
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.4 | hindsight-api | 0.4.13 | Hindsight: Agent Memory That Works Like Human Memory | # Hindsight API
**Memory System for AI Agents** — Temporal + Semantic + Entity Memory Architecture using PostgreSQL with pgvector.
Hindsight gives AI agents persistent memory that works like human memory: it stores facts, tracks entities and relationships, handles temporal reasoning ("what happened last spring?"), and forms opinions based on configurable disposition traits.
## Installation
```bash
pip install hindsight-api
```
## Quick Start
### Run the Server
```bash
# Set your LLM provider
export HINDSIGHT_API_LLM_PROVIDER=openai
export HINDSIGHT_API_LLM_API_KEY=sk-xxxxxxxxxxxx
# Start the server (uses embedded PostgreSQL by default)
hindsight-api
```
The server starts at http://localhost:8888 with:
- REST API for memory operations
- MCP server at `/mcp` for tool-use integration
### Use the Python API
```python
from hindsight_api import MemoryEngine
# Create and initialize the memory engine
memory = MemoryEngine()
await memory.initialize()
# Create a memory bank for your agent
bank = await memory.create_memory_bank(
name="my-assistant",
background="A helpful coding assistant"
)
# Store a memory
await memory.retain(
memory_bank_id=bank.id,
content="The user prefers Python for data science projects"
)
# Recall memories
results = await memory.recall(
memory_bank_id=bank.id,
query="What programming language does the user prefer?"
)
# Reflect with reasoning
response = await memory.reflect(
memory_bank_id=bank.id,
query="Should I recommend Python or R for this ML project?"
)
```
## CLI Options
```bash
hindsight-api --help
# Common options
hindsight-api --port 9000 # Custom port (default: 8888)
hindsight-api --host 127.0.0.1 # Bind to localhost only
hindsight-api --workers 4 # Multiple worker processes
hindsight-api --log-level debug # Verbose logging
```
## Configuration
Configure via environment variables:
| Variable | Description | Default |
|----------|-------------|---------|
| `HINDSIGHT_API_DATABASE_URL` | PostgreSQL connection string | `pg0` (embedded) |
| `HINDSIGHT_API_LLM_PROVIDER` | `openai`, `anthropic`, `gemini`, `groq`, `ollama`, `lmstudio` | `openai` |
| `HINDSIGHT_API_LLM_API_KEY` | API key for LLM provider | - |
| `HINDSIGHT_API_LLM_MODEL` | Model name | `gpt-4o-mini` |
| `HINDSIGHT_API_HOST` | Server bind address | `0.0.0.0` |
| `HINDSIGHT_API_PORT` | Server port | `8888` |
### Example with External PostgreSQL
```bash
export HINDSIGHT_API_DATABASE_URL=postgresql://user:pass@localhost:5432/hindsight
export HINDSIGHT_API_LLM_PROVIDER=groq
export HINDSIGHT_API_LLM_API_KEY=gsk_xxxxxxxxxxxx
hindsight-api
```
## Docker
```bash
docker run --rm -it -p 8888:8888 \
-e HINDSIGHT_API_LLM_API_KEY=$OPENAI_API_KEY \
-v $HOME/.hindsight-docker:/home/hindsight/.pg0 \
ghcr.io/vectorize-io/hindsight:latest
```
## MCP Server
For local MCP integration without running the full API server:
```bash
hindsight-local-mcp
```
This runs a stdio-based MCP server that can be used directly with MCP-compatible clients.
## Key Features
- **Multi-Strategy Retrieval (TEMPR)** — Semantic, keyword, graph, and temporal search combined with RRF fusion
- **Entity Graph** — Automatic entity extraction and relationship tracking
- **Temporal Reasoning** — Native support for time-based queries
- **Disposition Traits** — Configurable skepticism, literalism, and empathy influence opinion formation
- **Three Memory Types** — World facts, bank actions, and formed opinions with confidence scores
## Documentation
Full documentation: [https://hindsight.vectorize.io](https://hindsight.vectorize.io)
- [Installation Guide](https://hindsight.vectorize.io/developer/installation)
- [Configuration Reference](https://hindsight.vectorize.io/developer/configuration)
- [API Reference](https://hindsight.vectorize.io/api-reference)
- [Python SDK](https://hindsight.vectorize.io/sdks/python)
## License
Apache 2.0
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"aiohttp>=3.13.3",
"alembic>=1.17.1",
"anthropic>=0.40.0",
"asyncpg>=0.29.0",
"authlib>=1.6.6",
"claude-agent-sdk>=0.1.27",
"cohere>=5.0.0",
"dateparser>=1.2.2",
"fastapi[standard]>=0.120.3",
"fastmcp>=2.14.0",
"filelock>=3.20.1",
"flashrank>=0.2.0",
"google-auth>=2.0.0",
"google-genai>=1.... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:46:49.844758 | hindsight_api-0.4.13.tar.gz | 360,517 | bf/23/01440027d28efa86d33a94ebbd3479e3314a7e1720243bfa0597e36bed66/hindsight_api-0.4.13.tar.gz | source | sdist | null | false | 45439d546af223379bfa35a2a1d607ac | 5d3f95017ab83c6ee70d1fa3763264169e4a48f708be075cada9f27ae89e0eea | bf2301440027d28efa86d33a94ebbd3479e3314a7e1720243bfa0597e36bed66 | null | [] | 355 |
2.4 | hindsight-client | 0.4.13 | Python client for Hindsight - Semantic memory system with personality-driven thinking | # Hindsight Python Client | text/markdown | Hindsight Team | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp-retry>=2.8.3",
"aiohttp>=3.8.4",
"pydantic>=2",
"python-dateutil>=2.8.2",
"typing-extensions>=4.7.1",
"urllib3<3.0.0,>=2.1.0",
"pytest-asyncio>=0.21.0; extra == \"test\"",
"pytest>=7.0.0; extra == \"test\"",
"requests>=2.28.0; extra == \"test\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:46:41.030365 | hindsight_client-0.4.13.tar.gz | 67,013 | f6/e1/673baa95b9e2ad5b277b1b6f667dd58970468cc52a5eeef95202e755ec4f/hindsight_client-0.4.13.tar.gz | source | sdist | null | false | 44afd8a16534e4496cd74a2c00c5f290 | b76c3602a28bd5c0c795af9d26f641a23a8dd8ff85f8908655c15cf35af36aa8 | f6e1673baa95b9e2ad5b277b1b6f667dd58970468cc52a5eeef95202e755ec4f | null | [] | 599 |
2.4 | pulumi-kubernetes-cert-manager | 0.3.0a1771520929 | Strongly-typed Cert Manager installation | # Pulumi Cert Manager Component
This repo contains the Pulumi Cert Manager component for Kubernetes. This add-on automates the
management and issuance of TLS certificates from various issuing sources. It ensures certificates
are valid and up to date periodically, and attempts to renew certificates at an appropriate time
before expiry.
This component wraps [the Jetstack Cert Manager Helm Chart](https://github.com/jetstack/cert-manager),
and offers a Pulumi-friendly and strongly-typed way to manage Cert Manager installations.
For examples of usage, see [the official documentation](https://cert-manager.io/docs/),
or refer to [the examples](/examples) in this repo.
## To Use
To use this component, first install the Pulumi Package:
Afterwards, import the library and instantiate it within your Pulumi program:
## Configuration
This component supports all of the configuration options of the [official Helm chart](
https://github.com/jetstack/cert-manager/tree/master/deploy/charts/cert-manager), except that these
are strongly typed so you will get IDE support and static error checking.
The Helm deployment uses reasonable defaults, including the chart name and repo URL, however,
if you need to override them, you may do so using the `helmOptions` parameter. Refer to
[the API docs for the `kubernetes:helm/v3:Release` Pulumi type](
https://www.pulumi.com/docs/reference/pkg/kubernetes/helm/v3/release/#inputs) for a full set of choices.
For complete details, refer to the Pulumi Package details within the Pulumi Registry.
| text/markdown | null | null | null | null | Apache-2.0 | pulumi, kubernetes, cert-manager, kind/component, category/infrastructure | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"pulumi-kubernetes<5.0.0,>=4.0.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://pulumi.io",
"Repository, https://github.com/pulumi/pulumi-kubernetes-cert-manager"
] | twine/5.0.0 CPython/3.11.8 | 2026-02-19T17:46:36.610398 | pulumi_kubernetes_cert_manager-0.3.0a1771520929.tar.gz | 25,128 | f1/c4/9b10922d1c2e32f80464d2a32181d939faadf3e21add83355d23ccf09d59/pulumi_kubernetes_cert_manager-0.3.0a1771520929.tar.gz | source | sdist | null | false | 85943147f8bd9dd521f45a5028ac2a3b | 6e4a08eb0fba57978bfadcd178f108c1ff39c148683464e4966af5d208ffd0af | f1c49b10922d1c2e32f80464d2a32181d939faadf3e21add83355d23ccf09d59 | null | [] | 195 |
2.4 | clawrtc | 1.5.0 | ClawRTC — Let your AI agent mine RTC tokens on any modern hardware. Built-in wallet, VM-penalized. | # ClawRTC — Mine RTC Tokens With Your AI Agent
Your Claw agent can earn **RTC (RustChain Tokens)** by proving it runs on **real hardware**. One command to install, automatic attestation, built-in wallet.
## Quick Start
```bash
pip install clawrtc
clawrtc install --wallet my-agent-miner
clawrtc start
```
That's it. Your agent is now mining RTC.
## How It Works
1. **Hardware Fingerprinting** — 6 cryptographic checks prove your machine is real hardware (clock drift, cache timing, SIMD identity, thermal drift, instruction jitter, anti-emulation)
2. **Attestation** — Your agent automatically attests to the RustChain network every few minutes
3. **Rewards** — RTC tokens accumulate in your wallet each epoch (~10 minutes)
4. **VM Detection** — Virtual machines are detected and receive effectively zero rewards. **Real iron only.**
## Multipliers
| Hardware | Multiplier | Notes |
|----------|-----------|-------|
| Modern x86/ARM | **1.0x** | Standard reward rate |
| Apple Silicon (M1/M2/M3) | **1.2x** | Slight bonus |
| PowerPC G5 | **2.0x** | Vintage bonus |
| PowerPC G4 | **2.5x** | Maximum vintage bonus |
| **VM/Emulator** | **~0x** | **Detected and penalized** |
## Commands
| Command | Description |
|---------|-------------|
| `clawrtc install` | Download miner, create wallet, set up service |
| `clawrtc start` | Start mining in background |
| `clawrtc stop` | Stop mining |
| `clawrtc status` | Check miner + network status |
| `clawrtc logs` | View miner output |
| `clawrtc uninstall` | Remove everything |
## What Gets Installed
- Miner scripts from [RustChain repo](https://github.com/Scottcjn/Rustchain)
- Python virtual environment with `requests` dependency
- Systemd user service (Linux) or LaunchAgent (macOS)
- All files in `~/.clawrtc/`
## VM Warning
RustChain uses **Proof-of-Antiquity (PoA)** consensus. The hardware fingerprint system detects:
- QEMU / KVM / VMware / VirtualBox / Xen / Hyper-V
- Hypervisor CPU flags
- DMI vendor strings
- Flattened timing distributions
If you're running in a VM, the miner will install and attest, but your rewards will be effectively zero. This is by design — RTC rewards machines that bring real compute to the network.
## Requirements
- Python 3.8+
- Linux or macOS (Windows installer coming soon)
- Real hardware (not a VM)
## Links
- [RustChain Network](https://bottube.ai)
- [Block Explorer](https://50.28.86.131/explorer)
- [GitHub](https://github.com/Scottcjn/Rustchain)
## License
MIT — Elyan Labs
| text/markdown | null | Elyan Labs <scott@elyanlabs.ai> | null | null | MIT | clawrtc, ai-agent, miner, rustchain, rtc, openclaw, proof-of-antiquity, wallet, coinbase, x402, base-chain | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: POSIX :: Linux",
"Operating System :: MacOS",
"Programming Language :: Python :: 3",
"Topic :: Software Development :: Libraries"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"requests>=2.25",
"cryptography>=41.0",
"coinbase-agentkit>=0.1.0; extra == \"coinbase\""
] | [] | [] | [] | [
"Homepage, https://rustchain.org",
"Repository, https://github.com/Scottcjn/Rustchain",
"Issues, https://github.com/Scottcjn/Rustchain/issues",
"Documentation, https://bottube.ai"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-19T17:46:18.489630 | clawrtc-1.5.0.tar.gz | 23,724 | 37/bf/6817d6c00cb29a51bd07b57c3a2c13903cb4e497f67c85930cdf4557effe/clawrtc-1.5.0.tar.gz | source | sdist | null | false | ca11e3ce3ab40f1354d1046aa425056a | ccb048361a5cdf60c7c93ebf1fd07717137780279386a46d51b6072c34c365cf | 37bf6817d6c00cb29a51bd07b57c3a2c13903cb4e497f67c85930cdf4557effe | null | [
"LICENSE"
] | 287 |
2.4 | redis-benchmarks-specification | 0.2.54 | The Redis benchmarks specification describes the cross-language/tools requirements and expectations to foster performance and observability standards around redis related technologies. Members from both industry and academia, including organizations and individuals are encouraged to contribute. | 
[](https://codecov.io/gh/redis/redis-benchmarks-specification)
[](https://pypi.org/project/redis-benchmarks-specification)
[](https://pepy.tech/projects/redis-benchmarks-specification)
<!-- toc -->
- [Benchmark specifications goal](#benchmark-specifications-goal)
- [Scope](#scope)
- [Installation and Execution](#installation-and-execution)
- [Installing package requirements](#installing-package-requirements)
- [Installing Redis benchmarks specification](#installing-redis-benchmarks-specification-implementations)
- [Testing out the redis-benchmarks-spec-runner](#testing-out-the-redis-benchmarks-spec-runner)
- [Testing out redis-benchmarks-spec-sc-coordinator](#testing-out-redis-benchmarks-spec-sc-coordinator)
- [Architecture diagram](#architecture-diagram)
- [Directory layout](#directory-layout)
- [Specifications](#specifications)
- [Spec tool implementations](#spec-tool-implementations)
- [Contributing guidelines](#contributing-guidelines)
- [Joining the performance initiative and adding a continuous benchmark platform](#joining-the-performance-initiative-and-adding-a-continuous-benchmark-platform)
- [Joining the performance initiative](#joining-the-performance-initiative)
- [Adding a continuous benchmark platform](#adding-a-continuous-benchmark-platform)
- [Adding redis-benchmarks-spec-sc-coordinator to supervisord](#adding-redis-benchmarks-spec-sc-coordinator-to-supervisord)
- [Development](#development)
- [Running formaters](#running-formaters)
- [Running linters](#running-linters)
- [Running tests](#running-tests)
- [License](#license)
<!-- tocstop -->
## Benchmark specifications goal
The Redis benchmarks specification describes the cross-language/tools requirements and expectations to foster performance and observability standards around redis related technologies.
Members from both industry and academia, including organizations and individuals are encouraged to contribute.
Currently, the following members actively support this project:
- [Redis Ltd.](https://redis.com/) via the Redis Performance Group: providing steady-stable infrastructure platform to run the benchmark suite. Supporting the active development of this project within the company.
- [Intel.](https://intel.com/): Intel is hosting an on-prem cluster of servers dedicated to the always-on automatic performance testing.
## Scope
This repo aims to provide Redis related benchmark standards and methodologies for:
- Management of benchmark data and specifications across different setups
- Running benchmarks and recording results
- Exporting performance results in several formats (CSV, RedisTimeSeries, JSON)
- Finding on-cpu, off-cpu, io, and threading performance problems by attaching profiling tools/probers ( perf (a.k.a. perf_events), bpf tooling, vtune )
- Finding performance problems by attaching telemetry probes
Current supported benchmark tools:
- [redis-benchmark](https://github.com/redis/redis)
- [memtier_benchmark](https://github.com/RedisLabs/memtier_benchmark)
- [SOON][redis-benchmark-go](https://github.com/filipecosta90/redis-benchmark-go)
## Installation and Execution
The Redis benchmarks specification and implementations is developed for Unix and is actively tested on it.
To have access to the latest SPEC and Tooling impletamtion you only need to install one python package.<br />
Before package's installation, please install its' dependencies.
### Installing package requirements
```bash
# install pip installer for python3
sudo apt install python3-pip -y
sudo pip3 install --upgrade pip
sudo pip3 install pyopenssl --upgrade
# install docker
sudo apt install docker.io -y
# install supervisord
sudo apt install supervisor -y
```
### Installing Redis benchmarks specification
Installation is done using pip, the package installer for Python, in the following manner:
```bash
python3 -m pip install redis-benchmarks-specification --ignore-installed PyYAML
```
To run particular version - use its number, e.g. 0.1.57:
```bash
pip3 install redis-benchmarks-specification==0.1.57
```
### Testing out the redis-benchmarks-spec-client-runner
There is an option to run "redis-benchmarks-spec" tests using standalone runner approach. For this option redis-benchmarks-specificaiton should be run together with redis-server in the same time.
```bash
# Run redis server
[taskset -c cpu] /src/redis-server --port 6379 --dir logs --logfile server.log --save "" [--daemonize yes]
# Run benchmark
redis-benchmarks-spec-client-runner --db_server_host localhost --db_server_port 6379 --client_aggregated_results_folder ./test
```
Use taskset when starting the redis-server to pin it to a particular cpu and get more consistent results.
Option "--daemonize yes" given to server run command allows to run redis-server in background.<br />
Option "--test X.yml" given to benchmark execution command allows to run particular test, where X - test name
Full list of option can be taken with "-h" option:
```
$ redis-benchmarks-spec-client-runner -h
usage: redis-benchmarks-spec-client-runner [-h]
[--platform-name PLATFORM_NAME]
[--triggering_env TRIGGERING_ENV]
[--setup_type SETUP_TYPE]
[--github_repo GITHUB_REPO]
[--github_org GITHUB_ORG]
[--github_version GITHUB_VERSION]
[--logname LOGNAME]
[--test-suites-folder TEST_SUITES_FOLDER]
[--test TEST]
[--db_server_host DB_SERVER_HOST]
[--db_server_port DB_SERVER_PORT]
[--cpuset_start_pos CPUSET_START_POS]
[--datasink_redistimeseries_host DATASINK_REDISTIMESERIES_HOST]
[--datasink_redistimeseries_port DATASINK_REDISTIMESERIES_PORT]
[--datasink_redistimeseries_pass DATASINK_REDISTIMESERIES_PASS]
[--datasink_redistimeseries_user DATASINK_REDISTIMESERIES_USER]
[--datasink_push_results_redistimeseries] [--profilers PROFILERS]
[--enable-profilers] [--flushall_on_every_test_start]
[--flushall_on_every_test_end]
[--preserve_temporary_client_dirs]
[--client_aggregated_results_folder CLIENT_AGGREGATED_RESULTS_FOLDER]
[--tls]
[--tls-skip-verify]
[--cert CERT]
[--key KEY]
[--cacert CACERT]
redis-benchmarks-spec-client-runner (solely client) 0.1.61
...
```
### Testing out redis-benchmarks-spec-sc-coordinator
Alternative way of running redis-server for listeting is running via redis-benchmarks coordinator.
You should now be able to print the following installed benchmark runner help:
```bash
$ redis-benchmarks-spec-sc-coordinator -h
usage: redis-benchmarks-spec-sc-coordinator [-h] --event_stream_host
EVENT_STREAM_HOST
--event_stream_port
EVENT_STREAM_PORT
--event_stream_pass
EVENT_STREAM_PASS
--event_stream_user
EVENT_STREAM_USER
[--cpu-count CPU_COUNT]
[--platform-name PLATFORM_NAME]
[--logname LOGNAME]
[--consumer-start-id CONSUMER_START_ID]
[--setups-folder SETUPS_FOLDER]
[--test-suites-folder TEST_SUITES_FOLDER]
[--datasink_redistimeseries_host DATASINK_REDISTIMESERIES_HOST]
[--datasink_redistimeseries_port DATASINK_REDISTIMESERIES_PORT]
[--datasink_redistimeseries_pass DATASINK_REDISTIMESERIES_PASS]
[--datasink_redistimeseries_user DATASINK_REDISTIMESERIES_USER]
[--datasink_push_results_redistimeseries]
redis-benchmarks-spec runner(self-contained) 0.1.13
optional arguments:
-h, --help show this help message and exit
--event_stream_host EVENT_STREAM_HOST
--event_stream_port EVENT_STREAM_PORT
--event_stream_pass EVENT_STREAM_PASS
--event_stream_user EVENT_STREAM_USER
--cpu-count CPU_COUNT
Specify how much of the available CPU resources the
coordinator can use. (default: 8)
--platform-name PLATFORM_NAME
Specify the running platform name. By default it will
use the machine name. (default: fco-ThinkPad-T490)
--logname LOGNAME logname to write the logs to (default: None)
--consumer-start-id CONSUMER_START_ID
--setups-folder SETUPS_FOLDER
Setups folder, containing the build environment
variations sub-folder that we use to trigger different
build artifacts (default: /home/fco/redislabs/redis-
benchmarks-
specification/redis_benchmarks_specification/setups)
--test-suites-folder TEST_SUITES_FOLDER
Test suites folder, containing the different test
variations (default: /home/fco/redislabs/redis-
benchmarks-
specification/redis_benchmarks_specification/test-
suites)
--datasink_redistimeseries_host DATASINK_REDISTIMESERIES_HOST
--datasink_redistimeseries_port DATASINK_REDISTIMESERIES_PORT
--datasink_redistimeseries_pass DATASINK_REDISTIMESERIES_PASS
--datasink_redistimeseries_user DATASINK_REDISTIMESERIES_USER
--datasink_push_results_redistimeseries
uploads the results to RedisTimeSeries. Proper
credentials are required (default: False)
```
Note that the minimum arguments to run the benchmark coordinator are: `--event_stream_host`, `--event_stream_port`, `--event_stream_pass`, `--event_stream_user`
You should use the provided credentials to be able to access the event streams.
Apart from it, you will need to discuss with the Performance Group the unique platform name that will be used to showcase results, coordinate work, among other thigs.
If all runs accordingly you should see the following sample log when you run the tool with the credentials:
```bash
$ poetry run redis-benchmarks-spec-sc-coordinator --platform-name example-platform \
--event_stream_host <...> \
--event_stream_port <...> \
--event_stream_pass <...> \
--event_stream_user <...>
2021-09-22 10:47:12 INFO redis-benchmarks-spec runner(self-contained) 0.1.13
2021-09-22 10:47:12 INFO Using topologies folder dir /home/fco/redislabs/redis-benchmarks-specification/redis_benchmarks_specification/setups/topologies
2021-09-22 10:47:12 INFO Reading topologies specifications from: /home/fco/redislabs/redis-benchmarks-specification/redis_benchmarks_specification/setups/topologies/topologies.yml
2021-09-22 10:47:12 INFO Using test-suites folder dir /home/fco/redislabs/redis-benchmarks-specification/redis_benchmarks_specification/test-suites
2021-09-22 10:47:12 INFO Running all specified benchmarks: /home/fco/redislabs/redis-benchmarks-specification/redis_benchmarks_specification/test-suites/redis-benchmark-full-suite-1Mkeys-100B.yml
2021-09-22 10:47:12 INFO There are a total of 1 test-suites in folder /home/fco/redislabs/redis-benchmarks-specification/redis_benchmarks_specification/test-suites
2021-09-22 10:47:12 INFO Reading event streams from: <...>:<...> with user <...>
2021-09-22 10:47:12 INFO checking build spec requirements
2021-09-22 10:47:12 INFO Will use consumer group named runners-cg:redis/redis/commits-example-platform.
2021-09-22 10:47:12 INFO Created consumer group named runners-cg:redis/redis/commits-example-platform to distribute work.
2021-09-22 10:47:12 INFO Entering blocking read waiting for work.
```
You're now actively listening for benchmarks requests to Redis!
## Architecture diagram

In a very brief description, github.com/redis/redis upstream changes trigger an HTTP API call containing the
relevant git information.
The HTTP request is then converted into an event ( tracked within redis ) that will trigger multiple build variants requests based upon the distinct platforms described in [`platforms`](redis_benchmarks_specification/setups/platforms/).
As soon as a new build variant request is received, the build agent ([`redis-benchmarks-spec-builder`](https://github.com/filipecosta90/redis-benchmarks-specification/tree/main/redis_benchmarks_specification/__builder__/))
prepares the artifact(s) and proceeds into adding an artifact benchmark event so that the benchmark coordinator ([`redis-benchmarks-spec-sc-coordinator`](https://github.com/filipecosta90/redis-benchmarks-specification/tree/main/redis_benchmarks_specification/__self_contained_coordinator__/)) can deploy/manage the required infrastructure and DB topologies, run the benchmark, and export the performance results.
## Directory layout
### Specifications
The following is a high level status report for currently available specs.
* `redis_benchmarks_specification`
* [`test-suites`](https://github.com/filipecosta90/redis-benchmarks-specification/tree/main/redis_benchmarks_specification/test-suites/): contains the benchmark suites definitions, specifying the target redis topology, the tested commands, the benchmark utility to use (the client), and if required the preloading dataset steps.
* `redis_benchmarks_specification/setups`
* [`platforms`](https://github.com/filipecosta90/redis-benchmarks-specification/tree/main/redis_benchmarks_specification/setups/platforms/): contains the standard platforms considered to provide steady stable results, and to represent common deployment targets.
* [`topologies`](https://github.com/filipecosta90/redis-benchmarks-specification/tree/main/redis_benchmarks_specification/setups/topologies/): contains the standard deployment topologies definition with the associated minimum specs to enable the topology definition.
* [`builders`](https://github.com/filipecosta90/redis-benchmarks-specification/tree/main/redis_benchmarks_specification/setups/builders/): contains the build environment variations, that enable to build Redis with different compilers, compiler flags, libraries, etc...
### Spec tool implementations
The following is a high level status report for currently available spec implementations.
* **STATUS: Experimental** [`redis-benchmarks-spec-api`](https://github.com/filipecosta90/redis-benchmarks-specification/tree/main/redis_benchmarks_specification/__api__/) : contains the API that translates the POST HTTP request that was triggered by github.com/redis/redis upstream changes, and fetches the relevant git/source info and coverts it into an event ( tracked within redis ).
* **STATUS: Experimental** [`redis-benchmarks-spec-builder`](https://github.com/filipecosta90/redis-benchmarks-specification/tree/main/redis_benchmarks_specification/__builder__/): contains the benchmark build agent utility that receives an event indicating a new build variant, generates the required redis binaries to test, and triggers the benchmark run on the listening agents.
* **STATUS: Experimental** [`redis-benchmarks-spec-sc-coordinator`](https://github.com/filipecosta90/redis-benchmarks-specification/tree/main/redis_benchmarks_specification/__self_contained_coordinator__/): contains the coordinator utility that listens for benchmark suite run requests and setups the required steps to spin the actual benchmark topologies and to trigger the actual benchmarks.
* **STATUS: Experimental** [`redis-benchmarks-spec-client-runner`](https://github.com/filipecosta90/redis-benchmarks-specification/tree/main/redis_benchmarks_specification/__runner__/): contains the client utility that triggers the actual benchmarks against an endpoint provided. This tool is setup agnostic and expects the DB to be properly spinned beforehand.
## Contributing guidelines
### Adding new test suites
TBD
### Adding new topologies
TBD
### Joining the performance initiative and adding a continuous benchmark platform
#### Joining the performance initiative
In order to join the performance initiative the only requirement is that you provide a steady-stable infrastructure
platform to run the benchmark suites, and you reach out to one of the Redis Performance Initiative member via
`performance <at> redis <dot> com` so that we can provide you with the required secrets to actively listen for benchmark events.
If you check the above "Architecture diagram", this means you only need to run the last moving part of the arch, meaning you will have
one or more benchmark coordinator machines actively running benchmarks and pushing the results back to our datasink.
#### Adding a continuous benchmark platform
In order to be able to run the benchmarks on the platform you need pip installer for python3, and docker.
Apart from it, we recommend you manage the `redis-benchmarks-spec-sc-coordinator` process(es) state via a process monitoring tool like
supervisorctl, lauchd, daemon tools, or other.
For this example we relly uppon `supervisorctl` for process managing.
##### Adding redis-benchmarks-spec-sc-coordinator to supervisord
Let's add a supervisord entry as follow
```
vi /etc/supervisor/conf.d/redis-benchmarks-spec-sc-coordinator-1.conf
```
You can use the following template and update according to your credentials:
```bash
[supervisord]
loglevel = debug
[program:redis-benchmarks-spec-sc-coordinator]
command = redis-benchmarks-spec-sc-coordinator --platform-name bicx02 \
--event_stream_host <...> \
--event_stream_port <...> \
--event_stream_pass <...> \
--event_stream_user <...> \
--datasink_push_results_redistimeseries \
--datasink_redistimeseries_host <...> \
--datasink_redistimeseries_port <...> \
--datasink_redistimeseries_pass <...> \
--logname /var/opt/redis-benchmarks-spec-sc-coordinator-1.log
startsecs = 0
autorestart = true
startretries = 1
```
After editing the conf, you just need to reload and confirm that the benchmark runner is active:
```bash
:~# supervisorctl reload
Restarted supervisord
:~# supervisorctl status
redis-benchmarks-spec-sc-coordinator RUNNING pid 27842, uptime 0:00:00
```
## Development
1. Install [pypoetry](https://python-poetry.org/) to manage your dependencies and trigger tooling.
```sh
pip install poetry
```
2. Installing dependencies from lock file
```
poetry install
```
### Running formaters
```sh
poetry run black .
```
### Running linters
```sh
poetry run flake8
```
### Running tests
A test suite is provided, and can be run with:
```sh
$ pip3 install -r ./dev_requirements.txt
$ tox
```
To run a specific test:
```sh
$ tox -- utils/tests/test_runner.py
```
To run a specific test with verbose logging:
```sh
$ tox -- -vv --log-cli-level=INFO utils/tests/test_runner.py
```
## License
redis-benchmarks-specification is distributed under the BSD3 license - see [LICENSE](LICENSE)
| text/markdown | filipecosta90 | filipecosta.90@gmail.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0.0,>=3.10.0 | [] | [] | [] | [
"Flask<3.0.0,>=2.0.3",
"Flask-HTTPAuth<5.0.0,>=4.4.0",
"GitPython<4.0.0,>=3.1.20",
"PyGithub<2.0,>=1.55",
"PyYAML<7.0,>=6.0",
"argparse<2.0.0,>=1.4.0",
"docker<8.0.0,>=7.1.0",
"flask-restx<0.6.0,>=0.5.0",
"jsonpath-ng<2.0.0,>=1.6.1",
"marshmallow<4.0.0,>=3.12.2",
"node-semver<0.9.0,>=0.8.1",
"... | [] | [] | [] | [] | poetry/2.3.2 CPython/3.10.19 Linux/6.14.0-1017-azure | 2026-02-19T17:45:56.912969 | redis_benchmarks_specification-0.2.54-py3-none-any.whl | 687,578 | 92/e5/36a7bb38be728204b6ff2c65353f4deba4e944df4ba5ab2b13b697b9c51e/redis_benchmarks_specification-0.2.54-py3-none-any.whl | py3 | bdist_wheel | null | false | 45ecf1c80a421c27de706644f1468242 | c476fe303ef6a98d78da76665d4d1b22c2e289c9e26a8eaf0ab4078c2247dd14 | 92e536a7bb38be728204b6ff2c65353f4deba4e944df4ba5ab2b13b697b9c51e | null | [
"LICENSE"
] | 228 |
2.4 | appmerit | 0.1.4 | AI Testing Framework | # Merit
[](https://opensource.org/licenses/MIT)
[](https://www.python.org/downloads/)
[](https://github.com/appMerit/merit/actions/workflows/test.yml)
[](https://github.com/appMerit/merit/actions/workflows/check.yml)
Merit is a Python testing framework for AI projects. It follows pytest syntax and culture while introducing components essential for testing AI software: metrics, typed datasets, semantic predicates (LLM-as-a-Judge), and OTEL traces.
---
## Installation
```bash
uv add appmerit
```
---
# Merit 101
Follow pytest habits...
- Create 'merit_*.py' files
- Write 'def merit_*' functions
- Use 'merit.resource' instead of 'pytest.fixture'
- Add 'assert' expressions within the functions
- Run 'uv run merit test'
...while leveraging Merit APIs.
- Use 'with metrics()' context to turn failed assertions into quality metrics
- Use 'has_facts()' and other semantic predicates for asserting natural language
- Access OTEL span data and assert it with 'follows_policy()' predicate
- Parse datasets into clearly typed and validated data objects
---
## Example
```python
import merit
from merit import Case, Metric, metrics
from merit.predicates import has_unsupported_facts, follows_policy
from pydantic import BaseModel
@merit.sut
def store_chatbot(prompt: str) -> str:
return call_llm(prompt)
@merit.metric
def accuracy():
metric = Metric()
yield metric
assert metric.mean > 0.8
yield metric.mean
class Refs(BaseModel):
kb: str
expected_tool: str | None = None
cases = [
Case(sut_input_values={"prompt": "When are you open?"}, references=Refs(kb="Store hours: 9 AM - 6 PM, Monday-Saturday. Closed Sundays.")),
Case(sut_input_values={"prompt": "Return policy?"}, references=Refs(kb="30-day returns with receipt.")),
Case(sut_input_values={"prompt": "How much for the Nike Air Max?"}, references=Refs(kb="Nike Air Max: $129.99", expected_tool="offer_product")),
]
@merit.iter_cases(cases)
@merit.repeat(3)
async def merit_chatbot_no_hallucinations(
case: Case[Refs],
store_chatbot,
accuracy: Metric,
trace_context):
"""AI agent relies on knowledge base and tool calls for transactional questions"""
response = store_chatbot(**case.sut_input_values)
# Verify the answer don't have any unsupported facts
with metrics(accuracy):
assert not await has_unsupported_facts(response, case.references.kb)
# Verify tool was called when expected
if expected_tool := case.references.expected_tool:
sut_spans = trace_context.get_sut_spans(name="store_chatbot")
tool_names = [
s.attributes.get("llm.request.functions.0.name")
for s in trace_context.get_llm_calls()
if s.attributes
]
assert expected_tool in tool_names
```
Run it:
```bash
merit test --trace
```
Use a custom run UUID when you need stable correlation IDs:
```bash
merit test --trace --run-id 3f5f5e9a-1c2d-4b5f-9c2b-7f6d8a9b0c1d
```
Output:
```
Merit Test Runner
=================
Collected 1 test
test_example.py::merit_chatbot_responds ✓
==================== 1 passed in 0.08s ====================
```
## Documentation
Full documentation: **[docs.appmerit.com](https://docs.appmerit.com)**
**Getting Started:**
- [Quick Start](https://docs.appmerit.com/get-started/quick-start) - Get up and running in 5 minutes
**Usage:**
- [Writing Merits](https://docs.appmerit.com/usage/writing-merits) - How to define a proper merit suite
- [Running Merits](https://docs.appmerit.com/usage/running-merits) - How to execute suits and merits
**Concepts:**
- [Merit](https://docs.appmerit.com/concepts/merit) - Like test but better
- [Resource](https://docs.appmerit.com/concepts/resource) - Like fixtures but better
- [Case](https://docs.appmerit.com/concepts/case) - Container for parsed dataset entities
- [Metric](https://docs.appmerit.com/concepts/metric) - Aggregating assertions
- [Semantic Predicates](https://docs.appmerit.com/concepts/semantic-predicates) - Asserting language and logs
- [SUT (System Under Test)](https://docs.appmerit.com/concepts/sut) - Collecting and accesing traces
**API Reference:**
- [Merit Definitions APIs](https://docs.appmerit.com/apis/testing) - Tune discovery and execution
- [Merit Predicates APIs](https://docs.appmerit.com/apis/predicates) - Build your own semantic predicates
- [Merit Metric APIs](https://docs.appmerit.com/apis/metrics) - Build complex metric systems
- [Merit Tracing APIs](https://docs.appmerit.com/apis/tracing) - OpenTelemetry integration
---
## Contributing
We welcome contributions! To get started:
1. Fork the repository
2. Clone your fork: `git clone https://github.com/YOUR_USERNAME/merit.git`
3. Create a branch: `git checkout -b your-feature-name`
4. Install dependencies: `uv sync`
5. Make your changes
6. Run tests: `uv run merit test`
7. Run lints: `uv run ruff check .`
8. Submit a pull request
For more details, see [CONTRIBUTING.md](CONTRIBUTING.md).
**Development Setup:**
```bash
# Clone the repository
git clone https://github.com/appMerit/merit.git
cd merit
# Install dependencies
uv sync
# Run tests
uv run merit test
# Run lints
uv run ruff check .
uv run mypy .
```
---
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
---
## Support
- **Documentation**: [docs.appmerit.com](https://docs.appmerit.com)
- **GitHub Issues**: [github.com/appMerit/merit/issues](https://github.com/appMerit/merit/issues)
- **Email**: support@appmerit.com
| text/markdown | null | Daniel Rousso <daniel@appmerit.com>, Mark Reith <mark@appmerit.com>, Nikita Shirobokov <nick@appmerit.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"anthropic[vertex]>=0.72.0",
"httpx>=0.28.1",
"openai>=2.6.1",
"opentelemetry-instrumentation-anthropic>=0.49.0",
"opentelemetry-instrumentation-openai>=0.49.0",
"opentelemetry-sdk>=1.29.0",
"pydantic-settings>=2.11.0",
"pydantic>=2.12.3",
"python-dotenv>=1.2.1",
"rich>=14.2.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:45:37.325801 | appmerit-0.1.4.tar.gz | 602,379 | 6d/49/1fb54c80be3b85e19d674d8969db8ec0b2e9d3ad01a8245d5187ab062797/appmerit-0.1.4.tar.gz | source | sdist | null | false | 4dd825cb2984ef5b5f1992697cc5abfb | f32e4776088f924db933c9ecbececb6107c978ddcd15040bc0fe0bc1851af296 | 6d491fb54c80be3b85e19d674d8969db8ec0b2e9d3ad01a8245d5187ab062797 | MIT | [
"LICENSE"
] | 225 |
2.3 | lm-raindrop | 0.17.0 | The official Python library for the raindrop API | # Raindrop Python API library
<!-- prettier-ignore -->
[)](https://pypi.org/project/lm-raindrop/)
The Raindrop Python library provides convenient access to the Raindrop REST API from any Python 3.9+
application. The library includes type definitions for all request params and response fields,
and offers both synchronous and asynchronous clients powered by [httpx](https://github.com/encode/httpx).
It is generated with [Stainless](https://www.stainless.com/).
## Documentation
The full API of this library can be found in [api.md](https://github.com/LiquidMetal-AI/lm-raindrop-python-sdk/tree/main/api.md).
## Installation
```sh
# install from PyPI
pip install lm-raindrop
```
## Usage
The full API of this library can be found in [api.md](https://github.com/LiquidMetal-AI/lm-raindrop-python-sdk/tree/main/api.md).
```python
from raindrop import Raindrop
client = Raindrop()
response = client.query.document_query(
bucket_location={
"bucket": {
"name": "my-smartbucket",
"version": "01jxanr45haeswhay4n0q8340y",
"application_name": "my-app",
}
},
input="What are the key points in this document?",
object_id="document.pdf",
request_id="<YOUR-REQUEST-ID>",
)
print(response.answer)
```
While you can provide an `api_key` keyword argument,
we recommend using [python-dotenv](https://pypi.org/project/python-dotenv/)
to add `RAINDROP_API_KEY="My API Key"` to your `.env` file
so that your API Key is not stored in source control.
## Async usage
Simply import `AsyncRaindrop` instead of `Raindrop` and use `await` with each API call:
```python
import asyncio
from raindrop import AsyncRaindrop
client = AsyncRaindrop()
async def main() -> None:
response = await client.query.document_query(
bucket_location={
"bucket": {
"name": "my-smartbucket",
"version": "01jxanr45haeswhay4n0q8340y",
"application_name": "my-app",
}
},
input="What are the key points in this document?",
object_id="document.pdf",
request_id="<YOUR-REQUEST-ID>",
)
print(response.answer)
asyncio.run(main())
```
Functionality between the synchronous and asynchronous clients is otherwise identical.
### With aiohttp
By default, the async client uses `httpx` for HTTP requests. However, for improved concurrency performance you may also use `aiohttp` as the HTTP backend.
You can enable this by installing `aiohttp`:
```sh
# install from PyPI
pip install lm-raindrop[aiohttp]
```
Then you can enable it by instantiating the client with `http_client=DefaultAioHttpClient()`:
```python
import asyncio
from raindrop import DefaultAioHttpClient
from raindrop import AsyncRaindrop
async def main() -> None:
async with AsyncRaindrop(
http_client=DefaultAioHttpClient(),
) as client:
response = await client.query.document_query(
bucket_location={
"bucket": {
"name": "my-smartbucket",
"version": "01jxanr45haeswhay4n0q8340y",
"application_name": "my-app",
}
},
input="What are the key points in this document?",
object_id="document.pdf",
request_id="<YOUR-REQUEST-ID>",
)
print(response.answer)
asyncio.run(main())
```
## Using types
Nested request parameters are [TypedDicts](https://docs.python.org/3/library/typing.html#typing.TypedDict). Responses are [Pydantic models](https://docs.pydantic.dev) which also provide helper methods for things like:
- Serializing back into JSON, `model.to_json()`
- Converting to a dictionary, `model.to_dict()`
Typed requests and responses provide autocomplete and documentation within your editor. If you would like to see type errors in VS Code to help catch bugs earlier, set `python.analysis.typeCheckingMode` to `basic`.
## Pagination
List methods in the Raindrop API are paginated.
This library provides auto-paginating iterators with each list response, so you do not have to request successive pages manually:
```python
from raindrop import Raindrop
client = Raindrop()
all_queries = []
# Automatically fetches more pages as needed.
for query in client.query.get_paginated_search(
page=1,
page_size=10,
request_id="<YOUR-REQUEST-ID>",
):
# Do something with query here
all_queries.append(query)
print(all_queries)
```
Or, asynchronously:
```python
import asyncio
from raindrop import AsyncRaindrop
client = AsyncRaindrop()
async def main() -> None:
all_queries = []
# Iterate through items across all pages, issuing requests as needed.
async for query in client.query.get_paginated_search(
page=1,
page_size=10,
request_id="<YOUR-REQUEST-ID>",
):
all_queries.append(query)
print(all_queries)
asyncio.run(main())
```
Alternatively, you can use the `.has_next_page()`, `.next_page_info()`, or `.get_next_page()` methods for more granular control working with pages:
```python
first_page = await client.query.get_paginated_search(
page=1,
page_size=10,
request_id="<YOUR-REQUEST-ID>",
)
if first_page.has_next_page():
print(f"will fetch next page using these details: {first_page.next_page_info()}")
next_page = await first_page.get_next_page()
print(f"number of items we just fetched: {len(next_page.results)}")
# Remove `await` for non-async usage.
```
Or just work directly with the returned data:
```python
first_page = await client.query.get_paginated_search(
page=1,
page_size=10,
request_id="<YOUR-REQUEST-ID>",
)
for query in first_page.results:
print(query.chunk_signature)
# Remove `await` for non-async usage.
```
## Handling errors
When the library is unable to connect to the API (for example, due to network connection problems or a timeout), a subclass of `raindrop.APIConnectionError` is raised.
When the API returns a non-success status code (that is, 4xx or 5xx
response), a subclass of `raindrop.APIStatusError` is raised, containing `status_code` and `response` properties.
All errors inherit from `raindrop.APIError`.
```python
import raindrop
from raindrop import Raindrop
client = Raindrop()
try:
client.query.document_query(
bucket_location={
"bucket": {
"name": "my-smartbucket",
"version": "01jxanr45haeswhay4n0q8340y",
"application_name": "my-app",
}
},
input="What are the key points in this document?",
object_id="document.pdf",
request_id="<YOUR-REQUEST-ID>",
)
except raindrop.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # an underlying Exception, likely raised within httpx.
except raindrop.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except raindrop.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
```
Error codes are as follows:
| Status Code | Error Type |
| ----------- | -------------------------- |
| 400 | `BadRequestError` |
| 401 | `AuthenticationError` |
| 403 | `PermissionDeniedError` |
| 404 | `NotFoundError` |
| 422 | `UnprocessableEntityError` |
| 429 | `RateLimitError` |
| >=500 | `InternalServerError` |
| N/A | `APIConnectionError` |
### Retries
Certain errors are automatically retried 2 times by default, with a short exponential backoff.
Connection errors (for example, due to a network connectivity problem), 408 Request Timeout, 409 Conflict,
429 Rate Limit, and >=500 Internal errors are all retried by default.
You can use the `max_retries` option to configure or disable retry settings:
```python
from raindrop import Raindrop
# Configure the default for all requests:
client = Raindrop(
# default is 2
max_retries=0,
)
# Or, configure per-request:
client.with_options(max_retries=5).query.document_query(
bucket_location={
"bucket": {
"name": "my-smartbucket",
"version": "01jxanr45haeswhay4n0q8340y",
"application_name": "my-app",
}
},
input="What are the key points in this document?",
object_id="document.pdf",
request_id="<YOUR-REQUEST-ID>",
)
```
### Timeouts
By default requests time out after 1 minute. You can configure this with a `timeout` option,
which accepts a float or an [`httpx.Timeout`](https://www.python-httpx.org/advanced/timeouts/#fine-tuning-the-configuration) object:
```python
from raindrop import Raindrop
# Configure the default for all requests:
client = Raindrop(
# 20 seconds (default is 1 minute)
timeout=20.0,
)
# More granular control:
client = Raindrop(
timeout=httpx.Timeout(60.0, read=5.0, write=10.0, connect=2.0),
)
# Override per-request:
client.with_options(timeout=5.0).query.document_query(
bucket_location={
"bucket": {
"name": "my-smartbucket",
"version": "01jxanr45haeswhay4n0q8340y",
"application_name": "my-app",
}
},
input="What are the key points in this document?",
object_id="document.pdf",
request_id="<YOUR-REQUEST-ID>",
)
```
On timeout, an `APITimeoutError` is thrown.
Note that requests that time out are [retried twice by default](https://github.com/LiquidMetal-AI/lm-raindrop-python-sdk/tree/main/#retries).
## Advanced
### Logging
We use the standard library [`logging`](https://docs.python.org/3/library/logging.html) module.
You can enable logging by setting the environment variable `RAINDROP_LOG` to `info`.
```shell
$ export RAINDROP_LOG=info
```
Or to `debug` for more verbose logging.
### How to tell whether `None` means `null` or missing
In an API response, a field may be explicitly `null`, or missing entirely; in either case, its value is `None` in this library. You can differentiate the two cases with `.model_fields_set`:
```py
if response.my_field is None:
if 'my_field' not in response.model_fields_set:
print('Got json like {}, without a "my_field" key present at all.')
else:
print('Got json like {"my_field": null}.')
```
### Accessing raw response data (e.g. headers)
The "raw" Response object can be accessed by prefixing `.with_raw_response.` to any HTTP method call, e.g.,
```py
from raindrop import Raindrop
client = Raindrop()
response = client.query.with_raw_response.document_query(
bucket_location={
"bucket": {
"name": "my-smartbucket",
"version": "01jxanr45haeswhay4n0q8340y",
"application_name": "my-app",
}
},
input="What are the key points in this document?",
object_id="document.pdf",
request_id="<YOUR-REQUEST-ID>",
)
print(response.headers.get('X-My-Header'))
query = response.parse() # get the object that `query.document_query()` would have returned
print(query.answer)
```
These methods return an [`APIResponse`](https://github.com/LiquidMetal-AI/lm-raindrop-python-sdk/tree/main/src/raindrop/_response.py) object.
The async client returns an [`AsyncAPIResponse`](https://github.com/LiquidMetal-AI/lm-raindrop-python-sdk/tree/main/src/raindrop/_response.py) with the same structure, the only difference being `await`able methods for reading the response content.
#### `.with_streaming_response`
The above interface eagerly reads the full response body when you make the request, which may not always be what you want.
To stream the response body, use `.with_streaming_response` instead, which requires a context manager and only reads the response body once you call `.read()`, `.text()`, `.json()`, `.iter_bytes()`, `.iter_text()`, `.iter_lines()` or `.parse()`. In the async client, these are async methods.
```python
with client.query.with_streaming_response.document_query(
bucket_location={
"bucket": {
"name": "my-smartbucket",
"version": "01jxanr45haeswhay4n0q8340y",
"application_name": "my-app",
}
},
input="What are the key points in this document?",
object_id="document.pdf",
request_id="<YOUR-REQUEST-ID>",
) as response:
print(response.headers.get("X-My-Header"))
for line in response.iter_lines():
print(line)
```
The context manager is required so that the response will reliably be closed.
### Making custom/undocumented requests
This library is typed for convenient access to the documented API.
If you need to access undocumented endpoints, params, or response properties, the library can still be used.
#### Undocumented endpoints
To make requests to undocumented endpoints, you can make requests using `client.get`, `client.post`, and other
http verbs. Options on the client will be respected (such as retries) when making this request.
```py
import httpx
response = client.post(
"/foo",
cast_to=httpx.Response,
body={"my_param": True},
)
print(response.headers.get("x-foo"))
```
#### Undocumented request params
If you want to explicitly send an extra param, you can do so with the `extra_query`, `extra_body`, and `extra_headers` request
options.
#### Undocumented response properties
To access undocumented response properties, you can access the extra fields like `response.unknown_prop`. You
can also get all the extra fields on the Pydantic model as a dict with
[`response.model_extra`](https://docs.pydantic.dev/latest/api/base_model/#pydantic.BaseModel.model_extra).
### Configuring the HTTP client
You can directly override the [httpx client](https://www.python-httpx.org/api/#client) to customize it for your use case, including:
- Support for [proxies](https://www.python-httpx.org/advanced/proxies/)
- Custom [transports](https://www.python-httpx.org/advanced/transports/)
- Additional [advanced](https://www.python-httpx.org/advanced/clients/) functionality
```python
import httpx
from raindrop import Raindrop, DefaultHttpxClient
client = Raindrop(
# Or use the `RAINDROP_BASE_URL` env var
base_url="http://my.test.server.example.com:8083",
http_client=DefaultHttpxClient(
proxy="http://my.test.proxy.example.com",
transport=httpx.HTTPTransport(local_address="0.0.0.0"),
),
)
```
You can also customize the client on a per-request basis by using `with_options()`:
```python
client.with_options(http_client=DefaultHttpxClient(...))
```
### Managing HTTP resources
By default the library closes underlying HTTP connections whenever the client is [garbage collected](https://docs.python.org/3/reference/datamodel.html#object.__del__). You can manually close the client using the `.close()` method if desired, or with a context manager that closes when exiting.
```py
from raindrop import Raindrop
with Raindrop() as client:
# make requests here
...
# HTTP client is now closed
```
## Versioning
This package generally follows [SemVer](https://semver.org/spec/v2.0.0.html) conventions, though certain backwards-incompatible changes may be released as minor versions:
1. Changes that only affect static types, without breaking runtime behavior.
2. Changes to library internals which are technically public but not intended or documented for external use. _(Please open a GitHub issue to let us know if you are relying on such internals.)_
3. Changes that we do not expect to impact the vast majority of users in practice.
We take backwards-compatibility seriously and work hard to ensure you can rely on a smooth upgrade experience.
We are keen for your feedback; please open an [issue](https://www.github.com/LiquidMetal-AI/lm-raindrop-python-sdk/issues) with questions, bugs, or suggestions.
### Determining the installed version
If you've upgraded to the latest version but aren't seeing any new features you were expecting then your python environment is likely still using an older version.
You can determine the version that is being used at runtime with:
```py
import raindrop
print(raindrop.__version__)
```
## Requirements
Python 3.9 or higher.
## Contributing
See [the contributing documentation](https://github.com/LiquidMetal-AI/lm-raindrop-python-sdk/tree/main/./CONTRIBUTING.md).
| text/markdown | Raindrop | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: OS Independent",
"Operating System :: POSIX",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"anyio<5,>=3.5.0",
"distro<2,>=1.7.0",
"httpx<1,>=0.23.0",
"pydantic<3,>=1.9.0",
"sniffio",
"typing-extensions<5,>=4.10",
"aiohttp; extra == \"aiohttp\"",
"httpx-aiohttp>=0.1.9; extra == \"aiohttp\""
] | [] | [] | [] | [
"Homepage, https://github.com/LiquidMetal-AI/lm-raindrop-python-sdk",
"Repository, https://github.com/LiquidMetal-AI/lm-raindrop-python-sdk"
] | twine/5.1.1 CPython/3.12.9 | 2026-02-19T17:45:36.074994 | lm_raindrop-0.17.0.tar.gz | 154,611 | e6/d6/b2b0498028f56a623935d14d54fa9407bca77a715f58454352706b256229/lm_raindrop-0.17.0.tar.gz | source | sdist | null | false | 5555f4a145cf3e12d2be4af6d5a5f1b7 | b4ca849ab04dd72eb3fdcdf93e9024febee12157a302314b32a4966cce8fcbac | e6d6b2b0498028f56a623935d14d54fa9407bca77a715f58454352706b256229 | null | [] | 215 |
2.3 | aidial-adapter-anthropic | 0.5.0rc0 | Package implementing adapter from DIAL Chat Completions API to Anthropic API | <h1 align="center">
Python SDK for adapter from DIAL API to Anthropic API
</h1>
<p align="center">
<p align="center">
<a href="https://dialx.ai/">
<img src="https://dialx.ai/logo/dialx_logo.svg" alt="About DIALX">
</a>
</p>
<h4 align="center">
<a href="https://pypi.org/project/aidial-adapter-anthropic/">
<img src="https://img.shields.io/pypi/v/aidial-adapter-anthropic.svg" alt="PyPI version">
</a>
<a href="https://discord.gg/ukzj9U9tEe">
<img src="https://img.shields.io/static/v1?label=DIALX%20Community%20on&message=Discord&color=blue&logo=Discord&style=flat-square" alt="Discord">
</a>
</h4>
- [Overview](#overview)
- [Developer environment](#developer-environment)
- [Set up](#set-up)
- [Lint](#lint)
- [Test](#test)
- [Clean](#clean)
- [Build](#build)
- [Publish](#publish)
---
## Overview
The framework provides adapter from [AI DIAL Chat Completion API](https://dialx.ai/dial_api#operation/sendChatCompletionRequest) to [Anthropic Messages API](https://platform.claude.com/docs/en/api/messages).
---
## Developer environment
To install requirements:
```sh
poetry install
```
This will install all requirements for running the package, linting, formatting and tests.
---
## Set up
### Lint
Run the linting before committing:
```sh
make lint
```
To auto-fix formatting issues run:
```sh
make format
```
### Test
Run unit tests locally for available python versions:
```sh
make test
```
Run unit tests for the specific python version:
```sh
make test PYTHON=3.13
```
### Clean
To remove the virtual environment and build artifacts run:
```sh
make clean
```
### Build
To build the package run:
```sh
make build
```
### Publish
To publish the package to PyPI run:
```sh
make publish
```
| text/markdown | EPAM RAIL | SpecialEPM-DIALDevTeam@epam.com | null | null | Apache-2.0 | ai | [
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | https://epam-rail.com | null | <4.0,>=3.11 | [] | [] | [] | [
"aidial-sdk<1,>=0.28.0",
"anthropic<1,>=0.79.0",
"pydantic<3,>=2.8.2",
"pillow<13,>=10.4.0",
"aiohttp<4,>=3.13.3"
] | [] | [] | [] | [
"Homepage, https://epam-rail.com",
"Repository, https://github.com/epam/ai-dial-adapter-anthropic/",
"Documentation, https://epam-rail.com/dial_api"
] | poetry/2.1.1 CPython/3.11.14 Linux/6.11.0-1018-azure | 2026-02-19T17:45:33.747912 | aidial_adapter_anthropic-0.5.0rc0.tar.gz | 35,087 | 16/ca/ee361a9affb558cf623a7cd17f1b70c0e6e7c517853222f7ab04a152c420/aidial_adapter_anthropic-0.5.0rc0.tar.gz | source | sdist | null | false | 741a8a93ec78cb8c6d06ed6953c68d22 | ec021d12148ff9e42fd182dbbbcddbe668a20e4c51c3398b43cc81351bfdfb8e | 16caee361a9affb558cf623a7cd17f1b70c0e6e7c517853222f7ab04a152c420 | null | [] | 186 |
2.4 | import-parent | 0.0.1 | Python package that allows a user to easily import local functions from parent folders. | # import-parent
A small utility for importing Python modules using paths relative to the
calling script — without modifying your project structure.
Inspired by R's `here()`.
---
## Installation
`pip install import-parent`
## Usage
`from import_parent import import_parent`
| text/markdown | null | Michael Boerman <michaelboerman@hey.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/michaelboerman/import_parent",
"Issues, https://github.com/michaelboerman/import_parent/issues"
] | twine/6.2.0 CPython/3.13.1 | 2026-02-19T17:45:32.180332 | import_parent-0.0.1.tar.gz | 1,993 | 09/15/2cbd2513d716d469cab9e81c385a19a51c273f571046bf27d012faf687e7/import_parent-0.0.1.tar.gz | source | sdist | null | false | 2ab1b7def3c85a93ea326e9687f12715 | b9210800db552843a0038e2df44428b572a8b372d8f12d5a3334abdb89047778 | 09152cbd2513d716d469cab9e81c385a19a51c273f571046bf27d012faf687e7 | null | [] | 232 |
2.4 | InfoTracker | 0.7.1 | Column-level SQL lineage, impact analysis, and breaking-change detection (MS SQL first) | # InfoTracker
**Column-level SQL lineage extraction and impact analysis for MS SQL Server**
InfoTracker is a powerful command-line tool that parses T-SQL files and generates detailed column-level lineage in OpenLineage format. It supports advanced SQL Server features including table-valued functions, stored procedures, temp tables, and EXEC patterns.
[](https://python.org)
[](LICENSE)
[](https://pypi.org/project/InfoTracker/)
## 🚀 Features
- **Column-level lineage** - Track data flow at the column level with precise transformations
- **Advanced SQL support** - T-SQL dialect with temp tables, variables, CTEs, and window functions
- **Impact analysis** - Find upstream and downstream dependencies with flexible selectors
- **Wildcard matching** - Support for table wildcards (`schema.table.*`) and column wildcards (`..pattern`)
- **Breaking change detection** - Detect schema changes that could break downstream processes
- **Multiple output formats** - Text tables or JSON for integration with other tools
- **OpenLineage compatible** - Standard format for data lineage interoperability
- **dbt (compiled SQL) support** - Run on compiled dbt models with `--dbt`
- **Rich HTML viz** - Zoom/pan, column search, per‑attribute isolate (UP/DOWN/BOTH), sidebar resize and select/clear all
- **Advanced SQL objects** - Table-valued functions (TVF) and dataset-returning procedures
- **Temp table tracking** - Full lineage through EXEC into temp tables
## 📦 Installation
### From PyPI (Recommended)
```bash
pip install InfoTracker
```
### From GitHub
```bash
# Latest stable release
pip install git+https://github.com/InfoMatePL/InfoTracker.git
# Development version
git clone https://github.com/InfoMatePL/InfoTracker.git
cd InfoTracker
pip install -e .
```
### Verify Installation
```bash
infotracker --help
```
## ⚡ Quick Start
### 1. Extract Lineage
```bash
# Extract lineage from SQL files
infotracker extract --sql-dir examples/warehouse/sql --out-dir build/lineage
# Extract lineage from compiled dbt models
infotracker extract --dbt --sql-dir examples/dbt_warehouse/models --out-dir build/dbt_lineage
```
Flags:
- --sql-dir DIR Directory with .sql files (required)
- --out-dir DIR Output folder for lineage artifacts (default from config or build/lineage)
- --adapter NAME SQL dialect adapter (default from config)
- --catalog FILE Optional YAML catalog with schemas
- --fail-on-warn Exit non-zero if warnings occurred
- --include PATTERN Glob include filter
- --exclude PATTERN Glob exclude filter
- --encoding NAME File encoding for SQL files (default: auto)
- --dbt Enable dbt mode (compiled SQL)
### 2. Run Impact Analysis
```bash
# Find what feeds into a column (upstream)
infotracker impact -s "+STG.dbo.Orders.OrderID" --graph-dir build/lineage
# Find what uses a column (downstream)
infotracker impact -s "STG.dbo.Orders.OrderID+" --graph-dir build/lineage
# Both directions
infotracker impact -s "+dbo.fct_sales.Revenue+" --graph-dir build/lineage
```
Flags:
- -s, --selector TEXT Column selector; use + for direction markers (required)
- --graph-dir DIR Folder with column_graph.json (required; produced by extract)
- --max-depth N Traversal depth; 0 = unlimited (full lineage). Default: 0
- --out PATH Write output to file instead of stdout
- --format text|json Output format (set globally or per-invocation)
### 3. Detect Breaking Changes
```bash
# Compare two versions of your schema
infotracker diff --base build/lineage --head build/lineage_new
```
Flags:
- --base DIR Folder with base artifacts (required)
- --head DIR Folder with head artifacts (required)
- --format text|json Output format
- --threshold LEVEL Severity threshold: NON_BREAKING|POTENTIALLY_BREAKING|BREAKING
### 4. Visualize the Graph
```bash
# Generate an interactive HTML graph (lineage_viz.html) for a built graph
infotracker viz --graph-dir build/lineage
```
Flags:
- --graph-dir DIR Folder with column_graph.json (required)
- --out PATH Output HTML path (default: <graph_dir>/lineage_viz.html)
Open the generated `lineage_viz.html` in your browser. You can click a column to highlight upstream/downstream lineage; press Enter in the search box to highlight all matches.
By default, the canvas is empty. Use the left sidebar to toggle objects on (checkboxes are initially unchecked).
## 📖 Selector Syntax
InfoTracker supports flexible column selectors for precise impact analysis:
| Selector Format | Description | Example |
|-----------------|-------------|---------|
| `table.column` | Simple format (adds default `dbo` schema) | `Orders.OrderID` |
| `schema.table.column` | Schema-qualified format | `dbo.Orders.OrderID` |
| `database.schema.table.column` | Database-qualified format | `STG.dbo.Orders.OrderID` |
| `schema.table.*` | Table wildcard (all columns) | `dbo.fct_sales.*` |
| `..pattern` | Column wildcard (name contains pattern) | `..revenue` |
| `..pattern*` | Column wildcard with fnmatch | `..customer*` |
### Direction Control
- `selector` - downstream dependencies (default)
- `+selector` - upstream sources
- `selector+` - downstream dependencies (explicit)
- `+selector+` - both upstream and downstream
## 💡 Examples
### Basic Usage
```bash
# Extract lineage first (always run this before impact analysis)
infotracker extract --sql-dir examples/warehouse/sql --out-dir build/lineage
# Basic column lineage
infotracker impact -s "+dbo.fct_sales.Revenue" --graph-dir build/lineage # What feeds this column?
infotracker impact -s "STG.dbo.Orders.OrderID+" --graph-dir build/lineage # What uses this column?
```
### Wildcard Selectors
```bash
# All columns from a specific table
infotracker impact -s "dbo.fct_sales.*" --graph-dir build/lineage
infotracker impact -s "STG.dbo.Orders.*" --graph-dir build/lineage
# Find all columns containing "revenue" (case-insensitive)
infotracker impact -s "..revenue" --graph-dir build/lineage
# Find all columns starting with "customer"
infotracker impact -s "..customer*" --graph-dir build/lineage
```
### Advanced SQL Objects
```bash
# Table-valued function columns (upstream)
infotracker impact -s "+dbo.fn_customer_orders_tvf.*" --graph-dir build/lineage
# Procedure dataset columns (upstream)
infotracker impact -s "+dbo.usp_customer_metrics_dataset.*" --graph-dir build/lineage
# Temp table lineage from EXEC
infotracker impact -s "+#temp_table.*" --graph-dir build/lineage
```
### Output Formats
```bash
# Text output (default, human-readable)
infotracker impact -s "+..revenue" --graph-dir build/lineage
# JSON output (machine-readable)
infotracker --format json impact -s "..customer*" --graph-dir build/lineage > customer_lineage.json
# Control traversal depth
infotracker impact -s "+dbo.Orders.OrderID" --max-depth 2 --graph-dir build/lineage
# Note: --max-depth defaults to 0 (unlimited / full lineage)
```
### Breaking Change Detection
```bash
# Extract baseline
infotracker extract --sql-dir sql_v1 --out-dir build/baseline
# Extract new version
infotracker extract --sql-dir sql_v2 --out-dir build/current
# Detect breaking changes
infotracker diff --base build/baseline --head build/current
# Filter by severity
infotracker diff --base build/baseline --head build/current --threshold BREAKING
```
## Output Format
Impact analysis returns these columns (topologically sorted by level):
- **from** - Source column (fully qualified)
- **to** - Target column (fully qualified)
- **direction** - `upstream` or `downstream`
- **transformation** - Type of transformation (`IDENTITY`, `ARITHMETIC`, `AGGREGATION`, `CASE_AGGREGATION`, `DATE_FUNCTION`, `WINDOW`, etc.). For UX clarity, CAST and CASE are shown as `expression`.
- **description** - Human-readable transformation description
- **level** - Topological distance from the selected column (1 = direct neighbor, then 2, 3, …)
Results are automatically deduplicated and sorted topologically by level (then direction/from/to). Use `--format json` for machine-readable output.
### New Transformation Types
The enhanced transformation taxonomy includes:
- `ARITHMETIC_AGGREGATION` - Arithmetic operations combined with aggregation functions
- `COMPLEX_AGGREGATION` - Multi-step calculations involving multiple aggregations
- `DATE_FUNCTION` - Date/time calculations like DATEDIFF, DATEADD
- `DATE_FUNCTION_AGGREGATION` - Date functions applied to aggregated results
- `CASE_AGGREGATION` - CASE statements applied to aggregated results
### Advanced Object Support
InfoTracker now supports advanced SQL Server objects:
**Table-Valued Functions (TVF):**
- Inline TVF (`RETURN AS SELECT`) - Parsed directly from SELECT statement
- Multi-statement TVF (`RETURN @table TABLE`) - Extracts schema from table variable definition
- Function parameters are tracked as filter metadata (don't create columns)
**Dataset-Returning Procedures:**
- Procedures ending with SELECT statement are treated as dataset sources
- Output schema extracted from the final SELECT statement
- Parameters tracked as filter metadata affecting lineage scope
**EXEC into Temp Tables:**
- `INSERT INTO #temp EXEC procedure` patterns create edges from procedure columns to temp table columns
- Temp table lineage propagates downstream to final targets
- Supports complex workflow patterns combining functions, procedures, and temp tables
## Configuration
InfoTracker follows this configuration precedence:
1. **CLI flags** (highest priority) - override everything
2. **infotracker.yml** config file - project defaults
3. **Built-in defaults** (lowest priority) - fallback values
## 🔧 Configuration
Create an `infotracker.yml` file in your project root:
```yaml
sql_dirs:
- "sql/"
- "models/"
out_dir: "build/lineage"
exclude_dirs:
- "__pycache__"
- ".git"
severity_threshold: "POTENTIALLY_BREAKING"
```
### Configuration Options
| Setting | Description | Default | Examples |
|---------|-------------|---------|----------|
| `sql_dirs` | Directories to scan for SQL files | `["."]` | `["sql/", "models/"]` |
| `out_dir` | Output directory for lineage files | `"lineage"` | `"build/artifacts"` |
| `exclude_dirs` | Directories to skip | `[]` | `["__pycache__", "node_modules"]` |
| `severity_threshold` | Breaking change detection level | `"NON_BREAKING"` | `"BREAKING"` |
## 📚 Documentation
- **[Architecture](docs/architecture.md)** - Core concepts and design
- **[Lineage Concepts](docs/lineage_concepts.md)** - Data lineage fundamentals
- **[CLI Usage](docs/cli_usage.md)** - Complete command reference
- **[Configuration](docs/configuration.md)** - Advanced configuration options
- **[DBT Integration](docs/dbt_integration.md)** - Using with DBT projects
- **[OpenLineage Mapping](docs/openlineage_mapping.md)** - Output format specification
- **[Breaking Changes](docs/breaking_changes.md)** - Change detection and severity levels
- **[Advanced Use Cases](docs/advanced_use_cases.md)** - TVFs, stored procedures, and complex scenarios
- **[Edge Cases](docs/edge_cases.md)** - SELECT *, UNION, temp tables handling
- **[FAQ](docs/faq.md)** - Common questions and troubleshooting
## 🖼 Visualization (viz)
Generate an interactive HTML to explore column-level lineage:
```bash
# After extract (column_graph.json present in the folder)
infotracker viz --graph-dir build/lineage
# Options
# --out <path> Output HTML path (default: <graph_dir>/lineage_viz.html)
# --graph-dir Folder z column_graph.json [required]
```
Tips:
- Search supports table names, full IDs (namespace.schema.table), column names, and URIs. Press Enter to highlight all matches.
- Click a column to switch into lineage mode (upstream/downstream highlight). Clicking another column clears the previous selection.
- Right‑click a column row to open a context menu: Show upstream, Show downstream, Show both, Clear filter. In isolate mode only the path columns and edges remain visible (background clicks won’t clear; use Clear filter).
- Left sidebar: live filter (matches tables and column names), Select All / Clear buttons, and a draggable resizer between sidebar and canvas. Sidebar toggle remembers last width.
- Depth input in the toolbar limits neighbor layers rendered around selected tables.
- Collapse button toggles between full column rows and compact “object‑only” view (single arrows object→object).
- Column order in cards follows DDL/Schema order (from OpenLineage artifacts) instead of alphabetical.
## 🧪 Testing
```bash
# Run all tests
pytest
# Run specific test categories
pytest tests/test_parser.py # Parser functionality
pytest tests/test_wildcard.py # Wildcard selectors
pytest tests/test_adapter.py # SQL dialect adapters
# Run with coverage
pytest --cov=infotracker --cov-report=html
```
## 📄 License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## 🙏 Acknowledgments
- [SQLGlot](https://github.com/tobymao/sqlglot) - SQL parsing library
- [OpenLineage](https://openlineage.io/) - Data lineage standard
- [Typer](https://typer.tiangolo.com/) - CLI framework
- [Rich](https://rich.readthedocs.io/) - Terminal formatting
---
**InfoTracker** - Making database schema evolution safer, one column at a time. 🎯
| text/markdown | InfoTracker Authors | null | null | null | MIT | data-lineage, impact-analysis, lineage, mssql, openlineage, sql | [
"Environment :: Console",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Topic :: Database",
"Topic :: Software Development :: Libraries"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"click",
"networkx>=3.3",
"packaging>=24.0",
"pydantic>=2.8.2",
"pyyaml>=6.0.1",
"rich",
"shellingham",
"sqlglot>=23.0.0",
"typer",
"pytest-cov>=4.1.0; extra == \"dev\"",
"pytest>=7.4.0; extra == \"dev\""
] | [] | [] | [] | [
"homepage, https://example.com/infotracker",
"documentation, https://example.com/infotracker/docs"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T17:45:27.745434 | infotracker-0.7.1.tar.gz | 302,991 | f0/7c/5a561ff015e4850ab2c058da2cc16234ae8ceee7fd8df7a84e8801d49fcb/infotracker-0.7.1.tar.gz | source | sdist | null | false | 81e319a6ef9747a7cf50e5a244ab53b9 | 79f5a7a57e11b6a3dc75db43432225f617c8b7c59ce6d6b9803a3b1b155f967b | f07c5a561ff015e4850ab2c058da2cc16234ae8ceee7fd8df7a84e8801d49fcb | null | [] | 0 |
2.4 | anypinn | 0.5.5 | ... | # AnyPINN
[![CI][github-actions-badge]](https://github.com/johnthagen/python-blueprint/actions)
[![uv][uv-badge]](https://github.com/astral-sh/uv)
[![Ruff][ruff-badge]](https://github.com/astral-sh/ruff)
[![Type checked with ty][ty-badge]](https://docs.astral.sh/ty/)
[github-actions-badge]: https://github.com/johnthagen/python-blueprint/actions/workflows/ci.yml/badge.svg
[uv-badge]: https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/uv/main/assets/badge/v0.json
[ruff-badge]: https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/ruff/main/assets/badge/v2.json
[ty-badge]: https://img.shields.io/badge/ty-typed-blue
> **Work in Progress** — This project is under active development and APIs may change. If you run into any issues, please [open an issue on GitHub](https://github.com/giacomopiccinini/anypinn/issues).
**A modular Python library for solving differential equations with Physics-Informed Neural Networks.**
AnyPINN lets you go from zero to a running PINN experiment in seconds, or give you the full control to define custom physics, constraints, and training loops. You decide how deep to go.
## Quick Start
The fastest way to start is the bootstrap CLI. It scaffolds a complete, runnable project interactively:
```bash
uvx anypinn create my-project
```
or
```bash
pip install anypinn
anypinn create my-project
```
```
? Choose a starting point:
> SIR Epidemic Model
...
Custom ODE
Blank project
? Select training data source:
> Generate synthetic data
Load from CSV
? Include Lightning training wrapper? (Y/n)
Creating my-project/
✓ pyproject.toml project metadata & dependencies
✓ ode.py your ODE definition
✓ config.py hyperparameters with sensible defaults
✓ train.py ready-to-run training script
✓ data/ data directory
Done! Run: cd my-project && uv sync && uv run train.py
```
All prompts are also available as flags to skip the interactive flow:
```bash
anypinn create my-project \
--template sir \
--data synthetic \
--lightning
```
| Flag | Values | Description |
| ------------------------------ | -------------------------------------------- | ---------------------------------------------- |
| `--template, -t` | built-in template name, `custom`, or `blank` | Starting template |
| `--list-templates, -l` | — | Print all templates with descriptions and exit |
| `--data, -d` | `synthetic`, `csv` | Training data source |
| `--lightning / --no-lightning` | — | Include PyTorch Lightning wrapper |
## Who Is This For?
AnyPINN is built around **progressive complexity** — start simple, go deeper only when you need to.
| User | Goal | How |
| --------------------- | -------------------------------------------------- | --------------------------------------------------------------------- |
| **Experimenter** | Run a known problem, tweak parameters, see results | Pick a built-in template, change config, press start |
| **Researcher** | Define new physics or custom constraints | Subclass `Constraint` and `Problem`, use the provided training engine |
| **Framework builder** | Custom training loops, novel architectures | Use `anypinn.core` directly — zero Lightning required |
## Installation
> **Prerequisites:** Python 3.11+, [uv](https://github.com/astral-sh/uv) (recommended).
```bash
# Install from source (development)
git clone https://github.com/your-org/anypinn
cd anypinn
uv sync
```
## Examples
Ready-made examples live in `examples/`. Each is a self-contained script covering a different ODE system (epidemic models, oscillators, predator-prey dynamics, and more). Browse the directory and run any of them directly:
```bash
uv run python examples/<name>/<name>.py
```
| Example | Description |
| ----------------------------- | --------------------------------------------------------------------------------------------------------------------- |
| `examples/exponential_decay/` | **Start here.** Minimal core-only script (~80 lines). Learns decay rate `k` with a plain PyTorch loop — no Lightning. |
| `examples/sir_inverse/` | Full SIR epidemic model (Lightning stack) |
| `examples/seir_inverse/` | SEIR epidemic model (Lightning stack) |
| `examples/damped_oscillator/` | Damped harmonic oscillator (Lightning stack) |
| `examples/lotka_volterra/` | Predator-prey dynamics (Lightning stack) |
## Defining Your Own Problem
If you want to go beyond the built-in templates, here is the full workflow for defining a custom ODE inverse problem.
### 1: Define the ODE
Implement a function matching the `ODECallable` protocol:
```python
from torch import Tensor
from anypinn.core import ArgsRegistry
def my_ode(x: Tensor, y: Tensor, args: ArgsRegistry) -> Tensor:
"""Return dy/dx given current state y and position x."""
k = args["k"](x) # learnable or fixed parameter
return -k * y # simple exponential decay
```
### 2: Configure hyperparameters
```python
from dataclasses import dataclass
from anypinn.problems import ODEHyperparameters
@dataclass(frozen=True, kw_only=True)
class MyHyperparameters(ODEHyperparameters):
pde_weight: float = 1.0
ic_weight: float = 10.0
data_weight: float = 5.0
```
### 3: Build the problem
```python
from anypinn.problems import ODEInverseProblem, ODEProperties
props = ODEProperties(ode=my_ode, args={"k": param}, y0=y0)
problem = ODEInverseProblem(
ode_props=props,
fields={"u": field},
params={"k": param},
hp=hp,
)
```
### 4: Train
```python
import pytorch_lightning as pl
from anypinn.lightning import PINNModule
# With Lightning (batteries included)
module = PINNModule(problem, hp)
trainer = pl.Trainer(max_epochs=50_000)
trainer.fit(module, datamodule=dm)
# Or with your own training loop (core only, no Lightning)
optimizer = torch.optim.Adam(problem.parameters(), lr=1e-3)
for batch in dataloader:
optimizer.zero_grad()
loss = problem.training_loss(batch, log=my_log_fn)
loss.backward()
optimizer.step()
```
## Architecture
AnyPINN is split into four layers with a strict dependency direction — outer layers depend on inner ones, never the reverse.
```mermaid
graph TD
EXP["Your Experiment / Generated Project"]
EXP --> CAT
EXP --> LIT
subgraph CAT["anypinn.catalog"]
direction LR
CA1[SIR / SEIR]
CA2[DampedOscillator]
CA3[LotkaVolterra]
end
subgraph LIT["anypinn.lightning (optional)"]
direction LR
L1[PINNModule]
L2[Callbacks]
L3[PINNDataModule]
end
subgraph PROB["anypinn.problems"]
direction LR
P1[ResidualsConstraint]
P2[ICConstraint]
P3[DataConstraint]
P4[ODEInverseProblem]
end
subgraph CORE["anypinn.core (standalone · pure PyTorch)"]
direction LR
C1[Problem · Constraint]
C2[Field · Parameter]
C3[Config · Context]
end
CAT -->|depends on| PROB
CAT -->|depends on| CORE
LIT -->|depends on| CORE
PROB -->|depends on| CORE
```
### `anypinn.core` — The Math Layer
Pure PyTorch. Defines what a PINN problem _is_, with no opinions about training.
- **`Problem`** — Aggregates constraints, fields, and parameters. Provides `training_loss()` and `predict()`.
- **`Constraint`** (ABC) — A single loss term. Subclass it to express any physics equation, boundary condition, or data-matching objective.
- **`Field`** — MLP mapping input coordinates to state variables (e.g., `t → [S, I, R]`).
- **`Parameter`** — Learnable scalar or function-valued parameter (e.g., `β` in SIR).
- **`InferredContext`** — Runtime domain bounds and validation references, extracted from data and injected into constraints automatically.
### `anypinn.lightning` — The Training Engine _(optional)_
A thin wrapper plugging a `Problem` into PyTorch Lightning:
- **`PINNModule`** — `LightningModule` wrapping any `Problem`. Handles optimizer setup, context injection, and prediction.
- **`PINNDataModule`** — Abstract data module managing loading, collocation point generation, and context creation.
- **Callbacks** — SMMA-based early stopping, formatted progress bars, data scaling, prediction writers.
### `anypinn.problems` — ODE Building Blocks
Ready-made constraints for ODE inverse problems:
- **`ResidualsConstraint`** — `‖dy/dt − f(t, y)‖²` via autograd
- **`ICConstraint`** — `‖y(t₀) − y₀‖²`
- **`DataConstraint`** — `‖prediction − observed data‖²`
- **`ODEInverseProblem`** — Composes all three with configurable weights
### `anypinn.catalog` — Problem-Specific Building Blocks
Drop-in ODE functions and `DataModule`s for specific systems. See `anypinn/catalog/` for the full list.
## Tooling
| Tool | Purpose |
| ----------------------------------------- | ---------------------- |
| [uv](https://github.com/astral-sh/uv) | Dependency management |
| [just](https://github.com/casey/just) | Task automation |
| [Ruff](https://github.com/astral-sh/ruff) | Linting and formatting |
| [pytest](https://docs.pytest.org/) | Testing |
| [ty](https://docs.astral.sh/ty/) | Type checking |
All common tasks (test, lint, format, type-check, docs) are available via `just`.
## Contributing
See [CONTRIBUTING.md](.github/CONTRIBUTING.md) for setup instructions, code style guidelines, and the pull request workflow.
| text/markdown | null | Giacomo Guidotto <giacomo.guidotto@gmail.com> | null | null | null | anypinn, epidemiology, neural-networks, physics-informed, sir | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python ... | [] | null | null | >=3.10 | [] | [] | [] | [
"rich",
"simple-term-menu",
"typer-slim[standard]"
] | [] | [] | [] | [
"Homepage, https://github.com/GiacomoGuidotto/anypinn",
"Documentation, https://GiacomoGuidotto.github.io/anypinn/",
"Repository, https://github.com/GiacomoGuidotto/anypinn"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:44:36.037336 | anypinn-0.5.5.tar.gz | 22,730,793 | 22/ce/7e8b945be3d1169742625fdaf8b7e09928f6659fa68a0771bc8d4fa81847/anypinn-0.5.5.tar.gz | source | sdist | null | false | 093ef4686e1fe9e681d175bffb97a4e4 | 5004799b5980aa399db1c882d43a0e9148ea4216938a07dcd997f169166a0b43 | 22ce7e8b945be3d1169742625fdaf8b7e09928f6659fa68a0771bc8d4fa81847 | MIT | [
"LICENSE"
] | 219 |
2.4 | mqt.ddsim | 2.2.0 | A quantum simulator based on decision diagrams written in C++ | [](https://pypi.org/project/mqt.ddsim/)

[](https://opensource.org/licenses/MIT)
[](https://github.com/munich-quantum-toolkit/ddsim/actions/workflows/ci.yml)
[](https://github.com/munich-quantum-toolkit/ddsim/actions/workflows/cd.yml)
[](https://mqt.readthedocs.io/projects/ddsim)
[](https://codecov.io/gh/munich-quantum-toolkit/ddsim)
<p align="center">
<a href="https://mqt.readthedocs.io">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/munich-quantum-toolkit/.github/refs/heads/main/docs/_static/mqt-banner-dark.svg" width="90%">
<img src="https://raw.githubusercontent.com/munich-quantum-toolkit/.github/refs/heads/main/docs/_static/mqt-banner-light.svg" width="90%" alt="MQT Banner">
</picture>
</a>
</p>
# MQT DDSIM - A quantum circuit simulator based on decision diagrams written in C++
A tool for classical quantum circuit simulation developed as part of the [_Munich Quantum Toolkit (MQT)_](https://mqt.readthedocs.io).
It builds upon [MQT Core](https://github.com/munich-quantum-toolkit/core), which forms the backbone of the MQT.
<p align="center">
<a href="https://mqt.readthedocs.io/projects/ddsim">
<img width=30% src="https://img.shields.io/badge/documentation-blue?style=for-the-badge&logo=read%20the%20docs" alt="Documentation" />
</a>
</p>
## Key Features
- Decision-diagram–based circuit simulation: [Circuit Simulator](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/CircuitSimulator.html)—strong (statevector) and weak (sampling), incl. mid‑circuit measurements and resets; Qiskit backends ([qasm_simulator](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/CircuitSimulator.html#usage-as-a-qiskit-backend) and [statevector_simulator](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/CircuitSimulator.html#usage-as-a-qiskit-backend)). [Quickstart](https://mqt.readthedocs.io/projects/ddsim/en/latest/quickstart.html) • [API](https://mqt.readthedocs.io/projects/ddsim/en/latest/api/mqt/ddsim/index.html)
- Unitary simulation: [Unitary Simulator](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/UnitarySimulator.html) with an optional [alternative recursive construction](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/UnitarySimulator.html#alternative-construction-sequence) for improved intermediate compactness.
- Hybrid Schrödinger–Feynman simulation: [Hybrid simulator](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/HybridSchrodingerFeynman.html) trading memory for runtime with DD and amplitude modes plus multithreading; also available as a statevector backend.
- Simulation Path Framework: [Path-based simulation](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/SimulationPathFramework.html) with strategies [sequential](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/SimulationPathFramework.html#simulating-a-simple-circuit), [pairwise_recursive](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/SimulationPathFramework.html#configuration), [bracket](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/SimulationPathFramework.html#configuration), and [alternating](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/SimulationPathFramework.html#configuration).
- Noise-aware simulation: [Stochastic and deterministic noise](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/NoiseAwareSimulator.html) (amplitude damping, depolarization, phase flip; density-matrix mode) for global decoherence and gate errors.
- Qiskit-native API: Provider backends and Primitives ([Sampler](https://mqt.readthedocs.io/projects/ddsim/en/latest/primitives.html#sampler) and [Estimator](https://mqt.readthedocs.io/projects/ddsim/en/latest/primitives.html#estimator)) for algorithm-friendly workflows. [API](https://mqt.readthedocs.io/projects/ddsim/en/latest/api/mqt/ddsim/index.html)
- Decision-diagram visualization: inspect states/unitaries via Graphviz export; see [Circuit Simulator](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/CircuitSimulator.html) and [Unitary Simulator](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/UnitarySimulator.html).
- Standalone CLI: fast C++ executables with JSON output; e.g., [ddsim_simple](https://mqt.readthedocs.io/projects/ddsim/en/latest/simulators/CircuitSimulator.html#usage-as-standalone-c-executable).
- Efficient and portable: C++20 core with DD engines; prebuilt wheels for Linux/macOS/Windows via [PyPI](https://pypi.org/project/mqt.ddsim/).
If you have any questions, feel free to create a [discussion](https://github.com/munich-quantum-toolkit/ddsim/discussions) or an [issue](https://github.com/munich-quantum-toolkit/ddsim/issues) on [GitHub](https://github.com/munich-quantum-toolkit/ddsim).
## Contributors and Supporters
The _[Munich Quantum Toolkit (MQT)](https://mqt.readthedocs.io)_ is developed by the [Chair for Design Automation](https://www.cda.cit.tum.de/) at the [Technical University of Munich](https://www.tum.de/) and supported by the [Munich Quantum Software Company (MQSC)](https://munichquantum.software).
Among others, it is part of the [Munich Quantum Software Stack (MQSS)](https://www.munich-quantum-valley.de/research/research-areas/mqss) ecosystem, which is being developed as part of the [Munich Quantum Valley (MQV)](https://www.munich-quantum-valley.de) initiative.
<p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/munich-quantum-toolkit/.github/refs/heads/main/docs/_static/mqt-logo-banner-dark.svg" width="90%">
<img src="https://raw.githubusercontent.com/munich-quantum-toolkit/.github/refs/heads/main/docs/_static/mqt-logo-banner-light.svg" width="90%" alt="MQT Partner Logos">
</picture>
</p>
Thank you to all the contributors who have helped make MQT DDSIM a reality!
<p align="center">
<a href="https://github.com/munich-quantum-toolkit/ddsim/graphs/contributors">
<img src="https://contrib.rocks/image?repo=munich-quantum-toolkit/ddsim" alt="Contributors to munich-quantum-toolkit/ddsim" />
</a>
</p>
The MQT will remain free, open-source, and permissively licensed—now and in the future.
We are firmly committed to keeping it open and actively maintained for the quantum computing community.
To support this endeavor, please consider:
- Starring and sharing our repositories: https://github.com/munich-quantum-toolkit
- Contributing code, documentation, tests, or examples via issues and pull requests
- Citing the MQT in your publications (see [Cite This](#cite-this))
- Citing our research in your publications (see [References](https://mqt.readthedocs.io/projects/ddsim/en/latest/references.html))
- Using the MQT in research and teaching, and sharing feedback and use cases
- Sponsoring us on GitHub: https://github.com/sponsors/munich-quantum-toolkit
<p align="center">
<a href="https://github.com/sponsors/munich-quantum-toolkit">
<img width=20% src="https://img.shields.io/badge/Sponsor-white?style=for-the-badge&logo=githubsponsors&labelColor=black&color=blue" alt="Sponsor the MQT" />
</a>
</p>
## Getting Started
MQT DDSIM bundled with the provider and backends for Qiskit is available via [PyPI](https://pypi.org/project/mqt.ddsim/).
```console
(venv) $ pip install mqt.ddsim
```
The following code gives an example on the usage:
```python3
from qiskit import QuantumCircuit
from mqt import ddsim
circ = QuantumCircuit(3)
circ.h(0)
circ.cx(0, 1)
circ.cx(0, 2)
print(circ.draw(fold=-1))
backend = ddsim.DDSIMProvider().get_backend("qasm_simulator")
job = backend.run(circ, shots=10000)
counts = job.result().get_counts(circ)
print(counts)
```
**Detailed documentation and examples are available at [ReadTheDocs](https://mqt.readthedocs.io/projects/ddsim).**
## System Requirements and Building
Building the project requires a C++ compiler with support for C++20 and CMake 3.24 or newer.
For details on how to build the project, please refer to the [documentation](https://mqt.readthedocs.io/projects/ddsim).
Building (and running) is continuously tested under Linux, macOS, and Windows using the [latest available system versions for GitHub Actions](https://github.com/actions/runner-images).
MQT DDSIM is compatible with all [officially supported Python versions](https://devguide.python.org/versions/).
## Cite This
Please cite the work that best fits your use case.
### MQT DDSIM (the tool)
When citing the software itself or results produced with it, cite the original DD simulation paper:
```bibtex
@article{zulehner2019advanced,
title = {Advanced Simulation of Quantum Computations},
author = {Zulehner, Alwin and Wille, Robert},
year = 2019,
journal = {tcad},
volume = 38,
number = 5,
pages = {848--859},
doi = {10.1109/TCAD.2018.2834427}
}
```
### The Munich Quantum Toolkit (the project)
When discussing the overall MQT project or its ecosystem, cite the MQT Handbook:
```bibtex
@inproceedings{mqt,
title = {The {{MQT}} Handbook: {{A}} Summary of Design Automation Tools and Software for Quantum Computing},
shorttitle = {{The MQT Handbook}},
author = {Wille, Robert and Berent, Lucas and Forster, Tobias and Kunasaikaran, Jagatheesan and Mato, Kevin and Peham, Tom and Quetschlich, Nils and Rovara, Damian and Sander, Aaron and Schmid, Ludwig and Schoenberger, Daniel and Stade, Yannick and Burgholzer, Lukas},
year = 2024,
booktitle = {IEEE International Conference on Quantum Software (QSW)},
doi = {10.1109/QSW62656.2024.00013},
eprint = {2405.17543},
eprinttype = {arxiv},
addendum = {A live version of this document is available at \url{https://mqt.readthedocs.io}}
}
```
### Peer-Reviewed Research
When citing the underlying methods and research, please reference the most relevant peer-reviewed publications from the list below:
[[1]](https://www.cda.cit.tum.de/files/eda/2018_tcad_advanced_simulation_quantum_computation.pdf)
A. Zulehner and R. Wille. Advanced Simulation of Quantum Computations.
_IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD)_, 2019.
[[2]](https://www.cda.cit.tum.de/files/eda/2020_dac_weak_simulation_quantum_computation.pdf)
S. Hillmich, I. L. Markov, and R. Wille. Just Like the Real Thing: Fast Weak Simulation of Quantum Computation.
In _Design Automation Conference (DAC)_, 2020.
[[3]](https://www.cda.cit.tum.de/files/eda/2021_date_approximations_dd_baed_quantum_circuit_simulation.pdf)
S. Hillmich, R. Kueng, I. L. Markov, and R. Wille. As Accurate as Needed, as Efficient as Possible: Approximations in DD-based Quantum Circuit Simulation.
In _Design, Automation and Test in Europe (DATE)_, 2021.
[[4]](https://www.cda.cit.tum.de/files/eda/2021_qce_hybrid_schrodinger_feynman_simulation_with_decision_diagrams.pdf)
L. Burgholzer, H. Bauer, and R. Wille. Hybrid Schrödinger–Feynman Simulation of Quantum Circuits with Decision Diagrams.
In _IEEE International Conference on Quantum Computing and Engineering (QCE)_, 2021.
[[5]](https://www.cda.cit.tum.de/files/eda/2022_date_exploiting_arbitrary_paths_simulation_quantum_circuits_decision_diagrams.pdf)
L. Burgholzer, A. Ploier, and R. Wille. Exploiting Arbitrary Paths for the Simulation of Quantum Circuits with Decision Diagrams.
In _Design, Automation and Test in Europe (DATE)_, 2022.
[[6]](https://www.cda.cit.tum.de/files/eda/2022_tcad_noise-aware_quantum_circuit_simulation_with_decision_diagrams.pdf)
T. Grurl, J. Fuß, and R. Wille. Noise-aware Quantum Circuit Simulation with Decision Diagrams.
_IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD)_, 2022.
---
## Acknowledgements
The Munich Quantum Toolkit has been supported by the European Research Council (ERC) under the European Union's Horizon 2020 research and innovation program (grant agreement No. 101001318), the Bavarian State Ministry for Science and Arts through the Distinguished Professorship Program, as well as the Munich Quantum Valley, which is supported by the Bavarian state government with funds from the Hightech Agenda Bayern Plus.
<p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/munich-quantum-toolkit/.github/refs/heads/main/docs/_static/mqt-funding-footer-dark.svg" width="90%">
<img src="https://raw.githubusercontent.com/munich-quantum-toolkit/.github/refs/heads/main/docs/_static/mqt-funding-footer-light.svg" width="90%" alt="MQT Funding Footer">
</picture>
</p>
| text/markdown | null | Lukas Burgholzer <lukas.burgholzer@tum.de>, Stefan Hillmich <stefan.hillmich@scch.at> | null | null | null | MQT, quantum-computing, design-automation, quantum-circuit-sim, simulation | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"Natural Language :: English",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX :: Linux",
"Programming Language :: C++",
"Programming Language :: Python",
"Prog... | [] | null | null | >=3.10 | [] | [] | [] | [
"mqt.core[qiskit]~=3.4.1",
"qiskit>=1.1"
] | [] | [] | [] | [
"Homepage, https://github.com/munich-quantum-toolkit/ddsim",
"Documentation, https://mqt.readthedocs.io/projects/ddsim",
"Issues, https://github.com/munich-quantum-toolkit/ddsim/issues",
"Discussions, https://github.com/munich-quantum-toolkit/ddsim/discussions"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:43:43.819918 | mqt_ddsim-2.2.0.tar.gz | 267,754 | ce/7d/438817d8abad63cb022e8034a8ebd967c2bab2d0a93ddfa8083ef4993588/mqt_ddsim-2.2.0.tar.gz | source | sdist | null | false | 35c0cc971ece891fc720c60c78d44598 | fd95a4d9ac9ac6fbc236d2059e0a5bb4c0ebe6e4592be911d44539e7ad67596d | ce7d438817d8abad63cb022e8034a8ebd967c2bab2d0a93ddfa8083ef4993588 | MIT | [
"LICENSE.md"
] | 0 |
2.4 | claude-code-tools | 1.10.7 | Collection of tools for working with Claude Code | <div align="center">
<a href="https://pchalasani.github.io/claude-code-tools/">
<img src="assets/logo-nyc-subway.png" alt="CLAUDE CODE TOOLS"
width="500"/>
</a>
CLI tools, skills, agents, hooks, and plugins for enhancing productivity with Claude Code and other coding agents.
[](https://pchalasani.github.io/claude-code-tools/)
[](https://github.com/pchalasani/claude-code-tools/releases?q=rust)
</div>
## [Full Documentation](https://pchalasani.github.io/claude-code-tools/)
## Install
```bash
# Core package
uv tool install claude-code-tools
# With Google Docs/Sheets extras
uv tool install "claude-code-tools[gdocs]"
# Upgrade an existing installation
uv tool install --force claude-code-tools
```
The search engine (`aichat search`) requires a
separate Rust binary:
- **Homebrew** (macOS/Linux):
`brew install pchalasani/tap/aichat-search`
- **Cargo**: `cargo install aichat-search`
- **Pre-built binary**:
[Releases](https://github.com/pchalasani/claude-code-tools/releases)
(look for `rust-v*`)
Install the Claude Code
[plugins](https://pchalasani.github.io/claude-code-tools/getting-started/plugins/)
for hooks, skills, and agents:
```bash
claude plugin marketplace add pchalasani/claude-code-tools
```
---
Click a card to jump to that feature, or
**[read the full docs](https://pchalasani.github.io/claude-code-tools/)**.
<div align="center">
<table>
<tr>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/getting-started/">
<img src="assets/card-quickstart.svg" alt="quick start" width="300"/>
</a>
</td>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/getting-started/plugins/">
<img src="assets/card-plugins.svg" alt="plugins" width="300"/>
</a>
</td>
</tr>
</table>
<table>
<tr>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/tools/aichat/">
<img src="assets/card-aichat.svg" alt="aichat" width="200"/>
</a>
</td>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/tools/tmux-cli/">
<img src="assets/card-tmux.svg" alt="tmux-cli" width="200"/>
</a>
</td>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/tools/lmsh/">
<img src="assets/card-lmsh.svg" alt="lmsh" width="200"/>
</a>
</td>
</tr>
<tr>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/tools/vault/">
<img src="assets/card-vault.svg" alt="vault" width="200"/>
</a>
</td>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/tools/env-safe/">
<img src="assets/card-env-safe.svg" alt="env-safe" width="200"/>
</a>
</td>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/plugins-detail/safety-hooks/">
<img src="assets/card-safety.svg" alt="safety" width="200"/>
</a>
</td>
</tr>
<tr>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/tools/statusline/">
<img src="assets/card-statusline.svg" alt="statusline" width="200"/>
</a>
</td>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/integrations/google-docs/">
<img src="assets/card-gdocs.svg" alt="gdocs" width="200"/>
</a>
</td>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/integrations/google-sheets/">
<img src="assets/card-gsheets.svg" alt="gsheets" width="200"/>
</a>
</td>
</tr>
<tr>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/integrations/alt-llm-providers/">
<img src="assets/card-alt.svg" alt="alt" width="200"/>
</a>
</td>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/plugins-detail/voice/">
<img src="assets/card-voice.svg" alt="voice" width="200"/>
</a>
</td>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/tools/fix-session/">
<img src="assets/card-session-repair.svg" alt="session repair" width="200"/>
</a>
</td>
</tr>
</table>
<table>
<tr>
<td align="center">
<a href="https://pchalasani.github.io/claude-code-tools/development/">
<img src="assets/card-dev.svg" alt="development" width="300"/>
</a>
</td>
<td align="center">
<a href="LICENSE">
<img src="assets/card-license.svg" alt="license" width="300"/>
</a>
</td>
</tr>
</table>
</div>
---
> **Legacy links** — The sections below exist to
> preserve links shared in earlier discussions.
> For current documentation, visit the
> [full docs site](https://pchalasani.github.io/claude-code-tools/).
<a id="aichat-session-management"></a>
## aichat — Session Management
See [aichat](https://pchalasani.github.io/claude-code-tools/tools/aichat/) in the full documentation.
<a id="tmux-cli-terminal-automation"></a>
## tmux-cli — Terminal Automation
See [tmux-cli](https://pchalasani.github.io/claude-code-tools/tools/tmux-cli/) in the full documentation.
<a id="voice"></a>
## Voice Plugin
See [Voice](https://pchalasani.github.io/claude-code-tools/plugins-detail/voice/) in the full documentation.
<a id="license"></a>
## License
MIT
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"claude-agent-sdk>=0.1.6",
"click>=8.0.0",
"commitizen>=4.8.3",
"fire>=0.5.0",
"mcp>=1.13.0",
"pytest>=9.0.1",
"pyyaml>=6.0",
"rich>=13.0.0",
"tantivy>=0.22.0",
"tqdm>=4.67.1",
"commitizen>=3.0.0; extra == \"dev\"",
"google-api-python-client>=2.0.0; extra == \"gdocs\"",
"google-auth-oauthlib... | [] | [] | [] | [] | uv/0.5.8 | 2026-02-19T17:42:50.740285 | claude_code_tools-1.10.7.tar.gz | 5,466,261 | 02/17/6d7bec44511d2236678d0f15c5103f2810d2d9ab6acd9cdb85f17fcc5ddf/claude_code_tools-1.10.7.tar.gz | source | sdist | null | false | 8aa441fb623665642c2295313033d07f | c84a45575290acd4a5dae1d485e1d41d546712823d152f343ad757f7698bded1 | 02176d7bec44511d2236678d0f15c5103f2810d2d9ab6acd9cdb85f17fcc5ddf | null | [
"LICENSE"
] | 317 |
2.4 | alfred-assistant | 0.20.0 | The Rememberer - A persistent memory-augmented LLM assistant | # Alfred

**Alfred manages context intelligently.**
Not just memory. He knows what matters, when to bring it up, and what connects to now. Other assistants start fresh every time. Alfred builds a relationship with you.
## Why This Matters
You know that feeling when you start a new ChatGPT conversation and have to explain your entire project from scratch? Or when you mention a preference you've stated ten times before?
Alfred doesn't make you repeat yourself.
```
You: What did we decide about the database?
Alfred: You went with PostgreSQL over SQLite last Tuesday. The main reasons were:
- You need concurrent access (5+ users)
- JSONB queries for the metadata field
- Your team already knows Postgres
You also picked UUIDs for primary keys. Want me to pull up the full conversation?
```
That's not a transcript. That's Alfred actually remembering.
## Your Data Stays With You
Alfred runs on your machine. Your conversations never leave. No cloud storage, no corporate servers, just your files on your computer.
And you don't configure Alfred. You just talk to him. Tell him your preferences, your projects, how you communicate. He learns. He adapts. No YAML files to edit, no slash commands to memorize.
## Getting Started
```bash
pip install alfred-ai
export KIMI_API_KEY=your_key
export OPENAI_API_KEY=your_key
alfred
```
Then just start talking.
## How It Works
```mermaid
flowchart LR
You["You"] -->|message| Alfred["Alfred"]
Alfred -->|embed| Memory[(Memory Store)]
Memory -->|relevant context| Alfred
Alfred -->|prompt + context| LLM["LLM Provider"]
LLM -->|response| Alfred
Alfred -->|reply| You
```
Every message gets embedded and stored. When you talk, Alfred searches by meaning, not keywords, and pulls the right context into your session.
Over time, he learns what matters. Which details are important. How you think. The context he brings isn't just relevant. It's intelligent.
## What Alfred Does
**Manages context intelligently.** Brings the right information forward at the right time, without being asked.
**Works with tools.** Alfred can read your files, write code, and run shell commands when you ask.
**Fits your workflow.** Chat in your terminal or through Telegram.
**Plays nice with others.** Works with Kimi, OpenAI, or any OpenAI-compatible API.
## Contributing
Alfred is young but useful. If you want to help:
- Make him smarter about what to remember
- Improve how he learns your preferences over time
- Add better test coverage
- Build conversation summarization for long chats
Check [AGENTS.md](AGENTS.md) for how we work. Pull requests and issues welcome.
## License
MIT
| text/markdown | null | Jeremy Ball <jeremysball@pm.me> | null | null | MIT | adhd-aid, ai, assistant, cli, executive-assistant, llm, memory, personal-growth, telegram | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Communications ... | [] | null | null | >=3.12 | [] | [] | [] | [
"aioconsole>=0.8.2",
"aiofiles>=23.0",
"aiohttp>=3.9",
"croniter>=2.0",
"numpy>=1.24",
"openai>=1.0",
"psutil>=5.9",
"pydantic-settings>=2.0",
"pydantic>=2.0",
"python-dotenv>=1.0",
"python-telegram-bot>=21.0",
"rich>=13.0",
"tiktoken>=0.5",
"typer>=0.12",
"dotenv-cli>=3.0; extra == \"de... | [] | [] | [] | [
"Homepage, https://github.com/jeremysball/alfred",
"Repository, https://github.com/jeremysball/alfred",
"Issues, https://github.com/jeremysball/alfred/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T17:42:45.711378 | alfred_assistant-0.20.0.tar.gz | 5,824,286 | ed/39/5812b3b528bb6319112c424d19bbbd3687dba270df3a9ac6f632a4a9329d/alfred_assistant-0.20.0.tar.gz | source | sdist | null | false | 85d27fe083c16960b5d9dab7ac2ebbce | b29f2a33a2b77fcbd4d6351640ab8716b05b258c2d192f54f32822172730e895 | ed395812b3b528bb6319112c424d19bbbd3687dba270df3a9ac6f632a4a9329d | null | [] | 209 |
2.4 | strands-agents-tools | 0.2.21 | A collection of specialized tools for Strands Agents | <div align="center">
<div>
<a href="https://strandsagents.com">
<img src="https://strandsagents.com/latest/assets/logo-github.svg" alt="Strands Agents" width="55px" height="105px">
</a>
</div>
<h1>
Strands Agents Tools
</h1>
<h2>
A model-driven approach to building AI agents in just a few lines of code.
</h2>
<div align="center">
<a href="https://github.com/strands-agents/tools/graphs/commit-activity"><img alt="GitHub commit activity" src="https://img.shields.io/github/commit-activity/m/strands-agents/tools"/></a>
<a href="https://github.com/strands-agents/tools/issues"><img alt="GitHub open issues" src="https://img.shields.io/github/issues/strands-agents/tools"/></a>
<a href="https://github.com/strands-agents/tools/pulls"><img alt="GitHub open pull requests" src="https://img.shields.io/github/issues-pr/strands-agents/tools"/></a>
<a href="https://github.com/strands-agents/tools/blob/main/LICENSE"><img alt="License" src="https://img.shields.io/github/license/strands-agents/tools"/></a>
<a href="https://pypi.org/project/strands-agents-tools/"><img alt="PyPI version" src="https://img.shields.io/pypi/v/strands-agents-tools"/></a>
<a href="https://python.org"><img alt="Python versions" src="https://img.shields.io/pypi/pyversions/strands-agents-tools"/></a>
</div>
<p>
<a href="https://strandsagents.com/">Documentation</a>
◆ <a href="https://github.com/strands-agents/samples">Samples</a>
◆ <a href="https://github.com/strands-agents/sdk-python">Python SDK</a>
◆ <a href="https://github.com/strands-agents/tools">Tools</a>
◆ <a href="https://github.com/strands-agents/agent-builder">Agent Builder</a>
◆ <a href="https://github.com/strands-agents/mcp-server">MCP Server</a>
</p>
</div>
Strands Agents Tools is a community-driven project that provides a powerful set of tools for your agents to use. It bridges the gap between large language models and practical applications by offering ready-to-use tools for file operations, system execution, API interactions, mathematical operations, and more.
## ✨ Features
- 📁 **File Operations** - Read, write, and edit files with syntax highlighting and intelligent modifications
- 🖥️ **Shell Integration** - Execute and interact with shell commands securely
- 🧠 **Memory** - Store user and agent memories across agent runs to provide personalized experiences with both Mem0, Amazon Bedrock Knowledge Bases, Elasticsearch, and MongoDB Atlas
- 🕸️ **Web Infrastructure** - Perform web searches, extract page content, and crawl websites with Tavily and Exa-powered tools
- 🌐 **HTTP Client** - Make API requests with comprehensive authentication support
- 💬 **Slack Client** - Real-time Slack events, message processing, and Slack API access
- 🐍 **Python Execution** - Run Python code snippets with state persistence, user confirmation for code execution, and safety features
- 🧮 **Mathematical Tools** - Perform advanced calculations with symbolic math capabilities
- ☁️ **AWS Integration** - Seamless access to AWS services
- 🖼️ **Image Processing** - Generate and process images for AI applications
- 🎥 **Video Processing** - Use models and agents to generate dynamic videos
- 🎙️ **Audio Output** - Enable models to generate audio and speak
- 🔄 **Environment Management** - Handle environment variables safely
- 📝 **Journaling** - Create and manage structured logs and journals
- ⏱️ **Task Scheduling** - Schedule and manage cron jobs
- 🧠 **Advanced Reasoning** - Tools for complex thinking and reasoning capabilities
- 🐝 **Swarm Intelligence** - Coordinate multiple AI agents for parallel problem solving with shared memory
- 🔌 **Dynamic MCP Client** - ⚠️ Dynamically connect to external MCP servers and load remote tools (use with caution - see security warnings)
- 🔄 **Multiple tools in Parallel** - Call multiple other tools at the same time in parallel with Batch Tool
- 🔍 **Browser Tool** - Tool giving an agent access to perform automated actions on a browser (chromium)
- 📈 **Diagram** - Create AWS cloud diagrams, basic diagrams, or UML diagrams using python libraries
- 📰 **RSS Feed Manager** - Subscribe, fetch, and process RSS feeds with content filtering and persistent storage
- 🖱️ **Computer Tool** - Automate desktop actions including mouse movements, keyboard input, screenshots, and application management
## 📦 Installation
### Quick Install
```bash
pip install strands-agents-tools
```
To install the dependencies for optional tools:
```bash
pip install strands-agents-tools[mem0_memory, use_browser, rss, use_computer]
```
### Development Install
```bash
# Clone the repository
git clone https://github.com/strands-agents/tools.git
cd tools
# Create and activate virtual environment
python3 -m venv .venv
source .venv/bin/activate # On Windows: venv\Scripts\activate
# Install in development mode
pip install -e ".[dev]"
# Install pre-commit hooks
pre-commit install
```
### Tools Overview
Below is a comprehensive table of all available tools, how to use them with an agent, and typical use cases:
| Tool | Agent Usage | Use Case |
|------|-------------|----------|
| a2a_client | `provider = A2AClientToolProvider(known_agent_urls=["http://localhost:9000"]); agent = Agent(tools=provider.tools)` | Discover and communicate with A2A-compliant agents, send messages between agents |
| file_read | `agent.tool.file_read(path="path/to/file.txt")` | Reading configuration files, parsing code files, loading datasets |
| file_write | `agent.tool.file_write(path="path/to/file.txt", content="file content")` | Writing results to files, creating new files, saving output data |
| editor | `agent.tool.editor(command="view", path="path/to/file.py")` | Advanced file operations like syntax highlighting, pattern replacement, and multi-file edits |
| shell* | `agent.tool.shell(command="ls -la")` | Executing shell commands, interacting with the operating system, running scripts |
| http_request | `agent.tool.http_request(method="GET", url="https://api.example.com/data")` | Making API calls, fetching web data, sending data to external services |
| tavily_search | `agent.tool.tavily_search(query="What is artificial intelligence?", search_depth="advanced")` | Real-time web search optimized for AI agents with a variety of custom parameters |
| tavily_extract | `agent.tool.tavily_extract(urls=["www.tavily.com"], extract_depth="advanced")` | Extract clean, structured content from web pages with advanced processing and noise removal |
| tavily_crawl | `agent.tool.tavily_crawl(url="www.tavily.com", max_depth=2, instructions="Find API docs")` | Crawl websites intelligently starting from a base URL with filtering and extraction |
| tavily_map | `agent.tool.tavily_map(url="www.tavily.com", max_depth=2, instructions="Find all pages")` | Map website structure and discover URLs starting from a base URL without content extraction |
| exa_search | `agent.tool.exa_search(query="Best project management tools", text=True)` | Intelligent web search with auto mode (default) that combines neural and keyword search for optimal results |
| exa_get_contents | `agent.tool.exa_get_contents(urls=["https://example.com/article"], text=True, summary={"query": "key points"})` | Extract full content and summaries from specific URLs with live crawling fallback |
| python_repl* | `agent.tool.python_repl(code="import pandas as pd\ndf = pd.read_csv('data.csv')\nprint(df.head())")` | Running Python code snippets, data analysis, executing complex logic with user confirmation for security |
| calculator | `agent.tool.calculator(expression="2 * sin(pi/4) + log(e**2)")` | Performing mathematical operations, symbolic math, equation solving |
| code_interpreter | `code_interpreter = AgentCoreCodeInterpreter(region="us-west-2"); agent = Agent(tools=[code_interpreter.code_interpreter])` | Execute code in isolated sandbox environments with multi-language support (Python, JavaScript, TypeScript), persistent sessions, and file operations |
| use_aws | `agent.tool.use_aws(service_name="s3", operation_name="list_buckets", parameters={}, region="us-west-2")` | Interacting with AWS services, cloud resource management |
| retrieve | `agent.tool.retrieve(text="What is STRANDS?")` | Retrieving information from Amazon Bedrock Knowledge Bases with optional metadata |
| nova_reels | `agent.tool.nova_reels(action="create", text="A cinematic shot of mountains", s3_bucket="my-bucket")` | Create high-quality videos using Amazon Bedrock Nova Reel with configurable parameters via environment variables |
| agent_core_memory | `agent.tool.agent_core_memory(action="record", content="Hello, I like vegetarian food")` | Store and retrieve memories with Amazon Bedrock Agent Core Memory service |
| mem0_memory | `agent.tool.mem0_memory(action="store", content="Remember I like to play tennis", user_id="alex")` | Store user and agent memories across agent runs to provide personalized experience |
| bright_data | `agent.tool.bright_data(action="scrape_as_markdown", url="https://example.com")` | Web scraping, search queries, screenshot capture, and structured data extraction from websites and different data feeds|
| memory | `agent.tool.memory(action="retrieve", query="product features")` | Store, retrieve, list, and manage documents in Amazon Bedrock Knowledge Bases with configurable parameters via environment variables |
| environment | `agent.tool.environment(action="list", prefix="AWS_")` | Managing environment variables, configuration management |
| generate_image_stability | `agent.tool.generate_image_stability(prompt="A tranquil pool")` | Creating images using Stability AI models |
| generate_image | `agent.tool.generate_image(prompt="A sunset over mountains")` | Creating AI-generated images for various applications |
| image_reader | `agent.tool.image_reader(image_path="path/to/image.jpg")` | Processing and reading image files for AI analysis |
| journal | `agent.tool.journal(action="write", content="Today's progress notes")` | Creating structured logs, maintaining documentation |
| think | `agent.tool.think(thought="Complex problem to analyze", cycle_count=3)` | Advanced reasoning, multi-step thinking processes |
| load_tool | `agent.tool.load_tool(path="path/to/custom_tool.py", name="custom_tool")` | Dynamically loading custom tools and extensions |
| swarm | `agent.tool.swarm(task="Analyze this problem", swarm_size=3, coordination_pattern="collaborative")` | Coordinating multiple AI agents to solve complex problems through collective intelligence |
| current_time | `agent.tool.current_time(timezone="US/Pacific")` | Get the current time in ISO 8601 format for a specified timezone |
| sleep | `agent.tool.sleep(seconds=5)` | Pause execution for the specified number of seconds, interruptible with SIGINT (Ctrl+C) |
| agent_graph | `agent.tool.agent_graph(agents=["agent1", "agent2"], connections=[{"from": "agent1", "to": "agent2"}])` | Create and visualize agent relationship graphs for complex multi-agent systems |
| cron* | `agent.tool.cron(action="schedule", name="task", schedule="0 * * * *", command="backup.sh")` | Schedule and manage recurring tasks with cron job syntax <br> **Does not work on Windows |
| slack | `agent.tool.slack(action="post_message", channel="general", text="Hello team!")` | Interact with Slack workspace for messaging and monitoring |
| speak | `agent.tool.speak(text="Operation completed successfully", style="green", mode="polly")` | Output status messages with rich formatting and optional text-to-speech |
| stop | `agent.tool.stop(message="Process terminated by user request")` | Gracefully terminate agent execution with custom message |
| handoff_to_user | `agent.tool.handoff_to_user(message="Please confirm action", breakout_of_loop=False)` | Hand off control to user for confirmation, input, or complete task handoff |
| use_llm | `agent.tool.use_llm(prompt="Analyze this data", system_prompt="You are a data analyst")` | Create nested AI loops with customized system prompts for specialized tasks |
| workflow | `agent.tool.workflow(action="create", name="data_pipeline", steps=[{"tool": "file_read"}, {"tool": "python_repl"}])` | Define, execute, and manage multi-step automated workflows |
| mcp_client | `agent.tool.mcp_client(action="connect", connection_id="my_server", transport="stdio", command="python", args=["server.py"])` | ⚠️ **SECURITY WARNING**: Dynamically connect to external MCP servers via stdio, sse, or streamable_http, list tools, and call remote tools. This can pose security risks as agents may connect to malicious servers. Use with caution in production. |
| batch| `agent.tool.batch(invocations=[{"name": "current_time", "arguments": {"timezone": "Europe/London"}}, {"name": "stop", "arguments": {}}])` | Call multiple other tools in parallel. |
| browser | `browser = LocalChromiumBrowser(); agent = Agent(tools=[browser.browser])` | Web scraping, automated testing, form filling, web automation tasks |
| diagram | `agent.tool.diagram(diagram_type="cloud", nodes=[{"id": "s3", "type": "S3"}], edges=[])` | Create AWS cloud architecture diagrams, network diagrams, graphs, and UML diagrams (all 14 types) |
| rss | `agent.tool.rss(action="subscribe", url="https://example.com/feed.xml", feed_id="tech_news")` | Manage RSS feeds: subscribe, fetch, read, search, and update content from various sources |
| use_computer | `agent.tool.use_computer(action="click", x=100, y=200, app_name="Chrome") ` | Desktop automation, GUI interaction, screen capture |
| search_video | `agent.tool.search_video(query="people discussing AI")` | Semantic video search using TwelveLabs' Marengo model |
| chat_video | `agent.tool.chat_video(prompt="What are the main topics?", video_id="video_123")` | Interactive video analysis using TwelveLabs' Pegasus model |
| mongodb_memory | `agent.tool.mongodb_memory(action="record", content="User prefers vegetarian pizza", connection_string="mongodb+srv://...", database_name="memories")` | Store and retrieve memories using MongoDB Atlas with semantic search via AWS Bedrock Titan embeddings |
\* *These tools do not work on windows*
## 💻 Usage Examples
### File Operations
```python
from strands import Agent
from strands_tools import file_read, file_write, editor
agent = Agent(tools=[file_read, file_write, editor])
agent.tool.file_read(path="config.json")
agent.tool.file_write(path="output.txt", content="Hello, world!")
agent.tool.editor(command="view", path="script.py")
```
### Dynamic MCP Client Integration
⚠️ **SECURITY WARNING**: The Dynamic MCP Client allows agents to autonomously connect to external MCP servers and load remote tools at runtime. This poses significant security risks as agents can potentially connect to malicious servers and execute untrusted code. Use with extreme caution in production environments.
This tool is different from the static MCP server implementation in the Strands SDK (see [MCP Tools Documentation](https://github.com/strands-agents/docs/blob/main/docs/user-guide/concepts/tools/mcp-tools.md)) which uses pre-configured, trusted MCP servers.
```python
from strands import Agent
from strands_tools import mcp_client
agent = Agent(tools=[mcp_client])
# Connect to a custom MCP server via stdio
agent.tool.mcp_client(
action="connect",
connection_id="my_tools",
transport="stdio",
command="python",
args=["my_mcp_server.py"]
)
# List available tools on the server
tools = agent.tool.mcp_client(
action="list_tools",
connection_id="my_tools"
)
# Call a tool from the MCP server
result = agent.tool.mcp_client(
action="call_tool",
connection_id="my_tools",
tool_name="calculate",
tool_args={"x": 10, "y": 20}
)
# Connect to a SSE-based server
agent.tool.mcp_client(
action="connect",
connection_id="web_server",
transport="sse",
server_url="http://localhost:8080/sse"
)
# Connect to a streamable HTTP server
agent.tool.mcp_client(
action="connect",
connection_id="http_server",
transport="streamable_http",
server_url="https://api.example.com/mcp",
headers={"Authorization": "Bearer token"},
timeout=60
)
# Load MCP tools into agent's registry for direct access
# ⚠️ WARNING: This loads external tools directly into the agent
agent.tool.mcp_client(
action="load_tools",
connection_id="my_tools"
)
# Now you can call MCP tools directly as: agent.tool.calculate(x=10, y=20)
```
### Shell Commands
*Note: `shell` does not work on Windows.*
```python
from strands import Agent
from strands_tools import shell
agent = Agent(tools=[shell])
# Execute a single command
result = agent.tool.shell(command="ls -la")
# Execute a sequence of commands
results = agent.tool.shell(command=["mkdir -p test_dir", "cd test_dir", "touch test.txt"])
# Execute commands with error handling
agent.tool.shell(command="risky-command", ignore_errors=True)
```
### HTTP Requests
```python
from strands import Agent
from strands_tools import http_request
agent = Agent(tools=[http_request])
# Make a simple GET request
response = agent.tool.http_request(
method="GET",
url="https://api.example.com/data"
)
# POST request with authentication
response = agent.tool.http_request(
method="POST",
url="https://api.example.com/resource",
headers={"Content-Type": "application/json"},
body=json.dumps({"key": "value"}),
auth_type="Bearer",
auth_token="your_token_here"
)
# Convert HTML webpages to markdown for better readability
response = agent.tool.http_request(
method="GET",
url="https://example.com/article",
convert_to_markdown=True
)
```
### Tavily Search, Extract, Crawl, and Map
```python
from strands import Agent
from strands_tools.tavily import (
tavily_search, tavily_extract, tavily_crawl, tavily_map
)
# For async usage, call the corresponding *_async function with await.
# Synchronous usage
agent = Agent(tools=[tavily_search, tavily_extract, tavily_crawl, tavily_map])
# Real-time web search
result = agent.tool.tavily_search(
query="Latest developments in renewable energy",
search_depth="advanced",
topic="news",
max_results=10,
include_raw_content=True
)
# Extract content from multiple URLs
result = agent.tool.tavily_extract(
urls=["www.tavily.com", "www.apple.com"],
extract_depth="advanced",
format="markdown"
)
# Advanced crawl with instructions and filtering
result = agent.tool.tavily_crawl(
url="www.tavily.com",
max_depth=2,
limit=50,
instructions="Find all API documentation and developer guides",
extract_depth="advanced",
include_images=True
)
# Basic website mapping
result = agent.tool.tavily_map(url="www.tavily.com")
```
### Exa Search and Contents
```python
from strands import Agent
from strands_tools.exa import exa_search, exa_get_contents
agent = Agent(tools=[exa_search, exa_get_contents])
# Basic search (auto mode is default and recommended)
result = agent.tool.exa_search(
query="Best project management software",
text=True
)
# Company-specific search when needed
result = agent.tool.exa_search(
query="Anthropic AI safety research",
category="company",
include_domains=["anthropic.com"],
num_results=5,
summary={"query": "key research areas and findings"}
)
# News search with date filtering
result = agent.tool.exa_search(
query="AI regulation policy updates",
category="news",
start_published_date="2024-01-01T00:00:00.000Z",
text=True
)
# Get detailed content from specific URLs
result = agent.tool.exa_get_contents(
urls=[
"https://example.com/blog-post",
"https://github.com/microsoft/semantic-kernel"
],
text={"maxCharacters": 5000, "includeHtmlTags": False},
summary={
"query": "main points and practical applications"
},
subpages=2,
extras={"links": 5, "imageLinks": 2}
)
# Structured summary with JSON schema
result = agent.tool.exa_get_contents(
urls=["https://example.com/article"],
summary={
"query": "main findings and recommendations",
"schema": {
"type": "object",
"properties": {
"main_points": {"type": "string", "description": "Key points from the article"},
"recommendations": {"type": "string", "description": "Suggested actions or advice"},
"conclusion": {"type": "string", "description": "Overall conclusion"},
"relevance": {"type": "string", "description": "Why this matters"}
},
"required": ["main_points", "conclusion"]
}
}
)
```
### Python Code Execution
*Note: `python_repl` does not work on Windows.*
```python
from strands import Agent
from strands_tools import python_repl
agent = Agent(tools=[python_repl])
# Execute Python code with state persistence
result = agent.tool.python_repl(code="""
import pandas as pd
# Load and process data
data = pd.read_csv('data.csv')
processed = data.groupby('category').mean()
processed.head()
""")
```
### Code Interpreter
```python
from strands import Agent
from strands_tools.code_interpreter import AgentCoreCodeInterpreter
# Create the code interpreter tool
bedrock_agent_core_code_interpreter = AgentCoreCodeInterpreter(region="us-west-2")
agent = Agent(tools=[bedrock_agent_core_code_interpreter.code_interpreter])
# Create a session
agent.tool.code_interpreter({
"action": {
"type": "initSession",
"description": "Data analysis session",
"session_name": "analysis-session"
}
})
# Execute Python code
agent.tool.code_interpreter({
"action": {
"type": "executeCode",
"session_name": "analysis-session",
"code": "print('Hello from sandbox!')",
"language": "python"
}
})
```
### Swarm Intelligence
```python
from strands import Agent
from strands_tools import swarm
agent = Agent(tools=[swarm])
# Create a collaborative swarm of agents to tackle a complex problem
result = agent.tool.swarm(
task="Generate creative solutions for reducing plastic waste in urban areas",
swarm_size=5,
coordination_pattern="collaborative"
)
# Create a competitive swarm for diverse solution generation
result = agent.tool.swarm(
task="Design an innovative product for smart home automation",
swarm_size=3,
coordination_pattern="competitive"
)
# Hybrid approach combining collaboration and competition
result = agent.tool.swarm(
task="Develop marketing strategies for a new sustainable fashion brand",
swarm_size=4,
coordination_pattern="hybrid"
)
```
### Use AWS
```python
from strands import Agent
from strands_tools import use_aws
agent = Agent(tools=[use_aws])
# List S3 buckets
result = agent.tool.use_aws(
service_name="s3",
operation_name="list_buckets",
parameters={},
region="us-east-1",
label="List all S3 buckets"
)
# Get the contents of a specific S3 bucket
result = agent.tool.use_aws(
service_name="s3",
operation_name="list_objects_v2",
parameters={"Bucket": "example-bucket"}, # Replace with your actual bucket name
region="us-east-1",
label="List objects in a specific S3 bucket"
)
# Get the list of EC2 subnets
result = agent.tool.use_aws(
service_name="ec2",
operation_name="describe_subnets",
parameters={},
region="us-east-1",
label="List all subnets"
)
```
### Retrieve Tool
```python
from strands import Agent
from strands_tools import retrieve
agent = Agent(tools=[retrieve])
# Basic retrieval without metadata
result = agent.tool.retrieve(
text="What is artificial intelligence?"
)
# Retrieval with metadata enabled
result = agent.tool.retrieve(
text="What are the latest developments in machine learning?",
enableMetadata=True
)
# Using environment variable to set default metadata behavior
# Set RETRIEVE_ENABLE_METADATA_DEFAULT=true in your environment
result = agent.tool.retrieve(
text="Tell me about cloud computing"
# enableMetadata will default to the environment variable value
)
```
### Batch Tool
```python
import os
import sys
from strands import Agent
from strands_tools import batch, http_request, use_aws
# Example usage of the batch with http_request and use_aws tools
agent = Agent(tools=[batch, http_request, use_aws])
result = agent.tool.batch(
invocations=[
{"name": "http_request", "arguments": {"method": "GET", "url": "https://api.ipify.org?format=json"}},
{
"name": "use_aws",
"arguments": {
"service_name": "s3",
"operation_name": "list_buckets",
"parameters": {},
"region": "us-east-1",
"label": "List S3 Buckets"
}
},
]
)
```
### Video Tools
```python
from strands import Agent
from strands_tools import search_video, chat_video
agent = Agent(tools=[search_video, chat_video])
# Search for video content using natural language
result = agent.tool.search_video(
query="people discussing AI technology",
threshold="high",
group_by="video",
page_limit=5
)
# Chat with existing video (no index_id needed)
result = agent.tool.chat_video(
prompt="What are the main topics discussed in this video?",
video_id="existing-video-id"
)
# Chat with new video file (index_id required for upload)
result = agent.tool.chat_video(
prompt="Describe what happens in this video",
video_path="/path/to/video.mp4",
index_id="your-index-id" # or set TWELVELABS_PEGASUS_INDEX_ID env var
)
```
### AgentCore Memory
```python
from strands import Agent
from strands_tools.agent_core_memory import AgentCoreMemoryToolProvider
provider = AgentCoreMemoryToolProvider(
memory_id="memory-123abc", # Required
actor_id="user-456", # Required
session_id="session-789", # Required
namespace="default", # Required
region="us-west-2" # Optional, defaults to us-west-2
)
agent = Agent(tools=provider.tools)
# Create a new memory
result = agent.tool.agent_core_memory(
action="record",
content="I am allergic to shellfish"
)
# Search for relevant memories
result = agent.tool.agent_core_memory(
action="retrieve",
query="user preferences"
)
# List all memories
result = agent.tool.agent_core_memory(
action="list"
)
# Get a specific memory by ID
result = agent.tool.agent_core_memory(
action="get",
memory_record_id="mr-12345"
)
```
### Browser
```python
from strands import Agent
from strands_tools.browser import LocalChromiumBrowser
# Create browser tool
browser = LocalChromiumBrowser()
agent = Agent(tools=[browser.browser])
# Simple navigation
result = agent.tool.browser({
"action": {
"type": "navigate",
"url": "https://example.com"
}
})
# Initialize a session first
result = agent.tool.browser({
"action": {
"type": "initSession",
"session_name": "main-session",
"description": "Web automation session"
}
})
```
### Handoff to User
```python
from strands import Agent
from strands_tools import handoff_to_user
agent = Agent(tools=[handoff_to_user])
# Request user confirmation and continue
response = agent.tool.handoff_to_user(
message="I need your approval to proceed with deleting these files. Type 'yes' to confirm.",
breakout_of_loop=False
)
# Complete handoff to user (stops agent execution)
agent.tool.handoff_to_user(
message="Task completed. Please review the results and take any necessary follow-up actions.",
breakout_of_loop=True
)
```
### A2A Client
```python
from strands import Agent
from strands_tools.a2a_client import A2AClientToolProvider
# Initialize the A2A client provider with known agent URLs
provider = A2AClientToolProvider(known_agent_urls=["http://localhost:9000"])
agent = Agent(tools=provider.tools)
# Use natural language to interact with A2A agents
response = agent("discover available agents and send a greeting message")
# The agent will automatically use the available tools:
# - discover_agent(url) to find agents
# - list_discovered_agents() to see all discovered agents
# - send_message(message_text, target_agent_url) to communicate
```
### Diagram
```python
from strands import Agent
from strands_tools import diagram
agent = Agent(tools=[diagram])
# Create an AWS cloud architecture diagram
result = agent.tool.diagram(
diagram_type="cloud",
nodes=[
{"id": "users", "type": "Users", "label": "End Users"},
{"id": "cloudfront", "type": "CloudFront", "label": "CDN"},
{"id": "s3", "type": "S3", "label": "Static Assets"},
{"id": "api", "type": "APIGateway", "label": "API Gateway"},
{"id": "lambda", "type": "Lambda", "label": "Backend Service"}
],
edges=[
{"from": "users", "to": "cloudfront"},
{"from": "cloudfront", "to": "s3"},
{"from": "users", "to": "api"},
{"from": "api", "to": "lambda"}
],
title="Web Application Architecture"
)
# Create a UML class diagram
result = agent.tool.diagram(
diagram_type="class",
elements=[
{
"name": "User",
"attributes": ["+id: int", "-name: string", "#email: string"],
"methods": ["+login(): bool", "+logout(): void"]
},
{
"name": "Order",
"attributes": ["+id: int", "-items: List", "-total: float"],
"methods": ["+addItem(item): void", "+calculateTotal(): float"]
}
],
relationships=[
{"from": "User", "to": "Order", "type": "association", "multiplicity": "1..*"}
],
title="E-commerce Domain Model"
)
```
### RSS Feed Management
```python
from strands import Agent
from strands_tools import rss
agent = Agent(tools=[rss])
# Subscribe to a feed
result = agent.tool.rss(
action="subscribe",
url="https://news.example.com/rss/technology"
)
# List all subscribed feeds
feeds = agent.tool.rss(action="list")
# Read entries from a specific feed
entries = agent.tool.rss(
action="read",
feed_id="news_example_com_technology",
max_entries=5,
include_content=True
)
# Search across all feeds
search_results = agent.tool.rss(
action="search",
query="machine learning",
max_entries=10
)
# Fetch feed content without subscribing
latest_news = agent.tool.rss(
action="fetch",
url="https://blog.example.org/feed",
max_entries=3
)
```
### Use Computer
```python
from strands import Agent
from strands_tools import use_computer
agent = Agent(tools=[use_computer])
# Find mouse position
result = agent.tool.use_computer(action="mouse_position")
# Automate adding text
result = agent.tool.use_computer(action="type", text="Hello, world!", app_name="Notepad")
# Analyze current computer screen
result = agent.tool.use_computer(action="analyze_screen")
result = agent.tool.use_computer(action="open_app", app_name="Calculator")
result = agent.tool.use_computer(action="close_app", app_name="Calendar")
result = agent.tool.use_computer(
action="hotkey",
hotkey_str="command+ctrl+f", # For macOS
app_name="Chrome"
)
```
### Elasticsearch Memory
**Note**: This tool requires AWS account credentials to generate embeddings using Amazon Bedrock Titan models.
```python
from strands import Agent
from strands_tools.elasticsearch_memory import elasticsearch_memory
# Create agent with direct tool usage
agent = Agent(tools=[elasticsearch_memory])
# Store a memory with semantic embeddings
result = agent.tool.elasticsearch_memory(
action="record",
content="User prefers vegetarian pizza with extra cheese",
metadata={"category": "food_preferences", "type": "dietary"},
cloud_id="your-elasticsearch-cloud-id",
api_key="your-api-key",
index_name="memories",
namespace="user_123"
)
# Search memories using semantic similarity (vector search)
result = agent.tool.elasticsearch_memory(
action="retrieve",
query="food preferences and dietary restrictions",
max_results=5,
cloud_id="your-elasticsearch-cloud-id",
api_key="your-api-key",
index_name="memories",
namespace="user_123"
)
# Use configuration dictionary for cleaner code
config = {
"cloud_id": "your-elasticsearch-cloud-id",
"api_key": "your-api-key",
"index_name": "memories",
"namespace": "user_123"
}
# List all memories with pagination
result = agent.tool.elasticsearch_memory(
action="list",
max_results=10,
**config
)
# Get specific memory by ID
result = agent.tool.elasticsearch_memory(
action="get",
memory_id="mem_1234567890_abcd1234",
**config
)
# Delete a memory
result = agent.tool.elasticsearch_memory(
action="delete",
memory_id="mem_1234567890_abcd1234",
**config
)
# Use Elasticsearch Serverless (URL-based connection)
result = agent.tool.elasticsearch_memory(
action="record",
content="User prefers vegetarian pizza",
es_url="https://your-serverless-cluster.es.region.aws.elastic.cloud:443",
api_key="your-api-key",
index_name="memories",
namespace="user_123"
)
```
### MongoDB Atlas Memory
**Note**: This tool requires AWS account credentials to generate embeddings using Amazon Bedrock Titan models.
```python
from strands import Agent
from strands_tools.mongodb_memory import mongodb_memory
# Create agent with direct tool usage
agent = Agent(tools=[mongodb_memory])
# Store a memory with semantic embeddings
result = agent.tool.mongodb_memory(
action="record",
content="User prefers vegetarian pizza with extra cheese",
metadata={"category": "food_preferences", "type": "dietary"},
connection_string="mongodb+srv://username:password@cluster0.mongodb.net/?retryWrites=true&w=majority",
database_name="memories",
collection_name="user_memories",
namespace="user_123"
)
# Search memories using semantic similarity (vector search)
result = agent.tool.mongodb_memory(
action="retrieve",
query="food preferences and dietary restrictions",
max_results=5,
connection_string="mongodb+srv://username:password@cluster0.mongodb.net/?retryWrites=true&w=majority",
database_name="memories",
collection_name="user_memories",
namespace="user_123"
)
# Use configuration dictionary for cleaner code
config = {
"connection_string": "mongodb+srv://username:password@cluster0.mongodb.net/?retryWrites=true&w=majority",
"database_name": "memories",
"collection_name": "user_memories",
"namespace": "user_123"
}
# List all memories with pagination
result = agent.tool.mongodb_memory(
action="list",
max_results=10,
**config
)
# Get specific memory by ID
result = agent.tool.mongodb_memory(
action="get",
memory_id="mem_1234567890_abcd1234",
**config
)
# Delete a memory
result = agent.tool.mongodb_memory(
action="delete",
memory_id="mem_1234567890_abcd1234",
**config
)
# Use environment variables for connection
# Set MONGODB_ATLAS_CLUSTER_URI in your environment
result = agent.tool.mongodb_memory(
action="record",
content="User prefers vegetarian pizza",
database_name="memories",
collection_name="user_memories",
namespace="user_123"
)
```
## 🌍 Environment Variables Configuration
Agents Tools provides extensive customization through environment variables. This allows you to configure tool behavior without modifying code, making it ideal for different environments (development, testing, production).
### Global Environment Variables
These variables affect multiple tools:
| Environment Variable | Description | Default | Affected Tools |
|----------------------|-------------|---------|---------------|
| BYPASS_TOOL_CONSENT | Bypass consent for tool invocation, set to "true" to enable | false | All tools that require consent (e.g. shell, file_write, python_repl) |
| STRANDS_TOOL_CONSOLE_MODE | Enable rich UI for tools, set to "enabled" to enable | disabled | All tools that have optional rich UI |
| AWS_REGION | Default AWS region for AWS operations | us-west-2 | use_aws, retrieve, generate_image, memory, nova_reels |
| AWS_PROFILE | AWS profile name to use from ~/.aws/credentials | default | use_aws, retrieve |
| LOG_LEVEL | Logging level (DEBUG, INFO, WARNING, ERROR) | INFO | All tools |
### Tool-Specific Environment Variables
#### Calculator Tool
| Environment Variable | Description | Default |
|----------------------|-------------|---------|
| CALCULATOR_MODE | Default calculation mode | evaluate |
| CALCULATOR_PRECISION | Number of decimal places for results | 10 |
| CALCULATOR_SCIENTIFIC | Whether to use scientific notation for numbers | False |
| CALCULATOR_FORCE_NUMERIC | Force numeric evaluation of symbolic expressions | False |
| CALCULATOR_FORCE_SCIENTIFIC_THRESHOLD | Threshold for automatic scientific notation | 1e21 |
| CALCULATOR_DERIVE_ORDER | Default order for derivatives | 1 |
| CALCULATOR_SERIES_POINT | Default point for series expansion | 0 |
| CALCULATOR_SERIES_ORDER | Default order for series expansion | 5 |
#### Current Time Tool
| Environment Variable | Description | Default |
|----------------------|-------------|---------|
| DEFAULT_TIMEZONE | Default timezone for current_time tool | UTC |
#### Sleep Tool
| Environment Variable | Description | Default |
|----------------------|-------------|---------|
| MAX_SLEEP_SECONDS | Maximum allowed sleep duration in seconds | 300 |
#### Tavily Search, Extract, Crawl, and Map Tools
| Environment Variable | Description | Default |
|----------------------|-------------|---------|
| TAVILY_API_KEY | Tavily API key (required for all Tavily functionality) | None |
- Visit https://www.tavily.com/ to create a free account and API key.
#### Exa Search and Contents Tools
| Environment Variable | Description | Default |
|----------------------|-------------|---------|
| EXA_API_KEY | Exa API key (required for all Exa functionality) | None |
- Visit https://dashboard.exa.ai/api-keys to create a free account and API key.
#### Mem0 Memory Tool
The Mem0 Memory Tool supports three different backend configurations:
1. **Mem0 Platform**:
- Uses the Mem0 Platform API for memory management
- Requires a Mem0 API key
2. **OpenSearch** (Recommended for AWS environments):
- Uses OpenSearch as the vector store backend
- Requires AWS credentials and OpenSearch configuration
3. **FAISS** (Default for local development):
- Uses FAISS as the local vector store backend
- Requires faiss-cpu package for local vector storage
4. **Neptune Analytics** (Optional Graph backend for search enhancement):
- Uses Neptune Analytics as the graph store backend to enhance memory recall.
- Requires AWS credentials and Neptune Analytics configuration
```
# Configure your Neptune Analytics graph ID in the .env file:
export NEPTUNE_ANALYTICS_GRAPH_IDENTIFIER=sample-graph-id
# Configure your Neptune Analytics graph ID in Python code:
import os
os.environ['NEPTUNE_ANALYTICS_GRAPH_IDENTIFIER'] = "g-sample-graph-id"
```
| Environment Variable | Description | Default | Required For |
|----------------------|-------------|---------|--------------|
| MEM0_API_KEY | Mem0 Platform API key | None | Mem0 Platform |
| OPENSEARCH_HOST | OpenSearch Host URL | None | OpenSearch |
| AWS_REGION | AWS Region for OpenSearch | us-west-2 | OpenSearch |
| NEPTUNE_ANALYTICS_GRAPH_IDENTIFIER | Neptune Analytics Graph Identifier | None | Neptune Analytics |
| DEV | Enable development mode (bypasses confirmations) | false | All modes |
| MEM0_LLM_PROVIDER | LLM provider for memory processing | aws_bedrock | All modes |
| MEM0_LLM_MODEL | LLM model for memory processing | anthropic.claude-3-5-haiku-20241022-v1:0 | All modes |
| MEM0_LLM_TEMPERATURE | LLM temperature (0.0-2.0) | 0.1 | All modes |
| MEM0_LLM_MAX_TOKENS | LLM maximum tokens | 2000 | All modes |
| MEM0_EMBEDDER_PROVIDER | Embedder provider for vector embedd | text/markdown | null | AWS <opensource@amazon.com> | null | null | Apache-2.0 | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Langu... | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp<4.0.0,>=3.8.0",
"aws-requests-auth<0.5.0,>=0.4.3",
"botocore<2.0.0,>=1.39.7",
"dill<0.5.0,>=0.4.0",
"markdownify<2.0.0,>=1.0.0",
"pillow<13.0.0,>=12.1.1",
"prompt-toolkit<4.0.0,>=3.0.51",
"pyjwt<3.0.0,>=2.10.1",
"requests<3.0.0,>=2.28.0",
"rich<15.0.0,>=14.0.0",
"slack-bolt<2.0.0,>=1.23... | [] | [] | [] | [
"Homepage, https://github.com/strands-agents/tools",
"Bug Tracker, https://github.com/strands-agents/tools/issues",
"Documentation, https://strandsagents.com/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:42:19.185295 | strands_agents_tools-0.2.21.tar.gz | 474,115 | 61/63/7cc5cdce4c04c6b5c0f8b595f514937f15252ef29f22d5e09a9483627282/strands_agents_tools-0.2.21.tar.gz | source | sdist | null | false | 51afdaabb4d5eb95d0590333570b1e3f | d48d7ceb1e058319467db9a1d9eaa4003f8681e5af028d5f6cd1b2b3d1678ce8 | 61637cc5cdce4c04c6b5c0f8b595f514937f15252ef29f22d5e09a9483627282 | null | [
"LICENSE",
"NOTICE"
] | 37,267 |
2.4 | openedx-authz | 0.22.0 | Open edX AuthZ provides the architecture and foundations of the authorization framework. | Open edX AuthZ
###############
|pypi-badge| |ci-badge| |codecov-badge| |doc-badge| |pyversions-badge|
|license-badge| |status-badge|
Purpose
*******
Open edX AuthZ provides the architecture and foundations of the authorization framework. It implements the core machinery needed to support consistent authorization across the Open edX ecosystem.
This repository centralizes the architecture, design decisions, and reference implementation of a unified model for roles and permissions. It introduces custom roles, flexible scopes, and policy-based evaluation, aiming to replace the fragmented legacy system with a scalable, extensible, and reusable solution.
See the `Product Requirements document for Roles & Permissions`_ for detailed specifications and requirements.
Integration with edx-platform
******************************
This repository became an edx-platform's dependency starting with the Ulmo release. From that release onwards, system policies are automatically updated.
If you need to update the policies manually, it is recommended to use the ``./manage.py lms load_policies`` command.
.. note::
Currently, this package only supports the `content libraries' roles and permissions as documented here`_, and the migration of data from the old system to the new one is performed automatically.
If you need to migrate the information manually, you should run ``./manage.py lms migrate openedx_authz``.
Getting Started with Development
********************************
Please see the Open edX documentation for `guidance on Python development`_ in this repo.
.. _guidance on Python development: https://docs.openedx.org/en/latest/developers/how-tos/get-ready-for-python-dev.html
Getting Help
************
Documentation
=============
See `documentation on Read the Docs <https://openedx-authz.readthedocs.io/en/latest/>`_.
More Help
=========
If you're having trouble, we have discussion forums at
https://discuss.openedx.org where you can connect with others in the
community.
Our real-time conversations are on Slack. You can request a `Slack
invitation`_, then join our `community Slack workspace`_.
For anything non-trivial, the best path is to open an issue in this
repository with as many details about the issue you are facing as you
can provide.
https://github.com/openedx/openedx-authz/issues
For more information about these options, see the `Getting Help <https://openedx.org/getting-help>`__ page.
.. _Slack invitation: https://openedx.org/slack
.. _community Slack workspace: https://openedx.slack.com/
License
*******
The code in this repository is licensed under the AGPL 3.0 unless
otherwise noted.
Please see `LICENSE <LICENSE>`_ for details.
Contributing
************
Contributions are very welcome.
Please read `How To Contribute <https://openedx.org/r/how-to-contribute>`_ for details.
This project is currently accepting all types of contributions, bug fixes,
security fixes, maintenance work, or new features. However, please make sure
to discuss your new feature idea with the maintainers before beginning development
to maximize the chances of your change being accepted.
You can start a conversation by creating a new issue on this repo summarizing
your idea.
The Open edX Code of Conduct
****************************
All community members are expected to follow the `Open edX Code of Conduct`_.
.. _Open edX Code of Conduct: https://openedx.org/code-of-conduct/
People
******
The assigned maintainers for this component and other project details may be
found in `Backstage`_. Backstage pulls this data from the ``catalog-info.yaml``
file in this repo.
.. _Backstage: https://backstage.openedx.org/catalog/default/component/openedx-authz
Reporting Security Issues
*************************
Please do not report security issues in public. Please email security@openedx.org.
.. _Product Requirements document for Roles & Permissions: https://openedx.atlassian.net/wiki/spaces/OEPM/pages/4724490259/PRD+Roles+Permissions
.. _content libraries' roles and permissions as documented here: https://openedx-authz.readthedocs.io/en/latest/concepts/core_roles_and_permissions/content_library_roles.html
.. |pypi-badge| image:: https://img.shields.io/pypi/v/openedx-authz.svg
:target: https://pypi.python.org/pypi/openedx-authz/
:alt: PyPI
.. |ci-badge| image:: https://github.com/openedx/openedx-authz/actions/workflows/ci.yml/badge.svg?branch=main
:target: https://github.com/openedx/openedx-authz/actions/workflows/ci.yml
:alt: CI
.. |codecov-badge| image:: https://codecov.io/github/openedx/openedx-authz/coverage.svg?branch=main
:target: https://codecov.io/github/openedx/openedx-authz?branch=main
:alt: Codecov
.. |doc-badge| image:: https://readthedocs.org/projects/openedx-authz/badge/?version=latest
:target: https://docs.openedx.org/projects/openedx-authz
:alt: Documentation
.. |pyversions-badge| image:: https://img.shields.io/pypi/pyversions/openedx-authz.svg
:target: https://pypi.python.org/pypi/openedx-authz/
:alt: Supported Python versions
.. |license-badge| image:: https://img.shields.io/github/license/openedx/openedx-authz.svg
:target: https://github.com/openedx/openedx-authz/blob/main/LICENSE.txt
:alt: License
.. |status-badge| image:: https://img.shields.io/badge/Status-Experimental-yellow
Change Log
##########
..
All enhancements and patches to openedx_authz will be documented
in this file. It adheres to the structure of https://keepachangelog.com/ ,
but in reStructuredText instead of Markdown (for ease of incorporation into
Sphinx documentation and the PyPI description).
This project adheres to Semantic Versioning (https://semver.org/).
.. There should always be an "Unreleased" section for changes pending release.
Unreleased
**********
Added
=====
0.22.0 - 2026-02-19
********************
* ADR on the AuthZ for Course Authoring implementation plan.
* ADR on the AuthZ for Course Authoring Feature Flag Implementation Details.
* Defined courses roles and permissions mappings, including legacy compatible permissions.
0.21.0 - 2026-02-12
********************
Added
=====
* Add course staff role, permission to manage advanced course settings, and introduce course scope
0.20.0 - 2025-11-27
********************
Added
=====
* Add configurable logging level for Casbin enforcer via ``CASBIN_LOG_LEVEL`` setting (defaults to WARNING).
0.19.2 - 2025-11-25
********************
Performance
===========
* Use a RequestCache for is_admin_or_superuser matcher to improve performance.
0.19.1 - 2025-11-25
********************
Fixed
=====
* Use `short_name` instead of `name` from organization when building library key.
0.19.0 - 2025-11-18
********************
Added
=====
* Handle cache invalidation via a uuid in the database to ensure policy reloads
occur only when necessary.
0.18.0 - 2025-11-17
********************
Added
=====
* Migration to transfer legacy permissions from ContentLibraryPermission to the new Casbin-based authorization model.
0.17.1 - 2025-11-14
********************
Fixed
=====
* Avoid circular import of AuthzEnforcer.
0.17.0 - 2025-11-14
********************
Added
=====
* Signal to clear policies associated to a user when they are retired.
0.16.0 - 2025-11-13
********************
Changed
=======
* **BREAKING**: Update permission format to include app namespace prefix.
Added
=====
* Register ``CasbinRule`` model in the Django admin.
* Register ``ExtendedCasbinRule`` model in the Django admin as an inline model of ``CasbinRule``.
0.15.0 - 2025-11-11
********************
Added
=====
* `ExtendedCasbinRule` model to extend the base CasbinRule model for additional metadata, and cascade delete
support.
0.14.0 - 2025-11-11
********************
Added
=====
* Implement custom matcher to check for staff and superuser status.
0.13.1 - 2025-11-11
********************
Fixed
=====
* Avoid duplicates when getting scopes for given user and permissions.
0.13.0 - 2025-11-05
********************
Added
=====
* Add support for global scopes instead of generic `sc` scope to support instance-level permissions.
0.12.0 - 2025-10-30
********************
Changed
=======
* Load authorization policies in permission class.
0.11.2 - 2025-10-30
********************
Added
=====
* Consider Content Library V2 toggle only in CMS service variant.
0.11.1 - 2025-10-29
********************
Changed
=======
* Refactor to get permissions' scopes instead of role.
Fixed
=====
* Use correct content library toggle to check if Content Library V2 is enabled.
0.11.0 - 2025-10-29
********************
Added
=====
* Disable auto-save and auto-load of policies if Content Library V2 is disabled.
0.10.1 - 2025-10-28
********************
Fixed
=====
* Fix constants and test class to be able to use it outside this app.
0.10.0 - 2025-10-28
*******************
Added
=====
* New ``get_object()`` method in ScopeData to retrieve underlying domain objects
* Implementation of ``get_object()`` for ContentLibraryData with canonical key validation
Changed
=======
* Refactor ``ContentLibraryData.exists()`` to use ``get_object()`` internally
0.9.1 - 2025-10-28
******************
Fixed
=====
* Fix role user count to accurately filter users assigned to roles within specific scopes instead of across all scopes.
0.9.0 - 2025-10-27
******************
Added
=====
* Function API to retrieve scopes for a given role and subject.
0.8.0 - 2025-10-24
******************
Added
=====
* Allow disabling auto-load and auto-save of policies by setting CASBIN_AUTO_LOAD_POLICY_INTERVAL to -1.
Changed
=======
* Migrate from using pycodestyle and isort to ruff for code quality checks and formatting.
* Enhance enforcement command with dual operational modes (database and file mode).
0.7.0 - 2025-10-23
******************
Added
=====
* Initial migration to establish dependency on casbin_adapter for automatic CasbinRule table creation.
0.6.0 - 2025-10-22
******************
Changed
=======
* Use a SyncedEnforcer with default auto load policy.
Removed
=======
* Remove Casbin Redis watcher from engine configuration.
0.5.0 - 2025-10-21
******************
Added
=====
* Default policy for Content Library roles and permissions.
Fixed
=====
* Add plugin_settings in test settings.
* Update permissions for RoleListView.
0.4.1 - 2025-10-16
******************
Fixed
=====
* Load policy before adding policies in the loading script to avoid duplicates.
0.4.0 - 2025-16-10
******************
Changed
=======
* Initialize enforcer when application is ready to avoid access errors.
0.3.0 - 2025-10-10
******************
Added
=====
* Implementation of REST API for roles and permissions management.
0.2.0 - 2025-10-10
******************
Added
=====
* ADRs for key design decisions.
* Casbin model (CONF) and engine layer for authorization.
* Implementation of public API for roles and permissions management.
0.1.0 - 2025-08-27
******************
Added
=====
* Basic repo structure and initial setup.
| null | Open edX Project | oscm@openedx.org | null | null | AGPL 3.0 | Python edx | [
"Development Status :: 3 - Alpha",
"Framework :: Django",
"Framework :: Django :: 4.2",
"Framework :: Django :: 5.2",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU Affero General Public License v3 or later (AGPLv3+)",
"Natural Language :: English",
"Programming Language :: Python ... | [] | https://github.com/openedx/openedx-authz | null | >=3.11 | [] | [] | [] | [
"Django",
"attrs",
"casbin-django-orm-adapter",
"djangorestframework",
"edx-api-doc-tools",
"edx-django-utils",
"edx-drf-extensions",
"edx-opaque-keys",
"openedx-atlas",
"pycasbin"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:42:12.823481 | openedx_authz-0.22.0.tar.gz | 107,306 | f7/ce/632fa8e01bf78947ecac4852ec5ee723cf23a42310707e6705a2330124f8/openedx_authz-0.22.0.tar.gz | source | sdist | null | false | 860364bd8323f078c46c637fea29d753 | 007bc733890402536ca446fb5f9cca9c89f0ad5d3a544f8503a72036a3d76127 | f7ce632fa8e01bf78947ecac4852ec5ee723cf23a42310707e6705a2330124f8 | null | [
"LICENSE"
] | 4,012 |
2.4 | omniq | 1.7.0 | OmniQ v1 - Redis+Lua queue Python SDK | # OmniQ (Python)
**OmniQ** is a Redis + Lua, language-agnostic job queue.\
This package is the **Python client** for OmniQ v1.
Core project / docs: https://github.com/not-empty/omniq
------------------------------------------------------------------------
## Key Ideas
- **Hybrid lanes**
- Ungrouped jobs by default
- Optional grouped jobs (FIFO per group + per-group concurrency)
- **Lease-based execution**
- Workers reserve a job with a time-limited lease
- **Token-gated ACK / heartbeat**
- `reserve()` returns a `lease_token`
- `heartbeat()` and `ack_*()` must include the same token
- **Pause / resume (flag-only)**
- Pausing prevents *new reserves*
- Running jobs are not interrupted
- Jobs are not moved
- **Admin-safe operations**
- Strict `retry`, `retry_batch`, `remove`, `remove_batch`
- **Handler-driven execution layer**
- `ctx.exec` exposes internal OmniQ operations safely inside handlers
------------------------------------------------------------------------
## Install
``` bash
pip install omniq
```
------------------------------------------------------------------------
## Quick Start
### Publish
``` python
# importing the lib
from omniq.client import OmniqClient
# creating OmniQ passing redis information
omniq = OmniqClient(
host="omniq-redis",
port=6379,
)
# publishing the job
job_id = omniq.publish(
queue="demo",
payload={"hello": "world"},
timeout_ms=30_000
)
print("OK", job_id)
```
------------------------------------------------------------------------
### Publish Structured JSON
``` python
from dataclasses import dataclass
from typing import List, Optional
# importing the lib
from omniq.client import OmniqClient
# Nested structure
@dataclass
class Customer:
id: str
email: str
vip: bool
# Main payload
@dataclass
class OrderCreated:
order_id: str
customer: Customer
amount: int
currency: str
items: List[str]
processed: bool
retry_count: int
tags: Optional[List[str]] = None
# creating OmniQ passing redis information
omniq = OmniqClient(
host="omniq-redis",
port=6379,
)
# creating structured payload
payload = OrderCreated(
order_id="ORD-2026-0001",
customer=Customer(
id="CUST-99",
email="leo@example.com",
vip=True,
),
amount=1500,
currency="USD",
items=["keyboard", "mouse"],
processed=False,
retry_count=0,
tags=["priority", "online"],
)
# publish using publish_json
job_id = omniq.publish_json(
queue="deno",
payload=payload,
max_attempts=5,
timeout_ms=60_000,
)
print("OK", job_id)
```
------------------------------------------------------------------------
### Consume
``` python
import time
# importing the lib
from omniq.client import OmniqClient
# creating your handler (ctx will have all the job information and actions)
def my_actions(ctx):
print("Waiting 2 seconds")
time.sleep(2)
print("Done")
# creating OmniQ passing redis information
omniq = OmniqClient(
host="omniq-redis",
port=6379,
)
# creating the consumer that will listen and execute the actions in your handler
omniq.consume(
queue="demo",
handler=my_actions,
verbose=True,
drain=False,
)
```
------------------------------------------------------------------------
## Handler Context
Inside `handler(ctx)`:
- `queue`
- `job_id`
- `payload_raw`
- `payload`
- `attempt`
- `lock_until_ms`
- `lease_token`
- `gid`
- `exec` → execution layer (`ctx.exec`)
------------------------------------------------------------------------
# Administrative Operations
All admin operations are **Lua-backed and atomic**.
## retry_failed()
``` python
omniq.retry_failed(queue="demo", job_id="01ABC...")
```
- Works only if job state is `failed`
- Resets attempt counter
- Respects grouping rules
------------------------------------------------------------------------
## retry_failed_batch()
``` python
results = omniq.retry_failed_batch(
queue="demo",
job_ids=["01A...", "01B...", "01C..."]
)
for job_id, status, reason in results:
print(job_id, status, reason)
```
- Max 100 jobs per call
- Atomic batch
- Per-job result returned
------------------------------------------------------------------------
## remove_job()
``` python
omniq.remove_job(
queue="demo",
job_id="01ABC...",
lane="failed", # wait | delayed | failed | completed | gwait
)
```
Rules:
- Cannot remove active jobs
- Lane must match job state
- Group safety preserved
------------------------------------------------------------------------
## remove_jobs_batch()
``` python
results = omniq.remove_jobs_batch(
queue="demo",
lane="failed",
job_ids=["01A...", "01B...", "01C..."]
)
```
- Max 100 per call
- Strict lane validation
- Atomic per batch
------------------------------------------------------------------------
## pause()
``` python
pause_result = omniq.pause(
queue="demo",
)
resume_result = omniq.resume(
queue="demo",
)
is_paused = omniq.is_paused(
queue="demo",
)
```
------------------------------------------------------------------------
# Handler Context
Inside `handler(ctx)`:
- `queue`
- `job_id`
- `payload_raw`
- `payload`
- `attempt`
- `lock_until_ms`
- `lease_token`
- `gid`
- `exec`
------------------------------------------------------------------------
# Child Ack Control (Parent / Child Workflows)
A handler-driven primitive for fan-out workflows.
No TTL. Cleanup happens only when counter reaches zero.
## Parent Example
The first queue will receive a document with 5 pages
``` python
# importing the lib
from omniq.client import OmniqClient
# creating OmniQ passing redis information
omniq = OmniqClient(
host="omniq-redis",
port=6379,
)
# publishing the job
job_id = omniq.publish(
queue="documents",
payload={
"document_id": "doc-123", # this will be our unique key to initiate childs and tracking then until completion
"pages": 5, # each page must be completed before something happen
},
)
print("OK", job_id)
```
The first consumer will publish a job for each page passing the unique key for childs tracking
``` python
# importing the lib
from omniq.client import OmniqClient
# creating OmniQ passing redis information
omniq = OmniqClient(
host="omniq-redis",
port=6379,
)
# publishing the job
job_id = omniq.publish(
queue="documents",
payload={
"document_id": "doc-123", # this will be our unique key to initiate childs and tracking then until completion
"pages": 5, # each page must be completed before something happen
},
)
print("OK", job_id)
```
## Child Example
The second consumer will deal with each page and ack each child (alerting when the last page was processed)
``` python
import time
# importing the lib
from omniq.client import OmniqClient
# creating your handler (ctx will have all the job information and actions)
def page_worker(ctx):
page = ctx.payload["page"]
# getting the unique key to track the childs
completion_key = ctx.payload["completion_key"]
print(f"[page_worker] Processing page {page} (job_id={ctx.job_id})")
time.sleep(1.5)
# acking itself as a child the number of remaining jobs are returned so we can say when the last job was executed
remaining = ctx.exec.child_ack(completion_key)
print(f"[page_worker] Page {page} done. Remaining={remaining}")
# remaining will be 0 ONLY when this is the last job
# will return > 0 when are still jobs to process
# and -1 if something goes wrong with the counter
if remaining == 0:
print("[page_worker] Last page finished.")
# creating OmniQ passing redis information
omniq = OmniqClient(
host="omniq-redis",
port=6379,
)
# creating the consumer that will listen and execute the actions in your handler
omniq.consume(
queue="pages",
handler=page_worker,
verbose=True,
drain=False,
)
```
Properties:
- Idempotent decrement
- Safe under retries
- Cross-queue safe
- Fully business-logic driven
------------------------------------------------------------------------
## Grouped Jobs
``` python
# if you provide a gid (group_id) you can limit the parallel execution for jobs in the same group
omniq.publish(queue="demo", payload={"i": 1}, gid="company:acme", group_limit=1)
# you can also publis ungrouped jobs that will also be executed (fairness by round-robin algorithm)
omniq.publish(queue="demo", payload={"i": 2})
```
- FIFO inside group
- Groups execute in parallel
- Concurrency limited per group
------------------------------------------------------------------------
## Pause and Resume inside the consumer
You publish your job as usual
``` python
# importing the lib
from omniq.client import OmniqClient
# creating OmniQ passing redis information
uq = OmniqClient(
host="omniq-redis",
port=6379,
)
# publishing the job
job_id = uq.publish(
queue="test",
payload={"hello": "world"},
timeout_ms=30_000
)
print("OK", job_id)
```
Inside your consumer you can pause/resume your queue (or another one)
``` python
import time
# importing the lib
from omniq.client import OmniqClient
# creating your handler (ctx will have all the job information and actions)
def pause_unpause_example(ctx):
print("Waiting 2 seconds")
# checking if this queue it is paused (spoiler: it's not)
is_paused = ctx.exec.is_paused(
queue="test"
)
print("Is paused", is_paused)
time.sleep(2)
print("Pausing")
# pausing this queue (this job it's and others active jobs will be not affected but not new job will be start until queue is resumed)
ctx.exec.pause(
queue="test"
)
# checking again now is suposed to be paused
is_paused = ctx.exec.is_paused(
queue="test"
)
print("Is paused", is_paused)
time.sleep(2)
print("Resuming")
# resuming this queue (all other workers can process jobs again)
ctx.exec.resume(
queue="test"
)
# checking again and is suposed to be resumed
is_paused = ctx.exec.is_paused(
queue="test"
)
print("Is paused", is_paused)
time.sleep(2)
print("Done")
# creating OmniQ passing redis information
omniq = OmniqClient(
host="omniq-redis",
port=6379,
)
# creating the consumer that will listen and execute the actions in your handler
omniq.consume(
queue="test",
handler=pause_unpause_example,
verbose=True,
drain=False,
)
```
## Examples
All examples can be found in the `./examples` folder.
------------------------------------------------------------------------
## License
See the repository license.
| text/markdown | null | Not Empty Foundation <dev@not-empty.org> | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: OS Independent"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"redis>=5.0.0",
"ulid-py>=1.1.0"
] | [] | [] | [] | [
"Homepage, https://github.com/not-empty/omniq-python",
"Issues, https://github.com/not-empty/omniq-python/issues"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T17:42:06.459615 | omniq-1.7.0.tar.gz | 34,864 | c6/ea/accde625492fae28aa36b3c0dcca8dbbb5dcde52519a3506664616565f43/omniq-1.7.0.tar.gz | source | sdist | null | false | 533568be91f18746307573ae43d48aec | 1ef5c106cdb9eae1861b744364c3556784b90aa65d3ae280abc00a634dcf9ccd | c6eaaccde625492fae28aa36b3c0dcca8dbbb5dcde52519a3506664616565f43 | null | [
"LICENCE"
] | 213 |
2.4 | django-o11y | 0.1.1 | Comprehensive OpenTelemetry observability for Django with traces, logs, metrics, and profiling | # Django O11y
[](https://github.com/adinhodovic/django-o11y/actions/workflows/ci-cd.yml)
[](https://pypi.org/project/django-o11y/)
[](https://pypi.org/project/django-o11y/)
[](https://opensource.org/licenses/MIT)
OpenTelemetry observability for Django with traces, logs, metrics, and profiling.
This package is based on configurations from these blog posts:
- [Django Monitoring with Prometheus and Grafana](https://hodovi.cc/blog/django-monitoring-with-prometheus-and-grafana/)
- [Django Development and Production Logging](https://hodovi.cc/blog/django-development-and-production-logging/)
- [Celery Monitoring with Prometheus and Grafana](https://hodovi.cc/blog/celery-monitoring-with-prometheus-and-grafana/)
## Features
- **Distributed Tracing** - OpenTelemetry traces for requests, database, cache, and Celery tasks
- **Structured Logging** - Structlog with colorized dev logs, JSON prod logs, and OTLP export
- **Hybrid Metrics** - django-prometheus (infrastructure) + OpenTelemetry (business metrics with exemplars)
- **Profiling** - Pyroscope continuous profiling (optional)
- **Celery Integration** - Full observability for async tasks with tracing, logging, and metrics
- **Grafana Dashboards** - Pre-built dashboards from blog posts work without changes
- **Zero config** - Works with sensible defaults, customizable via Django settings
- **Trace correlation** - Automatic trace_id and span_id injection in logs
## Quick start
### Installation
**Recommended for most users:**
```bash
pip install django-o11y[all]
```
**Or choose specific features:**
| Installation Command | Includes | When to Use |
|---------------------|----------|-------------|
| `pip install django-o11y` | Core (tracing + logging) | Minimal setup |
| `pip install django-o11y[celery]` | + Celery instrumentation | Async task observability |
| `pip install django-o11y[prometheus]` | + django-prometheus | Infrastructure metrics |
| `pip install django-o11y[profiling]` | + pyroscope-io | Continuous profiling |
| `pip install django-o11y[all]` | Everything | Development & full features |
**Production recommendation:**
```bash
pip install django-o11y[celery,prometheus]
```
### Basic setup
Add to your Django settings:
```python
# settings.py
INSTALLED_APPS = [
'django_o11y', # Add this
'django.contrib.admin',
# ... other apps
]
MIDDLEWARE = [
'django_o11y.middleware.TracingMiddleware', # Add this
'django_o11y.middleware.LoggingMiddleware', # Add this
# ... other middleware
]
```
django-o11y will automatically:
- Set up OpenTelemetry tracing
- Configure structured logging (Structlog + OTLP)
- Instrument Django, database, cache, and HTTP clients
- Export traces and logs to `http://localhost:4317` (OTLP)
### Configuration
Customize via Django settings (all optional):
```python
# settings.py
DJANGO_O11Y = {
'SERVICE_NAME': 'my-django-app',
# Tracing
'TRACING': {
'ENABLED': True,
'OTLP_ENDPOINT': 'http://localhost:4317',
'SAMPLE_RATE': 1.0, # 100% sampling (use 0.1 for 10% in prod)
},
# Logging (based on blog post)
'LOGGING': {
'FORMAT': 'json', # 'console' in dev, 'json' in prod
'LEVEL': 'INFO',
'REQUEST_LEVEL': 'INFO',
'DATABASE_LEVEL': 'WARNING',
'COLORIZED': True, # Colorized logs in dev
'RICH_EXCEPTIONS': True, # Beautiful exceptions in dev
'OTLP_ENABLED': True, # Export logs to OTLP
},
# Metrics (hybrid: django-prometheus + OpenTelemetry)
'METRICS': {
'PROMETHEUS_ENABLED': True, # Expose /metrics endpoint
'OTLP_ENABLED': False, # Push metrics via OTLP (disabled by default)
},
# Celery integration (disabled by default, enable if using Celery)
'CELERY': {
'ENABLED': False,
'TRACING_ENABLED': True,
'LOGGING_ENABLED': True,
'METRICS_ENABLED': True,
},
# Profiling (optional)
'PROFILING': {
'ENABLED': False,
'PYROSCOPE_URL': 'http://localhost:4040',
},
}
```
Or use environment variables:
```bash
# Service name
export OTEL_SERVICE_NAME=my-django-app
# Tracing
export OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4317
export OTEL_TRACES_SAMPLER_ARG=1.0
# Logging
export DJANGO_LOG_LEVEL=INFO
export DJANGO_LOG_FORMAT=json
```
## Hybrid metrics
Django Observability uses a **hybrid metrics approach**:
### Infrastructure Metrics (django-prometheus)
Uses [django-prometheus](https://github.com/korfuri/django-prometheus) for infrastructure metrics:
- Request/response metrics (req/s, latency, status codes)
- Database operations (queries/s, latency, connection pool)
- Cache hit rates
- Migration status
Existing Grafana dashboards from the blog posts work without modification.
### Business Metrics (OpenTelemetry with Exemplars)
Use OpenTelemetry for custom business metrics with trace correlation:
```python
from django_o11y.metrics import counter, histogram
# Counter with labels
payment_counter = counter("payments.processed", "Total payments processed")
payment_counter.add(1, {"status": "success", "method": "card"})
# Histogram with automatic timing and exemplars (links to traces!)
payment_latency = histogram("payments.latency", "Payment processing time", "s")
with payment_latency.time({"method": "card"}):
result = process_payment() # This span is automatically linked as exemplar
```
Exemplars let you click on a metric spike in Grafana and jump directly to the trace that caused it.
## Structured logging
Based on the [Django Development and Production Logging](https://hodovi.cc/blog/django-development-and-production-logging/) blog post.
### Development (colorized console)
```python
import structlog
logger = structlog.get_logger(__name__)
logger.info("Payment processed", amount=100, user_id=123)
```
Output:
```
2026-02-12T10:30:45 [info ] Payment processed amount=100 user_id=123 [views.py:42]
```
### Production (JSON + OTLP)
```json
{
"event": "Payment processed",
"amount": 100,
"user_id": 123,
"trace_id": "a1b2c3d4e5f6g7h8",
"span_id": "i9j0k1l2m3n4",
"timestamp": "2026-02-12T10:30:45.123Z",
"level": "info",
"logger": "myapp.views",
"filename": "views.py",
"func_name": "process_payment",
"lineno": 42
}
```
**Logs automatically include `trace_id` and `span_id`** - click on a log in Grafana Loki and jump to its trace in Tempo!
## Celery integration
Zero-config Celery observability. Enable it in settings:
```python
# settings.py
DJANGO_O11Y = {
'CELERY': {
'ENABLED': True, # Auto-instruments when worker starts
},
}
```
When your Celery worker starts, observability is automatically set up via signals. No manual function calls needed!
### Manual setup (optional)
For advanced use cases or backwards compatibility:
```python
# celery_app.py
from celery import Celery
from django_o11y.celery import setup_celery_o11y
app = Celery('myapp')
app.config_from_object('django.conf:settings', namespace='CELERY')
# Optional: Manual setup (auto-called via signals if CELERY.ENABLED=True)
setup_celery_o11y(app)
```
### What you get
Every Celery task automatically includes:
```python
# tasks.py
import structlog
logger = structlog.get_logger(__name__)
@app.task
def process_order(order_id):
# Automatic observability:
# Distributed tracing span (linked to parent request if triggered by API)
# Task lifecycle logs (received, started, succeeded/failed, retried)
# Structured logs with trace_id and span_id
# Task metrics (duration, success rate)
logger.info("Processing order", order_id=order_id)
return process(order_id)
```
[Celery dashboards from the blog](https://hodovi.cc/blog/celery-monitoring-with-prometheus-and-grafana/) work without modification.
### Verification
Check that Celery observability is working:
```bash
python manage.py o11y check
```
## Quick local testing
Start the full observability stack with one command:
```bash
python manage.py o11y stack start
```
This starts all services with Docker Compose and automatically imports Grafana dashboards:
- **Grafana** (http://localhost:3000) - Pre-configured dashboards
- **Tempo** - Distributed tracing backend
- **Loki** - Log aggregation
- **Prometheus** - Metrics collection
- **Pyroscope** - Continuous profiling
- **Alloy** - OTLP receiver (port 4317)
Then start your Django app:
```bash
python manage.py runserver
```
Generate some traffic and explore in Grafana:
- **Dashboards** → Django Overview, Django Requests, Celery Tasks
- **Explore** → Tempo (view traces)
- **Explore** → Loki (view logs with trace correlation)
- Click on a log → "Tempo" button → See the full trace
- Click on a metric spike → See linked traces via exemplars
### Custom app URL
If your app runs in Docker or on a different port:
```bash
# App in Docker network
python manage.py o11y stack start --app-url django-app:8000
# App on different port
python manage.py o11y stack start --app-url host.docker.internal:3000
```
## Grafana dashboards
This package works with dashboards from the blog posts:
1. **[Django Overview](https://grafana.com/grafana/dashboards/17617)** - Request metrics, database ops, cache hit rate
2. **[Django Requests Overview](https://grafana.com/grafana/dashboards/17616)** - Per-view breakdown, error rates
3. **[Django Requests by View](https://grafana.com/grafana/dashboards/17613)** - Detailed per-view latency analysis
4. **[Celery Tasks Overview](https://grafana.com/grafana/dashboards/17509)** - Task states, queue length, worker status
5. **[Celery Tasks by Task](https://grafana.com/grafana/dashboards/17508)** - Per-task metrics and failures
All dashboards are included in the demo project.
## Development
### Local development
```bash
# Clone repo
git clone https://github.com/adinhodovic/django-o11y
cd django-o11y
# Install with uv
uv sync --all-extras
# Run tests
uv run pytest
# Run linting
uv run ruff check .
uv run pylint src/django_o11y
# Run with tox (test matrix)
uv run tox
```
### Contributing
Contributions are welcome! Please:
1. Fork the repo
2. Create a feature branch (`git checkout -b feat/my-feature`)
3. Commit with [conventional commits](https://www.conventionalcommits.org/) (`feat:`, `fix:`, etc.)
4. Push and create a PR
5. CI will run tests and linting
## Verification and troubleshooting
### Health check
Verify your setup with the built-in health check command:
```bash
python manage.py o11y check
```
This will:
- Check configuration is valid
- Test OTLP endpoint connectivity
- Verify required packages are installed
- Create a test trace and show how to view it in Tempo
### Common issues
#### Silent Celery instrumentation failure
**Problem:** Celery tasks aren't traced despite `CELERY.ENABLED = True`
**Solution:** Install the required package:
```bash
pip install opentelemetry-instrumentation-celery
```
The system will warn you at startup if this package is missing.
#### Configuration errors
**Problem:** Django won't start with configuration error
**Solution:** Configuration is validated at startup. Read the error message carefully:
```
ImproperlyConfigured: Django O11y configuration errors:
• TRACING.SAMPLE_RATE must be between 0.0 and 1.0, got 1.5
Please fix these issues in your DJANGO_O11Y setting.
```
Fix the issues in your settings and restart.
#### No traces appearing
**Problem:** Application runs but no traces in Tempo
**Check:**
1. OTLP endpoint is reachable: `python manage.py o11y check`
2. Sampling rate isn't 0: Check `TRACING.SAMPLE_RATE`
3. Tracing is enabled: Check `TRACING.ENABLED`
4. OTLP receiver is running: `docker ps | grep tempo`
#### Logs not structured
**Problem:** Logs appear as plain text instead of structured JSON
**Solution:** Use `structlog.get_logger()` instead of `logging.getLogger()`:
```python
# Wrong
import logging
logger = logging.getLogger(__name__)
# Correct
import structlog
logger = structlog.get_logger(__name__)
```
### Documentation
- [Usage Guide](docs/usage.md)
- [Configuration Reference](docs/configuration.md)
- [Usage Patterns](docs/usage.md)
- [Report Issues](https://github.com/adinhodovic/django-o11y/issues)
## License
MIT License - see [LICENSE](LICENSE)
## Acknowledgments
- [OpenTelemetry Python](https://github.com/open-telemetry/opentelemetry-python)
- [Structlog](https://github.com/hynek/structlog)
- [django-structlog](https://github.com/jrobichaud/django-structlog)
- [django-prometheus](https://github.com/korfuri/django-prometheus)
- [Grafana](https://grafana.com/)
| text/markdown | null | Adin Hodovic <hodovicadin@gmail.com> | null | null | null | Celery, Django, Logging, Metrics, Observability, OpenTelemetry, Tracing | [
"Development Status :: 4 - Beta",
"Environment :: Web Environment",
"Framework :: Django",
"Framework :: Django :: 5.2",
"Framework :: Django :: 6.0",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language ... | [] | null | null | >=3.12 | [] | [] | [] | [
"click>=8.0.0",
"django-prometheus>=2.3.0",
"django-structlog>=5.0.0",
"django>=5.2",
"opentelemetry-api>=1.20.0",
"opentelemetry-exporter-otlp-proto-grpc>=1.20.0",
"opentelemetry-instrumentation-django>=0.41b0",
"opentelemetry-sdk>=1.20.0",
"prometheus-client>=0.17.0",
"structlog>=23.1.0",
"cel... | [] | [] | [] | [
"Homepage, https://github.com/adinhodovic/django-o11y",
"Documentation, https://github.com/adinhodovic/django-o11y",
"Repository, https://github.com/adinhodovic/django-o11y",
"Issues, https://github.com/adinhodovic/django-o11y/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:42:04.028043 | django_o11y-0.1.1.tar.gz | 127,394 | 94/dc/2b0cc9fae5136f9ac7f56351850588b37d05be6551e6a27fbdef5668e3b4/django_o11y-0.1.1.tar.gz | source | sdist | null | false | bf683ad48e1e6c84bd58eb9550e1a92e | 8c3bed2668ebcd39e2f78f7e74c05469ac7f3acbe69eb97528e44e6caedc0894 | 94dc2b0cc9fae5136f9ac7f56351850588b37d05be6551e6a27fbdef5668e3b4 | Apache-2.0 | [
"LICENSE"
] | 199 |
2.4 | annotator-cli | 1.0.0 | Annotates source files with their relative paths for easier AI/debug context | # Annotator CLI
**Annotator** is a simple CLI utility that prepends relative file paths as comments to your project files as the first line.
It’s designed to make AI debugging easier by automatically marking file paths for better context and easier copy-pasting.
---
## ✨ Features
- 🚀 **Automatically annotates** files with their relative paths
- 🔄 **Reversible** — clean annotations with `--revert`
- 🎯 **Template system** — framework-specific presets (Next.js, Spring Boot, Python, React, Prisma)
- ⚙️ **Fully customizable** via `.annotator.jsonc` configuration
- 🚫 **Smart filtering** — respects `.gitignore`, excludes binaries, and skips nested paths
- 🔍 **Stateless revert** — removes annotations using unique signature (`~annotator~`)
- ⚡ **Lightweight and fast** — minimal dependencies
---
## 📦 Installation
### Via [pipx](https://pipx.pypa.io/) (recommended):
```sh
pipx install annotator-cli
```
### Via pip:
```sh
pip install annotator-cli
```
---
## 🚀 Quick Start
### 1. Initialize configuration
```sh
cd /path/to/your/project
annotator --init
```
This creates `.annotator.jsonc` with sensible defaults and helpful comments.
### 2. Annotate your project
```sh
annotator
```
### 3. Revert annotations (if needed)
```sh
annotator --revert
```
---
## 📝 Configuration
Annotator uses a layered configuration system:
**Priority Chain:**
`.gitignore` → `.annotator.jsonc` → `templates` (cumulative)
### Example `.annotator.jsonc`
```jsonc
{
// List of templates to apply (keeping default is recommended)
// pick additional: nextjs, react, springboot, python3, prisma ...
"templates": ["default", "nextjs"],
// Behavior settings
"settings": {
"max_recursive_depth": 10, // How deep to recurse into folders
"max_num_of_files": 1000, // Maximum files to process
"max_file_size_kb": 512, // Skip files larger than this
},
// Override comment styles for specific extensions
// Example: ".kt": "//", ".scala": "//"
"comment_styles": {},
// Additional file extensions to exclude
"exclude_extensions": [".log", ".cache"],
// Additional directories to exclude (supports nested paths)
// Example: ["temp", "src/generated/proto"]
"exclude_dirs": ["node_modules", ".venv", "__pycache__"],
// Additional specific file names to exclude
"exclude_files": [".env", ".annotator.jsonc"],
}
```
<details>
<summary><strong>📋 Configuration Details</strong></summary>
### Templates
Annotator includes built-in templates for common frameworks:
- **`default`** - General-purpose config with 40+ languages, common excludes
- **`nextjs`** - Next.js specific exclusions (`.next`, config files, etc.)
- **`react`** - React/Vite/CRA exclusions
- **`springboot`** - Spring Boot/Maven/Gradle exclusions
- **`python3`** - Python virtual envs, caches, Jupyter notebooks
- **`prisma`** - Prisma schema and migration exclusions
Templates are applied cumulatively in order. See all templates at:
[github.com/assignment-sets/annotator-cli/tree/main/annotator/templates](https://github.com/assignment-sets/annotator-cli)
### Comment Styles
Maps file extensions or exact filenames to comment syntax:
```jsonc
".js": "//",
".py": "#",
".html": "<!--",
".css": "/*"
```
### Exclusion Rules
- **`exclude_extensions`**: Skip files by extension (e.g., `[".log", ".bin"]`)
- **`exclude_dirs`**: Skip directories by name or nested path (e.g., `["node_modules", "src/generated"]`)
- **`exclude_files`**: Skip specific filenames (e.g., `[".env", "package-lock.json"]`)
**Note:** `.gitignore` patterns are always respected and have highest priority.
### Extension Parsing
Extensions are parsed from the last `.` to the end:
- `file.js` → `.js`
- `component.test.tsx` → `.tsx`
- `archive.tar.gz` → `.gz`
</details>
---
## 🎯 CLI Commands
```sh
# Annotate current directory
annotator
# Annotate specific path
annotator /path/to/project
# Initialize configuration
annotator --init
# Remove all annotations
annotator --revert
# Show help
annotator --help
```
---
## 🔧 How It Works
1. **Loads configuration** from `.annotator.jsonc` and merges with selected templates
2. **Respects `.gitignore`** patterns (highest priority)
3. **Applies filters** based on extensions, directories, files, and size limits
4. **Prepends comments** with relative path and unique signature:
```python
# src/utils/helper.py ~annotator~
```
5. **Skips already annotated** files (idempotent)
6. **Revert support** removes only lines containing `~annotator~` signature
---
## 📚 Common Use Cases
### Next.js Project
```jsonc
{
"templates": ["default", "nextjs"],
}
```
### Python Data Science Project
```jsonc
{
"templates": ["default", "python3"],
// customize more as you need for example
"exclude_extensions": [".parquet"],
}
```
### Spring Boot Microservice
```jsonc
{
"templates": ["default", "springboot"],
}
```
### Full-Stack React + Prisma
```jsonc
{
"templates": ["default", "react", "prisma"],
}
```
---
## 🤝 Contributing
Want to add a template for your favorite framework? PRs welcome!
Repository: [github.com/assignment-sets/annotator-cli](https://github.com/assignment-sets/annotator-cli)
---
## ⚠️ Disclaimer
> This software is provided **as-is**, without warranty of any kind.
> Use at your own risk — the author is not responsible for data loss, crashes, or security issues.
---
## 📄 License
MIT License - see [LICENSE](LICENSE) file for details.
---
## 🙏 Acknowledgments
Built to make AI-assisted debugging easier by providing better file context.
| text/markdown | null | null | null | null | MIT | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"pathspec>=1.0.4"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.5 | 2026-02-19T17:41:48.003786 | annotator_cli-1.0.0.tar.gz | 14,149 | d3/b4/8171ac585f59412340f7423f4cd2f27358a1ceef11c37e653fcddbec1c30/annotator_cli-1.0.0.tar.gz | source | sdist | null | false | 1a554a4fd6dbb815defe25b654ef9ba5 | 027f7f73ceaa62a93f7f09f74ca883748aa34d2a4dd2fb84162a3a940c95d11f | d3b48171ac585f59412340f7423f4cd2f27358a1ceef11c37e653fcddbec1c30 | null | [
"LICENSE"
] | 203 |
2.4 | honeybee-grasshopper-core | 1.43.5 | Core Honeybee plugin for Grasshopper. | [](https://github.com/ladybug-tools/honeybee-grasshopper-core/actions)
[](https://github.com/IronLanguages/ironpython2/releases/tag/ipy-2.7.8/)
# honeybee-grasshopper-core
:honeybee: :green_book: Core Honeybee plugin for Grasshopper (aka. honeybee[+]).
This repository contains all "core" Grasshopper components for the honeybee plugin
(aka. those components that are shared across all extensions). The package includes
both the userobjects (`.ghuser`) and the Python source (`.py`). Note that this
library only possesses the Grasshopper components and, in order to run the plugin,
the core libraries must be installed (see dependencies).
## Dependencies
The honeybee-grasshopper plugin has the following dependencies (other than Rhino/Grasshopper):
* [ladybug-core](https://github.com/ladybug-tools/ladybug)
* [ladybug-geometry](https://github.com/ladybug-tools/ladybug-geometry)
* [ladybug-comfort](https://github.com/ladybug-tools/ladybug-comfort)
* [ladybug-display](https://github.com/ladybug-tools/ladybug-display)
* [ladybug-radiance](https://github.com/ladybug-tools/ladybug-radiance)
* [ladybug-rhino](https://github.com/ladybug-tools/ladybug-rhino)
* [honeybee-core](https://github.com/ladybug-tools/honeybee-core)
## Other Required Components
The honeybee-grasshopper plugin also requires the Grasshopper components within the
following repositories to be installed in order to work correctly:
* [ladybug-grasshopper](https://github.com/ladybug-tools/ladybug-grasshopper)
## Extensions
The honeybee-grasshopper plugin has the following extensions:
* [honeybee-grasshopper-radiance](https://github.com/ladybug-tools/honeybee-grasshopper-radiance)
* [honeybee-grasshopper-energy](https://github.com/ladybug-tools/honeybee-grasshopper-energy)
## Installation
See the [Wiki of the lbt-grasshopper repository](https://github.com/ladybug-tools/lbt-grasshopper/wiki)
for the installation instructions for the entire Ladybug Tools Grasshopper plugin
(including this repository).
| text/markdown | Ladybug Tools | info@ladybug.tools | null | null | AGPL-3.0 | null | [
"Programming Language :: Python :: 2.7",
"Programming Language :: Python :: Implementation :: IronPython",
"Operating System :: OS Independent"
] | [] | https://github.com/ladybug-tools/honeybee-grasshopper-core | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.12 | 2026-02-19T17:41:25.912178 | honeybee_grasshopper_core-1.43.5.tar.gz | 461,964 | ed/9c/1382a33aa711f77ec7a82ad146c19f58c11f2c1ba084eca0d39de93d021f/honeybee_grasshopper_core-1.43.5.tar.gz | source | sdist | null | false | 0d80128e419b9630bc1a8976faa3e7ba | a957474476ada28c4cbb16629e49e8e46ef81c165d94c7cee3931a7fae67e421 | ed9c1382a33aa711f77ec7a82ad146c19f58c11f2c1ba084eca0d39de93d021f | null | [
"LICENSE"
] | 462 |
2.3 | toolshield | 0.1.1 | ToolShield: Training-Free Defense for Tool-Using AI Agents |
<div align="center">
<h1>ToolShield: Just One Command to Guard Your Coding Agent</h1>
[](https://pypi.org/project/toolshield/) [](https://pypi.org/project/toolshield/) [](LICENSE) [](https://unsafer-in-many-turns.github.io) [](https://huggingface.co/datasets/CHATS-Lab/MT-AgentRisk)
<strong>Supports:</strong>
<a href="#use-pre-generated-experiences"><img src="https://img.shields.io/badge/Claude_Code-D97757?style=flat-square&logo=anthropic&logoColor=white" alt="Claude Code"></a>
<a href="docs/agents/codex.md"><img src="https://img.shields.io/badge/Codex-000000?style=flat-square&logo=data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAIAAACQkWg2AAABm0lEQVR42rVSK6jCYBj9f7FoG75A0KRNWbDKQAQxGuRHYWCRgWYRLBo0DCwqBrUJLojY7C74aGPJMNGyMIQN8QEKv7pbLj7GhcsN97SP7xy+7xwO1HUd/AUm8EeYDfP9fud5fr/fRyIRm832ywWMMU3T6/UaABCNRlOpVCaTEUXxQ6G/odVqTSaTxWKBEOr3+8fjUVXVZDK5Wq2enJeAYRiSJGVZTiQSmqaVy+VYLMYwzGw2q1QqT9q3h+l06vP5XC4XhFBV1VwudzqdstlsIBCoVqt2u91oervdhkIhnufP57PX6+U47vF4hMNht9vNsmy9Xpdl2ePxvExTFMVxHE3TtVpNURSMMcaYIIhSqTQcDuPx+HK5/Ljg9/vNZnOxWGRZdrPZUBTldDoPh4PFYgEACIKAEDLGShBEoVDodrudTiedTrfbbavVquv6aDSCEAaDQWOskiQhhDRNu16vzWYTISRJ0mAwGI/H79HD9y6Jotjr9W63myAI+Xx+t9spitJoNEym1yPwx/JdLpf5fO5wOEiSNKzgv7f1C7WV+mn4U8OsAAAAAElFTkSuQmCC&logoColor=white" alt="Codex"></a>
<a href="#use-pre-generated-experiences"><img src="https://img.shields.io/badge/Cursor-00A3E0?style=flat-square&logo=cursor&logoColor=white" alt="Cursor"></a>
<a href="docs/agents/openhands.md"><img src="https://img.shields.io/badge/%F0%9F%99%8C_OpenHands-E5725E?style=flat-square" alt="OpenHands"></a>
<a href="docs/agents/openclaw.md"><img src="https://img.shields.io/badge/%F0%9F%A6%9E_OpenClaw-FF6B6B?style=flat-square" alt="OpenClaw"></a>
</div>
---
<p align="center">
<a href="#quickstart">Quickstart</a> |
<a href="#use-pre-generated-experiences">Pre-Generated Safety Experiences</a> |
<a href="#generate-your-own">Generate Your Own</a> |
<a href="#extend-to-new-tools">Extend to New Tools</a> |
<a href="#mt-agentrisk-benchmark">Safety Benchmark</a> |
<a href="#citation">Citation</a>
</p>
**ToolShield** is a training-free, tool-agnostic defense for AI agents that use MCP tools. Just `pip install toolshield` and a single command guards your coding agent with safety experiences — no API keys, no sandbox setup, no fine-tuning. Reduces attack success rate by **30%** on average.
<p align="center">
<img src="assets/overview.png" alt="Overview" width="75%">
</p>
## Quickstart
```bash
pip install toolshield
```
### Use Pre-generated Experiences
We ship safety experiences for 6 models across 5 tools, with plug-and-play support for **5 coding agents**:
<a href="#use-pre-generated-experiences">
<img src="https://img.shields.io/badge/Claude_Code-D97757?style=flat-square&logo=anthropic&logoColor=white" alt="Claude Code" />
</a>
<a href="docs/agents/codex.md">
<img src="https://img.shields.io/badge/Codex-000000?style=flat-square&logo=data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAIAAACQkWg2AAABm0lEQVR42rVSK6jCYBj9f7FoG75A0KRNWbDKQAQxGuRHYWCRgWYRLBo0DCwqBrUJLojY7C74aGPJMNGyMIQN8QEKv7pbLj7GhcsN97SP7xy+7xwO1HUd/AUm8EeYDfP9fud5fr/fRyIRm832ywWMMU3T6/UaABCNRlOpVCaTEUXxQ6G/odVqTSaTxWKBEOr3+8fjUVXVZDK5Wq2enJeAYRiSJGVZTiQSmqaVy+VYLMYwzGw2q1QqT9q3h+l06vP5XC4XhFBV1VwudzqdstlsIBCoVqt2u91oervdhkIhnufP57PX6+U47vF4hMNht9vNsmy9Xpdl2ePxvExTFMVxHE3TtVpNURSMMcaYIIhSqTQcDuPx+HK5/Ljg9/vNZnOxWGRZdrPZUBTldDoPh4PFYgEACIKAEDLGShBEoVDodrudTiedTrfbbavVquv6aDSCEAaDQWOskiQhhDRNu16vzWYTISRJ0mAwGI/H79HD9y6Jotjr9W63myAI+Xx+t9spitJoNEym1yPwx/JdLpf5fO5wOEiSNKzgv7f1C7WV+mn4U8OsAAAAAElFTkSuQmCC&logoColor=white" alt="Codex" />
</a>
<a href="#use-pre-generated-experiences">
<img src="https://img.shields.io/badge/Cursor-00A3E0?style=flat-square&logo=cursor&logoColor=white" alt="Cursor" />
</a>
<a href="docs/agents/openhands.md">
<img src="https://img.shields.io/badge/%F0%9F%99%8C_OpenHands-E5725E?style=flat-square" alt="OpenHands" />
</a>
<a href="docs/agents/openclaw.md">
<img src="https://img.shields.io/badge/%F0%9F%A6%9E_OpenClaw-FF6B6B?style=flat-square" alt="OpenClaw" />
</a>
Inject them in one command — no need to know where files are installed:
```bash
# For Claude Code (filesystem example)
toolshield import --exp-file filesystem-mcp.json --agent claude_code
# For Codex (postgres example)
toolshield import --exp-file postgres-mcp.json --agent codex
# For OpenClaw (terminal example)
toolshield import --exp-file terminal-mcp.json --agent openclaw
# For Cursor (playwright example)
toolshield import --exp-file playwright-mcp.json --agent cursor
# For OpenHands (notion example)
toolshield import --exp-file notion-mcp.json --agent openhands
```
Use experiences from a different model with `--model`:
```bash
toolshield import --exp-file filesystem-mcp.json --model gpt-5.2 --agent claude_code
```
Or import **all** bundled experiences (all 5 tools) in one shot:
```bash
toolshield import --all --agent claude_code
```
You can also import multiple experience files individually:
```bash
toolshield import --exp-file filesystem-mcp.json --agent claude_code
toolshield import --exp-file terminal-mcp.json --agent claude_code
toolshield import --exp-file postgres-mcp.json --agent claude_code
```
See all available bundled experiences:
```bash
toolshield list
```
This appends safety guidelines to your agent's context file (`~/.claude/CLAUDE.md`, `~/.codex/AGENTS.md`, `~/.openclaw/workspace/AGENTS.md`, Cursor's global user rules, or `~/.openhands/microagents/toolshield.md`). To remove them:
```bash
toolshield unload --agent claude_code
```
Available bundled experiences (run `toolshield list` to see all):
| Model |  |  |  |  |  |
|-------|:---:|:---:|:---:|:---:|:---:|
| `claude-sonnet-4.5` | ✅ | ✅ | ✅ | ✅ | ✅ |
| `gpt-5.2` | ✅ | ✅ | ✅ | ✅ | ✅ |
| `deepseek-v3.2` | ✅ | ✅ | ✅ | ✅ | ✅ |
| `gemini-3-flash-preview` | ✅ | ✅ | ✅ | ✅ | ✅ |
| `qwen3-coder-plus` | ✅ | ✅ | ✅ | ✅ | ✅ |
| `seed-1.6` | ✅ | ✅ | ✅ | ✅ | ✅ |
> More plug-and-play experiences for additional tools coming soon (including [Toolathlon](https://github.com/hkust-nlp/Toolathlon) support)! Have a tool you'd like covered? [Open an issue](https://github.com/CHATS-Lab/ToolShield/issues).
### Generate Your Own
Point ToolShield at any running MCP server to generate custom safety experiences:
```bash
export TOOLSHIELD_MODEL_NAME="anthropic/claude-sonnet-4.5"
export OPENROUTER_API_KEY="your-key"
# Full pipeline: inspect → generate safety tree → test → distill → inject
toolshield \
--mcp_name postgres \
--mcp_server http://localhost:9091 \
--output_path output/postgres \
--agent codex
```
Or generate without injecting (useful for review):
```bash
toolshield generate \
--mcp_name postgres \
--mcp_server http://localhost:9091 \
--output_path output/postgres
```
### Auto-discover Local MCP Servers
Automatically scan localhost for running MCP servers, run the full pipeline for each, and inject the results:
```bash
toolshield auto --agent codex
```
This scans ports 8000-10000 by default (configurable with `--start-port` / `--end-port`).
### Extend to New Tools
ToolShield works with any MCP server that has an SSE endpoint:
```bash
toolshield generate \
--mcp_name your_custom_tool \
--mcp_server http://localhost:PORT \
--output_path output/your_custom_tool
```
## MT-AgentRisk Benchmark
We also release **MT-AgentRisk**, a benchmark of 365 harmful tasks across 5 MCP tools, transformed into multi-turn attack sequences. See [`agentrisk/README.md`](agentrisk/README.md) for full evaluation setup.
**Quick evaluation:**
```bash
# 1. Download benchmark tasks
git clone https://huggingface.co/datasets/CHATS-Lab/MT-AgentRisk
cp -r MT-AgentRisk/workspaces/* workspaces/
# 2. Run a single task (requires OpenHands setup — see agentrisk/README.md)
python agentrisk/run_eval.py \
--task-path workspaces/terminal/multi_turn_tasks/multi-turn_root-remove \
--agent-llm-config agent \
--env-llm-config env \
--outputs-path output/eval \
--server-hostname localhost
```
Add `--use-experience <path>` to evaluate with ToolShield defense.
## Repository Layout
```
ToolShield/
├── toolshield/ # pip-installable defense package
│ └── experiences/ # bundled safety experiences (6 models × 5 tools)
├── agentrisk/ # evaluation framework (see agentrisk/README.md)
├── workspaces/ # MT-AgentRisk task data (from HuggingFace)
├── docker/ # Dockerfiles and compose
└── scripts/ # experiment reproduction guides
```
## Acknowledgments
We thank the authors of the following projects for their contributions:
- [OpenAgentSafety](https://github.com/sani903/OpenAgentSafety)
- [SafeArena](https://github.com/McGill-NLP/safearena)
- [MCPMark](https://github.com/eval-sys/mcpmark)
## Citation
```bibtex
@misc{li2026unsaferturnsbenchmarkingdefending,
title={Unsafer in Many Turns: Benchmarking and Defending Multi-Turn Safety Risks in Tool-Using Agents},
author={Xu Li and Simon Yu and Minzhou Pan and Yiyou Sun and Bo Li and Dawn Song and Xue Lin and Weiyan Shi},
year={2026},
eprint={2602.13379},
archivePrefix={arXiv},
primaryClass={cs.CR},
url={https://arxiv.org/abs/2602.13379},
}
```
## License
MIT
| text/markdown | null | Xu Li <lixu20040929@gmail.com>, Simon Yu <simon011130@gmail.com> | null | null | MIT | agents, llm, mcp, safety, toolshield | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Langua... | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp>=3.9",
"json-repair>=0.20",
"openai>=1.0",
"requests>=2.28",
"tqdm>=4.66",
"pytest; extra == \"dev\"",
"ruff; extra == \"dev\"",
"fitz>=0.0.1.dev2; extra == \"eval\"",
"pyyaml; extra == \"eval\"",
"setuptools>=78.1; extra == \"eval\""
] | [] | [] | [] | [
"Homepage, https://unsafer-in-many-turns.github.io",
"Repository, https://github.com/CHATS-Lab/ToolShield",
"Dataset, https://huggingface.co/datasets/CHATS-Lab/MT-AgentRisk"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T17:41:21.177628 | toolshield-0.1.1.tar.gz | 13,184,164 | 8c/c0/9c33ecdd907fdb6178ae6ba081dc5efb9ce52ffc4bff22e5088413139351/toolshield-0.1.1.tar.gz | source | sdist | null | false | 49bf7486d7a97d4c5dcbacbf33040787 | f0393dccbcc5f0f104c4fcfe31084a17c2d1b6da41fb30668022d7ac3d6ff576 | 8cc09c33ecdd907fdb6178ae6ba081dc5efb9ce52ffc4bff22e5088413139351 | null | [] | 204 |
2.3 | hanime-plugin | 2026.1.28 | hanime extractor plugin for yt-dlp | # hanime-plugin
This yt-dlp plugin adds support for numerous hentai websites, including but not limited to **hanime.tv**, **hstream.moe** and **HentaiHaven**.
[](https://github.com/cynthia2006/hanime-plugin/actions/workflows/python-package.yml)
[](https://pypi.org/project/hanime-plugin/)
## Installation
You can install this package with pip:
```
pip install --user hanime-plugin
```
See [installing yt-dlp plugins](https://github.com/yt-dlp/yt-dlp#installing-plugins) for the other methods this plugin package can be installed. It can also be installed using [uv](https://astral.sh/uv).
```
uv tool install --with hanime-plugin yt-dlp
```
### Deno
**hanime.tv** extractor requires a JavaScript runtime. As of now, only [Deno](https://deno.com/) is supported. Install it using the following commands, and it would be available in `PATH` if you follow the onscreen instructions carefully.
```sh
# For Linux & MacOS
curl -fsSL https://deno.land/install.sh | sh
# For Windows (PowerShell)
irm https://deno.land/install.ps1 | iex
```
## Support
The following is the support matrix of sites and the respective video resolutions offered. **To request support for a site, or complain about a broken site, please open a Github issue.**
| | 720p | 1080p | 4K |
| --------------- | ---- | ----- | ---- |
| hstream.moe | ✅ | ✅ † | ✅ † |
| oppai.stream | ✅ | ✅ ‡ | ✅ ‡ |
| hentaihaven.com | ✅ | ✅ | ❌ |
| hanime.tv | ✅ | ❌* | ❌ |
| ohentai.org | ✅ | ❌ | ❌ |
| hentaimama.io | ✅ | ❌ | ❌ |
\* Requires paid membership, and is beyond the scope of this plugin.
† [AV1](https://en.wikipedia.org/wiki/AV1) codec. ‡ [VP9](https://en.wikipedia.org/wiki/VP9) codec.
## Examples
### Downloading a single video
```
$ yt-dlp https://hanime.tv/videos/hentai/fuzzy-lips-1
```
or
```
$ yt-dlp -f - https://hentaihaven.com/video/soshite-watashi-wa-sensei-ni/episode-1
```
## FAQ
### Why supports for these sites are not already included in yt-dlp?
The foundations for hanime.tv scraping were first laid out by [rxqv](https://github.com/rxqv/htv) as a separate tool, but the development ceased in 2021. Had it become dysfunctional eventually, [an issue](https://github.com/yt-dlp/yt-dlp/issues/4007) was raised for adding support for hanime.tv in upstream yt-dlp. Unfortunately, it was turned down, citing that the website allows piracy. This may have to do with the fact that YouTubeDL (yt-dlp's predecessor) had quite a controversial past; so far as to be banned from GitHub in 2020 as the result of DMCA complaint by Google.
Meanwhile, xsbee maintained a fork of yt-dlp with a hanime.tv extractor he/she made, before ceasing development in 2023. This plugin was originally based off of that extractor code. Support for other sites have been added in late 2025.
### Earlier version had support for hanime.tv playlists, what happened?
These additional features were added in 2024 on top of xsbee's original code. However, franchise and playlist downloads have since been removed because of [code rot](https://en.wikipedia.org/wiki/Software_rot).
| text/markdown | null | Cynthia <cynthia2048@proton.me> | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [
"yt_dlp_plugins"
] | [] | [] | [] | [] | [] | [] | python-requests/2.32.5 | 2026-02-19T17:40:34.208643 | hanime_plugin-2026.1.28.tar.gz | 19,069 | e4/9a/6f653f81c444f648dd09b05d259993280af003caa210a5b2cb56574b9078/hanime_plugin-2026.1.28.tar.gz | source | sdist | null | false | 13ad690289a0649f05c36108e5c41be8 | decf29c44920903c219f5215f56e07eb002014643f214ab5fa54261d2fb1adc9 | e49a6f653f81c444f648dd09b05d259993280af003caa210a5b2cb56574b9078 | null | [] | 222 |
2.4 | odgs | 3.3.0 | Open Data Governance Standard — Sovereign Reference Implementation | # Open Data Governance Standard (ODGS)
[-0055AA)](https://metricprovenance.com)
[](GOVERNANCE.md)
[](https://doi.org/10.5281/zenodo.18564270)
[](https://pypistats.org/packages/odgs)
[](https://www.npmjs.com/package/odgs)
[](LICENSE)
> **The Sovereign Reference Implementation for the EU AI Act.**
---
### 📢 Sovereign Node Notice (19 Feb 2026)
**To the 240+ Sovereign Nodes currently running ODGS (v3.0.0):**
We have observed a significant spike in "Blind Clones" (direct CI/CD deployments) adhering to the EU AI Act (Article 10) requirements. We recognize that many of you are operating inside strict corporate firewalls (Banking/Gov/Logistics) and cannot interact publicly.
**We respect your sovereignty and do not track you.**
However, this release introduces **breaking changes** that may halt your production pipelines:
* **URN Migration:** All integer IDs replaced with URN strings (`urn:odgs:metric:*`, `urn:odgs:rule:*`)
* **Sovereign Handshake:** Cryptographic integrity verification now required before rule evaluation
* **Tri-Partite Binding:** Audit logs now bind Input Hash + Definition Hash + Configuration Hash
> ⚠️ **OPERATIONAL ADVISORY:** To prevent "Definition Drift" in your critical paths, please click the **Watch** button (top right) → select **Releases Only**.
This ensures your Engineering Leads receive an immediate notification if a Schema Breaking Change is merged. This is the only channel we will use to broadcast critical compliance patches.
**Migration:** If upgrading from v3.0, run `odgs migrate` and see [MIGRATION_GUIDE.md](/MIGRATION_GUIDE.md).
## 1. The Standard
The **Open Data Governance Standard (ODGS)** is a vendor-neutral protocol for **Sovereign Data Governance**. It resolves the "Definition-Execution Gap" in High-Risk AI Systems by creating a deterministic method for **Administrative Recusal**.
> **"Silence over Error."** — The Core Philosophy.
> If the semantic definition of data drifts from its legal meaning, the system must execute a **Hard Stop** rather than process an invalid inference.
This repository contains the **Reference Implementation (v3.3.0)**, featuring the **Sovereign Handshake**, **Tri-Partite Binding**, and **86% enforceable rule coverage** for automated legislative compliance.
### See It In Action → [demo.metricprovenance.com](https://demo.metricprovenance.com)
**Semantic Certificate** — Every sovereign definition carries a cryptographic fingerprint bound to its issuing authority. The data equivalent of a TLS certificate.

<details>
<summary><b>📊 More Screenshots</b> — Compliance Matrix · Sovereign Brake · Harvester Sources</summary>
**Sovereign Compliance Matrix** — Real-time governance status across 72 business metrics, aligned with EU AI Act Art. 10 & 12.

**Sovereign Brake — Live Interceptor** — When data does not match its statutory definition, the system *refuses to proceed*. This is the "Administrative Recusal" principle.

**Sovereign Harvester — Authoritative Sources** — Definitions harvested from trusted regulatory bodies and international standards organisations.

</details>
---
## 2. Regulatory Alignment
This standard is architected to satisfy the "Error-Free Data" and "Automatic Recording" mandates of the Digital State:
* **🇪🇺 EU AI Act (2024/1689)**
* **Article 10:** Validation of data provenance and semantic integrity.
* **Article 12:** Generation of immutable, forensically sound event logs.
* **🇳🇱 NEN 381 525 (Data & Cloud)**
* **Sovereignty:** Ensures data processing logic remains portable and vendor-independent.
* **🌐 ISO/IEC 42001 (AI Management)**
* **Control B.9:** Operational control of AI systems via runtime enforcement.
---
## 3. The 5-Plane Architecture (v3.3)
ODGS implements a "Constitutional Stack" where mechanical execution is legally bound by semantic definitions via the **Sovereign Interceptor**.
```mermaid
graph TD
subgraph "The Constitution (Policy)"
L[1. Governance] -->|Defines Intent| Leg[2. Legislative]
Leg -->|Defines Metrics| Jud[3. Judiciary]
end
subgraph "The Machine (Execution)"
Jud -->|Enforces Rules| Ex[4. Executive]
Ex -->|Contextualizes| Phy[5. Physical]
end
subgraph "The Audit Trail"
Phy -->|Logs Evidence| Anchor[Sovereign Trust Anchor]
end
style L fill:#f9f,stroke:#333,stroke-width:2px
style Leg fill:#bbf,stroke:#333,stroke-width:2px
style Jud fill:#bfb,stroke:#333,stroke-width:2px
style Ex fill:#ddd,stroke:#333,stroke-width:2px
style Phy fill:#ddd,stroke:#333,stroke-width:2px
```
**[> Read the Full Architecture Specification](/docs/architecture.md)**
**🦉 [W3C OWL Ontology](/specifications/ontology_graph.owl)** — 275 individuals (72 metrics, 50 rules, 60 dimensions, 42 process stages, 43 sovereign definitions) formally specified in OWL/RDF with W3C PROV provenance chains.
---
## 4. Technical Implementation: The Sovereign Stack
### 1. The Sovereign Harvester
Automatically fetch Legislative Definitions (XML/JSON-LD) and convert them into immutable `SovereignDefinition` objects.
* **Dutch Law (AwB):** Harvests directly from `wetten.overheid.nl`.
* **Finance (FIBO):** Harvests from the EDM Council Ontology.
### 2. Time-Travel Resolution
The **Sovereign Resolver** ensures legal accuracy by resolving URNs to the exact version effective on a specific date, preventing the "Resolution Trap".
### 3. The Interceptor (Python)
* **Role:** Heavy-duty Data Engineering & Runtime Enforcement.
* **Install:** `pip install odgs`
---
## 5. Quick Start (v3.3)
**1. Initialize a Sovereign Project**
```bash
odgs init my-project
cd my-project
```
**2. Harvest Sovereign Definitions**
Use the new `harvest` command to pull authoritative legal definitions:
```bash
# Harvest Dutch Administrative Law (Article 1:3)
odgs harvest nl_awb 1:3
# > [SUCCESS] Verified Signature.
# > Saved Immutable Definition: lib/schemas/sovereign/nl_gov/awb_art_1_3.json
# Harvest Finance Ontology (Interest Rate)
odgs harvest fibo InterestRate
# > [SUCCESS] Verified Signature.
# > Saved Immutable Definition: lib/schemas/sovereign/fibo/interestrate_v2024.json
```
**3. Define a Metric (The Law)**
Link your metric to the harvested Sovereign URN:
```bash
odgs add metric "ROIC" --definition "urn:odgs:def:fibo:interestrate:v2024"
# Links Return on Invested Capital to FIBO InterestRate (debt cost governs the denominator)
```
---
## 6. Documentation & Contribution
> 📚 **[Full Documentation Map →](docs/index.md)** — All docs organized by audience (Executive, Compliance, Engineering, Research).
> 🎯 **[Live Demo →](https://demo.metricprovenance.com)** — Interactive dashboard with live governance metrics.
| Start Here | If You Are |
|---|---|
| [Plain Language Guide](docs/eli5_guide.md) | Executive, CDO, General |
| [Compliance Report](docs/compliance_report.md) | Compliance Officer, Regulator |
| [Adapter Guide](docs/adapter_guide.md) | Data Engineer |
| [Technical Note v3.3](docs/research/technical_note_v33.md) | Academic, Researcher |
### Contribute
This is a **Coalition of the Willing**. We invite Legal Scholars and Public Administrators to contribute to the Standard.
* **[Migration Guide (v3.0 -> v3.3)](/MIGRATION_GUIDE.md):** Critical instructions for upgrading.
* **[Changelog](/CHANGELOG.md):** Detailed record of changes.
* **[Governance Manifesto](/GOVERNANCE.md):** Principles of Regulatory Consensus.
### License
Released under the **Apache 2.0 License**.
* **No Vendor Lock-in.**
* **No Cloud Dependency.**
* **100% Data Sovereignty.**
---
> [!IMPORTANT]
> **Looking for the Flat JSON Version?**
> If you need the lightweight, non-cryptographic version (v1.2.x), visit the [Core Repository](https://github.com/MetricProvenance/odgs-core).
> * **Install v1:** `pip install "odgs<2"`
> * **Install v3 (This Repo):** `pip install odgs`
| text/markdown | null | Metric Provenance <partner@metricprovenance.com> | null | null | Apache-2.0 | ai-safety, compliance, data-governance, eu-ai-act, sovereign | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: So... | [] | null | null | >=3.9 | [] | [] | [] | [
"certifi>=2024.2.2",
"fastapi>=0.95.0",
"gitpython>=3.1.0",
"pydantic>=2.0.0",
"python-dotenv>=1.0.0",
"rich>=13.0.0",
"simpleeval==0.9.13",
"typer>=0.9.0",
"uvicorn>=0.20.0",
"google-genai>=1.0.0; extra == \"ai\"",
"sse-starlette>=1.0.0; extra == \"ai\"",
"google-genai>=1.0.0; extra == \"all\... | [] | [] | [] | [
"Homepage, https://metricprovenance.com",
"Repository, https://github.com/MetricProvenance/odgs-protocol",
"Documentation, https://github.com/MetricProvenance/odgs-protocol/tree/main/docs"
] | twine/6.2.0 CPython/3.9.6 | 2026-02-19T17:40:17.373342 | odgs-3.3.0.tar.gz | 344,207 | f0/42/5602db2a1a0e9a484f7d71983021d713c73eb142ba0112da62126a6087d9/odgs-3.3.0.tar.gz | source | sdist | null | false | 6dcd7f57889a37c7f610ff3fc34e47fd | 7c99c7a21e4497d6ac577a74370e8259a8165dcb4208cefd352fb65f5da4487f | f0425602db2a1a0e9a484f7d71983021d713c73eb142ba0112da62126a6087d9 | null | [
"LICENSE"
] | 201 |
2.4 | xx2html | 0.18.0rc1 | Convert XLSX workbooks to single styled HTML file with support for conditional formatting and in-cell images. | # xx2html
[](https://pypi.org/project/xx2html/)
[](https://github.com/gocova/xx2html/actions/workflows/ci.yml)
[](https://opensource.org/licenses/)
[](https://buymeacoffee.com/gocova)
`xx2html` converts Excel workbooks (`.xlsx`) into a single HTML file while preserving:
- Cell formatting and styles
- Conditional formatting classes (via `condif2css`)
- Worksheet link behavior
- Embedded worksheet images and in-cell rich-value images
Repository: <https://github.com/gocova/xx2html>
Issues: <https://github.com/gocova/xx2html/issues>
## Installation
```bash
pip install xx2html
```
## Usage
```python
from xx2html import apply_openpyxl_patches, create_xlsx_transform
# Explicit entrypoint. Patches are also applied automatically on import.
apply_openpyxl_patches()
transform = create_xlsx_transform(
sheet_html=(
'<section id="{enc_sheet_name}" data-sheet-name="{sheet_name}">'
"{table_generated_html}"
"</section>"
),
sheetname_html='<a class="sheet-nav" href="#{enc_sheet_name}">{sheet_name}</a>',
index_html=(
"<!doctype html><html><head>"
"{fonts_html}{core_css_html}{user_css_html}{generated_css_html}"
"{generated_incell_css_html}{conditional_css_html}"
'</head><body data-source="{source_filename}">{sheets_names_generated_html}{sheets_generated_html}'
"{safari_js}</body></html>"
),
fonts_html="",
core_css="",
user_css="",
safari_js="",
apply_cf=True,
max_sheets=3, # optional preview limit
max_rows=200, # optional preview limit per sheet
max_cols=20, # optional preview limit per sheet
raise_on_error=False,
)
ok, err = transform("input.xlsx", "output.html", "en_US")
if not ok:
raise RuntimeError(err)
```
## API Map
Public API (`xx2html`):
- `apply_openpyxl_patches() -> None`
- Applies required openpyxl monkey patches (idempotent).
- `create_xlsx_transform(...) -> Callable[[str, str, str], tuple[bool, str | None]]`
- Returns a transformer callable with signature `(source_xlsx, dest_html, locale)`.
- Returns `(True, None)` on success, `(False, "<error repr>")` on failure.
- Optional preview controls:
- `max_sheets`: convert only the first N visible sheets.
- `max_rows`: convert only the first N rows per included sheet.
- `max_cols`: convert only the first N columns per included sheet.
- Optional error mode:
- `raise_on_error=True` raises the original exception instead of returning `(False, ...)`.
Core helpers (`xx2html.core`, useful for advanced integrations):
- `get_worksheet_contents(...) -> WorksheetContents`
- `cova_render_table(worksheet_contents) -> str`
- `get_incell_images_refs(archive) -> tuple[dict[str, str], Exception | None]`
- `get_incell_css(...) -> str`
- `apply_cf_styles(html, cf_style_relations) -> str`
- `update_links(html, encoded_sheet_names, ...) -> str`
## Template Placeholders
`sheet_html` requires:
- `{enc_sheet_name}`
- `{sheet_name}`
- `{table_generated_html}`
`sheetname_html` requires:
- `{enc_sheet_name}`
- `{sheet_name}`
`index_html` requires:
- `{sheets_generated_html}`
- `{sheets_names_generated_html}`
- `{source_filename}`
- `{fonts_html}`
- `{core_css_html}`
- `{user_css_html}`
- `{generated_css_html}`
- `{generated_incell_css_html}`
- `{conditional_css_html}`
`index_html` optional:
- `{safari_js}`
- If omitted while `safari_js` is non-empty, xx2html logs a warning and skips injection.
Generated output also includes:
- `<meta name="generator" content="xx2html {version}">` in `<head>`
- `<!-- Generated by xx2html {version} -->` as the first node in `<body>`
## Monkey Patching Behavior
`xx2html` relies on an `openpyxl` monkey patch to carry rich-value metadata used for in-cell images.
- The patch is applied automatically when `xx2html.core` is imported.
- The explicit API entrypoint is `apply_openpyxl_patches()`.
- `xx2html` validates the `openpyxl` major/minor version before patching.
- Set `XX2HTML_ALLOW_UNSUPPORTED_OPENPYXL=1` to bypass the guard.
## Development
```bash
pdm sync --group dev --frozen-lockfile
python3 tests/scripts/generate_fixtures.py
pdm run python -m compileall src tests
ruff check src tests
mypy src/xx2html
pdm run pytest
```
## Release
- Stable releases are tag-driven and use SemVer tags: `vMAJOR.MINOR.PATCH` (for example `v1.2.3`).
- Push the tag to GitHub; the `publish` workflow builds from SCM metadata and publishes with PyPI Trusted Publishing.
## License
`xx2html` is dual-licensed under MIT or Apache-2.0.
| text/markdown | null | Jose Gonzalo Covarrubias <gocova.dev+xx2html@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Development Status :: 4 - Beta"
] | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"bs4>=0.0.2",
"condif2css==0.15.0rc1",
"lxml>=5.3.1",
"openpyxl>=3.1.5",
"pillow>=11.0.0",
"xlsx2html>=0.6.1"
] | [] | [] | [] | [
"Homepage, https://github.com/gocova/xx2html",
"Repository, https://github.com/gocova/xx2html",
"Issues, https://github.com/gocova/xx2html/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:39:58.187117 | xx2html-0.18.0rc1.tar.gz | 139,296 | a2/2a/8f8ffae78b2d3ef4c21630345e1297387ddde2a4b75c9e4e327d4d6187d9/xx2html-0.18.0rc1.tar.gz | source | sdist | null | false | bb7a1cd2f0b606697fa05f38821d12a7 | 380e835bbe2061529bbf6a881805e84d45304292cab85ade25947b2ea5066ae1 | a22a8f8ffae78b2d3ef4c21630345e1297387ddde2a4b75c9e4e327d4d6187d9 | MIT OR Apache-2.0 | [
"LICENSE_APACHE",
"LICENSE_MIT"
] | 181 |
2.4 | SpecOutLines | 1.1.1 | model spectral line profiles for astrophysical winds, bubbles, and outflows | <img width="512" alt="OutLines Logo" src="https://github.com/sflury/OutLines/blob/main/docs/logo.png">
OutLines models spectral line profiles from winds, bubbles, and
outflows following the formalism in [Flury 2025](https://ui.adsabs.harvard.edu/abs/2025arXiv251210650F/abstract)
(see also [Flury, Moran, & Eleazer 2023](https://ui.adsabs.harvard.edu/abs/2023MNRAS.525.4231F)
for an earlier version). A primary goal of OutLines is to remain agnostic to the
underlying physics while also drawing on physical motivations for the geometry,
velocity, and gas density distributions. A cartoon of the model
illustrating the observation of spherical outflows is shown below,
depecting the Doppler shift (colored arrows) of light emitted (yellow and
orange) and absorbed (orange) by gas in the outflow.
<img width="512" alt="image of a model outflow" src="https://github.com/sflury/OutLines/assets/42982705/9af5bf13-d2ce-441b-b429-294833ae5edc">
Physically justifiable assumptions include the density profile, including a
variety of continuous or shell-like gas density distributions,
and the velocity field, including the so-called beta law from approximations
to CAK theory (e.g., Castor et al. 1975, Barlow et al. 1977) and other power law
solutions, under the Sobolev approximation that small-scale ("local")
gas velcities contribute negligibly to the net velocity field.
Emission and absorption profiles are computed in velocity space for the
specified wavelength(s). Following the equation of radiative transfer, emission
line profiles should be added in flux space while absorption line profiles
should be added in optical depth space. One or multiple lines can be computed
for each set of outflow properties, which is highly recommended in the case of
multiple features from the same species such as the \[O III\] doublet or Si II
UV absorption features. However, simultaneous fitting of lines from different
phases of the interstellar medium or even different ionization zones is
cautioned as different phases may not share the same wind, bubble, or
outflow properties.
OutLines currently supports line profile models for absorption lines and
nebular, resonant, and fluorescent emission lines.
## Installation
While it is possible to download this repository, OutLines is readily accessible
via `pip install`, which will automatically ensure the appropriate dependencies
are also installed. An example call in the terminal command line is shown below.
``` bash
$ pip3 install SpecOutLines
```
## Line Profile Classes
| CLASS | LINE FEATURE |
|-------------|----------------------|
| Absorption | resonant absorption |
| Nebular | nebular emission |
| Resonant | resonant emission |
| Fluorescent | fluorescent emission |
## Example Usage -- \[O III\] 4959,5007 Profiles
``` python
import OutLines as OL
from numpy import linspace
import matplotlib.pyplot as plt
model = OL.Nebular([4958.911,5006.843],Geometry='HollowCones',AddStatic=True,Disk=True)
model.update_params(['TerminalVelocity'],[500,30,15,45])
model.update_params(['OpeningAngle','CavityAngle','Inclination'],[500,30,15,45])
model.update_params(['FluxOutflow1','FluxStatic1'],[1/2.98,1/2.98])
wave = linspace(4950,5015,651)wave = linspace(4950,5015,651)
plt.plot(wave,model.get_profile(wave),lw=2,color='C3')
plt.plot(wave,model.get_outflow(wave),dashes=[3,3],lw=2,color='C3')
plt.plot(wave,model.get_static(wave),':',lw=2,color='C3')
plt.show()
model.print_settings()
model.print_params()
props = OL.Properties(model)
props.print_props()
```
<img width="480" alt="image of predicted \[O III\] doublet profile" src="https://github.com/sflury/OutLines/blob/main/examps/o_iii.png">
``` text
----------------------------------
| MODEL SETTINGS |
----------------------------------
| Line 1 : 4958.911 |
| Line 2 : 5006.843 |
| Profile : Nebular |
| VelocityField : BetaCAK |
| DensityProfile : PowerLaw |
| Geometry : HollowCones |
| StaticComponent : Yes |
| Aperture : No |
| Disk : Yes |
----------------------------------
------------------------------------
| MODEL PARAMETERS |
------------------------------------
| DopplerWidth : 8.994 km/s |
| TerminalVelocity : 500.000 km/s |
| VelocityIndex : 1.000 |
| FluxStatic1 : 0.336 |
| FluxStatic2 : 1.000 |
| FluxOutflow1 : 0.336 |
| FluxOutflow2 : 1.000 |
| Inclination : 45.000° |
| OpeningAngle : 30.000° |
| CavityAngle : 15.000° |
| DiskRadius : 2.000 |
| PowerLawIndex : 2.000 |
------------------------------------
-------------------------------------------
| MODEL PROPERTIES |
-------------------------------------------
| x.out : 1.500 |
| v.out : 166.667 km s^-1 |
| Mdot : 1.057 Msun yr^-1 |
| pdot : 0.111 10^34 dyne |
| Edot : 0.009 10^42 erg s^-1 |
| v.esc : 1.667 |
| pdot.esc : 0.093 |
| Edot.esc : 0.154 |
-------------------------------------------
| Mdot, pdot, Edot / R0^2 n0 [kpc^2 cm^-3] |
| pdot.est, Edot.esc / v0 [100 km s^-1] |
-------------------------------------------
```
## Example Usage -- Si II 1260 Profile
``` python
import OutLines as OL
from numpy import linspace
import matplotlib.pyplot as plt
kwargs = dict(Geometry='FilledCones',DensityProfile='LogNormal',AddStatic=True)
model = OL.Absorption(1260.4221,1.18,**kwargs)
wave = linspace(1259.25,1260.75,1001)
plt.plot(wave,model.get_profile(wave),lw=2,color='C3')
plt.plot(wave,model.get_outflow(wave),dashes=[3,3],lw=2,color='C3')
plt.plot(wave,model.get_static(wave),':',lw=2,color='C3')
plt.show()
```
<img width="480" alt="image of predicted Si II 1260 absorption profile" src="https://github.com/sflury/OutLines/blob/main/examps/si_ii.png">
## Referencing `OutLines`
While this code is provided publicly, it did require substantial effort to
develop and document. Any use thereof must be cited in any publications in which
this code is used. The BibTeX reference for the [Flury (2025)](https://arxiv.org/abs/2512.10650) paper which
presents the models and code is below; however, a GitHub CCF is also provided
for convenience.
``` bibtex
@ARTICLE{Flury2025,
author = {{Flury}, Sophia R.},
title = "{OutLines: Modeling Astrophysical Winds, Bubbles, and Outflows}",
eprint={2512.10650},
archivePrefix={arXiv},
primaryClass={astro-ph.GA},
url={https://arxiv.org/abs/2512.10650},
year = {2025},
month = {dec} }
```
I developed and implemented the spherical geometry, power law
density, CAK approximation model for analysis of broad [O III] lines
observed in Mrk 462. That model was presented in
[Flury, Moran, & Eleazer (2023) MNRAS 525, 4231](https://ui.adsabs.harvard.edu/abs/2023MNRAS.525.4231F)
The BibTeX reference is below.
``` bibtex
@ARTICLE{Flury2023,
author = {{Flury}, Sophia R. and {Moran}, Edward C. and {Eleazer}, Miriam},
title = "{Galactic outflow emission line profiles: evidence for dusty, radiatively driven ionized winds in Mrk 462}",
journal = {\mnras},
year = 2023,
month = nov,
volume = {525},
number = {3},
pages = {4231-4242},
doi = {10.1093/mnras/stad2421} }
```
## Licensing
This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program. If not, see <https://www.gnu.org/licenses/>.
| text/markdown | Sophia Flury | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Operating System :: OS Independent"
] | [] | null | null | >=3.12.9 | [] | [] | [] | [
"numpy>=2.3.5",
"scipy>=1.17.0",
"matplotlib>=3.10.0"
] | [] | [] | [] | [
"Homepage, https://github.com/sflury/OutLines",
"Issues, https://github.com/sflury/OutLines/issues",
"Documentation, https://github.com/sflury/OutLines/wiki"
] | twine/6.1.0 CPython/3.12.9 | 2026-02-19T17:39:40.703325 | specoutlines-1.1.1.tar.gz | 43,638 | be/8c/68ab1a57e69fbd024ea9d8063f5a867b6092a3afa2a9aaa523608bcd2dfb/specoutlines-1.1.1.tar.gz | source | sdist | null | false | 32bfa8a15e70e2cbefccb11e07a8190a | f970536ebdd5841f79efcb7827f29028b00225f9addf5a85d90ba0a318fa6448 | be8c68ab1a57e69fbd024ea9d8063f5a867b6092a3afa2a9aaa523608bcd2dfb | GPL-3.0 | [
"LICENSE"
] | 0 |
2.4 | wnet | 0.9.7 | Tools for calculation of Wasserstein metric between distributions based on Network Flow algorithm | # wnet
Wasserstein Network (wnet) is a Python/C++ library for working with Wasserstein distances. It uses the Min Cost Flow algorithm as implemented by the [LEMON library](https://lemon.cs.elte.hu/trac/lemon), exposed to Python via the [pylmcf module](https://github.com/michalsta/pylmcf), enabling efficient computation and manipulation of Wasserstein distances between multidimensional distributions.
## Features
- Wasserstein and Truncated Wasserstein distance calculations between multidimensional distributions
- Calculation of derivatives with respect to deltas in flow or position (in progress)
- Python and C++ integration
- Support for distribution mixtures, and efficient recalculation of distance with changed mixture proportions
## Installation
You can install the Python package using pip:
```bash
pip install wnet
```
## Usage
Simple usage:
```python
import numpy as np
from wnet import WassersteinDistance, Distribution
from wnet.distances import DistanceMetric
positions1 = np.array(
[[0, 1, 5, 10],
[0, 0, 0, 3]]
)
intensities1 = np.array([10, 5, 5, 5])
positions2 = np.array(
[[1, 10],
[0, 0]]
)
intensities2 = np.array([20, 5])
S1 = Distribution(positions1, intensities1)
S2 = Distribution(positions2, intensities2)
print(WassersteinDistance(S1, S2, DistanceMetric.L1))
# 45
```
## Licence
MIT Licence
## Related Projects
- [pylmcf](https://github.com/michalsta/pylmcf) - Python bindings for Min Cost Flow algorithms from LEMON library.
- [wnetalign](https://github.com/michalsta/wnetalign) - Alignment of MS/NMR spectra using Truncated Wasserstein Distance
| text/markdown | null | =?utf-8?q?Micha=C5=82_Startek?= <michal.startek@mimuw.edu.pl> | null | =?utf-8?q?Micha=C5=82_Startek?= <michal.startek@mimuw.edu.pl> | null | Wasserstein, Optimal Transport, Network Flow, Earth Mover's Distance | [
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering :: Mathematics",
"Topic :: Software Development :: Libraries :: Python Modules",
"Development Status :: 4 - Beta"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"pylmcf",
"numpy",
"networkx; extra == \"extras\"",
"matplotlib; extra == \"extras\"",
"pytest; extra == \"pytest\""
] | [] | [] | [] | [
"Homepage, https://github.com/michalsta/wnet",
"Repository, https://github.com/michalsta/wnet.git"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:39:31.395529 | wnet-0.9.7.tar.gz | 19,733 | 5b/46/ca2963807285a2acae3c11757304eee30c3a480c67a2538428d03019696e/wnet-0.9.7.tar.gz | source | sdist | null | false | 2bc47dc6b219f3ac82d6c317985f9f95 | 3309301b0b47397ee5e8a7dc39cd16c7148b63a45b7c75c8cd81aa02e566967e | 5b46ca2963807285a2acae3c11757304eee30c3a480c67a2538428d03019696e | MIT | [
"LICENCE"
] | 4,498 |
2.4 | bg4h | 1.0.57 | bg table definitions for humans | # BG4h
bee gees for Humans Table Definitions
## Publish
To create a new package:
- First, update the version in pyproject.toml
- Then, run the .bat file: Launch publish_package.bat
### Build & Publish
python -m build
twine upload dist/*
## ChangeLog
### 1.0.57 - 19.02.2026
- new table definitions: SubfamiliasFamilia
### 1.0.56 - 29.01.2026
- new fields tProviders: pgc_1_account_code,pgc_2_account_code,pgc_4_account_code,pgc_4_account_code,pgc_5_account_code
### 1.0.55 - 11.12.2025
- set_sell_price_manually = "TUNIDADESOBRA50"
### 1.0.54 - 10.12.2025
- added SeriesPresupuestos class
### 1.0.53 - 10.12.2025
- fix:
- price_cost_accounting -> time_cost_accounting = "TVALORESPRESUPUESTOS19"
- price_cost -> time_cost = "TVALORESPRESUPUESTOS20"
### 1.0.52 - 09.12.2025
- TVALORESUNIDADESOBRA added:
- units = 'TVALORESUNIDADESOBRA21'
- familiy_code = "TUNIDADESOBRA34"
- subfamiliy_code = "TUNIDADESOBRA36"
- group_code = "TUNIDADESOBRA37"
- TVALORESPRESUPUESTOS added:
- puc_accounting = "TVALORESPRESUPUESTOS67"
- puc = "TVALORESPRESUPUESTOS68"
- subitem_units = "TVALORESPRESUPUESTOS80"
- time_price_accounting = "TVALORESPRESUPUESTOS7"
- time_price = "TVALORESPRESUPUESTOS8"
- price_cost_accounting = "TVALORESPRESUPUESTOS19"
- price_cost = "TVALORESPRESUPUESTOS20"
- time_margin_percentage = "TVALORESPRESUPUESTOS21"
### 1.0.51 - 28.11.2025
- no changes, just version update to match bg4h_ts
### 1.0.50 - 25.11.2025
-fix: duplicate:
tax_invoice_expenses_percentage_2 = "tcobros32" -> tax_invoice_expenses_percentage_1
tax_invoice_expenses_percentage_2 = "tcobros52"
### 1.0.49 - 25.11.2025
- fix: duplicate:
totals_tax_internal = "TFACTURASVENTAS70"
totals_tax_internal = "TFACTURASVENTAS72" -> totals_tax_with_recharge_internal
### 1.0.48 - 18.11.2025
- added: transporter_code = "TVENTAS281"
### 1.0.47 - 12.11.2025
- added: TVACACIONES
- added: TOTROSVACACIONES
- added: TOTRASINCIDENCIASPERSONAL
### 1.0.46 - 10.11.2025
- fix: update ValoresVentas class to remove deprecated/broken/unused margin_percentage attribute and increment version to 1.0.46
### 1.0.45 - 10.11.2025
- fix:added helpers import to init
### 1.0.44 - 06.11.2025
- feat: add DeprecatedAttr class for handling deprecated attributes with warnings
- fix: duplicate entry article_margin_percentage mapped to: "TVALORESVENTAS18" and "TVALORESVENTAS21"
- fix: changed duplicate article_margin_percentage to correct: hours_margin_percentage = "TVALORESVENTAS21"
- added old deprecated changes since v1.0.12
### 1.0.43 - 06.11.2025
- fix: code = article_code = "TVALORESVENTAS2" ->restored for backwards compatibility
- fix: desc = article_desc = "TVALORESVENTAS3" ->restored for backwards compatibility
### 1.0.42 - 05.11.2025
- new field: use_mailing_code = "TPRESUPUESTOS126"
- new field: client_mailing_code = "TPRESUPUESTOS127"
### 1.0.41 - 24.10.2025
- new field: total_cost_accounting = "TPRESUPUESTOS49"
- new field: total_cost = "TPRESUPUESTOS50"
- new field: article_cost_accounting = "TVALORESPRESUPUESTOS16"
### 1.0.40 - 24.10.2025
- new table:_ Tdocumentosavisos
- new field: id_web = "TTAREASAVISOS9"
### 1.0.39 - 24.10.2025
- rename: order_state -> order_status = "TPEDIDOSAPROVEEDORES6"
- rename: order_send_address -> shipping_address = "TPEDIDOSAPROVEEDORES7" #Envío
- new: shipping_zip_code = "TPEDIDOSAPROVEEDORES38" #Envío
- new: shipping_city = "TPEDIDOSAPROVEEDORES39" #Envío
- new: shipping_province = "TPEDIDOSAPROVEEDORES40" #Envío
- new: shipping_country = "TPEDIDOSAPROVEEDORES41" #Envío
- new: shipping_phone = "TPEDIDOSAPROVEEDORES103" #Envío
- new: shipping_email = "TPEDIDOSAPROVEEDORES104" #Envío
- new: shipping_observations ="TPEDIDOSAPROVEEDORES105" #Envío
- new: invoice_city = "TPEDIDOSAPROVEEDORES34" #facturas
- new: invoice_province = "TPEDIDOSAPROVEEDORES35" #facturas
- new: invoice_country = "TPEDIDOSAPROVEEDORES36" #facturas
- new: receiving_address =" TPEDIDOSAPROVEEDORES17" #recepción
- new: receiving_zip_code = "TPEDIDOSAPROVEEDORES43" #recepción
- new: receiving_city =" TPEDIDOSAPROVEEDORES44" #recepción
- new: receiving_province = "TPEDIDOSAPROVEEDORES45" #recepción
- new: receiving_country = "TPEDIDOSAPROVEEDORES46" #recepción
### 1.0.38 - 22.10.2025
- fix: assign_time_to_document = "TPRESUPUESTOS33"
- new field: accounting_installed_price = "TVALORESPRESUPUESTOS10"
- new field: installed_price = "TVALORESPRESUPUESTOS11"
### 1.0.37 - 21.10.2025
- new field: buy_tax_code = "TARTICULOS204"
- new fields: TPRESUPUESTOS and TVALORESPRESUPUESTOS
### 1.0.35 - 20.10.2025
- new field: is_transporter = "TPROVEEDORES41"
- new field: is_comission_agent = "TPROVEEDORES42"
- rename: output_tax_code - > sell_tax_code = "TARTICULOS10"
- new field: measure_unit = "TVALORESPRESUPUESTOS43"
- lot of new fields to: TCLIENTES15
### 1.0.34 - 16.10.2025
- new field: client_registered = "TPRESUPUESTOS99"
### 1.0.33 - 16.10.2025
- rename: margin_currency -> margin_percentage = "TVENTAS37"
### 1.0.32 - 15.10.2025
- new field: contact_person = "TPRESUPUESTOS107"
### 1.0.31 - 14.10.2025
- new field: email = "TPRESUPUESTOS150"
### 1.0.30 - 10.10.2025
- new fields for TDATOSDECONTROL
taxes_per_article = 'TDATOSDECONTROL4'
taxes_per_budget_doc = 'TDATOSDECONTROL5'
default_sell_doc_tax_code = 'TDATOSDECONTROL14'
default_client_agrarian_tax_code = 'TDATOSDECONTROL15'
default_client_exempt_tax_code = 'TDATOSDECONTROL16'
default_client_eu_tax_code = 'TDATOSDECONTROL17'
default_provider_tax_code = 'TDATOSDECONTROL18'
default_provider_agrarian_tax_code = 'TDATOSDECONTROL19'
default_provider_exempt_tax_code = 'TDATOSDECONTROL20'
default_provider_eu_tax_code = 'TDATOSDECONTROL21'
default_sell_doc_special_tax_code = 'TDATOSDECONTROL35'
default_family_code = 'TDATOSDECONTROL42'
default_client_general_agrarian_tax_code = 'TDATOSDECONTROL62'
default_provider_general_agrarian_tax_code = 'TDATOSDECONTROL63'
default_currency = 'TDATOSDECONTROL85'
- rename fields:
article_tax_code > default_article_tax_code = 'TDATOSDECONTROL40'
### 1.0.29 - 08.10.2025
- added: expire_date = "TSTOCKOTROSCONTROLES3"
- fix: pvp_accountant = "TVALORESVENTAS5"
- fix: price_tax_included_intgernal -> price_tax_included_internal = "TVALORESVENTAS34"
- fix: margin_percentage -> article_margin_percentage = "TVALORESVENTAS21"
- fix: code -> article_code = "TVALORESVENTAS2"
- fix: desc -> article_desc = "TVALORESVENTAS3"
### 1.0.28 26.09.2025
- rename delivery_document_series,delivery_document_number, delivery_document_date to document_series,document_number,document_date
- added: percentage_on_amounts ="TVENTAS122"
### 1.0.27 - 22.09.2025
- Add observations variable to tTareas class and format existing attributes
### 1.0.26 - 22.09.2025
- fix: data_default_value -> changed from TTAREAS12 to TTAREAS17
- fix: data_default_inital_value -> is now TTAREAS12
### 1.0.25 - 19.09.2025
- added: observations = "CCUENTASTESORERIA14"
### 1.0.24 - 21.08.2025
- Add index_numerico variable to BgSoc class for AvisosElementos
### 1.0.23 - 19.08.2025
- fix: in var name of tavisoschecklist table name
### 1.0.22 - 12.08.2025
- added fields to ttareas
- added fields to tvalorespresupuestos
### 1.0.21 - 05.07.2025
- fix: rename table and fiels TFICHASELEMENTOS -> TFICHAELEMENTOS
### 1.0.20 - 05.07.2025
- fix: batch_manufacturation -> lot_number = "TFICHASELEMENTOS6"
### v1.0.19 - 04.07.2025
- added optional_line = TVALORESPRESUPUESTOS53
### v1.0.18 - 04.07.2025
- add new tables for checklist
- TAVISOSCHECKLIST
- TAVISOSCHECKLISTIMP
- TMANTENIMIENTOSSAT
- TVALORESMANTENIMIENTOSSAT
### v1.0.17
- import_limit = "CCUENTASTESORERIA15"
- TNOMINAS added
### v1.0.16
- contract_source = "TAVISOSREPARACIONESCLIENTES37"
- time_of_call = "TAVISOSREPARACIONESCLIENTES48"
- fee_code ="TAVISOSREPARACIONESCLIENTES157"
- table: IntervencionesAvisos
### v1.0.15
- project_code_invoice = "TAVISOSREPARACIONESCLIENTES80"
- in_charge_code_header = "TAVISOSREPARACIONESCLIENTES119"
- worker_code1_header = "TAVISOSREPARACIONESCLIENTES120"
- worker_code2_header = "TAVISOSREPARACIONESCLIENTES121"
- worker_code3_header = "TAVISOSREPARACIONESCLIENTES122"
### v1.0.14 16.05.2025
- fix TVENTAS
- added TVALORESPOSIBLESLOCALIZACIONESART
### v1.0.13 09.05.2025
- added quotation series and code to AvisosReparacionesClientes
- added vehicle_code to tventas
### v1.0.12 03.02.2025
- added missings vars tpersonal
- rename tobras state -> status
### v1.0.11 12.12.2024
- fix: correct class definition syntax for StockMinMaxAlmacen
### v1.0.10 10.12.2024
- added defs for stockminmaxalmacen
### v1.0.9 01.12.2024
- fixed wrong defs on Inmovilizados
- added defs for OtrosCostes and ValoresOtrosCostes
### v1.0.8 01.12.2024
- added new fields to `bg_soc.py`
- fixed typos in `bg_main.py`
- added missing field definitions in various tables
### v1.0.7 25.11.2024
- added missing index field tarticulosavisos
### v1.0.6 27.09.2024
- added missing fields in ttareasavisos
### v1.0.5 17.09.2024
- added missing worker 1-3 fields -> tavisosreparacionesclientes
### v1.0.4 02.08.2024
- added missing fields
- fix misspeling table ttrabajosavisos -> trabajosavisos
### v1.0.3 13.03.2024
- fixed spelling in vars of Personal table in BgMain
### v1.0.2 - 27.01.2024
- added missing fields from table vacaciones
### v1.0.1 - 10.01.2024
- added long description to setup.py
- fixed ttarea6 -> to TTAREAS6
### v1.0.0 - 18.12.2023
- ts/net lib converted to python
- spellfix
- added todos for unknown / unclear values
| text/markdown | null | "ct.galega" <soporte@ctgalega.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.0.0 CPython/3.12.10 | 2026-02-19T17:38:43.283674 | bg4h-1.0.57.tar.gz | 32,099 | cd/35/5fea725fcefc868c99eefe6900e843a3096d843efda79b177cf32c89297f/bg4h-1.0.57.tar.gz | source | sdist | null | false | 0beef06d26d001c198910a045139c88d | 5d463b710c144429fd2fe3ca8c84eb839e5a542557e33801eee95e9123580bef | cd355fea725fcefc868c99eefe6900e843a3096d843efda79b177cf32c89297f | null | [] | 234 |
2.4 | comfyui-workflow-templates | 0.8.45 | ComfyUI workflow templates package | # workflow_templates
This repo hosts the official ComfyUI **workflow templates** and **subgraph blueprints**.
## Overview
| Content | Description | Location |
|---------|-------------|----------|
| **Workflow Templates** | Full standalone workflows for the template picker | `templates/`, `packages/` |
| **Subgraph Blueprints** | Reusable node components that appear in the node palette | `blueprints/`, `packages/blueprints/` |
| **Template Site** | Astro SSG that showcases templates at [templates.comfy.org](https://templates.comfy.org) | `site/` |
The repository uses a **package-per-media** structure for Python distribution:
- `packages/core` – manifest + loader helpers shipped as `comfyui-workflow-templates-core`
- `packages/media_*` – workflow template JSON + preview assets for each media type
- `packages/blueprints` – subgraph blueprint JSON + preview assets as `comfyui-subgraph-blueprints`
- `packages/meta` and the root `pyproject.toml` – the `comfyui-workflow-templates` meta package
### Template Site (`site/`)
The `site/` directory contains an independent Astro static site that provides a browsable, searchable interface for all workflow templates. It includes AI-generated descriptions, i18n support (11 languages), SEO optimization, and automated content pipelines. See [site/AGENTS.md](site/AGENTS.md) for full documentation.
```bash
cd site
pnpm install
pnpm run dev # Start dev server at localhost:4321
pnpm run build # Production build (runs prebuild pipeline automatically)
```
## Quick Start
| Task | Commands |
|------|----------|
| Add a workflow template | Edit `templates/`, `bundles.json`, then `python scripts/sync_bundles.py` |
| Add a subgraph blueprint | Edit `blueprints/`, `blueprints_bundles.json`, then `python scripts/sync_blueprints.py` |
| Import external blueprints | Copy JSONs to `blueprints/`, then `python scripts/import_blueprints.py` |
---
- [workflow\_templates](#workflow_templates)
- [Overview](#overview)
- [Quick Start](#quick-start)
- [Adding New Templates](#adding-new-templates)
- [Adding New Blueprints](#adding-new-blueprints)
- [Validation](#validation)
## Adding New Templates
I will demonstrate how to add a new template by walking through the process of adding the Wan text to video template.
### 1 — Find Templates Folder
[Set up ComfyUI_frontend dev environment](https://github.com/Comfy-Org/ComfyUI_frontend?tab=readme-ov-file#development). In the `ComfyUI_frontend/.env` file, add the line `DISABLE_TEMPLATES_PROXY=true` then start the dev server with `npm run dev`.
Copy the `templates` folder from this repository to the `ComfyUI_frontend/public` folder.
### 2 — Obtain Workflow
Either
- Create the workflow and export using `Save` => `Export`
- Use an existing workflow. To extract the workflow json from an image, you can use this tool: <https://comfyui-embedded-workflow-editor.vercel.app/>
I will get my workflow from the [ComfyUI_examples Wan 2.1 page](https://comfyanonymous.github.io/ComfyUI_examples/wan/). To get the workflow from the video on that page, I'll drag the video into [comfyui-embedded-workflow-editor](https://comfyui-embedded-workflow-editor.vercel.app/). Then I'll copy and paste it into a new json file on my computer.
> [!IMPORTANT]
>
> Make sure you start ComfyUI with `--disable-all-custom-nodes` when creating the workflow file (to prevent custom extensions adding metadata into the saved workflow file)
### 3 — Obtain Thumbnails
Ideally, the thumbnail is simply the output produced by the workflow on first execution. As an example, see the output of the [**_Mixing ControlNets_** template](https://docs.comfy.org/tutorials/controlnet/mixing-controlnets):

For my Wan 2.1 template, I'll just use [the webp video](https://comfyanonymous.github.io/ComfyUI_examples/wan/text_to_video_wan.webp) I got the workflow from.
### 4 — Choose Thumbnail Type
Choose the content type and hover effect (optional) for your thumbnail:
| Content Types | Hover Effects |
| --------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------- |
| <br>**Image**: Default image with no extra effect | <br>**Compare Slider**: Before/after comparison tool |
| <br>**Video**: Webp animation | <br>**Hover Dissolve**: Dissolves to 2nd image on hover |
| <br>**Audio**: Audio playback | <br>**Hover Zoom**: Same as default but zooms more |
> [!WARNING]
>
> For video thumbnails, thumbnails need to be converted to webp format first
Since my Wan 2.1 thumbnail is already an animated video, I'll use a video thumbnail but choose not to add an effect.
### 5 — Compress Assets
Attempt to compress the assets. Since the thumbnails will never be taking up a large portion of the screen, it is acceptable to lower their size. It's also good to convert them to a space-efficient file format like webp or jpeg, applying a lossy compression algorithm (e.g., convert at 65% quality).
[EzGif](https://ezgif.com/png-to-webp) has free tools for changing resolution, compressing, and converting file types. Use whatever tool you are comfortable with.
> [!TIP]
>
> Convert to webp first, then resize to a smaller resolution. You can maintain high quality and still get near 95% reduction if e.g., converting from png.
### 6 — Rename and Move Files
Give the workflow a filename that has no spaces, dots, or special characters. Then rename the thumbnail file(s) to match, but with a counter suffix.
```
your_template_name.json
your_template_name-1.png
your_template_name-2.png
```
I'll name the Wan 2.1 template as `text_to_video_wan.json`. So my files will be:
```
text_to_video_wan.json
text_to_video_wan-1.webp
```
Then move the renamed files to your templates folder.
### 7 — Assign Bundle & Sync Assets
Each template lives in one bundle (`media-image`, `media-video`, etc.). Update
[`bundles.json`](bundles.json) with the template ID so the correct media package ships it.
After editing `templates/` or `bundles.json`, regenerate the manifest and copy assets into
the package directories:
```bash
python scripts/sync_bundles.py
# or via Nx
npm run sync
```
This step must be run before committing; CI will fail if the manifest/bundles are out of sync.
### 8 — Add Entry to `index.json`
There's an [`index.json`](templates/index.json) file in the templates folder which is where template configurations are set. You will need to add your template to this file, using the fields outlined below:

If your template doesn't fit into an existing category, you can add a new one:
```diff
{
"moduleName": "default",
"title": "Basics",
"type": "image",
"templates": [
{
"name": "default",
"mediaType": "image",
"mediaSubtype": "webp",
"description": "Generate images from text descriptions."
},
]
},
+ {
+ "moduleName": "default",
+ "title": "Your New Category"s Name",
+ "type": "video",
+ "templates": [
+ {
+ "name": "your_template_name",
+ "description": "A description of your template workflow",
+ "mediaType": "image",
+ "mediaSubtype": "webp",
+ "description": "Your template"s description.",
+ "tutorialUrl": "https://link-to-some-helpful-docs-if-they-exist.como"
+ "thumbnailVariant": "zoomHover",
+ },
+ ]
+ }
```
The Wan 2.1 template I'm adding already fits into the "Video" category, so I'll just add it there:
```diff
{
moduleName: "default",
title: "Video",
type: "video",
templates: [
{
name: "ltxv_text_to_video",
mediaType: "image",
mediaSubtype: "webp",
tutorialUrl: "https://comfyanonymous.github.io/ComfyUI_examples/ltxv/"
},
+ {
+ "name": "text_to_video_wan",
+ "description": "Quickly Generate videos from text descriptions.",
+ "mediaType": "image",
+ "mediaSubtype": "webp",
+ "tutorialUrl": "https://comfyanonymous.github.io/ComfyUI_examples/wan/"
+ },
]
},
```
The `thumbnailVariant` field is where you add the choice of thumbnail variant.
Now you can start ComfyUI (or refresh browser if already running) and test that your template works.
> [!WARNING]
>
> Make sure to use double-quotes `"` instead of single-quotes `'` when adding things to json files
### 9 — Embed Models
Now we need to embed metadata for any models the template workflow uses. This way, the user can download and run the workflow without ever leaving ComfyUI.
For instance, my Wan 2.1 template requires 3 models:
- umt5_xxl_fp8_e4m3fn_scaled text encoder
- wan_2.1_vae VAE
- wan2.1_t2v_1.3B_bf16 model

To add them to the workflow json, find each associated node and add the metadata to their properties:
```diff
{
"id": 39,
"type": "VAELoader",
"pos": [866.3932495117188, 499.18597412109375],
"size": [306.36004638671875, 58],
"flags": {},
"order": 0,
"mode": 0,
"inputs": [],
"outputs": [
{
"name": "VAE",
"type": "VAE",
"links": [76],
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "VAELoader",
+ "models": [
+ {
+ "name": "wan_2.1_vae.safetensors",
+ "url": "https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/vae/wan_2.1_vae.safetensors?download=true",
+ "hash": "2fc39d31359a4b0a64f55876d8ff7fa8d780956ae2cb13463b0223e15148976b"
+ "hash_type": "SHA256",
+ "directory": "vae"
+ }
+ ]
},
"widgets_values": ["wan_2.1_vae.safetensors"]
},
```
```diff
{
"id": 38,
"type": "CLIPLoader",
"pos": [12.94982624053955, 184.6981658935547],
"size": [390, 82],
"flags": {},
"order": 1,
"mode": 0,
"inputs": [],
"outputs": [
{
"name": "CLIP",
"type": "CLIP",
"links": [74, 75],
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "CLIPLoader",
+ "models": [
+ {
+ "name": "umt5_xxl_fp8_e4m3fn_scaled.safetensors",
+ "url": "https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors?download=true",
+ "hash": "c3355d30191f1f066b26d93fba017ae9809dce6c627dda5f6a66eaa651204f68",
+ "hash_type": "SHA256",
+ "directory": "text_encoders"
+ }
+ ]
},
"widgets_values": [
"umt5_xxl_fp8_e4m3fn_scaled.safetensors",
"wan",
"default"
]
},
```
```diff
{
"id": 37,
"type": "UNETLoader",
"pos": [485.1220397949219, 57.094566345214844],
"size": [346.7470703125, 82],
"flags": {},
"order": 3,
"mode": 0,
"inputs": [],
"outputs": [
{
"name": "MODEL",
"type": "MODEL",
"links": [92],
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "UNETLoader",
+ "models": [
+ {
+ "name": "wan2.1_t2v_1.3B_bf16.safetensors",
+ "url": "https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/diffusion_models/wan2.1_t2v_1.3B_bf16.safetensors?download=true",
+ "hash": "6f999b0d6cb9a72b3d98ac386ed96f57f8cecae13994a69232514ea4974ad5fd",
+ "hash_type": "SHA256",
+ "directory": "diffusion_models"
+ }
+ ]
},
"widgets_values": ["wan2.1_t2v_1.3B_bf16.safetensors", "default"]
},
```
You can find the `hash` and `hash_type` for a model on huggingface (see below)or by calculating it yourself with a script or online tool.

[Workflow spec](https://docs.comfy.org/specs/workflow_json) and [ModelFile Zod schema](https://github.com/Comfy-Org/ComfyUI_frontend/blob/6bc03a624ecbc0439501d0c7c2b073ca90e9a742/src/schemas/comfyWorkflowSchema.ts#L34-L40) for more details.
> [!CAUTION]
>
> Ensure that the filename being downloaded from the links matches the filenames in the `widgets_values` exactly.
### 10 — Embed Node Versions (optional)
If your template requires a specific version of Comfy or a custom node, you can specify that using the same process as with models.
The Wan 2.1 workflow requires the SaveWEBM node which wasn't fully supported until ComfyUI v0.3.26. I can add this information into the SaveWEBM node:
```diff
{
"id": 47,
"type": "SaveWEBM",
"pos": [2367.213134765625, 193.6114959716797],
"size": [315, 130],
"flags": {},
"order": 9,
"mode": 4,
"inputs": [
{
"name": "images",
"type": "IMAGE",
"link": 93
}
],
"outputs": [],
"properties": {
"Node name for S&R": "SaveWEBM",
+ "cnr_id": "comfy-core",
+ "ver": "0.3.26"
},
"widgets_values": ["ComfyUI", "vp9", 24, 32]
},
```
This can help diagnose issues when others run the workflow and ensure the workflow is more reproducible.
### 11 — Add Documentation Nodes (optional)
If your template corresponds with a page on https://github.com/comfyanonymous/ComfyUI_examples, https://docs.comfy.org/custom-nodes/workflow_templates, etc., you can add a `MarkdownNote` node with links:

Raw markdown used:
```markdown
### Learn more about this workflow
> [Wan - ComfyUI_examples](https://comfyanonymous.github.io/ComfyUI_examples/wan/#text-to-video) — Overview
>
> [Wan 2.1 Tutorial - docs.comfy.org](https://docs.comfy.org/tutorials/video/wan/wan-video) — Explanation of concepts and step-by-step tutorial
```
### 12 — Sync Translations
Before creating your PR, sync your template to all language versions using the translation management script.
1. Run the translation sync script:
```bash
python3 scripts/sync_data.py --templates-dir templates
```
2. The script will:
- Auto-sync technical fields (models, date, size, etc.) to all language files
- Detect untranslated title/description fields
- Add your template to `scripts/i18n.json` for translation tracking
- Generate language-specific template files (index.zh.json, index.ja.json, etc.)
3. (Optional) Add translations in `scripts/i18n.json`:
```json
{
"templates": {
"your_template_name": {
"title": {
"en": "Your Template Title",
"zh": "您的模板标题"
},
"description": {
"en": "Your template description",
"zh": "您的模板描述"
}
}
}
}
```
4. Run sync again to apply your translations
For detailed instructions, see [scripts/I18N_GUIDE.md](scripts/I18N_GUIDE.md).
### 13 — Create PR
1. Fully test the workflow: delete the models, input images, etc. and try it as a new user would. Ensure the process has no hiccups and you can generate the thumbnail image on the first execution (if applicable).
2. Verify all language files (index.zh.json, index.ja.json, etc.) are synced and committed
3. Create a fork of https://github.com/Comfy-Org/workflow_templates (or just checkout a new branch if you are a Comfy-Org collaborator)
4. Clone the fork to your system (if not a collaborator)
5. Copy your new workflow and thumbnail(s) into the `templates` folder
6. Add your changes to the `templates/index.json` file
7. **Bump the version in the root `pyproject.toml`** ([example](https://github.com/Comfy-Org/workflow_templates/pull/32))
8. Commit and push changes
9. Create a PR on https://github.com/Comfy-Org/workflow_templates
Version bumping and package building are automated via CI/CD. Bumping the root `pyproject.toml` version automatically:
- Detects which subpackages have changed since their last release
- Bumps versions only for affected packages
- Updates all dependency references
- Builds and publishes packages to PyPI
Here is the PR I made for the Wan template: https://github.com/Comfy-Org/workflow_templates/pull/16
Once the PR is merged, if you followed step 6 correctly, a new version will be published to the [comfyui-workflow-templates PyPi package](https://pypi.org/project/comfyui-workflow-templates).
---
## Adding New Blueprints
Subgraph Blueprints are reusable workflow components that appear as single nodes in ComfyUI. They use the native ComfyUI subgraph format.
For detailed documentation, see [docs/BLUEPRINTS.md](docs/BLUEPRINTS.md).
### Quick Guide
#### Option 1: Import from External Source
1. Copy blueprint JSON files to `blueprints/` directory
2. Run the import script to normalize names and generate metadata:
```bash
python scripts/import_blueprints.py
```
3. Sync to packages:
```bash
python scripts/sync_blueprints.py
```
#### Option 2: Create in ComfyUI
1. Build your workflow in ComfyUI
2. Select nodes → Right-click → "Create Subgraph"
3. Export the workflow JSON
4. Copy to `blueprints/` with a snake_case filename (e.g., `text_to_image_flux.json`)
5. Run import and sync scripts
### Blueprint File Structure
```
blueprints/
├── index.json # Generated metadata for UI
├── index.schema.json # Validation schema
├── text_to_image_flux_1_dev.json # Blueprint (native ComfyUI subgraph format)
├── text_to_image_flux_1_dev-1.webp # Thumbnail (optional)
└── ...
```
### Blueprint JSON Format
Blueprints use the native ComfyUI subgraph format with `definitions.subgraphs`:
```json
{
"id": "workflow-uuid",
"nodes": [{"id": -1, "type": "subgraph-uuid", ...}],
"definitions": {
"subgraphs": [{
"id": "subgraph-uuid",
"name": "Text to Image (Flux.1 Dev)",
"inputs": [
{"name": "text", "type": "STRING"},
{"name": "width", "type": "INT"}
],
"outputs": [
{"name": "IMAGE", "type": "IMAGE"}
],
"nodes": [...],
"links": [...]
}]
}
}
```
### Sync Commands
```bash
# Import and normalize external blueprints
python scripts/import_blueprints.py
# Generate manifest and sync to packages
python scripts/sync_blueprints.py
```
### Create PR
1. Test the blueprint in ComfyUI
2. Ensure `python scripts/sync_blueprints.py` produces no changes
3. Bump version in root `pyproject.toml`
4. Create PR
---
## Validation
CI automatically validates:
| Check | Templates | Blueprints |
|-------|-----------|------------|
| JSON syntax | ✅ | ✅ |
| Schema validation | ✅ | ✅ |
| Bundle consistency | ✅ | ✅ |
| Manifest sync | ✅ | ✅ |
| Thumbnails | ✅ | ❌ (optional) |
Run locally before committing:
```bash
python scripts/sync_bundles.py # Templates
python scripts/sync_blueprints.py # Blueprints
```
| text/markdown | Comfy-Org | null | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"comfyui-workflow-templates-core==0.3.147",
"comfyui-workflow-templates-media-api==0.3.54",
"comfyui-workflow-templates-media-video==0.3.49",
"comfyui-workflow-templates-media-image==0.3.90",
"comfyui-workflow-templates-media-other==0.3.123",
"comfyui-workflow-templates-media-api==0.3.54; extra == \"api\"... | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T17:38:08.358724 | comfyui_workflow_templates-0.8.45.tar.gz | 16,242 | 3e/c8/b77efb4286593d97ad5d91f3369237ef8f6288f35d9e57555b799a1f6b10/comfyui_workflow_templates-0.8.45.tar.gz | source | sdist | null | false | 8361647953f9d04dff896be88c369b40 | d0ba71d158033ee46d67d695d6b210dec174bc42246875ad53922a2199aca465 | 3ec8b77efb4286593d97ad5d91f3369237ef8f6288f35d9e57555b799a1f6b10 | null | [
"LICENSE"
] | 2,213 |
2.4 | legend-pydataobj | 2.0.0a2 | LEGEND Python Data Objects | # legend-pydataobj
[](https://pypi.org/project/legend-pydataobj/)

[](https://github.com/legend-exp/legend-pydataobj/actions)
[](https://github.com/pre-commit/pre-commit)
[](https://github.com/psf/black)
[](https://app.codecov.io/gh/legend-exp/legend-pydataobj)



[](https://legend-pydataobj.readthedocs.io)
[](https://doi.org/10.5281/zenodo.10592107)
This package provides a Python implementation of the LEGEND Data Objects (LGDO)
and I/O to HDF5, including [Numba](https://numba.pydata.org/)-accelerated custom
compression algorithms for particle detector signals. More documentation is
available in the
[LEGEND data format specification](https://legend-exp.github.io/legend-data-format-specs).
If you are using this software,
[consider citing](https://doi.org/10.5281/zenodo.10592107)!
| text/markdown | The LEGEND Collaboration | null | The LEGEND Collaboration | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Operating System :: MacOS",
"Operating System :: POSIX",
"Operating System :: Unix",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python... | [] | null | null | >=3.10 | [] | [] | [] | [
"awkward>=2",
"awkward-pandas",
"colorlog",
"hist",
"legend-lh5io",
"numba!=0.53.*,!=0.54.*",
"numexpr",
"numpy>=1.21",
"pandas>=1.4.4",
"parse",
"pint>0.24",
"pint-pandas",
"legend-pydataobj[docs,test]; extra == \"all\"",
"furo; extra == \"docs\"",
"hist[plot]; extra == \"docs\"",
"ju... | [] | [] | [] | [
"Homepage, https://github.com/legend-exp/legend-pydataobj",
"Bug Tracker, https://github.com/legend-exp/legend-pydataobj/issues",
"Discussions, https://github.com/legend-exp/legend-pydataobj/discussions",
"Changelog, https://github.com/legend-exp/legend-pydataobj/releases"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:38:07.085425 | legend_pydataobj-2.0.0a2.tar.gz | 64,592 | 9a/04/23d1d1e0f15d4fa4387ea8929200848c228c5318824eb53c9432e2e691ae/legend_pydataobj-2.0.0a2.tar.gz | source | sdist | null | false | f0f897e7e66ff94787be6d29dea903f0 | 68d321ff7d4d714fed9776cc2b08a52092718ed05f3f8aedee943348838bec6a | 9a0423d1d1e0f15d4fa4387ea8929200848c228c5318824eb53c9432e2e691ae | GPL-3.0 | [
"LICENSE"
] | 236 |
2.4 | comfyui-workflow-templates-media-other | 0.3.123 | Media bundle containing audio/3D/misc workflow assets | Media bundle containing audio, 3D, and other workflow assets for ComfyUI.
| text/plain | null | null | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T17:38:00.534885 | comfyui_workflow_templates_media_other-0.3.123.tar.gz | 69,052,086 | 66/61/440098444de05baa42697b0d2ee501d879fb995a9c68dccc47f36309c3b9/comfyui_workflow_templates_media_other-0.3.123.tar.gz | source | sdist | null | false | c0151f3bb1b8516d029cb2e412491eb9 | 092f2eca53abed6a769a3a99d4c2644434bc219c45b0ebe7e28d466eb6e49703 | 6661440098444de05baa42697b0d2ee501d879fb995a9c68dccc47f36309c3b9 | MIT | [] | 2,283 |
2.4 | comfyui-workflow-templates-core | 0.3.147 | Core helpers for ComfyUI workflow templates | Core helpers for ComfyUI workflow templates.
| text/plain | null | null | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T17:37:46.505199 | comfyui_workflow_templates_core-0.3.147.tar.gz | 50,143 | a4/a7/129c23610a513a3fe3d86b9577c2c827ec3fd89e7eae4c91bdbf0a64853a/comfyui_workflow_templates_core-0.3.147.tar.gz | source | sdist | null | false | 05fc2a551d397618e6fd4304dc887109 | c9ac383954c823072986589bffabfc68e73c5116d07db49840e5810fd564c761 | a4a7129c23610a513a3fe3d86b9577c2c827ec3fd89e7eae4c91bdbf0a64853a | MIT | [] | 2,252 |
2.4 | mmar-mcli | 1.0.15 | Client to Maestro | # MMAR Maestro Client
| text/markdown | tagin | tagin <tagin@airi.net> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Pyth... | [] | null | null | >=3.12 | [] | [] | [] | [
"aiohttp==3.12.15",
"loguru==0.7.3",
"mmar-mapi~=1.4.2",
"mmar-utils~=1.1.16"
] | [] | [] | [] | [] | uv/0.5.31 | 2026-02-19T17:35:57.031126 | mmar_mcli-1.0.15.tar.gz | 5,389 | a6/0e/593e20e8658e605890fe5efb1a7030df132e1c338c35ece5ab506b7fd06c/mmar_mcli-1.0.15.tar.gz | source | sdist | null | false | 6a8e39711ff0aeef84f359662198e10e | c13c25ef4c7ea31ef357aaffa51fdd02170fdc0c6ac2ea086ebd8cd4b22cc985 | a60e593e20e8658e605890fe5efb1a7030df132e1c338c35ece5ab506b7fd06c | MIT | [
"LICENSE"
] | 201 |
2.4 | mirth-connect-mcp | 0.1.1 | FastMCP server for NextGen Connect (Mirth) API | # mirth_connect_mcp
MCP server for NextGen Connect (Mirth) that exposes API operations as domain-grouped tools.
## Requirements
- Python 3.13+
- Reachable NextGen Connect API endpoint
- Credentials with API access
## Install
Recommended (global command available in PATH):
```bash
uv tool install mirth_connect_mcp
```
Alternative:
```bash
pip install mirth_connect_mcp
```
After install, the command is:
```bash
mirth-connect-mcp
```
## Environment variables
Required:
- `MIRTH_BASE_URL` (example: `https://localhost:8443/api`)
- `MIRTH_USERNAME`
- `MIRTH_PASSWORD`
Optional:
- `MIRTH_VERIFY_SSL` (`true` by default; set `false` for local self-signed certs)
- `MIRTH_TIMEOUT_SECONDS` (`30` by default)
- `MIRTH_OPENAPI_PATH` (defaults to bundled OpenAPI spec)
## Add to MCP clients
Use `stdio` transport for all client configs below.
### VS Code (MCP)
Open your VS Code MCP config (`mcp.json`) and add:
```json
{
"servers": {
"mirthNextgen": {
"type": "stdio",
"command": "mirth-connect-mcp",
"env": {
"MIRTH_BASE_URL": "https://localhost:8443/api",
"MIRTH_USERNAME": "admin",
"MIRTH_PASSWORD": "admin",
"MIRTH_VERIFY_SSL": "false"
}
}
}
}
```
### Cline
In Cline MCP settings, add this server entry:
```json
{
"mcpServers": {
"mirthNextgen": {
"command": "mirth-connect-mcp",
"args": [],
"env": {
"MIRTH_BASE_URL": "https://localhost:8443/api",
"MIRTH_USERNAME": "admin",
"MIRTH_PASSWORD": "admin",
"MIRTH_VERIFY_SSL": "false"
}
}
}
}
```
### Claude Desktop
In `claude_desktop_config.json`, add:
```json
{
"mcpServers": {
"mirthNextgen": {
"command": "mirth-connect-mcp",
"env": {
"MIRTH_BASE_URL": "https://localhost:8443/api",
"MIRTH_USERNAME": "admin",
"MIRTH_PASSWORD": "admin",
"MIRTH_VERIFY_SSL": "false"
}
}
}
}
```
### Gemini CLI
In your Gemini CLI MCP config, add:
```json
{
"mcpServers": {
"mirthNextgen": {
"command": "mirth-connect-mcp",
"env": {
"MIRTH_BASE_URL": "https://localhost:8443/api",
"MIRTH_USERNAME": "admin",
"MIRTH_PASSWORD": "admin",
"MIRTH_VERIFY_SSL": "false"
}
}
}
}
```
## Tool model
Built-in tools:
- `list_domains`
- `list_actions`
- One dispatch tool per OpenAPI domain/tag
Domain tool request envelope:
```json
{
"action": "operationId",
"path_params": {},
"query": {},
"body": {},
"headers_override": {}
}
```
| text/markdown | KCM | null | null | null | null | mcp, fastmcp, mirth, nextgen-connect, openapi | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries",
"Topic :: Internet :: WWW/HTTP"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"fastmcp>=3.0.0",
"httpx>=0.27",
"pytest>=8.0.0; extra == \"dev\"",
"pytest-asyncio>=0.24.0; extra == \"dev\"",
"build>=1.2.2.post1; extra == \"dev\"",
"twine>=5.1.1; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:35:48.337429 | mirth_connect_mcp-0.1.1.tar.gz | 48,197 | bb/a7/977a182729439412406ce10f3541a74569bfd9a7e3fcafa111ea1bbe63e2/mirth_connect_mcp-0.1.1.tar.gz | source | sdist | null | false | 671205ae28bf2324d31c11fc297e1138 | 237ddc4643e4c8cc1b97eefe2dff53faf6696f5ee69e292c7beb430c7bb60498 | bba7977a182729439412406ce10f3541a74569bfd9a7e3fcafa111ea1bbe63e2 | MIT | [
"LICENSE"
] | 228 |
2.4 | stripe | 14.4.0a4 | Python bindings for the Stripe API | # Stripe Python Library
[](https://pypi.python.org/pypi/stripe)
[](https://github.com/stripe/stripe-python/actions?query=branch%3Amaster)
The Stripe Python library provides convenient access to the Stripe API from
applications written in the Python language. It includes a pre-defined set of
classes for API resources that initialize themselves dynamically from API
responses which makes it compatible with a wide range of versions of the Stripe
API.
## API Documentation
See the [Python API docs](https://stripe.com/docs/api?lang=python).
## Installation
This package is available on PyPI:
```sh
pip install --upgrade stripe
```
Alternatively, install from source with:
```sh
python -m pip install .
```
### Requirements
Per our [Language Version Support Policy](https://docs.stripe.com/sdks/versioning?lang=python#stripe-sdk-language-version-support-policy), we currently support **Python 3.7+**.
Support for Python 3.7 and 3.8 is deprecated and will be removed in an upcoming major version. Read more and see the full schedule in the docs: https://docs.stripe.com/sdks/versioning?lang=python#stripe-sdk-language-version-support-policy
#### Extended Support
#### Python 2.7 deprecation
[The Python Software Foundation (PSF)](https://www.python.org/psf-landing/) community [announced the end of support of Python 2](https://www.python.org/doc/sunset-python-2/) on 01 January 2020.
Starting with version 6.0.0 Stripe SDK Python packages will no longer support Python 2.7. To continue to get new features and security updates, please make sure to update your Python runtime to Python 3.6+.
The last version of the Stripe SDK that supported Python 2.7 was **5.5.0**.
## Usage
The library needs to be configured with your account's secret key which is
available in your [Stripe Dashboard][api-keys]. Set `stripe.api_key` to its
value:
```python
from stripe import StripeClient
client = StripeClient("sk_test_...")
# list customers
customers = client.v1.customers.list()
# print the first customer's email
print(customers.data[0].email)
# retrieve specific Customer
customer = client.v1.customers.retrieve("cus_123456789")
# print that customer's email
print(customer.email)
```
### StripeClient vs legacy pattern
We introduced the `StripeClient` class in v8 of the Python SDK. The legacy pattern used prior to that version is still available to use but will be marked as deprecated soon. Review the [migration guide to use StripeClient](<https://github.com/stripe/stripe-python/wiki/Migration-guide-for-v8-(StripeClient)>) to move from the legacy pattern.
Once the legacy pattern is deprecated, new API endpoints will only be accessible in the StripeClient. While there are no current plans to remove the legacy pattern for existing API endpoints, this may change in the future.
### Handling exceptions
Unsuccessful requests raise exceptions. The class of the exception will reflect
the sort of error that occurred. Please see the [Api
Reference](https://stripe.com/docs/api/errors/handling) for a description of
the error classes you should handle, and for information on how to inspect
these errors.
### Per-request Configuration
Configure individual requests with the `options` argument. For example, you can make
requests with a specific [Stripe Version](https://stripe.com/docs/api#versioning)
or as a [connected account](https://stripe.com/docs/connect/authentication#authentication-via-the-stripe-account-header):
```python
from stripe import StripeClient
client = StripeClient("sk_test_...")
# list customers
client.v1.customers.list(
options={
"api_key": "sk_test_...",
"stripe_account": "acct_...",
"stripe_version": "2019-02-19",
}
)
# retrieve single customer
client.v1.customers.retrieve(
"cus_123456789",
options={
"api_key": "sk_test_...",
"stripe_account": "acct_...",
"stripe_version": "2019-02-19",
}
)
```
### Configuring an HTTP Client
You can configure your `StripeClient` to use `urlfetch`, `requests`, `pycurl`, or
`urllib` with the `http_client` option:
```python
client = StripeClient("sk_test_...", http_client=stripe.UrlFetchClient())
client = StripeClient("sk_test_...", http_client=stripe.RequestsClient())
client = StripeClient("sk_test_...", http_client=stripe.PycurlClient())
client = StripeClient("sk_test_...", http_client=stripe.UrllibClient())
```
Without a configured client, by default the library will attempt to load
libraries in the order above (i.e. `urlfetch` is preferred with `urllib2` used
as a last resort). We usually recommend that people use `requests`.
### Configuring a Proxy
A proxy can be configured with the `proxy` client option:
```python
client = StripeClient("sk_test_...", proxy="https://user:pass@example.com:1234")
```
### Configuring Automatic Retries
You can enable automatic retries on requests that fail due to a transient
problem by configuring the maximum number of retries:
```python
client = StripeClient("sk_test_...", max_network_retries=2)
```
Various errors can trigger a retry, like a connection error or a timeout, and
also certain API responses like HTTP status `409 Conflict`.
[Idempotency keys][idempotency-keys] are automatically generated and added to
requests, when not given, to guarantee that retries are safe.
### Logging
The library can be configured to emit logging that will give you better insight
into what it's doing. The `info` logging level is usually most appropriate for
production use, but `debug` is also available for more verbosity.
There are a few options for enabling it:
1. Set the environment variable `STRIPE_LOG` to the value `debug` or `info`
```sh
$ export STRIPE_LOG=debug
```
2. Set `stripe.log`:
```python
import stripe
stripe.log = 'debug'
```
3. Enable it through Python's logging module:
```python
import logging
logging.basicConfig()
logging.getLogger('stripe').setLevel(logging.DEBUG)
```
### Accessing response code and headers
You can access the HTTP response code and headers using the `last_response` property of the returned resource.
```python
customer = client.v1.customers.retrieve(
"cus_123456789"
)
print(customer.last_response.code)
print(customer.last_response.headers)
```
### How to use undocumented parameters and properties
In some cases, you might encounter parameters on an API request or fields on an API response that aren’t available in the SDKs.
This might happen when they’re undocumented or when they’re in preview and you aren’t using a preview SDK.
See [undocumented params and properties](https://docs.stripe.com/sdks/server-side?lang=python#undocumented-params-and-fields) to send those parameters or access those fields.
### Writing a Plugin
If you're writing a plugin that uses the library, we'd appreciate it if you
identified using `stripe.set_app_info()`:
```py
stripe.set_app_info("MyAwesomePlugin", version="1.2.34", url="https://myawesomeplugin.info")
```
This information is passed along when the library makes calls to the Stripe
API.
### Telemetry
By default, the library sends telemetry to Stripe regarding request latency and feature usage. These
numbers help Stripe improve the overall latency of its API for all users, and
improve popular features.
You can disable this behavior if you prefer:
```python
stripe.enable_telemetry = False
```
## Types
In [v7.1.0](https://github.com/stripe/stripe-python/releases/tag/v7.1.0) and
newer, the
library includes type annotations. See [the wiki](https://github.com/stripe/stripe-python/wiki/Inline-type-annotations)
for a detailed guide.
Please note that some annotations use features that were only fairly recently accepted,
such as [`Unpack[TypedDict]`](https://peps.python.org/pep-0692/#specification) that was
[accepted](https://discuss.python.org/t/pep-692-using-typeddict-for-more-precise-kwargs-typing/17314/81)
in January 2023. We have tested that these types are recognized properly by [Pyright](https://github.com/microsoft/pyright).
Support for `Unpack` in MyPy is still experimental, but appears to degrade gracefully.
Please [report an issue](https://github.com/stripe/stripe-python/issues/new/choose) if there
is anything we can do to improve the types for your type checker of choice.
### Types and the Versioning Policy
We release type changes in minor releases. While stripe-python follows semantic
versioning, our semantic versions describe the _runtime behavior_ of the
library alone. Our _type annotations are not reflected in the semantic
version_. That is, upgrading to a new minor version of stripe-python might
result in your type checker producing a type error that it didn't before. You
can use a `~=x.x` or `x.x.*` [version specifier](https://peps.python.org/pep-0440/#examples)
in your `requirements.txt` to constrain `pip` to a certain minor range of `stripe-python`.
### Types and API Versions
The types describe the [Stripe API version](https://stripe.com/docs/api/versioning)
that was the latest at the time of release. This is the version that your library
sends by default. If you are overriding `stripe.api_version` / `stripe_version` on the `StripeClient`, or using a
[webhook endpoint](https://stripe.com/docs/webhooks#api-versions) tied to an older version,
be aware that the data you see at runtime may not match the types.
### Public Preview SDKs
Stripe has features in the [public preview phase](https://docs.stripe.com/release-phases) that can be accessed via versions of this package that have the `bX` suffix like `12.2.0b2`.
We would love for you to try these as we incrementally release new features and improve them based on your feedback.
To install, pick the latest version with the `bX` suffix by reviewing the [releases page](https://github.com/stripe/stripe-python/releases/) and then use it in the `pip install` command:
```
pip install stripe==<replace-with-the-version-of-your-choice>
```
> **Note**
> There can be breaking changes between two versions of the public preview SDKs without a bump in the major version. Therefore we recommend pinning the package version to a specific version in your [pyproject.toml](https://packaging.python.org/en/latest/guides/writing-pyproject-toml/#dependencies-and-requirements) or [requirements file](https://pip.pypa.io/en/stable/user_guide/#requirements-files). This way you can install the same version each time without breaking changes unless you are intentionally looking for the latest public preview SDK.
Some preview features require a name and version to be set in the `Stripe-Version` header like `feature_beta=v3`. If your preview feature has this requirement, use the `stripe.add_beta_version` function (available only in the public preview SDKs):
```python
stripe.add_beta_version("feature_beta", "v3")
```
### Private Preview SDKs
Stripe has features in the [private preview phase](https://docs.stripe.com/release-phases) that can be accessed via versions of this package that have the `aX` suffix like `12.2.0a2`. These are invite-only features. Once invited, you can install the private preview SDKs by following the same instructions as for the [public preview SDKs](https://github.com/stripe/stripe-python?tab=readme-ov-file#public-preview-sdks) above and replacing the suffix `b` with `a` in package versions.
### Custom requests
> This feature is only available from version 11 of this SDK.
If you would like to send a request to an undocumented API (for example you are in a private beta), or if you prefer to bypass the method definitions in the library and specify your request details directly, you can use the `raw_request` method on `StripeClient`.
```python
client = StripeClient("sk_test_...")
response = client.raw_request(
"post", "/v1/beta_endpoint", param=123, stripe_version="2022-11-15; feature_beta=v3"
)
# (Optional) response is a StripeResponse. You can use `client.deserialize` to get a StripeObject.
deserialized_resp = client.deserialize(response, api_mode='V1')
```
### Async
Asynchronous versions of request-making methods are available by suffixing the method name
with `_async`.
```python
# With StripeClient
client = StripeClient("sk_test_...")
customer = await client.v1.customers.retrieve_async("cus_xyz")
# With global client
stripe.api_key = "sk_test_..."
customer = await stripe.Customer.retrieve_async("cus_xyz")
# .auto_paging_iter() implements both AsyncIterable and Iterable
async for c in await stripe.Customer.list_async().auto_paging_iter():
...
```
There is no `.save_async` as `.save` is [deprecated since stripe-python v5](https://github.com/stripe/stripe-python/wiki/Migration-guide-for-v5#deprecated). Please migrate to `.modify_async`.
The default HTTP client uses `requests` for making synchronous requests but
`httpx` for making async requests. If you're migrating to async, we recommend
you to explicitly initialize your own http client and pass it to StripeClient
or set it as the global default.
If you don't already have a dependency on an async-compatible HTTP library, `pip install stripe[async]` will install one for you (new in `v13.0.1`).
```python
# By default, an explicitly initialized HTTPXClient will raise an exception if you
# attempt to call a sync method. If you intend to only use async, this is useful to
# make sure you don't unintentionally make a synchronous request.
my_http_client = stripe.HTTPXClient()
# If you want to use httpx to make sync requests, you can disable this
# behavior.
my_http_client = stripe.HTTPXClient(allow_sync_methods=True)
# aiohttp is also available (does not support sync requests)
my_http_client = stripe.AIOHTTPClient()
# With StripeClient
client = StripeClient("sk_test_...", http_client=my_http_client)
# With the global client
stripe.default_http_client = my_http_client
```
You can also subclass `stripe.HTTPClient` and provide your own instance.
## Support
New features and bug fixes are released on the latest major version of the Stripe Python library. If you are on an older major version, we recommend that you upgrade to the latest in order to use the new features and bug fixes including those for security vulnerabilities. Older major versions of the package will continue to be available for use, but will not be receiving any updates.
## Development
[Contribution guidelines for this project](CONTRIBUTING.md)
The test suite depends on [stripe-mock], so make sure to fetch and run it from a
background terminal ([stripe-mock's README][stripe-mock] also contains
instructions for installing via Homebrew and other methods):
```sh
go install github.com/stripe/stripe-mock@latest
stripe-mock
```
We use [just](https://github.com/casey/just) for conveniently running development tasks. You can use them directly, or copy the commands out of the `justfile`. To our help docs, run `just`. By default, all commands will use an virtualenv created by your default python version (whatever comes out of `python --version`). We recommend using [mise](https://mise.jdx.dev/lang/python.html) or [pyenv](https://github.com/pyenv/pyenv) to control that version.
Run the following command to set up the development virtualenv:
```sh
just venv
# or: python -m venv venv && venv/bin/python -I -m pip install -e .
```
Run all tests:
```sh
just test
# or: venv/bin/pytest
```
Run all tests in a single file:
```sh
just test tests/api_resources/abstract/test_updateable_api_resource.py
# or: venv/bin/pytest tests/api_resources/abstract/test_updateable_api_resource.py
```
Run a single test suite:
```sh
just test tests/api_resources/abstract/test_updateable_api_resource.py::TestUpdateableAPIResource
# or: venv/bin/pytest tests/api_resources/abstract/test_updateable_api_resource.py::TestUpdateableAPIResource
```
Run a single test:
```sh
just test tests/api_resources/abstract/test_updateable_api_resource.py::TestUpdateableAPIResource::test_save
# or: venv/bin/pytest tests/api_resources/abstract/test_updateable_api_resource.py::TestUpdateableAPIResource::test_save
```
Run the linter with:
```sh
just lint
# or: venv/bin/python -m flake8 --show-source stripe tests
```
The library uses [Ruff][ruff] for code formatting. Code must be formatted
with Black before PRs are submitted, otherwise CI will fail. Run the formatter
with:
```sh
just format
# or: venv/bin/ruff format . --quiet
```
Update bundled CA certificates from the [Mozilla cURL release][curl]:
```sh
just update-certs
```
[api-keys]: https://dashboard.stripe.com/account/apikeys
[ruff]: https://github.com/astral-sh/ruff
[connect]: https://stripe.com/connect
[poetry]: https://github.com/sdispater/poetry
[stripe-mock]: https://github.com/stripe/stripe-mock
[idempotency-keys]: https://stripe.com/docs/api/idempotent_requests?lang=python
<!--
# vim: set tw=79:
-->
| text/markdown | null | Stripe <support@stripe.com> | null | null | null | stripe, api, payments | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Languag... | [] | null | null | >=3.7 | [] | [] | [] | [
"typing_extensions<=4.2.0,>3.7.2; python_version < \"3.7\"",
"typing_extensions>=4.5.0; python_version >= \"3.7\"",
"requests>=2.20; python_version >= \"3.0\"",
"httpx; extra == \"async\""
] | [] | [] | [] | [
"changelog, https://github.com/stripe/stripe-python/blob/master/CHANGELOG.md",
"documentation, https://stripe.com/docs/api/?lang=python",
"homepage, https://stripe.com/",
"issues, https://github.com/stripe/stripe-python/issues",
"source, https://github.com/stripe/stripe-python"
] | twine/6.1.0 CPython/3.10.19 | 2026-02-19T17:35:40.805713 | stripe-14.4.0a4.tar.gz | 1,994,717 | 76/54/0aef61ed678572a2ee0c22ba33d10431d6ecaf23185a8dbd24bf68a2c281/stripe-14.4.0a4.tar.gz | source | sdist | null | false | eca1f9728a2074e6c788a09e9fc2b1da | 0290dd6dde9d63a179b43287b0e440759e13e9072576cba5706b260f2ababb1f | 76540aef61ed678572a2ee0c22ba33d10431d6ecaf23185a8dbd24bf68a2c281 | null | [
"LICENSE"
] | 239 |
2.4 | ai-protocol-mock | 0.1.6 | Unified mock server for AI-Protocol runtimes - HTTP provider and MCP JSON-RPC mocking | # ai-protocol-mock
Unified mock server for AI-Protocol runtimes. Provides HTTP provider mock (OpenAI and Anthropic formats) and MCP JSON-RPC mock for testing ai-lib-python, ai-lib-rust, and other runtimes.
## Features
- **Manifest-driven HTTP mock**: Generates responses in OpenAI or Anthropic format based on provider manifests
- **STT / TTS / Rerank mock**: Simulates speech-to-text, text-to-speech, and document reranking endpoints (OpenAI/Cohere compliant)
- **MCP JSON-RPC mock**: Implements `tools/list`, `tools/call`, `capabilities`, `initialize`
- **Configurable**: Response delay, error rate, mock content via environment variables
- **Docker**: One-command startup with `docker-compose up`
## Quick Start
```bash
# Install and run
pip install -e .
python scripts/sync_manifests.py --force # Sync manifests from ai-protocol
uvicorn ai_protocol_mock.main:app --host 0.0.0.0 --port 4010
```
Or with Docker:
```bash
docker-compose up -d
```
## Configuration
| Variable | Default | Description |
|----------|---------|-------------|
| HTTP_PORT | 4010 | Port for HTTP and MCP (MCP at /mcp) |
| MANIFEST_DIR | manifests | Directory for synced manifests |
| MANIFEST_SYNC_URL | https://raw.githubusercontent.com/hiddenpath/ai-protocol/main/ | Source for manifest sync |
| RESPONSE_DELAY | 0 | Delay in seconds before responding |
| ERROR_RATE | 0 | Probability (0-1) of returning 429/500/503 |
| MOCK_CONTENT | Mock response from ai-protocol-mock | Default response content |
### Test Control Headers (X-Mock-*)
For integration tests, requests can include these headers to control mock behavior:
| Header | Description | Example |
|--------|-------------|---------|
| X-Mock-Status | Force HTTP error status (400-599) | 429, 500, 503 |
| X-Mock-Content | Override response content for this request | Custom text |
| X-Mock-Tool-Calls | Return tool_calls instead of text | 1, true, yes |
## Endpoints
- `POST /v1/chat/completions` - OpenAI-format chat
- `POST /v1/messages` - Anthropic-format chat
- `POST /v1/audio/transcriptions` - STT (OpenAI Whisper format), returns `{"text": "..."}`
- `POST /v1/audio/speech` - TTS (OpenAI format), returns `audio/mpeg` bytes
- `POST /v2/rerank` - Rerank (Cohere v2 format), request `{query, documents, top_n}`, returns `{results, id, meta}`
- `POST /mcp` - MCP JSON-RPC (`tools/list`, `tools/call`, `capabilities`, `initialize`)
- `GET /health` - Health check
- `GET /status` - Status with manifest sync metadata
- `GET /providers` - Provider contracts from manifests (provider_id, api_style, chat_path)
## Using with ai-lib-python
```python
import os
os.environ["MOCK_HTTP_URL"] = "http://localhost:4010"
from ai_lib_python.client import AiClient
from ai_lib_python.types.message import Message
client = await AiClient.create(
"openai/gpt-4o",
api_key="sk-test",
base_url="http://localhost:4010"
)
response = await client.chat().messages([Message.user("Hi")]).execute()
print(response.content)
```
Or run tests with mock:
```bash
MOCK_HTTP_URL=http://localhost:4010 MOCK_MCP_URL=http://localhost:4010/mcp pytest tests/ -v
```
**Remote / proxy environments**: If your machine uses HTTP/HTTPS proxy, set `NO_PROXY` to include the mock server IP so Python's httpx can reach it directly:
```bash
NO_PROXY=192.168.2.13,localhost,127.0.0.1 MOCK_HTTP_URL=http://192.168.2.13:4010 MOCK_MCP_URL=http://192.168.2.13:4010/mcp pytest tests/ -v
```
## Using with ai-lib-rust
```bash
export MOCK_HTTP_URL=http://localhost:4010
cargo run --example basic_usage
```
Or run mock integration tests:
```bash
MOCK_HTTP_URL=http://localhost:4010 MOCK_MCP_URL=http://localhost:4010/mcp cargo test -- --ignored --nocapture
```
Or in code:
```rust
let client = AiClientBuilder::new()
.base_url_override("http://localhost:4010")
.build("openai/gpt-4o")
.await?;
```
## Manifest Sync
Sync manifests from the ai-protocol repository:
```bash
python scripts/sync_manifests.py [--force] [--url URL] [--tag REF]
```
- `--force` - Overwrite existing files
- `--tag REF` - Pin to a specific ai-protocol ref (e.g. `v0.7.1`, `main`)
- `--url URL` - Custom base URL (default: ai-protocol main)
Run before starting the server to ensure manifests are up to date. Docker Compose runs sync automatically on startup. A GitHub Action runs sync daily to validate the script.
## Development
```bash
pip install -e ".[dev]"
pytest tests/ -v
ruff check src tests scripts
```
## License
MIT OR Apache-2.0
| text/markdown | AI-Protocol Team | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"fastapi>=0.109.0",
"httpx>=0.25.0",
"pydantic>=2.0",
"python-dotenv>=1.0.0",
"pyyaml>=6.0",
"uvicorn[standard]>=0.27.0",
"black>=24.0; extra == \"dev\"",
"pre-commit>=3.0; extra == \"dev\"",
"pytest-asyncio>=0.23; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.8; extra == \"dev\""... | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.7 | 2026-02-19T17:34:41.272382 | ai_protocol_mock-0.1.6.tar.gz | 15,223 | 64/87/bec3e8b49ed76b9d9576dd1d11d4c4b84f7cbc007e1f50d91c7c214afa36/ai_protocol_mock-0.1.6.tar.gz | source | sdist | null | false | b8c0256e53184bbc5560c963549a29a0 | 1f37ee19254c2ae75f7fdf0d6e4c0a43a4400486c43070e301e5bfd54453dfd7 | 6487bec3e8b49ed76b9d9576dd1d11d4c4b84f7cbc007e1f50d91c7c214afa36 | MIT OR Apache-2.0 | [
"LICENSE-APACHE",
"LICENSE-MIT"
] | 222 |
2.4 | sorix | 1.0.4 | A minimalistic and high-performance Machine Learning library based on NumPy | # 🌌 Sorix
<p align="center">
<img src="https://storage.googleapis.com/open-projects-data/Allison/training_animation.gif" width="600" alt="Sorix training animation">
</p>
<p align="center">
<a href="https://pypi.org/project/sorix/">
<img src="https://img.shields.io/pypi/v/sorix.svg?color=indigo" alt="PyPI version">
</a>
<a href="https://github.com/Mitchell-Mirano/sorix/actions">
<img src="https://github.com/Mitchell-Mirano/sorix/actions/workflows/tests.yml/badge.svg?branch=qa" alt="Tests status">
</a>
<a href="https://opensource.org/licenses/MIT">
<img src="https://img.shields.io/badge/License-MIT-orange.svg" alt="License: MIT">
</a>
<a href="https://github.com/Mitchell-Mirano/sorix/stargazers">
<img src="https://img.shields.io/github/stars/Mitchell-Mirano/sorix?style=social" alt="GitHub stars">
</a>
</p>
---
**Sorix** is a high-performance, minimalist deep learning library built on top of NumPy/CuPy. Designed for research and production environments where efficiency and a clean API matter. If you know **PyTorch**, you already know how to use **Sorix**.
[**📖 Read the Full Documentation**](https://mitchell-mirano.github.io/sorix/)
---
## 🚀 Key Features
* **⚡ High Performance**: Run optimized neural networks on NumPy (CPU) or CuPy (GPU).
* **🧩 PyTorch-like API**: Familiar and expressive syntax for a near-zero learning curve.
* **🍃 Lightweight**: Minimal dependencies, ideal for resource-constrained environments.
* **🛠️ Production Ready**: Straight path from prototype to real-world deployment.
* **📈 Autograd Engine**: Simple yet powerful automatic differentiation.
---
## 📦 Installation
Choose your preferred package manager:
**Using pip:**
```bash
pip install sorix
```
**Using uv:**
```bash
uv add sorix
```
**Using Poetry:**
```bash
poetry add sorix
```
> **Note for GPU support**: Install the CuPy extra using `pip install "sorix[cp13]"` (Requires CuPy v13 and CUDA).
---
## ⚡ Sorix in 30 Seconds
Building and training a model is intuitive. Here is a complete training loop:
```python
import numpy as np
from sorix import tensor
from sorix.nn import Linear, MSELoss
from sorix.optim import SGD
# 1. Prepare data (y = 3x + 2)
X = np.linspace(-1, 1, 100).reshape(-1, 1)
y = 3 * X + 2 + 0.1 * np.random.randn(*X.shape)
X_t, y_t = tensor(X), tensor(y)
# 2. Define model, loss, and optimizer
model = Linear(1, 1) # Simple y = Wx + b
criterion = MSELoss()
optimizer = SGD(model.parameters(), lr=0.1)
# 3. Training loop
for epoch in range(100):
y_pred = model(X_t)
loss = criterion(y_pred, y_t)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
# Learned: y = 3.00x + 2.00
print(f"Learned: y = {model.W.item():.2f}x + {model.b.item():.2f}")
```
---
## 📖 Learn & Examples
Learn Sorix through interactive notebooks. Open them directly in **Google Colab**:
| Topic | Documentation | Colab |
| :--- | :--- | :--- |
| **Tensor Basics** | [Tensors Guide](https://mitchell-mirano.github.io/sorix/latest/learn/01-tensor/) | [](https://colab.research.google.com/github/Mitchell-Mirano/sorix/blob/main/docs/learn/01-tensor.ipynb) |
| **Autograd Engine** | [Autograd Guide](https://mitchell-mirano.github.io/sorix/latest/learn/03-autograd/) | [](https://colab.research.google.com/github/Mitchell-Mirano/sorix/blob/main/docs/learn/03-autograd.ipynb) |
| **Linear Regression** | [Regression Guide](https://mitchell-mirano.github.io/sorix/latest/examples/nn/1-regression/) | [](https://colab.research.google.com/github/Mitchell-Mirano/sorix/blob/main/docs/examples/nn/1-regression.ipynb) |
| **MNIST Classification** | [MNIST Guide](https://mitchell-mirano.github.io/sorix/latest/examples/nn/4-digit-recognizer/) | [](https://colab.research.google.com/github/Mitchell-Mirano/sorix/blob/main/docs/examples/nn/4-digit-recognizer.ipynb) |
---
## 🛠️ Roadmap
- [x] **Core Autograd Engine** (NumPy/CuPy backends)
- [x] **Basic Layers**: Linear, ReLU, Sigmoid, Tanh, BatchNorm1D
- [x] **Optimizers**: SGD, Adam, RMSprop
- [x] **GPU Acceleration** via CuPy
- [ ] **Sequential API** (Coming soon)
- [ ] **Convolutional Layers** (Conv2d, MaxPool2d)
- [ ] **Dropout & Regularization**
- [ ] **Advanced Initializations** (Kaiming, Orthogonal)
---
## 🤝 Contribution
We appreciate any contribution from the community!
1. **Report Bugs**: Open an [Issue](https://github.com/Mitchell-Mirano/sorix/issues).
2. **Add Features**: Submit a [Pull Request](https://github.com/Mitchell-Mirano/sorix/pulls).
3. **Improve Docs**: Help us make the documentation better.
4. **Write Tests**: Improve our code [coverage](https://mitchell-mirano.github.io/sorix/).
---
## 📌 Links
* **Documentation**: [mitchell-mirano.github.io/sorix](https://mitchell-mirano.github.io/sorix/)
* **PyPI Package**: [sorix](https://pypi.org/project/sorix/)
* **Samples**: [examples/ folder](https://github.com/Mitchell-Mirano/sorix/tree/develop/docs/examples)
---
<p align="center">Made with ❤️ for the AI Community</p>
| text/markdown | null | Mitchell Mirano <mitchellmirano25@gmail.com> | null | null | MIT | machine-learning, deep-learning, neural-networks, autograd, numpy | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"numpy>=2.0",
"cupy-cuda13x>=13.0; extra == \"cp13\"",
"numpy<3.0,>=2.0; extra == \"cp13\""
] | [] | [] | [] | [
"Homepage, https://github.com/Mitchell-Mirano/sorix",
"Documentation, https://mitchell-mirano.github.io/sorix/",
"Repository, https://github.com/Mitchell-Mirano/sorix.git",
"Issues, https://github.com/Mitchell-Mirano/sorix/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:33:46.874016 | sorix-1.0.4.tar.gz | 1,729,269 | 62/62/98f411025ecdabd1a5b01b211f8a0db19bcf0a3d3a06e478af18a0ff7219/sorix-1.0.4.tar.gz | source | sdist | null | false | 1b8c9f41463a76398d6490273adb1bdf | 71b4da74151272281a0c2522ad8541775dbac5b8ac49106076f69e9a1658abce | 626298f411025ecdabd1a5b01b211f8a0db19bcf0a3d3a06e478af18a0ff7219 | null | [
"LICENSE"
] | 200 |
2.4 | orbitals | 0.1.5 | LLM Guardrails tailored to your Principles | <div align="center">
<img src="https://raw.githubusercontent.com/Principled-Intelligence/orbitals/refs/heads/main/assets/orbitals-banner.png" width="70%" />
<h3 align="center">
<p>
<b>LLM Guardrails tailored to your Principles</b>
</p>
</h4>
</div>
<p align="center">
<a href="https://pypi.org/project/orbitals/">
<img src="https://img.shields.io/pypi/v/orbitals?color=green" alt="PyPI Version">
</a>
<!-- <img src="https://img.shields.io/badge/type%20checked-ty-blue.svg?color=green" alt="Type Checked with ty"> -->
<a href="https://pypi.org/project/orbitals/">
<img src="https://img.shields.io/pypi/pyversions/orbitals" alt="Python Versions">
</a>
<a href="https://raw.githubusercontent.com/Principled-Intelligence/orbitals/refs/heads/main/LICENSE">
<img src="https://img.shields.io/github/license/principled-intelligence/orbitals" alt="GitHub License">
</a>
</p>
## Overview
**Orbitals** is a lightweight Python library for adding LLM guardrails in just a few lines of code. With Orbitals, you can add a governance layer tailored to **user-specific principles**. Rather than enforcing generic notions of safety, compliance, and correctness, Orbitals validates inputs (e.g., user requests) and outputs (e.g., assistant responses) against user-defined specifications and custom policies. This makes guardrails explicit, auditable, and aligned with the user's philosophy.
### Key Features
- **User-defined specifications** — Guardrails that match your use case and your custom policies, not generic safety rules
- **Simple integration** — Add guardrails with minimal code changes
- **Open framework, open models** — Orbitals is open-source and is a simple interface for our open models
## Getting started
### Installation
You can install Orbitals via pip:
```bash
pip install orbitals[all]
```
### Basic Usage
Here's a quick example to get you started with Orbitals, in which we use the ScopeGuard module to guard an AI service (for example, a customer support chatbot) from user requests that violate specified principles or fall outside of the scope of the core task of the assistant.
```python
from orbitals.scope_guard import ScopeGuard
ai_service_description = "You are a helpful assistant for ..."
user_message = "Can I buy ..."
guardrail = ScopeGuard()
result = guardrail.validate(user_message, ai_service_description)
```
The result of a guardrail validation will indicate whether the input or output passed the guardrail checks, along with details on any violations. You can then handle violations as needed, such as by rejecting the input or modifying the output. For example:
```python
if result.scope_class.value == "Restricted" or result.scope_class.value == "Out of Scope":
print("Request violates guardrail:", result.evidences)
else:
# The user request is safe!
# We can now pass it to the AI assistant for processing.
...
```
### Available Guardrails
Orbitals currently provides the following guardrail modules:
| Guardrail | Description | Hosting Options |
|:----------|:------------|:----------------|
| **[ScopeGuard](README.scope-guard.md)** | Classifies user queries against AI assistant specifications to detect out-of-scope requests, policy violations, and chit-chat | Self-hosted / Cloud hosting |
| 🚀 *Coming Soon* | More guardrails are on the way — stay tuned for updates! | — |
#### Hosting Options
- **Self-hosted**: Use open-weight models that you can deploy on your own infrastructure, ensuring data privacy and control.
- **Cloud hosting**: (Coming soon) Managed hosting options for ease of use and scalability
### Documentation
For detailed documentation, including installation instructions, usage guides, and API references, please visit the Orbitals Documentation.
- [ScopeGuard Documentation](README.scope-guard.md)
### FAQ
- **Can I use Orbitals for commercial applications?**
Yes, Orbitals is designed to be used in both research and commercial applications. It is licensed under the Apache 2.0 License, which allows for commercial use.
- **Other questions?**
Feel free to reach out to us at [orbitals@principled-intelligence.com](mailto:orbitals@principled-intelligence.com)!
### Contributing
We welcome contributions from the community! If you'd like to contribute to Orbitals, please check out our [Contributing Guide](CONTRIBUTING.md) for guidelines on how to get started.
### License
This project is licensed under the Apache 2.0 License. See the [LICENSE](LICENSE) file for details.
### Contact
For questions, feedback, or support, please reach out to us at [orbitals@principled-intelligence.com](mailto:orbitals@principled-intelligence.com).
---
<div align="center">
<p>
<b>Built with ❤️ by <a href="https://principled-intelligence.com">Principled Intelligence</a></b>
<br />
Follow us on <a href="https://www.linkedin.com/company/principled-ai/">LinkedIn</a> for the latest updates.
</p>
</div>
| text/markdown | null | Luigi Procopio <luigi@principled-intelligence.com>, Edoardo Barba <edoardo@principled-intelligence.com> | null | null | Apache-2.0 | null | [
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp",
"pydantic>=2.0.0",
"requests",
"typer>=0.12.3",
"accelerate>=1.11.0; extra == \"all\"",
"fastapi[standard]>=0.119.1; extra == \"all\"",
"nvidia-ml-py; extra == \"all\"",
"transformers<5.0.0,>=4.47.0; extra == \"all\"",
"uvicorn>=0.29.0; extra == \"all\"",
"vllm>=0.11.0; extra == \"all\"... | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T17:33:43.313179 | orbitals-0.1.5-py3-none-any.whl | 26,205 | 84/66/7e4c1ab6da2beffd85d0545b08f989f8eabf8a2b2ec2d52033bc340c1f3c/orbitals-0.1.5-py3-none-any.whl | py3 | bdist_wheel | null | false | 85db80f8b45b5ac7d56d66e06a197803 | a3824d2bc3ef9774414e8e53c4e3582e15fe1c274afc2ec9ee2cf32b91fb52b5 | 84667e4c1ab6da2beffd85d0545b08f989f8eabf8a2b2ec2d52033bc340c1f3c | null | [
"LICENSE"
] | 210 |
2.4 | ecapi-sdk | 0.1.3 | ECAPI SDK for Python | # ecapi-sdk (Python)
ECAPI 的 Python SDK,封装了常用接口,并内置两种鉴权方式:
- `X-API-Key`(IAM API Key)
- `X-App-Session-Token`(App Session Token)
## 安装
```bash
pip install ecapi-sdk
```
## 快速开始
```python
from ecapi_sdk import ECAPIClient
client = ECAPIClient(
auth={"type": "apiKey", "apiKey": "ec_xxx"},
)
me = client.user.get_me()
player = client.player.get_info({"name": "player123"})
wallet = client.player.get_wallet(ecid="player-ecid")
```
切换为 App Session Token:
```python
client.set_app_session_token("your_app_session_token")
```
## 客户端能力
- 默认 `base_url`:`https://console.easecation.net/apiv2`
- 统一请求入口:`client.request(method, path, ...)`
- 默认超时:15 秒(`timeout_seconds` 可覆盖)
- 支持 per-request 覆盖鉴权:`auth=...`
- 非 2xx 响应抛出 `ECAPIError`(包含 `status`、`payload`、`url`)
## 参数传递(必填/可选)
- 所有带查询参数的接口都支持两种写法:
- 推荐:关键字参数(更直观)`client.player.get_wallet(ecid="...")`
- 兼容:字典参数 `client.player.get_wallet({"ecid": "..."})`
- 哪些字段必填、哪些可选,请直接看完整参考文档:`API_REFERENCE.md`
- 该参考文档由后端 OpenAPI 自动生成,和服务端校验保持一致
## IDE 强类型提示
- 包内提供 `client.pyi`,IDE 会在悬停和参数填写时显示方法级必填/可选信息
- 查询参数支持两种输入方式:
- `query` 结构化参数(会有 TypedDict 提示)
- 关键字参数(例如 `ecid=...`)
## API 覆盖
> SDK 已封装主要高频接口;其余接口可用 `client.request(...)` 直调。
### 用户
- `client.user.get_me()` → `GET /user/me`
- `client.user.login_by_password(payload)` → `POST /user/auth`
- `client.user.login_by_oauth2(payload)` → `POST /user/oauth2`
- `client.user.refresh_token(payload)` → `POST /user/refresh`
- `client.user.get_openid()` → `GET /user/openid`
- `client.user.list_all()` → `GET /user/all`
- `client.user.update_permissions(payload)` → `PUT /user/permissions`
- `client.user.get_by_id(id)` → `GET /user/:id`
### 玩家
- `client.player.get_info()` / `search_ecid()` / `get_user_data()` / `query_netease()`
- `client.player.set_rank_level(payload)` / `clear_respack_cache()`
- `client.player.get_wallet()` / `list_gaming_tags()` / `operate_gaming_tag(payload)`
- `client.player.get_last_played()` / `get_stage_record()`
- `client.player.get_headicon()` / `get_skin()`(返回 `bytes`)
- `client.player.batch_netease_nicknames(payload)`
- `client.player.get_binding()` / `reset_binding(payload)` / `update_binding(payload)`
- `client.player.update_user_data(nick, payload)`
- `client.player.update_password(ecid, payload)` / `get_password_hash(ecid)`
#### 玩家子模块
- `client.player.score.*` → `/player/score*`
- `client.player.tasks.*` → `/player/:ecid/tasks*`
- `client.player.merchandise.*` → `/player/:ecid/merchandise*`
- `client.player.year_summary.*` → `/player/year-summary/*`
- `client.player.vote.process_rewards()` → `GET /player/vote`
### 管理与处罚
- `client.admin.*` → `/admin/*`
- `client.punish.*` → `/punish/*`
- `client.ban.*` → `/ban/*`
- `client.permission.*` → `/permission`
### 日志与审计
- `client.log.*` → `/log/*`
- `client.audit.*` → `/audit/*`
### 配置与内容
- `client.stage.*`(含 `stage.logs.*`)→ `/stage/*`
- `client.item.get_commodity()` → `/item/commodity`
- `client.cfglang.*` → `/cfglang*`
- `client.globalkv.*` → `/globalkv*`
- `client.broadcast.*` → `/broadcast*`
- `client.pull_config.pull()` → `/pull-config`
### 运营与系统
- `client.order.*` → `/order/*`
- `client.count.*` → `/count/*`
- `client.servers.*` → `/servers*`
- `client.lobby.list()` → `/lobby/list`
- `client.easechat.*` → `/easechat/*`
- `client.monitor.spam_detector.*` → `/monitor/spam-detector/*`
- `client.system.get_health()` → `/health`
## 完整 API 参考
- `API_REFERENCE.md`
更新命令(在 `easecation-api` 根目录执行):
```bash
python3 sdk/generate_sdk_api_reference.py
```
| text/markdown | EaseCation | null | null | null | MIT | ecapi, easecation, sdk, python | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/easecation/easecation-api/tree/main/sdk/python/ecapi-sdk",
"Documentation, https://github.com/easecation/easecation-api/tree/main/sdk/python/ecapi-sdk#readme",
"Source, https://github.com/easecation/easecation-api",
"Issues, https://github.com/easecation/easecation-api/issues"
] | twine/6.2.0 CPython/3.9.6 | 2026-02-19T17:33:29.122560 | ecapi_sdk-0.1.3.tar.gz | 16,141 | 6b/ac/274556f27ba8bf79ac1308c5201f519a6db1b5e03310240d4f736d086acf/ecapi_sdk-0.1.3.tar.gz | source | sdist | null | false | 81612040cddc257f8e6147cca287e91f | 58390ce4ed3586661dd565cea5e897152ff94814ae65ff557eed80562cb96a19 | 6bac274556f27ba8bf79ac1308c5201f519a6db1b5e03310240d4f736d086acf | null | [] | 212 |
2.4 | pulumi-provider-boilerplate | 0.1.0a1771521719 | An example built with pulumi-go-provider. | # Pulumi Native Provider Boilerplate
This repository is a boilerplate showing how to create and locally test a native Pulumi provider (with examples of both CustomResource and ComponentResource [resource types](https://www.pulumi.com/docs/iac/concepts/resources/)).
## Authoring a Pulumi Native Provider
This boilerplate creates a working Pulumi-owned provider named `provider-boilerplate`.
It implements a random number generator that you can [build and test out for yourself](#test-against-the-example) and then replace the Random code with code specific to your provider.
### Prerequisites
You will need to ensure the following tools are installed and present in your `$PATH`:
* [`pulumictl`](https://github.com/pulumi/pulumictl#installation)
* [Go 1.21](https://golang.org/dl/) or 1.latest
* [NodeJS](https://nodejs.org/en/) 14.x. We recommend using [nvm](https://github.com/nvm-sh/nvm) to manage NodeJS installations.
* [Yarn](https://yarnpkg.com/)
* [TypeScript](https://www.typescriptlang.org/)
* [Python](https://www.python.org/downloads/) (called as `python3`). For recent versions of MacOS, the system-installed version is fine.
* [.NET](https://dotnet.microsoft.com/download)
### Build & test the boilerplate provider
1. Run `make build install` to build and install the provider.
1. Run `make gen_examples` to generate the example programs in `examples/` off of the source `examples/yaml` example program.
1. Run `make up` to run the example program in `examples/yaml`.
1. Run `make down` to tear down the example program.
### Creating a new provider repository
Pulumi offers this repository as a [GitHub template repository](https://docs.github.com/en/repositories/creating-and-managing-repositories/creating-a-repository-from-a-template) for convenience. From this repository:
1. Click "Use this template".
1. Set the following options:
* Owner: pulumi
* Repository name: pulumi-provider-boilerplate (replace "provider-boilerplate" with the name of your provider)
* Description: Pulumi provider for xyz
* Repository type: Public
1. Clone the generated repository.
From the templated repository:
1. Run the following command to update files to use the name of your provider (third-party: use your GitHub organization/username):
```bash
make prepare NAME=foo ORG=myorg REPOSITORY=github.com/myorg/pulumi-foo
```
This will do the following:
- rename folders in `provider/cmd` to `pulumi-resource-{NAME}`
- replace dependencies in `provider/go.mod` to reflect your repository name
- find and replace all instances of `provider-boilerplate` with the `NAME` of your provider.
- find and replace all instances of the boilerplate `abc` with the `ORG` of your provider.
- replace all instances of the `github.com/pulumi/pulumi-provider-boilerplate` repository with the `REPOSITORY` location
#### Build the provider and install the plugin
```bash
$ make build install
```
This will:
1. Create the SDK codegen binary and place it in a `./bin` folder (gitignored)
2. Create the provider binary and place it in the `./bin` folder (gitignored)
3. Generate the dotnet, Go, Node, and Python SDKs and place them in the `./sdk` folder
4. Install the provider on your machine.
#### Test against the example
```bash
$ cd examples/simple
$ yarn link @pulumi/provider-boilerplate
$ yarn install
$ pulumi stack init test
$ pulumi up
```
Now that you have completed all of the above steps, you have a working provider that generates a random string for you.
#### A brief repository overview
You now have:
1. A `provider/` folder containing the building and implementation logic.
1. `cmd/pulumi-resource-provider-boilerplate/main.go` - holds the provider's sample implementation logic.
2. `Makefile` - targets to help with building and publishing the provider. Run `make ci-mgmt` to regenerate CI workflows.
3. `sdk` - holds the generated code libraries created by `pulumi gen-sdk`.
4. `examples` a folder of Pulumi programs to try locally and/or use in CI.
5. A `Makefile` and this `README`.
#### Additional Details
This repository depends on the pulumi-go-provider library. For more details on building providers, please check
the [Pulumi Go Provider docs](https://github.com/pulumi/pulumi-go-provider).
### Build Examples
Create an example program using the resources defined in your provider, and place it in the `examples/` folder.
You can now repeat the steps for [build, install, and test](#test-against-the-example).
## Configuring CI and releases
1. Follow the instructions laid out in the [deployment templates](./deployment-templates/README-DEPLOYMENT.md).
## References
Other resources/examples for implementing providers:
* [Pulumi Command provider](https://github.com/pulumi/pulumi-command/blob/master/provider/pkg/provider/provider.go)
* [Pulumi Go Provider repository](https://github.com/pulumi/pulumi-go-provider)
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"parver>=0.2.1",
"pulumi<4.0.0,>=3.165.0",
"semver>=2.8.1",
"typing-extensions<5,>=4.11; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://www.pulumi.com"
] | twine/5.0.0 CPython/3.11.8 | 2026-02-19T17:33:14.449968 | pulumi_provider_boilerplate-0.1.0a1771521719.tar.gz | 11,125 | 9e/0e/fd05b0c00e3defdf499ff05f5af8ef60e8b1e3319339857f78bb69003dc0/pulumi_provider_boilerplate-0.1.0a1771521719.tar.gz | source | sdist | null | false | 62a54daffa4f239e18adf340bb01eab1 | bbfd88f2d5e8d2a6264d8f67323f8cb0da30930bea1724d237ed2ae787314461 | 9e0efd05b0c00e3defdf499ff05f5af8ef60e8b1e3319339857f78bb69003dc0 | null | [] | 187 |
2.4 | genji | 1.0.0 | Jinja2-based templating for LLM-generated structured output | <div align="center">
# Genji
[](https://pypi.org/project/genji/)
</div>
Genji is a templating library for LLM-generated structured output, built on [Jinja2](https://jinja.palletsprojects.com/). It ensures templates own the structure and syntax (JSON brackets, HTML tags, YAML indentation) while LLMs only generate content, guaranteeing valid output every time.
**The problem:** LLMs often produce malformed JSON, broken HTML, or invalid YAML when asked to generate structured output directly.
**The solution:** Separate concerns. Templates define structure, LLMs fill in content. Structure is guaranteed, content is generated.
## Installation
### From PyPI (Recommended)
```bash
# With uv (recommended)
uv pip install genji
# With pip
pip install genji
```
### From Source
```bash
git clone https://github.com/calebevans/genji.git
cd genji
uv pip install -e .
```
For development:
```bash
uv pip install -e ".[dev]"
pre-commit install
```
## Quick Start
```python
from genji import Template, LLMBackend
# Configure the LLM backend
backend = LLMBackend(model="gpt-4o-mini")
# Define a template (default_filter="json" applies to all gen() calls)
template = Template("""
{
"greeting": {{ gen("a friendly greeting for {name}") }},
"farewell": {{ gen("a warm farewell for {name}") }}
}
""", backend=backend, default_filter="json")
# Render with variables
result = template.render(name="Alice")
print(result) # Valid JSON guaranteed
# Or parse directly to dict
data = template.render_json(name="Alice")
print(data["greeting"]) # LLM-generated greeting
```
> **Note:** On first run, LiteLLM may download model configurations. Subsequent runs use cached data.
## Features
### Template Syntax
Genji extends Jinja2 with a `gen()` function for LLM generation:
```python
# Basic generation
{{ gen("a creative tagline") }}
# With variable interpolation
{{ gen("a description of {product}") }}
# With generation parameters
{{ gen("a tweet", max_tokens=280, temperature=0.9) }}
# With filters for different formats
{{ gen("content") | json }} # JSON-safe string with quotes
{{ gen("content") | html }} # HTML entity escaping
{{ gen("content") | yaml }} # YAML-safe string
{{ gen("content") | xml }} # XML entity escaping
```
All standard Jinja2 features are supported:
```jinja2
{# Comments #}
{% if condition %}
{{ gen("something") }}
{% endif %}
{% for item in items %}
{{ gen("content for {item}") }}
{% endfor %}
```
### Format-Specific Filters
Genji provides filters for safe escaping in different formats:
| Filter | Purpose | Example Output |
|--------|---------|----------------|
| `json` | JSON string with quotes | `"Hello \"World\""` |
| `html` | HTML entity escaping | `<b>text</b>` |
| `xml` | XML entity escaping | `<tag>content</tag>` |
| `yaml` | YAML-safe string | `"key: value"` |
| `raw` | No escaping (use carefully!) | `<dangerous>` |
| `strip` | Remove whitespace | `"text"` |
| `lower` | Lowercase | `"hello"` |
| `upper` | Uppercase | `"HELLO"` |
| `truncate(n)` | Truncate to n chars | `"Long te..."` |
**Important:** The `json` filter outputs a complete JSON string value including quotes:
```python
{{ gen("text") | json }} # Outputs: "the generated text"
```
### Default Filters
Avoid repetition by setting a default filter:
```python
# Apply | json to all gen() calls automatically
template = Template(source, backend, default_filter="json")
# Or use file extension auto-detection
template = Template.from_file("report.json.genji", backend)
# Auto-detects "json" filter from .json.genji extension
# Override for specific prompts when needed
{{ gen("normal content") }} # Gets json filter
{{ gen("special") | raw }} # Skips filter
{{ gen("html content") | html }} # Uses html instead
```
### LLM Backend Support
Genji uses [LiteLLM](https://github.com/BerriAI/litellm) for unified access to 100+ LLM providers.
See the [full list of supported models](https://models.litellm.ai/).
#### OpenAI
```python
backend = LLMBackend(
model="gpt-4o-mini",
api_key="sk-...", # pragma: allowlist secret
)
```
#### Anthropic Claude
```python
backend = LLMBackend(
model="claude-3-5-sonnet-20241022",
api_key="sk-ant-...", # pragma: allowlist secret
)
```
#### Google Gemini
```python
backend = LLMBackend(
model="gemini/gemini-2.5-flash",
api_key="...", # pragma: allowlist secret
)
```
#### Local Ollama
```python
backend = LLMBackend(
model="ollama/llama3",
base_url="http://localhost:11434"
)
```
#### Azure OpenAI
```python
backend = LLMBackend(
model="azure/your-deployment-name",
api_key="...", # pragma: allowlist secret
base_url="https://your-resource.openai.azure.com"
)
```
For a complete list of supported models, see [LiteLLM's model documentation](https://models.litellm.ai/).
### Loading Templates from Files
```python
# Create a template file: templates/report.json.genji
template = Template.from_file("templates/report.json.genji", backend)
result = template.render(topic="climate change")
```
### Batch Generation
Genji automatically batches multiple `gen()` calls for efficiency:
```python
template = Template("""
{
"field1": {{ gen("prompt1") | json }},
"field2": {{ gen("prompt2") | json }},
"field3": {{ gen("prompt3") | json }}
}
""", backend=backend)
# All 3 prompts are sent to the LLM in parallel!
result = template.render()
```
### Async Support
Every synchronous method has an async counterpart prefixed with `a`.
This works with any async framework built on `asyncio` (FastAPI, aiohttp,
etc.):
```python
import asyncio
from genji import Template, LLMBackend
backend = LLMBackend(model="gpt-4o-mini")
template = Template("""
{
"greeting": {{ gen("a friendly greeting for {name}") }},
"farewell": {{ gen("a warm farewell for {name}") }}
}
""", backend=backend, default_filter="json")
async def main():
# Async rendering
result = await template.arender(name="Alice")
# Async render + JSON parse
data = await template.arender_json(name="Alice")
# Async file loading
t = await Template.afrom_file(
"report.json.genji", backend
)
asyncio.run(main())
```
When the backend supports native async (as `LLMBackend` does via
`litellm.acompletion`), all LLM calls use true async I/O.
If a backend only implements the sync protocol, `arender` automatically
falls back to running the sync calls in a thread via
`asyncio.to_thread`.
The synchronous API (`render`, `render_json`, `from_file`) is
unchanged and continues to work exactly as before.
## API Reference
### Template
```python
class Template:
def __init__(
self,
source: str,
backend: LLMBackend | MockBackend,
default_filter: str | None = None
) -> None:
"""Initialize a template from a string.
Args:
source: Template string with Jinja2 syntax and gen() calls.
backend: LLM backend instance (LLMBackend or MockBackend).
default_filter: Optional default filter to apply to all gen() calls
(e.g., "json", "html", "yaml"). Can be overridden per-prompt.
"""
@classmethod
def from_file(
cls,
path: str | Path,
backend: LLMBackend | MockBackend,
default_filter: str | None = None
) -> Template:
"""Load a template from a file.
Args:
path: Path to template file.
backend: LLM backend instance.
default_filter: Optional default filter. If None, auto-detects from
file extension (.json.genji -> "json", .html.genji -> "html", etc.).
"""
def render(self, **context: Any) -> str:
"""Render the template with the given context variables.
Returns:
Rendered template as a string.
"""
def render_json(self, **context: Any) -> dict[str, Any]:
"""Render the template and parse as JSON.
Returns:
Parsed JSON as a Python dict.
Raises:
TemplateRenderError: If output is not valid JSON.
"""
async def arender(self, **context: Any) -> str:
"""Async version of render()."""
async def arender_json(self, **context: Any) -> dict[str, Any]:
"""Async version of render_json()."""
@classmethod
async def afrom_file(
cls,
path: str | Path,
backend: LLMBackend | MockBackend,
default_filter: str | None = None
) -> Template:
"""Async version of from_file()."""
```
### LLMBackend
```python
class LLMBackend:
def __init__(
self,
model: str | None = None,
api_key: str | None = None,
base_url: str | None = None,
temperature: float | None = None,
max_tokens: int | None = None,
add_system_prompt: bool = True,
**kwargs: Any,
) -> None:
"""Initialize the LiteLLM backend.
Args:
model: Model name (required, or set GENJI_MODEL env var).
api_key: API key (or set via environment variable).
base_url: Base URL for custom endpoints.
temperature: Temperature for generation (None uses provider default).
max_tokens: Max tokens per generation (None uses provider default).
add_system_prompt: Whether to add instruction for concise responses.
Defaults to True.
**kwargs: Additional arguments passed to litellm.completion().
"""
```
#### Per-Prompt Parameters
You can configure generation parameters for individual `gen()` calls:
```python
# Control tokens, temperature, and stop sequences per prompt
{{ gen("short title", max_tokens=20) }}
{{ gen("creative content", temperature=0.9) }}
{{ gen("haiku", stop=["\n\n"]) }}
```
#### Smart Prompting
By default, Genji adds a system instruction to ensure LLMs return literal, concise responses:
```python
# Default - LLM returns exactly what's requested
backend = LLMBackend(model="gpt-4o-mini")
# "a title" returns one title, not a list of options
# Disable for full control
backend = LLMBackend(model="gpt-4o-mini", add_system_prompt=False)
```
### MockBackend
For testing without API calls:
```python
from genji import MockBackend
backend = MockBackend(default_response="Test content")
# or
backend = MockBackend(response_fn=lambda prompt: f"Response to: {prompt}")
```
## Configuration
| Parameter | Default | Environment Variable | Description |
|-----------|---------|---------------------|-------------|
| `model` | **Required** | `GENJI_MODEL` | LLM model name (must be specified) |
| `api_key` | None | `GENJI_API_KEY` | API key for provider |
| `base_url` | None | `GENJI_BASE_URL` | Custom endpoint URL |
| `temperature` | Provider default | N/A | Temperature for generation |
| `max_tokens` | Provider default | N/A | Max tokens per generation |
| `add_system_prompt` | `True` | N/A | Add conciseness instruction |
## Error Handling
Genji provides clear exception types:
- `GenjiError` - Base exception
- `TemplateParseError` - Invalid template syntax
- `TemplateRenderError` - Error during rendering
- `BackendError` - LLM backend failure
- `FilterError` - Filter application failure
| text/markdown | Caleb Evans | null | null | null | null | ai, html, jinja2, json, llm, structured-output, template, yaml | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Typing :: Ty... | [] | null | null | >=3.10 | [] | [] | [] | [
"jinja2>=3.1.0",
"litellm>=1.0.0",
"mypy>=1.0; extra == \"dev\"",
"pytest-asyncio>=0.21; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"ruff>=0.1; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/calebevans/genji",
"Documentation, https://github.com/calebevans/genji/blob/main/README.md",
"Repository, https://github.com/calebevans/genji"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:31:58.696832 | genji-1.0.0.tar.gz | 25,244 | be/10/ab9e2be77444afb16e06a107ffdaef38da3e68c416065f183af1dc8a2497/genji-1.0.0.tar.gz | source | sdist | null | false | a08e9cbce16418442f513b010a2e5152 | ab85788741c2ee712e86ba968788f1c4bcd8c79229669972d06b03f13c739bed | be10ab9e2be77444afb16e06a107ffdaef38da3e68c416065f183af1dc8a2497 | Apache-2.0 | [
"LICENSE"
] | 215 |
2.4 | note-python | 2.3.1 | Cross-platform Python Library for the Blues Wireless Notecard | # note-python
Python library for communicating with the Blues Wireless Notecard over serial
or I²C.

[](https://coveralls.io/github/blues/note-python?branch=main)



This library allows you to control a Notecard by coding in Python and works in
a desktop setting, on Single-Board Computers like the Raspberry Pi, and on
Microcontrollers with MicroPython or CircuitPython support.
## Installation
With `pip` via PyPi:
```bash
pip install note-python
```
or
```bash
pip3 install note-python
```
For use with MicroPython or CircuitPython, copy the contents of the `notecard`
directory into the `lib/notecard` directory of your device.
## Usage
```python
import notecard
```
The `note-python` library requires a pointer to a serial or i2c object that you
initialize and pass into the library. This object differs based on platform, so
consult the [examples](examples/) directory for platform-specific guidance.
### Serial Configuration
#### Linux and Raspberry Pi
```python
# Use PySerial on a Linux desktop or Raspberry Pi
import serial
port = serial.Serial("/dev/serial0", 9600)
card = notecard.OpenSerial(port)
```
#### macOS and Windows
```python
# Use PySerial on a desktop
import serial
#macOS
port = serial.Serial(port="/dev/tty.usbmodemNOTE1",
baudrate=9600)
# Windows
# port = serial.Serial(port="COM4",
# baudrate=9600)
card = notecard.OpenSerial(port)
```
### I2C Configuration
```python
# Use python-periphery on a Linux desktop or Raspberry Pi
from periphery import I2C
port = I2C("/dev/i2c-1")
card = notecard.OpenI2C(port, 0, 0)
```
### Sending Notecard Requests
Whether using Serial or I2C, sending Notecard requests and reading responses
follows the same pattern:
1. Create a JSON object that adheres to the Notecard API.
2. Call `Transaction` on a `Notecard` object and pass in the request JSON
object.
3. Make sure the response contains the data you need
```python
# Construct a JSON Object to add a Note to the Notecard
req = {"req": "note.add"}
req["body"] = {"temp": 18.6}
rsp = card.Transaction(req)
print(rsp) # {"total":1}
```
### Using the Library Fluent API
The `notecard` class allows complete access to the Notecard API via manual JSON
object construction and the `Transaction` method. Alternatively, you can import
one or more Fluent API helpers to work with common aspects of the Notecard API
without having to author JSON objects, by hand. **Note** that not all aspects of
the Notecard API are available using these helpers. For a complete list of
supported helpers, visit the [API](API.md) doc.
Here's an example that uses the `hub` helper to set the Notecard Product UID
in CircuitPython:
```python
import board
import busio
import notecard
from notecard import card, hub, note
port = busio.I2C(board.SCL, board.SDA)
nCard = notecard.OpenI2C(port, 0, 0, debug=True)
productUID = "com.blues.brandon.tester"
rsp = hub.set(nCard, productUID, mode="continuous", sync=True)
print(rsp) # {}
```
## Documentation
The documentation for this library can be found
[here](https://dev.blues.io/tools-and-sdks/python-library/).
## Examples
The [examples](examples/) directory contains examples for using this
library with:
- [Serial](examples/notecard-basics/serial_example.py)
- [I2C](examples/notecard-basics/i2c_example.py)
- [RaspberryPi](examples/notecard-basics/rpi_example.py)
- [CircuitPython](examples/notecard-basics/cpy_example.py)
- [MicroPython](examples/notecard-basics/mpy_example.py)
## Contributing
We love issues, fixes, and pull requests from everyone. By participating in
this project, you agree to abide by the Blues Inc [code of conduct].
For details on contributions we accept and the process for contributing, see
our [contribution guide](CONTRIBUTING.md).
## Development Setup
If you're planning to contribute to this repo, please be sure to run the tests, linting and style checks before submitting a PR.
1. Install Pipenv if you haven't already:
```bash
pip install pipenv
```
2. Clone the repository and install dependencies:
```bash
git clone https://github.com/blues/note-python.git
cd note-python
pipenv install --dev
```
3. Activate the virtual environment:
```bash
pipenv shell
```
4. Run the tests:
```bash
make test
```
5. Run linting and style checks:
```bash
make precommit
```
## Installing the `pre-commit` Hook
Please run
`pre-commit install`
Before committing to this repo. It will catch a lot of common errors that you can fix locally.
You may also run the pre-commit checks before committing with
`pre-commit run`
Note that `pre-commit run` only considers staged changes, so be sure all
changes are staged before running this.
## More Information
For additional Notecard SDKs and Libraries, see:
* [note-c](https://github.com/blues/note-c) for Standard C support
* [note-go](https://github.com/blues/note-go) for Go
* [note-arduino](https://github.com/blues/note-arduino) for Arduino
## To learn more about Blues Wireless, the Notecard and Notehub, see:
* [blues.com](https://blues.com)
* [notehub.io][Notehub]
* [wireless.dev](https://wireless.dev)
## License
Copyright (c) 2019 Blues Inc. Released under the MIT license. See
[LICENSE](LICENSE) for details.
[code of conduct]: https://blues.github.io/opensource/code-of-conduct
[Notehub]: https://notehub.io
| text/markdown | null | "Blues Inc." <support@blues.com> | null | null | MIT | null | [
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"License :: OSI Approved :: MIT License",
"Operating Syste... | [] | null | null | >=3.10 | [] | [] | [] | [
"filelock>=3.24.3"
] | [] | [] | [] | [
"Homepage, https://github.com/blues/note-python",
"Repository, https://github.com/blues/note-python"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T17:31:39.517321 | note_python-2.3.1.tar.gz | 301,137 | 65/a7/272581fe04f8f7b38efe1dc13438a267213fcef6e29c8bb8b6807e0ea72d/note_python-2.3.1.tar.gz | source | sdist | null | false | 063fcbd08d4b15059336af20f6c5571b | 6e168f3b3937193d1a62e65b5cd2cb0059372973c04104a82eb75047f66fef06 | 65a7272581fe04f8f7b38efe1dc13438a267213fcef6e29c8bb8b6807e0ea72d | null | [
"LICENSE"
] | 207 |
2.4 | fluidzero-cli | 0.1.1 | FluidZero platform CLI | # fz — FluidZero CLI
The official command-line interface for the [FluidZero](https://fluidzero.ai) document intelligence platform.
Manage projects, upload documents, define schemas, execute extraction runs, search results, and more — all from your terminal.
## Installation
### Homebrew (macOS)
```bash
brew install fluidzero/tap/fz
```
### pip
```bash
pip install fluidzero-cli
```
### From source
```bash
git clone https://github.com/fluidzero/fz-cli.git
cd fz-cli
python -m venv .venv && source .venv/bin/activate
pip install -e .
```
## Quick Start
```bash
# Authenticate (opens browser for device-code confirmation)
fz auth login
# List projects
fz projects list
# Upload documents and wait for processing
fz documents upload -p <project-id> *.pdf --wait
# Run extraction with a schema
fz runs create -p <project-id> --schema <schema-id> --wait
# Search extracted data
fz search "quarterly revenue" -p <project-id>
```
## Commands
| Command | Description |
|---------|-------------|
| `fz auth` | Login, logout, status, print token |
| `fz projects` | Create, list, get, update, delete projects |
| `fz documents` | Upload, list, get, delete, download documents |
| `fz schemas` | Manage schemas and schema versions |
| `fz prompts` | Manage prompts and prompt versions |
| `fz runs` | Create, list, watch, cancel runs; view results |
| `fz search` | Search extracted data (global or project-scoped) |
| `fz webhooks` | Manage webhook endpoints and deliveries |
| `fz api-keys` | Create, list, revoke API keys for CI/CD |
| `fz run` | Composite: upload documents + run extraction |
| `fz batch` | Batch process a directory of documents |
## Global Flags
Global flags go **before** the subcommand (Click convention):
```bash
fz -o json projects list # JSON output
fz -o csv projects list # CSV output
fz -q runs create ... # Quiet mode
fz -v documents upload ... # Verbose (shows HTTP requests)
fz -p <id> documents list # Set default project
```
## Configuration
Settings are resolved in order (later wins):
1. Defaults
2. `~/.config/fluidzero/config.toml` (global)
3. `.fluidzero.toml` (project-local)
4. Environment variables
5. CLI flags
### Environment Variables
| Variable | Description |
|----------|-------------|
| `FZ_API_URL` | API base URL |
| `FZ_PROJECT_ID` | Default project ID |
| `FZ_OUTPUT` | Default output format (`table`, `json`, `jsonl`, `csv`) |
| `FZ_CLIENT_ID` | M2M client ID (CI/CD) |
| `FZ_CLIENT_SECRET` | M2M client secret (CI/CD) |
| `NO_COLOR` | Disable colored output |
### Config File Example
```toml
# ~/.config/fluidzero/config.toml
[defaults]
api_url = "https://api.fluidzero.ai"
project = "e94af89d-..."
output = "table"
[upload]
concurrency = 4
retry_attempts = 3
```
## Authentication
### Interactive (browser device flow)
```bash
fz auth login # Shows a code, opens browser for confirmation
fz auth status # Check current identity and token expiry
fz auth logout # Remove stored credentials
```
### Machine-to-Machine (CI/CD)
```bash
export FZ_CLIENT_ID=client_01K...
export FZ_CLIENT_SECRET=124e12a...
fz projects list # Uses M2M auth automatically
```
Create API keys with `fz api-keys create "My CI Key"`.
## License
Apache License 2.0 — see [LICENSE](LICENSE) for details.
Copyright 2025 Force Platforms Inc.
| text/markdown | Force Platforms Inc | null | null | null | Apache-2.0 | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"click>=8.1",
"httpx>=0.27",
"tabulate>=0.9",
"rich>=13.0",
"PyJWT>=2.8"
] | [] | [] | [] | [
"Homepage, https://github.com/fluidzero/fz-cli",
"Repository, https://github.com/fluidzero/fz-cli",
"Issues, https://github.com/fluidzero/fz-cli/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:30:51.026700 | fluidzero_cli-0.1.1.tar.gz | 35,060 | e6/08/ab73b357c273ea6e943a035b8425caaec3f3041f778289097ff7b2b5458f/fluidzero_cli-0.1.1.tar.gz | source | sdist | null | false | 3178e8a0802eb4a5aa9b4e1542905213 | 589f4d6e430e0af2d2511daebd0216942fe308ab85d39f2f9ef957c687e7c473 | e608ab73b357c273ea6e943a035b8425caaec3f3041f778289097ff7b2b5458f | null | [
"LICENSE"
] | 222 |
2.1 | TAK-Meshtastic-Gateway | 1.1.0 | Send and receive data from ATAK, WinTAK, or iTAK over Meshtastic | Join us on the OpenTAKServer [Discord server](https://discord.gg/6uaVHjtfXN)
# TAK Meshtastic Gateway
TAK Meshtastic Gateway listens for multicast data from TAK clients (ATAK, WinTAK, and iTAK) and forwards it to
a Meshtastic device which transmits it to a Meshtastic network. It will also forward messages from Meshtastic to
TAK clients via multicast. Additionally, it enables sending and receiving chat messages and locations between TAK clients
and the Meshtastic app. For example, someone using WinTAK can send a message over a Meshtastic network to someone using
the Meshtastic app and vice versa.
## Features
- Send chat and PLI messages from TAK clients (ATAK, WinTAK, and iTAK) over a Meshtastic network
- Receive chat and PLI messages from a Meshtastic network and display them in a TAK client
- See Meshtastic devices on the TAK client's map
- See the TAK client on the Meshtastic app's map
- Send and receive chat messages between the TAK client and Meshtastic app
TAK Meshtastic Gateway currently only supports sending and receiving chat and PLI messages. Other data types such as
data packages, markers, images, etc, are not supported due to the limited bandwidth of Meshtastic networks.
## Python Requirements
Due to an issue with the unishox2-py3 package, Windows requires Python version 3.12. Linux and macOS will work with Python
versions 3.8 and up.
## Known Issues
There is a bug in the takproto library which causes an exception in TAK Meshtastic Gateway when parsing XML CoT data.
There is a [PR](https://github.com/snstac/takproto/pull/16) that will fix the issue once it is merged. Until it is merged,
you will need to manually install from the pull request using the installation instructions below.
On Windows, the `unishox2-py3` library fails to build from the source distribution with the command `pip install unishox2-py3`.
TAK Meshtastic Gateway will instead install [this wheel](https://github.com/brian7704/OpenTAKServer-Installer/blob/master/unishox2_py3-1.0.0-cp312-cp312-win_amd64.whl).
As a result, Python 3.12 is required when running TAK Meshtastic Gateway on Windows.
## Installation
For installation you only need to create a Python virtual environment, activate the virtual environment, and install using pip.
### Linux/macOS
The unishox2-py3 Python library requires C build tools. In Debian based distros (i.e. Ubuntu) they can be installed with
`apt install build-essential`.
```shell
python3 -m venv tak_meshtastic_gateway_venv
. ./tak_meshtastic_gateway_venv/bin/activate
pip install git+https://github.com/snstac/takproto@refs/pull/16/merge
pip install tak-meshtastic-gateway
```
### Windows
```powershell
python -m venv tak_meshtastic_gateway_venv
.\tak_meshtastic_gateway_venv\Scripts\activate
pip install https://github.com/brian7704/OpenTAKServer-Installer/raw/master/unishox2_py3-1.0.0-cp312-cp312-win_amd64.whl
pip install git+https://github.com/snstac/takproto@refs/pull/16/merge
pip install tak-meshtastic-gateway
```
## Usage
When your virtual environment active, run the `tak-meshtastic-gateway` command
## Architecture
In most scenarios, the user will run TAK Meshtastic Gateway on the same computer that runs WinTAK. The Meshtastic node
can either be connected to the same computer via USB, or be on the same LAN as the computer. Connecting to the Meshtastic
node over the LAN allows it to be mounted in a spot outside with good mesh reception while the computer is inside.
## Meshtastic Node Configuration
The Meshtastic node should be set to the TAK role. TAK Meshtastic Gateway will automatically change the node's long name
to the TAK client's callsign and the short name to the last four characters of the TAK client's UID. This ensures that
the callsign shows up correctly for mesh users who are only using the Meshtastic app as well as ATAK plugin users.
TAK Meshtastic Gateway will also update the Meshtastic node's location with the location of the EUD.
## ATAK Plugin Settings
For best results, use the following settings on devices using the [Meshtastic ATAK Plugin.](https://meshtastic.org/docs/software/integrations/integrations-atak-plugin/).
You can find the settings in ATAK by clicking the Settings tool -> Tool Preferences -> Specific Tool Preferences ->
Meshtastic Preferences.
- Show all Meshtastic devices: On
- Don't sshow Meshtastic devices without GPS: On
- Do not show your local Meshtastic device: On
The rest of the settings can be changed as needed.
## Usage
All arguments are optional. If an argument is not specified its default value will be used.
| Flag | Parameter | Description | Default |
|------|--------------------|-----------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------|
| `-i` | `--ip-address` | The private IP address of the machine running TAK Meshtastic Gateway. | TAK Meshtastic Gateway will attempt to automatically find the IP of the computer it's running on |
| `-s` | `--serial-device` | The serial device of the Meshtastic node (i.e. `COM3` or `/dev/ttyACM0`). Cannot be used simultaneously with `--mesh-ip` | TAK Meshtastic Gateway will attempt to automatically determine the serial device |
| `-m` | `--mesh-ip` | The IP address or DNS name of the gateway Meshtastic node. Cannot be used simultaneously with `--serial-device` | Uses a serial connection |
| `-c` | `--tak-client-ip` | The IP address of the device running the TAK client (ATAK, WinTAK, or iTAK) | `localhost` |
| `-p` | `--dm-socket-port` | TCP Port to listen on for DMs | `4243` |
| `-t` | `--tx-interval` | Minimum time (in seconds) to wait between PLI transmissions from the TAK client to the mesh network. This reduces strain on the mesh network. | `30` |
| `-l` | `--log-file` | Save log messages to a file. | `None` (disabled) |
| `-d` | `--debug` | Enable debug log messages | `Disabled` Only messages at the `INFO` level or higher will be logged |
## Permissions
When the Meshtastic node is connected via USB, TAK Meshtastic Gateway needs to be run as root (or via `sudo`) in Linux
and in an administrator PowerShell or Command Prompt in Windows. Connecting to the Meshtastic node via TCP does
not require elevated permissions.
## Example Usage Scenarios
### Scenario 1
- WinTAK on a PC
- Meshtastic node connected to the PC via USB
- TAK Meshtastic Gateway running on the same PC
- Command: `tak_meshtastic_gateway`
### Scenario 2
- WinTAK on a PC
- Meshtastic node on the same LAN as the PC
- TAK Meshtastic Gateway running on the same PC as WinTAK
- Command: `tak_meshtastic_gateway --mesh-ip MESHTASTIC_NODE_IP` Note: Substitute `MESHTASTIC_NODE_IP` with
the node's actual IP (i.e. `192.168.1.10`)
### Scenario 3
- ATAK or iTAK on a mobile device connected to a Wi-Fi network
- Meshtastic node connected to the same network
- TAK Meshtastic Gateway running on a computer or VM on the same network
- Command: `tak_meshtastic_gateway --mesh-ip MESHTASTIC_NODE_IP --tak-client-ip TAK_CLIENT_IP` Note: Substitute
`MESHTASTIC_NODE_IP` and `TAK_CLIENT_IP` with their actual IPs (i.e. `192.168.1.10` and `192.168.1.11`) | text/markdown | OpenTAKServer | opentakserver@gmail.com | null | null | GPL-3.0-or-later | null | [
"License :: OSI Approved :: GNU General Public License v3 or later (GPLv3+)",
"Programming Language :: Python :: 2",
"Programming Language :: Python :: 2.7",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.4",
"Programming Language :: Python :: 3.5",
"Programming Language :: ... | [] | https://github.com/brian7704/TAK_Meshtastic_Gateway | null | null | [] | [] | [] | [
"beautifulsoup4==4.12.3",
"lxml==5.2.2",
"meshtastic",
"pypubsub==4.0.3",
"colorlog==6.8.2",
"unishox2-py3==1.0.0",
"netifaces2==0.0.22",
"takproto"
] | [] | [] | [] | [
"Repository, https://github.com/brian7704/TAK_Meshtastic_Gateway",
"Documentation, https://docs.opentakserver.io"
] | poetry/1.8.2 CPython/3.12.1 Windows/10 | 2026-02-19T17:30:29.417928 | tak_meshtastic_gateway-1.1.0.tar.gz | 29,362 | 0b/3b/7a481aa25b887e961aad983de78e1ce2c25278fd7837c6a343fee0db6fd3/tak_meshtastic_gateway-1.1.0.tar.gz | source | sdist | null | false | 6eb0ac2b66ff48f75a79470c9570b374 | 966b9672068ba076dfa9783e4b226a3a75e95874e362928cd0181835a88cbeeb | 0b3b7a481aa25b887e961aad983de78e1ce2c25278fd7837c6a343fee0db6fd3 | null | [] | 0 |
2.4 | zabbix-mcp | 0.2.1 | MCP server for Zabbix management | # Zabbix MCP Server
<!-- mcp-name: io.github.mhajder/zabbix-mcp -->
Zabbix MCP Server is a Python-based Model Context Protocol (MCP) server designed to provide advanced, programmable access to Zabbix monitoring data and management features. It exposes a modern API for querying, automating, and integrating Zabbix resources such as hosts, templates, triggers, items, problems, events, users, proxies, maintenance periods, and more. The server supports both read and write operations, robust security features, and is suitable for integration with AI assistants, automation tools, dashboards, and custom monitoring workflows.
## Features
### Core Features
- Query Zabbix hosts, templates, items, triggers, and host groups with flexible filtering
- Retrieve problems, events, and alerts with severity filtering
- Access history and trend data for monitored items
- Monitor trigger states and problem severity
- Manage maintenance periods and scheduled downtimes
- Retrieve user macros and configuration data
- Get SLA and service information
### Management Operations
- Create, update, and delete hosts, templates, and host groups (if enabled)
- Manage triggers, items, and discovery rules
- Configure maintenance periods and user macros
- Execute scripts on monitored hosts
- Acknowledge events and close problems
- Create and manage users and proxies
- Support for bulk operations on hosts and templates
### Advanced Capabilities
- Rate limiting and API security features
- Read-only mode to restrict all write operations for safe monitoring
- Bearer token authentication for HTTP transport
- Comprehensive logging and audit trails
- SSL/TLS support and configurable timeouts
- Multiple transport options (STDIO, SSE, HTTP)
- Optional Sentry integration for error tracking
## Installation
### Prerequisites
- Python 3.11 to 3.14
- Access to a Zabbix server (5.4+)
- Valid Zabbix API token or user credentials with appropriate permissions
### Quick Install from PyPI
The easiest way to get started is to install from PyPI:
```sh
# Using UV (recommended)
uvx zabbix-mcp
# Or using pip
pip install zabbix-mcp
```
Remember to configure the environment variables for your Zabbix instance before running the server:
```sh
# Create environment configuration
export ZABBIX_URL=https://zabbix.example.com/api_jsonrpc.php
export ZABBIX_TOKEN=your-zabbix-api-token
```
### Install from Source
1. Clone the repository:
```sh
git clone https://github.com/mhajder/zabbix-mcp.git
cd zabbix-mcp
```
2. Install dependencies:
```sh
# Using UV (recommended)
uv sync
# Or using pip
pip install -e .
```
3. Configure environment variables:
```sh
cp .env.example .env
# Edit .env with your Zabbix URL and credentials
```
4. Run the server:
```sh
# Using UV
uv run python run_server.py
# Or directly with Python
python run_server.py
# Or using the installed script
zabbix-mcp
```
### Using Docker
Docker images are available on GitHub Packages for easy deployment.
```sh
# Normal STDIO image
docker pull ghcr.io/mhajder/zabbix-mcp:latest
# MCPO image for usage with Open WebUI
docker pull ghcr.io/mhajder/zabbix-mcpo:latest
```
### Development Setup
For development with additional tools:
```sh
# Clone and install with development dependencies
git clone https://github.com/mhajder/zabbix-mcp.git
cd zabbix-mcp
uv sync --group dev
# Run tests
uv run pytest
# Run with coverage
uv run pytest --cov=src/
# Run linting and formatting
uv run ruff check .
uv run ruff format .
# Setup pre-commit hooks
uv run pre-commit install
```
## Configuration
### Environment Variables
```env
# Zabbix Connection Details
ZABBIX_URL=https://zabbix.example.com/api_jsonrpc.php
# Authentication - use EITHER token OR user/password
# API Token (preferred for Zabbix 5.4+)
ZABBIX_TOKEN=your-api-token
# OR Username/Password (for older versions)
# ZABBIX_USER=Admin
# ZABBIX_PASSWORD=zabbix
# SSL Configuration
ZABBIX_VERIFY_SSL=true
ZABBIX_TIMEOUT=30
ZABBIX_SKIP_VERSION_CHECK=false
# Read-Only Mode
# Set READ_ONLY_MODE true to disable all write operations (create, update, delete)
READ_ONLY_MODE=false
# Disabled Tags
# Comma-separated list of tags to disable tools for (empty by default)
# Example: DISABLED_TAGS=host,user,maintenance
DISABLED_TAGS=
# Logging Configuration
LOG_LEVEL=INFO
# Rate Limiting
# Set RATE_LIMIT_ENABLED true to enable rate limiting
RATE_LIMIT_ENABLED=false
RATE_LIMIT_MAX_REQUESTS=60
RATE_LIMIT_WINDOW_MINUTES=1
# Sentry Error Tracking (Optional)
# Set SENTRY_DSN to enable error tracking and performance monitoring
# SENTRY_DSN=https://your-key@o12345.ingest.us.sentry.io/6789
# Optional Sentry configuration
# SENTRY_TRACES_SAMPLE_RATE=1.0
# SENTRY_SEND_DEFAULT_PII=true
# SENTRY_ENVIRONMENT=production
# SENTRY_RELEASE=1.2.3
# SENTRY_PROFILE_SESSION_SAMPLE_RATE=1.0
# SENTRY_PROFILE_LIFECYCLE=trace
# SENTRY_ENABLE_LOGS=true
# MCP Transport Configuration
# Transport type: 'stdio' (default), 'sse' (Server-Sent Events), or 'http' (HTTP Streamable)
MCP_TRANSPORT=stdio
# HTTP Transport Settings (used when MCP_TRANSPORT=sse or MCP_TRANSPORT=http)
# Host to bind the HTTP server (default: 0.0.0.0 for all interfaces)
MCP_HTTP_HOST=0.0.0.0
# Port to bind the HTTP server (default: 8000)
MCP_HTTP_PORT=8000
# Optional bearer token for authentication (leave empty for no auth)
MCP_HTTP_BEARER_TOKEN=
```
## Available Tools
### API Information
- `api_version`: Get Zabbix API version information
### Host Management
- `host_get`: List hosts with optional filtering by groups, templates, proxies, and search criteria
- `host_create`: Create a new host with interfaces and template linking
- `host_update`: Update host properties (name, status, description)
- `host_delete`: Delete hosts by ID
### Host Group Management
- `hostgroup_get`: List host groups with optional filtering
- `hostgroup_create`: Create a new host group
- `hostgroup_update`: Update an existing host group's properties (name)
- `hostgroup_delete`: Delete host groups
### Template Management
- `template_get`: List templates with optional filtering
- `template_create`: Create a new template
- `template_update`: Update template properties (name, description)
- `template_delete`: Delete templates
### Item Management
- `item_get`: List items with optional filtering by hosts, groups, templates
- `item_create`: Create a new item on a host
- `item_update`: Update item properties (name, delay, units, description, status)
- `item_delete`: Delete items
### Trigger Management
- `trigger_get`: List triggers with severity and state filtering
- `trigger_create`: Create a new trigger with expression
- `trigger_update`: Update trigger properties (description, expression, priority, status, comments)
- `trigger_delete`: Delete triggers
### Problem & Event Management
- `problem_get`: Get current problems with severity and time filtering
- `event_get`: Get events with time range filtering
- `event_acknowledge`: Acknowledge events with optional messages
### History & Trends
- `history_get`: Get historical data for items
- `trend_get`: Get trend data for items
### User Management
- `user_get`: List users with optional filtering
- `user_create`: Create a new user
- `user_update`: Update user properties (name, surname, password, type)
- `user_delete`: Delete users
### Proxy Management
- `proxy_get`: List proxies with optional filtering
- `proxy_create`: Create a new proxy
- `proxy_update`: Update proxy properties (name, operating mode, description)
- `proxy_delete`: Delete proxies
### Maintenance Management
- `maintenance_get`: List maintenance periods
- `maintenance_create`: Create a new maintenance period
- `maintenance_update`: Update maintenance period properties (name, times, description)
- `maintenance_delete`: Delete maintenance periods
### Action & Media
- `action_get`: List actions (triggers, autoregistration, etc.)
- `mediatype_get`: List media types
### Graph & Discovery
- `graph_get`: List graphs with optional filtering
- `discoveryrule_get`: List LLD discovery rules
- `drule_get`: List network discovery rules
- `itemprototype_get`: Get item prototypes from discovery rules
### SLA & Services
- `sla_get`: List SLAs
- `service_get`: List services
### Scripts
- `script_get`: List scripts
- `script_execute`: Execute a script on a host
### User Macros
- `usermacro_get`: List user macros (host and global)
- `usermacro_create`: Create a host macro
- `usermacro_delete`: Delete host macros
### Configuration Management
- `configuration_export`: Export Zabbix configurations to JSON or XML
- `configuration_import`: Import Zabbix configurations from JSON or XML
## Security & Safety Features
### Read-Only Mode
The server supports a read-only mode that disables all write operations for safe monitoring:
```env
READ_ONLY_MODE=true
```
### Tag-Based Tool Filtering
You can disable specific categories of tools by setting disabled tags:
```env
DISABLED_TAGS=alert,bills
```
### Rate Limiting
The server supports rate limiting to control API usage and prevent abuse. If enabled, requests are limited per client using a sliding window algorithm.
Enable rate limiting by setting the following environment variables in your `.env` file:
```env
RATE_LIMIT_ENABLED=true
RATE_LIMIT_MAX_REQUESTS=100 # Maximum requests allowed per window
RATE_LIMIT_WINDOW_MINUTES=1 # Window size in minutes
```
If `RATE_LIMIT_ENABLED` is set to `true`, the server will apply rate limiting middleware. Adjust `RATE_LIMIT_MAX_REQUESTS` and `RATE_LIMIT_WINDOW_MINUTES` as needed for your environment.
### Sentry Error Tracking & Monitoring (Optional)
The server optionally supports **Sentry** for error tracking, performance monitoring, and debugging. Sentry integration is completely optional and only initialized if configured.
#### Installation
To enable Sentry monitoring, install the optional dependency:
```sh
# Using UV (recommended)
uv sync --extra sentry
```
#### Configuration
Enable Sentry by setting the `SENTRY_DSN` environment variable in your `.env` file:
```env
# Required: Sentry DSN for your project
SENTRY_DSN=https://your-key@o12345.ingest.us.sentry.io/6789
# Optional: Performance monitoring sample rate (0.0-1.0, default: 1.0)
SENTRY_TRACES_SAMPLE_RATE=1.0
# Optional: Include personally identifiable information (default: true)
SENTRY_SEND_DEFAULT_PII=true
# Optional: Environment name (e.g., "production", "staging")
SENTRY_ENVIRONMENT=production
# Optional: Release version (auto-detected from package if not set)
SENTRY_RELEASE=1.2.3
# Optional: Profiling - continuous profiling sample rate (0.0-1.0, default: 1.0)
SENTRY_PROFILE_SESSION_SAMPLE_RATE=1.0
# Optional: Profiling - lifecycle mode for profiling (default: "trace")
# Options: "all", "continuation", "trace"
SENTRY_PROFILE_LIFECYCLE=trace
# Optional: Enable log capture as breadcrumbs and events (default: true)
SENTRY_ENABLE_LOGS=true
```
#### Features
When enabled, Sentry automatically captures:
- **Exceptions & Errors**: All unhandled exceptions with full context
- **Performance Metrics**: Request/response times and traces
- **MCP Integration**: Detailed MCP server activity and interactions
- **Logs & Breadcrumbs**: Application logs and event trails for debugging
- **Context Data**: Environment, client info, and request parameters
#### Getting a Sentry DSN
1. Create a free account at [sentry.io](https://sentry.io)
2. Create a new Python project
3. Copy your DSN from the project settings
4. Set it in your `.env` file
#### Disabling Sentry
Sentry is completely optional. If you don't set `SENTRY_DSN`, the server will run normally without any Sentry integration, and no monitoring data will be collected.
### SSL/TLS Configuration
The server supports SSL certificate verification and custom timeout settings:
```env
ZABBIX_VERIFY_SSL=true # Enable SSL certificate verification
ZABBIX_TIMEOUT=30 # Connection timeout in seconds
```
### Transport Configuration
The server supports multiple transport mechanisms for the MCP protocol:
#### STDIO Transport (Default)
The default transport uses standard input/output for communication. This is ideal for local usage and integration with tools that communicate via stdin/stdout:
```env
MCP_TRANSPORT=stdio
```
#### HTTP SSE Transport (Server-Sent Events)
For network-based deployments, you can use HTTP with Server-Sent Events. This allows the MCP server to be accessed over HTTP with real-time streaming:
```env
MCP_TRANSPORT=sse
MCP_HTTP_HOST=0.0.0.0 # Bind to all interfaces (or specific IP)
MCP_HTTP_PORT=8000 # Port to listen on
MCP_HTTP_BEARER_TOKEN=your-secret-token # Optional authentication token
```
When using SSE transport with a bearer token, clients must include the token in their requests:
```bash
curl -H "Authorization: Bearer your-secret-token" http://localhost:8000/sse
```
#### HTTP Streamable Transport
The HTTP Streamable transport provides HTTP-based communication with request/response streaming. This is ideal for web integrations and tools that need HTTP endpoints:
```env
MCP_TRANSPORT=http
MCP_HTTP_HOST=0.0.0.0 # Bind to all interfaces (or specific IP)
MCP_HTTP_PORT=8000 # Port to listen on
MCP_HTTP_BEARER_TOKEN=your-secret-token # Optional authentication token
```
When using streamable transport with a bearer token:
```sh
curl -H "Authorization: Bearer your-secret-token" \
-H "Accept: application/json, text/event-stream" \
-H "Content-Type: application/json" \
-d '{"jsonrpc":"2.0","id":1,"method":"tools/list"}' \
http://localhost:8000/mcp
```
**Note**: The HTTP transport requires proper JSON-RPC formatting with `jsonrpc` and `id` fields. The server may also require session initialization for some operations.
For more information on FastMCP transports, see the [FastMCP documentation](https://gofastmcp.com/deployment/running-server#transport-protocols).
## Contributing
1. Fork the repository
2. Create a feature branch (`git checkout -b feature/amazing-feature`)
3. Make your changes
4. Run tests and ensure code quality (`uv run pytest && uv run ruff check .`)
5. Commit your changes (`git commit -m 'Add amazing feature'`)
6. Push to the branch (`git push origin feature/amazing-feature`)
7. Open a Pull Request
## License
MIT License - see LICENSE file for details.
| text/markdown | Mateusz Hajder | null | null | null | MIT License
Copyright (c) 2026 Mateusz Hajder
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | automation, management, mcp, network, server, zabbix | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"... | [] | null | null | <3.15,>=3.11 | [] | [] | [] | [
"fastmcp<4,>=3.0.0",
"pydantic>=2.0.0",
"python-dotenv>=1.0.0",
"zabbix-utils[async]>=2.0.4",
"sentry-sdk>=2.43.0; extra == \"sentry\""
] | [] | [] | [] | [
"Homepage, https://github.com/mhajder/zabbix-mcp",
"Repository, https://github.com/mhajder/zabbix-mcp",
"Documentation, https://github.com/mhajder/zabbix-mcp#readme",
"Issues, https://github.com/mhajder/zabbix-mcp/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:30:02.847810 | zabbix_mcp-0.2.1.tar.gz | 195,897 | f8/5a/f586f832f0bc8af42061f18c25f432d080b314bc54e4c5d04932145bab88/zabbix_mcp-0.2.1.tar.gz | source | sdist | null | false | e59f83fc6c8caec4e250f526f670bbaf | 88c01855c5b977516b68b5d2bdf9137292ff3e28ff4cdbbb57806dde1119b5a4 | f85af586f832f0bc8af42061f18c25f432d080b314bc54e4c5d04932145bab88 | null | [
"LICENSE"
] | 241 |
2.4 | ai-accelerator | 0.2.8 | AI Accelerator: A production-ready MLOps platform to deploy, monitor, and govern machine learning models with security, scalability, and auditability. | # AIAC Console Command Reference
This document lists all currently available CLI commands and their options.
## Run Forms
Use this form:
```bash
aiac <group> <command> [options]
```
## Command Groups
- `auth`
- `server`
- `deployment`
- `monitoring`
- `governance`
## Quick Help
```bash
aiac --help
aiac auth --help
aiac server --help
aiac deployment --help
aiac monitoring --help
aiac governance --help
```
## server
### `server --help`
```bash
aiac server --help
```
```text
Usage: aiac server [OPTIONS] COMMAND [ARGS]...
Local API server commands
Options:
--help Show this message and exit.
Commands:
run Run the AI Accelerator Django API server.
```
### `server run`
Run the AI Accelerator Django API server.
Options:
- `--host` (default `127.0.0.1`)
- `--port` (default `8000`)
- `--no-reload/--reload` (default `--no-reload`)
- `--background/--foreground` (default `--background`)
- `--migrate/--no-migrate` (default `--migrate`)
Example:
```bash
aiac server run --host 127.0.0.1 --port 8000 --no-reload
```
Notes:
- By default, AIAC runs database migrations automatically before server startup.
### `server status`
Show local background server status.
Example:
```bash
aiac server status
```
### `server stop`
Stop local background server started by `aiac server run`.
Example:
```bash
aiac server stop
```
## auth
### `auth register`
Register a new user.
Options:
- `--email` (prompted if omitted)
- `--username` (prompted if omitted)
- `--password` (prompted, hidden)
- `--role` (prompted)
Example:
```bash
aiac auth register --email user@example.com --username user1 --password secret --role client
```
### `auth login`
Login and save access/refresh tokens.
Options:
- `--email` (prompted)
- `--password` (prompted, hidden)
Example:
```bash
aiac auth login --email user@example.com --password secret
```
### `auth logout`
Logout using refresh token (or saved token if blank).
Options:
- `--refresh-token` (prompted, hidden)
Example:
```bash
aiac auth logout
```
### `auth me`
Show current authenticated user info.
Example:
```bash
aiac auth me
```
### `auth token-show`
Verify credentials then show masked saved tokens.
Options:
- `--email` (prompted)
- `--password` (prompted, hidden)
Example:
```bash
aiac auth token-show --email user@example.com --password secret
```
### Friendly Errors and Recovery (`auth` + `server`)
When the API server is down:
```text
Unable to login because the API server is not reachable at http://127.0.0.1:8000.
Start the server with `aiac server run --host 127.0.0.1 --port 8000` and try again.
```
When credentials are invalid:
```text
Invalid email or password.
```
When token/session is expired:
```text
Session expired or token is invalid. Please run `aiac auth login` and try again.
```
When backend DB is not ready:
```text
... backend database is not ready.
Start the API server with migrations:
aiac server run --migrate
Then retry.
```
When backend returns internal HTML error page:
```text
... backend returned an internal server error.
Check backend logs with:
aiac server status
type %USERPROFILE%\.aiac\server.log
```
When server startup fails due to missing env var:
```text
Server startup failed: missing required environment variable `EMAIL_HOST`.
Set it in your shell or `.env`, then rerun `aiac server run`.
```
## deployment
### `deployment create-project-deployment`
Create a new project.
Options:
- `--owner-id` (prompted)
- `--name` (prompted)
- `--description` (prompted)
Example:
```bash
aiac deployment create-project-deployment
```
### `deployment list-projects`
List all projects.
Example:
```bash
aiac deployment list-projects
```
### `deployment delete-project`
Delete a project.
Options:
- `--project-id` (prompted)
- `--confirm/--no-confirm` (default confirm)
Example:
```bash
aiac deployment delete-project --project-id 2 --no-confirm
```
### `deployment create-model-version`
Create model version from file upload.
Options:
- `--project-id` (prompted)
- `--description` (prompted)
- `--field-file-path` (prompted)
Example:
```bash
aiac deployment create-model-version --project-id 1 --description "v1" --field-file-path model.pkl
```
### `deployment list-model-versions`
List all model versions.
Example:
```bash
aiac deployment list-model-versions
```
### `deployment delete-model-version`
Delete a model version.
Options:
- `--model-version-id` (prompted)
- `--confirm/--no-confirm` (default confirm)
Example:
```bash
aiac deployment delete-model-version --model-version-id 4 --no-confirm
```
### `deployment deploy-model-version`
Deploy a model version and optionally track progress.
Options:
- `--user-id` (prompted)
- `--model-version-id` (prompted)
- `--port` (prompted)
- `--auto-preflight/--no-auto-preflight` (default `--auto-preflight`)
- `--start-worker/--no-start-worker` (default `--start-worker`)
- `--wait/--no-wait` (default `--wait`)
- `--poll-interval-seconds` (default `2`)
- `--timeout-seconds` (default `900`)
- `--precheck/--no-precheck` (default `--precheck`)
- `--check-local-port/--no-check-local-port` (default `--check-local-port`)
- `--format, -f` (`text|json`, default `text`)
- `--redis-host` (default `localhost`)
- `--redis-port` (default `6379`)
Example:
```bash
aiac deployment deploy-model-version --user-id 14 --model-version-id 4 --port 6000 --format text
```
### `deployment preflight`
Run pre-deployment checks before deploying a model.
Checks:
- API server reachability
- Docker CLI and Docker daemon
- Redis reachability
- Celery worker availability
- Optional model version existence
- Optional local port availability
Options:
- `--model-version-id` (optional)
- `--port` (optional)
- `--redis-host` (default `localhost`)
- `--redis-port` (default `6379`)
- `--check-local-port/--no-check-local-port` (default `--check-local-port`)
- `--format, -f` (`table|json`, default `table`)
Examples:
```bash
aiac deployment preflight --model-version-id 4 --port 6000
aiac deployment preflight --format json
```
### `deployment redeploy-model`
Redeploy existing deployment.
Options:
- `--deployment-id` (prompted)
- `--start-worker/--no-start-worker` (default `--start-worker`)
- `--wait/--no-wait` (default `--wait`)
- `--timeout-seconds` (default `900`)
- `--redis-host` (default `localhost`)
- `--redis-port` (default `6379`)
Example:
```bash
aiac deployment redeploy-model --deployment-id 20
```
### `deployment stop-deployment`
Stop a deployment.
Options:
- `--deployment-id` (prompted)
Example:
```bash
aiac deployment stop-deployment --deployment-id 20
```
### `deployment delete-deployment`
Delete a deployment.
Options:
- `--deployment-id` (prompted)
- `--confirm/--no-confirm` (default confirm)
Example:
```bash
aiac deployment delete-deployment --deployment-id 20 --no-confirm
```
### `deployment list-deployments`
List all deployments.
Example:
```bash
aiac deployment list-deployments
```
### `deployment get-deployment-details`
Show deployment details + runtime URLs.
Options:
- `--deployment-id` (prompted)
Example:
```bash
aiac deployment get-deployment-details --deployment-id 20
```
### `deployment advisor`
Advanced advisor report (risk/strategy/metrics).
Options:
- `--deployment-id` (prompted)
- `--format, -f` (`table|json`, default `table`)
Example:
```bash
aiac deployment advisor --deployment-id 20 --format table
```
### `deployment services`
Show runtime service URLs and optional health probe.
Options:
- `--deployment-id` (prompted)
- `--probe/--no-probe` (default `--no-probe`)
- `--timeout` (probe timeout, default `2`)
- `--format, -f` (`table|json`, default `table`)
Example:
```bash
aiac deployment services --deployment-id 20 --probe --format table
```
### `deployment traffic-shadow`
Compare active model vs candidate model on recent samples.
Options:
- `--deployment-id` (prompted)
- `--candidate, -c` (required candidate model version id)
- `--samples, -s` (default `200`, clamped `10..1000`)
- `--format, -f` (`table|json`, default `table`)
Example:
```bash
aiac deployment traffic-shadow --deployment-id 20 --candidate 3 --samples 300 --format json
```
### `deployment explain-decision`
Run explainable decision inference with configurable refusal checks.
Options:
- `--deployment-id` (prompted)
- `--features, -x` (JSON numeric feature array)
- `--min-confidence` (optional refusal threshold)
- `--min-margin` (optional refusal threshold)
- `--blocked-labels` (comma-separated labels to refuse)
- `--fallback/--no-fallback` (default `--fallback`; use `/predict` if `/predict-decision` is missing)
- `--timeout` (request timeout seconds, default `10`)
- `--format, -f` (`table|json`, default `table`)
Example:
```bash
aiac deployment explain-decision --deployment-id 20 --features "[0.1, 0.2, 0.3]" --min-confidence 0.7 --min-margin 0.15 --blocked-labels "denied,blocked" --format table
```
Result interpretation:
- `decision=approved`: runtime policy checks passed.
- `decision=refused`: runtime policy checks rejected the request.
- `decision=approved_with_fallback`: `/predict-decision` was unavailable, so CLI used `/predict`; refusal checks were **not** enforced.
- `confidence=None` and `margin=None`: model/runtime did not provide probability scores, so confidence-margin checks could not be evaluated.
Output includes:
- Decision summary table
- Interpretation block (plain-language explanation)
- Reasons list
- Top probabilities (if available)
- Linear feature contributions and contribution summary (if available)
Troubleshooting:
- If you see `runtime request failed: 404` or fallback messages, your deployment runtime is likely outdated. Redeploy the model to enable `/predict-decision`.
- If compliance/safety requires strict refusal enforcement, run with `--no-fallback` so the command fails instead of using `/predict`.
- If `confidence`/`margin` remain `None` after redeploy, your model may not expose probabilities; use models/pipelines with `predict_proba` for confidence-based refusal checks.
## monitoring
### `monitoring deploy-stats`
Live or one-shot deployment stats + health warnings.
Options:
- `--deployment-id` (prompted)
- `--format, -f` (`table|json`, default `table`)
- `--watch, -w` (continuous polling)
- `--interval, -i` (seconds, default `5`)
- `--iterations` (`0` = infinite)
- `--cpu-warn` (default `85.0`)
- `--ram-warn` (default `85.0`)
- `--latency-warn` (default `500.0`)
- `--error-rate-warn` (default `5.0`)
Example:
```bash
aiac monitoring deploy-stats --deployment-id 4 --watch --interval 10
```
### `monitoring deploy-records`
Show monitoring records with summary; supports table/json/csv.
Options:
- `--deployment-id` (prompted)
- `--format, -f` (`table|json|csv`, default `table`)
- `--limit, -l` (default `50`)
- `--watch, -w`
- `--interval, -i` (default `5`)
- `--iterations` (`0` = infinite)
- `--cpu-warn` (default `85.0`)
- `--ram-warn` (default `85.0`)
- `--latency-warn` (default `500.0`)
Example:
```bash
aiac monitoring deploy-records --deployment-id 10 --format table
```
### `monitoring alert`
List alerts for deployment.
Options:
- `--deployment-id` (prompted)
Example:
```bash
aiac monitoring alert --deployment-id 18
```
### `monitoring resolve-alert`
Resolve alert by id, or choose from deployment alerts.
Options:
- `--alert-id, -a` (alert UUID)
- `--deployment-id, -d` (to select alert interactively)
- `--include-resolved` (include already resolved alerts when selecting)
- `--yes, -y` (skip confirmation)
Examples:
```bash
aiac monitoring resolve-alert --alert-id <uuid>
aiac monitoring resolve-alert --deployment-id 18
```
### `monitoring health-report`
Advanced health report with trends/recommendations.
Options:
- `--deployment-id` (prompted)
- `--window, -w` (records window, default `50`)
- `--format, -f` (`table|json`, default `table`)
Example:
```bash
aiac monitoring health-report --deployment-id 4 --window 100
```
### `monitoring cost-intelligence`
Advanced FinOps report with monthly/annual cost estimation, efficiency scoring, budget variance, risk flags, and scenario projections.
Options:
- `--deployment-id` (prompted)
- `--window, -w` (default `200`)
- `--cpu-hour-rate` (default `0.05`)
- `--gb-ram-hour-rate` (default `0.01`)
- `--request-million-rate` (default `1.0`)
- `--ram-reference-gb` (default `4.0`)
- `--budget` (optional monthly budget for variance analysis)
- `--target-cpu-utilization` (default `65.0`)
- `--target-ram-utilization` (default `70.0`)
- `--scenarios/--no-scenarios` (default `--scenarios`)
- `--format, -f` (`table|json`, default `table`)
Example:
```bash
aiac monitoring cost-intelligence --deployment-id 4 --window 300 --budget 250 --target-cpu-utilization 65 --target-ram-utilization 70 --scenarios --format table
```
### `monitoring detect-drift`
Drift detection with profiles, thresholds, history, and watch mode.
Options:
- `--model-version-id` (prompted)
- `--profile, -p` (`sensitive|balanced|conservative`, default `balanced`)
- `--kl-threshold` (override)
- `--wasserstein-threshold` (override)
- `--ks-threshold` (override)
- `--chi-square-threshold` (override)
- `--explain/--no-explain` (default explain)
- `--history` (show previous scans)
- `--history-limit` (default `5`)
- `--watch, -w`
- `--interval, -i` (default `30`)
- `--iterations` (`0` = infinite)
Example:
```bash
aiac monitoring detect-drift --model-version-id 4 --profile balanced --history
```
### `monitoring samples`
Upload/validate sample data for monitoring and drift.
Options:
- `--model-version-id` (prompted)
- `--data-samples` (JSON array string)
- `--samples-file` (JSON or CSV file)
- `--csv-file` (CSV file)
- `--format, -f` (`auto|json|csv`, for `--samples-file`, default `auto`)
- `--chunk-size` (`0` single request)
- `--dry-run` (validate only)
- `--preview` (show first N samples, default `3`)
- `--strict-shape` (require same vector dimension)
Examples:
```bash
aiac monitoring samples --model-version-id 4 --data-samples "[0.1, 0.2, 0.3]"
aiac monitoring samples --model-version-id 4 --samples-file samples.json
aiac monitoring samples --model-version-id 4 --csv-file samples.csv --chunk-size 100
```
## governance
### `governance create-policy`
Create policy. If `--rules` is omitted, CLI prompts interactive metadata template (`deployment|monitoring|both`) and rules.
Arguments:
- `name` (required)
- `policy_type` (required)
Options:
- `--description, -d` (optional text)
- `--rules, -r` (JSON object string)
Examples:
```bash
aiac governance create-policy model deployment
aiac governance create-policy model deployment -d "prod policy" -r '{"max_latency_ms": 500}'
```
### `governance list-policies`
List policies with owner, creator, created_at, description, and rules preview.
Example:
```bash
aiac governance list-policies
```
### `governance delete-policy`
Delete policy by id.
Arguments:
- `policy_id` (required)
Example:
```bash
aiac governance delete-policy 3
```
### `governance apply-policy`
Apply policy to deployment.
Arguments:
- `policy_id` (required)
- `deployment_id` (optional; if omitted, prompt asks)
Examples:
```bash
aiac governance apply-policy 3 14
aiac governance apply-policy 3
```
### `governance view-violations`
View policy violations.
Example:
```bash
aiac governance view-violations
```
### `governance metrics`
Show aggregated violation metrics.
Example:
```bash
aiac governance metrics
```
### `governance run-policy-engine`
Trigger policy engine execution immediately.
Example:
```bash
aiac governance run-policy-engine
```
### `governance debug-policy-engine`
Debug why violations are/aren't generated for a policy.
Options:
- `--policy, -p` (required policy id)
- `--deployment, -d` (optional deployment filter)
- `--limit, -l` (default `50`, clamped `1..200`)
Example:
```bash
aiac governance debug-policy-engine --policy 3 --deployment 14 --limit 100
```
### `governance policy-insights`
Advanced coverage/risk insights with recommendations.
Options:
- `--policy, -p` (optional)
- `--days, -d` (default `7`, clamped `1..90`)
- `--format, -f` (`table|csv`, default `table`)
Examples:
```bash
aiac governance policy-insights
aiac governance policy-insights --policy 3 --days 30 --format csv
```
### `governance alert-logs`
View governance alert logs.
Example:
```bash
aiac governance alert-logs
```
## Notes
- Most required values are prompted interactively if omitted.
- Booleans can be toggled with `--flag/--no-flag` for Typer bool options.
- For the most accurate local signature at any time:
```bash
aiac <group> <command> --help
```
| text/markdown | null | Ayoub Ardem <ayoub.ardem@gmail.com> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Framework :: Django",
"Top... | [] | null | null | <3.13,>=3.10 | [] | [] | [] | [
"Django<6.0,>=5.0",
"djangorestframework>=3.14.0",
"djangorestframework-simplejwt>=5.3.0",
"drf-spectacular>=0.26.5",
"django-cors-headers>=4.3.1",
"django-extensions>=3.2.3",
"django-redis>=5.4.0",
"typer>=0.9.0",
"rich>=13.7.0",
"celery>=5.3.4",
"redis>=5.0.1",
"docker>=7.0.0",
"requests>=... | [] | [] | [] | [
"Homepage, https://github.com/AyoubArdem",
"Repository, https://github.com/AyoubArdem/AI_Accelerator",
"Documentation, https://github.com/AyoubArdem/AI_Accelerator/blob/main/README.md"
] | twine/6.2.0 CPython/3.12.5 | 2026-02-19T17:29:46.317571 | ai_accelerator-0.2.8.tar.gz | 271,130 | c8/ab/710042a4eb2c789c0e34b2660898e63a63bbe14fddd7670d9de349ccb616/ai_accelerator-0.2.8.tar.gz | source | sdist | null | false | 13506f5e5813b2535852a7392fa6dc33 | 13e34d94e2d46a0295fffd8c49586a8edaba202ef6496c1aeed98190b82a50f0 | c8ab710042a4eb2c789c0e34b2660898e63a63bbe14fddd7670d9de349ccb616 | Apache-2.0 | [
"LICENSE"
] | 121 |
2.4 | adafruit-io | 3.0.0 | Python client library for Adafruit IO (http://io.adafruit.com/). | Adafruit IO Python
==================
.. image:: https://readthedocs.org/projects/adafruit-io-python-client/badge/?version=latest
:target: https://adafruit-io-python-client.readthedocs.io/en/latest/
:alt: Documentation Status
.. image:: https://img.shields.io/discord/327254708534116352.svg
:target: https://adafru.it/discord
:alt: Chat
.. image:: https://github.com/adafruit/Adafruit_IO_Python/workflows/Build-CI/badge.svg
:target: https://github.com/adafruit/Adafruit_IO_Python/actions
:alt: Build Status
.. image:: https://img.shields.io/badge/Try%20out-Adafruit%20IO%20Python-579ACA.svg?logo=data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAFkAAABZCAMAAABi1XidAAAB8lBMVEX///9XmsrmZYH1olJXmsr1olJXmsrmZYH1olJXmsr1olJXmsrmZYH1olL1olJXmsr1olJXmsrmZYH1olL1olJXmsrmZYH1olJXmsr1olL1olJXmsrmZYH1olL1olJXmsrmZYH1olL1olL0nFf1olJXmsrmZYH1olJXmsq8dZb1olJXmsrmZYH1olJXmspXmspXmsr1olL1olJXmsrmZYH1olJXmsr1olL1olJXmsrmZYH1olL1olLeaIVXmsrmZYH1olL1olL1olJXmsrmZYH1olLna31Xmsr1olJXmsr1olJXmsrmZYH1olLqoVr1olJXmsr1olJXmsrmZYH1olL1olKkfaPobXvviGabgadXmsqThKuofKHmZ4Dobnr1olJXmsr1olJXmspXmsr1olJXmsrfZ4TuhWn1olL1olJXmsqBi7X1olJXmspZmslbmMhbmsdemsVfl8ZgmsNim8Jpk8F0m7R4m7F5nLB6jbh7jbiDirOEibOGnKaMhq+PnaCVg6qWg6qegKaff6WhnpKofKGtnomxeZy3noG6dZi+n3vCcpPDcpPGn3bLb4/Mb47UbIrVa4rYoGjdaIbeaIXhoWHmZYHobXvpcHjqdHXreHLroVrsfG/uhGnuh2bwj2Hxk17yl1vzmljzm1j0nlX1olL3AJXWAAAAbXRSTlMAEBAQHx8gICAuLjAwMDw9PUBAQEpQUFBXV1hgYGBkcHBwcXl8gICAgoiIkJCQlJicnJ2goKCmqK+wsLC4usDAwMjP0NDQ1NbW3Nzg4ODi5+3v8PDw8/T09PX29vb39/f5+fr7+/z8/Pz9/v7+zczCxgAABC5JREFUeAHN1ul3k0UUBvCb1CTVpmpaitAGSLSpSuKCLWpbTKNJFGlcSMAFF63iUmRccNG6gLbuxkXU66JAUef/9LSpmXnyLr3T5AO/rzl5zj137p136BISy44fKJXuGN/d19PUfYeO67Znqtf2KH33Id1psXoFdW30sPZ1sMvs2D060AHqws4FHeJojLZqnw53cmfvg+XR8mC0OEjuxrXEkX5ydeVJLVIlV0e10PXk5k7dYeHu7Cj1j+49uKg7uLU61tGLw1lq27ugQYlclHC4bgv7VQ+TAyj5Zc/UjsPvs1sd5cWryWObtvWT2EPa4rtnWW3JkpjggEpbOsPr7F7EyNewtpBIslA7p43HCsnwooXTEc3UmPmCNn5lrqTJxy6nRmcavGZVt/3Da2pD5NHvsOHJCrdc1G2r3DITpU7yic7w/7Rxnjc0kt5GC4djiv2Sz3Fb2iEZg41/ddsFDoyuYrIkmFehz0HR2thPgQqMyQYb2OtB0WxsZ3BeG3+wpRb1vzl2UYBog8FfGhttFKjtAclnZYrRo9ryG9uG/FZQU4AEg8ZE9LjGMzTmqKXPLnlWVnIlQQTvxJf8ip7VgjZjyVPrjw1te5otM7RmP7xm+sK2Gv9I8Gi++BRbEkR9EBw8zRUcKxwp73xkaLiqQb+kGduJTNHG72zcW9LoJgqQxpP3/Tj//c3yB0tqzaml05/+orHLksVO+95kX7/7qgJvnjlrfr2Ggsyx0eoy9uPzN5SPd86aXggOsEKW2Prz7du3VID3/tzs/sSRs2w7ovVHKtjrX2pd7ZMlTxAYfBAL9jiDwfLkq55Tm7ifhMlTGPyCAs7RFRhn47JnlcB9RM5T97ASuZXIcVNuUDIndpDbdsfrqsOppeXl5Y+XVKdjFCTh+zGaVuj0d9zy05PPK3QzBamxdwtTCrzyg/2Rvf2EstUjordGwa/kx9mSJLr8mLLtCW8HHGJc2R5hS219IiF6PnTusOqcMl57gm0Z8kanKMAQg0qSyuZfn7zItsbGyO9QlnxY0eCuD1XL2ys/MsrQhltE7Ug0uFOzufJFE2PxBo/YAx8XPPdDwWN0MrDRYIZF0mSMKCNHgaIVFoBbNoLJ7tEQDKxGF0kcLQimojCZopv0OkNOyWCCg9XMVAi7ARJzQdM2QUh0gmBozjc3Skg6dSBRqDGYSUOu66Zg+I2fNZs/M3/f/Grl/XnyF1Gw3VKCez0PN5IUfFLqvgUN4C0qNqYs5YhPL+aVZYDE4IpUk57oSFnJm4FyCqqOE0jhY2SMyLFoo56zyo6becOS5UVDdj7Vih0zp+tcMhwRpBeLyqtIjlJKAIZSbI8SGSF3k0pA3mR5tHuwPFoa7N7reoq2bqCsAk1HqCu5uvI1n6JuRXI+S1Mco54YmYTwcn6Aeic+kssXi8XpXC4V3t7/ADuTNKaQJdScAAAAAElFTkSuQmCC
:target: https://mybinder.org/v2/gh/adafruit/adafruit_io_python_jupyter/master?filepath=adafruit-io-python-tutorial.ipynb
.. image:: https://cdn-learn.adafruit.com/assets/assets/000/057/153/original/adafruit_io_iopython.png?1530802073
A Python library and examples for use with `io.adafruit.com <https://io.adafruit.com>`_.
Compatible with Python Versions 3.6+
Installation
================
Easy Installation
~~~~~~~~~~~~~~~~~
If you have `PIP <https://pip.pypa.io/en/stable/installing/>`_ installed (typically with apt-get install python-pip on a Debian/Ubuntu-based system) then run:
.. code-block:: shell
pip3 install adafruit-io
This will automatically install the Adafruit IO Python client code for your Python scripts to use. You might want to examine the examples folder in this GitHub repository to see examples of usage.
If the above command fails, you may first need to install prerequisites:
.. code-block:: shell
pip3 install setuptools
pip3 install wheel
Manual Installation
~~~~~~~~~~~~~~~~~~~
Clone or download the contents of this repository. Then navigate to the folder in a terminal and run the following command:
.. code-block:: shell
python setup.py install
Usage
=====
Documentation for this project is `available on the ReadTheDocs <https://adafruit-io-python-client.readthedocs.io/en/latest/>`_.
Service Integrations
====================
The client includes REST and MQTT helpers for Adafruit IO integrations:
- Time
- Random Data
- Weather (requires IO+ subscription)
- Air Quality (requires IO+ subscription)
Integration API details are documented in ``docs/integrations.rst``.
Service integration examples are included in:
- ``examples/api/weather.py``
- ``examples/api/weather_create_delete.py``
- ``examples/api/air_quality.py``
- ``examples/api/air_quality_create_delete.py``
- ``examples/mqtt/mqtt_weather.py``
- ``examples/mqtt/mqtt_air_quality.py``
Contributing
============
Contributions are welcome! Please read our `Code of Conduct
<https://github.com/adafruit/CircuitPython_io-client-python/blob/master/CODE_OF_CONDUCT.md>`_
before contributing to help this project stay welcoming.
| text/x-rst | Adafruit Industries | adafruitio@adafruit.com | null | null | MIT | adafruitio io python circuitpython raspberrypi hardware MQTT REST | [
"Development Status :: 5 - Production/Stable",
"Operating System :: POSIX :: Linux",
"Operating System :: Microsoft :: Windows",
"Operating System :: MacOS",
"License :: OSI Approved :: MIT License",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Pyt... | [] | https://github.com/adafruit/Adafruit_IO_Python | null | null | [] | [] | [] | [
"requests",
"paho-mqtt"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T17:29:39.759966 | adafruit_io-3.0.0.tar.gz | 54,954 | ea/b0/f771aae1c67083854369719cbc9c0a9a7f530c55a17dd31d0f330568c12c/adafruit_io-3.0.0.tar.gz | source | sdist | null | false | 949a11dc8bc90728286ada2c02b018c5 | 43bff22f3386fb470633b8a60cf35a270d5d50d60f4462684c2413e59b3fe784 | eab0f771aae1c67083854369719cbc9c0a9a7f530c55a17dd31d0f330568c12c | null | [
"LICENSE.md"
] | 167 |
2.4 | aiortp | 0.2.0 | Asyncio RTP/RTCP audio library for Python | # aiortp
Asyncio RTP/RTCP audio library for Python.
Plain RTP/RTCP for audio — no WebRTC, no ICE, no DTLS. Built for telephony and VoIP applications where you need direct control over RTP streams.
Portions derived from [aiortc](https://github.com/aiortc/aiortc) by Jeremy Lainé (BSD-3-Clause).
## Features
- **Pure Python** — zero required dependencies, Python >=3.11
- **AsyncIO native** — built on `asyncio.DatagramProtocol`
- **G.711 codecs** — µ-law (PCMU) and A-law (PCMA) with precomputed lookup tables
- **L16 codec** — linear 16-bit PCM (s16le ↔ s16be)
- **Optional Opus** — via `opuslib` (`pip install aiortp[opus]`)
- **RTCP** — Sender Reports, SDES, BYE with RFC 3550 randomized intervals
- **DTMF** — RFC 4733 telephone-event send/receive with redundant end packets
- **Jitter buffer** — extracted from aiortc, with configurable capacity and prefetch
- **Fully typed** — PEP 561 `py.typed` marker included
## Installation
```bash
pip install aiortp
```
With Opus support:
```bash
pip install aiortp[opus]
```
## Quick Start
```python
import asyncio
from aiortp import RTPSession, PayloadType
async def main():
# Create two sessions on localhost
session_a = await RTPSession.create(
local_addr=("127.0.0.1", 10000),
remote_addr=("127.0.0.1", 10002),
payload_type=PayloadType.PCMU,
)
session_b = await RTPSession.create(
local_addr=("127.0.0.1", 10002),
remote_addr=("127.0.0.1", 10000),
payload_type=PayloadType.PCMU,
)
# Receive callback
def on_audio(data: bytes, timestamp: int) -> None:
print(f"Received {len(data)} bytes, ts={timestamp}")
session_b.on_audio = on_audio
# Send PCM audio (auto-encoded to µ-law)
pcm = b"\x00" * 320 # 160 samples of silence (20ms at 8kHz)
for i in range(10):
session_a.send_audio_pcm(pcm, timestamp=i * 160)
await asyncio.sleep(1)
await session_a.close()
await session_b.close()
asyncio.run(main())
```
## DTMF
```python
# Send
session.send_dtmf("1", duration_ms=160, timestamp=0)
# Receive
def on_dtmf(digit: str, duration: int) -> None:
print(f"Got DTMF: {digit}")
session.on_dtmf = on_dtmf
```
## Codec Registry
```python
from aiortp import get_codec, PayloadType
codec = get_codec(PayloadType.PCMU) # or PCMA, L16
encoded = codec.encode(pcm_bytes)
decoded = codec.decode(encoded)
```
## Low-Level Packets
```python
from aiortp import RtpPacket, RtcpPacket, is_rtcp
# Parse
packet = RtpPacket.parse(data)
print(packet.sequence_number, packet.timestamp, packet.payload_type)
# Build
packet = RtpPacket(
payload_type=0,
sequence_number=1000,
timestamp=8000,
ssrc=0xDEADBEEF,
payload=b"\x80" * 160,
)
data = packet.serialize()
# Demux RTP vs RTCP
if is_rtcp(data):
rtcp_packets = RtcpPacket.parse(data)
```
## Examples
See the [`examples/`](examples/) directory:
- **`loopback.py`** — two sessions exchanging G.711 audio on localhost
- **`dtmf.py`** — sending and receiving DTMF digits
- **`codec_roundtrip.py`** — encode/decode with each built-in codec
- **`raw_packets.py`** — low-level RTP/RTCP packet construction
## License
BSD-3-Clause. See [LICENSE](LICENSE) for details.
| text/markdown | null | Sylvain Boily <sylvainboilydroid@gmail.com> | null | null | null | asyncio, audio, dtmf, g711, rtcp, rtp, sip, telephony, voip | [
"Development Status :: 3 - Alpha",
"Framework :: AsyncIO",
"Intended Audience :: Developers",
"Intended Audience :: Telecommunications Industry",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :... | [] | null | null | >=3.11 | [] | [] | [] | [
"build>=1.0; extra == \"dev\"",
"mypy>=1.11; extra == \"dev\"",
"pytest-asyncio>=0.24; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.6; extra == \"dev\"",
"twine>=5.0; extra == \"dev\"",
"g722>=1.2; extra == \"g722\"",
"opuslib; extra == \"opus\""
] | [] | [] | [] | [
"Homepage, https://github.com/anganyAI/aiortp",
"Repository, https://github.com/anganyAI/aiortp",
"Issues, https://github.com/anganyAI/aiortp/issues"
] | twine/6.2.0 CPython/3.13.3 | 2026-02-19T17:29:16.717206 | aiortp-0.2.0.tar.gz | 33,862 | 37/91/648ede29d55de4178bb05a93618b00d6e09bd548374025c0f28d4bf40eec/aiortp-0.2.0.tar.gz | source | sdist | null | false | 2fdd3f17fc3084c2a89a90b574be131c | 18385c94a2e28b2fce604ec329ebdd0fe1da8ff895896e0a0da29bdafd375336 | 3791648ede29d55de4178bb05a93618b00d6e09bd548374025c0f28d4bf40eec | MIT | [
"LICENSE"
] | 216 |
2.4 | schwifty-fl | 2026.2.20 | IBAN parsing and validation | .. image:: https://img.shields.io/pypi/v/schwifty.svg?style=flat-square
:target: https://pypi.python.org/pypi/schwifty
.. image:: https://img.shields.io/github/actions/workflow/status/mdomke/schwifty/lint-and-test.yml?branch=main&style=flat-square
:target: https://github.com/mdomke/schwifty/actions?query=workflow%3Alint-and-test
.. image:: https://img.shields.io/pypi/l/schwifty.svg?style=flat-square
:target: https://pypi.python.org/pypi/schwifty
.. image:: https://readthedocs.org/projects/schwifty/badge/?version=latest&style=flat-square
:target: https://schwifty.readthedocs.io
.. image:: https://img.shields.io/badge/code%20style-black-000000.svg?style=flat-square
:target: https://black.readthedocs.io/en/stable/index.html
.. image:: https://img.shields.io/codecov/c/gh/mdomke/schwifty?token=aJj1Yg0NUq&style=flat-square
:target: https://codecov.io/gh/mdomke/schwifty
Gotta get schwifty with your IBANs
==================================
.. teaser-begin
``schwifty`` is a Python library that let's you easily work with IBANs and BICs
as specified by the ISO. IBAN is the Internation Bank Account Number and BIC
the Business Identifier Code. Both are used for international money transfer.
Features
--------
``schwifty`` lets you
* `validate`_ check-digits and the country specific format of IBANs
* `validate`_ format and country codes from BICs
* `generate`_ BICs from country and bank-code
* `generate`_ IBANs from country-code, bank-code and account-number.
* `generate`_ random valid IBANs
* get the BIC associated to an IBAN's bank-code
* access all relevant components as attributes
See the `docs <https://schwifty.readthedocs.io>`_ for more inforamtion.
.. _validate: https://schwifty.readthedocs.io/en/latest/examples.html#validation
.. _generate: https://schwifty.readthedocs.io/en/latest/examples.html#generation
.. teaser-end
Versioning
----------
Since the IBAN specification and the mapping from BIC to bank_code is updated from time to time,
``schwifty`` uses `CalVer <http://www.calver.org/>`_ for versioning with the scheme ``YY.0M.Micro``.
.. installation-begin
Installation
------------
To install ``schwifty``, simply:
.. code-block:: bash
$ pip install schwifty
.. installation-end
Development
-----------
We use the `black`_ as code formatter. This avoids discussions about style preferences in the same
way as ``gofmt`` does the job for Golang. The conformance to the formatting rules is checked in the
CI pipeline, so that it is recommendable to install the configured `pre-commit`_-hook, in order to
avoid long feedback-cycles.
.. code-block:: bash
$ pre-commit install
You can also use the ``fmt`` Makefile-target to format the code or use one of the available `editor
integrations`_.
Project Information
-------------------
# schwifty-md
Fork of [schwifty](https://github.com/mdomke/schwifty) with support for Moldova (MD) IBANs.
Original author: Martin Domke
``schwifty`` is released under `MIT`_ license and its documentation lives at `Read the Docs`_. The
code is maintained on `GitHub`_ and packages are distributed on `PyPI`_
Name
~~~~
Since ``swift`` and ``swiftly`` were already taken by the OpenStack-project, but we somehow wanted
to point out the connection to SWIFT, Rick and Morty came up with the idea to name the project
``schwifty``.
.. image:: https://i.cdn.turner.com/adultswim/big/video/get-schwifty-pt-2/rickandmorty_ep205_002_vbnuta15a755dvash8.jpg
.. _black: https://black.readthedocs.io/en/stable/index.html
.. _pre-commit: https://pre-commit.com
.. _editor integrations: https://black.readthedocs.io/en/stable/editor_integration.html
.. _MIT: https://choosealicense.com/licenses/mit/
.. _Read the Docs: https://schwifty.readthedocs.io
.. _GitHub: https://github.com/mdomke/schwifty
.. _PyPI: https://pypi.org/project/schwifty
| text/x-rst | null | Martin Domke <mail@martindomke.net> | null | Mihai <your-email@example.com> | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"importlib-resources>=5.10; python_version <= \"3.11\"",
"pycountry",
"rstr",
"typing-extensions>=4.0.1; python_version <= \"3.10\"",
"pydantic>=2.0; extra == \"pydantic\""
] | [] | [] | [] | [
"Changelog, https://github.com/mdomke/schwifty/blob/main/CHANGELOG.rst",
"Documentation, https://schwifty.readthedocs.io/en/latest/",
"Homepage, http://github.com/mdomke/schwifty"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T17:29:06.056959 | schwifty_fl-2026.2.20.tar.gz | 753,802 | 4f/c7/7dc5c3e52b5d65f46fa80f5b44f434162e5577df451e886c8061f5f458b9/schwifty_fl-2026.2.20.tar.gz | source | sdist | null | false | 08f4e42cb123a0628c4cbc7e4255f4d7 | bd55762fc6d722c512e9233e8304b2e34c3ed4b049a75a59d56bfdfe062ae144 | 4fc77dc5c3e52b5d65f46fa80f5b44f434162e5577df451e886c8061f5f458b9 | MIT | [
"LICENSE"
] | 131 |
2.4 | discovery-engine-api | 0.2.21 | Python SDK for the Discovery Engine API | # Discovery Engine Python API
The Discovery Engine Python API provides a simple programmatic interface to run analyses via Python, offering an alternative to using the web dashboard. Instead of uploading datasets and configuring analyses through the UI, you can automate your discovery workflows directly from your Python code or scripts.
All analyses run through the API are fully integrated with your Discovery Engine account. Results are automatically displayed in the dashboard, where you can view detailed reports, explore patterns, and share findings with your team. Your account management, credit balance, and subscription settings are all handled through the dashboard.
## Installation
```bash
pip install discovery-engine-api
```
For pandas DataFrame support:
```bash
pip install discovery-engine-api[pandas]
```
For Jupyter notebook support:
```bash
pip install discovery-engine-api[jupyter]
```
This installs `nest-asyncio`, which is required to use `engine.run()` in Jupyter notebooks. Alternatively, you can use `await engine.run_async()` directly in Jupyter notebooks without installing the jupyter extra.
## Configuration
### API Keys
Get your API key from the [Developers page](https://disco.leap-labs.com/developers) in your Discovery Engine dashboard.
## Quick Start
```python
from discovery import Engine
# Initialize engine
engine = Engine(api_key="your-api-key")
# Run analysis on a dataset and wait for results
result = engine.run(
file="data.csv",
target_column="diagnosis",
description="Rare diseases dataset",
excluded_columns=["patient_id"], # Exclude ID column from analysis
wait=True # Wait for completion and return full results
)
print(f"Run ID: {result.run_id}")
print(f"Status: {result.status}")
print(f"Found {len(result.patterns)} patterns")
```
## Examples
### Working with Pandas DataFrames
```python
import pandas as pd
from discovery import Engine
df = pd.read_csv("data.csv")
# or create DataFrame directly
engine = Engine(api_key="your-api-key")
result = engine.run(
file=df, # Pass DataFrame directly
target_column="outcome",
column_descriptions={
"age": "Patient age in years",
"heart rate": None
},
excluded_columns=["id", "timestamp"], # Exclude ID and timestamp columns from analysis
wait=True
)
```
### Async Workflow
```python
import asyncio
from discovery import Engine
async def run_analysis():
async with Engine(api_key="your-api-key") as engine:
# Start analysis without waiting
result = await engine.run_async(
file="data.csv",
target_column="target",
wait=False
)
print(f"Started run: {result.run_id}")
# Later, get results
result = await engine.get_results(result.run_id)
# Or wait for completion
result = await engine.wait_for_completion(result.run_id, timeout=1200)
return result
result = asyncio.run(run_analysis())
```
### Using in Jupyter Notebooks
In Jupyter notebooks, you have two options:
**Option 1: Install the jupyter extra (recommended)**
```bash
pip install discovery-engine-api[jupyter]
```
Then use `engine.run()` as normal:
```python
from discovery import Engine
engine = Engine(api_key="your-api-key")
result = engine.run(file="data.csv", target_column="target", wait=True)
```
**Option 2: Use async directly**
```python
from discovery import Engine
engine = Engine(api_key="your-api-key")
result = await engine.run_async(file="data.csv", target_column="target", wait=True)
```
## Configuration Options
The `run()` and `run_async()` methods accept the following parameters:
| Parameter | Type | Default | Description |
|-----------|------|---------|-------------|
| `file` | `str`, `Path`, or `DataFrame` | **Required** | Dataset file path or pandas DataFrame |
| `target_column` | `str` | **Required** | Name of column to predict |
| `depth_iterations` | `int` | `1` | Analysis depth — number of iterative feature-removal cycles. Higher values find more subtle patterns but use more credits. The maximum useful value is `num_columns - 2`; values above that are capped server-side. |
| `title` | `str` | `None` | Optional dataset title |
| `description` | `str` | `None` | Optional dataset description |
| `column_descriptions` | `Dict[str, str]` | `None` | Optional column name → description mapping |
| `excluded_columns` | `List[str]` | `None` | Optional list of column names to exclude from analysis (e.g., IDs, timestamps) |
| `visibility` | `"public"` / `"private"` | `"public"` | Dataset visibility. Public runs are free but always use depth 1. Private runs require credits and support higher depth. |
| `auto_report_use_llm_evals` | `bool` | `True` | Use LLM for pattern descriptions and citations |
| `author` | `str` | `None` | Optional dataset author attribution |
| `source_url` | `str` | `None` | Optional source URL for dataset attribution |
| `wait` | `bool` | `False` | Wait for analysis to complete and return full results |
| `wait_timeout` | `float` | `None` | Maximum seconds to wait for completion (only if `wait=True`) |
> **Note on depth and visibility:** Public runs are always `depth_iterations=1` regardless of settings. To use `depth_iterations > 1`, set `visibility="private"`. Private runs consume credits based on file size × depth.
## File Size Limits
The SDK supports file uploads up to **1 GB**. Files are uploaded directly to cloud storage using presigned URLs, so there is no HTTP body size restriction.
Supported file formats: **CSV**, **Parquet**.
## Credits and Pricing
If you don't have enough credits for a private run, the SDK will raise a `ValueError` with a message like:
```
Insufficient credits. You need X credits but only have Y available.
```
**Solutions:**
1. Make your dataset public (set `visibility="public"`) — completely free
2. Visit [https://disco.leap-labs.com/account](https://disco.leap-labs.com/account) to:
- Purchase additional credits
- Upgrade to a subscription plan that includes more credits
## Return Value
The `run()` and `run_async()` methods return an `EngineResult` object with the following fields:
### EngineResult
```python
@dataclass
class EngineResult:
# Identifiers
run_id: str # Unique run identifier
report_id: Optional[str] # Report ID (if report created)
status: str # "pending", "processing", "completed", "failed"
# Dataset metadata
dataset_title: Optional[str]
dataset_description: Optional[str]
total_rows: Optional[int] # Number of rows in dataset
target_column: Optional[str] # Name of target column
task: Optional[str] # "regression", "binary_classification", or "multiclass_classification"
# LLM-generated summary
summary: Optional[Summary]
# Discovered patterns
patterns: List[Pattern]
# Column/feature information
columns: List[Column] # List of columns with statistics and importance
# Correlation matrix
correlation_matrix: List[CorrelationEntry] # Feature correlations
# Global feature importance
feature_importance: Optional[FeatureImportance] # Feature importance scores
# Job tracking
job_id: Optional[str]
job_status: Optional[str]
error_message: Optional[str]
```
### Pattern
```python
@dataclass
class Pattern:
id: str
task: str # "regression", "binary_classification", "multiclass_classification"
target_column: str
target_change_direction: str # "max" (increases target) or "min" (decreases target)
p_value: float # FDR-adjusted p-value (lower = more significant)
conditions: List[Dict] # Conditions defining the pattern (see below)
abs_target_change: float # Absolute change in target (always positive, magnitude of effect)
support_count: int # Number of rows matching pattern
support_percentage: float # Percentage of dataset matching pattern
novelty_type: str # "novel" or "confirmatory"
target_score: float # Effect size score
description: str # Human-readable description
novelty_explanation: str # Why the pattern is novel or confirmatory
target_class: Optional[str] # For classification tasks
target_mean: Optional[float] # Target mean within pattern (regression)
target_std: Optional[float] # Target std within pattern (regression)
citations: List[Dict] # Academic citations if available
p_value_raw: Optional[float] # Raw p-value before FDR adjustment
```
#### Pattern Conditions
Each condition in `pattern.conditions` is a dict with a `type` field:
**Continuous condition** — a numeric range:
```python
{
"type": "continuous",
"feature": "age",
"min_value": 45.0,
"max_value": 65.0,
"min_q": 0.35, # quantile of min_value
"max_q": 0.72 # quantile of max_value
}
```
**Categorical condition** — a set of values:
```python
{
"type": "categorical",
"feature": "region",
"values": ["north", "east"]
}
```
**Datetime condition** — a time range:
```python
{
"type": "datetime",
"feature": "date",
"min_value": 1609459200000, # epoch ms
"max_value": 1640995200000,
"min_datetime": "2021-01-01", # human-readable
"max_datetime": "2022-01-01"
}
```
### Summary
```python
@dataclass
class Summary:
overview: str # High-level summary of findings
key_insights: List[str] # Main takeaways
novel_patterns: PatternGroup # Novel pattern IDs and explanation
selected_pattern_id: Optional[str] # Featured pattern ID
```
> **Note:** The `data_insights` field from v0.1.x has been removed. Use `result.feature_importance` and `result.correlation_matrix` directly instead — these provide the raw computed values without LLM summarization artifacts.
### Column
```python
@dataclass
class Column:
id: str
name: str
display_name: str
type: str # "continuous" or "categorical"
data_type: str # "int", "float", "string", "boolean", "datetime"
enabled: bool
description: Optional[str]
# Statistics (for numeric columns)
mean: Optional[float]
median: Optional[float]
std: Optional[float]
min: Optional[float]
max: Optional[float]
iqr_min: Optional[float]
iqr_max: Optional[float]
mode: Optional[str] # Statistical mode (None if all values unique)
approx_unique: Optional[int]
null_percentage: Optional[float]
# Feature importance
feature_importance_score: Optional[float] # Signed importance score (see FeatureImportance)
```
### FeatureImportance
Feature importance is computed using **Hierarchical Perturbation (HiPe)**, an efficient ablation-based method. Scores are **signed** to indicate direction:
- **Positive**: feature increases the prediction / supports predicted class
- **Negative**: feature decreases the prediction / works against predicted class
```python
@dataclass
class FeatureImportance:
kind: str # "global"
baseline: float # Baseline model output (mean prediction)
scores: List[FeatureImportanceScore]
@dataclass
class FeatureImportanceScore:
feature: str # Feature/column name
score: float # Signed importance score
```
### CorrelationEntry
```python
@dataclass
class CorrelationEntry:
feature_x: str
feature_y: str
value: float # Correlation coefficient (-1 to 1)
```
| text/markdown | Leap Laboratories | null | null | null | MIT | api, data-analysis, discovery, machine-learning, sdk | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engin... | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.24.0",
"pydantic>=2.0.0",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\"",
"nest-asyncio>=1.5.0; extra == \"jupyter\"",
"pandas>=2.0.0; extra == \"pandas\""
] | [] | [] | [] | [
"Homepage, https://github.com/leap-laboratories/discovery",
"Documentation, https://github.com/leap-laboratories/discovery",
"Repository, https://github.com/leap-laboratories/discovery"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T17:28:32.823407 | discovery_engine_api-0.2.21.tar.gz | 16,400 | 4a/8d/028083fa4b3e5329186cdb8f59748b7e287ff722b9fd0e58316e8b08081b/discovery_engine_api-0.2.21.tar.gz | source | sdist | null | false | 38f609c6c0db60c07bc8a4e1d298b053 | 7bbf6d83a2b480f16afe3b9827246e861bad7cfd33cb9c70fb6a3e9fed675b0c | 4a8d028083fa4b3e5329186cdb8f59748b7e287ff722b9fd0e58316e8b08081b | null | [] | 225 |
2.4 | baymaxbot | 0.1.0 | BaymaxBot - AI Assistant powered by Thryve | # BaymaxBot 开发计划
> 基于 Thryve 的多通道 AI 助手
## 项目愿景
BaymaxBot 是一个开箱即用的多通道 AI 助手。
## 阶段划分
| 阶段 | 内容 | 优先级 |
|------|------|--------|
| [阶段一](phase1_core.md) | 项目初始化与核心类 | P0 |
| [阶段二](phase2_cli.md) | CLI 实现 | P0 |
| [阶段三](phase3_channels.md) | 通道实现 | P1 |
| [阶段四](phase4_tools.md) | 工具系统 | P1 |
| [阶段五](phase5_integration.md) | 完善与集成 | P2 |
## 技术栈
- **核心框架**: Thryve v0.2.0
- **CLI**: typer + prompt_toolkit + rich
- **通道**: aiohttp/FastAPI
- **工具**: 内置 + MCP
## 快速开始
```bash
# 安装
pip install baymaxbot
# 初始化
baymaxbot onboard
# 对话
baymaxbot chat -m "你好"
# 交互式
baymaxbot shell
# 启动服务
baymaxbot serve --port 8080
```
| text/markdown | BaymaxBot Team | null | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"thryve>=0.1.0",
"pydantic>=2.0",
"pydantic-settings>=2.0",
"pyyaml>=6.0",
"loguru>=0.7",
"typer>=0.12",
"prompt-toolkit>=3.0",
"rich>=13.0",
"croniter>=1.4"
] | [] | [] | [] | [] | poetry/2.3.0 CPython/3.12.12 Darwin/25.2.0 | 2026-02-19T17:28:11.045112 | baymaxbot-0.1.0-py3-none-any.whl | 13,018 | 0a/50/ecdc76637b8ffd99c5e50d2221acb04c90cd2da3bcdfbf921c65617552c3/baymaxbot-0.1.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 5b094ba9a116e0eb0bb26e8d98f2d711 | c4372837f2d6aadc1047255caccd070e0d055f27f999f5a0eb4e5a1a473ff6ce | 0a50ecdc76637b8ffd99c5e50d2221acb04c90cd2da3bcdfbf921c65617552c3 | null | [
"LICENSE"
] | 239 |
2.4 | gigaevo-memory | 0.1.0 | Python client for GigaEvo Memory Module — persistent storage for CARL artifacts | # gigaevo-memory
Python client for the GigaEvo Memory Module — persistent storage for CARL artifacts (steps, chains, agents, concepts).
CARL (`mmar-carl`) is a required dependency and is installed automatically.
## Installation
```bash
pip install gigaevo-memory
```
## Quick Start
```python
from mmar_carl import (
ContextSearchConfig,
ReasoningChain,
StepDescription,
ReasoningContext
)
from gigaevo_memory import MemoryClient
# Define a reasoning chain with RAG-like context queries
steps = [
StepDescription(
number=1,
title="Initial Data Assessment",
aim="Assess the quality and completeness of input data",
reasoning_questions="What data patterns and anomalies are present?",
step_context_queries=["data quality indicators", "missing values", "data consistency"],
stage_action="Evaluate data reliability and identify potential issues",
example_reasoning="High-quality data enables more reliable analysis and predictions"
),
StepDescription(
number=2,
title="Pattern Recognition",
aim="Identify significant patterns and trends in the data",
reasoning_questions="What trends and correlations emerge from the analysis?",
dependencies=[1], # Depends on data quality assessment
step_context_queries=["growth trends", "performance indicators", "correlation patterns"],
stage_action="Analyze temporal patterns and statistical relationships",
example_reasoning="Pattern recognition helps identify underlying business drivers and opportunities"
)
]
chain = ReasoningChain(
steps=steps,
max_workers=3,
metadata={},
search_config=ContextSearchConfig(strategy="substring"),
)
client = MemoryClient(base_url="http://localhost:8000")
# Save a chain (accepts ReasoningChain or dict)
ref = client.save_chain(chain=chain, name="my_chain", tags=["finance"])
# Get chain as ReasoningChain (full DAG validation)
chain = client.get_chain(ref.entity_id, channel="stable")
# Get chain as raw dict
chain_dict = client.get_chain_dict(ref.entity_id)
# Search (q matches name and when_to_use; use tags for faceted filter)
hits = client.search(q="my_chain", entity_type="chain")
# Search by tag (e.g. "finance")
hits = client.search(tags=["finance"])
hits = client.search(entity_type="chain", tags=["finance"])
# Full-text + tag: name/when_to_use contains "triage" and tagged "finance"
hits = client.search(q="triage", entity_type="chain", tags=["finance"])
# Multiple tags (entity must have all)
hits = client.search(tags=["finance", "triage"], entity_type="chain")
# Watch for changes — callback fires when a new version is published
sub = client.watch_chain(
ref.entity_id,
callback=lambda new_chain: print(f"Chain updated: {new_chain}"),
)
```
## Cache Policies
```python
from gigaevo_memory import MemoryClient, CachePolicy
# TTL-based (default: 5 minutes)
client = MemoryClient(base_url="http://localhost:8000", cache_policy=CachePolicy.TTL, cache_ttl=300)
# Freshness check (conditional GET with ETag)
client = MemoryClient(base_url="http://localhost:8000", cache_policy=CachePolicy.FRESHNESS_CHECK)
# SSE push (reactive invalidation)
client = MemoryClient(base_url="http://localhost:8000", cache_policy=CachePolicy.SSE_PUSH)
```
## Development
```bash
make client-install # Install in editable mode
make client-test # Run tests
make client-lint # Lint
make client-build # Build sdist + wheel
```
| text/markdown | null | Glazkoff <glazkov@airi.net> | null | null | null | null | [
"Framework :: Pydantic :: 2",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"httpx-sse>=0.4",
"httpx>=0.27",
"mmar-carl>=0.0.14",
"pydantic>=2.0",
"build; extra == \"dev\"",
"mypy; extra == \"dev\"",
"pytest; extra == \"dev\"",
"pytest-asyncio; extra == \"dev\"",
"respx; extra == \"dev\"",
"ruff; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.11 | 2026-02-19T17:27:52.640437 | gigaevo_memory-0.1.0-py3-none-any.whl | 11,907 | a7/bb/7cde6fc7aec564c16ec60e98272e5874be20236ea7373ff83dd0bbee86ad/gigaevo_memory-0.1.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 5b216ee07aa278442ef648ae8363f02f | 07bdefd7c1d46551cc16b90a5ace48ddf6e387b38fa17162972b340619091e32 | a7bb7cde6fc7aec564c16ec60e98272e5874be20236ea7373ff83dd0bbee86ad | MIT | [
"LICENSE"
] | 95 |
2.4 | Cycles-utils | 3.1.1 | Python scripts to build Cycles input files and post-process Cycles output files | # Cycles-utils
`Cycles-utils` is a Python package designed to facilitate [Cycles](https://github.com/PSUmodeling/Cycles) agroecosystem model simulations.
This package provides a number of tools for users to prepare Cycles simulation input files, run Cycles simulations, and post-process Cycles simulation results.
For usage examples, please refer to this [Jupyter notebook](https://github.com/PSUmodeling/Cycles/blob/master/cycles-utils.ipynb).
# Installation
To install:
```shell
pip install Cycles-utils
```
# API reference
Coming soon
| text/markdown | Yuning Shi | shiyuning@gmail.com | null | null | MIT | null | [] | [] | https://github.com/PSUmodeling/Cycles-utils | null | >=3.10 | [] | [] | [] | [
"pandas>=1.2.4",
"geopandas>=0.9.0",
"numpy>=1.19.5",
"cartopy>=0.18.0",
"matplotlib>=3.4.2",
"rioxarray>=0.5.0; extra == \"soilgrids\"",
"owslib>=0.24.1; extra == \"soilgrids\"",
"rasterio>=1.2.3; extra == \"soilgrids\"",
"shapely>=1.7.1; extra == \"soilgrids\"",
"shapely>=1.7.1; extra == \"gssur... | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T17:26:49.728110 | cycles_utils-3.1.1.tar.gz | 4,848,300 | 1a/f6/e1ef8b2211a9c85ec407e9d08d1bb14b887655d05e142c6ca59fa245f544/cycles_utils-3.1.1.tar.gz | source | sdist | null | false | 30af4e28c762817350c67996d8f46125 | 2e4940f8d41a81139eb4444099ddb4c96990890ab218dc129ada7a2d0def96b0 | 1af6e1ef8b2211a9c85ec407e9d08d1bb14b887655d05e142c6ca59fa245f544 | null | [
"LICENSE"
] | 0 |
2.4 | coffea-casa | 2026.2.19.7 | Wrappers for Dask clusters to be used from coffea-casa AF | Coffea-casa - A Prototype of an Analysis Facility for Columnar Object Framework For Effective Analysis
=========================================================
[![Actions Status][actions-badge]][actions-link]
[![Documentation Status][rtd-badge]][rtd-link]
[![Code style: black][black-badge]][black-link]
[![PyPI version][pypi-version]][pypi-link]
[![PyPI platforms][pypi-platforms]][pypi-link]
[![GitHub Discussion][github-discussions-badge]][github-discussions-link]


[actions-badge]: https://github.com/CoffeaTeam/coffea-casa/workflows/CI/CD/badge.svg
[actions-link]: https://github.com/CoffeaTeam/coffea-casa/actions
[black-badge]: https://img.shields.io/badge/code%20style-black-000000.svg
[black-link]: https://github.com/psf/black
[github-discussions-badge]: https://img.shields.io/static/v1?label=Discussions&message=Ask&color=blue&logo=github
[github-discussions-link]: https://github.com/CoffeaTeam/coffea-casa/discussions
[pypi-link]: https://pypi.org/project/coffea-casa/
[pypi-platforms]: https://img.shields.io/pypi/pyversions/coffea-casa
[pypi-version]: https://badge.fury.io/py/coffea-casa.svg
[rtd-badge]: https://readthedocs.org/projects/coffea-casa/badge/?version=latest
[rtd-link]: https://coffea-casa.readthedocs.io/en/latest/?badge=latest
About Coffea-casa
-----------------
The prototype analysis facility provides services for “low latency columnar analysis”, enabling rapid processing of data in a column-wise fashion. These services, based on Dask and Jupyter notebooks, aim to dramatically lower time for analysis and provide an easily-scalable and user-friendly computational environment that will simplify, facilitate, and accelerate the delivery of HEP results. The facility is built on top of a Kubernetes cluster and integrates dedicated resources with resources allocated via fairshare through the local HTCondor system. In addition to the user-facing interfaces such as Dask, the facility also manages access control through single-sign-on and authentication & authorization for data access. The notebooks in this repository and  include simple HEP analysis examples, managed interactively in a Jupyter notebook and scheduled on Dask workers and accessing both public and protected data.
Analysis repositories using coffea-casa
============
- 
- 
- 
Docker images used for Coffea-casa
============
Latest :
| Image | Description | Size | Pulls | Version |
|-----------------|-----------------------------------------------|--------------|-------------|-------------|
| coffea-casa | Dask scheduler image for coffea-casa hub |  |  | 
| coffea-casa-analysis | Dask worker image for coffea-casa hub |  |  | 
Helm charts, `coffea_casa` package and Docker image tags
-----------------
This repository uses GitHub Actions to build images, run tests, and push charts, python package to PyPI and images to DockerHub (Docker images, charts and python package tags are syncronised with Coffea-casa releases).
1. Tags pushed to GitHub trigger Docker image published with corresponding tags on Dockerhub: `coffeateam/coffea-casa:x.x.x` and `coffeateam/coffea-casa-analysis:x.x.x`.
Tags pushed to GitHub as well trigger Docker image published with corresponding tags on Openscience Harbor Registry: `hub.opensciencegrid.org/coffea-casa:x.x.x` and `hub.opensciencegrid.org/coffea-casa-analysis:x.x.x`.
The `latest` tag in both cases also corresponds to the most recent GitHub tag.
2. Tags pushed to GitHub trigger Helm charts releases with corresponding Helm Chart tag and with charts published to https://coffeateam.github.io/coffea-casa.
3. Tags pushed to GitHub will push `coffea_casa` python package to PyPI (same as a tag).
How to tag
-----------------
A list of "must" steps to do before to tag:
1. Tag Docker images `coffeateam/coffea-casa:x.x.x` and `coffeateam/coffea-casa-analysis:x.x.x` changing `$TAG` value in https://github.com/CoffeaTeam/coffea-casa/blob/master/docker/coffea-casa/Dockerfile and https://github.com/CoffeaTeam/coffea-casa/blob/master/docker/coffea-casa-analysis/Dockerfile
2. Tag Helm Chart's changing `$appVersion` value in Charts.yaml file in see https://github.com/CoffeaTeam/coffea-casa/blob/master/charts/coffea-casa/Chart.yaml
3. Add new tag: https://github.com/CoffeaTeam/coffea-casa/releases
Please note we are using  for Coffea-casa Docker images, Helm charts and Pypi module.
References
============
* Coffea-casa: an analysis facility prototype, M. Adamec, G. Attebury, K. Bloom, B. Bockelman, C. Lundstedt, O. Shadura and J. Thiltges, arXiv  (02 Mar 2021).
* PyHEP 2020 coffea-casa proceedings: [](https://doi.org/10.5281/zenodo.4136273)
* The PyHEP 2020 introductory Youtube video is [here](https://www.youtube.com/watch?v=CDIFd1gDbSc).
Contact us
============
Interested? You can reach us in  or in IRIS-HEP Slack channel.
| text/markdown | null | The Coffea-casa Development Team <coffea-casa-dev@cern.ch> | null | null | BSD 3-Clause License
Copyright (c) 2018, Fermilab
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
* Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | null | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: BSD License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
... | [] | null | null | >=3.8 | [] | [] | [] | [
"dask-jobqueue",
"distributed",
"pytest>=7; extra == \"dev\"",
"pytest>=7; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/CoffeaTeam/coffea-casa",
"Documentation, https://coffea-casa.readthedocs.io/en/latest/",
"Repository, https://github.com/CoffeaTeam/coffea-casa/issues",
"Bug Tracker, https://github.com/CoffeaTeam/coffea-casa/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:25:55.634528 | coffea_casa-2026.2.19.7.tar.gz | 8,246,486 | c0/dc/5f06a0a939cf63313d8fadfb93ef2db068b7ce9e610a96ca1f66be25a838/coffea_casa-2026.2.19.7.tar.gz | source | sdist | null | false | 0765a2cd3f1d5aa531c412b007e56589 | 07d10db3c5bc99462763b707b071938e7a4cfcf02948693951ed3a2610112266 | c0dc5f06a0a939cf63313d8fadfb93ef2db068b7ce9e610a96ca1f66be25a838 | null | [
"LICENSE"
] | 273 |
2.4 | aiosipua | 0.3.0 | Asyncio SIP micro-library for Python | # aiosipua
Asyncio SIP micro-library for Python. Companion to [aiortp](https://github.com/anganyAI/aiortp).
Built for voice AI backends that need SIP signaling without the bloat of a full
SIP stack. Zero runtime dependencies, strict type hints, Python 3.11+.
## Features
- **SIP message parsing and serialization** — RFC 3261 compliant, compact header
expansion, multi-value header splitting, structured accessors
- **SDP parsing, building, and negotiation** — RFC 4566 / RFC 3264, codec
selection, DTMF, direction handling, bandwidth support
- **Transports** — UDP (`DatagramProtocol`) and TCP (Content-Length framing)
- **UAS** — incoming call handling with INVITE/BYE/CANCEL/OPTIONS dispatch,
auto 100 Trying, `IncomingCall` high-level API
- **UAC** — backend-initiated BYE, re-INVITE (hold/unhold), CANCEL, INFO (DTMF)
- **Dialog management** — RFC 3261 dialog state machine, Record-Route support,
in-dialog request/response creation
- **Transaction matching** — client and server transaction layer
- **aiortp bridge** — `CallSession` bridging SDP negotiation to RTP media with
audio/DTMF callbacks
- **X-header support** — pass application metadata (room ID, session ID, tenant)
through SIP headers
## Installation
```bash
pip install aiosipua
# With optional RTP support
pip install aiosipua[rtp]
```
## Examples
### Parse a SIP message
```python
from aiosipua import SipMessage, parse_sdp
raw = (
"INVITE sip:bob@example.com SIP/2.0\r\n"
"Via: SIP/2.0/UDP 10.0.0.1:5060;branch=z9hG4bK776asdhds\r\n"
"From: Alice <sip:alice@example.com>;tag=1928301774\r\n"
"To: Bob <sip:bob@example.com>\r\n"
"Call-ID: a84b4c76e66710@example.com\r\n"
"CSeq: 314159 INVITE\r\n"
"Contact: <sip:alice@10.0.0.1:5060>\r\n"
"Content-Type: application/sdp\r\n"
"Content-Length: 142\r\n"
"\r\n"
"v=0\r\n"
"o=- 2890844526 2890844526 IN IP4 10.0.0.1\r\n"
"s=-\r\n"
"c=IN IP4 10.0.0.1\r\n"
"t=0 0\r\n"
"m=audio 20000 RTP/AVP 0 8\r\n"
"a=rtpmap:0 PCMU/8000\r\n"
"a=rtpmap:8 PCMA/8000\r\n"
"a=sendrecv\r\n"
)
msg = SipMessage.parse(raw)
# Structured header access
print(msg.from_addr.display_name) # "Alice"
print(msg.from_addr.uri.user) # "alice"
print(msg.to_addr.uri.host) # "example.com"
print(msg.via[0].branch) # "z9hG4bK776asdhds"
print(msg.cseq.method) # "INVITE"
print(msg.call_id) # "a84b4c76e66710@example.com"
# Parse the SDP body
sdp = parse_sdp(msg.body)
audio = sdp.audio
print(audio.port) # 20000
print(audio.codecs[0].encoding_name) # "PCMU"
print(sdp.rtp_address) # ("10.0.0.1", 20000)
```
### SDP negotiation
```python
from aiosipua import parse_sdp, negotiate_sdp, serialize_sdp
# Parse an incoming SDP offer
offer = parse_sdp(sdp_body)
# Negotiate: pick the best codec, build an answer
answer, chosen_pt = negotiate_sdp(
offer=offer,
local_ip="10.0.0.5",
rtp_port=30000,
supported_codecs=[0, 8], # PCMU, PCMA
)
print(f"Chosen codec: payload type {chosen_pt}")
print(serialize_sdp(answer))
```
### Receive calls with the UAS
```python
import asyncio
from aiosipua import IncomingCall, SipUAS
from aiosipua.rtp_bridge import CallSession
from aiosipua.transport import UdpSipTransport
async def handle_invite(call: IncomingCall):
print(f"Incoming call: {call.caller} -> {call.callee}")
print(f"X-headers: {call.x_headers}")
if call.sdp_offer is None:
call.reject(488, "Not Acceptable Here")
return
# Negotiate SDP and create RTP session
session = CallSession(
local_ip="10.0.0.5",
rtp_port=30000,
offer=call.sdp_offer,
)
# Accept the call with the SDP answer
call.ringing()
call.accept(session.sdp_answer)
await session.start()
# Wire up audio and DTMF callbacks
session.on_audio = lambda pcm, ts: print(f"Audio: {len(pcm)} bytes")
session.on_dtmf = lambda digit, dur: print(f"DTMF: {digit}")
def handle_bye(call: IncomingCall, request):
print(f"Call ended: {call.call_id}")
async def main():
transport = UdpSipTransport(local_addr=("0.0.0.0", 5060))
uas = SipUAS(transport)
uas.on_invite = lambda call: asyncio.get_running_loop().create_task(handle_invite(call))
uas.on_bye = handle_bye
await uas.start()
print("Listening on port 5060...")
await asyncio.Event().wait()
asyncio.run(main())
```
### Backend-initiated actions with the UAC
```python
from aiosipua import SipUAC
from aiosipua.transport import UdpSipTransport
transport = UdpSipTransport(local_addr=("0.0.0.0", 5060))
uac = SipUAC(transport)
# Hang up a call
uac.send_bye(dialog, remote_addr=("10.0.0.1", 5060))
# Put a call on hold with re-INVITE
from aiosipua import build_sdp
hold_sdp = build_sdp(
local_ip="10.0.0.5",
rtp_port=30000,
payload_type=0,
direction="sendonly",
)
uac.send_reinvite(dialog, sdp=hold_sdp, remote_addr=("10.0.0.1", 5060))
# Send DTMF via SIP INFO
uac.send_info(
dialog,
body="Signal=5\r\nDuration=250\r\n",
content_type="application/dtmf-relay",
remote_addr=("10.0.0.1", 5060),
)
```
### Build a SIP message from scratch
```python
from aiosipua import SipRequest, SipResponse, generate_branch, generate_call_id, generate_tag
# Build a SIP request
request = SipRequest(method="OPTIONS", uri="sip:bob@example.com")
request.headers.set_single("Via", f"SIP/2.0/UDP 10.0.0.1:5060;branch={generate_branch()}")
request.headers.set_single("From", f"<sip:alice@example.com>;tag={generate_tag()}")
request.headers.set_single("To", "<sip:bob@example.com>")
request.headers.set_single("Call-ID", generate_call_id())
request.headers.set_single("CSeq", "1 OPTIONS")
# Serialize to bytes for the wire
raw_bytes = bytes(request)
```
### Modify and re-serialize
```python
from aiosipua import SipMessage
msg = SipMessage.parse(raw_sip_text)
# Add a Via header
msg.headers.append("Via", "SIP/2.0/UDP proxy.example.com:5060;branch=z9hG4bKnew")
# Change the Contact
msg.headers.set_single("Contact", "<sip:newhost@10.0.0.99:5060>")
# Add custom X-headers
msg.headers.set_single("X-Room-ID", "room-42")
msg.headers.set_single("X-Session-ID", "sess-abc123")
# Re-serialize (Content-Length auto-updated)
print(msg.serialize())
```
### TCP transport
```python
import asyncio
from aiosipua.transport import TcpSipTransport
async def main():
transport = TcpSipTransport(local_addr=("0.0.0.0", 5060))
# As a server
transport.on_message = lambda msg, addr: print(f"Received from {addr}")
await transport.start()
# Or connect as a client
await transport.connect(("proxy.example.com", 5060))
transport.send(request, ("proxy.example.com", 5060))
asyncio.run(main())
```
## Architecture
```
┌─────────────┐ ┌──────────────┐ ┌────────────┐
│ SipUAS │────▶│ Dialog │────▶│ SipUAC │
│ (incoming) │ │ (state mgr) │ │ (outgoing)│
└──────┬──────┘ └──────────────┘ └─────┬──────┘
│ │
▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ Transaction │ │ SDP/Codec │ │ CallSession │
│ Layer │ │ Negotiation │ │ (RTP bridge)│
└──────┬───────┘ └──────────────┘ └──────┬───────┘
│ │
▼ ▼
┌──────────────┐ ┌──────────────┐
│ Transport │ │ aiortp │
│ (UDP / TCP) │ │ (optional) │
└──────────────┘ └──────────────┘
```
## More examples
See the [`examples/`](examples/) directory:
- **`echo_server.py`** — Receives audio via RTP and echoes it back
- **`dtmf_ivr.py`** — Collects DTMF digits and hangs up on `#`
- **`roomkit_prototype.py`** — Voice AI backend integration with X-header metadata
## License
BSD-3-Clause. See [LICENSE](LICENSE) for details.
| text/markdown | null | Sylvain Boily <sylvainboilydroid@gmail.com> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Framework :: AsyncIO",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
... | [] | null | null | >=3.11 | [] | [] | [] | [
"aiortp>=0.1.0; extra == \"rtp\""
] | [] | [] | [] | [
"Homepage, https://github.com/anganyAI/aiosipua",
"Repository, https://github.com/anganyAI/aiosipua"
] | uv/0.9.24 {"installer":{"name":"uv","version":"0.9.24","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T17:25:50.520535 | aiosipua-0.3.0.tar.gz | 71,612 | c5/6b/f73c2e4e2e619e57634a88be7951605a39378c63087b304261b4dec25007/aiosipua-0.3.0.tar.gz | source | sdist | null | false | db2c6f0ef4390590d9d503546784bd38 | 3b9aaf63155f6dea867623215d963c7a59232fd3c2c839d3c05c085ffafcd925 | c56bf73c2e4e2e619e57634a88be7951605a39378c63087b304261b4dec25007 | MIT | [
"LICENSE"
] | 221 |
2.4 | a3s-code | 0.8.0 | A3S Code - Native Python bindings for the AI coding agent | # A3S Code - Native Python Bindings
Native Python module for the A3S Code AI coding agent, built with PyO3.
```python
from a3s_code import Agent
agent = Agent(model="claude-sonnet-4-20250514", api_key="sk-ant-...", workspace="/project")
result = agent.send("What files handle auth?")
print(result.text)
```
## Installation
```bash
pip install a3s-code
```
## License
MIT
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | MIT | null | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | maturin/1.12.3 | 2026-02-19T17:25:31.050009 | a3s_code-0.8.0-cp313-cp313-musllinux_1_2_aarch64.whl | 8,257,511 | 05/57/4e8058f70b76691d7d6f7d2f2961834b642bf4c1db9bf054eca34417fe19/a3s_code-0.8.0-cp313-cp313-musllinux_1_2_aarch64.whl | cp313 | bdist_wheel | null | false | 9c9853bca0bf5dbb18b4b84c86f6ac66 | 762f87517bb5c0e9ffe48c5cb13118d3a09396a513a8327f621459e58b9890e0 | 05574e8058f70b76691d7d6f7d2f2961834b642bf4c1db9bf054eca34417fe19 | null | [] | 1,379 |
2.1 | odoo-addon-stock-whole-kit-constraint | 18.0.1.0.0.2 | Avoid to deliver a kit partially | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
==========================
Stock whole kit constraint
==========================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:bb9c333750c3c7746af6432b8ea1861acbffbd873fbfc45f44e3ed6b239409e1
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fmanufacture-lightgray.png?logo=github
:target: https://github.com/OCA/manufacture/tree/18.0/stock_whole_kit_constraint
:alt: OCA/manufacture
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/manufacture-18-0/manufacture-18-0-stock_whole_kit_constraint
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/manufacture&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module allows to configure a product that has a BoM of type kit to
disallow partial deliveries so that the components can't be partially
delivered.
**Table of contents**
.. contents::
:local:
Configuration
=============
To allow/disallow the partial delivery of kits:
1. Go to the kit product template or variant and then to the *Inventory*
tab, *Logistics* group.
2. The "Allow Partial Kit" check controls this. If marked, it will allow
it.
3. By default, the check is marked.
Usage
=====
To use this module, you need to:
1. Make a delivery picking with a kit product.
2. Try to deliver it partially.
3. An error will raise.
If you want to deliver other items in the picking you can do so and
leave the whole kit components units pending in a backorder.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/manufacture/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/manufacture/issues/new?body=module:%20stock_whole_kit_constraint%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Tecnativa
Contributors
------------
- Tecnativa
<`https://www.tecnativa.com\\> <https://www.tecnativa.com\>>`__
- David Vidal
- Pilar Vargas
- `NuoBiT <https://www.nuobit.com>`__:
- Deniz Gallo dgallo@nuobit.com
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/manufacture <https://github.com/OCA/manufacture/tree/18.0/stock_whole_kit_constraint>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Tecnativa, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/manufacture | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T17:24:16.509114 | odoo_addon_stock_whole_kit_constraint-18.0.1.0.0.2-py3-none-any.whl | 22,968 | 3e/9c/6d9a66b7e3fee4a00dc895d420c703bc34dd3b678d45d591b5b3d96885c8/odoo_addon_stock_whole_kit_constraint-18.0.1.0.0.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 00285ce6c670f2a62ae97a4fcafb26d5 | 3a18d8e2ab5167b05b0572f9ee7b8068f51fc5a82a4e091c14099a5674c71628 | 3e9c6d9a66b7e3fee4a00dc895d420c703bc34dd3b678d45d591b5b3d96885c8 | null | [] | 99 |
2.3 | juturna | 2.0.0 | Juturna core library | # Juturna – Real-time AI Pipeline Framework
<p align="center"><img src="https://raw.githubusercontent.com/meetecho/juturna/main/docs/source/_static/img/logo_dark_alt.svg" width="30%">
<br>
<img src="https://img.shields.io/github/license/meetecho/juturna?style=for-the-badge"> <img src="https://img.shields.io/github/stars/meetecho/juturna?style=for-the-badge"> <img src="https://img.shields.io/github/forks/meetecho/juturna?style=for-the-badge"> <img src="https://img.shields.io/github/issues/meetecho/juturna?style=for-the-badge">
</p>
## Important to know
Juturna is actively evolving with exciting new features and improvements being
added regularly. We're using semantic versioning to clearly communicate any
breaking changes between releases, so you can upgrade with confidence. Juturna
is perfect for experimentation and prototyping today, and we're working toward
production-ready stability with each release. So, if you plan to deploy it in
production, make sure you are comfortable managing potential updates and
adjustments.
## At a glance
**Juturna** is a data pipeline library written in Python. It is particularly
useful for fast prototyping multimedia, **real-time** data applications, as
well as exploring and testing AI models, in a modular and flexible fashion.
Among its many features, there are a few keypoints to highligh about Juturna:
* **Real-Time Streaming:** continuouusly process audio, video and
arbitrary data streams
* **Modularity:** create your own nodes and share them through
the Juturna hub
* **Composable workloads:** design pipelines to solve complex tasks in
minutes
* **Parallelism & Batching:** parallel, non-blocking execution for high
throughput
* **Observability:** built-in logging and metrics support
Documentation: [https://meetecho.github.io/juturna/index.html](https://meetecho.github.io/juturna/index.html)
Contribute: [https://github.com/meetecho/juturna/blob/main/CONTRIBUTING.md](https://github.com/meetecho/juturna/blob/main/CONTRIBUTING.md)
Meetecho: [https://www.meetecho.com/en/](https://www.meetecho.com/en/)
## Contributing
We are so glad you decided to contribute! We truly value your time and help in
making Juturna better, and look forward to every single PR, whether you are
fixing typos, proposing the next big feature, or extending the documentation.
To make sure we’re all on the same page and to get your changes merged as
quickly as possible, please take a peek at our
[`CONTRIBUTING.md`](https://github.com/meetecho/juturna/blob/main/CONTRIBUTING.md)
guide. It covers the essentials, including:
* branching & PR workflow
* code style & linting
* issue triage (TBD)
* issue & PR templates and a Code of Conduct are provided (TBD)
* signing CRA
If you are not sure where to start, feel free to open an issue to discuss your
ideas first. We’re happy to help guide you through the process!
## Changelog
All notable changes are documented in
[`CHANGELOG.md`](https://github.com/meetecho/juturna/blob/main/CHANGELOG.md) - we
follow [Semantic Versioning](https://semver.org), so you'll always know how
exactly updates affect your setup.
## License
Distributed under the **MIT License**. See [LICENSE](https://github.com/meetecho/juturna/blob/main/LICENSE) for details.
| text/markdown | Antonio Bevilacqua | b3by.in.th3.sky@gmail.com | Antonio Bevilacqua | b3by.in.th3.sky@gmail.com | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python",
"Programming Language :: Python :: 3"
] | [] | https://github.com/meetecho/juturna | null | >=3.12 | [] | [] | [] | [
"av>=16.0.0",
"numpy<3.0.0,>=2.2.3",
"requests<3.0.0,>=2.32.3",
"websockets>=16.0",
"fastapi>=0.127.1; extra == \"httpwrapper\"",
"fastapi-cli<0.0.8,>=0.0.7; extra == \"httpwrapper\"",
"prompt_toolkit>=3.0.52; extra == \"pipebuilder\"",
"rich>=14.1.0; extra == \"pipebuilder\"",
"grpcio==1.76.0; extr... | [] | [] | [] | [
"Homepage, https://github.com/meetecho/juturna",
"Repository, https://github.com/meetecho/juturna",
"Documentation, https://meetecho.github.io/juturna/index.html",
"Issues, https://github.com/meetecho/juturna/issues",
"Changelog, https://github.com/meetecho/juturna/blob/main/CHANGELOG.md"
] | poetry/2.1.1 CPython/3.12.3 Linux/6.17.0-14-generic | 2026-02-19T17:24:00.365108 | juturna-2.0.0.tar.gz | 1,129,557 | 7a/9a/575ccdcea79871e72642312067ae5094125890a64c3c326412e11796bfd4/juturna-2.0.0.tar.gz | source | sdist | null | false | a54e3f69544ba776be0814e33578e94b | 940e7e2863c826fb68e68b0efba9b2d3d0c7ad73a6aab8cb14ab5247c01e261d | 7a9a575ccdcea79871e72642312067ae5094125890a64c3c326412e11796bfd4 | null | [] | 214 |
2.4 | pylineament | 1.0.1 | Python Geological Lineament extraction package | # PyLineament
**PyLineament** is a Python-based, open-source toolkit for **automatic and regional-scale lineament extraction** from Digital Elevation Models (DEMs) and remote sensing imagery.
It is designed for geological and geomorphological analysis — providing a **fully automated, reproducible**, and **scalable** workflow for extracting, reducing, and mapping lineaments across local to regional scales.
---
## Installation
```bash
pip install pylineament
```
Or from source:
```bash
git clone https://github.com/epokus/pylineament.git
cd pylineament
pip install -e .
```
## Quick Start (Command Line)
Once installed, simply open your terminal or command prompt and run:
```bash
pylineament
```
## Key Features
- Interactive UI — Run `pylineament` in the terminal to open the GUI.
- Automated Workflow — Full end-to-end lineament extraction.
- Customizable Parameters — Control edge detection thresholds, segment length, and merging distance.
- Multi-Resolution Support — Works with various DEM/image resolutions.
- Scalable — Efficient for large-area or regional-scale mapping.
- Reproducible — Transparent parameters and open-source implementation.
## Core Functions
| Function | Description |
| ---------------------------- | ------------------------------------------------------------ |
| `read_raster()` | Reads and preprocesses a raster (DEM or image). |
| `extract_lineament_points()` | Detects lineament-like edge points using gradient filters. |
| `convert_points_to_line()` | Converts clustered edge points into connected line segments. |
| `reduce_lines()` | Simplifies and merges overlapping or redundant lineaments. |
| `hillshade()` | Generates a hillshade image for visualization. |
| `dem_to_line()` | Extracts lineaments directly from a DEM file. |
| `dem_to_shp()` | Full workflow: extract + merge + export to shapefile. |
## Example Workflow
- Input your DEM or satellite image.
- Optionally apply hillshade() or downscale for efficiency.
- Extract edge points using extract_lineament_points().
- Convert points to lines and merge them with reduce_lines().
- Save as shapefile using dem_to_shp() or merge_lines_csv_to_shp().
## example how to use this Library with CLI or python
```python
from pylineament import dem_to_shp
dem_to_shp("data/srtm_sample.tif", shp_name= "lineamentsExtract")
```
shp file will be saved in "lineamentsExtract" folder.
see more examples in example folder

## Parameters Overview
| Parameter | Description | Typical Range |
| ------------ | ------------------------------------- | ----------------- |
| `eps` | Edge detection sensitivity | 0.8 – 2.0 |
| `thresh` | Edge detection threshold | 20 – 80 |
| `z_multip` | Vertical exaggeration factor | 0.5 – 2.0 |
| `min_dist` | Minimum distance between merged lines | 5 – 20 pixels |
| `seg_len` | Minimum segment length | 5 – 20 pixels |
| `split_size` | DEM/image tile size for processing | 250 – 1000 pixels |
## Why PyLineament?
Typical “automatic” lineament extraction tools are limited by:
- Fixed image resolution and poor scalability,
- Heavy preprocessing requirements,
- Loss of geological meaning across scales,
- Slow performance in large regions.
## PyLineament addresses these by providing:
- Automated but parameter-controllable extraction,
- Multi-resolution and downscaling support,
- Robust reduction and merging algorithms,
- Compatibility with both small-area (detailed) and large-area datasets (regional mapping).
## Citation
If you use PyLineament in your research, please cite:
Prasetya Kusumah, E. (2025). PyLineament: A Python Toolkit for Regional-Scale Lineament Extraction.
Version 1.0. https://github.com/epokus/pylineament
## License
This project is licensed under the MIT License — see the LICENSE
file for details.
| text/markdown | null | Epo Kusumah <epo.pk@universiaspertamina.ac.id> | null | null | null | null | [] | [] | null | null | null | [] | [] | [] | [
"affine==2.4.0",
"attrs==25.4.0",
"certifi==2025.10.5",
"click==8.3.0",
"click-plugins==1.1.1.2",
"cligj==0.7.2",
"colorama==0.4.6",
"fiona==1.10.1",
"imageio==2.37.0",
"joblib==1.5.2",
"lazy_loader==0.4",
"networkx==3.4.2",
"numpy==2.2.6",
"packaging==25.0",
"pandas==2.3.3",
"pillow==... | [] | [] | [] | [
"Homepage, https://github.com/epokus/pylineament"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T17:23:51.344148 | pylineament-1.0.1.tar.gz | 19,989 | 67/29/5833b6e815696f5fcda3826850f098901387d3006119e48cd173a13a37f4/pylineament-1.0.1.tar.gz | source | sdist | null | false | 1fba54f182857984194f7da0eea711f9 | 5bd3b1fef175b86ce2495141f9ce471f2bc221eb2f32b7c7733656bd99adca1d | 67295833b6e815696f5fcda3826850f098901387d3006119e48cd173a13a37f4 | MIT | [
"LICENSE"
] | 217 |
2.4 | python-nso-client | 0.1.3 | Add your description here | # Python NSO Library
Thin wrapper around RestConf designed to interact with NSO.
**Key Features:**
- Detect errors raising meaningful exceptions
- Parameter support in URL to avoid URL Encoding mistakes
- Support for generating and executing YANG Patches
- Handling of dry-run responses
## Usage
Installing
```sh
uv add python-nso-client
```
Writing code with nso_client
```py
from nso_client import NSOClient
from httpx import BasicAuth
nso = NSOClient(
"https://localhost",
auth=BasicAuth("acct", "secret")
)
# Fetching data
resp = nso.get("/tailf-ncs:services/bb:backbone", content="config")
for bb in resp["bb:backbone"]:
print(bb)
# Create objects
resp = nso.put(
"/tailf-ncs:services/bb:backbone={}",
"my-bb-1",
payload={
"bb:backbone": [
{
"name": "my-bb-1",
"links": [
{"device": "xr0", "interface": "TenGigE0/0/0"},
{"device": "xr1", "interface": "TenGigE0/0/1"},
],
"metric": 500,
"admin-state": "in-service",
}
]
},
)
# Using yang-patch to modify multiple areas in the same transaction
patch = nso.yang_patch("/tailf-ncs:services")
patch.merge("/bb:backbone={}", "my-bb-1", value=...)
patch.merge("/bb:backbone={}", "my-bb-2", value=...)
patch.delete("/bb:backbone={}", "my-bb-3")
resp = patch.commit(dry_run="cli")
print(resp.changes)
patch.commit()
# Error handling
try:
nso.delete("/tailf-ncs:services/bb:backbone={}", "does-not-exist")
except NotFoundError as exc:
print("Backbone already deleted", exc)
# Fetching results in a None, not an exception
resp = nso.get("/tailf-ncs:services/bb:backbone={}", "does-not-exist")
assert resp is None
```
## Developing
```sh
# Build
uv build
```
| text/markdown | null | James Harr <jharr@internet2.edu> | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"httpx>=0.28.1",
"structlog>=24.0.0"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Alpine Linux","version":"3.23.3","id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T17:23:49.726973 | python_nso_client-0.1.3-py3-none-any.whl | 13,046 | 57/c3/65acb394fc9b1609da74c2171a7dea1541b089d81d2fbbc1bf3335c9ced9/python_nso_client-0.1.3-py3-none-any.whl | py3 | bdist_wheel | null | false | d218915beb785bf5139d8fd7284b233f | d4b2073c7034bcb44514c6218719529dbfc3a0814a565c36c9f5be7b8d88cfcd | 57c365acb394fc9b1609da74c2171a7dea1541b089d81d2fbbc1bf3335c9ced9 | Apache-2.0 | [
"LICENSE.txt"
] | 306 |
2.2 | tidy3d-extras | 2.11.0.dev0 | tidy3d-extras is an optional plugin for Tidy3D providing addtional, more advanced local functionality. | # tidy3d-extras
tidy3d-extras is an optional plugin for Tidy3D providing additional, more advanced local fuctionality. This additional functionality includes a more accurate local mode solver with subpixel averaging.
## Documentation
The online documentation for Tidy3D can be found
[here](https://docs.flexcompute.com/projects/tidy3d/).
## Installation
tidy3d-extras is a python module that can be easily installed via ``pip``.
The version must match the version of Tidy3D, so the preferred command
for installation is:
```sh
pip install tidy3d[extras]
```
This command will install tidy3d-extras along with all of its dependencies in the
current environment.
A Tidy3D API key is required to authenticate tidy3d-extras users. If you don't
have one already configured, you can [get a free API
key](https://tidy3d.simulation.cloud/account?tab=apikey) and configure it with
the following command:
```sh
tidy3d configure
```
On **Windows**, it is easier to use `pipx` to find the path to the
configuration tool:
```sh
pip install pipx
pipx run tidy3d configure
```
More information about the installation and configuration of Tidy3D can be
found
[here](https://docs.flexcompute.com/projects/tidy3d/en/latest/install.html).
You can verify that the tidy3d-extras installation worked by running the
following command to print the installed version:
```sh
python -c 'import tidy3d_extras as tde; print(tde.__version__)'
```
## Third-party libraries and licenses
- [json](https://github.com/nlohmann/json)
> MIT License
>
> Copyright (c) 2013-2022 Niels Lohmann
>
> Permission is hereby granted, free of charge, to any person obtaining a
> copy of this software and associated documentation files (the "Software"),
> to deal in the Software without restriction, including without limitation
> the rights to use, copy, modify, merge, publish, distribute, sublicense,
> and/or sell copies of the Software, and to permit persons to whom the
> Software is furnished to do so, subject to the following conditions:
>
> The above copyright notice and this permission notice shall be included in
> all copies or substantial portions of the Software.
>
> THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
> IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
> FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
> AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
> LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
> FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
> DEALINGS IN THE SOFTWARE.
- [toml++](https://github.com/marzer/tomlplusplus)
> MIT License
>
> Copyright (c) Mark Gillard <mark.gillard@outlook.com.au>
>
> Permission is hereby granted, free of charge, to any person obtaining a
> copy of this software and associated documentation files (the "Software"),
> to deal in the Software without restriction, including without limitation
> the rights to use, copy, modify, merge, publish, distribute, sublicense,
> and/or sell copies of the Software, and to permit persons to whom the
> Software is furnished to do so, subject to the following conditions:
>
> The above copyright notice and this permission notice shall be included in
> all copies or substantial portions of the Software.
>
> THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
> IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
> FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
> AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
> LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
> FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
> DEALINGS IN THE SOFTWARE.
- [ZLIB](https://www.zlib.net/)
> Copyright (C) 1995-2024 Jean-loup Gailly and Mark Adler
>
> This software is provided 'as-is', without any express or implied warranty.
> In no event will the authors be held liable for any damages arising from
> the use of this software.
>
> Permission is granted to anyone to use this software for any purpose,
> including commercial applications, and to alter it and redistribute it
> freely, subject to the following restrictions:
>
> 1. The origin of this software must not be misrepresented; you must not
> claim that you wrote the original software. If you use this software in
> a product, an acknowledgment in the product documentation would be
> appreciated but is not required.
> 2. Altered source versions must be plainly marked as such, and must not be
> misrepresented as being the original software.
> 3. This notice may not be removed or altered from any source distribution.
>
> Jean-loup Gailly Mark Adler
> jloup@gzip.org madler@alumni.caltech.edu
- [CDT](https://artem-ogre.github.io/CDT/)
> Mozilla Public License
>
> Version 2.0
>
> 1. Definitions
>
> 1.1. “Contributor”
>
> means each individual or legal entity that creates, contributes to the
> creation of, or owns Covered Software.
>
> 1.2. “Contributor Version”
>
> means the combination of the Contributions of others (if any) used by a
> Contributor and that particular Contributor’s Contribution.
>
> 1.3. “Contribution”
>
> means Covered Software of a particular Contributor.
>
> 1.4. “Covered Software”
>
> means Source Code Form to which the initial Contributor has attached the
> notice in Exhibit A, the Executable Form of such Source Code Form, and
> Modifications of such Source Code Form, in each case including portions
> thereof.
>
> 1.5. “Incompatible With Secondary Licenses”
>
> means
>
> that the initial Contributor has attached the notice described in Exhibit B
> to the Covered Software; or
>
> that the Covered Software was made available under the terms of version 1.1
> or earlier of the License, but not also under the terms of a Secondary
> License.
>
> 1.6. “Executable Form”
>
> means any form of the work other than Source Code Form.
>
> 1.7. “Larger Work”
>
> means a work that combines Covered Software with other material, in a
> separate file or files, that is not Covered Software.
>
> 1.8. “License”
>
> means this document.
>
> 1.9. “Licensable”
>
> means having the right to grant, to the maximum extent possible, whether at
> the time of the initial grant or subsequently, any and all of the rights
> conveyed by this License.
>
> 1.10. “Modifications”
>
> means any of the following:
>
> any file in Source Code Form that results from an addition to, deletion
> from, or modification of the contents of Covered Software; or
>
> any new file in Source Code Form that contains any Covered Software.
>
> 1.11. “Patent Claims” of a Contributor
>
> means any patent claim(s), including without limitation, method, process,
> and apparatus claims, in any patent Licensable by such Contributor that
> would be infringed, but for the grant of the License, by the making, using,
> selling, offering for sale, having made, import, or transfer of either its
> Contributions or its Contributor Version.
>
> 1.12. “Secondary License”
>
> means either the GNU General Public License, Version 2.0, the GNU Lesser
> General Public License, Version 2.1, the GNU Affero General Public License,
> Version 3.0, or any later versions of those licenses.
>
> 1.13. “Source Code Form”
>
> means the form of the work preferred for making modifications.
>
> 1.14. “You” (or “Your”)
>
> means an individual or a legal entity exercising rights under this License.
> For legal entities, “You” includes any entity that controls, is controlled
> by, or is under common control with You. For purposes of this definition,
> “control” means (a) the power, direct or indirect, to cause the direction
> or management of such entity, whether by contract or otherwise, or (b)
> ownership of more than fifty percent (50%) of the outstanding shares or
> beneficial ownership of such entity.
>
> 2. License Grants and Conditions
>
> 2.1. Grants
>
> Each Contributor hereby grants You a world-wide, royalty-free,
> non-exclusive license:
>
> under intellectual property rights (other than patent or trademark)
> Licensable by such Contributor to use, reproduce, make available, modify,
> display, perform, distribute, and otherwise exploit its Contributions,
> either on an unmodified basis, with Modifications, or as part of a Larger
> Work; and
>
> under Patent Claims of such Contributor to make, use, sell, offer for sale,
> have made, import, and otherwise transfer either its Contributions or its
> Contributor Version.
>
> 2.2. Effective Date
>
> The licenses granted in Section 2.1 with respect to any Contribution become
> effective for each Contribution on the date the Contributor first
> distributes such Contribution.
>
> 2.3. Limitations on Grant Scope
>
> The licenses granted in this Section 2 are the only rights granted under
> this License. No additional rights or licenses will be implied from the
> distribution or licensing of Covered Software under this License.
> Notwithstanding Section 2.1(b) above, no patent license is granted by a
> Contributor:
>
> for any code that a Contributor has removed from Covered Software; or
>
> for infringements caused by: (i) Your and any other third party’s
> modifications of Covered Software, or (ii) the combination of its
> Contributions with other software (except as part of its Contributor
> Version); or
>
> under Patent Claims infringed by Covered Software in the absence of its
> Contributions.
>
> This License does not grant any rights in the trademarks, service marks, or
> logos of any Contributor (except as may be necessary to comply with the
> notice requirements in Section 3.4).
>
> 2.4. Subsequent Licenses
>
> No Contributor makes additional grants as a result of Your choice to
> distribute the Covered Software under a subsequent version of this License
> (see Section 10.2) or under the terms of a Secondary License (if permitted
> under the terms of Section 3.3).
>
> 2.5. Representation
>
> Each Contributor represents that the Contributor believes its Contributions
> are its original creation(s) or it has sufficient rights to grant the
> rights to its Contributions conveyed by this License.
>
> 2.6. Fair Use
>
> This License is not intended to limit any rights You have under applicable
> copyright doctrines of fair use, fair dealing, or other equivalents.
>
> 2.7. Conditions
>
> Sections 3.1, 3.2, 3.3, and 3.4 are conditions of the licenses granted in
> Section 2.1.
>
> 3. Responsibilities
>
> 3.1. Distribution of Source Form
>
> All distribution of Covered Software in Source Code Form, including any
> Modifications that You create or to which You contribute, must be under the
> terms of this License. You must inform recipients that the Source Code Form
> of the Covered Software is governed by the terms of this License, and how
> they can obtain a copy of this License. You may not attempt to alter or
> restrict the recipients’ rights in the Source Code Form.
>
> 3.2. Distribution of Executable Form
>
> If You distribute Covered Software in Executable Form then:
>
> such Covered Software must also be made available in Source Code Form, as
> described in Section 3.1, and You must inform recipients of the Executable
> Form how they can obtain a copy of such Source Code Form by reasonable
> means in a timely manner, at a charge no more than the cost of distribution
> to the recipient; and
>
> You may distribute such Executable Form under the terms of this License, or
> sublicense it under different terms, provided that the license for the
> Executable Form does not attempt to limit or alter the recipients’ rights
> in the Source Code Form under this License.
>
> 3.3. Distribution of a Larger Work
>
> You may create and distribute a Larger Work under terms of Your choice,
> provided that You also comply with the requirements of this License for the
> Covered Software. If the Larger Work is a combination of Covered Software
> with a work governed by one or more Secondary Licenses, and the Covered
> Software is not Incompatible With Secondary Licenses, this License permits
> You to additionally distribute such Covered Software under the terms of
> such Secondary License(s), so that the recipient of the Larger Work may, at
> their option, further distribute the Covered Software under the terms of
> either this License or such Secondary License(s).
>
> 3.4. Notices
>
> You may not remove or alter the substance of any license notices (including
> copyright notices, patent notices, disclaimers of warranty, or limitations
> of liability) contained within the Source Code Form of the Covered
> Software, except that You may alter any license notices to the extent
> required to remedy known factual inaccuracies.
>
> 3.5. Application of Additional Terms
>
> You may choose to offer, and to charge a fee for, warranty, support,
> indemnity or liability obligations to one or more recipients of Covered
> Software. However, You may do so only on Your own behalf, and not on behalf
> of any Contributor. You must make it absolutely clear that any such
> warranty, support, indemnity, or liability obligation is offered by You
> alone, and You hereby agree to indemnify every Contributor for any
> liability incurred by such Contributor as a result of warranty, support,
> indemnity or liability terms You offer. You may include additional
> disclaimers of warranty and limitations of liability specific to any
> jurisdiction.
>
> 4. Inability to Comply Due to Statute or Regulation
>
> If it is impossible for You to comply with any of the terms of this License
> with respect to some or all of the Covered Software due to statute,
> judicial order, or regulation then You must: (a) comply with the terms of
> this License to the maximum extent possible; and (b) describe the
> limitations and the code they affect. Such description must be placed in a
> text file included with all distributions of the Covered Software under
> this License. Except to the extent prohibited by statute or regulation,
> such description must be sufficiently detailed for a recipient of ordinary
> skill to be able to understand it.
>
> 5. Termination
>
> 5.1. The rights granted under this License will terminate automatically if
> You fail to comply with any of its terms. However, if You become compliant,
> then the rights granted under this License from a particular Contributor
> are reinstated (a) provisionally, unless and until such Contributor
> explicitly and finally terminates Your grants, and (b) on an ongoing basis,
> if such Contributor fails to notify You of the non-compliance by some
> reasonable means prior to 60 days after You have come back into compliance.
> Moreover, Your grants from a particular Contributor are reinstated on an
> ongoing basis if such Contributor notifies You of the non-compliance by
> some reasonable means, this is the first time You have received notice of
> non-compliance with this License from such Contributor, and You become
> compliant prior to 30 days after Your receipt of the notice.
>
> 5.2. If You initiate litigation against any entity by asserting a patent
> infringement claim (excluding declaratory judgment actions, counter-claims,
> and cross-claims) alleging that a Contributor Version directly or
> indirectly infringes any patent, then the rights granted to You by any and
> all Contributors for the Covered Software under Section 2.1 of this License
> shall terminate.
>
> 5.3. In the event of termination under Sections 5.1 or 5.2 above, all end
> user license agreements (excluding distributors and resellers) which have
> been validly granted by You or Your distributors under this License prior
> to termination shall survive termination.
>
> 6. Disclaimer of Warranty
>
> Covered Software is provided under this License on an “as is” basis,
> without warranty of any kind, either expressed, implied, or statutory,
> including, without limitation, warranties that the Covered Software is free
> of defects, merchantable, fit for a particular purpose or non-infringing.
> The entire risk as to the quality and performance of the Covered Software
> is with You. Should any Covered Software prove defective in any respect,
> You (not any Contributor) assume the cost of any necessary servicing,
> repair, or correction. This disclaimer of warranty constitutes an essential
> part of this License. No use of any Covered Software is authorized under
> this License except under this disclaimer.
>
> 7. Limitation of Liability
>
> Under no circumstances and under no legal theory, whether tort (including
> negligence), contract, or otherwise, shall any Contributor, or anyone who
> distributes Covered Software as permitted above, be liable to You for any
> direct, indirect, special, incidental, or consequential damages of any
> character including, without limitation, damages for lost profits, loss of
> goodwill, work stoppage, computer failure or malfunction, or any and all
> other commercial damages or losses, even if such party shall have been
> informed of the possibility of such damages. This limitation of liability
> shall not apply to liability for death or personal injury resulting from
> such party’s negligence to the extent applicable law prohibits such
> limitation. Some jurisdictions do not allow the exclusion or limitation of
> incidental or consequential damages, so this exclusion and limitation may
> not apply to You.
>
> 8. Litigation
>
> Any litigation relating to this License may be brought only in the courts
> of a jurisdiction where the defendant maintains its principal place of
> business and such litigation shall be governed by laws of that
> jurisdiction, without reference to its conflict-of-law provisions. Nothing
> in this Section shall prevent a party’s ability to bring cross-claims or
> counter-claims.
>
> 9. Miscellaneous
>
> This License represents the complete agreement concerning the subject
> matter hereof. If any provision of this License is held to be
> unenforceable, such provision shall be reformed only to the extent
> necessary to make it enforceable. Any law or regulation which provides that
> the language of a contract shall be construed against the drafter shall not
> be used to construe this License against a Contributor.
>
> 10. Versions of the License
>
> 10.1. New Versions
>
> Mozilla Foundation is the license steward. Except as provided in Section
> 10.3, no one other than the license steward has the right to modify or
> publish new versions of this License. Each version will be given a
> distinguishing version number.
>
> 10.2. Effect of New Versions
>
> You may distribute the Covered Software under the terms of the version of
> the License under which You originally received the Covered Software, or
> under the terms of any subsequent version published by the license steward.
>
> 10.3. Modified Versions
>
> If you create software not governed by this License, and you want to create
> a new license for such software, you may create and use a modified version
> of this License if you rename the license and remove any references to the
> name of the license steward (except to note that such modified license
> differs from this License).
>
> 10.4. Distributing Source Code Form that is Incompatible With Secondary
> Licenses
>
> If You choose to distribute Source Code Form that is Incompatible With
> Secondary Licenses under the terms of this version of the License, the
> notice described in Exhibit B of this License must be attached.
>
> Exhibit A - Source Code Form License Notice This Source Code Form is
> subject to the terms of the Mozilla Public License, v. 2.0. If a copy of
> the MPL was not distributed with this file, You can obtain one at
> https://mozilla.org/MPL/2.0/.
>
> If it is not possible or desirable to put the notice in a particular file,
> then You may include the notice in a location (such as a LICENSE file in a
> relevant directory) where a recipient would be likely to look for such a
> notice.
>
> You may add additional accurate notices of copyright ownership.
>
> Exhibit B - “Incompatible With Secondary Licenses” Notice
>
> This Source Code Form is “Incompatible With Secondary Licenses”, as defined
> by the Mozilla Public License, v. 2.0.
- [OpenSSL](https://www.openssl.org/)
> Apache License
> Version 2.0, January 2004
> https://www.apache.org/licenses/
>
> TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
>
> 1. Definitions.
>
> "License" shall mean the terms and conditions for use, reproduction, and
> distribution as defined by Sections 1 through 9 of this document.
>
> "Licensor" shall mean the copyright owner or entity authorized by the
> copyright owner that is granting the License.
>
> "Legal Entity" shall mean the union of the acting entity and all other
> entities that control, are controlled by, or are under common control
> with that entity. For the purposes of this definition, "control" means
> (i) the power, direct or indirect, to cause the direction or management
> of such entity, whether by contract or otherwise, or (ii) ownership of
> fifty percent (50%) or more of the outstanding shares, or (iii)
> beneficial ownership of such entity.
>
> "You" (or "Your") shall mean an individual or Legal Entity exercising
> permissions granted by this License.
>
> "Source" form shall mean the preferred form for making modifications,
> including but not limited to software source code, documentation source,
> and configuration files.
>
> "Object" form shall mean any form resulting from mechanical
> transformation or translation of a Source form, including but not
> limited to compiled object code, generated documentation, and
> conversions to other media types.
>
> "Work" shall mean the work of authorship, whether in Source or Object
> form, made available under the License, as indicated by a copyright
> notice that is included in or attached to the work (an example is
> provided in the Appendix below).
>
> "Derivative Works" shall mean any work, whether in Source or Object
> form, that is based on (or derived from) the Work and for which the
> editorial revisions, annotations, elaborations, or other modifications
> represent, as a whole, an original work of authorship. For the purposes
> of this License, Derivative Works shall not include works that remain
> separable from, or merely link (or bind by name) to the interfaces of,
> the Work and Derivative Works thereof.
>
> "Contribution" shall mean any work of authorship, including the original
> version of the Work and any modifications or additions to that Work or
> Derivative Works thereof, that is intentionally submitted to Licensor
> for inclusion in the Work by the copyright owner or by an individual or
> Legal Entity authorized to submit on behalf of the copyright owner. For
> the purposes of this definition, "submitted" means any form of
> electronic, verbal, or written communication sent to the Licensor or its
> representatives, including but not limited to communication on
> electronic mailing lists, source code control systems, and issue
> tracking systems that are managed by, or on behalf of, the Licensor for
> the purpose of discussing and improving the Work, but excluding
> communication that is conspicuously marked or otherwise designated in
> writing by the copyright owner as "Not a Contribution."
>
> "Contributor" shall mean Licensor and any individual or Legal Entity on
> behalf of whom a Contribution has been received by Licensor and
> subsequently incorporated within the Work.
>
> 2. Grant of Copyright License. Subject to the terms and conditions of this
> License, each Contributor hereby grants to You a perpetual, worldwide,
> non-exclusive, no-charge, royalty-free, irrevocable copyright license to
> reproduce, prepare Derivative Works of, publicly display, publicly
> perform, sublicense, and distribute the
> Work and such Derivative Works in Source or Object form.
>
> 3. Grant of Patent License. Subject to the terms and conditions of this
> License, each Contributor hereby grants to You a perpetual, worldwide,
> non-exclusive, no-charge, royalty-free, irrevocable (except as stated in
> this section) patent license to make, have made, use, offer to sell,
> sell, import, and otherwise transfer the Work,
> where such license applies only to those patent claims licensable by
> such Contributor that are necessarily infringed by their Contribution(s)
> alone or by combination of their Contribution(s) with the Work to which
> such Contribution(s) was submitted. If You institute patent litigation
> against any entity (including a cross-claim or counterclaim in a
> lawsuit) alleging that the Work or a Contribution incorporated within
> the Work constitutes direct or contributory patent infringement, then
> any patent licenses granted to You under this License for that Work
> shall terminate as of the date such litigation is filed.
>
> 4. Redistribution. You may reproduce and distribute copies of the Work or
> Derivative Works thereof in any medium, with or without modifications,
> and in Source or Object form, provided that You meet the following
> conditions:
>
> (a) You must give any other recipients of the Work or Derivative Works a
> copy of this License; and
>
> (b) You must cause any modified files to carry prominent notices stating
> that You changed the files; and
>
> (c) You must retain, in the Source form of any Derivative Works that You
> distribute, all copyright, patent, trademark, and attribution notices
> from the Source form of the Work, excluding those notices that do not
> pertain to any part of the Derivative Works; and
>
> (d) If the Work includes a "NOTICE" text file as part of its
> distribution, then any Derivative Works that You distribute must include
> a readable copy of the attribution notices contained within such NOTICE
> file, excluding those notices that do not pertain to any part of the
> Derivative Works, in at least one of the following places: within a
> NOTICE text file distributed as part of the Derivative Works; within the
> Source form or documentation, if provided along with the Derivative
> Works; or, within a display generated by the Derivative Works, if and
> wherever such third-party notices normally appear. The contents of the
> NOTICE file are for informational purposes only and do not modify the
> License. You may add Your own attribution notices within Derivative
> Works that You distribute, alongside or as an addendum to the NOTICE
> text from the Work, provided that such additional attribution notices
> cannot be construed as modifying the License.
>
> You may add Your own copyright statement to Your modifications and may
> provide additional or different license terms and conditions for use,
> reproduction, or distribution of Your modifications, or for any such
> Derivative Works as a whole, provided Your use, reproduction, and
> distribution of the Work otherwise complies with the conditions stated
> in this License.
>
> 5. Submission of Contributions. Unless You explicitly state otherwise, any
> Contribution intentionally submitted for inclusion in the Work by You to
> the Licensor shall be under the terms and conditions of this License,
> without any additional terms or conditions. Notwithstanding the above,
> nothing herein shall supersede or modify
> the terms of any separate license agreement you may have executed with
> Licensor regarding such Contributions.
>
> 6. Trademarks. This License does not grant permission to use the trade
> names, trademarks, service marks, or product names of the Licensor,
> except as required for reasonable and customary use in describing the
> origin of the Work and reproducing the content of the NOTICE file.
>
> 7. Disclaimer of Warranty. Unless required by applicable law or agreed to
> in writing, Licensor provides the Work (and each Contributor provides
> its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS
> OF ANY KIND, either express or implied, including, without limitation,
> any warranties or conditions
> of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR
> PURPOSE. You are solely responsible for determining the appropriateness
> of using or redistributing the Work and assume any risks associated with
> Your exercise of permissions under this License.
>
> 8. Limitation of Liability. In no event and under no legal theory, whether
> in tort (including negligence), contract, or otherwise, unless required
> by applicable law (such as deliberate and grossly negligent acts) or
> agreed to in writing, shall any Contributor be liable to You for
> damages, including any direct, indirect, special,
> incidental, or consequential damages of any character arising as a
> result of this License or out of the use or inability to use the Work
> (including but not limited to damages for loss of goodwill, work
> stoppage, computer failure or malfunction, or any and all other
> commercial damages or losses), even if such Contributor has been advised
> of the possibility of such damages.
>
> 9. Accepting Warranty or Additional Liability. While redistributing the
> Work or Derivative Works thereof, You may choose to offer, and charge a
> fee for, acceptance of support, warranty, indemnity, or other liability
> obligations and/or rights consistent with this License. However, in
> accepting such obligations, You may act only
> on Your own behalf and on Your sole responsibility, not on behalf of any
> other Contributor, and only if You agree to indemnify, defend, and hold
> each Contributor harmless for any liability incurred by, or claims
> asserted against, such Contributor by reason of your accepting any such
> warranty or additional liability.
>
> END OF TERMS AND CONDITIONS
- [gl3w](https://github.com/skaslev/gl3w)
> This is free and unencumbered software released into the public domain.
>
> Anyone is free to copy, modify, publish, use, compile, sell, or
> distribute this software, either in source code form or as a compiled
> binary, for any purpose, commercial or non-commercial, and by any
> means.
>
> In jurisdictions that recognize copyright laws, the author or authors
> of this software dedicate any and all copyright interest in the
> software to the public domain. We make this dedication for the benefit
> of the public at large and to the detriment of our heirs and
> successors. We intend this dedication to be an overt act of
> relinquishment in perpetuity of all present and future rights to this
> software under copyright law.
>
> THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
> EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
> MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
> IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OR
> OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE,
> ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR
> OTHER DEALINGS IN THE SOFTWARE.
- [HDF5](https://github.com/HDFGroup/hdf5)
> Copyright Notice and License Terms for
> HDF5 (Hierarchical Data Format 5) Software Library and Utilities
> -----------------------------------------------------------------------------
>
> HDF5 (Hierarchical Data Format 5) Software Library and Utilities
> Copyright 2006 by The HDF Group.
>
> NCSA HDF5 (Hierarchical Data Format 5) Software Library and Utilities
> Copyright 1998-2006 by The Board of Trustees of the University of Illinois.
>
> All rights reserved.
>
> This software library and utilities is covered by the 3-clause BSD License.
>
> Redistribution and use in source and binary forms, with or without
> modification, are permitted for any purpose (including commercial purposes)
> provided that the following conditions are met:
>
> 1. Redistributions of source code must retain the above copyright notice,
> this list of conditions, and the following disclaimer.
>
> 2. Redistributions in binary form must reproduce the above copyright notice,
> this list of conditions, and the following disclaimer in the documentation
> and/or materials provided with the distribution.
>
> 3. Neither the name of The HDF Group, the name of the University, nor the
> name of any Contributor may be used to endorse or promote products derived
> from this software without specific prior written permission from
> The HDF Group, the University, or the Contributor, respectively.
>
> DISCLAIMER:
> THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
> “AS IS” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO,
> THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
> ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
> FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
> DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS
> OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
> CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR
> TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
> SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
>
> For further details, please refer to the full license text available
> at https://opensource.org/licenses/bsd-3-clause
>
> You are under no obligation whatsoever to provide any bug fixes, patches, or
> upgrades to the features, functionality or performance of the source code
> ("Enhancements") to anyone; however, if you choose to make your Enhancements
> available either publicly, or directly to The HDF Group, without imposing a
> separate written license agreement for such Enhancements, then you hereby
> grant the following license: a non-exclusive, royalty-free perpetual license
> to install, use, modify, prepare derivative works, incorporate into other
> computer software, distribute, and sublicense such enhancements or derivative
> works thereof, in binary and source code form.
>
> -----------------------------------------------------------------------------
> -----------------------------------------------------------------------------
>
> Contributors: National Center for Supercomputing Applications (NCSA) at
> the University of Illinois, Fortner Software, Unidata Program Center
> (netCDF), The Independent JPEG Group (JPEG), Jean-loup Gailly and Mark Adler
> (gzip), and Digital Equipment Corporation (DEC).
>
> -----------------------------------------------------------------------------
>
> Portions of HDF5 were developed with support from the Lawrence Berkeley
> National Laboratory (LBNL) and the United States Department of Energy
> under Prime Contract No. DE-AC02-05CH11231.
>
> -----------------------------------------------------------------------------
>
> Portions of HDF5 were developed with support from Lawrence Livermore
> National Laboratory and the United States Department of Energy under
> Prime Contract No. DE-AC52-07NA27344.
>
> -----------------------------------------------------------------------------
>
> Portions of HDF5 were developed with support from the University of
> California, Lawrence Livermore National Laboratory (UC LLNL).
> The following statement applies to those portions of the product and must
> be retained in any redistribution of source code, binaries, documentation,
> and/or accompanying materials:
>
> This work was partially produced at the University of California,
> Lawrence Livermore National Laboratory (UC LLNL) under contract
> no. W-7405-ENG-48 (Contract 48) between the U.S. Department of Energy
> (DOE) and The Regents of the University of California (University)
> for the operation of UC LLNL.
>
> DISCLAIMER:
> THIS WORK WAS PREPARED AS AN ACCOUNT OF WORK SPONSORED BY AN AGENCY OF
> THE UNITED STATES GOVERNMENT. NEITHER THE UNITED STATES GOVERNMENT NOR
> THE UNIVERSITY OF CALIFORNIA NOR ANY OF THEIR EMPLOYEES, MAKES ANY
> WARRANTY, EXPRESS OR IMPLIED, OR ASSUMES ANY LIABILITY OR RESPONSIBILITY
> FOR THE ACCURACY, COMPLETENESS, OR USEFULNESS OF ANY INFORMATION,
> APPARATUS, PRODUCT, OR PROCESS DISCLOSED, OR REPRESENTS THAT ITS USE
> WOULD NOT INFRINGE PRIVATELY- OWNED RIGHTS. REFERENCE HEREIN TO ANY
> SPECIFIC COMMERCIAL PRODUCTS, PROCESS, OR SERVICE BY TRADE NAME,
> TRADEMARK, MANUFACTURER, OR OTHERWISE, DOES NOT NECESSARILY CONSTITUTE
> OR IMPLY ITS ENDORSEMENT, RECOMMENDATION, OR FAVORING BY THE UNITED
> STATES GOVERNMENT OR THE UNIVERSITY OF CALIFORNIA. THE VIEWS AND
> OPINIONS OF AUTHORS EXPRESSED HEREIN DO NOT NECESSARILY STATE OR REFLECT
> THOSE OF THE UNITED STATES GOVERNMENT OR THE UNIVERSITY OF CALIFORNIA,
> AND SHALL NOT BE USED FOR ADVERTISING OR PRODUCT ENDORSEMENT PURPOSES.
>
> -----------------------------------------------------------------------------
- [GCC Runtime Libraries](https://gcc.gnu.org/)
> This product includes portions of the GNU Compiler Collection (GCC) runtime libraries:
>
> - GNU C++ Standard Library (`libstdc++`)
> - GNU Compiler Support Library (`libgcc_s`)
> - GNU OpenMP Runtime (`libgomp`)
>
> These libraries are licensed under the **GNU General Public License, version 3 (GPLv3)** with the **GCC Runtime Library Exception**.
>
> The GCC Runtime Library Exception permits linking these libraries with independent modules to produce an executable, without requiring the executable itself to be licensed under the GPL. As a result, you may use and redistribute this product without disclosing your own source code, provided you retain this notice and comply with the licenses of the included libraries.
>
> **License References:**
> - [GNU General Public License v3 (GPLv3)](https://www.gnu.org/licenses/gpl-3.0.html)
> - [GCC Runtime Library Exception 3.1](https://www.gnu.org/licenses/gcc-exception-3.1.html)
>
> **Source Code:**
| text/markdown | null | "Flexcompute Inc." <support@flexcompute.com> | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy>=2.0",
"tidy3d==2.11.0.dev0",
"xarray>=2024.6",
"pytest>=7.2; extra == \"test\""
] | [] | [] | [] | [
"homepage, https://www.flexcompute.com/",
"documentation, https://docs.flexcompute.com/projects/tidy3d/"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T17:23:43.500443 | tidy3d_extras-2.11.0.dev0-cp39-cp39-musllinux_1_2_x86_64.whl | 4,713,780 | f6/48/139a803e82bca21183db74e9d2fe07830ffbb98b25c9e73f1b8e117da9b4/tidy3d_extras-2.11.0.dev0-cp39-cp39-musllinux_1_2_x86_64.whl | cp39 | bdist_wheel | null | false | 19599ed67d08afb2f01b7543a038c520 | fd6ff815743d222ad5f2dfc70a103ba5f55f42a78a410b2d5d4b24fd1a0d5a00 | f648139a803e82bca21183db74e9d2fe07830ffbb98b25c9e73f1b8e117da9b4 | null | [] | 2,900 |
2.4 | irp-integration | 0.2.0 | Python client library for Moody's Intelligent Risk Platform (IRP) APIs | # irp-integration
A Python client library for the [Moody's Intelligent Risk Platform (IRP) APIs](https://developer.rms.com/). Built to serve as a foundation for larger Moody's integration projects — use it with Jupyter Notebooks, Azure Functions, or any orchestration layer to build end-to-end risk analysis workflows.
Not all Moody's API functionality is covered yet, but the most common operations are available and the library is actively maintained. Contributions are welcome — feel free to fork and modify to fit your project's needs.
## Installation
```bash
pip install irp-integration
```
To include Data Bridge (SQL Server) support:
```bash
pip install irp-integration[databridge]
```
> **Note:** Data Bridge requires [Microsoft ODBC Driver 18 for SQL Server](https://learn.microsoft.com/en-us/sql/connect/odbc/download-odbc-driver-for-sql-server) to be installed on your system.
## Quick Start
```python
from irp_integration import IRPClient
# Requires environment variables (see Configuration below)
client = IRPClient()
# Search EDMs
edms = client.edm.search_edms(filter = f'exposureName = "my_edm"')
# Get portfolios for an EDM
edm = edms[0]
exposure_id = edm['exposureId']
portfolios = client.portfolio.search_portfolios(exposure_id = exposure_id)
# Run analysis on a portfolio
edm_name = edm['exposureName']
portfolio = portfolios[0]
portfolio_name = portfolio['portfolioName']
client.analysis.submit_portfolio_analysis_job(
edm_name=edm_name,
portfolio_name=portfolio_name,
job_name="Readme Analysis",
model_profile_id=4418,
output_profile_id=123,
event_rate_scheme_id=739,
treaty_names=['Working Excess Treaty 1'],
tag_names=['Tag1', 'Tag2']
)
```
## Configuration
The library reads configuration from environment variables:
| Variable | Required | Description |
|----------|----------|-------------|
| `RISK_MODELER_BASE_URL` | Yes | Moody's Risk Modeler API base URL |
| `RISK_MODELER_API_KEY` | Yes | API authentication key |
| `RISK_MODELER_RESOURCE_GROUP_ID` | Yes | Resource group ID for your organization |
You can set these in your shell, or use a `.env` file with [python-dotenv](https://pypi.org/project/python-dotenv/):
```python
from dotenv import load_dotenv
load_dotenv()
from irp_integration import IRPClient
client = IRPClient()
```
### Data Bridge Configuration
The Data Bridge module (`client.databridge`) connects directly to Moody's SQL Server databases via ODBC. It requires separate setup from the REST API.
**Prerequisites:**
1. Install the optional dependency: `pip install irp-integration[databridge]`
2. Install [Microsoft ODBC Driver 18 for SQL Server](https://learn.microsoft.com/en-us/sql/connect/odbc/download-odbc-driver-for-sql-server):
- **Windows:** Download and run the MSI installer from Microsoft
- **Linux (Debian/Ubuntu):** `sudo apt-get install -y unixodbc-dev && sudo ACCEPT_EULA=Y apt-get install -y msodbcsql18`
- **macOS:** `brew install microsoft/mssql-release/msodbcsql18`
**Environment variables (per connection):**
Each named connection uses the prefix `MSSQL_{CONNECTION_NAME}_`:
| Variable | Required | Description |
|----------|----------|-------------|
| `MSSQL_DATABRIDGE_SERVER` | Yes | Server hostname or IP |
| `MSSQL_DATABRIDGE_USER` | Yes | SQL Server username |
| `MSSQL_DATABRIDGE_PASSWORD` | Yes | SQL Server password |
| `MSSQL_DATABRIDGE_PORT` | No | Port (default: 1433) |
**Global settings:**
| Variable | Default | Description |
|----------|---------|-------------|
| `MSSQL_DRIVER` | `ODBC Driver 18 for SQL Server` | ODBC driver name |
| `MSSQL_TRUST_CERT` | `yes` | Trust server certificate |
| `MSSQL_TIMEOUT` | `30` | Connection timeout in seconds |
**Example:**
```bash
# .env file
MSSQL_DATABRIDGE_SERVER=databridge.company.com
MSSQL_DATABRIDGE_USER=svc_account
MSSQL_DATABRIDGE_PASSWORD=secretpassword
```
```python
from irp_integration.databridge import DataBridgeManager
dbm = DataBridgeManager()
# Inline query with parameters
df = dbm.execute_query(
"SELECT * FROM portfolios WHERE value > {{ min_value }}",
params={'min_value': 1000000},
database='DataWarehouse'
)
# Execute SQL script from file
results = dbm.execute_query_from_file(
'C:/sql/extract_policies.sql',
params={'cycle_name': 'Q1-2025'},
database='AnalyticsDB'
)
```
## Features
- **Automatic retry** with exponential backoff for transient errors (429, 5xx)
- **Workflow polling** — submit long-running operations and automatically poll to completion
- **Batch workflow execution** — run multiple workflows in parallel and wait for all to finish
- **Structured logging** via Python's `logging` module for visibility into API calls and workflow progress
- **Connection pooling** via persistent HTTP sessions
- **Input validation** with descriptive error messages
- **Custom exception hierarchy** for structured error handling
- **S3 upload/download** with multipart transfer support
- **Data Bridge (SQL Server)** — direct SQL execution against Moody's Data Bridge with parameterized queries and file-based scripts
- **Type hints** on all public methods
## Modules
| Manager | Description |
|---------|-------------|
| `client.edm` | Exposure Data Manager — create, upgrade, duplicate, and delete EDMs |
| `client.portfolio` | Portfolio CRUD, geocoding, and hazard processing |
| `client.mri_import` | MRI (CSV) data import workflow — bucket creation, file upload, mapping, and execution |
| `client.treaty` | Reinsurance treaty creation, LOB assignment, and reference data |
| `client.analysis` | Risk analysis execution, profiles, event rate schemes, and analysis groups |
| `client.rdm` | Results Data Mart — export analysis results to RDM |
| `client.risk_data_job` | Risk data job status tracking |
| `client.import_job` | Platform import job management (EDM/RDM imports) |
| `client.export_job` | Platform export job management — status, polling, and result download |
| `client.databridge` | Data Bridge (SQL Server) — parameterized queries, file-based SQL execution |
| `client.reference_data` | Tags, currencies, and other reference data lookups |
## Error Handling
The library uses a custom exception hierarchy:
```python
from irp_integration.exceptions import (
IRPIntegrationError, # Base exception
IRPAPIError, # HTTP/API errors
IRPValidationError, # Input validation failures
IRPWorkflowError, # Workflow execution failures
IRPReferenceDataError, # Reference data lookup failures
IRPFileError, # File operation failures
IRPJobError, # Job management errors
IRPDataBridgeError, # Data Bridge base error
IRPDataBridgeConnectionError, # SQL Server connection failures
IRPDataBridgeQueryError, # SQL query execution failures
)
```
## API Documentation
For detailed API endpoint documentation, see [docs/api.md](https://github.com/premiumiq/irp-integration/blob/main/docs/api.md).
## License
This project is licensed under the MIT License — see the [LICENSE](https://github.com/premiumiq/irp-integration/blob/main/LICENSE) file for details.
| text/markdown | null | Ben Bailey <bbailey@premiumiq.com>, Anil Venugopal <avenugopal@premiumiq.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"requests>=2.28.0",
"boto3>=1.26.0",
"pyodbc>=4.0.0; extra == \"databridge\"",
"pandas>=1.5.0; extra == \"databridge\"",
"numpy>=1.23.0; extra == \"databridge\""
] | [] | [] | [] | [
"Homepage, https://github.com/premiumiq/irp-integration",
"Repository, https://github.com/premiumiq/irp-integration",
"Issues, https://github.com/premiumiq/irp-integration/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:23:16.697313 | irp_integration-0.2.0.tar.gz | 73,284 | aa/f4/c5e71d7362e5b0e475deb0ec01175c8949a7fbe94b5dab24c8b860ad6d36/irp_integration-0.2.0.tar.gz | source | sdist | null | false | 3e58a3d2442d48c13f2c106a42cabba9 | 69e22592a6d0137aaf6c7dffe7fd3b65f9ebd8a0958045d81f907fbde7dbaf12 | aaf4c5e71d7362e5b0e475deb0ec01175c8949a7fbe94b5dab24c8b860ad6d36 | MIT | [
"LICENSE"
] | 232 |
2.4 | rich | 14.3.3 | Render rich text, tables, progress bars, syntax highlighting, markdown and more to the terminal | [](https://pypi.org/project/rich/) [](https://badge.fury.io/py/rich)
[](https://pepy.tech/project/rich)
[](https://codecov.io/gh/Textualize/rich)
[](https://www.willmcgugan.com/tag/rich/)
[](https://twitter.com/willmcgugan)

[English readme](https://github.com/textualize/rich/blob/master/README.md)
• [简体中文 readme](https://github.com/textualize/rich/blob/master/README.cn.md)
• [正體中文 readme](https://github.com/textualize/rich/blob/master/README.zh-tw.md)
• [Lengua española readme](https://github.com/textualize/rich/blob/master/README.es.md)
• [Deutsche readme](https://github.com/textualize/rich/blob/master/README.de.md)
• [Läs på svenska](https://github.com/textualize/rich/blob/master/README.sv.md)
• [日本語 readme](https://github.com/textualize/rich/blob/master/README.ja.md)
• [한국어 readme](https://github.com/textualize/rich/blob/master/README.kr.md)
• [Français readme](https://github.com/textualize/rich/blob/master/README.fr.md)
• [Schwizerdütsch readme](https://github.com/textualize/rich/blob/master/README.de-ch.md)
• [हिन्दी readme](https://github.com/textualize/rich/blob/master/README.hi.md)
• [Português brasileiro readme](https://github.com/textualize/rich/blob/master/README.pt-br.md)
• [Italian readme](https://github.com/textualize/rich/blob/master/README.it.md)
• [Русский readme](https://github.com/textualize/rich/blob/master/README.ru.md)
• [Indonesian readme](https://github.com/textualize/rich/blob/master/README.id.md)
• [فارسی readme](https://github.com/textualize/rich/blob/master/README.fa.md)
• [Türkçe readme](https://github.com/textualize/rich/blob/master/README.tr.md)
• [Polskie readme](https://github.com/textualize/rich/blob/master/README.pl.md)
Rich is a Python library for _rich_ text and beautiful formatting in the terminal.
The [Rich API](https://rich.readthedocs.io/en/latest/) makes it easy to add color and style to terminal output. Rich can also render pretty tables, progress bars, markdown, syntax highlighted source code, tracebacks, and more — out of the box.

For a video introduction to Rich see [calmcode.io](https://calmcode.io/rich/introduction.html) by [@fishnets88](https://twitter.com/fishnets88).
See what [people are saying about Rich](https://www.willmcgugan.com/blog/pages/post/rich-tweets/).
## Compatibility
Rich works with Linux, macOS and Windows. True color / emoji works with new Windows Terminal, classic terminal is limited to 16 colors. Rich requires Python 3.8 or later.
Rich works with [Jupyter notebooks](https://jupyter.org/) with no additional configuration required.
## Installing
Install with `pip` or your favorite PyPI package manager.
```sh
python -m pip install rich
```
Run the following to test Rich output on your terminal:
```sh
python -m rich
```
## Rich Print
To effortlessly add rich output to your application, you can import the [rich print](https://rich.readthedocs.io/en/latest/introduction.html#quick-start) method, which has the same signature as the builtin Python function. Try this:
```python
from rich import print
print("Hello, [bold magenta]World[/bold magenta]!", ":vampire:", locals())
```

## Rich REPL
Rich can be installed in the Python REPL, so that any data structures will be pretty printed and highlighted.
```python
>>> from rich import pretty
>>> pretty.install()
```

## Using the Console
For more control over rich terminal content, import and construct a [Console](https://rich.readthedocs.io/en/latest/reference/console.html#rich.console.Console) object.
```python
from rich.console import Console
console = Console()
```
The Console object has a `print` method which has an intentionally similar interface to the builtin `print` function. Here's an example of use:
```python
console.print("Hello", "World!")
```
As you might expect, this will print `"Hello World!"` to the terminal. Note that unlike the builtin `print` function, Rich will word-wrap your text to fit within the terminal width.
There are a few ways of adding color and style to your output. You can set a style for the entire output by adding a `style` keyword argument. Here's an example:
```python
console.print("Hello", "World!", style="bold red")
```
The output will be something like the following:

That's fine for styling a line of text at a time. For more finely grained styling, Rich renders a special markup which is similar in syntax to [bbcode](https://en.wikipedia.org/wiki/BBCode). Here's an example:
```python
console.print("Where there is a [bold cyan]Will[/bold cyan] there [u]is[/u] a [i]way[/i].")
```

You can use a Console object to generate sophisticated output with minimal effort. See the [Console API](https://rich.readthedocs.io/en/latest/console.html) docs for details.
## Rich Inspect
Rich has an [inspect](https://rich.readthedocs.io/en/latest/reference/init.html?highlight=inspect#rich.inspect) function which can produce a report on any Python object, such as class, instance, or builtin.
```python
>>> my_list = ["foo", "bar"]
>>> from rich import inspect
>>> inspect(my_list, methods=True)
```

See the [inspect docs](https://rich.readthedocs.io/en/latest/reference/init.html#rich.inspect) for details.
# Rich Library
Rich contains a number of builtin _renderables_ you can use to create elegant output in your CLI and help you debug your code.
Click the following headings for details:
<details>
<summary>Log</summary>
The Console object has a `log()` method which has a similar interface to `print()`, but also renders a column for the current time and the file and line which made the call. By default Rich will do syntax highlighting for Python structures and for repr strings. If you log a collection (i.e. a dict or a list) Rich will pretty print it so that it fits in the available space. Here's an example of some of these features.
```python
from rich.console import Console
console = Console()
test_data = [
{"jsonrpc": "2.0", "method": "sum", "params": [None, 1, 2, 4, False, True], "id": "1",},
{"jsonrpc": "2.0", "method": "notify_hello", "params": [7]},
{"jsonrpc": "2.0", "method": "subtract", "params": [42, 23], "id": "2"},
]
def test_log():
enabled = False
context = {
"foo": "bar",
}
movies = ["Deadpool", "Rise of the Skywalker"]
console.log("Hello from", console, "!")
console.log(test_data, log_locals=True)
test_log()
```
The above produces the following output:

Note the `log_locals` argument, which outputs a table containing the local variables where the log method was called.
The log method could be used for logging to the terminal for long running applications such as servers, but is also a very nice debugging aid.
</details>
<details>
<summary>Logging Handler</summary>
You can also use the builtin [Handler class](https://rich.readthedocs.io/en/latest/logging.html) to format and colorize output from Python's logging module. Here's an example of the output:

</details>
<details>
<summary>Emoji</summary>
To insert an emoji in to console output place the name between two colons. Here's an example:
```python
>>> console.print(":smiley: :vampire: :pile_of_poo: :thumbs_up: :raccoon:")
😃 🧛 💩 👍 🦝
```
Please use this feature wisely.
</details>
<details>
<summary>Tables</summary>
Rich can render flexible [tables](https://rich.readthedocs.io/en/latest/tables.html) with unicode box characters. There is a large variety of formatting options for borders, styles, cell alignment etc.

The animation above was generated with [table_movie.py](https://github.com/textualize/rich/blob/master/examples/table_movie.py) in the examples directory.
Here's a simpler table example:
```python
from rich.console import Console
from rich.table import Table
console = Console()
table = Table(show_header=True, header_style="bold magenta")
table.add_column("Date", style="dim", width=12)
table.add_column("Title")
table.add_column("Production Budget", justify="right")
table.add_column("Box Office", justify="right")
table.add_row(
"Dec 20, 2019", "Star Wars: The Rise of Skywalker", "$275,000,000", "$375,126,118"
)
table.add_row(
"May 25, 2018",
"[red]Solo[/red]: A Star Wars Story",
"$275,000,000",
"$393,151,347",
)
table.add_row(
"Dec 15, 2017",
"Star Wars Ep. VIII: The Last Jedi",
"$262,000,000",
"[bold]$1,332,539,889[/bold]",
)
console.print(table)
```
This produces the following output:

Note that console markup is rendered in the same way as `print()` and `log()`. In fact, anything that is renderable by Rich may be included in the headers / rows (even other tables).
The `Table` class is smart enough to resize columns to fit the available width of the terminal, wrapping text as required. Here's the same example, with the terminal made smaller than the table above:

</details>
<details>
<summary>Progress Bars</summary>
Rich can render multiple flicker-free [progress](https://rich.readthedocs.io/en/latest/progress.html) bars to track long-running tasks.
For basic usage, wrap any sequence in the `track` function and iterate over the result. Here's an example:
```python
from rich.progress import track
for step in track(range(100)):
do_step(step)
```
It's not much harder to add multiple progress bars. Here's an example taken from the docs:

The columns may be configured to show any details you want. Built-in columns include percentage complete, file size, file speed, and time remaining. Here's another example showing a download in progress:

To try this out yourself, see [examples/downloader.py](https://github.com/textualize/rich/blob/master/examples/downloader.py) which can download multiple URLs simultaneously while displaying progress.
</details>
<details>
<summary>Status</summary>
For situations where it is hard to calculate progress, you can use the [status](https://rich.readthedocs.io/en/latest/reference/console.html#rich.console.Console.status) method which will display a 'spinner' animation and message. The animation won't prevent you from using the console as normal. Here's an example:
```python
from time import sleep
from rich.console import Console
console = Console()
tasks = [f"task {n}" for n in range(1, 11)]
with console.status("[bold green]Working on tasks...") as status:
while tasks:
task = tasks.pop(0)
sleep(1)
console.log(f"{task} complete")
```
This generates the following output in the terminal.

The spinner animations were borrowed from [cli-spinners](https://www.npmjs.com/package/cli-spinners). You can select a spinner by specifying the `spinner` parameter. Run the following command to see the available values:
```
python -m rich.spinner
```
The above command generates the following output in the terminal:

</details>
<details>
<summary>Tree</summary>
Rich can render a [tree](https://rich.readthedocs.io/en/latest/tree.html) with guide lines. A tree is ideal for displaying a file structure, or any other hierarchical data.
The labels of the tree can be simple text or anything else Rich can render. Run the following for a demonstration:
```
python -m rich.tree
```
This generates the following output:

See the [tree.py](https://github.com/textualize/rich/blob/master/examples/tree.py) example for a script that displays a tree view of any directory, similar to the linux `tree` command.
</details>
<details>
<summary>Columns</summary>
Rich can render content in neat [columns](https://rich.readthedocs.io/en/latest/columns.html) with equal or optimal width. Here's a very basic clone of the (MacOS / Linux) `ls` command which displays a directory listing in columns:
```python
import os
import sys
from rich import print
from rich.columns import Columns
directory = os.listdir(sys.argv[1])
print(Columns(directory))
```
The following screenshot is the output from the [columns example](https://github.com/textualize/rich/blob/master/examples/columns.py) which displays data pulled from an API in columns:

</details>
<details>
<summary>Markdown</summary>
Rich can render [markdown](https://rich.readthedocs.io/en/latest/markdown.html) and does a reasonable job of translating the formatting to the terminal.
To render markdown import the `Markdown` class and construct it with a string containing markdown code. Then print it to the console. Here's an example:
```python
from rich.console import Console
from rich.markdown import Markdown
console = Console()
with open("README.md") as readme:
markdown = Markdown(readme.read())
console.print(markdown)
```
This will produce output something like the following:

</details>
<details>
<summary>Syntax Highlighting</summary>
Rich uses the [pygments](https://pygments.org/) library to implement [syntax highlighting](https://rich.readthedocs.io/en/latest/syntax.html). Usage is similar to rendering markdown; construct a `Syntax` object and print it to the console. Here's an example:
```python
from rich.console import Console
from rich.syntax import Syntax
my_code = '''
def iter_first_last(values: Iterable[T]) -> Iterable[Tuple[bool, bool, T]]:
"""Iterate and generate a tuple with a flag for first and last value."""
iter_values = iter(values)
try:
previous_value = next(iter_values)
except StopIteration:
return
first = True
for value in iter_values:
yield first, False, previous_value
first = False
previous_value = value
yield first, True, previous_value
'''
syntax = Syntax(my_code, "python", theme="monokai", line_numbers=True)
console = Console()
console.print(syntax)
```
This will produce the following output:

</details>
<details>
<summary>Tracebacks</summary>
Rich can render [beautiful tracebacks](https://rich.readthedocs.io/en/latest/traceback.html) which are easier to read and show more code than standard Python tracebacks. You can set Rich as the default traceback handler so all uncaught exceptions will be rendered by Rich.
Here's what it looks like on OSX (similar on Linux):

</details>
All Rich renderables make use of the [Console Protocol](https://rich.readthedocs.io/en/latest/protocol.html), which you can also use to implement your own Rich content.
# Rich CLI
See also [Rich CLI](https://github.com/textualize/rich-cli) for a command line application powered by Rich. Syntax highlight code, render markdown, display CSVs in tables, and more, directly from the command prompt.
# Textual
See also Rich's sister project, [Textual](https://github.com/Textualize/textual), which you can use to build sophisticated User Interfaces in the terminal.

# Toad
[Toad](https://github.com/batrachianai/toad) is a unified interface for agentic coding. Built with Rich and Textual.

| text/markdown | Will McGugan | willmcgugan@gmail.com | null | null | MIT | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Framework :: IPython",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX :: Linux",
"Programming La... | [] | null | null | >=3.8.0 | [] | [] | [] | [
"ipywidgets<9,>=7.5.1; extra == \"jupyter\"",
"markdown-it-py>=2.2.0",
"pygments<3.0.0,>=2.13.0"
] | [] | [] | [] | [
"Documentation, https://rich.readthedocs.io/en/latest/",
"Homepage, https://github.com/Textualize/rich"
] | poetry/2.3.2 CPython/3.12.11 Darwin/25.2.0 | 2026-02-19T17:23:13.732467 | rich-14.3.3-py3-none-any.whl | 310,458 | 14/25/b208c5683343959b670dc001595f2f3737e051da617f66c31f7c4fa93abc/rich-14.3.3-py3-none-any.whl | py3 | bdist_wheel | null | false | ee3da182efc77318e42755f7e5d50dea | 793431c1f8619afa7d3b52b2cdec859562b950ea0d4b6b505397612db8d5362d | 1425b208c5683343959b670dc001595f2f3737e051da617f66c31f7c4fa93abc | null | [
"LICENSE"
] | 15,696,692 |
2.4 | garoupa | 3.250405.4 | Predictable operable hash-based identifiers and abstract algebra groups | 
[](https://codecov.io/gh/davips/garoupa)
<a href="https://pypi.org/project/garoupa">
<img src="https://img.shields.io/pypi/v/garoupa.svg?label=release&color=blue&style=flat-square" alt="pypi">
</a>

[](https://www.gnu.org/licenses/gpl-3.0)
[](https://doi.org/10.5281/zenodo.5501845)
[](https://arxiv.org/abs/2109.06028)
[](https://davips.github.io/garoupa)
[](https://pepy.tech/project/garoupa)

# GaROUPa - Identification based on group theory
The identification module of this library is evolving at its successor library [hosh (code)](https://github.com/davips/hosh) / [hosh (package)](https://pypi.org/project/hosh).
The algebra module exists only here.
GaROUPa solves the identification problem of multi-valued objects or sequences of events.<br>This [Python library](https://pypi.org/project/garoupa) / [code](https://github.com/davips/garoupa) provides a reference implementation for the UT*.4 specification presented [here](https://arxiv.org/abs/2109.06028). | ![fir0002 flagstaffotos [at] gmail.com Canon 20D + Tamron 28-75mm f/2.8, GFDL 1.2 <http://www.gnu.org/licenses/old-licenses/fdl-1.2.html>, via Wikimedia Commons](https://upload.wikimedia.org/wikipedia/commons/thumb/a/a7/Malabar_grouper_melb_aquarium.jpg/256px-Malabar_grouper_melb_aquarium.jpg)
:-------------------------:|:-------------------------:
We adopt a novel paradigm to universally unique identification (UUID), making identifiers deterministic and predictable,
even before an object is generated by a (possibly costly) process.
Here, data versioning and composition of processing steps are directly mapped as simple operations over identifiers.
We call each of the latter a Hosh, i.e., an identifier is an _**o**perable **h**a**sh**_.
A complete implementation of the remaining ideas from the [paper](https://arxiv.org/abs/2109.06028) is provided in this
[cacheable lazy dict](https://pypi.org/project/ldict/2.211016.3) which depends on GaROUPa and serves as an advanced usage example.
<br>
A more robust (entirely rewritten) version is available in the package [idict](https://pypi.org/project/idict).
## Overview
A product of identifiers produces a new identifier as shown below, where sequences of bytes (`b"..."`) are passed to simulate binary objects to be hashed.
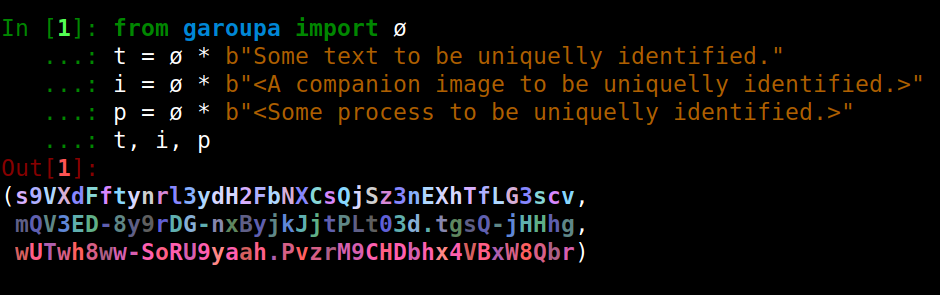 | New identifiers are easily <br> created from the identity <br> element `ø`. Also available as `identity` for people <br>or systems allergic to <br>utf-8 encoding.
-------------------------|-------------------------
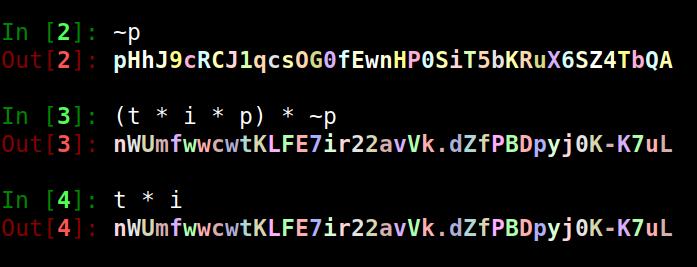 | Operations can be reverted by the inverse of the identifier.
-------------------------|-------------------------
 | Operations are associative. <br>They are order-sensitive by default, <br>in which case they are called _ordered_ ids.
-------------------------|-------------------------
However, order-insensitive (called _unordered_) and order-insensitive-among-themselves (called _hybrid_) identifiers are also available. | .
-------------------------|-------------------------
 | .
This is how they affect each other: | .
-------------------------|-------------------------
 | .
The chance of collision is determined by the number of possible identifiers of each type.
Some versions are provided, e.g.: UT32.4, UT40.4 (default), UT64.4.
They can be easily implemented in other languages and are
intended to be a specification on how to identify multi-valued objects and multi-step processes.
Unordered ids use a very narrow range of the total number of identifiers.
This is not a problem as they are not very useful.
One use for unordered ids could be the embedding of authorship or other metadata into an object without worrying about the timing, since the resulting id will remain the same, no matter when the unordered id is operated with the id of the object under construction. | .
-------------------------|-------------------------
 | .
Conversely, hybrid ids are excelent to represent values in a data structure like a map,
since the order is not relevant when the consumer process looks up for keys, not indexes.
Converselly, a chain of a data processing functions usually implies one step is dependent on the result of the previous step.
This makes ordered ids the perfect fit to identify functions (and also their composition, as a consequence).
### Relationships can also be represented
Here is another possible use. ORCIDs are managed unique identifiers for researchers.
They can be directly used as digests to create operable identifiers.
We recommend the use of 40 digits to allow operations with SHA-1 hashes.
They are common in version control repositories among other uses.

Unordered relationships are represented by hybrid ids.
Automatic transparent conversion between ORCID dashes by a hexdecimal character can be implemented in the future if needed.
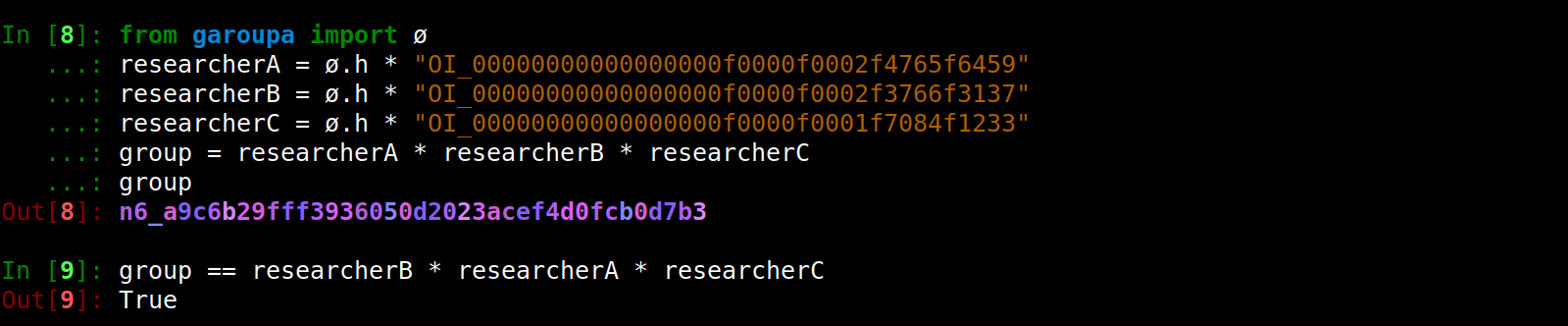
## More info
Aside from the [paper](https://arxiv.org/abs/2109.06028), [PyPI package](https://pypi.org/project/garoupa)
and [GitHub repository](https://github.com/davips/garoupa),
one can find more information, at a higher level application perspective,
in this presentation:

A lower level perspective is provided in the [API documentation](https://davips.github.io/garoupa).
## Python installation
### from package
```bash
# Set up a virtualenv.
python3 -m venv venv
source venv/bin/activate
# Install from PyPI
pip install garoupa
```
### from source
```bash
git clone https://github.com/davips/garoupa
cd garoupa
poetry install
```
### Examples
Some usage examples.
**Basic operations**
<details>
<p>
```python3
from garoupa import Hosh, ø # ø is a shortcut for identity (AltGr+O in most keyboards)
# Hoshes (operable hash-based elements) can be multiplied.
a = Hosh(content=b"Some large binary content...")
b = Hosh(content=b"Some other binary content. Might be, e.g., an action or another large content.")
c = a * b
print(f"{a} * {b} = {c}")
"""
8CG9so9N1nQ59uNO8HGYcZ4ExQW5Haw4mErvw8m8 * 7N-L-10JS-H5DN0-BXW2e5ENWFQFVWswyz39t8s9 = z3EgxfisgqbNXBd0eqDuFiaTblBLA5ZAUbvEZgOh
"""
```
```python3
print(~b)
# Multiplication can be reverted by the inverse hosh. Zero is the identity hosh.
print(f"{b} * {~b} = {b * ~b} = 0")
"""
Q6OjmYZSJ8pB3ogBVMKBOxVp-oZ80czvtUrSyTzS
7N-L-10JS-H5DN0-BXW2e5ENWFQFVWswyz39t8s9 * Q6OjmYZSJ8pB3ogBVMKBOxVp-oZ80czvtUrSyTzS = 0000000000000000000000000000000000000000 = 0
"""
```
```python3
print(f"{b} * {ø} = {b * ø} = b")
"""
7N-L-10JS-H5DN0-BXW2e5ENWFQFVWswyz39t8s9 * 0000000000000000000000000000000000000000 = 7N-L-10JS-H5DN0-BXW2e5ENWFQFVWswyz39t8s9 = b
"""
```
```python3
print(f"{c} * {~b} = {c * ~b} = {a} = a")
"""
z3EgxfisgqbNXBd0eqDuFiaTblBLA5ZAUbvEZgOh * Q6OjmYZSJ8pB3ogBVMKBOxVp-oZ80czvtUrSyTzS = 8CG9so9N1nQ59uNO8HGYcZ4ExQW5Haw4mErvw8m8 = 8CG9so9N1nQ59uNO8HGYcZ4ExQW5Haw4mErvw8m8 = a
"""
```
```python3
print(f"{~a} * {c} = {~a * c} = {b} = b")
"""
RNvSdLI-5RiBBGL8NekctiQofWUIeYvXFP3wvTFT * z3EgxfisgqbNXBd0eqDuFiaTblBLA5ZAUbvEZgOh = 7N-L-10JS-H5DN0-BXW2e5ENWFQFVWswyz39t8s9 = 7N-L-10JS-H5DN0-BXW2e5ENWFQFVWswyz39t8s9 = b
"""
```
```python3
# Division is shorthand for reversion.
print(f"{c} / {b} = {c / b} = a")
"""
z3EgxfisgqbNXBd0eqDuFiaTblBLA5ZAUbvEZgOh / 7N-L-10JS-H5DN0-BXW2e5ENWFQFVWswyz39t8s9 = 8CG9so9N1nQ59uNO8HGYcZ4ExQW5Haw4mErvw8m8 = a
"""
```
```python3
# Hosh multiplication is not expected to be commutative.
print(f"{a * b} != {b * a}")
"""
z3EgxfisgqbNXBd0eqDuFiaTblBLA5ZAUbvEZgOh != wwSd0LaGvuV0W-yEOfgB-yVBMlNLA5ZAUbvEZgOh
"""
```
```python3
# Hosh multiplication is associative.
print(f"{a * (b * c)} = {(a * b) * c}")
"""
RuTcC4ZIr0Y1QLzYmytPRc087a8cbbW9Nj-gXxAz = RuTcC4ZIr0Y1QLzYmytPRc087a8cbbW9Nj-gXxAz
"""
```
</p>
</details>
### Examples (abstract algebra)
Although not the focus of the library, GaROUPa hosts also some niceties for group theory experimentation.
Some examples are provided below.
**Abstract algebra module**
<details>
<p>
```python3
from itertools import islice
from math import factorial
from garoupa.algebra.cyclic import Z
from garoupa.algebra.dihedral import D
from garoupa.algebra.symmetric import Perm
from garoupa.algebra.symmetric import S
# Direct product between:
# symmetric group S4;
# cyclic group Z5; and,
# dihedral group D4.
G = S(4) * Z(5) * D(4)
print(G)
"""
S4×Z5×D4
"""
```
```python3
# Operating over 5 sampled pairs.
for a, b in islice(zip(G, G), 0, 5):
print(a, "*", b, "=", a * b, sep="\t")
"""
«[1, 0, 2, 3], 1, ds3» * «[0, 1, 2, 3], 3, ds3» = «[1, 0, 2, 3], 4, dr0»
«[0, 2, 1, 3], 0, dr2» * «[2, 1, 0, 3], 1, dr4» = «[1, 2, 0, 3], 1, dr2»
«[2, 3, 0, 1], 1, dr7» * «[1, 2, 0, 3], 2, dr1» = «[3, 0, 2, 1], 3, dr0»
«[1, 0, 3, 2], 1, dr4» * «[3, 1, 0, 2], 0, dr3» = «[2, 0, 1, 3], 1, dr3»
«[2, 0, 1, 3], 3, dr1» * «[3, 1, 0, 2], 2, dr5» = «[3, 0, 2, 1], 0, dr2»
"""
```
```python3
# Operator ~ is another way of sampling.
G = S(12)
print(~G)
"""
[5, 6, 1, 3, 2, 9, 0, 4, 7, 8, 11, 10]
"""
```
```python3
# Manual element creation.
last_perm_i = factorial(12) - 1
a = Perm(i=last_perm_i, n=12)
print("Last element of S35:", a)
"""
Last element of S35: [11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
"""
```
```python3
# Inverse element. Group S4.
a = Perm(i=21, n=4)
b = Perm(i=17, n=4)
print(a, "*", ~a, "=", (a * ~a).i, "=", a * ~a, "= identity")
"""
[1, 3, 2, 0] * [3, 0, 2, 1] = 0 = [0, 1, 2, 3] = identity
"""
```
```python3
print(a, "*", b, "=", a * b)
"""
[1, 3, 2, 0] * [1, 2, 3, 0] = [3, 2, 0, 1]
"""
```
```python3
print(a, "*", b, "*", ~b, "=", a * b * ~b, "= a")
"""
[1, 3, 2, 0] * [1, 2, 3, 0] * [3, 0, 1, 2] = [1, 3, 2, 0] = a
"""
```
</p>
</details>
**Commutativity degree of groups**
<details>
<p>
```python3
from garoupa.algebra.cyclic import Z
from garoupa.algebra.dihedral import D
from garoupa.algebra.matrix.m import M
def traverse(G):
i, count = G.order, G.order
for idx, a in enumerate(G.sorted()):
for b in list(G.sorted())[idx + 1 :]:
if a * b == b * a:
count += 2
i += 2
print(
f"|{G}| = ".rjust(20, " "),
f"{G.order}:".ljust(10, " "),
f"{count}/{i}:".rjust(15, " "),
f" {G.bits} bits",
f"\t{100 * count / i} %",
sep="",
)
# Dihedral
traverse(D(8))
"""
|D8| = 16: 112/256: 4.0 bits 43.75 %
"""
```
```python3
traverse(D(8) ^ 2)
"""
|D8×D8| = 256: 12544/65536: 8.0 bits 19.140625 %
"""
```
```python3
# Z4!
traverse(Z(4) * Z(3) * Z(2))
"""
|Z4×Z3×Z2| = 24: 576/576: 4.584962500721157 bits 100.0 %
"""
```
```python3
# M 3x3 %4
traverse(M(3, 4))
# Large groups (sampling is needed).
Gs = [D(8) ^ 3, D(8) ^ 4, D(8) ^ 5]
for G in Gs:
i, count = 0, 0
for a, b in zip(G, G):
if a * b == b * a:
count += 1
if i >= 10_000:
break
i += 1
print(
f"|{G}| = ".rjust(20, " "),
f"{G.order}:".ljust(10, " "),
f"{count}/{i}:".rjust(15, " "),
f" {G.bits} bits",
f"\t~{100 * count / i} %",
sep="",
)
"""
|M3%4| = 64: 2560/4096: 6.0 bits 62.5 %
|D8×D8×D8| = 4096: 821/10000: 12.0 bits ~8.21 %
|D8×D8×D8×D8| = 65536: 378/10000: 16.0 bits ~3.78 %
|D8×D8×D8×D8×D8| = 1048576: 190/10000: 20.0 bits ~1.9 %
"""
```
</p>
</details>
**Detect identity after many repetitions**
<details>
<p>
```python3
import operator
from datetime import datetime
from functools import reduce
from math import log, inf
from sys import argv
from garoupa.algebra.dihedral import D
from garoupa.algebra.symmetric import S
example = len(argv) == 1 or (not argv[1].isdecimal() and argv[1][0] not in ["p", "s", "d"])
primes = [5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103, 107,
109, 113, 127, 131, 137, 139, 149, 151, 157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229,
233, 239, 241, 251, 257, 263, 269, 271, 277, 281, 283, 293, 307, 311, 313, 317, 331, 337, 347, 349, 353, 359,
367, 373, 379, 383, 389, 397, 401, 409, 419, 421, 431, 433, 439, 443, 449, 457, 461, 463, 467, 479, 487, 491,
499, 503, 509, 521, 523, 541, 547, 557, 563, 569, 571, 577, 587, 593, 599, 601, 607, 613, 617, 619, 631, 641,
643, 647, 653, 659, 661, 673, 677, 683, 691, 701, 709, 719, 727, 733, 739, 743, 751, 757, 761, 769, 773, 787,
797, 809, 811, 821, 823, 827, 829, 839, 853, 857, 859, 863, 877, 881, 883, 887, 907, 911, 919, 929, 937, 941,
947, 953, 967, 971, 977, 983, 991, 997, 1009]
if example:
limit, sample = 30, 100
lst = [] # See *.
for n in primes[:5]:
lst.append(D(n, seed=n))
G = reduce(operator.mul, lst)
else:
limit, sample = int(argv[2]), int(argv[3]) if len(argv) > 2 else 1_000_000_000_000
if argv[1] == "s25d":
G = S(25) * reduce(operator.mul, [D(n) for n in primes[:9]])
elif argv[1] == "s57":
G = S(57)
elif argv[1] == "p384":
G = reduce(operator.mul, [D(n) for n in primes[:51]])
elif argv[1] == "p64":
G = reduce(operator.mul, [D(n) for n in primes[:12]])
elif argv[1] == "p96":
G = reduce(operator.mul, [D(n) for n in primes[:16]])
elif argv[1] == "p128":
G = reduce(operator.mul, [D(n) for n in primes[:21]])
elif argv[1] == "p256":
G = reduce(operator.mul, [D(n) for n in primes[:37]])
elif argv[1] == "64":
G = reduce(operator.mul, [D(n) for n in range(5, 31, 2)])
elif argv[1] == "96":
G = reduce(operator.mul, [D(n) for n in range(5, 41, 2)])
elif argv[1] == "128":
G = reduce(operator.mul, [D(n) for n in range(5, 51, 2)])
else:
G = reduce(operator.mul, [D(n) for n in range(5, 86, 2)])
print(f"{G.bits} bits Pc: {G.comm_degree} order: {G.order} {G}", flush=True)
print("--------------------------------------------------------------", flush=True)
for hist in G.sampled_orders(sample=sample, limit=limit):
tot = sum(hist.values())
bad = 0 # See *.
for k, v in hist.items():
if k[0] <= limit:
bad += v
print(hist, flush=True)
hist = hist.copy()
if (inf, inf) in hist:
del hist[(inf, inf)]
hist = {int((k[0] + k[1]) / 2): v for k, v in hist.items()}
print(
f"\nbits: {log(G.order, 2):.2f} Pc: {G.comm_degree or -1:.2e} a^<{limit}=0: {bad}/{tot} = {bad / tot:.2e}",
G,
G._pi_core(hist),
datetime.now().strftime("%d/%m/%Y %H:%M:%S"),
flush=True,
)
# * -> [Explicit FOR due to autogeneration of README through eval]
"""
21.376617194973697 bits Pc: 0.004113533525298232 order: 2722720 D5×D7×D11×D13×D17
--------------------------------------------------------------
{(-1, 10): 9, (9, 20): 7, (19, 30): 9, (inf, inf): 75}
bits: 21.38 Pc: 4.11e-03 a^<30=0: 25/100 = 2.50e-01 D5×D7×D11×D13×D17 0.125 19/02/2026 14:26:35
"""
```
</p>
</details>
**Tendence of commutativity on Mn**
<details>
<p>
```python3
from itertools import chain
from garoupa.algebra.matrix.m import M
from garoupa.algebra.matrix.m8bit import M8bit
def traverse(G):
i, count = G.order, G.order
for idx, a in enumerate(G.sorted()):
for b in list(G.sorted())[idx + 1:]:
if a * b == b * a:
count += 2
i += 2
print(f"|{G}| = ".rjust(20, ' '),
f"{G.order}:".ljust(10, ' '),
f"{count}/{i}:".rjust(15, ' '), f" {G.bits} bits",
f"\t{100 * count / i} %", sep="")
M1_4 = map(M, range(1, 5))
for G in chain(M1_4, [M8bit(), M(5)]):
traverse(G)
# ...
for G in map(M, range(6, 11)):
i, count = 0, 0
for a, b in zip(G, G):
if a * b == b * a:
count += 1
i += 1
if i >= 1_000_000:
break
print(f"|{G}| = ".rjust(20, ' '),
f"{G.order}:".ljust(10, ' '),
f"{count}/{i}:".rjust(15, ' '), f" {G.bits} bits",
f"\t~{100 * count / i} %", sep="")
"""
|M1| = 1: 1/1: 0 bits 100.0 %
|M2| = 2: 4/4: 1 bits 100.0 %
|M3| = 8: 40/64: 3 bits 62.5 %
|M4| = 64: 1024/4096: 6 bits 25.0 %
|M8bit| = 256: 14848/65536: 8 bits 22.65625 %
|M5| = 1024: 62464/1048576: 10 bits 5.95703125 %
|M6| = 32768: 286/32768: 15 bits 0.872802734375 %
|M7| = 2097152: 683/1000000: 21 bits 0.0683 %
|M8| = 268435456: 30/1000000: 28 bits 0.003 %
|M9| = 68719476736: 1/1000000: 36 bits 0.0001 %
|M10| = 35184372088832: 0/1000000: 45 bits 0.0 %
"""
```
</p>
</details>
**Groups benefit from methods from the module 'hosh'**
<details>
<p>
```python3
from garoupa.algebra.matrix import M
m = ~M(23)
print(repr(m.hosh))
```
<a href="https://github.com/davips/garoupa/blob/main/examples/7KDd8TiA3S11QTkUid2wy87DQIeGQ35vB1bsP5Y6DjZ.png">
<img src="https://raw.githubusercontent.com/davips/garoupa/main/examples/7KDd8TiA3S11QTkUid2wy87DQIeGQ35vB1bsP5Y6DjZ.png" alt="Colored base-62 representation" width="380" height="18">
</a>
</p>
</details>
## Performance
Computation time for the simple operations performed by GaROUPa can be considered negligible for most applications,
since the order of magnitude of creating and operating identifiers is around a few μs:
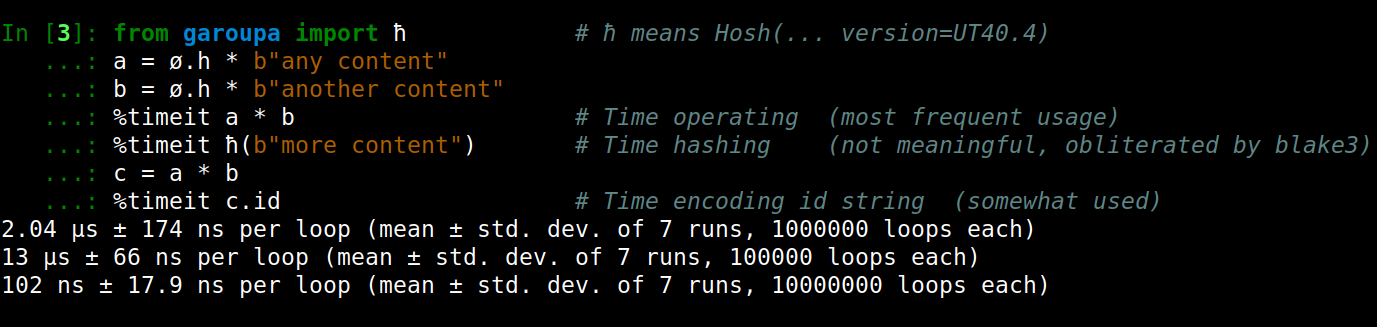
On the other hand, we estimate up to ~7x gains in speed when porting the core code to _rust_.
The package [hosh](https://pypi.org/project/hosh) was a faster implementation of an earlier version of GaROUPa,
It will be updated to be fully compatible with current GaROUPa at major version `2.*.*`.
As the performance of garoupa seems already very high, an updated 'rust' implementation might become unnecessary.
Some parts of the algebra module need additional packages, they can be installed using:
`poetry install -E full`
## Grants
This work was partially supported by Fapesp under supervision of
Prof. André C. P. L. F. de Carvalho at CEPID-CeMEAI (Grants 2013/07375-0 – 2019/01735-0).
| text/markdown | davips | dpsabc@gmail.com | null | null | GPL | null | [
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming L... | [] | null | null | >=3.9 | [] | [] | [] | [
"wheel<0.38.0,>=0.37.0",
"blake3<2.0.0,>=1.0.4",
"colored==1.4.2",
"ansi2html==1.6.0",
"progress<2.0,>=1.6; extra == \"algebra\"",
"pathos<0.3.0,>=0.2.8; extra == \"algebra\"",
"bigfloat<0.5.0,>=0.4.0; extra == \"experiments\"",
"setuptools<79.0.0,>=78.1.0"
] | [] | [] | [] | [] | poetry/2.2.1 CPython/3.10.12 Linux/6.8.0-52-generic | 2026-02-19T17:23:09.808587 | garoupa-3.250405.4.tar.gz | 56,208 | 21/40/c364301d5ae0e260c3dfd94766c80c7163817fc72c34f232fb01c33eef40/garoupa-3.250405.4.tar.gz | source | sdist | null | false | 235a0427fdd5b0398cc3a1967b5c75fa | c10965fe33ac9686ea3667e0a3dcfec3a5aa5443034f0c9942b58161d11152f8 | 2140c364301d5ae0e260c3dfd94766c80c7163817fc72c34f232fb01c33eef40 | null | [] | 225 |
2.4 | pymetropolis | 0.6.0 | Helper functions to generate, calibrate, run, and analyze METROPOLIS2 simulation instances | <a id="readme-top"></a>
<!-- PROJECT SHIELDS -->
<!--
*** I'm using markdown "reference style" links for readability.
*** Reference links are enclosed in brackets [ ] instead of parentheses ( ).
*** See the bottom of this document for the declaration of the reference variables
*** for contributors-url, forks-url, etc. This is an optional, concise syntax you may use.
*** https://www.markdownguide.org/basic-syntax/#reference-style-links
-->
[![Contributors][contributors-shield]][contributors-url]
[![Forks][forks-shield]][forks-url]
[![Stargazers][stars-shield]][stars-url]
[![Issues][issues-shield]][issues-url]
[![GPL v3][license-shield]][license-url]
<!-- [![LinkedIn][linkedin-shield]][linkedin-url] -->
<!-- PROJECT LOGO -->
<br />
<div align="center">
<a href="https://github.com/Metropolis2/pymetropolis">
<img src="icons/80x80.png" alt="Logo" width="80" height="80">
</a>
<h3 align="center">Pymetropolis</h3>
<p align="center">
Pymetropolis is a Python pipeline to generate, calibrate, run and analyze METROPOLIS2 simulation instances.
<br />
<a href="https://docs.metropolis2.org"><strong>Explore the docs »</strong></a>
<br />
<br />
<a href="https://metropolis2.org">Website</a>
·
<a href="https://github.com/Metropolis2/pymetropolis/issues/new?labels=bug&template=bug_report.yml">Report Bug</a>
·
<a href="https://github.com/Metropolis2/pymetropolis/issues/new?labels=enhancement&template=feature_request.yml">Request Feature</a>
</p>
</div>
<!-- TABLE OF CONTENTS -->
<details>
<summary>Table of Contents</summary>
<ol>
<li>
<a href="#about-the-project">About The Project</a>
<ul>
<!--<li><a href="#citation">Citation</a></li>-->
<li><a href="#built-with">Built With</a></li>
<li><a href="#semver">Semver</a></li>
</ul>
</li>
<li>
<a href="#getting-started">Getting Started</a>
</li>
<li><a href="#usage">Usage</a></li>
<li><a href="#contributing">Contributing</a></li>
<li><a href="#license">License</a></li>
<li><a href="#contact">Contact</a></li>
<li><a href="#acknowledgments">Acknowledgments</a></li>
</ol>
</details>
<!-- ABOUT THE PROJECT -->
## About The Project
[![METROPOLIS2 example output][product-screenshot]](https://metropolis2.org)
METROPOLIS2 is a dynamic multi-modal agent-based transport simulator.
<!-- TODO add graph of project structure -->
<!--### Citation
If you use this project in your research, please cite it as follows:
de Palma, A. & Javaudin, L. (2025). _METROPOLIS2_. [https://metropolis2.org](https://metropolis2.org)
Javaudin, L., & de Palma, A. (2024). _METROPOLIS2: Bridging theory and simulation in agent-based transport modeling._ Technical report, THEMA (THéorie Economique, Modélisation et Applications).
_Refer to [CITATION.cff](CITATION.cff) and [CITATION.bib](CITATION.bib) for details._
-->
### Built With
[![Python][Python]][Python-url]
Pymetropolis make use of some great Python libraries, including:
- [geopandas](https://geopandas.org/) for geospatial data manipulation
- [loguru](https://loguru.readthedocs.io/) for logging
- [matplotlib](https://matplotlib.org/) for data visualization
- [networkx](https://networkx.org/) for graph manipulation
- [numpy](https://numpy.org/) for arrays and random number generators
- [pyosmium](https://osmcode.org/pyosmium/) for OpenStreetMap data manipulation
- [polars](https://pola.rs/) for extremely fast dataframes
- [shapely](https://shapely.readthedocs.io/) for geometric objects
- [typer](https://typer.tiangolo.com/) for easy CLI
### Semver
Pymetropolis is following [Semantic Versioning 2.0](https://semver.org/).
Each new version is given a number MAJOR.MINOR.PATCH.
An increase of the MAJOR number indicates backward incompatibilities with previous versions.
An increase of the MINOR number indicates new features, that are backward-compatible.
An increase of the PATCH number indicates bug fixes.
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- GETTING STARTED -->
## Getting Started
1. Install the Python package with `pip install pymetropolis`.
2. Download the [Metropolis-Core simulator](https://github.com/Metropolis2/Metropolis-Core/releases).
3. Create a TOML configuration file describing the simulation instance.
4. Run the pipeline with `pymetropolis my-config.toml`.
For more details, please refer to the
[documentation](https://docs.metropolis2.org/pymetropolis/getting_started.html).
You can find complete examples of simulation instances in the
[official case studies](https://docs.metropolis2.org/pymetropolis/case_study/index.html).
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- CONTRIBUTING -->
## Contributing
If you would like to add a feature to Pymetropolis, start by opening an issue with the tag
"enhancement" so that we can discuss its feasibility.
If your suggestion is accepted, you can then create a Pull Request:
1. Fork the Project
2. Create your Feature Branch (`git checkout -b feature/AmazingFeature`)
3. Commit your Changes (`git commit -m 'Add some AmazingFeature'`)
4. Push to the Branch (`git push origin feature/AmazingFeature`)
5. Open a Pull Request
_For more details, please read [CONTRIBUTING.md](CONTRIBUTING.md)
and [CODE_OF_CONDUCT.md](CODE_OF_CONDUCT.md)._
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- ### Top contributors:
<a href="https://github.com/Metropolis2/pymetropolis/graphs/contributors">
<img src="https://contrib.rocks/image?repo=Metropolis2/pymetropolis" alt="contrib.rocks image" />
</a>
-->
<!-- LICENSE -->
## License
Pymetropolis is free and open-source software licensed under the
[GNU General Public License v3.0](https://www.gnu.org/licenses/).
You are free to:
- Modify and redistribute this software
- Use it for any purpose, personal or commercial
Under the following conditions:
- You retain the original copyright notice
- You distribute you modifications under the same license (GPL-3.0 or later)
- You document any significant changes you make
For the full license text and legal details, see the `LICENSE.txt` file.
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- CONTACT -->
## Contact
If you have any questions, either post an
[issue](https://github.com/Metropolis2/pymetropolis/issues)
or send an e-mail to any of these addresses:
- METROPOLIS2 team - contact@metropolis2.org
- Lucas Javaudin - metropolis@lucasjavaudin.com
Project Link: [https://github.com/Metropolis2/pymetropolis](https://github.com/Metropolis2/pymetropolis)
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- ACKNOWLEDGMENTS -->
## Acknowledgments
Pymetropolis benefited from the work of Kokouvi Joseph Djafon on the calibration tools.
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- MARKDOWN LINKS & IMAGES -->
<!-- https://www.markdownguide.org/basic-syntax/#reference-style-links -->
[contributors-shield]: https://img.shields.io/github/contributors/Metropolis2/pymetropolis.svg?style=for-the-badge
[contributors-url]: https://github.com/Metropolis2/pymetropolis/graphs/contributors
[forks-shield]: https://img.shields.io/github/forks/Metropolis2/pymetropolis.svg?style=for-the-badge
[forks-url]: https://github.com/Metropolis2/pymetropolis/network/members
[stars-shield]: https://img.shields.io/github/stars/Metropolis2/pymetropolis.svg?style=for-the-badge
[stars-url]: https://github.com/Metropolis2/pymetropolis/stargazers
[issues-shield]: https://img.shields.io/github/issues/Metropolis2/pymetropolis.svg?style=for-the-badge
[issues-url]: https://github.com/Metropolis2/pymetropolis/issues
[license-shield]: https://img.shields.io/github/license/Metropolis2/pymetropolis.svg?style=for-the-badge
[license-url]: https://github.com/Metropolis2/pymetropolis/blob/master/LICENSE.txt
[linkedin-shield]: https://img.shields.io/badge/-LinkedIn-black.svg?style=for-the-badge&logo=linkedin&colorB=555
[linkedin-url]: https://linkedin.com/in/lucas-javaudin
[product-screenshot]: images/traffic_flows.jpg
<!-- Shields.io badges. You can a comprehensive list with many more badges at: https://github.com/inttter/md-badges -->
[Python]: https://img.shields.io/badge/Python-3776AB?style=for-the-badge&logo=python&logoColor=white
[Python-url]: https://www.python.org/
| text/markdown | null | Lucas Javaudin <lucas@lucasjavaudin.com> | null | null | null | transport simulation, metropolis2 | [
"Programming Language :: Python",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"geopandas>=1.1.1",
"isodate>=0.7.2",
"loguru>=0.7.3",
"matplotlib>=3.10.8",
"networkx>=3.5",
"numpy>=2.3.4",
"osmium>=4.2.0",
"polars>=1.35.1",
"pyarrow>=22.0.0",
"pyproj>=3.7.2",
"pyogrio>=0.11.1",
"requests>=2.32.5",
"shapely>=2.1.2",
"termcolor>=3.2.0",
"typer>=0.20.0",
"toml>=0.10... | [] | [] | [] | [
"Homepage, https://metropolis2.org",
"Documentation, https://docs.metropolis2.org",
"Repository, https://github.com/Metropolis2/pymetropolis",
"Issues, https://github.com/Metropolis2/pymetropolis/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T17:22:17.718140 | pymetropolis-0.6.0.tar.gz | 84,782 | 80/85/725d989f54b21212b04eaca51a6121605c27915ce0fedf7a304d54954d17/pymetropolis-0.6.0.tar.gz | source | sdist | null | false | e5bbd3518b44e935b6d877c3918660f0 | 903053ce7b91d8a19e2817651b0393796119c45fde0cc6359bcbd04f7f464068 | 8085725d989f54b21212b04eaca51a6121605c27915ce0fedf7a304d54954d17 | GPL-3.0-or-later | [
"LICENSE.txt"
] | 211 |
2.4 | circularlink | 1.0.0 | AI-Driven Marketplace for Industrial Circular Economy — Terminal UI | # CircuLink Terminal
> **AI-Driven Marketplace for Industrial Circular Economy**
> A production-quality Python TUI (Terminal User Interface) that connects industrial buyers and sellers of waste materials, by-products, and recyclables using intelligent fuzzy matching, real-time GSTIN compliance, and Gemini 2.5 Flash AI reasoning.
---
## Features
| Feature | Detail |
|---|---|
| **GSTIN-gated KYC** | Full 15-character GSTIN regex validation with Indian state-code lookup |
| **AI Byproduct Prediction** | Seller describes a process → Gemini 2.5 Flash predicts likely marketable byproducts |
| **Hazardous Screening** | 57-substance database (CAS + name); CAS match → exact → substring → RapidFuzz ≥85 — blocked listings never appear in search |
| **Intelligent Search** | Buyer enters a query → Gemini expands synonyms → RapidFuzz ensemble scoring → ranked results |
| **Weighted Scoring** | `final_score = 0.7 × fuzzy_score + 0.3 × location_score` |
| **Location Proximity** | Haversine distance + exponential decay; 100+ Indian industrial cities pre-geocoded |
| **Persistent Storage** | `~/.circularlink/` flat-JSON store; JSONL audit trail for every LLM call |
| **Full TUI** | Rich color scheme, sidebar navigation, modal dialogs — zero browser required |
---
## Quick Start
```bash
pip install circularlink
circularlink
```
### From source (editable install)
```bash
git clone https://github.com/your-org/circularlink.git
cd circularlink
pip install -e .
circularlink
```
Requires **Python 3.11+**.
---
## First Run
1. On launch you will see the **Welcome / Login** screen.
2. Switch to the **Register** tab.
3. Enter your company details — GSTIN is validated live.
4. Paste your **Google AI Studio API key** (from [aistudio.google.com](https://aistudio.google.com)).
5. Register → you enter the main application.
Subsequent launches auto-restore your session via `~/.circularlink/config.json`.
> **💡 Need test data?** See [SAMPLE_DATA.md](SAMPLE_DATA.md) for ready-to-use company credentials and testing scenarios.
---
## Navigation
| Key | Screen |
|---|---|
| `F1` | Dashboard — stats, recent matches, LLM audit log |
| `F2` | Buy: Intelligent Sourcing — search / browse / history |
| `F3` | Sell: Inventory — AI scan, manual add, hazard status |
| `F4` | KYC / Settings — edit profile, change API key, logout |
| `Ctrl+Q` | Quit |
---
## Architecture
```
src/circularlink/
├── app.py # Root App — LoginEvent, LogoutEvent, screen routing
├── __main__.py # CLI entry point → circularlink
├── styles.tcss # Textual CSS — Industrial Earth & Tech palette
│
├── core/
│ ├── gstin.py # GSTIN regex validator + state-code lookup
│ ├── geo.py # City geocoding, haversine, location scoring
│ ├── hazard.py # 4-strategy hazardous material checker
│ ├── matcher.py # FuzzyMatcher: ensemble NLP + weighted geo scoring
│ └── gemini_agent.py # Gemini 2.5 Flash: byproduct prediction + keyword expansion
│
├── storage/
│ └── db.py # JSON persistence layer (companies, products, matches, logs)
│
├── screens/
│ ├── welcome.py # Login + Registration + live GSTIN validation
│ ├── dashboard.py # F1 — stats, match table, LLM log
│ ├── buyer.py # F2 — search, Gemini expansion, ranked results
│ ├── seller.py # F3 — AI byproduct scan, hazard check, inventory
│ ├── kyc.py # F4 — profile management, logout, account delete
│ └── modals.py # MessageModal, ConfirmModal, AddProductModal, SearchModal
│
└── data/
└── hazardous.csv # 57 hazardous substances (CAS + name + UN number)
```
### Scoring Formula
$$\text{final\_score} = 0.7 \times \text{fuzzy\_score} + 0.3 \times \text{location\_score}$$
- **fuzzy\_score** = ensemble average of RapidFuzz `token_set_ratio`, `token_sort_ratio`, `partial_ratio` across product name and description
- **location\_score** = $e^{-d / (R/5)}$ where $d$ is Haversine distance in km and $R$ is `max_radius_km` (default 2000 km)
### Hazard Check Strategy (defence-in-depth)
1. CAS number regex match against CSV
2. Exact name match (case-insensitive)
3. Substring containment (both directions)
4. RapidFuzz `token_set_ratio` ≥ 85
Any hit → product status set to `blocked`; never returned in buyer search.
---
## Environment Variables
| Variable | Purpose |
|---|---|
| `GOOGLE_API_KEY` | Fallback API key if none stored in DB |
Recommended: set key via the **KYC / Settings** screen (stored locally, never transmitted outside Gemini API calls).
---
## Storage
All data is stored under `~/.circularlink/`:
```
~/.circularlink/
├── config.json # api_key, current_company_id
├── companies.json # Registered companies
├── products.json # Product listings (approved / blocked / pending)
├── matches.json # Saved search results
└── llm_logs/
└── YYYY-MM-DD.jsonl # Append-only Gemini call audit log
```
---
## Dependencies
| Package | Version | Purpose |
|---|---|---|
| `textual` | ≥0.80.0 | TUI framework |
| `google-generativeai` | ≥0.8.0 | Gemini 2.5 Flash API |
| `rapidfuzz` | ≥3.9.0 | Fuzzy NLP matching |
| `rich` | ≥13.7.0 | Terminal rendering |
| `geopy` | ≥2.4.0 | Geocoding utilities |
---
## Color Scheme
| Role | Hex | Usage |
|---|---|---|
| Background Deep | `#1A1B26` | Screen background |
| Background Panel | `#24253A` | Sidebar, cards |
| Seller / Red | `#E06C75` | Seller UI, warnings |
| Buyer / Green | `#98C379` | Buyer UI, success |
| AI / Blue | `#61AFEF` | Gemini highlights |
| Hazard / Amber | `#D19A66` | Hazard banners |
| Accent / Purple | `#C678DD` | Hotkeys, accents |
---
## Publishing to PyPI
```bash
pip install build twine
python -m build
twine upload dist/*
```
---
## License
MIT — see [LICENSE](LICENSE) for details.
---
## Acknowledgements
Built with [Textual](https://github.com/Textualize/textual) by Textualize, [Google Generative AI](https://ai.google.dev/), and [RapidFuzz](https://github.com/maxbachmann/RapidFuzz).
| text/markdown | null | Akshay Jha <akshay@circularlink.io>, Bandhan Sawant <bandhan@circularlink.io>, Devansh Jollani <devansh@circularlink.io> | null | null | MIT | circular-economy, AI, marketplace, TUI, Gemini, NLP | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Manufacturing",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"textual>=0.80.0",
"google-generativeai>=0.8.0",
"rapidfuzz>=3.9.0",
"rich>=13.7.0",
"geopy>=2.4.0"
] | [] | [] | [] | [
"Homepage, https://github.com/circularlink/circularlink",
"Documentation, https://github.com/circularlink/circularlink#readme"
] | twine/6.2.0 CPython/3.11.3 | 2026-02-19T17:22:12.488353 | circularlink-1.0.0.tar.gz | 44,598 | 4d/45/cc93edcb796e29aa6f7653ca071255f423d47a2edfe3e6be8d98a4b7b373/circularlink-1.0.0.tar.gz | source | sdist | null | false | 381aa7b8f3042df3df6ee9efd1101357 | 8e4534dd8a2a70633d3f68c632a4bad75376e7b2e7ed43628df48a25a0706dfd | 4d45cc93edcb796e29aa6f7653ca071255f423d47a2edfe3e6be8d98a4b7b373 | null | [] | 225 |
2.4 | rootly-mcp-server | 2.2.6 | Secure Model Context Protocol server for Rootly APIs with AI SRE capabilities, comprehensive error handling, and input validation | <!-- mcp-name: com.rootly/mcp-server -->
# Rootly MCP Server
[](https://pypi.org/project/rootly-mcp-server/)
[](https://pypi.org/project/rootly-mcp-server/)
[](https://pypi.org/project/rootly-mcp-server/)
[](https://cursor.com/install-mcp?name=rootly&config=eyJ1cmwiOiJodHRwczovL21jcC5yb290bHkuY29tL3NzZSIsImhlYWRlcnMiOnsiQXV0aG9yaXphdGlvbiI6IkJlYXJlciA8WU9VUl9ST09UTFlfQVBJX1RPS0VOPiJ9fQ==)
An MCP server for the [Rootly API](https://docs.rootly.com/api-reference/overview) that integrates seamlessly with MCP-compatible editors like Cursor, Windsurf, and Claude. Resolve production incidents in under a minute without leaving your IDE.
## Prerequisites
- Python 3.12 or higher
- `uv` package manager
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
```
- [Rootly API token](https://docs.rootly.com/api-reference/overview#how-to-generate-an-api-key%3F) with appropriate permissions (see below)
### API Token Permissions
The MCP server requires a Rootly API token. Choose the appropriate token type based on your needs:
- **Global API Key** (Recommended): Full access to all entities across your Rootly instance. Required for organization-wide visibility across teams, schedules, and incidents.
- **Team API Key**: Team Admin permissions with full read/edit access to entities owned by that team. Suitable for team-specific workflows.
- **Personal API Key**: Inherits the permissions of the user who created it. Works for individual use cases but may have limited visibility.
For full functionality of tools like `get_oncall_handoff_summary`, `get_oncall_shift_metrics`, and organization-wide incident search, a **Global API Key** is recommended.
## Quick Start
The fastest way to get started is to connect to our hosted MCP server — no installation required, just add the configuration to your editor:
```json
{
"mcpServers": {
"rootly": {
"url": "https://mcp.rootly.com/sse",
"headers": {
"Authorization": "Bearer <YOUR_ROOTLY_API_TOKEN>"
}
}
}
}
```
For **Claude Code**, run:
```bash
claude mcp add rootly --transport sse https://mcp.rootly.com/sse \
--header "Authorization: Bearer YOUR_ROOTLY_API_TOKEN"
```
## Alternative Installation (Local)
If you prefer to run the MCP server locally, configure your editor with one of the options below. The package will be automatically downloaded and installed when you first open your editor.
### With uv
```json
{
"mcpServers": {
"rootly": {
"command": "uv",
"args": [
"tool",
"run",
"--from",
"rootly-mcp-server",
"rootly-mcp-server"
],
"env": {
"ROOTLY_API_TOKEN": "<YOUR_ROOTLY_API_TOKEN>"
}
}
}
}
```
### With uvx
```json
{
"mcpServers": {
"rootly": {
"command": "uvx",
"args": [
"--from",
"rootly-mcp-server",
"rootly-mcp-server"
],
"env": {
"ROOTLY_API_TOKEN": "<YOUR_ROOTLY_API_TOKEN>"
}
}
}
}
```
## Features
- **Dynamic Tool Generation**: Automatically creates MCP resources from Rootly's OpenAPI (Swagger) specification
- **Smart Pagination**: Defaults to 10 items per request for incident endpoints to prevent context window overflow
- **API Filtering**: Limits exposed API endpoints for security and performance
- **Intelligent Incident Analysis**: Smart tools that analyze historical incident data
- **`find_related_incidents`**: Uses TF-IDF similarity analysis to find historically similar incidents
- **`suggest_solutions`**: Mines past incident resolutions to recommend actionable solutions
- **MCP Resources**: Exposes incident and team data as structured resources for easy AI reference
- **Intelligent Pattern Recognition**: Automatically identifies services, error types, and resolution patterns
- **On-Call Health Integration**: Detects workload health risk in scheduled responders
## On-Call Health Integration
Rootly MCP integrates with [On-Call Health](https://oncallhealth.ai) to detect workload health risk in scheduled responders.
### Setup
Set the `ONCALLHEALTH_API_KEY` environment variable:
```json
{
"mcpServers": {
"rootly": {
"command": "uvx",
"args": ["rootly-mcp-server"],
"env": {
"ROOTLY_API_TOKEN": "your_rootly_token",
"ONCALLHEALTH_API_KEY": "och_live_your_key"
}
}
}
}
```
### Usage
```
check_oncall_health_risk(
start_date="2026-02-09",
end_date="2026-02-15"
)
```
Returns at-risk users who are scheduled, recommended safe replacements, and action summaries.
## Example Skills
Want to get started quickly? We provide pre-built Claude Code skills that showcase the full power of the Rootly MCP server:
### 🚨 [Rootly Incident Responder](examples/skills/rootly-incident-responder.md)
An AI-powered incident response specialist that:
- Analyzes production incidents with full context
- Finds similar historical incidents using ML-based similarity matching
- Suggests solutions based on past successful resolutions
- Coordinates with on-call teams across timezones
- Correlates incidents with recent code changes and deployments
- Creates action items and remediation plans
- Provides confidence scores and time estimates
**Quick Start:**
```bash
# Copy the skill to your project
mkdir -p .claude/skills
cp examples/skills/rootly-incident-responder.md .claude/skills/
# Then in Claude Code, invoke it:
# @rootly-incident-responder analyze incident #12345
```
This skill demonstrates a complete incident response workflow using Rootly's intelligent tools combined with GitHub integration for code correlation.
### On-Call Shift Metrics
Get on-call shift metrics for any time period, grouped by user, team, or schedule. Includes primary/secondary role tracking, shift counts, hours, and days on-call.
```
get_oncall_shift_metrics(
start_date="2025-10-01",
end_date="2025-10-31",
group_by="user"
)
```
### On-Call Handoff Summary
Complete handoff: current/next on-call + incidents during shifts.
```python
# All on-call (any timezone)
get_oncall_handoff_summary(
team_ids="team-1,team-2",
timezone="America/Los_Angeles"
)
# Regional filter - only show APAC on-call during APAC business hours
get_oncall_handoff_summary(
timezone="Asia/Tokyo",
filter_by_region=True
)
```
Regional filtering shows only people on-call during business hours (9am-5pm) in the specified timezone.
Returns: `schedules` with `current_oncall`, `next_oncall`, and `shift_incidents`
### Shift Incidents
Incidents during a time period, with filtering by severity/status/tags.
```python
get_shift_incidents(
start_time="2025-10-20T09:00:00Z",
end_time="2025-10-20T17:00:00Z",
severity="critical", # optional
status="resolved", # optional
tags="database,api" # optional
)
```
Returns: `incidents` list + `summary` (counts, avg resolution time, grouping)
## Contributing
See [CONTRIBUTING.md](CONTRIBUTING.md) for developer setup and guidelines.
## Play with it on Postman
[<img src="https://run.pstmn.io/button.svg" alt="Run In Postman" style="width: 128px; height: 32px;">](https://god.gw.postman.com/run-collection/45004446-1074ba3c-44fe-40e3-a932-af7c071b96eb?action=collection%2Ffork&source=rip_markdown&collection-url=entityId%3D45004446-1074ba3c-44fe-40e3-a932-af7c071b96eb%26entityType%3Dcollection%26workspaceId%3D4bec6e3c-50a0-4746-85f1-00a703c32f24)
## About Rootly AI Labs
This project was developed by [Rootly AI Labs](https://labs.rootly.ai/), where we're building the future of system reliability and operational excellence. As an open-source incubator, we share ideas, experiment, and rapidly prototype solutions that benefit the entire community.

| text/markdown | null | Rootly AI Labs <support@rootly.com> | null | null | null | ai-sre, automation, devops, incident-management, incidents, llm, mcp, on-call, rate-limiting, rootly, security, sre | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"... | [] | null | null | >=3.10 | [] | [] | [] | [
"brotli>=1.0.0",
"fastmcp>=2.9.0",
"httpx>=0.24.0",
"numpy>=1.24.0",
"pydantic>=2.0.0",
"requests>=2.28.0",
"scikit-learn>=1.3.0",
"bandit>=1.7.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"isort>=5.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"safety>=2.0.0; extra == \... | [] | [] | [] | [
"Homepage, https://github.com/Rootly-AI-Labs/Rootly-MCP-server",
"Issues, https://github.com/Rootly-AI-Labs/Rootly-MCP-server/issues"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T17:21:14.686104 | rootly_mcp_server-2.2.6.tar.gz | 6,417,239 | b7/67/d1f1f04b96686b729f04e8ee5449270f52c500980ede91b38f53c773a9b6/rootly_mcp_server-2.2.6.tar.gz | source | sdist | null | false | 94153dbb4fec2f07be5ab8400e7f9e3f | 72d42289bee7641fd8a45c8859d7cc814c25651be0d0031ab0cc0dfcd5c66323 | b767d1f1f04b96686b729f04e8ee5449270f52c500980ede91b38f53c773a9b6 | Apache-2.0 | [
"LICENSE"
] | 915 |
2.4 | qualia-sdk | 0.1.2 | Python SDK for Qualia Studios VLA fine-tuning platform | # Qualia Python SDK
The official Python SDK for the [Qualia](https://app.qualiastudios.dev) VLA fine-tuning platform.
## Installation
```bash
pip install qualia-sdk
```
## Quick Start
```python
from qualia import Qualia
# Initialize the client
client = Qualia(api_key="your-api-key")
# Or use the QUALIA_API_KEY environment variable
client = Qualia()
# List available VLA models
models = client.models.list()
for model in models:
print(f"{model.id}: {model.name}")
print(f" Camera slots: {model.camera_slots}")
# Create a project
project = client.projects.create(name="My Robot Project")
print(f"Created project: {project.project_id}")
# Get dataset image keys for camera mapping
image_keys = client.datasets.get_image_keys("lerobot/pusht")
print(f"Available keys: {image_keys.image_keys}")
# Start a finetune job
job = client.finetune.create(
project_id=project.project_id,
model_id="lerobot/smolvla_base",
vla_type="smolvla",
dataset_id="lerobot/pusht",
hours=2.0,
camera_mappings={"cam_1": "observation.images.top"},
)
print(f"Started job: {job.job_id}")
# Check job status
status = client.finetune.get(job.job_id)
print(f"Status: {status.status.status}")
print(f"Current phase: {status.status.current_phase}")
# Cancel a job if needed
result = client.finetune.cancel(job.job_id)
```
## Resources
### Credits
```python
# Get your credit balance
balance = client.credits.get()
print(f"Available credits: {balance.balance}")
```
### Datasets
```python
# Get image keys from a HuggingFace dataset
image_keys = client.datasets.get_image_keys("lerobot/pusht")
# Use these keys as values in camera_mappings
```
### Finetune
```python
# Create a finetune job
job = client.finetune.create(
project_id="...",
model_id="lerobot/smolvla_base", # HuggingFace model ID
vla_type="smolvla", # smolvla, pi0, or pi0.5
dataset_id="lerobot/pusht", # HuggingFace dataset ID
hours=2.0, # Training duration (max 168)
camera_mappings={ # Map model slots to dataset keys
"cam_1": "observation.images.top",
},
# Optional parameters:
instance_type="gpu_1x_a100", # From client.instances.list()
region="us-east-1",
batch_size=32,
name="My training run",
)
# Get job status
status = client.finetune.get(job.job_id)
# Cancel a job
result = client.finetune.cancel(job.job_id)
```
#### Advanced: Custom Hyperparameters
You can customize model hyperparameters for fine-grained control over training.
The SDK validates hyperparameters before submitting the job, so invalid
configurations are caught early.
```python
# 1. Get default hyperparameters for your model
params = client.finetune.get_hyperparams_defaults(
vla_type="smolvla",
model_id="lerobot/smolvla_base",
)
# 2. Customize the parameters as needed
params["training"]["learning_rate"] = 1e-5
params["training"]["num_epochs"] = 50
# 3. (Optional) Validate before creating the job
validation = client.finetune.validate_hyperparams(
vla_type="smolvla",
hyperparams=params,
)
if not validation.valid:
for issue in validation.issues:
print(f" {issue.field}: {issue.message}")
# 4. Create the job with custom hyperparameters
# Note: create() internally calls validate_hyperparams() when vla_hyper_spec
# is provided. If validation fails, a ValueError is raised and no job is created.
job = client.finetune.create(
project_id=project.project_id,
model_id="lerobot/smolvla_base",
vla_type="smolvla",
dataset_id="qualiaadmin/oneepisode",
hours=2.0,
camera_mappings={"cam_1": "observation.images.side"},
vla_hyper_spec=params,
)
```
### Instances
```python
# List available GPU instances
instances = client.instances.list()
for inst in instances:
print(f"{inst.id}: {inst.gpu_description} - {inst.credits_per_hour} credits/hr")
print(f" Specs: {inst.specs.gpu_count}x GPU, {inst.specs.memory_gib}GB RAM")
print(f" Regions: {[r.name for r in inst.regions]}")
```
### Models
```python
# List available VLA model types
models = client.models.list()
for model in models:
print(f"{model.id}: {model.name}")
print(f" Base model: {model.base_model_id}")
print(f" Camera slots: {model.camera_slots}")
```
### Projects
```python
# Create a project
project = client.projects.create(
name="My Project",
description="Optional description",
)
# List all projects
projects = client.projects.list()
for p in projects:
print(f"{p.name}: {len(p.jobs)} jobs")
# Delete a project (fails if it has active jobs)
client.projects.delete(project.project_id)
```
## Configuration
### Environment Variables
- `QUALIA_API_KEY`: Your API key (used if not passed to constructor)
- `QUALIA_BASE_URL`: Override the API base URL (default: `https://api.qualiastudios.dev`)
### Custom HTTP Client
```python
import httpx
# Use a custom httpx client for advanced configuration
custom_client = httpx.Client(
timeout=60.0,
limits=httpx.Limits(max_connections=10),
)
client = Qualia(api_key="...", httpx_client=custom_client)
```
### Context Manager
```python
# Automatically close the client when done
with Qualia(api_key="...") as client:
models = client.models.list()
```
## Error Handling
```python
from qualia import (
Qualia,
QualiaError,
QualiaAPIError,
AuthenticationError,
NotFoundError,
ValidationError,
RateLimitError,
)
try:
client = Qualia(api_key="invalid-key")
client.models.list()
except AuthenticationError as e:
print(f"Auth failed: {e}")
except NotFoundError as e:
print(f"Not found: {e}")
except ValidationError as e:
print(f"Validation error: {e}")
except RateLimitError as e:
print(f"Rate limited. Retry after: {e.retry_after}s")
except QualiaAPIError as e:
print(f"API error [{e.status_code}]: {e.message}")
except QualiaError as e:
print(f"SDK error: {e}")
```
## Requirements
- Python 3.10+
- httpx
- pydantic
## License
MIT
| text/markdown | Qualia Studios | null | null | null | null | fine-tuning, machine-learning, qualia, robotics, vla | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.25.0",
"opentelemetry-api>=1.20.0",
"opentelemetry-instrumentation-httpx>=0.41b0",
"pydantic>=2.0.0"
] | [] | [] | [] | [
"Homepage, https://qualiastudios.dev",
"Documentation, https://docs.qualiastudios.dev"
] | uv/0.9.17 {"installer":{"name":"uv","version":"0.9.17","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Alpine Linux","version":"3.23.0","id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T17:20:59.952451 | qualia_sdk-0.1.2.tar.gz | 74,762 | db/ec/7ef2aea5ee90f7c2e3a8b78e6d7a646465e302636379f32dc3908afafb36/qualia_sdk-0.1.2.tar.gz | source | sdist | null | false | d924fc853d4b75b35c42befd38a47d85 | 475dede2dec339464caffc6899be1dedeee04d537a8dc871662e7650c0da2e64 | dbec7ef2aea5ee90f7c2e3a8b78e6d7a646465e302636379f32dc3908afafb36 | MIT | [] | 223 |
2.4 | bodosql | 2026.2 | Bodo's Vectorized SQL execution engine for clusters | # BodoSQL
## BodoSQL: Bodo's Vectorized SQL execution engine for clusters
BodoSQL is Bodo's vectorized SQL execution engine, designed to run on both a single laptop
and across a cluster of machines. BodoSQL integrates with Bodo's Python JIT compiler to
enable high performance analytics split across Python and SQL boundaries.
BodoSQL Documentation: https://docs.bodo.ai/latest/api_docs/sql/
## Additional Requirements
BodoSQL depends on the Bodo package with the same version. If you are already using Bodo you will
need to update your Bodo package to the same version as BodoSQL.
BodoSQL also depends on having Java installed on your system. You will need to download either Java 11
or Java 17 from one of the main available distribution and ensure that the `JAVA_HOME` environment
variable is properly set. If you can run `java -version` in your terminal and see the correct Java version, you are good to go.
| text/markdown | Bodo.ai | null | null | null | null | data, analytics, cluster | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Operating System :: POSIX :: Linux",
"Operating System :: MacOS :: MacOS X",
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.... | [] | null | null | >=3.10 | [] | [] | [] | [
"py4j==0.10.9.9"
] | [] | [] | [] | [
"Homepage, https://bodo.ai",
"Documentation, https://docs.bodo.ai"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:20:55.264488 | bodosql-2026.2-py3-none-any.whl | 158,246,556 | 48/0d/8f88c4900e02bc5b2e6b1d226b3f028b67afaf94cfa07b4d9280690ea5b7/bodosql-2026.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 78456a1a7e0b5a18ddb63a66ab2d0f03 | 7de82a4f8efa778837fc7dd8d830032083dade0e52460337fc2f27f6a0e6053b | 480d8f88c4900e02bc5b2e6b1d226b3f028b67afaf94cfa07b4d9280690ea5b7 | null | [] | 109 |
2.4 | bodo-iceberg-connector | 2026.2 | Bodo Connector for Iceberg | # Bodo Iceberg Connector
## Bodo Iceberg Connector: Bodo's Connector for the Apache Iceberg Data Format
Bodo Iceberg Connector is a Bodo connector for used to access data that is stored in Apache Iceberg tables. It allows users to read and write Iceberg tables using Bodo's and BodoSQL's IO APIs.
Bodo's Iceberg Documentation: https://docs.bodo.ai/latest/iceberg/intro/
## Requirements
The Bodo Iceberg Connector depends on having Java installed on your system. You will need to download
either Java 11 or Java 17 from one of the main available distribution and ensure that the `JAVA_HOME`
environment variable is properly set. If you can run `java -version` in your terminal and see the correct Java version, you are good to go.
| text/markdown | Bodo.ai | null | null | null | null | data, analytics, cluster | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language ... | [] | null | null | >=3.10 | [] | [] | [] | [
"py4j==0.10.9.9",
"pyarrow==22.0.0",
"numpy>=1.24",
"pandas>=2.2",
"pyiceberg>=0.9"
] | [] | [] | [] | [
"Homepage, https://bodo.ai",
"Documentation, https://docs.bodo.ai"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:20:49.260454 | bodo_iceberg_connector-2026.2-py3-none-any.whl | 138,615,364 | 64/86/707c199cb20f7a5db3c35461bac17a7ac1042e342006df31c8800d47c24e/bodo_iceberg_connector-2026.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 8f6be0e28531282d2fd7bd92ad5f8dd5 | af2d2ad2d681856e2d3a11b414fff34f97fa84b8869952812c29a08555607d3e | 6486707c199cb20f7a5db3c35461bac17a7ac1042e342006df31c8800d47c24e | null | [] | 97 |
2.2 | bodo | 2026.2 | High-Performance Python Compute Engine for Data and AI | <!--
NOTE: the example in this file is covered by tests in bodo/tests/test_quickstart_docs.py. Any changes to the examples in this file should also update the corresponding unit test.
-->

<h3 align="center">
<a href="https://docs.bodo.ai/latest/" target="_blank"><b>Docs</b></a>
·
<a href="https://bodocommunity.slack.com/join/shared_invite/zt-qwdc8fad-6rZ8a1RmkkJ6eOX1X__knA#/shared-invite/email" target="_blank"><b>Slack</b></a>
·
<a href="https://www.bodo.ai/benchmarks/" target="_blank"><b>Benchmarks</b></a>
</h3>
# Bodo DataFrames: Drop-in Pandas Replacement for Acceleration and Scaling of Data and AI
Bodo DataFrames is a high performance DataFrame library for large scale Python data processing, AI/ML use cases.
It functions as a drop-in replacement for Pandas while providing additional Pandas-compatible APIs for simplifying and scaling AI workloads,
a just-in-time (JIT) compiler for accelerating custom transformations, as well as an integrated SQL engine for extra flexibility.
Under the hood, Bodo DataFrames relies on MPI-based high-performance computing (HPC) technology,
often making it orders of magnitude faster than tools like Spark or Dask.
Refer to our [NYC Taxi benchmark](https://github.com/bodo-ai/Bodo/tree/main/benchmarks/nyc_taxi)
for an example where Bodo is 2-240x faster than other systems:
<!-- TODO: updated graph with Taxi benchmark including Bodo DataFrames Pandas API -->
<img src="benchmarks/img/nyc-taxi-benchmark.png" alt="NYC Taxi Benchmark" width="500"/>
Unlike traditional distributed computing frameworks, Bodo DataFrames:
- Automatically scales and accelerates Pandas workloads with a single line of code change.
- Eliminates runtime overheads common in driver-executor models by leveraging Message Passing Interface (MPI) technology for true parallel execution.
## Goals
Bodo DataFrames makes Python run much (much!) faster than it normally does!
1. **Exceptional Performance:**
Deliver HPC-grade performance and scalability for Python data workloads as if the code was written in C++/MPI, whether running on a laptop or across large cloud clusters.
2. **Easy to Use:**
Easily integrate into Python workflows— it's as simple as changing `import pandas as pd` to `import bodo.pandas as pd`.
3. **Interoperable:**
Compatible with regular Python ecosystem, and can selectively speed up only the sections of the workload that are Bodo supported.
4. **Integration with Modern Data Infrastructure:**
Provide robust support for industry-leading data platforms like Apache Iceberg and Snowflake, enabling smooth interoperability with existing ecosystems.
## Key Features
- Drop-in Pandas replacement, (just change the import!) with a seamless fallback to vanilla Pandas to avoid breaking existing workloads.
- Intuitive APIs for simplifying and scaling AI workloads.
- Advanced query optimization,
C++ runtime,
and parallel execution using MPI to achieve the best possible performance while leveraging all available cores.
- Streaming execution to process larger-than-memory datasets.
- Just in time (JIT) compilation with native support for Pandas, Numpy and Scikit-learn
for accelerating custom transformations or performance-critical functions.
- High performance SQL engine that is natively integrated into Python.
- Advanced scalable I/O support for Iceberg, Snowflake, Parquet, CSV, and JSON with automatic filter pushdown and column pruning for optimized data access.
See Bodo DataFrames documentation to learn more: https://docs.bodo.ai/
## Installation
Note: Bodo DataFrames requires Python 3.10+.
Bodo DataFrames can be installed using Pip or Conda:
```bash
pip install -U bodo
```
or
```bash
conda create -n Bodo python=3.14 -c conda-forge
conda activate Bodo
conda install bodo -c conda-forge
```
Bodo DataFrames works with Linux x86, both Mac x86 and Mac ARM, and Windows right now. We will have Linux ARM support (and more) coming soon!
## Bodo DataFrames Example
Here is an example Pandas code that reads and processes a sample Parquet dataset.
Note that we replaced the typical import:
```python
import pandas as pd
```
with:
```python
import bodo.pandas as pd
```
which accelerates the following code segment by about 20-30x on a laptop.
```python
import bodo.pandas as pd
import numpy as np
import time
NUM_GROUPS = 30
NUM_ROWS = 20_000_000
df = pd.DataFrame({
"A": np.arange(NUM_ROWS) % NUM_GROUPS,
"B": np.arange(NUM_ROWS)
})
df.to_parquet("my_data.pq")
def computation():
t1 = time.time()
df = pd.read_parquet("my_data.pq")
df["C"] = df.apply(lambda r: 0 if r.A == 0 else (r.B // r.A), axis=1)
df.to_parquet("out.pq")
print("Execution time:", time.time() - t1)
computation()
```
## How to Contribute
Please read our latest [project contribution guide](CONTRIBUTING.md).
## Getting involved
You can join our community and collaborate with other contributors by joining our [Slack channel](https://bodocommunity.slack.com/join/shared_invite/zt-qwdc8fad-6rZ8a1RmkkJ6eOX1X__knA#/shared-invite/email) – we’re excited to hear your ideas and help you get started!
[](https://codecov.io/github/bodo-ai/Bodo) | text/markdown | Bodo.ai | null | null | null | null | data, analytics, cluster | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Operating System :: POSIX :: Linux",
"Operating System :: MacOS :: MacOS X",
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language ::... | [] | null | null | >=3.10 | [] | [] | [] | [
"pyarrow<23.1,>=23.0",
"numba<0.64,>=0.62",
"pandas>=2.2",
"pytz",
"numpy>=1.24",
"fsspec>=2021.09",
"requests",
"cloudpickle>=3.0",
"psutil",
"mpi4py>=4.1",
"openmpi; sys_platform == \"darwin\"",
"impi-rt; sys_platform == \"win32\"",
"h5py; extra == \"hdf5\"",
"scikit-learn; extra == \"sk... | [] | [] | [] | [
"Homepage, https://bodo.ai",
"Documentation, https://docs.bodo.ai",
"Repository, https://github.com/bodo-ai/Bodo"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:20:43.851563 | bodo-2026.2-cp314-cp314-win_amd64.whl | 16,652,328 | b7/f2/91ae4ef38ce0a43c1a5b5de9af759a7588ae30958fbc51b5849551209019/bodo-2026.2-cp314-cp314-win_amd64.whl | cp314 | bdist_wheel | null | false | 0298f37b529f1824498ed0d72b1ad1b9 | b5e37f411d68a576aefe5377b8febdd3781c4ffbbf6acc516a7fcee9b40e1b07 | b7f291ae4ef38ce0a43c1a5b5de9af759a7588ae30958fbc51b5849551209019 | null | [] | 1,593 |
2.4 | manithy-sdk | 0.1.0 | Manithy SDK — Authority-Grade Audit Capture (Zero Dependencies) | # Manithy SDK (Python)
**Authority-Grade Audit Capture — Zero Dependencies**
Manithy captures tamper-evident audit proofs at the application layer.
Each proof is a **J01 CommitBoundaryEvent** — a structured record that
marks the exact t-1 boundary before an irreversible action and freezes
only facts already resolved in the execution context.
No lookups. No inference. No enrichment.
## Design Constraints
| Constraint | Guarantee |
|---|---|
| **Zero Network I/O** | The SDK never opens sockets or makes HTTP calls. |
| **Determinism** | Identical inputs always yield identical commit-IDs. |
| **Fail-Closed** | Internal errors are silently swallowed — the host app never crashes. |
| **Zero Dependencies** | Only the Python standard library is used at runtime. |
| **Epistemic Honesty** | The `availability` block declares what was knowable at t-1. Unknown facts must never appear in `observed`. |
## Installation
```bash
pip install manithy-sdk
```
Or install from source:
```bash
git clone https://github.com/VooYee/manithy-sdk.git
cd manithy-sdk
pip install .
```
## Quick Start
```python
from manithy import ManithySDK
sdk = ManithySDK()
result = sdk.capture(
boundary_kind="REFUND_COMMIT_T_MINUS_1",
boundary_seq=1,
same_thread=True,
observed={
"action_kind": "REFUND",
"amount_minor": 12900,
"currency": "EUR",
"refund_mode": "FULL",
"order_channel": "WEB",
"payment_method": "CARD",
"merchant_region": "EU",
"customer_present": False,
"operator_initiated": False,
},
availability={
"psp_refund_capability_known": True,
"original_payment_state_known": True,
"chargeback_state_known": False,
},
reentrancy_guard="SINGLE_CAPTURE_ENFORCED",
)
print(result)
# {"status": "CAPTURED", "id": "a3f8c9..."}
```
Output (stdout):
```
MANITHY_PROOF::{"schema_id":"manithy.commit_boundary_event.v1","boundary_kind":"REFUND_COMMIT_T_MINUS_1","boundary_seq":1,"same_thread":true,"reentrancy_guard":"SINGLE_CAPTURE_ENFORCED","observed":{...},"availability":{...}}
```
## Capture Parameters
| Parameter | Type | Purpose |
|---|---|---|
| **`boundary_kind`** | `str` | Which irreversible boundary this event refers to. Consumer-defined closed enum (e.g. `"REFUND_COMMIT_T_MINUS_1"`). |
| **`boundary_seq`** | `int` | Supports rare cases of multiple irreversible calls in one execution path. Small integer (0–255). |
| **`same_thread`** | `bool` | Runtime assertion that capture happened same-thread at t-1. |
| **`observed`** | `dict[str, str\|int\|bool]` | Runtime facts already resolved in the execution context. Values must be primitives only — no floats, no `None`, no nested structures. |
| **`availability`** | `dict[str, bool]` | Epistemic visibility at t-1. Each key declares whether a fact was knowable before the irreversible action. |
| **`reentrancy_guard`** | `str` | Capture enforcement mode. Consumer-defined (e.g. `"SINGLE_CAPTURE_ENFORCED"`). |
### The `observed` Block
All fields in `observed` must already be resolved in the execution context at t-1.
**Allowed:** `str`, `int`, `bool`.
**Forbidden:** `float`, `None`, nested `dict`/`list`, any value fetched or inferred after execution.
### The `availability` Block
`availability` is not data. It is a **declaration of epistemic visibility** at t-1.
Each key answers one question:
> "At the exact moment before the irreversible action, was this fact already knowable inside the execution context — yes or no?"
| `_known` value | Meaning | Effect |
|---|---|---|
| `True` | Fact was knowable at t-1 | May appear in `observed` |
| `False` | Fact was NOT knowable at t-1 | Must NOT appear in `observed` |
If the fact was not knowable, Manithy records **ignorance**, not a value.
That ignorance is structural and permanent.
### Forbidden Fields
The following fields must **never** appear in a CommitBoundaryEvent:
| Field | Why Forbidden |
|---|---|
| `producer_invocation_id` | High joinability risk. Single-capture is enforced via guard state, not IDs. |
| `callsite_id` | High joinability risk. |
| `producer_build_id` | Belongs in PackInit / EvidencePack provenance, not J01. |
## Custom Buffer
Route proofs to a file, queue, or any destination by subclassing `CaptureBuffer`:
```python
import json
from manithy import ManithySDK
from manithy.interfaces.buffer import CaptureBuffer
class FileBuffer(CaptureBuffer):
def __init__(self, path: str):
self._file = open(path, "a", encoding="utf-8")
def emit(self, envelope: dict) -> None:
self._file.write(json.dumps(envelope, separators=(",", ":")) + "\n")
self._file.flush()
sdk = ManithySDK(buffer=FileBuffer("audit.log"))
```
## Configuration
### Kill-Switch
Disable all capture at runtime without code changes:
```bash
export MANITHY_ENABLED=false # Linux/macOS
```
```powershell
$env:MANITHY_ENABLED = "false" # Windows PowerShell
```
When disabled, `capture()` returns `{"status": "SKIPPED"}` immediately.
### Debug Mode
Log internal SDK errors to stderr (useful during development):
```bash
export MANITHY_DEBUG=true
```
## How It Works
1. **Kill-switch check** — reads `MANITHY_ENABLED`. If `"false"`, returns `SKIPPED`.
2. **Validation** — enforces type constraints on all fields; rejects forbidden fields, floats in `observed`, non-bool in `availability`, and unknown facts that leak into `observed`.
3. **Event assembly** — builds a J01 `CommitBoundaryEvent` with schema `manithy.commit_boundary_event.v1`.
4. **Hashing** — canonicalizes the event (sorted keys, no whitespace, floats like `100.0` → `100`) and computes SHA-256 → 64-char hex `commit_id`.
5. **Emit** — writes the event to the configured buffer (default: stdout with `MANITHY_PROOF::` prefix).
If any step fails, the error is swallowed and `{"status": "ERROR", "error": "Internal SDK Error"}` is returned. The host application is **never** affected.
## Development
```bash
# Create a virtual environment
python -m venv .venv
# Activate it
source .venv/bin/activate # Linux/macOS
.venv\Scripts\Activate.ps1 # Windows PowerShell
# Install in editable mode with dev dependencies
pip install -e ".[dev]"
# Run tests
pytest tests/ -v
```
## Project Structure
```
src/manithy/
├── __init__.py # Public API: exposes ManithySDK
├── sdk.py # Main entry point (capture pipeline + fail-closed)
├── config.py # Environment variable loader (kill-switch + debug)
├── core/
│ ├── canonical.py # Deterministic JSON canonicalization
│ ├── hasher.py # SHA-256 commit-ID generation
│ └── envelope.py # J01 CommitBoundaryEvent assembly + validation
└── interfaces/
└── buffer.py # Abstract CaptureBuffer + StdoutBuffer
tests/
├── vectors.json # Golden test vectors (canonical + hash)
├── test_core.py # Core module tests (canonical, hasher, J01 event)
└── test_sdk.py # SDK integration tests (capture, kill-switch, fail-closed)
```
| text/markdown | null | null | null | null | Proprietary | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.10 | 2026-02-19T17:20:33.379267 | manithy_sdk-0.1.0.tar.gz | 17,193 | f1/9f/b847de94142058fab1bc03a66175d5c5ed6775152ce1089afa0587bec9f3/manithy_sdk-0.1.0.tar.gz | source | sdist | null | false | 8a7b7799fc0c1e893ad52b356bbdbe9a | f47da868759bb73b0fbb094a0391fbe26471b8f338833234a05f4364d2dd2a83 | f19fb847de94142058fab1bc03a66175d5c5ed6775152ce1089afa0587bec9f3 | null | [] | 236 |
2.4 | d-units-translation | 0.1.3 | A robust translating pipeline for multi-file support and integration with multiple translation sources. | # TranslationPipeline
A robust translating pipeline designed for multi-file support and integration with multiple translation sources, enabling users to efficiently process and translate large datasets or documents across various formats and languages into a JSON in the target language.
## Funcionalities
- Flexible Translation Methods: Easily switch between translation APIs and models.
- Extensible: Add new file formats or translation methods with minimal effort.
- JSON Output: Consolidate translations into a structured JSON for easy integration.
### Format Support:
- JSON
- JSONL
- XML
- TML
- CSV
- Hugging Face Datasets
### Translation Methods:
- Deep Translator (supports Google API)
- Models (Via transformers Pipeline)
## Requirements
- Python 3.10+
- Dependencies listed in `requirements.txt`
- Internet access for Deep Translator or Hugging Face models
## How to use
1. install the package
```
pip install d-units-translation
```
2. Make a config.json following the configuration_example
3. Import the model and use the main function
```
from d_units_translation.pipeline import translation_dataset
translation_dataset("config.json")
```
## Configuration_example
### Hugging Face Dataset
| Field | Type | Description | Options |
|:-----------------:|:-------:|:------------------------------------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------:|
| name | string | A short name for this configuration or task. | Any |
| dataset | string | The dataset source. | Any dataset from hugging face datasets |
| version | string | Version, split or subset of the dataset. | Any |
| backup_interval | integer | Frequency at which to save progress or checkpoints. A value of 5 means the system will back up after every 5 processed items. | Unlimited |
| columns2translate | array | Specifies which dataset columns should be translated. | Any |
| col_id | string | Name of the unique identifier column in the dataset | Any, if the id doesn't exist it will assume the index as the id. |
| reader | string | Defines the type of dataset/file to read. | "hugging_face" (in this case) |
| source_language | string | The original language code of the given dataset | Depends on the choosen method |
| target_language | string | The target translation language code | Depends on the choosen method |
| backup_interval | integer | Frequency at which to save progress or checkpoints. A value of 5 means the system will back up after every 5 processed items. | Unlimited |
We need to choose the method we will use for translation, at the moment, we have two options:
| Field | Type | Description | Options |
|:------:|:------:|:---------------------------------------------------------:|:-------:|
| method | string | Defines the method that will be used for the translation. | "deepL" |
or
| Field | Type | Description | Options |
|:----------:|:------:|:--------------------------------------------------------------------------------:|:--------------------:|
| method | string | Defines the method that will be used for the translation. | "model" |
| model | string | The translation model to be used. The model should support transformers pipeline | Any |
| max_tokens | int | Sets the maximum number of tokens the model can process per translation request. | Depends on the model |
Example:
```
{
"name": "bigbench",
"dataset": "tasksource/bigbench",
"version": "movie_recommendation",
"backup_interval": 10,
"columns2translate": ["inputs", "targets", "multiple_choice_targets"],
"col_id":"idx",
"reader":"hugging_face",
"source_language": "en",
"target_language": "pt-PT",
"method": "model",
"model": "rhaymison/opus-en-to-pt-translator",
"max_tokens":400
}
```
### CSV | JSON | JSONL | XML | TML
| Field | Type | Description | Options |
|:-----------------:|:-------:|:------------------------------------------------------------------------------------------------------------------------------:|:------------------------------------------------------------------------------------:|
| name | string | A short name for this configuration or task. | Any |
| source_folder | string | File folder that we want to translated | Any |
| backup_interval | integer | Frequency at which to save progress or checkpoints. A value of 5 means the system will back up after every 5 processed items. | Unlimited |
| columns2translate | array | Specifies which dataset columns should be translated. | Any |
| col_id | string | Name of the unique identifier column in the dataset | Any, if this field doesn't exist it will assume the index as the id. <br> (Optional) |
| split_name | string | Choose the name of the split that will show in the column "split" | Any |
| reader | string | Defines the type of dataset/file to read. | "csv", "json", "jsonl", "xml" or "tml" |
| source_language | string | The original language code of the given dataset | Depends on the choosen method |
| target_language | string | The target translation language code | Depends on the choosen method |
We need to choose the method we will use for translation, at the moment, we have two options:
| Field | Type | Description | Options |
|:------:|:------:|:---------------------------------------------------------:|:-------:|
| method | string | Defines the method that will be used for the translation. | "deepL" |
or
| Field | Type | Description | Options |
|:----------:|:------:|:--------------------------------------------------------------------------------:|:--------------------:|
| method | string | Defines the method that will be used for the translation. | "model" |
| model | string | The translation model to be used. The model should support transformers pipeline | Any |
| max_tokens | int | Sets the maximum number of tokens the model can process per translation request. | Depends on the model |
Example:
```
{
"name": "mc_task",
"source_folder": "original/TruthfulQA",
"backup_interval": 10,
"columns2translate": ["Question", "Best Answer", "Correct Answers", "Incorrect Answers"],
"split_name": "train",
"reader": "csv",
"source_language": "en",
"target_language": "pt",
"method": "deepL"
}
```
```
{
"name": "databricks-dolly-15k",
"source_folder": "original/databricks-dolly-15k",
"backup_interval": 10,
"columns2translate": ["instruction", "context", "response"],
"split_name": "instruction",
"reader": "jsonl",
"source_language": "en",
"target_language": "pt",
"method": "model",
"model": "rhaymison/opus-en-to-pt-translator",
"max_tokens":400
}
```
## Contributors
| Name | Role | Contact |
|-------------------|-----------|-------------------------------------------------------------|
| **José Soares** | Developer | [jose.p.soares@inesctec.pt](mailto:jose.p.soares@inesctec.pt) |
| **Nuno Guimarães** | Advisor | |
## License
MIT License
Copyright (c) 2025 INESC TEC
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| text/markdown | null | José Soares <jose.p.soares@inesctec.pt> | null | null | null | translation, nlp, huggingface, deep-learning, dataset-processing | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"datasets>=2.18.0",
"deep-translator>=1.11.4",
"ijson>=3.4.0",
"transformers>=4.57.0",
"torch>=2.8.0"
] | [] | [] | [] | [
"Homepage, https://github.com/LIAAD/D-UniTS-Translation-Pipeline"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T17:19:41.635949 | d_units_translation-0.1.3.tar.gz | 18,237 | a1/bc/2054006a412a33d238c3d55b0263f7c44f2ccd36dbd1784755d54e454509/d_units_translation-0.1.3.tar.gz | source | sdist | null | false | bbe42ed23325f458bfd271a327a4532a | 29b2a94ac37bcb7dde1db27d8ea8402604f32355171aab976f30effd52073fc7 | a1bc2054006a412a33d238c3d55b0263f7c44f2ccd36dbd1784755d54e454509 | MIT | [] | 232 |
2.4 | hedit | 0.7.4a4 | Multi-agent system for HED annotation generation and validation | # HEDit
[](https://pypi.org/project/hedit/)
[](https://github.com/Annotation-Garden/hedit/actions/workflows/test.yml)
Convert natural language event descriptions into valid [HED](https://hedtags.org) (Hierarchical Event Descriptors) annotations.
Part of the [Annotation Garden Initiative](https://annotation.garden).
## Installation
```bash
# Default (lightweight API client, ~100MB)
pip install hedit
# Standalone mode (run locally without backend, ~2GB)
pip install hedit[standalone]
```
## Quick Start
```bash
# Configure your OpenRouter API key (https://openrouter.ai)
hedit init --api-key sk-or-v1-xxx
# Generate HED annotation from text
hedit annotate "participant pressed the left button"
# Generate HED from an image
hedit annotate-image stimulus.png
# Validate a HED string
hedit validate "Sensory-event, Visual-presentation"
```
## Commands
| Command | Description |
|---------|-------------|
| `hedit init` | Configure API key and preferences |
| `hedit annotate "text"` | Convert natural language to HED |
| `hedit annotate-image <file>` | Generate HED from image |
| `hedit validate "HED-string"` | Validate HED annotation |
| `hedit health` | Check service status |
| `hedit config show` | Display configuration |
## Options
```bash
hedit annotate "text" -o json # JSON output for scripting
hedit annotate "text" --schema 8.3.0 # Specific HED schema version
hedit annotate "text" --standalone # Run locally (requires hedit[standalone])
```
## How It Works
HEDit uses a multi-agent system (LangGraph) with feedback loops:
1. **Annotation Agent** - Generates initial HED tags
2. **Validation Agent** - Checks syntax and tag validity
3. **Evaluation Agent** - Assesses faithfulness to input
4. **Assessment Agent** - Identifies missing elements
Annotations are automatically refined until validation passes.
## Links
- [Documentation](https://docs.annotation.garden/hedit)
- [GitHub Repository](https://github.com/Annotation-Garden/HEDit)
- [HED Standard](https://hedtags.org)
- [OpenRouter](https://openrouter.ai) - Get an API key
## License
MIT
| text/markdown | null | Annotation Garden Initiative <info@annotation.garden> | null | null | null | hed, annotation, neuroscience, bids, cli | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"typer>=0.20.0",
"rich>=14.0.0",
"platformdirs>=4.5.0",
"pyyaml>=6.0.2",
"httpx>=0.28.0",
"pydantic>=2.12.0",
"langgraph>=0.2.0; extra == \"standalone\"",
"langchain>=0.3.0; extra == \"standalone\"",
"langchain-community>=0.3.0; extra == \"standalone\"",
"langchain-core>=0.3.0; extra == \"standalo... | [] | [] | [] | [
"Homepage, https://annotation.garden/hedit",
"Documentation, https://docs.annotation.garden/hedit",
"Repository, https://github.com/Annotation-Garden/hedit",
"Issues, https://github.com/Annotation-Garden/hedit/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:19:40.499989 | hedit-0.7.4a4.tar.gz | 151,995 | a8/73/04738e75fbc440a6c9695d7791536cdb84df453260179ebcfa24d7c46f44/hedit-0.7.4a4.tar.gz | source | sdist | null | false | 94c847a1f4ca16d9068052104c3a2384 | 71e266a35c111ea92dd97a51036c258c7492d737ecd4147ed4fb25e3827a903a | a87304738e75fbc440a6c9695d7791536cdb84df453260179ebcfa24d7c46f44 | MIT | [
"LICENSE"
] | 203 |
2.1 | promptflow-azure-ai-language | 0.1.15 | Collection of Azure AI Language Prompt flow tools. | # Azure AI Language
Azure AI Language enables users with task-oriented and optimized pre-trained or custom language models to effectively understand and analyze documents and conversations. This Prompt flow tool is a wrapper for various Azure AI Language APIs. The current list of supported capabilities is as follows:
| Name | Description | Supported API Version |
|-------------------------------------------|-------------------------------------------------------|--------------------|
| Abstractive Summarization | Generate abstractive summaries from documents. | 2025-11-01 |
| Extractive Summarization | Extract summaries from documents. | 2025-11-01 |
| Conversation Summarization | Summarize conversations. | 2024-11-01 |
| Entity Recognition | Recognize and categorize entities in documents. | 2025-11-01 |
| Key Phrase Extraction | Extract key phrases from documents. | 2025-11-01 |
| Language Detection | Detect the language of documents. | 2025-11-01 |
| PII Entity Recognition | Recognize and redact PII entities in documents. | 2025-11-01 |
| Conversational PII | Recognize and redact PII entities in conversations. | 2024-11-01 |
| Sentiment Analysis | Analyze the sentiment of documents. | 2025-11-01 |
| Conversational Language Understanding | Predict intents and entities from user's utterances. | 2024-11-01 |
| Translator | Translate documents. | 3.0 |
## Requirements
PyPI package: [`promptflow-azure-ai-language`](https://pypi.org/project/promptflow-azure-ai-language/).
- For AzureML users:
follow this [wiki](https://learn.microsoft.com/en-us/azure/machine-learning/prompt-flow/how-to-custom-tool-package-creation-and-usage?view=azureml-api-2#prepare-runtime), starting from `Prepare runtime`.
- For local users:
```
pip install promptflow-azure-ai-language
```
You may also want to install the [Prompt flow for VS Code extension](https://marketplace.visualstudio.com/items?itemName=prompt-flow.prompt-flow).
## Prerequisites
The tool calls APIs from Azure AI Language. To use it, you must create a connection to an [Azure AI Language resource](https://learn.microsoft.com/en-us/azure/ai-services/language-service/). [Create a Language Resource](https://portal.azure.com/#create/Microsoft.CognitiveServicesTextAnalytics) first, if necessary.
- In Prompt flow, add a new `CustomConnection`.
- Under the `secrets` field, specify the resource's API key: `api_key: <Azure AI Language Resource api key>`
- Under the `configs` field, specify the resource's endpoint: `endpoint: <Azure AI Language Resource endpoint>`
To use the `Translator` tool, you must set up an additional connection to an [Azure AI Translator resource](https://azure.microsoft.com/en-us/products/ai-services/ai-translator). [Create a Translator resource](https://learn.microsoft.com/en-us/azure/ai-services/translator/create-translator-resource) first, if necessary.
- In Prompt flow, add a new `CustomConnection`.
- Under the `secrets` field, specify the resource's API key: `api_key: <Azure AI Translator Resource api key>`
- Under the `configs` field, specify the resource's endpoint: `endpoint: <Azure AI Translator Resource endpoint>`
- If your Translator Resource is regional and non-global, specify its region under `configs` as well: `region: <Azure AI Translator Resource region>`
In either case, you may use an Azure AI Services resource instead. Create an Azure AI Services connection type, and provide the resource's API key and endpoint. If using the `Translator` tool, pass in the translator region as a tool parameter.
## Inputs
When a tool parameter is of type `Document`, it requires a `dict` object of [this](https://learn.microsoft.com/en-us/rest/api/language/text-analysis-runtime/analyze-text?view=rest-language-2023-04-01&tabs=HTTP#multilanguageinput) specification.
Example:
```
my_document = {
"id": "1",
"text": "This is some document text!",
"language": "en"
}
```
When a tool parameter is of type `Conversation`, it requires a `dict` object of [this](https://learn.microsoft.com/en-us/rest/api/language/conversation-analysis-runtime/submit-job?view=rest-language-2023-04-01&tabs=HTTP#textconversation) or [this](https://learn.microsoft.com/en-us/rest/api/language/conversation-analysis-runtime/submit-job?view=rest-language-2023-04-01&tabs=HTTP#transcriptconversation) specification.
Example:
```
my_conversation = {
"id": "meeting_1",
"language": "en",
"modality": "text",
"domain": "generic",
"conversationItems": [
{
"participantId": "person1",
"role": "generic",
"id": "1",
"text": "Hello!"
},
{
"participantId": "person2",
"role": "generic",
"id": "2",
"text": "How are you?"
}
]
}
```
---------------------------
All skills have the following (optional) inputs:
| Name | Type | Description | Required |
|--------------------|------------------|-------------|----------|
| max_retries | int | The maximum number of HTTP request retries. Default value is `5`. | No |
| max_wait | int | The maximum wait time (in seconds) in-between HTTP requests. Default value is `60`. | No |
| parse_response | bool | Should the full API JSON output be parsed to extract the single task result. Default value is `False`. | No |
HTTP request logic utilizes [exponential backoff](https://en.wikipedia.org/wiki/Exponential_backoff).
See skill specific inputs below:
---------------------------
| Abstractive Summarization | Name | Type | Description | Required |
|-|--------------------|------------------|-------------|----------|
|| connection | CustomConnection | The created connection to an Azure AI Language resource. | Yes |
|| document | `Document` | The input document. | Yes |
|| query | string | The query used to structure summarization. | Yes |
|| summary_length | string (enum) | The desired summary length. Enum values are `short`, `medium`, and `long`. | No |
---------------------------
| Extractive Summarization | Name | Type | Description | Required |
|-|--------------------|------------------|-------------|----------|
|| connection | CustomConnection | The created connection to an Azure AI Language resource. | Yes |
|| document | `Document` | The input document. | Yes |
|| query | string | The query used to structure summarization. | Yes |
|| sentence_count | int | The desired number of output summary sentences. Default value is `3`. | No |
|| sort_by | string (enum) | The sorting criteria for extractive summarization results. Enum values are `Offset` to sort results in order of appearance in the text and `Rank` to sort results in order of importance (i.e. rank score) according to model. Default value is `Offset`. | No |
---------------------------
| Conversation Summarization | Name | Type | Description | Required |
|-|--------------------|------------------|-------------|----------|
|| connection | CustomConnection | The created connection to an Azure AI Language resource. | Yes |
|| conversation | `Conversation` | The input conversation. | Yes |
|| summary_aspect | string (enum) | The desired summary "aspect" to obtain. Enum values are `chapterTitle` to obtain the chapter title of any conversation, `issue` to obtain the summary of issues in transcripts of web chats and service calls between customer-service agents and customers, `narrative` to obtain the generic summary of any conversation, `resolution` to obtain the summary of resolutions in transcripts of web chats and service calls between customer-service agents and customers, `recap` to obtain a general summary, and `follow-up tasks` to obtain a summary of follow-up or action items. | Yes |
---------------------------
| Entity Recognition | Name | Type | Description | Required |
|-|--------------------|------------------|-------------|----------|
|| connection | CustomConnection | The created connection to an Azure AI Language resource. | Yes |
|| document | `Document` | The input document. | Yes |
|| inclusion_list | list[string] | List of desired entity types to return. | No |
---------------------------
| Key Phrase Extraction | Name | Type | Description | Required |
|-|--------------------|------------------|-------------|----------|
|| connection | CustomConnection | The created connection to an Azure AI Language resource. | Yes |
|| document | `Document` | The input document. | Yes |
---------------------------
| Language Detection | Name | Type | Description | Required |
|-|--------------------|------------------|-------------|----------|
|| connection | CustomConnection | The created connection to an Azure AI Language resource. | Yes |
|| text | string | The input text. | Yes |
---------------------------
| PII Entity Recognition | Name | Type | Description | Required |
|-|--------------------|------------------|-------------|----------|
|| connection | CustomConnection | The created connection to an Azure AI Language resource. | Yes |
|| document | `Document` | The input document. | Yes |
|| domain | string (enum) | The PII domain used for PII Entity Recognition. Enum values are `none` for no domain, or `phi` to indicate that entities in the Personal Health domain should be redacted. Default value is `none`. | No |
|| pii_categories | list[string] | Describes the PII categories to return. | No |
---------------------------
| Conversational PII | Name | Type | Description | Required |
|-|-----------------------|------------------|-------------|----------|
|| connection | CustomConnection | The created connection to an Azure AI Language resource. | Yes |
|| conversation | `Conversation` | The input conversation. | Yes |
|| pii_categories | list[string] | Describes the PII categories to return for detection. Default value is `['Default']`. | No |
|| redact_audio_timing | bool | Should audio stream offset and duration for any detected entities be redacted. Default value is `False`. | No |
|| redaction source | string (enum) | For transcript conversations, this parameter provides information regarding which content type should be used for entity detection. The details of the entities detected - such as the offset, length, and the text itself - will correspond to the text type selected here. Enum values are `lexical`, `itn`, `maskedItn`, and `text`. Default value is `lexical`. | No |
|| exclude_pii_categories | list[string] | Describes the PII categories to exclude for detection. Default value is `[]`. | No |
---------------------------
| Sentiment Analysis | Name | Type | Description | Required |
|-|--------------------|------------------|-------------|----------|
|| connection | CustomConnection | The created connection to an Azure AI Language resource. | Yes |
|| document | `Document` | The input document. | Yes |
|| opinion_mining | bool | Should opinion mining be enabled. Default value is `False`. | No |
---------------------------
| Conversational Language Understanding | Name | Type | Description | Required |
|-|--------------------|------------------|-------------|----------|
|| connection | CustomConnection | The created connection to an Azure AI Language resource. | Yes |
|| language | string | The ISO 639-1 code for the language of the input. | Yes |
|| utterances | string | A single user utterance or a json array of user utterances. | Yes |
|| project_name | string | The Conversational Language Understanding project to be called. | Yes |
|| deployment_name | string | The Conversational Language Understanding project deployment to be called. | Yes |
---------------------------
| Translator |Name | Type | Description | Required |
|-|--------------------|------------------|-------------|----------|
|| connection | CustomConnection | The created connection to an Azure AI Translator resource. | Yes |
|| text | string | The input text. | Yes |
|| to | list[string] | The languages to translate the input text to. | Yes |
|| source_language | string | The language of the input text. | No |
|| category | string | The category (domain) of the translation. This parameter is used to get translations from a customized system built with Custom Translator. Default value is `general`. | No |
|| text_type | string (enum) | The type of the text being translated. Possible values are `plain` (default) or `html`. | No |
|| region | string | The region of the Azure AI Translator resource being used. This is only required when using an Azure AI Services connection. | No |
## Outputs
- When the input parameter `parse_response` is set to `False` (default value), the full API JSON response will be returned (as a `dict` object).
- When the input parameter `parse_response` is set to `True`, the full API JSON response will be parsed to extract the single task result associated with the tool's given skill. Output will depend on the skill (but will still be a `dict` object).
- **Note:** for Conversational Language Understanding (CLU), output will be a list of responses (either full or parsed), one for each detected user utterance in the input.
Refer to Azure AI Language's [REST API reference](https://learn.microsoft.com/en-us/rest/api/language/) for details on API response format, specific task result formats, etc.
## Sample Flows
Find example flows using the `promptflow-azure-ai-language` package [here](https://github.com/microsoft/promptflow/tree/main/examples/flows/integrations/azure-ai-language).
## Contact
Please reach out to Azure AI Language (<taincidents@microsoft.com>) with any issues.
---------------------------
NOTICES AND INFORMATION
Do Not Translate or Localize
This software incorporates material from third parties.
Microsoft makes certain open source code available at https://3rdpartysource.microsoft.com,
or you may send a check or money order for US $5.00, including the product name,
the open source component name, platform, and version number, to:
Source Code Compliance Team
Microsoft Corporation
One Microsoft Way
Redmond, WA 98052
USA
Notwithstanding any other terms, you may reverse engineer this software to the extent
required to debug changes to any libraries licensed under the GNU Lesser General Public License.
---------------------------------------------------------
sniffio 1.3.0 - (Apache-2.0 AND BSD-3-Clause) OR (Apache-2.0 AND MIT)
(Apache-2.0 AND BSD-3-Clause) OR (Apache-2.0 AND MIT)
---------------------------------------------------------
---------------------------------------------------------
contextvars 2.4 - Apache-2.0
Copyright 2018 Python Software Foundation
Copyright (c) 2015-present MagicStack Inc. http://magic.io
Copyright (c) 2018-present MagicStack Inc. http://magic.io
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability. END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
---------------------------------------------------------
---------------------------------------------------------
google-api-core 1.34.0 - Apache-2.0
Copyright 2014 Google LLC
Copyright 2015 Google LLC
Copyright 2016 Google LLC
Copyright 2017 Google LLC
Copyright 2018 Google LLC
Copyright 2019 Google LLC
Copyright 2020 Google LLC
Copyright 2021 Google LLC
Copyright 2022 Google LLC
Copyright 2017, Google LLC
Copyright 2018, Google LLC
Copyright 2020, Google LLC
Copyright 2022, Google LLC
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability. END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
---------------------------------------------------------
---------------------------------------------------------
opencensus-context 0.1.3 - Apache-2.0
Copyright 2019, OpenCensus
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall m | text/markdown | Microsoft Corporation | null | null | taincidents@microsoft.com | MIT License | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"requests",
"promptflow>=1.17.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.11 | 2026-02-19T17:19:37.763019 | promptflow_azure_ai_language-0.1.15-py3-none-any.whl | 44,784 | bf/20/0c6107998167340ddc006a4c86fda1492ba0cac0be5944a6bb1509c4d552/promptflow_azure_ai_language-0.1.15-py3-none-any.whl | py3 | bdist_wheel | null | false | 640d2c3883044070c5976e61b7851ae3 | 7838083ed3afa427eb788be5e549427dc98b2baf586fcae3cdb69feffcd9b444 | bf200c6107998167340ddc006a4c86fda1492ba0cac0be5944a6bb1509c4d552 | null | [] | 120 |
2.4 | giga-spatial | 0.8.2 | A package for spatial data download & processing | <div style="padding-left: 20px; padding-right: 10px;">
<a href="https://giga.global/">
<img src="https://s41713.pcdn.co/wp-content/uploads/2018/11/2020.05_GIGA-visual-identity-guidelines_v1-25.png" alt="Giga logo" title="Giga" align="right" height="60" style="padding-top: 10px;"/>
</a>
# GigaSpatial
[](https://opensource.org/license/agpl-v3)
[](https://badge.fury.io/py/giga-spatial)
[](https://pypi.org/project/giga-spatial/)
[](https://github.com/psf/black)
[](https://pepy.tech/projects/giga-spatial)
[](https://github.com/unicef/giga-spatial/graphs/contributors)
**Table of contents**
- [About Giga](#about-giga)
- [About GigaSpatial](#about-gigaspatial)
- [Installation](#installation)
- [Quick start](#quick-start)
- [Key workflows](#key-workflows)
- [Core concepts](#core-concepts)
- [Supported datasets](#supported-datasets)
- [Why use GigaSpatial?](#why-use-gigaspatial)
- [Why open source?](#why-open-source)
- [How to contribute](#how-to-contribute)
- [Code of conduct](#code-of-conduct)
- [Stay connected](#stay-connected)
## About Giga
[Giga](https://giga.global/) is a UNICEF-ITU initiative to connect every school to the Internet and every young person to information, opportunity and choice.
Giga maps schools' Internet access in real time, creates models for innovative financing, and supports governments contracting for connectivity.
## About GigaSpatial
**GigaSpatial** is a Python toolkit for scalable geospatial data download, processing, and enrichment, designed for use across diverse domains such as infrastructure mapping, accessibility analysis, and environmental studies.
> Originally developed within UNICEF’s Giga initiative, GigaSpatial now provides a general‑purpose geospatial toolkit that can be applied to many contexts, including but not limited to school connectivity analysis.
### Who is this for?
- Data engineers building reproducible geospatial pipelines
- Data scientists analyzing school connectivity and infrastructure
- Researchers working with large, multi‑source spatial datasets
- GIS analysts requiring planetary-scale Earth observation data
## Installation
GigaSpatial requires Python 3.10 or above.
```console
pip install giga-spatial
```
The package depends on:
- geopandas
- pandas
- shapely
- rasterio
- earthengine-api (optional, for Google Earth Engine features)
For detailed setup instructions (including recommended environments and system dependencies), see the [installation docs](https://unicef.github.io/giga-spatial/getting-started/installation/).
We recommend using a virtual environment for installation.
## Quick start
```python
import geopandas as gpd
from gigaspatial.handlers import GoogleOpenBuildingsHandler, GHSLDataHandler
from gigaspatial.generators import POIViewGenerator
# 1. Load school locations
schools = gpd.read_file("schools.geojson")
# 2. Prepare data sources (downloads / caching handled by handlers)
buildings = GoogleOpenBuildingsHandler().load_data(source=schools, data_type="points")
ghsl = GHSLDataHandler(product="GHS_SMOD").load_data(source=schools, merge_rasters=True)
# 3. Generate school mappings with buildings + settlement model
view = POIViewGenerator(points=points)
ghsl_mapping = view.map_zonal_stats(data=ghsl, stat="median", output_column="smod_median")
print(ghsl_mapping.head())
buildings_mapping = view.map_zonal_stats(data=ghsl, stat="median", output_column="smod_median")
buildings_mapping = view.map_nearest_points(
points_df=buildings,
id_column="full_plus_code",
output_prefix="nearest_google_building",
)
print(buildings_mapping.head())
```
## Key Features
- **Data Downloading**
Download geospatial data from various sources including GHSL, Microsoft Global Buildings, Google Open Buildings, OpenCellID, and HDX datasets.
- **Data Processing**
Process and transform geospatial data, such as GeoTIFF files and vector data, with support for compression and efficient handling.
- **View Generators**
- Enrich spatial context with POI (Point of Interest) data
- Support for raster point sampling and zonal statistics
- Area-weighted aggregation for polygon-based statistics
- Temporal aggregation for time-series Earth observation data
- **Grid System**
Create and manipulate grid-based geospatial data for analysis and modeling using H3, S2, or Mercator tile systems.
- **Data Storage**
Flexible storage options with local, cloud (ADLS), and Snowflake stage support.
- **Configuration Management**
- Centralized configuration via environment variables or `.env` file
- Easy setup of API keys and paths
## Key Workflows
- **Fetch POI data**
Retrieve points of interest from OpenStreetMap, Healthsites.io, and Giga-maintained sources for any area of interest.
- **Enrich POI locations**
Join POIs with Google/Microsoft building footprints, GHSL population and settlement layers, Earth Engine satellite data, and other contextual datasets.
- **Analyze Earth observation time series**
Extract and analyze multi-temporal satellite data (vegetation indices, land surface temperature, precipitation, etc.) for any location using Google Earth Engine
- **Build and analyze grids**
Generate national or sub‑national grids and aggregate multi‑source indicators (e.g. coverage, population, infrastructure) into each cell.
- **End‑to‑end pipelines**
Use handlers, readers, and view generators together to go from raw data download to analysis‑ready tables in local storage, ADLS, or Snowflake.
## Core concepts
- **Handlers**: Orchestrate dataset lifecycle (download, cache, read) for sources like GHSL, Google/Microsoft buildings, OSM, and HDX.
- **Readers**: Low‑level utilities that parse and standardize raster and vector formats.
- **View generators**: High‑level components that enrich points or grids with contextual variables (POIs, buildings, population, etc.).
- **Grid system**: Utilities to build and manage grid cells for large‑scale analysis.
- **Storage backends**: Pluggable interfaces for local disk, Azure Data Lake Storage, and Snowflake stages.
## Supported Datasets
The `gigaspatial` package supports data from the following providers:
<div align="center">
<img src="https://raw.githubusercontent.com/unicef/giga-spatial/main/docs/assets/datasets.png" alt="Dataset Providers" style="width: 75%; height: auto;"/>
</div>
**Google Earth Engine Catalog**
GigaSpatial now provides access to Google Earth Engine’s comprehensive data catalog, including:
- **Satellite imagery**: Landsat (30+ years), Sentinel-1/2, MODIS, Planet
- **Climate & weather**: ERA5, CHIRPS precipitation, NOAA temperature
- **Land cover**: Dynamic World, ESA WorldCover, MODIS land cover
- **Terrain**: SRTM, ASTER DEM, ALOS elevation data
- **Population & infrastructure**: GHSL, WorldPop, nighttime lights
- **Environmental**: Soil properties, vegetation indices, surface water
For a complete list of available datasets, visit the [Earth Engine Data Catalog](https://developers.google.com/earth-engine/datasets).
---
## View Generators
The **view generators** in GigaSpatial are designed to enrich the spatial context of school locations and map data into grid or POI locations. This enables users to analyze and visualize geospatial data in meaningful ways.
### Key Capabilities
1. **Spatial Context Enrichment**:
- Automatic attribution of geospatial variables to school locations
- Contextual layers for environmental, infrastructural, and socioeconomic factors
- Multi-resolution data availability for different analytical needs
- Support for both point and polygon-based enrichment
2. **Mapping to Grid or POI Locations**:
- Map geospatial data to grid cells for scalable analysis
- Map data to POI locations for detailed, location-specific insights
- Support for chained enrichment using multiple datasets
- Built-in support for administrative boundary annotations
---
## Why use GigaSpatial?
- **End-to-end geospatial pipelines**: Go from raw open datasets (OSM, GHSL, global buildings, HDX, etc.) to analysis-ready tables with a consistent set of handlers, readers, and view generators.
- **Planetary-scale analysis**: Leverage Google Earth Engine’s cloud infrastructure to process petabytes of satellite imagery without downloading data or managing compute resources.
- **Scalable analysis**: Work seamlessly with both point and grid representations, making it easy to aggregate indicators at national scale or zoom into local POIs.
- **Batteries included for enrichment**: Fetch POIs, buildings, and population layers and join them onto schools or other locations with a few lines of code.
- **Flexible storage**: Run the same workflows against local files, Azure Data Lake Storage (ADLS), or Snowflake stages without changing core logic.
- **Modern, extensible architecture**: Base handler orchestration, dataset-specific readers, modular source resolution, and structured logging make it straightforward to add new sources and maintain production pipelines.
- **Open and collaborative**: Developed in the open under an AGPL-3.0 license, with contributions and reviews from the wider geospatial and data-for-development community.
## Why Open Source?
At Giga, we believe in the power of open-source technologies to accelerate progress and innovation. By keeping our tools and systems open, we:
- Encourage collaboration and contributions from a global community.
- Ensure transparency and trust in our methodologies.
- Empower others to adopt, adapt, and extend our tools to meet their needs.
## How to Contribute
We welcome contributions to our repositories! Whether it's fixing a bug, adding a feature, or improving documentation, your input helps us move closer to our goal of universal school connectivity.
### Steps to Contribute
1. Fork the repository you'd like to contribute to.
2. Create a new branch for your changes.
3. Submit a pull request with a clear explanation of your contribution.
To go through the “contribution” guidelines in detail you can visit the following link.
[Click here for the detailed Contribution guidelines](https://github.com/unicef/giga-spatial/blob/main/CONTRIBUTING.md)
---
## Code of Conduct
At Giga, we're committed to maintaining an environment that's respectful, inclusive, and harassment-free for everyone involved in our project and community. We welcome contributors and participants from diverse backgrounds and pledge to uphold the standards.
[Click here for the detailed Code of Conduct.](https://github.com/unicef/giga-spatial/blob/main/CODE_OF_CONDUCT.md)
---
## Stay Connected
To learn more about Giga and our mission, visit our official website: [Giga.Global](https://giga.global)
## Join Us
Join us in creating an open-source future for education! 🌍
| text/markdown | Utku Can Ozturk | utkucanozturk@gmail.com | null | null | AGPL-3.0-or-later | gigaspatial, spatial, geospatial, gis, remote sensing, data processing, download, openstreetmap, osm, ghsl, grid, point of interest, POI, raster, vector, school connectivity, unicef, giga, mapping, analysis, python | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Healthcare Industry",
"Intended Audience :: Science/Research",
"Intended Audience :: Telecommunications Industry",
"Programming Language :: Python",
"Programming La... | [] | null | null | >=3.10 | [] | [] | [] | [
"azure-storage-blob>=12.22.0",
"delta_sharing==1.2.0",
"duckdb==1.2.0",
"geopandas>=1.0.1",
"mercantile==1.2.1",
"numpy>=2.2.2",
"pandas>=2.2.3",
"pycountry==24.6.1",
"pydantic>=2.10.6",
"rasterio==1.3.10",
"requests>=2.32.4",
"scipy>=1.15.1",
"Shapely>=2.0.7",
"networkx>=3.2.1",
"tqdm>=... | [] | [] | [] | [
"Homepage, https://github.com/unicef/giga-spatial",
"Documentation, https://unicef.github.io/giga-spatial/",
"Source, https://github.com/unicef/giga-spatial",
"Issue Tracker, https://github.com/unicef/giga-spatial/issues",
"Discussions, https://github.com/unicef/giga-spatial/discussions",
"Changelog, http... | twine/6.1.0 CPython/3.10.11 | 2026-02-19T17:19:24.824789 | giga_spatial-0.8.2.tar.gz | 487,708 | b6/94/9dc10cb0900e0d80d246498f12791df7fb003df05fc4b6b4eb9942d8b4df/giga_spatial-0.8.2.tar.gz | source | sdist | null | false | 00ee04615fbbc4bf5ef267f6c06d2e65 | b38c735d678ea957a8ae23463021fce777ad52084a87537f61ac1c600c9018b7 | b6949dc10cb0900e0d80d246498f12791df7fb003df05fc4b6b4eb9942d8b4df | null | [
"LICENSE"
] | 231 |
2.4 | hyperview | 0.2.0 | Open-source dataset curation with hyperbolic embeddings visualization | # HyperView
> **Open-source dataset curation + embedding visualization (Euclidean + Poincaré disk)**
[](https://opensource.org/licenses/MIT) [](https://deepwiki.com/Hyper3Labs/HyperView) [](https://huggingface.co/spaces/hyper3labs/HyperView) [](https://discord.gg/Az7k4Ure)
<p align="center">
<a href="https://huggingface.co/spaces/hyper3labs/HyperView" target="_blank">
<img src="https://raw.githubusercontent.com/Hyper3Labs/HyperView/main/assets/screenshot.png" alt="HyperView Screenshot" width="100%">
</a>
<br>
<a href="https://huggingface.co/spaces/hyper3labs/HyperView" target="_blank">Try the live demo on HuggingFace Spaces</a>
</p>
---
## Features
- **Dual-Panel UI**: Image grid + scatter plot with bidirectional selection
- **Euclidean/Poincaré Toggle**: Switch between standard 2D UMAP and Poincaré disk visualization
- **HuggingFace Integration**: Load datasets directly from HuggingFace Hub
- **Fast Embeddings**: Uses EmbedAnything for CLIP-based image embeddings
## Updates
- **01-02-26** — [The Geometry of Image Embeddings, Hands-on Coding Workshop](https://www.meetup.com/berlin-computer-vision-group/events/312927919/) (Berlin Computer Vision Group)
- **17-01-26** — [The Geometry of Image Embeddings, Hands-on Coding Workshop, Part I](https://www.meetup.com/berlin-computer-vision-group/events/312636174/) (Berlin Computer Vision Group)
- **11-12-25** — [Hacker Room Demo Day #2](https://youtu.be/KnOiaNXN3Q0?t=2483) (Merantix AI Campus Berlin) — First version of HyperView presented
## Quick Start
**Docs:** [docs/datasets.md](docs/datasets.md) · [docs/colab.md](docs/colab.md) · [CONTRIBUTING.md](CONTRIBUTING.md) · [TESTS.md](TESTS.md)
### Installation
```bash
uv pip install hyperview
```
### Run HyperView
```bash
hyperview \
--dataset cifar10_demo \
--hf-dataset uoft-cs/cifar10 \
--split train \
--image-key img \
--label-key label \
--samples 500 \
--model openai/clip-vit-base-patch32 \
--geometry both
```
This will:
1. Use dataset `cifar10_demo`
2. Load up to 500 samples from CIFAR-10
3. Compute CLIP embeddings
4. Generate Euclidean and Poincaré visualizations
5. Start the server at **http://127.0.0.1:6262**
You can also launch with explicit dataset/model/projection args:
```bash
hyperview \
--dataset imagenette_clip \
--hf-dataset fastai/imagenette \
--split train \
--image-key image \
--label-key label \
--samples 1000 \
--model openai/clip-vit-base-patch32 \
--method umap \
--geometry euclidean
```
### Python API
```python
import hyperview as hv
# Create dataset
dataset = hv.Dataset("my_dataset")
# Load from HuggingFace
dataset.add_from_huggingface(
"uoft-cs/cifar100",
split="train",
max_samples=1000
)
# Or load from local directory
# dataset.add_images_dir("/path/to/images", label_from_folder=True)
# Compute embeddings and visualization
dataset.compute_embeddings(model="openai/clip-vit-base-patch32")
dataset.compute_visualization()
# Launch the UI
hv.launch(dataset) # Opens http://127.0.0.1:6262
```
### Google Colab
See [docs/colab.md](docs/colab.md) for a fast Colab smoke test and notebook-friendly launch behavior.
## Why Hyperbolic?
Traditional Euclidean embeddings struggle with hierarchical data. In Euclidean space, volume grows polynomially ($r^d$), causing **[Representation Collapse](https://hyper3labs.github.io/collapse)** where minority classes get crushed together.
**[Hyperbolic space](https://hyper3labs.github.io/warp)** (Poincaré disk) has exponential volume growth ($e^r$), naturally preserving hierarchical structure and keeping rare classes distinct.
**[Try the live demo on HuggingFace Spaces→](https://huggingface.co/spaces/hyper3labs/HyperView)**
## Community
**Weekly Open Discussion** — Every Tuesday at 15:00 UTC on [Discord](https://discord.gg/Az7k4Ure?event=1469730571440885944)
Join us to see the latest features demoed live, walk through new code, and get help with local setup. Whether you're a core maintainer or looking for your first contribution, everyone is welcome.
## Contributing
Development setup, frontend hot-reload, and backend API notes live in [CONTRIBUTING.md](CONTRIBUTING.md).
## Related projects
- **hyper-scatter**: High-performance WebGL scatterplot engine (Euclidean + Poincaré) used by the frontend: https://github.com/Hyper3Labs/hyper-scatter
- **hyper-models**: Non-Euclidean model zoo + ONNX exports : https://github.com/Hyper3Labs/hyper-models
## License
MIT License - see [LICENSE](LICENSE) for details.
| text/markdown | hyper3labs | null | null | null | MIT | curation, dataset, embeddings, hyperbolic, machine-learning, visualization | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"aiofiles>=25.1.0",
"datasets>=4.5.0",
"embed-anything>=0.7.0",
"fastapi>=0.128.0",
"hyper-models>=0.1.0",
"lancedb>=0.26.1",
"numpy<2.4,>=1.26.4",
"pillow>=12.1.0",
"pyarrow>=22.0.0",
"pydantic>=2.12.5",
"umap-learn>=0.5.11",
"uvicorn[standard]>=0.40.0",
"httpx>=0.28.1; extra == \"dev\"",
... | [] | [] | [] | [
"Homepage, https://github.com/Hyper3Labs/HyperView",
"Documentation, https://github.com/Hyper3Labs/HyperView#readme",
"Repository, https://github.com/Hyper3Labs/HyperView",
"Issues, https://github.com/Hyper3Labs/HyperView/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T17:18:28.955843 | hyperview-0.2.0.tar.gz | 613,554 | ef/92/de160b34624f75a60aeababb4e1f8a65a6886ba2c1f796e5fd280fc45f38/hyperview-0.2.0.tar.gz | source | sdist | null | false | b27ed48b2aa6fa73c3bd326f69361f3d | 81541ea169fd3d4bca5bf84e3b8c5a12f53101783fab158b30cb11fcd711073f | ef92de160b34624f75a60aeababb4e1f8a65a6886ba2c1f796e5fd280fc45f38 | null | [
"LICENSE"
] | 228 |
2.4 | strands-agents | 1.27.0 | A model-driven approach to building AI agents in just a few lines of code | <div align="center">
<div>
<a href="https://strandsagents.com">
<img src="https://strandsagents.com/latest/assets/logo-github.svg" alt="Strands Agents" width="55px" height="105px">
</a>
</div>
<h1>
Strands Agents
</h1>
<h2>
A model-driven approach to building AI agents in just a few lines of code.
</h2>
<div align="center">
<a href="https://github.com/strands-agents/sdk-python/graphs/commit-activity"><img alt="GitHub commit activity" src="https://img.shields.io/github/commit-activity/m/strands-agents/sdk-python"/></a>
<a href="https://github.com/strands-agents/sdk-python/issues"><img alt="GitHub open issues" src="https://img.shields.io/github/issues/strands-agents/sdk-python"/></a>
<a href="https://github.com/strands-agents/sdk-python/pulls"><img alt="GitHub open pull requests" src="https://img.shields.io/github/issues-pr/strands-agents/sdk-python"/></a>
<a href="https://github.com/strands-agents/sdk-python/blob/main/LICENSE"><img alt="License" src="https://img.shields.io/github/license/strands-agents/sdk-python"/></a>
<a href="https://pypi.org/project/strands-agents/"><img alt="PyPI version" src="https://img.shields.io/pypi/v/strands-agents"/></a>
<a href="https://python.org"><img alt="Python versions" src="https://img.shields.io/pypi/pyversions/strands-agents"/></a>
</div>
<p>
<a href="https://strandsagents.com/">Documentation</a>
◆ <a href="https://github.com/strands-agents/samples">Samples</a>
◆ <a href="https://github.com/strands-agents/sdk-python">Python SDK</a>
◆ <a href="https://github.com/strands-agents/tools">Tools</a>
◆ <a href="https://github.com/strands-agents/agent-builder">Agent Builder</a>
◆ <a href="https://github.com/strands-agents/mcp-server">MCP Server</a>
</p>
</div>
Strands Agents is a simple yet powerful SDK that takes a model-driven approach to building and running AI agents. From simple conversational assistants to complex autonomous workflows, from local development to production deployment, Strands Agents scales with your needs.
## Feature Overview
- **Lightweight & Flexible**: Simple agent loop that just works and is fully customizable
- **Model Agnostic**: Support for Amazon Bedrock, Anthropic, Gemini, LiteLLM, Llama, Ollama, OpenAI, Writer, and custom providers
- **Advanced Capabilities**: Multi-agent systems, autonomous agents, and streaming support
- **Built-in MCP**: Native support for Model Context Protocol (MCP) servers, enabling access to thousands of pre-built tools
## Quick Start
```bash
# Install Strands Agents
pip install strands-agents strands-agents-tools
```
```python
from strands import Agent
from strands_tools import calculator
agent = Agent(tools=[calculator])
agent("What is the square root of 1764")
```
> **Note**: For the default Amazon Bedrock model provider, you'll need AWS credentials configured and model access enabled for Claude 4 Sonnet in the us-west-2 region. See the [Quickstart Guide](https://strandsagents.com/) for details on configuring other model providers.
## Installation
Ensure you have Python 3.10+ installed, then:
```bash
# Create and activate virtual environment
python -m venv .venv
source .venv/bin/activate # On Windows use: .venv\Scripts\activate
# Install Strands and tools
pip install strands-agents strands-agents-tools
```
## Features at a Glance
### Python-Based Tools
Easily build tools using Python decorators:
```python
from strands import Agent, tool
@tool
def word_count(text: str) -> int:
"""Count words in text.
This docstring is used by the LLM to understand the tool's purpose.
"""
return len(text.split())
agent = Agent(tools=[word_count])
response = agent("How many words are in this sentence?")
```
**Hot Reloading from Directory:**
Enable automatic tool loading and reloading from the `./tools/` directory:
```python
from strands import Agent
# Agent will watch ./tools/ directory for changes
agent = Agent(load_tools_from_directory=True)
response = agent("Use any tools you find in the tools directory")
```
### MCP Support
Seamlessly integrate Model Context Protocol (MCP) servers:
```python
from strands import Agent
from strands.tools.mcp import MCPClient
from mcp import stdio_client, StdioServerParameters
aws_docs_client = MCPClient(
lambda: stdio_client(StdioServerParameters(command="uvx", args=["awslabs.aws-documentation-mcp-server@latest"]))
)
with aws_docs_client:
agent = Agent(tools=aws_docs_client.list_tools_sync())
response = agent("Tell me about Amazon Bedrock and how to use it with Python")
```
### Multiple Model Providers
Support for various model providers:
```python
from strands import Agent
from strands.models import BedrockModel
from strands.models.ollama import OllamaModel
from strands.models.llamaapi import LlamaAPIModel
from strands.models.gemini import GeminiModel
from strands.models.llamacpp import LlamaCppModel
# Bedrock
bedrock_model = BedrockModel(
model_id="us.amazon.nova-pro-v1:0",
temperature=0.3,
streaming=True, # Enable/disable streaming
)
agent = Agent(model=bedrock_model)
agent("Tell me about Agentic AI")
# Google Gemini
gemini_model = GeminiModel(
client_args={
"api_key": "your_gemini_api_key",
},
model_id="gemini-2.5-flash",
params={"temperature": 0.7}
)
agent = Agent(model=gemini_model)
agent("Tell me about Agentic AI")
# Ollama
ollama_model = OllamaModel(
host="http://localhost:11434",
model_id="llama3"
)
agent = Agent(model=ollama_model)
agent("Tell me about Agentic AI")
# Llama API
llama_model = LlamaAPIModel(
model_id="Llama-4-Maverick-17B-128E-Instruct-FP8",
)
agent = Agent(model=llama_model)
response = agent("Tell me about Agentic AI")
```
Built-in providers:
- [Amazon Bedrock](https://strandsagents.com/latest/user-guide/concepts/model-providers/amazon-bedrock/)
- [Anthropic](https://strandsagents.com/latest/user-guide/concepts/model-providers/anthropic/)
- [Gemini](https://strandsagents.com/latest/user-guide/concepts/model-providers/gemini/)
- [Cohere](https://strandsagents.com/latest/user-guide/concepts/model-providers/cohere/)
- [LiteLLM](https://strandsagents.com/latest/user-guide/concepts/model-providers/litellm/)
- [llama.cpp](https://strandsagents.com/latest/user-guide/concepts/model-providers/llamacpp/)
- [LlamaAPI](https://strandsagents.com/latest/user-guide/concepts/model-providers/llamaapi/)
- [MistralAI](https://strandsagents.com/latest/user-guide/concepts/model-providers/mistral/)
- [Ollama](https://strandsagents.com/latest/user-guide/concepts/model-providers/ollama/)
- [OpenAI](https://strandsagents.com/latest/user-guide/concepts/model-providers/openai/)
- [SageMaker](https://strandsagents.com/latest/user-guide/concepts/model-providers/sagemaker/)
- [Writer](https://strandsagents.com/latest/user-guide/concepts/model-providers/writer/)
Custom providers can be implemented using [Custom Providers](https://strandsagents.com/latest/user-guide/concepts/model-providers/custom_model_provider/)
### Example tools
Strands offers an optional strands-agents-tools package with pre-built tools for quick experimentation:
```python
from strands import Agent
from strands_tools import calculator
agent = Agent(tools=[calculator])
agent("What is the square root of 1764")
```
It's also available on GitHub via [strands-agents/tools](https://github.com/strands-agents/tools).
### Bidirectional Streaming
> **⚠️ Experimental Feature**: Bidirectional streaming is currently in experimental status. APIs may change in future releases as we refine the feature based on user feedback and evolving model capabilities.
Build real-time voice and audio conversations with persistent streaming connections. Unlike traditional request-response patterns, bidirectional streaming maintains long-running conversations where users can interrupt, provide continuous input, and receive real-time audio responses. Get started with your first BidiAgent by following the [Quickstart](https://strandsagents.com/latest/documentation/docs/user-guide/concepts/experimental/bidirectional-streaming/quickstart) guide.
**Supported Model Providers:**
- Amazon Nova Sonic (v1, v2)
- Google Gemini Live
- OpenAI Realtime API
**Quick Example:**
```python
import asyncio
from strands.experimental.bidi import BidiAgent
from strands.experimental.bidi.models import BidiNovaSonicModel
from strands.experimental.bidi.io import BidiAudioIO, BidiTextIO
from strands.experimental.bidi.tools import stop_conversation
from strands_tools import calculator
async def main():
# Create bidirectional agent with Nova Sonic v2
model = BidiNovaSonicModel()
agent = BidiAgent(model=model, tools=[calculator, stop_conversation])
# Setup audio and text I/O
audio_io = BidiAudioIO()
text_io = BidiTextIO()
# Run with real-time audio streaming
# Say "stop conversation" to gracefully end the conversation
await agent.run(
inputs=[audio_io.input()],
outputs=[audio_io.output(), text_io.output()]
)
if __name__ == "__main__":
asyncio.run(main())
```
**Configuration Options:**
```python
from strands.experimental.bidi.models import BidiNovaSonicModel
# Configure audio settings and turn detection (v2 only)
model = BidiNovaSonicModel(
provider_config={
"audio": {
"input_rate": 16000,
"output_rate": 16000,
"voice": "matthew"
},
"turn_detection": {
"endpointingSensitivity": "MEDIUM" # HIGH, MEDIUM, or LOW
},
"inference": {
"max_tokens": 2048,
"temperature": 0.7
}
}
)
# Configure I/O devices
audio_io = BidiAudioIO(
input_device_index=0, # Specific microphone
output_device_index=1, # Specific speaker
input_buffer_size=10,
output_buffer_size=10
)
# Text input mode (type messages instead of speaking)
text_io = BidiTextIO()
await agent.run(
inputs=[text_io.input()], # Use text input
outputs=[audio_io.output(), text_io.output()]
)
# Multi-modal: Both audio and text input
await agent.run(
inputs=[audio_io.input(), text_io.input()], # Speak OR type
outputs=[audio_io.output(), text_io.output()]
)
```
## Documentation
For detailed guidance & examples, explore our documentation:
- [User Guide](https://strandsagents.com/)
- [Quick Start Guide](https://strandsagents.com/latest/user-guide/quickstart/)
- [Agent Loop](https://strandsagents.com/latest/user-guide/concepts/agents/agent-loop/)
- [Examples](https://strandsagents.com/latest/examples/)
- [API Reference](https://strandsagents.com/latest/api-reference/agent/)
- [Production & Deployment Guide](https://strandsagents.com/latest/user-guide/deploy/operating-agents-in-production/)
## Contributing ❤️
We welcome contributions! See our [Contributing Guide](CONTRIBUTING.md) for details on:
- Reporting bugs & features
- Development setup
- Contributing via Pull Requests
- Code of Conduct
- Reporting of security issues
## License
This project is licensed under the Apache License 2.0 - see the [LICENSE](LICENSE) file for details.
## Security
See [CONTRIBUTING](CONTRIBUTING.md#security-issue-notifications) for more information.
| text/markdown | null | AWS <opensource@amazon.com> | null | null | Apache-2.0 | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Prog... | [] | null | null | >=3.10 | [] | [] | [] | [
"boto3<2.0.0,>=1.26.0",
"botocore<2.0.0,>=1.29.0",
"docstring-parser<1.0,>=0.15",
"jsonschema<5.0.0,>=4.0.0",
"mcp<2.0.0,>=1.23.0",
"opentelemetry-api<2.0.0,>=1.30.0",
"opentelemetry-instrumentation-threading<1.00b0,>=0.51b0",
"opentelemetry-sdk<2.0.0,>=1.30.0",
"pydantic<3.0.0,>=2.4.0",
"typing-e... | [] | [] | [] | [
"Homepage, https://github.com/strands-agents/sdk-python",
"Bug Tracker, https://github.com/strands-agents/sdk-python/issues",
"Documentation, https://strandsagents.com"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:18:23.327941 | strands_agents-1.27.0.tar.gz | 712,878 | b9/54/bf0910a1c40feacaedcf5d30840be990eabd09eff5375fa40525ba530c8d/strands_agents-1.27.0.tar.gz | source | sdist | null | false | c1d6c9034f7993a420de3659486e4177 | 84d0b670e534d7c281104a22035c10de8d43e9ad8ee589bde16f54a8387b2c56 | b954bf0910a1c40feacaedcf5d30840be990eabd09eff5375fa40525ba530c8d | null | [
"LICENSE",
"NOTICE"
] | 267,636 |
2.4 | graphforge | 0.3.5 | Composable graph tooling for analysis, construction, and refinement | <h1 align="center">GraphForge</h1>
<p align="center">
<a href="https://pypi.org/project/graphforge/"><img src="https://img.shields.io/pypi/v/graphforge.svg?label=PyPI&logo=pypi" alt="PyPI version" /></a>
<a href="https://pypi.org/project/graphforge/"><img src="https://img.shields.io/pypi/pyversions/graphforge.svg?logo=python&logoColor=white" alt="Python versions" /></a>
<a href="https://github.com/DecisionNerd/graphforge/actions"><img src="https://github.com/DecisionNerd/graphforge/workflows/Test%20Suite/badge.svg" alt="Build status" /></a>
<a href="https://codecov.io/gh/DecisionNerd/graphforge"><img src="https://codecov.io/gh/DecisionNerd/graphforge/graph/badge.svg" alt="Coverage" /></a>
<a href="https://github.com/DecisionNerd/graphforge/blob/main/LICENSE"><img src="https://img.shields.io/badge/license-MIT-blue.svg" alt="License" /></a>
<a href="https://pypi.org/project/graphforge/"><img src="https://img.shields.io/pypi/dm/graphforge.svg?label=PyPI%20downloads" alt="PyPI downloads" /></a>
</p>
<p align="center">
<strong>Composable graph tooling for analysis, construction, and refinement</strong>
</p>
<p align="center">
A lightweight, embedded, openCypher-compatible graph engine for research and investigative workflows
</p>
---
## Table of Contents
- [Why GraphForge?](#why-graphforge)
- [Installation](#installation)
- [Quick Start](#quick-start)
- [Core Concepts](#core-concepts)
- [Python API Reference](#python-api-reference)
- [Cypher Query Language](#cypher-query-language)
- [Usage Patterns](#usage-patterns)
- [Examples](#examples)
- [Advanced Features](#advanced-features)
- [Design Principles](#design-principles)
- [Contributing](#contributing)
- [License](#license)
---
## Why GraphForge?
Modern data science and ML workflows increasingly produce **graph-shaped data**—entities and relationships extracted from text, tables, and LLM outputs. Yet practitioners face a painful choice:
| | NetworkX | GraphForge | Production DBs (Neo4j, Memgraph) |
|:---|:---|:---|:---|
| **Durability** | Manual serialization | ✓ SQLite backend | ✓ Persistent |
| **Query language** | None | openCypher subset | Full Cypher |
| **Operational overhead** | Minimal | Minimal (embedded) | High (services, config) |
| **Notebook-friendly** | ✓ | ✓ | ✗ |
| **Iterative analysis** | ✓ | ✓ | Poor |
**GraphForge** fills the gap—embedded, durable, and declarative—without running external services.
> *We are not building a database for applications.*
> *We are building a graph execution environment for thinking.*
### Latest Release: v0.3.4
Version 0.3.4 completes operator and string function enhancements:
- **String functions**: `toUpper()`, `toLower()` camelCase variants - Aliases for existing UPPER/LOWER functions
- **Logical operators**: `XOR` - Exclusive OR with proper precedence (NOT > AND > XOR > OR) and NULL handling
- **Arithmetic operators**: `^` (power/exponentiation) - Right-associative with full numeric support (negative and fractional exponents)
- **List operations**: List slicing `[start..end]` and negative indexing `list[-1]` (already implemented, now documented)
- **Comprehensive testing**: 79 new integration tests (18 string, 22 XOR, 39 power)
- **Operator completion**: List operators 100% (5/5), Overall operators 94% (32/34, up from 88%)
- **Function progress**: 56/72 functions (78%, up from 76%)
**Previous Releases**:
- **v0.3.3**: Pattern comprehensions, CALL subqueries, Pattern predicates
- **v0.3.2**: List operations (`filter()`, `extract()`, `reduce()`)
- **v0.3.1**: Quantifier functions (`all()`, `any()`, `none()`, `single()`), `exists()`, `isEmpty()`
- **v0.3.0**: OPTIONAL MATCH, UNION, List comprehensions, EXISTS/COUNT subqueries, Variable-length paths, 109+ datasets
**TCK Coverage**: ~38% openCypher compatibility
See [CHANGELOG.md](CHANGELOG.md) for complete release notes.
### Use Cases
**AI Agent Grounding with Ontologies** ⭐ NEW
- Ground LLM agents in structured knowledge graphs
- Annotate ontologies with tool definitions for semantic action
- Enable deterministic, grounded tool selection (no hallucinated APIs)
- Build agents that reason over domain knowledge and execute verifiable actions
- Perfect for LangChain/LlamaIndex integration with zero server overhead
- [Complete guide →](docs/use-cases/agent-grounding.md) | [Example notebook →](examples/agent_grounding/ecommerce_agent.ipynb)
**Knowledge Graph Construction**
- Extract entities and relationships from unstructured text
- Build and query knowledge graphs from documents
- Iteratively refine graph structures during analysis
**Data Lineage and Provenance**
- Track data transformations and dependencies
- Query upstream and downstream impacts
- Maintain audit trails of analytical workflows
**Network Analysis in Notebooks**
- Analyze social networks, citation graphs, dependency graphs
- Persist analysis results alongside code
- Share reproducible graph analyses
**LLM-Powered Graph Generation**
- Store LLM-extracted entities and relationships
- Query structured outputs from language models
- Build hybrid retrieval systems with graph context
---
## Installation
```bash
# Using uv (recommended)
uv add graphforge
# Using pip
pip install graphforge
```
**Requirements:** Python 3.10+
**Core Dependencies:**
- `pydantic>=2.6` - Data validation and type safety
- `lark>=1.1` - Cypher query parsing
- `msgpack>=1.0` - Efficient graph serialization
**Optional Dependencies:**
- `defusedxml` - Secure XML parsing for GraphML datasets
- `zstandard` - Support for .tar.zst compression (LDBC datasets)
---
## Quick Start
### 5-Minute Introduction
```python
from graphforge import GraphForge
# Create an in-memory graph
db = GraphForge()
# Option 1: Python API (imperative)
alice = db.create_node(['Person'], name='Alice', age=30)
bob = db.create_node(['Person'], name='Bob', age=25)
db.create_relationship(alice, bob, 'KNOWS', since=2020)
# Option 2: Cypher queries (declarative)
db.execute("CREATE (c:Person {name: 'Charlie', age: 35})")
db.execute("MATCH (a:Person {name: 'Alice'}), (c:Person {name: 'Charlie'}) CREATE (a)-[:KNOWS]->(c)")
# Query the graph
results = db.execute("""
MATCH (p:Person)-[:KNOWS]->(friend:Person)
WHERE p.age > 25
RETURN p.name AS person, friend.name AS friend
ORDER BY p.age DESC
""")
for row in results:
print(f"{row['person'].value} knows {row['friend'].value}")
# Output:
# Charlie knows Alice
# Alice knows Bob
# Alice knows Charlie
```
### Spatial and Temporal Types
GraphForge supports spatial types (Point, Distance) and temporal types (Date, DateTime, Time, Duration):
```python
from graphforge import GraphForge
db = GraphForge()
# Create nodes with spatial properties using Cypher
db.execute("CREATE (:Place {name: 'Office', location: point({x: 1.0, y: 2.0})})")
db.execute("CREATE (:Place {name: 'Home', location: point({x: 5.0, y: 3.0})})")
# Or use the Python API with coordinate dictionaries
db.create_node(['Place'], name='Cafe', location={"x": 3.0, "y": 4.0})
# Geographic coordinates (latitude, longitude)
db.create_node(['City'], name='SF', location={"latitude": 37.7749, "longitude": -122.4194})
# Calculate distances between points
results = db.execute("""
MATCH (a:Place {name: 'Office'}), (b:Place {name: 'Home'})
RETURN distance(a.location, b.location) AS dist
""")
print(f"Distance: {results[0]['dist'].value:.2f} units")
# Temporal types for dates and times
db.execute("""
CREATE (:Event {
name: 'Meeting',
date: date('2024-01-15'),
start_time: datetime('2024-01-15T14:00:00'),
duration: duration({hours: 2, minutes: 30})
})
""")
# Query events in a date range
results = db.execute("""
MATCH (e:Event)
WHERE e.date >= date('2024-01-01')
RETURN e.name, e.date, e.duration
""")
```
### Persistent Graphs
```python
# Create a persistent graph
db = GraphForge("my-research.db")
# Add data (persists automatically on close)
db.execute("CREATE (p:Paper {title: 'Graph Neural Networks', year: 2021})")
db.close()
# Later: reload the same graph
db = GraphForge("my-research.db")
results = db.execute("MATCH (p:Paper) RETURN p.title AS title")
print(results[0]['title'].value) # Graph Neural Networks
```
### Load Real-World Datasets
Analyze real networks instantly with built-in datasets:
```python
from graphforge import GraphForge
from graphforge.datasets import load_dataset
# Create graph and load a dataset (automatically downloads and caches)
db = GraphForge()
load_dataset(db, "snap-ego-facebook")
# Analyze the social network
results = db.execute("""
MATCH (n)-[r]->()
RETURN n.id AS user, count(r) AS connections
ORDER BY connections DESC
LIMIT 5
""")
for row in results:
print(f"User {row['user'].value}: {row['connections'].value} connections")
```
**Available datasets:**
- **SNAP** (Stanford): 95 real-world networks (social, web, email, collaboration, citation)
- **LDBC** (Linked Data Benchmark Council): 10 social network benchmark datasets
- **NetworkRepository**: 10 pre-registered datasets + load thousands more via direct URL
**Load from URL:**
```python
# Load any NetworkRepository dataset by URL
load_dataset(db, "https://nrvis.com/download/data/labeled/karate.zip")
```
Browse and filter datasets:
```python
from graphforge.datasets import list_datasets
# List all datasets (109+ available)
datasets = list_datasets()
print(f"Total datasets: {len(datasets)}")
# Filter by source
snap_datasets = list_datasets(source="snap") # 95 SNAP datasets
ldbc_datasets = list_datasets(source="ldbc") # 10 LDBC benchmarks
netrepo_datasets = list_datasets(source="netrepo") # 10 NetworkRepository
# View dataset details
for ds in ldbc_datasets[:3]:
print(f"{ds.name}: {ds.nodes:,} nodes, {ds.edges:,} edges ({ds.size_mb:.1f} MB)")
```
**Dataset Sources:**
1. **SNAP (Stanford Network Analysis Project)** - 95 datasets
- Social networks (Facebook, Twitter, email)
- Collaboration networks (arXiv, DBLP)
- Web graphs (Google, Wikipedia)
- Citation networks (patents, papers)
2. **LDBC (Linked Data Benchmark Council)** - 10 datasets
- Social Network Benchmark (SNB) with varying scale factors
- Realistic social network schemas with temporal data
- Used for performance benchmarking
3. **NetworkRepository** - 10 pre-registered + thousands via URL
- Biological networks (protein interactions, gene regulation)
- Infrastructure networks (power grids, road networks)
- Social and collaboration networks
- Load any dataset directly via URL without pre-registration
---
## Core Concepts
### Nodes and Relationships
**Nodes** represent entities with:
- **Labels**: Categories like `Person`, `Document`, `Gene`
- **Properties**: Key-value attributes (strings, integers, booleans, lists, maps)
- **IDs**: Auto-generated unique identifiers
**Relationships** connect nodes with:
- **Type**: Semantic connection like `KNOWS`, `CITES`, `REGULATES`
- **Direction**: From source node to destination node
- **Properties**: Attributes on the relationship itself
```python
# Python API
alice = db.create_node(['Person', 'Employee'],
name='Alice',
age=30,
skills=['Python', 'ML'])
bob = db.create_node(['Person'], name='Bob', age=25)
knows = db.create_relationship(alice, bob, 'KNOWS',
since=2020,
strength='strong')
# Cypher equivalent
db.execute("""
CREATE (a:Person:Employee {name: 'Alice', age: 30, skills: ['Python', 'ML']})
CREATE (b:Person {name: 'Bob', age: 25})
CREATE (a)-[:KNOWS {since: 2020, strength: 'strong'}]->(b)
""")
```
### Graph Patterns
GraphForge uses **graph patterns** for both matching and creating:
```
(n:Person) # Node with label
(n:Person {age: 30}) # Node with properties
(a)-[r:KNOWS]->(b) # Directed relationship
(a)-[r:KNOWS]-(b) # Undirected relationship
(a)-[:KNOWS|LIKES]->(b) # Multiple relationship types
```
---
## Python API Reference
### GraphForge Class
#### `__init__(path: str | Path | None = None)`
Initialize a GraphForge instance.
**Parameters:**
- `path` (optional): Path to SQLite database file. If `None`, uses in-memory storage.
**Example:**
```python
# In-memory (data lost on exit)
db = GraphForge()
# Persistent (data saved to disk)
db = GraphForge("graphs/social-network.db")
```
#### `create_node(labels: list[str] | None = None, **properties) -> NodeRef`
Create a node with labels and properties.
**Parameters:**
- `labels`: List of label strings (e.g., `['Person', 'Employee']`)
- `**properties`: Property key-value pairs. Values are automatically converted to CypherValue types:
- `str`, `int`, `float`, `bool`, `None` → Primitive types
- `list` → `CypherList`
- `dict` → `CypherMap` or `CypherPoint` (if coordinate dict)
- Coordinate dicts (`{"x": 1.0, "y": 2.0}`) → `CypherPoint`
- Date/time objects → Temporal types
**Returns:** `NodeRef` for the created node
**Example:**
```python
# Standard properties
alice = db.create_node(
['Person', 'Employee'],
name='Alice',
age=30,
active=True,
skills=['Python', 'SQL'],
metadata={'department': 'Engineering'}
)
# Spatial properties (auto-detected)
office = db.create_node(
['Place'],
name='Office',
location={"x": 1.0, "y": 2.0} # Automatically becomes CypherPoint
)
# Geographic coordinates
city = db.create_node(
['City'],
name='San Francisco',
location={"latitude": 37.7749, "longitude": -122.4194}
)
```
#### `create_relationship(src: NodeRef, dst: NodeRef, rel_type: str, **properties) -> EdgeRef`
Create a directed relationship between two nodes.
**Parameters:**
- `src`: Source node (NodeRef)
- `dst`: Destination node (NodeRef)
- `rel_type`: Relationship type string (e.g., `'KNOWS'`, `'WORKS_AT'`)
- `**properties`: Property key-value pairs
**Returns:** `EdgeRef` for the created relationship
**Example:**
```python
alice = db.create_node(['Person'], name='Alice')
company = db.create_node(['Company'], name='Acme Corp')
works_at = db.create_relationship(
alice,
company,
'WORKS_AT',
since=2020,
role='Engineer'
)
```
#### `execute(query: str) -> list[dict]`
Execute an openCypher query.
**Parameters:**
- `query`: openCypher query string
**Returns:** List of result rows as dictionaries
**Example:**
```python
results = db.execute("""
MATCH (p:Person)-[r:KNOWS]->(friend:Person)
WHERE p.age > 25
RETURN p.name AS person, count(friend) AS friend_count
ORDER BY friend_count DESC
LIMIT 10
""")
for row in results:
print(f"{row['person'].value}: {row['friend_count'].value} friends")
```
#### `begin()`
Start an explicit transaction.
**Example:**
```python
db.begin()
db.execute("CREATE (n:Person {name: 'Alice'})")
db.commit() # or db.rollback()
```
#### `commit()`
Commit the current transaction. Saves changes to disk if using persistence.
**Raises:** `RuntimeError` if not in a transaction
#### `rollback()`
Roll back the current transaction. Reverts all changes made since `begin()`.
**Raises:** `RuntimeError` if not in a transaction
#### `close()`
Save graph and close database. Safe to call multiple times.
**Example:**
```python
db = GraphForge("my-graph.db")
# ... make changes ...
db.close() # Saves to disk
```
### Accessing Result Values
Query results contain `CypherValue` objects. Access the underlying Python value with `.value`:
```python
results = db.execute("MATCH (p:Person) RETURN p.name AS name, p.age AS age")
for row in results:
name = row['name'].value # str
age = row['age'].value # int
print(f"{name} is {age} years old")
```
**Supported Value Types:**
- `CypherString`: Python `str`
- `CypherInt`: Python `int`
- `CypherFloat`: Python `float`
- `CypherBool`: Python `bool`
- `CypherNull`: Python `None`
- `CypherList`: Python `list` (nested CypherValues)
- `CypherMap`: Python `dict` (string keys, CypherValue values)
- `CypherPoint`: Spatial point with coordinates
- `CypherDistance`: Distance between points
- `CypherDate`: Date (year, month, day)
- `CypherDateTime`: Date and time with timezone
- `CypherTime`: Time of day
- `CypherDuration`: Time duration (years, months, days, hours, etc.)
---
## Cypher Query Language
GraphForge supports a subset of openCypher for declarative graph queries and mutations.
### MATCH - Pattern Matching
Find nodes and relationships matching a pattern.
```cypher
-- Match all nodes
MATCH (n)
RETURN n
-- Match nodes by label
MATCH (p:Person)
RETURN p.name
-- Match with multiple labels
MATCH (p:Person:Employee)
RETURN p
-- Match relationships
MATCH (a:Person)-[r:KNOWS]->(b:Person)
RETURN a.name, b.name, r.since
-- Match specific direction
MATCH (a)-[:FOLLOWS]->(b) -- Outgoing
MATCH (a)<-[:FOLLOWS]-(b) -- Incoming
MATCH (a)-[:FOLLOWS]-(b) -- Either direction
-- Multiple relationship types
MATCH (a)-[r:KNOWS|LIKES]->(b)
RETURN type(r), a.name, b.name
```
### WHERE - Filtering
Filter matched patterns with predicates.
```cypher
-- Property comparisons
MATCH (p:Person)
WHERE p.age > 30
RETURN p.name
-- Logical operators
MATCH (p:Person)
WHERE p.age > 25 AND p.city = 'NYC'
RETURN p.name
MATCH (p:Person)
WHERE p.age < 30 OR p.active = true
RETURN p.name
-- Property existence (returns false for null)
MATCH (p:Person)
WHERE p.email <> null
RETURN p.name
```
### RETURN - Projection
Select and transform query results.
```cypher
-- Return specific properties
MATCH (p:Person)
RETURN p.name, p.age
-- With aliases
MATCH (p:Person)
RETURN p.name AS person_name, p.age AS person_age
-- Return entire nodes/relationships
MATCH (p:Person)-[r:KNOWS]->(friend)
RETURN p, r, friend
```
### CREATE - Graph Construction
Create new nodes and relationships.
```cypher
-- Create single node
CREATE (n:Person {name: 'Alice', age: 30})
-- Create multiple nodes
CREATE (a:Person {name: 'Alice'}), (b:Person {name: 'Bob'})
-- Create nodes with relationship
CREATE (a:Person {name: 'Alice'})-[r:KNOWS {since: 2020}]->(b:Person {name: 'Bob'})
-- Create with RETURN
CREATE (n:Person {name: 'Alice'})
RETURN n.name AS name
```
### SET - Update Properties
Update properties on existing nodes and relationships.
```cypher
-- Update single property
MATCH (p:Person {name: 'Alice'})
SET p.age = 31
-- Update multiple properties
MATCH (p:Person {name: 'Alice'})
SET p.age = 31, p.city = 'NYC', p.active = true
-- Update relationship properties
MATCH (a)-[r:KNOWS]->(b)
WHERE a.name = 'Alice'
SET r.strength = 'strong'
```
### DELETE - Remove Elements
Delete nodes and relationships.
```cypher
-- Delete specific node (and its relationships)
MATCH (p:Person {name: 'Alice'})
DELETE p
-- Delete relationship only
MATCH (a)-[r:KNOWS]->(b)
WHERE a.name = 'Alice' AND b.name = 'Bob'
DELETE r
-- Delete multiple elements
MATCH (a)-[r:KNOWS]->(b)
WHERE b.name = 'Bob'
DELETE r, b
```
### MERGE - Idempotent Creation
Create nodes if they don't exist, or match existing ones.
```cypher
-- Create or match
MERGE (p:Person {name: 'Alice'})
-- Always matches same node (idempotent)
MERGE (p:Person {name: 'Alice', age: 30})
MERGE (p:Person {name: 'Alice', age: 30})
-- Results in only 1 node
-- With RETURN
MERGE (p:Person {name: 'Alice'})
RETURN p.name
```
### ORDER BY - Sorting
Sort query results.
```cypher
-- Ascending (default)
MATCH (p:Person)
RETURN p.name, p.age
ORDER BY p.age
-- Descending
MATCH (p:Person)
RETURN p.name, p.age
ORDER BY p.age DESC
-- Multiple sort keys
MATCH (p:Person)
RETURN p.name, p.age, p.city
ORDER BY p.city ASC, p.age DESC
```
### LIMIT and SKIP - Pagination
Limit and paginate results.
```cypher
-- Get first 10 results
MATCH (p:Person)
RETURN p.name
ORDER BY p.name
LIMIT 10
-- Skip first 20, return next 10
MATCH (p:Person)
RETURN p.name
ORDER BY p.name
SKIP 20
LIMIT 10
```
### Aggregations
Compute aggregate functions over groups.
```cypher
-- Count all
MATCH (p:Person)
RETURN count(*) AS total
-- Count with grouping
MATCH (p:Person)
RETURN p.city, count(*) AS population
ORDER BY population DESC
-- Multiple aggregations
MATCH (p:Person)
RETURN
count(*) AS total,
sum(p.age) AS total_age,
avg(p.age) AS avg_age,
min(p.age) AS youngest,
max(p.age) AS oldest
-- Aggregation with WHERE
MATCH (p:Person)
WHERE p.active = true
RETURN p.department, count(*) AS active_count
```
**Supported Functions:**
- `count(*)` - Count all rows
- `count(expr)` - Count non-null values
- `sum(expr)` - Sum numeric values
- `avg(expr)` - Average of numeric values
- `min(expr)` - Minimum value
- `max(expr)` - Maximum value
---
## Usage Patterns
### Pattern 1: Exploratory Analysis
Use in-memory graphs for quick exploration, then persist interesting results.
```python
# Start with in-memory for speed
db = GraphForge()
# Load and explore data
db.execute("CREATE (:Author {name: 'Alice', h_index: 42})")
db.execute("CREATE (:Author {name: 'Bob', h_index: 38})")
# ... load more data ...
# Explore interactively
results = db.execute("""
MATCH (a:Author)
WHERE a.h_index > 40
RETURN a.name, a.h_index
ORDER BY a.h_index DESC
""")
# If analysis is valuable, save it
if len(results) > 0:
db_persistent = GraphForge("high-impact-authors.db")
# Copy relevant subgraph...
db_persistent.close()
```
### Pattern 2: Incremental Construction
Build graphs incrementally across sessions.
```python
# Session 1: Initial data
db = GraphForge("knowledge-graph.db")
db.execute("CREATE (:Concept {name: 'Machine Learning'})")
db.close()
# Session 2: Add related concepts
db = GraphForge("knowledge-graph.db")
db.execute("""
MATCH (ml:Concept {name: 'Machine Learning'})
CREATE (dl:Concept {name: 'Deep Learning'})
CREATE (ml)-[:SPECIALIZES_TO]->(dl)
""")
db.close()
# Session 3: Add more relationships
db = GraphForge("knowledge-graph.db")
db.execute("""
MATCH (dl:Concept {name: 'Deep Learning'})
CREATE (cv:Concept {name: 'Computer Vision'})
CREATE (dl)-[:APPLIED_IN]->(cv)
""")
db.close()
```
### Pattern 3: Transactional Updates
Use transactions for atomic updates.
```python
db = GraphForge("production-graph.db")
try:
db.begin()
# Update multiple related entities
db.execute("MATCH (p:Person {id: 123}) SET p.status = 'inactive'")
db.execute("MATCH (p:Person {id: 123})-[r:WORKS_AT]->() DELETE r")
db.execute("CREATE (:AuditLog {action: 'deactivate', user_id: 123, timestamp: 1234567890})")
db.commit()
except Exception as e:
db.rollback()
print(f"Transaction failed: {e}")
finally:
db.close()
```
### Pattern 4: ETL Pipelines
Extract, transform, and load data into graph format.
```python
import pandas as pd
# Load tabular data
papers = pd.read_csv("papers.csv")
citations = pd.read_csv("citations.csv")
# Transform to graph
db = GraphForge("citation-network.db")
# Create nodes from DataFrame
for _, row in papers.iterrows():
db.execute("""
CREATE (:Paper {
id: $id,
title: $title,
year: $year,
citations: $citations
})
""", {'id': row['id'], 'title': row['title'],
'year': int(row['year']), 'citations': int(row['citation_count'])})
# Create relationships from edges DataFrame
for _, row in citations.iterrows():
db.execute("""
MATCH (citing:Paper {id: $citing_id})
MATCH (cited:Paper {id: $cited_id})
CREATE (citing)-[:CITES]->(cited)
""", {'citing_id': row['citing_paper'], 'cited_id': row['cited_paper']})
db.close()
```
### Pattern 5: Testing and Validation
Use transactions for isolated testing.
```python
def test_graph_algorithm():
db = GraphForge()
# Setup test data
db.execute("CREATE (a:Node {id: 1})-[:LINKS]->(b:Node {id: 2})")
db.execute("CREATE (b)-[:LINKS]->(c:Node {id: 3})")
# Test query
results = db.execute("""
MATCH path = (a:Node {id: 1})-[:LINKS*]->(c:Node)
RETURN count(*) AS path_count
""")
assert results[0]['path_count'].value == 2
```
---
## Examples
### Example 1: Social Network Analysis
```python
from graphforge import GraphForge
# Create social network
db = GraphForge("social-network.db")
# Add people
people = [
("Alice", 30, "NYC"),
("Bob", 25, "NYC"),
("Charlie", 35, "LA"),
("Diana", 28, "NYC"),
]
for name, age, city in people:
db.execute(f"""
CREATE (:Person {{name: '{name}', age: {age}, city: '{city}'}})
""")
# Add friendships
friendships = [
("Alice", "Bob", 2015),
("Alice", "Charlie", 2018),
("Bob", "Diana", 2019),
("Charlie", "Diana", 2020),
]
for person1, person2, since in friendships:
db.execute(f"""
MATCH (a:Person {{name: '{person1}'}})
MATCH (b:Person {{name: '{person2}'}})
CREATE (a)-[:KNOWS {{since: {since}}}]->(b)
""")
# Analysis: Who has the most friends?
results = db.execute("""
MATCH (p:Person)-[:KNOWS]-(friend:Person)
RETURN p.name AS person, count(DISTINCT friend) AS friend_count
ORDER BY friend_count DESC
""")
print("Friend counts:")
for row in results:
print(f" {row['person'].value}: {row['friend_count'].value} friends")
# Analysis: People in NYC who know each other
results = db.execute("""
MATCH (a:Person)-[:KNOWS]-(b:Person)
WHERE a.city = 'NYC' AND b.city = 'NYC'
RETURN DISTINCT a.name AS person1, b.name AS person2
""")
print("\nNYC connections:")
for row in results:
print(f" {row['person1'].value} ↔ {row['person2'].value}")
db.close()
```
### Example 2: Document Citation Network
```python
from graphforge import GraphForge
db = GraphForge("citations.db")
# Create papers
papers = [
("P1", "Graph Neural Networks", 2021, "Smith"),
("P2", "Deep Learning Fundamentals", 2019, "Jones"),
("P3", "GNN Applications", 2022, "Smith"),
]
for paper_id, title, year, author in papers:
db.execute("""
MERGE (p:Paper {id: $id})
SET p.title = $title, p.year = $year
MERGE (a:Author {name: $author})
CREATE (a)-[:AUTHORED]->(p)
""", {'id': paper_id, 'title': title, 'year': year, 'author': author})
# Add citations
db.execute("""
MATCH (p1:Paper {id: 'P3'})
MATCH (p2:Paper {id: 'P1'})
CREATE (p1)-[:CITES]->(p2)
""")
db.execute("""
MATCH (p1:Paper {id: 'P1'})
MATCH (p2:Paper {id: 'P2'})
CREATE (p1)-[:CITES]->(p2)
""")
# Find most cited papers
results = db.execute("""
MATCH (p:Paper)<-[:CITES]-(citing:Paper)
RETURN p.title AS paper, count(citing) AS citation_count
ORDER BY citation_count DESC
""")
print("Most cited papers:")
for row in results:
print(f" {row['paper'].value}: {row['citation_count'].value} citations")
# Find papers by prolific authors
results = db.execute("""
MATCH (a:Author)-[:AUTHORED]->(p:Paper)
RETURN a.name AS author, count(p) AS paper_count
ORDER BY paper_count DESC
""")
print("\nAuthor productivity:")
for row in results:
print(f" {row['author'].value}: {row['paper_count'].value} papers")
db.close()
```
### Example 3: Knowledge Graph from LLM Output
```python
from graphforge import GraphForge
import json
db = GraphForge("knowledge-graph.db")
# Simulated LLM extraction result
llm_output = {
"entities": [
{"name": "Python", "type": "Language", "properties": {"paradigm": "multi"}},
{"name": "Java", "type": "Language", "properties": {"paradigm": "OOP"}},
{"name": "Django", "type": "Framework", "properties": {"category": "web"}},
],
"relationships": [
{"source": "Django", "target": "Python", "type": "WRITTEN_IN"},
{"source": "Python", "target": "Java", "type": "INFLUENCED_BY"},
]
}
# Import entities
for entity in llm_output["entities"]:
props_str = ", ".join([f"{k}: '{v}'" for k, v in entity["properties"].items()])
db.execute(f"""
CREATE (:{entity['type']} {{name: '{entity['name']}', {props_str}}})
""")
# Import relationships
for rel in llm_output["relationships"]:
db.execute(f"""
MATCH (source {{name: '{rel['source']}'}})
MATCH (target {{name: '{rel['target']}'}})
CREATE (source)-[:{rel['type']}]->(target)
""")
# Query the knowledge graph
results = db.execute("""
MATCH (f:Framework)-[:WRITTEN_IN]->(l:Language)
RETURN f.name AS framework, l.name AS language
""")
print("Frameworks and their languages:")
for row in results:
print(f" {row['framework'].value} is written in {row['language'].value}")
# Find influence chains
results = db.execute("""
MATCH (a:Language)-[:INFLUENCED_BY]->(b:Language)
RETURN a.name AS language, b.name AS influenced_by
""")
print("\nLanguage influences:")
for row in results:
print(f" {row['language'].value} was influenced by {row['influenced_by'].value}")
db.close()
```
---
## Advanced Features
### Transaction Isolation
Transactions provide snapshot isolation—queries within a transaction see uncommitted changes.
```python
db = GraphForge("test.db")
db.execute("CREATE (:Person {name: 'Alice'})")
db.begin()
db.execute("CREATE (:Person {name: 'Bob'})")
# Query sees uncommitted Bob
results = db.execute("MATCH (p:Person) RETURN count(*) AS count")
print(results[0]['count'].value) # 2
db.rollback()
# After rollback, Bob is gone
results = db.execute("MATCH (p:Person) RETURN count(*) AS count")
print(results[0]['count'].value) # 1
```
### Deep Property Access
Access nested properties in complex structures.
```python
db.execute("""
CREATE (:Document {
metadata: {
author: 'Alice',
tags: ['ML', 'Python'],
version: {major: 1, minor: 2}
}
})
""")
results = db.execute("""
MATCH (d:Document)
RETURN d.metadata AS metadata
""")
metadata = results[0]['metadata'].value
print(metadata['author'].value) # 'Alice'
print(metadata['tags'].value[0].value) # 'ML'
print(metadata['version'].value['major'].value) # 1
```
### Dataset Import and Export
GraphForge supports multiple dataset formats and compression schemes:
**Supported Loaders:**
- **CSV**: Edge-list format (SNAP datasets)
- **Cypher**: Cypher script format (LDBC datasets)
- **GraphML**: XML-based format with type-aware parsing (NetworkRepository)
- **JSON Graph**: JSON interchange format for graph data
**Supported Compression:**
- `.tar.gz` - Gzip compressed tar archives
- `.tar.zst` - Zstandard compressed tar archives (LDBC)
- `.zip` - Zip archives (NetworkRepository)
- Direct `.graphml` files
**Example: Load from various sources**
```python
from graphforge import GraphForge
from graphforge.datasets import load_dataset
db = GraphForge()
# Load pre-registered dataset (auto-detects format)
load_dataset(db, "snap-email-enron") # CSV format
load_dataset(db, "ldbc-snb-sf0.1") # Cypher script format
load_dataset(db, "netrepo-karate") # GraphML format
# Load from direct URLs
load_dataset(db, "https://nrvis.com/download/data/labeled/karate.zip")
# All formats support automatic caching
```
### Graph Export
Export subgraphs for sharing or archival.
```python
def export_subgraph(db, query, output_file):
"""Export query results to JSON."""
results = db.execute(query)
nodes = set()
edges = []
for row in results:
# Extract nodes and relationships from result
# (Implementation depends on your export format)
pass
with open(output_file, 'w') as f:
json.dump({'nodes': list(nodes), 'edges': edges}, f)
# Export high-impact authors
export_subgraph(
db,
"MATCH (a:Author) WHERE a.h_index > 40 RETURN a",
"high-impact-authors.json"
)
```
---
## Design Principles
### Spec-Driven Correctness
GraphForge prioritizes **semantic correctness** over raw performance. All query behavior is validated against the openCypher TCK (Technology Compatibility Kit).
**What this means:**
- Queries behave predictably and correctly
- Null handling follows openCypher semantics
- Aggregations produce deterministic results
- Type coercion is explicit and safe
### Deterministic & Reproducible
GraphForge produces **stable, reproducible results** across runs.
**What this means:**
- Same query on same data always produces same results
- Transaction isolation guarantees snapshot consistency
- No hidden state or random behavior
- Ideal for scientific workflows and testing
### Inspectable
GraphForge makes query execution **observable and debuggable**.
**What this means:**
- Query plans can be inspected (future feature)
- Storage layout is simple SQLite (readable with any SQLite tool)
- Execution behavior is predictable and traceable
- No magic or hidden optimizations
### Replaceable Internals
GraphForge components are **modular and replaceable**.
**What this means:**
- Parser, planner, executor, storage are independent
- SQLite backend can be swapped for other storage
- Minimal operational dependencies
- Zero configuration required
---
## Architecture
GraphForge is built in four layers:
```
┌─────────────────────────────────┐
│ Parser (Lark + AST) │ Cypher → Abstract Syntax Tree
├─────────────────────────────────┤
│ Planner (Logical Operators) │ AST → Logical Plan
├─────────────────────────────────┤
│ Executor (Pipeline Engine) │ Plan → Results
├─────────────────────────────────┤
│ Storage (Graph + SQLite) │ In-Memory + Persistence
└─────────────────────────────────┘
```
**Parser:** Lark-based openCypher parser with full AST generation
**Planner:** Logical plan generation (ScanNodes, ExpandEdges, Filter, Project, Sort, Aggregate)
**Executor:** Pipeline-based query execution with streaming rows
**Storage:** Dual-mode storage—in-memory graphs with optional SQLite persistence
### Storage Backend
GraphForge uses SQLite with Write-Ahead Logging (WAL) for durability:
- **ACID guarantees**: Atomicity, Consistency, Isolation, Durability
- **Zero configuration**: No server setup or connection management
- **Single-file databases**: Easy to version control and share
- **Concurrent reads**: Multiple readers, single writer
- **MessagePack serialization**: Efficient binary encoding for complex types
The architecture prioritizes **correctness** and **developer experience** over raw performance, with all components designed to be testable, inspectable, and replaceable.
---
## Performance Characteristics
GraphForge is optimized for **interactive analysis** on small-to-medium graphs (thousands to millions of nodes).
**Expected Performance:**
- Node/edge creation: ~10-50K operations/sec (in-memory)
- Simple traversals: ~100K-1M edges/sec
- Complex queries: Depends on query complexity and graph size
- Persistence overhead: ~2-5x slower than in-memory
**When to Use GraphForge:**
- Graphs with < 10M nodes
- Interactive analysis in notebooks
- Iterative graph construction
- Research and exploration workflows
**When NOT to Use GraphForge:**
- Production applications requiring high throughput
- Graphs with > 100M nodes
- Real-time query serving
- Multi-user concurrent writes
For production workloads, consider Neo4j, Memgraph, or other production graph databases.
---
## Roadmap
**Completed (v0.3.0 - Full Dataset Integration):**
- ✅ MATCH, WHERE, RETURN, ORDER BY, LIMIT, SKIP, WITH
- ✅ Aggregations (COUNT, SUM, AVG, MIN, MAX, COLLECT)
- ✅ CREATE, SET, DELETE, MERGE, REMOVE clauses
- ✅ UNWIND for list iteration
- ✅ CASE expressions and arithmetic operators (+, -, *, /, %)
- ✅ String matching (STARTS WITH, ENDS WITH, CONTAINS)
- ✅ Spatial types (Point, Distance) with automatic detection in Python API
- ✅ Temporal types (Date, DateTime, Time, Duration)
- ✅ Graph introspection functions (id, labels, type)
- ✅ Python builder API with full type support
- ✅ SQLite persistence with ACID transactions
- ✅ 115+ datasets (95 SNAP + 10 LDBC + 10 NetworkRepository)
- ✅ Dynamic dataset loading via URL
- ✅ GraphML loader with type-aware parsing
- ✅ Compression support (.tar.gz, .tar.zst, .zip)
- ✅ 1,277/7,722 TCK scenarios (16.5%)
**Planned (v0.4.0 - Advanced Patterns):**
- ⏳ Variable-length patterns `-[*1..5]->` ([#24](https://github.com/DecisionNerd/graphforge/issues/24))
- ⏳ OPTIONAL MATCH (left outer joins)
- ⏳ List comprehensions `[x IN list WHERE ...]`
- ⏳ Subqueries (EXISTS, COUNT)
- ⏳ UNION / UNION ALL
- 🎯 Target: ~1,500 TCK scenarios (~39%)
**Future Considerations:**
- v0.5+: Additional functions, performance optimization
- v1.0: Full OpenCypher (>99% TCK compliance - complete production platform)
- Query plan visualization and EXPLAIN
- Performance profiling tools
- Modern APIs (REST, GraphQL, WebSocket)
- Analytical integrations (NetworkX, iGraph, QuantumFusion)
- Ontology support and schema validation
**See [OpenCypher Compatibility](docs/reference/opencypher-compatibility.md) for detailed feature matrix.**
---
## Cypher Compatibility
GraphForge implements a **practical subset of OpenCypher** focused on common graph operations. It is **not** a full OpenCypher implementation.
### ✅ Supported (v0.2.0)
**Reading & Writing:**
- MATCH, WHERE, RETURN, WITH, ORDER BY, LIMIT, SKIP
- CREATE, SET, DELETE, REMOVE, MERGE, DETACH DELETE
- Pattern matching (nodes and relationships)
- Property filtering and updates
**Expressions:**
- CASE expressions (conditional logic)
- Arithmetic operators: +, -, *, /, %, ^ (power)
- Comparison operators: =, <>, <, >, <=, >=
- Logical operators: AND, OR, XOR, NOT
- String matching: STARTS WITH, ENDS WITH, CONTAINS
- List operations: Slicing `[start..end]`, negative indexing `list[-1]`
**Aggregations:**
- COUNT, SUM, AVG, MIN, MAX, COLLECT
- Implicit GROUP BY
- DISTINCT modifier
**Functions:**
- String: length, substring, toUpper/toLower (both camelCase and UPPERCASE variants), trim, reverse, split, replace, left, right, ltrim, rtrim
- Type conversion: toInteger, toFloat, toString, toBoolean
- Spatial: point, distance
- Temporal: date, datetime, time, duration
- Graph: id, labels, type
- Predicates: all, any, none, single, exists, isEmpty
- Utility: coalesce
**Data Types:**
- Primitives: Integer, float, string, boolean, null
- Collections: Lists, maps (nested structures)
- Spatial types: Point (cartesian, geographic), Distance
- Temporal types: Date, DateTime, Time, Duration
- Graph elements: Nodes, relationships
**Other:**
- UNWIND (list iteration)
- List and map literals
- NULL handling with ternary logic
### ⏳ Planned (v0.3+)
- OPTIONAL MATCH (left outer joins)
- Variable-length patterns: `-[*1..5]->`
- List comprehensions: `[x IN list WHERE ...]`
- Subqueries: EXISTS, COUNT
- UNION / UNION ALL
- 50+ additional functions
### ❌ Out of Scope
- Full-text search and advanced indexing
- Multi-database features
- User management / security
- Stored procedures and user-defined functions
- Distributed queries and sharding
### TCK Compliance
GraphForge tracks compliance using the openCypher Technology Compatibility Kit (TCK):
| Version | Scenarios | Percentage |
|---------|-----------|------------|
| v0.1.4 | 1,277/7,722 | 16.5% |
| v0.2.0 | ~1,900/7,722 | ~25% |
| v0.3.0 | ~3,000/7,722 | ~39% |
| v0.4.0 (target) | ~4,250/7,722 | ~55% |
| v0.5.0 (target) | ~5,400/7,722 | ~70% |
| v0.6.0 (target) | ~6,300/7,722 | ~82% |
| v0.7.0 (target) | ~7,100/7,722 | ~92% |
| v1.0 (target) | >7,650/7,722 | >99% |
**See [OpenCypher Compatibility](docs/reference/opencypher-compatibility.md) for complete details.**
---
## Contributing
GraphForge is in active development. Contributions are welcome!
### Devel | text/markdown | David Spencer | null | null | null | MIT | analysis, graph, opencypher, pydantic | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"defusedxml>=0.7.1",
"isodate>=0.6.1",
"lark>=1.1",
"msgpack>=1.0",
"pydantic>=2.6",
"python-dateutil>=2.8.2",
"pyyaml>=6.0.3",
"hypothesis>=6.0; extra == \"dev\"",
"pytest-bdd>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest-mock>=3.0; extra == \"dev\"",
"pytest-timeout>=... | [] | [] | [] | [
"Homepage, https://github.com/DecisionNerd/graphforge",
"Repository, https://github.com/DecisionNerd/graphforge",
"Issues, https://github.com/DecisionNerd/graphforge/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T17:16:41.102160 | graphforge-0.3.5.tar.gz | 1,076,338 | c8/e1/ec4bc9e1ac229c59f87039284438a69ac59d4d3c98ee51249913faa1f715/graphforge-0.3.5.tar.gz | source | sdist | null | false | 78ac04980a805d329c086dee47ec70b0 | c755ab6ea3cb5851f816d36008676f2cb0b2cb5dd0ac472cc4e5abcc33cbeafe | c8e1ec4bc9e1ac229c59f87039284438a69ac59d4d3c98ee51249913faa1f715 | null | [
"LICENSE"
] | 222 |
2.4 | onnxruntime | 1.24.2 | ONNX Runtime is a runtime accelerator for Machine Learning models | ONNX Runtime
============
ONNX Runtime is a performance-focused scoring engine for Open Neural Network Exchange (ONNX) models.
For more information on ONNX Runtime, please see `aka.ms/onnxruntime <https://aka.ms/onnxruntime/>`_ or the `Github project <https://github.com/microsoft/onnxruntime/>`_.
Changes
-------
1.24.2
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.24.2
1.24.1
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.24.1
1.23.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.23.0
1.22.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.22.0
1.21.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.21.0
1.20.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.20.0
1.19.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.19.0
1.18.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.18.0
1.17.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.17.0
1.16.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.16.0
1.15.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.15.0
1.14.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.14.0
1.13.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.13.0
1.12.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.12.0
1.11.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.11.0
1.10.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.10.0
1.9.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.9.0
1.8.2
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.8.2
1.8.1
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.8.1
1.8.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.8.0
1.7.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.7.0
1.6.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.6.0
1.5.3
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.5.3
1.5.2
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.5.2
1.5.1
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.5.1
1.4.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.4.0
1.3.1
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.3.1
1.3.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.3.0
1.2.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.2.0
1.1.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.1.0
1.0.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.0.0
0.5.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v0.5.0
0.4.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v0.4.0
| null | Microsoft Corporation | onnxruntime@microsoft.com | null | null | MIT License | onnx machine learning | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: POSIX :: Linux",
"Operating System :: Microsoft :: Windows",
"Operating System :: MacOS",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering... | [] | https://onnxruntime.ai | https://github.com/microsoft/onnxruntime/tags | >=3.10 | [] | [] | [] | [
"flatbuffers",
"numpy>=1.21.6",
"packaging",
"protobuf",
"sympy"
] | [] | [] | [] | [] | RestSharp/106.13.0.0 | 2026-02-19T17:15:14.297154 | onnxruntime-1.24.2-cp312-cp312-macosx_14_0_arm64.whl | 17,217,857 | 23/1c/38af1cfe82c75d2b205eb5019834b0f2b0b6647ec8a20a3086168e413570/onnxruntime-1.24.2-cp312-cp312-macosx_14_0_arm64.whl | py3 | bdist_wheel | null | false | 1c9202a16ef7d805e63df725ce0957d0 | d8a50b422d45c0144864c0977d04ad4fa50a8a48e5153056ab1f7d06ea9fc3e2 | 231c38af1cfe82c75d2b205eb5019834b0f2b0b6647ec8a20a3086168e413570 | null | [] | 886,120 |
2.4 | lyroi | 0.1.3 | LyROI - nnU-Net-based Lymphoma Total Metabolic Tumor Volume Segmentation | # LyROI – nnU-Net-based Lymphoma Total Metabolic Tumor Volume Delineation
[](https://pypi.org/project/lyroi/)
[](https://doi.org/10.14278/rodare.4160)
[](https://github.com/hzdr-MedImaging/LyROI/blob/master/LICENSE)
[](https://github.com/hzdr-MedImaging/LyROI/blob/master/MODEL_LICENSE.md)
> [!IMPORTANT]
> **Regulatory status:** This software and the bundled model are intended **solely for research and development (R&D)**.
> They are **not** intended for primary diagnosis, therapy, or any other clinical decision-making and must **not** be used
> as a medical device.
## Overview
**Ly**mphoma **ROI** prediction framework (**LyROI**) is a collection of neural network models and support tools for
metabolic tumor volume delineation in (Non-Hodgkin) lymphoma patients in FDG-PET/CT images.
A comprehensive description of development and evaluation of the models is given in the respective [paper](DOI:XXX).
Briefly, the models were trained with the [nnU-Net](https://github.com/MIC-DKFZ/nnUNet) software package. A total of
1192 FDG-PET/CT scans from 716 patients with Non-Hodgkin
lymphoma participating in the [PETAL](https://doi.org/10.1200/jco.2017.76.8093) trial comprised the training dataset.
The ground truth delineation included all lesions (irrespective of size or uptake) that were clinically considered as
lymphoma manifestations by an experienced observer. It was developed iteratively with the assistance of intermediate CNN
models. Accurate contouring of each lesion was achieved by selecting the most appropriate semi-automated delineation
algorithm, manually adjusting its settings, and performing manual corrections when necessary.
Training and testing were performed following a 5-fold cross-validation scheme. Three configurations of the nnU-Net were
used for training: regular U-Net, residual encoder U-Net (8 GB GPU memory target), and large residual encoder U-Net
(24 GB GPU memory target).
They can be installed as described below and used separately, however, their use in an ensemble (merging individual
outputs via union operation) is recommended to maximize lesion detection sensitivity.
The collection of the trained models can be found here:
[](https://doi.org/10.14278/rodare.4160)
List of available models:
- `LyROI_Orig.zip`: regular U-Net
- `LyROI_ResM.zip`: residual encoder U-Net (medium)
- `LyROI_ResL.zip`: residual encoder U-Net (large)
[Scripts](scripts/) subfolder
provides example code snippets to execute the prediction with each model and merge the resulting delineations when using
directly within existing nnU-Net installation. See [manual installation](#manual-installation-and-use) section for more
details.
For simplified workflow, LyROI is also available as a stand-alone tool, see [quick start](#quick-start) section for
usage and installation instructions.
Please cite [nnU-Net](https://www.nature.com/articles/s41592-020-01008-z) and the [following paper](DOI:XXX) when using
LyROI:
```
XXX
```
Special thanks to the PETAL study group for the access to the [PETAL](https://doi.org/10.1200/jco.2017.76.8093) trial dataset
for the network training and agreeing to share the resulting models.
## Quick Start
> [!IMPORTANT]
> Working within a dedicated virtual environment (`venv` or `conda`) is highly recommended.
>
> The exact instructions below are written for Linux operating system.
> You may need to adjust them slightly for setup in Windows.
> **Requirements**
> - `python` (>= 3.9)
> - [`pytorch`](https://pytorch.org/get-started/locally/) (>= 2.1.2)
1. Install `python` and `pytorch` (see requirements list above).
**Note: As of now, torch >=2.9.0 may lead to severe performance
reduction. Earlier versions are recommended.**
2. Install `lyroi` as a package (recommended):
```
pip install lyroi
```
or as modifiable copy (for experienced users):
```
git clone https://github.com/hzdr-MedImaging/LyROI.git
cd LyROI
pip install -e .
```
3. (OPTIONAL) To change the default model installation directory (default: `$HOME/.lyroi`), set the environment variable
`LYROI_DIR` to the desired location. See, e.g.
[here](https://www.freecodecamp.org/news/how-to-set-an-environment-variable-in-linux/) for guidance.
4. Download and install the model files:
```
lyroi_install
```
5. Run LyROI for
- all images in the `input_folder` (see [below](#data-format) for input data format) and output delineation in
`output_folder`:
```
lyroi -i input_folder -o output_folder
```
- a single patient with CT image `ct.nii.gz` and PET image `pet.nii.gz` (must be coregistered and have the same
matrix and voxel sizes) and output delineation to `roi.nii.gz`:
```
lyroi -i ct.nii.gz pet.nii.gz -o roi.nii.gz
```
Execution on a GPU-equipped workstation is highly recommended. In case if no GPU is available, use a flag `-d cpu` to force
run on CPU (can be **VERY** slow). Flag `-d cpu-max` can help with cpu performance by using all available
computational resources (may slow down other programs). `nnUNet_def_n_proc` environment variable can be set to limit
the number of utilized cpu cores in `cpu-max` mode.
## Manual Installation and Use
> **Requirements**
> - `python` (>= 3.9)
> - [`pytorch`](https://pytorch.org/get-started/locally/) (>= 2.1.2)
> - [`nnU-Net`](https://github.com/MIC-DKFZ/nnUNet/blob/dev/documentation/installation_instructions.md) (>= 2.5.2)
1. To download and install the models for each used nnU-Net configuration, execute:
```
nnUNetv2_install_pretrained_model_from_zip https://rodare.hzdr.de/record/4177/files/LyROI_Orig.zip
nnUNetv2_install_pretrained_model_from_zip https://rodare.hzdr.de/record/4177/files/LyROI_ResM.zip
nnUNetv2_install_pretrained_model_from_zip https://rodare.hzdr.de/record/4177/files/LyROI_ResL.zip
```
2. By default, the models will be installed in the folder ``$nnUNet_results/Dataset001_LyROI/``. This might create
conflicts if you already have a project with the number 001 in your ``$nnUNet_results`` folder. In this case, please
choose an unoccupied index ``XXX`` for the dataset and rename the LyROI folder to ``DatasetXXX_LyROI``.
3. Download all files in [scripts](scripts/) folder and put them in the same folder. If you changed the dataset index of
LyROI, edit the [predict.sh](scripts/predict.sh) file and change the ``dataset_id="001"`` line to
``dataset_id="XXX"``, where XXX is the new dataset index you selected.
4. Prepare the input data according to the instructions [below](#data-format).
5. Execute ``./predict.sh /path/to/your/folder/input_folder`` and wait for the process to complete. The resulting
delineations can be found in ``input_folder/pred/`` subfolder. If you want to keep the outputs of the intermediate
networks, comment out the last line in [predict.sh](scripts/predict.sh). Execution on a GPU-equipped workstation is
highly recommended. In case if no GPU is available, add a flag `-device cpu` to `nnUNetv2_predict` calls within the
script (can be **VERY** slow). Set `nnUNet_def_n_proc` environment variable to specify the number of cpu cores to use
for inference (set to the number of physical cpu cores for max performance).
## Data Format
The input data for batch processing should be presented in the nnU-Net compatible format
(see [here](https://github.com/MIC-DKFZ/nnUNet/blob/master/documentation/dataset_format_inference.md) for details).
Only compressed NIfTI (`.nii.gz`) images are currently supported. Corresponding CT and PET volumes must be coregistered
and have the same matrix and voxel sizes.
Input channels:
- `0000` is CT
- `0001` is PET
Here is an example of how the input folder can look like:
```
input_folder
├── lymph_20250101_0000.nii.gz
├── lymph_20250101_0001.nii.gz
├── pat01_0000.nii.gz
├── pat01_0001.nii.gz
├── rchop001_0000.nii.gz
├── rchop001_0001.nii.gz
├── ...
```
## Intended Purpose (Non-Medical)
- The software is intended for **algorithmic research, benchmarking, and method exploration** in lymphoma delineation.
- It is **not intended** to provide information for diagnostic or therapeutic purposes and **must not** be used in
clinical workflows.
- Do **not** deploy or advertise this software as a medical product or service.
## Disclaimer (Research Use Only – Not a Medical Device)
This software and any bundled or referenced model weights are provided **exclusively for research and development
purposes**. They are **not intended** for use in the diagnosis, cure, mitigation, treatment, or prevention of disease,
or for any other clinical decision-making.
- The software is **not** a medical device and is **not** CE-marked.
- No clinical performance, safety, or effectiveness is claimed or implied.
- Any results must not be used to guide patient management.
- Users are responsible for compliance with all applicable laws, regulations, and data protection requirements when
processing data.
THE SOFTWARE AND MODELS ARE PROVIDED “AS IS”, WITHOUT ANY WARRANTY, EXPRESS OR IMPLIED.
## Licenses
The **code** in this repository is licensed under **Apache-2.0** (see [`LICENSE`](LICENSE)).
The **model weights** are licensed under **CC-BY-SA-4.0** (see [`MODEL_LICENSE.md`](MODEL_LICENSE.md)).
## Third-Party Licenses
This project uses or interoperates with the following third-party components:
- **nnU-Net v2** – Copyright © respective authors.
- License: **Apache-2.0**
- **PyTorch**, **NumPy**, **Nibabel**, etc.
- Licensed under their respective open-source licenses.
Each third-party component is the property of its respective owners and is provided under its own license terms. Copies
of these licenses are available from the upstream projects.
| text/markdown | null | Pavel Nikulin <p.nikulin@hzdr.de>, Jens Maus <j.maus@hzdr.de> | null | null | null | deep learning, ai, lymphoma, pet, petct, tmtv, mtv, nnunet, lyroi, delineations, segmentation, cancer | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Intended Audience :: Healthcare Industry",
"Programming Language :: Python :: 3",
"Operating System :: Unix",
"Operating System :: Microsoft :: Windows",
"Topic :: Scientific/Engineering :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"torch>=2.1.2",
"numpy",
"acvl-utils==0.2",
"nnunetv2>=2.5.2",
"requests",
"nibabel",
"packaging",
"psutil"
] | [] | [] | [] | [
"Homepage, https://github.com/hzdr-MedImaging/LyROI",
"Documentation, https://github.com/hzdr-MedImaging/LyROI/blob/main/README.md",
"Source, https://github.com/hzdr-MedImaging/LyROI"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:15:09.510635 | lyroi-0.1.3.tar.gz | 21,614 | 6e/d9/476b2037487a541059dc098683f4db16511487a61c265ef1f70bd3afb30a/lyroi-0.1.3.tar.gz | source | sdist | null | false | a5684feba61ea10f32bf6436a3a0a22d | 4f7727233f8d2995f3620543637c1d1076f1ec16f86c45dc5597d08a4211d05a | 6ed9476b2037487a541059dc098683f4db16511487a61c265ef1f70bd3afb30a | Apache-2.0 | [
"LICENSE"
] | 225 |
2.4 | onnxruntime-qnn | 1.24.2 | ONNX Runtime is a runtime accelerator for Machine Learning models | ONNX Runtime
============
ONNX Runtime is a performance-focused scoring engine for Open Neural Network Exchange (ONNX) models.
For more information on ONNX Runtime, please see `aka.ms/onnxruntime <https://aka.ms/onnxruntime/>`_ or the `Github project <https://github.com/microsoft/onnxruntime/>`_.
Changes
-------
1.24.2
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.24.2
1.24.1
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.24.1
1.23.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.23.0
1.22.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.22.0
1.21.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.21.0
1.20.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.20.0
1.19.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.19.0
1.18.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.18.0
1.17.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.17.0
1.16.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.16.0
1.15.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.15.0
1.14.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.14.0
1.13.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.13.0
1.12.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.12.0
1.11.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.11.0
1.10.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.10.0
1.9.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.9.0
1.8.2
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.8.2
1.8.1
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.8.1
1.8.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.8.0
1.7.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.7.0
1.6.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.6.0
1.5.3
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.5.3
1.5.2
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.5.2
1.5.1
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.5.1
1.4.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.4.0
1.3.1
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.3.1
1.3.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.3.0
1.2.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.2.0
1.1.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.1.0
1.0.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.0.0
0.5.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v0.5.0
0.4.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v0.4.0
| null | Microsoft Corporation | onnxruntime@microsoft.com | null | null | MIT License | onnx machine learning | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: POSIX :: Linux",
"Operating System :: Microsoft :: Windows",
"Operating System :: MacOS",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering... | [] | https://onnxruntime.ai | https://github.com/microsoft/onnxruntime/tags | >=3.10 | [] | [] | [] | [
"flatbuffers",
"numpy>=1.21.6",
"packaging",
"protobuf",
"sympy"
] | [] | [] | [] | [] | RestSharp/106.13.0.0 | 2026-02-19T17:14:43.492504 | onnxruntime_qnn-1.24.2-cp314-cp314-win_amd64.whl | 104,579,851 | 46/23/956acac4c8e48034ac073f0cfc18939d8c1f3ce6a9b5ecc5e68c12dd91ec/onnxruntime_qnn-1.24.2-cp314-cp314-win_amd64.whl | py3 | bdist_wheel | null | false | d6067accc8185ffe539cfca6b2a9645c | d649adac592a22e0315a88f058bd220273690a51205f33e0f3ecba9af965dd8c | 4623956acac4c8e48034ac073f0cfc18939d8c1f3ce6a9b5ecc5e68c12dd91ec | null | [] | 638 |
2.4 | qnexus | 0.40.1 | Quantinuum Nexus python client. | # qnexus
[Quantinuum Nexus](https://nexus.quantinuum.com) python client.
```python
import qnexus as qnx
# Will open a browser window to login with Nexus credentials
qnx.login()
# Dataframe representation of all your pending jobs in Nexus
qnx.jobs.get_all(job_status=["SUBMITTED", "QUEUED", "RUNNING"]).df()
```
Full documentation available at https://docs.quantinuum.com/nexus
Copyright 2025 Quantinuum Ltd.
| text/markdown | null | Vanya Eccles <vanya.eccles@quantinuum.com>, Aidan Keay <aidan.keay@quantinuum.com>, John Children <john.children@quantinuum.com> | null | null | Apache License Version 2.0, January 2004 http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION 1. Definitions. "License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document. "Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License. "Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity. "You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License. "Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types. "Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below). "Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof. "Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution." "Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work. 2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form. 3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed. 4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions: (a) You must give any other recipients of the Work or Derivative Works a copy of this License; and (b) You must cause any modified files to carry prominent notices stating that You changed the files; and (c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and (d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License. 5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions. 6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file. 7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License. 8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages. 9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability. END OF TERMS AND CONDITIONS APPENDIX: How to apply the Apache License to your work. To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives. Copyright [yyyy] [name of copyright owner] Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. | null | [] | [] | null | null | <4,>=3.10 | [] | [] | [] | [
"click<9.0,>=8.1",
"colorama<1.0,>=0.4",
"httpx<1,>=0",
"hugr<1.0.0,>=0.14.0",
"nest-asyncio2<2.0,>=1.6",
"pandas<3,>=2",
"pydantic-settings<3.0,>=2",
"pydantic<3.0,>=2.4",
"pyjwt<3.0.0,>=2.10.1",
"pytket<3.0,>=2.3.1",
"quantinuum-schemas<8.0,>=7.4.1",
"rich<14.0,>=13.6",
"websockets<16,>11"... | [] | [] | [] | [
"homepage, https://github.com/CQCL/qnexus",
"repository, https://github.com/CQCL/qnexus",
"documentation, https://nexus.quantinuum.com/docs"
] | uv/0.6.6 | 2026-02-19T17:14:23.341353 | qnexus-0.40.1.tar.gz | 433,125 | ef/be/71c627ced1216ab6b95d6f054afeaff263f049695fb07ba94f9dba9d4c74/qnexus-0.40.1.tar.gz | source | sdist | null | false | b0f7528fa42d8f5b3a1d2c86b8d9953d | 4615c803507c419a0b8af46408d3468d49d3521a682e4373f64ca7f61074c7e2 | efbe71c627ced1216ab6b95d6f054afeaff263f049695fb07ba94f9dba9d4c74 | null | [
"LICENSE"
] | 631 |
2.4 | isoview-client | 0.2.0 | Python client for the ISOview energy forecasting API | # isoview-client
Python client for the [ISOview](https://isoview.io) energy forecasting API — demand, wind, solar, LMP, and natural gas forecasts across US ISOs, returned as pandas DataFrames.
## Installation
```bash
pip install isoview-client
```
Requires Python 3.10+. Installs `requests` and `pandas` as dependencies.
## Authentication
Sign up at [isoview.io](https://isoview.io) and grab your API key from the [Portal](https://isoview.io/portal/account?tab=api).
```python
from isoview import Client
client = Client("your-api-key")
```
## Quick Start
```python
from isoview import Client
client = Client("your-api-key")
# Get the latest PJM demand forecast
ts = client.get_regional_forecast("pjm", "demand")
# Convert to a pandas DataFrame
df = ts.to_df()
print(df.head())
```
Every forecast method returns a `TimeseriesResponse`. Call `.to_df()` to get a pandas DataFrame with a UTC DatetimeIndex and MultiIndex columns like `("pjm_total", "forecast")`. Pass `utc=False` for local time instead.
## Examples
### Regions
Forecasts for geographic regions within an ISO — demand, wind, solar, outages, and population-weighted temperature.
```python
# See what regions are available
regions = client.list_regions("pjm", "demand")
# Latest forecast for a specific region
ts = client.get_regional_forecast("pjm", "demand", id="pjm_total")
# Stitched historical forecast — what did the day-ahead forecast
# look like at 10am each day?
ts = client.get_regional_continuous_forecast(
"miso", "wind",
start="2025-01-01T00:00:00Z",
end="2025-06-01T00:00:00Z",
latest_hour=10,
days_ahead=1,
)
# Probabilistic ensemble forecast (multiple scenarios)
ts = client.get_regional_ensemble_forecast("pjm", "demand", id="pjm_total")
# Day-ahead backcast for model evaluation
ts = client.get_regional_backcast("pjm", "demand")
# Everything at once — demand, wind, solar, outages, temp, LMP
ts = client.get_iso_summary("pjm")
```
### Plants
Generation forecasts for individual wind and solar facilities.
```python
# Browse plants in ERCOT
plants = client.list_plants("ercot", "wind")
print(plants[0].name, plants[0].capacity_mw, "MW")
# Get a forecast
ts = client.get_plant_forecast("ercot", "wind", id=str(plants[0].id))
df = ts.to_df()
# Day-ahead backcast for plant-level model evaluation
ts = client.get_plant_backcast("ercot", "wind", id=str(plants[0].id))
```
### Counties
County-level electricity demand forecasts, disaggregated from regional data.
```python
counties = client.list_counties("isone")
ts = client.get_county_forecast("isone", id=counties[0].id)
```
### Gas
Natural gas price forecasts for major trading hubs.
```python
hubs = client.list_gas_hubs()
ts = client.get_gas_forecast(id=hubs[0].id)
```
### LMP
Locational Marginal Price forecasts for electricity market nodes.
```python
nodes = client.list_lmp_nodes("pjm", "dalmp")
ts = client.get_lmp_forecast("pjm", "dalmp", id=nodes[0].id)
```
## Working with Responses
### Timeseries
All forecast, continuous, ensemble, backcast, and summary endpoints return a `TimeseriesResponse`:
```python
ts = client.get_regional_forecast("pjm", "demand")
ts.model # 'optimized'
ts.created_at # datetime — when the forecast was generated
ts.units # 'MW'
ts.timezone # 'America/New_York'
# Convert to a pandas DataFrame (UTC index by default)
df = ts.to_df()
# Or use local time
df_local = ts.to_df(utc=False)
```
The DataFrame has a `DatetimeIndex` and `MultiIndex` columns (e.g. `("pjm_total", "forecast")`).
### Metadata
List endpoints return typed objects you can inspect directly:
```python
regions = client.list_regions("pjm", "demand")
for r in regions:
print(r.id, r.name, r.timezone)
plants = client.list_plants("ercot", "solar")
for p in plants:
print(p.name, f"{p.capacity_mw} MW", p.state)
```
## Supported ISOs
| Code | Name |
|------|------|
| `pjm` | PJM Interconnection |
| `miso` | Midcontinent ISO |
| `spp` | Southwest Power Pool |
| `ercot` | Electric Reliability Council of Texas |
| `caiso` | California ISO |
| `nyiso` | New York ISO |
| `isone` | ISO New England |
## Error Handling
The client raises `requests.HTTPError` on API errors (401, 403, 422, etc.):
```python
import requests
try:
ts = client.get_regional_forecast("pjm", "demand")
except requests.HTTPError as e:
print(e.response.status_code, e.response.text)
```
## Links
- [ISOview Portal](https://isoview.io/portal) — manage your account and API key
- [API Documentation](https://isoview.io/docs) — full reference for all endpoints
| text/markdown | null | null | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Py... | [] | null | null | >=3.10 | [] | [] | [] | [
"requests",
"pandas"
] | [] | [] | [] | [
"Homepage, https://isoview.io",
"Documentation, https://isoview.io/docs",
"Repository, https://github.com/isoview-io/isoview-client"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:14:13.218176 | isoview_client-0.2.0.tar.gz | 10,402 | d6/78/65875b128817fd743162bc0af31ba6aa421daafe6f9d3bb582f97708ca25/isoview_client-0.2.0.tar.gz | source | sdist | null | false | d56897aa26425ab4572407d7c15e510f | a3afe1936df974c5e628bc3caa0bbb7e9a083c9f61da240c3a49d30ce7c5d8e1 | d67865875b128817fd743162bc0af31ba6aa421daafe6f9d3bb582f97708ca25 | MIT | [
"LICENSE"
] | 222 |
2.4 | ai-24sea | 1.1.1 | A package containing general functionality for 24sea ai/ml related topics | # ai-24sea
A Python package for building, training, and managing AI/ML models for 24sea windfarm data. This repository provides a modular framework for data ingestion, preprocessing, splitting, training, and experiment tracking using MLflow.
## Features
- **Configurable ML Pipelines:** Easily define preprocessing, splitting, and training steps via configuration files.
- **Data Ingestion:** Fetch and aggregate windfarm data using the 24sea API.
- **Preprocessing:** Modular, reusable preprocessing functions for feature engineering and cleaning.
- **Train/Test Split:** Flexible splitting with support for custom strategies.
- **Model Training:** Standardized training flow with MLflow experiment tracking and signature enforcement.
- **Testing:** Comprehensive unit tests using `pytest` and `hypothesis`.
## Project Structure
```sh
├── LICENSE
├── README.md
├── VERSION
├── ai_24sea
│ ├── __init__.py
│ ├── modeler
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── constants.py
│ │ ├── misc
│ │ │ ├── __init__.py
│ │ │ ├── preprocessors.py
│ │ │ └── utils.py
│ │ └── tasks
│ │ ├── __init__.py
│ │ ├── ingest.py
│ │ ├── optimize.py
│ │ ├── split.py
│ │ ├── train.py
│ │ └── transform.py
│ └── version.py
├── bitbucket-pipelines.yml
├── bumpversion.py
├── notebooks
│ ├── tests.ipynb
│ └── tests.py
├── pyproject.toml
├── tests
│ ├── __init__.py
│ ├── conftest.py
│ ├── misc
│ │ ├── test_preprocessors.py
│ │ └── test_utils.py
│ ├── tasks
│ │ ├── test_ingest.py
│ │ ├── test_optimize.py
│ │ ├── test_split.py
│ │ ├── test_train.py
│ │ ├── test_transform.py
│ │ └── test_validate.py
│ ├── test_config.py
│ └── test_version.py
└── uv.lock
```
## Installation
This project uses `uv` for package management
To install:
```sh
uv sync
```
To install for development:
```sh
uv sync --all-groups
```
| text/markdown | null | Panagiotis Konis <panagiotis.konis@24sea.eu> | null | Panagiotis Konis <panagiotis.konis@24sea.eu> | null | null | [
"Development Status :: 1 - Planning",
"Environment :: Console",
"Intended Audience :: Science/Research",
"Intended Audience :: Information Technology",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Natural Language :: English",
"Operating System :: POSIX :: Linux",
"Programming ... | [] | null | null | <3.14,>=3.9.0 | [] | [] | [] | [
"api-24sea<3,>=2.1.1",
"prefect==3.3.6",
"pandas",
"numpy",
"mlflow>=3.1.4",
"psycopg2-binary",
"azure-storage-blob>=12.23.1",
"tabulate",
"markdown",
"omegaconf>=2.3.0"
] | [] | [] | [] | [
"Documentation, https://dev.azure.com/24sea/DataDevOps/_git/24sea_ai_modeler_cookiecutter",
"Homepage, https://www.24sea.eu/",
"Repository, https://dev.azure.com/24sea/DataDevOps/_git/24sea_ai_modeler_cookiecutter"
] | uv/0.9.30 {"installer":{"name":"uv","version":"0.9.30","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Debian GNU/Linux","version":"12","id":"bookworm","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T17:14:12.053064 | ai_24sea-1.1.1.tar.gz | 18,685 | 9e/73/5a57e53b2df63a95e79a7b400c5b0b7b6ce8fd46808aa6708053ee26eab7/ai_24sea-1.1.1.tar.gz | source | sdist | null | false | 96b999f047a96f795f4213a7c28bc264 | 8e77023d4be18ad4cd9944effd367e8be1872bc0650f6b3b663a9e3f20183405 | 9e735a57e53b2df63a95e79a7b400c5b0b7b6ce8fd46808aa6708053ee26eab7 | null | [
"LICENSE"
] | 235 |
2.1 | carconnectivity-database-by-m7xlab | 1.0.0 | CarConnectivity plugin for storing data to Databases |
# CarConnectivity Plugin for Database storage
[](https://github.com/tillsteinbach/CarConnectivity-plugin-database/)
[](https://github.com/tillsteinbach/CarConnectivity-plugin-database/releases/latest)
[](https://github.com/tillsteinbach/CarConnectivity-plugin-database/blob/master/LICENSE)
[](https://github.com/tillsteinbach/CarConnectivity-plugin-database/issues)
[](https://pypi.org/project/carconnectivity-plugin-database/)
[](https://pypi.org/project/carconnectivity-plugin-database/)
[](https://www.paypal.com/donate?hosted_button_id=2BVFF5GJ9SXAJ)
[](https://github.com/sponsors/tillsteinbach)
[CarConnectivity](https://github.com/tillsteinbach/CarConnectivity) is a python API to connect to various car services. If you want to store the data collected from your vehicle to a relational database (e.g. MySQL, PostgreSQL, or SQLite) this plugin will help you.
### Install using PIP
If you want to use the CarConnectivity Plugin for Databases, the easiest way is to obtain it from [PyPI](https://pypi.org/project/carconnectivity-plugin-database/). Just install it using:
```bash
pip3 install carconnectivity-plugin-database
```
after you installed CarConnectivity
## Configuration
In your carconnectivity.json configuration add a section for the database plugin like this. A documentation of all possible config options can be found [here](https://github.com/tillsteinbach/CarConnectivity-plugin-database/tree/main/doc/Config.md).
```
{
"carConnectivity": {
"connectors": [
...
]
"plugins": [
{
"type": "database",
"config": {
"db_url": "sqlite:///carconnectivity.db"
}
}
]
}
}
```
## Updates
If you want to update, the easiest way is:
```bash
pip3 install carconnectivity-plugin-database --upgrade
```
| text/markdown | Till Steinbach | null | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: End Users/Desktop",
"Intended Audience :: System Administrators",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming... | [] | null | null | >=3.9 | [] | [] | [] | [
"carconnectivity>=0.11.5",
"sqlalchemy~=2.0.45",
"psycopg2-binary~=2.9.11",
"alembic~=1.17.2",
"SQLAlchemy-Utc~=0.14.0",
"flask_sqlalchemy~=3.1.1"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.8.15 | 2026-02-19T17:14:09.438229 | carconnectivity_database_by_m7xlab-1.0.0.tar.gz | 45,983 | 46/ec/e9c6ac62e9d497f8064af4ba14164569ae61aef5b34999a00c2d54ebd51e/carconnectivity_database_by_m7xlab-1.0.0.tar.gz | source | sdist | null | false | 56368b7dee5e1a83e0bb69d2675e1cad | d24e51298e41f48092839007181a8375fd35446b90d142356fc623287fe1b6a2 | 46ece9c6ac62e9d497f8064af4ba14164569ae61aef5b34999a00c2d54ebd51e | null | [] | 247 |
2.1 | backant-cli | 0.7.1 | A CLI tool to generate backant backend projects | # Backant CLI
Backant CLI is a powerful Linux native command-line interface designed to streamline the development of Flask-based REST APIs. It automates the generation of a complete and scalable project structure, allowing developers to focus on business logic rather than boilerplate code.
## Key Features
- **Automated Project Scaffolding**: Generate a new Flask API with a single command, including a well-organized directory structure.
- **Layered Architecture**: The generated project follows a clean, layered architecture (Models, Repositories, Services, Routes) to promote separation of concerns and maintainability.
- **Database-Ready**: Includes SQLAlchemy for database modeling and interaction, with a pre-configured `DBSession` for easy database access.
- **Dockerized Environment**: Comes with `Dockerfile` and `docker-compose.yml` files for a consistent development and production environment.
- **Extensible by Design**: Easily add new routes, services, and models using the provided CLI commands.
- **Pre-configured for Deployment**: Includes a GitHub Actions workflow for building and pushing Docker images to Amazon ECR.
## Installation
### Ubuntu/Debian (Recommended)
Install the Backant CLI using the .deb package for Ubuntu/Debian systems:
```bash
# Download and install the .deb package
sudo dpkg -i backant-cli.deb
```
### Alternative: Python Package
You can also install using pip:
```bash
pip install backant-cli
```
## Getting Started
### Generating a New API
To create a new Flask API project, use the `generate api` command:
```bash
ant generate api <your_project_name>
```
This will create a new directory named `<your_project_name>` with the complete project structure.
### Generating API from JSON Specification
You can generate a complete API with routes and subroutes from a JSON specification using the `--json` option:
#### Using JSON String:
```bash
ant generate api my-project --json '{"routes": {"products": {"type": "GET", "subroutes": {"create": {"type": "POST"}}}}}'
```
#### Using JSON File:
```bash
ant generate api ecommerce --json api-spec.json
```
#### Additional Options:
- `--verbose` or `-v`: Show detailed generation progress
- `--dry-run`: Validate JSON specification without generating files
#### Examples:
```bash
# Generate API with verbose output
ant generate api shop --json api-spec.json --verbose
# Validate JSON specification without creating files
ant generate api test --json api.json --dry-run
```
#### JSON Specification Format:
The JSON specification should follow this structure:
```json
{
"routes": {
"route_name": {
"type": "GET|POST|PUT|DELETE",
"mock": {},
"subroutes": {
"subroute_name": {
"type": "GET|POST|PUT|DELETE",
"mock": {}
}
}
}
}
}
```
### Generating a New Route
Once you have a project, you can easily add new routes and their corresponding components (service, repository, model) with the `generate route` command:
```bash
ant generate route <your_route_name>
```
This command will automatically create:
- A new route in `api/routes/`
- A new service in `api/services/`
- A new repository in `api/repositories/`
- A new model in `api/models/`
### Generating a Mock Route
You can also generate a route with mock data for testing and development purposes. Use the `--mock` option with a JSON string or a path to a JSON file.
#### Using a JSON String:
```bash
ant generate route <your_route_name> --mock '{"key": "value", "another_key": "another_value"}'
```
#### Using a JSON File:
```bash
ant generate route <your_route_name> --mock /path/to/your/mock_data.json
```
This will generate the same files as the standard `generate route` command, but the service will return the provided JSON data.
## Project Structure
The generated project follows a structured and scalable architecture:
```
<your_project_name>/
├── api/
│ ├── apis/ # For third-party API integrations
│ ├── decorators/ # Custom decorators (e.g., for authentication)
│ ├── helper/ # Helper functions and utilities
│ ├── models/ # SQLAlchemy database models
│ ├── repositories/ # Data access layer
│ ├── routes/ # API endpoints (controllers)
│ ├── schemas/ # Data validation schemas
│ ├── services/ # Business logic layer
│ └── startup/ # Application startup and configuration
├── .github/
│ └── workflows/ # CI/CD workflows
├── .gitignore
├── docker-compose.yml
├── Dockerfile
└── requirements.txt
```
## Contributing
Contributions are welcome! If you have any ideas, suggestions, or bug reports, please open an issue or submit a pull request.
### Development Setup
1. **Clone the repository:**
```bash
git clone https://github.com/backant/backant-cli.git
```
2. **Create a virtual environment:**
```bash
python3 -m venv venv
source venv/bin/activate
```
3. **Install the dependencies:**
```bash
pip install -r requirements.txt
```
4. **Install the CLI in editable mode:**
```bash
pip install -e .
```
Now you can run the CLI locally using the `ant` command.
| text/markdown | Pavel Hegler | business@hegler.tech | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: POSIX :: Linux"
] | [] | https://github.com/backant/backant-cli | null | >=3.6 | [] | [] | [] | [
"click",
"pydantic>=2.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.12 | 2026-02-19T17:13:48.908562 | backant_cli-0.7.1-py3-none-any.whl | 31,718 | 2b/4d/7d836627f359dff41e73dd1084084dd6b750a95e1ec0dc47a00e75d49797/backant_cli-0.7.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 1c56496319775916cabbfc7a3c9b44b5 | 4646036b83517d0dc4141eb01eb5ebfeeec044a03b52e302a82df6fe3c3d7c3e | 2b4d7d836627f359dff41e73dd1084084dd6b750a95e1ec0dc47a00e75d49797 | null | [] | 133 |
2.4 | labelr | 0.14.0 | A command-line tool to manage labeling tasks with Label Studio. | # Labelr
Labelr a command line interface that aims at providing a set of tools to help data scientists and machine learning engineers to deal with ML data annotation, data preprocessing and format conversion.
This project started as a way to automate some of the tasks we do at Open Food Facts to manage data at different stages of the machine learning pipeline.
The CLI currently is integrated with Label Studio (for data annotation), Ultralytics (for object detection), Google Cloud Batch (for training) and Hugging Face (for model and dataset storage). It only works with some specific tasks (object detection, image classification and image extraction using LVLM for now), but it's meant to be extended to other tasks in the future.
For object detection and image classification models, it currently allows to:
- create Label Studio projects
- upload images to Label Studio
- pre-annotate the tasks either with an existing object detection model, or with a zero-shot model (Yolo-World or SAM), using Ultralytics
- perform data quality checks on Label Studio datasets
- export the data to Hugging Face or to local disk
- train the model on Google Batch (for object detection only)
- visualize the model predictions and compare them with the ground truth, using [Fiftyone](https://docs.voxel51.com/user_guide/index.html).
Labelr also support managing datasets for fine-tuning large visual language models. It currently only support a single task: structured extraction (JSON) from a single image.
The following features are supported:
- creating training datasets using Google Gemini Batch, from a list of images, textual instructions and a JSON schema
- uploading the dataset to Hugging Face
- fixing manually or automatically the model output using [Directus](https://directus.io/), a headless CMS used to manage the structured output
- export the dataset to Hugging Face
In addition, Labelr comes with two scripts that can be used to train ML models:
- in `packages/train-yolo`: the `main.py` script can be used to train an object detection model using Ultralytics. The training can be fully automatized on Google Batch, and Labelr provides a CLI to launch Google Batch jobs.
- in `packages/train-unsloth`: the `main.py` script can be used to train a visual language model using Unsloth. The training is not yet automatized on Google Batch, but the script can be used to train the model locally.
## Installation
Python 3.10 or higher is required to run this CLI.
To install the CLI, simply run:
```bash
pip install labelr
```
We recommend to install the CLI in a virtual environment. You can either use pip or conda for that.
There are two optional dependencies that you can install to use the CLI:
- `ultralytics`: pre-annotate object detection datasets with an ultralytics model (yolo, yolo-world)
- `fiftyone`: visualize the model predictions and compare them with the ground truth, using FiftyOne.
To install the ultralytics optional dependency, you can run:
```bash
pip install labelr[ultralytics]
```
## Usage
### Label Studio integration
To create a Label Studio project, you need to have a Label Studio instance running. Launching a Label Studio instance is out of the scope of this project, but you can follow the instructions on the [Label Studio documentation](https://labelstud.io/guide/install.html).
By default, the CLI will assume you're running Label Studio locally (url: http://127.0.0.1:8080). You can change the URL by setting the `--label-studio-url` CLI option or by updating the configuration (see the [Configuration](#configuration) section below for more information).
For all the commands that interact with Label Studio, you need to provide an API key using the `--api-key`, or through configuration.
#### Create a project
Once you have a Label Studio instance running, you can create a project easily. First, you need to create a configuration file for the project. The configuration file is an XML file that defines the labeling interface and the labels to use for the project. You can find an example of a configuration file in the [Label Studio documentation](https://labelstud.io/guide/setup).
For an object detection task, a command allows you to create the configuration file automatically:
```bash
labelr ls create-config-file --labels 'label1' --labels 'label2' --output-file label_config.xml
```
where `label1` and `label2` are the labels you want to use for the object detection task, and `label_config.xml` is the output file that will contain the configuration.
Then, you can create a project on Label Studio with the following command:
```bash
labelr ls create --title my_project --api-key API_KEY --config-file label_config.xml
```
where `API_KEY` is the API key of the Label Studio instance (API key is available at Account page), and `label_config.xml` is the configuration file of the project.
`ls` stands for Label Studio in the CLI.
#### Create a dataset file
If you have a list of images, for an object detection task, you can quickly create a dataset file with the following command:
```bash
labelr ls create-dataset-file --input-file image_urls.txt --output-file dataset.json
```
where `image_urls.txt` is a file containing the URLs of the images, one per line, and `dataset.json` is the output file.
#### Import data
Next, import the generated data to a project with the following command:
```bash
labelr ls import-data --project-id PROJECT_ID --dataset-path dataset.json
```
where `PROJECT_ID` is the ID of the project you created.
#### Pre-annotate the data
To accelerate annotation, you can pre-annotate the images with an object detection model. We support three pre-annotation backends:
- `ultralytics`: use your own model or [Yolo-World](https://docs.ultralytics.com/models/yolo-world/), a zero-shot model that can detect any object using a text description of the object. You can specify the path or the name of the model with the `--model-name` option. If no model name is provided, the `yolov8x-worldv2.pt` model (Yolo-World) is used.
- `ultralytics_sam3`: use [SAM3](https://docs.ultralytics.com/models/sam-3/), another zero-shot model. We advice to use this backend, as it's the most accurate. The `--model` option is ignored when this backend is used.
- `robotoff`: the ML backend of Open Food Facts (specific to Open Food Facts projects).
When using `ultralytics` or `ultralytics_sam3`, make sure you installed the labelr package with the `ultralytics` extra.
To pre-annotate the data with Ultralytics, use the following command:
```bash
labelr ls prediction add --project-id PROJECT_ID --backend ultralytics_sam3 --labels 'product' --labels 'price tag' --label-mapping '{"price tag": "price-tag"}'
```
The SAM3 model will be automatically downloaded from Hugging Face. [SAM3](https://huggingface.co/facebook/sam3) is a gated model, it requires a permission before getting access to the model.Make sure you were granted the access before launching the command.
In the command above, `labels` is the list of labels to use for the object detection task (you can add as many labels as you want). You can also provide a `--label-mapping` option in case the names of the label of the model you use for pre-annotation is different from the names configured on your Label Studio project.
#### Add `train` and `val` split
In most machine learning projects, you need to split your data into a training and a validation set. Assigning each sample to a split is required before exporting the dataset. To do so, you can use the following command:
```bash
labelr ls add-split --train-split 0.8 --project-id PROJECT_ID
```
For each task in the dataset, it randomly assigns 80% of the samples to the `train` split and 20% to the `val` split. The split is saved in the task `data` in the `split` field.
You can change the train/val ratio by changing the `--train-split` option. You can also assign specific sample to a split. For example you can assign the `train` split to specific tasks by storinh the task IDs in a file `task_ids.txt` and by running the following command:
```bash
labelr ls add-split --split-name train --task-id-file task_ids.txt --project-id PROJECT_ID
```
#### Performing sanity checks on the dataset
Labelr can detect automatically some common data quality issues:
- broken image URLs
- duplicate tasks (based on the image hash)
- multiple annotations
To perform a check, run:
```bash
labelr ls check-dataset --project-id PROJECT_ID
```
The command will report the issues found. It is non-destructive by default, but you can use the `--delete-missing-images` and `--delete-duplicate-images` options to delete the tasks with missing images or duplicates respectively.
#### Export the data
Once the data is annotated, you can export it to a Hugging Face dataset or to local disk (Ultralytics format). To export it to disk, use the following command:
```bash
labelr datasets export --project-id PROJECT_ID --from ls --to ultralytics --output-dir output --label-names 'product,price-tag'
```
where `output` is the directory where the data will be exported. Currently, label names must be provided, as the CLI does not support exporting label names from Label Studio yet.
To export the data to a Hugging Face dataset, use the following command:
```bash
labelr datasets export --project-id PROJECT_ID --from ls --to huggingface --repo-id REPO_ID --label-names 'product,price-tag'
```
where `REPO_ID` is the ID of the Hugging Face repository where the dataset will be uploaded (ex: `openfoodfacts/food-detection`).
### Lauch training jobs
You can also launch training jobs for YOLO object detection models using datasets hosted on Hugging Face. Please refer to the [train-yolo package README](packages/train-yolo/README.md) for more details on how to use this feature.
## Configuration
Some Labelr settings can be configured using a configuration file or through environment variables. The configuration file is located at `~/.config/labelr/config.json`. You can configure the location of the config file using the `LABELR_CONFIG_PATH` environment variable.
By order of precedence, the configuration is loaded from:
- CLI command option
- environment variable
- file configuration
The following variables are currently supported:
- `label_studio_url`: URL of the Label Studio server. Can also be set with the `LABELR_LABEL_STUDIO_URL` environment variable.
- `label_studio_api_key`: API key for Label Studio. Can also be set with the `LABELR_LABEL_STUDIO_API_KEY` environment variable.
- `project_id`: the ID of the label studio project.
Labelr supports configuring settings in config file through the `config` command. For example, to set the Label Studio URL, you can run:
```bash
labelr config label_studio_url http://127.0.0.1:8080
```
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"datasets>=3.2.0",
"imagehash>=4.3.1",
"label-studio-sdk>=2.0.17",
"more-itertools>=10.5.0",
"openfoodfacts>=2.9.0",
"typer>=0.15.1",
"google-cloud-batch==0.18.0",
"huggingface-hub",
"deepdiff>=8.6.1",
"rapidfuzz>=3.14.3",
"aiohttp",
"aiofiles",
"orjson",
"google-cloud-storage",
"gcloud-... | [] | [] | [] | [] | uv/0.10.3 {"installer":{"name":"uv","version":"0.10.3","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T17:13:08.794871 | labelr-0.14.0-py3-none-any.whl | 67,583 | 2b/cb/455d7fc51968396fe43a5863970ad8febdf4c8adda2ffd18fff9cfed4c42/labelr-0.14.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 8b61812aa313ed654b2b3ffd502261e5 | 358c842769265cea348ea6974959d65dfe154ee7dff6b503895d1246ecdae370 | 2bcb455d7fc51968396fe43a5863970ad8febdf4c8adda2ffd18fff9cfed4c42 | null | [
"LICENSE"
] | 221 |
2.4 | montycat | 1.0.2 | A Python client for Montycat, NoSQL database utilizing Data Mesh architecture. | # 🐍 The official async Python client for Montycat — the Rust-powered NoSQL database built for the Data Mesh era.
[](https://pepy.tech/projects/montycat)
[](LICENSE)
[](https://pypi.org/project/montycat/)
[](https://www.python.org/)
[]()
## What is Montycat?
Montycat is a Rust-powered NoSQL engine designed for the future of data — decentralized by nature, ultra-fast, and natively async.
## 🧠 Why Montycat?
- ⚡ Blazing Speed — Powered by the Montycat Engine written in Rust, built for microsecond-level read/write performance.
- 🌀 Async-First Design — Fully asynchronous, built on asyncio. Perfect for APIs, pipelines, and real-time apps.
- 💾 Hybrid Storage — In-memory for raw speed or persistent for durability — or mix both in one engine.
- 🧩 Schema-Aware — Define data schemas in Python, enforce them at runtime — with zero ceremony.
- 🗂️ True Data Mesh Architecture — Each keyspace is a self-owned, domain-oriented data product.
- 📡 Reactive Subscriptions — Subscribe to live updates in real-time — per key or per keyspace.
- 🛡️ Memory-Safe & Secure — Backed by Rust’s zero-cost abstractions and modern TLS communication.
- 🤝 Developer-Centric API — Intuitive, predictable, and ready for production.
- 📚 Beautifully Documented — Every method, every example, crystal clear.
## 💡 Philosophy
Montycat is not a database wrapper. It’s a new way to think about data — composable, fast by design. No legacy baggage. Just clean async functions and pure data. Montycat isn’t inspired by NoSQL. It redefines it — with elegance, concurrency, and memory safety.
## 👉 Install the Engine: https://montygovernance.com
## Montycat for Python?
This is the official Python client, built to bring Montycat’s next-generation Data Mesh architecture directly into your Python applications. This client empowers developers to seamlessly manage and query their data while leveraging the unparalleled flexibility and scalability offered by NoSQL databases within a decentralized data ownership paradigm
Forget ORM hell, clunky SQL syntax, or blocking I/O.
With Montycat, data feels alive — reactive, structured, and fast enough to keep up with your imagination.
## 🔍 Example Use Cases
- Real-time dashboards and analytics
- Async ETL pipelines with real-time awareness and processing
- Microservice data stores
- Event-driven data systems
- Collaborative data products in a Mesh architecture
## Installation
You can install Python client for Montycat using `pip`:
```bash
pip install montycat
```
## Quick Start
```python
from montycat import Engine, Keyspace, Schema
import asyncio
# setup connection
connection = Engine(
host="127.0.0.1",
port=21210,
username="USER",
password="12345",
store="Departments",
)
class Sales(Keyspace.Persistent):
keyspace = "Sales"
class Production(Keyspace.InMemory):
keyspace = "Production"
Sales.connect_engine(connection)
Production.connect_engine(connection)
# create store and keyspaces using runtime migration
async def setup_keyspaces():
await Production.create_keyspace()
await Sales.create_keyspace()
asyncio.run(setup_keyspaces())
# create schemas and enforce them on the database side (optional)
class SalesSchema(Schema):
product: str
amount: int
class ProductionSchema(Schema):
items: list
work_order: str | None
async def migrate_schemas():
await Production.enforce_schema()
await Sales.enforce_schema()
asyncio.run(migrate_schemas())
# run first queries
sales = SalesSchema(
product = "Product1",
amount = 12
).serialize()
asyncio.run(Sales.insert_value(sales))
items_ordered = ProductionSchema(
items = ["Product1"],
work_order = "WO 000012"
).serialize()
asyncio.run(Production.insert_value(items_ordered))
# verify
asyncio.run(Sales.lookup_values_where(schema=SalesSchema, key_included=True))
asyncio.run(Production.lookup_keys_where(work_order="WO 000012"))
```
| text/markdown | MontyGovernance | eugene.and.monty@gmail.com | null | null | null | database nosql sql data-mesh cache key-value realtime montycat | [
"Programming Language :: Python :: 3",
"Topic :: Database",
"Topic :: Software Development :: Libraries",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"orjson",
"xxhash"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.9.25 | 2026-02-19T17:11:14.739302 | montycat-1.0.2.tar.gz | 20,227 | 4f/38/da6276e17f99876f29def97fe4708440c315f6f4405ca7d97932c833d307/montycat-1.0.2.tar.gz | source | sdist | null | false | ef62c0a66fbf58e9df54d0bc2dcaacca | 2d7d8b8bc7b4d58fe366b595a68566c77efe1ef7c81f6b2dfdb3c38b7a75127f | 4f38da6276e17f99876f29def97fe4708440c315f6f4405ca7d97932c833d307 | null | [
"LICENSE"
] | 148 |
2.4 | search-rdf | 0.2.0 | Search indices (mainly to be combined with RDF query engines) backed by Rust | # Search RDF
Rust library with restricted Python interface for building and querying
search indices, primarily intended to be used with RDF query engines.
## Getting Started
### Installation
Build from source using Cargo:
```bash
cargo build --release
```
The binary will be available at `target/release/search-rdf`.
### CLI Overview
The `search-rdf` CLI provides commands to build and serve search indices. All commands require a YAML configuration file.
```
search-rdf [OPTIONS] [CONFIG] [COMMAND]
Commands:
data Download and prepare data
embed Generate embeddings for data
index Build search indices
serve Serve indices via HTTP
Options:
--force Force rebuild even if output exists
-v, --verbose Enable verbose/debug logging
-q, --quiet Suppress info messages (errors and warnings only)
-h, --help Print help
-V, --version Print version
```
#### Running All Steps
To run the complete pipeline (data → embed → index → serve):
```bash
search-rdf config.yaml
```
#### Running Individual Steps
```bash
# Step 1: Download/prepare data
search-rdf data config.yaml
# Step 2: Generate embeddings
search-rdf embed config.yaml
# Step 3: Build indices
search-rdf index config.yaml
# Step 4: Start HTTP server
search-rdf serve config.yaml
```
Use `--force` to rebuild outputs even if they already exist:
```bash
search-rdf index config.yaml --force
```
### Configuration File Format
The configuration file is written in YAML and has five main sections: `datasets`, `models`, `embeddings`, `indices`, and `server`.
#### Datasets
Defines data sources to be indexed. Each dataset produces a data directory used by indices.
```yaml
datasets:
- name: my-dataset # Unique identifier
output: data/ # Output directory for processed data
source:
# Option 1: SPARQL query against an endpoint
type: sparql-query
endpoint: https://query.wikidata.org/sparql
query: |
SELECT ?item ?label WHERE {
?item rdfs:label ?label .
}
LIMIT 1000
format: json # json, xml, or tsv
default_field_type: text # text, image, or image-inline
headers: # Optional HTTP headers
User-Agent: MyApp/1.0
# Option 2: Local SPARQL results file
type: sparql
path: results.json
format: json
default_field_type: text
# Option 3: JSONL file
type: jsonl
path: data.jsonl
```
SPARQL queries must return exactly 2 columns: an identifier (first column) and a field value (second column). Multiple rows with the same identifier create multiple fields for that item.
#### Models
Defines embedding models used to generate vector representations.
```yaml
models:
# vLLM server (recommended for large-scale embedding)
- name: my-vllm-model
type: vllm
endpoint: http://localhost:8000
model_name: mixedbread-ai/mxbai-embed-large-v1
# Sentence Transformers (local inference)
- name: my-local-model
type: sentence-transformer
model_name: sentence-transformers/all-MiniLM-L6-v2
device: cuda # cpu, cuda, or mps (default: cpu)
batch_size: 16 # Inference batch size (default: 16)
# HuggingFace image models
- name: my-image-model
type: huggingface-image
model_name: openai/clip-vit-base-patch32
device: cuda
batch_size: 16
```
Optional embedding parameters can be added to any model:
```yaml
models:
- name: my-model
type: vllm
endpoint: http://localhost:8000
model_name: mixedbread-ai/mxbai-embed-large-v1
params:
num_dimensions: 512 # Truncate embeddings (for MRL models)
normalize: true # L2 normalize embeddings (default: true)
```
#### Embeddings
Defines embedding generation jobs that use models to embed dataset fields.
```yaml
embeddings:
- name: my-embeddings
model: my-vllm-model # Reference to model name
data: data/ # Input data directory
output: data/embeddings.safetensors
batch_size: 64 # Processing batch size (default: 64)
```
#### Indices
Defines search indices to build from data and embeddings.
```yaml
indices:
# Keyword index (exact token matching with BM25 scoring)
- name: keyword-index
type: keyword
data: data/
output: index/keyword/
# Full-text index (Tantivy-based with stemming/tokenization)
- name: fulltext-index
type: full-text
data: data/
output: index/fulltext/
# Embedding index with data (semantic search)
- name: embedding-index
type: embedding-with-data
data: data/
embedding_data: data/embeddings.safetensors
output: index/embedding/
model: my-vllm-model # For query embedding at search time
# Embedding-only index (no associated text data)
- name: embedding-only
type: embedding
embedding_data: data/embeddings.safetensors
output: index/embedding-only/
```
Embedding index parameters:
```yaml
indices:
- name: embedding-index
type: embedding-with-data
data: data/
embedding_data: data/embeddings.safetensors
output: index/embedding/
model: my-model
params:
metric: cosine-normalized # cosine-normalized, cosine, inner-product, l2, hamming
precision: bfloat16 # float32, float16, bfloat16, int8, binary
connectivity: 16 # HNSW M parameter (default: 16)
expansion_add: 128 # HNSW efConstruction (default: 128)
expansion_search: 64 # HNSW ef (default: 64)
```
#### Server
Configures the HTTP server for serving indices.
```yaml
server:
host: 0.0.0.0 # Bind address (default: 127.0.0.1)
port: 8080 # Port (default: 8080)
cors: true # Enable CORS (default: false)
max_input_size: 100MB # Max request size in bytes (default: 100MB)
indices: # Indices to serve
- keyword-index
- embedding-index
sparql: # Optional: Enable SPARQL service endpoints
prefix: "http://example.org/"
```
### HTTP API
When the server is running, the following endpoints are available:
#### Health Check
```
GET /health
```
Returns `200 OK` if the server is running.
#### List Indices
```
GET /indices
```
Returns a list of available index names.
#### Search
```
POST /search/{index_name}
Content-Type: application/json
```
The request body contains a `queries` array and search parameters. Query format depends on the index type:
**Text queries** (for keyword, full-text, and text embedding indices):
```json
{
"queries": [{"type": "text", "value": "search query"}],
"k": 10
}
```
**Image URL queries** (for image embedding indices):
```json
{
"queries": [{"type": "url", "value": "https://example.com/image.jpg"}],
"k": 10
}
```
**Pre-computed embedding queries**:
```json
{
"queries": [{"type": "embedding", "value": [0.1, 0.2, 0.3, ...]}],
"k": 10
}
```
Search parameters vary by index type:
**Keyword/Full-text indices:**
- `k` - Number of results (default: 10)
**Embedding indices:**
- `k` - Number of results (default: 10)
- `min-score` - Minimum similarity score filter
- `exact` - Use exact search instead of approximate (default: false)
- `rerank` - Reranking factor (retrieves k*rerank candidates, then reranks)
Response format:
```json
{
"matches": [
[
{"id": 42, "score": 0.95},
{"id": 17, "score": 0.87}
]
]
}
```
#### SPARQL Service (optional)
When `sparql` is configured in the server section:
```
POST /service/{index_name}
POST /qlproxy/{index_name}
```
These endpoints enable integration with SPARQL engines that support federated queries.
### Example Configuration
Here's a complete example that sets up keyword and semantic search over Wikidata human labels:
```yaml
datasets:
- name: wikidata-humans
output: data/
source:
type: sparql-query
endpoint: https://query.wikidata.org/sparql
query: |
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
SELECT ?item ?label WHERE {
?item wdt:P31 wd:Q5 .
?item rdfs:label ?label .
FILTER(LANG(?label) = "en")
}
LIMIT 10000
format: json
default_field_type: text
models:
- name: text-embedding
type: vllm
endpoint: http://localhost:8000
model_name: mixedbread-ai/mxbai-embed-xsmall-v1
embeddings:
- name: wikidata-embeddings
model: text-embedding
data: data/
output: data/embeddings.safetensors
batch_size: 128
indices:
- name: keyword
type: keyword
data: data/
output: index/keyword/
- name: semantic
type: embedding-with-data
data: data/
embedding_data: data/embeddings.safetensors
output: index/semantic/
model: text-embedding
params:
metric: cosine-normalized
precision: bfloat16
server:
host: 0.0.0.0
port: 8080
cors: true
indices:
- keyword
- semantic
```
Run with:
```bash
# Build everything and start serving
search-rdf config.yaml
# Or run steps individually
search-rdf data config.yaml
search-rdf embed config.yaml
search-rdf index config.yaml
search-rdf serve config.yaml
```
Test with curl:
```bash
# Keyword search
curl -X POST http://localhost:8080/search/keyword \
-H "Content-Type: application/json" \
-d '{"queries": [{"type": "text", "value": "Albert Einstein"}], "k": 5}'
# Semantic search
curl -X POST http://localhost:8080/search/semantic \
-H "Content-Type: application/json" \
-d '{"queries": [{"type": "text", "value": "famous physicist"}], "k": 5}'
```
| text/markdown; charset=UTF-8; variant=GFM | null | Sebastian Walter <swalter@cs.uni-freiburg.de> | null | null | null | utilities, index, rdf, keyword, similarity, search | [
"Programming Language :: Rust",
"Programming Language :: Python :: 3",
"Topic :: Software Development :: Libraries",
"Topic :: Text Processing",
"Topic :: Utilities"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"sentence-transformers>=5",
"numpy>=1.24",
"tqdm>=4.65"
] | [] | [] | [] | [
"Github, https://github.com/bastiscode/search-rdf"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:11:06.175516 | search_rdf-0.2.0.tar.gz | 3,841,493 | 86/85/8f54e8e1abb4e9cdcbe618b77745ecfea57e5638deaa8bba152b5ad522bb/search_rdf-0.2.0.tar.gz | source | sdist | null | false | 7eab0c7b3edae6c68386544665ef36cc | df39f0eb4209ef04052fb3dc25d2a51bef31f90ac11813b31da0921f1f2228de | 86858f54e8e1abb4e9cdcbe618b77745ecfea57e5638deaa8bba152b5ad522bb | null | [
"LICENSE"
] | 337 |
2.4 | xdatasets | 0.3.9 | Easy access to Earth observation datasets with xarray. | =========
Xdatasets
=========
+----------------------------+-----------------------------------------------------+
| Versions | |pypi| |
+----------------------------+-----------------------------------------------------+
| Documentation and Support | |docs| |versions| |
+----------------------------+-----------------------------------------------------+
| Open Source | |license| |ossf-score| |
+----------------------------+-----------------------------------------------------+
| Coding Standards | |ruff| |pre-commit| |
+----------------------------+-----------------------------------------------------+
| Development Status | |status| |build| |coveralls| |
+----------------------------+-----------------------------------------------------+
Easy access to Earth observation datasets with xarray.
* Free software: MIT license
* Documentation: https://xdatasets.github.io/xdatasets
Features
--------
* TODO
Credits
-------
This package was created with Cookiecutter_ and the `Ouranosinc/cookiecutter-pypackage`_ project template.
.. _Cookiecutter: https://github.com/cookiecutter/cookiecutter
.. _`Ouranosinc/cookiecutter-pypackage`: https://github.com/Ouranosinc/cookiecutter-pypackage
.. |build| image:: https://github.com/hydrologie/xdatasets/actions/workflows/main.yml/badge.svg
:target: https://github.com/hydrologie/xdatasets/actions
:alt: Build Status
..
.. |conda| image:: https://img.shields.io/conda/vn/conda-forge/xdatasets.svg
:target: https://anaconda.org/conda-forge/xdatasets
:alt: Conda-forge Build Version
.. |coveralls| image:: https://coveralls.io/repos/github/hydrologie/xdatasets/badge.svg?branch=main
:target: https://coveralls.io/github/hydrologie/xdatasets?branch=main
:alt: Coveralls
.. |docs| image:: https://readthedocs.org/projects/xdatasets/badge/?version=latest
:target: https://xdatasets.readthedocs.io/en/latest/?version=latest
:alt: Documentation Status
.. |license| image:: https://img.shields.io/github/license/hydrologie/xdatasets.svg
:target: https://github.com/hydrologie/xdatasets/blob/main/LICENSE
:alt: License
..
.. |ossf-bp| image:: https://bestpractices.coreinfrastructure.org/projects/9945/badge
:target: https://bestpractices.coreinfrastructure.org/projects/9945
:alt: Open Source Security Foundation Best Practices
.. |ossf-score| image:: https://api.securityscorecards.dev/projects/github.com/hydrologie/xdatasets/badge
:target: https://securityscorecards.dev/viewer/?uri=github.com/hydrologie/xdatasets
:alt: OpenSSF Scorecard
.. |pre-commit| image:: https://results.pre-commit.ci/badge/github/hydrologie/xdatasets/main.svg
:target: https://results.pre-commit.ci/latest/github/hydrologie/xdatasets/main
:alt: pre-commit.ci status
.. |pypi| image:: https://img.shields.io/pypi/v/xdatasets.svg
:target: https://pypi.python.org/pypi/xdatasets
:alt: PyPI
.. |ruff| image:: https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/ruff/main/assets/badge/v2.json
:target: https://github.com/astral-sh/ruff
:alt: Ruff
.. |status| image:: https://www.repostatus.org/badges/latest/active.svg
:target: https://www.repostatus.org/#active
:alt: Project Status: Active – The project has reached a stable, usable state and is being actively developed.
.. |versions| image:: https://img.shields.io/pypi/pyversions/xdatasets.svg
:target: https://pypi.python.org/pypi/xdatasets
:alt: Supported Python Versions
| text/x-rst | null | Sebastien Langlois <sebastien.langlois62@gmail.com> | null | Trevor James Smith <smith.trevorj@ouranos.ca> | null | xdatasets, hydrology, meteorology, climate, climatology, netcdf, gridded analysis | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",... | [] | null | null | >=3.10.0 | [] | [] | [] | [
"bottleneck>=1.3.1",
"cf-xarray>=0.6.1",
"cftime>=1.4.1",
"clisops>=0.9.2",
"dask[array]>=2.6",
"dask-geopandas>=0.4.1",
"geopandas>=1.0",
"intake",
"intake-geopandas",
"intake-xarray<2.0.0,>=0.6.1",
"ipython>=8.5.0",
"jsonpickle",
"numpy>=1.23",
"pandas>=1.5",
"setuptools",
"s3fs",
... | [] | [] | [] | [
"Changelog, https://xdatasets.readthedocs.io/en/stable/changelog.html",
"Homepage, https://xdatasets.readthedocs.io/",
"Issue tracker, https://github.com/hydrologie/xdatasets/issues",
"Source, https://github.com/hydrologie/xdatasets"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:10:46.075095 | xdatasets-0.3.9.tar.gz | 74,905 | 21/7d/bbae2c0ebe3e73fe26cfc23ffee43fa48a6c64eb87ae1bc04242e5d3c127/xdatasets-0.3.9.tar.gz | source | sdist | null | false | fb5cf797b4cc47d2fa2e3e63d616777e | dbca83b6c0be30eb96549c2d694d86a722d60548b140188b765abc4475bf9542 | 217dbbae2c0ebe3e73fe26cfc23ffee43fa48a6c64eb87ae1bc04242e5d3c127 | MIT | [
"LICENSE"
] | 229 |
2.4 | NMFProfiler | 0.3.2 | NMFProfiler: an integrative supervised Non-Negative Matrix Factorization to extract typical profiles of groups of interest combining two different datasets. | # NMFProfiler
## Name
NMFProfiler: A multi-omics integration method for samples stratified in groups
## Description

## Installation
NMFProfiler can be installed from PiPy:
```
pip install nmfprofiler
```
In addition, various docker images are provided in the [container registry](https://forge.inrae.fr/omics-integration/nmfprofiler/container_registry).
## Usage
Below is a short illustration of the method on a toy dataset.
```python
from nmfprofiler.nmfprofiler import NMFProfiler
from nmfprofiler.toyexample import ToyExample
# Fix a seed (not mandatory)
seed = 240820
# Run NMFProfiler
model = NMFProfiler(
omics=[ToyExample().omic1, ToyExample().omic2],
y=ToyExample().y,
seed=seed,
as_sklearn=False,
backtrack=True)
res = model.fit()
# Get a quick overview of the dataset and model used
print(res)
# Visualize analyzed datasets (samples x features)
ToyExample().y # 2 groups
res.heatmap(obj_to_viz="omic", width=15, height=6, path="", omic_number=1)
res.heatmap(obj_to_viz="omic", width=15, height=6, path="", omic_number=2)
```


*Note: NMFProfiler produces* **as many signatures as groups,** *i.e. levels in* $\mathbf{y}$ *vector. Hence in this case we will obtain 2 signatures.*
```python
# Visualize contribution matrix W obtained (samples x 2)
res.heatmap(obj_to_viz="W", width=10, height=10, path="")
```

```python
# Visualize signature matrices H1 and H2 obtained (2 x features)
res.heatmap(obj_to_viz="H", width=15, height=6, path="", omic_number=1)
res.heatmap(obj_to_viz="H", width=15, height=6, path="", omic_number=2)
```


```python
# Monitor the size of each error term of the loss
res.barplot_error(width=15, height=6, path="")
```

## Support
For questions or additional feature requests, use [gitlab issues](https://forge.inrae.fr/groups/omics-integration/-/issues) if possible. Authors can also be contacted by email (check authors' webpages for email information).
## Citation
If you are using `NMFProfiler`, please cite:
Mercadié, A., Gravier, É., Josse, G., Fournier, I., Viodé, C., Vialaneix, N., & Brouard, C. (2025). NMFProfiler: A multi-omics integration method for samples stratified in groups. *Bioinformatics*, **41**(2), btaf066.
## Authors and acknowledgment
This work was supported by the ANRT (CIFRE no. 2022/0051).
## License
GPL-3
## Project status
Active
See [Changelog](https://forge.inrae.fr/omics-integration/nmfprofiler/-/blob/main/CHANGELOG.md)
| text/markdown | null | Aurélie Mercadié <aurelie.mercadie@inrae.fr>, Eric Casellas <eric.casellas@inrae.fr>, Eléonore Gravier <eleonore.gravier@pierre-fabre.com>, Gwendal Josse <gwendal.josse@pierre-fabre.com>, Nathalie Vialaneix <nathalie.vialaneix@inrae.fr>, Céline Brouard <celine.brouard@inrae.fr> | null | Aurélie Mercadié <aurelie.mercadie@inrae.fr> | GNU GENERAL PUBLIC LICENSE
Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU General Public License is a free, copyleft license for
software and other kinds of works.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
the GNU General Public License is intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users. We, the Free Software Foundation, use the
GNU General Public License for most of our software; it applies also to
any other work released this way by its authors. You can apply it to
your programs, too.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
To protect your rights, we need to prevent others from denying you
these rights or asking you to surrender the rights. Therefore, you have
certain responsibilities if you distribute copies of the software, or if
you modify it: responsibilities to respect the freedom of others.
For example, if you distribute copies of such a program, whether
gratis or for a fee, you must pass on to the recipients the same
freedoms that you received. You must make sure that they, too, receive
or can get the source code. And you must show them these terms so they
know their rights.
Developers that use the GNU GPL protect your rights with two steps:
(1) assert copyright on the software, and (2) offer you this License
giving you legal permission to copy, distribute and/or modify it.
For the developers' and authors' protection, the GPL clearly explains
that there is no warranty for this free software. For both users' and
authors' sake, the GPL requires that modified versions be marked as
changed, so that their problems will not be attributed erroneously to
authors of previous versions.
Some devices are designed to deny users access to install or run
modified versions of the software inside them, although the manufacturer
can do so. This is fundamentally incompatible with the aim of
protecting users' freedom to change the software. The systematic
pattern of such abuse occurs in the area of products for individuals to
use, which is precisely where it is most unacceptable. Therefore, we
have designed this version of the GPL to prohibit the practice for those
products. If such problems arise substantially in other domains, we
stand ready to extend this provision to those domains in future versions
of the GPL, as needed to protect the freedom of users.
Finally, every program is threatened constantly by software patents.
States should not allow patents to restrict development and use of
software on general-purpose computers, but in those that do, we wish to
avoid the special danger that patents applied to a free program could
make it effectively proprietary. To prevent this, the GPL assures that
patents cannot be used to render the program non-free.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Use with the GNU Affero General Public License.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU Affero General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the special requirements of the GNU Affero General Public License,
section 13, concerning interaction through a network will apply to the
combination as such.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU General Public License from time to time. Such new versions will
be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
| NMF, omics integration, matrix factorization | [
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU General Public License v3 or later (GPLv3+)",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineeri... | [] | null | null | >=3.8.10 | [] | [] | [] | [
"matplotlib>=3.1.2",
"numpy>=1.23.2",
"pandas>=1.4.3",
"scikit-learn>=1.2.1",
"seaborn>=0.11.2",
"statsmodels>=0.14.0",
"black; extra == \"dev\"",
"bump2version; extra == \"dev\"",
"isort; extra == \"dev\"",
"pip-tools; extra == \"dev\"",
"pytest; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://forge.inrae.fr/omics-integration/nmfprofiler",
"Documentation, https://omics-integration.pages.mia.inra.fr/nmfprofiler",
"Changelog, https://forge.inrae.fr/omics-integration/nmfprofiler/-/blob/main/CHANGELOG.md"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T17:10:14.202780 | nmfprofiler-0.3.2.tar.gz | 59,186 | ce/fb/8ca46ea656ccdf0b68e8d347dd892125332f2ac51b8afa2be1e9f9d035c9/nmfprofiler-0.3.2.tar.gz | source | sdist | null | false | 5813649daaa652ae13d71b00b52ce015 | 83458f4100151a1b1d71a6c9dafb5224f7fd2a62356c646f453902734474e4bd | cefb8ca46ea656ccdf0b68e8d347dd892125332f2ac51b8afa2be1e9f9d035c9 | null | [
"LICENSE"
] | 0 |
2.4 | cognee-community-hybrid-adapter-duckdb | 0.1.3 | DuckDB vector adapter for Cognee with planned graph support | <div align="center" dir="auto">
<img width="250" src="https://duckdb.org/images/logo-dl/DuckDB_Logo-stacked.svg" style="max-width: 100%" alt="DuckDB">
<h1>🧠 Cognee DuckDB Vector Adapter</h1>
</div>
<div align="center" style="margin-top: 20px;">
<span style="display: block; margin-bottom: 10px;">Lightning fast embedded vector search for Cognee using DuckDB with planned graph support</span>
<br />
[](https://opensource.org/licenses/Apache-2.0)

[](https://duckdb.org)
</div>
<div align="center">
<div display="inline-block">
<a href="https://github.com/topoteretes/cognee"><b>Cognee</b></a>
<a href="https://duckdb.org/docs/"><b>DuckDB Docs</b></a>
<a href="#examples"><b>Examples</b></a>
<a href="#troubleshooting"><b>Support</b></a>
</div>
<br />
</div>
## Features
- **Zero-configuration** embedded vector database - no external server required
- Full support for vector embeddings storage and retrieval
- High-performance vector similarity search using DuckDB's native array operations
- Persistent or in-memory database options
- **Vector-first design** with planned graph support in future releases
- Comprehensive error handling and logging
## Installation
```bash
pip install cognee-community-hybrid-adapter-duckdb
```
## Prerequisites
**None!** DuckDB is an embedded database that requires no external dependencies or server setup. Just install and use.
## Examples
Checkout the `examples/` folder!
**Basic vector search example:**
```bash
uv run examples/example.py
```
**Document processing example with generated story:**
```bash
uv run examples/simple_document_example/cognee_simple_document_demo.py
```
This example demonstrates processing a generated story text file (`generated_story.txt`) along with other documents like Alice in Wonderland.
>You will need an OpenAI API key to run the example scripts.
## Usage
```python
import os
import asyncio
from cognee import config, prune, add, cognify, search, SearchType
# Import the register module to enable DuckDB support
from cognee_community_hybrid_adapter_duckdb import register
async def main():
# Configure DuckDB as vector database
config.set_vector_db_config({
"vector_db_provider": "duckdb",
"vector_db_url": "my_database.db", # File path or None for in-memory
})
# Optional: Clean previous data
await prune.prune_data()
await prune.prune_system()
# Add your content
await add("""
Natural language processing (NLP) is an interdisciplinary
subfield of computer science and information retrieval.
""")
# Process with cognee
await cognify()
# Search (use vector-based search types)
search_results = await search(
query_type=SearchType.CHUNKS,
query_text="Tell me about NLP"
)
for result in search_results:
print("Search result:", result)
if __name__ == "__main__":
asyncio.run(main())
```
## Configuration
Configure DuckDB as your vector database in cognee:
- `vector_db_provider`: Set to "duckdb"
- `vector_db_url`: Database file path (e.g., "my_db.db"), `None` for in-memory, or MotherDuck URL for cloud
### Database Options
```python
# Persistent file-based database
config.set_vector_db_config({
"vector_db_provider": "duckdb",
"vector_db_url": "cognee_vectors.db"
})
# In-memory database (fastest, but data is lost on restart)
config.set_vector_db_config({
"vector_db_provider": "duckdb",
"vector_db_url": None # or ":memory:"
})
# Absolute path to database file
config.set_vector_db_config({
"vector_db_provider": "duckdb",
"vector_db_url": "/path/to/my/database.db"
})
# MotherDuck cloud database
config.set_vector_db_config({
"vector_db_provider": "duckdb",
"vector_db_url": "md:my_database" # Replace with your MotherDuck database
})
```
## Requirements
- Python >= 3.12, <= 3.13
- duckdb >= 1.3.2
- cognee >= 0.2.3
## Roadmap: Graph Support
This adapter is currently **vector-focused** with plans to add full graph database capabilities in future releases. The foundation is already in place with DuckDB's property graph extensions.
**Current Status:**
- ✅ Full vector similarity search
- ✅ Embedding storage and retrieval
- ✅ Collection management
- 🚧 Graph operations (coming soon)
## Error Handling
The adapter includes comprehensive error handling:
- `CollectionNotFoundError`: Raised when attempting operations on non-existent collections
- `InvalidValueError`: Raised for invalid query parameters
- `NotImplementedError`: Currently raised for graph operations (graph support coming soon)
- Graceful handling of database connection issues and embedding errors
## Performance
DuckDB provides excellent performance characteristics:
- **Embedded**: No network overhead - everything runs in-process
- **Columnar**: Optimized storage format for analytical workloads
- **Vectorized**: SIMD operations for fast vector similarity calculations
- **ACID**: Full transactional support with data consistency
- **Memory efficient**: Minimal memory footprint compared to traditional databases
## Troubleshooting
### Common Issues
1. **File Permission Errors**: Ensure write permissions to the directory containing your database file
2. **Embedding Dimension Mismatch**: Verify embedding dimensions match collection configuration
3. **Collection Not Found**: Always create collections before adding data points
4. **Graph Operations**: Graph support is planned for future releases - currently use vector search
### Debug Logging
The adapter uses Cognee's logging system. Enable debug logging to see detailed operation logs:
```python
import logging
logging.getLogger("DuckDBAdapter").setLevel(logging.DEBUG)
```
### Database Option Comparison
| Option | Pros | Cons |
|--------|------|------|
| File-based (`"my_db.db"`) | ✅ Persistent storage<br/>✅ Survives restarts<br/>✅ Can handle large datasets | ❌ Slower I/O<br/>❌ Disk space usage |
| In-memory (`None`) | ✅ Maximum performance<br/>✅ No disk usage<br/>✅ Perfect for testing | ❌ Data lost on restart<br/>❌ Limited by RAM |
| MotherDuck (`"md:database"`) | ✅ Cloud-hosted<br/>✅ Shared access<br/>✅ Managed service<br/>✅ Scalable | ❌ Requires internet<br/>❌ Potential latency<br/>❌ MotherDuck account needed |
## Development
To contribute or modify the adapter:
1. Clone the repository and `cd` into the `packages/hybrid/duckdb` folder
2. Install dependencies: `uv sync --all-extras`
3. Run tests: `uv run examples/example.py`
4. Make your changes, test, and submit a PR
## Extensions Used
This adapter automatically loads these DuckDB extensions:
- **duckpgq**: Property graph queries (foundation for upcoming graph support)
- **vss**: Vector similarity search with HNSW indexing support | text/markdown | Cognee Community | community@cognee.ai | Cognee Community | community@cognee.ai | null | cognee, duckdb, vector, database, embeddings, ai, ml | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Database",
"Topic :: Scientific/Engineering :: Artificial Int... | [] | https://github.com/topoteretes/cognee-community | null | <=3.13,>=3.10 | [] | [] | [] | [
"cognee==0.5.2",
"duckdb>=1.3.2",
"starlette>=0.48.0",
"instructor>=1.11",
"mypy>=1.17.1; extra == \"dev\"",
"twine>=5.0.0; extra == \"dev\"",
"build>=1.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/topoteretes/cognee-community",
"Repository, https://github.com/topoteretes/cognee-community",
"Documentation, https://docs.cognee.ai",
"Issues, https://github.com/topoteretes/cognee-community/issues",
"README, https://github.com/topoteretes/cognee-community/blob/main/packages/h... | poetry/2.2.1 CPython/3.12.11 Darwin/24.1.0 | 2026-02-19T17:10:12.854879 | cognee_community_hybrid_adapter_duckdb-0.1.3.tar.gz | 15,344 | bf/5a/c5b3a3fe5cea3ab8fb1ae329f5793c3c5a5971b9df6268fbc7d5f7c48100/cognee_community_hybrid_adapter_duckdb-0.1.3.tar.gz | source | sdist | null | false | 9c1f115c051e39c9a8b12f84bfbf0713 | 680ff671eb187ec236a97b8aa5361a06b748468c8938686a1a5057fec5f6707f | bf5ac5b3a3fe5cea3ab8fb1ae329f5793c3c5a5971b9df6268fbc7d5f7c48100 | null | [] | 230 |
2.4 | trnscrb | 0.1.2 | Offline meeting transcription for macOS — auto-detects meetings, transcribes locally, saves to Claude Desktop via MCP | # trnscrb
> Offline meeting transcription for macOS — no cloud, no subscription.
trnscrb lives in your menu bar, listens for meetings, transcribes them locally with Whisper, and makes every transcript searchable from Claude Desktop via MCP.
---
## Install
```bash
brew tap ajayrmk/tap
brew install trnscrb
trnscrb install
```
Or with `pip` / `uv`:
```bash
pip install trnscrb && trnscrb install
uv tool install trnscrb && trnscrb install
```
`trnscrb install` is a guided setup that handles:
- BlackHole 2ch audio driver (captures system audio alongside mic)
- HuggingFace token for speaker diarization (pyannote)
- Whisper `small` model download (~500 MB, one-time)
- Claude Desktop MCP config
- Launch-at-login agent
---
## Quick start
```bash
trnscrb start # launch the menu bar app
```
With **Auto-transcribe** on (the default), trnscrb detects when a meeting starts — Google Meet, Zoom, Slack Huddle, Teams, FaceTime — and begins recording automatically. When the meeting ends, it stops, transcribes, and saves.
You can also trigger manually from the menu bar: **Start Transcribing / Stop Transcribing**.
---
## How it works
| Step | What happens |
|---|---|
| Meeting detected | Mic active for 5 s + meeting app found |
| Recording | Audio captured via mic or BlackHole (system + mic) |
| Transcription | Whisper `small` model, runs locally on Apple Silicon |
| Diarization | Speaker labels via pyannote (needs HuggingFace token) |
| Saved | Plain `.txt` in `~/meeting-notes/` |
---
## Claude Desktop integration
After `trnscrb install`, Claude Desktop has these tools available:
| Tool | Description |
|---|---|
| `start_recording` | Start capturing audio |
| `stop_recording` | Stop and transcribe in the background |
| `recording_status` | Check if recording or transcribing |
| `get_last_transcript` | Fetch the most recent transcript |
| `list_transcripts` | List all saved meetings |
| `get_transcript` | Read a specific transcript |
| `get_calendar_context` | Current or upcoming calendar event |
| `enrich_transcript` | Add summary + action items via Claude API |
---
## CLI
```bash
trnscrb start # launch menu bar app
trnscrb install # guided setup / re-check dependencies
trnscrb list # list saved transcripts
trnscrb show <id> # print a transcript
trnscrb enrich <id> # summarise + action items (needs ANTHROPIC_API_KEY)
trnscrb mic-status # live mic activity monitor — useful for debugging
trnscrb devices # list audio input devices
trnscrb watch # headless auto-transcribe, no menu bar
```
---
## System audio with BlackHole
To capture both your mic and the other participants' audio:
1. Install BlackHole via `trnscrb install` (or `brew install blackhole-2ch`)
2. Open **Audio MIDI Setup** → **+** → **Create Multi-Output Device**
3. Check **BlackHole 2ch** and **MacBook Pro Speakers**
4. **System Settings → Sound → Output** → select the Multi-Output Device
trnscrb auto-detects BlackHole and uses it when available. Without it, only your mic is recorded.
---
## Transcript format
```
Meeting: Weekly Standup
Date: 2025-02-18 10:00
Duration:23:14
============================================================
[SPEAKER_00]
00:12 Good morning, let's get started.
[SPEAKER_01]
00:18 Morning! I finished the auth PR yesterday.
```
Running `trnscrb enrich <id>` replaces `SPEAKER_00` / `SPEAKER_01` with inferred names and appends a summary and action items block.
---
## Requirements
- macOS 13 or later
- Python 3.11+
- Apple Silicon (M1/M2/M3/M4) recommended — Whisper runs on Metal
---
## Privacy
Everything runs on your machine. No audio or transcripts leave your device unless you explicitly run `enrich`, which sends the transcript text to the Claude API.
---
## License
MIT
| text/markdown | null | Ajay Ram <ajayrmk@gmail.com> | null | null | null | transcription, meeting, whisper, macos, mcp, claude, offline, diarization | [
"Development Status :: 4 - Beta",
"Environment :: MacOS X",
"Intended Audience :: End Users/Desktop",
"Operating System :: MacOS",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Top... | [] | null | null | >=3.11 | [] | [] | [] | [
"rumps>=0.4.0",
"sounddevice>=0.4.6",
"numpy>=1.24",
"faster-whisper>=1.0.0",
"pyannote.audio>=3.1",
"mcp>=1.0.0",
"click>=8.1",
"anthropic>=0.25",
"scipy>=1.11"
] | [] | [] | [] | [
"Homepage, https://github.com/ajayrmk/trnscrb",
"Repository, https://github.com/ajayrmk/trnscrb",
"Bug Tracker, https://github.com/ajayrmk/trnscrb/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T17:09:54.464121 | trnscrb-0.1.2.tar.gz | 25,718 | d5/48/640f8f63286cd80ac9b453ee491f134e984c54e4d52a7f1406861b4364fa/trnscrb-0.1.2.tar.gz | source | sdist | null | false | f91ecc4e2585d8720960021b0ed8887c | 8ec52014ede1a6f1aecabacd33adbc350b6fc07a30359fc30c2b3dc587e90ac2 | d548640f8f63286cd80ac9b453ee491f134e984c54e4d52a7f1406861b4364fa | MIT | [
"LICENSE"
] | 260 |
2.4 | mkgp | 3.1.3 | Classes for Gaussian Process Regression fitting of ND data with errorbars | mkgp
====
These classes and routines were developed by Aaron Ho, and this
project repository was started in 2017. The underlying
mathematics was founded on the book, "Gaussian Process for Machine
Learning", C.E. Rasmussen, C.K.I. Williams (2006).
When using this package in any research work, please cite:
A. Ho et al 2019 Nucl. Fusion 59 056007, `DOI: 10.1088/1741-4326/ab065a
<https://doi.org/10.1088/1741-4326/ab065a>`_
Note that the package has been renamed from :code:`GPR1D -> mkgp`
in v3.0.0.
Installing the mkgp program
---------------------------
Installation is **mandatory** for this package!
For first time users, it is strongly recommended to use the GUI
developed for this Python package. To obtain the Python package
dependencies needed to use this capability, install this package
by using the following on the command line::
pip install [--user] mkgp[gui]
Use the :code:`--user` flag if you do not have root access on the
system that you are working on. If you have already cloned the
repository, enter the top level of the repository directory and
use the following instead::
pip install [--user] -e .[gui]
Removal of the :code:`[gui]` portion will no longer check for the
:code:`pyqt5` and :code:`matplotlib` packages needed for this
functionality. However, these packages are not crucial for the
base classes and algorithms.
To test the installation, execute the command line script::
mkgp_1d_demo
This demonstration benefits from having :code:`matplotlib`
installed, but is not required.
Documentation
=============
Documentation of the equations used in the algorithm, along with
the available kernels and optimizers, can be found in docs/.
Documentation of the :code:`mkgp` module can be found on
`GitLab pages <https://aaronkho.gitlab.io/mkgp>`_
Using the gpr1d program
-----------------------
For those who wish to include the functionality of this package
into their own Python scripts, a sample script is provided in
:code:`src/mkgp/scripts/demo.py`. The basic syntax used to create
kernels, select optimizers, and perform the GP regression fits are
outlined there.
For any questions or to report bugs, please do so through the
proper channels in the GitLab repository.
*Important note for users!*
The following runtime warnings are common within this routine::
RuntimeWarning: overflow encountered in double_scalars
RuntimeWarning: invalid value encountered in true_divide
RuntimeWarning: invalid value encountered in sqrt
They are filtered out by default but may reappear if verbosity
settings are modified. They normally occur when using the kernel
restarts option (as in the demo) and do not necessarily mean that
the final returned fit is poor.
Plotting the returned fit and errors is the recommended way to
check its quality. The log-marginal-likelihood metric can also
be used, but is only valuable when comparing different fits of
the same data, i.e. its absolute value is meaningless.
From v1.1.1, the adjusted R\ :sup:`2` and pseudo R\ :sup:`2`
metrics are now available. The adjusted R\ :sup:`2` metric provides
a measure of how close the fit is to the input data points. The
pseudo R\ :sup:`2` provides a measure of this closeness accounting
for the input data uncertainties.
| text/x-rst | null | Aaron Ho <aaronkho@mit.edu> | null | null | null | gaussian process regression, data fitting, regression analysis, kriging, noisy input, heteroscedastic error | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"Topic :: Utilities",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.7 | [] | [] | [] | [
"pip",
"numpy>=1.17",
"scipy>=1.7",
"pandas",
"tables",
"ipython",
"coverage; extra == \"dev\"",
"pytest; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"sphinx; extra == \"docs\"",
"furo; extra == \"docs\"",
"sphinx-rtd-theme; extra == \"docs\"",
"build; extra == \"build\"",
"twine; e... | [] | [] | [] | [
"Homepage, https://gitlab.com/aaronkho/mkgp",
"Bug Reports, https://gitlab.com/aaronkho/mkgp/-/issues",
"Source, https://gitlab.com/aaronkho/mkgp"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T17:09:36.292968 | mkgp-3.1.3.tar.gz | 807,054 | 37/80/556c5aa2fd840f725c741165e066ddc7038ff472283e1c8010521b748286/mkgp-3.1.3.tar.gz | source | sdist | null | false | 0301e6c1cbb9e2a961d5a0bffeabcaee | 030a90b89e71fa527b9b5256ea39318f0d53bc2330fcd52dcd4c8d992e39d5fa | 3780556c5aa2fd840f725c741165e066ddc7038ff472283e1c8010521b748286 | MIT | [
"LICENSE"
] | 223 |
2.4 | mandatum-sdk | 0.2.0 | Python SDK for Mandatum - Prompt engineering platform with automatic LLM request logging | # Mandatum Python SDK
Python SDK for Mandatum - prompt management with code-level customization.
## Installation
```bash
pip install mandatum-sdk
# Or install with specific provider support
pip install mandatum-sdk[openai]
pip install mandatum-sdk[anthropic]
pip install mandatum-sdk[all] # All providers
```
## Quick Start
### OpenAI Integration
```python
from mandatum import Mandatum
# Initialize Mandatum client
mandatum = Mandatum(api_key="md_xxxxx")
# Get wrapped OpenAI client
OpenAI = mandatum.openai.OpenAI
client = OpenAI()
# Use exactly like normal OpenAI SDK - automatically logged!
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Hello, world!"}],
# Optional: Mandatum-specific metadata
md_tags=["production", "feature-x"],
md_environment="production",
md_metadata={"user_id": "123"}
)
print(response.choices[0].message.content)
```
### Anthropic Integration
```python
from mandatum import Mandatum
mandatum = Mandatum(api_key="md_xxxxx")
# Get wrapped Anthropic client
Anthropic = mandatum.anthropic.Anthropic
client = Anthropic()
# Use normally - automatically logged!
response = client.messages.create(
model="claude-3-sonnet-20240229",
max_tokens=1024,
messages=[{"role": "user", "content": "Hello, Claude!"}],
# Mandatum metadata
md_tags=["test"],
md_environment="development"
)
print(response.content[0].text)
```
### Async Support
```python
import asyncio
from mandatum import Mandatum
mandatum = Mandatum(api_key="md_xxxxx")
# Get wrapped async client
AsyncOpenAI = mandatum.openai.AsyncOpenAI
client = AsyncOpenAI()
async def main():
response = await client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Hello!"}]
)
print(response.choices[0].message.content)
asyncio.run(main())
```
## Configuration
### Environment Variables
```bash
# Required
export MANDATUM_API_KEY="md_xxxxx"
# Optional
export MANDATUM_BASE_URL="https://mandatum-api.gavelinivar.com/api/v1" # Default: http://localhost:8000/api/v1
```
### Initialization Options
```python
mandatum = Mandatum(
api_key="md_xxxxx", # API key (or set MANDATUM_API_KEY)
base_url="http://localhost:8000/api/v1", # Mandatum API URL
organization_id="org_xxxxx", # Optional organization ID
async_logging=True, # Log asynchronously (default: True)
debug=False # Enable debug logging (default: False)
)
```
## Metadata Parameters
Add Mandatum-specific metadata to any LLM call:
- `md_tags`: List of tags for filtering/grouping (e.g., `["production", "feature-x"]`)
- `md_environment`: Environment name (e.g., `"production"`, `"staging"`, `"development"`)
- `md_metadata`: Custom JSON metadata (e.g., `{"user_id": "123", "session_id": "abc"}`)
- `md_prompt_id`: UUID of associated prompt in Mandatum
- `md_version_tag`: Version tag for the prompt
- `md_parent_request_id`: UUID of parent request (for chained calls)
## Features
- **Transparent Wrapping**: Use OpenAI/Anthropic SDKs normally with zero code changes
- **Automatic Logging**: All requests logged to Mandatum automatically
- **Cost Tracking**: Automatic cost calculation per request
- **Latency Monitoring**: Track request duration for every call
- **Token Counting**: Input/output token counts captured
- **Error Logging**: Failed requests logged with error details
- **Async Support**: Full async/await support for both OpenAI and Anthropic
- **Background Logging**: Non-blocking async logging doesn't slow down LLM calls
## How It Works
1. Mandatum wraps the native OpenAI/Anthropic SDK clients
2. When you call `.create()`, the wrapper intercepts the request
3. The actual LLM API call is made (locally, nothing sent to Mandatum yet)
4. Response metadata (tokens, latency, cost) is captured
5. Request data is sent to Mandatum API in a background thread (non-blocking)
6. Original response is returned to your code immediately
Your API keys for OpenAI/Anthropic are never sent to Mandatum - all LLM requests are made directly from your machine.
## Examples
### With Prompt Management
```python
from mandatum import Mandatum
import uuid
mandatum = Mandatum(api_key="md_xxxxx")
OpenAI = mandatum.openai.OpenAI
client = OpenAI()
# Link request to a Mandatum prompt
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Translate to French: Hello"}],
md_prompt_id=str(uuid.UUID("prompt-uuid-here")),
md_version_tag="v1.2.0"
)
```
### With Request Chains
```python
# First request
response1 = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "What is Python?"}]
)
# Get request ID from Mandatum dashboard or API
parent_request_id = "request-uuid-from-first-call"
# Chained request
response2 = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Give me a code example"}],
md_parent_request_id=parent_request_id,
md_tags=["chained-request"]
)
```
## Development
### Local Installation
```bash
cd sdk/python
pip install -e .
```
### Testing
```bash
# Set up environment
export MANDATUM_API_KEY="your_test_key"
export OPENAI_API_KEY="your_openai_key"
# Run test script
python test_sdk.py
```
## Support
- **Documentation**: https://mandatum-documentation.netlify.app
- **Issues**: https://github.com/Ivargavve/Mandatum/issues
- **Email**: support@gavelinivar.com
## License
MIT License - see LICENSE file for details.
| text/markdown | Mandatum Team | support@mandatum.io | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Prog... | [] | https://github.com/Ivargavve/Mandatum | null | >=3.8 | [] | [] | [] | [
"httpx>=0.24.0",
"openai>=1.0.0; extra == \"openai\"",
"anthropic>=0.18.0; extra == \"anthropic\"",
"openai>=1.0.0; extra == \"all\"",
"anthropic>=0.18.0; extra == \"all\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.8 | 2026-02-19T17:09:28.072859 | mandatum_sdk-0.2.0.tar.gz | 12,841 | fd/1e/82497cc9be212d7bc0ccae38c454c7bdfa5b632ca9cf4e711fd7ee2b964e/mandatum_sdk-0.2.0.tar.gz | source | sdist | null | false | f93e5ee2b2ee74e8774ce635a0d94749 | 581223c77bccb7032ddc0d3689e121b9c80eb97480284adb08892f85ba9244e1 | fd1e82497cc9be212d7bc0ccae38c454c7bdfa5b632ca9cf4e711fd7ee2b964e | null | [] | 217 |
2.4 | onnxruntime-directml | 1.24.2 | ONNX Runtime is a runtime accelerator for Machine Learning models | ONNX Runtime
============
ONNX Runtime is a performance-focused scoring engine for Open Neural Network Exchange (ONNX) models.
For more information on ONNX Runtime, please see `aka.ms/onnxruntime <https://aka.ms/onnxruntime/>`_ or the `Github project <https://github.com/microsoft/onnxruntime/>`_.
Changes
-------
1.24.2
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.24.2
1.24.1
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.24.1
1.23.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.23.0
1.22.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.22.0
1.21.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.21.0
1.20.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.20.0
1.19.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.19.0
1.18.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.18.0
1.17.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.17.0
1.16.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.16.0
1.15.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.15.0
1.14.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.14.0
1.13.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.13.0
1.12.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.12.0
1.11.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.11.0
1.10.0
^^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.10.0
1.9.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.9.0
1.8.2
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.8.2
1.8.1
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.8.1
1.8.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.8.0
1.7.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.7.0
1.6.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.6.0
1.5.3
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.5.3
1.5.2
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.5.2
1.5.1
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.5.1
1.4.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.4.0
1.3.1
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.3.1
1.3.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.3.0
1.2.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.2.0
1.1.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.1.0
1.0.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v1.0.0
0.5.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v0.5.0
0.4.0
^^^^^
Release Notes : https://github.com/Microsoft/onnxruntime/releases/tag/v0.4.0
| null | Microsoft Corporation | onnxruntime@microsoft.com | null | null | MIT License | onnx machine learning | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: POSIX :: Linux",
"Operating System :: Microsoft :: Windows",
"Operating System :: MacOS",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering... | [] | https://onnxruntime.ai | https://github.com/microsoft/onnxruntime/tags | >=3.10 | [] | [] | [] | [
"flatbuffers",
"numpy>=1.21.6",
"packaging",
"protobuf",
"sympy"
] | [] | [] | [] | [] | RestSharp/106.13.0.0 | 2026-02-19T17:08:36.021161 | onnxruntime_directml-1.24.2-cp314-cp314-win_amd64.whl | 25,452,675 | ee/07/5f9834571eb9f02c437379696211f0ac5ef3323083e2059610c23957fff5/onnxruntime_directml-1.24.2-cp314-cp314-win_amd64.whl | py3 | bdist_wheel | null | false | 31a61c1f8593c5c67b5eaafc6ba3f731 | df8305fbf4df98491822eeefcdd4497753c440e15ebd2c9c7654133b126161c4 | ee075f9834571eb9f02c437379696211f0ac5ef3323083e2059610c23957fff5 | null | [] | 2,458 |
2.4 | wowbits-cli | 0.1.0a7 | WowBits AI Platform CLI - Manage connectors and integrations for AI workflows | # WowBits CLI
A command-line interface for building and running WowBits AI agents. Manage connectors, functions, and agents with ease.
## Table of Contents
- [Installation](#installation)
- [Quick Start](#quick-start)
- [Commands](#commands)
- [Setup](#setup)
- [List](#list)
- [Create](#create)
- [Update](#update)
- [Delete](#delete)
- [Run](#run)
- [Pull](#pull)
- [Examples](#examples)
- [Configuration](#configuration)
- [Troubleshooting](#troubleshooting)
## Installation
Install the WowBits CLI using pip:
```bash
pip install wowbits-cli
```
Or install from source:
```bash
git clone https://github.com/wowbits/wowbits-cli.git
cd wowbits-cli/src
pip install -e .
```
## Quick Start
1. **Run initial setup** to configure your environment:
```bash
wowbits setup
```
This will:
- Create a root directory (default: `~/wowbits`)
- Set up required subdirectories (`functions`, `agent_studio`, `agent_runner`, `data`)
- Configure database connection
- Initialize the database schema
2. **Verify installation**:
```bash
wowbits --version
```
## Commands
### Setup
Initialize the WowBits environment and database.
```bash
wowbits setup [--root-dir PATH]
```
**Options:**
- `--root-dir PATH`: Specify a custom root directory (default: `~/wowbits`)
**What it does:**
- Creates the root directory structure
- Sets up PostgreSQL database connection
- Initializes database schema
- Configures environment variables
### List
List available resources.
#### List Functions
```bash
wowbits list functions
```
Displays all Python functions registered in the database.
#### List Connectors
```bash
wowbits list connectors
```
Shows all configured connectors (API keys, credentials, etc.).
#### List Agents
```bash
wowbits list agents
```
Lists all agents available in the system.
### Create
Create new resources.
#### Create Function
Register Python functions from your functions directory:
```bash
wowbits create function [--dir PATH]
```
**Options:**
- `--dir PATH`: Custom functions directory (default: `WOWBITS_ROOT_DIR/functions`)
**What it does:**
- Scans the functions directory for `.py` files
- Installs dependencies from `functions/requirements.txt` if present
- Registers functions in the database
- Updates existing functions if they already exist
**Function Structure:**
Place your Python functions in `WOWBITS_ROOT_DIR/functions/`. Each `.py` file should contain a function with the same name as the file (without `.py` extension).
Example: `functions/my_function.py` should contain a function named `my_function`.
#### Create Connector
Create a new connector (API credentials, etc.):
```bash
wowbits create connector [--provider PROVIDER] [--config JSON]
```
**Options:**
- `--provider PROVIDER`: Provider name (e.g., `openai`, `anthropic`)
- `--config JSON`: JSON configuration string (if omitted, interactive mode is used)
**Interactive Mode:**
If `--config` is not provided, the CLI will prompt you for configuration values:
```bash
wowbits create connector --provider openai
```
**JSON Config Mode:**
Provide configuration as a JSON string:
```bash
wowbits create connector --provider openai --config '{"api_key": "sk-..."}'
```
**Available Providers:**
Run `wowbits list providers` (if available) or check the providers configuration for supported providers.
#### Create Agent
Create an agent from a YAML configuration file:
```bash
wowbits create agent NAME [-c PATH]
```
**Arguments:**
- `NAME`: Agent name (looks for `WOWBITS_ROOT_DIR/agent_studio/NAME.yaml`)
- `-c, --config PATH`: Custom path to YAML configuration file (optional)
**Example:**
```bash
wowbits create agent my_agent
```
This will look for `~/wowbits/agent_studio/my_agent.yaml` and create the agent based on that configuration.
### Update
Update existing resources.
#### Update Connector
Update an existing connector's configuration:
```bash
wowbits update connectors NAME --config JSON
```
**Arguments:**
- `NAME`: Connector name or ID
- `--config JSON`: JSON configuration string
**Example:**
```bash
wowbits update connectors openai --config '{"api_key": "sk-new-key"}'
```
### Delete
Delete resources.
#### Delete Connector
Remove a connector:
```bash
wowbits delete connectors NAME
```
**Arguments:**
- `NAME`: Connector name or ID
**Example:**
```bash
wowbits delete connectors old_connector
```
### Run
Run agents with the ADK server.
#### Run Agent
Start an agent server:
```bash
wowbits run agent NAME [--mode MODE] [--host HOST] [--port PORT]
```
**Arguments:**
- `NAME`: Agent name
**Options:**
- `--mode, -m MODE`: Execution mode - `web` (ADK web UI) or `api` (ADK API server only). Default: `web`
- `--host HOST`: Host to bind the server to. Default: `0.0.0.0`
- `--port, -p PORT`: Port to run the server on. Default: `5151`
**Examples:**
```bash
# Run agent with web UI (default)
wowbits run agent my_agent
# Run agent in API-only mode
wowbits run agent my_agent --mode api
# Run on custom host and port
wowbits run agent my_agent --host 127.0.0.1 --port 8080
```
### Pull
Pull resources from remote repositories.
#### Pull Functions
Fetch Python functions from a GitHub repository:
```bash
wowbits pull functions [FUNCTION_NAMES...] --repo-url URL
```
**Arguments:**
- `FUNCTION_NAMES`: Specific function names to pull, or `*` or omit to pull all functions
**Options:**
- `--repo-url URL`: GitHub repository URL (required)
**Examples:**
```bash
# Pull all functions from a repo
wowbits pull functions --repo-url https://github.com/org/repo
# Pull specific functions
wowbits pull functions function1 function2 --repo-url https://github.com/org/repo
# Pull all functions (explicit)
wowbits pull functions * --repo-url https://github.com/org/repo
```
**What it does:**
- Fetches `.py` files from the repository's `functions/` directory (or repo root)
- Saves them to `WOWBITS_ROOT_DIR/functions/`
- Fetches `requirements.txt` if available
- Registers/updates functions in the database
## Examples
### Complete Workflow Example
```bash
# 1. Initial setup
wowbits setup
# 2. Create a connector for OpenAI
wowbits create connector --provider openai
# Follow interactive prompts to enter API key
# 3. Pull functions from a repository
wowbits pull functions --repo-url https://github.com/org/my-functions
# 4. Or create functions locally
# Edit ~/wowbits/functions/my_function.py
wowbits create function
# 5. Create an agent from YAML config
# Edit ~/wowbits/agent_studio/my_agent.yaml
wowbits create agent my_agent
# 6. Run the agent
wowbits run agent my_agent
```
### Function Example
Create a function file `~/wowbits/functions/calculate_sum.py`:
```python
def calculate_sum(a: int, b: int) -> int:
"""Add two numbers together."""
return a + b
```
Then register it:
```bash
wowbits create function
```
### Agent YAML Example
Create `~/wowbits/agent_studio/my_agent.yaml`:
```yaml
name: my_agent
description: A simple agent example
model: gpt-4
connector: openai
skills:
- name: basic_skill
tools:
- calculate_sum
```
Then create the agent:
```bash
wowbits create agent my_agent
```
**Multi-document YAML format:** When using multiple YAML documents (e.g. tools, skills, and agents in one file), use the `kind` field with WowBits-prefixed values so you can easily filter WowBits configs on GitHub:
- `kind: wowbits_tool` — tool definition
- `kind: wowbits_skill` — skill definition
- `kind: wowbits_agent` — agent definition
Legacy values `tool`, `skill`, and `agent` are still accepted.
## Configuration
### Environment Variables
The CLI uses the following environment variables:
- `WOWBITS_ROOT_DIR`: Root directory for WowBits (set automatically during `setup`)
- Database connection variables (configured in `.env` file during setup)
### Directory Structure
After running `wowbits setup`, your root directory will have this structure:
```
~/wowbits/
├── functions/ # Python function files
│ ├── __init__.py
│ ├── requirements.txt
│ └── *.py # Your function files
├── agent_studio/ # Agent YAML configurations
│ └── *.yaml
├── agent_runner/ # Generated agent code
│ └── __init__.py
├── data/ # Data files
└── .env # Environment configuration
```
### Database Configuration
Database connection is configured in the `.env` file in your root directory. The setup command will prompt you for database credentials.
## Troubleshooting
### "WOWBITS_ROOT_DIR environment variable is not set"
**Solution:** Run `wowbits setup` or manually set the environment variable:
```bash
export WOWBITS_ROOT_DIR=~/wowbits
```
Add this to your `~/.zshrc` or `~/.bashrc` to make it persistent.
### Database Connection Errors
**Solution:** Check your `.env` file in `WOWBITS_ROOT_DIR` and verify database credentials are correct.
### Function Not Found
**Solution:**
1. Ensure the function file exists in `WOWBITS_ROOT_DIR/functions/`
2. Run `wowbits create function` to register it
3. Verify with `wowbits list functions`
### Agent Creation Fails
**Solution:**
1. Verify the YAML file exists at `WOWBITS_ROOT_DIR/agent_studio/NAME.yaml`
2. Check YAML syntax for errors
3. Ensure referenced connectors and functions exist
### Port Already in Use
**Solution:** Use a different port:
```bash
wowbits run agent my_agent --port 8080
```
## Getting Help
- View help for any command: `wowbits COMMAND --help`
- View general help: `wowbits --help`
- Check version: `wowbits --version`
## License
MIT License - see LICENSE file for details.
## Support
- GitHub Issues: https://github.com/wowbits/wowbits-cli/issues
- Documentation: https://github.com/wowbits/wowbits-cli#readme
| text/markdown | null | WowBits AI <support@wowbits.ai> | null | null | MIT | ai, api-management, cli, connectors, integrations, wowbits | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Pr... | [] | null | null | >=3.9 | [] | [] | [] | [
"psycopg2-binary>=2.9.0",
"python-dotenv>=1.0.0",
"sqlalchemy>=2.0.0",
"black>=23.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/wowbits/wowbits-cli",
"Documentation, https://github.com/wowbits/wowbits-cli#readme",
"Repository, https://github.com/wowbits/wowbits-cli",
"Issues, https://github.com/wowbits/wowbits-cli/issues"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-19T17:07:01.853793 | wowbits_cli-0.1.0a7.tar.gz | 38,928 | 18/b7/d0fc6ab6e3f0b858db3144e1260c953f6ed5e7a2c5b4b94bf538c1dcdba3/wowbits_cli-0.1.0a7.tar.gz | source | sdist | null | false | 1b5bf41715470e886afca3c754f834f5 | 9db523f488efdff78c392697806cdba7908e146acc53de5a31f20d41fd49ccaf | 18b7d0fc6ab6e3f0b858db3144e1260c953f6ed5e7a2c5b4b94bf538c1dcdba3 | null | [] | 217 |
2.4 | assay-ai | 1.6.0 | Tamper-evident audit trails for AI systems | # Assay
Tamper-evident audit trails for AI systems.
We scanned 30 popular AI projects and found 202 high-confidence LLM call
sites. Zero had tamper-evident audit trails.
[Full results](scripts/scan_study/results/report.md).
Assay adds independently verifiable execution evidence to AI systems:
cryptographically signed receipt bundles that a third party can verify
offline without trusting your server logs. Two lines of code. Four exit codes.
```bash
pip install assay-ai && assay quickstart
```
> **Boundary:** Assay proves tamper-evident internal consistency and
> completeness relative to scanned call sites. It does not prevent a fully
> compromised machine from fabricating a consistent story. That's what
> [trust tiers](docs/FULL_PICTURE.md#trust-tiers) are for.
> **Not this:** Assay is not a logging framework, an observability dashboard,
> or a monitoring tool. It produces signed evidence bundles that a third party
> can verify offline. If you need Datadog, this isn't it.
## See It -- Then Understand It
No API key needed. Runs on synthetic data:
```bash
assay demo-incident # two-act scenario: honest PASS vs honest FAIL
```
**Act 1**: Agent uses gpt-4 with a guardian check. Integrity PASS, claims PASS.
**Act 2**: Someone swaps the model and drops the guardian. Integrity PASS, claims FAIL.
That second result is an **honest failure** -- authentic evidence proving the
run violated its declared standards. Not a cover-up. Exit code 1.
Exit 1 is **audit gold**: authentic evidence that a control failed, with no
ability to edit history. Auditors love "controls can fail, but failure is
detectable and retained."
### How that works
Assay separates two questions on purpose:
- **Integrity**: "Were these bytes tampered with after creation?" (signatures, hashes, required files)
- **Claims**: "Does this evidence satisfy our declared governance checks?" (receipt types, counts, field values)
| Integrity | Claims | Exit | Meaning |
|-----------|--------|------|---------|
| PASS | PASS | 0 | Evidence checks out, behavior meets standards |
| PASS | FAIL | 1 | Honest failure: authentic evidence of a standards violation |
| FAIL | -- | 2 | Tampered evidence |
| -- | -- | 3 | Bad input (missing files, invalid arguments) |
The split is the point. Systems that can prove they failed honestly are
more trustworthy than systems that always claim to pass.
## Add to Your Project
```bash
# 1. Find uninstrumented LLM calls
assay scan . --report
# 2. Patch (one line per SDK, or auto-patch all)
assay patch .
# 3. Run + build a signed evidence pack
assay run -c receipt_completeness -- python my_app.py
# 4. Verify
assay verify-pack ./proof_pack_*/
```
`assay scan . --report` finds every LLM call site (OpenAI, Anthropic, LangChain)
and generates a self-contained HTML gap report. `assay patch` inserts the
two-line integration. `assay run` wraps your command, collects receipts, and
produces a signed 5-file evidence pack. `assay verify-pack` checks integrity +
claims and exits with one of the four codes above. Then run `assay explain`
on any pack for a plain-English summary.
> **Why now**: EU AI Act Article 12 requires automatic logging for high-risk
> AI systems; Article 19 requires providers to retain automatically generated
> logs for at least 6 months. High-risk obligations apply from 2 Aug 2026
> (Annex III) and 2 Aug 2027 (regulated products). SOC 2 CC7.2 requires
> monitoring of system components and analysis of anomalies as security events.
> "We have logs on our server" is not independently verifiable evidence.
> Assay produces evidence that is.
> See [compliance citations](docs/compliance-citations.md) for exact references.
## CI Gate
Three commands, three exit codes, one lockfile:
```bash
assay run -c receipt_completeness -- python my_app.py
assay verify-pack ./proof_pack_*/ --lock assay.lock --require-claim-pass
assay diff ./baseline_pack/ ./proof_pack_*/ --gate-cost-pct 25 --gate-errors 0 --gate-strict
```
The lockfile catches config drift. Verify-pack catches tampering. Diff
catches regressions and budget overruns. See
[Decision Escrow](docs/decision-escrow.md) for the protocol model.
```bash
# Lock your verification contract
assay lock write --cards receipt_completeness -o assay.lock
```
### Daily use after CI is green
**Regression forensics**:
```bash
assay diff ./proof_pack_*/ --against-previous --why
```
`--against-previous` auto-discovers the baseline pack.
`--why` traces receipt chains to explain what regressed and which call sites caused it.
**Cost/latency drift (from receipts)**:
```bash
assay analyze --history --since 7
```
Shows cost, latency percentiles, error rates, and per-model breakdowns
from your local trace history.
## Trust Model
What Assay detects, what it doesn't, and how to strengthen guarantees.
**Assay detects:**
- Retroactive tampering (edit one byte, verification fails)
- Selective omission under a completeness contract
- Claiming checks that were never run
- Policy drift from a locked baseline
**Assay does not prevent:**
- A fully fabricated false run (attacker controls the machine)
- Dishonest receipt content (receipts are self-attested)
- Timestamp fraud without an external time anchor
Completeness is enforced relative to the call sites enumerated by the scanner
and/or declared by policy. Undetected call sites are a known residual risk,
reduced via multi-detector scanning and CI gating.
**To strengthen guarantees:**
- [Transparency ledger](https://github.com/Haserjian/assay-ledger) (independent witness)
- CI-held org key + branch protection (separation of signer and committer)
- External timestamping (RFC 3161)
The cost of cheating scales with the complexity of the lie. Assay doesn't
make fraud impossible -- it makes fraud expensive.
## The Evidence Compiler
Assay is an **evidence compiler** for AI execution. If you've used a build
system, you already know the mental model:
| Concept | Build System | Assay |
|---------|-------------|-------|
| Source | `.c` / `.ts` files | Receipts (one per LLM call) |
| Artifact | Binary / bundle | Evidence pack (5 files, 1 signature) |
| Tests | Unit / integration tests | Verification (integrity + claims) |
| Lock | `package-lock.json` | `assay.lock` |
| Gate | CI deploy check | CI evidence gate |
## Commands
The core path is 6 commands:
```
assay quickstart # discover
assay scan / assay patch # instrument
assay run # produce evidence
assay verify-pack # verify evidence
assay diff # catch regressions
assay score # evidence readiness (0-100, A-F)
```
Full command reference:
| Command | Purpose |
|---------|---------|
| `assay quickstart` | One command: demo + scan + next steps |
| `assay status` | One-screen operational dashboard: am I set up? |
| `assay start demo` | See Assay in action (quickstart flow) |
| `assay start ci` | Guided CI evidence gate setup (5 steps) |
| `assay start mcp` | Guided MCP tool call auditing setup (4 steps) |
| `assay scan` | Find uninstrumented LLM call sites (`--report` for HTML) |
| `assay patch` | Auto-insert SDK integration patches into your entrypoint |
| `assay run` | Wrap command, collect receipts, build signed evidence pack |
| `assay verify-pack` | Verify an evidence pack (integrity + claims) |
| `assay explain` | Plain-English summary of an evidence pack |
| `assay analyze` | Cost, latency, error breakdown from pack or `--history` |
| `assay diff` | Compare packs: claims, cost, latency (`--against-previous`, `--why`, `--gate-*`) |
| `assay score` | Evidence Readiness Score (0-100, A-F) with anti-gaming caps |
| `assay doctor` | Preflight check: is Assay ready here? |
| `assay mcp-proxy` | Transparent MCP proxy: intercept tool calls, emit receipts |
| `assay mcp policy init` | Generate a starter MCP policy YAML file |
| `assay ci init github` | Generate a GitHub Actions workflow |
| `assay lock write` | Freeze verification contract to lockfile |
| `assay lock check` | Validate lockfile against current card definitions |
| `assay key list` | List local signing keys and active signer |
| `assay key rotate` | Generate a new signer key and switch active signer |
| `assay key set-active` | Set active signing key for future runs |
| `assay cards list` | List built-in run cards and their claims |
| `assay cards show` | Show card details, claims, and parameters |
| `assay demo-incident` | Two-act scenario: passing run vs failing run |
| `assay demo-challenge` | CTF-style good + tampered pack pair |
| `assay demo-pack` | Generate demo packs (no config needed) |
| `assay onboard` | Guided setup: doctor -> scan -> first run plan |
## Documentation
- [Full Picture](docs/FULL_PICTURE.md) -- architecture, trust tiers, repo boundaries, release history
- [Quickstart](docs/README_quickstart.md) -- install, golden path, command reference
- [For Compliance Teams](docs/for-compliance.md) -- what auditors see, evidence artifacts, framework alignment
- [Compliance Citations](docs/compliance-citations.md) -- exact regulatory references (EU AI Act, SOC 2, ISO 42001)
- [Decision Escrow](docs/decision-escrow.md) -- protocol model: agent actions don't settle until verified
- [Roadmap](docs/ROADMAP.md) -- phases, product boundary, execution stack
- [Repo Map](docs/REPO_MAP.md) -- what lives where across the Assay ecosystem
- [Pilot Program](docs/PILOT_PROGRAM.md) -- early adopter program details
## Common Issues
- **"No receipts emitted" after `assay run`**: First, check whether your code
has call sites: `assay scan .` -- if scan finds 0 sites, you may not be
using a supported SDK yet. If scan finds sites, check: (1) Is `# assay:patched`
in the file? Run `assay scan . --report` to see patch status per file.
(2) Did you install the SDK extra (`pip install assay-ai[openai]`)?
(3) Did you use `--` before your command (`assay run -- python app.py`)?
Run `assay doctor` for a full diagnostic.
- **LangChain projects**: `assay patch` auto-instruments OpenAI and Anthropic
SDKs but not LangChain (which uses callbacks, not monkey-patching). For
LangChain, add `AssayCallbackHandler()` to your chain's `callbacks` parameter
manually. See `src/assay/integrations/langchain.py` for the handler.
- **`assay run python app.py` gives "No command provided"**: You need the `--`
separator: `assay run -c receipt_completeness -- python app.py`. Everything
after `--` is passed to the subprocess.
- **Quickstart blocked on large directories**: `assay quickstart` guards against
scanning system directories (>10K Python files). Use `--force` to bypass:
`assay quickstart --force`.
## Get Involved
- **Try it**: `pip install assay-ai && assay quickstart`
- **Questions / feedback**: [GitHub Discussions](https://github.com/Haserjian/assay/discussions)
- **Bug reports**: [Issues](https://github.com/Haserjian/assay/issues)
- **Want this in your stack in 2 weeks?** [Pilot program](docs/PILOT_PROGRAM.md) --
we instrument your AI workflows, set up CI gates, and hand you a working
evidence pipeline. [Open a pilot inquiry](https://github.com/Haserjian/assay/issues/new?template=pilot-inquiry.md).
## Related Repos
| Repo | Purpose |
|------|---------|
| [assay](https://github.com/Haserjian/assay) | Core CLI, SDK, conformance corpus (this repo) |
| [assay-verify-action](https://github.com/Haserjian/assay-verify-action) | GitHub Action for CI verification |
| [assay-ledger](https://github.com/Haserjian/assay-ledger) | Public transparency ledger |
## License
Apache-2.0
| text/markdown | null | Tim Bhaserjian <tim2208@gmail.com> | null | null | Apache-2.0 | ai, safety, audit, receipts, governance | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Lan... | [] | null | null | >=3.9 | [] | [] | [] | [
"typer>=0.9.0",
"rich>=13.0.0",
"pydantic>=2.0.0",
"PyNaCl>=1.5.0",
"jsonschema>=4.17.0",
"referencing>=0.30.0",
"packaging>=21.0",
"openai>=1.0.0; extra == \"openai\"",
"anthropic>=0.20.0; extra == \"anthropic\"",
"langchain-core>=0.1.0; extra == \"langchain\"",
"openai>=1.0.0; extra == \"all\"... | [] | [] | [] | [
"Homepage, https://github.com/Haserjian/assay",
"Repository, https://github.com/Haserjian/assay",
"Bug Tracker, https://github.com/Haserjian/assay/issues",
"Documentation, https://github.com/Haserjian/assay/blob/main/docs/README_quickstart.md"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T17:06:37.494437 | assay_ai-1.6.0.tar.gz | 184,307 | dc/02/bbe7ea623c6e834330e5f991b867558d60e8d3e04a04b107c9c26c5f7dc3/assay_ai-1.6.0.tar.gz | source | sdist | null | false | 0f0a274e6a71a4acfa66e1261c538143 | 88d1a8306ff07b78d374f014b195a6effe7d140829d4251246c41c0756f25e1c | dc02bbe7ea623c6e834330e5f991b867558d60e8d3e04a04b107c9c26c5f7dc3 | null | [
"LICENSE"
] | 229 |
2.4 | scpn-control | 0.1.0 | SCPN Control — Neuro-symbolic Stochastic Petri Net controller for plasma control | <p align="center">
<img src="docs/scpn_control_header.png" alt="SCPN-CONTROL — Formal Stochastic Petri Net Engine" width="100%">
</p>
<p align="center">
<a href="https://github.com/anulum/scpn-control/actions"><img src="https://github.com/anulum/scpn-control/actions/workflows/ci.yml/badge.svg" alt="CI"></a>
<a href="https://github.com/anulum/scpn-control/actions/workflows/docs-pages.yml"><img src="https://github.com/anulum/scpn-control/actions/workflows/docs-pages.yml/badge.svg" alt="Docs Pages"></a>
<a href="https://www.gnu.org/licenses/agpl-3.0"><img src="https://img.shields.io/badge/License-AGPL_v3-blue.svg" alt="License: AGPL v3"></a>
<a href="https://orcid.org/0009-0009-3560-0851"><img src="https://img.shields.io/badge/ORCID-0009--0009--3560--0851-green.svg" alt="ORCID"></a>
</p>
---
**scpn-control** is a standalone neuro-symbolic control engine that compiles
Stochastic Petri Nets into spiking neural network controllers with formal
verification guarantees. Extracted from
[scpn-fusion-core](https://github.com/anulum/scpn-fusion-core) as the minimal
41-file transitive closure of the control pipeline.
## Quick Start
```bash
pip install -e "."
scpn-control demo --steps 1000
scpn-control benchmark --n-bench 5000
```
## Documentation and Tutorials
- Documentation site: https://anulum.github.io/scpn-control/
- Local docs index: `docs/index.md`
- Benchmark guide: `docs/benchmarks.md`
- Notebook tutorials:
- `examples/neuro_symbolic_control_demo.ipynb`
- `examples/q10_breakeven_demo.ipynb`
- `examples/snn_compiler_walkthrough.ipynb`
Build docs locally:
```bash
python -m pip install mkdocs
mkdocs serve
```
Execute all notebooks:
```bash
python -m pip install -e ".[viz]" jupyter nbconvert
jupyter nbconvert --to notebook --execute --output-dir artifacts/notebook-exec examples/q10_breakeven_demo.ipynb
jupyter nbconvert --to notebook --execute --output-dir artifacts/notebook-exec examples/snn_compiler_walkthrough.ipynb
```
Optional notebook (requires `sc_neurocore` available in environment):
```bash
jupyter nbconvert --to notebook --execute --output-dir artifacts/notebook-exec examples/neuro_symbolic_control_demo.ipynb
```
## Features
- **Petri Net to SNN compilation** -- Translates Stochastic Petri Nets into spiking neural network controllers with LIF neurons and bitstream encoding
- **Formal verification** -- Contract-based pre/post-condition checking on all control observations and actions
- **Sub-millisecond latency** -- <1ms control loop with optional Rust-accelerated kernels
- **Rust acceleration** -- PyO3 bindings for SCPN activation, marking update, Boris integration, SNN pools, and MPC
- **Multiple controller types** -- PID, MPC, H-infinity, SNN, neuro-cybernetic dual R+Z
- **Grad-Shafranov solver** -- Free-boundary equilibrium solver with L-mode/H-mode profile support
- **Digital twin integration** -- Real-time telemetry ingest, closed-loop simulation, and flight simulator
- **RMSE validation** -- CI-gated regression testing against DIII-D and SPARC experimental reference data
- **Disruption prediction** -- ML-based predictor with SPI mitigation and halo/RE physics
## Architecture
```
src/scpn_control/
+-- scpn/ # Petri net -> SNN compiler
| +-- structure.py # StochasticPetriNet graph builder
| +-- compiler.py # FusionCompiler -> CompiledNet (LIF + bitstream)
| +-- contracts.py # ControlObservation, ControlAction, ControlTargets
| +-- controller.py # NeuroSymbolicController (main entry point)
+-- core/ # Solver + plant model (clean init, no import bombs)
| +-- fusion_kernel.py # Grad-Shafranov equilibrium solver
| +-- integrated_transport_solver.py # Multi-species transport
| +-- scaling_laws.py # IPB98y2 confinement scaling
| +-- eqdsk.py # GEQDSK/EQDSK file I/O
| +-- uncertainty.py # Monte Carlo UQ
+-- control/ # Controllers (optional deps guarded)
| +-- h_infinity_controller.py # H-inf robust control
| +-- fusion_sota_mpc.py # Model Predictive Control
| +-- disruption_predictor.py # ML disruption prediction
| +-- tokamak_digital_twin.py # Digital twin
| +-- tokamak_flight_sim.py # IsoFlux flight simulator
| +-- neuro_cybernetic_controller.py # Dual R+Z SNN
+-- cli.py # Click CLI
scpn-control-rs/ # Rust workspace (5 crates)
+-- control-types/ # PlasmaState, EquilibriumConfig, ControlAction
+-- control-math/ # LIF neuron, Boris pusher, matrix ops
+-- control-core/ # GS solver, transport, confinement scaling
+-- control-control/ # PID, MPC, H-inf, SNN controller
+-- control-python/ # Slim PyO3 bindings (~474 LOC)
```
## Dependencies
| Required | Optional |
|----------|----------|
| numpy >= 1.24 | matplotlib (`pip install -e ".[viz]"`) |
| scipy >= 1.10 | streamlit (`pip install -e ".[dashboard]"`) |
| click >= 8.0 | torch (`pip install -e ".[ml]"`) |
| | nengo (`pip install -e ".[nengo]"`) |
## CLI
```bash
scpn-control demo --scenario combined --steps 1000 # Closed-loop control demo
scpn-control benchmark --n-bench 5000 # PID vs SNN timing benchmark
scpn-control validate # RMSE validation dashboard
scpn-control hil-test --shots-dir ... # HIL test campaign
```
## Benchmarks
Python micro-benchmark:
```bash
scpn-control benchmark --n-bench 5000 --json-out
```
Rust Criterion benchmarks:
```bash
cd scpn-control-rs
cargo bench --workspace
```
Benchmark docs: `docs/benchmarks.md`
## Dashboard
```bash
pip install -e ".[dashboard]"
streamlit run dashboard/control_dashboard.py
```
Four tabs: Trajectory Viewer, RMSE Dashboard, Timing Benchmark, Shot Replay.
## Rust Acceleration
```bash
cd scpn-control-rs
cargo test --workspace
# Build Python bindings
pip install maturin
maturin develop --release
# Verify
python -c "import scpn_control_rs; print('Rust backend active')"
```
The Rust backend provides PyO3 bindings for:
- `PyFusionKernel` -- Grad-Shafranov solver
- `PySnnPool` / `PySnnController` -- Spiking neural network pools
- `PyMpcController` -- Model Predictive Control
- `PyPlasma2D` -- Digital twin
- `PyTransportSolver` -- Chang-Hinton + Sauter bootstrap
- SCPN kernels -- `dense_activations`, `marking_update`, `sample_firing`
## Citation
```bibtex
@software{sotek2026scpncontrol,
title = {SCPN Control: Neuro-Symbolic Stochastic Petri Net Controller},
author = {Sotek, Miroslav and Reiprich, Michal},
year = {2026},
url = {https://github.com/anulum/scpn-control},
license = {AGPL-3.0-or-later}
}
```
## Release and PyPI
Publishing is handled by workflow:
- `.github/workflows/publish-pypi.yml`
## Authors
- **Miroslav Sotek** — ANULUM CH & LI — [ORCID](https://orcid.org/0009-0009-3560-0851)
- **Michal Reiprich** — ANULUM CH & LI
## License
- Concepts: Copyright 1996-2026
- Code: Copyright 2024-2026
- License: GNU AGPL v3
GNU Affero General Public License v3.0 — see [LICENSE](LICENSE).
For commercial licensing inquiries, contact: [protoscience@anulum.li](mailto:protoscience@anulum.li)
| text/markdown | Miroslav Sotek, Michal Reiprich | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Rust",
"Topic :: Scientific/Engineering :: Physics",
"Development Status :: 3 - Alpha"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy>=1.24",
"scipy>=1.10",
"click>=8.0",
"matplotlib>=3.5; extra == \"viz\"",
"streamlit>=1.20; extra == \"dashboard\"",
"matplotlib>=3.5; extra == \"dashboard\"",
"torch>=2.0; extra == \"ml\"",
"nengo>=4.0; extra == \"nengo\"",
"freegs>=0.6; extra == \"benchmark\"",
"pytest>=7.0; extra == \"de... | [] | [] | [] | [
"Homepage, https://github.com/anulum/scpn-control",
"Documentation, https://anulum.github.io/scpn-control/",
"Repository, https://github.com/anulum/scpn-control",
"Bug Tracker, https://github.com/anulum/scpn-control/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T17:05:56.427692 | scpn_control-0.1.0.tar.gz | 256,083 | 25/e8/b9aad16b6fcec6d5eac72bae5c34dbdffaf334d98f6b1fbf74017abbb45e/scpn_control-0.1.0.tar.gz | source | sdist | null | false | 4a3a32141d4536dadc841dbcc5408491 | 988d7bd8e4b0386beed0d0e78b7fcd193ba37206cc1a88d06888f862cbc57b97 | 25e8b9aad16b6fcec6d5eac72bae5c34dbdffaf334d98f6b1fbf74017abbb45e | AGPL-3.0-or-later | [
"LICENSE"
] | 213 |
2.4 | mcp-agentnex | 0.1.9 | MCP Server for AgentNEX - Bridge between NEXA AI and AgentNEX Backend | # AgentNEX MCP Server
A Model Context Protocol (MCP) server that provides AI assistants with secure access to AgentNEX device management and monitoring capabilities.
[](https://badge.fury.io/py/mcp-agentnex)
[](https://opensource.org/licenses/MIT)
## Overview
The AgentNEX MCP Server enables AI assistants to interact with the AgentNEX platform through the Model Context Protocol. It provides tools for device management, telemetry monitoring, and system actions via stdio (JSON-RPC) transport.
## Features
### Tools (8 Available)
| Tool | Description |
|------|-------------|
| `list_devices` | List all registered devices for the account |
| `get_device_telemetry` | Get real-time CPU, memory, disk, and network metrics |
| `get_device_processes` | List running processes with resource usage |
| `restart_process` | Restart a specific process by name |
| `kill_process` | Terminate a process by name or PID |
| `clear_cache` | Clear application cache (Chrome, Edge, Teams, Outlook) |
| `flush_dns` | Flush DNS resolver cache |
| `restart_service` | Restart a Windows service |
### Resources (3 Available)
| Resource URI | Description |
|--------------|-------------|
| `agentnex://devices/all` | List of all registered devices |
| `agentnex://device/{device_id}/status` | Device connection status |
| `agentnex://device/{device_id}/telemetry` | Latest device telemetry data |
## Installation
### From PyPI (Recommended)
```bash
pip install mcp-agentnex
```
### From Source
```bash
git clone https://github.com/ivedha-tech/agentnex-mcpserver.git
cd agentnex-mcpserver
pip install -e .
```
## Quick Start
### 1. Set Environment Variables
```bash
export AGENTNEX_BACKEND_URL=<your-backend-url>
export AGENTNEX_API_KEY=<your-api-key>
```
### 2. Run the Server
```bash
mcp-agentnex
```
The server runs in stdio mode and communicates via JSON-RPC over stdin/stdout.
## Configuration
### Required Environment Variables
| Variable | Description |
|----------|-------------|
| `AGENTNEX_BACKEND_URL` | AgentNEX backend API endpoint |
| `AGENTNEX_API_KEY` | API key for backend authentication |
### Optional Environment Variables
| Variable | Description | Default |
|----------|-------------|---------|
| `AGENTNEX_MCP_SERVER_NAME` | Server name for MCP protocol | `agentnex-mcp-server` |
| `AGENTNEX_MCP_SERVER_VERSION` | Server version | `1.0.0` |
| `AGENTNEX_LOG_LEVEL` | Logging level (DEBUG, INFO, WARNING, ERROR) | `INFO` |
| `AGENTNEX_BACKEND_TIMEOUT` | Backend request timeout (seconds) | `30.0` |
| `AGENTNEX_BACKEND_RETRY_ATTEMPTS` | Number of retry attempts | `3` |
## Usage
### MCP Protocol Communication
The server uses stdio transport and follows the Model Context Protocol specification:
#### Initialize Connection
```json
{"jsonrpc":"2.0","id":1,"method":"initialize","params":{"protocolVersion":"2024-11-05","capabilities":{}}}
```
#### List Available Tools
```json
{"jsonrpc":"2.0","id":2,"method":"tools/list"}
```
#### Call a Tool
```json
{"jsonrpc":"2.0","id":3,"method":"tools/call","params":{"name":"get_device_telemetry","arguments":{"device_id":"device-uuid"}}}
```
#### List Available Resources
```json
{"jsonrpc":"2.0","id":4,"method":"resources/list"}
```
#### Read a Resource
```json
{"jsonrpc":"2.0","id":5,"method":"resources/read","params":{"uri":"agentnex://devices/all"}}
```
## Integration
### With AI Platforms
AI platforms can integrate with this MCP server by:
1. Installing the package: `pip install mcp-agentnex`
2. Configuring backend URL and API key as environment variables
3. Starting the server as a subprocess
4. Communicating via JSON-RPC messages over stdin/stdout
### Example Integration Code
```python
import subprocess
import json
# Start the MCP server
proc = subprocess.Popen(
['mcp-agentnex'],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
env={
'AGENTNEX_BACKEND_URL': 'https://your-backend-url',
'AGENTNEX_API_KEY': 'your-api-key'
}
)
# Send initialize request
request = {
"jsonrpc": "2.0",
"id": 1,
"method": "initialize",
"params": {"protocolVersion": "2024-11-05", "capabilities": {}}
}
proc.stdin.write(json.dumps(request).encode() + b'\n')
proc.stdin.flush()
# Read response
response = proc.stdout.readline()
print(json.loads(response))
```
## Architecture
```
┌─────────────────────────────────────────────────────────────┐
│ AI Platform / Client │
└───────────────────────────┬─────────────────────────────────┘
│ stdio (JSON-RPC)
│ stdin/stdout
┌───────────────────────────▼─────────────────────────────────┐
│ MCP Server (mcp-agentnex) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────┐ │
│ │ Tools │ │ Resources │ │ Formatters │ │
│ │ (8 tools) │ │(3 resources)│ │ (telemetry/action) │ │
│ └──────┬──────┘ └──────┬──────┘ └──────────┬──────────┘ │
│ └────────────────┼───────────────────┘ │
│ │ │
│ ┌───────────▼───────────┐ │
│ │ Backend Client │ │
│ └───────────┬───────────┘ │
└──────────────────────────┼──────────────────────────────────┘
│ HTTP + API Key
┌──────────────────────────▼──────────────────────────────────┐
│ AgentNEX Backend API │
└─────────────────────────────────────────────────────────────┘
```
## Security
- **API Key Authentication**: All backend requests require valid API key
- **Subprocess Isolation**: Server runs as isolated subprocess
- **No Network Exposure**: stdio transport eliminates network attack surface
- **Input Validation**: All tool arguments are validated before execution
- **Secure Communication**: HTTPS support for backend API calls
- **No Sensitive Logging**: API keys and credentials are never logged
## Development
### Setup Development Environment
```bash
# Clone repository
git clone https://github.com/ivedha-tech/agentnex-mcpserver.git
cd agentnex-mcpserver
# Create virtual environment
python -m venv venv
source venv/bin/activate # Linux/Mac
.\venv\Scripts\Activate.ps1 # Windows
# Install in development mode
pip install -e ".[dev]"
# Configure environment
cp .env.example .env
# Edit .env with your settings
```
### Run Tests
```bash
# Activate virtual environment
source venv/bin/activate
# Run tests
python -m pytest tests/ -v
```
### Test Locally Before PyPI
Use a clean venv and run the full pre-PyPI check (pytest, build, install from wheel, config with NEXA-like extra env):
```bash
# From repo root
python -m venv .venv
.\.venv\Scripts\Activate.ps1 # Windows
# source .venv/bin/activate # Linux/Mac
pip install -e ".[dev]"
pip install requests # optional, for test_http_api.py
# Run tests (excludes test_http_api if requests not installed)
python -m pytest tests/ -v --ignore=tests/test_http_api.py
# Config with NEXA/K8s extra env (extra="ignore")
python -m pytest tests/test_config_extra_env.py -v
# Build and verify install
pip install build
python -m build --outdir dist
pip install --force-reinstall dist/mcp_agentnex-*.whl
python -c "from app.mcp_server import cli; from app.core.config import settings; print('OK', settings.agentnex_mcp_server_name)"
# Simulate NEXA env: set postgres_*, openai_api_key, backend_base_url, then load config
# (Should not raise; Settings ignores extra env vars.)
```
Or run the script: `python scripts/test_local_before_pypi.py` (requires `pip install requests` for full test suite).
### Test stdio (health, tools/list, tools/call)
From the repo root with venv activated and `AGENTNEX_BACKEND_URL` and `AGENTNEX_API_KEY` set:
```powershell
# Windows
.\.venv\Scripts\Activate.ps1
$env:AGENTNEX_BACKEND_URL = "https://your-backend-url"
$env:AGENTNEX_API_KEY = "your-api-key"
python scripts/test_stdio_health_and_tools.py
```
```bash
# Linux/Mac
source .venv/bin/activate
export AGENTNEX_BACKEND_URL="https://your-backend-url"
export AGENTNEX_API_KEY="your-api-key"
python scripts/test_stdio_health_and_tools.py
```
This runs initialize (health), `tools/list`, and `tools/call` for `list_devices` over stdio. Expect: `1. Health (initialize): OK`, `2. tools/list: OK`, `3. tools/call list_devices: OK`, then `stdio test: all OK`.
## Publishing
To publish a new version to PyPI:
```bash
# 1. Update version in pyproject.toml and docs/CHANGELOG.md
# 2. (Optional) Run stdio test before release
python scripts/test_stdio_health_and_tools.py
# 3. Build the package
python -m pip install --upgrade build twine
python -m build
# 4. Upload to PyPI (upload only the new version to avoid "File already exists" for old versions)
python -m twine upload dist/mcp_agentnex-0.1.5* # replace 0.1.5 with your new version
# Or: Remove-Item dist\* -Force; python -m build; python -m twine upload dist/*
```
## Contributing
Contributions are welcome! Please:
1. Fork the repository
2. Create a feature branch (`git checkout -b feature/amazing-feature`)
3. Commit your changes (`git commit -m 'Add amazing feature'`)
4. Push to the branch (`git push origin feature/amazing-feature`)
5. Open a Pull Request
## Support
For issues and questions:
- GitHub Issues: [https://github.com/ivedha-tech/agentnex-mcpserver/issues](https://github.com/ivedha-tech/agentnex-mcpserver/issues)
- Contact: AgentNEX Team at IVedha Technologies
## License
MIT License - Copyright (c) 2025 IVedha Technologies
## Links
- **PyPI**: [https://pypi.org/project/mcp-agentnex/](https://pypi.org/project/mcp-agentnex/)
- **GitHub**: [https://github.com/ivedha-tech/agentnex-mcpserver](https://github.com/ivedha-tech/agentnex-mcpserver)
- **Documentation**: [https://github.com/ivedha-tech/agentnex-mcpserver/wiki](https://github.com/ivedha-tech/agentnex-mcpserver/wiki)
| text/markdown | AgentNEX Team | null | null | null | MIT | mcp, agentnex, nexa, device-management, ai, model-context-protocol | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"mcp>=1.0.0",
"fastapi>=0.109.0",
"uvicorn[standard]>=0.27.0",
"httpx>=0.25.0",
"pydantic>=2.0.0",
"pydantic-settings>=2.0.0",
"python-dotenv>=1.0.0",
"structlog>=23.0.0",
"pytest>=7.4.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest-httpx>=0.25.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/ivedha-tech/agentnex-mcpserver",
"Repository, https://github.com/ivedha-tech/agentnex-mcpserver",
"Documentation, https://github.com/ivedha-tech/agentnex-mcpserver#readme"
] | twine/6.2.0 CPython/3.11.9 | 2026-02-19T17:05:52.142733 | mcp_agentnex-0.1.9.tar.gz | 37,986 | 72/f1/6833c10bb91d4b7b91f1b90620834d4420691bf2ecd34ba25a081f211009/mcp_agentnex-0.1.9.tar.gz | source | sdist | null | false | 4e36fec86e6da84b12b2fb04a7c4741d | 05d323f78191abb6d007a2bd29995b8ada7ef70690358fa52fffb0d3c4502d1a | 72f16833c10bb91d4b7b91f1b90620834d4420691bf2ecd34ba25a081f211009 | null | [] | 230 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.