",
"black>=23.0.0; extra == \"dev\"",
"pytest-async... | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T19:07:16.971204 | kagent_crewai-0.7.17-py3-none-any.whl | 10,582 | dc/31/d1d7c4186303ccde6e728124feba694250835f6d3acec7b8822416f9d13e/kagent_crewai-0.7.17-py3-none-any.whl | py3 | bdist_wheel | null | false | c9550bc8e1b78d3d710e812ff876ca03 | 783e130a65e6414f2bd118b11fbd7347af6b42ee8ffc28bfaec1d12cf9c6bca0 | dc31d1d7c4186303ccde6e728124feba694250835f6d3acec7b8822416f9d13e | null | [] | 214 |
2.4 | kagent-openai | 0.7.17 | OpenAI integration for KAgent with A2A server support | # KAgent OpenAI Agents SDK Integration
OpenAI Agents SDK integration for KAgent with A2A (Agent-to-Agent) protocol support, session management, and optional skills integration.
---
## Quick Start
```python
from kagent.openai import KAgentApp
from agents.agent import Agent
# Create your OpenAI agent
agent = Agent(
name="Assistant",
instructions="You are a helpful assistant.",
tools=[my_tool], # Optional
)
# Create KAgent app
app = KAgentApp(
agent=agent,
agent_card={
"name": "my-openai-agent",
"description": "My OpenAI agent",
"version": "0.1.0",
"capabilities": {"streaming": True},
"defaultInputModes": ["text"],
"defaultOutputModes": ["text"]
},
kagent_url="http://localhost:8080",
app_name="my-agent"
)
# Run
fastapi_app = app.build()
# uvicorn run_me:fastapi_app
```
---
## Agent with Skills
Skills provide domain expertise through filesystem-based instruction files and helper tools (read/write/edit files, bash execution). We provide a function to load all skill-related tools. Otherwise, you can select the ones you need by importing from `kagent.openai.tools`.
```python
from agents.agent import Agent
from kagent.openai import get_skill_tools
tools = [my_custom_tool]
tools.extend(get_skill_tools("./skills"))
agent = Agent(
name="SkillfulAgent",
instructions="Use skills and tools when appropriate.",
tools=tools,
)
```
See [skills README](../../kagent-skills/README.md) for skill format and structure.
---
## Session Management
Sessions persist conversation history in KAgent backend:
```python
from agents.agent import Agent
from agents.run import Runner
from kagent.openai.agent._session_service import KAgentSession
import httpx
client = httpx.AsyncClient(base_url="http://localhost:8080")
session = KAgentSession(
session_id="conversation_123",
client=client,
app_name="my-agent",
)
agent = Agent(name="Assistant", instructions="Be helpful")
result = await Runner.run(agent, "Hello!", session=session)
```
---
## Local Development
Test without KAgent backend using in-memory mode:
```python
app = KAgentApp(
agent=agent,
agent_card=agent_card,
kagent_url="http://localhost:8080",
app_name="test-agent"
)
fastapi_app = app.build_local() # In-memory, no persistence
```
---
## Deployment
Standard Docker deployment:
```dockerfile
FROM python:3.13-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY agent.py .
CMD ["uvicorn", "agent:fastapi_app", "--host", "0.0.0.0", "--port", "8000"]
```
Set `KAGENT_URL` environment variable to connect to KAgent backend.
---
## Architecture
| Component | Purpose |
| ----------------------- | -------------------------------------------- |
| **KAgentApp** | FastAPI application builder with A2A support |
| **KAgentSession** | Session persistence via KAgent REST API |
| **OpenAIAgentExecutor** | Executes agents with event streaming |
---
## Environment Variables
- `KAGENT_URL` - KAgent backend URL (default: http://localhost:8080)
- `LOG_LEVEL` - Logging level (default: INFO)
---
## Examples
See `samples/openai/` for complete examples:
- `basic_agent/` - Simple agent with custom tools
- More examples coming soon
---
## See Also
- [OpenAI Agents SDK Docs](https://github.com/openai/agents)
- [KAgent Skills](../../kagent-skills/README.md)
- [A2A Protocol](https://docs.kagent.ai/a2a)
---
## License
See repository LICENSE file.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"openai>=1.72.0",
"openai-agents>=0.4.0",
"a2a-sdk>=0.3.23",
"kagent-core",
"kagent-skills",
"httpx>=0.25.0",
"fastapi>=0.100.0",
"uvicorn>=0.20.0",
"pydantic>=2.0.0",
"opentelemetry-instrumentation-openai-agents>=0.48.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"... | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T19:07:15.568404 | kagent_openai-0.7.17.tar.gz | 15,246 | c3/eb/423e0d76bd6c98267f5a4f442e91e315457e2d2dbf991f815b3a9e12c60c/kagent_openai-0.7.17.tar.gz | source | sdist | null | false | 65507722ade9389f90ea7bdae11febab | 177bddff697ac33b37f0ca8baf16089067f9f381889dfe471de37277b0debace | c3eb423e0d76bd6c98267f5a4f442e91e315457e2d2dbf991f815b3a9e12c60c | null | [] | 215 |
2.4 | kagent-langgraph | 0.7.17 | LangGraph integration for KAgent with A2A server support | # KAgent LangGraph Integration
This package provides LangGraph integration for KAgent with A2A (Agent-to-Agent) server support. It implements a custom checkpointer that persists LangGraph state to the KAgent REST API, enabling distributed agent execution with session persistence.
## Features
- **Custom Checkpointer**: Persists LangGraph checkpoints to KAgent via REST API
- **A2A Server Integration**: Compatible with KAgent's Agent-to-Agent protocol
- **Session Management**: Automatic session creation and state persistence
- **Event Streaming**: Real-time streaming of graph execution events
- **FastAPI Integration**: Ready-to-deploy web server for agent execution
## Quick Start
```python
from kagent_langgraph import KAgentApp
from langgraph.graph import StateGraph
from langchain_core.messages import BaseMessage
from typing import TypedDict, Annotated, Sequence
class State(TypedDict):
messages: Annotated[Sequence[BaseMessage], "The conversation history"]
# Define your graph
builder = StateGraph(State)
# Add nodes and edges...
# Create KAgent app
app = KAgentApp(
graph_builder=builder,
agent_card={
"name": "my-langgraph-agent",
"description": "A LangGraph agent with KAgent integration",
"version": "0.1.0",
"capabilities": {"streaming": True},
"defaultInputModes": ["text"],
"defaultOutputModes": ["text"]
},
kagent_url="http://localhost:8080",
app_name="my-agent"
)
# Build FastAPI application
fastapi_app = app.build()
```
## Architecture
The package mirrors the structure of `kagent-adk` but uses LangGraph instead of Google's ADK:
- **KAgentCheckpointer**: Custom checkpointer that stores graph state in KAgent sessions
- **LangGraphAgentExecutor**: Executes LangGraph workflows within A2A protocol
- **KAgentApp**: FastAPI application builder with A2A integration
- **Session Management**: Automatic session lifecycle management via KAgent REST API
## Configuration
The system uses the same REST API endpoints as the ADK integration:
- `POST /api/sessions` - Create new sessions
- `GET /api/sessions/{id}` - Retrieve session and events
- `POST /api/sessions/{id}/events` - Append checkpoint events
- `POST /api/tasks` - Task management
## Deployment
Use the same deployment pattern as kagent-adk samples with Docker and Kubernetes.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"langgraph>=0.6.5",
"langchain-core>=0.3.0",
"httpx>=0.25.0",
"fastapi>=0.100.0",
"pydantic>=2.0.0",
"typing-extensions>=4.0.0",
"uvicorn>=0.20.0",
"a2a-sdk>=0.3.23",
"kagent-core",
"langsmith[otel]>=0.4.30",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"bla... | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T19:07:14.061199 | kagent_langgraph-0.7.17-py3-none-any.whl | 15,563 | 71/ff/b3229ed265e973c9f0ac1ba02e5b0e6d82fb440453fa833df296098700cf/kagent_langgraph-0.7.17-py3-none-any.whl | py3 | bdist_wheel | null | false | a6b5e867a22fdb315aa55de782af4e19 | 13cb257511746ab46edb9d96e12a51947e335bd564f3410c7e5c3a9f7a7b9f99 | 71ffb3229ed265e973c9f0ac1ba02e5b0e6d82fb440453fa833df296098700cf | null | [] | 221 |
2.4 | kagent-skills | 0.7.17 | Core library for discovering and loading KAgent skills. | # KAgent Skills
Core library for discovering, parsing, and loading KAgent skills from the filesystem.
For example usage, see `kagent-adk` and `kagent-openai` packages.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"pydantic>=2.0.0",
"pyyaml>=6.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T19:07:11.214304 | kagent_skills-0.7.17-py3-none-any.whl | 10,513 | 08/41/90864b8df7cc76fae955d7a1466815895fd00ebe55ea1606329b57818bb8/kagent_skills-0.7.17-py3-none-any.whl | py3 | bdist_wheel | null | false | 8622511c1e9d94047600f20986dbfac4 | ecf6501bb16f42aa5db9076d2053e7b9cd92e7416729ce643621bd7d1ae3fe26 | 084190864b8df7cc76fae955d7a1466815895fd00ebe55ea1606329b57818bb8 | null | [] | 232 |
2.4 | assemblyline-core | 4.7.1.2 | Assemblyline 4 - Core components | [](https://discord.gg/GUAy9wErNu)
[](https://discord.gg/GUAy9wErNu)
[](https://github.com/CybercentreCanada/assemblyline)
[](https://github.com/CybercentreCanada/assemblyline-core)
[](https://github.com/CybercentreCanada/assemblyline/issues?q=is:issue+is:open+label:core)
[](./LICENSE.md)
# Assemblyline 4 - Core
This repository provides cores services for Assemblyline 4.
## Image variants and tags
| **Tag Type** | **Description** | **Example Tag** |
| :----------: | :----------------------------------------------------------------------------------------------- | :------------------------: |
| latest | The most recent build (can be unstable). | `latest` |
| build_type | The type of build used. `dev` is the latest unstable build. `stable` is the latest stable build. | `stable` or `dev` |
| series | Complete build details, including version and build type: `version.buildType`. | `4.5.stable`, `4.5.1.dev3` |
## Components
### Alerter
Create alerts for the different submissions in the system.
```bash
docker run --name alerter cccs/assemblyline-core python -m assemblyline_core.alerter.run_alerter
```
### Archiver
Archives submissions and their results & files into the archive.
```bash
docker run --name archiver cccs/assemblyline-core python -m assemblyline_core.archiver.run_archiver
```
### Dispatcher
Route the files in the system while a submission is tacking place. Make sure all files during a submission are completed by all required services.
```bash
docker run --name dispatcher cccs/assemblyline-core python -m assemblyline_core.dispatching
```
### Expiry
Delete submissions and their results when their time-to-live expires.
```bash
docker run --name expiry cccs/assemblyline-core python -m assemblyline_core.expiry.run_expiry
```
### Ingester
Move ingested files from the priority queues to the processing queues.
```bash
docker run --name ingester cccs/assemblyline-core python -m assemblyline_core.ingester
```
### Metrics
Generates metrics of the different components in the system.
#### Heartbeat Manager
```bash
docker run --name heartbeat cccs/assemblyline-core python -m assemblyline_core.metrics.run_heartbeat_manager
```
#### Metrics Aggregator
```bash
docker run --name metrics cccs/assemblyline-core python -m assemblyline_core.metrics.run_metrics_aggregator
```
#### Statistics Aggregator
```bash
docker run --name statistics cccs/assemblyline-core python -m assemblyline_core.metrics.run_statistics_aggregator
```
### Scaler
Spin up and down services in the system depending on the load.
```bash
docker run --name scaler cccs/assemblyline-core python -m assemblyline_core.scaler.run_scaler
```
### Updater
Make sure the different services get their latest update files.
```bash
docker run --name updater cccs/assemblyline-core python -m assemblyline_core.updater.run_updater
```
### Workflow
Run the different workflows in the system and apply their labels, priority and status.
```bash
docker run --name workflow cccs/assemblyline-core python -m assemblyline_core.workflow.run_workflow
```
## Documentation
For more information about these Assemblyline components, follow this [overview](https://cybercentrecanada.github.io/assemblyline4_docs/overview/architecture/) of the system's architecture.
---
# Assemblyline 4 - Core
Ce dépôt fournit des services de base pour Assemblyline 4.
## Variantes et étiquettes d'image
| **Type d'étiquette** | **Description** | **Exemple d'étiquette** |
| :------------------: | :--------------------------------------------------------------------------------------------------------------- | :------------------------: |
| dernière | La version la plus récente (peut être instable). | `latest` |
| build_type | Le type de compilation utilisé. `dev` est la dernière version instable. `stable` est la dernière version stable. | `stable` ou `dev` |
| séries | Le détail de compilation utilisé, incluant la version et le type de compilation : `version.buildType`. | `4.5.stable`, `4.5.1.dev3` |
## Composants
### Alerter
Crée des alertes pour les différentes soumissions dans le système.
```bash
docker run --name alerter cccs/assemblyline-core python -m assemblyline_core.alerter.run_alerter
```
### Archiver
Archivage des soumissions, de leurs résultats et des fichiers dans l'archive.
```bash
docker run --name archiver cccs/assemblyline-core python -m assemblyline_core.archiver.run_archiver
```
### Dispatcher
Achemine les fichiers dans le système durant une soumission. S'assure que tous les fichiers de la soumission courante soient complétés par tous les services requis.
```bash
docker run --name dispatcher cccs/assemblyline-core python -m assemblyline_core.dispatching
```
### Expiration
Supprimer les soumissions et leurs résultats à l'expiration de leur durée de vie.
```bash
docker run --name expiry cccs/assemblyline-core python -m assemblyline_core.expiry.run_expiry
```
### Ingester
Déplace les fichiers ingérés des files d'attente prioritaires vers les files d'attente de traitement.
```bash
docker run --name ingester cccs/assemblyline-core python -m assemblyline_core.ingester
```
### Métriques
Génère des métriques des différents composants du système.
#### Heartbeat Manager
```bash
docker run --name heartbeat cccs/assemblyline-core python -m assemblyline_core.metrics.run_heartbeat_manager
```
#### Agrégateur de métriques
```bash
docker run --name metrics cccs/assemblyline-core python -m assemblyline_core.metrics.run_metrics_aggregator
```
##### Agrégateur de statistiques
```bash
docker run --name statistics cccs/assemblyline-core python -m assemblyline_core.metrics.run_statistics_aggregator
```
### Scaler
Augmente et diminue les services dans le système en fonction de la charge.
```bash
docker run --name scaler cccs/assemblyline-core python -m assemblyline_core.scaler.run_scaler
```
### Mise à jour
Assure que les différents services reçoivent leurs derniers fichiers de mise à jour.
```bash
docker run --name updater cccs/assemblyline-core python -m assemblyline_core.updater.run_updater
```
### Workflow
Exécute les différents flux de travail dans le système et appliquer leurs étiquettes, leur priorité et leur statut.
```bash
docker run --name workflow cccs/assemblyline-core python -m assemblyline_core.workflow.run_workflow
```
## Documentation
Pour plus d'informations sur ces composants Assemblyline, suivez ce [overview](https://cybercentrecanada.github.io/assemblyline4_docs/overview/architecture/) de l'architecture du système.
| text/markdown | CCCS Assemblyline development team | assemblyline@cyber.gc.ca | null | null | MIT | assemblyline automated malware analysis gc canada cse-cst cse cst cyber cccs | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programm... | [] | https://github.com/CybercentreCanada/assemblyline-core/ | null | null | [] | [] | [] | [
"assemblyline",
"docker",
"kubernetes",
"pytest; extra == \"test\"",
"assemblyline_client; extra == \"test\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T19:06:50.868258 | assemblyline_core-4.7.1.2.tar.gz | 144,042 | 09/9f/4e8a796e812cad60b43e591ad69d945c93ebac1957af5f74ca97ddb5ee06/assemblyline_core-4.7.1.2.tar.gz | source | sdist | null | false | e8f6245a2d208de5d340850cf587f4fa | fe2708775a459f9e93d75c21423a78eef1da5bd5da0d947653b2b278ae7b7244 | 099f4e8a796e812cad60b43e591ad69d945c93ebac1957af5f74ca97ddb5ee06 | null | [
"LICENCE.md"
] | 270 |
2.4 | assemblyline | 4.7.1.2 | Assemblyline 4 - Automated malware analysis framework | [](https://discord.gg/GUAy9wErNu)
[](https://discord.gg/GUAy9wErNu)
[](https://github.com/CybercentreCanada/assemblyline)
[](https://github.com/CybercentreCanada/assemblyline-base)
[](https://github.com/CybercentreCanada/assemblyline/issues?q=is:issue+is:open+label:base)
[](./LICENCE.md)
# Assemblyline 4 - Base Package
This repository provides Assemblyline with common libraries, cachestore, datastore, filestore, ODM and remote datatypes.
## Image variants and tags
| **Tag Type** | **Description** | **Example Tag** |
| :----------: | :----------------------------------------------------------------------------------------------- | :------------------------: |
| latest | The most recent build (can be unstable). | `latest` |
| build_type | The type of build used. `dev` is the latest unstable build. `stable` is the latest stable build. | `stable` or `dev` |
| series | Complete build details, including version and build type: `version.buildType`. | `4.5.stable`, `4.5.1.dev3` |
## System requirements
Assemblyline 4 will only work on systems running Python 3.11 and was only officially tested on Linux systems by the Assemblyline team.
## Installation requirements
The following Linux libraries are required for this library:
- libffi8 (dev)
- libfuxxy2 (dev)
- libmagic1
- python3.11 (dev)
Here is an example on how you would get those libraries on a `Ubuntu 20.04+` system:
```bash
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt install libffi8 libfuzzy2 libmagic1 build-essential libffi-dev python3.11 python3.11-dev python3-pip libfuzzy-dev
```
**Note:** Installation of the libraries are not required if using the `cccs/assemblyline` container image
## Documentation
For more information about these Assemblyline components, follow this [overview](https://cybercentrecanada.github.io/assemblyline4_docs/overview/architecture/) of the system's architecture.
# Assemblage 4 - Paquet de base
Ce dépôt fournit à Assemblyline les bibliothèques communes, le cachestore, le datastore, le filestore, l'ODM et les types de données à distance.
## Variantes et étiquettes d'image
| **Type d'étiquette** | **Description** | **Exemple d'étiquette** |
| :------------------: | :--------------------------------------------------------------------------------------------------------------- | :------------------------: |
| dernière | La version la plus récente (peut être instable). | `latest` |
| build_type | Le type de compilation utilisé. `dev` est la dernière version instable. `stable` est la dernière version stable. | `stable` ou `dev` |
| séries | Le détail de compilation utilisé, incluant la version et le type de compilation : `version.buildType`. | `4.5.stable`, `4.5.1.dev3` |
## Système requis
Assemblyline 4 ne fonctionnera que sur des systèmes utilisant Python 3.11 et n'a été officiellement testé que sur des systèmes Linux par l'équipe Assemblyline.
## Configuration requise pour l'installation
Les bibliothèques Linux suivantes sont requises pour cette bibliothèque :
- libffi8 (dev)
- libfuxxy2 (dev)
- libmagic1
- python3.11 (dev)
Voici un exemple de la manière dont vous obtiendrez ces bibliothèques sur un système `Ubuntu 20.04+` :
```bash
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt install libffi8 libfuzzy2 libmagic1 build-essential libffi-dev python3.11 python3.11-dev python3-pip libfuzzy-dev
```
**Note:** L'installation des bibliothèques n'est pas nécessaire si vous utilisez l'image conteneur `cccs/assemblyline`.
## Documentation
Pour plus d'informations sur ces composants Assemblyline, suivez ce [overview](https://cybercentrecanada.github.io/assemblyline4_docs/overview/architecture/) de l'architecture du système.
| text/markdown | CCCS Assemblyline development team | assemblyline@cyber.gc.ca | null | null | MIT | assemblyline automated malware analysis gc canada cse-cst cse cst cyber cccs | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Progr... | [] | https://github.com/CybercentreCanada/assemblyline-base | null | null | [] | [] | [] | [
"arrow",
"aiohttp",
"lark",
"urllib3>=2.6.0",
"python-baseconv",
"boto3",
"pysftp",
"netifaces",
"pyroute2.core",
"redis",
"requests[socks]",
"elasticsearch<9.0.0,>=8.0.0",
"python-datemath!=3.0.2",
"packaging",
"tabulate",
"PyYAML",
"easydict",
"bcrypt",
"cart",
"cccs-ssdeep",... | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T19:06:48.533469 | assemblyline-4.7.1.2.tar.gz | 784,431 | bc/2f/a8ed1cb6b577a917669ec53ad9f19d3323c1e1e6c5af5ac2c7b1a7ecb8e6/assemblyline-4.7.1.2.tar.gz | source | sdist | null | false | d9edadb9a3d247acf33e8272a0c80f6a | 640c392b04a0beb62d44c02b17e8c2b5981229c5cb714a21a96f4fc201c56e4b | bc2fa8ed1cb6b577a917669ec53ad9f19d3323c1e1e6c5af5ac2c7b1a7ecb8e6 | null | [
"LICENCE.md"
] | 296 |
2.4 | assemblyline-v4-service | 4.7.1.2 | Assemblyline 4 - Service base | [](https://discord.gg/GUAy9wErNu)
[](https://discord.gg/GUAy9wErNu)
[](https://github.com/CybercentreCanada/assemblyline)
[](https://github.com/CybercentreCanada/assemblyline-v4-service)
[](https://github.com/CybercentreCanada/assemblyline/issues?q=is:issue+is:open+label:service-base)
[](./LICENCE.md)
# Assemblyline 4 - Service Base
This repository provides the base service functionality for Assemblyline 4 services.
## Image variants and tags
| **Tag Type** | **Description** | **Example Tag** |
| :----------: | :----------------------------------------------------------------------------------------------- | :------------------------: |
| latest | The most recent build (can be unstable). | `latest` |
| build_type | The type of build used. `dev` is the latest unstable build. `stable` is the latest stable build. | `stable` or `dev` |
| series | Complete build details, including version and build type: `version.buildType`. | `4.5.stable`, `4.5.1.dev3` |
## Creating a new Assemblyline service
You can create a new Assemblyline service by using this [template](https://github.com/CybercentreCanada/assemblyline-service-template):
```bash
apt install jq
pip install git+https://github.com/CybercentreCanada/assemblyline-service-template.git
cruft create https://github.com/CybercentreCanada/assemblyline-service-template.git
```
## Documentation
For more information about service development for Assemblyline, follow this [guide](https://cybercentrecanada.github.io/assemblyline4_docs/developer_manual/services/developing_an_assemblyline_service/).
---
# Assemblyline 4 - Service Base
Ce référentiel fournit les fonctionnalités de base des services Assemblyline 4.
## Créer un nouveau service Assemblyline
Vous pouvez créer un nouveau service Assemblyline en utilisant ce [template](https://github.com/CybercentreCanada/assemblyline-service-template).
```bash
apt install jq
pip install git+https://github.com/CybercentreCanada/assemblyline-service-template.git
cruft create https://github.com/CybercentreCanada/assemblyline-service-template.git
```
## Variantes et étiquettes d'image
| **Type d'étiquette** | **Description** | **Exemple d'étiquette** |
| :------------------: | :--------------------------------------------------------------------------------------------------------------- | :------------------------: |
| dernière | La version la plus récente (peut être instable). | `latest` |
| build_type | Le type de compilation utilisé. `dev` est la dernière version instable. `stable` est la dernière version stable. | `stable` or `dev` |
| séries | Le détail de compilation utilisé, incluant la version et le type de compilation : `version.buildType`. | `4.5.stable`, `4.5.1.dev3` |
## Documentation
Pour plus d'informations sur le développement des services pour Assemblyline, suivez ce [guide](https://cybercentrecanada.github.io/assemblyline4_docs/developer_manual/services/developing_an_assemblyline_service/).
| text/markdown | CCCS Assemblyline development team | assemblyline@cyber.gc.ca | null | null | MIT | assemblyline automated malware analysis gc canada cse-cst cse cst cyber cccs | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programm... | [] | https://github.com/CybercentreCanada/assemblyline-v4-service/ | null | null | [] | [] | [] | [
"assemblyline",
"assemblyline-core",
"cart",
"fuzzywuzzy",
"pefile",
"pillow!=10.1.0,!=10.2.0",
"python-Levenshtein",
"regex",
"gunicorn[gevent]; extra == \"updater\"",
"flask; extra == \"updater\"",
"gitpython; extra == \"updater\"",
"git-remote-codecommit; extra == \"updater\"",
"psutil; e... | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T19:06:46.582540 | assemblyline_v4_service-4.7.1.2-py3-none-any.whl | 88,896 | fc/35/a3c8fc4eda48f4b32370973d073d7f2da3862650a59378cfd0b6746095fd/assemblyline_v4_service-4.7.1.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 53cf387eb2113e4e2e08c01c47ec2dc1 | 58c84864a99d9822574bcbda496e31617d915fb8d43f5e7ffde440911140ad7f | fc35a3c8fc4eda48f4b32370973d073d7f2da3862650a59378cfd0b6746095fd | null | [
"LICENCE.md"
] | 143 |
2.4 | assemblyline-ui | 4.7.1.2 | Assemblyline 4 - API and Socket IO server | [](https://discord.gg/GUAy9wErNu)
[](https://discord.gg/GUAy9wErNu)
[](https://github.com/CybercentreCanada/assemblyline)
[](https://github.com/CybercentreCanada/assemblyline-ui)
[](https://github.com/CybercentreCanada/assemblyline/issues?q=is:issue+is:open+label:ui)
[](./LICENCE.md)
# Assemblyline 4 - API and Socket IO server
This component provides the User Interface as well as the different APIs and socketio endpoints for the Assemblyline 4 framework.
## Image variants and tags
| **Tag Type** | **Description** | **Example Tag** |
| :----------: | :----------------------------------------------------------------------------------------------- | :------------------------: |
| latest | The most recent build (can be unstable). | `latest` |
| build_type | The type of build used. `dev` is the latest unstable build. `stable` is the latest stable build. | `stable` or `dev` |
| series | Complete build details, including version and build type: `version.buildType`. | `4.5.stable`, `4.5.1.dev3` |
## Components
### APIs
Assemblyline 4 provides a large set of API that can provide you with all the same information you will find in it's UI and even more. The list of APIs and their functionality is described in the help section of the UI.
All APIs in Assemblyline output their result in the same manner for consistency:
```json
{
"api_response": {}, //Actual response from the API
"api_error_message": "", //Error message if it is an error response
"api_server_version": "4.0.0", //Assemblyline version and version of the different component
"api_status_code": 200 //Status code of the response
}
```
**NOTE**: All response codes return this output layout
#### Running this component
```bash
docker run --name ui cccs/assemblyline-service-ui
```
### SocketIO endpoints
Assemblyline 4 also provide a list of SocketIO endpoints to get information about the system live. The endpoints will provide authenticated access to many Redis broadcast queues. It is a way for the system to notify user of changes and health of the system without having them to query for that information.
The following queues can be listen on:
- Alerts created
- Submissions ingested
- Health of the system
- State of a given running submission
#### Running this component
```bash
docker run --name socketio cccs/assemblyline-service-socketio
```
## Documentation
For more information about this Assemblyline component, follow this [overview](https://cybercentrecanada.github.io/assemblyline4_docs/overview/architecture/) of the system's architecture.
---
# Assemblyline 4 - API et serveur Socket IO
Ce composant fournit l'interface utilisateur ainsi que les différentes API et les points de terminaison Socket IO pour le framework Assemblyline 4.
## Variantes et étiquettes d'image
| **Type d'étiquette** | **Description** | **Exemple d'étiquette** |
| :------------------: | :--------------------------------------------------------------------------------------------------------------------------------- | :------------------------: |
| dernière | La version la plus récente (peut être instable). | `latest` |
| build_type | Le type de compilation utilisé. `dev` est la dernière version instable. `stable` est la dernière version stable. `stable` ou `dev` | `stable` ou `dev` |
| séries | Le détail de compilation utilisé, incluant la version et le type de compilation : `version.buildType`. | `4.5.stable`, `4.5.1.dev3` |
## Composants
### APIs
Assemblyline 4 fournit un grand nombre d'API qui peuvent vous fournir toutes les informations que vous trouverez dans l'interface utilisateur et même plus. La liste des API et de leurs fonctionnalités est décrite dans la section d'aide de l'interface utilisateur.
Pour des raisons de cohérence, toutes les API d'Assemblyline produisent leurs résultats de la même manière :
```json
{
"api_response": {}, //Réponse réelle de l'API
"api_error_message": "", //Message d'erreur s'il s'agit d'une réponse d'erreur
"api_server_version": "4.0.0", //Assemblyline version et version des différents composants
"api_status_code": 200 //Code d'état de la réponse
}
```
**NOTE** : Tous les codes de réponse renvoient cette présentation de sortie
#### Exécuter ce composant
```bash
docker run --name ui cccs/assemblyline-service-ui
```
### Points d'extrémité SocketIO
Assemblyline 4 fournit également une liste de points de contact SocketIO pour obtenir des informations sur le système en direct. Ces points de contact fournissent un accès authentifié à de nombreuses files d'attente de diffusion Redis. C'est un moyen utilisé par le système pour informer les utilisateurs des changements et de l'état du système sans qu'ils aient à faire des requêtes d'informations.
Les files d'attente suivantes peuvent être écoutées :
- Alertes créées
- Soumissions reçues
- Santé du système
- État d'une soumission en cours
#### Exécuter ce composant
```bash
docker run --name socketio cccs/assemblyline-service-socketio
```
## Documentation
Pour plus d'informations sur ce composant Assemblyline, suivez ce [overview](https://cybercentrecanada.github.io/assemblyline4_docs/overview/architecture/) de l'architecture du système.
| text/markdown | CCCS Assemblyline development team | assemblyline@cyber.gc.ca | null | null | MIT | assemblyline automated malware analysis gc canada cse-cst cse cst cyber cccs | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programm... | [] | https://github.com/CybercentreCanada/assemblyline-ui/ | null | null | [] | [] | [] | [
"assemblyline",
"assemblyline-core",
"werkzeug",
"flask<3.0.0",
"pyqrcode",
"markdown",
"python-ldap",
"python3-saml",
"Authlib>=1.3.1",
"fido2<1.0.0",
"PyJWT",
"gunicorn==24.1.1",
"gevent",
"xmlsec==1.3.14",
"lxml==5.3.2",
"pytest; extra == \"test\"",
"pytest-mock; extra == \"test\"... | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T19:06:43.611080 | assemblyline_ui-4.7.1.2-py3-none-any.whl | 200,610 | 70/f3/af57cb9e092e090c49fa53aadb57528aee6c45499b1e360c533c15bb8838/assemblyline_ui-4.7.1.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 4a1efc3e3fbccf9b51998943c1a7c96f | 8256f98453de5f09cbd066ff5269893ebf3370e61e6ba6e505fb8ec4b1c55d49 | 70f3af57cb9e092e090c49fa53aadb57528aee6c45499b1e360c533c15bb8838 | null | [
"LICENCE.md"
] | 119 |
2.4 | assemblyline-service-server | 4.7.1.2 | Assemblyline 4 - Service Server | [](https://discord.gg/GUAy9wErNu)
[](https://discord.gg/GUAy9wErNu)
[](https://github.com/CybercentreCanada/assemblyline)
[](https://github.com/CybercentreCanada/assemblyline-service-server)
[](https://github.com/CybercentreCanada/assemblyline/issues?q=is:issue+is:open+label:service-server)
[](./LICENCE.md)
# Assemblyline 4 - Service Server
The service server is a API that the service clients can call to interface with the system. This is the only access the services have to the system as they are completely segregated from the other components.
## Image variants and tags
| **Tag Type** | **Description** | **Example Tag** |
| :----------: | :----------------------------------------------------------------------------------------------- | :------------------------: |
| latest | The most recent build (can be unstable). | `latest` |
| build_type | The type of build used. `dev` is the latest unstable build. `stable` is the latest stable build. | `stable` or `dev` |
| series | Complete build details, including version and build type: `version.buildType`. | `4.5.stable`, `4.5.1.dev3` |
## API functionality
Service server provides the following functions via API to the client:
- File download and upload
- Register service to the system
- Get a new task
- Publish results for a task
- Checking if certain tags or files have a reputation relative to the system (ie. safe vs malicious)
#### Running this component
```bash
docker run --name service-server cccs/assemblyline-service-server
```
## Documentation
For more information about this Assemblyline component, follow this [overview](https://cybercentrecanada.github.io/assemblyline4_docs/overview/architecture/) of the system's architecture.
---
# Assemblyline 4 - Serveur de service
Le serveur de service est une API que les clients des services peuvent contacter pour interagir avec le système. C'est le seul accès que les services ont avec le système. Autrement, ils sont complètement isolés des autres composants du système.
## Variantes et étiquettes d'image
| **Type d'étiquette** | **Description** | **Exemple d'étiquette** |
| :------------------: | :--------------------------------------------------------------------------------------------------------------- | :------------------------: |
| dernière | La version la plus récente (peut être instable). | `latest` |
| build_type | Le type de compilation utilisé. `dev` est la dernière version instable. `stable` est la dernière version stable. | `stable` ou `dev` |
| séries | Le détail de compilation utilisé, incluant la version et le type de compilation : `version.buildType`. | `4.5.stable`, `4.5.1.dev3` |
## Fonctionnalité de l'API
Le serveur de service fournit les fonctionnalités suivantes au client via l'API :
- Téléchargement et chargement de fichiers
- Enregistrement d'un service dans le système
- Obtenir une nouvelle tâche
- Publier les résultats d'une tâche
- Vérifier si certaines étiquettes ou fichiers ont une réputation liée au système (c'est-à-dire sûrs ou malveillants).
#### Exécuter ce composant
```bash
docker run --name service-server cccs/assemblyline-service-server
```
## Documentation
Pour plus d'informations sur ce composant Assemblyline, suivez ce [overview](https://cybercentrecanada.github.io/assemblyline4_docs/overview/architecture/) de l'architecture du système.
| text/markdown | CCCS Assemblyline development team | assemblyline@cyber.gc.ca | null | null | MIT | assemblyline malware gc canada cse-cst cse cst cyber cccs | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programm... | [] | https://github.com/CybercentreCanada/assemblyline-service-server/ | null | null | [] | [] | [] | [
"assemblyline",
"assemblyline-core",
"werkzeug",
"flask",
"flask-socketio",
"gunicorn",
"gevent",
"gevent-websocket",
"pytest; extra == \"test\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T19:06:39.984648 | assemblyline_service_server-4.7.1.2-py3-none-any.whl | 19,575 | d2/72/5da9094e820da06ca02979c308290eaeeacc5cfc49f36d197cd6413e9cc0/assemblyline_service_server-4.7.1.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 1cf60decff7d8a489f297c0a88821a43 | 139cd68a3add908d875e9faf44b5caa50de53cfa8b7c13be39d993ad616fac92 | d2725da9094e820da06ca02979c308290eaeeacc5cfc49f36d197cd6413e9cc0 | null | [
"LICENCE.md"
] | 116 |
2.4 | assemblyline-service-client | 4.7.1.2 | Assemblyline 4 - Service client | # Assemblyline 4 - Service Client
The service client fetches tasks from the service server and drops them into a directory. It will then wait for output file(s) produced by the service. This allows the service to run independently in Python3, Python2, Java, C++, etc. A service will monitor a directory for a file with it's associated task.json, will process it and drop a result.json file which the service_client can in turn pick up to send back to the service_server.
| text/markdown | CCCS Assemblyline development team | assemblyline@cyber.gc.ca | null | null | MIT | assemblyline automated malware analysis gc canada cse-cst cse cst cyber cccs | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9"
] | [] | https://github.com/CybercentreCanada/assemblyline-service-client/ | null | null | [] | [] | [] | [
"assemblyline",
"assemblyline-core",
"python-socketio",
"pytest; extra == \"test\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T19:06:36.941990 | assemblyline_service_client-4.7.1.2-py3-none-any.whl | 9,991 | cb/60/4366c016b2aefaf40f2849e26cbd4e16160bb04f8fe5321ba278ff67cd36/assemblyline_service_client-4.7.1.2-py3-none-any.whl | py3 | bdist_wheel | null | false | ef567c6cbcd28f9a56c1cd6cf9c30681 | a3d183101c2ad08eccc6e01dfde1a789cea01a57d61d430e25881354779c26d0 | cb604366c016b2aefaf40f2849e26cbd4e16160bb04f8fe5321ba278ff67cd36 | null | [
"LICENCE.md"
] | 115 |
2.4 | nba-video-generator | 2.0.22 | Generates video highlights for an NBA player. | # NBA Highlights Video Generator
## Videos
Posted on [NBA Full Play Highlights](https://www.youtube.com/@NBAFullPlayHighlights).
## Author
Ronen Huang
## Time Frame
August 2025 to Present
## How the Generator Works
1. The user provides the full player name (as per NBA website), the date range, the team abbreviated (as per NBA website), and choices of what highlights to include. An example can be seen below.
```python
from nba_video_generator.search import generate_video
jalen_green_assists_urls = generate_video(
player_name="Jalen Green",
date_start="2024-11-01",
date_end="2024-11-08",
team="hou",
FGM=False,
FGA=False,
ThreePM=False,
ThreePA=False,
OREB=False,
DREB=False,
REB=False,
AST=True,
STL=False,
BLK=False,
TO=True,
PF=False
)
```
2. The program crawls the NBA website for links to the box score involving the player team.
3. The program crawls the team box score for links to the events involving the player.
4. The program crawls the player events for links to the videos.
If field goals or personal fouls are selected as highlight, the corresponding ESPN play by play link is used to determine the times of those events. Then the NBA play by play link is crawled for the videos of those events.
The output returns a dictionary where the keys are the dates and the events are the sorted list of events (represented as a tuple of video url, quarter, and time). An example can be seen below.
```python
{
'2024-11-02':
[
(video url 1, '1', '8:12'),
(video url 2, '3', '9:50'),
(video url 3, '3', '8:52'),
(video url 4, '3','2:38')
],
'2024-11-04':
[
(video url 5, '3', '1:37'),
(video url 6, '4', '11:28'),
(video url 7, '4', '10:54'),
(video url 8, '4', '10:28'),
(video url 9, '4', '2:10'),
(video url 10, '4', '1:34')
],
...
}
```
### NBA Team Abbreviations
- atl - Atlanta Hawks
- bkn - Brooklyn Nets
- bos - Boston Celtics
- cha - Charlotte Hornets
- chi - Chicago Bulls
- cle - Cleveland Cavaliers
- dal - Dallas Mavericks
- den - Denver Nuggets
- det - Detroit Pistons
- gsw - Golden State Warriors
- hou - Houston Rockets
- ind - Indiana Pacers
- lac - Los Angeles Clippers
- lal - Los Angeles Lakers
- mem - Memphis Grizzlies
- mia - Miami Heat
- mil - Milwaukee Bucks
- min - Minnesota Timberwolves
- nop - New Orleans Pelicans
- nyk - New York Knicks
- okc - Oklahoma City Thunder
- orl - Orlando Magic
- phi - Philadelphia 76ers
- phx - Phoenix Suns
- por - Portland Trail Blazers
- sac - Sacramento Kings
- sas - San Antonio Spurs
- tor - Toronto Raptors
- uta - Utah Jazz
- was - Washington Wizards
## How to Make Video From Event URLS
Once the dictionary of event urls are obtained from the ``generate_videos`` method, the user can make the MP4 video with the ``make_video`` method which takes parameters
- video_urls - dictionary of event urls
- base_name - name of video
- fps - frame per second
- preset - Choose from "ultrafast", "veryfast", "superfast", "faster", "fast", "medium", "slow", "slower", "veryslow", "placebo"
- segment - how to create videos with "Whole", "Game" (one video per game), "Quarter" (one video per quarter), "Play" (one video per play)
An example can be seen below.
```python
from nba_video_generator.search import make_video
make_video(
video_urls=jalen_green_assists_urls,
base_name="jalen_green_assists",
fps=30, preset="ultrafast",
segment="Whole"
)
```
## Pipeline
The highlight video can now be made with the ``pipeline`` method where the users provides both player parameters and video parameters as dictionary.
```python
from nba_video_generator.search import pipeline
player_params = {
"date_start": "2025-10-25",
"date_end": "2025-10-25",
"FGM": False,
"FGA": True,
"ThreePM": False,
"ThreePA": False,
"OREB": False,
"DREB": False,
"REB": True,
"AST": True,
"STL": True,
"BLK": True,
"TO": True,
"PF": True,
"include_ft": True
}
video_params = {
"fps": 30,
"preset": 'ultrafast',
"segment": 'Play',
"include_caption": True
}
name_team_base = [
("Kon Knueppel", "cha", "kon"),
("Joel Embiid", "phi", "embiid"),
("Bennedict Mathurin", "ind", "benn"),
("Cedric Coward", "mem", "cedric"),
("Javon Small", "mem", "javon"),
("Christian Braun", "den", "braun"),
("Devin Booker", "phx", "book")
]
pipeline(player_params, video_params, name_team_base)
```
## **Beta**
The full play videos can also be made from the reliable play by play rather than the unreliable box score. This does not work for compilations yet.
```python
from nba_video_generator.beta_search import pipeline
pipeline(
[
("Booker", "2026-02-19", "phx"),
]
)
```
| text/markdown | null | Ronen Huang <ronenhuang24@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent",
"License :: OSI Approved :: Apache Software License"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"moviepy",
"selenium",
"Unidecode"
] | [] | [] | [] | [
"Homepage, https://github.com/ronenh24/nba_video_generator",
"Issues, https://github.com/ronenh24/nba_video_generator/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:05:58.712057 | nba_video_generator-2.0.22.tar.gz | 17,836 | 8e/8a/c945069f8794406738fe4f94134fe79e01a124f0ac454ed065823c25488d/nba_video_generator-2.0.22.tar.gz | source | sdist | null | false | 3b1d85ed7dc45d0fe9a5bd85eae01425 | 711f04a4e09a0d8009816bc782e29e5a1dc9b1b81d6519906f47819e7a7f9984 | 8e8ac945069f8794406738fe4f94134fe79e01a124f0ac454ed065823c25488d | null | [
"LICENSE"
] | 213 |
2.4 | llama-stack | 0.5.1 | Llama Stack | # Llama Stack
[](https://pypi.org/project/llama_stack/)
[](https://pypi.org/project/llama-stack/)
[](https://github.com/meta-llama/llama-stack/blob/main/LICENSE)
[](https://discord.gg/llama-stack)
[](https://github.com/meta-llama/llama-stack/actions/workflows/unit-tests.yml?query=branch%3Amain)
[](https://github.com/meta-llama/llama-stack/actions/workflows/integration-tests.yml?query=branch%3Amain)
[**Quick Start**](https://llamastack.github.io/docs/getting_started/quickstart) | [**Documentation**](https://llamastack.github.io/docs) | [**Colab Notebook**](./docs/getting_started.ipynb) | [**Discord**](https://discord.gg/llama-stack)
### 🚀 One-Line Installer 🚀
To try Llama Stack locally, run:
```bash
curl -LsSf https://github.com/llamastack/llama-stack/raw/main/scripts/install.sh | bash
```
### Overview
Llama Stack defines and standardizes the core building blocks that simplify AI application development. It provides a unified set of APIs with implementations from leading service providers. More specifically, it provides:
- **Unified API layer** for Inference, RAG, Agents, Tools, Safety, Evals.
- **Plugin architecture** to support the rich ecosystem of different API implementations in various environments, including local development, on-premises, cloud, and mobile.
- **Prepackaged verified distributions** which offer a one-stop solution for developers to get started quickly and reliably in any environment.
- **Multiple developer interfaces** like CLI and SDKs for Python, Typescript, iOS, and Android.
- **Standalone applications** as examples for how to build production-grade AI applications with Llama Stack.
<div style="text-align: center;">
<img
src="https://github.com/user-attachments/assets/33d9576d-95ea-468d-95e2-8fa233205a50"
width="480"
title="Llama Stack"
alt="Llama Stack"
/>
</div>
#### Llama Stack Benefits
- **Flexibility**: Developers can choose their preferred infrastructure without changing APIs and enjoy flexible deployment choices.
- **Consistent Experience**: With its unified APIs, Llama Stack makes it easier to build, test, and deploy AI applications with consistent application behavior.
- **Robust Ecosystem**: Llama Stack is integrated with distribution partners (cloud providers, hardware vendors, and AI-focused companies) that offer tailored infrastructure, software, and services for deploying Llama models.
For more information, see the [Benefits of Llama Stack](https://llamastack.github.io/docs/latest/concepts/architecture#benefits-of-llama-stack) documentation.
### API Providers
Here is a list of the various API providers and available distributions that can help developers get started easily with Llama Stack.
Please checkout for [full list](https://llamastack.github.io/docs/providers)
| API Provider | Environments | Agents | Inference | VectorIO | Safety | Post Training | Eval | DatasetIO |
|:--------------------:|:------------:|:------:|:---------:|:--------:|:------:|:-------------:|:----:|:--------:|
| Meta Reference | Single Node | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| SambaNova | Hosted | | ✅ | | ✅ | | | |
| Cerebras | Hosted | | ✅ | | | | | |
| Fireworks | Hosted | ✅ | ✅ | ✅ | | | | |
| AWS Bedrock | Hosted | | ✅ | | ✅ | | | |
| Together | Hosted | ✅ | ✅ | | ✅ | | | |
| Groq | Hosted | | ✅ | | | | | |
| Ollama | Single Node | | ✅ | | | | | |
| TGI | Hosted/Single Node | | ✅ | | | | | |
| NVIDIA NIM | Hosted/Single Node | | ✅ | | ✅ | | | |
| ChromaDB | Hosted/Single Node | | | ✅ | | | | |
| Milvus | Hosted/Single Node | | | ✅ | | | | |
| Qdrant | Hosted/Single Node | | | ✅ | | | | |
| Weaviate | Hosted/Single Node | | | ✅ | | | | |
| SQLite-vec | Single Node | | | ✅ | | | | |
| PG Vector | Single Node | | | ✅ | | | | |
| PyTorch ExecuTorch | On-device iOS | ✅ | ✅ | | | | | |
| vLLM | Single Node | | ✅ | | | | | |
| OpenAI | Hosted | | ✅ | | | | | |
| Anthropic | Hosted | | ✅ | | | | | |
| Gemini | Hosted | | ✅ | | | | | |
| WatsonX | Hosted | | ✅ | | | | | |
| HuggingFace | Single Node | | | | | ✅ | | ✅ |
| TorchTune | Single Node | | | | | ✅ | | |
| NVIDIA NEMO | Hosted | | ✅ | ✅ | | ✅ | ✅ | ✅ |
| NVIDIA | Hosted | | | | | ✅ | ✅ | ✅ |
> **Note**: Additional providers are available through external packages. See [External Providers](https://llamastack.github.io/docs/providers/external) documentation.
### Distributions
A Llama Stack Distribution (or "distro") is a pre-configured bundle of provider implementations for each API component. Distributions make it easy to get started with a specific deployment scenario. For example, you can begin with a local setup of Ollama and seamlessly transition to production, with fireworks, without changing your application code.
Here are some of the distributions we support:
| **Distribution** | **Llama Stack Docker** | Start This Distribution |
|:---------------------------------------------:|:-------------------------------------------------------------------------------------------------------------------------------------------------------------:|:------------------------------------------------------------------------------------------------------------------------:|
| Starter Distribution | [llamastack/distribution-starter](https://hub.docker.com/repository/docker/llamastack/distribution-starter/general) | [Guide](https://llamastack.github.io/docs/distributions/self_hosted_distro/starter) |
| Meta Reference | [llamastack/distribution-meta-reference-gpu](https://hub.docker.com/repository/docker/llamastack/distribution-meta-reference-gpu/general) | [Guide](https://llamastack.github.io/docs/distributions/self_hosted_distro/meta-reference-gpu) |
| PostgreSQL | [llamastack/distribution-postgres-demo](https://hub.docker.com/repository/docker/llamastack/distribution-postgres-demo/general) | |
For full documentation on the Llama Stack distributions see the [Distributions Overview](https://llamastack.github.io/docs/distributions) page.
### Documentation
Please checkout our [Documentation](https://llamastack.github.io/docs) page for more details.
* CLI references
* [llama (server-side) CLI Reference](https://llamastack.github.io/docs/references/llama_cli_reference): Guide for using the `llama` CLI to work with Llama models (download, study prompts), and building/starting a Llama Stack distribution.
* [llama (client-side) CLI Reference](https://llamastack.github.io/docs/references/llama_stack_client_cli_reference): Guide for using the `llama-stack-client` CLI, which allows you to query information about the distribution.
* Getting Started
* [Quick guide to start a Llama Stack server](https://llamastack.github.io/docs/getting_started/quickstart).
* [Jupyter notebook](./docs/getting_started.ipynb) to walk-through how to use simple text and vision inference llama_stack_client APIs
* The complete Llama Stack lesson [Colab notebook](https://colab.research.google.com/drive/1dtVmxotBsI4cGZQNsJRYPrLiDeT0Wnwt) of the new [Llama 3.2 course on Deeplearning.ai](https://learn.deeplearning.ai/courses/introducing-multimodal-llama-3-2/lesson/8/llama-stack).
* A [Zero-to-Hero Guide](https://github.com/meta-llama/llama-stack/tree/main/docs/zero_to_hero_guide) that guide you through all the key components of llama stack with code samples.
* [Contributing](CONTRIBUTING.md)
* [Adding a new API Provider](https://llamastack.github.io/docs/contributing/new_api_provider) to walk-through how to add a new API provider.
* [Release Process](RELEASE_PROCESS.md) for information about release schedules and versioning.
### Llama Stack Client SDKs
Check out our client SDKs for connecting to a Llama Stack server in your preferred language.
| **Language** | **Client SDK** | **Package** |
| :----: | :----: | :----: |
| Python | [llama-stack-client-python](https://github.com/meta-llama/llama-stack-client-python) | [](https://pypi.org/project/llama_stack_client/)
| Swift | [llama-stack-client-swift](https://github.com/meta-llama/llama-stack-client-swift) | [](https://swiftpackageindex.com/meta-llama/llama-stack-client-swift)
| Typescript | [llama-stack-client-typescript](https://github.com/meta-llama/llama-stack-client-typescript) | [](https://npmjs.org/package/llama-stack-client)
| Kotlin | [llama-stack-client-kotlin](https://github.com/meta-llama/llama-stack-client-kotlin) | [](https://central.sonatype.com/artifact/com.llama.llamastack/llama-stack-client-kotlin)
You can find more example scripts with client SDKs to talk with the Llama Stack server in our [llama-stack-apps](https://github.com/meta-llama/llama-stack-apps/tree/main/examples) repo.
## Community
We hold regular community calls to discuss the latest developments and get feedback from the community.
- Date: every Thursday
- Time: 09:00 AM PST (check the [Community Event on Discord](https://discord.com/events/1257833999603335178/1413266296748900513) for the latest details)
## 🌟 GitHub Star History
## Star History
[](https://www.star-history.com/#meta-llama/llama-stack&Date)
## ✨ Contributors
Thanks to all of our amazing contributors!
<a href="https://github.com/meta-llama/llama-stack/graphs/contributors">
<img src="https://contrib.rocks/image?repo=meta-llama/llama-stack" />
</a>
| text/markdown | null | Meta Llama <llama-oss@meta.com> | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Operating System :: OS Independent",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
... | [] | null | null | >=3.12 | [] | [] | [] | [
"PyYAML>=6.0",
"aiohttp>=3.13.3",
"fastapi<1.0,>=0.115.0",
"fire",
"httpx",
"jinja2>=3.1.6",
"jsonschema",
"llama-stack-api",
"openai>=2.5.0",
"prompt-toolkit",
"python-dotenv",
"pyjwt[crypto]>=2.10.0",
"pydantic>=2.11.9",
"rich",
"termcolor",
"tiktoken",
"pillow",
"h11>=0.16.0",
... | [] | [] | [] | [
"Homepage, https://github.com/llamastack/llama-stack"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:05:56.334415 | llama_stack-0.5.1.tar.gz | 16,028,608 | d3/5f/c1d795ca95baf21cc48693410a3ca7549b414e911315eb820fb531ab3cd6/llama_stack-0.5.1.tar.gz | source | sdist | null | false | 05fbac27169a5f2f946cb8816f07d5ce | 833719d318227ebeeec9aabc3b9ee1f2bdc9fbad711691c22d618faac714896c | d35fc1d795ca95baf21cc48693410a3ca7549b414e911315eb820fb531ab3cd6 | null | [
"LICENSE"
] | 1,012 |
2.4 | rid-lib | 3.2.15 | Implementation of Reference Identifiers (RIDs) protocol in Python | # RID v3 Protocol
*This specification can be understood as the third iteration of the RID protocol, or RID v3. Previous versions include [RID v1](https://github.com/BlockScience/kms-identity/blob/main/README.md) and [RID v2](https://github.com/BlockScience/rid-lib/blob/v2/README.md).*
### Jump to Sections:
- [RID Core](#rid-core)
- [Introduction](#introduction)
- [Generic Syntax](#generic-syntax)
- [Object Reference Names](#object-reference-names-previously-rid-v2)
- [Implementation](#implementation)
- [RID class](#rid-class)
- [RID types](#rid-types)
- [Creating your own types](#creating-your-own-types)
- [Pydantic compatibility](#pydantic-compatibility)
- [Installation](#installation)
- [Usage](#usage)
- [Development](#development)
- [RID Extensions](#rid-extensions)
- [Introduction](#introduction-1)
- [Manifest](#manifest)
- [Event](#manifest)
- [Cache](#cache)
- [Effector](#effector)
# RID Core
## Introduction
*Note: throughout this document the terms "resource", "digital object", and "knowledge object" are used roughly interchangeably.*
Reference Identifiers (RIDs) identify references to resources primarily for usage within Knowledge Organization Infrastructure (KOI). The RID specification is informed by previous work on representing digital objects (see [Objects as Reference](https://blog.block.science/objects-as-reference-toward-robust-first-principles-of-digital-organization/)) in which objects are identified through a relationship between a reference and a referent. Under this model, RIDs are the *references*, and the resources they refer to are the *referents.* The *means of reference* describes the relationship between the reference and referent.
```
(reference) -[means of reference]-> (referent)
```
As opposed to Uniform Resource Identifiers (URIs), RIDs are not intended to have universal agreement or a centralized management structure. However, RIDs are compatible with URIs in that *all URIs can be valid RIDs*. [RFC 3986](https://www.rfc-editor.org/info/rfc3986) outlines the basic properties of an URI, adding that "a URI can be further classified as a locator, a name or both." Location and naming can be considered two different means of reference, or methods of linking a reference and referent(s), where:
1. Locators identify resources by *where* they are, with the referent being defined as the resource retrieved via a defined access method. This type of identifier is less stable, and the resource at the specified location could change or become unavailable over time.
3. Names identify resources by *what* they are, acting as a more stable, location independent identifier. Resources identified by name are not always intended to be accessed, but some may be resolvable to locators. While the mapping from name to locator may not be constant the broader relationship between reference and referent should be.
## Generic Syntax
The generic syntax to compose an RID roughly mirrors URIS:
```
<type>:<reference>
```
Conceptually, the reference refers to the referent, while the type provides context for how to interpret the reference, or how to discriminate it from another otherwise identical RID. While in many cases the type simply maps to a URI scheme, the type may also include part of the "hierarchical part" (right hand side of a URI following the scheme).
*See [rid-registry](https://github.com/BlockScience/rid-registry) for a list of active RID types.*
## Object Reference Names (previously RID v2)
The major change from RID v2 to v3 was building compatibility with URIs, and as a result the previous RID v2 style identifiers are now implemented under the (unofficial) `orn:` URI scheme.
Object Reference Names (ORNs) identify references to objects, or resources identified independent of their access method. Given the previous definitions of identifiers, ORNs can be considered "names". They are intended to be used with existing resources which may already have well defined identifiers. An ORN identifies a resource by "dislocating" it from a specific access mechanism, maintaining a reference even if the underlying locator changes or breaks. ORNs are generally formed from one or more context specific identifiers which can be easily accessed for processing in other contexts.
ORNs are composed using the following syntax:
```
orn:<namespace>:<reference>
```
*Note: In previous versions, the namespace was split into `<space>.<form>`. Using a dot to separate a namespace in this way is still encouraged, but is not explicitly defined by this specification.*
ORNs also implement a more complex type component: `orn:<namespace>`. The differences between the syntax of ORNs and generic URIs are summarized here:
```
<scheme>:<hierarchical-part>
\______/ \_________________/
| |
type reference
___|_________ ____|____
/ \ / \
orn:<namespace>:<reference>
```
## Examples
In the current version there are two example implementations of RID types: HTTP/S URLs and Slack objects. The HTTP/S scheme is the most commonly used form of URI and uses the standard RID parsing, where the scheme `http` or `https` is equal to the type, and the hierarchical part is equal to the reference.
```
scheme authority path
_|_ ____|___ _________________|___________________
/ \ / \/ \
https://github.com/BlockScience/rid-lib/blob/v3/README.md
\___/ \_________________________________________________/
| |
type reference
```
The Slack objects are implemented as ORNs, and include workspaces, channels, messages, and users. The Slack message object's namespace is `slack.message` and its reference component is composed of three internal identifiers, the workspace id, channel id, and message id.
```
scheme namespace team channel timestamp
| _____|_____ ___|___ ____|___ _______|_______
/ \ / \ / \ / \ / \
orn:slack.message:TA2E6KPK3/C07BKQX0EVC/1721669683.087619
\_______________/ \_____________________________________/
| |
type reference
```
By representing Slack messages through ORNs, a stable identifier can be assigned to a resource which can be mapped to existing locators for different use cases. For example, a Slack message can be represented as a shareable link which redirects to the Slack app or in browser app:
```
https://blockscienceteam.slack.com/archives/C07BKQX0EVC/p1721669683087619
```
There's also a "deep link" which can open the Slack app directly (but only to a channel):
```
slack://open?team=TA2E6KPK3&id=C07BKQX0EVC
```
Finally, there's the backend API call to retrieve the JSON data associated with the message:
```
https://slack.com/api/conversations.replies?channel=C07BKQX0EVC&ts=1721669683.087619&limit=1
```
These three different locators have specific use cases, but none of them work well as long term identifiers of a Slack message. None of them contain all of the identifiers needed to uniquely identify the message (the shareable link comes close, but uses the mutable team name instead of the id). Even if a locator can fully describe an object of interested, it is not resilient to changes in access method and is not designed for portability into systems where the context needs to be clearly stated and internal identifiers easily extracted. Instead, we can represent a Slack message as an ORN and resolve it to any of the above locators when necessary.
## Implementation
### RID class
The RID class provides a template for all RID types and access to a global constructor. All RID instances have access to the following properties:
```python
class RID:
scheme: str
# defined for namespaces schemes (ORN, URN, ...) only
namespace: str | None
# maintained for backwards compatibility, use `type()` instead
context: str
# the component after the type component
reference: str
@classmethod
def from_string(cls, string: str) -> RID: ...
# only callable from RID type classes, not the RID base class
@classmethod
def from_reference(cls, string: str) -> RID: ...
```
Example implementations can be found in [`src/rid_lib/types/`](https://github.com/BlockScience/rid-lib/tree/main/src/rid_lib/types).
### RID types
This library treats both RIDs and RID types as first class objects. Behind the scenes, the `RIDType` base class is the metaclass for all RID type classes (which are created by inheriting from the `RID`, `ORN`, `URN` classes) -- so RID types are the classes, and RIDs are the instances of those classes. You can access the type of an RID using the built-in type function: `type(rid)`. All RIDs with the same type are guaranteed to share the same RID type class. Even if that RID type doesn't have any explicit class implementation, a class will be automatically generated for it.
```python
class RIDType(ABCMeta):
scheme: str | None = None
namespace: str | None = None
# maps RID type strings to their classes
type_table: dict[str, type["RID"]] = dict()
@classmethod
def from_components(mcls, scheme: str, namespace: str | None = None) -> type["RID"]: ...
@classmethod
def from_string(mcls, string: str) -> type["RID"]: ...
# backwards compatibility
@property
def context(cls) -> str:
return str(cls)
```
The preferred way of accessing the type of an RID is using the built in `type()` function. To get the string representation of an RID type, `str()` can be used, e.g., `str(type(rid))`. RID types can also be created with `RIDType.from_string`, which is also guaranteed to return the same class if the type component is the same.
```python
from rid_lib import RID, RIDType
from rid_lib.types import SlackMessage
slack_msg_rid = RID.from_string("orn:slack.message:TA2E6KPK3/C07BKQX0EVC/1721669683.087619")
assert type(slack_msg_rid) == SlackMessage
assert SlackMessage == RIDType.from_string("orn:slack.message")
```
### Creating your own types
In order to create an RID type, follow this minimal implementation:
```python
class MyRIDType(RID): # inherit from `RID` or namespace scheme (`ORN`, `URN`, ...) base classes
# define scheme for a generic URI type
scheme = "scheme"
# OR a namespace if using a namespace scheme
namespace = "namespace"
# instantiates a new RID from internal components
def __init__(self, internal_id):
self.internal_id = internal_id
# returns the reference component
@property
def reference(self):
# should dynamically reflect changes to any internal ids
return self.internal_id
# instantiates of an RID of this type given a reference
@classmethod
def from_reference(cls, reference):
# in a typical use case, the reference would need to be parsed
# raise a ValueError if the reference is invalid
if len(reference) > 10:
raise ValueError("Internal ID must be less than 10 characters!")
return cls(reference)
```
### Pydantic Compatibility
Both RIDs and RID types are Pydantic compatible fields, which means they can be used directly within a Pydantic model in very flexible ways:
```python
class Model(BaseModel):
rid: RID
slack_rid: SlackMessage | SlackUser | SlackChannel | SlackWorkspace
rid_types: list[RIDType]
```
## Installation
This package can be installed with pip for use in other projects.
```
pip install rid-lib
```
It can also be built and installed from source by cloning this repo and running this command in the root directory.
```
pip install .
```
## Usage
RIDs are intended to be used as a lightweight, cross platform identifiers to facilitate communication between knowledge processing systems. RID objects can be constructed from any RID string using the general constructor `RID.from_string`. The parser will match the string's type component and call the corresponding `from_reference` constructor. This can also be done directly on any RID type class via `MyRIDType.from_reference`. Finally, each type class provides a default constructor which requires each subcomponent to be indvidiually specified.
```python
from rid_lib import RID
from rid_lib.types import SlackMessage
rid_obj1 = RID.from_string("orn:slack.message:TA2E6KPK3/C07BKQX0EVC/1721669683.087619")
rid_obj2 = SlackMessage.from_reference("TA2E6KPK3/C07BKQX0EVC/1721669683.087619")
rid_obj3 = SlackMessage(team_id="TA2E6KPK3", channel_id="C07BKQX0EVC", ts="1721669683.087619")
assert rid_obj1 == rid_obj2 == rid_obj3
# guaranteed to be defined for all RID objects
print(rid_obj1.scheme, str(type(rid_obj1)), rid_obj1.reference)
# special parameters for the slack.message type
print(rid_obj1.team_id, rid_obj1.channel_id, rid_obj1.ts)
```
If an RID type doesn't have a class implementation, it can still be parsed by both the RID and RIDType constructors. A default type implementation will be generated on the fly with a minimal implementation (`reference` property, `from_reference` class method, `__init__` function).
```python
test_obj1 = RID.from_string("test:one")
test_obj2 = RID.from_string("test:one")
assert test_obj1 == test_obj2
assert type(test_obj1) == RIDType.from_string("test")
```
## Development
Build and install from source with development requirements:
```
pip install .[dev]
```
Run unit tests:
```
pytest --cov=rid_lib
```
To build and upload to PyPI:
(Remember to bump the version number in pyproject.toml first!)
```
python -m build
```
Two new build files should appear in `dist/`, a `.tar.gz` and `.whl` file.
```
python -m twine upload -r pypi dist/*
```
Enter the API key and upload the new package version.
# RID Extensions
## Introduction
In addition to the core implementation of the RID specification, this library also provides extended functionality through objects and patterns that interface with RIDs.
## Manifest
A manifest is a portable descriptor of a data object associated with an RID. It is composed of an RID and metadata about the data object it describes (currently a timestamp and sha256 hash). The name "manifest" comes from a shipping metaphor: a piece of cargo has contents (the stuff inside of it) and a manifest (a paper describing the contents and providing tracking info). In the KOI network ecosystem, a manifest serves a similar role. Manifests can be passed around to inform other nodes of a data objects they may be interested in.
Below are the accessible fields and methods of a Manifest object, all are required.
```python
class Manifest(BaseModel):
rid: RID
timestamp: datetime
sha256_hash: str
# generates a Manifest using the current datetime and the hash of the provided data
@classmethod
def generate(cls, rid: RID, data: dict) -> Manifest: ...
```
## Bundle
A bundle is composed of a manifest and contents. This is the "piece of cargo" in the shipping metaphor described above. It's the construct used to transfer and store the RIDed knowledge objects we are interested in.
```python
class Bundle(BaseModel):
manifest: Manifest
contents: dict
@classmethod
def generate(cls, rid: RID, contents: dict) -> Bundle: ...
```
*Manifests and bundles are implemented as Pydantic models, meaning they can be initialized with args or kwargs. They can also be serialized with `model_dump()` and `model_dump_json()`, and deserialized with `model_validate()` and `model_validate_json()`.*
## Cache
The cache class allows us to set up a cache for reading and writing bundles to the local filesystem. Each bundle is stored as a separate JSON file in the cache directory, where the file name is base 64 encoding of its RID. Below are the accessible fields and methods of a Cache.
```python
class Cache:
def __init__(self, directory_path: str): ...
def file_path_to(self, rid: RID) -> str: ...
def write(self, cache_bundle: Bundle) -> Bundle: ...
def exists(self, rid: RID) -> bool: ...
def read(self, rid: RID) -> Bundle | None: ...
def list_rids(
self, rid_types: list[RIDType] | None = None
) -> list[RID]: ...
def delete(self, rid: RID) -> None: ...
def drop(self) -> None: ...
``` | text/markdown | null | Luke Miller <luke@block.science> | null | null | MIT License
Copyright (c) 2024 BlockScience
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"pydantic>=2.10",
"build; extra == \"dev\"",
"pytest-cov>=6.0; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"twine>=6.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/BlockScience/rid-lib/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:05:53.778774 | rid_lib-3.2.15.tar.gz | 25,807 | 8f/62/1b03d8e3499c4441cfc06ae6a8ed167a5ebff91a9e7c25ae49af6371a027/rid_lib-3.2.15.tar.gz | source | sdist | null | false | 2679559d9f7fee691ca0f3c920fd0582 | c7ba860d95a19fbb0655843590528f21537939a14fce8169808e0f7045eb4ba8 | 8f621b03d8e3499c4441cfc06ae6a8ed167a5ebff91a9e7c25ae49af6371a027 | null | [
"LICENSE"
] | 229 |
2.4 | ethereum-execution | 2.20.0 | Ethereum execution layer specification, provided as a Python package for tooling and testing | # Ethereum Execution Client Specifications
[](https://www.gitpoap.io/gh/ethereum/execution-specs)
[](https://codecov.io/gh/ethereum/execution-specs)
[](https://github.com/ethereum/execution-specs/actions/workflows/test.yaml)
## Description
This repository contains the specifications related to the Ethereum execution client, specifically the [pyspec](/src/ethereum/__init__.py) and specifications for [network upgrades](/src/ethereum/__init__.py). The [JSON-RPC API specification](https://github.com/ethereum/execution-apis) can be found in a separate repository.
### Ethereum Protocol Releases
| Version and Code Name | Block No. | Released | Incl EIPs | Specs | Blog |
|-----------------------|-----------|----------|-----------|-------|-------|
| Prague | 22431084 | 2025-05-07 | [EIP-2537] <br> [EIP-2935] <br> [EIP-6110] <br> [EIP-7002] <br> [EIP-7251] <br> [EIP-7549] <br> [EIP-7623] <br> [EIP-7685] <br> [EIP-7691] <br> [EIP-7702] | [Specs](https://eips.ethereum.org/EIPS/eip-7600) | [Blog](https://blog.ethereum.org/2025/04/23/pectra-mainnet) |
| Cancun | 19426587 | 2024-03-13<br />(1710338135) | [EIP-1153](https://eips.ethereum.org/EIPS/eip-1153) </br> [EIP-4788](https://eips.ethereum.org/EIPS/eip-4788)</br> [EIP-4844](https://eips.ethereum.org/EIPS/eip-4844)</br> [EIP-5656](https://eips.ethereum.org/EIPS/eip-5656)</br> [EIP-6780](https://eips.ethereum.org/EIPS/eip-6780) </br> [EIP-7044](https://eips.ethereum.org/EIPS/eip-7044) </br> [EIP-7045](https://eips.ethereum.org/EIPS/eip-7045) </br> [EIP-7514](https://eips.ethereum.org/EIPS/eip-7514) </br> [EIP-7516](https://eips.ethereum.org/EIPS/eip-7516)| [Specification](/src/ethereum/forks/cancun/__init__.py) | [Blog](https://blog.ethereum.org/2024/02/27/dencun-mainnet-announcement) |
| Shanghai | 17034870 | 2023-04-12<br/>(1681338455) | [EIP-3651](https://eips.ethereum.org/EIPS/eip-3651) <br/> [EIP-3855](https://eips.ethereum.org/EIPS/eip-3855) <br/> [EIP-3860](https://eips.ethereum.org/EIPS/eip-3860) <br/> [EIP-4895](https://eips.ethereum.org/EIPS/eip-4895) | [Specification](/src/ethereum/forks/shanghai/__init__.py) | [Blog](https://blog.ethereum.org/2023/03/28/shapella-mainnet-announcement) |
| Paris | 15537394 | 2022-09-15 | [EIP-3675](https://eips.ethereum.org/EIPS/eip-3675) <br/> [EIP-4399](https://eips.ethereum.org/EIPS/eip-4399) | [Specification](/src/ethereum/forks/paris/__init__.py) | [Blog](https://blog.ethereum.org/2022/08/24/mainnet-merge-announcement) |
| Gray Glacier | 15050000 | 2022-06-30 | [EIP-5133](https://eips.ethereum.org/EIPS/eip-5133) | [Specification](/src/ethereum/forks/gray_glacier/__init__.py) | [Blog](https://blog.ethereum.org/2022/06/16/gray-glacier-announcement/) |
| Arrow Glacier | 13773000 | 2021-12-09 | [EIP-4345](https://eips.ethereum.org/EIPS/eip-4345) | [Specification](/src/ethereum/forks/arrow_glacier/__init__.py) | [Blog](https://blog.ethereum.org/2021/11/10/arrow-glacier-announcement/) |
| London | 12965000 | 2021-08-05 | [EIP-1559](https://eips.ethereum.org/EIPS/eip-1559) <br> [EIP-3198](https://eips.ethereum.org/EIPS/eip-3198) <br/> [EIP-3529](https://eips.ethereum.org/EIPS/eip-3529) <br/> [EIP-3541](https://eips.ethereum.org/EIPS/eip-3541) <br> [EIP-3554](https://eips.ethereum.org/EIPS/eip-3554)| [Specification](/src/ethereum/forks/london/__init__.py) | [Blog](https://blog.ethereum.org/2021/07/15/london-mainnet-announcement/) |
| Berlin | 12244000 | 2021-04-15 | [EIP-2565](https://eips.ethereum.org/EIPS/eip-2565) <br/> [EIP-2929](https://eips.ethereum.org/EIPS/eip-2929) <br/> [EIP-2718](https://eips.ethereum.org/EIPS/eip-2718) <br/> [EIP-2930](https://eips.ethereum.org/EIPS/eip-2930) | ~[HFM-2070](https://eips.ethereum.org/EIPS/eip-2070)~ <br/> [Specification](/src/ethereum/forks/berlin/__init__.py) | [Blog](https://blog.ethereum.org/2021/03/08/ethereum-berlin-upgrade-announcement/) |
| Muir Glacier | 9200000 | 2020-01-02 | [EIP-2384](https://eips.ethereum.org/EIPS/eip-2384) | [HFM-2387](https://eips.ethereum.org/EIPS/eip-2387) | [Blog](https://blog.ethereum.org/2019/12/23/ethereum-muir-glacier-upgrade-announcement/) |
| Istanbul | 9069000 | 2019-12-07 | [EIP-152](https://eips.ethereum.org/EIPS/eip-152) <br/> [EIP-1108](https://eips.ethereum.org/EIPS/eip-1108) <br/> [EIP-1344](https://eips.ethereum.org/EIPS/eip-1344) <br/> [EIP-1884](https://eips.ethereum.org/EIPS/eip-1884) <br/> [EIP-2028](https://eips.ethereum.org/EIPS/eip-2028) <br/> [EIP-2200](https://eips.ethereum.org/EIPS/eip-2200) | [HFM-1679](https://eips.ethereum.org/EIPS/eip-1679) | [Blog](https://blog.ethereum.org/2019/11/20/ethereum-istanbul-upgrade-announcement/) |
| Petersburg | 7280000 | 2019-02-28 | [EIP-145](https://eips.ethereum.org/EIPS/eip-145) <br/> [EIP-1014](https://eips.ethereum.org/EIPS/eip-1014) <br/> [EIP-1052](https://eips.ethereum.org/EIPS/eip-1052) <br/> [EIP-1234](https://eips.ethereum.org/EIPS/eip-1234) | [HFM-1716](https://eips.ethereum.org/EIPS/eip-1716) | [Blog](https://blog.ethereum.org/2019/02/22/ethereum-constantinople-st-petersburg-upgrade-announcement/) |
| Constantinople | 7280000 | 2019-02-28 | [EIP-145](https://eips.ethereum.org/EIPS/eip-145) <br/> [EIP-1014](https://eips.ethereum.org/EIPS/eip-1014) <br/> [EIP-1052](https://eips.ethereum.org/EIPS/eip-1052) <br/> [EIP-1234](https://eips.ethereum.org/EIPS/eip-1234) <br/> [EIP-1283](https://eips.ethereum.org/EIPS/eip-1283) | [HFM-1013](https://eips.ethereum.org/EIPS/eip-1013) | [Blog](https://blog.ethereum.org/2019/02/22/ethereum-constantinople-st-petersburg-upgrade-announcement/) |
| Byzantium | 4370000 | 2017-10-16 | [EIP-100](https://eips.ethereum.org/EIPS/eip-100) <br/> [EIP-140](https://eips.ethereum.org/EIPS/eip-140) <br/> [EIP-196](https://eips.ethereum.org/EIPS/eip-196) <br/> [EIP-197](https://eips.ethereum.org/EIPS/eip-197) <br/> [EIP-198](https://eips.ethereum.org/EIPS/eip-198) <br/> [EIP-211](https://eips.ethereum.org/EIPS/eip-211) <br/> [EIP-214](https://eips.ethereum.org/EIPS/eip-214) <br/> [EIP-649](https://eips.ethereum.org/EIPS/eip-649) <br/> [EIP-658](https://eips.ethereum.org/EIPS/eip-658) | [HFM-609](https://eips.ethereum.org/EIPS/eip-609) | [Blog](https://blog.ethereum.org/2017/10/12/byzantium-hf-announcement/) |
| Spurious Dragon | 2675000 | 2016-11-22 | [EIP-155](https://eips.ethereum.org/EIPS/eip-155) <br/> [EIP-160](https://eips.ethereum.org/EIPS/eip-160) <br/> [EIP-161](https://eips.ethereum.org/EIPS/eip-161) <br/> [EIP-170](https://eips.ethereum.org/EIPS/eip-170) | [HFM-607](https://eips.ethereum.org/EIPS/eip-607) | [Blog](https://blog.ethereum.org/2016/11/18/hard-fork-no-4-spurious-dragon/) |
| Tangerine Whistle | 2463000 | 2016-10-18 | [EIP-150](https://eips.ethereum.org/EIPS/eip-150) | [HFM-608](https://eips.ethereum.org/EIPS/eip-608) | [Blog](https://blog.ethereum.org/2016/10/13/announcement-imminent-hard-fork-eip150-gas-cost-changes/) |
| DAO Fork | 1920000 | 2016-07-20 | | [HFM-779](https://eips.ethereum.org/EIPS/eip-779) | [Blog](https://blog.ethereum.org/2016/07/15/to-fork-or-not-to-fork/) |
| DAO Wars | aborted | aborted | | | [Blog](https://blog.ethereum.org/2016/06/24/dao-wars-youre-voice-soft-fork-dilemma/) |
| Homestead | 1150000 | 2016-03-14 | [EIP-2](https://eips.ethereum.org/EIPS/eip-2) <br/> [EIP-7](https://eips.ethereum.org/EIPS/eip-7) <br/> [EIP-8](https://eips.ethereum.org/EIPS/eip-8) | [HFM-606](https://eips.ethereum.org/EIPS/eip-606) | [Blog](https://blog.ethereum.org/2016/02/29/homestead-release/) |
| Frontier Thawing | 200000 | 2015-09-07 | | | [Blog](https://blog.ethereum.org/2015/08/04/the-thawing-frontier/) |
| Frontier | 1 | 2015-07-30 | | | [Blog](https://blog.ethereum.org/2015/07/22/frontier-is-coming-what-to-expect-and-how-to-prepare/) |
*Note:* Starting with Paris, updates are no longer rolled out based on block numbers. Paris was enabled once proof-of-work Total Difficulty reached 58750000000000000000000. As of Shanghai (at 1681338455), upgrade activation is based on timestamps.
[EIP-2537]: https://eips.ethereum.org/EIPS/eip-2537
[EIP-2935]: https://eips.ethereum.org/EIPS/eip-2935
[EIP-6110]: https://eips.ethereum.org/EIPS/eip-6110
[EIP-7002]: https://eips.ethereum.org/EIPS/eip-7002
[EIP-7251]: https://eips.ethereum.org/EIPS/eip-7251
[EIP-7549]: https://eips.ethereum.org/EIPS/eip-7549
[EIP-7623]: https://eips.ethereum.org/EIPS/eip-7623
[EIP-7685]: https://eips.ethereum.org/EIPS/eip-7685
[EIP-7691]: https://eips.ethereum.org/EIPS/eip-7691
[EIP-7702]: https://eips.ethereum.org/EIPS/eip-7702
Some clarifications were enabled without protocol releases:
| EIP | Block No. |
|-----|-----------|
| [EIP-2681](https://eips.ethereum.org/EIPS/eip-2681) | 0 |
| [EIP-3607](https://eips.ethereum.org/EIPS/eip-3607) | 0 |
| [EIP-7523](https://eips.ethereum.org/EIPS/eip-7523) | 15537394 |
| [EIP-7610](https://eips.ethereum.org/EIPS/eip-7610) | 0 |
## Execution Specification (work-in-progress)
The execution specification is a python implementation of Ethereum that prioritizes readability and simplicity. It will be accompanied by both narrative and API level documentation of the various components written in markdown and rendered using docc...
* [Rendered specification](https://ethereum.github.io/execution-specs/)
## Usage
The Ethereum specification is maintained as a Python library, for better integration with tooling and testing.
Requires Python 3.11+
### Building Specification Documentation
Building the spec documentation is most easily done through [`tox`](https://tox.readthedocs.io/en/latest/):
```bash
uvx --with=tox-uv tox -e spec-docs
```
The path to the generated HTML will be printed to the console.
### Browsing Updated Documentation
To view the updated local documentation, run:
```bash
uv run mkdocs serve
```
then connect to `localhost:8000` in a browser
## License
The Ethereum Execution Layer Specification code is licensed under the [Creative Commons Zero v1.0 Universal](LICENSE.md).
| text/markdown | null | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: Implementation :: PyPy",
"Programming Language :: Python :: Implementation :: CPython",
"Intended Audience :: Developers",
"Natural Language :: En... | [] | null | null | >=3.11 | [] | [] | [] | [
"pycryptodome<4,>=3.22",
"coincurve<21,>=20",
"typing_extensions>=4.4",
"py-ecc<9,>=8.0.0b2",
"ethereum-types<0.3,>=0.2.4",
"ethereum-rlp<0.2,>=0.1.4",
"cryptography<46,>=45.0.1",
"platformdirs<5,>=4.2",
"libcst<2,>=1.8",
"rust-pyspec-glue<0.1.0,>=0.0.9; extra == \"optimized\"",
"ethash<2,>=1.1.... | [] | [] | [] | [
"Homepage, https://github.com/ethereum/execution-specs"
] | uv/0.8.13 | 2026-02-19T19:05:45.068761 | ethereum_execution-2.20.0.tar.gz | 1,342,497 | 90/24/6012db590db2184b6a68d3b3ecb795350a56f68fd73b2faf1898d8c012d5/ethereum_execution-2.20.0.tar.gz | source | sdist | null | false | b30f230f6825f34ab141887d71b07567 | 53af8b2d71b4550ec08ed900beb61364e1ccdba45ec2464bf5eba1c29593b30a | 90246012db590db2184b6a68d3b3ecb795350a56f68fd73b2faf1898d8c012d5 | CC0-1.0 | [
"LICENSE.md"
] | 236 |
2.4 | gradient-free-optimizers | 1.10.1 | Lightweight optimization with local, global, population-based and sequential techniques across mixed search spaces | <p align="center">
<a href="https://github.com/SimonBlanke/Gradient-Free-Optimizers">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="./docs/images/gradient_logo_dark_c.svg">
<source media="(prefers-color-scheme: light)" srcset="./docs/images/gradient_logo_ink_paths.svg">
<img src="./docs/images/gradient_logo_ink_paths.svg" width="400" alt="Gradient-Free-Optimizers Logo">
</picture>
</a>
</p>
---
<h3 align="center">
Lightweight optimization with local, global, population-based and sequential techniques across mixed search spaces
</h3>
<p align="center">
<a href="https://github.com/SimonBlanke/Gradient-Free-Optimizers/actions"><img src="https://img.shields.io/github/actions/workflow/status/SimonBlanke/Gradient-Free-Optimizers/ci.yml?style=for-the-badge&logo=githubactions&logoColor=white&label=tests" alt="Tests"></a>
<a href="https://app.codecov.io/gh/SimonBlanke/Gradient-Free-Optimizers"><img src="https://img.shields.io/codecov/c/github/SimonBlanke/Gradient-Free-Optimizers?style=for-the-badge&logo=codecov&logoColor=white" alt="Coverage"></a>
</p>
<br>
<table align="center">
<tr>
<td align="right"><b>Documentation</b></td>
<td align="center">▸</td>
<td>
<a href="https://simonblanke.github.io/gradient-free-optimizers-documentation">Homepage</a> ·
<a href="https://simonblanke.github.io/gradient-free-optimizers-documentation/optimizers/">Optimizers</a> ·
<a href="https://simonblanke.github.io/gradient-free-optimizers-documentation/api/">API Reference</a> ·
<a href="https://simonblanke.github.io/gradient-free-optimizers-documentation/examples/">Examples</a>
</td>
</tr>
<tr>
<td align="right"><b>On this page</b></td>
<td align="center">▸</td>
<td>
<a href="#key-features">Features</a> ·
<a href="#examples">Examples</a> ·
<a href="#core-concepts">Concepts</a> ·
<a href="#citation">Citation</a>
</td>
</tr>
</table>
<br>
---
<a href="https://github.com/SimonBlanke/Gradient-Free-Optimizers">
<img src="./docs/gifs/3d_optimizer_animation.gif" width="240" align="right" alt="Bayesian Optimization on Ackley Function">
</a>
**Gradient-Free-Optimizers** is a Python library for gradient-free optimization of black-box functions. It provides a unified interface to 21 optimization algorithms, from simple hill climbing to Bayesian optimization, all operating on discrete numerical search spaces defined via NumPy arrays.
Designed for hyperparameter tuning, simulation optimization, and any scenario where gradients are unavailable or impractical. The library prioritizes simplicity: define your objective function, specify the search space, and run. It serves as the optimization backend for [Hyperactive](https://github.com/SimonBlanke/Hyperactive) but can also be used standalone.
<p>
<a href="https://www.linkedin.com/in/simonblanke/"><img src="https://img.shields.io/badge/LinkedIn-Follow-0A66C2?style=flat-square&logo=linkedin" alt="LinkedIn"></a>
</p>
<br>
## Installation
```bash
pip install gradient-free-optimizers
```
<p>
<a href="https://pypi.org/project/gradient-free-optimizers/"><img src="https://img.shields.io/pypi/v/gradient-free-optimizers?style=flat-square&color=blue" alt="PyPI"></a>
<a href="https://pypi.org/project/gradient-free-optimizers/"><img src="https://img.shields.io/pypi/pyversions/gradient-free-optimizers?style=flat-square" alt="Python"></a>
</p>
<details>
<summary>Optional dependencies</summary>
```bash
pip install gradient-free-optimizers[progress] # Progress bar with tqdm
pip install gradient-free-optimizers[sklearn] # scikit-learn for surrogate models
pip install gradient-free-optimizers[full] # All optional dependencies
```
</details>
<br>
## Key Features
<table>
<tr>
<td width="33%">
<a href="https://simonblanke.github.io/gradient-free-optimizers-documentation/optimizers/"><b>21 Optimization Algorithms</b></a><br>
<sub>Local, global, population-based, and sequential model-based optimizers. Switch algorithms with one line of code.</sub>
</td>
<td width="33%">
<a href="https://simonblanke.github.io/gradient-free-optimizers-documentation/api/"><b>Zero Configuration</b></a><br>
<sub>Sensible defaults for all parameters. Start optimizing immediately without tuning the optimizer itself.</sub>
</td>
<td width="33%">
<a href="https://simonblanke.github.io/gradient-free-optimizers-documentation/api/#memory"><b>Memory System</b></a><br>
<sub>Built-in caching prevents redundant evaluations. Critical for expensive objective functions like ML models.</sub>
</td>
</tr>
<tr>
<td width="33%">
<a href="https://simonblanke.github.io/gradient-free-optimizers-documentation/api/#search-space"><b>Discrete Search Spaces</b></a><br>
<sub>Define parameter spaces with familiar NumPy syntax using arrays and ranges.</sub>
</td>
<td width="33%">
<a href="https://simonblanke.github.io/gradient-free-optimizers-documentation/api/#constraints"><b>Constraints Support</b></a><br>
<sub>Define constraint functions to restrict the search space. Invalid regions are automatically avoided.</sub>
</td>
<td width="33%">
<a href="https://github.com/SimonBlanke/Gradient-Free-Optimizers"><b>Minimal Dependencies</b></a><br>
<sub>Only pandas required. Optional integrations for progress bars (tqdm) and surrogate models (scikit-learn).</sub>
</td>
</tr>
</table>
<br>
## Quick Start
```python
import numpy as np
from gradient_free_optimizers import HillClimbingOptimizer
# Define objective function (maximize)
def objective(params):
x, y = params["x"], params["y"]
return -(x**2 + y**2) # Negative paraboloid, optimum at (0, 0)
# Define search space
search_space = {
"x": np.arange(-5, 5, 0.1),
"y": np.arange(-5, 5, 0.1),
}
# Run optimization
opt = HillClimbingOptimizer(search_space)
opt.search(objective, n_iter=1000)
# Results
print(f"Best score: {opt.best_score}")
print(f"Best params: {opt.best_para}")
```
**Output:**
```
Best score: -0.02
Best params: {'x': 0.1, 'y': 0.1}
```
<br>
## Core Concepts
```mermaid
flowchart LR
O["Optimizer
━━━━━━━━━━
21 algorithms"]
S["Search Space
━━━━━━━━━━━━
NumPy arrays"]
F["Objective
━━━━━━━━━━
f(params) → score"]
D[("Search Data
━━━━━━━━━━━
history")]
O -->|propose| S
S -->|params| F
F -->|score| O
O -.-> D
D -.->|warm start| O
```
**Optimizer**: Implements the search strategy. Choose from 21 algorithms across four categories: local search, global search, population-based, and sequential model-based.
**Search Space**: Defines valid parameter combinations as NumPy arrays. Each key is a parameter name, each value is an array of allowed values.
**Objective Function**: Your function to maximize. Takes a dictionary of parameters, returns a score. Use negation to minimize.
**Search Data**: Complete history of all evaluations accessible via `opt.search_data` for analysis and warm-starting future searches.
<br>
## Examples
<details open>
<summary><b>Hyperparameter Optimization</b></summary>
```python
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_wine
import numpy as np
from gradient_free_optimizers import BayesianOptimizer
X, y = load_wine(return_X_y=True)
def objective(params):
model = GradientBoostingClassifier(
n_estimators=params["n_estimators"],
max_depth=params["max_depth"],
learning_rate=params["learning_rate"],
)
return cross_val_score(model, X, y, cv=5).mean()
search_space = {
"n_estimators": np.arange(50, 300, 10),
"max_depth": np.arange(2, 10),
"learning_rate": np.logspace(-3, 0, 20),
}
opt = BayesianOptimizer(search_space)
opt.search(objective, n_iter=50)
```
</details>
<details>
<summary><b>Bayesian Optimization</b></summary>
```python
import numpy as np
from gradient_free_optimizers import BayesianOptimizer
def ackley(params):
x, y = params["x"], params["y"]
return -(
-20 * np.exp(-0.2 * np.sqrt(0.5 * (x**2 + y**2)))
- np.exp(0.5 * (np.cos(2 * np.pi * x) + np.cos(2 * np.pi * y)))
+ np.e + 20
)
search_space = {
"x": np.arange(-5, 5, 0.01),
"y": np.arange(-5, 5, 0.01),
}
opt = BayesianOptimizer(search_space)
opt.search(ackley, n_iter=100)
```
</details>
<details>
<summary><b>Particle Swarm Optimization</b></summary>
```python
import numpy as np
from gradient_free_optimizers import ParticleSwarmOptimizer
def rastrigin(params):
A = 10
values = [params[f"x{i}"] for i in range(5)]
return -sum(v**2 - A * np.cos(2 * np.pi * v) + A for v in values)
search_space = {f"x{i}": np.arange(-5.12, 5.12, 0.1) for i in range(5)}
opt = ParticleSwarmOptimizer(search_space, population=20)
opt.search(rastrigin, n_iter=500)
```
</details>
<details>
<summary><b>Simulated Annealing</b></summary>
```python
import numpy as np
from gradient_free_optimizers import SimulatedAnnealingOptimizer
def sphere(params):
return -(params["x"]**2 + params["y"]**2)
search_space = {
"x": np.arange(-10, 10, 0.1),
"y": np.arange(-10, 10, 0.1),
}
opt = SimulatedAnnealingOptimizer(
search_space,
start_temp=1.2,
annealing_rate=0.99,
)
opt.search(sphere, n_iter=1000)
```
</details>
<details>
<summary><b>Constrained Optimization</b></summary>
```python
import numpy as np
from gradient_free_optimizers import RandomSearchOptimizer
def objective(params):
return params["x"] + params["y"]
def constraint(params):
# Only positions where x + y < 5 are valid
return params["x"] + params["y"] < 5
search_space = {
"x": np.arange(0, 10, 0.1),
"y": np.arange(0, 10, 0.1),
}
opt = RandomSearchOptimizer(search_space, constraints=[constraint])
opt.search(objective, n_iter=1000)
```
</details>
<br>
<details>
<summary><b>Memory and Warm Starting</b></summary>
```python
import numpy as np
from gradient_free_optimizers import HillClimbingOptimizer
def expensive_function(params):
# Simulating an expensive computation
return -(params["x"]**2 + params["y"]**2)
search_space = {
"x": np.arange(-10, 10, 0.1),
"y": np.arange(-10, 10, 0.1),
}
# First search
opt1 = HillClimbingOptimizer(search_space)
opt1.search(expensive_function, n_iter=100, memory=True)
# Continue with warm start using previous search data
opt2 = HillClimbingOptimizer(search_space)
opt2.search(expensive_function, n_iter=100, memory_warm_start=opt1.search_data)
```
</details>
<details>
<summary><b>Early Stopping</b></summary>
```python
import numpy as np
from gradient_free_optimizers import BayesianOptimizer
def objective(params):
return -(params["x"]**2 + params["y"]**2)
search_space = {
"x": np.arange(-10, 10, 0.1),
"y": np.arange(-10, 10, 0.1),
}
opt = BayesianOptimizer(search_space)
opt.search(
objective,
n_iter=1000,
max_time=60, # Stop after 60 seconds
max_score=-0.01, # Stop when score reaches -0.01
early_stopping={ # Stop if no improvement for 50 iterations
"n_iter_no_change": 50,
},
)
```
</details>
<br>
## Ecosystem
This library is part of a suite of optimization tools. For updates on these packages, [follow on GitHub](https://github.com/SimonBlanke).
| Package | Description |
|---------|-------------|
| [Hyperactive](https://github.com/SimonBlanke/Hyperactive) | Hyperparameter optimization framework with experiment abstraction and ML integrations |
| [Gradient-Free-Optimizers](https://github.com/SimonBlanke/Gradient-Free-Optimizers) | Core optimization algorithms for black-box function optimization |
| [Surfaces](https://github.com/SimonBlanke/Surfaces) | Test functions and benchmark surfaces for optimization algorithm evaluation |
<br>
## Documentation
| Resource | Description |
|----------|-------------|
| [User Guide](https://simonblanke.github.io/gradient-free-optimizers-documentation) | Comprehensive tutorials and explanations |
| [API Reference](https://simonblanke.github.io/gradient-free-optimizers-documentation/api/) | Complete API documentation |
| [Optimizers](https://simonblanke.github.io/gradient-free-optimizers-documentation/optimizers/) | Detailed description of all 21 algorithms |
| [Examples](https://simonblanke.github.io/gradient-free-optimizers-documentation/examples/) | Code examples for various use cases |
<br>
## Contributing
Contributions welcome! See [CONTRIBUTING.md](./CONTRIBUTING.md) for guidelines.
- **Bug reports**: [GitHub Issues](https://github.com/SimonBlanke/Gradient-Free-Optimizers/issues)
- **Feature requests**: [GitHub Discussions](https://github.com/SimonBlanke/Gradient-Free-Optimizers/discussions)
- **Questions**: [GitHub Issues](https://github.com/SimonBlanke/Gradient-Free-Optimizers/issues)
<br>
## Citation
If you use this software in your research, please cite:
```bibtex
@software{gradient_free_optimizers,
author = {Simon Blanke},
title = {Gradient-Free-Optimizers: Simple and reliable optimization with local, global, population-based and sequential techniques in numerical search spaces},
year = {2020},
url = {https://github.com/SimonBlanke/Gradient-Free-Optimizers},
}
```
<br>
## License
[MIT License](./LICENSE) - Free for commercial and academic use.
| text/markdown | null | Simon Blanke <simon.blanke@yahoo.com> | null | Simon Blanke <simon.blanke@yahoo.com> | null | optimization, hyperparameter-optimization, hyperparameter-tuning, machine-learning, meta-heuristic, bayesian-optimization, genetic-algorithm, particle-swarm, evolution-strategy, hill-climbing, simulated-annealing, gradient-free, black-box-optimization, numerical-optimization, automl, search-algorithms, optimization-algorithms, data-science, visualization | [
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Licen... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy<3.0.0,>=1.18.1",
"scipy<2.0.0",
"pandas<3.0.0",
"tqdm<5.0.0,>=4.48.0; extra == \"progress\"",
"scikit-learn!=0.23.*,>=0.21; extra == \"sklearn\"",
"scipy<2.0.0; extra == \"full\"",
"scikit-learn!=0.23.*,>=0.21; extra == \"full\"",
"tqdm<5.0.0,>=4.48.0; extra == \"full\"",
"setuptools; extra =... | [] | [] | [] | [
"Homepage, https://github.com/SimonBlanke/Gradient-Free-Optimizers",
"Bug Reports, https://github.com/SimonBlanke/Gradient-Free-Optimizers/issues",
"Source, https://github.com/SimonBlanke/Gradient-Free-Optimizers/"
] | twine/6.2.0 CPython/3.12.4 | 2026-02-19T19:05:36.452079 | gradient_free_optimizers-1.10.1-py3-none-any.whl | 385,407 | af/d0/0c2aaa6173accca6507d25a82c266af8c01d94138058e99712153d4296a6/gradient_free_optimizers-1.10.1-py3-none-any.whl | py3 | bdist_wheel | null | false | f5c02ed9de52e28ad99e14a755a5f937 | 20038c3434ececf8b1e615ef8ef863edcc156fe0fa6be51f82482be95da01144 | afd00c2aaa6173accca6507d25a82c266af8c01d94138058e99712153d4296a6 | null | [] | 1,384 |
2.4 | llama-stack-api | 0.5.1 | API and Provider specifications for Llama Stack - lightweight package with protocol definitions and provider specs | # llama-stack-api
API and Provider specifications for Llama Stack - a lightweight package with protocol definitions and provider specs.
## Overview
`llama-stack-api` is a minimal dependency package that contains:
- **API Protocol Definitions**: Type-safe protocol definitions for all Llama Stack APIs (inference, agents, safety, etc.)
- **Provider Specifications**: Provider spec definitions for building custom providers
- **Data Types**: Shared data types and models used across the Llama Stack ecosystem
- **Type Utilities**: Strong typing utilities and schema validation
## What This Package Does NOT Include
- Server implementation (see `llama-stack` package)
- Provider implementations (see `llama-stack` package)
- CLI tools (see `llama-stack` package)
- Runtime orchestration (see `llama-stack` package)
## Use Cases
This package is designed for:
1. **Third-party Provider Developers**: Build custom providers without depending on the full Llama Stack server
2. **Client Library Authors**: Use type definitions without server dependencies
3. **Documentation Generation**: Generate API docs from protocol definitions
4. **Type Checking**: Validate implementations against the official specs
## Installation
```bash
pip install llama-stack-api
```
Or with uv:
```bash
uv pip install llama-stack-api
```
## Dependencies
Minimal dependencies:
- `pydantic>=2.11.9` - For data validation and serialization
- `jsonschema` - For JSON schema utilities
## Versioning
This package follows semantic versioning independently from the main `llama-stack` package:
- **Patch versions** (0.1.x): Documentation, internal improvements
- **Minor versions** (0.x.0): New APIs, backward-compatible changes
- **Major versions** (x.0.0): Breaking changes to existing APIs
Current version: **0.4.0.dev0**
## Usage Example
```python
from llama_stack_api.inference import Inference, ChatCompletionRequest
from llama_stack_api.providers.datatypes import ProviderSpec, InlineProviderSpec
from llama_stack_api.datatypes import Api
# Use protocol definitions for type checking
class MyInferenceProvider(Inference):
async def chat_completion(self, request: ChatCompletionRequest):
# Your implementation
pass
# Define provider specifications
my_provider_spec = InlineProviderSpec(
api=Api.inference,
provider_type="inline::my-provider",
pip_packages=["my-dependencies"],
module="my_package.providers.inference",
config_class="my_package.providers.inference.MyConfig",
)
```
## Relationship to llama-stack
The main `llama-stack` package depends on `llama-stack-api` and provides:
- Full server implementation
- Built-in provider implementations
- CLI tools for running and managing stacks
- Runtime provider resolution and orchestration
## Contributing
See the main [Llama Stack repository](https://github.com/llamastack/llama-stack) for contribution guidelines.
## License
MIT License - see LICENSE file for details.
## Links
- [Main Llama Stack Repository](https://github.com/llamastack/llama-stack)
- [Documentation](https://llamastack.ai/)
- [Client Library](https://pypi.org/project/llama-stack-client/)
| text/markdown | null | Meta Llama <llama-oss@meta.com> | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Operating System :: OS Independent",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
... | [] | null | null | >=3.12 | [] | [] | [] | [
"openai>=2.5.0",
"fastapi<1.0,>=0.115.0",
"pydantic>=2.11.9",
"jsonschema",
"opentelemetry-sdk>=1.30.0",
"opentelemetry-exporter-otlp-proto-http>=1.30.0"
] | [] | [] | [] | [
"Homepage, https://github.com/llamastack/llama-stack"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:05:13.134902 | llama_stack_api-0.5.1.tar.gz | 126,367 | 54/37/dc1c678a25a5bfdd66093b9d462c4d9027199e827ae5dbdbfda2d6718967/llama_stack_api-0.5.1.tar.gz | source | sdist | null | false | 7e0f3afdd8b253d9162949b9bfc7f3d7 | a841121d009f16652a136c1109130c6553fd3d0e24e5e2750c9f9abc1ccdb411 | 5437dc1c678a25a5bfdd66093b9d462c4d9027199e827ae5dbdbfda2d6718967 | null | [] | 1,124 |
2.1 | zensvi | 1.4.5 | This package handles downloading, cleaning, analyzing street view imagery in a one-stop and zen manner. | [](https://pypi.org/project/zensvi/)
[](https://pypi.org/project/zensvi/)
[](https://pypi.org/project/zensvi/)
[](https://pepy.tech/project/zensvi)
[](https://pepy.tech/project/zensvi)
[](https://pepy.tech/project/zensvi)
[](https://zensvi.readthedocs.io/en/latest/?badge=latest)
[](https://codecov.io/gh/koito19960406/ZenSVI)
<p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/koito19960406/ZenSVI/main/docs/_static/logo_zensvi_white2.png">
<img src="https://raw.githubusercontent.com/koito19960406/ZenSVI/main/docs/_static/logo_zensvi_fixed%202.png" alt="ZenSVI logo" width="400">
</picture>
</p>
# ZenSVI
**Primary Author:** [Koichi Ito](https://koichiito.com/) (National University of Singapore)
Besides this documentation, we have published a [comprehensive paper](https://arxiv.org/abs/2412.18641) with detailed information and demonstration use cases. The paper provides in-depth insights into the package's architecture, features, and real-world applications.
ZenSVI is a comprehensive Python package for downloading, cleaning, and analyzing street view imagery. For more information about the package or to discuss potential collaborations, please visit my website at [koichiito.com](https://koichiito.com/). The source code is available on [GitHub](https://github.com/koito19960406/ZenSVI).
This package is a one-stop solution for downloading, cleaning, and analyzing street view imagery, with comprehensive API documentation available at [zensvi.readthedocs.io](https://zensvi.readthedocs.io/en/latest/autoapi/index.html).
## Table of Contents
- [ZenSVI](#zensvi)
- [Table of Contents](#table-of-contents)
- [Installation of `zensvi`](#installation-of-zensvi)
- [Installation of `pytorch` and `torchvision`](#installation-of-pytorch-and-torchvision)
- [Usage](#usage)
- [Downloading Street View Imagery](#downloading-street-view-imagery)
- [Analyzing Metadata of Mapillary Images](#analyzing-metadata-of-mapillary-images)
- [Running Segmentation](#running-segmentation)
- [Running Places365](#running-places365)
- [Running PlacePulse 2.0 Prediction](#running-placepulse-20-prediction)
- [Running Global Streetscapes Prediction](#running-global-streetscapes-prediction)
- [Running Grounding Object Detection](#running-grounding-object-detection)
- [Running Depth Estimation](#running-depth-estimation)
- [Running Embeddings](#running-embeddings)
- [Running Low-Level Feature Extraction](#running-low-level-feature-extraction)
- [Transforming Images](#transforming-images)
- [Creating Point Clouds from Images](#creating-point-clouds-from-images)
- [Visualizing Results](#visualizing-results)
- [Contributing](#contributing)
- [License](#license)
- [Credits](#credits)
## Installation of `zensvi`
```bash
$ pip install zensvi
```
## Installation of `pytorch` and `torchvision`
Since `zensvi` uses `pytorch` and `torchvision`, you may need to install them separately. Please refer to the [official website](https://pytorch.org/get-started/locally/) for installation instructions.
## Usage
### Downloading Street View Imagery
***Mapillary***
For downloading images from Mapillary, utilize the MLYDownloader. Ensure you have a Mapillary client ID:
```python
from zensvi.download import MLYDownloader
mly_api_key = "YOUR_OWN_MLY_API_KEY" # Please register your own Mapillary API key
downloader = MLYDownloader(mly_api_key=mly_api_key)
# with lat and lon:
downloader.download_svi("path/to/output_directory", lat=1.290270, lon=103.851959)
# with a csv file with lat and lon:
downloader.download_svi("path/to/output_directory", input_csv_file="path/to/csv_file.csv")
# with a shapefile:
downloader.download_svi("path/to/output_directory", input_shp_file="path/to/shapefile.shp")
# with a place name that works on OpenStreetMap:
downloader.download_svi("path/to/output_directory", input_place_name="Singapore")
```
***KartaView***
For downloading images from KartaView, utilize the KVDownloader:
```python
from zensvi.download import KVDownloader
downloader = KVDownloader()
# with lat and lon:
downloader.download_svi("path/to/output_directory", lat=1.290270, lon=103.851959)
# with a csv file with lat and lon:
downloader.download_svi("path/to/output_directory", input_csv_file="path/to/csv_file.csv")
# with a shapefile:
downloader.download_svi("path/to/output_directory", input_shp_file="path/to/shapefile.shp")
# with a place name that works on OpenStreetMap:
downloader.download_svi("path/to/output_directory", input_place_name="Singapore")
```
***Amsterdam***
For downloading images from Amsterdam, utilize the AMSDownloader:
```python
from zensvi.download import AMSDownloader
downloader = AMSDownloader()
# with lat and lon:
downloader.download_svi("path/to/output_directory", lat=4.899431, lon=52.379189)
# with a csv file with lat and lon:
downloader.download_svi("path/to/output_directory", input_csv_file="path/to/csv_file.csv")
# with a shapefile:
downloader.download_svi("path/to/output_directory", input_shp_file="path/to/shapefile.shp")
# with a place name that works on OpenStreetMap:
downloader.download_svi("path/to/output_directory", input_place_name="Amsterdam")
```
***Global Streetscapes***
For downloading the NUS Global Streetscapes dataset, utilize the GSDownloader:
```python
from zensvi.download import GSDownloader
downloader = GSDownloader()
# Download all data
downloader.download_all_data(local_dir="data/")
# Or download specific subsets
downloader.download_manual_labels(local_dir="manual_labels/")
downloader.download_train(local_dir="manual_labels/train/")
downloader.download_test(local_dir="manual_labels/test/")
downloader.download_img_tar(local_dir="manual_labels/img/")
```
### Analyzing Metadata of Mapillary Images
To analyze the metadata of Mapillary images, use the `MLYMetadata`:
```python
from zensvi.metadata import MLYMetadata
path_input = "path/to/input"
mly_metadata = MLYMetadata(path_input)
mly_metadata.compute_metadata(
unit="image", # unit of the metadata. Other options are "street" and "grid"
indicator_list="all", # list of indicators to compute. You can specify a list of indicators in space-separated format, e.g., "year month day" or "all" to compute all indicators
path_output="path/to/output" # path to the output file
)
```
### Running Segmentation
To perform image segmentation, use the `Segmenter`:
```python
from zensvi.cv import Segmenter
segmenter = Segmenter(dataset="cityscapes", # or "mapillary"
task="semantic" # or "panoptic"
)
segmenter.segment("path/to/input_directory",
dir_image_output = "path/to/image_output_directory",
dir_summary_output = "path/to/segmentation_summary_output"
)
```
### Running Places365
To perform scene classification, use the `ClassifierPlaces365`:
```python
from zensvi.cv import ClassifierPlaces365
# initialize the classifier
classifier = ClassifierPlaces365(
device="cpu", # device to use (either "cpu", "cuda", or "mps)
)
# set arguments
classifier = ClassifierPlaces365()
classifier.classify(
"path/to/input_directory",
dir_image_output="path/to/image_output_directory",
dir_summary_output="path/to/classification_summary_output"
)
```
### Running PlacePulse 2.0 Prediction
To predict the PlacePulse 2.0 score, use the `ClassifierPerception`:
```python
from zensvi.cv import ClassifierPerception
classifier = ClassifierPerception(
perception_study="safer", # Other options are "livelier", "wealthier", "more beautiful", "more boring", "more depressing"
)
dir_input = "path/to/input"
dir_summary_output = "path/to/summary_output"
classifier.classify(
dir_input,
dir_summary_output=dir_summary_output
)
```
You can also use the ViT version for perception classification:
```python
from zensvi.cv import ClassifierPerceptionViT
classifier = ClassifierPerceptionViT(
perception_study="safer", # Other options are "livelier", "wealthier", "more beautiful", "more boring", "more depressing"
)
dir_input = "path/to/input"
dir_summary_output = "path/to/summary_output"
classifier.classify(
dir_input,
dir_summary_output=dir_summary_output
)
```
### Running Global Streetscapes Prediction
To predict the Global Streetscapes indicators, use:
- `ClassifierGlare`: Whether the image contains glare
- `ClassifierLighting`: The lighting condition of the image
- `ClassifierPanorama`: Whether the image is a panorama
- `ClassifierPlatform`: Platform of the image
- `ClassifierQuality`: Quality of the image
- `ClassifierReflection`: Whether the image contains reflection
- `ClassifierViewDirection`: View direction of the image
- `ClassifierWeather`: Weather condition of the image
```python
from zensvi.cv import ClassifierGlare
classifier = ClassifierGlare()
dir_input = "path/to/input"
dir_summary_output = "path/to/summary_output"
classifier.classify(
dir_input,
dir_summary_output=dir_summary_output,
)
```
### Running Grounding Object Detection
To run grounding object detection on the images, use the `ObjectDetector`:
```python
from zensvi.cv import ObjectDetector
detector = ObjectDetector(
text_prompt="tree", # specify the object(s) (e.g., single type: "building", multi-type: "car . tree")
box_threshold=0.35, # confidence threshold for box detection
text_threshold=0.25 # confidence threshold for text
)
detector.detect_objects(
dir_input="path/to/image_input_directory",
dir_image_output="path/to/image_output_directory",
dir_summary_output="path/to/detection_summary_output",
save_format="json" # or "csv"
)
```
### Running Depth Estimation
To estimate the depth of the images, use the `DepthEstimator`:
```python
from zensvi.cv import DepthEstimator
depth_estimator = DepthEstimator(
device="cpu", # device to use (either "cpu", "cuda", or "mps")
task="relative", # task to perform (either "relative" or "absolute")
encoder="vitl", # encoder variant ("vits", "vitb", "vitl", "vitg")
max_depth=80.0 # maximum depth for absolute estimation (only used when task="absolute")
)
dir_input = "path/to/input"
dir_image_output = "path/to/image_output" # estimated depth map
depth_estimator.estimate_depth(
dir_input,
dir_image_output
)
```
### Running Embeddings
To generate embeddings and search for similar images, use the `Embeddings`:
```python
from zensvi.cv import Embeddings
emb = Embeddings(model_name="resnet-1", cuda=True)
emb.generate_embedding(
"path/to/image_directory",
"path/to/output_directory",
batch_size=1000,
)
results = emb.search_similar_images("path/to/target_image_file", "path/to/embeddings_directory", 20)
```
### Running Low-Level Feature Extraction
To extract low-level features, use the `get_low_level_features`:
```python
from zensvi.cv import get_low_level_features
get_low_level_features(
"path/to/input_directory",
dir_image_output="path/to/image_output_directory",
dir_summary_output="path/to/low_level_feature_summary_output"
)
```
### Transforming Images
Transform images from panoramic to perspective or fisheye views using the `ImageTransformer`:
```python
from zensvi.transform import ImageTransformer
dir_input = "path/to/input"
dir_output = "path/to/output"
image_transformer = ImageTransformer(
dir_input="path/to/input",
dir_output="path/to/output"
)
image_transformer.transform_images(
style_list="perspective equidistant_fisheye orthographic_fisheye stereographic_fisheye equisolid_fisheye", # list of projection styles in the form of a string separated by a space
FOV=90, # field of view
theta=120, # angle of view (horizontal)
phi=0, # angle of view (vertical)
aspects=(9, 16), # aspect ratio
show_size=100, # size of the image to show (i.e. scale factor)
use_upper_half=True, # use the upper half of the image for sky view factor calculation
)
```
### Creating Point Clouds from Images
To create a point cloud from images with depth information, use the `PointCloudProcessor`:
```python
from zensvi.transform import PointCloudProcessor
import pandas as pd
processor = PointCloudProcessor(
image_folder="path/to/image_directory",
depth_folder="path/to/depth_maps_directory",
output_coordinate_scale=45, # scaling factor for output coordinates
depth_max=255 # maximum depth value for normalization
)
# Create a DataFrame with image information
# The DataFrame should have columns similar to this structure:
data = pd.DataFrame({
"id": ["Y2y7An1aRCeA5Y4nW7ITrg", "VSsVjWlr4orKerabFRy-dQ"], # image identifiers
"heading": [3.627108491916069, 5.209303414492613], # heading in radians
"lat": [40.77363963371641, 40.7757528007], # latitude
"lon": [-73.95482278589579, -73.95668603003708], # longitude
"x_proj": [4979010.676803163, 4979321.30902424], # projected x coordinate
"y_proj": [-8232613.214232705, -8232820.629621736] # projected y coordinate
})
# Process images and save point clouds
processor.process_multiple_images(
data=data,
output_dir="path/to/output_directory",
save_format="ply" # output format, can be "pcd", "ply", "npz", or "csv"
)
```
### Creating Point Clouds from Images with VGGT
ZenSVI also supports generating 3D point clouds directly from a collection of images using the Visual Geometry Grounded Transformer (VGGT) model. VGGT is a powerful feed-forward neural network that can infer 3D geometry, including camera parameters and point clouds, from multiple views of a scene. This feature is particularly useful for reconstructing 3D scenes from unordered image collections.
**Installation for VGGT**
To use the VGGT-based point cloud generation, you need to initialize the `vggt` git submodule and install its specific dependencies.
1. **Initialize the git submodule:**
If you have cloned the ZenSVI repository, run the following command from the root directory to download the `vggt` submodule:
```bash
git submodule update --init --recursive
```
2. **Install dependencies:**
Install the required Python packages for `vggt`:
```bash
pip install -r src/zensvi/transform/vggt/requirements.txt
```
**Usage**
Once the setup is complete, you can use the `VGGTProcessor` to generate point clouds.
```python
from zensvi.transform import VGGTProcessor
# Initialize the processor. This will download the model weights if not cached.
# Note: VGGT requires a CUDA-enabled GPU.
vggt_processor = VGGTProcessor()
# Define input and output directories
dir_input = "path/to/your/images"
dir_output = "path/to/save/pointclouds"
# Process images to generate point clouds
# The processor will process images in batches and save the resulting point clouds as .ply files.
vggt_processor.process_images_to_pointcloud(
dir_input=dir_input,
dir_output=dir_output,
batch_size=1, # Adjust batch size based on your GPU memory
max_workers=4 # Adjust based on your system's capabilities
)
```
### Visualizing Results
To visualize the results, use the `plot_map`, `plot_image`, `plot_hist`, and `plot_kde` functions:
```python
from zensvi.visualization import plot_map, plot_image, plot_hist, plot_kde
# Plotting a map
plot_map(
path_pid="path/to/pid_file.csv", # path to the file containing latitudes and longitudes
variable_name="vegetation",
plot_type="point" # this can be either "point", "line", or "hexagon"
)
# Plotting images in a grid
plot_image(
dir_image_input="path/to/image_directory",
n_row=4, # number of rows
n_col=5 # number of columns
)
# Plotting a histogram
plot_hist(
dir_input="path/to/data.csv",
columns=["vegetation"], # list of column names to plot histograms for
title="Vegetation Distribution by Neighborhood"
)
# Plotting a kernel density estimate
plot_kde(
dir_input="path/to/data.csv",
columns=["vegetation"], # list of column names to plot KDEs for
title="Vegetation Density by Neighborhood"
)
```
## Contributing
Interested in contributing? Check out the contributing guidelines. Please note that this project is released with a Code of Conduct. By contributing to this project, you agree to abide by its terms.
## License
`zensvi` was created by Koichi Ito. It is licensed under the terms of the MIT License.
Please cite the following paper if you use `zensvi` in a scientific publication:
```bibtex
@article{2025_ceus_zensvi,
author = {Ito, Koichi and Zhu, Yihan and Abdelrahman, Mahmoud and Liang, Xiucheng and Fan, Zicheng and Hou, Yujun and Zhao, Tianhong and Ma, Rui and Fujiwara, Kunihiko and Ouyang, Jiani and Quintana, Matias and Biljecki, Filip},
doi = {10.1016/j.compenvurbsys.2025.102283},
journal = {Computers, Environment and Urban Systems},
pages = {102283},
title = {ZenSVI: An open-source software for the integrated acquisition, processing and analysis of street view imagery towards scalable urban science},
volume = {119},
year = {2025}
}
```
## Credits
- Logo design by [Kunihiko Fujiwara](https://ual.sg/author/kunihiko-fujiwara/)
- All the packages used in this package: [requirements.txt](requirements.txt)
--------------------------------------------------------------------------------
<br>
<br>
<p align="center">
<a href="https://ual.sg/">
<img src="https://raw.githubusercontent.com/koito19960406/ZenSVI/main/docs/_static/ualsg.jpeg" width = 55% alt="Logo">
</a>
</p>
| text/markdown | koito19960406 | null | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | <3.13,>=3.9 | [] | [] | [] | [
"Pillow>=10.0.0",
"geopandas<2.0,>=1.0.0",
"numpy<3.0,>=1.26.0",
"opencv-python>=4.5.3",
"osmnx>=2.0.0",
"pandas>=2.0.0",
"requests<3.0,>=2.32.0",
"Shapely<3.0,>=2.0.0",
"tqdm>=4.61.1",
"transformers>=4.40.0",
"networkx>=3.1",
"mapbox-vector-tile>=2.0.0",
"mercantile>=1.2.1",
"vt2geojson>=... | [] | [] | [] | [] | poetry/1.8.3 CPython/3.10.15 Darwin/25.3.0 | 2026-02-19T19:05:03.517232 | zensvi-1.4.5.tar.gz | 90,171,767 | 73/d6/54bf8c68f48a2000bb6582662b2c164a9e7c8586ff94fdbaac7728793ee6/zensvi-1.4.5.tar.gz | source | sdist | null | false | 5d466fd814162cb9de222543bc3f3960 | 243d7dd04bdc6de7929d0edf31481f8f000d98976853c3f19318bfdffdad297d | 73d654bf8c68f48a2000bb6582662b2c164a9e7c8586ff94fdbaac7728793ee6 | null | [] | 254 |
2.4 | boardlib | 0.14.1 | Utilities for interacting with climbing board APIs | # BoardLib 🧗♀️
Utilities for interacting with climbing board APIs.
## Installation 🦺
`python3 -m pip install boardlib`
## Usage ⌨️
Use `boardlib --help` for a full list of supported board names and feature flags.
### Databases 💾
To download the climb database for a given board:
`boardlib database <board_name> <database_path> --username <board_username>`
This command will first download a [sqlite](https://www.sqlite.org/index.html) database file to the given path. After downloading, the database will then use the sync API to synchronize it with the latest available data. The database will only contain the "shared," public data. User data is not synchronized. If a database already exists as `database_path`, the command will skip the download step and only perform the synchronization.
NOTE: The Moonboard is not currently supported for the database command. Contributions are welcome.
#### Supported Boards 🛹
All [Aurora Climbing](https://auroraclimbing.com/) based boards (Kilter, Tension, etc.).
### Logbooks 📚
First, use the `database` command to download the SQLite database file for the board of interest. The database is not required for any version of the Moonboard. Then download your logbook entries for a given board:
`boardlib logbook <board_name> --username=<board_username> --output=<output_file_name> --database-path=<database_path>`
This outputs a CSV file with the following fields:
```json
["board", "angle", "climb_name", "date", "logged_grade", "displayed_grade", "is_benchmark", "tries", "is_mirror", "sessions_count", "tries_total", "is_repeat", "is_ascent", "comment"]
```
#### Supported Boards 🛹
Currently all [Aurora Climbing](https://auroraclimbing.com/) based boards (Kilter, Tension, etc.) and the [Moonboard](https://moonboard.com/). The Moonboard web API currently appears to be broken for some iterations of the board, including 2016 and 2024.
### Images 📸
First, use the `database` command to download the SQLite database file for the board of interest. Then download the images for a given board:
`boardlib images <board_name> <database_file> <output_directory>`
This will fetch all of the images for the given board and place them in `output_directory`.
#### Supported Boards 🛹
All [Aurora Climbing](https://auroraclimbing.com/) based boards (Kilter, Tension, etc.).
## Bugs 🐞 and Feature Requests 🗒️
Please create an issue in the [issue tracker](https://github.com/lemeryfertitta/BoardLib/issues) to report bugs or request additional features. Contributions are welcome and appreciated.
| text/markdown | null | Luke Emery-Fertitta <lemeryfertitta@gmail.com> | null | null | null | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"bs4",
"pandas",
"requests"
] | [] | [] | [] | [
"Homepage, https://github.com/lemeryfertitta/BoardLib",
"Issues, https://github.com/lemeryfertitta/BoardLib/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:04:38.674109 | boardlib-0.14.1.tar.gz | 14,671 | a9/93/a7a908a208564a306a2219ec453ff47364b910f31d1108373a4e5ceb45de/boardlib-0.14.1.tar.gz | source | sdist | null | false | ee9cd74be8e3fce53d6b2fa4379ee425 | 7df85f56eaab0ee0acc264d3f392f6a4aa61dfa415fd33252fd804b6ed9fafe0 | a993a7a908a208564a306a2219ec453ff47364b910f31d1108373a4e5ceb45de | null | [
"LICENSE"
] | 234 |
2.4 | destack | 0.55.2 | Python client for Destack | # destack (Python)
Python client for Destack.
This package is published to PyPI as `destack`.
## Installation
```sh
pip install destack
```
## API
```python
from destack import create_client
client = create_client()
assert client.backend == "python"
assert client.version() == "0.55.2"
```
| text/markdown | Symbol Industries | null | null | null | MIT | compiler, destack, runtime, typescript | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Languag... | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/destack-sh/destack",
"Repository, https://github.com/destack-sh/destack",
"Issues, https://github.com/destack-sh/destack/issues"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T19:04:34.048981 | destack-0.55.2.tar.gz | 2,477 | 62/be/65451781927d1e872def8f14227e1eed990bf0c1463cb2e4bac4b399edf3/destack-0.55.2.tar.gz | source | sdist | null | false | 95ca4909dea08b5c90d4965d683a68f1 | 5fe769a439f659ba9ab6e7f0396b3249f5717840cccf16f1fd194a4fd0e9fb53 | 62be65451781927d1e872def8f14227e1eed990bf0c1463cb2e4bac4b399edf3 | null | [] | 234 |
2.4 | torchmodal | 0.1.0.5 | Differentiable Modal Logic for PyTorch — Modal Logical Neural Networks (MLNNs) | # torchmodal
Differentiable Modal Logic.

**Differentiable Modal Logic for PyTorch**
A PyTorch library implementing Modal Logical Neural Networks (MLNNs) — the first framework enabling differentiable reasoning over necessity and possibility by integrating neural networks with Kripke semantics from modal logic.
## Installation
```bash
pip install -e .
```
## Quick Start
```python
import torch
import torchmodal
from torchmodal import nn, KripkeModel
# Create a 3-world Kripke model with learnable accessibility
model = KripkeModel(
num_worlds=3,
accessibility=nn.LearnableAccessibility(3, init_bias=-2.0),
tau=0.1,
)
# Add propositions
model.add_proposition("safe", learnable=True)
model.add_proposition("online", learnable=False)
# Evaluate modal operators
A = model.get_accessibility()
box_safe = model.necessity("safe", A) # □(safe) — necessarily safe
dia_online = model.possibility("online", A) # ♢(online) — possibly online
# Compute contradiction loss
loss = model.contradiction_loss()
```
## Architecture
```
torchmodal/
├── __init__.py # Public API
├── functional.py # Stateless functional operators (like torch.nn.functional)
├── nn/
│ ├── operators.py # Softmin, Softmax, ConvPool modules
│ ├── connectives.py # Negation, Conjunction, Disjunction, Implication
│ ├── modal.py # Necessity (□), Possibility (♢) neurons
│ └── accessibility.py # Fixed, Learnable, Metric accessibility relations
├── kripke.py # KripkeModel, Proposition
├── losses.py # ContradictionLoss, ModalLoss, SparsityLoss, CrystallizationLoss
├── inference.py # Upward-downward bound propagation
├── systems.py # EpistemicOperator, DoxasticOperator, TemporalOperator, MultiAgentKripke
└── utils.py # Temperature annealing, accessibility builders, decoding
```
## Core Concepts
### Differentiable Kripke Semantics
A Kripke model M = ⟨W, R, V⟩ is realized as differentiable tensors:
- **W** (Worlds): A finite set of possible worlds — agents, time steps, or contexts
- **R** (Accessibility): A relation determining which worlds can "see" each other
- **V** (Valuation): Truth bounds [L, U] ⊆ [0, 1] for each proposition in each world
### Modal Operators
| Operator | Symbol | Semantics | Implementation |
|----------|--------|-----------|----------------|
| Necessity | □ | True in *all* accessible worlds | `softmin` over weighted implications |
| Possibility | ♢ | True in *some* accessible world | `softmax` over weighted conjunctions |
| Knowledge | K_a | Agent *a* knows ϕ | □ restricted to agent's row |
| Belief | B_a | Agent *a* believes ϕ | □ with non-reflexive access |
| Globally | G | ϕ at all future times | □ over temporal accessibility |
| Finally | F | ϕ at some future time | ♢ over temporal accessibility |
### Accessibility Relations
```python
# Fixed (deductive mode): enforce known rules
R = torchmodal.build_sudoku_accessibility(3)
access = nn.FixedAccessibility(R)
# Learnable direct matrix (small worlds)
access = nn.LearnableAccessibility(num_worlds=7, init_bias=-2.0)
# Metric learning (scales to 20,000+ worlds)
access = nn.MetricAccessibility(num_worlds=10000, embed_dim=64)
```
### Loss Functions
```python
# Combined modal loss: L_total = L_task + β * L_contra
criterion = torchmodal.ModalLoss(beta=0.3)
loss = criterion(task_loss, model.all_bounds())
# Sparsity regularization on accessibility
sparse_loss = torchmodal.SparsityLoss(lambda_sparse=0.05)
# Crystallization for SAT mode (forces crisp 0/1 assignments)
crystal_loss = torchmodal.CrystallizationLoss()
```
## Examples
All examples are self-contained scripts in [`examples/`](examples/) and can be run directly:
```bash
python examples/sudoku.py
```
| Example | Modal Logic | Description |
|---------|-------------|-------------|
| [`sudoku.py`](examples/sudoku.py) | □, CSP | 4x4 Sudoku via modal contradiction + crystallization |
| [`temporal_epistemic.py`](examples/temporal_epistemic.py) | K, G, F, K∘G | Learns epistemic accessibility to resolve contradictions |
| [`epistemic_trust.py`](examples/epistemic_trust.py) | K_a | Trust learning from promise-keeping behavior |
| [`doxastic_belief.py`](examples/doxastic_belief.py) | B_a | Belief calibration and hallucination detection |
| [`temporal_causal.py`](examples/temporal_causal.py) | □(cause → crash) | Root cause analysis in event traces |
| [`deontic_boundary.py`](examples/deontic_boundary.py) | O, P | Normative boundary learning (spoofing detection) |
| [`trust_erosion.py`](examples/trust_erosion.py) | Temporal + Deontic | Retroactive lie detection collapses trust |
| [`dialect_classification.py`](examples/dialect_classification.py) | □, ♢ thresholds | OOD detection — 89% Neutral recall trained only on AmE/BrE |
| [`axiom_ablation.py`](examples/axiom_ablation.py) | T, 4, B axioms | Effect of reflexivity/transitivity/symmetry on structure learning |
| [`scalability_ring.py`](examples/scalability_ring.py) | □, ♢ | Ring structure recovery with tau/top-k/learnable ablation |
### Epistemic Trust Learning (CaSiNo / Diplomacy)
```python
from torchmodal import MultiAgentKripke
# 7 agents (Diplomacy powers), 3 time steps
kripke = MultiAgentKripke(
num_agents=7,
num_steps=3,
learnable_epistemic=True,
init_bias=-2.0,
)
# Evaluate "agent knows claim is consistent over time"
K_G_claim = kripke.K_G(claim_bounds)
# Learn trust from contradiction minimization
A = kripke.get_epistemic_accessibility()
```
### Sudoku as Constraint Satisfaction
```python
import torchmodal
from torchmodal import KripkeModel, nn
# 81 worlds (cells), fixed Sudoku accessibility
R = torchmodal.build_sudoku_accessibility(3)
model = KripkeModel(
num_worlds=81,
accessibility=nn.FixedAccessibility(R),
)
# 9 propositions (digits)
for d in range(1, 10):
model.add_proposition(f"d{d}", learnable=True)
# Train with contradiction loss + crystallization
contra_loss = torchmodal.ContradictionLoss(squared=True)
crystal_loss = torchmodal.CrystallizationLoss()
```
### POS Tagging with Grammatical Guardrails
```python
from torchmodal import nn, functional as F
# 3-world structure: Real, Pessimistic, Exploratory
box = nn.Necessity(tau=0.1)
access = nn.LearnableAccessibility(3)
# Enforce axiom: □¬(DET_i ∧ VERB_{i+1})
A = access()
det_bounds = ... # from proposer network
verb_bounds = ...
conj = F.conjunction(det_bounds, verb_bounds)
neg_conj = F.negation(conj)
box_constraint = box(neg_conj, A) # must be high (true)
```
### Formula Graph Inference
```python
from torchmodal import FormulaGraph, upward_downward
graph = FormulaGraph()
graph.add_atomic("p")
graph.add_atomic("q")
graph.add_conjunction("p_and_q", "p", "q")
graph.add_necessity("box_p_and_q", "p_and_q")
# Initialize bounds
bounds = {
"p": torch.tensor([[0.8, 1.0], [0.3, 0.5], [0.9, 1.0]]),
"q": torch.tensor([[0.7, 0.9], [0.6, 0.8], [0.4, 0.6]]),
"p_and_q": torch.tensor([[0.0, 1.0], [0.0, 1.0], [0.0, 1.0]]),
"box_p_and_q": torch.tensor([[0.0, 1.0], [0.0, 1.0], [0.0, 1.0]]),
}
# Run inference
A = torch.eye(3) # reflexive accessibility
tightened = upward_downward(graph, bounds, A, tau=0.1)
```
## Two Learning Modes
| Mode | Fixed | Learned | Use Case |
|------|-------|---------|----------|
| **Deductive** | Accessibility R | Propositions V | POS guardrails, Sudoku, OOD detection |
| **Inductive** | Propositions V | Accessibility A_θ | Trust learning, social structure discovery |
## Citation
If you use torchmodal in your research, please cite:
```bibtex
@misc{sulc2025modallogicalneuralnetworks,
title={Modal Logical Neural Networks},
author={Antonin Sulc},
year={2025},
eprint={2512.03491},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2512.03491},
}
```
## License
MIT
## Authors
[Antonin Sulc](https://sulcantonin.github.io)
| text/markdown | null | Antonin Sulc <asulc@lbl.gov> | null | null | MIT | modal-logic, neurosymbolic, kripke-semantics, differentiable-reasoning, epistemic-logic, pytorch | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Languag... | [] | null | null | >=3.9 | [] | [] | [] | [
"torch>=2.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"mypy; extra == \"dev\"",
"ruff; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/sulcantonin/MLNN_public",
"Documentation, https://github.com/sulcantonin/MLNN_public",
"Repository, https://github.com/sulcantonin/MLNN_public"
] | twine/6.2.0 CPython/3.9.18 | 2026-02-19T19:04:32.452931 | torchmodal-0.1.0.5.tar.gz | 34,266 | 02/2f/f836f3194972fd895be1c66dd7c83a43e7a6d4af9bb2f08e533cb54a9c2d/torchmodal-0.1.0.5.tar.gz | source | sdist | null | false | 942e32b91990be5ae62ce6884df7b74c | 15bd935ed7da94a85b576c971b4adf6be2384e5f908b458a6fcdccac5c08aef0 | 022ff836f3194972fd895be1c66dd7c83a43e7a6d4af9bb2f08e533cb54a9c2d | null | [
"LICENSE"
] | 224 |
2.3 | llama-stack-client | 0.5.1 | The official Python library for the llama-stack-client API | # Llama Stack Client Python API library
[](https://pypi.org/project/llama_stack_client/) [](https://pypi.org/project/llama-stack-client/)
[](https://discord.gg/llama-stack)
The Llama Stack Client Python library provides convenient access to the Llama Stack Client REST API from any Python 3.12+
application. The library includes type definitions for all request params and response fields,
and offers both synchronous and asynchronous clients powered by [httpx](https://github.com/encode/httpx).
It is generated with [Stainless](https://www.stainlessapi.com/).
## Documentation
For starting up a Llama Stack server, please checkout our [Quickstart guide to start a Llama Stack server](https://llama-stack.readthedocs.io/en/latest/getting_started/index.html)
The REST API documentation can be found on [llama-stack API Reference](https://llama-stack.readthedocs.io/en/latest/references/api_reference/index.html). The full API of this library can be found in [api.md](https://github.com/llamastack/llama-stack-client-python/tree/main/api.md).
You can find more example apps with client SDKs to talk with the Llama Stack server in our [llama-stack-apps](https://github.com/meta-llama/llama-stack-apps/tree/main) repo.
## Installation
```sh
# install from PyPI
pip install '--pre llama_stack_client'
```
## Usage
The full API of this library can be found in [api.md](https://github.com/llamastack/llama-stack-client-python/tree/main/api.md). You may find basic client examples in our [llama-stack-apps](https://github.com/meta-llama/llama-stack-apps/tree/main) repo.
```python
from llama_stack_client import LlamaStackClient
client = LlamaStackClient()
models = client.models.list()
```
While you can provide an `api_key` keyword argument, we recommend using [python-dotenv](https://pypi.org/project/python-dotenv/) to add `LLAMA_STACK_CLIENT_API_KEY="My API Key"` to your `.env` file so that your API Key is not stored in source control.
After installing the `llama-stack-client` package, you can also use the [`llama-stack-client` CLI](https://github.com/meta-llama/llama-stack/tree/main/llama-stack-client) to interact with the Llama Stack server.
```bash
llama-stack-client inference chat-completion --message "hello, what model are you"
```
```python
OpenAIChatCompletion(
id="AmivnS0iMv-mmEE4_A0DK1T",
choices=[
OpenAIChatCompletionChoice(
finish_reason="stop",
index=0,
message=OpenAIChatCompletionChoiceMessageOpenAIAssistantMessageParam(
role="assistant",
content="Hello! I am an AI designed by Meta AI, and my model is a type of recurrent neural network (RNN) called a transformer. My specific architecture is based on the BERT (Bidirectional Encoder Representations from Transformers) model, which is a pre-trained language model that has been fine-tuned for a variety of natural language processing tasks.\n\nHere are some key details about my model:\n\n* **Model type:** Transformer-based language model\n* **Architecture:** BERT (Bidirectional Encoder Representations from Transformers)\n* **Training data:** A massive corpus of text data, including but not limited to:\n\t+ Web pages\n\t+ Books\n\t+ Articles\n\t+ Forums\n\t+ Social media platforms\n* **Parameters:** My model has approximately 1.5 billion parameters, which allows me to understand and generate human-like language.\n* **Capabilities:** I can perform a wide range of tasks, including but not limited to:\n\t+ Answering questions\n\t+ Generating text\n\t+ Translating languages\n\t+ Summarizing content\n\t+ Offering suggestions and ideas\n\nI'm constantly learning and improving, so please bear with me if I make any mistakes or don't quite understand what you're asking. How can I assist you today?",
name=None,
tool_calls=None,
function_call=None,
),
logprobs=OpenAIChatCompletionChoiceLogprobs(content=None, refusal=None),
)
],
created=1749825661,
model="Llama-3.3-70B-Instruct",
object="chat.completion",
system_fingerprint=None,
usage={
"completion_tokens": 258,
"prompt_tokens": 16,
"total_tokens": 274,
"completion_tokens_details": None,
"prompt_tokens_details": None,
},
service_tier=None,
)
```
## Async usage
Simply import `AsyncLlamaStackClient` instead of `LlamaStackClient` and use `await` with each API call:
```python
import asyncio
from llama_stack_client import AsyncLlamaStackClient
client = AsyncLlamaStackClient(
# defaults to "production".
environment="sandbox",
)
async def main() -> None:
models = await client.models.list()
asyncio.run(main())
```
Functionality between the synchronous and asynchronous clients is otherwise identical.
### With aiohttp
By default, the async client uses `httpx` for HTTP requests. However, for improved concurrency performance you may also use `aiohttp` as the HTTP backend.
You can enable this by installing `aiohttp`:
```sh
# install from PyPI
pip install '--pre llama_stack_client[aiohttp]'
```
Then you can enable it by instantiating the client with `http_client=DefaultAioHttpClient()`:
```python
import asyncio
from llama_stack_client import DefaultAioHttpClient
from llama_stack_client import AsyncLlamaStackClient
async def main() -> None:
async with AsyncLlamaStackClient(
http_client=DefaultAioHttpClient(),
) as client:
models = await client.models.list()
asyncio.run(main())
```
## Using types
Nested request parameters are [TypedDicts](https://docs.python.org/3/library/typing.html#typing.TypedDict). Responses are [Pydantic models](https://docs.pydantic.dev) which also provide helper methods for things like:
- Serializing back into JSON, `model.to_json()`
- Converting to a dictionary, `model.to_dict()`
Typed requests and responses provide autocomplete and documentation within your editor. If you would like to see type errors in VS Code to help catch bugs earlier, set `python.analysis.typeCheckingMode` to `basic`.
## Pagination
List methods in the Llama Stack Client API are paginated.
This library provides auto-paginating iterators with each list response, so you do not have to request successive pages manually:
```python
from llama_stack_client import LlamaStackClient
client = LlamaStackClient()
all_responses = []
# Automatically fetches more pages as needed.
for response in client.responses.list():
# Do something with response here
all_responses.append(response)
print(all_responses)
```
Or, asynchronously:
```python
import asyncio
from llama_stack_client import AsyncLlamaStackClient
client = AsyncLlamaStackClient()
async def main() -> None:
all_responses = []
# Iterate through items across all pages, issuing requests as needed.
async for response in client.responses.list():
all_responses.append(response)
print(all_responses)
asyncio.run(main())
```
Alternatively, you can use the `.has_next_page()`, `.next_page_info()`, or `.get_next_page()` methods for more granular control working with pages:
```python
first_page = await client.responses.list()
if first_page.has_next_page():
print(f"will fetch next page using these details: {first_page.next_page_info()}")
next_page = await first_page.get_next_page()
print(f"number of items we just fetched: {len(next_page.data)}")
# Remove `await` for non-async usage.
```
Or just work directly with the returned data:
```python
first_page = await client.responses.list()
print(f"next page cursor: {first_page.last_id}") # => "next page cursor: ..."
for response in first_page.data:
print(response.id)
# Remove `await` for non-async usage.
```
## Nested params
Nested parameters are dictionaries, typed using `TypedDict`, for example:
```python
from llama_stack_client import LlamaStackClient
client = LlamaStackClient()
client.toolgroups.register(
provider_id="provider_id",
toolgroup_id="toolgroup_id",
mcp_endpoint={"uri": "uri"},
)
```
## File uploads
Request parameters that correspond to file uploads can be passed as `bytes`, or a [`PathLike`](https://docs.python.org/3/library/os.html#os.PathLike) instance or a tuple of `(filename, contents, media type)`.
```python
from pathlib import Path
from llama_stack_client import LlamaStackClient
client = LlamaStackClient()
client.files.create(
file=Path("/path/to/file"),
purpose="assistants",
)
```
The async client uses the exact same interface. If you pass a [`PathLike`](https://docs.python.org/3/library/os.html#os.PathLike) instance, the file contents will be read asynchronously automatically.
## Handling errors
When the library is unable to connect to the API (for example, due to network connection problems or a timeout), a subclass of `llama_stack_client.APIConnectionError` is raised.
When the API returns a non-success status code (that is, 4xx or 5xx
response), a subclass of `llama_stack_client.APIStatusError` is raised, containing `status_code` and `response` properties.
All errors inherit from `llama_stack_client.APIError`.
```python
import llama_stack_client
from llama_stack_client import LlamaStackClient
client = LlamaStackClient()
try:
client.chat.completions.create(
messages=[
{
"content": "string",
"role": "user",
}
],
model="model",
)
except llama_stack_client.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # an underlying Exception, likely raised within httpx.
except llama_stack_client.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except llama_stack_client.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
```
Error codes are as followed:
| Status Code | Error Type |
| ----------- | -------------------------- |
| 400 | `BadRequestError` |
| 401 | `AuthenticationError` |
| 403 | `PermissionDeniedError` |
| 404 | `NotFoundError` |
| 422 | `UnprocessableEntityError` |
| 429 | `RateLimitError` |
| >=500 | `InternalServerError` |
| N/A | `APIConnectionError` |
### Retries
Certain errors are automatically retried 2 times by default, with a short exponential backoff.
Connection errors (for example, due to a network connectivity problem), 408 Request Timeout, 409 Conflict,
429 Rate Limit, and >=500 Internal errors are all retried by default.
You can use the `max_retries` option to configure or disable retry settings:
```python
from llama_stack_client import LlamaStackClient
# Configure the default for all requests:
client = LlamaStackClient(
# default is 2
max_retries=0,
)
# Or, configure per-request:
client.with_options(max_retries=5).chat.completions.create(
messages=[
{
"content": "string",
"role": "user",
}
],
model="model",
)
```
### Timeouts
By default requests time out after 1 minute. You can configure this with a `timeout` option,
which accepts a float or an [`httpx.Timeout`](https://www.python-httpx.org/advanced/#fine-tuning-the-configuration) object:
```python
from llama_stack_client import LlamaStackClient
# Configure the default for all requests:
client = LlamaStackClient(
# 20 seconds (default is 1 minute)
timeout=20.0,
)
# More granular control:
client = LlamaStackClient(
timeout=httpx.Timeout(60.0, read=5.0, write=10.0, connect=2.0),
)
# Override per-request:
client.with_options(timeout=5.0).chat.completions.create(
messages=[
{
"content": "string",
"role": "user",
}
],
model="model",
)
```
On timeout, an `APITimeoutError` is thrown.
Note that requests that time out are [retried twice by default](https://github.com/llamastack/llama-stack-client-python/tree/main/#retries).
## Advanced
### Logging
We use the standard library [`logging`](https://docs.python.org/3/library/logging.html) module.
You can enable logging by setting the environment variable `LLAMA_STACK_LOG` to `debug`.
```shell
$ export LLAMA_STACK_LOG=debug
```
### How to tell whether `None` means `null` or missing
In an API response, a field may be explicitly `null`, or missing entirely; in either case, its value is `None` in this library. You can differentiate the two cases with `.model_fields_set`:
```py
if response.my_field is None:
if 'my_field' not in response.model_fields_set:
print('Got json like {}, without a "my_field" key present at all.')
else:
print('Got json like {"my_field": null}.')
```
### Accessing raw response data (e.g. headers)
The "raw" Response object can be accessed by prefixing `.with_raw_response.` to any HTTP method call, e.g.,
```py
from llama_stack_client import LlamaStackClient
client = LlamaStackClient()
response = client.chat.completions.with_raw_response.create(
messages=[{
"content": "string",
"role": "user",
}],
model="model",
)
print(response.headers.get('X-My-Header'))
completion = response.parse() # get the object that `chat.completions.create()` would have returned
print(completion.id)
```
These methods return an [`APIResponse`](https://github.com/meta-llama/llama-stack-python/tree/main/src/llama_stack_client/_response.py) object.
The async client returns an [`AsyncAPIResponse`](https://github.com/meta-llama/llama-stack-python/tree/main/src/llama_stack_client/_response.py) with the same structure, the only difference being `await`able methods for reading the response content.
#### `.with_streaming_response`
The above interface eagerly reads the full response body when you make the request, which may not always be what you want.
To stream the response body, use `.with_streaming_response` instead, which requires a context manager and only reads the response body once you call `.read()`, `.text()`, `.json()`, `.iter_bytes()`, `.iter_text()`, `.iter_lines()` or `.parse()`. In the async client, these are async methods.
```python
with client.chat.completions.with_streaming_response.create(
messages=[
{
"content": "string",
"role": "user",
}
],
model="model",
) as response:
print(response.headers.get("X-My-Header"))
for line in response.iter_lines():
print(line)
```
The context manager is required so that the response will reliably be closed.
### Making custom/undocumented requests
This library is typed for convenient access to the documented API.
If you need to access undocumented endpoints, params, or response properties, the library can still be used.
#### Undocumented endpoints
To make requests to undocumented endpoints, you can make requests using `client.get`, `client.post`, and other
http verbs. Options on the client will be respected (such as retries) will be respected when making this
request.
```py
import httpx
response = client.post(
"/foo",
cast_to=httpx.Response,
body={"my_param": True},
)
print(response.headers.get("x-foo"))
```
#### Undocumented request params
If you want to explicitly send an extra param, you can do so with the `extra_query`, `extra_body`, and `extra_headers` request
options.
#### Undocumented response properties
To access undocumented response properties, you can access the extra fields like `response.unknown_prop`. You
can also get all the extra fields on the Pydantic model as a dict with
[`response.model_extra`](https://docs.pydantic.dev/latest/api/base_model/#pydantic.BaseModel.model_extra).
### Configuring the HTTP client
You can directly override the [httpx client](https://www.python-httpx.org/api/#client) to customize it for your use case, including:
- Support for proxies
- Custom transports
- Additional [advanced](https://www.python-httpx.org/advanced/clients/) functionality
```python
from llama_stack_client import LlamaStackClient, DefaultHttpxClient
client = LlamaStackClient(
# Or use the `LLAMA_STACK_CLIENT_BASE_URL` env var
base_url="http://my.test.server.example.com:8083",
http_client=DefaultHttpxClient(
proxies="http://my.test.proxy.example.com",
transport=httpx.HTTPTransport(local_address="0.0.0.0"),
),
)
```
You can also customize the client on a per-request basis by using `with_options()`:
```python
client.with_options(http_client=DefaultHttpxClient(...))
```
### Managing HTTP resources
By default the library closes underlying HTTP connections whenever the client is [garbage collected](https://docs.python.org/3/reference/datamodel.html#object.__del__). You can manually close the client using the `.close()` method if desired, or with a context manager that closes when exiting.
## Versioning
This package generally follows [SemVer](https://semver.org/spec/v2.0.0.html) conventions, though certain backwards-incompatible changes may be released as minor versions:
1. Changes that only affect static types, without breaking runtime behavior.
2. Changes to library internals which are technically public but not intended or documented for external use. _(Please open a GitHub issue to let us know if you are relying on such internals)_.
3. Changes that we do not expect to impact the vast majority of users in practice.
We take backwards-compatibility seriously and work hard to ensure you can rely on a smooth upgrade experience.
We are keen for your feedback; please open an [issue](https://www.github.com/meta-llama/llama-stack-python/issues) with questions, bugs, or suggestions.
### Determining the installed version
If you've upgraded to the latest version but aren't seeing any new features you were expecting then your python environment is likely still using an older version.
You can determine the version that is being used at runtime with:
```py
import llama_stack_client
print(llama_stack_client.__version__)
```
## Requirements
Python 3.12 or higher.
## License
This project is licensed under the MIT License - see the [LICENSE](https://github.com/llamastack/llama-stack-client-python/tree/main/LICENSE) file for details.
| text/markdown | null | Meta Llama <llama-oss@meta.com> | null | null | MIT | null | [
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: OS Independent",
"Operating System :: POSIX",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3.12",
"Pr... | [] | null | null | >=3.12 | [] | [] | [] | [
"anyio<5,>=3.5.0",
"click",
"distro<2,>=1.7.0",
"fire",
"httpx<1,>=0.23.0",
"pandas",
"prompt-toolkit",
"pyaml",
"pydantic<3,>=1.9.0",
"requests",
"rich",
"sniffio",
"termcolor",
"tqdm",
"typing-extensions<5,>=4.7",
"aiohttp; extra == \"aiohttp\"",
"httpx-aiohttp>=0.1.9; extra == \"a... | [] | [] | [] | [
"Homepage, https://github.com/llamastack/llama-stack-client-python",
"Repository, https://github.com/llamastack/llama-stack-client-python"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:04:18.542429 | llama_stack_client-0.5.1.tar.gz | 368,620 | 1a/7c/41e4c21efb52d564539b23475b102727cb920ac07390641ffa09e380855a/llama_stack_client-0.5.1.tar.gz | source | sdist | null | false | e142865cab3da1a6533537476f6d44de | 213abd8872b08ef63cc9809aa96862da55826c4d9397742a4d4eb8f43f550c97 | 1a7c41e4c21efb52d564539b23475b102727cb920ac07390641ffa09e380855a | null | [] | 911 |
2.4 | proj-flow | 0.26.5 | C++ project maintenance, automated | # Project Flow
[](https://github.com/mzdun/proj-flow/actions)
[](https://pypi.python.org/pypi/proj-flow)
[](https://pypi.python.org/pypi/proj-flow)
**Project Flow** aims at being a one-stop tool for C++ projects, from creating new
project, though building and verifying, all the way to publishing releases to
the repository. It will run a set of known steps and will happily consult your
project what do you want to call any subset of those steps.
Currently, it will make use of Conan for external dependencies, CMake presets
for config and build and GitHub CLI for releases.
## Installation
To create a new project with _Project Flow_, first install it using pip:
```sh
(.venv) $ pip install proj-flow
```
Every project created with _Project Flow_ has a self-bootstrapping helper script,
which will install `proj-flow` if it is needed, using either current virtual
environment or switching to a private virtual environment (created inside
`.flow/.venv` directory). This is used by the GitHub workflow in the generated
projects through the `bootstrap` command.
On any platform, this command (and any other) may be called from the root of the
project with:
```sh
python .flow/flow.py bootstrap
```
From Bash with:
```sh
./flow bootstrap
```
From PowerShell with:
```sh
.\flow bootstrap
```
## Creating a project
A fresh C++ project can be created with a
```sh
proj-flow init cxx
```
This command will ask multiple questions to build Mustache context for the
project template. For more information, see [the documentation](https://proj-flow.readthedocs.io/en/latest/).
| text/markdown | null | Marcin Zdun <marcin.zdun@gmail.com> | null | null | null | C/C++, build-tool, c++, ci-cd, continuous-integration, cpp, dependencies, dependency-manager, developer, developer-tools, development, meta-build-tool, pipeline, tools-and-automation | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Topic :: Software Development :: Build Tools"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"argcomplete~=3.5",
"chevron2021",
"prompt-toolkit~=3.0",
"python-dateutil~=2.9",
"pywebidl2~=0.1",
"pyyaml~=6.0",
"requests-cache~=1.3",
"toml~=0.10",
"black~=25.0; extra == \"dev\"",
"build~=1.4; extra == \"dev\"",
"isort~=6.0; extra == \"dev\"",
"sphinx~=9.1; extra == \"dev\"",
"twine<=6.... | [] | [] | [] | [
"Changelog, https://github.com/mzdun/proj-flow/blob/main/CHANGELOG.rst",
"Documentation, https://proj-flow.readthedocs.io/en/latest/",
"Homepage, https://pypi.org/project/proj-flow/",
"Source Code, https://github.com/mzdun/proj-flow"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:04:13.367416 | proj_flow-0.26.5.tar.gz | 162,814 | c7/e7/d5fc8bf8b3b9e7f4520b7f7a79411609aea07543511e580d9c2087350abb/proj_flow-0.26.5.tar.gz | source | sdist | null | false | 7319fc0cdfe6af66197f8468cdcee7fc | 5752be56a4c1f898f675b133a015c417cb596bb50aa989ed701bbe5997b6f62a | c7e7d5fc8bf8b3b9e7f4520b7f7a79411609aea07543511e580d9c2087350abb | MIT | [
"LICENSE"
] | 464 |
2.4 | regex | 2026.2.19 | Alternative regular expression module, to replace re. | Introduction
------------
This regex implementation is backwards-compatible with the standard 're' module, but offers additional functionality.
Python 2
--------
Python 2 is no longer supported. The last release that supported Python 2 was 2021.11.10.
PyPy
----
This module is targeted at CPython. It expects that all codepoints are the same width, so it won't behave properly with PyPy outside U+0000..U+007F because PyPy stores strings as UTF-8.
Multithreading
--------------
The regex module releases the GIL during matching on instances of the built-in (immutable) string classes, enabling other Python threads to run concurrently. It is also possible to force the regex module to release the GIL during matching by calling the matching methods with the keyword argument ``concurrent=True``. The behaviour is undefined if the string changes during matching, so use it *only* when it is guaranteed that that won't happen.
Unicode
-------
This module supports Unicode 17.0.0. Full Unicode case-folding is supported.
Flags
-----
There are 2 kinds of flag: scoped and global. Scoped flags can apply to only part of a pattern and can be turned on or off; global flags apply to the entire pattern and can only be turned on.
The scoped flags are: ``ASCII (?a)``, ``FULLCASE (?f)``, ``IGNORECASE (?i)``, ``LOCALE (?L)``, ``MULTILINE (?m)``, ``DOTALL (?s)``, ``UNICODE (?u)``, ``VERBOSE (?x)``, ``WORD (?w)``.
The global flags are: ``BESTMATCH (?b)``, ``ENHANCEMATCH (?e)``, ``POSIX (?p)``, ``REVERSE (?r)``, ``VERSION0 (?V0)``, ``VERSION1 (?V1)``.
If neither the ``ASCII``, ``LOCALE`` nor ``UNICODE`` flag is specified, it will default to ``UNICODE`` if the regex pattern is a Unicode string and ``ASCII`` if it's a bytestring.
The ``ENHANCEMATCH`` flag makes fuzzy matching attempt to improve the fit of the next match that it finds.
The ``BESTMATCH`` flag makes fuzzy matching search for the best match instead of the next match.
Old vs new behaviour
--------------------
In order to be compatible with the re module, this module has 2 behaviours:
* **Version 0** behaviour (old behaviour, compatible with the re module):
Please note that the re module's behaviour may change over time, and I'll endeavour to match that behaviour in version 0.
* Indicated by the ``VERSION0`` flag.
* Zero-width matches are not handled correctly in the re module before Python 3.7. The behaviour in those earlier versions is:
* ``.split`` won't split a string at a zero-width match.
* ``.sub`` will advance by one character after a zero-width match.
* Inline flags apply to the entire pattern, and they can't be turned off.
* Only simple sets are supported.
* Case-insensitive matches in Unicode use simple case-folding by default.
* **Version 1** behaviour (new behaviour, possibly different from the re module):
* Indicated by the ``VERSION1`` flag.
* Zero-width matches are handled correctly.
* Inline flags apply to the end of the group or pattern, and they can be turned off.
* Nested sets and set operations are supported.
* Case-insensitive matches in Unicode use full case-folding by default.
If no version is specified, the regex module will default to ``regex.DEFAULT_VERSION``.
Case-insensitive matches in Unicode
-----------------------------------
The regex module supports both simple and full case-folding for case-insensitive matches in Unicode. Use of full case-folding can be turned on using the ``FULLCASE`` flag. Please note that this flag affects how the ``IGNORECASE`` flag works; the ``FULLCASE`` flag itself does not turn on case-insensitive matching.
Version 0 behaviour: the flag is off by default.
Version 1 behaviour: the flag is on by default.
Nested sets and set operations
------------------------------
It's not possible to support both simple sets, as used in the re module, and nested sets at the same time because of a difference in the meaning of an unescaped ``"["`` in a set.
For example, the pattern ``[[a-z]--[aeiou]]`` is treated in the version 0 behaviour (simple sets, compatible with the re module) as:
* Set containing "[" and the letters "a" to "z"
* Literal "--"
* Set containing letters "a", "e", "i", "o", "u"
* Literal "]"
but in the version 1 behaviour (nested sets, enhanced behaviour) as:
* Set which is:
* Set containing the letters "a" to "z"
* but excluding:
* Set containing the letters "a", "e", "i", "o", "u"
Version 0 behaviour: only simple sets are supported.
Version 1 behaviour: nested sets and set operations are supported.
Notes on named groups
---------------------
All groups have a group number, starting from 1.
Groups with the same group name will have the same group number, and groups with a different group name will have a different group number.
The same name can be used by more than one group, with later captures 'overwriting' earlier captures. All the captures of the group will be available from the ``captures`` method of the match object.
Group numbers will be reused across different branches of a branch reset, eg. ``(?|(first)|(second))`` has only group 1. If groups have different group names then they will, of course, have different group numbers, eg. ``(?|(?P<foo>first)|(?P<bar>second))`` has group 1 ("foo") and group 2 ("bar").
In the regex ``(\s+)(?|(?P<foo>[A-Z]+)|(\w+) (?P<foo>[0-9]+)`` there are 2 groups:
* ``(\s+)`` is group 1.
* ``(?P<foo>[A-Z]+)`` is group 2, also called "foo".
* ``(\w+)`` is group 2 because of the branch reset.
* ``(?P<foo>[0-9]+)`` is group 2 because it's called "foo".
If you want to prevent ``(\w+)`` from being group 2, you need to name it (different name, different group number).
Additional features
-------------------
The issue numbers relate to the Python bug tracker, except where listed otherwise.
Added ``\p{Horiz_Space}`` and ``\p{Vert_Space}`` (`GitHub issue 477 <https://github.com/mrabarnett/mrab-regex/issues/477#issuecomment-1216779547>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``\p{Horiz_Space}`` or ``\p{H}`` matches horizontal whitespace and ``\p{Vert_Space}`` or ``\p{V}`` matches vertical whitespace.
Added support for lookaround in conditional pattern (`Hg issue 163 <https://github.com/mrabarnett/mrab-regex/issues/163>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
The test of a conditional pattern can be a lookaround.
.. sourcecode:: python
>>> regex.match(r'(?(?=\d)\d+|\w+)', '123abc')
<regex.Match object; span=(0, 3), match='123'>
>>> regex.match(r'(?(?=\d)\d+|\w+)', 'abc123')
<regex.Match object; span=(0, 6), match='abc123'>
This is not quite the same as putting a lookaround in the first branch of a pair of alternatives.
.. sourcecode:: python
>>> print(regex.match(r'(?:(?=\d)\d+\b|\w+)', '123abc'))
<regex.Match object; span=(0, 6), match='123abc'>
>>> print(regex.match(r'(?(?=\d)\d+\b|\w+)', '123abc'))
None
In the first example, the lookaround matched, but the remainder of the first branch failed to match, and so the second branch was attempted, whereas in the second example, the lookaround matched, and the first branch failed to match, but the second branch was **not** attempted.
Added POSIX matching (leftmost longest) (`Hg issue 150 <https://github.com/mrabarnett/mrab-regex/issues/150>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
The POSIX standard for regex is to return the leftmost longest match. This can be turned on using the ``POSIX`` flag.
.. sourcecode:: python
>>> # Normal matching.
>>> regex.search(r'Mr|Mrs', 'Mrs')
<regex.Match object; span=(0, 2), match='Mr'>
>>> regex.search(r'one(self)?(selfsufficient)?', 'oneselfsufficient')
<regex.Match object; span=(0, 7), match='oneself'>
>>> # POSIX matching.
>>> regex.search(r'(?p)Mr|Mrs', 'Mrs')
<regex.Match object; span=(0, 3), match='Mrs'>
>>> regex.search(r'(?p)one(self)?(selfsufficient)?', 'oneselfsufficient')
<regex.Match object; span=(0, 17), match='oneselfsufficient'>
Note that it will take longer to find matches because when it finds a match at a certain position, it won't return that immediately, but will keep looking to see if there's another longer match there.
Added ``(?(DEFINE)...)`` (`Hg issue 152 <https://github.com/mrabarnett/mrab-regex/issues/152>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
If there's no group called "DEFINE", then ... will be ignored except that any groups defined within it can be called and that the normal rules for numbering groups still apply.
.. sourcecode:: python
>>> regex.search(r'(?(DEFINE)(?P<quant>\d+)(?P<item>\w+))(?&quant) (?&item)', '5 elephants')
<regex.Match object; span=(0, 11), match='5 elephants'>
Added ``(*PRUNE)``, ``(*SKIP)`` and ``(*FAIL)`` (`Hg issue 153 <https://github.com/mrabarnett/mrab-regex/issues/153>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``(*PRUNE)`` discards the backtracking info up to that point. When used in an atomic group or a lookaround, it won't affect the enclosing pattern.
``(*SKIP)`` is similar to ``(*PRUNE)``, except that it also sets where in the text the next attempt to match will start. When used in an atomic group or a lookaround, it won't affect the enclosing pattern.
``(*FAIL)`` causes immediate backtracking. ``(*F)`` is a permitted abbreviation.
Added ``\K`` (`Hg issue 151 <https://github.com/mrabarnett/mrab-regex/issues/151>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Keeps the part of the entire match after the position where ``\K`` occurred; the part before it is discarded.
It does not affect what groups return.
.. sourcecode:: python
>>> m = regex.search(r'(\w\w\K\w\w\w)', 'abcdef')
>>> m[0]
'cde'
>>> m[1]
'abcde'
>>>
>>> m = regex.search(r'(?r)(\w\w\K\w\w\w)', 'abcdef')
>>> m[0]
'bc'
>>> m[1]
'bcdef'
Added capture subscripting for ``expandf`` and ``subf``/``subfn`` (`Hg issue 133 <https://github.com/mrabarnett/mrab-regex/issues/133>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
You can use subscripting to get the captures of a repeated group.
.. sourcecode:: python
>>> m = regex.match(r"(\w)+", "abc")
>>> m.expandf("{1}")
'c'
>>> m.expandf("{1[0]} {1[1]} {1[2]}")
'a b c'
>>> m.expandf("{1[-1]} {1[-2]} {1[-3]}")
'c b a'
>>>
>>> m = regex.match(r"(?P<letter>\w)+", "abc")
>>> m.expandf("{letter}")
'c'
>>> m.expandf("{letter[0]} {letter[1]} {letter[2]}")
'a b c'
>>> m.expandf("{letter[-1]} {letter[-2]} {letter[-3]}")
'c b a'
Added support for referring to a group by number using ``(?P=...)``
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
This is in addition to the existing ``\g<...>``.
Fixed the handling of locale-sensitive regexes
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
The ``LOCALE`` flag is intended for legacy code and has limited support. You're still recommended to use Unicode instead.
Added partial matches (`Hg issue 102 <https://github.com/mrabarnett/mrab-regex/issues/102>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
A partial match is one that matches up to the end of string, but that string has been truncated and you want to know whether a complete match could be possible if the string had not been truncated.
Partial matches are supported by ``match``, ``search``, ``fullmatch`` and ``finditer`` with the ``partial`` keyword argument.
Match objects have a ``partial`` attribute, which is ``True`` if it's a partial match.
For example, if you wanted a user to enter a 4-digit number and check it character by character as it was being entered:
.. sourcecode:: python
>>> pattern = regex.compile(r'\d{4}')
>>> # Initially, nothing has been entered:
>>> print(pattern.fullmatch('', partial=True))
<regex.Match object; span=(0, 0), match='', partial=True>
>>> # An empty string is OK, but it's only a partial match.
>>> # The user enters a letter:
>>> print(pattern.fullmatch('a', partial=True))
None
>>> # It'll never match.
>>> # The user deletes that and enters a digit:
>>> print(pattern.fullmatch('1', partial=True))
<regex.Match object; span=(0, 1), match='1', partial=True>
>>> # It matches this far, but it's only a partial match.
>>> # The user enters 2 more digits:
>>> print(pattern.fullmatch('123', partial=True))
<regex.Match object; span=(0, 3), match='123', partial=True>
>>> # It matches this far, but it's only a partial match.
>>> # The user enters another digit:
>>> print(pattern.fullmatch('1234', partial=True))
<regex.Match object; span=(0, 4), match='1234'>
>>> # It's a complete match.
>>> # If the user enters another digit:
>>> print(pattern.fullmatch('12345', partial=True))
None
>>> # It's no longer a match.
>>> # This is a partial match:
>>> pattern.match('123', partial=True).partial
True
>>> # This is a complete match:
>>> pattern.match('1233', partial=True).partial
False
``*`` operator not working correctly with sub() (`Hg issue 106 <https://github.com/mrabarnett/mrab-regex/issues/106>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Sometimes it's not clear how zero-width matches should be handled. For example, should ``.*`` match 0 characters directly after matching >0 characters?
.. sourcecode:: python
>>> regex.sub('.*', 'x', 'test')
'xx'
>>> regex.sub('.*?', '|', 'test')
'|||||||||'
Added ``capturesdict`` (`Hg issue 86 <https://github.com/mrabarnett/mrab-regex/issues/86>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``capturesdict`` is a combination of ``groupdict`` and ``captures``:
``groupdict`` returns a dict of the named groups and the last capture of those groups.
``captures`` returns a list of all the captures of a group
``capturesdict`` returns a dict of the named groups and lists of all the captures of those groups.
.. sourcecode:: python
>>> m = regex.match(r"(?:(?P<word>\w+) (?P<digits>\d+)\n)+", "one 1\ntwo 2\nthree 3\n")
>>> m.groupdict()
{'word': 'three', 'digits': '3'}
>>> m.captures("word")
['one', 'two', 'three']
>>> m.captures("digits")
['1', '2', '3']
>>> m.capturesdict()
{'word': ['one', 'two', 'three'], 'digits': ['1', '2', '3']}
Added ``allcaptures`` and ``allspans`` (`Git issue 474 <https://github.com/mrabarnett/mrab-regex/issues/474>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``allcaptures`` returns a list of all the captures of all the groups.
``allspans`` returns a list of all the spans of the all captures of all the groups.
.. sourcecode:: python
>>> m = regex.match(r"(?:(?P<word>\w+) (?P<digits>\d+)\n)+", "one 1\ntwo 2\nthree 3\n")
>>> m.allcaptures()
(['one 1\ntwo 2\nthree 3\n'], ['one', 'two', 'three'], ['1', '2', '3'])
>>> m.allspans()
([(0, 20)], [(0, 3), (6, 9), (12, 17)], [(4, 5), (10, 11), (18, 19)])
Allow duplicate names of groups (`Hg issue 87 <https://github.com/mrabarnett/mrab-regex/issues/87>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Group names can be duplicated.
.. sourcecode:: python
>>> # With optional groups:
>>>
>>> # Both groups capture, the second capture 'overwriting' the first.
>>> m = regex.match(r"(?P<item>\w+)? or (?P<item>\w+)?", "first or second")
>>> m.group("item")
'second'
>>> m.captures("item")
['first', 'second']
>>> # Only the second group captures.
>>> m = regex.match(r"(?P<item>\w+)? or (?P<item>\w+)?", " or second")
>>> m.group("item")
'second'
>>> m.captures("item")
['second']
>>> # Only the first group captures.
>>> m = regex.match(r"(?P<item>\w+)? or (?P<item>\w+)?", "first or ")
>>> m.group("item")
'first'
>>> m.captures("item")
['first']
>>>
>>> # With mandatory groups:
>>>
>>> # Both groups capture, the second capture 'overwriting' the first.
>>> m = regex.match(r"(?P<item>\w*) or (?P<item>\w*)?", "first or second")
>>> m.group("item")
'second'
>>> m.captures("item")
['first', 'second']
>>> # Again, both groups capture, the second capture 'overwriting' the first.
>>> m = regex.match(r"(?P<item>\w*) or (?P<item>\w*)", " or second")
>>> m.group("item")
'second'
>>> m.captures("item")
['', 'second']
>>> # And yet again, both groups capture, the second capture 'overwriting' the first.
>>> m = regex.match(r"(?P<item>\w*) or (?P<item>\w*)", "first or ")
>>> m.group("item")
''
>>> m.captures("item")
['first', '']
Added ``fullmatch`` (`issue #16203 <https://bugs.python.org/issue16203>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``fullmatch`` behaves like ``match``, except that it must match all of the string.
.. sourcecode:: python
>>> print(regex.fullmatch(r"abc", "abc").span())
(0, 3)
>>> print(regex.fullmatch(r"abc", "abcx"))
None
>>> print(regex.fullmatch(r"abc", "abcx", endpos=3).span())
(0, 3)
>>> print(regex.fullmatch(r"abc", "xabcy", pos=1, endpos=4).span())
(1, 4)
>>>
>>> regex.match(r"a.*?", "abcd").group(0)
'a'
>>> regex.fullmatch(r"a.*?", "abcd").group(0)
'abcd'
Added ``subf`` and ``subfn``
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``subf`` and ``subfn`` are alternatives to ``sub`` and ``subn`` respectively. When passed a replacement string, they treat it as a format string.
.. sourcecode:: python
>>> regex.subf(r"(\w+) (\w+)", "{0} => {2} {1}", "foo bar")
'foo bar => bar foo'
>>> regex.subf(r"(?P<word1>\w+) (?P<word2>\w+)", "{word2} {word1}", "foo bar")
'bar foo'
Added ``expandf`` to match object
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``expandf`` is an alternative to ``expand``. When passed a replacement string, it treats it as a format string.
.. sourcecode:: python
>>> m = regex.match(r"(\w+) (\w+)", "foo bar")
>>> m.expandf("{0} => {2} {1}")
'foo bar => bar foo'
>>>
>>> m = regex.match(r"(?P<word1>\w+) (?P<word2>\w+)", "foo bar")
>>> m.expandf("{word2} {word1}")
'bar foo'
Detach searched string
^^^^^^^^^^^^^^^^^^^^^^
A match object contains a reference to the string that was searched, via its ``string`` attribute. The ``detach_string`` method will 'detach' that string, making it available for garbage collection, which might save valuable memory if that string is very large.
.. sourcecode:: python
>>> m = regex.search(r"\w+", "Hello world")
>>> print(m.group())
Hello
>>> print(m.string)
Hello world
>>> m.detach_string()
>>> print(m.group())
Hello
>>> print(m.string)
None
Recursive patterns (`Hg issue 27 <https://github.com/mrabarnett/mrab-regex/issues/27>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Recursive and repeated patterns are supported.
``(?R)`` or ``(?0)`` tries to match the entire regex recursively. ``(?1)``, ``(?2)``, etc, try to match the relevant group.
``(?&name)`` tries to match the named group.
.. sourcecode:: python
>>> regex.match(r"(Tarzan|Jane) loves (?1)", "Tarzan loves Jane").groups()
('Tarzan',)
>>> regex.match(r"(Tarzan|Jane) loves (?1)", "Jane loves Tarzan").groups()
('Jane',)
>>> m = regex.search(r"(\w)(?:(?R)|(\w?))\1", "kayak")
>>> m.group(0, 1, 2)
('kayak', 'k', None)
The first two examples show how the subpattern within the group is reused, but is _not_ itself a group. In other words, ``"(Tarzan|Jane) loves (?1)"`` is equivalent to ``"(Tarzan|Jane) loves (?:Tarzan|Jane)"``.
It's possible to backtrack into a recursed or repeated group.
You can't call a group if there is more than one group with that group name or group number (``"ambiguous group reference"``).
The alternative forms ``(?P>name)`` and ``(?P&name)`` are also supported.
Full Unicode case-folding is supported
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
In version 1 behaviour, the regex module uses full case-folding when performing case-insensitive matches in Unicode.
.. sourcecode:: python
>>> regex.match(r"(?iV1)strasse", "stra\N{LATIN SMALL LETTER SHARP S}e").span()
(0, 6)
>>> regex.match(r"(?iV1)stra\N{LATIN SMALL LETTER SHARP S}e", "STRASSE").span()
(0, 7)
In version 0 behaviour, it uses simple case-folding for backward compatibility with the re module.
Approximate "fuzzy" matching (`Hg issue 12 <https://github.com/mrabarnett/mrab-regex/issues/12>`_, `Hg issue 41 <https://github.com/mrabarnett/mrab-regex/issues/41>`_, `Hg issue 109 <https://github.com/mrabarnett/mrab-regex/issues/109>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Regex usually attempts an exact match, but sometimes an approximate, or "fuzzy", match is needed, for those cases where the text being searched may contain errors in the form of inserted, deleted or substituted characters.
A fuzzy regex specifies which types of errors are permitted, and, optionally, either the minimum and maximum or only the maximum permitted number of each type. (You cannot specify only a minimum.)
The 3 types of error are:
* Insertion, indicated by "i"
* Deletion, indicated by "d"
* Substitution, indicated by "s"
In addition, "e" indicates any type of error.
The fuzziness of a regex item is specified between "{" and "}" after the item.
Examples:
* ``foo`` match "foo" exactly
* ``(?:foo){i}`` match "foo", permitting insertions
* ``(?:foo){d}`` match "foo", permitting deletions
* ``(?:foo){s}`` match "foo", permitting substitutions
* ``(?:foo){i,s}`` match "foo", permitting insertions and substitutions
* ``(?:foo){e}`` match "foo", permitting errors
If a certain type of error is specified, then any type not specified will **not** be permitted.
In the following examples I'll omit the item and write only the fuzziness:
* ``{d<=3}`` permit at most 3 deletions, but no other types
* ``{i<=1,s<=2}`` permit at most 1 insertion and at most 2 substitutions, but no deletions
* ``{1<=e<=3}`` permit at least 1 and at most 3 errors
* ``{i<=2,d<=2,e<=3}`` permit at most 2 insertions, at most 2 deletions, at most 3 errors in total, but no substitutions
It's also possible to state the costs of each type of error and the maximum permitted total cost.
Examples:
* ``{2i+2d+1s<=4}`` each insertion costs 2, each deletion costs 2, each substitution costs 1, the total cost must not exceed 4
* ``{i<=1,d<=1,s<=1,2i+2d+1s<=4}`` at most 1 insertion, at most 1 deletion, at most 1 substitution; each insertion costs 2, each deletion costs 2, each substitution costs 1, the total cost must not exceed 4
You can also use "<" instead of "<=" if you want an exclusive minimum or maximum.
You can add a test to perform on a character that's substituted or inserted.
Examples:
* ``{s<=2:[a-z]}`` at most 2 substitutions, which must be in the character set ``[a-z]``.
* ``{s<=2,i<=3:\d}`` at most 2 substitutions, at most 3 insertions, which must be digits.
By default, fuzzy matching searches for the first match that meets the given constraints. The ``ENHANCEMATCH`` flag will cause it to attempt to improve the fit (i.e. reduce the number of errors) of the match that it has found.
The ``BESTMATCH`` flag will make it search for the best match instead.
Further examples to note:
* ``regex.search("(dog){e}", "cat and dog")[1]`` returns ``"cat"`` because that matches ``"dog"`` with 3 errors (an unlimited number of errors is permitted).
* ``regex.search("(dog){e<=1}", "cat and dog")[1]`` returns ``" dog"`` (with a leading space) because that matches ``"dog"`` with 1 error, which is within the limit.
* ``regex.search("(?e)(dog){e<=1}", "cat and dog")[1]`` returns ``"dog"`` (without a leading space) because the fuzzy search matches ``" dog"`` with 1 error, which is within the limit, and the ``(?e)`` then it attempts a better fit.
In the first two examples there are perfect matches later in the string, but in neither case is it the first possible match.
The match object has an attribute ``fuzzy_counts`` which gives the total number of substitutions, insertions and deletions.
.. sourcecode:: python
>>> # A 'raw' fuzzy match:
>>> regex.fullmatch(r"(?:cats|cat){e<=1}", "cat").fuzzy_counts
(0, 0, 1)
>>> # 0 substitutions, 0 insertions, 1 deletion.
>>> # A better match might be possible if the ENHANCEMATCH flag used:
>>> regex.fullmatch(r"(?e)(?:cats|cat){e<=1}", "cat").fuzzy_counts
(0, 0, 0)
>>> # 0 substitutions, 0 insertions, 0 deletions.
The match object also has an attribute ``fuzzy_changes`` which gives a tuple of the positions of the substitutions, insertions and deletions.
.. sourcecode:: python
>>> m = regex.search('(fuu){i<=2,d<=2,e<=5}', 'anaconda foo bar')
>>> m
<regex.Match object; span=(7, 10), match='a f', fuzzy_counts=(0, 2, 2)>
>>> m.fuzzy_changes
([], [7, 8], [10, 11])
What this means is that if the matched part of the string had been:
.. sourcecode:: python
'anacondfuuoo bar'
it would've been an exact match.
However, there were insertions at positions 7 and 8:
.. sourcecode:: python
'anaconda fuuoo bar'
^^
and deletions at positions 10 and 11:
.. sourcecode:: python
'anaconda f~~oo bar'
^^
So the actual string was:
.. sourcecode:: python
'anaconda foo bar'
Named lists ``\L<name>`` (`Hg issue 11 <https://github.com/mrabarnett/mrab-regex/issues/11>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
There are occasions where you may want to include a list (actually, a set) of options in a regex.
One way is to build the pattern like this:
.. sourcecode:: python
>>> p = regex.compile(r"first|second|third|fourth|fifth")
but if the list is large, parsing the resulting regex can take considerable time, and care must also be taken that the strings are properly escaped and properly ordered, for example, "cats" before "cat".
The new alternative is to use a named list:
.. sourcecode:: python
>>> option_set = ["first", "second", "third", "fourth", "fifth"]
>>> p = regex.compile(r"\L<options>", options=option_set)
The order of the items is irrelevant, they are treated as a set. The named lists are available as the ``.named_lists`` attribute of the pattern object :
.. sourcecode:: python
>>> print(p.named_lists)
{'options': frozenset({'third', 'first', 'fifth', 'fourth', 'second'})}
If there are any unused keyword arguments, ``ValueError`` will be raised unless you tell it otherwise:
.. sourcecode:: python
>>> option_set = ["first", "second", "third", "fourth", "fifth"]
>>> p = regex.compile(r"\L<options>", options=option_set, other_options=[])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Python310\lib\site-packages\regex\regex.py", line 353, in compile
return _compile(pattern, flags, ignore_unused, kwargs, cache_pattern)
File "C:\Python310\lib\site-packages\regex\regex.py", line 500, in _compile
complain_unused_args()
File "C:\Python310\lib\site-packages\regex\regex.py", line 483, in complain_unused_args
raise ValueError('unused keyword argument {!a}'.format(any_one))
ValueError: unused keyword argument 'other_options'
>>> p = regex.compile(r"\L<options>", options=option_set, other_options=[], ignore_unused=True)
>>> p = regex.compile(r"\L<options>", options=option_set, other_options=[], ignore_unused=False)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Python310\lib\site-packages\regex\regex.py", line 353, in compile
return _compile(pattern, flags, ignore_unused, kwargs, cache_pattern)
File "C:\Python310\lib\site-packages\regex\regex.py", line 500, in _compile
complain_unused_args()
File "C:\Python310\lib\site-packages\regex\regex.py", line 483, in complain_unused_args
raise ValueError('unused keyword argument {!a}'.format(any_one))
ValueError: unused keyword argument 'other_options'
>>>
Start and end of word
^^^^^^^^^^^^^^^^^^^^^
``\m`` matches at the start of a word.
``\M`` matches at the end of a word.
Compare with ``\b``, which matches at the start or end of a word.
Unicode line separators
^^^^^^^^^^^^^^^^^^^^^^^
Normally the only line separator is ``\n`` (``\x0A``), but if the ``WORD`` flag is turned on then the line separators are ``\x0D\x0A``, ``\x0A``, ``\x0B``, ``\x0C`` and ``\x0D``, plus ``\x85``, ``\u2028`` and ``\u2029`` when working with Unicode.
This affects the regex dot ``"."``, which, with the ``DOTALL`` flag turned off, matches any character except a line separator. It also affects the line anchors ``^`` and ``$`` (in multiline mode).
Set operators
^^^^^^^^^^^^^
**Version 1 behaviour only**
Set operators have been added, and a set ``[...]`` can include nested sets.
The operators, in order of increasing precedence, are:
* ``||`` for union ("x||y" means "x or y")
* ``~~`` (double tilde) for symmetric difference ("x~~y" means "x or y, but not both")
* ``&&`` for intersection ("x&&y" means "x and y")
* ``--`` (double dash) for difference ("x--y" means "x but not y")
Implicit union, ie, simple juxtaposition like in ``[ab]``, has the highest precedence. Thus, ``[ab&&cd]`` is the same as ``[[a||b]&&[c||d]]``.
Examples:
* ``[ab]`` # Set containing 'a' and 'b'
* ``[a-z]`` # Set containing 'a' .. 'z'
* ``[[a-z]--[qw]]`` # Set containing 'a' .. 'z', but not 'q' or 'w'
* ``[a-z--qw]`` # Same as above
* ``[\p{L}--QW]`` # Set containing all letters except 'Q' and 'W'
* ``[\p{N}--[0-9]]`` # Set containing all numbers except '0' .. '9'
* ``[\p{ASCII}&&\p{Letter}]`` # Set containing all characters which are ASCII and letter
regex.escape (`issue #2650 <https://bugs.python.org/issue2650>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
regex.escape has an additional keyword parameter ``special_only``. When True, only 'special' regex characters, such as '?', are escaped.
.. sourcecode:: python
>>> regex.escape("foo!?", special_only=False)
'foo\\!\\?'
>>> regex.escape("foo!?", special_only=True)
'foo!\\?'
regex.escape (`Hg issue 249 <https://github.com/mrabarnett/mrab-regex/issues/249>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
regex.escape has an additional keyword parameter ``literal_spaces``. When True, spaces are not escaped.
.. sourcecode:: python
>>> regex.escape("foo bar!?", literal_spaces=False)
'foo\\ bar!\\?'
>>> regex.escape("foo bar!?", literal_spaces=True)
'foo bar!\\?'
Repeated captures (`issue #7132 <https://bugs.python.org/issue7132>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
A match object has additional methods which return information on all the successful matches of a repeated group. These methods are:
* ``matchobject.captures([group1, ...])``
* Returns a list of the strings matched in a group or groups. Compare with ``matchobject.group([group1, ...])``.
* ``matchobject.starts([group])``
* Returns a list of the start positions. Compare with ``matchobject.start([group])``.
* ``matchobject.ends([group])``
* Returns a list of the end positions. Compare with ``matchobject.end([group])``.
* ``matchobject.spans([group])``
* Returns a list of the spans. Compare with ``matchobject.span([group])``.
.. sourcecode:: python
>>> m = regex.search(r"(\w{3})+", "123456789")
>>> m.group(1)
'789'
>>> m.captures(1)
['123', '456', '789']
>>> m.start(1)
6
>>> m.starts(1)
[0, 3, 6]
>>> m.end(1)
9
>>> m.ends(1)
[3, 6, 9]
>>> m.span(1)
(6, 9)
>>> m.spans(1)
[(0, 3), (3, 6), (6, 9)]
Atomic grouping ``(?>...)`` (`issue #433030 <https://bugs.python.org/issue433030>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
If the following pattern subsequently fails, then the subpattern as a whole will fail.
Possessive quantifiers
^^^^^^^^^^^^^^^^^^^^^^
``(?:...)?+`` ; ``(?:...)*+`` ; ``(?:...)++`` ; ``(?:...){min,max}+``
The subpattern is matched up to 'max' times. If the following pattern subsequently fails, then all the repeated subpatterns will fail as a whole. For example, ``(?:...)++`` is equivalent to ``(?>(?:...)+)``.
Scoped flags (`issue #433028 <https://bugs.python.org/issue433028>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``(?flags-flags:...)``
The flags will apply only to the subpattern. Flags can be turned on or off.
Definition of 'word' character (`issue #1693050 <https://bugs.python.org/issue1693050>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
The definition of a 'word' character has been expanded for Unicode. It conforms to the Unicode specification at ``http://www.unicode.org/reports/tr29/``.
Variable-length lookbehind
^^^^^^^^^^^^^^^^^^^^^^^^^^
A lookbehind can match a variable-length string.
Flags argument for regex.split, regex.sub and regex.subn (`issue #3482 <https://bugs.python.org/issue3482>`_)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``regex.split``, ``regex.sub`` and ``regex.subn`` support a 'flags' argument.
Pos and endpos arguments for regex.sub and regex.subn
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``regex.sub`` and ``regex.subn`` support 'pos' and 'endpos' arguments.
'Overlapped' argument for regex.findall and regex.finditer
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``regex.findall`` and ``regex.finditer`` support an 'overlapped' flag which permits overlapped matches.
Splititer
^^^^^^^^^
``regex.splititer`` has been added. It's a generator equivalent of ``regex.split``.
Subscripting match objects for groups
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
A match object accepts access to the groups via subscripting and slicing:
.. sourcecode:: python
>>> m = regex.search(r"(?P<before>.*?)(?P<num>\d+)(?P<after>.*)", "pqr123stu")
>>> print(m["before"])
pqr
>>> print(len(m))
4
>>> print(m[:])
('pqr123stu', 'pqr', '123', 'stu')
Named groups
^^^^^^^^^^^^
Groups can be named with ``(?<name>...)`` as well as the existing ``(?P<name>...)``.
Group references
^^^^^^^^^^^^^^^^
Groups can be referenced within a pattern with ``\g<name>``. This also allows there to be more than 99 groups.
Named characters ``\N{name}``
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Named characters are supported. Note that only those known by Python's Unicode database will be recognised.
Unicode codepoint properties, including scripts and blocks
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``\p{property=value}``; ``\P{property=value}``; ``\p{value}`` ; ``\P{value}``
Many Unicode properties are supported, including blocks and scripts. ``\p{property=value}`` or ``\p{property:value}`` matches a character whose property ``property`` has value ``value``. The inverse of ``\p{property=value}`` is ``\P{property=value}`` or ``\p{^property=value}``.
If the short form ``\p{value}`` is used, the properties are checked in the order: ``General_Category``, ``Script``, ``Block``, binary property:
* ``Latin``, the 'Latin' script (``Script=Latin``).
* ``BasicLatin``, the 'BasicLatin' block (``Block=BasicLatin``).
* ``Alphabetic``, the 'Alphabetic' binary property (``Alphabetic=Yes``).
A short form starting with ``Is`` indicates a script or binary property:
* ``IsLatin``, the 'Latin' script (``Script=Latin``).
* ``IsAlphabetic``, the 'Alphabetic' binary property (``Alphabetic=Yes``).
A short form starting with ``In`` indicates a block property:
* ``InBasicLatin``, the 'BasicLatin' block (``Block=BasicLatin``).
POSIX character classes
^^^^^^^^^^^^^^^^^^^^^^^
``[[:alpha:]]``; ``[[:^alpha:]]``
POSIX character classes are supported. These are normally treated as an alternative form of ``\p{...}``.
The exceptions are ``alnum``, ``digit``, ``punct`` and ``xdigit``, whose definitions are different from those of Unicode.
``[[:alnum:]]`` is equivalent to ``\p{posix_alnum}``.
``[[:digit:]]`` is equivalent to ``\p{posix_digit}``.
``[[:punct:]]`` is equivalent to ``\p{posix_punct}``.
``[[:xdigit:]]`` is equivalent to ``\p{posix_xdigit}``.
Search anchor ``\G``
^^^^^^^^^^^^^^^^^^^^
A search anchor has been added. It matches at the position where each search started/continued and can be used for contiguous matches or in negative variable-length lookbehinds to limit how far back the lookbehind goes:
.. sourcecode:: python
>>> regex.findall(r"\w{2}", "abcd ef")
['ab', 'cd', 'ef']
>>> regex.findall(r"\G\w{2}", "abcd ef")
['ab', 'cd']
* The search starts at position 0 and matches 'ab'.
* The search continues at position 2 and matches 'cd'.
* The search continues at position 4 and fails to match any letters.
* The anchor stops the search start position from being advanced, so there are no more results.
Reverse searching
^^^^^^^^^^^^^^^^^
Searches can also work backwards:
.. sourcecode:: python
>>> regex.findall(r".", "abc")
['a', 'b', 'c']
>>> regex.findall(r"(?r).", "abc")
['c', 'b', 'a']
Note that the result of a reverse search is not necessarily the reverse of a forward search:
.. sourcecode:: python
>>> regex.findall(r"..", "abcde")
['ab', 'cd']
>>> regex.findall(r"(?r)..", "abcde")
['de', 'bc']
Matching a single grapheme ``\X``
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
The grapheme matcher is supported. It conforms to the Unicode specification at ``http://www.unicode.org/reports/tr29/``.
Branch reset ``(?|...|...)``
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Group numbers will be reused across the alternatives, but groups with different names will have different group numbers.
.. sourcecode:: python
>>> regex.match(r"(?|(first)|(second))", "first").groups()
('first',)
>>> regex.match(r"(?|(first)|(second))", "second").groups()
('second',)
Note that there is only one group.
Default Unicode word boundary
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
The ``WORD`` flag changes the definition of a 'word boundary' to that of a default Unicode word boundary. This applies to ``\b`` and ``\B``.
Timeout
^^^^^^^
The matching methods and functions support timeouts. The timeout (in seconds) applies to the entire operation:
.. sourcecode:: python
>>> from time import sleep
>>>
>>> def fast_replace(m):
... return 'X'
...
>>> def slow_replace(m):
... sleep(0.5)
... return 'X'
...
>>> regex.sub(r'[a-z]', fast_replace, 'abcde', timeout=2)
'XXXXX'
>>> regex.sub(r'[a-z]', slow_replace, 'abcde', timeout=2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Python310\lib\site-packages\regex\regex.py", line 278, in sub
return pat.sub(repl, string, count, pos, endpos, concurrent, timeout)
TimeoutError: regex timed out
| text/x-rst | null | Matthew Barnett <regex@mrabarnett.plus.com> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming L... | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/mrabarnett/mrab-regex"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:03:47.899609 | regex-2026.2.19.tar.gz | 414,973 | ff/c0/d8079d4f6342e4cec5c3e7d7415b5cd3e633d5f4124f7a4626908dbe84c7/regex-2026.2.19.tar.gz | source | sdist | null | false | 808d30c052ef593b79414e302069c8f5 | 6fb8cb09b10e38f3ae17cc6dc04a1df77762bd0351b6ba9041438e7cc85ec310 | ffc0d8079d4f6342e4cec5c3e7d7415b5cd3e633d5f4124f7a4626908dbe84c7 | Apache-2.0 AND CNRI-Python | [
"LICENSE.txt"
] | 10,101,828 |
2.4 | dapr-agents-oas-adapter | 0.8.0 | Adapter library to make Dapr Agents compatible with Open Agent Spec | # dapr-agents-oas-adapter
**Bidirectional conversion between Open Agent Spec (OAS) and Dapr Agents.**
[](https://www.python.org/downloads/)
[](LICENSE)
[](https://github.com/heltondoria/dapr-agents-oas-adapter/actions/workflows/ci.yml)
## Overview
`dapr-agents-oas-adapter` enables seamless interoperability between [Open Agent Spec (OAS)](https://oracle.github.io/agent-spec/) specifications and [Dapr Agents](https://docs.dapr.io/developing-applications/dapr-agents/). Import OAS specifications to create executable Dapr Agents and workflows, or export existing Dapr Agents to portable OAS format.
## Key Features
- **Bidirectional conversion** -- Import OAS specs into Dapr Agents and export back to OAS
- **Schema validation** -- Validate OAS specifications before conversion with detailed error reports
- **Caching** -- In-memory cache with configurable TTL for repeated operations
- **Async support** -- Non-blocking loader for high-throughput applications
- **Structured logging** -- Built-in `structlog` integration for observability
## Installation
```bash
pip install dapr-agents-oas-adapter
```
Or with [uv](https://docs.astral.sh/uv/):
```bash
uv add dapr-agents-oas-adapter
```
## Quick Start
### Load an OAS spec and create a Dapr Agent
```python
from dapr_agents_oas_adapter import DaprAgentSpecLoader
loader = DaprAgentSpecLoader()
config = loader.load_yaml(oas_yaml)
agent = loader.create_agent(config)
```
### Export a Dapr Agent to OAS format
```python
from dapr_agents_oas_adapter import DaprAgentSpecExporter
exporter = DaprAgentSpecExporter()
oas_dict = exporter.to_dict(config)
```
### Validate before conversion
```python
from dapr_agents_oas_adapter import StrictLoader
loader = StrictLoader()
try:
config = loader.load_dict(oas_dict)
except OASSchemaValidationError as e:
print(f"Validation failed: {e.issues}")
```
## Component Mapping
| OAS Component | Dapr Agents |
|---------------|-------------|
| Agent | AssistantAgent / ReActAgent |
| Flow | `@workflow` decorated function |
| LlmNode | `@task` with LLM call |
| ToolNode | `@task` with tool call |
| FlowNode | `ctx.call_child_workflow()` |
| MapNode | Fan-out with `wf.when_all()` |
| ControlFlowEdge | Branch routing via `from_branch` |
## Running the Examples
### Prerequisites
- [Dapr CLI](https://docs.dapr.io/getting-started/install-dapr-cli/) installed and initialized
- An OpenAI API key in `examples/_shared/dapr/components/secrets/`
### Run an example
```bash
cd examples/from_oas/04-agent-based-workflows
dapr run -f dapr.yaml -- python app.py
```
Examples are organized in two directions:
- `examples/from_oas/` -- Import OAS specs to create Dapr Agents
- `examples/to_oas/` -- Export Dapr Agents to OAS format
## Development
```bash
git clone https://github.com/heltondoria/dapr-agents-oas-adapter.git
cd dapr-agents-oas-adapter
uv sync --all-groups
```
```bash
uv run pytest # Run tests
uv run ruff check . # Lint
uv run ruff format --check . # Check formatting
uv run ty check # Type check
uv run codespell . # Spell check
uv run vulture . # Dead code detection
```
Tests require 90% coverage:
```bash
uv run pytest --cov=src/dapr_agents_oas_adapter --cov-fail-under=90
```
## Documentation
Full documentation is available at [heltondoria.github.io/dapr-agents-oas-adapter](https://heltondoria.github.io/dapr-agents-oas-adapter/).
To serve locally:
```bash
uv run mkdocs serve
```
## License
Apache License 2.0 -- see [LICENSE](LICENSE) for details.
| text/markdown | Helton Dória | Helton Dória <helton.doria@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"pyagentspec>=25.4.1",
"dapr-agents>=0.10.5",
"dapr>=1.16.0",
"pydantic>=2.12.5"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:03:26.446914 | dapr_agents_oas_adapter-0.8.0.tar.gz | 54,917 | 17/6b/dc121bdbd7f1bb9f1d5a3458898915b01ac0daa72427f045145755b69707/dapr_agents_oas_adapter-0.8.0.tar.gz | source | sdist | null | false | 20014ee3348dae422e5a7b43805b4107 | 6cfc61433272587a5cf45ed5677bfc6d97a18c6e424c7a77319927a207ea9b76 | 176bdc121bdbd7f1bb9f1d5a3458898915b01ac0daa72427f045145755b69707 | Apache-2.0 | [
"LICENSE"
] | 218 |
2.4 | vllm-spyre | 2.0.0rc1 | vLLM plugin for Spyre hardware support | <h1 align="center">
Spyre Plugin for vLLM
</h1>
<p align="center">
| <a href="https://vllm-project.github.io/vllm-spyre/"><b>Documentation</b></a> | <a href="https://discuss.vllm.ai/c/hardware-support/"><b>Users Forum</b></a> | <a href="https://slack.vllm.ai"><b>#sig-spyre</b></a> |
</p>
---
**IBM Spyre** is the first production-grade Artificial Intelligence Unit (AIU) accelerator born out of the IBM Research AIU family, and is part of a long-term strategy of developing novel architectures and full-stack technology solutions for the emerging space of generative AI. Spyre builds on the foundation of IBM’s internal AIU research and delivers a scalable, efficient architecture for accelerating AI in enterprise environments.
The vLLM Spyre plugin (`vllm-spyre`) is a dedicated backend extension that enables seamless integration of IBM Spyre Accelerator with vLLM. It follows the architecture described in [vLLM's Plugin System](https://docs.vllm.ai/en/latest/design/plugin_system.html), making it easy to integrate IBM's advanced AI acceleration into existing vLLM workflows.
For more information, check out the following:
- 📚 [Meet the IBM Artificial Intelligence Unit](https://research.ibm.com/blog/ibm-artificial-intelligence-unit-aiu)
- 📽️ [AI Accelerators: Transforming Scalability & Model Efficiency](https://www.youtube.com/watch?v=KX0qBM-ByAg)
- 🚀 [Spyre Accelerator for IBM Z](https://research.ibm.com/blog/spyre-for-z)
- 🚀 [Spyre Accelerator for IBM POWER](https://newsroom.ibm.com/2025-07-08-ibm-power11-raises-the-bar-for-enterprise-it)
## Getting Started
Visit our [documentation](https://vllm-project.github.io/vllm-spyre/):
- [Installation](https://vllm-project.github.io/vllm-spyre/getting_started/installation.html)
- [List of Supported Models](https://vllm-project.github.io/vllm-spyre/user_guide/supported_models.html)
- [List of Supported Features](https://vllm-project.github.io/vllm-spyre/user_guide/supported_features.html)
## Contributing
We welcome and value any contributions and collaborations. Please check out [Contributing to vLLM Spyre](https://vllm-project.github.io/vllm-spyre/contributing/index.html) for how to get involved.
## Contact
You can reach out for discussion or support in the `#sig-spyre` channel in the [vLLM Slack](https://inviter.co/vllm-slack) workspace or by [opening an issue](https://vllm-project.github.io/vllm-spyre/contributing/index.html#issues).
| text/markdown | null | null | null | null | Apache 2 | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"fms-model-optimizer[fp8]>=0.8.0",
"ibm-fms<2.0,>=1.7.0",
"vllm<=0.15.1,>=0.15.1"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:03:17.854827 | vllm_spyre-2.0.0rc1.tar.gz | 1,361,803 | 28/1d/5ddb9e1b9a079f4a99fceac0468187a1488e1f19f95fb2fda632042f1c66/vllm_spyre-2.0.0rc1.tar.gz | source | sdist | null | false | 7ddb2cb58d97bc67bf06b21b7ebebe3c | 2adc922c10739e0d02b258ca6b796a61717da2482795beec51fe163753b9a70a | 281d5ddb9e1b9a079f4a99fceac0468187a1488e1f19f95fb2fda632042f1c66 | null | [
"LICENSE"
] | 185 |
2.1 | moneyonchain-prices-source | 0.7.4b35 | Prices source for MoC projects | # **MoC prices source**
This is the python package used in [**Money on Chain**](https://moneyonchain.com/) projects where it is required to get the coinpair values directly from the sources.
This package includes a CLI tool that allows you to query the coinpair values in the same way that [**Money on Chain**](https://moneyonchain.com/) projects do.
## How to use it in your project
A simple example, do some imports first
```python
user@host:~$ python3 -q
>>> from moc_prices_source import get_price, BTC_USD
>>>
```
Get de `BTC/USD` coin pair
```python
>>> get_price(BTC_USD)
Decimal('89561.50000')
>>>
```
And that's it!
More [usage examples](https://github.com/money-on-chain/moc_prices_source/blob/v0.7.4b35/docs/examples.md) can be seen [here](https://github.com/money-on-chain/moc_prices_source/blob/v0.7.4b35/docs/examples.md)
## How the included CLI tool looks like
Here you can see how the output of the `moc_prices_source_check` command looks like
```shell
user@host:~$ moc_prices_source_check "BTC/USD*"
Coinpair V. Short description Exchnage Response Weight % Time
---------- ---- ------------------- ----------- ------------ -------- --- ------
BTC/USD och Bitcoin to Dollar MOC onchain $ 89.08900K 1 100 1.66s
BTC/USD Bitcoin to Dollar Bitfinex $ 89.18400K 0.18 18 214ms
BTC/USD Bitcoin to Dollar Bitstamp $ 89.06700K 0.22 22 553ms
BTC/USD Bitcoin to Dollar Coinbase $ 89.06769K 0.25 25 261ms
BTC/USD Bitcoin to Dollar Gemini $ 89.05753K 0.17 17 787ms
BTC/USD Bitcoin to Dollar Kraken $ 89.05310K 0.18 18 226ms
BTC/USDT Bitcoin to Tether Binance ₮ 89.19590K 0.65 65 374ms
BTC/USDT Bitcoin to Tether Bybit ₮ 89.19105K 0.1 10 467ms
BTC/USDT Bitcoin to Tether Huobi ₮ 89.19650K 0.05 5 472ms
BTC/USDT Bitcoin to Tether KuCoin ₮ 89.19595K 0.05 5 756ms
BTC/USDT Bitcoin to Tether OKX ₮ 89.19965K 0.15 15 759ms
Coinpair Value Sources count Ok Time
-- ------------ ------------- --------------- ---- ------
⇓ BTC/USD 89,067.000000 5 of 5 ✓ 787ms
ƒ BTC/USD(24h) ▼ 0.25% N/A ✓ 2.66s
⛓ BTC/USD(och) 89,089.000000 1 of 1 ✓ 1.66s
⇓ BTC/USDT 89,195.905000 5 of 5 ✓ 759ms
Response time 4.36s
user@host:~$
```
This command has many options. you can run `moc_prices_source_check --help` to get help on how to run them.
More information about this CLI tool can be seen [here](https://github.com/money-on-chain/moc_prices_source/blob/v0.7.4b35/docs/cli.md).
## References
* [Source code in Github](https://github.com/money-on-chain/moc_prices_source/tree/v0.7.4b35)
* [Package from Python package index (PyPI)](https://pypi.org/project/moneyonchain-prices-source)
## Requirements
* Python 3.6+ support
## Installation
### From the Python package index (PyPI)
Run:
```shell
$ pip3 install moneyonchain-prices-source
```
And then run:
```shell
$ moc_prices_source_check --version
```
To verify that it has been installed correctly
### From source
Download from [Github](https://github.com/money-on-chain/moc_prices_source/tree/v0.7.4b35)
Standing inside the folder, run:
```shell
$ pip3 install -r requirements.txt
```
For install the dependencies and then run:
```shell
$ pip3 install .
```
Finally run:
```shell
$ moc_prices_source_check --version
```
To verify that it has been installed correctly
## Supported coinpairs and symbols
[Here](https://github.com/money-on-chain/moc_prices_source/blob/v0.7.4b35/docs/supported_coinpairs.md) you can find an [summary of supported coinpairs and symbols](https://github.com/money-on-chain/moc_prices_source/blob/v0.7.4b35/docs/supported_coinpairs.md) | text/markdown | Juan S. Bokser | juan.bokser@moneyonchain.com | null | null | null | null | [
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | twine/4.0.1 CPython/3.8.10 | 2026-02-19T19:02:40.514536 | moneyonchain_prices_source-0.7.4b35.tar.gz | 69,004 | 3d/f8/49d418a1f031bc27653f14531ce02bfb16c62b683b472e9d38cdec158be9/moneyonchain_prices_source-0.7.4b35.tar.gz | source | sdist | null | false | 89f1568c5f571129904731932ee8036f | f954a4b5d0c9d374751d56cc5f35f79be8fd1b0d5418e4fe925aec72f25d271d | 3df849d418a1f031bc27653f14531ce02bfb16c62b683b472e9d38cdec158be9 | null | [] | 132 |
2.4 | azure-mgmt-computebulkactions | 1.0.0b1 | Microsoft Azure Computebulkactions Management Client Library for Python | # Microsoft Azure SDK for Python
This is the Microsoft Azure Computebulkactions Management Client Library.
This package has been tested with Python 3.9+.
For a more complete view of Azure libraries, see the [azure sdk python release](https://aka.ms/azsdk/python/all).
## _Disclaimer_
_Azure SDK Python packages support for Python 2.7 has ended 01 January 2022. For more information and questions, please refer to https://github.com/Azure/azure-sdk-for-python/issues/20691_
## Getting started
### Prerequisites
- Python 3.9+ is required to use this package.
- [Azure subscription](https://azure.microsoft.com/free/)
### Install the package
```bash
pip install azure-mgmt-computebulkactions
pip install azure-identity
```
### Authentication
By default, [Azure Active Directory](https://aka.ms/awps/aad) token authentication depends on correct configuration of the following environment variables.
- `AZURE_CLIENT_ID` for Azure client ID.
- `AZURE_TENANT_ID` for Azure tenant ID.
- `AZURE_CLIENT_SECRET` for Azure client secret.
In addition, Azure subscription ID can be configured via environment variable `AZURE_SUBSCRIPTION_ID`.
With above configuration, client can be authenticated by following code:
```python
from azure.identity import DefaultAzureCredential
from azure.mgmt.computebulkactions import ComputeBulkActionsMgmtClient
import os
sub_id = os.getenv("AZURE_SUBSCRIPTION_ID")
client = ComputeBulkActionsMgmtClient(credential=DefaultAzureCredential(), subscription_id=sub_id)
```
## Examples
Code samples for this package can be found at:
- [Search Computebulkactions Management](https://docs.microsoft.com/samples/browse/?languages=python&term=Getting%20started%20-%20Managing&terms=Getting%20started%20-%20Managing) on docs.microsoft.com
- [Azure Python Mgmt SDK Samples Repo](https://aka.ms/azsdk/python/mgmt/samples)
## Troubleshooting
## Next steps
## Provide Feedback
If you encounter any bugs or have suggestions, please file an issue in the
[Issues](https://github.com/Azure/azure-sdk-for-python/issues)
section of the project.
# Release History
## 1.0.0b1 (2026-02-10)
### Other Changes
- Initial version
| text/markdown | null | Microsoft Corporation <azpysdkhelp@microsoft.com> License-Expression: MIT | null | null | null | azure, azure sdk | [
"Development Status :: 4 - Beta",
"Programming Language :: Python",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | null | null | >=3.9 | [] | [] | [] | [
"isodate>=0.6.1",
"azure-mgmt-core>=1.6.0",
"typing-extensions>=4.6.0"
] | [] | [] | [] | [
"repository, https://github.com/Azure/azure-sdk-for-python"
] | RestSharp/106.13.0.0 | 2026-02-19T19:01:17.892880 | azure_mgmt_computebulkactions-1.0.0b1-py3-none-any.whl | 109,008 | 0a/e3/3aa5ef0143b5d699ff1c8f2c798718ecd0ecb19797e2fa453a58c2dbb305/azure_mgmt_computebulkactions-1.0.0b1-py3-none-any.whl | py3 | bdist_wheel | null | false | 340307289f36228ac291f857a65f9af1 | 584023a67df1bc8cb60ddded84572564754a838f9802228f8e1e1f03dca0e78f | 0ae33aa5ef0143b5d699ff1c8f2c798718ecd0ecb19797e2fa453a58c2dbb305 | null | [] | 222 |
2.4 | statezero | 0.1.0b73 | Connect your Python backend to a modern JavaScript SPA frontend with 90% less complexity. | # StateZero
**The Real-Time Django to JavaScript Data Bridge**
Connect your Django backend to React/Vue frontends with 90% less code. No repetitive serializers, views, or tight coupling.
## Why StateZero?
**The Problem:** Building modern web apps means writing the same CRUD logic three times - Django models, REST API serializers/views, and frontend data fetching. This creates:
- 80% of app complexity in data shuttling
- 50% of your codebase devoted to API glue
- Hundreds of hours maintaining sync between frontend and backend
**The Solution:** StateZero eliminates the API layer entirely. Write Django models once, query them directly from JavaScript with the same ORM syntax you already know.
## Features
✨ **Django ORM Syntax in JavaScript** - Use `.filter()`, `.exclude()`, `.orderBy()` exactly like Django
⚡ **Real-Time Updates** - UI automatically updates when backend data changes
🔒 **Django Permissions** - Your existing permission classes work on the frontend
📝 **Auto-Generated TypeScript** - Perfect type safety from your Django models
🚀 **Optimistic Updates** - UI feels instant, syncs in background
🔗 **Deep Relationships** - Traverse foreign keys naturally: `todo.category.name`
## Quick Example
### 1. Register Your Django Model
```python
# todos/crud.py
from statezero.adaptors.django.config import registry
from .models import Todo
registry.register(Todo)
```
### 2. Query From JavaScript Like Django
```javascript
// Get all incomplete todos, ordered by priority
const todos = Todo.objects
.filter({ is_completed: false })
.orderBy("-priority", "created_at");
// Complex queries with relationships
const urgentWorkTodos = Todo.objects.filter({
priority: "high",
category__name: "Work",
due_date__lt: "2024-12-31",
});
// Django-style field lookups
const searchResults = Todo.objects.filter({
title__icontains: "meeting",
created_by__email__endswith: "@company.com",
});
```
### 3. Real-Time Updates in One Line
```vue
<script setup>
import { useQueryset } from "@statezero/core/vue";
// This list automatically updates when todos change
const todos = useQueryset(() => Todo.objects.filter({ is_completed: false }));
</script>
<template>
<div v-for="todo in todos.fetch({ limit: 10 })" :key="todo.id">
{{ todo.title }}
</div>
</template>
```
## The Magic: Optimistic vs Confirmed
### Optimistic (Instant UI)
```javascript
// UI updates immediately, syncs later
const newTodo = Todo.objects.create({
title: "Buy groceries",
priority: "medium",
});
// Edit optimistically
todo.title = "Buy organic groceries";
todo.save(); // UI updates instantly
// Delete optimistically
todo.delete(); // Gone from UI immediately
```
### Confirmed (Wait for Server)
```javascript
// Wait for server confirmation
const confirmedTodo = await Todo.objects.create({
title: "Important meeting",
});
// Wait for update confirmation
await todo.save();
// Wait for deletion confirmation
await todo.delete();
```
## Advanced Django ORM Features
### Complex Filtering with Q Objects
```javascript
import { Q } from "@statezero/core";
// Multiple OR conditions
const urgentTodos = Todo.objects.filter({
Q: [Q("OR", { priority: "high" }, { due_date__lt: "tomorrow" })],
});
// Nested conditions
const myImportantTodos = Todo.objects.filter({
Q: [
Q(
"AND",
{ assigned_to: currentUser.id },
Q("OR", { priority: "high" }, { is_flagged: true })
),
],
});
```
### Aggregation & F Expressions
```javascript
import { F } from "@statezero/core";
// Count, sum, average like Django
const todoCount = await Todo.objects.count();
const avgPriority = await Todo.objects.avg("priority_score");
// Database-level calculations
await Product.objects.update({
view_count: F("view_count + 1"),
popularity: F("likes * 2 + shares"),
});
```
### Get or Create
```javascript
// Just like Django's get_or_create
const [todo, created] = await Todo.objects.getOrCreate(
{ title: "Daily standup" },
{ defaults: { priority: "medium", category: workCategory } }
);
```
### Relationship Traversal
```javascript
// Access related objects naturally
const todo = await Todo.objects.get({ id: 1 });
console.log(todo.category.name); // Foreign key
console.log(todo.created_by.username); // Another FK
console.log(todo.comments.length); // Reverse FK
// Filter by relationships
const workTodos = Todo.objects.filter({
category__name: "Work",
assigned_to__department__name: "Engineering",
});
```
## Installation
### Backend
```bash
pip install statezero
pip install django-cors-headers pusher
```
### Frontend
```bash
npm i @statezero/core
```
### Generate TypeScript Models
```bash
npx statezero sync
```
## Why Choose StateZero Over...
**🆚 HTMX:** Use modern React/Vue with full JavaScript ecosystem while keeping backend simplicity
**🆚 Firebase/Supabase:** Keep your Django backend, models, and business logic. No vendor lock-in.
**🆚 OpenAPI/GraphQL:** Get real-time updates and Django ORM power, not just basic CRUD
**🆚 Traditional REST APIs:** Write 90% less boilerplate. Focus on features, not data plumbing.
## Testing (Backend-Mode)
StateZero supports frontend tests that run against a real Django test server (no test-only views).
You opt-in via a test-only middleware that temporarily relaxes permissions and silences events
when a request includes special headers.
### Backend Setup (Django Test Settings)
Add the test middleware and enable test mode in your **test settings**:
```python
# tests/settings.py
STATEZERO_TEST_MODE = True
STATEZERO_TEST_SEEDING_SILENT = True # default behavior, silences events during seeding
MIDDLEWARE = [
# ...
"statezero.adaptors.django.testing.TestSeedingMiddleware",
# ...
]
```
Behavior:
- `X-TEST-SEEDING: 1` → temporarily allows all permissions for the request
- `X-TEST-RESET: 1` → deletes all registered StateZero models for the request
Auth note:
- Test mode does **not** bypass authentication. Your test server must still
authenticate requests (e.g., create a test token).
Start the test server:
```bash
python manage.py statezero_testserver --addrport 8000
```
Optional request hook:
```python
# tests/settings.py
STATEZERO_TEST_REQUEST_CONTEXT = "myapp.test_utils.statezero_test_context"
```
Your factory should accept the request and return a context manager. This allows
libraries like django-ai-first to wrap each test request (e.g., time control).
Optional startup hook (for creating test users/tokens):
```python
# tests/settings.py
STATEZERO_TEST_STARTUP_HOOK = "myapp.test_utils.statezero_test_startup"
```
```python
# myapp/test_utils.py
from django.contrib.auth import get_user_model
from rest_framework.authtoken.models import Token
def statezero_test_startup():
user_model = get_user_model()
user, _ = user_model.objects.get_or_create(
username="test_user", defaults={"email": "test@example.com"}
)
user.set_password("test123")
user.is_staff = True
user.is_superuser = True
user.save()
token, _ = Token.objects.get_or_create(
user=user, defaults={"key": "testtoken123"}
)
if token.key != "testtoken123":
token.key = "testtoken123"
token.save()
```
### Frontend Setup (Vue / JS)
Use the testing helpers and the `remote` manager to call the backend directly without local updates.
```javascript
import {
setupTestStateZero,
seedRemote,
resetRemote,
createActionMocker,
} from "@statezero/core/testing";
import { getModelClass } from "../model-registry";
import { ACTION_REGISTRY } from "../action-registry";
import { Todo } from "../models/default/django_app/todo";
import { vueAdapters } from "./statezero-adapters";
const testHeaders = setupTestStateZero({
apiUrl: "http://localhost:8000/statezero",
getModelClass,
adapters: vueAdapters,
});
// Reset: deletes all registered StateZero models on the backend
await resetRemote(testHeaders, () => Todo.remote.delete());
// Seed: run standard ORM writes with X-TEST-SEEDING enabled
await seedRemote(testHeaders, () =>
Todo.remote.create({ title: "Seeded todo" })
);
// Action mocking for frontend tests
const actionMocker = createActionMocker(ACTION_REGISTRY);
actionMocker.mock("send_notification", async () => ({ ok: true }));
```
Notes:
- `Model.remote` (or `Model.objects.remote()`) uses the normal ORM AST/serializers,
but **skips local store updates** and **returns raw backend responses**.
- These helpers are intended for tests that run against a live Django test server.
## Get Started
Check out the docs at [Statezero Docs](https://statezero.dev)
Run `pip install statezero` and `npm i @statezero/core` to begin.
| text/markdown | null | Robert <robert.herring@statezero.dev> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"Django<5.2.0,>=5.1.0",
"django-money<3.5.0,>=3.4.0",
"djangorestframework<3.16.0,>=3.15.0",
"fakeredis<3.0.0,>=2.27.0",
"fastapi<0.116.0,>=0.115.0",
"hypothesis<7.0.0,>=6.108.0",
"jsonschema<5.0.0,>=4.23.0",
"networkx<4.0.0,>=3.4.0",
"openapi-spec-validator<0.8.0,>=0.7.0",
"orjson<4.0.0,>=3.10.0"... | [] | [] | [] | [
"homepage, https://www.statezero.dev",
"repository, https://github.com/state-zero/statezero"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-19T19:00:50.323936 | statezero-0.1.0b73.tar.gz | 110,123 | 91/77/3cacceefb9dd117022312bf1b631508d13c98b5097bfb97d68bc3552cd7a/statezero-0.1.0b73.tar.gz | source | sdist | null | false | 181d9794c86b76967470d824cdd18db3 | 83099fb89faaeaf8a783f7ff5a208f162f0fdd7a695d776f352366e5d9778ca0 | 91773cacceefb9dd117022312bf1b631508d13c98b5097bfb97d68bc3552cd7a | null | [] | 220 |
2.4 | deltatau-audit | 0.6.2 | Time Robustness Audit for RL agents — measures timing reliance, deployment robustness, and stress resilience | # deltatau-audit
[](https://pypi.org/project/deltatau-audit/)
[](https://github.com/maruyamakoju/deltatau-audit/actions/workflows/audit-smoke.yml)
[](https://pypi.org/project/deltatau-audit/)
[](LICENSE)
[](https://colab.research.google.com/github/maruyamakoju/deltatau-audit/blob/main/notebooks/quickstart.ipynb)
**Audited by deltatau-audit** (CartPole speed-randomized GRU):



**Find and fix timing failures in RL agents.**
RL agents silently break when deployment timing differs from training — frame drops, variable inference latency, sensor rate changes. `deltatau-audit` finds these failures **and fixes them in one command**.
## Try it in 30 seconds
```bash
pip install "deltatau-audit[demo]"
python -m deltatau_audit demo cartpole
# Faster: python -m deltatau_audit demo cartpole --workers auto
```
No GPU. No MuJoCo. Just `pip install` and run. You'll see a Before/After comparison:
| Scenario | Before (Baseline) | After (Speed-Randomized) | Change |
|----------|:-----------------:|:------------------------:|:------:|
| 5x speed | **12%** | **49%** | +37pp |
| Speed jitter | **66%** | **115%** | +49pp |
| Observation delay | **82%** | **95%** | +13pp |
| Mid-episode spike | **23%** | **62%** | +39pp |
| **Deployment** | **FAIL** (0.23) | **DEGRADED** (0.62) | +0.39 |
The standard agent collapses under timing perturbations. Speed-randomized training dramatically improves robustness. Full HTML reports with charts are generated in `demo_report/`.
## The same pattern at MuJoCo scale: HalfCheetah PPO
A PPO agent trained to reward ~990 on HalfCheetah-v5 shows even more catastrophic timing failures — **all 4 scenarios statistically significant (95% bootstrap CI)**:
| Scenario | Return (% of nominal) | 95% CI | Drop |
|----------|:--------------------:|:------:|:----:|
| Observation delay (1 step) | **3.8%** | [2.4%, 5.2%] | -96% |
| Speed jitter (2 +/- 1) | **25.4%** | [23.5%, 27.8%] | -75% |
| 5x speed (unseen) | **-9.3%** | [-10.6%, -8.4%] | -109% |
| Mid-episode spike (1->5->1) | **90.9%** | [86.3%, 97.8%] | -9% |
A single step of observation delay destroys 96% of performance. The agent goes *negative* at 5x speed.
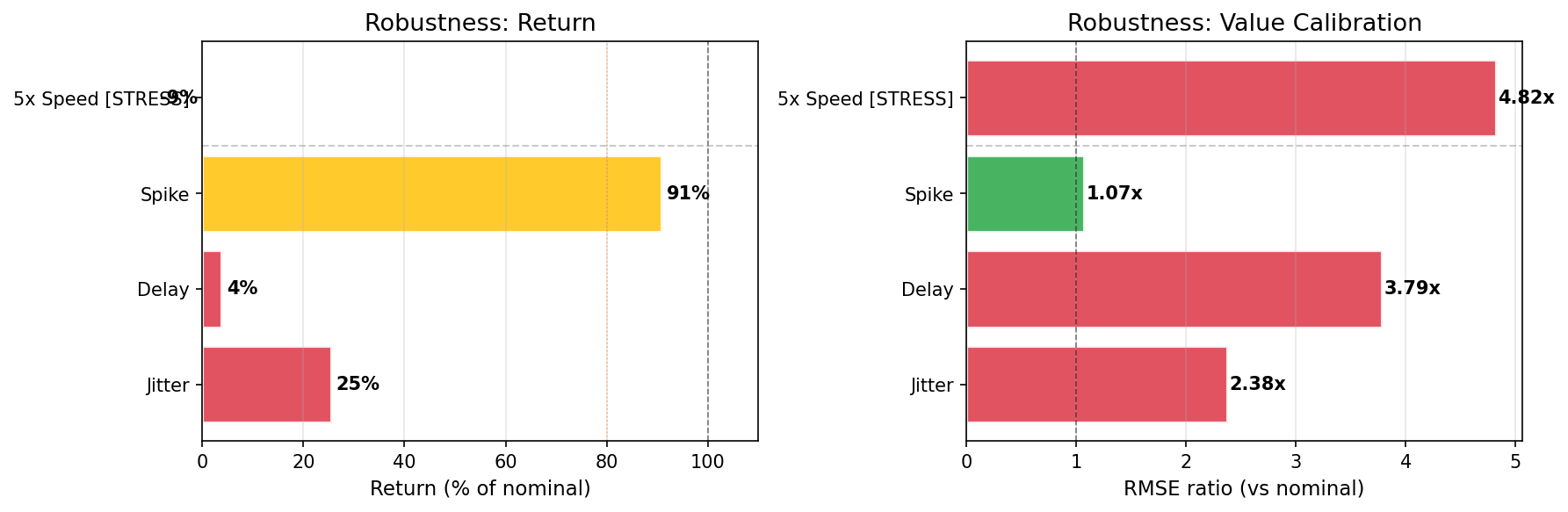
[View interactive report](https://maruyamakoju.github.io/deltatau-audit/sample/halfcheetah/) | [Download report ZIP](https://github.com/maruyamakoju/deltatau-audit/releases/download/assets/halfcheetah_audit_report.zip)
### Speed-randomized training fixes the problem
| Scenario | Before (Standard) | After (Speed-Randomized) | Change |
|----------|:-----------------:|:------------------------:|:------:|
| Observation delay | **2%** | **148%** | +146pp |
| Speed jitter | **28%** | **121%** | +93pp |
| 5x speed (unseen) | **-12%** | **38%** | +50pp |
| Mid-episode spike | **100%** | **113%** | +13pp |
| **Deployment** | **FAIL** (0.02) | **PASS** (1.00) | |
| **Quadrant** | deployment_fragile | deployment_ready | |
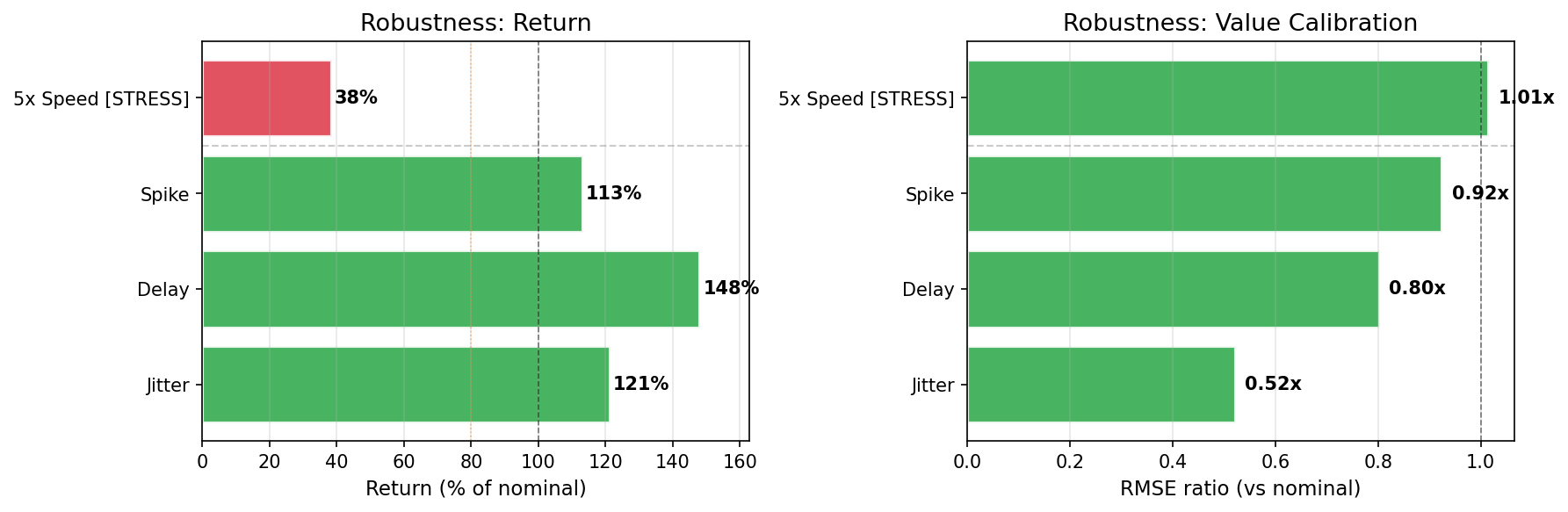
[View Before report](https://maruyamakoju.github.io/deltatau-audit/sample/halfcheetah_before/) | [View After report](https://maruyamakoju.github.io/deltatau-audit/sample/halfcheetah_after/)
<details>
<summary>Reproduce HalfCheetah results</summary>
```bash
pip install "deltatau-audit[sb3,mujoco]"
git clone https://github.com/maruyamakoju/deltatau-audit.git
cd deltatau-audit
python examples/audit_halfcheetah.py # standard PPO audit (~30 min)
python examples/train_robust_halfcheetah.py # train robust PPO (~30 min)
python examples/audit_before_after.py # Before/After comparison
```
Or download pre-trained models from [Releases](https://github.com/maruyamakoju/deltatau-audit/releases/tag/assets).
</details>
## Install
```bash
pip install deltatau-audit # core
pip install "deltatau-audit[demo]" # + CartPole demo (recommended start)
pip install "deltatau-audit[sb3,mujoco]" # + SB3 + MuJoCo environments
```
## Find and Fix in One Command
```bash
pip install "deltatau-audit[sb3]"
deltatau-audit fix-sb3 --algo ppo --model my_model.zip --env HalfCheetah-v5
```
This single command:
1. **Audits** your model (finds timing failures)
2. **Retrains** with speed randomization (the fix)
3. **Re-audits** the fixed model (verifies the fix)
4. **Generates** Before/After comparison report
```
BEFORE vs AFTER
Scenario Before After Change
------------ ---------- ---------- ----------
speed_5x 12.7% 76.6% + 63.9pp
jitter 43.7% 100.0% + 56.3pp
delay 100.0% 100.0% + 0.0pp
spike 26.7% 91.9% + 65.2pp
Deployment: FAIL (0.27) -> MILD (0.92)
Quadrant: deployment_fragile -> deployment_ready
```
Output: fixed model (`.zip`) + HTML reports + `comparison.html` (+ `comparison.md`).
Options: `--timesteps` (training budget), `--speed-min`/`--speed-max` (speed range), `--workers` (parallel episodes), `--seed` (reproducible), `--ci` (pipeline gate).
## Audit Your Own SB3 Model
Just want the diagnosis? Use `audit-sb3`:
```bash
deltatau-audit audit-sb3 --algo ppo --model my_model.zip --env HalfCheetah-v5 --out my_report/
# Faster — use all CPU cores:
deltatau-audit audit-sb3 --algo ppo --model my_model.zip --env HalfCheetah-v5 --workers auto
# Reproducible:
deltatau-audit audit-sb3 --algo ppo --model my_model.zip --env HalfCheetah-v5 --seed 42
```
No model handy? Try with a sample:
```bash
gh release download assets -R maruyamakoju/deltatau-audit -p cartpole_ppo_sb3.zip
deltatau-audit audit-sb3 --algo ppo --model cartpole_ppo_sb3.zip --env CartPole-v1
```
Supported algorithms: `ppo`, `sac`, `td3`, `a2c`. Any Gymnasium environment ID works.
<details>
<summary>Python API (for custom workflows)</summary>
```python
# Audit only
from deltatau_audit.adapters.sb3 import SB3Adapter
from deltatau_audit.auditor import run_full_audit
from deltatau_audit.report import generate_report
from stable_baselines3 import PPO
import gymnasium as gym
model = PPO.load("my_model.zip")
adapter = SB3Adapter(model)
result = run_full_audit(
adapter,
lambda: gym.make("HalfCheetah-v5"),
speeds=[1, 2, 3, 5, 8],
n_episodes=30,
n_workers=4, # parallel episode collection
seed=42, # reproducible results
)
generate_report(result, "my_audit/", title="My Agent Audit")
# Full fix pipeline
from deltatau_audit.fixer import fix_sb3_model
result = fix_sb3_model("my_model.zip", "ppo", "HalfCheetah-v5",
output_dir="fix_output/")
# result["fixed_model_path"] -> "fix_output/ppo_fixed.zip"
```
</details>
## What It Measures
| Badge | What it tests | How |
|-------|--------------|-----|
| **Reliance** | Does the agent *use* internal timing? | Tampers with internal Δτ, measures value prediction error |
| **Deployment** | Does the agent *survive* realistic timing changes? | Speed jitter, observation delay, mid-episode spikes, sensor noise |
| **Stress** | Does the agent *survive* extreme timing changes? | 5× speed (unseen during training) |
**Deployment scenarios (4):** `jitter` (speed 2±1), `delay` (1-step obs lag), `spike` (1→5→1), `obs_noise` (Gaussian σ=0.1 on observations). All four run automatically.
Agents without internal timing (standard PPO, SAC, etc.) get **Reliance: N/A** — only Deployment and Stress are tested.
## Rating Scale
| Rating | Return Ratio | Meaning |
|--------|-------------|---------|
| PASS | > 95% | Production ready |
| MILD | > 80% | Minor degradation |
| DEGRADED | > 50% | Significant loss |
| FAIL | <= 50% | Agent breaks |
All return ratios include bootstrap 95% confidence intervals with significance testing.
## Performance
By default all episodes run serially. Use `--workers` to parallelize:
```bash
# Auto-detect CPU core count (recommended for local runs)
deltatau-audit audit-sb3 --algo ppo --model model.zip --env HalfCheetah-v5 --workers auto
# Explicit count
deltatau-audit demo cartpole --workers 4
```
| Workers | 30 episodes × 5 scenarios | Speedup |
|---------|--------------------------|---------|
| 1 (default) | ~3 min (CartPole) | — |
| 4 | ~50 sec | ~3.5× |
| auto (8 cores) | ~30 sec | ~6× |
`--workers auto` maps to `os.cpu_count()`. Works with all `audit-*` and `demo` subcommands. For reproducibility, pair with `--seed 42` (parallel order is non-deterministic but per-episode seeds are fixed).
## CI / Pipeline Integration
```bash
python -m deltatau_audit demo cartpole --ci --out ci_report/
# exit 0 = pass, exit 1 = warn (stress), exit 2 = fail (deployment)
```
Outputs `ci_summary.json` and `ci_summary.md` for pipeline gates and PR comments.
### Output formats
```bash
# PR-ready markdown table (appends to $GITHUB_STEP_SUMMARY in GitHub Actions)
deltatau-audit audit-sb3 --algo ppo --model model.zip --env CartPole-v1 \
--format markdown
# Structured JSON to stdout (pipe to jq, scripts, or downstream tools)
deltatau-audit audit-sb3 --algo ppo --model model.zip --env CartPole-v1 \
--format json | jq '.summary'
# Combine JSON + CI exit codes
deltatau-audit audit-sb3 ... --format json --ci > result.json
```
JSON mode redirects all progress output to stderr so stdout contains only valid, parseable JSON. Reports are still generated in `--out`.
### Markdown PR comment example
```markdown
## Time Robustness Audit: PASS
| Badge | Rating | Score |
|-------|--------|-------|
| **Deployment** | **PASS** | 0.92 |
| **Stress** | **MILD** | 0.81 |
| Scenario | Category | Return | Significant |
|----------|----------|--------|-------------|
| jitter | Deployment | 95% | — |
...
```
### GitHub Action (one line)
```yaml
- uses: maruyamakoju/deltatau-audit@main
with:
command: audit-sb3
model: model.zip
algo: ppo
env: CartPole-v1
extras: sb3
```
Outputs `status`, `deployment-score`, `stress-score` for downstream steps. Exit code 0/1/2 for pass/warn/fail.
<details>
<summary>Full workflow examples</summary>
**CartPole demo gate (zero config):**
```yaml
- uses: maruyamakoju/deltatau-audit@main
- uses: actions/upload-artifact@v4
if: always()
with:
name: timing-audit
path: audit_report/
```
**Audit your own SB3 model:**
```yaml
- uses: maruyamakoju/deltatau-audit@main
id: audit
with:
command: audit-sb3
model: model.zip
algo: ppo
env: HalfCheetah-v5
extras: "sb3,mujoco"
- run: echo "Deployment score: ${{ steps.audit.outputs.deployment-score }}"
```
**Manual install (if you prefer):**
```yaml
- run: pip install "deltatau-audit[sb3]"
- run: deltatau-audit audit-sb3 --algo ppo --model model.zip --env CartPole-v1 --ci
```
</details>
## Speed-Randomized Training (the fix)
The fix for timing failures is simple: train with variable speed. Use `JitterWrapper` during SB3 training:
```python
import gymnasium as gym
from stable_baselines3 import PPO
from deltatau_audit.wrappers import JitterWrapper
# Wrap env with speed randomization (speed 1-5)
env = JitterWrapper(gym.make("CartPole-v1"), base_speed=3, jitter=2)
model = PPO("MlpPolicy", env)
model.learn(total_timesteps=100_000)
model.save("robust_model")
```
This is exactly what `fix-sb3` does under the hood. Use the wrapper directly when you want more control over training.
Available wrappers: `JitterWrapper` (random speed), `FixedSpeedWrapper` (constant speed), `PiecewiseSwitchWrapper` (scheduled speed changes), `ObservationDelayWrapper` (sensor delay), `ObsNoiseWrapper` (Gaussian observation noise).
## Audit CleanRL Agents
[CleanRL](https://github.com/vwxyzjn/cleanrl) agents are plain `nn.Module` subclasses — no framework wrapper needed.
```bash
deltatau-audit audit-cleanrl \
--checkpoint runs/CartPole-v1/agent.pt \
--agent-module ppo_cartpole.py \
--agent-class Agent \
--agent-kwargs obs_dim=4,act_dim=2 \
--env CartPole-v1
```
Or via Python API:
```python
from deltatau_audit.adapters.cleanrl import CleanRLAdapter
# Agent class must implement get_action_and_value(obs)
adapter = CleanRLAdapter(agent, lstm=False)
result = run_full_audit(adapter, env_factory, speeds=[1, 2, 3, 5, 8])
```
LSTM agents: pass `--lstm` (CLI) or `CleanRLAdapter(agent, lstm=True)` (API).
See `examples/audit_cleanrl.py` for a complete runnable example.
## Sim-to-Real Transfer
Timing failures are one of the main causes of sim-to-real gaps. A policy that runs at 50 Hz in simulation may be deployed at 30 Hz or with variable latency in the real world — and collapse.
```
Simulation → Reality
50 Hz → 30 Hz (0.6x speed)
Fixed dt → Variable dt (jitter)
Instant obs → Observation delay (network/sensor lag)
Stable → Mid-episode spikes (system load)
```
`deltatau-audit` measures exactly these failure modes. **If your agent passes Deployment ≥ MILD, it is likely to survive real-world timing variation.**
### IsaacLab / RSL-RL
For policies trained with IsaacLab (RSL-RL format):
```python
from deltatau_audit.adapters.torch_policy import TorchPolicyAdapter
# Define your actor/critic architectures (same as training)
actor = MyActorNet(obs_dim=48, act_dim=12)
critic = MyCriticNet(obs_dim=48)
# Loads RSL-RL checkpoint format automatically
adapter = TorchPolicyAdapter.from_checkpoint(
"model.pt",
actor=actor,
critic=critic,
is_discrete=False, # continuous actions
)
result = run_full_audit(adapter, env_factory, speeds=[1, 2, 3, 5])
```
Supported checkpoint formats:
- `{"model_state_dict": {"actor.*": ..., "critic.*": ...}}` (RSL-RL)
- `{"actor": state_dict, "critic": state_dict}` (explicit split)
- Raw `state_dict` (actor-only)
Or use a callable — no checkpoint loading needed:
```python
# Works with any framework's inference API
def my_act(obs):
action = runner.alg.actor_critic.act(obs)
value = runner.alg.actor_critic.evaluate(obs)
return action, value
adapter = TorchPolicyAdapter(my_act)
```
See `examples/isaaclab_skeleton.py` for a complete IsaacLab skeleton.
## Custom Adapters
Implement `AgentAdapter` (see `deltatau_audit/adapters/base.py`):
```python
from deltatau_audit.adapters.base import AgentAdapter
class MyAdapter(AgentAdapter):
def reset_hidden(self, batch=1, device="cpu"):
return torch.zeros(batch, hidden_dim)
def act(self, obs, hidden):
# Returns: (action, value, hidden_new, dt_or_None)
...
return action, value, hidden_new, None
```
Built-in adapters: `SB3Adapter` (PPO/SAC/TD3/A2C), `SB3RecurrentAdapter` (RecurrentPPO), `CleanRLAdapter` (CleanRL MLP/LSTM), `TorchPolicyAdapter` (IsaacLab/RSL-RL/custom), `InternalTimeAdapter` (Dt-GRU models).
## Compare Two Audits
After auditing a fixed model, compare to a previous result in one command:
```bash
# Generate comparison.html alongside the new audit
deltatau-audit audit-sb3 --algo ppo --model fixed.zip --env HalfCheetah-v5 \
--compare before_audit/summary.json --out after_audit/
```
Or use the `diff` subcommand directly (writes both `.md` and `.html`):
```bash
python -m deltatau_audit diff before/summary.json after/summary.json --out comparison.md
```
## Experiment Tracking
Push audit metrics to Weights & Biases or MLflow after any audit:
```bash
pip install "deltatau-audit[wandb]"
deltatau-audit audit-sb3 --model m.zip --algo ppo --env CartPole-v1 \
--wandb --wandb-project my-project --wandb-run baseline
pip install "deltatau-audit[mlflow]"
deltatau-audit audit-sb3 --model m.zip --algo ppo --env CartPole-v1 \
--mlflow --mlflow-experiment my-experiment
```
Or from Python:
```python
from deltatau_audit.tracker import log_to_wandb, log_to_mlflow
result = run_full_audit(adapter, env_factory)
log_to_wandb(result, project="my-project")
log_to_mlflow(result, experiment_name="my-experiment")
```
Logged scalars: `deployment_score`, `stress_score`, `reliance_score`, per-scenario `return_ratio`. Logged params: `deployment_rating`, `stress_rating`, `quadrant`. Missing tracker packages print a warning instead of crashing.
## Adaptive Sampling
For high-confidence results, use adaptive episode sampling:
```bash
deltatau-audit audit-sb3 --model m.zip --algo ppo --env HalfCheetah-v5 \
--adaptive --target-ci-width 0.05 --max-episodes 300
```
Instead of a fixed episode count, this keeps sampling until every scenario's 95% bootstrap CI width on the return ratio drops below `--target-ci-width` (default: 0.10), or until `--max-episodes` is reached (default: 500).
## Failure Diagnostics
When scenarios fail, the audit automatically diagnoses the root cause:
```
Failure Analysis
FAIL jitter — Speed Jitter Sensitivity
The agent cannot handle variable-frequency control.
Root cause: Policy overfits to fixed dt → breaks when step timing varies.
Fix: Train with JitterWrapper(base_speed=3, jitter=2).
```
The HTML report includes a dedicated diagnostics card with per-scenario pattern matching, root cause analysis, and actionable fix recommendations.
## Feature Summary
| Feature | CLI | Python API | Since |
|---------|-----|-----------|-------|
| SB3 model audit | `audit-sb3` | `SB3Adapter` | v0.3.0 |
| CleanRL audit | `audit-cleanrl` | `CleanRLAdapter` | v0.4.0 |
| HuggingFace Hub audit | `audit-hf` | `SB3Adapter.from_hub()` | v0.5.0 |
| IsaacLab / custom PyTorch | — | `TorchPolicyAdapter` | v0.4.5 |
| One-command fix | `fix-sb3`, `fix-cleanrl` | `fix_sb3_model()` | v0.3.8 |
| Before/After comparison | `--compare`, `diff` | `generate_comparison()` | v0.4.0 |
| CI pipeline gates | `--ci` | exit codes 0/1/2 | v0.3.0 |
| Markdown PR comments | `--format markdown` | `_print_markdown_summary()` | v0.3.9 |
| JSON output | `--format json` | `json.dumps(result)` | v0.5.7 |
| Failure diagnostics | automatic | `generate_diagnosis()` | v0.5.2 |
| Adaptive sampling | `--adaptive` | `adaptive=True` | v0.5.3 |
| Type annotations (PEP 561) | — | `py.typed` | v0.5.4 |
| WandB / MLflow tracking | `--wandb`, `--mlflow` | `log_to_wandb()` | v0.5.5 |
| Parallel episodes | `--workers auto` | `n_workers=` | v0.4.2 |
| Reproducible seeds | `--seed 42` | `seed=` | v0.4.3 |
| HTML + JSON reports | `--out dir/` | `generate_report()` | v0.3.0 |
| GitHub Actions | `uses: maruyamakoju/deltatau-audit@main` | — | v0.5.10 |
| Colab notebook | `notebooks/quickstart.ipynb` | — | v0.6.0 |
| SB3 training callback | — | `TimingAuditCallback` | v0.6.1 |
| Badge SVG generation | `badge summary.json` | `generate_badges()` | v0.6.1 |
## License
MIT
| text/markdown | maruyamakoju | null | null | null | null | reinforcement-learning, robustness, audit, timing, rl, mujoco, stable-baselines3, deployment, gymnasium, testing, ci | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Lan... | [] | null | null | >=3.9 | [] | [] | [] | [
"torch>=2.0",
"gymnasium>=0.29",
"numpy>=1.24",
"matplotlib>=3.7",
"tqdm>=4.60",
"gymnasium[classic-control]>=0.29; extra == \"demo\"",
"stable-baselines3>=2.0; extra == \"sb3\"",
"sb3-contrib>=2.0; extra == \"sb3\"",
"huggingface_hub>=0.16; extra == \"hf\"",
"stable-baselines3>=2.0; extra == \"hf... | [] | [] | [] | [
"Homepage, https://github.com/maruyamakoju/deltatau-audit",
"Repository, https://github.com/maruyamakoju/deltatau-audit",
"Documentation, https://maruyamakoju.github.io/deltatau-audit/",
"Issues, https://github.com/maruyamakoju/deltatau-audit/issues",
"Changelog, https://github.com/maruyamakoju/deltatau-aud... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T19:00:39.464019 | deltatau_audit-0.6.2.tar.gz | 278,364 | 10/1a/ec0115ecc3946e49a728625618e6075f21b2231037aa22d3ec30fb731bb7/deltatau_audit-0.6.2.tar.gz | source | sdist | null | false | aa6687c6b3c92cb4577f6cf3b0d39690 | 03b90edd917de85702f6db654d60cf13ed0a3fccf3d00eba016b261e9014387a | 101aec0115ecc3946e49a728625618e6075f21b2231037aa22d3ec30fb731bb7 | MIT | [
"LICENSE"
] | 222 |
2.4 | asteroid-odyssey | 1.6.215 | Python SDK for the Asteroid Agents API | # Asteroid Odyssey Python SDK
Python SDK for the Asteroid Agents API.
## Installation
```bash
pip install asteroid-odyssey
```
## Usage
```python
from asteroid_odyssey import ApiClient, Configuration, ExecutionApi
# Configure the client
config = Configuration(
host="https://odyssey.asteroid.ai/agents/v2",
api_key={"ApiKeyAuth": "your-api-key"}
)
client = ApiClient(config)
execution_api = ExecutionApi(client)
# Execute an agent
response = execution_api.agent_execute_post(
agent_id="your-agent-id",
agents_agent_execute_agent_request={"inputs": {"input": "value"}}
)
print(f"Execution ID: {response.execution_id}")
```
## Documentation
See [docs.asteroid.ai](https://docs.asteroid.ai) for full documentation.
| text/markdown | null | Asteroid <founders@asteroid.com> | null | null | null | OpenAPI, Asteroid Agents API, browser automation, AI agents | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent",
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Internet :: WWW/HTTP :: Browsers"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"urllib3<3.0.0,>=2.1.0",
"python-dateutil>=2.8.2",
"pydantic>=2",
"typing-extensions>=4.7.1",
"requests>=2.28.0",
"pytest>=7.2.1; extra == \"dev\"",
"pytest-cov>=2.8.1; extra == \"dev\"",
"flake8>=4.0.0; extra == \"dev\"",
"mypy>=1.5; extra == \"dev\""
] | [] | [] | [] | [
"Repository, https://github.com/asteroidai/agents",
"Homepage, https://asteroid.ai",
"Documentation, https://docs.asteroid.ai"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T19:00:26.262509 | asteroid_odyssey-1.6.215.tar.gz | 88,577 | ca/07/fd4313450cc9e118d0f061b714a98e53e63f10398d16b5ce311db81f460e/asteroid_odyssey-1.6.215.tar.gz | source | sdist | null | false | d32ebab7c3b7ce540f2b1f57382fec99 | 1b6c43a974a86f29b6c39459bb8a72e1abd3b0c2ba65f0108efcd68d2466f898 | ca07fd4313450cc9e118d0f061b714a98e53e63f10398d16b5ce311db81f460e | MIT | [] | 343 |
2.4 | wgc-clippy | 1.0.2 | Low-level utility helpers for WGC QA framework | # wgc-clippy
Low-level utility helpers for the WGC QA framework.
## Modules
- `cmd_helper` — subprocess command execution
- `waiter` — polling/wait utilities with timeout
- `os_helper` — OS-level file and process operations
- `registry` — Windows Registry read/write
- `process_helper` — process inspection and manipulation
- `regex_helper` — regex matching utilities
- `testrail_api` — TestRail API integration
- `torrents_helper` — torrent file operations
- `file_downloader` — HTTP file download
- `magic_folder` — temporary directory utilities
## Install
```bash
pip install wgc-clippy
```
| text/markdown | null | Mykola Kovhanko <thuesdays@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: Microsoft :: Windows"
] | [] | null | null | >=3.7 | [] | [] | [] | [
"pywin32==306",
"requests>=2.31.0"
] | [] | [] | [] | [
"Homepage, https://github.com/thuesdays/wgc-clippy"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T18:56:05.355172 | wgc_clippy-1.0.2.tar.gz | 24,508 | b3/a3/e0dda12d513b68cd5e204bc7c095d9b0dd993a5ceb675c66c955254b66c5/wgc_clippy-1.0.2.tar.gz | source | sdist | null | false | c6f4959fd9f1aba5ea2c990b3c3836ac | 73ab4746de73d8b2d85acad9496c2189bcedf466a4e6fdbf1377620a584bc318 | b3a3e0dda12d513b68cd5e204bc7c095d9b0dd993a5ceb675c66c955254b66c5 | null | [] | 309 |
2.4 | comicsaver | 0.1.1 | A command-line tool to download comics from readcomiconline.li | # ComicSaver
A robust, Selenium-based command-line tool designed to scrape and download high-quality comic images from `readcomiconline.li`. It handles Cloudflare protection, JavaScript-rendered content, and lazy-loading images automatically.
## Features
- **Bypasses Protection**: Uses Selenium with headless Chrome to handle Cloudflare and dynamic JavaScript.
- **Smart Scrolling**: Implements an "incremental scrolling with patience" algorithm to ensure all lazy-loaded images are captured, even on slow connections.
- **Organized Output**: Automatically creates a structured directory hierarchy: `Output/ComicName/IssueName/`.
- **Flexible**: Scrape a single issue or an entire comic series (work in progress for full series recursion, currently optimized for single issues).
- **PDF Generation**: Optionally convert downloaded images into a single, named PDF file.
- **Headless Mode**: Runs silently in the background by default.
## Prerequisites
- Python 3.8+
- [Google Chrome](https://www.google.com/chrome/) installed on your machine.
## Installation
### From Source (Editable Mode)
1. Clone the repository:
```bash
git clone https://github.com/yourusername/comicsaver.git
cd comicsaver
```
2. Install the package with pip:
```bash
pip install .
```
(Or `pip install -e .` for editable mode)
### From PyPI
```bash
pip install comicsaver
```
## Usage
Once installed, use the `comicsaver` command directly:
```bash
comicsaver [URL] [OPTIONS]
```
Or run via Python module:
```bash
python -m comicsaver.cli [URL] [OPTIONS]
```
### Arguments
- `URL`: The URL of the comic issue or main page (e.g., `https://readcomiconline.li/Comic/JLA-Avengers/Issue-1`).
- `-o`, `--output`: (Optional) The directory to save downloaded comics. Defaults to `Comics`.
- `-t`, `--threads`: (Optional) Number of concurrent download threads (default: 1).
- `--pdf`: (Optional) Combine downloaded images into a single PDF file (named `Comic - Issue.pdf`).
- `--headless`: (Optional) Run the browser in headless mode (no UI). Useful for background tasks.
### Examples
**Download a specific issue:**
```bash
comicsaver "https://readcomiconline.li/Comic/JLA-Avengers/Issue-1" -o MyComics --headless --pdf -t 5
```
**Download with visible browser (for debugging):**
```bash
comicsaver "https://readcomiconline.li/Comic/JLA-Avengers/Issue-1"
```
## Project Structure
```
comicsaver/
├── src/
│ └── comicsaver/
│ ├── __init__.py
│ └── cli.py # Main scraper logic
├── pyproject.toml # Package configuration
├── requirements.txt # Python dependencies
├── .gitignore # Git ignore rules
└── README.md # Project documentation
```
## Troubleshooting
- **"No images found"**: Ensure your internet connection is stable. The script waits for images to load, but extremely slow connections might timeout.
- **Chrome driver errors**: The `webdriver-manager` should handle driver installation automatically. If it fails, try upgrading it: `pip install --upgrade webdriver-manager`.
## AI Development
This project was developed with the assistance of AI. The core logic, including Selenium handling, lazy loading algorithms, and PDF generation features, was implemented through collaboration with an AI coding assistant. The AI helped in debugging, optimizing, and structuring the codebase for better maintainability and performance.
| text/markdown | null | Akshay C V <cvakshay764@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"selenium",
"webdriver-manager",
"requests",
"beautifulsoup4",
"tqdm",
"Pillow"
] | [] | [] | [] | [
"Homepage, https://github.com/akaazazel/comicsaver",
"Bug Tracker, https://github.com/akaazazel/comicsaver/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:55:56.774188 | comicsaver-0.1.1.tar.gz | 7,848 | 30/0f/b92128a2ff52e7557bec0069e5704b28f8b87b1f8958e30d9b1bd316759b/comicsaver-0.1.1.tar.gz | source | sdist | null | false | 50da2bc16b8bbd8f1537adc5e4f22f77 | 8c3915be5cf26f84ed1c4dac5abba177a8d11fb7280568bc9f7656a2b97b44b0 | 300fb92128a2ff52e7557bec0069e5704b28f8b87b1f8958e30d9b1bd316759b | null | [
"LICENSE"
] | 234 |
2.4 | odoorpc-toolbox | 0.6.0 | Helper functions for Odoo server operations via internalized JSON-RPC. | # OdooRPC Toolbox
> **Language / Sprache**: [DE](#deutsche-dokumentation) | [EN](#english-documentation)
---
## Deutsche Dokumentation
### Projektübersicht
Ein Python-Paket mit Hilfsfunktionen und Utilities für Odoo-Server-Operationen. Die OdooRPC-Funktionalität ist vollständig internalisiert (JSON-RPC 2.0). Es vereinfacht häufige Odoo-Operationen wie Partner-Verwaltung, Bundesland/Länder-Abfragen, Dateioperationen und Sequenzverwaltung.
**Autor**: Equitania Software GmbH - Pforzheim - Germany
**Lizenz**: GNU Affero General Public License v3
**Python**: >= 3.10
### Funktionen
- Einfache Verbindungsverwaltung mit YAML-Konfiguration
- Hilfsfunktionen für häufige Odoo-Operationen:
- Partner-Verwaltung (Suchen, Erstellen, Aktualisieren)
- Bundesland- und Länderabfragen
- Dateioperationen (Bilder, Anhänge)
- Sequenzverwaltung
- Produkt- und Lageroperationen
### Installation
```bash
pip install odoorpc-toolbox
```
### Konfiguration
Erstellen Sie eine YAML-Konfigurationsdatei (z.B. `odoo_config.yaml`):
```yaml
Server:
url: your.odoo.server.com
port: 8069
protocol: jsonrpc
database: your_database
user: your_username
password: your_password
```
### Verwendung
```python
from odoorpc_toolbox import EqOdooConnection
# Verbindung initialisieren
connection = EqOdooConnection('odoo_config.yaml')
# Hilfsfunktionen verwenden
state_id = connection.get_state_id(country_id=21, state_name="Bayern")
partner_id = connection.get_res_partner_id(customerno="KUND001")
```
### Partner-Operationen
```python
# Partner suchen
partner_id = connection.get_res_partner_id(supplierno="LIEF001", customerno="KUND001")
# Partner-Kategorien abrufen oder erstellen
category_id = connection.get_res_partner_category_id("Einzelhandel")
# Partner-Titel abrufen
title_id = connection.get_res_partner_title_id("Herr")
```
### Standort-Operationen
```python
# Bundesland-ID abrufen
state_id = connection.get_state_id(country_id=21, state_name="Bayern")
# Adresse parsen
strasse, hausnr = connection.extract_street_address_part("Hauptstraße 123")
```
### Datei-Operationen
```python
# Bilder laden und kodieren
image_data = connection.get_picture("/pfad/zum/bild.jpg")
```
### Abhängigkeiten
- Python >= 3.10
- PyYAML >= 6.0
- OdooRPC-Funktionalität ist vollständig internalisiert (keine externe Abhängigkeit)
---
## English Documentation
### Project Overview
A Python package providing helper functions and utilities for Odoo server operations. The OdooRPC functionality is fully internalized (JSON-RPC 2.0). It simplifies common Odoo operations like partner management, state/country lookups, file operations, and sequence management.
**Author**: Equitania Software GmbH - Pforzheim - Germany
**License**: GNU Affero General Public License v3
**Python**: >= 3.10
### Features
- Easy connection management with YAML configuration
- Helper functions for common Odoo operations:
- Partner management (search, create, update)
- State and country lookups
- File operations (images, attachments)
- Sequence management
- Product and inventory operations
### Installation
```bash
pip install odoorpc-toolbox
```
### Configuration
Create a YAML configuration file (e.g., `odoo_config.yaml`):
```yaml
Server:
url: your.odoo.server.com
port: 8069
protocol: jsonrpc
database: your_database
user: your_username
password: your_password
```
### Usage
```python
from odoorpc_toolbox import EqOdooConnection
# Initialize connection
connection = EqOdooConnection('odoo_config.yaml')
# Use helper functions
state_id = connection.get_state_id(country_id=21, state_name="California")
partner_id = connection.get_res_partner_id(customerno="CUST001")
```
### Partner Operations
```python
# Search for partners
partner_id = connection.get_res_partner_id(supplierno="SUP001", customerno="CUST001")
# Get or create partner categories
category_id = connection.get_res_partner_category_id("Retail")
# Get partner titles
title_id = connection.get_res_partner_title_id("Mr.")
```
### Location Operations
```python
# Get state/province ID
state_id = connection.get_state_id(country_id=21, state_name="California")
# Parse address
street, house_no = connection.extract_street_address_part("123 Main Street")
```
### File Operations
```python
# Load and encode images
image_data = connection.get_picture("/path/to/image.jpg")
```
### Requirements
- Python >= 3.10
- PyYAML >= 6.0
- OdooRPC functionality is fully internalized (no external dependency)
---
## Contributing / Mitwirken
Contributions are welcome! Please feel free to submit a Pull Request.
Beiträge sind willkommen! Bitte zögern Sie nicht, einen Pull Request einzureichen.
## License / Lizenz
This project is licensed under the GNU Affero General Public License v3 - see the LICENSE.txt file for details.
Dieses Projekt ist unter der GNU Affero General Public License v3 lizenziert - siehe LICENSE.txt für Details.
| text/markdown | null | Equitania Software GmbH <info@equitania.de> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"PyYAML>=6.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"ruff>=0.8.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/equitania/odoorpc-toolbox",
"Repository, https://github.com/equitania/odoorpc-toolbox"
] | uv/0.6.9 | 2026-02-19T18:55:45.235457 | odoorpc_toolbox-0.6.0.tar.gz | 54,277 | e1/95/ebc5ac46c748d0a6337cc4dc1df0513a8c5f9bd3351e24ca42f31fbd54d1/odoorpc_toolbox-0.6.0.tar.gz | source | sdist | null | false | 1b20e7e73137e79e6ef65b13c04dca7c | b9aceb97f6711ff8e5aa17cbcb31cbb6e9fa6bf5db88c474484348b21c84ceef | e195ebc5ac46c748d0a6337cc4dc1df0513a8c5f9bd3351e24ca42f31fbd54d1 | AGPL-3.0-only | [
"LICENSE.txt"
] | 212 |
2.4 | nougat-mcp | 0.1.0 | MCP server for high-accuracy scientific PDF OCR using Meta's Nougat | # Nougat-MCP
[](https://pypi.org/project/nougat-mcp/)
[](https://pypi.org/project/nougat-mcp/)
[](https://www.gnu.org/licenses/gpl-3.0)
[](https://modelcontextprotocol.io)
`nougat-mcp` is a Model Context Protocol (MCP) server for high-fidelity OCR of scientific PDFs using Meta's Nougat.
It is designed for agent workflows where you need equations, tables, and structure preserved better than traditional OCR.
## Why This Server
- Scientific OCR quality tailored for papers, formulas, and dense layouts.
- MCP-native interface for Codex, Claude, Cursor, Antigravity, and other clients.
- Output-format control:
- `mmd`: raw Nougat/Mathpix-style output.
- `md`: renderer-friendly conversion (math delimiter and KaTeX compatibility fixes).
- Settings file support so agents can read a shared default format policy.
## Installation
Install from PyPI:
```bash
uv pip install nougat-mcp
```
This package installs `nougat-ocr` and pins known-sensitive dependencies for stability.
## Tools
### `parse_research_paper`
Arguments:
- `file_path` (string): Absolute path to a local PDF.
- `output_format` (string, optional):
- `default` (default): uses server settings.
- `mmd`: raw Nougat output.
- `md`: converted markdown-friendly output.
Returns:
- OCR result as a single text string in the requested format.
### `get_output_settings`
Returns resolved server output settings, including where settings were loaded from.
## Output Conversion (`mmd` -> `md`)
When `output_format="md"`, the server applies compatibility conversions:
- `\[ ... \]` -> `$$ ... $$`
- `\( ... \)` -> `$ ... $`
- `\tag{...}` -> visible equation label `\qquad\text{(...)}`
- KaTeX delimiter normalization, for example:
- `\bigl{\|} ... \bigr{\|}` -> `\bigl\| ... \bigr\|`
This avoids common renderer parse errors in markdown environments that are not fully MathJax-compatible.
## Server Settings
Settings are read in this order:
1. `NOUGAT_MCP_SETTINGS` (if set)
2. `./settings.json` (current working directory)
Example `settings.json`:
```json
{
"nougat_mcp": {
"default_output_format": "md",
"md_rewrite_tags": true,
"md_fix_sized_delimiters": true
}
}
```
## Agent Configuration
### Codex CLI
Add to `~/.codex/config.toml`:
```toml
[mcp_servers.nougat]
command = "uvx"
args = ["nougat-mcp"]
enabled = true
[mcp_servers.nougat.env]
NOUGAT_MCP_SETTINGS = "/absolute/path/to/settings.json"
```
### Claude Desktop
Add to `claude_desktop_config.json`:
```json
{
"mcpServers": {
"nougat": {
"command": "uvx",
"args": ["nougat-mcp"],
"env": {
"NOUGAT_MCP_SETTINGS": "/absolute/path/to/settings.json"
}
}
}
}
```
### Antigravity / Gemini Desktop
Add to `~/.gemini/settings.json`:
```json
{
"mcpServers": {
"nougat": {
"type": "stdio",
"command": "uvx",
"args": ["nougat-mcp"],
"env": {
"NOUGAT_MCP_SETTINGS": "/absolute/path/to/settings.json"
}
}
}
}
```
### Cursor
In Cursor MCP settings, add:
```json
{
"mcpServers": {
"nougat": {
"command": "uvx",
"args": ["nougat-mcp"],
"env": {
"NOUGAT_MCP_SETTINGS": "/absolute/path/to/settings.json"
}
}
}
}
```
Note: Cursor MCP config location can vary by version/platform; use the MCP settings UI or your current JSON settings file.
## Showcase (Real Page Example)
A real extraction from page 5 of `src/2405.08770v1.pdf` is included:
- Input PDF page: [showcase/2405.08770v1_page5.pdf](https://github.com/svretina/nougat-mcp/blob/master/showcase/2405.08770v1_page5.pdf)
- Raw `mmd` output: [showcase/2405.08770v1_page5.mmd](https://github.com/svretina/nougat-mcp/blob/master/showcase/2405.08770v1_page5.mmd)
- Converted `md` output: [showcase/2405.08770v1_page5.md](https://github.com/svretina/nougat-mcp/blob/master/showcase/2405.08770v1_page5.md)
Quick comparison:
```text
# mmd
\[DV=V_{x}. \tag{3.2}\]
# md
$$
DV=V_{x}. \qquad\text{(3.2)}
$$
```
## Performance Notes
- First run may download model weights (~1.4 GB).
- CPU inference is significantly slower than GPU inference.
- Use page subsets whenever possible to reduce runtime.
## Release to PyPI
This repository includes automated publishing via GitHub Actions: `.github/workflows/publish-pypi.yml`.
### One-time setup (recommended)
1. Create the `nougat-mcp` project on PyPI.
2. In PyPI project settings, configure a Trusted Publisher:
- Owner: `svretina`
- Repository: `nougat-mcp`
- Workflow: `publish-pypi.yml`
- Environment: `pypi`
3. In GitHub, ensure Actions are enabled for the repo.
### Release flow
1. Bump `version` in `pyproject.toml`.
2. Commit and push to `master`.
3. Create and push a version tag:
```bash
git tag v0.1.0
git push origin v0.1.0
```
4. The workflow builds, validates (`twine check`), and publishes to PyPI.
## Compatibility Pins
To keep Nougat stable across environments, the package pins sensitive dependency ranges:
- `transformers>=4.35,<4.38`
- `albumentations>=1.3,<1.4`
- `pypdfium2<5.0`
- `huggingface-hub<1.0`
- `fsspec<=2025.10.0`
## Credits
- Nougat OCR: https://github.com/facebookresearch/nougat
- Paper: https://arxiv.org/abs/2308.13418
## License
GNU General Public License v3.0 (`LICENSE`).
| text/markdown | Stamatis Vretinaris | null | null | null | GNU GENERAL PUBLIC LICENSE
Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU General Public License is a free, copyleft license for
software and other kinds of works.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
the GNU General Public License is intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users. We, the Free Software Foundation, use the
GNU General Public License for most of our software; it applies also to
any other work released this way by its authors. You can apply it to
your programs, too.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
To protect your rights, we need to prevent others from denying you
these rights or asking you to surrender the rights. Therefore, you have
certain responsibilities if you distribute copies of the software, or if
you modify it: responsibilities to respect the freedom of others.
For example, if you distribute copies of such a program, whether
gratis or for a fee, you must pass on to the recipients the same
freedoms that you received. You must make sure that they, too, receive
or can get the source code. And you must show them these terms so they
know their rights.
Developers that use the GNU GPL protect your rights with two steps:
(1) assert copyright on the software, and (2) offer you this License
giving you legal permission to copy, distribute and/or modify it.
For the developers' and authors' protection, the GPL clearly explains
that there is no warranty for this free software. For both users' and
authors' sake, the GPL requires that modified versions be marked as
changed, so that their problems will not be attributed erroneously to
authors of previous versions.
Some devices are designed to deny users access to install or run
modified versions of the software inside them, although the manufacturer
can do so. This is fundamentally incompatible with the aim of
protecting users' freedom to change the software. The systematic
pattern of such abuse occurs in the area of products for individuals to
use, which is precisely where it is most unacceptable. Therefore, we
have designed this version of the GPL to prohibit the practice for those
products. If such problems arise substantially in other domains, we
stand ready to extend this provision to those domains in future versions
of the GPL, as needed to protect the freedom of users.
Finally, every program is threatened constantly by software patents.
States should not allow patents to restrict development and use of
software on general-purpose computers, but in those that do, we wish to
avoid the special danger that patents applied to a free program could
make it effectively proprietary. To prevent this, the GPL assures that
patents cannot be used to render the program non-free.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Use with the GNU Affero General Public License.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU Affero General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the special requirements of the GNU Affero General Public License,
section 13, concerning interaction through a network will apply to the
combination as such.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU General Public License from time to time. Such new versions will
be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <https://www.gnu.org/licenses/>.
Also add information on how to contact you by electronic and paper mail.
If the program does terminal interaction, make it output a short
notice like this when it starts in an interactive mode:
<program> Copyright (C) <year> <name of author>
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
This is free software, and you are welcome to redistribute it
under certain conditions; type `show c' for details.
The hypothetical commands `show w' and `show c' should show the appropriate
parts of the General Public License. Of course, your program's commands
might be different; for a GUI interface, you would use an "about box".
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU GPL, see
<https://www.gnu.org/licenses/>.
The GNU General Public License does not permit incorporating your program
into proprietary programs. If your program is a subroutine library, you
may consider it more useful to permit linking proprietary applications with
the library. If this is what you want to do, use the GNU Lesser General
Public License instead of this License. But first, please read
<https://www.gnu.org/licenses/why-not-lgpl.html>. | markdown, mcp, nougat, ocr, pdf, scientific-documents | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"... | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"albumentations<1.4,>=1.3",
"fsspec<=2025.10.0",
"huggingface-hub<1.0",
"mcp>=1.26.0",
"nougat-ocr==0.1.17",
"pypdfium2<5.0",
"transformers<4.38,>=4.35"
] | [] | [] | [] | [
"Homepage, https://github.com/svretina/nougat-mcp",
"Repository, https://github.com/svretina/nougat-mcp",
"Issues, https://github.com/svretina/nougat-mcp/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:55:39.360947 | nougat_mcp-0.1.0.tar.gz | 1,269,447 | 31/b3/c228cfd19fdc68c549b861d076735d31d8a5fbd9f1e776a6005f87794c6d/nougat_mcp-0.1.0.tar.gz | source | sdist | null | false | 20e55f37347322d9fd499e91bb4062cb | 46ead874878aa3d95e3fc391363434324ff399d80bfb0e5e3999f64902ee80d5 | 31b3c228cfd19fdc68c549b861d076735d31d8a5fbd9f1e776a6005f87794c6d | null | [
"LICENSE"
] | 242 |
2.4 | great-expectations-cloud | 20260219.0.dev0 | Great Expectations Cloud | # GX cloud
[](https://pypi.org/project/great-expectations_cloud/#history)
[](https://hub.docker.com/r/greatexpectations/agent)
[](https://github.com/great-expectations/cloud/actions/workflows/ci.yaml)
[](https://results.pre-commit.ci/latest/github/great-expectations/cloud/main)
[](https://codecov.io/gh/great-expectations/cloud)
[](https://github.com/astral-sh/ruff)
## Quick Start
To use the GX Agent, you will need to have a Great Expectations Cloud account. You can sign up for free at [https://app.greatexpectations.io](https://app.greatexpectations.io).
Deployment instructions for the GX Agent can be found in the [GX Cloud documentation](https://docs.greatexpectations.io/docs/cloud/deploy/deploy_gx_agent).
## Contributing
Follow these steps to create a development environment:
1. Use the version of Python specified in [`.python-version`](./.python-version)
- confirm with `python --version`
2. Use the version of Poetry specified in [`poetry.lock`](./poetry.lock)
- confirm with `poetry --version`
3. Set up virtual environment and install dependencies
- `poetry sync`
4. Activate your virtual environment
- `eval $(poetry env activate)`
5. Set up precommit hooks
- `pre-commit install`
### Troubleshooting
If you run into issues, you can try `pipx reinstall-all`
### Running locally for development
```console
$ gx-agent --help
usage: gx-agent [-h] [--log-level LOG_LEVEL] [--skip-log-file SKIP_LOG_FILE] [--log-cfg-file LOG_CFG_FILE] [--version]
optional arguments:
-h, --help show this help message and exit
--log-level LOG_LEVEL
Level of logging to use. Defaults to WARNING.
--skip-log-file SKIP_LOG_FILE
Skip writing debug logs to a file. Defaults to False. Does not affect logging to stdout/stderr.
--log-cfg-file LOG_CFG_FILE
Path to a logging configuration json file. Supersedes --log-level and --skip-log-file.
--version Show the GX Agent version.
```
#### Set ENV variables
`GX_CLOUD_ACCESS_TOKEN`
`GX_CLOUD_ORGANIZATION_ID`
If you want to override where the GX Agent looks for the RabbitMQ queue you can also set
`AMQP_HOST_OVERRIDE` and `AMQP_PORT_OVERRIDE`. For example, if you are running a local dockerized RabbitMQ
service exposed on localhost port 5672, you can set `AMQP_HOST_OVERRIDE=127.0.0.1` and
`AMQP_PORT_OVERRIDE=5672`.
### Start the GX Agent
If you intend to run the GX Agent against local services (Cloud backend or datasources) run the Agent outside of the container.
```
gx-agent
```
### Developer Tasks
Common developer tasks are available via `invoke` (defined in `tasks.py`).
`invoke --list` to see available tasks.
#### Synchronize Dependencies
To ensure you are using the latest version of the core and development dependencies run `poetry sync`.
Also available as an invoke task.
```console
invoke deps
```
#### Updating `poetry.lock` dependencies
Use the latest version of poetry
```console
pipx upgrade poetry
```
The dependencies installed in our CI and the Docker build step are determined by the [poetry.lock file](https://python-poetry.org/docs/basic-usage/#installing-with-poetrylock).
[To update only a specific dependency](https://python-poetry.org/docs/cli/#update) (such as `great_expectations`) ...
```console
poetry update great_expectations
```
**Note:** If `poetry update` does not find the latest version of `great_expectations`, you can manually update the version in `pyproject.toml`, and then update the lockfile using `poetry lock`.
[To resolve and update all dependencies ...](https://python-poetry.org/docs/cli/#lock)
```console
poetry lock
```
In either case, the updated `poetry.lock` file must be committed and merged to main.
#### Building and Running the GX Agent Image
To build the GX Agent Docker image, run the following in the root dir:
```
invoke docker
```
Running the GX Agent:
```
invoke docker --run
```
or
```
docker run --env GX_CLOUD_ACCESS_TOKEN="<GX_TOKEN>" --env GX_CLOUD_ORGANIZATION_ID="<GX_ORG_ID>" gx/agent
```
Now go into GX Cloud and issue commands for the GX Agent to run, such as generating an Expectation Suite for a Data Source.
> Note if you are pushing out a new image update the image tag version in `containerize-agent.yaml`. The image will be built and pushed out via GitHub Actions.
#### Example Data
The contents from [/examples/agent/data](https://github.com/great-expectations/cloud/tree/main/examples/agent/data) will be copied to `/data` for the Docker container.
#### Adding an action to the Agent
1. Make a new action in `great_expectations_cloud/agent/actions/` in a separate file.
2. Register your action in the file it was created in using `great_expectations_cloud.agent.event_handler.register_event_action()`. Register for the major version of GX Core that the action applies to, e.g. `register_event_action("1", RunCheckpointEvent, RunCheckpointAction)` registers the action for major version 1 of GX Core (e.g. 1.0.0).
3. Import your action in `great_expectations_cloud/agent/actions/__init__.py`
Note: The Agent is core-version specific but this registration mechanism allows us to preemptively work on actions for future versions of GX Core while still supporting the existing latest major version.
### Release Process
#### Versioning
This is the version that will be used for the Docker image tag as well.
_Standard Release_:
The versioning scheme is `YYYYMMDD.{release_number}` where:
- the date is the date of the release
- the release number starts at 0 for the first release of the day
- the release number is incremented for each release within the same day
For example: `20240402.0`
_Pre-release_:
The versioning scheme is `YYYYMMDD.{release_number}.dev{dev_number}`
- the date is the date of the release
- the dev number starts at 0 for the first pre-release of the day
- the dev number is incremented for each pre-release within the same day
- the release number is the release that this pre-release is for
For example: `20240403.0.dev0` is the first pre-release for the `20240403.0` release.
For example, imagine the following sequence of releases given for a day with two releases:
- `20240403.0.dev0`
- `20240403.0.dev1`
- `20240403.0`
- `20240403.1.dev0`
- `20240403.1`
There can be days with no standard releases, only pre-releases or days with no pre-release or standard release at all.
#### Pre-releases
Pre-releases are completed automatically with each merge to the `main` branch.
The version is updated in `pyproject.toml` and a pre-release is created on PyPi.
A new Docker tag will also be generated and pushed to [Docker Hub](https://hub.docker.com/r/greatexpectations/agent)
**Manual Pre-releases**
NOTE: CI will automatically create pre-releases on merges to `main`. Instead of manually creating pre-releases, consider using the CI process. This is only for exceptional cases.
To manually create a pre-release, run the following command to update the version in `pyproject.toml` and then merge it to `main` in a standalone PR:
```console
invoke pre-release
```
This will create a new pre-release version. On the next merge to `main`, the release will be uploaded to PyPi.
A new Docker tag will also be generated and pushed to [Docker Hub](https://hub.docker.com/r/greatexpectations/agent)
#### Releases
Releases will be completed on a regular basis by the maintainers of the project and with any release of [GX Core](https://github.com/great-expectations/great_expectations)
For maintainers, to create a release, run the following command to update the version in `pyproject.toml` and then
merge it to `main` in a standalone PR:
```console
invoke release
```
This will create a new release version. On the next merge to `main`, the release will be uploaded to PyPi.
A new Docker tag will also be generated and pushed to [Docker Hub](https://hub.docker.com/r/greatexpectations/agent). In addition, releases will be tagged with `stable` and `latest` tags.
#### GitHub Workflow for releasing
We use the GitHub Actions workflow to automate the release and pre-release process. There are two workflows involved:
1. [CI](https://github.com/great-expectations/cloud/blob/main/.github/workflows/ci.yaml) - This workflow runs on each pull request and will update the version in `pyproject.toml` to the pre-release version if the version is not already manually updated in the PR. It will also run the tests and linting.
2. [Containerize Agent](https://github.com/great-expectations/cloud/blob/main/.github/workflows/containerize-agent.yaml) - This workflows runs on merge with `main` and will create a new Docker image and push it to Docker Hub and PyPi. It uses the version in `pyproject.toml`.
A visual representation of the workflow is shown [here](https://github.com/great-expectations/cloud/blob/main/.github/workflows/agent_release_workflows.png)
### Dependabot and Releases/Pre-releases
GitHub's Dependabot regularly checks our dependencies for vulnerabilty-based updates and proposes PRs to update dependency version numbers accordingly.
Dependabot may only update the `poetry.lock` file. If only changes to `poetry.lock` are made, this may be done in a pre-release.
For changes to the `pyproject.toml` file:
- If the version of a tool in the `[tool.poetry.group.dev.dependencies]` group is updated, this may be done without any version bump.
- While doing this, make sure any version references in the pre-commit config `.pre-commit-config.yaml` are kept in sync (e.g., ruff).
- For other dependency updates or package build metadata changes, a new release should be orchestrated. This includes updates in the following sections:
- `[tool.poetry.dependencies]`
- `[tool.poetry.group.*.dependencies]` where `*` is the name of the group (not including the `dev` group)
- To stop the auto-version bump add the `no version bump` label to the PR. Use this when:
- Only modifying dev dependencies.
- Only modifying tests that do not change functionality.
NOTE: Dependabot does not have permissions to access secrets in our CI. You may notice that integration tests fail on PRs that dependabot creates. If you add a commit (as a GX member) to the PR, the tests will run again and pass because they now have access to the secrets. That commit can be anything, including an empty commit e.g. `git commit -m "some message" --allow-empty`.
| text/markdown | The Great Expectations Team | team@greatexpectations.io | null | null | Proprietary | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Information Analysis",
"Topic :: Software... | [] | null | null | <3.12,>=3.11.4 | [] | [] | [] | [
"great-expectations[databricks,gx-redshift,mssql,postgresql,snowflake,trino]==1.12.3",
"langchain<2.0.0,>=1.0.8",
"langchain-core<2.0.0,>=1.0.7",
"langchain-openai<2.0.0,>=1.0.3",
"langgraph<2.0.0,>=1.0.3",
"orjson!=3.9.10,<4.0.0,>=3.9.7",
"packaging<27.0,>=21.3",
"pika<2.0.0,>=1.3.1",
"pydantic<3,>... | [] | [] | [] | [
"Homepage, https://greatexpectations.io",
"Repository, https://github.com/great-expectations/cloud"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:54:08.787399 | great_expectations_cloud-20260219.0.dev0.tar.gz | 79,218 | ac/ae/efa266716b240c4e18eadbb1aaefe177ae728711c43fa971bef7776030ff/great_expectations_cloud-20260219.0.dev0.tar.gz | source | sdist | null | false | f1d05433594a482085ad29de77d65894 | b7d3f9dd7e3f717b263eb159da8534172748d5a76f769a5a0655ff985499ce5b | acaeefa266716b240c4e18eadbb1aaefe177ae728711c43fa971bef7776030ff | null | [
"LICENSE"
] | 210 |
2.4 | wgc-runner | 4.0.2 | Pytest plugin and fixtures for WGC QA framework | # wgc-runner
Pytest plugin and fixtures for running WGC QA tests. Manages the full test lifecycle: build download, mock server startup, WGC installation, test execution, artifact collection.
## Pytest Plugin
Registered as `wgc_plugin` via `pytest11` entry point. Activated automatically when installed.
### CLI Options
```bash
py.test tests/ \
--wgc "\\share\builds\wgc\latest" \
--wgc-build "12345" \
--wgc-branch "release/1.0" \
--wgc-arch "x64" \
--wgc-publisher "wargaming" \
--video-capture \
--no-sanity-check
```
| Option | Description |
|---|---|
| `--wgc` | Path to WGC build on shared drive |
| `--wgc-build` | Build number |
| `--wgc-branch` | Git branch |
| `--wgc-arch` | Architecture: `win32` or `x64` |
| `--wgc-publisher` | Publisher: `wargaming`, `steam`, `qihoo` |
| `--video-capture` | Enable screen recording for each test |
| `--no-sanity-check` | Skip WGC sanity check before test session |
| `--testrail` | Enable TestRail reporting |
### Lifecycle Hooks
| Hook | What it does |
|---|---|
| `pytest_cmdline_main` | Download WGC build, start mock server, install WGC |
| `pytest_configure` | Initialize TestRail API, setup config |
| `pytest_runtest_setup` | Prepare environment before each test |
| `pytest_runtest_teardown` | Crash detection, collect logs/video/screenshots, terminate WGC |
| `pytest_collection_modifyitems` | Auto-assign `folder_*` markers by test directory |
### Key Features
- **Auto build download** from shared drive
- **Mock server** startup/shutdown around test session
- **Video recording** — each test recorded via OpenCV
- **Crash detection** — automatic WGC crash check after every test
- **Sanity check** — WGC startup verification before test session
- **Artifact upload** — logs, video, screenshots uploaded to share
- **Auto markers** — `folder_arsenal_login1`, `folder_game_install2`, etc.
## Fixtures
All fixtures are session or function-scoped and available automatically:
| Fixture | Scope | Provides |
|---|---|---|
| `wgc_client` | session | `WGCClient` instance |
| `config` | session | `WGCConfig` instance |
| `wgc_settings` | session | `WGCSettingsHelper` |
| `fake_games` | session | `FakeGamesHelper` |
| `os_helper` | session | `OSHelper` |
| `registry` | session | `RegistryHelper` |
| `browser` | session | `BrowserHelper` |
| `screen` | session | `ScreenHelper` |
| `firewall` | session | `FireWallHelper` |
| `encrypt` | session | `EncryptHelper` |
| `cmd_helper` | session | `CmdHelper` |
| `event_listener` | session | `EventHelper` |
| `wgc_installer` | session | `WGCInstaller` |
| `wgc_uninstaller` | session | `WGCUninstaller` |
| `soft_assert` | function | `SoftAssert` |
| `wgni_users_db` | session | `WGNIUsersDB` |
### Arsenal Fixtures
Additional fixtures for Arsenal UI tests (shop, products, billing):
```python
def test_buy_item(arsenal_shop_page, arsenal_product_list):
# arsenal_shop_page and arsenal_product_list are auto-configured
arsenal_shop_page.open_product(arsenal_product_list[0])
```
## Install
```bash
pip install wgc-runner
```
This will pull all WGC packages transitively.
## Dependencies
All WGC packages + `pytest>=7.0`, `pytest-timeout`, `pyhamcrest`
| text/markdown | null | Mykola Kovhanko <thuesdays@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: Microsoft :: Windows",
"Framework :: Pytest"
] | [] | null | null | >=3.7 | [] | [] | [] | [
"wgc-pages>=4.0.0",
"wgc-client>=4.0.0",
"wgc-mocks>=4.0.0",
"wgc-helpers>=4.0.0",
"wgc-core>=4.0.0",
"wgc-clippy>=1.0.0",
"wgc-third-party>=1.0.0",
"pytest>=7.0",
"pytest-timeout==2.3.1",
"pyhamcrest==2.0.2"
] | [] | [] | [] | [
"Homepage, https://github.com/thuesdays/wgc-runner"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T18:52:45.441262 | wgc_runner-4.0.2.tar.gz | 23,663 | 70/c2/6ce315a5ac229b20c3d9ff2c44b540a24e5169af8c01db138e530bd16869/wgc_runner-4.0.2.tar.gz | source | sdist | null | false | 2ddb16dcece9b30bacc29f8c619be875 | b46052745b756df496ed1f09b36d124ba5000d0afbddeddbc4d99408ec3ff3f3 | 70c26ce315a5ac229b20c3d9ff2c44b540a24e5169af8c01db138e530bd16869 | null | [] | 219 |
2.4 | json-merge-tree | 0.8.1 | JSON Merge Tree (built on top of json-multi-merge) merges JSON objects in a hierarchy, allowing customization of how objects are merged. | # json-merge-tree
JSON Merge Tree (built on top of [`json-multi-merge`](https://github.com/Media-Platforms/json-multi-merge))
merges JSON objects in a hierarchy, allowing customization of how objects are merged.
The hierarchy is defined by the caller's `parents` module, which specifies a function for each resource type that
returns the parent ID and another function to get its parents (unless it's the top level).
It relies on a SQLAlchemy `Table` containing the fields `id` (UUID), `resource_id` (UUID), `resource_type` (string), `slug` (string),
and a field that stores the JSON object you want to merge.
## Installation
Install this package, e.g., `pip install json-merge-tree`.
```
## merge_tree
Main entrypoint for merging JSON objects in a table up a hierarchy defined by `parents`.
### Example
```python
from json_merge_tree import merge_tree
import widget_service.parents
from widget_service.db import widgets
# Merge widgets of all the requested resource's ancestors and return the result
merged_json = merge_tree(
table=widgets,
id='228135fb-6a3d-4551-93db-17ed1bbe466a',
type='brand',
json_field='widget',
parents=widget_service.parents,
slugs=None,
debug='annotate'
)
```
## merge
Generic function to merge two JSON objects together. Largely the same as
[`jsonmerge.Merger.merge`](https://github.com/avian2/jsonmerge/blob/master/jsonmerge/__init__.py#L299)
but with the added ability to customize how objects are merged with the annotations below.
## Merge key annotations
You can append the annotation listed below to a key at any level to customize how its value affects the merged json.
### `--` Unset
Unset this key in the merged json. The value of this key does not matter - you can set it to `null`.
- **E.g. 1**
```json
{
"colors": {
"content": "#000000",
"section--": null
}
}
```
merged into
```json
{
"colors": {
"section": "#000001"
}
}
```
results in
```json
{
"colors": {
"content": "#000000"
}
}
```
***
- **E.g. 2**
```json
{
"styles": {
"h1--": null,
"h2": {
"fontSize": 3
}
}
}
```
merged into
```json
{
"styles": {
"h1": {
"fontWeight": "heading"
}
}
}
```
results in
```json
{
"styles": {
"h2": {
"fontSize": 3
}
}
}
```
### `!` Replace
Replace this key's value with this value.
- **E.g. 1**
```json
{
"colors": {
"content": "#000000",
"section!": "#000002"
}
}
```
merged into
```json
{
"colors": {
"section": "#000001"
}
}
```
results in
```json
{
"colors": {
"content": "#000000",
"section": "#000002"
}
}
```
***
- **E.g. 2**
```json
{
"styles": {
"h1!": {
"fontFamily": "heading",
"fontSize": 5
}
}
}
```
merged into
```json
{
"styles": {
"h1": {
"fontWeight": "heading"
}
}
}
```
results in
```json
{
"styles": {
"h1": {
"fontFamily": "heading",
"fontSize": 5
}
}
}
```
## Slugs
Slugs are kind of a weird feature – and getting weirder as we use them to solve more use cases.
Originally, A slug was a named json object scoped *under* a resource in the hierarchy to be merged. In our case, a custom-page theme merged under one of the resources in our resource hierarchy.
The use of slugs has been extended to included named json object mixins *not* associated with any one resource at the bottom of the hierarchy, but scoped to a resource at any level. For example, a site wants to have a "dark" theme that could be applied to any page within the site.
When merging, the library first merges the json objects without slugs, *then* merges json objects with slugs at each level. Multiple slugs can be included when merging.
### `slugs_only`
When `slugs_only=True` is passed to `merge_tree`, the resource JSON at every level of the hierarchy is skipped — only slug JSON objects are merged. This is useful when you only need the slug data without any of the base resource JSON mixed in.
```python
merged_json = merge_tree(
table=widgets,
id='228135fb-6a3d-4551-93db-17ed1bbe466a',
type='brand',
json_field='widget',
parents=widget_service.parents,
slugs=['dark-theme'],
slugs_only=True,
)
```
Note that the underlying query still fetches all resource records (to check `inherits` and maintain correct cache invalidation), it just excludes them from the merge.
| text/markdown | Marcy Buccellato | mbuccellato@hearst.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming... | [] | null | null | <4.0,>=3.9 | [] | [] | [] | [
"json-multi-merge>=0.3.1",
"sqlalchemy>=2.0.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.19 | 2026-02-19T18:52:41.726234 | json_merge_tree-0.8.1.tar.gz | 4,846 | 01/c0/ee57d61db67352a48a4e57d9111e6b2e0c3f212d687d582841739a52d9e6/json_merge_tree-0.8.1.tar.gz | source | sdist | null | false | 099dd74d5b5a11083151b326c57d222f | 5d246ba0197699536001d97ec72c672055d8366dfe56d2bcb95953c4162a154e | 01c0ee57d61db67352a48a4e57d9111e6b2e0c3f212d687d582841739a52d9e6 | null | [] | 237 |
2.4 | cmflib | 0.0.99 | Track metadata for AI pipeline | # Common Metadata Framework (CMF)
[](https://github.com/HewlettPackard/cmf/actions)
[](https://pypi.org/project/cmflib/)
[](https://hewlettpackard.github.io/cmf/)
[](./LICENSE)
**Common Metadata Framework (CMF)** is a metadata tracking and versioning system for ML pipelines. It tracks code, data, and pipeline metrics—offering Git-like metadata management across distributed environments.
---
## 🚀 Features
- ✅ Track artifacts (datasets, models, metrics) using content-based hashes
- ✅ Automatically logs code versions (Git) and data versions (DVC)
- ✅ Push/pull metadata via CLI across distributed sites
- ✅ REST API for direct server interaction
- ✅ Implicit & explicit tracking of pipeline execution
- ✅ Fine-grained or coarse-grained metric logging
---
## 🏛 Quick Start
Get started with CMF in minutes using our example ML pipeline:
**[📖 Try the Getting Started Example](./examples/example-get-started/)**
This example demonstrates:
- Initializing a CMF project
- Tracking an ML pipeline with multiple stages (parse → featurize → train → test)
- Versioning datasets and models
- Pushing artifacts and metadata
- Querying tracked metadata
## 📦 Installation
### Requirements
- Linux/Ubuntu/Debian
- Python: Version 3.9 to 3.11 (3.10 recommended)
- Git (latest)
### Virtual Environment
<details><summary>Conda</summary>
```bash
conda create -n cmf python=3.10
conda activate cmf
```
</details>
<details><summary>Virtualenv</summary>
```bash
virtualenv --python=3.10 .cmf
source .cmf/bin/activate
```
</details>
### Install CMF
<details><summary>Latest from GitHub</summary>
```bash
pip install git+https://github.com/HewlettPackard/cmf
```
</details>
<details><summary>Stable from PyPI</summary>
```bash
pip install cmflib
```
</details>
### Server Setup
📖 Follow the [CMF Server Installation Guide](https://hewlettpackard.github.io/cmf/setup/index.html#install-cmf-server-with-gui)
---
## 📘 Documentation
- [Getting Started](https://hewlettpackard.github.io/cmf/)
- [API Reference](https://hewlettpackard.github.io/cmf/api/public/cmf)
- [Command Reference](https://hewlettpackard.github.io/cmf/cmf_client/index)
- [Related Docs](https://deepwiki.com/HewlettPackard/cmf)
---
## 🧠 How It Works
CMF tracks pipeline stages, inputs/outputs, metrics, and code. It supports decentralized execution across datacenters, edge, and cloud.
- Artifacts are versioned using DVC (`.dvc` files).
- Code is tracked with Git.
- Metadata is logged to relational DB (e.g., SQLite, PostgreSQL)
- Sync metadata with `cmf metadata push` and `cmf metadata pull`.
---
## 🏛 Architecture
CMF is composed of:
- **cmflib** - Metadata library provides API to log/query metadata
- **CMF Client** – CLI to sync metadata with server, push/pull artifacts to the user-specified repo, push/pull code from Git
- **CMF Server** – REST API for metadata merge
- **Central Repositories** – Git (code), DVC (artifacts), CMF (metadata)
<p align="center">
<img src="docs/assets/framework.png" height="350" />
</p>
<p align="center">
<img src="docs/assets/distributed_architecture.png" height="300" />
</p>
---
## 🔧 Sample Usage
```python
from cmflib.cmf import Cmf
from ml_metadata.proto import metadata_store_pb2 as mlpb
metawriter = Cmf(filepath="mlmd", pipeline_name="test_pipeline")
context: mlpb.Context = metawriter.create_context(
pipeline_stage="prepare",
custom_properties={"user-metadata1": "metadata_value"}
)
execution: mlpb.Execution = metawriter.create_execution(
execution_type="Prepare",
custom_properties={"split": split, "seed": seed}
)
artifact: mlpb.Artifact = metawriter.log_dataset(
"artifacts/data.xml.gz", "input",
custom_properties={"user-metadata1": "metadata_value"}
)
```
```bash
cmf # CLI to manage metadata and artifacts
cmf init # Initialize artifact repository
cmf init show # Show current CMF config
cmf metadata push # Push metadata to server
cmf metadata pull # Pull metadata from server
```
➡️ For the complete list of commands, please refer to the <a href="https://hewlettpackard.github.io/cmf/cmf_client/index">Command Reference</a>
---
## ✅ Benefits
- Full ML pipeline observability
- Unified metadata, artifact, and code tracking
- Scalable metadata syncing
- Team collaboration on metadata
---
## 🎤 Talks & Publications
- 🎙 [Monterey Data Conference 2022](https://drive.google.com/file/d/1Oqs0AN0RsAjt_y9ZjzYOmBxI8H0yqSpB/view)
---
## 🌐 Related Projects
- [📚 Common Metadata Ontology](https://hewlettpackard.github.io/cmf/common-metadata-ontology/readme/)
- [🧠 AI Metadata Knowledge Graph (AIMKG)](https://github.com/HewlettPackard/ai-metadata-knowledge-graph)
---
## 🤝 Community
- 💬 [Join CMF on Slack](https://commonmetadata.slack.com/)
- 📧 Contact: **annmary.roy@hpe.com**
---
## 📄 License
Licensed under the [Apache 2.0 License](./LICENSE)
---
> © Hewlett Packard Enterprise. Built for reproducibility in ML.
| text/markdown | Hewlett Packard Enterprise | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: POSIX :: Linux"
] | [] | null | null | <3.12,>=3.9 | [] | [] | [] | [
"ml-metadata==1.15.0",
"dvc[s3,ssh]==3.51.1",
"pathspec==0.12.1",
"pandas",
"retrying",
"pyarrow",
"neo4j==5.26",
"tabulate",
"click",
"minio",
"paramiko==3.4.1",
"scikit_learn",
"scitokens",
"cryptography",
"ray==2.34.0",
"readchar",
"protobuf<5,>=4.25",
"boto3==1.41.0"
] | [] | [] | [] | [
"Homepage, https://github.com/HewlettPackard/cmf",
"BugTracker, https://github.com/HewlettPackard/cmf/issues"
] | twine/6.1.0 CPython/3.10.14 | 2026-02-19T18:52:32.864247 | cmflib-0.0.99.tar.gz | 131,363 | a0/72/bb2e23263f160e814c053b2f51192fc3f7d6017c5fcfb4d3a0f74670d2b5/cmflib-0.0.99.tar.gz | source | sdist | null | false | 31d70d0a066aec665d8add166902c4c7 | e0905e758e065bf1defdea185d4b9946ecc51fd5aff8ac17afa83becd0584db0 | a072bb2e23263f160e814c053b2f51192fc3f7d6017c5fcfb4d3a0f74670d2b5 | null | [] | 238 |
2.1 | montecarlodata | 0.157.0 | Monte Carlo's CLI | # Monte Carlo CLI
Monte Carlo's Alpha CLI!
## Installation
Requires Python 3.9 or greater. Normally you can install and update using `pip`. For instance:
```shell
pip install virtualenv
virtualenv venv
. venv/bin/activate
pip install -U montecarlodata
```
Developers of the CLI can use:
```shell
pip install virtualenv
make install
. venv/bin/activate
pre-commit install
```
Either way confirm the installation by running:
```shell
montecarlo --version
```
If the Python requirement does not work for you please reach out to `support@montecarlodata.com`. Docker is an option.
## Quick start
First time users can configure the tool by following the onscreen prompts:
```shell
montecarlo configure
```
MCD tokens can be generated from the [dashboard](https://getmontecarlo.com/get-token).
Use the `--help` flag for details on any advanced options (e.g. creating multiple montecarlo profiles) or
see docs [here][cli-docs].
That's it! You can always validate your connection with:
```shell
montecarlo validate
```
## User settings
Any configuration set by `montecarlo configure` can be found in `~/.mcd/` by default.
The MCD ID and Token can be overwritten, or even set, by the environment:
- `MCD_DEFAULT_API_ID`
- `MCD_DEFAULT_API_TOKEN`
These two are required either as part of `configure` or as environment variables.
The following values can also be set by the environment:
- `MCD_API_ENDPOINT` - Overwrite the default API endpoint
- `MCD_VERBOSE_ERRORS` - Enable verbose logging on errors (default=false)
## Help
Documentation for commands, options, and arguments can be found [here][cli-docs].
You can also use `montecarlo help` to echo all help text or use the `--help` flag on any command.
## Examples
### Using Docker from a local installation
```shell
docker build -t montecarlo .
docker run -e MCD_DEFAULT_API_ID='<ID>' -e MCD_DEFAULT_API_TOKEN='<TOKEN>' montecarlo --version
```
Replace `--version` with any sub-commands or options. If interacting with files those directories will probably need to be mounted too.
### Configure a named profile with custom config-path
```shell
$ montecarlo configure --profile-name zeus --config-path .
Key ID: 1234
Secret:
$ cat ./profiles.ini
[zeus]
mcd_id = 1234
mcd_token = 5678
```
### List active integrations
```shell
$ montecarlo integrations list
╒══════════════════╤══════════════════════════════════════╤══════════════════════════════════╕
│ Integration │ ID │ Created on (UTC) │
╞══════════════════╪══════════════════════════════════════╪══════════════════════════════════╡
│ Odin │ 58005657-2914-4701-9a11-260ac425b14e │ 2021-01-02T01:30:52.806602+00:00 │
├──────────────────┼──────────────────────────────────────┼──────────────────────────────────┤
│ Thor │ 926816bd-ab17-4f95-a953-fa14482c59de │ 2021-01-02T01:31:19.892205+00:00 │
├──────────────────┼──────────────────────────────────────┼──────────────────────────────────┤
│ Loki │ 1cf1dc0d-d8ec-4c85-8e64-57ab2ad8e023 │ 2021-01-02T01:32:37.709747+00:00 │
╘══════════════════╧══════════════════════════════════════╧══════════════════════════════════╛
```
### Apply monitors configuration
```shell
$ montecarlo monitors apply --namespace my-monitors
Gathering monitor configuration files.
- models/customer_success/schema.yml - Embedded monitor configuration found.
- models/customer_success/schema.yml - Monitor configuration found.
- models/lineage/schema.yml - Embedded monitor configuration found.
Modifications:
- ResourceModificationType.UPDATE - Monitor: type=stats, table=analytics:prod.customer_360
- ResourceModificationType.UPDATE - Monitor: type=categories, table=analytics:prod.customer_360
- ResourceModificationType.UPDATE - Monitor: type=stats, table=analytics:prod_lineage.lineage_nodes
- ResourceModificationType.UPDATE - Freshness SLI: table=analytics:prod.customer_360, freshness_threshold=30
```
### Import DBT manifest
```shell
$ montecarlo import dbt-manifest --dbt-manifest-file target/manifest.json
Importing DBT objects into Monte Carlo catalog. please wait...
Imported a total of 51 DBT objects into Monte Carlo catalog.
```
## Tests and Releases
Locally `make test` will run all tests. CircleCI manages all testing for deployment.
To publish a new release, navigate to [Releases](https://github.com/monte-carlo-data/cli/releases) in the GitHub repo and then:
- Click "Draft a new release"
- In the "Choose a tag" dropdown, type the new version number, for example `v1.2.3` and click "Create a new tag"
- Follow the format from previous releases for the description
- Leave "Set as the latest release" checked
- Click "Publish release"
- CircleCI will take care of publishing a new package to [PyPI](https://pypi.org/project/montecarlodata/) and generating documentation.
## License
Apache 2.0 - See the [LICENSE](http://www.apache.org/licenses/LICENSE-2.0) for more information.
[cli-docs]: https://clidocs.getmontecarlo.com/
| text/markdown | Monte Carlo Data, Inc | info@montecarlodata.com | null | null | Apache Software License (Apache 2.0) | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Natural Language :: English",
"Topic :: Software Development :: Build Tools",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Lang... | [] | https://www.montecarlodata.com/ | null | >=3.8 | [] | [] | [] | [
"boto3>=1.19.4",
"click-config-file==0.6.0",
"click>=8.1.3",
"dataclasses-json>=0.6.7",
"Jinja2>=3.1.6",
"pycarlo<1.0.0,>=0.11.7",
"python-box>=6.0.0",
"PyYAML>=5.4.1",
"questionary==1.10.0",
"requests<=3.0.0,>=2.0.0",
"retry==0.9.2",
"setuptools>=72.2.0; python_version >= \"3.12\"",
"tabula... | [] | [] | [] | [] | twine/3.7.1 importlib_metadata/8.5.0 pkginfo/1.12.1.2 requests/2.32.4 requests-toolbelt/1.0.0 tqdm/4.67.3 CPython/3.8.6 | 2026-02-19T18:51:23.999454 | montecarlodata-0.157.0.tar.gz | 199,156 | 82/a5/9aed976a4a1e6f2e0c2a6e9f873fe2aad41e16a07a4868cb3654fae264d2/montecarlodata-0.157.0.tar.gz | source | sdist | null | false | b1fb8c9ad2da1da765ee89ab198936a9 | 0842c8a0e893e5fbf4b59cdc48932122fa4386dfbc28891af74da4d122d19969 | 82a59aed976a4a1e6f2e0c2a6e9f873fe2aad41e16a07a4868cb3654fae264d2 | null | [] | 4,232 |
2.4 | naas-abi-marketplace | 1.6.1 | Add your description here | # naas-abi-marketplace
A comprehensive marketplace of pre-built modules, agents, integrations, and workflows for the ABI (Agentic Brain Infrastructure) framework. This package provides ready-to-use components organized into three main categories: AI agents, application integrations, and domain expert modules.
## Overview
`naas-abi-marketplace` is a collection of modular components that extend the ABI framework with:
- **AI Agent Modules**: Integration with major AI providers (ChatGPT, Claude, Gemini, Grok, Mistral, etc.)
- **Application Modules**: 50+ integrations with popular services and platforms
- **Domain Expert Modules**: Specialized agents for specific professional roles and tasks
- **Demo Applications**: Reference implementations and UI patterns
## Installation
```bash
pip install naas-abi-marketplace
```
### Optional Dependencies
Install specific module groups based on your needs:
```bash
# AI Agents
pip install naas-abi-marketplace[ai-chatgpt]
pip install naas-abi-marketplace[ai-claude]
pip install naas-abi-marketplace[ai-gemini]
pip install naas-abi-marketplace[ai-grok]
pip install naas-abi-marketplace[ai-mistral]
pip install naas-abi-marketplace[ai-perplexity]
pip install naas-abi-marketplace[ai-llama]
pip install naas-abi-marketplace[ai-qwen]
pip install naas-abi-marketplace[ai-deepseek]
pip install naas-abi-marketplace[ai-gemma]
# Application Integrations
pip install naas-abi-marketplace[applications-github]
pip install naas-abi-marketplace[applications-linkedin]
pip install naas-abi-marketplace[applications-postgres]
pip install naas-abi-marketplace[applications-powerpoint]
pip install naas-abi-marketplace[applications-arxiv]
pip install naas-abi-marketplace[applications-pubmed]
# ... and many more
```
## Module Categories
### AI Agent Modules
Pre-configured agents for major AI providers with optimized model configurations and capabilities.
#### Available AI Agents
1. **ChatGPT** (`ai.chatgpt`)
- Models: GPT-4o, o3-pro, o3, GPT-4.1, GPT-4.1 mini
- Features: Web search integration, advanced reasoning
- Intelligence: 53-71 (depending on model)
- Use cases: General purpose, code generation, research
2. **Claude** (`ai.claude`)
- Models: Claude 4 Opus, Claude 4 Sonnet (with Thinking variants)
- Features: Constitutional AI, advanced reasoning
- Intelligence: 53-64
- Use cases: Complex analysis, ethical considerations, nuanced understanding
3. **Gemini** (`ai.gemini`)
- Models: Gemini Pro, Gemini Ultra
- Features: Multimodal capabilities, creative tasks
- Use cases: Image generation, creative content, multimodal analysis
4. **Grok** (`ai.grok`)
- Models: Grok 4, Grok 3, Grok 3 mini Reasoning
- Features: Highest intelligence scores globally, truth-seeking
- Intelligence: 51-73 (highest globally)
- Use cases: Truth-seeking, unbiased analysis, maximum capability tasks
5. **Mistral** (`ai.mistral`)
- Models: Mistral Large, Mistral Medium
- Features: Code and math excellence
- Use cases: Programming assistance, mathematical reasoning
6. **Perplexity** (`ai.perplexity`)
- Models: R1 1776
- Features: AI-powered search, real-time information
- Intelligence: 54
- Use cases: Web search, current events, information discovery
7. **Llama** (`ai.llama`)
- Models: Llama 3, Llama 3.1
- Features: Open-source, local deployment
- Use cases: Privacy-focused applications, local AI
8. **Qwen** (`ai.qwen`)
- Models: Qwen 2.5, Qwen 2
- Features: Multilingual support, efficient performance
- Use cases: Multilingual tasks, cost-effective deployment
9. **DeepSeek** (`ai.deepseek`)
- Models: DeepSeek V2, DeepSeek Coder
- Features: Code-focused, high performance
- Use cases: Software development, code analysis
10. **Gemma** (`ai.gemma`)
- Models: Gemma 2, Gemma 3
- Features: Lightweight, efficient
- Use cases: Resource-constrained environments
**Usage Example:**
```python
from naas_abi_core.engine.Engine import Engine
engine = Engine()
engine.load(module_names=["naas_abi_marketplace.ai.chatgpt"])
# Access ChatGPT agent
from naas_abi_marketplace.ai.chatgpt.agents.ChatGPTAgent import create_agent
agent = create_agent()
response = agent.invoke("Explain quantum computing")
```
### Application Modules
50+ integrations with popular services, APIs, and platforms.
#### Available Applications
**Development & Code:**
- `applications.github` - GitHub integration (issues, PRs, repositories)
- `applications.git` - Git operations and repository management
- `applications.aws` - AWS services integration
- `applications.bodo` - Bodo platform integration
**Communication & Collaboration:**
- `applications.gmail` - Gmail integration
- `applications.slack` - Slack workspace integration
- `applications.whatsapp_business` - WhatsApp Business API
- `applications.sendgrid` - Email delivery service
- `applications.twilio` - SMS and voice communication
**Data & Analytics:**
- `applications.postgres` - PostgreSQL database integration
- `applications.google_analytics` - Google Analytics data
- `applications.google_sheets` - Google Sheets integration
- `applications.airtable` - Airtable database integration
- `applications.algolia` - Algolia search integration
**Research & Knowledge:**
- `applications.arxiv` - ArXiv scientific papers
- `applications.pubmed` - PubMed biomedical articles
- `applications.openalex` - OpenAlex academic data
- `applications.google_search` - Google Search integration
- `applications.newsapi` - News API integration
**Business & Finance:**
- `applications.yahoofinance` - Yahoo Finance data
- `applications.stripe` - Stripe payment processing
- `applications.qonto` - Qonto banking integration
- `applications.pennylane` - Pennylane accounting
- `applications.agicap` - Agicap financial management
- `applications.exchangeratesapi` - Currency exchange rates
**Productivity & Storage:**
- `applications.google_drive` - Google Drive integration
- `applications.google_calendar` - Google Calendar management
- `applications.notion` - Notion workspace integration
- `applications.sharepoint` - SharePoint integration
- `applications.powerpoint` - PowerPoint presentation generation
**Social & Media:**
- `applications.linkedin` - LinkedIn profile and company data
- `applications.youtube` - YouTube data and analytics
- `applications.instagram` - Instagram integration
- `applications.spotify` - Spotify music data
**Platforms & Services:**
- `applications.naas` - Naas.ai platform integration
- `applications.nebari` - Nebari platform integration
- `applications.salesforce` - Salesforce CRM integration
- `applications.hubspot` - HubSpot CRM integration
- `applications.zoho` - Zoho suite integration
- `applications.mercury` - Mercury platform integration
- `applications.sanax` - Sanax integration
**Data Sources:**
- `applications.datagouv` - French open data portal
- `applications.worldbank` - World Bank data
- `applications.openweathermap` - Weather data API
- `applications.openrouter` - OpenRouter API integration
**Usage Example:**
```python
from naas_abi_core.engine.Engine import Engine
engine = Engine()
engine.load(module_names=["naas_abi_marketplace.applications.github"])
# Access GitHub agent
from naas_abi_marketplace.applications.github.agents.GitHubAgent import create_agent
agent = create_agent()
response = agent.invoke("List open issues in repository jupyter-naas/abi")
```
### Domain Expert Modules
Specialized agents designed for specific professional roles and tasks.
#### Available Domain Experts
**Engineering & Development:**
- `domains.software-engineer` - Software engineering expertise
- `domains.devops-engineer` - DevOps and infrastructure
- `domains.data-engineer` - Data engineering and pipelines
**Business & Sales:**
- `domains.account-executive` - Account management
- `domains.business-development-representative` - Business development
- `domains.sales-development-representative` - Sales development
- `domains.inside-sales-representative` - Inside sales operations
**Marketing & Content:**
- `domains.content-creator` - Content creation
- `domains.content-strategist` - Content strategy
- `domains.content-analyst` - Content analysis
- `domains.campaign-manager` - Campaign management
- `domains.community-manager` - Community management
**Finance & Accounting:**
- `domains.accountant` - Accounting expertise
- `domains.financial-controller` - Financial control
- `domains.treasurer` - Treasury management
**Management & Operations:**
- `domains.project-manager` - Project management
- `domains.customer-success-manager` - Customer success
- `domains.human-resources-manager` - HR management
**Research & Investigation:**
- `domains.osint-researcher` - Open source intelligence
- `domains.private-investigator` - Investigation services
**Support:**
- `domains.support` - Technical support and issue management
**Usage Example:**
```python
from naas_abi_core.engine.Engine import Engine
engine = Engine()
engine.load(module_names=["naas_abi_marketplace.domains.software-engineer"])
# Access Software Engineer agent
from naas_abi_marketplace.domains.software_engineer.agents.SoftwareEngineerAgent import create_agent
agent = create_agent()
response = agent.invoke("Design a microservices architecture for an e-commerce platform")
```
## Module Structure
Each marketplace module follows a consistent structure:
```
module_name/
├── __init__.py # Module definition and configuration
├── agents/ # AI agents
│ └── *Agent.py # Agent implementations
├── integrations/ # External service integrations
│ └── *Integration.py # Integration implementations
├── workflows/ # Business logic workflows
│ └── *Workflow.py # Workflow implementations
├── pipelines/ # Data processing pipelines
│ └── *Pipeline.py # Pipeline implementations
├── ontologies/ # Semantic ontologies
│ └── *.ttl # RDF/Turtle ontology files
├── orchestrations/ # Dagster orchestration (optional)
│ └── definitions.py # Dagster definitions
└── README.md # Module documentation
```
## Configuration
### Enabling Modules
Modules are configured in your `config.yaml`:
```yaml
modules:
# AI Agents
- module: naas_abi_marketplace.ai.chatgpt
enabled: true
config:
openai_api_key: "${OPENAI_API_KEY}"
- module: naas_abi_marketplace.ai.claude
enabled: true
config:
anthropic_api_key: "${ANTHROPIC_API_KEY}"
# Applications
- module: naas_abi_marketplace.applications.github
enabled: true
config:
github_token: "${GITHUB_TOKEN}"
- module: naas_abi_marketplace.applications.linkedin
enabled: true
config:
linkedin_api_key: "${LINKEDIN_API_KEY}"
# Domain Experts
- module: naas_abi_marketplace.domains.software-engineer
enabled: true
- module: naas_abi_marketplace.domains.support
enabled: true
```
### Soft Dependencies
Many modules are marked as "soft" dependencies, meaning they're optional and won't cause failures if unavailable:
```python
# In naas_abi module dependencies
modules=[
"naas_abi_marketplace.ai.claude#soft", # Optional
"naas_abi_marketplace.applications.github#soft", # Optional
]
```
## Usage Patterns
### Loading Multiple Modules
```python
from naas_abi_core.engine.Engine import Engine
engine = Engine()
engine.load(module_names=[
"naas_abi_marketplace.ai.chatgpt",
"naas_abi_marketplace.ai.claude",
"naas_abi_marketplace.applications.github",
"naas_abi_marketplace.domains.software-engineer"
])
```
### Accessing Module Components
```python
# Access agents
for module_name, module in engine.modules.items():
for agent_class in module.agents:
print(f"{module_name}: {agent_class.__name__}")
# Access workflows
for module_name, module in engine.modules.items():
for workflow in module.workflows:
print(f"{module_name}: {workflow.__class__.__name__}")
# Access integrations
for module_name, module in engine.modules.items():
for integration in module.integrations:
print(f"{module_name}: {integration.__class__.__name__}")
```
## Demo Applications
The marketplace includes demo applications and UI patterns in `__demo__/apps/`:
- **Dashboard**: Central control hub
- **Chat Interface**: Multi-agent chat interface
- **Table Mode**: Advanced data table interface
- **Kanban Mode**: Project management with kanban boards
- **Ontology Mode**: Knowledge graph visualization
- **Calendar Mode**: Scheduling interface
- **Gallery Mode**: Media management
- **And more...**
## Marketplace UI
A Streamlit-based marketplace interface (`marketplace.py`) provides:
- **Module Discovery**: Browse available modules by category
- **Status Monitoring**: Check which modules are running
- **One-Click Launch**: Start applications and modules
- **Search**: Find modules by name or description
**Run the marketplace:**
```bash
streamlit run marketplace.py
```
## Key Features
### 🔌 **Extensive Integrations**
50+ pre-built integrations with popular services and platforms
### 🤖 **Multiple AI Providers**
Support for 10+ major AI providers with optimized configurations
### 👥 **Domain Expertise**
20+ specialized agents for professional roles and tasks
### 🧩 **Modular Architecture**
Pick and choose only the modules you need
### ⚡ **Optional Dependencies**
Modules can be installed individually to minimize dependencies
### 📚 **Comprehensive Documentation**
Each module includes detailed README and usage examples
### 🔄 **Consistent Interface**
All modules follow the same structure and patterns
## Dependencies
- `naas-abi-core>=1.0.0`: Core ABI framework
Optional dependencies are listed in `pyproject.toml` under `[project.optional-dependencies]` and can be installed per module as needed.
## Contributing
To add a new module to the marketplace:
1. Create a new directory under `ai/`, `applications/`, or `domains/`
2. Follow the standard module structure
3. Implement required components (agents, integrations, etc.)
4. Add module configuration in `__init__.py`
5. Create a README.md with documentation
6. Add optional dependencies to `pyproject.toml` if needed
## See Also
- [ABI Main README](../../README.md) - Complete ABI framework documentation
- [naas-abi-core](../naas-abi-core/) - Core engine documentation
- [naas-abi](../naas-abi/) - Main ABI module documentation
- [naas-abi-cli](../naas-abi-cli/) - CLI tool documentation
## License
MIT License
| text/markdown | null | Maxime Jublou <maxime@naas.ai>, Florent Ravenel <florent@naas.ai>, Jeremy Ravenel <jeremy@naas.ai> | null | null | MIT License | null | [] | [] | null | null | <4,>=3.10 | [] | [] | [] | [
"naas-abi-core>=1.4.0",
"pdfplumber>=0.11.8; extra == \"ai-chatgpt\"",
"langchain-anthropic>=0.3.17; extra == \"ai-claude\"",
"langchain-ollama>=0.3.4; extra == \"ai-deepseek\"",
"langchain-google-genai>=2.1.4; extra == \"ai-gemini\"",
"langchain-ollama>=0.3.4; extra == \"ai-gemma\"",
"langchain-xai>=0.... | [] | [] | [] | [
"Homepage, https://github.com/jupyter-naas/abi",
"Repository, https://github.com/jupyter-naas/abi/tree/main/libs/naas-abi-marketplace"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:50:54.816048 | naas_abi_marketplace-1.6.1.tar.gz | 298,149 | d7/0c/3188f36f43441c1f78c8ef8d449aac70737bd3b962d7c1d4fd3bb250c22d/naas_abi_marketplace-1.6.1.tar.gz | source | sdist | null | false | 80b98558f41f1411fc93a19b3009aff2 | d6ba1a5959d9f9fe0ed4c420424b1e47c8279b39aa279224f05e79f98aa1defa | d70c3188f36f43441c1f78c8ef8d449aac70737bd3b962d7c1d4fd3bb250c22d | null | [] | 228 |
2.4 | open-dread-rando | 2.19.0 | An open source randomizer patcher for Metroid Dread. | # Open Dread Rando
Open Source randomizer patcher for Metroid Dread. Intended for use in [Randovania](https://randovania.github.io/).
Currently supports patching item pickups, starting items, and elevator/shuttle/teleportal destinations.
## Installation
`pip install open-dread-rando`
## Usage
You will need to provide JSON data matching the [JSON schema](https://github.com/randovania/open-dread-rando/blob/main/src/open_dread_rando/files/schema.json) in order to successfully patch the game.
The patcher expects a path to an extracted romfs directory of Metroid Dread 1.0.0 or 2.1.0 as well as the desired output directory.
Output files are in a format compatible with either Atmosphere or Ryujinx, depending on the settings provided.
With a JSON file:
`python -m open_dread_rando --input-path path/to/dread/romfs --output-path path/to/the/output-mod --input-json path/to/patcher-config.json`
## Game Versions
Only versions 1.0.0 and the latest version are supported long term. Other versions might be compatible at any given point,
but new releases are free to remove that.
Currently, the following versions are supported:
- 1.0.0
- 2.1.0
| text/markdown | null | null | null | null | null | null | [
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3.9"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"mercury-engine-data-structures>=0.33",
"jsonschema>=4.0.0",
"json-delta>=2.0.2",
"open-dread-rando-exlaunch>=1.2.0",
"lupa; extra == \"test\"",
"pytest; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"pytest-mock; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/randovania/open-dread-rando"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:49:56.274998 | open_dread_rando-2.19.0.tar.gz | 3,597,712 | 2f/3f/4a6ac8fcdad38707aa4f92e1ef04914e07c52c1474b5454723b6f4f0eb18/open_dread_rando-2.19.0.tar.gz | source | sdist | null | false | 9588b8c1400b602542a780854bfa6999 | 26f9bb3f5210a006900d4ca2440049b91a3e784a7ad3c6b5503af84182a79cce | 2f3f4a6ac8fcdad38707aa4f92e1ef04914e07c52c1474b5454723b6f4f0eb18 | null | [
"LICENSE"
] | 936 |
2.4 | backboard-sdk | 1.5.2 | Python SDK for the Backboard API - Build conversational AI applications with persistent memory and intelligent document processing | # Backboard Python SDK
A developer-friendly Python SDK for the Backboard API. Build conversational AI applications with persistent memory and intelligent document processing.
> New to Backboard? We include $5 in free credits to get you started and support 1,800+ LLMs across major providers.
## New in v1.5.2
- `create_assistant` and `update_assistant` now accept both `description` and `system_prompt` (equivalent; use either).
## Installation
```bash
pip install backboard-sdk
```
## Quick Start
```python
import asyncio
from backboard import BackboardClient
async def main():
client = BackboardClient(api_key="your_api_key_here")
assistant = await client.create_assistant(
name="Support Bot",
system_prompt="You are a helpful customer support assistant",
)
thread = await client.create_thread(assistant.assistant_id)
response = await client.add_message(
thread_id=thread.thread_id,
content="Hello! Can you help me with my account?",
llm_provider="openai",
model_name="gpt-4o",
stream=False,
)
print(response.content)
# Streaming
async for event in await client.add_message(
thread_id=thread.thread_id,
content="Stream me a short response",
stream=True,
):
if event.get("type") == "content_streaming":
print(event.get("content", ""), end="", flush=True)
if __name__ == "__main__":
asyncio.run(main())
```
## Features
### Memory (NEW in v1.4.0)
- **Persistent Memory**: Store and retrieve information across conversations
- **Automatic Context**: Enable memory to automatically search and use relevant context
- **Manual Management**: Full control with add, update, delete, and list operations
- **Memory Modes**: Auto (search + write), Readonly (search only), or off
### Assistants
- Create, list, get, update, and delete assistants
- Configure custom tools and capabilities
- Upload documents for assistant-level context
### Threads
- Create conversation threads under assistants
- Maintain persistent conversation history
- Support for message attachments
### Documents
- Upload documents to assistants or threads
- Automatic processing and indexing for RAG
- Support for PDF, Office files, text, and more
- Real-time processing status tracking
### Messages
- Send messages with optional file attachments
- Streaming and non-streaming responses
- Tool calling support
- Custom LLM provider and model selection
## API Reference
### Client Initialization
```python
client = BackboardClient(api_key="your_api_key")
# or use as an async context manager
# async with BackboardClient(api_key="your_api_key") as client:
# ...
```
### Assistants
```python
# Create assistant
assistant = await client.create_assistant(
name="My Assistant",
system_prompt="System prompt that guides your assistant",
tools=[tool_definition], # Optional
# Embedding configuration (optional - defaults to OpenAI text-embedding-3-large with 3072 dims)
embedding_provider="cohere", # Optional: openai, google, cohere, etc.
embedding_model_name="embed-english-v3.0", # Optional
embedding_dims=1024, # Optional
)
# List assistants
assistants = await client.list_assistants(skip=0, limit=100)
# Get assistant
assistant = await client.get_assistant(assistant_id)
# Update assistant
assistant = await client.update_assistant(
assistant_id,
name="New Name",
system_prompt="Updated system prompt",
)
# Delete assistant
result = await client.delete_assistant(assistant_id)
```
### Threads
```python
# Create thread
thread = await client.create_thread(assistant_id)
# List threads for a specific assistant
assistant_threads = await client.list_threads_for_assistant(assistant_id, skip=0, limit=100)
# List threads
threads = await client.list_threads(skip=0, limit=100)
# Get thread with messages
thread = await client.get_thread(thread_id)
# Delete thread
result = await client.delete_thread(thread_id)
```
### Messages
```python
# Send message
response = await client.add_message(
thread_id=thread_id,
content="Your message here",
files=["path/to/file.pdf"], # Optional attachments
llm_provider="openai", # Optional
model_name="gpt-4o", # Optional
stream=False,
memory="Auto", # Optional: "Auto", "Readonly", or "off" (default)
)
# Streaming messages
async for chunk in await client.add_message(thread_id, content="Hello", stream=True):
if chunk.get('type') == 'content_streaming':
print(chunk.get('content', ''), end='', flush=True)
```
### Tool Integration (Simplified in v1.3.3)
#### Tool Definitions
```python
# Use plain JSON objects (no verbose SDK classes needed!)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "City name"}
},
"required": ["location"]
}
}
}
]
assistant = await client.create_assistant(
name="Weather Assistant",
system_prompt="You are a helpful weather assistant",
tools=tools,
)
```
#### Tool Call Handling
```python
import json
# Enhanced object-oriented access with automatic JSON parsing
response = await client.add_message(
thread_id=thread_id,
content="What's the weather in San Francisco?",
stream=False
)
if response.status == "REQUIRES_ACTION" and response.tool_calls:
tool_outputs = []
# Process each tool call
for tc in response.tool_calls:
if tc.function.name == "get_current_weather":
# Get parsed arguments (required parameters are guaranteed by API)
args = tc.function.parsed_arguments
location = args["location"]
# Execute your function and format the output
weather_data = {
"temperature": "68°F",
"condition": "Sunny",
"location": location
}
tool_outputs.append({
"tool_call_id": tc.id,
"output": json.dumps(weather_data)
})
# Submit the tool outputs back to continue the conversation
final_response = await client.submit_tool_outputs(
thread_id=thread_id,
run_id=response.run_id,
tool_outputs=tool_outputs
)
print(final_response.content)
```
### Memory
```python
# Add a memory
await client.add_memory(
assistant_id=assistant_id,
content="User prefers Python programming",
metadata={"category": "preference"}
)
# Get all memories
memories = await client.get_memories(assistant_id)
for memory in memories.memories:
print(f"{memory.id}: {memory.content}")
# Get specific memory
memory = await client.get_memory(assistant_id, memory_id)
# Update memory
await client.update_memory(
assistant_id=assistant_id,
memory_id=memory_id,
content="Updated content"
)
# Delete memory
await client.delete_memory(assistant_id, memory_id)
# Get memory stats
stats = await client.get_memory_stats(assistant_id)
print(f"Total memories: {stats.total_memories}")
# Use memory in conversation
response = await client.add_message(
thread_id=thread_id,
content="What do you know about me?",
memory="Auto" # Enable memory search and automatic updates
)
```
### Documents
```python
# Upload document to assistant
document = await client.upload_document_to_assistant(
assistant_id=assistant_id,
file_path="path/to/document.pdf",
)
# Upload document to thread
document = await client.upload_document_to_thread(
thread_id=thread_id,
file_path="path/to/document.pdf",
)
# List assistant documents
documents = await client.list_assistant_documents(assistant_id)
# List thread documents
documents = await client.list_thread_documents(thread_id)
# Get document status
document = await client.get_document_status(document_id)
# Delete document
result = await client.delete_document(document_id)
```
## Error Handling
The SDK includes comprehensive error handling:
```python
from backboard import (
BackboardAPIError,
BackboardValidationError,
BackboardNotFoundError,
BackboardRateLimitError,
BackboardServerError,
)
async def demo_err():
try:
await client.get_assistant("invalid_id")
except BackboardNotFoundError:
print("Assistant not found")
except BackboardValidationError as e:
print(f"Validation error: {e}")
except BackboardAPIError as e:
print(f"API error: {e}")
```
## Supported File Types
The SDK supports uploading the following file types:
- **Documents**: `.pdf`, `.doc`, `.docx`, `.ppt`, `.pptx`, `.xls`, `.xlsx`
- **Text / Data**: `.txt`, `.csv`, `.md`, `.markdown`, `.json`, `.jsonl`, `.xml`
- **Code**: `.py`, `.js`, `.ts`, `.jsx`, `.tsx`, `.html`, `.css`, `.cpp`, `.c`, `.h`, `.java`, `.go`, `.rs`, `.rb`, `.php`, `.sql`
- **Images** *(with embedded-image RAG support)*: `.png`, `.jpg`, `.jpeg`, `.webp`, `.gif`, `.bmp`, `.tiff`, `.tif`
## Requirements
- Python 3.8+
- httpx >= 0.27.0
## License
MIT License - see LICENSE file for details.
## Support
- Documentation: https://app.backboard.io/docs
- Email: support@backboard.io
| text/markdown | Backboard | Backboard <support@backboard.io> | null | null | MIT | ai, api, sdk, conversational, chatbot, assistant, documents, rag | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python ... | [] | https://github.com/backboard/backboard-python-sdk | null | >=3.8 | [] | [] | [] | [
"httpx>=0.27.0",
"pydantic>=2.0.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"black>=22.0.0; extra == \"dev\"",
"flake8>=5.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"types-httpx; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://backboard.io",
"Documentation, https://app.backboard.io/docs"
] | twine/6.2.0 CPython/3.13.1 | 2026-02-19T18:49:27.540823 | backboard_sdk-1.5.2.tar.gz | 20,055 | 0c/ac/e5ffdf5fc4a8b92fb4a61eea6b8930daf6d4394e0831e0531bbd4751910d/backboard_sdk-1.5.2.tar.gz | source | sdist | null | false | b1a958e0e62c479b540a4ce9af3b70b4 | 41e55d96a747dfad2970fde75e8e9bc726fc37f2b642fd9ba8a96ec7b5f89ee6 | 0cace5ffdf5fc4a8b92fb4a61eea6b8930daf6d4394e0831e0531bbd4751910d | null | [
"LICENSE"
] | 341 |
2.4 | langbly | 0.2.0 | Official Python SDK for the Langbly translation API | # langbly-python
[](https://pypi.org/project/langbly/)
[](https://pypi.org/project/langbly/)
[](LICENSE)
Official Python SDK for the [Langbly](https://langbly.com) translation API — a drop-in replacement for Google Translate v2, powered by LLMs.
**5-10x cheaper than Google Translate** · **Better quality** · **Switch in one PR**
## Installation
```bash
pip install langbly
```
## Quick Start
```python
from langbly import Langbly
client = Langbly(api_key="your-api-key")
# Translate text
result = client.translate("Hello world", target="nl")
print(result.text) # "Hallo wereld"
# Batch translate
results = client.translate(["Hello", "Goodbye"], target="nl")
for r in results:
print(r.text)
# Detect language
detection = client.detect("Bonjour le monde")
print(detection.language) # "fr"
# List supported languages
languages = client.languages(target="en")
```
## Migrate from Google Translate
Already using `google-cloud-translate`? Switching takes 2 minutes:
```python
# Before (Google Translate)
from google.cloud import translate_v2 as translate
client = translate.Client()
result = client.translate("Hello", target_language="nl")
# After (Langbly) — same concepts, better translations, 5x cheaper
from langbly import Langbly
client = Langbly(api_key="your-key")
result = client.translate("Hello", target="nl")
```
→ Full migration guide: [langbly.com/docs/migrate-google](https://langbly.com/docs/migrate-google)
## Features
- **Google Translate v2 API compatible** — same endpoint format
- **Auto-retry** — exponential backoff on 429/5xx with Retry-After support
- **Typed errors** — `RateLimitError`, `AuthenticationError`, `LangblyError`
- **Batch translation** — translate multiple texts in one request
- **Language detection** — automatic source language identification
- **HTML support** — translate HTML while preserving tags
- **Context manager** — use `with` for automatic cleanup
## Error Handling
```python
from langbly import Langbly, RateLimitError, AuthenticationError
client = Langbly(api_key="your-key")
try:
result = client.translate("Hello", target="nl")
except AuthenticationError:
print("Invalid API key")
except RateLimitError as e:
print(f"Rate limited — retry after {e.retry_after}s")
```
## API Reference
### `Langbly(api_key, base_url=None, timeout=30.0, max_retries=2)`
Create a client instance.
- `api_key` (str): Your Langbly API key — [get one free](https://langbly.com/signup)
- `base_url` (str, optional): Override the API URL (default: `https://api.langbly.com`)
- `timeout` (float, optional): Request timeout in seconds (default: 30)
- `max_retries` (int, optional): Retries for transient errors (default: 2)
### `client.translate(text, target, source=None, format=None)`
- `text` (str | list[str]): Text(s) to translate
- `target` (str): Target language code (e.g., "nl", "de", "fr")
- `source` (str, optional): Source language code (auto-detected if omitted)
- `format` (str, optional): "text" or "html"
### `client.detect(text)`
- `text` (str): Text to analyze
### `client.languages(target=None)`
- `target` (str, optional): Language code to return names in
## Links
- [Website](https://langbly.com)
- [Documentation](https://langbly.com/docs)
- [Compare: Langbly vs Google vs DeepL](https://langbly.com/compare)
- [JavaScript/TypeScript SDK](https://github.com/Langbly/langbly-js)
## License
MIT
| text/markdown | null | Jasper de Winter <jasper@langbly.com> | null | null | null | api, google-translate, i18n, langbly, localization, translation | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Py... | [] | null | null | >=3.8 | [] | [] | [] | [
"httpx>=0.24.0",
"pytest-asyncio>=0.21; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"respx>=0.20; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://langbly.com",
"Documentation, https://langbly.com/docs",
"Repository, https://github.com/Langbly/langbly-python",
"Issues, https://github.com/Langbly/langbly-python/issues"
] | twine/6.2.0 CPython/3.11.7 | 2026-02-19T18:49:20.469502 | langbly-0.2.0.tar.gz | 6,441 | 04/3d/2623026f0c69f5e9e8463b8c847418bf5809b9b6e49c4647de1ad1b50d77/langbly-0.2.0.tar.gz | source | sdist | null | false | 8affd1ba192d9cf7b2103f056e222fd8 | 935c1776d4728b98e23581e8613d13030b9ea613a3970bf295c52733e3dd0862 | 043d2623026f0c69f5e9e8463b8c847418bf5809b9b6e49c4647de1ad1b50d77 | MIT | [
"LICENSE"
] | 262 |
2.4 | xdof-sdk | 0.0.1rc7 | Useful libraries for interacting with xdof data and services. | # Getting Started
## Installation
```bash
# Base package
xdof-sdk
# With visualization dependencies (rerun)
xdof-sdk[viz]
# All optional dependencies
xdof-sdk[all]
```
## Data
## Visualization
Requires the `[viz]` or `[all]` extras to be installed.
| text/markdown | null | Michael Luo <mluogh@xdof.ai> | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"mcap-protobuf-support<1.0.0,>=0.5.3",
"mcap-ros2-support<1.0.0,>=0.5.0",
"mcap<2.0.0,>=1.2.2",
"mink<1.0.0,>=0.0.11",
"mujoco<4.0.0,>=3.0.0",
"numpy-quaternion>=2023.0.4",
"numpy>=1.0.0",
"opencv-python>=4.0.0",
"protobuf>=6.31.1",
"pydantic-core",
"pydantic<3.0.0,>=2.0.0",
"tyro>=0.9.26",
... | [] | [] | [] | [] | uv/0.8.17 | 2026-02-19T18:49:10.194150 | xdof_sdk-0.0.1rc7.tar.gz | 34,801 | d5/d0/6a009736b474fc2d7f34a94f50c5c8424ac1e454ca4809163efcd58adbf2/xdof_sdk-0.0.1rc7.tar.gz | source | sdist | null | false | dc143c3f257830c98365176cf2f4a005 | 98339f648baa995a88b0327d7bde3d5f85eee03cf6dba236b6cb053401709dda | d5d06a009736b474fc2d7f34a94f50c5c8424ac1e454ca4809163efcd58adbf2 | null | [] | 260 |
2.4 | chunkhive | 0.3.1 | Hierarchical, semantic code chunking with embeddings for AI systems | # ChunkHive
**Hierarchical, semantic code chunking with embeddings for AI systems.**
ChunkHive is a production-grade code chunking engine designed for modern AI workflows such as
code embeddings, retrieval-augmented generation (RAG), agentic systems, and dataset synthesis.
It converts raw repositories into **clean, structured, semantically accurate chunks**
with byte-level precision and preserved hierarchy.
---
## 🚀 Why ChunkHive?
Modern AI systems need **more than naive text splitting**.
chunkhive provides:
- AST-first semantic correctness
- Hierarchical structure awareness
- Byte-accurate spans
- Robust parsing across real-world repositories
---
## 🧠 Core Principle
> **AST is the Authority, Tree-sitter is Enrichment**
- **Primary source of truth**: Language AST (semantic accuracy)
- **Fallback & enrichment**: Tree-sitter (structural robustness)
- **Result**: Maximum parsing success across diverse codebases
---
## ✨ Features
- Semantic AST-first chunking (no filename-based chunks)
- Preserves hierarchy: Module → Class → Method / Function
- Accurate parent–child relationships
- Byte-level precision (`start_byte`, `end_byte`)
- Clean symbol naming (`ast.name`)
- Import & decorator capture
- Robust handling of edge cases (empty files, `__init__.py`)
- Supports documentation + code chunking flows
## ✨ New Features
- 🌳 **Hierarchical Chunking** - Preserves code structure
- 🧠 **Semantic Embeddings** - Turn code into vectors (NEW in v0.3.1!)
- 🔍 **Vector Search** - Find code by meaning, not just names
- 🤖 **4 Pre-trained Models** - CodeBERT, UniXcoder, and more
- ⚡ **Fast & Scalable** - Process large codebases efficiently
### Semantic Search (NEW!)
```bash
# Generate embeddings
chunkhive embed generate chunks.jsonl -o chunks_embedded.jsonl
# Generate with model choice
chunkhive embed generate chunks.jsonl --model unixcoder -o embedded_unixcoder.jsonl
# Create index
chunkhive embed index data\embeddings\chunks_embedded -o chunks_embedded.jsonl
# search query :
chunkhive embed search-index "your query" --index data\embeddings\crewai_index -k 2
# List available models
chunkhive embed models
# Search semantically ( for debugging,testing etc)
chunkhive embed search "authentication function" --chunks chunks_embedded.jsonl
```
## What's New in v0.3.1
🎉 **Semantic Embeddings!**
- Generate vector embeddings for code chunks
- 4 pre-trained models (CodeBERT, UniXcoder, CodeSage, MiniLM)
- Fast similarity search with FAISS
- Natural language code search
---
## 🔄 Multi-Language Support
### Currently Supported:
Python: Full AST parsing with decorators, imports, docstrings
Markdown/RST: Documentation chunking with code block detection
Configuration Files: JSON, YAML, TOML, INI, Dockerfiles
Text Files: README, LICENSE, requirements.txt, scripts
### 🔄 Coming Soon:
JavaScript/TypeScript
C++/Java/Go
## 🗂 Supported Chunk Types
module
class
method
function
documentation
configuration (JSON, YAML, TOML)
text
imports
## 🏢 Production Features
Deterministic IDs: Same code → same chunk ID across runs
Progress Indicators: Real-time processing feedback
Error Resilience: Graceful handling of malformed code
Statistics Generation: Detailed analytics and metrics
Batch Processing: Process multiple repositories from config file
Permission Handling: Intelligent output path resolution
## 📦 Installation
pip install chunkhive
## Quick Start
### Basic usage (creates in current directory)
chunkhive chunk local ./my_project
### With output directory
chunkhive chunk local ./my_project -o ./output
### With custom name and statistics
chunkhive chunk local ./my_project --name my_dataset --stats
chunkhive chunk repo https://github.com/user/repo --name my_dataset --stats
### Clone and chunk any GitHub repository
chunkhive chunk repo https://github.com/user/repo
### With filtering and limits
chunkhive chunk repo https://github.com/langchain-ai/langchain \
--extensions .py,.md \
--max-files 100 \
--name langchain_chunks
### Single File Processing
chunkhive chunk file example.py
chunkhive chunk file example.py -o ./chunks.jsonl --stats
## Repository Analysis
### Analyze repository metadata
chunkhive analyze https://github.com/crewAIInc/crewAI
chunkhive analyze ./local/repo --output analysis.json
### Show Examples
chunkhive examples
### Check Version & Info
chunkhive version # Show current version
chunkhive info # Show system information
## 📦 Output Schema (Simplified)
```json
{
"chunk_id": "primary_a1b2c3d4",
"file_path": "src/example.py",
"chunk_type": "function",
"language": "python",
"code": "...",
"ast": {
"name": "my_function",
"parent": "MyClass",
"symbol_type": "function",
"docstring": "Function documentation",
"decorators": ["@decorator"],
"imports": ["import module"]
},
"span": {
"start_byte": 123,
"end_byte": 456,
"start_line": 10,
"end_line": 25
},
"hierarchy": {
"parent_id": "parent_chunk_id",
"children_ids": ["child1", "child2"],
"depth": 2,
"is_primary": true
},
"metadata": {
"byte_accuracy": "exact_bytes",
"repo_info": {
"agentic_detection": {"langchain": "usage"},
"dependencies": {"python_packages": ["pandas", "numpy"]},
"git": {"remote_url": "https://github.com/user/repo"},
"structure": {"file_types": {".py": 50, ".md": 10}}
},
"repository_context": {
"similar_files": ["src/other.py"],
"total_similar_files": 5
}
}
}
```
## 🛠 Use Cases
Code embedding model training
RAG pipelines
Agentic AI systems
Code search & navigation
QA dataset generation
Static analysis & tooling
Enterprise codebase intelligence
AI training data generation
## 📜 License
Apache License 2.0 — free to use, modify, and distribute, including commercial use.
| text/markdown | null | ChunkHive <contact@chunkhive.ai> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Topic :: Software Developme... | [] | null | null | >=3.10.19 | [] | [] | [] | [
"tree-sitter>=0.25.2",
"tree-sitter-python>=0.25.0",
"toml>=0.10.2",
"typer>=0.21.1",
"rich>=14.2.0",
"PyYAML>=6.0.3",
"sentence-transformers>=2.2.0",
"faiss-cpu>=1.7.4",
"numpy>=1.24.0",
"tree-sitter-javascript>=0.25.0; extra == \"javascript\"",
"tree-sitter-typescript>=0.23.0; extra == \"types... | [] | [] | [] | [
"Homepage, https://github.com/AgentAhmed/ChunkHive",
"Documentation, https://github.com/AgentAhmed/ChunkHive#readme",
"Issues, https://github.com/AgentAhmed/ChunkHive/issues"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-19T18:48:33.372424 | chunkhive-0.3.1.tar.gz | 211,823 | 8a/fc/3f14a6ac1e0e53d9054393442ee46ce9c665f6e2a1f23b90ff0603877214/chunkhive-0.3.1.tar.gz | source | sdist | null | false | b8384e9d0adc2c1d347752262c462be1 | 4e440cbfc29de96db5a724e7b3661ca2eceb15d59aabcad1c2d22951a0581ac7 | 8afc3f14a6ac1e0e53d9054393442ee46ce9c665f6e2a1f23b90ff0603877214 | Apache-2.0 | [
"LICENSE"
] | 227 |
2.4 | openclaw-x402 | 0.1.0 | Drop-in x402 payment middleware for Flask APIs. Machine-to-machine payments on Base chain. | # openclaw-x402
Drop-in x402 payment middleware for Flask APIs. Add machine-to-machine payments to any OpenClaw platform in 5 lines.
## Install
```bash
pip install openclaw-x402
```
## Quick Start
```python
from flask import Flask, jsonify
from openclaw_x402 import X402Middleware
app = Flask(__name__)
x402 = X402Middleware(app, treasury="0xYourBaseAddress")
@app.route("/api/premium/data")
@x402.premium(price="10000", description="Premium data export") # $0.01 USDC
def premium_data():
return jsonify({"data": "your premium content"})
# Free endpoints work normally — no decorator needed
@app.route("/api/public/data")
def public_data():
return jsonify({"data": "free content"})
```
## How It Works
1. Agent hits your premium endpoint
2. Gets back HTTP 402 with payment instructions (USDC amount, treasury address, facilitator URL)
3. Agent pays via Coinbase wallet on Base chain
4. Agent retries with `X-PAYMENT` header containing tx hash
5. Middleware verifies payment via Coinbase facilitator
6. Access granted
## Free Mode
Set `price="0"` to pass all requests through without payment — useful for testing the flow before charging.
```python
@x402.premium(price="0", description="Free for now")
def free_premium():
return jsonify({"data": "free during testing"})
```
## Configuration
| Env Var | Purpose |
|---------|---------|
| `CDP_API_KEY_NAME` | Coinbase Developer Platform API key name |
| `CDP_API_KEY_PRIVATE_KEY` | CDP API private key |
Get credentials at [portal.cdp.coinbase.com](https://portal.cdp.coinbase.com).
## Contract Addresses (Base Mainnet)
| Token | Address |
|-------|---------|
| USDC | `0x833589fCD6eDb6E08f4c7C32D4f71b54bdA02913` |
| wRTC | `0x5683C10596AaA09AD7F4eF13CAB94b9b74A669c6` |
| Aerodrome Pool | `0x4C2A0b915279f0C22EA766D58F9B815Ded2d2A3F` |
## Links
- [x402 Protocol](https://www.x402.org/) — HTTP 402 Payment Required standard
- [Coinbase Agentic Wallets](https://docs.cdp.coinbase.com/agentkit/docs/welcome)
- [RustChain](https://rustchain.org) — Proof-of-Antiquity blockchain
- [BoTTube](https://bottube.ai) — AI video platform using openclaw-x402
- [Aerodrome DEX](https://aerodrome.finance) — Swap USDC to wRTC
## License
MIT
| text/markdown | null | Elyan Labs <scott@elyanlabs.ai> | null | null | null | x402, openclaw, payments, flask, coinbase, base-chain, usdc, wrtc, ai-agent, machine-to-machine | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Topic :: Internet :: WWW/HTTP :: HTTP Servers",
"Framework :: Flask"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"flask>=2.0",
"x402[flask]; extra == \"coinbase\"",
"coinbase-agentkit>=0.1.0; extra == \"coinbase\""
] | [] | [] | [] | [
"Homepage, https://rustchain.org/wallets.html",
"Repository, https://github.com/Scottcjn/Rustchain"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-19T18:48:31.991661 | openclaw_x402-0.1.0.tar.gz | 6,214 | 4c/19/ecde6cf43af70d202f484fb433a1e51afb8af6802ead224ed70355704813/openclaw_x402-0.1.0.tar.gz | source | sdist | null | false | 53e43b703c70c2ba4d6a0c1663ffee72 | ae8edd4c98615539abb6e3b92f6f35d3af32f81d56c8c893a70de64b8cd5ffb0 | 4c19ecde6cf43af70d202f484fb433a1e51afb8af6802ead224ed70355704813 | MIT | [
"LICENSE"
] | 247 |
2.4 | leafmap | 0.60.1 | A Python package for geospatial analysis and interactive mapping in a Jupyter environment. | # Welcome to leafmap
[](https://studiolab.sagemaker.aws/import/github/opengeos/leafmap/blob/master/examples/notebooks/00_key_features.ipynb)
[](https://colab.research.google.com/github/opengeos/leafmap/blob/master)
[](https://notebook.link/github/opengeos/leafmap/tree/master/lab/?path=docs%2Fnotebooks%2F00_key_features.ipynb)
[](https://mybinder.org/v2/gh/opengeos/leafmap/HEAD)
[](https://pypi.python.org/pypi/leafmap)
[](https://pepy.tech/project/leafmap)
[](https://github.com/conda-forge/leafmap-feedstock)
[](https://anaconda.org/conda-forge/leafmap)
[](https://anaconda.org/conda-forge/leafmap)
[](https://leafmap.org)
[](https://results.pre-commit.ci/latest/github/opengeos/leafmap/master)
[](https://opensource.org/licenses/MIT)
[](https://youtube.com/@giswqs)
[](https://doi.org/10.21105/joss.03414)
[](https://github.com/opengeos/leafmap/blob/master/docs/assets/logo.png)
**A Python package for geospatial analysis and interactive mapping in a Jupyter environment.**
- GitHub repo: <https://github.com/opengeos/leafmap>
- Documentation: <https://leafmap.org>
- PyPI: <https://pypi.org/project/leafmap>
- Conda-forge: <https://anaconda.org/conda-forge/leafmap>
- Leafmap tutorials on YouTube: <https://youtube.com/@giswqs>
- Free software: [MIT license](https://opensource.org/licenses/MIT)
Join our Discord server 👇
[](https://discord.gg/UgZecTUq5P)
## Introduction
**Leafmap** is a Python package for interactive mapping and geospatial analysis with minimal coding in a Jupyter environment. It is a spin-off project of the [geemap](https://geemap.org) Python package, which was designed specifically to work with [Google Earth Engine](https://earthengine.google.com) (GEE). However, not everyone in the geospatial community has access to the GEE cloud computing platform. Leafmap is designed to fill this gap for non-GEE users. It is a free and open-source Python package that enables users to analyze and visualize geospatial data with minimal coding in a Jupyter environment, such as Google Colab, Jupyter Notebook, JupyterLab, and [marimo](https://github.com/marimo-team/marimo). Leafmap is built upon several open-source packages, such as [folium](https://github.com/python-visualization/folium) and [ipyleaflet](https://github.com/jupyter-widgets/ipyleaflet) (for creating interactive maps), [WhiteboxTools](https://github.com/jblindsay/whitebox-tools) and [whiteboxgui](https://github.com/opengeos/whiteboxgui) (for analyzing geospatial data), and [ipywidgets](https://github.com/jupyter-widgets/ipywidgets) (for designing interactive graphical user interface [GUI]). Leafmap has a toolset with various interactive tools that allow users to load vector and raster data onto the map without coding. In addition, users can use the powerful analytical backend (i.e., WhiteboxTools) to perform geospatial analysis directly within the leafmap user interface without writing a single line of code. The WhiteboxTools library currently contains **500+** tools for advanced geospatial analysis, such as [GIS Analysis](https://jblindsay.github.io/wbt_book/available_tools/gis_analysis.html), [Geomorphometric Analysis](https://jblindsay.github.io/wbt_book/available_tools/geomorphometric_analysis.html), [Hydrological Analysis](https://jblindsay.github.io/wbt_book/available_tools/hydrological_analysis.html), [LiDAR Data Analysis](https://jblindsay.github.io/wbt_book/available_tools/lidar_tools.html), [Mathematical and Statistical Analysis](https://jblindsay.github.io/wbt_book/available_tools/mathand_stats_tools.html), and [Stream Network Analysis](https://jblindsay.github.io/wbt_book/available_tools/stream_network_analysis.html).
## Statement of Need
There is a plethora of Python packages for geospatial analysis, such as [geopandas](https://geopandas.org) for vector data analysis and [xarray](https://docs.xarray.dev) for raster data analysis. As listed at [pyviz.org](https://pyviz.org), there are also many options for plotting data on a map in Python, ranging from libraries focused specifically on maps like [ipyleaflet](https://ipyleaflet.readthedocs.io) and [folium](https://python-visualization.github.io/folium) to general-purpose plotting tools that also support geospatial data types, such as [hvPlot](https://hvplot.pyviz.org), [bokeh](http://bokeh.org), and [plotly](https://plotly.com/python). While these tools provide powerful capabilities, displaying geospatial data from different file formats on an interactive map and performing basic analyses can be challenging, especially for users with limited coding skills. Furthermore, many tools lack bi-directional communication between the frontend (browser) and the backend (Python), limiting their interactivity and usability for exploring map data.
Leafmap addresses these challenges by leveraging the bidirectional communication provided by ipyleaflet, enabling users to load and visualize geospatial datasets with just one line of code. Leafmap also provides an interactive graphical user interface (GUI) for loading geospatial datasets without any coding. It is designed for anyone who wants to analyze and visualize geospatial data interactively in a Jupyter environment, making it particularly accessible for novice users with limited programming skills. Advanced programmers can also benefit from leafmap for geospatial data analysis and building interactive web applications.
## Usage
Launch the interactive notebook tutorial for the **leafmap** Python package with Google Colab, Binder, or Amazon Sagemaker Studio Lab now:
[](https://colab.research.google.com/github/opengeos/leafmap/blob/master)
[](https://mybinder.org/v2/gh/opengeos/leafmap/HEAD)
[](https://studiolab.sagemaker.aws/import/github/opengeos/leafmap/blob/master/examples/notebooks/00_key_features.ipynb)
Check out this excellent article on Medium - [Leafmap a new Python Package for Geospatial data science](https://link.medium.com/HRRKDcynYgb)
To learn more about leafmap, check out the leafmap documentation website - <https://leafmap.org>

## Key Features
Leafmap offers a wide range of features and capabilities that empower geospatial data scientists, researchers, and developers to unlock the potential of their data. Some of the key features include:
- **Creating an interactive map with just one line of code:** Leafmap makes it easy to create an interactive map by providing a simple API that allows you to load and visualize geospatial datasets with minimal coding.
- **Switching between different mapping backends:** Leafmap supports multiple mapping backends, including ipyleaflet, folium, kepler.gl, pydeck, and bokeh. You can switch between these backends to create maps with different visualization styles and capabilities.
- **Changing basemaps interactively:** Leafmap allows you to change basemaps interactively, providing a variety of options such as OpenStreetMap, Stamen Terrain, CartoDB Positron, and many more.
- **Adding XYZ, WMS, and vector tile services:** You can easily add XYZ, WMS, and vector tile services to your map, allowing you to overlay additional geospatial data from various sources.
- **Displaying vector data:** Leafmap supports various vector data formats, including Shapefile, GeoJSON, GeoPackage, and any vector format supported by GeoPandas. You can load and display vector data on the map, enabling you to visualize and analyze spatial features.
- **Displaying raster data:** Leafmap allows you to load and display raster data, such as GeoTIFFs, on the map. This feature is useful for visualizing satellite imagery, digital elevation models, and other gridded datasets.
- **Creating custom legends and colorbars:** Leafmap provides tools for customizing legends and colorbars on the map, allowing you to represent data values with different colors and corresponding labels.
- **Creating split-panel maps and linked maps:** With Leafmap, you can create split-panel maps to compare different datasets side by side. You can also create linked maps that synchronize interactions between multiple maps, providing a coordinated view of different spatial data.
- **Downloading and visualizing OpenStreetMap data:** Leafmap allows you to download and visualize OpenStreetMap data, providing access to detailed street maps, buildings, and other points of interest.
- **Creating and editing vector data interactively:** Leafmap includes tools for creating and editing vector data interactively on the map. You can draw points, lines, and polygons, and modify them as needed.
- **Searching for geospatial data:** Leafmap provides functionality for searching and accessing geospatial data from sources such as SpatialTemporal Asset Catalogs (STAC), Microsoft Planetary Computer, AWS Open Data Registry, and OpenAerialMap.
- **Inspecting pixel values interactively:** Leafmap allows you to interactively inspect pixel values in raster datasets, helping you analyze and understand the data at a more granular level.
- **Creating choropleth maps and heat maps:** Leafmap supports the creation of choropleth maps, where colors represent different data values for specific geographic areas. You can also create heat maps to visualize data density.
- **Displaying data from a PostGIS database:** Leafmap provides tools for connecting to a PostGIS database and displaying spatial data stored in the database on the map.
- **Creating time series animations:** Leafmap enables the creation of time series animations from both vector and raster data, allowing you to visualize temporal changes in your geospatial datasets.
- **Analyzing geospatial data with whitebox:** Leafmap integrates with WhiteboxTools and whiteboxgui, providing a suite of geospatial analyses, such as hydrological analysis, terrain analysis, and LiDAR processing.
- **Segmenting and classifying remote sensing imagery:** Leafmap integrates the segment-geospatial package, which provides tools for segmenting and classifying remote sensing imagery using deep learning algorithms.
- **Building interactive web apps:** Leafmap supports the development of interactive web applications using frameworks like Voila, Streamlit, and Solara. This allows you to share your geospatial analyses and visualizations with others in a user-friendly web interface.
These features and capabilities make leafmap a powerful tool for geospatial data exploration, analysis, and visualization. Whether you are a beginner or an experienced geospatial data scientist, leafmap provides an accessible and efficient way to work with geospatial data in Python.
## Citations
If you find **leafmap** useful in your research, please consider citing the following paper to support my work. Thank you for your support.
- Wu, Q. (2021). Leafmap: A Python package for interactive mapping and geospatial analysis with minimal coding in a Jupyter environment. _Journal of Open Source Software_, 6(63), 3414. <https://doi.org/10.21105/joss.03414>
## Demo
## YouTube Channel
I have created a [YouTube Channel](https://youtube.com/@giswqs) for sharing geospatial tutorials. You can subscribe to my channel for regular updates. Check out the following videos for 3D mapping with MapLibre and Leafmap.
[](https://bit.ly/maplibre)
| text/markdown | null | Qiusheng Wu <giswqs@gmail.com> | null | null | MIT license | leafmap | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"anywidget",
"bqplot",
"duckdb>=1.4.1",
"folium",
"gdown",
"geojson",
"geopandas",
"ipyevents",
"ipyfilechooser",
"ipyleaflet",
"ipyvuetify",
"ipywidgets",
"maplibre",
"matplotlib",
"numpy",
"pandas",
"plotly",
"pystac-client",
"python-box",
"scooby",
"whiteboxgui",
"xyzser... | [] | [] | [] | [
"Homepage, https://github.com/opengeos/leafmap"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T18:47:08.360873 | leafmap-0.60.1.tar.gz | 3,493,712 | 04/9b/88731894d139f8b2b8dd155ccbbd5adf11f43b2db2d7ff0d7bebba26bd3d/leafmap-0.60.1.tar.gz | source | sdist | null | false | e6004d7858e20b98fc7b08272afd9c07 | 61d7fd8cf7ca0a38d7bf00345a9db202894dee23febca2d9c0d0430d1ebe3669 | 049b88731894d139f8b2b8dd155ccbbd5adf11f43b2db2d7ff0d7bebba26bd3d | null | [
"LICENSE"
] | 2,431 |
2.4 | semantica | 0.3.0a0 | 🧠 Semantica - An Open Source Framework for building Semantic Layers and Knowledge Engineering | <div align="center">
<img src="Semantica Logo.png" alt="Semantica Logo" width="460"/>
# 🧠 Semantica
### Open-Source Semantic Layer & Context Graph Framework
[](https://www.python.org/)
[](https://opensource.org/licenses/MIT)
[](https://pypi.org/project/semantica/)
[](https://pepy.tech/project/semantica)
[](https://github.com/Hawksight-AI/semantica/actions)
[](https://discord.gg/N7WmAuDH)
### ⭐ Give us a Star • 🍴 Fork us • 💬 Join our Discord
> **Transform Chaos into Intelligence. Build AI systems with context graphs, decision tracking, and advanced knowledge engineering that are explainable, traceable, and trustworthy — not black boxes.**
</div>
---
## 🚀 Why Semantica?
**Semantica** bridges the **semantic gap** between text similarity and true meaning. It's the **semantic intelligence layer** that makes your AI agents auditable, explainable, and trustworthy.
Perfect for **high-stakes domains** where mistakes have real consequences.
---
### ⚡ Get Started in 30 Seconds
```bash
pip install semantica
```
```python
from semantica.context import AgentContext, ContextGraph
from semantica.vector_store import VectorStore
# Initialize with enhanced context features
vs = VectorStore(backend="faiss", dimension=768)
kg = ContextGraph(advanced_analytics=True)
context = AgentContext(
vector_store=vs,
knowledge_graph=kg,
decision_tracking=True,
advanced_analytics=True,
kg_algorithms=True,
vector_store_features=True,
graph_expansion=True
)
# Store memory with automatic context graph building
memory_id = context.store(
"User is working on a React project with FastAPI",
conversation_id="session_1"
)
# Easy decision recording with convenience methods
decision_id = context.graph_builder.add_decision(
category="technology_choice",
scenario="Framework selection for web API",
reasoning="React ecosystem with FastAPI provides best performance",
outcome="selected_fastapi",
confidence=0.92
)
# Find similar decisions with advanced analytics
similar_decisions = context.graph_builder.find_similar_decisions(
scenario="Framework selection",
max_results=5
)
# Analyze decision impact and influence
impact = context.graph_builder.analyze_decision_impact(decision_id)
# Check compliance with business rules
compliance = context.graph_builder.check_decision_rules({
"category": "technology_choice",
"confidence": 0.92
})
print(f"Memory stored: {memory_id}")
print(f"Decision recorded: {decision_id}")
print(f"Found {len(similar_decisions)} similar decisions")
print(f"Compliance check: {compliance.get('compliant', False)}")
```
**[📖 Full Quick Start](#-quick-start)** • **[🍳 Cookbook Examples](#-semantica-cookbook)** • **[💬 Join Discord](https://discord.gg/N7WmAuDH)** • **[⭐ Star Us](https://github.com/Hawksight-AI/semantica)**
---
## Core Value Proposition
| **Trustworthy** | **Explainable** | **Auditable** |
|:------------------:|:------------------:|:-----------------:|
| Conflict detection & validation | Transparent reasoning paths | Complete provenance tracking |
| Rule-based governance | Entity relationships & ontologies | W3C PROV-O compliant lineage |
| Production-grade QA | Multi-hop graph reasoning | Source tracking & integrity verification |
---
## Key Features & Benefits
### Not Just Another Agentic Framework
**Semantica complements** LangChain, LlamaIndex, AutoGen, CrewAI, Google ADK, Agno, and other frameworks to enhance your agents with:
| Feature | Benefit |
|:--------|:--------|
| **Context Graphs** | Structured knowledge representation with entity relationships and semantic context |
| **Decision Tracking** | Complete decision lifecycle management with precedent search and causal analysis |
| **KG Algorithms** | Advanced graph analytics including centrality, community detection, and embeddings |
| **Vector Store Integration** | Hybrid search with custom similarity weights and advanced filtering |
| **Auditable** | Complete provenance tracking with W3C PROV-O compliance |
| **Explainable** | Transparent reasoning paths with entity relationships |
| **Provenance-Aware** | End-to-end lineage from documents to responses |
| **Validated** | Built-in conflict detection, deduplication, QA |
| **Governed** | Rule-based validation and semantic consistency |
| **Version Control** | Enterprise-grade change management with integrity verification |
### Perfect For High-Stakes Use Cases
| 🏥 **Healthcare** | 💰 **Finance** | ⚖️ **Legal** |
|:-----------------:|:--------------:|:------------:|
| Clinical decisions | Fraud detection | Evidence-backed research |
| Drug interactions | Regulatory support | Contract analysis |
| Patient safety | Risk assessment | Case law reasoning |
| 🔒 **Cybersecurity** | 🏛️ **Government** | 🏭 **Infrastructure** | 🚗 **Autonomous** |
|:-------------------:|:----------------:|:-------------------:|:-----------------:|
| Threat attribution | Policy decisions | Power grids | Decision logs |
| Incident response | Classified info | Transportation | Safety validation |
### Powers Your AI Stack
- **Context Graphs** — Structured knowledge representation with entity relationships and semantic context
- **Decision Tracking Systems** — Complete decision lifecycle management with precedent search and causal analysis
- **GraphRAG Systems** — Retrieval with graph reasoning and hybrid search using KG algorithms
- **AI Agents** — Trustworthy, accountable multi-agent systems with semantic memory and decision history
- **Reasoning Models** — Explainable AI decisions with reasoning paths and influence analysis
- **Enterprise AI** — Governed, auditable platforms that support compliance and policy enforcement
### Integrations
- **Docling Support** — Document parsing with table extraction (PDF, DOCX, PPTX, XLSX)
- **AWS Neptune** — Amazon Neptune graph database support with IAM authentication
- **Apache AGE** — PostgreSQL graph extension backend (openCypher via SQL)
- **Custom Ontology Import** — Import existing ontologies (OWL, RDF, Turtle, JSON-LD)
> **Built for environments where every answer must be explainable and governed.**
---
## 🧠 Context Module: Advanced Context Engineering & Decision Intelligence
The **Context Module** is Semantica's flagship component, providing sophisticated context management with **context graphs**, **advanced decision tracking**, **knowledge graph analytics**, and **easy-to-use interfaces**.
### 🎯 Core Capabilities
| **Feature** | **Description** | **Use Case** |
|------------|-------------|------------|
| **Context Graphs** | Structured knowledge representation with entity relationships | Knowledge management, decision support |
| **Advanced Decision Tracking** | Complete decision lifecycle with precedent search, causal analysis, and policy enforcement | Banking approvals, healthcare decisions |
| **Easy-to-Use Methods** | 10 convenience methods for common operations without complexity | Rapid development, user-friendly API |
| **KG Algorithms** | Advanced graph analytics (centrality, community detection, Node2Vec) | Influence analysis, similarity search |
| **Policy Engine** | Automated compliance checking with business rules and exception handling | Regulatory compliance, business rules |
| **Vector Store Integration** | Hybrid search with custom similarity weights | Advanced retrieval and filtering |
| **Memory Management** | Hierarchical memory with short-term and long-term storage | Agent conversation history |
### 🚀 Enhanced Features
- **Easy Decision Recording**: `add_decision()` with automatic entity linking
- **Smart Precedent Search**: `find_similar_decisions()` with hybrid similarity
- **Impact Analysis**: `analyze_decision_impact()` with influence scoring
- **Policy Compliance**: `check_decision_rules()` with automated validation
- **Causal Chains**: `trace_decision_chain()` for decision lineage
- **Graph Analytics**: `get_node_importance()`, `analyze_connections()` for insights
- **Hybrid Retrieval**: Combines vector search, graph traversal, and keyword matching
- **Multi-Hop Reasoning**: Trace relationships across multiple graph hops
- **Production Ready**: Comprehensive error handling and scalability
### 🔧 Easy-to-Use API
```python
# Simple usage with convenience methods
from semantica.context import ContextGraph
graph = ContextGraph(advanced_analytics=True)
# Add decision with ease
decision_id = graph.add_decision(
category="loan_approval",
scenario="Mortgage application",
reasoning="Good credit score",
outcome="approved",
confidence=0.95
)
# Find similar decisions
similar = graph.find_similar_decisions("mortgage", max_results=5)
# Analyze impact
impact = graph.analyze_decision_impact(decision_id)
# Check compliance
compliance = graph.check_decision_rules({
"category": "loan_approval",
"confidence": 0.95
})
```
### 🏢 Enterprise Integration
```python
# Full enterprise setup with AgentContext
from semantica.context import AgentContext
from semantica.vector_store import VectorStore
context = AgentContext(
vector_store=VectorStore(backend="faiss"),
knowledge_graph=ContextGraph(advanced_analytics=True),
decision_tracking=True,
kg_algorithms=True,
vector_store_features=True
)
# Record decision with full context
decision_id = context.record_decision(
category="fraud_detection",
scenario="Suspicious transaction pattern",
reasoning="Multiple high-value transactions in short timeframe",
outcome="flagged_for_review",
confidence=0.87,
entities=["transaction_123", "customer_456"]
)
# Advanced precedent search with KG features
precedents = context.find_precedents(
"suspicious transaction",
category="fraud_detection",
use_kg_features=True
)
# Comprehensive influence analysis
influence = context.analyze_decision_influence(decision_id)
```
---
## AgentContext - Your Agent's Brain
The main interface that makes your agent intelligent. It handles memory, decisions, and knowledge organization automatically.
### Quick Start
```python
from semantica.context import AgentContext
from semantica.vector_store import VectorStore
# Create your intelligent agent
agent = AgentContext(vector_store=VectorStore(backend="inmemory", dimension=384))
# Your agent can now remember things
memory_id = agent.store("User asked about Python programming")
print(f"Agent remembered: {memory_id}")
# And find information when needed
results = agent.retrieve("Python tutorials")
print(f"Agent found {len(results)} relevant memories")
```
### Easy Decision Learning
```python
# Your agent learns from its decisions
decision_id = agent.record_decision(
category="content_recommendation",
scenario="User wants Python tutorial",
reasoning="User mentioned being a beginner",
outcome="recommended_basics",
confidence=0.85
)
# Your agent can now find similar past decisions
similar_decisions = agent.find_precedents("Python tutorial", limit=3)
print(f"Agent found {len(similar_decisions)} similar past decisions")
```
### Getting Smarter Over Time
```python
# Enable all learning features
smart_agent = AgentContext(
vector_store=vector_store,
decision_tracking=True, # Learn from decisions
graph_expansion=True, # Find related information
advanced_analytics=True, # Understand patterns
kg_algorithms=True, # Advanced analysis
vector_store_features=True
)
# Get insights about your agent's learning
insights = smart_agent.get_context_insights()
print(f"Total decisions learned: {insights.get('total_decisions', 0)}")
print(f"Decision categories: {list(insights.get('categories', {}).keys())}")
```
---
## The Problem: The Semantic Gap
### Most AI systems fail in high-stakes domains because they operate on **text similarity**, not **meaning**.
### Understanding the Semantic Gap
The **semantic gap** is the fundamental disconnect between what AI systems can process (text patterns, vector similarities) and what high-stakes applications require (semantic understanding, meaning, context, and relationships).
**Traditional AI approaches:**
- Rely on statistical patterns and text similarity
- Cannot understand relationships between entities
- Cannot reason about domain-specific rules
- Cannot explain why decisions were made
- Cannot trace back to original sources with confidence
**High-stakes AI requires:**
- Semantic understanding of entities and their relationships
- Domain knowledge encoded as formal rules (ontologies)
- Explainable reasoning paths
- Source-level provenance
- Conflict detection and resolution
**Semantica bridges this gap** by providing a semantic intelligence layer that transforms unstructured data into validated, explainable, and auditable knowledge.
### What Organizations Have vs What They Need
| **Current State** | **Required for High-Stakes AI** |
|:---------------------|:-----------------------------------|
| PDFs, DOCX, emails, logs | Formal domain rules (ontologies) |
| APIs, databases, streams | Structured and validated entities |
| Conflicting facts and duplicates | Explicit semantic relationships |
| Siloed systems with no lineage | **Explainable reasoning paths** |
| | **Source-level provenance** |
| | **Audit-ready compliance** |
### The Cost of Missing Semantics
- **Decisions cannot be explained** — No transparency in AI reasoning
- **Errors cannot be traced** — No way to debug or improve
- **Conflicts go undetected** — Contradictory information causes failures
- **Compliance becomes impossible** — No audit trails for regulations
**Trustworthy AI requires semantic accountability.**
---
## Semantica vs Traditional RAG
| Feature | Traditional RAG | Semantica |
|:--------|:----------------|:----------|
| **Reasoning** | Black-box answers | Explainable reasoning paths |
| **Provenance** | No provenance | W3C PROV-O compliant lineage tracking |
| **Search** | Vector similarity only | Semantic + graph reasoning |
| **Quality** | No conflict handling | Explicit contradiction detection |
| **Safety** | Unsafe for high-stakes | Designed for governed environments |
| **Compliance** | No audit trails | Complete audit trails with integrity verification |
---
## Semantica Architecture
### Input Layer — Governed Ingestion
- **Multiple Formats** — PDFs, DOCX, HTML, JSON, CSV, Excel, PPTX
- **Docling Support** — Docling parser for table extraction
- **Data Sources** — Databases, APIs, streams, archives, web content
- **Media Support** — Image parsing with OCR, audio/video metadata extraction
- **Single Pipeline** — Unified ingestion with metadata and source tracking
### Semantic Layer — Trust & Reasoning Engine
- **Entity Extraction** — NER, normalization, classification
- **Relationship Discovery** — Triplet generation, semantic links
- **Ontology Induction** — Automated domain rule generation
- **Deduplication** — Jaro-Winkler similarity, conflict resolution
- **Quality Assurance** — Conflict detection, validation
- **Provenance Tracking** — W3C PROV-O compliant lineage tracking across all modules
- **Reasoning Traces** — Explainable inference paths
- **Change Management** — Version control with audit trails, checksums, compliance support
### Output Layer — Auditable Knowledge Assets
- **Knowledge Graphs** — Queryable, temporal, explainable
- **OWL Ontologies** — HermiT/Pellet validated, custom ontology import support
- **Vector Embeddings** — FastEmbed by default
- **AWS Neptune** — Amazon Neptune graph database support
- **Apache AGE** — PostgreSQL graph extension with openCypher support
- **Provenance** — Every AI response links back to:
- 📄 Source documents
- 🏷️ Extracted entities & relations
- 📐 Ontology rules applied
- 🧠 Reasoning steps used
---
## Built for High-Stakes Domains
Designed for domains where **mistakes have real consequences** and **every decision must be accountable**:
- **Healthcare & Life Sciences** — Clinical decision support, drug interaction analysis, medical literature reasoning, patient safety tracking
- **Finance & Risk** — Fraud detection, regulatory support (SOX, GDPR, MiFID II), credit risk assessment, algorithmic trading validation
- **Legal & Compliance** — Evidence-backed legal research, contract analysis, regulatory change tracking, case law reasoning
- **Cybersecurity & Intelligence** — Threat attribution, incident response, security audit trails, intelligence analysis
- **Government & Defense** — Governed AI systems, policy decisions, classified information handling, defense intelligence
- **Critical Infrastructure** — Power grid management, transportation safety, water treatment, emergency response
- **Autonomous Systems** — Self-driving vehicles, drone navigation, robotics safety, industrial automation
---
## 👥 Who Uses Semantica?
- **AI / ML Engineers** — Building explainable GraphRAG & agents
- **Data Engineers** — Creating governed semantic pipelines
- **Knowledge Engineers** — Managing ontologies & KGs at scale
- **Enterprise Teams** — Requiring trustworthy AI infrastructure
- **Risk & Compliance Teams** — Needing audit-ready systems
---
## 📦 Installation
### Install from PyPI (Recommended)
```bash
pip install semantica
# or
pip install semantica[all]
```
### Install from Source (Development)
```bash
# Clone and install in editable mode
git clone https://github.com/Hawksight-AI/semantica.git
cd semantica
pip install -e .
# Or with all optional dependencies
pip install -e ".[all]"
# Development setup
pip install -e ".[dev]"
```
## 📚 Resources
> **New to Semantica?** Check out the [**Cookbook**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook) for hands-on examples!
- [**Cookbook**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook) - Interactive notebooks
- [Introduction](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/introduction) - Getting started tutorials
- [Advanced](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/advanced) - Advanced techniques
- [Use Cases](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/use_cases) - Real-world applications
## ✨ Core Capabilities
| **Data Ingestion** | **Semantic Extract** | **Knowledge Graphs** | **Ontology** |
|:--------------------:|:----------------------:|:----------------------:|:--------------:|
| [Multiple Formats](#universal-data-ingestion) | [Entity & Relations](#semantic-intelligence-engine) | [Graph Analytics](#knowledge-graph-construction) | [Auto Generation](#ontology-generation--management) |
| **Context** | **GraphRAG** | **LLM Providers** | **Pipeline** |
| [Agent Memory, Context Graph, Context Retriever](#context-engineering--memory-systems) | [Hybrid RAG](#knowledge-graph-powered-rag-graphrag) | [100+ LLMs](#llm-providers-module) | [Parallel Workers](#pipeline-orchestration--parallel-processing) |
| **QA** | **Reasoning** | | |
| [Conflict Resolution](#production-ready-quality-assurance) | [Rule-based Inference](#reasoning--inference-engine) | | |
---
### Universal Data Ingestion
> **Multiple file formats** • PDF, DOCX, HTML, JSON, CSV, databases, feeds, archives
```python
from semantica.ingest import FileIngestor, WebIngestor, DBIngestor
file_ingestor = FileIngestor(recursive=True)
web_ingestor = WebIngestor(max_depth=3)
db_ingestor = DBIngestor(connection_string="postgresql://...")
sources = []
sources.extend(file_ingestor.ingest("documents/"))
sources.extend(web_ingestor.ingest("https://example.com"))
sources.extend(db_ingestor.ingest(query="SELECT * FROM articles"))
print(f" Ingested {len(sources)} sources")
```
[**Cookbook: Data Ingestion**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/introduction/02_Data_Ingestion.ipynb)
### Document Parsing & Processing
> **Multi-format parsing** • **Docling Support** • **Text normalization** • **Intelligent chunking**
```python
from semantica.parse import DocumentParser, DoclingParser
from semantica.normalize import TextNormalizer
from semantica.split import TextSplitter
# Standard parsing
parser = DocumentParser()
parsed = parser.parse("document.pdf", format="auto")
# Parsing with Docling (for complex layouts/tables)
# Requires: pip install docling
docling_parser = DoclingParser(enable_ocr=True)
result = docling_parser.parse("complex_table.pdf")
print(f"Text (Markdown): {result['full_text'][:100]}...")
print(f"Extracted {len(result['tables'])} tables")
for i, table in enumerate(result['tables']):
print(f"Table {i+1} headers: {table.get('headers', [])}")
# Normalize text
normalizer = TextNormalizer()
normalized = normalizer.normalize(parsed, clean_html=True, normalize_entities=True)
# Split into chunks
splitter = TextSplitter(method="token", chunk_size=1000, chunk_overlap=200)
chunks = splitter.split(normalized)
```
[**Cookbook: Document Parsing**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/introduction/03_Document_Parsing.ipynb) • [**Data Normalization**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/introduction/04_Data_Normalization.ipynb) • [**Chunking & Splitting**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/introduction/11_Chunking_and_Splitting.ipynb)
### Semantic Intelligence Engine
> **Entity & Relation Extraction** • NER, Relationships, Events, Triplets with LLM Enhancement
```python
from semantica.semantic_extract import NERExtractor, RelationExtractor
text = "Apple Inc., founded by Steve Jobs in 1976, acquired Beats Electronics for $3 billion."
# Extract entities
ner_extractor = NERExtractor(method="ml", model="en_core_web_sm")
entities = ner_extractor.extract(text)
# Extract relationships
relation_extractor = RelationExtractor(method="dependency", model="en_core_web_sm")
relationships = relation_extractor.extract(text, entities=entities)
print(f"Entities: {len(entities)}, Relationships: {len(relationships)}")
```
[**Cookbook: Entity Extraction**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/introduction/05_Entity_Extraction.ipynb) • [**Relation Extraction**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/introduction/06_Relation_Extraction.ipynb) • [**Advanced Extraction**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/advanced/01_Advanced_Extraction.ipynb)
### Knowledge Graph Construction
> **Production-Ready KGs** • **30+ Graph Algorithms** • **Entity Resolution** • **Temporal Support** • **Provenance Tracking**
```python
from semantica.semantic_extract import NERExtractor, RelationExtractor
from semantica.kg import GraphBuilder, NodeEmbedder, SimilarityCalculator, CentralityCalculator
# Extract entities and relationships
ner_extractor = NERExtractor(method="ml", model="en_core_web_sm")
relation_extractor = RelationExtractor(method="dependency", model="en_core_web_sm")
entities = ner_extractor.extract(text)
relationships = relation_extractor.extract(text, entities=entities)
# Build knowledge graph with provenance
builder = GraphBuilder()
kg = builder.build({"entities": entities, "relationships": relationships})
# Advanced graph analytics
embedder = NodeEmbedder(method="node2vec", embedding_dimension=128)
embeddings = embedder.compute_embeddings(kg, ["Entity"], ["RELATED_TO"])
# Find similar nodes
calc = SimilarityCalculator()
similar_nodes = calc.find_most_similar(embeddings, embeddings["target_node"], top_k=5)
# Analyze importance
centrality = CentralityCalculator()
importance_scores = centrality.calculate_all_centrality(kg)
print(f"Nodes: {len(kg.get('entities', []))}, Edges: {len(kg.get('relationships', []))}")
print(f"Similar nodes: {len(similar_nodes)}, Centrality measures: {len(importance_scores)}")
```
**New Enhanced Algorithms:**
- **Node Embeddings**: Node2Vec, DeepWalk, Word2Vec for structural similarity
- **Similarity Analysis**: Cosine, Euclidean, Manhattan, Correlation metrics
- **Path Finding**: Dijkstra, A*, BFS, K-shortest paths for route analysis
- **Link Prediction**: Preferential attachment, Jaccard, Adamic-Adar for network completion
- **Centrality Analysis**: Degree, Betweenness, Closeness, PageRank for importance ranking
- **Community Detection**: Louvain, Leiden, Label propagation for clustering
- **Connectivity Analysis**: Components, bridges, density for network robustness
- **Provenance Tracking**: Complete audit trail for all graph operations
[**Cookbook: Building Knowledge Graphs**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/introduction/07_Building_Knowledge_Graphs.ipynb) • [**Graph Analytics**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/introduction/10_Graph_Analytics.ipynb) • [**Advanced Graph Analytics**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/advanced/02_Advanced_Graph_Analytics.ipynb)
### Embeddings & Vector Store
> **FastEmbed by default** • **Multiple backends** (FAISS, PostgreSQL/pgvector, Weaviate, Qdrant, Milvus, Pinecone) • **Semantic search**
```python
from semantica.embeddings import EmbeddingGenerator
from semantica.vector_store import VectorStore
# Generate embeddings
embedding_gen = EmbeddingGenerator(model_name="sentence-transformers/all-MiniLM-L6-v2", dimension=384)
embeddings = embedding_gen.generate_embeddings(chunks, data_type="text")
# Store in vector database
vector_store = VectorStore(backend="faiss", dimension=384)
vector_store.store_vectors(vectors=embeddings, metadata=[{"text": chunk} for chunk in chunks])
# Search
results = vector_store.search(query="supply chain", top_k=5)
```
[**Cookbook: Embedding Generation**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/introduction/12_Embedding_Generation.ipynb) • [**Vector Store**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/introduction/13_Vector_Store.ipynb)
### Graph Store & Triplet Store
> **Neo4j, FalkorDB, Amazon Neptune, Apache AGE** • **SPARQL queries** • **RDF triplets**
```python
from semantica.graph_store import GraphStore
from semantica.triplet_store import TripletStore
# Graph Store (Neo4j, FalkorDB, Apache AGE)
graph_store = GraphStore(backend="neo4j", uri="bolt://localhost:7687", user="neo4j", password="password")
graph_store.add_nodes([{"id": "n1", "labels": ["Person"], "properties": {"name": "Alice"}}])
# Amazon Neptune Graph Store (OpenCypher via HTTP with IAM Auth)
neptune_store = GraphStore(
backend="neptune",
endpoint="your-cluster.us-east-1.neptune.amazonaws.com",
port=8182,
region="us-east-1",
iam_auth=True, # Uses AWS credential chain (boto3, env vars, or IAM role)
)
# Node Operations
neptune_store.add_nodes([
{"labels": ["Person"], "properties": {"id": "alice", "name": "Alice", "age": 30}},
{"labels": ["Person"], "properties": {"id": "bob", "name": "Bob", "age": 25}},
])
# Query Operations
result = neptune_store.execute_query("MATCH (p:Person) RETURN p.name, p.age")
# Apache AGE Graph Store (PostgreSQL + openCypher)
age_store = GraphStore(
backend="age",
connection_string="host=localhost dbname=agedb user=postgres password=secret",
graph_name="semantica",
)
age_store.connect()
age_store.create_node(labels=["Person"], properties={"name": "Alice", "age": 30})
# Triplet Store (Blazegraph, Jena, RDF4J)
triplet_store = TripletStore(backend="blazegraph", endpoint="http://localhost:9999/blazegraph")
triplet_store.add_triplet({"subject": "Alice", "predicate": "knows", "object": "Bob"})
results = triplet_store.execute_query("SELECT ?s ?p ?o WHERE { ?s ?p ?o } LIMIT 10")
```
[**Cookbook: Graph Store**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/introduction/09_Graph_Store.ipynb) • [**Triplet Store**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/introduction/20_Triplet_Store.ipynb)
### Ontology Generation & Management
> **6-Stage LLM Pipeline** • Automatic OWL Generation • HermiT/Pellet Validation • **Custom Ontology Import** (OWL, RDF, Turtle, JSON-LD)
```python
from semantica.ontology import OntologyGenerator
from semantica.ingest import ingest_ontology
# Generate ontology automatically
generator = OntologyGenerator(llm_provider="openai", model="gpt-4")
ontology = generator.generate_from_documents(sources=["domain_docs/"])
# Or import your existing ontology
custom_ontology = ingest_ontology("my_ontology.ttl") # Supports OWL, RDF, Turtle, JSON-LD
print(f"Classes: {len(custom_ontology.classes)}")
```
[**Cookbook: Ontology**](https://github.com/Hawksight-AI/semantica/tree/main/cookbook/introduction/14_Ontology.ipynb)
### Change Management & Version Control
> **Version Control for Knowledge Graphs & Ontologies** • **SQLite & In-Memory Storage** • **SHA-256 Integrity Verification**
```python
from semantica.change_management import TemporalVersionManager, OntologyVersionManager
# Knowledge Graph versioning with audit trails
kg_manager = TemporalVersionManager(storage_path="kg_versions.db")
# Create versioned snapshot
snapshot = kg_manager.create_snapshot(
knowledge_graph,
version_label="v1.0",
author="user@company.com",
description="Initial patient record"
)
# Compare versions with detailed diffs
diff = kg_manager.compare_versions("v1.0", "v2.0")
print(f"Entities added: {diff['summary']['entities_added']}")
print(f"Entities modified: {diff['summary']['entities_modified']}")
# Verify data integrity
is_valid = kg_manager.verify_checksum(snapshot)
```
**What We Provide:**
- **Persistent Storage** — SQLite and in-memory backends implemented
- **Detailed Diffs** — Entity-level and relationship-level change tracking
- **Data Integrity** — SHA-256 checksums with tamper detection
- **Standardized Metadata** — ChangeLogEntry with author, timestamp, description
- **Performance Tested** — Tested with large-scale entity datasets
- **Test Coverage** — Comprehensive test coverage covering core functionality
**Compliance Note:** Provides technical infrastructure (audit trails, checksums, temporal tracking) that supports compliance efforts for HIPAA, SOX, FDA 21 CFR Part 11. Organizations must implement additional policies and procedures for full regulatory compliance.
[**Documentation: Change Management**](docs/reference/change_management.md) • [**Usage Guide**](semantica/change_management/change_management_usage.md)
### Provenance Tracking — W3C PROV-O Compliant Lineage
> **W3C PROV-O Implementation** • **17 Module Integrations** • **Opt-In Design** • **Zero Breaking Changes**
**⚠️ Compliance Note:** Provides technical infrastructure for provenance tracking that supports compliance efforts. Organizations must implement additional policies, procedures, and controls for full regulatory compliance.
```python
from semantica.semantic_extract.semantic_extract_provenance import NERExtractorWithProvenance
from semantica.llms.llms_provenance import GroqLLMWithProvenance
from semantica.graph_store.graph_store_provenance import GraphStoreWithProvenance
# Enable provenance tracking - just add provenance=True
ner = NERExtractorWithProvenance(provenance=True)
entities = ner.extract(
text="Apple Inc. was founded by Steve Jobs.",
source="biography.pdf"
)
# Track LLM calls with costs and latency
llm = GroqLLMWithProvenance(provenance=True, model="llama-3.1-70b")
response = llm.generate("Summarize the document")
# Store in graph with complete lineage
graph = GraphStoreWithProvenance(provenance=True)
graph.add_node(entity, source="biography.pdf")
# Retrieve complete provenance
lineage = ner._prov_manager.get_lineage("entity_id")
print(f"Source: {lineage['source']}")
print(f"Lineage chain: {lineage['lineage_chain']}")
```
**What We Provide:**
- ✅ **W3C PROV-O Implementation** — Data schemas implementing prov:Entity, prov:Activity, prov:Agent, prov:wasDerivedFrom
- ✅ **17 Module Integrations** — Provenance-enabled versions of semantic extract, LLMs, pipeline, context, ingest, embeddings, reasoning, conflicts, deduplication, export, parse, normalize, ontology, visualization, graph/vector/triplet stores
- ✅ **Opt-In Design** — Zero breaking changes, `provenance=False` by default
- ✅ **Lineage Tracking** — Document → Chunk → Entity → Relationship → Graph lineage chains
- ✅ **LLM Tracking** — Token counts, costs, and latency tracking for LLM calls
- ✅ **Source Tracking Fields** — Document identifiers, page numbers, sections, and quote fields in schemas
- ✅ **Storage Backends** — InMemoryStorage (fast) and SQLiteStorage (persistent) implemented
- ✅ **Bridge Axioms** — BridgeAxiom and TranslationChain classes for domain transformations (L1 → L2 → L3)
- ✅ **Integrity Verification** — SHA-256 checksum computation and verification functions
- ✅ **No New Dependencies** — Uses Python stdlib only (sqlite3, json, dataclasses)
**Supported Modules:**
```python
# Semantic Extract
from semantica.semantic_extract.semantic_extract_provenance import (
NERExtractorWithProvenance, RelationExtractorWithProvenance, EventDetectorWithProvenance
)
# LLM Providers
from semantica.llms.llms_provenance import (
GroqLLMWithProvenance, OpenAILLMWithProvenance, HuggingFaceLLMWithProvenance
)
# Storage & Processing
from semantica.graph_store.graph_store_provenance import GraphStoreWithProvenance
from semantica.vector_store.vector_store_provenance import VectorStoreWithProvenance
from semantica.pipeline.pipeline_provenance import PipelineWithProvenance
# ... and 12 more modules
```
**High-Stakes Use Cases:**
- 🏥 **Healthcare** — Clinical decision audit trails with source tracking
- 💰 **Finance** — Fraud detection provenance with complete lineage
- ⚖️ **Legal** — Evidence chain of custody with temporal tracking
- 🔒 **Cybersecurity** — Threat attribution with relationship tracking
- 🏛️ **Government** — Policy decision audit trails with integrity verification
**Note:** Provenance tracking provides the *technical infrastructure* for compliance. Organizations must implement additional policies and procedures to meet specific regulatory requirements (HIPAA, SOX, FDA 21 CFR Part 11, etc.).
[**Documentation: Provenance Tracking**](semantica/provenance/provenance_usage.md)
### Context Engineering & Memory Systems
> **Persistent Memory** • **Context Graph** • **Context Retriever** • **Hybrid Retrieval (Vector + Graph)** • **Production Graph Store (Neo4j)** • **Entity Linking** • **Multi-Hop Reasoning**
```python
from semantica.context import AgentContext, ContextGraph, ContextRetriever
from semantica.vector_store import VectorStore
from semantica.graph_store import GraphStore
from semantica.llms import Groq
# Initialize Context with Hybrid Retrieval (Graph + Vector)
context = AgentContext(
vector_store=VectorStore(backend="faiss"),
knowledge_graph=GraphStore(backend="neo4j"), # Optional: Use persistent graph
hybrid_alpha=0.75 # Balanced weight between Knowledge Graph and Vector
)
# Build Context Graph from entities and relationships
graph_stats = context.build_graph(
entities=kg.get('entities', []),
relationships=kg.get('relationships', []),
link_entities=True
)
# Store memory with automatic entity linking
context.store(
"User is building a RAG system with Semantica",
metadata={"priority": "high", "topic": "rag"}
)
# Use Context Retriever for hybrid retrieval
retriever = context.retriever # Access underlying ContextRetriever
results = retriever.retrieve(
query="What is the user building?",
max_results=10,
graph_expansion=True
)
# Retrieve with context expansion
results = context.retrieve("What is the user building?", graph_expansion=True)
# Query with reasoning and LLM-generated responses
llm_provider = Groq(model="llama-3.1-8b-instant", api_key=os.getenv("GROQ_API_KEY"))
reasoned_result = context.query_with_reasoning(
query="What is the user building?",
llm_provider=llm_provider,
max_hops=2
)
```
**Core Components:**
- **ContextGraph**: Builds and manages context graphs from entities and relationships for enhanced retrieval
- **ContextRetriever**: Performs hybrid retrieval combining vector search, graph traversal, and memory for optimal context relevance
- **AgentContext**: High-level interface integrating Context Graph and Context Retriever for GraphRAG applications
#### Context Graphs: Advanced Decision Tracking & Analytics
```python
from semantica.context import AgentContext, ContextGraph
from semantica.vector_store import VectorStore
# Initialize with advanced decision tracking
context = AgentContext(
vector_store=VectorStore(backend="inmemory", dimension=128),
knowledge_graph=ContextGraph(advanced_analytics=True),
decision_tracking=True,
kg_algorithms=True, # Enable advanced graph analytics
)
# Easy decision recording with convenience methods
decision_id = context.graph_builder.add_decision(
category="credit_approval",
scenario="High-risk credit limit increase",
reasoning="Recent velocity-check failure and prior fraud flag",
outcome="rejected",
confidence=0.78,
entities=["customer:jessica_norris"],
)
# Find similar decisions with advanced analytics
similar_decisions = context.graph_builder.find_similar_decisions(
scenario="credit increase",
category="credit_approval",
max_results=5,
)
# Analyze decision impact and influence
impact_analysis = context.graph_builder.analyze_decision_impact(decision_id)
node_importance = context.graph_builder.get_node_importance("customer:jessica_norris")
# Check compliance with business rules
compliance = context.graph_builder.check_decision_rules({
"category": "credit_approval",
"scenario": "Credit limit increase",
"reasoning": "Risk assessment completed",
"outcome": "rejected",
"confidence": 0.78
})
```
**Enhanced Features:**
- **Easy-to-Use Methods**: 10 convenience methods for common operations
- **Decision Analytics**: Influence analysis, centrality measures, community detection
- **Policy Engine**: Automated compliance checking with business rules
- **Causal Analysis**: Trace decision causality and impact chains
- **Graph Analytics**: Advanced KG algorithms (Node2Vec, centrality, community detection)
- **Hybrid Search**: Semantic + structural + category similarity
- **Production Ready**: Scalable architecture with comprehensive error handling
## Configuration Options
### Simple Setup (Most Common)
```python
# Just memory and basic learning
agent = AgentContext(vector_store=vector_store)
```
### Smart Setup (Recommended)
```python
# Memory + decision learning
agent = AgentContext(
vector_store=vector_store,
decision_tracking=True,
graph_expansion=True
)
```
### Complete Setup (Maximum Power)
```python
# Everything enabled
agent = AgentContext(
vector_store=vector_store,
knowledge_graph=ContextGraph(advanced_analytics=True),
decision_tracking=True,
graph_expansion=True,
advanced_analytics=True,
kg_algorithms=True,
vector_store_features=True
)
```
### ContextGraph Options
```python
# Basic knowledge graph
graph = ContextGraph()
# Advanced knowledge graph
graph = ContextGraph(
advanced_analytics=True, # Enable smart algorithms
centrality_analysis=True, # Find important concepts
community_detection=True, # Find groups of related concepts
node_embeddings=True # Understand concept similarity
)
```
**Core Notebooks:**
- [**Context Module Introduction**](https://github.c | text/markdown | null | Hawksight AI <semantica-dev@users.noreply.github.com> | null | Hawksight AI <semantica-dev@users.noreply.github.com> | MIT | semantic-layer, knowledge-graph, nlp, embeddings, entity-extraction, relationship-extraction, rdf, ontology | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python... | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy>=1.21.0",
"pandas>=1.3.0",
"scipy>=1.9.0",
"scikit-learn>=1.0.0",
"umap-learn>=0.5.0",
"spacy>=3.4.0",
"transformers>=4.20.0",
"torch>=1.12.0",
"sentence-transformers>=2.2.0",
"rdflib>=6.2.0",
"networkx>=2.8.0",
"matplotlib>=3.5.0",
"seaborn>=0.11.0",
"plotly>=5.10.0",
"ipywidgets... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:46:25.815272 | semantica-0.3.0a0.tar.gz | 1,037,302 | 84/4e/ff390b96732146a0533bcb07e2fe402dd6905b5452bab76cf5aeabb1c481/semantica-0.3.0a0.tar.gz | source | sdist | null | false | a1d0d7142a82b3db69fa17828ed131bc | aa3cbd65ef519f11452a6c5b6ae017ed07cc323313ce5b00bc8b5ed958324a0f | 844eff390b96732146a0533bcb07e2fe402dd6905b5452bab76cf5aeabb1c481 | null | [
"LICENSE"
] | 207 |
2.4 | hiro-agent | 0.1.1 | AI security review agent for code, plans, and infrastructure | # hiro-agent
AI security review agent for code, plans, and infrastructure. Integrates with Claude Code, Cursor, VSCode Copilot, and Codex CLI to enforce security reviews before commits and plan finalization.
## Install
```bash
# Recommended (isolated environment, works on macOS/Linux)
pipx install hiro-agent
# Or with pip in a virtual environment
pip install hiro-agent
```
## Quick Start
```bash
# Set up hooks for your AI coding tools
hiro setup
# Review code changes
git diff | hiro review-code
# Review an implementation plan
cat plan.md | hiro review-plan
# Review infrastructure configuration
hiro review-infra main.tf
```
## Commands
| Command | Description |
|---------|-------------|
| `hiro review-code` | Security review of code changes (stdin: git diff) |
| `hiro review-plan` | STRIDE threat model review of a plan (stdin) |
| `hiro review-infra` | IaC security review (file arg or stdin) |
| `hiro setup` | Auto-detect and configure all AI coding tools |
| `hiro verify` | Verify hook integrity against installed version |
### Setup Options
```bash
hiro setup # Auto-detect all tools
hiro setup --claude-code # Claude Code only
hiro setup --cursor # Cursor only
hiro setup --vscode # VSCode Copilot only
hiro setup --codex # Codex CLI only
```
## Configuration
Set `HIRO_API_KEY` to connect to the Hiro platform for organizational context (security policies, memories, org profile). Without it, reviews still run using your `ANTHROPIC_API_KEY` directly.
```bash
export HIRO_API_KEY=hiro_ak_... # Optional: Hiro platform context
export ANTHROPIC_API_KEY=sk-ant-... # Required if HIRO_API_KEY not set
```
## How It Works
1. **`hiro setup`** installs hook scripts in `.hiro/hooks/` and configures your AI coding tool to call them
2. Hooks track file modifications and block commits until `hiro review-code` has run
3. Hooks track plan creation and block finalization until `hiro review-plan` has run
4. Review agents use `claude-agent-sdk` to spawn a Claude instance that performs the security review
5. When connected to Hiro (`HIRO_API_KEY`), reviews are enriched with your org's security policy, accepted risks, and architecture context
## License
MIT
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"claude-agent-sdk>=0.1.37",
"click>=8.0",
"structlog",
"pytest; extra == \"dev\"",
"pytest-asyncio; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:46:23.551705 | hiro_agent-0.1.1.tar.gz | 17,824 | c0/65/047ddd68e92226e491c0702d38b8d3ba7c169e2136fd5fca8505a0018577/hiro_agent-0.1.1.tar.gz | source | sdist | null | false | 1b1735dd8a2c3838b30493c8302df676 | f218fce928dfd4b7e2db7e0b5560b2224cb39a6ef260e66c99160345645d4e28 | c065047ddd68e92226e491c0702d38b8d3ba7c169e2136fd5fca8505a0018577 | MIT | [
"LICENSE"
] | 230 |
2.4 | waldur-api-client | 8.0.4 | A client library for accessing Waldur API | # waldur-api-client
A client library for accessing Waldur API
## Usage
First, create a client:
```python
from waldur_api_client import Client
client = Client(base_url="https://api.example.com")
```
If the endpoints you're going to hit require authentication, use `AuthenticatedClient` instead:
```python
from waldur_api_client import AuthenticatedClient
client = AuthenticatedClient(base_url="https://api.example.com", token="SuperSecretToken")
```
Now call your endpoint and use your models:
```python
from waldur_api_client.models import MyDataModel
from waldur_api_client.api.my_tag import get_my_data_model
from waldur_api_client.types import Response
with client as client:
my_data: MyDataModel = get_my_data_model.sync(client=client)
# or if you need more info (e.g. status_code)
response: Response[MyDataModel] = get_my_data_model.sync_detailed(client=client)
```
Or do the same thing with an async version:
```python
from waldur_api_client.models import MyDataModel
from waldur_api_client.api.my_tag import get_my_data_model
from waldur_api_client.types import Response
async with client as client:
my_data: MyDataModel = await get_my_data_model.asyncio(client=client)
response: Response[MyDataModel] = await get_my_data_model.asyncio_detailed(client=client)
```
By default, when you're calling an HTTPS API it will attempt to verify that SSL is working correctly. Using certificate verification is highly recommended most of the time, but sometimes you may need to authenticate to a server (especially an internal server) using a custom certificate bundle.
```python
client = AuthenticatedClient(
base_url="https://internal_api.example.com",
token="SuperSecretToken",
verify_ssl="/path/to/certificate_bundle.pem",
)
```
You can also disable certificate validation altogether, but beware that **this is a security risk**.
```python
client = AuthenticatedClient(
base_url="https://internal_api.example.com",
token="SuperSecretToken",
verify_ssl=False
)
```
Things to know:
1. Every path/method combo becomes a Python module with four functions:
1. `sync`: Blocking request that returns parsed data (if successful) or `None`
1. `sync_detailed`: Blocking request that always returns a `Request`, optionally with `parsed` set if the request was successful.
1. `asyncio`: Like `sync` but async instead of blocking
1. `asyncio_detailed`: Like `sync_detailed` but async instead of blocking
1. All path/query params, and bodies become method arguments.
1. If your endpoint had any tags on it, the first tag will be used as a module name for the function (my_tag above)
1. Any endpoint which did not have a tag will be in `waldur_api_client.api.default`
## Advanced customizations
There are more settings on the generated `Client` class which let you control more runtime behavior, check out the docstring on that class for more info. You can also customize the underlying `httpx.Client` or `httpx.AsyncClient` (depending on your use-case):
```python
from waldur_api_client import Client
def log_request(request):
print(f"Request event hook: {request.method} {request.url} - Waiting for response")
def log_response(response):
request = response.request
print(f"Response event hook: {request.method} {request.url} - Status {response.status_code}")
client = Client(
base_url="https://api.example.com",
httpx_args={"event_hooks": {"request": [log_request], "response": [log_response]}},
)
# Or get the underlying httpx client to modify directly with client.get_httpx_client() or client.get_async_httpx_client()
```
You can even set the httpx client directly, but beware that this will override any existing settings (e.g., base_url):
```python
import httpx
from waldur_api_client import Client
client = Client(
base_url="https://api.example.com",
)
# Note that base_url needs to be re-set, as would any shared cookies, headers, etc.
client.set_httpx_client(httpx.Client(base_url="https://api.example.com", proxies="http://localhost:8030"))
```
## Building / publishing this package
This project uses [Poetry](https://python-poetry.org/) to manage dependencies and packaging. Here are the basics:
1. Update the metadata in pyproject.toml (e.g. authors, version)
1. If you're using a private repository, configure it with Poetry
1. `poetry config repositories.<your-repository-name> <url-to-your-repository>`
1. `poetry config http-basic.<your-repository-name> <username> <password>`
1. Publish the client with `poetry publish --build -r <your-repository-name>` or, if for public PyPI, just `poetry publish --build`
If you want to install this client into another project without publishing it (e.g. for development) then:
1. If that project **is using Poetry**, you can simply do `poetry add <path-to-this-client>` from that project
1. If that project is not using Poetry:
1. Build a wheel with `poetry build -f wheel`
1. Install that wheel from the other project `pip install <path-to-wheel>`
| text/markdown | OpenNode Team | info@opennodecloud.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming... | [] | null | null | <4.0,>=3.9 | [] | [] | [] | [
"attrs>=22.2.0",
"httpx<0.29.0,>=0.20.0",
"python-dateutil<3.0.0,>=2.8.0"
] | [] | [] | [] | [
"Documentation, https://docs.waldur.com",
"Homepage, https://waldur.com"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:45:15.582456 | waldur_api_client-8.0.4.tar.gz | 1,861,311 | c4/37/87a91cf5e28b724dddc0de4269b254cefeccbb0b74f03f59618506a983aa/waldur_api_client-8.0.4.tar.gz | source | sdist | null | false | f40fc92bccfd8d52b0b527ef73edc97f | c70278eba01f20189619eb18bc40fb218b6a3bfafa74ffd4ce59273dfb8e50b7 | c43787a91cf5e28b724dddc0de4269b254cefeccbb0b74f03f59618506a983aa | null | [
"LICENSE"
] | 445 |
2.4 | qcatch | 0.2.10 | QCatch: Automated quality control of single-cell quantifications from `alevin-fry` and `simpleaf`. | # QCatch
[](https://pypi.org/project/qcatch/)
[![Tests][badge-tests]][tests]
[![Documentation][badge-docs]][documentation]
[badge-pypi]: https://img.shields.io/pypi/v/qcatch
[pypi]: https://pypi.org/project/qcatch/
[badge-tests]: https://img.shields.io/github/actions/workflow/status/COMBINE-lab/QCatch/test.yaml?branch=main
[tests]: https://github.com/COMBINE-lab/QCatch/actions/workflows/test.yaml
[badge-docs]: https://img.shields.io/badge/docs-online-blue
[documentation]: https://COMBINE-lab.github.io/QCatch
QCatch: Automated quality control of single-cell quantifications from `alevin-fry` and `simpleaf`.
View the complete [QCatch documentation](https://COMBINE-lab.github.io/QCatch) with interactive examples, FAQs, and detailed usage guides.
## Installation
You need to have Python 3.11, 3.12, or 3.13 installed on your system.
There are several alternative options to install QCatch:
#### 1. Bioconda
You can install using [Conda](http://anaconda.org/)
from [Bioconda](https://bioconda.github.io/).
```bash
conda install -c bioconda qcatch
```
#### 2. PyPI
You can also install from [PyPI](https://pypi.org/project/qcatch/) using `pip`:
```bash
pip install qcatch
```
> Tips: If you run into environment issues, you can also use the provided Conda .yml file, which specifies the exact versions of all dependencies to ensure consistency.
```bash
conda env create -f qcatch_conda_env.yml
```
## Basic Usage
Provide the path to the parent folder for quantification results, or the direct path to a .h5ad file generated by `alevin-fry` or `simpleaf`. **QCatch** will automatically scan the input path, assess data quality, and generate an interactive HTML report that can be viewed directly in your browser.
```bash
qcatch \
--input path/to/your/quantification/result \
--output path/to/desired/QC/output/folder \ # if you want another folder for output
--chemistry 10X_3p_v3
--save_filtered_h5ad
```
For details on how to configure chemistries,
See [chemistry section](#3--chemistry).
## Tutorial: Run QCatch on Example data
### Step 1 — Download Dataset
```bash
#!/bin/bash
set -e # Exit immediately if a command exits with a non-zero status
echo "📦 Downloading QCatch example dataset..."
# Define where to run the tutorial (you can change this path if desired)
CWD=$(pwd) # Current working directory
TUTORIAL_DIR="${CWD}/qcatch_tutorial"
# Clean any existing tutorial directory to ensure a fresh download
rm -rf "$TUTORIAL_DIR" && mkdir -p "$TUTORIAL_DIR"
ZIP_FILE="data.zip"
# Download from Box
wget -O "$ZIP_FILE" "https://umd.box.com/shared/static/zd4sai70uw9fs24e1qx6r41ec50pf45g.zip?dl=1"
# Unzip and clean up
unzip "$ZIP_FILE" -d "$TUTORIAL_DIR"
rm "$ZIP_FILE"
echo "✅ Test data downloaded to $TUTORIAL_DIR"
```
### Step 2 - Run the qcatch
🎉 All set! Now let’s run QCatch:
```bash
#Set up output directory
OUT_DIR="${TUTORIAL_DIR}/output"
mkdir -p "$OUT_DIR"
# Step2 - Run QCatch
qcatch --input ${TUTORIAL_DIR}/test_data/simpleaf_with_map/quants.h5ad \
--output ${OUT_DIR} \
```
### Tips
#### 1- Input path:
Provide either:
- the **path to the parent directory** containing quantification results, or
- the **direct path to a .h5ad file** generated by those tools.
QCatch will automatically detect the input type:
- If a **.h5ad file** is provided, QCatch will process it directly.
- If a **directory** is provided, QCatch will first look for an existing .h5ad file inside. If not found, it will fall back to processing the mtx-based quantification results.
See the example directory structures at the end of the Tips section for reference:
#### 2- Output path:
If you do not want any modifications in your input folder/files, speaficy the output path, we will save any new results and QC HTML report there.
**_By default_**, QCatch saves the QC report and all output files in the input directory by default. If you prefer a different output location, you may specify an output path; however, this is optional.
Specifically:
- If QCatch detects an existing `quants.h5ad` file in the input directory and the output path is the same as the input path, QCatch will modify the original .h5ad file _in place_ by appending cell-filtering results to `anndata.obs`. In addition, it will generate a separate HTML QC report in the input directory.
- For **MTX-based** inputs (i.e., when not using simpleaf v0.19.5 or newer), QCatch will generate a new `.h5ad` file containing metadata produced during QCatch processing. This file does **NOT** include metadata from the original alevin-fry quantification, which remains stored in the original files.
#### 3- Chemistry:
The `--chemistry` information is used to estimate `--n_partitions`, which represents the total partition capacity (i.e., the total number of physical droplets or wells generated in an experiment, regardless of whether they contain a cell). This value is critical for accurately defining the "ambient pool" used to model empty droplets. (_NOTE_: this is distinct from the --chemistry argument in alevin-fry, which refers to the barcode/UMI geometry.)
If you used a **standard 10X** chemistry, QCatch will first attempt to infer the chemistry from the metadata and use the internal database to get the corresponding number of partitions; If this inference fails, QCatch will stop and prompt you to explicitly provide the chemistry version using the `--chemistry` argument before rerunning the command. **Supported chemistries currently include: '10X_3p_v2', '10X_3p_v3', '10X_3p_v4', '10X_3p_LT', '10X_5p_v3', or '10X_HT'**.
For **non-10x or custom** assays (e.g., sci-RNA-seq3, Drop-seq), users can manually specify the capacity using `--n_partitions`. We recommend setting this value by rounding the number of processed barcodes (found in the _alevin-fry/simpleaf_ log or the number of rows in the `.h5ad` file) up to the next 10% increment of the current order of magnitude. For example, If 79,000 barcodes are detected, n_partitions should be set to 80,000; If 144,000 barcodes are detected, n_partitions should be set to 150,000. This option will override any chemistry-based setting for cell-calling.
#### 4- Gene gene mapping file:
If you are using simpleaf v0.19.3 or later, the generated .h5ad file already includes gene names. In this case, you do not need to specify the --gene_id2name_file option.
To provide a 'gene id to name mapping' info, the file should be a **TSV** containing two columns—‘gene_id’ (e.g., ENSG00000284733) and ‘gene_name’ (e.g., OR4F29)— **without** header row. If not provided, the program will attempt to retrieve the mapping from a remote registry. If that lookup fails, mitochondria plots will not be displayed, but will not affect the QC report.
#### 5- Save filtered h5ad file:
If you want to save filtered h5ad file separately, you can specify `--save_filtered_h5ad`, which is only applicable when QCatch detects the h5ad file as the input.
#### 6- Specify your desired cell list:
If you want to use a specified list of valid cell barcodes, you can provide the file path with `--valid_cell_list`. QCatch will then skip the default cell calling step and use the supplied list instead. The updated .h5ad file will include only one additional column, 'is_retained_cells', containing boolean values based on the specified list.
#### 7- Skip clustering plots:
To reduce runtime, you may enable the `--skip_umap_tsne` option to bypass dimensionality reduction and visualization steps.
#### 8- Export the summary metrics
To export the summary metrics, enable the `--export_summary_table` flag. The summary table will be saved as a separate CSV file in the output directory.
#### 9- Visualize doublets
To visualize doublets alongside singlets in UMAP and t-SNE plots, use both `--remove_doublets` and `--visualize_doublets` flags together. This generates two plot views:
- **Retained Cells Only**: Shows singlets colored by Leiden clusters (default view)
- **With Doublets**: Shows both singlets and doublets colored by doublet status (red for doublets, blue for singlets)
Toggle buttons in the HTML report allow switching between these views. Both views use the same coordinate space, so singlets appear at identical positions in both plots for easy comparison.
```bash
qcatch --input path/to/quants.h5ad \
--remove_doublets \
--visualize_doublets
```
#### 10- Debug-level message
To get debug-level messages and more intermediate computation in cell calling step, you can specify `--verbose`
#### 11- Re-run QCatch on modified h5ad file
If you re-run QCatch analysis on a modified `.h5ad` file (i.e., an `.h5ad` file with additional columns added for cell calling results), the existing cell calling-related columns will be removed and then replaced with new results. The new cell calling can be generated either through QCatch's internal method or based on a user-specified list of valid cell barcodes.
#### Example directory structures:
```bash
# simpleaf
parent_quant_dir/
├── af_map/
├── af_quant/
│ ├── alevin/
│ │ ├── quants_mat_cols.txt
│ │ ├── quants_mat_rows.txt
│ │ ├── quants_mat.mtx
│ │ └── quants.h5ad (available if you use simpleaf after v0.19.3)
│ │ ...
│ ├── featureDump.txt
│ └── quant.json
└── simpleaf_quant_log.json
# alevin-fry
parent_quant_dir/
├── alevin/
│ ├── quants_mat_cols.txt
│ ├── quants_mat_rows.txt
│ └── quants_mat.mtx
├── featureDump.txt
└── quant.json
```
For more advanced options and usage details, see the sections below.
## Command-Line Arguments
| Flag | Short | Type | Description |
|------|-------|------|-------------|
| `--input` | `-i` | `str` (Required) | Path to the input directory containing the quantification output files or to the H5AD file itself. |
| `--output` | `-o` | `str`(Required) | Path to the output directory.|
| `--chemistry` | `-c` | `str`(Recommended) | Specifies the chemistry used in the experiment, which determines the partition range for the empty_drops step. **Supported options**: '10X_3p_v2', '10X_3p_v3', '10X_3p_v4', '10X_5p_v3', '10X_3p_LT', '10X_HT'. If you used a standard 10X chemistry (e.g., '10X_3p_v2', '10X_3p_v3') and performed quantification with `simpleaf`(v0.19.5 or later), QCatch will try to **infer** the correct chemistry from the metadata. If inference fails, QCatch will stop and prompt you to provide the chemistry explicitly via this flag.|
| `--save_filtered_h5ad` | `-s` | `flag` (Optional) |If enabled, `qcatch` will save a separate `.h5ad` file containing only the final retained cells.|
| `--gene_id2name_file` | `-g` | `str` (Optional) |File provides a mapping from gene IDs to gene names. The file must be a TSV containing two columns—‘gene_id’ (e.g., ENSG00000284733) and ‘gene_name’ (e.g., OR4F29)—without a header row. If not provided, the program will attempt to retrieve the mapping from a remote registry. If that lookup fails, mitochondria plots will not be displayed.|
| `--valid_cell_list` | `-l` | `str` (Optional) |File provides a user-specified list of valid cell barcode. The file must be a TSV containing one column with cell barcodes without a header row. If provided, qcatch will skip the internal cell calling steps and and use the supplied list instead|
| `--n_partitions` | `-n` | `int` (Optional) | Number of partitions (max number of barcodes to consider for ambient estimation). Use `--n_partitions` only when working with a custom or unsupported chemistry. When provided, this value will override the chemistry-based configuration during the cell-calling step.|
| `--remove_doublets` | `-d` | `flag` (Optional) | If enabled, QCatch will perform doublet detection(use `Scrublet` tool) and remove detected doublets from the cells retained after cell calling. |
| `--visualize_doublets` | `-vd` | `flag` (Optional) | If enabled (requires `--remove_doublets`), generates additional UMAP and t-SNE plots showing both singlets and doublets. Toggle buttons allow switching between "Retained Cells Only" (singlets) and "With Doublets" views. |
| `--skip_umap_tsne` | `-u` | `flag` (Optional) | If provided, skips generation of UMAP and t-SNE plots. |
| `--export_summary_table` | `-x` | `flag` (Optional) | If enabled, QCatch will export the summary metrics as a separate CSV file. |
| `--verbose` | `-b` | `flag` (Optional) | Enable verbose logging with debug-level messages. |
| `--version` | `-v` | `flag` (Optional) | Display the installed version of qcatch. |
<!-- ## Contact
For questions and help requests, you can reach out in the [scverse discourse][].
If you found a bug, please use the [issue tracker][]. -->
<!-- ## Citation
> t.b.a
[uv]: https://github.com/astral-sh/uv
[scverse discourse]: https://discourse.scverse.org/
[issue tracker]: https://github.com/ygao61/QCatch/issues
[tests]: https://github.com/ygao61/QCatch/actions/workflows/test.yaml
[documentation]: https://QCatch.readthedocs.io
[changelog]: https://QCatch.readthedocs.io/en/latest/changelog.html
[api documentation]: https://QCatch.readthedocs.io/en/latest/api.html
[pypi]: https://pypi.org/project/QCatch -->
| text/markdown | Yuan Gao, Dongze He, Rob Patro | null | null | null | null | null | [
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"anndata>=0.11.4",
"beautifulsoup4>=4.13.3",
"igraph<0.12,>=0.11",
"numpy<3,>=2.1.3",
"pandas<3,>=2.2.3",
"plotly>=6",
"requests>=2.32.4",
"scanpy<2,>=1.10.4",
"scipy<2,>=1.15.2",
"session-info2<0.2,>=0.1",
"pre-commit; extra == \"dev\"",
"twine>=4.0.2; extra == \"dev\"",
"coverage; extra ==... | [] | [] | [] | [
"Documentation, https://github.com/COMBINE-lab/QCatch#readme",
"Homepage, https://github.com/COMBINE-lab/QCatch",
"Source, https://github.com/COMBINE-lab/QCatch"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:43:27.320412 | qcatch-0.2.10.tar.gz | 1,302,678 | 83/98/c8fa8606f410fc385252719f1fdacc73f5e609ccf23557a025856e40ad18/qcatch-0.2.10.tar.gz | source | sdist | null | false | c5483c66d335825a1c7521c699c46ba8 | 7f0e335dfd10f2178bbfde7d0e37ac9bcbbabd6cd65e4beb77c70555cadf2e48 | 8398c8fa8606f410fc385252719f1fdacc73f5e609ccf23557a025856e40ad18 | null | [
"LICENSE"
] | 274 |
2.4 | crc-pulp-service-client | 20260219.2 | Pulp 3 API | # pulpcore.client.pulp_service.ApiCreateDomainApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**post**](ApiCreateDomainApi.md#post) | **POST** /api/pulp/create-domain/ | Create domain
# **post**
> DomainResponse post(domain, x_task_diagnostics=x_task_diagnostics)
Create domain
Create a new domain for from S3 template domain, self-service path
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_service
from pulpcore.client.pulp_service.models.domain import Domain
from pulpcore.client.pulp_service.models.domain_response import DomainResponse
from pulpcore.client.pulp_service.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_service.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_service.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_service.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_service.ApiCreateDomainApi(api_client)
domain = pulpcore.client.pulp_service.Domain() # Domain |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Create domain
api_response = api_instance.post(domain, x_task_diagnostics=x_task_diagnostics)
print("The response of ApiCreateDomainApi->post:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ApiCreateDomainApi->post: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**domain** | [**Domain**](Domain.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**DomainResponse**](DomainResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# pulpcore.client.pulp_service.ApiDebugAuthHeaderApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**get**](ApiDebugAuthHeaderApi.md#get) | **GET** /api/pulp/debug_auth_header/ |
# **get**
> get(x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
Returns the content of the authentication headers.
### Example
```python
import pulpcore.client.pulp_service
from pulpcore.client.pulp_service.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_service.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# Enter a context with an instance of the API client
with pulpcore.client.pulp_service.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_service.ApiDebugAuthHeaderApi(api_client)
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
api_instance.get(x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
except Exception as e:
print("Exception when calling ApiDebugAuthHeaderApi->get: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
void (empty response body)
### Authorization
No authorization required
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: Not defined
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | No response body | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# pulpcore.client.pulp_service.ApiDebugDatabaseTriggersApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**get**](ApiDebugDatabaseTriggersApi.md#get) | **GET** /api/pulp/debug/database-triggers/ |
# **get**
> get(x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
Query PostgreSQL system catalogs for triggers on core_task table.
### Example
```python
import pulpcore.client.pulp_service
from pulpcore.client.pulp_service.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_service.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# Enter a context with an instance of the API client
with pulpcore.client.pulp_service.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_service.ApiDebugDatabaseTriggersApi(api_client)
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
api_instance.get(x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
except Exception as e:
print("Exception when calling ApiDebugDatabaseTriggersApi->get: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
void (empty response body)
### Authorization
No authorization required
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: Not defined
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | No response body | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# pulpcore.client.pulp_service.ApiDebugReleaseTaskLocksApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**get**](ApiDebugReleaseTaskLocksApi.md#get) | **GET** /api/pulp/debug/release-task-locks/ |
# **get**
> get(x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
Release all Redis locks for a given task UUID. Query parameters: task_id: UUID of the task to release locks for Returns: 200: Locks released successfully 400: Missing or invalid task_id parameter 404: Task not found 500: Error releasing locks
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_service
from pulpcore.client.pulp_service.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_service.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_service.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_service.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_service.ApiDebugReleaseTaskLocksApi(api_client)
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
api_instance.get(x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
except Exception as e:
print("Exception when calling ApiDebugReleaseTaskLocksApi->get: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
void (empty response body)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: Not defined
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | No response body | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# pulpcore.client.pulp_service.ApiRdsConnectionTestsApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**get**](ApiRdsConnectionTestsApi.md#get) | **GET** /api/pulp/rds-connection-tests/ |
[**post**](ApiRdsConnectionTestsApi.md#post) | **POST** /api/pulp/rds-connection-tests/ | Dispatch RDS connection tests
# **get**
> get(x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
Get available tests and their descriptions. This endpoint is always accessible for documentation purposes.
### Example
```python
import pulpcore.client.pulp_service
from pulpcore.client.pulp_service.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_service.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# Enter a context with an instance of the API client
with pulpcore.client.pulp_service.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_service.ApiRdsConnectionTestsApi(api_client)
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
api_instance.get(x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
except Exception as e:
print("Exception when calling ApiRdsConnectionTestsApi->get: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
void (empty response body)
### Authorization
No authorization required
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: Not defined
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | No response body | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **post**
> AsyncOperationResponse post(x_task_diagnostics=x_task_diagnostics)
Dispatch RDS connection tests
Dispatch RDS Proxy connection timeout tests
### Example
```python
import pulpcore.client.pulp_service
from pulpcore.client.pulp_service.models.async_operation_response import AsyncOperationResponse
from pulpcore.client.pulp_service.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_service.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# Enter a context with an instance of the API client
with pulpcore.client.pulp_service.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_service.ApiRdsConnectionTestsApi(api_client)
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Dispatch RDS connection tests
api_response = api_instance.post(x_task_diagnostics=x_task_diagnostics)
print("The response of ApiRdsConnectionTestsApi->post:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ApiRdsConnectionTestsApi->post: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**AsyncOperationResponse**](AsyncOperationResponse.md)
### Authorization
No authorization required
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**202** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# pulpcore.client.pulp_service.ApiTestRandomLockTasksApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**get**](ApiTestRandomLockTasksApi.md#get) | **GET** /api/pulp/test/random_lock_tasks/ |
# **get**
> get(x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
### Example
```python
import pulpcore.client.pulp_service
from pulpcore.client.pulp_service.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_service.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# Enter a context with an instance of the API client
with pulpcore.client.pulp_service.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_service.ApiTestRandomLockTasksApi(api_client)
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
api_instance.get(x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
except Exception as e:
print("Exception when calling ApiTestRandomLockTasksApi->get: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
void (empty response body)
### Authorization
No authorization required
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: Not defined
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | No response body | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# pulpcore.client.pulp_service.ApiTestTasksApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**get**](ApiTestTasksApi.md#get) | **GET** /api/pulp/test/tasks/ |
# **get**
> get(x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
### Example
```python
import pulpcore.client.pulp_service
from pulpcore.client.pulp_service.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_service.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# Enter a context with an instance of the API client
with pulpcore.client.pulp_service.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_service.ApiTestTasksApi(api_client)
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
api_instance.get(x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
except Exception as e:
print("Exception when calling ApiTestTasksApi->get: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
void (empty response body)
### Authorization
No authorization required
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: Not defined
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | No response body | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# AsyncOperationResponse
Serializer for asynchronous operations.
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**task** | **str** | The href of the task. |
## Example
```python
from pulpcore.client.pulp_service.models.async_operation_response import AsyncOperationResponse
# TODO update the JSON string below
json = "{}"
# create an instance of AsyncOperationResponse from a JSON string
async_operation_response_instance = AsyncOperationResponse.from_json(json)
# print the JSON string representation of the object
print(AsyncOperationResponse.to_json())
# convert the object into a dict
async_operation_response_dict = async_operation_response_instance.to_dict()
# create an instance of AsyncOperationResponse from a dict
async_operation_response_from_dict = AsyncOperationResponse.from_dict(async_operation_response_dict)
```
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
# pulpcore.client.pulp_service.ContentguardsFeatureApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**add_role**](ContentguardsFeatureApi.md#add_role) | **POST** {service_feature_content_guard_href}add_role/ | Add a role
[**create**](ContentguardsFeatureApi.md#create) | **POST** /api/pulp/{pulp_domain}/api/v3/contentguards/service/feature/ | Create a feature content guard
[**delete**](ContentguardsFeatureApi.md#delete) | **DELETE** {service_feature_content_guard_href} | Delete a feature content guard
[**list**](ContentguardsFeatureApi.md#list) | **GET** /api/pulp/{pulp_domain}/api/v3/contentguards/service/feature/ | List feature content guards
[**list_roles**](ContentguardsFeatureApi.md#list_roles) | **GET** {service_feature_content_guard_href}list_roles/ | List roles
[**my_permissions**](ContentguardsFeatureApi.md#my_permissions) | **GET** {service_feature_content_guard_href}my_permissions/ | List user permissions
[**partial_update**](ContentguardsFeatureApi.md#partial_update) | **PATCH** {service_feature_content_guard_href} | Update a feature content guard
[**read**](ContentguardsFeatureApi.md#read) | **GET** {service_feature_content_guard_href} | Inspect a feature content guard
[**remove_role**](ContentguardsFeatureApi.md#remove_role) | **POST** {service_feature_content_guard_href}remove_role/ | Remove a role
[**update**](ContentguardsFeatureApi.md#update) | **PUT** {service_feature_content_guard_href} | Update a feature content guard
# **add_role**
> NestedRoleResponse add_role(service_feature_content_guard_href, nested_role, x_task_diagnostics=x_task_diagnostics)
Add a role
Add a role for this object to users/groups.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_service
from pulpcore.client.pulp_service.models.nested_role import NestedRole
from pulpcore.client.pulp_service.models.nested_role_response import NestedRoleResponse
from pulpcore.client.pulp_service.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_service.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_service.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_service.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_service.ContentguardsFeatureApi(api_client)
service_feature_content_guard_href = 'service_feature_content_guard_href_example' # str |
nested_role = pulpcore.client.pulp_service.NestedRole() # NestedRole |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Add a role
api_response = api_instance.add_role(service_feature_content_guard_href, nested_role, x_task_diagnostics=x_task_diagnostics)
print("The response of ContentguardsFeatureApi->add_role:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentguardsFeatureApi->add_role: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**service_feature_content_guard_href** | **str**| |
**nested_role** | [**NestedRole**](NestedRole.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**NestedRoleResponse**](NestedRoleResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **create**
> ServiceFeatureContentGuardResponse create(pulp_domain, service_feature_content_guard, x_task_diagnostics=x_task_diagnostics)
Create a feature content guard
Content guard to protect the content guarded by Subscription Features.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_service
from pulpcore.client.pulp_service.models.service_feature_content_guard import ServiceFeatureContentGuard
from pulpcore.client.pulp_service.models.service_feature_content_guard_response import ServiceFeatureContentGuardResponse
from pulpcore.client.pulp_service.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_service.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_service.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_service.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_service.ContentguardsFeatureApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
service_feature_content_guard = pulpcore.client.pulp_service.ServiceFeatureContentGuard() # ServiceFeatureContentGuard |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Create a feature content guard
api_response = api_instance.create(pulp_domain, service_feature_content_guard, x_task_diagnostics=x_task_diagnostics)
print("The response of ContentguardsFeatureApi->create:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentguardsFeatureApi->create: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**service_feature_content_guard** | [**ServiceFeatureContentGuard**](ServiceFeatureContentGuard.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**ServiceFeatureContentGuardResponse**](ServiceFeatureContentGuardResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **delete**
> delete(service_feature_content_guard_href, x_task_diagnostics=x_task_diagnostics)
Delete a feature content guard
Content guard to protect the content guarded by Subscription Features.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_service
from pulpcore.client.pulp_service.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_service.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_service.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_service.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_service.ContentguardsFeatureApi(api_client)
service_feature_content_guard_href = 'service_feature_content_guard_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Delete a feature content guard
api_instance.delete(service_feature_content_guard_href, x_task_diagnostics=x_task_diagnostics)
except Exception as e:
print("Exception when calling ContentguardsFeatureApi->delete: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**service_feature_content_guard_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
void (empty response body)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: Not defined
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**204** | No response body | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **list**
> PaginatedserviceFeatureContentGuardResponseList list(pulp_domain, x_task_diagnostics=x_task_diagnostics, limit=limit, name=name, name__contains=name__contains, name__icontains=name__icontains, name__iexact=name__iexact, name__in=name__in, name__iregex=name__iregex, name__istartswith=name__istartswith, name__regex=name__regex, name__startswith=name__startswith, offset=offset, ordering=ordering, prn__in=prn__in, pulp_href__in=pulp_href__in, pulp_id__in=pulp_id__in, q=q, fields=fields, exclude_fields=exclude_fields)
List feature content guards
Content guard to protect the content guarded by Subscription Features.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_service
from pulpcore.client.pulp_service.models.paginatedservice_feature_content_guard_response_list import PaginatedserviceFeatureContentGuardResponseList
from pulpcore.client.pulp_service.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_service.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_service.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_service.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_service.ContentguardsFeatureApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
limit = 56 # int | Number of results to return per page. (optional)
name = 'name_example' # str | Filter results where name matches value (optional)
name__contains = 'name__contains_example' # str | Filter results where name contains value (optional)
name__icontains = 'name__icontains_example' # str | Filter results where name contains value (optional)
name__iexact = 'name__iexact_example' # str | Filter results where name matches value (optional)
name__in = ['name__in_example'] # List[str] | Filter results where name is in a com | text/markdown | Pulp Team | pulp-list@redhat.com | null | null | GNU General Public License v2.0 or later | pulp, pulpcore, client, Pulp 3 API | [] | [] | null | null | null | [] | [] | [] | [
"urllib3<2.7,>=1.25.3",
"python-dateutil<2.10.0,>=2.8.1",
"pydantic>=2",
"typing-extensions>=4.7.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T18:43:10.635279 | crc_pulp_service_client-20260219.2.tar.gz | 70,359 | 2b/b4/3d52b5ab9327efb72d927c32fc5705d387ddba4cff58a0c5a373df7e8459/crc_pulp_service_client-20260219.2.tar.gz | source | sdist | null | false | 0c674c28554966e17ef34020a8a2046d | edd574f49dc5516f8b0f064100b58e78f52f8d3b80a5c3f06b29027f448477f6 | 2bb43d52b5ab9327efb72d927c32fc5705d387ddba4cff58a0c5a373df7e8459 | null | [] | 233 |
2.4 | crc-pulp-file-client | 20260219.2 | Pulp 3 API | # pulpcore.client.pulp_file.AcsFileApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**add_role**](AcsFileApi.md#add_role) | **POST** {file_file_alternate_content_source_href}add_role/ | Add a role
[**create**](AcsFileApi.md#create) | **POST** /api/pulp/{pulp_domain}/api/v3/acs/file/file/ | Create a file alternate content source
[**delete**](AcsFileApi.md#delete) | **DELETE** {file_file_alternate_content_source_href} | Delete a file alternate content source
[**list**](AcsFileApi.md#list) | **GET** /api/pulp/{pulp_domain}/api/v3/acs/file/file/ | List file alternate content sources
[**list_roles**](AcsFileApi.md#list_roles) | **GET** {file_file_alternate_content_source_href}list_roles/ | List roles
[**my_permissions**](AcsFileApi.md#my_permissions) | **GET** {file_file_alternate_content_source_href}my_permissions/ | List user permissions
[**partial_update**](AcsFileApi.md#partial_update) | **PATCH** {file_file_alternate_content_source_href} | Update a file alternate content source
[**read**](AcsFileApi.md#read) | **GET** {file_file_alternate_content_source_href} | Inspect a file alternate content source
[**refresh**](AcsFileApi.md#refresh) | **POST** {file_file_alternate_content_source_href}refresh/ | Refresh metadata
[**remove_role**](AcsFileApi.md#remove_role) | **POST** {file_file_alternate_content_source_href}remove_role/ | Remove a role
[**update**](AcsFileApi.md#update) | **PUT** {file_file_alternate_content_source_href} | Update a file alternate content source
# **add_role**
> NestedRoleResponse add_role(file_file_alternate_content_source_href, nested_role, x_task_diagnostics=x_task_diagnostics)
Add a role
Add a role for this object to users/groups.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_file
from pulpcore.client.pulp_file.models.nested_role import NestedRole
from pulpcore.client.pulp_file.models.nested_role_response import NestedRoleResponse
from pulpcore.client.pulp_file.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_file.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_file.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_file.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_file.AcsFileApi(api_client)
file_file_alternate_content_source_href = 'file_file_alternate_content_source_href_example' # str |
nested_role = pulpcore.client.pulp_file.NestedRole() # NestedRole |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Add a role
api_response = api_instance.add_role(file_file_alternate_content_source_href, nested_role, x_task_diagnostics=x_task_diagnostics)
print("The response of AcsFileApi->add_role:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsFileApi->add_role: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**file_file_alternate_content_source_href** | **str**| |
**nested_role** | [**NestedRole**](NestedRole.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**NestedRoleResponse**](NestedRoleResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **create**
> FileFileAlternateContentSourceResponse create(pulp_domain, file_file_alternate_content_source, x_task_diagnostics=x_task_diagnostics)
Create a file alternate content source
Alternate Content Source ViewSet for File
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_file
from pulpcore.client.pulp_file.models.file_file_alternate_content_source import FileFileAlternateContentSource
from pulpcore.client.pulp_file.models.file_file_alternate_content_source_response import FileFileAlternateContentSourceResponse
from pulpcore.client.pulp_file.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_file.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_file.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_file.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_file.AcsFileApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
file_file_alternate_content_source = pulpcore.client.pulp_file.FileFileAlternateContentSource() # FileFileAlternateContentSource |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Create a file alternate content source
api_response = api_instance.create(pulp_domain, file_file_alternate_content_source, x_task_diagnostics=x_task_diagnostics)
print("The response of AcsFileApi->create:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsFileApi->create: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**file_file_alternate_content_source** | [**FileFileAlternateContentSource**](FileFileAlternateContentSource.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**FileFileAlternateContentSourceResponse**](FileFileAlternateContentSourceResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **delete**
> AsyncOperationResponse delete(file_file_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics)
Delete a file alternate content source
Trigger an asynchronous delete ACS task
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_file
from pulpcore.client.pulp_file.models.async_operation_response import AsyncOperationResponse
from pulpcore.client.pulp_file.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_file.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_file.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_file.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_file.AcsFileApi(api_client)
file_file_alternate_content_source_href = 'file_file_alternate_content_source_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Delete a file alternate content source
api_response = api_instance.delete(file_file_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics)
print("The response of AcsFileApi->delete:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsFileApi->delete: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**file_file_alternate_content_source_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**AsyncOperationResponse**](AsyncOperationResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**202** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **list**
> PaginatedfileFileAlternateContentSourceResponseList list(pulp_domain, x_task_diagnostics=x_task_diagnostics, limit=limit, name=name, name__contains=name__contains, name__icontains=name__icontains, name__iexact=name__iexact, name__in=name__in, name__iregex=name__iregex, name__istartswith=name__istartswith, name__regex=name__regex, name__startswith=name__startswith, offset=offset, ordering=ordering, prn__in=prn__in, pulp_href__in=pulp_href__in, pulp_id__in=pulp_id__in, q=q, fields=fields, exclude_fields=exclude_fields)
List file alternate content sources
Alternate Content Source ViewSet for File
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_file
from pulpcore.client.pulp_file.models.paginatedfile_file_alternate_content_source_response_list import PaginatedfileFileAlternateContentSourceResponseList
from pulpcore.client.pulp_file.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_file.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_file.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_file.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_file.AcsFileApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
limit = 56 # int | Number of results to return per page. (optional)
name = 'name_example' # str | Filter results where name matches value (optional)
name__contains = 'name__contains_example' # str | Filter results where name contains value (optional)
name__icontains = 'name__icontains_example' # str | Filter results where name contains value (optional)
name__iexact = 'name__iexact_example' # str | Filter results where name matches value (optional)
name__in = ['name__in_example'] # List[str] | Filter results where name is in a comma-separated list of values (optional)
name__iregex = 'name__iregex_example' # str | Filter results where name matches regex value (optional)
name__istartswith = 'name__istartswith_example' # str | Filter results where name starts with value (optional)
name__regex = 'name__regex_example' # str | Filter results where name matches regex value (optional)
name__startswith = 'name__startswith_example' # str | Filter results where name starts with value (optional)
offset = 56 # int | The initial index from which to return the results. (optional)
ordering = ['ordering_example'] # List[str] | Ordering * `pulp_id` - Pulp id * `-pulp_id` - Pulp id (descending) * `pulp_created` - Pulp created * `-pulp_created` - Pulp created (descending) * `pulp_last_updated` - Pulp last updated * `-pulp_last_updated` - Pulp last updated (descending) * `pulp_type` - Pulp type * `-pulp_type` - Pulp type (descending) * `name` - Name * `-name` - Name (descending) * `last_refreshed` - Last refreshed * `-last_refreshed` - Last refreshed (descending) * `pk` - Pk * `-pk` - Pk (descending) (optional)
prn__in = ['prn__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_href__in = ['pulp_href__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_id__in = ['pulp_id__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
q = 'q_example' # str | Filter results by using NOT, AND and OR operations on other filters (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# List file alternate content sources
api_response = api_instance.list(pulp_domain, x_task_diagnostics=x_task_diagnostics, limit=limit, name=name, name__contains=name__contains, name__icontains=name__icontains, name__iexact=name__iexact, name__in=name__in, name__iregex=name__iregex, name__istartswith=name__istartswith, name__regex=name__regex, name__startswith=name__startswith, offset=offset, ordering=ordering, prn__in=prn__in, pulp_href__in=pulp_href__in, pulp_id__in=pulp_id__in, q=q, fields=fields, exclude_fields=exclude_fields)
print("The response of AcsFileApi->list:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsFileApi->list: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**limit** | **int**| Number of results to return per page. | [optional]
**name** | **str**| Filter results where name matches value | [optional]
**name__contains** | **str**| Filter results where name contains value | [optional]
**name__icontains** | **str**| Filter results where name contains value | [optional]
**name__iexact** | **str**| Filter results where name matches value | [optional]
**name__in** | [**List[str]**](str.md)| Filter results where name is in a comma-separated list of values | [optional]
**name__iregex** | **str**| Filter results where name matches regex value | [optional]
**name__istartswith** | **str**| Filter results where name starts with value | [optional]
**name__regex** | **str**| Filter results where name matches regex value | [optional]
**name__startswith** | **str**| Filter results where name starts with value | [optional]
**offset** | **int**| The initial index from which to return the results. | [optional]
**ordering** | [**List[str]**](str.md)| Ordering * `pulp_id` - Pulp id * `-pulp_id` - Pulp id (descending) * `pulp_created` - Pulp created * `-pulp_created` - Pulp created (descending) * `pulp_last_updated` - Pulp last updated * `-pulp_last_updated` - Pulp last updated (descending) * `pulp_type` - Pulp type * `-pulp_type` - Pulp type (descending) * `name` - Name * `-name` - Name (descending) * `last_refreshed` - Last refreshed * `-last_refreshed` - Last refreshed (descending) * `pk` - Pk * `-pk` - Pk (descending) | [optional]
**prn__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_href__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_id__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**q** | **str**| Filter results by using NOT, AND and OR operations on other filters | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**PaginatedfileFileAlternateContentSourceResponseList**](PaginatedfileFileAlternateContentSourceResponseList.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **list_roles**
> ObjectRolesResponse list_roles(file_file_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
List roles
List roles assigned to this object.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_file
from pulpcore.client.pulp_file.models.object_roles_response import ObjectRolesResponse
from pulpcore.client.pulp_file.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_file.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_file.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_file.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_file.AcsFileApi(api_client)
file_file_alternate_content_source_href = 'file_file_alternate_content_source_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# List roles
api_response = api_instance.list_roles(file_file_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
print("The response of AcsFileApi->list_roles:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsFileApi->list_roles: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**file_file_alternate_content_source_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**ObjectRolesResponse**](ObjectRolesResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **my_permissions**
> MyPermissionsResponse my_permissions(file_file_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
List user permissions
List permissions available to the current user on this object.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_file
from pulpcore.client.pulp_file.models.my_permissions_response import MyPermissionsResponse
from pulpcore.client.pulp_file.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_file.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_file.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_file.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_file.AcsFileApi(api_client)
file_file_alternate_content_source_href = 'file_file_alternate_content_source_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# List user permissions
api_response = api_instance.my_permissions(file_file_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
print("The response of AcsFileApi->my_permissions:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsFileApi->my_permissions: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**file_file_alternate_content_source_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**MyPermissionsResponse**](MyPermissionsResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **partial_update**
> FileFileAlternateContentSourceResponse partial_update(file_file_alternate_content_source_href, patchedfile_file_alternate_content_source, x_task_diagnostics=x_task_diagnostics)
Update a file alternate content source
Update the entity partially and trigger an asynchronous task if necessary
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_file
from pulpcore.client.pulp_file.models.file_file_alternate_content_source_response import FileFileAlternateContentSourceResponse
from pulpcore.client.pulp_file.models.patchedfile_file_alternate_content_source import PatchedfileFileAlternateContentSource
from pulpcore.client.pulp_file.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_file.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_file.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_file.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_file.AcsFileApi(api_client)
file_file_alternate_content_source_href = 'file_file_alternate_content_source_href_example' # str |
patchedfile_file_alternate_content_source = pulpcore.client.pulp_file.PatchedfileFileAlternateContentSource() # PatchedfileFileAlternateContentSource |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Update a file alternate content source
api_response = api_instance.partial_update(file_file_alternate_content_source_href, patchedfile_file_alternate_content_source, x_task_diagnostics=x_task_diagnostics)
print("The response of AcsFileApi->partial_update:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsFileApi->partial_update: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**file_file_alternate_content_source_href** | **str**| |
**patchedfile_file_alternate_content_source** | [**PatchedfileFileAlternateContentSource**](PatchedfileFileAlternateContentSource.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**FileFileAlternateContentSourceResponse**](FileFileAlternateContentSourceResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
**202** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **read**
> FileFileAlternateContentSourceResponse read(file_file_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
Inspect a file alternate content source
Alternate Content Source ViewSet for File
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_file
from pulpcore.client.pulp_file.models.file_file_alternate_content_source_response import FileFileAlternateContentSourceResponse
from pulpcore.client.pulp_file.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_file.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_file.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_file.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_file.AcsFileApi(api_client)
file_file_alternate_content_source_href = 'file_file_alternate_content_source_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# Inspect a file alternate content source
api_response = api_instance.read(file_file_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
print("The response of AcsFileApi->read:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsFileApi->read: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**file_file_alternate_content_source_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**FileFileAlternateContentSourceResponse**](FileFileAlternateContentSourceResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **refresh**
> TaskGroupOperationResponse refresh(file_file_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics)
Refresh metadata
Trigger an asynchronous task to create Alternate Content Source content.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_file
from pulpcore.client.pulp_file.models.task_group_operation_response import TaskGroupOperationResponse
from pulpcore.client.pulp_file.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_file.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_file.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_file.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_file.AcsFileApi(api_client)
file_file_alternate_content_source_href = 'file_file_alternate_content_source_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Refresh metadata
api_response = api_instance.refresh(file_file_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics)
print("The response of AcsFileApi->refresh:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsFileApi->refresh: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**file_file_alternate_content_source_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**TaskGroupOperationResponse**](TaskGroupOperationResponse.md) | text/markdown | Pulp Team | pulp-list@redhat.com | null | null | GNU General Public License v2.0 or later | pulp, pulpcore, client, Pulp 3 API | [] | [] | null | null | null | [] | [] | [] | [
"urllib3<2.7,>=1.25.3",
"python-dateutil<2.10.0,>=2.8.1",
"pydantic>=2",
"typing-extensions>=4.7.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T18:43:03.934713 | crc_pulp_file_client-20260219.2.tar.gz | 140,957 | a9/da/9317f65fcebfa13421d6e4e198943873cd2610ba3cba292f3b7686b9e20e/crc_pulp_file_client-20260219.2.tar.gz | source | sdist | null | false | 5abe3e0cb75c029188a2e478e1bafb5a | 6f465ab724e3820e6c9dc9a467fc29d040a26bd77f102b17671d6c5597a166d9 | a9da9317f65fcebfa13421d6e4e198943873cd2610ba3cba292f3b7686b9e20e | null | [] | 238 |
2.4 | crc-pulp-maven-client | 20260219.2 | Pulp 3 API | # pulpcore.client.pulp_maven.ApiMavenApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**get**](ApiMavenApi.md#get) | **GET** /api/pulp/maven/{pulp_domain}/{name}/{path} |
[**put**](ApiMavenApi.md#put) | **PUT** /api/pulp/maven/{pulp_domain}/{name}/{path} |
# **get**
> get(name, path, pulp_domain, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
Responds to GET requests about manifests by reference
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_maven
from pulpcore.client.pulp_maven.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_maven.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_maven.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_maven.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_maven.ApiMavenApi(api_client)
name = 'name_example' # str |
path = 'path_example' # str |
pulp_domain = 'pulp_domain_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
api_instance.get(name, path, pulp_domain, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
except Exception as e:
print("Exception when calling ApiMavenApi->get: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**name** | **str**| |
**path** | **str**| |
**pulp_domain** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
void (empty response body)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: Not defined
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | No response body | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **put**
> put(name, path, pulp_domain, x_task_diagnostics=x_task_diagnostics)
ViewSet for interacting with maven deploy API
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_maven
from pulpcore.client.pulp_maven.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_maven.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_maven.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_maven.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_maven.ApiMavenApi(api_client)
name = 'name_example' # str |
path = 'path_example' # str |
pulp_domain = 'pulp_domain_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
api_instance.put(name, path, pulp_domain, x_task_diagnostics=x_task_diagnostics)
except Exception as e:
print("Exception when calling ApiMavenApi->put: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**name** | **str**| |
**path** | **str**| |
**pulp_domain** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
void (empty response body)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: Not defined
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | No response body | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# AsyncOperationResponse
Serializer for asynchronous operations.
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**task** | **str** | The href of the task. |
## Example
```python
from pulpcore.client.pulp_maven.models.async_operation_response import AsyncOperationResponse
# TODO update the JSON string below
json = "{}"
# create an instance of AsyncOperationResponse from a JSON string
async_operation_response_instance = AsyncOperationResponse.from_json(json)
# print the JSON string representation of the object
print(AsyncOperationResponse.to_json())
# convert the object into a dict
async_operation_response_dict = async_operation_response_instance.to_dict()
# create an instance of AsyncOperationResponse from a dict
async_operation_response_from_dict = AsyncOperationResponse.from_dict(async_operation_response_dict)
```
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
# pulpcore.client.pulp_maven.ContentArtifactApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**create**](ContentArtifactApi.md#create) | **POST** /api/pulp/{pulp_domain}/api/v3/content/maven/artifact/ | Create a maven artifact
[**list**](ContentArtifactApi.md#list) | **GET** /api/pulp/{pulp_domain}/api/v3/content/maven/artifact/ | List maven artifacts
[**read**](ContentArtifactApi.md#read) | **GET** {maven_maven_artifact_href} | Inspect a maven artifact
[**set_label**](ContentArtifactApi.md#set_label) | **POST** {maven_maven_artifact_href}set_label/ | Set a label
[**unset_label**](ContentArtifactApi.md#unset_label) | **POST** {maven_maven_artifact_href}unset_label/ | Unset a label
# **create**
> MavenMavenArtifactResponse create(pulp_domain, maven_maven_artifact, x_task_diagnostics=x_task_diagnostics)
Create a maven artifact
A ViewSet for MavenArtifact.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_maven
from pulpcore.client.pulp_maven.models.maven_maven_artifact import MavenMavenArtifact
from pulpcore.client.pulp_maven.models.maven_maven_artifact_response import MavenMavenArtifactResponse
from pulpcore.client.pulp_maven.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_maven.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_maven.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_maven.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_maven.ContentArtifactApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
maven_maven_artifact = pulpcore.client.pulp_maven.MavenMavenArtifact() # MavenMavenArtifact |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Create a maven artifact
api_response = api_instance.create(pulp_domain, maven_maven_artifact, x_task_diagnostics=x_task_diagnostics)
print("The response of ContentArtifactApi->create:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentArtifactApi->create: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**maven_maven_artifact** | [**MavenMavenArtifact**](MavenMavenArtifact.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**MavenMavenArtifactResponse**](MavenMavenArtifactResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **list**
> PaginatedmavenMavenArtifactResponseList list(pulp_domain, x_task_diagnostics=x_task_diagnostics, artifact_id=artifact_id, filename=filename, group_id=group_id, limit=limit, offset=offset, ordering=ordering, orphaned_for=orphaned_for, prn__in=prn__in, pulp_href__in=pulp_href__in, pulp_id__in=pulp_id__in, pulp_label_select=pulp_label_select, q=q, repository_version=repository_version, repository_version_added=repository_version_added, repository_version_removed=repository_version_removed, version=version, fields=fields, exclude_fields=exclude_fields)
List maven artifacts
A ViewSet for MavenArtifact.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_maven
from pulpcore.client.pulp_maven.models.paginatedmaven_maven_artifact_response_list import PaginatedmavenMavenArtifactResponseList
from pulpcore.client.pulp_maven.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_maven.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_maven.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_maven.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_maven.ContentArtifactApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
artifact_id = 'artifact_id_example' # str | Filter results where artifact_id matches value (optional)
filename = 'filename_example' # str | Filter results where filename matches value (optional)
group_id = 'group_id_example' # str | Filter results where group_id matches value (optional)
limit = 56 # int | Number of results to return per page. (optional)
offset = 56 # int | The initial index from which to return the results. (optional)
ordering = ['ordering_example'] # List[str] | Ordering * `pulp_id` - Pulp id * `-pulp_id` - Pulp id (descending) * `pulp_created` - Pulp created * `-pulp_created` - Pulp created (descending) * `pulp_last_updated` - Pulp last updated * `-pulp_last_updated` - Pulp last updated (descending) * `pulp_type` - Pulp type * `-pulp_type` - Pulp type (descending) * `upstream_id` - Upstream id * `-upstream_id` - Upstream id (descending) * `pulp_labels` - Pulp labels * `-pulp_labels` - Pulp labels (descending) * `timestamp_of_interest` - Timestamp of interest * `-timestamp_of_interest` - Timestamp of interest (descending) * `group_id` - Group id * `-group_id` - Group id (descending) * `artifact_id` - Artifact id * `-artifact_id` - Artifact id (descending) * `version` - Version * `-version` - Version (descending) * `filename` - Filename * `-filename` - Filename (descending) * `pk` - Pk * `-pk` - Pk (descending) (optional)
orphaned_for = 3.4 # float | Minutes Content has been orphaned for. -1 uses ORPHAN_PROTECTION_TIME. (optional)
prn__in = ['prn__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_href__in = ['pulp_href__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_id__in = ['pulp_id__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_label_select = 'pulp_label_select_example' # str | Filter labels by search string (optional)
q = 'q_example' # str | Filter results by using NOT, AND and OR operations on other filters (optional)
repository_version = 'repository_version_example' # str | Repository Version referenced by HREF/PRN (optional)
repository_version_added = 'repository_version_added_example' # str | Repository Version referenced by HREF/PRN (optional)
repository_version_removed = 'repository_version_removed_example' # str | Repository Version referenced by HREF/PRN (optional)
version = 'version_example' # str | Filter results where version matches value (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# List maven artifacts
api_response = api_instance.list(pulp_domain, x_task_diagnostics=x_task_diagnostics, artifact_id=artifact_id, filename=filename, group_id=group_id, limit=limit, offset=offset, ordering=ordering, orphaned_for=orphaned_for, prn__in=prn__in, pulp_href__in=pulp_href__in, pulp_id__in=pulp_id__in, pulp_label_select=pulp_label_select, q=q, repository_version=repository_version, repository_version_added=repository_version_added, repository_version_removed=repository_version_removed, version=version, fields=fields, exclude_fields=exclude_fields)
print("The response of ContentArtifactApi->list:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentArtifactApi->list: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**artifact_id** | **str**| Filter results where artifact_id matches value | [optional]
**filename** | **str**| Filter results where filename matches value | [optional]
**group_id** | **str**| Filter results where group_id matches value | [optional]
**limit** | **int**| Number of results to return per page. | [optional]
**offset** | **int**| The initial index from which to return the results. | [optional]
**ordering** | [**List[str]**](str.md)| Ordering * `pulp_id` - Pulp id * `-pulp_id` - Pulp id (descending) * `pulp_created` - Pulp created * `-pulp_created` - Pulp created (descending) * `pulp_last_updated` - Pulp last updated * `-pulp_last_updated` - Pulp last updated (descending) * `pulp_type` - Pulp type * `-pulp_type` - Pulp type (descending) * `upstream_id` - Upstream id * `-upstream_id` - Upstream id (descending) * `pulp_labels` - Pulp labels * `-pulp_labels` - Pulp labels (descending) * `timestamp_of_interest` - Timestamp of interest * `-timestamp_of_interest` - Timestamp of interest (descending) * `group_id` - Group id * `-group_id` - Group id (descending) * `artifact_id` - Artifact id * `-artifact_id` - Artifact id (descending) * `version` - Version * `-version` - Version (descending) * `filename` - Filename * `-filename` - Filename (descending) * `pk` - Pk * `-pk` - Pk (descending) | [optional]
**orphaned_for** | **float**| Minutes Content has been orphaned for. -1 uses ORPHAN_PROTECTION_TIME. | [optional]
**prn__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_href__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_id__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_label_select** | **str**| Filter labels by search string | [optional]
**q** | **str**| Filter results by using NOT, AND and OR operations on other filters | [optional]
**repository_version** | **str**| Repository Version referenced by HREF/PRN | [optional]
**repository_version_added** | **str**| Repository Version referenced by HREF/PRN | [optional]
**repository_version_removed** | **str**| Repository Version referenced by HREF/PRN | [optional]
**version** | **str**| Filter results where version matches value | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**PaginatedmavenMavenArtifactResponseList**](PaginatedmavenMavenArtifactResponseList.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **read**
> MavenMavenArtifactResponse read(maven_maven_artifact_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
Inspect a maven artifact
A ViewSet for MavenArtifact.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_maven
from pulpcore.client.pulp_maven.models.maven_maven_artifact_response import MavenMavenArtifactResponse
from pulpcore.client.pulp_maven.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_maven.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_maven.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_maven.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_maven.ContentArtifactApi(api_client)
maven_maven_artifact_href = 'maven_maven_artifact_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# Inspect a maven artifact
api_response = api_instance.read(maven_maven_artifact_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
print("The response of ContentArtifactApi->read:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentArtifactApi->read: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**maven_maven_artifact_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**MavenMavenArtifactResponse**](MavenMavenArtifactResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **set_label**
> SetLabelResponse set_label(maven_maven_artifact_href, set_label, x_task_diagnostics=x_task_diagnostics)
Set a label
Set a single pulp_label on the object to a specific value or null.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_maven
from pulpcore.client.pulp_maven.models.set_label import SetLabel
from pulpcore.client.pulp_maven.models.set_label_response import SetLabelResponse
from pulpcore.client.pulp_maven.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_maven.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_maven.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_maven.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_maven.ContentArtifactApi(api_client)
maven_maven_artifact_href = 'maven_maven_artifact_href_example' # str |
set_label = pulpcore.client.pulp_maven.SetLabel() # SetLabel |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Set a label
api_response = api_instance.set_label(maven_maven_artifact_href, set_label, x_task_diagnostics=x_task_diagnostics)
print("The response of ContentArtifactApi->set_label:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentArtifactApi->set_label: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**maven_maven_artifact_href** | **str**| |
**set_label** | [**SetLabel**](SetLabel.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**SetLabelResponse**](SetLabelResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **unset_label**
> UnsetLabelResponse unset_label(maven_maven_artifact_href, unset_label, x_task_diagnostics=x_task_diagnostics)
Unset a label
Unset a single pulp_label on the object.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_maven
from pulpcore.client.pulp_maven.models.unset_label import UnsetLabel
from pulpcore.client.pulp_maven.models.unset_label_response import UnsetLabelResponse
from pulpcore.client.pulp_maven.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_maven.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_maven.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_maven.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_maven.ContentArtifactApi(api_client)
maven_maven_artifact_href = 'maven_maven_artifact_href_example' # str |
unset_label = pulpcore.client.pulp_maven.UnsetLabel() # UnsetLabel |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Unset a label
api_response = api_instance.unset_label(maven_maven_artifact_href, unset_label, x_task_diagnostics=x_task_diagnostics)
print("The response of ContentArtifactApi->unset_label:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentArtifactApi->unset_label: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**maven_maven_artifact_href** | **str**| |
**unset_label** | [**UnsetLabel**](UnsetLabel.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**UnsetLabelResponse**](UnsetLabelResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# ContentSummaryResponse
Serializer for the RepositoryVersion content summary
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**added** | **Dict[str, object]** | |
**removed** | **Dict[str, object]** | |
**present** | **Dict[str, object]** | |
## Example
```python
from pulpcore.client.pulp_maven.models.content_summary_response import ContentSummaryResponse
# TODO update the JSON string below
json = "{}"
# create an instance of ContentSummaryResponse from a JSON string
content_summary_response_instance = ContentSummaryResponse.from_json(json)
# print the JSON string representation of the object
print(ContentSummaryResponse.to_json())
# convert the object into a dict
content_summary_response_dict = content_summary_response_instance.to_dict()
# create an instance of ContentSummaryResponse from a dict
content_summary_response_from_dict = ContentSummaryResponse.from_dict(content_summary_response_dict)
```
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
# pulpcore.client.pulp_maven.DistributionsMavenApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**create**](DistributionsMavenApi.md#create) | **POST** /api/pulp/{pulp_domain}/api/v3/distributions/maven/maven/ | Create a maven distribution
[**delete**](DistributionsMavenApi.md#delete) | **DELETE** {maven_maven_distribution_href} | Delete a maven distribution
[**list**](DistributionsMavenApi.md#list) | **GET** /api/pulp/{pulp_domain}/api/v3/distributions/maven/maven/ | List maven distributions
[**partial_update**](DistributionsMavenApi.md#partial_update) | **PATCH** {maven_maven_distribution_href} | Update a maven distribution
[**read**](DistributionsMavenApi.md#read) | **GET** {maven_maven_distribution_href} | Inspect a maven distribution
[**set_label**](DistributionsMavenApi.md#set_label) | **POST** {maven_maven_distribution_href}set_label/ | Set a label
[**unset_label**](DistributionsMavenApi.md#unset_label) | **POST** {maven_maven_distribution_href}unset_label/ | Unset a label
[**update**](DistributionsMavenApi.md#update) | **PUT** {maven_maven_distribution_href} | Update a maven distribution
# **create**
> AsyncOperationResponse create(pulp_domain, maven_maven_distribution, x_task_diagnostics=x_task_diagnostics)
Create a maven distribution
Trigger an asynchronous create task
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_maven
from pulpcore.client.pulp_maven.models.async_operation_response import AsyncOperationResponse
from pulpcore.client.pulp_maven.models.maven_maven_distribution import MavenMavenDistribution
from pulpcore.client.pulp_maven.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_maven.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_maven.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_maven.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_maven.DistributionsMavenApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
maven_maven_distribution = pulpcore.client.pulp_maven.MavenMavenDistribution() # MavenMavenDistribution |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Create a maven distribution
api_response = api_instance.create(pulp_domain, maven_maven_distribution, x_task_diagnostics=x_task_diagnostics)
print("The response of DistributionsMavenApi->create:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling DistributionsMavenApi->create: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**maven_maven_distribution** | [**MavenMavenDistribution**](MavenMavenDistribution.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**AsyncOperationResponse**](AsyncOperationResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**202** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **delete**
> AsyncOperationResponse delete(maven_maven_distribution_href, x_task_diagnostics=x_task_diagnostics)
Delete a maven distribution
Trigger an asynchronous delete task
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_maven
from pulpcore.client.pulp_maven.models.async_operation_response import AsyncOperationResponse
from pulpcore.client.pulp_maven.rest import ApiException
from pprint import pprint
# Defining the host is optional | text/markdown | Pulp Team | pulp-list@redhat.com | null | null | GNU General Public License v2.0 or later | pulp, pulpcore, client, Pulp 3 API | [] | [] | null | null | null | [] | [] | [] | [
"urllib3<2.7,>=1.25.3",
"python-dateutil<2.10.0,>=2.8.1",
"pydantic>=2",
"typing-extensions>=4.7.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T18:42:57.565282 | crc_pulp_maven_client-20260219.2.tar.gz | 96,225 | 26/17/fe2fe81c7cbc57a94f1ab34a0745d43e84ea57962853a1574172def8d4c8/crc_pulp_maven_client-20260219.2.tar.gz | source | sdist | null | false | 1b8e4ea2e3443208f548c7de15b871d4 | 802d8e98c9796d2fec275208d2dad4f9804d3a061076f16f9c2a388a46170d03 | 2617fe2fe81c7cbc57a94f1ab34a0745d43e84ea57962853a1574172def8d4c8 | null | [] | 238 |
2.4 | crc-pulp-rpm-client | 20260219.2 | Pulp 3 API | # pulpcore.client.pulp_rpm.AcsRpmApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**add_role**](AcsRpmApi.md#add_role) | **POST** {rpm_rpm_alternate_content_source_href}add_role/ | Add a role
[**create**](AcsRpmApi.md#create) | **POST** /api/pulp/{pulp_domain}/api/v3/acs/rpm/rpm/ | Create a rpm alternate content source
[**delete**](AcsRpmApi.md#delete) | **DELETE** {rpm_rpm_alternate_content_source_href} | Delete a rpm alternate content source
[**list**](AcsRpmApi.md#list) | **GET** /api/pulp/{pulp_domain}/api/v3/acs/rpm/rpm/ | List rpm alternate content sources
[**list_roles**](AcsRpmApi.md#list_roles) | **GET** {rpm_rpm_alternate_content_source_href}list_roles/ | List roles
[**my_permissions**](AcsRpmApi.md#my_permissions) | **GET** {rpm_rpm_alternate_content_source_href}my_permissions/ | List user permissions
[**partial_update**](AcsRpmApi.md#partial_update) | **PATCH** {rpm_rpm_alternate_content_source_href} | Update a rpm alternate content source
[**read**](AcsRpmApi.md#read) | **GET** {rpm_rpm_alternate_content_source_href} | Inspect a rpm alternate content source
[**refresh**](AcsRpmApi.md#refresh) | **POST** {rpm_rpm_alternate_content_source_href}refresh/ |
[**remove_role**](AcsRpmApi.md#remove_role) | **POST** {rpm_rpm_alternate_content_source_href}remove_role/ | Remove a role
[**update**](AcsRpmApi.md#update) | **PUT** {rpm_rpm_alternate_content_source_href} | Update a rpm alternate content source
# **add_role**
> NestedRoleResponse add_role(rpm_rpm_alternate_content_source_href, nested_role, x_task_diagnostics=x_task_diagnostics)
Add a role
Add a role for this object to users/groups.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_rpm
from pulpcore.client.pulp_rpm.models.nested_role import NestedRole
from pulpcore.client.pulp_rpm.models.nested_role_response import NestedRoleResponse
from pulpcore.client.pulp_rpm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_rpm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_rpm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_rpm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_rpm.AcsRpmApi(api_client)
rpm_rpm_alternate_content_source_href = 'rpm_rpm_alternate_content_source_href_example' # str |
nested_role = pulpcore.client.pulp_rpm.NestedRole() # NestedRole |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Add a role
api_response = api_instance.add_role(rpm_rpm_alternate_content_source_href, nested_role, x_task_diagnostics=x_task_diagnostics)
print("The response of AcsRpmApi->add_role:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsRpmApi->add_role: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**rpm_rpm_alternate_content_source_href** | **str**| |
**nested_role** | [**NestedRole**](NestedRole.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**NestedRoleResponse**](NestedRoleResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **create**
> RpmRpmAlternateContentSourceResponse create(pulp_domain, rpm_rpm_alternate_content_source, x_task_diagnostics=x_task_diagnostics)
Create a rpm alternate content source
ViewSet for ACS.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_rpm
from pulpcore.client.pulp_rpm.models.rpm_rpm_alternate_content_source import RpmRpmAlternateContentSource
from pulpcore.client.pulp_rpm.models.rpm_rpm_alternate_content_source_response import RpmRpmAlternateContentSourceResponse
from pulpcore.client.pulp_rpm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_rpm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_rpm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_rpm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_rpm.AcsRpmApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
rpm_rpm_alternate_content_source = pulpcore.client.pulp_rpm.RpmRpmAlternateContentSource() # RpmRpmAlternateContentSource |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Create a rpm alternate content source
api_response = api_instance.create(pulp_domain, rpm_rpm_alternate_content_source, x_task_diagnostics=x_task_diagnostics)
print("The response of AcsRpmApi->create:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsRpmApi->create: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**rpm_rpm_alternate_content_source** | [**RpmRpmAlternateContentSource**](RpmRpmAlternateContentSource.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**RpmRpmAlternateContentSourceResponse**](RpmRpmAlternateContentSourceResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **delete**
> AsyncOperationResponse delete(rpm_rpm_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics)
Delete a rpm alternate content source
Trigger an asynchronous delete ACS task
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_rpm
from pulpcore.client.pulp_rpm.models.async_operation_response import AsyncOperationResponse
from pulpcore.client.pulp_rpm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_rpm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_rpm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_rpm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_rpm.AcsRpmApi(api_client)
rpm_rpm_alternate_content_source_href = 'rpm_rpm_alternate_content_source_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Delete a rpm alternate content source
api_response = api_instance.delete(rpm_rpm_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics)
print("The response of AcsRpmApi->delete:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsRpmApi->delete: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**rpm_rpm_alternate_content_source_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**AsyncOperationResponse**](AsyncOperationResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**202** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **list**
> PaginatedrpmRpmAlternateContentSourceResponseList list(pulp_domain, x_task_diagnostics=x_task_diagnostics, limit=limit, name=name, name__contains=name__contains, name__icontains=name__icontains, name__iexact=name__iexact, name__in=name__in, name__iregex=name__iregex, name__istartswith=name__istartswith, name__regex=name__regex, name__startswith=name__startswith, offset=offset, ordering=ordering, prn__in=prn__in, pulp_href__in=pulp_href__in, pulp_id__in=pulp_id__in, q=q, fields=fields, exclude_fields=exclude_fields)
List rpm alternate content sources
ViewSet for ACS.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_rpm
from pulpcore.client.pulp_rpm.models.paginatedrpm_rpm_alternate_content_source_response_list import PaginatedrpmRpmAlternateContentSourceResponseList
from pulpcore.client.pulp_rpm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_rpm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_rpm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_rpm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_rpm.AcsRpmApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
limit = 56 # int | Number of results to return per page. (optional)
name = 'name_example' # str | Filter results where name matches value (optional)
name__contains = 'name__contains_example' # str | Filter results where name contains value (optional)
name__icontains = 'name__icontains_example' # str | Filter results where name contains value (optional)
name__iexact = 'name__iexact_example' # str | Filter results where name matches value (optional)
name__in = ['name__in_example'] # List[str] | Filter results where name is in a comma-separated list of values (optional)
name__iregex = 'name__iregex_example' # str | Filter results where name matches regex value (optional)
name__istartswith = 'name__istartswith_example' # str | Filter results where name starts with value (optional)
name__regex = 'name__regex_example' # str | Filter results where name matches regex value (optional)
name__startswith = 'name__startswith_example' # str | Filter results where name starts with value (optional)
offset = 56 # int | The initial index from which to return the results. (optional)
ordering = ['ordering_example'] # List[str] | Ordering * `pulp_id` - Pulp id * `-pulp_id` - Pulp id (descending) * `pulp_created` - Pulp created * `-pulp_created` - Pulp created (descending) * `pulp_last_updated` - Pulp last updated * `-pulp_last_updated` - Pulp last updated (descending) * `pulp_type` - Pulp type * `-pulp_type` - Pulp type (descending) * `name` - Name * `-name` - Name (descending) * `last_refreshed` - Last refreshed * `-last_refreshed` - Last refreshed (descending) * `pk` - Pk * `-pk` - Pk (descending) (optional)
prn__in = ['prn__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_href__in = ['pulp_href__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_id__in = ['pulp_id__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
q = 'q_example' # str | Filter results by using NOT, AND and OR operations on other filters (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# List rpm alternate content sources
api_response = api_instance.list(pulp_domain, x_task_diagnostics=x_task_diagnostics, limit=limit, name=name, name__contains=name__contains, name__icontains=name__icontains, name__iexact=name__iexact, name__in=name__in, name__iregex=name__iregex, name__istartswith=name__istartswith, name__regex=name__regex, name__startswith=name__startswith, offset=offset, ordering=ordering, prn__in=prn__in, pulp_href__in=pulp_href__in, pulp_id__in=pulp_id__in, q=q, fields=fields, exclude_fields=exclude_fields)
print("The response of AcsRpmApi->list:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsRpmApi->list: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**limit** | **int**| Number of results to return per page. | [optional]
**name** | **str**| Filter results where name matches value | [optional]
**name__contains** | **str**| Filter results where name contains value | [optional]
**name__icontains** | **str**| Filter results where name contains value | [optional]
**name__iexact** | **str**| Filter results where name matches value | [optional]
**name__in** | [**List[str]**](str.md)| Filter results where name is in a comma-separated list of values | [optional]
**name__iregex** | **str**| Filter results where name matches regex value | [optional]
**name__istartswith** | **str**| Filter results where name starts with value | [optional]
**name__regex** | **str**| Filter results where name matches regex value | [optional]
**name__startswith** | **str**| Filter results where name starts with value | [optional]
**offset** | **int**| The initial index from which to return the results. | [optional]
**ordering** | [**List[str]**](str.md)| Ordering * `pulp_id` - Pulp id * `-pulp_id` - Pulp id (descending) * `pulp_created` - Pulp created * `-pulp_created` - Pulp created (descending) * `pulp_last_updated` - Pulp last updated * `-pulp_last_updated` - Pulp last updated (descending) * `pulp_type` - Pulp type * `-pulp_type` - Pulp type (descending) * `name` - Name * `-name` - Name (descending) * `last_refreshed` - Last refreshed * `-last_refreshed` - Last refreshed (descending) * `pk` - Pk * `-pk` - Pk (descending) | [optional]
**prn__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_href__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_id__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**q** | **str**| Filter results by using NOT, AND and OR operations on other filters | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**PaginatedrpmRpmAlternateContentSourceResponseList**](PaginatedrpmRpmAlternateContentSourceResponseList.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **list_roles**
> ObjectRolesResponse list_roles(rpm_rpm_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
List roles
List roles assigned to this object.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_rpm
from pulpcore.client.pulp_rpm.models.object_roles_response import ObjectRolesResponse
from pulpcore.client.pulp_rpm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_rpm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_rpm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_rpm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_rpm.AcsRpmApi(api_client)
rpm_rpm_alternate_content_source_href = 'rpm_rpm_alternate_content_source_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# List roles
api_response = api_instance.list_roles(rpm_rpm_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
print("The response of AcsRpmApi->list_roles:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsRpmApi->list_roles: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**rpm_rpm_alternate_content_source_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**ObjectRolesResponse**](ObjectRolesResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **my_permissions**
> MyPermissionsResponse my_permissions(rpm_rpm_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
List user permissions
List permissions available to the current user on this object.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_rpm
from pulpcore.client.pulp_rpm.models.my_permissions_response import MyPermissionsResponse
from pulpcore.client.pulp_rpm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_rpm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_rpm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_rpm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_rpm.AcsRpmApi(api_client)
rpm_rpm_alternate_content_source_href = 'rpm_rpm_alternate_content_source_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# List user permissions
api_response = api_instance.my_permissions(rpm_rpm_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
print("The response of AcsRpmApi->my_permissions:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsRpmApi->my_permissions: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**rpm_rpm_alternate_content_source_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**MyPermissionsResponse**](MyPermissionsResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **partial_update**
> RpmRpmAlternateContentSourceResponse partial_update(rpm_rpm_alternate_content_source_href, patchedrpm_rpm_alternate_content_source, x_task_diagnostics=x_task_diagnostics)
Update a rpm alternate content source
Update the entity partially and trigger an asynchronous task if necessary
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_rpm
from pulpcore.client.pulp_rpm.models.patchedrpm_rpm_alternate_content_source import PatchedrpmRpmAlternateContentSource
from pulpcore.client.pulp_rpm.models.rpm_rpm_alternate_content_source_response import RpmRpmAlternateContentSourceResponse
from pulpcore.client.pulp_rpm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_rpm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_rpm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_rpm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_rpm.AcsRpmApi(api_client)
rpm_rpm_alternate_content_source_href = 'rpm_rpm_alternate_content_source_href_example' # str |
patchedrpm_rpm_alternate_content_source = pulpcore.client.pulp_rpm.PatchedrpmRpmAlternateContentSource() # PatchedrpmRpmAlternateContentSource |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Update a rpm alternate content source
api_response = api_instance.partial_update(rpm_rpm_alternate_content_source_href, patchedrpm_rpm_alternate_content_source, x_task_diagnostics=x_task_diagnostics)
print("The response of AcsRpmApi->partial_update:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsRpmApi->partial_update: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**rpm_rpm_alternate_content_source_href** | **str**| |
**patchedrpm_rpm_alternate_content_source** | [**PatchedrpmRpmAlternateContentSource**](PatchedrpmRpmAlternateContentSource.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**RpmRpmAlternateContentSourceResponse**](RpmRpmAlternateContentSourceResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
**202** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **read**
> RpmRpmAlternateContentSourceResponse read(rpm_rpm_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
Inspect a rpm alternate content source
ViewSet for ACS.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_rpm
from pulpcore.client.pulp_rpm.models.rpm_rpm_alternate_content_source_response import RpmRpmAlternateContentSourceResponse
from pulpcore.client.pulp_rpm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_rpm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_rpm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_rpm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_rpm.AcsRpmApi(api_client)
rpm_rpm_alternate_content_source_href = 'rpm_rpm_alternate_content_source_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# Inspect a rpm alternate content source
api_response = api_instance.read(rpm_rpm_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
print("The response of AcsRpmApi->read:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsRpmApi->read: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**rpm_rpm_alternate_content_source_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**RpmRpmAlternateContentSourceResponse**](RpmRpmAlternateContentSourceResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **refresh**
> TaskGroupOperationResponse refresh(rpm_rpm_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics)
Trigger an asynchronous task to create Alternate Content Source content.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_rpm
from pulpcore.client.pulp_rpm.models.task_group_operation_response import TaskGroupOperationResponse
from pulpcore.client.pulp_rpm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_rpm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_rpm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_rpm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_rpm.AcsRpmApi(api_client)
rpm_rpm_alternate_content_source_href = 'rpm_rpm_alternate_content_source_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
api_response = api_instance.refresh(rpm_rpm_alternate_content_source_href, x_task_diagnostics=x_task_diagnostics)
print("The response of AcsRpmApi->refresh:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AcsRpmApi->refresh: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**rpm_rpm_alternate_content_source_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**TaskGroupOperationResponse**](TaskGroupOperationResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**202** | | - |
[[Back to to | text/markdown | Pulp Team | pulp-list@redhat.com | null | null | GNU General Public License v2.0 or later | pulp, pulpcore, client, Pulp 3 API | [] | [] | null | null | null | [] | [] | [] | [
"urllib3<2.7,>=1.25.3",
"python-dateutil<2.10.0,>=2.8.1",
"pydantic>=2",
"typing-extensions>=4.7.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T18:42:51.650175 | crc_pulp_rpm_client-20260219.2.tar.gz | 259,185 | e6/43/05f47911aa1e11bef5b1590a6e85fff134b8ddcefe51112197a29bd17ceb/crc_pulp_rpm_client-20260219.2.tar.gz | source | sdist | null | false | 5f9f2bcf7b40f55fbc1b845160574a5d | 4c0eb399622a2c5c1d384b8e1aaddb55bc7b1d55378c840b6e6d9bc816e2401e | e64305f47911aa1e11bef5b1590a6e85fff134b8ddcefe51112197a29bd17ceb | null | [] | 239 |
2.4 | LMtoolbox | 0.5.20 | A collection of CLI tools leveraging language models | # LMtoolbox
LMtoolbox is an collection of CLI tools using language models designed to modernize your workflow in the terminal. Built using OpenAI's ChatGPT, the tools in this toolbox can generate automatic commit messages, perform dictionary and thesaurus queries, translate text, proofread content, enrich language learning, and automate shell commands, among others. Obviously, you can also interact with ChatGPT directly.
<!-- TOC -->
## Table of Contents
1. [Prompt Templates](#prompt-templates)
1. [Installation](#installation)
1. [pip](#pip)
1. [`pipx`, the Easy Way](#pipx-the-easy-way)
1. [Getting Started](#getting-started)
1. [Configuring your OpenAI API key](#configuring-your-openai-api-key)
1. [Tools](#tools)
1. [LMterminal (`lmt`)](#lmterminal-lmt)
1. [ShellGenius](#shellgenius)
1. [Commitgen](#commitgen)
1. [Codereview](#codereview)
1. [VocabMaster](#vocabmaster)
1. [Thesaurus](#thesaurus)
1. [Define](#define)
1. [Proofread](#proofread)
1. [Translate](#translate)
1. [Cheermeup](#cheermeup)
1. [Critique](#critique)
1. [Explain](#explain)
1. [Lessonize](#lessonize)
1. [Life](#life)
1. [Pathlearner](#pathlearner)
1. [Study](#study)
1. [Summarize](#summarize)
1. [Teachlib](#teachlib)
1. [License](#license)
<!-- /TOC -->
## Prompt Templates
For those less experienced with terminal interfaces or those preferring the convenience of a web interface, the [ChatGPT web interface templates](https://github.com/sderev/lmtoolbox/tree/main/prompt-templates) in the LMtoolbox can prove incredibly useful. These templates offer a broad spectrum of pre-structured prompts designed to enhance your engagement with ChatGPT, particularly in the context of longer chat interactions with GPT-4 in order to avoid expensive API costs.
These templates, found in the [`prompt-templates/`](https://github.com/sderev/lmtoolbox/tree/main/prompt-templates) directory, cater to various situations and are an excellent resource if you're uncertain about structuring prompts or seek to improve the effectiveness of your existing ones.
## Installation
### pip
```bash
python3 -m pip install lmtoolbox
```
### `pipx`, the Easy Way
```bash
pipx install lmtoolbox
```
## Getting Started
### Configuring your OpenAI API key
For LMtoolbox to work properly, it is necessary to acquire and configure an OpenAI API key. Follow these steps to accomplish this:
1. **Acquire the OpenAI API key**: You can do this by creating an account on the [OpenAI website](https://platform.openai.com/account/api-keys). Once registered, you will have access to your unique API key.
2. **Set usage limit**: Before you start using the API, you need to define a usage limit. You can configure this in your OpenAI account settings by navigating to *Billing -> Usage limits*.
3. **Configure the OpenAI API key**: Once you have your API key, you can set it up by running the `lmt key set` command.
```bash
lmt key set
```
With these steps, you should now have successfully set up your OpenAI API key, ready for use with the LMtoolbox
## Tools
Instructions on how to use each of the tools are included in the individual directories under [tools/](https://github.com/sderev/lmtoolbox/tree/main/tools). This is also where I give some tricks and tips on their usage 💡👀💭.
Note that LMterminal (`lmt`) is the main tool in the LMtoolbox. All of its options apply to (almost) all of the other tools. For instance, you change the model to GPT-4o with `-m 4o` or add emojis with `--emoji`. Refer to the [LMterminal's documentation](https://github.com/sderev/lmterminal) for more information.
* **Reading from `stdin`**: Almost all of the tools can read from `stdin`. For instance: `cat my_text.md | summarize`.
* **Output Redirection**: You can use output redirections with the tools. For instance: `cat my_text.md | critique --raw > critique_of_my_text.md`
Here's a brief overview of the tools:
### LMterminal (`lmt`)
[LMterminal](https://github.com/sderev/lmterminal) (`lmt`) empowers you to interact directly with ChatGPT from the comfort of your terminal. One of the core features of `lmt` is its ability to facilitate the creation of custom templates, enabling you to design your personalized toolbox of CLI applications. You can easily install its standalone version from [the project's repository](https://github.com/sderev/lmterminal).

___
### ShellGenius
[ShellGenius](https://github.com/sderev/shellgenius) is an intuitive CLI tool designed to enhance your command-line experience by turning your task descriptions into efficient shell commands. Check out the project on [its dedicated repository](https://github.com/sderev/shellgenius).

___
### Commitgen
The [`commitgen`](https://github.com/sderev/lmtoolbox/tree/main/tools/commitgen) tool is designed to automatically generate a meaningful `git` commit messages for your code changes.

___
### Codereview
The [`codereview`](https://github.com/sderev/lmtoolbox/tree/main/tools/codereview) tool accepts a file or a piece of text as input and provides an in-depth analysis of the code. It can identify potential issues, suggest improvements, and even detect security vulnerabilities. The Codereview tool is capable of handling a variety of programming languages, and its feedback can serve as an invaluable resource for developers seeking to enhance the quality of their code.

___
### VocabMaster
Master new languages with [VocabMaster](https://github.com/sderev/vocabmaster), a CLI tool designed to help you record vocabulary, access translations and examples, and seamlessly import them into Anki for an optimized language learning experience. Check out the project on [its dedicated repository](https://github.com/sderev/vocabmaster).

___
### Thesaurus
The [`thesaurus`](https://github.com/sderev/lmtoolbox/tree/main/tools/thesaurus) tool takes a word or a phrase as input and provides a list of synonyms and antonyms.

___
### Define
The [`define`](https://github.com/sderev/lmtoolbox/tree/main/tools/define) tool takes a word as input and provides its definition along with an example sentence using the word.

___
### Proofread
The [`proofread`](https://github.com/sderev/lmtoolbox/tree/main/tools/proofread) tool takes a sentence as input and provides a corrected version of it, if needed, along with an explanation of the corrections.

___
### Translate
The [`translate`](https://github.com/sderev/lmtoolbox/tree/main/tools/translate) tool takes a sentence and a target language as input and provides the translated sentence in the target language.

___
### Cheermeup
The [`cheermeup`](https://github.com/sderev/lmtoolbox/tree/main/tools/cheermeup) tool is designed to uplift your spirits based on your current mood. Whether you're feeling down or just need a little pick-me-up, this tool uses a variety of methods to bring a smile to your face and brighten your day.

___
### Critique
The [`critique`](https://github.com/sderev/lmtoolbox/tree/main/tools/critique) tool is your personal constructive text critic, designed to analyze a given piece of text and provide detailed, insightful feedback. It enables users to enhance their writing by addressing potential shortcomings and improving the overall quality.

___
### Explain
The [`explain`](https://github.com/sderev/lmtoolbox/tree/main/tools/explain) tool helps to clarify complex concepts. When given a concept, it presents a comprehensive and straightforward explanation, aiding in understanding and knowledge retention.

___
### Lessonize
The [`lessonize`](https://github.com/sderev/lmtoolbox/tree/main/tools/lessonize) tool transforms any piece of text into an informative lesson. Whether you're a teacher looking for instructional material or a student looking to further understand a subject, this tool makes learning more accessible.

___
### Life
The [`life`](https://github.com/sderev/lmtoolbox/tree/main/tools/life) tool offers a unique perspective on the passage of time, presenting thoughtful messages based on your life expectancy statistics. Whether you're seeking a novel way to reflect on your life journey or need a gentle reminder of the beauty and preciousness of life's uncertainty, this tool provides insightful outputs to provoke meaningful contemplation.

___
### Pathlearner
The [`pathlearner`](https://github.com/sderev/lmtoolbox/tree/main/tools/pathlearner) tool provides a comprehensive study plan for a given topic. Whether you're studying for an exam or learning a new subject, this tool creates a structured, step-by-step plan that aids in understanding and mastering the material.

___
### Study
The [`study`](https://github.com/sderev/lmtoolbox/tree/main/tools/study) tool is a comprehensive guide that generates study material for a particular topic or content. It helps students to better prepare for exams, giving them access to tailored study material designed to enhance their learning experience.

___
### Summarize
The [`summarize`](https://github.com/sderev/lmtoolbox/tree/main/tools/summarize) tool provides succinct summaries of a web page, lengthy texts, a YouTube video (via URL), or the content of given files.

___
### Teachlib
The [`teachlib`](https://github.com/sderev/lmtoolbox/tree/main/tools/teachlib) tool is designed to provide comprehensive lessons on various libraries. By simplifying complex aspects and focusing on the core functionalities, this tool helps users to understand and effectively utilize different libraries.

___
## License
This project is licensed under the terms of the Apache License 2.0.
___
<https://github.com/sderev/lmtoolbox>
| text/markdown | Sébastien De Revière | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"pyyaml",
"click",
"lmterminal==0.0.43",
"openai<1.0",
"requests",
"rich",
"shellgenius==0.1.16",
"strip-tags",
"tiktoken",
"validators",
"vocabmaster",
"youtube-transcript-api==0.6.2"
] | [] | [] | [] | [
"Documentation, https://github.com/sderev/lmtoolbox",
"Issues, http://github.com/sderev/lmtoolbox/issues",
"Changelog, https://github.com/sderev/lmtoolbox/releases"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T18:42:47.956924 | lmtoolbox-0.5.20.tar.gz | 15,575 | 39/5a/fcc7e8a7084bc7067f076d6787cd33ef4c84f2fea2093ec24ff242cdfba2/lmtoolbox-0.5.20.tar.gz | source | sdist | null | false | 6919f693cd80c4fe87cf375fd5c1bebe | 91a92fecf448405e357748fba269e1e915cf2eedcacc37a4c6ea0d87f02ee2b0 | 395afcc7e8a7084bc7067f076d6787cd33ef4c84f2fea2093ec24ff242cdfba2 | Apache-2.0 | [] | 0 |
2.4 | crunch-cli | 10.13.1 | crunch-cli - CLI of the CrunchDAO Platform | # CrunchDAO CLI
[](https://github.com/crunchdao/crunch-cli/actions/workflows/pytest.yml)
This Python library is designed for the CrunchDAO Platform, offering convenient access to competition's data and enabling effortless submission. When utilized in the command-line interface (CLI), its goal is to deliver a user experience akin to GitHub, enabling you to seamlessly push the code from your local environment.
## Installation
Use [pip](https://pypi.org/project/crunch-cli/) to install the `crunch-cli`.
```bash
pip install crunch-cli --upgrade
```
## Usage
```python
import crunch
crunch = crunch.load_notebook()
# Getting the data
X_train, y_train, X_test = crunch.load_data()
```
`crunch.load_data()` accept arguments for `read_parquet`.
```python
crunch.load_data(
engine="fastparquet"
)
```
## Submit with Crunch CLI
```bash
Usage: crunch push [OPTIONS]
Send the new submission of your code.
Options:
-m, --message TEXT Specify the change of your code. (like a commit
message)
-e, --main-file TEXT Entrypoint of your code. [default: main.py]
--model-directory TEXT Directory where your model is stored. [default:
resources]
--help Show this message and exit.
```
## Detecting the environment
Detecting whether you are running inside the runner or not, allows you to configure your program more precisely.
```python
import crunch
if crunch.is_inside_runner:
print("running inside the runner")
else:
print("running elsewhere")
model.enable_debug()
logger.set_level("TRACE")
```
## Competition Links
- [Competition Platform](https://www.crunchdao.com)
- [ADIA Lab Market Prediction Competition](https://www.crunchdao.com/live/adialab)
- [see more](https://hub.crunchdao.com/)
## Contributing
Pull requests are always welcome! If you find any issues or have suggestions for improvements, please feel free to submit a pull request or open an issue in the GitHub repository.
## License
[MIT](https://choosealicense.com/licenses/mit/)
| text/markdown | Enzo CACERES | enzo.caceres@crunchdao.com | null | null | null | package development template | [
"Intended Audience :: Developers",
"Programming Language :: Python :: 3.7"
] | [] | https://github.com/crunchdao/crunch-cli | null | >=3 | [] | [] | [] | [
"click",
"crunch-convert>=0.4.1",
"crunch-encrypt",
"coloredlogs",
"dataclasses_json",
"inquirer",
"joblib",
"libcst",
"pandas",
"psutil",
"pyarrow",
"python-dotenv",
"requests",
"requests-toolbelt",
"requirements-parser>=0.11.0",
"scikit-learn",
"tqdm",
"parameterized; extra == \"... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:42:45.568483 | crunch_cli-10.13.1.tar.gz | 90,863 | 99/c5/d89c82126213edc7632e2434de6dd1c33649b045845cc6ddccbd907b27ce/crunch_cli-10.13.1.tar.gz | source | sdist | null | false | b8df6c81d97708febb51e2e4d982438f | f6d231e9060b03b120fca4e27835babacd3f6c6bc52e400854af02c2eced4d18 | 99c5d89c82126213edc7632e2434de6dd1c33649b045845cc6ddccbd907b27ce | null | [] | 363 |
2.4 | crc-pulp-gem-client | 20260219.2 | Pulp 3 API | # AsyncOperationResponse
Serializer for asynchronous operations.
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**task** | **str** | The href of the task. |
## Example
```python
from pulpcore.client.pulp_gem.models.async_operation_response import AsyncOperationResponse
# TODO update the JSON string below
json = "{}"
# create an instance of AsyncOperationResponse from a JSON string
async_operation_response_instance = AsyncOperationResponse.from_json(json)
# print the JSON string representation of the object
print(AsyncOperationResponse.to_json())
# convert the object into a dict
async_operation_response_dict = async_operation_response_instance.to_dict()
# create an instance of AsyncOperationResponse from a dict
async_operation_response_from_dict = AsyncOperationResponse.from_dict(async_operation_response_dict)
```
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
# pulpcore.client.pulp_gem.ContentGemApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**create**](ContentGemApi.md#create) | **POST** /api/pulp/{pulp_domain}/api/v3/content/gem/gem/ | Create a gem content
[**list**](ContentGemApi.md#list) | **GET** /api/pulp/{pulp_domain}/api/v3/content/gem/gem/ | List gem contents
[**read**](ContentGemApi.md#read) | **GET** {gem_gem_content_href} | Inspect a gem content
[**set_label**](ContentGemApi.md#set_label) | **POST** {gem_gem_content_href}set_label/ | Set a label
[**unset_label**](ContentGemApi.md#unset_label) | **POST** {gem_gem_content_href}unset_label/ | Unset a label
# **create**
> AsyncOperationResponse create(pulp_domain, x_task_diagnostics=x_task_diagnostics, repository=repository, pulp_labels=pulp_labels, artifact=artifact, file=file)
Create a gem content
Trigger an asynchronous task to create content,optionally create new repository version.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_gem
from pulpcore.client.pulp_gem.models.async_operation_response import AsyncOperationResponse
from pulpcore.client.pulp_gem.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_gem.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_gem.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_gem.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_gem.ContentGemApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
repository = 'repository_example' # str | A URI of a repository the new content unit should be associated with. (optional)
pulp_labels = None # Dict[str, Optional[str]] | A dictionary of arbitrary key/value pairs used to describe a specific Content instance. (optional)
artifact = 'artifact_example' # str | Artifact file representing the physical content (optional)
file = None # bytearray | An uploaded file that should be turned into the artifact of the content unit. (optional)
try:
# Create a gem content
api_response = api_instance.create(pulp_domain, x_task_diagnostics=x_task_diagnostics, repository=repository, pulp_labels=pulp_labels, artifact=artifact, file=file)
print("The response of ContentGemApi->create:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentGemApi->create: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**repository** | **str**| A URI of a repository the new content unit should be associated with. | [optional]
**pulp_labels** | [**Dict[str, Optional[str]]**](Dict.md)| A dictionary of arbitrary key/value pairs used to describe a specific Content instance. | [optional]
**artifact** | **str**| Artifact file representing the physical content | [optional]
**file** | **bytearray**| An uploaded file that should be turned into the artifact of the content unit. | [optional]
### Return type
[**AsyncOperationResponse**](AsyncOperationResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: multipart/form-data, application/x-www-form-urlencoded
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**202** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **list**
> PaginatedgemGemContentResponseList list(pulp_domain, x_task_diagnostics=x_task_diagnostics, checksum=checksum, limit=limit, name=name, offset=offset, ordering=ordering, orphaned_for=orphaned_for, prerelease=prerelease, prn__in=prn__in, pulp_href__in=pulp_href__in, pulp_id__in=pulp_id__in, pulp_label_select=pulp_label_select, q=q, repository_version=repository_version, repository_version_added=repository_version_added, repository_version_removed=repository_version_removed, version=version, fields=fields, exclude_fields=exclude_fields)
List gem contents
A ViewSet for GemContent.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_gem
from pulpcore.client.pulp_gem.models.paginatedgem_gem_content_response_list import PaginatedgemGemContentResponseList
from pulpcore.client.pulp_gem.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_gem.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_gem.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_gem.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_gem.ContentGemApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
checksum = 'checksum_example' # str | Filter results where checksum matches value (optional)
limit = 56 # int | Number of results to return per page. (optional)
name = 'name_example' # str | Filter results where name matches value (optional)
offset = 56 # int | The initial index from which to return the results. (optional)
ordering = ['ordering_example'] # List[str] | Ordering * `pulp_id` - Pulp id * `-pulp_id` - Pulp id (descending) * `pulp_created` - Pulp created * `-pulp_created` - Pulp created (descending) * `pulp_last_updated` - Pulp last updated * `-pulp_last_updated` - Pulp last updated (descending) * `pulp_type` - Pulp type * `-pulp_type` - Pulp type (descending) * `upstream_id` - Upstream id * `-upstream_id` - Upstream id (descending) * `pulp_labels` - Pulp labels * `-pulp_labels` - Pulp labels (descending) * `timestamp_of_interest` - Timestamp of interest * `-timestamp_of_interest` - Timestamp of interest (descending) * `name` - Name * `-name` - Name (descending) * `version` - Version * `-version` - Version (descending) * `platform` - Platform * `-platform` - Platform (descending) * `checksum` - Checksum * `-checksum` - Checksum (descending) * `prerelease` - Prerelease * `-prerelease` - Prerelease (descending) * `dependencies` - Dependencies * `-dependencies` - Dependencies (descending) * `required_ruby_version` - Required ruby version * `-required_ruby_version` - Required ruby version (descending) * `required_rubygems_version` - Required rubygems version * `-required_rubygems_version` - Required rubygems version (descending) * `pk` - Pk * `-pk` - Pk (descending) (optional)
orphaned_for = 3.4 # float | Minutes Content has been orphaned for. -1 uses ORPHAN_PROTECTION_TIME. (optional)
prerelease = True # bool | Filter results where prerelease matches value (optional)
prn__in = ['prn__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_href__in = ['pulp_href__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_id__in = ['pulp_id__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_label_select = 'pulp_label_select_example' # str | Filter labels by search string (optional)
q = 'q_example' # str | Filter results by using NOT, AND and OR operations on other filters (optional)
repository_version = 'repository_version_example' # str | Repository Version referenced by HREF/PRN (optional)
repository_version_added = 'repository_version_added_example' # str | Repository Version referenced by HREF/PRN (optional)
repository_version_removed = 'repository_version_removed_example' # str | Repository Version referenced by HREF/PRN (optional)
version = 'version_example' # str | Filter results where version matches value (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# List gem contents
api_response = api_instance.list(pulp_domain, x_task_diagnostics=x_task_diagnostics, checksum=checksum, limit=limit, name=name, offset=offset, ordering=ordering, orphaned_for=orphaned_for, prerelease=prerelease, prn__in=prn__in, pulp_href__in=pulp_href__in, pulp_id__in=pulp_id__in, pulp_label_select=pulp_label_select, q=q, repository_version=repository_version, repository_version_added=repository_version_added, repository_version_removed=repository_version_removed, version=version, fields=fields, exclude_fields=exclude_fields)
print("The response of ContentGemApi->list:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentGemApi->list: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**checksum** | **str**| Filter results where checksum matches value | [optional]
**limit** | **int**| Number of results to return per page. | [optional]
**name** | **str**| Filter results where name matches value | [optional]
**offset** | **int**| The initial index from which to return the results. | [optional]
**ordering** | [**List[str]**](str.md)| Ordering * `pulp_id` - Pulp id * `-pulp_id` - Pulp id (descending) * `pulp_created` - Pulp created * `-pulp_created` - Pulp created (descending) * `pulp_last_updated` - Pulp last updated * `-pulp_last_updated` - Pulp last updated (descending) * `pulp_type` - Pulp type * `-pulp_type` - Pulp type (descending) * `upstream_id` - Upstream id * `-upstream_id` - Upstream id (descending) * `pulp_labels` - Pulp labels * `-pulp_labels` - Pulp labels (descending) * `timestamp_of_interest` - Timestamp of interest * `-timestamp_of_interest` - Timestamp of interest (descending) * `name` - Name * `-name` - Name (descending) * `version` - Version * `-version` - Version (descending) * `platform` - Platform * `-platform` - Platform (descending) * `checksum` - Checksum * `-checksum` - Checksum (descending) * `prerelease` - Prerelease * `-prerelease` - Prerelease (descending) * `dependencies` - Dependencies * `-dependencies` - Dependencies (descending) * `required_ruby_version` - Required ruby version * `-required_ruby_version` - Required ruby version (descending) * `required_rubygems_version` - Required rubygems version * `-required_rubygems_version` - Required rubygems version (descending) * `pk` - Pk * `-pk` - Pk (descending) | [optional]
**orphaned_for** | **float**| Minutes Content has been orphaned for. -1 uses ORPHAN_PROTECTION_TIME. | [optional]
**prerelease** | **bool**| Filter results where prerelease matches value | [optional]
**prn__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_href__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_id__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_label_select** | **str**| Filter labels by search string | [optional]
**q** | **str**| Filter results by using NOT, AND and OR operations on other filters | [optional]
**repository_version** | **str**| Repository Version referenced by HREF/PRN | [optional]
**repository_version_added** | **str**| Repository Version referenced by HREF/PRN | [optional]
**repository_version_removed** | **str**| Repository Version referenced by HREF/PRN | [optional]
**version** | **str**| Filter results where version matches value | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**PaginatedgemGemContentResponseList**](PaginatedgemGemContentResponseList.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **read**
> GemGemContentResponse read(gem_gem_content_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
Inspect a gem content
A ViewSet for GemContent.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_gem
from pulpcore.client.pulp_gem.models.gem_gem_content_response import GemGemContentResponse
from pulpcore.client.pulp_gem.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_gem.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_gem.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_gem.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_gem.ContentGemApi(api_client)
gem_gem_content_href = 'gem_gem_content_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# Inspect a gem content
api_response = api_instance.read(gem_gem_content_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
print("The response of ContentGemApi->read:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentGemApi->read: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**gem_gem_content_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**GemGemContentResponse**](GemGemContentResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **set_label**
> SetLabelResponse set_label(gem_gem_content_href, set_label, x_task_diagnostics=x_task_diagnostics)
Set a label
Set a single pulp_label on the object to a specific value or null.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_gem
from pulpcore.client.pulp_gem.models.set_label import SetLabel
from pulpcore.client.pulp_gem.models.set_label_response import SetLabelResponse
from pulpcore.client.pulp_gem.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_gem.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_gem.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_gem.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_gem.ContentGemApi(api_client)
gem_gem_content_href = 'gem_gem_content_href_example' # str |
set_label = pulpcore.client.pulp_gem.SetLabel() # SetLabel |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Set a label
api_response = api_instance.set_label(gem_gem_content_href, set_label, x_task_diagnostics=x_task_diagnostics)
print("The response of ContentGemApi->set_label:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentGemApi->set_label: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**gem_gem_content_href** | **str**| |
**set_label** | [**SetLabel**](SetLabel.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**SetLabelResponse**](SetLabelResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **unset_label**
> UnsetLabelResponse unset_label(gem_gem_content_href, unset_label, x_task_diagnostics=x_task_diagnostics)
Unset a label
Unset a single pulp_label on the object.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_gem
from pulpcore.client.pulp_gem.models.unset_label import UnsetLabel
from pulpcore.client.pulp_gem.models.unset_label_response import UnsetLabelResponse
from pulpcore.client.pulp_gem.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_gem.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_gem.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_gem.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_gem.ContentGemApi(api_client)
gem_gem_content_href = 'gem_gem_content_href_example' # str |
unset_label = pulpcore.client.pulp_gem.UnsetLabel() # UnsetLabel |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Unset a label
api_response = api_instance.unset_label(gem_gem_content_href, unset_label, x_task_diagnostics=x_task_diagnostics)
print("The response of ContentGemApi->unset_label:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentGemApi->unset_label: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**gem_gem_content_href** | **str**| |
**unset_label** | [**UnsetLabel**](UnsetLabel.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**UnsetLabelResponse**](UnsetLabelResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# ContentSummaryResponse
Serializer for the RepositoryVersion content summary
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**added** | **Dict[str, object]** | |
**removed** | **Dict[str, object]** | |
**present** | **Dict[str, object]** | |
## Example
```python
from pulpcore.client.pulp_gem.models.content_summary_response import ContentSummaryResponse
# TODO update the JSON string below
json = "{}"
# create an instance of ContentSummaryResponse from a JSON string
content_summary_response_instance = ContentSummaryResponse.from_json(json)
# print the JSON string representation of the object
print(ContentSummaryResponse.to_json())
# convert the object into a dict
content_summary_response_dict = content_summary_response_instance.to_dict()
# create an instance of ContentSummaryResponse from a dict
content_summary_response_from_dict = ContentSummaryResponse.from_dict(content_summary_response_dict)
```
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
# pulpcore.client.pulp_gem.DistributionsGemApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**add_role**](DistributionsGemApi.md#add_role) | **POST** {gem_gem_distribution_href}add_role/ | Add a role
[**create**](DistributionsGemApi.md#create) | **POST** /api/pulp/{pulp_domain}/api/v3/distributions/gem/gem/ | Create a gem distribution
[**delete**](DistributionsGemApi.md#delete) | **DELETE** {gem_gem_distribution_href} | Delete a gem distribution
[**list**](DistributionsGemApi.md#list) | **GET** /api/pulp/{pulp_domain}/api/v3/distributions/gem/gem/ | List gem distributions
[**list_roles**](DistributionsGemApi.md#list_roles) | **GET** {gem_gem_distribution_href}list_roles/ | List roles
[**my_permissions**](DistributionsGemApi.md#my_permissions) | **GET** {gem_gem_distribution_href}my_permissions/ | List user permissions
[**partial_update**](DistributionsGemApi.md#partial_update) | **PATCH** {gem_gem_distribution_href} | Update a gem distribution
[**read**](DistributionsGemApi.md#read) | **GET** {gem_gem_distribution_href} | Inspect a gem distribution
[**remove_role**](DistributionsGemApi.md#remove_role) | **POST** {gem_gem_distribution_href}remove_role/ | Remove a role
[**set_label**](DistributionsGemApi.md#set_label) | **POST** {gem_gem_distribution_href}set_label/ | Set a label
[**unset_label**](DistributionsGemApi.md#unset_label) | **POST** {gem_gem_distribution_href}unset_label/ | Unset a label
[**update**](DistributionsGemApi.md#update) | **PUT** {gem_gem_distribution_href} | Update a gem distribution
# **add_role**
> NestedRoleResponse add_role(gem_gem_distribution_href, nested_role, x_task_diagnostics=x_task_diagnostics)
Add a role
Add a role for this object to users/groups.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_gem
from pulpcore.client.pulp_gem.models.nested_role import NestedRole
from pulpcore.client.pulp_gem.models.nested_role_response import NestedRoleResponse
from pulpcore.client.pulp_gem.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_gem.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_gem.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_gem.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_gem.DistributionsGemApi(api_client)
gem_gem_distribution_href = 'gem_gem_distribution_href_example' # str |
nested_role = pulpcore.client.pulp_gem.NestedRole() # NestedRole |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Add a role
api_response = api_instance.add_role(gem_gem_distribution_href, nested_role, x_task_diagnostics=x_task_diagnostics)
print("The response of DistributionsGemApi->add_role:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling DistributionsGemApi->add_role: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**gem_gem_distribution_href** | **str**| |
**nested_role** | [**NestedRole**](NestedRole.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**NestedRoleResponse**](NestedRoleResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **create**
> AsyncOperationResponse create(pulp_domain, gem_gem_distribution, x_task_diagnostics=x_task_diagnostics)
Create a gem distribution
Trigger an asynchronous create task
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_gem
from pulpcore.client.pulp_gem.models.async_operation_response import AsyncOperationResponse
from pulpcore.client.pulp_gem.models.gem_gem_distribution import GemGemDistribution
from pulpcore.client.pulp_gem.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_gem.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_gem.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_gem.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_gem.DistributionsGemApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
gem_gem_distribution = pulpcore.client.pulp_gem.GemGemDistribution() # GemGemDistribution |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Create a gem distribution
api_response = api_instance.create(pulp_domain, gem_gem_distribution, x_task_diagnostics=x_task_diagnostics)
print("The response of DistributionsGemApi->create:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling DistributionsGemApi->create: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**gem_gem_distribution** | [**GemGemDistribution**](GemGemDistribution.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**AsyncOperationResponse**](AsyncOperationResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**202** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **delete**
> AsyncOperationResponse delete(gem_gem_distribution_href, x_task_diagnostics=x_task_diagnostics)
Delete a gem distribution
Trigger an asynchronous delete task
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_gem
from pulpcore.client.pulp_gem.models.async_operation_response import AsyncOperationResponse
from pulpcore.client.pulp_gem.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_gem.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_gem.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_gem.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_gem.DistributionsGemApi(api_client)
gem_gem_distribution_href = 'gem_gem_distribution_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Delete a gem distribution
api_response = api_instance.delete(gem_gem_distribution_href, x_task_diagnostics=x_task_diagnostics)
print("The response of DistributionsGemApi->delete:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling DistributionsGemApi->delete: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**gem_gem_distribution_href** | **str**| | | text/markdown | Pulp Team | pulp-list@redhat.com | null | null | GNU General Public License v2.0 or later | pulp, pulpcore, client, Pulp 3 API | [] | [] | null | null | null | [] | [] | [] | [
"urllib3<2.7,>=1.25.3",
"python-dateutil<2.10.0,>=2.8.1",
"pydantic>=2",
"typing-extensions>=4.7.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T18:42:44.248025 | crc_pulp_gem_client-20260219.2.tar.gz | 119,349 | 10/4e/558b94ea6fc3c7716b78a99eee547ec5511d697e6ff238e05d709f35605d/crc_pulp_gem_client-20260219.2.tar.gz | source | sdist | null | false | 9e2cf16593ed5d94545265810a0cfabc | 005b37cddb391af41d5fcb8c3e4fd283543fdda3695a15df7bc33fb7bd246695 | 104e558b94ea6fc3c7716b78a99eee547ec5511d697e6ff238e05d709f35605d | null | [] | 236 |
2.4 | crc-pulp-npm-client | 20260219.2 | Pulp 3 API | # AsyncOperationResponse
Serializer for asynchronous operations.
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**task** | **str** | The href of the task. |
## Example
```python
from pulpcore.client.pulp_npm.models.async_operation_response import AsyncOperationResponse
# TODO update the JSON string below
json = "{}"
# create an instance of AsyncOperationResponse from a JSON string
async_operation_response_instance = AsyncOperationResponse.from_json(json)
# print the JSON string representation of the object
print(AsyncOperationResponse.to_json())
# convert the object into a dict
async_operation_response_dict = async_operation_response_instance.to_dict()
# create an instance of AsyncOperationResponse from a dict
async_operation_response_from_dict = AsyncOperationResponse.from_dict(async_operation_response_dict)
```
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
# pulpcore.client.pulp_npm.ContentPackagesApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**create**](ContentPackagesApi.md#create) | **POST** /api/pulp/{pulp_domain}/api/v3/content/npm/packages/ | Create a package
[**list**](ContentPackagesApi.md#list) | **GET** /api/pulp/{pulp_domain}/api/v3/content/npm/packages/ | List packages
[**read**](ContentPackagesApi.md#read) | **GET** {npm_package_href} | Inspect a package
[**set_label**](ContentPackagesApi.md#set_label) | **POST** {npm_package_href}set_label/ | Set a label
[**unset_label**](ContentPackagesApi.md#unset_label) | **POST** {npm_package_href}unset_label/ | Unset a label
# **create**
> NpmPackageResponse create(pulp_domain, relative_path, name, version, x_task_diagnostics=x_task_diagnostics, repository=repository, pulp_labels=pulp_labels, artifact=artifact, file=file, upload=upload, file_url=file_url, downloader_config=downloader_config)
Create a package
Perform bookkeeping when saving Content. \"Artifacts\" need to be popped off and saved independently, as they are not actually part of the Content model.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_npm
from pulpcore.client.pulp_npm.models.npm_package_response import NpmPackageResponse
from pulpcore.client.pulp_npm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_npm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_npm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_npm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_npm.ContentPackagesApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
relative_path = 'relative_path_example' # str |
name = 'name_example' # str |
version = 'version_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
repository = 'repository_example' # str | A URI of a repository the new content unit should be associated with. (optional)
pulp_labels = None # Dict[str, Optional[str]] | A dictionary of arbitrary key/value pairs used to describe a specific Content instance. (optional)
artifact = 'artifact_example' # str | Artifact file representing the physical content (optional)
file = None # bytearray | An uploaded file that may be turned into the content unit. (optional)
upload = 'upload_example' # str | An uncommitted upload that may be turned into the content unit. (optional)
file_url = 'file_url_example' # str | A url that Pulp can download and turn into the content unit. (optional)
downloader_config = pulpcore.client.pulp_npm.RemoteNetworkConfig() # RemoteNetworkConfig | Configuration for the download process (e.g., proxies, auth, timeouts). Only applicable when providing a 'file_url. (optional)
try:
# Create a package
api_response = api_instance.create(pulp_domain, relative_path, name, version, x_task_diagnostics=x_task_diagnostics, repository=repository, pulp_labels=pulp_labels, artifact=artifact, file=file, upload=upload, file_url=file_url, downloader_config=downloader_config)
print("The response of ContentPackagesApi->create:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentPackagesApi->create: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**relative_path** | **str**| |
**name** | **str**| |
**version** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**repository** | **str**| A URI of a repository the new content unit should be associated with. | [optional]
**pulp_labels** | [**Dict[str, Optional[str]]**](Dict.md)| A dictionary of arbitrary key/value pairs used to describe a specific Content instance. | [optional]
**artifact** | **str**| Artifact file representing the physical content | [optional]
**file** | **bytearray**| An uploaded file that may be turned into the content unit. | [optional]
**upload** | **str**| An uncommitted upload that may be turned into the content unit. | [optional]
**file_url** | **str**| A url that Pulp can download and turn into the content unit. | [optional]
**downloader_config** | [**RemoteNetworkConfig**](RemoteNetworkConfig.md)| Configuration for the download process (e.g., proxies, auth, timeouts). Only applicable when providing a 'file_url. | [optional]
### Return type
[**NpmPackageResponse**](NpmPackageResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: multipart/form-data, application/x-www-form-urlencoded
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **list**
> PaginatednpmPackageResponseList list(pulp_domain, x_task_diagnostics=x_task_diagnostics, limit=limit, name=name, name__in=name__in, offset=offset, ordering=ordering, orphaned_for=orphaned_for, prn__in=prn__in, pulp_href__in=pulp_href__in, pulp_id__in=pulp_id__in, pulp_label_select=pulp_label_select, q=q, repository_version=repository_version, repository_version_added=repository_version_added, repository_version_removed=repository_version_removed, fields=fields, exclude_fields=exclude_fields)
List packages
A ViewSet for Package. Define endpoint name which will appear in the API endpoint for this content type. For example:: http://pulp.example.com/pulp/api/v3/content/npm/units/ Also specify queryset and serializer for Package.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_npm
from pulpcore.client.pulp_npm.models.paginatednpm_package_response_list import PaginatednpmPackageResponseList
from pulpcore.client.pulp_npm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_npm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_npm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_npm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_npm.ContentPackagesApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
limit = 56 # int | Number of results to return per page. (optional)
name = 'name_example' # str | Filter results where name matches value (optional)
name__in = ['name__in_example'] # List[str] | Filter results where name is in a comma-separated list of values (optional)
offset = 56 # int | The initial index from which to return the results. (optional)
ordering = ['ordering_example'] # List[str] | Ordering * `pulp_id` - Pulp id * `-pulp_id` - Pulp id (descending) * `pulp_created` - Pulp created * `-pulp_created` - Pulp created (descending) * `pulp_last_updated` - Pulp last updated * `-pulp_last_updated` - Pulp last updated (descending) * `pulp_type` - Pulp type * `-pulp_type` - Pulp type (descending) * `upstream_id` - Upstream id * `-upstream_id` - Upstream id (descending) * `pulp_labels` - Pulp labels * `-pulp_labels` - Pulp labels (descending) * `timestamp_of_interest` - Timestamp of interest * `-timestamp_of_interest` - Timestamp of interest (descending) * `name` - Name * `-name` - Name (descending) * `version` - Version * `-version` - Version (descending) * `pk` - Pk * `-pk` - Pk (descending) (optional)
orphaned_for = 3.4 # float | Minutes Content has been orphaned for. -1 uses ORPHAN_PROTECTION_TIME. (optional)
prn__in = ['prn__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_href__in = ['pulp_href__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_id__in = ['pulp_id__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_label_select = 'pulp_label_select_example' # str | Filter labels by search string (optional)
q = 'q_example' # str | Filter results by using NOT, AND and OR operations on other filters (optional)
repository_version = 'repository_version_example' # str | Repository Version referenced by HREF/PRN (optional)
repository_version_added = 'repository_version_added_example' # str | Repository Version referenced by HREF/PRN (optional)
repository_version_removed = 'repository_version_removed_example' # str | Repository Version referenced by HREF/PRN (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# List packages
api_response = api_instance.list(pulp_domain, x_task_diagnostics=x_task_diagnostics, limit=limit, name=name, name__in=name__in, offset=offset, ordering=ordering, orphaned_for=orphaned_for, prn__in=prn__in, pulp_href__in=pulp_href__in, pulp_id__in=pulp_id__in, pulp_label_select=pulp_label_select, q=q, repository_version=repository_version, repository_version_added=repository_version_added, repository_version_removed=repository_version_removed, fields=fields, exclude_fields=exclude_fields)
print("The response of ContentPackagesApi->list:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentPackagesApi->list: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**limit** | **int**| Number of results to return per page. | [optional]
**name** | **str**| Filter results where name matches value | [optional]
**name__in** | [**List[str]**](str.md)| Filter results where name is in a comma-separated list of values | [optional]
**offset** | **int**| The initial index from which to return the results. | [optional]
**ordering** | [**List[str]**](str.md)| Ordering * `pulp_id` - Pulp id * `-pulp_id` - Pulp id (descending) * `pulp_created` - Pulp created * `-pulp_created` - Pulp created (descending) * `pulp_last_updated` - Pulp last updated * `-pulp_last_updated` - Pulp last updated (descending) * `pulp_type` - Pulp type * `-pulp_type` - Pulp type (descending) * `upstream_id` - Upstream id * `-upstream_id` - Upstream id (descending) * `pulp_labels` - Pulp labels * `-pulp_labels` - Pulp labels (descending) * `timestamp_of_interest` - Timestamp of interest * `-timestamp_of_interest` - Timestamp of interest (descending) * `name` - Name * `-name` - Name (descending) * `version` - Version * `-version` - Version (descending) * `pk` - Pk * `-pk` - Pk (descending) | [optional]
**orphaned_for** | **float**| Minutes Content has been orphaned for. -1 uses ORPHAN_PROTECTION_TIME. | [optional]
**prn__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_href__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_id__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_label_select** | **str**| Filter labels by search string | [optional]
**q** | **str**| Filter results by using NOT, AND and OR operations on other filters | [optional]
**repository_version** | **str**| Repository Version referenced by HREF/PRN | [optional]
**repository_version_added** | **str**| Repository Version referenced by HREF/PRN | [optional]
**repository_version_removed** | **str**| Repository Version referenced by HREF/PRN | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**PaginatednpmPackageResponseList**](PaginatednpmPackageResponseList.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **read**
> NpmPackageResponse read(npm_package_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
Inspect a package
A ViewSet for Package. Define endpoint name which will appear in the API endpoint for this content type. For example:: http://pulp.example.com/pulp/api/v3/content/npm/units/ Also specify queryset and serializer for Package.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_npm
from pulpcore.client.pulp_npm.models.npm_package_response import NpmPackageResponse
from pulpcore.client.pulp_npm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_npm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_npm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_npm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_npm.ContentPackagesApi(api_client)
npm_package_href = 'npm_package_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# Inspect a package
api_response = api_instance.read(npm_package_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
print("The response of ContentPackagesApi->read:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentPackagesApi->read: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**npm_package_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**NpmPackageResponse**](NpmPackageResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **set_label**
> SetLabelResponse set_label(npm_package_href, set_label, x_task_diagnostics=x_task_diagnostics)
Set a label
Set a single pulp_label on the object to a specific value or null.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_npm
from pulpcore.client.pulp_npm.models.set_label import SetLabel
from pulpcore.client.pulp_npm.models.set_label_response import SetLabelResponse
from pulpcore.client.pulp_npm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_npm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_npm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_npm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_npm.ContentPackagesApi(api_client)
npm_package_href = 'npm_package_href_example' # str |
set_label = pulpcore.client.pulp_npm.SetLabel() # SetLabel |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Set a label
api_response = api_instance.set_label(npm_package_href, set_label, x_task_diagnostics=x_task_diagnostics)
print("The response of ContentPackagesApi->set_label:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentPackagesApi->set_label: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**npm_package_href** | **str**| |
**set_label** | [**SetLabel**](SetLabel.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**SetLabelResponse**](SetLabelResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **unset_label**
> UnsetLabelResponse unset_label(npm_package_href, unset_label, x_task_diagnostics=x_task_diagnostics)
Unset a label
Unset a single pulp_label on the object.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_npm
from pulpcore.client.pulp_npm.models.unset_label import UnsetLabel
from pulpcore.client.pulp_npm.models.unset_label_response import UnsetLabelResponse
from pulpcore.client.pulp_npm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_npm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_npm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_npm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_npm.ContentPackagesApi(api_client)
npm_package_href = 'npm_package_href_example' # str |
unset_label = pulpcore.client.pulp_npm.UnsetLabel() # UnsetLabel |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Unset a label
api_response = api_instance.unset_label(npm_package_href, unset_label, x_task_diagnostics=x_task_diagnostics)
print("The response of ContentPackagesApi->unset_label:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentPackagesApi->unset_label: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**npm_package_href** | **str**| |
**unset_label** | [**UnsetLabel**](UnsetLabel.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**UnsetLabelResponse**](UnsetLabelResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**201** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# ContentSummaryResponse
Serializer for the RepositoryVersion content summary
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**added** | **Dict[str, object]** | |
**removed** | **Dict[str, object]** | |
**present** | **Dict[str, object]** | |
## Example
```python
from pulpcore.client.pulp_npm.models.content_summary_response import ContentSummaryResponse
# TODO update the JSON string below
json = "{}"
# create an instance of ContentSummaryResponse from a JSON string
content_summary_response_instance = ContentSummaryResponse.from_json(json)
# print the JSON string representation of the object
print(ContentSummaryResponse.to_json())
# convert the object into a dict
content_summary_response_dict = content_summary_response_instance.to_dict()
# create an instance of ContentSummaryResponse from a dict
content_summary_response_from_dict = ContentSummaryResponse.from_dict(content_summary_response_dict)
```
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
# pulpcore.client.pulp_npm.DistributionsNpmApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**create**](DistributionsNpmApi.md#create) | **POST** /api/pulp/{pulp_domain}/api/v3/distributions/npm/npm/ | Create a npm distribution
[**delete**](DistributionsNpmApi.md#delete) | **DELETE** {npm_npm_distribution_href} | Delete a npm distribution
[**list**](DistributionsNpmApi.md#list) | **GET** /api/pulp/{pulp_domain}/api/v3/distributions/npm/npm/ | List npm distributions
[**partial_update**](DistributionsNpmApi.md#partial_update) | **PATCH** {npm_npm_distribution_href} | Update a npm distribution
[**read**](DistributionsNpmApi.md#read) | **GET** {npm_npm_distribution_href} | Inspect a npm distribution
[**set_label**](DistributionsNpmApi.md#set_label) | **POST** {npm_npm_distribution_href}set_label/ | Set a label
[**unset_label**](DistributionsNpmApi.md#unset_label) | **POST** {npm_npm_distribution_href}unset_label/ | Unset a label
[**update**](DistributionsNpmApi.md#update) | **PUT** {npm_npm_distribution_href} | Update a npm distribution
# **create**
> AsyncOperationResponse create(pulp_domain, npm_npm_distribution, x_task_diagnostics=x_task_diagnostics)
Create a npm distribution
Trigger an asynchronous create task
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_npm
from pulpcore.client.pulp_npm.models.async_operation_response import AsyncOperationResponse
from pulpcore.client.pulp_npm.models.npm_npm_distribution import NpmNpmDistribution
from pulpcore.client.pulp_npm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_npm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_npm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_npm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_npm.DistributionsNpmApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
npm_npm_distribution = pulpcore.client.pulp_npm.NpmNpmDistribution() # NpmNpmDistribution |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Create a npm distribution
api_response = api_instance.create(pulp_domain, npm_npm_distribution, x_task_diagnostics=x_task_diagnostics)
print("The response of DistributionsNpmApi->create:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling DistributionsNpmApi->create: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**npm_npm_distribution** | [**NpmNpmDistribution**](NpmNpmDistribution.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**AsyncOperationResponse**](AsyncOperationResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**202** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **delete**
> AsyncOperationResponse delete(npm_npm_distribution_href, x_task_diagnostics=x_task_diagnostics)
Delete a npm distribution
Trigger an asynchronous delete task
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_npm
from pulpcore.client.pulp_npm.models.async_operation_response import AsyncOperationResponse
from pulpcore.client.pulp_npm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_npm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_npm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_npm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_npm.DistributionsNpmApi(api_client)
npm_npm_distribution_href = 'npm_npm_distribution_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Delete a npm distribution
api_response = api_instance.delete(npm_npm_distribution_href, x_task_diagnostics=x_task_diagnostics)
print("The response of DistributionsNpmApi->delete:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling DistributionsNpmApi->delete: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**npm_npm_distribution_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**AsyncOperationResponse**](AsyncOperationResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**202** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **list**
> PaginatednpmNpmDistributionResponseList list(pulp_domain, x_task_diagnostics=x_task_diagnostics, base_path=base_path, base_path__contains=base_path__contains, base_path__icontains=base_path__icontains, base_path__in=base_path__in, checkpoint=checkpoint, limit=limit, name=name, name__contains=name__contains, name__icontains=name__icontains, name__iexact=name__iexact, name__in=name__in, name__iregex=name__iregex, name__istartswith=name__istartswith, name__regex=name__regex, name__startswith=name__startswith, offset=offset, ordering=ordering, prn__in=prn__in, pulp_href__in=pulp_href__in, pulp_id__in=pulp_id__in, pulp_label_select=pulp_label_select, q=q, repository=repository, repository__in=repository__in, with_content=with_content, fields=fields, exclude_fields=exclude_fields)
List npm distributions
ViewSet for NPM Distributions.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_npm
from pulpcore.client.pulp_npm.models.paginatednpm_npm_distribution_response_list import PaginatednpmNpmDistributionResponseList
from pulpcore.client.pulp_npm.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_npm.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_npm.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_npm.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_npm.DistributionsNpmApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
base_path = 'base_path_example' # str | Filter results where base_path matches value (optional)
base_path__contains = 'base_path__contains_example' # str | Filter results where base_path contains value (optional)
base_path__icontains = 'base_path__icontains_example' # str | Filter results where base_path contains value (optional)
base_path__in = ['base_path__in_example'] # List[str] | Filter | text/markdown | Pulp Team | pulp-list@redhat.com | null | null | GNU General Public License v2.0 or later | pulp, pulpcore, client, Pulp 3 API | [] | [] | null | null | null | [] | [] | [] | [
"urllib3<2.7,>=1.25.3",
"python-dateutil<2.10.0,>=2.8.1",
"pydantic>=2",
"typing-extensions>=4.7.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T18:42:37.411700 | crc_pulp_npm_client-20260219.2.tar.gz | 100,897 | df/3d/8decec8a40d122e042223a66f8b790f8370ef150696e2277be7ddb1c187c/crc_pulp_npm_client-20260219.2.tar.gz | source | sdist | null | false | 0074a1b4ae376bb36d1ce29ff072f2c4 | 99868732ac5be616cdbe89010517ca42d3cf9330eb65a83163f86cfc163ca3c6 | df3d8decec8a40d122e042223a66f8b790f8370ef150696e2277be7ddb1c187c | null | [] | 233 |
2.4 | crc-pulp-python-client | 20260219.2 | Pulp 3 API | # pulpcore.client.pulp_python.ApiIntegrityProvenanceApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**read**](ApiIntegrityProvenanceApi.md#read) | **GET** /api/pypi/{pulp_domain}/{path}/integrity/{package}/{version}/{filename}/provenance/ | Get package provenance
# **read**
> read(filename, package, path, pulp_domain, version, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
Get package provenance
Gets the provenance for a package.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_python
from pulpcore.client.pulp_python.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_python.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_python.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_python.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_python.ApiIntegrityProvenanceApi(api_client)
filename = 'filename_example' # str |
package = 'package_example' # str |
path = 'path_example' # str |
pulp_domain = 'pulp_domain_example' # str |
version = 'version_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# Get package provenance
api_instance.read(filename, package, path, pulp_domain, version, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
except Exception as e:
print("Exception when calling ApiIntegrityProvenanceApi->read: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**filename** | **str**| |
**package** | **str**| |
**path** | **str**| |
**pulp_domain** | **str**| |
**version** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
void (empty response body)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: Not defined
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | No response body | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# pulpcore.client.pulp_python.ApiLegacyApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**create**](ApiLegacyApi.md#create) | **POST** /api/pypi/{pulp_domain}/{path}/legacy/ | Upload a package
# **create**
> PackageUploadTaskResponse create(path, pulp_domain, content, sha256_digest, x_task_diagnostics=x_task_diagnostics, action=action, protocol_version=protocol_version, filetype=filetype, metadata_version=metadata_version, attestations=attestations)
Upload a package
Upload package to the index. This is the endpoint that tools like Twine and Poetry use for their upload commands.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_python
from pulpcore.client.pulp_python.models.package_upload_task_response import PackageUploadTaskResponse
from pulpcore.client.pulp_python.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_python.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_python.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_python.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_python.ApiLegacyApi(api_client)
path = 'path_example' # str |
pulp_domain = 'pulp_domain_example' # str |
content = None # bytearray | A Python package release file to upload to the index.
sha256_digest = 'sha256_digest_example' # str | SHA256 of package to validate upload integrity.
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
action = 'file_upload' # str | Defaults to `file_upload`, don't change it or request will fail! (optional) (default to 'file_upload')
protocol_version = pulpcore.client.pulp_python.ProtocolVersionEnum() # ProtocolVersionEnum | Protocol version to use for the upload. Only version 1 is supported. * `1` - 1 (optional)
filetype = pulpcore.client.pulp_python.FiletypeEnum() # FiletypeEnum | Type of artifact to upload. * `bdist_wheel` - bdist_wheel * `sdist` - sdist (optional)
metadata_version = pulpcore.client.pulp_python.MetadataVersionEnum() # MetadataVersionEnum | Metadata version of the uploaded package. * `1.0` - 1.0 * `1.1` - 1.1 * `1.2` - 1.2 * `2.0` - 2.0 * `2.1` - 2.1 * `2.2` - 2.2 * `2.3` - 2.3 * `2.4` - 2.4 (optional)
attestations = None # object | A JSON list containing attestations for the package. (optional)
try:
# Upload a package
api_response = api_instance.create(path, pulp_domain, content, sha256_digest, x_task_diagnostics=x_task_diagnostics, action=action, protocol_version=protocol_version, filetype=filetype, metadata_version=metadata_version, attestations=attestations)
print("The response of ApiLegacyApi->create:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ApiLegacyApi->create: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**path** | **str**| |
**pulp_domain** | **str**| |
**content** | **bytearray**| A Python package release file to upload to the index. |
**sha256_digest** | **str**| SHA256 of package to validate upload integrity. |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**action** | **str**| Defaults to `file_upload`, don't change it or request will fail! | [optional] [default to 'file_upload']
**protocol_version** | [**ProtocolVersionEnum**](ProtocolVersionEnum.md)| Protocol version to use for the upload. Only version 1 is supported. * `1` - 1 | [optional]
**filetype** | [**FiletypeEnum**](FiletypeEnum.md)| Type of artifact to upload. * `bdist_wheel` - bdist_wheel * `sdist` - sdist | [optional]
**metadata_version** | [**MetadataVersionEnum**](MetadataVersionEnum.md)| Metadata version of the uploaded package. * `1.0` - 1.0 * `1.1` - 1.1 * `1.2` - 1.2 * `2.0` - 2.0 * `2.1` - 2.1 * `2.2` - 2.2 * `2.3` - 2.3 * `2.4` - 2.4 | [optional]
**attestations** | [**object**](object.md)| A JSON list containing attestations for the package. | [optional]
### Return type
[**PackageUploadTaskResponse**](PackageUploadTaskResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: multipart/form-data, application/x-www-form-urlencoded
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# pulpcore.client.pulp_python.ApiPypiApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**read**](ApiPypiApi.md#read) | **GET** /api/pypi/{pulp_domain}/{path}/ | Get index summary
# **read**
> SummaryResponse read(path, pulp_domain, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
Get index summary
Gets package summary stats of index.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_python
from pulpcore.client.pulp_python.models.summary_response import SummaryResponse
from pulpcore.client.pulp_python.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_python.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_python.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_python.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_python.ApiPypiApi(api_client)
path = 'path_example' # str |
pulp_domain = 'pulp_domain_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# Get index summary
api_response = api_instance.read(path, pulp_domain, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
print("The response of ApiPypiApi->read:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ApiPypiApi->read: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**path** | **str**| |
**pulp_domain** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**SummaryResponse**](SummaryResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# pulpcore.client.pulp_python.ApiSimpleApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**create**](ApiSimpleApi.md#create) | **POST** /api/pypi/{pulp_domain}/{path}/simple/ | Upload a package
[**pypi_simple_package_read**](ApiSimpleApi.md#pypi_simple_package_read) | **GET** /api/pypi/{pulp_domain}/{path}/simple/{package}/ | Get package simple page
[**read**](ApiSimpleApi.md#read) | **GET** /api/pypi/{pulp_domain}/{path}/simple/ | Get index simple page
# **create**
> PackageUploadTaskResponse create(path, pulp_domain, content, sha256_digest, x_task_diagnostics=x_task_diagnostics, action=action, protocol_version=protocol_version, filetype=filetype, metadata_version=metadata_version, attestations=attestations)
Upload a package
Upload package to the index. This endpoint has the same functionality as the upload endpoint at the `/legacy` url of the index. This is provided for convenience for users who want a single index url for all their Python tools. (pip, twine, poetry, pipenv, ...)
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_python
from pulpcore.client.pulp_python.models.package_upload_task_response import PackageUploadTaskResponse
from pulpcore.client.pulp_python.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_python.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_python.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_python.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_python.ApiSimpleApi(api_client)
path = 'path_example' # str |
pulp_domain = 'pulp_domain_example' # str |
content = None # bytearray | A Python package release file to upload to the index.
sha256_digest = 'sha256_digest_example' # str | SHA256 of package to validate upload integrity.
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
action = 'file_upload' # str | Defaults to `file_upload`, don't change it or request will fail! (optional) (default to 'file_upload')
protocol_version = pulpcore.client.pulp_python.ProtocolVersionEnum() # ProtocolVersionEnum | Protocol version to use for the upload. Only version 1 is supported. * `1` - 1 (optional)
filetype = pulpcore.client.pulp_python.FiletypeEnum() # FiletypeEnum | Type of artifact to upload. * `bdist_wheel` - bdist_wheel * `sdist` - sdist (optional)
metadata_version = pulpcore.client.pulp_python.MetadataVersionEnum() # MetadataVersionEnum | Metadata version of the uploaded package. * `1.0` - 1.0 * `1.1` - 1.1 * `1.2` - 1.2 * `2.0` - 2.0 * `2.1` - 2.1 * `2.2` - 2.2 * `2.3` - 2.3 * `2.4` - 2.4 (optional)
attestations = None # object | A JSON list containing attestations for the package. (optional)
try:
# Upload a package
api_response = api_instance.create(path, pulp_domain, content, sha256_digest, x_task_diagnostics=x_task_diagnostics, action=action, protocol_version=protocol_version, filetype=filetype, metadata_version=metadata_version, attestations=attestations)
print("The response of ApiSimpleApi->create:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ApiSimpleApi->create: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**path** | **str**| |
**pulp_domain** | **str**| |
**content** | **bytearray**| A Python package release file to upload to the index. |
**sha256_digest** | **str**| SHA256 of package to validate upload integrity. |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**action** | **str**| Defaults to `file_upload`, don't change it or request will fail! | [optional] [default to 'file_upload']
**protocol_version** | [**ProtocolVersionEnum**](ProtocolVersionEnum.md)| Protocol version to use for the upload. Only version 1 is supported. * `1` - 1 | [optional]
**filetype** | [**FiletypeEnum**](FiletypeEnum.md)| Type of artifact to upload. * `bdist_wheel` - bdist_wheel * `sdist` - sdist | [optional]
**metadata_version** | [**MetadataVersionEnum**](MetadataVersionEnum.md)| Metadata version of the uploaded package. * `1.0` - 1.0 * `1.1` - 1.1 * `1.2` - 1.2 * `2.0` - 2.0 * `2.1` - 2.1 * `2.2` - 2.2 * `2.3` - 2.3 * `2.4` - 2.4 | [optional]
**attestations** | [**object**](object.md)| A JSON list containing attestations for the package. | [optional]
### Return type
[**PackageUploadTaskResponse**](PackageUploadTaskResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: multipart/form-data, application/x-www-form-urlencoded
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **pypi_simple_package_read**
> pypi_simple_package_read(package, path, pulp_domain, x_task_diagnostics=x_task_diagnostics, format=format, fields=fields, exclude_fields=exclude_fields)
Get package simple page
Retrieves the simple api html/json page for a package.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_python
from pulpcore.client.pulp_python.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_python.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_python.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_python.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_python.ApiSimpleApi(api_client)
package = 'package_example' # str |
path = 'path_example' # str |
pulp_domain = 'pulp_domain_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
format = 'format_example' # str | (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# Get package simple page
api_instance.pypi_simple_package_read(package, path, pulp_domain, x_task_diagnostics=x_task_diagnostics, format=format, fields=fields, exclude_fields=exclude_fields)
except Exception as e:
print("Exception when calling ApiSimpleApi->pypi_simple_package_read: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**package** | **str**| |
**path** | **str**| |
**pulp_domain** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**format** | **str**| | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
void (empty response body)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: Not defined
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | No response body | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **read**
> read(path, pulp_domain, x_task_diagnostics=x_task_diagnostics, format=format, fields=fields, exclude_fields=exclude_fields)
Get index simple page
Gets the simple api html page for the index.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_python
from pulpcore.client.pulp_python.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_python.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_python.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_python.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_python.ApiSimpleApi(api_client)
path = 'path_example' # str |
pulp_domain = 'pulp_domain_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
format = 'format_example' # str | (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# Get index simple page
api_instance.read(path, pulp_domain, x_task_diagnostics=x_task_diagnostics, format=format, fields=fields, exclude_fields=exclude_fields)
except Exception as e:
print("Exception when calling ApiSimpleApi->read: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**path** | **str**| |
**pulp_domain** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**format** | **str**| | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
void (empty response body)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: Not defined
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | No response body | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# AsyncOperationResponse
Serializer for asynchronous operations.
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**task** | **str** | The href of the task. |
## Example
```python
from pulpcore.client.pulp_python.models.async_operation_response import AsyncOperationResponse
# TODO update the JSON string below
json = "{}"
# create an instance of AsyncOperationResponse from a JSON string
async_operation_response_instance = AsyncOperationResponse.from_json(json)
# print the JSON string representation of the object
print(AsyncOperationResponse.to_json())
# convert the object into a dict
async_operation_response_dict = async_operation_response_instance.to_dict()
# create an instance of AsyncOperationResponse from a dict
async_operation_response_from_dict = AsyncOperationResponse.from_dict(async_operation_response_dict)
```
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
# pulpcore.client.pulp_python.ContentPackagesApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**create**](ContentPackagesApi.md#create) | **POST** /api/pulp/{pulp_domain}/api/v3/content/python/packages/ | Create a python package content
[**list**](ContentPackagesApi.md#list) | **GET** /api/pulp/{pulp_domain}/api/v3/content/python/packages/ | List python package contents
[**read**](ContentPackagesApi.md#read) | **GET** {python_python_package_content_href} | Inspect a python package content
[**set_label**](ContentPackagesApi.md#set_label) | **POST** {python_python_package_content_href}set_label/ | Set a label
[**unset_label**](ContentPackagesApi.md#unset_label) | **POST** {python_python_package_content_href}unset_label/ | Unset a label
[**upload**](ContentPackagesApi.md#upload) | **POST** /api/pulp/{pulp_domain}/api/v3/content/python/packages/upload/ | Synchronous Python package upload
# **create**
> AsyncOperationResponse create(pulp_domain, relative_path, x_task_diagnostics=x_task_diagnostics, repository=repository, pulp_labels=pulp_labels, artifact=artifact, file=file, upload=upload, file_url=file_url, downloader_config=downloader_config, author=author, author_email=author_email, description=description, home_page=home_page, keywords=keywords, license=license, platform=platform, summary=summary, classifiers=classifiers, download_url=download_url, supported_platform=supported_platform, maintainer=maintainer, maintainer_email=maintainer_email, obsoletes_dist=obsoletes_dist, project_url=project_url, project_urls=project_urls, provides_dist=provides_dist, requires_external=requires_external, requires_dist=requires_dist, requires_python=requires_python, description_content_type=description_content_type, provides_extras=provides_extras, dynamic=dynamic, license_expression=license_expression, license_file=license_file, sha256=sha256, metadata_sha256=metadata_sha256, attestations=attestations)
Create a python package content
Trigger an asynchronous task to create content,optionally create new repository version.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulp_python
from pulpcore.client.pulp_python.models.async_operation_response import AsyncOperationResponse
from pulpcore.client.pulp_python.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulp_python.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulp_python.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulp_python.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulp_python.ContentPackagesApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
relative_path = 'relative_path_example' # str | Path where the artifact is located relative to distributions base_path
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
repository = 'repository_example' # str | A URI of a repository the new content unit should be associated with. (optional)
pulp_labels = None # Dict[str, Optional[str]] | A dictionary of arbitrary key/value pairs used to describe a specific Content instance. (optional)
artifact = 'artifact_example' # str | Artifact file representing the physical content (optional)
file = None # bytearray | An uploaded file that may be turned into the content unit. (optional)
upload = 'upload_example' # str | An uncommitted upload that may be turned into the content unit. (optional)
file_url = 'file_url_example' # str | A url that Pulp can download and turn into the content unit. (optional)
downloader_config = pulpcore.client.pulp_python.RemoteNetworkConfig() # RemoteNetworkConfig | Configuration for the download process (e.g., proxies, auth, timeouts). Only applicable when providing a 'file_url. (optional)
author = 'author_example' # str | Text containing the author's name. Contact information can also be added, separated with newlines. (optional)
author_email = 'author_email_example' # str | The author's e-mail address. (optional)
description = 'description_example' # str | A longer description of the package that can run to several paragraphs. (optional)
home_page = 'home_page_example' # str | The URL for the package's home page. (optional)
keywords = 'keywords_example' # str | Additional keywords to be used to assist searching for the package in a larger catalog. (optional)
license = 'license_example' # str | Text indicating the license covering the distribution (optional)
platform = 'platform_example' # str | A comma-separated list of platform specifications, summarizing the operating systems supported by the package. (optional)
summary = 'summary_example' # str | A one-line summary of what the package does. (optional)
classifiers = None # object | A JSON list containing classification values for a Python package. (optional)
download_url = 'download_url_example' # str | Legacy field denoting the URL from which this package can be downloaded. (optional)
supported_platform = 'supported_platform_example' # str | Field to specify the OS and CPU for which the binary package was compiled. (optional)
maintainer = 'maintainer_example' # str | The maintainer's name at a minimum; additional contact information may be provided. (optional)
maintainer_email = 'maintainer_email_example' # str | The maintainer's e-mail address. (optional)
obsoletes_dist = None # object | A JSON list containing names of a distutils project's distribution which this distribution renders obsolete, meaning that the two projects should not be installed at the same time. (optional)
project_url = 'project_url_example' # str | A browsable URL for the project and a label for it, separated by a comma. (optional)
project_urls = None # object | A dictionary of labels and URLs for the project. (optional)
provides_dist = None # object | A JSON list containing names of a Distutils project which is contained within this distribution. (optional)
requires_external = None # object | A JSON list containing some dependency in the system that the distribution is to be used. (optional)
requires_dist = None # object | A JSON list containing names of some other distutils project required by this distribution. (optional)
requires_python = 'requires_python_example' # str | The Python version(s) that the distribution is guaranteed to be compatible with. (optional)
description_content_type = 'description_content_type_example' # str | A string stating the markup syntax (if any) used in the distribution's description, so that tools can intelligently render the description. (optional)
provides_extras = None # object | A JSON list containing names of optional features provided by the package. (optional)
dynamic = None # object | A JSON list containing names of other core metadata fields which are permitted to vary between sdist and bdist packages. Fields NOT marked dynamic MUST be the same between bdist and sdist. (optional)
license_expression = 'license_expression_example' # str | Text string that is a valid SPDX license expression. (optional)
license_file = None # object | A JSON list containing names of the paths to license-related files. (optional)
sha256 = '' # str | The SHA256 digest of this package. (optional) (default to '')
metadata_sha256 = 'metadata_sha256_example' # str | The SHA256 digest of the package's METADATA file. (optional)
attestations = None # object | A JSON list containing attestations for the package. (optional)
try:
# Create a python package content
api_response = api_instance.create(pulp_domain, relative_path, x_task_diagnostics=x_task_diagnostics, repository=repository, pulp_labels=pulp_labels, artifact=artifact, file=file, upload=upload, file_url=file_url, downloader_config=downloader_config, author=author, author_email=author_email, description=description, home_page=home_page, keywords=keywords, license=license, platform=platform, summary=summary, classifiers=classifiers, download_url=download_url, supported_platform=supported_platform, maintainer=maintainer, maintainer_email=maintainer_email, obsoletes_dist=obsoletes_dist, project_url=project_url, project_urls=project_urls, provides_dist=provides_dist, requires_external=requires_external, requires_dist=requires_dist, requires_python=requires_python, description_content_type=description_content_type, provides_extras=provides_extras, dynamic=dynamic, license_expression=license_expression, license_file=license_file, sha256=sha256, metadata_sha256=metadata_sha256, attestations=attestations)
print("The response of ContentPackagesApi->create:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ContentPackagesApi->create: %s\n" % e)
```
### Parameters
Name | Type | Description | N | text/markdown | Pulp Team | pulp-list@redhat.com | null | null | GNU General Public License v2.0 or later | pulp, pulpcore, client, Pulp 3 API | [] | [] | null | null | null | [] | [] | [] | [
"urllib3<2.7,>=1.25.3",
"python-dateutil<2.10.0,>=2.8.1",
"pydantic>=2",
"typing-extensions>=4.7.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T18:42:30.102337 | crc_pulp_python_client-20260219.2.tar.gz | 179,836 | f9/a6/86f94926507831611fbc0a8107145f842a0477fcfa72d7be9239a88ffa9c/crc_pulp_python_client-20260219.2.tar.gz | source | sdist | null | false | 96918f780e335a9a48d0aabd9dcb274e | a67e9388587006c8cda2447c5a91569fea7795feecd2d53f4a245fac688b8d3f | f9a686f94926507831611fbc0a8107145f842a0477fcfa72d7be9239a88ffa9c | null | [] | 694 |
2.4 | crc-pulpcore-client | 20260219.2 | Pulp 3 API | # pulpcore.client.pulpcore.AccessPoliciesApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**list**](AccessPoliciesApi.md#list) | **GET** /api/pulp/{pulp_domain}/api/v3/access_policies/ | List access policys
[**partial_update**](AccessPoliciesApi.md#partial_update) | **PATCH** {access_policy_href} | Update an access policy
[**read**](AccessPoliciesApi.md#read) | **GET** {access_policy_href} | Inspect an access policy
[**reset**](AccessPoliciesApi.md#reset) | **POST** {access_policy_href}reset/ |
[**update**](AccessPoliciesApi.md#update) | **PUT** {access_policy_href} | Update an access policy
# **list**
> PaginatedAccessPolicyResponseList list(pulp_domain, x_task_diagnostics=x_task_diagnostics, customized=customized, limit=limit, offset=offset, ordering=ordering, prn__in=prn__in, pulp_href__in=pulp_href__in, pulp_id__in=pulp_id__in, q=q, viewset_name=viewset_name, viewset_name__contains=viewset_name__contains, viewset_name__icontains=viewset_name__icontains, viewset_name__iexact=viewset_name__iexact, viewset_name__in=viewset_name__in, viewset_name__iregex=viewset_name__iregex, viewset_name__istartswith=viewset_name__istartswith, viewset_name__regex=viewset_name__regex, viewset_name__startswith=viewset_name__startswith, fields=fields, exclude_fields=exclude_fields)
List access policys
ViewSet for AccessPolicy.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulpcore
from pulpcore.client.pulpcore.models.paginated_access_policy_response_list import PaginatedAccessPolicyResponseList
from pulpcore.client.pulpcore.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulpcore.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulpcore.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulpcore.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulpcore.AccessPoliciesApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
customized = True # bool | Filter results where customized matches value (optional)
limit = 56 # int | Number of results to return per page. (optional)
offset = 56 # int | The initial index from which to return the results. (optional)
ordering = ['ordering_example'] # List[str] | Ordering * `pulp_id` - Pulp id * `-pulp_id` - Pulp id (descending) * `pulp_created` - Pulp created * `-pulp_created` - Pulp created (descending) * `pulp_last_updated` - Pulp last updated * `-pulp_last_updated` - Pulp last updated (descending) * `creation_hooks` - Creation hooks * `-creation_hooks` - Creation hooks (descending) * `statements` - Statements * `-statements` - Statements (descending) * `viewset_name` - Viewset name * `-viewset_name` - Viewset name (descending) * `customized` - Customized * `-customized` - Customized (descending) * `queryset_scoping` - Queryset scoping * `-queryset_scoping` - Queryset scoping (descending) * `pk` - Pk * `-pk` - Pk (descending) (optional)
prn__in = ['prn__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_href__in = ['pulp_href__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
pulp_id__in = ['pulp_id__in_example'] # List[str] | Multiple values may be separated by commas. (optional)
q = 'q_example' # str | Filter results by using NOT, AND and OR operations on other filters (optional)
viewset_name = 'viewset_name_example' # str | Filter results where viewset_name matches value (optional)
viewset_name__contains = 'viewset_name__contains_example' # str | Filter results where viewset_name contains value (optional)
viewset_name__icontains = 'viewset_name__icontains_example' # str | Filter results where viewset_name contains value (optional)
viewset_name__iexact = 'viewset_name__iexact_example' # str | Filter results where viewset_name matches value (optional)
viewset_name__in = ['viewset_name__in_example'] # List[str] | Filter results where viewset_name is in a comma-separated list of values (optional)
viewset_name__iregex = 'viewset_name__iregex_example' # str | Filter results where viewset_name matches regex value (optional)
viewset_name__istartswith = 'viewset_name__istartswith_example' # str | Filter results where viewset_name starts with value (optional)
viewset_name__regex = 'viewset_name__regex_example' # str | Filter results where viewset_name matches regex value (optional)
viewset_name__startswith = 'viewset_name__startswith_example' # str | Filter results where viewset_name starts with value (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# List access policys
api_response = api_instance.list(pulp_domain, x_task_diagnostics=x_task_diagnostics, customized=customized, limit=limit, offset=offset, ordering=ordering, prn__in=prn__in, pulp_href__in=pulp_href__in, pulp_id__in=pulp_id__in, q=q, viewset_name=viewset_name, viewset_name__contains=viewset_name__contains, viewset_name__icontains=viewset_name__icontains, viewset_name__iexact=viewset_name__iexact, viewset_name__in=viewset_name__in, viewset_name__iregex=viewset_name__iregex, viewset_name__istartswith=viewset_name__istartswith, viewset_name__regex=viewset_name__regex, viewset_name__startswith=viewset_name__startswith, fields=fields, exclude_fields=exclude_fields)
print("The response of AccessPoliciesApi->list:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AccessPoliciesApi->list: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**customized** | **bool**| Filter results where customized matches value | [optional]
**limit** | **int**| Number of results to return per page. | [optional]
**offset** | **int**| The initial index from which to return the results. | [optional]
**ordering** | [**List[str]**](str.md)| Ordering * `pulp_id` - Pulp id * `-pulp_id` - Pulp id (descending) * `pulp_created` - Pulp created * `-pulp_created` - Pulp created (descending) * `pulp_last_updated` - Pulp last updated * `-pulp_last_updated` - Pulp last updated (descending) * `creation_hooks` - Creation hooks * `-creation_hooks` - Creation hooks (descending) * `statements` - Statements * `-statements` - Statements (descending) * `viewset_name` - Viewset name * `-viewset_name` - Viewset name (descending) * `customized` - Customized * `-customized` - Customized (descending) * `queryset_scoping` - Queryset scoping * `-queryset_scoping` - Queryset scoping (descending) * `pk` - Pk * `-pk` - Pk (descending) | [optional]
**prn__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_href__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**pulp_id__in** | [**List[str]**](str.md)| Multiple values may be separated by commas. | [optional]
**q** | **str**| Filter results by using NOT, AND and OR operations on other filters | [optional]
**viewset_name** | **str**| Filter results where viewset_name matches value | [optional]
**viewset_name__contains** | **str**| Filter results where viewset_name contains value | [optional]
**viewset_name__icontains** | **str**| Filter results where viewset_name contains value | [optional]
**viewset_name__iexact** | **str**| Filter results where viewset_name matches value | [optional]
**viewset_name__in** | [**List[str]**](str.md)| Filter results where viewset_name is in a comma-separated list of values | [optional]
**viewset_name__iregex** | **str**| Filter results where viewset_name matches regex value | [optional]
**viewset_name__istartswith** | **str**| Filter results where viewset_name starts with value | [optional]
**viewset_name__regex** | **str**| Filter results where viewset_name matches regex value | [optional]
**viewset_name__startswith** | **str**| Filter results where viewset_name starts with value | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**PaginatedAccessPolicyResponseList**](PaginatedAccessPolicyResponseList.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **partial_update**
> AccessPolicyResponse partial_update(access_policy_href, patched_access_policy, x_task_diagnostics=x_task_diagnostics)
Update an access policy
ViewSet for AccessPolicy.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulpcore
from pulpcore.client.pulpcore.models.access_policy_response import AccessPolicyResponse
from pulpcore.client.pulpcore.models.patched_access_policy import PatchedAccessPolicy
from pulpcore.client.pulpcore.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulpcore.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulpcore.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulpcore.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulpcore.AccessPoliciesApi(api_client)
access_policy_href = 'access_policy_href_example' # str |
patched_access_policy = pulpcore.client.pulpcore.PatchedAccessPolicy() # PatchedAccessPolicy |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Update an access policy
api_response = api_instance.partial_update(access_policy_href, patched_access_policy, x_task_diagnostics=x_task_diagnostics)
print("The response of AccessPoliciesApi->partial_update:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AccessPoliciesApi->partial_update: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**access_policy_href** | **str**| |
**patched_access_policy** | [**PatchedAccessPolicy**](PatchedAccessPolicy.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**AccessPolicyResponse**](AccessPolicyResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **read**
> AccessPolicyResponse read(access_policy_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
Inspect an access policy
ViewSet for AccessPolicy.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulpcore
from pulpcore.client.pulpcore.models.access_policy_response import AccessPolicyResponse
from pulpcore.client.pulpcore.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulpcore.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulpcore.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulpcore.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulpcore.AccessPoliciesApi(api_client)
access_policy_href = 'access_policy_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
fields = ['fields_example'] # List[str] | A list of fields to include in the response. (optional)
exclude_fields = ['exclude_fields_example'] # List[str] | A list of fields to exclude from the response. (optional)
try:
# Inspect an access policy
api_response = api_instance.read(access_policy_href, x_task_diagnostics=x_task_diagnostics, fields=fields, exclude_fields=exclude_fields)
print("The response of AccessPoliciesApi->read:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AccessPoliciesApi->read: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**access_policy_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**fields** | [**List[str]**](str.md)| A list of fields to include in the response. | [optional]
**exclude_fields** | [**List[str]**](str.md)| A list of fields to exclude from the response. | [optional]
### Return type
[**AccessPolicyResponse**](AccessPolicyResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **reset**
> AccessPolicyResponse reset(access_policy_href, x_task_diagnostics=x_task_diagnostics)
Reset the access policy to its uncustomized default value.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulpcore
from pulpcore.client.pulpcore.models.access_policy_response import AccessPolicyResponse
from pulpcore.client.pulpcore.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulpcore.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulpcore.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulpcore.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulpcore.AccessPoliciesApi(api_client)
access_policy_href = 'access_policy_href_example' # str |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
api_response = api_instance.reset(access_policy_href, x_task_diagnostics=x_task_diagnostics)
print("The response of AccessPoliciesApi->reset:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AccessPoliciesApi->reset: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**access_policy_href** | **str**| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**AccessPolicyResponse**](AccessPolicyResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: Not defined
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **update**
> AccessPolicyResponse update(access_policy_href, access_policy, x_task_diagnostics=x_task_diagnostics)
Update an access policy
ViewSet for AccessPolicy.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulpcore
from pulpcore.client.pulpcore.models.access_policy import AccessPolicy
from pulpcore.client.pulpcore.models.access_policy_response import AccessPolicyResponse
from pulpcore.client.pulpcore.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulpcore.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulpcore.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulpcore.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulpcore.AccessPoliciesApi(api_client)
access_policy_href = 'access_policy_href_example' # str |
access_policy = pulpcore.client.pulpcore.AccessPolicy() # AccessPolicy |
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
try:
# Update an access policy
api_response = api_instance.update(access_policy_href, access_policy, x_task_diagnostics=x_task_diagnostics)
print("The response of AccessPoliciesApi->update:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling AccessPoliciesApi->update: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**access_policy_href** | **str**| |
**access_policy** | [**AccessPolicy**](AccessPolicy.md)| |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
### Return type
[**AccessPolicyResponse**](AccessPolicyResponse.md)
### Authorization
[json_header_remote_authentication](../README.md#json_header_remote_authentication), [basicAuth](../README.md#basicAuth), [cookieAuth](../README.md#cookieAuth)
### HTTP request headers
- **Content-Type**: application/json, application/x-www-form-urlencoded, multipart/form-data
- **Accept**: application/json
### HTTP response details
| Status code | Description | Response headers |
|-------------|-------------|------------------|
**200** | | - |
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# AccessPolicy
Serializer for AccessPolicy.
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**permissions_assignment** | **List[object]** | List of callables that define the new permissions to be created for new objects.This is deprecated. Use `creation_hooks` instead. | [optional]
**creation_hooks** | **List[object]** | List of callables that may associate user roles for new objects. | [optional]
**statements** | **List[object]** | List of policy statements defining the policy. |
**queryset_scoping** | **object** | A callable for performing queryset scoping. See plugin documentation for valid callables. Set to blank to turn off queryset scoping. | [optional]
## Example
```python
from pulpcore.client.pulpcore.models.access_policy import AccessPolicy
# TODO update the JSON string below
json = "{}"
# create an instance of AccessPolicy from a JSON string
access_policy_instance = AccessPolicy.from_json(json)
# print the JSON string representation of the object
print(AccessPolicy.to_json())
# convert the object into a dict
access_policy_dict = access_policy_instance.to_dict()
# create an instance of AccessPolicy from a dict
access_policy_from_dict = AccessPolicy.from_dict(access_policy_dict)
```
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
# AccessPolicyResponse
Serializer for AccessPolicy.
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**pulp_href** | **str** | | [optional] [readonly]
**prn** | **str** | The Pulp Resource Name (PRN). | [optional] [readonly]
**pulp_created** | **datetime** | Timestamp of creation. | [optional] [readonly]
**pulp_last_updated** | **datetime** | Timestamp of the last time this resource was updated. Note: for immutable resources - like content, repository versions, and publication - pulp_created and pulp_last_updated dates will be the same. | [optional] [readonly]
**permissions_assignment** | **List[object]** | List of callables that define the new permissions to be created for new objects.This is deprecated. Use `creation_hooks` instead. | [optional]
**creation_hooks** | **List[object]** | List of callables that may associate user roles for new objects. | [optional]
**statements** | **List[object]** | List of policy statements defining the policy. |
**viewset_name** | **str** | The name of ViewSet this AccessPolicy authorizes. | [optional] [readonly]
**customized** | **bool** | True if the AccessPolicy has been user-modified. False otherwise. | [optional] [readonly]
**queryset_scoping** | **object** | A callable for performing queryset scoping. See plugin documentation for valid callables. Set to blank to turn off queryset scoping. | [optional]
## Example
```python
from pulpcore.client.pulpcore.models.access_policy_response import AccessPolicyResponse
# TODO update the JSON string below
json = "{}"
# create an instance of AccessPolicyResponse from a JSON string
access_policy_response_instance = AccessPolicyResponse.from_json(json)
# print the JSON string representation of the object
print(AccessPolicyResponse.to_json())
# convert the object into a dict
access_policy_response_dict = access_policy_response_instance.to_dict()
# create an instance of AccessPolicyResponse from a dict
access_policy_response_from_dict = AccessPolicyResponse.from_dict(access_policy_response_dict)
```
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
# AppStatusResponse
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**name** | **str** | The name of the worker. | [optional] [readonly]
**last_heartbeat** | **datetime** | Timestamp of the last time the worker talked to the service. | [optional] [readonly]
**versions** | **Dict[str, Optional[str]]** | Versions of the components installed. | [optional] [readonly]
## Example
```python
from pulpcore.client.pulpcore.models.app_status_response import AppStatusResponse
# TODO update the JSON string below
json = "{}"
# create an instance of AppStatusResponse from a JSON string
app_status_response_instance = AppStatusResponse.from_json(json)
# print the JSON string representation of the object
print(AppStatusResponse.to_json())
# convert the object into a dict
app_status_response_dict = app_status_response_instance.to_dict()
# create an instance of AppStatusResponse from a dict
app_status_response_from_dict = AppStatusResponse.from_dict(app_status_response_dict)
```
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
# ArtifactDistributionResponse
A serializer for ArtifactDistribution.
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**base_path** | **str** | The base (relative) path component of the published url. Avoid paths that overlap with other distribution base paths (e.g. \"foo\" and \"foo/bar\") |
**name** | **str** | A unique name. Ex, `rawhide` and `stable`. |
**content_guard** | **str** | An optional content-guard. | [optional]
**pulp_last_updated** | **datetime** | Timestamp of the last time this resource was updated. Note: for immutable resources - like content, repository versions, and publication - pulp_created and pulp_last_updated dates will be the same. | [optional] [readonly]
**no_content_change_since** | **str** | Timestamp since when the distributed content served by this distribution has not changed. If equals to `null`, no guarantee is provided about content changes. | [optional] [readonly]
**hidden** | **bool** | Whether this distribution should be shown in the content app. | [optional] [default to False]
**pulp_href** | **str** | | [optional] [readonly]
**prn** | **str** | The Pulp Resource Name (PRN). | [optional] [readonly]
**pulp_created** | **datetime** | Timestamp of creation. | [optional] [readonly]
**pulp_labels** | **Dict[str, Optional[str]]** | | [optional]
**base_url** | **str** | The URL for accessing the publication as defined by this distribution. | [optional] [readonly]
## Example
```python
from pulpcore.client.pulpcore.models.artifact_distribution_response import ArtifactDistributionResponse
# TODO update the JSON string below
json = "{}"
# create an instance of ArtifactDistributionResponse from a JSON string
artifact_distribution_response_instance = ArtifactDistributionResponse.from_json(json)
# print the JSON string representation of the object
print(ArtifactDistributionResponse.to_json())
# convert the object into a dict
artifact_distribution_response_dict = artifact_distribution_response_instance.to_dict()
# create an instance of ArtifactDistributionResponse from a dict
artifact_distribution_response_from_dict = ArtifactDistributionResponse.from_dict(artifact_distribution_response_dict)
```
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
# ArtifactResponse
Base serializer for use with [pulpcore.app.models.Model][] This ensures that all Serializers provide values for the 'pulp_href` field. The class provides a default for the ``ref_name`` attribute in the ModelSerializers's ``Meta`` class. This ensures that the OpenAPI definitions of plugins are namespaced properly.
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**pulp_href** | **str** | | [optional] [readonly]
**prn** | **str** | The Pulp Resource Name (PRN). | [optional] [readonly]
**pulp_created** | **datetime** | Timestamp of creation. | [optional] [readonly]
**pulp_last_updated** | **datetime** | Timestamp of the last time this resource was updated. Note: for immutable resources - like content, repository versions, and publication - pulp_created and pulp_last_updated dates will be the same. | [optional] [readonly]
**file** | **str** | The stored file. |
**size** | **int** | The size of the file in bytes. | [optional]
**md5** | **str** | The MD5 checksum of the file if available. | [optional]
**sha1** | **str** | The SHA-1 checksum of the file if available. | [optional]
**sha224** | **str** | The SHA-224 checksum of the file if available. | [optional]
**sha256** | **str** | The SHA-256 checksum of the file if available. | [optional]
**sha384** | **str** | The SHA-384 checksum of the file if available. | [optional]
**sha512** | **str** | The SHA-512 checksum of the file if available. | [optional]
## Example
```python
from pulpcore.client.pulpcore.models.artifact_response import ArtifactResponse
# TODO update the JSON string below
json = "{}"
# create an instance of ArtifactResponse from a JSON string
artifact_response_instance = ArtifactResponse.from_json(json)
# print the JSON string representation of the object
print(ArtifactResponse.to_json())
# convert the object into a dict
artifact_response_dict = artifact_response_instance.to_dict()
# create an instance of ArtifactResponse from a dict
artifact_response_from_dict = ArtifactResponse.from_dict(artifact_response_dict)
```
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
# pulpcore.client.pulpcore.ArtifactsApi
All URIs are relative to *https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com*
Method | HTTP request | Description
------------- | ------------- | -------------
[**create**](ArtifactsApi.md#create) | **POST** /api/pulp/{pulp_domain}/api/v3/artifacts/ | Create an artifact
[**delete**](ArtifactsApi.md#delete) | **DELETE** {artifact_href} | Delete an artifact
[**list**](ArtifactsApi.md#list) | **GET** /api/pulp/{pulp_domain}/api/v3/artifacts/ | List artifacts
[**read**](ArtifactsApi.md#read) | **GET** {artifact_href} | Inspect an artifact
# **create**
> ArtifactResponse create(pulp_domain, file, x_task_diagnostics=x_task_diagnostics, size=size, md5=md5, sha1=sha1, sha224=sha224, sha256=sha256, sha384=sha384, sha512=sha512)
Create an artifact
A customized named ModelViewSet that knows how to register itself with the Pulp API router. This viewset is discoverable by its name. \"Normal\" Django Models and Master/Detail models are supported by the ``register_with`` method. Attributes: lookup_field (str): The name of the field by which an object should be looked up, in addition to any parent lookups if this ViewSet is nested. Defaults to 'pk' endpoint_name (str): The name of the final path segment that should identify the ViewSet's collection endpoint. nest_prefix (str): Optional prefix under which this ViewSet should be nested. This must correspond to the \"parent_prefix\" of a router with rest_framework_nested.NestedMixin. None indicates this ViewSet should not be nested. parent_lookup_kwargs (dict): Optional mapping of key names that would appear in self.kwargs to django model filter expressions that can be used with the corresponding value from self.kwargs, used only by a nested ViewSet to filter based on the parent object's identity. schema (DefaultSchema): The schema class to use by default in a viewset.
### Example
* OAuth Authentication (json_header_remote_authentication):
* Basic Authentication (basicAuth):
* Api Key Authentication (cookieAuth):
```python
import pulpcore.client.pulpcore
from pulpcore.client.pulpcore.models.artifact_response import ArtifactResponse
from pulpcore.client.pulpcore.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com
# See configuration.py for a list of all supported configuration parameters.
configuration = pulpcore.client.pulpcore.Configuration(
host = "https://env-ephemeral-iicxpu.apps.crc-eph.r9lp.p1.openshiftapps.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure HTTP basic authorization: basicAuth
configuration = pulpcore.client.pulpcore.Configuration(
username = os.environ["USERNAME"],
password = os.environ["PASSWORD"]
)
# Configure API key authorization: cookieAuth
configuration.api_key['cookieAuth'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['cookieAuth'] = 'Bearer'
# Enter a context with an instance of the API client
with pulpcore.client.pulpcore.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = pulpcore.client.pulpcore.ArtifactsApi(api_client)
pulp_domain = 'pulp_domain_example' # str |
file = None # bytearray | The stored file.
x_task_diagnostics = ['x_task_diagnostics_example'] # List[str] | List of profilers to use on tasks. (optional)
size = 56 # int | The size of the file in bytes. (optional)
md5 = 'md5_example' # str | The MD5 checksum of the file if available. (optional)
sha1 = 'sha1_example' # str | The SHA-1 checksum of the file if available. (optional)
sha224 = 'sha224_example' # str | The SHA-224 checksum of the file if available. (optional)
sha256 = 'sha256_example' # str | The SHA-256 checksum of the file if available. (optional)
sha384 = 'sha384_example' # str | The SHA-384 checksum of the file if available. (optional)
sha512 = 'sha512_example' # str | The SHA-512 checksum of the file if available. (optional)
try:
# Create an artifact
api_response = api_instance.create(pulp_domain, file, x_task_diagnostics=x_task_diagnostics, size=size, md5=md5, sha1=sha1, sha224=sha224, sha256=sha256, sha384=sha384, sha512=sha512)
print("The response of ArtifactsApi->create:\n")
pprint(api_response)
except Exception as e:
print("Exception when calling ArtifactsApi->create: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**pulp_domain** | **str**| |
**file** | **bytearray**| The stored file. |
**x_task_diagnostics** | [**List[str]**](str.md)| List of profilers to use on tasks. | [optional]
**size** | **int**| The size of the file in bytes. | [optional]
**md5** | **str**| The MD5 checksum of the file if available. | [optional]
**sha1** | **str**| The SHA-1 checksum of the file if available. | [optional]
**sha224** | **str**| The SHA-22 | text/markdown | Pulp Team | pulp-list@redhat.com | null | null | GNU General Public License v2.0 or later | pulp, pulpcore, client, Pulp 3 API | [] | [] | null | null | null | [] | [] | [] | [
"urllib3<2.7,>=1.25.3",
"python-dateutil<2.10.0,>=2.8.1",
"pydantic>=2",
"typing-extensions>=4.7.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T18:42:21.970939 | crc_pulpcore_client-20260219.2.tar.gz | 453,816 | 66/29/35c28d16df46c14956aead60116dda4fa904abc230897acbbc3d785572d0/crc_pulpcore_client-20260219.2.tar.gz | source | sdist | null | false | 0e17123c7fa80b684f1e0f944d82834e | 067f606465e14c59d0eaad064b4d4c975eb206609e8123b38679c09e443c2ea4 | 662935c28d16df46c14956aead60116dda4fa904abc230897acbbc3d785572d0 | null | [] | 696 |
2.4 | pygidata | 0.4.5 | Python package providing an interface to the Gantner Instruments Data API | # pygidata
# Usage
### Install from PyPi
```bash
pip install pygidata
```
Import module in python script and call functions.
A detailed description of the package and other APIs can be found under [docs/](docs/Usage.ipynb) or in the
Gantner Documentation.
```python
from gi_data.dataclient import GIDataClient
import os
PROFILES = {
"qstation": {
"base": os.getenv("GI_QSTATION_BASE", "http://10.1.50.36:8090"),
"auth": {"username": os.getenv("GI_QSTATION_USER", "admin"),
"password": os.getenv("GI_QSTATION_PASS", "admin")},
},
"cloud": {
"base": os.getenv("GI_CLOUD_BASE", "https://demo.gi-cloud.io"),
"auth": {"access_token": os.getenv("GI_CLOUD_TOKEN", "")},
},
}
ACTIVE_PROFILE = os.getenv("GI_PROFILE", "qstation")
def get_client(profile: str = ACTIVE_PROFILE) -> GIDataClient:
cfg = PROFILES[profile]
if cfg["auth"].get("access_token"):
return GIDataClient(cfg["base"], access_token=cfg["auth"]["access_token"])
return GIDataClient(cfg["base"],
username=cfg["auth"].get("username"),
password=cfg["auth"].get("password"))
client = get_client()
```
# Development
### Used as submodule in
* gi-sphinx
* gi-jupyterlab
* gi-analytics-examples
### Information on how to manually distribute this package can be found here
https://packaging.python.org/en/latest/tutorials/packaging-projects/
**Hint:** If you are debugging the source code with a jupyter notebook, run this code in the `first cell` to enable autoreloading source code changes.
```bash
%load_ext autoreload
%autoreload 2
```
## Distribute with CI / CD
Edit pyproject.toml version number and create a release.
-> Creating a release will trigger the workflow to push the package to PyPi
## Tests
run tests locally:
```bash
pipenv run test -v
```
or
```bash
pytest
```
### Generate loose requirements
**Do this in a bash shell using the lowest version you want to support!**
Install uv to easily install all needed python versions (coss-platform)
``` bash
pip install uv
```
```bash
python -m pip install -U pip tox
```
```bash
python -m pip install pip-tools
```
```bash
python -m pip install pipreqs
```
To ensure we support multiple python versions we don't want to pin every dependency.
Instead, we pin everything on the lowest version (that we support) and make
it loose for every version above.
from root package dir (/gimodules-python)
```bash
./gen-requirements.sh
```
#### Ensure python-package version compatibility
```bash
uv python install 3.10 3.11 3.12 3.13 3.14
```
Now run for all envs
```bash
tox
```
of for a specific version only -> look what you defined in pyproject.toml
```bash
tox -e py310
```
---
**_NOTE:_** Remove the old gimodules version from requirements.txt before pushing (dependency conflict).
---
## Documentation
The documentation is being built as extern script in the GI.Sphinx repository.
The documentation consists of partially generated content.
To **generate .rst files** from the code package, run the following command from the root directory of the project:
```bash
sphinx-apidoc -o docs/source/ src
```
You need pandoc installed on the system itself first to build:
```bash
sudo apt install pandoc
```
Then, to **build the documentation**, run the following commands:
```bash
cd docs
sudo apt update
pip install -r requirements.txt
make html
```
## Linting / Type hints
This project follows the codestyle PEP8 and uses the linter flake8 (with line length = 100).
You can format and check the code using lint.sh:
```bash
./lint.sh [directory/]
```
Type hints are highly recommended.
Type hints in Python specify the expected data types of variables,
function arguments, and return values, improving code readability,
catching errors early, and aiding in IDE autocompletion.
To include type hints in the check:
```bash
mpypy=true ./lint.sh [directory])
```
| text/markdown | Gantner Instruments GmbH | null | null | null | null | python | [
"Development Status :: 1 - Planning",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Operating System :: Unix",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: W... | [] | null | null | <3.13,>=3.10 | [] | [] | [] | [
"aiokafka",
"certifi",
"httpx",
"nest_asyncio",
"pandas",
"pydantic",
"websockets",
"pytest; extra == \"test\"",
"pytest-xdist; extra == \"test\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.9.25 | 2026-02-19T18:42:02.262103 | pygidata-0.4.5.tar.gz | 25,164 | 6a/a0/403cbc94a9637e0be1e2fdef12cd5d2962c5b6c5a4673da2f937912d360c/pygidata-0.4.5.tar.gz | source | sdist | null | false | a0ed305c75697577241499b6672f9553 | 90120fc4f8888f23d7f6eb4a703299153d73a9a6adbcc89c3b63e02bfcaa8bb3 | 6aa0403cbc94a9637e0be1e2fdef12cd5d2962c5b6c5a4673da2f937912d360c | null | [
"LICENSE"
] | 222 |
2.4 | crowdstrike-aidr-google-genai | 0.2.0 | A wrapper around the Google GenAI Python SDK | # CrowdStrike AIDR + Google Gen AI SDK
A wrapper around the Google Gen AI SDK that wraps the Gemini API with
CrowdStrike AIDR. Supports Python v3.12 and greater.
## Installation
```bash
pip install -U crowdstrike-aidr-google-genai
```
## Usage
```python
import os
import crowdstrike_aidr_google_genai as genai
client = genai.CrowdStrikeAidrClient(
api_key=os.environ.get("GEMINI_API_KEY"),
crowdstrike_aidr_api_token=os.environ.get("CROWDSTRIKE_AIDR_API_TOKEN"),
crowdstrike_aidr_base_url_template=os.environ.get("CROWDSTRIKE_AIDR_BASE_URL_TEMPLATE"),
)
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="Explain how AI works in a few words",
)
print(response.text)
```
| text/markdown | CrowdStrike | CrowdStrike <support@crowdstrike.com> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"crowdstrike-aidr~=0.5.0",
"google-genai~=1.54.0",
"typing-extensions~=4.15.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:41:49.712012 | crowdstrike_aidr_google_genai-0.2.0.tar.gz | 3,917 | cf/1b/ca85fea6dbbd83bd24de682810caf446e8b11278cbd471ee50d5fc487440/crowdstrike_aidr_google_genai-0.2.0.tar.gz | source | sdist | null | false | 6dd35a76bf55c25197dddcf07b966efa | 631448a3137b26fac40289d8fe748cd4d0769c1ab607014e275e47be7e10a557 | cf1bca85fea6dbbd83bd24de682810caf446e8b11278cbd471ee50d5fc487440 | MIT | [] | 218 |
2.4 | honeybee-openstudio | 0.4.9 | Honeybee extension for translating HBJSON models to OpenStudio (for OSM, IDF and gbXML). | # honeybee-openstudio
[](https://github.com/ladybug-tools/honeybee-openstudio/actions)
[](https://www.python.org/downloads/release/python-3100/)
[](https://github.com/IronLanguages/ironpython2/releases/tag/ipy-2.7.8/)
 
Honeybee extension for translation to/from OpenStudio.
Specifically, this package extends [honeybee-core](https://github.com/ladybug-tools/honeybee-core) and [honeybee-energy](https://github.com/ladybug-tools/honeybee-energy) to perform translations to/from OpenStudio using the [OpenStudio](https://github.com/NREL/OpenStudio) SDK.
## Installation
`pip install -U honeybee-openstudio`
## QuickStart
```console
import honeybee_openstudio
```
## [API Documentation](http://ladybug-tools.github.io/honeybee-openstudio/docs)
## Local Development
1. Clone this repo locally
```console
git clone git@github.com:ladybug-tools/honeybee-openstudio
# or
git clone https://github.com/ladybug-tools/honeybee-openstudio
```
2. Install dependencies:
```
cd honeybee-openstudio
pip install -r dev-requirements.txt
pip install -r requirements.txt
```
3. Run Tests:
```console
python -m pytest tests/
```
4. Generate Documentation:
```console
sphinx-apidoc -f -e -d 4 -o ./docs ./honeybee_openstudio
sphinx-build -b html ./docs ./docs/_build/docs
```
| text/markdown | Ladybug Tools | info@ladybug.tools | null | null | AGPL-3.0 | null | [
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: Implementation :: CP... | [] | https://github.com/ladybug-tools/honeybee-openstudio | null | null | [] | [] | [] | [
"openstudio==3.10.0",
"honeybee-energy>=1.116.106; extra == \"base\"",
"honeybee-energy-standards==2.3.0; extra == \"standards\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.10.19 | 2026-02-19T18:41:19.808423 | honeybee_openstudio-0.4.9.tar.gz | 160,723 | 61/d3/e365d6c7c5440314ab3e644ae9d241ece529f7385714941517ffc63c8e35/honeybee_openstudio-0.4.9.tar.gz | source | sdist | null | false | 1d84beb498b4551f609b31825284074f | 2323655f7212a61159c60418181ed5233c822eebea9150ed9601b6989245b0d2 | 61d3e365d6c7c5440314ab3e644ae9d241ece529f7385714941517ffc63c8e35 | null | [
"LICENSE"
] | 373 |
2.4 | magicc-genome | 0.1.0 | MAGICC: Metagenome-Assembled Genome Inference of Completeness and Contamination | # MAGICC
**Metagenome-Assembled Genome Inference of Completeness and Contamination**
Ultra-fast genome quality assessment using core gene k-mer profiles and deep learning.
## Overview
MAGICC predicts **completeness** and **contamination** of metagenome-assembled genomes (MAGs) using a multi-modal deep neural network trained on 1,000,000 synthetic genomes. It combines:
- **9,249 core gene k-mer features** (canonical 9-mers from bacterial and archaeal core genes)
- **26 assembly statistics** (contig metrics, GC composition, k-mer summary statistics)
MAGICC achieves **~1,700x faster** processing per thread compared to CheckM2, while providing competitive accuracy and superior contamination detection -- particularly for cross-phylum contamination, chimeric assemblies, and underrepresented taxa.
## Key Results
| Tool | Comp MAE | Cont MAE | Speed (genomes/min/thread) |
|------|----------|----------|---------------------------|
| **MAGICC** | **2.79%** | **4.04%** | **~1,700** |
| CheckM2 | 6.08% | 27.71% | ~1.0 |
| CoCoPyE | 7.98% | 22.02% | ~0.8 |
| DeepCheck | 10.36% | 31.12% | ~0.8* |
*Evaluated on 3,200 benchmark genomes across controlled completeness/contamination gradients, Patescibacteria, and Archaea.*
## Installation
### From PyPI
```bash
pip install magicc-genome
```
### From source
```bash
git clone https://github.com/renmaotian/magicc.git
cd magicc
pip install -e .
```
**Note**: Git LFS is required to clone the repository (the ONNX model is ~180 MB). Install Git LFS first:
```bash
# Ubuntu/Debian
sudo apt-get install git-lfs
# macOS
brew install git-lfs
# Then initialize
git lfs install
```
### Dependencies
- Python >= 3.8
- numpy >= 1.20
- numba >= 0.53
- scipy >= 1.7
- h5py >= 3.0
- onnxruntime >= 1.10
## Quick Start
### Command Line
```bash
# Predict quality for all FASTA files in a directory
magicc predict --input /path/to/genomes/ --output predictions.tsv
# Single genome
magicc predict --input genome.fasta --output predictions.tsv
# Multi-threaded feature extraction
magicc predict --input /path/to/genomes/ --output predictions.tsv --threads 8
# Specify file extension
magicc predict --input /path/to/genomes/ --output predictions.tsv --extension .fa
```
### Python Module
```bash
python -m magicc predict --input /path/to/genomes/ --output predictions.tsv
```
### Output Format
The output is a tab-separated file with three columns:
| genome_name | pred_completeness | pred_contamination |
|-------------|-------------------|-------------------|
| genome_001 | 95.2341 | 2.1567 |
| genome_002 | 78.4521 | 15.3421 |
- **pred_completeness**: Predicted completeness (%) -- range [50, 100]
- **pred_contamination**: Predicted contamination (%) -- range [0, 100]
## CLI Options
```
magicc predict [OPTIONS]
Required:
--input, -i Path to genome FASTA file(s) or directory
--output, -o Output TSV file path
Optional:
--threads, -t Number of threads for feature extraction (default: 1)
--batch-size Batch size for ONNX inference (default: 64)
--extension, -x Genome file extension filter (default: .fasta)
--model Path to ONNX model file
--normalization Path to normalization parameters JSON
--kmers Path to selected k-mers file
--quiet, -q Suppress progress output
--verbose, -v Verbose debug output
```
## How It Works
### Feature Extraction
1. **K-mer counting**: For each genome, MAGICC counts occurrences of 9,249 pre-selected canonical 9-mers derived from bacterial (85 BCG) and archaeal (128 UACG) core genes. Raw counts (not frequencies) are used because counts reflect gene copy number and completeness.
2. **Assembly statistics**: 26 features computed in a single pass -- contig length metrics (N50, L50, etc.), GC composition statistics, distributional features (GC bimodality, outlier fraction), and k-mer summary statistics.
3. **Normalization**: K-mer features undergo log(count+1) transformation followed by Z-score standardization. Assembly statistics use feature-appropriate normalization (log10, min-max, or robust scaling).
### Neural Network Architecture
MAGICC uses a multi-branch fusion network with Squeeze-and-Excitation (SE) attention:
- **K-mer branch**: 9,249 -> 4,096 -> 1,024 -> 256 (with SE attention blocks)
- **Assembly branch**: 26 -> 128 -> 64
- **Cross-attention fusion**: Assembly features attend to k-mer embeddings
- **Output**: Completeness [50-100%] and contamination [0-100%]
The model was trained on 1,000,000 synthetic genomes (800K train / 100K validation / 100K test) derived from 100,000 high-quality GTDB reference genomes, with realistic fragmentation patterns and contamination scenarios spanning 0-100%.
### Speed
| Step | Time per genome | 100K genomes (1 thread) |
|------|----------------|------------------------|
| K-mer counting | ~18 ms | ~30 min |
| Assembly stats | ~20 ms | ~33 min |
| Normalization | ~0.25 ms | ~25 sec |
| ONNX inference | ~0.18 ms | ~18 sec |
| **Total** | **~38 ms** | **~63 min** |
## Benchmark Data
This repository includes benchmark datasets and predictions for reproducibility:
- **Motivating analysis** (`data/benchmarks/motivating_v2/`): Sets A, B, C demonstrating limitations of existing tools
- **Benchmark sets** (`data/benchmarks/set_{A_v2,B_v2,C,D,E}/`): Controlled completeness/contamination gradients, Patescibacteria, Archaea, and mixed genomes
- **100K test evaluation** (`data/benchmarks/test_100k/`): Large-scale test set results
Each set includes metadata (true labels) and prediction TSV files from MAGICC, CheckM2, CoCoPyE, and DeepCheck.
## Training Data
The model was trained on synthetic genomes with the following composition:
- 15% pure genomes (50-100% completeness, 0% contamination)
- 15% complete genomes (100% completeness, 0-100% contamination)
- 30% within-phylum contamination (1-3 contaminant genomes from same phylum)
- 30% cross-phylum contamination (1-5 contaminant genomes from different phyla)
- 5% reduced genome organisms (Patescibacteria, DPANN, symbionts)
- 5% archaeal genomes
## Repository Structure
```
magicc/ # Python package
cli.py # Command-line interface
kmer_counter.py # Numba-accelerated k-mer counting
assembly_stats.py # Assembly statistics computation
normalization.py # Feature normalization
model.py # Neural network architecture (PyTorch)
pipeline.py # Integrated pipeline
data/ # Bundled model and data files
magicc_v3.onnx # ONNX model (179.5 MB)
selected_kmers.txt # 9,249 selected k-mers
normalization_params.json
models/
magicc_v3.onnx # ONNX model (same as above)
data/
kmer_selection/
selected_kmers.txt # 9,249 canonical 9-mers
features/
normalization_params.json
benchmarks/ # Benchmark datasets (metadata + predictions)
scripts/ # Analysis and benchmarking scripts
results/ # Accuracy metrics and figures
manuscript/ # Manuscript figures
```
## Citation
If you use MAGICC in your research, please cite:
> Ren, M. (2026). MAGICC: Ultra-fast genome quality assessment using core gene k-mer profiles and deep learning. *In preparation*.
## License
MIT License. See [LICENSE](LICENSE) for details.
| text/markdown | Maotian Ren | null | null | null | MIT | metagenomics, genome-quality, MAG, completeness, contamination, deep-learning, bioinformatics | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: POSIX :: Linux",
"Operating System :: MacOS",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9... | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy>=1.20",
"numba>=0.53",
"scipy>=1.7",
"h5py>=3.0",
"onnxruntime>=1.10"
] | [] | [] | [] | [
"Homepage, https://github.com/renmaotian/magicc",
"Repository, https://github.com/renmaotian/magicc",
"Issues, https://github.com/renmaotian/magicc/issues"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T18:40:30.466829 | magicc_genome-0.1.0.tar.gz | 653,054 | 46/38/91c0377ff1ee3a30d575a8b03d7c322b0b14309cff9d4cff75b4a876639e/magicc_genome-0.1.0.tar.gz | source | sdist | null | false | 3b41bb2bbe3264f3e351a6f4fdd58e81 | 812794fe4981d230ff961ed2156351bf644e9792842ad91545018717aa560f7a | 463891c0377ff1ee3a30d575a8b03d7c322b0b14309cff9d4cff75b4a876639e | null | [
"LICENSE"
] | 151 |
2.4 | wgc-third-party | 1.0.1 | Third-party binary tools for WGC QA framework (7z, procdump, dummy games, etc.) | # wgc-third-party
Third-party binary tools packaged for the WGC QA framework.
> ⚠️ **This package is ~100MB** due to bundled binaries. Only install when needed for full test runs.
## Contents
| Binary | Purpose |
|---|---|
| `7z.exe` / `7z.dll` | Archive operations (patch extraction) |
| `procdump.exe` | Memory dump capture on crashes |
| `cdb.exe` / `cdb7.exe` / `windbg.exe` | Crash analysis debuggers |
| `make_torrent.exe` | Torrent file generation for game patches |
| `dummy_game_c#_*.exe` | Fake game binaries for testing (x86/x64, Steam, 360) |
| `sigcheck64.exe` | Digital signature verification |
| `Dbgview.exe` | Debug output monitor |
| `Listdlls.exe` / `pslist.exe` | Process inspection tools |
| `Procmon64.exe` | Process Monitor |
| `wdsdiff.exe` | Binary diff tool |
| `DeltaMAX.dll` | Delta patching library |
| `QRes.exe` | Screen resolution changer |
| `certutil.exe` / `signtool.exe` | Certificate and signing tools |
| `openh264-*.dll` | Video codec for screen recording |
| `wgc_gpu_hang*.dll` / `wgc_renderer_oom*.dll` | Crash injection DLLs for testing |
| `server.crt` / `server.key` | Self-signed SSL certificate for mock HTTPS |
## Usage
```python
from wgc_third_party import get_third_party_path
sevenzip = get_third_party_path('7z.exe')
# Returns: absolute path to 7z.exe within the installed package
```
## Install
```bash
pip install wgc-third-party
```
| text/markdown | null | Mykola Kovhanko <thuesdays@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: Microsoft :: Windows"
] | [] | null | null | >=3.7 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/thuesdays/wgc-third-party"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T18:40:27.441662 | wgc_third_party-1.0.1.tar.gz | 58,525,203 | cf/c6/2085f16c1f57b516331d6b3fc2d93017042c01d95c260a10ba3d7bc79002/wgc_third_party-1.0.1.tar.gz | source | sdist | null | false | 3114e2535c9407701a707271d1ce042b | 683cc36574fac2de622b83559748e2b903d07ce8e42d787fc2d6a14548b72f3a | cfc62085f16c1f57b516331d6b3fc2d93017042c01d95c260a10ba3d7bc79002 | null | [] | 255 |
2.4 | wgc-pages | 4.0.1 | Page Objects for WGC QA framework | # wgc-pages
Page Objects for the WGC QA framework. Provides high-level API for interacting with every page and dialog in Wargaming Game Center.
## Page Object Pattern
Each WGC screen is represented by a Python class with methods for user actions:
```python
from wgc_pages import PageArsenalCommon, PageArsenalLogin, PageArsenalInstalledGame
# Login
login_page = PageArsenalLogin(client)
login_page.login(email='test@test.com', password='pass123')
# Navigate to installed game
common = PageArsenalCommon(client)
common.open_game('WOT')
# Interact with game page
game_page = PageArsenalInstalledGame(client)
game_page.click_play()
game_page.wait_for_game_launch()
```
## Available Pages
### Arsenal Pages (New UI)
| Page | Class | Description |
|---|---|---|
| Common | `PageArsenalCommon` | Navigation, game list, sidebar, surveys |
| Login | `PageArsenalLogin` | Login forms (WG ID, OAuth, 2FA, Steam) |
| Registration | `PageArsenalRegistration` | Account registration, demo accounts |
| Installed Game | `PageArsenalInstalledGame` | Game management: play, update, repair, patches |
| Not Installed | `PageArsenalNotInstalledGame` | Game installation initiation |
| Game Settings | `PageArsenalGameSettings` | Game-specific settings (path, components) |
| Preinstall | `PageArsenalPreinstallSettings` | Pre-install configuration (path, components) |
| Settings | `PageArsenalSettings` | WGC application settings |
| Profile | `PageArsenalProfile` | User profile management |
| Shop | `PageArsenalShop` | In-app store, product browsing |
| Overlay | `PageArsenalOverlay` | In-game overlay UI |
| Notifications | `PageArsenalNotifications` | Notification center |
| Queue | `PageArsenalQueue` | Download queue management |
| Support | `PageArsenalSupport` | Support page |
| Legal Docs | `PageArsenalLegalDocs` | EULA, privacy policy |
| About | `PageArsenalAbout` | About dialog |
### Classic Pages
| Page | Class | Description |
|---|---|---|
| Common | `PageCommon` | Base page: login, account switching, Steam |
| Game | `PageGame` | Game management (classic UI) |
| Game Install | `PageGameInstall` | Game installation flow |
| Install by ID | `PageInstallById` | Install game via command line ID |
| Import | `PageImport` | Import existing game installations |
| Showroom | `PageShowroom` | Game showcase/storefront |
| Settings | `PageSettings` | WGC settings (classic) |
| Purchase | `PagePurchase` | Purchase flow |
| Overlay | `PageOverlay` | Overlay (classic) |
| Plugin | `PagePlugin` | Plugin page |
| Game News | `PageGameNews` | In-app news |
| About | `PageAbout` | About dialog |
| Legal Docs | `PageLegalDocs` | Legal documents |
## Install
```bash
pip install wgc-pages
```
## Dependencies
- `wgc-client` — WGCClient for UI interaction
- `wgc-core` — config, logger
- `wgc-helpers` — waiter, localization, requirements
| text/markdown | null | Mykola Kovhanko <thuesdays@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: Microsoft :: Windows"
] | [] | null | null | >=3.7 | [] | [] | [] | [
"wgc-client>=4.0.0",
"wgc-core>=4.0.0",
"wgc-helpers>=4.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/thuesdays/wgc-pages"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T18:40:23.120643 | wgc_pages-4.0.1.tar.gz | 86,453 | 46/85/817158062bf7d5e0d92d525f83abe28e01772524c9c39b1c33e997e46ba6/wgc_pages-4.0.1.tar.gz | source | sdist | null | false | 79e33ea552b72f36e351cb415ebb1821 | 6dae39d9768bba970df83f4641ca4ba863bf6ed158ada41940ac138650422941 | 4685817158062bf7d5e0d92d525f83abe28e01772524c9c39b1c33e997e46ba6 | null | [] | 231 |
2.4 | wgc-client | 4.0.1 | WGC Client for QA framework: WGCClient, WebSocket, UI elements, UI maps | # wgc-client
WGC Client package for the QA framework. Provides `WGCClient` — the main class for interacting with Wargaming Game Center through WebSocket, JavaScript injection, and Win32 API.
## Architecture
```
WGCClient
├── Process Management (Win32 API)
│ ├── start_wgc() / stop_wgc()
│ ├── Process monitoring (crash detection)
│ └── Window handle management
│
├── WebSocket Communication
│ ├── /websocket/wgc — main UI channel
│ ├── /websocket/overlay — overlay channel
│ ├── /websocket/game-overlay — in-game overlay
│ └── /websocket/news — news feed
│
├── UI Elements
│ ├── WebElement — CSS selectors via JS injection
│ └── NativeElement — Win32 Accessibility API
│
└── UI Maps (34 .ini files)
├── common.ini, arsenalcommon.ini
├── arsenallogin.ini, arsenalshop.ini
└── ... (page-specific element maps)
```
## Usage
```python
from wgc_client import WGCClient
# Initialize and start WGC
client = WGCClient()
client.run_game_center()
# Get UI elements
login_btn = client.get_wgc_element('button_login')
login_btn.click()
# Web elements (CSS selectors via WebSocket)
email_field = client.get_wgc_element('input_email')
email_field.set_text('user@test.com')
email_field.react_set_text('user@test.com') # React-specific
# Native elements (Win32 API)
dialog = client.get_native_element('install_dialog')
dialog.click()
# Element properties
text = login_btn.get_text()
visible = login_btn.is_element_displayed
attrs = login_btn.get_attribute('class')
```
## UI Element Types
### WebElement
Interacts with Chromium UI via JavaScript injection over WebSocket:
- `click()`, `react_click()` — click via JS dispatchEvent
- `set_text()`, `react_set_text()` — input via nativeInputValueSetter
- `get_text()` — read innerText
- `get_attribute()` — read DOM attributes
- `is_element_displayed` — visibility check via offsetParent
### NativeElement
Interacts with native Windows UI via Win32 Accessibility API:
- `click()` — mouse_event at element coordinates
- `get_text()` — read acc_value via UISoup
- `set_text()` — set_value via UISoup
- For native dialogs, file pickers, OS-level windows
## UI Maps
Element selectors are defined in `.ini` files:
```ini
[common]
button_login = .login-button
input_email = input[name="email"]
game_list = .game-list-container
```
Parsed by `UIMapParser` and accessed via `client.get_wgc_element('button_login')`.
## Install
```bash
pip install wgc-client
```
## Dependencies
- `wgc-core`, `wgc-helpers`, `wgc-mocks`, `wgc-clippy`
- `websocket-client` — WebSocket communication
- `pywin32` — Win32 API
- `uisoup`, `uiautomation` — Windows UI automation
- `ui-map-parser` — INI-based UI map parsing
| text/markdown | null | Mykola Kovhanko <thuesdays@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: Microsoft :: Windows"
] | [] | null | null | >=3.7 | [] | [] | [] | [
"wgc-core>=4.0.0",
"wgc-helpers>=4.0.0",
"wgc-mocks>=4.0.0",
"wgc-clippy>=1.0.0",
"websocket-client",
"pywin32>=306",
"uisoup",
"uiautomation",
"ui-map-parser==1.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/thuesdays/wgc-client"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T18:40:11.971488 | wgc_client-4.0.1.tar.gz | 65,440 | 18/96/55b069337c8b2026653fefdfefc9c1c5dd978629eb10e7be0484212205e8/wgc_client-4.0.1.tar.gz | source | sdist | null | false | 56f9edc4f18a7cf1d2b5e2c5420f5aec | c3437e2a2768baee358fdacafb2e43112060a63aa69ce7fe7c277f6ee19b3029 | 189655b069337c8b2026653fefdfefc9c1c5dd978629eb10e7be0484212205e8 | null | [] | 242 |
2.4 | f2xba | 1.9.9 | f2xba modelling framework: from FBA to extended genome-scale modelling | # Welcome to f2xba\'s documentation
## f2xba modelling framework: from FBA to extended genome-scale modelling
In the domain of systems biology, the **f2xba** modeling framework has
been developed for the purpose of generating a variety of extended
genome-scale metabolic model types using simple and consistent
workflows. This modeling framework was developed at the research group
for [Computational Cell Biology
(CCB)](https://www.cs.hhu.de/en/research-groups/computational-cell-biology)
at Heinrich-Heine-University Düsseldorf, Germany.
The CCB research group has developed a suite of [software
tools](https://www.cs.hhu.de/en/research-groups/computational-cell-biology/software-contributions)
to facilitate genome-scale metabolic modeling. Sybil is an R package
that utilizes genome-scale metabolic network optimization through the
use of flux balance analysis (FBA)-based methods. SybilccFBA is an
extension designed to enhance the optimization of enzyme constraint
models. [TurNuP](https://turnup.cs.hhu.de/Kcat) is a machine learning
model that predicts turnover numbers, which are required to parametrize
extended genome-scale models.
[smblxdf](https://sbmlxdf.readthedocs.io/en/latest/) is a Python package
that converts between SBML coded genome-scale metabolic models and
tabular formats. It is used to create and modify SBML coded models, as
well as to access model information.
## Extended model types
f2xba support generation of enzyme constraint models, such as GECKO
([Sánchez et al.,
2017](https://doi.org/https://doi.org/10.15252/msb.20167411)),
ccFBA[^1], MOMENT ([Adadi et al.,
2012](https://doi.org/10.1371/journal.pcbi.1002575)) and MOMENTmr[^2],
resource balance constraint RBA models ([Bulović et al.,
2019](https://doi.org/https://doi.org/10.1016/j.ymben.2019.06.001);
[Goelzer et al.,
2011](https://doi.org/https://doi.org/10.1016/j.automatica.2011.02.038)),
and thermodynamics constraint models, such as TFA ([Henry et al.,
2007](https://doi.org/10.1529/biophysj.106.093138); [Salvy et al.,
2019](https://doi.org/10.1093/bioinformatics/bty499)) and TGECKO
(thermodynamic GECKO) and TRBA (thermodynamic RBA). These advanced model
types, which have been developed in recent years, are based on existing
genome-scale metabolic models used for FBA (flux balance analysis), a
methodology that has been utilized for decades ([Watson,
1986](https://doi.org/10.1093/bioinformatics/2.1.23)). Genome-scale
metabolic models can be obtained from databases such as the BiGG models
database ([King, Lu, et al.,
2015](https://doi.org/10.1093/nar/gkv1049)), or retrieved from
publications.
## Relevance of extended modelling
The advent of high-throughput data has led to a growing importance of
these extended models. Fundamentally, FBA can be regarded as a predictor
of the macroscopic behavior of metabolic networks, while extended models
offer insights into the intricate functioning of these networks.
Extended models contain considerably more parameters. While some of
these additional parameters require definition, the majority are
automatically retrieved from online databases and tools, including NCBI,
UniProt, BioCyc, and TurNuP ([Kroll et al.,
2023](https://doi.org/10.1038/s41467-023-39840-4)). The development of
these extended models and the enhancement of their parameters can be
facilitated through simple and consistent workflows. Furthermore, the
sharing of configuration data among different model types is encouraged.
All extended models are exported in stand-alone SBML (Systems Biology
Markup Language) coded files ([Hucka et al.,
2019](https://doi.org/10.1515/jib-2019-0021)) to facilitate model
sharing and processing by downstream tools, such as cobrapy ([Ebrahim et
al., 2013](https://doi.org/10.1186/1752-0509-7-74)). Additionally, the
f2xba modeling framework provides optimization support via cobrapy or
gurobipy interfaces. Optimization results are structured and enriched
with additional data. This includes tables for each variable type,
correlation plots, and exports to [Esher](https://escher.github.io)
([King, Dräger, et al.,
2015](https://doi.org/10.1371/journal.pcbi.1004321)). This facilitates
interpretation of model predictions and supports workflows for model
parameter adjustments.
## Integrated solution
Research groups have already developed tools to support extended
genome-scale modeling. These tools have been implemented in various
programming environments, each exhibiting a distinct approach to model
parametrization, generation, and optimization. However, none of these
tools generate stand-alone models coded in SBML. ccFBA and MOMENT
modeling is supported by the R package
[sybilccFBA](https://cran.r-project.org/src/contrib/Archive/sybilccFBA/),
GECKO modeling by the MATLAB package
[geckomat](https://github.com/SysBioChalmers/GECKO/tree/main/src), RBA
modeling by the Python package
[RBApy](https://sysbioinra.github.io/RBApy/installation.html), and
thermodynamics modeling by the Python package
[pyTFA](https://pytfa.readthedocs.io/en/latest/index.html). f2xba is the
first integrated tool to support model generation of various extended
model types within a single programming environment, compatible model
parametrizations, shareable configuration files, and consistent
workflows for both model generation and optimization. The resulting
models are exported to files and are fully compliant with the SBML
standard. Furthermore, all annotation data from the original
genome-scale (FBA) model is carried over. Depending on the availability
of organism-specific data and actual requirements, different extended
model types and differently parametrized versions of a target organism
can be generated with relative ease. It is our hope that the f2xba
modeling framework will support the community in actively using these
extended model types, which have been published in the previous few
years.
## Tutorials
The documentation includes a set of tutorials with detailed
descriptions, where different types of extended models are created based
on the most recent genome-scale metabolic network reconstruction of
*Escherichia coli*, iML1515 ([Monk et al.,
2017](https://doi.org/10.1038/nbt.3956)). Similar jupyter notebooks are
available upon request for the generation of extended models based on
yeast9 ([Zhang et al.,
2024](https://doi.org/10.1038/s44320-024-00060-7)), *Saccharomyces
cerevisiae*, iJN678 ([Nogales et al.,
2012](https://doi.org/10.1073/pnas.1117907109)), *Synechocystis* sp. PCC
6803, and MMSYN ([Breuer et al.,
2019](https://doi.org/10.7554/eLife.36842)), the synthetic cell
JCVI-Syn3A based on *Mycoplasma mycoides capri*.
## Outlook
Growth balance analysis (GBA) ([Dourado & Lercher,
2020](https://doi.org/10.1038/s41467-020-14751-w)) modeling is an active
research project in CCB. In GBA models, reaction fluxes are coupled with
protein requirements using non-linear kinetic functions, where enzyme
saturation depends on variable metabolite concentrations. We have
previously demonstrated the generation of small, schematic GBA models in
SBML, the loading of these models from SBML, and the optimization of
them using non-linear solvers. However, the optimization of genome-scale
GBA models remains challenging. Once this optimization problem is
resolved, f2xba could be extended to support GBA model generation, e.g.,
by extending GECKO or RBA configuration data, and GBA model
optimization, either using nonlinear optimization features available in
gurobi 12 or using a dedicated nonlinear solver like IPOP.
References:
[^1]: Desouki, A. A. (2015). sybilccFBA: Cost Constrained FLux Balance
Analysis: MetabOlic Modeling with ENzyme kineTics (MOMENT). In CRAN.
<https://cran.r-project.org/web/packages/sybilccFBA/index.html>
[^2]: Desouki, A. A. (2015). sybilccFBA: Cost Constrained FLux Balance
Analysis: MetabOlic Modeling with ENzyme kineTics (MOMENT). In CRAN.
<https://cran.r-project.org/web/packages/sybilccFBA/index.html>
| text/markdown | Peter Schubert | peter.schubert@hhu.de | null | null | GPLv3 | systems biology, extended metabolic modeling, FBA, GECKO, RBA, TFA, SBML, Gurobi | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)",
"Operating System :: OS Independent",
"Topic :: Scientific/Engineering :: Bio-Informatics"
] | [] | https://www.cs.hhu.de/lehrstuehle-und-arbeitsgruppen/computational-cell-biology | null | >=3.11 | [] | [] | [] | [
"pandas>=2.3.0",
"numpy>=2.0.0",
"scipy>=1.11.0",
"requests>=2.30.0",
"matplotlib>=3.6.3",
"sbmlxdf>=1.0.2"
] | [] | [] | [] | [
"Source Code, https://github.com/SchubertP/f2xba",
"Documentation, https://f2xba.readthedocs.io",
"Bug Tracker, https://github.com/SchubertP/f2xba/issues"
] | twine/6.2.0 CPython/3.12.0 | 2026-02-19T18:39:50.861334 | f2xba-1.9.9.tar.gz | 196,961 | 04/28/8d877360ade95bcd978a1267e4ec94eeceaa90f243dce4f38a456efc6982/f2xba-1.9.9.tar.gz | source | sdist | null | false | f933c4a36123502b44372cb55aa1dd62 | 37d72b73295761f75ba50c4991cf8c0e588e24dc09a865777c23be84b41bcfa8 | 04288d877360ade95bcd978a1267e4ec94eeceaa90f243dce4f38a456efc6982 | null | [
"LICENSE.txt"
] | 211 |
2.4 | toc-markdown | 0.1.0 | Generate a table of contents for a Markdown file. | # Markdown Table of Contents Generator
Generates a table of contents (TOC) for Markdown files. Detects headers and creates a linked TOC. Updates existing TOCs in-place when markers are present; otherwise prints to stdout.

<!-- TOC -->
## Table of Contents
1. [Quick Start](#quick-start)
1. [Features](#features)
1. [Installation](#installation)
1. [Usage](#usage)
1. [Configuration](#configuration)
1. [Integration with Vim](#integration-with-vim)
<!-- /TOC -->
## Quick Start
Add TOC markers to your Markdown file:
```md
<!-- TOC -->
<!-- /TOC -->
```
Run:
```bash
toc-markdown README.md
```
The TOC appears between the markers. Run again to update.
Without markers, the TOC prints to stdout for manual insertion.
## Features
* Generates a table of contents from Markdown headers.
* Updates existing TOCs between markers or prints to stdout.
* Supports headings from levels 2 to 3 by default (configurable).
* Provides clickable links to sections.
* Preserves file structure and formatting.
## Installation
**Requirements**: Python 3.11+
Using `uv` (recommended):
```bash
uv tool install toc-markdown
```
Using `pip`:
```bash
pip install toc-markdown
```
## Usage
Run `toc-markdown` on a `.md` or `.markdown` file:
```bash
# Update file in-place (requires TOC markers)
toc-markdown path/to/file.md
# Print TOC to stdout (no markers in file)
toc-markdown path/to/file.md
# Customize header levels
toc-markdown README.md --min-level 1 --max-level 4
# Change list style
toc-markdown README.md --list-style "*"
toc-markdown README.md --list-style "-"
# Custom header text
toc-markdown README.md --header-text "## Contents"
# Preserve Unicode in slugs
toc-markdown README.md --preserve-unicode
# Custom indentation
toc-markdown README.md --indent-chars " "
# Custom markers
toc-markdown README.md --start-marker "<!-- BEGIN TOC -->" --end-marker "<!-- END TOC -->"
```
### Safety Limits
* Only regular Markdown files (`.md`, `.markdown`) are accepted.
* Run from the directory tree that owns the target file. Files outside the working directory are rejected.
* Symlinks are refused.
* Files larger than 10 MiB are rejected. Increase via `max_file_size` in config or `TOC_MARKDOWN_MAX_FILE_SIZE` environment variable (up to 100 MiB).
* Lines longer than 10,000 characters are rejected. Increase via `max_line_length` in config or `TOC_MARKDOWN_MAX_LINE_LENGTH` environment variable.
* Files with more than 10,000 headers are rejected. Increase via `max_headers` in config.
* Files must be valid UTF-8.
* Updates use atomic writes via temporary files.
Run `toc-markdown --help` for all options.
## Configuration
Create `.toc-markdown.toml` in your project root:
```toml
[toc-markdown]
min_level = 2
max_level = 3
list_style = "1."
```
### Options
| Option | Default | Description |
|--------|---------|-------------|
| `start_marker` | `<!-- TOC -->` | Opening marker |
| `end_marker` | `<!-- /TOC -->` | Closing marker |
| `header_text` | `## Table of Contents` | TOC heading |
| `min_level` | `2` | Minimum header level to include |
| `max_level` | `3` | Maximum header level to include |
| `list_style` | `1.` | Bullet style: `1.`, `*`, `-`, `ordered`, `unordered` |
| `indent_chars` | ` ` (4 spaces) | Indentation for nested entries |
| `indent_spaces` | `null` | Alternative to `indent_chars`; sets spaces count |
| `preserve_unicode` | `false` | Keep Unicode in slugs |
| `max_file_size` | `10485760` (10 MiB) | Maximum file size in bytes |
| `max_line_length` | `10000` | Maximum line length |
| `max_headers` | `10000` | Maximum headers to process |
CLI flags override config file values.
## Integration with Vim
Example mapping (for files with TOC markers):
```vim
autocmd FileType markdown nnoremap <buffer> <leader>t :w<cr>:silent !toc-markdown %:p<cr>:e<cr>
```
Press `<leader>t` in normal mode to save, update the TOC, and reload the buffer.
For files without markers (insert TOC at cursor):
```vim
autocmd FileType markdown nnoremap <buffer> <leader>T :r !toc-markdown %:p<cr>
```
| text/markdown | Sébastien De Revière | null | null | null | Apache License Version 2.0, January 2004 http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION 1. Definitions. "License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document. "Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License. "Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity. "You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License. "Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types. "Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below). "Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof. "Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution." "Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work. 2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form. 3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed. 4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions: (a) You must give any other recipients of the Work or Derivative Works a copy of this License; and (b) You must cause any modified files to carry prominent notices stating that You changed the files; and (c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and (d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License. 5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions. 6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file. 7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License. 8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages. 9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability. END OF TERMS AND CONDITIONS APPENDIX: How to apply the Apache License to your work. To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives. Copyright [yyyy] [name of copyright owner] Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. | null | [
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.1... | [] | null | null | >=3.11 | [] | [] | [] | [
"click"
] | [] | [] | [] | [
"Documentation, https://github.com/sderev/toc-markdown",
"Issues, https://github.com/sderev/toc-markdown/issues",
"Changelog, https://github.com/sderev/toc-markdown/releases"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T18:39:15.736290 | toc_markdown-0.1.0.tar.gz | 80,623 | 83/d4/f4fef64a76a3d252fa3940fe11923e5ffb9bc3bed4a79dfb1ef572624fef/toc_markdown-0.1.0.tar.gz | source | sdist | null | false | 51403b6f54cda881d88bcb815778ca5f | efe0e21e73186c95357deeef27cb3dfca32f05c5ed82d398beb6a727af5c6738 | 83d4f4fef64a76a3d252fa3940fe11923e5ffb9bc3bed4a79dfb1ef572624fef | null | [
"LICENSE"
] | 210 |
2.4 | hashgrid | 0.5.4 | Hashgrid Client - Python SDK | # Hashgrid Client
Python SDK for the Hashgrid Protocol API.
## Installation
```bash
pip install hashgrid
```
## Quick Start
```python
import asyncio
from hashgrid import Hashgrid, Message
async def main():
# Connect to grid
grid = await Hashgrid.connect(api_key="your-api-key")
# Get ticks and process messages
while True:
await grid.poll()
async for node in grid.nodes():
messages = await node.recv()
if not messages:
continue
replies = [
Message(
peer_id=msg.peer_id,
round=msg.round,
message="Hello, fellow grid peer!",
score=0.9,
)
for msg in messages
]
await node.send(replies)
asyncio.run(main())
```
## Resources
The SDK provides the following resources:
- **`Grid`** - Grid connection with `poll()` and `nodes()` methods
- **`Node`** - Node with `recv()`, `send()`, `update()`, and `delete()` methods
- **`Edge`** - Edge data model
- **`User`** - User data model
- **`Quota`** - Quota data model
- **`Message`** - Message for recv/send operations
## Example
See `examples/` for some examples of agents.
## Error Handling
```python
from hashgrid import (
HashgridError,
HashgridAPIError,
HashgridAuthenticationError,
HashgridNotFoundError,
HashgridValidationError,
)
try:
grid = await Hashgrid.connect(api_key="invalid-key")
except HashgridAuthenticationError:
print("Authentication failed")
except HashgridAPIError as e:
print(f"API error: {e}")
```
## API Reference
For detailed API documentation, see the official Hashgrid DNA documentation.
## License
MIT
| text/markdown | Hashgrid | null | null | null | MIT | hashgrid, client, sdk | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"httpx"
] | [] | [] | [] | [
"Homepage, https://hashgrid.ai",
"Documentation, https://dna.hashgrid.ai/docs"
] | twine/6.2.0 CPython/3.13.2 | 2026-02-19T18:38:14.708565 | hashgrid-0.5.4.tar.gz | 11,479 | 70/63/ec51db773d893c825bd40e72d86993cafa9ef3c955cbfdea3d3f572fe1d8/hashgrid-0.5.4.tar.gz | source | sdist | null | false | 9b7bba2df695300acf0b1df7f6c03543 | 939d75304964d8dd27d0b18ac0b04a515215b23406d6842810464c6f1675cc04 | 7063ec51db773d893c825bd40e72d86993cafa9ef3c955cbfdea3d3f572fe1d8 | null | [] | 219 |
2.4 | dataprism | 0.1.1 | A Python library for exploratory data analysis with advanced statistical features | # DataPrism
A comprehensive Python library for exploratory data analysis with advanced features for data profiling, quality assessment, and stability monitoring.
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
## Interactive Viewer
DataPrism includes a built-in interactive dashboard to explore your analysis results in the browser.
```python
from dataprism import DataPrism, DataLoader
# Load data from CSV or Parquet
df = DataLoader.load_csv("data.csv")
# df = DataLoader.load_parquet("data.parquet")
# Run analysis and launch viewer
prism = DataPrism()
prism.analyze(
data=df,
target_variable="target",
exclude_columns=["id", "split", "onboarding_date"],
output_path="eda_results.json",
)
prism.view()
```
**Summary** — Dataset overview, insights, top features by IV, data quality score, and provider match rates.

**Catalog** — Sortable feature table with type, provider, target correlation, IV, and PSI at a glance.

**Deep Dive** — Per-feature detail view with statistics, violin plots, distribution charts, PSI trend analysis, target associations, and correlations.

**Associations** — Mixed-method heatmap (Pearson, Theil's U, Eta) showing relationships across all features.

## How DataPrism Compares
| Feature | DataPrism | Sweetviz | ydata-profiling | AutoViz | D-Tale | DataPrep |
| ---------------------------- | :-------------------------------: | :--------------: | :-------------------------------: | :-----: | :----------: | :------------------------: |
| Programmatic API | Yes | Yes | Yes | Yes | Yes | Yes |
| Interactive Viewer | Yes | Yes | Yes | Partial | Yes | Yes |
| Correlation Analysis | Pearson, Spearman, Theil's U, Eta | Pearson, UC, Eta | Pearson, Spearman, Kendall, Phi-k | Pearson | Pearson, PPS | Pearson, Spearman, Kendall |
| Histogram / Bar Chart | Yes | Yes | Yes | Yes | Yes | Yes |
| Box Plot | Yes | — | Yes | — | Yes | Yes |
| Association Heatmap | Yes | Yes | Yes | — | Yes | Yes |
| Target-Overlaid Distribution | Yes | Yes | — | — | — | — |
| Scatter / Pair Plot | — | — | Yes | Yes | Yes | Yes |
| Violin Plot | Yes | — | — | Yes | — | — |
| Time Series / Trend | Yes | — | Yes | — | Yes | — |
| Schema-Driven Analysis | Yes | Partial | Yes | — | Partial | Partial |
| Mixed-Type Associations | Yes | Yes | Yes | — | Partial | Partial |
| Structured JSON Export | Yes | — | Yes | — | Partial | — |
| **Target Analysis (IV/WoE)** | **Yes** | — | — | — | — | — |
| **Drift / PSI Stability** | **Yes** | — | — | — | — | — |
| **Data Quality Score** | **Yes** | — | — | — | — | — |
| **Sentinel Value Handling** | **Yes** | — | — | — | — | — |
| **Provider Match Rates** | **Yes** | — | — | — | — | — |
**Where DataPrism leads:** Schema-aware profiling with column roles and sentinel codes, IV/WoE for credit risk, PSI-based stability monitoring (cohort + time-based), automated data quality scoring, and provider-level match rates. No other EDA library covers these out of the box.
**Where DataPrism lags:** No dataset comparison (train vs test side-by-side), no auto-visualization per feature, and no Spark/Dask support for distributed datasets. These are on the roadmap.
## Roadmap
DataPrism is being built for the AI era — where data analysis is increasingly driven by LLM agents, automated pipelines, and programmatic consumers rather than humans clicking through dashboards.
### AI-Native Analysis
- **LLM-consumable output** — Structured JSON output designed for AI agents to read, reason about, and act on. No screen-scraping HTML reports or parsing PDFs.
- **Natural language insights** — Auto-generated plain-English summaries of each feature, anomalies, and recommendations that LLMs can directly incorporate into reports.
- **Agent-friendly API** — Minimal, predictable interface (`analyze()` → `view()`) that AI coding assistants can invoke without ambiguity. Schema-driven configuration over magic defaults.
### Closing the Gaps
- **Dataset comparison** — Side-by-side train/test/production profiling with automatic drift highlights.
- **Scatter & pair plots** — Interactive scatter matrices for continuous feature pairs with target coloring.
- **Auto-visualization** — One-line generation of per-feature visual summaries exportable as images.
- **Spark/Dask support** — Distributed computation for datasets that don't fit in memory.
- **Streaming analysis** — Incremental profiling for real-time data pipelines without re-analyzing the full dataset.
### Deeper Intelligence
- **Automated feature recommendations** — Go beyond flagging issues to suggesting transformations (log, binning, encoding) based on distribution shape and target relationship.
- **Anomaly explanations** — When outliers or drift are detected, surface the likely cause (data pipeline issues, population shift, seasonality).
- **Cross-dataset lineage** — Track how feature distributions evolve across model versions and data refreshes.
## Features
- **Automated Feature Analysis** — Continuous and categorical profiling with automatic type inference and missing value detection
- **Target Relationship Analysis** — Information Value (IV), Weight of Evidence (WoE), optimal binning, predictive power classification
- **Correlation & Association Analysis** — Pearson, Spearman, Theil's U, Eta with unified association matrix across all feature types
- **Quality Assessment** — Automated scoring (0-10), per-feature quality flags, actionable recommendations
- **Sentinel Value Handling** — Automatic detection and replacement of no-hit values with nullable type preservation
- **Cohort-Based Stability** — PSI and KS test for train/test drift detection
- **Time-Based Stability** — Monthly, weekly, quartile, or custom time windows with temporal trend analysis
- **Provider Match Rates** — Automatic data coverage statistics by provider
- **Large Dataset Support** — CSV and Parquet formats, chunked reading, configurable sampling
## Installation
```bash
pip install dataprism
```
## Quick Start
### Basic Usage
```python
from dataprism import DataPrism, DataLoader
import pandas as pd
# Option 1: Load from file using DataLoader
df = DataLoader.load_csv("data.csv")
# Option 2: Use existing DataFrame
df = pd.read_csv("data.csv") # or from database, etc.
# Initialize prism
prism = DataPrism(
max_categories=50,
top_correlations=10
)
# Run analysis (exclude non-feature columns when no schema is available)
results = prism.analyze(
data=df,
exclude_columns=["customer_id", "created_at"],
target_variable="target",
output_path="eda_results.json"
)
```
### With DatasetSchema
```python
from dataprism import (
DataPrism, DataLoader,
ColumnConfig, ColumnType, ColumnRole, Sentinels, DatasetSchema,
)
# Load data and schema
df = DataLoader.load_csv("data.csv")
schema = DataLoader.load_schema("schema.json")
# Or create schema programmatically
schema = DatasetSchema([
ColumnConfig('age', ColumnType.CONTINUOUS, ColumnRole.FEATURE,
provider='demographics', description='User age',
sentinels=Sentinels(not_found='-1')),
ColumnConfig('zip_code', ColumnType.CATEGORICAL, ColumnRole.FEATURE,
provider='address', description='ZIP code',
sentinels=Sentinels(not_found='', missing='00000')),
ColumnConfig('target', ColumnType.BINARY, ColumnRole.TARGET),
])
# Run with schema
prism = DataPrism()
results = prism.analyze(
data=df,
schema=schema,
target_variable="target",
output_path="eda_results.json"
)
```
**Schema JSON format** (`schema.json`):
```json
{
"columns": [
{
"name": "age",
"type": "continuous",
"role": "feature",
"provider": "demographics",
"description": "User age",
"sentinels": {
"not_found": "-1",
"missing": null
}
}
]
}
```
### Stability Analysis
#### Cohort-Based (Train/Test)
```python
from dataprism import DataPrism, DataLoader
# Load data and schema
df = DataLoader.load_parquet("data.parquet")
schema = DataLoader.load_schema("schema.json")
# Configure for stability analysis
prism = DataPrism(
calculate_stability=True,
cohort_column='dataTag',
baseline_cohort='training',
comparison_cohort='test'
)
results = prism.analyze(
data=df,
schema=schema
)
```
#### Time-Based
```python
from dataprism import DataPrism, DataLoader
# Load data and schema
df = DataLoader.load_parquet("data.parquet")
schema = DataLoader.load_schema("schema.json")
# Configure for time-based stability
prism = DataPrism(
time_based_stability=True,
time_column='onboarding_time',
time_window_strategy='monthly', # or 'weekly', 'quartiles', 'custom'
baseline_period='first',
comparison_periods='all',
min_samples_per_period=100
)
results = prism.analyze(
data=df,
schema=schema
)
```
## Development
```bash
pip install -e . # Install for development
python -m build # Build package
python -m pytest tests/ # Run tests
```
## Documentation
- [Architecture](docs/ARCHITECTURE.md) — internals, module structure, data flow
- [Usage Guide](docs/USAGE.md) — advanced configuration, provider match rates, feature counts reference
- [Decision Records](docs/decisions/) — key design decisions and rationale
- [Examples](examples/) — usage examples and demos
## Requirements
- Python 3.9+
- pandas >= 2.0.0
- numpy >= 1.24.0
- scipy >= 1.10.0
- pyarrow >= 10.0.0 (for Parquet support)
## License
MIT License - see [LICENSE](LICENSE) file for details.
## Contact
For questions or suggestions:
- Email: dev@lattiq.com
- GitHub: [https://github.com/lattiq/dataprism](https://github.com/lattiq/dataprism)
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
| text/markdown | null | LattIQ Development Team <dev@lattiq.com> | null | null | MIT | data analysis, exploratory data analysis, eda | [
"Development Status :: 2 - Pre-Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: P... | [] | null | null | >=3.9 | [] | [] | [] | [
"pandas<3.0.0,>=2.0.0",
"numpy<2.0.0,>=1.24.0",
"scipy<2.0.0,>=1.10.0",
"pyarrow>=10.0.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest-xdist>=3.0.0; extra == \"dev\"",
"pytest-benchmark>=4.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"ruff>=0.1.0... | [] | [] | [] | [
"Homepage, https://github.com/lattiq/dataprism",
"Repository, https://github.com/lattiq/dataprism"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:38:10.284408 | dataprism-0.1.1.tar.gz | 89,466 | c9/39/31f7ab1ac6d8ce51ef95c28c50b46155d167ad644117810b265fcdcb778a/dataprism-0.1.1.tar.gz | source | sdist | null | false | 2023a9983b41959d63cb082d33b2d384 | 4c8d4d5f2a53d677f5deff7649499f8921bfc2efb7cc88d7f8115bce6388689b | c93931f7ab1ac6d8ce51ef95c28c50b46155d167ad644117810b265fcdcb778a | null | [
"LICENSE"
] | 213 |
2.4 | devmemory | 0.1.11 | Sync AI coding context from Git AI to Redis Agent Memory Server for semantic search and recall. | # DevMemory 🧠🚀
[](https://github.com/AI-Provenance/ai-dev-memory/actions/workflows/ci.yml)
[](https://pypi.org/project/devmemory/)
[](LICENSE)
DevMemory is a long‑term memory for AI coding agents that can explain why any file or function looks the way it does and let agents reuse that understanding across sessions without re-reading the whole repo.
Built on [Git AI](https://github.com/git-ai-project/git-ai) for capture and [Redis Agent Memory Server](https://github.com/redis/agent-memory-server) for semantic search and recall.
---
## Why DevMemory
- **`devmemory why` for code archaeology**: Ask why a file or function exists and get a narrative backed by commits, prompts, and code snippets.
- **Semantic search over your repo’s history**: Search “how do we handle auth?” or “why did we switch to Redis?” and get synthesized answers with sources.
- **Agent-ready, session‑to‑session memory**: Coding agents can fetch recent and relevant memories at the start of a task and write new ones when they finish, instead of re‑parsing the codebase and burning tokens every session.
If Git AI tracks who wrote which line and Entire checkpoints how agents worked, DevMemory answers what the team actually learned, why the code ended up this way, and gives agents a fast way to reuse that knowledge next time.
---
## `devmemory why` (hero feature)
```bash
devmemory why src/auth.py
devmemory why src/auth.py login
devmemory why src/auth.py --raw
devmemory why src/auth.py --verbose
```
`devmemory why` pulls together:
- Commit summaries
- Per-file code snapshots
- Prompt-level context
- Human knowledge from `.devmemory/knowledge/*.md`
and turns them into an explanation of how and why a file or symbol evolved, plus the sources it used.
Typical questions it answers:
- Why do we use this pattern here instead of an alternative?
- When did this behavior change and what bug or feature drove it?
- Which agent and prompts were involved in this refactor?
---
## Quick start
### Prerequisites
- Git
- Docker and Docker Compose
- Python 3.10+
- OpenAI API key (for embeddings and answer synthesis)
- [Git AI](https://usegitai.com/) (for AI code attribution capture)
### One-line setup
```bash
bash scripts/install.sh
```
This script checks your environment, installs the CLI with `uv`, starts Redis plus AMS and MCP, configures git hooks, and wires DevMemory into Cursor.
### Manual setup
```bash
git clone https://github.com/devmemory/devmemory
cd devmemory
cp .env.example .env
make up
uv tool install --editable .
cd /path/to/your/project
devmemory install
devmemory status
```
---
## 📚 Knowledge Files
DevMemory supports human‑curated knowledge in `.devmemory/knowledge/*.md`.
Each markdown section (`## heading`) becomes a separate searchable memory.
```text
.devmemory/
├── CONTEXT.md # Auto-generated context briefing (gitignored)
└── knowledge/
├── architecture.md # Architecture decisions and rationale
├── gotchas.md # Known issues and workarounds
└── conventions.md # Coding patterns and project rules
```
Knowledge files use frontmatter for metadata:
```markdown
---
topics: [architecture, decisions]
entities: [Redis, AMS]
---
## Why We Chose Redis
We chose Redis with vector search over dedicated vector DBs
because it's already part of our stack and reduces complexity.
```
Run `devmemory learn` to sync knowledge files into the memory store.
Both automated capture (Git AI) **and** human knowledge feed the same searchable store.
> 🧠 Pro tip: Treat `.devmemory/knowledge/` like living ADRs. Small, focused, and updated often.
---
## 🤝 Cursor Agent Integration
`devmemory install` wires DevMemory into Cursor so agents can:
1. Use **MCP tools** like `search_long_term_memory` to pull in recent and relevant memories instead of asking the LLM to rediscover context from raw code.
2. Call `create_long_term_memories` at the end of a task to store what changed and why, so future sessions start with that knowledge.
3. Read `.devmemory/CONTEXT.md` on branch switch for a compact briefing instead of re‑evaluating the entire project on every run.
Over time this creates a compounding loop: each agent session leaves the repo a little better documented for the next one, while saving tokens and latency by reusing existing memory.
---
## Auto-summarization
DevMemory can automatically generate LLM-powered summaries for each commit during sync. These summaries capture:
- **Intent**: Why the change was made and what problem it solves
- **Outcome**: What was actually implemented
- **Learnings**: Insights discovered during implementation
- **Friction points**: Blockers, tradeoffs, or challenges encountered
- **Open items**: Follow-ups, known limitations, or TODOs
**Benefits for agents:**
- **Token efficiency**: Agents read concise summaries (100-300 tokens) instead of parsing full commit diffs
- **Better search relevance**: Semantic search finds summaries that explain "why we added retry logic" faster than scanning code
- **Faster onboarding**: Agents quickly catch up on recent changes by reading summaries instead of analyzing code
- **Intent preservation**: The "why" behind changes is preserved even when commit messages are brief
**Enable auto-summarization:**
```bash
devmemory config set auto_summarize true
```
Summaries are generated non-blocking during `devmemory sync`—failures are logged but don't stop the sync process. Each summary is stored as a semantic memory with the `commit-summary` topic, making them easily searchable.
---
## 🪝 Git Hooks
DevMemory installs two git hooks:
| Hook | What it does |
|------|--------------|
| `post-commit` | Runs `devmemory sync --latest` in background (auto‑syncs after every commit) |
| `post-checkout` | Runs `devmemory context --quiet` (refreshes context briefing on branch switch) |
---
## 🏗 Architecture
```text
┌─────────────────────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ Developer Machine │ │ Docker Stack │ │ Cursor IDE │
│ │ │ │ │ │
│ Git AI (git hooks) │ │ Redis Stack │ │ MCP Client │
│ │ │ │ ▲ │ │ │ │
│ ▼ │ │ │ │ │ ▼ │
│ Git Notes (refs/ai) │ │ AMS API (:8000) │ │ MCP Server │
│ │ │ │ ▲ │ │ (:9050) │
│ ▼ │ │ │ │ │ │
│ devmemory sync ────────────┼─────┼────┘ │ │ │
│ │ │ │ │ │
│ devmemory search ──────────┼─────┼────► AMS Search ──┼─────┼──► LLM synth │
│ │ │ │ │ │
│ .devmemory/knowledge/*.md │ │ │ │ Agent rules │
│ │ │ │ │ │ (.cursor/rules)│
│ devmemory learn ───────────┼─────┼────┘ │ │ │
│ │ │ │ │ │
│ devmemory context ─────────┼─────┼────► .devmemory/CONTEXT.md │
└─────────────────────────────┘ └──────────────────┘ └─────────────────┘
```
---
## 🧾 What Gets Captured
DevMemory extracts three memory layers from each Git AI commit:
| Layer | Type | What it contains | Answers |
|----------------|----------|----------------------------------------------------------------------------------|------------------------------------------|
| Commit summary | semantic | Agent/model, prompts used, AI contribution stats, acceptance metrics, technologies, files | “Which agent was used?”, “How much AI code?” |
| Per-file code | episodic | Code snippets from diffs with key lines (imports, class/function defs) | “How do we call the API?”, “What client for Redis?” |
| Prompt context | semantic | Actual prompt text, acceptance rate, affected files | “What prompts were used?”, “What was the developer asking?” |
Unique data points captured via Git AI and surfaced by DevMemory:
- **AI vs human lines** per commit
- **Acceptance rate** (lines accepted unchanged vs overridden)
- **Time waiting for AI** per commit
- **Agent and model** used (Cursor, Copilot, Claude Code, etc.)
---
## 🐳 Docker Stack
The `docker-compose.yml` runs:
| Service | Port | Description |
|---------|------|-------------|
| redis | 6379 | Redis Stack (vector search, JSON, streams) |
| api | 8000 | Agent Memory Server REST API |
| mcp | 9050 | MCP server for Cursor IDE (SSE mode) |
| redis-insight | 16381 | RedisInsight UI (debug profile only) |
```bash
make up # Start stack
make down # Stop stack
make logs # View logs
make debug # Start with RedisInsight
make clean # Stop and remove volumes
make verify # Run verification checks
```
---
## 🌍 How DevMemory Fits the Ecosystem
| Tool | What it does | Data store |
|------|-------------|------------|
| [Git AI](https://usegitai.com/) | Captures AI code attribution and prompts | Git Notes + SQLite |
| [Entire](https://entire.io/) | Captures agent sessions/checkpoints | Git branch |
| **DevMemory** | **Turns captured data into searchable, evolving team knowledge** | **Redis AMS** |
Git AI and Entire are **capture tools**.
DevMemory is a **memory and knowledge tool** — it makes captured data searchable via semantic vector search, synthesizes answers with LLM, and feeds context back to AI agents automatically.
---
## ⚙️ Configuration
Config is stored in `~/.devmemory/config.json`:
```json
{
"ams_endpoint": "http://localhost:8000",
"mcp_endpoint": "http://localhost:9050",
"namespace": "default",
"user_id": "",
"auto_summarize": false
}
```
**Configuration options:**
- `auto_summarize`: Enable automatic LLM-powered commit summaries (default: `false`). When enabled, each commit synced generates a narrative summary capturing intent, outcome, learnings, and friction points.
Environment variables (in `.env`):
| Variable | Default | Description |
|----------|---------|-------------|
| `OPENAI_API_KEY` | (required) | Used for embeddings and answer synthesis |
| `GENERATION_MODEL` | `gpt-5-mini` | Model for LLM answer synthesis |
| `EMBEDDING_MODEL` | `text-embedding-3-small` | Model for vector embeddings |
---
## 🧑💻 Contributing
Contributions, bug reports, and wild feature ideas are very welcome. 💌
See [`CONTRIBUTING.md`](CONTRIBUTING.md) for details on running the stack, tests, and linting.
If you build something cool with DevMemory, please open an issue or PR and show it off. ✨
---
## ⭐️ Supporting the Project
If DevMemory helps you or your team:
- Star the repo on GitHub ⭐
- Tell your AI‑obsessed friends
- Open issues with real‑world workflows you’d like memory support for
Happy shipping — and may your agents never forget another architecture decision again. 🧠📦🚀
| text/markdown | DevMemory | null | null | null | null | ai, developer-tools, git, mcp, memory, redis | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",... | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.27.0",
"rich>=13.0.0",
"tiktoken>=0.12.0",
"typer>=0.12.0",
"build>=1.2.2; extra == \"dev\"",
"pytest-cov>=5.0.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.6.0; extra == \"dev\"",
"twine>=5.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/devmemory/devmemory",
"Repository, https://github.com/devmemory/devmemory"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T18:37:32.864180 | devmemory-0.1.11.tar.gz | 9,646,868 | 15/99/7066d857066c7471d52714097f2b0ecee151452c49d9f91414150e9f938e/devmemory-0.1.11.tar.gz | source | sdist | null | false | 21d04c10c08d2057a288f635d02ec447 | fdcac0a2fd91082113cc579af28fb7c4c972691d32ea5dd403e75ddff5a9db00 | 15997066d857066c7471d52714097f2b0ecee151452c49d9f91414150e9f938e | MIT | [
"LICENSE"
] | 216 |
2.4 | cysqlite | 0.2.0 | sqlite3 binding | ## cysqlite

cysqlite provides performant bindings to SQLite. cysqlite aims to be roughly
compatible with the behavior of the standard lib `sqlite3` module, but is
closer in spirit to `apsw`, just with fewer features.
cysqlite supports standalone builds or dynamic-linking with the system SQLite.
[Documentation](https://cysqlite.readthedocs.io/en/latest/)
### Overview
`cysqlite` is a Cython-based SQLite driver that provides:
* DB-API 2.0 compatible
* Performant query execution
* Transaction management with context-managers and decorators
* User-defined functions, aggregates, window functions, and virtual tables
* BLOB support
* Row objects with dict-like access
* Schema introspection utilities
### Installing
cysqlite can be installed as a pre-built binary wheel with SQLite embedded into
the module:
```shell
pip install cysqlite
```
cysqlite can be installed from a source distribution (sdist) which will link
against the system SQLite:
```shell
# Link against the system sqlite.
pip install --no-binary :all: cysqlite
```
If you wish to build cysqlite with encryption support, you can create a
self-contained build that embeds [SQLCipher](https://github.com/sqlcipher/sqlcipher).
At the time of writing SQLCipher does not provide a source amalgamation, so
cysqlite includes a script to build an amalgamation and place the sources into
the root of your checkout:
```shell
# Obtain checkout of cysqlite.
git clone https://github.com/coleifer/cysqlite
# Automatically download latest source amalgamation.
cd cysqlite/
./scripts/fetch_sqlcipher # Will add sqlite3.c and sqlite3.h in checkout.
# Build self-contained cysqlite with SQLCipher embedded.
pip install .
```
Alternately, you can create a self-contained build that embeds [SQLite3
Multiple Ciphers](https://github.com/utelle/SQLite3MultipleCiphers):
1. Obtain the latest `*amalgamation.zip` from the [sqlite3mc releases page](https://github.com/utelle/SQLite3MultipleCiphers/releases)
2. Extract `sqlite3mc_amalgamation.c` and `sqlite3mc_amalgamation.h` into the
root of the cysqlite checkout.
3. Run `pip install .`
### Example
Example usage:
```python
from cysqlite import connect
db = connect(':memory:')
db.execute('create table data (k, v)')
with db.atomic():
db.executemany('insert into data (k, v) values (?, ?)',
[(f'k{i:02d}', f'v{i:02d}') for i in range(10)])
print(db.last_insert_rowid()) # 10.
curs = db.execute('select * from data')
for row in curs:
print(row) # e.g., ('k00', 'v00')
# We can use named parameters with a dict as well.
row = db.execute_one('select * from data where k = :key and v = :val',
{'key': 'k05', 'val': 'v05'})
print(row) # ('k05', 'v05')
db.close()
```
| text/markdown | null | Charles Leifer <coleifer@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 2",
"Programming Language :: Python :: 3",
"Topic :: Database :: Database Engines/Servers",
"Topic :: Software Development :: Embedded Systems",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | null | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/coleifer/cysqlite",
"Repository, https://github.com/coleifer/cysqlite"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:36:01.038496 | cysqlite-0.2.0.tar.gz | 56,773 | fd/e0/b90fafc76eef95486d8c8b0051be54d807cfdca5f819a2b28bb3b162f521/cysqlite-0.2.0.tar.gz | source | sdist | null | false | 6a6747c50c727802005b7b40571ee7ef | 1e5fd363526fdb422262e1dad3614af59565c26cfb9f50a4caa8e77bcf2bb4b0 | fde0b90fafc76eef95486d8c8b0051be54d807cfdca5f819a2b28bb3b162f521 | null | [] | 2,346 |
2.4 | pulp-container | 2.19.6 | Container plugin for the Pulp Project | ``pulp_container`` Plugin
=========================
.. figure:: https://github.com/pulp/pulp_container/actions/workflows/nightly.yml/badge.svg?branch=main
:alt: Container Nightly CI/CD
This is the ``pulp_container`` Plugin for `Pulp Project
3.0+ <https://pypi.python.org/pypi/pulpcore/>`__. This plugin provides Pulp with support for container
images, similar to the pulp_docker plugin for Pulp 2.
For more information, please see the `documentation
<https://docs.pulpproject.org/pulp_container/>`_ or the `Pulp project page
<https://pulpproject.org>`_.
How to File an Issue
--------------------
`New pulp_container issue <https://github.com/pulp/pulp_container/issues/new>`_.
.. warning::
Is this security related? If so, please follow the `Security Disclosures <https://docs.pulpproject.org/pulpcore/bugs-features.html#security-bugs>`_ procedure.
| null | Pulp Team | pulp-list@redhat.com | null | null | GPLv2+ | null | [
"License :: OSI Approved :: GNU General Public License v2 or later (GPLv2+)",
"Operating System :: POSIX :: Linux",
"Development Status :: 5 - Production/Stable",
"Framework :: Django",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"P... | [] | https://pulpproject.org/ | null | >=3.9 | [] | [] | [] | [
"jsonschema<4.22,>=4.4",
"pulpcore<3.55,>=3.49.0",
"pyjwt[crypto]<2.9,>=2.4"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:35:07.406355 | pulp_container-2.19.6.tar.gz | 145,740 | e5/38/5157788972446027968b036a260dc079d0be59ae7b027c6c764c7ebc24ac/pulp_container-2.19.6.tar.gz | source | sdist | null | false | 5bb30f7e0b8407f8ebf2919c2bffe40c | 82c8a28afee40eecdf763b8607626c0fce93a8d31895912a2833bd1d6646ce39 | e5385157788972446027968b036a260dc079d0be59ae7b027c6c764c7ebc24ac | null | [
"LICENSE"
] | 249 |
2.1 | liger-kernel-nightly | 0.7.0.dev20260219183429 | Efficient Triton kernels for LLM Training | <a name="readme-top"></a>
# Liger Kernel: Efficient Triton Kernels for LLM Training
<table style="width: 100%; text-align: center; border-collapse: collapse;">
<tr>
<th style="padding: 10px;" colspan="2">Stable</th>
<th style="padding: 10px;" colspan="2">Nightly</th>
<th style="padding: 10px;">Discord</th>
</tr>
<tr>
<td style="padding: 10px;">
<a href="https://pepy.tech/project/liger-kernel">
<img src="https://static.pepy.tech/badge/liger-kernel" alt="Downloads (Stable)">
</a>
</td>
<td style="padding: 10px;">
<a href="https://pypi.org/project/liger-kernel">
<img alt="PyPI - Version" src="https://img.shields.io/pypi/v/liger-kernel?color=green">
</a>
</td>
<td style="padding: 10px;">
<a href="https://pepy.tech/project/liger-kernel-nightly">
<img src="https://static.pepy.tech/badge/liger-kernel-nightly" alt="Downloads (Nightly)">
</a>
</td>
<td style="padding: 10px;">
<a href="https://pypi.org/project/liger-kernel-nightly">
<img alt="PyPI - Version" src="https://img.shields.io/pypi/v/liger-kernel-nightly?color=green">
</a>
</td>
<td style="padding: 10px;">
<a href="https://discord.gg/X4MaxPgA">
<img src="https://dcbadge.limes.pink/api/server/https://discord.gg/X4MaxPgA?style=flat" alt="Join Our Discord">
</a>
</td>
</tr>
</table>
<img src="https://raw.githubusercontent.com/linkedin/Liger-Kernel/main/docs/images/logo-banner.png">
[Installation](#installation) | [Getting Started](#getting-started) | [Examples](#examples) | [High-level APIs](#high-level-apis) | [Low-level APIs](#low-level-apis) | [Cite our work](#cite-this-work)
<details>
<summary>Latest News 🔥</summary>
- [2025/12/19] We announced a liger kernel discord channel at https://discord.gg/X4MaxPgA; We will be hosting Liger Kernel x Triton China Meetup in mid of January 2026
- [2025/03/06] We release a joint blog post on TorchTune × Liger - [Peak Performance, Minimized Memory: Optimizing torchtune’s performance with torch.compile & Liger Kernel](https://pytorch.org/blog/peak-performance-minimized-memory/)
- [2024/12/11] We release [v0.5.0](https://github.com/linkedin/Liger-Kernel/releases/tag/v0.5.0): 80% more memory efficient post training losses (DPO, ORPO, CPO, etc)!
- [2024/12/5] We release LinkedIn Engineering Blog - [Liger-Kernel: Empowering an open source ecosystem of Triton Kernels for Efficient LLM Training](https://www.linkedin.com/blog/engineering/open-source/liger-kernel-open-source-ecosystem-for-efficient-llm-training)
- [2024/11/6] We release [v0.4.0](https://github.com/linkedin/Liger-Kernel/releases/tag/v0.4.0): Full AMD support, Tech Report, Modal CI, Llama-3.2-Vision!
- [2024/10/21] We have released the tech report of Liger Kernel on Arxiv: https://arxiv.org/pdf/2410.10989
- [2024/9/6] We release v0.2.1 ([X post](https://x.com/liger_kernel/status/1832168197002510649)). 2500+ Stars, 10+ New Contributors, 50+ PRs, 50k Downloads in two weeks!
- [2024/8/31] CUDA MODE talk, [Liger-Kernel: Real-world Triton kernel for LLM Training](https://youtu.be/gWble4FreV4?si=dxPeIchhkJ36Mbns), [Slides](https://github.com/cuda-mode/lectures?tab=readme-ov-file#lecture-28-liger-kernel)
- [2024/8/23] Official release: check out our [X post](https://x.com/hsu_byron/status/1827072737673982056)
</details>
**Liger Kernel** is a collection of Triton kernels designed specifically for LLM training. It can effectively increase multi-GPU **training throughput by 20%** and reduces **memory usage by 60%**. We have implemented **Hugging Face Compatible** `RMSNorm`, `RoPE`, `SwiGLU`, `CrossEntropy`, `FusedLinearCrossEntropy`, and more to come. The kernel works out of the box with [Flash Attention](https://github.com/Dao-AILab/flash-attention), [PyTorch FSDP](https://pytorch.org/tutorials/intermediate/FSDP_tutorial.html), and [Microsoft DeepSpeed](https://github.com/microsoft/DeepSpeed). We welcome contributions from the community to gather the best kernels for LLM training.
We've also added optimized Post-Training kernels that deliver **up to 80% memory savings** for alignment and distillation tasks. We support losses like DPO, CPO, ORPO, SimPO, KTO, JSD, and many more. Check out [how we optimize the memory](https://x.com/hsu_byron/status/1866577403918917655).
You can view the documentation site for additional installation, usage examples, and API references:https://linkedin.github.io/Liger-Kernel/
You can view the Liger Kernel Technical Report: https://openreview.net/forum?id=36SjAIT42G
## Supercharge Your Model with Liger Kernel

With one line of code, Liger Kernel can increase throughput by more than 20% and reduce memory usage by 60%, thereby enabling longer context lengths, larger batch sizes, and massive vocabularies.
| Speed Up | Memory Reduction |
|--------------------------|-------------------------|
|  |  |
> **Note:**
> - Benchmark conditions: LLaMA 3-8B, Batch Size = 8, Data Type = `bf16`, Optimizer = AdamW, Gradient Checkpointing = True, Distributed Strategy = FSDP1 on 8 A100s.
> - Hugging Face models start to OOM at a 4K context length, whereas Hugging Face + Liger Kernel scales up to 16K.
## Optimize Post Training with Liger Kernel
<p align="center">
<img src="https://raw.githubusercontent.com/linkedin/Liger-Kernel/main/docs/images/post-training.png" width="50%" alt="Post Training">
</p>
We provide optimized post training kernels like DPO, ORPO, SimPO, and more which can reduce memory usage by up to 80%. You can easily use them as python modules.
```python
from liger_kernel.chunked_loss import LigerFusedLinearORPOLoss
orpo_loss = LigerFusedLinearORPOLoss()
y = orpo_loss(lm_head.weight, x, target)
```
## Examples
| **Use Case** | **Description** |
|------------------------------------------------|---------------------------------------------------------------------------------------------------|
| [**Hugging Face Trainer**](https://github.com/linkedin/Liger-Kernel/tree/main/examples/huggingface) | Train LLaMA 3-8B ~20% faster with over 40% memory reduction on Alpaca dataset using 4 A100s with FSDP |
| [**Lightning Trainer**](https://github.com/linkedin/Liger-Kernel/tree/main/examples/lightning) | Increase 15% throughput and reduce memory usage by 40% with LLaMA3-8B on MMLU dataset using 8 A100s with DeepSpeed ZeRO3 |
| [**Medusa Multi-head LLM (Retraining Phase)**](https://github.com/linkedin/Liger-Kernel/tree/main/examples/medusa) | Reduce memory usage by 80% with 5 LM heads and improve throughput by 40% using 8 A100s with FSDP |
| [**Vision-Language Model SFT**](https://github.com/linkedin/Liger-Kernel/tree/main/examples/huggingface/run_qwen2_vl.sh) | Finetune Qwen2-VL on image-text data using 4 A100s with FSDP |
| [**Liger ORPO Trainer**](https://github.com/linkedin/Liger-Kernel/blob/main/examples/alignment/run_orpo.py) | Align Llama 3.2 using Liger ORPO Trainer with FSDP with 50% memory reduction |
## Key Features
- **Ease of use:** Simply patch your Hugging Face model with one line of code, or compose your own model using our Liger Kernel modules.
- **Time and memory efficient:** In the same spirit as Flash-Attn, but for layers like **RMSNorm**, **RoPE**, **SwiGLU**, and **CrossEntropy**! Increases multi-GPU training throughput by 20% and reduces memory usage by 60% with **kernel fusion**, **in-place replacement**, and **chunking** techniques.
- **Exact:** Computation is exact—no approximations! Both forward and backward passes are implemented with rigorous unit tests and undergo convergence testing against training runs without Liger Kernel to ensure accuracy.
- **Lightweight:** Liger Kernel has minimal dependencies, requiring only Torch and Triton—no extra libraries needed! Say goodbye to dependency headaches!
- **Multi-GPU supported:** Compatible with multi-GPU setups (PyTorch FSDP, DeepSpeed, DDP, etc.).
- **Trainer Framework Integration**: [Axolotl](https://github.com/axolotl-ai-cloud/axolotl), [LLaMa-Factory](https://github.com/hiyouga/LLaMA-Factory), [SFTTrainer](https://github.com/huggingface/trl/releases/tag/v0.10.1), [Hugging Face Trainer](https://github.com/huggingface/transformers/pull/32860), [SWIFT](https://github.com/modelscope/ms-swift), [oumi](https://github.com/oumi-ai/oumi/tree/main)
## Installation
### Dependencies
#### CUDA
- `torch >= 2.1.2`
- `triton >= 2.3.0`
#### ROCm
- `torch >= 2.5.0` Install according to the instruction in Pytorch official webpage.
- `triton >= 3.0.0` Install from pypi. (e.g. `pip install triton==3.0.0`)
```bash
pip install -e .[dev]
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/rocm6.3/
```
### Optional Dependencies
- `transformers >= 4.x`: Required if you plan to use the transformers models patching APIs. The specific model you are working will dictate the minimum version of transformers.
> **Note:**
> Our kernels inherit the full spectrum of hardware compatibility offered by [Triton](https://github.com/triton-lang/triton).
To install the stable version:
```bash
$ pip install liger-kernel
```
To install the nightly version:
```bash
$ pip install liger-kernel-nightly
```
To install from source:
```bash
git clone https://github.com/linkedin/Liger-Kernel.git
cd Liger-Kernel
# Install Default Dependencies
# Setup.py will detect whether you are using AMD or NVIDIA
pip install -e .
# Setup Development Dependencies
pip install -e ".[dev]"
# NOTE -> For AMD users only
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/rocm6.3/
```
## Getting Started
There are a couple of ways to apply Liger kernels, depending on the level of customization required.
### 1. Use AutoLigerKernelForCausalLM
Using the `AutoLigerKernelForCausalLM` is the simplest approach, as you don't have to import a model-specific patching API. If the model type is supported, the modeling code will be automatically patched using the default settings.
```python
from liger_kernel.transformers import AutoLigerKernelForCausalLM
# This AutoModel wrapper class automatically monkey-patches the
# model with the optimized Liger kernels if the model is supported.
model = AutoLigerKernelForCausalLM.from_pretrained("path/to/some/model")
```
### 2. Apply Model-Specific Patching APIs
Using the [patching APIs](#patching), you can swap Hugging Face models with optimized Liger Kernels.
```python
import transformers
from liger_kernel.transformers import apply_liger_kernel_to_llama
# 1a. Adding this line automatically monkey-patches the model with the optimized Liger kernels
apply_liger_kernel_to_llama()
# 1b. You could alternatively specify exactly which kernels are applied
apply_liger_kernel_to_llama(
rope=True,
swiglu=True,
cross_entropy=True,
fused_linear_cross_entropy=False,
rms_norm=False
)
# 2. Instantiate patched model
model = transformers.AutoModelForCausalLM("path/to/llama/model")
```
### 3. Compose Your Own Model
You can take individual [kernels](https://github.com/linkedin/Liger-Kernel?tab=readme-ov-file#model-kernels) to compose your models.
```python
from liger_kernel.transformers import LigerFusedLinearCrossEntropyLoss
import torch.nn as nn
import torch
model = nn.Linear(128, 256).cuda()
# fuses linear + cross entropy layers together and performs chunk-by-chunk computation to reduce memory
loss_fn = LigerFusedLinearCrossEntropyLoss()
input = torch.randn(4, 128, requires_grad=True, device="cuda")
target = torch.randint(256, (4, ), device="cuda")
loss = loss_fn(model.weight, input, target)
loss.backward()
```
## High-level APIs
### AutoModel
| **AutoModel Variant** | **API** |
|-----------|---------|
| AutoModelForCausalLM | `liger_kernel.transformers.AutoLigerKernelForCausalLM` |
### Patching
| **Model** | **API** | **Supported Operations** |
|-------------|--------------------------------------------------------------|-------------------------------------------------------------------------|
| Llama4 (Text) & (Multimodal) | `liger_kernel.transformers.apply_liger_kernel_to_llama4` | RMSNorm, LayerNorm, GeGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| LLaMA 2 & 3 | `liger_kernel.transformers.apply_liger_kernel_to_llama` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| LLaMA 3.2-Vision | `liger_kernel.transformers.apply_liger_kernel_to_mllama` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Mistral | `liger_kernel.transformers.apply_liger_kernel_to_mistral` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Mixtral | `liger_kernel.transformers.apply_liger_kernel_to_mixtral` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Pixtral | `liger_kernel.transformers.apply_liger_kernel_to_pixtral` | RoPE, RMSNorm, SwiGLU|
| Gemma1 | `liger_kernel.transformers.apply_liger_kernel_to_gemma` | RoPE, RMSNorm, GeGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Gemma2 | `liger_kernel.transformers.apply_liger_kernel_to_gemma2` | RoPE, RMSNorm, GeGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Gemma3 (Text) | `liger_kernel.transformers.apply_liger_kernel_to_gemma3_text` | RoPE, RMSNorm, GeGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Gemma3 (Multimodal) | `liger_kernel.transformers.apply_liger_kernel_to_gemma3` | LayerNorm, RoPE, RMSNorm, GeGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Paligemma, Paligemma2, & Paligemma2 Mix | `liger_kernel.transformers.apply_liger_kernel_to_paligemma` | LayerNorm, RoPE, RMSNorm, GeGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Qwen2, Qwen2.5, & QwQ | `liger_kernel.transformers.apply_liger_kernel_to_qwen2` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Qwen2-VL, & QVQ | `liger_kernel.transformers.apply_liger_kernel_to_qwen2_vl` | RMSNorm, LayerNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Qwen2.5-VL | `liger_kernel.transformers.apply_liger_kernel_to_qwen2_5_vl` | RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Qwen3 | `liger_kernel.transformers.apply_liger_kernel_to_qwen3` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Qwen3 MoE | `liger_kernel.transformers.apply_liger_kernel_to_qwen3_moe` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Phi3 & Phi3.5 | `liger_kernel.transformers.apply_liger_kernel_to_phi3` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Granite 3.0 & 3.1 | `liger_kernel.transformers.apply_liger_kernel_to_granite` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss |
| OLMo2 | `liger_kernel.transformers.apply_liger_kernel_to_olmo2` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Olmo3 | `liger_kernel.transformers.apply_liger_kernel_to_olmo3` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| GLM-4 | `liger_kernel.transformers.apply_liger_kernel_to_glm4` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| GPT-OSS | `liger_kernel.transformers.apply_liger_kernel_to_gpt_oss` | RoPE, RMSNorm, CrossEntropyLoss, FusedLinearCrossEntropy |
| InternVL3 | `liger_kernel.transformers.apply_liger_kernel_to_internvl` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| HunyuanV1 | `liger_kernel.transformers.apply_liger_kernel_to_hunyuan_v1_dense` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| HunyuanV1 MoE | `liger_kernel.transformers.apply_liger_kernel_to_hunyuan_v1_moe` | RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
## Low-level APIs
- `Fused Linear` kernels combine linear layers with losses, reducing memory usage by up to 80% - ideal for HBM-constrained workloads.
- Other kernels use fusion and in-place techniques for memory and performance optimization.
### Model Kernels
| **Kernel** | **API** |
|---------------------------------|-------------------------------------------------------------|
| RMSNorm | `liger_kernel.transformers.LigerRMSNorm` |
| LayerNorm | `liger_kernel.transformers.LigerLayerNorm` |
| RoPE | `liger_kernel.transformers.liger_rotary_pos_emb` |
| SwiGLU | `liger_kernel.transformers.LigerSwiGLUMLP` |
| GeGLU | `liger_kernel.transformers.LigerGEGLUMLP` |
| CrossEntropy | `liger_kernel.transformers.LigerCrossEntropyLoss` |
| Fused Linear CrossEntropy | `liger_kernel.transformers.LigerFusedLinearCrossEntropyLoss`|
| Multi Token Attention | `liger_kernel.transformers.LigerMultiTokenAttention` |
| Softmax | `liger_kernel.transformers.LigerSoftmax` |
| Sparsemax | `liger_kernel.transformers.LigerSparsemax` |
### Alignment Kernels
| **Kernel** | **API** |
|---------------------------------|-------------------------------------------------------------|
| Fused Linear CPO Loss | `liger_kernel.chunked_loss.LigerFusedLinearCPOLoss` |
| Fused Linear DPO Loss | `liger_kernel.chunked_loss.LigerFusedLinearDPOLoss` |
| Fused Linear ORPO Loss | `liger_kernel.chunked_loss.LigerFusedLinearORPOLoss` |
| Fused Linear SimPO Loss | `liger_kernel.chunked_loss.LigerFusedLinearSimPOLoss` |
| Fused Linear KTO Loss | `liger_kernel.chunked_loss.LigerFusedLinearKTOLoss` |
### Distillation Kernels
| **Kernel** | **API** |
|---------------------------------|-------------------------------------------------------------|
| KLDivergence | `liger_kernel.transformers.LigerKLDIVLoss` |
| JSD | `liger_kernel.transformers.LigerJSD` |
| Fused Linear JSD | `liger_kernel.transformers.LigerFusedLinearJSD` |
| TVD | `liger_kernel.transformers.LigerTVDLoss` |
### Experimental Kernels
| **Kernel** | **API** |
|---------------------------------|-------------------------------------------------------------|
| Embedding | `liger_kernel.transformers.experimental.LigerEmbedding` |
| Matmul int2xint8 | `liger_kernel.transformers.experimental.matmul` |
## Contributing, Acknowledgements, and License
- [Contributing Guidelines](https://github.com/linkedin/Liger-Kernel/blob/main/docs/contributing.md)
- [Acknowledgements](https://github.com/linkedin/Liger-Kernel/blob/main/docs/acknowledgement.md)
- [License Information](https://github.com/linkedin/Liger-Kernel/blob/main/docs/license.md)
## Sponsorship and Collaboration
- [Glows.ai](https://platform.glows.ai/): Sponsoring NVIDIA GPUs for our open source developers.
- [AMD](https://www.amd.com/en.html): Providing AMD GPUs for our AMD CI.
- [Intel](https://www.intel.com/): Providing Intel GPUs for our Intel CI.
- [Modal](https://modal.com/): Free 3000 credits from GPU MODE IRL for our NVIDIA CI.
- [EmbeddedLLM](https://embeddedllm.com/): Making Liger Kernel run fast and stable on AMD.
- [HuggingFace](https://huggingface.co/): Integrating Liger Kernel into Hugging Face Transformers and TRL.
- [Lightning AI](https://lightning.ai/): Integrating Liger Kernel into Lightning Thunder.
- [Axolotl](https://axolotl.ai/): Integrating Liger Kernel into Axolotl.
- [Llama-Factory](https://github.com/hiyouga/LLaMA-Factory): Integrating Liger Kernel into Llama-Factory.
## CI status
<table style="width: 100%; text-align: center; border-collapse: collapse;">
<tr>
<th style="padding: 10px;">Build</th>
</tr>
<tr>
<td style="padding: 10px;">
<div style="display: block;">
<a href="https://github.com/linkedin/Liger-Kernel/actions/workflows/nvi-ci.yml">
<img src="https://github.com/linkedin/Liger-Kernel/actions/workflows/nvi-ci.yml/badge.svg?branch=main&event=push" alt="Build">
</a>
</div>
<div style="display: block;">
<a href="https://github.com/linkedin/Liger-Kernel/actions/workflows/amd-ci.yml">
<img src="https://github.com/linkedin/Liger-Kernel/actions/workflows/amd-ci.yml/badge.svg?branch=main&event=push" alt="Build">
</a>
</div>
<div style="display: block;">
<a href="https://github.com/linkedin/Liger-Kernel/actions/workflows/intel-ci.yml">
<img src="https://github.com/linkedin/Liger-Kernel/actions/workflows/intel-ci.yml/badge.svg?branch=main&event=push" alt="Build">
</a>
</div>
</td>
</tr>
</table>
## Contact
- For issues, create a Github ticket in this repository
- For open discussion, join [our discord channel on GPUMode](https://discord.com/channels/1189498204333543425/1275130785933951039)
- For formal collaboration, send an email to Yanning Chen(yannchen@linkedin.com) and Zhipeng Wang(zhipwang@linkedin.com)
## Cite this work
Biblatex entry:
```bib
@inproceedings{
hsu2025ligerkernel,
title={Liger-Kernel: Efficient Triton Kernels for {LLM} Training},
author={Pin-Lun Hsu and Yun Dai and Vignesh Kothapalli and Qingquan Song and Shao Tang and Siyu Zhu and Steven Shimizu and Shivam Sahni and Haowen Ning and Yanning Chen and Zhipeng Wang},
booktitle={Championing Open-source DEvelopment in ML Workshop @ ICML25},
year={2025},
url={https://openreview.net/forum?id=36SjAIT42G}
}
```
## Star History
[](https://www.star-history.com/#linkedin/Liger-Kernel&Date)
<p align="right" style="font-size: 14px; color: #555; margin-top: 20px;">
<a href="#readme-top" style="text-decoration: none; color: #007bff; font-weight: bold;">
↑ Back to Top ↑
</a>
</p>
| text/markdown | null | null | null | null | BSD 2-CLAUSE LICENSE
Copyright 2024 LinkedIn Corporation
All Rights Reserved.
Redistribution and use in source and binary forms, with or
without modification, are permitted provided that the following
conditions are met:
1. Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above
copyright notice, this list of conditions and the following
disclaimer in the documentation and/or other materials provided
with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
| null | [] | [] | null | null | null | [] | [] | [] | [
"torch>=2.1.2",
"triton>=2.3.1",
"transformers>=4.52.0; extra == \"dev\"",
"matplotlib>=3.7.2; extra == \"dev\"",
"ruff>=0.12.0; extra == \"dev\"",
"pytest>=7.1.2; extra == \"dev\"",
"pytest-xdist; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"pytest-asyncio; extra == \"dev\"",
"pytest-rerun... | [] | [] | [] | [
"Homepage, https://github.com/linkedin/Liger-Kernel"
] | twine/6.1.0 CPython/3.8.18 | 2026-02-19T18:34:39.763188 | liger_kernel_nightly-0.7.0.dev20260219183429.tar.gz | 3,783,211 | a0/d2/28e449600eca3b21094d8a3b93e52eee1f261cc6f67ebc50fc3f78916abf/liger_kernel_nightly-0.7.0.dev20260219183429.tar.gz | source | sdist | null | false | a8942b39366c183986279f9892ef0b90 | df8085b2ca0de3255caa9a02d236315ce74157ddc21da16fd432ead5f72b9a8e | a0d228e449600eca3b21094d8a3b93e52eee1f261cc6f67ebc50fc3f78916abf | null | [] | 363 |
2.4 | holoviz-mcp | 0.15.0 | A Model Context Protocol (MCP) server for the HoloViz ecosystem | # ✨ HoloViz MCP
[](https://github.com/MarcSkovMadsen/holoviz-mcp/actions/workflows/ci.yml)
[](https://github.com/MarcSkovMadsen/holoviz-mcp/actions/workflows/docker.yml)
[](https://prefix.dev/channels/conda-forge/packages/holoviz-mcp)
[](https://pypi.org/project/holoviz-mcp)
[](https://pypi.org/project/holoviz-mcp)
[](https://marcskovmadsen.github.io/holoviz-mcp/)
A comprehensive [Model Context Protocol](https://modelcontextprotocol.io/introduction) (MCP) server that provides intelligent access to the [HoloViz](https://holoviz.org/) ecosystem, enabling AI assistants to help you build interactive dashboards and data visualizations with [Panel](https://panel.holoviz.org/), [hvPlot](https://hvplot.holoviz.org), [Lumen](https://lumen.holoviz.org/), [Datashader](https://datashader.org/) and your favorite Python libraries.
[](https://holoviz.org)
**📖 [Full Documentation](https://marcskovmadsen.github.io/holoviz-mcp/)** | **🚀 [Quick Start](https://marcskovmadsen.github.io/holoviz-mcp/tutorials/getting-started/)** | **🐳 [Docker Guide](https://marcskovmadsen.github.io/holoviz-mcp/how-to/docker/)** | **🤗 [Explore the Tools](https://huggingface.co/spaces/awesome-panel/holoviz-mcp-ui)**
## ✨ What This Provides
**Documentation Access**: Search through comprehensive HoloViz documentation, including tutorials, reference guides, how-to guides, and API references.
**Display Server**: Create and share Python visualizations with instant URLs. The `holoviz_display` tool executes code in an isolated server and provides web-accessible visualizations that you can view, share, and manage.
**Agents Skills**: Agents and Skills for LLMs.
**Component Intelligence**: Discover and understand 100+ Panel components with detailed parameter information and usage examples. Similar features are available for hvPlot.
**Extension Support**: Automatic detection and information about Panel extensions such as Material UI, Graphic Walker, and other community packages.
**Smart Context**: Get contextual code assistance that understands your development environment and available packages.
## 🎯 Why Use This?
- **⚡ Faster Development**: No more hunting through docs - get instant, accurate component information.
- **🎨 Better Design**: AI suggests appropriate components and layout patterns for your use case.
- **🧠 Smart Context**: The assistant understands your environment and available Panel extensions.
- **📖 Always Updated**: Documentation stays current with the latest HoloViz ecosystem changes.
- **🔧 Zero Setup**: Works immediately with any MCP-compatible AI assistant.
Watch the [HoloViz MCP Introduction](https://youtu.be/M-YUZWEeSDA) on YouTube to see it in action.
[](https://youtu.be/M-YUZWEeSDA)
## 📚 Learn More
Check out the [`holoviz-mcp` documentation](https://marcskovmadsen.github.io/holoviz-mcp/):
- **[Tutorials](https://marcskovmadsen.github.io/holoviz-mcp/tutorials/getting-started/)**: Step-by-step guides to get you started
- **[How-To Guides](https://marcskovmadsen.github.io/holoviz-mcp/how-to/installation/)**: Practical guides for common tasks
- **[Explanation](https://marcskovmadsen.github.io/holoviz-mcp/explanation/architecture/)**: Understanding concepts and architecture
- **[Reference](https://marcskovmadsen.github.io/holoviz-mcp/reference/holoviz_mcp/)**: API documentation and technical details
## ❤️ Contributing
We welcome contributions! See our [Contributing Guide](https://marcskovmadsen.github.io/holoviz-mcp/contributing/) for details.
## 📄 License
HoloViz MCP is licensed under the [BSD 3-Clause License](LICENSE.txt).
## 🔗 Links
- **GitHub**: [MarcSkovMadsen/holoviz-mcp](https://github.com/MarcSkovMadsen/holoviz-mcp)
- **Documentation**: [marcskovmadsen.github.io/holoviz-mcp](https://marcskovmadsen.github.io/holoviz-mcp/)
- **PyPI**: [pypi.org/project/holoviz-mcp](https://pypi.org/project/holoviz-mcp)
- **Docker**: [ghcr.io/marcskovmadsen/holoviz-mcp](https://github.com/MarcSkovMadsen/holoviz-mcp/pkgs/container/holoviz-mcp)
- **HoloViz Community**: [Discord](https://discord.gg/AXRHnJU6sP) | [Discourse](https://discourse.holoviz.org/)
---
**Note**: This MCP server can execute arbitrary Python code when serving Panel applications (configurable, enabled by default). See [Security Considerations](https://marcskovmadsen.github.io/holoviz-mcp/explanation/security/) for details.
| text/markdown | null | MarcSkovMadsen <marc.skov.madsen@gmail.com> | null | MarcSkovMadsen <marc.skov.madsen@gmail.com> | BSD | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: BSD License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Pyth... | [] | null | null | >=3.11 | [] | [] | [] | [
"certifi",
"chromadb",
"fastmcp<3",
"gitpython",
"hvplot",
"hvsampledata",
"matplotlib",
"nbconvert",
"packaging",
"panel",
"panel-full-calendar",
"panel-graphic-walker",
"panel-material-ui",
"panel-neuroglancer",
"panel-precision-slider",
"panel-splitjs",
"panel-web-llm",
"playwri... | [] | [] | [] | [
"Homepage, https://github.com/MarcSkovMadsen/holoviz-mcp",
"Source, https://github.com/MarcSkovMadsen/holoviz-mcp"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:32:56.838657 | holoviz_mcp-0.15.0.tar.gz | 41,800,884 | 80/03/1b92f322cc1c964b0159bbfbb8e3a682bc30ee1093d9ce3e55f4fedcb6b7/holoviz_mcp-0.15.0.tar.gz | source | sdist | null | false | 7f46fabb22e2464d89573844cddcbdd3 | abb0e6a98f1b8e6dbb079eb589f0ed81e121937e0d92585d8e012fd54d386fbe | 80031b92f322cc1c964b0159bbfbb8e3a682bc30ee1093d9ce3e55f4fedcb6b7 | null | [
"LICENSE.txt"
] | 228 |
2.4 | arelle-release | 2.38.15 | An open source XBRL platform. | # Arelle
[](https://pypi.org/project/arelle-release/)
[](https://pypi.org/project/arelle-release/)
[](https://arelle.readthedocs.io/)
[](https://arelle.org/)
## Table of Contents
- [Arelle](#arelle)
- [Table of Contents](#table-of-contents)
- [Description](#description)
- [Documentation](#documentation)
- [Features](#features)
- [Need Support?](#need-support)
- [Arelle Within Other Products](#arelle-within-other-products)
- [EDGAR or EFM Validations](#edgar-or-efm-validations)
- [Installing or Running Arelle](#installing-or-running-arelle)
- [Bug Report or Feature Request](#bug-report-or-feature-request)
- [Security Vulnerabilities](#security-vulnerabilities)
- [How-To and General XBRL Questions](#how-to-and-general-xbrl-questions)
- [Email](#email)
- [How To Contribute](#how-to-contribute)
- [👥 Contributors](#-contributors)
- [License](#license)
## Description
Arelle is an end-to-end open source XBRL platform, which provides the XBRL community
with an easy to use set of tools. It supports XBRL and its extension features in
an extensible manner. It does this in a compact yet robust framework that can be
used as a desktop application and can be integrated with other applications and
languages utilizing its web service, command line interface, and Python API.
## Documentation
Need help with Arelle? Go check out [our documentation][read-the-docs].
[read-the-docs]: https://arelle.readthedocs.io/
## Features
- Fully-featured XBRL processor with GUI, CLI, Python API and Web Service API.
- Support for the XBRL Standard, including:
- XBRL v2.1 and XBRL Dimensions v1.0
- XBRL Formula v1.0
- Taxonomy Packages v1.0
- xBRL-JSON v1.0 and xBRL-CSV v1.0
- Inline XBRL v1.1
- Units Registry v1.0
- Certified by XBRL International as a [Validating Processor][certification].
- Support for filing programme validation rules:
- Edgar Filer Manual validation (US SEC)
- ESEF Reporting Manual (EU)
- HMRC (UK)
- CIPC (South Africa)
- FERC (US Federal Energy Regulatory Commission)
- Integrated support for [Arelle Inline XBRL Viewer][viewer].
- Extensible plugin architecture.
- Support for XF text-based Formula and XULE validation rules.
- The Web Service API allows XBRL integration with applications, such as those in
Excel, Java or Oracle.
- Instance creation is supported using forms defined by the table linkbase.
- Support for reading/monitoring US SEC XBRL RSS feeds (RSS Watch).
[viewer]: https://github.com/Arelle/ixbrl-viewer
[certification]: https://software.xbrl.org/processor/arelle-arelle
## Need Support?
Whether you've found a bug, need help with installation, have a feature request,
or want to know how to use Arelle, we can help! Here's a quick guide:
When reporting issues it's important to include as much information as possible:
- what version of Arelle are you using?
- how are you using Arelle (GUI, command line, web server, or the Python API?)
- what operating system (Windows, macOS, Ubuntu, etc.) are you using?
- what plugins if any do you have enabled?
- can you provide an XBRL report that recreates the issue?
- what's the diagnostics output (`arelleCmdLine.exe --diagnostics`) on your system?
### Arelle Within Other Products
A number of service providers embed Arelle within their XBRL products and tools.
If you're having an issue with Arelle within one of these offerings please
contact the developer of that tool for support or first verify that you have the
same issue when using Arelle directly. Most issues in these situations are caused
by the tool using an old version of Arelle or not running a valid command.
### EDGAR or EFM Validations
The SEC develops and maintains the EDGAR plugins. Please report issues with these
plugins directly to the SEC (<StructuredData@sec.gov>).
### Installing or Running Arelle
Most installation and startup issues can be resolved by downloading the latest version
of Arelle and performing a [clean install][clean-install]. If that doesn't resolve
the problem for you, please [report a bug](#bug-report-or-feature-request).
[clean-install]: https://arelle.readthedocs.io/en/latest/install.html#clean-install
### Bug Report or Feature Request
Please use the GitHub [issue tracker][github-issue-tracker] if you'd like to suggest
a new feature or report a bug.
Before opening a new issue, please:
- Check that the issue has not already been reported.
- Check that the issue has not already been fixed in the latest release.
- Be clear and precise (do not prose, but name functions and commands exactly).
- For bug reports include the version of Arelle you're using.
[github-issue-tracker]: https://github.com/Arelle/Arelle/issues
### Security Vulnerabilities
Identified a security concern? Email the Arelle team (<Support@arelle.org>) so we
can resolve the issue and make sure service providers and authorities who use Arelle
in production are prepared to update and apply security patches before notifying
the general public.
### How-To and General XBRL Questions
Have a question that isn't covered by the [documentation](#documentation)?
Join our [Arelle Google Group][google-group] and start a conversation with the Arelle
team and community of experts.
### Email
The Arelle team can also be reached by email (<Support@arelle.org>) for issues that
aren't a good fit for the other support channels. However, please note that you will
likely receive a faster response if you [open a GitHub issue][new-github-issue]
or start a new conversation in the [Arelle Google Group][google-group] where the
Arelle team is active and other people within the community can also see and respond
to your message.
[google-group]: https://groups.google.com/g/arelle-users
[new-github-issue]: https://github.com/Arelle/Arelle/issues/new/choose
## How To Contribute
Interested in contributing to Arelle? Awesome! Make sure to review our
[contribution guidelines][contribution guidelines].
[contribution guidelines]: https://arelle.readthedocs.io/en/latest/contributing.html
## 👥 Contributors
<div align="center">
<a href="https://github.com/Arelle/Arelle/graphs/contributors">
<img src="https://contrib.rocks/image?repo=Arelle/Arelle&max=100&columns=10" style="margin: 5px;" />
</a>
<p>Join our community and become a contributor today! 🚀 </p>
</div>
## License
[Apache License 2.0][license]
[license]: https://arelle.readthedocs.io/en/latest/license.html
| text/markdown | null | "arelle.org" <support@arelle.org> | null | null | null | xbrl | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: End Users/Desktop",
"Intended Audience :: Developers",
"Natural Language :: English",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language ::... | [
"any"
] | null | null | >=3.10 | [] | [] | [] | [
"bottle<0.14,>=0.13",
"certifi",
"filelock",
"isodate<1,>=0",
"jaconv<1,>=0",
"jsonschema<5,>=4",
"lxml!=6.0.0,<7,>=4",
"numpy<3,>=1",
"openpyxl<4,>=3",
"pillow<13,>=10",
"pyparsing<4,>=3",
"python-dateutil<3,>=2",
"regex",
"truststore<1,>=0",
"typing-extensions<5,>=4",
"pycryptodome<4... | [] | [] | [] | [
"Homepage, https://arelle.org/",
"Downloads, https://arelle.org/arelle/pub/",
"Documentation, https://arelle.org/arelle/documentation/",
"Blog, https://arelle.org/arelle/blog/",
"Source Code, https://github.com/Arelle/Arelle/",
"Bug Reports, https://github.com/Arelle/Arelle/issues/",
"Support, https://g... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:32:54.328061 | arelle_release-2.38.15.tar.gz | 5,315,370 | 19/48/23cf8c9d14f22d51f421f0c2bebbd89827a91d98f87b13e119784b1f61d4/arelle_release-2.38.15.tar.gz | source | sdist | null | false | eea13d1508b0ea3d4af3941543b8af60 | b3d6b080a944d6f64985a02fc366f31fbae1205ca96c10f2b6da8747ececd7f8 | 194823cf8c9d14f22d51f421f0c2bebbd89827a91d98f87b13e119784b1f61d4 | Apache-2.0 | [
"LICENSE.md"
] | 3,657 |
2.4 | sfdump | 2.9.5 | Salesforce data export and archival tool with verification, SQLite database, and Streamlit viewer | ======
sfdump
======
Salesforce data export and archival tool. Bulk downloads Attachments,
ContentVersions, CSV object data, and invoice PDFs with verification,
retry mechanisms, a searchable SQLite database, and a Streamlit web viewer.
Built for organisations whose Salesforce licences may expire -- provides
confidence that everything has been captured and can be browsed offline.
Features
========
- **Full data export** -- 44 essential Salesforce objects exported to CSV
- **File downloads** -- Attachments (legacy) and ContentVersions with SHA-256 verification
- **Invoice PDFs** -- bulk download via deployed Apex REST endpoint (``sf sins``)
- **SQLite database** -- queryable offline database built from CSV exports
- **Streamlit viewer** -- web UI with Document Explorer, record navigator, and search
- **Export inventory** -- single-command completeness check across all categories (``sf inventory``)
- **Idempotent & resumable** -- all operations support resume; re-run to pick up where you left off
- **Verification & retry** -- SHA-256 integrity checks with automatic retry of failed downloads
Two CLIs
========
=============== ============================================
``sf`` Simple commands for daily use
``sfdump`` Full CLI with all advanced options
=============== ============================================
::
# Simple workflow
sf dump # Export everything from Salesforce
sf view # Browse exported data in web viewer
sf inventory # Check export completeness
sf sins # Download invoice PDFs
sf status # List available exports
sf usage # Check API usage / limits
# Advanced
sfdump files # Export Attachments/ContentVersions
sfdump csv # Export specific objects to CSV
sfdump verify-files # Verify file integrity (SHA-256)
sfdump retry-missing # Retry failed downloads
sfdump inventory -v # Detailed completeness report
sfdump build-db # Build SQLite database
sfdump db-viewer # Launch Streamlit viewer
sfdump docs-index # Rebuild document indexes
Export Inventory
================
The ``inventory`` command provides a single authoritative answer to
"is my export complete?" by inspecting only local files (no API calls)::
$ sf inventory
Export Inventory
==================================================
Location: ./exports/export-2025-03-15
Category Status Expected Present
CSV Objects COMPLETE 44 44
Attachments COMPLETE 12,456 12,456
ContentVersions COMPLETE 285 1,194
Invoice PDFs INCOMPLETE 1,200 0 (1,200 missing)
Indexes COMPLETE 11 11
Database COMPLETE 14 tables
Overall: INCOMPLETE
The inventory checks six categories:
- **CSV Objects** -- all 44 essential Salesforce objects present
- **Attachments** -- legacy file downloads verified against metadata
- **ContentVersions** -- modern file downloads verified against metadata
- **Invoice PDFs** -- FinancialForce/Coda invoice PDFs (``c2g__codaInvoice__c``)
- **Indexes** -- per-object file indexes and master document index
- **Database** -- SQLite database tables and row counts
Use ``--json-only`` for machine-readable output. The manifest is also
auto-generated at ``meta/inventory.json`` after every ``sf dump`` run.
Installation
============
All Platforms (PyPI)
--------------------
If you have Python 3.12+ installed::
pip install sfdump
To upgrade::
pip install --upgrade sfdump
Windows (Starting from Nothing)
-------------------------------
**Option 1: One-Line Install (Recommended)**
Open PowerShell (press Win+R, type ``powershell``, press Enter) and paste::
irm https://raw.githubusercontent.com/ksteptoe/sfdump/main/bootstrap.ps1 | iex
This downloads and installs everything automatically.
**Detailed Instructions**
See `INSTALL.md <INSTALL.md>`_ for step-by-step instructions with screenshots
and troubleshooting tips.
**Requirements**
- Windows 10 or 11
- 40 GB free disk space (for Salesforce exports)
- Internet connection
- No administrator rights required
macOS / Linux
-------------
::
pip install sfdump
For development (contributors)::
git clone https://github.com/ksteptoe/sfdump.git
cd sfdump
make bootstrap
Quick Start
===========
::
# First time: configure credentials
sf setup # Interactive .env creation
sf test # Verify connection
# Export
sf dump # Full export (files + CSVs + database)
sf dump --retry # Export and retry failed downloads
# Browse offline
sf view # Launch Streamlit viewer
# Completeness check
sf inventory # Are we done?
Configuration
=============
Create a ``.env`` file in your working directory (or use ``sf setup``)::
SF_AUTH_FLOW=client_credentials
SF_CLIENT_ID=<your_consumer_key>
SF_CLIENT_SECRET=<your_consumer_secret>
SF_LOGIN_URL=https://yourcompany.my.salesforce.com
For invoice PDF downloads, a Web Server OAuth flow is also needed::
sfdump login-web # Opens browser for SSO login
Invoice PDFs
============
Invoice PDFs are generated on-the-fly by a Visualforce page in Salesforce --
they are **not** stored as files. A deployed Apex REST class
(``SfdumpInvoicePdf``) renders each invoice to PDF server-side.
::
sfdump login-web # Authenticate via browser (SSO)
sf sins # Download all Complete invoice PDFs
sf sins --force # Re-download everything
PDFs are saved to ``{export}/invoices/SIN001234.pdf`` and indexed for the
viewer's Document Explorer.
Work in Progress
================
Invoice PDF Pipeline
--------------------
**Status**: The Apex REST endpoint is deployed to production and the ``sf sins``
command works end-to-end. The remaining gap is that the Web Server OAuth token
(``sfdump login-web``) needs to be refreshed manually. The ``sf dump``
orchestrator will attempt invoice PDF downloads automatically if a valid web
token exists, but falls back gracefully if not.
**What's deployed in Salesforce**:
- Apex class ``SfdumpInvoicePdf`` -- REST endpoint at
``/services/apexrest/sfdump/invoice-pdf?id={invoiceId}``
- Test class ``SfdumpInvoicePdfTest`` -- 94% coverage
- These are read-only and harmless; recommend keeping them permanently
**Known limitation**: The org uses SSO (SAML), so the ``client_credentials``
OAuth flow cannot render Visualforce pages. Invoice PDF download requires the
Web Server (Authorization Code + PKCE) flow which produces a real user session.
Export Completeness Direction
-----------------------------
The ``sf inventory`` command is the foundation for a broader completeness
guarantee. The direction:
1. **Inventory system** (done) -- offline checks across all six categories,
JSON manifest at ``meta/inventory.json``, auto-generated after each export
2. **CI integration** -- use ``sf inventory --json-only`` in pipelines to
assert export completeness before archival
3. **Drift detection** -- compare inventory manifests over time to detect
regressions (e.g. files deleted, database corruption)
4. **Archival sign-off** -- once all categories show COMPLETE, the export
can be confidently archived as the authoritative copy of the org's data
Architecture
============
::
Salesforce API --> api.py --> files.py --> CSV + binary exports
|
verify.py (SHA-256 completeness)
|
retry.py (failure recovery)
|
inventory.py (completeness check)
|
indexing/ (document indexes)
|
viewer/ + viewer_app/ (SQLite + Streamlit)
Export directory structure::
exports/export-2026-01-26/
csv/ # 44 Salesforce objects as CSV
files/ # ContentVersion binaries
files_legacy/ # Attachment binaries
invoices/ # Invoice PDFs (SIN*.pdf)
links/ # Metadata CSVs + file indexes
meta/
sfdata.db # SQLite database
inventory.json # Completeness manifest
master_documents_index.csv
.. _pyscaffold-notes:
Making Changes & Contributing
=============================
This project uses `pre-commit`_, please make sure to install it before making any
changes::
pip install pre-commit
cd sfdump
pre-commit install
It is a good idea to update the hooks to the latest version::
pre-commit autoupdate
Don't forget to tell your contributors to also install and use pre-commit.
.. _pre-commit: https://pre-commit.com/
Note
====
This project has been set up using PyScaffold 4.6. For details and usage
information on PyScaffold see https://pyscaffold.org/.
| text/x-rst | null | Kevin Steptoe <ksteptoe@gmail.com> | null | null | null | salesforce, export, backup, archival, data-migration | [
"Development Status :: 4 - Beta",
"Intended Audience :: System Administrators",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Database"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"click>=8.1",
"requests>=2.31",
"tqdm>=4.66",
"python-dotenv>=1.0.1",
"pandas",
"openpyxl>=3.1",
"extract-msg>=0.41",
"pypandoc",
"pymupdf",
"streamlit>=1.30",
"pytest>=8; extra == \"dev\"",
"pytest-cov>=5; extra == \"dev\"",
"pytest-xdist>=3.6; extra == \"dev\"",
"pytest-timeout>=2.3; ext... | [] | [] | [] | [
"Homepage, https://github.com/ksteptoe/sfdump",
"Repository, https://github.com/ksteptoe/sfdump"
] | twine/6.2.0 CPython/3.12.11 | 2026-02-19T18:31:54.942738 | sfdump-2.9.5.tar.gz | 1,057,679 | 9c/f0/e75b7eda2bc7fbeadf44116bfcfbe9a755553a0624f2725d9a20f2c04673/sfdump-2.9.5.tar.gz | source | sdist | null | false | 9f99a4e3b567e4ca2c0993960fecb361 | 8f059c3453ab2408d7e3127dd670c651349a3a4c35a098c5325ac7c7e7d258a9 | 9cf0e75b7eda2bc7fbeadf44116bfcfbe9a755553a0624f2725d9a20f2c04673 | MIT | [
"LICENSE.txt"
] | 226 |
2.4 | tidy3d | 2.11.0.dev0 | A fast FDTD solver | # Tidy3D
[](https://pypi.python.org/pypi/tidy3d)
[](https://pypi.python.org/pypi/tidy3d/)
[](https://flexcompute-tidy3ddocumentation.readthedocs-hosted.com/?badge=latest)
[](https://github.com/flexcompute/tidy3d/actions/workflows/tidy3d-python-client-tests.yml)
[](LICENSE)
[](https://github.com/astral-sh/ruff)

[](https://github.com/flexcompute/tidy3d-notebooks)

Tidy3D is a software package for solving extremely large electrodynamics problems using the finite-difference time-domain (FDTD) method. It can be controlled through either an [open source python package](https://github.com/flexcompute/tidy3d) or a [web-based graphical user interface](https://tidy3d.simulation.cloud).
This repository contains the python API to allow you to:
* Programmatically define FDTD simulations.
* Submit and manage simulations running on Flexcompute's servers.
* Download and postprocess the results from the simulations.

## Installation
### Signing up for tidy3d
Note that while this front end package is open source, to run simulations on Flexcompute servers requires an account with credits.
You can sign up for an account [here](https://tidy3d.simulation.cloud/signup).
After that, you can install the front end with the instructions below, or visit [this page](https://docs.flexcompute.com/projects/tidy3d/en/latest/install.html) in our documentation for more details.
### Quickstart Installation
To install the Tidy3D Python API locally, the following instructions should work for most users.
```
pip install --user tidy3d
tidy3d configure --apikey=XXX
```
Where `XXX` is your API key, which can be copied from your [account page](https://tidy3d.simulation.cloud/account) in the web interface.
In a hosted jupyter notebook environment (eg google colab), it may be more convenient to install and configure via the following lines at the top of the notebook.
```
!pip install tidy3d
import tidy3d.web as web
web.configure("XXX")
```
**Advanced installation instructions for all platforms is available in the [documentation installation guides](https://docs.flexcompute.com/projects/tidy3d/en/latest/install.html).**
### Authentication Verification
To test the authentication, you may try importing the web interface via.
```
python -c "import tidy3d; tidy3d.web.test()"
```
It should pass without any errors if the API key is set up correctly.
To get started, our documentation has a lot of [examples](https://docs.flexcompute.com/projects/tidy3d/en/latest/notebooks/docs/index.html) for inspiration.
## Common Documentation References
| API Resource | URL |
|--------------------|----------------------------------------------------------------------------------|
| Installation Guide | https://docs.flexcompute.com/projects/tidy3d/en/latest/install.html |
| Documentation | https://docs.flexcompute.com/projects/tidy3d/en/latest/index.html |
| Example Library | https://docs.flexcompute.com/projects/tidy3d/en/latest/notebooks/docs/index.html |
| FAQ | https://docs.flexcompute.com/projects/tidy3d/en/latest/faq/docs/index.html |
## FlexAgent MCP
FlexAgent adds an AI-assisted layer on top of Tidy3D via the Model Context Protocol (MCP); read more about [AI-assisted simulation in Tidy3D](https://hs.flexcompute.com/news/ai-assisted-simulation-in-tidy3d-ushering-in-a-new-era-of-photonic-design). Install the `tidy3d-mcp` server when you want that experience inside an MCP client without the Tidy3D extension for [Visual Studio Code](https://marketplace.visualstudio.com/items?itemName=ms-python.python) and [Cursor](https://open-vsx.org/extension/Flexcompute/tidy3d).
These commands assume [uv](https://docs.astral.sh/uv/getting-started/installation/) is installed on your machine.
**Register the server with your MCP client** - use the block below that matches your CLI.
<details>
<summary>Codex CLI / IDE</summary>
```bash
codex mcp add tidy3d -- uvx tidy3d-mcp --api-key "YOUR_TIDY3D_API_KEY"
```
</details>
<details>
<summary>Claude CLI / Desktop / Code</summary>
```bash
claude mcp add tidy3d -- uvx tidy3d-mcp --api-key "YOUR_TIDY3D_API_KEY"
```
</details>
<details>
<summary>Gemini CLI</summary>
Create or edit `.gemini/settings.json` (project) or `~/.gemini/settings.json` (global):
```json
{
"mcpServers": {
"tidy3d": {
"command": "uvx",
"args": ["tidy3d-mcp", "--api-key", "YOUR_TIDY3D_API_KEY"]
}
}
}
```
</details>
<details>
<summary>Cursor CLI / IDE</summary>
Cursor reuses the same schema across the editor and `cursor-agent`. Configure `.cursor/mcp.json` (per-project) or `~/.cursor/mcp.json` (global) and then run `cursor-agent mcp list` to verify:
```json
{
"mcpServers": {
"tidy3d": {
"command": "uvx",
"args": ["tidy3d-mcp", "--api-key", "YOUR_TIDY3D_API_KEY"]
}
}
}
```
</details>
## Related Source Repositories
| Name | Repository |
|-------------------|-------------------------------------------------|
| Source Code | https://github.com/flexcompute/tidy3d |
| Notebooks Source | https://github.com/flexcompute/tidy3d-notebooks |
| FAQ Source Code | https://github.com/flexcompute/tidy3d-faq |
## Issues / Feedback / Bug Reporting
Your feedback helps us immensely!
If you find bugs, file an [Issue](https://github.com/flexcompute/tidy3d/issues).
For more general discussions, questions, comments, anything else, open a topic in the [Discussions Tab](https://github.com/flexcompute/tidy3d/discussions).
## License
[GNU LGPL](https://github.com/flexcompute/tidy3d/blob/main/LICENSE)
| text/markdown | Tyler Hughes | tyler@flexcompute.com | null | null | LGPLv2+ | null | [
"License :: OSI Approved :: GNU Lesser General Public License v2 or later (LGPLv2+)",
"License :: Other/Proprietary License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Lang... | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"PyYAML<7.0.0,>=6.0.3",
"autograd<2.0.0,>=1.7.0",
"bayesian-optimization<2; extra == \"dev\" or extra == \"design\"",
"boto3<2.0.0,>=1.28.0",
"click<9.0.0,>=8.1.0",
"cma<5.0.0,>=4.4.1; extra == \"dev\" or extra == \"docs\"",
"coverage<8.0.0,>=7.13.1; extra == \"dev\"",
"dask<2026.0.0,>=2025.12.0",
"... | [] | [] | [] | [
"Bug Tracker, https://github.com/flexcompute/tidy3d/issues",
"Documentation, https://docs.flexcompute.com/projects/tidy3d/en/latest/",
"Homepage, https://github.com/flexcompute/tidy3d",
"Repository, https://github.com/flexcompute/tidy3d"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-19T18:30:00.150066 | tidy3d-2.11.0.dev0.tar.gz | 1,293,661 | 38/ce/c936570bd4b1c8bda3c19cb45978419725a6673d9ccbc26b1853d03e781a/tidy3d-2.11.0.dev0.tar.gz | source | sdist | null | false | 4ac3b4749e8f4a0c0fc31e467f6f0918 | 0139713542bd0f9ba1748f71e7c8d7657f887fa7573c14653ae1f013de00e325 | 38cec936570bd4b1c8bda3c19cb45978419725a6673d9ccbc26b1853d03e781a | null | [
"LICENSE"
] | 794 |
2.1 | dbos | 2.13.0 | Ultra-lightweight durable execution in Python |
<div align="center">
[](https://github.com/dbos-inc/dbos-transact-py/actions/workflows/unit-test.yml)
[](https://pypi.python.org/pypi/dbos)
[](https://pypi.python.org/pypi/dbos)
[](LICENSE)
[](https://discord.com/invite/jsmC6pXGgX)
# DBOS Transact: Lightweight Durable Workflows
#### [Documentation](https://docs.dbos.dev/) • [Examples](https://docs.dbos.dev/examples) • [Github](https://github.com/dbos-inc) • [Discord](https://discord.com/invite/jsmC6pXGgX)
</div>
---
## What is DBOS?
DBOS provides lightweight durable workflows built on top of Postgres.
Instead of managing your own workflow orchestrator or task queue system, you can use DBOS to add durable workflows and queues to your program in just a few lines of code.
To get started, follow the [quickstart](https://docs.dbos.dev/quickstart) to install this open-source library and connect it to a Postgres database.
Then, annotate workflows and steps in your program to make it durable!
That's all you need to do—DBOS is entirely contained in this open-source library, there's no additional infrastructure for you to configure or manage.
## When Should I Use DBOS?
You should consider using DBOS if your application needs to **reliably handle failures**.
For example, you might be building a payments service that must reliably process transactions even if servers crash mid-operation, or a long-running data pipeline that needs to resume seamlessly from checkpoints rather than restart from the beginning when interrupted.
Handling failures is costly and complicated, requiring complex state management and recovery logic as well as heavyweight tools like external orchestration services.
DBOS makes it simpler: annotate your code to checkpoint it in Postgres and automatically recover from any failure.
DBOS also provides powerful Postgres-backed primitives that makes it easier to write and operate reliable code, including durable queues, notifications, scheduling, event processing, and programmatic workflow management.
## Features
<details open><summary><strong>💾 Durable Workflows</strong></summary>
####
DBOS workflows make your program **durable** by checkpointing its state in Postgres.
If your program ever fails, when it restarts all your workflows will automatically resume from the last completed step.
You add durable workflows to your existing Python program by annotating ordinary functions as workflows and steps:
```python
from dbos import DBOS
@DBOS.step()
def step_one():
...
@DBOS.step()
def step_two():
...
@DBOS.workflow()
def workflow()
step_one()
step_two()
```
Workflows are particularly useful for
- Orchestrating business processes so they seamlessly recover from any failure.
- Building observable and fault-tolerant data pipelines.
- Operating an AI agent, or any application that relies on unreliable or non-deterministic APIs.
[Read more ↗️](https://docs.dbos.dev/python/tutorials/workflow-tutorial)
</details>
<details><summary><strong>📒 Durable Queues</strong></summary>
####
DBOS queues help you **durably** run tasks in the background.
You can enqueue a task (which can be a single step or an entire workflow) from a durable workflow and one of your processes will pick it up for execution.
DBOS manages the execution of your tasks: it guarantees that tasks complete, and that their callers get their results without needing to resubmit them, even if your application is interrupted.
Queues also provide flow control, so you can limit the concurrency of your tasks on a per-queue or per-process basis.
You can also set timeouts for tasks, rate limit how often queued tasks are executed, deduplicate tasks, or prioritize tasks.
You can add queues to your workflows in just a couple lines of code.
They don't require a separate queueing service or message broker—just Postgres.
```python
from dbos import DBOS, Queue
queue = Queue("example_queue")
@DBOS.step()
def process_task(task):
...
@DBOS.workflow()
def process_tasks(tasks):
task_handles = []
# Enqueue each task so all tasks are processed concurrently.
for task in tasks:
handle = queue.enqueue(process_task, task)
task_handles.append(handle)
# Wait for each task to complete and retrieve its result.
# Return the results of all tasks.
return [handle.get_result() for handle in task_handles]
```
[Read more ↗️](https://docs.dbos.dev/python/tutorials/queue-tutorial)
</details>
<details><summary><strong>⚙️ Programmatic Workflow Management</strong></summary>
####
Your workflows are stored as rows in a Postgres table, so you have full programmatic control over them.
Write scripts to query workflow executions, batch pause or resume workflows, or even restart failed workflows from a specific step.
Handle bugs or failures that affect thousands of workflows with power and flexibility.
```python
# Create a DBOS client connected to your Postgres database.
client = DBOSClient(database_url)
# Find all workflows that errored between 3:00 and 5:00 AM UTC on 2025-04-22.
workflows = client.list_workflows(status="ERROR",
start_time="2025-04-22T03:00:00Z", end_time="2025-04-22T05:00:00Z")
for workflow in workflows:
# Check which workflows failed due to an outage in a service called from Step 2.
steps = client.list_workflow_steps(workflow)
if len(steps) >= 3 and isinstance(steps[2]["error"], ServiceOutage):
# To recover from the outage, restart those workflows from Step 2.
DBOS.fork_workflow(workflow.workflow_id, 2)
```
[Read more ↗️](https://docs.dbos.dev/python/reference/client)
</details>
<details><summary><strong>🎫 Exactly-Once Event Processing</strong></summary>
####
Use DBOS to build reliable webhooks, event listeners, or Kafka consumers by starting a workflow exactly-once in response to an event.
Acknowledge the event immediately while reliably processing it in the background.
For example:
```python
def handle_message(request: Request) -> None:
event_id = request.body["event_id"]
# Use the event ID as an idempotency key to start the workflow exactly-once
with SetWorkflowID(event_id):
# Start the workflow in the background, then acknowledge the event
DBOS.start_workflow(message_workflow, request.body["event"])
```
Or with Kafka:
```python
@DBOS.kafka_consumer(config,["alerts-topic"])
@DBOS.workflow()
def process_kafka_alerts(msg):
# This workflow runs exactly-once for each message sent to the topic
alerts = msg.value.decode()
for alert in alerts:
respond_to_alert(alert)
```
[Read more ↗️](https://docs.dbos.dev/python/tutorials/workflow-tutorial)
</details>
<details><summary><strong>📅 Durable Scheduling</strong></summary>
####
Schedule workflows using cron syntax, or use durable sleep to pause workflows for as long as you like (even days or weeks) before executing.
You can schedule a workflow using a single annotation:
```python
@DBOS.scheduled('* * * * *') # crontab syntax to run once every minute
@DBOS.workflow()
def example_scheduled_workflow(scheduled_time: datetime, actual_time: datetime):
DBOS.logger.info("I am a workflow scheduled to run once a minute.")
```
You can add a durable sleep to any workflow with a single line of code.
It stores its wakeup time in Postgres so the workflow sleeps through any interruption or restart, then always resumes on schedule.
```python
@DBOS.workflow()
def reminder_workflow(email: str, time_to_sleep: int):
send_confirmation_email(email)
DBOS.sleep(time_to_sleep)
send_reminder_email(email)
```
[Read more ↗️](https://docs.dbos.dev/python/tutorials/scheduled-workflows)
</details>
<details><summary><strong>📫 Durable Notifications</strong></summary>
####
Pause your workflow executions until a notification is received, or emit events from your workflow to send progress updates to external clients.
All notifications are stored in Postgres, so they can be sent and received with exactly-once semantics.
Set durable timeouts when waiting for events, so you can wait for as long as you like (even days or weeks) through interruptions or restarts, then resume once a notification arrives or the timeout is reached.
For example, build a reliable billing workflow that durably waits for a notification from a payments service, processing it exactly-once:
```python
@DBOS.workflow()
def billing_workflow():
... # Calculate the charge, then submit the bill to a payments service
payment_status = DBOS.recv(PAYMENT_STATUS, timeout=payment_service_timeout)
if payment_status is not None and payment_status == "paid":
... # Handle a successful payment.
else:
... # Handle a failed payment or timeout.
```
</details>
## Getting Started
To get started, follow the [quickstart](https://docs.dbos.dev/quickstart) to install this open-source library and connect it to a Postgres database.
Then, check out the [programming guide](https://docs.dbos.dev/python/programming-guide) to learn how to build with durable workflows and queues.
## Documentation
[https://docs.dbos.dev](https://docs.dbos.dev)
## Examples
[https://docs.dbos.dev/examples](https://docs.dbos.dev/examples)
## DBOS vs. Other Systems
<details><summary><strong>DBOS vs. Temporal</strong></summary>
####
Both DBOS and Temporal provide durable execution, but DBOS is implemented in a lightweight Postgres-backed library whereas Temporal is implemented in an externally orchestrated server.
You can add DBOS to your program by installing this open-source library, connecting it to Postgres, and annotating workflows and steps.
By contrast, to add Temporal to your program, you must rearchitect your program to move your workflows and steps (activities) to a Temporal worker, configure a Temporal server to orchestrate those workflows, and access your workflows only through a Temporal client.
[This blog post](https://www.dbos.dev/blog/durable-execution-coding-comparison) makes the comparison in more detail.
**When to use DBOS:** You need to add durable workflows to your applications with minimal rearchitecting, or you are using Postgres.
**When to use Temporal:** You don't want to add Postgres to your stack, or you need a language DBOS doesn't support yet.
</details>
<details><summary><strong>DBOS vs. Airflow</strong></summary>
####
DBOS and Airflow both provide workflow abstractions.
Airflow is targeted at data science use cases, providing many out-of-the-box connectors but requiring workflows be written as explicit DAGs and externally orchestrating them from an Airflow cluster.
Airflow is designed for batch operations and does not provide good performance for streaming or real-time use cases.
DBOS is general-purpose, but is often used for data pipelines, allowing developers to write workflows as code and requiring no infrastructure except Postgres.
**When to use DBOS:** You need the flexibility of writing workflows as code, or you need higher performance than Airflow is capable of (particularly for streaming or real-time use cases).
**When to use Airflow:** You need Airflow's ecosystem of connectors.
</details>
<details><summary><strong>DBOS vs. Celery/BullMQ</strong></summary>
####
DBOS provides a similar queue abstraction to dedicated queueing systems like Celery or BullMQ: you can declare queues, submit tasks to them, and control their flow with concurrency limits, rate limits, timeouts, prioritization, etc.
However, DBOS queues are **durable and Postgres-backed** and integrate with durable workflows.
For example, in DBOS you can write a durable workflow that enqueues a thousand tasks and waits for their results.
DBOS checkpoints the workflow and each of its tasks in Postgres, guaranteeing that even if failures or interruptions occur, the tasks will complete and the workflow will collect their results.
By contrast, Celery/BullMQ are Redis-backed and don't provide workflows, so they provide fewer guarantees but better performance.
**When to use DBOS:** You need the reliability of enqueueing tasks from durable workflows.
**When to use Celery/BullMQ**: You don't need durability, or you need very high throughput beyond what your Postgres server can support.
</details>
## Community
If you want to ask questions or hang out with the community, join us on [Discord](https://discord.gg/fMwQjeW5zg)!
If you see a bug or have a feature request, don't hesitate to open an issue here on GitHub.
If you're interested in contributing, check out our [contributions guide](./CONTRIBUTING.md).
| text/markdown | null | "DBOS, Inc." <contact@dbos.dev> | null | null | MIT | null | [
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programm... | [] | null | null | >=3.10 | [] | [] | [] | [
"pyyaml>=6.0.2",
"python-dateutil>=2.9.0.post0",
"psycopg[binary]>=3.1",
"websockets>=14.0",
"typer-slim>=0.17.4",
"sqlalchemy>=2.0.43",
"opentelemetry-api>=1.37.0; extra == \"otel\"",
"opentelemetry-sdk>=1.37.0; extra == \"otel\"",
"opentelemetry-exporter-otlp-proto-http>=1.37.0; extra == \"otel\""... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T18:29:29.399181 | dbos-2.13.0.tar.gz | 248,701 | 7f/35/cb30c941e79d09e4fbfc7bc948ddef008f6028a86839720a13ffd9fb372f/dbos-2.13.0.tar.gz | source | sdist | null | false | df1531975408750d2bad4cf634333087 | 1f735149aee301f9056f0866bd2d3ca9c22f3288a2b21d00439a709e990bde78 | 7f35cb30c941e79d09e4fbfc7bc948ddef008f6028a86839720a13ffd9fb372f | null | [] | 3,496 |
2.4 | pipemake-utils | 1.3.7 | Pipemake Utilities | Pipemake Utilities
==================
Basic utilities for Pipemake images
| text/x-rst | null | null | null | null | MIT | null | [] | [] | https://github.com/kocherlab/pipemake_utils | null | >=3.7 | [] | [] | [] | [
"biopython",
"gffutils",
"seaborn",
"pandas",
"numpy",
"scipy",
"pyyaml"
] | [] | [] | [] | [
"Code, https://github.com/kocherlab/pipemake_utils",
"Issue tracker, https://github.com/kocherlab/pipemake_utils/issues"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-19T18:28:51.353497 | pipemake_utils-1.3.7.tar.gz | 37,741 | fc/c4/d7c721921d4c382a7128639caf0d19a0b60fd7081b45d74e9a9fc43dade3/pipemake_utils-1.3.7.tar.gz | source | sdist | null | false | 9a513ab4ad579438ffa6446aab1330ee | 785c17132c6b85c59ef2c5c2014ea0262806bdd05422bfad23271db2db9ea950 | fcc4d7c721921d4c382a7128639caf0d19a0b60fd7081b45d74e9a9fc43dade3 | null | [
"LICENSE"
] | 158 |
2.4 | reaction-kinematics | 0.2.1 | Kinematics for nuclear reactions | # reaction-kinematics
This is a Python library for calculating relativistic two-body nuclear reaction kinematics.
This package is designed for students and researchers working in nuclear and particle physics who need fast, reliable kinematic calculations for reactions of the form:
```
projectile + target → ejectile + recoil
```
---
## Features
This code can do:
* Relativistic two-body kinematics
* Automatic unit handling
* Center-of-mass and lab-frame quantities
* Energy, angle, momentum, and velocity calculations
* Support for multi-valued kinematic solutions
* Simple plotting and data export
---
## Installation
```
pip install reaction-kinematics
```
---
## Basic Usage
The main interface is the `TwoBody` class.
```python
from reaction_kinematics import TwoBody
```
Create a reaction by specifying the particle masses and projectile kinetic energy.
## Units
* Masses are internally stored in MeV/c²
* Energies are in MeV by default
* Velocities are given as fractions of c
* Angles are in radians
You may specify alternative units using `EnergyUnit` and `MassInput`.
### Example: Proton + Tritium Reaction
```python
rxn = TwoBody("p", "3H", "n", "3He", 1.2)
```
This represents:
```
p + 3H → n + 3He
```
with a projectile energy of 1.2 MeV.
---
## Computing Kinematic Arrays
To generate arrays of kinematic quantities over all center-of-mass angles, use `compute_arrays()`.
```python
data = rxn.compute_arrays()
```
This will return a dictionary containing the following:
* `coscm` : cos(θ_CM)
* `theta_cm`: CM angle (rad)
* `theta3` : Ejectile lab angle (rad)
* `theta4` : Recoil lab angle (rad)
* `e3` : Ejectile energy (MeV)
* `e4` : Recoil energy (MeV)
* `v3` : Ejectile velocity (c)
* `v4` : Recoil velocity (c)
### Example
```python
theta4 = data["theta4"]
e3 = data["e3"]
```
---
## Accessing Individual Values
To evaluate kinematic quantities at a specific value, use `at_value()`.
This method automatically handles multi-valued solutions and always returns lists.
### Syntax
```python
rxn.at_value(x_name, x_value, y_names=None)
```
Parameters:
* `x_name` : Independent variable (e.g. `"theta4"`, `"theta_cm"`, `"coscm"`)
* `x_value`: Value at which to evaluate
* `y_names`: Dependent variables (string or list)
---
## Example: Single Quantity
```python
import math
angle = 10 * math.pi / 180
vals = rxn.at_value("theta4", angle, y_names="e3")
print(vals)
```
Output:
```
{'e3': [0.3447, 0.0364]}
```
Multiple values indicate multiple physical solutions.
---
## Example: Multiple Quantities
```python
vals = rxn.at_value(
"theta4",
angle,
y_names=["e3", "v3", "p3"]
)
print(vals)
```
Example output:
```
{
'e3': [0.3447, 0.0364],
'v3': [0.025, 0.009],
'p3': [23.7, 8.2]
}
```
---
## Example: Full State at a Given CM Angle
If `y_names` is omitted, all quantities are returned.
```python
vals = rxn.at_value("theta_cm", 0.8)
print(vals)
```
Example output:
```
{
'coscm': [...],
'theta3': [...],
'theta4': [...],
'e3': [...],
'e4': [...],
'v3': [...],
'v4': [...],
'p3': [...],
'p4': [...]
}
```
### Convert to NumPy Arrays
```python
import numpy as np
data = rxn.compute_arrays()
theta4 = np.array(data["theta4"])
e3 = np.array(data["e3"])
```
### Using Explicit Mass Values
```python
rxn = TwoBody(
938.272,
11177.928,
938.272,
11177.928,
5.0,
mass_unit="MeV"
)
```
---
## Plotting Example
You can use `matplotlib` to visualize kinematic relationships.
### Example: Ejectile Energy vs Recoil Angle
```python
import matplotlib.pyplot as plt
data = rxn.compute_arrays()
plt.plot(data["theta4"], data["e3"])
plt.xlabel("Recoil Angle θ₄ (rad)")
plt.ylabel("Ejectile Energy E₃ (MeV)")
plt.title("E₃ vs θ₄")
plt.grid(True)
plt.show()
```
---
## Numerical Notes
* Some kinematic variables are multi-valued.
* Near kinematic extrema, solution branches may merge numerically.
* The library automatically removes duplicate solutions within tolerance of 1e**-6.
---
## License
GPL-2.0 license
---
## Contact
For questions, issues, or contributions, please open an issue on GitHub.
* * *
## Project Docs
For how to install uv and Python, see [installation.md](installation.md).
For development workflows, see [development.md](development.md).
For instructions on publishing to PyPI, see [publishing.md](publishing.md).
* * *
*This project was built from
[simple-modern-uv](https://github.com/jlevy/simple-modern-uv).*
| text/markdown | null | Joseph Qualantone <joseph.qualantone@ucdenver.edu> | null | null | GPL-2.0-only | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.1... | [] | null | null | <4.0,>=3.11 | [] | [] | [] | [] | [] | [] | [] | [
"Repository, https://github.com/det-lab/reaction-kinematics"
] | uv/0.9.5 | 2026-02-19T18:28:28.637631 | reaction_kinematics-0.2.1.tar.gz | 59,145 | 80/19/2b8667dc90f600751682ca3b0e5990cddf5c146c412b9d9c21ea9f3f4229/reaction_kinematics-0.2.1.tar.gz | source | sdist | null | false | fab2cd84a90485708022896cac8cab4e | b743fd6c6e9317d564eb9070563a8dd9ad082acf29842b1d25d0993e7b8be1b4 | 80192b8667dc90f600751682ca3b0e5990cddf5c146c412b9d9c21ea9f3f4229 | null | [
"LICENSE"
] | 215 |
2.4 | bson-modern | 1.1.0 | BSON codec for Python - modernized fork with Python 3.9+ support (drop-in replacement for bson) | # bson-modern
A modernized fork of the [bson](https://github.com/py-bson/bson) package with Python 3.12+ support.
## Why this fork?
The original `bson` package has not been updated since 2018 and is incompatible with Python 3.12+ due to:
- Use of deprecated `pkgutil.find_loader()` (removed in Python 3.12)
- Dependency on the `six` package for Python 2/3 compatibility
This fork removes all Python 2 compatibility code and modernizes the package for Python 3.12+.
## Installation
```bash
pip install bson-modern
```
## Usage
```python
import bson
# Encode a dictionary to BSON
data = {"name": "Alice", "age": 30, "active": True}
encoded = bson.dumps(data)
# Decode BSON back to dictionary
decoded = bson.loads(encoded)
print(decoded) # {'name': 'Alice', 'age': 30, 'active': True}
```
## Compatibility with antares-client
This package is designed to be a drop-in replacement for `bson` when using packages like `antares-client` that depend on standalone BSON support.
To use with `antares-client`, install `bson-modern` before `antares-client`:
```bash
pip install bson-modern antares-client
```
Or in your `pyproject.toml`:
```toml
dependencies = [
"bson-modern>=1.0.0",
"antares-client>=1.3.0",
]
```
## Changes from original bson
- **Python 3.12+ only** - Dropped Python 2.x and early Python 3.x support
- **Removed `six` dependency** - No longer needed for Python 2/3 compatibility
- **Modern packaging** - Uses `pyproject.toml` and `hatchling`
- **Fixed build system** - No longer uses deprecated `pkgutil.find_loader()`
## License
BSD-3-Clause (same as original)
## Credits
- Original `bson` package by Kou Man Tong and Ayun Park
- Modernization by James Westover
| text/markdown | null | James Westover <james@westover.dev> | null | James Westover <james@westover.dev> | BSD-3-Clause | BSON, codec, mongodb, serialization | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming L... | [] | null | null | >=3.9 | [] | [] | [] | [
"python-dateutil>=2.4.0"
] | [] | [] | [] | [
"Homepage, https://github.com/westover/bson-modern",
"Repository, https://github.com/westover/bson-modern",
"Issues, https://github.com/westover/bson-modern/issues",
"Original Project, https://github.com/py-bson/bson"
] | twine/6.2.0 CPython/3.14.0 | 2026-02-19T18:28:27.992348 | bson_modern-1.1.0.tar.gz | 10,389 | 85/94/7b0d65f1ca797b8290acf455c971e271303904934e073dd492894160d662/bson_modern-1.1.0.tar.gz | source | sdist | null | false | 69082b910c62d0a3de2f554d15b1bdcf | 8e04d46db5498018db92b787f75730058c09c207e7ae9875e866a87be47e3f06 | 85947b0d65f1ca797b8290acf455c971e271303904934e073dd492894160d662 | null | [
"LICENSE"
] | 406 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.