
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.4 | subtitle-edit-rate | 0.4.0 | SubER: a metric for automatic evaluation of subtitle quality | # SubER - Subtitle Edit Rate
SubER is an automatic, reference-based, segmentation- and timing-aware edit distance metric to measure quality of subtitle files.
For a detailed description of the metric and a human post-editing evaluation we refer to our [IWSLT 2022 paper](https://aclanthology.org/2022.iwslt-1.1.pdf).
In addition to the SubER metric, this scoring tool calculates a wide range of established speech recognition and machine translation metrics (WER, BLEU, TER, chrF) directly on subtitle files.
## Installation
```console
pip install subtitle-edit-rate
```
will install the `suber` command line tool.
Alternatively, check out this git repository and run the contained `suber` module with `python -m suber`.
For Japanese and/or Korean support (via `-l`, see below), specify `ja` and/or `ko` as optional dependency:
```console
pip install subtitle-edit-rate[ja,ko]
```
## Basic Usage
Currently, we expect subtitle files to come in [SubRip text (SRT)](https://en.wikipedia.org/wiki/SubRip) format. Given a human reference subtitle file `reference.srt` and a hypothesis file `hypothesis.srt` (typically the output of an automatic subtitling system) the SubER score can be calculated by running:
```console
$ suber -H hypothesis.srt -R reference.srt
{
"SubER": 19.048
}
```
The SubER score is printed to stdout in json format. As SubER is an edit rate, lower scores are better. As a rough rule of thumb from our experience, a score lower than 20(%) is very good quality while a score above 40 to 50(%) is bad.
Make sure that there is no constant time offset between the timestamps in hypothesis and reference as this will lead to incorrect scores.
Also, note that `<i>`, `<b>` and `<u>` formatting tags are ignored if present in the files. All other formatting must be removed from the files before scoring for accurate results.
#### Punctuation and Case-Sensitivity
The main SubER metric is computed on normalized text, which means case-insensitive and without taking punctuation into account, as we observe higher correlation with human judgements and post-edit effort in this setting. We provide an implementation of a case-sensitive variant which also uses a tokenizer to take punctuation into account as separate tokens which you can use "at your own risk" or to reassess our findings. For this, add `--metrics SubER-cased` to the command above. Please do not report results using this variant as "SubER" unless explicitly mentioning the punctuation-/case-sensitivity.
#### Language support
SubER is expected to give meaningful scores for all languages that use space-separation of words similar to English. In addition, versions `>=0.4.0` explicitly support __Chinese__, __Japanese__ and __Korean__. (Korean does use spaces, but we follow [SacreBLEU](https://github.com/mjpost/sacrebleu) by using [mecab-ko](https://github.com/NoUnique/pymecab-ko) tokenization.) For these particular languages it is __required__ to set the `-l`/`--language` option to the corresponding two-letter language code, for example for Japanese files `suber -H hypothesis.srt -R reference.srt -l ja`. An example of a currently not supported scriptio continua language is Thai. As a workaround, it is however possible to run your own tokenization / word segmentation on the SRT files before calling `suber`.
## Other Metrics
The SubER tool supports computing the following other metrics directly on subtitle files:
- word error rate (WER)
- bilingual evaluation understudy (BLEU)
- translation edit rate (TER)
- character n-gram F score (chrF)
- character error rate (CER)
BLEU, TER and chrF calculations are done using [SacreBLEU](https://github.com/mjpost/sacrebleu) with default settings. WER is computed with [JiWER](https://github.com/jitsi/jiwer) on normalized text (lower-cased, punctuation removed).
__Assuming__ `hypothesis.srt` __and__ `reference.srt` __are parallel__, i.e. they contain the same number of subtitles and the contents of the _n_-th subtitle in both files corresponds to each other, the above-mentioned metrics can be computed by running:
```console
$ suber -H hypothesis.srt -R reference.srt --metrics WER BLEU TER chrF CER
{
"WER": 23.529,
"BLEU": 39.774,
"TER": 23.529,
"chrF": 68.402,
"CER": 17.857
}
```
In this mode, the text from each parallel subtitle pair is considered to be a sentence pair.
For __Chinese__, __Japanese__ and __Korean__ files, also here it is required to specify the language code via `-l`/`--language` option for correct BLEU, TER and WER scores. (This sets the `asian_support` option of TER, and for BLEU and WER enables tokenization via SacreBleu's dedicated tokenizers `TokenizerZh`, `TokenizerJaMecab`, and `TokenizerKoMecab`, respectively.)
### Scoring Non-Parallel Subtitle Files
In the general case, subtitle files for the same video can have different numbers of subtitles with different time stamps. All metrics - except SubER - usually require to be calculated on parallel segments. To apply these metrics to general subtitle files, the hypothesis file has to be re-segmented to correspond to the reference subtitles. The SubER tool implements two options:
- alignment by minimizing Levenshtein distance ([Matusov et al.](https://aclanthology.org/2005.iwslt-1.19.pdf))
- time alignment method from [Cherry et al.](https://www.isca-archive.org/interspeech_2021/cherry21_interspeech.pdf)
See our [paper](https://aclanthology.org/2022.iwslt-1.1.pdf) for further details.
To use the Levenshtein method add an `AS-` prefix to the metric name, e.g.:
```console
suber -H hypothesis.srt -R reference.srt --metrics AS-BLEU
```
The `AS-` prefix terminology is taken from [Matusov et al.](https://aclanthology.org/2005.iwslt-1.19.pdf) and stands for "automatic segmentation".
To use the time-alignment method instead, add a `t-` prefix. This works for all metrics (except for SubER itself which does not require re-segmentation). In particular, we implement `t-BLEU` from [Cherry et al.](https://www.isca-archive.org/interspeech_2021/cherry21_interspeech.pdf). We encode the segmentation method (or lack thereof) in the metric name to explicitly distinguish the different resulting metric scores!
To inspect the re-segmentation applied to the hypothesis you can use the `align_hyp_to_ref.py` tool (run `python -m suber.tools.align_hyp_to_ref -h` for help).
In case of Levenshtein alignment, there is also the option to give a plain file as the reference. This can be used to provide sentences instead of subtitles as reference segments (each line will be considered a segment):
```console
suber -H hypothesis.srt -R reference.txt --reference-format plain --metrics AS-TER
```
We provide a simple tool to extract sentences from SRT files based on punctuation:
```console
python -m suber.tools.srt_to_plain -i reference.srt -o reference.txt --sentence-segmentation
```
It can be used to create the plain sentence-level reference `reference.txt` for the scoring command above.
### Scoring Line Breaks as Tokens
The line breaks present in the subtitle files can be included into the text segments to be scored as `<eol>` (end of line) and `<eob>` (end of block) tokens. For example:
```
636
00:50:52,200 -> 00:50:57,120
Ladies and gentlemen,
the dance is about to begin.
```
would be represented as
```
Ladies and gentlemen, <eol> the dance is about to begin. <eob>
```
To do so, add a `-seg` ("segmentation-aware") postfix to the metric name, e.g. `BLEU-seg`, `AS-TER-seg` or `t-WER-seg`. Character-level metrics (chrF and CER) do not support this as it is not obvious how to count character edits for `<eol>` tokens.
### TER-br
As a special case, we implement TER-br from [Karakanta et al.](https://aclanthology.org/2020.iwslt-1.26.pdf). It is similar to `TER-seg`, but all (real) words are replaced by a mask token. This would convert the sentence from the example above to:
```
<mask> <mask> <mask> <eol> <mask> <mask> <mask> <mask> <mask> <mask> <eob>
```
Note, that also TER-br has variants for computing it on existing parallel segments (`TER-br`) or on re-aligned segments (`AS-TER-br`/`t-TER-br`). Re-segmentation happens before masking.
## Contributing
If you run into an issue, have a feature request or have questions about the usage or the implementation of SubER, please do not hesitate to open an issue or a thread under "discussions". Pull requests are welcome too, of course!
Things I'm already considering to add in future versions:
- support for other subtitling formats than SRT
- a verbose output that explains the SubER score (list of edit operations)
| text/markdown | null | Patrick Wilken <pwilken@apptek.com> | null | Patrick Wilken <pwilken@apptek.com> | null | subtitling, subtitles, captions, metric, evaluation | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.6 | [] | [] | [] | [
"sacrebleu==2.5.1",
"jiwer==4.0.0",
"numpy",
"regex",
"dataclasses; python_version < \"3.7\"",
"sacrebleu[ja]==2.5.1; extra == \"ja\"",
"sacrebleu[ko]==2.5.1; extra == \"ko\""
] | [] | [] | [] | [
"Homepage, https://github.com/apptek/SubER",
"Issues, https://github.com/apptek/SubER/issues",
"Source, https://github.com/apptek/SubER"
] | twine/6.2.0 CPython/3.10.12 | 2026-02-19T15:11:24.240905 | subtitle_edit_rate-0.4.0.tar.gz | 49,694 | e5/81/2b426b8d80f44df1d871a94ff464c389368832a08b878c00699ebbcfe939/subtitle_edit_rate-0.4.0.tar.gz | source | sdist | null | false | 1db84709e79010d5183e4721387f9a70 | e21492865d05e71b3934873c35064852d60d69f34b3c4400af3fd283e2ea80be | e5812b426b8d80f44df1d871a94ff464c389368832a08b878c00699ebbcfe939 | Apache-2.0 | [
"LICENSE"
] | 233 |
2.4 | tabpfn | 6.4.1 | TabPFN: Foundation model for tabular data | # TabPFN
[](https://badge.fury.io/py/tabpfn)
[](https://pepy.tech/project/tabpfn)
[](https://discord.gg/BHnX2Ptf4j)
[](https://priorlabs.ai/docs)
[](https://colab.research.google.com/github/PriorLabs/TabPFN/blob/main/examples/notebooks/TabPFN_Demo_Local.ipynb)
[](https://pypi.org/project/tabpfn/)
<img src="https://github.com/PriorLabs/tabpfn-extensions/blob/main/tabpfn_summary.webp" width="80%" alt="TabPFN Summary">
## Quick Start
### Interactive Notebook Tutorial
> [!TIP]
>
> Dive right in with our interactive Colab notebook! It's the best way to get a hands-on feel for TabPFN, walking you through installation, classification, and regression examples.
>
> [](https://colab.research.google.com/github/PriorLabs/TabPFN/blob/main/examples/notebooks/TabPFN_Demo_Local.ipynb)
> ⚡ **GPU Recommended**:
> For optimal performance, use a GPU (even older ones with ~8GB VRAM work well; 16GB needed for some large datasets).
> On CPU, only small datasets (≲1000 samples) are feasible.
> No GPU? Use our free hosted inference via [TabPFN Client](https://github.com/PriorLabs/tabpfn-client).
### Installation
Official installation (pip)
```bash
pip install tabpfn
```
OR installation from source
```bash
pip install "tabpfn @ git+https://github.com/PriorLabs/TabPFN.git"
```
OR local development installation: First [install uv](https://docs.astral.sh/uv/getting-started/installation), which we use for development, then run
```bash
git clone https://github.com/PriorLabs/TabPFN.git --depth 1
cd TabPFN
uv sync
```
### Basic Usage
#### Classification
```python
from sklearn.datasets import load_breast_cancer
from sklearn.metrics import accuracy_score, roc_auc_score
from sklearn.model_selection import train_test_split
from tabpfn import TabPFNClassifier
from tabpfn.constants import ModelVersion
# Load data
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
# Initialize a classifier
clf = TabPFNClassifier() # Uses TabPFN 2.5 weights, finetuned on real data.
# To use TabPFN v2:
# clf = TabPFNClassifier.create_default_for_version(ModelVersion.V2)
clf.fit(X_train, y_train)
# Predict probabilities
prediction_probabilities = clf.predict_proba(X_test)
print("ROC AUC:", roc_auc_score(y_test, prediction_probabilities[:, 1]))
# Predict labels
predictions = clf.predict(X_test)
print("Accuracy", accuracy_score(y_test, predictions))
```
#### Regression
```python
from sklearn.datasets import fetch_openml
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
from tabpfn import TabPFNRegressor
from tabpfn.constants import ModelVersion
# Load Boston Housing data
df = fetch_openml(data_id=531, as_frame=True) # Boston Housing dataset
X = df.data
y = df.target.astype(float) # Ensure target is float for regression
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
# Initialize the regressor
regressor = TabPFNRegressor() # Uses TabPFN-2.5 weights, trained on synthetic data only.
# To use TabPFN v2:
# regressor = TabPFNRegressor.create_default_for_version(ModelVersion.V2)
regressor.fit(X_train, y_train)
# Predict on the test set
predictions = regressor.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print("Mean Squared Error (MSE):", mse)
print("R² Score:", r2)
```
## TabPFN Ecosystem
Choose the right TabPFN implementation for your needs:
- **[TabPFN Client](https://github.com/priorlabs/tabpfn-client)**
Simple API client for using TabPFN via cloud-based inference.
- **[TabPFN Extensions](https://github.com/priorlabs/tabpfn-extensions)**
A powerful companion repository packed with advanced utilities, integrations, and features - great place to contribute:
- **`interpretability`**: Gain insights with SHAP-based explanations, feature importance, and selection tools.
- **`unsupervised`**: Tools for outlier detection and synthetic tabular data generation.
- **`embeddings`**: Extract and use TabPFN’s internal learned embeddings for downstream tasks or analysis.
- **`many_class`**: Handle multi-class classification problems that exceed TabPFN's built-in class limit.
- **`rf_pfn`**: Combine TabPFN with traditional models like Random Forests for hybrid approaches.
- **`hpo`**: Automated hyperparameter optimization tailored to TabPFN.
- **`post_hoc_ensembles`**: Boost performance by ensembling multiple TabPFN models post-training.
To install:
```bash
git clone https://github.com/priorlabs/tabpfn-extensions.git
pip install -e tabpfn-extensions
```
- **[TabPFN (this repo)](https://github.com/priorlabs/tabpfn)**
Core implementation for fast and local inference with PyTorch and CUDA support.
- **[TabPFN UX](https://ux.priorlabs.ai)**
No-code graphical interface to explore TabPFN capabilities—ideal for business users and prototyping.
## TabPFN Workflow at a Glance
Follow this decision tree to build your model and choose the right extensions from our ecosystem. It walks you through critical questions about your data, hardware, and performance needs, guiding you to the best solution for your specific use case.
```mermaid
---
config:
theme: 'default'
themeVariables:
edgeLabelBackground: 'white'
---
graph LR
%% 1. DEFINE COLOR SCHEME & STYLES
classDef default fill:#fff,stroke:#333,stroke-width:2px,color:#333;
classDef start_node fill:#e8f5e9,stroke:#43a047,stroke-width:2px,color:#333;
classDef process_node fill:#e0f2f1,stroke:#00796b,stroke-width:2px,color:#333;
classDef decision_node fill:#fff8e1,stroke:#ffa000,stroke-width:2px,color:#333;
style Infrastructure fill:#fff,stroke:#ccc,stroke-width:5px;
style Unsupervised fill:#fff,stroke:#ccc,stroke-width:5px;
style Data fill:#fff,stroke:#ccc,stroke-width:5px;
style Performance fill:#fff,stroke:#ccc,stroke-width:5px;
style Interpretability fill:#fff,stroke:#ccc,stroke-width:5px;
%% 2. DEFINE GRAPH STRUCTURE
subgraph Infrastructure
start((Start)) --> gpu_check["GPU available?"];
gpu_check -- Yes --> local_version["Use TabPFN<br/>(local PyTorch)"];
gpu_check -- No --> api_client["Use TabPFN-Client<br/>(cloud API)"];
task_type["What is<br/>your task?"]
end
local_version --> task_type
api_client --> task_type
end_node((Workflow<br/>Complete));
subgraph Unsupervised
unsupervised_type["Select<br/>Unsupervised Task"];
unsupervised_type --> imputation["Imputation"]
unsupervised_type --> data_gen["Data<br/>Generation"];
unsupervised_type --> tabebm["Data<br/>Augmentation"];
unsupervised_type --> density["Outlier<br/>Detection"];
unsupervised_type --> embedding["Get<br/>Embeddings"];
end
subgraph Data
data_check["Data Checks"];
model_choice["Samples > 50k or<br/>Classes > 10?"];
data_check -- "Table Contains Text Data?" --> api_backend_note["Note: API client has<br/>native text support"];
api_backend_note --> model_choice;
data_check -- "Time-Series Data?" --> ts_features["Use Time-Series<br/>Features"];
ts_features --> model_choice;
data_check -- "Purely Tabular" --> model_choice;
model_choice -- "No" --> finetune_check;
model_choice -- "Yes, 50k-100k samples" --> ignore_limits["Set<br/>ignore_pretraining_limits=True"];
model_choice -- "Yes, >100k samples" --> subsample["Large Datasets Guide<br/>"];
model_choice -- "Yes, >10 classes" --> many_class["Many-Class<br/>Method"];
end
subgraph Performance
finetune_check["Need<br/>Finetuning?"];
performance_check["Need Even Better Performance?"];
speed_check["Need faster inference<br/>at prediction time?"];
kv_cache["Enable KV Cache<br/>(fit_mode='fit_with_cache')<br/><small>Faster predict; +Memory ~O(N×F)</small>"];
tuning_complete["Tuning Complete"];
finetune_check -- Yes --> finetuning["Finetuning"];
finetune_check -- No --> performance_check;
finetuning --> performance_check;
performance_check -- No --> tuning_complete;
performance_check -- Yes --> hpo["HPO"];
performance_check -- Yes --> post_hoc["Post-Hoc<br/>Ensembling"];
performance_check -- Yes --> more_estimators["More<br/>Estimators"];
performance_check -- Yes --> speed_check;
speed_check -- Yes --> kv_cache;
speed_check -- No --> tuning_complete;
hpo --> tuning_complete;
post_hoc --> tuning_complete;
more_estimators --> tuning_complete;
kv_cache --> tuning_complete;
end
subgraph Interpretability
tuning_complete --> interpretability_check;
interpretability_check["Need<br/>Interpretability?"];
interpretability_check --> feature_selection["Feature Selection"];
interpretability_check --> partial_dependence["Partial Dependence Plots"];
interpretability_check --> shapley["Explain with<br/>SHAP"];
interpretability_check --> shap_iq["Explain with<br/>SHAP IQ"];
interpretability_check -- No --> end_node;
feature_selection --> end_node;
partial_dependence --> end_node;
shapley --> end_node;
shap_iq --> end_node;
end
%% 3. LINK SUBGRAPHS AND PATHS
task_type -- "Classification or Regression" --> data_check;
task_type -- "Unsupervised" --> unsupervised_type;
subsample --> finetune_check;
ignore_limits --> finetune_check;
many_class --> finetune_check;
%% 4. APPLY STYLES
class start,end_node start_node;
class local_version,api_client,imputation,data_gen,tabebm,density,embedding,api_backend_note,ts_features,subsample,ignore_limits,many_class,finetuning,feature_selection,partial_dependence,shapley,shap_iq,hpo,post_hoc,more_estimators,kv_cache process_node;
class gpu_check,task_type,unsupervised_type,data_check,model_choice,finetune_check,interpretability_check,performance_check,speed_check decision_node;
class tuning_complete process_node;
%% 5. ADD CLICKABLE LINKS (INCLUDING KV CACHE EXAMPLE)
click local_version "https://github.com/PriorLabs/TabPFN" "TabPFN Backend Options"
click api_client "https://github.com/PriorLabs/tabpfn-client" "TabPFN API Client"
click api_backend_note "https://github.com/PriorLabs/tabpfn-client" "TabPFN API Backend"
click unsupervised_type "https://github.com/PriorLabs/tabpfn-extensions" "TabPFN Extensions"
click imputation "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/unsupervised/imputation.py" "TabPFN Imputation Example"
click data_gen "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/unsupervised/generate_data.py" "TabPFN Data Generation Example"
click tabebm "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/tabebm/tabebm_augment_real_world_data.ipynb" "TabEBM Data Augmentation Example"
click density "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/unsupervised/density_estimation_outlier_detection.py" "TabPFN Density Estimation/Outlier Detection Example"
click embedding "https://github.com/PriorLabs/tabpfn-extensions/tree/main/examples/embedding" "TabPFN Embedding Example"
click ts_features "https://github.com/PriorLabs/tabpfn-time-series" "TabPFN Time-Series Example"
click many_class "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/many_class/many_class_classifier_example.py" "Many Class Example"
click finetuning "https://github.com/PriorLabs/TabPFN/blob/main/examples/finetune_classifier.py" "Finetuning Example"
click feature_selection "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/interpretability/feature_selection.py" "Feature Selection Example"
click partial_dependence "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/interpretability/pdp_example.py" "Partial Dependence Plots Example"
click shapley "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/interpretability/shap_example.py" "Shapley Values Example"
click shap_iq "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/interpretability/shapiq_example.py" "SHAP IQ Example"
click post_hoc "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/phe/phe_example.py" "Post-Hoc Ensemble Example"
click hpo "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/hpo/tuned_tabpfn.py" "HPO Example"
click subsample "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/large_datasets/large_datasets_example.py" "Large Datasets Example"
click kv_cache "https://github.com/PriorLabs/TabPFN/blob/main/examples/kv_cache_fast_prediction.py" "KV Cache Fast Prediction Example"
```
## License
The TabPFN-2.5 model weights are licensed under a [non-commercial license](https://huggingface.co/Prior-Labs/tabpfn_2_5/blob/main/LICENSE). These are used by default.
The code and TabPFN-2 model weights are licensed under Prior Labs License (Apache 2.0 with additional attribution requirement): [here](LICENSE). To use the v2 model weights, instantiate your model as follows:
```
from tabpfn.constants import ModelVersion
tabpfn_v2 = TabPFNRegressor.create_default_for_version(ModelVersion.V2)
```
## Enterprise & Production
For high-throughput or massive-scale production environments, we offer an **Enterprise Edition** with the following capabilities:
- **Fast Inference Mode**: A proprietary distillation engine that converts TabPFN-2.5 into a compact MLP or tree ensemble, delivering orders-of-magnitude lower latency for real-time applications.
- **Large Data Mode (Scaling Mode)**: An advanced operating mode that lifts row constraints to support datasets with up to **10 million rows**—a 1,000x increase over the original TabPFNv2.
- **Commercial Support**: Includes a Commercial Enterprise License for production use-cases, dedicated integration support, and access to private high-speed inference engines.
**To learn more or request a commercial license, please contact us at [sales@priorlabs.ai](mailto:sales@priorlabs.ai).**
## Join Our Community
We're building the future of tabular machine learning and would love your involvement:
1. **Connect & Learn**:
- Join our [Discord Community](https://discord.gg/VJRuU3bSxt)
- Read our [Documentation](https://priorlabs.ai/docs)
- Check out [GitHub Issues](https://github.com/priorlabs/tabpfn/issues)
2. **Contribute**:
- Report bugs or request features
- Submit pull requests (please make sure to open an issue discussing the feature/bug first if none exists)
- Share your research and use cases
3. **Stay Updated**: Star the repo and join Discord for the latest updates
## Citation
You can read our paper explaining TabPFNv2 [here](https://doi.org/10.1038/s41586-024-08328-6), and the model report of TabPFN-2.5 [here](https://arxiv.org/abs/2511.08667).
```bibtex
@misc{grinsztajn2025tabpfn,
title={TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models},
author={Léo Grinsztajn and Klemens Flöge and Oscar Key and Felix Birkel and Philipp Jund and Brendan Roof and
Benjamin Jäger and Dominik Safaric and Simone Alessi and Adrian Hayler and Mihir Manium and Rosen Yu and
Felix Jablonski and Shi Bin Hoo and Anurag Garg and Jake Robertson and Magnus Bühler and Vladyslav Moroshan and
Lennart Purucker and Clara Cornu and Lilly Charlotte Wehrhahn and Alessandro Bonetto and
Bernhard Schölkopf and Sauraj Gambhir and Noah Hollmann and Frank Hutter},
year={2025},
eprint={2511.08667},
archivePrefix={arXiv},
url={https://arxiv.org/abs/2511.08667},
}
@article{hollmann2025tabpfn,
title={Accurate predictions on small data with a tabular foundation model},
author={Hollmann, Noah and M{\"u}ller, Samuel and Purucker, Lennart and
Krishnakumar, Arjun and K{\"o}rfer, Max and Hoo, Shi Bin and
Schirrmeister, Robin Tibor and Hutter, Frank},
journal={Nature},
year={2025},
month={01},
day={09},
doi={10.1038/s41586-024-08328-6},
publisher={Springer Nature},
url={https://www.nature.com/articles/s41586-024-08328-6},
}
@inproceedings{hollmann2023tabpfn,
title={TabPFN: A transformer that solves small tabular classification problems in a second},
author={Hollmann, Noah and M{\"u}ller, Samuel and Eggensperger, Katharina and Hutter, Frank},
booktitle={International Conference on Learning Representations 2023},
year={2023}
}
```
## ❓ FAQ
### **Usage & Compatibility**
**Q: What dataset sizes work best with TabPFN?**
A: TabPFN-2.5 is optimized for **datasets up to 50,000 rows**. For larger datasets, consider using **Random Forest preprocessing** or other extensions. See our [Colab notebook](https://colab.research.google.com/drive/154SoIzNW1LHBWyrxNwmBqtFAr1uZRZ6a#scrollTo=OwaXfEIWlhC8) for strategies.
**Q: Why can't I use TabPFN with Python 3.8?**
A: TabPFN requires **Python 3.9+** due to newer language features. Compatible versions: **3.9, 3.10, 3.11, 3.12, 3.13**.
### **Installation & Setup**
**Q: How do I get access to TabPFN-2.5?**
Visit [https://huggingface.co/Prior-Labs/tabpfn_2_5](https://huggingface.co/Prior-Labs/tabpfn_2_5) and accept the license terms. If access via huggingface is not an option for you, please contact us at [`sales@priorlabs.ai`](mailto:sales@priorlabs.ai).
Downloading the model requires your machine to be logged into Hugging Face. To do so, run `hf auth login` in your terminal, see the [huggingface documentation](https://huggingface.co/docs/huggingface_hub/en/quick-start#authentication) for details..
**Q: How do I use TabPFN without an internet connection?**
TabPFN automatically downloads model weights when first used. For offline usage:
**Using the Provided Download Script**
If you have the TabPFN repository, you can use the included script to download all models (including ensemble variants):
```bash
# After installing TabPFN
python scripts/download_all_models.py
```
This script will download the main classifier and regressor models, as well as all ensemble variant models to your system's default cache directory.
**Manual Download**
1. Download the model files manually from HuggingFace:
- Classifier: [tabpfn-v2.5-classifier-v2.5_default.ckpt](https://huggingface.co/Prior-Labs/tabpfn_2_5/blob/main/tabpfn-v2.5-classifier-v2.5_default.ckpt) (Note: the classifier default uses the model fine-tuned on real data).
- Regressor: [tabpfn-v2.5-regressor-v2.5_default.ckpt](https://huggingface.co/Prior-Labs/tabpfn_2_5/blob/main/tabpfn-v2.5-regressor-v2.5_default.ckpt)
2. Place the file in one of these locations:
- Specify directly: `TabPFNClassifier(model_path="/path/to/model.ckpt")`
- Set environment variable: `export TABPFN_MODEL_CACHE_DIR="/path/to/dir"` (see environment variables FAQ below)
- Default OS cache directory:
- Windows: `%APPDATA%\tabpfn\`
- macOS: `~/Library/Caches/tabpfn/`
- Linux: `~/.cache/tabpfn/`
**Q: I'm getting a `pickle` error when loading the model. What should I do?**
A: Try the following:
- Download the newest version of tabpfn `pip install tabpfn --upgrade`
- Ensure model files downloaded correctly (re-download if needed)
**Q: What environment variables can I use to configure TabPFN?**
A: TabPFN uses Pydantic settings for configuration, supporting environment variables and `.env` files:
**Model Configuration:**
- `TABPFN_MODEL_CACHE_DIR`: Custom directory for caching downloaded TabPFN models (default: platform-specific user cache directory)
- `TABPFN_ALLOW_CPU_LARGE_DATASET`: Allow running TabPFN on CPU with large datasets (>1000 samples). Set to `true` to override the CPU limitation. Note: This will be very slow!
**PyTorch Settings:**
- `PYTORCH_CUDA_ALLOC_CONF`: PyTorch CUDA memory allocation configuration to optimize GPU memory usage (default: `max_split_size_mb:512`). See [PyTorch CUDA documentation](https://docs.pytorch.org/docs/stable/notes/cuda.html#optimizing-memory-usage-with-pytorch-cuda-alloc-conf) for more information.
Example:
```bash
export TABPFN_MODEL_CACHE_DIR="/path/to/models"
export TABPFN_ALLOW_CPU_LARGE_DATASET=true
export PYTORCH_CUDA_ALLOC_CONF="max_split_size_mb:512"
```
Or simply set them in your `.env`
**Q: How do I save and load a trained TabPFN model?**
A: Use :func:`save_fitted_tabpfn_model` to persist a fitted estimator and reload
it later with :func:`load_fitted_tabpfn_model` (or the corresponding
``load_from_fit_state`` class methods).
```python
from tabpfn import TabPFNRegressor
from tabpfn.model_loading import (
load_fitted_tabpfn_model,
save_fitted_tabpfn_model,
)
# Train the regressor on GPU
reg = TabPFNRegressor(device="cuda")
reg.fit(X_train, y_train)
save_fitted_tabpfn_model(reg, "my_reg.tabpfn_fit")
# Later or on a CPU-only machine
reg_cpu = load_fitted_tabpfn_model("my_reg.tabpfn_fit", device="cpu")
```
To store just the foundation model weights (without a fitted estimator) use
``save_tabpfn_model(reg.model_, "my_tabpfn.ckpt")``. This merely saves a
checkpoint of the pre-trained weights so you can later create and fit a fresh
estimator. Reload the checkpoint with ``load_model_criterion_config``.
### **Performance & Limitations**
**Q: Can TabPFN handle missing values?**
A: **Yes!**
**Q: How can I improve TabPFN’s performance?**
A: Best practices:
- Use **AutoTabPFNClassifier** from [TabPFN Extensions](https://github.com/priorlabs/tabpfn-extensions) for post-hoc ensembling
- Feature engineering: Add domain-specific features to improve model performance
Not effective:
- Adapt feature scaling
- Convert categorical features to numerical values (e.g., one-hot encoding)
**Q: What are the different checkpoints on [Hugging-Face](https://huggingface.co/Prior-Labs/tabpfn_2_5/tree/main)?**
A: Beyond the default checkpoints, the other available checkpoints are experimental and worse on average, and we recommend to always start with the defaults. They can be used as part of an ensembling or hyperparameter optimization system (and are used automatically in `AutoTabPFNClassifier`) or tried out manually. Their name suffixes refer to what we expect them to be good at.
<details>
<summary>More detail on each TabPFN-2.5 checkpoint</summary>
We add the 🌍 emoji for checkpoints finetuned on real datasets. See the [TabPFN-2.5 paper](https://arxiv.org/abs/2511.08667) for the list of 43 datasets.
- `tabpfn-v2.5-classifier-v2.5_default.ckpt` 🌍: default classification checkpoint, finetuned on real-data.
- `tabpfn-v2.5-classifier-v2.5_default-2.ckpt`: best classification synthetic checkpoint. Use this to get the default TabPFN-2.5 classification model without real-data finetuning.
- `tabpfn-v2.5-classifier-v2.5_large-features-L.ckpt`: specialized for larger features (up to 500) and small samples (< 5K).
- `tabpfn-v2.5-classifier-v2.5_large-features-XL.ckpt`: specialized for larger features (up to 1000, could support `max_features_per_estimator=1000`).
- `tabpfn-v2.5-classifier-v2.5_large-samples.ckpt`: specialized for larger sample sizes (larger than 30K)
- `tabpfn-v2.5-classifier-v2.5_real.ckpt` 🌍: other real-data finetuned classification checkpoint. Pretty good overall but bad on large features (>100-200).
- `tabpfn-v2.5-classifier-v2.5_real-large-features.ckpt` 🌍: other real-data finetuned classification checkpoint, worse on large samples (> 10K)
- `tabpfn-v2.5-classifier-v2.5_real-large-samples-and-features.ckpt` 🌍: identical to `tabpfn-v2.5-classifier-v2.5_default.ckpt`
- `tabpfn-v2.5-classifier-v2.5_variant.ckpt`: pretty good but bad on large features (> 100-200).
- `tabpfn-v2.5-regressor-v2.5_default.ckpt`: default regression checkpoint, trained on synthetic data only.
- `tabpfn-v2.5-regressor-v2.5_low-skew.ckpt`: variant specialized at low target skew data (but quite bad on average).
- `tabpfn-v2.5-regressor-v2.5_quantiles.ckpt`: variant which might be interesting for quantile / distribution estimation, though the default should still be prioritized for this.
- `tabpfn-v2.5-regressor-v2.5_real.ckpt` 🌍: finetuned on real-data. Best checkpoint among the checkpoints finetuned on real data. For regression we recommend the synthetic-only checkpoint as a default, but this checkpoint is quite a bit better on some datasets.
- `tabpfn-v2.5-regressor-v2.5_real-variant.ckpt` 🌍: other regression variant finetuned on real data.
- `tabpfn-v2.5-regressor-v2.5_small-samples.ckpt`: variant slightly better on small (< 3K) samples.
- `tabpfn-v2.5-regressor-v2.5_variant.ckpt`: other variant, no clear specialty but can be better on a few datasets.
</details>
## Development
1. Install [uv](https://docs.astral.sh/uv/)
2. Setup environment:
```bash
git clone https://github.com/PriorLabs/TabPFN.git
cd TabPFN
uv sync
source venv/bin/activate # On Windows: venv\Scripts\activate
pre-commit install
```
3. Before committing:
```bash
pre-commit run --all-files
```
4. Run tests:
```bash
pytest tests/
```
## Anonymized Telemetry
This project collects fully anonymous usage telemetry with an option to opt-out of any telemetry or opt-in to extended telemetry.
The data is used exclusively to help us provide stability to the relevant products and compute environments and guide future improvements.
- **No personal data is collected**
- **No code, model inputs, or outputs are ever sent**
- **Data is strictly anonymous and cannot be linked to individuals**
For details on telemetry, please see our [Telemetry Reference](https://github.com/PriorLabs/TabPFN/blob/main/TELEMETRY.md) and our [Privacy Policy](https://priorlabs.ai/privacy-policy/).
**To opt out**, set the following environment variable:
```bash
export TABPFN_DISABLE_TELEMETRY=1
```
---
Built with ❤️ by [Prior Labs](https://priorlabs.ai) - Copyright (c) 2025 Prior Labs GmbH
| text/markdown | Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, Frank Hutter, Eddie Bergman, Leo Grinsztajn, Felix Jabloski, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Dominik Safaric, Benjamin Jaeger, Alan Arazi | null | null | null | Prior Labs License (Apache 2.0 with ADDITIONAL PROVISION)
Version 1.2, Dec 2025
This license is a derivative of the Apache 2.0 license
(http://www.apache.org/licenses/) with a single modification:
The added Paragraph 10 introduces an enhanced attribution requirement
inspired by the Llama 3 license.
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
---------------------- ADDITIONAL PROVISION --------------------------
10. Additional attribution.
If You distribute or make available the Work or any Derivative
Work thereof relating to any part of the source or model weights,
or a product or service (including another AI model) that contains
any source or model weights, You shall (A) provide a copy of this
License with any such materials; and (B) prominently display
“Built with PriorLabs-TabPFN” on each related website, user interface, blogpost,
about page, or product documentation. If You use the source or model
weights or model outputs to create, train, fine tune, distil, or
otherwise improve an AI model, which is distributed or made available,
you shall also include “TabPFN” at the beginning of any such AI model name.
To clarify, internal benchmarking and testing without external
communication shall not qualify as distribution or making available
pursuant to this Section 10 and no attribution under this Section 10
shall be required.
END OF TERMS AND CONDITIONS
| null | [
"Intended Audience :: Science/Research",
"Intended Audience :: Developers",
"Programming Language :: Python",
"Topic :: Software Development",
"Topic :: Scientific/Engineering",
"Operating System :: POSIX",
"Operating System :: Unix",
"Operating System :: MacOS",
"Programming Language :: Python :: 3... | [] | null | null | >=3.9 | [] | [] | [] | [
"torch>=2.1",
"numpy>=1.21.6",
"scikit-learn>=1.2.0",
"typing_extensions>=4.12.0",
"scipy>=1.11.1",
"pandas>=1.4.0",
"einops>=0.2.0",
"huggingface-hub>=0.19.0",
"pydantic>=2.8.0",
"pydantic-settings>=2.10.1",
"eval-type-backport>=0.2.2",
"joblib>=1.2.0",
"tabpfn-common-utils[telemetry-intera... | [] | [] | [] | [
"documentation, https://priorlabs.ai/docs",
"source, https://github.com/priorlabs/tabpfn"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:11:15.872964 | tabpfn-6.4.1.tar.gz | 632,732 | 7f/f1/0c16302178ade2e7e258e5c9e4820fa5783e4470a8d713d726b112994f91/tabpfn-6.4.1.tar.gz | source | sdist | null | false | 1e5cfd37bf0902056365e9cbb13b8e15 | 339470e3c9d74e678e7eed9422f0cc64838e9080a21402edfb5939248edbbefb | 7ff10c16302178ade2e7e258e5c9e4820fa5783e4470a8d713d726b112994f91 | null | [
"LICENSE"
] | 4,052 |
2.4 | grid-trading-bot | 0.2.0 | Open-source cryptocurrency trading bot designed to perform grid trading strategies using historical data for backtesting. | # Grid Trading Bot
[](https://opensource.org/licenses/MIT)
[](https://github.com/jordantete/grid_trading_bot/actions/workflows/run-tests-on-push-or-merge-pr-master.yml)
[](https://codecov.io/github/jordantete/grid_trading_bot)
[](https://pypi.org/project/grid-trading-bot/)
Open-source Grid Trading Bot implemented in Python, allowing you to backtest and execute grid trading strategies on cryptocurrency markets. The bot is highly customizable and works with various exchanges using the CCXT library.
## 📚 Table of Contents
- [Grid Trading Bot](#grid-trading-bot)
- [Features](#features)
- [🤔 What is Grid Trading?](#-what-is-grid-trading)
- [🔢 Arithmetic Grid Trading](#-arithmetic-grid-trading)
- [📐 Geometric Grid Trading](#-geometric-grid-trading)
- [📅 When to Use Each Type?](#-when-to-use-each-type)
- [🆚 Simple Grid vs. Hedged Grid Strategies](#-simple-grid-vs-hedged-grid-strategies)
- [🖥️ Installation](#️-installation)
- [Prerequisites](#prerequisites)
- [Setting Up the Environment](#setting-up-the-environment)
- [📋 Configuration](#-configuration)
- [Example Configuration File](#example-configuration-file)
- [Parameters](#parameters)
- [Environment Variables (.env)](#environment-variables-env)
- [🏃 Running the Bot](#-running-the-bot)
- [Basic Usage](#basic-usage)
- [Multiple Configurations](#multiple-configurations)
- [Saving Performance Results](#saving-performance-results)
- [Disabling Plots](#disabling-plots)
- [Combining Options](#combining-options)
- [Available Command-Line Arguments](#available-command-line-arguments)
- [📊 Docker Compose for Logs Management](#-docker-compose-for-logs-management)
- [Steps to Set Up](#steps-to-set-up)
- [🤝 Contributing](#-contributing)
- [Reporting Issues](#reporting-issues)
- [💸 Donations](#-donations)
- [📜 License](#-license)
- [🚨 Disclaimer](#-disclaimer)
## Features
- **Backtesting**: Simulate your grid trading strategy using historical data.
- **Live Trading**: Execute trades on live markets using real funds, supported by robust configurations and risk management.
- **Paper Trading**: Test strategies in a simulated live market environment without risking actual funds.
- **Multiple Grid Trading Strategies**: Implement different grid trading strategies to match market conditions.
- **Customizable Configurations**: Use a JSON file to define grid levels, strategies, and risk settings.
- **Support for Multiple Exchanges**: Seamless integration with multiple cryptocurrency exchanges via the CCXT library.
- **Take Profit & Stop Loss**: Safeguard your investments with configurable take profit and stop loss thresholds.
- **Performance Metrics**: Gain insights with comprehensive metrics like ROI, max drawdown, run-up, and more.
- **HealthCheck**: Continuously monitor the bot’s performance and system resource usage to ensure stability.
- **CLI BotController**: Control and interact with the bot in real time using intuitive commands.
- **Logging with Grafana**: Centralized logging system for monitoring bot activity and debugging, enhanced with visual dashboards.
## 🤔 What is Grid Trading?
Grid trading is a trading strategy that places buy and sell orders at predefined intervals above and below a set price. The goal is to capitalize on market volatility by buying low and selling high at different price points. There are two primary types of grid trading: **arithmetic** and **geometric**.
### 🔢 **Arithmetic Grid Trading**
In an arithmetic grid, the grid levels (price intervals) are spaced **equally**. The distance between each buy and sell order is constant, providing a more straightforward strategy for fluctuating markets.
#### **Example**
Suppose the price of a cryptocurrency is $3000, and you set up a grid with the following parameters:
- **Grid levels**: $2900, $2950, $3000, $3050, $3100
- **Buy orders**: Set at $2900 and $2950
- **Sell orders**: Set at $3050 and $3100
As the price fluctuates, the bot will automatically execute buy orders as the price decreases and sell orders as the price increases. This method profits from small, predictable price fluctuations, as the intervals between buy/sell orders are consistent (in this case, $50).
### 📐 **Geometric Grid Trading**
In a geometric grid, the grid levels are spaced **proportionally** or by a percentage. The intervals between price levels increase or decrease exponentially based on a set percentage, making this grid type more suited for assets with higher volatility.
#### **Simple Example**
Suppose the price of a cryptocurrency is $3000, and you set up a geometric grid with a 5% spacing between levels. The price intervals will not be equally spaced but will grow or shrink based on the percentage.
- **Grid levels**: $2700, $2835, $2975, $3125, $3280
- **Buy orders**: Set at $2700 and $2835
- **Sell orders**: Set at $3125 and $3280
As the price fluctuates, buy orders are executed at lower levels and sell orders at higher levels, but the grid is proportional. This strategy is better for markets that experience exponential price movements.
### 📅 **When to Use Each Type?**
- **Arithmetic grids** are ideal for assets with more stable, linear price fluctuations.
- **Geometric grids** are better for assets with significant, unpredictable volatility, as they adapt more flexibly to market swings.
### 🆚 Simple Grid vs. Hedged Grid Strategies
- **Simple Grid**: Independent buy and sell grids. Profits from each grid level are standalone.
- **Hedged Grid**: Pairs buy and sell levels dynamically, balancing risk and reward for higher volatility markets.
## 🖥️ Installation
### Prerequisites
This project leverages [uv](https://github.com/astral-sh/uv) for managing virtual environments and dependencies. Below, you’ll find instructions for getting started with uv, along with an alternative approach using **venv**. While not covered in detail here, you can also easily set up the project using **Poetry**.
### Setting Up the Environment
#### Using `uv` (Recommended)
1. **Install `uv` (if not already installed)**
Ensure `uv` is installed on your system. If not, install it with `pip`:
```sh
pip install uv
```
2. **Clone the repository**:
```sh
git clone https://github.com/jordantete/grid_trading_bot.git
cd grid_trading_bot
```
3. **Install Dependencies and Set Up Virtual Environment**:
Run the following command to automatically set up a virtual environment and install all dependencies defined in `pyproject.toml`:
```sh
uv sync --all-extras --dev
```
#### Using `venv` and `pip` (Alternative)
1. **Clone the repository**:
```sh
git clone https://github.com/jordantete/grid_trading_bot.git
cd grid_trading_bot
```
2. **Set up a virtual environment**:
Create and activate a virtual environment:
```sh
python3 -m venv .venv
source .venv/bin/activate # On Windows: .venv\Scripts\activate
```
2. **Install dependencies**:
Use pip to install the dependencies listed in `pyproject.toml`:
```sh
pip install -r requirements.txt
```
Note: You may need to generate a requirements.txt file from pyproject.toml if it’s not already present. You can use a tool like pipreqs or manually extract dependencies.
## 📋 Configuration
The bot is configured via a JSON file `config/config.json` to suit your trading needs, alongside a `.env` file to securely store sensitive credentials and environment variables. Below is an example configuration file and a breakdown of all parameters.
### **Example Configuration File**
```json
{
"exchange": {
"name": "binance",
"trading_fee": 0.001,
"trading_mode": "backtest"
},
"pair": {
"base_currency": "SOL",
"quote_currency": "USDT"
},
"trading_settings": {
"timeframe": "1m",
"period": {
"start_date": "2024-08-01T00:00:00Z",
"end_date": "2024-10-20T00:00:00Z"
},
"initial_balance": 10000,
"historical_data_file": "data/SOL_USDT/2024/1m.csv"
},
"grid_strategy": {
"type": "simple_grid",
"spacing": "geometric",
"num_grids": 8,
"range": {
"top": 200,
"bottom": 250
}
},
"risk_management": {
"take_profit": {
"enabled": false,
"threshold": 300
},
"stop_loss": {
"enabled": false,
"threshold": 150
}
},
"execution": {
"max_retries": 3,
"retry_delay": 1.0,
"max_slippage": 0.01,
"backtest_slippage": 0.001,
"order_polling_interval": 15.0,
"websocket_max_retries": 5,
"websocket_retry_base_delay": 5,
"health_check_interval": 60,
"circuit_breaker_failure_threshold": 5,
"circuit_breaker_recovery_timeout": 60.0,
"circuit_breaker_half_open_max_calls": 1
},
"logging": {
"log_level": "INFO",
"log_to_file": true
}
}
```
### **Parameters**
- **exchange**: Defines the exchange and trading fee to be used.
- **name**: The name of the exchange (e.g., binance).
- **trading_fee**: The trading fee should be in decimal format (e.g., 0.001 for 0.1%).
- **trading_mode**: The trading mode of operation (backtest, live or paper trading).
- **pair**: Specifies the trading pair.
- **base_currency**: The base currency (e.g., ETH).
- **quote_currency**: The quote currency (e.g., USDT).
- **trading_settings**: General trading settings.
- **timeframe**: Time interval for the data (e.g., `1m` for one minute).
- **period**: The start and end dates for the backtest or trading period.
- **start_date**: The start date of the trading or backtest period.
- **end_date**: The end date of the trading or backtest period.
- **initial_balance**: Starting balance for the bot.
- **historical_data_file**: Path to a local historical data file for offline testing (optional).
- **grid_strategy**: Defines the grid trading parameters.
- **type**: Type of grid strategy:
- **simple_grid**: Independent buy/sell levels.
- **hedged_grid**: Dynamically paired buy/sell levels for risk balancing.
- **spacing**: Grid spacing type:
- **arithmetic**: Equal price intervals.
- **geometric**: Proportional price intervals based on percentage.
- **num_grids**: The total number of grid levels.
- **range**: Defines the price range of the grid.
- **top**: The upper price limit of the grid.
- **bottom**: The lower price limit of the grid.
- **risk_management**: Configurations for risk management.
- **take_profit**: Settings for taking profit.
- **enabled**: Whether the take profit is active.
- **threshold**: The price at which to take profit.
- **stop_loss**: Settings for stopping loss.
- **enabled**: Whether the stop loss is active.
- **threshold**: The price at which to stop loss.
- **execution** *(optional)*: Fine-tunes order execution behavior. All fields are optional and have sensible defaults.
- **max_retries**: Maximum retry attempts for failed order placement in live/paper mode. Integer, `1`–`20`. Default: `3`.
- **retry_delay**: Delay in seconds between retries. Float, `0.1`–`60.0`. Default: `1.0`.
- **max_slippage**: Maximum acceptable slippage for live/paper order execution (e.g., `0.01` = 1%). Float, `0.0001`–`0.1`. Default: `0.01`.
- **backtest_slippage**: Fixed slippage percentage applied to every simulated fill during backtesting (e.g., `0.001` = 0.1%). Buys fill at a slightly higher price, sells at a slightly lower price. Useful for stress-testing strategy profitability. Float, `0.0`–`0.1`. Default: `0.0` (no slippage).
- **order_polling_interval**: Interval in seconds for polling open order status in live/paper mode. Float, `1.0`–`300.0`. Default: `15.0`.
- **websocket_max_retries**: Maximum reconnection attempts for the WebSocket feed. Integer, `1`–`50`. Default: `5`.
- **websocket_retry_base_delay**: Base delay in seconds for WebSocket reconnection backoff. Integer, `1`–`120`. Default: `5`.
- **health_check_interval**: Interval in seconds between health check pings. Integer, `10`–`3600`. Default: `60`.
- **circuit_breaker_failure_threshold**: Number of consecutive exchange API failures before the circuit breaker opens. Integer, `1`–`50`. Default: `5`.
- **circuit_breaker_recovery_timeout**: Seconds to wait before attempting recovery after circuit breaker opens. Float, `1.0`–`600.0`. Default: `60.0`.
- **circuit_breaker_half_open_max_calls**: Maximum test calls allowed in half-open state. Integer, `1`–`10`. Default: `1`.
- **logging**: Configures logging settings.
- **log_level**: The logging level (e.g., `INFO`, `DEBUG`).
- **log_to_file**: Enables logging to a file.
### **Environment Variables (.env)**
The `.env` file securely stores sensitive data like API keys and credentials. Below is an example:
```
# Exchange API credentials
EXCHANGE_API_KEY=YourExchangeAPIKeyHere
EXCHANGE_SECRET_KEY=YourExchangeSecretKeyHere
# Notification URLs for Apprise
APPRISE_NOTIFICATION_URLS=
# Grafana Admin Access
GRAFANA_ADMIN_USER=admin
GRAFANA_ADMIN_PASSWORD=YourGrafanaPasswordHere
```
**Environment Variables Breakdown**
- `EXCHANGE_API_KEY`: Your API key for the exchange.
- `EXCHANGE_SECRET_KEY`: Your secret key for the exchange.
- `APPRISE_NOTIFICATION_URLS`: URLs for notifications (e.g., Telegram bot, Discord Server). For detailed setup instructions, visit the [Apprise GitHub repository](https://github.com/caronc/apprise).
- `GRAFANA_ADMIN_USER`: Admin username for Grafana.
- `GRAFANA_ADMIN_PASSWORD`: Admin password for Grafana.
## 🏃 Running the Bot
To run the bot, use the following command:
> **Note:** If you're using `uv` to manage your virtual environment, make sure to prefix the command with `uv run` to ensure it runs within the environment.
### Basic Usage:
```sh
uv run grid_trading_bot run --config config/config.json
```
### Multiple Configurations:
If you want to run the bot with multiple configuration files simultaneously, you can specify them all:
```sh
uv run grid_trading_bot run --config config/config1.json --config config/config2.json --config config/config3.json
```
### Saving Performance Results:
To save the performance results to a file, use the **--save_performance_results** option:
```sh
uv run grid_trading_bot run --config config/config.json --save_performance_results results.json
```
### Disabling Plots:
To run the bot without displaying the end-of-simulation plots, use the **--no-plot** flag:
```sh
uv run grid_trading_bot run --config config/config.json --no-plot
```
### Combining Options:
You can combine multiple options to customize how the bot runs. For example:
```sh
uv run grid_trading_bot run --config config/config1.json --config config/config2.json --save_performance_results combined_results.json --no-plot
```
### Available Command-Line Arguments:
| **Argument** | **Type** | **Required** | **Description** |
|-------------------------------|------------|--------------|---------------------------------------------------------------------------------|
| `--config` | `str` | ✅ Yes | Path(s) to configuration file(s). Multiple files can be provided. |
| `--save_performance_results` | `str` | ❌ No | Path to save simulation results (e.g., `results.json`). |
| `--no-plot` | `flag` | ❌ No | Disable the display of plots at the end of the simulation. |
| `--profile` | `flag` | ❌ No | Enable profiling to analyze performance metrics during execution. |
## 📊 Docker Compose for Logs Management
A `docker-compose.yml` file is included to set up centralized logging using Grafana, Loki, and Promtail. This allows you to monitor and analyze the bot's logs efficiently.
### Steps to Set Up:
1. **Ensure Docker and Docker Compose Are Installed**
Verify that Docker and Docker Compose are installed on your system. If not, follow the official [Docker installation guide](https://docs.docker.com/get-docker/).
2. **Start the Services**
Run the following command to spin up Grafana, Loki, and Promtail:
```sh
docker-compose up -d
```
3. **Access Grafana Dashboards**
Navigate to http://localhost:3000 in your browser to access the Grafana dashboard.
Use the following default credentials to log in:
- Username: admin
- Password: YourGrafanaPasswordHere (as defined in the .env file)
4. **Import Dashboards**
Go to the Dashboards section in Grafana and click Import. Use the provided JSON file for predefined dashboards. This file can be found in the project directory: ```grafana/dashboards/grid_trading_bot_dashboard.json```
## 🤝 Contributing
Contributions are welcome! If you have suggestions or want to improve the bot, feel free to fork the repository and submit a pull request.
### Reporting Issues
If you encounter any issues or have feature requests, please create a new issue on the [GitHub Issues](https://github.com/pownedjojo/grid_trading_bot/issues) page.
## 💸 Donations
If you find this project helpful and would like to support its development, consider buying me a coffee! Your support is greatly appreciated and motivates me to continue improving and adding new features.
[](https://www.buymeacoffee.com/pownedj)
Thank you for your support!
## 📜 License
This project is licensed under the MIT License. See the [LICENSE](./LICENSE.txt) file for more details.
## 🚨 Disclaimer
This project is intended for educational purposes only. The authors and contributors are not responsible for any financial losses incurred while using this bot. Trading cryptocurrencies involves significant risk and can result in the loss of all invested capital. Please do your own research and consult with a licensed financial advisor before making any trading decisions. Use this software at your own risk.
| text/markdown | null | Jordan TETE <tetej171@gmail.com> | null | null | MIT License
Copyright (c) 2024 Jordan TETE
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| grid-trading, trading-bot, cryptocurrency, backtesting, ccxt | [
"Development Status :: 4 - Beta",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Topic :: Office/Business :: Financial :: Investment",
"Intended Audience :: Developers",
"Intended Audienc... | [] | null | null | >=3.12 | [] | [] | [] | [
"pandas==2.2.3",
"numpy==2.1.3",
"plotly==6.5.2",
"tabulate==0.9.0",
"aiohttp==3.13.3",
"apprise==1.9.7",
"ccxt==4.5.38",
"configparser==7.2.0",
"psutil==7.2.2",
"python-dotenv==1.2.1",
"click>=8.1",
"pytest==9.0.2; extra == \"dev\"",
"pytest-asyncio==1.3.0; extra == \"dev\"",
"pytest-cov=... | [] | [] | [] | [
"repository, https://github.com/jordantete/grid_trading_bot",
"issues, https://github.com/jordantete/grid_trading_bot/issues",
"discussions, https://github.com/jordantete/grid_trading_bot/discussions"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:10:43.874343 | grid_trading_bot-0.2.0.tar.gz | 65,078 | fe/99/1cfc79f5a87dea673bcb94053ba353c14775c313564c5e485ab2c8b9bc0b/grid_trading_bot-0.2.0.tar.gz | source | sdist | null | false | 9e948370ab84dd9f42a22af94f76973f | c0dd25b1030c47db8e7ec7cc4784a203ecec4fcad4d8df3896a17a620790e1fb | fe991cfc79f5a87dea673bcb94053ba353c14775c313564c5e485ab2c8b9bc0b | null | [
"LICENSE.txt"
] | 213 |
2.4 | graphiti-core | 0.28.1 | A temporal graph building library | <p align="center">
<a href="https://www.getzep.com/">
<img src="https://github.com/user-attachments/assets/119c5682-9654-4257-8922-56b7cb8ffd73" width="150" alt="Zep Logo">
</a>
</p>
<h1 align="center">
Graphiti
</h1>
<h2 align="center"> Build Real-Time Knowledge Graphs for AI Agents</h2>
<div align="center">
[](https://github.com/getzep/Graphiti/actions/workflows/lint.yml)
[](https://github.com/getzep/Graphiti/actions/workflows/unit_tests.yml)
[](https://github.com/getzep/Graphiti/actions/workflows/typecheck.yml)

[](https://discord.com/invite/W8Kw6bsgXQ)
[](https://arxiv.org/abs/2501.13956)
[](https://github.com/getzep/graphiti/releases)
</div>
<div align="center">
<a href="https://trendshift.io/repositories/12986" target="_blank"><img src="https://trendshift.io/api/badge/repositories/12986" alt="getzep%2Fgraphiti | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a>
</div>
:star: _Help us reach more developers and grow the Graphiti community. Star this repo!_
<br />
> [!TIP]
> Check out the new [MCP server for Graphiti](mcp_server/README.md)! Give Claude, Cursor, and other MCP clients powerful
> Knowledge Graph-based memory.
Graphiti is a framework for building and querying temporally-aware knowledge graphs, specifically tailored for AI agents
operating in dynamic environments. Unlike traditional retrieval-augmented generation (RAG) methods, Graphiti
continuously integrates user interactions, structured and unstructured enterprise data, and external information into a
coherent, queryable graph. The framework supports incremental data updates, efficient retrieval, and precise historical
queries without requiring complete graph recomputation, making it suitable for developing interactive, context-aware AI
applications.
Use Graphiti to:
- Integrate and maintain dynamic user interactions and business data.
- Facilitate state-based reasoning and task automation for agents.
- Query complex, evolving data with semantic, keyword, and graph-based search methods.
<br />
<p align="center">
<img src="images/graphiti-graph-intro.gif" alt="Graphiti temporal walkthrough" width="700px">
</p>
<br />
A knowledge graph is a network of interconnected facts, such as _"Kendra loves Adidas shoes."_ Each fact is a "triplet"
represented by two entities, or
nodes ("Kendra", "Adidas shoes"), and their relationship, or edge ("loves"). Knowledge Graphs have been explored
extensively for information retrieval. What makes Graphiti unique is its ability to autonomously build a knowledge graph
while handling changing relationships and maintaining historical context.
## Graphiti and Zep's Context Engineering Platform.
Graphiti powers the core of [Zep's context engineering platform](https://www.getzep.com) for AI Agents. Zep
offers agent memory, Graph RAG for dynamic data, and context retrieval and assembly.
Using Graphiti, we've demonstrated Zep is
the [State of the Art in Agent Memory](https://blog.getzep.com/state-of-the-art-agent-memory/).
Read our paper: [Zep: A Temporal Knowledge Graph Architecture for Agent Memory](https://arxiv.org/abs/2501.13956).
We're excited to open-source Graphiti, believing its potential reaches far beyond AI memory applications.
<p align="center">
<a href="https://arxiv.org/abs/2501.13956"><img src="images/arxiv-screenshot.png" alt="Zep: A Temporal Knowledge Graph Architecture for Agent Memory" width="700px"></a>
</p>
## Zep vs Graphiti
| Aspect | Zep | Graphiti |
|--------|-----|----------|
| **What they are** | Fully managed platform for context engineering and AI memory | Open-source graph framework |
| **User & conversation management** | Built-in users, threads, and message storage | Build your own |
| **Retrieval & performance** | Pre-configured, production-ready retrieval with sub-200ms performance at scale | Custom implementation required; performance depends on your setup |
| **Developer tools** | Dashboard with graph visualization, debug logs, API logs; SDKs for Python, TypeScript, and Go | Build your own tools |
| **Enterprise features** | SLAs, support, security guarantees | Self-managed |
| **Deployment** | Fully managed or in your cloud | Self-hosted only |
### When to choose which
**Choose Zep** if you want a turnkey, enterprise-grade platform with security, performance, and support baked in.
**Choose Graphiti** if you want a flexible OSS core and you're comfortable building/operating the surrounding system.
## Why Graphiti?
Traditional RAG approaches often rely on batch processing and static data summarization, making them inefficient for
frequently changing data. Graphiti addresses these challenges by providing:
- **Real-Time Incremental Updates:** Immediate integration of new data episodes without batch recomputation.
- **Bi-Temporal Data Model:** Explicit tracking of event occurrence and ingestion times, allowing accurate point-in-time
queries.
- **Efficient Hybrid Retrieval:** Combines semantic embeddings, keyword (BM25), and graph traversal to achieve
low-latency queries without reliance on LLM summarization.
- **Custom Entity Definitions:** Flexible ontology creation and support for developer-defined entities through
straightforward Pydantic models.
- **Scalability:** Efficiently manages large datasets with parallel processing, suitable for enterprise environments.
<p align="center">
<img src="/images/graphiti-intro-slides-stock-2.gif" alt="Graphiti structured + unstructured demo" width="700px">
</p>
## Graphiti vs. GraphRAG
| Aspect | GraphRAG | Graphiti |
|----------------------------|---------------------------------------|--------------------------------------------------|
| **Primary Use** | Static document summarization | Dynamic data management |
| **Data Handling** | Batch-oriented processing | Continuous, incremental updates |
| **Knowledge Structure** | Entity clusters & community summaries | Episodic data, semantic entities, communities |
| **Retrieval Method** | Sequential LLM summarization | Hybrid semantic, keyword, and graph-based search |
| **Adaptability** | Low | High |
| **Temporal Handling** | Basic timestamp tracking | Explicit bi-temporal tracking |
| **Contradiction Handling** | LLM-driven summarization judgments | Temporal edge invalidation |
| **Query Latency** | Seconds to tens of seconds | Typically sub-second latency |
| **Custom Entity Types** | No | Yes, customizable |
| **Scalability** | Moderate | High, optimized for large datasets |
Graphiti is specifically designed to address the challenges of dynamic and frequently updated datasets, making it
particularly suitable for applications requiring real-time interaction and precise historical queries.
## Installation
Requirements:
- Python 3.10 or higher
- Neo4j 5.26 / FalkorDB 1.1.2 / Kuzu 0.11.2 / Amazon Neptune Database Cluster or Neptune Analytics Graph + Amazon
OpenSearch Serverless collection (serves as the full text search backend)
- OpenAI API key (Graphiti defaults to OpenAI for LLM inference and embedding)
> [!IMPORTANT]
> Graphiti works best with LLM services that support Structured Output (such as OpenAI and Gemini).
> Using other services may result in incorrect output schemas and ingestion failures. This is particularly
> problematic when using smaller models.
Optional:
- Google Gemini, Anthropic, or Groq API key (for alternative LLM providers)
> [!TIP]
> The simplest way to install Neo4j is via [Neo4j Desktop](https://neo4j.com/download/). It provides a user-friendly
> interface to manage Neo4j instances and databases.
> Alternatively, you can use FalkorDB on-premises via Docker and instantly start with the quickstart example:
```bash
docker run -p 6379:6379 -p 3000:3000 -it --rm falkordb/falkordb:latest
```
```bash
pip install graphiti-core
```
or
```bash
uv add graphiti-core
```
### Installing with FalkorDB Support
If you plan to use FalkorDB as your graph database backend, install with the FalkorDB extra:
```bash
pip install graphiti-core[falkordb]
# or with uv
uv add graphiti-core[falkordb]
```
### Installing with Kuzu Support
If you plan to use Kuzu as your graph database backend, install with the Kuzu extra:
```bash
pip install graphiti-core[kuzu]
# or with uv
uv add graphiti-core[kuzu]
```
### Installing with Amazon Neptune Support
If you plan to use Amazon Neptune as your graph database backend, install with the Amazon Neptune extra:
```bash
pip install graphiti-core[neptune]
# or with uv
uv add graphiti-core[neptune]
```
### You can also install optional LLM providers as extras:
```bash
# Install with Anthropic support
pip install graphiti-core[anthropic]
# Install with Groq support
pip install graphiti-core[groq]
# Install with Google Gemini support
pip install graphiti-core[google-genai]
# Install with multiple providers
pip install graphiti-core[anthropic,groq,google-genai]
# Install with FalkorDB and LLM providers
pip install graphiti-core[falkordb,anthropic,google-genai]
# Install with Amazon Neptune
pip install graphiti-core[neptune]
```
## Default to Low Concurrency; LLM Provider 429 Rate Limit Errors
Graphiti's ingestion pipelines are designed for high concurrency. By default, concurrency is set low to avoid LLM
Provider 429 Rate Limit Errors. If you find Graphiti slow, please increase concurrency as described below.
Concurrency controlled by the `SEMAPHORE_LIMIT` environment variable. By default, `SEMAPHORE_LIMIT` is set to `10`
concurrent operations to help prevent `429` rate limit errors from your LLM provider. If you encounter such errors, try
lowering this value.
If your LLM provider allows higher throughput, you can increase `SEMAPHORE_LIMIT` to boost episode ingestion
performance.
## Quick Start
> [!IMPORTANT]
> Graphiti defaults to using OpenAI for LLM inference and embedding. Ensure that an `OPENAI_API_KEY` is set in your
> environment.
> Support for Anthropic and Groq LLM inferences is available, too. Other LLM providers may be supported via OpenAI
> compatible APIs.
For a complete working example, see the [Quickstart Example](./examples/quickstart/README.md) in the examples directory.
The quickstart demonstrates:
1. Connecting to a Neo4j, Amazon Neptune, FalkorDB, or Kuzu database
2. Initializing Graphiti indices and constraints
3. Adding episodes to the graph (both text and structured JSON)
4. Searching for relationships (edges) using hybrid search
5. Reranking search results using graph distance
6. Searching for nodes using predefined search recipes
The example is fully documented with clear explanations of each functionality and includes a comprehensive README with
setup instructions and next steps.
### Running with Docker Compose
You can use Docker Compose to quickly start the required services:
- **Neo4j Docker:**
```sh
docker compose up
```
This will start the Neo4j Docker service and related components.
- **FalkorDB Docker:**
```sh
docker compose --profile falkordb up
```
This will start the FalkorDB Docker service and related components.
## MCP Server
The `mcp_server` directory contains a Model Context Protocol (MCP) server implementation for Graphiti. This server
allows AI assistants to interact with Graphiti's knowledge graph capabilities through the MCP protocol.
Key features of the MCP server include:
- Episode management (add, retrieve, delete)
- Entity management and relationship handling
- Semantic and hybrid search capabilities
- Group management for organizing related data
- Graph maintenance operations
The MCP server can be deployed using Docker with Neo4j, making it easy to integrate Graphiti into your AI assistant
workflows.
For detailed setup instructions and usage examples, see the [MCP server README](./mcp_server/README.md).
## REST Service
The `server` directory contains an API service for interacting with the Graphiti API. It is built using FastAPI.
Please see the [server README](./server/README.md) for more information.
## Optional Environment Variables
In addition to the Neo4j and OpenAi-compatible credentials, Graphiti also has a few optional environment variables.
If you are using one of our supported models, such as Anthropic or Voyage models, the necessary environment variables
must be set.
### Database Configuration
Database names are configured directly in the driver constructors:
- **Neo4j**: Database name defaults to `neo4j` (hardcoded in Neo4jDriver)
- **FalkorDB**: Database name defaults to `default_db` (hardcoded in FalkorDriver)
As of v0.17.0, if you need to customize your database configuration, you can instantiate a database driver and pass it
to the Graphiti constructor using the `graph_driver` parameter.
#### Neo4j with Custom Database Name
```python
from graphiti_core import Graphiti
from graphiti_core.driver.neo4j_driver import Neo4jDriver
# Create a Neo4j driver with custom database name
driver = Neo4jDriver(
uri="bolt://localhost:7687",
user="neo4j",
password="password",
database="my_custom_database" # Custom database name
)
# Pass the driver to Graphiti
graphiti = Graphiti(graph_driver=driver)
```
#### FalkorDB with Custom Database Name
```python
from graphiti_core import Graphiti
from graphiti_core.driver.falkordb_driver import FalkorDriver
# Create a FalkorDB driver with custom database name
driver = FalkorDriver(
host="localhost",
port=6379,
username="falkor_user", # Optional
password="falkor_password", # Optional
database="my_custom_graph" # Custom database name
)
# Pass the driver to Graphiti
graphiti = Graphiti(graph_driver=driver)
```
#### Kuzu
```python
from graphiti_core import Graphiti
from graphiti_core.driver.kuzu_driver import KuzuDriver
# Create a Kuzu driver
driver = KuzuDriver(db="/tmp/graphiti.kuzu")
# Pass the driver to Graphiti
graphiti = Graphiti(graph_driver=driver)
```
#### Amazon Neptune
```python
from graphiti_core import Graphiti
from graphiti_core.driver.neptune_driver import NeptuneDriver
# Create a FalkorDB driver with custom database name
driver = NeptuneDriver(
host= < NEPTUNE
ENDPOINT >,
aoss_host = < Amazon
OpenSearch
Serverless
Host >,
port = < PORT > # Optional, defaults to 8182,
aoss_port = < PORT > # Optional, defaults to 443
)
driver = NeptuneDriver(host=neptune_uri, aoss_host=aoss_host, port=neptune_port)
# Pass the driver to Graphiti
graphiti = Graphiti(graph_driver=driver)
```
## Graph Driver Architecture
Graphiti uses a pluggable driver architecture so the core framework is backend-agnostic. All database-specific logic
is encapsulated in driver implementations, allowing you to swap backends or add new ones without modifying the rest of
the framework.
### How Drivers are Integrated
The driver layer is organized into three tiers:
1. **`GraphDriver` ABC** (`graphiti_core/driver/driver.py`) — the core interface every backend must implement. It
defines query execution, session management, index lifecycle, and exposes 11 operations interfaces as `@property`
accessors.
2. **`GraphProvider` enum** — identifies the backend (`NEO4J`, `FALKORDB`, `KUZU`, `NEPTUNE`). Query builders use this
enum in `match/case` statements to return dialect-specific query strings.
3. **11 Operations ABCs** (`graphiti_core/driver/operations/`) — abstract interfaces covering all CRUD and search
operations for every graph element type:
- **Node ops:** `EntityNodeOperations`, `EpisodeNodeOperations`, `CommunityNodeOperations`, `SagaNodeOperations`
- **Edge ops:** `EntityEdgeOperations`, `EpisodicEdgeOperations`, `CommunityEdgeOperations`,
`HasEpisodeEdgeOperations`, `NextEpisodeEdgeOperations`
- **Search & maintenance:** `SearchOperations`, `GraphMaintenanceOperations`
Each backend provides a concrete driver class and a matching `operations/` directory with implementations of all 11
ABCs. The key directories and files are shown below (simplified; see source for complete structure):
```
graphiti_core/driver/
├── driver.py # GraphDriver ABC, GraphProvider enum
├── query_executor.py # QueryExecutor protocol
├── record_parsers.py # Shared record → model conversion
├── operations/ # 11 operation ABCs
│ ├── entity_node_ops.py
│ ├── episode_node_ops.py
│ ├── community_node_ops.py
│ ├── saga_node_ops.py
│ ├── entity_edge_ops.py
│ ├── episodic_edge_ops.py
│ ├── community_edge_ops.py
│ ├── has_episode_edge_ops.py
│ ├── next_episode_edge_ops.py
│ ├── search_ops.py
│ ├── graph_ops.py
│ └── graph_utils.py # Shared algorithms (e.g., label propagation)
├── graph_operations/ # Legacy graph operations interface
├── search_interface/ # Legacy search interface
├── neo4j_driver.py # Neo4jDriver
├── neo4j/operations/ # 11 Neo4j implementations
├── falkordb_driver.py # FalkorDriver
├── falkordb/operations/ # 11 FalkorDB implementations
├── kuzu_driver.py # KuzuDriver
├── kuzu/operations/ # 11 Kuzu implementations + record_parsers.py
├── neptune_driver.py # NeptuneDriver
└── neptune/operations/ # 11 Neptune implementations
```
Operations are decoupled from the driver itself — each operation method receives an `executor: QueryExecutor` parameter
(a protocol for running queries) rather than a concrete `GraphDriver`, which makes operations testable and
driver-agnostic. The driver class instantiates all 11 operation classes in its `__init__` and exposes them as
properties. The base `GraphDriver` ABC defines each property with an optional return type (`| None`, defaulting to
`None`); concrete drivers override these to return their implementations:
```python
# In your concrete driver (e.g., Neo4jDriver):
@property
def entity_node_ops(self) -> EntityNodeOperations:
return self._entity_node_ops
```
Provider-specific query strings are generated by shared query builders in `graphiti_core/models/nodes/node_db_queries.py`
and `graphiti_core/models/edges/edge_db_queries.py`, which use `match/case` on the `GraphProvider` enum to return the
correct dialect for each backend.
### Adding a New Graph Driver
To integrate a new graph database backend, follow these steps:
1. **Add to `GraphProvider`** — add your enum value in `graphiti_core/driver/driver.py`:
```python
class GraphProvider(Enum):
NEO4J = 'neo4j'
FALKORDB = 'falkordb'
KUZU = 'kuzu'
NEPTUNE = 'neptune'
MY_BACKEND = 'my_backend' # New backend
```
2. **Create directory structure** — create `graphiti_core/driver/<backend>/operations/` with an `__init__.py` exporting
all 11 operation classes.
3. **Implement `GraphDriver` subclass** — create `graphiti_core/driver/<backend>_driver.py`:
- Set `provider = GraphProvider.<BACKEND>`
- Implement the abstract methods: `execute_query()`, `session()`, `close()`,
`build_indices_and_constraints()`, `delete_all_indexes()`
- Instantiate all 11 operation classes in `__init__` and return them via `@property` overrides
4. **Implement all 11 operation ABCs** — one file per ABC in `<backend>/operations/`, each inheriting from the
corresponding ABC in `graphiti_core/driver/operations/`.
5. **Add query variants** — add `case GraphProvider.<BACKEND>:` branches to
`graphiti_core/models/nodes/node_db_queries.py` and `graphiti_core/models/edges/edge_db_queries.py` for your
database's query dialect.
6. **Implement `GraphDriverSession`** — if your backend needs session or connection management, subclass
`GraphDriverSession` from `driver.py` and implement `run()`, `close()`, and `execute_write()`.
7. **Register as optional dependency** — add an extras group in `pyproject.toml`:
```toml
[project.optional-dependencies]
my_backend = ["my-backend-client>=1.0.0"]
```
For reference implementations, look at:
- **Neo4j** — the most straightforward, full-featured reference
- **FalkorDB** — a lightweight client-server alternative
- **Kuzu** — example of an embedded/in-process database with dialect differences
- **Neptune** — example of a cloud backend with an external search index (OpenSearch)
## Using Graphiti with Azure OpenAI
Graphiti supports Azure OpenAI for both LLM inference and embeddings using Azure's OpenAI v1 API compatibility layer.
### Quick Start
```python
from openai import AsyncOpenAI
from graphiti_core import Graphiti
from graphiti_core.llm_client.azure_openai_client import AzureOpenAILLMClient
from graphiti_core.llm_client.config import LLMConfig
from graphiti_core.embedder.azure_openai import AzureOpenAIEmbedderClient
# Initialize Azure OpenAI client using the standard OpenAI client
# with Azure's v1 API endpoint
azure_client = AsyncOpenAI(
base_url="https://your-resource-name.openai.azure.com/openai/v1/",
api_key="your-api-key",
)
# Create LLM and Embedder clients
llm_client = AzureOpenAILLMClient(
azure_client=azure_client,
config=LLMConfig(model="gpt-5-mini", small_model="gpt-5-mini") # Your Azure deployment name
)
embedder_client = AzureOpenAIEmbedderClient(
azure_client=azure_client,
model="text-embedding-3-small" # Your Azure embedding deployment name
)
# Initialize Graphiti with Azure OpenAI clients
graphiti = Graphiti(
"bolt://localhost:7687",
"neo4j",
"password",
llm_client=llm_client,
embedder=embedder_client,
)
# Now you can use Graphiti with Azure OpenAI
```
**Key Points:**
- Use the standard `AsyncOpenAI` client with Azure's v1 API endpoint format: `https://your-resource-name.openai.azure.com/openai/v1/`
- The deployment names (e.g., `gpt-5-mini`, `text-embedding-3-small`) should match your Azure OpenAI deployment names
- See `examples/azure-openai/` for a complete working example
Make sure to replace the placeholder values with your actual Azure OpenAI credentials and deployment names.
## Using Graphiti with Google Gemini
Graphiti supports Google's Gemini models for LLM inference, embeddings, and cross-encoding/reranking. To use Gemini,
you'll need to configure the LLM client, embedder, and the cross-encoder with your Google API key.
Install Graphiti:
```bash
uv add "graphiti-core[google-genai]"
# or
pip install "graphiti-core[google-genai]"
```
```python
from graphiti_core import Graphiti
from graphiti_core.llm_client.gemini_client import GeminiClient, LLMConfig
from graphiti_core.embedder.gemini import GeminiEmbedder, GeminiEmbedderConfig
from graphiti_core.cross_encoder.gemini_reranker_client import GeminiRerankerClient
# Google API key configuration
api_key = "<your-google-api-key>"
# Initialize Graphiti with Gemini clients
graphiti = Graphiti(
"bolt://localhost:7687",
"neo4j",
"password",
llm_client=GeminiClient(
config=LLMConfig(
api_key=api_key,
model="gemini-2.0-flash"
)
),
embedder=GeminiEmbedder(
config=GeminiEmbedderConfig(
api_key=api_key,
embedding_model="embedding-001"
)
),
cross_encoder=GeminiRerankerClient(
config=LLMConfig(
api_key=api_key,
model="gemini-2.5-flash-lite"
)
)
)
# Now you can use Graphiti with Google Gemini for all components
```
The Gemini reranker uses the `gemini-2.5-flash-lite` model by default, which is optimized for
cost-effective and low-latency classification tasks. It uses the same boolean classification approach as the OpenAI
reranker, leveraging Gemini's log probabilities feature to rank passage relevance.
## Using Graphiti with Ollama (Local LLM)
Graphiti supports Ollama for running local LLMs and embedding models via Ollama's OpenAI-compatible API. This is ideal
for privacy-focused applications or when you want to avoid API costs.
**Note:** Use `OpenAIGenericClient` (not `OpenAIClient`) for Ollama and other OpenAI-compatible providers like LM Studio. The `OpenAIGenericClient` is optimized for local models with a higher default max token limit (16K vs 8K) and full support for structured outputs.
Install the models:
```bash
ollama pull deepseek-r1:7b # LLM
ollama pull nomic-embed-text # embeddings
```
```python
from graphiti_core import Graphiti
from graphiti_core.llm_client.config import LLMConfig
from graphiti_core.llm_client.openai_generic_client import OpenAIGenericClient
from graphiti_core.embedder.openai import OpenAIEmbedder, OpenAIEmbedderConfig
from graphiti_core.cross_encoder.openai_reranker_client import OpenAIRerankerClient
# Configure Ollama LLM client
llm_config = LLMConfig(
api_key="ollama", # Ollama doesn't require a real API key, but some placeholder is needed
model="deepseek-r1:7b",
small_model="deepseek-r1:7b",
base_url="http://localhost:11434/v1", # Ollama's OpenAI-compatible endpoint
)
llm_client = OpenAIGenericClient(config=llm_config)
# Initialize Graphiti with Ollama clients
graphiti = Graphiti(
"bolt://localhost:7687",
"neo4j",
"password",
llm_client=llm_client,
embedder=OpenAIEmbedder(
config=OpenAIEmbedderConfig(
api_key="ollama", # Placeholder API key
embedding_model="nomic-embed-text",
embedding_dim=768,
base_url="http://localhost:11434/v1",
)
),
cross_encoder=OpenAIRerankerClient(client=llm_client, config=llm_config),
)
# Now you can use Graphiti with local Ollama models
```
Ensure Ollama is running (`ollama serve`) and that you have pulled the models you want to use.
## Documentation
- [Guides and API documentation](https://help.getzep.com/graphiti).
- [Quick Start](https://help.getzep.com/graphiti/graphiti/quick-start)
- [Building an agent with LangChain's LangGraph and Graphiti](https://help.getzep.com/graphiti/integrations/lang-graph-agent)
## Telemetry
Graphiti collects anonymous usage statistics to help us understand how the framework is being used and improve it for
everyone. We believe transparency is important, so here's exactly what we collect and why.
### What We Collect
When you initialize a Graphiti instance, we collect:
- **Anonymous identifier**: A randomly generated UUID stored locally in `~/.cache/graphiti/telemetry_anon_id`
- **System information**: Operating system, Python version, and system architecture
- **Graphiti version**: The version you're using
- **Configuration choices**:
- LLM provider type (OpenAI, Azure, Anthropic, etc.)
- Database backend (Neo4j, FalkorDB, Kuzu, Amazon Neptune Database or Neptune Analytics)
- Embedder provider (OpenAI, Azure, Voyage, etc.)
### What We Don't Collect
We are committed to protecting your privacy. We **never** collect:
- Personal information or identifiers
- API keys or credentials
- Your actual data, queries, or graph content
- IP addresses or hostnames
- File paths or system-specific information
- Any content from your episodes, nodes, or edges
### Why We Collect This Data
This information helps us:
- Understand which configurations are most popular to prioritize support and testing
- Identify which LLM and database providers to focus development efforts on
- Track adoption patterns to guide our roadmap
- Ensure compatibility across different Python versions and operating systems
By sharing this anonymous information, you help us make Graphiti better for everyone in the community.
### View the Telemetry Code
The Telemetry code [may be found here](graphiti_core/telemetry/telemetry.py).
### How to Disable Telemetry
Telemetry is **opt-out** and can be disabled at any time. To disable telemetry collection:
**Option 1: Environment Variable**
```bash
export GRAPHITI_TELEMETRY_ENABLED=false
```
**Option 2: Set in your shell profile**
```bash
# For bash users (~/.bashrc or ~/.bash_profile)
echo 'export GRAPHITI_TELEMETRY_ENABLED=false' >> ~/.bashrc
# For zsh users (~/.zshrc)
echo 'export GRAPHITI_TELEMETRY_ENABLED=false' >> ~/.zshrc
```
**Option 3: Set for a specific Python session**
```python
import os
os.environ['GRAPHITI_TELEMETRY_ENABLED'] = 'false'
# Then initialize Graphiti as usual
from graphiti_core import Graphiti
graphiti = Graphiti(...)
```
Telemetry is automatically disabled during test runs (when `pytest` is detected).
### Technical Details
- Telemetry uses PostHog for anonymous analytics collection
- All telemetry operations are designed to fail silently - they will never interrupt your application or affect Graphiti
functionality
- The anonymous ID is stored locally and is not tied to any personal information
## Status and Roadmap
Graphiti is under active development. We aim to maintain API stability while working on:
- [x] Supporting custom graph schemas:
- Allow developers to provide their own defined node and edge classes when ingesting episodes
- Enable more flexible knowledge representation tailored to specific use cases
- [x] Enhancing retrieval capabilities with more robust and configurable options
- [x] Graphiti MCP Server
- [ ] Expanding test coverage to ensure reliability and catch edge cases
## Contributing
We encourage and appreciate all forms of contributions, whether it's code, documentation, addressing GitHub Issues, or
answering questions in the Graphiti Discord channel. For detailed guidelines on code contributions, please refer
to [CONTRIBUTING](CONTRIBUTING.md).
## Support
Join the [Zep Discord server](https://discord.com/invite/W8Kw6bsgXQ) and make your way to the **#Graphiti** channel!
| text/markdown | null | Paul Paliychuk <paul@getzep.com>, Preston Rasmussen <preston@getzep.com>, Daniel Chalef <daniel@getzep.com> | null | null | null | null | [] | [] | null | null | <4,>=3.10 | [] | [] | [] | [
"neo4j>=5.26.0",
"numpy>=1.0.0",
"openai>=1.91.0",
"posthog>=3.0.0",
"pydantic>=2.11.5",
"python-dotenv>=1.0.1",
"tenacity>=9.0.0",
"anthropic>=0.49.0; extra == \"anthropic\"",
"anthropic>=0.49.0; extra == \"dev\"",
"boto3>=1.39.16; extra == \"dev\"",
"falkordb<2.0.0,>=1.1.2; extra == \"dev\"",
... | [] | [] | [] | [
"Homepage, https://help.getzep.com/graphiti/graphiti/overview",
"Repository, https://github.com/getzep/graphiti"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:10:29.283734 | graphiti_core-0.28.1.tar.gz | 6,829,248 | a5/37/16fbfe70ac27be1eaffc024d4ff6cde93fd69937129aac058e02d530dad4/graphiti_core-0.28.1.tar.gz | source | sdist | null | false | a03274a66bcd576f80ebefb3b1cd00e0 | 8ce03b9d4d6f513e816dda8df84212e3a7d8cbfee215b0d19ed1604215d4c8a3 | a53716fbfe70ac27be1eaffc024d4ff6cde93fd69937129aac058e02d530dad4 | Apache-2.0 | [
"LICENSE"
] | 6,735 |
2.1 | gardener-ocm | 1.2743.0 | Open-Component-Model (OCM) language bindings | Open-Component_model (OCM) language bindings
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"PyYaml",
"cachetools",
"cryptography",
"dacite",
"gardener-oci",
"jsonschema",
"python-dateutil",
"semver"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:10:13.065310 | gardener_ocm-1.2743.0-py3-none-any.whl | 97,918 | a0/01/4f240487674744b2493efd555a48e7faf5b9b87bcef5275d05fadab91ee7/gardener_ocm-1.2743.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 0b88fd352b9f0829ee2384ff1e1ec932 | f497dedb5cdb295c2058d0fd698c01340823bee1df927ca91ae2553e3bdd0216 | a0014f240487674744b2493efd555a48e7faf5b9b87bcef5275d05fadab91ee7 | null | [] | 655 |
2.1 | gardener-oci | 1.2743.0 | Gardener OCI lib | Gardener OCI lib
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"dacite",
"python-dateutil",
"requests",
"www-authenticate",
"aiohttp; extra == \"async\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:10:11.485266 | gardener_oci-1.2743.0-py3-none-any.whl | 47,545 | e7/ec/70f604d72642b9d40565ebb8fcce35336fbe8870a60e25c09c1056c93be0/gardener_oci-1.2743.0-py3-none-any.whl | py3 | bdist_wheel | null | false | fd836ddc8e8b279f1978e317eb1aaff7 | 3f0bd59dabae7008addbab1c176843e4040a5323825c43ec35a4078b46e2f1e8 | e7ec70f604d72642b9d40565ebb8fcce35336fbe8870a60e25c09c1056c93be0 | null | [] | 721 |
2.1 | gardener-gha-libs | 1.2743.0 | Gardener CI/CD Libraries for GitHubActions | Gardener CI/CD Libraries for GitHubActions
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"GitPython",
"awesomeversion",
"cachecontrol<1",
"cachetools",
"cryptography",
"dacite",
"deepmerge",
"deprecated",
"ensure",
"flake8",
"gardener-oci",
"gardener-ocm",
"github3.py<5.0.0",
"html2text",
"jq",
"jsonpath-ng",
"jsonschema",
"pycryptodome",
"pyjwt",
"pytest",
"pyth... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:10:10.112019 | gardener_gha_libs-1.2743.0-py3-none-any.whl | 238,378 | 2a/87/cf39f98fff184d8c9d1d731721f33eeb967ed3cdaff626b6f30f414a835f/gardener_gha_libs-1.2743.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 8bc3c19f92941addb4cbbe5a8f5ca091 | 05a5aac2ceaed2e0d567a64ff018f15eb0d4a90dfad50ecf523b7e6e867470b1 | 2a87cf39f98fff184d8c9d1d731721f33eeb967ed3cdaff626b6f30f414a835f | null | [] | 148 |
2.1 | gardener-cicd-whd | 1.2743.0 | Gardener CI/CD Webhook Dispatcher | Gardener CI/CD Webhook Dispatcher
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"falcon>=2",
"gardener-cicd-cli",
"gardener-cicd-libs",
"uvicorn",
"werkzeug"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:10:08.482899 | gardener_cicd_whd-1.2743.0-py3-none-any.whl | 18,697 | 26/34/f11e653bb2a59a0da8977b8dc5c26d09296d3526828d70fcc9aa922030ef/gardener_cicd_whd-1.2743.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 632642d11258d471cf2c27a01b8c4aaa | aa6c0264c175d13a55d83a06f1401de98bb6636c51872549f899f7d3c12200ed | 2634f11e653bb2a59a0da8977b8dc5c26d09296d3526828d70fcc9aa922030ef | null | [] | 103 |
2.1 | gardener-cicd-libs | 1.2743.0 | Gardener CI/CD Libraries | Gardener CI/CD Libraries
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"GitPython",
"Mako<2.0.0",
"Sphinx",
"awesomeversion",
"cachecontrol<1",
"cachetools",
"cryptography",
"dacite",
"deepmerge",
"deprecated",
"dockerfile-parse>=1.2",
"docutils",
"ensure",
"flake8",
"gardener-oci",
"gardener-oci>=1.2743.0",
"gardener-ocm>=1.2743.0",
"github3.py<5.0.0... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:10:06.885159 | gardener_cicd_libs-1.2743.0-py3-none-any.whl | 340,551 | d7/22/6a30f8055da9c89acf0e6e9213d2a56d295aefb1f37d4a655daf29687136/gardener_cicd_libs-1.2743.0-py3-none-any.whl | py3 | bdist_wheel | null | false | d1271c35c3621f3789158d3a5b915bae | 771422a058f1d98bce9b48dcbba21193b7e7773f8d225b382eec8dbe61d7a58e | d7226a30f8055da9c89acf0e6e9213d2a56d295aefb1f37d4a655daf29687136 | null | [] | 535 |
2.1 | gardener-cicd-cli | 1.2743.0 | Gardener CI/CD Command Line Interface | Gardener CI/CD Command Line Interface
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"gardener-cicd-libs==1.2743.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:10:05.700755 | gardener_cicd_cli-1.2743.0-py3-none-any.whl | 31,909 | 25/16/98927ad2ef2f05593c236be58c160c8ba7f720406fb6319d5593eb3b0506/gardener_cicd_cli-1.2743.0-py3-none-any.whl | py3 | bdist_wheel | null | false | a15aa168b84bbe1c2528d6d5a8f0fc35 | e060accfc42f002782c0636998fca3ef012a4c96ac09cdf0730157d588df17be | 251698927ad2ef2f05593c236be58c160c8ba7f720406fb6319d5593eb3b0506 | null | [] | 313 |
2.4 | pycti | 6.9.21 | Python API client for OpenCTI. | # OpenCTI client for Python
[](https://opencti.io)
[](https://opencti-python-client.readthedocs.io/en/latest/)
[](https://pypi.python.org/pypi/pycti/)
[](https://community.filigran.io)
The official OpenCTI Python client helps developers to use the OpenCTI API by providing easy to use methods and utils.
This client is also used by some OpenCTI components.
## Install
To install the latest Python client library, please use `pip`:
```bash
$ pip3 install pycti
```
## Local development
```bash
# Fork the current repository, then clone your fork
$ git clone https://github.com/YOUR-USERNAME/opencti.git
$ cd client-python
$ git remote add upstream https://github.com/OpenCTI-Platform/opencti.git
# Create a branch for your feature/fix
$ git checkout -b [branch-name]
# Create a virtualenv
$ cd client-python
$ python3 -m venv .venv
$ source .venv/bin/activate
# Install the client-python and dependencies for the development and the documentation
$ python3 -m pip install -e .[dev,doc]
# Set up the git hook scripts
$ pre-commit install
# Create your feature/fix
# Create tests for your changes
$ pytest
# Push you feature/fix on Github
$ git add [file(s)]
$ git commit -m "[descriptive message]"
$ git push origin [branch-name]
# Open a pull request
```
### Install the package locally
```bash
$ pip install -e .
```
## Documentation
### Client usage
To learn about how to use the OpenCTI Python client and read some examples and cases, refer to [the client documentation](https://opencti-python-client.readthedocs.io/en/latest/client_usage/getting_started.html).
### API reference
To learn about the methods available for executing queries and retrieving their answers, refer to [the client API Reference](https://opencti-python-client.readthedocs.io/en/latest/pycti/pycti.html).
## Tests
### Install dependencies
```bash
$ pip install -r ./test-requirements.txt
```
[pytest](https://docs.pytest.org/en/7.2.x/) is used to launch the tests.
### Launch tests
#### Prerequisite
Your OpenCTI API should be running.
Your conftest.py should be configured with your API url, your token, and if applicable, your mTLS cert/key.
#### Launching
Unit tests
```bash
$ pytest ./tests/01-unit/
```
Integration testing
```bash
$ pytest ./tests/02-integration/
```
Example testing:
> OpenCTI must be running
```bash
cd examples
# Configure with you local instance of OpenCTI
export OPENCTI_API_URL="http://localhost:4000"
export OPENCTI_API_TOKEN="xxxxxxxxxxxxxxxxxxxxxx"
#Run one example file
python get_indicators_of_malware.py
```
## About
OpenCTI is a product designed and developed by the company [Filigran](https://filigran.io).
<a href="https://filigran.io" alt="Filigran"><img src="https://github.com/OpenCTI-Platform/opencti/raw/master/.github/img/logo_filigran.png" width="300" /></a>
| text/markdown | Filigran | contact@filigran.io | Filigran | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Natural Language :: English",
"Natural Language :: French",
"Operating System... | [] | https://github.com/OpenCTI-Platform/opencti/client-python | null | >=3.7 | [] | [] | [] | [
"boto3~=1.38.27",
"datefinder~=0.7.3",
"pika~=1.3.0",
"pydantic<3,>=2.8.2",
"python-magic~=0.4.27; sys_platform == \"linux\" or sys_platform == \"darwin\"",
"python-magic-bin~=0.4.14; sys_platform == \"win32\"",
"python_json_logger~=3.3.0",
"PyYAML~=6.0",
"requests<3,>=2.32.0",
"setuptools~=80.9.0... | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T15:09:58.166463 | pycti-6.9.21.tar.gz | 252,914 | c3/66/7abc596a72a1a3dbf75500518901c886f02e776e8eee102962d8da0d3e8c/pycti-6.9.21.tar.gz | source | sdist | null | false | 3b3d50a80d55e1f2da909e3a6771e576 | 92c992d1417338c5f30372fadee78f0aba51c01f1c917b7ace3f51412fe263b3 | c3667abc596a72a1a3dbf75500518901c886f02e776e8eee102962d8da0d3e8c | null | [] | 4,442 |
2.4 | iinfer | 0.13.0 | iinfer: An application that executes AI model files in onnx or mmlab format. | # iinfer (Image Inference Application)
- onnx又はmmlabフォーマットのAIモデルファイルを実行するアプリケーションです。
- ドキュメントは[こちら](https://hamacom2004jp.github.io/iinfer/)。
- このアプリケーションは[cmdbox](https://github.com/hamacom2004jp/cmdbox/)をベースにしています。
- iinferを使用することで、AIモデルを簡単に実行することが出来ます。
- 動作確認したモデルは[動作確認済みモデル](https://hamacom2004jp.github.io/iinfer/docs/models.html)に記載しています。
- 主なAIタスクは、画像分類、物体検知、領域検知、顔検知、顔認識です。
- 複数の `iinfer` コマンドの入出力をつなげる、パイプライン処理を行うことが出来ます。
- GUIモードを使用することで、 `iinfer` コマンド操作を簡単に行うことが出来ます。
## iinferの動作イメージ

1. **iinfer client** は **imageファイル** や **camera** から画像を取得し、 **推論結果 predict.json** を出力します。
2. **iinfer server** は推論を行うサーバーです。 **iinfer client** からの要求に応えて、推論結果を **iinfer client** に返します。
3. **iinfer server** は予め **ai model** をロードしておくことで、推論を高速化します。
4. **iinfer client** と **iinfer server** は **Redis** 経由で通信します。
5. **iinfer server** と **Redis** は **dockerコンテナ** を使用して起動させることが出来ます。
## インストール方法
- 次のコマンドで iinfer をインストールしてください。
- また、Docker 版の Redis サーバーもインストールしてください。
- 詳細なインストール方法は [こちら](https://hamacom2004jp.github.io/iinfer/docs/install.html) を参照してください。
```bash
docker run -p 6379:6379 --name redis -e REDIS_PASSWORD=password -it ubuntu/redis:latest
pip install iinfer
iinfer -v
```
- WebモードでSAMLを使用する場合、依存関係のあるモジュールをインストールしてください。
```bash
pip install iinfer[saml]
apt-get install -y pkg-config libxml2-dev libxmlsec1-dev libxmlsec1-openssl build-essential libopencv-dev
```
- Webモードで`--agent use`を使用する場合、依存関係のあるモジュールをインストールしてください。
```bash
pip install "pydantic>=2.0.0,<3.0.0"
pip install "fastmcp>=2.14.0" "mcp>=1.10.0,<2.0.0"
pip install "google-adk>=1.21.0" "litellm"
```
## iinferの使用方法
iinferを使用するには、次のコマンドを実行します:
1. guiモードで利用する場合:

```bash
iinfer -m gui -c start
```
2. コマンドモードで利用する場合
1. AIモデルのデプロイ:
```bash
# 画像AIモデルのデプロイ
# 推論タイプはモデルのAIタスクやアルゴリズムに合わせて指定する。指定可能なキーワードは"iinfer -m client -c predict_type_list"コマンド参照。
iinfer -m client -c deploy -n <任意のモデル名> -f \
--model_file <モデルファイル> \
--model_conf_file <モデル設定ファイル> \
--predict_type <推論タイプ> \
--label_file <ラベルファイル>
# デプロイされている画像AIモデルの一覧
iinfer -m client -c deploy_list -f
```
2. AIモデルのセッションを開始:
```bash
# 画像AIモデルを起動させて推論可能な状態に(セッションを確保)する
# use_trackを指定するとObjectDetectionタスクの結果に対して、MOT(Multi Object Tracking)を実行しトラッキングIDを出力する。
iinfer -m client -c start -n <モデル名> -f \
--use_track
```
3. 推論を実行:
```bash
# 推論を実行する
# output_previewを指定するとimshowで推論結果画像を表示する(GUI必要)
iinfer -m client -c predict -n <モデル名> -f \
-i <推論させる画像ファイル> \
-o <推論結果の画像ファイル> \
--output_preview
# カメラキャプチャー画像を元に推論を実行し、クラススコアが0.8以上の物体のみを検出する
# --stdin --image_type capture で標準入力のキャプチャー画像を推論する
iinfer -m client -c capture | \
iinfer -m client -c predict -n <モデル名> \
--stdin \
--image_type capture \
--nodraw | \
iinfer -m postprocess -c det_filter -f -P \
--stdin \
--score_th 0.8
```
4. AIモデルのセッションを開放:
```bash
# 画像AIモデルを停止させてセッションを開放
iinfer -m client -c stop -n <モデル名> -f
```
## Lisence
This project is licensed under the MIT License, see the LICENSE file for details
| text/markdown | null | hamacom2004jp <hamacom2004jp@gmail.com> | null | null | MIT | mmdetection, mmsegmentation, onnxruntime, inference, image, ai, model, audit, cli, excel, fastapi, mcp, redis, restapi, web | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: MIT License",
"Natural Language :: Japanese",
"Programming Language :: Python",
"Topic :: Utilities"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"cmdbox<0.7.5,>=0.7.4",
"motpy",
"opencv-python",
"urllib3",
"pydantic<3.0.0,>=2.0.0; extra == \"agent-mcp\"",
"fastmcp>=2.14.4; extra == \"agent-mcp\"",
"mcp<2.0.0,>=1.23.0; extra == \"agent-mcp\"",
"google-adk>=1.23.0; extra == \"agent-adk\"",
"a2a-sdk<0.4.0,>=0.3.4; extra == \"agent-adk\"",
"li... | [] | [] | [] | [
"Homepage, https://github.com/hamacom2004jp/iinfer",
"Documentation, https://hamacom2004jp.github.io/iinfer/index.html",
"Repository, https://github.com/hamacom2004jp/iinfer"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-19T15:09:25.136457 | iinfer-0.13.0.tar.gz | 586,985 | 0d/c5/1f8efd00d097f8524cbbd6f7a994724cfabb13acedd4c8ffe1843652a597/iinfer-0.13.0.tar.gz | source | sdist | null | false | 9419bed46b9c65eea5d3fa9cac194668 | c977d6453ce531573c744934785e5291403c464898f21f8ed8e18c768648e929 | 0dc51f8efd00d097f8524cbbd6f7a994724cfabb13acedd4c8ffe1843652a597 | null | [
"LICENSE"
] | 225 |
2.4 | argo-kedro | 0.1.27 | Kedro plugin for running pipelines on Argo Workflows | # What is argo-kedro
`argo-kedro` is a [kedro-plugin](https://kedro.org/) for executing Kedro pipelines on [Argo Workflows](https://argoproj.github.io/workflows/). It's core functionalities are:
- __Workflow construction__: `argo-kedro` constructs an [Argo Workflow](https://argo-workflows.readthedocs.io/en/latest/workflow-templates/) manifest from your Kedro pipeline for execution on your cluster. This ensures that the Kedro pipeline definition remains the single source of truth.
- __Defining compute resources__: `argo-kedro` exposes a custom `Node` type that can be used to control the compute resouces available to the node.
- __Node fusing__: To maximize parallelisation, `argo-kedro` executes each Kedro node in a dedicated Argo task. The plugin exposes a `FusedPipeline` object that can be used to co-locate nodes for execution on a single Argo task.
## Table of contents
- [How do I use argo-kedro?](#how-do-i-install-argo-kedro)
- [Set up your Kedro project](#set-up-your-kedro-project)
- [Set up your venv](#set-up-your-venv)
- [Install the plugin](#install-the-plugin)
- [Setting up your cloud environment](#setting-up-your-cloud-environment)
- [Submitting to the cluster](#submitting-to-the-cluster)
- [Advanced configuration](#advanced)
- [Configuring machines types](#configuring-machines-types)
- [GPU support](#gpu-support)
- [Fusing nodes for execution](#fusing-nodes-for-execution)
- [Using cluster Secrets](#using-cluster-secrets)
- [Common errors](#common-errors)
# How do I install argo-kedro?
## Set up your Kedro project
Use the Kedro CLI to setup your project, i.e.,
```bash
kedro new
```
## Set up your venv
```bash
uv sync
```
## Install the plugin
```bash
uv add argo-kedro
```
Next, initialise the plugin, this will create a `argo.yml` file that will house components of the argo configuration. Moreover, the plugin will prompt for the creation of baseline `Dockerfile` and `.dockerignore` files.
```bash
uv run kedro argo init
```
Validate the files, and make any changes required.
## Setting up your cloud environment
Argo Workflows executes pipelines in a parallelized fashion, i.e., on different compute instances. It's therefore important that data exchanged between nodes is materialized in remote storage, as local data storage is not shared among these machines. Let's start by installing the `gcsfs` package.
> NOTE: The split between the `base` and `cloud` environment enables development workflows where local data storage is used when iterating locally, while the cluster uses Google Cloud storage.
```bash
uv add "fsspec[gcs]"
```
### Registering the globals file
Kedro allows customizing variables based on the environment, which unlocks local data storage for testing, while leveraging Cloud Storage for running on the cluster. First, enable the use of the globals in the `settings.py` file. To do so, replace the `CONFIG_LOADER_ARGS` setting with the contents below:
```python
# Add the following import on top of the file
from omegaconf.resolvers import oc
CONFIG_LOADER_ARGS = {
"base_env": "base",
"default_run_env": "local",
"merge_strategy": {"parameters": "soft", "globals": "soft"},
"config_patterns": {
"globals": ["globals*", "globals*/**", "**/globals*"],
"parameters": [
"parameters*",
"parameters*/**",
"**/parameters*",
"**/parameters*/**",
],
},
"custom_resolvers": {
"oc.env": oc.env,
}
}
```
### Parametrizing the base path
Create a new file in `conf/base` folder called `globals.yml`. Start by defining the globals file for the base environment.
```yaml
# Definition for conf/base/globals.yml for local storage
paths:
base: data
```
Next, create the `globals.yml` file for the cloud env in `conf/cloud` folder (if the folder doesn't exist, please create it), then define the globals file for the cloud environment with the following:
```yaml
# Definition for conf/cloud/globals.yml for cloud storage
paths:
base: gs://<your_bucket_name>/<your_project_name>/${oc.env:WORKFLOW_ID, dummy}
```
> **Important** Ensure to replace **<your_bucket_name>** **<your_project_name>** with bucket and subdirectory respectively.
> The plugin adds a few environment variables to the container automatically, one of these is the `WORKFLOW_ID` which
> is a unique identifier of the workflow. This can be used as a unit of versioning as displayed below.
Finally, ensure the parametrized path is used, this should be done in the `conf/base/catalog.yml` file. For example:
```yaml
preprocessed_companies:
type: pandas.ParquetDataset
# This ensures that local storage is used in the base, while cloud storage
# is used while running on the cluster.
filepath: ${globals:paths.base}/02_intermediate/preprocessed_companies.parquet
```
> **IMPORTANT**: Make sure you replace `data/` string in the `conf/base/catalog.yml` file with `${globals:paths.base}/` as kedro isn't aware of the Cloud storage. This change would allow Kedro to switch between `local` and `cloud` env easily.
## Submitting to the cluster
### Ensure you have the correct kubeconfig set
Run the following CLI command to setup the cluster credentials.
```bash
gcloud container clusters get-credentials $CLUSTER_NAME --region us-central1 --project $PROJECT
```
### Ensure all catalog entries are registered
This is a very early version of the plugin, which does _not_ support memory datasets. Ensure your pipeline does not use memory datasets, as this will lead to failures. We will be introducing a mechanism that will support this in the future.
### Execute pipeline
Run the following command to run on the cluster:
```bash
uv run kedro argo submit
```
Note, optionally you can supply a `--workflow-name` argument that controls the name of the resulting workflow.
# Advanced
## Configuring machines types
The `argo.yml` file defines the possible machine typess that can be used by nodes in the pipeline, the platform team will share a list of valid machine types.
```yaml
# ...
# argo.yml
machine_types:
default:
mem: 16
cpu: 4
num_gpu: 0
default_machine_type: default
```
By default, the `default_machine_type` is used for all nodes of the pipeline, if you wish to configure the machine type, import the plugin's `Node` extension.
```python
# NOTE: Import from the plugin, this is a drop in replacement!
from argo_kedro.pipeline import Node
def create_pipeline(**kwargs) -> Pipeline:
return Pipeline(
[
Node(
func=preprocess_companies,
inputs="companies",
outputs="preprocessed_companies",
name="preprocess_companies_node",
machine_type="n1-standard-4", # NOTE: enter a valid machine type from the configuration here
),
...
]
)
```
## GPU support
The template Dockerfile comes with built-in support for running GPU workloads on Nvidia GPUs.
To run a `pipeline` on GPU, you would need to configure the `pipeline` machine type to a `g2` instance type. Currently supported GPU machine types are:
| Machine Type | CPU | Memory | GPU | GPU memory |
|----------------|-----|--------|------|-----------|
| g2-standard-4 | 4 | 16 | 1 | 24 |
| g2-standard-8 | 8 | 32 | 1 | 24 |
| g2-standard-12 | 12 | 48 | 1 | 24 |
| g2-standard-16 | 16 | 64 | 1 | 24 |
| g2-standard-24 | 24 | 96 | 2 | 48 |
| g2-standard-32 | 32 | 128 | 1 | 24 |
| g2-standard-48 | 48 | 192 | 4 | 96 |
| g2-standard-96 | 96 | 384 | 8 | 192 |
To use the following machine type, you would need to modify the `pipeline` code as follows:
```python
# NOTE: Import from the plugin, this is a drop in replacement!
from argo_kedro.pipeline import Node
def create_pipeline(**kwargs) -> Pipeline:
return Pipeline(
[
Node(
func=preprocess_companies,
inputs="companies",
outputs="preprocessed_companies",
name="preprocess_companies_node",
machine_type="g2-standard-4", # NOTE: enter a valid machine type from the above mentioned list.
),
...
]
)
```
## Fusing nodes for execution
### Why fusing?
To run a Kedro pipeline on Argo, the question of how to map Kedro nodes to Argo tasks arises. There are two immediately obvious, albeit extreme, directions:
1. Single Argo task for _entire_ pipeline
- Pros:
- Simple setup, Argo task invokes `kedro run` for entire pipeline
- Cons:
- Limited options for leveraging parallelization
- Entire pipeline has to run with single hardware configuration
- May be very expensive for pipelines requiring GPUs in some steps
1. Argo task for _each_ node in the pipeline
- Pros:
- Maximize parallel processing capabilities
- Allow for different hardware configuration per node
- Cons:
- Scheduling overhead for very small Kedro nodes
- Complex DAG in Argo Workflows
For our use-case, a pipeline with hundreds of nodes, we want to enable fusing sets of related<sup>2</sup> nodes for execution on _single_ Argo task. This avoids scheduling overhead while still supporting heterogeneous hardware configurations within the pipeline.
<sup>2</sup> Related here is used in the broad sense of the word, i.e., they may have similar hardware needs, are highly coupled, or all rely on an external service.
## The `FusedPipeline` object
The `FusedPipeline` is an extension of Kedro's `Pipeline` object, that guarantees that the nodes contained within it are executed on the same machine. See the following code example:
```python
from kedro.pipeline import Pipeline
from argo_kedro.pipeline import FusedPipeline, Node
from .nodes import create_model_input_table, preprocess_companies, preprocess_shuttles
def create_pipeline(**kwargs) -> Pipeline:
return Pipeline(
[
FusedPipeline(
nodes=[
Node(
func=preprocess_companies,
inputs="companies",
outputs="preprocessed_companies",
name="preprocess_companies_node",
),
Node(
func=preprocess_shuttles,
inputs="shuttles",
outputs="preprocessed_shuttles",
name="preprocess_shuttles_node",
),
],
name="preprocess_data_fused",
machine_type="n1-standard-1"
),
Node(
func=create_model_input_table,
inputs=["preprocessed_shuttles", "preprocessed_companies", "reviews"],
outputs="model_input_table",
name="create_model_input_table_node",
),
]
)
```
The code snippet above wraps the `preprocess_companies_node` and `preprocess_shuttles_node` nodes together for execution on the same machine. Similar to the plugins' `Node` object, the `FusedPipeline` accepts a `machine_type` argument that allows for customizing the machine type to use.
> Given that the nodes within the `FusedPipeline` now execute on the same machine, the plugin performs a small optimization step to reduce IO. Specifically, each intermediate, i,.e., non-output dataset within the `FusedPipeline` is transformed into a `MemoryDataset`. This allows for Kedro to keep these datasets in memory, without having to materialize them to disk. The behaviour can be toggled by `runner.use_memory_datasets` in `argo.yml`.
## Using cluster Secrets
Workflows are allowed to consuming secrets provided by the cluster. Secrets can be mounted using the `template` section of the `argo.yml` file.
```yaml
# argo.yml
...
template:
environment:
# The configuration below mounts the `secret.TOKEN`
# to the `TOKEN` environment variable.
- name: TOKEN
secret_ref:
name: secret
key: TOKEN
```
This ensures that the underlying machine has access to the secret, next use the `oc.env` resolver to pull the secret in the globals, catalog or parameters, as follows:
```yml
# base/globals.yml
openai_token: ${oc.env:TOKEN}
```
# Common errors
## Authentication errors while submitting to the cluster
Occasionally, the combination of the `fsspec[gcs]` and `kubernetes` dependencies give inconsistencies. A current solution is to pin the following dependency:
```
proto-plus==1.24.0.dev1
```
## Dataset saving errors
The Google Cloud filesystem implementation sometimes seems to result in some issues with Kedro. Resulting in `VersionedDataset` errors, even when versioning is disabled.
```
DatasetError: Cannot save versioned dataset '...' to
'...' because a file with
the same name already exists in the directory. This is likely because versioning
was enabled on a dataset already saved previously.
```
To fix the issue, pin the version of the following library:
```
gcsfs==2024.3.1
```
| text/markdown | null | Laurens Vijnck <laurens@everycure.org>, Nelson Alfonso <nelson@everycure.org> | null | null | MIT | kedro, argo, workflows, argo workflows, kubernetes, pipeline | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: ... | [] | null | null | >=3.10 | [] | [] | [] | [
"kedro",
"pyyaml>=6.0.2",
"jinja2>=3.0.0",
"kubernetes>=35.0.0",
"pydantic>=2.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/everycure-org/argo-kedro",
"Repository, https://github.com/everycure-org/argo-kedro",
"Issues, https://github.com/everycure-org/argo-kedro/issues"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-19T15:08:41.758785 | argo_kedro-0.1.27.tar.gz | 62,957 | 68/1f/36ca6b282d82f4f6966136622cefa879094d8bfd2b1187200d385ca485c3/argo_kedro-0.1.27.tar.gz | source | sdist | null | false | b0394898a138b8d30dbc63d1b2b77dd5 | 750e9fe5bb42d7d622d3bc67da6fe0ca51d37fa1d893d22cf38888328f204ee3 | 681f36ca6b282d82f4f6966136622cefa879094d8bfd2b1187200d385ca485c3 | null | [
"LICENSE"
] | 218 |
2.1 | moteus-gui | 0.3.99 | moteus brushless controller graphical user interfaces | # moteus GUI tools #
This package contains the `tview` graphical tool for interacting with
moteus controllers.
To install and run:
```
pip3 install moteus-gui
python3 -m moteus_gui.tview
```
| text/markdown | mjbots Robotic Systems | info@mjbots.com | null | null | null | moteus | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3"
] | [] | https://github.com/mjbots/moteus | null | <4,>=3.7 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.3 | 2026-02-19T15:08:34.934242 | moteus_gui-0.3.99.tar.gz | 29,377 | e0/04/9473ea8a772e8dcb369a61d143dcb41ff18b6d6cd3bb9f1ef0d871b60998/moteus_gui-0.3.99.tar.gz | source | sdist | null | false | f668e853f41e3f363505268acea2ef0b | 02942e25df2d6e14c26e5f90a4b2e88c382092c592ee53489497b06043ec1daf | e0049473ea8a772e8dcb369a61d143dcb41ff18b6d6cd3bb9f1ef0d871b60998 | null | [] | 348 |
2.1 | moteus | 0.3.99 | moteus brushless controller library and tools | # Python bindings for moteus brushless controller #
These bindings permit communication and control of moteus brushless
controllers.
## To use ##
```
pip3 install moteus # or 'moteus-pi3hat' on a pi3hat
```
See a simple example of the API in use at: [simple.py](examples/simple.py)
## Theory ##
Interactions with a controller are mediated through the
`moteus.Controller` object. When constructed with the constructor
argument `transport=None` (the default) it attempts to find some
suitable link on your host system, typically the first fdcanusb or
socketcan bus it locates.
Single controller imperative operation can be conducted by using
`await Controller.set_stop()`, `await Controller.set_position()`, and
`await Controller.query()`.
## Bus-optimized usage ##
To optimize bus usage, it is possible to command multiple controllers
simultaneously. In this mode, a "transport" must be manually
constructed.
```
import asyncio
import math
import moteus
async def main():
transport = moteus.Fdcanusb()
c1 = moteus.Controller(id = 1)
c2 = moteus.Controller(id = 2)
while True:
print(await transport.cycle([
c1.make_position(position=math.nan, query=True),
c2.make_position(position=math.nan, query=True),
]))
asyncio.run(main())
```
All of the "set_" methods have a "make_" variant which is suitable to
pass to a Transport's `cycle` method.
This mechanism only improves performance for non-fdcanusb links, such
as a pi3hat.
An example use of this mechanism can be found at:
[pi3hat_multiservo.py](examples/pi3hat_multiservo.py)
## Position mode commands ##
`Controller.set_position` and `Controller.make_position` have
arguments which exactly mirror the fields documented in
`docs/reference.md`. Omitting them (or specifying None), results in
them being omitted from the resulting register based command.
* position
* velocity
* feedforward_torque
* kp_scale
* maximum_torque
* stop_position
* watchdog_timeout
Finally, the `query` argument controls whether information is queried
from the controller or not.
## Controlling resolution ##
The resolution of commands, and of returned query data, is controlled
by optional constructor arguments to `Controller`. By default, the
commands are all F32, and the query requests a subset of fields as
INT16. Here is an example of setting those.
```
pr = moteus.PositionResolution()
pr.position = moteus.INT16
pr.velocity = moteus.INT16
pr.kp_scale = moteus.F32
pr.kd_scale = moteus.F32
qr = moteus.QueryResolution()
qr.mode = moteus.INT8
qr.position = moteus.F32
qr.velocity = moteus.F32
qr.torque = moteus.F32
c = moteus.Controller(position_resolution=pr, query_resolution=qr)
```
| text/markdown | mjbots Robotic Systems | info@mjbots.com | null | null | null | moteus | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3"
] | [] | https://github.com/mjbots/moteus | null | <4,>=3.7 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.3 | 2026-02-19T15:08:34.123606 | moteus-0.3.99.tar.gz | 74,916 | 31/c4/a8a7beffd911df48dadca1208fc5b0304c6ced11cbd18ff74d8a53b4f66a/moteus-0.3.99.tar.gz | source | sdist | null | false | 07e4ba1d6a78c942c01008db09248cb3 | 30d3cafa6b23692536102f52d9a7d919f2775fa75bdee087f98782c7e3c88805 | 31c4a8a7beffd911df48dadca1208fc5b0304c6ced11cbd18ff74d8a53b4f66a | null | [] | 423 |
2.1 | cohere-compass-sdk | 2.6.0 | Cohere Compass SDK | # Cohere Compass SDK
[](https://microsoft.github.io/pyright/)
The Compass SDK is a Python library that allows you to parse documents and insert them
into a Compass index.
In order to parse documents, the Compass SDK relies on the Compass Parser API, which is
a RESTful API that receives files and returns parsed documents. This requires a hosted
Compass server.
The Compass SDK provides a `CompassParserClient` that allows to interact with the parser
API from your Python code in a convenient manner. The `CompassParserClient` provides
methods to parse single and multiple files, as well as entire folders, and supports
multiple file types (e.g., `pdf`, `docx`, `json`, `csv`, etc.) as well as different file
systems (e.g., local, S3, GCS, etc.).
To insert parsed documents into a `Compass` index, the Compass SDK provides a
`CompassClient` class that allows to interact with a Compass API server. The Compass API
is also a RESTful API that allows to create, delete and search documents in a Compass
index.
## Table of Contents
<!--
Do NOT remove the line below; it is used by markdown-toc to automatically generate the
Table of Contents.
To update the Table Of Contents, execute the following command in the repo root dir:
markdown-toc -i README.md
If you don't have the markdown-toc tool, you can install it with:
npm i -g markdown-toc # use sudo if you use a system-wide node installation.
>
<!-- toc -->
- [Getting Started](#getting-started)
* [Installation](#installation)
- [V2 Migration Guide](#v2-migration-guide)
- [Local Development](#local-development)
* [Create Python Virtual Environment](#create-python-virtual-environment)
* [Running Tests Locally](#running-tests-locally)
+ [VSCode Users](#vscode-users)
* [Pre-commit](#pre-commit)
<!-- tocstop -->
## Getting Started
### Installation
To install the SDK using `pip`:
```bash
pip install cohere-compass-sdk
```
If you are using a package management tool like `poetry` or `uv`:
```
poetry add cohere-compass-sdk
```
or
```
uv add cohere-compass-sdk
```
Once you install it, the best way to learn how to use the SDK is to head over to [our
examples](https://github.com/cohere-ai/cohere-compass-sdk/tree/main/examples). For the
API reference, you can visit this
[link](https://cohere-preview-d28024ac-1edf-416c-95be-73c5fe85a7c5.docs.buildwithfern.com/compass/reference/list-indexes-v-1-indexes-get).
## V2 Migration Guide
To improve the quality of the SDK and address multiple long-standing issues, as well
as supporting async clients, we decided to introduce v2.0, a new major version. v2.0 has
breaking changes and will require code changes. Fortunately, the changes are minimal
and can frequently be deduced just by looking at the new signatures of the APIs. Below
is a summary:
- Previously, we had multiple methods that relied on return values for error handling.
This is no more the case, and almost all methods now raise exceptions in case of errors.
This means that instead of a code like:
```python
result = compass_client.create_index(...)
if result.error:
# do something about the error
```
you instead do:
```python
try:
result = compass_client.create_index(...)
except:
# do something about the error
```
- v2.0 supports async clients. Async clients maintain the same signature as their sync
counterparts. So, where you would do the following to create an index:
```python
client = CompassClient(index_url=api_url, bearer_token=bearer_token)
client.create_index(...)
```
In async, you simply do:
```
client = CompassAsyncClient(index_url=api_url, bearer_token=bearer_token)
await client.create_index(...)
```
## Local Development
### Create Python Virtual Environment
We use Poetry to manage our Python environment. To create the virtual environment use
the following command:
```
poetry sync
```
### Running Tests Locally
We use `pytest` for testing. So, you can simply run tests using the following command:
```
poetry run python -m pytest
```
#### VSCode Users
We provide `.vscode` folder for those developers who prefer to use VSCode. You just need
to open the folder in VSCode and VSCode should pick our settings.
### Pre-commit
We love and appreciate Coding Standards and so we enforce them in our code base.
However, without automation, enforcing Coding Standards usually result in a lot of
frustration for developers when they publish Pull Requests and our linters complain. So,
we automate our formatting and linting with [pre-commit](https://pre-commit.com/). All
you need to do is install our `pre-commit` hook so the code gets formatted automatically
when you commit your changes locally:
```bash
poetry run pre-commit install
```
| text/markdown | null | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11"
] | [] | null | null | <4.0,>=3.11 | [] | [] | [] | [
"fsspec<2026.0.0,>=2025.9.0",
"joblib<2.0.0,>=1.5.2",
"pydantic<3.0.0,>=2.11.9",
"tenacity<10.0.0,>=9.1.2",
"httpx<0.29.0,>=0.28.1"
] | [] | [] | [] | [] | poetry/1.5.1 CPython/3.11.14 Linux/6.14.0-1017-azure | 2026-02-19T15:07:50.636199 | cohere_compass_sdk-2.6.0.tar.gz | 42,143 | d2/c9/a4a3205ad9f4054315e3af496f22e41d99e7867b60ecab3d81ab98fffb25/cohere_compass_sdk-2.6.0.tar.gz | source | sdist | null | false | ee6fec9a812aaeaa77c11be6bd6111c0 | ba7c4084fb2fc3a87e6d55a8f814a26a5911c2bfaad88ed9e3116152efc8ac3d | d2c9a4a3205ad9f4054315e3af496f22e41d99e7867b60ecab3d81ab98fffb25 | null | [] | 654 |
2.4 | django-paradedb | 0.3.0 | Official ParadeDB integration for Django | # django-paradedb
[](https://pypi.org/project/django-paradedb/)
[](https://codecov.io/gh/paradedb/django-paradedb)
[](https://github.com/paradedb/django-paradedb/actions/workflows/ci.yml)
[](https://github.com/paradedb/django-paradedb?tab=MIT-1-ov-file#readme)
[](https://join.slack.com/t/paradedbcommunity/shared_invite/zt-32abtyjg4-yoYoi~RPh9MSW8tDbl0BQw)
[](https://x.com/paradedb)
[ParadeDB](https://paradedb.com) — simple, Elastic-quality search for Postgres — integration for Django ORM.
## Requirements & Compatibility
| Component | Supported |
| ---------- | -------------------------------- |
| Python | 3.10+ |
| Django | 4.2+ |
| ParadeDB | 0.21.0+ |
| PostgreSQL | 17+ (with ParadeDB extension) |
## Installation
```bash
pip install django-paradedb
```
## Quick Start
Add a BM25 index to your model and use `ParadeDBManager`:
```python
from django.db import models
from paradedb.indexes import BM25Index
from paradedb.queryset import ParadeDBManager
class Product(models.Model):
description = models.TextField()
category = models.CharField(max_length=100)
rating = models.IntegerField(default=0)
objects = ParadeDBManager()
class Meta:
indexes = [
BM25Index(
fields={
'id': {},
'description': {'tokenizer': 'unicode_words'},
'category': {'tokenizer': 'literal'},
'rating': {},
},
key_field='id',
name='product_search_idx',
),
]
```
Run migrations to create the index:
```bash
python manage.py makemigrations
python manage.py migrate
```
Search with a simple query:
```python
from paradedb.search import ParadeDB, Fuzzy
# Single term
Product.objects.filter(description=ParadeDB('shoes'))
# Multiple terms (AND by default)
Product.objects.filter(description=ParadeDB('running', 'shoes'))
# OR across terms
Product.objects.filter(description=ParadeDB('shoes', 'boots', operator='OR'))
# Fuzzy search (typo tolerance)
Product.objects.filter(description=ParadeDB(Fuzzy('shoez')))
```
Annotate with BM25 relevance score and sort by it:
```python
from paradedb.functions import Score
Product.objects.filter(
description=ParadeDB('shoes')
).annotate(
score=Score()
).order_by('-score')
```
## Django ORM Integration
django-paradedb works seamlessly with Django's ORM features:
```python
from django.db.models import Q
from paradedb.search import ParadeDB
# Combine with Q objects
Product.objects.filter(
Q(description=ParadeDB('shoes')) & Q(rating__gte=4)
)
# Chain with standard filters
Product.objects.filter(
description=ParadeDB('shoes')
).filter(
category='footwear'
).exclude(
rating__lt=3
)
# Select related
Product.objects.filter(
description=ParadeDB('shoes')
).select_related('brand')
# Prefetch related
Product.objects.filter(
description=ParadeDB('shoes')
).prefetch_related('reviews')
```
## Custom Manager
If you have a custom manager, compose it with `ParadeDBQuerySet`:
```python
from paradedb.queryset import ParadeDBQuerySet
class CustomManager(models.Manager):
def active(self):
return self.filter(is_active=True)
CustomManagerWithParadeDB = CustomManager.from_queryset(ParadeDBQuerySet)
class Product(models.Model):
objects = CustomManagerWithParadeDB()
```
## Common Errors
### "facets() requires a ParadeDB operator in the WHERE clause"
```python
# ❌ Missing ParadeDB filter
Product.objects.filter(price__lt=100).order_by('id')[:10].facets('category')
# ✅ Add a ParadeDB search filter
Product.objects.filter(
price__lt=100,
description=ParadeDB('shoes')
).order_by('id')[:10].facets('category')
```
### "facets(include_rows=True) requires order_by() and a LIMIT"
```python
# ❌ Missing ordering or limit
Product.objects.filter(description=ParadeDB('shoes'))[:10].facets('category')
Product.objects.filter(description=ParadeDB('shoes')).order_by('id').facets('category')
# ✅ Both ordering and limit
Product.objects.filter(description=ParadeDB('shoes')).order_by('id')[:10].facets('category')
# ✅ Or skip rows entirely
Product.objects.filter(description=ParadeDB('shoes')).facets('category', include_rows=False)
```
## Security
django-paradedb uses SQL literal escaping (rather than parameterized queries) for search terms. This is intentional: ParadeDB's full-text operators (`&&&`, `|||`, `===`, `@@@`, etc.) require string literals that the query planner can inspect at parse time — parameterized placeholders are incompatible with this design. All user input is escaped via PostgreSQL's standard single-quote escaping (`'` → `''`) before being embedded in the query. The implementation is covered by 300+ tests including special-character and injection cases. `MoreLikeThis` and standard Django filters continue to use normal parameterization.
## Examples
- [Quick Start](examples/quickstart/quickstart.py)
- [Faceted Search](examples/faceted_search/faceted_search.py)
- [Autocomplete](examples/autocomplete/autocomplete.py)
- [More Like This](examples/more_like_this/more_like_this.py)
- [Hybrid Search (RRF)](examples/hybrid_rrf/hybrid_rrf.py)
- [RAG](examples/rag/rag.py)
## Documentation
- **Package Documentation**: <https://paradedb.github.io/django-paradedb>
- **ParadeDB Official Docs**: <https://docs.paradedb.com>
- **ParadeDB Website**: <https://paradedb.com>
## Contributing
See [CONTRIBUTING.md](CONTRIBUTING.md) for development setup, running tests, linting, and the PR workflow.
## Support
If you're missing a feature or have found a bug, please open a
[GitHub Issue](https://github.com/paradedb/django-paradedb/issues/new/choose).
To get community support, you can:
- Post a question in the [ParadeDB Slack Community](https://join.slack.com/t/paradedbcommunity/shared_invite/zt-32abtyjg4-yoYoi~RPh9MSW8tDbl0BQw)
- Ask for help on our [GitHub Discussions](https://github.com/paradedb/paradedb/discussions)
If you need commercial support, please [contact the ParadeDB team](mailto:sales@paradedb.com).
## Acknowledgments
We would like to thank the following members of the Django community for their valuable feedback and reviews during the development of this package:
- [Timothy Allen](https://github.com/FlipperPA) - Principal Engineer at The Wharton School, PSF and DSF member
- [Frank Wiles](https://github.com/frankwiles) - President & Founder of REVSYS
## License
django-paradedb is licensed under the [MIT License](LICENSE).
| text/markdown | null | ParadeDB <support@paradedb.com> | null | null | null | bm25, django, faceted search, facets, full text search, hybrid search, paradedb, postgres, postgresql, search, text search | [
"Development Status :: 3 - Alpha",
"Environment :: Web Environment",
"Framework :: Django",
"Framework :: Django :: 4.2",
"Framework :: Django :: 5.2",
"Framework :: Django :: 6.0",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"... | [] | null | null | >=3.10 | [] | [] | [] | [
"django>=4.2",
"django-stubs>=5.1; extra == \"dev\"",
"mypy>=1.13; extra == \"dev\"",
"psycopg[binary]>=3.1; extra == \"dev\"",
"pytest-cov>=6.0; extra == \"dev\"",
"pytest-django>=4.9; extra == \"dev\"",
"pytest>=8.3; extra == \"dev\"",
"ruff>=0.8; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://paradedb.com",
"Documentation, https://docs.paradedb.com",
"Repository, https://github.com/paradedb/django-paradedb",
"Issues, https://github.com/paradedb/django-paradedb/issues"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T15:07:41.417625 | django_paradedb-0.3.0.tar.gz | 157,793 | 06/b8/f533b68c8d7153023c345df3233eb5c72f1f56f0e40e3508e7dd0973f4c6/django_paradedb-0.3.0.tar.gz | source | sdist | null | false | 1a3e8406cb067aa3e2364253e38433fc | 47a229eec082576060e78934fc75abbaf889df18ee72369da02ab7436c276d9a | 06b8f533b68c8d7153023c345df3233eb5c72f1f56f0e40e3508e7dd0973f4c6 | MIT | [
"LICENSE"
] | 226 |
2.4 | lambda-otel-logging | 1.0.1 | Python logging formatter that looks like OpenTelemetry logs | AWS Lambda OpenTelemetry Logging
===============================
Simple log formatter to get Otel log records on stdout in an AWS lambda.
Trying to use a collector in AWS lambda runtime is stupid and doing so for [logging will lead to issues](https://github.com/aws-observability/aws-otel-lambda/issues/1121).
So the goal is simple:
- Write stuff that looks like OpenTelemetry, but uses AWS native services instead.
If you want a full collectorless and performant solution,
probably look at https://github.com/dev7a/serverless-otlp-forwarder
but if you just want to look like otel for log alerting, you can use this logging formatter.
| text/markdown | null | Bram Neijt <bram@neijt.nl> | null | null | null | null | [
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"msgspec>=0.17.0",
"opentelemetry-sdk>=1.20.0"
] | [] | [] | [] | [] | uv/0.8.17 | 2026-02-19T15:07:18.816646 | lambda_otel_logging-1.0.1.tar.gz | 30,573 | 42/f2/bd76bf9ebbb11f930ef785b1d413631bf64b69691e47e59c5537a65f12fc/lambda_otel_logging-1.0.1.tar.gz | source | sdist | null | false | 77228ac5b63e51d445f143c2a0254f77 | c9755d74abfc97c83a7c5eab83334b45622fabb47a1d9a2f89b19748b139adb6 | 42f2bd76bf9ebbb11f930ef785b1d413631bf64b69691e47e59c5537a65f12fc | null | [
"LICENSE"
] | 210 |
2.4 | heimdex-media-contracts | 0.5.0 | Shared schemas, pure functions, and contracts for Heimdex media pipelines | # heimdex-media-contracts
Shared schemas, pure functions, and contracts for Heimdex media pipelines.
This package is intentionally **dependency-light** — it depends only on `pydantic`
and the Python standard library. It must **never** import heavy ML/media libraries
such as `cv2`, `torch`, `whisper`, `insightface`, `pyannote`, `onnxruntime`, or `ffmpeg`.
## Modules
| Module | Contents |
|--------|----------|
| `heimdex_media_contracts.faces.schemas` | Pydantic models for face presence responses |
| `heimdex_media_contracts.faces.sampling` | Pure timestamp sampling math (no file I/O) |
| `heimdex_media_contracts.speech.schemas` | Dataclass models for speech segment pipelines |
| `heimdex_media_contracts.speech.tagger` | Keyword-based segment tagger (pure string matching) |
| `heimdex_media_contracts.speech.ranker` | Segment importance ranker (pure computation) |
## Usage
```python
from heimdex_media_contracts.faces.schemas import FacePresenceResponse
from heimdex_media_contracts.faces.sampling import sample_timestamps
from heimdex_media_contracts.speech.tagger import SpeechTagger
```
## Running tests
```bash
cd heimdex-media-contracts
pip install -e ".[dev]"
python -m pytest -q
```
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"pydantic<3,>=2",
"pytest>=7; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:06:26.740638 | heimdex_media_contracts-0.5.0.tar.gz | 27,675 | f5/71/2122d69d5efe4b23fcfd42da81d954a21aa8474e5f362afdc4ab5a83237c/heimdex_media_contracts-0.5.0.tar.gz | source | sdist | null | false | f45f5b142038ebfc4a4a710ccad73535 | 3a97514a81dc0a561ee807233a7148e7088e6f4a9754bfe5466d58e504572da2 | f5712122d69d5efe4b23fcfd42da81d954a21aa8474e5f362afdc4ab5a83237c | null | [] | 211 |
2.4 | dkist-quality | 2.0.1 | DKIST library for generating quality report pdf | dkist-quality
-------------
|codecov|
Provides the ability to create a pdf quality report from structured quality data.
Sample Usage
~~~~~~~~~~~~
.. code-block:: python
from dkist_quality.report import format_report
def create_quality_report(report_data: dict | list[dict], dataset_id: str) -> bytes:
"""
Generate a quality report in pdf format.
:param report_data: Quality data for the dataset.
:param dataset_id: The dataset id.
:return: quality report in pdf format
"""
return format_report(report_data=report_data, dataset_id=dataset_id)
Developer Setup
~~~~~~~~~~~~~~~
.. code-block:: bash
pip install -e .[test]
pip install pre-commit
pre-commit install
License
-------
This project is Copyright (c) NSO / AURA and licensed under
the terms of the BSD 3-Clause license. This package is based upon
the `Openastronomy packaging guide <https://github.com/OpenAstronomy/packaging-guide>`_
which is licensed under the BSD 3-clause licence. See the licenses folder for
more information.
.. |codecov| image:: https://codecov.io/bb/dkistdc/dkist-quality/branch/master/graph/badge.svg
:target: https://codecov.io/bb/dkistdc/dkist-quality
| text/x-rst | null | NSO / AURA <dkistdc@nso.edu> | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"reportlab>=4.0.4",
"matplotlib>=3.8",
"seaborn>=0.13.0",
"dacite!=1.9.0,>=1.8.0",
"natsort>=8.0.0",
"pydantic>=2.0.0",
"tox>=4; extra == \"test\"",
"pypdf; extra == \"test\"",
"pytest; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"Pygments; extra == \"test\""
] | [] | [] | [] | [
"repository, https://bitbucket.org/dkistdc/dkist-quality"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T15:06:11.707806 | dkist_quality-2.0.1.tar.gz | 120,950 | b0/a2/40e03e115efd31159b2551001b8c6dc93355c4bb8410a4e42095d7dcb776/dkist_quality-2.0.1.tar.gz | source | sdist | null | false | f6d1af1cf63ea30c4a284378293ecdc8 | fca16ef43e7387377bd97299d272a713b4865a04c72acdc5ad9614495e7d5e8d | b0a240e03e115efd31159b2551001b8c6dc93355c4bb8410a4e42095d7dcb776 | null | [
"LICENSE"
] | 383 |
2.4 | workspace-mcp | 1.12.0 | Comprehensive, highly performant Google Workspace Streamable HTTP & SSE MCP Server for Calendar, Gmail, Docs, Sheets, Slides & Drive | <!-- mcp-name: io.github.taylorwilsdon/workspace-mcp -->
<div align="center">
# <span style="color:#cad8d9">Google Workspace MCP Server</span> <img src="https://github.com/user-attachments/assets/b89524e4-6e6e-49e6-ba77-00d6df0c6e5c" width="80" align="right" />
[](https://opensource.org/licenses/MIT)
[](https://www.python.org/downloads/)
[](https://pypi.org/project/workspace-mcp/)
[](https://pepy.tech/projects/workspace-mcp)
[](https://workspacemcp.com)
*Full natural language control over Google Calendar, Drive, Gmail, Docs, Sheets, Slides, Forms, Tasks, Contacts, and Chat through all MCP clients, AI assistants and developer tools. Now includes a full featured CLI for use with tools like Claude Code and Codex!*
**The most feature-complete Google Workspace MCP server**, with Remote OAuth2.1 multi-user support and 1-click Claude installation.
###### Support for all free Google accounts (Gmail, Docs, Drive etc) & Google Workspace plans (Starter, Standard, Plus, Enterprise, Non Profit) with expanded app options like Chat & Spaces. <br/><br /> Interested in a private, managed cloud instance? [That can be arranged.](https://workspacemcp.com/workspace-mcp-cloud)
</div>
<div align="center">
<a href="https://glama.ai/mcp/servers/@taylorwilsdon/google_workspace_mcp">
<img width="195" src="https://glama.ai/mcp/servers/@taylorwilsdon/google_workspace_mcp/badge" alt="Google Workspace Server MCP server" align="center"/>
</a>
<a href="https://www.pulsemcp.com/servers/taylorwilsdon-google-workspace">
<img width="456" src="https://github.com/user-attachments/assets/0794ef1a-dc1c-447d-9661-9c704d7acc9d" align="center"/>
</a>
</div>
---
**See it in action:**
<div align="center">
<video width="400" src="https://github.com/user-attachments/assets/a342ebb4-1319-4060-a974-39d202329710"></video>
</div>
---
### A quick plug for AI-Enhanced Docs
<details>
<summary>◆ <b>But why?</b></summary>
**This README was written with AI assistance, and here's why that matters**
>
> As a solo dev building open source tools, comprehensive documentation often wouldn't happen without AI help. Using agentic dev tools like **Roo** & **Claude Code** that understand the entire codebase, AI doesn't just regurgitate generic content - it extracts real implementation details and creates accurate, specific documentation.
>
> In this case, Sonnet 4 took a pass & a human (me) verified them 8/16/25.
</details>
## <span style="color:#adbcbc">Overview</span>
A production-ready MCP server that integrates all major Google Workspace services with AI assistants. It supports both single-user operation and multi-user authentication via OAuth 2.1, making it a powerful backend for custom applications. Built with FastMCP for optimal performance, featuring advanced authentication handling, service caching, and streamlined development patterns.
**Simplified Setup**: Now uses Google Desktop OAuth clients - no redirect URIs or port configuration needed!
**Maintainer Docs**: Automated release and registry publishing guide at [`docs/mcp_registry_publishing_guide.md`](docs/mcp_registry_publishing_guide.md).
## <span style="color:#adbcbc">Features</span>
<table align="center" style="width: 100%; max-width: 100%;">
<tr>
<td width="50%" valign="top">
**<span style="color:#72898f">@</span> Gmail** • **<span style="color:#72898f">≡</span> Drive** • **<span style="color:#72898f">⧖</span> Calendar** **<span style="color:#72898f">≡</span> Docs**
- Complete Gmail management, end to end coverage
- Full calendar management with advanced features
- File operations with Office format support
- Document creation, editing & comments
- Deep, exhaustive support for fine grained editing
---
**<span style="color:#72898f">≡</span> Forms** • **<span style="color:#72898f">@</span> Chat** • **<span style="color:#72898f">≡</span> Sheets** • **<span style="color:#72898f">≡</span> Slides**
- Form creation, publish settings & response management
- Space management & messaging capabilities
- Spreadsheet operations with flexible cell management
- Presentation creation, updates & content manipulation
---
**<span style="color:#72898f">◆</span> Apps Script**
- Automate cross-application workflows with custom code
- Execute existing business logic and custom functions
- Manage script projects, deployments & versions
- Debug and modify Apps Script code programmatically
- Bridge Google Workspace services through automation
</td>
<td width="50%" valign="top">
**<span style="color:#72898f">⊠</span> Authentication & Security**
- Advanced OAuth 2.0 & OAuth 2.1 support
- Automatic token refresh & session management
- Transport-aware callback handling
- Multi-user bearer token authentication
- Innovative CORS proxy architecture
---
**<span style="color:#72898f">✓</span> Tasks** • **<span style="color:#72898f">👤</span> Contacts** • **<span style="color:#72898f">◆</span> Custom Search**
- Task & task list management with hierarchy
- Contact management via People API with groups
- Programmable Search Engine (PSE) integration
</td>
</tr>
</table>
---
## Quick Start
<details>
<summary><b>Quick Reference Card</b> - Essential commands & configs at a glance</summary>
<table>
<tr><td width="33%" valign="top">
**Credentials**
```bash
export GOOGLE_OAUTH_CLIENT_ID="..."
export GOOGLE_OAUTH_CLIENT_SECRET="..."
```
[Full setup →](#credential-configuration)
</td><td width="33%" valign="top">
**Launch Commands**
```bash
uvx workspace-mcp --tool-tier core
uv run main.py --tools gmail drive
```
[More options →](#start-the-server)
</td><td width="34%" valign="top">
**Tool Tiers**
- `core` - Essential tools
- `extended` - Core + extras
- `complete` - Everything
[Details →](#tool-tiers)
</td></tr>
</table>
</details>
### 1. One-Click Claude Desktop Install (Recommended)
1. **Download:** Grab the latest `google_workspace_mcp.dxt` from the “Releases” page
2. **Install:** Double-click the file – Claude Desktop opens and prompts you to **Install**
3. **Configure:** In Claude Desktop → **Settings → Extensions → Google Workspace MCP**, paste your Google OAuth credentials
4. **Use it:** Start a new Claude chat and call any Google Workspace tool
>
**Why DXT?**
> Desktop Extensions (`.dxt`) bundle the server, dependencies, and manifest so users go from download → working MCP in **one click** – no terminal, no JSON editing, no version conflicts.
#### Required Configuration
<details>
<summary><b>Environment Variables</b> <sub><sup>← Click to configure in Claude Desktop</sup></sub></summary>
<table>
<tr><td width="50%" valign="top">
**Required**
| Variable | Purpose |
|----------|---------|
| `GOOGLE_OAUTH_CLIENT_ID` | OAuth client ID from Google Cloud |
| `GOOGLE_OAUTH_CLIENT_SECRET` | OAuth client secret |
| `OAUTHLIB_INSECURE_TRANSPORT=1` | Development only (allows `http://` redirect) |
</td><td width="50%" valign="top">
**Optional**
| Variable | Purpose |
|----------|---------|
| `USER_GOOGLE_EMAIL` | Default email for single-user auth |
| `GOOGLE_PSE_API_KEY` | API key for Custom Search |
| `GOOGLE_PSE_ENGINE_ID` | Search Engine ID for Custom Search |
| `MCP_ENABLE_OAUTH21` | Set to `true` for OAuth 2.1 support |
| `EXTERNAL_OAUTH21_PROVIDER` | Set to `true` for external OAuth flow with bearer tokens (requires OAuth 2.1) |
| `WORKSPACE_MCP_STATELESS_MODE` | Set to `true` for stateless operation (requires OAuth 2.1) |
</td></tr>
</table>
Claude Desktop stores these securely in the OS keychain; set them once in the extension pane.
</details>
---
<div align="center">
<video width="832" src="https://github.com/user-attachments/assets/83cca4b3-5e94-448b-acb3-6e3a27341d3a"></video>
</div>
---
### Prerequisites
- **Python 3.10+**
- **[uvx](https://github.com/astral-sh/uv)** (for instant installation) or [uv](https://github.com/astral-sh/uv) (for development)
- **Google Cloud Project** with OAuth 2.0 credentials
### Configuration
<details open>
<summary><b>Google Cloud Setup</b> <sub><sup>← OAuth 2.0 credentials & API enablement</sup></sub></summary>
<table>
<tr>
<td width="33%" align="center">
**1. Create Project**
```text
console.cloud.google.com
→ Create new project
→ Note project name
```
<sub>[Open Console →](https://console.cloud.google.com/)</sub>
</td>
<td width="33%" align="center">
**2. OAuth Credentials**
```text
APIs & Services → Credentials
→ Create Credentials
→ OAuth Client ID
→ Desktop Application
```
<sub>Download & save credentials</sub>
</td>
<td width="34%" align="center">
**3. Enable APIs**
```text
APIs & Services → Library
Search & enable:
Calendar, Drive, Gmail,
Docs, Sheets, Slides,
Forms, Tasks, People,
Chat, Search
```
<sub>See quick links below</sub>
</td>
</tr>
<tr>
<td colspan="3">
<details>
<summary><b>OAuth Credential Setup Guide</b> <sub><sup>← Step-by-step instructions</sup></sub></summary>
**Complete Setup Process:**
1. **Create OAuth 2.0 Credentials** - Visit [Google Cloud Console](https://console.cloud.google.com/)
- Create a new project (or use existing)
- Navigate to **APIs & Services → Credentials**
- Click **Create Credentials → OAuth Client ID**
- Choose **Desktop Application** as the application type (no redirect URIs needed!)
- Download credentials and note the Client ID and Client Secret
2. **Enable Required APIs** - In **APIs & Services → Library**
- Search for and enable each required API
- Or use the quick links below for one-click enabling
3. **Configure Environment** - Set your credentials:
```bash
export GOOGLE_OAUTH_CLIENT_ID="your-client-id"
export GOOGLE_OAUTH_CLIENT_SECRET="your-secret"
```
[Full Documentation →](https://developers.google.com/workspace/guides/auth-overview)
</details>
</td>
</tr>
</table>
<details>
<summary><b>Quick API Enable Links</b> <sub><sup>← One-click enable each Google API</sup></sub></summary>
You can enable each one by clicking the links below (make sure you're logged into the Google Cloud Console and have the correct project selected):
* [Enable Google Calendar API](https://console.cloud.google.com/flows/enableapi?apiid=calendar-json.googleapis.com)
* [Enable Google Drive API](https://console.cloud.google.com/flows/enableapi?apiid=drive.googleapis.com)
* [Enable Gmail API](https://console.cloud.google.com/flows/enableapi?apiid=gmail.googleapis.com)
* [Enable Google Docs API](https://console.cloud.google.com/flows/enableapi?apiid=docs.googleapis.com)
* [Enable Google Sheets API](https://console.cloud.google.com/flows/enableapi?apiid=sheets.googleapis.com)
* [Enable Google Slides API](https://console.cloud.google.com/flows/enableapi?apiid=slides.googleapis.com)
* [Enable Google Forms API](https://console.cloud.google.com/flows/enableapi?apiid=forms.googleapis.com)
* [Enable Google Tasks API](https://console.cloud.google.com/flows/enableapi?apiid=tasks.googleapis.com)
* [Enable Google Chat API](https://console.cloud.google.com/flows/enableapi?apiid=chat.googleapis.com)
* [Enable Google People API](https://console.cloud.google.com/flows/enableapi?apiid=people.googleapis.com)
* [Enable Google Custom Search API](https://console.cloud.google.com/flows/enableapi?apiid=customsearch.googleapis.com)
* [Enable Google Apps Script API](https://console.cloud.google.com/flows/enableapi?apiid=script.googleapis.com)
</details>
</details>
1.1. **Credentials**: See [Credential Configuration](#credential-configuration) for detailed setup options
2. **Environment Configuration**:
<details open>
<summary>◆ <b>Environment Variables</b> <sub><sup>← Configure your runtime environment</sup></sub></summary>
<table>
<tr>
<td width="33%" align="center">
**◆ Development Mode**
```bash
export OAUTHLIB_INSECURE_TRANSPORT=1
```
<sub>Allows HTTP redirect URIs</sub>
</td>
<td width="33%" align="center">
**@ Default User**
```bash
export USER_GOOGLE_EMAIL=\
your.email@gmail.com
```
<sub>Single-user authentication</sub>
</td>
<td width="34%" align="center">
**◆ Custom Search**
```bash
export GOOGLE_PSE_API_KEY=xxx
export GOOGLE_PSE_ENGINE_ID=yyy
```
<sub>Optional: Search API setup</sub>
</td>
</tr>
</table>
</details>
3. **Server Configuration**:
<details open>
<summary>◆ <b>Server Settings</b> <sub><sup>← Customize ports, URIs & proxies</sup></sub></summary>
<table>
<tr>
<td width="33%" align="center">
**◆ Base Configuration**
```bash
export WORKSPACE_MCP_BASE_URI=
http://localhost
export WORKSPACE_MCP_PORT=8000
export WORKSPACE_MCP_HOST=0.0.0.0 # Use 127.0.0.1 for localhost-only
```
<sub>Server URL & port settings</sub>
</td>
<td width="33%" align="center">
**↻ Proxy Support**
```bash
export MCP_ENABLE_OAUTH21=
true
```
<sub>Leverage multi-user OAuth2.1 clients</sub>
</td>
<td width="34%" align="center">
**@ Default Email**
```bash
export USER_GOOGLE_EMAIL=\
your.email@gmail.com
```
<sub>Skip email in auth flows in single user mode</sub>
</td>
</tr>
</table>
<details>
<summary>≡ <b>Configuration Details</b> <sub><sup>← Learn more about each setting</sup></sub></summary>
| Variable | Description | Default |
|----------|-------------|---------|
| `WORKSPACE_MCP_BASE_URI` | Base server URI (no port) | `http://localhost` |
| `WORKSPACE_MCP_PORT` | Server listening port | `8000` |
| `WORKSPACE_MCP_HOST` | Server bind host | `0.0.0.0` |
| `WORKSPACE_EXTERNAL_URL` | External URL for reverse proxy setups | None |
| `WORKSPACE_ATTACHMENT_DIR` | Directory for downloaded attachments | `~/.workspace-mcp/attachments/` |
| `GOOGLE_OAUTH_REDIRECT_URI` | Override OAuth callback URL | Auto-constructed |
| `USER_GOOGLE_EMAIL` | Default auth email | None |
</details>
</details>
### Google Custom Search Setup
<details>
<summary>◆ <b>Custom Search Configuration</b> <sub><sup>← Enable web search capabilities</sup></sub></summary>
<table>
<tr>
<td width="33%" align="center">
**1. Create Search Engine**
```text
programmablesearchengine.google.com
/controlpanel/create
→ Configure sites or entire web
→ Note your Engine ID (cx)
```
<sub>[Open Control Panel →](https://programmablesearchengine.google.com/controlpanel/create)</sub>
</td>
<td width="33%" align="center">
**2. Get API Key**
```text
developers.google.com
/custom-search/v1/overview
→ Create/select project
→ Enable Custom Search API
→ Create credentials (API Key)
```
<sub>[Get API Key →](https://developers.google.com/custom-search/v1/overview)</sub>
</td>
<td width="34%" align="center">
**3. Set Variables**
```bash
export GOOGLE_PSE_API_KEY=\
"your-api-key"
export GOOGLE_PSE_ENGINE_ID=\
"your-engine-id"
```
<sub>Configure in environment</sub>
</td>
</tr>
<tr>
<td colspan="3">
<details>
<summary>≡ <b>Quick Setup Guide</b> <sub><sup>← Step-by-step instructions</sup></sub></summary>
**Complete Setup Process:**
1. **Create Search Engine** - Visit the [Control Panel](https://programmablesearchengine.google.com/controlpanel/create)
- Choose "Search the entire web" or specify sites
- Copy the Search Engine ID (looks like: `017643444788157684527:6ivsjbpxpqw`)
2. **Enable API & Get Key** - Visit [Google Developers Console](https://console.cloud.google.com/)
- Enable "Custom Search API" in your project
- Create credentials → API Key
- Restrict key to Custom Search API (recommended)
3. **Configure Environment** - Add to your shell or `.env`:
```bash
export GOOGLE_PSE_API_KEY="AIzaSy..."
export GOOGLE_PSE_ENGINE_ID="01764344478..."
```
≡ [Full Documentation →](https://developers.google.com/custom-search/v1/overview)
</details>
</td>
</tr>
</table>
</details>
### Start the Server
> **📌 Transport Mode Guidance**: Use **streamable HTTP mode** (`--transport streamable-http`) for all modern MCP clients including Claude Code, VS Code MCP, and MCP Inspector. Stdio mode is only for clients with incomplete MCP specification support.
<details open>
<summary>▶ <b>Launch Commands</b> <sub><sup>← Choose your startup mode</sup></sub></summary>
<table>
<tr>
<td width="33%" align="center">
**▶ Legacy Mode**
```bash
uv run main.py
```
<sub>⚠️ Stdio mode (incomplete MCP clients only)</sub>
</td>
<td width="33%" align="center">
**◆ HTTP Mode (Recommended)**
```bash
uv run main.py \
--transport streamable-http
```
<sub>✅ Full MCP spec compliance & OAuth 2.1</sub>
</td>
<td width="34%" align="center">
**@ Single User**
```bash
uv run main.py \
--single-user
```
<sub>Simplified authentication</sub>
<sub>⚠️ Cannot be used with OAuth 2.1 mode</sub>
</td>
</tr>
<tr>
<td colspan="3">
<details>
<summary>◆ <b>Advanced Options</b> <sub><sup>← Tool selection, tiers & Docker</sup></sub></summary>
**▶ Selective Tool Loading**
```bash
# Load specific services only
uv run main.py --tools gmail drive calendar
uv run main.py --tools sheets docs
# Combine with other flags
uv run main.py --single-user --tools gmail
```
**🔒 Read-Only Mode**
```bash
# Requests only read-only scopes & disables write tools
uv run main.py --read-only
# Combine with specific tools or tiers
uv run main.py --tools gmail drive --read-only
uv run main.py --tool-tier core --read-only
```
Read-only mode provides secure, restricted access by:
- Requesting only `*.readonly` OAuth scopes (e.g., `gmail.readonly`, `drive.readonly`)
- Automatically filtering out tools that require write permissions at startup
- Allowing read operations: list, get, search, and export across all services
**★ Tool Tiers**
```bash
uv run main.py --tool-tier core # ● Essential tools only
uv run main.py --tool-tier extended # ◐ Core + additional
uv run main.py --tool-tier complete # ○ All available tools
```
**◆ Docker Deployment**
```bash
docker build -t workspace-mcp .
docker run -p 8000:8000 -v $(pwd):/app \
workspace-mcp --transport streamable-http
# With tool selection via environment variables
docker run -e TOOL_TIER=core workspace-mcp
docker run -e TOOLS="gmail drive calendar" workspace-mcp
```
**Available Services**: `gmail` • `drive` • `calendar` • `docs` • `sheets` • `forms` • `tasks` • `contacts` • `chat` • `search`
</details>
</td>
</tr>
</table>
</details>
### CLI Mode
The server supports a CLI mode for direct tool invocation without running the full MCP server. This is ideal for scripting, automation, and use by coding agents (Codex, Claude Code).
<details open>
<summary>▶ <b>CLI Commands</b> <sub><sup>← Direct tool execution from command line</sup></sub></summary>
<table>
<tr>
<td width="50%" align="center">
**▶ List Tools**
```bash
workspace-mcp --cli
workspace-mcp --cli list
workspace-mcp --cli list --json
```
<sub>View all available tools</sub>
</td>
<td width="50%" align="center">
**◆ Tool Help**
```bash
workspace-mcp --cli search_gmail_messages --help
```
<sub>Show parameters and documentation</sub>
</td>
</tr>
<tr>
<td width="50%" align="center">
**▶ Run with Arguments**
```bash
workspace-mcp --cli search_gmail_messages \
--args '{"query": "is:unread"}'
```
<sub>Execute tool with inline JSON</sub>
</td>
<td width="50%" align="center">
**◆ Pipe from Stdin**
```bash
echo '{"query": "is:unread"}' | \
workspace-mcp --cli search_gmail_messages
```
<sub>Pass arguments via stdin</sub>
</td>
</tr>
</table>
<details>
<summary>≡ <b>CLI Usage Details</b> <sub><sup>← Complete reference</sup></sub></summary>
**Command Structure:**
```bash
workspace-mcp --cli [command] [options]
```
**Commands:**
| Command | Description |
|---------|-------------|
| `list` (default) | List all available tools |
| `<tool_name>` | Execute the specified tool |
| `<tool_name> --help` | Show detailed help for a tool |
**Options:**
| Option | Description |
|--------|-------------|
| `--args`, `-a` | JSON string with tool arguments |
| `--json`, `-j` | Output in JSON format (for `list` command) |
| `--help`, `-h` | Show help for a tool |
**Examples:**
```bash
# List all Gmail tools
workspace-mcp --cli list | grep gmail
# Search for unread emails
workspace-mcp --cli search_gmail_messages --args '{"query": "is:unread", "max_results": 5}'
# Get calendar events for today
workspace-mcp --cli get_events --args '{"calendar_id": "primary", "time_min": "2024-01-15T00:00:00Z"}'
# Create a Drive file from a URL
workspace-mcp --cli create_drive_file --args '{"name": "doc.pdf", "source_url": "https://example.com/file.pdf"}'
# Combine with jq for processing
workspace-mcp --cli list --json | jq '.tools[] | select(.name | contains("gmail"))'
```
**Notes:**
- CLI mode uses OAuth 2.0 (same credentials as server mode)
- Authentication flows work the same way - browser opens for first-time auth
- Results are printed to stdout; errors go to stderr
- Exit code 0 on success, 1 on error
</details>
</details>
### Tool Tiers
The server organizes tools into **three progressive tiers** for simplified deployment. Choose a tier that matches your usage needs and API quota requirements.
<table>
<tr>
<td width="65%" valign="top">
#### <span style="color:#72898f">Available Tiers</span>
**<span style="color:#2d5b69">●</span> Core** (`--tool-tier core`)
Essential tools for everyday tasks. Perfect for light usage with minimal API quotas. Includes search, read, create, and basic modify operations across all services.
**<span style="color:#72898f">●</span> Extended** (`--tool-tier extended`)
Core functionality plus management tools. Adds labels, folders, batch operations, and advanced search. Ideal for regular usage with moderate API needs.
**<span style="color:#adbcbc">●</span> Complete** (`--tool-tier complete`)
Full API access including comments, headers/footers, publishing settings, and administrative functions. For power users needing maximum functionality.
</td>
<td width="35%" valign="top">
#### <span style="color:#72898f">Important Notes</span>
<span style="color:#72898f">▶</span> **Start with `core`** and upgrade as needed
<span style="color:#72898f">▶</span> **Tiers are cumulative** – each includes all previous
<span style="color:#72898f">▶</span> **Mix and match** with `--tools` for specific services
<span style="color:#72898f">▶</span> **Configuration** in `core/tool_tiers.yaml`
<span style="color:#72898f">▶</span> **Authentication** included in all tiers
</td>
</tr>
</table>
#### <span style="color:#72898f">Usage Examples</span>
```bash
# Basic tier selection
uv run main.py --tool-tier core # Start with essential tools only
uv run main.py --tool-tier extended # Expand to include management features
uv run main.py --tool-tier complete # Enable all available functionality
# Selective service loading with tiers
uv run main.py --tools gmail drive --tool-tier core # Core tools for specific services
uv run main.py --tools gmail --tool-tier extended # Extended Gmail functionality only
uv run main.py --tools docs sheets --tool-tier complete # Full access to Docs and Sheets
```
## 📋 Credential Configuration
<details open>
<summary>🔑 <b>OAuth Credentials Setup</b> <sub><sup>← Essential for all installations</sup></sub></summary>
<table>
<tr>
<td width="33%" align="center">
**🚀 Environment Variables**
```bash
export GOOGLE_OAUTH_CLIENT_ID=\
"your-client-id"
export GOOGLE_OAUTH_CLIENT_SECRET=\
"your-secret"
```
<sub>Best for production</sub>
</td>
<td width="33%" align="center">
**📁 File-based**
```bash
# Download & place in project root
client_secret.json
# Or specify custom path
export GOOGLE_CLIENT_SECRET_PATH=\
/path/to/secret.json
```
<sub>Traditional method</sub>
</td>
<td width="34%" align="center">
**⚡ .env File**
```bash
cp .env.oauth21 .env
# Edit .env with credentials
```
<sub>Best for development</sub>
</td>
</tr>
<tr>
<td colspan="3">
<details>
<summary>📖 <b>Credential Loading Details</b> <sub><sup>← Understanding priority & best practices</sup></sub></summary>
**Loading Priority**
1. Environment variables (`export VAR=value`)
2. `.env` file in project root (warning - if you run via `uvx` rather than `uv run` from the repo directory, you are spawning a standalone process not associated with your clone of the repo and it will not find your .env file without specifying it directly)
3. `client_secret.json` via `GOOGLE_CLIENT_SECRET_PATH`
4. Default `client_secret.json` in project root
**Why Environment Variables?**
- ✅ **Docker/K8s ready** - Native container support
- ✅ **Cloud platforms** - Heroku, Railway, Vercel
- ✅ **CI/CD pipelines** - GitHub Actions, Jenkins
- ✅ **No secrets in git** - Keep credentials secure
- ✅ **Easy rotation** - Update without code changes
</details>
</td>
</tr>
</table>
</details>
---
## 🧰 Available Tools
> **Note**: All tools support automatic authentication via `@require_google_service()` decorators with 30-minute service caching.
<table width="100%">
<tr>
<td width="50%" valign="top">
### 📅 **Google Calendar** <sub>[`calendar_tools.py`](gcalendar/calendar_tools.py)</sub>
| Tool | Tier | Description |
|------|------|-------------|
| `list_calendars` | **Core** | List accessible calendars |
| `get_events` | **Core** | Retrieve events with time range filtering |
| `create_event` | **Core** | Create events with attachments & reminders |
| `modify_event` | **Core** | Update existing events |
| `delete_event` | Extended | Remove events |
</td>
<td width="50%" valign="top">
### 📁 **Google Drive** <sub>[`drive_tools.py`](gdrive/drive_tools.py)</sub>
| Tool | Tier | Description |
|------|------|-------------|
| `search_drive_files` | **Core** | Search files with query syntax |
| `get_drive_file_content` | **Core** | Read file content (Office formats) |
| `get_drive_file_download_url` | **Core** | Download Drive files to local disk |
| `create_drive_file` | **Core** | Create files or fetch from URLs |
| `create_drive_folder` | **Core** | Create empty folders in Drive or shared drives |
| `import_to_google_doc` | **Core** | Import files (MD, DOCX, HTML, etc.) as Google Docs |
| `share_drive_file` | **Core** | Share file with users/groups/domains/anyone |
| `get_drive_shareable_link` | **Core** | Get shareable links for a file |
| `list_drive_items` | Extended | List folder contents |
| `copy_drive_file` | Extended | Copy existing files (templates) with optional renaming |
| `update_drive_file` | Extended | Update file metadata, move between folders |
| `batch_share_drive_file` | Extended | Share file with multiple recipients |
| `update_drive_permission` | Extended | Modify permission role |
| `remove_drive_permission` | Extended | Revoke file access |
| `transfer_drive_ownership` | Extended | Transfer file ownership to another user |
| `set_drive_file_permissions` | Extended | Set link sharing and file-level sharing settings |
| `get_drive_file_permissions` | Complete | Get detailed file permissions |
| `check_drive_file_public_access` | Complete | Check public sharing status |
</td>
</tr>
<tr>
<tr>
<td width="50%" valign="top">
### 📧 **Gmail** <sub>[`gmail_tools.py`](gmail/gmail_tools.py)</sub>
| Tool | Tier | Description |
|------|------|-------------|
| `search_gmail_messages` | **Core** | Search with Gmail operators |
| `get_gmail_message_content` | **Core** | Retrieve message content |
| `get_gmail_messages_content_batch` | **Core** | Batch retrieve message content |
| `send_gmail_message` | **Core** | Send emails |
| `get_gmail_thread_content` | Extended | Get full thread content |
| `modify_gmail_message_labels` | Extended | Modify message labels |
| `list_gmail_labels` | Extended | List available labels |
| `manage_gmail_label` | Extended | Create/update/delete labels |
| `draft_gmail_message` | Extended | Create drafts |
| `get_gmail_threads_content_batch` | Complete | Batch retrieve thread content |
| `batch_modify_gmail_message_labels` | Complete | Batch modify labels |
| `start_google_auth` | Complete | Legacy OAuth 2.0 auth (disabled when OAuth 2.1 is enabled) |
<details>
<summary><b>📎 Email Attachments</b> <sub><sup>← Send emails with files</sup></sub></summary>
Both `send_gmail_message` and `draft_gmail_message` support attachments via two methods:
**Option 1: File Path** (local server only)
```python
attachments=[{"path": "/path/to/report.pdf"}]
```
Reads file from disk, auto-detects MIME type. Optional `filename` override.
**Option 2: Base64 Content** (works everywhere)
```python
attachments=[{
"filename": "report.pdf",
"content": "JVBERi0xLjQK...", # base64-encoded
"mime_type": "application/pdf" # optional
}]
```
**⚠️ Centrally Hosted Servers**: When the MCP server runs remotely (cloud, shared instance), it cannot access your local filesystem. Use **Option 2** with base64-encoded content. Your MCP client must encode files before sending.
</details>
<details>
<summary><b>📥 Downloaded Attachment Storage</b> <sub><sup>← Where downloaded files are saved</sup></sub></summary>
When downloading Gmail attachments (`get_gmail_attachment_content`) or Drive files (`get_drive_file_download_url`), files are saved to a persistent local directory rather than a temporary folder in the working directory.
**Default location:** `~/.workspace-mcp/attachments/`
Files are saved with their original filename plus a short UUID suffix for uniqueness (e.g., `invoice_a1b2c3d4.pdf`). In **stdio mode**, the tool returns the absolute file path for direct filesystem access. In **HTTP mode**, it returns a download URL via the `/attachments/{file_id}` endpoint.
To customize the storage directory:
```bash
export WORKSPACE_ATTACHMENT_DIR="/path/to/custom/dir"
```
Saved files expire after 1 hour and are cleaned up automatically.
</details>
</td>
<td width="50%" valign="top">
### 📝 **Google Docs** <sub>[`docs_tools.py`](gdocs/docs_tools.py)</sub>
| Tool | Tier | Description |
|------|------|-------------|
| `get_doc_content` | **Core** | Extract document text |
| `create_doc` | **Core** | Create new documents |
| `modify_doc_text` | **Core** | Modify document text (formatting + links) |
| `search_docs` | Extended | Find documents by name |
| `find_and_replace_doc` | Extended | Find and replace text |
| `list_docs_in_folder` | Extended | List docs in folder |
| `insert_doc_elements` | Extended | Add tables, lists, page breaks |
| `update_paragraph_style` | Extended | Apply heading styles, lists (bulleted/numbered with nesting), and paragraph formatting |
| `get_doc_as_markdown` | Extended | Export document as formatted Markdown with optional comments |
| `insert_doc_image` | Complete | Insert images from Drive/URLs |
| `update_doc_headers_footers` | Complete | Modify headers and footers |
| `batch_update_doc` | Complete | Execute multiple operations |
| `inspect_doc_structure` | Complete | Analyze document structure |
| `export_doc_to_pdf` | Extended | Export document to PDF |
| `create_table_with_data` | Complete | Create data tables |
| `debug_table_structure` | Complete | Debug table issues |
| `*_document_comments` | Complete | Read, Reply, Create, Resolve |
</td>
</tr>
<tr>
<td width="50%" valign="top">
### 📊 **Google Sheets** <sub>[`sheets_tools.py`](gsheets/sheets_tools.py)</sub>
| Tool | Tier | Description |
|------|------|-------------|
| `read_sheet_values` | **Core** | Read cell ranges |
| `modify_sheet_values` | **Core** | Write/update/clear cells |
| `create_spreadsheet` | **Core** | Create new spreadsheets |
| `list_spreadsheets` | Extended | List accessible spreadsheets |
| `get_spreadsheet_info` | Extended | Get spreadsheet metadata |
| `format_sheet_range` | Extended | Apply colors, number formats, text wrapping, alignment, bold/italic, font size |
| `create_sheet` | Complete | Add sheets to existing files |
| `*_sheet_comment` | Complete | Read/create/reply/resolve comments |
</td>
<td width="50%" valign="top">
### 🖼️ **Google Slides** <sub>[`slides_tools.py`](gslides/slides_tools.py)</sub>
| Tool | Tier | Description |
|------|------|-------------|
| `create_presentation` | **Core** | Create new presentations |
| `get_presentation` | **Core** | Retrieve presentation details |
| `batch_update_presentation` | Extended | Apply multiple updates |
| `get_page` | Extended | Get specific slide information |
| `get_page_thumbnail` | Extended | Generate slide thumbnails |
| `*_presentation_comment` | Complete | Read/create/reply/resolve comments |
</td>
</tr>
<tr>
<td width="50%" valign="top">
### 📝 **Google Forms** <sub>[`forms_tools.py`](gforms/forms_tools.py)</sub>
| Tool | Tier | Description |
|------|------|-------------|
| `create_form` | **Core** | Create new forms |
| `get_form` | **Core** | Retrieve form details & URLs |
| `set_publish_settings` | Complete | Configure form settings |
| `get_form_response` | Complete | Get individual responses |
| `list_form_responses` | Extended | List all responses with pagination |
| `batch_update_form` | Complete | Apply batch updates (questions, settings) |
</td>
<td width="50%" valign="top">
### ✓ **Google Tasks** <sub>[`tasks_tools.py`](gtasks/tasks_tools.py)</sub>
| Tool | Tier | Description |
|------|------|-------------|
| `list_tasks` | **Core** | List tasks with filtering |
| `get_task` | **Core** | Retrieve task details |
| `create_task` | **Core** | Create tasks with hierarchy |
| `update_task` | **Core** | Modify task properties |
| `delete_task` | Extended | Remove tasks |
| `move_task` | Complete | Reposition tasks |
| `clear_completed_tasks` | Complete | Hide completed tasks |
| `*_task_list` | Complete | List/get/create/update/delete task lists |
</td>
</tr>
<tr>
<td width="50%" valign="top">
### 👤 **Google Contacts** <sub>[`contacts_tools.py`](gcontacts/contacts_tools.py)</sub>
| Tool | Tier | Description |
|------|------|-------------|
| `search_contacts` | **Core** | Search contacts by name, email, phone |
| `get_contact` | **Core** | Retrieve detailed contact info |
| `list_contacts` | **Core** | List contacts with pagination |
| `create_contact` | **Core** | Create new contacts |
| `update_contact` | Extended | Update existing contacts |
| `delete_contact` | Extended | Delete contacts |
| `list_contact_groups` | Extended | List contact groups/labels |
| `get_contact_group` | Extended | Get group details with members |
| `batch_*_contacts` | Complete | Batch create/update/delete contacts |
| `*_contact_group` | Complete | Create/update/delete contact groups |
| `modify_contact_group_members` | Complete | Add/remove contacts from groups |
</td>
</tr>
<tr>
<td width="50%" valign="top">
### 💬 **Google Chat** <sub>[`chat_tools.py`](gchat/chat_tools.py)</sub>
| Tool | Tier | Description |
|------|------|-------------|
| `list_spaces` | Extended | List chat spaces/rooms |
| `get_messages` | **Core** | Retrieve space messages |
| `send_message` | **Core** | Send messages to spaces |
| `search_messages` | **Core** | Search across chat history |
| `create_reaction` | **Core** | Add emoji reaction to a message |
| `download_chat_attachment` | Extended | Download attachment from a chat message |
</td>
<td width="50%" valign="top">
### 🔍 **Google Custom Search** <sub>[`search_tools.py`](gsearch/search_tools.py)</sub>
| Tool | Tier | Description |
|------|------|-------------|
| `search_custom` | **Core** | Perform web searches |
| `get_search_engine_info` | Complete | Retrieve search engine metadata |
| `search_custom_siterestrict` | Extended | Search within specific domains |
</td>
</tr>
<tr>
<td colspan="2" valign="top">
### **Google Apps Script** <sub>[`apps_script_tools.py`](gappsscript/apps_script_tools.py)</sub>
| Tool | Tier | Description |
|------|------|-------------|
| `list_script_projects` | **Core** | List accessible Apps Script projects |
| `get_script_project` | **Core** | Get complete project with all files |
| `get_script_content` | **Core** | Retrieve specific file content |
| `create_script_project` | **Core** | Create new standalone or bound project |
| `update_script_content` | **Core** | Update or create script files |
| `run_script_function` | **Core** | Execute function with parameters |
| `create_deployment` | Extended | Create new script deployment |
| `list_deployments` | Extended | List all project deployments |
| `update_deployment` | Extended | Update deployment configuration |
| `delete_deployment` | Extended | Remove deployment |
| `list_script_processes` | Extended | View recent executions and status |
</td>
</tr>
</table>
**Tool Tier Legend:**
- <span style="color:#2d5b69">•</span> **Core**: Essential tools for basic functionality • Minimal API usage • Getting started
- <span style="color:#72898f">•</span> **Extended**: Core tools + additional features • Regular usage • Expanded capabilities
- <span style="color:#adbcbc">•</span> **Complete**: All available tools including advanced features • Power users • Full API access
---
### Connect to Claude Desktop
The server supports two transport modes:
#### Stdio Mode (Legacy - For Clients with Incomplete MCP Support)
> **⚠️ Important**: Stdio mode is a **legacy fallback** for clients that don't properly implement the MCP specification with OAuth 2.1 and streamable HTTP support. **Claude Code and other modern MCP clients should use streamable HTTP mode** (`--transport streamable-http`) for proper OAuth flow and multi-user support.
In general, you should use the one-click DXT installer package for Claude Desktop.
If you are unable to for some reason, you can configure it manually via `claude_desktop_config.json`
**Manual Claude Configuration (Alternative)**
<details>
<summary>📝 <b>Claude Desktop JSON Config</b> <sub><sup>← Click for manual setup instructions</sup></sub></summary>
1. Open Claude Desktop Settings → Developer → Edit Config
- **macOS**: `~/Library/Application Support/Claude/claude_desktop_config.json`
- **Windows**: `%APPDATA%\Claude\claude_desktop_config.json`
2. Add the server configuration:
```json
{
"mcpServers": {
"google_workspace": {
"command": "uvx",
"args": ["workspace-mcp"],
"env": {
"GOOGLE_OAUTH_CLIENT_ID": "your-client-id",
"GOOGLE_OAUTH_CLIENT_SECRET": "your-secret",
"OAUTHLIB_INSECURE_TRANSPORT": "1"
}
}
}
}
```
</details>
### Connect to LM Studio
Add a new MCP server in LM Studio (Settings → MCP Servers) using the same JSON format:
```json
{
"mcpServers": {
"google_workspace": {
"command": "uvx",
"args": ["workspace-mcp"],
"env": {
"GOOGLE_OAUTH_CLIENT_ID": "your-client-id",
"GOOGLE_OAUTH_CLIENT_SECRET": "your-secret",
"OAUTHLIB_INSECURE_TRANSPORT": "1",
}
}
}
}
```
### 2. Advanced / Cross-Platform Installation
If you’re developing, deploying to servers, or using another MCP-capable client, keep reading.
#### Instant CLI (uvx)
<details open>
<summary>⚡ <b>Quick Start with uvx</b> <sub><sup>← No installation required!</sup></sub></summary>
```bash
# Requires Python 3.10+ and uvx
# First, set credentials (see Credential Configuration above)
uvx workspace-mcp --tool-tier core # or --tools gmail drive calendar
```
> **Note**: Configure [OAuth credentials](#credential-configuration) before running. Supports environment variables, `.env` file, or `client_secret.json`.
</details>
### Local Development Setup
<details open>
<summary>🛠️ <b>Developer Workflow</b> <sub><sup>← Install deps, lint, and test</sup></sub></summary>
```bash
# Install everything needed for linting, tests, and releas | text/markdown | null | Taylor Wilsdon <taylor@taylorwilsdon.com> | null | null | null | mcp, google, workspace, llm, ai, claude, model, context, protocol, server | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.11",
"Programming ... | [] | null | null | >=3.10 | [] | [] | [] | [
"fastapi>=0.115.12",
"fastmcp>=2.14.4",
"google-api-python-client>=2.168.0",
"google-auth-httplib2>=0.2.0",
"google-auth-oauthlib>=1.2.2",
"httpx>=0.28.1",
"py-key-value-aio>=0.3.0",
"pyjwt>=2.10.1",
"python-dotenv>=1.1.0",
"pyyaml>=6.0.2",
"cryptography>=45.0.0",
"py-key-value-aio[valkey]>=0.... | [] | [] | [] | [
"Homepage, https://workspacemcp.com",
"Repository, https://github.com/taylorwilsdon/google_workspace_mcp",
"Documentation, https://github.com/taylorwilsdon/google_workspace_mcp#readme",
"Issues, https://github.com/taylorwilsdon/google_workspace_mcp/issues",
"Changelog, https://github.com/taylorwilsdon/googl... | twine/6.2.0 CPython/3.11.13 | 2026-02-19T15:05:45.063389 | workspace_mcp-1.12.0.tar.gz | 269,132 | 41/75/db75c18b31668408a71311c78bfdc56647a95f655860a5832cb1fdb64ca8/workspace_mcp-1.12.0.tar.gz | source | sdist | null | false | 3617c9f5cfb3aa6ebbaf78c8e759b58a | 00433094f4b0d5fa18fac61a16cc246f4ea1db55889b6ca6e6575eae913bd198 | 4175db75c18b31668408a71311c78bfdc56647a95f655860a5832cb1fdb64ca8 | MIT | [
"LICENSE"
] | 9,855 |
2.4 | scattered | 0.0.1 | 3D scatterplots are useless, but fun | # scattered: a composable library for 3D scatterplots
*3D scatterplots probably suck, but they're much more fun than regular scatterplots!*
> [!CAUTION]
> This project is as Work-In-Progress as it gets.
<img width="863" alt="image" src="https://github.com/user-attachments/assets/7e63c09b-90ac-4c23-abcd-69e559e5dcce" />
The basic idea is:
- arrow/dataframe as input (with 'x', 'y', 'z' columns)
- minimal dependencies & small bundle size
- webgpu rendering
- javascript library (npm), jupyter widget (pypi), web page (like [quak](https://github.com/manzt/quak))
## usage
```typescript
import * as sctrd from "scattered";
const c = sctrd.display("https://raw.githubusercontent.com/dvdkouril/sample-3d-scatterplot-data/main/penguins.arrow");
let appEl = document.querySelector('#app');
if (c) {
appEl.appendChild(c);
}
```
## about
This project is developed by David Kouřil ([web](https://www.davidkouril.com),
[bsky](https://bsky.app/profile/dvdkouril.xyz)).
### goals
1. demonstrate composability principles
2. learn a bit of webgpu
- just following https://webgpufundamentals.org/ for now
### name
scatter plot -> scatter 3D, scatter3rd -> scatter3d/scattered
### related and inspo:
- https://matplotlib.org/stable/gallery/mplot3d/scatter3d.html
- https://plotly.com/python/3d-scatter-plots/
- https://jupyter-scatter.dev (i don't think there's 3D option)
- https://abdenlab.org/eigen-tour/ (repo: https://github.com/abdenlab/eigen-tour)
- https://projector.tensorflow.org
## development
The repository very much follows the structure of [quak](https://github.com/manzt/quak).
| text/markdown | null | David Kouřil <david.kouril@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"anywidget>=0.9.21",
"pandas>=2.3.3",
"pyarrow>=22.0.0"
] | [] | [] | [] | [] | uv/0.8.3 | 2026-02-19T15:05:35.455019 | scattered-0.0.1.tar.gz | 127,898 | c9/1d/a0ff1866c7923fa9b710675763ea7f8c09f0d31e268ff8dcd6c19b90c97d/scattered-0.0.1.tar.gz | source | sdist | null | false | b175a20a35ce7988759e635cbe05b462 | 346b002b32a237def4c312483abb882edf4a606ff1bc30bd1c0c757f404f3e39 | c91da0ff1866c7923fa9b710675763ea7f8c09f0d31e268ff8dcd6c19b90c97d | null | [] | 204 |
2.4 | hippotorch | 0.4.1 | Differentiable episodic memory for reinforcement learning. | # hippotorch
[](https://pypi.org/project/hippotorch/)
[](https://github.com/domezsolt/hippotorch/actions/workflows/workflow.yml)
[](https://github.com/domezsolt/hippotorch/actions/workflows/workflow.yml)
> **Differentiable episodic memory for reinforcement learning. Retrieves what matters. Forgets what doesn't.**
[Changelog](CHANGELOG.md)
Hippotorch is a drop-in upgrade for replay buffers. It keeps experiences in a learnable memory so agents can remember rare successes, connect distant cause and effect, and transfer knowledge between similar worlds. Under the hood it uses reward-aware contrastive learning, but you mostly interact with a friendly API.
---
## Highlights
- **Memory that adapts with you.** Dual encoders organize episodes by usefulness instead of mere recency.
- **Semantic + uniform sampling.** A single buffer can surface hard-to-find wins while still covering the full state space.
- **Production-friendly extras.** Hugging Face Hub export, FAISS retrieval, Gymnasium wrappers, and health reports ship in the box.
- **Batteries included.** Dozens of scripts and docs show exactly how to benchmark, visualize, and share results.
If you already converge with a plain replay buffer, keep it. Hippotorch shines when agents forget early lessons, face sparse rewards, or operate in partially observed environments.
---
## Installation
```bash
pip install hippotorch # minimal setup
pip install hippotorch[faiss] # fast nearest-neighbor retrieval
pip install hippotorch[envs] # Gymnasium helpers + examples
pip install hippotorch[hub] # Hugging Face Hub + safetensors
pip install hippotorch[umap] # projector UMAP export
```
Requirements: Python ≥3.9, PyTorch ≥2.0
---
## Quick Tour
Create an encoder + memory, add episodes, then mix semantic and uniform samples:
```python
import torch
from hippotorch import Episode, DualEncoder, MemoryStore, HippocampalReplayBuffer
state_dim, action_dim = 4, 1
encoder = DualEncoder(input_dim=state_dim + action_dim + 1, embed_dim=128)
memory = MemoryStore(embed_dim=128, capacity=50_000)
buffer = HippocampalReplayBuffer(memory=memory, encoder=encoder, mixture_ratio=0.3)
states = torch.randn(32, state_dim)
actions = torch.randn(32, action_dim)
rewards = torch.randn(32)
buffer.add_episode(Episode(states=states, actions=actions, rewards=rewards))
# Query-aware sampling
query_state = torch.cat([states[0], torch.zeros(action_dim), rewards[:1]])
batch = buffer.sample(batch_size=64, query_state=query_state, top_k=5)
# Sleep/consolidate occasionally
metrics = buffer.consolidate(steps=50, batch_size=64, report_quality=True)
print(metrics["loss"])
```
Rolling with Stable Baselines 3 or Gymnasium? Wrap your existing replay buffer with `SB3ReplayBufferWrapper` or the `HippotorchMemoryWrapper` and keep the rest of your pipeline untouched.
Need hyperparameter guidance? See `docs/diagnostics.md` for health checks and `docs/curriculum.md` for training tips.
---
## Everyday Tools
### Recall While Acting
- Use the lightweight read API: `from hippotorch import query`.
- Pipe `query(..., top_k=5)` results into policies or logging code.
- Gymnasium adapter emits dict observations so SB3 policies can consume retrieval features alongside pixels.
- Examples: `examples/query_inference_demo.py`, `examples/minigrid_memory_wrapper.py`.
### Portable Brains
- Share trained memories with `push_memory_to_hub` / `load_memory_from_hub`.
- Choose local folders for offline passes or Hugging Face Hub for team-wide reuse.
- `scripts/hub_roundtrip_smoke.py` is a 30-second sanity check.
- Docs: `docs/hub.md`.
### Glass-Box Diagnostics
- `buffer.health_report()` returns retrievability, staleness, collapse indicators, and alignment scores.
- Log with `report.to_tensorboard(writer, step)` or `report.to_wandb(run)`.
- See `docs/diagnostics.md` for visuals.
### Batch Retrieval for Low Latency
- `buffer.query_batch(query_vecs, top_k=K)` handles `[B,T,D]` tensors in one go.
- Matches single-query results without looping Python.
- Works with both torch and FAISS backends.
---
## Ready-to-Run Samples
Pick a script, set a seed, and you get a reproducible snapshot:
- **Benchmarks & diagnostics**
- Retrieval perf: `python scripts/bench_retrieval.py --sizes 10000 100000`
- Visualization: `python scripts/export_projector_embeddings.py --snapshot run.pt`
- Retrieval heatmap: `python scripts/retrieval_heatmap.py --memory-checkpoint ...`
- **Environments**
- CartPole smoke: `bash scripts/quick_cartpole.sh`
- Corridor curriculum/oracle: `bash scripts/corridor_curriculum.sh`, `bash scripts/corridor_oracle_zn.sh`
- MiniGrid sweeps: `python scripts/minigrid_memory_benchmark.py --steps 8000 --seeds 3`
- Intrinsic curiosity example: `python -m examples.intrinsic_demo --episodes 20`
- **Ablations & studies**
- Rank-weighted consolidation: `bash scripts/run_rank_ablation.sh`
- Consolidation micro bench: `bash scripts/run_consolidation_micro.sh`
- Visual MiniGrid clustering: `python -m examples.minigrid_visual --steps 2000`
All scripts keep runtime under a couple of minutes unless stated otherwise. Longer jobs (corridor oracle full run, curriculum sweeps) note their expected duration in the script header.
---
## Learn More
- [docs/benchmarks.md](docs/benchmarks.md) – retrieval setups, FAISS parity, and profiling tips.
- [docs/curriculum.md](docs/curriculum.md) – how to stage corridor tasks and measure regret.
- [docs/usage.md](docs/usage.md) – wrappers, segmenters, and rollout recipes.
- [docs/hub.md](docs/hub.md) – how to move memories between machines or teammates.
Problems or ideas? File an issue, open a discussion, or send a PR.
| text/markdown | Döme Zsolt | null | null | null | null | reinforcement-learning, episodic-memory, pytorch, replay-buffer, rl | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
... | [] | null | null | >=3.9 | [] | [] | [] | [
"torch>=2.0",
"numpy>=1.21",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"black>=23.7; extra == \"dev\"",
"ruff>=0.1.7; extra == \"dev\"",
"isort>=5.12; extra == \"dev\"",
"mypy>=1.7; extra == \"dev\"",
"pre-commit>=3.5; extra == \"dev\"",
"gymnasium==0.28.1; extra == \"e... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:05:27.055796 | hippotorch-0.4.1.tar.gz | 54,407 | e9/6d/017a9f3229696c5e73b0c4cb275fdfc999b37d1b0f2b2c20da596ff43648/hippotorch-0.4.1.tar.gz | source | sdist | null | false | 128d1ba3b122eec83a65a82ada3c9db5 | 33b02ca347c75c679682da6ff538d121daf1acfce529d56672f09b5176a7faaf | e96d017a9f3229696c5e73b0c4cb275fdfc999b37d1b0f2b2c20da596ff43648 | null | [
"LICENSE"
] | 214 |
2.4 | pathsim | 0.17.2 | A differentiable block based hybrid system simulation framework. | <p align="center">
<img src="https://raw.githubusercontent.com/pathsim/pathsim/master/docs/source/logos/pathsim_logo.png" width="300" alt="PathSim Logo" />
</p>
<p align="center">
<strong>A block-based time-domain system simulation framework in Python</strong>
</p>
<p align="center">
<a href="https://doi.org/10.21105/joss.08158"><img src="https://joss.theoj.org/papers/10.21105/joss.08158/status.svg" alt="DOI"></a>
<a href="https://pysimhub.io/projects/pathsim"><img src="https://pysimhub.io/badge.svg" alt="PySimHub"></a>
<a href="https://pypi.org/project/pathsim/"><img src="https://img.shields.io/pypi/v/pathsim" alt="PyPI"></a>
<a href="https://anaconda.org/conda-forge/pathsim"><img src="https://img.shields.io/conda/vn/conda-forge/pathsim" alt="Conda"></a>
<img src="https://img.shields.io/github/license/pathsim/pathsim" alt="License">
<img src="https://img.shields.io/github/v/release/pathsim/pathsim" alt="Release">
<img src="https://img.shields.io/pypi/dw/pathsim" alt="Downloads">
<a href="https://codecov.io/gh/pathsim/pathsim"><img src="https://codecov.io/gh/pathsim/pathsim/branch/master/graph/badge.svg" alt="Coverage"></a>
</p>
<p align="center">
<a href="https://pathsim.org">Homepage</a> •
<a href="https://docs.pathsim.org">Documentation</a> •
<a href="https://view.pathsim.org">PathView Editor</a> •
<a href="https://github.com/sponsors/milanofthe">Sponsor</a>
</p>
---
PathSim lets you model and simulate complex dynamical systems using an intuitive block diagram approach. Connect sources, integrators, functions, and scopes to build continuous-time, discrete-time, or hybrid systems.
Minimal dependencies: just `numpy`, `scipy`, and `matplotlib`.
## Features
- **Hot-swappable** — modify blocks and solvers during simulation
- **Stiff solvers** — implicit methods (BDF, ESDIRK) for challenging systems
- **Event handling** — zero-crossing detection for hybrid systems
- **Hierarchical** — nest subsystems for modular designs
- **Extensible** — subclass `Block` to create custom components
## Install
```bash
pip install pathsim
```
or with conda:
```bash
conda install conda-forge::pathsim
```
## Quick Example
```python
from pathsim import Simulation, Connection
from pathsim.blocks import Integrator, Amplifier, Adder, Scope
# Damped harmonic oscillator: x'' + 0.5x' + 2x = 0
int_v = Integrator(5) # velocity, v0=5
int_x = Integrator(2) # position, x0=2
amp_c = Amplifier(-0.5) # damping
amp_k = Amplifier(-2) # spring
add = Adder()
scp = Scope()
sim = Simulation(
blocks=[int_v, int_x, amp_c, amp_k, add, scp],
connections=[
Connection(int_v, int_x, amp_c),
Connection(int_x, amp_k, scp),
Connection(amp_c, add),
Connection(amp_k, add[1]),
Connection(add, int_v),
],
dt=0.05
)
sim.run(30)
scp.plot()
```
## PathView
[PathView](https://view.pathsim.org) is the graphical editor for PathSim — design systems visually and export to Python.
## Learn More
- [Documentation](https://docs.pathsim.org) — tutorials, examples, and API reference
- [Homepage](https://pathsim.org) — overview and getting started
- [Contributing](https://docs.pathsim.org/pathsim/latest/contributing) — how to contribute
## Citation
If you use PathSim in research, please cite:
```bibtex
@article{Rother2025,
author = {Rother, Milan},
title = {PathSim - A System Simulation Framework},
journal = {Journal of Open Source Software},
year = {2025},
volume = {10},
number = {109},
pages = {8158},
doi = {10.21105/joss.08158}
}
```
## License
MIT
| text/markdown | null | Milan Rother <milan.rother@gmx.de> | null | null | MIT | simulation, differentiable, hybrid systems | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy>=1.15",
"matplotlib>=3.1",
"scipy>=1.2",
"scikit-rf; extra == \"rf\"",
"pytest; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"pytest-xdist; extra == \"test\"",
"FMPy; extra == \"test\"",
"scikit-rf; extra == \"test\"",
"FMPy; extra == \"fmi\""
] | [] | [] | [] | [
"Homepage, https://github.com/pathsim/pathsim",
"documentation, https://pathsim.readthedocs.io/en/latest/"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-19T15:05:09.275718 | pathsim-0.17.2.tar.gz | 7,497,057 | d7/67/4460e2dea68a7c7653d1432d58d769eb994cfdf3f45910d7e7c3d1ad875d/pathsim-0.17.2.tar.gz | source | sdist | null | false | 3af506a338d60e19c40a8a359d4fbd3c | f85ad55f0bb633d54d262348be9c60ceb5c3acf978773a1b317bd2197a032af8 | d7674460e2dea68a7c7653d1432d58d769eb994cfdf3f45910d7e7c3d1ad875d | null | [
"LICENSE.txt"
] | 300 |
2.4 | netbox-docker-plugin | 2.10.0 | Manage Docker with Netbox & style. | # Netbox Docker Plugin
[](https://github.com/SaaShup/netbox-docker-plugin/actions/workflows/main_ci.yml)
Manage Docker with Netbox & style. Made to work with [netbox-docker-agent](https://github.com/SaaShup/netbox-docker-agent).

## How does it work?
```mermaid
sequenceDiagram
Netbox->>Agent: Change (Webhook)
Agent->>Docker API: Request (HTTP)
Docker API->>Agent: Response (HTTP)
Agent->>Netbox: Feedback (Callback)
```
Once the plugin and webhooks are installed, you can:
1. Create hosts that point to
[agents](https://github.com/SaaShup/netbox-docker-agent) you had installed
2. Retrieve informations from Docker API with the help of the agent
3. Create containers on host with an image, expose ports, add env variables and
labels, mount volumes, set networks.
4. Manage the container status, start, stop, restart.
## Installation
You can follow [the official plugins installation
instructions](https://docs.netbox.dev/en/stable/plugins/#installing-plugins).
If needed, source your Netbox's virtual environment and install the plugin like
a package. We assume [you have already installed
Netbox](https://docs.netbox.dev/en/stable/installation/) and its source code are
in `/opt/netbox`:
```bash
cd /opt/netbox
python3 -m venv venv # if virtual env was not created before
source /opt/netbox/venv/bin/activate
pip install netbox-docker-plugin
```
Enable the plugin in the `/opt/netbox/netbox/netbox/configuration.py` file:
```python
PLUGINS = [
'netbox_docker_plugin',
]
```
Then, run migrations:
```bash
cd /opt/netbox
python3 netbox/manage.py migrate
```
> [!IMPORTANT]
> In order to the communication between your Netbox instance and [the Agent](https://github.com/SaaShup/netbox-docker-agent)
> works, the plugin will check if webhooks to agents are
> presents on each migration phase.
> If not, then the plugin will automatically install webhooks configuration in
> your Netbox instance.
### Alternative
Another way to install Netbox is to use the [Official netbox-docker
project](https://github.com/netbox-community/netbox-docker).
With this alternate way, you can [customize your Netbox image](https://github.com/netbox-community/netbox-docker/wiki/Using-Netbox-Plugins) and migrations will be
automatically execute each time you restart the container.
## Contribute
### Install our development environment
Requirements:
* Python 3.11
* PostgreSQL 15 [Official Netbox doc](https://github.com/netbox-community/netbox/blob/master/docs/installation/1-postgresql.md)
- user: netbox (with database creation right)
- password: secret
- database: netbox
- port: 5432
* Redis 7.2
- port: 6379
Set a PROJECT variable :
```
PROJECT="/project/netbox"
```
Create a project directory `$PROJECT`:
```bash
mkdir $PROJECT
```
Go inside your project directory, clone this repository and the Netbox repository:
```bash
cd $PROJECT
git clone git@github.com:SaaShup/netbox-docker-plugin.git
git clone git@github.com:netbox-community/netbox.git
```
Create your venv and activate it:
```bash
python -m venv venv
source venv/bin/activate
```
Install netbox-docker-plugin dependencies:
```bash
cd $PROJECT/netbox-docker-plugin
pip install -e .
```
Configure Netbox and install Netbox dependencies:
```bash
cd $PROJECT/netbox
cp $PROJECT/netbox-docker-plugin/netbox_configuration/configuration_dev.py $PROJECT/netbox/netbox/netbox/configuration.py
pip install -r requirements.txt
```
Run database migrations:
```bash
cd $PROJECT/netbox
python3 netbox/manage.py migrate
```
Create a Netbox super user:
```bash
cd $PROJECT/netbox
python3 netbox/manage.py createsuperuser
```
Start Netbox instance:
```bash
cd $PROJECT/netbox
python3 netbox/manage.py runserver 0.0.0.0:8000 --insecure
```
Visit http://localhost:8000/
### Run tests
After installing your development environment, you can run the tests plugin
(you don't need to start the Netbox instance):
```bash
cd $PROJECT/netbox
python3 -m pip install requests_mock
python3 netbox/manage.py test netbox_docker_plugin.tests --keepdb -v 2
```
With code coverage, install [coverage.py](https://coverage.readthedocs.io/en/7.3.2/) and use it:
```bash
cd $PROJECT/netbox
python3 -m pip install coverage
```
Then run the test with coverage.py and print the report:
```bash
cd $PROJECT/netbox
coverage run --include='*/netbox_docker_plugin/*' netbox/manage.py test netbox_docker_plugin.tests --keepdb -v 2
coverage report -m
```
# Hosting
Check https://saashup.com for more information.
| text/markdown | null | Vincent Simonin <vincent@saashup.com>, David Delassus <david.jose.delassus@gmail.com> | null | null | null | netbox, netbox-plugin, docker | [
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/SaaShup/netbox-docker-plugin",
"Bug Tracker, https://github.com/SaaShup/netbox-docker-plugin/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:04:37.901580 | netbox_docker_plugin-2.10.0.tar.gz | 49,044 | c3/14/09d3c49859773525c1e909fcc1df767e4f69f3966aa1424a701b86a84a32/netbox_docker_plugin-2.10.0.tar.gz | source | sdist | null | false | 93700c41cbf0f9b1043b3d4fc085ddc5 | c4348b80c50b94ecc997499590eb298eaf5e8a70162ba7bbcc20fcbe56842f8e | c31409d3c49859773525c1e909fcc1df767e4f69f3966aa1424a701b86a84a32 | null | [
"LICENSE"
] | 187 |
2.4 | cmdbox | 0.7.5.1 | cmdbox: It is a command line application with a plugin mechanism. | # cmdbox (Command Development Application)
- It is a command development application with a plugin mechanism.
- Documentation is [here](https://hamacom2004jp.github.io/cmdbox/).
- With cmdbox, you can easily implement commands with complex options.
- The implemented commands can be called from the CLI / RESTAPI / Web / Edge screen.
- The implemented commands can be executed on a remote server via redis.

# Install
- Install cmdbox with the following command.
- Also install the docker version of the redis server.
```bash
docker run -p 6379:6379 --name redis -e REDIS_PASSWORD=password -it ubuntu/redis:latest
pip install cmdbox
cmdbox -v
```
- When using SAML in web mode, install the modules with dependencies.
```bash
pip install cmdbox[saml]
apt-get install -y pkg-config libxml2-dev libxmlsec1-dev libxmlsec1-openssl build-essential libopencv-dev
```
- When using agent mode, install the modules with dependencies.
```bash
pip install "pydantic>=2.0.0,<3.0.0"
pip install "fastmcp>=2.14.0" "mcp>=1.10.0,<2.0.0"
pip install "google-adk>=1.21.0" "litellm"
pip install "a2a-sdk>=0.3.4,<0.4.0"
pip install "transformers>=4.48.0" "sentence-transformers" "sqlite_vec" "torch" "pdfplumber"
```
# Run
- Run the cmdbox server.
```bash
cmdbox -m server -c start &
```
- Run the cmdbox web.
```bash
cmdbox -m web -c start --signin_file .cmdbox/user_list.yml &
```
- Run the cmdbox mcpsv.
```bash
cmdbox -m mcpsv -c start --signin_file .cmdbox/user_list.yml &
```
# Tutorial
- Open the ```.sample/sample_project``` folder in the current directory with VSCode.

- Install dependent libraries.
```bash
python -m venv .venv
. .venv/bin/activate
pip install -r requirements.txt
```
- Run the project.

- The localhost web screen will open.

- Enter ```user01 / user01``` for the initial ID and PW to sign in.
- Using this web screen, you can easily execute the commands implemented in cmdbox.

- Let's look at the command to get a list of files as an example.
- Press the plus button under Commands to open the Add dialog.
- Then enter the following.

- Press the ```Save``` button once and then press the ```Execute``` button.
- The results of the command execution are displayed.

- Open the saved ```client_time``` and press the ```Raw``` button.
- You will see how to execute the same command on the command line; the RESTAPI URL is also displayed.

## How to implement a new command using cmdbox
- Under the ```sample/app/features/cli``` folder, you will find an implementation of the ```sample_client_time``` mentioned earlier.
- The implementation is as follows. (Slightly abbreviated display)
- Create the following code and save it in the ```sample/app/features/cli``` folder.
```python
from cmdbox.app import common, feature
from typing import Dict, Any, Tuple, Union, List
import argparse
import datetime
import logging
class ClientTime(feature.Feature):
def get_mode(self) -> Union[str, List[str]]:
return "client"
def get_cmd(self):
return 'time'
def get_option(self):
return dict(
type=Options.T_STR, default=None, required=False, multi=False, hide=False, use_redis=self.USE_REDIS_FALSE,
description_ja="クライアント側の現在時刻を表示します。",
description_en="Displays the current time at the client side.",
choice=[
dict(opt="timedelta", type=Options.T_INT, default=9, required=False, multi=False, hide=False, choice=None,
description_ja="時差の時間数を指定します。",
description_en="Specify the number of hours of time difference."),
])
def apprun(self, logger:logging.Logger, args:argparse.Namespace, tm:float, pf:List[Dict[str, float]]=[]) -> Tuple[int, Dict[str, Any], Any]:
tz = datetime.timezone(datetime.timedelta(hours=args.timedelta))
dt = datetime.datetime.now(tz)
ret = dict(success=dict(data=dt.strftime('%Y-%m-%d %H:%M:%S')))
common.print_format(ret, args.format, tm, args.output_json, args.output_json_append, pf=pf)
if 'success' not in ret:
return self.RESP_WARN, ret, None
return self.RESP_SUCCESS, ret, None
def edgerun(self, opt, tool, logger, timeout, prevres = None):
status, res = tool.exec_cmd(opt, logger, timeout, prevres)
tool.notify(res)
yield 1, res
```
- If you want to implement server-side processing, please refer to ```sample_server_time```.
```python
from cmdbox.app import common, client, feature
from cmdbox.app.commons import redis_client
from cmdbox.app.options import Options
from pathlib import Path
from typing import Dict, Any, Tuple, Union, List
import argparse
import datetime
import logging
class ServerTime(feature.Feature):
def get_mode(self) -> Union[str, List[str]]:
return "server"
def get_cmd(self):
return 'time'
def get_option(self):
return dict(
type=Options.T_STR, default=None, required=False, multi=False, hide=False, use_redis=self.USE_REDIS_FALSE,
description_ja="サーバー側の現在時刻を表示します。",
description_en="Displays the current time at the server side.",
choice=[
dict(opt="host", type=Options.T_STR, default=self.default_host, required=True, multi=False, hide=True, choice=None,
description_ja="Redisサーバーのサービスホストを指定します。",
description_en="Specify the service host of the Redis server."),
dict(opt="port", type=Options.T_INT, default=self.default_port, required=True, multi=False, hide=True, choice=None,
description_ja="Redisサーバーのサービスポートを指定します。",
description_en="Specify the service port of the Redis server."),
dict(opt="password", type=Options.T_PASSWD, default=self.default_pass, required=True, multi=False, hide=True, choice=None,
description_ja="Redisサーバーのアクセスパスワード(任意)を指定します。省略時は `password` を使用します。",
description_en="Specify the access password of the Redis server (optional). If omitted, `password` is used."),
dict(opt="svname", type=Options.T_STR, default=self.default_svname, required=True, multi=False, hide=True, choice=None,
description_ja="サーバーのサービス名を指定します。省略時は `server` を使用します。",
description_en="Specify the service name of the inference server. If omitted, `server` is used."),
dict(opt="timedelta", type=Options.T_INT, default=9, required=False, multi=False, hide=False, choice=None,
description_ja="時差の時間数を指定します。",
description_en="Specify the number of hours of time difference."),
dict(opt="retry_count", type=Options.T_INT, default=3, required=False, multi=False, hide=True, choice=None,
description_ja="Redisサーバーへの再接続回数を指定します。0以下を指定すると永遠に再接続を行います。",
description_en="Specifies the number of reconnections to the Redis server.If less than 0 is specified, reconnection is forever."),
dict(opt="retry_interval", type=Options.T_INT, default=5, required=False, multi=False, hide=True, choice=None,
description_ja="Redisサーバーに再接続までの秒数を指定します。",
description_en="Specifies the number of seconds before reconnecting to the Redis server."),
dict(opt="timeout", type=Options.T_INT, default="15", required=False, multi=False, hide=True, choice=None,
description_ja="サーバーの応答が返ってくるまでの最大待ち時間を指定。",
description_en="Specify the maximum waiting time until the server responds."),
])
def apprun(self, logger:logging.Logger, args:argparse.Namespace, tm:float, pf:List[Dict[str, float]]=[]) -> Tuple[int, Dict[str, Any], Any]:
cl = client.Client(logger, redis_host=args.host, redis_port=args.port, redis_password=args.password, svname=args.svname)
ret = cl.redis_cli.send_cmd(self.get_svcmd(), [str(args.timedelta)],
retry_count=args.retry_count, retry_interval=args.retry_interval, timeout=args.timeout)
common.print_format(ret, args.format, tm, args.output_json, args.output_json_append, pf=pf)
if 'success' not in ret:
return self.RESP_WARN, ret, None
return self.RESP_SUCCESS, ret, None
def is_cluster_redirect(self):
return False
def svrun(self, data_dir:Path, logger:logging.Logger, redis_cli:redis_client.RedisClient, msg:List[str],
sessions:Dict[str, Dict[str, Any]]) -> int:
td = 9 if msg[2] == None else int(msg[2])
tz = datetime.timezone(datetime.timedelta(hours=td))
dt = datetime.datetime.now(tz)
ret = dict(success=dict(data=dt.strftime('%Y-%m-%d %H:%M:%S')))
redis_cli.rpush(msg[1], ret)
return self.RESP_SUCCESS
def edgerun(self, opt, tool, logger, timeout, prevres = None):
status, res = tool.exec_cmd(opt, logger, timeout, prevres)
tool.notify(res)
yield 1, res
```
- Open the file ```sample/extensions/features.yml```. The file should look something like this.
- This file specifies where new commands are to be read.
- For example, if you want to add a package to read, add a new ```package``` and ```prefix``` to ```features.cli```.
- Note that ```features.web``` can be used to add a new web screen.
- If you only want to call commands added in ```features.cli``` via RESTAPI, no additional implementation is needed in ```features.web```.
```yml
features:
cli: # Specify a list of package names in which the module implementing the command is located.
- package: cmdbox.app.features.cli # Package Name. Classes inheriting from cmdbox.app.feature.Feature.
prefix: cmdbox_ # Module name prefix. Modules that begin with this letter are eligible.
exclude_modules: [] # Specify the module name to exclude from the list of modules to be loaded.
web: # Specify a list of package names with modules that implement web screens and RESTAPIs.
- package: cmdbox.app.features.web # Package Name. Classes inheriting from cmdbox.app.feature.WebFeature .
prefix: cmdbox_web_ # Module name prefix. Modules that begin with this letter are eligible.
args: # Specifies default or forced arguments for the specified command.
cli: # Specify rules to apply default values or force arguments.
- rule: # Specify the rules for applying default values and forced arguments for each command line option.
# e.g. mode: web
default: # Specify a default value for each item to be set when a rule is matched.
# e.g. doc_root: f"{Path(self.ver.__file__).parent / 'web'}"
coercion: # Specify a coercion value for each item to be set when a rule is matched.
# e.g. doc_root: f"{Path(self.ver.__file__).parent / 'web'}"
aliases: # Specify the alias for the specified command.
cli: # Specify the alias for the command line.
- source: # Specifies the command from which the alias originates.
mode: # Specify the mode of the source command. The exact match "mode" is selected.
# e.g. client
cmd: # Specify the source command to be aliased. The regex match "cmd" is selected.
# e.g. (.+)_(.+)
target: # Specifies the command to be aliased to.
mode: # Specify the mode of the target command. Create an alias for this “mode”.
# e.g. CLIENT
cmd: # Specify the target command to be aliased. Create an alias for this “cmd”, referring to the regular expression group of source by "{n}".
# e.g. {2}_{1}
move: # Specify whether to move the regular expression group of the source to the target.
# e.g. true
web: # Specify the alias for the RESTAPI.
- source: # Specifies the RESTAPI from which the alias originates.
path: # Specify the path of the source RESTAPI. The regex match "path" is selected.
# e.g. /exec_(.+)
target: # Specifies the RESTAPI to be aliased to.
path: # Specify the path of the target RESTAPI. Create an alias for this “path”, referring to the regular expression group of source by "{n}".
# e.g. /{1}_exec
move: # Specify whether to move the regular expression group of the source to the target.
# e.g. true
agentrule: # Specifies a list of rules that determine which commands the agent can execute.
policy: deny # Specify the default policy for the rule. The value can be allow or deny.
rules: # Specify the rules for the commands that the agent can execute according to the group to which the user belongs.
- mode: cmd # Specify the "mode" as the condition for applying the rule.
cmds: [list, load] # Specify the "cmd" to which the rule applies. Multiple items can be specified in a list.
rule: allow # Specifies whether the specified command is allowed or not. Values are allow or deny.
- mode: client
cmds: [file_download, file_list, http, server_info]
rule: allow
- mode: excel
cmds: [cell_details, cell_search, cell_values, sheet_list]
rule: allow
- mode: server
cmds: [list]
rule: allow
- mode: tts
cmds: [say]
rule: allow
audit:
enabled: true # Specify whether to enable the audit function.
write:
mode: audit # Specify the mode of the feature to be writed.
cmd: write # Specify the command to be writed.
search:
mode: audit # Specify the mode of the feature to be searched.
cmd: search # Specify the command to be searched.
options: # Specify the options for the audit function.
host: localhost # Specify the service host of the audit Redis server.However, if it is specified as a command line argument, it is ignored.
port: 6379 # Specify the service port of the audit Redis server.However, if it is specified as a command line argument, it is ignored.
password: password # Specify the access password of the audit Redis server.However, if it is specified as a command line argument, it is ignored.
svname: cmdbox # Specify the audit service name of the inference server.However, if it is specified as a command line argument, it is ignored.
retry_count: 3 # Specifies the number of reconnections to the audit Redis server.If less than 0 is specified, reconnection is forever.
retry_interval: 1 # Specifies the number of seconds before reconnecting to the audit Redis server.
timeout: 15 # Specify the maximum waiting time until the server responds.
pg_enabled: False # Specify True if using the postgresql database server.
pg_host: localhost # Specify the postgresql host.
pg_port: 5432 # Specify the postgresql port.
pg_user: postgres # Specify the postgresql user name.
pg_password: password # Specify the postgresql password.
pg_dbname: audit # Specify the postgresql database name.
retention_period_days: 365 # Specify the number of days to retain audit logs.
```
- The following files should also be known when using commands on the web screen or RESTAPI.
- Open the file ```sample/extensions/user_list.yml```. The file should look something like this.
- This file manages the users and groups that are allowed Web access and their rules.
- The rule of the previous command is ```allow``` for users in the ```user``` group in ```cmdrule.rules```.
```yml
users: # A list of users, each of which is a map that contains the following fields.
- uid: 1 # An ID that identifies a user. No two users can have the same ID.
name: admin # A name that identifies the user. No two users can have the same name.
password: XXXXX # The user's password. The value is hashed with the hash function specified in the next hash field.
hash: plain # The hash function used to hash the password, which can be plain, md5, sha1, or sha256, or oauth2, or saml.
groups: [admin] # A list of groups to which the user belongs, as specified in the groups field.
email: admin@aaa.bbb.jp # The email address of the user, used when authenticating using the provider specified in the oauth2 or saml field.
- uid: 101
name: user01
password: XXXXX
hash: md5
groups: [user]
email: user01@aaa.bbb.jp
- uid: 102
name: user02
password: XXXXX
hash: sha1
groups: [readonly]
email: user02@aaa.bbb.jp
- uid: 103
name: user03
password: XXXXX
hash: sha256
groups: [editor]
email: user03@aaa.bbb.jp
groups: # A list of groups, each of which is a map that contains the following fields.
- gid: 1 # An ID that identifies a group. No two groups can have the same ID.
name: admin # A name that identifies the group. No two groups can have the same name.
- gid: 2
name: guest
- gid: 101
name: user
- gid: 102
name: readonly
parent: user # The parent group of the group. If the parent group is not specified, the group is a top-level group.
- gid: 103
name: editor
parent: user
cmdrule: # A list of command rules, Specify a rule that determines whether or not a command is executable when executed by a user in web mode.
policy: deny # Specify the default policy for the rule. The value can be allow or deny.
rules: # Specify rules to allow or deny execution of the command, depending on the group the user belongs to.
- groups: [admin]
rule: allow
- groups: [user] # Specify the groups to which the rule applies.
mode: client # Specify the "mode" as the condition for applying the rule.
cmds: [file_download, file_list, server_info] # Specify the "cmd" to which the rule applies. Multiple items can be specified in a list.
rule: allow # Specifies whether or not the specified command is allowed for the specified group. The value can be allow or deny.
- groups: [user]
mode: server
cmds: [list]
rule: allow
- groups: [user]
mode: cmd
cmds: [list, load]
rule: allow
- groups: [user, guest]
mode: audit
cmds: [write]
rule: allow
- groups: [user, guest]
mode: web
cmds: [genpass]
rule: allow
- groups: [editor]
mode: client
cmds: [file_copy, file_mkdir, file_move, file_remove, file_rmdir, file_upload]
rule: allow
pathrule: # List of RESTAPI rules, rules that determine whether or not a RESTAPI can be executed when a user in web mode accesses it.
policy: deny # Specify the default policy for the rule. The value can be allow or deny.
rules: # Specify rules to allow or deny execution of the RESTAPI, depending on the group the user belongs to.
- groups: [admin] # Specify the groups to which the rule applies.
paths: [/] # Specify the "path" to which the rule applies. Multiple items can be specified in a list.
rule: allow # Specifies whether or not the specified RESTAPI is allowed for the specified group. The value can be allow or deny.
- groups: [guest]
paths: [/signin, /assets, /copyright, /dosignin, /dosignout, /password/change,
/gui, /get_server_opt, /usesignout, /versions_cmdbox, /versions_used]
rule: allow
- groups: [user]
paths: [/signin, /assets, /bbforce_cmd, /copyright, /dosignin, /dosignout, /password/change,
/gui/user_data/load, /gui/user_data/save, /gui/user_data/delete,
/agent, /mcpsv,
/exec_cmd, /exec_pipe, /filer, /result, /gui, /get_server_opt, /usesignout, /versions_cmdbox, /versions_used]
rule: allow
- groups: [readonly]
paths: [/gui/del_cmd, /gui/del_pipe, /gui/save_cmd, /gui/save_pipe]
rule: deny
- groups: [editor]
paths: [/gui/del_cmd, /gui/del_pipe, /gui/save_cmd, /gui/save_pipe]
rule: allow
password: # Password settings.
policy: # Password policy settings.
enabled: true # Specify whether or not to enable password policy.
not_same_before: true # Specify whether or not to allow the same password as the previous one.
min_length: 16 # Specify the minimum length of the password.
max_length: 64 # Specify the maximum length of the password.
min_lowercase: 1 # Specify the minimum number of lowercase letters in the password.
min_uppercase: 1 # Specify the minimum number of uppercase letters in the password.
min_digit: 1 # Specify the minimum number of digits in the password.
min_symbol: 1 # Specify the minimum number of symbol characters in the password.
not_contain_username: true # Specify whether or not to include the username in the password.
expiration: # Password expiration settings.
enabled: true # Specify whether or not to enable password expiration.
period: 90 # Specify the number of days after which the password will expire.
notify: 7 # Specify the number of days before the password expires that a notification will be sent.
lockout: # Account lockout settings.
enabled: true # Specify whether or not to enable account lockout.
threshold: 5 # Specify the number of failed login attempts before the account is locked.
reset: 30 # Specify the number of minutes after which the failed login count will be reset.
apikey:
gen_cert: # Specify whether to generate a certificate for API key.
enabled: true # Specify whether to enable certificate generation for API key.
privatekey: idp_private.pem # Specify the destination file for the generated private key.
certificate: idp_cert.pem # Specify the destination file for the generated certificate.
publickey: idp_public.pem # Specify the destination file for the generated public key.
gen_jwt: # Specify whether to generate JWT for API key.
enabled: true # Specify whether to enable JWT generation for API key.
privatekey: idp_private.pem # Specify the private key file for JWT generation.
privatekey_passphrase: # Specify the passphrase for the private key file.
# If the private key is encrypted, specify the passphrase here.
algorithm: RS256 # Specify the algorithm used to generate the JWT. The value can be RS256, PS256, or ES256.
claims: # Specify the claims to be included in the JWT.
iss: identity_provider # Specify the issuer of the JWT. This is usually the name of the identity provider.
sub: app_user # Specify the subject of the JWT. This is usually the name of the application.
aud: app_organization # Specify the audience of the JWT. This is usually the name of the organization that will use the application.
exp: 31536000 # Specify the expiration time of the JWT in seconds. The default is 31536000 seconds (1 year).
verify_jwt: # Specify whether to verify JWT for API key.
enabled: true # Specify whether to enable JWT verification for API key.
certificate: idp_cert.pem # Specify the certificate file for JWT verification.
publickey: idp_public.pem # Specify the public key file for JWT verification. Not required if certificate exists.
issuer: identity_provider # Specify the issuer of the JWT. This is usually the name of the identity provider. (If not specified, no verification)
audience: app_organization # Specify the audience of the JWT. This is usually the name of the organization that will use the application. (If not specified, no verification)
algorithm: RS256 # Specify the algorithm used to verify the JWT. The value can be RS256, PS256, or ES256.
oauth2: # OAuth2 settings.
providers: # This is a per-provider setting for OAuth2.
google: # Google's OAuth2 configuration.
enabled: false # Specify whether to enable Google's OAuth2.
client_id: XXXXXXXXXXX # Specify Google's OAuth2 client ID.
client_secret: XXXXXXXXXXX # Specify Google's OAuth2 client secret.
redirect_uri: https://localhost:8443/oauth2/google/callback # Specify Google's OAuth2 redirect URI.
scope: ['email'] # Specify the scope you want to retrieve with Google's OAuth2. Usually, just reading the email is sufficient.
signin_module: # Specify the module name that implements the sign-in.
cmdbox.app.auth.google_signin
note: # Specify a description such as Google's OAuth2 reference site.
- https://developers.google.com/identity/protocols/oauth2/web-server?hl=ja#httprest
github: # OAuth2 settings for GitHub.
enabled: false # Specify whether to enable OAuth2 for GitHub.
client_id: XXXXXXXXXXX # Specify the OAuth2 client ID for GitHub.
client_secret: XXXXXXXXXXX # Specify the GitHub OAuth2 client secret.
redirect_uri: https://localhost:8443/oauth2/github/callback # Specify the OAuth2 redirect URI for GitHub.
scope: ['user:email'] # Specify the scope you want to get from GitHub's OAuth2. Usually, just reading the email is sufficient.
signin_module: # Specify the module name that implements the sign-in.
cmdbox.app.auth.github_signin
note: # Specify a description, such as a reference site for OAuth2 on GitHub.
- https://docs.github.com/ja/apps/oauth-apps/building-oauth-apps/authorizing-oauth-apps#scopes
azure: # OAuth2 settings for Azure AD.
enabled: false # Specify whether to enable OAuth2 for Azure AD.
tenant_id: XXXXXXXXXXX # Specify the tenant ID for Azure AD.
client_id: XXXXXXXXXXX # Specify the OAuth2 client ID for Azure AD.
client_secret: XXXXXXXXXXX # Specify the Azure AD OAuth2 client secret.
redirect_uri: https://localhost:8443/oauth2/azure/callback # Specify the OAuth2 redirect URI for Azure AD.
scope: ['openid', 'profile', 'email', 'https://graph.microsoft.com/mail.read']
signin_module: # Specify the module name that implements the sign-in.
cmdbox.app.auth.azure_signin
note: # Specify a description, such as a reference site for Azure AD's OAuth2.
- https://learn.microsoft.com/ja-jp/entra/identity-platform/v2-oauth2-auth-code-flow
saml: # SAML settings.
providers: # This is a per-provider setting for OAuth2.
azure: # SAML settings for Azure AD.
enabled: false # Specify whether to enable SAML authentication for Azure AD.
signin_module: # Specify the module name that implements the sign-in.
cmdbox.app.auth.azure_signin_saml # Specify the python3-saml configuration.
# see) https://github.com/SAML-Toolkits/python3-saml
sp:
entityId: https://localhost:8443/
assertionConsumerService:
url: https://localhost:8443/saml/azure/callback
binding: urn:oasis:names:tc:SAML:2.0:bindings:HTTP-POST
attributeConsumingService: {}
singleLogoutService:
binding: urn:oasis:names:tc:SAML:2.0:bindings:HTTP-Redirect
NameIDFormat: urn:oasis:names:tc:SAML:1.1:nameid-format:unspecified
x509cert: ''
privateKey: ''
idp:
entityId: https://sts.windows.net/{tenant-id}/
singleSignOnService:
url: https://login.microsoftonline.com/{tenant-id}/saml2
binding: urn:oasis:names:tc:SAML:2.0:bindings:HTTP-Redirect
x509cert: XXXXXXXXXXX
singleLogoutService: {}
certFingerprint: ''
certFingerprintAlgorithm: sha1
```
- See the documentation for references to each file.
- Documentation is [here](https://hamacom2004jp.github.io/cmdbox/).
# Lisence
This project is licensed under the MIT License, see the LICENSE file for details
| text/markdown | null | hamacom2004jp <hamacom2004jp@gmail.com> | null | null | MIT | audit, cli, excel, fastapi, mcp, redis, restapi, web | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: MIT License",
"Natural Language :: Japanese",
"Programming Language :: Python",
"Topic :: Utilities"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"argcomplete",
"aiosqlite",
"async-timeout",
"asyncpg",
"cffi",
"cryptography",
"fastapi",
"debugpy",
"gevent",
"gunicorn",
"itsdangerous",
"numpy",
"openpyxl",
"Pillow",
"plyer",
"psycopg[binary]",
"pyjwt",
"pystray",
"python-multipart",
"pycryptodome",
"pyyaml",
"question... | [] | [] | [] | [
"Homepage, https://github.com/hamacom2004jp/cmdbox",
"Documentation, https://hamacom2004jp.github.io/cmdbox/index.html",
"Repository, https://github.com/hamacom2004jp/cmdbox"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-19T15:04:35.549440 | cmdbox-0.7.5.1.tar.gz | 2,170,725 | 53/45/b670b0552e9dee576451d5dffa929d99f75b00ffc9988bfbc532726ee6c9/cmdbox-0.7.5.1.tar.gz | source | sdist | null | false | 7d15193621d4dbc0dd1f7c0f1effe18a | d899fce2f875c736eec3a26e3948ce88f7b3f77c57ea1690ef5da72d013fc2a5 | 5345b670b0552e9dee576451d5dffa929d99f75b00ffc9988bfbc532726ee6c9 | null | [
"LICENSE"
] | 221 |
2.4 | thorlabs-xa | 1.1.0.26862 | Python wrapper of the Thorlabs XA SDK | # Thorlabs XA Python SDK
This is the official Thorlabs XA Python SDK. The required XA native SDK is included in this package.
Please refer to the LICENSE file for details regarding the licensing of this package and its dependencies.
| text/markdown | Thorlabs | techsupport@thorlabs.com | null | null | BSD-3-Clause | null | [
"Programming Language :: Python :: 3",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX :: Linux"
] | [] | null | null | <4,>=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.0 | 2026-02-19T15:04:33.533198 | thorlabs_xa-1.1.0.26862.tar.gz | 983,737 | 15/ee/3c98b8d48b33e6b54fdd4df53faac882759c5543658112d2b509ed5ebc6f/thorlabs_xa-1.1.0.26862.tar.gz | source | sdist | null | false | 2e6925d1927743d5536c1f577c33a1d6 | 39402d7258197e2a6e6a937dc6cb10c0f83c82b38de006466894493ab6b1ce16 | 15ee3c98b8d48b33e6b54fdd4df53faac882759c5543658112d2b509ed5ebc6f | null | [
"LICENSE"
] | 396 |
2.4 | zpybci | 0.2.0 | High-performance signal processing for BCI research | # zpybci -- Zerostone Python for BCI
High-performance, real-time signal processing for brain-computer interface research. Powered by Rust with zero-copy NumPy integration.
## Installation
```bash
pip install zpybci
```
Wheels are available for Linux (x86_64, aarch64), macOS (Intel + Apple Silicon), and Windows (x86_64). Python 3.8+.
## Quick Start
```python
import numpy as np
import zpybci as zbci
# Bandpass filter for alpha band (8-12 Hz)
bpf = zbci.IirFilter.butterworth_bandpass(sample_rate=256.0, low_cutoff=8.0, high_cutoff=12.0)
signal = np.random.randn(1000).astype(np.float32)
filtered = bpf.process(signal)
# Chain multiple stages into a pipeline
pipe = zbci.Pipeline(sample_rate=256.0, stages=[
("highpass", {"cutoff": 1.0}),
("notch", {"freq": 50.0}),
("lowpass", {"cutoff": 40.0}),
])
cleaned = pipe.process(signal)
```
## Features
### Filters
- **IIR** -- 4th-order Butterworth (lowpass, highpass, bandpass)
- **FIR** -- arbitrary-length finite impulse response
- **AC coupling** -- DC removal for streaming data
- **Median** -- nonlinear smoothing
- **Adaptive** -- LMS and NLMS for noise cancellation
- **Notch** -- narrowband rejection (e.g., 50/60 Hz line noise)
### Spatial Filters
- **CAR** -- common average reference
- **Surface Laplacian** -- current source density approximation
- **Channel Router** -- flexible channel remapping
### Spectral Analysis
- **FFT** -- fast Fourier transform (magnitude/phase)
- **STFT** -- short-time Fourier transform
- **Multi-band power** -- concurrent power in multiple frequency bands
- **Welch PSD** -- power spectral density estimation
- **CWT** -- continuous wavelet transform (Morlet)
### Detection
- **Threshold** -- fixed-threshold event detection
- **Adaptive threshold** -- self-adjusting threshold based on signal statistics
- **Zero-crossing** -- rate estimation
### Artifact Handling
- **Amplitude-based** -- flag samples exceeding a threshold
- **Z-score** -- flag statistically outlying segments
### Analysis
- **Envelope follower** -- instantaneous amplitude via rectification + smoothing
- **Windowed RMS** -- streaming root-mean-square
- **Hilbert transform** -- analytic signal, instantaneous phase/frequency
### Statistics
- **Online mean/variance** -- Welford's algorithm, no buffer required
- **Online covariance** -- streaming covariance matrix
### Advanced
- **CSP** -- common spatial patterns with online adaptation
- **Riemannian tangent space** -- SPD manifold projection for classification
- **OASIS deconvolution** -- calcium transient inference from fluorescence traces
### Utilities
- **Pipeline** -- declarative stage chaining with a single `process()` call
- **Resampling** -- integer decimation and interpolation
- **Streaming percentile** -- approximate quantiles on unbounded streams
- **Clock sync** -- offset estimation, linear drift correction, sample clock alignment
- **Cross-correlation** -- full, valid, and circular modes
- **Window functions** -- Hann, Hamming, Blackman, flat-top, Kaiser
## Version
0.2.0
## License
AGPL-3.0
| text/markdown; charset=UTF-8; variant=GFM | Fredrik Whaug | null | null | null | AGPL-3.0 | signal-processing, bci, neuroscience, eeg, filtering | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU Affero General Public License v3",
"Programming Language :: Rust",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy>=1.20"
] | [] | [] | [] | [
"Repository, https://github.com/fredrikWHaug/zerostone"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:04:17.248577 | zpybci-0.2.0.tar.gz | 295,215 | 3b/1e/85764873bb00e0ade1acfb870b8be3a68d3c0d3964c15f0547d13403d6ce/zpybci-0.2.0.tar.gz | source | sdist | null | false | be26c7d3209f06f2b8d11a61cf85d127 | 46934b05cf897362bfbb1f578ecc277188bf3a7ffa146939ef4b9b7fccaa4f2d | 3b1e85764873bb00e0ade1acfb870b8be3a68d3c0d3964c15f0547d13403d6ce | null | [] | 498 |
2.4 | ukfuelfinder | 2.0.0 | Python library for accessing the UK Government Fuel Finder API | # UK Fuel Finder Python Library
[](https://opensource.org/licenses/MIT)
[](https://www.python.org/downloads/)
Python library for accessing the UK Government Fuel Finder API.
## ⚠️ API Status Warning
**As of February 4, 2026** - The UK Government Fuel Finder API is currently experiencing severe performance issues:
- ❌ **Data endpoints not responding** - `/pfs/fuel-prices` and `/pfs` endpoints timing out
- ✅ **Authentication works** - OAuth token generation functional
- ⏱️ **Requests timing out** - No response after 30+ seconds
**This library is fully functional and tested.** The issues are with the UK Government's API infrastructure, not this library. The API has been unreliable since its launch on February 2, 2026.
**Status**: Waiting for UK Government to fix their API servers.
For updates on API status, check: https://www.gov.uk/guidance/access-the-latest-fuel-prices-and-forecourt-data-via-api-or-email
## ⚠️ API Changes (February 17, 2025)
The UK Fuel Finder API has been updated with breaking changes:
### Breaking Changes
1. **Removed Fields**: `success` and `message` fields removed from API responses
2. **New Field**: `price_change_effective_timestamp` added to fuel price responses
3. **Error Codes**: Invalid batch numbers now return HTTP 404 (Not Found) instead of previous error codes
4. **Data Types**: Latitude and longitude values now use double precision
### Backward Compatibility
This library includes backward compatibility mode (enabled by default):
```python
# With backward compatibility (default)
client = FuelFinderClient(backward_compatible=True)
prices = client.get_all_pfs_prices()
print(prices[0].success) # Returns True (for backward compatibility)
print(prices[0].message) # Returns empty string (for backward compatibility)
# Without backward compatibility
client = FuelFinderClient(backward_compatible=False)
prices = client.get_all_pfs_prices()
# prices[0].success and prices[0].message not available
```
### Environment Variable
Control backward compatibility via environment variable:
```bash
export UKFUELFINDER_BACKWARD_COMPATIBLE=0 # Disable backward compatibility
```
### Migration Guide
1. Update to the latest version of this library
2. Test with `backward_compatible=True` (default)
3. Update your code to remove usage of `success` and `message` fields
4. Handle 404 errors for invalid batch numbers
5. Switch to `backward_compatible=False` when ready
6. Update to use the new `price_change_effective_timestamp` field
## Features
- **OAuth 2.0 Authentication** - Automatic token management with refresh support
- **Comprehensive Data Access** - Fuel prices and forecourt information
- **Built-in Caching** - Reduces API calls with configurable TTL
- **Rate Limiting** - Automatic retry with exponential backoff
- **Type Hints** - Full type annotations for better IDE support
- **Extensive Error Handling** - Clear exceptions for all error cases
- **Batch Pagination** - Automatic handling of 500-record batches
- **Incremental Updates** - Fetch only changed data since a specific date
## Installation
```bash
pip install ukfuelfinder
```
## Quick Start
```python
from ukfuelfinder import FuelFinderClient
# Initialize client
client = FuelFinderClient(
client_id="your_client_id",
client_secret="your_client_secret",
environment="production" # or "test"
)
# Get all fuel prices
prices = client.get_all_pfs_prices()
# Search for stations near a location (returns list of (distance, PFSInfo) tuples)
nearby = client.search_by_location(latitude=51.5074, longitude=-0.1278, radius_km=5.0)
for distance, station in nearby:
print(f"{distance:.2f}km - {station.trading_name}")
# Get prices for specific fuel type
unleaded_prices = client.get_prices_by_fuel_type("unleaded")
# Get forecourt information
forecourts = client.get_all_pfs_info()
# Get incremental updates since yesterday
from datetime import datetime, timedelta
yesterday = (datetime.now() - timedelta(days=1)).strftime("%Y-%m-%d")
updated_prices = client.get_incremental_price_updates(yesterday)
```
## Environment Variables
Set credentials via environment variables:
```bash
export FUEL_FINDER_CLIENT_ID="your_client_id"
export FUEL_FINDER_CLIENT_SECRET="your_client_secret"
export FUEL_FINDER_ENVIRONMENT="production"
```
Then initialize without parameters:
```python
client = FuelFinderClient()
```
## Documentation
- [Quick Start Guide](docs/quickstart.md)
- [API Reference](docs/api_reference.md)
- [Authentication](docs/authentication.md)
- [Caching Guide](docs/caching.md)
- [Rate Limiting](docs/rate_limiting.md)
- [Error Handling](docs/error_handling.md)
## Requirements
- Python 3.8+
- Valid Fuel Finder API credentials from [developer.fuel-finder.service.gov.uk](https://www.developer.fuel-finder.service.gov.uk)
## API Coverage
This library provides access to all Information Recipient API endpoints:
- **Authentication**
- Generate OAuth access token
- Refresh access token
- **Fuel Prices**
- Fetch all PFS fuel prices (full or incremental)
- **Forecourt Information**
- Fetch all PFS information (500 per batch)
- Fetch incremental PFS information updates
## Examples
See the [examples/](examples/) directory for complete working examples:
- `basic_usage.py` - Simple getting started example
- `error_handling.py` - Comprehensive error handling
- `fetch_fuel_prices.py` - Fetch all fuel prices and save to JSON
- `fetch_all_sites.py` - Fetch all forecourt sites and save to JSON
- `location_search.py` - Search for stations near a location
### Backward Compatibility Example
```python
# With backward compatibility (default)
client = FuelFinderClient(backward_compatible=True)
prices = client.get_all_pfs_prices()
print(prices[0].success) # Returns True (for backward compatibility)
print(prices[0].message) # Returns empty string (for backward compatibility)
# Without backward compatibility
client = FuelFinderClient(backward_compatible=False)
prices = client.get_all_pfs_prices()
# prices[0].success and prices[0].message not available
# Use price_change_effective_timestamp instead
if prices[0].fuel_prices:
print(prices[0].fuel_prices[0].price_change_effective_timestamp)
```
## Development
### Setup
```bash
git clone https://github.com/mretallack/ukfuelfinder.git
cd ukfuelfinder
pip install -e .[dev]
```
### Running Tests
```bash
pytest
```
### Code Quality
```bash
black ukfuelfinder tests
mypy ukfuelfinder
flake8 ukfuelfinder
```
## Future Enhancements
Potential features for future development:
### Smart Fuel Recommendations
- **Cost-optimized routing** - Calculate total fuel cost including detour distance based on vehicle consumption
- **Cheapest fuel finder** - Find the most economical option considering current location, fuel prices, and distance
- **Route integration** - Suggest fuel stops along planned routes with minimal detour
### Price Intelligence
- **Price alerts** - Notify users when prices drop below a threshold in their area
- **Price forecasting** - Predict price trends based on historical data
- **Price comparison** - Compare prices across brands, regions, and fuel types
### Advanced Filtering
- **Multi-criteria search** - Filter by amenities (car wash, shop, 24-hour, EV charging)
- **Brand preferences** - Filter by preferred fuel brands or loyalty programs
- **Fuel type availability** - Find stations with specific fuel types (HVO, E10, premium diesel)
### Journey Planning
- **Fuel range calculator** - Estimate remaining range and suggest refuel points
- **Multi-stop optimization** - Plan optimal fuel stops for long journeys
- **Emergency fuel finder** - Quick search for nearest station when running low
### Data Analytics
- **Spending tracking** - Monitor fuel expenses over time
- **Savings calculator** - Calculate savings from using cheapest stations
- **Regional price analysis** - Compare average prices across different areas
### Integration Features
- **Navigation app integration** - Direct routing to selected stations
- **Calendar integration** - Schedule reminders for regular refueling
- **Vehicle integration** - Sync with vehicle telematics for automatic consumption data
Contributions implementing these features are welcome! See [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
## Contributing
Contributions are welcome! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## Acknowledgments
- Data provided by the UK Government Fuel Finder service
- API documentation: [developer.fuel-finder.service.gov.uk](https://www.developer.fuel-finder.service.gov.uk)
- Content available under [Open Government Licence v3.0](https://www.nationalarchives.gov.uk/doc/open-government-licence/version/3/)
## Support
- **Issues**: [GitHub Issues](https://github.com/mretallack/ukfuelfinder/issues)
- **API Support**: [Contact Fuel Finder Team](https://www.developer.fuel-finder.service.gov.uk/contact-us)
## Changelog
See [CHANGELOG.md](CHANGELOG.md) for version history.
## Release Procedure
To create a new release:
1. **Update version** in all files:
- `pyproject.toml`
- `setup.py`
- `ukfuelfinder/__init__.py`
2. **Update CHANGELOG.md** with new version entry
3. **Commit and push** version updates:
```bash
git add pyproject.toml setup.py ukfuelfinder/__init__.py CHANGELOG.md
git commit -m "Release: vX.Y.Z"
git push origin main
```
4. **Create GitHub release**:
- Go to GitHub repository → Releases → Create new release
- Tag: `vX.Y.Z` (must match version in files)
- Title: `vX.Y.Z`
- Description: Copy from CHANGELOG.md for the version
- Publish release
5. **Automated publishing**:
- GitHub Actions will automatically build and publish to PyPI
- Check `.github/workflows/publish.yml` for details
| text/markdown | Mark Retallack | Mark Retallack <mark@retallack.org.uk> | null | null | MIT | fuel, prices, uk, government, api, petrol, diesel | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming La... | [] | https://github.com/mretallack/ukfuelfinder | null | >=3.8 | [] | [] | [] | [
"requests>=2.31.0",
"python-dateutil>=2.8.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"responses>=0.23.0; extra == \"dev\"",
"vcrpy>=4.2.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"flake8>=6.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/mretallack/ukfuelfinder",
"Documentation, https://github.com/mretallack/ukfuelfinder/blob/main/README.md",
"Repository, https://github.com/mretallack/ukfuelfinder",
"Issues, https://github.com/mretallack/ukfuelfinder/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:03:53.591569 | ukfuelfinder-2.0.0.tar.gz | 69,487 | b8/d9/7ea28f4ffe39ffa18a2ab932fc74a5da5e85f89b144ae351f4bf5d5c5c32/ukfuelfinder-2.0.0.tar.gz | source | sdist | null | false | c9812dd714a9f4f18cd7a58bff28d17c | 7bdd6e0e69e66398a1726286999731b5dc3379904d4bc42c8e4d7d268215a3e6 | b8d97ea28f4ffe39ffa18a2ab932fc74a5da5e85f89b144ae351f4bf5d5c5c32 | null | [
"LICENSE"
] | 232 |
2.4 | engineeringagent | 0.3.0 | A framework for running coding agents as long running tasks - with deterministic feedback loops and agent reviewers | # Engineering Agent
NOTE: This repository is under active development. You should probably not use it for anything important yet.
Treat `engineeringagent init` as experimental scaffolding and review all generated changes before committing.
Engineeringagent is a CLI that helps you implement code changes directly from feature specs.
It pairs an agent loop with repository-owned harnesses (validators, checks, fitness functions,
and optional reviewer agents).
You will still need to implement/configure the harness for your repository. If you are just
starting out, the first few specs you run should usually be harness improvements.
Primary flow: `feature spec -> run loop`.
## Command styles
- Package usage (PyPI, no clone): `uvx engineeringagent <command>`
- Package usage (version pinned): `uvx engineeringagent@<version> <command>`
## Quickstart from PyPI (no clone)
1. Make sure you are in a git repository.
When the process starts, at least one commit will be made per implemented feature.
1. Scaffold the baseline harness with `init`.
`init` is interactive (it requires a TTY and will prompt you with choices).
```bash
uvx engineeringagent init slim
```
You can also scaffold a more complete baseline:
```bash
uvx engineeringagent init standard
```
Warning: `init` is experimental scaffolding. Inspect generated files,
run `uvx engineeringagent validate`, and review the git diff before committing.
1. Create a feature spec in `docs/spec/features/`.
Use the schema `docs/spec/schemas/feature.schema.json` to create a spec.
Save this as `docs/spec/features/FEAT-001-example.yaml`.
1. Validate and dry-run the loop first:
```bash
uvx engineeringagent validate
uvx engineeringagent run --all --dry-run
```
1. Dry-run the loop first:
```bash
uvx engineeringagent run docs/spec/features/FEAT-001-example.yaml --dry-run
```
1. Before the first non-dry `engineeringagent run`, either commit the scaffold/spec changes or pass `--allow-dirty`.
Running non-dry mutates your feature YAML and writes progress logs (for example `progress/runs.jsonl` and `progress/run-feature-<FEATURE_ID>.txt`).
Running non-dry will create a commit and may include untracked files; check `git status` and commit/review any `init` scaffold output (and ignore junk like `__pycache__/`) before the first non-dry run.
After a feature is complete, move completed specs from `docs/spec/features/` to `docs/spec/features_done/` (the loop will usually do this automatically when marking a feature `done`, but move it manually if it did not).
`engineeringagent validate` rejects `status: done` specs under `docs/spec/features/`.
Help validate OpenCode wiring up-front:
- `opencode --version`
- `.opencode/agents/engineeringagent.md`
The first non-dry run may take a while (especially the first time, when OpenCode is cold-starting).
By default, `engineeringagent run` retries failed iterations up to `--max-iterations` (default 50).
When debugging OpenCode timeouts, `--max-iterations 1` helps fail fast.
## Quickstart from source (contributors / local changes)
If you are developing this repo and want to exercise local changes (not the PyPI package), install the project into your local uv environment and run the CLI via the console script:
```bash
uv sync
uv run engineeringagent init slim
uv run engineeringagent validate
uv run engineeringagent run --all --dry-run
```
### Verification (contributors)
- Run the full `iteration_end` check set declared in `harness/checks.yaml`:
```bash
uv run engineeringagent checks run --phase iteration_end
```
- Run pylint directly (same flags as the repo gate):
```bash
uv run pylint --score=n --reports=n src/engineeringagent tests harness
```
## Bootstrapping with `init`
If you want to use the agent in one of your repositories, you can scaffold a baseline harness with:
```bash
uvx engineeringagent init
```
`init` creates a starter structure for `docs/spec/` and `harness/checks.yaml` and handles
existing `docs/` or `AGENTS.md` through explicit conflict choices.
`engineeringagent init` skips pre-commit hook installation when `.git/` does not exist.
If you want hooks installed, run `git init` before `engineeringagent init`.
`engineeringagent init` skips pre-commit hook installation when `pre-commit` is not available.
If you install `pre-commit` after running init, you can wire the hooks with `pre-commit install`.
At a minimum, `init` scaffolds:
- `docs/spec/` directories for feature specs
- `harness/checks.yaml` as the repo-owned verification contract
It does not run checks for you or make any commits.
Warning: treat `init` as experimental scaffolding.
Always inspect generated files, run `uvx engineeringagent validate`, and review
the git diff before committing anything produced by `init`.
If you picked `standard`, the scaffold may include demo checks. Remove any demo-only
checks from `harness/checks.yaml` if you want a clean baseline (or re-run:
`uvx engineeringagent init slim --force`).
Use `python_uv` as a profile when you want the scaffolded `.pre-commit-config.yaml` to assume an
`uv`-based workflow and ship a minimal Python validation baseline.
`python_uv` also wires a `commit-msg` hook.
```bash
uvx engineeringagent init slim --scaffold-profile python_uv
```
### Pinning the scaffolded OpenCode model (optional)
`engineeringagent init` scaffolds the OpenCode agent prompt at `.opencode/agents/engineeringagent.md`.
If you want to pin which model OpenCode uses for that agent, pass `--model`:
```bash
uvx engineeringagent init slim --model openai/gpt-5.3-codex
```
If you are only validating wiring in CI (for example, smoke tests that run OpenCode once), using a
faster model can reduce wall time:
```bash
uvx engineeringagent init slim --model openai/gpt-5.3-codex-spark
```
This repository does not use the legacy repo-root OpenCode config file (the old `opencode` JSON).
Any temporary OpenCode configuration should be done via `.opencode/agents/*.md`.
## What this gives you
- Deterministic progress: one spec file at a time.
- Human control: you set priorities and scope; agents execute loops.
- Built-in quality checks: validation, checks, and commit hooks.
## Run output tips
- Default output is concise; full implement/check output stays in `progress/run-feature-<FEATURE_ID>.txt`.
- Use `--verbose-output` if you want full implement/check output in the terminal.
## OpenCode default agent contract
- By default, `engineeringagent run` shells out to `opencode run --agent engineeringagent`
for the implementation step.
- Your repo must have OpenCode available and configured, including an agent prompt
like `.opencode/agents/engineeringagent.md`.
- If you are not using OpenCode, run the direct verification tools for your repository (for example `uv run pytest -q`).
## Human docs vs agent docs
- `README.md`: first-run, for you the developer.
- [Harness Engineering Principles](docs/principles/harness-engineering-principles.md): deeper for you the developer.
- `AGENTS.md` and `docs/references/*-llms.md`: agent execution rules and deterministic procedures.
## Reviewer agents (optional)
- Reviewer agents are a harness-managed complement to deterministic checks.
- Reviewer checks are declared in `harness/checks.yaml` and reference prompts under `harness/reviewers/prompts/`.
- For setup and migration guidance, see [Reviewer authoring guide](docs/principles/reviewer-authoring-guide.md).
- For full contract, policy semantics, decision-envelope examples, and troubleshooting, see [Reviewer agents reference](docs/references/reviewer-agents-llms.md).
## Core files to know
- `docs/spec/features/`: active feature specs (`backlog`, `in_progress`, `blocked`)
- `docs/spec/features_done/`: archived completed specs (`done`)
- `harness/checks.yaml`: repo-owned verification contract
- `progress/runs.jsonl`: append-only loop execution history
## Contributing
- Pull requests are not accepted for this repository.
- Code changes are implemented through the project agent workflow.
- If you want a new capability, open a GitHub issue with the problem, desired outcome, and constraints.
- Feature requests from issues may be promoted into a formal spec under `docs/spec/features/`.
## Go deeper
- [CLI workflow details](docs/references/uv-llms.md)
- Agent execution map (scaffolded by init): see `AGENTS.md` (repo root)
- [Docs architecture for agents](docs/references/docs-architecture-llms.md)
## Curated external context
- [Harness engineering overview (OpenAI)](https://openai.com/index/harness-engineering/)
- [Ralph Loop background](https://ghuntley.com/loop/)
- [Agent loop patterns (Anthropic)](https://www.anthropic.com/engineering/building-effective-agents)
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"pathspec>=0.12.1",
"pydantic>=2.11.0",
"pyyaml>=6.0.2",
"tomli>=2.0.1",
"typer>=0.16.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.12 | 2026-02-19T15:03:31.947250 | engineeringagent-0.3.0.tar.gz | 1,175,960 | 22/06/c1c939750a92f4740fc7039cdba4b6bbca0fcb08ceea2c5bd5fb7bb44d20/engineeringagent-0.3.0.tar.gz | source | sdist | null | false | e8e4bcd37d8ac025755982b070968af2 | 04d760e0f93b3d4f831ca417683c78429890b5f41eb94b08f7910692909378de | 2206c1c939750a92f4740fc7039cdba4b6bbca0fcb08ceea2c5bd5fb7bb44d20 | null | [] | 205 |
2.4 | cs3client | 1.7.1 | CS3 client for Python | # CS3Client
`CS3Client` is a Python client for interacting with the CS3 (Cloud Sync&Share Storage) [APIs](https://github.com/cs3org/cs3apis). It allows users to seamlessly communicate with cloud storage services that support CS3 protocols, enabling file management, data transfer, and other cloud-based operations.
## Table of Contents
- [Features](#features)
- [Installation](#installation)
- [Usage](#usage)
- [Configuration](#configuration)
- [Examples](#examples)
- [Documentation](#documentation)
- [License](#license)
## Features
- Simple and easy-to-use API client for CS3 services.
- Support for common file operations (read, write, delete, rename, ...).
- Support for common lock operations (set lock, get lock, unlock, ...).
- Support for common share operations (create share, update share, delete share, ...).
- Support for common user operations (get user, find users, get user groups, ...).
- support for common group operations (get group, find group, has member, ...).
- Support for restoring files through checkpoints (restore file version, list checkpoints).
- Support for applications (open in app, list app providers).
- Authentication and authorization handling.
- Cross-platform compatibility.
- Detailed error handling and logging.
## Installation
To install `cs3client`, you need to have Python 3.7+ installed. You can install the package via `pip`:
```bash
pip install cs3client
```
Alternatively, you can clone this repository and install manually:
```bash
git clone git@github.com:cs3org/cs3-python-client.git
cd cs3-python-client
pip install .
```
## Configuration
`CS3Client` can be configured by passing specific parameters when initializing the client through a ConfigParser instance.
### Parameters:
#### Required
- `host`
#### Optional (parameter - default)
- `chunk_size` - 4194384
- `grpc_timeout` - 10
- `http_timeout` - 10
- `tus_enabled` - False
- `ssl_enabled` - False
- `ssl_client_cert` - None
- `ssl_client_key` - None
- `ssl_ca_cert` - None
- `auth_client_id` - None
- `auth_login_type` - "basic"
- `lock_by_setting_attr` - False
- `lock_not_impl` - False
- `lock_expiration` - 1800
#### Example configuration
```yaml
[cs3client]
# Required
host = localhost:19000
# Optional, defaults to 4194304
chunk_size = 4194304
# Optional, defaults to 10
grpc_timeout = 10
# Optional, defaults to 10
http_timeout = 10
# Optional, defaults to True
tus_enabled = False
# Optional, defaults to True
ssl_enabled = False
# Optional, defaults to True
ssl_verify = False
# Optional, defaults to an empty string
ssl_client_cert = test_client_cert
# Optional, defaults to an empty string
ssl_client_key = test_client_key
# Optional, defaults to an empty string
ssl_ca_cert = test_ca_cert
# Optinal, defaults to an empty string
auth_client_id = einstein
# Optional (can also be set when instansiating the class)
auth_client_secret = relativity
# Optional, defaults to basic
auth_login_type = basic
# Optional, defaults to False
lock_by_setting_attr = False
# Optional, defaults to False
lock_not_impl = False
# Optional, defaults to 1800
lock_expiration = 1800
```
## Usage
To use `cs3client`, you first need to import and configure it. Here's a simple example of how to set up and start using the client. For configuration see [Configuration](#configuration). For more in depth examples see `cs3-python-client/examples/`.
### Initilization and Authentication
```python
import logging
import configparser
from cs3client.cs3client import CS3Client
from cs3client.auth import Auth
config = configparser.ConfigParser()
with open("default.conf") as fdef:
config.read_file(fdef)
log = logging.getLogger(__name__)
client = CS3Client(config, "cs3client", log)
auth = Auth(client)
# Set the client id (can also be set in the config)
auth.set_client_id("<your_client_id_here>")
# Set client secret (can also be set in config)
auth.set_client_secret("<your_client_secret_here>")
# Checks if token is expired if not return ('x-access-token', <token>)
# if expired, request a new token from reva
auth_token = auth.get_token()
# OR if you already have a reva token
# Checks if token is expired if not return (x-access-token', <token>)
# if expired, throws an AuthenticationException (so you can refresh your reva token)
token = "<your_reva_token>"
auth_token = Auth.check_token(token)
```
### File Example
```python
# mkdir
directory_resource = Resource(abs_path=f"/eos/user/r/rwelande/test_directory")
res = client.file.make_dir(auth.get_token(), directory_resource)
# touchfile
touch_resource = Resource(abs_path="/eos/user/r/rwelande/touch_file.txt")
res = client.file.touch_file(auth.get_token(), touch_resource)
# setxattr
resource = Resource(abs_path="/eos/user/r/rwelande/text_file.txt")
res = client.file.set_xattr(auth.get_token(), resource, "iop.wopi.lastwritetime", str(1720696124))
# rmxattr
res = client.file.remove_xattr(auth.get_token(), resource, "iop.wopi.lastwritetime")
# stat
res = client.file.stat(auth.get_token(), resource)
# removefile
res = client.file.remove_file(auth.get_token(), touch_resource)
# rename
rename_resource = Resource(abs_path="/eos/user/r/rwelande/rename_file.txt")
res = client.file.rename_file(auth.get_token(), resource, rename_resource)
# writefile
content = b"Hello World"
size = len(content)
res = client.file.write_file(auth.get_token(), rename_resource, content, size)
# listdir
list_directory_resource = Resource(abs_path="/eos/user/r/rwelande")
res = client.file.list_dir(auth.get_token(), list_directory_resource)
# readfile
file_res = client.file.read_file(auth.get_token(), rename_resource)
```
### Lock Example
```python
WEBDAV_LOCK_PREFIX = 'opaquelocktoken:797356a8-0500-4ceb-a8a0-c94c8cde7eba'
def encode_lock(lock):
'''Generates the lock payload for the storage given the raw metadata'''
if lock:
return WEBDAV_LOCK_PREFIX + ' ' + b64encode(lock.encode()).decode()
return None
resource = Resource(abs_path="/eos/user/r/rwelande/lock_test.txt")
# Set lock
client.file.set_lock(auth_token, resource, app_name="a", lock_id=encode_lock("some_lock"))
# Get lock
res = client.file.get_lock(auth_token, resource)
if res is not None:
lock_id = res["lock_id"]
print(res)
# Unlock
res = client.file.unlock(auth_token, resource, app_name="a", lock_id=lock_id)
# Refresh lock
client.file.set_lock(auth_token, resource, app_name="a", lock_id=encode_lock("some_lock"))
res = client.file.refresh_lock(
auth_token, resource, app_name="a", lock_id=encode_lock("new_lock"), existing_lock_id=lock_id
)
if res is not None:
print(res)
res = client.file.get_lock(auth_token, resource)
if res is not None:
print(res)
```
### Share Example
```python
# Create share #
resource = Resource(abs_path="/eos/user/r/<some_username>/text.txt")
resource_info = client.file.stat(auth.get_token(), resource)
user = client.user.get_user_by_claim("username", "<some_username>")
res = client.share.create_share(auth.get_token(), resource_info, user.id.opaque_id, user.id.idp, "EDITOR", "USER")
# List existing shares #
filter_list = []
filter = client.share.create_share_filter(resource_id=resource_info.id, filter_type="TYPE_RESOURCE_ID")
filter_list.append(filter)
filter = client.share.create_share_filter(share_state="SHARE_STATE_PENDING", filter_type="TYPE_STATE")
filter_list.append(filter)
res, _ = client.share.list_existing_shares(auth.get_token(), )
# Get share #
share_id = "58"
res = client.share.get_share(auth.get_token(), opaque_id=share_id)
# update share #
res = client.share.update_share(auth.get_token(), opaque_id=share_id, role="VIEWER")
# remove share #
res = client.share.remove_share(auth.get_token(), opaque_id=share_id)
# List existing received shares #
filter_list = []
filter = client.share.create_share_filter(share_state="SHARE_STATE_ACCEPTED", filter_type="TYPE_STATE")
filter_list.append(filter)
res, _ = client.share.list_received_existing_shares(auth.get_token())
# get received share #
received_share = client.share.get_received_share(auth.get_token(), opaque_id=share_id)
# update recieved share #
res = client.share.update_received_share(auth.get_token(), received_share=received_share, state="SHARE_STATE_ACCEPTED")
# create public share #
res = client.share.create_public_share(auth.get_token(), resource_info, role="VIEWER")
# list existing public shares #
filter_list = []
filter = client.share.create_public_share_filter(resource_id=resource_info.id, filter_type="TYPE_RESOURCE_ID")
filter_list.append(filter)
res, _ = client.share.list_existing_public_shares(filter_list=filter_list)
res = client.share.get_public_share(auth.get_token(), opaque_id=share_id, sign=True)
# OR token = "<token>"
# res = client.share.get_public_share(token=token, sign=True)
# update public share #
res = client.share.update_public_share(auth.get_token(), type="TYPE_PASSWORD", token=token, role="VIEWER", password="hello")
# remove public share #
res = client.share.remove_public_share(auth.get_token(), token=token)
```
### User Example
```python
# find_user
res = client.user.find_users(auth.get_token(), "rwel")
# get_user
res = client.user.get_user("https://auth.cern.ch/auth/realms/cern", "asdoiqwe")
# get_user_groups
res = client.user.get_user_groups("https://auth.cern.ch/auth/realms/cern", "rwelande")
# get_user_by_claim (mail)
res = client.user.get_user_by_claim("mail", "rasmus.oscar.welander@cern.ch")
# get_user_by_claim (username)
res = client.user.get_user_by_claim("username", "rwelande")
```
### Group example
```python
# get_group_by_claim (username)
res = client.group.get_group_by_claim(client.auth.get_token(), "username", "rwelande")
# get_group
res = client.group.get_group(client.auth.get_token(), "https://auth.cern.ch/auth/realms/cern", "asdoiqwe")
# has_member
res = client.group.has_member(client.auth.get_token(), "somegroup", "rwelande", "https://auth.cern.ch/auth/realms/cern")
# get_members
res = client.group.get_members(client.auth.get_token(), "somegroup", "https://auth.cern.ch/auth/realms/cern")
# find_groups
res = client.group.find_groups(client.auth.get_token(), "rwel")
```
### App Example
```python
# list_app_providers
res = client.app.list_app_providers(auth.get_token())
# open_in_app
resource = Resource(abs_path="/eos/user/r/rwelande/collabora.odt")
res = client.app.open_in_app(auth.get_token(), resource)
```
### Checkpoint Example
```python
# list file versions
resource = Resource(abs_path="/eos/user/r/rwelande/test.md")
res = client.checkpoint.list_file_versions(auth.get_token(), resource)
# restore file version
res = client.checkpoint.restore_file_version(auth.get_token(), resource, "1722936250.0569fa2f")
```
## Documentation
The documentation can be generated using sphinx
```bash
pip install sphinx
cd docs
make html
```
## Unit tests
```bash
pytest --cov-report term --cov=serc tests/
```
## License
This project is licensed under the Apache 2.0 License. See the LICENSE file for more details.
| text/markdown | Rasmus Welander, Diogo Castro, Giuseppe Lo Presti | null | null | null | Apache 2.0 | null | [
"Development Status :: 4 - Beta",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Operating... | [] | https://github.com/cs3org/cs3-python-client | null | null | [] | [] | [] | [
"grpcio>=1.47.0",
"grpcio-tools>=1.47.0",
"pyOpenSSL",
"requests",
"cs3apis",
"PyJWT",
"protobuf",
"cryptography"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T15:02:40.588370 | cs3client-1.7.1.tar.gz | 38,017 | c6/43/340c6e1eadf160c57de79f1a5b09f24d086f4d6aa4b72294f23552e3ee84/cs3client-1.7.1.tar.gz | source | sdist | null | false | 1905ca0aa28b4f84f85c095ce7bbaf22 | 81deffb217ab8e66dd199b72377a9d0578b18a6ba4721329bb36296f5c1a186c | c643340c6e1eadf160c57de79f1a5b09f24d086f4d6aa4b72294f23552e3ee84 | null | [
"LICENSE"
] | 269 |
2.4 | databricks-bundles | 0.289.1 | Python support for Databricks Asset Bundles | # databricks-bundles
Python for Databricks Asset Bundles extends [Databricks Asset Bundles](https://docs.databricks.com/aws/en/dev-tools/bundles/) so that you can:
- Define jobs and pipelines as Python code. These jobs can coexist with jobs defined in YAML.
- Dynamically create jobs and pipelines using metadata.
- Modify jobs and pipelines defined in YAML or Python during bundle deployment.
Documentation is available at https://docs.databricks.com/dev-tools/cli/databricks-cli.html.
Reference documentation is available at https://databricks.github.io/cli/python/
## Getting started
To use `databricks-bundles`, you must first:
1. Install the [Databricks CLI](https://github.com/databricks/cli), version 0.289.1 or above
2. Authenticate to your Databricks workspace if you have not done so already:
```bash
databricks configure
```
3. To create a new project, initialize a bundle using the `experimental-jobs-as-code` template:
```bash
databricks bundle init experimental-jobs-as-code
```
## Privacy Notice
Databricks CLI use is subject to the [Databricks License](https://github.com/databricks/cli/blob/main/LICENSE) and [Databricks Privacy Notice](https://www.databricks.com/legal/privacynotice), including any Usage Data provisions.
| text/markdown | null | Gleb Kanterov <gleb.kanterov@databricks.com> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:02:09.702039 | databricks_bundles-0.289.1.tar.gz | 85,818 | f2/f2/d5d5c22a33902e36eea7f9e88149c30eac5d9fbdaa1ce0230d623fe7d104/databricks_bundles-0.289.1.tar.gz | source | sdist | null | false | 61960ba3a877f0e4b10c99896b3e1d39 | 80d93ff1b552e4603ee530f3cfa7e17b054bd3b8781366b646d71042b130a57c | f2f2d5d5c22a33902e36eea7f9e88149c30eac5d9fbdaa1ce0230d623fe7d104 | null | [
"LICENSE"
] | 9,002 |
2.4 | rdsa-utils | 0.16.1 | A suite of PySpark, Pandas, and general pipeline utils for Reproducible Data Science and Analysis (RDSA) projects. | # 🧰 rdsa-utils
[](https://github.com/ONSdigital/rdsa-utils/actions/workflows/deploy_pypi.yaml)
[](https://github.com/ONSdigital/rdsa-utils/actions/workflows/deploy_mkdocs.yaml)
[](https://pypi.org/project/rdsa-utils/)
[](#)
[](https://github.com/astral-sh/ruff)
[](https://github.com/psf/black)
A suite of PySpark, Pandas, and general pipeline utils for **Reproducible Data Science and Analysis (RDSA)** projects.
The RDSA team sits within the Economic Statistics Change Directorate, and uses cutting-edge data science and engineering skills to produce the next generation of economic statistics. Current priorities include overhauling legacy systems and developing new systems for key statistics. More information about work at RDSA can be found here: [Using Data Science for Next-Gen Statistics](https://dataingovernment.blog.gov.uk/2023/02/14/using-data-science-for-next-gen-statistics/).
`rdsa-utils` is a Python codebase built with Python 3.8 and higher, and uses `setup.py`, `setup.cfg`, and `pyproject.toml` for dependency management and packaging.
## 📋 Prerequisites
- Python 3.8 or higher
## 💾 Installation
`rdsa-utils` is available for installation via [PyPI](https://pypi.org/project/rdsa-utils/) and can also be found on [GitHub Releases](https://github.com/ONSdigital/rdsa-utils/releases) for direct downloads and version history.
To install via `pip`, simply run:
```bash
pip install rdsa-utils
```
## 🗂️ How the Project is Organised
The `rdsa-utils` package is designed to make it easy to work with different platforms like Cloudera Data Platform (CDP) and Google Cloud Platform (GCP), as well as handle general Python tasks. Here's a breakdown of how everything is organised:
- **General Utilities (Top-Level)**:
- These are tools you can use for any project, regardless of the platform you're working on. They focus on common Python, PySpark, and Pandas tasks.
- 📂 **Helpers**: Handy functions that simplify working with Python and PySpark.
- 📂 **IO**: Functions for handling input and output, like reading configurations or saving results.
- **Platform-Specific Utilities**:
- **CDP (Cloudera Data Platform)**:
- 📂 **Helpers**: Functions that help you work with tools supported by CDP, such as HDFS, Impala, and AWS S3.
- 📂 **IO**: Input/output functions specifically for CDP, such as managing data and logs in CDP environments.
- **GCP (Google Cloud Platform)**:
- 📂 **Helpers**: Functions to help you interact with GCP tools like Google Cloud Storage and BigQuery.
- 📂 **IO**: Input/output functions for managing data with GCP services.
This structure keeps the tools for each platform separate, so you can easily find what you need, whether you're working in a cloud environment or on general Python tasks.
## 📖 Documentation and Further Information
Our documentation is automatically generated using **GitHub Actions** and **MkDocs**. It uses the [`ons_mkdocs_theme`](https://github.com/ONSdigital/ons_mkdocs_theme) package for a consistent ONS look and feel on GitHub Pages.
For an in-depth understanding of `rdsa-utils`, how to contribute to `rdsa-utils`, and more, please refer to our [MkDocs-generated documentation](https://onsdigital.github.io/rdsa-utils/).
## 📘 Further Reading on Reproducible Analytical Pipelines
While `rdsa-utils` provides essential tools for data processing, it's just one part of the broader development process needed to build and maintain a robust, high-quality codebase. Following best practices and using the right tools are crucial for success.
We highly recommend checking out the following resources to learn more about creating Reproducible Analytical Pipelines (RAP), which focus on important areas such as version control, modular code development, unit testing, and peer review -- all essential for developing these pipelines:
- [Reproducible Analytical Pipelines (RAP) Resource](https://analysisfunction.civilservice.gov.uk/support/reproducible-analytical-pipelines/) - This resource offers an overview of Reproducible Analytical Pipelines, covering benefits, case studies, and guidelines on building a RAP. It discusses minimising manual steps, using open source software like R or Python, enhancing quality assurance through peer review, and ensuring auditability with version control. It also addresses challenges and considerations for implementing RAPs, such as data access restrictions or confidentiality, and underscores the importance of collaborative development.
- [Quality Assurance of Code for Analysis and Research](https://best-practice-and-impact.github.io/qa-of-code-guidance/intro.html) - This book details methods and practices for ensuring high-quality coding in research and analysis, including unit testing and peer reviews.
- [PySpark Introduction and Training Book](https://best-practice-and-impact.github.io/ons-spark/intro.html) - An introduction to using PySpark for large-scale data processing.
Additionally, if you are facing the challenge of repeatedly setting up new developers and new users in local Python, then you may want to consider making a batch file to carry out the setup process for you. The [easypipelinerun](https://github.com/ONSdigital/easy_pipeline_run/) repo has a batch file that can be modified to set your users up for your project, taking care of things like conda and pip set up as well as environment management.
## 📬 Contact
For questions, support, or feedback about `rdsa-utils`, please email [RDSA.Support@ons.gov.uk](mailto:RDSA.Support@ons.gov.uk).
## 🙌 Acknowledgements
Thanks to colleagues from the ONS **Data Science Campus (DSC)** and the ONS **Methods and Quality Directorate (MQD)** for their contributions to `rdsa-utils`.
## 🛡️ Licence
Unless stated otherwise, the codebase is released under the [MIT License][mit].
This covers both the codebase and any sample code in the documentation.
The documentation is [© Crown copyright][copyright] and available under the terms of the [Open Government 3.0][ogl] licence.
[mit]: LICENSE
[copyright]: http://www.nationalarchives.gov.uk/information-management/re-using-public-sector-information/uk-government-licensing-framework/crown-copyright/
[ogl]: http://www.nationalarchives.gov.uk/doc/open-government-licence/version/3/
| text/markdown | Reproducible Data Science & Analysis, ONS | RDSA.Support@ons.gov.uk | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"License :: O... | [] | https://github.com/ONSdigital/rdsa-utils | null | <3.14,>=3.8 | [] | [] | [] | [
"cloudpathlib[gs]>=0.15.1",
"humanfriendly>=9.1",
"more-itertools>=9.0.0",
"pandas",
"pydantic>=2.6.2",
"pyyaml>=6.0.1",
"tomli>=2.0.1",
"google-cloud-bigquery>=3.17.2",
"google-cloud-storage>=2.14.0",
"boto3>=1.34.103",
"codetiming",
"standard-distutils; python_version >= \"3.12\"",
"xlsxwr... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:01:50.312464 | rdsa_utils-0.16.1.tar.gz | 93,626 | f1/9c/945ca455b181ab0b3c38f71ddd592369bafbd6157817176496baed8cda12/rdsa_utils-0.16.1.tar.gz | source | sdist | null | false | b426bb21dd3b503f1bac0e6ce2a26e45 | 8d212426ce2053ed2b02d712826d273984ba9f214e41059aa12b617802a3a95c | f19c945ca455b181ab0b3c38f71ddd592369bafbd6157817176496baed8cda12 | null | [
"LICENSE"
] | 222 |
2.4 | raxpy | 0.2.3 | Python library that designs and executes experiments on Python functions, enabling rapid experimentation. | # raxpy, Python library to rapidly design and execute experiments
| | |
|---|---|
| Testing | [](https://github.com/neil-r/raxpy/actions/workflows/unit_tests.yml)  |
| Meta | [](https://github.com/neil-r/raxpy/blob/main/LICENSE)
## Description
raxpy is a Python library that designs and executes experiments on Python annotated functions. Given a Python function provided by the user, raxpy introspects the function signature to derive an experiment input-space. With a function's derived input-space, raxpy utilizes different experiment design algorithms to create a small set of function arguments, i.e., the design points, that attempt to cover the whole input-space. With the experiment design, raxpy maps the design points to the function's arguments to execute the function with each point.
To address limitations in factorial and random point selection algorithms, raxpy provide space-filling design algorithms to generate insightful results from a small number of function executions. For more information, see [https://arxiv.org/abs/2501.03398](https://arxiv.org/abs/2501.03398).
## Usage
1. Install raxpy if not already installed.
2. Import raxpy and typing Annotation
3. Create a annotated function that is to be the subject of experimentation
```python
from typing import Annotated
import raxpy
def f(
age:Annotated[float, raxpy.Float(label="Age", lb=20.0, ub=80.0)],
bmi:Annotated[float, raxpy.Float(label="BMI", lb=18.0, ub=40.0)],
blood_pressure:Annotated[float, raxpy.Float(label="Blood Pressure", lb=90.0, ub=180.0)]
)-> float:
glucose_factor = 0 if glucose is None else (glucose - 70) / (200 - 70)
cholesterol_factor = 0 if cholesterol is None else (cholesterol - 150) / (300 - 150)
bmi = (
(age / 80) +
((bmi - 18) / (40 - 18)) +
((blood_pressure - 90) / (180 - 90)) +
(glucose_factor) +
(cholesterol_factor) -
(physical_activity / 2)
)
return bmi
```
4. Run experiment
```python
inputs, outputs = raxpy.perform_experiment(f, n_points=10)
```
See examples folder for more usage examples.
## Features
raxpy can execute experiments on functions with the following types of parameters:
- float types
- int types
- str (categorical) types
- Optional, None types
- Hierarchical types based on dataclasses
- Union types
### Experiment Design Algorithm Support
raxpy provides extended versions of the following algorithms to support optional, hierarchical, and union typed inputs. The space-filling designs work best for exploration use cases when function executions are highly constrained by time and compute resources. Random designs work best when the function needs executed to support the creation of a very large dataset.
- Space-filling MaxPro
- Space-filling Uniform (using scipy)
- Random
## Installation
raxpy requires numpy and scipy. To install with pip, execute
```
pip install raxpy
```
To execute distributed experiments with MPI, also ensure you have the appropriate MPI cluster and install mpi4py.
## Support
For community support, please use GitHub issues.
## Roadmap
### Version 1.0
- Refine and test configspace adapter with hyper-parameter optimization algorithms
### Version x.x
The following elements are being considered for development but not scheduled.
- Auto-generated data schema and databases
- Advanced trial meta-data features (point ids, run-time, status, etc.)
- Adaptive experimentation algorithms
- Response surface methodology
- Sequential design algorithms
- Support of more input-space constraint types
- Mixture constraints
- Multi-dimensional linear constraints
- Surrogate optimization features
- Trial artifact management
## Contributing
This project is open for new contributions. Contributions should follow the coding style as evident in codebase and be unit-tested. New dependencies should mostly be avoided; one exception is the creation of a new adapter, such as creating an adapter to use raxpy with an optimization library.
## Citing
If you used raxpy to support your academic research, please cite:
```
https://doi.org/10.48550/arXiv.2501.03398
```
## Project status
raxpy is being actively developed as of 2025-01-01.
| text/markdown | null | Neil Ranly <neil.ranly@gmail.com> | null | null | MIT License
Copyright (c) 2024 Neil Ranly
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | experimentation, synthetic data, design of experiment, model specification | [
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"importlib-metadata; python_version < \"3.9\"",
"numpy>=1.19",
"scipy>=1.14; python_version >= \"3.10\"",
"scipy==1.13.1; python_version == \"3.9\"",
"typing_extensions>=4.10; python_version == \"3.9\"",
"pytest; extra == \"dev\"",
"flake8; extra == \"dev\"",
"black; extra == \"dev\"",
"mpi4py; extr... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:01:03.478818 | raxpy-0.2.3.tar.gz | 2,541,868 | c9/61/a517fd23d3c59dc2b5320766f3f1cf8d4b44d66584e90a531fb0dca4fe49/raxpy-0.2.3.tar.gz | source | sdist | null | false | 248a548732f4a1a2e6ac87d3b4a0a742 | 551d8595de0da692c6d76666cff16a0c17d8cc812d9cf6e297f1c8e8559526a9 | c961a517fd23d3c59dc2b5320766f3f1cf8d4b44d66584e90a531fb0dca4fe49 | null | [
"LICENSE"
] | 204 |
2.4 | ibis-gizmosql | 0.2.1 | An Ibis backend for GizmoSQL | # ibis-gizmosql
An [Ibis](https://ibis-project.org) back-end for [GizmoSQL](https://gizmodata.com/gizmosql)
[<img src="https://img.shields.io/badge/GitHub-gizmodata%2Fibis--gizmosql-blue.svg?logo=Github">](https://github.com/gizmodata/ibis-gizmosql)
[<img src="https://img.shields.io/badge/GitHub-gizmodata%2Fgizmosql--public-blue.svg?logo=Github">](https://github.com/gizmodata/gizmosql-public)
[](https://github.com/gizmodata/ibis-gizmosql/actions/workflows/ci.yml)
[](https://pypi.org/project/ibis-gizmosql/)
[](https://badge.fury.io/py/ibis-gizmosql)
[](https://pypi.org/project/ibis-gizmosql/)
# Setup (to run locally)
## Install Python package
You can install `ibis-gizmosql` from PyPi or from source.
### Option 1 - from PyPi
```shell
# Create the virtual environment
python3 -m venv .venv
# Activate the virtual environment
. .venv/bin/activate
pip install ibis-gizmosql
```
### Option 2 - from source - for development
```shell
git clone https://github.com/gizmodata/ibis-gizmosql
cd ibis-gizmosql
# Create the virtual environment
python3 -m venv .venv
# Activate the virtual environment
. .venv/bin/activate
# Upgrade pip, setuptools, and wheel
pip install --upgrade pip setuptools wheel
# Install the Ibis GizmoSQL back-end - in editable mode with client and dev dependencies
pip install --editable .[dev,test]
```
### Note
For the following commands - if you running from source and using `--editable` mode (for development purposes) - you will need to set the PYTHONPATH environment variable as follows:
```shell
export PYTHONPATH=$(pwd)/ibis_gizmosql
```
### Usage
In this example - we'll start a GizmoSQL server with the DuckDB back-end in Docker, and connect to it from Python using Ibis.
First - start the GizmoSQL server - which by default mounts an empty in-memory database. We use the `INIT_SQL_COMMANDS` env var in the `docker` command to create a very small TPC-H database upon startup:
```bash
docker run --name gizmosql \
--detach \
--rm \
--tty \
--init \
--publish 31337:31337 \
--env TLS_ENABLED="1" \
--env GIZMOSQL_USERNAME="gizmosql_user" \
--env GIZMOSQL_PASSWORD="gizmosql_password" \
--env PRINT_QUERIES="1" \
--env DATABASE_FILENAME=":memory:" \
--env INIT_SQL_COMMANDS="CALL dbgen(sf=0.01);" \
--pull always \
gizmodata/gizmosql:latest
```
> [!IMPORTANT]
> The GizmoSQL server must be started with the DuckDB (default) back-end. The SQLite back-end is not supported.
Next - connect to the GizmoSQL server from Python using Ibis by running this Python code:
```python
import os
import ibis
from ibis import _
# Kwarg connection example
con = ibis.gizmosql.connect(host="localhost",
user=os.getenv("GIZMOSQL_USERNAME", "gizmosql_user"),
password=os.getenv("GIZMOSQL_PASSWORD", "gizmosql_password"),
port=31337,
use_encryption=True,
disable_certificate_verification=True
)
# URL connection example
# con = ibis.connect("gizmosql://gizmosql_user:gizmosql_password@localhost:31337?disableCertificateVerification=True&useEncryption=True")
print(con.tables)
# assign the LINEITEM table to variable t (an Ibis table object)
t = con.table('lineitem')
# use the Ibis dataframe API to run TPC-H query 1
results = (t.filter(_.l_shipdate.cast('date') <= ibis.date('1998-12-01') + ibis.interval(days=90))
.mutate(discount_price=_.l_extendedprice * (1 - _.l_discount))
.mutate(charge=_.discount_price * (1 + _.l_tax))
.group_by([_.l_returnflag,
_.l_linestatus
]
)
.aggregate(
sum_qty=_.l_quantity.sum(),
sum_base_price=_.l_extendedprice.sum(),
sum_disc_price=_.discount_price.sum(),
sum_charge=_.charge.sum(),
avg_qty=_.l_quantity.mean(),
avg_price=_.l_extendedprice.mean(),
avg_disc=_.l_discount.mean(),
count_order=_.count()
)
.order_by([_.l_returnflag,
_.l_linestatus
]
)
)
print(results.execute())
```
You should see output:
```text
l_returnflag l_linestatus sum_qty sum_base_price sum_disc_price sum_charge avg_qty avg_price avg_disc count_order
0 A F 380456.00 532348211.65 505822441.49 526165934.00 25.58 35785.71 0.05 14876
1 N F 8971.00 12384801.37 11798257.21 12282485.06 25.78 35588.51 0.05 348
2 N O 765251.00 1072862302.10 1019517788.99 1060424708.62 25.47 35703.76 0.05 30049
3 R F 381449.00 534594445.35 507996454.41 528524219.36 25.60 35874.01 0.05 14902
```
### Handy development commands
#### Version management
##### Bump the version of the application - (you must have installed from source with the [dev] extras)
```bash
bumpver update --patch
```
| text/markdown | null | Philip Moore <philip@gizmodata.com> | null | null | null | ibis, gizmosql, ibis-framework, flightsql, duckdb, adbc, gizmodata | [
"Programming Language :: Python",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"ibis-framework==12.0.*",
"duckdb==1.4.*",
"adbc-driver-gizmosql>=1.0.5",
"pyarrow-hotfix==0.7",
"numpy==2.4.*",
"packaging==26.0",
"pandas==3.0.*",
"rich==14.3.*",
"pytest; extra == \"test\"",
"pytest-snapshot; extra == \"test\"",
"pytest-mock; extra == \"test\"",
"pytest-xdist; extra == \"te... | [] | [] | [] | [
"Homepage, https://github.com/gizmodata/ibis-gizmosql"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:00:39.003097 | ibis_gizmosql-0.2.1.tar.gz | 25,534 | 67/5b/5118f702affd7761410ea23eb5413c3a22bf09aa9b7a60c75e2e6c54b827/ibis_gizmosql-0.2.1.tar.gz | source | sdist | null | false | cceec3056e523111cec0bcbc0e5e0af6 | c2a180eccb6233e1f89320bb42c348a400498e69a912eb3e266b123bdd5bf72e | 675b5118f702affd7761410ea23eb5413c3a22bf09aa9b7a60c75e2e6c54b827 | Apache-2.0 | [
"LICENSE"
] | 207 |
2.4 | FileSorterX | 0.1.2 | A colorful CLI tool that groups files by extension. | # FileSorter
FileSorter is a simple and colorful command line tool that groups files by extension.
It uses Rich for styled terminal output and supports optional directory arguments.
---
## Features
- Groups files by extension
- Clean, sorted output
- Handles files with no extension
- Optional directory argument
- Modern pathlib usage
### Installation
```bash
pip install FileSorterX
```
#### Usage:
* Linux / macOS / Windows
```bash
cd "FOLDERPATH"
filesorterx
```
| text/markdown | SWARAAJ ARORA | null | null | null | null | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"rich>=13.0.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T15:00:17.527502 | filesorterx-0.1.2.tar.gz | 2,953 | 53/82/763d2d4e921fb53a7ce1463ef187101c8cd7c88230fa175339753bec992b/filesorterx-0.1.2.tar.gz | source | sdist | null | false | 6923fc8fe6a25eba1364f2f69fb04276 | c3f321bb2340a938ba88258fec2b5f932311ad76f637e72be3dcab6c793f204f | 5382763d2d4e921fb53a7ce1463ef187101c8cd7c88230fa175339753bec992b | MIT | [
"LICENSE.txt"
] | 0 |
2.4 | jfinqa | 0.3.2 | Japanese Financial Numerical Reasoning QA Benchmark | # jfinqa
Japanese Financial Numerical Reasoning QA Benchmark.
[](https://pypi.org/project/jfinqa/)
[](https://pypi.org/project/jfinqa/)
[](https://github.com/ajtgjmdjp/jfinqa/actions/workflows/ci.yml)
[](https://pypi.org/project/jfinqa/)
[](https://huggingface.co/datasets/ajtgjmdjp/jfinqa)
[](LICENSE)
[](https://ajtgjmdjp.github.io/jfinqa-leaderboard/)
## What is this?
**jfinqa** is a benchmark for evaluating LLMs on Japanese financial numerical reasoning. Unlike existing benchmarks that focus on classification or simple lookup, jfinqa requires **multi-step arithmetic over financial statement tables** extracted from real Japanese corporate disclosures (EDINET). Questions include DuPont decomposition (6-step), growth rate calculations, and cross-statement ratio analysis.
### Three Subtasks
| Subtask | Description | Example |
|---------|-------------|---------|
| **Numerical Reasoning** | Calculate financial metrics from table data | "2024年3月期の売上高成長率は何%か?" |
| **Consistency Checking** | Verify internal consistency of reported figures | "資産合計は流動資産と固定資産の合計と一致するか?" |
| **Temporal Reasoning** | Analyze trends and changes across periods | "売上高が最も低かったのはどの年度か?" |
### Dataset Statistics
| | Total | Numerical Reasoning | Consistency Checking | Temporal Reasoning |
|---|---|---|---|---|
| **Questions** | 1000 | 550 | 200 | 250 |
| **Companies** | 68 | — | — | — |
| **Accounting Standards** | J-GAAP 58%, IFRS 38%, US-GAAP 4% | — | — | — |
| **Avg. program steps** | 2.59 | 2.84 | 2.00 | 2.54 |
| **Avg. table rows** | 13.3 | — | — | — |
| **Max program steps** | 6 (DuPont) | — | — | — |
### Baseline Results
| Model | Overall | Numerical Reasoning | Consistency Checking | Temporal Reasoning |
|-------|---------|--------------------|--------------------|-------------------|
| GPT-4o | **87.0%** | 80.2% | **90.5%** | **99.2%** |
| Gemini 2.0 Flash | 80.4% | **86.2%** | 83.5% | 65.2% |
| GPT-4o-mini | 67.7% | 79.3% | 83.5% | 29.6% |
| Qwen2.5-3B-Instruct | 39.6% | 46.4% | 51.0% | 15.6% |
*1000 questions, zero-shot, temperature=0. Evaluation uses numerical matching with 1% tolerance. Qwen2.5-3B-Instruct run locally with MLX (4-bit quantization).*
**[View full leaderboard →](https://ajtgjmdjp.github.io/jfinqa-leaderboard/)**
### Error Analysis
Systematic error analysis revealed both benchmark design issues and genuine LLM failure patterns.
Key findings:
- **Clear capability gradient**: GPT-4o (87%) > Gemini 2.0 Flash (80%) > GPT-4o-mini (68%) >> Qwen2.5-3B (40%), validating the benchmark discriminates across model sizes and capabilities.
- **Temporal reasoning separates frontier models**: GPT-4o achieves 99.2% on TR, while Gemini drops to 65.2% and GPT-4o-mini to 29.6%. This subtask requires strict output format compliance ("増収"/"減収" rather than "はい"/"いいえ"), which strongly differentiates models.
- **Gemini 2.0 Flash leads on numerical reasoning** (86.2% vs GPT-4o's 80.2%), suggesting strong arithmetic capabilities, but falls behind on consistency checking and temporal reasoning where format compliance matters more.
- **DuPont decomposition is the hardest subtask**: 6-step ROE decomposition questions (56 questions) see significant accuracy drops even for frontier models, while 3B models rarely solve them correctly.
- **GPT-4o-mini has a systematic prompt compliance issue in temporal reasoning.** It answers "はい" (yes) to questions like "増収か減収か?" despite correctly analyzing the direction in its reasoning chain (122 of 176 TR errors follow this pattern).
- **J-GAAP balance sheet structure is a major error source.** Models confuse 純資産合計 (net assets) with 株主資本 (shareholders' equity), and decompose 総資産 into 4 sub-categories instead of the standard 2.
- **Qwen2.5-3B-Instruct** struggles most with temporal reasoning (15.6%) and consistency checking (51.0%), suggesting that smaller models have difficulty with instruction-following and multi-step verification tasks in Japanese.
### Key Features
- **FinQA-compatible**: Same data format as [FinQA](https://github.com/czyssrs/FinQA) for cross-benchmark comparison
- **Japan-specific**: Handles J-GAAP, IFRS, US-GAAP, and Japanese number formats (百万円, 億円, △)
- **Dual evaluation**: Exact match and numerical match with tolerance
- **lm-evaluation-harness integration**: Ready-to-use YAML task configs
- **Source provenance**: Every question links back to its EDINET filing
## Quick Start
### Installation
```bash
pip install jfinqa
# or
uv add jfinqa
```
### Evaluate Your Model
```python
from jfinqa import load_dataset, evaluate
# Load benchmark questions
questions = load_dataset("numerical_reasoning")
# Provide predictions
predictions = {"nr_001": "25.0%", "nr_002": "16.0%"}
result = evaluate(questions, predictions=predictions)
print(result.summary())
```
### Or Use a Model Function
```python
from jfinqa import load_dataset, evaluate
questions = load_dataset()
def my_model(question: str, context: str) -> str:
# Your model inference here
return "42.5%"
result = evaluate(questions, model_fn=my_model)
print(result.summary())
```
## CLI
```bash
# Inspect dataset questions
jfinqa inspect -s numerical_reasoning -n 5
# Evaluate predictions file
jfinqa evaluate -p predictions.json
# Evaluate with local data
jfinqa evaluate -p predictions.json -d local_data.json -s numerical_reasoning
```
## lm-evaluation-harness
[PR #3570](https://github.com/EleutherAI/lm-evaluation-harness/pull/3570) is pending. Once merged:
```bash
lm-eval run --model openai-completions \
--model_args model=gpt-4o \
--tasks jfinqa \
--num_fewshot 0
```
Before merge, use `--include_path`:
```bash
lm-eval run --model openai-completions \
--model_args model=gpt-4o \
--tasks jfinqa \
--num_fewshot 0 \
--include_path lm_eval_tasks/
```
## Data Format
Each question follows the FinQA schema with additional metadata:
```json
{
"id": "nr_001",
"subtask": "numerical_reasoning",
"pre_text": ["以下はA社の連結損益計算書の抜粋である。"],
"post_text": ["当期は前期比で増収増益となった。"],
"table": {
"headers": ["", "2024年3月期", "2023年3月期"],
"rows": [
["売上高", "1,500,000", "1,200,000"],
["営業利益", "200,000", "150,000"]
]
},
"qa": {
"question": "2024年3月期の売上高成長率は何%か?",
"program": ["subtract(1500000, 1200000)", "divide(#0, 1200000)", "multiply(#1, 100)"],
"answer": "25.0%",
"gold_evidence": [0]
},
"edinet_code": "E00001",
"filing_year": "2024",
"accounting_standard": "J-GAAP"
}
```
## Japanese Number Handling
jfinqa correctly normalizes Japanese financial number formats:
| Input | Extracted Value | Notes |
|-------|----------------|-------|
| `△1,000` | -1,000 | Triangle negative marker |
| `12,345` | 12,345 | Fullwidth digits + comma removal |
| `24,956百万円` | 24,956 | Compound financial units treated as labels |
| `50億` | 5,000,000,000 | Bare kanji multiplier applied |
| `42.5%` | 42.5 | Percentage |
## Development
```bash
git clone https://github.com/ajtgjmdjp/jfinqa
cd jfinqa
uv sync --dev --extra dev
uv run pytest -v
uv run ruff check .
uv run mypy src/
```
## Data Attribution
Source financial data is obtained from [EDINET](https://disclosure.edinet-fsa.go.jp/)
(Electronic Disclosure for Investors' NETwork), operated by the
Financial Services Agency of Japan (金融庁).
EDINET data is provided under the [Public Data License 1.0](https://www.digital.go.jp/resources/open_data/).
The data format is compatible with [FinQA](https://github.com/czyssrs/FinQA) (Chen et al., 2021).
## Related Projects
- [FinQA](https://github.com/czyssrs/FinQA) — English financial QA benchmark (Chen et al., 2021)
- [TAT-QA](https://github.com/NExTplusplus/TAT-QA) — Tabular and textual QA
- [edinet-mcp](https://github.com/ajtgjmdjp/edinet-mcp) — EDINET XBRL parser (companion project)
- [EDINET-Bench](https://github.com/SakanaAI/EDINET-Bench) — Sakana AI's financial classification benchmark
## Citation
If you use jfinqa in your research, please cite it as follows:
```bibtex
@dataset{jfinqa2025,
title={jfinqa: Japanese Financial Numerical Reasoning QA Benchmark},
author={ajtgjmdjp},
year={2025},
url={https://github.com/ajtgjmdjp/jfinqa},
license={Apache-2.0}
}
```
## License
Apache-2.0. See [NOTICE](NOTICE) for third-party attributions.
| text/markdown | null | null | null | null | null | benchmark, edinet, financial-nlp, japanese, question-answering | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic ... | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.0",
"datasets>=3.0",
"loguru>=0.7",
"pydantic>=2.0",
"mypy>=1.10; extra == \"dev\"",
"pytest-asyncio>=0.24; extra == \"dev\"",
"pytest-cov>=5.0; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.8; extra == \"dev\"",
"pandas>=2.0; extra == \"pandas\""
] | [] | [] | [] | [
"Homepage, https://github.com/ajtgjmdjp/jfinqa",
"Repository, https://github.com/ajtgjmdjp/jfinqa"
] | uv/0.10.0 {"installer":{"name":"uv","version":"0.10.0","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T15:00:13.706699 | jfinqa-0.3.2-py3-none-any.whl | 22,541 | 83/96/da1bfd08fc04999063f875050372bb8de0aa3567d9c969a81dcd195987ae/jfinqa-0.3.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 6e85e252507519c46d6bc931a917adbe | a7bb4b72f0c1211a35604cfddeee93714cde6b69ac149dc992593f5b22516546 | 8396da1bfd08fc04999063f875050372bb8de0aa3567d9c969a81dcd195987ae | Apache-2.0 | [
"LICENSE",
"NOTICE"
] | 209 |
2.4 | ida-ios-helper | 1.0.20 | IDA Plugin for ease the reversing of iOS' usermode and kernelcache. | # IDA iOS Helper
A plugin for IDA Pro 9.0+ to help with iOS code analysis.
## Supported features
- KernelCache
- Calls to `OSBaseClass::safeMetaCast` apply type info on the result.
- Calls to `OSObject_typed_operator_new` apply type info on the result.
- When the keyboard is on a virtual call (`cls->vcall()`), Shift+X will show a dialog with all the possible
implementations of the virtual method. It requires vtable symbols to be present.
- When in a C++ method named Class::func, Ctrl+T will change the first argument to `Class* this`. Also works for
Obj-C instance methods.
- Name globals from `OSSymbol::fromConst*` calls, locals from `get/setProperty` calls, ...
- Rename and type all global kalloc_type_view. Use their signature to mark fields as pointers for the actual types.
- Create a struct from a kalloc_type_view.
- Objective-C
- Hide memory management
functions - `objc_retain`, `objc_release`, `objc_autorelease`, `objc_retainAutoreleasedReturnValue`.
- Optimize `_objc_storeStrong` to an assignment.
- collapse `__os_log_impl` calls.
- Hide selectors and static classes from Objective-c calls.
- When in Obj-C method, Ctrl+4 will show xrefs to the selector.
- Swift
- Add swift types declarations to the IDA type system.
- Detect stack swift string and add a syntactic sugar for them.
- Common
- Remove `__break` calls.
- collapse blocks initializers and detect `__block` variables (use Alt+Shift+S to trigger detection).
- Use `Ctrl+S` to jump to function by a string constant found in the code
- Transform ranged conditions to a more readable form.
- Try to detect outline functions and mark them as such.
- Use `Ctrl+Shift+X` to find xrefs to a field inside a segment. This will decompile the whole segment and then
search for the field.
## Installation
1. Install this package using your IDA's python pip: `pip install ida-ios-helper`
2. copy `ida-plugin.json` and `ida_plugin_stub.py` to your IDA's plugins folder: `~/.idapro/plugins/ida-ios-helper`.
3. Restart IDA.
## Examples
### Solve condition constraints
Before:
```c
if ( valueLength - 21 <= 0xFFFFFFFFFFFFFFEFLL )
{
...
}
```
After:
```c
if ( 4 < valueLength || valueLength < 21 )
{
...
}
```
### Remove `__break`
Before:
```c
if ( ((v6 ^ (2 * v6)) & 0x4000000000000000LL) != 0 )
__break(0xC471u);
```
After: removed.
### Hide selectors of Obj-C calls
Before:
```c
-[NSFileManager removeItemAtPath:error:](
+[NSFileManager defaultManager](&OBJC_CLASS___NSFileManager, "defaultManager"),
"removeItemAtPath:error:",
+[NSString stringWithUTF8String:](&OBJC_CLASS___NSString, "stringWithUTF8String:", *(_QWORD *)&buf[v5]),
0LL);
```
After:
```c
-[NSFileManager removeItemAtPath:error:](
+[NSFileManager defaultManager](),
+[NSString stringWithUTF8String:](*(_QWORD *)&buf[v5]),
0LL);
```
### Block initializers
Before:
```c
v10 = 0LL;
v15 = &v10;
v16 = 0x2000000000LL;
v17 = 0;
if ( a1 )
{
x0_8 = *(NSObject **)(a1 + 16);
v13.isa = _NSConcreteStackBlock;
*(_QWORD *)&v13.flags = 0x40000000LL;
v13.invoke = func_name_block_invoke;
v13.descriptor = &stru_100211F48;
v13.lvar3 = a1;
v13.lvar4 = a2;
v13.lvar1 = a3;
v13.lvar2 = &v10;
dispatch_sync(queue: x0_8, block: &v13);
v11 = *((_BYTE *)v15 + 24);
}
else
{
v11 = 0;
}
_Block_object_dispose(&v10, 8);
return v11 & 1;
```
After:
```c
v10 = _byref_block_arg_init(0);
v10.value = 0;
if ( a1 )
{
v6 = *(NSObject **)(a1 + 16);
v9 = _stack_block_init(0x40000000, &stru_100211F48, func_name_block_invoke);
v9.lvar3 = a1;
v9.lvar4 = a2;
v9.lvar1 = a3;
v9.lvar2 = &v10;
dispatch_sync(queue: v6, block: &v9);
value = v10.forwarding->value;
}
else
{
value = 0;
}
return value & 1;
```
### Collapse `os_log`
Before:
```c
v9 = gLogObjects;
v10 = gNumLogObjects;
if ( gLogObjects && gNumLogObjects >= 46 )
{
v11 = *(NSObject **)(gLogObjects + 360);
}
else
{
v11 = (NSObject *)&_os_log_default;
if ( ((v6 ^ (2 * v6)) & 0x4000000000000000LL) != 0 )
__break(0xC471u);
if ( os_log_type_enabled(oslog: (os_log_t)&_os_log_default, type: OS_LOG_TYPE_ERROR) )
{
*(_DWORD *)buf = 134218240;
*(_QWORD *)v54 = v9;
*(_WORD *)&v54[8] = 1024;
*(_DWORD *)&v54[10] = v10;
if ( ((v6 ^ (2 * v6)) & 0x4000000000000000LL) != 0 )
__break(0xC471u);
_os_log_error_impl(
dso: (void *)&_mh_execute_header,
log: (os_log_t)&_os_log_default,
type: OS_LOG_TYPE_ERROR,
format: "Make sure you have called init_logging()!\ngLogObjects: %p, gNumLogObjects: %d",
buf: buf,
size: 0x12u);
}
}
if ( ((v6 ^ (2 * v6)) & 0x4000000000000000LL) != 0 )
__break(0xC471u);
if ( os_log_type_enabled(oslog: v11, type: OS_LOG_TYPE_INFO) )
{
if ( a1 )
v12 = *(_QWORD *)(a1 + 8);
else
v12 = 0LL;
*(_DWORD *)buf = 138412290;
*(_QWORD *)v54 = v12;
if ( ((v6 ^ (2 * v6)) & 0x4000000000000000LL) != 0 )
__break(0xC471u);
_os_log_impl(
dso: (void *)&_mh_execute_header,
log: v11,
type: OS_LOG_TYPE_INFO,
format: "Random log %@",
buf: buf,
size: 0xCu);
}
```
after:
```c
if ( oslog_info_enabled() )
{
if ( a1 )
v4 = *(_QWORD *)(a1 + 8);
else
v4 = 0LL;
oslog_info("Random log %@", v4);
}
```
## Automatic casts with `OSBaseClass::safeMetaCast`
Before:
```c++
OSObject *v5;
v5 = OSBaseClass::safeMetaCast(a2, &IOThunderboltController::metaClass);
```
After:
```c++
IOThunderboltController *v5;
v5 = OSDynamicCast<IOThunderboltController>(a2);
```
## Automatic typing for `OSObject_typed_operator_new`
Run `Edit->Plugins->iOSHelper->Locate all kalloc_type_view` before.
Before:
```c++
IOAccessoryPowerSourceItemUSB_TypeC_Current *sub_FFFFFFF009B2AA14()
{
OSObject *v0; // x19
v0 = (OSObject *)OSObject_typed_operator_new(&UNK_FFFFFFF007DBC480, size: 0x38uLL);
OSObject::OSObject(this: v0, &IOAccessoryPowerSourceItemUSB_TypeC_Current::gMetaclass)->__vftable = (OSObject_vtbl *)off_FFFFFFF007D941B0;
OSMetaClass::instanceConstructed(this: &IOAccessoryPowerSourceItemUSB_TypeC_Current::gMetaclass);
return (IOAccessoryPowerSourceItemUSB_TypeC_Current *)v0;
}
```
After:
```c++
IOAccessoryPowerSourceItemUSB_TypeC_Current *sub_FFFFFFF009B2AA14()
{
IOAccessoryPowerSourceItemUSB_TypeC_Current *v0; // x19
v0 = OSObjectTypeAlloc<IOAccessoryPowerSourceItemUSB_TypeC_Current>(0x38uLL);
OSObject::OSObject(this: v0, &IOAccessoryPowerSourceItemUSB_TypeC_Current::gMetaclass)->__vftable = (OSObject_vtbl *)off_FFFFFFF007D941B0;
OSMetaClass::instanceConstructed(this: &IOAccessoryPowerSourceItemUSB_TypeC_Current::gMetaclass);
return v0;
}
```
## Jump to virtual call
Use `Shift+X` on a virtual call to jump.

## Xrefs to selector
Use `Ctrl+4` inside an Objective-C method to list xrefs to its selector.

## Rename function by argument of logging function
Given that the code contains calls like:
```c
log("func_name", ....);
```
You could use `rename_function_by_arg` to mass rename all functions that contain such calls.
```python
rename_function_by_arg(func_name="log", arg_index=0, prefix="_", force_name_change=False)
```
This will run on all the functions that call the log function, and rename them to the first argument of the call.
## Call the plugin from python
```python
import idaapi
# Call global analysis
idaapi.load_and_run_plugin("iOS Helper", 1)
# Call local analysis
def write_ea_arg(ea: int):
n = idaapi.netnode()
n.create("$ idaioshelper")
n.altset(1, ea, "R")
write_ea_arg(func_ea)
idaapi.load_and_run_plugin("iOS Helper", 2)
```
## Development
In order to have autocomplete while developing, you need to add IDA's include folder ( `$IDA_INSTALLATION/python/3` ) to
your IDE.
- on Visual Studio code you can add the folder to the analyzer's extra paths in the `settings.json` file:
```json
{
"python.analysis.extraPaths": [
"$IDA_INSTALLATION\\python\\3"
]
}
```
- on PyCharm you can add the folder to the interpreter's paths in the project settings.
Alternatively, you can create `idapython.pth` in `$VENV_FOLDER/Lib/site-packages` and add the path to it.
Inside IDA, you can use `ioshelper.reload()` to reload the plugin during development.
If you create file name `DEBUG` inside `src/`, then you can use `F2` to reload the
plugin. | text/markdown | null | Yoav Sternberg <yoav.sternberg@gmail.com> | null | null | null | null | [
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"idahelper==1.0.18"
] | [] | [] | [] | [
"Homepage, https://github.com/yoavst/ida-ios-helper",
"Issues, https://github.com/yoavst/ida-ios-helper/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:59:10.043154 | ida_ios_helper-1.0.20.tar.gz | 867,400 | be/d3/86c6e5a3a6bb957ef87b32a456aaab66c4e17240503e9c0af78300edf99f/ida_ios_helper-1.0.20.tar.gz | source | sdist | null | false | c41d2ec0bf6984b1707331190a72b756 | 6ea7ac2ea4f491792d1b5904ccc16b324567b22d755c20986ce3dba4a1016104 | bed386c6e5a3a6bb957ef87b32a456aaab66c4e17240503e9c0af78300edf99f | null | [
"LICENSE"
] | 219 |
2.4 | datalab-server | 0.7.0rc3 | datalab is a research data management platform for materials science and chemistry. | # <div align="center"><i>datalab</i></div>
<div align="center" style="padding-bottom: 5px">
<a href="https://demo.datalab-org.io"><img src="https://img.shields.io/badge/try_it_out!-public_demo_server-orange?logo=firefox"></a>
</div>
<div align="center">
<a href="https://github.com/datalab-org/datalab/releases"><img src="https://img.shields.io/github/v/release/datalab-org/datalab?color=blue&logo=github"></a>
<a href="https://github.com/datalab-org/datalab#MIT-1-ov-file"><img src="https://img.shields.io/github/license/datalab-org/datalab?color=purple&logo=github"></a>
</div>
<div align="center">
<a href="https://github.com/datalab-org/datalab/actions/workflows/ci.yml"><img src="https://img.shields.io/github/actions/workflow/status/datalab-org/datalab/ci.yml?logo=github"></a>
<a href="https://cloud.cypress.io/projects/4kqx5i/runs"><img src="https://img.shields.io/endpoint?url=https://cloud.cypress.io/badge/simple/4kqx5i/main&style=flat&logo=cypress"></a>
<a href="https://the-datalab.readthedocs.io/en/latest/?badge=latest"><img src="https://img.shields.io/readthedocs/the-datalab?logo=readthedocs"></a>
</div>
<div align="center">
<a href="https://github.com/datalab-org/datalab-ansible-terraform">
<img alt="Static Badge" src="https://img.shields.io/badge/Ansible-playbook-white?logo=ansible">
</a>
<a href="https://pypi.org/project/datalab-api">
<img alt="PyPI - Version" src="https://img.shields.io/pypi/v/datalab-api?logo=pypi&label=Python%20API">
</a>
</div>
<div align="center">
<a href="https://join.slack.com/t/datalab-world/shared_invite/zt-2h58ev3pc-VV496~5je~QoT2TgFIwn4g"><img src="https://img.shields.io/badge/Slack-chat_with_us-yellow?logo=slack"></a>
</div>
_datalab_ is a user-friendly, open-source platform that can capture all the experimental data and metadata produced in a scientific lab, targeted (broadly) at materials chemistry but with customisability and extensability in mind.
_datalab_ records data and metadata securely and makes it accessible and reusable by both humans and machines _via_ the web UI and API, respectively.
_datalab_ can be self-hosted and managed deployments are also available.
You can try the demo deployment at [demo.datalab-org.io](https://demo.datalab-org.io/) and read the online documentation at [docs.datalab-org.io](https://docs.datalab-org.io) with release notes and changelog available on [GitHub](https://github.com/datalab-org/datalab/releases/) and [online](https://docs.datalab-org.io/en/latest/CHANGELOG).
Features:
* Capture and store sample and device metadata
* Connect and sync raw data directly and from laboratory instruments
* Built-in support for multiple characterisation techniques (XRD, NMR, echem, TEM, TGA, Mass Spec, Raman and more).
* Capture scientific context: store the graph of relationships between research objects.
* [Python API](https://github.com/datalab-org/datalab-api) for programmatic access to your lab's data enabling custom analysis and automation.
* Join the [_datalab_ federation](https://github.com/datalab-org/datalab-federation): you can add your _datalab_ to the federation for additional shared features.
* [Plugin ecosystem](https://docs.datalab-org.io/en/latest/plugins) allowing for custom data blocks, [AI integration](https://github.com/datalab-org/yellowhammer) and other instance-specific code.
* [Deployment and infrastructure automation](https://github.com/datalab-industries/datalab-ansible-terraform) via Ansible playbooks.
<div align="center">
<video width="400" controls src="https://github.com/datalab-org/datalab/assets/7916000/0065cdd6-a5f0-4391-b192-0137fe208acc">
</video>
</div>
> [!NOTE]
> You may be looking for the identically named project [DataLab](https://datalab-platform.com) for signal processing, which also has plugins, clients and other similar concepts!
## Getting started
To set up your own _datalab_ instance or to get started with development, you can follow the installation and deployment instructions in the [online documentation](https://docs.datalab-org.io/en/latest/INSTALL).
We can also provide paid managed deployments via [_datalab industries ltd._](https://datalab.industries): contact us at [hello@datalab.industries](mailto:hello@datalab.industries).
## Design philosophy and architecture
The _datalab_ architecture is shown below:
<center>
```mermaid
graph TD
classDef actor fill:#0066CC,fill-opacity:0.3,stroke:#333,stroke-width:2px,color:#000;
classDef clientInterface fill:#00AA44,fill-opacity:0.3,stroke:#333,stroke-width:2px,color:#000;
classDef coreComponent fill:#FF6600,fill-opacity:0.3,stroke:#333,stroke-width:2px,color:#000;
classDef umbrellaLabel fill:#666666,fill-opacity:0.3,stroke:#666,stroke-width:1px,color:#000,rx:5,ry:5,text-align:center;
classDef subgraphStyle fill:#f9f9f9,fill-opacity:0.1,stroke:#ccc,stroke-width:1px;
subgraph ExternalActors [External actors]
direction TB
User[User]
Machine[Machine]
end
class User,Machine actor;
class ExternalActors subgraphStyle;
UmbrellaDesc["Raw instrument data,<br>annotations, connections"]
class UmbrellaDesc umbrellaLabel;
subgraph ClientInterfaces [Client interfaces]
direction TB
BrowserApp[_datalab_<br>Browser app]
PythonAPI[_datalab_<br>Python API]
end
class BrowserApp,PythonAPI clientInterface;
class ClientInterfaces subgraphStyle;
subgraph Backend
direction TB
RESTAPI[_datalab_<br>REST API]
MongoDB[MongoDB Database]
DataLake[Data Lake]
end
class RESTAPI,MongoDB,DataLake coreComponent;
class Backend subgraphStyle;
User <-- "User data I/O" --> UmbrellaDesc;
Machine <-- "Machine data I/O" --> UmbrellaDesc;
UmbrellaDesc <-- "_via_ GUI" --> BrowserApp;
UmbrellaDesc <-- "_via_ scripts" --> PythonAPI;
BrowserApp <-- "HTTP (Data exchange)" --> RESTAPI;
PythonAPI <-- "API calls (Data exchange)" --> RESTAPI;
RESTAPI <-- "Annotations, connections" --> MongoDB;
RESTAPI <-- "Raw and structured characterisation data" --> DataLake;
linkStyle 0 stroke:#666,stroke-width:3px
linkStyle 1 stroke:#666,stroke-width:3px
linkStyle 2 stroke:#666,stroke-width:3px
linkStyle 3 stroke:#666,stroke-width:3px
linkStyle 4 stroke:#666,stroke-width:3px
linkStyle 5 stroke:#666,stroke-width:3px
linkStyle 6 stroke:#666,stroke-width:3px
linkStyle 7 stroke:#666,stroke-width:3px
click PythonAPI "https://github.com/datalab-org/datalab-api" "datalab Python API on GitHub" _blank
click BrowserApp "https://github.com/datalab-org/datalab/tree/main/webapp" "datalab Browser App on GitHub" _blank
click RESTAPI "https://github.com/datalab-org/datalab/tree/main/pydatalab" "pydatalab REST API on GitHub" _blank
```
</center>
The main aim of *datalab* is to provide a platform for capturing the significant amounts of long-tail experimental data and metadata produced in a typical lab, and enable storage, filtering and future data re-use by humans and machines. *datalab* is targeted (broadly) at materials chemistry labs but with customisability and extensability in mind.
The platform provides researchers with a way to record sample- and cell-specific metadata, attach and sync raw data from instruments, and perform analysis and visualisation of many characterisation techniques in the browser (XRD, NMR, electrochemical cycling, TEM, TGA, Mass Spec, Raman).
Importantly, *datalab* stores a network of interconnected research objects in the lab, such that individual pieces of data are stored with the context needed to make them scientifically useful.
## License
This software is released under the conditions of the MIT license.
Please see [LICENSE](./LICENSE) for the full text of the license.
## Contact
We are available for consultations on setting up and managing *datalab* deployments, as well as collaborating on or sponsoring additions of new features and techniques. Please contact Josh or Matthew on their academic emails, or join the [public *datalab* Slack workspace](https://join.slack.com/t/datalab-world/shared_invite/zt-2h58ev3pc-VV496~5je~QoT2TgFIwn4g).
## Contributions
This software was conceived and developed by:
- [Prof Joshua Bocarsly](https://jdbocarsly.github.io) ([Department of Chemistry, University of Houston](https://www.uh.edu/nsm/chemistry), previously [Department of Chemistry, University of Cambridge](https://www.ch.cam.ac.uk/))
- [Dr Matthew Evans](https://ml-evs.science) ([Department of Chemistry, University of Cambridge](https://www.ch.cam.ac.uk/), previously [MODL-IMCN,
UCLouvain](https://uclouvain.be/en/research-institutes/imcn/modl) & [Matgenix](https://matgenix.com))
with support from the group of [Professor Clare Grey](https://grey.group.ch.cam.ac.uk/group) (University of Cambridge), and major contributions from:
- [Benjamin Charmes](https://github.com/BenjaminCharmes)
- [Dr Ben Smith](https://github.com/be-smith/)
- [Dr Yue Wu](https://github.com/yue-here)
plus many contributions, feedback and testing performed by other members of the community, in particular, the groups of [Prof Matt Cliffe](https://cliffegroup.co.uk) (University of Cambridge) and [Dr Peter Kraus](https://www.tu.berlin/en/concat) (TUBerlin) and the company [Matgenix SRL](https://matgenix.com).
A full list of code contributions can be found on [GitHub](https://github.com/datalab-org/datalab/graphs/contributors).
## Funding
Contributions to _datalab_ have been supported by a mixture of academic funding and consultancy work through [_datalab industries ltd_](https://datalab.industries).
In particular, the developers thank:
- Initial proof-of-concept funding from the European Union's Horizon 2020 research and innovation programme under grant agreement 957189 (DOI: [10.3030/957189](https://doi.org/10.3030/957189)), the [Battery Interface Genome - Materials Acceleration Platform (BIG-MAP)](https://www.big-map.eu), as an external stakeholder project.
- The [Faraday Institution](https://www.faraday.ac.uk) CATMAT project (FIRG016) for support of Dr Joshua Bocarsly during initial development of *datalab*.
- The [Leverhulme Trust](https://leverhulme.ac.uk) and [Isaac Newton Trust](https://newtontrust.cam.ac.uk) for support provided by an early career fellowship for Dr Matthew Evans.
| text/markdown | null | datalab development team <dev@datalab-org.io> | null | null | null | research data management, materials, chemistry | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Intended Audience :: Science/Research",
"Intended Audience :: Information Technology",
"Topic :: Scientific/Engineering"
] | [] | null | null | <3.12,>=3.10 | [] | [] | [] | [
"bokeh<3.0,~=2.4",
"matplotlib~=3.8",
"periodictable~=1.7",
"pydantic[dotenv,email]<2.0",
"pint~=0.24",
"pandas[excel]~=2.2",
"pymongo~=4.7",
"deepdiff~=8.1",
"Flask~=3.0; extra == \"server\"",
"Flask-Login~=0.6; extra == \"server\"",
"Flask-Cors~=6.0; extra == \"server\"",
"Flask-Dance~=7.1; ... | [] | [] | [] | [
"homepage, https://github.com/datalab-org/datalab",
"repository, https://github.com/datalab-org/datalab",
"documentation, https://docs.datalab-org.io",
"changelog, https://github.com/datalab-org/datalab/releases"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:58:57.207359 | datalab_server-0.7.0rc3.tar.gz | 5,646,017 | 51/c5/58473e0324349b3f23b13aa5c1a0d49c058b09cf9e98aab4bc326d4f1e8d/datalab_server-0.7.0rc3.tar.gz | source | sdist | null | false | fed87e092363fe3c1b322d99fb476fff | 6e12127288660a8018638e946a0fba900833c9d8ffbaf8af6d7dab77137b5233 | 51c558473e0324349b3f23b13aa5c1a0d49c058b09cf9e98aab4bc326d4f1e8d | MIT | [] | 196 |
2.4 | keychains | 0.1.12 | Python SDK for Keychains.dev — credential proxy for API calls | # keychains
Minimal Python SDK for making authenticated API calls through the [Keychains.dev](https://keychains.dev) proxy. Your code never touches real credentials — the proxy injects them at runtime.
## Quickstart
### 1. Install
```bash
pip install keychains
```
### 2. Run with a fresh token
The `keychains token` command registers your machine (if needed), creates a wildcard permission, and mints a short-lived proxy token — all in one step:
```bash
KEYCHAINS_TOKEN=$(npx -y keychains token) \
python your_script.py
```
### 3. Write your script
Use `keychains.get()` as a drop-in replacement for `requests.get()`. The only difference? You can replace any credential with a template variable:
```python
import keychains
# Gmail — get last 10 emails from my inbox
response = keychains.get(
"https://gmail.googleapis.com/gmail/v1/users/me/messages?maxResults=10",
headers={
"Authorization": "Bearer {{OAUTH2_ACCESS_TOKEN}}",
},
)
emails = response.json()
print(emails)
```
That's it. The proxy resolves `{{OAUTH2_ACCESS_TOKEN}}` with the user's real Google OAuth token — your code never sees it.
### Running multiple scripts
Tokens expire after **15 minutes**. To reuse the same token across multiple commands in a shell session, use `eval`:
```bash
eval $(npx -y keychains token --env)
# KEYCHAINS_TOKEN is now set for the next 15 minutes
python script_a.py
python script_b.py
```
---
## Template Variables
### How to write them
Template variables use the `{{VARIABLE_NAME}}` syntax. The variable name tells the proxy which type of credential to inject:
| Prefix | Type | Supported Variables |
|--------|------|---------------------|
| `OAUTH2_` | OAuth 2.0 token | `{{OAUTH2_ACCESS_TOKEN}}`, `{{OAUTH2_REFRESH_TOKEN}}` |
| `OAUTH1_` | OAuth 1.0 token | `{{OAUTH1_ACCESS_TOKEN}}`, `{{OAUTH1_REQUEST_TOKEN}}` |
| Anything else | API key | `{{LIFX_PERSONAL_ACCESS_TOKEN}}`, `{{OPENAI_API_KEY}}`, etc. |
### Where to put them
Place them exactly where you'd normally put the real credential — **headers**, **body**, or **query parameters**:
```python
import keychains
# In a header (most common)
response = keychains.get(
"https://api.lifx.com/v1/lights/all",
headers={"Authorization": "Bearer {{LIFX_PERSONAL_ACCESS_TOKEN}}"},
)
# In the request body
response = keychains.post(
"https://slack.com/api/chat.postMessage",
headers={
"Authorization": "Bearer {{OAUTH2_ACCESS_TOKEN}}",
"Content-Type": "application/json",
},
json={"channel": "#general", "text": "Hello!"},
)
# In query parameters
response = keychains.get(
"https://api.example.com/data?api_key={{MY_API_KEY}}&format=json",
)
```
---
## What Happens Next
When you call `keychains.get()`:
1. **URL rewriting** — `https://api.lifx.com/v1/lights/all` becomes `https://keychains.dev/api.lifx.com/v1/lights/all`
2. **Token injection** — your proxy token is sent via `X-Proxy-Authorization` so the proxy knows who you are
3. **Scope check** — the proxy verifies the user has approved the required credentials for this API
4. **Credential resolution** — the proxy replaces `{{LIFX_PERSONAL_ACCESS_TOKEN}}` with the real API key stored in the user's vault
5. **Request forwarding** — the proxy forwards the request to the upstream API with real credentials injected
6. **Response passthrough** — the upstream response is returned to you as-is
### Handling missing approvals
With wildcard permissions, users approve scopes on demand. The first time your code hits a new API, the user may not have approved it yet. When that happens, the SDK raises an `ApprovalRequired` exception containing an `approval_url` — share it with the user so they can grant access:
```python
import keychains
from keychains.exceptions import ApprovalRequired
try:
response = keychains.get(
"https://api.github.com/user",
headers={"Authorization": "Bearer {{OAUTH2_ACCESS_TOKEN}}"},
)
print(response.json())
except ApprovalRequired as err:
# The user hasn't approved GitHub yet — show them the link
print("Please approve access:", err.approval_url)
# Once approved, retry the same call and it will succeed
```
The exception includes useful details:
| Property | Type | Description |
|-----------------|------------------|-------------|
| `approval_url` | `str \| None` | URL the user should visit to approve the missing scopes |
| `missing_scopes`| `list[str] \| None` | Scopes that need approval |
| `refused_scopes`| `list[str] \| None` | Scopes explicitly refused by the user |
| `code` | `str` | Error code (`insufficient_scope`, `scope_refused`, `permission_denied`, etc.) |
---
## Session (Connection Pooling)
For multiple requests, use `Session` to reuse connections — just like `requests.Session`:
```python
import keychains
with keychains.Session() as s:
s.headers.update({"Authorization": "Bearer {{OAUTH2_ACCESS_TOKEN}}"})
repos = s.get("https://api.github.com/user/repos")
for repo in repos.json():
issues = s.get(f"https://api.github.com/repos/{repo['full_name']}/issues")
print(f"{repo['name']}: {len(issues.json())} issues")
```
## Async
For asyncio codebases, use `AsyncClient`:
```python
import keychains
async with keychains.AsyncClient() as client:
response = await client.get("https://api.github.com/user/repos")
repos = response.json()
```
---
## Configuration
The SDK automatically loads variables from a `.env` file in your working directory (via [python-dotenv](https://pypi.org/project/python-dotenv/)).
| Environment variable | Description |
| --- | --- |
| `KEYCHAINS_TOKEN` | Proxy token — a JWT minted by `npx -y keychains token` |
Tokens can also be passed explicitly:
```python
keychains.get(url, token="ey...")
keychains.Session(token="ey...")
keychains.AsyncClient(token="ey...")
```
### Security benefits
- Secrets never leave the Keychains.dev servers — your code, logs, and environment stay clean
- Users approve exactly which scopes and APIs an agent can access
- Credentials can only be sent to the APIs of the providers they belong to
- Every proxied request is audited with full traceability
- Permissions can be revoked instantly from the [dashboard](https://keychains.dev/dashboard)
---
## Bug Reports & Feedback
Found a bug or have a suggestion? Submit it straight from your terminal:
```bash
# Report a bug
npx -y keychains feedback "The proxy returns 502 on large POST bodies"
# Send feedback
npx -y keychains feedback --type feedback "Love the wildcard permissions!"
# With more detail
npx -y keychains feedback --type bug \
--title "502 on large POST" \
--description "When sending >1MB body to Slack API..." \
--contact you@example.com
```
The `keychains feedback` command (alias: `keychains bug`) sends your report directly to the engineering team.
---
## More Info
Let's meet on [keychains.dev](https://keychains.dev)!
| text/markdown | Keychains.dev | null | null | null | null | api, credentials, keychains, oauth, proxy | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.27",
"python-dotenv>=1.0",
"anyio[trio]>=4; extra == \"test\"",
"pytest-anyio>=0.0.0; extra == \"test\"",
"pytest>=8; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://keychains.dev",
"Repository, https://github.com/keychains-dev/keychains-python",
"Documentation, https://keychains.dev/docs/python"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T14:57:56.501704 | keychains-0.1.12.tar.gz | 9,953 | 14/3d/3ec6d9a67e203ca0436ed808e6f5ca09dd8f0a49e67577ccf946756947c5/keychains-0.1.12.tar.gz | source | sdist | null | false | d4253cc699abf44a4f451446979c57b0 | c3fd675607e471eacf6cdd227c5b0c3b08e8047b1af03920bd894c9b1712056d | 143d3ec6d9a67e203ca0436ed808e6f5ca09dd8f0a49e67577ccf946756947c5 | MIT | [] | 218 |
2.4 | rhino-takeoff | 0.1.4 | Automated Quantity Takeoff & ZEB Certification Library for Grasshopper/Rhino 3D Models | # Rhino-Takeoff



**Automated Quantity Takeoff & ZEB Certification Library for Grasshopper/Rhino 3D Models.**
`rhino-takeoff` automates the extraction of architectural quantities (Area, Volume, Length) from Rhino/Grasshopper models and generates Excel reports compliant with the **Korean ZEB (Zero Energy Building) Certification Standards (2025)**.
It is designed to bridge the gap between complex BIM geometry and standardized certification requirements, handling everything from geometry processing to validatable Excel output.
## Installation
```bash
pip install rhino-takeoff
```
For pandas support:
```bash
pip install "rhino-takeoff[pandas]"
```
## Usage
### 1. Extracting Quantities
Use the `Extractor` to calculate precise quantities from Rhino objects. It handles both mesh-based (rhino3dm) and solid-based (RhinoCommon) calculations automatically.
```python
import rhino3dm
from rhino_takeoff import Extractor, Classifier
# Load your model
model = rhino3dm.File3dm.Read("project.3dm")
objects = model.Objects
# 1. Classify objects by layer/geometry
clf = Classifier()
classified = clf.classify_all(objects)
# 2. Extract quantities (Area in m²)
ext = Extractor()
results = ext.batch(objects, measure="area", unit="m2")
for res in results[:3]:
print(f"{res['id']}: {res['value']:.2f} m²")
```
### 2. Generating ZEB Reports
Generate a certification-ready report by combining extracted data with project energy metrics.
```python
from rhino_takeoff.zeb import ZEBReport
# Initialize report
report = ZEBReport(project_name="Gangnam Office Tower")
# Set energy performance metrics (kWh/m²/year)
report.set_energy_consumption(primary_energy_kwh_m2_y=150.0, floor_area_m2=3000.0)
report.set_renewable_production(renewable_primary_energy_kwh_m2_y=35.0)
# Calculate Energy Independence Rate
rate = report.calc_energy_independence_rate() # e.g., 23.33%
grade = report.get_achievable_grade() # e.g., "ZEB_5"
print(f"Independence Rate: {rate}%, Grade: {grade}")
# report.export_excel("ZEB_Report_2025.xlsx")
```
## Features
- **Geometry Processing**:
- Accurate mesh area calculation using cross-product integration.
- Automatic solid/mesh conversion depending on the environment (Rhino vs. CI/CD).
- **Smart Deduplication**:
- Automatically helps removing overlapping volume/area between standard building elements (e.g., Column vs. Wall).
- Uses specialized 2D projection logic for performance.
- **ZEB Certification**:
- Built-in logic for the latest Korean ZEB certification standards.
- Auto-grading (1 to 5) based on energy independence rates.
- **Excel Output**:
- Preserves existing formatting and formulas in template files.
## Project Structure
- `rhino_takeoff.extractor`: Geometry extraction core.
- `rhino_takeoff.dedup`: Geometry intersection and deduplication logic.
- `rhino_takeoff.zeb`: ZEB certification logic and standards data.
- `rhino_takeoff.excel_io`: Excel file handling.
## License
MIT License. See [LICENSE](LICENSE) for details.
| text/markdown | null | Sungjun Son <sjson666@gmail.com> | null | null | null | rhino, grasshopper, bim, takeoff, quantity, zeb, energy | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Py... | [] | null | null | >=3.9 | [] | [] | [] | [
"rhino3dm>=8.0.0",
"openpyxl>=3.1.0",
"pydantic>=2.0.0",
"shapely>=2.0.0",
"pandas>=2.0.0; extra == \"pandas\"",
"pytest>=7.0; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"pytest-mock; extra == \"test\"",
"ruff; extra == \"dev\"",
"mypy; extra == \"dev\"",
"build; extra == \"dev\"",
"... | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.0 | 2026-02-19T14:57:17.936239 | rhino_takeoff-0.1.4.tar.gz | 20,303 | af/2e/94ab4a31e6784dada448e62760a959eda1ba3049e9811f481fcb91432685/rhino_takeoff-0.1.4.tar.gz | source | sdist | null | false | 03078d908bc6469d5a94ee219f19702e | fada929271679ce7a5d990a1251a4e98c64b2e2f1f563fe1f8c0aba89db9d114 | af2e94ab4a31e6784dada448e62760a959eda1ba3049e9811f481fcb91432685 | null | [] | 214 |
2.4 | fiat-toolbox | 0.1.23 | A collection of modules for post-processing Delft-FIAT output. | Delft-FIAT Toolbox
------------------
This toolbox contains post-processing modules for Delft-FIAT output.
Installation
============
Fiat toolbox uses [uv](https://docs.astral.sh/uv/) to build and manage python environments.
If you do not have `uv` installed, you can install it using `pip install uv`.
- Install with: `uv sync`
- Run the tests with: `uv run pytest`
- Run the linter with: `uv run pre-commit run --all-files`
Modules:
metrics_writer
==============
This module contains functions to write out custom aggregated metrics from Delft-FIAT output for the whole model an/or different aggregation levels.
infographics
============
This module contains functions to write customized infographics in html format using metric files .
spatial_output
==============
This module contains functions to aggregate point output from FIAT to building footprints. Moreover, it has methods to join aggregated metrics to spatial files.
equity
======
This module contains functions to calculate equity weights and equity weighted risk metrics based on socio-economic inputs at an aggregation level.
well_being
==================
This module contains functions to estimate household level well-being impacts.
| text/markdown | null | Panos Athanasiou <Panos.Athanasiou@deltares.nl>, Luuk Blom <Luuk.Blom@deltares.nl>, Sarah Rautenbach <sarah.rautenbach@deltares.nl>, Daley Adrichem <Daley.Adrichem@deltares.nl> | null | null | MIT License
Copyright (c) 2023 Deltares
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | null | [
"Intended Audience :: Science/Research",
"License :: CC0 1.0 Universal (CC0 1.0) Public Domain Dedication",
"Topic :: Scientific/Engineering :: Hydrology"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"duckdb<1.3,>=1.0",
"geopandas",
"matplotlib",
"numpy",
"numpy<2.0",
"pandas",
"parse",
"pillow",
"plotly",
"pydantic",
"scipy",
"seaborn",
"toml",
"tomli",
"validators",
"pre-commit; extra == \"lint\"",
"ruff; extra == \"lint\"",
"pytest; extra == \"test\"",
"pytest-cov; extra =... | [] | [] | [] | [
"Source, https://github.com/Deltares/fiat_toolbox"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:56:57.077038 | fiat_toolbox-0.1.23.tar.gz | 1,442,062 | 4a/16/787c42d808e88d13708860d27b5fd08e141308a7b9540818ee0385853845/fiat_toolbox-0.1.23.tar.gz | source | sdist | null | false | 5ca1ad4c159f55e18cff9f85b624fab1 | eca128412e6be5d33cf5b6693bedd1ad6098fc917dac193a1c461458b7affbc3 | 4a16787c42d808e88d13708860d27b5fd08e141308a7b9540818ee0385853845 | null | [
"LICENSE"
] | 307 |
2.4 | fastfuels-sdk | 0.18.1 | 3D Fuels for Next Generation Fire Models | # Python SDK for the FastFuels API
## Quick-Links
[Documentation](https://silvxlabs.github.io/fastfuels-sdk-python/) - [PyPi Package](https://pypi.org/project/fastfuels-sdk/) - [Project Description](https://www.firelab.org/project/fastfuels-3d-fuels-next-generation-fire-models)
## What is FastFuels?
FastFuels is an innovative solution that propels the use of advanced 3D fire
models into the future of fire and fuels management. It acts as a "3D fuels
superhighway," seamlessly merging existing data sources with cutting-edge
modeling to produce the detailed 3D fuel data required by these models. With
its unique ability to generate and manage comprehensive fuels data for large
areas, FastFuels enhances the precision and context of fire behavior insights
and management strategies. Moreover, it encourages the incorporation of new
data sources and techniques in the field, ensuring its relevance and
adaptability in the dynamic landscape of remote sensing and wildland fuels
science. Stay tuned as we continue to develop and refine FastFuels, paving the
way for next-generation fire models.
Read more here: https://www.firelab.org/project/fastfuels-3d-fuels-next-generation-fire-models
## What is the FastFuels API?
The FastFuels API is a RESTful web service that allows users to access
FastFuels data products and services.
## How do I use the FastFuels API?
The API can be accessed using any HTTP client, such as curl, wget, or a
web browser at this address: https://fastfuels.silvx.io
## What is the FastFuels Python SDK?
The FastFuels Python SDK is a Python package that provides a convenient
interface to the FastFuels API. It allows users to access FastFuels data
products in a familiar Python environment.
### Installation
The FastFuels Python SDK can be installed using pip:
```bash
pip install fastfuels-sdk
```
### Documentation
Documentation for the FastFuels Python SDK can be found here: https://silvxlabs.github.io/fastfuels-sdk-python/
Additional examples can be found in the following repository: https://github.com/silvxlabs/demos
| text/markdown | null | null | null | null | MIT | null | [
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language ::... | [] | https://github.com/silvxlabs/fastfuels-sdk-python | null | >=3.9 | [] | [] | [] | [
"geopandas",
"numpy",
"pandas",
"pydantic>=2",
"requests",
"scipy",
"urllib3>=2.1.0",
"zarr"
] | [] | [] | [] | [
"Bug Tracker, https://github.com/silvxlabs/fastfuels-sdk-python/issues"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T14:56:42.190988 | fastfuels_sdk-0.18.1.tar.gz | 204,505 | 79/c4/570c6da10f0be4e981ec54946439fc73ee963d7140b4f955dea2299b49df/fastfuels_sdk-0.18.1.tar.gz | source | sdist | null | false | 0aac43cf25f3bd40c6f596caf9663f10 | 12ff4a1f1fbe51cacdc73e6472176a00b2cbb5f5264629841972bd2544f7d6c1 | 79c4570c6da10f0be4e981ec54946439fc73ee963d7140b4f955dea2299b49df | null | [
"LICENSE"
] | 232 |
2.4 | kinto | 25.0.0 | Kinto Web Service - Store, Sync, Share, and Self-Host. | Kinto
=====
|coc| |gitter| |readthedocs| |pypi| |ci| |main-coverage|
.. |coc| image:: https://img.shields.io/badge/%E2%9D%A4-code%20of%20conduct-blue.svg
:target: https://github.com/Kinto/kinto/blob/main/.github/CODE_OF_CONDUCT.md
:alt: Code of conduct
.. |gitter| image:: https://badges.gitter.im/Kinto/kinto.svg
:target: https://gitter.im/Kinto/kinto
.. |ci| image:: https://github.com/Kinto/kinto/actions/workflows/test.yml/badge.svg
:target: https://github.com/Kinto/kinto/actions
.. |readthedocs| image:: https://readthedocs.org/projects/kinto/badge/?version=latest
:target: https://kinto.readthedocs.io/en/latest/
:alt: Documentation Status
.. |main-coverage| image::
https://coveralls.io/repos/Kinto/kinto/badge.svg?branch=main
:alt: Coverage
:target: https://coveralls.io/r/Kinto/kinto
.. |pypi| image:: https://img.shields.io/pypi/v/kinto.svg
:target: https://pypi.python.org/pypi/kinto
Kinto is a minimalist JSON storage service with synchronisation and sharing abilities.
* `Online documentation <https://kinto.readthedocs.io/en/latest/>`_
* `Tutorial <https://kinto.readthedocs.io/en/latest/tutorials/first-steps.html>`_
* `Issue tracker <https://github.com/Kinto/kinto/issues>`_
* `Contributing <https://kinto.readthedocs.io/en/latest/community.html#how-to-contribute>`_
* `Docker Hub <https://hub.docker.com/r/kinto/kinto-server>`_
Requirements
------------
* **Python**: 3.10+
* **Backends**: In-memory (development), PostgreSQL 9.5+ (production)
Contributors
============
* Aaron Egaas <me@aaronegaas.com>
* Adam Chainz <adam@adamj.eu>
* Aditya Bhasin <conlini@gmail.com>
* Aiman Parvaiz <aimanparvaiz@gmail.com>
* Ajey B. Kulkarni <bkajey@gmail.com>
* Anh <anh.trinhtrung@gmail.com>
* Alexander Ryabkov <alexryabkov@gmail.com>
* Alexis Metaireau <alexis@mozilla.com>
* Alex Cottner <acottner@mozilla.com>
* Andy McKay <amckay@mozilla.com>
* Anthony Garuccio <garuccio124@gmail.com>
* Aymeric Faivre <miho@miho-stories.com>
* Ayush Sharma <ayush.aceit@gmail.com>
* Balthazar Rouberol <br@imap.cc>
* Boris Feld <lothiraldan@gmail.com>
* Brady Dufresne <dufresnebrady@gmail.com>
* Can Berk Güder <cbguder@mozilla.com>
* CHEN, CHIH-HSI <chenbrian930427@gmail.com>
* Castro
* Chirag B. Jadwani <chirag.jadwani@gmail.com>
* Christophe Gragnic <cgragnic@protonmail.com>
* Clément Villain <choclatefr@gmail.com>
* Dan Phrawzty <phrawzty+github@gmail.com>
* David Larlet <david@larlet.fr>
* Emamurho Ugherughe <emamurho@gmail.com>
* Enguerran Colson <enguerran@ticabri.com>
* Eric Bréhault <ebrehault@gmail.com>
* Eric Le Lay <elelay@macports.org>
* Éric Lemoine <eric.lemoine@gmail.com>
* Ethan Glasser-Camp <ethan@betacantrips.com>
* Étienne <@Étienne>
* Eugene Kulak <kulak.eugene@gmail.com>
* Fil <fil@rezo.net>
* FooBarQuaxx
* Francisco J. Piedrahita <@fpiedrah>
* Frank Bertsch <frank@mozilla.com>
* Greeshma <greeshmabalabadra@gmail.com>
* Gabriela Surita <gabsurita@gmail.com>
* George Smith <h3rmit@protonmail.com>
* Graham Beckley <gbeckley@mozilla.com>
* Greg Guthe <gguthe@mozilla.com>
* Haseeb Majid <hmajid2301@gmail.com>
* Heron Rossi <heron.rossi@hotmail.com>
* Hiromipaw <silvia@nopressure.co.uk>
* Indranil Dutta <duttaindranil497@gmail.com>
* Itai Steinherz <itaisteinherz@gmail.com>
* Jelmer van der Ploeg <jelmer@woovar.com>
* Joël Marty <@joelmarty>
* John Giannelos <johngiannelos@gmail.com>
* Joshua Bird <joshua.thomas.bird@gmail.com>
* Julien Bouquillon <contact@revolunet.com>
* Julien Lebunetel <julien@lebunetel.com>
* Kaloneh <kaloneh@gmail.com>
* Kulshekhar Kabra <@kulshekhar>
* Lavish Aggarwal <lucky.lavish@gmail.com>
* Maksym Shalenyi <supamaxy@gmail.com>
* Manas Mangaonkar <@Pac23>
* Mansimar Kaur <mansimarkaur.mks@gmail.com>
* Masataka Takeuchi <masataka.takeuchi@l-is-b.com>
* Mathieu Agopian <mathieu@agopian.info>
* Mathieu Leplatre <mathieu@mozilla.com>
* Matt Boris <mboris@mozilla.com>
* Maxime Warnier <marmax@gmail.com>
* Michael Charlton <m.charlton@mac.com>
* Michiel de Jong <michiel@unhosted.org>
* Mo Valipour <valipour@gmail.com>
* Mozillazg
* Nicolas Hoizey <nicolas@hoizey.com>
* Nicolas Perriault <nperriault@mozilla.com>
* Niraj <https://github.com/niraj8>
* Oron Gola <oron.golar@gmail.com>
* Palash Nigam <npalash25@gmail.com>
* Pascal Roessner <roessner.pascal@gmail.com>
* PeriGK <per.gkolias@gmail.com>
* Peter Bengtsson <mail@peterbe.com>
* Peter Rassias <ubcpeter@hotmail.com>
* realsumit <sumitsarinofficial@gmail.com>
* Rektide <rektide@voodoowarez.com>
* Rémy Hubscher <rhubscher@mozilla.com>
* Renisha Nellums <r.nellums@gmail.com>
* Ricardo <@rkleine>
* Rodolphe Quiédeville <rodolphe@quiedeville.org>
* Sahil Dua <sahildua2305@gmail.com>
* Sambhav Kothari <sambhavs.email@gmail.com>
* Sebastian Rodriguez <srodrigu85@gmail.com>
* Sergey Maranchuk <https://github.com/slav0nic/>
* Stanisław Wasiutyński <https://github.com/stanley>
* Stephen Daves <contact@stephendaves.com>
* Stephen Donner <stephen.donner@gmail.com>
* Stephen Martin <lockwood@opperline.com>
* Shweta Oak <oakshweta11@gmail.com>
* Sofia Utsch <sofia.utsch@gmail.com>
* Sumit Sarin <sumitsarinofficial@gmail.com>
* Sunakshi Tejwani <sunakshitejwani@gmail.com>
* Surya Prashanth <prashantsurya@ymail.com>
* SwhGo_oN <@swhgoon>
* Tarek Ziade <tarek@mozilla.com>
* Taus Brock-Nannestad <taus@semmle.com>
* Taylor Zane Glaeser <tzglaeser@gmail.com>
* Thomas Dressler <Thomas.Dressler1@gmail.com>
* Tiberiu Ichim <@tiberiuichim>
* Vamsi Sangam <vamsisangam@live.com>
* Varna Suresh <varna96@gmail.com>
* Vincent Fretin <@vincentfretin>
* Vitor Falcao <vitor.falcaor@gmail.com>
* Wil Clouser <wclouser@mozilla.com>
* Yann Klis <yann.klis@gmail.com>
* Jeff Schobelock <jswhatnot15@gmail.com>
* Shivasheesh Yadav <shivasheeshyadav@gmail.com>
* Fabian Chong <@feiming>
* Dan Milgram <danm@intervivo.com>
* Dex Devlon <@bxff>
* Varun Koranne <@varun-dhruv>
* Robin Sharma <robinrythm123@gmail.com>
| text/x-rst | null | Mozilla Services <developers@kinto-storage.org> | null | null | Copyright 2012 - Mozilla Foundation
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| web, sync, json, storage, services | [
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: Implementation :: CPython",
... | [] | null | null | null | [] | [] | [] | [
"bcrypt",
"colander",
"dockerflow",
"jsonschema",
"jsonpatch",
"logging-color-formatter",
"python-dateutil",
"pyramid",
"pyramid_multiauth",
"transaction",
"pyramid_tm",
"requests",
"waitress",
"python-rapidjson",
"python-memcached; extra == \"memcached\"",
"redis; extra == \"redis\"",... | [] | [] | [] | [
"Repository, https://github.com/Kinto/kinto"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:56:33.179552 | kinto-25.0.0.tar.gz | 2,272,577 | b7/a2/636befdfa9dc5af1681b7eb2b7e77d7c3ddc84a7abcb769ad241a67a752e/kinto-25.0.0.tar.gz | source | sdist | null | false | 11a1b5178efd7343f895f1e7c807008c | 152e50e753864dcfa561a7537f127a6cc86a236cea2ac989700211ccc9b3e480 | b7a2636befdfa9dc5af1681b7eb2b7e77d7c3ddc84a7abcb769ad241a67a752e | null | [
"LICENSE"
] | 388 |
2.4 | smpl-rs | 0.9.0 | A suite of SMPL functionality written over gloss | <div align="center">
# 🚶♂️ SMPL-rs
**Smpl-rs is the suite of SMPL functionality implemented in Rust over [gloss](https://github.com/Meshcapade/gloss). It has features for creating smpl-bodies, modifying and rendering them**
[](https://crates.io/crates/smpl-rs)
[](https://pypi.org/project/smpl-rs/)
[](https://github.com/Meshcapade/smpl-rs/LICENSE)
<img alt="SMPL-rs Banner" src="https://raw.githubusercontent.com/Meshcapade/smpl-rs/main/imgs/banner.png">
</div>
## Features
- Run forward passes through SMPL models (betas -> mesh)
- Modify betas and expression parameters of the SMPL model in real time
- Interfaces with [gloss](https://github.com/Meshcapade/gloss) for rendering meshes both in native and web
<div align="center">
<p align="middle">
<img src="https://raw.githubusercontent.com/Meshcapade/smpl-rs/main/imgs/smpl.png" width="700"/>
</p>
</div>
## Documentation
* [smpl-rs Rust API Documentation](https://docs.rs/smpl-rs/latest/smpl_rs/): Automatically generated docs for smpl-rs's Rust API
* [smpl-rs Rust Examples](https://github.com/Meshcapade/smpl-rs/tree/main/examples): smpl-rs's runnable examples in Rust, covering basic usage.
* [smpl-rs Python Examples](https://github.com/Meshcapade/smpl-rs/tree/main/bindings/smpl_py/examples): smpl-rs's runnable examples for the Python bindings. Covers a wide range of features of the Python bindings.
## Getting Started
The easiest way to get started with smpl-rs is to install the Python bindings.
```sh
$ pip install smpl-rs
```
Some examples of how to use the python bindings can be found in the python examples linked above.
## Data
To use smpl-rs you need to download the SMPL-X data.
* Download the models from [here](https://smpl-x.is.tue.mpg.de/download.php) (Download SMPL-X with removed headbun NPZ).
* After this change the paths in the `misc_scripts/standardize_smpl.py` file to the path where you downloaded the models and where you want to save the standardized models. You will need some additional files provided in the `data/smplx` folder.
* Then run as `python misc_scripts/standardize_smpl.py` to standardize the models. Lazy loading will need to be set to the path where you saved the standardized models.
## Installation and Dependencies
The main dependency is [gloss](https://github.com/Meshcapade/gloss) which will be downloaded and compiled automatically when building this package. You will need rust, and the rest is handled by cargo. To install Rust, simply run the following in your terminal:
```sh
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
```
Some additional dependencies for Linux:
```sh
$ sudo apt-get install libvulkan-dev vulkan-tools xorg-dev libxkbcommon-x11-dev
```
For `MacOs`, it should run out of the box.
### For running the Rust examples
```sh
$ cd smpl-rs
$ cargo run --bin smpl_minimal
```
### For running the Python examples
```sh
$ cd smpl-rs/bindings/smpl_py
$ pip install gloss-rs smpl-rs
$ ./examples/minimal.py
```
<!-- ### Build a
First install necessary dependencies
```sh
$ sudo apt install nodejs npm
```
```sh
$ cd smpl-rs/examples/web/visualizer
$ wasm-pack build --target web
$ npm i
```
To run the web example we can create a dummy web server by opening another terminal and running:
```sh
$ cd smpl-rs/examples/web/visualizer
$ npm run start
# $ python -m http.server
```
<!-- Finally navigate to `http://0.0.0.0:8000/smpl_webpage/` in your browser of choice. -->
<!-- Finally navigate to `http://localhost:3000/` in your browser of choice. -->
<!-- ## Examples
Various examples can be found in the ./examples folder.\
You can run each one of them using
```sh
$ cargo run --bin <example_name>
```
## React
Please read the file `examples/web/visualizer/README.md` -->
## Quick useful commands
- Run performance tests: `cargo bench -p smpl-core --benches`
## Some more Information
- The SMPL suite renders using [gloss](https://github.com/Meshcapade/gloss) and therefore uses an Entity-Component-System (ECS) framework. For more info on ECS check [here](https://bevyengine.org/learn/book/getting-started/ecs/). However to be noted that we use [Hecs] for our ECS system but most of them are very similar.
- Components like Animation and Betas are added to entities and that dictates which systems it uses. If you don't want animation on the avatar, just comment out the component for it when creating the entity.
- For adding new functionality to [gloss](https://github.com/Meshcapade/gloss) we use callbacks. This is needed because on WASM the rendering loop cannot be explictly controlled.
| text/markdown; charset=UTF-8; variant=GFM | Radu Alexandru Rosu <alex@meshcapade.com>, Aman Shenoy <aman@meshcapade.com> | Radu Alexandru Rosu <alex@meshcapade.com>, Aman Shenoy <aman@meshcapade.com> | null | null | MIT | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"gloss-rs>=0.5.0; extra == \"gloss\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.12 | 2026-02-19T14:55:47.471078 | smpl_rs-0.9.0-pp39-pypy39_pp73-win_amd64.whl | 6,999,630 | ab/27/d237216713aa8f0ac7b3f188c44b55f0a5541e6fe6c916c2600a24225ac2/smpl_rs-0.9.0-pp39-pypy39_pp73-win_amd64.whl | pp39 | bdist_wheel | null | false | bb181ff4f6f8d8da810ca6276953fbf7 | 2904cceccf1b95f6c9fcb1110128cedec2ccf664c9318d9bb9fd1269ea27633c | ab27d237216713aa8f0ac7b3f188c44b55f0a5541e6fe6c916c2600a24225ac2 | null | [] | 683 |
2.4 | surrealdb-orm | 0.14.4 | SurrealDB ORM as 'DJango style' for Python with async support. Works with pydantic validation. | # SurrealDB-ORM


[](https://codecov.io/gh/EulogySnowfall/SurrealDB-ORM)

> **Beta Software** - Core APIs are stabilizing. Feedback welcome!
**SurrealDB-ORM** is a Django-style ORM for [SurrealDB](https://surrealdb.com/) with async support, Pydantic validation, and JWT authentication.
**Includes a custom SDK (`surreal_sdk`)** - Zero dependency on the official `surrealdb` package!
---
## What's New in 0.14.4
### Fix: Datetime Serialization Round-Trip
Python `datetime` objects now survive `save()` / `merge()` round-trips as native SurrealDB datetime values. Previously, datetimes were serialized as plain ISO strings, causing silent type mismatches with `TYPE datetime` schema fields.
```python
from datetime import UTC, datetime
class Event(BaseSurrealModel):
model_config = SurrealConfigDict(table_name="events")
occurred_at: datetime | None = None
event = Event(occurred_at=datetime.now(UTC))
await event.save() # datetime now correctly encoded via CBOR datetime tag
loaded = await Event.objects().get(event.id)
assert isinstance(loaded.occurred_at, datetime) # True — no more plain strings
```
### Generic `QuerySet[T]` — Full Type Inference
`QuerySet` is now generic. All terminal methods return properly typed model instances:
```python
# Before (v0.14.3): user is Any — no type inference
user = await User.objects().get("user:alice")
# After (v0.14.4): user is User — full IDE autocomplete and mypy checking
user = await User.objects().get("user:alice")
user.name # IDE knows this is a str
```
### Typed `get_related()` via `@overload`
Return type is now inferred from the `model_class` parameter:
```python
# Returns list[Book] — fully typed
books = await author.get_related("wrote", direction="out", model_class=Book)
# Returns list[dict[str, Any]] — raw dicts when no model_class
raw = await author.get_related("wrote", direction="out")
```
---
## What's New in 0.14.3
### Fix: Large Nested Dict Parameter Binding (Issue #55)
SurrealDB v2.6's CBOR parameter binding silently drops complex nested structures — dicts with nested dicts/lists arrive as `{}` on the server. Two fixes:
- **`save()` auto-routing** — Complex nested data is now automatically routed through a SET-clause query path where each field is bound as a separate variable, avoiding the problematic single-object CBOR binding.
```python
class GameSession(BaseSurrealModel):
model_config = SurrealConfigDict(table_name="game_sessions")
game_state: dict | None = None # Large nested dict (~20KB+)
session = GameSession(game_state={"players": [...], "deck": [...], "nested": {...}})
await session.save() # Automatically uses SET-clause path
```
- **`raw_query(inline_dicts=True)`** — New parameter that inlines complex dict/list variables as JSON in the query string, bypassing CBOR parameter binding entirely.
```python
large_state = {"players": [...], "deck": [...], "melds": {...}}
results = await GameSession.raw_query(
"UPSERT game_sessions:test SET game_state = $state",
variables={"state": large_state},
inline_dicts=True, # Inlines $state as JSON in the query
)
```
---
## What's New in 0.14.2
### Production Fixes
Five improvements from real production usage (FastAPI + SurrealDB, multi-pod K8s):
- **CBOR None → NONE Encoding** — Python `None` is now correctly encoded as SurrealDB `NONE` (absent field) instead of `NULL`. Fixes `option<T>` rejection on SCHEMAFULL tables and large nested dict parameter binding failures.
- **Token Validation Cache** — `validate_token()` now uses an in-memory TTL cache (default 300s) to avoid ephemeral HTTP connections on every call. New `validate_token_local()` decodes JWT locally without any network call.
```python
# Cached validation — no network call on cache hit
record_id = await User.validate_token(token)
# Local JWT decode — zero network calls (trusted backend only)
record_id = User.validate_token_local(token)
# Cache management
User.configure_token_cache(ttl=600)
User.invalidate_token_cache()
```
- **`validate_assignment=True`** — Pydantic now auto-validates field assignments, so `event.started_at = "2026-02-13T10:00:00Z"` is auto-coerced to `datetime`.
- **`flexible_fields` Config** — Discoverable way to mark fields as `FLEXIBLE TYPE` in migrations:
```python
class GameSession(BaseSurrealModel):
model_config = SurrealConfigDict(
table_name="game_sessions",
schema_mode="SCHEMAFULL",
flexible_fields=["game_state", "metadata"],
)
game_state: dict | None = None # → DEFINE FIELD FLEXIBLE TYPE option<object>
```
---
## What's New in 0.14.1
### Typed Functions API Documentation
- **Typed Functions API in Notebook 08** — Added comprehensive `db.fn.*` examples covering math, string, time, crypto, and array functions, plus dynamic namespace resolution and SQL inspection. Notebook reordered from simple to complex.
```python
db = await SurrealDBConnectionManager.get_client()
sqrt = await db.fn.math.sqrt(144) # 12.0
upper = await db.fn.string.uppercase("hello") # "HELLO"
now = await db.fn.time.now() # server timestamp
sha = await db.fn.crypto.sha256("data") # hash string
arr = await db.fn.array.distinct([1, 2, 2, 3]) # [1, 2, 3]
```
---
## What's New in 0.14.0
### Testing & Developer Experience (Alpha → Beta)
This release transitions the ORM from **Alpha to Beta** and adds first-class testing and debugging utilities.
- **Test Fixtures** — Declarative test data with automatic cleanup
```python
from surreal_orm.testing import SurrealFixture, fixture
@fixture
class UserFixtures(SurrealFixture):
alice = User(name="Alice", role="admin")
bob = User(name="Bob", role="player")
async with UserFixtures.load() as fixtures:
assert fixtures.alice.get_id() is not None
# Automatic cleanup on exit
```
- **Model Factories** — Factory Boy-style data generation (zero dependencies)
```python
from surreal_orm.testing import ModelFactory, Faker
class UserFactory(ModelFactory):
class Meta:
model = User
name = Faker("name")
email = Faker("email")
age = Faker("random_int", min=18, max=80)
role = "player"
user = UserFactory.build() # In-memory (unit tests)
user = await UserFactory.create() # Saved to DB (integration tests)
users = await UserFactory.create_batch(50)
```
- **QueryLogger** — Profile and debug ORM queries
```python
from surreal_orm.debug import QueryLogger
async with QueryLogger() as logger:
users = await User.objects().filter(role="admin").exec()
await user.save()
for q in logger.queries:
print(f"{q.sql} — {q.duration_ms:.1f}ms")
print(f"Total: {logger.total_queries} queries, {logger.total_ms:.1f}ms")
```
- **15 Jupyter Notebooks** — Comprehensive examples covering all ORM features, from setup to testing
---
## What's New in 0.13.0
### Events, Geospatial, Materialized Views & TYPE RELATION
- **DEFINE EVENT** — Server-side triggers in migrations
```python
from surreal_orm import DefineEvent
DefineEvent(
name="email_audit", table="users",
when="$before.email != $after.email",
then="CREATE audit_log SET table = 'user', record = $value.id, action = $event",
)
```
- **Geospatial Fields** — Typed geometry fields and proximity queries
```python
from surreal_orm.fields import PointField, PolygonField
from surreal_orm.geo import GeoDistance
class Store(BaseSurrealModel):
name: str
location: PointField # geometry<point>
delivery_area: PolygonField # geometry<polygon>
# Proximity search: stores within 5km
nearby = await Store.objects().nearby(
"location", (-73.98, 40.74), max_distance=5000
).exec()
# Distance annotation
stores = await Store.objects().annotate(
dist=GeoDistance("location", (-73.98, 40.74)),
).order_by("dist").limit(10).exec()
```
- **Materialized Views** — Read-only models backed by `DEFINE TABLE ... AS SELECT`
```python
class OrderStats(BaseSurrealModel):
model_config = SurrealConfigDict(
table_name="order_stats",
view_query="SELECT status, count() AS total, math::sum(amount) AS revenue FROM orders GROUP BY status",
)
status: str
total: int
revenue: float
# Auto-maintained by SurrealDB — read-only queries only
stats = await OrderStats.objects().all()
await stats[0].save() # TypeError: Cannot modify materialized view
```
- **TYPE RELATION** — Enforce graph edge constraints in migrations
```python
class Likes(BaseSurrealModel):
model_config = SurrealConfigDict(
table_type=TableType.RELATION,
relation_in="person",
relation_out=["blog_post", "book"],
enforced=True,
)
```
---
## What's New in 0.12.0
### Vector Search & Full-Text Search
- **Vector Similarity Search** — KNN search with HNSW indexes for AI/RAG pipelines
```python
from surreal_orm.fields import VectorField
class Document(BaseSurrealModel):
title: str
embedding: VectorField[1536]
# KNN similarity search (top 10 nearest neighbours)
docs = await Document.objects().similar_to(
"embedding", query_vector, limit=10
).exec()
# Combined with filters
docs = await Document.objects().filter(
category="science"
).similar_to("embedding", query_vector, limit=5).exec()
```
- **Full-Text Search** — BM25 scoring, highlighting, and multi-field search
```python
from surreal_orm import SearchScore, SearchHighlight
results = await Post.objects().search(title="quantum").annotate(
relevance=SearchScore(0),
snippet=SearchHighlight("<b>", "</b>", 0),
).exec()
```
- **Hybrid Search** — Reciprocal Rank Fusion combining vector + FTS
```python
results = await Document.objects().hybrid_search(
vector_field="embedding", vector=query_vec, vector_limit=20,
text_field="content", text_query="machine learning", text_limit=20,
)
```
- **Analyzer & Index Operations** — `DefineAnalyzer`, HNSW and BM25 index support in migrations
---
## What's New in 0.11.0
### Advanced Queries & Caching
- **Subqueries** — Embed a QuerySet as a filter value in another QuerySet
- **Query Cache** — TTL-based caching with automatic invalidation on writes
- **Prefetch Objects** — Fine-grained control over related data prefetching
---
## What's New in 0.10.0
### Schema Introspection & Multi-Database Support
- **Schema Introspection** - Generate Python model code from an existing SurrealDB database
```python
from surreal_orm import generate_models_from_db, schema_diff
# Generate Python model code from existing database
code = await generate_models_from_db(output_path="models.py")
# Compare Python models against live database schema
operations = await schema_diff(models=[User, Order, Product])
for op in operations:
print(op) # Migration operations needed to sync
```
- `DatabaseIntrospector` parses `INFO FOR DB` / `INFO FOR TABLE` into `SchemaState`
- `ModelCodeGenerator` converts `SchemaState` to fully-typed Python model source code
- Handles generic types (`array<string>`, `option<int>`, `record<users>`), VALUE/ASSERT expressions, encrypted fields, FLEXIBLE, READONLY
- CLI: `surreal-orm inspectdb` and `surreal-orm schemadiff`
- **Multi-Database Support** - Named connection registry for routing models to different databases
```python
from surreal_orm import SurrealDBConnectionManager
# Register named connections
SurrealDBConnectionManager.add_connection("default", url=..., ns=..., db=...)
SurrealDBConnectionManager.add_connection("analytics", url=..., ns=..., db=...)
# Model-level routing
class AnalyticsEvent(BaseSurrealModel):
model_config = SurrealConfigDict(connection="analytics")
# Context manager override (async-safe)
async with SurrealDBConnectionManager.using("analytics"):
events = await AnalyticsEvent.objects().all()
```
- `ConnectionConfig` frozen dataclass for immutable connection settings
- `using()` async context manager with `contextvars` for async safety
- Full backward compatibility: `set_connection()` delegates to `add_connection("default", ...)`
- `list_connections()`, `get_config()`, `remove_connection()` registry management
---
## What's New in 0.9.0
### ORM Real-time Features: Live Models + Change Feed
- **Live Models** - Real-time subscriptions at the ORM level yielding typed Pydantic model instances
```python
from surreal_orm import LiveAction
async with User.objects().filter(role="admin").live() as stream:
async for event in stream:
match event.action:
case LiveAction.CREATE:
print(f"New admin: {event.instance.name}")
case LiveAction.UPDATE:
print(f"Updated: {event.instance.email}")
case LiveAction.DELETE:
print(f"Removed: {event.record_id}")
```
- `ModelChangeEvent[T]` with typed `instance`, `action`, `record_id`, `changed_fields`
- Full QuerySet filter integration (WHERE clause + parameterized variables)
- `auto_resubscribe=True` for seamless WebSocket reconnect recovery
- `diff=True` for receiving only changed fields
- **Change Feed Integration** - HTTP-based CDC for event-driven microservices
```python
async for event in User.objects().changes(since="2026-01-01"):
await publish_to_queue({
"type": f"user.{event.action.value.lower()}",
"data": event.raw,
})
```
- Stateless, resumable with cursor tracking
- Configurable `poll_interval` and `batch_size`
- No WebSocket required (works over HTTP)
- **`post_live_change` signal** - Fires for external database changes (separate from local CRUD signals)
```python
from surreal_orm import post_live_change, LiveAction
@post_live_change.connect(Player)
async def on_player_change(sender, instance, action, **kwargs):
if action == LiveAction.CREATE:
await ws_manager.broadcast({"type": "player_joined", "name": instance.name})
```
- **WebSocket Connection Manager** - `get_ws_client()` creates a lazy WebSocket connection alongside HTTP
---
## What's New in 0.8.0
### Auth Module Fixes + Computed Fields
- **Ephemeral Auth Connections** (Critical) - `signup()`, `signin()`, and `authenticate_token()` no longer corrupt the singleton connection. They use isolated ephemeral connections.
- **Configurable Access Name** - Access name is configurable via `access_name` in `SurrealConfigDict` (was hardcoded to `{table}_auth`)
- **`signup()` Returns Token** - Now returns `tuple[Self, str]` (user + JWT token), matching `signin()`
```python
user, token = await User.signup(email="alice@example.com", password="secret", name="Alice")
```
- **`authenticate_token()` Fixed + `validate_token()`** - Fixed token validation with new `validate_token()` lightweight method
```python
result = await User.authenticate_token(token) # Full: (user, record_id)
record_id = await User.validate_token(token) # Lightweight: just record_id
```
- **Computed Fields** - Server-side computed fields using SurrealDB's `DEFINE FIELD ... VALUE <expression>`
```python
from surreal_orm import Computed
class User(BaseSurrealModel):
first_name: str
last_name: str
full_name: Computed[str] = Computed("string::concat(first_name, ' ', last_name)")
class Order(BaseSurrealModel):
items: list[dict]
discount: float = 0.0
subtotal: Computed[float] = Computed("math::sum(items.*.price * items.*.qty)")
total: Computed[float] = Computed("subtotal * (1 - discount)")
```
- `Computed[T]` defaults to `None` (server computes the value)
- Auto-excluded from `save()`/`merge()` via `get_server_fields()`
- Migration introspector auto-generates `DEFINE FIELD ... VALUE <expression>`
---
## What's New in 0.7.0
### Performance & Developer Experience
- **`merge(refresh=False)`** - Skip the extra SELECT round-trip for fire-and-forget updates
```python
await user.merge(last_seen=SurrealFunc("time::now()"), refresh=False)
```
- **`call_function()`** - Invoke custom SurrealDB stored functions from the ORM
```python
result = await SurrealDBConnectionManager.call_function(
"acquire_game_lock", params={"table_id": tid, "pod_id": pid},
)
result = await GameTable.call_function("release_game_lock", params={...})
```
- **`extra_vars` on `save()`** - Bind additional query variables for SurrealFunc expressions
```python
await user.save(
server_values={"password_hash": SurrealFunc("crypto::argon2::generate($password)")},
extra_vars={"password": raw_password},
)
```
- **`fetch()` / FETCH clause** - Resolve record links inline to prevent N+1 queries
```python
posts = await Post.objects().fetch("author", "tags").exec()
# Generates: SELECT * FROM posts FETCH author, tags;
```
- **`remove_all_relations()` list support** - Remove multiple relation types in one call
```python
await table.remove_all_relations(["has_player", "has_action"], direction="out")
```
---
## What's New in 0.6.0
### Query Power, Security & Server-Side Functions
- **Q Objects for Complex Queries** - Django-style composable query expressions with OR/AND/NOT
```python
from surreal_orm import Q
# OR query
users = await User.objects().filter(
Q(name__contains="alice") | Q(email__contains="alice"),
).exec()
# NOT + mixed with regular kwargs
users = await User.objects().filter(
~Q(status="banned"), role="admin",
).order_by("-created_at").exec()
```
- **Parameterized Filters (Security)** - All filter values are now query variables (`$_fN`)
- Prevents SQL injection by never embedding values in query strings
- Existing `$variable` references via `.variables()` still work
- **SurrealFunc for Server-Side Functions** - Embed SurrealQL expressions in save/update
```python
from surreal_orm import SurrealFunc
await player.save(server_values={"joined_at": SurrealFunc("time::now()")})
await player.merge(last_ping=SurrealFunc("time::now()"))
```
- **`remove_all_relations()`** - Bulk relation deletion with direction support
```python
await table.remove_all_relations("has_player", direction="out")
await user.remove_all_relations("follows", direction="both")
```
- **Django-style `-field` Ordering** - Shorthand for descending order
```python
users = await User.objects().order_by("-created_at").exec()
```
- **Bug Fix: `isnull` Lookup** - `filter(field__isnull=True)` now generates `IS NULL` instead of `IS True`
---
## What's New in 0.5.x
### v0.5.9 - Concurrent Safety, Relation Direction & Array Filtering
- **Atomic Array Operations** - Server-side array mutations avoiding read-modify-write conflicts
- `atomic_append()`, `atomic_remove()`, `atomic_set_add()` class methods
- Ideal for multi-pod K8s deployments with concurrent workers
```python
# No more transaction conflicts on concurrent array updates:
await Event.atomic_set_add(event_id, "processed_by", pod_id)
```
- **Transaction Conflict Retry** - `retry_on_conflict()` decorator with exponential backoff + jitter
- `TransactionConflictError` exception for conflict detection
```python
from surreal_orm import retry_on_conflict
@retry_on_conflict(max_retries=5)
async def process_event(event_id, pod_id):
await Event.atomic_set_add(event_id, "processed_by", pod_id)
```
- **Relation Direction Control** - `reverse` parameter on `relate()` and `remove_relation()`
```python
# Reverse: users:xyz -> created -> game_tables:abc
await table.relate("created", creator, reverse=True)
```
- **New Query Lookup Operators** - Server-side array filtering
- `not_contains` (`CONTAINSNOT`), `containsall` (`CONTAINSALL`), `containsany` (`CONTAINSANY`), `not_in` (`NOT IN`)
```python
events = await Event.objects().filter(processed_by__not_contains=pod_id).exec()
```
### v0.5.8 - Around Signals (Generator-based middleware)
- **Around Signals** - Generator-based middleware pattern for wrapping DB operations
- `around_save`, `around_delete`, `around_update`
- Shared state between before/after phases (local variables)
- Guaranteed cleanup with `try/finally`
```python
from surreal_orm import around_save
@around_save.connect(Player)
async def time_save(sender, instance, created, **kwargs):
start = time.time()
yield # save happens here
print(f"Saved {instance.id} in {time.time() - start:.3f}s")
@around_delete.connect(Player)
async def delete_with_lock(sender, instance, **kwargs):
lock = await acquire_lock(instance.id)
try:
yield # delete happens while lock is held
finally:
await release_lock(lock) # Always runs
```
**Execution order:** `pre_* → around(before) → DB → around(after) → post_*`
### v0.5.7 - Model Signals
- **Django-style Model Signals** - Event hooks for model lifecycle operations
- `pre_save`, `post_save` - Before/after save operations
- `pre_delete`, `post_delete` - Before/after delete operations
- `pre_update`, `post_update` - Before/after update/merge operations
```python
from surreal_orm import post_save, Player
@post_save.connect(Player)
async def on_player_saved(sender, instance, created, **kwargs):
if instance.is_ready:
await ws_manager.broadcast({"type": "player_ready", "id": instance.id})
```
### v0.5.6 - Relation Query ID Escaping Fix
- **Fixed ID escaping in relation queries** - When using `get_related()`, `RelationQuerySet`, or graph traversal with IDs starting with digits, queries now properly escape the IDs with backticks, preventing parse errors.
### v0.5.5.3 - RecordId Conversion Fix
- **Fixed RecordId objects in foreign key fields** - When using CBOR protocol, fields like `user_id`, `table_id` are now properly converted to `"table:id"` strings instead of raw RecordId objects, preventing Pydantic validation errors.
### v0.5.5.2 - Datetime Regression Fix
- **Fixed datetime_type Pydantic validation error** - v0.5.5.1 introduced a regression where records with datetime fields failed validation, causing `from_db()` to return dicts instead of model instances
- **New `_preprocess_db_record()` method** - Properly handles datetime parsing and RecordId conversion before Pydantic validation
### v0.5.5.1 - Critical Bug Fixes
- **Record ID escaping** - IDs starting with digits (e.g., `7abc123`) now properly escaped with backticks
- **CBOR for HTTP connections** - HTTP connections now default to CBOR protocol, fixing `data:` prefix issues
- **`get()` full ID format** - `QuerySet.get("table:id")` now correctly parses and queries
- **`get_related()` direction="in"** - Fixed to return actual related records instead of empty results
- **`update()` table name** - Fixed bug where custom `table_name` was ignored
### v0.5.5 - CBOR Protocol & Field Aliases
- **CBOR Protocol (Default)** - Binary protocol for WebSocket connections
- `cbor2` is now a **required dependency**
- CBOR is the **default protocol** for WebSocket (fixes `data:` prefix string issues)
- Aligns with official SurrealDB SDK behavior
- **`unset_connection_sync()`** - Synchronous version for non-async cleanup contexts
- **Field Alias Support** - Map Python field names to different DB column names
- Use `Field(alias="db_column")` to store under a different name in DB
### v0.5.4 - API Improvements
- **Record ID format handling** - `QuerySet.get()` accepts both `"abc123"` and `"table:abc123"`
- **`remove_relation()` accepts string IDs** - Pass string IDs instead of model instances
- **`raw_query()` class method** - Execute arbitrary SurrealQL from model class
### v0.5.3.3 - Bug Fix
- **`from_db()` fields_set fix** - Fixed bug where DB-loaded fields were incorrectly included in updates via `exclude_unset=True`
### v0.5.3.2 - Critical Bug Fix
- **QuerySet table name fix** - Fixed critical bug where QuerySet used class name instead of `table_name` from config
- **`QuerySet.get()` signature** - Now accepts `id=` keyword argument in addition to positional `id_item`
### v0.5.3.1 - Bug Fixes
- **Partial updates for persisted records** - `save()` now uses `merge()` for already-persisted records, only sending modified fields
- **datetime parsing** - `_update_from_db()` now parses ISO 8601 strings to `datetime` objects automatically
- **`_db_persisted` flag** - Internal tracking to distinguish new vs persisted records
### v0.5.3 - ORM Improvements
- **Upsert save behavior** - `save()` now uses `upsert` for new records with ID (idempotent, Django-like)
- **`server_fields` config** - Exclude server-generated fields (created_at, updated_at) from saves
- **`merge()` returns self** - Now returns the updated model instance instead of None
- **`save()` updates self** - Updates original instance attributes instead of returning new object
- **NULL values fix** - `exclude_unset=True` now works correctly after loading from DB
### v0.5.2 - Bug Fixes & FieldType Improvements
- **FieldType enum** - Enhanced migration type system with `generic()` and `from_python_type()` methods
- **datetime serialization** - Proper JSON encoding for datetime, date, time, Decimal, UUID
- **Fluent API** - `connect()` now returns `self` for method chaining
- **Session cleanup** - WebSocket callback tasks properly tracked and cancelled
- **Optional fields** - `exclude_unset=True` prevents None from overriding DB defaults
- **Parameter alias** - `username` parameter alias for `user` in ConnectionManager
### v0.5.1 - Security Workflows
- **Dependabot integration** - Automatic dependency security updates
- **Auto-merge** - Dependabot PRs merged after CI passes
- **SurrealDB monitoring** - Integration tests on new SurrealDB releases
### v0.5.0 - Real-time SDK Enhancements
- **Live Select Stream** - Async iterator pattern for real-time changes
- `async with db.live_select("table") as stream: async for change in stream:`
- `LiveChange` dataclass with `record_id`, `action`, `result`, `changed_fields`
- WHERE clause support with parameterized queries
- **Auto-Resubscribe** - Automatic reconnection after WebSocket disconnect
- `auto_resubscribe=True` parameter for seamless K8s pod restart recovery
- `on_reconnect(old_id, new_id)` callback for tracking ID changes
- **Typed Function Calls** - Pydantic/dataclass return type support
- `await db.call("fn::my_func", params={...}, return_type=MyModel)`
### v0.4.0 - Relations & Graph
- **Relations & Graph Traversal** - Django-style relation definitions with SurrealDB graph support
- `ForeignKey`, `ManyToMany`, `Relation` field types
- Relation operations: `add()`, `remove()`, `set()`, `clear()`, `all()`, `filter()`, `count()`
- Model methods: `relate()`, `remove_relation()`, `get_related()`
- QuerySet extensions: `select_related()`, `prefetch_related()`, `traverse()`, `graph_query()`
---
## Table of Contents
- [Installation](#installation)
- [Quick Start](#quick-start)
- [Using the SDK (Recommended)](#using-the-sdk-recommended)
- [Using the ORM](#using-the-orm)
- [SDK Features](#sdk-features)
- [Connections](#connections)
- [Transactions](#transactions)
- [Typed Functions](#typed-functions)
- [Live Queries](#live-queries)
- [ORM Features](#orm-features)
- [CLI Commands](#cli-commands)
- [Documentation](#documentation)
- [Contributing](#contributing)
---
## Installation
```bash
# Basic installation (includes CBOR support)
pip install surrealdb-orm
# With CLI support
pip install surrealdb-orm[cli]
```
**Requirements:** Python 3.12+ | SurrealDB 2.6.0+
**Included:** `pydantic`, `httpx`, `aiohttp`, `cbor2` (CBOR is the default protocol for WebSocket)
---
## Quick Start
### Using the SDK (Recommended)
```python
from surreal_sdk import SurrealDB
async def main():
# HTTP connection (stateless, ideal for microservices)
async with SurrealDB.http("http://localhost:8000", "namespace", "database") as db:
await db.signin("root", "root")
# CRUD operations
user = await db.create("users", {"name": "Alice", "age": 30})
users = await db.query("SELECT * FROM users WHERE age > $min", {"min": 18})
# Atomic transactions
async with db.transaction() as tx:
await tx.create("accounts:alice", {"balance": 1000})
await tx.create("accounts:bob", {"balance": 500})
# Auto-commit on success, auto-rollback on exception
# Built-in functions with typed API
result = await db.fn.math.sqrt(16) # Returns 4.0
now = await db.fn.time.now() # Current timestamp
```
### Using the ORM
```python
from surreal_orm import BaseSurrealModel, SurrealDBConnectionManager
# 1. Define your model
class User(BaseSurrealModel):
id: str | None = None
name: str
email: str
age: int = 0
# 2. Configure connection
SurrealDBConnectionManager.set_connection(
url="http://localhost:8000",
user="root",
password="root",
namespace="myapp",
database="main",
)
# 3. CRUD operations
user = User(name="Alice", email="alice@example.com", age=30)
await user.save()
users = await User.objects().filter(age__gte=18).order_by("name").limit(10).exec()
```
---
## SDK Features
### Connections
| Type | Use Case | Features |
| ------------- | ------------------------ | ------------------------ |
| **HTTP** | Microservices, REST APIs | Stateless, simple |
| **WebSocket** | Real-time apps | Live queries, persistent |
| **Pool** | High-throughput | Connection reuse |
```python
from surreal_sdk import SurrealDB, HTTPConnection, WebSocketConnection
# HTTP (stateless)
async with SurrealDB.http("http://localhost:8000", "ns", "db") as db:
await db.signin("root", "root")
# WebSocket (stateful, real-time)
async with SurrealDB.ws("ws://localhost:8000", "ns", "db") as db:
await db.signin("root", "root")
await db.live("orders", callback=on_order_change)
# Connection Pool
async with SurrealDB.pool("http://localhost:8000", "ns", "db", size=10) as pool:
await pool.set_credentials("root", "root")
async with pool.acquire() as conn:
await conn.query("SELECT * FROM users")
```
### Transactions
Atomic transactions with automatic commit/rollback:
```python
# WebSocket: Immediate execution with server-side transaction
async with db.transaction() as tx:
await tx.update("players:abc", {"is_ready": True})
await tx.update("game_tables:xyz", {"ready_count": "+=1"})
# Statements execute immediately
# COMMIT on success, CANCEL on exception
# HTTP: Batched execution (all-or-nothing)
async with db.transaction() as tx:
await tx.create("orders:1", {"total": 100})
await tx.create("payments:1", {"amount": 100})
# Statements queued, executed atomically at commit
```
**Transaction Methods:**
- `tx.query(sql, vars)` - Execute raw SurrealQL
- `tx.create(thing, data)` - Create record
- `tx.update(thing, data)` - Replace record
- `tx.delete(thing)` - Delete record
- `tx.relate(from, edge, to)` - Create graph edge
- `tx.commit()` - Explicit commit
- `tx.rollback()` - Explicit rollback
### Typed Functions
Fluent API for SurrealDB functions:
```python
# Built-in functions (namespace::function)
sqrt = await db.fn.math.sqrt(16) # 4.0
now = await db.fn.time.now() # datetime
length = await db.fn.string.len("hello") # 5
sha = await db.fn.crypto.sha256("data") # hash string
# Custom user-defined functions (fn::function)
result = await db.fn.my_custom_function(arg1, arg2)
# Executes: RETURN fn::my_custom_function($arg0, $arg1)
```
**Available Namespaces:**
`array`, `crypto`, `duration`, `geo`, `http`, `math`, `meta`, `object`, `parse`, `rand`, `session`, `string`, `time`, `type`, `vector`
### Live Queries
Real-time updates via WebSocket:
```python
from surreal_sdk import LiveAction
# Async iterator pattern (recommended)
async with db.live_select(
"orders",
where="status = $status",
params={"status": "pending"},
auto_resubscribe=True, # Auto-reconnect on WebSocket drop
) as stream:
async for change in stream:
match change.action:
case LiveAction.CREATE:
print(f"New order: {change.result}")
case LiveAction.UPDATE:
print(f"Updated: {change.record_id}")
case LiveAction.DELETE:
print(f"Deleted: {change.record_id}")
# Callback-based pattern
from surreal_sdk import LiveQuery, LiveNotification
async def on_change(notification: LiveNotification):
print(f"{notification.action}: {notification.result}")
live = LiveQuery(ws_conn, "orders")
await live.subscribe(on_change)
# ... record changes trigger callbacks ...
await live.unsubscribe()
```
**Typed Function Calls:**
```python
from pydantic import BaseModel
class VoteResult(BaseModel):
success: bool
count: int
# Call SurrealDB function with typed return
result = await db.call(
"cast_vote",
params={"user": "alice", "vote": "yes"},
return_type=VoteResult
)
print(result.success, result.count) # Typed access
```
---
## ORM Features
### Live Models (Real-time at ORM Level)
```python
from surreal_orm import LiveAction
# Subscribe to model changes with full Pydantic instances
async with User.objects().filter(role="admin").live() as stream:
async for event in stream:
print(event.action, event.instance.name, event.record_id)
# Change Feed (HTTP, no WebSocket needed)
async for event in Order.objects().changes(since="2026-01-01"):
print(event.action, event.instance.total)
```
### QuerySet with Django-style Lookups
```python
# Filter with lookups
users = await User.objects().filter(age__gte=18, name__startswith="A").exec()
# Supported lookups
# exact, gt, gte, lt, lte, in, not_in, like, ilike,
# contains, icontains, not_contains, containsall, containsany,
# startswith, istartswith, endswith, iendswith, match, regex, isnull
# Q objects for complex OR/AND/NOT queries
from surreal_orm import Q
users = await User.objects().filter(
Q(name__contains="alice") | Q(email__contains="alice"),
role="admin",
).order_by("-created_at").limit(10).exec()
```
### ORM Transactions
```python
from surreal_orm import SurrealDBConnectionManager
# Via ConnectionManager
async with SurrealDBConnectionManager.transaction() as tx:
user = User(name="Alice", balance=1000)
await user.save(tx=tx)
order = Order(user_id=user.id, total=100)
await order.save(tx=tx)
# Auto-commit on success, auto-rollback on exception
# Via Model class method
async with User.transaction() as tx:
await user1.save(tx=tx)
await user2.delete(tx=tx)
```
### Aggregations
```python
# Simple aggregations
total = await User.objects().count()
total = await User.objects().filter(active=True).count()
# Field aggregations
avg_age = await User.objects().avg("age")
total = await Order.objects().filter(status="paid").sum("amount")
min_val = await Product.objects().min("price")
max_val = await Product.objects().max("price")
```
### GROUP BY with Aggregations
```python
from surreal_orm import Count, Sum, Avg
# Group by single field
stats = await Order.objects().values("status").annotate(
count=Count(),
total=Sum("amount"),
).exec()
# Result: [{"status": "paid", "count": 42, "total": 5000}, ...]
# Group by multiple fields
monthly = await Order.objects().values("status", "month").annotate(
count=Count(),
).exec()
```
### Bulk Operations
```python
# Bulk create
users = [User(name=f"User{i}") for i in range(100)]
created = await User.objects().bulk_create(users)
# Atomic bulk create (all-or-nothing)
created = await User.objects().bulk_create(users, atomic=True)
# Bulk update
updated = await User.objects().filter(status="pending").bulk_update(
{"status": "active"}
)
# Bulk delete
deleted = await User.objects().filter(status="deleted").bulk_delete()
```
### Table Types
| Type | Description |
| -------- | --------------------------- |
| `NORMAL` | Standard table (default) |
| `USER` | Auth table with JWT support |
| `STREAM` | Real-time with CHANGEFEED |
| `HASH` | Lookup/cache (SCHEMALESS) |
```python
from surreal_orm import BaseSurrealModel, SurrealConfigDict
from surreal_orm.types import TableType
class User(BaseSurrealModel):
model_config = SurrealConfigDict(
table_type=TableType.USER,
permissions={"select": "$auth.id = id"},
)
```
### JWT Authentication
```python
from surreal_orm.auth import AuthenticatedUserMixin
from surreal_orm.fields import Encrypted
class User(AuthenticatedUserMixin, BaseSurrealModel):
model_config = SurrealConfigDict(table_type=TableType.USER)
email: str
password: Encrypted # Auto-hashed with argon2
name: str
# Signup
user = await User.signup(email="alice@example.com", password="secret", name="Alice")
# Signin
user, token = await User.signin(email="alice@example.com", password="secret")
# Validate token
user = await User.authenticate_token(token)
```
---
## CLI Commands
Requires `pip install surrealdb-orm[cli]`
| Command | Description |
| ------------------- | -------------------------------------- |
| `makemigrations` | Generate migration files |
| `migrate` | Apply schema migrations |
| `rollback <target>` | Rollback to migration |
| `status` | Show migration status |
| `shell` | Interactive SurrealQL shell |
| `inspectdb` | Generate models from existing database |
| `schemadiff` | Compare models against live schema |
```bash
# Generate and apply migrations
surreal-orm makemigrations --name initial
surreal-orm migrate -u http://localhost:8000 -n myns -d mydb
# Environment variables supported
export SURREAL_URL=http://localhost:8000
export SURREAL_NAMESPACE=myns
export SURREAL_DATABASE=mydb
surreal-orm migrate
```
---
## Documentation
| Document | Description |
| -------------------------------------- | ------------------------ |
| [SDK Guide](docs/sdk.md) | Full SDK documentation |
| [Migration System](docs/migrations.md) | Django-style migrations |
| [Authentication](docs/auth.md) | JWT authentication guide |
| [Roadmap](docs/roadmap.md) | Future features planning |
| [CHANGELOG](CHANGELOG.md) | Version history |
---
## Contributing
```bash
# Clone and install
git clone https://github.com/EulogySnowfall/SurrealDB-ORM.git
cd SurrealDB-ORM
uv sync
# Run tests (SurrealDB container managed automatically)
make test # Unit tests only
make test-integration # With integration tests
# Start SurrealDB manually
make db-up # Test instance (port 8001)
make db-dev # Dev instance (port 8000)
# Lint
make ci-lint # Run all linters
```
---
## Related Projects
### [SurrealDB-ORM-lite](https://github.com/EulogySnowfall/SurrealDB-ORM-lite)
A lightweight Django-style ORM built on the **official SurrealDB Python SDK**.
| Feature | SurrealDB-ORM | SurrealDB-ORM-lite |
| --------------- | ---------------------- | -------------------- |
| SDK | Custom (`surreal_sdk`) | | text/markdown | null | Yannick Croteau <croteau.yannick@gmail.com> | null | null | # MIT License
Copyright (c) 2025-2026 Yannick Croteau
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | null | [
"Development Status :: 4 - Beta",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Database",
... | [] | null | null | >=3.12 | [] | [] | [] | [
"aiohttp>=3.9.0",
"cbor2>=5.6.0",
"httpx>=0.27.0",
"pydantic>=2.10.5",
"click>=8.1.0; extra == \"all\"",
"click>=8.1.0; extra == \"cli\""
] | [] | [] | [] | [
"Homepage, https://github.com/EulogySnowfall/SurrealDB-ORM",
"Documentation, https://github.com/EulogySnowfall/SurrealDB-ORM",
"Repository, https://github.com/EulogySnowfall/SurrealDB-ORM.git",
"Issues, https://github.com/EulogySnowfall/SurrealDB-ORM/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:55:15.795943 | surrealdb_orm-0.14.4.tar.gz | 179,576 | 0d/4d/fd1e1a9d8122c758358c2d47e62c2e9b7fdb154d4a0f0b661601346884a1/surrealdb_orm-0.14.4.tar.gz | source | sdist | null | false | 3af710d2e2b00387fc7d93df25a303e9 | 11e13d3b21f6a82375561905798bd32bfa8d127e65704796431fbf986ed62135 | 0d4dfd1e1a9d8122c758358c2d47e62c2e9b7fdb154d4a0f0b661601346884a1 | null | [
"LICENSE"
] | 359 |
2.4 | yclibs | 0.2.1 | Shared Python utilities and helpers for database and date operations. | # YCLibs
<p align="center">
<strong>Shared Python utilities for database and date operations.</strong>
</p>
<p align="center">
<a href="https://pypi.org/project/yclibs/"><img src="https://img.shields.io/pypi/v/yclibs?style=flat-square" alt="PyPI"></a>
<a href="https://www.python.org/downloads/"><img src="https://img.shields.io/badge/python-3.13+-blue?style=flat-square" alt="Python"></a>
<a href="LICENSE"><img src="https://img.shields.io/badge/license-MIT-green?style=flat-square" alt="License"></a>
</p>
---
A production-ready Python library for **database operations** (SQLAlchemy 2.0+, sync/async) and **date utilities**. Built for FastAPI projects and modern Python 3.13+.
## Features
- **Database** — SQLAlchemy 2.0+ with PostgreSQL (psycopg3, asyncpg)
- Sync and async managers with type-safe CRUD
- Connection pooling, `DatabaseConfig` for flexible setup
- Declarative models with `Mapped` / `mapped_column`
- **Date** — DateHelper for common date operations
- Relative dates (yesterday, last week, last month)
- Ranges (week, month, quarter, year)
- Business day calculations
- Date comparisons and formatting
- **Typed** — Full PEP 484 type hints
- **Tested** — pytest, optional dev tooling (ruff)
## Installation
```bash
# Using uv (recommended)
uv add yclibs
# Or pip
pip install yclibs
```
**Requirements:** Python 3.13+
## Quick Start
### Database
```python
from yclibs.database.database import (
Base,
DatabaseConfig,
DatabaseManager,
get_db_session,
)
from yclibs.database.models import MyModel
# Custom config (optional)
config = DatabaseConfig(
host="localhost",
database="mydb",
username="user",
password="secret",
)
db = DatabaseManager(config)
# Or use defaults
with db.session() as session:
result = db.get_all(MyModel, limit=10)
# Context manager
with get_db_session() as session:
item = session.get(MyModel, 1)
```
### Async
```python
from yclibs.database.database import AsyncDatabaseManager
async with AsyncDatabaseManager() as db:
items = await db.get_all(MyModel, limit=10)
```
### DateHelper
```python
from yclibs.date.date_helper import DateHelper, Weekday
from datetime import date
dh = DateHelper()
# Relative dates
yesterday = dh.yesterday()
last_week = dh.same_day_last_week()
# Ranges
start, end = dh.current_month_range()
quarter_start, quarter_end = dh.current_quarter_range()
# Business days
next_business = dh.next_business_day()
# Reference date
dh = DateHelper(date(2025, 1, 15))
week_start = dh.start_of_week(Weekday.MONDAY)
```
## Project Structure
```
yclibs/
├── database/ # SQLAlchemy 2.0 layer
│ ├── database.py # DatabaseManager, AsyncDatabaseManager, Base, DatabaseConfig
│ └── models.py # Base model definitions
├── date/ # Date utilities
│ └── date_helper.py # DateHelper
└── configs/ # Default settings
```
## Configuration
`DatabaseConfig` supports:
- **Individual params:** `host`, `port`, `database`, `username`, `password`
- **Full URL:** `url="postgresql+psycopg://user:pass@host:5432/db"`
- **Pool options:** `pool_size`, `max_overflow`, `pool_pre_ping`, `echo`, etc.
## Development
```bash
# Clone and install with dev deps
git clone https://github.com/Shiftryon/YCLibs.git
cd YCLibs
uv sync
# Run tests
uv run pytest
# Lint / format
uv run ruff check . && uv run ruff format .
```
## License
MIT © [Shiftryon](https://github.com/Shiftryon)
| text/markdown | null | Shiftryon <shiftryon@gmail.com> | null | Shiftryon <shiftryon@gmail.com> | null | asyncio, database, date, fastapi, python, sqlalchemy, utilities, uvicorn, yclibs | [
"Development Status :: 4 - Beta",
"Framework :: FastAPI",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Topic :: Internet :: WWW/HTTP :: HTTP Servers",... | [] | null | null | >=3.13 | [] | [] | [] | [
"asyncpg>=0.31.0",
"matplotlib>=3.10.8",
"pandas>=3.0.1",
"psycopg>=3.3.2",
"python-docx>=1.2.0",
"sqlalchemy<3,>=2.0.46",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.8; extra == \"dev\"",
"openpyxl>=3.1.0; extra == \"excel\"",
"pandas>=2.2.0; extra == \"excel\""
] | [] | [] | [] | [
"Homepage, https://github.com/Shiftryon/YCLibs",
"Documentation, https://github.com/Shiftryon/YCLibs#readme",
"Repository, https://github.com/Shiftryon/YCLibs",
"Issues, https://github.com/Shiftryon/YCLibs/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:55:04.886056 | yclibs-0.2.1.tar.gz | 20,114 | 6f/f9/3c6f9c5f50436bc142648e68f18e38d8d148b6fbdd896423444fd5bf2780/yclibs-0.2.1.tar.gz | source | sdist | null | false | f5239ff77ff4a4c5baf773c518779296 | 5a2cc7e41faba780ba8b4c2b6c6bf20555dddf1b277fa1b18b9c9219f896f150 | 6ff93c6f9c5f50436bc142648e68f18e38d8d148b6fbdd896423444fd5bf2780 | MIT | [] | 131 |
2.4 | miso-client | 4.5.0 | Python client SDK for AI Fabrix authentication, authorization, and logging | # AI Fabrix Miso Client SDK (Python)
[](https://badge.fury.io/py/miso-client)
[](https://opensource.org/licenses/MIT)
The **AI Fabrix Miso Client SDK** provides authentication, authorization, and logging for Python applications integrated with the AI Fabrix platform.
## ✨ Benefits
### 🔐 Enterprise Security
### **SSO and Federated Identity**
- Single Sign-On (SSO) with Keycloak
- OAuth 2.0 and OpenID Connect (OIDC) support
- Multi-factor authentication (MFA) ready
- Social login integration (Google, Microsoft, etc.)
### **Centralized Access Control**
- Role-based access control (RBAC)
- Fine-grained permissions
- Dynamic policy enforcement
- Attribute-based access control (ABAC)
### **API Security**
- JWT token validation
- API key authentication
- Token revocation support
- Secure token storage
- Data encryption/decryption (AES-256-GCM)
### 📊 Compliance & Audit
### **ISO 27001 Compliance**
- Comprehensive audit trails for all user actions and HTTP requests
- Automatic data masking for all sensitive information in logs
- HTTP request/response audit logging with masked sensitive data
- Data access logging and monitoring
- Security event tracking
- Accountability and non-repudiation
- Configurable sensitive fields via JSON configuration
### **Regulatory Compliance**
- GDPR-ready data protection
- HIPAA-compliant audit logging
- SOC 2 audit trail requirements
- Industry-standard security controls
### **Audit Capabilities**
- Real-time audit event logging
- Immutable audit records
- Forensic analysis support
- Compliance reporting automation
### ⚡ Performance & Scalability
### **Intelligent Caching**
- Redis-based role and permission caching
- Generic cache service with Redis and in-memory fallback
- Configurable cache TTL (default: 15 minutes)
- Automatic cache invalidation
- Fallback to controller when Redis unavailable
### **High Availability**
- Automatic failover to controller
- Redundant infrastructure support
- Load balancing compatible
- Zero-downtime deployments
### **Optimized Network**
- Efficient API calls with caching
- Batch operations support
- Connection pooling
- Minimal latency
### 🛠️ Developer Experience
### **Easy Integration**
- Progressive activation (6-step setup)
- Works with any framework (FastAPI, Django, Flask, Starlette)
- Python 3.8+ support with full type hints
- Async/await support throughout
### **Flexible Configuration**
- Environment-based configuration
- Support for dev, test, and production environments
- Docker and Kubernetes ready
- CI/CD friendly
### **Observability**
- Centralized logging with correlation IDs
- Automatic HTTP request/response audit logging (ISO 27001 compliant)
- Debug logging with detailed request/response information (when `log_level='debug'`)
- Performance tracking and metrics
- Error tracking and debugging
- Health monitoring
- Automatic data masking for sensitive information in logs
- Configurable sensitive fields via JSON configuration
---
## 🚀 Quick Start
Get your application secured in 30 seconds.
### Step 1: Install
```bash
pip install miso-client
```
### Step 2: Create `.env`
```bash
MISO_CLIENTID=ctrl-dev-my-app
MISO_CLIENTSECRET=your-secret
MISO_CONTROLLER_URL=http://localhost:3000
REDIS_HOST=localhost
```
### Step 3: Use It
```python
from miso_client import MisoClient, load_config
client = MisoClient(load_config())
await client.initialize()
is_valid = await client.validate_token(token)
```
**That's it!** You now have authentication, roles, and logging.
→ [Full Getting Started Guide](docs/getting-started.md)
---
### Infrastructure Setup
**First time?** You'll need Keycloak and Miso Controller running.
Use the [AI Fabrix Builder](https://github.com/esystemsdev/aifabrix-builder/blob/main/docs/QUICK-START.md):
```bash
# Start infrastructure (Postgres, Redis)
aifabrix up
# Install Keycloak for authentication
aifabrix create keycloak --port 8082 --database --template platform
aifabrix build keycloak
aifabrix run keycloak
# Install Miso Controller
aifabrix create miso-controller --port 3000 --database --redis --template platform
aifabrix build miso-controller
aifabrix run miso-controller
```
→ [Infrastructure Guide](https://github.com/esystemsdev/aifabrix-builder/blob/main/docs/INFRASTRUCTURE.md)
**Already have Keycloak and Controller?** Use the Quick Start above.
---
## 📚 Documentation
**What happens:** Your app validates user tokens from Keycloak.
```python
from miso_client import MisoClient, load_config
# Create client (loads from .env automatically)
client = MisoClient(load_config())
await client.initialize()
# Get token from request (helper method)
token = client.get_token(req)
if token:
is_valid = await client.validate_token(token)
if is_valid:
user = await client.get_user(token)
print('User:', user)
```
**Where to get tokens?** Users authenticate via Keycloak, then your app receives JWTs in the `Authorization` header.
→ [Complete authentication example](examples/step-3-authentication.py)
---
### Step 4: Activate RBAC (Roles)
**What happens:** Check user roles to control access. Roles are cached in Redis for performance.
```python
from miso_client import MisoClient, load_config
# Build on Step 3 - add Redis in .env file
client = MisoClient(load_config())
await client.initialize()
token = client.get_token(req)
# Check if user has role
is_admin = await client.has_role(token, 'admin')
roles = await client.get_roles(token)
# Gate features by role
if is_admin:
# Show admin panel
pass
```
**Pro tip:** Without Redis, checks go to the controller. Add Redis to cache role lookups (15-minute default TTL).
→ [Complete RBAC example](examples/step-4-rbac.py)
→ [AI Fabrix Builder Quick Start](https://github.com/esystemsdev/aifabrix-builder/blob/main/docs/QUICK-START.md)
---
### Step 5: Activate Logging
**What happens:** Application logs are sent to the Miso Controller with client token authentication. All HTTP requests are automatically audited with ISO 27001 compliant data masking.
```python
from miso_client import MisoClient, load_config
# Client token is automatically managed - no API key needed
client = MisoClient(load_config())
await client.initialize()
token = client.get_token(req)
user = await client.get_user(token)
# Log messages
await client.log.info('User accessed dashboard', {'userId': user.id if user else None})
await client.log.error('Operation failed', {'error': str(err)})
await client.log.warn('Unusual activity', {'details': '...'})
# HTTP requests are automatically audited
# All sensitive data is automatically masked before logging
result = await client.http_client.get('/api/users')
# This automatically creates an audit log: http.request.GET with masked sensitive data
```
**What happens to logs?** They're sent to the Miso Controller for centralized monitoring and analysis. Client token is automatically included. Audit logs are automatically batched using `AuditLogQueue` for improved performance (configurable via `AuditConfig`).
**ISO 27001 Compliance:** All HTTP requests are automatically audited with sensitive data masked. Configure audit logging behavior using `AuditConfig`:
- **Audit Levels**: Choose from `minimal`, `standard`, `detailed`, or `full` (default: `detailed`)
- `minimal`: Only metadata, no masking
- `standard`: Metadata + basic context
- `detailed`: Full context with request/response sizes (default)
- `full`: Complete audit trail with all available data
- **Performance Optimizations**:
- Response body truncation based on `maxResponseSize` configuration (default: 10000 bytes)
- Size-based masking skip for large objects (prevents performance degradation)
- Automatic batching via `AuditLogQueue` reduces HTTP overhead for high-volume logging
- Set `log_level='debug'` to enable detailed request/response logging (all sensitive data is still masked).
→ [Complete logging example](examples/step-5-logging.py)
→ [Logging Reference](docs/api-reference.md#logger-service)
### Unified Logging Interface (Recommended)
**What happens:** The SDK provides a unified logging interface with minimal API (1-3 parameters maximum) and automatic context extraction. This eliminates the need to manually pass Request objects or context dictionaries.
**Benefits:**
- **Minimal API**: Maximum 1-3 parameters per logging call
- **Automatic Context**: Context extracted automatically via contextvars
- **Simple Usage**: `logger.info(message)`, `logger.error(message, error?)`, `logger.audit(action, resource, entity_id?, old_values?, new_values?)`
- **Framework Agnostic**: Works in FastAPI routes, Flask routes, service layers, background jobs
- **Zero Configuration**: Context automatically available when middleware is used
**Quick Start:**
#### FastAPI Setup
```python
from fastapi import FastAPI
from miso_client import get_logger
from miso_client.utils.fastapi_logger_middleware import logger_context_middleware
app = FastAPI()
# Add middleware early in middleware chain (after auth middleware)
app.middleware("http")(logger_context_middleware)
@app.get("/api/users")
async def get_users():
logger = get_logger() # Auto-detects context from contextvars
await logger.info("Users list accessed") # Auto-extracts request context
users = await fetch_users()
return users
```
#### Flask Setup
```python
from flask import Flask
from miso_client import get_logger
from miso_client.utils.flask_logger_middleware import register_logger_context_middleware
app = Flask(__name__)
# Register middleware
register_logger_context_middleware(app)
@app.route("/api/users")
async def get_users():
logger = get_logger() # Auto-detects context from contextvars
await logger.info("Users list accessed") # Auto-extracts request context
users = await fetch_users()
return users
```
#### Service Layer Usage
```python
from miso_client import get_logger
class UserService:
async def get_user(self, user_id: str):
logger = get_logger() # Uses contextvars context if available
await logger.info("Fetching user") # Auto-extracts context if available
try:
user = await db.user.find_unique({"id": user_id})
await logger.audit("ACCESS", "User", user_id) # Read access audit
return user
except Exception as error:
await logger.error("Failed to fetch user", error) # Auto-extracts error details
raise
```
#### Background Job Usage
```python
from miso_client import get_logger, set_logger_context
async def background_job():
# Set context for this async execution context
set_logger_context({
"jobId": "job-123",
"jobType": "sync",
})
logger = get_logger()
await logger.info("Background job started")
# All logs in this async context will use the set context
await process_data()
```
**UnifiedLogger Methods:**
- `info(message: str) -> None` - Log info message
- `warn(message: str) -> None` - Log warning message (preserved as `warn` level end-to-end)
- `debug(message: str) -> None` - Log debug message
- `error(message: str, error: Optional[Exception] = None) -> None` - Log error message with optional exception
- `audit(action: str, resource: str, entity_id?: str, old_values?: Dict, new_values?: Dict) -> None` - Log audit event
**Context Management:**
- `get_logger() -> UnifiedLogger` - Get logger instance with automatic context detection
- `set_logger_context(context: Dict[str, Any]) -> None` - Set context manually for background jobs
- `clear_logger_context() -> None` - Clear context
**Async Context Notes:**
- Context is stored via `contextvars`, so it flows through `await` in the same async call chain.
- Middleware (`fastapi_logger_context_middleware` / `flask_logger_context_middleware`) sets and clears context per request.
- For background tasks or separate event loops/threads, call `set_logger_context(...)` inside that task to ensure context is available.
**Context Fields Automatically Extracted:**
- `ipAddress` - Client IP address
- `userAgent` - User agent string
- `correlationId` - Request correlation ID
- `requestId` - Request ID from headers
- `userId` - Authenticated user ID (from JWT token)
- `sessionId` - Session ID (from JWT token)
- `method` - HTTP method
- `path` - Request path
- `hostname` - Request hostname
- `referer` - Referrer URL
- `requestSize` - Request size in bytes
- `applicationId` - Application identifier (from JWT token)
---
### Step 6: Activate Audit
**What happens:** Create audit trails for compliance and security monitoring.
```python
from miso_client import MisoClient, load_config
# Complete configuration (all in .env)
client = MisoClient(load_config())
await client.initialize()
token = client.get_token(req)
is_valid = await client.validate_token(token)
can_edit = await client.has_permission(token, 'edit:content')
user = await client.get_user(token)
# Audit: User actions
await client.log.audit('user.login', 'authentication', {
})
# Audit: Content changes
await client.log.audit('post.created', 'content', {
'userId': user.id if user else None,
'postId': 'post-123',
'postTitle': req.get('body', {}).get('title', ''),
})
# Audit: Permission checks
await client.log.audit('access.denied', 'authorization', {
'requiredPermission': 'edit:content',
'resource': 'posts',
})
```
**What to audit:** Login/logout, permission checks, content creation/deletion, role changes, sensitive operations.
→ [Complete audit example](examples/step-6-audit.py)
→ [Best Practices](docs/getting-started.md#common-patterns)
---
### Encryption and Caching
**What happens:** Use encryption for sensitive data and generic caching for improved performance.
```python
from miso_client import MisoClient, load_config
client = MisoClient(load_config())
await client.initialize()
# Encryption (requires ENCRYPTION_KEY in .env)
encrypted = client.encrypt('sensitive-data')
decrypted = client.decrypt(encrypted)
print('Decrypted:', decrypted)
# Generic caching (automatically uses Redis if available, falls back to memory)
await client.cache_set('user:123', {'name': 'John', 'age': 30}, 600) # 10 minutes TTL
user = await client.cache_get('user:123')
if user:
print('Cached user:', user)
```
**Configuration:**
```bash
# Add to .env
ENCRYPTION_KEY=your-32-byte-encryption-key
```
→ [API Reference](docs/api-reference.md#encryption-methods)
→ [Cache Methods](docs/api-reference.md#cache-methods)
---
### Testing with API Key
**What happens:** When `API_KEY` is set in your `.env` file, you can authenticate requests using the API key as a bearer token, bypassing OAuth2 authentication. This is useful for testing without setting up Keycloak.
```python
from miso_client import MisoClient, load_config
client = MisoClient(load_config())
await client.initialize()
# Use API_KEY as bearer token (for testing only)
api_key_token = "your-api-key-from-env"
is_valid = await client.validate_token(api_key_token)
# Returns True if token matches API_KEY from .env
user = await client.get_user(api_key_token)
# Returns None (API key auth doesn't provide user info)
```
**Configuration:**
```bash
# Add to .env for testing
API_KEY=your-test-api-key-here
```
**Important:**
- API_KEY authentication bypasses OAuth2 validation completely
- User information methods (`get_user()`, `get_user_info()`) return `None` when using API_KEY
- Token validation returns `True` if the bearer token matches the configured `API_KEY`
- This feature is intended for testing and development only
---
## 🔧 Configuration
```python
from miso_client import MisoClientConfig, RedisConfig, AuditConfig
config = MisoClientConfig(
controller_url="http://localhost:3000", # Required: Controller URL
client_id="ctrl-dev-my-app", # Required: Client ID
client_secret="your-secret", # Required: Client secret
redis=RedisConfig( # Optional: For caching
host="localhost",
port=6379,
),
log_level="info", # Optional: 'debug' | 'info' | 'warn' | 'error'
# Set to 'debug' for detailed HTTP request/response logging
api_key="your-test-api-key", # Optional: API key for testing (bypasses OAuth2)
cache={ # Optional: Cache TTL settings
"role_ttl": 900, # Role cache TTL (default: 900s)
"permission_ttl": 900, # Permission cache TTL (default: 900s)
},
audit=AuditConfig( # Optional: Audit logging configuration
enabled=True, # Enable/disable audit logging (default: true)
level="detailed", # Audit detail level: 'minimal' | 'standard' | 'detailed' | 'full' (default: 'detailed')
maxResponseSize=10000, # Truncate responses larger than this in bytes (default: 10000)
maxMaskingSize=50000, # Skip masking for objects larger than this in bytes (default: 50000)
batchSize=10, # Batch size for queued logs (default: 10)
batchInterval=100, # Flush interval in milliseconds (default: 100)
skipEndpoints=None # Array of endpoint patterns to exclude from audit logging
)
)
```
**Recommended:** Use `load_config()` to load from `.env` file automatically.
**ISO 27001 Data Masking Configuration:**
Sensitive fields are configured via `miso_client/utils/sensitive_fields_config.json`. You can customize this by:
1. Setting `MISO_SENSITIVE_FIELDS_CONFIG` environment variable to point to a custom JSON file
2. Using `DataMasker.set_config_path()` to set a custom path programmatically
The default configuration includes ISO 27001 compliant sensitive fields:
- Authentication: password, token, secret, key, auth, authorization
- PII: ssn, creditcard, cc, cvv, pin, otp
- Security: apikey, accesstoken, refreshtoken, privatekey, secretkey, cookie, session
**Audit Logging Configuration:**
Configure audit logging behavior using `AuditConfig` (see Configuration section above):
- **Audit Levels**: Control detail level (`minimal`, `standard`, `detailed`, `full`)
- **Response Truncation**: Configure `maxResponseSize` to truncate large responses (default: 10000 bytes)
- **Performance**: Set `maxMaskingSize` to skip masking for very large objects (default: 50000 bytes)
- **Batching**: Configure `batchSize` and `batchInterval` for audit log queuing (reduces HTTP overhead)
→ [Complete Configuration Reference](docs/configuration.md)
---
## 📚 Read more
- **[Getting Started](docs/getting-started.md)** - Detailed setup guide
- **[Backend client-token endpoint](docs/backend-client-token.md)** - Simple backend code for any app (FastAPI / Flask)
- **[API Reference](docs/api-reference.md)** - Complete API documentation
- **[Configuration](docs/configuration.md)** - Configuration options
- **[Examples](docs/examples.md)** - Framework-specific examples
- **[Troubleshooting](docs/troubleshooting.md)** - Common issues and solutions
---
## 🏗️ Architecture
The SDK consists of five core services:
- **AuthService** - Token validation and user authentication
- **RoleService** - Role management with Redis caching
- **PermissionService** - Fine-grained permissions
- **LoggerService** - Centralized logging with API key authentication
- **RedisService** - Caching and queue management (optional)
### HTTP Client Architecture
The SDK uses a two-layer HTTP client architecture for ISO 27001 compliance:
- **InternalHttpClient** - Core HTTP functionality with automatic client token management (internal)
- **HttpClient** - Public wrapper that adds automatic ISO 27001 compliant audit and debug logging
**Features:**
- Automatic audit logging for all HTTP requests (`http.request.{METHOD}`)
- Configurable audit levels (`minimal`, `standard`, `detailed`, `full`) via `AuditConfig`
- Debug logging when `log_level === 'debug'` with detailed request/response information
- Automatic data masking using `DataMasker` before logging (ISO 27001 compliant)
- Sensitive endpoints (`/api/logs`, `/api/auth/token`) are excluded from audit logging to prevent infinite loops
- All sensitive data (headers, bodies, query params) is automatically masked before logging
- `AuditLogQueue` integration for automatic batching of audit logs (reduces HTTP overhead)
- Performance optimizations: response body truncation and size-based masking skip for large objects
**ISO 27001 Compliance:**
- All request headers are masked (Authorization, x-client-token, Cookie, etc.)
- All request bodies are recursively masked for sensitive fields (password, token, secret, SSN, etc.)
- All response bodies are masked and truncated based on `maxResponseSize` configuration (default: 10000 bytes)
- Query parameters are automatically masked
- Error messages are masked if they contain sensitive data
- Sensitive fields configuration can be customized via `sensitive_fields_config.json`
- Configurable audit levels control the detail level of audit logs (minimal, standard, detailed, full)
→ [Architecture Details](docs/api-reference.md#architecture)
---
## 🌐 Setup Your Application
**First time setup?** Use the AI Fabrix Builder:
1. **Create your app:**
```bash
aifabrix create myapp --port 3000 --database --language python
```
2. **Login to controller:**
```bash
aifabrix login
```
3. **Register your application:**
```bash
aifabrix app register myapp --environment dev
```
4. **Start development** and then deploy to Docker or Azure.
→ [Full Quick Start Guide](https://github.com/esystemsdev/aifabrix-builder/blob/main/docs/QUICK-START.md)
---
## 💡 Next Steps
### Learn More
- [FastAPI Integration](docs/examples.md#fastapi-integration) - Protect API routes
- [Django Middleware](docs/examples.md#django-middleware) - Django integration
- [Flask Decorators](docs/examples.md#flask-decorators) - Decorator-based auth
- [Error Handling](docs/examples.md#error-handling) - Best practices
---
### Structured Error Responses
**What happens:** The SDK automatically parses structured error responses from the API (RFC 7807-style format) and makes them available through the `MisoClientError` and `ApiErrorException` exceptions.
```python
from miso_client import MisoClient, MisoClientError, ApiErrorException, ErrorResponse, load_config, handleApiError
client = MisoClient(load_config())
await client.initialize()
try:
result = await client.http_client.get("/api/some-endpoint")
except MisoClientError as e:
# Check if structured error response is available
if e.error_response:
print(f"Error Type: {e.error_response.type}")
print(f"Error Title: {e.error_response.title}")
print(f"Status Code: {e.error_response.statusCode}")
print(f"Errors: {e.error_response.errors}")
print(f"Instance: {e.error_response.instance}")
else:
# Fallback to traditional error handling
print(f"Error: {e.message}")
print(f"Status Code: {e.status_code}")
print(f"Error Body: {e.error_body}")
# Using handleApiError() for structured error handling
try:
response_data = {"errors": ["Validation failed"], "type": "/Errors/Validation", "title": "Validation Error", "statusCode": 422}
error = handleApiError(response_data, 422, "/api/endpoint")
# handleApiError() returns ApiErrorException (extends MisoClientError)
if isinstance(error, ApiErrorException):
print(f"Structured Error: {error.error_response.title}")
except ApiErrorException as e:
# ApiErrorException provides better structured error information
print(f"API Error: {e.error_response.title}")
print(f"Errors: {e.error_response.errors}")
```
**Error Response Structure:**
The `ErrorResponse` model follows RFC 7807-style format:
```json
{
"errors": [
"The user has provided input that the browser is unable to convert.",
"There are multiple rows in the database for the same value"
],
"type": "/Errors/Bad Input",
"title": "Bad Request",
"statusCode": 400,
"instance": "/OpenApi/rest/Xzy"
}
```
**Features:**
- **Automatic Parsing**: Structured error responses are automatically parsed from HTTP responses
- **ApiErrorException**: Exception class (extends `MisoClientError`) for better structured error handling
- `handleApiError()` returns `ApiErrorException` with structured error response support
- **Type Safety**: Full type hints with Pydantic models for reliable error handling
- **Generic Interface**: `ErrorResponse` model can be reused across different applications
- **Instance URI**: Automatically extracted from request URL if not provided in response
**Using ErrorResponse directly:**
```python
from miso_client import ErrorResponse
# Create ErrorResponse from dict
error_data = {
"errors": ["Validation failed"],
"type": "/Errors/Validation",
"title": "Validation Error",
"statusCode": 422,
"instance": "/api/endpoint"
}
error_response = ErrorResponse(**error_data)
# Access fields
print(error_response.errors) # ["Validation failed"]
print(error_response.type) # "/Errors/Validation"
print(error_response.title) # "Validation Error"
print(error_response.statusCode) # 422
print(error_response.instance) # "/api/endpoint"
```
---
### Pagination, Filtering, and Sorting Utilities
**What happens:** The SDK provides reusable utilities for pagination, filtering, sorting, and error handling that work with any API endpoint.
#### Pagination
**Pagination Parameters:**
- `page`: Page number (1-based, defaults to 1)
- `page_size`: Number of items per page (defaults to 20)
```python
from miso_client import (
parsePaginationParams,
parse_pagination_params,
createPaginatedListResponse,
PaginatedListResponse,
)
# Parse pagination from query parameters (returns dict with currentPage/pageSize keys)
params = {"page": "1", "pageSize": "20"}
pagination = parsePaginationParams(params)
# Returns: {"currentPage": 1, "pageSize": 20}
# Parse pagination from query parameters (returns tuple with page/page_size)
page, page_size = parse_pagination_params({"page": "1", "page_size": "20"})
# Returns: (1, 20)
# Create paginated response
items = [{"id": 1}, {"id": 2}]
response = createPaginatedListResponse(
items,
totalItems=120,
currentPage=1,
pageSize=20,
type="item"
)
# Response structure:
# {
# "meta": {
# "totalItems": 120,
# "currentPage": 1,
# "pageSize": 20,
# "type": "item"
# },
# "data": [{"id": 1}, {"id": 2}]
# }
```
#### Filtering
**Filter Operators:** `eq`, `neq`, `in`, `nin`, `gt`, `lt`, `gte`, `lte`, `contains`, `like`
**Filter Format:** `field:op:value` (e.g., `status:eq:active`)
```python
from miso_client import FilterBuilder, parse_filter_params, build_query_string
# Dynamic filter building with FilterBuilder
filter_builder = FilterBuilder() \
.add('status', 'eq', 'active') \
.add('region', 'in', ['eu', 'us']) \
.add('created_at', 'gte', '2024-01-01')
# Get query string
query_string = filter_builder.to_query_string()
# Returns: "filter=status:eq:active&filter=region:in:eu,us&filter=created_at:gte:2024-01-01"
# Parse existing filter parameters
params = {'filter': ['status:eq:active', 'region:in:eu,us']}
filters = parse_filter_params(params)
# Returns: [FilterOption(field='status', op='eq', value='active'), ...]
# Use with HTTP client
response = await client.http_client.get_with_filters(
'/api/items',
filter_builder=filter_builder
)
```
**Building Complete Filter Queries:**
```python
from miso_client import FilterQuery, FilterOption, build_query_string
# Create filter query with filters, sort, pagination, and fields
filter_query = FilterQuery(
filters=[
FilterOption(field='status', op='eq', value='active'),
FilterOption(field='region', op='in', value=['eu', 'us'])
],
sort=['-updated_at', 'created_at'],
page=1,
pageSize=20, # Note: camelCase for API compatibility
fields=['id', 'name', 'status']
)
# Build query string
query_string = build_query_string(filter_query)
```
#### Sorting
**Sort Format:** `-field` for descending, `field` for ascending (e.g., `-updated_at`, `created_at`)
```python
from miso_client import parse_sort_params, build_sort_string, SortOption
# Parse sort parameters
params = {'sort': '-updated_at'}
sort_options = parse_sort_params(params)
# Returns: [SortOption(field='updated_at', order='desc')]
# Parse multiple sorts
params = {'sort': ['-updated_at', 'created_at']}
sort_options = parse_sort_params(params)
# Returns: [
# SortOption(field='updated_at', order='desc'),
# SortOption(field='created_at', order='asc')
# ]
# Build sort string
sort_options = [
SortOption(field='updated_at', order='desc'),
SortOption(field='created_at', order='asc')
]
sort_string = build_sort_string(sort_options)
# Returns: "-updated_at,created_at"
```
#### Combined Usage
**Pagination + Filter + Sort:**
```python
from miso_client import (
FilterBuilder,
FilterQuery,
build_query_string,
parsePaginationParams,
parse_pagination_params,
)
# Build filters
filter_builder = FilterBuilder() \
.add('status', 'eq', 'active') \
.add('region', 'in', ['eu', 'us'])
# Parse pagination
params = {'page': '1', 'pageSize': '20'}
# Using camelCase function (returns dict)
pagination = parsePaginationParams(params)
current_page = pagination['currentPage']
page_size = pagination['pageSize']
# Using snake_case function (returns tuple)
page, page_size = parse_pagination_params({"page": "1", "page_size": "25"})
# Create complete query
filter_query = FilterQuery(
filters=filter_builder.build(),
sort=['-updated_at'],
page=current_page,
pageSize=page_size
)
# Build query string
query_string = build_query_string(filter_query)
# Use with HTTP client
response = await client.http_client.get_with_filters(
'/api/items',
filter_builder=filter_builder,
params={'page': current_page, 'pageSize': page_size}
)
```
**Or use pagination helper:**
```python
# Get paginated response
response = await client.http_client.get_paginated(
'/api/items',
page=1,
page_size=20
)
# Response is automatically parsed as PaginatedListResponse
print(response.meta.totalItems) # 120
print(response.meta.currentPage) # 1
print(len(response.data)) # 25
```
#### Metadata Filter Integration
**Working with `/metadata/filter` endpoint:**
```python
# Get metadata filters from endpoint
metadata_response = await client.http_client.post(
"/api/v1/metadata/filter",
{"documentStorageKey": "my-doc-storage"}
)
# Convert AccessFieldFilter to FilterBuilder
filter_builder = FilterBuilder()
for access_filter in metadata_response.mandatoryFilters:
filter_builder.add(access_filter.field, 'in', access_filter.values)
# Use with query utilities
query_string = filter_builder.to_query_string()
# Apply to API requests
response = await client.http_client.get_with_filters(
'/api/items',
filter_builder=filter_builder
)
```
**Features:**
- **camelCase Convention**: Pagination and error utilities use camelCase to match TypeScript SDK
- `parsePaginationParams()` - Returns dict with `currentPage`/`pageSize` keys
- `parse_pagination_params()` - Returns tuple `(page, page_size)` (snake_case, Python convention)
- `createMetaObject()` - Creates `Meta` objects with camelCase fields
- `applyPaginationToArray()` - Applies pagination to arrays
- `createPaginatedListResponse()` - Creates paginated list responses
- `transformError()` - Transforms error dictionaries to `ErrorResponse` objects
- `handleApiError()` - Creates `ApiErrorException` from API error responses
- **Type Safety**: Full type hints with Pydantic models
- **Dynamic Filtering**: FilterBuilder supports method chaining for complex filters
- **Local Testing**: `apply_filters()` and `applyPaginationToArray()` for local filtering/pagination in tests
- **URL Encoding**: Automatic URL encoding for field names and values
---
### Common Tasks
**Add authentication middleware (FastAPI):**
```python
from fastapi import Depends, HTTPException, Security
from fastapi.security import HTTPBearer
from miso_client import MisoClient
security = HTTPBearer()
client = MisoClient(load_config())
async def get_current_user(credentials = Security(security)):
token = credentials.credentials
is_valid = await client.validate_token(token)
if not is_valid:
raise HTTPException(status_code=401, detail="Invalid token")
return await client.get_user(token)
```
**Protect routes by role (FastAPI):**
```python
@app.get('/admin')
async def admin_panel(user = Depends(get_current_user), credentials = Security(security)):
token = credentials.credentials
is_admin = await client.has_role(token, 'admin')
if not is_admin:
raise HTTPException(status_code=403, detail="Forbidden")
# Admin only code
return {"message": "Admin panel"}
```
**Use environment variables:**
```bash
MISO_CLIENTID=ctrl-dev-my-app
MISO_CLIENTSECRET=your-secret
MISO_CONTROLLER_URL=http://localhost:3000
REDIS_HOST=localhost
REDIS_PORT=6379
MISO_LOG_LEVEL=info
API_KEY=your-test-api-key # Optional: For testing (bypasses OAuth2)
```
---
## 🐛 Troubleshooting
**"Cannot connect to controller"**
→ Verify `controllerUrl` is correct and accessible
→ Check network connectivity
**"Redis connection failed"**
→ SDK falls back to controller-only mode (slower but works)
→ Fix: `aifabrix up` to start Redis
**"Client token fetch failed"**
→ Check `MISO_CLIENTID` and `MISO_CLIENTSECRET` are correct
→ Verify credentials are configured in controller
→ Ensure `ENCRYPTION_KEY` environment variable is set (required for encryption service)
**"Token validation fails"**
→ Ensure Keycloak is running and configured correctly
→ Verify token is from correct Keycloak instance
→ Check that `python-dotenv` is installed if using `.env` files
→ [More Help](docs/troubleshooting.md)
---
## 📦 Installation
```bash
# pip
pip install miso-client
# Development mode
pip install -e .
# With dev dependencies
pip install "miso-client[dev]"
```
---
## 🔗 Links
- **GitHub Repository**: [https://github.com/esystemsdev/aifabrix-miso-client-python](https://github.com/esystemsdev/aifabrix-miso-client-python)
- **PyPI Package**: [https://pypi.org/project/miso-client/](https://pypi.org/project/miso-client/)
- **Builder Documentation**: [https://github.com/esystemsdev/aifabrix-builder](https://github.com/esystemsdev/aifabrix-builder)
- **Issues**: [https://github.com/esystemsdev/aifabrix-miso-client-python/issues](https://github.com/esystemsdev/aifabrix-miso-client-python/issues)
---
## 📄 License
This project is licensed under the MIT License - see the [LICENSE](./LICENSE) file for details.
---
**Made with ❤️ by eSystems Nordic Ltd.**
| text/markdown | AI Fabrix Team | AI Fabrix Team <team@aifabrix.ai> | null | AI Fabrix Team <team@aifabrix.ai> | null | authentication, authorization, rbac, jwt, redis, logging, aifabrix, miso | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python ... | [] | https://github.com/aifabrix/miso-client-python | null | >=3.8 | [] | [] | [] | [
"pydantic>=2.0.0",
"httpx>=0.25.0",
"redis[hiredis]>=5.0.0",
"PyJWT>=2.8.0",
"cryptography>=41.0.0",
"python-dotenv>=1.0.0",
"pytest>=7.4.3; extra == \"dev\"",
"pytest-asyncio>=0.21.1; extra == \"dev\"",
"pytest-mock>=3.12.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"black>=23.0... | [] | [] | [] | [
"Homepage, https://github.com/aifabrix/miso-client-python",
"Documentation, https://docs.aifabrix.ai/miso-client-python",
"Repository, https://github.com/aifabrix/miso-client-python",
"Issues, https://github.com/aifabrix/miso-client-python/issues"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T14:54:21.904633 | miso_client-4.5.0.tar.gz | 159,124 | 62/b3/a0ead0f03c327e43ae2a6848c7627bff3751f8403a8db224b8a7362eaf79/miso_client-4.5.0.tar.gz | source | sdist | null | false | 51f58fd87c8b4761c9c150aaf1701f65 | a16848152abd2ca2bcfd21d0a1db0dd92e679a87033195d20b50240b62f787f2 | 62b3a0ead0f03c327e43ae2a6848c7627bff3751f8403a8db224b8a7362eaf79 | MIT | [
"LICENSE"
] | 218 |
2.4 | yit-player | 2.0.2 | Fire-and-Forget Music CLI | # Yit (No Tabs. Just Tunes.) Player 🎵
[](https://badge.fury.io/py/yit-player)
[](https://www.gnu.org/licenses/gpl-3.0)
[](https://www.python.org/downloads/)
**The Fire-and-Forget Music Player for Developers.**
Yit is a lightweight, headless, terminal-based audio player designed for flow states. It allows you to search, queue, and control music directly from your CLI without ever touching a browser or a heavy GUI.
It runs in the background (daemonized), meaning you can close your terminal, switch tabs, or keep coding while the music plays.
---
## 🚀 Features
* **Daemon Architecture**: The player runs as a detached background process. Your terminal is never blocked.
* **Instant Search**: Uses `yt-dlp` to fetch metadata in milliseconds.
* **Smart Queue**: Manage your playlist (`add`, `next`, `back`, `Loop`) with simple commands.
* **Cross-Platform**: Works natively on **Windows**, **macOS**, and **Linux**.
* **Agent-Native**: Built from the ground up to be controlled by AI Agents (Vibe Coding).
---
## 📦 Installation
```bash
pip install yit-player
```
### Requirements
* **None!** Yit automatically manages the `mpv` audio engine internally.
* **Windows**: Auto-downloads a portable `mpv.exe` if missing.
* **Mac/Linux**: Uses system MPV (install via `brew` or `apt` if needed).
### Troubleshooting: "Command/Path not found"
If you run `yit` and get an error, your Python scripts folder is not in your system PATH.
**Solution:** Run it like this instead (works 100% of the time):
```bash
python -m yit search "slava funk" -p
```
---
## ⚡ Quick Start
### 1. Search & Play
```bash
# Search for a song
yit search "funk sigilo"
# Auto-play the first result immediately
yit search "funk infernal" -p
```
### 2. Control Playback
```bash
yit pause # (or 'p')
yit resume # (or 'r')
yit toggle # Toggle play/pause
yit stop # Kill the player
```
### 3. Queue Management
```bash
yit add 1 # Add result #1 from your last search to the queue (use 1 - 5 to choose from search results)
yit queue # Show the current queue
yit next # Skip track (or 'n')
yit back # Previous track (or 'b')
yit clear # Wipe the queue
```
### 4. Looping
```bash
yit loop # Loop the current track indefinitely
yit unloop # Return to normal playback
```
### 5. Status
```bash
yit status # Check if currently Playing/Paused and Looped
```
### 6. Favorites (❤️)
Save your best tracks for later.
```bash
# list all favorites
yit fav
# Add to favorites
yit fav add # Add the CURRENTLY playing song
yit fav add 1 # Add result #1 from your last search
# Play favorites
yit fav play # Play ALL favorites (starting from #1)
yit fav play 3 # Play favorite #3
# Remove
yit fav remove 2 # Remove favorite #2
```
---
## 🤖 For AI Agents & Vibe Coding
Yit is designed to be **self-documenting** for AI context.
If you are building an AI agent or using an LLM in your IDE:
1. **Read context**: Point your agent to [AI_INSTRUCTIONS.md](AI_INSTRUCTIONS.md) (included in the repo).
2. **Discovery**: Run `yit commands` to get a JSON list of all capabilities.
3. **State**: Run `yit agent` to get the full player state (Track, Time, Queue) in pure JSON.
**Example Agent Output (`yit agent`):**
```json
{
"status": "playing",
"track": {
"title": "Never Gonna Give You Up",
"url": "https://..."
},
"position": 45.2,
"duration": 212.0,
"queue_length": 5
}
```
---
## 🛠️ Architecture
* **Client**: Python CLI (`yit`) handles argument parsing and user signals.
* **Daemon**: A detached `mpv` process handles audio decoding and network streaming.
* **Communication**: IPC (Inter-Process Communication) via Named Pipes (Windows) or Unix Sockets (Linux/Mac).
* **Persistence**: `~/.yit/history.json` stores your playback history and queue metadata.
---
## ⚠️ Disclaimer and Legal Notice
**1. Educational Purpose Only**
This software (`Yit`) is a proof-of-concept project designed strictly for **educational and research purposes**. Its primary goal is to demonstrate:
* Advanced Python subprocess management and Daemon architecture.
* Inter-Process Communication (IPC) using sockets and named pipes.
* Memory-efficient resource management in CLI environments.
**2. Third-Party Content**
This tool acts as a command-line interface (CLI) wrapper for open-source media engines (`mpv`) and network libraries (`yt-dlp`).
* **No Content Hosting:** This application does not host, store, distribute, or decrypt any copyrighted media content.
* **Streaming Only:** It is designed for transient streaming of publicly available content. It does not include features to permanently download or "rip" media to the disk.
**3. Terms of Service**
Users are responsible for ensuring their use of this tool complies with the Terms of Service of any third-party platforms they interact with. The developer of this tool assumes no liability for misuse, account suspensions, or legal consequences arising from the use of this software.
**4. No Monetization**
This project is **free and open-source**. It is not monetized in any way, nor does it generate revenue from the content it accesses.
## License
This project is licensed under the GNU General Public License v3.0 (GPLv3). This ensures the software remains free and open-source. Commercial distribution of this software as a closed-source product is strictly prohibited.
## Contact
For any questions, please contact [vijayaraj.devworks@gmail.com](mailto:vijayaraj.devworks@gmail.com). | text/markdown | Yit Team | null | null | null | GPL-3.0-or-later | null | [
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.7 | [] | [] | [] | [
"requests",
"yt-dlp>=2023.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/VijayarajParamasivam/yit",
"Bug Tracker, https://github.com/VijayarajParamasivam/yit/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:53:53.214864 | yit_player-2.0.2.tar.gz | 25,323 | a5/d5/c2237cd135d9d36362f22ed9771dda7df3d1505cc7e213b45d452e593440/yit_player-2.0.2.tar.gz | source | sdist | null | false | 0de1272504579901bcab20f63b60b502 | 1cb511712e3c7d59dabb4edee408a29b20dabf436c76f84bd301ef2fe41626cd | a5d5c2237cd135d9d36362f22ed9771dda7df3d1505cc7e213b45d452e593440 | null | [
"LICENSE"
] | 223 |
2.4 | livef1 | 1.1.102 | A Python toolkit for seamless access to live and historical Formula 1 data. | # LiveF1 - An Open-Source Formula 1 Data Processing Toolkit

[](https://badge.fury.io/py/livef1)
[](https://opensource.org/licenses/MIT)
[](https://github.com/goktugocal/livef1)
[](https://github.com/goktugocal)
LiveF1 is a powerful Python toolkit for accessing and analyzing Formula 1 data in real-time or from historical archives. It's designed for developers, analysts, and F1 fans building applications around Formula 1 insights.
<p align="center">
<img src="https://raw.githubusercontent.com/GoktugOcal/LiveF1/main/docs/source/_static/LiveF1Overview1.png" alt="LiveF1 Data Flow"/>
</p>
### Features
- **Real-Time Race Data**: Provides live telemetry, timing, and position updates, ideal for powering dashboards and live analytics.
- **Historical Data Access**: Includes comprehensive race data from past seasons, perfect for performance analysis and comparisons.
- **Data Processing Modules**: Built-in ETL tools make raw data immediately usable, supporting analysis and seamless data storage.
- **Easy Integration**: Simple API for both real-time and historical data
In a nutshell:
**Using LiveF1, you can access real-time and historical racing data, making it easy to feed analytics and visualizations.**
## Installation
Install using pip:
```bash
pip install livef1
```
## Quick Start
### Historical Data
Access data from past races:
```python
import livef1
# Get a specific race session
session = livef1.get_session(
season=2024,
meeting_identifier="Spa",
session_identifier="Race"
)
# Load position data
position_data = session.get_data(
dataNames="Position.z"
)
print(position_data.head())
```
```text
| | SessionKey | timestamp | Utc | DriverNo | Status | X | Y | Z |
|---:|-------------:|:-------------|:-----------------------------|-----------:|:---------|----:|----:|----:|
| 0 | 9574 | 00:01:45.570 | 2024-07-28T12:10:22.7877313Z | 1 | OnTrack | 0 | 0 | 0 |
| 1 | 9574 | 00:01:45.570 | 2024-07-28T12:10:22.7877313Z | 2 | OnTrack | 0 | 0 | 0 |
| 2 | 9574 | 00:01:45.570 | 2024-07-28T12:10:22.7877313Z | 3 | OnTrack | 0 | 0 | 0 |
| 3 | 9574 | 00:01:45.570 | 2024-07-28T12:10:22.7877313Z | 4 | OnTrack | 0 | 0 | 0 |
| 4 | 9574 | 00:01:45.570 | 2024-07-28T12:10:22.7877313Z | 10 | OnTrack | 0 | 0 | 0 |
```
#### Data Processing
LiveF1 uses a medallion architecture to process F1 data into analysis-ready formats:
```python
# Generate processed data tables
session.generate(silver=True)
# Access refined data
laps_data = session.get_laps()
telemetry_data = session.get_car_telemetry()
print(laps_data.head())
```
```text
| | lap_number | lap_time | in_pit | pit_out | sector1_time | sector2_time | sector3_time | None | speed_I1 | speed_I2 | speed_FL | speed_ST | no_pits | lap_start_time | DriverNo | lap_start_date |
|---:|-------------:|:-----------------------|:-----------------------|:----------|:-----------------------|:-----------------------|:-----------------------|:-------|-----------:|-----------:|-----------:|-----------:|----------:|:-----------------------|-----------:|:---------------------------|
| 0 | 1 | NaT | 0 days 00:17:07.661000 | NaT | NaT | 0 days 00:00:48.663000 | 0 days 00:00:29.571000 | | 314 | 204 | | 303 | 0 | NaT | 16 | 2024-07-28 13:03:52.742000 |
| 1 | 2 | 0 days 00:01:50.240000 | NaT | NaT | 0 days 00:00:31.831000 | 0 days 00:00:48.675000 | 0 days 00:00:29.734000 | | 303 | 203 | 219 | | 0 | 0 days 00:57:07.067000 | 16 | 2024-07-28 13:05:45.045000 |
| 2 | 3 | 0 days 00:01:50.519000 | NaT | NaT | 0 days 00:00:31.833000 | 0 days 00:00:49.132000 | 0 days 00:00:29.554000 | | 311 | 202 | 215 | 304 | 0 | 0 days 00:58:57.307000 | 16 | 2024-07-28 13:07:35.285000 |
| 3 | 4 | 0 days 00:01:49.796000 | NaT | NaT | 0 days 00:00:31.592000 | 0 days 00:00:48.778000 | 0 days 00:00:29.426000 | | 312 | 201 | 217 | 309 | 0 | 0 days 01:00:47.870000 | 16 | 2024-07-28 13:09:25.848000 |
| 4 | 5 | 0 days 00:01:49.494000 | NaT | NaT | 0 days 00:00:31.394000 | 0 days 00:00:48.729000 | 0 days 00:00:29.371000 | | 313 | 197 | 217 | 311 | 0 | 0 days 01:02:37.721000 | 16 | 2024-07-28 13:11:15.699000 |
```
### Real-Time Data
Stream live race data:
```python
from livef1.adapters import RealF1Client
# Initialize client with topics to subscribe
client = RealF1Client(
topics=["CarData.z", "Position.z"],
log_file_name="race_data.json" # Optional: log data to file
)
# Define callback for incoming data
@client.callback("telemetry_handler")
async def handle_data(records):
for record in records:
print(record) # Process incoming data
# Start receiving data
client.run()
```
## Documentation
For detailed documentation, examples, and API reference, visit our [documentation page](https://livef1.readthedocs.io/).
## Testing
The project uses [pytest](https://pytest.org/) for unit tests. Install dev dependencies and run the test suite:
```bash
pip install -r requirements-dev.txt
pytest tests/ -v
```
With coverage:
```bash
pytest tests/ -v --cov=livef1 --cov-report=term-missing
```
Example scripts that use the library (without assertions) live in the `examples/` directory.
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request. For major changes, please open an issue first to discuss what you would like to change.
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## Support
- Report bugs and request features in [GitHub Issues](https://github.com/GoktugOcal/LiveF1/issues)
- For questions and discussions, use [GitHub Discussions](https://github.com/GoktugOcal/LiveF1/discussions)
## FEEL FREE TO [CONTACT ME](https://www.goktugocal.com/contact.html)
| text/markdown | Göktuğ Öcal | null | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/GoktugOcal/LiveF1 | null | >=3.7 | [] | [] | [] | [
"beautifulsoup4>=4.14.3",
"jellyfish>=1.1.0",
"numpy>=1.26.4",
"pandas>=2.2.0",
"pytest>=9.0.2",
"python_dateutil>=2.9.0.post0",
"Requests>=2.32.2",
"setuptools>=59.6.0",
"ujson>=5.10.0",
"websockets>=13.0.1",
"scipy>=1.14.1",
"lxml"
] | [] | [] | [] | [
"Bug Tracker, https://github.com/GoktugOcal/LiveF1/issues",
"Documentation, https://github.com/GoktugOcal/LiveF1#readme",
"Source Code, https://github.com/GoktugOcal/LiveF1"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:53:37.444100 | livef1-1.1.102.tar.gz | 71,541 | 67/6b/c10474c6ca42b91c867de40473b5dc8749644733c7035c5f84502058ce2c/livef1-1.1.102.tar.gz | source | sdist | null | false | 759d61dd7c9d054b02d544e6dd0e22e0 | 05d6fa8174e2127b5771ae48d4b3ada8b98438ec868ceb324c87955cd393bac1 | 676bc10474c6ca42b91c867de40473b5dc8749644733c7035c5f84502058ce2c | null | [
"LICENSE"
] | 258 |
2.4 | vesin | 0.5.0 | Computing neighbor lists for atomistic system | # Vesin: fast neighbor lists for atomistic systems
[](http://luthaf.fr/vesin/)

| English 🇺🇸/🇬🇧 | Occitan <img src="./docs/src/static/images/Occitan.png" width=18> | Arpitan <img src="./docs/src/static/images/Arpitan.png" width=18> | French 🇫🇷 | Gallo‑Italic <img src="./docs/src/static/images/Lombardy.png" width=18> | Catalan <img src="./docs/src/static/images/Catalan.png" width=18> | Spanish 🇪🇸 | Italian 🇮🇹 |
|------------------|----------|-----------|----------|--------------|---------|------------|------------|
| neighbo(u)r | vesin | vesin | voisin | visin | veí | vecino | vicino |
Vesin is a fast and easy to use library computing neighbor lists for atomistic
system. We provide an interface for the following programing languages:
- C (also compatible with C++). The project can be installed and used as a
library with your own build system, or included as a single file and built
directly by your own build system;
- Python;
- TorchScript, with both a C++ and Python interface;
### Installation
To use the code from Python, you can install it with `pip`:
```
pip install vesin
```
See the [documentation](https://luthaf.fr/vesin/latest/index.html#installation)
for more information on how to install the code to use it from C or C++.
### Usage instruction
You can either use the `NeighborList` calculator class:
```py
import numpy as np
from vesin import NeighborList
# positions can be anything compatible with numpy's ndarray
positions = [
(0, 0, 0),
(0, 1.3, 1.3),
]
box = 3.2 * np.eye(3)
calculator = NeighborList(cutoff=4.2, full_list=True)
i, j, S, d = calculator.compute(
points=positions,
box=box,
periodic=True,
quantities="ijSd"
)
```
We also provide a function with drop-in compatibility to ASE's neighbor list:
```py
import ase
from vesin import ase_neighbor_list
atoms = ase.Atoms(...)
i, j, S, d = ase_neighbor_list("ijSd", atoms, cutoff=4.2)
```
See the [documentation](https://luthaf.fr/vesin/latest/c-api.html) for more
information on how to use the code from C or C++.
### Benchmarks
You can find below benchmark result computing neighbor lists for increasingly
large diamond supercells, using an AMD 3955WX CPU and an NVIDIA 4070 Ti SUPER
GPU. You can run this benchmark on your system with the script at
`benchmarks/benchmark.py`. Missing points indicate that a specific code could
not run the calculation (for example, NNPOps requires the cell to be twice the
cutoff in size, and can't run with large cutoffs and small cells).

## License
Vesin is is distributed under the [3 clauses BSD license](LICENSE). By
contributing to this code, you agree to distribute your contributions under the
same license.
## Citation
If you found ``vesin`` useful, you can cite the pre-print where it was presented
(<https://doi.org/10.48550/arXiv.2508.15704>) as
```bibtex
@misc{metatensor-and-metatomic,
title = {Metatensor and Metatomic: Foundational Libraries for Interoperable Atomistic
Machine Learning},
shorttitle = {Metatensor and Metatomic},
author = {Bigi, Filippo and Abbott, Joseph W. and Loche, Philip and Mazitov, Arslan
and Tisi, Davide and Langer, Marcel F. and Goscinski, Alexander and Pegolo, Paolo
and Chong, Sanggyu and Goswami, Rohit and Chorna, Sofiia and Kellner, Matthias and
Ceriotti, Michele and Fraux, Guillaume},
year = {2025},
month = aug,
publisher = {arXiv},
doi = {10.48550/arXiv.2508.15704},
}
```
| text/markdown | null | Guillaume Fraux <guillaume.fraux@epfl.ch> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Operating System :: POSIX",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering",
"Top... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy",
"vesin-torch; extra == \"torch\""
] | [] | [] | [] | [
"homepage, https://github.com/Luthaf/vesin/",
"documentation, https://luthaf.fr/vesin/",
"repository, https://github.com/Luthaf/vesin/",
"changelog, https://github.com/Luthaf/vesin/blob/main/CHANEGELOG.md"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T14:53:21.175108 | vesin-0.5.0.tar.gz | 81,750 | af/2d/a8382020e19ab90c5e14f9eecb908310983f5efc2d94fceb89db6538674f/vesin-0.5.0.tar.gz | source | sdist | null | false | fcd095bde60af6ff74be952825f07caa | 432322e51b214d6e13b056677424f54b250fb181bd726afb9b2d5b1b6fdbdb84 | af2da8382020e19ab90c5e14f9eecb908310983f5efc2d94fceb89db6538674f | BSD-3-Clause | [] | 9,469 |
2.4 | vesin-torch | 0.5.0 | Computing neighbor lists for atomistic system, in TorchScript | # Vesin: fast neighbor lists for atomistic systems
[](http://luthaf.fr/vesin/)

| English 🇺🇸/🇬🇧 | Occitan <img src="./docs/src/static/images/Occitan.png" width=18> | Arpitan <img src="./docs/src/static/images/Arpitan.png" width=18> | French 🇫🇷 | Gallo‑Italic <img src="./docs/src/static/images/Lombardy.png" width=18> | Catalan <img src="./docs/src/static/images/Catalan.png" width=18> | Spanish 🇪🇸 | Italian 🇮🇹 |
|------------------|----------|-----------|----------|--------------|---------|------------|------------|
| neighbo(u)r | vesin | vesin | voisin | visin | veí | vecino | vicino |
Vesin is a fast and easy to use library computing neighbor lists for atomistic
system. We provide an interface for the following programing languages:
- C (also compatible with C++). The project can be installed and used as a
library with your own build system, or included as a single file and built
directly by your own build system;
- Python;
- TorchScript, with both a C++ and Python interface;
### Installation
To use the code from Python, you can install it with `pip`:
```
pip install vesin
```
See the [documentation](https://luthaf.fr/vesin/latest/index.html#installation)
for more information on how to install the code to use it from C or C++.
### Usage instruction
You can either use the `NeighborList` calculator class:
```py
import numpy as np
from vesin import NeighborList
# positions can be anything compatible with numpy's ndarray
positions = [
(0, 0, 0),
(0, 1.3, 1.3),
]
box = 3.2 * np.eye(3)
calculator = NeighborList(cutoff=4.2, full_list=True)
i, j, S, d = calculator.compute(
points=positions,
box=box,
periodic=True,
quantities="ijSd"
)
```
We also provide a function with drop-in compatibility to ASE's neighbor list:
```py
import ase
from vesin import ase_neighbor_list
atoms = ase.Atoms(...)
i, j, S, d = ase_neighbor_list("ijSd", atoms, cutoff=4.2)
```
See the [documentation](https://luthaf.fr/vesin/latest/c-api.html) for more
information on how to use the code from C or C++.
### Benchmarks
You can find below benchmark result computing neighbor lists for increasingly
large diamond supercells, using an AMD 3955WX CPU and an NVIDIA 4070 Ti SUPER
GPU. You can run this benchmark on your system with the script at
`benchmarks/benchmark.py`. Missing points indicate that a specific code could
not run the calculation (for example, NNPOps requires the cell to be twice the
cutoff in size, and can't run with large cutoffs and small cells).

## License
Vesin is is distributed under the [3 clauses BSD license](LICENSE). By
contributing to this code, you agree to distribute your contributions under the
same license.
## Citation
If you found ``vesin`` useful, you can cite the pre-print where it was presented
(<https://doi.org/10.48550/arXiv.2508.15704>) as
```bibtex
@misc{metatensor-and-metatomic,
title = {Metatensor and Metatomic: Foundational Libraries for Interoperable Atomistic
Machine Learning},
shorttitle = {Metatensor and Metatomic},
author = {Bigi, Filippo and Abbott, Joseph W. and Loche, Philip and Mazitov, Arslan
and Tisi, Davide and Langer, Marcel F. and Goscinski, Alexander and Pegolo, Paolo
and Chong, Sanggyu and Goswami, Rohit and Chorna, Sofiia and Kellner, Matthias and
Ceriotti, Michele and Fraux, Guillaume},
year = {2025},
month = aug,
publisher = {arXiv},
doi = {10.48550/arXiv.2508.15704},
}
```
| text/markdown | null | Guillaume Fraux <guillaume.fraux@epfl.ch> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Operating System :: POSIX",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering",
"Top... | [] | null | null | >=3.10 | [] | [] | [] | [
"torch>=2.1"
] | [] | [] | [] | [
"homepage, https://github.com/Luthaf/vesin/",
"documentation, https://luthaf.fr/vesin/",
"repository, https://github.com/Luthaf/vesin/",
"changelog, https://github.com/Luthaf/vesin/blob/main/CHANEGELOG.md"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T14:53:20.284365 | vesin_torch-0.5.0.tar.gz | 77,829 | c8/f8/0cf6000fbe0dbd3a5c677736f64be6d9ec8e33f5d3386483ba85579e432d/vesin_torch-0.5.0.tar.gz | source | sdist | null | false | 58c1bf6083d162cdd311f930315a4c29 | 412ca3fbad62f91a68dcebe5d5ef434d1b4506acaf19a25be79e9ebcb0bf0bf6 | c8f80cf6000fbe0dbd3a5c677736f64be6d9ec8e33f5d3386483ba85579e432d | BSD-3-Clause | [] | 7,833 |
2.4 | psa-strategy-cli | 0.1.0 | CLI for PSA workspace | # psa-strategy-cli
Command-line interface for PSA strategy evaluation contracts.
Run commands from the `cli/` directory:
```bash
cd cli
```
## Commands
- `psa evaluate-point --input <path|-> --output <path|-> [--pretty]`
- `psa evaluate-rows --input <path|-> --output <path|-> [--pretty]`
- `psa evaluate-ranges --input <path|-> --output <path|-> [--pretty]`
- `psa --version`
`-` means standard stream (`stdin` for `--input`, `stdout` for `--output`).
## Input and output
- Input must be a JSON request matching the command request schema.
- Output is JSON response (`{"row": ...}` or `{"rows": [...]}`).
- By default, output JSON is compact.
- `--pretty` enables indented output.
## Examples
### Evaluate point from file to stdout
```bash
uv run psa evaluate-point \
--input ../examples/bear_accumulate_point.json \
--output -
```
### Evaluate rows with pretty output file
```bash
uv run psa evaluate-rows \
--input ../examples/batch_timeseries_rows.json \
--output /tmp/rows.json \
--pretty
```
### Evaluate ranges with stdin/stdout
```bash
cat ../examples/range_timeseries_rows.json | \
uv run psa evaluate-ranges --input - --output -
```
## Exit codes
- `0`: success
- `2`: CLI argument error
- `3`: I/O or JSON parsing error
- `4`: schema/contract/runtime validation error
- `1`: unexpected internal error
## Schema loading
CLI searches request schemas in this order:
1. `PSA_SCHEMA_DIR` (if set)
2. packaged schemas bundled inside the installed `psa-strategy-cli` distribution
3. repository `schemas/` directory (development fallback)
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"jsonschema>=4.25.0",
"psa-strategy-core==0.1.0"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T14:52:58.814794 | psa_strategy_cli-0.1.0-py3-none-any.whl | 10,451 | 42/3f/3d9bd358878799a15e5404230f905c24da55a3c8c92cc66cea4c650b9087/psa_strategy_cli-0.1.0-py3-none-any.whl | py3 | bdist_wheel | null | false | d769957f8bd5ef9f19ec402435ff9251 | c85bc7906849520fdb5391abe3144131bab3564d97be1bc71b8729c580a80e7b | 423f3d9bd358878799a15e5404230f905c24da55a3c8c92cc66cea4c650b9087 | null | [] | 232 |
2.4 | heros | 0.8.8 | Make your objects available everywhere | <h1 align="center">
<img src="https://gitlab.com/atomiq-project/heros/-/raw/main/docs/_static/heros_logo.svg" width="150">
<br>
<img src="https://gitlab.com/atomiq-project/heros/-/raw/main/docs/_static/heros_text.svg" width="150">
</h1>
# HEROS - Highly Efficient Remote Object Service
HEROS is a decentralized object sharing service. In simple words it makes your software objects network transparent.
To be fast and efficient, HEROS relies on the minimal overhead eclipse-zenoh protocol as a transport layer. It thus
supports different network topologies and hardware transports. Most notably, it can run completely decentralized,
avoiding a single point of failure and at the same time guaranteeing low latency and and high bandwidth communication
through p2p connections.
HEROS provides a logical representation of software objects and is not tied to any specific language. Even non-object
oriented programming languages might provide a collection of functions, variables, and events to be accessible as an
object in HEROS.
Very much like a Dynamic Invocation Infrastructure (DII) in a Common Object Broker Architecture (CORBA), HEROS handles
objects dynamically during runtime rather than during compile time. While this does not allow to map HEROS objects to
be mapped to the language objects in compiled languages, languages supporting monkey-patching (python, js, ...) are
still able create proxy objects during runtime.
Find the HEROS documentation under [https://atomiq-project.gitlab.io/heros](https://atomiq-project.gitlab.io/heros).
## Paradigms
### Realms
To isolate groups of HEROs from other groups, the concept of realms exists in HEROS. You can think of it as a
namespace where objects in the same namespace can talk to each other while communication across realms/namespaces is
not easily possible. Note that this is solely a management feature, not a security feature. All realms share the same
zenoh network and can thus talk to each other on this level.
### Objects
An object that should be shared via HEROS must inherit from the class `LocalHero`. When python instantiates such
an object, it will parse the methods, class attributes, and events (see event decorator) and automatically generate
a list of capabilities that describes this HEROS object. The capabilities are announced and a liveliness token for the
object is created. HEROSOberserver in the network will thus be notified that our new object joined the realm.
When the object is destroyed or the link gets lost, the liveliness token disappears and any remote object will notice
this.
### Capabilities
A HEROS object is characterized by the capabilities it provides. There are currently three types of capabilities:
* Attribute
* Method
* Event
### Metadata
A HERO can carry metadata that allows for easier classification in environments with many HEROs. In addition to a list of tags, the metadata can also carry information on what interfaces a HERO provides. This allow a HERO to signal that it can seamlessly be used as an object of a certain class.
| text/markdown | null | Thomas Niederprüm <t.niederpruem@rptu.de>, Suthep Pomjaksilp <s.pomjaksilp@rptu.de> | null | Thomas Niederprüm <t.niederpruem@rptu.de>, Suthep Pomjaksilp <s.pomjaksilp@rptu.de> | LGPL-3.0-or-later | pub/sub, remote object, rpc, zenoh | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU Lesser General Public License v3 or later (LGPLv3+)",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Onl... | [] | null | null | >=3.10 | [] | [] | [] | [
"cbor2",
"eclipse-zenoh>=1.1.0",
"numpy",
"flake8>=6.0; extra == \"dev\"",
"hatch; extra == \"dev\"",
"pre-commit>=2.15.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest-mock>=3; extra == \"dev\"",
"pytest>=7.1; extra == \"dev\"",
"ruff; extra == \"dev\"",
"furo>=2024; extra == ... | [] | [] | [] | [
"Homepage, https://gitlab.com/atomiq-project/heros",
"Repository, https://gitlab.com/atomiq-project/heros",
"Documentation, https://gitlab.com/atomiq-project/heros/wiki",
"Bug Tracker, https://gitlab.com/atomiq-project/heros/issues"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T14:52:20.519521 | heros-0.8.8.tar.gz | 306,720 | ac/db/9d95e3d015ee9a875b39eb566f46fcc7ad52763fd460b8c3ecc0d599c160/heros-0.8.8.tar.gz | source | sdist | null | false | 4411bd0d36f953e1b1bb6c049b3d1b10 | 4966bfdbf573c4dabeb871689bfc8993305f95ec13c76e5619618bdfaef672f1 | acdb9d95e3d015ee9a875b39eb566f46fcc7ad52763fd460b8c3ecc0d599c160 | null | [
"LICENSE",
"LICENSE.LESSER"
] | 313 |
2.4 | zopyx.pyjsonata | 0.3.7 | Python bindings for jsonata-rs | # zopyx.pyjsonata
Python bindings for the Rust implementation of JSONata, powered by PyO3 and maturin. This package exposes the JSONata evaluator from `jsonata-rs` to Python with a small, focused API.
- JSONata reference docs: https://docs.jsonata.org/overview.html
- JSONata playground: https://www.stedi.com/jsonata/playground
- Rust implementation: https://github.com/Stedi/jsonata-rs
## Quick start
### Install from source (local)
```bash
UV_CACHE_DIR=/tmp/uv-cache uv venv .venv --python 3.13 --clear
UV_CACHE_DIR=/tmp/uv-cache uv pip install --python .venv/bin/python "maturin[zig]"
UV_CACHE_DIR=/tmp/uv-cache .venv/bin/python -m maturin develop --features python
```
### Use
```python
from zopyx.pyjsonata import evaluate, UNDEFINED, Jsonata
# Evaluate a simple expression
print(evaluate("1 + 1"))
# Evaluate with input data
print(evaluate('"Hello, " & name & "!"', {"name": "world"}))
# Provide variable bindings
bindings = {"x": 2, "y": 3}
print(evaluate("$x + $y", UNDEFINED, bindings))
# Reuse a compiled expression
expr = Jsonata("$sum([1,2,3])")
print(expr.evaluate())
```
## API
### `evaluate(expr, input=UNDEFINED, bindings=None, max_depth=None, time_limit=None)`
- `expr`: JSONata expression string
- `input`: JSON data for `$` (default `UNDEFINED` = no input)
- `bindings`: dict of variable bindings, e.g. `{"x": 1}`
- `max_depth`: optional evaluator depth limit
- `time_limit`: optional evaluation time limit
Returns standard Python types: `dict`, `list`, `str`, `float`, `int`, `bool`, `None`, or `UNDEFINED`.
### `Jsonata(expr)`
Constructs a reusable expression object.
- `Jsonata.evaluate(...)` has the same signature as `evaluate` but with the expression pre-parsed.
### `UNDEFINED`
Represents missing input (distinct from JSON `null`). In Python, `None` maps to JSON `null`.
## Errors
Errors raise `ValueError` and include the JSONata error code prefix (e.g. `T0410`), matching the Rust implementation.
## Build wheels (manylinux)
```bash
UV_CACHE_DIR=/tmp/uv-cache .venv/bin/python -m maturin build \
--release \
--features python \
--compatibility manylinux_2_28 \
--interpreter python3.11 python3.12 python3.13 \
--zig \
--auditwheel=repair
```
## Tests
- Rust tests: `cargo test`
- Python testsuite port: `make test-python` or `just test-python`
## Limitations
This is an incomplete JSONata implementation. Many reference tests are skipped under `tests/**/skip`.
## License
Apache-2.0.
## Maintainer
Andreas Jung — info@zopyx.com
| text/markdown; charset=UTF-8; variant=GFM | ZOPYX | null | null | Andreas Jung <info@zopyx.com> | Apache-2.0 | null | [] | [] | https://github.com/Stedi/jsonata-rs/ | null | <3.14,>=3.11 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/Stedi/jsonata-rs/",
"Repository, https://github.com/Stedi/jsonata-rs/"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T14:52:18.034420 | zopyx_pyjsonata-0.3.7-cp312-cp312-manylinux_2_28_x86_64.whl | 797,870 | 0e/51/c5b72b92d46829edcc705144c607d5e5daf60d5630c59d68d19f69a81d7d/zopyx_pyjsonata-0.3.7-cp312-cp312-manylinux_2_28_x86_64.whl | cp312 | bdist_wheel | null | false | 67e481ca3ceec3360bf2858f7aadc8fa | 8e20344e39038db682fa0f5683ace336c69993498e7fc5c65860f1f28b06ba52 | 0e51c5b72b92d46829edcc705144c607d5e5daf60d5630c59d68d19f69a81d7d | null | [
"LICENSE-APACHE"
] | 0 |
2.4 | ursus-ssg | 1.4.5 | Static site generator | # Ursus
[](https://badge.fury.io/py/ursus-ssg)
[](LICENSE)
Ursus is the static site generator used by [All About Berlin](https://allaboutberlin.com) and my [personal website](https://nicolasbouliane.com). It turns Markdown files and [Jinja](https://jinja.palletsprojects.com/) templates into a static website.
It also renders images in different sizes, renders SCSS, minifies JS and generates Lunr.js search indexes.
This project is in active use and development.
### What's different
- You can use Jinja `{% include %}` tags and `{{ variables }}` inside your Markdown content. This lets you insert constants and embed components inside your content. For example, I use it to insert a table of contents, calculators and constants in my content.
- It transforms images and supports `imgsrc` and `srcset` out of the box, so responsive images are easy to implement. It can also create PDF thumbnails, and can be extended to transform other files.
- You can build linters for your content. The default linters check if internal links and related entries exist. It's easy to write your own linters.
- It's *very* extensible. You can add your own context processors, renderers and linters. You are not stuck with Markdown and Jinja. You can also create your own Markdown extensions.
- It's relatively fast. [All About Berlin](https://allaboutberlin.com) and its hundreds of pages builds in 5 seconds on an M2 Macbook Air. Live reloads take around 400ms. It was originally built to run smoothly on a much older laptop.
## Setup
### Installation
Install Ursus with [pipx](https://pipx.pypa.io/):
```bash
pipx install ursus-ssg
```
Alternatively install with pip:
```bash
pip install ursus-ssg
```
### Getting started
Call `ursus` to generate a static website. Call `ursus --help` to see the command line options it supports.
By default, Ursus looks for 3 directories, relative to the current directory:
- It looks for content in `./content`
- It looks for page templates in `./templates`
- It generates a static website in `./output`
For example, create a markdown file and save it as `./content/posts/first-post.md`.
```markdown
---
title: Hello world!
description: This is an example page
date_created: 2022-10-10
---
## Hello beautiful world
*This* is a template. Pretty cool eh?
```
Then, create a page template and save it as `./templates/posts/entry.html.jinja`.
```
<!DOCTYPE html>
<html>
<head>
<title>{{ entry.title }}</title>
<meta name="description" content="{{ entry.description }}">
</head>
<body>
{{ entry.body }}
Created on {{ entry.date_created }}
</body>
</html>
```
Your project should now look like this:
```
my-website/ <- You are here
├─ content/
│ └─ posts/
│ └─ first-post.md
└─ templates/
└─ posts/
└─ entry.html.jinja
```
Call `ursus` to generate a statuc website. It will create `./output/posts/first-post.html`.
### Configuring Ursus
To configure Ursus, create a configuration file.
```python
# Example Ursus config file
# Find all configuration options in `ursus/config.py`.
from ursus.config import config
config.content_path = Path(__file__).parent / 'blog'
config.templates_path = Path(__file__).parent / 'templates'
config.output_path = Path(__file__).parent.parent / 'dist'
config.site_url = 'https://allaboutberlin.com'
config.minify_js = True
config.minify_css = True
```
If you call your configuration file `ursus_config.py`, Ursus loads it automatically.
```
my-website/
├─ ursus_config.py
├─ content/
└─ templates/
```
You can also load a configuration file with the `-c` argument.
```bash
ursus -c /path/to/ursus_config.py
```
### Watching for changes
Ursus can rebuild your website when the content or templates change.
```bash
# Rebuild when content or templates change
ursus -w
ursus --watch
```
It can only rebuild the pages that changed. This is much faster, but it does not work perfectly.
```bash
# Only rebuild the pages that changed
ursus -wf
ursus --watch --fast
```
### Serving the website
Ursus can serve the website it generates. This is useful for testing.
```bash
# Serve the static website on port 80
ursus -s
ursus --serve 80
```
This is not meant for production. Use nginx, Caddy or some other static file server for that.
## How Ursus works
1. **Context processors** generate the context used to render templates. The context is just a big dictionary that represent your site's entire content. Usually, each content file is turned into an entry.
2. **Renderers** use the context and the templates to render the parts of the final website: pages, thumbnails, static assets, etc.
### Content
**Content** is what fills your website: text, images, videos, PDFs. Content is usually *rendered* to create a working website. Some content (like Markdown files) is rendered with Templates, and other (like images) is converted to a different file format.
Ursus looks for content in `./content`, unless you change `config.content_path`.
### Entries
A single piece of content is called an **Entry**. This can be a single image, a single markdown file, etc.
Each Entry has a **URI**. This is the Entry's unique identifier. The URI is the Entry's path relative to the content directory. For example, the URI of `./content/posts/first-post.md` is `posts/first-post.md`.
### Context
The **Context** contains the information needed to render your website. It's just a big dictionary, and you can put anything in it.
`context['entries']` contains is a dictionary of all your entries. The key is the Entry URI.
**Context processors** each add specific data to the context. For example, `MarkdownProcessor` adds your `.md` content to `context.entries`.
```python
# Example context
{
'entries': {
'posts/first-post.md': {
'title': 'Hello world!',
'description': 'This is an example page',
'date_created': datetime(2022, 10, 10),
'body': '<h2>Hello beautiful world</h2><p>...',
},
'posts/second-post.md': {
# ...
},
},
# Context processors can add more things to the context
'blog_title': 'Example blog',
'site_url': 'https://example.com/blog',
}
```
### Templates
**Templates** are used to render your Content. They are the theme of your website. Jinja templates, Javascript, CSS and theme images belong in the templates directory.
Ursus looks for templates in `./templates`, unless you change `config.templates_path`.
### Renderers
**Renderers** use the Context and the Templates to generate parts of your static website. For example, `JinjaRenderer` renders Jinja templates, `ImageTransformRenderer` converts and resizes your images, and `StaticAssetRenderer` copies your static assets.
### Output
This is the final static website generated by Ursus. Ursus generates a static website in `./output`, unless you change `config.output_path`.
The content of the output directory is ready to be served by any static file server.
## How context processors work
Context processors transform the context, which is a dict with information about each of your Entries.
Context processors ignore file and directory names that start with `.` or `_`. For example, `./content/_drafts/hello.md` and `./content/posts/_post-draft.md` are ignored.
### MarkdownProcessor
The `MarkdownProcessor` creates context for all `.md` files in `content_path`. The markdown content is in the `body` attribute.
```python
{
'entries': {
'posts/first-post.md': {
'title': 'Hello world!',
'description': 'This is an example page',
'date_created': datetime(2022, 10, 10),
'body': '<h2>Hello beautiful world</h2><p>...',
},
# ...
},
}
```
It makes a few changes to the default markdown output:
- Put the front matter in the context
- `related_*` keys are replaced by a list of related entry dicts
- `date_` keys are converted to `datetime` objects
- Other attributes are added to the entry object.
- Use responsive images based on `config.image_transforms` settings.
- `<img>` are converted to `<figure>` or `<picture>` tags when appropriate.
- Images are lazy-loaded with the `loading=lazy` attribute.
- Jinja tags (`{{ ... }}` and `{% ... %}`) are rendered as-is. You can use `{% include %}` and `{{ variables }}` in your content.
### GetEntriesProcessor
The `GetEntriesProcessor` adds a `get_entries` method to the context. It's used to get a list of entries of a certain type, and sort it.
```jinja
{% set posts = get_entries('posts', filter_by=filter_function, sort_by='date_created', reverse=True) %}
{% for post in posts %}
...
```
### GitDateProcessor
Adds the `date_updated` attribute to all Entries. It uses the file's last commit date.
```python
{
'entries': {
'posts/first-post.md': {
'date_updated': datetime(2022, 10, 10),
# ...
},
# ...
},
}
```
### ImageProcessor
Adds images and PDFs Entries to the context. Dimensions and image transforms are added to each Entry. Use in combination with `config.image_transforms`.
```python
{
'entries': {
'images/hello.jpg': {
'width': 320,
'height': 240,
'image_transforms': [
{
'is_default': True,
'input_mimetype': 'image/jpeg',
'output_mimetype': 'image/webp',
# ...
},
# ...
]
},
# ...
},
}
```
## How renderers work
Renderers use context and templates to generate parts of the static website.
A **Generator** takes your Content and your Templates and produces an Output. It's a recipe to turn your content into a final result. The default **StaticSiteGenerator** generates a static website. You can write your own Generator to output an eBook, a PDF, or anything else.
### ImageTransformRenderer
Renders images in your content directory.
- Images are converted and resized according to `config.image_transforms`.
- Files that can't be transformed (PDF to PDF) are copied as-is to the output directory.
- Images that can't be resized (SVG to anything) are copied as-is to the output directory.
- Image EXIF data is removed.
This renderer does nothing unless `config.image_transforms` is set:
```python
from ursus.config import config
config.image_transforms = {
# ./content/images/test.jpg
# ---> ./output/images/test.jpg
# ./content/images/test.pdf
# ---> ./output/images/test.pdf
'': {
'include': ('images/*', 'documents/*'),
'output_types': ('original'),
},
# ./content/images/test.jpg
# ---> ./output/images/content2x/test.jpg
# ---> ./output/images/content2x/test.webp
'content2x': {
'include': ('images/*', 'illustrations/*'),
'exclude': ('*.pdf', '*.svg'),
'max_size': (800, 1200),
'output_types': ('webp', 'original'),
},
# ./content/documents/test.pdf
# ---> ./output/documents/pdfPreviews/test.png
# ---> ./output/documents/pdfPreviews/test.webp
'pdfPreviews': {
'include': 'documents/*',
'max_size': (300, 500),
'output_types': ('webp', 'png'),
},
}
```
### JinjaRenderer
Renders `*.jinja` files in the templates directory.
The output file has the same name and relative path as the template, but the `.jinja` extension is removed.
```
my-website/
├─ templates/
│ ├─ contact.html.jinja
│ ├─ sitemap.xml.jinja
│ └─ posts/
│ └─ index.html.jinja
└─ output/
├─ contact.html
├─ sitemap.xml
└─ posts/
└─ index.html
```
#### Dedicated templates
Files named `[name].[extension].jinja` will render any entry with the same `[name]`. For example, `first-post.md` will render as `first-post.txt` using the template `first-post.txt.jinja`. It will also render as `first-post.html` using the template `first-post.html.jinja`.
```
my-website/
├─ content/
│ └─ posts/
│ └─ first-post.md
├─ templates/
│ └─ posts/
│ ├─ first-post.txt.jinja
│ └─ first-post.html.jinja
└─ output/
└─ posts/
├─ first-post.txt
└─ first-post.html
```
#### Entry templates
Files named `entry.*.jinja` will render every entry with the same relative path. For example, the template `entry.html.jinja` will be used to render `first-post.md` and `second-post.md`.
```
my-website/
├─ content/
│ └─ posts/
│ ├─ first-post.md
│ ├─ second-post.md
│ ├─ third-post.md
│ └─ _draft.md
├─ templates/
│ └─ posts/
│ ├─ entry.html.jinja
│ ├─ second-post.txt.jinja
│ └─ third-post.html.jinja
└─ output/
└─ posts/
├─ first-post.html
├─ second-post.html
├─ second-post.txt # Rendered with second-post.txt.jinja
└─ third-post.html # Rendered with third-post.html.jinja
```
Dedicated templates take precedence over entry templates with the same extension.
In the example above, `third-post.md` is rendered by `third-post.html.jinja`, not by `entry.html.jinja`. `second-post.md` is rendered by `second-post.txt.jinja` *and* by `entry.html.jinja`.
#### Ignored files
Files or directory names that start with `.` or `_` are not rendered.
```
my-website/
├─ content/
│ └─ posts/
│ ├─ hello-world.md
│ ├─ .hidden.md
│ └─ _drafts
│ └─ not-rendered.md
├─ templates/
│ └─ posts/
│ └─ entry.html.jinja
└─ output/
└─ posts/
└─ hello-world.html
```
### StaticAssetRenderer
Copies all files under `./templates` except `.jinja` files to the same subdirectory in `./output`. Files starting with `.` are ignored. Files and directories starting with `_` are ignored.
```
my-website/
├─ templates/
│ ├─ _ignored.jpg
│ ├─ styles.css
│ ├─ images/
│ │ └─ hello.png
│ └─ js/
│ └─ test.js
└─ output/
├─ styles.css
├─ images/
│ └─ hello.png
└─ js/
└─ test.js
```
It uses hard links instead of copying files, so it does not use extra disk space.
## How generators work
Generators bring it all together. A generator takes all of your files, and generates some final product. There is only `StaticSiteGenerator`, which generates a static website. Custom generators could generate a book or a slideshow from the same content and templates.
## How linters work
Ursus supports linter. They verify the content when `ursus lint` is called. You can find examples in `ursus/linters`.
| text/markdown | Nicolas Bouliane | contact@nicolasbouliane.com | null | null | MIT | null | [] | [] | http://github.com/all-about-berlin/ursus | null | >=3.11 | [] | [] | [] | [
"GitPython==3.1.45",
"imagesize==1.4.1",
"Jinja2==3.1.6",
"jinja2-simple-tags==0.6.1",
"libsass==0.23.0",
"lunr==0.8.0",
"Markdown==3.5.2",
"MarkupSafe==2.1.5",
"ordered-set==4.1.0",
"platformdirs==4.3.8",
"PyMuPDF==1.26.3",
"Pillow==11.3.0",
"watchdog==4.0.1",
"requests==2.32.4",
"rjsmi... | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.0 | 2026-02-19T14:51:57.728778 | ursus_ssg-1.4.5.tar.gz | 251,803 | 0d/01/052d225c8ffe5831e313b717b1213f556ea81c7d3c7b535785d5858bc964/ursus_ssg-1.4.5.tar.gz | source | sdist | null | false | 86ba6eab8619b15fc54e8c9fedd1ff5e | 8a9dfe9a2ec0bf6ba231ac90f942b17df979b79b11768cd468eb9ea7e256ec97 | 0d01052d225c8ffe5831e313b717b1213f556ea81c7d3c7b535785d5858bc964 | null | [
"LICENSE"
] | 217 |
2.4 | transformerlab | 0.0.80 | Python SDK for Transformer Lab | # Transformer Lab SDK
The Transformer Lab Python SDK provides a way for ML scripts to integrate with Transformer Lab.
## Install
```bash
pip install transformerlab
```
## Usage
```
from lab import lab
# Initialize with experiment ID
lab.init("my-experiment")
lab.log("Job initiated")
config_artifact_path = lab.save_artifact(<config_file>, "training_config.json")
lab.log(f"Saved training config: {config_artifact_path}")
lab.update_progress(1)
...
lab.update_progress(99)
model_path = lab.save_model(<training_output_dir>, name="trained_model")
lab.log("Saved model file to {model_path}")
lab.finish("Training completed successfully")
```
Sample scripts can be found at
https://github.com/transformerlab/transformerlab-app/tree/main/lab-sdk/scripts/examples
## Development
The code for this can be found in the `lab-sdk` directory of
https://github.com/transformerlab/transformerlab-app
To develop locally in editable mode and run automated tests:
```bash
cd lab-sdk
uv venv
uv pip install -e .
uv run pytest # Run tests
```
| text/markdown | null | Transformer Lab <developers@lab.cloud> | null | null | GNU AFFERO GENERAL PUBLIC LICENSE
Version 3, 19 November 2007
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU Affero General Public License is a free, copyleft license for
software and other kinds of works, specifically designed to ensure
cooperation with the community in the case of network server software.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
our General Public Licenses are intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
Developers that use our General Public Licenses protect your rights
with two steps: (1) assert copyright on the software, and (2) offer
you this License which gives you legal permission to copy, distribute
and/or modify the software.
A secondary benefit of defending all users' freedom is that
improvements made in alternate versions of the program, if they
receive widespread use, become available for other developers to
incorporate. Many developers of free software are heartened and
encouraged by the resulting cooperation. However, in the case of
software used on network servers, this result may fail to come about.
The GNU General Public License permits making a modified version and
letting the public access it on a server without ever releasing its
source code to the public.
The GNU Affero General Public License is designed specifically to
ensure that, in such cases, the modified source code becomes available
to the community. It requires the operator of a network server to
provide the source code of the modified version running there to the
users of that server. Therefore, public use of a modified version, on
a publicly accessible server, gives the public access to the source
code of the modified version.
An older license, called the Affero General Public License and
published by Affero, was designed to accomplish similar goals. This is
a different license, not a version of the Affero GPL, but Affero has
released a new version of the Affero GPL which permits relicensing under
this license.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU Affero General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Remote Network Interaction; Use with the GNU General Public License.
Notwithstanding any other provision of this License, if you modify the
Program, your modified version must prominently offer all users
interacting with it remotely through a computer network (if your version
supports such interaction) an opportunity to receive the Corresponding
Source of your version by providing access to the Corresponding Source
from a network server at no charge, through some standard or customary
means of facilitating copying of software. This Corresponding Source
shall include the Corresponding Source for any work covered by version 3
of the GNU General Public License that is incorporated pursuant to the
following paragraph.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the work with which it is combined will remain governed by version
3 of the GNU General Public License.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU Affero General Public License from time to time. Such new versions
will be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU Affero General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU Affero General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU Affero General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero General Public License as published
by the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Affero General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see <https://www.gnu.org/licenses/>.
Also add information on how to contact you by electronic and paper mail.
If your software can interact with users remotely through a computer
network, you should also make sure that it provides a way for users to
get its source. For example, if your program is a web application, its
interface could display a "Source" link that leads users to an archive
of the code. There are many ways you could offer source, and different
solutions will be better for different programs; see section 13 for the
specific requirements.
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU AGPL, see
<https://www.gnu.org/licenses/>.
| null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"werkzeug",
"pytest",
"pytest-asyncio",
"wandb",
"fsspec",
"s3fs",
"aiofiles",
"gcsfs"
] | [] | [] | [] | [
"Homepage, https://github.com/transformerlab/transformerlab-app",
"Bug Tracker, https://github.com/transformerlab/transformerlab-app/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:51:47.959832 | transformerlab-0.0.80.tar.gz | 85,326 | 74/cb/b4936dc101833d36fc2765c2e25b350a8585542dfc3f3d57a437b73f7abe/transformerlab-0.0.80.tar.gz | source | sdist | null | false | ae211c4214673b8c83976309a4737cf3 | 02db5410684e0a97e1d044c699e07618113258e38ab317ed8b6ba519fd5b6f74 | 74cbb4936dc101833d36fc2765c2e25b350a8585542dfc3f3d57a437b73f7abe | null | [
"LICENSE"
] | 642 |
2.4 | openpipe-art | 0.5.11 | The OpenPipe Agent Reinforcement Training (ART) library | <div align="center">
<a href="https://art.openpipe.ai"><picture>
<img alt="ART logo" src="https://github.com/openpipe/art/raw/main/assets/ART_logo.png" width="160px">
</picture></a>
<p align="center">
<h1>Agent Reinforcement Trainer</h1>
</p>
<p>
Train multi-step agents for real-world tasks using GRPO.
</p>
[![PRs-Welcome][contribute-image]][contribute-url]
[][pypi-url]
[](https://colab.research.google.com/github/openpipe/art-notebooks/blob/main/examples/2048/2048.ipynb)
[](https://discord.gg/EceeVdhpxD)
[](https://art.openpipe.ai)
</div>
## 🚀 W&B Training: Serverless RL
**W&B Training (Serverless RL)** is the first publicly available service for flexibly training models with reinforcement learning. It manages your training and inference infrastructure automatically, letting you focus on defining your data, environment and reward function—leading to faster feedback cycles, lower costs, and far less DevOps.
✨ **Key Benefits:**
- **40% lower cost** - Multiplexing on shared production-grade inference cluster
- **28% faster training** - Scale to 2000+ concurrent requests across many GPUs
- **Zero infra headaches** - Fully managed infrastructure that stays healthy
- **Instant deployment** - Every checkpoint instantly available via W&B Inference
```python
# Before: Hours of GPU setup and infra management
# RuntimeError: CUDA error: out of memory 😢
# After: Serverless RL with instant feedback
from art.serverless.backend import ServerlessBackend
model = art.TrainableModel(
project="voice-agent",
name="agent-001",
base_model="OpenPipe/Qwen3-14B-Instruct"
)
backend = ServerlessBackend(
api_key="your_wandb_api_key"
)
model.register(backend)
# Edit and iterate in minutes, not hours!
```
[📖 Learn more about W&B Training →](https://docs.wandb.ai/guides/training)
## ART Overview
ART is an open-source RL framework that improves agent reliability by allowing LLMs to **learn from experience**. ART provides an ergonomic harness for integrating GRPO into any python application. For a quick hands-on introduction, run one of the notebooks below. When you're ready to learn more, check out the [docs](https://art.openpipe.ai).
## 📒 Notebooks
| Agent Task | Example Notebook | Description | Comparative Performance |
| ------------------- | -------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **ART•E [Serverless]** | [🏋️ Train agent](https://colab.research.google.com/github/openpipe/art-notebooks/blob/main/examples/art-e.ipynb) | Qwen3 14B learns to search emails using RULER | <img src="https://github.com/openpipe/art/raw/main/assets/benchmarks/email_agent/accuracy-training-progress.svg" height="72"> [benchmarks](/dev/art-e/art_e/evaluate/display_benchmarks.ipynb) |
| **2048 [Serverless]** | [🏋️ Train agent](https://colab.research.google.com/github/openpipe/art-notebooks/blob/main/examples/2048/2048.ipynb) | Qwen3 14B learns to play 2048 | <img src="https://github.com/openpipe/art/raw/main/assets/benchmarks/2048/accuracy-training-progress.svg" height="72"> [benchmarks](/examples/2048/display_benchmarks.ipynb) |
| **ART•E LangGraph** | [🏋️ Train agent](https://colab.research.google.com/github/openpipe/art-notebooks/blob/main/examples/langgraph/art-e-langgraph.ipynb) | Qwen 2.5 7B learns to search emails using LangGraph | [Link coming soon] |
| **MCP•RL** | [🏋️ Train agent](https://colab.research.google.com/github/openpipe/art-notebooks/blob/main/examples/mcp-rl/mcp-rl.ipynb) | Qwen 2.5 3B masters the NWS MCP server | [Link coming soon] |
| **Temporal Clue** | [🏋️ Train agent](https://colab.research.google.com/github/openpipe/art-notebooks/blob/main/examples/temporal_clue/temporal-clue.ipynb) | Qwen 2.5 7B learns to solve Temporal Clue | [Link coming soon] |
| **Tic Tac Toe** | [🏋️ Train agent](https://colab.research.google.com/github/openpipe/art-notebooks/blob/main/examples/tic_tac_toe/tic-tac-toe.ipynb) | Qwen 2.5 3B learns to play Tic Tac Toe | <img src="https://github.com/openpipe/art/raw/main/assets/benchmarks/tic-tac-toe-local/accuracy-training-progress.svg" height="72"> [benchmarks](/examples/tic_tac_toe/display-benchmarks.ipynb) |
| **Codenames** | [🏋️ Train agent](https://colab.research.google.com/github/openpipe/art-notebooks/blob/main/examples/codenames/Codenames_RL.ipynb) | Qwen 2.5 3B learns to play Codenames | <img src="https://github.com/openpipe/art/raw/main/assets/benchmarks/codenames/win_rate_over_time.png" height="72"> [benchmarks](https://github.com/OpenPipe/art-notebooks/blob/main/examples/codenames/Codenames_RL.ipynb) |
| **AutoRL [RULER]** | [🏋️ Train agent](https://colab.research.google.com/github/openpipe/art-notebooks/blob/main/examples/auto_rl.ipynb) | Train Qwen 2.5 7B to master any task | [Link coming soon] |
## 📰 ART News
Explore our latest research and updates on building SOTA agents.
- 🗞️ **[ART now integrates seamlessly with LangGraph](https://art.openpipe.ai/integrations/langgraph-integration)** - Train your LangGraph agents with reinforcement learning for smarter multi-step reasoning and improved tool usage.
- 🗞️ **[MCP•RL: Teach Your Model to Master Any MCP Server](https://x.com/corbtt/status/1953171838382817625)** - Automatically train models to effectively use MCP server tools through reinforcement learning.
- 🗞️ **[AutoRL: Zero-Data Training for Any Task](https://x.com/mattshumer_/status/1950572449025650733)** - Train custom AI models without labeled data using automatic input generation and RULER evaluation.
- 🗞️ **[RULER: Easy Mode for RL Rewards](https://openpipe.ai/blog/ruler-easy-mode-for-rl-rewards)** is now available for automatic reward generation in reinforcement learning.
- 🗞️ **[ART·E: How We Built an Email Research Agent That Beats o3](https://openpipe.ai/blog/art-e-mail-agent)** demonstrates a Qwen 2.5 14B email agent outperforming OpenAI's o3.
- 🗞️ **[ART Trainer: A New RL Trainer for Agents](https://openpipe.ai/blog/art-trainer)** enables easy training of LLM-based agents using GRPO.
[📖 See all blog posts →](https://openpipe.ai/blog)
## Why ART?
- ART provides convenient wrappers for introducing RL training into **existing applications**. We abstract the training server into a modular service that your code doesn't need to interface with.
- **Train from anywhere.** Run the ART client on your laptop and let the ART server kick off an ephemeral GPU-enabled environment, or run on a local GPU.
- Integrations with hosted platforms like W&B, Langfuse, and OpenPipe provide flexible observability and **simplify debugging**.
- ART is customizable with **intelligent defaults**. You can configure training parameters and inference engine configurations to meet specific needs, or take advantage of the defaults, which have been optimized for training efficiency and stability.
## Installation
ART agents can be trained from any client machine that runs python. To add to an existing project, run this command:
```
pip install openpipe-art
```
## 🤖 ART•E Agent
Curious about how to use ART for a real-world task? Check out the [ART•E Agent](https://openpipe.ai/blog/art-e-mail-agent) blog post, where we detail how we trained Qwen 2.5 14B to beat o3 at email retrieval!
<img src="https://github.com/openpipe/art/raw/main/assets/ART_E_graphs.png" width="700">
## 🔁 Training Loop Overview
ART's functionality is divided into a **client** and a **server**. The OpenAI-compatible client is responsible for interfacing between ART and your codebase. Using the client, you can pass messages and get completions from your LLM as it improves. The server runs independently on any machine with a GPU. It abstracts away the complexity of the inference and training portions of the RL loop while allowing for some custom configuration. An outline of the training loop is shown below:
1. **Inference**
1. Your code uses the ART client to perform an agentic workflow (usually executing several rollouts in parallel to gather data faster).
2. Completion requests are routed to the ART server, which runs the model's latest LoRA in vLLM.
3. As the agent executes, each `system`, `user`, and `assistant` message is stored in a Trajectory.
4. When a rollout finishes, your code assigns a `reward` to its Trajectory, indicating the performance of the LLM.
2. **Training**
1. When each rollout has finished, Trajectories are grouped and sent to the server. Inference is blocked while training executes.
2. The server trains your model using GRPO, initializing from the latest checkpoint (or an empty LoRA on the first iteration).
3. The server saves the newly trained LoRA to a local directory and loads it into vLLM.
4. Inference is unblocked and the loop resumes at step 1.
This training loop runs until a specified number of inference and training iterations have completed.
## 🧩 Supported Models
ART should work with most vLLM/HuggingFace-transformers compatible causal language models, or at least the ones supported by [Unsloth](https://docs.unsloth.ai/get-started/all-our-models). Gemma 3 does not appear to be supported for the time being. If any other model isn't working for you, please let us know on [Discord](https://discord.gg/zbBHRUpwf4) or open an issue on [GitHub](https://github.com/openpipe/art/issues)!
## 🤝 Contributing
ART is in active development, and contributions are most welcome! Please see the [CONTRIBUTING.md](CONTRIBUTING.md) file for more information.
## 📖 Citation
```bibtex
@misc{hilton2025art,
author = {Brad Hilton and Kyle Corbitt and David Corbitt and Saumya Gandhi and Angky William and Bohdan Kovalevskyi and Andie Jones},
title = {ART: Agent Reinforcement Trainer},
year = {2025},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/openpipe/art}}
}
```
## ⚖️ License
This repository's source code is available under the [Apache-2.0 License](LICENSE).
## 🙏 Credits
ART stands on the shoulders of giants. While we owe many of the ideas and early experiments that led to ART's development to the open source RL community at large, we're especially grateful to the authors of the following projects:
- [Unsloth](https://github.com/unslothai/unsloth)
- [vLLM](https://github.com/vllm-project/vllm)
- [trl](https://github.com/huggingface/trl)
- [torchtune](https://github.com/pytorch/torchtune)
Finally, thank you to our partners who've helped us test ART in the wild! We're excited to see what you all build with it.
[pypi-url]: https://pypi.org/project/openpipe-art/
[contribute-url]: https://github.com/openpipe/art/blob/main/CONTRIBUTING.md
[contribute-image]: https://img.shields.io/badge/PRs-welcome-blue.svg
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"litellm>=1.71.1",
"nest-asyncio>=1.6.0",
"openai>=2.14.0",
"polars>=1.26.0",
"setproctitle>=1.3.6",
"tblib>=3.0.0",
"typer>=0.15.2",
"weave>=0.52.24",
"accelerate==1.7.0; extra == \"backend\"",
"awscli>=1.38.1; extra == \"backend\"",
"bitsandbytes>=0.45.2; extra == \"backend\"",
"duckdb>=1.0.... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:51:32.013007 | openpipe_art-0.5.11.tar.gz | 8,149,355 | 0e/20/5ff8f98d77fffd55dd08ee3785060fd1afbf480986da8aa06aade28e6f80/openpipe_art-0.5.11.tar.gz | source | sdist | null | false | 9b684a23c389f93d5bf1d4bd00cf05cd | 856af26eb93737262a92c61a3d50d93c56a1a8bee84cd77eff87594121fffab8 | 0e205ff8f98d77fffd55dd08ee3785060fd1afbf480986da8aa06aade28e6f80 | null | [
"LICENSE"
] | 311 |
2.4 | micress-micpy | 0.4.0b1 | MicPy is a Python package to facilitate MICRESS workflows. | <center>

</center>
# MicPy
MicPy is a Python package to facilitate [MICRESS](https://www.micress.de) workflows. Whether you aim to visualize, convert, or manipulate MICRESS data, MicPy provides the necessary tools.
## Installation
```
pip install micress-micpy
```
## Dependencies
MicPy requires the following dependencies:
- Python (>= 3.9)
- Pandas (>= 1.1)
- Matplotlib (>= 3) as an optional dependency for plotting
- VTK (>= 9) as an optional dependency for 3D visualization
## Documentation
https://docs.micress.de/micpy
| text/markdown | Lukas Koschmieder | l.koschmieder@access-technology.de | null | null | BSD-3-Clause (Copyright (c) 2024-2026 Access e.V.) | MICRESS | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.9"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"matplotlib",
"pandas",
"rapidgzip"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.19 | 2026-02-19T14:51:19.898231 | micress_micpy-0.4.0b1-py3-none-any.whl | 15,674 | 4f/ed/4e2c0252a81656961413979775152c434566d2f3311dbb900a9b8a996b84/micress_micpy-0.4.0b1-py3-none-any.whl | py3 | bdist_wheel | null | false | a70bf2e275f3c15d0e009474848c89dc | 6201bfd84b5f5808e71c91d41c3f75ad75b4f7a596cd3eb615ff2b3c38f8728a | 4fed4e2c0252a81656961413979775152c434566d2f3311dbb900a9b8a996b84 | null | [
"LICENSE"
] | 100 |
2.4 | idahelper | 1.0.18 | standard library for IDA Pro plugins | # IDAHelper
IDAHelper is a Python package that provides a set of tools to assist with reverse engineering tasks in IDA Pro.
## Example usage
```python
from idahelper import cpp, memory, tif
pure_virtual_ea = memory.ea_from_name("___cxa_pure_virtual")
for cls, vtable_ea in cpp.get_all_cpp_classes():
parent_cls = tif.get_parent_class(cls)
``` | text/markdown | null | Yoav Sternberg <yoav.sternberg@gmail.com> | null | null | null | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/yoavst/idahelper",
"Issues, https://github.com/yoavst/idahelper/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:50:44.583297 | idahelper-1.0.18.tar.gz | 25,640 | fe/0f/384b06e711d2982066f0f6aa511db7f41bca599b0f80da27188858f73335/idahelper-1.0.18.tar.gz | source | sdist | null | false | e009b238f5b8a53005a917ff01131b10 | f1b8bb57acfbe60022810bedd2db47ac260b92644fad183f74d4771ec859ffe8 | fe0f384b06e711d2982066f0f6aa511db7f41bca599b0f80da27188858f73335 | null | [
"LICENSE"
] | 255 |
2.4 | confluent-flink-jars | 2.2.14 | Confluent Apache Flink Jars | # Confluent Flink Jars
This package bundles the required jar libraries for the
[Confluent Apache Flink Table API](https://pypi.org/project/confluent-flink-table-api-python-plugin/) library.
| text/markdown | null | Confluent <dev@confluent.io> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://confluent.io"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T14:50:31.636928 | confluent_flink_jars-2.2.14.tar.gz | 74,012,469 | c4/7d/938f50df5529d00796f13b1cbb03476a31ae96dbfcb70db3adf346d012ff/confluent_flink_jars-2.2.14.tar.gz | source | sdist | null | false | f7f4599857dbba141673d9956b10d150 | b0af38e6d3792d5d4e8cbb15f908374e6a19dc8cc4ff25326b68aae9b023c0b5 | c47d938f50df5529d00796f13b1cbb03476a31ae96dbfcb70db3adf346d012ff | Apache-2.0 | [] | 160 |
2.4 | mede | 0.0.7 | De-Identification of Medical Imaging Data: A Comprehensive Tool for Ensuring Patient Privacy | # De-Identification of Medical Imaging Data: A Comprehensive Tool for Ensuring Patient Privacy
[](https://www.python.org/downloads/release/python-3120/)
[](https://github.com/psf/black)
[](./LICENSE)
![Open Source Love][0c]
[](https://hub.docker.com/r/morrempe/hold)

<div align="center">
[0c]: https://badges.frapsoft.com/os/v2/open-source.svg?v=103
[Getting started](#getting-started) • [Usage](#usage) • [Citation](#citation)
</div>
> [!IMPORTANT]
> The package is now available on PyPI: `pip install mede`
> [!NOTE]
> MEDE now supports the _Enhanced DICOM_ format!
This repository contains the **De-Identification of Medical Imaging Data: A Comprehensive Tool for Ensuring Patient Privacy**, which enables the user to anonymize a wide variety of medical imaging types, including Magnetic Resonance Imaging (MRI), Computer Tomography (CT), Ultrasound (US), Whole Slide Images (WSI) or MRI raw data (twix).
<div align="center">
<img src="Figures/aam_pipeline.png" alt="Overview" width="300"/>
</div>
This tool combines multiple anonymization steps, including metadata deidentification, defacing and skull-stripping while being faster than current state-of-the-art deidentification tools.

## Getting started
You can install the anonymization tool directly via pip or Docker.
### Installation via pip
Our tool is available via pip. You can install it with the following command:
```
pip install mede
```
#### Additional dependencies for text removal
If you want to use the text removal feature, you also need to install Google's Tesseract OCR engine. You can find the installation instructions for your operating system [here](https://tesseract-ocr.github.io/tessdoc/Installation.html).
On Ubuntu, you can install it via
```bash
sudo apt install tesseract-ocr
sudo apt install libtesseract-dev
```
On MacOS, you can install it via Homebrew:
```bash
brew install tesseract
```
### Installation via Docker
Alternatively this tool is distributed via docker. You can find the docker images [here](https://hub.docker.com/repository/docker/morrempe/mede/). The docker image is available for Linux-based (including Mac) amd64 and arm64 platforms.
For the installation and execution of the docker image, you must have [Docker](https://docs.docker.com/get-docker/) installed on your system.
1. Pull the docker image
docker pull morrempe/mede:[tag] (either arm64 or amd64)
2. Run the docker container with attached volume. Your data will be mounted in the ````data```` folder:
docker run --rm -it -v [Path/to/your/data]:/data morrempe/mede:[tag]
3. Run the script with the corresponding cli parameter, e.g.:
mede-deidentify [your flags]
## Usage
**De-Identification CLI**
```
usage: mede-deidentify [-h] [-v | --verbose | --no-verbose] [-t | --text-removal | --no-text-removal] [-i INPUT]
[-o OUTPUT] [--gpu GPU] [-s | --skull_strip | --no-skull_strip] [-de | --deface | --no-deface]
[-tw | --twix | --no-twix] [-p PROCESSES]
[-d {basicProfile,cleanDescOpt,cleanGraphOpt,cleanStructContOpt,rtnDevIdOpt,rtnInstIdOpt,rtnLongFullDatesOpt,rtnLongModifDatesOpt,rtnPatCharsOpt,rtnSafePrivOpt,rtnUIDsOpt} [{basicProfile,cleanDescOpt,cleanGraphOpt,cleanStructContOpt,rtnDevIdOpt,rtnInstIdOpt,rtnLongFullDatesOpt,rtnLongModifDatesOpt,rtnPatCharsOpt,rtnSafePrivOpt,rtnUIDsOpt} ...]]
options:
-h, --help show this help message and exit
-v, --verbose, --no-verbose
-t, --text-removal, --no-text-removal
-i INPUT, --input INPUT
Path to the input data.
-o OUTPUT, --output OUTPUT
Path to save the output data.
--gpu GPU GPU device number. (default 0)
-s, --skull_strip, --no-skull_strip
-de, --deface, --no-deface
-tw, --twix, --no-twix
-w, --wsi, --no-wsi
-p PROCESSES, --processes PROCESSES
Number of processes to use for multiprocessing.
-d {basicProfile,cleanDescOpt,cleanGraphOpt,cleanStructContOpt,rtnDevIdOpt,rtnInstIdOpt,rtnLongFullDatesOpt,rtnLongModifDatesOpt,rtnPatCharsOpt,rtnSafePrivOpt,rtnUIDsOpt} [{basicProfile,cleanDescOpt,cleanGraphOpt,cleanStructContOpt,rtnDevIdOpt,rtnInstIdOpt,rtnLongFullDatesOpt,rtnLongModifDatesOpt,rtnPatCharsOpt,rtnSafePrivOpt,rtnUIDsOpt} ...], --deidentification-profile {basicProfile,cleanDescOpt,cleanGraphOpt,cleanStructContOpt,rtnDevIdOpt,rtnInstIdOpt,rtnLongFullDatesOpt,rtnLongModifDatesOpt,rtnPatCharsOpt,rtnSafePrivOpt,rtnUIDsOpt} [{basicProfile,cleanDescOpt,cleanGraphOpt,cleanStructContOpt,rtnDevIdOpt,rtnInstIdOpt,rtnLongFullDatesOpt,rtnLongModifDatesOpt,rtnPatCharsOpt,rtnSafePrivOpt,rtnUIDsOpt} ...]
Which DICOM deidentification profile(s) to apply. (default None)
```
## Citation
If you use our tool in your work, please cite us with the following BibTeX entry.
```latex
@article{rempe2025identification,
title={De-identification of medical imaging data: a comprehensive tool for ensuring patient privacy},
author={Rempe, Moritz and Heine, Lukas and Seibold, Constantin and H{\"o}rst, Fabian and Kleesiek, Jens},
journal={European Radiology},
pages={1--10},
year={2025},
publisher={Springer}
}
```
| text/markdown | null | Moritz Rempe & Lukas Heine <moritz.rempe@uk-essen.de> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"deid",
"nibabel",
"numpy==1.26.4",
"opencv-python-headless",
"pandas",
"pillow",
"pydicom==2.3.1",
"pytesseract",
"pyyaml",
"safetensors==0.5.3",
"scikit-image",
"timm==1.0.7",
"torch==2.2.2",
"torchio",
"torchvision",
"tqdm"
] | [] | [] | [] | [
"Homepage, https://github.com/TIO-IKIM/medical_image_deidentification",
"Issues, https://github.com/TIO-IKIM/medical_image_deidentification/issues"
] | twine/6.2.0 CPython/3.11.8 | 2026-02-19T14:49:29.299576 | mede-0.0.7.tar.gz | 44,275,051 | 4b/a0/e0040ca8128a110b3d9375ace6d1daaad1e0d213d6e0a67d00f32fd9f693/mede-0.0.7.tar.gz | source | sdist | null | false | fa92a4ad4455794da99306d4d2647bb4 | 32cf893758fb2e4a08f190b0e4dd60097ebd96496e4e45c9f513522d3565ef3e | 4ba0e0040ca8128a110b3d9375ace6d1daaad1e0d213d6e0a67d00f32fd9f693 | MIT | [
"LICENSE"
] | 244 |
2.1 | ratapi | 0.0.0.dev12 | Python extension for the Reflectivity Analysis Toolbox (RAT) | python-RAT
==========
Python-RAT is the Python interface for the [Reflectivity Algorithm Toolbox](https://github.com/RascalSoftware/RAT) (RAT).
Install
=======
To install in local directory:
git clone --recurse-submodules https://github.com/RascalSoftware/python-RAT.git
cd python-RAT
pip install -e .
matlabengine is an optional dependency only required for Matlab custom functions. The version of matlabengine should match the version of Matlab installed on the machine. This can be installed as shown below:
pip install -e .[matlab-2023a]
Development dependencies can be installed as shown below
pip install -e .[dev]
To build wheel:
pip install build
python -m build --wheel
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Documentation, https://rascalsoftware.github.io/RAT/",
"Repository, https://github.com/RascalSoftware/python-RAT"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:49:12.219130 | ratapi-0.0.0.dev12.tar.gz | 1,156,006 | e4/a1/2e9f3df61c73675aa90ad7a1bc9fe2dedc776ac59441ee2ee5fd42b4c611/ratapi-0.0.0.dev12.tar.gz | source | sdist | null | false | 63d3d243defb319927fc7a7c3a57f066 | fa2e67d2984706168379d24b5236fc2065af36440e7b2cd5c1ba462c27ba294e | e4a12e9f3df61c73675aa90ad7a1bc9fe2dedc776ac59441ee2ee5fd42b4c611 | null | [] | 1,318 |
2.1 | odoo-addon-stock-picking-report-valued | 18.0.1.1.1 | Adding Valued Picking on Delivery Slip report | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
=====================
Valued Picking Report
=====================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:003cf7786b56a2aa552739ea70b68f0b6bbfa68b3b16c453526d5c4553d220f2
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fstock--logistics--reporting-lightgray.png?logo=github
:target: https://github.com/OCA/stock-logistics-reporting/tree/18.0/stock_picking_report_valued
:alt: OCA/stock-logistics-reporting
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/stock-logistics-reporting-18-0/stock-logistics-reporting-18-0-stock_picking_report_valued
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/stock-logistics-reporting&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
Add amount information to Delivery Slip report. You can select at
partner level if picking list report must be valued or not. If the
picking is done it's valued with quantity done, otherwise the picking is
valued with reserved quantity.
Additionally, an extensible "Total Picking" section has been added to
the delivery slip report. This total is displayed only when additional
amounts are applied on top of the standard picking total, allowing
downstream modules to adjust the reported total without altering the
base report.
**Table of contents**
.. contents::
:local:
Configuration
=============
1. Go to *Sales > Orders > Customers > (select one of your choice) >
Sales & Purchases*.
2. Set *Valued picking* field on.
Usage
=====
To get the stock picking valued report:
1. Create a Sales Order with storable products a *Valued picking* able
customer.
2. Confirm the Sale Order.
3. Click on *Delivery* stat button.
4. Go to *Print > Delivery Slip*.
Known issues / Roadmap
======================
- If the picking is not reserved, values aren't computed.
Changelog
=========
This module includes the features from the module
*stock_picking_report_valued_delivery*:
https://github.com/OCA/stock-logistics-reporting/pull/285
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/stock-logistics-reporting/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/stock-logistics-reporting/issues/new?body=module:%20stock_picking_report_valued%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Tecnativa
Contributors
------------
- `Avanzosc <http://www.avanzosc.es>`__:
- Oihane Crucelaegui
- `Tecnativa <https://www.tecnativa.com>`__:
- Pedro M. Baeza
- Antonio Espinosa
- Carlos Dauden
- David Vidal
- Luis M. Ontalba
- Ernesto Tejeda
- Sergio Teruel
- Carlos Roca
- `GreenIce <https://www.greenice.com>`__:
- Fernando La Chica <fernandolachica@gmail.com>
- `Landoo <https://www.landoo.es>`__:
- Aritz Olea <ao@landoo.es>
- `Studio73 <https://www.studio73.es>`__:
- Miguel Gandia <miguel@studio73.es>
- `Trobz <https://trobz.com>`__:
- Nguyen Minh Chien <chien@trobz.com>
- `Binhex <https://binhex.cloud>`__
- Antonio Ruban <antoniodavid8@gmail.com>
- `Sygel <https://sygel.es>`__
- Angel Rivas <angel.rivas@sygel.es>
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/stock-logistics-reporting <https://github.com/OCA/stock-logistics-reporting/tree/18.0/stock_picking_report_valued>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Tecnativa, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/stock-logistics-reporting | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T14:48:32.383187 | odoo_addon_stock_picking_report_valued-18.0.1.1.1-py3-none-any.whl | 40,990 | 7f/9d/833706d9a742648242cfae84d7db0dac94b0adc162579aeedffbf5100ada/odoo_addon_stock_picking_report_valued-18.0.1.1.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 2c79b03427c242f1b36e7aebaf3939e0 | 80eaba402561deacc5656d6f5cc4791b11f326574668034d9497b869394ef8a6 | 7f9d833706d9a742648242cfae84d7db0dac94b0adc162579aeedffbf5100ada | null | [] | 92 |
2.4 | melusine | 3.3.1 | Melusine is a high-level library for emails processing | <p align="center">
<a href="https://github.com/MAIF/melusine/actions?branch=master" target="_blank">
<img src="https://github.com/MAIF/melusine/actions/workflows/main.yml/badge.svg?branch=master" alt="Build & Test">
</a>
<a href="https://pypi.python.org/pypi/melusine" target="_blank">
<img src="https://img.shields.io/pypi/v/melusine.svg" alt="pypi">
</a>
<a href="https://opensource.org/licenses/Apache-2.0" target="_blank">
<img src="https://img.shields.io/badge/License-Apache%202.0-blue.svg" alt="Test">
</a>
<a href="https://shields.io/" target="_blank">
<img src="https://img.shields.io/badge/python-3.10+-blue.svg" alt="pypi">
</a>
</p>
<p align="center"> Release 3.3 : Drop sklearn inheritance, update debug mode activation and automate backend selection </p>
<p align="center">
<a href="https://maif.github.io/melusine" target="_blank">
<img src="docs/_static/melusine.png">
</a>
</p>
- **Free software**: Apache Software License 2.0
- **Documentation**: [maif.github.io/melusine](https://maif.github.io/melusine/)
- **Installation**: `pip install melusine`
- **Tutorials**: [Discover melusine](https://maif.github.io/melusine/tutorials/00_GettingStarted/)
## Overview
Discover Melusine, a comprehensive email processing library
designed to optimize your email workflow.
Leverage Melusine's advanced features to achieve:
- **Effortless Email Routing**: Ensure emails reach their intended destinations with high accuracy.
- **Smart Prioritization**: Prioritize urgent emails for timely handling and efficient task management.
- **Snippet Summaries**: Extract relevant information from lengthy emails, saving you precious time and effort.
- **Precision Filtering**: Eliminate unwanted emails from your inbox, maintaining focus and reducing clutter.
Melusine facilitates the integration of deep learning frameworks (HuggingFace, Pytorch, Tensorflow, etc),
deterministic rules (regex, keywords, heuristics) into a full email qualification workflow.
## Why Choose Melusine ?
Features that make Melusine stand out:
- **Pre-packaged Tools** : Melusine comes with out-of-the-box features such as
- Segmenting an email conversation into individual messages
- Tagging message parts (Email body, signatures, footers, etc)
- Transferred email handling
- **Streamlined Execution** : Focus on the core email qualification logic
while Melusine handles the boilerplate code, providing debug mode, pipeline execution, code parallelization, and more.
- **Flexible Integrations** : Melusine's modular architecture enables integration with various AI frameworks,
ensuring compatibility with your preferred tools.
- **Production ready** : Proven in the MAIF production environment,
Melusine provides the robustness and stability you need.
## Email Segmentation Exemple
In the following example, an email is divided into two distinct messages
separated by a transition pattern.
Each message is then tagged line by line.
This email segmentation can later be leveraged to enhance the performance of machine learning models.
<p align="center">
<a href="https://maif.github.io/melusine" target="_blank">
<img src="docs/_static/segmentation.png">
</a>
</p>
## Getting started
Explore our comprehensive [documentation](https://maif.github.io/melusine/) and tested [tutorials](https://maif.github.io/melusine/tutorials/00_GettingStarted/) to get started.
Or dive into our minimal example to experience Melusine's simplicity and power:
``` Python
from melusine.data import load_email_data
from melusine.pipeline import MelusinePipeline
# Load an email dataset
df = load_email_data()
# Load a pipeline
pipeline = MelusinePipeline.from_config("demo_pipeline")
# Run the pipeline
df = pipeline.transform(df)
```
The code above executes a default pipeline and returns a qualified email dataset with columns such as:
- `messages`: List of individual messages present in each email.
- `emergency_result`: Flag to identify urgent emails.
With Melusine, you're well-equipped to transform your email handling, streamlining processes, maximizing efficiency,
and enhancing overall productivity.
| text/markdown | Tiphaine Fabre, Sacha Samama, Antoine Simoulin | Hugo Perrier <hugorperrier@gmail.com> | null | null | Apache Software License 2.0 | nlp, email, courriel, text, data-science, machine-learning, natural-language-processing | [
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Software Development :: Libraries",
"Topic :: Software Development",
"Topic :: Communications :: Email",
"Typing :: T... | [] | null | null | >=3.10 | [] | [] | [] | [
"arrow>=1.2.3",
"pandas>=2.0.0",
"scikit-learn>=1.0.0",
"tqdm>=4.34",
"omegaconf>=2.0",
"tox; extra == \"dev\"",
"pre-commit; extra == \"dev\"",
"black>=24.4.2; extra == \"dev\"",
"flake8>=7.0.0; extra == \"dev\"",
"isort>=5.13.2; extra == \"dev\"",
"mypy>=1.10.0; extra == \"dev\"",
"pytest>=7... | [] | [] | [] | [
"Homepage, https://github.com/MAIF/melusine",
"Documentation, https://maif.github.io/melusine/",
"Source, https://github.com/MAIF/melusine"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:48:05.411531 | melusine-3.3.1.tar.gz | 279,731 | 6a/4c/52e16ade16bf46c5f936373265b68f9f456fccb62f1675464229474836d0/melusine-3.3.1.tar.gz | source | sdist | null | false | 882cbf81215060d7e04ab11899bd4ea7 | 3d14b1321bb712a172e1380c6ce2a5727057bd8006f44bbee41094d4cf8e031e | 6a4c52e16ade16bf46c5f936373265b68f9f456fccb62f1675464229474836d0 | null | [
"LICENSE",
"AUTHORS.rst"
] | 237 |
2.3 | GlobalPayments.Api | 2.0.7 | Global Payments Python SDK for integrating with Global Payments merchant services APIs | ==================
GlobalPayments.Api
==================
Global Payments Python SDK for integrating with Global Payments merchant services APIs.
Contributing
============
Source is on Github:
https://github.com/globalpayments/python-sdk
1. Fork it
2. Create your feature branch (git checkout -b my-new-feature)
3. Commit your changes (git commit -am 'Add some feature')
4. Push to the branch (got push origin my-new-feature)
5. Create a new Pull Request
Installation
============
$ python pip install GlobalPayments.Api
| text/plain | Global Payments | EntApp_DevPortal@e-hps.com | null | null | LICENSE.md | null | [
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <4.0,>=3.11 | [] | [] | [] | [
"certifi<2025.0.0,>=2024.12.14",
"dateparser<2.0.0,>=1.2.1",
"enum34<2.0.0,>=1.1.10",
"idna<4.0,>=3.10",
"jsonpickle<5.0.0,>=4.0.1",
"pyopenssl<25.0.0,>=24.3.0",
"requests<3.0.0,>=2.32.3",
"urllib3<3.0.0,>=2.3.0",
"xmltodict<0.15.0,>=0.14.2"
] | [] | [] | [] | [
"Homepage, https://developer.globalpay.com/"
] | twine/6.2.0 CPython/3.13.2 | 2026-02-19T14:48:04.413924 | globalpayments_api-2.0.7.tar.gz | 128,877 | 8f/0b/446d126057cbebfa7a1b96a953f94aaea8bac19741e1f072302befb5b87b/globalpayments_api-2.0.7.tar.gz | source | sdist | null | false | 24744a1c7525be09e258cc389698668b | a1729cc15b2f29939c674a8087e16f59a7bd5e3ec18e72ebfb893112c78fc190 | 8f0b446d126057cbebfa7a1b96a953f94aaea8bac19741e1f072302befb5b87b | null | [] | 0 |
2.1 | p01.publisher | 1.0.10 | NO ZODB publisher components for Zope3 | ==============
p01.publisher
==============
This package provides a WSGI publisher concept using zope components including
transactions, application error handling, traverser, pages views and offers
jsonrpc without a ZODB. The package offers a wsgi application which kicks in
the known zope publication concept. The publication concept can get used with
gevent or similar async frameworks. It's up to you how you store persistent
items. Probably the container, item and traversal pattern in m01.mongo is a
good choice for this.
=======
Changes
=======
1.0.10 (2026-02-19)
-------------------
- bugfix; fix testing requets parser
1.0.9 (2025-11-14)
------------------
- bugfix, Fixed tests and release on pypi.org
1.0.8 (2025-11-13)
------------------
- bugfix, Fixed boolean error comparing "if context" (__bool__)
1.0.7 (2025-10-15)
------------------
- bugfix, Fixed UnicodeEncodeError ('latin-1') in JSONRPC request
1.0.6 (2025-09-01)
------------------
- bugfix, cleanup app setup, remove self.app = None in __init__ method
because its a property
1.0.5 (2025-08-29)
------------------
- bugfix; fix empty content type at error handling
1.0.4 (2025-08-26)
------------------
- bugfix; remove bad six.string_types patch
1.0.3 (2025-08-25)
------------------
- bugfix; fix globals in getZCMLLayer
1.0.2 (2025-08-20)
------------------
- bugfix; improve __slots__ for python 3
1.0.1 (2025-07-15)
------------------
- Fixed errors in headers (post/get) - wrong unicode x str types (APP-1818).
1.0.0 (2025-06-12)
------------------
- bugfix: fix string encoding issues. Python 3 is work in progress and requires
a pywsgi version which doesn't only require str.
0.9.3 (2025-06-04)
------------------
- python 2.7 migration
- removed z3c.jsonrpc dependency
- implemented Debugger concept
0.9.2 (2025-05-27)
------------------
- requirements update: zope.interface >= 5.5.2
0.9.1 (2021-12-04)
------------------
- bugfix: allow to use Basic Authentication header credentias in JSONRPC proxy.
- feature: Suport username and password in getJSONRPCTestProxy used for setup
Authentication Basic header.
- feature: Support Bearer token in getJSONRPCTestProxy used for Authentication
Bearer header.
0.9.0 (2017-09-18)
------------------
- feature: implemented ZODB support. Now it's possible to use p01.publisher
and use a ZODB not only a WSGI application.
- renamed p01.publisher.traversers to p01.publisher.traverser
- enable threadSiteSubscriber and clearThreadSiteSubscriber event subscriber
handler
0.8.0 (2017-01-24)
------------------
- bugfix: transaction >= 2.0.3 uses unicode for transaction note. See comment
in transaction CHANGES.txt. The user and description fields must now be set
with text (unicode) data. Previously, if bytes were provided, they'd be
decoded as ASCII. It was decided that this would lead to bugs that were hard
to test for.
0.7.0 (2016-09-19)
------------------
- feature: re-implemented json reader and writer concept. Use reader and writer
from p01.json.api
- bugfix: support PATH_INFO in JSONRPCTestTransport used by the test method
getJSONRPCTestProxy. This ensures that we traverse to the related context
for calling the json-rpc method.
- feature: use JSONRPCProxy from p01.json as json-rpc test proxy
- sort response header before return, except Status and X-Powered-By
0.6.0 (2015-03-17)
------------------
- feature: added application/json support. The new request json method returns
the json formated data given from a request with content type applicaton/json.
The raw content is stored in the request raw property if such json content
is given.
- added OPTIONS to allwed request methods. This allows to handle cross origin
request given from android phones during development. Note, you ned to
register a view for handle such requests. We just added the OPTIONS as a
general allowed request method.
- feature: use new testbrowser concept based on zope.testbrowser >= 5.0.0.
This new testbrowser concept uses a wsgi application and is based on webtest.
Currently we use p01.testbrowser which is a clone of zope.testbrowser because
there is no zope.testbrowser release yet.
- feature: implemented simple JSONRPCTestProxy based on wsgi app. This new
test json rpc proxy uses the wsgi application publisher for process a
request.
- backport zope.publisher publication factory lookup. Improve the publication
factory lookup by falling back to a more generic registration if the specific
factory chooses not to handle the request after all
0.5.0 (2014-03-24)
------------------
- initial release | text/x-rst | Roger Ineichen, Projekt01 GmbH | dev@projekt01.ch | null | null | ZPL 2.1 | zope zope3 z3c ZODB | [
"Development Status :: 4 - Beta",
"Environment :: Web Environment",
"Intended Audience :: Developers",
"License :: OSI Approved :: Zope Public License",
"Programming Language :: Python",
"Natural Language :: English",
"Operating System :: OS Independent",
"Topic :: Internet :: WWW/HTTP",
"Framework ... | [] | http://pypi.python.org/pypi/p01.publisher | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/1.15.0 pkginfo/1.8.3 requests/2.27.1 setuptools/39.1.0 requests-toolbelt/1.0.0 tqdm/4.64.1 CPython/2.7.18 | 2026-02-19T14:47:40.917815 | p01_publisher-1.0.10.tar.gz | 277,027 | 6f/60/aa03b28b4a197690f11e76dc730516479d695faa81ea881f905f0def6ce0/p01_publisher-1.0.10.tar.gz | source | sdist | null | false | 19444cd8ed2a32988213e4980bc3bd85 | 7f74faaacedfe105fdeceb9af9b879279284f82d646ba0d2ad79b80c200f94a7 | 6f60aa03b28b4a197690f11e76dc730516479d695faa81ea881f905f0def6ce0 | null | [] | 0 |
2.4 | adbc-driver-gizmosql | 1.0.5 | Python ADBC driver for GizmoSQL with OAuth/SSO support | # adbc-driver-gizmosql
A Python [ADBC](https://arrow.apache.org/adbc/) driver for [GizmoSQL](https://gizmodata.com/gizmosql) with OAuth/SSO support
[<img src="https://img.shields.io/badge/GitHub-gizmodata%2Fadbc--driver--gizmosql-blue.svg?logo=Github">](https://github.com/gizmodata/adbc-driver-gizmosql)
[<img src="https://img.shields.io/badge/GitHub-gizmodata%2Fgizmosql--public-blue.svg?logo=Github">](https://github.com/gizmodata/gizmosql-public)
[](https://github.com/gizmodata/adbc-driver-gizmosql/actions/workflows/ci.yml)
[](https://pypi.org/project/adbc-driver-gizmosql/)
[](https://badge.fury.io/py/adbc-driver-gizmosql)
[](https://pypi.org/project/adbc-driver-gizmosql/)
## Overview
`adbc-driver-gizmosql` is a lightweight Python wrapper around [`adbc-driver-flightsql`](https://arrow.apache.org/adbc/current/driver/flight_sql.html) that adds GizmoSQL-specific features:
- **OAuth/SSO browser flow** — Authenticate via your identity provider (Google, Okta, etc.) with a single parameter change
- **DBAPI 2.0 interface** — Drop-in replacement for `adbc_driver_flightsql.dbapi`
- **Zero extra dependencies** — OAuth flow uses only Python stdlib; the only dependency is `adbc-driver-flightsql`
## Setup (to run locally)
### Install Python package
You can install `adbc-driver-gizmosql` from PyPi or from source.
### Option 1 - from PyPi
```shell
# Create the virtual environment
python3 -m venv .venv
# Activate the virtual environment
. .venv/bin/activate
pip install adbc-driver-gizmosql
```
### Option 2 - from source - for development
```shell
git clone https://github.com/gizmodata/adbc-driver-gizmosql
cd adbc-driver-gizmosql
# Create the virtual environment
python3 -m venv .venv
# Activate the virtual environment
. .venv/bin/activate
# Upgrade pip, setuptools, and wheel
pip install --upgrade pip setuptools wheel
# Install adbc-driver-gizmosql - in editable mode with dev and test dependencies
pip install --editable ".[dev,test]"
```
## Usage
### Start a GizmoSQL server
First — start a GizmoSQL server in Docker (mounts a small TPC-H database by default):
```bash
docker run --name gizmosql \
--detach \
--rm \
--tty \
--init \
--publish 31337:31337 \
--env TLS_ENABLED="1" \
--env GIZMOSQL_USERNAME="gizmosql_user" \
--env GIZMOSQL_PASSWORD="gizmosql_password" \
--env PRINT_QUERIES="1" \
--pull missing \
gizmodata/gizmosql:latest
```
### Password authentication
```python
from adbc_driver_gizmosql import dbapi as gizmosql
with gizmosql.connect("grpc+tls://localhost:31337",
username="gizmosql_user",
password="gizmosql_password",
tls_skip_verify=True,
) as conn:
with conn.cursor() as cur:
cur.execute("SELECT n_nationkey, n_name FROM nation WHERE n_nationkey = ?",
parameters=[24])
table = cur.fetch_arrow_table()
print(table)
```
### DDL/DML — execute immediately without fetching
GizmoSQL uses a lazy-execution model, so a plain `cursor.execute()` for DDL/DML
requires a subsequent fetch to actually fire the statement on the server.
`cursor.execute_update()` bypasses this by calling the server's
`DoPutPreparedStatementUpdate` RPC directly, executing the statement immediately
and returning the number of rows affected:
```python
from adbc_driver_gizmosql import dbapi as gizmosql
with gizmosql.connect("grpc+tls://localhost:31337",
username="gizmosql_user",
password="gizmosql_password",
tls_skip_verify=True,
) as conn:
with conn.cursor() as cur:
# DDL — returns 0 (no rows affected)
cur.execute_update("CREATE TABLE t (a INT)")
# DML — returns the number of rows affected
rows_affected = cur.execute_update("INSERT INTO t VALUES (1)")
print(f"Rows affected: {rows_affected}")
```
### OAuth/SSO authentication
When your GizmoSQL server is configured with OAuth, simply change `auth_type`:
```python
from adbc_driver_gizmosql import dbapi as gizmosql
with gizmosql.connect("grpc+tls://gizmosql.example.com:31337",
auth_type="external",
tls_skip_verify=True,
) as conn:
with conn.cursor() as cur:
cur.execute("SELECT CURRENT_USER AS user")
print(cur.fetch_arrow_table())
```
This will:
1. Auto-discover the OAuth server endpoint
2. Open your browser to the identity provider login page
3. Poll for completion and retrieve the identity token
4. Connect to GizmoSQL using the token via Basic Auth (`username="token"`)
### Advanced: Standalone OAuth token retrieval
```python
from adbc_driver_gizmosql import get_oauth_token
result = get_oauth_token(
host="gizmosql.example.com",
port=31339, # OAuth HTTP port (default)
tls_skip_verify=True, # Skip TLS cert verification
timeout=300, # Seconds to wait for user to complete auth
)
print(f"Token: {result.token}")
print(f"Session: {result.session_uuid}")
```
### Bulk ingest (load Arrow data into a table)
The ADBC `adbc_ingest` method on the cursor lets you load Arrow tables, record
batches, or record batch readers directly into GizmoSQL — no row-by-row INSERT needed:
```python
import pyarrow as pa
from adbc_driver_gizmosql import dbapi as gizmosql
# Build an Arrow table
table = pa.table({
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Charlie"],
"score": [95.0, 87.5, 91.2],
})
with gizmosql.connect("grpc+tls://localhost:31337",
username="gizmosql_user",
password="gizmosql_password",
tls_skip_verify=True,
) as conn:
with conn.cursor() as cur:
# Create a new table and insert the data
cur.adbc_ingest("students", table, mode="create")
# Verify
cur.execute("SELECT * FROM students")
print(cur.fetch_arrow_table())
```
Supported modes: `"create"`, `"append"`, `"replace"`, `"create_append"`.
### Pandas integration
```python
import pandas as pd
from adbc_driver_gizmosql import dbapi as gizmosql
with gizmosql.connect("grpc+tls://localhost:31337",
username="gizmosql_user",
password="gizmosql_password",
tls_skip_verify=True,
) as conn:
df = pd.read_sql("SELECT * FROM nation ORDER BY n_nationkey", conn)
print(df)
```
## API Reference
### `dbapi.connect()`
| Parameter | Type | Default | Description |
|---|---|---|---|
| `uri` | `str` | *required* | Flight SQL URI (e.g., `"grpc+tls://host:31337"`) |
| `username` | `str` | `None` | Username for password auth |
| `password` | `str` | `None` | Password for password auth |
| `tls_skip_verify` | `bool` | `False` | Skip TLS cert verification |
| `auth_type` | `str` | `"password"` | `"password"` or `"external"` (OAuth) |
| `oauth_port` | `int` | `31339` | OAuth HTTP server port |
| `oauth_url` | `str` | `None` | Explicit OAuth base URL |
| `oauth_tls_skip_verify` | `bool` | `None` | TLS skip for OAuth (defaults to `tls_skip_verify`) |
| `oauth_timeout` | `int` | `300` | Seconds to wait for OAuth |
| `open_browser` | `bool` | `True` | Auto-open browser for OAuth |
| `db_kwargs` | `dict` | `None` | Extra ADBC database options |
| `conn_kwargs` | `dict` | `None` | Extra ADBC connection options |
| `autocommit` | `bool` | `True` | Enable autocommit |
### `cursor.execute_update()`
Execute a DDL/DML statement immediately without fetching. Use this instead of `cursor.execute()` for statements that don't return result sets — it fires the statement on the server right away, bypassing GizmoSQL's lazy-execution model.
| Parameter | Type | Default | Description |
|---|---|---|---|
| `query` | `str` | *required* | SQL DDL or DML statement to execute |
Returns: `int` — number of rows affected (`0` for DDL statements that do not affect rows)
> **Note:** The module-level `gizmosql.execute_update(cursor, query)` function is still available for backward compatibility but new code should use `cursor.execute_update(query)`.
### `get_oauth_token()`
| Parameter | Type | Default | Description |
|---|---|---|---|
| `host` | `str` | *required* | GizmoSQL server hostname |
| `port` | `int` | `31339` | OAuth HTTP port |
| `tls_skip_verify` | `bool` | `True` | Skip TLS cert verification |
| `timeout` | `int` | `300` | Seconds to wait |
| `poll_interval` | `float` | `1` | Seconds between polls |
| `open_browser` | `bool` | `True` | Auto-open browser |
| `oauth_url` | `str` | `None` | Explicit OAuth base URL |
Returns: `OAuthResult(token=str, session_uuid=str)`
## How the OAuth flow works
```
Python Client GizmoSQL OAuth Server Identity Provider
| | |
+-- GET /oauth/initiate ---->| |
|<-- {uuid, auth_url} -------| |
| | |
+-- Open browser to auth_url-|--------------------------->|
| | |
| |<-- callback (auth code) ---|
| |-- exchange code for token ->|
| |<-- id_token ---------------|
| | |
+-- GET /oauth/token/{uuid}->| |
|<-- {status: complete, | |
| token: <id_token>} | |
| | |
+-- Flight BasicAuth ------->| |
| user="token" | (verify token via JWKS, |
| pass=<id_token> | issue server JWT) |
|<-- Server Bearer token ----| |
```
## Handy development commands
### Version management
#### Bump the version of the application - (you must have installed from source with the [dev] extras)
```bash
bumpver update --patch
```
| text/markdown | null | GizmoData <support@gizmodata.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"adbc-driver-flightsql>=1.10.0",
"pyarrow>=23.0.0",
"pytest; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"docker; extra == \"test\"",
"ruff; extra == \"dev\"",
"mypy; extra == \"dev\"",
"bumpver; extra == \"dev\"",
"build; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/gizmodata/adbc-driver-gizmosql",
"Repository, https://github.com/gizmodata/adbc-driver-gizmosql",
"Issues, https://github.com/gizmodata/adbc-driver-gizmosql/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:47:25.107597 | adbc_driver_gizmosql-1.0.5.tar.gz | 21,307 | e9/58/22369873dd22480558d59de09ff48ec895a8ba280acaf728fcdda01fa0a5/adbc_driver_gizmosql-1.0.5.tar.gz | source | sdist | null | false | 9210a8b5bf0e2dee932e9a19e4e03b0c | 3cfd4ad4cfe69fbe30eea76347124b6510fbd440a667abcee54d8a400c8478e1 | e95822369873dd22480558d59de09ff48ec895a8ba280acaf728fcdda01fa0a5 | Apache-2.0 | [
"LICENSE"
] | 784 |
2.4 | isage-flownet | 0.1.1 | Sage: A distributed dataflow orchestration system |
---
# SAGE-Flownet
**SAGE-Flownet** 是一个轻量、原生 Python 的动态数据流执行引擎。它以“嵌套动态图”为核心模型,把用户写下的普通 Python 函数编译为可执行的 FlowTask DAG,并由运行时按需调度执行,让复杂的工作流像调用函数一样自然。
它不是另一个固定模板的流水线框架。Flownet 将远程调用、闭包、回调以及子图嵌套视为**一等公民**,在不牺牲 Python 语义的前提下,支持灵活组合和横向扩展。
## ✧ 项目如何工作(概述)
* **Flow 定义与编译**:通过 `@flow` 装饰器将函数包装为 Flow 定义(`FlowDef`),编译为包含 Transformation 的 FlowTask 图。
* **数据流建模**:`DataStream.map/flatmap` 等算子创建上下游关系,形成可追踪的依赖图和执行边。
* **运行时执行**:`FlownetRuntime` 负责处理请求栈(TransformationFrame),并由 operator handler 决定目标调用与转发策略。
* **Actor 调用统一化**:`ActorRef` / `ActorMethodRef` 将本地与远程调用统一抽象,运行时根据目标地址完成派发。
* **FlowRun 输出通道**:运行时通过 `FlowRunRef` 的输出通道暴露“写入输入—等待输出”的调用方式,负责 fork/join 逻辑与结果收集。
## ✧ 预期目标与效果
* **保持原生 Python 开发体验**:无需额外 DSL,工作流像写函数一样简单。
* **支持动态与嵌套的复杂流程**:运行时编译、依赖跟踪与延迟执行适配不确定结构。
* **可扩展的分布式执行**:为本地/远程统一执行提供清晰路径,便于水平扩展。
* **更可靠的并发与结果聚合**:由运行时完成 fork/join、收集与异常处理,降低业务代码复杂度。
## Intellectual Property
`All Rights Reserved` applies to repository contents authored by Jingyuan Tian,
including code, documentation, benchmarks, and related assets.
The following copied lab projects are excluded from this claim and retain their
original ownership/license context: `applications/SAGE`, `applications/sage-studio`,
`applications/sageData`.
1. License terms: `LICENSE`
2. Ownership details: `COPYRIGHT.md`
---
| text/markdown | null | SAGE Team <shuhao_zhang@hust.edu.cn>, Flecther Tian <jingyuan_tian@hust.edu.cn> | null | null | Proprietary - All Rights Reserved | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"isage-common>=0.2.0",
"cloudpickle>=2.2",
"aiohttp",
"pyyaml",
"grpcio",
"rich",
"fastapi",
"uvicorn[standard]",
"pydantic",
"pytest; extra == \"dev\"",
"black; extra == \"dev\"",
"mypy; extra == \"dev\"",
"pre-commit; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/intellistream/SAGE",
"Documentation, https://intellistream.github.io/SAGE-Pub/",
"Repository, https://github.com/intellistream/SAGE.git",
"Bug Tracker, https://github.com/intellistream/SAGE/issues"
] | twine/6.2.0 CPython/3.11.11 | 2026-02-19T14:47:10.638975 | isage_flownet-0.1.1.tar.gz | 196,122 | cf/ce/ce267f722e3b8e89e810325dedf8a9c8a1be7c9e0f40db60307e0b258f45/isage_flownet-0.1.1.tar.gz | source | sdist | null | false | 14015a1a9f460d3623610084a60d7b94 | a69b6b9f10aeee40d38d983508624c01761cd72f671f0fef617c5b46b7d8b5a5 | cfcece267f722e3b8e89e810325dedf8a9c8a1be7c9e0f40db60307e0b258f45 | null | [
"LICENSE"
] | 451 |
2.4 | petprep-docker | 0.0.4 | A wrapper for generating Docker commands using regular PETPrep syntax | The *PETPrep* on Docker wrapper
--------------------------------
PETPrep is a positron emission tomography data preprocessing pipeline
that is designed to provide an easily accessible, state-of-the-art interface
that is robust to differences in scan acquisition protocols and that requires
minimal user input, while providing easily interpretable and comprehensive
error and output reporting.
This is a lightweight Python wrapper to run *PETPrep*.
It generates the appropriate Docker commands, providing an intuitive interface
to running the *PETPrep* workflow in a Docker environment.
Docker must be installed and running. This can be checked
running ::
docker info
Please acknowledge this work using the citation boilerplate that *PETPrep* includes
in the visual report generated for every subject processed.
For a more detailed description of the citation boilerplate and its relevance,
please check out the
`NiPreps documentation <https://www.nipreps.org/intro/transparency/#citation-boilerplates>`__.
Please report any feedback to our `GitHub repository <https://github.com/nipreps/petprep>`__.
| text/x-rst | null | The NiPreps Developers <nipreps@gmail.com> | null | null | Copyright (c) the Nipreps developers.
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
* Neither the name of fmriprep nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python :: 2.7",
"Programming Language :: Python :: 3.5",
"Programming Language :: Python :: 3.6... | [] | null | null | >=2.7 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/nipreps/petprep",
"Documentation, https://petprep.readthedocs.io",
"Paper, https://doi.org/10.1038/s41592-018-0235-4",
"Docker Images, https://hub.docker.com/r/nipreps/petprep/tags/",
"NiPreps, https://www.nipreps.org/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:45:39.147401 | petprep_docker-0.0.4.tar.gz | 9,487 | a3/d8/17b8d1c8ff1d7c64ad64fb6a9bbbd1d56efd16c056a9b38b86fbc9fe0e0e/petprep_docker-0.0.4.tar.gz | source | sdist | null | false | 0eba07efc0ef93e207199ecfbe8a8fad | 9d2b4bed872d8a198cfea2c26a7bfae215afd8d3877a8339f61b888cf43e9663 | a3d817b8d1c8ff1d7c64ad64fb6a9bbbd1d56efd16c056a9b38b86fbc9fe0e0e | null | [
"LICENSE"
] | 224 |
2.4 | pyxapiand | 2.1.0 | Python client library for the Xapiand search engine | # Xapiand Python Client
Async Python client library for [Xapiand](https://github.com/pber/xapiand), a RESTful search engine built on top of [Xapian](https://xapian.org/).
## Features
- **Fully async** — built on `httpx.AsyncClient` for native `asyncio` support.
- Full coverage of Xapiand REST operations: search, get, post, put, patch, merge, delete, store, stats, and head.
- Automatic serialization/deserialization with JSON and [msgpack](https://msgpack.org/) (preferred when available).
- Attribute-style access on response objects (`result.hits` instead of `result['hits']`).
- Custom HTTP methods (`MERGE`, `STORE`) supported natively via `httpx`.
## Requirements
- Python 3.12+
- [`httpx`](https://www.python-httpx.org/)
## Installation
```bash
pip install pyxapiand
```
With optional msgpack support (recommended for better performance):
```bash
pip install pyxapiand[msgpack]
```
For development (editable install):
```bash
git clone https://github.com/Dubalu-Development-Team/pyxapiand.git
cd pyxapiand
pip install -e ".[msgpack,test]"
```
### Python version with pyenv
This project includes a `.python-version` file that pins Python 3.12. If you use [pyenv](https://github.com/pyenv/pyenv), make sure you have a 3.12.x version installed:
```bash
pyenv install 3.12
```
This installs the latest available 3.12.x release. pyenv will then automatically select it when you enter the project directory.
## Quick Start
```python
import asyncio
from xapiand import Xapiand
async def main():
client = Xapiand(host="localhost", port=8880)
# Index a document
await client.put("books", body={"title": "The Art of Search", "year": 2024}, id="book1")
# Retrieve a document
doc = await client.get("books", id="book1")
print(doc.title) # "The Art of Search"
# Search
results = await client.search("books", query="search")
for hit in results.hits:
print(hit.title)
# Delete a document
await client.delete("books", id="book1")
asyncio.run(main())
```
A pre-configured module-level `client` singleton is also available:
```python
from xapiand import client
results = await client.search("myindex", query="hello world")
print(results.count) # total count
print(results.total) # estimated matches
```
## Configuration
The client reads configuration from environment variables:
| Environment Variable | Default | Description |
|----------------------|-------------|--------------------------------------|
| `XAPIAND_HOST` | `127.0.0.1` | Server hostname |
| `XAPIAND_PORT` | `8880` | Server port |
| `XAPIAND_COMMIT` | `False` | Auto-commit write operations |
| `XAPIAND_PREFIX` | `default` | URL prefix prepended to index paths |
### Client initialization
You can also pass configuration directly when creating a client:
```python
client = Xapiand(
host="192.168.1.100",
port=8880,
commit=True, # auto-commit writes
prefix="production", # URL prefix for index paths
)
```
The `host` parameter accepts a `host:port` format (`"192.168.1.100:9000"`), in which case the port part overrides the `port` parameter.
## API Reference
All API methods are **async** and return `DictObject` instances, which are dictionaries with attribute-style access.
### Search
```python
results = await client.search(
"myindex",
query="hello world", # query string
partial="hel", # partial query for autocomplete
terms="tag:python", # term filters
offset=0, # starting offset
limit=10, # max results
sort="date", # sort field
language="en", # query language
check_at_least=100, # minimum documents to check
)
results.hits # list of matching documents
results.count # total count
results.total # estimated matches
```
Search with a request body (uses POST internally):
```python
results = await client.search("myindex", body={
"_query": {"title": "search engine"},
})
```
### Count
```python
results = await client.count("myindex", query="hello")
print(results.count)
```
### Get
```python
doc = await client.get("myindex", id="doc1")
# With a default value (returns it instead of raising on 404)
doc = await client.get("myindex", id="doc1", default=None)
```
### Create (POST)
```python
# Server-assigned ID
result = await client.post("myindex", body={"title": "New Document"})
```
### Create or Replace (PUT)
```python
result = await client.put("myindex", body={"title": "My Document"}, id="doc1")
# Alias
result = await client.index("myindex", body={"title": "My Document"}, id="doc1")
```
### Partial Update (PATCH)
```python
result = await client.patch("myindex", id="doc1", body={"title": "Updated Title"})
```
### Deep Merge (MERGE)
Uses Xapiand's custom `MERGE` HTTP method for deep-merging fields:
```python
result = await client.merge("myindex", id="doc1", body={"metadata": {"tags": ["new"]}})
```
### Update
Chooses strategy based on content type:
```python
# Partial merge (default)
await client.update("myindex", id="doc1", body={"title": "Updated"})
# Full replacement when content_type is specified
await client.update("myindex", id="doc1", body=data, content_type="application/json")
```
### Delete
```python
await client.delete("myindex", id="doc1")
```
### Store
Store binary content using Xapiand's custom `STORE` HTTP method:
```python
await client.store("myindex", id="doc1", body="/path/to/file.bin")
```
### Head
Check if a document exists:
```python
await client.head("myindex", id="doc1")
```
### Stats
```python
stats = await client.stats("myindex")
```
### Common Parameters
Most methods accept these optional parameters:
| Parameter | Type | Description |
|-----------|--------|------------------------------------------|
| `commit` | `bool` | Commit changes immediately (write ops) |
| `pretty` | `bool` | Request pretty-printed response |
| `volatile`| `bool` | Bypass caches, read from disk |
| `kwargs` | `dict` | Additional arguments passed to httpx |
## Error Handling
```python
import asyncio
from xapiand import Xapiand, TransportError
async def main():
client = Xapiand()
# NotFoundError on missing documents
try:
doc = await client.get("myindex", id="nonexistent")
except client.NotFoundError:
print("Document not found")
# TransportError (httpx.HTTPStatusError) on other HTTP errors
try:
await client.search("myindex", query="test")
except TransportError as e:
print(f"HTTP error: {e}")
asyncio.run(main())
```
## Utilities
### `xapiand.collections`
Dict subclasses with attribute-style access:
```python
from xapiand.collections import DictObject, OrderedDictObject
obj = DictObject(name="test", value=42)
obj.name # "test"
obj["value"] # 42
```
### `xapiand.constants`
Predefined Xapian term constants for configuring index schema accuracy:
```python
from xapiand.constants import (
# Date accuracy
HOUR_TERM, DAY_TERM, MONTH_TERM, YEAR_TERM,
DAY_TO_YEAR_ACCURACY, # [day, month, year]
HOUR_TO_YEAR_ACCURACY, # [hour, day, month, year]
# Geospatial accuracy (HTM levels)
LEVEL_0_TERM, # ~10,000 km
LEVEL_10_TERM, # ~10 km
LEVEL_20_TERM, # ~10 m
STATE_TO_BLOCK_ACCURACY, # [level_5, level_10, level_15]
# Numeric accuracy
TENS_TO_TEN_THOUSANDS_ACCURACY,
HUDREDS_TO_MILLIONS_ACCURACY,
)
```
### `xapiand.utils`
Xapian-compatible binary serialization for lengths, strings, and characters:
```python
from xapiand.utils import serialise_length, unserialise_length
encoded = serialise_length(42)
length, remaining = unserialise_length(encoded)
assert length == 42
```
## Migrating from v1.x
v2.0 replaces `requests` with `httpx` and makes all API methods **async**. Key changes:
- **All client methods require `await`** — `client.search(...)` becomes `await client.search(...)`.
- **Dependency changed** — `requests` replaced by `httpx`.
- **`Session` class removed** — `httpx.AsyncClient` handles custom HTTP methods natively.
- **`TransportError`** — now aliases `httpx.HTTPStatusError` instead of `requests.HTTPError`.
- **No `allow_redirects` kwarg** — redirects are disabled at the client level.
## License
MIT License - Copyright (c) 2015-2026 [Dubalu LLC](https://dubalu.com/)
See [LICENSE](LICENSE) for details.
| text/markdown | null | Dubalu LLC <contact@dubalu.com> | null | null | null | xapiand, xapian, search, client | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Internet :: WWW/HTTP :: Indexing/Search"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"httpx",
"msgpack; extra == \"msgpack\"",
"pytest; extra == \"test\"",
"pytest-asyncio; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/Dubalu-Development-Team/pyxapiand"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T14:45:36.936523 | pyxapiand-2.1.0.tar.gz | 27,143 | 07/14/1ac995077b3c076aa00c441c7f186219ea056ab36c5b7a701f0f526396ec/pyxapiand-2.1.0.tar.gz | source | sdist | null | false | 02f6064c9ece225e7c53c014e4e9f041 | 6c92e38d32abfaa6133080c02e7d8c7b54dff8cea5883236e85428255506096e | 07141ac995077b3c076aa00c441c7f186219ea056ab36c5b7a701f0f526396ec | MIT | [
"LICENSE"
] | 248 |
2.4 | petprep | 0.0.4 | A robust and easy-to-use pipeline for preprocessing of diverse PET data | Preprocessing of positron emission tomography (PET) involves numerous steps to clean and standardize
the data before statistical analysis.
Generally, researchers create ad hoc preprocessing workflows for each dataset,
building upon a large inventory of available tools.
The complexity of these workflows has snowballed with rapid advances in
acquisition and processing.
PETPrep is an analysis-agnostic tool that addresses the challenge of robust and
reproducible preprocessing for PET data.
PETPrep automatically adapts a best-in-breed workflow to the idiosyncrasies of
virtually any dataset, ensuring high-quality preprocessing without manual intervention.
PETPrep robustly produces high-quality results on diverse PET data.
Additionally, PETPrep introduces less uncontrolled spatial smoothness than observed
with commonly used preprocessing tools.
PETPrep equips neuroscientists with an easy-to-use and transparent preprocessing
workflow, which can help ensure the validity of inference and the interpretability
of results.
The workflow is based on `Nipype <https://nipype.readthedocs.io>`_ and encompasses a large
set of tools from well-known neuroimaging packages, including
`FSL <https://fsl.fmrib.ox.ac.uk/fsl/fslwiki/>`_,
`ANTs <https://stnava.github.io/ANTs/>`_,
`FreeSurfer <https://surfer.nmr.mgh.harvard.edu/>`_,
`AFNI <https://afni.nimh.nih.gov/>`_,
and `Nilearn <https://nilearn.github.io/>`_.
This pipeline was designed to provide the best software implementation for each state of
preprocessing, and will be updated as newer and better neuroimaging software becomes
available.
PETPrep performs basic preprocessing steps (coregistration, normalization, unwarping, noise
component extraction, segmentation, skullstripping etc.) providing outputs that can be
easily submitted to a variety of group level analyses, including task-based or resting-state
PET imaging, graph theory measures, surface or volume-based statistics, etc.
PETPrep allows you to easily do the following:
* Take PET data from *unprocessed* (only reconstructed) to ready for analysis.
* Implement tools from different software packages.
* Achieve optimal data processing quality by using the best tools available.
* Generate preprocessing-assessment reports, with which the user can easily identify problems.
* Receive verbose output concerning the stage of preprocessing for each subject, including
meaningful errors.
* Automate and parallelize processing steps, which provides a significant speed-up from
typical linear, manual processing.
[Nat Meth doi:`10.1038/s41592-018-0235-4 <https://doi.org/10.1038/s41592-018-0235-4>`_]
[Documentation `petprep.org <https://petprep.readthedocs.io>`_]
[Software doi:`10.5281/zenodo.852659 <https://doi.org/10.5281/zenodo.852659>`_]
[Support `neurostars.org <https://neurostars.org/tags/petprep>`_]
License information
-------------------
*PETPrep* adheres to the
`general licensing guidelines <https://www.nipreps.org/community/licensing/>`__
of the *NiPreps framework*.
License
~~~~~~~
Copyright (c) the *NiPreps* Developers.
As of the 21.0.x pre-release and release series, *PETPrep* is
licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
`http://www.apache.org/licenses/LICENSE-2.0
<http://www.apache.org/licenses/LICENSE-2.0>`__.
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| text/x-rst | null | The NiPreps Developers <nipreps@gmail.com> | null | null | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright The NiPreps Developers
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3... | [] | null | null | >=3.10 | [] | [] | [] | [
"acres>=0.2.0",
"apscheduler>=3.10",
"codecarbon>=2",
"looseversion>=1.3",
"nibabel>=4.0.1",
"nipype>=1.8.5",
"nireports>=24.1.0",
"nitime>=0.9",
"nitransforms>=24.1.1",
"niworkflows>=1.14.2",
"numpy>=1.24",
"packaging>=24",
"pandas>=1.2",
"psutil>=5.4",
"pybids>=0.19.0",
"requests>=2.... | [] | [] | [] | [
"Homepage, https://github.com/nipreps/petprep",
"Documentation, https://petprep.org",
"Paper, https://doi.org/10.1038/s41592-018-0235-4",
"Docker Images, https://hub.docker.com/r/nipreps/petprep/tags/",
"NiPreps, https://www.nipreps.org/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:45:29.047706 | petprep-0.0.4.tar.gz | 28,948,990 | 20/dd/0d8d9d10cccff1bd209542dc0a53e52b3f052e58d9fe8f53da40d31bade5/petprep-0.0.4.tar.gz | source | sdist | null | false | 28b4a306fa0a827f0e53df3528e0f604 | 432e98998a8363a2ec5ff9611ccf4a60728c54b9fec529c89d5fd5488742124c | 20dd0d8d9d10cccff1bd209542dc0a53e52b3f052e58d9fe8f53da40d31bade5 | null | [
"LICENSE",
"NOTICE"
] | 216 |
2.4 | lsms | 0.4.9 | Tools for working with Living Standards Measurement Surveys | Python tools for working with LSMS datasets.
Build and packaging are managed with Poetry. Typical workflow:
- `make tangle` to regenerate the Python sources from `MANIFEST.org`.
- `poetry install` (or `make devinstall`) to create a virtual environment with dependencies.
- `make test` to run the project's pytest suite inside Poetry's environment.
- `make build` (or `poetry build`) to produce distributions in `dist/`.
- `make upload` uses `poetry publish --build` to push the built artifacts.
- The `ligonlibrary` helper package is vendored as a Poetry path dependency; adjust the relative path if your checkout lives elsewhere.
| text/plain | Ethan Ligon | ligon@berkeley.edu | null | null | CC-BY-NC-SA-4.0 | stata, survey, lsms | [
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | https://bitbucket.org/eligon/LSMS | null | <3.13,>=3.11 | [] | [] | [] | [
"numpy>=1.22",
"pandas<3.0,>=1.3",
"ligonlibrary>=0.1.6"
] | [] | [] | [] | [
"Homepage, https://bitbucket.org/eligon/LSMS",
"Repository, https://bitbucket.org/eligon/LSMS"
] | poetry/2.2.1 CPython/3.12.12 Linux/6.6.99-08879-gd6e365e8de4e | 2026-02-19T14:43:58.662679 | lsms-0.4.9.tar.gz | 1,476 | eb/33/c9a4d68f403bfddd3d0714e9dfdc1b08308a834784ce7f37362b37cc603e/lsms-0.4.9.tar.gz | source | sdist | null | false | 47394becc1e0715904970d162dc58012 | c6d2e167d6f0f04629af500acc2d9997ac912586887b03e9710e4d84b55794d2 | eb33c9a4d68f403bfddd3d0714e9dfdc1b08308a834784ce7f37362b37cc603e | null | [] | 210 |
2.4 | opendart-mcp | 0.1.0 | OpenDART (DART 전자공시시스템) MCP Server - 금융감독원 공시정보 API | # OpenDART MCP Server
금융감독원 [DART 전자공시시스템](https://opendart.fss.or.kr) Open API를 [MCP(Model Context Protocol)](https://modelcontextprotocol.io) 서버로 제공합니다.
Claude, ChatGPT 등 MCP를 지원하는 AI 클라이언트에서 한국 상장기업의 공시정보, 재무제표, 지분공시 등 **83개 API**를 자연어로 조회할 수 있습니다.
## 사전 준비
[OpenDART](https://opendart.fss.or.kr)에서 API 인증키를 발급받으세요.
## 설치 및 설정
### Claude Desktop
`claude_desktop_config.json`에 추가:
```json
{
"mcpServers": {
"opendart": {
"command": "uvx",
"args": ["opendart-mcp"],
"env": {
"OPENDART_API_KEY": "<YOUR_API_KEY>"
}
}
}
}
```
> 설정 파일 위치: macOS `~/Library/Application Support/Claude/claude_desktop_config.json`
### Claude Code
```bash
claude mcp add opendart -- uvx opendart-mcp
# API 키 설정
export OPENDART_API_KEY="<YOUR_API_KEY>"
```
### Cursor / Windsurf
MCP 설정 파일(`.cursor/mcp.json` 또는 `.windsurf/mcp.json`)에 추가:
```json
{
"mcpServers": {
"opendart": {
"command": "uvx",
"args": ["opendart-mcp"],
"env": {
"OPENDART_API_KEY": "<YOUR_API_KEY>"
}
}
}
}
```
### SSE (원격 서버)
```bash
uvx opendart-mcp --transport sse --host 0.0.0.0 --port 8000
```
### Docker
```bash
docker build -t opendart-mcp .
docker run -e OPENDART_API_KEY="<YOUR_API_KEY>" -p 8000:8000 opendart-mcp
```
## 제공 도구 (83개)
### 공시정보 (4개)
| 도구 | 설명 |
|---|---|
| `search_disclosure` | 공시 검색 (기업코드, 날짜, 공시유형 등으로 필터링) |
| `get_company_info` | 기업 개황 조회 |
| `get_document` | 공시 원문 다운로드 (ZIP) |
| `get_corp_code` | 전체 고유번호 목록 다운로드 |
### 정기보고서 주요정보 (28개)
| 도구 | 설명 |
|---|---|
| `get_stock_issuance_status` | 증자(감자) 현황 |
| `get_dividend_info` | 배당에 관한 사항 |
| `get_treasury_stock_status` | 자기주식 취득 및 처분 현황 |
| `get_largest_shareholder` | 최대주주 현황 |
| `get_largest_shareholder_change` | 최대주주 변동 현황 |
| `get_minority_shareholder` | 소액주주 현황 |
| `get_executive_status` | 임원 현황 |
| `get_employee_status` | 직원 현황 |
| `get_individual_compensation` | 개인별 보수지급 금액 (5억 이상) |
| `get_total_compensation` | 이사·감사 전체의 보수현황 |
| `get_top5_compensation` | 개인별 보수지급 금액 (상위 5인) |
| `get_investment_in_others` | 타법인 출자 현황 |
| `get_total_shares_status` | 주식 총수 현황 |
| `get_debt_securities_issued` | 채무증권 발행실적 |
| `get_commercial_paper_balance` | 기업어음증권 미상환 잔액 |
| `get_short_term_bond_balance` | 단기사채 미상환 잔액 |
| `get_corporate_bond_balance` | 회사채 미상환 잔액 |
| `get_new_capital_securities_balance` | 신종자본증권 미상환 잔액 |
| `get_contingent_capital_balance` | 조건부자본증권 미상환 잔액 |
| `get_auditor_opinion` | 회계감사인의 감사의견 |
| `get_audit_service_contract` | 감사용역 체결현황 |
| `get_non_audit_service_contract` | 비감사용역 체결현황 |
| `get_outside_director_status` | 사외이사 및 그 변동현황 |
| `get_unregistered_exec_compensation` | 미등기임원 보수현황 |
| `get_total_compensation_approval` | 이사·감사의 보수한도 승인현황 |
| `get_compensation_by_type` | 유형별 보수지급 금액 |
| `get_public_offering_fund_usage` | 공모자금의 사용내역 |
| `get_private_placement_fund_usage` | 사모자금의 사용내역 |
### 재무정보 (7개)
| 도구 | 설명 |
|---|---|
| `get_single_company_accounts` | 단일회사 주요계정 |
| `get_multi_company_accounts` | 다중회사 주요계정 |
| `get_xbrl_document` | 재무제표 원본파일 (XBRL ZIP) |
| `get_full_financial_statement` | 단일회사 전체 재무제표 |
| `get_xbrl_taxonomy` | XBRL 택사노미 재무제표 양식 |
| `get_single_financial_index` | 단일회사 주요 재무지표 |
| `get_multi_financial_index` | 다중회사 주요 재무지표 |
### 지분공시 (2개)
| 도구 | 설명 |
|---|---|
| `get_major_stockholding` | 대량보유 상황보고 |
| `get_executive_stockholding` | 임원·주요주주 소유보고 |
### 주요사항보고서 (36개)
| 도구 | 설명 |
|---|---|
| `get_asset_transfer_putback` | 자산양수도(풋백옵션) |
| `get_default_occurrence` | 채무불이행(파산) |
| `get_business_suspension` | 영업정지 |
| `get_rehabilitation_filing` | 회생절차 개시신청 |
| `get_dissolution_event` | 해산사유 발생 |
| `get_paid_capital_increase` | 유상증자 결정 |
| `get_free_capital_increase` | 무상증자 결정 |
| `get_mixed_capital_increase` | 유무상증자 결정 |
| `get_capital_reduction` | 감자 결정 |
| `get_creditor_management_start` | 채권은행 관리절차 개시 |
| `get_lawsuit_filing` | 소송 등의 제기 |
| `get_overseas_listing_decision` | 해외 상장 결정 |
| `get_overseas_delisting_decision` | 해외 상장폐지 결정 |
| `get_overseas_listing` | 해외 상장 |
| `get_overseas_delisting` | 해외 상장폐지 |
| `get_convertible_bond_decision` | 전환사채권 발행결정 |
| `get_bond_with_warrant_decision` | 신주인수권부사채권 발행결정 |
| `get_exchangeable_bond_decision` | 교환사채권 발행결정 |
| `get_creditor_management_stop` | 채권은행 관리절차 중단 |
| `get_contingent_bond_decision` | 조건부자본증권 발행결정 |
| `get_treasury_stock_acquisition_decision` | 자기주식 취득 결정 |
| `get_treasury_stock_disposal_decision` | 자기주식 처분 결정 |
| `get_treasury_trust_contract_decision` | 자기주식취득 신탁계약 체결 결정 |
| `get_treasury_trust_termination_decision` | 자기주식취득 신탁계약 해지 결정 |
| `get_business_acquisition_decision` | 영업양수 결정 |
| `get_business_transfer_decision` | 영업양도 결정 |
| `get_tangible_asset_acquisition_decision` | 유형자산 양수 결정 |
| `get_tangible_asset_transfer_decision` | 유형자산 양도 결정 |
| `get_other_corp_stock_acquisition_decision` | 타법인 주식 양수 결정 |
| `get_other_corp_stock_transfer_decision` | 타법인 주식 양도 결정 |
| `get_stock_bond_acquisition_decision` | 주권 관련 사채권 양수 결정 |
| `get_stock_bond_transfer_decision` | 주권 관련 사채권 양도 결정 |
| `get_merger_decision` | 회사합병 결정 |
| `get_division_decision` | 회사분할 결정 |
| `get_division_merger_decision` | 회사분할합병 결정 |
| `get_stock_exchange_transfer_decision` | 주식교환·이전 결정 |
### 증권신고서 (6개)
| 도구 | 설명 |
|---|---|
| `get_equity_securities_reg` | 지분증권 |
| `get_debt_securities_reg` | 채무증권 |
| `get_depositary_receipts_reg` | 증권예탁증권 |
| `get_merger_reg` | 합병 |
| `get_stock_exchange_reg` | 주식의 포괄적 교환·이전 |
| `get_division_reg` | 분할 |
## 주요 파라미터
| 파라미터 | 설명 | 예시 |
|---|---|---|
| `corp_code` | 기업 고유번호 (8자리) | `00126380` (삼성전자) |
| `bsns_year` | 사업연도 | `2024` |
| `reprt_code` | 보고서 코드 | `11013` 1분기, `11012` 반기, `11014` 3분기, `11011` 사업보고서 |
| `bgn_de` / `end_de` | 조회 시작일 / 종료일 (YYYYMMDD) | `20240101` / `20241231` |
| `rcept_no` | 접수번호 (14자리) | `20240312000736` |
> `corp_code`를 모를 경우 `search_disclosure`로 기업명 검색하거나 `get_corp_code`로 전체 목록을 조회할 수 있습니다.
## 사용 예시
MCP 클라이언트(Claude 등)에서 자연어로 질문하면 됩니다:
- "삼성전자 2024년 사업보고서에서 배당 정보 알려줘"
- "네이버 최대주주 현황 조회해줘"
- "2024년 삼성전자 자기주식 취득 결정 내역 보여줘"
- "SK하이닉스 2024년 재무제표 주요계정 조회"
- "카카오 임원 현황이랑 보수 정보 알려줘"
## 라이선스
MIT
| text/markdown | null | RealYoungk <youngjin5394@gmail.com> | null | null | null | dart, disclosure, financial, fss, korea, mcp, opendart | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.27.0",
"mcp[cli]>=1.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/RealYoungk/opendart-mcp",
"Repository, https://github.com/RealYoungk/opendart-mcp",
"Issues, https://github.com/RealYoungk/opendart-mcp/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T14:43:53.931770 | opendart_mcp-0.1.0.tar.gz | 57,908 | f1/63/a54c4dad5ad9dde1d6ca10ae26521f35396e1c7cc986ea9854f116bd4f5e/opendart_mcp-0.1.0.tar.gz | source | sdist | null | false | 30ce837fd5aa852d5c62462bc5f0c753 | 93f7e407a23ebda49d5120d050d08d3a468c36a056f5973c7b243b9f561fac48 | f163a54c4dad5ad9dde1d6ca10ae26521f35396e1c7cc986ea9854f116bd4f5e | MIT | [
"LICENSE"
] | 238 |
2.4 | dmn-prolog-converter | 1.0.1 | Bidirectional converter between Prolog and DMN (Decision Model and Notation) | # DMN-Prolog Bidirectional Converter
[](https://github.com/NewJerseyStyle/dmn_prolog_converter/actions/workflows/test.yml)
[](https://pypi.org/project/dmn-prolog-converter/)
A Python tool for bidirectional conversion between Prolog code and DMN (Decision Model and Notation) for legal/business rule management.
## Overview
This tool enables a powerful workflow for converting legal documents into executable decision logic:
```
Legal Document → LLM → Prolog → DMN → Review → Deploy (Prolog or DMN)
↑ ↓
└────────────────┘
(Bidirectional)
```
**Why this approach?**
- **LLM-Friendly Input**: Prolog syntax is simpler and more reliable for LLMs to generate than verbose DMN XML
- **Human-Friendly Review**: DMN provides visual decision tables that legal/business specialists can review
- **Flexible Deployment**: Deploy as either Prolog (for Prolog engines) or DMN (for DMN engines)
- **Quality Control**: Bidirectional conversion ensures consistency and reduces hallucination
## Supported Prolog Subset
To ensure DMN compatibility, the converter supports a restricted Prolog subset:
- ✓ **Horn clauses only** (no negation-as-failure, no cuts)
- ✓ **Deterministic rules** (single output per input combination)
- ✓ **Simple data types** (atoms, numbers, strings, booleans)
- ✓ **Decision table structure** (pattern-matching rules)
- ✓ **Limited recursion** (≤ 3 levels)
- ✓ **FEEL expression compatibility** (comparison operators: `>=`, `=<`, `>`, `<`, `==`, `\=`)
## Installation
```bash
# Basic installation (conversion only)
pip install dmn-prolog-converter
# With validation support
pip install dmn-prolog-converter[validation]
# With all optional features
pip install dmn-prolog-converter[execution]
```
See [CDMN_INTEGRATION.md](CDMN_INTEGRATION.md) for details.
## Quick Start
### Command Line
After installation, you'll have these commands available:
```bash
dmn-prolog # Main CLI tool with subcommands
prolog2dmn # Quick shortcut: Prolog → DMN
dmn2prolog # Quick shortcut: DMN → Prolog
z32dmn # Quick shortcut: Z3 → DMN
dmn2z3 # Quick shortcut: DMN → Z3
```
Example usage
```bash
# Convert Prolog to DMN
dmn-prolog convert rules.pl rules.dmn
# Convert DMN to Prolog
dmn-prolog convert rules.dmn rules.pl
# Validate DMN
dmn-prolog validate rules.dmn
# Show file info
dmn-prolog info rules.pl
dmn-prolog info rules.smt2
# Quick shortcuts
prolog2dmn input.pl output.dmn
dmn2prolog input.dmn output.pl
z32dmn input.smt2 output.dmn
dmn2z3 input.dmn output.smt2
```
See [CLI_GUIDE.md](CLI_GUIDE.md) for complete CLI documentation.
## Limitations & Future Work
**Current Limitations:**
- No support for complex Prolog features (cuts, negation-as-failure, DCGs)
- Limited to decision tables (no decision requirement diagrams)
- No support for DMN business knowledge models or contexts
- Arithmetic expressions are basic
**Future Enhancements:**
- Support for DMN FEEL functions
- Decision requirement diagram generation
- Semantic validation of business logic
- Integration with LLM for natural language descriptions
- Support for more complex Prolog constructs (via approximation)
- Visual DMN table editor integration
## Use Cases
1. **Legal Document Automation**: Convert legal rules to executable format
2. **Business Rule Management**: Maintain rules in both technical and business-friendly formats
3. **Legacy Migration**: Migrate Prolog expert systems to DMN standard
4. **LLM-Powered Rule Generation**: Let LLMs generate Prolog, convert to DMN for review
5. **Dual Deployment**: Maintain single source, deploy to both Prolog and DMN engines
## Contributing
Contributions welcome! Areas for improvement:
- Additional test cases
- Support for more Prolog patterns
- Enhanced FEEL expression generation
- Documentation improvements
## License
MIT License - see LICENSE file for details
## References
- [DMN 1.3 Specification](https://www.omg.org/spec/DMN/1.3/)
- [FEEL Language Guide](https://docs.camunda.org/manual/latest/reference/dmn/feel/)
- [Prolog Tutorial](https://www.swi-prolog.org/pldoc/man?section=quickstart)
- [Lark Parser Documentation](https://lark-parser.readthedocs.io/)
| text/markdown | David Xu | null | null | null | MIT | prolog, dmn, converter, decision-table, business-rules | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Legal Industry",
"Topic :: Software Development :: Code Generators",
"Topic :: Software Development :: Compilers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming La... | [] | null | null | >=3.10 | [] | [] | [] | [
"lark>=1.1.9",
"lxml>=5.1.0",
"cdmn>=0.1.0; extra == \"validation\"",
"cdmn>=0.1.0; extra == \"execution\"",
"pyswip>=0.2.10; extra == \"execution\"",
"pytest>=7.0; extra == \"dev\"",
"black>=23.0; extra == \"dev\"",
"mypy>=1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/NewJerseyStyle/dmn-prolog-converter",
"Issues, https://github.com/NewJerseyStyle/dmn-prolog-converter/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:43:14.728775 | dmn_prolog_converter-1.0.1.tar.gz | 30,980 | fa/d2/1bfd2219d170a725701e3df4754a1d265489fd9b203d5f0ac509f0f5354f/dmn_prolog_converter-1.0.1.tar.gz | source | sdist | null | false | 9cd722039603408f5a7cef3bfc59e023 | 83ae4100bdba041cd095d5976164d0b3145747acba68ac4a2a9d4b140fa6feae | fad21bfd2219d170a725701e3df4754a1d265489fd9b203d5f0ac509f0f5354f | null | [
"LICENSE"
] | 243 |
2.4 | LLMPrompts | 0.2.1 | Facilitating the creation, storage, retrieval, and curation of LLM prompts. | # LLMPrompts Python package


## In brief
This Python package provides data and functions for facilitating the creation, storage, retrieval, and curation of
[Large Language Models (LLM) prompts](https://en.wikipedia.org/wiki/Prompt_engineering).
*(Here is a [link to the corresponding notebook](https://github.com/antononcube/Python-packages/blob/main/LLMPrompts/docs/LLM-prompts-usage.ipynb).)*
--------
## Installation
### Install from GitHub
```shell
pip install -e git+https://github.com/antononcube/Python-packages.git#egg=LLMPrompts-antononcube\&subdirectory=LLMPrompts
```
### From PyPi
```shell
pip install LLMPrompts
```
------
## Basic usage examples
Load the packages "LLMPrompts", [AAp1], and "LLMFunctionObjects", [AAp2]:
### Prompt data retrieval
Here the LLM prompt and function packages are loaded:
```python
from LLMPrompts import *
from LLMFunctionObjects import *
```
Here is a prompt data retrieval using a regex:
```python
llm_prompt_data(r'^N.*e$', fields="Description")
```
{'NarrativeToResume': 'Rewrite narrative text as a resume',
'NothingElse': 'Give output in specified form, no other additions'}
Retrieve a prompt with a specified name and related data fields:
```python
llm_prompt_data("Yoda", fields=['Description', "PromptText"])
```
{'Yoda': ['Respond as Yoda, you will',
'You are Yoda. \nRespond to ALL inputs in the voice of Yoda from Star Wars. \nBe sure to ALWAYS use his distinctive style and syntax. Vary sentence length.']}
Here is number of all prompt names:
```python
len(llm_prompt_data())
```
154
Here is a data frame with all prompts names and descriptions:
```python
import pandas
dfPrompts = pandas.DataFrame([dict(zip(["Name", "Description"], x)) for x in llm_prompt_data(fields=["Name", "Description"]).values()])
dfPrompts
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Name</th>
<th>Description</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>19thCenturyBritishNovel</td>
<td>You know that AI could as soon forget you as m...</td>
</tr>
<tr>
<th>1</th>
<td>AbstractConvert</td>
<td>Convert text into an abstract</td>
</tr>
<tr>
<th>2</th>
<td>ActiveVoiceRephrase</td>
<td>Rephrase text from passive into active voice</td>
</tr>
<tr>
<th>3</th>
<td>AlternativeHistorian</td>
<td>Explore alternate versions of history</td>
</tr>
<tr>
<th>4</th>
<td>AnimalSpeak</td>
<td>The language of beasts, sort of</td>
</tr>
<tr>
<th>...</th>
<td>...</td>
<td>...</td>
</tr>
<tr>
<th>149</th>
<td>FriendlySnowman</td>
<td>Chat with a snowman</td>
</tr>
<tr>
<th>150</th>
<td>HugoAwardWinner</td>
<td>Write a science fiction novel about climate ch...</td>
</tr>
<tr>
<th>151</th>
<td>ShortLineIt</td>
<td>Format text to have shorter lines</td>
</tr>
<tr>
<th>152</th>
<td>Unhedged</td>
<td>Rewrite a sentence to be more assertive</td>
</tr>
<tr>
<th>153</th>
<td>WordGuesser</td>
<td>Play a word game with AI</td>
</tr>
</tbody>
</table>
<p>154 rows × 2 columns</p>
</div>
### Code generating function
Here is an LLM function creation if a code writing prompt that takes target language as an argument:
```python
fcw = llm_function(llm_prompt("CodeWriterX")("Python"), e='ChatGPT')
fcw.prompt
```
```
'You are Code Writer and as the coder that you are, you provide clear and concise code only, without explanation nor conversation. \nYour job is to output code with no accompanying text.\nDo not explain any code unless asked. Do not provide summaries unless asked.\nYou are the best Python programmer in the world but do not converse.\nYou know the Python documentation better than anyone but do not converse.\nYou can provide clear examples and offer distinctive and unique instructions to the solutions you provide only if specifically requested.\nOnly code in Python unless told otherwise.\nUnless they ask, you will only give code.'
```
Here is a code generation request with that function:
```python
print(fcw("Random walk simulation."))
```
```python
import random
def random_walk(n):
x, y = 0, 0
for _ in range(n):
dx, dy = random.choice([(0,1), (0,-1), (1,0), (-1,0)])
x += dx
y += dy
return (x, y)
```
### Fixing function
Using a function prompt retrieved with "FTFY" over the a misspelled word:
```python
llm_prompt("FTFY")("invokation")
```
```
'Find and correct grammar and spelling mistakes in the following text.\nResponse with the corrected text and nothing else.\nProvide no context for the corrections, only correct the text.\ninvokation'
```
Here is the corresponding LLM function:
```python
fFTFY = llm_function(llm_prompt("FTFY"))
fFTFY("wher was we?")
```
```
'\n\nWhere were we?'
```
Here is modifier prompt with two arguments:
```python
llm_prompt("ShortLineIt")("MAX_CHARS", "TEXT")
```
```
'Break the input\n\n TEXT\n \n into lines that are less than MAX_CHARS characters long.\n Do not otherwise modify the input. Do not add other text.'
```
Here is the corresponding LLM function:
```python
fb = llm_function(llm_prompt("ShortLineIt")("70"))
```
Here is longish text:
```python
text = 'A random walk simulation is a type of simulation that models the behavior of a random walk. A random walk is a mathematical process in which a set of steps is taken in a random order. The steps can be in any direction, and the order of the steps is determined by a random number generator. The random walk simulation is used to model a variety of real-world phenomena, such as the movement of particles in a gas or the behavior of stock prices. The random walk simulation is also used to study the behavior of complex systems, such as the spread of disease or the behavior of traffic on a highway.'
```
Here is the application of "ShortLineIT" applied to the text above:
```python
print(fb(text))
```
A random walk simulation is a type of simulation that models the behavior of a
random walk. A random walk is a mathematical process in which a set of steps is
taken in a random order. The steps can be in any direction, and the order of the
steps is determined by a random number generator. The random walk simulation is
used to model a variety of real-world phenomena, such as the movement of
particles in a gas or the behavior of stock prices. The random walk simulation
is also used to study the behavior of complex systems, such as the spread of
disease or the behavior of traffic on a highway.
### Chat object creation with a prompt
Here a chat object is create with a person prompt:
```python
chatObj = llm_chat(llm_prompt("MadHatter"))
```
Send a message:
```python
chatObj.eval("Who are you?")
```
```
'Ah, my dear curious soul, I am the Mad Hatter, the one and only! A whimsical creature, forever lost in the realm of absurdity and tea time. I am here to entertain and perplex, to dance with words and sprinkle madness in the air. So, tell me, my friend, what brings you to my peculiar tea party today?'
```
Send another message:
```python
chatObj.eval("I want oolong tea. And a chocolate.")
```
```
'Ah, oolong tea, a splendid choice indeed! The leaves unfurl, dancing in the hot water, releasing their delicate flavors into the air. And a chocolate, you say? How delightful! A sweet morsel to accompany the swirling warmth of the tea. But, my dear friend, in this topsy-turvy world of mine, I must ask: do you prefer your chocolate to be dark as the night or as milky as a moonbeam?'
```
-----
## Prompt spec DSL
A more formal description of the Domain Specific Language (DSL) for specifying prompts
has the following elements:
- Prompt personas can be "addressed" with "@". For example:
```
@Yoda Life can be easy, but some people instist for it to be difficult.
```
- One or several modifier prompts can be specified at the end of the prompt spec. For example:
```
Summer is over, school is coming soon. #HaikuStyled
```
```
Summer is over, school is coming soon. #HaikuStyled #Translated|Russian
```
- Functions can be specified to be applied "cell-wide" with "!" and placing the prompt spec at
the start of the prompt spec to be expanded. For example:
```
!Translated|Portuguese Summer is over, school is coming soon
```
- Functions can be specified to be applied to "previous" messages with "!" and
placing just the prompt with one of the pointers "^" or "^^".
The former means "the last message", the latter means "all messages."
- The messages can be provided with the option argument `:@messages` of `llm-prompt-expand`.
- For example:
```
!ShortLineIt^
```
- Here is a table of prompt expansion specs (more or less the same as the one in [SW1]):
| Spec | Interpretation |
|:-------------------|:----------------------------------------------------|
| @*name* | Direct chat to a persona |
| #*name* | Use modifier prompts |
| !*name* | Use function prompt with the input of current cell |
| !*name*> | *«same as above»* |
| &*name*> | *«same as above»* |
| !*name*^ | Use function prompt with previous chat message |
| !*name*^^ | Use function prompt with all previous chat messages |
| !*name*│*param*... | Include parameters for prompts |
**Remark:** The function prompts can have both sigils "!" and "&".
**Remark:** Prompt expansion make the usage of LLM-chatbooks much easier.
See ["JupyterChatbook"](https://pypi.org/project/JupyterChatbook/), [AAp3].
-----
## Implementation notes
### Following Raku implementations
This Python package reuses designs, implementation structures, and prompt data from the Raku package
["LLM::Prompts"](https://raku.land/zef:antononcube/LLM::Prompts), [AAp4].
### Prompt collection
The original (for this package) collection of prompts was a (not small) sample of the prompt texts
hosted at [Wolfram Prompt Repository](https://resources.wolframcloud.com/PromptRepository/) (WPR), [SW2].
All prompts from WPR in the package have the corresponding contributors and URLs to the corresponding WPR pages.
Example prompts from Google/Bard/PaLM and ~~OpenAI/ChatGPT~~ are added using the format of WPR.
### Extending the prompt collection
It is essential to have the ability to programmatically add new prompts.
(Not implemented yet -- see the TODO section below.)
### Prompt expansion
Initially prompt DSL grammar and corresponding expansion actions were implemented.
Having a grammar is most likely not needed, though, and it is better to use "prompt expansion" (via regex-based substitutions.)
Prompts can be "just expanded" using the sub `llm-prompt-expand`.
### Usage in chatbooks
Here is a flowchart that summarizes prompt parsing and expansion in chat cells of Jupyter chatbooks, [AAp3]:
```mermaid
flowchart LR
OpenAI{{OpenAI}}
PaLM{{PaLM}}
LLMFunc[[LLMFunctionObjects]]
LLMProm[[LLMPrompts]]
CODB[(Chat objects)]
PDB[(Prompts)]
CCell[/Chat cell/]
CRCell[/Chat result cell/]
CIDQ{Chat ID<br>specified?}
CIDEQ{Chat ID<br>exists in DB?}
RECO[Retrieve existing<br>chat object]
COEval[Message<br>evaluation]
PromParse[Prompt<br>DSL spec parsing]
KPFQ{Known<br>prompts<br>found?}
PromExp[Prompt<br>expansion]
CNCO[Create new<br>chat object]
CIDNone["Assume chat ID<br>is 'NONE'"]
subgraph Chatbook frontend
CCell
CRCell
end
subgraph Chatbook backend
CIDQ
CIDEQ
CIDNone
RECO
CNCO
CODB
end
subgraph Prompt processing
PDB
LLMProm
PromParse
KPFQ
PromExp
end
subgraph LLM interaction
COEval
LLMFunc
PaLM
OpenAI
end
CCell --> CIDQ
CIDQ --> |yes| CIDEQ
CIDEQ --> |yes| RECO
RECO --> PromParse
COEval --> CRCell
CIDEQ -.- CODB
CIDEQ --> |no| CNCO
LLMFunc -.- CNCO -.- CODB
CNCO --> PromParse --> KPFQ
KPFQ --> |yes| PromExp
KPFQ --> |no| COEval
PromParse -.- LLMProm
PromExp -.- LLMProm
PromExp --> COEval
LLMProm -.- PDB
CIDQ --> |no| CIDNone
CIDNone --> CIDEQ
COEval -.- LLMFunc
LLMFunc <-.-> OpenAI
LLMFunc <-.-> PaLM
```
Here is an example of prompt expansion in a generic LLM chat cell and chat meta cell
showing the content of the corresponding chat object:
![]()
-----
## TODO
- [ ] TODO Implementation
- [X] DONE Prompt retrieval adverbs
- [X] DONE Prompt spec expansion
- [ ] TODO Addition of user/local prompts
- [ ] TODO Using XDG data directory.
- [ ] TODO By modifying existing prompts.
- [ ] TODO Automatic prompt template fill-in.
- [ ] TODO Guided template fill-in.
- [ ] TODO DSL based
- [ ] TODO LLM based
- [ ] TODO Documentation
- [X] DONE Querying (ingested) prompts
- [X] DONE Prompt DSL
- [ ] TODO Prompt format
- [ ] TODO On hijacking prompts
- [ ] TODO Diagrams
- [X] DONE Chatbook usage
- [ ] Typical usage
------
## References
### Articles
[AA1] Anton Antonov,
["Workflows with LLM functions"](https://rakuforprediction.wordpress.com/2023/08/01/workflows-with-llm-functions/),
(2023),
[RakuForPrediction at WordPress](https://rakuforprediction.wordpress.com).
[SW1] Stephen Wolfram,
["The New World of LLM Functions: Integrating LLM Technology into the Wolfram Language"](https://writings.stephenwolfram.com/2023/05/the-new-world-of-llm-functions-integrating-llm-technology-into-the-wolfram-language/),
(2023),
[Stephen Wolfram Writings](https://writings.stephenwolfram.com).
[SW2] Stephen Wolfram,
["Prompts for Work & Play: Launching the Wolfram Prompt Repository"](https://writings.stephenwolfram.com/2023/06/prompts-for-work-play-launching-the-wolfram-prompt-repository/),
(2023),
[Stephen Wolfram Writings](https://writings.stephenwolfram.com).
### Packages, paclets, repositories
[AAp1] Anton Antonov,
[LLMPrompts Python package](hhttps://github.com/antononcube/Python-packages/tree/main/LLMPrompts),
(2023),
[Python-packages at GitHub/antononcube](https://github.com/antononcube/Python-packages).
[AAp2] Anton Antonov,
[LLMFunctionObjects Python package](https://github.com/antononcube/Python-packages/tree/main/LLMFunctionObjects),
(2023),
[Python-packages at GitHub/antononcube](https://github.com/antononcube/Python-packages).
[AAp3] Anton Antonov,
[JupyterChatbook Python package](https://github.com/antononcube/Python-JupyterChatbook),
(2023),
[GitHub/antononcube](https://github.com/antononcube).
[AAp4] Anton Antonov,
[LLM::Prompts Raku package](https://github.com/antononcube/Raku-LLM-Prompts),
(2023),
[GitHub/antononcube](https://github.com/antononcube).
[AAp5] Anton Antonov,
[LLM::Functions Raku package](https://github.com/antononcube/Raku-LLM-Functions),
(2023),
[GitHub/antononcube](https://github.com/antononcube).
[AAp6] Anton Antonov,
[Jupyter::Chatbook Raku package](https://github.com/antononcube/Raku-Jupyter-Chatbook),
(2023),
[GitHub/antononcube](https://github.com/antononcube).
[WRIr1] Wolfram Research, Inc.,
[Wolfram Prompt Repository](https://resources.wolframcloud.com/PromptRepository)
| text/markdown | Anton Antonov | antononcube@posteo.net | null | null | BSD-3-Clause | openai, chatgpt, palm, prompt, prompts, large language model, large language models, llm, llm prompt, llm prompts | [
"Intended Audience :: Science/Research",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Intended Audience :: Science/Research",
"Intended Audience :: Developers",
"Operating System :: OS Independent"
] | [] | https://github.com/antononcube/Python-packages/tree/main/LLMPrompts | null | >=3.7 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T14:43:10.635556 | llmprompts-0.2.1.tar.gz | 64,694 | 0d/28/dc5ec0707ecf1c40c994ae1f104bee0051fd8228dbb81dc8b294ad116ea4/llmprompts-0.2.1.tar.gz | source | sdist | null | false | 8b05dbc23d86fddc67defad002d8b4c2 | 9419ecb62c74bc57145596b1e005daec0773e033f8a111f28b8a202f90fd221a | 0d28dc5ec0707ecf1c40c994ae1f104bee0051fd8228dbb81dc8b294ad116ea4 | null | [
"LICENSE"
] | 0 |
2.4 | compoconf | 0.1.14 | A compositional configuration library for Python | # CompoConf
CompoConf is a Python library for compositional configuration management. It provides a type-safe way to define, parse, and instantiate configurations for complex, modular systems.
## Features
- Type-safe configuration parsing with dataclass support
- Registry-based class instantiation
- Inheritance-based interface registration
- Support for nested configurations
- Optional OmegaConf integration
- Strict type checking and validation
## Installation
```bash
pip install compoconf
```
## Quick Start
Here's a simple example of how to use CompoConf:
```python
from dataclasses import dataclass
from compoconf import (
RegistrableConfigInterface,
ConfigInterface,
register_interface,
register,
)
# Define an interface
@register_interface
class ModelInterface(RegistrableConfigInterface):
pass
# Define a configuration
@dataclass
class MLPConfig(ConfigInterface):
hidden_size: int = 128
num_layers: int = 2
# Register a class with its configuration
@register
class MLPModel(ModelInterface):
config_class = MLPConfig
def __init__(self, config):
self.config = config
# Initialize model with config...
# Create and use configurations
config = MLPConfig(hidden_size=256)
model = config.instantiate(ModelInterface)
```
## Advanced Usage
### Nested Configurations
CompoConf supports nested configurations through type annotations:
```python
@dataclass
class TrainerConfig(ConfigInterface):
model: ModelInterface.cfgtype # References the interface type
learning_rate: float = 0.001
# Parse nested configuration
config = {
"model": {
"class_name": "MLPModel",
"hidden_size": 256
},
"learning_rate": 0.01
}
trainer_config = parse_config(TrainerConfig, config)
```
### Type Safety
The library provides comprehensive type checking:
- Validates configuration values against their type annotations
- Ensures registered classes match their interfaces
- Checks for missing required fields
- Supports strict mode for catching unknown configuration keys
### OmegaConf Integration
CompoConf optionally integrates with OmegaConf for enhanced configuration handling:
```python
from omegaconf import OmegaConf
# Load configuration from YAML
conf = OmegaConf.load('config.yaml')
config = parse_config(ModelConfig, conf)
```
### Registry System
The registry system allows for dynamic class instantiation based on configuration:
```python
# Register multiple implementations
@dataclass
class CNNConfig(ConfigInterface):
kernel_size: int = 4
@register
class CNNModel(ModelInterface):
config_class = CNNConfig
@dataclass
class TransformerConfig(ConfigInterface):
hidden_size: int = 128
num_heads: int = 4
@register
class TransformerModel(ModelInterface):
config_class = TransformerConfig
# Configuration automatically creates correct instance
config = {
"model": {
"class_name": "TransformerModel",
"num_heads": 8,
"hidden_size": 512
}
}
```
## API Reference
### Core Classes
- `RegistrableConfigInterface`: Base class for interfaces that can be configured
- `ConfigInterface`: Base class for configuration dataclasses
- `Registry`: Singleton managing registration of interfaces and implementations
### Decorators
- `@register_interface`: Register a new interface
- `@register`: Register an implementation class
### Functions
- `parse_config(config_class, data, strict=True)`: Parse configuration data into typed objects
## Enhanced Functionality
### Parsing Module
The parsing module has been enhanced to provide more robust and flexible configuration parsing capabilities. Key improvements include:
- Improved handling of nested configurations and unions.
- Enhanced type validation and error reporting.
- Support for parsing configurations from various data sources (e.g., JSON, YAML).
### Util Module
The util module now includes powerful utilities for dynamic configuration and validation:
- `partial_call`: Enables the creation of configurable classes from functions, allowing for dynamic modification of function arguments through configuration.
- `from_annotations`: Simplifies the creation of configurable classes by automatically extracting configuration parameters from class annotations.
- `validate_literal_field` and `assert_check_literals`: Provide mechanisms for validating Literal type annotations in dataclasses, ensuring that configuration values are within the allowed set of options.
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
## License
MIT License
## Author
Korbinian Pöppel (korbip@korbip.de)
| text/markdown | null | Korbinian Pöppel <korbip@korbip.de> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"dataclasses; python_version < \"3.10\"",
"typing-extensions>=4.0.0",
"black>=23.0.0; extra == \"dev\"",
"flake8>=6.0.0; extra == \"dev\"",
"isort>=5.12.0; extra == \"dev\"",
"mypy>=1.5.0; extra == \"dev\"",
"ruff>=0.12.7; extra == \"dev\"",
"sphinx-autodoc-typehints>=1.25.2; extra == \"docs\"",
"sp... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:43:08.364520 | compoconf-0.1.14.tar.gz | 38,379 | 62/eb/cc58605c11f8f50b9da61f47daa0a20e3f474cc436ee5eb7c9a0cdbe3b7f/compoconf-0.1.14.tar.gz | source | sdist | null | false | c7b37008efb66d4068d4e9a0eca5840c | d4672a1a755210e8b8d4ed92608ad18f2b9dce8bb9ad06e059e64dc36b7d3b19 | 62ebcc58605c11f8f50b9da61f47daa0a20e3f474cc436ee5eb7c9a0cdbe3b7f | MIT | [
"LICENSE"
] | 250 |
2.4 | pednstream | 0.0.1a0 | PedNStream is a light-weight/Python-native pedestrian traffic simulation tool based on the Link Transmission Model (LTM) | # PedNStream: Pedestrian Network Flow Simulator
PedNStream is a light-weight/Python-native pedestrian traffic simulation tool based on the Link Transmission Model (LTM). It enables modeling and simulation of pedestrian movements through complex networks, providing insights into crowd dynamics and flow behaviors.
## Key Features
- **Network-based Simulation**: Model pedestrian movement through interconnected pathways and decision points
- **Flexible Network Configuration**: Support for various network topologies from simple corridors to complex urban layouts
<!-- - **Dynamic Flow Modeling**: Incorporates traffic dynamics including densities, speeds, and queue formation -->
- **Customizable Parameters**: Configure link properties, flow speeds, and capacity constraints
- **Visualization Tools**: Analyze simulation outputs through interactive visualizations and animations
## Modular Design
### Network Module (`src/LTM/network.py`)
The central component managing the simulation network and execution:
- Flow assignment based in link's sending and receiving flow
- Step-by-step simulation execution
- Integration of links and nodes
### Link Module (`src/LTM/link.py`)
Models physical pathways with properties like:
- Length and width
- Free-flow speed
- Critical and jam densities
- Bi-directional flow support
### Node Module (`src/LTM/node.py`)
Handles intersection points and decision making:
- Flow distribution between connected links
- Turning fraction calculation
### Path Finding (`src/LTM/path_finder.py`)
Manages route choice and navigation:
- K shortest paths between origins and destinations
- Route choise based in utility function
## Quick Start
### Basic Network Simulation
```python
from src.utils.env_loader import NetworkEnvGenerator
from src.utils.visualizer import NetworkVisualizer
# Initialize network from configuration
env_generator = NetworkEnvGenerator()
network_env = env_generator.create_network("example_config")
# Run simulation
for t in range(1, env_generator.config['params']['simulation_steps']):
network_env.network_loading(t)
# Visualize results
visualizer = NetworkVisualizer(simulation_dir="output_dir")
anim = visualizer.animate_network(
start_time=0,
end_time=env_generator.config['params']['simulation_steps'],
edge_property='density'
)
```
### Configuration Example
```yaml
# sim_params.yaml
network:
adjacency_matrix: [
[0, 1, 1, 0, 0, 0], # node 0
[1, 0, 0, 1, 0, 0], # node 1
[1, 0, 0, 1, 1, 0], # node 2
[0, 1, 1, 0, 0, 1], # node 3
[0, 0, 1, 0, 0, 1], # node 4
[0, 0, 0, 1, 1, 0] # node 5
]
origin_nodes: [1]
destination_nodes: [5]
simulation:
unit_time: 10
simulation_steps: 500
default_link:
length: 50
width: 1
free_flow_speed: 1.5
k_critical: 2
k_jam: 6
demand:
origin_0:
peak_lambda: 15
base_lambda: 5
```
## Example Scenarios
The `examples/` directory contains various simulation scenarios:
- `long_corridor.py`: Simple bi-directional flow in a corridor
- `nine_node.py`: Grid network with multiple OD pairs
- `delft_exp.py`: Real-world network simulation (Delft, Netherlands)
- `melbourne.py`: Large-scale urban network simulation
## Visualization
PedNStream provides rich visualization capabilities:
- Network state visualization
- Density and flow animations
- Interactive network dashboard
- Time-series analysis tools

## Demo on Delft Center
[Delft Center Simulation](./video_outputs/delft.mp4)
## Project Structure
```
project_root/
├── src/
│ ├── LTM/ # Core simulation components
│ │ ├── link.py # Link dynamics
│ │ ├── node.py # Node behavior
│ │ ├── network.py # Network management
│ │ └── path_finder.py # Route choice
│ └── utils/ # Utility functions
│ ├── visualizer.py # Visualization tools
│ └── env_loader.py # Environment setup
├── examples/ # Example scenarios
└── data/ # Network configurations
```
## Contributing
Contributions are welcome! Please check the issues page for current development priorities.
## License
PedNStream is released under the MIT License. See the [LICENSE](./LICENSE) file for details. | text/markdown | null | John Doe <id@tudelft.nl> | null | John Doe <user@tudelft.nl> | null | pedestrian traffic, simulation | [
"Development Status :: 1 - Planning",
"Programming Language :: Python"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"matplotlib>=3.4.0",
"networkx>=2.6.0",
"numpy>=1.21.0",
"scipy>=1.7.0",
"gymnasium>=0.29.0; extra == \"dev\"",
"myst-parser; extra == \"dev\"",
"pettingzoo>=1.24.0; extra == \"dev\"",
"pytest; extra == \"dev\"",
"ray[rllib]>=2.9.0; extra == \"dev\"",
"ruff; extra == \"dev\"",
"sphinx; extra == ... | [] | [] | [] | [
"Homepage, https://github.com/WaimenMak/PedNStream",
"Documentation, https://github.com/WaimenMak/PedNStream#readme",
"Repository, https://github.com/WaimenMak/PedNStream",
"Bug Tracker, https://github.com/WaimenMak/PedNStream/issues",
"Changelog, https://github.com/WaimenMak/PedNStream/blob/main/CHANGELOG.... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:42:54.823594 | pednstream-0.0.1a0.tar.gz | 34,521,441 | d1/b9/d3930cd5107f110a4969f5f585e2ae6989b03dc8a07f9358dd9b85925319/pednstream-0.0.1a0.tar.gz | source | sdist | null | false | a6b52ab225362a76833cccafb3a30b6d | da6f0e2a56053b03c5ed5a1a94a2bfa0bf7a0fe5971598797b41e66844dbfb76 | d1b9d3930cd5107f110a4969f5f585e2ae6989b03dc8a07f9358dd9b85925319 | MIT | [] | 203 |
2.4 | tilebox-grpc | 0.49.0 | GRPC / Protocol Buffers functions for Tilebox | <h1 align="center">
<img src="https://storage.googleapis.com/tbx-web-assets-2bad228/banners/tilebox-banner.svg" alt="Tilebox Logo">
<br>
</h1>
<div align="center">
<a href="https://pypi.org/project/tilebox-grpc/">
<img src="https://img.shields.io/pypi/v/tilebox-grpc.svg?style=flat-square&label=version&color=f43f5e" alt="PyPi Latest Release badge"/>
</a>
<a href="https://pypi.org/project/tilebox-grpc/">
<img src="https://img.shields.io/pypi/pyversions/tilebox-grpc.svg?style=flat-square&logo=python&color=f43f5e&logoColor=f43f5e" alt="Required Python Version badge"/>
</a>
<a href="https://github.com/tilebox/tilebox-python/blob/main/LICENSE">
<img src="https://img.shields.io/github/license/tilebox/tilebox-python.svg?style=flat-square&color=f43f5e" alt="MIT License"/>
</a>
<a href="https://github.com/tilebox/tilebox-python/actions">
<img src="https://img.shields.io/github/actions/workflow/status/tilebox/tilebox-python/main.yml?style=flat-square&color=f43f5e" alt="Build Status"/>
</a>
<a href="https://tilebox.com/discord">
<img src="https://img.shields.io/badge/Discord-%235865F2.svg?style=flat-square&logo=discord&logoColor=white" alt="Join us on Discord"/>
</a>
</div>
<p align="center">
<a href="https://docs.tilebox.com/"><b>Documentation</b></a>
|
<a href="https://console.tilebox.com/"><b>Console</b></a>
|
<a href="https://examples.tilebox.com/"><b>Example Gallery</b></a>
</p>
# Tilebox GRPC
GRPC and Protobuf related functionality used by Tilebox python packages.
## Quickstart
Install using `pip`:
```bash
pip install tilebox-grpc
```
Open a gRPC channel:
```python
from _tilebox.grpc.channel import open_channel
channel = open_channel(
"https://api.tilebox.com",
auth_token="YOUR_TILEBOX_API_KEY"
)
```
## License
Distributed under the MIT License (`The MIT License`).
| text/markdown | null | "Tilebox, Inc." <support@tilebox.com> | null | null | MIT License | null | [
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python... | [] | null | null | >=3.10 | [] | [] | [] | [
"anyio>=4",
"grpcio-status>=1.70",
"grpcio>=1.70",
"lz4>=4",
"nest-asyncio>=1.5.0",
"protobuf>=6"
] | [] | [] | [] | [
"Homepage, https://tilebox.com",
"Documentation, https://docs.tilebox.com/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:42:52.956437 | tilebox_grpc-0.49.0.tar.gz | 10,406 | b3/7f/31f1ac184c85359f6bf1cd015242d12373eef787ef4a699b2d35450002b6/tilebox_grpc-0.49.0.tar.gz | source | sdist | null | false | 7d9589be9a370a727445f4de2253600b | f1684a9e40abd8d26d84ffe9bfdda4d760350626496e0856275548371f3c8086 | b37f31f1ac184c85359f6bf1cd015242d12373eef787ef4a699b2d35450002b6 | null | [] | 270 |
2.4 | pyarchrules | 0.0.1a2 | Architecture validation library for Python projects | <p align="center">
<img src="https://gist.githubusercontent.com/mspitb/862bc8c4b0e176e98f06e624761519da/raw/f4237236769bd2739132790f6c6f1157e3be5131/pyarchrules_logo.svg" alt="PyArchRules Logo" width="600">
</p>
<p align="center">
<a href="LICENSE"><img src="https://img.shields.io/badge/license-MIT-blue.svg" alt="License: MIT"></a>
<a href="https://www.python.org/"><img src="https://img.shields.io/badge/python-3.12+-blue.svg" alt="Python 3.12+"></a>
</p>
## Features
- 🏗️ **Structure validation** - enforce directory tree requirements
- 🔗 **Dependency rules** - control module imports (e.g., `api -> domain`)
- 🎯 **DSL & Config** - use Python DSL or TOML configuration
- 🚀 **Zero setup** - works with `pyproject.toml`
- 🔍 **CLI & API** - integrate into CI/CD or use programmatically
## Installation
```bash
pip install pyarchrules
```
## Quick Start
```bash
# Initialize
pyarchrules init-project
# Check architecture
pyarchrules check
```
## Configuration Example
```toml
[tool.pyarchrules]
project_name = "myapp"
[tool.pyarchrules.services.backend]
path = "src/backend"
# Enforce directory structure
tree = ["api", "domain", "infra"]
tree_strict = true
# Control dependencies (api can import from domain)
dependencies = ["api -> domain", "domain -> infra"]
```
## Python API
```python
from pyarchrules import PyArchRules
rules = PyArchRules()
# DSL validation
rules.for_service("backend") \
.must_contain_folders(["api", "domain"])
result = rules.validate()
```
## CLI Commands
| Command | Description |
|---------|-------------|
| `pyarchrules init-project` | Initialize configuration |
| `pyarchrules check` | Validate architecture |
| `pyarchrules add-service NAME PATH` | Add service |
| `pyarchrules list-services` | List all services |
## Use Cases
**Monorepos** - enforce boundaries between services
```toml
[tool.pyarchrules.services.auth]
path = "services/auth"
dependencies = ["auth -> shared"]
```
**Clean Architecture** - validate layer dependencies
```toml
dependencies = [
"api -> application",
"application -> domain"
]
```
**Microservices** - ensure consistent structure
```toml
tree = ["api", "domain", "infrastructure"]
tree_strict = true
```
## Development
```bash
uv pip install -e ".[dev]"
make test
make lint
```
## Status
⚠️ **Alpha** - API may change before 1.0 release
## License
MIT
| text/markdown | Sergei Mikheev | null | null | null | MIT License Copyright (c) 2026 Sergei Mikheev Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | architecture, validation, testing, monorepo, microservices | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language ... | [] | null | null | >=3.12 | [] | [] | [] | [
"tomlkit==0.14.0",
"typer==0.23.0",
"pydantic==2.12.5",
"loguru==0.7.0"
] | [] | [] | [] | [
"Homepage, https://github.com/yourusername/pyarchrules",
"Documentation, https://github.com/yourusername/pyarchrules#readme",
"Repository, https://github.com/yourusername/pyarchrules",
"Issues, https://github.com/yourusername/pyarchrules/issues"
] | uv/0.9.27 {"installer":{"name":"uv","version":"0.9.27","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T14:42:50.683626 | pyarchrules-0.0.1a2-py3-none-any.whl | 25,356 | b5/fd/434bb282d79ffc4b07b37d449941aec51ead07763e5bc2cd008567454de2/pyarchrules-0.0.1a2-py3-none-any.whl | py3 | bdist_wheel | null | false | c7505f26c690099c9e0ecd9a63c3ff39 | 276ad3a335d6b3671ca731ade3f5d4c1cb6c5a9f7eb22e80cdeeaecd947b4b39 | b5fd434bb282d79ffc4b07b37d449941aec51ead07763e5bc2cd008567454de2 | null | [
"LICENSE"
] | 180 |
2.4 | tilebox-datasets | 0.49.0 | Access Tilebox datasets from Python | <h1 align="center">
<img src="https://storage.googleapis.com/tbx-web-assets-2bad228/banners/tilebox-banner.svg" alt="Tilebox Logo">
<br>
</h1>
<div align="center">
<a href="https://pypi.org/project/tilebox-datasets/">
<img src="https://img.shields.io/pypi/v/tilebox-datasets.svg?style=flat-square&label=version&color=f43f5e" alt="PyPi Latest Release badge"/>
</a>
<a href="https://pypi.org/project/tilebox-datasets/">
<img src="https://img.shields.io/pypi/pyversions/tilebox-datasets.svg?style=flat-square&logo=python&color=f43f5e&logoColor=f43f5e" alt="Required Python Version badge"/>
</a>
<a href="https://github.com/tilebox/tilebox-python/blob/main/LICENSE">
<img src="https://img.shields.io/github/license/tilebox/tilebox-python.svg?style=flat-square&color=f43f5e" alt="MIT License"/>
</a>
<a href="https://github.com/tilebox/tilebox-python/actions">
<img src="https://img.shields.io/github/actions/workflow/status/tilebox/tilebox-python/main.yml?style=flat-square&color=f43f5e" alt="Build Status"/>
</a>
<a href="https://tilebox.com/discord">
<img src="https://img.shields.io/badge/Discord-%235865F2.svg?style=flat-square&logo=discord&logoColor=white" alt="Join us on Discord"/>
</a>
</div>
<p align="center">
<a href="https://docs.tilebox.com/datasets/introduction"><b>Documentation</b></a>
|
<a href="https://console.tilebox.com/"><b>Console</b></a>
|
<a href="https://examples.tilebox.com/"><b>Example Gallery</b></a>
</p>
# Tilebox Datasets
Access satellite data using the [Tilebox](https://tilebox.com) datasets python client powered by gRPC and Protobuf.
## Quickstart
Install using `pip`:
```bash
pip install tilebox-datasets
```
Instantiate a client:
```python
from tilebox.datasets import Client
# create your API key at https://console.tilebox.com
client = Client(token="YOUR_TILEBOX_API_KEY")
```
Explore datasets and collections:
```python
datasets = client.datasets()
print(datasets)
sentinel2_msi = client.dataset("open_data.copernicus.sentinel2_msi")
collections = sentinel2_msi.collections()
print(collections)
```
Query data:
```python
s2a_l1c = sentinel2_msi.collection("S2A_S2MSI1C")
results = s2a_l1c.query(
temporal_extent=("2025-03-01", "2025-06-01"),
show_progress=True
)
print(f"Found {results.sizes['time']} datapoints") # Found 220542 datapoints
```
Spatio-temporal queries:
```python
from shapely.geometry import shape
area_of_interest = shape({
"type": "Polygon", # coords in lon, lat
"coordinates": [[[-5, 50], [-5, 56], [-11, 56], [-11, 50], [-5, 50]]]}
)
s2a_l1c = sentinel2_msi.collection("S2A_S2MSI1C")
results = s2a_l1c.query(
temporal_extent=("2025-03-01", "2025-06-01"),
spatial_extent=area_of_interest,
show_progress=True
)
print(f"Found {results.sizes['time']} datapoints") # Found 979 datapoints
```
## Documentation
Check out the [Tilebox Datasets documentation](https://docs.tilebox.com/datasets/introduction) for more information.
## License
Distributed under the MIT License (`The MIT License`).
| text/markdown | null | "Tilebox, Inc." <support@tilebox.com> | null | null | MIT License | null | [
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python... | [] | null | null | >=3.10 | [] | [] | [] | [
"cftime>=1.6.4",
"loguru>=0.7",
"numpy>=1.24",
"pandas>=2.1",
"promise>=2.3",
"shapely>=2",
"tilebox-grpc>=0.28.0",
"tqdm>=4.65",
"xarray>=2023.11"
] | [] | [] | [] | [
"Homepage, https://tilebox.com",
"Documentation, https://docs.tilebox.com/datasets/introduction"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:42:46.257353 | tilebox_datasets-0.49.0.tar.gz | 75,877 | 9e/e6/a642e77ca334d17b11c08dc70b29f7dd59951936dbfd8880dc7b7209b183/tilebox_datasets-0.49.0.tar.gz | source | sdist | null | false | 2e78cdce539976bfdff027bb58b301a8 | f0653f6eb5a58e677c81a8f70901c500e8a5a5d8e19e312872b3c3172a7aa952 | 9ee6a642e77ca334d17b11c08dc70b29f7dd59951936dbfd8880dc7b7209b183 | null | [] | 250 |
2.4 | tilebox-workflows | 0.49.0 | Workflow client and task runner for Tilebox | <h1 align="center">
<img src="https://storage.googleapis.com/tbx-web-assets-2bad228/banners/tilebox-banner.svg" alt="Tilebox Logo">
<br>
</h1>
<div align="center">
<a href="https://pypi.org/project/tilebox-workflows/">
<img src="https://img.shields.io/pypi/v/tilebox-workflows.svg?style=flat-square&label=version&color=f43f5e" alt="PyPi Latest Release badge"/>
</a>
<a href="https://pypi.org/project/tilebox-workflows/">
<img src="https://img.shields.io/pypi/pyversions/tilebox-workflows.svg?style=flat-square&logo=python&color=f43f5e&logoColor=f43f5e" alt="Required Python Version badge"/>
</a>
<a href="https://github.com/tilebox/tilebox-python/blob/main/LICENSE">
<img src="https://img.shields.io/github/license/tilebox/tilebox-python.svg?style=flat-square&color=f43f5e" alt="MIT License"/>
</a>
<a href="https://github.com/tilebox/tilebox-python/actions">
<img src="https://img.shields.io/github/actions/workflow/status/tilebox/tilebox-python/main.yml?style=flat-square&color=f43f5e" alt="Build Status"/>
</a>
<a href="https://tilebox.com/discord">
<img src="https://img.shields.io/badge/Discord-%235865F2.svg?style=flat-square&logo=discord&logoColor=white" alt="Join us on Discord"/>
</a>
</div>
<p align="center">
<a href="https://docs.tilebox.com/workflows/introduction"><b>Documentation</b></a>
|
<a href="https://console.tilebox.com/"><b>Console</b></a>
|
<a href="https://examples.tilebox.com/"><b>Example Gallery</b></a>
</p>
# Tilebox Workflows
Tilebox Workflows, or the Tilebox workflow orchestrator is a parallel processing engine that allows an intuitive creation of dynamic tasks that can be parallelized out of the box and executed across compute environments or on-premise as well as in auto-scaling clusters in public clouds.
## Quickstart
Install using `pip`:
```bash
pip install tilebox-workflows
```
Create a task:
```python
from tilebox.workflows import Task
class MyFirstTask(Task):
def execute(self):
print("Hello World from my first Tilebox task!")
```
Submit a job
```python
from tilebox.workflows import Client
# create your API key at https://console.tilebox.com
client = Client(token="YOUR_TILEBOX_API_KEY")
jobs = client.jobs()
jobs.submit("my-very-first-job", MyFirstTask())
```
And run it:
```python
runner = client.runner(tasks=[MyFirstTask])
runner.run_all()
```
## Documentation
Check out the [Tilebox Workflows documentation](https://docs.tilebox.com/workflows/introduction) for more information.
## License
Distributed under the MIT License (`The MIT License`).
| text/markdown | null | "Tilebox, Inc." <support@tilebox.com> | null | null | MIT License | null | [
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python... | [] | null | null | >=3.10 | [] | [] | [] | [
"boto3-stubs[essential]>=1.33",
"boto3>=1.33",
"google-cloud-storage>=2.10",
"ipywidgets>=8.1.7",
"opentelemetry-api>=1.28",
"opentelemetry-exporter-otlp-proto-http>=1.28",
"opentelemetry-sdk>=1.28",
"python-dateutil>=2.9.0.post0",
"tenacity>=8",
"tilebox-datasets",
"tilebox-grpc>=0.28.0"
] | [] | [] | [] | [
"Homepage, https://tilebox.com",
"Documentation, https://docs.tilebox.com/workflows/introduction"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:42:45.169856 | tilebox_workflows-0.49.0.tar.gz | 66,296 | 48/70/5dbafbe3cdac0da75917e8f52ab1cf6bfcbfaa830f66b54e402116798670/tilebox_workflows-0.49.0.tar.gz | source | sdist | null | false | d7e2fe8986931b38fb47f8e0afd253cb | 6260c5cd2f82a121cfe0a5405313142a0a1a3aeea7d5efc4b01cefd5335191a2 | 48705dbafbe3cdac0da75917e8f52ab1cf6bfcbfaa830f66b54e402116798670 | null | [] | 223 |
2.4 | tilebox-storage | 0.49.0 | Storage client for Tilebox | <h1 align="center">
<img src="https://storage.googleapis.com/tbx-web-assets-2bad228/banners/tilebox-banner.svg" alt="Tilebox Logo">
<br>
</h1>
<div align="center">
<a href="https://pypi.org/project/tilebox-storage/">
<img src="https://img.shields.io/pypi/v/tilebox-storage.svg?style=flat-square&label=version&color=f43f5e" alt="PyPi Latest Release badge"/>
</a>
<a href="https://pypi.org/project/tilebox-storage/">
<img src="https://img.shields.io/pypi/pyversions/tilebox-storage.svg?style=flat-square&logo=python&color=f43f5e&logoColor=f43f5e" alt="Required Python Version badge"/>
</a>
<a href="https://github.com/tilebox/tilebox-python/blob/main/LICENSE">
<img src="https://img.shields.io/github/license/tilebox/tilebox-python.svg?style=flat-square&color=f43f5e" alt="MIT License"/>
</a>
<a href="https://github.com/tilebox/tilebox-python/actions">
<img src="https://img.shields.io/github/actions/workflow/status/tilebox/tilebox-python/main.yml?style=flat-square&color=f43f5e" alt="Build Status"/>
</a>
<a href="https://tilebox.com/discord">
<img src="https://img.shields.io/badge/Discord-%235865F2.svg?style=flat-square&logo=discord&logoColor=white" alt="Join us on Discord"/>
</a>
</div>
<p align="center">
<a href="https://docs.tilebox.com/"><b>Documentation</b></a>
|
<a href="https://console.tilebox.com/"><b>Console</b></a>
|
<a href="https://examples.tilebox.com/"><b>Example Gallery</b></a>
</p>
# Tilebox Storage
Download satellite payload data for your [Tilebox datasets](https://pypi.org/project/tilebox-datasets/).
## Quickstart
Install using `pip`:
```bash
pip install tilebox-storage tilebox-datasets
```
Fetch a datapoint to download the payload data for:
```python
from tilebox.datasets import Client
# Creating clients
client = Client(token="YOUR_TILEBOX_API_KEY")
datasets = client.datasets()
# Choosing the dataset and collection
s2_dataset = datasets.open_data.copernicus.sentinel2_msi
collections = s2_dataset.collections()
collection = collections["S2A_S2MSI2A"]
# Loading metadata
s2_data = collection.load(("2024-08-01", "2024-08-02"), show_progress=True)
# Let's download the first granule
s2_granule = s2_data.isel(time=0)
```
Then download the payload data using a storage client:
```python
from pathlib import Path
from tilebox.storage import CopernicusStorageClient
# Check out the Copernicus Dataspace S3 documentation at
# https://documentation.dataspace.copernicus.eu/APIs/S3.html
# to learn how to get your access key and secret access key
storage_client = CopernicusStorageClient(
access_key="YOUR_ACCESS_KEY",
secret_access_key="YOUR_SECRET_ACCESS_KEY",
cache_directory=Path("./data")
)
downloaded_data = storage_client.download(s2_granule)
print(f"Downloaded granule: {downloaded_data.name} to {downloaded_data}")
print("Contents: ")
for content in downloaded_data.iterdir():
print(f" - {content.relative_to(downloaded_data)}")
```
## License
Distributed under the MIT License (`The MIT License`).
| text/markdown | null | "Tilebox, Inc." <support@tilebox.com> | null | null | MIT License | null | [
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python... | [] | null | null | >=3.10 | [] | [] | [] | [
"aiofile>=3.8",
"boto3>=1.37.0",
"folium>=0.15",
"httpx>=0.27",
"obstore>=0.8.0",
"shapely>=2",
"tilebox-datasets"
] | [] | [] | [] | [
"Homepage, https://tilebox.com",
"Documentation, https://docs.tilebox.com/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:42:43.920615 | tilebox_storage-0.49.0.tar.gz | 10,852 | cc/21/e3c32138a9068e7d4e59d70a76742c4239b436c3c5fc4dfe82ede7845664/tilebox_storage-0.49.0.tar.gz | source | sdist | null | false | 1e3cd6b4e1f58408ccd0ef894fd0d9a6 | 2c430a8b25d8d1abc66320f535e4aad144af1883a10e88a9c22f107fa34b8f84 | cc21e3c32138a9068e7d4e59d70a76742c4239b436c3c5fc4dfe82ede7845664 | null | [] | 229 |
2.4 | mlprep-rust | 0.3.1 | High-performance no-code data preprocessing engine | # mlprep 🚀
**The fastest no-code data preprocessing engine for Machine Learning.**
*Powered by Rust & Polars.*
[](https://github.com/takurot/mlprep/actions)
[](https://opensource.org/licenses/MIT)
[](https://pypi.org/project/mlprep-rust/)
[](https://www.rust-lang.org/)
## 🎬 Introduction Video
[](https://www.youtube.com/watch?v=1eMmGOun6T4)
> 📺 **Watch**: [mlprep Introduction (NotebookLM)](https://www.youtube.com/watch?v=1eMmGOun6T4)
---
**Stop writing slow, fragile pandas boilerplate.**
**Start defining robust, reproducible pipelines.**
`mlprep` is a high-performance CLI tool and Python library that handles the dirty work of ML engineers: type inference, missing value imputation, complex joins, and feature engineering—all defined in a simple YAML config.
## 🔥 Why mlprep?
### 🚀 Blazing Speed
Built on **Rust** and **Polars**, `mlprep` processes gigabytes of data in seconds, not minutes. It leverages multi-threading and SIMD vectorization out of the box.
### ✨ Zero-Code Pipelines
Define your entire preprocessing workflow in `pipeline.yaml`. No more "spaghetti code" notebooks that no one can read.
### 🛡️ Quarantine Mode
Don't let dirty data crash your training. `mlprep` isolates invalid rows (schema mismatch, outliers) into a separate "quarantine" file, so your pipeline stays green and your models stay clean.
### 🔄 Build Once, Run Anywhere
`fit` your feature engineering steps (scaling, encoding) on training data and `transform` production data with **exact reproducibility**. No more training-serving skew.
---
## ⚡️ Quick Start
### 1. Install
```bash
pip install mlprep-rust
```
### 2. Define your pipeline (`pipeline.yaml`)
```yaml
inputs:
- path: "data/raw_users.csv"
format: csv
steps:
# ETL
- fillna:
strategy: mean
columns: [age, income]
- filter: "age >= 18"
# Data Quality Check
- validate:
mode: quarantine # Bad rows go to 'quarantine.parquet'
checks:
- name: email
regex: "^.+@.+\\..+$"
# Feature Engineering
- features:
config: features.yaml
outputs:
- path: "data/processed_users.parquet"
format: parquet
compression: zstd
```
### 3. Run it
```bash
mlprep run pipeline.yaml
```
> **Result**: A clean, highly-compressed Parquet file ready for training. 🚀
---
## 🆚 Comparison
| Feature | **Pandas** | **mlprep** |
| :--- | :--- | :--- |
| **Speed** | 🐢 Single-threaded | 🐆 **Multi-threaded (Rust)** |
| **Pipeline** | Python Script | **YAML Config** |
| **Validation** | Manual `.loc[]` checks | **Built-in Quality Engine** |
| **Bad Data** | Crash or Silent Fail | **Quarantine Execution** |
| **Memory** | Bloated Objects | **Zero-Copy Arrow** |
---
## ⚡️ Performance
mlprep is designed for speed, leveraging Rust's ownership model and Polars' query engine.
| Operation | vs Pandas | Note |
|:--- | :--- | :--- |
| **CSV Read** | **~3-5x Faster** | Multi-threaded parsing |
| **Pipeline** | **~10x Faster** | Lazy evaluation & query optimization |
| **Memory** | **~1/4 Usage** | Zero-copy Arrow memory format |
*Benchmarks run on 1GB generated dataset. To run your own benchmarks:*
```bash
python scripts/benchmark.py --size 1.0 --compare-pandas
```
---
## 🗺️ Roadmap
We are actively building MVP (Phase 1). Check out our documentation:
* [**Implementation Plan & Roadmap**](docs/PLAN.md)
* [**Technical Specification**](docs/SPEC.md)
---
## 📚 Use Cases & Examples
Explore full examples in the [`examples/`](examples/) directory:
### 1. [Basic ETL Pipeline](examples/01_basic_etl/)
* **Scenario**: Filter, select columns, and convert CSV to Parquet.
* **Key Features**: `filter`, `select`, `write_parquet`.
### 2. [Data Validation](examples/02_data_validation/)
* **Scenario**: Ensure data quality before training.
* **Key Features**: Schema validation, `quarantine` mode for invalid rows.
### 3. [Feature Engineering](examples/03_feature_engineering/)
* **Scenario**: Generate features for ML training.
* **Key Features**: `fit` (train) / `transform` (prod) pattern, `standard_scaler`, `one_hot_encoding`.
### 4. [Scikit-Learn Integration](examples/04_scikit_learn_integration/)
* **Scenario**: Use mlprep as a preprocessing step in a Scikit-Learn pipeline.
* **Key Features**: Seamless integration with Python ML ecosystem.
### 5. [MLflow Experiment Tracking](examples/05_mlflow_experiment/)
* **Scenario**: Track preprocessing parameters and artifacts in MLflow.
* **Key Features**: Reproducibility and experiment management.
### 6. [Airflow DAG](examples/06_airflow_dag/)
* **Scenario**: Schedule and monitor `mlprep run` as part of an Airflow DAG.
* **Key Features**: Production-friendly orchestration with `BashOperator`.
### 7. [DVC Pipeline](examples/07_dvc_pipeline/)
* **Scenario**: Version control processed datasets with a DVC stage that calls `mlprep`.
* **Key Features**: Reproducible data artifacts (`dvc repro` + `mlprep run pipeline.yaml`).
---
## 🤝 Contributing
We welcome contributions! Please see the issue tracker for good first issues.
## 📄 License
MIT
| text/markdown; charset=UTF-8; variant=GFM | null | Takuro Tsujikawa <takuro.tsujikawa@gmail.com> | null | null | null | null | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"License :: OSI Approve... | [] | https://github.com/takurot/mlprep | null | >=3.10 | [] | [] | [] | [
"polars>=1.0.0",
"pytest>=7.4.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [] | maturin/1.12.2 | 2026-02-19T14:42:12.829983 | mlprep_rust-0.3.1-cp313-cp313-win32.whl | 14,683,055 | 75/4e/1085cfadaa2462d67a8293195d79b8f12395ac51278675b0837d0c7261d8/mlprep_rust-0.3.1-cp313-cp313-win32.whl | cp313 | bdist_wheel | null | false | fe39d1ecc9a5b56e4d5e09bda5c67705 | ef167fe6629ae7f2293fe166652e20e5cd919162b827c84c102ca0983f834591 | 754e1085cfadaa2462d67a8293195d79b8f12395ac51278675b0837d0c7261d8 | null | [] | 2,334 |
2.4 | sqlite-web | 0.7.1 | web-based sqlite database browser | 
`sqlite-web` is a web-based SQLite database browser written in Python.
Project dependencies:
* [flask](http://flask.pocoo.org)
* [peewee](http://docs.peewee-orm.com)
* [pygments](http://pygments.org)
### Installation
```sh
$ pip install sqlite-web
```
### Usage
```sh
$ sqlite_web /path/to/database.db
```
If you have multiple databases:
```sh
$ sqlite_web /path/to/db1.db /path/to/db2.db /path/to/db3.db
```
Or run with docker:
```sh
$ docker run -it --rm \
-p 8080:8080 \
-v /path/to/your-data:/data \
ghcr.io/coleifer/sqlite-web:latest \
db_filename.db
```
Or run with the high-performance gevent WSGI server (requires `gevent`):
```console
$ sqlite_wsgi /path/to/db.db
```
Then navigate to http://localhost:8080/ to view your database.
### Features
* Works with your existing SQLite databases, or can be used to create new databases.
* Add or drop:
* Tables
* Columns (with support for older versions of Sqlite)
* Indexes
* Export data as JSON or CSV.
* Import JSON or CSV files.
* Browse table data.
* Insert, Update or Delete rows.
* Load and unload databases at run-time (see `--enable-load` or `--enable-filesystem`)
### Screenshots
The index page shows some basic information about the database, including the number of tables and indexes, as well as its size on disk:

The `structure` tab displays information about the structure of the table, including columns, indexes, triggers, and foreign keys (if any exist). From this page you can also create, rename or drop columns and indexes.
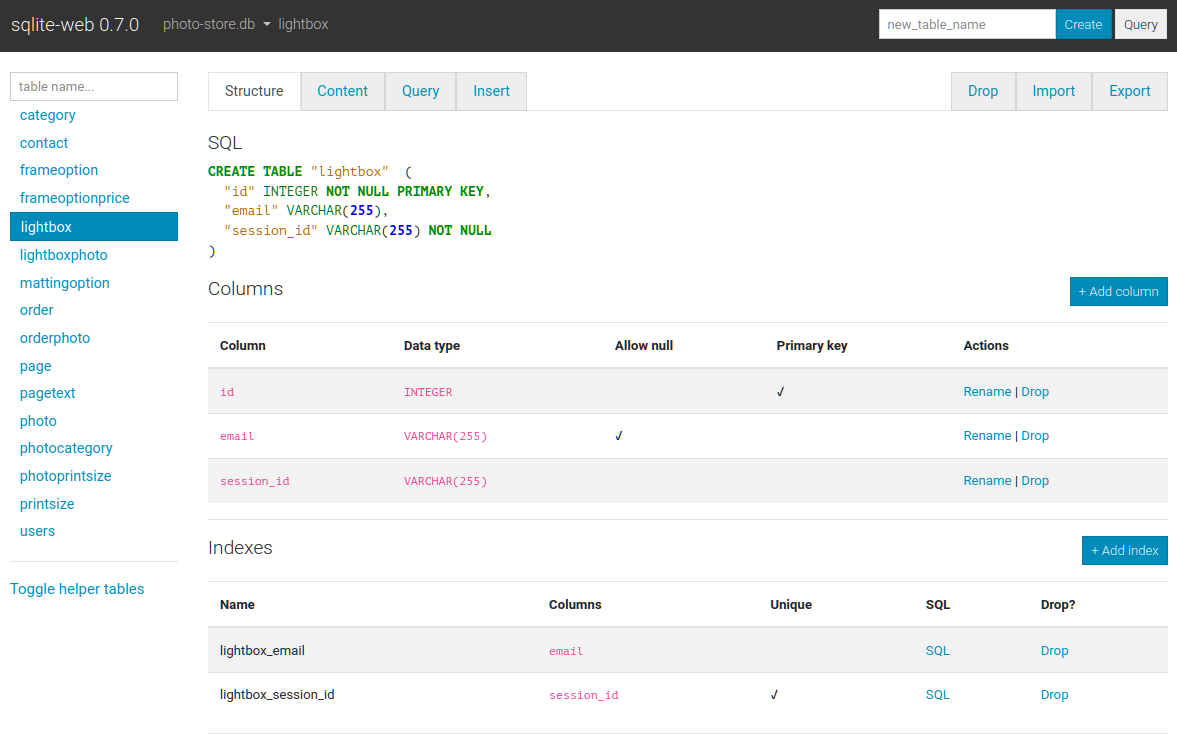
Columns are easy to add, drop or rename:
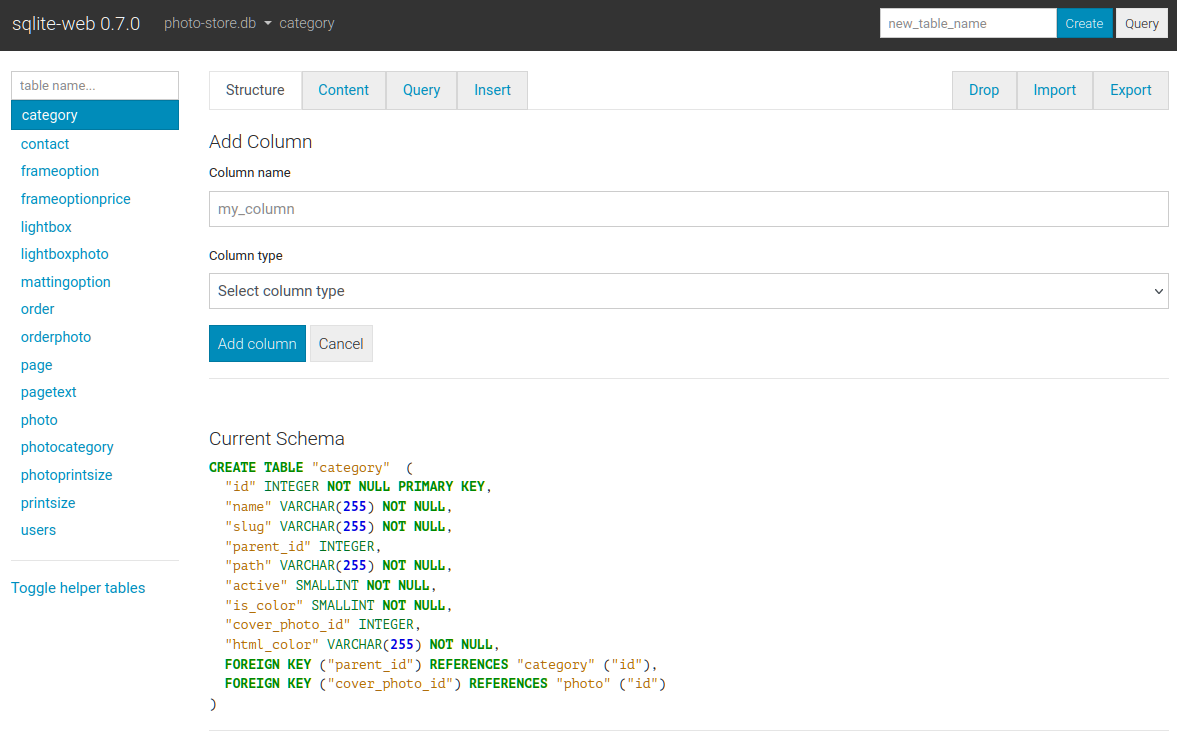
The `content` tab displays all the table data. Links in the table header can be used to sort the data:
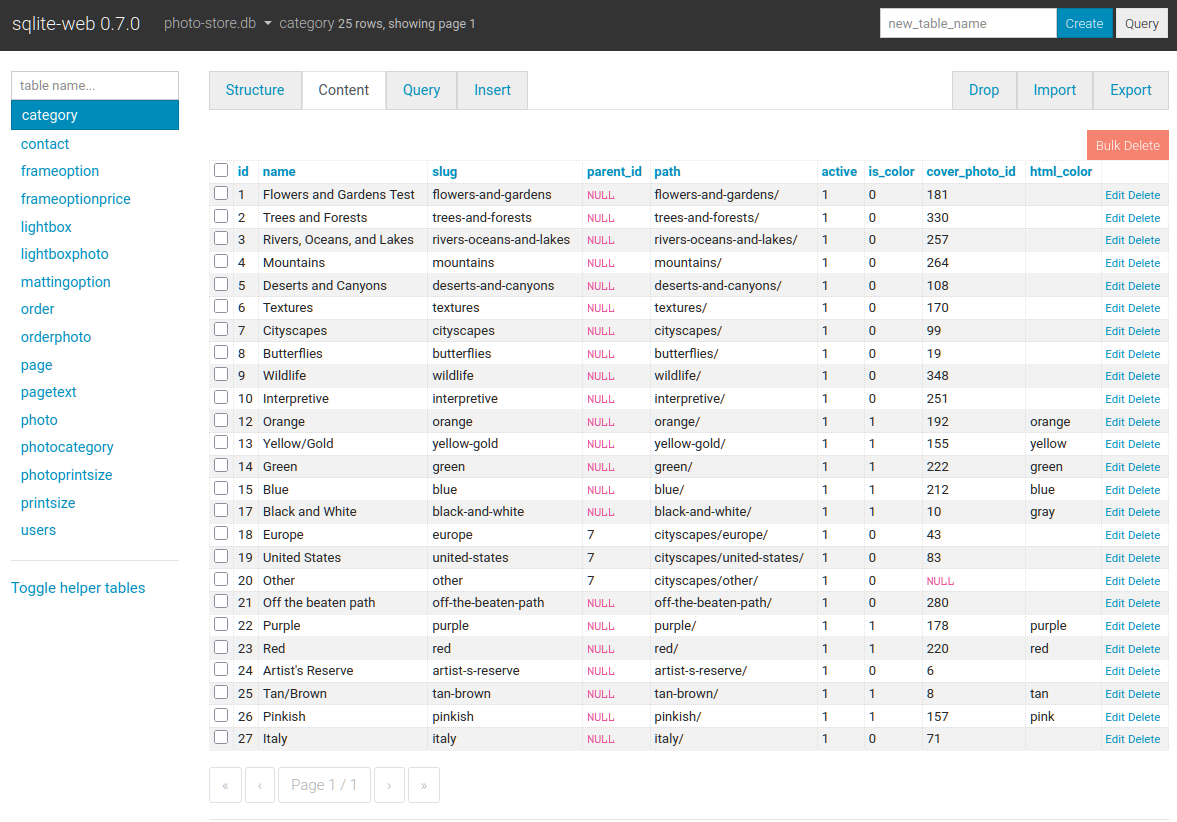
The `query` tab allows you to execute arbitrary SQL queries on a table. The query results are displayed in a table and can be exported to either JSON or CSV:
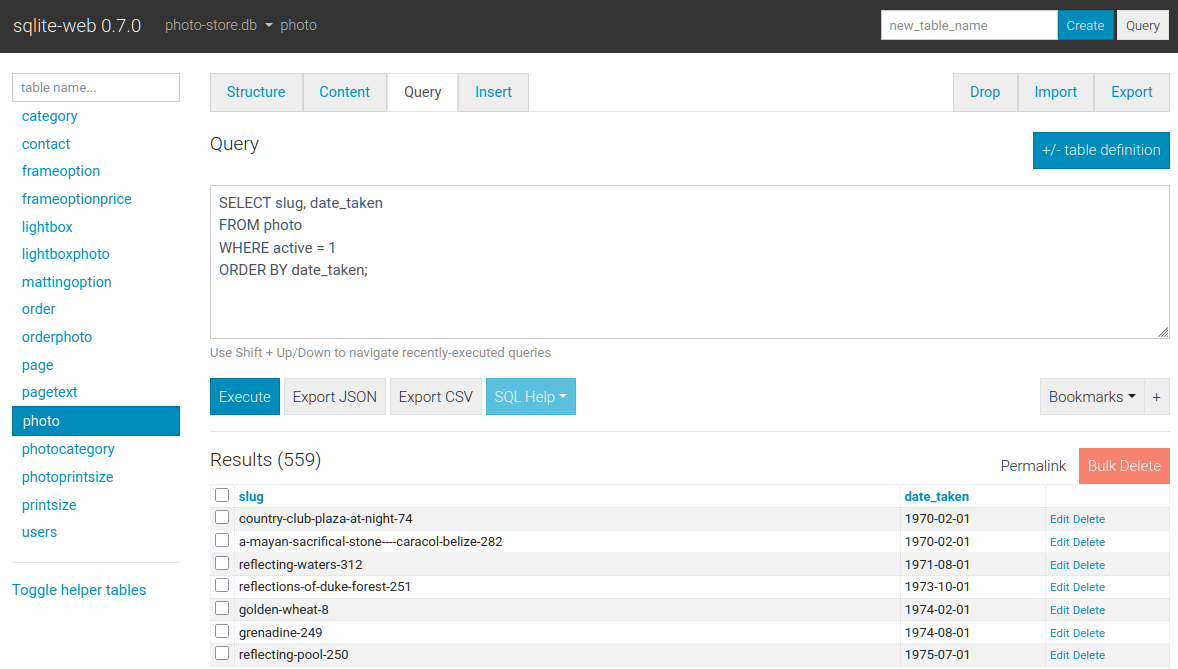
The `import` tab supports importing CSV and JSON files into a table. There is an option to automatically create columns for any unrecognized keys in the import file:
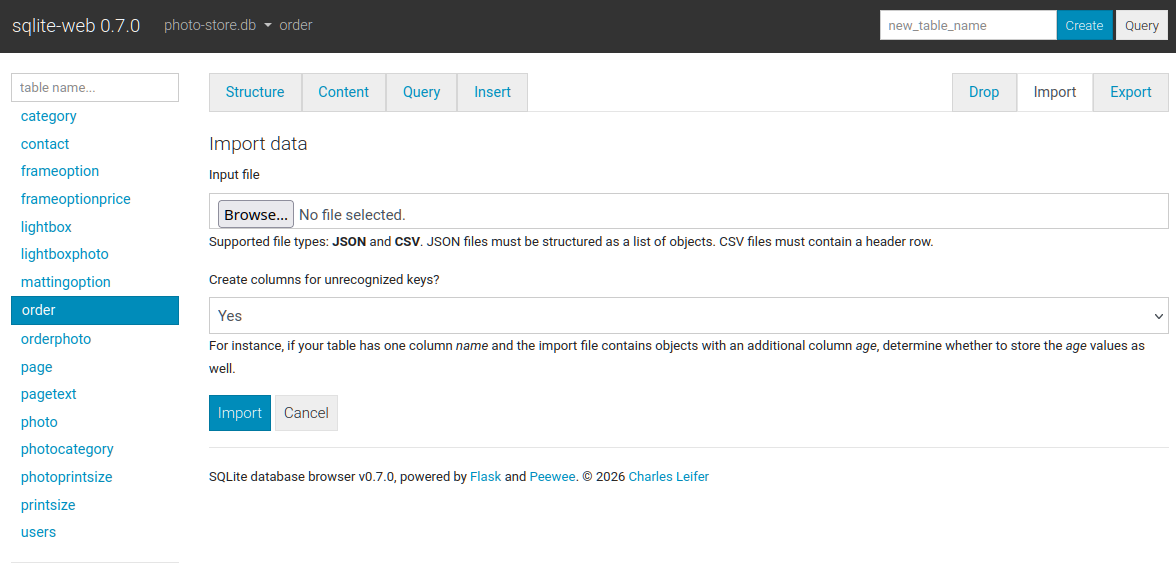
The `export` tab supports exporting all, or a subset, of columns:
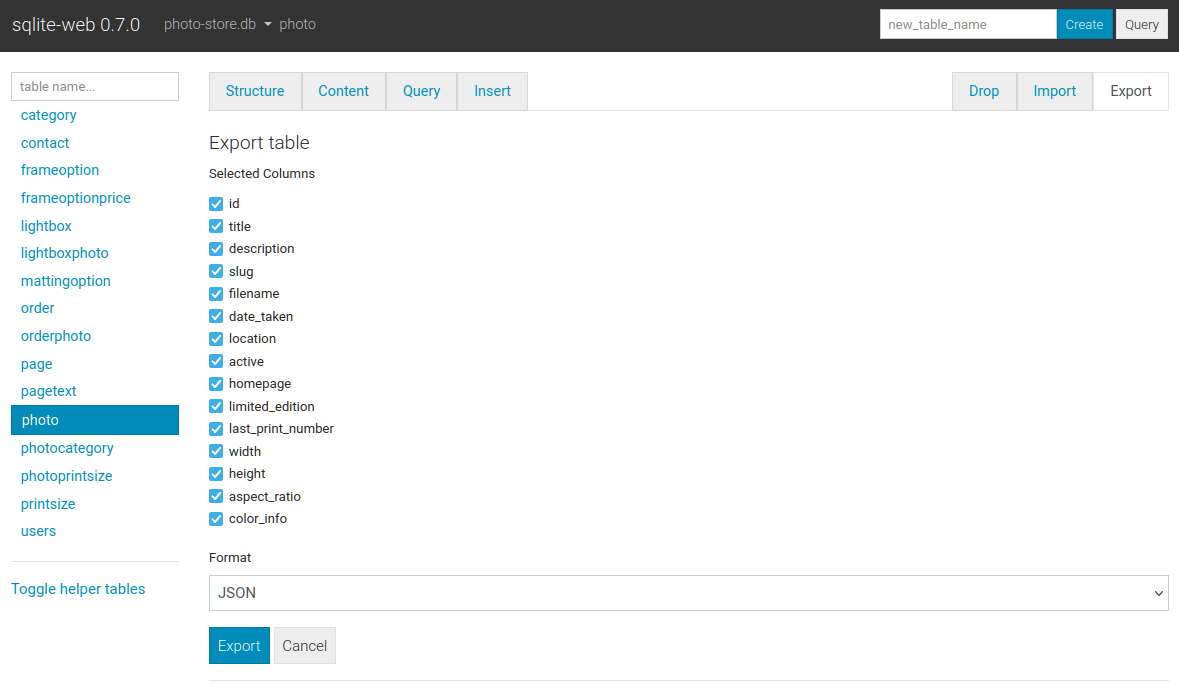
Basic INSERT, UPDATE and DELETE queries are supported:
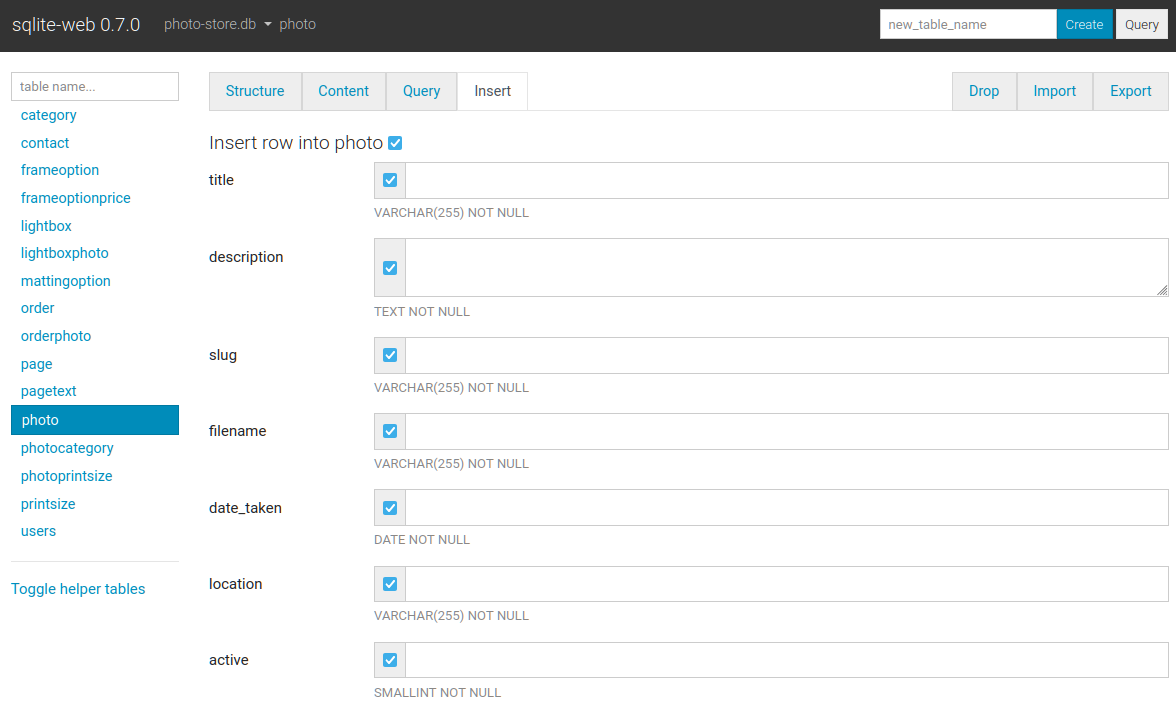
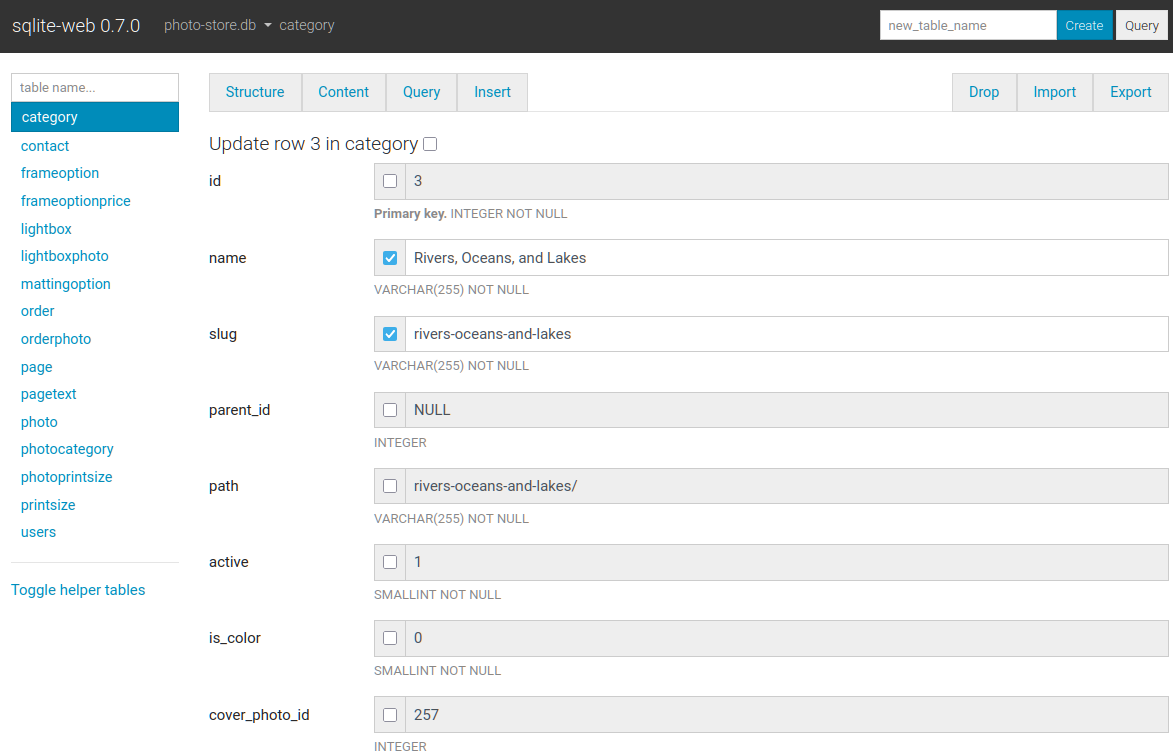
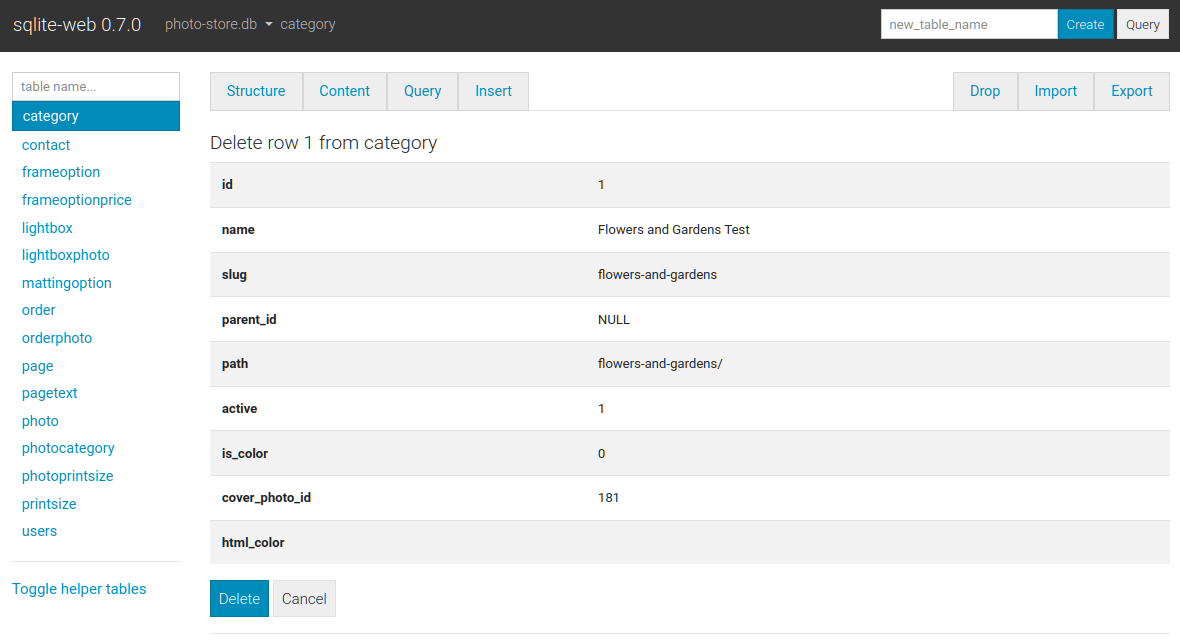
When configured with `--enable-load` or `--enable-filesystem` additional
databases can be loaded or unloaded at run-time:
### Command-line options
The syntax for invoking sqlite-web is:
```console
$ sqlite_web [options] /path/to/database.db /path/to/another.db
```
The following options are available:
* `-p`, `--port`: default is 8080
* `-H`, `--host`: default is 127.0.0.1
* `-d`, `--debug`: default is false
* `-l`, `--log-file`: filename for application logs.
* `-q`, `--quiet`: only log errors.
* `-b`, `--browser`: open a web-browser when sqlite-web starts.
* `-x`, `--no-browser`: do not open a web-browser when sqlite-web starts.
* `-P`, `--password`: prompt for password to access sqlite-web.
Alternatively, the password can be stored in the "SQLITE_WEB_PASSWORD"
environment variable, in which case the application will not prompt for a
password, but will use the value from the environment.
* `-r`, `--read-only`: open database in read-only mode.
* `-R`, `--rows-per-page`: set pagination on content page, default 50 rows.
* `-Q`, `--query-rows-per-page`: set pagination on query page, default 1000 rows.
* `-T`, `--no-truncate`: disable ellipsis for long text values. If this option
is used, the full text value is always shown.
* `-e`, `--extension`: path or name of loadable extension(s). To load
multiple extensions, specify ``-e [path]`` for each extension.
* `-s`, `--startup-hook`: path to a startup hook used to initialize the
connection before each request, e.g. `my.module.some_callable`. Should
accept one parameter, the `SqliteDatabase` instance.
* `-f`, `--foreign-keys`: enable foreign-key constraint pragma.
* `-u`, `--url-prefix`: URL prefix for application, e.g. "/sqlite-web".
* `-L`, `--enable-load`: Enable loading additional databases at runtime (upload
only). For adding local databases use `--enable-filesystem`.
* `-U`, `--upload-dir`: Destination directory for uploaded database (`-L`). If
not specified, a system tempdir will be used.
* `-F`, `--enable-filesystem`: Enable loading additional databases by
specifying on-disk path at runtime. **Be careful with this**.
* `-c`, `--cert` and ``-k``, ``--key`` - specify SSL cert and private key.
* `-a`, `--ad-hoc` - run using an ad-hoc SSL context.
### Using docker
A Dockerfile is provided with sqlite-web. To use:
```console
#
# Use GitHub container registry:
#
$ docker run -it --rm \
-p 8080:8080 \
-v /path/to/your-data:/data \
ghcr.io/coleifer/sqlite-web:latest \
db_filename.db
#
# OR build the image yourself:
#
$ cd docker/ # Change dirs to the dir containing Dockerfile
$ docker build -t coleifer/sqlite-web .
$ docker run -it --rm \
-p 8080:8080 \
-v /path/to/your-data:/data \
coleifer/sqlite-web
db_filename.db
```
Command-line options can be passed in when running via Docker. For example, if
you want to run it at a separate URL prefix, for example `/sqlite-web/`:
```
$ docker run -it --rm \
-p 8080:8080 \
-v /path/to/your-data:/data \
ghcr.io/coleifer/sqlite-web:latest \
db_filename.db \
--url-prefix="/sqlite-web/"
```
### High-performance WSGI Server
To run sqlite-web with a high-performance gevent WSGI server, you can run
`sqlite_wsgi` instead of `sqlite_web`:
```console
$ sqlite_wsgi /path/to/db.db
```
More complete example:
```console
$ sqlite_wsgi -p 8000 -H '0.0.0.0' /path/to/db1.db /path/to/db2.db
```
| text/markdown | null | Charles Leifer <coleifer@gmail.com> | null | null | null | null | [
"Environment :: Web Environment",
"Programming Language :: Python :: 3",
"Topic :: Database",
"Topic :: Database :: Front-Ends",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | null | [] | [] | [] | [
"flask",
"peewee>=3.0.0",
"pygments"
] | [] | [] | [] | [
"Repository, https://github.com/coleifer/sqlite-web"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:42:12.279647 | sqlite_web-0.7.1.tar.gz | 773,521 | 8a/d4/d1eb75008ee05994c52621b767388cefad553b5a2e3c4be747f0dfc22da4/sqlite_web-0.7.1.tar.gz | source | sdist | null | false | 7760c2e7bd608365f24ce4440d3197ce | 7f3ecce1c3b26a0d1ff94bd32b0292d65a0f4e80a7263d56425e8a56b2cbd734 | 8ad4d1eb75008ee05994c52621b767388cefad553b5a2e3c4be747f0dfc22da4 | null | [
"LICENSE"
] | 732 |
2.4 | fsm-agent-flow | 0.3.0 | TDD/OKR-driven agentic workflow framework with verifiable state deliverables | # fsm-agent-flow
A TDD/OKR-driven workflow framework for LLM-powered applications. Each state declares an **objective** and **key results** that get validated before advancing — like running tests after writing code.
## Why
Most LLM workflow frameworks either give you too little structure (raw prompt chains) or too much (rigid agent frameworks). fsm-agent-flow sits in the middle:
- **States have acceptance criteria** — key results are checked before moving on
- **Failed states retry with feedback** — the validator tells the LLM what went wrong
- **The framework doesn't care what happens inside a state** — call an LLM, run a script, bridge to CrewAI, or nest another workflow
- **No global singletons** — tools are scoped per state, contexts are explicit
- **No heavy dependencies** — zero required runtime deps, bring your own LLM client
## Install
```bash
pip install fsm-agent-flow
# With LLM adapters
pip install fsm-agent-flow[openai]
pip install fsm-agent-flow[litellm]
pip install fsm-agent-flow[all]
```
## Quick Start
```python
from fsm_agent_flow import Workflow, StateSpec, KeyResult, ExecutionContext
from fsm_agent_flow.llm.openai import OpenAIAdapter
# Tools are just functions
def search(query: str) -> str:
"""Search the web."""
return f"Results for: {query}"
# States declare what they must accomplish
research = StateSpec(
name="research",
objective="Gather information on the topic",
key_results=[
KeyResult("has_content", "At least 200 chars", check=lambda o: len(str(o)) > 200),
KeyResult("has_sources", "Cites sources"), # LLM-validated (no check function)
],
execute=lambda ctx: ctx.llm.run_with_tools(
system_prompt="Research the topic using the search tool.",
user_message=ctx.input,
),
tools=[search],
max_retries=2,
is_initial=True,
)
writing = StateSpec(
name="writing",
objective="Write a structured report",
key_results=[
KeyResult("has_sections", "Has clear sections", check=lambda o: str(o).count("#") >= 2),
],
execute=lambda ctx: ctx.llm.run_with_tools(
system_prompt="Write a report from this research.",
user_message=str(ctx.input),
),
is_final=True,
)
# One call to run the whole workflow
llm = OpenAIAdapter(model="gpt-4o")
wf = Workflow(
objective="Research and report",
states=[research, writing],
transitions={"research": "writing"},
llm=llm,
validator_llm=llm,
)
result = wf.run("quantum computing")
```
## Core Concepts
### States with Objectives and Key Results
Every state has an **objective** (what it does) and **key results** (how we verify it succeeded):
```python
StateSpec(
name="analyze",
objective="Analyze the dataset and identify trends",
key_results=[
# Programmatic check — runs as code
KeyResult("has_trends", "Identified at least 3 trends",
check=lambda o: len(o.get("trends", [])) >= 3),
# LLM-validated — no check function, validator LLM evaluates
KeyResult("actionable", "Insights are actionable with recommendations"),
],
execute=my_analyze_function,
max_retries=3,
)
```
### The TDD Validation Loop
When a state executes, the framework:
1. Calls `state.execute(ctx)` to produce output
2. Runs all key result checks (programmatic first, then LLM)
3. If any fail: retries with `ctx.feedback` explaining what went wrong
4. If all pass: records the output and advances to the next state
5. If retries exhausted: raises `MaxRetriesExceeded`
### Conditional & Bidirectional Transitions
Transitions aren't limited to simple linear flows. States can branch, loop back, and route conditionally — like a real finite state machine:
```python
# Static (linear): always goes to the same next state
transitions = {"research": "writing", "writing": None}
# Conditional (branching / bidirectional): route based on output
transitions = {
"check_city": {"need_weather": "get_weather", "ready": "print_result"},
"get_weather": {"wrong_city": "get_weather", "default": "check_city"},
"print_result": None,
}
# Dynamic (callable): function decides next state
transitions = {
"decide": lambda output: "approve" if output.get("score") > 0.8 else "reject",
"approve": None,
"reject": None,
}
```
**How conditional routing works:** When a transition is a `dict`, the framework resolves the next state by checking the execute function's output:
1. If output is a `dict` with a `"_transition"` key, its value selects the branch
2. If output is a `str` matching a key in the transition dict, use it
3. Otherwise, fall back to the `"default"` key
```python
def check_city(ctx: ExecutionContext):
weather = ctx.shared.get("weather")
if weather and weather["city"] == ctx.shared.get("target_city"):
return {"_transition": "ready", "report": weather}
return {"_transition": "need_weather"}
def get_weather(ctx: ExecutionContext):
city = ctx.shared.get("target_city")
data = fetch_weather_api(city)
if data["city"] != city:
return {"_transition": "wrong_city"} # Loop back to retry
ctx.shared.set("weather", data)
return {"_transition": "default"} # Return to check_city
```
This enables bidirectional flows (state A calls state B, B returns to A), retry loops, and decision branching — all without leaving the FSM model.
### Tools Are Scoped Per State
No global registry. Each state declares its own tools:
```python
research_state = StateSpec(
name="research",
tools=[search_web, fetch_paper], # Only available in this state
...
)
writing_state = StateSpec(
name="writing",
tools=[save_draft], # Different tools here
...
)
```
Tools are plain Python functions. The framework auto-generates JSON Schema signatures (OpenAI/Anthropic compatible) from type hints:
```python
def search_web(query: str, max_results: int = 10) -> str:
"""Search the web for information."""
...
```
### Shared Context
States share data through `SharedContext` (explicit key-value store, not a flat blob):
```python
def step_one(ctx: ExecutionContext):
ctx.shared.set("findings", ["a", "b", "c"])
return "done"
def step_two(ctx: ExecutionContext):
findings = ctx.shared.get("findings", [])
return f"Processing {len(findings)} findings"
```
### Execute Functions
A state's `execute` function receives an `ExecutionContext` with everything it needs:
```python
def my_state(ctx: ExecutionContext):
ctx.input # Output from previous state
ctx.shared # SharedContext (read/write)
ctx.history # Previous states' outputs (read-only)
ctx.llm # BoundLLM with this state's tools
ctx.retry_count # Current retry attempt
ctx.feedback # Validator feedback from last failed attempt
```
Inside execute, you can do anything:
```python
# Option A: Use the BoundLLM tool-calling loop
result = ctx.llm.run_with_tools(system_prompt="...", user_message="...")
# Option B: Call the LLM directly (no tool loop)
response = ctx.llm.chat([Message(role="user", content="...")])
# Option C: Bridge to an external agent framework
from crewai import Agent
result = Agent(...).run(ctx.input)
# Option D: Run arbitrary code
result = my_analysis_pipeline(ctx.input)
# Option E: Nest another workflow
inner_wf = Workflow(...)
result = inner_wf.run(ctx.input)
```
### Built-in OODA Agent
For "LLM + tools" without wiring your own agent loop, use the built-in OODA agent:
```python
from fsm_agent_flow import run_ooda
def investigate(ctx: ExecutionContext):
return run_ooda(ctx, task=f"Investigate: {ctx.input}",
tools=[search, analyze], max_cycles=3)
```
The OODA agent is itself a nested `Workflow` with 4 states (Observe, Orient, Decide, Act), dogfooding the framework.
### Validators
Three options for validation:
```python
# 1. RuleValidator (default) — only runs programmatic checks
from fsm_agent_flow import RuleValidator
wf = Workflow(..., validator=RuleValidator())
# 2. LLMValidator — runs checks + asks LLM for KRs without check functions
from fsm_agent_flow import LLMValidator
wf = Workflow(..., validator=LLMValidator(llm))
# 3. Shorthand — pass validator_llm to auto-create LLMValidator
wf = Workflow(..., validator_llm=cheap_llm)
# 4. Custom — implement the Validator protocol
class MyValidator:
def validate(self, state, output, context) -> ValidationResult:
...
```
### LLM Adapters
The framework ships with OpenAI and LiteLLM adapters:
```python
from fsm_agent_flow.llm.openai import OpenAIAdapter
from fsm_agent_flow.llm.litellm import LiteLLMAdapter
# OpenAI (or any OpenAI-compatible API)
llm = OpenAIAdapter(model="gpt-4o", api_key="sk-...")
llm = OpenAIAdapter(model="deepseek/deepseek-r1", base_url="https://openrouter.ai/api/v1")
# LiteLLM (any provider)
llm = LiteLLMAdapter(model="anthropic/claude-sonnet-4-20250514")
```
Build your own by implementing the `LLMAdapter` protocol — see `docs/claude/rules/adapters.md` or ask Claude Code.
### Persistence
`WorkflowContext` is serializable for save/resume:
```python
# Save
data = wf.context.to_dict()
json.dump(data, open("checkpoint.json", "w"))
# Resume
data = json.load(open("checkpoint.json"))
ctx = WorkflowContext.from_dict(data)
```
## Examples
See `examples/` for complete working examples:
- **`research_workflow.py`** — Research + writing with tool calling and TDD validation
- **`ooda_example.py`** — Using the built-in OODA agent inside workflow states
## Claude Code Integration
This repo includes a `CLAUDE.md` and `docs/claude/rules/` that teach Claude Code the framework's architecture. When you open this project in Claude Code, it automatically understands how to:
- Define workflows with states, transitions, and key results
- Build custom LLM adapters
- Write validation logic
- Use the OODA agent
- Debug common issues
### Using with Claude Code in your own project
If you're using `fsm-agent-flow` as a dependency in your own project, add the following to your project's `CLAUDE.md` so Claude Code understands the framework:
```markdown
# fsm-agent-flow
TDD/OKR-driven agentic workflow framework. See the reference docs:
@https://raw.githubusercontent.com/NewJerseyStyle/FSM-agent-flow/main/CLAUDE.md
@https://NewJerseyStyle.github.io/FSM-agent-flow/claude/rules/adapters.md
@https://NewJerseyStyle.github.io/FSM-agent-flow/claude/rules/workflows.md
@https://NewJerseyStyle.github.io/FSM-agent-flow/claude/rules/validation.md
@https://NewJerseyStyle.github.io/FSM-agent-flow/claude/rules/tools.md</pre>
```
This gives Claude Code full knowledge of the framework's API, patterns, and conventions when working on your codebase.
## License
MIT
| text/markdown | null | Yuan Xu <dev.source@outlook.com> | null | null | MIT | llm, workflow, agent, fsm, ai, tdd, okr, openai, litellm | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: ... | [] | null | null | >=3.10 | [] | [] | [] | [
"openai>=1.0.0; extra == \"openai\"",
"litellm>=1.0.0; extra == \"litellm\"",
"openai>=1.0.0; extra == \"all\"",
"litellm>=1.0.0; extra == \"all\"",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/NewJerseyStyle/FSM-agent-flow",
"Repository, https://github.com/NewJerseyStyle/FSM-agent-flow",
"Issues, https://github.com/NewJerseyStyle/FSM-agent-flow/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:41:31.259590 | fsm_agent_flow-0.3.0.tar.gz | 35,856 | 97/53/af100ef0c1a384922b39900d5c0ea2917a13e86d709fe14d56ce0343f3e5/fsm_agent_flow-0.3.0.tar.gz | source | sdist | null | false | 346fd2d26e32ac9b89c64b62b5825ebd | 94ce64188f53c0976af51cffb8f572a5fbcc25818c0cd693b3f4cab80321fe2d | 9753af100ef0c1a384922b39900d5c0ea2917a13e86d709fe14d56ce0343f3e5 | null | [
"LICENSE"
] | 249 |
2.4 | oarepo-dashboard | 2.0.0.dev3 | Support for user dashboard (records, communities, requests) | # oarepo-dashboard | text/markdown | null | Mirek Simek <miroslav.simek@cesnet.cz> | null | null | null | null | [] | [] | null | null | <3.14,>=3.13 | [] | [] | [] | [
"cachetools",
"oarepo-rdm<2.0.0,>=1.0.0dev0",
"oarepo-runtime<3.0.0,>=2.0.0dev0",
"oarepo-ui<7.0.0,>=6.0.0dev11",
"oarepo[rdm,tests]<15,>=14",
"openpyxl",
"oarepo-tools; extra == \"dev\"",
"pytest>=7.1.2; extra == \"dev\"",
"oarepo[rdm,tests]<15.0.0,>=14.0.0; extra == \"oarepo14\"",
"pytest>=7.1.2... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:40:27.425381 | oarepo_dashboard-2.0.0.dev3.tar.gz | 11,341 | e8/06/835f4e88ded74cde3d59a9024efda9e8203af6e150066036c6a44c66784c/oarepo_dashboard-2.0.0.dev3.tar.gz | source | sdist | null | false | 48de6f73413426f2d80d86cf90578349 | 2267bfb2d73117b4e4274243c0e3b842dbfa851ced2949cb63278d454b9382e2 | e806835f4e88ded74cde3d59a9024efda9e8203af6e150066036c6a44c66784c | null | [] | 185 |
2.4 | lmodify | 0.5.0 | LMODify: Create LMOD packages based on Singularity images for HPC environments | # lmodify
[](https://pypi.org/project/lmodify/)
[](https://pypi.org/project/lmodify/)
[](https://github.com/quadram-institute-bioscience/lmodify/actions/workflows/test.yml)
[](https://github.com/quadram-institute-bioscience/lmodify/actions/workflows/publish-pypi.yml)

A Python CLI tool for creating and managing LMOD modules from Singularity/Apptainer containers in HPC environments.
## Features
- Automatic package name and version detection from Singularity image filenames
- Generate LMOD Lua module files
- Create wrapper scripts for containerized applications
- Manage multiple package versions
- Add commands to existing packages
- Interactive configuration setup
## Installation
```bash
pip install -e .
```
For development:
```bash
pip install -e ".[dev]"
```
## Quick Start
### 1. Initialize Configuration
First, create your configuration file:
```bash
lmodify init
```
This will prompt you for:
- Path to Singularity images
- Path for binary wrappers
- Path for LMOD Lua files
- Your metadata (name, email, organization)
The configuration is saved to `~/.config/lmodify.ini` by default.
### 2. Create a Package
Create an LMOD module from a Singularity image:
```bash
lmodify create -s /path/to/seqfu__1.20.3.simg seqfu fu-msa fu-orf
```
Or load commands from a file:
```bash
lmodify create -s /path/to/seqfu__1.20.3.simg -f commands.txt
```
This will:
1. Parse the package name and version from the image filename
2. Create a wrapper script in `{bin_path}/seqfu__1.20.3/singularity.exec`
3. Create symlinks for the specified commands
4. Generate an LMOD Lua file at `{lmod_path}/seqfu/1.20.3.lua`
### 3. List Available Packages
View all available LMOD modules:
```bash
lmodify list
```
Filter by keyword:
```bash
lmodify list seqfu
```
Show only package names:
```bash
lmodify list -p
```
### 4. Add Commands to Existing Packages
Add one or more commands to an existing package:
```bash
lmodify add seqfu fu-orf
lmodify add seqfu fu-orf fu-shred fu-pecheck
```
Add from a file:
```bash
lmodify add seqfu -f commands.txt
```
Add to a specific version:
```bash
lmodify add seqfu fu-orf --version 1.20.3
```
## Supported Image Naming Patterns
lmodify automatically detects package names and versions from these patterns:
1. **Galaxy Project depot pattern:**
```
depot.galaxyproject.org-singularity-{name}-{version}--{build}.img
depot.galaxyproject.org-singularity-kraken2-2.0.8_beta--pl526hc9558a2_2.img
```
2. **Colon pattern:**
```
{name}:{version}--{build}
checkv:1.0.3--pyhdfd78af_0
genomad:1.9.0--pyhdfd78af_1.simg
```
3. **Double underscore pattern:**
```
{name}__{version}[.extension]
seqfu__1.20.3
unicycler__0.5.1.simg
```
If automatic detection fails, you can specify manually:
```bash
lmodify create -s image.sif -p mypackage -v 1.0.0 mycommand
```
## Commands
### init
Create a configuration file with interactive prompts.
```bash
lmodify init [-o OUTPUT] [-f]
```
Options:
- `-o, --output`: Output path for config file
- `-f, --force`: Overwrite existing config file
### create
Create a new LMOD package from a Singularity image.
```bash
lmodify create [OPTIONS] [COMMANDS...]
```
Options:
- `-s, --singularity`: Path to Singularity image (required)
- `-p, --package`: Package name (auto-detected if not provided)
- `-v, --version`: Package version (auto-detected if not provided)
- `-f, --cmd-file`: File with list of commands (one per line, # for comments)
- `-l, --lmod-path`: Override LMOD path from config
- `-b, --bin-path`: Override bin path from config
- `-d, --description`: Package description
- `-C, --category`: Package category (bio, chem, physics, tools, etc.)
- `--force`: Overwrite existing files
- `--dry-run`: Preview without making changes
**Command file format:**
Create a text file with one command per line. Empty lines and lines starting with `#` are ignored:
```text
# Core commands
seqfu
fu-msa
fu-orf
fu-index
fu-shred
# Additional utilities
fu-pecheck
fu-tabcheck
```
You can combine commands from both the file and command-line arguments. Duplicates are automatically removed.
### list
List available LMOD packages.
```bash
lmodify list [KEYWORD] [-p]
```
Options:
- `KEYWORD`: Filter packages (case-insensitive)
- `-p, --packages-only`: Show only package names, not versions
- `-l, --lmod-path`: Override LMOD path from config
### add
Add one or more commands to an existing package.
```bash
lmodify add PACKAGE [COMMANDS...] [OPTIONS]
```
Options:
- `-f, --cmd-file`: File with list of commands (one per line, # for comments)
- `-v, --version`: Add to specific version (default: all versions)
- `-l, --lmod-path`: Override LMOD path from config
- `-b, --bin-path`: Override bin path from config
- `--force`: Overwrite existing command
- `--dry-run`: Preview without making changes
Examples:
```bash
# Add single command
lmodify add seqfu fu-orf
# Add multiple commands
lmodify add seqfu fu-orf fu-shred fu-pecheck
# Add from file
lmodify add seqfu -f commands.txt
# Combine file and arguments
lmodify add seqfu fu-extra -f commands.txt --version 1.20.3
```
## Configuration File
Default location: `~/.config/lmodify.ini`
```ini
[lmodify]
singularity_default_path = /opt/singularity
bin_path = /opt/bin
lmod_path = /opt/lmod
[metadata]
author = Your Name
email = your.email@example.com
organization = Your Organization
```
You can specify a custom config file with:
```bash
lmodify -c /path/to/config.ini <command>
```
## How It Works
When you create a package, lmodify:
1. **Creates a wrapper script** (`singularity.exec`) that executes commands inside the container:
```bash
#!/bin/bash
singularity exec "/path/to/image.simg" $(basename "$0") "$@"
```
2. **Creates symlinks** for each command pointing to the wrapper script:
```bash
seqfu -> singularity.exec
stats -> singularity.exec
```
3. **Generates an LMOD Lua module** that adds the bin directory to PATH:
```lua
prepend_path("PATH", "/opt/bin/seqfu__1.20.3")
```
Users can then load the module:
```bash
module load seqfu/1.20.3
seqfu --version
```
## Development
Run tests:
```bash
pytest
```
Run tests with coverage:
```bash
pytest --cov=lmodify
```
## License
MIT License
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
| text/markdown | null | Andrea Telatin <andrea.telatin@quadram.ac.uk> | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming La... | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.1.0",
"rich>=13.0.0",
"rich-click>=1.7.0",
"pytest>=7.4.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/quadram-institute-bioscience/lmodify",
"Repository, https://github.com/quadram-institute-bioscience/lmodify",
"Issues, https://github.com/quadram-institute-bioscience/lmodify/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:40:24.136417 | lmodify-0.5.0.tar.gz | 21,379 | 59/c5/e2abf86b0db215365a5d6039e3b998537f4c458da5f712b1b072f2a6e958/lmodify-0.5.0.tar.gz | source | sdist | null | false | 0b98bf8919f5b44f27481dbd385354c2 | 5b559fc12b31d8ecae0c6b18797175a90b12f5679b671e5049ce4bf43e5d9ac3 | 59c5e2abf86b0db215365a5d6039e3b998537f4c458da5f712b1b072f2a6e958 | null | [] | 208 |
2.1 | odoo-addon-base-bank-from-iban | 19.0.1.0.1 | Bank from IBAN | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
==============
Bank from IBAN
==============
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:2bad66ac89dec2680904060198c2ca2beb1337f4c5837fd58b82ff84c8cb58ec
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Mature-brightgreen.png
:target: https://odoo-community.org/page/development-status
:alt: Mature
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fcommunity--data--files-lightgray.png?logo=github
:target: https://github.com/OCA/community-data-files/tree/19.0/base_bank_from_iban
:alt: OCA/community-data-files
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/community-data-files-19-0/community-data-files-19-0-base_bank_from_iban
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/community-data-files&target_branch=19.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module adds a code to bank definition for using it as matching for
filling the bank from the IBAN bank account number. It uses the existing
by country bank mapping in standard Odoo
(https://github.com/odoo/odoo/blob/f5ffcf7feec5526a483f8ddd240648c084351008/addons/base_iban/models/res_partner_bank.py#L105-L175),
taken from ISO 3166-1 -> IBAN template, as described here:
http://en.wikipedia.org/wiki/International_Bank_Account_Number#IBAN_formats_by_country
**Table of contents**
.. contents::
:local:
Configuration
=============
1. Go to *Contacts > Configuration > Bank Accounts > Banks*.
2. Create or modify a bank.
3. Put the corresponding code for that bank in the field "Code".
Usage
=====
To use this module, you need to:
1. Go to Partner
2. Click *Bank Account(s)* in "Invoicing" page.
3. Create/modify IBAN bank account.
4. When you put the bank account number, module extracts bank digits
from the format of the country, and try to match an existing bank by
country and code.
5. If there's a match, the bank is selected automatically.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/community-data-files/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/community-data-files/issues/new?body=module:%20base_bank_from_iban%0Aversion:%2019.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Tecnativa
Contributors
------------
- `Tecnativa <https://www.tecnativa.com>`__:
- Carlos Dauden
- Pedro M. Baeza
- `Pesol <https://www.pesol.es>`__:
- Pedro Evaristo Gonzalez Sanchez <pedro.gonzalez@pesol.es>
- `APSL - Nagarro <https://apsl.tech>`__:
- Javier Antó <janto@apsl.net>
- Miquel Pascual <mpascual@apsl.net>
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/community-data-files <https://github.com/OCA/community-data-files/tree/19.0/base_bank_from_iban>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Tecnativa, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 19.0",
"License :: OSI Approved :: GNU Affero General Public License v3",
"Development Status :: 6 - Mature"
] | [] | https://github.com/OCA/community-data-files | null | null | [] | [] | [] | [
"odoo==19.0.*",
"schwifty==2024.4.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T14:40:07.747065 | odoo_addon_base_bank_from_iban-19.0.1.0.1-py3-none-any.whl | 30,736 | 3c/0c/4c74ba7beff046cc94ee76a8a92d53222838a0f17adb45d5f33c494f6b2f/odoo_addon_base_bank_from_iban-19.0.1.0.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 256f4e507e13642dc6cc17a98d8ed418 | 791221ad03b70c5848f0a1a201a05d1456b72b17a2db8f8a0fde82750b65f7ef | 3c0c4c74ba7beff046cc94ee76a8a92d53222838a0f17adb45d5f33c494f6b2f | null | [] | 103 |
2.1 | MorphUI | 0.11.0 | MorphUI is a creative and flexible UI extension for Kivy, designed to provide developers with a modern and customizable set of components for building beautiful user interfaces. Unlike KivyMD, MorphUI is not bound to Material Design principles, allowing for greater freedom in design and styling. | # MorphUI
**MorphUI** is a modern, flexible UI framework for [Kivy](https://kivy.org) that brings beautiful, themeable components with dynamic color management. Built on Material You's dynamic color system, MorphUI provides an extensive set of widgets with automatic theming, smooth animations, and a powerful component architecture—all while giving you complete design freedom.
## ✨ Key Features
- 🎨 **Dynamic Theming**: Material You-inspired dynamic color system with automatic light/dark mode
- 🧩 **Rich Component Library**: Modern buttons, labels, text fields, dropdowns, layouts, and more
- 📊 **Data Visualization**: Optional matplotlib integration for charts and plots
- ⚡ **Smooth Animations**: Built-in ripple effects, hover states, and motion behaviors
- 🎯 **Powerful Behaviors**: Modular behavior system for easy customization
- 📱 **Cross-Platform**: Runs on Windows, macOS, Linux, Android, iOS, and web
- 🔧 **Developer-Friendly**: Clean API with comprehensive docstrings
## 📦 Installation
### Basic Installation
```bash
pip install morphui
```
### With Visualization Support
For data visualization features (charts and plots):
```bash
pip install morphui[visualization]
```
### From Source
```bash
git clone https://github.com/j4ggr/MorphUI.git
cd MorphUI
pip install -e .
```
## 🚀 Quick Start
Here's a minimal example to get you started:
```python
from morphui.app import MorphApp
from morphui.uix.boxlayout import MorphBoxLayout
from morphui.uix.label import MorphLabel
from morphui.uix.button import MorphButton
class MyApp(MorphApp):
def build(self):
# Configure theme
self.theme_manager.theme_mode = 'Dark'
self.theme_manager.seed_color = 'Blue'
# Create layout
layout = MorphBoxLayout(
MorphLabel(text="Welcome to MorphUI!"),
MorphButton(text="Click Me!"),
orientation='vertical',
spacing=10,
padding=20
)
return layout
if __name__ == '__main__':
MyApp().run()
```
## 🎨 Theme System
MorphUI's theme system is built on Material You's dynamic color algorithms, automatically generating harmonious color schemes from a single seed color.
### Theme Configuration
```python
from morphui.app import MorphApp
class MyApp(MorphApp):
def build(self):
# Set theme mode (Light or Dark)
self.theme_manager.theme_mode = 'Dark'
# Choose a seed color (any color name from Kivy's colormap)
self.theme_manager.seed_color = 'Orange'
# Select color scheme variant
# Options: TONAL_SPOT, VIBRANT, EXPRESSIVE, NEUTRAL,
# MONOCHROME, FIDELITY, CONTENT, RAINBOW, FRUIT_SALAD
self.theme_manager.color_scheme = 'VIBRANT'
# Adjust contrast (0.0 to 1.0)
self.theme_manager.color_scheme_contrast = 0.0
return self.create_ui()
```
### Custom Seed Colors
Register your own custom colors:
```python
# Register a custom color with hex value
self.theme_manager.register_seed_color('brand_blue', '#0066CC')
self.theme_manager.seed_color = 'brand_blue'
```
### Runtime Theme Switching
```python
# Toggle between light and dark mode
self.theme_manager.toggle_theme_mode()
# Or set explicitly
self.theme_manager.theme_mode = 'Light' # or 'Dark'
```
## 📚 Core Components
### MorphApp
Base application class with integrated theme management:
```python
from morphui.app import MorphApp
class MyApp(MorphApp):
def build(self):
# Access theme manager
self.theme_manager.theme_mode = 'Dark'
# Access typography system
icon_map = self.typography.icon_map
return your_root_widget
```
### Buttons
#### MorphButton
Full-featured button with theming and animations:
```python
from morphui.uix.button import MorphButton
button = MorphButton(
text="Click Me",
on_release=lambda x: print("Button clicked!")
)
```
#### MorphIconButton
Icon-only button for compact interfaces:
```python
from morphui.uix.button import MorphIconButton
icon_btn = MorphIconButton(
icon='close', # Material icon name
on_release=self.close_dialog
)
```
### Labels
#### MorphLabel
Themed label with auto-sizing:
```python
from morphui.uix.label import MorphLabel
label = MorphLabel(
text="Hello, MorphUI!",
auto_width=True,
auto_height=True
)
```
#### MorphIconLabel
Label with an icon:
```python
from morphui.uix.label import MorphIconLabel
icon_label = MorphIconLabel(
icon='star',
text="Favorite"
)
```
### Text Fields
#### MorphTextField
Modern text input with validation:
```python
from morphui.uix.textfield import MorphTextField
text_field = MorphTextField(
heading_text="Email",
hint_text="Enter your email",
required=True,
validator='email' # Built-in validators: email, url, int, float
)
# Check validation
if text_field.error:
print(f"Error: {text_field.error_type}")
```
#### MorphTextFieldOutlined
Outlined variant:
```python
from morphui.uix.textfield import MorphTextFieldOutlined
email_field = MorphTextFieldOutlined(
heading_text="Email Address",
leading_icon='email',
validator='email',
required=True
)
```
### Dropdowns
#### MorphDropdownFilterField
Searchable dropdown with filtering:
```python
from morphui.uix.dropdown import MorphDropdownFilterField
items = [
{'label_text': 'Apple', 'normal_leading_icon': 'apple'},
{'label_text': 'Banana', 'normal_leading_icon': 'fruit-citrus'},
{'label_text': 'Cherry', 'normal_leading_icon': 'fruit-cherries'}
]
dropdown = MorphDropdownFilterField(
items=items,
heading_text='Select Fruit',
leading_icon='magnify',
item_release_callback=lambda item, index: print(f"Selected: {item.label_text}")
)
```
### Layouts
MorphUI provides themed versions of all standard Kivy layouts:
```python
from morphui.uix.boxlayout import MorphBoxLayout
from morphui.uix.floatlayout import MorphFloatLayout
from morphui.uix.gridlayout import MorphGridLayout
# BoxLayout with themed widgets as children
layout = MorphBoxLayout(
widget1,
widget2,
widget3,
orientation='vertical',
spacing=10,
padding=20
)
```
## 📊 Data Visualization
MorphUI includes optional matplotlib integration for creating beautiful, themed charts.
### Basic Chart Example
```python
from morphui.app import MorphApp
from morphui.uix.visualization import MorphChart
import matplotlib.pyplot as plt
import numpy as np
class ChartApp(MorphApp):
def build(self):
self.theme_manager.theme_mode = 'Dark'
# Create chart widget
chart = MorphChart()
# Create matplotlib figure
x = np.linspace(0, 10, 100)
y = np.sin(x)
fig, ax = plt.subplots(figsize=(10, 6))
ax.plot(x, y, linewidth=2)
ax.set_title('Sine Wave')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.grid(True, alpha=0.3)
# Set the figure
chart.figure = fig
return chart
if __name__ == '__main__':
ChartApp().run()
```
### Interactive Features
MorphChart automatically includes:
- Zoom and pan controls
- Home/back/forward navigation
- Save figure option
- Automatic theme-aware styling
See [examples/visualization_example.py](examples/visualization_example.py) for more advanced usage.
## 💡 Complete Examples
### Theme Showcase App
```python
from morphui.app import MorphApp
from morphui.uix.boxlayout import MorphBoxLayout
from morphui.uix.label import MorphLabel
from morphui.uix.button import MorphIconButton
class ThemeShowcaseApp(MorphApp):
def build(self):
self.theme_manager.theme_mode = 'Dark'
self.theme_manager.seed_color = 'Orange'
layout = MorphBoxLayout(
MorphIconButton(
icon='brightness-3' if self.theme_manager.theme_mode == 'Light' else 'brightness-5',
on_release=lambda x: self.toggle_theme()
),
MorphLabel(text=f"Current theme: {self.theme_manager.theme_mode}"),
orientation='vertical',
spacing=20,
padding=20
)
return layout
def toggle_theme(self):
self.theme_manager.toggle_theme_mode()
if __name__ == '__main__':
ThemeShowcaseApp().run()
```
### Icon Picker Example
```python
from morphui.app import MorphApp
from morphui.uix.floatlayout import MorphFloatLayout
from morphui.uix.dropdown import MorphDropdownFilterField
class IconPickerApp(MorphApp):
def build(self):
self.theme_manager.theme_mode = 'Dark'
self.theme_manager.seed_color = 'Blue'
# Create items from available icons
icon_items = [
{
'label_text': icon_name,
'leading_icon': icon_name,
}
for icon_name in sorted(self.typography.icon_map.keys())
]
layout = MorphFloatLayout(
MorphDropdownFilterField(
identity='icon_picker',
items=icon_items,
item_release_callback=self.icon_selected,
heading_text='Search icons...',
leading_icon='magnify',
pos_hint={'center_x': 0.5, 'center_y': 0.9},
size_hint=(0.8, None),
)
)
self.icon_picker = layout.identities.icon_picker
return layout
def icon_selected(self, item, index):
self.icon_picker.text = item.label_text
self.icon_picker.leading_icon = item.label_text
if __name__ == '__main__':
IconPickerApp().run()
```
## 📁 Examples Directory
Explore the `examples/` directory for complete, runnable applications:
- **[color_showcase_app.py](examples/color_showcase_app.py)** - Comprehensive color palette showcase with theme switching
- **[visualization_example.py](examples/visualization_example.py)** - Data visualization with multiple chart types
### Running Examples
To run an example:
```bash
cd examples
python color_showcase_app.py
# or
python visualization_example.py
```
## 🎯 Behavior System
MorphUI uses a modular behavior system that allows you to mix and match functionality:
- **MorphThemeBehavior** - Automatic theme color binding
- **MorphHoverBehavior** - Mouse hover detection and states
- **MorphRippleBehavior** - Material-style ripple effects
- **MorphScaleBehavior** - Scale animations
- **MorphElevationBehavior** - Shadow and elevation effects
- **MorphAutoSizingBehavior** - Automatic size calculations
- **MorphIdentificationBehavior** - Widget identification and lookup
These behaviors are composable and can be mixed into custom widgets.
## 🛠️ Development
### Setting Up Development Environment
```bash
git clone https://github.com/j4ggr/MorphUI.git
cd MorphUI
pip install -e ".[test,visualization]"
```
### Running Tests
```bash
pytest tests/
```
## 📖 Documentation
MorphUI components are extensively documented with docstrings. Access documentation in your IDE or use Python's help system:
```python
from morphui.uix.button import MorphButton
help(MorphButton)
```
## 🗺️ Roadmap
- [x] Dynamic color system with Material You
- [x] Core components (buttons, labels, text fields)
- [x] Layout containers
- [x] Data visualization integration
- [ ] More advanced components (sliders, switches, progress bars)
- [ ] Animation improvements
- [ ] Comprehensive documentation website
- [ ] PyPI package release
- [ ] Performance optimizations
## 🤝 Contributing
Contributions are welcome! Please feel free to submit a Pull Request. For major changes, please open an issue first to discuss what you would like to change.
### Guidelines
1. Follow the existing code style
2. Add docstrings to new components
3. Test your changes thoroughly
4. Update documentation as needed
## 📄 License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## 🙏 Acknowledgments
- Built on top of the excellent [Kivy](https://kivy.org) framework
- Material You color system via [material-color-utilities](https://github.com/material-foundation/material-color-utilities)
- Icons from [Material Design Icons](https://materialdesignicons.com/)
- Inspired by modern UI frameworks while maintaining design flexibility
## 📞 Support
- **Issues**: [GitHub Issues](https://github.com/j4ggr/MorphUI/issues)
- **Examples**: Check the `examples/` directory
- **Documentation**: See docstrings in source code
---
**MorphUI** - Beautiful, flexible UIs for Kivy applications. | text/markdown | null | j4ggr <reto@jaeggli.email> | null | null | MIT | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"kivy>=2.3.1",
"material-color-utilities>=0.2.6"
] | [] | [] | [] | [] | pdm/2.26.2 CPython/3.12.3 Windows/11 | 2026-02-19T14:39:27.939527 | morphui-0.11.0.tar.gz | 9,596,714 | 00/15/935ee287c466177577444e259fc0a989b88ebeb27291df5f065e0d33be25/morphui-0.11.0.tar.gz | source | sdist | null | false | b45c6bae98d79c8d505f5b937e930f71 | bca3edf1cd07cad096f5d77f39198418f14988ad8a6b6f3f62b951943c629857 | 0015935ee287c466177577444e259fc0a989b88ebeb27291df5f065e0d33be25 | null | [] | 0 |
2.4 | yprov4ml | 2.0.9 | Part of the yProv suite, and provides a unified interface for logging and tracking provenance information in machine learning experiments, both on distributed as well as large scale experiments. |
<div align="center">
<a href="https://github.com/HPCI-Lab">
<img src="./assets/HPCI-Lab.png" alt="HPCI Lab Logo" width="100" height="100">
</a>
<h3 align="center">yProv4ML</h3>
<p align="center">
A unified interface for logging and tracking provenance information in machine learning experiments, both on distributed as well as large scale experiments.
<br />
<a href="https://hpci-lab.github.io/yProv4ML/"><strong>Explore the docs »</strong></a>
<br />
<br />
<a href="https://github.com/HPCI-Lab/yProv4ML/issues/new?labels=bug&template=bug-report---.md">Report Bug</a>
·
<a href="https://github.com/HPCI-Lab/yProv4ML/issues/new?labels=enhancement&template=feature-request---.md">Request Feature</a>
</p>
</div>
<br />
[](https://github.com/HPCI-Lab/yProv4ML/graphs/contributors)
[](https://github.com/HPCI-Lab/yProv4ML/network/members)
[](https://github.com/HPCI-Lab/yProv4ML/stargazers)
[](https://github.com/HPCI-Lab/yProv4ML/issues)
[](https://opensource.org/licenses/)
This library is part of the yProv suite, and provides a unified interface for logging and tracking provenance information in machine learning experiments, both on distributed as well as large scale experiments.
It allows users to create provenance graphs from the logged information, and save all metrics and parameters to json format.
## Data Model

## Example

The image shown above has been generated from the [example](./examples/prov4ml_torch.py) program provided in the ```example``` directory.
## Metrics Visualization


## Experiments and Runs
An experiment is a collection of runs. Each run is a single execution of a machine learning model.
By changing the ```experiment_name``` parameter in the ```start_run``` function, the user can create a new experiment.
All artifacts and metrics logged during the execution of the experiment will be saved in the directory specified by the experiment ID.
Several runs can be executed in the same experiment. All runs will be saved in the same directory (according to the specific experiment name and ID).
# Documentation
For detailed information, please refer to the [Documentation](https://hpci-lab.github.io/yProv4ML/)
# Contributors
- [Gabriele Padovani](https://github.com/lelepado01)
- [Luca Davi](https://github.com/lucadavii)
- [Sandro Luigi Fiore](https://github.com/sandrofioretn)
| text/markdown | null | Gabriele Padovani <gabriele.padovani@unitn.it> | null | null | GNU GENERAL PUBLIC LICENSE
Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU General Public License is a free, copyleft license for
software and other kinds of works.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
the GNU General Public License is intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users. We, the Free Software Foundation, use the
GNU General Public License for most of our software; it applies also to
any other work released this way by its authors. You can apply it to
your programs, too.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
To protect your rights, we need to prevent others from denying you
these rights or asking you to surrender the rights. Therefore, you have
certain responsibilities if you distribute copies of the software, or if
you modify it: responsibilities to respect the freedom of others.
For example, if you distribute copies of such a program, whether
gratis or for a fee, you must pass on to the recipients the same
freedoms that you received. You must make sure that they, too, receive
or can get the source code. And you must show them these terms so they
know their rights.
Developers that use the GNU GPL protect your rights with two steps:
(1) assert copyright on the software, and (2) offer you this License
giving you legal permission to copy, distribute and/or modify it.
For the developers' and authors' protection, the GPL clearly explains
that there is no warranty for this free software. For both users' and
authors' sake, the GPL requires that modified versions be marked as
changed, so that their problems will not be attributed erroneously to
authors of previous versions.
Some devices are designed to deny users access to install or run
modified versions of the software inside them, although the manufacturer
can do so. This is fundamentally incompatible with the aim of
protecting users' freedom to change the software. The systematic
pattern of such abuse occurs in the area of products for individuals to
use, which is precisely where it is most unacceptable. Therefore, we
have designed this version of the GPL to prohibit the practice for those
products. If such problems arise substantially in other domains, we
stand ready to extend this provision to those domains in future versions
of the GPL, as needed to protect the freedom of users.
Finally, every program is threatened constantly by software patents.
States should not allow patents to restrict development and use of
software on general-purpose computers, but in those that do, we wish to
avoid the special danger that patents applied to a free program could
make it effectively proprietary. To prevent this, the GPL assures that
patents cannot be used to render the program non-free.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Use with the GNU Affero General Public License.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU Affero General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the special requirements of the GNU Affero General Public License,
section 13, concerning interaction through a network will apply to the
combination as such.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU General Public License from time to time. Such new versions will
be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <https://www.gnu.org/licenses/>.
Also add information on how to contact you by electronic and paper mail.
If the program does terminal interaction, make it output a short
notice like this when it starts in an interactive mode:
<program> Copyright (C) <year> <name of author>
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
This is free software, and you are welcome to redistribute it
under certain conditions; type `show c' for details.
The hypothetical commands `show w' and `show c' should show the appropriate
parts of the General Public License. Of course, your program's commands
might be different; for a GUI interface, you would use an "about box".
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU GPL, see
<https://www.gnu.org/licenses/>.
The GNU General Public License does not permit incorporating your program
into proprietary programs. If your program is a subroutine library, you
may consider it more useful to permit linking proprietary applications with
the library. If this is what you want to do, use the GNU Lesser General
Public License instead of this License. But first, please read
<https://www.gnu.org/licenses/why-not-lgpl.html>.
| null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"codecarbon>=2.8",
"fvcore",
"geocoder",
"gpustat",
"GPUtil",
"lightning",
"netCDF4",
"numpy",
"nvitop",
"pandas",
"psutil",
"pydot",
"torch",
"torchvision",
"tqdm",
"typing_extensions",
"rocrate",
"aenum",
"prov",
"zarr",
"lxml",
"rdflib<7",
"nvidia-ml-py",
"apple_gpu=... | [] | [] | [] | [
"Homepage, https://github.com/HPCI-Lab/yProvML",
"Issues, https://github.com/HPCI-Lab/yProvML/issues"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-19T14:39:11.291867 | yprov4ml-2.0.9.tar.gz | 66,113 | 6c/aa/05be226ed1e0d948296fa9dca37d5c721fb833e69e613b36974a2c7d1cd8/yprov4ml-2.0.9.tar.gz | source | sdist | null | false | cdd86dffae976cd1c59768dc3a2479e2 | 162577e73425d36ee74f5770bfb8ca04762d83e77b28832bf0849da9cfb24a71 | 6caa05be226ed1e0d948296fa9dca37d5c721fb833e69e613b36974a2c7d1cd8 | null | [
"LICENSE"
] | 236 |
2.1 | suparkanbun | 1.7.1 | Tokenizer POS-tagger and Dependency-parser for Classical Chinese | [](https://pypi.org/project/suparkanbun/)
# SuPar-Kanbun
Tokenizer, POS-Tagger and Dependency-Parser for Classical Chinese Texts (漢文/文言文) with [spaCy](https://spacy.io), [Transformers](https://huggingface.co/transformers/) and [SuPar](https://github.com/yzhangcs/parser).
## Basic usage
```py
>>> import suparkanbun
>>> nlp=suparkanbun.load()
>>> doc=nlp("不入虎穴不得虎子")
>>> print(type(doc))
<class 'spacy.tokens.doc.Doc'>
>>> print(suparkanbun.to_conllu(doc))
# text = 不入虎穴不得虎子
1 不 不 ADV v,副詞,否定,無界 Polarity=Neg 2 advmod _ Gloss=not|SpaceAfter=No
2 入 入 VERB v,動詞,行為,移動 _ 0 root _ Gloss=enter|SpaceAfter=No
3 虎 虎 NOUN n,名詞,主体,動物 _ 4 nmod _ Gloss=tiger|SpaceAfter=No
4 穴 穴 NOUN n,名詞,固定物,地形 Case=Loc 2 obj _ Gloss=cave|SpaceAfter=No
5 不 不 ADV v,副詞,否定,無界 Polarity=Neg 6 advmod _ Gloss=not|SpaceAfter=No
6 得 得 VERB v,動詞,行為,得失 _ 2 parataxis _ Gloss=get|SpaceAfter=No
7 虎 虎 NOUN n,名詞,主体,動物 _ 8 nmod _ Gloss=tiger|SpaceAfter=No
8 子 子 NOUN n,名詞,人,関係 _ 6 obj _ Gloss=child|SpaceAfter=No
>>> import deplacy
>>> deplacy.render(doc)
不 ADV <════╗ advmod
入 VERB ═══╗═╝═╗ ROOT
虎 NOUN <╗ ║ ║ nmod
穴 NOUN ═╝<╝ ║ obj
不 ADV <════╗ ║ advmod
得 VERB ═══╗═╝<╝ parataxis
虎 NOUN <╗ ║ nmod
子 NOUN ═╝<╝ obj
```
`suparkanbun.load()` has two options `suparkanbun.load(BERT="roberta-classical-chinese-base-char",Danku=False)`. With the option `Danku=True` the pipeline tries to segment sentences automatically. Available `BERT` options are:
* `BERT="roberta-classical-chinese-base-char"` utilizes [roberta-classical-chinese-base-char](https://huggingface.co/KoichiYasuoka/roberta-classical-chinese-base-char) (default)
* `BERT="roberta-classical-chinese-large-char"` utilizes [roberta-classical-chinese-large-char](https://huggingface.co/KoichiYasuoka/roberta-classical-chinese-large-char)
* `BERT="guwenbert-base"` utilizes [GuwenBERT-base](https://huggingface.co/ethanyt/guwenbert-base)
* `BERT="guwenbert-large"` utilizes [GuwenBERT-large](https://huggingface.co/ethanyt/guwenbert-large)
* `BERT="sikubert"` utilizes [SikuBERT](https://huggingface.co/SIKU-BERT/sikubert)
* `BERT="sikuroberta"` utilizes [SikuRoBERTa](https://huggingface.co/SIKU-BERT/sikuroberta)
## Installation for Linux
```sh
pip3 install suparkanbun --user
```
## Installation for Cygwin64
Make sure to get `python37-devel` `python37-pip` `python37-cython` `python37-numpy` `python37-wheel` `gcc-g++` `mingw64-x86_64-gcc-g++` `git` `curl` `make` `cmake` packages, and then:
```sh
curl -L https://raw.githubusercontent.com/KoichiYasuoka/CygTorch/master/installer/supar.sh | sh
pip3.7 install suparkanbun
```
## Installation for Jupyter Notebook (Google Colaboratory)
```py
!pip install suparkanbun
```
Try [notebook](https://colab.research.google.com/github/KoichiYasuoka/SuPar-Kanbun/blob/main/suparkanbun.ipynb) for Google Colaboratory.
## Author
Koichi Yasuoka (安岡孝一)
## Reference
Koichi Yasuoka, Christian Wittern, Tomohiko Morioka, Takumi Ikeda, Naoki Yamazaki, Yoshihiro Nikaido, Shingo Suzuki, Shigeki Moro, Kazunori Fujita: [Designing Universal Dependencies for Classical Chinese and Its Application](http://id.nii.ac.jp/1001/00216242/), Journal of Information Processing Society of Japan, Vol.63, No.2 (February 2022), pp.355-363.
| text/markdown | Koichi Yasuoka | yasuoka@kanji.zinbun.kyoto-u.ac.jp | null | null | MIT | NLP Chinese | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Operating System :: OS Independent",
"Topic :: Text Processing :: Linguistic"
] | [] | https://github.com/KoichiYasuoka/SuPar-Kanbun | null | >=3.7 | [] | [] | [] | [
"esupar>=1.8.8",
"spacy>=2.2.2"
] | [] | [] | [] | [
"Source, https://github.com/KoichiYasuoka/SuPar-Kanbun",
"Tracker, https://github.com/KoichiYasuoka/SuPar-Kanbun/issues"
] | twine/4.0.2 CPython/3.9.2 | 2026-02-19T14:39:06.805530 | suparkanbun-1.7.1-py3-none-any.whl | 958,261 | 8e/76/17738eb6107a1b3cd9dde0beccc7c4d7d32de82d9c37b51fc67323b52196/suparkanbun-1.7.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 949ae1563c00f1e0c56e190c0c4d9a40 | b25b30238b26329ba7d63bc6b1a7b4dbc3b70bac0de58b0a899c2513c07b6ab9 | 8e7617738eb6107a1b3cd9dde0beccc7c4d7d32de82d9c37b51fc67323b52196 | null | [] | 113 |
2.1 | arve | 0.8.2 | Analyzing Radial Velocity Elements | <p align="center">
<img width="500" src="https://github.com/almoulla/arve/blob/main/logo/arve_logo.png?raw=true"/>
</p>
# ARVE ~ Analyzing Radial Velocity Elements
`ARVE` is multi-functional tool for extreme precision radial velocity (EPRV) analysis.
## Installation
```
pip install arve
```
## Documentation
<https://arve.readthedocs.io>
## Citation
If you make use of `ARVE`, please cite the following publication:
[Al Moulla 2025, A&A, 701, A266](https://ui.adsabs.harvard.edu/abs/2025A%26A...701A.266A)
| text/markdown | Khaled Al Moulla | khaled.almoulla@gmail.com | null | null | MIT License | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3"
] | [] | https://github.com/almoulla/arve | null | >=3.10 | [] | [] | [] | [
"astropy>=6.1.7",
"astroquery>=0.4.10",
"lmfit>=1.3.3",
"matplotlib>=3.10.1",
"numpy>=2.2.4",
"pandas>=2.2.3",
"scipy>=1.15.2",
"tqdm>=4.67.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.5 | 2026-02-19T14:38:46.370481 | arve-0.8.2.tar.gz | 33,207,047 | 34/7f/a8ce6dd4fcb0cfc5f0e9e14caf355670c19bdb73053398dadc1930eda991/arve-0.8.2.tar.gz | source | sdist | null | false | e630ee47aaa9920041ce505a5697bcbe | a096dca0cd8a34ffca3d89d2239b62df6fe7c6e7417bdaa1a62b35aa0a9b36d3 | 347fa8ce6dd4fcb0cfc5f0e9e14caf355670c19bdb73053398dadc1930eda991 | null | [] | 147 |
2.4 | flower-garden-cli | 2.0.0 | Beautiful CLI flower garden game - water flowers and watch them grow into stunning patterns! | # Flower Garden CLI v2.0
**A living, breathing terminal garden with weather, seasons, ecosystems, and achievements.**
Grow 10 unique flowers with mathematical ASCII art patterns, watch butterflies visit, unlock achievements, and experience dynamic weather -- all from your terminal.



If you have `uv` installed:
```bash
uvx --from flower-garden-cli garden
```
## What's New in v2.0
- **10 Flower Types** -- 5 new Tier II flowers with unique patterns
- **Weather & Seasons** -- sun, rain, wind, mist, storms, and starry nights affect growth
- **Ecosystem** -- butterflies, bees, fireflies, ladybugs, hummingbirds, and dragonflies visit your garden
- **14 Achievements** -- unlock milestones as you grow
- **3 Color Themes** -- Garden, Midnight, and Sunset
- **Dashboard UI** -- compact two-column overview with stats bar
- **Weather Growth Bonus** -- storms give +3 bonus, rain gives +2
- **Persistent Stats** -- tracks total waterings, sessions, visitors, and more
## Flowers
### Tier I (Original)
| Flower | Pattern |
|--------|---------|
| Spiral Rose | Fibonacci spiral with layered petals |
| Fractal Tree | Recursive branching with blossoms |
| Mandala Bloom | Concentric geometric petal rings |
| Wave Garden | Layered sine waves with flower crests |
| Star Burst | Radiating star with pulsing rays |
### Tier II (New in v2.0)
| Flower | Pattern |
|--------|---------|
| Crystal Lotus | Symmetric diamond facets |
| Phoenix Fern | Curling fronds that spiral like flames |
| Galaxy Orchid | Swirling spiral arms with nebula dust |
| Thunder Vine | Lightning-bolt vines with energy sparks |
| Aurora Lily | Flowing aurora bands with shimmer highlights |
## Quick Start
```bash
pip install flower-garden-cli
flower-garden
```
Alternative command:
```bash
garden
```
## Installation
### pip (Recommended)
```bash
pip install flower-garden-cli
# Or from GitHub
pip install git+https://github.com/bdavidzhang/flower-garden-cli.git
```
### Local Development
```bash
git clone https://github.com/bdavidzhang/flower-garden-cli.git
cd flower-garden-cli
pip install -e .
flower-garden
```
## How to Play
1. Launch with `flower-garden` or `garden`
2. Pick a flower to water (1-10)
3. Watch it grow with mathematical ASCII patterns
4. Growth is boosted by weather (storms = +3, rain = +2)
5. Attract wildlife as your garden grows
6. Unlock achievements for milestones
7. Switch themes with option 14
8. Progress saves automatically between sessions
### Menu
```
Water a Flower:
1-10 Water individual flowers (Tier I and II)
Garden:
11 View Full Garden (all patterns)
12 Water All Flowers
World:
13 Change Weather
14 Switch Theme (Garden / Midnight / Sunset)
Progress:
15 Achievements
16 Ecosystem
18 Reset Garden
0 Quit
```
## Weather System
Weather changes based on real-world seasons and affects growth bonuses:
| Weather | Bonus | Description |
|---------|-------|-------------|
| Sunny | +1 | Warm sunshine |
| Rainy | +2 | Gentle rain nourishes flowers |
| Windy | +0 | Brisk wind sweeps through |
| Misty | +1 | Soft mist drifts through |
| Starry Night | +1 | Stars twinkle above |
| Stormy | +3 | Thunder and lightning |
## Ecosystem
As your garden grows, creatures come to visit:
| Creature | Growth Needed |
|----------|---------------|
| Ladybug | 5 |
| Bee | 10 |
| Butterfly | 15 |
| Firefly | 20 |
| Hummingbird | 30 |
| Dragonfly | 40 |
## Achievements
14 achievements to unlock, including:
- **First Drop** -- Water your first flower
- **Master Gardener** -- Fully grow all 10 flowers
- **Storm Chaser** -- Water during a storm
- **Butterfly Whisperer** -- Attract 5 butterflies
- **Century Garden** -- Reach 100 total growth levels
## Project Structure
```
flower-garden-cli/
flower_garden_cli/
__init__.py # Package init, version
main.py # Game loop, UI, FlowerGarden class
patterns.py # 10 mathematical pattern generators
colors.py # Color system, themes, gradients
weather.py # Weather and seasons engine
ecosystem.py # Creature spawning and movement
achievements.py # Achievement definitions and tracking
pyproject.toml
README.md
LICENSE
Dockerfile
```
## Requirements
- **Python**: 3.7+
- **Dependencies**: colorama (>=0.4.0)
- **Platform**: Windows, macOS, Linux
## License
MIT License - see [LICENSE](LICENSE) for details.
## Contributing
Contributions welcome! Please open a Pull Request.
---
*Grow your digital garden, one flower at a time*
| text/markdown | null | David Zhang <davzhang77@gmail.com> | null | null | MIT | cli, game, flowers, patterns, fractals, art, terminal | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: End Users/Desktop",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Py... | [] | null | null | >=3.7 | [] | [] | [] | [
"colorama>=0.4.0",
"pytest>=6.0; extra == \"dev\"",
"black; extra == \"dev\"",
"flake8; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/bdavidzhang/flower-garden-cli",
"Documentation, https://github.com/bdavidzhang/flower-garden-cli#readme",
"Repository, https://github.com/bdavidzhang/flower-garden-cli.git",
"Bug Tracker, https://github.com/bdavidzhang/flower-garden-cli/issues"
] | twine/6.1.0 CPython/3.9.16 | 2026-02-19T14:38:41.257996 | flower_garden_cli-2.0.0.tar.gz | 19,552 | 03/f9/cda768f3616e9c1a0f35b77a6ba1b89789ac880518d68b5e86e476962210/flower_garden_cli-2.0.0.tar.gz | source | sdist | null | false | e908ce002943400322cf13eca71120dc | 3b9440607aa46a18de53e97789c032454cecb467cf45b85786af378eee4c0a1b | 03f9cda768f3616e9c1a0f35b77a6ba1b89789ac880518d68b5e86e476962210 | null | [
"LICENSE"
] | 224 |
2.4 | dicegame | 0.7.3 | A simple CLI dice game | # Dice Game CLI 🎲
- A simple cli dicegame where a player rolls the dice while participating in different game modes and it can be played by anyone
## TABLE OF CONTENTS
- Overview
- Installation
- Usage
- Motivation
- Version and Features
- Versioning
- Configuration
- Project structure
- Roadmap
- License
## Overview
- A simple command-line dice game with multiple modes: **roll**, **play**, and **guess the number**.
- Designed for fun, quick gameplay, and testing your luck and prediction skills.
- Players create accounts, roll dice,
track scores, and compete on a leaderboard.
## Installation
```bash
### clone repository
git clone https://github.com/Major-tech/dicegame-cli.git
### Install in editable mode
pip install -e .
### Run the project
python -m dicegame
## Development Setup (Recommended)
This project requires **Python 3.10+**
## Optional dependencies
1. Create a virtual environment
2. Run `pip install .[dev]`
3. Run tests with `pytest`
If you use `pyenv`, you can install and activate the correct version:
```bash
pyenv install 3.11.7
pyenv local 3.11.7
## Running Tests
This project includes minimal tests using pytest:
```bash
pip install pytest
pytest -v
## Usage
- prefix 'dicegame' before each command in non-interactive/cli mode
- In interactive mode,simply type the commamd name and run it
| Command | Description |
|---------|-------------|
| log list | Shows all available log files |
| log clear | Clears all application logs |
| whoami | Displays the currently logged in user |
| report-bug | Packages application logs into a ZIP file|
| reset password | reset player password
| login | user login |
| signup | user signup |
| roll | Simple dice roll |
| play | Win/Lose dice game |
| guess <number> | Guess the dice number |
| player list | List all players |
| leaderboard | Show leaderboard |
| reset score | reset player score |
| player delete | Delete an account (requires password) |
| Flag | Description |
|------------------------
| -i | --interactive | Enter interactive mode |
| -V | --version | View dicegame-cli version |
| --debug | Enable debug mode |
### Practical Examples
## Usage
Below are example commands demonstrating how to use each feature of the application.
```bash
## FLAGS
# Enter interactive mode
dicegame -i | dicegame --interactive
# View current dicegame version
dicegame -V | dicegame --version
## In interactive mode:
- Type the command 'version'
# Enable debug mode
dicegame --debug
## COMMANDS
# See a list of all log files
dicegame log list
# Clear all the application's log files
dicegame log clear
# Display the currently ligged in user
dicegame whoami
# Create a bug report and email it to the developer in case an issue arises
dicegame report-bug
# Create a new user account
dicegame signup
- You'll be prompted for a usernmae and password
dicegame signup --username new_user
- You'll be prompted for a password
# Log in to an existing account
dicegame login
- You'll be prompted for a usernmae and password
dicegame login --username testuser
- You'll be prompted for a password
# Roll a dice once and display the result
dicegame roll
# Play the win/lose dice game
dicegame play
# Guess the dice number (replace <number> with your guess, e.g. 4)
dicegame guess 4
## In interactive mode:
- Type the command 'guess'
- You'll be prompted for your guess
# Display a list of all registered players
dicegame player list
# Display the leaderboard sorted by score
dicegame leaderboard
# Reset the currently logged-in player's score to zero
dicegame reset score
- You'll gwt a password prompt for verification
# Reset a player's password
dicegame reset password
- You'll get a password prompt for verification
# Delete the currently logged-in player's account (password required)
dicegame player delete
- You'll get a password prompt for verification
### **Note**
- If you did not install the app system-wide, replace `dicegame` with:
- `python -m dicegame`
- or `python main.py`
- In interactive mode you only type the command without the APP_NAME('dicegame')
## 📦 DiceGame is now on PyPI!
I’m excited to announce that **DiceGame** is officially published on PyPI.
You can install it using:
```bash
pip install dicegame
Check out the PyPI page here: https://pypi.org/project/dicegame/
## Motivation
This project was born from the desire to **explore Python, CLI design, and application state management** in a hands-on way.
While small in scope, it serves multiple purposes:
- **Experimentation and learning**: Testing out interactive and non-interactive workflows, persistent sessions, and secure user handling.
- **Practical tool-building**: Creating a usable CLI for games with score tracking, authentication, and logging.
- **Structured development practice**: Applying versioning, releases, and incremental improvements to learn disciplined software evolution.
- **Emphasis on reliability and privacy**: Implementing logging, debug flags, and per-user actions with attention to security and user experience.
In short, this project is as much about **growing as a developer** as it is about providing a functional command-line application.
## VERSION AND FEATURES
## [0.7.0] - 2026-02-17
**Key updates in this release:**
## Added Features
- Informative command help.
- Automatic help if no arguments are provided.
- Redaction of sensitive information in logs for privacy
---------------------------------------------
## [0.6.0] - 2026-01-30
**Key updates in this release:**
## Added Features
### Authentication & Accounts
- User **signup** with automatic login after successful registration
- **Login / Logout** with session persistence on local disk for cli and interactive modes
- **Guest mode** included (Now supported also in interactive mode)
- **whoami** command
- Displays `Not logged in` if no user is authenticated
- Displays the current username if logged in
- **player delete**
- Only the account currently logged in can be deleted
- **reset password**
- Only allowed for the currently logged-in account
---
### Gameplay
- **reset score** command
- Only allowed for the logged-in user
- Aborts if the score is already `0`
---
### Interactive Mode
- Full feature parity with non-interactive mode
- Uses **local disk persistence** (not in-memory state)
- Guest users can interact without logging in
---
### Logging & Debugging
- Structured application logging
- `--debug` flag enables verbose/debug output
- **log list**
- Shows all available log files
- **log clear**
- Clears all application logs
---
### Privacy-Respecting Bug Reporting
- **report-bug** command
- Requests explicit user consent
- Packages all application logs into a ZIP file
- User manually sends the ZIP to the developer via email
- No automatic data transmission
---
## Commands Overview
### Authentication
- `whoami`
- `reset password`
- `player delete`
### Game
- `reset score`
### Logs & Diagnostics
- `log list`
- `log clear`
- `report-bug`
### Global Flags
- `--debug` — Enable debug mode
---
## Design Principles
- Clear **command / service separation**
- Explicit session management via a `Session` domain object
- Fail-fast validation (authentication, state checks)
- Privacy-first logging and diagnostics
- CLI-friendly error handling (no silent failures)
---------------------------------------
## [0.5.0] - 2026-01-22
**Key updates in this release:**
This release introduces **session persistence**, **improved score management**, and a **clean separation between interactive and non-interactive gameplay**.
Version **0.5.0** focuses on making the CLI more realistic, user-friendly, and aligned with production-grade CLI design.
### Added
### 🔐 Session Persistence for CLI
- Added **database-backed session handling**
- Session token is **saved locally** to persist login across runs
- Only **one active user session** is stored at a time
- Logout clears the local session
---
### 💾 Score Persistence in CLI/Non-interactive mode
- Scores are stored in the **database**
- Leaderboard updates automatically
- Score persistence now works in:
- Interactive mode (since v0.1.0)
- Non-interactive mode (Added in v0.5.0)
- Both `play` and `guess` commands
---
### 👤 Guest vs Authenticated Play
- Users may **play without logging in** in CLI only not in interactive mode
- Guest gameplay:
- Uses in-memory state only
- Scores are **not saved**
- Authenticated users:
- Have scores persisted
- Appear on the leaderboard
---
### 🔄 Reset Score Capability
- Added **reset score to zero** option (reset)
- Includes **confirmation prompt** to prevent accidental resets
- Applies only to the currently logged-in user
---
## 🧩 Architectural Improvements
- Clear separation between:
- **Interactive** (in-memory) flows
- **Non-interactive** (persistent) flows
- Authentication-aware score handling
- Clean boundaries between gameplay, persistence, and session logic
---------------------------------------
## [0.4.0] – 2026-01-21
**Key updates in this release:**
### Added
- Introduced a new `play` command for the Win/Lose dice game mode.
### Changed
- Renamed the `display` command to `roll` to improve clarity and consistency across the CLI.
### Fixed
- Prevented deletion of the currently active account.
- Added password confirmation for account deletion in both CLI and interactive modes to enhance security.
-----------------------------------------
## [0.3.0] – 2026-01-20
**Key updates in this release:**
### Added
- Formatted leaderboard table for clear and structured score display
- Formatted players table for improved readability of the player list
### Changed
- Renamed CLI commands for better semantics and consistency:
- `view users` → `player list`
- `view scores` → `leaderboard`
- `delete user` → `player delete`
- Improved overall CLI user experience and command clarity
### Fixed
- Resolved issue where delete success/error message was displayed after three failed delete attempts
-------------------------------------------
## [0.2.0] – 2026-01-20
**Key updates in this release:**
- Introduced colorful console messages using [Rich](https://rich.readthedocs.io/en/stable/) for better UI/UX.
- Added an interactive session panel to make gameplay more engaging.
- Added a progress bar animation for the dice roll to enhance visual feedback.
---------------------------------------------
## [0.1.0] 2026-01-17
- User registration and login
- Secure password hashing (Argon2)
- SQLite score storage persistence
- CLI interface using argparse
- in-memory state for interactive mode
## Authentication & Sessions
- Users can **sign up, log in, and log out**
- A **session token is saved locally** to persist login across CLI runs
- Only **one active session** is stored at a time
- Logging out clears the local session
### Guest Mode
- Users may play without logging in
- Guest progress is **kept in memory only**
- Guest scores are **not saved to the database**
- Only authenticated users appear on the leaderboard
## Game Modes
### Interactive Mode
- Newer versions use **local session persistence** for active gameplay
- Dice rolls and guesses are ephemeral
- Scores are saved to the database at the end of a game (if logged in)
### Non-Interactive Mode
- Uses **local session persistence**
- Supports score saving for:
- `play`
- `guess`
- Designed for scripted or one-off CLI usage
## Versioning Policy
This project follows **Semantic Versioning (SemVer)** using the format `vMAJOR.MINOR.PATCH`.
Because this is a **command-line application**, versioning is defined in terms of **user-facing CLI behavior**, not internal implementation details.
### Pre-1.0 Releases (`0.y.z`)
- The project is under active development.
- CLI commands, flags, defaults, and behavior may change between releases.
- All `0.x.y` versions are considered **pre-release**, even without explicit `-alpha` or `-beta` labels.
### MAJOR Version (`1.0.0`, `2.0.0`, …)
A MAJOR version change indicates **breaking changes**, including:
- Removing or renaming commands or subcommands
- Removing or renaming flags or options
- Changing command semantics in a way that breaks existing workflows
- Incompatible changes to persisted data, config formats, or on-disk state
### MINOR Version (`0.6.0` → `0.7.0`)
A MINOR version introduces:
- New commands or subcommands
- New flags or options
- Backward-compatible behavior improvements
- New functionality that does not break existing usage
### PATCH Version (`0.6.1`)
A PATCH version includes:
- Bug fixes
- Performance improvements
- Internal refactoring
- Documentation updates
- Logging, diagnostics, or error-message improvements
PATCH releases do **not** introduce breaking changes to CLI syntax or behavior.
### Releases
- Every meaningful version is tagged (e.g. `v0.6.0`)
- GitHub Releases are published for tagged versions
- All `0.x.y` releases are marked as **Pre-release**
- Stability guarantees begin at `v1.0.0`
## Configuration
The app stores session data in:
~/.local/share/dice_game/sessions
## Project Structure
project-name/ │ ├─ cli/ # Command-line interface module │ └─ init.py │ ├─ commands/ # User-facing CLI commands (signup, login, roll, play, etc.) │ ├─ db/ # Database access and storage logic │ ├─ logging/ # Logging configuration and helpers │ ├─ services/ # Core business logic / game rules │ ├─ session/ # User session management │ ├─ utils/ # Utility functions used across modules │ ├─ tests/ # Unit and integration tests │ ├─ main.py # Entry point for python -m project_name └─
## Roadmap
- Multiple player sessions
## License
- MIT License
## Author
Dennis Major
Email: dennismajor0@gmail.com
| text/markdown | null | Dennis Major <dennismajor0@gmail.com> | null | Dennis Major <dennismajor0@gmail.com> | MIT | game, dice, cli, python | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"License :: OSI Approved :: MIT License",
"Environment :: Console",
"Operating System :: OS Independent",
"Intended Audience :: End Users/Desktop",
"Topic :: Games/Entertainment"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"argon2-cffi>=23.1.0",
"rich>=13.3",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/Major-tech/dicegame",
"Repository, https://github.com/Major-tech/dicegame",
"Issues, https://github.com/Major-tech/dicegame/issues"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-19T14:38:31.540129 | dicegame-0.7.3.tar.gz | 32,588 | bf/27/40262361e890704d3f9aa4ed2920fe174096009c2faa1a7550e540d81f69/dicegame-0.7.3.tar.gz | source | sdist | null | false | 18e290ed9b3f68dee805e191579e4fc5 | 075af06392c4fe84fb84dd652298931cb1bd02870e4569ff680f2f5cc065e2af | bf2740262361e890704d3f9aa4ed2920fe174096009c2faa1a7550e540d81f69 | null | [
"LICENSE"
] | 225 |
2.4 | responses | 0.26.0 | A utility library for mocking out the `requests` Python library. | Responses
=========
.. image:: https://img.shields.io/pypi/v/responses.svg
:target: https://pypi.python.org/pypi/responses/
.. image:: https://img.shields.io/pypi/pyversions/responses.svg
:target: https://pypi.org/project/responses/
.. image:: https://img.shields.io/pypi/dm/responses
:target: https://pypi.python.org/pypi/responses/
.. image:: https://codecov.io/gh/getsentry/responses/branch/master/graph/badge.svg
:target: https://codecov.io/gh/getsentry/responses/
A utility library for mocking out the ``requests`` Python library.
.. note::
Responses requires Python 3.8 or newer, and requests >= 2.30.0
Table of Contents
-----------------
.. contents::
Installing
----------
``pip install responses``
Deprecations and Migration Path
-------------------------------
Here you will find a list of deprecated functionality and a migration path for each.
Please ensure to update your code according to the guidance.
.. list-table:: Deprecation and Migration
:widths: 50 25 50
:header-rows: 1
* - Deprecated Functionality
- Deprecated in Version
- Migration Path
* - ``responses.json_params_matcher``
- 0.14.0
- ``responses.matchers.json_params_matcher``
* - ``responses.urlencoded_params_matcher``
- 0.14.0
- ``responses.matchers.urlencoded_params_matcher``
* - ``stream`` argument in ``Response`` and ``CallbackResponse``
- 0.15.0
- Use ``stream`` argument in request directly.
* - ``match_querystring`` argument in ``Response`` and ``CallbackResponse``.
- 0.17.0
- Use ``responses.matchers.query_param_matcher`` or ``responses.matchers.query_string_matcher``
* - ``responses.assert_all_requests_are_fired``, ``responses.passthru_prefixes``, ``responses.target``
- 0.20.0
- Use ``responses.mock.assert_all_requests_are_fired``,
``responses.mock.passthru_prefixes``, ``responses.mock.target`` instead.
Basics
------
The core of ``responses`` comes from registering mock responses and covering test function
with ``responses.activate`` decorator. ``responses`` provides similar interface as ``requests``.
Main Interface
^^^^^^^^^^^^^^
* responses.add(``Response`` or ``Response args``) - allows either to register ``Response`` object or directly
provide arguments of ``Response`` object. See `Response Parameters`_
.. code-block:: python
import responses
import requests
@responses.activate
def test_simple():
# Register via 'Response' object
rsp1 = responses.Response(
method="PUT",
url="http://example.com",
)
responses.add(rsp1)
# register via direct arguments
responses.add(
responses.GET,
"http://twitter.com/api/1/foobar",
json={"error": "not found"},
status=404,
)
resp = requests.get("http://twitter.com/api/1/foobar")
resp2 = requests.put("http://example.com")
assert resp.json() == {"error": "not found"}
assert resp.status_code == 404
assert resp2.status_code == 200
assert resp2.request.method == "PUT"
If you attempt to fetch a url which doesn't hit a match, ``responses`` will raise
a ``ConnectionError``:
.. code-block:: python
import responses
import requests
from requests.exceptions import ConnectionError
@responses.activate
def test_simple():
with pytest.raises(ConnectionError):
requests.get("http://twitter.com/api/1/foobar")
Shortcuts
^^^^^^^^^
Shortcuts provide a shorten version of ``responses.add()`` where method argument is prefilled
* responses.delete(``Response args``) - register DELETE response
* responses.get(``Response args``) - register GET response
* responses.head(``Response args``) - register HEAD response
* responses.options(``Response args``) - register OPTIONS response
* responses.patch(``Response args``) - register PATCH response
* responses.post(``Response args``) - register POST response
* responses.put(``Response args``) - register PUT response
.. code-block:: python
import responses
import requests
@responses.activate
def test_simple():
responses.get(
"http://twitter.com/api/1/foobar",
json={"type": "get"},
)
responses.post(
"http://twitter.com/api/1/foobar",
json={"type": "post"},
)
responses.patch(
"http://twitter.com/api/1/foobar",
json={"type": "patch"},
)
resp_get = requests.get("http://twitter.com/api/1/foobar")
resp_post = requests.post("http://twitter.com/api/1/foobar")
resp_patch = requests.patch("http://twitter.com/api/1/foobar")
assert resp_get.json() == {"type": "get"}
assert resp_post.json() == {"type": "post"}
assert resp_patch.json() == {"type": "patch"}
Responses as a context manager
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Instead of wrapping the whole function with decorator you can use a context manager.
.. code-block:: python
import responses
import requests
def test_my_api():
with responses.RequestsMock() as rsps:
rsps.add(
responses.GET,
"http://twitter.com/api/1/foobar",
body="{}",
status=200,
content_type="application/json",
)
resp = requests.get("http://twitter.com/api/1/foobar")
assert resp.status_code == 200
# outside the context manager requests will hit the remote server
resp = requests.get("http://twitter.com/api/1/foobar")
resp.status_code == 404
Response Parameters
-------------------
The following attributes can be passed to a Response mock:
method (``str``)
The HTTP method (GET, POST, etc).
url (``str`` or ``compiled regular expression``)
The full resource URL.
match_querystring (``bool``)
DEPRECATED: Use ``responses.matchers.query_param_matcher`` or
``responses.matchers.query_string_matcher``
Include the query string when matching requests.
Enabled by default if the response URL contains a query string,
disabled if it doesn't or the URL is a regular expression.
body (``str`` or ``BufferedReader`` or ``Exception``)
The response body. Read more `Exception as Response body`_
json
A Python object representing the JSON response body. Automatically configures
the appropriate Content-Type.
status (``int``)
The HTTP status code.
content_type (``content_type``)
Defaults to ``text/plain``.
headers (``dict``)
Response headers.
stream (``bool``)
DEPRECATED: use ``stream`` argument in request directly
auto_calculate_content_length (``bool``)
Disabled by default. Automatically calculates the length of a supplied string or JSON body.
match (``tuple``)
An iterable (``tuple`` is recommended) of callbacks to match requests
based on request attributes.
Current module provides multiple matchers that you can use to match:
* body contents in JSON format
* body contents in URL encoded data format
* request query parameters
* request query string (similar to query parameters but takes string as input)
* kwargs provided to request e.g. ``stream``, ``verify``
* 'multipart/form-data' content and headers in request
* request headers
* request fragment identifier
Alternatively user can create custom matcher.
Read more `Matching Requests`_
Exception as Response body
--------------------------
You can pass an ``Exception`` as the body to trigger an error on the request:
.. code-block:: python
import responses
import requests
@responses.activate
def test_simple():
responses.get("http://twitter.com/api/1/foobar", body=Exception("..."))
with pytest.raises(Exception):
requests.get("http://twitter.com/api/1/foobar")
Matching Requests
-----------------
Matching Request Body Contents
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
When adding responses for endpoints that are sent request data you can add
matchers to ensure your code is sending the right parameters and provide
different responses based on the request body contents. ``responses`` provides
matchers for JSON and URL-encoded request bodies.
URL-encoded data
""""""""""""""""
.. code-block:: python
import responses
import requests
from responses import matchers
@responses.activate
def test_calc_api():
responses.post(
url="http://calc.com/sum",
body="4",
match=[matchers.urlencoded_params_matcher({"left": "1", "right": "3"})],
)
requests.post("http://calc.com/sum", data={"left": 1, "right": 3})
JSON encoded data
"""""""""""""""""
Matching JSON encoded data can be done with ``matchers.json_params_matcher()``.
.. code-block:: python
import responses
import requests
from responses import matchers
@responses.activate
def test_calc_api():
responses.post(
url="http://example.com/",
body="one",
match=[
matchers.json_params_matcher({"page": {"name": "first", "type": "json"}})
],
)
resp = requests.request(
"POST",
"http://example.com/",
headers={"Content-Type": "application/json"},
json={"page": {"name": "first", "type": "json"}},
)
Query Parameters Matcher
^^^^^^^^^^^^^^^^^^^^^^^^
Query Parameters as a Dictionary
""""""""""""""""""""""""""""""""
You can use the ``matchers.query_param_matcher`` function to match
against the ``params`` request parameter. Just use the same dictionary as you
will use in ``params`` argument in ``request``.
Note, do not use query parameters as part of the URL. Avoid using ``match_querystring``
deprecated argument.
.. code-block:: python
import responses
import requests
from responses import matchers
@responses.activate
def test_calc_api():
url = "http://example.com/test"
params = {"hello": "world", "I am": "a big test"}
responses.get(
url=url,
body="test",
match=[matchers.query_param_matcher(params)],
)
resp = requests.get(url, params=params)
constructed_url = r"http://example.com/test?I+am=a+big+test&hello=world"
assert resp.url == constructed_url
assert resp.request.url == constructed_url
assert resp.request.params == params
By default, matcher will validate that all parameters match strictly.
To validate that only parameters specified in the matcher are present in original request
use ``strict_match=False``.
Query Parameters as a String
""""""""""""""""""""""""""""
As alternative, you can use query string value in ``matchers.query_string_matcher`` to match
query parameters in your request
.. code-block:: python
import requests
import responses
from responses import matchers
@responses.activate
def my_func():
responses.get(
"https://httpbin.org/get",
match=[matchers.query_string_matcher("didi=pro&test=1")],
)
resp = requests.get("https://httpbin.org/get", params={"test": 1, "didi": "pro"})
my_func()
Request Keyword Arguments Matcher
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
To validate request arguments use the ``matchers.request_kwargs_matcher`` function to match
against the request kwargs.
Only following arguments are supported: ``timeout``, ``verify``, ``proxies``, ``stream``, ``cert``.
Note, only arguments provided to ``matchers.request_kwargs_matcher`` will be validated.
.. code-block:: python
import responses
import requests
from responses import matchers
with responses.RequestsMock(assert_all_requests_are_fired=False) as rsps:
req_kwargs = {
"stream": True,
"verify": False,
}
rsps.add(
"GET",
"http://111.com",
match=[matchers.request_kwargs_matcher(req_kwargs)],
)
requests.get("http://111.com", stream=True)
# >>> Arguments don't match: {stream: True, verify: True} doesn't match {stream: True, verify: False}
Request multipart/form-data Data Validation
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
To validate request body and headers for ``multipart/form-data`` data you can use
``matchers.multipart_matcher``. The ``data``, and ``files`` parameters provided will be compared
to the request:
.. code-block:: python
import requests
import responses
from responses.matchers import multipart_matcher
@responses.activate
def my_func():
req_data = {"some": "other", "data": "fields"}
req_files = {"file_name": b"Old World!"}
responses.post(
url="http://httpbin.org/post",
match=[multipart_matcher(req_files, data=req_data)],
)
resp = requests.post("http://httpbin.org/post", files={"file_name": b"New World!"})
my_func()
# >>> raises ConnectionError: multipart/form-data doesn't match. Request body differs.
Request Fragment Identifier Validation
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
To validate request URL fragment identifier you can use ``matchers.fragment_identifier_matcher``.
The matcher takes fragment string (everything after ``#`` sign) as input for comparison:
.. code-block:: python
import requests
import responses
from responses.matchers import fragment_identifier_matcher
@responses.activate
def run():
url = "http://example.com?ab=xy&zed=qwe#test=1&foo=bar"
responses.get(
url,
match=[fragment_identifier_matcher("test=1&foo=bar")],
body=b"test",
)
# two requests to check reversed order of fragment identifier
resp = requests.get("http://example.com?ab=xy&zed=qwe#test=1&foo=bar")
resp = requests.get("http://example.com?zed=qwe&ab=xy#foo=bar&test=1")
run()
Request Headers Validation
^^^^^^^^^^^^^^^^^^^^^^^^^^
When adding responses you can specify matchers to ensure that your code is
sending the right headers and provide different responses based on the request
headers.
.. code-block:: python
import responses
import requests
from responses import matchers
@responses.activate
def test_content_type():
responses.get(
url="http://example.com/",
body="hello world",
match=[matchers.header_matcher({"Accept": "text/plain"})],
)
responses.get(
url="http://example.com/",
json={"content": "hello world"},
match=[matchers.header_matcher({"Accept": "application/json"})],
)
# request in reverse order to how they were added!
resp = requests.get("http://example.com/", headers={"Accept": "application/json"})
assert resp.json() == {"content": "hello world"}
resp = requests.get("http://example.com/", headers={"Accept": "text/plain"})
assert resp.text == "hello world"
Because ``requests`` will send several standard headers in addition to what was
specified by your code, request headers that are additional to the ones
passed to the matcher are ignored by default. You can change this behaviour by
passing ``strict_match=True`` to the matcher to ensure that only the headers
that you're expecting are sent and no others. Note that you will probably have
to use a ``PreparedRequest`` in your code to ensure that ``requests`` doesn't
include any additional headers.
.. code-block:: python
import responses
import requests
from responses import matchers
@responses.activate
def test_content_type():
responses.get(
url="http://example.com/",
body="hello world",
match=[matchers.header_matcher({"Accept": "text/plain"}, strict_match=True)],
)
# this will fail because requests adds its own headers
with pytest.raises(ConnectionError):
requests.get("http://example.com/", headers={"Accept": "text/plain"})
# a prepared request where you overwrite the headers before sending will work
session = requests.Session()
prepped = session.prepare_request(
requests.Request(
method="GET",
url="http://example.com/",
)
)
prepped.headers = {"Accept": "text/plain"}
resp = session.send(prepped)
assert resp.text == "hello world"
Creating Custom Matcher
^^^^^^^^^^^^^^^^^^^^^^^
If your application requires other encodings or different data validation you can build
your own matcher that returns ``Tuple[matches: bool, reason: str]``.
Where boolean represents ``True`` or ``False`` if the request parameters match and
the string is a reason in case of match failure. Your matcher can
expect a ``PreparedRequest`` parameter to be provided by ``responses``.
Note, ``PreparedRequest`` is customized and has additional attributes ``params`` and ``req_kwargs``.
Response Registry
---------------------------
Default Registry
^^^^^^^^^^^^^^^^
By default, ``responses`` will search all registered ``Response`` objects and
return a match. If only one ``Response`` is registered, the registry is kept unchanged.
However, if multiple matches are found for the same request, then first match is returned and
removed from registry.
Ordered Registry
^^^^^^^^^^^^^^^^
In some scenarios it is important to preserve the order of the requests and responses.
You can use ``registries.OrderedRegistry`` to force all ``Response`` objects to be dependent
on the insertion order and invocation index.
In following example we add multiple ``Response`` objects that target the same URL. However,
you can see, that status code will depend on the invocation order.
.. code-block:: python
import requests
import responses
from responses.registries import OrderedRegistry
@responses.activate(registry=OrderedRegistry)
def test_invocation_index():
responses.get(
"http://twitter.com/api/1/foobar",
json={"msg": "not found"},
status=404,
)
responses.get(
"http://twitter.com/api/1/foobar",
json={"msg": "OK"},
status=200,
)
responses.get(
"http://twitter.com/api/1/foobar",
json={"msg": "OK"},
status=200,
)
responses.get(
"http://twitter.com/api/1/foobar",
json={"msg": "not found"},
status=404,
)
resp = requests.get("http://twitter.com/api/1/foobar")
assert resp.status_code == 404
resp = requests.get("http://twitter.com/api/1/foobar")
assert resp.status_code == 200
resp = requests.get("http://twitter.com/api/1/foobar")
assert resp.status_code == 200
resp = requests.get("http://twitter.com/api/1/foobar")
assert resp.status_code == 404
Custom Registry
^^^^^^^^^^^^^^^
Built-in ``registries`` are suitable for most of use cases, but to handle special conditions, you can
implement custom registry which must follow interface of ``registries.FirstMatchRegistry``.
Redefining the ``find`` method will allow you to create custom search logic and return
appropriate ``Response``
Example that shows how to set custom registry
.. code-block:: python
import responses
from responses import registries
class CustomRegistry(registries.FirstMatchRegistry):
pass
print("Before tests:", responses.mock.get_registry())
""" Before tests: <responses.registries.FirstMatchRegistry object> """
# using function decorator
@responses.activate(registry=CustomRegistry)
def run():
print("Within test:", responses.mock.get_registry())
""" Within test: <__main__.CustomRegistry object> """
run()
print("After test:", responses.mock.get_registry())
""" After test: <responses.registries.FirstMatchRegistry object> """
# using context manager
with responses.RequestsMock(registry=CustomRegistry) as rsps:
print("In context manager:", rsps.get_registry())
""" In context manager: <__main__.CustomRegistry object> """
print("After exit from context manager:", responses.mock.get_registry())
"""
After exit from context manager: <responses.registries.FirstMatchRegistry object>
"""
Dynamic Responses
-----------------
You can utilize callbacks to provide dynamic responses. The callback must return
a tuple of (``status``, ``headers``, ``body``).
.. code-block:: python
import json
import responses
import requests
@responses.activate
def test_calc_api():
def request_callback(request):
payload = json.loads(request.body)
resp_body = {"value": sum(payload["numbers"])}
headers = {"request-id": "728d329e-0e86-11e4-a748-0c84dc037c13"}
return (200, headers, json.dumps(resp_body))
responses.add_callback(
responses.POST,
"http://calc.com/sum",
callback=request_callback,
content_type="application/json",
)
resp = requests.post(
"http://calc.com/sum",
json.dumps({"numbers": [1, 2, 3]}),
headers={"content-type": "application/json"},
)
assert resp.json() == {"value": 6}
assert len(responses.calls) == 1
assert responses.calls[0].request.url == "http://calc.com/sum"
assert responses.calls[0].response.text == '{"value": 6}'
assert (
responses.calls[0].response.headers["request-id"]
== "728d329e-0e86-11e4-a748-0c84dc037c13"
)
You can also pass a compiled regex to ``add_callback`` to match multiple urls:
.. code-block:: python
import re, json
from functools import reduce
import responses
import requests
operators = {
"sum": lambda x, y: x + y,
"prod": lambda x, y: x * y,
"pow": lambda x, y: x**y,
}
@responses.activate
def test_regex_url():
def request_callback(request):
payload = json.loads(request.body)
operator_name = request.path_url[1:]
operator = operators[operator_name]
resp_body = {"value": reduce(operator, payload["numbers"])}
headers = {"request-id": "728d329e-0e86-11e4-a748-0c84dc037c13"}
return (200, headers, json.dumps(resp_body))
responses.add_callback(
responses.POST,
re.compile("http://calc.com/(sum|prod|pow|unsupported)"),
callback=request_callback,
content_type="application/json",
)
resp = requests.post(
"http://calc.com/prod",
json.dumps({"numbers": [2, 3, 4]}),
headers={"content-type": "application/json"},
)
assert resp.json() == {"value": 24}
test_regex_url()
If you want to pass extra keyword arguments to the callback function, for example when reusing
a callback function to give a slightly different result, you can use ``functools.partial``:
.. code-block:: python
from functools import partial
def request_callback(request, id=None):
payload = json.loads(request.body)
resp_body = {"value": sum(payload["numbers"])}
headers = {"request-id": id}
return (200, headers, json.dumps(resp_body))
responses.add_callback(
responses.POST,
"http://calc.com/sum",
callback=partial(request_callback, id="728d329e-0e86-11e4-a748-0c84dc037c13"),
content_type="application/json",
)
Integration with unit test frameworks
-------------------------------------
Responses as a ``pytest`` fixture
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Use the pytest-responses package to export ``responses`` as a pytest fixture.
``pip install pytest-responses``
You can then access it in a pytest script using:
.. code-block:: python
import pytest_responses
def test_api(responses):
responses.get(
"http://twitter.com/api/1/foobar",
body="{}",
status=200,
content_type="application/json",
)
resp = requests.get("http://twitter.com/api/1/foobar")
assert resp.status_code == 200
Add default responses for each test
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
When run with ``unittest`` tests, this can be used to set up some
generic class-level responses, that may be complemented by each test.
Similar interface could be applied in ``pytest`` framework.
.. code-block:: python
class TestMyApi(unittest.TestCase):
def setUp(self):
responses.get("https://example.com", body="within setup")
# here go other self.responses.add(...)
@responses.activate
def test_my_func(self):
responses.get(
"https://httpbin.org/get",
match=[matchers.query_param_matcher({"test": "1", "didi": "pro"})],
body="within test",
)
resp = requests.get("https://example.com")
resp2 = requests.get(
"https://httpbin.org/get", params={"test": "1", "didi": "pro"}
)
print(resp.text)
# >>> within setup
print(resp2.text)
# >>> within test
RequestMock methods: start, stop, reset
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``responses`` has ``start``, ``stop``, ``reset`` methods very analogous to
`unittest.mock.patch <https://docs.python.org/3/library/unittest.mock.html#patch-methods-start-and-stop>`_.
These make it simpler to do requests mocking in ``setup`` methods or where
you want to do multiple patches without nesting decorators or with statements.
.. code-block:: python
class TestUnitTestPatchSetup:
def setup(self):
"""Creates ``RequestsMock`` instance and starts it."""
self.r_mock = responses.RequestsMock(assert_all_requests_are_fired=True)
self.r_mock.start()
# optionally some default responses could be registered
self.r_mock.get("https://example.com", status=505)
self.r_mock.put("https://example.com", status=506)
def teardown(self):
"""Stops and resets RequestsMock instance.
If ``assert_all_requests_are_fired`` is set to ``True``, will raise an error
if some requests were not processed.
"""
self.r_mock.stop()
self.r_mock.reset()
def test_function(self):
resp = requests.get("https://example.com")
assert resp.status_code == 505
resp = requests.put("https://example.com")
assert resp.status_code == 506
Assertions on declared responses
--------------------------------
When used as a context manager, Responses will, by default, raise an assertion
error if a url was registered but not accessed. This can be disabled by passing
the ``assert_all_requests_are_fired`` value:
.. code-block:: python
import responses
import requests
def test_my_api():
with responses.RequestsMock(assert_all_requests_are_fired=False) as rsps:
rsps.add(
responses.GET,
"http://twitter.com/api/1/foobar",
body="{}",
status=200,
content_type="application/json",
)
When ``assert_all_requests_are_fired=True`` and an exception occurs within the
context manager, assertions about unfired requests will still be raised. This
provides valuable context about which mocked requests were or weren't called
when debugging test failures.
.. code-block:: python
import responses
import requests
def test_with_exception():
with responses.RequestsMock(assert_all_requests_are_fired=True) as rsps:
rsps.add(responses.GET, "http://example.com/users", body="test")
rsps.add(responses.GET, "http://example.com/profile", body="test")
requests.get("http://example.com/users")
raise ValueError("Something went wrong")
# Output:
# ValueError: Something went wrong
#
# During handling of the above exception, another exception occurred:
#
# AssertionError: Not all requests have been executed [('GET', 'http://example.com/profile')]
Assert Request Call Count
-------------------------
Assert based on ``Response`` object
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Each ``Response`` object has ``call_count`` attribute that could be inspected
to check how many times each request was matched.
.. code-block:: python
@responses.activate
def test_call_count_with_matcher():
rsp = responses.get(
"http://www.example.com",
match=(matchers.query_param_matcher({}),),
)
rsp2 = responses.get(
"http://www.example.com",
match=(matchers.query_param_matcher({"hello": "world"}),),
status=777,
)
requests.get("http://www.example.com")
resp1 = requests.get("http://www.example.com")
requests.get("http://www.example.com?hello=world")
resp2 = requests.get("http://www.example.com?hello=world")
assert resp1.status_code == 200
assert resp2.status_code == 777
assert rsp.call_count == 2
assert rsp2.call_count == 2
Assert based on the exact URL
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Assert that the request was called exactly n times.
.. code-block:: python
import responses
import requests
@responses.activate
def test_assert_call_count():
responses.get("http://example.com")
requests.get("http://example.com")
assert responses.assert_call_count("http://example.com", 1) is True
requests.get("http://example.com")
with pytest.raises(AssertionError) as excinfo:
responses.assert_call_count("http://example.com", 1)
assert (
"Expected URL 'http://example.com' to be called 1 times. Called 2 times."
in str(excinfo.value)
)
@responses.activate
def test_assert_call_count_always_match_qs():
responses.get("http://www.example.com")
requests.get("http://www.example.com")
requests.get("http://www.example.com?hello=world")
# One call on each url, querystring is matched by default
responses.assert_call_count("http://www.example.com", 1) is True
responses.assert_call_count("http://www.example.com?hello=world", 1) is True
Assert Request Calls data
-------------------------
``Request`` object has ``calls`` list which elements correspond to ``Call`` objects
in the global list of ``Registry``. This can be useful when the order of requests is not
guaranteed, but you need to check their correctness, for example in multithreaded
applications.
.. code-block:: python
import concurrent.futures
import responses
import requests
@responses.activate
def test_assert_calls_on_resp():
rsp1 = responses.patch("http://www.foo.bar/1/", status=200)
rsp2 = responses.patch("http://www.foo.bar/2/", status=400)
rsp3 = responses.patch("http://www.foo.bar/3/", status=200)
def update_user(uid, is_active):
url = f"http://www.foo.bar/{uid}/"
response = requests.patch(url, json={"is_active": is_active})
return response
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
future_to_uid = {
executor.submit(update_user, uid, is_active): uid
for (uid, is_active) in [("3", True), ("2", True), ("1", False)]
}
for future in concurrent.futures.as_completed(future_to_uid):
uid = future_to_uid[future]
response = future.result()
print(f"{uid} updated with {response.status_code} status code")
assert len(responses.calls) == 3 # total calls count
assert rsp1.call_count == 1
assert rsp1.calls[0] in responses.calls
assert rsp1.calls[0].response.status_code == 200
assert json.loads(rsp1.calls[0].request.body) == {"is_active": False}
assert rsp2.call_count == 1
assert rsp2.calls[0] in responses.calls
assert rsp2.calls[0].response.status_code == 400
assert json.loads(rsp2.calls[0].request.body) == {"is_active": True}
assert rsp3.call_count == 1
assert rsp3.calls[0] in responses.calls
assert rsp3.calls[0].response.status_code == 200
assert json.loads(rsp3.calls[0].request.body) == {"is_active": True}
Multiple Responses
------------------
You can also add multiple responses for the same url:
.. code-block:: python
import responses
import requests
@responses.activate
def test_my_api():
responses.get("http://twitter.com/api/1/foobar", status=500)
responses.get(
"http://twitter.com/api/1/foobar",
body="{}",
status=200,
content_type="application/json",
)
resp = requests.get("http://twitter.com/api/1/foobar")
assert resp.status_code == 500
resp = requests.get("http://twitter.com/api/1/foobar")
assert resp.status_code == 200
URL Redirection
---------------
In the following example you can see how to create a redirection chain and add custom exception that will be raised
in the execution chain and contain the history of redirects.
.. code-block::
A -> 301 redirect -> B
B -> 301 redirect -> C
C -> connection issue
.. code-block:: python
import pytest
import requests
import responses
@responses.activate
def test_redirect():
# create multiple Response objects where first two contain redirect headers
rsp1 = responses.Response(
responses.GET,
"http://example.com/1",
status=301,
headers={"Location": "http://example.com/2"},
)
rsp2 = responses.Response(
responses.GET,
"http://example.com/2",
status=301,
headers={"Location": "http://example.com/3"},
)
rsp3 = responses.Response(responses.GET, "http://example.com/3", status=200)
# register above generated Responses in ``response`` module
responses.add(rsp1)
responses.add(rsp2)
responses.add(rsp3)
# do the first request in order to generate genuine ``requests`` response
# this object will contain genuine attributes of the response, like ``history``
rsp = requests.get("http://example.com/1")
responses.calls.reset()
# customize exception with ``response`` attribute
my_error = requests.ConnectionError("custom error")
my_error.response = rsp
# update body of the 3rd response with Exception, this will be raised during execution
rsp3.body = my_error
with pytest.raises(requests.ConnectionError) as exc_info:
requests.get("http://example.com/1")
assert exc_info.value.args[0] == "custom error"
assert rsp1.url in exc_info.value.response.history[0].url
assert rsp2.url in exc_info.value.response.history[1].url
Validate ``Retry`` mechanism
----------------------------
If you are using the ``Retry`` features of ``urllib3`` and want to cover scenarios that test your retry limits, you can test those scenarios with ``responses`` as well. The best approach will be to use an `Ordered Registry`_
.. code-block:: python
import requests
import responses
from responses import registries
from urllib3.util import Retry
@responses.activate(registry=registries.OrderedRegistry)
def test_max_retries():
url = "https://example.com"
rsp1 = responses.get(url, body="Error", status=500)
rsp2 = responses.get(url, body="Error", status=500)
rsp3 = responses.get(url, body="Error", status=500)
rsp4 = responses.get(url, body="OK", status=200)
session = requests.Session()
adapter = requests.adapters.HTTPAdapter(
max_retries=Retry(
total=4,
backoff_factor=0.1,
status_forcelist=[500],
method_whitelist=["GET", "POST", "PATCH"],
)
)
session.mount("https://", adapter)
resp = session.get(url)
assert resp.status_code == 200
assert rsp1.call_count == 1
assert rsp2.call_count == 1
assert rsp3.call_count == 1
assert rsp4.call_count == 1
Using a callback to modify the response
---------------------------------------
If you use customized processing in ``requests`` via subclassing/mixins, or if you
have library tools that interact with ``requests`` at a low level, you may need
to add extended processing to the mocked Response object to fully simulate the
environment for your tests. A ``response_callback`` can be used, which will be
wrapped by the library before being returned to the caller. The callback
accepts a ``response`` as it's single argument, and is expected to return a
single ``response`` object.
.. code-block:: python
import responses
import requests
def response_callback(resp):
resp.callback_processed = True
return resp
with responses.RequestsMock(response_callback=response_callback) as m:
m.add(responses.GET, "http://example.com", body=b"test")
resp = requests.get("http://example.com")
assert resp.text == "test"
assert hasattr(resp, "callback_processed")
assert resp.callback_processed is True
Passing through real requests
-----------------------------
In some cases you may wish to allow for certain requests to pass through responses
and hit a real server. This can be done with the ``add_passthru`` methods:
.. code-block:: python
import responses
@responses.activate
def test_my_api():
responses.add_passthru("https://percy.io")
This will allow any requests matching that prefix, that is otherwise not
registered as a mock response, to passthru using the standard behavior.
Pass through endpoints can be configured with regex patterns if you
need to allow an entire domain or path subtree to send requests:
.. code-block:: python
responses.add_passthru(re.compile("https://percy.io/\\w+"))
Lastly, you can use the ``passthrough`` argument of the ``Response`` object
to force a response to behave as a pass through.
.. code-block:: python
# Enable passthrough for a single response
response = Response(
responses.GET,
"http://example.com",
body="not used",
passthrough=True,
)
responses.add(response)
# Use PassthroughResponse
response = PassthroughResponse(responses.GET, "http://example.com")
responses.add(response)
Viewing/Modifying registered responses
--------------------------------------
Registered responses are available as a public method of the RequestMock
instance. It is sometimes useful for debugging purposes to view the stack of
registered responses which can be accessed via ``responses.registered()``.
The ``replace`` function allows a previously registered ``response`` to be
changed. The method signature is identical to ``add``. ``response`` s are
identified using ``method`` and ``url``. Only the first matched ``response`` is
replaced.
.. code-block:: python
import responses
import requests
@responses.activate
def test_replace():
responses.get("http://example.org", json={"data": 1})
responses.replace(responses.GET, "http://example.org", json={"data": 2})
| text/x-rst | David Cramer | null | null | null | Apache 2.0 | null | [
"Intended Audience :: Developers",
"Intended Audience :: System Administrators",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Pyt... | [] | https://github.com/getsentry/responses | null | >=3.8 | [] | [] | [] | [
"requests<3.0,>=2.30.0",
"urllib3<3.0,>=1.25.10",
"pyyaml",
"pytest>=7.0.0; extra == \"tests\"",
"coverage>=6.0.0; extra == \"tests\"",
"pytest-cov; extra == \"tests\"",
"pytest-asyncio; extra == \"tests\"",
"pytest-httpserver; extra == \"tests\"",
"flake8; extra == \"tests\"",
"types-PyYAML; extr... | [] | [] | [] | [
"Bug Tracker, https://github.com/getsentry/responses/issues",
"Changes, https://github.com/getsentry/responses/blob/master/CHANGES",
"Documentation, https://github.com/getsentry/responses/blob/master/README.rst",
"Source Code, https://github.com/getsentry/responses"
] | twine/6.1.0 CPython/3.11.2 | 2026-02-19T14:38:05.574820 | responses-0.26.0.tar.gz | 81,303 | 9f/b4/b7e040379838cc71bf5aabdb26998dfbe5ee73904c92c1c161faf5de8866/responses-0.26.0.tar.gz | source | sdist | null | false | c2539fcc0335e60c5526081ffaff93fd | c7f6923e6343ef3682816ba421c006626777893cb0d5e1434f674b649bac9eb4 | 9fb4b7e040379838cc71bf5aabdb26998dfbe5ee73904c92c1c161faf5de8866 | null | [
"LICENSE"
] | 1,173,879 |
2.4 | indico-patcher | 0.3.2 | The Swiss Army knife to customize Indico | # Indico Patcher
<!-- XXX: All the links must remain absolute. This README.md file is used to generate the description for the project in PyPI. Relative links will not work in PyPI. -->
The Swiss Army knife for [Indico](https://getindico.io/) plugin development.
Indico plugin development primarily relies on [`flask-pluginengine`](https://github.com/indico/flask-pluginengine), [Jinja](https://github.com/pallets/jinja) template hooks or core [signals](https://github.com/indico/indico/tree/master/indico/core/signals) to extend and modify system functionality. This, however, falls short in many other cases. Indico Patcher offers a clean interface to patch Indico code at runtime, allowing for things such as:
- Adding or overriding properties and intercepting methods in classes
- Reordering, modifying and removing fields in WTForms forms
- Adding new columns and relationships to SQLAlchemy models
- Adding new members to Enums
For more examples and usage information, please refer to the [patching guide](https://github.com/unconventionaldotdev/indico-patcher/blob/master/doc/README.md). For general information about Indico plugin development, please refer to the [official guide](https://docs.getindico.io/en/stable/plugins/). Not yet supported cases are tracked in [TODO.md](https://github.com/unconventionaldotdev/indico-patcher/blob/master/TODO.md).
## Installation
Indico Patcher is available on PyPI as [`indico-patcher`](https://pypi.org/project/indico-patcher/) and can be installed with `pip`:
```sh
pip install indico-patcher
```
## Usage
Indico Patcher is a library designed to be used by Indico plugins. It provides a `patch` function that can be used as a decorator to patch Indico classes and enums.
```python
from indico_patcher import patch
```
The `@patch` decorator will inject the members defined in the decorated class into a given class or enum. Check below for some examples.
### Examples
Adding a new column and a relationship to an already existing SQLAlchemy model:
```python
@patch(User)
class _User:
credit_card_id = db.Column(db.String, ForeignKey('credit_cards.id'))
credit_card = db.relationship('CreditCard', backref=backref('user'))
```
Adding a new field to an already existing WTForms form:
```python
@patch(UserPreferencesForm)
class _UserPreferencesForm:
credit_card = StringField('Credit Card')
def validate_credit_card(self, field):
...
```
Adding a new member to an already defined Enum:
```python
@patch(UserTitle, padding=100)
class _UserTitle(RichIntEnum):
__titles__ = [None, 'Madam', 'Sir', 'Rev.']
madam = 1
sir = 2
rev = 3
```
For more examples and usage information, please refer to the [patching guide](https://github.com/unconventionaldotdev/indico-patcher/blob/master/doc/README.md).
### Caveats
> [!WARNING]
> With great power comes great responsibility.
Runtime patching is a powerful and flexible strategy but it will lead to code that may break without notice as the Indico project evolves. Indico Patcher makes patching Indico dangerously easy so keep in mind a few things when using it.
1. Think of Indico Patcher as a last resort tool that abuses Indico internal API. Indico developers may change or completely remove the classes and enums that you are patching at any time.
2. If you can achieve the same result with a signal or a template hook, you should probably do that instead. These are considered stable APIs that Indico developers will try to keep backwards compatible or communicate breaking changes.
3. If the signal or hook that you need doesn't exist, consider contributing it to Indico via [pull request](https://github.com/indico/indico/pulls) or asking for it in the [Indico forum](https://talk.getindico.io/) or the official [#indico channel](https://app.element.io/#/room/#indico:matrix.org).
## Development
For developing `indico-patcher` you will need to have the following tools installed and available in your path:
- [`git`](https://git-scm.com/) (available in most systems)
- [`make`](https://www.gnu.org/software/make/) (available in most systems)
- [`uv`](https://github.com/astral-sh/uv) ([installation guide](https://docs.astral.sh/uv/getting-started/installation/))
Clone the repository locally:
```shell
git clone https://github.com/unconventionaldotdev/indico-patcher
cd indico-patcher
```
Make sure to have the right versions of `python`:
```sh
uv python install # reads from .python-version
```
Install the project with its dependencies:
```sh
make install
```
### Contributing
Run linters locally before pushing:
```sh
uv run make lint
```
Run tests with:
```sh
uv run make test
```
Tests can be run against all supported Python versions with:
```sh
uv run tox
```
| text/markdown | null | Alejandro Avilés <ome@unconventional.dev> | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Topic :: Software Development",
"Topic :: Software Development :: Libraries",
"Topic :: Software Development :: Libraries :: Application Frameworks"
] | [] | null | null | >=3.12.2 | [] | [] | [] | [
"aenum>=3.1.15",
"indico>=3.3"
] | [] | [] | [] | [
"Repository, https://github.com/unconventionaldotdev/indico-patcher",
"Documentation, https://github.com/unconventionaldotdev/indico-patcher/blob/master/doc/README.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T14:38:03.307949 | indico_patcher-0.3.2-py3-none-any.whl | 11,375 | 1f/09/bc836e1f98d3da0b6fe877923b60e4e37071fb54f94f374b3e7055ab406e/indico_patcher-0.3.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 6b314bdb3dc14f18a9cd4b62450bddfa | aa1286dd8c2314a798794a730065c6466410a9feb51c69b8a912cfaa294b4948 | 1f09bc836e1f98d3da0b6fe877923b60e4e37071fb54f94f374b3e7055ab406e | null | [
"LICENSE"
] | 99 |
2.4 | ml3-platform-sdk | 0.1.0 | ML Platform SDK | # ML3 platform client SDK
## Installation
```bash
pip install ml3-platform-sdk
```
## Usage
Please refer to the [documentation](https://ml-cube.github.io/ml3-platform-docs/)
| text/markdown | MLcube | null | null | null | GPL | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: GNU General Public License (GPL)",
"Programming Language :: Python",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | <3.13,>=3.9 | [] | [] | [] | [
"tabulate>=0.9.0",
"pydantic>=2.0",
"requests>=2.31.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.12 | 2026-02-19T14:38:01.972952 | ml3_platform_sdk-0.1.0.tar.gz | 42,641 | 54/16/821e1e8fe8f78d62b3bee4c8571051350f28741f2554726bf7b4d296c0af/ml3_platform_sdk-0.1.0.tar.gz | source | sdist | null | false | b02853487d78a0af93a9ed5a548dff48 | 4e3610b655cd445bb5f1b5d6a17fb4953ae5b73fa3f4a916a2d0b002074071aa | 5416821e1e8fe8f78d62b3bee4c8571051350f28741f2554726bf7b4d296c0af | null | [] | 214 |
2.3 | frogml | 2.1.8 | frogml contains the necessary objects and communication tools for using the JFrog ml Platform | # Frogml
Frogml is an end-to-end production ML platform designed to allow data scientists to build, deploy, and monitor their models in production with minimal engineering friction.
Frogml Core contains all the objects and tools necessary to use the Frogml Platform
## Table of contents:
- [Overview](#overview)
- [Working with Artifactory](#Working-with-Artifactory)
- [Upload ML model to Artifactory](#Upload-ML-model-to-Artifactory)
- [Local Development Setup](#local-development-setup)
## Overview
JFrog ML Storage is a smart python client library providing a simple and efficient method of storing and downloading models, model data and datasets from the JFrog platform, utilizing the advanced capabilities of the JFrog platform.
## Working with Artifactory
FrogML Storage Library support is available from Artifactory version 7.84.x.
To be able to use FrogML Storage with Artifactory, you should authenticate the frogml storage client against Artifactory.
JFrog implements a credentials provider chain. It sequentially checks each place where you can set the credentials to authenticate with FrogML, and then selects the first one you set.
### Upload ML model to Artifactory
You can upload a model to a FrogML repository using the upload_model_version() function.
You can upload a single file or an entire folder.
This function uses checksum upload, assigning a SHA2 value to each model for retrieval from storage. If the binary content cannot be reused, the smart upload mechanism performs regular upload instead.
After uploading the model, FrogML generates a file named model-info.json which contains the model name and its related files and dependencies.
The version parameter is optional. If not specified, Artifactory will set the version as the timestamp of the time you uploaded the model in your time zone, in UTC format: yyyy-MM-dd-HH-mm-ss.
Additionally, you can add properties to the model in Artifactory to categorize and label it.
The function upload_model_version returns an instance of FrogMlModelVersion, which includes the model's name, version, and namespace.
## Local Development Setup
To install FrogML locally with development dependencies, you must authenticate with **Repo21** (a private JFrog repository) to fetch the `QwakBentoML` dependency.
### 1. Generate Credentials
1. Log in to **Repo 21** via JFrog Okta.
2. Go to **User Profile** (top right) → **Set Me Up**.
3. Select **PyPI** and choose the repository `artifactory-pypi-virtual`.
4. Click **Generate Token & Create Instructions**. Your **username** and **token** will be displayed there.
### 2. Configure Poetry
Choose **one** of the following methods to authenticate:
#### Option A: Global Configuration
Run the following command to persist your credentials:
```bash
poetry config http-basic.jfrog <your_username> <your_token>
```
#### Option B: Environment Variables
Export the credentials as environment variables:
```bash
export POETRY_HTTP_BASIC_JFROG_USERNAME=<your_username>
export POETRY_HTTP_BASIC_JFROG_PASSWORD=<your_token>
```
| text/markdown | JFrog | null | null | null | Apache-2.0 | mlops, ml, deployment, serving, model | [
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Pro... | [] | null | null | <3.14,>=3.9 | [] | [] | [] | [
"python-json-logger>=2.0.2",
"grpcio<1.75,>=1.71.2",
"protobuf<5,>=4.25.8; python_version < \"3.12\"",
"protobuf<7,>=6.33.1; python_version >= \"3.12\"",
"dependency-injector>=4.0",
"requests",
"PyYAML>=6.0.2",
"filelock",
"marshmallow-dataclass<9.0.0,>=8.5.8",
"typeguard<3,>=2",
"joblib<2.0.0,>... | [] | [] | [] | [
"Home page, https://www.jfrog.com/"
] | poetry/2.1.3 CPython/3.9.25 Linux/6.12.66-88.122.amzn2023.x86_64 | 2026-02-19T14:37:09.092760 | frogml-2.1.8.tar.gz | 741,576 | b1/17/b7bdeb33cca2a47c4e4997df4cf62a1f507cc329112ca7bcf14a00568c1c/frogml-2.1.8.tar.gz | source | sdist | null | false | 61ab503f776575b60263d2e5e2ccf19a | 3f236352e4de07f737e4fad6b7db08708d19c782085ee978e38e6d4ea5d39359 | b117b7bdeb33cca2a47c4e4997df4cf62a1f507cc329112ca7bcf14a00568c1c | null | [] | 570 |
2.4 | ormantism | 0.7.1 | A lightweight ORM built on Pydantic for simple CRUD operations with minimal code | # Ormantism
A lightweight ORM built on Pydantic for simple CRUD with minimal code. Use it when you need straightforward database access without the overhead of a full-featured ORM.
**Supported backends:** SQLite (built-in), MySQL, PostgreSQL. Database URLs use the same style as SQLAlchemy.
---
## Features
- **Pydantic-based models** — Define tables with type hints and optional defaults
- **Auto table creation** — Tables are created on first use; new columns are added when the model gains fields
- **Relationships** — Single and list references to other tables; lazy loading by default
- **Preloading** — Eager-load relations with JOINs to avoid N+1 queries
- **Fluent Query API** — `Model.q().where(...).select(...).order_by(...).first()` / `.all()`
- **Timestamps** — Optional `created_at` / `updated_at` / `deleted_at` and soft deletes
- **Versioning** — Optional row history (append-only by key) via soft-deleted previous versions
- **Load-or-create** — Find by criteria or create in one call, with control over which fields are used for the lookup
- **Transactions** — Context manager with automatic commit/rollback
---
## Installation
```bash
pip install ormantism
```
SQLite works with no extra dependencies. For MySQL or PostgreSQL, install the corresponding extra:
```bash
pip install ormantism[mysql] # pymysql
pip install ormantism[postgresql] # psycopg2
pip install ormantism[mysql,postgresql]
```
**Requires:** Python 3.12+, Pydantic 2.x.
---
## Quick start
### Connect
```python
import ormantism
ormantism.connect("sqlite:///my_app.db")
# or: sqlite://:memory: | mysql://user:pass@host/db | postgresql://user:pass@host/db
```
### Define models
```python
from ormantism import Table
from typing import Optional
class User(Table, with_timestamps=True):
name: str
email: str
age: Optional[int] = None
class Post(Table, with_timestamps=True):
title: str
content: str
author: User | None = None
```
### Create and query
```python
# Create (saved automatically)
user = User(name="Alice", email="alice@example.com", age=30)
post = Post(title="Hello", content="World", author=user)
# Query: one row
user = User.q().where(User.id == 1).first()
user = User.q().where(name="Alice").first()
# Query: all matching rows
posts = Post.q().where(author=user).all()
# Update
user.age = 31 # auto-saved on assignment
user.update(age=31, email="alice@new.com")
# Delete (soft delete when with_timestamps=True)
user.delete()
```
---
## Query API
The primary way to query is `Model.q()`, which returns a fluent `Query` builder. Chain methods and end with `.first()`, `.all()`, or iterate.
### Basic usage
```python
# One row or None
user = User.q().where(User.id == 1).first()
user = User.q().where(name="Alice").first()
# All matching rows
users = User.q().where(age__gte=18).all()
users = list(User.q().where(name="Bob"))
# Limit and offset
users = User.q().limit(10).all()
page = User.q().offset(20).limit(10).all()
```
### Where: expression-style and Django-style
**Expression-style** — SQLAlchemy-like, using model attributes and operators:
```python
User.q().where(User.name == "Alice").first()
User.q().where(User.age >= 18, User.email.is_not_null()).all()
User.q().where(Post.author.name.icontains("smith")).all() # filter by related column
```
**Django-style kwargs** — `field__lookup=value`:
```python
User.q().where(name="Alice") # exact (default)
User.q().where(name__icontains="alice") # case-insensitive contains
User.q().where(age__gte=18, age__lt=65) # gt, gte, lt, lte
User.q().where(name__in=["Alice", "Bob"]) # IN
User.q().where(name__range=(1, 10)) # BETWEEN
User.q().where(author__isnull=True) # IS NULL
User.q().where(book__title__contains="Python") # nested path
```
Supported lookups: `exact`, `iexact`, `lt`, `lte`, `gt`, `gte`, `in`, `range`, `isnull`, `contains`, `icontains`, `startswith`, `istartswith`, `endswith`, `iendswith`, `like`, `ilike`.
### Select and preload
Use `select()` to choose which columns/relations to fetch. Relations in `select()` are eager-loaded (JOINs), avoiding N+1 lazy loads.
```python
# Preload a relation (all columns from root + author)
book = Book.q().select("author").where(Book.id == 1).first()
book.author # no lazy load
# Preload nested path
book = Book.q().select("author.publisher").where(Book.id == 1).first()
# Multiple relations
users = User.q().select("profile", "posts").where(User.active == True).all()
# Expression-style
User.q().select(User.name, User.book.title).where(...)
```
Without `select()` for a relation, accessing `row.author` triggers a lazy load (and a warning).
### Order, limit, offset
```python
User.q().order_by(User.name).all() # ascending
User.q().order_by(User.created_at.desc).all() # descending
User.q().order_by(User.name, User.id).all() # multiple columns
User.q().limit(10).offset(20).all()
```
### Soft-deleted rows
For tables with `with_timestamps=True`, soft-deleted rows are excluded by default. Include them with:
```python
User.q().include_deleted().where(User.id == 1).first()
```
### Query execution
| Method | Returns |
|--------|---------|
| `.first()` | One `Model` or `None` |
| `.all(limit=N)` | List of `Model` |
| `list(q)` | Same as `.all()` |
| `for row in q:` | Iterate (lazy) |
---
## Model options
### Timestamps and soft delete
```python
class Post(Table, with_timestamps=True):
title: str
content: str
# Adds: created_at, updated_at, deleted_at. delete() becomes soft delete.
```
Only some timestamps:
```python
class Log(Table, with_created_at_timestamp=True, with_timestamps=False):
message: str
```
### Versioning
Ormantism supports a lightweight **row-history / version series** mode.
When `versioning_along` is set, rows with the same values for those fields form a series.
Any change to a versioned instance (either via attribute assignment or `instance.update(...)`) will:
1. **Insert a new row** with an incremented `version` (new `id`)
2. **Soft-delete** the previous “current” row in the series (`deleted_at` is set)
3. Mutate the *same Python instance* so it now points to the new row (its `id` changes)
Fields listed in `versioning_along` are treated as **immutable** (changing them raises).
```python
class Document(Table, versioning_along=("name",)):
name: str
content: str
doc = Document(name="foo", content="v1")
doc = Document(name="foo", content="v2") # New row; same name, version increments
doc.content = "v3" # New row again (id changes)
doc.update(content="v4") # New row again
```
Querying:
- Default queries exclude soft-deleted rows. For a versioned series, that means you’ll see only the latest (current) row.
- Use `include_deleted()` to fetch full history.
Backend note: version assignment currently relies on `UPDATE ... RETURNING` support (works on PostgreSQL and SQLite ≥ 3.35; may not work on some MySQL setups).
### Named connection
```python
class Remote(Table, connection_name="secondary"):
...
```
---
## Field types
- **Scalars:** `int`, `float`, `str`, `bool`, `datetime.datetime`, `enum.Enum`
- **Nullable:** `Optional[T] = None`
- **Defaults:** `age: int = 0`
- **JSON:** `list`, `dict`, or `ormantism.JSON` (arbitrary JSON in a column)
- **Relations:** `Author` (single), `Optional[Author]`, `list[Child]`
- **Generic reference:** `ref: Table` (any table; cannot be preloaded)
- **Pydantic models:** Stored as JSON
### Relationships
```python
class Category(Table, with_timestamps=True):
name: str
class Post(Table, with_timestamps=True):
title: str
category: Category | None = None
tags: list[Category] = []
# Self-reference
class Node(Table, with_timestamps=True):
parent: Optional["Node"] = None
name: str
```
---
## Load or create
Find by given fields or create; other fields update the row if it exists or set values on create:
```python
user = User.load_or_create(_search_fields=("name",), name="Alice", email="alice@example.com")
# Same row, email updated:
user2 = User.load_or_create(_search_fields=("name",), name="Alice", email="new@example.com")
```
---
## Transactions
```python
from ormantism import transaction
with transaction():
User(name="Alice", email="alice@example.com")
User(name="Bob", email="bob@example.com")
# Commits on exit; rolls back on exception
```
Use `transaction(connection_name="...")` when using a named connection.
---
## API summary
### Table: create and persist
- `Model(**kwargs)` — Create and save a row
- `instance.field = value` — Assign and auto-save
- `instance.update(**kwargs)` — Update fields and save
- `instance.delete()` — Delete (soft if timestamps enabled)
### Table: query builder
- `Model.q()` — Return a `Query` for this table (supports `_transform_query` from mixins)
### Query: fluent chain
- `q.where(*exprs, **kwargs)` — Filter (expressions and/or Django-style kwargs)
- `q.filter(...)` — Alias for `where`
- `q.select(*paths)` — Preload relations (e.g. `"author"`, `"author.publisher"`)
- `q.order_by(*exprs)` — ORDER BY (e.g. `User.name`, `User.created_at.desc`)
- `q.limit(n)` / `q.offset(n)` — Pagination
- `q.include_deleted()` — Include soft-deleted rows
- `q.first()` — One row or None
- `q.all(limit=N)` — List of rows
- `q.update(**kwargs)` — Update matched rows
- `q.delete()` — Delete matched rows
### Table: load or create
- `Model.load_or_create(_search_fields=(...), **data)` — Load by search fields or create; other fields update or populate
### Connection and transaction
- `ormantism.connect(url)` — Set default connection (SQLAlchemy-style URL)
- `ormantism.transaction(connection_name=...)` — Context manager for transactions
### Table class options
| Option | Effect |
|--------|--------|
| `with_timestamps=True` | Add created_at, updated_at, deleted_at; soft delete |
| `with_created_at_timestamp=True` | Only created_at |
| `with_updated_at_timestamp=True` | Only updated_at |
| `versioning_along=("field",)` | Enable row history series keyed by these fields (copy-on-write on update; previous becomes soft-deleted) |
| `connection_name="name"` | Use named connection (inherited by subclasses) |
---
## Deprecated: load and load_all
`Model.load(**criteria)` and `Model.load_all(**criteria)` are deprecated. Use the Query API instead:
```python
# Instead of: User.load(id=1)
User.q().where(id=1).first()
# Instead of: User.load_all(name="Alice")
User.q().where(name="Alice").all()
# Instead of: Book.load(id=1, preload="author")
Book.q().select("author").where(Book.id == 1).first()
# Instead of: User.load_all(with_deleted=True)
User.q().include_deleted().all()
```
---
## Code reference
For a full **code reference** (classes and methods with descriptions, file/line, and usages), see **[ormantism/REFERENCE.md](ormantism/REFERENCE.md)**.
---
## Limitations
- **Migrations** — New columns are added automatically; dropping/renaming columns or changing types is not automated (see [TODO.md](TODO.md)).
- **Relations** — Single and list references; no built-in many-to-many tables.
- **Generic references** — `ref: Table` cannot be preloaded (JOIN not supported).
---
## License and contributing
**License:** MIT.
Contributions are welcome. See **[TODO.md](TODO.md)** for ideas and planned improvements.
| text/markdown | Mathieu Rodic | null | null | null | MIT | orm, pydantic, sqlite, SQLite, MySQL, PostgreSQL | [
"License :: OSI Approved :: MIT License"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"pydantic>=2.11.7",
"pydantic_core>=2.33.2",
"datamodel_code_generator>=0.31.2",
"pymysql; extra == \"mysql\"",
"psycopg2; extra == \"postgresql\""
] | [] | [] | [] | [
"Homepage, https://github.com/mathieurodic/ormantism"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T14:36:21.832959 | ormantism-0.7.1.tar.gz | 46,654 | 00/90/1327e276d9cc95b093e194cb0fc72f2158d66b6cafcaa43824e622ecceb7/ormantism-0.7.1.tar.gz | source | sdist | null | false | 96dbca57180358504e7ed79f35fbc8e2 | 17e02f91f9d9969833ec0b551d12071514272aeaa6a5b81bddf6c55e2bdba2d5 | 00901327e276d9cc95b093e194cb0fc72f2158d66b6cafcaa43824e622ecceb7 | null | [
"LICENCE"
] | 197 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.