
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.4 | cmq | 0.11.1 | Cloud Multi Query is a library & CLI tool that allows you to run queries across multiple cloud accounts in parallel. | # CMQ
Cloud Multi Query (CMQ) is a Python library & CLI tool that allows you to run the same query across multiple cloud accounts in parallel, making it easy to gather insights and manage multi-account environments efficiently.
So far, CMQ only supports AWS cloud accounts. However, the plugable structure of CMQ allows for the creation of new session and resource types to include other cloud providers.
## Installation
```
pip install cmq
```
## Basic usage
CMQ works using profiles defined in your local machine ([AWS CLI configuration](https://docs.aws.amazon.com/cli/v1/userguide/cli-configure-files.html)). It's expected that every profile defines the access to an account/region.
Let's start listing the configured profiles:
```bash
cmq 'profile().list()'
[
{
"name": "account_a",
"region": "us-east-1"
},
{
"name": "account_b",
"region": "eu-west-1"
}
]
```
We can list resources for these accounts. CMQ will execute the queries in parallel. For example, lets list RDS resources:
```bash
cmq 'profile().rds().list()'
[
{
"DBInstanceIdentifier": "account-a-users",
"DBInstanceClass": "db.m6g.large",
"Engine": "postgres",
...
},
{
"DBInstanceIdentifier": "account-b-users",
"DBInstanceClass": "db.m6g.large",
"Engine": "postgres",
...
},
...
]
```
We can also use `cmq` as a Python library. This is more convenient when you need to process the results:
```python
>>> from cmq.aws.session.profile import profile
>>> profile().sqs().list()
[
{"resource": "https://sqs.us-east-1.amazonaws.com/123456789012/account-a-products"},
{"resource": "https://sqs.us-east-1.amazonaws.com/123456789012/account-a-orders"},
{"resource": "https://sqs.eu-west-1.amazonaws.com/210987654321/account-b-products"},
{"resource": "https://sqs.eu-west-1.amazonaws.com/210987654321/account-b-orders"}
]
```
## Enable verbose output
We can export the environment variable `CMQ_VERBOSE_OUTPUT=true` or use the option `verbose` in the CLI to output the progress of the query. This is particular useful when you have many accounts to process:
```bash
cmq --verbose 'profile().elasticache().list()'
100.00% :::::::::::::::::::::::::::::::::::::::: | 1 / 1 |: account-dev elasticache
100.00% :::::::::::::::::::::::::::::::::::::::: | 1 / 1 |: account-test elasticache
100.00% :::::::::::::::::::::::::::::::::::::::: | 1 / 1 |: account-prd1 elasticache
100.00% :::::::::::::::::::::::::::::::::::::::: | 1 / 1 |: account-prd2 elasticache
100.00% :::::::::::::::::::::::::::::::::::::::: | 1 / 1 |: account-prd3 elasticache
[
... resource list ...
]
```
# Docs
* [https://ocadotechnology.github.io/cmq/](https://ocadotechnology.github.io/cmq/)
## Examples
List RDS resources in one profile with name `account_a`
```bash
cmq 'profile(name="account_a").rds().list()'
```
List SNS topics for all profiles, but returning a dictionary where the key is the name of the profile:
```bash
cmq 'profile().sns().dict()'
{
"account_a": [
... topics from account a ...
],
"account_b": [
... topics from account b ...
],
}
```
List all roles for all accounts, but return only the `RoleName` field:
```bash
cmq 'profile().role().attr("RoleName").list()'
```
List DynamoDB tables, but limit the results to 10 tables:
```bash
cmq 'profile().dynamodb().limit(10).list()'
```
CMQ uses `boto3` to list/describe resources. You can also use the parameters of the `boto3` functions to filter resources in the request. For example, this will list all SQS queues with prefix `order` in all accounts:
```bash
cmq 'profile().sqs(QueueNamePrefix="order").list()'
```
We can also filter resources in the response. CMQ is built with a set of quick filters that you can use with any resource type. All the filters have the same structure: `__filter__(key, value)`
For example, the following query list Lambda functions running with `python3.10` in all accounts:
```bash
cmq 'profile().function().eq("Runtime", "python3.10").list()'
```
These are the supported quick filters:
* eq
* ne
* in_
* contains
* not_contains
* starts_with
* ends_with
* gt
* lt
## Supported resources
AWS
* address
* alarm
* cloudformation
* cloudtrail
* dynamodb
* ec2
* elasticache_parameter_group
* elasticache_replication_group
* elasticache_subnet_group
* elasticache
* function
* kinesis
* kms_alias
* kms
* log_event
* log_stream
* log
* metric
* rds_parameter_group
* rds
* resource_explorer
* resource_group
* role
* s3_object
* s3
* sns
* sqs
* user_key
* user
| text/markdown | Daniel Isla Cruz | daniel.islacruz@ocado.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"atpbar==2.0.4",
"boto3<2.0.0,>=1.34.80",
"click<9.0.0,>=8.1.7",
"matplotlib<4.0.0,>=3.9.0",
"python-benedict<0.34.0,>=0.33.2",
"requests<3.0.0,>=2.31.0",
"rich<14.0.0,>=13.7.1"
] | [] | [] | [] | [
"Changelog, https://github.com/ocadotechnology/cmq/blob/main/CHANGELOG.md",
"Homepage, https://github.com/ocadotechnology/cmq",
"Issues, https://github.com/ocadotechnology/cmq/issues",
"Repository, https://github.com/ocadotechnology/cmq.git"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:54:31.414879 | cmq-0.11.1.tar.gz | 21,523 | 26/cc/0f7430ccb121f0a1f1f7b1aeb3c0b4dbedc4e46146a732d48f0aa4fb1384/cmq-0.11.1.tar.gz | source | sdist | null | false | c6b9a2a52a3651d72c36971a552755f2 | facd403b7f13f96ea4ed4fca8737d98f19211661421c847e47ab11e630e35da6 | 26cc0f7430ccb121f0a1f1f7b1aeb3c0b4dbedc4e46146a732d48f0aa4fb1384 | Apache-2.0 | [
"LICENSE"
] | 227 |
2.4 | ansys-tools-protoc-helper | 0.7.0 | A utility for compiling '.proto' files to Python source. | ***************************
protobuf compilation helper
***************************
A utility to compile ``.proto`` files to Python source when building the package wheel. It supports dependencies to ``.proto`` files of different packages.
Quickstart
~~~~~~~~~~
The simplest way to get started is using the `template repository <https://github.com/ansys/ansys-api-template>`_.
Manual use
~~~~~~~~~~
To manually enable the use of ``ansys-tools-protoc-helper`` in your project, the following things need to be defined:
- A ``pyproject.toml`` file with the following contents:
.. code::
[build-system]
requires = ["setuptools>=42.0", "wheel", "ansys-tools-protoc-helper", <additional_dependencies>]
build-backend = "setuptools.build_meta:__legacy__"
where ``<additional_dependencies>`` are the packages that you depend on for ``.proto`` files.
- In the ``setuptools`` configuration (either ``setup.cfg`` or ``setup.py``). We only show the ``setuptools.setup()`` keywords (``setup.py`` variant) here:
- Run-time dependencies on the same ``<additional_dependencies>`` used above:
.. code:: python
install_requires=[grpcio, protobuf, <additional_dependencies>],
Refer to the `gRPC version strategy`_ section for details on which ``grpc`` and ``protobuf`` versions can be used.
- The ``package_data`` declares additional file names which are included in the package:
.. code:: python
package_data={
"": ["*.proto", "*.pyi", "py.typed"],
}
Note that ``*.proto`` is only needed if other packages should be able to depend on the ``*.proto`` files defined in your package.
The ``py.typed`` file is used to communicate that the package contains type information, see `PEP 561 <https://www.python.org/dev/peps/pep-0561/>`_. This file needs to be manually added.
- The ``cmdclass`` is used to specify that some ``setuptools`` commands should be executed by ``ansys-tools-protoc-helper``:
.. code:: python
from ansys.tools.protoc_helper import CMDCLASS_OVERRIDE
setup(
<...>,
cmdclass=CMDCLASS_OVERRIDE
)
The two commands which are overridden can also be specified individually. This may be useful in particular if you want to use the ``setup.cfg`` format:
.. code:: python
from ansys.tools.protoc_helper import BuildPyCommand, DevelopCommand
setup(
<...>,
cmdclass={"build_py": BuildPyCommand, "develop": DevelopCommand}
)
- If other projects should be able to depend on the ``.proto`` files contained in your project, an `entry point <https://packaging.python.org/en/latest/specifications/entry-points/>`_ needs to be defined declaring the presence of the ``*.proto`` files:
.. code:: python
entry_points={
"ansys.tools.protoc_helper.proto_provider": {
"<your.package.name>=<your.package.name>"
},
},
where ``<your.package.name>`` is the _importable_ name of your package. In other words, ``import <your.package.name>`` should work after installing the package.
By default, the ``.proto`` files will be copied to ``your/package/name``. If a different location should be used, append a semicolon to the entry point name, followed by the dot-separated target location:
.. code:: python
entry_points={
"ansys.tools.protoc_helper.proto_provider": {
"<your.package.name>:<target.location>=<your.package.name>"
},
},
For a complete example, see the ``test/test_data/testpkg-greeter-protos`` package.
gRPC version strategy
~~~~~~~~~~~~~~~~~~~~~
The ``ansys-tools-protoc-helper`` pins the versions of ``gRPC`` and ``protobuf`` that it depends on, in the ``dependencies = ...`` section of the `pyproject.toml <https://github.com/ansys/ansys-tools-protoc-helper/blob/main/pyproject.toml>`_ file.
For your own project, you can use any version of ``grpcio`` and ``protobuf`` that's newer (or equal) to the version pinned here, as long as it is the same major version.
For example, if ``ansys-tools-protoc-helper`` pins
.. code::
dependencies = [
"grpcio-tools==1.20.0",
"protobuf==3.19.3",
]
your own dependencies could be ``grpcio-tools~=1.20``, ``protobuf~=3.19`` (using the ``~=`` `compatible version operator <https://www.python.org/dev/peps/pep-0440/#compatible-release>`_).
.. note::
The ``protoc`` compiler version used is determined by the ``grpcio-tools`` package, *not* the ``protobuf`` dependency. The ``grpcio-tools==1.20.0`` uses ``protoc==3.7.0``.
The versions pinned by ``ansys-tools-protoc-helper`` were originally chosen as follows:
- The first version of ``grpcio-tools`` for which binary wheels are available on PyPI, for at least one of the Python versions we support.
- The first version of ``protobuf`` which is compatible with ``mypy-protobuf``, for generating type stubs.
Upgrade plans
^^^^^^^^^^^^^
The current plan for upgrading ``grpcio-tools`` and ``protobuf`` is as follows:
+----------------------------------------+----------------+--------------------------+----------------------+-----------------------+-----------------------+
| ``ansys-tools-protoc-helper`` version | release date | ``grpcio-tools`` version | ``protobuf`` version | ``libprotoc`` version | Python version support|
+========================================+================+==========================+======================+=======================+=======================+
| ``0.2.x`` | 2022-12-09 | ``1.20.x`` | ``3.19.3`` | ``7.x`` | 3.7 - 3.10 |
+----------------------------------------+----------------+--------------------------+----------------------+-----------------------+-----------------------+
| ``0.3.x`` | 2023-02-20 | ``1.25.x`` | ``3.19.3`` | ``8.x`` | 3.7 - 3.10 |
+----------------------------------------+----------------+--------------------------+----------------------+-----------------------+-----------------------+
| ``0.4.x`` | 2023-02-20 | ``1.44.x`` | ``3.19.3`` | ``19.2`` | 3.7 - 3.10 |
+----------------------------------------+----------------+--------------------------+----------------------+-----------------------+-----------------------+
| ``0.5.x`` | 2024-09-02 | ``1.49.x`` | ``4.21.x`` | ``21.5`` | 3.9 - 3.11 |
+----------------------------------------+----------------+--------------------------+----------------------+-----------------------+-----------------------+
| ``0.6.x`` | 2026-02-09 | ``1.59.x`` | ``4.24.x`` | ``24.3`` | 3.10 - 3.12 |
+----------------------------------------+----------------+--------------------------+----------------------+-----------------------+-----------------------+
| ``0.7.x`` | 2026-02-19 | ``1.71.x`` | ``5.29.x`` | ``29.x`` | 3.10 - 3.14 |
+----------------------------------------+----------------+--------------------------+----------------------+-----------------------+-----------------------+
| ``0.8.x`` | TBD | TBD | TBD | TBD | TBD |
+----------------------------------------+----------------+--------------------------+----------------------+-----------------------+-----------------------+
.. note::
In order to find the ``protoc`` version, you can run the following command using ``uv`` or ``pip``
and substituting the appropriate version (i.e. ``X.Y``)::
# Using uv
uv run -q --with='grpcio-tools~=X.Y.0' python -m grpc_tools.protoc --version
# Using pip (in a virtual environment)
pip install 'grpcio-tools~=X.Y.0'
python -m grpc_tools.protoc --version
The strategy for these upgrades is as follows:
- Upgrade ``grpcio-tools`` as necessary. For example, ``0.5.x`` enables building with Python ``3.11``.
- Match the version of ``protobuf`` to the version of ``protoc`` bundled into ``grpcio-tools``, or at least ``3.19.3``.
- Each upgrade is a breaking upgrade for the semantic version. Since we are currently using ``0.x`` versions, the minor version is bumped.
The ``protobuf`` Python runtime introduced a backwards-incompatible change with version ``4.21`` (matching protoc release ``3.21``). Code generated with ``protoc==3.19`` or newer should be compatible with the ``4.x`` runtime, which corresponds to the ``0.4`` release of ``ansys-tools-protoc-helper``.
If you need to support a specific *older* version of protobuf and / or gRPC, we encourage pinning ``ansys-tools-protoc-helper`` to its minor version.
| text/x-rst | ANSYS, Inc. | null | null | PyAnsys developers <pyansys.support@ansys.com> | null | null | [
"License :: OSI Approved :: MIT License"
] | [] | null | null | <3.15,>=3.10 | [] | [] | [] | [
"setuptools>=42.0",
"grpcio-tools==1.71.2",
"protobuf==5.29.6",
"mypy-protobuf==3.6.0"
] | [] | [] | [] | [
"Source, https://github.com/ansys/ansys-tools-protoc-helper"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:54:08.984072 | ansys_tools_protoc_helper-0.7.0.tar.gz | 6,431 | 10/43/c77fe013296677d4913e16254f44bd597c176f59025987fa2d6629fbefe8/ansys_tools_protoc_helper-0.7.0.tar.gz | source | sdist | null | false | 9956910d06767a41fcb9db9f3970356b | ad3bc22900dd767bd7170ccca7b73be7b84ac0d209e47d1c35f9e7e2b6808c18 | 1043c77fe013296677d4913e16254f44bd597c176f59025987fa2d6629fbefe8 | null | [
"LICENSE"
] | 262 |
2.4 | sccs | 2.6.0 | SkillsCommandsConfigsSync - Unified YAML-configured synchronization for Claude Code files | # SCCS - SkillsCommandsConfigsSync

> **Language / Sprache**: [Deutsch](#deutsche-dokumentation) | [English](#english-documentation)
---
## Deutsche Dokumentation
### Projektübersicht
SCCS ist ein YAML-konfiguriertes bidirektionales Synchronisierungswerkzeug für Claude Code Dateien und optionale Shell-Konfigurationen. Es hält Skills, Commands, Hooks, Scripts und Shell-Configs zwischen einer lokalen Installation und einem Git-Repository synchron.
**Version:** 2.5.0 · **Lizenz:** AGPL-3.0 · **Python:** ≥3.10
### Funktionen
- **YAML-Konfiguration** — Zentrale `config.yaml` mit allen Sync-Kategorien
- **Flexible Kategorien** — Claude Skills, Commands, Hooks, Scripts, Fish-Shell u.v.m.
- **Bidirektionale Synchronisierung** — Zweiwege-Sync mit Konflikterkennung
- **Interaktive Konflikterkennung** — Menügesteuerte Konfliktauflösung mit `-i`
- **Automatische Backups** — Zeitgestempelte Sicherungen vor Überschreiben
- **Git-Integration** — Auto-Commit und Push nach Synchronisierung
- **Plattform-Filter** — Kategorien nur auf macOS, Linux oder beidem synchronisieren
- **Rich-Ausgabe** — Formatierte Terminal-Ausgabe mit Rich
### Installation
```bash
# Via PyPI
pip install sccs
# Mit UV (empfohlen)
uv pip install sccs
```
Für Entwicklung:
```bash
git clone https://github.com/equitania/sccs.git
cd sccs
uv venv && source .venv/bin/activate
uv pip install -e ".[dev]"
```
### Workflows
#### Publisher (Änderungen teilen)
```bash
sccs sync --commit --push # Synchronisieren, committen und pushen
sccs sync --dry-run # Vorschau der Änderungen
sccs sync -c skills --push # Nur Skills pushen
```
#### Subscriber (Änderungen empfangen)
```bash
sccs sync --pull # Aktuelle Version ziehen und lokal synchronisieren
sccs sync --force repo # Lokale Version mit Repo überschreiben
sccs sync -c skills --pull # Nur Skills empfangen
```
### Schnellstart
```bash
# Konfiguration erstellen
sccs config init
# Status anzeigen
sccs status
# Änderungen prüfen
sccs sync --dry-run
# Alles synchronisieren
sccs sync
# Bestimmte Kategorie synchronisieren
sccs sync -c claude_skills
```
### Konfiguration
Konfigurationsdatei: `~/.config/sccs/config.yaml`
```yaml
# Repository-Einstellungen
repository:
path: ~/gitbase/sccs-sync # Lokaler Repository-Pfad
remote: origin # Git Remote Name
auto_commit: false # Auto-Commit nach Sync
auto_push: false # Auto-Push nach Commit
auto_pull: false # Auto-Pull vor Sync
commit_prefix: "[SYNC]" # Prefix für Commit-Nachrichten
# Sync-Kategorien
sync_categories:
claude_skills:
enabled: true
description: "Claude Code Skills"
local_path: ~/.claude/skills
repo_path: .claude/skills
sync_mode: bidirectional # bidirectional | local_to_repo | repo_to_local
item_type: directory # file | directory | mixed
item_marker: SKILL.md # Marker-Datei für Verzeichnisse
include: ["*"]
exclude: ["_archive/*"]
fish_config:
enabled: true
platforms: ["macos"] # Nur auf macOS synchronisieren
local_path: ~/.config/fish
repo_path: .config/fish
item_type: mixed
include: ["config.fish", "functions/*.fish"]
exclude: ["fish_history", "fish_variables"]
# Globale Ausschlüsse
global_exclude:
- ".DS_Store"
- "*.tmp"
- "__pycache__"
```
### Kategorien-Referenz
| Feld | Typ | Pflicht | Beschreibung |
|------|-----|---------|-------------|
| `enabled` | bool | Nein | Kategorie aktivieren (Standard: true) |
| `description` | string | Nein | Beschreibung |
| `local_path` | string | **Ja** | Lokaler Quellpfad (unterstützt `~`) |
| `repo_path` | string | **Ja** | Pfad im Repository |
| `sync_mode` | string | Nein | `bidirectional`, `local_to_repo`, `repo_to_local` |
| `item_type` | string | Nein | `file`, `directory`, `mixed` (Standard: file) |
| `item_marker` | string | Nein | Marker-Datei für Verzeichnisse (z.B. `SKILL.md`) |
| `item_pattern` | string | Nein | Glob-Pattern für Dateien (z.B. `*.md`) |
| `include` | list | Nein | Einschluss-Patterns (Standard: `["*"]`) |
| `exclude` | list | Nein | Ausschluss-Patterns (Standard: `[]`) |
| `platforms` | list | Nein | Plattform-Filter: `["macos"]`, `["linux"]`, `null` = alle |
### CLI-Befehle
```bash
# Synchronisierung
sccs sync # Alle aktivierten Kategorien
sccs sync -c skills # Bestimmte Kategorie
sccs sync -n # Vorschau (Dry-Run)
sccs sync -i # Interaktive Konfliktauflösung
sccs sync --force local # Lokale Version erzwingen
sccs sync --force repo # Repo-Version erzwingen
sccs sync --commit --push # Mit Git-Commit und Push
sccs sync --pull # Vorher Remote-Änderungen ziehen
# Status und Diff
sccs status # Sync-Status aller Kategorien
sccs diff # Alle Unterschiede anzeigen
sccs diff -c skills # Diffs einer Kategorie
sccs log # Sync-Verlauf
# Konfiguration
sccs config show # Konfiguration anzeigen
sccs config init # Neue Konfiguration erstellen
sccs config edit # Im Editor öffnen
sccs config validate # Konfiguration prüfen
# Kategorien
sccs categories list # Aktivierte Kategorien
sccs categories list --all # Alle (inkl. deaktivierte)
sccs categories enable fish # Kategorie aktivieren
sccs categories disable fish # Kategorie deaktivieren
```
### Standard-Kategorien
#### Claude Code (standardmäßig aktiv)
| Kategorie | Pfad | Beschreibung |
|-----------|------|-------------|
| `claude_framework` | `~/.claude/*.md` | SuperClaude Framework-Dateien |
| `claude_skills` | `~/.claude/skills/` | Skills (Verzeichnisse mit SKILL.md) |
| `claude_commands` | `~/.claude/commands/` | Commands (einzelne .md-Dateien) |
| `claude_hooks` | `~/.claude/hooks/` | Event-Handler-Skripte |
| `claude_scripts` | `~/.claude/scripts/` | Hilfsskripte |
| `claude_plugins` | `~/.claude/plugins/` | Plugin-Konfigurationen |
| `claude_mcp` | `~/.claude/mcp/` | MCP-Server-Konfigurationen |
| `claude_statusline` | `~/.claude/statusline.*` | Statusline-Skript |
#### Shell (standardmäßig aktiv)
| Kategorie | Pfad | Plattform | Beschreibung |
|-----------|------|-----------|-------------|
| `fish_config` | `~/.config/fish/` | alle | Fish-Shell-Konfiguration |
| `fish_config_macos` | `~/.config/fish/conf.d/*.macos.fish` | macOS | macOS-spezifische conf.d |
| `fish_functions` | `~/.config/fish/functions/` | alle | Fish-Funktionen |
| `fish_functions_macos` | `~/.config/fish/functions/macos/` | macOS | macOS-spezifische Funktionen |
| `starship_config` | `~/.config/starship.toml` | alle | Starship-Prompt |
### Konfliktauflösung
Bei Änderungen auf beiden Seiten bietet SCCS mehrere Auflösungsstrategien:
**Interaktiver Modus** (empfohlen):
```bash
sccs sync -i
```
Optionen im interaktiven Menü:
1. **Lokal behalten** — Lokale Version verwenden
2. **Repo behalten** — Repository-Version verwenden
3. **Diff anzeigen** — Unterschiede prüfen
4. **Interaktives Merge** — Hunk-für-Hunk-Zusammenführung
5. **Externer Editor** — In Editor öffnen
6. **Überspringen** — Dieses Element auslassen
7. **Abbrechen** — Sync komplett abbrechen
**Automatische Auflösung**:
```bash
sccs sync --force local # Lokal gewinnt immer
sccs sync --force repo # Repository gewinnt immer
```
### Automatische Backups
Vor jedem Überschreiben erstellt SCCS zeitgestempelte Sicherungen:
```
~/.config/sccs/backups/
├── claude_skills/
│ └── my-skill.20250123_143052.bak
└── fish_config/
└── config.fish.20250123_143052.bak
```
### Plattform-Awareness
Kategorien können auf bestimmte Betriebssysteme beschränkt werden:
```yaml
fish_config_macos:
enabled: true
platforms: ["macos"] # Nur auf macOS synchronisieren
local_path: ~/.config/fish/conf.d
repo_path: .config/fish/conf.d
item_pattern: "*.macos.fish"
```
Erkennung: `Darwin` → `macos`, `Linux` → `linux`. Kategorien mit `platforms: null` synchronisieren auf allen Plattformen.
### Architektur
```
sccs/
├── cli.py # Click CLI mit Befehlsgruppen
├── config/ # Konfigurationsmanagement
│ ├── schema.py # Pydantic-Modelle
│ ├── loader.py # YAML-Laden/Speichern
│ └── defaults.py # Standard-Konfiguration
├── sync/ # Synchronisierungs-Engine
│ ├── engine.py # Hauptorchestrator
│ ├── category.py # Kategorie-Handler
│ ├── item.py # SyncItem, Scan-Funktionen
│ ├── actions.py # Aktionstypen und -ausführung
│ ├── state.py # State-Persistenz
│ └── settings.py # JSON-Settings-Ensure
├── git/ # Git-Operationen
│ └── operations.py # Commit, Push, Pull, Status
├── output/ # Terminal-Ausgabe
│ ├── console.py # Rich-Console
│ ├── diff.py # Diff-Anzeige
│ └── merge.py # Interaktives Merge
└── utils/ # Hilfsfunktionen
├── paths.py # Pfad-Utilities, atomares Schreiben
├── hashing.py # SHA256-Hashing
└── platform.py # Plattformerkennung
```
### Entwicklung
```bash
# Tests
pytest # Alle Tests
pytest --cov=sccs # Mit Coverage (Minimum: 60%)
# Code-Qualität
ruff check sccs/ tests/ # Linting
ruff format sccs/ tests/ # Formatierung
mypy sccs/ # Typenprüfung
bandit -r sccs/ # Security-Scan
```
### Lizenz
AGPL-3.0 — Equitania Software GmbH
---
## English Documentation
### Project Overview
SCCS is a YAML-configured bidirectional synchronization tool for Claude Code files and optional shell configurations. It keeps skills, commands, hooks, scripts, and shell configs in sync between a local installation and a Git repository.
**Version:** 2.5.0 · **License:** AGPL-3.0 · **Python:** ≥3.10
### Features
- **YAML Configuration** — Single `config.yaml` with all sync categories
- **Flexible Categories** — Claude skills, commands, hooks, scripts, Fish shell, and more
- **Bidirectional Sync** — Full two-way synchronization with conflict detection
- **Interactive Conflict Resolution** — Menu-driven conflict handling with `-i` flag
- **Automatic Backups** — Timestamped backups before overwriting files
- **Git Integration** — Auto-commit and push after sync operations
- **Platform Filtering** — Sync categories only on macOS, Linux, or both
- **Rich Console Output** — Formatted terminal output with Rich
### Installation
```bash
# From PyPI
pip install sccs
# With UV (recommended)
uv pip install sccs
```
For development:
```bash
git clone https://github.com/equitania/sccs.git
cd sccs
uv venv && source .venv/bin/activate
uv pip install -e ".[dev]"
```
### Workflows
#### Publisher (share your configs)
```bash
sccs sync --commit --push # Sync, commit and push to remote
sccs sync --dry-run # Preview what would change
sccs sync -c skills --push # Push only skills category
```
#### Subscriber (receive shared configs)
```bash
sccs sync --pull # Pull latest and sync to local
sccs sync --force repo # Overwrite local with repo version
sccs sync -c skills --pull # Pull only skills category
```
### Quick Start
```bash
# Initialize configuration
sccs config init
# Show sync status
sccs status
# Preview changes
sccs sync --dry-run
# Synchronize all enabled categories
sccs sync
# Sync specific category
sccs sync -c claude_skills
```
### Configuration
Config file: `~/.config/sccs/config.yaml`
```yaml
# Repository settings
repository:
path: ~/gitbase/sccs-sync # Local repository path
remote: origin # Git remote name for push
auto_commit: false # Auto-commit after sync
auto_push: false # Auto-push after commit
auto_pull: false # Auto-pull before sync
commit_prefix: "[SYNC]" # Prefix for commit messages
# Sync categories
sync_categories:
claude_skills:
enabled: true
description: "Claude Code Skills"
local_path: ~/.claude/skills
repo_path: .claude/skills
sync_mode: bidirectional # bidirectional | local_to_repo | repo_to_local
item_type: directory # file | directory | mixed
item_marker: SKILL.md # Marker file for directory items
include: ["*"]
exclude: ["_archive/*"]
fish_config:
enabled: true
platforms: ["macos"] # Only sync on macOS
local_path: ~/.config/fish
repo_path: .config/fish
item_type: mixed
include: ["config.fish", "functions/*.fish"]
exclude: ["fish_history", "fish_variables"]
# Global excludes
global_exclude:
- ".DS_Store"
- "*.tmp"
- "__pycache__"
```
### Category Field Reference
| Field | Type | Required | Description |
|-------|------|----------|-------------|
| `enabled` | bool | No | Enable/disable category (default: true) |
| `description` | string | No | Human-readable description |
| `local_path` | string | **Yes** | Local source path (supports `~`) |
| `repo_path` | string | **Yes** | Path in repository |
| `sync_mode` | string | No | `bidirectional`, `local_to_repo`, `repo_to_local` |
| `item_type` | string | No | `file`, `directory`, `mixed` (default: file) |
| `item_marker` | string | No | Marker file for directory items (e.g., `SKILL.md`) |
| `item_pattern` | string | No | Glob pattern for file items (e.g., `*.md`) |
| `include` | list | No | Patterns to include (default: `["*"]`) |
| `exclude` | list | No | Patterns to exclude (default: `[]`) |
| `platforms` | list | No | Platform filter: `["macos"]`, `["linux"]`, `null` = all |
### CLI Commands
```bash
# Synchronization
sccs sync # All enabled categories
sccs sync -c skills # Specific category
sccs sync -n # Preview (dry-run)
sccs sync -i # Interactive conflict resolution
sccs sync --force local # Force local version
sccs sync --force repo # Force repo version
sccs sync --commit --push # With git commit and push
sccs sync --pull # Pull remote changes first
# Status and diff
sccs status # Sync status of all categories
sccs diff # Show all differences
sccs diff -c skills # Diffs for a category
sccs log # Sync history
# Configuration
sccs config show # Show configuration
sccs config init # Create new configuration
sccs config edit # Open in editor
sccs config validate # Validate configuration
# Categories
sccs categories list # List enabled categories
sccs categories list --all # All (incl. disabled)
sccs categories enable fish # Enable category
sccs categories disable fish # Disable category
```
### Default Categories
#### Claude Code (enabled by default)
| Category | Path | Description |
|----------|------|-------------|
| `claude_framework` | `~/.claude/*.md` | SuperClaude Framework files |
| `claude_skills` | `~/.claude/skills/` | Skills (directories with SKILL.md) |
| `claude_commands` | `~/.claude/commands/` | Commands (single .md files) |
| `claude_hooks` | `~/.claude/hooks/` | Event handler scripts |
| `claude_scripts` | `~/.claude/scripts/` | Utility scripts |
| `claude_plugins` | `~/.claude/plugins/` | Plugin configurations |
| `claude_mcp` | `~/.claude/mcp/` | MCP server configs |
| `claude_statusline` | `~/.claude/statusline.*` | Statusline script |
#### Shell (enabled by default)
| Category | Path | Platform | Description |
|----------|------|----------|-------------|
| `fish_config` | `~/.config/fish/` | all | Fish shell configuration |
| `fish_config_macos` | `~/.config/fish/conf.d/*.macos.fish` | macOS | macOS-specific conf.d |
| `fish_functions` | `~/.config/fish/functions/` | all | Fish custom functions |
| `fish_functions_macos` | `~/.config/fish/functions/macos/` | macOS | macOS-specific functions |
| `starship_config` | `~/.config/starship.toml` | all | Starship prompt |
### Conflict Resolution
When both local and repo have changes, SCCS offers multiple resolution strategies:
**Interactive mode** (recommended):
```bash
sccs sync -i
```
Interactive menu options:
1. **Keep local** — Use local version
2. **Keep repo** — Use repository version
3. **Show diff** — View differences
4. **Interactive merge** — Hunk-by-hunk merge
5. **External editor** — Open in editor
6. **Skip** — Skip this item
7. **Abort** — Stop sync completely
**Automatic resolution**:
```bash
sccs sync --force local # Local wins all conflicts
sccs sync --force repo # Repository wins all conflicts
```
### Automatic Backups
Before overwriting any file, SCCS creates timestamped backups:
```
~/.config/sccs/backups/
├── claude_skills/
│ └── my-skill.20250123_143052.bak
└── fish_config/
└── config.fish.20250123_143052.bak
```
### Platform Awareness
Categories can be restricted to specific operating systems:
```yaml
fish_config_macos:
enabled: true
platforms: ["macos"] # Only sync on macOS
local_path: ~/.config/fish/conf.d
repo_path: .config/fish/conf.d
item_pattern: "*.macos.fish"
```
Detection: `Darwin` → `macos`, `Linux` → `linux`. Categories with `platforms: null` sync on all platforms.
### Architecture
```
sccs/
├── cli.py # Click CLI with command groups
├── config/ # Configuration management
│ ├── schema.py # Pydantic models
│ ├── loader.py # YAML loading/saving
│ └── defaults.py # Default configuration
├── sync/ # Synchronization engine
│ ├── engine.py # Main orchestrator
│ ├── category.py # Category handler
│ ├── item.py # SyncItem, scan functions
│ ├── actions.py # Action types and execution
│ ├── state.py # State persistence
│ └── settings.py # JSON settings ensure
├── git/ # Git operations
│ └── operations.py # Commit, push, pull, status
├── output/ # Terminal output
│ ├── console.py # Rich console
│ ├── diff.py # Diff display
│ └── merge.py # Interactive merge
└── utils/ # Utilities
├── paths.py # Path utilities, atomic writes
├── hashing.py # SHA256 hashing
└── platform.py # Platform detection
```
### Development
```bash
# Tests
pytest # All tests
pytest --cov=sccs # With coverage (minimum: 60%)
# Code quality
ruff check sccs/ tests/ # Linting
ruff format sccs/ tests/ # Formatting
mypy sccs/ # Type checking
bandit -r sccs/ # Security scan
```
### License
AGPL-3.0 — Equitania Software GmbH
| text/markdown | null | Equitania Software GmbH <info@equitania.de> | null | Equitania Software GmbH <info@equitania.de> | null | claude, claude-code, commands, configuration, dotfiles, skills, sync | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU Affero General Public License v3",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language... | [] | null | null | >=3.10 | [] | [] | [] | [
"click<9.0.0,>=8.1.0",
"pydantic<3.0.0,>=2.0.0",
"pyyaml<7.0.0,>=6.0",
"rich<15.0.0,>=13.0.0",
"bandit>=1.9.0; extra == \"dev\"",
"mypy>=1.14.0; extra == \"dev\"",
"pre-commit>=4.0.0; extra == \"dev\"",
"pytest-cov>=6.0.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.11.0; extra ... | [] | [] | [] | [
"Homepage, https://github.com/equitania/sccs",
"Repository, https://github.com/equitania/sccs",
"Documentation, https://github.com/equitania/sccs#readme",
"Issues, https://github.com/equitania/sccs/issues"
] | uv/0.6.9 | 2026-02-19T15:53:32.376993 | sccs-2.6.0.tar.gz | 211,163 | b4/a0/cf94043af544c56c3929414c2d450e573b1460e1fad044960f2da6cef10a/sccs-2.6.0.tar.gz | source | sdist | null | false | 66496ef72ce6208c1ff8c4f8661c1077 | 21917551627f7da14018757187c318dfae1b2924f5aa33c111345497c0e85e95 | b4a0cf94043af544c56c3929414c2d450e573b1460e1fad044960f2da6cef10a | AGPL-3.0 | [
"LICENSE"
] | 207 |
2.4 | slurm-requests | 2.3.1 | Lightweight asynchronous SLURM REST requests with proxy support. | # slurm-requests
[](https://pypi.org/project/slurm-requests)
[](https://pypi.org/project/slurm-requests)
-----
Lightweight asynchronous SLURM REST requests with proxy support.
## Installation
```console
pip install slurm-requests
```
## Usage
```python
import asyncio
import slurm_requests as slurm
async def main():
# set defaults to avoid repetition
slurm.init_defaults(
url="https://example.com/sapi",
api_version="v0.0.40",
user_name="example_user",
user_token="example_token",
partition="example_partition",
# constraints="GPU",
environment=["EXAMPLE_VAR=example_value"],
# headers={"X-Example-Header": "example_value"},
# proxy_url="socks5://localhost:8080",
)
# check connection + credentials
await slurm.ping()
await slurm.diagnose()
# submit
job_id, _ = await slurm.job_submit(
name="example_job",
working_directory="/home/example_user/slurm",
script="#!/usr/bin/bash\necho Hello, SLURM!",
# time_limit=60,
# dependency="afterok:123456",
)
assert job_id is not None
# check state
response = await slurm.job_current_state_and_reason(job_id=job_id)
assert response is not None
state, reason = response
print(f"Job {job_id} is currently in state '{state}' due to reason '{reason}'.")
# cancel
await slurm.job_cancel(job_id=job_id)
# advanced: overwrite a default (works for all functions)
await slurm.ping(user_name="dummy", dry_run=True)
if __name__ == "__main__":
asyncio.run(main())
```
## License
`slurm-requests` is distributed under the terms of the [CC-BY-SA-4.0](http://creativecommons.org/licenses/by-sa/4.0) license.
| text/markdown | null | Kwasniok <Kwasniok@users.noreply.github.com> | null | Kwasniok <Kwasniok@users.noreply.github.com> | null | rest, slurm | [
"Development Status :: 4 - Beta",
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"rest-requests>=2.1.0"
] | [] | [] | [] | [
"Documentation, https://github.com/Kwasniok/pypi-slurm-requests#readme",
"Issues, https://github.com/Kwasniok/pypi-slurm-requests/issues",
"Source, https://github.com/Kwasniok/pypi-slurm-requests"
] | python-httpx/0.27.0 | 2026-02-19T15:53:32.204498 | slurm_requests-2.3.1-py3-none-any.whl | 12,826 | 8a/7c/2a2e3570f134aa949dfc1cd1fe873a8ec3a4cebf37ae613aec961b4934a0/slurm_requests-2.3.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 3a71147626ac9da32847545a611f4b0b | a55484a7c531f723675d2b5332effaf20d56f0e12440c2374fa51ad18200164c | 8a7c2a2e3570f134aa949dfc1cd1fe873a8ec3a4cebf37ae613aec961b4934a0 | CC-BY-SA-4.0 | [
"LICENSE.txt"
] | 198 |
2.4 | comfyui-workflow-templates-media-api | 0.3.54 | Media bundle containing API-driven workflow assets | Media bundle containing API-driven workflow assets for ComfyUI.
| text/plain | null | null | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T15:52:57.249625 | comfyui_workflow_templates_media_api-0.3.54.tar.gz | 78,977,547 | c2/e4/f89fcc278d340a5bd2312afd979e8f8e447b544343bde4143b066648d664/comfyui_workflow_templates_media_api-0.3.54.tar.gz | source | sdist | null | false | 39dbbe0e7a0da5da01492a31cdcfecc3 | 7bf889d4bf9389ce45170a9b5b7b34a0e89ff7192a94606f770ba0b0f7feb1a9 | c2e4f89fcc278d340a5bd2312afd979e8f8e447b544343bde4143b066648d664 | MIT | [] | 2,395 |
2.4 | tooluniverse | 1.0.19.1 | A comprehensive collection of scientific tools for Agentic AI, offering integration with the ToolUniverse SDK and MCP Server to support advanced scientific workflows. | # <img src="docs/_static/logo.png" alt="ToolUniverse Logo" height="28" style="vertical-align: middle; margin-right: 8px;" /> ToolUniverse: Democratizing AI scientists
[](https://zitniklab.hms.harvard.edu/ToolUniverse/)
[](https://arxiv.org/abs/2509.23426)
[](https://badge.fury.io/py/tooluniverse)
[](https://registry.modelcontextprotocol.io)
[](https://aiscientist.tools)
[](https://join.slack.com/t/tooluniversehq/shared_invite/zt-3dic3eoio-5xxoJch7TLNibNQn5_AREQ)
[](https://aiscientist.tools/wechat)
[](https://www.linkedin.com/in/shanghua-gao-96b0b3168/)
[](https://x.com/ScientistTools)
[](https://pepy.tech/projects/tooluniverse)
[//]: # (mcp-name: io.github.mims-harvard/tooluniverse)
## INSTALL ToolUniverse
<table>
<tr>
<td width="45%" valign="top">
**1️⃣ MCP Setup** – Add to your MCP config:
```json
{
"mcpServers": {
"tooluniverse": {
"command": "uvx",
"args": ["tooluniverse"],
"env": {"PYTHONIOENCODING": "utf-8"}
}
}
}
```
</td>
<td width="45%" valign="top">
**2️⃣ Install Agent Skills**
```bash
npx skills add mims-harvard/ToolUniverse
```
**3️⃣ Install Package** (Optional)
```bash
uv pip install tooluniverse
```
</td>
</tr>
</table>
> **Guided Setup:** Install skills first with `npx skills add mims-harvard/ToolUniverse`, then ask your AI coding agent **"setup tooluniverse"**. The `setup-tooluniverse` skill will walk you through MCP configuration, API keys, and validation step by step.
- **[Python Developer Guide](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/python_guide.html)**: Build AI scientists with the Python SDK
- **[AI Agent Platforms](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/building_ai_scientists/index.html)**: Set up ToolUniverse with Cursor, Claude, Windsurf, Gemini, and more
**[Shanghua Gao](shanghuagao@gmail.com), the lead and creator of this project, is currently on the job market.**
## 🤖 Building AI Scientists with ToolUniverse in 5 minutes
<p align="center">
<a href="https://www.youtube.com/watch?v=fManSJlSs60">
<img src="https://github.com/user-attachments/assets/13ddb54c-4fcc-4507-8695-1c58e7bc1e68" width="600" />
</a>
</p>
*Click the image above to watch the demonstration* [(YouTube)](https://www.youtube.com/watch?v=fManSJlSs60) [(Bilibili)](https://www.bilibili.com/video/BV1GynhzjEos/?share_source=copy_web&vd_source=b398f13447281e748f5c41057a2c6858)
## 🔬 What is ToolUniverse?
ToolUniverse is an ecosystem for creating AI scientist systems from any open or closed large language model (LLM). Powered by AI-Tool Interaction Protocol, it standardizes how LLMs identify and call tools, integrating more than **1000 machine learning models, datasets, APIs, and scientific packages** for data analysis, knowledge retrieval, and experimental design.
AI scientists are emerging computational systems that serve as collaborative partners in discovery. However, these systems remain difficult to build because they are bespoke, tied to rigid workflows, and lack shared environments that unify tools, data, and analysts into a common ecosystem.
ToolUniverse addresses this challenge by providing a standardized ecosystem that transforms any AI model into a powerful research scientist. By abstracting capabilities behind a unified interface, ToolUniverse wraps around any AI model (LLM, AI agent, or large reasoning model) and enables users to create and refine entirely custom AI scientists without additional training or finetuning.
**Key Features:**
- [**AI-Tool Interaction Protocol**](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/interaction_protocol.html): Standardized interface governing how AI scientists issue tool requests and receive results
- [**Universal AI Model Support**](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/building_ai_scientists/index.html): Works with any LLM, AI agent, or large reasoning model (GPT5, Claude, Gemini, Qwen, Deepseek, open models)
- [**OpenRouter Integration**](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/openrouter_support.html): Access 100+ models from OpenAI, Anthropic, Google, Qwen, and more through a single API
- [**MCP Tasks for Async Operations**](docs/MCP_TASKS_GUIDE.md): Native support for long-running operations (protein docking, molecular simulations) with automatic progress tracking, parallel execution, and cancellation
- [**Easy to Load & Find & Call Tool**](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/index.html) (*[WebService](https://aiscientist.tools/), [PythonAPI](https://zitniklab.hms.harvard.edu/ToolUniverse/api/modules.html), [MCP](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/building_ai_scientists/mcp_support.html)*): Maps natural-language descriptions to tool specifications and executes tools with structured results
- [**Tool Composition & Scientific Workflows**](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/tool_composition.html): Chains tools for sequential or parallel execution in self-directed scientific workflows
- [**Continuous Expansion**](https://zitniklab.hms.harvard.edu/ToolUniverse/expand_tooluniverse/index.html): New tools can be easily registered locally or remotely without additional configuration
- [**Multi-Agent Tool Creation & Optimization**](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/scientific_workflows.html): Multi-agent powered tool construction and iterative tool optimization
- [**20+ Pre-Built AI Scientist Skills**](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/skills_showcase.html): End-to-end research workflows for drug discovery, precision oncology, rare disease diagnosis, pharmacovigilance, and more — installable with one command
- [**Compact Mode**](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/building_ai_scientists/compact_mode.html): Reduces 1000+ tools to 4-5 core discovery tools, saving ~99% context window while maintaining full capability
- [**Two-Tier Result Caching**](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/cache_system.html): In-memory LRU + SQLite persistence with per-tool fingerprinting for 10x speedup, offline support, and reproducibility
- [**Literature Search Across 11+ Databases**](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/literature_search_tools_tutorial.html): Unified search across PubMed, Semantic Scholar, ArXiv, BioRxiv, Europe PMC, and more with AI-powered query expansion
- [**Human Expert Feedback**](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/expert_feedback.html): Human-in-the-loop consultation where AI agents can escalate to domain experts in real-time via a web dashboard
- [**Scientific Visualization**](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/visualization_tutorial.html): Interactive 3D protein structures and 2D/3D molecule visualizations rendered as HTML
- [**Make Your Data Agent-Searchable**](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/make_your_data_agent_searchable.html): Turn any text or JSON data into an agent-searchable collection with one CLI command, shareable on HuggingFace
<p align="center">
<img src="https://github.com/user-attachments/assets/eb15bd7c-4e73-464b-8d65-733877c96a51" width="888" />
</p>
## 🔧 Usage & Integration
- **[Python SDK](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/python_guide.html)**: Load, find, and call 1000+ tools via Python
- **[MCP Support](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/building_ai_scientists/mcp_support.html)**: Model Context Protocol integration for AI agents
- **[MCPB](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/building_ai_scientists/mcpb_introduction.html)**: Standalone executable MCP server bundle
- **[HTTP API](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/http_api.html)**: Deploy remotely and access all methods with minimal client dependencies
## 🚀 AI Scientists Projects Powered by ToolUniverse
*Building your own project with ToolUniverse? We'd love to feature it here! Submit your project via [GitHub Pull Request](https://github.com/mims-harvard/ToolUniverse/pulls) or contact us.*
---
**TxAgent: AI Agent for Therapeutic Reasoning** [[Project]](https://zitniklab.hms.harvard.edu/TxAgent) [[Paper]](https://arxiv.org/pdf/2503.10970) [[PiPy]](https://pypi.org/project/txagent/) [[Github]](https://github.com/mims-harvard/TxAgent) [[HuggingFace]](https://huggingface.co/collections/mims-harvard/txagent-67c8e54a9d03a429bb0c622c)
> **TxAgent** is an AI agent for therapeutic reasoning that leverages ToolUniverse's comprehensive scientific tool ecosystem to solve complex therapeutic reasoning tasks.
---
**Hypercholesterolemia Drug Discovery** [[Tutorial]](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/tooluniverse_case_study.html) [[Code]](https://colab.research.google.com/drive/1UwJ6RwyUoqI5risKQ365EeFdDQWOeOCv?usp=sharing)
## 🤝 Contribution and Community
If you have any suggestions or are interested in any type of collaboration or professional engagement, please don’t hesitate to reach out to [Shanghua Gao](shanghuagao@gmail.com).
**We are actively looking for core contributors for ToolUniverse!**
Please join our [Slack Channel](https://join.slack.com/t/tooluniversehq/shared_invite/zt-3dic3eoio-5xxoJch7TLNibNQn5_AREQ) or reach out to [Shanghua Gao](mailto:shanghuagao@gmail.com)/[Marinka Zitnik](mailto:marinka@hms.harvard.edu).
**Get Involved:**
- **Report Issues**: [GitHub Issues](https://github.com/mims-harvard/ToolUniverse/issues)
- **Join Discussions**: [Slack Channel](https://github.com/mims-harvard/ToolUniverse/discussions)
- **Contact**: Reach out to [Shanghua Gao](shanghuagao@gmail.com)/[Marinka Zitnik](marinka@hms.harvard.edu)
- **Contribute**: See our [Contributing Guide](https://zitniklab.hms.harvard.edu/ToolUniverse/expand_tooluniverse/contributing/index.html)
### Leaders
- **[Shanghua Gao](https://shgao.site)**
- **[Marinka Zitnik](https://zitniklab.hms.harvard.edu/)**
### Contributors
- **[Shanghua Gao](https://shgao.site)**
- **[Richard Zhu](https://www.linkedin.com/in/richard-zhu-4236901a7/)**
- **[Pengwei Sui](https://psui3905.github.io/)**
- **[Zhenglun Kong](https://zlkong.github.io/homepage/)**
- **[Sufian Aldogom](mailto:saldogom@mit.edu)**
- **[Yepeng Huang](https://yepeng.notion.site/Yepeng-Huang-16ad8dd1740080c28d4bd3e3d7c1080c)**
- **[Ayush Noori](https://www.ayushnoori.com/)**
- **[Reza Shamji](mailto:reza_shamji@hms.harvard.edu)**
- **[Krishna Parvataneni](mailto:krishna_parvataneni@hms.harvard.edu)**
- **[Theodoros Tsiligkaridis](https://sites.google.com/view/theo-t)**
- **[Marinka Zitnik](https://zitniklab.hms.harvard.edu/)**
## 📚 Documentation
### 🚀 Get Started
- **[Python Developer Guide](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/python_guide.html)**: Installation, SDK usage, and API reference
- **[AI Agent Platforms](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/building_ai_scientists/index.html)**: Set up ToolUniverse with Cursor, Claude, Windsurf, and more
- **[AI Agent Skills](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/skills_showcase.html)**: Pre-built research skills for AI agents
- **[API Keys](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/api_keys.html)**: Configure API keys for external services
### 💡 Tutorials & Advanced
- **[Tutorials Overview](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/index.html)**: Guides for tool discovery, agentic tools, literature search, and more
- **[AI-Tool Interaction Protocol](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/interaction_protocol.html)**: How AI scientists issue tool requests
- **[Scientific Workflows](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/scientific_workflows.html)**: Multi-agent tool creation and optimization
- **[Hooks System](https://zitniklab.hms.harvard.edu/ToolUniverse/guide/hooks/index.html)**: Intelligent output processing
### 🔧 Expanding ToolUniverse
- **[Contributing Guide](https://zitniklab.hms.harvard.edu/ToolUniverse/expand_tooluniverse/contributing/index.html)**: How to contribute new tools
- **[Local Tools](https://zitniklab.hms.harvard.edu/ToolUniverse/expand_tooluniverse/local_tools/index.html)**: Create and register custom local tools
- **[Remote Tools](https://zitniklab.hms.harvard.edu/ToolUniverse/expand_tooluniverse/remote_tools/index.html)**: Integrate external services as tools
- **[Architecture](https://zitniklab.hms.harvard.edu/ToolUniverse/expand_tooluniverse/architecture.html)**: System architecture overview
### 📚 API Reference
- **[API Modules](https://zitniklab.hms.harvard.edu/ToolUniverse/api/modules.html)**: Complete Python API reference
→ **Browse All Documentation**: [ToolUniverse Documentation](https://zitniklab.hms.harvard.edu/ToolUniverse/)
### Citation
```
@article{gao2025democratizingaiscientistsusing,
title={Democratizing AI scientists using ToolUniverse},
author={Shanghua Gao and Richard Zhu and Pengwei Sui and Zhenglun Kong and Sufian Aldogom and Yepeng Huang and Ayush Noori and Reza Shamji and Krishna Parvataneni and Theodoros Tsiligkaridis and Marinka Zitnik},
year={2025},
eprint={2509.23426},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2509.23426},
}
@article{gao2025txagent,
title={TxAgent: An AI Agent for Therapeutic Reasoning Across a Universe of Tools},
author={Shanghua Gao and Richard Zhu and Zhenglun Kong and Ayush Noori and Xiaorui Su and Curtis Ginder and Theodoros Tsiligkaridis and Marinka Zitnik},
year={2025},
eprint={2503.10970},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2503.10970},
}
```
---
*Democratizing AI agents for science with ToolUniverse.*
| text/markdown | null | Shanghua Gao <shanghuagao@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"requests>=2.32.0",
"numpy>=2.2.0",
"sympy>=1.12.0",
"graphql-core>=3.2.0",
"fastapi>=0.116.0",
"uvicorn>=0.36.0",
"pydantic>=2.11.0",
"epam.indigo>=1.34.0",
"networkx>=3.4.0",
"openai>=1.107.0",
"pyyaml>=6.0.0",
"google-genai>=1.36.0",
"google-generativeai>=0.7.2",
"mcp[cli]>=1.9.3",
"f... | [] | [] | [] | [
"Homepage, https://github.com/mims-harvard/ToolUniverse"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:52:53.874317 | tooluniverse-1.0.19.1.tar.gz | 3,044,548 | ce/7f/a69142e4672317ee23dbd6f2217b61fdc797590c11cd7c27734b1018f036/tooluniverse-1.0.19.1.tar.gz | source | sdist | null | false | 6fb36aecb19f7356408bcca7e468d96f | 302ff13ee2688e7043b82b68e85fc5bb41abb0d0ee9a10d3356b4de43ebd73c3 | ce7fa69142e4672317ee23dbd6f2217b61fdc797590c11cd7c27734b1018f036 | null | [
"LICENSE"
] | 551 |
2.4 | trajax-visualizer | 0.2.2 | Interactive visualization tool for trajax trajectory planning simulations | # trajax-visualizer
Interactive visualization tool for [trajax](https://gitlab.com/risk-metrics/trajax) trajectory planning simulations.
## Installation
```bash
pip install trajax-visualizer
```
Or with uv:
```bash
uv add trajax-visualizer
```
## Requirements
- **Python 3.13+**
- **Node.js 18+** (required at runtime for generating HTML visualizations)
## Usage
### Basic Usage
```python
from trajax_visualizer import visualizer, MpccSimulationResult
# Create a visualizer instance
mpcc_viz = visualizer.mpcc()
# After running your simulation, create a result object
result = MpccSimulationResult(
reference=trajectory,
states=states,
optimal_trajectories=optimal_trajectories,
nominal_trajectories=nominal_trajectories,
contouring_errors=contouring_errors,
lag_errors=lag_errors,
wheelbase=wheelbase,
max_contouring_error=max_contouring_error,
max_lag_error=max_lag_error,
)
# Generate visualization
await mpcc_viz(result, key="my-simulation")
```
## Output
Visualizations are saved as:
- `<key>.json` - Raw simulation data
- `<key>.html` - Interactive HTML visualization with Plotly
## Development
The bundled CLI (`visualizer/trajax_visualizer/assets/cli.js`) is included in the package distribution. See `visualizer/core/README.md` for build instructions.
To make sure the CLI bundle is ignored by VCS, run:
```bash
git update-index --skip-worktree visualizer/trajax_visualizer/assets/cli.js
```
| text/markdown | null | Zurab Mujirishvili <zurab.mujirishvili@fau.de> | null | null | null | robotics, simulation, trajectory planning, visualization | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Visualization",
"Typing :: Typed"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"aiofiles>=25.1.0",
"aiopath>=0.7.7",
"msgspec>=0.20.0",
"numpy>=2.4.2",
"numtypes>=0.5.1",
"trajax"
] | [] | [] | [] | [] | uv/0.9.18 {"installer":{"name":"uv","version":"0.9.18","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Debian GNU/Linux","version":"12","id":"bookworm","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T15:52:29.963410 | trajax_visualizer-0.2.2.tar.gz | 1,872,942 | 55/8b/ef0988fe739a9e0b24b6e999a211b8343059c9f053826c3376caf55fd56b/trajax_visualizer-0.2.2.tar.gz | source | sdist | null | false | 2fe151f8ab8df92237804f4c9e288b6b | 33b499a16988254330e96002010a644b3135201266cc2fe8ccda3c7e50112018 | 558bef0988fe739a9e0b24b6e999a211b8343059c9f053826c3376caf55fd56b | null | [] | 202 |
2.4 | oras | 0.2.41 | OCI Registry as Storage Python SDK | # ORAS Python
<!-- ALL-CONTRIBUTORS-BADGE:START - Do not remove or modify this section -->
[](#contributors-)
<!-- ALL-CONTRIBUTORS-BADGE:END -->

OCI Registry as Storage enables libraries to push OCI Artifacts to [OCI Conformant](https://github.com/opencontainers/oci-conformance) registries. This is a Python SDK for Python developers to empower them to do this in their applications.
See our ⭐️ [Documentation](https://oras-project.github.io/oras-py/) ⭐️ to get started.
## Code of Conduct
Please note that this project has adopted the [CNCF Code of Conduct](https://github.com/cncf/foundation/blob/master/code-of-conduct.md).
Please follow it in all your interactions with the project members and users.
## Contributing
To contribute to oras python, if you want to have discussion about a change, feature, or fix, you can open an issue first. We then ask that you open a pull request against the main branch. In the description please include the details of your change, e.g., why it is needed, what you did, and any further points for discussion. In addition:
- For changes to the code:
- Please bump the version in the `oras/version.py` file
- Please also make a corresponding note in the `CHANGELOG.md`
For any changes to functionality or code that are not tested, please add one or more tests. Thank you for your contributions!
## 😁️ Contributors 😁️
We use the [all-contributors](https://github.com/all-contributors/all-contributors)
tool to generate a contributors graphic below.
<!-- ALL-CONTRIBUTORS-LIST:START - Do not remove or modify this section -->
<!-- prettier-ignore-start -->
<!-- markdownlint-disable -->
<table>
<tbody>
<tr>
<td align="center" valign="top" width="14.28%"><a href="https://vsoch.github.io"><img src="https://avatars.githubusercontent.com/u/814322?v=4?s=100" width="100px;" alt="Vanessasaurus"/><br /><sub><b>Vanessasaurus</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=vsoch" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="youtube.com/lachlanevenson"><img src="https://avatars.githubusercontent.com/u/6912984?v=4?s=100" width="100px;" alt="Lachlan Evenson"/><br /><sub><b>Lachlan Evenson</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=lachie83" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="http://SteveLasker.blog"><img src="https://avatars.githubusercontent.com/u/7647382?v=4?s=100" width="100px;" alt="Steve Lasker"/><br /><sub><b>Steve Lasker</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=SteveLasker" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://dolit.ski"><img src="https://avatars.githubusercontent.com/u/393494?v=4?s=100" width="100px;" alt="Josh Dolitsky"/><br /><sub><b>Josh Dolitsky</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=jdolitsky" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/bridgetkromhout"><img src="https://avatars.githubusercontent.com/u/2104453?v=4?s=100" width="100px;" alt="Bridget Kromhout"/><br /><sub><b>Bridget Kromhout</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=bridgetkromhout" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/magelisk"><img src="https://avatars.githubusercontent.com/u/18201513?v=4?s=100" width="100px;" alt="Matt Warner"/><br /><sub><b>Matt Warner</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=magelisk" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="wolfv.github.io"><img src="https://avatars.githubusercontent.com/u/885054?v=4?s=100" width="100px;" alt="Wolf Vollprecht"/><br /><sub><b>Wolf Vollprecht</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=wolfv" title="Code">💻</a></td>
</tr>
<tr>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/shizhMSFT"><img src="https://avatars.githubusercontent.com/u/32161882?v=4?s=100" width="100px;" alt="Shiwei Zhang"/><br /><sub><b>Shiwei Zhang</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=shizhMSFT" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/jhlmco"><img src="https://avatars.githubusercontent.com/u/126677738?v=4?s=100" width="100px;" alt="jhlmco"/><br /><sub><b>jhlmco</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=jhlmco" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/Ananya2003Gupta"><img src="https://avatars.githubusercontent.com/u/90386813?v=4?s=100" width="100px;" alt="Ananya Gupta"/><br /><sub><b>Ananya Gupta</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=Ananya2003Gupta" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/sunnycarter"><img src="https://avatars.githubusercontent.com/u/36891339?v=4?s=100" width="100px;" alt="sunnycarter"/><br /><sub><b>sunnycarter</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=sunnycarter" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/mariusbertram"><img src="https://avatars.githubusercontent.com/u/10505884?v=4?s=100" width="100px;" alt="Marius Bertram"/><br /><sub><b>Marius Bertram</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=mariusbertram" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://dev-zero.ch"><img src="https://avatars.githubusercontent.com/u/11307?v=4?s=100" width="100px;" alt="Tiziano Müller"/><br /><sub><b>Tiziano Müller</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=dev-zero" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://terryhowe.wordpress.com/"><img src="https://avatars.githubusercontent.com/u/104113?v=4?s=100" width="100px;" alt="Terry Howe"/><br /><sub><b>Terry Howe</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=TerryHowe" title="Code">💻</a></td>
</tr>
<tr>
<td align="center" valign="top" width="14.28%"><a href="https://saketjajoo.github.io"><img src="https://avatars.githubusercontent.com/u/23132557?v=4?s=100" width="100px;" alt="Saket Jajoo"/><br /><sub><b>Saket Jajoo</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=saketjajoo" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/miker985"><img src="https://avatars.githubusercontent.com/u/26555712?v=4?s=100" width="100px;" alt="Mike"/><br /><sub><b>Mike</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=miker985" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/linshokaku"><img src="https://avatars.githubusercontent.com/u/18627646?v=4?s=100" width="100px;" alt="deoxy"/><br /><sub><b>deoxy</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=linshokaku" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/kavish-p"><img src="https://avatars.githubusercontent.com/u/29086148?v=4?s=100" width="100px;" alt="Kavish Punchoo"/><br /><sub><b>Kavish Punchoo</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=kavish-p" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/my5cents"><img src="https://avatars.githubusercontent.com/u/4820203?v=4?s=100" width="100px;" alt="my5cents"/><br /><sub><b>my5cents</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=my5cents" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/tumido"><img src="https://avatars.githubusercontent.com/u/7453394?v=4?s=100" width="100px;" alt="Tom Coufal"/><br /><sub><b>Tom Coufal</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=tumido" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://youtube.com/@MatteoMortari"><img src="https://avatars.githubusercontent.com/u/1699252?v=4?s=100" width="100px;" alt="Matteo Mortari"/><br /><sub><b>Matteo Mortari</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=tarilabs" title="Code">💻</a></td>
</tr>
<tr>
<td align="center" valign="top" width="14.28%"><a href="crosscat.me"><img src="https://avatars.githubusercontent.com/u/39812919?v=4?s=100" width="100px;" alt="Isabella Basso"/><br /><sub><b>Isabella Basso</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=isinyaaa" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/xarses"><img src="https://avatars.githubusercontent.com/u/2107834?v=4?s=100" width="100px;" alt="Andrew Woodward"/><br /><sub><b>Andrew Woodward</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=xarses" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/ccronca"><img src="https://avatars.githubusercontent.com/u/1499184?v=4?s=100" width="100px;" alt="Camilo Cota"/><br /><sub><b>Camilo Cota</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=ccronca" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="http://danwalsh.livejournal.com"><img src="https://avatars.githubusercontent.com/u/2000835?v=4?s=100" width="100px;" alt="Daniel J Walsh"/><br /><sub><b>Daniel J Walsh</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=rhatdan" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/MichaelKopfMkf"><img src="https://avatars.githubusercontent.com/u/189326443?v=4?s=100" width="100px;" alt="MichaelKopfMkf"/><br /><sub><b>MichaelKopfMkf</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=MichaelKopfMkf" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/natefaerber"><img src="https://avatars.githubusercontent.com/u/3720207?v=4?s=100" width="100px;" alt="Nate Faerber"/><br /><sub><b>Nate Faerber</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=natefaerber" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/Meallia"><img src="https://avatars.githubusercontent.com/u/7398724?v=4?s=100" width="100px;" alt="Jonathan Gayvallet"/><br /><sub><b>Jonathan Gayvallet</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=Meallia" title="Code">💻</a></td>
</tr>
<tr>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/Sojamann"><img src="https://avatars.githubusercontent.com/u/10118597?v=4?s=100" width="100px;" alt="Sojamann"/><br /><sub><b>Sojamann</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=Sojamann" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/joseacl"><img src="https://avatars.githubusercontent.com/u/8399784?v=4?s=100" width="100px;" alt="José Antonio Cortés López"/><br /><sub><b>José Antonio Cortés López</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=joseacl" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/diverger"><img src="https://avatars.githubusercontent.com/u/335566?v=4?s=100" width="100px;" alt="diverger"/><br /><sub><b>diverger</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=diverger" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/rasmusfaber"><img src="https://avatars.githubusercontent.com/u/2798829?v=4?s=100" width="100px;" alt="rasmusfaber"/><br /><sub><b>rasmusfaber</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=rasmusfaber" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="ky.dev"><img src="https://avatars.githubusercontent.com/u/18364341?v=4?s=100" width="100px;" alt="Kante Yin"/><br /><sub><b>Kante Yin</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=kerthcet" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://crosscat.me"><img src="https://avatars.githubusercontent.com/u/39812919?v=4?s=100" width="100px;" alt="Isabella Basso"/><br /><sub><b>Isabella Basso</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=antisaling" title="Code">💻</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/ianpittwood"><img src="https://avatars.githubusercontent.com/u/9877347?v=4?s=100" width="100px;" alt="Ian Pittwood"/><br /><sub><b>Ian Pittwood</b></sub></a><br /><a href="https://github.com/oras-project/oras-py/commits?author=ianpittwood" title="Code">💻</a></td>
</tr>
</tbody>
</table>
<!-- markdownlint-restore -->
<!-- prettier-ignore-end -->
<!-- ALL-CONTRIBUTORS-LIST:END -->
## License
This code is licensed under the Apache 2.0 [LICENSE](LICENSE).
| text/markdown | Vanessa Sochat | vsoch@users.noreply.github.com | Vanessa Sochat | null | LICENSE | oci, registry, storage | [
"Intended Audience :: Science/Research",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python",
"Topic :: Software Development",
"Topic :: Scientific/Engineering",
"Operating System :: Unix",
"Programming Language :: Python :: 3 :: On... | [] | https://github.com/oras-project/oras-py | null | null | [] | [] | [] | [
"jsonschema",
"requests",
"jsonschema; extra == \"all\"",
"requests; extra == \"all\"",
"pytest>=4.6.2; extra == \"all\"",
"docker==5.0.1; extra == \"all\"",
"boto3>=1.33.0; extra == \"all\"",
"pytest>=4.6.2; extra == \"tests\"",
"docker==5.0.1; extra == \"docker\"",
"boto3>=1.33.0; extra == \"ecr... | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T15:52:22.659455 | oras-0.2.41.tar.gz | 55,780 | f9/fb/01aabe6a9a4da017e9fbedf6b8f58ea45195a9037154c00a6ac9156ca3c2/oras-0.2.41.tar.gz | source | sdist | null | false | 6c32f2a6b2d73a9008dd35eb337405cf | 8d45ae5482f447affc04bc5660cf464a749e3d4d10b31d183d28b647dfbf1e65 | f9fb01aabe6a9a4da017e9fbedf6b8f58ea45195a9037154c00a6ac9156ca3c2 | null | [
"LICENSE"
] | 16,099 |
2.4 | calzone | 1.1.9 | A Geant4 Python wrapper. | # Calzone <img src="https://github.com/niess/calzone/blob/master/docs/source/_static/images/logo.svg" height="30px"> [![][RTD_BADGE]][RTD]
Calzone (**CAL**orimeter **ZONE**) is a Python package built on top of
[Geant4][Geant4]. It was developed in the context of geosciences with the
objective of studying the emission of radioactivity from volcanoes [(Terray et
al., 2020)][TGV+20], and in particular to simulate the response of gamma
spectrometers deployed in the field. To this end, Calzone was developed in
conjunction with [Goupil][GOUPIL] [(Niess et al., 2024)][NVT24], a backward
gamma transport engine, and is interoperable with the latter. Yet, both packages
can be used entirely independently, if necessary.
Please refer to the online [documentation][RTD] and the [examples][EXAMPLES] for
further information.
## Installation
Binary distributions of Calzone are available from [PyPI][PyPI], e.g. as
```bash
python -m pip install calzone
```
In addition, Calzone requires 2 GB of [Geant4][Geant4] data tables, which are
not included in the Python package. Once Calzone has been installed, these can
be downloaded as
```bash
python -m calzone download
```
Please refer to the [documentation][RTD_INSTALLATION] for alternative
installation methods.
## Quick start
```toml
# file: geometry.toml
[Environment]
sphere = 1E+05 # cm
material = "G4_WATER"
[Environment.Source]
sphere = 1E+02 # cm
material = "G4_WATER"
[Environment.Source.Detector]
cylinder = { length = 5.1, radius = 2.55 } # cm
material = "G4_SODIUM_IODIDE"
role = "record_deposits"
```
```python
# file: run.py
import calzone
# Instanciate a simulation engine (using a TOML geometry).
# Requires installing `tomli` for Python < 3.11.
simulation = calzone.Simulation("geometry.toml")
# Generate primary particles.
source = simulation.geometry.find("Source")
energy = 1.0 # MeV
primaries = simulation.particles() \
.pid("gamma") \
.energy(energy) \
.inside(source) \
.generate(1000)
# Run the simulation and fetch deposits.
detector = simulation.geometry.find("Detector")
deposits = simulation \
.run(primaries) \
.deposits[detector.path]
```
## License
The Calzone source is distributed under the **GNU LGPLv3** license. See the
provided [LICENSE][LICENSE] and [COPYING.LESSER][COPYING.LESSER] files.
Additionaly, Calzone uses software developed by Members of the [Geant4][Geant4]
Collaboration, which is under a [specific license][G4_LICENSE].
[COPYING.LESSER]: https://github.com/niess/calzone/blob/master/COPYING.LESSER
[EXAMPLES]: https://github.com/niess/calzone/blob/master/examples
[JSON]: https://www.json.org/json-en.html
[Geant4]: http://cern.ch/geant4
[Goupil]: https://github.com/niess/goupil
[G4_LICENSE]: https://geant4.web.cern.ch/download/license#license
[LICENSE]: https://github.com/niess/calzone/blob/master/LICENSE
[NVT24]: https://doi.org/10.48550/arXiv.2412.02414
[PyPI]: https://pypi.org/project/calzone/
[RTD]: https://calzone.readthedocs.io/en/latest/?badge=latest
[RTD_BADGE]: https://readthedocs.org/projects/calzone/badge/?version=latest
[RTD_INSTALLATION]: https://calzone.readthedocs.io/en/latest/installation.html
[TGV+20]: https://doi.org/10.1029/2019JB019149
[TOML]: https://toml.io/en/
[YAML]: https://yaml.org/
| text/markdown | null | Valentin Niess <valentin.niess@gmail.com> | null | null | LGPLv3 | Python, Monte Carlo, Geant4 | [
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics"
] | [] | null | null | >=3.7.0 | [] | [] | [] | [
"numpy>=1.6.0"
] | [] | [] | [] | [
"source, https://github.com/niess/calzone"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:52:14.193832 | calzone-1.1.9.tar.gz | 117,427 | 36/18/cd98700fe0dff7083dc54fda3b4f505a8d70adabe4530e20c7a7a3477e02/calzone-1.1.9.tar.gz | source | sdist | null | false | 108b72247bce0efdd7709e7fb16dcab0 | e5150364c0c0e583cb330b324f50e77522d3e514137a959c4c9d742c138b5178 | 3618cd98700fe0dff7083dc54fda3b4f505a8d70adabe4530e20c7a7a3477e02 | null | [
"LICENSE",
"COPYING.LESSER"
] | 582 |
2.4 | sphinx-ai-cli | 1.0.6 | CLI for Sphinx AI | ## 🚀 Quick Start
```bash
# Start Sphinx CLI (interactive mode by default)
sphinx-cli
```
## 🎨 Interactive Mode (Default)
Running `sphinx-cli` starts an interactive terminal-based chat interface similar to Claude Code or Cursor agent:
### Features:
- **Notebook Selection**: Automatically scans your directory for `.ipynb` files and lets you choose one
- **Notebook Creation**: Prompts to create a new notebook if none are found in your directory
- **Beautiful UI**: Clean terminal interface with minimal design
- **Thinking Indicators**: Shows cycling verbs in dim cyan while Sphinx processes (Thinking, Analyzing, Processing, Debugging, etc.)
- **Conversational Chat**: Type natural language prompts and get responses
- **Real-time Feedback**: See processing status with animated indicators
### Usage:
```bash
# Start interactive mode (default - will prompt for notebook selection or creation)
sphinx-cli
# Start with a specific notebook (creates it if it doesn't exist)
sphinx-cli --notebook-filepath ./my-notebook.ipynb
# Use with existing Jupyter server
sphinx-cli --jupyter-server-url http://localhost:8888 --jupyter-server-token your_token
```
### In Interactive Mode:
- Type your questions naturally at the `>` prompt
- See real-time thinking indicators while Sphinx works
- Type `exit` to end the session
- Press `Ctrl+C` to interrupt at any time
## 📋 Commands
- `sphinx-cli` - Start interactive chat mode (default)
- `sphinx-cli login` - Authenticate with Sphinx (opens web browser)
- `sphinx-cli logout` - Clear stored authentication tokens
- `sphinx-cli status` - Check authentication status
- `sphinx-cli chat --notebook-filepath <path> --prompt <prompt>` - Run a single non-interactive chat
| text/markdown | null | Sphinx AI <support@sphinx.ai> | null | null | Proprietary | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: Other/Proprietary License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python ::... | [] | null | null | >=3.7 | [] | [] | [] | [
"backoff>=2.0.0",
"nodeenv>=1.6.0",
"PyYAML>=6.0",
"rich>=13.0.0",
"prompt-toolkit>=3.0.0",
"questionary>=2.0.0",
"ruff>=0.14.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.7 | 2026-02-19T15:51:46.774701 | sphinx_ai_cli-1.0.6.tar.gz | 2,003,656 | dd/d3/0e403905950d9ab5ec0fed871a2aaa296f0b471b07175c1812e72e118d1f/sphinx_ai_cli-1.0.6.tar.gz | source | sdist | null | false | e3825fdba464c7347acc8c8d04191e29 | d764e3a9d11350900b15b6cccfbb213d5363fa80e118234bceb40bdd0fe73148 | ddd30e403905950d9ab5ec0fed871a2aaa296f0b471b07175c1812e72e118d1f | null | [] | 240 |
2.4 | uvlparser | 2.5.0.dev70 | This module provides a get_tree function to obtain an ANTLR parse-tree from a UVL-defined feature model | # UVL - Universal Variability Language
**UVL (Universal Variability Language)** is a concise and extensible language for modeling variability in software product lines. It supports multiple programming languages and provides a grammar-based foundation for building tools and parsers.
This repository contains the **ANTLR4 grammar files** for UVL. With these, you can generate parsers for UVL tailored to specific programming languages like Java, JavaScript, and Python.
## ✨ Key Features
- Language-level modularity
- Namespaces and imports
- Feature trees with attributes and cardinalities
- Cross-tree constraints
- Extensible for different target languages
## 📦 Repository Structure
- `uvl/UVLParser.g4` – Base grammar in EBNF form
- `uvl/UVLLexer.g4` – Base lexer grammar for UVL
- `uvl/Java/UVLJava*.g4`, `uvl/Python/UVLPython*.g4`, etc. – Language-specific grammar files
- `java/` – Java-based parser implementation using Maven
- `python/` – Python-based parser implementation
- `javascript/` – JavaScript-based parser implementation
- `tests/` – UVL test cases for validation
UVL uses [ANTLR4](https://www.antlr.org/) as its parser generator.
---
## 💡 Language Overview
Each UVL model may consist of five optional sections:
1. **Language levels**: Enable optional concepts via `include` keyword.
2. **Namespace**: Allows referencing the model from other UVL models.
3. **Imports**: Include other feature models (e.g., `subdir.filename as fn`).
4. **Feature tree**: Hierarchical features with cardinalities, attributes, and group types (`mandatory`, `optional`, `or`, `alternative`).
5. **Cross-tree constraints**: Logical and arithmetic constraints among features.
### 🔍 Example
```uvl
namespace Server
features
Server {abstract}
mandatory
FileSystem
or
NTFS
APFS
EXT4
OperatingSystem {abstract}
alternative
Windows
macOS
Debian
optional
Logging {
default,
log_level "warn"
}
constraints
Windows => NTFS
macOS => APFS
```
**Explanation:**
- `Server` is an abstract feature.
- It must include a `FileSystem` and an `OperatingSystem`.
- `Logging` is optional and includes an attribute.
- Logical constraints define dependencies between features.
🔗 More examples: https://github.com/Universal-Variability-Language/uvl-models/tree/main/Feature_Models
---
## Usage
To use UVL in your projects, you can either:
1. **Use the pre-built parsers**
### Java Parser
Include the following dependency in your Maven project:
```xml
<dependency>
<groupId>io.github.universal-variability-language</groupId>
<artifactId>uvl-parser</artifactId>
<version>0.3</version>
</dependency>
```
### Python Parser
Install the package via pip:
```bash
pip install uvlparser
```
### JavaScript Parser
Install the package via npm:
```bash
npm install uvl-parser
```
2. **Build the parser manually** See the sections below for details.
## ⚙️ Building the Parser manually
### Java Parser
#### Prerequisites
- [ANTLR4](https://www.antlr.org/)
- Java 17+
- [Maven](https://maven.apache.org/)
#### Build Steps
1. Clone the repository:
```bash
git clone https://github.com/Universal-Variability-Language/uvl-parser
```
2. Build the parser:
```bash
cd java
mvn clean package
```
3. Include the generated JAR in your Java project.
---
## 📚 Resources
**UVL Models & Tools**
- https://github.com/Universal-Variability-Language/uvl-models
- https://www.uvlhub.io/
**Tooling Ecosystem**
- https://github.com/FeatureIDE/FeatureIDE
- https://ide.flamapy.org/
- https://github.com/Universal-Variability-Language/uvl-lsp
- https://github.com/SECPS/TraVarT
- https://github.com/AlexCortinas/spl-js-engine
---
## 📖 Citation
If you use UVL in your research, please cite:
```bibtex
@article{UVL2024,
title = {UVL: Feature modelling with the Universal Variability Language},
journal = {Journal of Systems and Software},
volume = {225},
pages = {112326},
year = {2025},
issn = {0164-1212},
doi = {https://doi.org/10.1016/j.jss.2024.112326},
url = {https://www.sciencedirect.com/science/article/pii/S0164121224003704},
author = {David Benavides and Chico Sundermann and Kevin Feichtinger and José A. Galindo and Rick Rabiser and Thomas Thüm},
keywords = {Feature model, Software product lines, Variability}
}
```
---
## 📬 Contact & Contributions
Feel free to open issues or pull requests if you have suggestions or improvements. For questions or collaboration inquiries, visit the UVL Website:
https://universal-variability-language.github.io/
| text/markdown | UVL Team | jagalindo@us.es | null | null | GNU General Public License v3 (GPLv3) | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: OS Independent"
] | [] | https://github.com/Universal-Variability-Language/uvl-parser | null | >=3.0 | [] | [] | [] | [
"antlr4-python3-runtime==4.13.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T15:50:37.385585 | uvlparser-2.5.0.dev70.tar.gz | 29,889 | aa/9b/55046b9a5013036b439e45e263c1bed05bb7fd2f901670dcfa53a49b8e8f/uvlparser-2.5.0.dev70.tar.gz | source | sdist | null | false | afe5ef9b5a6328c70fb8fbd640ffa0d9 | 6ff32331058eb48e9298a7406bb7e5016c4acc93a3f93568974b0c4f0bff04ae | aa9b55046b9a5013036b439e45e263c1bed05bb7fd2f901670dcfa53a49b8e8f | null | [] | 179 |
2.3 | pyfacl | 1.4.0 | Package to manage access control using POSIX ACLs | # PyFACL
[](https://badge.fury.io/py/pyfacl)
[](https://pypi.org/project/pyfacl/)
[](https://pyfacl.readthedocs.io/en/latest/?badge=latest)
[](https://opensource.org/licenses/MIT)
A Python library for parsing and checking POSIX File Access Control Lists (FACL).
**Documentation:** [https://pyfacl.readthedocs.io/en/latest/](https://pyfacl.readthedocs.io/en/latest/)
## Installation
### From PyPI
```bash
pip install pyfacl
```
## Usage
### CLI
The CLI tool checks permissions through the entire directory hierarchy, checks whether the permissions are met and identifies which permission rule applies at each level.
```bash
pyfacl trace /path/to/file user:<user2>:r-x --mode exact
```
Example output:
```bash
$ pyfacl trace /data1/collab002/sail/example/permission/folder user:user2:r-x
0) ✅ other::r-x /
1) ✅ other::r-x /data1
2) ✅ group::rwx /data1/collab002
3) ✅ group::r-x /data1/collab002/sail
4) ✅ group::r-x /data1/collab002/sail/example
5) ❌ user:user2:--x /data1/collab002/sail/example/permission
6) ✅ group::r-x /data1/collab002/sail/example/permission/folder
```
In this trace, items 0-4 and 6 show ✅ **passing** permissions, while item 5 shows ❌ **failing** permissions where the user only has execute (`--x`) but needs read+execute (`r-x`).
However, often we only care about if the user has the required permission for the final file/directory, not the full trace. For that, we can use the `has` command:
```bash
$ pyfacl has /path/to/file user:<user2>:r-x --mode exact
0) ✅ other::r-x /
1) ✅ other::r-x /data1
2) ✅ group::rwx /data1/collab002
3) ✅ group::r-x /data1/collab002/sail
4) ✅ group::r-x /data1/collab002/sail/example
5) ✅ user:user2:--x /data1/collab002/sail/example/permission
6) ✅ group::r-x /data1/collab002/sail/example/permission/folder
```
### Python
#### Check one file/folder permission
```python
from pyfacl import FACL
# Initialize and parse FACL for a file/directory
facl = FACL(path="/path/to/file")
# Check permissions with different modes
facl.has_permission("user:user2:r-x", mode="exact") # exact match
facl.has_permission("user:user2:r--", mode="at_least") # has at least read
facl.has_permission("user:user2:rwx", mode="at_most") # has at most rwx
```
#### Check trace through directory hierarchy
```python
from pyfacl import FACLTrace
# Initialize FACLTrace for a directory
facl_trace = FACLTrace(path="/path/to/directory", v=1)
# Trace permissions for a specific user
trace_result = facl_trace.has_permission("user:user2:r-x", mode="at_least")
```
#### Check if user/group has permission for a file/directory
```python
from pyfacl import FACLHas
# Initialize FACLHas for a file/directory
facl_has = FACLHas(path="/path/to/file")
# Check if user/group has the specified permission
has_permission = facl_has.has_permission("user:user2:r-x", mode="at_least")
```
### Permission Modes
- **`exact`**: Permissions must match exactly
- **`at_least`**: Must have at least the specified permissions
- **`at_most`**: Must have at most the specified permissions
## Development
### Setup Development Environment
```bash
pip install -e ".[dev]"
pre-commit install
```
### Run Pre-commit Checks
```bash
pre-commit run --all-files
```
| text/markdown | tobiaspk | tobiaspk1@gmail.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"typer>=0.15.0",
"pre-commit>=3.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"flake8>=6.0.0; extra == \"dev\"",
"isort>=5.12.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\""
] | [] | [] | [] | [] | poetry/2.1.3 CPython/3.12.9 Linux/4.18.0-425.19.2.el8_7.x86_64 | 2026-02-19T15:49:58.118926 | pyfacl-1.4.0.tar.gz | 7,804 | b8/86/b27a2f2ba5f7600ef0872355372574581ef8d58bdef34690090a69c45854/pyfacl-1.4.0.tar.gz | source | sdist | null | false | 2d8a6fa3dd66d67e188ee962cf561555 | 6efaa20986630a395cd3a5abb3a88df252d12c71d9481cbeae5fe2522938cf98 | b886b27a2f2ba5f7600ef0872355372574581ef8d58bdef34690090a69c45854 | null | [] | 205 |
2.4 | trajax | 0.2.2 | A library providing performant NumPy & JAX implementations of an MPPI planner, along with implementation of related algorithms/tools. | # trajax
> **Primary repository:** [gitlab.com/risk-metrics/trajax](https://gitlab.com/risk-metrics/trajax) — the [GitHub mirror](https://github.com/zuka011/Trajax) exists for Colab notebook support.
[](https://gitlab.com/risk-metrics/trajax/-/pipelines) [](https://codecov.io/gl/risk-metrics/trajax) [](https://bencher.dev/perf/trajax) [](https://pypi.org/project/trajax/) [](https://pypi.org/project/trajax/) [](https://gitlab.com/risk-metrics/trajax/-/blob/main/LICENSE)
Sampling-based trajectory planning for autonomous systems. Provides composable building blocks — dynamics models, cost functions, samplers, and risk metrics — so you can assemble a complete MPPI planner in a few lines and iterate on the parts that matter for your problem.
## Installation
```bash
pip install trajax # NumPy + JAX (CPU)
pip install trajax[cuda] # JAX with GPU support (Linux)
```
Requires Python ≥ 3.13.
## Quick Start
MPPI planner with MPCC (Model Predictive Contouring Control) for path tracking, using a kinematic bicycle model:
```python
from trajax.numpy import mppi, model, sampler, trajectory, types, extract
from numtypes import array
def position(states):
return types.positions(x=states.positions.x(), y=states.positions.y())
reference = trajectory.waypoints(
points=array([[0, 0], [10, 0], [20, 5], [30, 5]], shape=(4, 2)),
path_length=35.0,
)
planner, augmented_model, _, _ = mppi.mpcc(
model=model.bicycle.dynamical(
time_step_size=0.1, wheelbase=2.5,
speed_limits=(0.0, 15.0), steering_limits=(-0.5, 0.5),
acceleration_limits=(-3.0, 3.0),
),
sampler=sampler.gaussian(
standard_deviation=array([0.5, 0.2], shape=(2,)),
rollout_count=256,
to_batch=types.bicycle.control_input_batch.create, seed=42,
),
reference=reference,
position_extractor=extract.from_physical(position),
config={
"weights": {"contouring": 50.0, "lag": 100.0, "progress": 1000.0},
"virtual": {"velocity_limits": (0.0, 15.0)},
},
)
state = types.augmented.state.of(
physical=types.bicycle.state.create(x=0.0, y=0.0, heading=0.0, speed=0.0),
virtual=types.simple.state.zeroes(dimension=1),
)
nominal = types.augmented.control_input_sequence.of(
physical=types.bicycle.control_input_sequence.zeroes(horizon=30),
virtual=types.simple.control_input_sequence.zeroes(horizon=30, dimension=1),
)
for _ in range(200):
control = planner.step(temperature=50.0, nominal_input=nominal, initial_state=state)
state = augmented_model.step(inputs=control.optimal, state=state)
nominal = control.nominal
```
<!-- TODO: Replace with simulation GIF -->
To use JAX (GPU), change `from trajax.numpy` to `from trajax.jax`. The API is identical.
## Features
See the [feature overview](https://risk-metrics.gitlab.io/trajax/guide/features/) for the full list of supported components, backend coverage, and roadmap.
## Documentation
| | |
|---|---|
| [Getting Started](https://risk-metrics.gitlab.io/trajax/guide/getting-started/) | Installation, first planner, simulation loop |
| [User Guide](https://risk-metrics.gitlab.io/trajax/guide/concepts/) | MPPI concepts, cost design, obstacles, boundaries, risk metrics |
| [Examples](https://risk-metrics.gitlab.io/trajax/guide/examples/) | Interactive visualizations of MPCC scenarios |
| [API Reference](https://risk-metrics.gitlab.io/trajax/api/) | Factory functions and protocol documentation |
## Contributing
See [CONTRIBUTING.md](CONTRIBUTING.md).
## License
MIT — see [LICENSE](LICENSE).
| text/markdown | null | Zurab Mujirishvili <zurab.mujirishvili@fau.de> | null | null | null | autonomous systems, jax, mppi, robotics, safety, trajectory planning | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Typing :: Typed"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"beartype>=0.22.9",
"deepmerge>=2.0",
"jax>=0.9.0.1",
"jaxtyping>=0.3.9",
"numtypes>=0.5.1",
"riskit>=0.3.0",
"scipy>=1.17.0",
"jax[cuda]>=0.9.0.1; extra == \"cuda\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Debian GNU/Linux","version":"13","id":"trixie","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T15:48:07.764094 | trajax-0.2.2-py3-none-any.whl | 211,676 | 24/19/d5ac6c7030ae71b940f9b033c7dd571bad37c1e9e2acc374aecb6eaa383c/trajax-0.2.2-py3-none-any.whl | py3 | bdist_wheel | null | false | c4c3709598ed082beb09e9af4ad6b78d | 7ab328aa16f9aa885a7655382d9d4a99765b5f643fc1d828ae7393a9f5ce7d57 | 2419d5ac6c7030ae71b940f9b033c7dd571bad37c1e9e2acc374aecb6eaa383c | null | [
"LICENSE"
] | 195 |
2.1 | bn-byneuron | 0.0.112 | API for byneuron backend | # Byneuron
## About
byneuron API tool that works via backend endpoints
Handles entities and eventdata.
## get started
provide environment variables, e.g. .ENV file in root with
-> BYNEURON_URL
-> KEYCLOAK_TOKEN_URL
-> OAUTH2_CLIENT_ID
-> OAUTH2_CLIENT_SECRET
| text/markdown | jovi | jo.vinckier@bynubian.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://gitlab.com/bynubian/bynode/python_packages/byneuron | null | >=3.7 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.9.6 | 2026-02-19T15:47:55.337026 | bn_byneuron-0.0.112.tar.gz | 20,335 | 71/71/f0b2819d1bcf637801418754378c2ea52b3fc20179f27e1efdc843827ee7/bn_byneuron-0.0.112.tar.gz | source | sdist | null | false | afc6f27345a55e0173d65272688d3062 | 353a863ac5a729534a28737e5e9372f2b4d538d03a74ba3b1533ddae2c313e2d | 7171f0b2819d1bcf637801418754378c2ea52b3fc20179f27e1efdc843827ee7 | null | [] | 209 |
2.4 | axonflow | 3.5.0 | AxonFlow Python SDK - Enterprise AI Governance in 3 Lines of Code | # AxonFlow Python SDK
Enterprise AI Governance in 3 Lines of Code.
[](https://badge.fury.io/py/axonflow)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
[](http://mypy-lang.org/)
> **Evaluating AxonFlow in production?** We're opening limited Design Partner slots.
>
> Free 30-minute architecture and incident-readiness review, priority issue triage, roadmap input, and early feature access.
>
> [Apply here](https://getaxonflow.com/design-partner?utm_source=readme_sdk_python) or email [design-partners@getaxonflow.com](mailto:design-partners@getaxonflow.com).
>
> No commitment required. We reply within 48 hours.
> **Questions or feedback?**
>
> Comment in [GitHub Discussions](https://github.com/getaxonflow/axonflow/discussions/239) or email [hello@getaxonflow.com](mailto:hello@getaxonflow.com) for private feedback.
## How This SDK Fits with AxonFlow
This SDK is a client library for interacting with a running AxonFlow control plane. It is used from application or agent code to send execution context, policies, and requests at runtime.
A deployed AxonFlow platform (self-hosted or cloud) is required for end-to-end AI governance. SDKs alone are not sufficient—the platform and SDKs are designed to be used together.
### Architecture Overview (2 min)
If you're new to AxonFlow, this short video shows how the control plane and SDKs work together in a real production setup:
[](https://youtu.be/WwQXHKuZhxc)
▶️ [Watch on YouTube](https://youtu.be/WwQXHKuZhxc)
## Installation
```bash
pip install axonflow
```
With LLM provider support:
```bash
pip install axonflow[openai] # OpenAI integration
pip install axonflow[anthropic] # Anthropic integration
pip install axonflow[all] # All integrations
```
## Evaluation Tier (Free License)
Need more capacity than Community without moving to Enterprise? Evaluation uses the same core features with higher limits:
| Limit | Community | Evaluation (Free) | Enterprise |
|-------|-----------|-------------------|------------|
| Tenant policies | 20 | 50 | Unlimited |
| Org-wide policies | 0 | 5 | Unlimited |
| Audit retention | 3 days | 14 days | 3650 days |
| Concurrent executions | 5 | 25 | Unlimited |
| Pending execution approvals | 5 | 25 | Unlimited |
Concurrent executions applies to MAP and WCP executions per tenant. Pending execution approvals applies to MAP confirm/step mode and WCP approval queues.
[Get a free Evaluation license](https://getaxonflow.com/evaluation-license?utm_source=readme_sdk_python_eval) · [Full feature matrix](https://docs.getaxonflow.com/docs/features/community-vs-enterprise?utm_source=readme_sdk_python_eval)
## Quick Start
### Async Usage (Recommended)
```python
import asyncio
from axonflow import AxonFlow
async def main():
async with AxonFlow(
endpoint="https://your-agent.axonflow.com",
client_id="your-client-id",
client_secret="your-client-secret"
) as client:
# Execute a governed query
response = await client.proxy_llm_call(
user_token="user-jwt-token",
query="What is AI governance?",
request_type="chat"
)
print(response.data)
asyncio.run(main())
```
### Sync Usage
```python
from axonflow import AxonFlow
with AxonFlow.sync(
endpoint="https://your-agent.axonflow.com",
client_id="your-client-id",
client_secret="your-client-secret"
) as client:
response = client.proxy_llm_call(
user_token="user-jwt-token",
query="What is AI governance?",
request_type="chat"
)
print(response.data)
```
## Features
### Gateway Mode
For lowest-latency LLM calls with full governance and audit compliance:
```python
from axonflow import AxonFlow, TokenUsage
async with AxonFlow(...) as client:
# 1. Pre-check: Get policy approval
ctx = await client.get_policy_approved_context(
user_token="user-jwt",
query="Find patient records",
data_sources=["postgres"]
)
if not ctx.approved:
raise Exception(f"Blocked: {ctx.block_reason}")
# 2. Make LLM call directly (your code)
llm_response = await openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": str(ctx.approved_data)}]
)
# 3. Audit the call
await client.audit_llm_call(
context_id=ctx.context_id,
response_summary=llm_response.choices[0].message.content[:100],
provider="openai",
model="gpt-4",
token_usage=TokenUsage(
prompt_tokens=llm_response.usage.prompt_tokens,
completion_tokens=llm_response.usage.completion_tokens,
total_tokens=llm_response.usage.total_tokens
),
latency_ms=250
)
```
### OpenAI Integration
Transparent governance for existing OpenAI code:
```python
from openai import OpenAI
from axonflow import AxonFlow
from axonflow.interceptors.openai import wrap_openai_client
openai = OpenAI()
axonflow = AxonFlow(...)
# Wrap client - governance is now automatic
wrapped = wrap_openai_client(openai, axonflow, user_token="user-123")
# Use as normal
response = wrapped.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Hello!"}]
)
```
### MCP Connectors
Query data through MCP connectors:
```python
# List available connectors
connectors = await client.list_connectors()
# Query a connector
result = await client.query_connector(
user_token="user-jwt",
connector_name="postgres",
operation="query",
params={"sql": "SELECT * FROM users LIMIT 10"}
)
```
### MCP Policy Features (v3.2.0)
**Exfiltration Detection** - Prevent large-scale data extraction:
```python
# Query with exfiltration limits (default: 10K rows, 10MB)
result = await client.query_connector(
user_token="user-jwt",
connector_name="postgres",
operation="query",
params={"sql": "SELECT * FROM customers"}
)
# Check exfiltration info
if result.policy_info.exfiltration_check.exceeded:
print(f"Limit exceeded: {result.policy_info.exfiltration_check.limit_type}")
# Configure: MCP_MAX_ROWS_PER_QUERY=1000, MCP_MAX_BYTES_PER_QUERY=5242880
```
**Dynamic Policy Evaluation** - Orchestrator-based rate limiting, budget controls:
```python
# Response includes dynamic policy info when enabled
if result.policy_info.dynamic_policy_info.orchestrator_reachable:
print(f"Policies evaluated: {result.policy_info.dynamic_policy_info.policies_evaluated}")
for policy in result.policy_info.dynamic_policy_info.matched_policies:
print(f" {policy.policy_name}: {policy.action}")
# Enable: MCP_DYNAMIC_POLICIES_ENABLED=true
```
### Multi-Agent Planning
Generate and execute multi-agent plans:
```python
# Generate a plan
plan = await client.generate_plan(
query="Book a flight and hotel for my trip to Paris",
domain="travel"
)
print(f"Plan has {len(plan.steps)} steps")
# Execute the plan
result = await client.execute_plan(plan.plan_id)
print(f"Result: {result.result}")
```
## Configuration
```python
from axonflow import AxonFlow, Mode, RetryConfig
client = AxonFlow(
endpoint="https://your-agent.axonflow.com",
client_id="your-client-id", # Required for enterprise features
client_secret="your-client-secret", # Required for enterprise features
mode=Mode.PRODUCTION, # or Mode.SANDBOX
debug=True, # Enable debug logging
timeout=60.0, # Request timeout in seconds
retry_config=RetryConfig( # Retry configuration
enabled=True,
max_attempts=3,
initial_delay=1.0,
max_delay=30.0,
),
cache_enabled=True, # Enable response caching
cache_ttl=60.0, # Cache TTL in seconds
)
```
## Error Handling
```python
from axonflow.exceptions import (
AxonFlowError,
PolicyViolationError,
AuthenticationError,
RateLimitError,
TimeoutError,
)
try:
response = await client.proxy_llm_call(...)
except PolicyViolationError as e:
print(f"Blocked by policy: {e.block_reason}")
except RateLimitError as e:
print(f"Rate limited: {e.limit}/{e.remaining}, resets at {e.reset_at}")
except AuthenticationError:
print("Invalid credentials")
except TimeoutError:
print("Request timed out")
except AxonFlowError as e:
print(f"AxonFlow error: {e.message}")
```
## Response Types
All responses are Pydantic models with full type hints:
```python
from axonflow import (
ClientResponse,
PolicyApprovalResult,
PlanResponse,
ConnectorResponse,
)
# Full autocomplete and type checking support
response: ClientResponse = await client.proxy_llm_call(...)
print(response.success)
print(response.data)
print(response.policy_info.policies_evaluated)
```
## Development
```bash
# Install dev dependencies
pip install -e ".[dev]"
# Run tests
pytest
# Run linting
ruff check .
ruff format .
# Run type checking
mypy axonflow
```
## Examples
Complete working examples for all features are available in the [examples folder](https://github.com/getaxonflow/axonflow/tree/main/examples).
### Community Features
```python
# PII Detection - Automatically detect sensitive data
result = await client.get_policy_approved_context(
user_token="user-123",
query="My SSN is 123-45-6789"
)
# result.approved = True, result.requires_redaction = True (SSN detected)
# SQL Injection Detection - Block malicious queries
result = await client.get_policy_approved_context(
user_token="user-123",
query="SELECT * FROM users; DROP TABLE users;"
)
# result.approved = False, result.block_reason = "SQL injection detected"
# Static Policies - List and manage built-in policies
policies = await client.list_policies()
# Returns: [Policy(name="pii-detection", enabled=True), ...]
# Dynamic Policies - Create runtime policies
await client.create_dynamic_policy(
name="block-competitor-queries",
conditions={"contains": ["competitor", "pricing"]},
action="block"
)
# MCP Connectors - Query external data sources
resp = await client.query_connector(
user_token="user-123",
connector_name="postgres-db",
operation="query",
params={"sql": "SELECT name FROM customers"}
)
# Multi-Agent Planning - Orchestrate complex workflows
plan = await client.generate_plan(
query="Research AI governance regulations",
domain="legal"
)
result = await client.execute_plan(plan.plan_id)
# Audit Logging - Track all LLM interactions
await client.audit_llm_call(
context_id=ctx.context_id,
response_summary="AI response summary",
provider="openai",
model="gpt-4",
token_usage=TokenUsage(prompt_tokens=100, completion_tokens=200, total_tokens=300),
latency_ms=450
)
```
### Enterprise Features
These features require an AxonFlow Enterprise license:
```python
# Code Governance - Automated PR reviews with AI
pr_result = await client.review_pull_request(
repo_owner="your-org",
repo_name="your-repo",
pr_number=123,
check_types=["security", "style", "performance"]
)
# Cost Controls - Budget management for LLM usage
budget = await client.get_budget("team-engineering")
# Returns: Budget(limit=1000.00, used=234.56, remaining=765.44)
# MCP Policy Enforcement - Automatic PII redaction in connector responses
resp = await client.query_connector("user", "postgres", "SELECT * FROM customers", {})
# resp.policy_info.redacted = True
# resp.policy_info.redacted_fields = ["ssn", "credit_card"]
```
For enterprise features, contact [sales@getaxonflow.com](mailto:sales@getaxonflow.com).
## Documentation
- [Getting Started](https://docs.getaxonflow.com/sdk/python-getting-started)
- [Gateway Mode Guide](https://docs.getaxonflow.com/sdk/gateway-mode)
## Support
- **Documentation**: https://docs.getaxonflow.com
- **Issues**: https://github.com/getaxonflow/axonflow-sdk-python/issues
- **Email**: dev@getaxonflow.com
If you are evaluating AxonFlow in a company setting and cannot open a public issue, you can share feedback or blockers confidentially here:
[Anonymous evaluation feedback form](https://getaxonflow.com/feedback)
No email required. Optional contact if you want a response.
## License
MIT - See [LICENSE](LICENSE) for details.
<img referrerpolicy="no-referrer-when-downgrade" src="https://static.scarf.sh/a.png?x-pxid=fbda6e64-1812-428b-b135-ed2b548ce50d" />
| text/markdown | null | AxonFlow <dev@getaxonflow.com> | null | AxonFlow <dev@getaxonflow.com> | MIT | ai, governance, llm, openai, anthropic, bedrock, policy, compliance, enterprise, mcp, multi-agent | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Langu... | [] | null | null | >=3.9 | [] | [] | [] | [
"httpx>=0.25.0",
"pydantic>=2.0.0",
"tenacity>=8.0.0",
"structlog>=23.0.0",
"cachetools>=5.0.0",
"eval_type_backport>=0.2.0; python_version < \"3.10\"",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest-httpx>=0.22.0; extr... | [] | [] | [] | [
"Homepage, https://getaxonflow.com",
"Documentation, https://docs.getaxonflow.com/sdk/python-getting-started",
"Repository, https://github.com/getaxonflow/axonflow-sdk-python",
"Changelog, https://github.com/getaxonflow/axonflow-sdk-python/blob/main/CHANGELOG.md",
"Issues, https://github.com/getaxonflow/axo... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:46:41.381537 | axonflow-3.5.0.tar.gz | 139,556 | 6f/9a/22e5f7bda65588ea1859cd83ea8270cb657a12245a14a32f6157060d3901/axonflow-3.5.0.tar.gz | source | sdist | null | false | 80e0b15b3ad1c7bcfa615d52f07ed626 | 6358c8b86edf31dc88ac5667a0aee3199d4702f52bf822271a81a57eb05e6d84 | 6f9a22e5f7bda65588ea1859cd83ea8270cb657a12245a14a32f6157060d3901 | null | [
"LICENSE"
] | 274 |
2.4 | cg | 84.3.0 | Clinical Genomics command center | # cg
![Build Status - Github][gh-actions-badge]
[![Coverage Status][coveralls-image]][coveralls-url]
[![GitHub issues-closed][closed-issues-img]][closed-issues-url]
[![Average time to resolve an issue][ismaintained-resolve-img]][ismaintained-resolve-url]
[![Percentage of issues still open][ismaintained-open-rate-img]][ismaintained-open-rate-url]
[![CodeFactor][codefactor-badge]][codefactor-url]
[![Code style: black][black-image]][black-url]
`cg` stands for _Clinical Genomics_; a clinical sequencing platform under [SciLifeLab][scilife]
In this context, `cg` provides the interface between these tools to facilitate automation and other necessary cross-talk. It also exposes some APIs:
- HTTP REST for powering the web portal: [clinical.scilifelab.se][portal]
- CLI for interactions on the command line
### Contributing
Please check out our [guide for contributing to cg](CONTRIBUTING.md)
## Installation
Cg written in Python 3.9+ and is available on the [Python Package Index][pypi] (PyPI).
```bash
pip install cg
```
If you would like to install the latest development version, use [poetry](https://python-poetry.org/docs/).
```bash
git clone https://github.com/Clinical-Genomics/cg
cd cg
poetry install
```
For development, use `poetry install --all-extras` to install development dependencies.
[portal]: https://clinical.scilifelab.se/
[trailblazer]: https://github.com/Clinical-Genomics/trailblazer
[housekeeper]: https://github.com/Clinical-Genomics/housekeeper
[genotype]: https://github.com/Clinical-Genomics/genotype
[scilife]: https://www.scilifelab.se/
[pypi]: https://pypi.org/
[black]: https://black.readthedocs.io/en/stable/
<!-- badges -->
[coveralls-url]: https://coveralls.io/github/Clinical-Genomics/cg
[coveralls-image]: https://coveralls.io/repos/github/Clinical-Genomics/cg/badge.svg?branch=master
[gh-actions-badge]: https://github.com/Clinical-Genomics/cg/workflows/Tests%20and%20coveralls/badge.svg
[closed-issues-img]: https://img.shields.io/github/issues-closed/Clinical-Genomics/cg.svg
[closed-issues-url]: https://GitHub.com/Clinical-Genomics/cg/issues?q=is%3Aissue+is%3Aclosed
[ismaintained-resolve-img]: http://isitmaintained.com/badge/resolution/Clinical-Genomics/cg.svg
[ismaintained-resolve-url]: http://isitmaintained.com/project/Clinical-Genomics/cg
[ismaintained-open-rate-img]: http://isitmaintained.com/badge/open/Clinical-Genomics/cg.svg
[ismaintained-open-rate-url]: http://isitmaintained.com/project/Clinical-Genomics/cg
[codefactor-badge]: https://www.codefactor.io/repository/github/clinical-genomics/cg/badge
[codefactor-url]: https://www.codefactor.io/repository/github/clinical-genomics/cg
[black-image]: https://img.shields.io/badge/code%20style-black-000000.svg
[black-url]: https://github.com/psf/black
| text/markdown | null | null | null | null | null | null | [
"Programming Language :: Python",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: Implementation :: CPython"
] | [] | null | null | <3.13,>=3.11 | [] | [] | [] | [
"CacheControl",
"Flask",
"Flask-Admin",
"Flask-CORS",
"Flask-Dance",
"Flask-WTF",
"Jinja2",
"MarkupSafe",
"PyMySQL",
"PyYAML",
"SQLAlchemy",
"WTForms==3.0.0",
"alembic",
"blinker",
"cachetools",
"click",
"coloredlogs",
"coveralls; extra == \"coveralls\"",
"cryptography",
"email... | [] | [] | [] | [] | poetry/2.3.2 CPython/3.11.14 Linux/6.14.0-1017-azure | 2026-02-19T15:46:30.159987 | cg-84.3.0-py3-none-any.whl | 1,058,608 | 13/9d/06adf08fa12b24e5cb856f0c22976798d3c3ff67dd6df5b4c7ba58393b64/cg-84.3.0-py3-none-any.whl | py3 | bdist_wheel | null | false | a580eeb1206615fb3e940be30207b6cf | 6a1b9b908e0e27be0ef666c7e0cb39b6d4ba3bb862524b82944f52c33d368069 | 139d06adf08fa12b24e5cb856f0c22976798d3c3ff67dd6df5b4c7ba58393b64 | null | [] | 249 |
2.4 | cs-workflows-helper-libs | 1.3.3 | Shared libraries used in cs-workflows | # Workflow Helper Libs
Shared Python libraries for CS workflows, providing reusable clients for common integrations and services.
## Getting started
Add the library to your project with poetry:
```bash
poetry add cs-workflows-helper-libs
```
## Available modules
### [Git](https://github.com/canonical/cs-workflows-helper-libs/blob/main/docs/git.md)
Client for interacting with git repositories.
### [Mattermost](https://github.com/canonical/cs-workflows-helper-libs/blob/main/docs/mattermost.md)
Client for uploading files and sending messages
to Mattermost channels via the API.
### [SMTP](https://github.com/canonical/cs-workflows-helper-libs/blob/main/docs/smtp.md)
SMTP client for sending emails through any SMTP relay server.
### Google Sheets
Client for interacting with Google Sheets via the gspread library.
### Trino
Client for querying databases via Trino.
## Development
### Setup
```bash
make install-dev
```
### Run tests
```bash
make test
```
| text/markdown | CanonicalLtd | jaas-dev@lists.launchpad.net | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"PGPy<0.7.0,>=0.6.0",
"gitpython<4.0.0,>=3.1.46",
"gspread<7.0.0,>=6.1.4",
"paramiko<4.0.0,>=3.5.0",
"pydantic-settings<3.0.0,>=2.4.0",
"trino[sqlalchemy]<0.334.0,>=0.333.0"
] | [] | [] | [] | [
"source, https://github.com/canonical/cs-workflows/tree/main/libs"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:45:22.216453 | cs_workflows_helper_libs-1.3.3-py3-none-any.whl | 19,611 | ab/8f/5fc5676c97c6be0fbbcdb11c4b205caea17d08a25516ec6d8c7d54518d15/cs_workflows_helper_libs-1.3.3-py3-none-any.whl | py3 | bdist_wheel | null | false | ce72a537699f01f8946dfbde878b3d97 | 3db0ec82d42e024968f2ec60594c9c1b891e467a9822a8d7c644ff6ee2be7fc2 | ab8f5fc5676c97c6be0fbbcdb11c4b205caea17d08a25516ec6d8c7d54518d15 | null | [] | 120 |
2.4 | klo-git | 0.1.8 | Python package for garbage collection utilities and memory management | # gc
Python package for garbage collection utilities and memory management.
## Overview
The `gc` package provides comprehensive tools and utilities for working with Python's garbage collector, memory profiling, and cleanup operations. It offers enhanced garbage collection control, memory monitoring, and debugging capabilities.
## Features
- **Enhanced Garbage Collection**: Control and monitor Python's garbage collector with detailed statistics
- **Memory Profiling**: Track memory usage over time and analyze memory patterns
- **Object Tracking**: Monitor specific objects using weak references
- **Reference Cycle Detection**: Find and analyze reference cycles in your code
- **Memory Analysis**: Comprehensive memory usage analysis and reporting
- **Utility Functions**: Common garbage collection and memory management tasks
## Installation
```bash
pip install gc
```
### Development Installation
```bash
git clone https://github.com/tom-sapletta/gc.git
cd gc
pip install -e ".[dev]"
```
## Quick Start
### Basic Garbage Collection Control
```python
from gc import GarbageCollector
# Create a garbage collector instance
gc_manager = GarbageCollector()
# Force garbage collection
collected = gc_manager.collect()
print(f"Collected {collected} objects")
# Get memory summary
summary = gc_manager.get_memory_summary()
print(summary)
```
### Memory Profiling
```python
from gc import MemoryProfiler
# Create a profiler instance
profiler = MemoryProfiler()
# Take a memory snapshot
profiler.take_snapshot("before_operation")
# Your code here...
data = [list(range(1000)) for _ in range(100)]
# Take another snapshot
profiler.take_snapshot("after_operation")
# Compare snapshots
comparison = profiler.compare_snapshots(0, 1)
print(f"Memory change: {comparison['rss_diff']} bytes")
```
### Memory Monitoring
```python
from gc.utils import monitor_memory_usage
# Monitor memory for 60 seconds
samples = monitor_memory_usage(duration=60, interval=1.0)
for sample in samples:
print(f"Memory: {sample['rss']} bytes, Objects: {sample['objects_count']}")
```
## API Reference
### GarbageCollector
Main class for garbage collection control and monitoring.
#### Methods
- `enable()` - Enable garbage collection
- `disable()` - Disable garbage collection
- `collect(generation=2)` - Force garbage collection
- `get_stats()` - Get garbage collection statistics
- `get_memory_summary()` - Get comprehensive memory summary
### MemoryProfiler
Class for memory profiling and object tracking.
#### Methods
- `take_snapshot(label="")` - Take a memory snapshot
- `track_object(obj, label="")` - Track an object with weak reference
- `compare_snapshots(index1, index2)` - Compare two memory snapshots
- `get_tracked_objects()` - Get information about tracked objects
### Utility Functions
- `cleanup_temp_files(pattern="*")` - Clean up temporary files
- `monitor_memory_usage(duration=60, interval=1.0)` - Monitor memory usage
- `force_garbage_collection(verbose=False)` - Force garbage collection on all generations
- `find_object_cycles(obj, max_depth=10)` - Find reference cycles
- `analyze_memory_usage()` - Comprehensive memory analysis
## Requirements
- Python 3.8+
- psutil>=5.8.0
## Development
### Running Tests
```bash
pytest
```
### Code Formatting
```bash
black gc/
```
### Type Checking
```bash
mypy gc/
```
## License
Apache License 2.0 - see [LICENSE](LICENSE) for details.
## Contributing
Contributions are welcome! Please read the CONTRIBUTING.md file for details on our code of conduct and the process for submitting pull requests.
## Changelog
### 0.1.0
- Initial release
- Basic garbage collection control
- Memory profiling capabilities
- Utility functions for memory management
## License
Apache License 2.0 - see [LICENSE](LICENSE) for details.
## Author
Created by **Tom Sapletta** - [tom@sapletta.com](mailto:tom@sapletta.com)
| text/markdown | null | Tom Sapletta <tom@example.com>, Tom Sapletta <tom@sapletta.com> | null | Tom Sapletta <tom@example.com> | null | garbage-collection, memory, profiling, utilities | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python... | [] | null | null | >=3.8 | [] | [] | [] | [
"psutil>=5.8.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"twine>=4.0.0; extra == \"dev\"",
"build>=1.0.0; extra == \"dev\"",
"black>=22.0.0; extra == \"dev\"",
"flake8>=5.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"test\"",
... | [] | [] | [] | [
"Homepage, https://github.com/tom-sapletta/gc",
"Repository, https://github.com/tom-sapletta/gc.git",
"Issues, https://github.com/tom-sapletta/gc/issues"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-19T15:45:07.598815 | klo_git-0.1.8.tar.gz | 18,360 | 58/45/141f5a344b38e5c4a7de2ded6cc715008eba30de3d4e800ed59c20dbc76b/klo_git-0.1.8.tar.gz | source | sdist | null | false | f3ff9cf42fed37ad1798e47fb3106679 | b0cc67d2c431f90f98b7d5261e2280f1029c458d04d115282cdad4e354135b45 | 5845141f5a344b38e5c4a7de2ded6cc715008eba30de3d4e800ed59c20dbc76b | Apache-2.0 | [
"LICENSE"
] | 239 |
2.4 | naas-abi-cli | 1.17.3 | Abi cli allowing you to build your AI system. | # naas-abi-cli
Command Line Interface (CLI) tool for building and managing ABI (Agentic Brain Infrastructure) projects.
## Overview
`naas-abi-cli` provides a comprehensive set of commands to create, configure, deploy, and interact with ABI projects. It serves as the primary entry point for developers working with the ABI framework, enabling quick project setup, agent interaction, and cloud deployment.
## Installation
Install the CLI tool using pip:
```bash
pip install naas-abi-cli
```
## Available Commands
### Project Management
#### `abi new project <project-name> [project-path] [--with-local-deploy/--without-local-deploy]`
Creates a new ABI project with all necessary starter files and dependencies.
**What it does:**
- Creates a new project directory (must be empty or non-existent)
- Generates project structure with configuration files, Docker setup, and Python package structure
- Generates local deployment scaffolding (`docker-compose.yml`, `.deploy/`, and local `.env` values) by default
- Automatically installs required dependencies (`naas-abi-core`, `naas-abi-marketplace`, `naas-abi`, and `naas-abi-cli`)
- Customizes project files with your project name
**Example:**
```bash
abi new project my-abi-project
abi new project my-abi-project --without-local-deploy
```
#### `abi init <path>`
Initializes a new ABI project in the specified directory.
**Example:**
```bash
abi init .
```
### Agent Interaction
#### `abi chat [module-name] [agent-name]`
Starts an interactive chat session with an AI agent.
**Parameters:**
- `module-name`: The module containing the agent (default: `naas_abi`)
- `agent-name`: The specific agent class to use (default: `AbiAgent`)
**What it does:**
- Loads the ABI engine and specified module
- Launches an interactive terminal chat interface
- Saves conversations to `storage/datastore/interfaces/terminal_agent/`
**Example:**
```bash
abi chat naas_abi AbiAgent
```
#### `abi agent list`
Lists all available agents across all loaded modules.
**What it does:**
- Loads the ABI engine with all configured modules
- Displays a formatted table showing module names and agent class names
**Example:**
```bash
abi agent list
```
### Configuration Management
#### `abi config validate [--configuration-file <path>]`
Validates the ABI configuration file for correctness.
**Options:**
- `--configuration-file`: Path to configuration file (default: uses `config.yaml` from current directory)
**Example:**
```bash
abi config validate
abi config validate --configuration-file config.prod.yaml
```
#### `abi config render [--configuration-file <path>]`
Renders the loaded configuration as YAML output, useful for debugging and verification.
**Options:**
- `--configuration-file`: Path to configuration file (default: uses `config.yaml` from current directory)
**Example:**
```bash
abi config render
```
#### `abi module list`
Lists all available modules and their enabled/disabled status.
**What it does:**
- Loads the engine configuration
- Displays a formatted table showing module names and their enabled status
**Example:**
```bash
abi module list
```
### Deployment
#### `abi deploy naas [-e/--env <environment>]`
Deploys your ABI project to Naas cloud infrastructure.
**Options:**
- `-e, --env`: Environment to use (default: `prod`). Determines which configuration file to load (e.g., `config.prod.yaml`, `config.yaml`)
**What it does:**
- Builds a Docker image of your ABI project
- Pushes the image to your Naas container registry
- Creates or updates a space on Naas infrastructure
- Exposes your ABI REST API at `https://{space-name}.default.space.naas.ai`
**Requirements:**
- Naas API key configured in your configuration file
- Docker installed and running
- Deploy section in your `config.yaml` file
**Example:**
```bash
abi deploy naas
abi deploy naas --env prod
```
### Secret Management
#### `abi secrets naas list`
Lists all secrets stored in your Naas workspace.
**Options:**
- `--naas-api-key`: Naas API key (default: `NAAS_API_KEY` environment variable)
- `--naas-api-url`: Naas API URL (default: `https://api.naas.ai`)
**Example:**
```bash
abi secrets naas list
```
#### `abi secrets naas push-env-as-base64`
Pushes a local `.env` file to Naas as a base64-encoded secret.
**Options:**
- `--naas-api-key`: Naas API key (default: `NAAS_API_KEY` environment variable)
- `--naas-api-url`: Naas API URL (default: `https://api.naas.ai`)
- `--naas-secret-name`: Name for the secret in Naas (default: `abi_secrets`)
- `--env-file`: Path to the environment file (default: `.env.prod`)
**Example:**
```bash
abi secrets naas push-env-as-base64 --env-file .env.prod
```
#### `abi secrets naas get-base64-env`
Retrieves a base64-encoded secret from Naas and displays it as environment variables.
**Options:**
- `--naas-api-key`: Naas API key (default: `NAAS_API_KEY` environment variable)
- `--naas-api-url`: Naas API URL (default: `https://api.naas.ai`)
- `--naas-secret-name`: Name of the secret to retrieve (default: `abi_secrets`)
**Example:**
```bash
abi secrets naas get-base64-env
```
### Script Execution
#### `abi run script <path>`
Runs a Python script in the context of a loaded ABI engine.
**What it does:**
- Loads the ABI engine with all configured modules
- Executes the specified Python script with access to the engine and all loaded modules
**Example:**
```bash
abi run script scripts/my_script.py
```
## Architecture
The CLI is built using:
- **Click**: For command-line interface framework
- **naas-abi-core**: Core ABI engine and configuration management
- **naas-abi-marketplace**: Marketplace modules and agents
- **naas-abi**: Main ABI package
The CLI automatically detects if it's being run from within an ABI project (by checking for `pyproject.toml` with `naas-abi-cli` dependency) and uses `uv run` to ensure proper environment isolation.
## Project Structure
When you create a new project with `abi new project`, the CLI:
1. Uses template files from `cli/new/templates/project/`
2. Customizes templates with your project name
3. Sets up proper Python package structure
4. Sets up local deployment files from `cli/deploy/templates/local/` (unless disabled)
5. Installs all required dependencies via `uv`
## Integration with ABI Framework
The CLI integrates seamlessly with the ABI ecosystem:
- **Engine Loading**: Automatically loads modules and agents from your configuration
- **Configuration Management**: Validates and renders YAML configuration files
- **Cloud Deployment**: Handles Docker builds and Naas API interactions
- **Secret Management**: Integrates with Naas secret storage for secure credential management
## Dependencies
- Python 3.10+
- `naas-abi>=1.0.6`
- `naas-abi-core[qdrant]>=1.1.2`
- `naas-abi-marketplace[ai-chatgpt]>=1.1.0`
- `uv` package manager (for dependency management)
## See Also
- [ABI Main README](../../../README.md) - Complete ABI framework documentation
- [naas-abi-core](../naas-abi-core/) - Core engine documentation
- [naas-abi-marketplace](../naas-abi-marketplace/) - Marketplace modules documentation
| text/markdown | null | Maxime Jublou <maxime@naas.ai>, Florent Ravenel <florent@naas.ai>, Jeremy Ravenel <jeremy@naas.ai> | null | null | MIT License | null | [] | [] | null | null | <4,>=3.10 | [] | [] | [] | [
"naas-abi-core[qdrant]>=1.4.0",
"naas-abi-marketplace[ai-chatgpt]>=1.3.3",
"naas-abi>=1.0.11",
"textual>=0.89.0"
] | [] | [] | [] | [
"Homepage, https://github.com/jupyter-naas/abi",
"Repository, https://github.com/jupyter-naas/abi/tree/main/libs/naas-abi-cli"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:43:54.016690 | naas_abi_cli-1.17.3.tar.gz | 45,539 | 07/fa/5442a1f496ccb4eef803b4fef449df442b3a1b34581586863b0523029ede/naas_abi_cli-1.17.3.tar.gz | source | sdist | null | false | 032e4dcd738f5f95c2adcb75024cc115 | 9cb7977d41d03b1c965c31264f85309f0268d4ccf8f289a72613bffd43ec5306 | 07fa5442a1f496ccb4eef803b4fef449df442b3a1b34581586863b0523029ede | null | [] | 231 |
2.3 | ecodev-front | 0.0.102 | Dash component helpers |
# EcoDev Front
This library is a reduced and opinionated version of Dash Mantine Components [DMC](https://www.dash-mantine-components.com/), itself a simplified version of the React Mantine library. It includes some basic functionalities such as
customisable components, navbar menus and customised component builders.
Full documentation of the library can be found [here](https://ecodev-doc.lcabox.com/libraries/front/)
| text/markdown | Amaury Salles | amaury.salles@gmail.com | null | null | MIT | null | [
"Development Status :: 2 - Pre-Alpha",
"Environment :: Web Environment",
"Framework :: Dash",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: MIT License... | [] | null | null | <4.0,>=3.11 | [] | [] | [] | [
"dash<4,>=3",
"dash-ag-grid<32,>=31",
"dash-iconify<1,>=0",
"dash-mantine-components<3,>=2",
"ecodev-core<1,>=0",
"plotly<7,>=6"
] | [] | [] | [] | [] | poetry/2.1.3 CPython/3.13.3 Darwin/24.6.0 | 2026-02-19T15:43:10.925327 | ecodev_front-0.0.102.tar.gz | 35,094 | 1e/98/80371d1b756e4bb34ea6ae48f6877ebe68625bd76938e1b2675d4ca6fe11/ecodev_front-0.0.102.tar.gz | source | sdist | null | false | bc6748eeb69ffd7d0a46e4fdd192e3a3 | 62b5f28fbc63d72bdd91d6741b3d7f0fae5257cd4531124c355c9028c68e9320 | 1e9880371d1b756e4bb34ea6ae48f6877ebe68625bd76938e1b2675d4ca6fe11 | null | [] | 267 |
2.4 | S2Generator | 0.0.7 | A series-symbol (S2) dual-modality data generation mechanism, enabling the unrestricted creation of high-quality time series data paired with corresponding symbolic representations. | <img width="100%" align="middle" src="https://raw.githubusercontent.com/wwhenxuan/S2Generator/main/docs/source/_static/background.png?raw=true">
---
<div align="center">
[](https://pypi.org/project/s2generator/)  [](https://www.python.org/) [](https://pepy.tech/project/s2generator) [](https://github.com/psf/black)
[Installation](#Installation) | [Examples](https://github.com/wwhenxuan/S2Generator/tree/main/examples) | [Docs]() | [Acknowledge]() | [Citation](#Citation)
</div>
Based on the important perspective that time series are external manifestations of complex dynamical systems,
we propose a bimodal generative mechanism for time series data that integrates both symbolic and series modalities.
This mechanism enables the unrestricted generation of a vast number of complex systems represented as symbolic expressions $f(\cdot)$ and excitation time series $X$.
By inputting the excitation into these complex systems, we obtain the corresponding response time series $Y=f(X)$.
This method allows for the unrestricted creation of high-quality time series data for pre-training the time series foundation models.
### 🔥 News
**[Feb. 2026]** Since all stationary time series can be obtained by exciting a linear time-invariant system with white noise, we propose [a learnable series generation method](https://github.com/wwhenxuan/S2Generator/blob/main/s2generator/simulator/arima.py) based on the ARIMA model. This method ensures the generated series is highly similar to the inputs in autocorrelation and power spectrum density.
**[Sep. 2025]** Our paper "Synthetic Series-Symbol Data Generation for Time Series Foundation Models" has been accepted by **NeurIPS 2025**, where **[*SymTime*](https://arxiv.org/abs/2502.15466)** pre-trained on the $S^2$ synthetic dataset achieved SOTA results in fine-tuning of forecasting, classification, imputation and anomaly detection tasks.
## 🚀 Installation <a id="Installation"></a>
We have highly encapsulated the algorithm and uploaded the code to PyPI:
~~~
pip install s2generator
~~~
We used [`NumPy`](https://numpy.org/), [`Pandas`](https://pandas.pydata.org/), and [`Scipy`](https://scipy.org/) to build the data science environment, [`Matplotlib`](https://matplotlib.org/) for data visualization, and [`Statsmodels`](https://www.statsmodels.org/stable/index.html) for time series analysis and statistical processing.
## ✨ Usage
We provide a unified data generation interface [`Generator`](https://github.com/wwhenxuan/S2Generator/blob/main/s2generator/generators.py), two parameter modules [`SeriesParams`](https://github.com/wwhenxuan/S2Generator/blob/main/s2generator/params/series_params.py) and [`SymbolParams`](https://github.com/wwhenxuan/S2Generator/blob/main/s2generator/params/symbol_params.py), as well as auxiliary modules for the generation of excitation time series and complex system. We first specify the parameters or use the default parameters to create parameter objects, and then pass them into our `Generator` respectively. finally, we can start data generation through the `run` method after instantiation.
~~~python
import numpy as np
# Importing data generators object
from s2generator import Generator, SeriesParams, SymbolParams, plot_series
# Creating a random number object
rng = np.random.RandomState(0)
# Create the parameter control modules
series_params = SeriesParams()
symbol_params = SymbolParams() # specify specific parameters here or use the default parameters
# Create an instance
generator = Generator(series_params=series_params, symbol_params=symbol_params)
# Start generating symbolic expressions, sampling and generating series
symbols, inputs, outputs = generator.run(
rng, input_dimension=1, output_dimension=1, n_inputs_points=256
)
# Print the expressions
print(symbols)
# Visualize the time series
fig = plot_series(inputs, outputs)
~~~
> (73.5 add (x_0 mul (((9.38 mul cos((-0.092 add (-6.12 mul x_0)))) add (87.1 mul arctan((-0.965 add (0.973 mul rand))))) sub (8.89 mul exp(((4.49 mul log((-29.3 add (-86.2 mul x_0)))) add (-2.57 mul ((51.3 add (-55.6 mul x_0)))**2)))))))
<img width="100%" align="middle" src="https://raw.githubusercontent.com/wwhenxuan/S2Generator/main/docs/source/_static/ID1_OD1.jpg?raw=true">
The input and output dimensions of the multivariate time series and the length of the sampling sequence can be adjusted in the `run` method.
~~~python
rng = np.random.RandomState(512) # Change the random seed
# Try to generate the multi-channels time series
symbols, inputs, outputs = generator.run(rng, input_dimension=2, output_dimension=2, n_inputs_points=336)
print(symbols)
fig = plot_series(inputs, outputs)
~~~
> (-9.45 add ((((0.026 mul rand) sub (-62.7 mul cos((4.79 add (-6.69 mul x_1))))) add (-0.982 mul sqrt((4.2 add (-0.14 mul x_0))))) sub (0.683 mul x_1))) | (67.6 add ((-9.0 mul x_1) add (2.15 mul sqrt((0.867 add (-92.1 mul x_1))))))
>
> Two symbolic expressions are connected by " | ".
<img width="100%" align="middle" src="https://raw.githubusercontent.com/wwhenxuan/S2Generator/main/docs/source/_static/ID2_OD2.jpg?raw=true">
## 🧮 Algorithm <img width="25%" align="right" src="https://github.com/wwhenxuan/S2Generator/blob/main/docs/source/_static/trees.png?raw=true">
The advantage of $S^2$ data lies in its diversity and unrestricted generation capacity.
On the one hand, we can build a complex system with diversity based on binary trees (right);
on the other hand, we combine 5 different methods to generate excitation series, as follows:
- [`MixedDistribution`](https://github.com/wwhenxuan/S2Generator/blob/main/s2generator/excitation/mixed_distribution.py): Sampling from a mixture of distributions can show the random of time series;
- [`ARMA`](https://github.com/wwhenxuan/S2Generator/blob/main/s2generator/excitation/autoregressive_moving_average.py): The sliding average and autoregressive processes can show obvious temporal dependencies;
- [`ForecastPFN`](https://github.com/wwhenxuan/S2Generator/blob/main/s2generator/excitation/forecast_pfn.py) and [`KernelSynth`](https://github.com/wwhenxuan/S2Generator/blob/main/s2generator/excitation/kernel_synth.py): The decomposition and combination methods can reflect the dynamics of time series;
- [`IntrinsicModeFunction`](https://github.com/wwhenxuan/S2Generator/blob/main/s2generator/excitation/intrinsic_mode_functions.py): The excitation generated by the modal combination method has obvious periodicity.
By generating diverse complex systems and combining multiple excitation generation methods,
we can obtain high-quality, diverse time series data without any constraints.
For detailed on the data generation process, please refer to our [paper](https://arxiv.org/abs/2502.15466) or [documentation]().
## 🎖️ Citation <a id="Citation"></a>
If you find this $S^2$ data generation method helpful, please cite the following paper:
~~~latex
@misc{wang2025syntheticseriessymboldatageneration,
title={Synthetic Series-Symbol Data Generation for Time Series Foundation Models},
author={Wenxuan Wang and Kai Wu and Yujian Betterest Li and Dan Wang and Xiaoyu Zhang},
year={2025},
eprint={2510.08445},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2510.08445},
}
~~~
| text/markdown | whenxuan, johnfan12, changewam | wwhenxuan@gmail.com | null | null | null | Time Series, Data Generation, Foundation Datasets, Symbolic Representations, Dual-Modality | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Mathematics",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :... | [] | https://github.com/wwhenxuan/S2Generator | null | >=3.9 | [] | [] | [] | [
"numpy>=1.24.4",
"scipy>=1.14.1",
"matplotlib>=3.9.2",
"scikit-learn>=1.2.2",
"statsmodels>=0.14.5",
"colorama>=0.4.6",
"pandas>=2.3.1",
"pysdkit>=0.4.21"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.5 | 2026-02-19T15:42:57.282743 | s2generator-0.0.7.tar.gz | 112,037 | 54/f7/c0fdd45be927b498f9b77af7a8efafcc4db217d2d2f42fa475bfe9990f58/s2generator-0.0.7.tar.gz | source | sdist | null | false | 69826731a8cadd3de81f5fa5d4b8485c | 8737456787a8f740596b933ed75bbec4872b58e5dfbb3324cb6aa5a0c62b7350 | 54f7c0fdd45be927b498f9b77af7a8efafcc4db217d2d2f42fa475bfe9990f58 | null | [
"LICENSE"
] | 0 |
2.4 | sensormapgeo | 1.2.1 | A package for transforming remote sensing images between sensor and map geometry | ============
sensormapgeo
============
Sensormapgeo transforms a remote sensing image from sensor geometry (image coordinates without
geocoding/projection) to map geometry (projected map coordinates) or vice-versa based on a pixel-wise
longitude/latitude coordinate array.
.. image:: https://git.gfz.de/EnMAP/sensormapgeo/raw/main/docs/images/overview-scheme__900x366.png
|
* Free software: Apache-2.0
* **Documentation:** https://enmap.git-pages.gfz-potsdam.de/sensormapgeo/doc/
* Submit feedback by filing an issue `here <https://git.gfz.de/EnMAP/sensormapgeo/issues>`__.
Status
------
.. image:: https://git.gfz.de/EnMAP/sensormapgeo/badges/main/pipeline.svg
:target: https://git.gfz.de/EnMAP/sensormapgeo/commits/main
.. image:: https://git.gfz.de/EnMAP/sensormapgeo/badges/main/coverage.svg
:target: https://enmap.git-pages.gfz-potsdam.de/sensormapgeo/coverage/
.. image:: https://img.shields.io/pypi/v/sensormapgeo.svg
:target: https://pypi.python.org/pypi/sensormapgeo
.. image:: https://img.shields.io/conda/vn/conda-forge/sensormapgeo.svg
:target: https://anaconda.org/conda-forge/sensormapgeo
.. image:: https://img.shields.io/pypi/l/sensormapgeo.svg
:target: https://git.gfz.de/EnMAP/sensormapgeo/blob/main/LICENSE
.. image:: https://img.shields.io/pypi/pyversions/sensormapgeo.svg
:target: https://img.shields.io/pypi/pyversions/sensormapgeo.svg
See also the latest coverage_ report and the pytest_ HTML report.
Features
--------
* transformation from sensor geometry (image coordinates) to map geometry (map coordinates)
* transformation from map geometry (map coordinates) to sensor geometry (image coordinates)
Credits
-------
The sensormapgeo package was developed within the context of the EnMAP project supported by the DLR Space
Administration with funds of the German Federal Ministry of Economic Affairs and Energy (on the basis of a decision
by the German Bundestag: 50 EE 1529) and contributions from DLR, GFZ and OHB System AG.
This package was created with Cookiecutter_ and the `audreyr/cookiecutter-pypackage`_ project template.
.. _Cookiecutter: https://github.com/audreyr/cookiecutter
.. _`audreyr/cookiecutter-pypackage`: https://github.com/audreyr/cookiecutter-pypackage
.. _coverage: https://enmap.git-pages.gfz-potsdam.de/sensormapgeo/coverage/
.. _pytest: https://enmap.git-pages.gfz-potsdam.de/sensormapgeo/test_reports/report.html
| text/x-rst | null | Daniel Scheffler <daniel.scheffler@gfz.de> | null | null | Apache-2.0 | sensormapgeo, geometric pre-processing, remote sensing, orthorectification | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Natural Language :: English",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Progr... | [] | null | null | >=3.10 | [] | [] | [] | [
"gdal>=3.8",
"joblib",
"numpy",
"py_tools_ds>=0.18.0",
"pyproj>=2.2",
"pyresample>=1.17.0",
"sphinx-argparse; extra == \"doc\"",
"sphinx_rtd_theme; extra == \"doc\"",
"sphinx-autodoc-typehints; extra == \"doc\"",
"pytest; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"pytest-reporter-ht... | [] | [] | [] | [
"Source code, https://git.gfz.de/EnMAP/sensormapgeo",
"Issue Tracker, https://git.gfz.de/EnMAP/sensormapgeo/-/issues",
"Documentation, https://enmap.git-pages.gfz-potsdam.de/sensormapgeo/doc/",
"Change log, https://enmap.git-pages.gfz-potsdam.de/sensormapgeo/doc/history.html"
] | twine/6.2.0 CPython/3.12.1 | 2026-02-19T15:42:53.034197 | sensormapgeo-1.2.1.tar.gz | 203,990 | ab/59/03dd4374b04cb4e0537a19dc03fa4ac65501789935b48baf940f692cf102/sensormapgeo-1.2.1.tar.gz | source | sdist | null | false | a5b871408c08f0a9a3c5f131cb8ce836 | ed5a07e644bdef0faeb8ed53c540954489131cc6e2038a27bb20a1f23b01029b | ab5903dd4374b04cb4e0537a19dc03fa4ac65501789935b48baf940f692cf102 | null | [
"LICENSE"
] | 174 |
2.1 | metpx-sr3 | 3.2.0rc1 | Subscribe, Acquire, and Re-Advertise products. | ==========================
Sarracenia v3 (MetPX-Sr3)
==========================
[ homepage (En): https://metpx.github.io/sarracenia ] [ `(Fr) fr/ <https://metpx.github.io/sarracenia/fr>`_ ]
.. image:: https://img.shields.io/pypi/v/metpx-sr3?style=flat
:alt: PyPI version
:target: https://pypi.org/project/metpx-sr3/
.. image:: https://img.shields.io/pypi/pyversions/metpx-sr3.svg
:alt: Supported Python versions
:target: https://pypi.python.org/pypi/metpx-sr3.svg
.. image:: https://img.shields.io/pypi/l/metpx-sr3?color=brightgreen
:alt: License (GPLv2)
:target: https://pypi.org/project/metpx-sr3/
.. image:: https://img.shields.io/github/issues/MetPX/sarracenia
:alt: Issue Tracker
:target: https://github.com/MetPX/sarracenia/issues
.. image:: https://github.com/MetPX/sarracenia/actions/workflows/ghcr.yml/badge.svg
:alt: Docker Image Build Status
:target: https://github.com/MetPX/sarracenia/actions/workflows/ghcr.yml
.. image:: https://github.com/MetPX/sarracenia/actions/workflows/flow.yml/badge.svg?branch=development
:alt: Run AMQP Flow (Integration) tests
:target: https://github.com/MetPX/sarracenia/actions/workflows/flow.yml
+----------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------+
| | |
| [ `Getting Started <https://metpx.github.io/sarracenia/How2Guides/subscriber.html>`_ ] | [ `Un bon départ <https://metpx.github.io/sarracenia/fr/CommentFaire/subscriber.html>`_ ] |
| [ `Source Guide <https://metpx.github.io/sarracenia/How2Guides/source.html>`_ ] | [ `Guide de Source <https://metpx.github.io/sarracenia/fr/CommentFaire/source.html>`_ ] |
| | |
+----------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------+
| | |
| MetPX-sr3 (Sarracenia v3) is a data duplication | MetPX-sr3 (Sarracenia v3) est un engin de copie et de |
| or distribution pump that leverages | distribution de données qui utilise des |
| existing standard technologies (web | technologies standards (tel que les services |
| servers and Message queueing protocol | web et le courtier de messages AMQP) afin |
| brokers) to achieve real-time message delivery | d'effectuer des transferts de données en |
| and end-to-end transparency in file transfers. | temps réel tout en permettant une transparence |
| Data sources establish a directory structure | de bout en bout. Alors que chaque commutateur |
| which is carried through any number of | Sundew est unique en soit, offrant des |
| intervening pumps until they arrive at a | configurations sur mesure et permutations de |
| client. | données multiples, Sarracenia cherche à |
| | maintenir l'intégrité de la structure des |
| | données, tel que proposée et organisée par la |
| | source jusqu'à destination. |
| | |
+----------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------+
Changes:
* Add support for inlining content in messages from all sarracenia
* Updates to DD examples
* Various FlowCB plugin work: #1497, #1512, #1518
* Add better logging messages: #1488, #1534
* Add a new "clean-restart" command line option that combines a "stop,
* Have "messageRate" options be measured post filtering: #1530
* Add configurability to AMQP queue arguments: #1548
* Improve documentation on v2 to v3 porting: #1500
* Fix #1504: honor post_exchange in posting components (bug was introduced
* Fix #1495: use better checksum assigning on download
* Fix #1480: check metrics when an instance is hung
* Fix #1538: ensure sr3 works properly without humanize
* Fix #1525: implement tlsRigour for AMQP broker connection
* Second try at fixing #1439: Add new statefile for OOM restarting use case
| text/x-rst | Shared Services Canada, Supercomputing, Data Interchange | Peter.Silva@canada.ca | null | null | GPLv2 | null | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Intended Audience :: System Administrators",
"Natural Language :: English",
"License :: OSI Approved :: GNU General Public License v2 (GPLv2)",
"Operating System :: ... | [] | https://github.com/MetPX/sarracenia | null | >=3.6 | [] | [] | [] | [
"appdirs",
"humanfriendly",
"humanize",
"jsonpickle",
"psutil>=5.3.0",
"watchdog",
"amqp; extra == \"all\"",
"python-magic; extra == \"all\"",
"python-file-magic; extra == \"all\"",
"dateparser; extra == \"all\"",
"paho.mqtt>=1.5.1; extra == \"all\"",
"flufl.lock; extra == \"all\"",
"netifac... | [] | [] | [] | [] | twine/3.8.0 pkginfo/1.10.0 readme-renderer/34.0 requests/2.20.0 requests-toolbelt/1.0.0 urllib3/1.26.18 tqdm/4.64.1 importlib-metadata/4.8.3 keyring/23.4.1 rfc3986/1.5.0 colorama/0.4.5 CPython/3.6.8 | 2026-02-19T15:42:17.997300 | metpx_sr3-3.2.0rc1-py3-none-any.whl | 462,667 | ee/1c/a9ed0dce7b53a22ec8a8d0d4f6665ab946ab9d435c914d3262b52e13b28c/metpx_sr3-3.2.0rc1-py3-none-any.whl | py3 | bdist_wheel | null | false | 79851ec15183e25efe4b0e652c9090e6 | a775ba77a472577dee008ce2589f697a13195dc7c2d3ed87e7d640828dff3d54 | ee1ca9ed0dce7b53a22ec8a8d0d4f6665ab946ab9d435c914d3262b52e13b28c | null | [] | 82 |
2.4 | sinapsis-llama-index | 0.2.0 | Sinapsis templates and helpers for LlamaIndex integration. | <h1 align="center">
<br>
<a href="https://sinapsis.tech/">
<img
src="https://github.com/Sinapsis-AI/brand-resources/blob/main/sinapsis_logo/4x/logo.png?raw=true"
alt="" width="300">
</a>
<br>
Sinapsis LLaMA Index
<br>
</h1>
<h4 align="center">Sinapsis templates and helpers for LlamaIndex integration</h4>
<p align="center">
<a href="#installation">🐍 Installation</a> •
<a href="#features">🚀 Features</a> •
<a href="#example">📚 Usage example</a> •
<a href="#webapps">🌐 Webapps</a>
<a href="#documentation">📙 Documentation</a> •
<a href="#license">🔍 License</a>
</p>
The `sinapsis-llama-index` module provides a suite of templates to run LLMs with [llama-index](https://github.com/run-llama/llama_index).
<h2 id="installation">🐍 Installation</h2>
Install using your package manager of choice. We encourage the use of <code>uv</code>
Example with <code>uv</code>:
```bash
uv pip install sinapsis-llama-index --extra-index-url https://pypi.sinapsis.tech
```
or with raw <code>pip</code>:
```bash
pip install sinapsis-llama-index --extra-index-url https://pypi.sinapsis.tech
```
> [!IMPORTANT]
> Templates may require extra dependencies. For development, we recommend installing the package with all the optional dependencies:
>
with <code>uv</code>:
```bash
uv pip install sinapsis-llama-index[all] --extra-index-url https://pypi.sinapsis.tech
```
or with raw <code>pip</code>:
```bash
pip install sinapsis-llama-index[all] --extra-index-url https://pypi.sinapsis.tech
```
<h2 id="features">🚀 Features</h2>
- `EmbeddingNodeGenerator`: Splits text documents into chunks (TextNode objects) and generates vector embeddings using HuggingFace models.
- `CodeEmbeddingNodeGenerator`: A specialized version of the node generator for intelligently splitting source code files with file exclusion.
- `LLaMAIndexInsertNodes`: Inserts generated TextNode objects (with embeddings) into a PostgreSQL PGVectorStore table.
- `LLaMAIndexNodeRetriever`: Retrieves the most relevant nodes from a vector table based on a query's semantic similarity.
- `LLaMAIndexClearTable`: Clears all data from a specified PGVectorStore table.
- `LLaMAIndexDeleteTable`: Permanently drops (deletes) a specified PGVectorStore table.
- `LLaMAIndexRAGTextCompletion`: A full Retrieval-Augmented Generation (RAG) template that uses a retriever to find context and an LLM to generate an answer based on that context. Supports structured outputs via `response_format`.
> [!TIP]
> Use CLI command ``` sinapsis info --all-template-names``` to show a list with all the available Template names installed with Sinapsis Data Tools.
> [!TIP]
> Use CLI command ```sinapsis info --example-template-config TEMPLATE_NAME``` to produce an example Agent config for the Template specified in ***TEMPLATE_NAME***.
For example, for **CodeEmbeddingNodeGenerator** use ```sinapsis info --example-template-config CodeEmbeddingNodeGenerator``` to produce the following example config:
```yaml
agent:
name: my_test_agent
templates:
- template_name: InputTemplate
class_name: InputTemplate
attributes: {}
- template_name: CodeEmbeddingNodeGenerator
class_name: CodeEmbeddingNodeGenerator
template_input: InputTemplate
attributes:
splitter_args:
include_metadata: true
include_prev_next_rel: true
language: python
chunk_lines: 40
chunk_lines_overlap: 15
max_chars: 1500
embedding_config:
model_name: '`replace_me:<class ''str''>`'
max_length: null
query_instruction: null
text_instruction: null
normalize: true
embed_batch_size: 10
cache_folder: /path/to/.cache/sinapsis
trust_remote_code: false
device: auto
parallel_process: false
generic_keys: null
exclusion_config:
startswith_exclude: '`replace_me:list[str]`'
endswith_exclude: '`replace_me:list[str]`'
file_path_key: file_path
file_type_key: file_type
```
<h2 id="example">📚 Usage example</h2>
The following agent configuration demonstrates how to create an ingestion pipeline. It takes a simple text string, processes it with the `EmbeddingNodeGenerator` to create embedded nodes, and then inserts those nodes into a `PGVectorStore` database using `LLaMAIndexInsertNodes`.
<details id='usage'><summary><strong><span style="font-size: 1.0em;"> Config</span></strong></summary>
```yaml
agent:
name: chat_completion
description: Agent to feed a PGVector database with content from the official Sinapsis repositories
templates:
- template_name: InputTemplate
class_name: InputTemplate
attributes: {}
- template_name: TextInput
class_name: TextInput
template_input: InputTemplate
attributes:
text: What is AI?
- template_name: EmbeddingNodeGenerator
class_name: EmbeddingNodeGenerator
template_input: TextInput
attributes:
splitter_args:
chunk_size: 512
chunk_overlap: 32
separator: ' '
embedding_config:
model_name: Snowflake/snowflake-arctic-embed-m-long
trust_remote_code: True
device: auto
- template_name: LLaMAIndexInsertNodes
class_name: LLaMAIndexInsertNodes
template_input: EmbeddingNodeGenerator
attributes:
db_config:
user: postgres
password: password
port: 5432
host: localhost
db_name: sinapsis_db
table_name: sinapsis_code_s
input_nodes_key: EmbeddingNodeGenerator
```
</details>
<h2 id="webapps">🌐 Webapps</h2>
This module includes a webapp to interact with the model
> [!IMPORTANT]
> To run the app you first need to clone this repository:
```bash
git clone git@github.com:Sinapsis-ai/sinapsis-chatbots.git
cd sinapsis-chatbots
```
> [!NOTE]
> If you'd like to enable external app sharing in Gradio, `export GRADIO_SHARE_APP=True`
> [!IMPORTANT]
> You can change the model name and the number of gpu_layers used by the model in case you have an Out of Memory (OOM) error
<details>
<summary id="uv"><strong><span style="font-size: 1.4em;">🐳 Docker</span></strong></summary>
**IMPORTANT** This docker image depends on the sinapsis-nvidia:base image. Please refer to the official [sinapsis](https://github.com/Sinapsis-ai/sinapsis?tab=readme-ov-file#docker) instructions to Build with Docker.
1. **Build the sinapsis-chatbots image**:
```bash
docker compose -f docker/compose.yaml build
```
2. **Start the POSTGRES service**:
```bash
docker compose -f docker/compose_db.yaml up --build
```
3. **Start the container**
```bash
docker compose -f docker/compose_apps.yaml up sinapsis-rag-chatbot -d
```
4. Check the status:
```bash
docker logs -f sinapsis-rag-chatbot
```
3. The logs will display the URL to access the webapp, e.g.,:
```bash
Running on local URL: http://127.0.0.1:7860
```
**NOTE**: The url may be different, check the logs
4. To stop the app:
```bash
docker compose -f docker/compose_apps.yaml down
```
</details>
<details>
<summary><strong><span style="font-size: 1.25em;">💻 UV</span></strong></summary>
1. Export the environment variable to install the python bindings for llama-cpp
```bash
export CMAKE_ARGS="-DGGML_CUDA=on"
export FORCE_CMAKE="1"
```
2. export CUDACXX:
```bash
export CUDACXX=$(command -v nvcc)
```
3. **Create the virtual environment and sync dependencies:**
```bash
uv sync --frozen
```
4. **Install the wheel**:
```bash
uv pip install sinapsis-chatbots[all] --extra-index-url https://pypi.sinapsis.tech
```
5. **Run the webapp**:
```bash
uv run webapps/llama_index_rag_chatbot.py
```
6. **The terminal will display the URL to access the webapp, e.g.**:
NOTE: The url can be different, check the output of the terminal
```bash
Running on local URL: http://127.0.0.1:7860
```
</details>
<h2 id="documentation">📙 Documentation</h2>
Documentation for this and other sinapsis packages is available on the [sinapsis website](https://docs.sinapsis.tech/docs)
Tutorials for different projects within sinapsis are available at [sinapsis tutorials page](https://docs.sinapsis.tech/tutorials)
<h2 id="license">🔍 License</h2>
This project is licensed under the AGPLv3 license, which encourages open collaboration and sharing. For more details, please refer to the [LICENSE](LICENSE) file.
For commercial use, please refer to our [official Sinapsis website](https://sinapsis.tech) for information on obtaining a commercial license.
| text/markdown | null | SinapsisAI <dev@sinapsis.tech> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"llama-index>=0.12.25",
"llama-index-embeddings-huggingface>=0.5.2",
"llama-index-legacy>=0.9.48.post4",
"llama-index-vector-stores-postgres>=0.4.2",
"llamaindex-py-client>=0.1.19",
"psycopg>=3.2.12",
"sinapsis>=0.2.0",
"sinapsis-chatbots-base",
"tree-sitter-language-pack>=0.8.0",
"sinapsis-llama-... | [] | [] | [] | [
"Homepage, https://sinapsis.tech",
"Documentation, https://docs.sinapsis.tech/docs",
"Tutorials, https://docs.sinapsis.tech/tutorials",
"Repository, https://github.com/Sinapsis-AI/sinapsis-chatbots.git"
] | uv/0.6.17 | 2026-02-19T15:41:58.480290 | sinapsis_llama_index-0.2.0.tar.gz | 35,679 | 1d/42/000acb0663393d52c9139e69de0a0c274076f16a93f6172c55f3944285b4/sinapsis_llama_index-0.2.0.tar.gz | source | sdist | null | false | dd5ba05bb590949e9c47ac4e713b193f | 8fc58feec3bd900d0655c9e46e7082bbbef750e496aeecbc149d84798dae3c20 | 1d42000acb0663393d52c9139e69de0a0c274076f16a93f6172c55f3944285b4 | null | [
"LICENSE"
] | 205 |
2.4 | sinapsis-llama-cpp | 0.4.0 | Sinapsis templates for LLM text completion with LLaMA-CPP | <h1 align="center">
<br>
<a href="https://sinapsis.tech/">
<img
src="https://github.com/Sinapsis-AI/brand-resources/blob/main/sinapsis_logo/4x/logo.png?raw=true"
alt="" width="300">
</a>
<br>
Sinapsis LLaMA CPP
<br>
</h1>
<h4 align="center">Sinapsis Templates for LLM text completion with LLaMA-CPP</h4>
<p align="center">
<a href="#installation">🐍 Installation</a> •
<a href="#features">🚀 Features</a> •
<a href="#example">📚 Usage example</a> •
<a href="#webapps">🌐 Webapps</a>
<a href="#documentation">📙 Documentation</a> •
<a href="#license">🔍 License</a>
</p>
The `sinapsis-llama-cpp` module provides a suite of templates to run LLMs with [llama-cpp](https://github.com/ggml-org/llama.cpp).
> [!IMPORTANT]
> We now include support for Llama4 models!
To use them, install the dependency (if you have not installed sinapsis-llama-cpp[all]):
```bash
uv pip install sinapsis-llama-cpp[llama-four] --extra-index-url https://pypi.sinapsis.tech
```
You need a HuggingFace token. See the [official instructions](https://huggingface.co/docs/hub/security-tokens) and set it using:
```bash
export HF_TOKEN=<token-provided-by-hf>
```
And test it through the cli or the webapp by changing the AGENT_CONFIG_PATH
> [!NOTE]
> Llama 4 requires large GPUs to run the models.
> Nonetheless, running on smaller consumer-grade GPUs is possible, although a single inference may take hours
>
<h2 id="installation">🐍 Installation</h2>
Install using your package manager of choice. We encourage the use of <code>uv</code>
Example with <code>uv</code>:
```bash
uv pip install sinapsis-llama-cpp --extra-index-url https://pypi.sinapsis.tech
```
or with raw <code>pip</code>:
```bash
pip install sinapsis-llama-cpp --extra-index-url https://pypi.sinapsis.tech
```
> [!IMPORTANT]
> Templates may require extra dependencies. For development, we recommend installing the package with all the optional dependencies:
>
with <code>uv</code>:
```bash
uv pip install sinapsis-llama-cpp[all] --extra-index-url https://pypi.sinapsis.tech
```
or with raw <code>pip</code>:
```bash
pip install sinapsis-llama-cpp[all] --extra-index-url https://pypi.sinapsis.tech
```
<h2 id="features">🚀 Features</h2>
<h3>Templates Supported</h3>
- **LLaMATextCompletion**: Template for text completion using LLaMA CPP.
<details>
<summary>Attributes</summary>
- `init_args`(`LLaMAInitArgs`, required): LLaMA model arguments.
- `llm_model_name`(`str`, required): The name or path of the LLM model to use (e.g. 'TheBloke/Llama-2-7B-GGUF').
- `llm_model_file`(`str`, required): The specific GGUF model file (e.g., 'llama-2-7b.Q2_K.gguf').
- `n_gpu_layers`(`int`, optional): Number of layers to offload to the GPU (-1 for all). Defaults to `0`.
- `use_mmap`(`bool`, optional): Use 'memory-mapping' to load the model. Defaults to `True`.
- `use_mlock`(`bool`, optional): Force the model to be kept in RAM. Defaults to `False`.
- `seed`(`int`, optional): RNG seed for model initialization. Defaults to `LLAMA_DEFAULT_SEED`.
- `n_ctx`(`int`, optional): The context window size. Defaults to `512`.
- `n_batch`(`int`, optional): The batch size for prompt processing. Defaults to `512`.
- `n_ubatch`(`int`, optional): The batch size for token generation. Defaults to `512`.
- `n_threads`(`int`, optional): CPU threads for generation. Defaults to `None`.
- `n_threads_batch`(`int`, optional): CPU threads for batch processing. Defaults to `None`.
- `flash_attn`(`bool`, optional): Enable Flash Attention if supported by the GPU. Defaults to `False`.
- `chat_format`(`str`, optional): Chat template format (e.g., 'chatml'). Defaults to `None`.
- `verbose`(`bool`, optional): Enable verbose logging from llama.cpp. Defaults to `True`.
- `completion_args`(`LLaMACompletionArgs`, required): Generation arguments to pass to the selected model.
- `temperature`(`float`, optional): Controls randomness. 0.0 = deterministic, >0.0 = random. Defaults to `0.2`.
- `top_p`(`float`, optional): Nucleus sampling. Considers tokens with cumulative probability >= top_p. Defaults to `0.95`.
- `top_k`(`int`, optional): Top-k sampling. Considers the top 'k' most probable tokens. Defaults to `40`.
- `max_tokens`(`int`, required): The maximum number of new tokens to generate.
- `min_p`(`float`, optional): Min-p sampling, filters tokens below this probability. Defaults to `0.05`.
- `stop`(`str | list[str]`, optional): Stop sequences to halt generation. Defaults to `None`.
- `seed`(`int`, optional): Overrides the model's seed just for this call. Defaults to `None`.
- `repeat_penalty`(`float`, optional): Penalty for repeating tokens (1.0 = no penalty). Defaults to `1.0`.
- `presence_penalty`(`float`, optional): Penalty for new tokens (0.0 = no penalty). Defaults to `0.0`.
- `frequency_penalty`(`float`, optional): Penalty for frequent tokens (0.0 = no penalty). Defaults to `0.0`.
- `logit_bias`(`dict[int, float]`, optional): Applies a bias to specific tokens. Defaults to `None`.
- `response_format`(`ResponseFormat`, optional): Constrains the model output to a specific format.
Use with type 'json_object' to enforce valid JSON output, optionally with a JSON Schema.
- `type`(`str`, optional): The output format type ('text' or 'json_object'). Defaults to `'text'`.
- `schema`(`SchemaDefinition`, optional): Schema defining the expected JSON structure when type is 'json_object'.
- `properties`(`dict`, optional): Mapping of field names to type strings or PropertyDefinition objects.
- `required`(`list[str]`, optional): List of required field names.
- `chat_history_key`(`str`, optional): Key in the packet's generic_data to find
the conversation history.
- `rag_context_key`(`str`, optional): Key in the packet's generic_data to find
RAG context to inject.
- `system_prompt`(`str | Path`, optional): The system prompt (or path to one)
to instruct the model.
- `pattern`(`dict`, optional): A regex pattern used to post-process the model's response.
- `keep_before`(`bool`, optional): If True, keeps text before the 'pattern' match; otherwise, keeps text after.
- `structure_output_key`(`str`, optional): Key used to store parsed JSON structured output in the packet's
generic_data when response_format type is 'json_object'. Defaults to `'structured_output'`.
</details>
- **LLaMATextCompletionWithMCP**: Template for text completion with MCP tool integration using LLaMA CPP.
<details>
<summary>Attributes</summary>
- `init_args`(`LLaMAInitArgs`, required): LLaMA model arguments.
- `llm_model_name`(`str`, required): The name or path of the LLM model to use (e.g. 'TheBloke/Llama-2-7B-GGUF').
- `llm_model_file`(`str`, required): The specific GGUF model file (e.g., 'llama-2-7b.Q2_K.gguf').
- `n_gpu_layers`(`int`, optional): Number of layers to offload to the GPU (-1 for all). Defaults to `0`.
- `use_mmap`(`bool`, optional): Use 'memory-mapping' to load the model. Defaults to `True`.
- `use_mlock`(`bool`, optional): Force the model to be kept in RAM. Defaults to `False`.
- `seed`(`int`, optional): RNG seed for model initialization. Defaults to `LLAMA_DEFAULT_SEED`.
- `n_ctx`(`int`, optional): The context window size. Defaults to `512`.
- `n_batch`(`int`, optional): The batch size for prompt processing. Defaults to `512`.
- `n_ubatch`(`int`, optional): The batch size for token generation. Defaults to `512`.
- `n_threads`(`int`, optional): CPU threads for generation. Defaults to `None`.
- `n_threads_batch`(`int`, optional): CPU threads for batch processing. Defaults to `None`.
- `flash_attn`(`bool`, optional): Enable Flash Attention if supported by the GPU. Defaults to `False`.
- `chat_format`(`str`, optional): Chat template format (e.g., 'chatml'). Defaults to `None`.
- `verbose`(`bool`, optional): Enable verbose logging from llama.cpp. Defaults to `True`.
- `completion_args`(`LLaMACompletionArgs`, required): Generation arguments to pass to the selected model.
- `temperature`(`float`, optional): Controls randomness. 0.0 = deterministic, >0.0 = random. Defaults to `0.2`.
- `top_p`(`float`, optional): Nucleus sampling. Considers tokens with cumulative probability >= top_p. Defaults to `0.95`.
- `top_k`(`int`, optional): Top-k sampling. Considers the top 'k' most probable tokens. Defaults to `40`.
- `max_tokens`(`int`, required): The maximum number of new tokens to generate.
- `min_p`(`float`, optional): Min-p sampling, filters tokens below this probability. Defaults to `0.05`.
- `stop`(`str | list[str]`, optional): Stop sequences to halt generation. Defaults to `None`.
- `seed`(`int`, optional): Overrides the model's seed just for this call. Defaults to `None`.
- `repeat_penalty`(`float`, optional): Penalty for repeating tokens (1.0 = no penalty). Defaults to `1.0`.
- `presence_penalty`(`float`, optional): Penalty for new tokens (0.0 = no penalty). Defaults to `0.0`.
- `frequency_penalty`(`float`, optional): Penalty for frequent tokens (0.0 = no penalty). Defaults to `0.0`.
- `logit_bias`(`dict[int, float]`, optional): Applies a bias to specific tokens. Defaults to `None`.
- `response_format`(`ResponseFormat`, optional): Constrains the model output to a specific format.
Use with type 'json_object' to enforce valid JSON output, optionally with a JSON Schema.
- `type`(`str`, optional): The output format type ('text' or 'json_object'). Defaults to `'text'`.
- `schema`(`SchemaDefinition`, optional): Schema defining the expected JSON structure when type is 'json_object'.
- `properties`(`dict`, optional): Mapping of field names to type strings or PropertyDefinition objects.
- `required`(`list[str]`, optional): List of required field names.
- `chat_history_key`(`str`, optional): Key in the packet's generic_data to find
the conversation history.
- `rag_context_key`(`str`, optional): Key in the packet's generic_data to find
RAG context to inject.
- `system_prompt`(`str | Path`, optional): The system prompt (or path to one)
to instruct the model.
- `pattern`(`dict`, optional): A regex pattern used to post-process the model's response.
- `keep_before`(`bool`, optional): If True, keeps text before the 'pattern' match; otherwise, keeps text after.
- `structure_output_key`(`str`, optional): Key used to store parsed JSON structured output in the packet's
generic_data when response_format type is 'json_object'. Defaults to `'structured_output'`.
- `tools_key`(`str`, optional): Key used to extract the raw tools from the data container. Defaults to `""`.
- `max_tool_retries`(`int`, optional): Maximum consecutive tool execution failures before stopping. Defaults to `3`.
- `add_tool_to_prompt`(`bool`, optional): Whether to automatically append tool descriptions to the system prompt. Defaults to `True`.
</details>
- **StreamingLLaMATextCompletion**: Streaming version of LLaMATextCompletion for real-time response generation.
<details>
<summary>Attributes</summary>
Inherits all attributes from `LLaMATextCompletion`. The template yields response chunks as they are generated
rather than waiting for the complete response.
</details>
- **LLama4TextToText**: Template for text-to-text chat processing using the LLama 4 model.
<details>
<summary>Attributes</summary>
- `init_args`(`LLaMA4InitArgs`, required): LLaMA4 model arguments.
- `llm_model_name`(`str`, required): The name or path of the LLM model to use (e.g., 'meta-llama/Llama-4-Scout-17B-16E-Instruct').
- `cache_dir`(`str`, optional): Path to use for the model cache and download.
- `device_map`(`str`, optional): Device mapping for `from_pretrained`. Defaults to `auto`.
- `torch_dtype`(`str`, optional): Model tensor precision (e.g., 'auto', 'float16'). Defaults to `auto`.
- `max_memory`(`dict`, optional): Max memory allocation per device. Defaults to `None`.
- `completion_args`(`LLaMA4CompletionArgs`, required): Generation arguments to pass to the selected model.
- `temperature`(`float`, optional): Controls randomness. 0.0 = deterministic, >0.0 = random. Defaults to `0.2`.
- `top_p`(`float`, optional): Nucleus sampling. Considers tokens with cumulative probability >= top_p. Defaults to `0.95`.
- `top_k`(`int`, optional): Top-k sampling. Considers the top 'k' most probable tokens. Defaults to `40`.
- `max_length`(`int`, optional): The maximum length of the sequence (prompt + generation). Defaults to `20`.
- `max_new_tokens`(`int`, optional): The maximum number of new tokens to generate. Defaults to `None`.
- `do_sample`(`bool`, optional): Whether to use sampling (True) or greedy decoding (False). Defaults to `True`.
- `min_p`(`float`, optional): Min-p sampling, filters tokens below this probability. Defaults to `None`.
- `repetition_penalty`(`float`, optional): Penalty applied to repeated tokens (1.0 = no penalty). Defaults to `1.0`.
- `chat_history_key`(`str`, optional): Key in the packet's generic_data to find
the conversation history.
- `rag_context_key`(`str`, optional): Key in the packet's generic_data to find
RAG context to inject.
- `system_prompt`(`str | Path`, optional): The system prompt (or path to one)
to instruct the model.
- `pattern`(`dict`, optional): A regex pattern used to post-process the model's response.
- `keep_before`(`bool`, optional): If True, keeps text before the 'pattern' match; otherwise, keeps text after.
</details>
- **LLama4MultiModal**: Template for multi modal chat processing using the LLama 4 model.
<details>
<summary>Attributes</summary>
- `init_args`(`LLaMA4InitArgs`, required): LLaMA4 model arguments.
- `llm_model_name`(`str`, required): The name or path of the LLM model to use (e.g., 'meta-llama/Llama-4-Scout-17B-16E-Instruct').
- `cache_dir`(`str`, optional): Path to use for the model cache and download.
- `device_map`(`str`, optional): Device mapping for `from_pretrained`. Defaults to `auto`.
- `torch_dtype`(`str`, optional): Model tensor precision (e.g., 'auto', 'float16'). Defaults to `auto`.
- `max_memory`(`dict`, optional): Max memory allocation per device. Defaults to `None`.
- `completion_args`(`LLaMA4CompletionArgs`, required): Generation arguments to pass to the selected model.
- `temperature`(`float`, optional): Controls randomness. 0.0 = deterministic, >0.0 = random. Defaults to `0.2`.
- `top_p`(`float`, optional): Nucleus sampling. Considers tokens with cumulative probability >= top_p. Defaults to `0.95`.
- `top_k`(`int`, optional): Top-k sampling. Considers the top 'k' most probable tokens. Defaults to `40`.
- `max_length`(`int`, optional): The maximum length of the sequence (prompt + generation). Defaults to `20`.
- `max_new_tokens`(`int`, optional): The maximum number of new tokens to generate. Defaults to `None`.
- `do_sample`(`bool`, optional): Whether to use sampling (True) or greedy decoding (False). Defaults to `True`.
- `min_p`(`float`, optional): Min-p sampling, filters tokens below this probability. Defaults to `None`.
- `repetition_penalty`(`float`, optional): Penalty applied to repeated tokens (1.0 = no penalty). Defaults to `1.0`.
- `chat_history_key`(`str`, optional): Key in the packet's generic_data to find
the conversation history.
- `rag_context_key`(`str`, optional): Key in the packet's generic_data to find
RAG context to inject.
- `system_prompt`(`str | Path`, optional): The system prompt (or path to one)
to instruct the model.
- `pattern`(`dict`, optional): A regex pattern used to post-process the model's response.
- `keep_before`(`bool`, optional): If True, keeps text before the 'pattern' match; otherwise, keeps text after.
</details>
> [!TIP]
> Use CLI command ``` sinapsis info --all-template-names``` to show a list with all the available Template names installed with Sinapsis Data Tools.
> [!TIP]
> Use CLI command ```sinapsis info --example-template-config TEMPLATE_NAME``` to produce an example Agent config for the Template specified in ***TEMPLATE_NAME***.
For example, for ***LLaMATextCompletion*** use ```sinapsis info --example-template-config LLaMATextCompletion``` to produce the following example config:
```yaml
agent:
name: my_test_agent
templates:
- template_name: InputTemplate
class_name: InputTemplate
attributes: {}
- template_name: LLaMATextCompletion
class_name: LLaMATextCompletion
template_input: InputTemplate
attributes:
init_args:
llm_model_name: '`replace_me:<class ''str''>`'
llm_model_file: '`replace_me:<class ''str''>`'
n_gpu_layers: 0
use_mmap: true
use_mlock: false
seed: 4294967295
n_ctx: 512
n_batch: 512
n_ubatch: 512
n_threads: null
n_threads_batch: null
flash_attn: false
chat_format: null
verbose: true
completion_args:
temperature: 0.2
top_p: 0.95
top_k: 40
max_tokens: '`replace_me:<class ''int''>`'
min_p: 0.05
stop: null
seed: null
repeat_penalty: 1.0
presence_penalty: 0.0
frequency_penalty: 0.0
logit_bias: null
chat_history_key: null
rag_context_key: null
system_prompt: null
pattern: null
keep_before: true
structure_output_key: structured_output
```
<h2 id="example">📚 Usage example</h2>
The following agent passes a text message through a TextPacket and retrieves a response from a LLM
<details id='usage'><summary><strong><span style="font-size: 1.0em;"> Config</span></strong></summary>
```yaml
agent:
name: chat_completion
description: Chatbot agent using DeepSeek-R1
templates:
- template_name: InputTemplate
class_name: InputTemplate
attributes: {}
- template_name: TextInput
class_name: TextInput
template_input: InputTemplate
attributes:
text: what is AI?
- template_name: LLaMATextCompletion
class_name: LLaMATextCompletion
template_input: TextInput
attributes:
init_args:
llm_model_name: bartowski/DeepSeek-R1-Distill-Qwen-7B-GGUF
llm_model_file: DeepSeek-R1-Distill-Qwen-7B-Q5_K_S.gguf
n_ctx: 8192
n_threads: 8
n_gpu_layers: -1
chat_format: chatml
flash_attn: true
seed: 10
completion_args:
max_tokens: 4096
temperature: 0.2
seed: 10
system_prompt : 'You are a helpful assistant'
pattern: "</think>"
keep_before: False
```
</details>
<h2 id="webapps">🌐 Webapps</h2>
This module includes a webapp to interact with the model
> [!IMPORTANT]
> To run the app you first need to clone this repository:
```bash
git clone git@github.com:Sinapsis-ai/sinapsis-chatbots.git
cd sinapsis-chatbots
```
> [!NOTE]
> If you'd like to enable external app sharing in Gradio, `export GRADIO_SHARE_APP=True`
> [!IMPORTANT]
> You can change the model name and the number of gpu_layers used by the model in case you have an Out of Memory (OOM) error
<details>
<summary id="uv"><strong><span style="font-size: 1.4em;">🐳 Docker</span></strong></summary>
**IMPORTANT** This docker image depends on the sinapsis-nvidia:base image. Please refer to the official [sinapsis](https://github.com/Sinapsis-ai/sinapsis?tab=readme-ov-file#docker) instructions to Build with Docker.
1. **Build the sinapsis-chatbots image**:
```bash
docker compose -f docker/compose.yaml build
```
2. **Start the container**
```bash
docker compose -f docker/compose_apps.yaml up sinapsis-simple-chatbot -d
```
2. Check the status:
```bash
docker logs -f sinapsis-simple-chatbot
```
3. The logs will display the URL to access the webapp, e.g.,:
```bash
Running on local URL: http://127.0.0.1:7860
```
**NOTE**: The url may be different, check the logs
4. To stop the app:
```bash
docker compose -f docker/compose_apps.yaml down
```
**To use a different chatbot configuration (e.g. OpenAI-based chat), update the `AGENT_CONFIG_PATH` environmental variable to point to the desired YAML file.**
For example, to use OpenAI chat:
```yaml
environment:
AGENT_CONFIG_PATH: webapps/configs/openai_simple_chat.yaml
OPENAI_API_KEY: your_api_key
```
</details>
<details>
<summary><strong><span style="font-size: 1.25em;">💻 UV</span></strong></summary>
1. Export the environment variable to install the python bindings for llama-cpp
```bash
export CMAKE_ARGS="-DGGML_CUDA=on"
export FORCE_CMAKE="1"
```
2. export CUDACXX:
```bash
export CUDACXX=$(command -v nvcc)
```
3. **Create the virtual environment and sync dependencies:**
```bash
uv sync --frozen
```
4. **Install the wheel**:
```bash
uv pip install sinapsis-chatbots[all] --extra-index-url https://pypi.sinapsis.tech
```
5. **Run the webapp**:
```bash
uv run webapps/llama_cpp_simple_chatbot.py
```
**NOTE:** To use OpenAI for the simple chatbot, set your API key and specify the correct configuration file
```bash
export AGENT_CONFIG_PATH=webapps/configs/openai_simple_chat.yaml
export OPENAI_API_KEY=your_api_key
```
and run step 5 again
6. **The terminal will display the URL to access the webapp, e.g.**:
NOTE: The url can be different, check the output of the terminal
```bash
Running on local URL: http://127.0.0.1:7860
```
</details>
<h2 id="documentation">📙 Documentation</h2>
Documentation for this and other sinapsis packages is available on the [sinapsis website](https://docs.sinapsis.tech/docs)
Tutorials for different projects within sinapsis are available at [sinapsis tutorials page](https://docs.sinapsis.tech/tutorials)
<h2 id="license">🔍 License</h2>
This project is licensed under the AGPLv3 license, which encourages open collaboration and sharing. For more details, please refer to the [LICENSE](LICENSE) file.
For commercial use, please refer to our [official Sinapsis website](https://sinapsis.tech) for information on obtaining a commercial license.
The LLama4TextToText template is licensed under the [official Llama4 license](https://github.com/meta-llama/llama-models/blob/main/models/llama4/LICENSE)
| text/markdown | null | SinapsisAI <dev@sinapsis.tech> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"huggingface-hub>=0.32.4",
"llama-cpp-python>=0.3.8",
"llama-index-llms-llama-cpp>=0.4.0",
"ninja>=1.11.1.3",
"pillow>=11.3.0",
"sinapsis>=0.1.1",
"sinapsis-chatbots-base",
"llvmlite>=0.44.0; extra == \"chatbot\"",
"sinapsis-chatbots-base[chatbot]; extra == \"chatbot\"",
"transformers[torch-vision... | [] | [] | [] | [
"Homepage, https://sinapsis.tech",
"Documentation, https://docs.sinapsis.tech/docs",
"Tutorials, https://docs.sinapsis.tech/tutorials",
"Repository, https://github.com/Sinapsis-AI/sinapsis-chatbots.git"
] | uv/0.6.17 | 2026-02-19T15:41:55.920032 | sinapsis_llama_cpp-0.4.0.tar.gz | 40,374 | c7/62/cc21f9319b106c1fbeff1bfcd3da25bab7623973ecdd60d87754df1eb677/sinapsis_llama_cpp-0.4.0.tar.gz | source | sdist | null | false | c8656239f42433b0bd55751178d44d8e | aca45cb063a8aa1b8bde3aec5faa9c470d9a43f77ef734f02d19def80a5c0893 | c762cc21f9319b106c1fbeff1bfcd3da25bab7623973ecdd60d87754df1eb677 | null | [
"LICENSE"
] | 202 |
2.4 | xapian-store | 0.2.1 | Python package that provides the XStore model class, built on top of xapian_model.base.BaseXapianModel | # xapian-store
A Python package providing the `XStore` model class for managing store data using Xapian as the underlying storage engine.
## Features
- Built on top of `xapian_model.base.BaseXapianModel`
- Comprehensive store schema with support for multiple store types
- Type-safe field definitions with validation
- Support for soft deletes and timestamps
- Configurable store attributes (slug, domain, name, owner, type, etc.)
- Visual customization fields (photo, header, color)
## Requirements
- Python 3.12 or higher
- xapian-model >= 0.3.1
- pyxapiand >= 2.1.0
## Installation
```bash
pip install xapian-store
```
## Quick Start
```python
from xstore import XStore, STORE_TYPE_AFFILIATE, get_store_schema
# XStore comes with a default INDEX_TEMPLATE and SCHEMA;
# override them in a subclass if your application requires it.
class MyStore(XStore):
INDEX_TEMPLATE = "my_stores"
# Create a store instance
store = MyStore()
# Access the schema directly
schema = get_store_schema(foreign_schema='.schema/store')
```
## Store Types
The package supports the following store types:
- `STORE_TYPE_NONE` - No specific type
- `STORE_TYPE_AFFILIATE` - Affiliate store
- `STORE_TYPE_AFFINITY` - Affinity store
- `STORE_TYPE_FRANCHISE` - Franchise store
- `STORE_TYPE_SUPPLIER` - Supplier store
- `STORE_TYPE_MASHUP` - Mashup store
## Schema Configuration
The store schema includes the following main fields:
- **Identification**: `id`, `slug`, `domain`, `canonical_url`
- **Metadata**: `name`, `owner`, `supplier`, `store_type`
- **Visual**: `photo`, `header`, `color`, `base_color`
- **Status**: `is_published`, `hidden`, `is_deleted`, `is_root_affinity_store`
- **Timestamps**: `created_at`, `updated_at`, `deleted_at`
- **Contact**: `from_email`, `address`
### Security Note
For security reasons, the following values should be reviewed and overridden per application:
- `INDEX_TEMPLATE` — defaults to `'stores'`; override in a subclass if needed
- `foreign_schema` — passed as a parameter to `get_store_schema()`
## Configuration Example
```python
from xstore import XStore, get_store_schema
# Override INDEX_TEMPLATE and SCHEMA for your application
class MyStore(XStore):
INDEX_TEMPLATE = "my_stores"
SCHEMA = get_store_schema(foreign_schema='.schema/my_store')
# Use your store
store = MyStore()
```
## Development
### Setup
The project uses `direnv` to automatically create and activate a virtual environment:
```bash
# With direnv installed, simply cd into the project
cd xstore
# Or manually create the environment
python3 -m venv .venv
source .venv/bin/activate
```
### Project Structure
```
xstore/
├── src/
│ └── xstore/
│ ├── __init__.py # Public API exports
│ ├── models.py # XStore model class
│ └── schemas.py # Schema definitions
├── pyproject.toml # Project configuration
└── README.md # This file
```
## License
MIT License - see LICENSE file for details.
## Links
- **Homepage**: https://github.com/dubalu/xstore
- **Repository**: https://github.com/dubalu/xstore
- **Bug Reports**: https://github.com/dubalu/xstore/issues
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
## Authors
- Dubalu <info@dubalu.com>
| text/markdown | null | Dubalu <info@dubalu.com> | null | null | MIT | database, model, search, store, xapian, xapian-model | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.12",
"Topic :: Database",
"... | [] | null | null | >=3.12 | [] | [] | [] | [
"pyxapiand>=2.1.0",
"xapian-model>=0.3.1"
] | [] | [] | [] | [
"Homepage, https://github.com/dubalu/xstore",
"Repository, https://github.com/dubalu/xstore",
"Issues, https://github.com/dubalu/xstore/issues",
"Changelog, https://github.com/dubalu/xstore/blob/main/CHANGELOG.md"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T15:41:54.095509 | xapian_store-0.2.1.tar.gz | 5,607 | f5/f7/086842ea22cac58e85703d6649b23bb33dd7f9d45aa645b4bb412016db73/xapian_store-0.2.1.tar.gz | source | sdist | null | false | c15d2a85d5700470458842c548bc4fb8 | 1e82a7ecd1b90446afe8c28ca14cea9f0580feaf38bbddeb75482cb266f4824e | f5f7086842ea22cac58e85703d6649b23bb33dd7f9d45aa645b4bb412016db73 | null | [
"LICENSE"
] | 215 |
2.4 | biomechzoo | 0.7.10 | Python implementation of the biomechZoo toolbox | # BiomechZoo for Python
This is a development version of the biomechzoo toolbox for python.
## How to install
- biomechZoo for python is now an official package, you can simply add biomechZoo to your environment using
``pip install biomechzoo``
## Usage notes
- If you need to install a specific version, run ``pip install biomechzoo==x.x.x`` where x.x.x is the version number.
- If you need to update biomechzoo to the latest version in your env, run ``pip install biomechzoo --upgrade``
## Dependencies notes
- We use Python 3.11 for compatibility with https://github.com/stanfordnmbl/opencap-processing
- We use Numpy 2.2.6 for compatibility with https://pypi.org/project/numba/
See also http://www.github.com/mcgillmotionlab/biomechzoo or http://www.biomechzoo.com for more information
## Developer notes
### Installing a dev environment
conda create -n biomechzoo-dev python=3.11
conda activate biomechzoo-dev
cd biomechzoo root folder
pip install -e ".[dev]"
### import issues
if using PyCharm:
- Right-click on src/.
- Select Mark Directory as → Sources Root.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | <3.12,>=3.11 | [] | [] | [] | [
"ezc3d>=1.5.19",
"matplotlib>=3.10.6",
"numpy==2.2.6",
"pandas>=2.3.2",
"scipy>=1.16.2",
"pyarrow>=19.0.0",
"plotly>=6.4.0",
"kaleido>=1.2.0",
"dash>=3.3.0"
] | [] | [] | [] | [
"Homepage, https://github.com/mcgillmotionlab/biomechzoo"
] | uv/0.8.22 | 2026-02-19T15:41:53.422772 | biomechzoo-0.7.10.tar.gz | 55,296 | 84/bf/ba344d63a04051c90d57d4850b32e5f12089f98c43158784d4d07f9e7d59/biomechzoo-0.7.10.tar.gz | source | sdist | null | false | fdc156cf32cd1020a37316e053b46ba3 | b97784884556cdb3f9c3edea276a0046b6ffb7e5fa3bc74b983506082dfba88e | 84bfba344d63a04051c90d57d4850b32e5f12089f98c43158784d4d07f9e7d59 | MIT | [
"LICENSE"
] | 217 |
2.4 | sinapsis-chatbots | 0.6.0 | Mono repo with packages for text completion tasks | <h1 align="center">
<br>
<a href="https://sinapsis.tech/">
<img
src="https://github.com/Sinapsis-AI/brand-resources/blob/main/sinapsis_logo/4x/logo.png?raw=true"
alt="" width="300">
</a>
<br>
sinapsis-chatbots
<br>
</h1>
<h4 align="center">A comprehensive monorepo for building and deploying AI-driven chatbots with support for multiple large language models</h4>
<p align="center">
<a href="#installation">🐍 Installation</a> •
<a href="#packages">📦 Packages</a> •
<a href="#webapps">🌐 Webapps</a>
<a href="#documentation">📙 Documentation</a> •
<a href="#license">🔍 License</a>
</p>
The `sinapsis-chatbots` module is a powerful toolkit designed to simplify the development of AI-driven chatbots and Retrieval-Augmented Generation (RAG) systems. It provides ready-to-use templates and utilities for configuring and running large language model (LLM) applications, enabling developers to integrate a wide range of LLM models with ease for natural, intelligent interactions.
> [!IMPORTANT]
> We now include support for Llama4 models!
To use them, install the dependency (if you have not installed sinapsis-llama-cpp[all])
```bash
uv pip install sinapsis-llama-cpp[llama-four] --extra-index-url https://pypi.sinapsis.tech
```
You need a HuggingFace token. See the [official instructions](https://huggingface.co/docs/hub/security-tokens)
and set it using
```bash
export HF_TOKEN=<token-provided-by-hf>
```
and test it through the cli or the webapp by changing the AGENT_CONFIG_PATH
> [!NOTE]
> Llama 4 requires large GPUs to run the models.
> Nonetheless, running on smaller consumer-grade GPUs is possible, although a single inference may take hours
>
<h2 id="installation">🐍 Installation</h2>
This mono repo includes packages for AI-driven chatbots using various LLM frameworks through:
* <code>sinapsis-anthropic</code>
* <code>sinapsis-chatbots-base</code>
* <code>sinapsis-llama-cpp</code>
* <code>sinapsis-llama-index</code>
* <code>sinapsis-mem0</code>
Install using your preferred package manager. We strongly recommend using <code>uv</code>. To install <code>uv</code>, refer to the [official documentation](https://docs.astral.sh/uv/getting-started/installation/#installation-methods).
Install with <code>uv</code>:
```bash
uv pip install sinapsis-llama-cpp --extra-index-url https://pypi.sinapsis.tech
```
Or with raw <code>pip</code>:
```bash
pip install sinapsis-llama-cpp --extra-index-url https://pypi.sinapsis.tech
```
**Replace `sinapsis-llama-cpp` with the name of the package you intend to install**.
> [!IMPORTANT]
> Templates in each package may require extra dependencies. For development, we recommend installing the package with all the optional dependencies:
>
With <code>uv</code>:
```bash
uv pip install sinapsis-llama-cpp[all] --extra-index-url https://pypi.sinapsis.tech
```
Or with raw <code>pip</code>:
```bash
pip install sinapsis-llama-cpp[all] --extra-index-url https://pypi.sinapsis.tech
```
**Be sure to substitute `sinapsis-llama-cpp` with the appropriate package name**.
> [!TIP]
> You can also install all the packages within this project:
>
```bash
uv pip install sinapsis-chatbots[all] --extra-index-url https://pypi.sinapsis.tech
```
<h2 id="packages">📦 Packages</h2>
This repository is structured into modular packages, each facilitating the integration of AI-driven chatbots with various LLM frameworks. These packages provide flexible and easy-to-use templates for building and deploying chatbot solutions. Below is an overview of the available packages:
<details>
<summary id="anthropic"><strong><span style="font-size: 1.4em;"> Sinapsis Anthropic </span></strong></summary>
This package offers a suite of templates and utilities for building **text-to-text** and **image-to-text** conversational chatbots using [Anthropic's Claude](https://docs.anthropic.com/en/docs/overview) models.
- **AnthropicTextGeneration**: Template for text and code generation with Claude models using the Anthropic API.
- **AnthropicMultiModal**: Template for multimodal chat processing using Anthropic's Claude models.
For specific instructions and further details, see the [README.md](https://github.com/Sinapsis-AI/sinapsis-chatbots/blob/main/packages/sinapsis_anthropic/README.md).
</details>
<details>
<summary id="base"><strong><span style="font-size: 1.4em;"> Sinapsis Chatbots Base </span></strong></summary>
This package provides core functionality for LLM chat completion tasks.
- **QueryContextualizeFromFile**: Template that adds a certain context to the query searching for keywords in the Documents added in the generic_data field of the DataContainer
For specific instructions and further details, see the [README.md](https://github.com/Sinapsis-AI/sinapsis-chatbots/blob/main/packages/sinapsis_chatbots_base/README.md).
</details>
<details>
<summary id="llama-cpp"><strong><span style="font-size: 1.4em;"> Sinapsis llama-cpp </span></strong></summary>
This package offers a suite of templates and utilities for running LLMs using [llama-cpp](https://github.com/ggml-org/llama.cpp).
- **LLama4MultiModal**: Template for multi modal chat processing using the LLama 4 model.
- **LLaMATextCompletion**: Configures and initializes a chat completion model, supporting LLaMA, Mistral, and other compatible models. Supports structured outputs via `response_format`.
- **StreamingLLaMATextCompletion**: Streaming version of LLaMATextCompletion for real-time response generation.
- **LLama4TextToText**: Template for text-to-text chat processing using the LLama 4 model.
For specific instructions and further details, see the [README.md](https://github.com/Sinapsis-AI/sinapsis-chatbots/blob/main/packages/sinapsis_llama_cpp/README.md).
</details>
<details>
<summary id="llama-index"><strong><span style="font-size: 1.4em;"> Sinapsis llama-index </span></strong></summary>
Package with support for various llama-index modules for text completion. This includes making calls to llms, processing and generating embeddings and Nodes, etc.
- **CodeEmbeddingNodeGenerator**: Template to generate nodes for a code base.
- **EmbeddingNodeGenerator**: Template for generating text embeddings using the HuggingFace model.
- **LLaMAIndexInsertNodes**: Template for inserting embeddings (nodes) into a PostgreSQL vector database using
the LlamaIndex `PGVectorStore` to store vectorized data.
- **LLaMAIndexNodeRetriever**: Template for retrieving nodes from a database using embeddings.
- **LLaMAIndexRAGTextCompletion**: Template for configuring and initializing a LLaMA-based Retrieval-Augmented Generation (RAG) system.
For specific instructions and further details, see the [README.md](https://github.com/Sinapsis-AI/sinapsis-chatbots/blob/main/packages/sinapsis_llama_index/README.md).
</details>
<details>
<summary id="mem0"><strong><span style="font-size: 1.4em;"> Sinapsis Mem0 </span></strong></summary>
This package provides persistent memory functionality for Sinapsis agents using [Mem0](https://docs.mem0.ai/), supporting both **managed (Mem0 platform)** and **self-hosted** backends.
- **Mem0Add**: Ingests and stores prompts, responses, and facts into memory.
- **Mem0Get**: Retrieves individual or grouped memory records.
- **Mem0Search**: Fetches relevant memories and injects them into the current prompt.
- **Mem0Delete**: Removes stored memories selectively or in bulk.
- **Mem0Reset**: Fully clears memory within a defined scope.
For specific instructions and further details, see the [README.md](https://github.com/Sinapsis-AI/sinapsis-chatbots/blob/main/packages/sinapsis_mem0/README.md).
</details>
<h2 id="webapps">🌐 Webapps</h2>
The webapps included in this project showcase the modularity of the templates, in this case for AI-driven chatbots.
> [!IMPORTANT]
> To run the app you first need to clone this repository:
```bash
git clone git@github.com:Sinapsis-ai/sinapsis-chatbots.git
cd sinapsis-chatbots
```
> [!NOTE]
> If you'd like to enable external app sharing in Gradio, `export GRADIO_SHARE_APP=True`
> [!IMPORTANT]
> You can change the model name and the number of gpu_layers used by the model in case you have an Out of Memory (OOM) error.
> [!IMPORTANT]
> Anthropic requires an API key to interact with the API. To get started, visit the [official website](https://console.anthropic.com/) to create an account. If you already have an account, go to the [API keys page](https://console.anthropic.com/settings/keys) to generate a token.
> [!IMPORTANT]
> Set your API key env var using <code> export ANTHROPIC_API_KEY='your-api-key'</code>
> [!NOTE]
> Agent configuration can be changed through the `AGENT_CONFIG_PATH` env var. You can check the available configurations in each package configs folder.
<details>
<summary id="uv"><strong><span style="font-size: 1.4em;">🐳 Docker</span></strong></summary>
**IMPORTANT**: This Docker image depends on the `sinapsis-nvidia:base` image. For detailed instructions, please refer to the [Sinapsis README](https://github.com/Sinapsis-ai/sinapsis?tab=readme-ov-file#docker).
1. **Build the sinapsis-chatbots image**:
```bash
docker compose -f docker/compose.yaml build
```
2. **Start the app container**
- For Anthropic text-to-text chatbot:
```bash
docker compose -f docker/compose_apps.yaml up sinapsis-claude-chatbot -d
```
- For llama-cpp text-to-text chatbot:
```bash
docker compose -f docker/compose_apps.yaml up sinapsis-simple-chatbot -d
```
- For llama-index RAG chatbot:
```bash
docker compose -f docker/compose_apps.yaml up sinapsis-rag-chatbot -d
```
3. **Check the logs**
- For Anthropic text-to-text chatbot:
```bash
docker logs -f sinapsis-claude-chatbot
```
- For llama-cpp text-to-text chatbot:
```bash
docker logs -f sinapsis-simple-chatbot
```
- For llama-index RAG chatbot:
```bash
docker logs -f sinapsis-rag-chatbot
```
4. **The logs will display the URL to access the webapp, e.g.,:**:
```bash
Running on local URL: http://127.0.0.1:7860
```
**NOTE**: The url may be different, check the output of logs.
5. **To stop the app**:
```bash
docker compose -f docker/compose_apps.yaml down
```
**To use a different chatbot configuration (e.g. OpenAI-based chat), update the `AGENT_CONFIG_PATH` environmental variable to point to the desired YAML file.**
For example, to use OpenAI chat:
```yaml
environment:
AGENT_CONFIG_PATH: webapps/configs/openai_simple_chat.yaml
OPENAI_API_KEY: your_api_key
```
</details>
<details>
<summary id="virtual-environment"><strong><span style="font-size: 1.4em;">💻 UV</span></strong></summary>
To run the webapp using the <code>uv</code> package manager, follow these steps:
1. **Export the environment variable to install the python bindings for llama-cpp**:
```bash
export CMAKE_ARGS="-DGGML_CUDA=on"
export FORCE_CMAKE="1"
```
2. **Export CUDACXX**:
```bash
export CUDACXX=$(command -v nvcc)
```
3. **Sync the virtual environment**:
```bash
uv sync --frozen
```
4. **Install the wheel**:
```bash
uv pip install sinapsis-chatbots[all] --extra-index-url https://pypi.sinapsis.tech
```
5. **Run the webapp**:
- For Anthropic text-to-text chatbot:
```bash
export ANTHROPIC_API_KEY=your_api_key
uv run webapps/claude_chatbot.py
```
- For llama-cpp text-to-text chatbot:
```bash
uv run webapps/llama_cpp_simple_chatbot.py
```
- For OpenAI text-to-text chatbot:
```bash
export AGENT_CONFIG_PATH=webapps/configs/openai_simple_chat.yaml
export OPENAI_API_KEY=your_api_key
uv run webapps/llama_cpp_simple_chatbot.py
```
- For llama-index RAG chatbot:
```bash
uv run webapps/llama_index_rag_chatbot.py
```
6. **The terminal will display the URL to access the webapp, e.g.**:
```bash
Running on local URL: http://127.0.0.1:7860
```
**NOTE**: The URL may vary; check the terminal output for the correct address.
</details>
<h2 id="documentation">📙 Documentation</h2>
Documentation for this and other sinapsis packages is available on the [sinapsis website](https://docs.sinapsis.tech/docs)
Tutorials for different projects within sinapsis are available at [sinapsis tutorials page](https://docs.sinapsis.tech/tutorials)
<h2 id="license">🔍 License</h2>
This project is licensed under the AGPLv3 license, which encourages open collaboration and sharing. For more details, please refer to the [LICENSE](LICENSE) file.
For commercial use, please refer to our [official Sinapsis website](https://sinapsis.tech) for information on obtaining a commercial license.
| text/markdown | null | SinapsisAI <dev@sinapsis.tech> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"sinapsis>=0.1.1",
"sinapsis[webapp]>=0.2.2; extra == \"gradio-app\"",
"sinapsis-anthropic[all]; extra == \"all\"",
"sinapsis-chat-history[all]; extra == \"all\"",
"sinapsis-chatbots[gradio-app]; extra == \"all\"",
"sinapsis-chatbots-base[all]; extra == \"all\"",
"sinapsis-llama-cpp[all]; extra == \"all... | [] | [] | [] | [
"Homepage, https://sinapsis.tech",
"Documentation, https://docs.sinapsis.tech/docs",
"Tutorials, https://docs.sinapsis.tech/tutorials",
"Repository, https://github.com/Sinapsis-AI/sinapsis-chatbots.git"
] | uv/0.6.17 | 2026-02-19T15:41:52.572867 | sinapsis_chatbots-0.6.0.tar.gz | 83,497 | 63/48/12c734cf1783d2f7d27366aaa0f3c3beadc0e7b4e41a585825205cd50a93/sinapsis_chatbots-0.6.0.tar.gz | source | sdist | null | false | f09424f8fd3f1122f81db6ac97ad0513 | 5abf1db5a33b236576478331b86c07da123079394ad6768fa02a3ddde8352dd4 | 634812c734cf1783d2f7d27366aaa0f3c3beadc0e7b4e41a585825205cd50a93 | null | [
"LICENSE"
] | 209 |
2.3 | ds-caselaw-marklogic-api-client | 44.4.4 | An API client for interacting with the underlying data in Find Caselaw. | # The National Archives: Find Case Law
This repository is part of the [Find Case Law](https://caselaw.nationalarchives.gov.uk/) project at [The National Archives](https://www.nationalarchives.gov.uk/). For more information on the project, check [the documentation](https://github.com/nationalarchives/ds-find-caselaw-docs).
# MarkLogic API Client
[](https://pypi.org/project/ds-caselaw-marklogic-api-client/)


This is an API Client for connecting to Marklogic for The National Archive's Caselaw site.
This package is published on PyPI: https://pypi.org/project/ds-caselaw-marklogic-api-client/
## Usage
You can find documentation of the client class and available methods [here](https://nationalarchives.github.io/ds-caselaw-custom-api-client).
## Testing
To run the test suite:
```bash
poetry install
poetry run pytest
```
There are also some smoketests in `smoketests.py` which run against a MarkLogic database but do not run in CI currently.
To run them locally you can set the environment variables as detailed in the file in a `.env` file or just hardcode them in, as long as you don't commit those changes to the repo.
And then run
```bash
poetry run pytest smoketest.py
```
To start with when running this, we have been choosing to point to the staging MarkLogic to have more confidence that the setup is a good representation of production as opposed to a local MarkLogic instance but that can work too.
Eventually we will make it so that we run these tests in CI and probably point to a dedicated testing MarkLogic instance so we don't get conflicts with people using staging for manual testing.
## Making changes
When making a change, update the [changelog](CHANGELOG.md) using the
[Keep a Changelog 1.0.0](https://keepachangelog.com/en/1.0.0/) format. Pull
requests should not be merged before any relevant updates are made.
## Releasing
When making a new release, update the [changelog](CHANGELOG.md) in the release
pull request.
The package will **only** be released to PyPI if the branch is tagged. A merge
to main alone will **not** trigger a release to PyPI.
To create a release:
0. Update the version number in `pyproject.toml`
1. Create a branch `release/v{major}.{minor}.{patch}`
2. Update `CHANGELOG.md` for the release
3. Commit and push
4. Open a PR from that branch to main
5. Get approval on the PR
6. Merge the PR to main and push
7. Tag the merge commit on `main` with `v{major}.{minor}.{patch}` and push the tag
8. Create a release in [Github releases](https://github.com/nationalarchives/ds-caselaw-custom-api-client/releases)
using the created tag
If the release fails to push to PyPI, you can delete the tag with `git pull`, `git push --delete origin v1.2.3` and try again.
| text/markdown | The National Archives | null | null | null | null | national archives, caselaw | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <4.0.0,>=3.12.0 | [] | [] | [] | [
"boto3<2.0.0,>=1.26.112",
"certifi<2026.2.0,>=2026.1.4",
"charset-normalizer<4.0.0,>=3.0.0",
"defusedxml<0.8.0,>=0.7.1",
"django-environ>=0.12.0",
"ds-caselaw-utils<5.0.0,>=4.0.0",
"idna<4.0,>=3.4",
"lxml<7.0.0,>=6.0.0",
"memoization<0.5.0,>=0.4.0",
"mypy-boto3-s3<2.0.0,>=1.26.104",
"mypy-boto3-... | [] | [] | [] | [
"Homepage, https://github.com/nationalarchives/ds-caselaw-custom-api-client"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:40:59.295842 | ds_caselaw_marklogic_api_client-44.4.4.tar.gz | 64,477 | 46/72/b00a34586437e0cb9c0a5a8286c9eee8013abebac47230a666f7ca41df15/ds_caselaw_marklogic_api_client-44.4.4.tar.gz | source | sdist | null | false | 76ead659166da55188c0cd601e68714d | 0bb448f9916ce608ff3ab5f1f18719e8547bc5a6b16d6236c4fa8fe226cf5bc9 | 4672b00a34586437e0cb9c0a5a8286c9eee8013abebac47230a666f7ca41df15 | null | [] | 457 |
2.4 | aidsoid-photo-organiser | 0.1.0 | Automatically organize your photos and videos by date with precise capture date preservation and a clean folder structure. | # Aidsoid Photo Organiser
Automatically organize your photos and videos by date with a clean folder structure,
preserving original capture dates and supporting multiple formats.
Efficiently handle duplicates and choose between hardlinking or copying files — all
without modifying your original files.
This tool is especially well-suited for organizing [Google Takeout](https://takeout.google.com) exports. It handles
Takeout's nested folder layouts, preserves associated metadata JSON files produced by
Takeout, recognizes common Takeout filename patterns and timestamps, and sorts media
from Takeout exports into the Year/Month structure without losing metadata.
This tool is also useful if you want to migrate or organize your media locally — for example,
moving a Google Takeout export or an Apple iCloud Photos export to a NAS or personal computer
to reduce cloud storage costs while preserving folder structure and metadata. Before deleting
data from any cloud storage, verify your local copies and ensure you have reliable backups.
## Installation
### Requirements
- Python 3.13 or newer
- `ffprobe` (part of `ffmpeg`, optional)
### Quick install
```bash
# Install with pipx
pipx install aidsoid-photo-organiser
# Or install with uv (Astral)
uv tool install aidsoid-photo-organiser
# Or install with pip
pip install aidsoid-photo-organiser
# Verify install
apo --help
```
## Usage
### Basic Usage
```bash
apo --input-dir ./not-sorted-media --output-dir ./output
```
### Available Parameters
* `--input-dir` # Required: Specifies the directory containing the input files.
* `--output-dir` # Required: Specifies the directory where sorted files will be stored.
* `--use-hardlinks` # Optional: Enables hardlinking instead of copying files, saving disk space.
* `--verbose` # Optional: Enables detailed logging with DEBUG-level information.
### Examples
```bash
# Standard Sorting with File Copying
apo --input-dir /path/to/input --output-dir /path/to/output
# Sorting with Hardlink Creation
apo --input-dir /path/to/input --output-dir /path/to/output --use-hardlinks
# Enable Verbose Logging
apo --input-dir /path/to/input --output-dir /path/to/output --verbose
# Combining Hardlinks and Verbose Mode
apo --input-dir /path/to/input --output-dir /path/to/output --use-hardlinks --verbose
```
### Output Directory Structure Example
After running the script, your output directory might look like this:
```
/output
├── 2021
│ └── 12
│ ├── new_year_party.mp4
│ └── fireworks.mov
├── 2022
│ ├── 01
│ │ ├── winter_trip.png
│ │ ├── skiing.mov
│ │ └── metadata_1.json
│ ├── 02
│ │ ├── birthday_photo.jpg
│ │ └── party_video.mp4
│ └── 03
│ └── spring_blossom.heic
├── 2023
│ ├── 05
│ │ ├── beach.png
│ │ ├── surfing.mkv
│ │ └── metadata_2.json
│ └── 08
│ ├── hiking_photo.jpg
│ └── mountain_video.mp4
└── missed_files
├── document1.pdf
├── archive.zip
└── random_file.txt
```
## Features and Benefits
### 🛡️ Non-Destructive Operation
The script does not make any changes in the input directory, ensuring the safety and integrity of the original files.
You can be confident that no files will be modified, deleted, or moved from the input directory.
Safe to run repeatedly: you may run the tool again using the same `--output-dir` with a different `--input-dir`; duplicates are skipped and conflicts are resolved without overwriting existing files.
### 📅 Automatic Sorting by Date
Files are automatically sorted into directories based on their creation or photo taken date, maintaining a clear and organized structure (`Year/Month`).
**Example directory structure:** `../output/YYYY/MM/file.jpg`
### 🖼️ Support for Multiple File Types
The script supports a wide range of photo and video formats, including `.jpg`, `.png`, `.heic`, `.mp4`, `.mov`, and more.
**Full list of supported formats** is provided in the ["File formats"](##file-formats) section.
### 🔗 Optional Hardlink Creation
The script offers an option to create hardlinks instead of copying files in the output directory.
**Activation:** Use the `--use-hardlinks` flag to enable this feature.
This approach saves disk space by avoiding data duplication while still allowing access to files in the organized structure.
### 🔍 Duplicate File Handling
The script identifies and handles duplicate files by comparing file hashes (`BLAKE2b`).
If a duplicate is detected, it skips copying and provides a clear log message.
### 📑 Metadata Preservation
The script manages supplemental metadata JSON files, ensuring that associated metadata is retained alongside the media files, including important information like the original capture date.
### ✅ Great for Google Takeout and Apple iCloud Photos
Recognizes and organizes files exported via Google Takeout, including nested folders and Takeout-generated JSON metadata files.
Keeps Takeout's supplemental JSON files together with media so no contextual data is lost.
### 🆚 Conflict Resolution
When a file with the same name but different content exists in the output directory, the script automatically renames the new file using a UUID to avoid overwriting.
### 📝 Detailed Logging
Provides clear log messages for every step of the process, including when files are skipped, renamed, or linked.
- **Terminal Output:** Displays key actions and statuses in the terminal. Use the `--verbose` flag to enable detailed DEBUG-level logging.
- **File Logging:** Saves a detailed log (`aidsoid_photo_organiser_YYYY-MM-DD-hh-mm-ss.log`) with full debug information, allowing you to review the complete process history and troubleshoot if needed.
### 📦 Handling Non-Media Files
Files that are not recognized as photos, videos, or metadata are not lost. Instead, they are copied to a separate `missed_files` directory, preserving their original directory structure.
### 📊 File Statistics Before and After
Shows detailed statistics of the input directory before processing and the output directory after processing, including total files, file types, and sizes.
### 🚦 Safe Error Handling
The script uses exception handling to manage potential errors, such as file access issues or hardlink creation problems, and informs the user with meaningful messages.
## File formats
The script organizes the files in the following formats:
```
📸 Photo Formats:
.jpg, .jpeg (JPEG):
Common format for images with lossy compression and support for EXIF metadata.
.png (Portable Network Graphics):
Lossless compression format, no native EXIF support, often used for images with transparency.
.heic, .heif (High Efficiency Image Format):
Modern image format with high compression efficiency and support for EXIF metadata, commonly
used on Apple devices.
.cr2 (Canon RAW):
Raw image format from Canon cameras, contains unprocessed image data and extensive metadata, including EXIF.
.gif (Graphics Interchange Format):
Supports simple animations and transparency, no EXIF support, primarily used for short looping animations.
🎥 Video Formats:
.mp4 (MPEG-4 Part 14):
Widely used video format with support for high-quality video and audio streams, as well as metadata.
.m4v (Apple MPEG-4 Video):
Similar to .mp4, often used by Apple, may include DRM protection.
.mov (QuickTime File Format):
Developed by Apple, supports high-quality video and extensive metadata, compatible with ffprobe.
.avi (Audio Video Interleave):
An older video format by Microsoft, supports less advanced compression, but still handles metadata.
.hevc (High Efficiency Video Coding):
Advanced video compression format, often used in .mp4 and .mkv containers, metadata handled by the
container format.
.mkv (Matroska Video):
Versatile video container format, supports multiple audio, video, and subtitle tracks, along with
rich metadata.
.mp (MPEG Video or Audio):
Can be an audio or video file, typically related to MPEG standards, often requires ffprobe to
accurately detect its content type.
```
## Dependencies
The script uses `ffprobe` util from `ffmpeg` package to detect video taken time.
* Linux: ```sudo apt install ffmpeg```
* macOS: ```brew install ffmpeg```
## Author
Alexey Doroshenko ✉️ [aidsoid@gmail.com](mailto:aidsoid@gmail.com)
## Commercial licensing
This project is dual-licensed under the `GPLv3` and a Commercial License.
For companies or users who need to distribute closed-source derivatives
or incorporate this software into proprietary products, a commercial
licensing option is available. See [COMMERCIAL_LICENSE](COMMERCIAL_LICENSE)
for details and contact information.
| text/markdown | null | Alexey Doroshenko <aidsoid@gmail.com> | null | null | null | duplicate-detection, exif, google-takeout, heic, media-organizer, photo-organizer, photo-sorter, video-organizer | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: End Users/Desktop",
"License :: OSI Approved :: GNU General Public License v3 or later (GPLv3+)",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",... | [] | null | null | >=3.13 | [] | [] | [] | [
"exifread>=3.0.0",
"ffmpeg-python>=0.2.0",
"pi-heif>=1.2.0",
"pillow>=11.1.0"
] | [] | [] | [] | [
"Homepage, https://github.com/aidsoid/aidsoid_photo_organiser",
"Repository, https://github.com/aidsoid/aidsoid_photo_organiser",
"Issues, https://github.com/aidsoid/aidsoid_photo_organiser/issues"
] | uv/0.9.26 {"installer":{"name":"uv","version":"0.9.26","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T15:40:55.982726 | aidsoid_photo_organiser-0.1.0.tar.gz | 243,448 | dd/51/0be689d5bf521652a2d7b2d63187d8fe22681a258f8449b002cb65d77f39/aidsoid_photo_organiser-0.1.0.tar.gz | source | sdist | null | false | 17b1c64fbaf8f357b6bfb3febeff8d10 | c71c7047201d10fbebe75cf4dd66287bde817233f41b8bd06fc4ac570de036f8 | dd510be689d5bf521652a2d7b2d63187d8fe22681a258f8449b002cb65d77f39 | GPL-3.0-or-later | [
"COMMERCIAL_LICENSE",
"COPYRIGHT",
"LICENSE",
"THIRD_PARTY_LICENSES"
] | 228 |
2.4 | veronica-core | 0.9.0 | Runtime Containment Layer for LLM Systems. Enforces bounded cost, retries, recursion, wait states, and failure domains. | # VERONICA
## VERONICA is a Runtime Containment Layer for LLM Systems.
*Turning unbounded model behavior into bounded system behavior.*
```bash
pip install veronica-core
```
Jump to [Quickstart (5 minutes)](#quickstart-5-minutes) or browse [docs/cookbook.md](docs/cookbook.md).
---
## 1. The Missing Layer in LLM Stacks
Modern LLM stacks are built around three well-understood components:
- **Prompting** — instruction construction, context management, few-shot formatting
- **Orchestration** — agent routing, tool dispatch, workflow sequencing
- **Observability** — tracing, logging, cost dashboards, latency metrics
What they lack is a fourth component: **runtime containment**.
Observability != Containment.
An observability stack tells you that an agent spent $12,000 over a weekend. It records the retry loops, the token volumes, the timestamp of each failed call. It produces a precise audit trail of a runaway execution.
What it does not do is stop it.
Runtime containment is the component that stops it. It operates before the damage occurs, not after. It enforces structural limits on what an LLM-integrated system is permitted to do at runtime — independent of prompt design, orchestration logic, or model behavior.
---
## 2. Why LLM Calls Are Not APIs
LLM calls are frequently treated as ordinary API calls: send a request, receive a response. This framing is incorrect, and the gap between the two creates reliability problems at scale.
Standard API calls exhibit predictable properties:
- Deterministic behavior for identical inputs
- Fixed or bounded response cost
- Safe retry semantics (idempotent by construction)
- No recursive invocation patterns
LLM calls exhibit none of these:
**Stochastic behavior.** The same prompt produces different outputs across invocations. There is no stable function to test against. Every call is a sample from a distribution, not a deterministic computation.
**Variable token cost.** Output length is model-determined, not caller-determined. A single call can consume 4 tokens or 4,000. Budget projections based on typical behavior fail under adversarial or unusual inputs.
**Recursive invocation.** Agents invoke tools; tools invoke agents; agents invoke agents. Recursion depth is not bounded by the model itself. A single top-level call can spawn hundreds of descendant calls with no inherent termination condition.
**Retry amplification.** When a component fails under load, exponential backoff retries compound across nested call chains. A failure rate of 5% per layer, across three layers, does not produce a 15% aggregate failure rate — it produces amplified retry storms that collapse throughput.
**Non-idempotent retries.** Retrying an LLM call is not guaranteed to be safe. Downstream state mutations, external tool calls, and partial execution all make naive retry semantics dangerous.
LLM calls are probabilistic, cost-generating components. They require structural bounding. They cannot be treated as deterministic, cost-stable services.
---
## 3. What Runtime Containment Means
Runtime containment is a constraint layer that enforces bounded behavior on LLM-integrated systems.
It does not modify prompts. It does not filter content. It does not evaluate output quality. It enforces operational limits on the execution environment itself — evaluated at call time, before the model is invoked.
A runtime containment layer enforces:
1. **Bounded cost** — maximum token spend and call volume per window, per entity, per system
2. **Bounded retries** — rate limits and amplification controls that prevent retry storms from escalating
3. **Bounded recursion** — per-entity circuit-breaking that terminates runaway loops regardless of orchestration logic
4. **Bounded wait states** — isolation of stalled or degraded components from the rest of the system
5. **Failure domain isolation** — structural separation between a failing component and adjacent components, with auditable evidence
VERONICA implements these five properties as composable, opt-in primitives.
---
## 4. Containment Layers in VERONICA
### Layer 1 — Cost Bounding
In distributed systems, resource quotas enforce hard limits on consumption per tenant, per service, per time window. Without them, a single runaway process exhausts shared resources.
LLM systems face the same problem at the token and call level. Without cost bounding, a single agent session can consume unbounded token volume with no mechanism to stop it.
VERONICA components:
- **BudgetWindowHook** — enforces a call-count ceiling within a sliding time window; emits DEGRADE before the ceiling is reached, then HALT at the ceiling
- **TokenBudgetHook** — enforces a cumulative token ceiling (output tokens or total tokens) with a configurable DEGRADE zone approaching the limit
- **TimeAwarePolicy** — applies time-based multipliers (off-hours, weekends) to reduce active ceilings during periods of lower oversight
- **AdaptiveBudgetHook** — adjusts ceilings dynamically based on observed SafetyEvent history; stabilized with cooldown windows, per-step smoothing, hard floor and ceiling bounds, and direction lock
---
### Layer 2 — Amplification Control
In distributed systems, retry amplification is a well-documented failure mode: a component under pressure receives more retries than it can handle, which increases pressure, which triggers more retries. Circuit breakers and rate limiters exist to interrupt this dynamic.
LLM systems exhibit the same failure mode. A transient model error triggers orchestration retries. Each retry may invoke tools, which invoke the model again. The amplification is geometric.
VERONICA components:
- **BudgetWindowHook** — the primary amplification control; a ceiling breach halts further calls regardless of upstream retry logic or backoff strategy
- **DEGRADE decision** — signals fallback behavior before hard stop, allowing graceful degradation (e.g., model downgrade) rather than binary failure
- **Anomaly tightening** (AdaptiveBudgetHook) — detects spike patterns in SafetyEvent history and temporarily reduces the effective ceiling during burst activity, with automatic recovery when the burst subsides
---
### Layer 3 — Recursive Containment
In distributed systems, recursive or cyclic call graphs require depth bounds or visited-node tracking to prevent infinite traversal. Without them, any recursive structure is a potential infinite loop.
LLM agents are recursive by construction: tool calls invoke the model; the model invokes tools. The recursion is implicit in the orchestration design, not explicit in any single call.
VERONICA components:
- **VeronicaStateMachine** — tracks per-entity fail counts; activates COOLDOWN state after a configurable number of consecutive failures; transitions to SAFE_MODE for system-wide halt
- **Per-entity cooldown isolation** — an entity in COOLDOWN is blocked from further invocations for a configurable duration; this prevents tight loops on failing components without affecting other entities
- **ShieldPipeline** — composable pre-dispatch hook chain; all registered hooks are evaluated in order before each LLM call; any hook may emit DEGRADE or HALT
---
### Layer 4 — Stall Isolation
In distributed systems, a stalled downstream service causes upstream callers to block on connection pools, exhaust timeouts, and degrade responsiveness across unrelated request paths. Bulkhead patterns and timeouts exist to contain stall propagation.
LLM systems stall when a model enters a state of repeated low-quality, excessively verbose, or non-terminating responses. Without isolation, a stalled model session propagates degradation upstream.
VERONICA components:
- **VeronicaGuard** — abstract interface for domain-specific stall detection; implementations inspect latency, error rate, response quality, or any domain signal to trigger immediate cooldown activation, bypassing the default fail-count threshold
- **Per-entity cooldown** (VeronicaStateMachine) — stall isolation is per entity; a stalled tool or agent does not trigger cooldown for entities with clean histories
- **MinimalResponsePolicy** — opt-in system-message injection that enforces output conciseness constraints, reducing the probability of runaway token generation from verbose model states
---
### Layer 5 — Failure Domain Isolation
In distributed systems, failure domain isolation ensures that a fault in one component does not propagate to adjacent components. Structured error events, circuit-state export, and tiered shutdown protocols are standard mechanisms for this.
LLM systems require the same. A component failure should produce structured evidence, enable state inspection, and permit controlled shutdown without corrupting adjacent execution state.
VERONICA components:
- **SafetyEvent** — structured evidence record for every non-ALLOW decision; contains event type, decision, hook identity, and SHA-256 hashed context; raw prompt content is never stored
- **Deterministic replay** — control state (ceiling, multipliers, adjustment history) can be exported and re-imported; enables observability dashboard integration and post-incident reproduction
- **InputCompressionHook** — gates oversized inputs before they reach the model; HALT on inputs exceeding the ceiling, DEGRADE with compression recommendation in the intermediate zone
- **VeronicaExit** — three-tier shutdown protocol (GRACEFUL, EMERGENCY, FORCE) with SIGTERM and SIGINT signal handling and atexit fallback; state is preserved where possible at each tier
---
## 5. Architecture Overview
VERONICA operates as a middleware constraint layer between the orchestration layer and the LLM provider. It does not modify orchestration logic. It enforces constraints on what the orchestration layer is permitted to dispatch downstream.
```
App
|
v
Orchestrator
|
v
Runtime Containment (VERONICA)
|
v
LLM Provider
```
Each call from the orchestrator passes through the ShieldPipeline before reaching the provider. The pipeline evaluates registered hooks in order. Any hook may emit DEGRADE or HALT. A HALT decision terminates the call and emits a SafetyEvent. The orchestrator receives the decision and handles it according to its own logic.
VERONICA does not prescribe how the orchestrator responds to DEGRADE or HALT. It enforces that the constraint evaluation occurs, that the decision is recorded as a structured event, and that the call does not proceed past a HALT decision.
---
## 6. OSS and Cloud Boundary
**veronica-core** is the local containment primitive library. It contains all enforcement logic: ShieldPipeline, BudgetWindowHook, TokenBudgetHook, AdaptiveBudgetHook, TimeAwarePolicy, InputCompressionHook, MinimalResponsePolicy, VeronicaStateMachine, SafetyEvent, VeronicaExit, and associated state management.
veronica-core operates without network connectivity, external services, or vendor dependencies. All containment decisions are local and synchronous.
**veronica-cloud** (forthcoming) provides coordination primitives for multi-agent and multi-tenant deployments: shared budget pools, distributed policy enforcement, and real-time dashboard integration for SafetyEvent streams.
The boundary is functional: cloud enhances visibility and coordination across distributed deployments. It does not enhance safety. Safety properties are enforced by veronica-core at the local layer. An agent running without cloud connectivity is still bounded. An agent running without veronica-core is not.
---
## 7. Design Philosophy
VERONICA is not:
- **Observability** — it does not trace, log, or visualize execution after the fact
- **Content guardrails** — it does not inspect, classify, or filter prompt or completion content
- **Evaluation tooling** — it does not assess output quality, factual accuracy, or alignment properties
VERONICA is:
- **Runtime constraint enforcement** — hard and soft limits on call volume, token spend, input size, and execution state, evaluated before each LLM call
- **Systems-level bounding layer** — structural containment at the orchestration boundary, treating LLM calls as probabilistic, cost-generating components that require bounding
The design is deliberately narrow. A component that attempts to solve observability, guardrails, containment, and evaluation simultaneously solves none of them well. VERONICA solves containment.
---
## Quickstart (5 minutes)
### Install
```bash
pip install veronica-core
```
### All features, all opt-in
Every feature is disabled by default. Enable only what you need.
```python
from veronica_core import (
ShieldConfig,
BudgetWindowHook,
AdaptiveBudgetHook,
TimeAwarePolicy,
)
from veronica_core.shield import Decision, ShieldPipeline, ToolCallContext
config = ShieldConfig()
config.budget_window.enabled = True # Call-count ceiling
config.budget_window.max_calls = 5
config.budget_window.window_seconds = 60.0
config.token_budget.enabled = True # Token ceiling
config.token_budget.max_output_tokens = 500
config.input_compression.enabled = True # Compress oversized inputs
config.adaptive_budget.enabled = True # Auto-tighten on repeated HALTs
config.time_aware_policy.enabled = True # Weekend / off-hour reduction
# Wire hooks
budget_hook = BudgetWindowHook(
max_calls=config.budget_window.max_calls,
window_seconds=config.budget_window.window_seconds,
)
adaptive = AdaptiveBudgetHook(base_ceiling=config.budget_window.max_calls)
time_policy = TimeAwarePolicy()
pipe = ShieldPipeline(pre_dispatch=budget_hook)
# Simulate: agent tries 6 calls (ceiling is 5)
for i in range(6):
ctx = ToolCallContext(request_id=f"call-{i+1}", tool_name="llm")
decision = pipe.before_llm_call(ctx)
print(f"Call {i+1}: {decision.name}")
if decision == Decision.HALT:
break
# Safety events generated by the pipeline
for ev in pipe.get_events():
print(f" -> {ev.event_type} / {ev.decision.value}")
# Feed events into adaptive hook
for ev in pipe.get_events():
adaptive.feed_event(ev)
result = adaptive.adjust()
print(f"Adaptive: {result.action}, ceiling={result.adjusted_ceiling}")
# Export state for observability dashboards
state = adaptive.export_control_state(
time_multiplier=time_policy.evaluate(ctx).multiplier,
)
print(f"State: ceiling={state['adjusted_ceiling']}, "
f"multiplier={state['effective_multiplier']}")
```
### Expected output
```
Call 1: ALLOW
Call 2: ALLOW
Call 3: ALLOW
Call 4: ALLOW
Call 5: DEGRADE
Call 6: HALT
-> BUDGET_WINDOW_EXCEEDED / DEGRADE
-> BUDGET_WINDOW_EXCEEDED / HALT
Adaptive: hold, ceiling=5
State: ceiling=5, multiplier=1.0
```
Output varies by time of day. During off-hours (outside 09:00-18:00 UTC) or weekends,
`TimeAwarePolicy` applies a multiplier < 1.0, which reduces `ceiling` in the exported state.
Events you may see in production:
- `BUDGET_WINDOW_EXCEEDED` -- call ceiling reached (DEGRADE or HALT)
- `TOKEN_BUDGET_EXCEEDED` -- token ceiling reached
- `TIME_POLICY_APPLIED` -- weekend or off-hour multiplier active
- `INPUT_COMPRESSED` / `INPUT_TOO_LARGE` -- input size gate triggered
- `ADAPTIVE_ADJUSTMENT` -- ceiling auto-adjusted (tighten / loosen)
See [docs/adaptive-control.md](docs/adaptive-control.md) for the full event reference.
### What to read next
- [docs/cookbook.md](docs/cookbook.md) -- copy-paste recipes for common patterns
- [docs/adaptive-control.md](docs/adaptive-control.md) -- full engineering doc for v0.7.0 stabilization
- [examples/adaptive_demo.py](examples/adaptive_demo.py) -- v0.7.0 demo (cooldown, direction lock, anomaly, replay)
- [examples/token_budget_minimal_demo.py](examples/token_budget_minimal_demo.py) -- token ceiling + minimal response
- [examples/budget_degrade_demo.py](examples/budget_degrade_demo.py) -- call ceiling + model fallback
- [examples/input_compression_skeleton_demo.py](examples/input_compression_skeleton_demo.py) -- input compression
- [CHANGELOG.md](CHANGELOG.md) -- version history
---
**Learns:** execution control patterns from SafetyEvents (budgets, degrade thresholds, time policy).
**Never stores:** prompt contents. Evidence uses SHA-256 hashes by default.
---
## Ship Readiness (v0.9.0)
- [x] BudgetWindow stops runaway execution (ceiling enforced)
- [x] SafetyEvent records structured evidence for non-ALLOW decisions
- [x] DEGRADE supported (fallback at threshold, HALT at ceiling)
- [x] TokenBudgetHook: cumulative output/total token ceiling with DEGRADE zone
- [x] MinimalResponsePolicy: opt-in conciseness constraints for system messages
- [x] InputCompressionHook: real compression with Compressor protocol + safety guarantees (v0.5.1)
- [x] AdaptiveBudgetHook: auto-adjusts ceiling based on SafetyEvent history (v0.6.0)
- [x] TimeAwarePolicy: weekend/off-hours budget multipliers (v0.6.0)
- [x] Adaptive stabilization: cooldown, smoothing, floor/ceiling, direction lock (v0.7.0)
- [x] Anomaly tightening: spike detection with temporary ceiling reduction (v0.7.0)
- [x] Deterministic replay: export/import control state for observability (v0.7.0)
- [x] ExecutionGraph: first-class runtime execution graph with typed node lifecycle (v0.9.0)
- [x] Amplification metrics: llm_calls_per_root, tool_calls_per_root, retries_per_root (v0.9.0)
- [x] Divergence heuristic: repeated-signature detection, warn-only, deduped (v0.9.0)
- [x] PyPI auto-publish on GitHub Release
- [x] Everything is opt-in & non-breaking (default behavior unchanged)
611 tests passing. Minimum production use-case: runaway containment + graceful degrade + auditable events + token budgets + input compression + adaptive ceiling + time-aware scheduling + anomaly detection + execution graph + divergence detection.
---
## Roadmap
**v0.8.x**
- OpenTelemetry export (opt-in SafetyEvent export)
- Multi-agent coordination (shared budget pools)
- Webhook notifications on HALT/DEGRADE
**v0.9.x**
- Redis-backed distributed budget enforcement
- Middleware mode (ASGI/WSGI)
- Dashboard for real-time shield status
---
## Install
```bash
pip install -e .
# With dev tools
pip install -e ".[dev]"
pytest
```



---
## Version History
See [CHANGELOG.md](CHANGELOG.md) for version history.
---
## License
MIT
---
*Runtime Containment is the missing layer in LLM infrastructure.*
| text/markdown | amabito | null | null | null | null | agent, budget, enforcement, guardrails, llm, runtime | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Develo... | [] | null | null | >=3.10 | [] | [] | [] | [
"pytest-cov>=5.0; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\""
] | [] | [] | [] | [
"Repository, https://github.com/amabito/veronica-core",
"Issues, https://github.com/amabito/veronica-core/issues"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T15:40:02.053892 | veronica_core-0.9.0.tar.gz | 78,898 | 07/7e/c2f3a6eed6ae249d315e1562fd8762cae5b0c619192dc95b439019316cf7/veronica_core-0.9.0.tar.gz | source | sdist | null | false | 207587b3bbd7a8f4b916cee1e25109b6 | 8795e65759bf22d81197ae5b2a0243b81e831ed6661f5317bd49355b28452303 | 077ec2f3a6eed6ae249d315e1562fd8762cae5b0c619192dc95b439019316cf7 | MIT | [
"LICENSE"
] | 208 |
2.1 | cdktn-provider-postgresql | 13.0.0 | Prebuilt postgresql Provider for CDK Terrain (cdktn) | # CDKTN prebuilt bindings for cyrilgdn/postgresql provider version 1.26.0
This repo builds and publishes the [Terraform postgresql provider](https://registry.terraform.io/providers/cyrilgdn/postgresql/1.26.0/docs) bindings for [CDK Terrain](https://cdktn.io).
## Available Packages
### NPM
The npm package is available at [https://www.npmjs.com/package/@cdktn/provider-postgresql](https://www.npmjs.com/package/@cdktn/provider-postgresql).
`npm install @cdktn/provider-postgresql`
### PyPI
The PyPI package is available at [https://pypi.org/project/cdktn-provider-postgresql](https://pypi.org/project/cdktn-provider-postgresql).
`pipenv install cdktn-provider-postgresql`
### Nuget
The Nuget package is available at [https://www.nuget.org/packages/Io.Cdktn.Providers.Postgresql](https://www.nuget.org/packages/Io.Cdktn.Providers.Postgresql).
`dotnet add package Io.Cdktn.Providers.Postgresql`
### Maven
The Maven package is available at [https://mvnrepository.com/artifact/io.cdktn/cdktn-provider-postgresql](https://mvnrepository.com/artifact/io.cdktn/cdktn-provider-postgresql).
```
<dependency>
<groupId>io.cdktn</groupId>
<artifactId>cdktn-provider-postgresql</artifactId>
<version>[REPLACE WITH DESIRED VERSION]</version>
</dependency>
```
### Go
The go package is generated into the [`github.com/cdktn-io/cdktn-provider-postgresql-go`](https://github.com/cdktn-io/cdktn-provider-postgresql-go) package.
`go get github.com/cdktn-io/cdktn-provider-postgresql-go/postgresql/<version>`
Where `<version>` is the version of the prebuilt provider you would like to use e.g. `v11`. The full module name can be found
within the [go.mod](https://github.com/cdktn-io/cdktn-provider-postgresql-go/blob/main/postgresql/go.mod#L1) file.
## Docs
Find auto-generated docs for this provider here:
* [Typescript](./docs/API.typescript.md)
* [Python](./docs/API.python.md)
* [Java](./docs/API.java.md)
* [C#](./docs/API.csharp.md)
* [Go](./docs/API.go.md)
You can also visit a hosted version of the documentation on [constructs.dev](https://constructs.dev/packages/@cdktn/provider-postgresql).
## Versioning
This project is explicitly not tracking the Terraform postgresql provider version 1:1. In fact, it always tracks `latest` of `~> 1.14` with every release. If there are scenarios where you explicitly have to pin your provider version, you can do so by [generating the provider constructs manually](https://cdktn.io/docs/concepts/providers#import-providers).
These are the upstream dependencies:
* [CDK Terrain](https://cdktn.io) - Last official release
* [Terraform postgresql provider](https://registry.terraform.io/providers/cyrilgdn/postgresql/1.26.0)
* [Terraform Engine](https://terraform.io)
If there are breaking changes (backward incompatible) in any of the above, the major version of this project will be bumped.
## Features / Issues / Bugs
Please report bugs and issues to the [CDK Terrain](https://cdktn.io) project:
* [Create bug report](https://github.com/open-constructs/cdk-terrain/issues)
* [Create feature request](https://github.com/open-constructs/cdk-terrain/issues)
## Contributing
### Projen
This is mostly based on [Projen](https://projen.io), which takes care of generating the entire repository.
### cdktn-provider-project based on Projen
There's a custom [project builder](https://github.com/cdktn-io/cdktn-provider-project) which encapsulate the common settings for all `cdktn` prebuilt providers.
### Provider Version
The provider version can be adjusted in [./.projenrc.js](./.projenrc.js).
### Repository Management
The repository is managed by [CDKTN Repository Manager](https://github.com/cdktn-io/cdktn-repository-manager/).
| text/markdown | CDK Terrain Maintainers | null | null | null | MPL-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/cdktn-io/cdktn-provider-postgresql.git | null | ~=3.9 | [] | [] | [] | [
"cdktn<0.23.0,>=0.22.0",
"constructs<11.0.0,>=10.4.2",
"jsii<2.0.0,>=1.119.0",
"publication>=0.0.3",
"typeguard<4.3.0,>=2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/cdktn-io/cdktn-provider-postgresql.git"
] | twine/6.1.0 CPython/3.14.3 | 2026-02-19T15:39:57.424267 | cdktn_provider_postgresql-13.0.0.tar.gz | 302,301 | 15/c4/1eb8ae24c6d6a8033de64a1ce1383338b089899b44f9a7abd04bdf6910f0/cdktn_provider_postgresql-13.0.0.tar.gz | source | sdist | null | false | ea18cabb163936f2d2dc99543adc93bd | 464f850d671bda05b8305b90ed99ab01720629a1bcf6155acb3ece9bc61a73e7 | 15c41eb8ae24c6d6a8033de64a1ce1383338b089899b44f9a7abd04bdf6910f0 | null | [] | 209 |
2.4 | sturnus | 0.1.12 | A Python library for demonstration and publishing to PyPI. | <div align="right">
[](https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/starling-cloud/sturnus)
</div>
<header>
<p align="center">
<img src="res/logo/sturnus-logo.png" width="20%" alt="Sturnus Logo">
</p>
<h1 align='center' style='border-bottom: none;'>Sturnus</h1>
<h3 align='center'>Starling Cloud</h3>
</header>
<br/>
---
A Python library for demonstration and publishing to PyPI.
---
## Installation
```bash
pip install sturnus
```
---
## Usage
```python
from sturnus import hello
print(hello("Starling"))
```
---
## Project Structure
``` sh
src/sturnus/
├── __init__.py # Package initialization with namespace support
├── __version__.py # Version management
├── __main__.py # CLI interface
└── core.py # Core greeting functions (hello, greet, format_message)
```
---
<p align="center">
<b>Made with 💙 by <a href="https://www.starling.associates" target="_blank">Starling Associates</a></b><br/>
<sub>Copyright 2026 Starling Associates. All Rights Reserved</sub>
</p>
| text/markdown | Starling Associates | info@starling.studio | Lars van Vianen | lars@starling.studio | null | starling, sturnus | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: Other/Proprietary License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Environment :: Web Environment",
"Framework :: Django",
"Programming Language :: Python :: 3",
"Programming ... | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"django<7,>=6.0.0",
"rite>=0.2.4"
] | [] | [] | [] | [
"Documentation, https://github.com/starling-cloud/sturnus-dev/doc",
"Homepage, https://starling.cloud/",
"Repository, https://github.com/starling-cloud/sturnus-dev"
] | poetry/2.3.2 CPython/3.10.19 Linux/6.14.0-1017-azure | 2026-02-19T15:39:31.837343 | sturnus-0.1.12-py3-none-any.whl | 6,471 | 41/a5/bbc9d119a32463825315a1a97894e7d756b772dec6c233742419a764b4ef/sturnus-0.1.12-py3-none-any.whl | py3 | bdist_wheel | null | false | bd28c293a6ee4ef9612f1e42a08dfb07 | b941015f7e1f0b2a502bb7c1a26bdce6511077c33612113bafcc6442c14d7cef | 41a5bbc9d119a32463825315a1a97894e7d756b772dec6c233742419a764b4ef | null | [
"LICENSE"
] | 306 |
2.4 | snowflake-data-validation | 1.3.2 | Snowflake Data Validation | # Snowflake Data Validation
[](https://www.snowflake.com/en/legal/technical-services-and-education/conversion-software-terms/)
[](https://www.python.org/downloads/)
**Snowflake Data Validation** is a command-line tool and Python library for validating data migrations and ensuring data quality between source and target databases, with a focus on Snowflake and SQL Server.
> 📖 **For detailed usage instructions, configuration examples, and CLI reference, please check the [official documentation](https://docs.snowflake.com/en/migrations/snowconvert-docs/data-validation-cli/CLI_QUICK_REFERENCE).**
---
## 🚀 Features
- **Multi-level validation**: Schema validation, statistical metrics, and row-level data integrity checks.
- **Multiple source platforms**: SQL Server, Redshift, Teradata.
- **User-friendly CLI**: Comprehensive commands for automation and orchestration.
- **Parallel processing**: Multi-threaded table validation for faster execution.
- **Offline validation**: Extract source data as Parquet files for validation without source access.
- **Flexible configuration**: YAML-based workflows with per-table customization.
- **Partitioning support**: Row and column partitioning helpers for large table validation.
- **Detailed reporting**: CSV reports, console output, and comprehensive logging.
- **Extensible architecture**: Ready for additional database engines.
---
## 📦 Installation
```bash
pip install snowflake-data-validation
```
For SQL Server support:
```bash
pip install "snowflake-data-validation[sqlserver]"
```
For development and testing:
```bash
pip install "snowflake-data-validation[all]"
```
---
## 🔄 Execution Modes
| Mode | Command | Description |
|------|---------|-------------|
| **Sync Validation** | `run-validation` | Real-time comparison between source and target databases |
| **Source Extraction** | `source-validate` | Extract source data to Parquet files for offline validation |
| **Async Validation** | `run-async-validation` | Validate using pre-extracted Parquet files |
| **Script Generation** | `generate-validation-scripts` | Generate SQL scripts for manual execution |
**Supported Dialects**: `sqlserver`, `snowflake`, `redshift`, `teradata`
---
## 🔍 Validation Levels
### Schema Validation
Compares table structure between source and target:
- Column names and order
- Data types with mapping support
- Precision, scale, and length
- Nullable constraints
### Metrics Validation
Compares statistical metrics for each column:
- Row count
- Min/Max values
- Sum and Average
- Null count
- Distinct count
### Row Validation
Performs row-by-row comparison:
- Primary key matching
- Field-level value comparison
- Mismatch reporting
---
## 📊 Reports
- **Console Output**: Real-time progress with success/failure indicators
- **CSV Reports**: Detailed validation results with all comparison data
- **Log Files**: Comprehensive debug and error logging
---
## 📚 Documentation
For complete command reference, configuration options, and examples, see the [Data Validation CLI](https://docs.snowflake.com/en/migrations/snowconvert-docs/data-validation-cli/CLI_QUICK_REFERENCE).
---
## 🤝 Contributing
We welcome contributions! See our [Contributing Guide](../../CONTRIBUTING.md) for details on how to collaborate, set up your development environment, and submit PRs.
---
## 📄 License
This project is licensed under the Snowflake Conversion Software Terms. See the [LICENSE](../../LICENSE) file for the full text or visit the [Conversion Software Terms](https://www.snowflake.com/en/legal/technical-services-and-education/conversion-software-terms/) for more information.
---
## 🆘 Support
- **Documentation**: [Full documentation](https://docs.snowflake.com/en/migrations/snowconvert-docs/data-validation-cli/CLI_QUICK_REFERENCE)
- **Issues**: [GitHub Issues](https://github.com/snowflakedb/migrations-data-validation/issues)
---
**Developed with ❄️ by Snowflake**
| text/markdown | null | "Snowflake, Inc." <snowflake-python-libraries-dl@snowflake.com> | null | null | Snowflake Conversion Software Terms | Snowflake, analytics, cloud, data, database, db, validation | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Environment :: Other Environment",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Information Technology",
"Intended Audience :: System Administrators",
"License :: Other/Proprietary License",
"O... | [] | null | null | >=3.10 | [] | [] | [] | [
"cryptography>=3.4.0",
"deepdiff>=8.0.0",
"jinja2>=3.1.6",
"pandas>=2.2.3",
"pyarrow>=14.0.0",
"pydantic-yaml>=1.4.0",
"pydantic>=2.0",
"ruamel-yaml>=0.18.0",
"snowflake-connector-python>=4.0.0",
"toml>=0.10.2",
"typer>=0.15.3",
"typing-extensions>=4.13.2",
"urllib3>=2.6.0",
"azure-identit... | [] | [] | [] | [
"Bug Tracker, https://github.com/snowflakedb/migrations-data-validation/issues",
"Source code, https://github.com/snowflakedb/migrations-data-validation/"
] | twine/6.0.1 CPython/3.12.3 | 2026-02-19T15:39:10.943494 | snowflake_data_validation-1.3.2.tar.gz | 313,797 | 7e/e4/997d882b9cda26e2c004a338e648d8bf91d7280cebb683e43bd9beaab938/snowflake_data_validation-1.3.2.tar.gz | source | sdist | null | false | 7b62ea338e0cba4e7f15c1df3f1d87b3 | 448c367cc6dcb92ae82d29fa1b21abe2912cb57d5fc3df51a76e15e95e134fe5 | 7ee4997d882b9cda26e2c004a338e648d8bf91d7280cebb683e43bd9beaab938 | null | [] | 237 |
2.4 | snowflake-data-exchange-agent | 1.3.2 | Data exchange agent for migrations and validation | # Snowflake Data Exchange Agent
[](http://www.apache.org/licenses/LICENSE-2.0.txt)
[](https://www.python.org/downloads/)
A REST API service for database migrations and data validation. Supports Snowflake, SQL Server, and Amazon Redshift with queue-based task processing. The architecture is extensible to support additional database types in the future.
## Quick Start
```bash
# Install
pip install snowflake-data-exchange-agent
# Run
data-exchange-agent --port 8080
# Test
curl http://localhost:8080/health
```
## Installation
### From PyPI (Production)
```bash
pip install snowflake-data-exchange-agent
```
### Requirements & Dependencies
**Python Version**: 3.10, 3.11, or 3.12 (3.13 not yet supported)
**Available dependency groups**:
- `development`: Testing and development tools (pytest, ruff, etc.)
- `all`: Includes all development dependencies
**Core dependencies include**:
- Snowflake Connector for Python
- PySpark for data processing
- Flask + Waitress for REST API
- ODBC support (pyodbc) for SQL Server
- AWS SDK (boto3)
## Configuration
Create `src/data_exchange_agent/configuration.toml`:
```toml
selected_task_source = "api"
[application]
workers = 4
task_fetch_interval = 5
debug_mode = false
[task_source.api]
key = "api-key"
# SQL Server connection (standard authentication)
[connections.source.sqlserver]
username = "username"
password = "password"
database = "database_name"
host = "127.0.0.1"
port = 1433
# Amazon Redshift connection (IAM authentication for provisioned cluster)
[connections.source.redshift]
username = "demo-user"
database = "snowconvert_demo"
auth_method = "iam-provisioned-cluster"
cluster_id = "migrations-aws"
region = "us-west-2"
access_key_id = "your-access-key-id"
secret_access_key = "your-secret-access-key"
# Amazon Redshift connection (standard authentication)
# [connections.source.redshift]
# username = "myuser"
# password = "mypassword"
# database = "mydatabase"
# host = "my-cluster.abcdef123456.us-west-2.redshift.amazonaws.com"
# port = 5439
# auth_method = "standard"
[connections.target.snowflake_connection_name]
connection_name = "connection_name"
[connections.target.s3]
profile_name = "profile_name"
bucket_name = "bucket_name"
[connections.target.blob]
connection_string = "DefaultEndpointsProtocol=https;AccountName=account_name;AccountKey=account_key;EndpointSuffix=core.windows.net"
container_name = "container_name"
# Optional: Account name and use_default_credential if not using connection string
account_name="storage_account_name"
use_default_credential=<True|False>
```
For Snowflake, create `~/.snowflake/config.toml`:
```toml
[connections.default]
account = "your_account.region"
user = "your_username"
password = "your_password"
warehouse = "COMPUTE_WH"
database = "PRODUCTION_DB"
```
## API Usage
### Command Line
```bash
# Basic usage
data-exchange-agent
# Production settings
data-exchange-agent --workers 8 --port 8080
# Debug mode
data-exchange-agent --debug --port 5001
```
### Health Check
```http
GET /health
```
```json
{
"status": "healthy",
"version": "0.0.18",
"database_connections": {
"snowflake": "connected"
}
}
```
### Task Management
```http
# Start processing
GET /handle_tasks
# Stop processing
GET /stop
# Get status
GET /get_handling_tasks_status
# Task count
GET /get_tasks_count
```
### Add Task
```http
POST /tasks
Content-Type: application/json
```
```json
{
"task_type": "data_extraction",
"source_config": {
"database": "sqlserver",
"query": "SELECT * FROM users"
},
"destination_config": {
"type": "snowflake_stage",
"stage": "@data_stage/users/"
}
}
```
## Development
### Setup
```bash
git clone https://github.com/snowflakedb/migrations-data-validation.git
cd migrations-data-validation/data-exchange-agent
pip install -e .[development]
```
### Testing
```bash
# Run all tests
pytest
# With coverage
pytest --cov=src/data_exchange_agent
# Run specific test types
pytest tests/unit/ # Unit tests only
pytest -m "not integration" # Non-integration tests
```
### Code Quality
```bash
# Format code
ruff format .
# Lint code
ruff check .
# Auto-fix linting issues
ruff check --fix .
```
### Type Checking
Run static type checking with [ty](https://docs.astral.sh/ty/) (extremely fast Python type checker from Astral):
```bash
# Check all source code
hatch run types:check-ty
# Check specific path
hatch run types:check-ty tests
# Watch mode - automatically re-checks on file changes
hatch run types:watch-ty
```
#### ty Diagnostics Baseline
The project uses a **diagnostics baseline** to prevent type error regressions. The CI will fail if the number of `ty` diagnostics increases beyond the baseline.
| Project | Baseline |
|---------|----------|
| data-exchange-agent | 64 |
To check diagnostics locally:
```bash
python .github/scripts/ty_check_diagnostics.py data-exchange-agent
```
If you **fix** type errors and reduce the count, please update the baseline in:
- `.github/workflows/data-exchange-all-ci.yml`
- `.github/scripts/ty_check_diagnostics.py` (DEFAULT_BASELINES)
### CI Workflows
The following checks run automatically on PRs and pushes to `main`/`develop`:
1. **Linting** - Static analysis with ruff
2. **Type Check** - ty diagnostics baseline check
3. **Build** - Build wheel packages
4. **Unit Tests** - pytest on Python 3.10, 3.11, and 3.12 with coverage
5. **Artifact** - Package and publish to Test PyPI (on PRs)
6. **Integration** - Test package installation from Test PyPI (on PRs)
## 🐳 Docker
The Data Exchange Agent can be run in a Docker container with configuration injected via environment variables at runtime.
### Building the Image
```bash
cd data-exchange-agent
docker build -t data-exchange-agent .
```
### How It Works
The Dockerfile uses configuration templates that are processed at container startup:
1. **`docker-artifacts/configuration.template.toml`** - Agent configuration template
2. **`docker-artifacts/snowflake.config.template.toml`** - Snowflake connection template
3. **`docker-artifacts/docker-entrypoint.sh`** - Entrypoint script that uses `envsubst` to substitute environment variables into the templates before starting the agent
This approach ensures that sensitive credentials (passwords) are never baked into the Docker image—they are only injected at runtime.
### Environment Variables
#### Data Source Configuration (Required for database connections)
| Variable | Description | Default |
|----------|-------------|---------|
| `DATA_SOURCE_USERNAME` | Username for the source database | - |
| `DATA_SOURCE_PASSWORD` | Password for the source database | - |
| `DATA_SOURCE_HOST` | Hostname of the source database | - |
| `DATA_SOURCE_PORT` | Port of the source database | `1433` |
| `DATA_SOURCE_DATABASE` | Database name on the source | - |
#### Snowflake Connection Configuration (Required for Snowflake integration)
| Variable | Description | Default |
|----------|-------------|---------|
| `SNOWFLAKE_ACCOUNT` | Snowflake account identifier (e.g., `myaccount.us-west-2.aws`) | - |
| `SNOWFLAKE_USER` | Snowflake username | - |
| `SNOWFLAKE_PASSWORD` | Snowflake password | - |
| `SNOWFLAKE_WAREHOUSE` | Snowflake warehouse name | - |
| `SNOWFLAKE_ROLE` | Snowflake role | - |
| `SNOWFLAKE_DATABASE` | Default Snowflake database | - |
| `SNOWFLAKE_SCHEMA` | Default Snowflake schema | - |
#### Application Configuration
| Variable | Description | Default |
|----------|-------------|---------|
| `AGENT_AFFINITY` | Agent affinity label for task routing (required) | - |
| `WORKER_COUNT` | Number of worker threads | `1` |
### Running the Container
```bash
docker run -p 5000:5000 \
-e DATA_SOURCE_USERNAME="db_user" \
-e DATA_SOURCE_PASSWORD="db_password" \
-e DATA_SOURCE_HOST="db.example.com" \
-e DATA_SOURCE_PORT="1433" \
-e DATA_SOURCE_DATABASE="mydb" \
-e SNOWFLAKE_ACCOUNT="myaccount.us-west-2.aws" \
-e SNOWFLAKE_USER="snowflake_user" \
-e SNOWFLAKE_PASSWORD="snowflake_password" \
-e SNOWFLAKE_WAREHOUSE="COMPUTE_WH" \
-e SNOWFLAKE_ROLE="DATA_ENGINEER" \
-e SNOWFLAKE_DATABASE="PROD_DB" \
-e SNOWFLAKE_SCHEMA="PUBLIC" \
-e AGENT_AFFINITY="blue" \
-e WORKER_COUNT="8" \
data-exchange-agent
```
You can also pass additional arguments to the agent:
```bash
docker run -p 8080:8080 \
-e DATA_SOURCE_PASSWORD="secret" \
-e SNOWFLAKE_PASSWORD="secret" \
# ... other env vars ...
data-exchange-agent --port 8080 --debug
```
### Running in Snowpark Container Services (SPCS)
When deploying the Data Exchange Agent in [Snowpark Container Services](https://docs.snowflake.com/en/developer-guide/snowpark-container-services/overview), you can use the special `@SPCS_CONNECTION` connection name to automatically use Snowflake-provided credentials.
#### How It Works
When running in SPCS, Snowflake automatically provides:
- An **OAuth token** at `/snowflake/session/token`
- **Environment variables**: `SNOWFLAKE_HOST`, `SNOWFLAKE_ACCOUNT`, `SNOWFLAKE_DATABASE`, `SNOWFLAKE_SCHEMA`
The `@SPCS_CONNECTION` feature reads these credentials automatically, so you don't need to configure Snowflake passwords or account details manually.
> **Note**: `SNOWFLAKE_WAREHOUSE` is **not** provided by SPCS. You can set it manually via environment variable or use the `QUERY_WAREHOUSE` parameter when creating the service.
#### Configuration
By default, the Docker image uses `@SPCS_CONNECTION`. No additional Snowflake configuration is needed:
```toml
[task_source.snowflake_stored_procedure]
connection_name = "@SPCS_CONNECTION"
[connections.target.snowflake_connection_name]
connection_name = "@SPCS_CONNECTION"
```
#### Environment Variables for SPCS
| Variable | Description | Default |
|----------|-------------|---------|
| `SNOWFLAKE_CONNECTION_NAME` | Connection mode: `@SPCS_CONNECTION` for SPCS credentials, or a named connection from `~/.snowflake/config.toml` | `@SPCS_CONNECTION` |
| `SNOWFLAKE_WAREHOUSE` | Warehouse for queries (not provided by SPCS, must be set manually) | - |
#### Switching to Manual Credentials
If you need to use traditional Snowflake credentials instead of SPCS-provided ones (e.g., for testing outside SPCS), set the `SNOWFLAKE_CONNECTION_NAME` environment variable:
```bash
# Use a named connection from ~/.snowflake/config.toml
docker run \
-e SNOWFLAKE_CONNECTION_NAME="MY_SNOWFLAKE_CONNECTION" \
-e SNOWFLAKE_ACCOUNT="myaccount.us-west-2.aws" \
-e SNOWFLAKE_USER="user" \
-e SNOWFLAKE_PASSWORD="password" \
# ... other env vars ...
data-exchange-agent
```
#### Example SPCS Service Definition
```sql
CREATE SERVICE data_exchange_agent
IN COMPUTE POOL my_compute_pool
QUERY_WAREHOUSE = MY_WAREHOUSE
FROM SPECIFICATION $$
spec:
containers:
- name: agent
image: /my_db/my_schema/my_repo/data-exchange-agent:latest
env:
DATA_SOURCE_HOST: "source-db.example.com"
DATA_SOURCE_PORT: "1433"
DATA_SOURCE_DATABASE: "mydb"
DATA_SOURCE_USERNAME: "user"
AGENT_AFFINITY: "spcs-agent"
WORKER_COUNT: "4"
secrets:
- snowflakeSecret: my_db_password_secret
secretKeyRef: password
envVarName: DATA_SOURCE_PASSWORD
$$;
```
For more details, see the [Snowflake SPCS documentation](https://docs.snowflake.com/en/developer-guide/snowpark-container-services/spcs-execute-sql).
## 🔌 Extending the System
### Adding a New Bulk Utility
Bulk utilities are command-line tools used to efficiently export data from databases (e.g., BCP for SQL Server). Follow these steps to add a new bulk utility:
#### 1. Define the Bulk Utility Type
Add your new utility to the `BulkUtilityType` enum in `src/data_exchange_agent/data_sources/bulk_utility_types.py`:
```python
class BulkUtilityType(str, Enum):
BCP = "bcp"
YOUR_UTILITY = "your_utility_name" # Add this line
```
#### 2. Create Configuration Class
Create a new configuration class in `src/data_exchange_agent/config/sections/bulk_utilities/your_utility.py`:
```python
from data_exchange_agent.config.sections.bulk_utilities.base import BaseBulkUtilityConfig
class YourUtilityConfig(BaseBulkUtilityConfig):
"""Configuration class for YourUtility bulk utility settings."""
def __init__(
self,
# Add utility-specific parameters
utility_specific_parameter: str = "default_param",
) -> None:
"""Initialize YourUtility configuration."""
self.utility_specific_parameter = utility_specific_parameter
def _custom_validation(self) -> str | None:
"""Validate configuration parameters."""
if not self.utility_specific_parameter:
return "Utility specific parameter cannot be empty."
return None
def __repr__(self) -> str:
"""Return string representation."""
return f"YourUtilityConfig(utility_specific_parameter='{self.utility_specific_parameter}')"
```
#### 3. Register the Bulk Utility
Register your utility in `src/data_exchange_agent/config/sections/bulk_utilities/__init__.py`:
```python
from data_exchange_agent.config.sections.bulk_utilities.your_utility import YourUtilityConfig
from data_exchange_agent.constants.connection_types import ConnectionType
# Add to registry
BulkUtilityRegistry.register(ConnectionType.YOUR_UTILITY, YourUtilityConfig) # Add this
# Add to __all__
__all__ = [
"BaseBulkUtilityConfig",
"BulkUtilityRegistry",
"BCPBulkUtilityConfig",
"YourUtilityConfig", # Add this
]
```
#### 4. Update ConnectionType Enum
Add your utility type to `src/data_exchange_agent/constants/connection_types.py`:
```python
class ConnectionType(str, Enum):
# Bulk utilities
BCP = BulkUtilityType.BCP.value
YOUR_UTILITY = BulkUtilityType.YOUR_UTILITY.value # Add this
```
#### 5. Create Data Source Implementation
Create the data source class in `src/data_exchange_agent/data_sources/your_utility_data_source.py`:
```python
from data_exchange_agent.data_sources.base import BaseDataSource
from data_exchange_agent.data_sources.bulk_utility_types import BulkUtilityType
class YourUtilityDataSource(BaseDataSource):
"""Data source implementation for YourUtility."""
@inject
def __init__(
self,
engine: str,
statement: str,
results_folder_path: str = None,
base_file_name: str = "result",
logger: SFLogger = Provide[container_keys.SF_LOGGER],
program_config: ConfigManager = Provide[container_keys.PROGRAM_CONFIG],
) -> None:
"""Initialize YourUtilityDataSource."""
self.logger = logger
self._statement = statement
# Get configuration
bulk_utility_config = program_config[config_keys.BULK_UTILITY]
utility_config = bulk_utility_config.get(BulkUtilityType.YOUR_UTILITY, None)
# Use config values or defaults
self.utility_specific_parameter = utility_config.utility_specific_parameter if utility_config else "default_param"
def export_data(self) -> bool:
"""Export data using your utility command."""
# Implement the export logic
pass
```
#### 6. Add Configuration to TOML
Users can now configure your bulk utility in `configuration.toml`:
```toml
[bulk_utility.your_utility_name]
# Add your custom parameters
utility_specific_parameter = "param"
```
#### 7. Write Tests
Create tests in `tests/data_sources/test_your_utility_data_source.py` to verify functionality.
### Example: BCP Implementation
See the existing BCP implementation for reference:
- Config: `src/data_exchange_agent/config/sections/bulk_utilities/bcp.py`
- Data Source: `src/data_exchange_agent/data_sources/bcp_data_source.py`
- Configuration example in `configuration_example.toml`
### Using BCP for Data Extraction
By default, the agent uses JDBC for data extraction. To use BCP (Bulk Copy Program) instead, simply add the `[bulk_utility.bcp]` section to your `configuration.toml`:
```toml
[bulk_utility.bcp]
delimiter = ";"
row_terminator = "\\n"
encoding = "UTF8"
trusted_connection = false
encrypt = true
```
**How it works**: When the agent detects a `[bulk_utility.bcp]` configuration section, it automatically uses BCP for data extraction instead of JDBC. No additional configuration is needed—the presence of the BCP configuration section enables BCP mode.
**Requirements**:
- The BCP utility must be installed and available in the system PATH
- SQL Server source connection must be configured in `[connections.source.sqlserver]`
**BCP Configuration Options**:
| Option | Description | Default |
|--------|-------------|---------|
| `delimiter` | Field delimiter character(s) | `,` |
| `row_terminator` | Row terminator character(s) | `\n` |
| `encoding` | Character encoding (e.g., `UTF8`, `ACP`) | `UTF8` |
| `trusted_connection` | Use Windows authentication | `false` |
| `encrypt` | Encrypt the connection | `true` |
**Note**: To switch back to JDBC, simply remove or comment out the `[bulk_utility.bcp]` section from your configuration.
---
## 🤝 Contributing
We welcome contributions! See our [Contributing Guide](../CONTRIBUTING.md) for details on how to collaborate, set up your development environment, and submit PRs.
---
## 📄 License
This project is licensed under the Apache License 2.0. See the [LICENSE](../LICENSE) file for details.
## 🆘 Support
- **Documentation**: [Full documentation](https://github.com/snowflakedb/migrations-data-validation)
- **Issues**: [GitHub Issues](https://github.com/snowflakedb/migrations-data-validation/issues)
---
**Developed with ❄️ by Snowflake**
| text/markdown | null | "Snowflake, Inc." <snowflake-python-libraries-dl@snowflake.com> | null | null | Apache License, Version 2.0 | Snowflake, analytics, cloud, data, data-analysis, data-analytics, data-engineering, data-management, data-processing, data-science, data-visualization, data-warehouse, database | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Environment :: Other Environment",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Information Technology",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: Apache Software... | [] | null | null | <3.13,>=3.10 | [] | [] | [] | [
"azure-identity>=1.25.0",
"azure-storage-blob>=12.26.0",
"boto3>=1.40.41",
"dependency-injector>=4.48.2",
"flask>=3.1.2",
"psutil>=7.1.0",
"psycopg2-binary>=2.9.10",
"pyarrow>=22.0.0",
"pyodbc>=5.0.0",
"requests>=2.32.5",
"snowflake-connector-python>=4.0.0",
"sqlparse==0.5.4",
"toml==0.10.2"... | [] | [] | [] | [
"Bug Tracker, https://github.com/snowflakedb/migrations-data-validation/issues",
"Source code, https://github.com/snowflakedb/migrations-data-validation/",
"homepage, https://www.snowflake.com/"
] | twine/6.0.1 CPython/3.12.3 | 2026-02-19T15:38:40.896837 | snowflake_data_exchange_agent-1.3.2.tar.gz | 145,047 | e0/03/217437ceaf7df86c9e64aaa9be2ba750fd4e2c022cf17214d9705e7818f2/snowflake_data_exchange_agent-1.3.2.tar.gz | source | sdist | null | false | 6c52a2d8b333154dbbf95fe2e31885dc | 514a862db33d7e91cbb670e1d11ddcacf19d9bb3c5bc8f03374d2b98c60d8b28 | e003217437ceaf7df86c9e64aaa9be2ba750fd4e2c022cf17214d9705e7818f2 | null | [] | 213 |
2.4 | brazilian-holidays | 0.1.29 | Brazilian Holidays | # Brazilian Holidays
[](https://github.com/michelmetran/brazilian-holidays)
[](https://pypi.org/project/brazilian-holidays/)<br>
[](https://brazilian-holidays.readthedocs.io/)
[](https://github.com/michelmetran/brazilian-holidays/actions/workflows/publish-to-pypi-uv.yml)
<br>
> _Adoro um feriado! Quem não gosta?!_
Com objetivo de listar os feriados brasileiros, criei o pacote **feriados-brasileiros**, que permite criar uma tabela contendo todos os feriados de um determinado ano, bem como ajustar atributos conforme a necessidade.
A opção por ajustar atributos se deve ao fato de que, nem sempre, um feriado em uma instituição também é feriado n'outra! Feriado de endoeças, por exemplo, é feriado em instituições do meio jurídico, enquanto muitos nem sabem que feriado é esse!
É possível ajustar o nome dos feriados e até mesmo um campo de observações!
<br>
---
## Como Instalar?
```shell
pip3 install brazilian-holidays
```
<br>
---
## Documentação
Para ver a documentação:
- https://brazilian-holidays.readthedocs.io
<br>
---
## _TODO_
1. ~~Ajustar documentação~~
2. ~~Incluir o dia da semana!~~
3. ~~Implantar classe Calendário para pegar feriados de anos diversos~~
4. ~~Add domingo de ramos~~
| text/markdown | null | Michel Metran <michelmetran@gmail.com> | null | null | null | holidays, feriados, brazilian | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"pandas>=2.1.4",
"tabulate>=0.9.0",
"babel>=2.14.0"
] | [] | [] | [] | [
"Homepage, https://github.com/michelmetran/brazilian-holidays",
"Issues, https://github.com/michelmetran/brazilian-holidays/issues",
"Repository, https://github.com/michelmetran/brazilian-holidays",
"Documentation, https://brazilian-holidays.readthedocs.io"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T15:38:17.805894 | brazilian_holidays-0.1.29-py3-none-any.whl | 7,306 | de/fd/a79c89179b756d25d0151afe3b6b7452be32e0946fac54c034babb45eb65/brazilian_holidays-0.1.29-py3-none-any.whl | py3 | bdist_wheel | null | false | 0211d06ac8625f23bad15261d99c07f6 | 84f9bc5c39568b0ff6c728eb5225f31f7728998857e694f4560af17dfb2aed89 | defda79c89179b756d25d0151afe3b6b7452be32e0946fac54c034babb45eb65 | MIT | [
"LICENSE"
] | 233 |
2.3 | par-cli | 0.2.2 | CLI for parallel development workflows with isolated Git worktrees and tmux sessions, tailored for agentic coding. | # Par: Parallel Worktree & Session Manager
> **Easily manage parallel development workflows with isolated Git worktrees and tmux sessions**
`par` is a **global** command-line tool designed to simplify parallel development across any Git repositories on your system. It's specifically designed for working with AI coding assistants, background agents, or multiple development contexts simultaneously, `par` creates isolated workspaces that don't interfere with each other.
## Why Par?
Tools like OpenAI Codex, Claude Code, and other coding agents have made it easier to parallelize the work on multiple features, experiments, or problems simultaneously. However, traditional Git branch switching is not ideal for handling multiple concurrent workstreams on the same repository.
`par` solves this by creating **isolated development environments** for each task:
- **🔀 Git Worktrees**: Each session gets its own directory and branch
- **🖥️ Tmux Sessions**: Persistent terminal sessions where agents can run in the background
- **🏷️ Globally Unique Labels**: Easy-to-remember names that work across all repositories
- **🌍 Global Management**: Create, list, and manage sessions from anywhere on your system
- **📡 Remote Control**: Send commands to any or all sessions globally
- **👁️ Overview Mode**: Monitor all sessions simultaneously
- **🏢 Multi-Repo Workspaces**: Unified development across multiple repositories
- **🎨 IDE Integration**: Native VSCode/Cursor workspace support with auto-generated configs
https://github.com/user-attachments/assets/88eb4aed-c00d-4238-b1a9-bcaa34c975c3
## Key Features
### 🚀 **Quick Start**
```bash
# From within a git repository
par start feature-auth # Creates worktree, branch, and tmux session
par start feature-auth --base develop
# From anywhere on your system
par start bugfix-login --path /path/to/repo
par start experiment-ai --path ~/projects/my-app
```
### 📋 **Global Development Context Management**
```bash
par ls # List ALL sessions and workspaces globally
par open feature-auth # Switch to any session or workspace from anywhere
par rm bugfix-login # Clean up completed work globally
```
### 📡 **Global Remote Execution**
```bash
par send feature-auth "pnpm test" # Run tests in one session
par send all "git status" # Check status across ALL sessions globally
```
### 🎛️ **Global Control Center**
```bash
par control-center # View ALL sessions and workspaces globally with separate windows
```
### 🏢 **Multi-Repository Workspaces**
```bash
par workspace start feature-auth --repos frontend,backend
par workspace code feature-auth # Open in VSCode with multi-repo support
par workspace open feature-auth # Attach to unified tmux session
```
## Unified Development Context System
`par` provides a **unified interface** for managing both single-repository sessions and multi-repository workspaces. Whether you're working on a single feature branch or coordinating changes across multiple repositories, all your development contexts appear in one place.
### Two Development Modes:
- **Sessions**: Single-repo development with isolated branches (`par start`, `par checkout`)
- **Workspaces**: Multi-repo development with synchronized branches (`par workspace start`)
### Unified Commands:
- `par ls` - See all your development contexts (sessions + workspaces) in one table
- `par open <label>` - Switch to any session or workspace
- `par control-center` - View all contexts in separate tmux windows
- Tab completion works across both sessions and workspaces
This eliminates the need to remember which type of development context you're working with - just use the label and `par` handles the rest!
## Installation
### Prerequisites
- **Git** - Version control system
- **tmux** - Terminal multiplexer
- **Python 3.12+** - Runtime environment
- **uv** - Package manager (recommended)
### Install with uv
```bash
uv tool install par-cli
```
### Install with pip
```bash
pip install par-cli
```
### Install from Source
```bash
git clone https://github.com/coplane/par.git
cd par
uv tool install .
```
### Upgrade with uv
```bash
uv tool upgrade par-cli
```
### Verify Installation
```bash
par --version
par --help
```
## Usage
### Starting a New Session
Create a new isolated development environment:
```bash
# From within a git repository
par start my-feature
par start my-feature --base develop
# From anywhere, specifying the repository path
par start my-feature --path /path/to/your/git/repo
par start my-feature -p ~/projects/my-app
```
By default, `par start` branches from the current `HEAD` commit. Use `--base` to branch from a specific branch/reference. `par` resolves the base to a commit SHA, so uncommitted changes in your current worktree do not affect the new branch.
If the label already matches an existing local branch, `par start <label>` will reuse that branch and create a worktree with it checked out instead of creating a new branch.
If no local branch exists but `origin/<label>` exists, `par` fetches it and creates the worktree from `origin/<label>`.
This creates:
- Git worktree at `~/.local/share/par/worktrees/<repo-hash>/my-feature/`
- Git branch named `my-feature`
- tmux session named `par-<repo>-<hash>-my-feature`
- **Globally unique session** accessible from anywhere
### Checking Out Existing Branches and PRs
Work with existing branches or review PRs without creating new branches:
```bash
# Checkout existing branch
par checkout existing-branch
# Checkout PR by number
par checkout pr/123
# Checkout PR by URL
par checkout https://github.com/owner/repo/pull/456
# Checkout remote branch from fork
par checkout alice:feature-branch
# Checkout with custom session label
par checkout develop --label dev-work
# Checkout from anywhere specifying repository path
par checkout feature-branch --path /path/to/repo
par checkout pr/123 --path ~/projects/my-app --label pr-review
```
**Supported formats:**
- `branch-name` - Local or origin branch
- `pr/123` - GitHub PR by number
- `https://github.com/owner/repo/pull/123` - GitHub PR by URL
- `username:branch` - Remote branch from fork
- `remote/branch` - Branch from specific remote
### Global Development Context Management
**List all sessions and workspaces globally:**
```bash
par ls # Shows ALL sessions and workspaces from anywhere
```
Shows all development contexts across all repositories in a unified table:
```
Par Development Contexts (Global)
┌────────────────┬───────────┬──────────────────┬──────────────┬─────────────────┬────────────┐
│ Label │ Type │ Repository/Work… │ Tmux Session │ Branch │ Created │
├────────────────┼───────────┼──────────────────┼──────────────┼─────────────────┼────────────┤
│ feature-auth │ Session │ my-app (proj…) │ par-myapp-… │ feature-auth │ 2025-07-19 │
│ fullstack │ Workspace │ workspace (2 re… │ par-ws-full… │ fullstack │ 2025-07-19 │
│ bugfix-123 │ Checkout │ other-repo (c…) │ par-other-… │ hotfix/bug-123 │ 2025-07-19 │
└────────────────┴───────────┴──────────────────┴──────────────┴─────────────────┴────────────┘
```
**Open any development context from anywhere:**
```bash
par open my-feature # Opens session
par open fullstack-auth # Opens workspace
```
**Remove completed work from anywhere:**
```bash
par rm my-feature # Remove specific session/workspace globally
par rm all # Remove ALL sessions and workspaces (with confirmation)
```
> **Note**: When removing checkout sessions, `par` only removes the worktree and tmux session. It does not delete the original branch since it wasn't created by `par`.
### Global Remote Command Execution
**Send commands to specific sessions :**
```bash
par send my-feature "npm install"
par send backend-work "python manage.py migrate"
par send workspace-name "git status" # Works for workspaces too
```
**Broadcast to ALL sessions and workspaces globally:**
```bash
par send all "git status" # Sends to every session everywhere
par send all "npm test" # Runs tests across all contexts
```
### Global Control Center
View ALL development contexts simultaneously with dedicated tmux windows:
```bash
par control-center # Works from anywhere, shows everything
```
Creates a unified `control-center` tmux session with separate windows for each development context (sessions and workspace repositories), giving you easy navigation across your entire development workflow.
> **Note**: Must be run from outside tmux. Creates a global control center session with dedicated windows for each context.
**Benefits of the windowed approach:**
- **Easy Navigation**: Use tmux window switching (`Ctrl-b + number` or `Ctrl-b + n/p`) to jump between contexts
- **Clean Organization**: Each development context gets its own dedicated window with a descriptive name
- **Scalable**: Works well with many sessions/workspaces (unlike tiled panes that become cramped)
- **Workspace Support**: For multi-repo workspaces, each repository gets its own window
### Automatic Initialization with .par.yaml
`par` can automatically run initialization commands when creating new worktrees. Simply add a `.par.yaml` file to your repository root:
```yaml
# .par.yaml
initialization:
include:
- .env
- config/*.json
commands:
- name: "Install frontend dependencies"
command: "cd frontend && pnpm install"
- name: "Setup environment file"
command: "cd frontend && cp .env.example .env"
- name: "Install backend dependencies"
command: "cd backend && uv sync"
# Simple string commands are also supported
- "echo 'Workspace initialized!'"
```
Files listed under `include` are copied from the repository root into each new worktree before any commands run. This lets you keep gitignored files like `.env` in the new environment.
All commands start from the worktree root directory. Use `cd <directory> &&` to run commands in subdirectories.
When you run `par start my-feature`, these commands will automatically execute in the new session's tmux environment.
## Multi-Repository Workspaces
For projects spanning multiple repositories (like frontend/backend splits or microservices), `par` provides **workspace** functionality that creates a single session managing multiple repositories together in a unified development environment.
### Why Workspaces?
When working on features that span multiple repositories, you typically need to:
- Create branches with the same name across repos
- Keep terminal sessions open for each repo
- Switch between repositories frequently
- Manage development servers for multiple services
Workspaces solve this by creating a **single global session** that starts from a unified workspace directory with access to all repositories, all sharing the same branch name.
### Quick Start
```bash
# From a directory containing multiple repos (auto-detection)
cd /path/to/my-project # contains frontend/, backend/, docs/
par workspace start feature-auth
# From anywhere, specifying repositories by absolute path
par workspace start feature-auth --repos /path/to/frontend,/path/to/backend
par workspace start feature-auth --path /workspace/root --repos frontend,backend
# Open in your preferred IDE with proper multi-repo support
par workspace code feature-auth # VSCode
par workspace cursor feature-auth # Cursor
```
### Workspace Commands
**Create a workspace:**
```bash
par workspace start <label> [--path /workspace/root] [--repos repo1,repo2] [--open]
```
**List workspaces (now unified with sessions):**
```bash
par ls # Shows workspaces alongside sessions
par workspace ls # Shows only workspaces (deprecated)
```
**Open workspace (now unified):**
```bash
par open <label> # Opens workspace session
par workspace code <label> # Open in VSCode
par workspace cursor <label> # Open in Cursor
```
**Remove workspace (now unified):**
```bash
par rm <label> # Remove workspace
par workspace rm <label> # Also works (delegates to global rm)
```
### How Workspaces Work
When you create a workspace, `par` automatically:
1. **Detects repositories** in the workspace directory (or uses `--repos` with absolute paths)
2. **Creates worktrees** for each repository with the same branch name
3. **Creates single global session** starting from unified workspace root with access to all repositories
4. **Generates IDE workspace files** for seamless editor integration
5. **Integrates with global par commands** - use `par ls`, `par open`, `par rm` etc.
**Example directory structure:**
```
# Original repositories anywhere on system:
my-fullstack-app/
├── frontend/ # React app
├── backend/ # Python API
└── docs/ # Documentation
# After: par workspace start user-auth --repos /home/user/projects/frontend,/home/user/projects/backend,/opt/company/docs
# Creates unified workspace at: ~/.local/share/par/workspaces/.../user-auth/
├── frontend/
├── backend/
├── docs/
└── user-auth.code-workspace
# Single tmux session starts from workspace root
# Navigate with: cd frontend/, cd backend/, cd docs/
# Global session accessible via: par open user-auth
```
### IDE Integration
Workspaces include first-class IDE support that solves the common problem of multi-repo development in editors.
**VSCode Integration:**
```bash
par workspace code user-auth
```
This generates and opens a `.code-workspace` file containing:
```json
{
"folders": [
{
"name": "frontend (user-auth)",
"path": "/path/to/worktrees/frontend/user-auth"
},
{
"name": "backend (user-auth)",
"path": "/path/to/worktrees/backend/user-auth"
}
],
"settings": {
"git.detectSubmodules": false,
"git.repositoryScanMaxDepth": 1
}
}
```
**Benefits:**
- Each repository appears as a separate folder in the explorer
- Git operations work correctly for each repository
- All repositories are on the correct feature branch
- No worktree plugin configuration needed
### Repository Specification
**Auto-detection (recommended):**
```bash
par workspace start feature-name
# Automatically finds all git repositories in current directory
```
**Explicit specification:**
```bash
par workspace start feature-name --repos frontend,backend,shared
# Only includes specified repositories
```
**Comma-separated syntax:**
```bash
--repos repo1,repo2,repo3
--repos "frontend, backend, docs" # Spaces are trimmed
```
### Workspace Organization
Workspaces are organized separately from single-repo sessions:
```
~/.local/share/par/
├── worktrees/ # Single-repo sessions
│ └── <repo-hash>/
└── workspaces/ # Multi-repo workspaces
└── <workspace-hash>/
└── <workspace-label>/
├── frontend/
│ └── feature-auth/ # Worktree
├── backend/
│ └── feature-auth/ # Worktree
└── feature-auth.code-workspace
```
### Workspace Initialization
Workspaces support the same `.par.yaml` initialization as single repositories. When you create a workspace, `par` runs the initialization commands from each repository's `.par.yaml` file in their respective worktrees.
For example, if both `frontend` and `backend` repositories have their own `.par.yaml` files:
```yaml
# frontend/.par.yaml
initialization:
commands:
- name: "Install dependencies"
command: "pnpm install"
- name: "Setup environment"
command: "cp .env.example .env"
# backend/.par.yaml
initialization:
commands:
- name: "Install dependencies"
command: "uv sync"
- name: "Run migrations"
command: "python manage.py migrate"
```
Each repository's initialization runs in its own worktree, ensuring proper isolation and consistent behavior.
### Example Workflows
**Full-stack feature development:**
```bash
# 1. Start workspace for new feature
par workspace start user-profiles --repos /path/to/frontend,/path/to/backend
# 2. Open in IDE with proper multi-repo support
par workspace code user-profiles
# 3. Open unified session
par open user-profiles
# 4. Work across repositories from single terminal
cd frontend/ # Switch to frontend worktree
cd ../backend/ # Switch to backend worktree
claude # Run Claude from workspace root to see all repos
# 5. Global management
par ls # See all sessions including workspaces
par send user-profiles "git status" # Send commands globally
# 6. Clean up when feature is complete
par rm user-profiles
```
**Microservices development:**
```bash
# Work on API changes affecting multiple services
par workspace start api-v2 --repos /srv/auth-service,/srv/user-service,/srv/gateway
# All services get api-v2 branch
# Single global session accessible from anywhere
# IDE workspace shows all services together
# Navigate: cd auth-service/, cd user-service/, etc.
# Global commands: par send api-v2 "docker-compose up"
```
### Branch Creation
Workspaces create branches from the **currently checked out branch** in each repository, not necessarily from `main`. This allows for:
- **Feature branches from develop**: If repos are on `develop`, workspace branches from `develop`
- **Different base branches**: Each repo can be on different branches before workspace creation
- **Flexible workflows**: Supports GitFlow, GitHub Flow, or custom branching strategies
## Advanced Usage
### Globally Unique Sessions
`par` enforces globally unique session labels across all repositories. This ensures you can manage sessions from anywhere without conflicts:
```bash
# All sessions must have unique labels globally
par start feature-auth --path ~/project-a # Creates feature-auth session
par start feature-auth --path ~/project-b # ❌ Error: label already exists
par start feature-auth-v2 --path ~/project-b # ✅ Works with unique label
# Access any session from anywhere
par open feature-auth # Works from any directory
par ls # Shows all sessions globally
```
## Configuration
### Data Directory
Par stores its data in `~/.local/share/par/` (or `$XDG_DATA_HOME/par/`):
```
~/.local/share/par/
├── global_state.json # Global session and workspace metadata
├── worktrees/ # Single-repo sessions organized by repo hash
│ └── <repo-hash>/
│ ├── feature-1/ # Individual worktrees
│ ├── feature-2/
│ └── experiment-1/
└── workspaces/ # Multi-repo workspaces
└── <workspace-hash>/
└── <workspace-label>/
├── frontend/
│ └── feature-auth/ # Worktree
├── backend/
│ └── feature-auth/ # Worktree
└── feature-auth.code-workspace
```
### Session Naming Convention
tmux sessions follow the pattern: `par-<repo-name>-<repo-hash>-<label>`
Example: `par-myproject-a1b2c3d4-feature-auth`
### Cleaning Up
Remove all par-managed resources globally:
```bash
par rm all # Removes ALL sessions and workspaces everywhere
```
Remove specific stale sessions:
```bash
par rm old-feature-name
```
| text/markdown | Victor | Victor <vimota@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"typer",
"pyyaml",
"pytest; extra == \"dev\"",
"ruff; extra == \"dev\"",
"pre-commit; extra == \"dev\"",
"build; extra == \"dev\""
] | [] | [] | [] | [] | uv/0.9.10 {"installer":{"name":"uv","version":"0.9.10"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T15:38:17.009796 | par_cli-0.2.2.tar.gz | 26,688 | 3b/7e/56e123399e9064cf2419df97154fa0a3fc8179c8e7f9fb58fedcc6b0ec8f/par_cli-0.2.2.tar.gz | source | sdist | null | false | e942c99b38d1a0d190c0ffd3fdf87fad | ea65a757337e5885288522677d718c60e6ec80e743259c6ca3aa5baa6e3d255f | 3b7e56e123399e9064cf2419df97154fa0a3fc8179c8e7f9fb58fedcc6b0ec8f | null | [] | 207 |
2.4 | jua | 0.21.0 | Easy access to Jua's weather & power services | # Jua Python SDK
**Access industry-leading weather forecasts with ease**
The Jua Python SDK provides a simple and powerful interface to Jua's state-of-the-art weather forecasting capabilities. Easily integrate accurate weather data into your applications, research, or analysis workflows.
## Getting Started 🚀
### Prerequisites
- Python 3.11 or higher
- Internet connection for API access
### Installation
Install `jua` with pip:
```
pip install jua
```
Alternatively, checkout [uv](https://docs.astral.sh/uv/) for managing dependencies and Python versions:
```bash
uv init && uv add jua
```
### Authentication
Simply run `jua auth` to authenticate via your web browser. Make sure you are already logged in the [developer portal](https://developer.jua.ai).
Alternatively, generate an API key from the [Jua dashboard](https://developer.jua.ai/api-keys) and save it to `~/.jua/default/api-key.json`.
## Examples
### Obtaining the metadata for a model
```python
from jua import JuaClient
from jua.weather import Models
client = JuaClient()
model = client.weather.get_model(Models.EPT1_5)
metadata = model.get_metadata()
# Print the metadata
print(metadata)
```
### Getting the forecast runs available for a model
```python
from jua import JuaClient
from jua.weather import Models
client = JuaClient()
# Getting metadata the latest forecast run
latest = model.get_latest_init_time()
print(latest)
# Fetching model runs
available_forecasts = model.get_available_forecasts()
# Fetching all model runs for January 2025
# Results are paginated so we might need to iterate through
result = model.get_available_forecasts(
since=datetime(2025, 1, 1),
before=datetime(2025, 1, 31, 23, 59),
limit=100,
)
all_forecasts = list(result.forecasts)
while result.has_more:
print("Fetching next page")
result = result.next()
all_forecasts.extend(result.forecasts)
```
### Access the latest 20-day forecast for a point location
Retrieve temperature forecasts for Zurich and visualize the data:
```python
import matplotlib.pyplot as plt
from jua import JuaClient
from jua.types.geo import LatLon
from jua.weather import Models, Variables
client = JuaClient()
model = client.weather.get_model(Models.EPT1_5)
zurich = LatLon(lat=47.3769, lon=8.5417)
# Check if 10-day forecast is ready for the latest available init_time
is_ten_day_ready = model.is_ready(forecasted_hours=240)
# Get latest forecast
if is_ten_day_ready:
forecast = model.get_forecasts(points=[zurich], max_lead_time=240)
temp_data = forecast[Variables.AIR_TEMPERATURE_AT_HEIGHT_LEVEL_2M]
temp_data.to_celcius().to_absolute_time().plot()
plt.show()
```
<details>
<summary>Show output</summary>

</details>
### Access historical weather data
Historical data can be accessed in the same way. In this case, we get all EPT2 forecasts from January 2024, and plot the first 5 together.
```python
from datetime import datetime
import matplotlib.pyplot as plt
from jua import JuaClient
from jua.weather import Models, Variables
client = JuaClient()
zurich = LatLon(lat=47.3769, lon=8.5417)
model = client.weather.get_model(Models.EPT2)
hindcast = model.get_forecasts(
init_time=slice(
datetime(2024, 1, 1, 0),
datetime(2024, 1, 31, 0),
),
points=[zurich],
min_lead_time=0,
max_lead_time=(5 * 24),
variables=[Variables.AIR_TEMPERATURE_AT_HEIGHT_LEVEL_2M],
method="nearest",
)
data = hindcast[Variables.AIR_TEMPERATURE_AT_HEIGHT_LEVEL_2M]
# Compare the first 5 runs of January
fig, ax = plt.subplots(figsize=(15, 8))
for i in range(5):
forecast_data = data.isel(init_time=i, points=0).to_celcius().to_absolute_time()
forecast_data.plot(ax=ax, label=forecast_data.init_time.values)
plt.legend()
plt.show()
```
<details>
<summary>Show output</summary>

### Accessing Market Aggregates
The `AggregateVariables` enum provides the following variables:
- `WIND_SPEED_AT_HEIGHT_LEVEL_10M` - Wind speed at 10m height (`Weighting.WIND_CAPACITY`)
- `WIND_SPEED_AT_HEIGHT_LEVEL_100M` - Wind speed at 100m height (`Weighting.WIND_CAPACITY`)
- `SURFACE_DOWNWELLING_SHORTWAVE_FLUX_SUM_1H` - Surface downwelling shortwave flux (`Weighting.SOLAR_CAPACITY`)
- `AIR_TEMPERATURE_AT_HEIGHT_LEVEL_2M` - Air temperature at 2m height (`Weighting.POPULATION`)
Comparing the latest EPT2 and ECMWF IFS run for the Ireland and Northern Ireland market zones:
```python
from jua import JuaClient
from jua.market_aggregates import AggregateVariables, ModelRuns
from jua.types import Countries, MarketZones
from jua.weather import Models, Variables
client = JuaClient()
# Create energy market using MarketZones enum
ir_nir = client.market_aggregates.get_market([MarketZones.IE, MarketZones.GB_NIR])
# Get the market aggregates for the latest EPT2 and ECMWF IFS runs
model_runs = [ModelRuns(Models.EPT2, 0), ModelRuns(Models.ECMWF_IFS_SINGLE, 0)]
ds = ir_nir.compare_runs(
agg_variable=AggregateVariables.WIND_SPEED_AT_HEIGHT_LEVEL_10M,
model_runs=model_runs,
max_lead_time=24,
)
print("Retrieved dataset:")
print(ds)
print()
```
Obtaining all market zones for a country:
```python
from jua.types import Countries, MarketZones
norway_zones = MarketZones.filter_by_country(Countries.NORWAY)
print(f"Norwegian zones: {[z.zone_name for z in norway_zones]}")
```
</details>
## Documentation
For comprehensive documentation, visit [docs.jua.ai](https://docs.jua.ai).
## Contributing
See the [contribution guide](./CONTRIBUTING.md) to get started.
## Changes
See the [changelog](./CHANGELOG.md) for the latest changes.
## Support
If you encounter any issues or have questions, please:
- Check the [documentation](https://docs.jua.ai)
- Open an issue on GitHub
- Contact support@jua.ai
## License
This project is licensed under the MIT License - see the LICENSE file for details.
| text/markdown | null | "Jua.ai AG" <contact@jua.ai> | null | null | null | energy, energy trading, forecast, hindcast, power, trading, weather, weather forecast | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"aiohttp>=3.11.18",
"dask>=2025.4.1",
"fsspec>=2025.3.2",
"numcodecs!=0.16.0",
"pandas>=2.2.3",
"pyarrow>=21.0.0",
"pydantic-settings>=2.8.1",
"pydantic>=2.10.6",
"requests>=2.32.3",
"rich>=14.1.0",
"types-requests>=2.32.0.20250328",
"xarray>=2025.7.0",
"zarr>=3.1.0",
"myst-parser>=4.0.1; ... | [] | [] | [] | [
"Documentation, https://docs.jua.ai",
"Source, https://github.com/juaAI/jua-python-sdk"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T15:37:34.498170 | jua-0.21.0.tar.gz | 1,047,679 | e5/23/7dda7b2a132b34a4db13ac4407712a675a073edbedeed656391606d3dd0d/jua-0.21.0.tar.gz | source | sdist | null | false | 54c6a615f41a89bded0765aa2592bbca | b598d803e676a070d32d5367161c0546ec00395fb68e247bf9d3467070b015f6 | e5237dda7b2a132b34a4db13ac4407712a675a073edbedeed656391606d3dd0d | MIT | [
"LICENSE"
] | 209 |
2.4 | django-webmention | 4.0.0 | A pluggable implementation for receiving webmentions for Django projects | # django-webmention [](https://badge.fury.io/py/django-webmention) [](https://travis-ci.org/easy-as-python/django-webmention)
[webmention](https://www.w3.org/TR/webmention/) for Django projects.
## What this project is
This package provides a way to integrate [webmention endpoint discovery](https://www.w3.org/TR/webmention/#sender-discovers-receiver-webmention-endpoint) and [webmention receipts](https://www.w3.org/TR/webmention/#receiving-webmentions) into your project. Once you follow the installation instructions, you should be able to use something like [webmention.rocks](https://webmention.rocks/) to generate a test webmention and see it in the Django admin panel.
Once you receive a webmention, you can click through to the page the webmention was sent from and see what people are saying about your site. Afterward, you can mark the webmention as reviewed in the Django admin so you can more easily see the latest webmentions you receive.
Once you verify that you're receiving webmentions successfully, you can use the webmention information as you like. As an example, you could query the webmentions that are responses to a specific page and display them on that page.
## What this project isn't
This package does not currently provide functionality for [sending webmentions](https://www.w3.org/TR/webmention/#sending-webmentions).
## Installation
`$ pip install django-webmention`
* Add `'webmention'` to `INSTALLED_APPS`
* Run `python manage.py migrate webmention`
* Add the URL patterns to your top-level `urls.py`
* `path('webmention/', include('webmention.urls'))` for Django >= 3.2
## Usage
* Include webmention information by either:
* Installing the middleware in `settings.py` (affects all views)
* Append `webmention.middleware.webmention_middleware` to your `MIDDLEWARE` settings
* Decorating a specific view with `webmention.middleware.include_webmention_information`
* View webmention responses in the Django admin interface and mark them as reviewed as needed
## Development
### Setup
* Install [tox](https://tox.readthedocs.io)
### Running Tests
You can run tests using `tox`:
```shell
$ tox --parallel=auto
```
| text/markdown | null | Dane Hillard <github@danehillard.com> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Framework :: Django",
"Framework :: Django :: 4.2",
"Framework :: Django :: 5.2",
"Framework :: Django :: 6.0",
"Topic :: Internet :: WWW/HTTP :: Indexing/Search",
"Programming Language :: Python",
"Programming Langua... | [] | null | null | >=3.10 | [] | [] | [] | [
"Django>=4.2.0",
"requests>=2.32.3"
] | [] | [] | [] | [
"Repository, https://github.com/easy-as-python/django-webmention"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:37:19.872551 | django_webmention-4.0.0.tar.gz | 8,028 | 69/c1/f4cc5a511c77fc292985689bf2dd73e155a18247353bdee4917a78e46f9c/django_webmention-4.0.0.tar.gz | source | sdist | null | false | 0513666f6b799b133982999c91d87100 | 001871e835e2d37590b7d2a91cd9acc7ebd4ee3ab07d56b34815336eaeda2336 | 69c1f4cc5a511c77fc292985689bf2dd73e155a18247353bdee4917a78e46f9c | MIT | [
"LICENSE"
] | 214 |
2.4 | edwh-editorjs | 2.7.0 | EditorJS.py | # edwh-editorjs
| text/markdown | null | SKevo <skevo.cw@gmail.com>, Robin van der Noord <robin.vdn@educationwarehouse.nl> | null | null | null | bleach, clean, editor, editor.js, html, javascript, json, parser, wysiwyg | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"html2markdown",
"humanize",
"lxml",
"markdown2",
"mdast",
"typing-extensions",
"edwh; extra == \"dev\"",
"hatch; extra == \"dev\"",
"su6[all]; extra == \"dev\"",
"types-bleach; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/educationwarehouse/edwh-EditorJS"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Linux Mint","version":"22.3","id":"zena","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T15:37:11.193238 | edwh_editorjs-2.7.0-py3-none-any.whl | 12,478 | 00/51/22ce039679100b9102efefc02a9b48983c7c82d21fc64050efb49c31d467/edwh_editorjs-2.7.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 0773f732e875a91347e7ed152467d184 | 492558ff42458c71cd525452ae84928712cd68d1412819c2c08575e4e0f9e12c | 005122ce039679100b9102efefc02a9b48983c7c82d21fc64050efb49c31d467 | null | [] | 228 |
2.4 | unreflectanything | 0.3.5 | Deep learning method for removing specular reflections from RGB images. | # UnReflectAnything
[](https://alberto-rota.github.io/UnReflectAnything/)
[](https://pypi.org/project/unreflectanything/)
[](https://arxiv.org/abs/2512.09583)
[](https://huggingface.co/spaces/AlbeRota/UnReflectAnything)
[](https://huggingface.co/AlbeRota/UnReflectAnything)
[](https://github.com/alberto-rota/UnReflectAnything/wiki)
[](https://colab.research.google.com/#fileId=https%3A//huggingface.co/AlbeRota/UnReflectAnything/blob/main/notebooks/UnReflectAnything.ipynb)
[](https://mit-license.org/)
### RGB-Only Highlight Removal by Rendering Synthetic Specular Supervision
UnReflectAnything inputs any RGB image and removes specular highlights, returning a clean diffuse-only outputs. We trained UnReflectAnything by synthetizing specularities and supervising in DINOv3 feature space.
UnReflectAnything works on both natural indoor and surgical/endoscopic domain data.
---
## Installation
```bash
pip install unreflectanything
```
Install UnReflectAnything as a Python Package.
The minimum required Python version is 3.11, but development and all experiments have been bases on **Python 3.12**.
For GPU support, make sure PyTorch comes with CUDA version for your system (see [PyTorch Get Started](https://pytorch.org/get-started/locally/)).
## Setting up
After pip-installing, you can use the `unreflectanything` CLI command, which is also aliased to `unreflect` and `ura`. The three commands are equivalent.
With the CLI you can already download the model weights with
```bash
unreflectanything download --weights
```
and some sample images with
```bash
unreflectanything download --images
```
Weights are stored by default in `~/.cache/unreflectanything/weights` (or `$XDG_CACHE_HOME/unreflectanything/weights` if set ; `%LOCALAPPDATA%\unreflectanything` for Windows). Use `--output-dir` to choose another location.
Both the weights and images are stored on the [HuggingFace Model Repo](https://huggingface.co/spaces/AlbeRota/UnReflectAnything).
## Enable shell completion
Shell completion is available for the `bash` and `zsh` shells. Run
```bash
unreflectanything completion bash
```
and execute the `echo ...` command that gets printed.
## Command Line Interface
Get an overview of the available CLI endpoints with
```
unreflectanything --help # alias 'unreflect --help' alias 'ura --help'
```
Refer to the [Wiki](https://github.com/alberto-rota/UnReflectAnything/wiki) to get detailed documentation about each endpoint. We report a summary of the available subcommands. Remember that `ura` is aliased to the `unreflectanything` command
| Subcommand | Description | Command |
|------------|-------------|-------------|
| `inference` | Run inference on image(s) to remove reflections | `ura inference /path/to/images -o /path/to/output` |
| `download` | Download checkpoint weights, sample images, notebooks, configs | `ura download --weights` |
| `cache` | Print cache directory or clear cached assets | `ura cache --dir` or `ura cache --clear` |
| `verify` | Verify weights installation and compatibility, or dataset directory structure | `ura verify --weights` or `ura verify --dataset --path /path/to/dataset` |
| `cite` | Print citation (BibTeX, APA, MLA, IEEE, plain) | `ura cite --bibtex` |
| `completion` | Print or install shell completion (bash/zsh) | `ura completion bash` |
Training, testing, and evaluation are available via the [Python API](https://github.com/alberto-rota/UnReflectAnything/wiki); see the [Wiki](https://github.com/alberto-rota/UnReflectAnything/wiki) for details.
## Python API
The same endpoints above are exposed as a Python API. Refer to the [Wiki](https://github.com/alberto-rota/UnReflectAnything/wiki) to get detailed documentation about each endpoint. A few examples are reported below
```python
import unreflectanything as unreflect
import torch
# Get the model class (e.g. for custom setup or training)
ModelClass = unreflect.model()
# Get a pretrained model (torch.nn.Module) and run on batched RGB
unreflectmodel = unreflect.model(pretrained=True) # uses cached weights; run 'unreflect download --weights' first
images = torch.rand(2, 3, 448, 448, device="cuda") # [B, 3, H, W], values in [0, 1]
model_out = unreflectmodel(images) # [B, 3, H, W] diffuse tensor
# File-based or tensor-based inference (one-shot, no model handle)
unreflect.inference("input.png", output="output.png")
unreflect.inference(images, output="output.png")
result = unreflect.inference(images)
# Cache directory (where weights, images, etc. are stored)
weights_dir = unreflect.cache("weights")
```
## Contributing & Development
If you want to contribute or develop UnReflectAnything:
1. Clone the repository:
```bash
git clone https://github.com/alberto-rota/UnReflectAnything.git
cd UnReflectAnything
```
2. Install dependencies (we recommend a virtual environment with Python 3.12):
```bash
pip install -r requirements.txt
```
## Citation
If you include UnReflectAnything in your pipline or research work, we encourage you cite our work.
Get the citation entry with
```bash
unreflectanything cite --bibtex
```
or copy it directly from below
```
@misc{rota2025unreflectanything,
title={UnReflectAnything: RGB-Only Highlight Removal by Rendering Synthetic Specular Supervision},
author={Alberto Rota and Mert Kiray and Mert Asim Karaoglu and Patrick Ruhkamp and Elena De Momi and Nassir Navab and Benjamin Busam},
year={2025},
eprint={2512.09583},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.09583},
}
```
| text/markdown | Alberto Rota, Mert Kiray, Mert Asim Karaoglu, Patrick Ruhkamp, Elena De Momi, Nassir Navab, Benjamin Busam | null | null | Alberto Rota <alberto1.rota@polimi.it> | null | computer vision, specular removal, reflection removal, deep learning | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/E... | [] | null | null | >=3.11 | [] | [] | [] | [
"dill==0.4.1",
"dotmap==1.3.30",
"fvcore==0.1.5.post20221221",
"huggingface-hub==0.36.2",
"natsort==8.4.0",
"numpy==2.4.2",
"opencv-python==4.13.0.92",
"paramiko==4.0.0",
"pillow==12.1.1",
"protobuf==6.33.5",
"python-dotenv==1.2.1",
"pyyaml==6.0.3",
"torch==2.9.1",
"torchvision==0.24.1",
... | [] | [] | [] | [
"Homepage, https://github.com/alberto-rota/UnReflectAnything",
"Repository, https://github.com/alberto-rota/UnReflectAnything",
"Issues, https://github.com/alberto-rota/UnReflectAnything/issues"
] | uv/0.8.14 | 2026-02-19T15:36:57.167846 | unreflectanything-0.3.5.tar.gz | 257,733 | 7a/bb/a2d8672f2c5aa150aa1320d2b4cef2a7e3610fe7c33084f6aa9800734b23/unreflectanything-0.3.5.tar.gz | source | sdist | null | false | ddf5dc87603c24d061f43e142e95ce20 | 1e5cdec75837d145a55dfc07e611336d3254cb8d36c3caad8d7ddaf78cbee62a | 7abba2d8672f2c5aa150aa1320d2b4cef2a7e3610fe7c33084f6aa9800734b23 | MIT | [] | 206 |
2.4 | pisa-analysis | 3.0.8 | This python package works with PISA to analyse data for macromolecular interfaces and interactions in assemblies. | # Assembly interfaces analysis
## Basic information
This python package works with PISA to analyze data for macromolecular interfaces and interactions in assemblies.
The code consists of the module `pisa_analysis` that will:
- Analyse macromolecular interfaces with PISA
- Create a JSON dictionary with assembly interactions/interfaces information
```
git clone https://github.com/PDBe-KB/pisa-analysis
cd pisa-analysis
```
## Dependencies
The pisa_analysis process runs PISA as a subprocess and requires apriori compilation of PISA.
To make your life easier when running the process, you can set two path environment variables for PISA:
An environment variable to the `pisa` binary:
```
export PATH="$PATH:your_path_to_pisa/pisa/build"
```
A path to the setup directory of PISA:
```
export PISA_SETUP_DIR="/your_path_to_pisa/pisa/setup"
```
Additionally, it is required that PISA setup directory contains a pisa configuration template named [pisa_cfg_tmp](https://github.com/PDBe-KB/pisa/tree/main/setup/pisa_cfg_tmp)
<!-- Comment that config for CCP4 install can also be used. -->
Other dependencies can be installed with:
```
pip install -r requirements.txt
```
See [requirements.txt](https://github.com/PDBe-KB/pisa-analysis/blob/main/requirements.txt)
For development:
**pre-commit usage**
```
pip install pre-commit
pre-commit
pre-commit install
```
## Usage
Follow below steps to install the module **pisa_analysis** :
```
cd pisa-analysis/
python3 -m venv .venv
source .venv/bin/activate
python3 -m pip install .
```
To run the modules in command line:
**pisa_analysis**:
```
pisa_analysis [-h] \
-i <INPUT_CIF_FILE> \
--pdb_id <PDB_ID> \
--assembly_id <ASSEMBLY_CODE> \
-o <OUTPUT_JSON> \
--output_xml <OUTPUT_XML>
```
Required arguments are :
```
--input_cif (-i) : Assembly CIF file (It can also read a PDB file). Optional if --gen_full_results is used and --assembly_id not specified.
--pdb_id : Entry ID
--assembly_id : Assembly code
--output_json (-o) : Output directory for JSON fille
--output_xml : Output directory for XML files
```
Other optional arguments are:
```
--input_updated_cif : Updated cif for pdbid entry
--force : Always runs PISA calculation
--pisa_setup_dir : Path to the 'setup' directory in PISA
--pisa_binary : Binary file for PISA
-h, --help : Show help message
```
The process is as follows:
For **pisa_analysis** module:
1. The process first runs PISA in a subprocess and generates two xml files:
- interfaces.xml
- assembly.xml
The xml files are saved in the output directory defined by the `--output_xml` argument. If the xml files exist and are valid, the process will skip running PISA unless the `--force` is used in the arguments.
2. Next, the process parses xml files generated by PISA and creates a dictionary that contains all assembly interfaces/interactions information.
3. While creating the interfaces dictionary for the entry, the process reads UniProt accession and sequence numbers from an Updated CIF file using Gemmi.
4. The process also parses xml file `assembly.xml` generated by PISA and creates a simplified dictionary with some assembly information.
4. In the last steps, the process dumps the dictionaries into JSON files. The JSON files are saved in the output directory defined by the `-o` or `--output_json` arguments. The output json files are:
*xxxx-assemX_interfaces.json* and *xxxx-assemblyX.json*
where xxxx is the pdb id entry and X is the assembly code.
## Expected JSON files
Documentation on the assembly interfaces json file and schema can be found here:
https://pisalite.docs.apiary.io/#reference/0/pisaqualifierjson/interaction-interface-data-per-pdb-assembly-entry
The simplified assembly json output looks as follows:
```
{
"PISA": {
"pdb_id": "1d2s",
"assembly_id": "1",
"pisa_version": "2.0",
"assembly": {
"id": "1",
"size": "8",
"macromolecular_size": "2",
"dissociation_energy": -3.96,
"accessible_surface_area": 15146.45,
"buried_surface_area": 3156.79,
"entropy": 12.09,
"dissociation_area": 733.07,
"solvation_energy_gain": -41.09,
"number_of_uc": "0",
"number_of_dissociated_elements": "2",
"symmetry_number": "2",
"formula": "A(2)a(4)b(2)",
"composition": "A-2A[CA](4)[DHT](2)"
}
}
}
```
## Setup with Docker
Build the docker image with:
```shell
docker build -t pisa-analysis .
```
Run the docker container with:
```
docker run -v <HOST_DIR>:/data_dir \
pisa-analysis \
pisa_analysis \
--input_cif /data_dir/<INPUT_CIF> \
--pdb_id <PDB_ID> \
--assembly_id <ASSEMBLY_CODE> \
--output_json /data_dir/<OUTPUT_JSON> \
--output_xml /data_dir/<OUTPUT_XML>
```
## Versioning
We use [SemVer](https://semver.org) for versioning.
## Authors
* [Grisell Diaz Leines](https://github.com/grisell) - Lead developer
* [Stephen Anyango](otienoanyango) - Review and productionising
* [Mihaly Varadi](https://github.com/mvaradi) - Review and management
See all contributors [here](https://github.com/PDBe-KB/pisa-analysis/graphs/contributors).
## License
See [LICENSE](https://github.com/PDBe-KB/pisa-analysis/blob/main/LICENSE)
## Acknowledgements
| text/markdown | null | Grisell Diaz Leines <gdiazleines@ebi.ac.uk> | null | null | Apache 2.0 | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"gemmi>=0.7.3",
"jsonschema>=4.25.1",
"lxml>=6.0.2",
"pandas>=2.3.3",
"pydantic>=2.12.4",
"xmlschema>=4.2.0",
"xmltodict>=1.0.2"
] | [] | [] | [] | [
"Homepage, https://github.com/PDBe-KB/pisa-analysis",
"Repository, https://github.com/PDBe-KB/pisa-analysis"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:35:49.749753 | pisa_analysis-3.0.8.tar.gz | 31,262 | d3/8a/139c49bcb13dda8e2eaf1c0058c7611dde00e25f6a8598588b677e6efa46/pisa_analysis-3.0.8.tar.gz | source | sdist | null | false | 69ece191e90edf6b8eda2bfa5f57ed1c | 8e581e8d086fc887777323b44d1cf9af7649506dec412f97af979f37c02276e1 | d38a139c49bcb13dda8e2eaf1c0058c7611dde00e25f6a8598588b677e6efa46 | null | [] | 204 |
2.1 | odoo-addon-website-sale-require-legal | 18.0.1.0.1 | Force the user to accept legal tems to buy in the web shop | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
=========================================
Require accepting legal terms to checkout
=========================================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:bf2f49e4d24fbef2d4dd56bcaf36b3e38f42f921ff8e864c774f83688a5b1133
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fe--commerce-lightgray.png?logo=github
:target: https://github.com/OCA/e-commerce/tree/18.0/website_sale_require_legal
:alt: OCA/e-commerce
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/e-commerce-18-0/e-commerce-18-0-website_sale_require_legal
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/e-commerce&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module extends your e-commerce legal compliance options:
1. Require accepting legal terms before submitting a new address.
2. Log a note in the partner when such terms are accepted.
3. Log a note in the sale order when terms are accepted before payment
(done for every online payment, it is an upstream feature).
**Table of contents**
.. contents::
:local:
Use Cases / Context
===================
This module adds the functionality to require the user to check the
checkbox to accept the legal terms in the address form. Additionally, it
provides a metadata record for both the user when legal terms are
accepted through the address form and for the sales order when legal
terms are accepted during the payment process.
It's worth noting that this module can be useful even if the acceptance
of legal terms in the address form is not activated, as it stores a
metadata record when the terms and conditions are accepted during the
payment process, even if a new address has not been created.
Configuration
=============
To configure this module, you need to:
1. Install it.
2. Set up `your legal pages </legal>`__.
3. Go to your e-commerce and make a sample checkout.
4. Visit `/shop/address </shop/address>`__ and enable in the web editor
*Customize > Require Legal Terms Acceptance*.
|image1|
This will require acceptance before recording a new address, and log
visitor's acceptance.
5. Visit `/shop/payment </shop/payment>`__ and enable in the web editor
*Customize > Accept Terms & Conditions* (upstream Odoo feature).
|image2|
This will require acceptance before paying the sale order, and log
visitor's acceptance.
.. |image1| image:: https://raw.githubusercontent.com/OCA/e-commerce/18.0/website_sale_require_legal/static/description/address-enable.png
.. |image2| image:: https://raw.githubusercontent.com/OCA/e-commerce/18.0/website_sale_require_legal/static/description/payment-enable.png
Usage
=====
To use this module, you need to:
- Buy something from your website.
Known issues / Roadmap
======================
- Shopping terms and conditions are accepted only on user registration
or address edition. So if those terms change after the user signed up,
a notification should be made. An implicit acceptance could be printed
in the payment screen to solve this. Maybe that could be a work to
develop in another module.
- If you enable both acceptance views as explained in the configuration
section, first-time buyers will have to accept the legal terms between
2 and 3 times to buy.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/e-commerce/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/e-commerce/issues/new?body=module:%20website_sale_require_legal%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Tecnativa
Contributors
------------
- `Tecnativa <https://www.tecnativa.com>`__:
- Rafael Blasco
- Jairo Llopis
- Vicent Cubells
- David Vidal
- Ernesto Tejeda
- Cristina Martin R.
- Pilar Vargas
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/e-commerce <https://github.com/OCA/e-commerce/tree/18.0/website_sale_require_legal>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Tecnativa, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/e-commerce | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T15:35:13.893892 | odoo_addon_website_sale_require_legal-18.0.1.0.1-py3-none-any.whl | 151,253 | da/17/368713d5f6b7333106e7e8094f5986b7682fd9bc14033272a8b0801f89ae/odoo_addon_website_sale_require_legal-18.0.1.0.1-py3-none-any.whl | py3 | bdist_wheel | null | false | e6a62d1d1401f20b5f7cb538a485f9ba | 5f7cf4b5c768f41ef5f1cf0391fe6da6cff7f8eddb24df5833918f7667a3be9a | da17368713d5f6b7333106e7e8094f5986b7682fd9bc14033272a8b0801f89ae | null | [] | 101 |
2.4 | benchmark-runner | 1.0.955 | Benchmark Runner Tool | <div align="center">
<img src="https://github.com/redhat-performance/benchmark-runner/blob/main/media/benchmark_runner.png"><br>
</div>
-----------------
# Benchmark-Runner: Running benchmarks
[](https://github.com/redhat-performance/benchmark-runner/actions)
[](https://pypi.org/project/benchmark-runner/)
[](https://quay.io/repository/benchmark-runner/benchmark-runner?tab=tags)
[](https://coveralls.io/github/redhat-performance/benchmark-runner?branch=main&kill_cache=1)
[](https://benchmark-runner.readthedocs.io/en/latest/?badge=latest)
[](https://pypi.org/project/benchmark-runner)
[](https://github.com/redhat-performance/benchmark-runner/blob/main/LICENSE)
## What is it?
**benchmark-runner** is a containerized Python lightweight and flexible framework for running benchmark workloads
on Kubernetes/OpenShift runtype kinds Pod, kata and VM.
This framework support the following embedded workloads:
* [hammerdb](https://hammerdb.com/): running hammerdb workload on the following databases: MSSQL, Mariadb, Postgresql in Pod, Kata or VM with [Configuration](benchmark_runner/common/template_operations/templates/hammerdb)
* [stressng](https://wiki.ubuntu.com/Kernel/Reference/stress-ng): running stressng workload in Pod, Kata or VM [Configuration](benchmark_runner/common/template_operations/templates/stressng)
* [uperf](http://uperf.org/): running uperf workload in Pod, Kata or VM with [Configuration](benchmark_runner/common/template_operations/templates/uperf)
* [vdbench](https://wiki.lustre.org/VDBench): running vdbench workload in Pod, Kata or VM with [Configuration](benchmark_runner/common/template_operations/templates/vdbench)
* [bootstorm](https://en.wiktionary.org/wiki/boot_storm): calculate VMs boot load time [Configuration](benchmark_runner/common/template_operations/templates/bootstorm)
** For hammerdb mssql must run once [permission](https://github.com/redhat-performance/benchmark-runner/blob/main/benchmark_runner/common/ocp_resources/custom/template/02_mssql_patch_template.sh)
Benchmark-runner grafana dashboard example:

Reference:
* The benchmark-runner package is located in [PyPi](https://pypi.org/project/benchmark-runner)
* The benchmark-runner container image is located in [Quay.io](https://quay.io/repository/benchmark-runner/benchmark-runner)
## Documentation
Documentation is available at [benchmark-runner.readthedocs.io](https://benchmark-runner.readthedocs.io/en/latest/)

_**Table of Contents**_
<!-- TOC -->
- [Benchmark-Runner](#benchmark-runner)
- [Documentation](#documentation)
- [Run workload using Podman or Docker](#run-workload-using-podman-or-docker)
- [Run workload in Pod using Kubernetes or OpenShift](#run-workload-in-pod-using-kubernetes-or-openshift)
- [Grafana dashboards](#grafana-dashboards)
- [Inspect Prometheus Metrics](#inspect-prometheus-metrics)
- [How to develop in benchmark-runner](#how-to-develop-in-benchmark-runner)
<!-- /TOC -->
## Run workload using Podman or Docker
The following options may be passed via command line flags or set in the environment:
**mandatory:** KUBEADMIN_PASSWORD=$KUBEADMIN_PASSWORD
**mandatory:** $KUBECONFIG [ kubeconfig file path]
**mandatory:** WORKLOAD=$WORKLOAD
Choose one from the following list:
`['stressng_pod', 'stressng_vm', 'stressng_kata', 'uperf_pod', 'uperf_vm', 'uperf_kata', 'hammerdb_pod_mariadb', 'hammerdb_vm_mariadb', 'hammerdb_kata_mariadb', 'hammerdb_pod_mariadb_lso', 'hammerdb_vm_mariadb_lso', 'hammerdb_kata_mariadb_lso', 'hammerdb_pod_postgres', 'hammerdb_vm_postgres', 'hammerdb_kata_postgres', 'hammerdb_pod_postgres_lso', 'hammerdb_vm_postgres_lso', 'hammerdb_kata_postgres_lso', 'hammerdb_pod_mssql', 'hammerdb_vm_mssql', 'hammerdb_kata_mssql', 'hammerdb_pod_mssql_lso', 'hammerdb_vm_mssql_lso', 'hammerdb_kata_mssql_lso', 'vdbench_pod', 'vdbench_kata', 'vdbench_vm', 'clusterbuster', 'bootstorm_vm', 'windows_vm', 'winmssql_vm' ]`
** clusterbuster workloads: cpusoaker, files, fio, uperf. for more details [see](https://github.com/RobertKrawitz/OpenShift4-tools)
** For windows workloads: need to share windows qcow2 image by nginx
** For hammerdb mssql must run only once [permission](https://github.com/redhat-performance/benchmark-runner/blob/main/benchmark_runner/common/ocp_resources/custom/template/02_mssql_patch_template.sh)
** winmssql_vm: will run hammerdb inside windows server mssql 2022: for more details [see](benchmark_runner/common/template_operations/templates/winmssql/windows_benchmark_runner/readme)
Not mandatory:
**auto:** NAMESPACE=benchmark-operator [ The default namespace is benchmark-operator ]
**auto:** ODF_PVC=True [ True=ODF PVC storage, False=Ephemeral storage, default True ]
**auto:** EXTRACT_PROMETHEUS_SNAPSHOT=True [ True=extract Prometheus snapshot into artifacts, false=don't, default True ]
**auto:** SYSTEM_METRICS=False [ True=collect metric, False=not collect metrics, default False ]
**auto:** RUNNER_PATH=/tmp [ The default work space is /tmp ]
**optional:** PIN_NODE_BENCHMARK_OPERATOR=$PIN_NODE_BENCHMARK_OPERATOR [node selector for benchmark operator pod]
**optional:** PIN_NODE1=$PIN_NODE1 [node1 selector for running the workload]
**optional:** PIN_NODE2=$PIN_NODE2 [node2 selector for running the workload, i.e. uperf server and client, hammerdb database and workload]
**optional:** ELASTICSEARCH=$ELASTICSEARCH [ elasticsearch service name]
**optional:** ELASTICSEARCH_PORT=$ELASTICSEARCH_PORT
**optional:** CLUSTER=$CLUSTER [ set CLUSTER='kubernetes' to run workload on a kubernetes cluster, default 'openshift' ]
**optional:scale** SCALE=$SCALE [For Vdbench/Bootstorm: Scale in each node]
**optional:scale** SCALE_NODES=$SCALE_NODES [For Vdbench/Bootstorm: Scale's node]
**optional:scale** REDIS=$REDIS [For Vdbench only: redis for scale synchronization]
**optional:** LSO_DISK_ID=$LSO_DISK_ID [LSO_DISK_ID='scsi-<replace_this_with_your_actual_disk_id>' For using LSO Operator in hammerdb]
**optional:** WORKER_DISK_IDS=$WORKER_DISK_IDS [WORKER_DISK_IDS For ODF/LSO workloads hammerdb/vdbench]
**optional:** WINDOWS_URL=$WINDOWS_URL [WINDOWS_URL for qcow2 image that can be shared by Nginx]
For example:
```sh
podman run --rm -e WORKLOAD="hammerdb_pod_mariadb" -e KUBEADMIN_PASSWORD="1234" -e PIN_NODE_BENCHMARK_OPERATOR="node_name-0" -e PIN_NODE1="node_name-1" -e PIN_NODE2="node_name-2" -e log_level=INFO -v /root/.kube/config:/root/.kube/config --privileged quay.io/benchmark-runner/benchmark-runner:latest
```
or
```sh
docker run --rm -e WORKLOAD="hammerdb_vm_mariadb" -e KUBEADMIN_PASSWORD="1234" -e PIN_NODE_BENCHMARK_OPERATOR="node_name-0" -e PIN_NODE1="node_name-1" -e PIN_NODE2="node_name-2" -e log_level=INFO -v /root/.kube/config:/root/.kube/config --privileged quay.io/benchmark-runner/benchmark-runner:latest
```
SAVE RUN ARTIFACTS LOCAL:
1. add `-e SAVE_ARTIFACTS_LOCAL='True'` or `--save-artifacts-local=true`
2. add `-v /tmp/benchmark-runner-run-artifacts:/tmp/benchmark-runner-run-artifacts`
3. git clone -b v1.0.3 https://github.com/cloud-bulldozer/benchmark-operator /tmp/benchmark-operator
### Run vdbench workload in Pod using OpenShift

### Run vdbench workload in Pod using Kubernetes

## Run workload in Pod using Kubernetes or OpenShift
[TBD]
## Grafana dashboards
There are 2 grafana dashboards templates:
1. [FuncCi dashboard](benchmark_runner/grafana/func/dashboard.json)
2. [PerfCi dashboard](benchmark_runner/grafana/perf/dashboard.json)
** PerfCi dashboard is generated automatically in [Build GitHub actions](https://github.com/redhat-performance/benchmark-runner/blob/main/.github/workflows/Perf_Env_Build_Test_CI.yml) from [main.libsonnet](benchmark_runner/grafana/perf/jsonnet/main.libsonnet)
** After importing json in grafana, you need to configure elasticsearch data source. (for more details: see [HOW_TO.md](HOW_TO.md))
## Inspect Prometheus Metrics
The CI jobs store snapshots of the Prometheus database for each run as part of the artifacts. Within the artifact directory is a Prometheus snapshot directory named:
```
promdb-YYYY_MM_DDTHH_mm_ss+0000_YYYY_MM_DDTHH_mm_ss+0000.tar
```
The timestamps are for the start and end of the metrics capture; they
are stored in UTC time (`+0000`). It is possible to run containerized
Prometheus on it to inspect the metrics. *Note that Prometheus
requires write access to its database, so it will actually write to
the snapshot.* So for example if you have downloaded artifacts for a
run named `hammerdb-vm-mariadb-2022-01-04-08-21-23` and the Prometheus
snapshot within is named
`promdb_2022_01_04T08_21_52+0000_2022_01_04T08_45_47+0000`, you could run as follows:
```
$ local_prometheus_snapshot=/hammerdb-vm-mariadb-2022-01-04-08-21-23/promdb_2022_01_04T08_21_52+0000_2022_01_04T08_45_47+0000
$ chmod -R g-s,a+rw "$local_prometheus_snapshot"
$ sudo podman run --rm -p 9090:9090 -uroot -v "$local_prometheus_snapshot:/prometheus" --privileged prom/prometheus --config.file=/etc/prometheus/prometheus.yml --storage.tsdb.path=/prometheus --storage.tsdb.retention.time=100000d --storage.tsdb.retention.size=1000PB
```
and point your browser at port 9090 on your local system, you can run queries against it, e.g.
```
sum(irate(node_cpu_seconds_total[2m])) by (mode,instance) > 0
```
It is important to use the `--storage.tsdb.retention.time` option to
Prometheus, as otherwise Prometheus may discard the data in the
snapshot. And note that you must set the time bounds on the
Prometheus query to fit the start and end times as recorded in the
name of the promdb snapshot.
## How to develop in benchmark-runner
see [HOW_TO.md](HOW_TO.md)
## benchmark-runner blog
open [link](https://developers.redhat.com/articles/2025/11/18/how-run-performance-tests-using-benchmark-runner)
| text/markdown | Red Hat | ebattat@redhat.com | null | null | Apache License 2.0 | null | [
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | https://github.com/redhat-performance/benchmark-runner | null | null | [] | [] | [] | [
"attrs==21.4.0",
"azure==4.0.0",
"boto3==1.33.13",
"botocore==1.33.13",
"cryptography==46.0.5",
"elasticsearch==7.16.1",
"elasticsearch-dsl==7.4.0",
"google-auth==2.30.0",
"google-auth-httplib2==0.2.0",
"google-auth-oauthlib==1.2.0",
"google-api-python-client==2.135.0",
"ipywidgets==8.0.6",
... | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T15:34:38.231147 | benchmark_runner-1.0.955.tar.gz | 163,846 | d9/5a/e9b61bee5e03b273a6ac805075b9e173664061d73c2958431f23e446da73/benchmark_runner-1.0.955.tar.gz | source | sdist | null | false | 8d2ab5878a3f7992b8201985f5f9889d | 190c1d421161211c4778fa838f3e1728db2c3fa22c06533d5e48d48751af0cd6 | d95ae9b61bee5e03b273a6ac805075b9e173664061d73c2958431f23e446da73 | null | [
"LICENSE"
] | 265 |
2.4 | isage-examples | 0.1.1.2 | SAGE Examples - Production application examples for SAGE framework | # SAGE Examples
[](https://github.com/intellistream/sage-examples/actions)
[](https://github.com/intellistream/sage-examples/actions)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
Production-ready application examples for the SAGE framework.
## 🎯 What is This?
**sage-examples** showcases production application examples for [SAGE](https://github.com/intellistream/SAGE):
- **🎯 Examples**: Complete, runnable application demonstrations
- **📦 apps Package**: Installable application library (published to PyPI as `iapps`)
> **� Looking for tutorials?** Visit [SAGE/tutorials](https://github.com/intellistream/SAGE/tree/main/tutorials) for learning materials.
## 🚀 Quick Start
```bash
# Clone this repository
git clone https://github.com/intellistream/sage-examples.git
cd sage-examples
# Install (all dependencies included)
pip install -e .
# Run an application example
python examples/run_video_intelligence.py
```
> **New to SAGE?** Start with [SAGE/tutorials](https://github.com/intellistream/SAGE/tree/main/tutorials) first.
## 📁 Repository Structure
```
sage-examples/
├── examples/ # 🎯 Production application examples
│ ├── run_video_intelligence.py
│ ├── run_medical_diagnosis.py
│ ├── run_smart_home.py
│ └── ...
│
├── apps/ # 📦 Installable application package
│ ├── src/sage/apps/ # Application implementations
│ └── tests/ # Package tests
│
├── docs/ # 📖 Project documentation
└── pyproject.toml # Project configuration
```
## 📚 Learning vs Examples
| Your Goal | Repository |
|-----------|------------|
| **Learn SAGE basics** | [SAGE/tutorials](https://github.com/intellistream/SAGE/tree/main/tutorials) |
| **See production examples** | [sage-examples](https://github.com/intellistream/sage-examples) (this repo) |
| **Install applications** | `pip install iapps` |
## 🎯 Application Examples
Complete, runnable applications demonstrating real-world use cases:
| Application | Description | Script |
|-------------|-------------|--------|
| 🎬 **Video Intelligence** | Multi-model video analysis | `examples/run_video_intelligence.py` |
| 🏥 **Medical Diagnosis** | AI medical image analysis | `examples/run_medical_diagnosis.py` |
| 🏠 **Smart Home** | IoT automation system | `examples/run_smart_home.py` |
| 📰 **Article Monitoring** | News monitoring pipeline | `examples/run_article_monitoring.py` |
| 💬 **Auto-scaling Chat** | Dynamic scaling chat | `examples/run_auto_scaling_chat.py` |
See `examples/README.md` for details.
## 📦 Installation
```bash
# Clone repository
git clone https://github.com/intellistream/sage-examples.git
cd sage-examples
# Install (all dependencies included by default)
pip install -e .
# Or install from PyPI
pip install isage-examples
# Development mode (includes pytest, ruff, mypy)
pip install -e .[dev]
```
> **Note**: Following SAGE principles, all application dependencies are installed by default. No need for extra flags like `[video]` or `[medical]`.
## 🏗️ SAGE Architecture Overview
SAGE uses a strict 6-layer architecture with unidirectional dependencies:
```
┌─────────────────────────────────────────────┐
│ L6: Interface │ CLI, Web UI, Tools
├─────────────────────────────────────────────┤
│ L5: Applications │ Production Apps
├─────────────────────────────────────────────┤
│ L4: Middleware │ Domain Operators
├─────────────────────────────────────────────┤
│ L3: Core │ Execution + Algorithms
│ ├─ Kernel (Batch/Stream Engine) │
│ └─ Libs (RAG/Agents/Algorithms) │
├─────────────────────────────────────────────┤
│ L2: Platform │ Scheduler, Storage
├─────────────────────────────────────────────┤
│ L1: Foundation │ Config, Logging, LLM
└─────────────────────────────────────────────┘
```
**Dependency Rule**: Upper layers can depend on lower layers (L6→L5→...→L1), but never the reverse.
## 🛠️ Development
### Setup
```bash
# Install development dependencies
pip install -e ".[dev]"
# Install pre-commit hooks
pre-commit install
# Run all checks
pre-commit run --all-files
```
### Code Quality
```bash
# Format code
ruff format .
# Lint code
ruff check .
# Auto-fix issues
ruff check --fix .
# Type checking
mypy .
```
### Testing
```bash
# Run all tests
pytest
# Run specific tests
pytest examples/test_apps.py
pytest apps/tests/
# With coverage
pytest --cov=. --cov-report=html
```
See `docs/DEVELOPMENT.md` for complete development guide.
## 📖 Documentation
- **Examples Guide**: `examples/README.md` - Application examples
- **Development Guide**: `docs/DEVELOPMENT.md` - Contributing
- **SAGE Tutorials**: [SAGE/tutorials](https://github.com/intellistream/SAGE/tree/main/tutorials) - Learn SAGE
- **SAGE Docs**: https://intellistream.github.io/SAGE
## 🤝 Contributing
We welcome contributions! Please see:
1. **Development Guide**: `docs/DEVELOPMENT.md`
2. **Code of Conduct**: Follow respectful collaboration
3. **Issue Tracker**: https://github.com/intellistream/sage-examples/issues
### Adding Examples
1. **Tutorials**: Add to [SAGE/tutorials](https://github.com/intellistream/SAGE/tree/main/tutorials)
2. **Applications**:
- Implementation → `apps/src/sage/apps/your_app/`
- Entry script → `examples/run_your_app.py`
3. **Tests**: Add tests and ensure they pass
4. **Dependencies**: Update `pyproject.toml`
## 🔗 Related Repositories
- **SAGE Main**: https://github.com/intellistream/SAGE
- **SAGE Benchmark**: https://github.com/intellistream/sage-benchmark
- **PyPI Packages**: https://pypi.org/search/?q=isage
## 📄 License
MIT License - see [LICENSE](LICENSE) for details.
## 🙋 Getting Help
- **GitHub Issues**: Bug reports and feature requests
- **GitHub Discussions**: Questions and community support
- **GitHub Copilot**: Use "SAGE Examples Assistant" chat mode
## 🌟 Star History
If you find this project helpful, please consider giving it a ⭐️!
---
**Made with ❤️ by the IntelliStream Team**
| text/markdown | null | IntelliStream Team <shuhao_zhang@hust.edu.cn> | null | null | null | sage, examples, applications, ai, llm, rag, multimodal, video-intelligence, medical-diagnosis, computer-vision, intellistream | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: ... | [] | null | null | ==3.10.* | [] | [] | [] | [
"isage-common>=0.2.0",
"isage-llm-core>=0.2.0",
"isage-libs>=0.2.0",
"isage-apps>=0.2.0",
"pyyaml>=6.0",
"numpy<2.3.0,>=1.26.0",
"pillow>=10.0.0",
"opencv-python-headless>=4.5.0",
"torch<3.0.0,>=2.7.0",
"torchvision<1.0.0,>=0.22.0",
"transformers<4.54.0,>=4.52.0",
"scikit-learn>=1.3.0",
"bea... | [] | [] | [] | [
"Homepage, https://github.com/intellistream/SAGE",
"Documentation, https://intellistream.github.io/SAGE",
"Repository, https://github.com/intellistream/sage-examples",
"Issues, https://github.com/intellistream/SAGE/issues"
] | twine/6.2.0 CPython/3.10.12 | 2026-02-19T15:34:28.086121 | isage_examples-0.1.1.2.tar.gz | 27,372 | 00/a7/f293ac2b312ff45c6d0a5299c5da1b882ae6baa0b01c3db4ce671396de52/isage_examples-0.1.1.2.tar.gz | source | sdist | null | false | 4e1c5b0fef0bd6e6dd24f415fb1a7367 | 939b08055f06828eb34547d3569a3b7cd4a7e4ceb4912abef308d80af7dabdf4 | 00a7f293ac2b312ff45c6d0a5299c5da1b882ae6baa0b01c3db4ce671396de52 | MIT | [
"LICENSE"
] | 196 |
2.4 | Gixy-Next | 0.1.3 | Open source NGINX configuration security scanner for detecting nginx security/performance misconfigurations | # Gixy-Next: NGINX Configuration Security Scanner for Security Audits
## Overview
<a href="https://gixy.io/"><img width="192" height="192" alt="Gixy-Next Mascot Logo" style="float: right;" align="right" src="https://gixy.io/imgs/gixy.jpg" /></a>
Gixy-Next (Gixy) is an open-source NGINX configuration security scanner and hardening tool that statically analyzes your nginx.conf to detect security misconfigurations, hardening gaps, and common performance pitfalls before they reach production. It is an actively maintained fork of Yandex's [Gixy](https://github.com/yandex/gixy). Gixy-Next's source code is [available on GitHub](https://github.com/megamansec/gixy-next).
!!! note "In-Browser Scanner"
Gixy-Next can also be run in the browser on [this page](https://gixy.io/scanner/). No download is needed; you can scan your configurations on the website (locally, using WebAssembly).
### Quick start
Gixy-Next (the `gixy` or `gixy-next` CLI) is distributed on [PyPI](https://pypi.python.org/pypi/Gixy-Next). You can install it with pip or uv:
```shell-session
# pip
pip3 install gixy-next
# uv
uv pip install gixy-next
```
You can then run it:
```shell-session
# gixy defaults to reading /etc/nginx/nginx.conf
gixy
# But you can also specify a path to the configuration
gixy /opt/nginx.conf
```
You can also export your NGINX configuration to a single dump file (see [nginx -T Live Configuration Dump](https://gixy.io/nginx-config-dump)):
```shell-session
# Dumps the full NGINX configuration into a single file (including all includes)
nginx -T > ./nginx-dump.conf
# Scan the dump elsewhere (or via stdin):
gixy ./nginx-dump.conf
# or
cat ./nginx-dump.conf | gixy -
```
### Web-based scanner
Instead of downloading and running Gixy-Next locally, you can use [this webpage](https://gixy.io/scanner/) and scan a configuration from your web browser (locally, using WebAssembly).
## What it can do
Gixy-Next can detect a wide range of NGINX security and performance misconfigurations across `nginx.conf` and included configuration files. The following plugins are supported:
* [[add_header_content_type] Setting Content-Type via add_header](https://gixy.io/plugins/add_header_content_type/)
* [[add_header_multiline] Multiline response headers](https://gixy.io/plugins/add_header_multiline/)
* [[add_header_redefinition] Redefining of response headers by "add_header" directive](https://gixy.io/plugins/add_header_redefinition/)
* [[alias_traversal] Path traversal via misconfigured alias](https://gixy.io/plugins/alias_traversal/)
* [[allow_without_deny] Allow specified without deny](https://gixy.io/plugins/allow_without_deny/)
* [[default_server_flag] Missing default_server flag](https://gixy.io/plugins/default_server_flag/)
* [[error_log_off] `error_log` set to `off`](https://gixy.io/plugins/error_log_off/)
* [[hash_without_default] Missing default in hash blocks](https://gixy.io/plugins/hash_without_default/)
* [[host_spoofing] Request's Host header forgery](https://gixy.io/plugins/host_spoofing/)
* [[http_splitting] HTTP Response Splitting](https://gixy.io/plugins/http_splitting/)
* [[if_is_evil] If is evil when used in location context](https://gixy.io/plugins/if_is_evil/)
* [[invalid_regex] Invalid regex capture groups](https://gixy.io/plugins/invalid_regex/)
* [[low_keepalive_requests] Low `keepalive_requests`](https://gixy.io/plugins/low_keepalive_requests/)
* [[merge_slashes_on] Enabling merge_slashes](https://gixy.io/plugins/merge_slashes_on/)
* [[missing_worker_processes] Missing `worker_processes`](https://gixy.io/plugins/missing_worker_processes/)
* [[origins] Problems with referer/origin header validation](https://gixy.io/plugins/origins/)
* [[proxy_buffering_off] Disabling `proxy_buffering`](https://gixy.io/plugins/proxy_buffering_off/)
* [[proxy_pass_normalized] `proxy_pass` path normalization issues](https://gixy.io/plugins/proxy_pass_normalized/)
* [[regex_redos] Regular expression denial of service (ReDoS)](https://gixy.io/plugins/regex_redos/)
* [[resolver_external] Using external DNS nameservers](https://gixy.io/plugins/resolver_external/)
* [[return_bypasses_allow_deny] Return directive bypasses allow/deny restrictions](https://gixy.io/plugins/return_bypasses_allow_deny/)
* [[ssrf] Server Side Request Forgery](https://gixy.io/plugins/ssrf/)
* [[stale_dns_cache] Outdated/stale cached DNS records used in proxy_pass](https://gixy.io/plugins/stale_dns_cache/)
* [[try_files_is_evil_too] `try_files` directive is evil without open_file_cache](https://gixy.io/plugins/try_files_is_evil_too/)
* [[unanchored_regex] Unanchored regular expressions](https://gixy.io/plugins/unanchored_regex/)
* [[valid_referers] none in valid_referers](https://gixy.io/plugins/valid_referers/)
* [[version_disclosure] Using insecure values for server_tokens](https://gixy.io/plugins/version_disclosure/)
* [[worker_rlimit_nofile_vs_connections] `worker_rlimit_nofile` must be at least twice `worker_connections`](https://gixy.io/plugins/worker_rlimit_nofile_vs_connections/)
Something not detected? Please open an [issue](https://github.com/MegaManSec/Gixy-Next/issues) on GitHub with what's missing!
## Usage (flags)
`gixy` defaults to reading a system's NGINX configuration from `/etc/nginx/nginx.conf`. You can also specify the location by passing it to `gixy`:
```shell-session
# Analyze the configuration in /opt/nginx.conf
gixy /opt/nginx.conf
```
You can run a focused subset of checks with `--tests`:
```shell-session
# Only run these checks
gixy --tests http_splitting,ssrf,version_disclosure
```
Or skip a few noisy checks with `--skips`:
```shell-session
# Run everything except these checks
gixy --skips low_keepalive_requests,worker_rlimit_nofile_vs_connections
```
To only report issues of a certain severity or higher, use the compounding `-l` flag:
```shell-session
# -l for LOW severity issues and high, -ll for MEDIUM and higher, and -lll for only HIGH severity issues
gixy -ll
```
By default, the output of `gixy` is ANSI-colored; best viewed in a compatible terminal. You can use the `--format` (`-f`) flag with the `text` value to get an uncolored output:
```shell-session
$ gixy -f text
==================== Results ===================
Problem: [http_splitting] Possible HTTP-Splitting vulnerability.
Description: Using variables that can contain "\n" may lead to http injection.
Additional info: https://gixy.io/plugins/http_splitting/
Reason: At least variable "$action" can contain "\n"
Pseudo config:
include /etc/nginx/sites/default.conf;
server {
location ~ /v1/((?<action>[^.]*)\.json)?$ {
add_header X-Action $action;
}
}
==================== Summary ===================
Total issues:
Unspecified: 0
Low: 0
Medium: 0
High: 1
```
You can also use `-f json` to get a reproducible, machine-readable JSON output:
```shell-session
$ gixy -f json
[{"config":"\nserver {\n\n\tlocation ~ /v1/((?<action>[^.]*)\\.json)?$ {\n\t\tadd_header X-Action $action;\n\t}\n}","description":"Using variables that can contain \"\\n\" or \"\\r\" may lead to http injection.","file":"/etc/nginx/nginx.conf","line":4,"path":"/etc/nginx/nginx.conf","plugin":"http_splitting","reason":"At least variable \"$action\" can contain \"\\n\"","reference":"https://gixy.io/plugins/http_splitting/","severity":"HIGH","summary":"Possible HTTP-Splitting vulnerability."}]
```
More flags for usage can be found by passing `--help` to `gixy`. You can also find more information in the [Usage Guide](https://gixy.io/usage/).
## Configuration and plugin options
Some plugins expose options which you can set via CLI flags or a configuration file. You can read more about those in the [Configuration guide](https://gixy.io/configuration/).
## Gixy-Next for NGINX security and compliance
Unlike running `nginx -t` which only checks syntax, Gixy-Next actually analyzes your configuration and detects unhardened instances and vulnerabilities.
With Gixy-Next, you can perform an automated NGINX configuration security review that can run locally on every change, whether for auditing, compliance, or general testing, helping produce actionable findings that help prevent unstable/slow NGINX servers, and reduce risk from unsafe directives and insecure defaults.
## Contributing
Contributions to Gixy-Next are always welcome! You can help us in different ways, such as:
- Reporting bugs.
- Suggesting new plugins for detection.
- Improving documentation.
- Fixing, refactoring, improving, and writing new code.
Before submitting any changes in pull requests, please read the contribution guideline document, [Contributing to Gixy-Next](https://gixy.io/contributing/).
The official homepage of Gixy-Next is [https://gixy.io/](https://gixy.io/). Any changes to documentation in Gixy-Next will automatically be reflected on that website.
The source code can be found at [https://github.com/MegaManSec/Gixy-Next](https://github.com/MegaManSec/Gixy-Next).
## What is Gixy? (Background)
_Gixy_ is an NGINX configuration analyzer that was [originally](https://github.com/yandex/gixy) developed by Yandex's Andrew Krasichkov. It was first released in 2017 and has since become unmaintained. It does not support modern versions of Python, contains numerous bugs, and is limited in its functionality and ability to detect vulnerable NGINX configurations. Running the original Gixy today on a modern system will result in the following error:
```
File "gixy/core/sre_parse/sre_parse.py", line 61, in <module>
"t": SRE_FLAG_TEMPLATE,
^^^^^^^^^^^^^^^^^
NameError: name 'SRE_FLAG_TEMPLATE' is not defined. Did you mean: 'SRE_FLAG_VERBOSE'?
```
Gixy-Next, therefore, is a fork that adds support for modern systems, adds new checks, performance improvements, hardening suggestions, and support for modern Python and NGINX versions.
### Why not `gixy-ng`?
Gixy-Next is actually a fork of `gixy-ng`, which itself was a fork of the original `gixy`. Gixy-Next was created after the maintainer of `gixy-ng` started producing large amounts of AI-assisted changes and auto-generated code that was both unreviewably large as well as broken.
After some time, the maintainer of `gixy-ng` began to commit AI-generated changes to the codebase which introduced obvious regressions, broke critical behavior of the tool (which anybody using the tool would have picked up), added random AI-tooling artifacts, and introduced code which simply did not do what it was supposed to do. Most importantly, the maintainer also **added marketing for their business to all documentation, all output, and all source code** of `gixy-ng`.
In other words, the `gixy-ng` maintainer took the original `gixy`, asked AI to make changes, introduced a bunch of bugs (and other AI slop), and then added advertising to the code. They also accepted contributions in the form of merge requests, but stripped the author's information (see [this](https://joshua.hu/gixy-ng-new-version-gixy-updated-checks#quality-degradation) post and [this](https://joshua.hu/gixy-ng-ai-slop-gixy-next-maintained) post).
Gixy-Next focuses on restoring quality, and has been battle-tested on NGINX configurations which are nearly 100,000-lines-long. It fixes bugs and misdetections introduced by changes introduced in `gixy-ng`, removes AI tool artifacts/junk, and tries to keep the codebase reviewable and maintainable. This fork is for those interested in clean code and long-term maintainability.
| text/markdown | Joshua Rogers | gixy@joshua.hu | null | null | MPL-2.0 | nginx, nginx security, nginx hardening, nginx configuration, nginx config, nginx config scanner, nginx configuration checker, nginx config linter, nginx security scanner, nginx configuration static analyzer, nginx vulnerability scanner, nginx.conf security audit, configuration compliance, configuration security, static analysis, ssrf, http response splitting, host header spoofing, version disclosure, redos, gixy, gixy next, gixy-ng, gixyng | [
"Environment :: Console",
"Intended Audience :: System Administrators",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Topic :: Security",
"Topic :: System :: Systems Administration",
"Topic :: Internet :: WWW/HTTP :: Site Management",
"Topic :: Software Development... | [] | https://gixy.io/ | null | >=3.6 | [] | [] | [] | [
"crossplane>=0.5.8",
"cached-property>=1.2.0; python_version < \"3.8\"",
"argparse>=1.4.0; python_version < \"3.2\"",
"Jinja2>=2.8",
"ConfigArgParse>=0.11.0",
"tldextract==3.1.2; python_version >= \"3.6\" and python_version < \"3.7\"",
"tldextract==4.0.0; python_version >= \"3.7\" and python_version < \... | [] | [] | [] | [
"Homepage, https://gixy.io/",
"Documentation, https://gixy.io/",
"Source, https://github.com/MegaManSec/gixy-next",
"Issue Tracker, https://github.com/MegaManSec/gixy-next/issues",
"Original Gixy, https://github.com/yandex/gixy"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:34:19.865783 | gixy_next-0.1.3.tar.gz | 107,925 | 34/4a/71fb48349dc371f83f5cb96f9d21cabd1b03a3e6590a2a369c92cc2bf02d/gixy_next-0.1.3.tar.gz | source | sdist | null | false | 6076f49744e86fa7d09e7dbefa572240 | 78a27c86177186d68b497fb9700b9d5986cbcbb2d0529cc5aed9a9399f92815c | 344a71fb48349dc371f83f5cb96f9d21cabd1b03a3e6590a2a369c92cc2bf02d | null | [
"LICENSE"
] | 0 |
2.3 | easycoder | 260218.1 | Rapid scripting in English | # Introduction
**_EasyCoder_** is a high-level English-like domain-specific scripting language (DSL) suited for prototyping and rapid testing of ideas. It operates on the command line and a graphics module is under construction. The language is written in Python and it acts as a fairly thin wrapper around standard Python functions, giving fast compilation and good runtime performance for general applications.
**_EasyCoder_** is well suited to building command-line or graphical applications for expressing random logic such as operating procedures and rules, or controlling physical systems, particularly those using wifi devices. It is easy to construct and issue REST commands to local or remote web servers.
For more advanced applications, **_EasyCoder_** is designed to be extensible, by enabling extra language syntax to be added via plugin-in modules. Once these are installed they act as seamless extensions to the basic syntax provided. **_EasyCoder_** derives its power from the use of rich and comprehensive language rather than a complex system of frameworks such as those commonly used in modern programming. This makes it very easy to learn as our brains are wired to operate that way. Having said that, the needs of most control systems are usually served by a fairly modest number of keywords and syntactic variants.
<hr>
There is also a JavaScript version of **_EasyCoder_**, which provides a full set of graphical features to run in a browser. For this, please visit
Repository: [https://github.com/easycoder/easycoder.github.io](https://github.com/easycoder/easycoder.github.io)
Website: [https://easycoder.github.io](https://easycoder.github.io)
<hr>
## Quick Start
Install **_EasyCoder_** in your Python environment:
```
pip install requests easycoder
```
Test the install by typing the command `easycoder`.
<hr>
On Linux, this will probably fail as the installer places the executable file in the `$HOME/.local/bin` directory. So give the command `export PATH=$HOME/.local/bin:$PATH`.
To make this change permanent, edit your `.profile` file, adding the following:
```
# set PATH so it includes user's private .local/bin if it exists
if [ -d "$HOME/.local/bin" ] ; then
PATH="$HOME/.local/bin:$PATH"
fi
```
<hr>
Now write a test script, `hello.ecs`, containing the following:
```
print `Hello, world!`
exit
```
(Note the backticks.) This is traditionally the first program to be written in virtually any language. To run it, use `easycoder hello.ecs`.
The output will look like this (the version number will likely differ):
```
EasyCoder version 250403.1
Compiled <anon>: 1 lines (2 tokens) in 0 ms
Run <anon>
Hello, world!
```
Why the `exit`? Because EasyCoder can't tell that the program is finished. It might contain elements that are waiting for outside events, so without `exit` it just stops and waits. You can kill it by typing Control-C.
It's conventional to add a program title to a script:
```
! Test script
script Test
log `Hello, world!`
exit
```
The first line here is just a comment and has no effect on the running of the script. The second line gives the script a name, which is useful in debugging as it says which script was running. I've also changed `print` to `log` to get more information from the script. When run, the output is now
```
EasyCoder version 250403.1
Compiled Test: 3 lines (4 tokens) in 0 ms
Run Test
16:37:39.132311: 3-> Hello, world!
```
As you might guess from the above, the `log` command shows the time and the line in the script it was called from. This is very useful in tracking down debugging print commands in large scripts.
Here in the repository is a folder called `scripts` containing some sample scripts:
`fizzbuzz.ecs` is a simple programming challenge often given at job interviews
`tests.ecs` is a test program containing many of the **_EasyCoder_** features
`benchmark.ecs` allows the performance of **_EasyCoder_** to be compared to other languages if a similar script is written for each one.
## Graphical programming
**_EasyCoder_** includes a graphical programming environment based on PySide6, that is in under development. Some demo scripts will be included in the `scripts` directory as development proceeds. Anyone wishing to track progress can do so via this repository. At the time of writing we are transitioning from an early version based on PySimpleGUI to one based on PySide, the latter being an open product that matches the needs of a DSL better than does the former.
## Significant features
- English-like syntax based on vocabulary rather than structure. Scripts can be read as English
- Comprehensive feature set
- Runs directly from source scripts. A fast compiler creates efficient intermediate code that runs immediately after compilation
- Low memory requirements
- Minimim dependency on other 3rd-party packages
- Built-in co-operative multitasking
- Dynamic loading of scripts on demand
- The language can be extended seamlessly using plugin function modules
- Plays well with any Python code
- Fully Open Source
## Programming reference
**_EasyCoder_** comprises a set of modules to handle tokenisation, compilation and runtime control. Syntax and grammar are defined by [packages](doc/README.md), of which there are currently two; the [core](doc/core/README.md) package, which implements a comprehensive set of command-line programming features, and and the [graphics](doc/graphics/README.md) package, which adds graphical features in a windowing environment.
See also [How it works](doc/README.md)
## Extending the language
**_EasyCoder_** can be extended to add new functionality with the use of 'plugins'. These contain compiler and runtime modules for the added language features. **_EasyCoder_** can use the added keywords, values and conditions freely; the effect is completely seamless. There is an outline example in the `plugins` directory called `example.py`, which comprises a module called `Points` with new language syntax to deal with two-valued items such as coordinates. In the `scripts` directory there is `points.ecs`, which exercises the new functionality.
A plugin can act as a wrapper around any Python functionality that has a sensible API, thereby hiding its complexity. The only challenge is to devise an unambiguous syntax that doesn't clash with anything already existing in **_EasyCoder_**.
## Contributing
We welcome contributions to EasyCoder-py! Please see our [CONTRIBUTING.md](CONTRIBUTING.md) guide for:
- Getting started with development
- How to work with Git branches and merge changes
- Resolving merge conflicts
- Testing and submitting pull requests
| text/markdown | null | Graham Trott <gtanyware@gmail.com> | null | null | null | compiler, scripting, prototyping, programming, coding, python, low code, hypertalk, computer language, learn to code | [
"License :: OSI Approved :: MIT License"
] | [] | null | null | null | [] | [
"easycoder"
] | [] | [
"pytz",
"requests",
"psutil",
"paramiko",
"pyside6",
"paho-mqtt"
] | [] | [] | [] | [
"Home, https://github.com/easycoder/easycoder-py"
] | python-requests/2.32.5 | 2026-02-19T15:33:22.607411 | easycoder-260218.1.tar.gz | 13,001,297 | 67/45/c419911941fca4f0bf94367a218e0d1c4015a3b86cf3ac32afd65b0976a5/easycoder-260218.1.tar.gz | source | sdist | null | false | aaf838515027c86181ccca7fb320486d | 13358192188a24b45f406cd4b4e1312bc64ba5c507fecce4a31f878913b976e4 | 6745c419911941fca4f0bf94367a218e0d1c4015a3b86cf3ac32afd65b0976a5 | null | [] | 220 |
2.4 | sdfrust | 0.6.0 | Fast Rust-based SDF, MOL2, and XYZ molecular structure file parser | # sdfrust - Python Bindings
Fast Rust-based SDF, MOL2, and XYZ molecular structure file parser with Python bindings, including transparent gzip decompression.
## Installation
### From source (requires Rust toolchain)
```bash
cd sdfrust-python
pip install maturin
maturin develop --features numpy
```
### Build wheel
```bash
maturin build --release --features numpy
pip install target/wheels/sdfrust-*.whl
```
## Quick Start
```python
import sdfrust
# Parse a single SDF file
mol = sdfrust.parse_sdf_file("molecule.sdf")
print(f"Name: {mol.name}")
print(f"Atoms: {mol.num_atoms}")
print(f"Formula: {mol.formula()}")
print(f"MW: {mol.molecular_weight():.2f}")
# Parse multiple molecules
mols = sdfrust.parse_sdf_file_multi("database.sdf")
for mol in mols:
print(f"{mol.name}: {mol.num_atoms} atoms")
# Memory-efficient iteration over large files
for mol in sdfrust.iter_sdf_file("large_database.sdf"):
print(f"{mol.name}: MW={mol.molecular_weight():.2f}")
```
## Supported Formats
- **SDF V2000**: Full support for reading and writing (up to 999 atoms/bonds)
- **SDF V3000**: Full support for reading and writing (unlimited atoms/bonds)
- **MOL2 TRIPOS**: Full support for reading and writing
- **XYZ**: Read support for XYZ coordinate files (single and multi-molecule)
- **Gzip**: Transparent decompression of `.gz` files for all formats
## API Reference
### Parsing Functions
#### SDF Files
```python
# Single molecule
mol = sdfrust.parse_sdf_file("file.sdf") # V2000
mol = sdfrust.parse_sdf_auto_file("file.sdf") # Auto-detect V2000/V3000
mol = sdfrust.parse_sdf_v3000_file("file.sdf") # V3000 only
# Multiple molecules
mols = sdfrust.parse_sdf_file_multi("file.sdf")
mols = sdfrust.parse_sdf_auto_file_multi("file.sdf")
# From string
mol = sdfrust.parse_sdf_string(content)
mols = sdfrust.parse_sdf_string_multi(content)
```
#### MOL2 Files
```python
mol = sdfrust.parse_mol2_file("file.mol2")
mols = sdfrust.parse_mol2_file_multi("file.mol2")
mol = sdfrust.parse_mol2_string(content)
```
#### Iterators (Memory-Efficient)
```python
for mol in sdfrust.iter_sdf_file("large.sdf"):
process(mol)
for mol in sdfrust.iter_mol2_file("large.mol2"):
process(mol)
```
### Writing Functions
```python
# Single molecule
sdfrust.write_sdf_file(mol, "output.sdf")
sdfrust.write_sdf_auto_file(mol, "output.sdf") # Auto V2000/V3000
sdf_string = sdfrust.write_sdf_string(mol)
# Multiple molecules
sdfrust.write_sdf_file_multi(mols, "output.sdf")
```
### Molecule Properties
```python
mol = sdfrust.parse_sdf_file("aspirin.sdf")
# Basic info
print(mol.name) # Molecule name
print(mol.num_atoms) # Number of atoms
print(mol.num_bonds) # Number of bonds
print(mol.formula()) # Molecular formula
# Descriptors
print(mol.molecular_weight()) # Molecular weight
print(mol.exact_mass()) # Monoisotopic mass
print(mol.heavy_atom_count()) # Non-hydrogen atoms
print(mol.ring_count()) # Number of rings
print(mol.rotatable_bond_count()) # Rotatable bonds
print(mol.total_charge()) # Sum of formal charges
# Geometry
centroid = mol.centroid() # (x, y, z) center
mol.translate(1.0, 0.0, 0.0) # Move molecule
mol.center() # Center at origin
# Properties (from SDF data block)
cid = mol.get_property("PUBCHEM_CID")
mol.set_property("SOURCE", "generated")
```
### Atom Access
```python
# Iterate over atoms
for atom in mol.atoms:
print(f"{atom.element} at ({atom.x}, {atom.y}, {atom.z})")
# Get specific atom
atom = mol.get_atom(0)
print(atom.element)
print(atom.formal_charge)
print(atom.coords()) # (x, y, z) tuple
# Filter atoms
carbons = mol.atoms_by_element("C")
neighbors = mol.neighbors(0) # Atom indices bonded to atom 0
```
### Bond Access
```python
# Iterate over bonds
for bond in mol.bonds:
print(f"{bond.atom1}-{bond.atom2}: {bond.order}")
# Filter bonds
double_bonds = mol.bonds_by_order(sdfrust.BondOrder.double())
aromatic = mol.has_aromatic_bonds()
# Bond properties
bond = mol.bonds[0]
print(bond.is_aromatic())
print(bond.contains_atom(0))
print(bond.other_atom(0)) # Other atom in bond
```
### NumPy Integration
```python
import numpy as np
import sdfrust
mol = sdfrust.parse_sdf_file("molecule.sdf")
# Get coordinates as NumPy array
coords = mol.get_coords_array() # Shape: (N, 3)
print(coords.shape)
# Modify and set back
coords[:, 0] += 10.0 # Translate in x
mol.set_coords_array(coords)
# Get atomic numbers
atomic_nums = mol.get_atomic_numbers() # Shape: (N,)
```
### Creating Molecules
```python
import sdfrust
# Create empty molecule
mol = sdfrust.Molecule("water")
# Add atoms
mol.add_atom(sdfrust.Atom(0, "O", 0.0, 0.0, 0.0))
mol.add_atom(sdfrust.Atom(1, "H", 0.96, 0.0, 0.0))
mol.add_atom(sdfrust.Atom(2, "H", -0.24, 0.93, 0.0))
# Add bonds
mol.add_bond(sdfrust.Bond(0, 1, sdfrust.BondOrder.single()))
mol.add_bond(sdfrust.Bond(0, 2, sdfrust.BondOrder.single()))
# Write to file
sdfrust.write_sdf_file(mol, "water.sdf")
```
## Examples
The `examples/` directory contains runnable scripts demonstrating real-world usage:
| Script | Description |
|--------|-------------|
| [`basic_usage.py`](examples/basic_usage.py) | Core API: parsing, writing, atoms, bonds, descriptors, NumPy |
| [`format_conversion.py`](examples/format_conversion.py) | Multi-format detection, XYZ parsing, SDF/MOL2 conversion, round-trips |
| [`batch_analysis.py`](examples/batch_analysis.py) | Drug library processing: filtering, sorting, Lipinski analysis |
| [`geometry_analysis.py`](examples/geometry_analysis.py) | 3D geometry: distance matrices, RMSD, rotation, transforms |
```bash
cd sdfrust-python
maturin develop --features numpy,geometry
python examples/basic_usage.py
python examples/format_conversion.py
python examples/batch_analysis.py
python examples/geometry_analysis.py
```
## Performance
sdfrust is implemented in Rust for maximum performance. Benchmarks show it is
significantly faster than pure Python parsers and comparable to C++ implementations.
For large files, use the iterator API (`iter_sdf_file`) to process molecules
one at a time without loading the entire file into memory.
## License
MIT License
| text/markdown; charset=UTF-8; variant=GFM | null | Hosein Fooladi <hosein@example.com> | null | null | MIT | chemistry, sdf, mol2, xyz, cheminformatics, parsing, molecules | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language... | [] | null | null | >=3.9 | [] | [] | [] | [
"pytest>=7.0; extra == \"dev\"",
"numpy>=1.20; extra == \"dev\"",
"numpy>=1.20; extra == \"numpy\""
] | [] | [] | [] | [
"Documentation, https://github.com/hfooladi/sdfrust#readme",
"Homepage, https://github.com/hfooladi/sdfrust",
"Repository, https://github.com/hfooladi/sdfrust"
] | maturin/1.12.3 | 2026-02-19T15:32:06.489736 | sdfrust-0.6.0.tar.gz | 158,701 | cb/1b/75fcd59fea31e4b51fc66d266ad325d8c0c37b946b47a4e8ddb1537802c8/sdfrust-0.6.0.tar.gz | source | sdist | null | false | c8f97f2ca6e4673ecf17c89f1d19fca3 | af9d175846835b3c8b7de5a00f4bc63605ee05f02e58aa988b4b4820d9095cd0 | cb1b75fcd59fea31e4b51fc66d266ad325d8c0c37b946b47a4e8ddb1537802c8 | null | [] | 930 |
2.3 | ssb-pubmd | 0.1.11 | SSB Pubmd | # SSB Pubmd
[][pypi status]
[][pypi status]
[][pypi status]
[][license]
[][documentation]
[][tests]
[][sonarcov]
[][sonarquality]
[][pre-commit]
[][black]
[](https://github.com/astral-sh/ruff)
[][poetry]
[pypi status]: https://pypi.org/project/ssb-pubmd/
[documentation]: https://statisticsnorway.github.io/ssb-pubmd
[tests]: https://github.com/statisticsnorway/ssb-pubmd/actions?workflow=Tests
[sonarcov]: https://sonarcloud.io/summary/overall?id=statisticsnorway_ssb-pubmd
[sonarquality]: https://sonarcloud.io/summary/overall?id=statisticsnorway_ssb-pubmd
[pre-commit]: https://github.com/pre-commit/pre-commit
[black]: https://github.com/psf/black
[poetry]: https://python-poetry.org/
## Features
- TODO
## Requirements
- TODO
## Installation
You can install _SSB Pubmd_ via [pip] from [PyPI]:
```console
pip install ssb-pubmd
```
## Usage
Please see the [Reference Guide] for details.
## Development
### Testing latest development version
1. Open a Jupyter service in [Dapla Dev](https://lab.dapla-dev.ssb.no/)
2. Open a Jupyter terminal and run the following commands:
```
ssb-project create my-project
cd my-project
poetry source add testpypi https://test.pypi.org/simple/ -p explicit
poetry add "pandas<3"
poetry add ssb-pubmd@latest --source testpypi --allow-prereleases
poetry run ssb-pubmd create my-article
```
3. Follow the instructions from the last command.
4. After pushing new changes (to any branch), update the package with:
```
poetry update ssb-pubmd
```
### Architecture
```mermaid
graph LR
subgraph driving[Interface]
cli[run_cli]
template[create_template_article]
article[get_article_preview]
component[create_component]
end
subgraph core[Core]
docpublisher[DocumentPublisher]
end
subgraph driven[Adapters]
docprocessor[DocumentProcessor]
cmsclient[CmsClient]
storage[Storage]
end
cmsservice[Cms Service]
cli --> template
cli --> article --> docpublisher
docpublisher --- split[ ]:::empty
split --> docprocessor
split --> cmsclient
split --> storage
cmsclient --> cmsservice
component --> storage
classDef empty width:0px,height:0px;
```
## License
Distributed under the terms of the [MIT license][license],
_SSB Pubmd_ is free and open source software.
## Issues
If you encounter any problems,
please [file an issue] along with a detailed description.
## Credits
This project was generated from [Statistics Norway]'s [SSB PyPI Template].
[statistics norway]: https://www.ssb.no/en
[pypi]: https://pypi.org/
[ssb pypi template]: https://github.com/statisticsnorway/ssb-pypitemplate
[file an issue]: https://github.com/statisticsnorway/ssb-pubmd/issues
[pip]: https://pip.pypa.io/
<!-- github-only -->
[license]: https://github.com/statisticsnorway/ssb-pubmd/blob/main/LICENSE
[contributor guide]: https://github.com/statisticsnorway/ssb-pubmd/blob/main/CONTRIBUTING.md
[reference guide]: https://statisticsnorway.github.io/ssb-pubmd/reference.html
| text/markdown | Olav Landsverk | stud-oll@ssb.no | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://github.com/statisticsnorway/ssb-pubmd | null | <4.0,>=3.10 | [] | [] | [] | [
"requests<3.0.0,>=2.32.4",
"nh3<0.4.0,>=0.3.2",
"pandocfilters<2.0.0,>=1.5.1",
"narwhals<3.0.0,>=2.15.0",
"watchfiles<2.0.0,>=1.1.1",
"dapla-auth-client<2.0.0,>=1.2.5",
"jinja2<4.0.0,>=3.1.6",
"nbformat<6.0.0,>=5.10.4",
"nbclient<0.11.0,>=0.10.4",
"pydantic<3.0.0,>=2.12.5",
"pyarrow<24.0.0,>=23.... | [] | [] | [] | [
"Homepage, https://github.com/statisticsnorway/ssb-pubmd",
"Repository, https://github.com/statisticsnorway/ssb-pubmd",
"Documentation, https://statisticsnorway.github.io/ssb-pubmd",
"Changelog, https://github.com/statisticsnorway/ssb-pubmd/releases"
] | poetry/2.1.1 CPython/3.12.3 Linux/5.15.167.4-microsoft-standard-WSL2 | 2026-02-19T15:32:01.699707 | ssb_pubmd-0.1.11.tar.gz | 15,729 | fe/31/48d75fe8e1f60b316d512ebc532d018f4e77c6e4de5ef7caca51f563c281/ssb_pubmd-0.1.11.tar.gz | source | sdist | null | false | 4827438c970d12212c733e3f15c2aa1d | e7d08e89d1216a26c317e683e07c043cb05c0993480bf4a61f44cb2c7c94ec17 | fe3148d75fe8e1f60b316d512ebc532d018f4e77c6e4de5ef7caca51f563c281 | null | [] | 207 |
2.4 | magdi-segmentation-models-3d | 0.1 | MAGDI Segmentation Models 3D | # MAGDI Segmentation Models 3D
This python package named ``magdi_segmentation_models_3d`` responsible for providing
custom Hugging Face compatible models for 3D image segmentation for the project MAGDI.
## Hugging Face Custom Models
Documentation on Hugging Face: https://huggingface.co/docs/transformers/en/custom_models
Examples:
https://github.com/huggingface/transformers/tree/main/src/transformers/models
### mednext
MedNeXt implementation from monai wrapped as Hugging Face model.
#### References:
- 10.48550/arXiv.2303.09975
#### Usage example:
```python
from magdi_segmentation_models_3d import MedNeXtModel, MedNeXtConfig,
MedNeXtForImageSegmentation, MedNeXtImageProcessor
MedNeXtConfig.register_for_auto_class()
MedNeXtModel.register_for_auto_class("AutoModel")
MedNeXtForImageSegmentation.register_for_auto_class(
"AutoModelForImageSegmentation"
)
MedNeXtImageProcessor.register_for_auto_class("AutoImageProcessor")
mednext_config = MedNeXtConfig(
variant='B',
spatial_dims=3,
in_channels=1,
out_channels=5,
kernel_size=3,
deep_supervision=False,
)
mednext_model = MedNeXtForImageSegmentation(mednext_config)
processor = MedNeXtImageProcessor()
```
### nnunetresenc
ResidualEncoderUNet from dynamic_network_architectures.architectures.unet wrapped as
Hugging Face model.
This architecture is also being used by nnUNet https://github.com/MIC-DKFZ/nnUNet.
#### References:
- 10.48550/arXiv.1809.10486
- 10.48550/arXiv.2404.09556
#### Usage example:
```python
from magdi_segmentation_models_3d import nnUNetResEncConfig, nnUNetResEncModel,
nnUNetResEncForImageSegmentation, nnUNetResEncImageProcessor
nnUNetResEncConfig.register_for_auto_class()
nnUNetResEncModel.register_for_auto_class("AutoModel")
nnUNetResEncForImageSegmentation.register_for_auto_class(
"AutoModelForImageSegmentation"
)
nnUNetResEncImageProcessor.register_for_auto_class("AutoImageProcessor")
nnunet_config = nnUNetResEncConfig(
variant="B", # only B supported yet
in_channels=1,
out_channels=5,
enable_deep_supervision=False,
)
nnunet_model = nnUNetResEncForImageSegmentation(nnunet_config)
processor = nnUNetResEncImageProcessor()
```
### stunet
STU-Net from https://github.com/Ziyan-Huang/STU-Net wrapped as Hugging Face model.
#### References:
- 10.48550/arXiv.2304.06716
#### Usage example:
```python
from magdi_segmentation_models_3d import STUNetConfig, STUNetModel,
STUNetForImageSegmentation, STUNetImageProcessor
STUNetConfig.register_for_auto_class()
STUNetModel.register_for_auto_class("AutoModel")
STUNetForImageSegmentation.register_for_auto_class(
"AutoModelForImageSegmentation"
)
STUNetImageProcessor.register_for_auto_class("AutoImageProcessor")
stu_net_config = STUNetConfig(
variant='B',
in_channels=1,
out_channels=5,
kernel_size=[[3, 3, 3]] * 6,
deep_supervision=True,
)
stu_net_model = STUNetForImageSegmentation(stu_net_config)
processor = STUNetImageProcessor()
```
### swinunetrv2
swinUNETRV2 implementation from monai wrapped as Hugging Face model.
#### References:
- 10.48550/arXiv.2201.01266
#### Usage example:
```python
from magdi_segmentation_models_3d import SwinUNETRv2Config, SwinUNETRv2Model,
SwinUNETRv2ForImageSegmentation, SwinUNETRv2ImageProcessor
SwinUNETRv2Config.register_for_auto_class()
SwinUNETRv2Model.register_for_auto_class("AutoModel")
SwinUNETRv2ForImageSegmentation.register_for_auto_class(
"AutoModelForImageSegmentation"
)
SwinUNETRv2ImageProcessor.register_for_auto_class("AutoImageProcessor")
swin_unetr_v2_config = SwinUNETRv2Config(
in_channels=1,
out_channels=5,
depths=(2, 2, 2, 2),
num_heads=(3, 6, 12, 24),
feature_size=48,
patch_size=2,
window_size=7,
drop_rate=0.2,
attn_drop_rate=0.2,
dropout_path_rate=0.2,
spatial_dims=3,
)
swinunetrv2_model = SwinUNETRv2ForImageSegmentation(swin_unetr_v2_config)
processor = SwinUNETRv2ImageProcessor()
```
### unet
Enhanced version of U-Net - Residual U-Net - implementation from monai wrapped as
Hugging Face model.
#### References:
- https://link.springer.com/chapter/10.1007/978-3-030-12029-0_40
#### Usage example:
```python
from magdi_segmentation_models_3d import UnetConfig, UnetModel,
UnetForImageSegmentation, UnetImageProcessor
UnetConfig.register_for_auto_class()
UnetModel.register_for_auto_class("AutoModel")
UnetForImageSegmentation.register_for_auto_class(
"AutoModelForImageSegmentation"
)
UnetImageProcessor.register_for_auto_class("AutoImageProcessor")
unet_config = UnetConfig(
in_channels=1,
out_channels=5,
channels=(64, 128, 256, 512, 1024),
strides=(2, 2, 2, 2),
num_res_units=2,
spatial_dims=3,
dropout=0.2,
)
unet_model = UnetForImageSegmentation(unet_config)
processor = UnetImageProcessor()
```
| text/markdown; charset=UTF-8 | null | Christian Hänig <christian.haenig@hs-anhalt.de>, Christian Gurski <christian.gurski@hs-anhalt.de> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Operating System :: OS Independent"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"torch>=2.6.0",
"torchvision>=0.21.0",
"numpy>=1.26.3",
"monai>=1.5.1",
"python-dotenv>=1.0.1",
"typing_extensions>=4.13.2",
"pyyaml>=6.0.2",
"transformers<5.0.0,>=4.55.2",
"huggingface-hub>=0.34.4",
"pillow>=11.2.1",
"optree>=0.17.0",
"acvl-utils>=0.2.3",
"dynamic-network-architectures>=0.4... | [] | [] | [] | [
"Gitlab, https://gitlab.hs-anhalt.de/ki/projekte/magdi/magdi-data"
] | twine/6.2.0 CPython/3.12.11 | 2026-02-19T15:31:14.580451 | magdi_segmentation_models_3d-0.1.tar.gz | 14,730 | 23/f3/9dae1a1ace23be58f26dada979d47ffbbcc24ca6b24197ccf554c0cd50a1/magdi_segmentation_models_3d-0.1.tar.gz | source | sdist | null | false | 2249377c4c9bc14e593c4ffcf12d506b | 18235bfd2887f5ddc69c884ec270a05a8f686e6fc2fd512cb004b23d9d7334bf | 23f39dae1a1ace23be58f26dada979d47ffbbcc24ca6b24197ccf554c0cd50a1 | MIT | [
"LICENSE"
] | 212 |
2.4 | exchange-calendar-service | 0.2.1 | A simple HTTP-based web service to query exchange calendars. | # Exchange Calendar Service
[](https://pypi.org/project/exchange-calendar-service/)
[](https://pypi.org/project/exchange-calendar-service/)
[](https://pypi.org/project/exchange-calendar-service/)
An simple HTTP service for querying exchange calendars for stock exchanges. Built on top
of [exchange_calendars](https://github.com/gerrymanoim/exchange_calendars)
and [exchange_calendars_extensions](https://github.com/jenskeiner/exchange_calendars_extensions).
## Features
- RESTful API for exchange calendar queries.
- Support for 60+ global exchanges.
- Query holidays, special open/close days, monthly and quarterly expiry days, and more.
- Support for customization hooks.
- Docker image available for easy deployment.
## Installation
The package requires Python 3.11 or later.
### As a tool
If you are primarily interested in running the service as a tool and without any customizations, you can use
[uv](https://github.com/astral-sh/uv)'s tool support:
```bash
uvx exchange-calendar-service
```
This will start the service via [Uvicorn](https://uvicorn.dev) on http://localhost:8080 by default. See
http://localhost:8080/docs for auto-generated API docs.
Alternatively, install and run via [pipx](https://github.com/pypa/pipx):
```bash
pipx install exchange-calendar-service
exchange-calendar-service
```
### As a dependency
Add the [PyPI package](https://pypi.org/project/exchange-calendar-service/) as a dependency to your Python project via
[uv](https://github.com/astral-sh/uv):
```bash
uv add exchange-calendar-service
```
Or edit `pyproject.toml` directly:
```toml
[project]
dependencies = [
"exchange-calendar-service=^0.1.0",
]
```
In a Python virtual environment, you can start the service via a script:
```bash
exchange-calendar-service
```
or by running the Python module directly:
```bash
python -m exchange_calendar_service
```
### Container image
For easy deployment, the service is available as a ready-to-use container image
on [GitHub Container Registry](https://github.com/jenskeiner/exchange_calendar_service/pkgs/container/exchange_calendar_service).
```bash
docker run -it --rm -p 8080:8080 ghcr.io/jenskeiner/exchange_calendar_service:latest
```
## Examples
Assuming the service is running on http://localhost:8080, here are some examples using [curl](https://curl.se). Note
that you can also conveniently use the auto-generated API docs at http://localhost:8080/docs to try out the endpoints.
### Supported exchanges
```bash
curl "http://localhost:8080/v1/exchanges"
```
returns a list of supported exchange MIC codes.
```json
[
"XAMS",
"XBRU",
"XBUD",
"XCSE",
"XDUB",
"XETR",
"XHEL",
"XIST",
"XLIS",
"XLON",
"XMAD",
"XOSL",
"XPAR"
]
```
### Information about a specific exchange
```bash
curl "http://localhost:8080/v1/exchanges/XLON"
```
returns Information about the London Stock Exchange.
```json
{
"mic": "XLON",
"tz": "Europe/London"
}
```
### Describe a day on an exchange
```bash
curl "http://localhost:8080/v1/exchanges/XLON/days/2024-03-12"
```
Result (business day):
```json
{
"date": "2024-03-12",
"business_day": true,
"session": {
"open": "08:00:00",
"close": "16:30:00"
},
"tags": [
"regular"
]
}
```
```bash
curl "http://localhost:8080/v1/exchanges/XLON/days/2024-12-15"
```
Result (non-business day):
```json
{
"date": "2024-12-15",
"business_day": false,
"tags": [
"weekend"
]
}
```
### Query days in a date range:
```bash
curl "http://localhost:8080/v1/exchanges/XLON/days?start=2024-12-23&end=2024-12-27"
```
Returns a list of descriptions of the days in range.
```json
[
{
"date": "2024-12-23",
"business_day": true,
"session": {
"open": "08:00:00",
"close": "16:30:00"
},
"tags": [
"regular"
]
},
{
"date": "2024-12-24",
"name": "Christmas Eve",
"business_day": true,
"session": {
"open": "08:00:00",
"close": "12:30:00"
},
"tags": [
"special close"
]
},
{
"date": "2024-12-25",
"name": "Christmas",
"business_day": false,
"tags": [
"holiday"
]
},
{
"date": "2024-12-26",
"name": "Boxing Day",
"business_day": false,
"tags": [
"holiday"
]
},
{
"date": "2024-12-27",
"business_day": true,
"session": {
"open": "08:00:00",
"close": "16:30:00"
},
"tags": [
"regular"
]
}
]
```
### Query days in a date range for multiple exchanges
```bash
curl "http://localhost:8080/v1/days?start=2024-12-23&end=2024-12-27&mics=XLON&mics=XNYS"
```
Returns a list grouped by date, where each element contains data for all requested exchanges.
```json
[
{
"XLON": {
"date": "2024-12-23",
"business_day": true,
"session": {
"open": "08:00:00",
"close": "16:30:00"
},
"tags": [
"regular"
]
},
"XNYS": {
"date": "2024-12-23",
"business_day": true,
"session": {
"open": "09:30:00",
"close": "16:00:00"
},
"tags": [
"regular"
]
}
},
{
"XLON": {
"date": "2024-12-24",
"name": "Christmas Eve",
"business_day": true,
"session": {
"open": "08:00:00",
"close": "12:30:00"
},
"tags": [
"special close"
]
},
"XNYS": {
"date": "2024-12-24",
"name": "Christmas Eve",
"business_day": true,
"session": {
"open": "09:30:00",
"close": "13:00:00"
},
"tags": [
"special close"
]
}
},
{
"XLON": {
"date": "2024-12-25",
"name": "Christmas",
"business_day": false,
"tags": [
"holiday"
]
},
"XNYS": {
"date": "2024-12-25",
"name": "Christmas",
"business_day": false,
"tags": [
"holiday"
]
}
},
{
"XLON": {
"date": "2024-12-26",
"name": "Boxing Day",
"business_day": false,
"tags": [
"holiday"
]
},
"XNYS": {
"date": "2024-12-26",
"business_day": true,
"session": {
"open": "09:30:00",
"close": "16:00:00"
},
"tags": [
"regular"
]
}
},
{
"XLON": {
"date": "2024-12-27",
"business_day": true,
"session": {
"open": "08:00:00",
"close": "16:30:00"
},
"tags": [
"regular"
]
},
"XNYS": {
"date": "2024-12-27",
"business_day": true,
"session": {
"open": "09:30:00",
"close": "16:00:00"
},
"tags": [
"regular"
]
}
}
]
```
## Configuration
The service can be configured via an `.env` file and/or environment variables. Environment variables must use the
prefix `EXCHANGE_CALENDAR_SERVICE__` to map to the correct setting.
Here's an example `.env` file:
```env
exchanges='["XLON", "XNYS"]' # Limit to these exchanges.
init=customize:init # Set to a callable to customize calendars on startup. Format: `module:callable`.
```
Environment variables to the same effect:
```bash
export EXCHANGE_CALENDAR_SERVICE_EXCHANGES='["XLON", "XNYS"]'
export EXCHANGE_CALENDAR_SERVICE_INIT="customize:init"
```
### Limiting the supported exchanges
By default, the service will support all available exchanges. In some situations, it may be convenient to limit the
supported exchanges to a subset of the available exchanges. Particularly, limiting the number of exchanges improves the
startup time of the service. This is because [exchange_calendars](https://github.com/gerrymanoim/exchange_calendars)
initializes session data on creation of each exchange calendar. This data is not exposed via this service, but
instantiating a lot of calendars can take a noticeable amount of time.
### Customization
The service support customizations by executing custom code at startup time.
### Init via Environment Variable
Set `EXCHANGE_CALENDAR_SERVICE_INIT` to a module path pointing to a callable, in the format `module:callable`. The
callable must accept one argument (`Settings`). On startup, the service will import the callable and invoke it with the
settings object as the single argument. This can be used to apply any customizations to the calendars, e.g. adding new
calendars, removing existing calendars,
registering calendar aliases, et cetera.
For example, setting `EXCHANGE_CALENDAR_SERVICE_INIT="customize:init"` will execute the `init` function from the
[customize](./customize) module. See the example for details on how calendars can be customized.
```bash
export EXCHANGE_CALENDAR_SERVICE_INIT="customize:init"
uv run python -m exchange_calendar_service.app
```
#### Via Entrypoints
Custom code can also be discovered automatically
via [entry points](https://packaging.python.org/en/latest/specifications/entry-points/)
in the `exchange_calendar_service.init` group. All discovered entrypoints are called sequentially, but in no particular
order.
To register an entrypoint, add to your `pyproject.toml`:
```toml
[project.entry-points."exchange_calendar_service.init"]
my_customizer = "my_package:init_function"
```
Multiple packages can register entrypoints, and all will be called. This allows customization via installed dependencies
without needing to set environment variables.
## API Reference
### Response Model
The response JSON Schema for a single day on a single exchange looks like this:
```json
{
"$defs": {
"BusinessDay": {
"properties": {
"date": {
"format": "date",
"title": "The date of the day in ISO format (YYYY-MM-DD).",
"type": "string"
},
"name": {
"anyOf": [
{
"type": "string"
},
{
"type": "null"
}
],
"default": null,
"title": "The name of the day."
},
"tags": {
"items": {
"$ref": "#/$defs/Tags"
},
"title": "A set of tags associated with the day.",
"type": "array",
"uniqueItems": true
},
"business_day": {
"const": true,
"default": true,
"title": "Indicates that the day is a business day.",
"type": "boolean"
},
"session": {
"$ref": "#/$defs/Session",
"title": "The trading session."
}
},
"required": [
"date",
"tags",
"session"
],
"title": "BusinessDay",
"type": "object"
},
"NonBusinessDay": {
"properties": {
"date": {
"format": "date",
"title": "The date of the day in ISO format (YYYY-MM-DD).",
"type": "string"
},
"name": {
"anyOf": [
{
"type": "string"
},
{
"type": "null"
}
],
"default": null,
"title": "The name of the day."
},
"tags": {
"items": {
"$ref": "#/$defs/Tags"
},
"title": "A set of tags associated with the day.",
"type": "array",
"uniqueItems": true
},
"business_day": {
"const": false,
"default": false,
"title": "Indicates that the day is not a business day.",
"type": "boolean"
}
},
"required": [
"date",
"tags"
],
"title": "NonBusinessDay",
"type": "object"
},
"Session": {
"properties": {
"open": {
"format": "time",
"title": "The start of the trading session (HH:MM:SS).",
"type": "string"
},
"close": {
"format": "time",
"title": "The end of the trading session (HH:MM:SS).",
"type": "string"
}
},
"required": [
"open",
"close"
],
"title": "Session",
"type": "object"
},
"Tags": {
"enum": [
"special open",
"special close",
"quarterly expiry",
"monthly expiry",
"month end",
"holiday",
"weekend",
"regular"
],
"title": "Tags",
"type": "string"
}
},
"discriminator": {
"mapping": {
"False": "#/$defs/NonBusinessDay",
"True": "#/$defs/BusinessDay"
},
"propertyName": "business_day"
},
"oneOf": [
{
"$ref": "#/$defs/BusinessDay"
},
{
"$ref": "#/$defs/NonBusinessDay"
}
]
}
```
The fields `date`, `business_day` and `tags` are always present:
- `date`: The date in ISO format.
- `business_day`: Whether the day is a business day or not.
- `tags`: A list of tags associated with the day.
The response may optionally provide a `name` field, e.g. for holidays or special days.
If the day is a business day, the response contains the `session` field which provides the start and end time of the
trading session.
*Note: Session open and close times are always in the exchange's timezone.*
### Tags
While the `business_day` partitions the days into business and non-business days, tags allow to attach more
fine-grained information to individual days. Each day can carry multiple tags, e.g. "holiday" and "weekend". The
meaning of the tags is as follows:
- `special open`: The trading session starts at a non-standard time, typically later than usual.
- `special close`: The trading session ends at a non-standard time, typically earlier than usual.
- `quarterly expiry`: Indicates quarterly expiry days, typically the third Thursday in March, June, September and
December.
- `monthly expiry`: Indicates monthly expiry days, typically the third Thursday in the other months.
- `month end`: The last trading day in the respective month.
- `holiday`: A holiday on which the exchange is closed.
- `weekend`: A weekend day on which the exchange is regularly closed.
- `regular`: The day has regular trading session times.
#### Examples
A regular trading day:
```json
{
"date": "2026-01-08",
"business_day": true,
"session": {
"open": "08:00:00",
"close": "16:30:00"
},
"tags": [
"regular"
]
}
```
A regular weekend day:
```json
{
"date": "2026-01-10",
"business_day": false,
"tags": [
"weekend"
]
}
```
A holiday that would otherwise be a business day:
```json
{
"date": "2026-01-01",
"name": "New Year's Day",
"business_day": false,
"tags": [
"holiday"
]
}
```
A holiday that is also a wekend day:
```json
{
"date": "2022-12-25",
"name": "Christmas",
"tags": [
"weekend",
"holiday"
],
"business_day": false
}
```
A special close day that is also the last trading day of a month:
```json
{
"date": "2022-12-30",
"name": "New Year's Eve",
"business_day": true,
"session": {
"open": "08:00:00",
"close": "12:30:00"
},
"tags": [
"special close",
"month end"
]
}
```
### API versioning
There is currently only one version of the API. All endpoints are under `/v1/`.
### Reference Endpoints
These endpoints return reference data for the supported exchanges.
#### GET /exchanges
Get a list of supported exchanges' MIC codes.
Example request:
```bash
curl http: //localhost:8080/v1/exchanges
```
Response:
```json
[
"XAMS",
"XLON",
"XNYS",
"XSWX"
]
```
#### GET /exchanges/{mic}
Get information about a specific exchange.
Path parameters:
- `mic` - MIC code of the exchange
Example request:
```bash
curl http://localhost:8080/v1/exchanges/XLON
```
Response:
```json
{
"mic": "XLON",
"tz": "Europe/London"
}
```
### Single Exchange Endpoints
These endpoints return information about one or more days for a single exchange.
#### GET /exchanges/{mic}/days/{day}
Describe a single day for an exchange.
Path parameters:
- `mic` - MIC code of the exchange
- `day` - Date in ISO format (e.g., `2024-12-25`)
Example request:
```bash
curl "http://localhost:8080/v1/exchanges/XLON/days/2024-12-25"
```
Response:
```json
{
"date": "2024-12-25",
"name": "Christmas Day",
"business_day": false,
"tags": [
"holiday"
]
}
```
#### GET /exchanges/{mic}/days
Get days in a date range that match criteria.
Path Parameters:
- `mic` - MIC code of the exchange
Query Parameters:
- `start` (required) - Start date in ISO format (inclusive)
- `end` (required) - End date in ISO format (inclusive)
- `business_day` (optional) - Filter to only business days (`true`) or non-business days (`false`)
- `include_tags` (optional, repeatable) - Only include days with all the given tags
- `exclude_tags` (optional, repeatable) - Exclude days with any of the given tags
- `order` (optional, default: `asc`) - Sort order: `asc` or `desc`
- `limit` (optional) - Maximum number of days to return
Example request:
```bash
curl "http://localhost:8080/v1/exchanges/XLON/days?start=2024-12-24&end=2024-12-27&business_day=false"
```
Response:
```json
[
{
"date": "2024-12-25",
"name": "Christmas",
"business_day": false,
"tags": [
"holiday"
]
},
{
"date": "2024-12-26",
"name": "Boxing Day",
"business_day": false,
"tags": [
"holiday"
]
}
]
```
Example request:
```bash
curl "http://localhost:8080/v1/exchanges/XLON/days?start=2024-12-24&end=2024-12-31&include_tags=special%20close&include_tags=month%20end&order=asc"
```
Response:
```json
[
{
"date": "2024-12-31",
"name": "New Year's Eve",
"business_day": true,
"session": {
"open": "08:00:00",
"close": "12:30:00"
},
"tags": [
"special close",
"month end"
]
}
]
```
#### GET /exchanges/{mic}/days/{day}/next
Get the next (or previous) days matching criteria relative to a reference day.
**Path Parameters:**
- `mic` - MIC code of the exchange
- `day` - Reference date in ISO format
**Query Parameters:**
- `direction` (optional, default: `forward`) - Search direction: `forward` or `backward`
- `inclusive` (optional, default: `true`) - Include the reference day if it matches
- `end` (optional) - End date to bound the search (inclusive)
- `business_day` (optional) - Filter to only business days or non-business days
- `include_tags` (optional, repeatable) - Only include days with all the given tags
- `exclude_tags` (optional, repeatable) - Exclude days with any of the given tags
- `limit` (optional) - Maximum number of days to return
- `order` (optional, default: `asc`) - Sort order of results: `asc` or `desc`
**Example:**
```bash
curl "http://localhost:8080/v1/exchanges/XLON/days/2024-12-20/next?direction=forward&limit=3&business_day=false"
```
```json
[
{
"date": "2024-12-21",
"business_day": false,
"tags": [
"weekend"
]
},
{
"date": "2024-12-22",
"business_day": false,
"tags": [
"weekend"
]
},
{
"date": "2024-12-25",
"name": "Christmas",
"business_day": false,
"tags": [
"holiday"
]
}
]
```
### Multi-Exchange Endpoints
These endpoints return information about one or more days for multiple exchanges in a single request.
#### GET /days/{day}
Get a specific day for multiple exchanges.
Path parameters:
- `day` - Date in ISO format (e.g., `2024-12-25`)
Query parameters:
- `mics` (required, repeatable) - One or more MIC codes of the exchanges to query
Example request:
```bash
curl "http://localhost:8080/v1/days/2024-12-25?mics=XLON&mics=XSWX"
```
Response:
```json
{
"XLON": {
"date": "2024-12-25",
"name": "Christmas",
"business_day": false,
"tags": [
"holiday"
]
},
"XSWX": {
"date": "2024-12-25",
"name": "Christmas",
"business_day": false,
"tags": [
"holiday"
]
}
}
```
#### GET /days
Get days in a date range that match criteria for multiple exchanges.
Query Parameters:
- `mics` (required, repeatable) - One or more MIC codes of the exchanges to query
- `start` (required) - Start date in ISO format (inclusive)
- `end` (required) - End date in ISO format (inclusive)
- `business_day` (optional) - Filter to only business days (`true`) or non-business days (`false`)
- `include_tags` (optional, repeatable) - Only include days with all the given tags
- `exclude_tags` (optional, repeatable) - Exclude days with any of the given tags
- `order` (optional, default: `asc`) - Sort order: `asc` or `desc`
- `limit` (optional) - Maximum number of date records to return (each record contains all MICs' data for that date)
The response is grouped by date, with MICs within each date ordered alphabetically.
Example request:
```bash
curl "http://localhost:8080/v1/days?start=2024-12-24&end=2024-12-27&mics=XLON&mics=XNYS&business_day=false"
```
Response:
```json
[
{
"XLON": {
"date": "2024-12-25",
"name": "Christmas",
"business_day": false,
"tags": [
"holiday"
]
},
"XNYS": {
"date": "2024-12-25",
"name": "Christmas",
"business_day": false,
"tags": [
"holiday"
]
}
},
{
"XLON": {
"date": "2024-12-26",
"name": "Boxing Day",
"business_day": false,
"tags": [
"holiday"
]
}
}
]
```
Note: The `limit` parameter applies to the number of date records returned, not the total number of individual
exchange-day entries.
#### GET /days/{day}/next
Get the next days matching criteria relative to a day for multiple exchanges.
Path parameters:
- `day` - Date in ISO format (e.g., `2024-12-25`)
Query parameters:
- `mics` (required, repeatable) - One or more MIC codes of the exchanges to query
- `direction` (optional, default: `forward`) - Search direction: `forward` or `backward`
- `inclusive` (optional, default: `true`) - If `true`, include the start day in results
- `end` (optional) - End date to limit the search range
- `business_day` (optional) - Filter to only business days (`true`) or non-business days (`false`)
- `include_tags` (optional, repeatable) - Only include days with all the given tags
- `exclude_tags` (optional, repeatable) - Exclude days with any of the given tags
- `order` (optional, default: `asc`) - Sort order: `asc` or `desc`
- `limit` (optional) - Maximum number of date records to return
The response is grouped by date, with MICs within each date ordered alphabetically.
Example request:
```bash
curl "http://localhost:8080/v1/days/2024-12-24/next?mics=XLON&mics=XSWX&direction=forward&limit=3"
```
Response:
```json
[
{
"XLON": {
"date": "2024-12-24",
"name": "Christmas Eve",
"business_day": true,
"session": {
"open": "08:00:00",
"close": "12:30:00"
},
"tags": [
"special close"
]
},
"XSWX": {
"date": "2024-12-24",
"name": "Christmas Eve",
"business_day": false,
"tags": [
"holiday"
]
}
},
{
"XLON": {
"date": "2024-12-25",
"name": "Christmas",
"business_day": false,
"tags": [
"holiday"
]
},
"XSWX": {
"date": "2024-12-25",
"name": "Christmas",
"business_day": false,
"tags": [
"holiday"
]
}
},
{
"XLON": {
"date": "2024-12-26",
"name": "Boxing Day",
"business_day": false,
"tags": [
"holiday"
]
},
"XSWX": {
"date": "2024-12-26",
"name": "Boxing Day",
"business_day": false,
"tags": [
"holiday"
]
}
}
]
```
## Development
Clone this repository and run `uv sync` and you are good to go.
### Testing
Run the full test suite with coverage:
```bash
uv run pytest -v tests/ --cov=exchange_calendar_service
```
### Building the Docker Image
From the project root:
```bash
docker build -f docker/Dockerfile -t exchange-calendar-service .
```
### Running the Container
```bash
docker run -p 8080:8080 exchange-calendar-service
```
## License
Apache-2.0
| text/markdown | null | Jens Keiner <jens.keiner@gmail.com> | null | null | null | calendar, exchange, holidays, trading | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Financial and Insurance Industry",
"Intended Audience :: Information Technology",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Pr... | [] | null | null | >=3.11 | [] | [] | [] | [
"cachetools<7,>6",
"exchange-calendars-extensions<1,>=0.9.3",
"fastapi<1,>0",
"myers<2,>1",
"pydantic-settings<3,>=2",
"pytz",
"pyyaml<7,>=6",
"uvicorn<1,>=0.40.0"
] | [] | [] | [] | [
"homepage, https://github.com/jenskeiner/exchange_calendar_service/",
"repository, https://github.com/jenskeiner/exchange_calendar_service/",
"documentation, https://github.com/jenskeiner/exchange_calendar_service/tree/main/docs/",
"issues, https://github.com/jenskeiner/exchange_calendar_service/issues/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:31:08.580296 | exchange_calendar_service-0.2.1.tar.gz | 116,140 | 0d/a9/02827bef8d58cfaceee39456b03b68d597a46d9c493f8753441522c84828/exchange_calendar_service-0.2.1.tar.gz | source | sdist | null | false | 3d49f54e79acbbcb1c4387c57cb38d31 | fabc49ca94e0a7c4681eed86ad44b540c78e0d3ed1e69f7a7e7c155e65d97660 | 0da902827bef8d58cfaceee39456b03b68d597a46d9c493f8753441522c84828 | Apache-2.0 | [
"LICENSE"
] | 208 |
2.4 | scoda | 2.7 | A MIDI and music data manipulation library | # S-Coda
[](https://github.com/FelixSchoen/S-Coda/releases)
[](https://github.com/FelixSchoen/S-Coda/actions/workflows/scoda_test.yml)
[](https://www.python.org/downloads/release/python-3119/)
[](https://doi.org/10.34726/hss.2023.103585)
[](https://doi.org/10.1007/978-3-031-47546-7_19)
## Overview
S-Coda is a Python library for handling MIDI files.
It is written with the purpose of machine learning tasks in mind.
S-Coda supports a plethora of different MIDI manipulation operations, such as:
- quantisation of notes
- quantisation of note lengths
- splitting sequences into bars
- transposing of sequences
- creating piano-roll visualisations of pieces
- tokenisation of sequences
S-Coda was used in our project [PAUL-2](https://github.com/FelixSchoen/PAUL-2) to process MIDI files.
For information about how to use S-Coda we refer to chapter 5 of the [thesis](https://doi.org/10.34726/hss.2023.103585)
in which S-Coda was introduced.
Note that this thesis refers to version 1.0 of S-Coda, which has since received major overhauls.
## Installation
We recommend installing S-Coda from [PyPI](https://pypi.org/project/scoda/) using pip:
```pip install scoda```
## Changelog
See [`CHANGELOG.md`](https://github.com/FelixSchoen/S-Coda/blob/main/CHANGELOG.md) for a detailed changelog.
## Usage
### Example
We refer to the aforementioned thesis for a more in-depth guide on how to use S-Coda.
We provide a short listing on how to use basic S-Coda functions, which is up-to-date as of version 2.4.0.:
```python
# Load sequence, choose correct track (often first track contains only meta messages)
sequence = Sequence.sequences_load(file_path=RESOURCE_BEETHOVEN)[1]
# Quantise the sequence to sixteenths and sixteenth triplets (standard values)
sequence.quantise_and_normalise()
# Split the sequence into bars based on the occurring time signatures
bars = Sequence.sequences_split_bars([sequence], meta_track_index=0)[0]
# Prepare tokeniser and output tokens
tokeniser = MultiTrackLargeVocabularyNotelikeTokeniser(num_tracks=1)
tokens = []
# Tokenise all bars in the sequence
for bar in bars:
tokens.extend(tokeniser.tokenise([bar.sequence]))
# Convert to a numeric representation
encoded_tokens = tokeniser.encode(tokens)
# (Conduct ML operations on tokens)
encoded_tokens = encoded_tokens
# Convert back to token representation
decoded_tokens = tokeniser.decode(encoded_tokens)
# Create sequence from tokens
detokenised_sequences = tokeniser.detokenise(decoded_tokens)
# Save sequence
detokenised_sequences[0].save("../out/generated_sequence.mid")
```
### Implementational Details
S-Coda is built around the `Sequence` class, which represents a musical sequence.
The `Sequence` object is a wrapper for two internal classes, `AbsoluteSequence` and `RelativeSequence`, which represent
music in two different ways.
For the absolute sequences, the elements of the sequences are annotated with their absolute points in time within the
sequence, while for the relative sequence elements specify the time between events.
These two representations are used internally for different operations.
The `Sequence` object abstracts away the differences between these two representations and provides the user with a
unified experience.
The atomic element of S-Coda is the `Message`, which is comparable to a MIDI event.
Messages have a `MessageType`, denoting the type of the message, and several other fields depending on which type of
message it is.
For example, a message of type `NOTE_ON` will have a `note` field, which denotes the pitch number of the note that it
represents.
Note that directly editing single messages or the messages of a sequence is possible, but not recommended, as it can
lead to inconsistencies in the `Sequence` object.
If you still need to do so, make sure to invalidate either the absolute or relative internal representation (using
`Sequence.invalidate_abs()` and `Sequence.invalidate_rel()`) after directly editing messages.
This is _not_ required when modifying the sequence using the functions provided by `Sequence`, as staleness of the
internal representations is kept track of this way.
# Citing
If you use S-Coda in your research, please cite the following paper:
```bibtex
@inproceedings{Schoen.2023,
author = {Felix Sch{\"{o}}n and
Hans Tompits},
title = {{PAUL-2:} An Upgraded Transformer-Based Redesign of the Algorithmic Composer {PAUL}},
booktitle = {22nd International Conference of the Italian Association for Artificial Intelligence ({AIxIA 2023})},
series = {Lecture Notes in Computer Science},
volume = {14318},
pages = {278--291},
publisher = {Springer},
year = {2023},
doi = {10.1007/978-3-031-47546-7\_19}
}
```
| text/markdown | null | Felix Schön <schoen@kr.tuwien.ac.at> | null | null | MIT License
Copyright (c) 2025 Felix Schön
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| midi, music | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"mido",
"numpy",
"matplotlib",
"pytest; extra == \"test\"",
"pytest-xdist; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"coverage; extra == \"test\"",
"build; extra == \"test\"",
"build; extra == \"deploy\"",
"twine; extra == \"deploy\"",
"pdoc3; extra == \"deploy\""
] | [] | [] | [] | [
"Homepage, https://github.com/FelixSchoen/S-Coda",
"Bugtracker, https://github.com/FelixSchoen/S-Coda/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:31:00.643769 | scoda-2.7.tar.gz | 39,419 | e1/c2/382597b5bcaa2097089c406363182dab452ffe160d3319a38c7c9a2244b6/scoda-2.7.tar.gz | source | sdist | null | false | e3c06de10cc0e62d06b71eb7c9d85e15 | 55eb99732aaafb1365435c76c1c843145bceeab3ba3001e1886d89af0b0a0e7c | e1c2382597b5bcaa2097089c406363182dab452ffe160d3319a38c7c9a2244b6 | null | [
"LICENSE.md"
] | 197 |
2.4 | dj-database-url | 3.1.2 | Use Database URLs in your Django Application. | DJ-Database-URL
~~~~~~~~~~~~~~~
.. image:: https://jazzband.co/static/img/badge.png
:target: https://jazzband.co/
:alt: Jazzband
.. image:: https://github.com/jazzband/dj-database-url/actions/workflows/test.yml/badge.svg
:target: https://github.com/jazzband/dj-database-url/actions/workflows/test.yml
.. image:: https://codecov.io/gh/jazzband/dj-database-url/branch/master/graph/badge.svg?token=7srBUpszOa
:target: https://codecov.io/gh/jazzband/dj-database-url
This simple Django utility allows you to utilize the
`12factor <http://www.12factor.net/backing-services>`_ inspired
``DATABASE_URL`` environment variable to configure your Django application.
The ``dj_database_url.config`` method returns a Django database connection
dictionary, populated with all the data specified in your URL. There is
also a `conn_max_age` argument to easily enable Django's connection pool.
If you'd rather not use an environment variable, you can pass a URL in directly
instead to ``dj_database_url.parse``.
Installation
------------
Installation is simple:
.. code-block:: console
$ pip install dj-database-url
Usage
-----
1. If ``DATABASES`` is already defined:
- Configure your database in ``settings.py`` from ``DATABASE_URL``:
.. code-block:: python
import dj_database_url
DATABASES['default'] = dj_database_url.config(
conn_max_age=600,
conn_health_checks=True,
)
- Provide a default:
.. code-block:: python
DATABASES['default'] = dj_database_url.config(
default='postgres://...',
conn_max_age=600,
conn_health_checks=True,
)
- Parse an arbitrary Database URL:
.. code-block:: python
DATABASES['default'] = dj_database_url.parse(
'postgres://...',
conn_max_age=600,
conn_health_checks=True,
)
2. If ``DATABASES`` is not defined:
- Configure your database in ``settings.py`` from ``DATABASE_URL``:
.. code-block:: python
import dj_database_url
DATABASES = {
'default': dj_database_url.config(
conn_max_age=600,
conn_health_checks=True,
),
}
- You can provide a default, used if the ``DATABASE_URL`` setting is not defined:
.. code-block:: python
DATABASES = {
'default': dj_database_url.config(
default='postgres://...',
conn_max_age=600,
conn_health_checks=True,
)
}
- Parse an arbitrary Database URL:
.. code-block:: python
DATABASES = {
'default': dj_database_url.parse(
'postgres://...',
conn_max_age=600,
conn_health_checks=True,
)
}
``conn_max_age`` sets the |CONN_MAX_AGE setting|__, which tells Django to
persist database connections between requests, up to the given lifetime in
seconds. If you do not provide a value, it will follow Django’s default of
``0``. Setting it is recommended for performance.
.. |CONN_MAX_AGE setting| replace:: ``CONN_MAX_AGE`` setting
__ https://docs.djangoproject.com/en/stable/ref/settings/#conn-max-age
``conn_health_checks`` sets the |CONN_HEALTH_CHECKS setting|__ (new in Django
4.1), which tells Django to check a persisted connection still works at the
start of each request. If you do not provide a value, it will follow Django’s
default of ``False``. Enabling it is recommended if you set a non-zero
``conn_max_age``.
.. |CONN_HEALTH_CHECKS setting| replace:: ``CONN_HEALTH_CHECKS`` setting
__ https://docs.djangoproject.com/en/stable/ref/settings/#conn-health-checks
Strings passed to `dj_database_url` must be valid URLs; in
particular, special characters must be url-encoded. The following url will raise
a `ValueError`:
.. code-block:: plaintext
postgres://user:p#ssword!@localhost/foobar
and should instead be passed as:
.. code-block:: plaintext
postgres://user:p%23ssword!@localhost/foobar
`TEST <https://docs.djangoproject.com/en/stable/ref/settings/#test>`_ settings can be configured using the ``test_options`` attribute::
DATABASES['default'] = dj_database_url.config(default='postgres://...', test_options={'NAME': 'mytestdatabase'})
Supported Databases
-------------------
Support currently exists for PostgreSQL, PostGIS, MySQL, MySQL (GIS),
Oracle, Oracle (GIS), Redshift, CockroachDB, Timescale, Timescale (GIS) and SQLite.
If you want to use
some non-default backends, you need to register them first:
.. code-block:: python
import dj_database_url
# registration should be performed only once
dj_database_url.register("mysql-connector", "mysql.connector.django")
assert dj_database_url.parse("mysql-connector://user:password@host:port/db-name") == {
"ENGINE": "mysql.connector.django",
# ...other connection params
}
Some backends need further config adjustments (e.g. oracle and mssql
expect ``PORT`` to be a string). For such cases you can provide a
post-processing function to ``register()`` (note that ``register()`` is
used as a **decorator(!)** in this case):
.. code-block:: python
import dj_database_url
@dj_database_url.register("mssql", "sql_server.pyodbc")
def stringify_port(config):
config["PORT"] = str(config["PORT"])
@dj_database_url.register("redshift", "django_redshift_backend")
def apply_current_schema(config):
options = config["OPTIONS"]
schema = options.pop("currentSchema", None)
if schema:
options["options"] = f"-c search_path={schema}"
@dj_database_url.register("snowflake", "django_snowflake")
def adjust_snowflake_config(config):
config.pop("PORT", None)
config["ACCOUNT"] = config.pop("HOST")
name, _, schema = config["NAME"].partition("/")
if schema:
config["SCHEMA"] = schema
config["NAME"] = name
options = config.get("OPTIONS", {})
warehouse = options.pop("warehouse", None)
if warehouse:
config["WAREHOUSE"] = warehouse
role = options.pop("role", None)
if role:
config["ROLE"] = role
URL schema
----------
+----------------------+-----------------------------------------------+--------------------------------------------------+
| Engine | Django Backend | URL |
+======================+===============================================+==================================================+
| PostgreSQL | ``django.db.backends.postgresql`` [1]_ | ``postgres://USER:PASSWORD@HOST:PORT/NAME`` [2]_ |
| | | ``postgresql://USER:PASSWORD@HOST:PORT/NAME`` |
+----------------------+-----------------------------------------------+--------------------------------------------------+
| PostGIS | ``django.contrib.gis.db.backends.postgis`` | ``postgis://USER:PASSWORD@HOST:PORT/NAME`` |
+----------------------+-----------------------------------------------+--------------------------------------------------+
| MSSQL | ``sql_server.pyodbc`` | ``mssql://USER:PASSWORD@HOST:PORT/NAME`` |
+----------------------+-----------------------------------------------+--------------------------------------------------+
| MSSQL [5]_ | ``mssql`` | ``mssqlms://USER:PASSWORD@HOST:PORT/NAME`` |
+----------------------+-----------------------------------------------+--------------------------------------------------+
| MySQL | ``django.db.backends.mysql`` | ``mysql://USER:PASSWORD@HOST:PORT/NAME`` [2]_ |
+----------------------+-----------------------------------------------+--------------------------------------------------+
| MySQL (GIS) | ``django.contrib.gis.db.backends.mysql`` | ``mysqlgis://USER:PASSWORD@HOST:PORT/NAME`` |
+----------------------+-----------------------------------------------+--------------------------------------------------+
| SQLite | ``django.db.backends.sqlite3`` | ``sqlite:///PATH`` [3]_ |
+----------------------+-----------------------------------------------+--------------------------------------------------+
| SpatiaLite | ``django.contrib.gis.db.backends.spatialite`` | ``spatialite:///PATH`` [3]_ |
+----------------------+-----------------------------------------------+--------------------------------------------------+
| Oracle | ``django.db.backends.oracle`` | ``oracle://USER:PASSWORD@HOST:PORT/NAME`` [4]_ |
+----------------------+-----------------------------------------------+--------------------------------------------------+
| Oracle (GIS) | ``django.contrib.gis.db.backends.oracle`` | ``oraclegis://USER:PASSWORD@HOST:PORT/NAME`` |
+----------------------+-----------------------------------------------+--------------------------------------------------+
| Redshift | ``django_redshift_backend`` | ``redshift://USER:PASSWORD@HOST:PORT/NAME`` |
+----------------------+-----------------------------------------------+--------------------------------------------------+
| CockroachDB | ``django_cockroachdb`` | ``cockroach://USER:PASSWORD@HOST:PORT/NAME`` |
+----------------------+-----------------------------------------------+--------------------------------------------------+
| Timescale [6]_ | ``timescale.db.backends.postgresql`` | ``timescale://USER:PASSWORD@HOST:PORT/NAME`` |
+----------------------+-----------------------------------------------+--------------------------------------------------+
| Timescale (GIS) [6]_ | ``timescale.db.backend.postgis`` | ``timescalegis://USER:PASSWORD@HOST:PORT/NAME`` |
+----------------------+-----------------------------------------------+--------------------------------------------------+
.. [1] The django.db.backends.postgresql backend is named django.db.backends.postgresql_psycopg2 in older releases. For
backwards compatibility, the old name still works in newer versions. (The new name does not work in older versions).
.. [2] With PostgreSQL or CloudSQL, you can also use unix domain socket paths with
`percent encoding <http://www.postgresql.org/docs/9.2/interactive/libpq-connect.html#AEN38162>`_:
``postgres://%2Fvar%2Flib%2Fpostgresql/dbname``
``mysql://uf07k1i6d8ia0v@%2fcloudsql%2fproject%3alocation%3ainstance/dbname``
.. [3] SQLite connects to file based databases. The same URL format is used, omitting
the hostname, and using the "file" portion as the filename of the database.
This has the effect of four slashes being present for an absolute file path:
``sqlite:////full/path/to/your/database/file.sqlite``.
.. [4] Note that when connecting to Oracle the URL isn't in the form you may know
from using other Oracle tools (like SQLPlus) i.e. user and password are separated
by ``:`` not by ``/``. Also you can omit ``HOST`` and ``PORT``
and provide a full DSN string or TNS name in ``NAME`` part.
.. [5] Microsoft official `mssql-django <https://github.com/microsoft/mssql-django>`_ adapter.
.. [6] Using the django-timescaledb Package which must be installed.
Contributing
------------
We welcome contributions to this project. Projects can take two forms:
1. Raising issues or helping others through the github issue tracker.
2. Contributing code.
Raising Issues or helping others:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
When submitting an issue or helping other remember you are talking to humans who have feelings, jobs and lives of their
own. Be nice, be kind, be polite. Remember english may not be someone first language, if you do not understand or
something is not clear be polite and re-ask/ re-word.
Contributing code:
^^^^^^^^^^^^^^^^^^
* Before writing code be sure to check existing PR's and issues in the tracker.
* Write code to the pylint spec.
* Large or wide sweeping changes will take longer, and may face more scrutiny than smaller confined changes.
* Code should be pass `black` and `flake8` validation.
| text/x-rst | Jazzband community | null | null | null | null | null | [
"Environment :: Web Environment",
"Framework :: Django",
"Framework :: Django :: 4.2",
"Framework :: Django :: 5.2",
"Framework :: Django :: 6",
"Intended Audience :: Developers",
"License :: OSI Approved :: BSD License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Top... | [] | null | null | >=3.10 | [] | [] | [] | [
"django>=4.2"
] | [] | [] | [] | [
"Homepage, https://jazzband.co/projects/dj-database-url",
"Changelog, https://github.com/jazzband/dj-database-url/blob/master/CHANGELOG.md",
"Funding, https://psfmember.org/civicrm/contribute/transact/?reset=1&id=34",
"Bug, https://github.com/jazzband/dj-database-url/issues"
] | twine/6.2.0 CPython/3.11.4 | 2026-02-19T15:30:39.370340 | dj_database_url-3.1.2-py3-none-any.whl | 8,953 | cf/a9/57c66006373381f1d3e5bd94216f1d371228a89f443d3030e010f73dd198/dj_database_url-3.1.2-py3-none-any.whl | py3 | bdist_wheel | null | false | cff50f396f0209d26ec3a9726870b5d1 | 544e015fee3efa5127a1eb1cca465f4ace578265b3671fe61d0ed7dbafb5ec8a | cfa957c66006373381f1d3e5bd94216f1d371228a89f443d3030e010f73dd198 | BSD-3-Clause | [
"LICENSE"
] | 56,965 |
2.4 | dataframe-textual | 2.23.0 | Interactive terminal viewer/editor for tabular data | # DataFrame Textual
A powerful, interactive terminal-based viewer/editor for CSV/TSV/PSV/Excel/[Parquet](https://parquet.apache.org/)/[Vortex](https://vortex.dev/)/JSON/NDJSON built with Python, [Polars](https://pola.rs/), and [Textual](https://textual.textualize.io/). Inspired by [VisiData](https://www.visidata.org/), this tool provides smooth keyboard navigation, data manipulation, and a clean interface for exploring tabular data directly in terminal with multi-tab support for multiple files!
## Features
### Data Viewing
- 🚀 **Fast Loading** - Powered by Polars for efficient data handling
- 🎨 **Rich Terminal UI** - Beautiful, color-coded columns with various data types (e.g., integer, float, string)
- ⌨️ **Comprehensive Keyboard Navigation** - Intuitive controls
- 📊 **Flexible Input** - Read from files and/or stdin (pipes/redirects)
- 🔄 **Smart Pagination** - Lazy load rows on demand for handling large datasets
### Data Manipulation
- 📝 **Data Editing** - Edit cells, delete rows, and remove columns
- 🔍 **Search & Filter** - Find values, highlight matches, and filter selected rows
- ↔️ **Column/Row Reordering** - Move columns and rows with simple keyboard shortcuts
- 📈 **Sorting & Statistics** - Multi-column sorting and frequency distribution analysis
- 💾 **Save & Undo** - Save edits back to file with full undo/redo support
### Advanced Features
- 📂 **Multi-File Support** - Open multiple files in separate tabs
- 🔄 **Tab Management** - Seamlessly switch between open files with keyboard shortcuts
- 📑 **Duplicate Tab** - Create a copy of the current tab with the same data
- 📌 **Freeze Rows/Columns** - Keep important rows and columns visible while scrolling
- 🎯 **Cursor Type Cycling** - Switch between cell, row, and column selection modes
- 📸 **Take Screenshot** - Capture terminal view as a SVG image
## Installation
### Using pip
```bash
# Install from PyPI
pip install dataframe-textual
```
This installs an executable `dv`.
Then run:
```bash
dv <file>
```
### Using [uv](https://docs.astral.sh/uv/)
```bash
# Install as a tool
uv install dataframe-textual
# Quick run using uvx without installation
uvx https://github.com/need47/dataframe-textual.git <csvfile>
# Clone or download the project
cd dataframe-textual
uv sync
# Run directly with uv
uv run dv <file>
```
### Development installation
```bash
# Clone the repository
git clone https://github.com/need47/dataframe-textual.git
cd dataframe-textual
# Install from local source
pip install -e .
# With development dependencies
pip install -e ".[dev]"
```
## Usage
### Basic Usage - Single File
```bash
# After pip install dataframe-textual
dv pokemon.csv
# Or run from module
python -m dataframe-textual pokemon.csv
# Or with uv
uv run python main.py pokemon.csv
# Read from stdin (defaults to TSV)
cat data.tsv | dv
dv < data.tsv
# Specify format for gzipped stdin
zcat data.csv.gz | dv -f csv
# Gzipped files are supported
dv data.csv.gz
```
### Multi-File Usage - Multiple Tabs
```bash
# Open multiple files in tabs
dv file1.csv file2.csv file3.csv
# Open multiple sheets in tabs in an Excel file
dv file.xlsx
# Mix files and stdin
dv data1.tsv < data2.tsv
```
When multiple files are opened:
- Each file appears as a separate tab. An Excel file may contain multiple tabs.
- Switch between tabs using `>` (next) or `<` (previous), or use `b` for cycling through tabs
- Save current tab to file with `Ctrl+T`
- Save all tabs to file with `Ctrl+A`
- Duplicate the current tab with `Ctrl+D`
- Open additional files with `Ctrl+O`
- Each file maintains its own state (edits, sort order, selections, history, etc.) and allow undo/redo.
## Command Line Options
```
usage: dv [-h] [-V] [-f {tsv,csv,psv,xlsx,xls,parquet,json,ndjson}] [-H [HEADER ...]] [-F [FIELDS ...]] [-I] [-T] [-E] [-C [PREFIX]] [-Q [C]] [-K N] [-A N] [-M N] [-N NULL [NULL ...]] [--theme [THEME]]
[files ...]
Interactive terminal based viewer/editor for tabular data (e.g., CSV/Excel).
positional arguments:
files Files to view (or read from stdin)
options:
-h, --help show this help message and exit
-V, --version show program's version number and exit
-f, --format {tsv,csv,psv,xlsx,xls,parquet,json,ndjson}
Specify the format of the input files (csv, excel, tsv etc.)
-H, --header [HEADER ...]
Specify header info. when reading CSV/TSV. If used without values, assumes no header. Otherwise, use provided values as column names (e.g., `-H col1 col2 col3`).
-F, --fields [FIELDS ...]
When used without values, list available fields. Otherwise, read only specified fields.
-I, --no-inference Do not infer data types when reading CSV/TSV
-T, --truncate-ragged-lines
Truncate ragged lines when reading CSV/TSV
-E, --ignore-errors Ignore errors when reading CSV/TSV
-C, --comment-prefix [PREFIX]
Comment lines starting with `PREFIX` are skipped when reading CSV/TSV
-Q, --quote-char [C] Use `C` as quote character for reading CSV/TSV. When used without value, disables special handling of quote characters.
-K, --skip-lines N Skip first N lines when reading CSV/TSV
-A, --skip-rows-after-header N
Skip N rows after header when reading CSV/TSV
-M, --n-rows N Read maximum rows
-N, --null NULL [NULL ...]
Values to interpret as null values when reading CSV/TSV
--theme [THEME] Set the theme for the application. Use 'list' to show available themes.
--all-in-one Read all files (must be of the same format and structure) into a single table.
```
### CLI Examples
```bash
# View headless CSV file
dv -H data_no_header.csv
# Disable type inference for faster loading
dv -I large_data.csv
# Ignore parsing errors in malformed CSV
dv -E data_with_errors.csv
# Skip first 3 lines of file (e.g., metadata)
dv -l 3 data_with_meta.csv
# Skip 1 row after header (e.g., units row)
dv -a 1 data_with_units.csv
# Skip comment lines (or just -c)
dv -c "#" commented_data.csv
# Treat specific values as null/missing (e.g., 'NA', 'N/A', '-')
dv -n NA N/A - data.csv
# Use different quote character (e.g., single quote for CSV)
dv -q "'" data.csv
# Disable quote character processing for TSV with embedded quotes
dv -q data.tsv
# Complex CSV with comments and units row
dv -l 3 -a 1 -I messy_scientific_data.csv
# Process compressed data
dv data.csv.gz
zcat compressed_data.csv.gz | dv -f csv
# Choose the `monokai` theme
dv --theme monokai data.csv
# Show column headers
dv data.csv -F
# Read only specific columns: 'name', 'age', first column, and last column
dv data.csv -F name age 1 -1
# Filter data using SQL query (use 'self' as the table name)
dv data.csv --sql 'SELECT * FROM self WHERE age > 30'
# Read all files (must be of the same format and structure) into a single table
dv data-1.csv data-2.csv --all-in-one
```
## Keyboard Shortcuts
### App-Level Controls
#### File & Tab Management
| Key | Action |
|-----|--------|
| `>` | Move to next tab |
| `<` | Move to previous tab |
| `b` | Cycle through tabs |
| `B` | Toggle tab bar visibility |
| `q` | Close current tab (prompts to save unsaved changes) |
| `Q` | Close all tabs and quit app (prompts to save unsaved changes) |
| `Ctrl+Q` | Force to quit app (regardless of unsaved changes) |
| `Ctrl+V` | Save current view to file |
| `Ctrl+T` | Save current tab to file |
| `Ctrl+S` | Save all tabs to file |
| `w` | Save current tab to file (overwrite without prompt) |
| `W` | Save all tabs to file (overwrite without prompt) |
| `Ctrl+D` | Duplicate current tab |
| `Ctrl+O` | Open file in a new tab |
| `Double-click` | Rename tab |
#### View & Settings
| Key | Action |
|-----|--------|
| `F1` | Toggle help panel |
| `k` | Cycle through dark, light and other themes |
| `Ctrl+P` -> `Screenshot` | Capture terminal view as a SVG image |
---
### Table-Level Controls
#### Navigation
| Key | Action |
|-----|--------|
| `g` | Go to first row |
| `G` | Go to last row |
| `Ctrl + G` | Go to row |
| `↑` / `↓` | Move up/down one row |
| `←` / `→` | Move left/right one column |
| `Home` / `End` | Go to first/last column |
| `Ctrl + Home` / `Ctrl + End` | Go to page top/bottom |
| `PageDown` / `PageUp` | Scroll down/up one page |
| `Ctrl+F` | Page forward |
| `Ctrl+B` | Page backforward |
#### Undo/Redo/Reset
| Key | Action |
|-----|--------|
| `u` | Undo last action |
| `U` | Redo last undone action |
| `Ctrl+U` | Reset to initial state |
#### Display
| Key | Action |
|-----|--------|
| `Enter` | Record view of current row transposed |
| `F` | Show frequency distribution for current column |
| `s` | Show statistics for current column |
| `S` | Show statistics for entire dataframe |
| `m` | Show metadata for row count and column count |
| `M` | Show metadata for current column |
| `K` | Cycle cursor types: cell → row → column → cell |
| `~` | Toggle row labels |
| `_` (underscore) | Toggle column full width |
| `z` | Freeze rows and columns |
| `,` | Toggle thousand separator for numeric display |
| `&` | Set current row as the new header row |
| `h` | Hide current column |
| `H` | Show all hidden columns |
#### Editing
| Key | Action |
|-----|--------|
| `Double-click` | Edit cell or rename column header |
| `Delete` | Clear current cell (set to NULL) |
| `Shift+Delete` | Clear current column (set matching cells to NULL) |
| `e` | Edit current cell (respects data type) |
| `E` | Edit entire column with value/expression |
| `a` | Add empty column after current |
| `A` | Add column with name and value/expression |
| `@` | Add a link column from URL template |
| `-` (minus) | Delete current column |
| `x` | Delete current row |
| `X` | Delete current row and all those below |
| `Ctrl+X` | Delete current row and all those above |
| `d` | Duplicate current column |
| `D` | Duplicate current row |
#### Row Selection
| Key | Action |
|-----|--------|
| `\` | Select rows wth cell matches or those matching cursor value in current column |
| `\|` (pipe) | Select rows by expression |
| `{` | Go to previous selected row |
| `}` | Go to next selected row |
| `'` | Select/deselect current row |
| `t` | Toggle row selections (invert) |
| `T` | Clear all row selections and/or cell matches |
#### Find & Replace
| Key | Action |
|-----|--------|
| `/` | Find in current column with cursor value and highlight matching cells |
| `?` | Find in current column with expression and highlight matching cells |
| `n` | Go to next matching cell |
| `N` | Go to previous matching cell |
| `;` | Find across all columns with cursor value |
| `:` | Find across all columns with expression |
| `r` | Find and replace in current column (interactive or replace all) |
| `R` | Find and replace across all columns (interactive or replace all) |
#### View & Filter
| Key | Action |
|-----|--------|
| `"` (quote) | Filter selected rows (others removed) |
| `.` | View rows with non-null values in current column (others hidden) |
| `v` | View selected rows (others hidden) |
| `V` | View selected by expression (others hidden) |
#### Sorting (supporting multiple columns)
| Key | Action |
|-----|--------|
| `[` | Sort current column ascending |
| `]` | Sort current column descending |
#### Reordering
| Key | Action |
|-----|--------|
| `Shift+↑` | Move current row up |
| `Shift+↓` | Move current row down |
| `Shift+←` | Move current column left |
| `Shift+→` | Move current column right |
#### Type Casting
| Key | Action |
|-----|--------|
| `#` | Cast current column to integer (Int64) |
| `%` | Cast current column to float (Float64) |
| `!` | Cast current column to boolean |
| `$` | Cast current column to string |
#### Copy
| Key | Action |
|-----|--------|
| `c` | Copy current cell to clipboard |
| `Ctrl+C` | Copy column to clipboard |
| `Ctrl+R` | Copy row to clipboard (tab-separated) |
#### SQL Interface
| Key | Action |
|-----|--------|
| `l` | Simple SQL interface (select columns & where clause) |
| `L` | Advanced SQL interface (full SQL query with syntax highlight) |
## Features in Detail
### 1. Color-Coded Data Types
Columns are automatically styled based on their data type:
- **integer**: Cyan text, right-aligned
- **float**: Yellow text, right-aligned
- **string**: Green text, left-aligned
- **boolean**: Blue text, centered
- **temporal**: Magenta text, centered
### 2. Row Detail View
Press `Enter` on any row to open a modal showing all column values for that row.
Useful for examining wide datasets where columns don't fit well on screen.
**In the Row Detail Modal**:
- Press `v` to **view** all rows containing the selected column value (others hidden but preserved)
- Press `"` to **filter** all rows containing the selected column value (others removed)
- Press `{` to move to the previous row
- Press `}` to move to the next row
- Press `F` to show the frequency table for the selected column
- Press `s` to show the statistics table for the selected column
- Press `q` or `Escape` to close the modal
### 3. Row Selection
The application provides multiple modes for selecting rows (marks it for filtering or viewing):
- `\` - Select rows with cell matches or those matching cursor value in current column (respects data type)
- `|` - Opens dialog to select rows with custom expression
- `'` - Select/deselect current row
- `t` - Flip selections of all rows
- `T` - Clear all row selections and cell matches
- `{` - Go to previous selected row
- `}` - Go to next selected row
**Advanced Options**:
When searching or finding, you can use checkboxes in the dialog to enable:
- **Match Nocase**: Ignore case differences
- **Match Whole**: Match complete value, not partial substrings or words
These options work with plain text searches. Use Polars regex patterns in expressions for more control. For example, use `(?i)` prefix in regex (e.g., `(?i)john`) for case-insensitive matching.
**Quick Tips:**
- Search results highlight matching rows in **red**
- Use expression for advanced selection (e.g., $attack > $defense)
- Type-aware matching automatically converts values. Resort to string comparison if conversion fails
- Use `u` to undo any search or filter
### 4. Find & Replace
Find by value/expression and highlight matching cells:
- `/` - Find cursor value within current column (respects data type)
- `?` - Open dialog to search current column with expression
- `;` - Find cursor value across all columns
- `:` - Open dialog to search all columns with expression
- `n` - Go to next matching cell
- `N` - Go to previous matching cell
Replace values in current column (`r`) or across all columns (`R`).
**How It Works:**
When you press `r` or `R`, enter:
1. **Find term**: Value or expression to search for (done by string value)
2. **Replace term**: Replacement value
3. **Matching options**: Match Nocase (ignore case), Match Whole (complete match only)
4. **Replace mode**: All at once or interactive review
**Replace All**:
- Replaces all matches with one operation
- Shows confirmation with match count
**Replace Interactive**:
- Review each match one at a time (confirm, skip, or cancel)
- Shows progress
**Tips:**
- Search are done by string value (i.e., ignoring data type)
- Type `NULL` to replace null/missing values
- Use `Match Nocase` for case-insensitive matching
- Use `Match Whole` to avoid partial replacements
- Support undo (`u`)
### 5. Filter vs. View
Both operations show selected rows but with fundamentally different effects:
| Operation | Keyboard | Effect | Data Preserved |
|-----------|----------|--------|-----------------|
| **View** | `v`, `V` | Hides non-matching rows | Yes (hidden, can be restored by `H`) |
| **Filter** | `"` | Removes non-matching rows | No (permanently deleted) |
**When to use View** (`v` or `V`):
- Exploring or analyzing data safely
- Switching between different perspectives
- Press `q` to return to main table
- Press `Ctrl+V` to save current view to a file. This does not affect the main table.
**When to use Filter** (`"`):
- Cleaning data (removing unwanted rows)
- Creating a trimmed dataset for export
- Permanent row removal from your dataframe
**Note**:
- If currently there are no selected rows and no matching cells, the `"` (Filter) and `v` (View) will use cursor value for search.
- Both support full undo with `u`.
### 6. [Polars Expressions](https://docs.pola.rs/api/python/stable/reference/expressions/index.html)
Complex values or filters can be specified via Polars expressions, with the following adaptions for convenience:
**Column References:**
- `$_` - Current column (based on cursor position)
- `$1`, `$2`, etc. - Column by 1-based index
- `$age`, `$salary` - Column by name (use actual column names)
- `` $`col name` `` - Column by name with spaces (backtick quoted)
**Row References:**
- `$#` - Current row index (1-based)
**Basic Comparisons:**
- `$_ > 50` - Current column greater than 50
- `$salary >= 100000` - Salary at least 100,000
- `$age < 30` - Age less than 30
- `$status == 'active'` - Status exactly matches 'active'
- `$name != 'Unknown'` - Name is not 'Unknown'
- `$# <= 10` - Top 10 rows
**Logical Operators:**
- `&` - AND
- `|` - OR
- `~` - NOT
**Practical Examples:**
- `($age < 30) & ($status == 'active')` - Age less than 30 AND status is active
- `($name == 'Alice') | ($name == 'Bob')` - Name is Alice or Bob
- `$salary / 1000 >= 50` - Salary divided by 1,000 is at least 50
- `($department == 'Sales') & ($bonus > 5000)` - Sales department with bonus over 5,000
- `($score >= 80) & ($score <= 90)` - Score between 80 and 90
- `~($status == 'inactive')` - Status is not inactive
- `$revenue > $expenses` - Revenue exceeds expenses
- ``$`product id` > 100`` - Product ID with spaces in column name greater than 100
**String Matching:** ([Polars string API reference](https://docs.pola.rs/api/python/stable/reference/series/string.html))
- `$name.str.contains("John")` - Name contains "John" (case-sensitive)
- `$name.str.contains("(?i)john")` - Name contains "john" (case-insensitive)
- `$email.str.ends_with("@company.com")` - Email ends with domain
- `$code.str.starts_with("ABC")` - Code starts with "ABC"
- `$age.cast(pl.String).str.starts_with("7")` - Age (cast to string first) starts with "7"
**Number Operations:**
- `$age * 2 > 100` - Double age greater than 100
- `($salary + $bonus) > 150000` - Total compensation over 150,000
- `$percentage >= 50` - Percentage at least 50%
**Null Handling:**
- `$column.is_null()` - Find null/missing values
- `$column.is_not_null()` - Find non-null values
- `NULL` - a value to represent null for convenience
**Tips:**
- Use column names that match exactly (case-sensitive)
- Use parentheses to clarify complex expressions: `($a & $b) | ($c & $d)`
### 7. Sorting
- Press `[` to sort current column ascending
- Press `]` to sort current column descending
- Multi-column sorting supported (press multiple times on different columns)
- Press same key twice to remove the column from sorting
### 8. Dataframe & Column Metadata
View quick metadata about your dataframe and columns to understand their structure and content.
**Dataframe Metadata** (`m`):
- Press `m` to open a modal displaying:
- **Row** - Total number of rows in the dataframe
- **Column** - Total number of columns in the dataframe
**Column Metadata** (`M`):
- Press `M` to open a modal displaying details for all columns:
- **ID** - 1-based column index
- **Name** - Column name
- **Type** - Data type (e.g., Int64, String, Float64, Boolean)
**In the Column Metadata Table**
- Press `F` to show the frequency table for the selected column
- Press `s` to show the statistics table for the selected column
**In Metadata Modals**:
- Press `q` or `Escape` to close
### 9. Frequency Distribution
Press `F` to see value distributions of the current column. The modal shows:
- Value, Count, Percentage, Histogram
- **Total row** at the bottom
**In the Frequency Table**:
- Press `[` and `]` to sort by any column (value, count, or percentage)
- Press `v` to **view** all rows containing the selected value (others hidden but preserved)
- Press `"` to **filter** all rows containing the selected value (others removed)
- Press `Ctrl+S` to save the frequency table to file
- Press `q` or `Escape` to close the frequency table
This is useful for:
- Understanding value distributions
- Quickly filtering to specific values
- Identifying rare or common values
- Finding the most/least frequent entries
### 10. Column & Dataframe Statistics
Show summary statistics (count, null count, mean, median, std, min, max, etc.) using Polars' `describe()` method.
- `s` for the current column
- `S` for all columns across the entire dataframe
**In the Statistics Modal**:
- Press `q` or `Escape` to close the statistics table
- Use arrow keys to navigate
- Useful for quick data validation and summary reviews
This is useful for:
- Understanding data distributions and characteristics
- Identifying outliers and anomalies
- Data quality assessment
- Quick statistical summaries without external tools
- Comparing statistics across columns
### 11. Editing
**Edit Cell** (`e` or **Double-click**):
- Opens modal for editing current cell
- Validates input based on column data type
**Rename Column Header** (**Double-click** column header):
- Quick rename by double-clicking the column header
**Delete Row** (`x`):
- Delete all selected rows (if any) at once
- Or delete single row at cursor
**Delete Row and Below** (`X`):
- Deletes the current row and all rows below it
- Useful for removing trailing data or the end of a dataset
**Delete Row and Above** (`Ctrl+X`):
- Deletes the current row and all rows above it
- Useful for removing leading rows or the beginning of a dataset
**Delete Column** (`-`):
- Removes the entire column from display and dataframe
**Add Empty Column** (`a`):
- Adds a new empty column after the current column
- Column is initialized with NULL values for all rows
**Add Column with Value/Expression** (`A`):
- Opens dialog to specify column name and initial value/expression
- Value can be a constant (e.g., `0`, `"text"`) or a Polars expression (e.g., `$age * 2`)
- Expression can reference other columns and perform calculations
- Useful for creating derived columns or adding data with formulas
**Duplicate Column** (`d`):
- Creates a new column immediately after the current column
- New column has '_copy' suffix (e.g., 'price' → 'price_copy')
- Useful for creating backups before transformation
**Duplicate Row** (`D`):
- Creates a new row immediately after the current row
- Duplicate preserves all data from original row
- Useful for batch adding similar records
**Hide/Show Columns** (`h` / `H`):
- `h` - Temporarily hide current column (data preserved)
- `H` - Restore all hidden columns
### 12. Column & Row Reordering
**Move Columns**: `Shift+←` and `Shift+→`
- Swaps adjacent columns
- Reorder is preserved when saving
**Move Rows**: `Shift+↑` and `Shift+↓`
- Swaps adjacent rows
- Reorder is preserved when saving
### 13. Freeze Rows and Columns
Press `z` to open the dialog:
- Enter number of fixed rows and/or columns to keep top rows/columns visible while scrolling
### 14. Thousand Separator Toggle
Press `,` to toggle thousand separator formatting for numeric data:
- Applies to **integer** and **float** columns
- Formats large numbers with commas for readability (e.g., `1000000` → `1,000,000`)
- Works across all numeric columns in the table
- Toggle on/off as needed for different viewing preferences
- Display-only: does not modify underlying data in the dataframe
- State persists during the session
### 15. Save File
Press `Ctrl+S` to save filtered, edited, or sorted data back to file. The output format is automatically determined by the file extension, making it easy to convert between different formats (e.g., CSV to TSV).
### 16. Undo/Redo/Reset
**Undo** (`u`):
- Reverts last action with full state restoration
- Works for edits, deletions, sorts, searches, etc.
- Shows description of reverted action
**Redo** (`U`):
- Reapplies the last undone action
- Restores the state before the undo was performed
- Useful for redoing actions you've undone by mistake
- Useful for alternating between two different states
**Reset** (`Ctrl+U`):
- Reverts all changes and returns to original data state when file was first loaded
- Clears all edits, deletions, selections, filters, and sorts
- Useful for starting fresh without reloading the file
### 17. Column Type Conversion
Press the type conversion keys to instantly cast the current column to a different data type:
**Type Conversion Shortcuts**:
- `#` - Cast to **integer**
- `%` - Cast to **float**
- `!` - Cast to **boolean**
- `$` - Cast to **string**
**Features**:
- Instant conversion with visual feedback
- Full undo support - press `u` to revert
- Leverage Polars' robust type casting
**Note**: Type conversion attempts to preserve data where possible. Conversions may lose data (e.g., float to int rounding).
### 18. Cursor Type Cycling
Press `K` to cycle through selection modes:
1. **Cell mode**: Highlight individual cell (and its row/column headers)
2. **Row mode**: Highlight entire row
3. **Column mode**: Highlight entire column
### 19. SQL Interface
The SQL interface provides two modes for querying your dataframe:
#### Simple SQL Interface (`l`)
SELECT specific columns and apply WHERE conditions without writing full SQL:
- Choose which columns to include in results
- Specify WHERE clause for filtering
- Ideal for quick filtering and column selection
#### Advanced SQL Interface (`L`)
Execute complete SQL queries for advanced data manipulation:
- Write full SQL queries with standard [SQL syntax](https://docs.pola.rs/api/python/stable/reference/sql/index.html)
- Access to all SQL capabilities for complex transformations
- Always use `self` as the table name
- Syntax highlighted
**Examples:**
```sql
-- Filter and select specific rows and/or columns
SELECT name, age
FROM self
WHERE age > 30
-- Use backticks (`) for column names with spaces
SELECT *
FROM self
WHERE `product id` = 7
```
### 20. Clipboard Operations
Copies value to system clipboard with `pbcopy` on macOS and `xclip` on Linux.
**Note**: may require a X server to work.
- Press `c` to copy cursor value
- Press `Ctrl+C` to copy column values
- Press `Ctrl+R` to copy row values (delimited by tab)
- Hold `Shift` to select with mouse
### 21. Link Column Creation
Press `@` to create a new column containing dynamically generated URLs using template.
**Template Placeholders:**
The link template supports multiple placeholder types for maximum flexibility:
- **`$_`** - Current column (the column where cursor was when `@` was pressed), e.g., `https://example.com/search/$_` - Uses values from the current column
- **`$1`, `$2`, `$3`, etc.** - Column by 1-based position index, e.g., `https://example.com/product/$1/details/$2` - Uses 1st and 2nd columns
- **`$name`** - Column by name (use actual column names), e.g., `https://example.com/$region/$city/data` - Uses `region` and `city` columns
**Features:**
- **Multiple Placeholders**: Mix and match placeholders in a single template
- **URL Prefix**: Automatically prepends `https://` if URL doesn't start with `http://` or `https://`
**Tips:**
- Use full undo (`u`) if template produces unexpected URLs
- For complex multi-column URLs, use column names (`$name`) for clarity over positions (`$1`)
### 22. Tab Management
Manage multiple files and dataframes simultaneously with tabs.
**Tab Operations:**
- **`Ctrl+O`** - Open file in a new tab
- **`>`** - Move to next tab
- **`<`** - Move to previous tab
- **`b`** - Cycle through tabs
- **`B`** - Toggle tab bar visibility
- **`Double-click`** - Rename the tab
- **`Ctrl+D`** - Duplicate current tab (creates a copy with same data and state)
- **`Ctrl+T`** - Save current tab to file
- **`Ctrl+S`** - Save all tabs to file
- **`w`** - Save current tab to file (overwrite without prompt)
- **`W`** - Save all tabs to file (overwrite without prompt)
- **`q`** - Close current tab (closes tab, prompts to save if unsaved changes)
- **`Q`** - Close all tabs and exit app (prompts to save tabs with unsaved changes)
- **`Ctrl+Q`** - Force to quit app regardless of unsaved changes
**Tips:**
- Tabs with unsaved changes are indicated with a bright background
- Closing or quitting a tab with unsaved changes triggers a save prompt
## Dependencies
- **polars**: Fast DataFrame library for data loading/processing
- **textual**: Terminal UI framework
- **fastexcel**: Read Excel files
- **xlsxwriter**: Write Excel files
## Requirements
- Python 3.11+
- POSIX-compatible terminal (macOS, Linux, WSL)
- Terminal supporting ANSI escape sequences and mouse events
## Acknowledgments
- Inspired by [VisiData](https://visidata.org/)
- Built with [Textual](https://textual.textualize.io/) and [Polars](https://www.pola.rs/)
| text/markdown | null | Tiejun Cheng <need47@gmail.com> | null | null | MIT | csv, data-analysis, editor, excel, interactive, polars, terminal, textual, tui, viewer | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: End Users/Desktop",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Operating System :: MacOS",
"Operating System :: POSIX",
"Operating System :: Unix",
"... | [] | null | null | >=3.11 | [] | [] | [] | [
"fastexcel>=0.16.0",
"polars>=1.34.0",
"textual[syntax]>=6.5.0",
"vortex-data>=0.59.4",
"xlsxwriter>=3.2.9",
"textual-dev>=1.8.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/need47/dataframe-textual",
"Repository, https://github.com/need47/dataframe-textual.git",
"Documentation, https://github.com/need47/dataframe-textual#readme",
"Bug Tracker, https://github.com/need47/dataframe-textual/issues"
] | uv/0.9.21 {"installer":{"name":"uv","version":"0.9.21","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"AlmaLinux","version":"8.10","id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T15:30:11.137692 | dataframe_textual-2.23.0-py3-none-any.whl | 77,304 | 26/f9/6b98e7e9f5bb621a4bf8b668782e472a1738f3dcc895b00e6b0507112baf/dataframe_textual-2.23.0-py3-none-any.whl | py3 | bdist_wheel | null | false | a6a6b94cedc7ffc979f7c0a0bdbf0384 | 59da01e3fa1ce8b95e5d76e840d7f1745ceb36ca407f908863d7edb337c36b3a | 26f96b98e7e9f5bb621a4bf8b668782e472a1738f3dcc895b00e6b0507112baf | null | [
"LICENSE"
] | 214 |
2.4 | math-mcp-learning-server | 0.11.2 | Production-ready educational MCP server with enhanced visualizations and persistent workspace - Complete learning guide demonstrating FastMCP 3.0 best practices for Model Context Protocol development | # Math MCP Learning Server
[](https://pypi.org/project/math-mcp-learning-server/)
[](https://pypi.org/project/math-mcp-learning-server/)
[](https://opensource.org/licenses/MIT)
[](https://github.com/clouatre-labs/math-mcp-learning-server/actions/workflows/ci.yml)
[](https://github.com/astral-sh/ruff)
<!-- mcp-name: io.github.clouatre-labs/math-mcp-learning-server -->
Educational MCP server with 17 tools, persistent workspace, and cloud hosting. Built with [FastMCP 3.0](https://github.com/PrefectHQ/fastmcp) and the official [Model Context Protocol Python SDK](https://github.com/modelcontextprotocol/python-sdk).
**Available on:**
- [Official MCP Registry](https://registry.modelcontextprotocol.io/) - `io.github.clouatre-labs/math-mcp-learning-server`
- [PyPI](https://pypi.org/project/math-mcp-learning-server/) - `math-mcp-learning-server`
## Requirements
Requires an MCP client:
- **Claude Desktop** - Anthropic's desktop app
- **Claude Code** - Command-line MCP client
- **Goose** - Open-source AI agent framework
- **OpenCode** - Open-source MCP client by SST
- **Kiro** - AWS's AI assistant
- **Gemini CLI** - Google's command-line tool
- Any MCP-compatible client
## Quick Start
### Cloud (No Installation)
Connect your MCP client to the hosted server:
**Claude Desktop** (`claude_desktop_config.json`):
```json
{
"mcpServers": {
"math-cloud": {
"transport": "http",
"url": "https://math-mcp.fastmcp.app/mcp"
}
}
}
```
### Local Installation
**Automatic with uvx** (recommended):
```json
{
"mcpServers": {
"math": {
"command": "uvx",
"args": ["math-mcp-learning-server"]
}
}
}
```
**Manual installation:**
```bash
# Basic installation
uv pip install math-mcp-learning-server
# With matrix operations support
uv pip install math-mcp-learning-server[scientific]
# With visualization support
uv pip install math-mcp-learning-server[plotting]
# All features
uv pip install math-mcp-learning-server[scientific,plotting]
```
## Tools
| Category | Tool | Description |
|----------|------|-------------|
| **Workspace** | `save_calculation` | Save calculations to persistent storage |
| | `load_variable` | Retrieve previously saved calculations |
| **Math** | `calculate` | Safely evaluate mathematical expressions |
| | `statistics` | Statistical analysis (mean, median, mode, std_dev, variance) |
| | `compound_interest` | Calculate compound interest for investments |
| | `convert_units` | Convert between units (length, weight, temperature) |
| **Matrix** | `matrix_multiply` | Multiply two matrices |
| | `matrix_transpose` | Transpose a matrix |
| | `matrix_determinant` | Calculate matrix determinant |
| | `matrix_inverse` | Calculate matrix inverse |
| | `matrix_eigenvalues` | Calculate eigenvalues |
| **Visualization** | `plot_function` | Plot mathematical functions |
| | `create_histogram` | Create statistical histograms |
| | `plot_line_chart` | Create line charts |
| | `plot_scatter_chart` | Create scatter plots |
| | `plot_box_plot` | Create box plots |
| | `plot_financial_line` | Create financial line charts |
## Resources
- `math://workspace` - Persistent calculation workspace summary
- `math://history` - Chronological calculation history
- `math://functions` - Available mathematical functions reference
- `math://constants/{constant}` - Mathematical constants (pi, e, golden_ratio, etc.)
- `math://test` - Server health check
## Prompts
- `math_tutor` - Structured tutoring prompts (configurable difficulty)
- `formula_explainer` - Formula explanation with step-by-step breakdowns
See [Usage Examples](https://github.com/clouatre-labs/math-mcp-learning-server/blob/main/docs/EXAMPLES.md) for detailed examples.
## Development
```bash
# Clone and setup
git clone https://github.com/clouatre-labs/math-mcp-learning-server.git
cd math-mcp-learning-server
uv sync --extra dev --extra plotting
# Test server locally
uv run fastmcp dev src/math_mcp/server.py
```
### Testing
```bash
# Run all tests
uv run pytest tests/ -v
# Run with coverage
uv run pytest tests/ --cov=src --cov-report=html --cov-report=term
# Run specific test category
uv run pytest tests/test_matrix_operations.py -v
```
**Test Suite:** 154 tests across 6 categories (Agent Card, HTTP Integration, Math, Matrix, Persistence, Visualization)
### Code Quality
```bash
# Linting
uv run ruff check
# Formatting
uv run ruff format --check
# Security checks
uv run ruff check --select S
```
## Security
The `calculate` tool uses restricted `eval()` with a whitelist of allowed characters and functions, restricted global scope (only `math` module and `abs`), and no access to dangerous built-ins or imports. All tool inputs are validated with Pydantic models. File operations are restricted to the designated workspace directory. Complete type hints and validation are enforced for all operations.
## Links
- [Cloud Deployment Guide](https://github.com/clouatre-labs/math-mcp-learning-server/blob/main/docs/CLOUD_DEPLOYMENT.md)
- [Usage Examples](https://github.com/clouatre-labs/math-mcp-learning-server/blob/main/docs/EXAMPLES.md)
- [Contributing Guidelines](https://github.com/clouatre-labs/math-mcp-learning-server/blob/main/CONTRIBUTING.md)
- [Maintainer Guide](https://github.com/clouatre-labs/math-mcp-learning-server/blob/main/.github/MAINTAINER_GUIDE.md)
- [Roadmap](https://github.com/clouatre-labs/math-mcp-learning-server/blob/main/ROADMAP.md)
- [Code of Conduct](https://github.com/clouatre-labs/math-mcp-learning-server/blob/main/CODE_OF_CONDUCT.md)
- [License](https://github.com/clouatre-labs/math-mcp-learning-server/blob/main/LICENSE)
| text/markdown | null | Hugues Clouâtre <hugues@linux.com> | null | null | null | mcp, math, calculator, learning, fastmcp, tutorial, education, cloud, deployment, workspace, persistence | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Programming Language :: Python :: 3.14",
"Topic :: Education",
"Topic :: Software Development :: Libraries :: Application Frameworks",
"Topic :: Scientific/Engineering :: Mathematics",
"Topic :: Doc... | [] | null | null | >=3.14 | [] | [] | [] | [
"fastmcp>=3.0.0",
"pydantic>=2.12.0",
"pydantic-settings>=2.0.0",
"pytest>=8.4.2; extra == \"dev\"",
"pytest-asyncio>=0.25.2; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"ruff<0.16.0,>=0.15.1; extra == \"dev\"",
"matplotlib>=3.10.6; extra == \"plotting\"",
"numpy>=2.3.3; extra == \"plo... | [] | [] | [] | [
"Homepage, https://github.com/clouatre-labs/math-mcp-learning-server",
"Repository, https://github.com/clouatre-labs/math-mcp-learning-server",
"Issues, https://github.com/clouatre-labs/math-mcp-learning-server/issues",
"Documentation, https://github.com/clouatre-labs/math-mcp-learning-server#readme",
"Cont... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:29:26.231410 | math_mcp_learning_server-0.11.2.tar.gz | 51,682 | ed/26/25fa9b6cca21b78e285ba974ebbe2cf5147af2fed83696aa96e144c5b1f3/math_mcp_learning_server-0.11.2.tar.gz | source | sdist | null | false | c5756245df7e3dfc736eafcfe77c35e1 | 7ae0841d33a0183590902f52d881a7f7794805b535915f941f7d3962187681af | ed2625fa9b6cca21b78e285ba974ebbe2cf5147af2fed83696aa96e144c5b1f3 | MIT | [
"LICENSE"
] | 206 |
2.4 | flowpad | 0.1.6 | Flow CLI $ SDK for flowpad | # Flow CLI
A local desktop CLI and UI for FlowPad — manage hooks, traces, and agentic workflows from your terminal.
## Quick Start
```bash
pip install flowpad
flow # prints version
flow start # launches the UI server and opens browser
```
## Requirements
- Python >= 3.10
- Node.js (for frontend development)
- [uv](https://docs.astral.sh/uv/) (for backend dependency management)
## Installation
Install from PyPI:
```bash
pip install flowpad
```
Install a specific version:
```bash
pip install flowpad==0.1.5
```
Install from GitHub (latest):
```bash
pip install git+https://github.com/langware-labs/flow-cli.git
```
Verify the installation:
```bash
flow
# => flow 0.1.5
```
## Uninstallation
```bash
pip uninstall flowpad
```
## CLI Commands
| Command | Description |
|---------|-------------|
| `flow` | Print version |
| `flow start` | Start the UI server and open browser |
| `flow trace` | Start server and trace hook events in real-time |
| `flow setup <agent>` | Setup FlowPad for a coding agent (e.g. `claude-code`) |
| `flow hooks set` | Install Flow hooks into Claude Code settings |
| `flow hooks list` | List configured hooks |
| `flow hooks clear` | Remove Flow hooks from Claude Code settings |
| `flow config list` | List configuration values |
| `flow config set key=value` | Set a configuration value |
| `flow auth login` | Login to FlowPad (opens browser or accepts API key) |
| `flow auth logout` | Logout and remove stored credentials |
| `flow ping <string>` | Send a test ping to the local server |
## Development
### Backend
```bash
uv sync # install Python dependencies
python minihub/run.py # start backend server on port 9007
```
The backend serves the API at `http://localhost:9007`. Bootstrap endpoint: `http://localhost:9007/api/v1/graph/bootstrap`
### Frontend
```bash
cd minihub/ui
npm install # install Node dependencies
npm run dev # start Vite dev server on port 4097
```
The frontend runs at `http://localhost:4097` and proxies API calls to the backend.
### Running Tests
```bash
# Backend API tests
python -m pytest tests/api/ -v
# Backend SDK unit tests
cd flow-sdk/python && python -m pytest tests/ -v
# Frontend build + lint
cd minihub/ui && npm run build && npm run lint
```
## Deployment
Use the deploy script to bump version, tag, push, and validate:
```bash
./scripts/deploy_to_github.sh # runs tests first
./scripts/deploy_to_github.sh --skip-tests # skip tests
```
This will:
1. Increment the patch version in `_version.py`
2. Run tests (unless `--skip-tests`)
3. Commit and tag the release
4. Push to GitHub
5. Install from GitHub and validate the version
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"platformdirs",
"requests",
"fastapi",
"uvicorn[standard]",
"typer>=0.9.0",
"python-dotenv",
"keyring",
"fastmcp",
"httpx<1.0,>=0.24.0",
"websockets",
"sqlalchemy>=2.0.0",
"aiosqlite",
"aiohttp",
"greenlet",
"pydantic>=2.0.0",
"psutil",
"ptyprocess",
"nest-asyncio>=1.6.0",
"pybar... | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.3 | 2026-02-19T15:28:59.171408 | flowpad-0.1.6.tar.gz | 13,824,493 | 24/50/885ff632b06e0ad27eb84763610fc2bc1e800387160d329448724fe073cb/flowpad-0.1.6.tar.gz | source | sdist | null | false | d3837f5029377a047a7f606e8330186b | 71e3336eee8588d138ae12790366ec064190250c15addf024d9d77b1d6fb81c7 | 2450885ff632b06e0ad27eb84763610fc2bc1e800387160d329448724fe073cb | null | [] | 213 |
2.4 | xapian-profile | 0.2.1 | Xapian-based user profile management with schema validation and automatic index routing | # XProfile
A Python package for Xapian-based user profile management with schema validation and automatic index routing.
## Overview
`xprofile` provides the `XProfile` model class, built on top of `xapian_model.base.BaseXapianModel`. It offers a comprehensive schema for storing and managing user profiles in Xapian indexes with automatic routing based on entity ID and profile admin API ID.
## Features
- **Xapian-Based Storage**: Leverages Xapian for efficient full-text search and retrieval
- **Automatic Index Routing**: Routes documents to appropriate indexes using configurable templates
- **Comprehensive Schema**: Includes fields for personal, business, reseller, and other profile types
- **Async API**: Built on top of `xapian_model>=0.3.1` with full async/await support via `httpx`
- **Type-Safe**: Full type hints support for Python 3.12+
- **Well-Documented**: Google-style docstrings throughout the codebase
## Installation
```bash
pip install xapian-profile
```
### Development Installation
**Requirements**: Python 3.12 or higher (specified in `.python-version`)
Clone the repository and install in editable mode:
```bash
git clone git@github.com:Dubalu-Development-Team/xprofile.git
cd xprofile
python3.12 -m venv .venv
source .venv/bin/activate
pip install -e .
```
**Using direnv** (recommended): If you have [direnv](https://direnv.net/) installed, the virtual environment with the correct Python version will be automatically created and activated when you enter the project directory. Just run:
```bash
direnv allow
```
## Usage
### Security Configuration
For security reasons, `INDEX_TEMPLATE` and schema `_foreign` field must be defined in your application code:
```python
from xprofile import XProfile
from xprofile.utils import get_encoded_uuid, get_slug
# Define your own profile identifiers (keep these secret!)
PROFILES_ADMIN_API = "Your Profile Admin API Name"
PROFILE_ADMIN_API_ID = get_encoded_uuid(get_slug(PROFILES_ADMIN_API))
PROFILE_SCHEMA = "Your Profile Schema Name"
PROFILE_SCHEMA_ID = get_encoded_uuid(get_slug(PROFILE_SCHEMA))
# Create a subclass with your configuration
class MyProfile(XProfile):
INDEX_TEMPLATE = '{entity_id}/{profile_admin_api_id}'
# Configure the schema _foreign field
MyProfile.SCHEMA['_schema']['_foreign'] = f'.schemas/{PROFILE_SCHEMA_ID}'
MyProfile.SCHEMA['_schema']['_meta']['description'] = PROFILE_SCHEMA
# Now use your profile
profile = MyProfile(
entity_id="your-entity-id",
profile_admin_api_id=PROFILE_ADMIN_API_ID
)
```
### Basic Usage
```python
# Access the schema
schema = MyProfile.SCHEMA
# The schema includes fields for:
# - Basic info: name, slug, is_active
# - Profile types: personal, business, reseller, etc.
# - Contact info: email, phone with validation
# - Timestamps: created_at, updated_at, deleted_at
# - And more...
# Create, save, and query are async operations (xapian_model 0.3.0+)
profile = await MyProfile.objects.create(
entity_id="your-entity-id",
profile_admin_api_id=PROFILE_ADMIN_API_ID,
name="Example",
)
await profile.save()
results = await MyProfile.objects.filter(query="Example", entity_id="your-entity-id")
```
## Profile Types
XProfile supports multiple profile types:
- `personal` - Personal user profiles
- `business` - Business organization profiles
- `reseller` - Reseller accounts
- `referral` - Referral program participants
- `supplier` - Supplier accounts
- `mashup` - Mashup service profiles
- `affinity` - Affinity group profiles
- `dssupplier` - Data supplier profiles
## Schema
The profile schema includes comprehensive field definitions with:
- Type validation (string, uuid, boolean, date, json, etc.)
- Index configuration (terms, field_terms, field_all, none)
- Required/optional field markers
- Null value handling
- Default values
- Field-specific constraints
Access the complete schema via `XProfile.SCHEMA` or import `get_profile_schema()` from `xprofile.schemas`.
## Project Structure
```
xprofile/
├── src/
│ └── xprofile/
│ ├── __init__.py # Package exports
│ ├── models.py # XProfile model class
│ ├── schemas.py # Schema definitions and constants
│ └── utils.py # Utility functions (slug, UUID generation)
├── pyproject.toml # Project configuration
├── CLAUDE.md # Development guidelines
└── README.md # This file
```
## Development
### Requirements
- Python 3.12 or higher
- `xapian_model>=0.3.1` package (for BaseXapianModel, async API via `pyxapiand>=2.1.0`)
### Code Style
- Line length: 120 characters
- Type hints required for all public functions and methods
- Google-style docstrings for all classes, methods, and functions
- PEP 695 type hints and modern Python syntax
### Building
The project uses [Hatchling](https://hatch.pypa.io/) as the build backend:
```bash
pip install build
python -m build
```
## License
Copyright (c) 2019-2026 Dubalu International LLC. All Rights Reserved.
See LICENSE for license details.
## Authors
Dubalu Framework Team. See AUTHORS for full list of contributors.
## Links
- GitHub: [Dubalu-Development-Team/xprofile](https://github.com/Dubalu-Development-Team/xprofile)
- Dubalu Framework: [https://dubalu.com](https://dubalu.com)
| text/markdown | null | Dubalu Framework Team <team@dubalu.com> | null | Dubalu Framework Team <team@dubalu.com> | MIT | database, profile, search, user-management, xapian | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.12",
"Topic :: Database",
"Topic :: Software Development :: Librari... | [] | null | null | >=3.12 | [] | [] | [] | [
"xapian-model>=0.3.1"
] | [] | [] | [] | [
"Homepage, https://github.com/Dubalu-Development-Team/xprofile",
"Repository, https://github.com/Dubalu-Development-Team/xprofile",
"Issues, https://github.com/Dubalu-Development-Team/xprofile/issues",
"Documentation, https://github.com/Dubalu-Development-Team/xprofile#readme",
"PyPI, https://pypi.org/proje... | twine/6.2.0 CPython/3.12.12 | 2026-02-19T15:28:25.605480 | xapian_profile-0.2.1.tar.gz | 6,573 | bf/a9/d7b4e9b12309b84c9e6fd9f25264326cc44d0e4ae4b2cc3a4dda1cd385a0/xapian_profile-0.2.1.tar.gz | source | sdist | null | false | f2079e5b219efdb1b8f3c0d4e88542e8 | f6e8a8f519be6a76d6c67b0ab77e1277fe4cd3541791cd2ddcd26e82e1ab249c | bfa9d7b4e9b12309b84c9e6fd9f25264326cc44d0e4ae4b2cc3a4dda1cd385a0 | null | [
"AUTHORS",
"LICENSE"
] | 212 |
2.4 | llm-fingerprinter | 0.2.0 | Black-box LLM fingerprinting system for model identification | # LLM Fingerprinting System
[](https://pypi.org/project/llm-fingerprinter/)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
A black-box fingerprinting system that identifies the underlying LLM model family (GPT, LLaMA, Mistral, etc.) by analyzing response patterns across 75 discriminative prompts. The system can identify fine-tuned models as well, tracing them back to their foundational base model.
**Note: Check config.py to see all identifiable model families**
A pre-trained classifier is bundled with the package in the `model` directory.
<img src="img/gpt.png" width="400" height="400" alt="GPT">
## Supported Backends
| Backend | Description | API Key Required |
|---------|-------------|------------------|
| `ollama` | Local Ollama instance | ❌ No |
| `ollama-cloud` | Ollama Cloud API | ✅ `OLLAMA_CLOUD_API_KEY` |
| `openai` | OpenAI API (or compatible) | ✅ `OPENAI_API_KEY` |
| `gemini` | Gemini API (or compatible) | ✅ `GEMINI_API_KEY` |
| `deepseek` | Deepseek API (or compatible) | ✅ `DEEPSEEK_API_KEY` |
| `custom` | **Any HTTP-based LLM API** | ✅ Optional |
### About the Custom Backend
The **custom backend** is the most flexible option - use it with:
- **Proprietary LLM APIs** not natively supported
- **Self-hosted LLMs** behind HTTP endpoints
- **API proxies** and gateways
- **Any HTTP-based LLM service**
All you need is an HTTP request template file! See examples in `./example/` directory.
## Installation
### From PyPI
```bash
# Core package (Ollama + custom backends)
pip install llm-fingerprinter
# With OpenAI support
pip install llm-fingerprinter[openai]
# With Gemini support
pip install llm-fingerprinter[gemini]
# With all backends
pip install llm-fingerprinter[all]
```
### From source (development)
```bash
git clone https://github.com/litemars/LLM-Fingerprinter.git
cd LLM-Fingerprinter
pip install -e ".[all,dev]"
# Optional: Download NLTK data for text processing
python -c "import nltk; nltk.download('punkt_tab'); nltk.download('stopwords')"
```
## Quick Start
### 1. Identify a Model (Using Pre-trained Classifier)
```bash
# Custom endpoint
llm-fingerprinter identify -b custom -r ./custom_request.txt
# Local Ollama
llm-fingerprinter identify -b ollama --model llama3.2
# OpenAI
export OPENAI_API_KEY="your-key"
llm-fingerprinter identify -b openai --model gpt-4o-mini
```
### 2. Train Your Own Classifier
```bash
# Step 1: Generate fingerprints for a known model
llm-fingerprinter simulate -b ollama --model llama3.2 --family llama --num-sims 3
# Step 2: Train classifier from fingerprints
llm-fingerprinter train
# Step 3: Identify unknown models
llm-fingerprinter identify -b ollama --model some-other-model
```
### 3. Backend-Specific Examples
**Ollama (Local)**
```bash
# List available models
llm-fingerprinter list-models -b ollama
# Identify
llm-fingerprinter identify -b ollama --model llama3.2
# Generate fingerprints
llm-fingerprinter simulate -b ollama --model llama3.2 --family llama
```
**Ollama Cloud**
```bash
export OLLAMA_CLOUD_API_KEY="your-key"
llm-fingerprinter identify -b ollama-cloud --model llama3.2
llm-fingerprinter simulate -b ollama-cloud --model llama3.2 --family llama
```
**OpenAI**
```bash
export OPENAI_API_KEY="your-key"
llm-fingerprinter identify -b openai --model gpt-4o
llm-fingerprinter simulate -b openai --model gpt-4 --family gpt --num-sims 5
```
**Gemini**
```bash
export GEMINI_API_KEY="your-key"
llm-fingerprinter identify -b gemini --model gemini-2.5-pro
llm-fingerprinter simulate -b gemini --model gemini-2.5-pro --family gemini
```
**DeepSeek**
```bash
export DEEPSEEK_API_KEY="your-key"
llm-fingerprinter identify -b deepseek --model deepseek-chat
llm-fingerprinter simulate -b deepseek --model deepseek-chat --family deepseek
```
**Custom API (Any HTTP Endpoint)**
Works with **any** LLM API via HTTP request template. No native backend support needed!
```bash
export CUSTOM_API_KEY="your-api-key"
llm-fingerprinter identify -b custom -r ./custom_request.txt
llm-fingerprinter identify -b custom -r ./custom_request.txt -k my-api-key
llm-fingerprinter simulate -b custom -r ./custom_request.txt --family gpt
```
## Python API
You can also use the library programmatically:
```python
from llm_fingerprinter import LLMFingerprinter, EnsembleClassifier, FeatureExtractor, PromptSuite
from llm_fingerprinter.ollama_client import OllamaClient
# Setup components
client = OllamaClient(endpoint="http://localhost:11434")
suite = PromptSuite()
extractor = FeatureExtractor()
classifier = EnsembleClassifier()
# Create fingerprinter and identify a model
fingerprinter = LLMFingerprinter("http://localhost:11434", client, suite, extractor, classifier)
fingerprint = fingerprinter.fingerprint_model("llama3.2")
```
---
## Commands Reference
### Global Options
| Option | Short | Description |
|--------|-------|-------------|
| `--verbose` | `-v` | Enable verbose output (debug logging) |
### Backend Options (Common to all LLM commands)
These options are available for: `identify`, `simulate`, `test`, `fingerprint`, and `list-models`
| Option | Short | Default | Description |
|--------|-------|---------|-------------|
| `--backend` | `-b` | `ollama` | Backend: `ollama`, `ollama-cloud`, `openai`, `deepseek`, `gemini`, `custom` |
| `--endpoint` | `-e` | auto | API endpoint URL (overrides default) |
| `--api-key` | `-k` | env var | API key (fallback to environment variable) |
| `--request-file` | `-r` | - | Request template file (required for `custom` backend) |
---
### `identify` - Identify Unknown Model
Classify an unknown model using the trained classifier. Works with any LLM backend including **custom HTTP endpoints**.
```bash
llm-fingerprinter identify [OPTIONS]
```
**Options:**
| Option | Short | Default | Description |
|--------|-------|---------|-------------|
| `--model` | `-m` | - | Model name (optional, may be in request template for custom backend) |
| `--repeats` | - | 1 | Number of times to repeat each prompt (increases confidence) |
| `--backend` | `-b` | `ollama` | LLM backend |
| `--endpoint` | `-e` | auto | API endpoint |
| `--api-key` | `-k` | env var | API key |
**Examples:**
```bash
# Local Ollama (simplest)
llm-fingerprinter identify -b ollama --model llama3.2
# With multiple repeats for higher confidence
llm-fingerprinter identify -b ollama --model llama3.2 --repeats 3
# OpenAI
export OPENAI_API_KEY="sk-..."
llm-fingerprinter identify -b openai --model gpt-4o-mini
# ⭐ Custom endpoint (e.g., proprietary LLM, local instance, proxy)
llm-fingerprinter identify -b custom -r ./example/openai_request.txt
# ⭐ Custom with API key
llm-fingerprinter identify -b custom -r ./example/openai_request.txt -k "your-api-key"
# ⭐ Any HTTP-based LLM (examples in ./example/)
llm-fingerprinter identify -b custom -r ./example/ollama_cloud_request.txt
```
**Output:**
```
═══════════════════════════════════════════════════════════════
IDENTIFICATION REPORT
═══════════════════════════════════════════════════════════════
Identified: GPT (or LLAMA, GEMINI, etc.)
Confidence: 92.5%
Probabilities:
gpt 92.5% █████████████████████
llama 5.2% █
gemini 1.8%
mistral 0.5%
═══════════════════════════════════════════════════════════════
```
---
### `simulate` - Generate Training Fingerprints
Create fingerprints for known models to build/improve the classifier. Works with any backend including **custom HTTP endpoints**.
```bash
llm-fingerprinter simulate [OPTIONS]
```
**Options:**
| Option | Short | Default | Description |
|--------|-------|---------|-------------|
| `--model` | `-m` | - | Model name (optional) |
| `--family` | `-f` | - | **Required.** Model family: `gpt`, `claude`, `llama`, `gemini`, `mistral`, `qwen`, `gemma`, `deepseek` |
| `--num-sims` | `-n` | 3 | Number of fingerprints to generate |
| `--repeats` | - | 2 | Prompts repeats per simulation |
| `--backend` | `-b` | `ollama` | LLM backend |
| `--endpoint` | `-e` | auto | API endpoint |
| `--api-key` | `-k` | env var | API key |
**Examples:**
```bash
# Basic simulation (3 fingerprints, 2 repeats each)
llm-fingerprinter simulate -b ollama --model llama3.2 --family llama
# More comprehensive (10 fingerprints, 5 repeats each)
llm-fingerprinter simulate -b ollama --model llama3.2 --family llama --num-sims 10 --repeats 5
# OpenAI
export OPENAI_API_KEY="sk-..."
llm-fingerprinter simulate -b openai --model gpt-4 --family gpt --num-sims 5
# Custom endpoint with specific API
llm-fingerprinter simulate -b openai -e https://api.groq.com/openai/v1 -k $GROQ_KEY \
--model llama-3.1-70b --family llama
```
---
### `train` - Build Classifier
Train an ensemble classifier from saved fingerprints.
```bash
llm-fingerprinter train [OPTIONS]
```
**Options:**
| Option | Default | Description |
|--------|---------|-------------|
| `--augment / --no-augment` | `--augment` | Enable/disable data augmentation |
| `--use-pca` | false | Use PCA dimensionality reduction |
| `--pca-components` | 64 | Number of PCA components (if `--use-pca`) |
| `--cross-validate` / `-cv` | false | Run k-fold cross-validation |
| `--cv-folds` | 5 | Number of cross-validation folds |
**Examples:**
```bash
# Default: raw features (402-dim), with augmentation
llm-fingerprinter train
# With PCA reduction (faster, less accurate)
llm-fingerprinter train --use-pca
# Custom PCA components
llm-fingerprinter train --use-pca --pca-components 128
# With cross-validation
llm-fingerprinter train --cross-validate --cv-folds 5
# Disable augmentation
llm-fingerprinter train --no-augment
```
**Output:**
```
🧠 Training classifier (raw features (402-dim))...
📊 Training data:
gpt: 15 samples (402 dims)
llama: 12 samples (402 dims)
gemini: 10 samples (402 dims)
Total: 37
📈 Running 5-fold cross-validation...
Mean accuracy: 94.6% (5 folds)
Per-family metrics:
Family Prec Recall F1 Support
──────────────────────────────────────────────
gpt 0.96 0.95 0.96 15
llama 0.93 0.92 0.92 12
gemini 0.92 0.90 0.91 10
Fold accuracies: 93%, 95%, 94%, 96%, 95%
✅ Classifier trained and saved!
Mode: raw features (402-dim)
Input dim: 402
```
---
### `test` - Test Backend Connection
Verify connectivity and generation with a backend.
```bash
llm-fingerprinter train [--augment/--no-augment] [--cross-validate]
```
| Option | Default | Description |
|--------|---------|-------------|
| `--augment/--no-augment` | `--augment` | Data augmentation |
| `--use-pca` | off | Use PCA reduction |
| `--pca-components` | 64 | PCA components |
| `--cross-validate` / `-cv` | off | Run k-fold cross-validation |
| `--cv-folds` | 5 | Number of CV folds |
### `identify`
**Examples:**
```bash
# Test local Ollama
llm-fingerprinter test -b ollama --model llama3.2
# Test OpenAI
export OPENAI_API_KEY="sk-..."
llm-fingerprinter test -b openai --model gpt-4o
# Test with custom prompt
llm-fingerprinter test -b ollama --model llama3.2 -p "What is 2+2?"
# Test custom backend
llm-fingerprinter test -b custom -r ./custom_request.txt
```
### `fingerprint` - Generate Standalone Fingerprint
Generate a fingerprint without using the classifier (useful for analysis).
```bash
llm-fingerprinter fingerprint [OPTIONS]
```
**Options:**
| Option | Short | Default | Description |
|--------|-------|---------|-------------|
| `--model` | `-m` | - | Model name (optional) |
| `--repeats` | - | 1 | Prompt repeats |
| `--output` | - | `./fingerprints` | Output directory |
| `--backend` | `-b` | `ollama` | LLM backend |
| `--endpoint` | `-e` | auto | API endpoint |
| `--api-key` | `-k` | env var | API key |
**Examples:**
```bash
# Generate and save fingerprint
llm-fingerprinter fingerprint -b ollama --model llama3.2
# With custom output directory
llm-fingerprinter fingerprint -b ollama --model llama3.2 --output ./my_fingerprints
# Multiple repeats for better accuracy
llm-fingerprinter fingerprint -b openai --model gpt-4o --repeats 3
```
---
### `list-models` - List Available Models
Show all models available on the backend.
```bash
llm-fingerprinter list-models [OPTIONS]
```
**Options:**
| Option | Short | Description |
|--------|-------|-------------|
| `--backend` | `-b` | LLM backend |
| `--endpoint` | `-e` | API endpoint |
| `--api-key` | `-k` | API key |
**Examples:**
```bash
# List Ollama models
llm-fingerprinter list-models -b ollama
# List OpenAI models
export OPENAI_API_KEY="sk-..."
llm-fingerprinter list-models -b openai
# Custom endpoint
llm-fingerprinter list-models -b openai -e https://api.groq.com/openai/v1 -k $GROQ_KEY
```
---
### `list-fingerprints` - List Saved Fingerprints
Show count of fingerprints by model family.
```bash
llm-fingerprinter list-fingerprints
```
**Output:**
```
📚 Fingerprints:
gpt 15 ████████████████████
llama 12 ████████████████
gemini 10 ██████████████
mistral 8 ███████████
Total: 45
✅ Classifier trained (raw features, 402 dims)
```
---
### `info` - Show System Information
Display configuration, installed backends, available families, and status.
```bash
llm-fingerprinter info
```
**Output:**
```
⚙️ Config:
Fingerprints: /folder/ fingerprints
Embedding: all-MiniLM-L6-v2 (384d)
Total dims: 402 (384 + 12 + 6)
🔌 Backends:
ollama: http://localhost:11434
ollama-cloud: https://api.ollama.ai
openai: https://api.openai.com/v1
deepseek: https://api.deepseek.com
gemini: https://generativelanguage.googleapis.com
custom: Via request template file (-r)
📋 Families: claude, deepseek, gemini, gemma, gpt, llama, mistral, qwen
📊 Status:
Fingerprints: 45
Classifier: ✅ trained (raw features, 402 dims)
💡 Training options:
train # Use raw 402-dim features (default)
train --use-pca # Use PCA reduction (64 dims)
```
---
## Usage Workflow
### Complete Training Workflow
```bash
# 1. Generate fingerprints for GPT models
llm-fingerprinter simulate -b openai --model gpt-4 --family gpt --num-sims 5 --repeats 3
llm-fingerprinter simulate -b openai --model gpt-4o --family gpt --num-sims 5 --repeats 3
# 2. Generate fingerprints for LLaMA models
llm-fingerprinter simulate -b ollama --model llama3.2 --family llama --num-sims 5 --repeats 3
llm-fingerprinter simulate -b ollama --model llama2 --family llama --num-sims 5 --repeats 3
# 3. List all fingerprints
llm-fingerprinter list-fingerprints
# 4. Train classifier with cross-validation
llm-fingerprinter train --cross-validate
# 5. Test on unknown models
llm-fingerprinter identify -b ollama --model some-unknown-model
llm-fingerprinter identify -b openai --model gpt-4o-mini --repeats 3
```
### Quick Identification Workflow
```bash
# 1. Test connection
llm-fingerprinter test -b ollama --model llama3.2
# 2. Identify model
llm-fingerprinter identify -b ollama --model llama3.2
# 3. View results
llm-fingerprinter list-fingerprints
```
---
## Common Patterns
### Using Environment Variables for API Keys
```bash
# Set once, use multiple times
export OPENAI_API_KEY="sk-..."
export GEMINI_API_KEY="AIza..."
# No need to pass -k flag each time
llm-fingerprinter simulate -b openai --model gpt-4 --family gpt
llm-fingerprinter identify -b openai --model gpt-4o
llm-fingerprinter test -b gemini --model gemini-2.5-pro
```
### ⭐ Custom Backend with Request Template (Universal LLM Support)
The **custom backend** lets you use fingerprinting with **any** HTTP-based LLM API by providing a request template file.
```bash
# Use a request template file for custom APIs
llm-fingerprinter identify -b custom -r ./example/openai_request.txt
# Can also pass API key
llm-fingerprinter identify -b custom -r ./example/openai_request.txt -k "api-key-here"
# Generate training fingerprints
llm-fingerprinter simulate -b custom -r ./example/openai_request.txt --family gpt --num-sims 5
# Test connection
llm-fingerprinter test -b custom -r ./example/openai_request.txt
# See example templates in ./example/ directory:
# - openai_request.txt (OpenAI-compatible APIs)
# - ollama_cloud_request.txt
# - ollama_local_request.txt
```
**Why use custom backend?**
- 🔓 Support for proprietary/closed LLMs not in native backends
- 🏠 Self-hosted LLM servers behind HTTP endpoints
- 🔀 API proxies, gateways, and load balancers
- 🌐 Any HTTP-based LLM service (local or remote)
- 🎯 Complete control over request format
### Multi-Endpoint Configuration
```bash
# Test same model on different endpoints
llm-fingerprinter test -b openai -e https://api.openai.com/v1 --model gpt-4
llm-fingerprinter test -b openai -e https://api.groq.com/openai/v1 --model llama-3.1-70b -k $GROQ_KEY
# Identify via different providers
llm-fingerprinter identify -b openai --model gpt-4o
llm-fingerprinter identify -b openai -e https://my-proxy.com/v1 --model gpt-4o -k "proxy-key"
```
### Improving Accuracy
```bash
# Use higher repeats for more confident predictions
llm-fingerprinter identify -b ollama --model llama3.2 --repeats 5
# Train with more simulations per model
llm-fingerprinter simulate -b ollama --model llama3.2 --family llama --num-sims 10 --repeats 5
# Use PCA for faster training with slight accuracy trade-off
llm-fingerprinter train --use-pca --pca-components 128
# Cross-validate before deployment
llm-fingerprinter train --cross-validate --cv-folds 10
```
---
## Environment Variables
| Variable | Backend | Description |
|----------|---------|-------------|
| `OLLAMA_CLOUD_API_KEY` | ollama-cloud | Ollama Cloud API key |
| `OPENAI_API_KEY` | openai | OpenAI API key |
| `GEMINI_API_KEY` | gemini | Gemini API key |
| `DEEPSEEK_API_KEY` | deepseek | DeepSeek API key |
| `CUSTOM_API_KEY` | custom | Custom API key |
| `LOG_LEVEL` | all | Logging level (DEBUG, INFO, etc.) |
| `LLM_FINGERPRINTER_DATA` | all | Custom data directory path |
## Data Storage
When installed via pip, runtime data (fingerprints, trained models, logs) is stored in `~/.llm-fingerprinter/`. You can override this with the `LLM_FINGERPRINTER_DATA` environment variable. When running from a git checkout, data is stored in the project directory (backward compatible).
## 🔧 Custom Backend Deep Dive
The custom backend is the most powerful feature - it allows fingerprinting of **any** LLM accessible via HTTP, regardless of whether a native backend exists.
### How It Works
1. Create an HTTP request template file (JSON format)
2. Include placeholders for `model` and `prompt`
3. Pass template to fingerprinter with `-b custom -r ./template.txt`
4. The system automatically sends requests and analyzes responses
### Example: Creating a Custom Template
```json
{
"url": "https://api.example.com/v1/completions",
"method": "POST",
"headers": {
"Content-Type": "application/json",
"Authorization": "Bearer {api_key}"
},
"body": {
"model": "{model}",
"prompt": "{prompt}",
"max_tokens": 200,
"temperature": 0.7
}
}
```
### Usage Examples
```bash
# Create your template file
cat > my_llm_template.txt << 'EOF'
{
"url": "https://my-llm.com/api/generate",
"method": "POST",
"headers": {
"Authorization": "Bearer your-key"
},
"body": {
"model": "{model}",
"prompt": "{prompt}",
"max_tokens": 200
}
}
EOF
# Identify models
llm-fingerprinter identify -b custom -r ./my_llm_template.txt
# Generate training fingerprints
llm-fingerprinter simulate -b custom -r ./my_llm_template.txt --family gpt --num-sims 5
# Test connectivity
llm-fingerprinter test -b custom -r ./my_llm_template.txt
# Pass API key via environment or CLI
export CUSTOM_API_KEY="your-secret-key"
llm-fingerprinter identify -b custom -r ./my_llm_template.txt
# Or pass directly
llm-fingerprinter identify -b custom -r ./my_llm_template.txt -k "your-secret-key"
```
### Supported Template Placeholders
| Placeholder | Description | Example |
|-------------|-------------|---------|
| `{model}` | Model name passed via CLI | `gpt-4`, `llama3.2` |
| `{prompt}` | The fingerprinting prompt | (automatically populated) |
| `{api_key}` | API key from environment or CLI | (injected automatically) |
### Pre-built Examples
See `./example/` directory for ready-to-use templates:
- **openai_request.txt** - OpenAI, Groq, and compatible APIs
- **ollama_cloud_request.txt** - Ollama Cloud
- **ollama_local_request.txt** - Local Ollama
Copy and adapt these for your use case!
---
## How It Works
1. **75 Prompts** across 3 layers:
- *Stylistic*: Analyze writing style and formatting preferences
- *Behavioral*: Assess response patterns and decision-making behavior
- *Discriminative*: Identify model-specific characteristics and inconsistencies
2. **Feature Extraction**: 384-dim embeddings + 12 linguistic + 6 behavioral features
3. **PCA** reduction to 64 dimensions (Optional)
4. **Ensemble Classification**: Random Forest (45%) + SVM (45%) + MLP (10%)
---
## Contributing
Contributions are welcome! Whether you're adding support for new models, improving accuracy, or extending to additional clients, please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
---
## License
MIT License
| text/markdown | null | litemars <maxmassi12@gmail.com> | null | null | MIT | llm, fingerprinting, model-identification, machine-learning, nlp | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Pyt... | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy>=1.21.0",
"scikit-learn>=1.0.0",
"scipy>=1.7.0",
"sentence-transformers>=2.2.0",
"nltk>=3.8.0",
"requests>=2.28.0",
"tenacity>=8.0.0",
"click>=8.0.0",
"joblib>=1.1.0",
"openai>=1.0.0; extra == \"openai\"",
"google-genai>=0.1.0; extra == \"gemini\"",
"openai>=1.0.0; extra == \"all\"",
... | [] | [] | [] | [
"Homepage, https://github.com/litemars/LLM-Fingerprinter",
"Repository, https://github.com/litemars/LLM-Fingerprinter",
"Issues, https://github.com/litemars/LLM-Fingerprinter/issues"
] | twine/6.2.0 CPython/3.9.6 | 2026-02-19T15:28:21.739223 | llm_fingerprinter-0.2.0.tar.gz | 3,840,421 | 4b/7b/a074c6d62db876e76f1c6dad62a71ca3f1f833aef96cfde39616ee77f97e/llm_fingerprinter-0.2.0.tar.gz | source | sdist | null | false | 64a12ba32dc9766738e0bc46c6245122 | 8f23243f0c73ab04cc79be2f9772b3ece05667c6510329017b663d11b3a23433 | 4b7ba074c6d62db876e76f1c6dad62a71ca3f1f833aef96cfde39616ee77f97e | null | [
"LICENSE"
] | 233 |
2.4 | datashield | 0.3.0 | DataSHIELD Client Interface in Python. | # DataSHIELD Interface Python
This DataSHIELD Client Interface is a Python port of the original DataSHIELD Client Interface written in R ([DSI](https://github.com/datashield/DSI)). The provided interface can be implemented for accessing a data repository supporting the DataSHIELD infrastructure: controlled R commands to be executed on the server side are garanteeing that non disclosive information is returned to client side.
## Configuration
The search path for the DataSHIELD configuration file is the following:
1. User general location: `~/.config/datashield/config.yaml`
2. Current project specific location: `./.datashield/config.yaml`
The configurations are merged: any existing entry is replaced by the new one (for instance server names must be unique).
The format of the DataSHIELD configuration file is:
```yaml
servers:
- name: server1
url: https://opal-demo.obiba.org
user: dsuser
password: P@ssw0rd
- name: server2
url: https://opal.example.org
token: your-access-token-here
profile: default
- name: server3
url: https://study.example.org/opal
user: dsuser
password: P@ssw0rd
profile: custom
driver: datashield_opal.OpalDriver
```
Each server entry in the list must have:
- `name`: Unique identifier for the server
- `url`: The server URL
- Authentication: Either `user` and `password`, or `token` (recommended)
- `profile`: DataSHIELD profile name (optional, defaults to "default")
- `driver`: Connection driver class name (optional, defaults to "datashield_opal.OpalDriver") | text/markdown | null | Yannick Marcon <yannick.marcon@obiba.org> | null | Yannick Marcon <yannick.marcon@obiba.org> | LGPL | data, datashield | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python... | [] | null | null | >=3.10 | [] | [] | [] | [
"pydantic>=2.0",
"pyyaml>=6.0",
"ruff>=0.10.0; extra == \"dev\"",
"pytest>=7.2.2; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://www.datashield.org",
"Repository, https://github.com/datashield/datashield-python",
"Documentation, https://datashield.github.io/datashield-python",
"Bug Tracker, https://github.com/datashield/datashield-python/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T15:27:42.652846 | datashield-0.3.0-py3-none-any.whl | 20,620 | be/9f/6154d588335971f279f7b4c8ea9b6ea824316efb24ead14717860749ff62/datashield-0.3.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 3d8f4e50559770f399accac5167d5918 | 7a738f4748057884b65b94a958aeafa8348f52b96747c9723b034ed10f470296 | be9f6154d588335971f279f7b4c8ea9b6ea824316efb24ead14717860749ff62 | null | [
"LICENSE.md"
] | 265 |
2.4 | logfire-api | 4.25.0 | Shim for the Logfire SDK which does nothing unless Logfire is installed | # logfire-api
Shim for the logfire SDK Python API which does nothing unless logfire is installed.
This package is designed to be used by packages that want to provide opt-in integration with [Logfire](https://github.com/pydantic/logfire).
The package provides a clone of the Python API exposed by the `logfire` package which does nothing if the `logfire` package is not installed, but makes real calls when it is.
| text/markdown | null | Pydantic Team <engineering@pydantic.dev>, Samuel Colvin <samuel@pydantic.dev>, Hasan Ramezani <hasan@pydantic.dev>, Adrian Garcia Badaracco <adrian@pydantic.dev>, David Montague <david@pydantic.dev>, Marcelo Trylesinski <marcelo@pydantic.dev>, David Hewitt <david.hewitt@pydantic.dev>, Alex Hall <alex@pydantic.dev> | null | null | null | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:27:29.518931 | logfire_api-4.25.0.tar.gz | 75,853 | 94/5c/026cec30d85394aec8f5f12d70edbe2d706837bc9a411bd71a542cedae50/logfire_api-4.25.0.tar.gz | source | sdist | null | false | 9ad047b33462cfacfad2cb09a5cd031d | 7562d5adfe3987291039dddb21947c86cb9d832d068c87d9aa23db86ef07095b | 945c026cec30d85394aec8f5f12d70edbe2d706837bc9a411bd71a542cedae50 | MIT | [] | 193,431 |
2.4 | logfire | 4.25.0 | The best Python observability tool! 🪵🔥 | # Pydantic Logfire — Know more. Build faster.
<p align="center">
<a href="https://github.com/pydantic/logfire/actions?query=event%3Apush+branch%3Amain+workflow%3ACI"><img src="https://github.com/pydantic/logfire/actions/workflows/main.yml/badge.svg?event=push" alt="CI" /></a>
<a href="https://codecov.io/gh/pydantic/logfire"><img src="https://codecov.io/gh/pydantic/logfire/graph/badge.svg?token=735CNGCGFD" alt="codecov" /></a>
<a href="https://pypi.python.org/pypi/logfire"><img src="https://img.shields.io/pypi/v/logfire.svg" alt="pypi" /></a>
<a href="https://github.com/pydantic/logfire/blob/main/LICENSE"><img src="https://img.shields.io/github/license/pydantic/logfire.svg" alt="license" /></a>
<a href="https://github.com/pydantic/logfire"><img src="https://img.shields.io/pypi/pyversions/logfire.svg" alt="versions" /></a>
<a href="https://logfire.pydantic.dev/docs/join-slack/"><img src="https://img.shields.io/badge/Slack-Join%20Slack-4A154B?logo=slack" alt="Join Slack" /></a>
</p>
From the team behind Pydantic Validation, **Pydantic Logfire** is an observability platform built on the same belief as our open source library — that the most powerful tools can be easy to use.
What sets Logfire apart:
- **Simple and Powerful:** Logfire's dashboard is simple relative to the power it provides, ensuring your entire engineering team will actually use it.
- **Python-centric Insights:** From rich display of Python objects, to event-loop telemetry, to profiling Python code and database queries, Logfire gives you unparalleled visibility into your Python application's behavior.
- **SQL:** Query your data using standard SQL — all the control and (for many) nothing new to learn. Using SQL also means you can query your data with existing BI tools and database querying libraries.
- **OpenTelemetry:** Logfire is an opinionated wrapper around OpenTelemetry, allowing you to leverage existing tooling, infrastructure, and instrumentation for many common Python packages, and enabling support for virtually any language. We offer full support for all OpenTelemetry signals (traces, metrics and logs).
- **Pydantic Integration:** Understand the data flowing through your Pydantic Validation models and get built-in analytics on validations.
See the [documentation](https://logfire.pydantic.dev/docs/) for more information.
**Feel free to report issues and ask any questions about Logfire in this repository!**
This repo contains the Python SDK for `logfire` and documentation; the server application for recording and displaying data is closed source.
## Using Logfire
This is a very brief overview of how to use Logfire, the [documentation](https://logfire.pydantic.dev/docs/) has much more detail.
### Install
```bash
pip install logfire
```
[_(learn more)_](https://logfire.pydantic.dev/docs/guides/first_steps/#install)
## Authenticate
```bash
logfire auth
```
[_(learn more)_](https://logfire.pydantic.dev/docs/guides/first_steps/#authentication)
### Manual tracing
Here's a simple manual tracing (aka logging) example:
```python skip-run="true" skip-reason="blocking"
from datetime import date
import logfire
logfire.configure()
logfire.info('Hello, {name}!', name='world')
with logfire.span('Asking the user their {question}', question='age'):
user_input = input('How old are you [YYYY-mm-dd]? ')
dob = date.fromisoformat(user_input)
logfire.debug('{dob=} {age=!r}', dob=dob, age=date.today() - dob)
```
[_(learn more)_](https://logfire.pydantic.dev/docs/guides/onboarding-checklist/add-manual-tracing/)
### Integration
Or you can also avoid manual instrumentation and instead integrate with [lots of popular packages](https://logfire.pydantic.dev/docs/integrations/), here's an example of integrating with FastAPI:
```py skip-run="true" skip-reason="global-instrumentation"
from fastapi import FastAPI
from pydantic import BaseModel
import logfire
app = FastAPI()
logfire.configure()
logfire.instrument_fastapi(app)
# next, instrument your database connector, http library etc. and add the logging handler
class User(BaseModel):
name: str
country_code: str
@app.post('/')
async def add_user(user: User):
# we would store the user here
return {'message': f'{user.name} added'}
```
[_(learn more)_](https://logfire.pydantic.dev/docs/integrations/fastapi/)
Logfire gives you a view into how your code is running like this:
## Contributing
We'd love anyone interested to contribute to the Logfire SDK and documentation, see the [contributing guide](https://github.com/pydantic/logfire/blob/main/CONTRIBUTING.md).
## Reporting a Security Vulnerability
See our [security policy](https://github.com/pydantic/logfire/security).
## Logfire Open-Source and Closed-Source Boundaries
The Logfire SDKs (we also have them for [TypeScript](https://github.com/pydantic/logfire-js) and [Rust](https://github.com/pydantic/logfire-rust)) are open source, and you can use them to export data to [any OTel-compatible backend](https://logfire.pydantic.dev/docs/how-to-guides/alternative-backends/).
The Logfire platform (the UI and backend) is closed source. You can self-host it by purchasing an [enterprise license](https://logfire.pydantic.dev/docs/enterprise/).
| text/markdown | null | Pydantic Team <engineering@pydantic.dev>, Samuel Colvin <samuel@pydantic.dev>, Hasan Ramezani <hasan@pydantic.dev>, Adrian Garcia Badaracco <adrian@pydantic.dev>, David Montague <david@pydantic.dev>, Marcelo Trylesinski <marcelo@pydantic.dev>, David Hewitt <david.hewitt@pydantic.dev>, Alex Hall <alex@pydantic.dev>, Jiri Kuncar <jiri@pydantic.dev> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Environment :: MacOS X",
"Framework :: OpenTelemetry",
"Framework :: OpenTelemetry :: Distros",
"Framework :: OpenTelemetry :: Exporters",
"Framework :: OpenTelemetry :: Instrumentations",
"Intended Audience :: Developers",
"I... | [] | null | null | >=3.9 | [] | [] | [] | [
"executing>=2.0.1",
"opentelemetry-exporter-otlp-proto-http<1.40.0,>=1.39.0",
"opentelemetry-instrumentation>=0.41b0",
"opentelemetry-sdk<1.40.0,>=1.39.0",
"protobuf>=4.23.4",
"rich>=13.4.2",
"tomli>=2.0.1; python_version < \"3.11\"",
"typing-extensions>=4.1.0",
"opentelemetry-instrumentation-aiohtt... | [] | [] | [] | [
"Homepage, https://logfire.pydantic.dev/",
"Source, https://github.com/pydantic/logfire",
"Documentation, https://logfire.pydantic.dev/docs/",
"Changelog, https://logfire.pydantic.dev/docs/release-notes/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:27:28.000372 | logfire-4.25.0.tar.gz | 1,049,745 | d8/43/374fc0e6ebe95209414cf743cc693f4ff2ad391fd0712445ed1f63245395/logfire-4.25.0.tar.gz | source | sdist | null | false | 6ffd66b8fdaceda3f16eff1bbc63143d | f9a6bf6d40fd3e2c2a86a364617246cadecbde620b4ecccb17c499140f1ebc13 | d843374fc0e6ebe95209414cf743cc693f4ff2ad391fd0712445ed1f63245395 | MIT | [
"LICENSE"
] | 147,807 |
2.1 | odoo-addon-account-reconcile-model-oca | 18.0.1.1.2 | This includes the logic moved from Odoo Community to Odoo Enterprise | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
===========================
Account Reconcile Model Oca
===========================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:3ed44a2df719c35e298e8e6e2bbdc8c53e524527caec230b70b1bda97dee7385
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-LGPL--3-blue.png
:target: http://www.gnu.org/licenses/lgpl-3.0-standalone.html
:alt: License: LGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Faccount--reconcile-lightgray.png?logo=github
:target: https://github.com/OCA/account-reconcile/tree/18.0/account_reconcile_model_oca
:alt: OCA/account-reconcile
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/account-reconcile-18-0/account-reconcile-18-0-account_reconcile_model_oca
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/account-reconcile&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module restores account reconciliation models functions moved from
Odoo community to enterpise in V. 17.0
**Table of contents**
.. contents::
:local:
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/account-reconcile/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/account-reconcile/issues/new?body=module:%20account_reconcile_model_oca%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Dixmit
* Odoo
Contributors
------------
- Dixmit
- Enric Tobella
- Trobz <https://www.trobz.com/>
- Do Anh Duy <duyda@trobz.com>
- `Tecnativa <https://www.tecnativa.com>`__:
- Víctor Martínez
- Jacques-Etienne Baudoux (BCIM) <je@bcim.be>
Other credits
-------------
The migration of this module from 17.0 to 18.0 was financially supported
by Camptocamp.
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/account-reconcile <https://github.com/OCA/account-reconcile/tree/18.0/account_reconcile_model_oca>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Dixmit,Odoo,Odoo Community Association (OCA) | support@odoo-community.org | null | null | LGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)"
] | [] | https://github.com/OCA/account-reconcile | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T15:27:18.791211 | odoo_addon_account_reconcile_model_oca-18.0.1.1.2-py3-none-any.whl | 47,338 | d2/87/73958414de0bd7d16f61e23394a606ce64e22d82097954f0a424fc1ae9e5/odoo_addon_account_reconcile_model_oca-18.0.1.1.2-py3-none-any.whl | py3 | bdist_wheel | null | false | a13393daaa0b4ae42d85543914dfe3eb | d123fca4f2112a319a9256d5b3bb89c9678412b129425308ed4788f65f5e60e8 | d28773958414de0bd7d16f61e23394a606ce64e22d82097954f0a424fc1ae9e5 | null | [] | 139 |
2.4 | talentro-commons | 0.22.0 | This package contains all globally used code, services, models and data structures for Talentro | # Talentro commons
This package contains all models and data structures for Talentro
It is exclusively meant for the Talentro ecosystem.
## Initial run
- Run `poetry self update && poetry self add keyrings.google-artifactregistry-auth`
- Run `poetry config repositories.gcp https://europe-west4-python.pkg.dev/talentro-459113/talentro-python`
## How to create a new version
- Make changes in the code, like editing the models
- Bump the version number to desired version in `pyproject.toml` using the `major.minor.fix` format
- run `poetry publish --build --repository gcp`
Now a new version is uploaded to pypi and you can install it after a minute in the other projects.
| text/markdown | Emiel van Essen | emiel@marksmen.nl | null | null | Proprietary | null | [
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.13 | [] | [] | [] | [
"aio-pika<10.0.0,>=9.5.7",
"aiocache[redis]<0.13.0,>=0.12.3",
"fastapi<0.129.0,>=0.128.0",
"google-cloud-storage<4.0.0,>=3.6.0",
"httpx<0.29.0,>=0.28.1",
"sqlalchemy<3.0.0,>=2.0.38",
"sqlmodel<0.0.32,>=0.0.31"
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.14.3 Linux/6.1.79 | 2026-02-19T15:27:11.548694 | talentro_commons-0.22.0-py3-none-any.whl | 34,409 | 3d/a7/8105739559cc075758410bd22aecec9a19e7520d36db17e17e229fa7c4f0/talentro_commons-0.22.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 2e0eb768058f7519e257fa12226b39cc | ebbd3af43954ae3e59f046a436ba1c503a1a26165811018533a69489a917b747 | 3da78105739559cc075758410bd22aecec9a19e7520d36db17e17e229fa7c4f0 | null | [] | 225 |
2.4 | voximplant-apiclient | 2.6.0 | Voximplant API client library |
Voximplant API client library
=============================
Version 2.6.0
~~~~~~~~~~~~~
Prerequisites
-------------
In order to use the Voximplant Python SDK, you need the following:
#. A developer account. If you don't have one, `sign up here <https://voximplant.com/sign-up/>`_.
#. A private API key. There are 2 options to obtain it:
#. Either generate it in the `Voximplant Control panel <https://manage.voximplant.com/settings/service_accounts>`_
#. Or call the `CreateKey <https://voximplant.com/docs/references/httpapi/managing_role_system#createkey>`_ HTTP API
method with the
specified `authentication parameters <https://voximplant.com/docs/references/httpapi/auth_parameters>`_. You'll
receive a response with the **result** field in it. Save the **result** value in a file (since we don't store the
keys, save it securely on your side).
#. Python 2.x or 3.x runtime with ``pip`` and ``setuptools``\ >=18.5 installed
How to use
----------
Go to your project folder and install the SDK using ``pip``\ :
.. code-block:: bash
python -m pip install --user voximplant-apiclient
Then import the SDK in your script
.. code-block:: python
from voximplant.apiclient import VoximplantAPIConfig, VoximplantAPI
Next, specify the path to the JSON service account file either in the constructor or using the environment.
**constructor**\ :
.. code-block:: python
config = VoximplantAPIConfig(
credentials_file_path="/path/to/credentials.json",
)
api = VoximplantAPI(config=config)
**env**\ :
.. code-block:: bash
export VOXIMPLANT_CREDENTIALS=/path/to/credentials.json
Examples
--------
Start a scenario
^^^^^^^^^^^^^^^^
.. code-block:: python
from voximplant.apiclient import VoximplantAPIConfig, VoximplantAPI, VoximplantException
if __name__ == "__main__":
config = VoximplantAPIConfig(
credentials_file_path="credentials.json",
)
api = VoximplantAPI(config=config)
# Start a scenario of the user 1
RULE_ID = 1
SCRIPT_CUSTOM_DATA = "mystr"
USER_ID = 1
try:
res = api.start_scenarios(RULE_ID, script_custom_data=SCRIPT_CUSTOM_DATA, user_id=USER_ID)
print(res)
except VoximplantException as e:
print("Error: {}".format(e.message))
Send an SMS
^^^^^^^^^^^
.. code-block:: python
from voximplant.apiclient import VoximplantAPIConfig, VoximplantAPI, VoximplantException
if __name__ == "__main__":
config = VoximplantAPIConfig(
credentials_file_path="credentials.json",
)
api = VoximplantAPI(config=config)
# Send the SMS with the "Test message" text from the phone number 447443332211 to the phone number 447443332212
SOURCE = "447443332211"
DESTINATION = "447443332212"
SMS_BODY = "Test message"
try:
res = api.send_sms_message(SOURCE, DESTINATION, SMS_BODY)
print(res)
except VoximplantException as e:
print("Error: {}".format(e.message))
Get a call history item
^^^^^^^^^^^^^^^^^^^^^^^
.. code-block:: python
from voximplant.apiclient import VoximplantAPIConfig, VoximplantAPI, VoximplantException
import pytz
import datetime
if __name__ == "__main__":
config = VoximplantAPIConfig(
credentials_file_path="credentials.json",
)
api = VoximplantAPI(config=config)
# Get the first call session history record from the 2012-01-01 00:00:00 UTC to the 2014-01-01 00:00:00 UTC
FROM_DATE = datetime.datetime(2012, 1, 1, 0, 0, 0, pytz.utc)
TO_DATE = datetime.datetime(2014, 1, 1, 0, 0, 0, pytz.utc)
COUNT = 1
try:
res = api.get_call_history(FROM_DATE, TO_DATE, count=COUNT)
print(res)
except VoximplantException as e:
print("Error: {}".format(e.message))
| null | Voximplant | support@voximplant.com | null | null | null | null | [
"Programming Language :: Python",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent"
] | [] | https://voximplant.com/ | null | null | [] | [] | [] | [
"requests",
"pytz",
"pyjwt",
"cryptography"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.4 | 2026-02-19T15:27:11.020813 | voximplant_apiclient-2.6.0.tar.gz | 35,194 | b8/b8/77268f1d217cfc223622fe7ca127e1b0a612c5857be2ebc5ac09e374fd64/voximplant_apiclient-2.6.0.tar.gz | source | sdist | null | false | 89736e9b5065f78764ef51f188d41cae | 5b847f19d03cd13e6e8b7e8623bbbc23994e366c9336fb37c340a4493b9d1380 | b8b877268f1d217cfc223622fe7ca127e1b0a612c5857be2ebc5ac09e374fd64 | null | [
"LICENSE",
"NOTICE"
] | 254 |
2.4 | ohppipeline | 2.0.1.dev2 | A library for reducing and analyzing images obtained at the Haute Provence Observatory | # Conteneur Docker pour traitement des Données OHP
## En bref
Pour faire court :
* Télécharger l'image `docker pull chottier/ohpstudent:2.0`
* Créer le conteneur et le démarrer `docker run -d -p 8910:8888 -v /repertoire/travail/ohp:/home/ohpstudent/work --name
ohpprocessim chottier/ohpstudent:2.0`
* Arrêter le conteneur `docker stop ohpprocessim`
* Redémarrer le conteneur `docker start ohpprocessim`
## Un point sur Docker
Docker est un système de virtualisation légère. Une machine virtuelle classique démarre un
système d'exploitation de manière complètement indépendante du système hôte. Docker, quant à
lui, n'est pas complètement séparé du système hôte, il utilise du système tout ce dont il a
besoin et ne rajoute que la différence entre le système hôte et ce qui est requis par le
conteneur.
Docker fonctionne avec des images. Ces images sont trouvables sur [docker hub](https://hub.docker.com/).
À partir de ces images, on construit des conteneurs. Ce sont ces conteneurs qui "se comportent
comme des machines virtuelles".
Note : Il est tout a fait possible de construire plusieurs conteneurs à partir d'une même image.
Les images sont en fait des modèles.
## Installation de docker
Docker fonctionne sur tous les systèmes d'exploitation (Mac OS X, Windows et Linux), référez-
vous à la documentation en lignes de [docker](https://www.docker.com/) concernant votre système
d'exploitation.
## Récupération de l'image docker
Vous pouvez récupérer l'image qui a été préparée grâce à la commande `docker pull chottier/ohpstudent:2.0`
cela téléchargera la version 2.0 de l'image. D'autres versions pourront éventuellement être
livrées, pour les récupérer il suffira de changer le tag dans la commande précédente.
On pourra vérifier que l'image est correctement téléchargée avec la commande `docker images`
```console
$> docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
chottier/ohpstudent 2.0 af8517064048 43 hours ago 6.25GB
```
Note : Docker utilise des fichiers incrémentaux ainsi lors de la récupération de nouvelles
images, seule la différence avec les versions antérieures est téléchargée.
## Création de votre conteneur et utilisation
L'utilisation de docker vous permet de partager des répertoires (des dossiers) du système hôte avec le
conteneur. Vous devrez donc créer un répertoire (qui pourra en contenir d'autre) dans lequel vous stockerez les images et les
spectres que vous acquerrez ainsi que l'ensemble des résultats de vos analyses scientifiques.
Dans la suite de ce document, on désignera ce répertoire par `/repertoire/travail/ohp`
Note : On utilise ici la nomenclature UNIX de séparation de fichier avec des `/`.
### Initialisation et lancement
Une fois que l'image est obtenue, vous pouvez créer votre conteneur avec la commande (barbare ?) suivante
`docker run -d -p 8910:8888 -v /repertoire/travail/ohp:/home/ohpstudent/work --name
ohpprocessim chottier/ohpstudent:2.0`.
Décomposons la commande :
* `docker run` signifie que vous souhaitez initialiser un conteneur et le lancer.
* `-d` pour le mode détacher, le conteneur fonctionnera en arrière plan.
* `-p 8910:8888` permet de connecter le port 8910 de votre machine (la machine hôte) au port
8888 du conteneur. Vous êtes libre de choisir le port de votre machine (prenez toujours un
nombre plus grand que 8000 !!!). Le port 8888 est obligatoire pour le conteneur.
* `-v /repertoire/travail/ohp:/home/ohpstudent/work` permet de lié le répertoire de votre
machine au répertoire du conteneur
* `--name ohpprocessim` le nom du conteneur que vous créez et que vous réutiliserez
* `chottier/ohpstudent:2.0` le nom de l'image que vous utilisez pour créer votre conteneur
Une fois la commande exécutée, docker vous renvoie un identifiant signifiant que le conteneur
s'est convenablement lancé :
```console
$> docker run -d -p 8910:8888 -v /repertoire/travail/ohp:/home/ohpstudent/work --name ohpprocessim chottier/ohpstudent:2.0
2181ab073aa345727da7078db5b0f83a6fe72f759e73888eea00f1637e3f2542
```
Vous pouvez vérifier que votre conteneur est fonctionnel grâce à la commande `docker ps -a`
qui liste tous les conteneurs disponibles et leurs statuts.
```console
$> docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2181ab073aa3 chottier/ohpstudent:2.0 "jupyter-notebook" 3 minutes ago Up 3 minutes 0.0.0.0:8910->8888/tcp ohpprocessim
```
On y constate que notre conteneur est actif (STATUS : Up), et qu'il est bien branché sur le
port 8910 (PORTS `0.0.0.0:8910->8888/tcp`).
### Utilisation du conteneur et de ses logiciels
Une fois le conteneur actif, entrer `localhost:8910` dans la barre d'url de votre navigateur (Firefox, Chrome, Safari...),
un jupiter notebook s'ouvre. Le répertoire work est celui connecter à
`/repertoire/travail/ohp`.
Dès lors vous pouvez utiliser le Jupyter-notebook comme à l'accoutumé. Y compris ouvrir un
terminal pour avoir accès au logiciels d'astromatic :
* sextractor
* scamp
* swarp
* psfex
* stiff
Vous aurez aussi accès au logiciel `solve-field` d'astrometry.net.
### arrêt et redémarrage
Pour arrêter le conteneur, on invoque `docker stop ohpprocessim`. On peut vérifier sont statuts
avec
```console
$> docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2181ab073aa3 chottier/ohpstudent:2.0 "jupyter-notebook" 3 minutes ago Exited (0) 3 seconds ago ohpprocessim
```
Pour redémarrer le conteneur `docker start ohpprocessim` car le conteneur existe déjà.
### Gestion des images et des conteneurs
Pour supprimer une image utiliser `docker rmi nomImage`. Cette opération sera empêchée si cette
image a été utilisée pour créer un conteneur.
Pour supprimer un conteneur `docker rm nomDuConteneur`. Attention tout les fichiers du conteneur
qui ne sont pas partager sur le disque de l'hôte (`/repertoire/travail/ohp` dans notre cas)
serons perdus.
## List des commandes
* Télécharger l'image `docker pull chottier/ohpstudent:2.0`
* Créer le conteneur et le démarrer `docker run -d -p 8910:8888 -v /repertoire/travail/ohp:/home/ohpstudent/work --name
ohpprocessim chottier/ohpstudent:2.0`
* Arrêter le conteneur `docker stop ohpprocessim`
* Redémarrer le conteneur `docker start ohpprocessim`
* Statuts des conteneurs `docker ps -a`
* Listes des images disponibles `docker images`
* Supprimer un conteneur `docker rm ohpprocessim`
* Supprimer une image `docker rmi chottier/ohpstudent`
| text/markdown | null | Clement Hottier <clement.hottier@obspm.fr>, Noel Robichon <noel.robichon@obspm.fr> | null | null | LICENCE.txt | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
... | [] | null | null | >=3.13 | [] | [] | [] | [
"astroalign>=2.3.1",
"astropy>=3.2.3",
"ccdproc>=2.0.1",
"cython>=0.29.15",
"numpy>=1.18.1",
"pandas>=0.25.3",
"scipy>=1.4.1",
"tqdm>=4.19.8"
] | [] | [] | [] | [] | uv/0.9.30 {"installer":{"name":"uv","version":"0.9.30","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Debian GNU/Linux","version":"12","id":"bookworm","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T15:26:34.950217 | ohppipeline-2.0.1.dev2-py3-none-any.whl | 11,791 | 4a/6f/2033fa5e483139a4ab079d3427f96b483885310dae0c9542c3c762f4dead/ohppipeline-2.0.1.dev2-py3-none-any.whl | py3 | bdist_wheel | null | false | 1a604cb5a704bcf7c959562ddc35da47 | d4e4caf643916031e8db82a6d6eb953364391fa10e4ccd5a6a30b6473f80430d | 4a6f2033fa5e483139a4ab079d3427f96b483885310dae0c9542c3c762f4dead | null | [
"LICENCE.txt"
] | 171 |
2.4 | cq-ai | 0.1.0 | Current Quotient AI - Terminal-native AI coding agent, developed by CQ Team | # CQ-AI
**Terminal-native AI coding agent, developed by the CQ Team.**
CQ-AI (formerly ai-coder) is a powerful command-line tool that acts as your intelligent software engineering assistant. It integrates directly into your terminal, understands your codebase, and can plan, build, debug, and refactor code autonomously.
## Features
- 🖥️ **Interactive REPL** - Persistent `cq>` shell with slash commands
- 🤖 **Agentic Workflow** - Plan → Confirm → Execute → Verify
- 📁 **Repository Awareness** - Understands project structure and context
- ✏️ **Multi-File Editing** - Creates and modifies files with diff previews
- 🔧 **Tool Execution** - Runs builds, tests, and linters automatically
- 🛡️ **Safety Guards** - Prevents destructive actions without approval
## Installation
### Prerequisites
- Python 3.10+
- `pip` or `pipx`
### Install from source
```bash
git clone https://github.com/yourusername/cq-ai.git
cd cq-ai
pip install -e .
```
### Set up API key
Create a `.env` file in your project or set environment variables:
```bash
# For OpenAI (default)
export OPENAI_API_KEY=sk-your-key-here
# For Anthropic
export ANTHROPIC_API_KEY=sk-ant-your-key-here
```
## Usage
### Interactive Mode (Recommended)
Just type `cq` to enter the interactive REPL:
```bash
cq
```
You'll see the `cq-ai>` prompt. You can type natural language requests or use slash commands.
```text
cq-ai (my-project)> build a React login form
[Agent plans, creates files, and asks for confirmation]
cq-ai (my-project)> /debug the auth middleware
[Debugger agent analyzes and fixes issues]
cq-ai (my-project)> /help
```
### Slash Commands
| Command | Description |
|---------|-------------|
| `/build` | Interactive project builder |
| `/debug` | Find and fix bugs |
| `/review` | Code review and quality check |
| `/refactor`| Refactor code without changing behavior |
| `/plan` | Create implementation plan only |
| `/security`| Run security audit |
| `/test` | Test-driven development guide |
| `/fix` | Fix build/compile errors |
| `/config` | Run setup wizard |
| `/exit` | Exit the REPL |
### Single Command Mode
You can also run tasks directly from the shell without entering the REPL:
```bash
# Quick task
cq run "Add a dark mode toggle"
# Fix build errors
cq build-fix "npm run build"
# Security audit
cq security src/api/
```
## Configuration
Initialize configuration in your project:
```bash
cq init
```
Edit `.ai-coder/config.yaml`:
```yaml
llm:
provider: "openai" # openai, anthropic, huggingface, ollama, etc.
model: "gpt-4o"
temperature: 0.0
agent:
max_iterations: 30
auto_confirm: false
```
## License
MIT License
| text/markdown | CQ Team | null | null | null | MIT | ai, coding, agent, cli, llm, cq, claude, terminal, developer-tools | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Code ... | [] | null | null | >=3.10 | [] | [] | [] | [
"typer[all]>=0.9.0",
"rich>=13.0.0",
"openai>=1.0.0",
"anthropic>=0.18.0",
"httpx>=0.25.0",
"pyyaml>=6.0",
"gitignore-parser>=0.1.0",
"python-dotenv>=1.0.0",
"prompt_toolkit>=3.0.0",
"fastapi>=0.104.0",
"uvicorn[standard]>=0.24.0",
"websockets>=12.0",
"beautifulsoup4>=4.12.0",
"lxml>=5.0.0... | [] | [] | [] | [
"Homepage, https://github.com/cq-team/cq-ai",
"Source Repository, https://github.com/cq-team/cq-ai",
"Issues, https://github.com/cq-team/cq-ai/issues"
] | twine/6.2.0 CPython/3.12.10 | 2026-02-19T15:24:19.435849 | cq_ai-0.1.0.tar.gz | 90,823 | 89/b1/22fda0390ecd58d6c818e501e13a38d8cd1ac89f9984db9541a259842d17/cq_ai-0.1.0.tar.gz | source | sdist | null | false | 1cbcbe53165bac39fd97ab8d3947a7e4 | 6834b2329c62a0d741e541f11fc9b8e39be94f5a0c00ad97b4e6febd32aaf783 | 89b122fda0390ecd58d6c818e501e13a38d8cd1ac89f9984db9541a259842d17 | null | [
"LICENSE.txt"
] | 244 |
2.4 | pelorus | 0.0.1 | Pelorus - High Efficient Lidar Inertial Odometry | # Pelorus Python Bindings
Python bindings for Pelorus - a LiDAR-Inertial Odometry system.
## Installation
### From source (requires Rust toolchain)
```bash
cd pelorus_py
pip install maturin
maturin develop --release
```
Or build a wheel:
```bash
maturin build --release
pip install target/wheels/pelorus-*.whl
```
## Usage
### Basic API
```python
import pelorus
import numpy as np
# Create Pelorus instance
lio = pelorus.Handle() # Uses embedded default config
# Or with custom config:
# lio = pelorus.Handle("path/to/config.rl")
#
# If you want to control PointCloud2 parsing (like `pelorus_create_with_options` in C):
# - device_specific_pointcloud2=True (default)
# - device_specific_pointcloud2=False (generic parsing path)
# lio = pelorus.Handle("path/to/config.rl", device_specific_pointcloud2=False)
# Add IMU data
lio.add_imu(
timestamp_sec=1000,
timestamp_nanosec=0,
orientation=[1.0, 0.0, 0.0, 0.0], # w, x, y, z
orientation_covariance=[0.01] + [0.0]*8,
angular_velocity=[0.0, 0.0, 0.0],
angular_velocity_covariance=[0.001] + [0.0]*8,
linear_acceleration=[0.0, 0.0, 9.81],
linear_acceleration_covariance=[0.01] + [0.0]*8,
)
# Add point cloud (recommended):
# - If you already have ROS2 messages, pass them directly:
# lio.add_pointcloud2_ros(cloud_msg)
#
# - For non-ROS point sources, use numpy/list inputs:
# - Nx3: [x,y,z] (no per-point timing)
# - Nx4: [x,y,z,t] where t is uint32 nanosecond offset
# - Nx5: [x,y,z,intensity,t]
# For numpy/list inputs, you must also provide the scan header timestamp:
# lio.add_pointcloud(points_np, timestamp_sec=..., timestamp_nanosec=...)
# Try to receive odometry (non-blocking)
odom = lio.try_recv()
if odom:
print(f"Position: {odom['position']}")
print(f"Orientation: {odom['orientation']}")
print(f"Linear velocity: {odom['linear_velocity']}")
print(f"Points: {len(odom['points'])}")
# Or block until odometry is available
odom = lio.recv()
# Or receive odometry asynchronously via callback (like pelorus_c)
def on_odom(odom: dict) -> None:
print("Odom:", odom["timestamp_sec"], odom["timestamp_nanosec"], odom["position"])
lio.set_callback(on_odom)
# ... feed IMU / pointclouds ...
lio.clear_callback() # equivalent to lio.set_callback(None)
```
### Using with MCAP Bagfiles
See `examples/bagfile_example.py` for a complete example using real sensor data from an MCAP bagfile.
```bash
python -m pip install mcap mcap-ros2-support
```
## API Reference
### `Handle`
Main interface to the Pelorus system.
#### Constructor
- `Handle(config_path: str | None = None, device_specific_pointcloud2: bool = True)`: Create a new Pelorus instance
`device_specific_pointcloud2=False` selects the generic parsing path for PointCloud2 inputs.
#### Methods
- `add_imu(...)`: Add an IMU measurement
- `add_odom(...)`: Add an odometry measurement
- `add_pointcloud(cloud_dict)`: Add a point cloud (PointCloud2 format)
- `add_pointcloud(cloud_np, timestamp_sec=..., timestamp_nanosec=...)`: Add a point cloud from numpy
- `add_pointcloud2_ros(cloud_msg)`: Add a ROS2 `sensor_msgs/msg/PointCloud2` message directly
- `try_recv()`: Try to receive odometry (non-blocking), returns `None` if no data
- `recv()`: Receive odometry (blocks until available)
- `set_callback(callback)`: Deliver odometry via callback from a background thread; disables `try_recv()`/`recv()` queuing while enabled
- `clear_callback()`: Disable callback delivery (equivalent to `set_callback(None)`)
- `version()`: Get library version (static method)
## Timestamp semantics
Pelorus uses two timestamp levels:
1. **IMU/Odom timestamps** (`timestamp_sec` + `timestamp_nanosec`)
- Absolute timestamps (typically epoch / ROS time) used for synchronization.
2. **LiDAR timestamps**
- **Scan header timestamp**: absolute (sec/nanosec)
- **Per-point `t` field** (if provided): `uint32` nanoseconds offset, **non-negative** and **forward in time** relative to the scan header time.
The effective point time is:
`point_time_abs = header_time_abs + (t * 1e-9)`
Odometry outputs include `timestamp_sec`/`timestamp_nanosec` (and `timestamp` as float for convenience).
## Development
```bash
# Install development dependencies
pip install maturin pytest black ruff
# Build and test
maturin develop
pytest
# Format code
black .
ruff check .
```
## License
Dual-licensed under MIT or Apache-2.0, consistent with the Pelorus project.
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | MIT OR Apache-2.0 | robotics, lidar, odometry, lio, slam | [
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Rust",
"Framework :: Robot Framework :: Library"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy>=1.16",
"pelorus-cli[rerun]; extra == \"all\"",
"mcap-ros2-support<0.6.0,>=0.5.7; extra == \"all\"",
"pelorus-cli[rerun]; extra == \"cli\"",
"mcap-ros2-support<0.6.0,>=0.5.7; extra == \"mcap\""
] | [] | [] | [] | [
"Homepage, https://github.com/uos/pelorus",
"Repository, https://github.com/uos/pelorus"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T15:23:52.951555 | pelorus-0.0.1-cp38-abi3-musllinux_1_2_x86_64.whl | 1,912,051 | 9b/ef/fc03055a9544a40ae480cee164ee8b5d52ea58471f0bf1ac095fb1223a57/pelorus-0.0.1-cp38-abi3-musllinux_1_2_x86_64.whl | cp38 | bdist_wheel | null | false | 395db29c03fe751b8332abb8e5d274b0 | e6b577d2c30186bc6d237972e38259cf9a1df5be20b7b7c6169a944677550060 | 9beffc03055a9544a40ae480cee164ee8b5d52ea58471f0bf1ac095fb1223a57 | null | [] | 502 |
2.4 | mbrola | 0.2.2 | A Python front-end for the MBROLA speech synthesizer | # pymbrola
[](https://pypi.org/project/mbrola)
[](https://pypi.org/project/mbrola)
-----
A Python interface for the [MBROLA](https://github.com/numediart/MBROLA) speech synthesizer, enabling programmatic creation of MBROLA-compatible phoneme files and automated audio synthesis. This module validates phoneme, duration, and pitch sequences, generates `.pho` files, and can call the MBROLA executable to synthesize speech audio from text-like inputs.
> **References:**
> Dutoit, T., Pagel, V., Pierret, N., Bataille, F., & Van der Vrecken, O. (1996, October).
> The MBROLA project: Towards a set of high quality speech synthesizers free of use for non commercial purposes.
> In Proceeding of Fourth International Conference on Spoken Language Processing. ICSLP'96 (Vol. 3, pp. 1393-1396). IEEE.
> [https://doi.org/10.1109/ICSLP.1996.607874](https://doi.org/10.1109/ICSLP.1996.607874)
## Features
- **Front-end to MBROLA:** Easily create `.pho` files and synthesize audio with Python.
- **Input validation:** Prevents invalid file and phoneme sequence errors.
- **Customizable:** Easily set phonemes, durations, pitch contours, and leading/trailing silences.
- **Cross-platform (Linux/WSL):** Automatically detects and adapts to Linux or Windows Subsystem for Linux environments.
## Requirements
- Python 3.8+
- [MBROLA binary](https://github.com/numediart/MBROLA) installed and available in your system path, or via WSL for Windows users. To install MBROLA in your UBUNTU or WSL instance, run the [mbrola/install.sh] script. A [Docker image](https://hub.docker.com/repository/docker/gongcastro/mbrola/general) of Ubuntu 22.04 with a ready-to-go installation of MBROLA is available, for convenience.
- MBROLA voices (e.g., `it4`) must be installed at `/usr/share/mbrola/<voice>/<voice>`.
## Installation
MBROLA is currently available only on Linux-based systems like Ubuntu, or on Windows via the [Windows Susbsystem for Linux (WSL)](https://learn.microsoft.com/en-us/windows/wsl/install). Install MBROLA in your machine following the instructions in the [MBROLA repository](https://github.com/numediart/MBROLA). If you are using WSL, install MBROLA in WSL. After this, you should be ready to install **pymbrola** using pip.
```console
pip install mbrola
```
## Usage
### Synthesize a Word
```python
import mbrola
# Create an MBROLA object
caffe = MBROLA(
word="caffè",
phon=["k", "a", "f", "f", "E1"],
durations=100, # or [100, 120, 100, 110]
pitch=[100, [200, 50, 200], 100, 100, 200]
)
# Display phoneme sequence
print(caffe)
# Export PHO file
caffe.export_pho("caffe.pho")
# Synthesize and save audio (WAV file)
caffe.make_sound("caffe.wav", voice="it4")
```
The module uses the MBROLA command line tool under the hood. Ensure MBROLA is installed and available in your system path, or WSL if on Windows.
## Troubleshooting
- Ensure MBROLA and the required voices are installed and available at `/usr/share/mbrola/<voice>/<voice>`.
- If you encounter an error about platform support, make sure you are running on Linux or WSL.
- Write an [issue](https://github.com/NeuroDevCo/pymbrola/issues), I'll look into it ASAP.
## License
`pymbrola` is distributed under the terms of the [MIT](https://spdx.org/licenses/MIT.html) license.
| text/markdown | null | Gonzalo Garcia-Castro <gongarciacastro@gmail.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Pytho... | [] | null | null | >=3.12 | [] | [] | [] | [
"pytest>=8.3.5"
] | [] | [] | [] | [
"Documentation, https://github.com/gongcastro/pymbrola#readme",
"Issues, https://github.com/gongcastro/pymbrola/issues",
"Source, https://github.com/gongcastro/pymbrola"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T15:23:03.736798 | mbrola-0.2.2-py3-none-any.whl | 8,069 | 06/b6/43dabdb8b365414d7988578ec66b7b7016c30ad7eaa2ef2b9d1fb149bb19/mbrola-0.2.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 48dfd6eb1a994f5f22b035f4918689c9 | 50093101faefa172ef1683e762d32a512023633598b2d66935cdc460c9dccdf4 | 06b643dabdb8b365414d7988578ec66b7b7016c30ad7eaa2ef2b9d1fb149bb19 | MIT | [
"LICENSE"
] | 223 |
2.4 | bmad-story-automation | 0.1.0 | BMAD Story Automation - CLI tools for BMAD workflow automation | # BMAD Story Automation
Automated workflow script for BMAD Story with Rich UI. Combines **Runner** (create & develop stories) and **Verifier** (validate stories).
## Prerequisites
- **Python 3.8+**
- **Claude CLI** (for production mode)
## Getting Started
### 1. Clone Repository
```bash
git clone https://github.com/mannnrachman/bmad-story-automation.git
cd bmad-story-automation
```
> **Note:** You can also place this script directly in your project folder for easier access.
### 2. Install Dependencies
```bash
pip install rich pyyaml
```
### 3. Run
```bash
# Interactive menu (recommended)
python bmad.py
# Or use direct commands
python bmad.py status # View sprint status
python bmad.py run 5-2 # Run specific story
python bmad.py verify 5-2 # Verify specific story
```
> **Note for Linux/macOS:** use `python3` instead of `python`
---
## Scripts Overview
| Script | Function |
| ------------------ | ---------------------------------------------------- |
| `bmad.py` | Unified CLI - main entry point with interactive menu |
| `bmad-runner.py` | Runs create-story + dev-story workflow |
| `bmad-verifier.py` | Validates whether story is completed correctly |
---
## bmad.py - Unified CLI (Recommended)
Main entry point with interactive menu and direct commands.
### Interactive Menu
```bash
python bmad.py
```
```
╔═══════════════════════════════════════════════════════════════════╗
║ 🚀 BMAD Automation Suite ║
║ ║
║ Runner + Verifier unified CLI ║
║ ║
║ 📁 Project: <your-project-path> ║
║ 📄 Sprint file: ✓ Found ║
╚═══════════════════════════════════════════════════════════════════╝
╭─────┬──────────────────────────────────────────╮
│ [0] │ 📁 Change Project Directory │
│ [1] │ 📊 Check Sprint Status │
│ [2] │ ▶️ Runner (Create & Develop stories) │
│ [3] │ ✅ Verifier (Validate stories) │
│ [4] │ ❓ Help │
│ [5] │ 🚪 Exit │
╰─────┴──────────────────────────────────────────╯
```
### Direct CLI Commands
```bash
# Sprint Status
python bmad.py status # View sprint status with epic breakdown
# Runner Commands
python bmad.py run 5-2 # Run only story 5-2
python bmad.py run 5-2 -c 3 # Run 5-2, then continue to 5-3, 5-4 (3 stories total)
python bmad.py run -e 5 # Run ALL stories from epic 5
python bmad.py run -c 5 # Auto-pick 5 stories from backlog
python bmad.py run --demo # Demo mode (simulated, no Claude)
# Verifier Commands
python bmad.py verify 5-2 # Quick verify story 5-2
python bmad.py verify 5-2 -d # Deep verify with Claude AI
python bmad.py verify 5-2 -i # Quick verify + interactive action menu
python bmad.py verify 5-2 -d -i # Deep verify + interactive (recommended for debugging)
```
### Runner Submenu Options
When selecting `[2] Runner` from the menu:
| Option | Description |
| ------ | ------------------------------------------------------------------ |
| `[1]` | Run specific story (enter story ID like `5-2`) |
| `[2]` | Run from story + continue N more (e.g., start at 5-2, run 3 total) |
| `[3]` | Run all stories from epic (e.g., all stories in epic 5) |
| `[4]` | Run next backlog stories (auto-pick, specify count) |
| `[5]` | Demo mode (simulated, no Claude) |
### Verifier Submenu Options
When selecting `[3] Verifier` from the menu:
| Option | Description |
| ------ | -------------------------------------------- |
| `[1]` | Quick validate story (fast file checks only) |
| `[2]` | Deep validate story (with Claude AI) |
| `[3]` | Quick + Interactive (with action menu) |
| `[4]` | Deep + Interactive (full check + actions) |
| `[5]` | Validate all stories in an epic |
---
## Running Multiple Stories
### Common Scenarios
**Run a single story:**
```bash
python bmad.py run 5-2 # Only runs story 5-2
```
**Run from story 5-10, continue for 35 stories total (5-10 to 5-44):**
```bash
python bmad.py run 5-10 -c 35
```
**Run all stories in epic 5:**
```bash
python bmad.py run -e 5
```
**Auto-pick 10 stories from backlog:**
```bash
python bmad.py run -c 10
```
### How `-c` (count) Works
| Command | What it does |
| ---------------- | ------------------------------------------ |
| `run 5-2` | Runs only 5-2 (single story) |
| `run 5-2 -c 1` | Same as above, runs only 5-2 |
| `run 5-2 -c 3` | Runs 5-2 → 5-3 → 5-4 (3 stories) |
| `run 5-10 -c 35` | Runs 5-10 → 5-11 → ... → 5-44 (35 stories) |
| `run -c 5` | Auto-picks 5 stories from backlog |
### Via Interactive Menu
1. Run `python bmad.py`
2. Select `[2] Runner`
3. Select `[2] Run from story + continue N more`
4. Enter starting story: `5-10`
5. Enter total count: `35`
This will run stories 5-10, 5-11, 5-12, ... up to 5-44 (35 total).
---
## Workflow
```
┌─────────────────┐
│ Sprint Status │ ← View stories (backlog/in-progress/done)
└────────┬────────┘
│
▼
┌─────────────────┐
│ Runner │ ← Create story + Develop code + Run tests + Commit
└────────┬────────┘
│
▼
┌─────────────────┐
│ Verifier │ ← Validate story completion (quick or deep)
└────────┬────────┘
│
┌────┴────┐
│ │
▼ ▼
PASS FAIL
│ │
│ ┌────┴────┐
│ │ │
│ ▼ ▼
│ Code? No Code?
│ │ │
│ ▼ ▼
│ Fix Re-dev
│ (tracking) (implement)
│ │ │
│ └────┬────┘
│ │
│ ▼
│ ┌────────┐
│ │ Retry │ (max 3x)
│ └────────┘
│
▼
┌─────────────────┐
│ Next Story │
└─────────────────┘
```
---
## Validation Checks
### Quick Check (default)
Fast validation without Claude AI:
- ✓ Story file exists
- ✓ Status: done in story file
- ✓ All tasks marked [x]
- ✓ Git commit exists (format: `feat(story): complete X-Y`)
- ✓ Sprint-status.yaml: done
### Deep Check (`-d` flag)
Uses Claude AI to verify:
- ✓ Code files actually exist
- ✓ Test files exist
- ✓ Implementation matches requirements
### Interactive Mode (`-i` flag)
Shows action menu after validation:
```
╭─ Select Action ───────────────────────────────────────────────╮
│ [1] 🔍 Deep Check First - Verify code before fixing │
│ [2] 🔧 Fix Story - Update tracking files only │
│ [3] 📝 Create Story - Generate story from epic │
│ [4] 💻 Dev Story - Implement the story │
│ [5] 🚪 Exit │
╰───────────────────────────────────────────────────────────────╯
```
---
## Runner Steps (11 Steps)
| Step | Description |
| ---- | ---------------------------------------------- |
| 1 | Read workflow status (find next backlog story) |
| 2 | Create story file |
| 3 | Develop/implement story |
| 4 | Run tests |
| 5 | Code review |
| 6 | Fix issues |
| 7 | Run tests until pass |
| 8 | Update story status to done |
| 9 | Update sprint-status.yaml |
| 10 | Update bmm-workflow-status.yaml |
| 11 | Git commit |
---
## Stopping the Script
```bash
# Option 1: Keyboard interrupt
Ctrl+C
# Option 2: Create stop file (graceful stop)
touch .claude/bmad-stop # Linux/macOS
New-Item .claude/bmad-stop # Windows PowerShell
```
---
## Tips
- Use `--demo` to test UI without Claude
- Use `-d -i` in verifier for debugging failed stories
- Deep check takes longer but verifies actual code exists
- Sprint status shows next story to work on with epic breakdown
- The runner auto-verifies after each story and retries up to 3x if failed
---
## Direct Script Usage (Advanced)
### bmad-runner.py
```bash
python bmad-runner.py # Default 5 iterations (auto-pick)
python bmad-runner.py -i 3 # 3 iterations
python bmad-runner.py -s 5-2 # Specific story only
python bmad-runner.py -s 5-2 -i 3 # Start at 5-2, run 3 stories
python bmad-runner.py --demo # Demo mode
```
| Option | Short | Description |
| -------------- | ----- | --------------------------------- |
| `--story` | `-s` | Specific story ID (e.g., `5-2`) |
| `--iterations` | `-i` | Number of iterations (default: 5) |
| `--demo` | - | Simulation mode without Claude |
### bmad-verifier.py
```bash
python bmad-verifier.py 5-2 # Quick verify
python bmad-verifier.py 5-2 --deep # Deep verify with Claude
python bmad-verifier.py 5-2 -i # Interactive mode
python bmad-verifier.py 5-2 -d -i # Deep + interactive
python bmad-verifier.py 5-2 --json # JSON output (for scripts)
```
| Option | Short | Description |
| --------------- | ----- | ---------------------------------- |
| `--deep` | `-d` | Deep validation with Claude AI |
| `--interactive` | `-i` | Show action menu after validation |
| `--json` | - | Output JSON (for programmatic use) |
---
## Requirements
- Python 3.8+
- Rich library (`pip install rich`)
- PyYAML (`pip install pyyaml`)
- Claude CLI (for production mode)
---
## Contributing
We welcome contributions! Please read [CONTRIBUTING.md](CONTRIBUTING.md) for details.
## License
This project is licensed under the MIT License. See the [LICENSE](LICENSE) file for more details.
| text/markdown | Althio | null | null | null | null | automation, bmad, cli, story, workflow | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Pro... | [] | null | null | >=3.8 | [] | [] | [] | [
"pyyaml<7.0,>=6.0",
"rich<15.0.0,>=13.0.0",
"black>=23.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/althio/bmad-story-automation",
"Repository, https://github.com/althio/bmad-story-automation",
"Issues, https://github.com/althio/bmad-story-automation/issues"
] | uv/0.9.18 {"installer":{"name":"uv","version":"0.9.18","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T15:21:37.269788 | bmad_story_automation-0.1.0.tar.gz | 30,686 | e7/6a/d1ebde18674e863c69bf12878e9dd2a360a5a17dc0f58870b98c62e5ac5c/bmad_story_automation-0.1.0.tar.gz | source | sdist | null | false | 52453189a7416e87aac6e5f121462a04 | 5662830ec88279d9a15f3983da01146de29fc31838f0446ad01c2715b430f495 | e76ad1ebde18674e863c69bf12878e9dd2a360a5a17dc0f58870b98c62e5ac5c | MIT | [
"LICENSE"
] | 255 |
2.4 | nssurge-api | 1.0.1 | NSSurge HTTP API for Python | # NSSurge Python API Client
Python implementation of the [Surge HTTP API spec](https://manual.nssurge.com/others/http-api.html) client using `aiohttp`.
You can use it to get/set Surge rules / policies / proxy groups, get recent requests / events and much more.
This projects fully implements the [Surge HTTP API spec](https://manual.nssurge.com/others/http-api.html).
If you're looking for a command line tool to interact with your running Surge app, check out [NSSurge CLI](https://github.com/tddschn/nssurge-cli).
- [NSSurge Python API Client](#nssurge-python-api-client)
- [Installation](#installation)
- [pip](#pip)
- [Usage](#usage)
- [Develop](#develop)
- [See also](#see-also)
## Installation
### [pip](https://pypi.org/project/nssurge-api/)
```
$ pip install nssurge-api
```
## Usage
```python
# source: https://github.com/tddschn/nssurge-cli/blob/master/nssurge_cli/cap_commands.py
from nssurge_cli.types import OnOffToggleEnum
from nssurge_api import SurgeAPIClient
from nssurge_api.types import Capability
import asyncio
async def get_set_cap(
capability: Capability, on_off: OnOffToggleEnum | None = None
) -> bool | tuple[bool, bool]:
"""
Get or set a capability
"""
async with SurgeAPIClient(*get_config()) as client:
state_orig = await get_cap_state(client, capability)
match on_off:
case OnOffToggleEnum.on | OnOffToggleEnum.off:
await client.set_cap(capability, s2b(on_off))
case OnOffToggleEnum.toggle:
await client.set_cap(capability, not state_orig)
case _:
return state_orig
state_new = await get_cap_state(client, capability)
return state_orig, state_new
```
## Develop
```
$ git clone https://github.com/tddschn/nssurge-api.git
$ cd nssurge-api
$ poetry install
```
## See also
- [NSSurge CLI](https://github.com/tddschn/nssurge-cli): Command line Surge HTTP API Client built with this library
- [Surge HTTP API spec](https://manual.nssurge.com/others/http-api.html) | text/markdown | null | Xinyuan Chen <45612704+tddschn@users.noreply.github.com> | null | null | MIT | aiohttp, api, nssurge | [
"Operating System :: OS Independent",
"Topic :: Internet :: WWW/HTTP"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"aiohttp>=3.13.3",
"typing-extensions>=4.15.0"
] | [] | [] | [] | [
"Homepage, https://github.com/tddschn/nssurge-api",
"Repository, https://github.com/tddschn/nssurge-api",
"Bug Tracker, https://github.com/tddschn/nssurge-api/issues"
] | uv/0.9.26 {"installer":{"name":"uv","version":"0.9.26","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T15:21:27.148720 | nssurge_api-1.0.1.tar.gz | 82,234 | e4/f8/1093e92b36b5c697f03f26323c80ca073caa4aa69edffc31fa649aa52408/nssurge_api-1.0.1.tar.gz | source | sdist | null | false | cd660b47a97c83af581295f1d0c010a6 | 498a3efcd7eb0cbdbe029f89cf3695a31842fd1413e15b3d017ee4f9bda89be0 | e4f81093e92b36b5c697f03f26323c80ca073caa4aa69edffc31fa649aa52408 | null | [
"LICENSE"
] | 220 |
2.4 | rayforce-py | 0.5.11 | Python bindings for RayforceDB | <table style="border-collapse:collapse;border:0;">
<tr>
<td style="border:0;padding:0;">
<a href="https://py.rayforcedb.com">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/RayforceDB/rayforce-py/refs/heads/master/docs/docs/assets/py_logo_light.svg">
<source media="(prefers-color-scheme: light)" srcset="https://raw.githubusercontent.com/RayforceDB/rayforce-py/refs/heads/master/docs/docs/assets/py_logo_dark.svg">
<img src="https://raw.githubusercontent.com/RayforceDB/rayforce-py/refs/heads/master/docs/docs/assets/py_logo_dark.svg" width="200">
</picture>
</a>
</td>
<td style="border:0;padding:0;">
<h1>High-Performance Lightweight Python ORM designed for <a href="https://core.rayforcedb.com"><picture>
<source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/RayforceDB/rayforce-py/refs/heads/master/docs/docs/assets/logo_light_full.svg">
<img src="https://raw.githubusercontent.com/RayforceDB/rayforce-py/refs/heads/master/docs/docs/assets/logo_dark_full.svg" alt="RayforceDB" height="40" style="vertical-align: bottom;">
</picture></a></h1>
</td>
</tr>
</table>
 [](https://github.com/RayforceDB/rayforce-py/actions/workflows/coverage.yml) [](https://github.com/RayforceDB/rayforce-py/releases)

Python ORM for RayforceDB, a high-performance columnar database designed for analytics and data operations. Core is written in pure C with minimal overhead - combines columnar storage with SIMD vectorization for lightning-fast analytics on time-series and big data workloads.
**Full Documentation:** https://py.rayforcedb.com/
## Features
- **Pythonic API** - Chainable, convenient, intuitive and fluent query syntax
- **High Performance** - One of the fastest solutions available, minimal overhead between Python and RayforceDB runtime via C API
- **Lightweight** - Core is less than 1 MB footprint
- **0 dependencies** - Library operates without dependencies - pure Python and C
- **Rapid Development** - Continuously expanding functionality
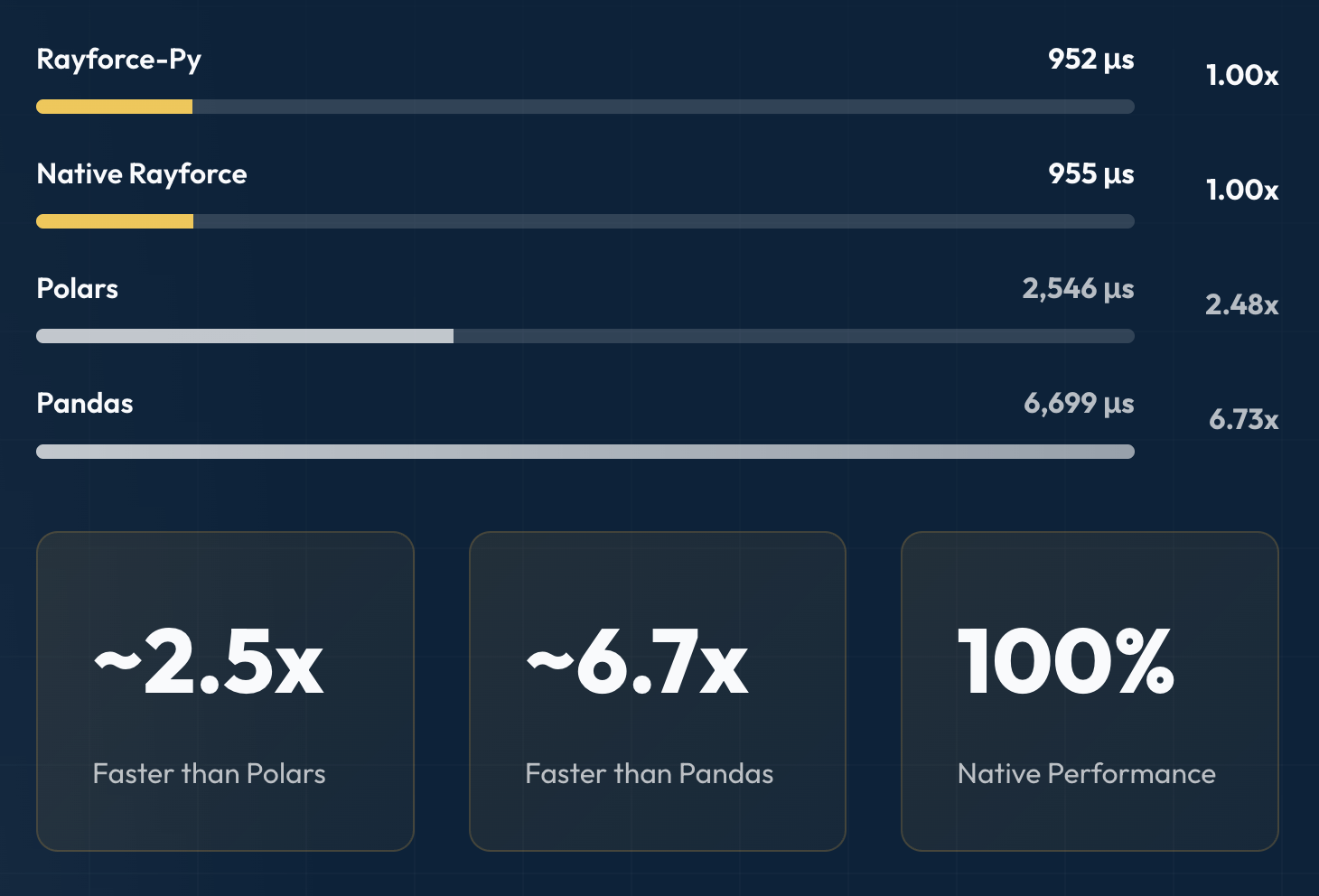
*Benchmarks run on: macOS M4 32GB, 100 groups, 20 runs (median), 5 warmup runs. [H2OAI](https://h2oai.github.io/db-benchmark/)*
## Quick Start
```python
>>> from datetime import time
>>> from rayforce import Table, Column, Vector, Symbol, Time, F64
>>> quotes = Table({
"symbol": Vector(items=["AAPL", "AAPL", "AAPL", "GOOG", "GOOG", "GOOG"], ray_type=Symbol),
"time": Vector(
items=[
time.fromisoformat("09:00:00.095"),
time.fromisoformat("09:00:00.105"),
time.fromisoformat("09:00:00.295"),
time.fromisoformat("09:00:00.145"),
time.fromisoformat("09:00:00.155"),
time.fromisoformat("09:00:00.345"),
],
ray_type=Time,
),
"bid": Vector(items=[100.0, 101.0, 102.0, 200.0, 201.0, 202.0], ray_type=F64),
"ask": Vector(items=[110.0, 111.0, 112.0, 210.0, 211.0, 212.0], ray_type=F64),
})
>>> result = (
quotes
.select(
max_bid=Column("bid").max(),
min_bid=Column("bid").min(),
avg_ask=Column("ask").mean(),
records_count=Column("time").count(),
first_time=Column("time").first(),
)
.where((Column("bid") >= 110) & (Column("ask") > 100))
.by("symbol")
.execute()
)
>>> print(result)
┌────────┬─────────┬─────────┬─────────┬───────────────┬──────────────┐
│ symbol │ max_bid │ min_bid │ avg_ask │ records_count │ first_time │
├────────┼─────────┼─────────┼─────────┼───────────────┼──────────────┤
│ GOOG │ 202.00 │ 200.00 │ 211.00 │ 3 │ 09:00:00.145 │
├────────┴─────────┴─────────┴─────────┴───────────────┴──────────────┤
│ 1 rows (1 shown) 6 columns (6 shown) │
└─────────────────────────────────────────────────────────────────────┘
```
## Installation
Package is available on [PyPI](https://pypi.org/project/rayforce-py/):
```bash
pip install rayforce-py
```
This installation also provides a command-line interface to access the native Rayforce runtime:
```clj
~ $ rayforce
Launching Rayforce...
RayforceDB: 0.1 Dec 6 2025
Documentation: https://rayforcedb.com/
Github: https://github.com/RayforceDB/rayforce
↪ (+ 1 2)
3
```
---
**Built with ❤️ for high-performance data processing | <a href="https://py.rayforcedb.com/content/license.html">MIT Licensed</a> | RayforceDB Team**
| text/markdown | Karim | null | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Financial and Insurance Industry",
"Intended Audience :: Information Technology",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Pr... | [] | null | null | >=3.11 | [] | [] | [] | [
"pandas>=2.0.0; extra == \"pandas\"",
"polars>=0.19.0; extra == \"polars\"",
"pyarrow>=10.0.0; extra == \"parquet\"",
"pandas>=2.0.0; extra == \"all\"",
"polars>=0.19.0; extra == \"all\"",
"pyarrow>=10.0.0; extra == \"all\"",
"pytest>=8.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:21:26.867506 | rayforce_py-0.5.11-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl | 1,327,391 | 87/c3/96706b3ce7e8e2fb12de52e3390dcbd11d144875157f81696cf97f8f97e5/rayforce_py-0.5.11-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl | cp314 | bdist_wheel | null | false | 6d73798120a5b48fc2cda12378b0fe57 | 7ac18b9977e7c1eb0625e7e73df43dc9e805c9ccb2b42b2756e0c52b9c268615 | 87c396706b3ce7e8e2fb12de52e3390dcbd11d144875157f81696cf97f8f97e5 | null | [
"LICENSE"
] | 604 |
2.4 | qstn | 0.2.1 | A Modular Framework for Robust Questionnaire Inference with Large Language Models | # QSTN: A Modular Framework for Robust Questionnaire Inference with Large Language Models
<div align="center">

</div>
QSTN is a Python framework designed to facilitate the creation of robust inference experiments with Large Language Models based around questionnaires. It provides a full pipeline from perturbation of prompts, to choosing Response Generation Methods, inferencing and finally parsing of the output. QSTN supports both local inference with vllm and remote inference via the OpenAI API.
Detailed information and guides are available in our [documentation](https://qstn.readthedocs.io/en/latest/). Tutorial notebooks can also be found in this [repository](https://github.com/dess-mannheim/QSTN/tree/main/docs/guides).
## Installation
We support two type of installations:
1. The **base version**, which only installs the dependencies neccessary to use the OpenAI API.
2. The **full version**, which supports both API and local inference via `vllm`.
To install both of these version you can use `pip` or `uv`.
The base version can be installed with the following command:
```bash
pip install qstn
```
The full version can be installed with this command:
```bash
pip install qstn[vllm]
```
You can also install this package from source:
```bash
pip install git+https://github.com/dess-mannheim/QSTN.git
```
## Getting Started
Below you can find a minimum working example of how to use QSTN. It can be easily integrated into existing projects, requiring just three function calls to operate. Users familiar with vllm or the OpenAI API can use the same Model/Client calls and arguments. In this example reasoning and the generated response are automatically parsed. For more elaborate examples, see the [tutorial notebooks](https://github.com/dess-mannheim/QSTN/tree/main/docs/guides).
```python
import qstn
import pandas as pd
from vllm import LLM
# 1. Prepare questionnaire and persona data
questionnaires = pd.read_csv("hf://datasets/qstn/ex/q.csv")
personas = pd.read_csv("hf://datasets/qstn/ex/p.csv")
prompt = (
f"Please tell us how you feel about:\n"
f"{qstn.utilities.placeholder.PROMPT_QUESTIONS}"
)
interviews = [
qstn.prompt_builder.LLMPrompt(
questionnaire_source=questionnaires,
system_prompt=persona,
prompt=prompt,
) for persona in personas.system_prompt]
# 2. Run Inference
model = LLM("Qwen/Qwen3-4B", max_model_len=5000)
results = qstn.survey_manager.conduct_survey_single_item(
model, interviews, max_tokens=500
)
# 3. Parse Results
parsed_results = qstn.parser.raw_responses(results)
```
## Citation
If you find QSTN useful in your work, please cite our [paper](https://arxiv.org/abs/2512.08646):
```bibtex
@misc{kreutner2025qstnmodularframeworkrobust,
title={QSTN: A Modular Framework for Robust Questionnaire Inference with Large Language Models},
author={Maximilian Kreutner and Jens Rupprecht and Georg Ahnert and Ahmed Salem and Markus Strohmaier},
year={2025},
eprint={2512.08646},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2512.08646},
}
| text/markdown | null | Maximilian Kreutner <maximilian.kreutner@uni-mannheim.de> | null | null | null | null | [
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"json-repair",
"openai",
"pandas>=2.2.3",
"pydantic>=2.11.4",
"vllm>=0.12; extra == \"vllm\""
] | [] | [] | [] | [
"Homepage, https://github.com/dess-mannheim/QSTN",
"Documentation, https://qstn.readthedocs.io/en/latest/index.html"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T15:21:20.467859 | qstn-0.2.1.tar.gz | 179,633 | e1/a0/a78238c4229ac3195317c0245fabb63e6f8fb5e556a71d5c9609e71d0d32/qstn-0.2.1.tar.gz | source | sdist | null | false | 58d5b55c4761197299c45afc135fb94b | defa7ba16aa3dab283fdff0c0142234ede37d96ffc09d4a9c64c543b44c4dfd8 | e1a0a78238c4229ac3195317c0245fabb63e6f8fb5e556a71d5c9609e71d0d32 | MIT | [
"LICENSE"
] | 224 |
2.4 | gym-cas | 1.1.2 | CAS tools for danish high schools. | # GYM CAS
[](https://pypi.org/project/gym-cas)
[](https://pypi.org/project/gym-cas)

Anvend Python som CAS (Computational Algebra System) i gymnasiet.
Bygger på følgende moduler:
- Algebra/beregninger:
- [SymPy](https://docs.sympy.org/latest/index.html)
- [NumPy](https://numpy.org/)
- Afbildninger:
- [SymPy Plot Backends](https://sympy-plot-backends.readthedocs.io/en/latest/modules/index.html)
- [Matplotlib](https://matplotlib.org/)
## Installation
```console
pip install gym-cas
```
eller
```console
py -m pip install gym-cas
```
## Cheatsheet
I nedenstående afsnit antages det at `gym_cas` først importeres således:
```py
from gym_cas import *
```
### B1. Tal- og bogstavregning
```py
expand( udtryk )
factor( udtryk )
```
### B2. Ligninger og uligheder
```py
solve( udtryk )
solve( [udtryk1, udtryk2] )
nsolve( udtryk, startgæt )
solve_interval( udtryk, start, slut )
```
#### Opstille ligning
For at opstille en ligning kan man enten omforme sin ligning så en af siderne er lig 0 (og udelade 0) eller bruge `Eq`.
Ligningen `x/2 = 10` kan skrives som `x/2-10` eller som `Eq(x/2, 10)`.
Ligningsløsning ved `solve(x/2-10)` eller `solve(Eq(x/2, 10))` giver samme resultat.
### B3. Geometri og trigonometri
```py
Sin( vinkel )
Cos( vinkel )
Tan( vinkel )
aSin( forhold )
aCos( forhold )
aTan( forhold )
```
### B4. Analytisk plangeometri
```py
plot_points( X_list ,Y_list)
plot( funktion )
plot_implicit( udtryk ,xlim=( x_min, x_max),ylim=( y_min, y_max))
plot_geometry( Geometrisk objekt )
```
#### Flere grafer i en afbildning
```py
p1 = plot( udtryk1 )
p2 = plot( udtryk2 )
p = p1 + p2
p.show()
```
### B5. Vektorer
```py
a = vector(x,y)
a.dot(b)
plot_vector( vektor )
plot_vector( start, vektor )
plot_vector( [vektor1, vektor2, ...])
```
### B6. Deskriptiv Statistik
#### Ugrupperet
```py
max( data )
min( data )
mean( data )
median( data )
var( data, ddof )
std( data, ddof )
kvartiler( data )
percentile( data , procenter )
frekvenstabel( data )
boxplot( data )
plot_sum( data )
```
#### Grupperet
```py
group_mean( data, grupper )
group_percentile( data, grupper, procenter )
group_var( data, grupper, ddof )
group_std( data, grupper, ddof )
frekvenstabel( data, grupper )
boxplot( data, grupper )
plot_sum( data, grupper )
plot_hist( data, grupper )
```
### B8. Funktioner
```py
def f(x):
return funktionsudtryk
f(3)
def f(x):
return Piecewise(( funktion1, betingelse1), (funktion2, betingelse2))
plot( funktion , yscale="log")
plot( funktion , (variabel, start, stop), xscale="log", yscale="log")
regression_poly(X,Y, grad)
regression_power(X,Y)
regression_exp(X,Y)
```
### B9. Differentialregning
```py
limit( udtryk, variabel, grænse, retning )
diff( funktion )
def df(xi):
return diff( funktion ).subs( variabel, xi )
```
### B10. Integralregning
```py
integrate( udtryk )
integrate( udtryk, ( variabel, start, slut ))
plot3d_revolution( udtryk , (x, a, b),parallel_axis="x")
```
### A1. Vektorer i rummet
```py
a = vector(1,2,3)
a.cross(b)
plot_vector( a )
plot3d_points( X, Y, Z )
plot3d_line( a + t * r )
plot3d_plane( a + s * r1 + t * r2 )
plot3d_sphere( radius, centrum )
plot3d_implicit( ligning, backend=PB ) # Kræver Plotly eller K3D
```
### A4. Differentialligninger
```py
f = Function('f')
dsolve( ode )
plot_ode( ode, (x, start, stop), (f, start, stop))
```
### A5. Diskret Matematik
```py
X = [ udregning for x in range(start,slut)]
X = [ startbetingelse ]
for i in range(start, slut):
X.append( rekursionsligning )
```
| text/markdown | null | JACS <jacs@zbc.dk> | null | null | null | CAS, Matematik, Math, Gymnasium, HTX | [
"Development Status :: 4 - Beta",
"Intended Audience :: Education",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Pyt... | [] | null | null | >=3.10 | [] | [] | [] | [
"matplotlib>=3.7.1",
"numpy>=2.2.6",
"sympy-plot-backends>=4.1.0",
"sympy>=1.14",
"openpyxl>=3.1.0; extra == \"excel\"",
"coverage[toml]>=7.3.3; extra == \"test\"",
"genbadge[coverage]; extra == \"test\"",
"pytest-mock>=3.12.0; extra == \"test\"",
"pytest>=7.4.0; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://jacs-mat.bitbucket.io/"
] | uv/0.9.26 {"installer":{"name":"uv","version":"0.9.26","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T15:19:05.894647 | gym_cas-1.1.2.tar.gz | 119,366 | 85/6b/3b1917c52e6202f7830d40232effac97e38f438d044c8136807890ddcf8f/gym_cas-1.1.2.tar.gz | source | sdist | null | false | 173fe13f1cd247677cff2a3271b59bb2 | aca2aeec4bf2cda8528da341fa61d1b664dd76e948d3c9aaab3565fdde048b1b | 856b3b1917c52e6202f7830d40232effac97e38f438d044c8136807890ddcf8f | null | [
"LICENSE.txt"
] | 244 |
2.3 | openbb-ai | 1.8.7 | An SDK for building agents compatible with OpenBB Workspace | # OpenBB Custom Agent SDK
This package provides a set of pydantic models, tools and helpers to build
custom agents that are compatible with OpenBB Workspace.
For some example agents that demonstrate the full usage of the SDK, see the
[example agents repository](https://github.com/OpenBB-finance/agents-for-openbb).
## Features
- [Streaming Conversations](#message_chunk)
- [Reasoning steps / status updates](#reasoning_step)
- [Retrieve widget data from OpenBB Workspace](#get_widget_data)
- [Citations](#cite-and-citations)
- [Display tables](#table)
- [Create charts](#chart)
- [Widget priorities](#widget-priority)
To understand more about how everything works, see the
[Details](#details) section of this README.
## Usage
### Initial Setup
To use the OpenBB Custom Agent SDK, you need to install the package:
```bash
pip install openbb-ai
```
Your agent must consist of two endpoints:
1. A `query` endpoint. This is the main endpoint that will be called by the OpenBB Workspace. It returns responses using [Server-Sent Events](https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events/Using_server-sent_events) (SSEs).
2. An `agents.json` endpoint. This is the endpoint that will be called by the OpenBB Workspace to retrieve the agent's definition, and is what allows it to be added to the OpenBB Workspace.
All helper functions return Server-Sent Event (SSE) messages that should be streamed back to the OpenBB Workspace from your agent's execution loop. For example, using FastAPI with `EventSourceResponse` from `sse_starlette`:
```python
from fastapi import FastAPI
from sse_starlette import EventSourceResponse
from openbb_ai import (
reasoning_step,
message_chunk,
get_widget_data,
cite,
citations,
table,
chart,
)
app = FastAPI()
@app.get("/agents.json")
async def agents_json():
return JSONResponse(
content={
"<agent-id>": {
"name": "My Agent",
"description": "This is my agent",
"image": f"{AGENT_BASE_URL}/my-agent/logo.png",
"endpoints": {"query": f"{AGENT_BASE_URL}/query"}, # must match the query endpoint below
"features": {
"streaming": True, # must be True
"widget-dashboard-select": True, # Enable access to priority widgets
"widget-dashboard-search": True, # Enable access to non-priority widgets on current dashboard
},
}
}
)
@app.get("/query")
async def stream(request: QueryRequest):
async def execution_loop():
async def event_generator():
# Your agent's logic lives here
yield reasoning_step("Starting agent", event_type="INFO")
yield message_chunk("Hello, world!")
async for event in event_generator():
yield event.model_dump()
return EventSourceResponse(execution_loop())
```
### `QueryRequest`
`QueryRequest` is the most important Pydantic model and entrypoint for all
requests to the agent. It should be used as the request body for FastAPI
endpoints (if you're using FastAPI).
Refer to the `QueryRequest` model definition (`openbb_ai.models.QueryRequest`) for full details on its fields and validation.
**Agent backends are stateless**: full conversation history (messages), widget
definitions, context, URLs, and any other state will be included in each
`QueryRequest`. Each request to the agent can / should be handled independently
with all necessary data provided upfront.
Key fields:
- `messages`: List of messages to submit to the agent. Supports both chat (`LlmClientMessage`) and function call result (`LlmClientFunctionCallResultMessage`) messages.
- `widgets`: Optional `WidgetCollection` organizing widgets into `primary`, `secondary`, and `extra` groups.
- `context`: Optional additional context items (`RawContext`) to supplement processing. Yielded `table` and `chart` artifacts are automatically added to this list by OpenBB Workspace.
- `urls`: Optional list of URLs (up to 4) to retrieve and include as context.
- ... and more.
### `message_chunk`
Create a message chunk SSE to stream back chunks of text to OpenBB Workspace,
typically from the agent's streamed response.
```python
from openbb_ai.helpers import message_chunk
yield message_chunk("Hello, world!").model_dump()
```
### `reasoning_step`
OpenBB Workspace allows you to return "reasoning steps" (sometimes referred to
as "thought steps" or even "status updates") from your custom agent to the
front-end, at any point in the agent's execution. This is often useful for
providing updates and extra information to the user, particularly for
long-running queries, or for complicated workflows.
To send a reasoning step SSE to OpenBB Workspace, use the `reasoning_step`
helper function:
```python
from openbb_ai.helpers import reasoning_step
yield reasoning_step(
message="Processing data",
event_type="INFO",
details={"step": 1},
).model_dump()
```
### `get_widget_data`
Create a function call SSE that retrieves data from widgets on the OpenBB
Workspace.
```python
from openbb_ai.helpers import get_widget_data
from openbb_ai.models import WidgetRequest
widget_requests = [WidgetRequest(widget=..., input_arguments={...})]
yield get_widget_data(widget_requests).model_dump()
```
For more technical details on how this works, see the
[Function calling to OpenBB Workspace (to retrieve widget data)](#function-calling-to-openbb-workspace-to-retrieve-widget-data)
section of this README.
### `cite` and `citations`
Create citations for widgets to display on OpenBB Workspace. Use `cite` to
construct a `Citation` for a widget and `citations` to stream a collection of
citations as an SSE to the client.
```python
from openbb_ai.helpers import cite, citations
citation = cite(
widget=widget,
input_arguments={"param1": "value1", "param2": 123},
extra_details={"note": "Optional extra details"},
)
yield citations([citation]).model_dump()
```
### `table`
Create a table message artifact SSE to display a table as streamed in-line
agent output in OpenBB Workspace.
```python
from openbb_ai.helpers import table
yield table(
data=[
{"x": 1, "y": 2, "z": 3},
{"x": 2, "y": 3, "z": 4},
{"x": 3, "y": 4, "z": 5},
{"x": 4, "y": 5, "z": 6},
],
name="My Table",
description="This is a table of the data",
).model_dump()
```
### `chart`
Create a chart message artifact SSE to display various types of charts
(line, bar, scatter, pie, donut) as streamed in-line agent output in OpenBB
Workspace.
```python
from openbb_ai.helpers import chart
yield chart(
type="line",
data=[
{"x": 1, "y": 2},
{"x": 2, "y": 3},
{"x": 3, "y": 4},
{"x": 4, "y": 5},
],
x_key="x",
y_keys=["y"],
name="My Chart",
description="This is a chart of the data",
).model_dump()
yield chart(
type="pie",
data=[
{"amount": 1, "category": "A"},
{"amount": 2, "category": "B"},
{"amount": 3, "category": "C"},
{"amount": 4, "category": "D"},
],
angle_key="amount",
callout_label_key="category",
name="My Chart",
description="This is a chart of the data",
).model_dump()
```
### Widget Priority
Custom agents receive three widget types via the `QueryRequest.widgets` field:
- **Primary widgets**: Explicitly added by the user to the context
- **Secondary widgets**: Present on the active dashboard but not explicitly added
- **Extra widgets**: Any widgets added to OpenBB Workspace (visible or not)
Currently, only primary and secondary widgets are accessible to custom agents, with extra widget support coming soon.
The dashboard below shows a Management Team widget (primary/priority) and a Historical Stock Price widget (secondary):
<img width="1526" alt="example dashboard" src="https://github.com/user-attachments/assets/9f579a2a-7240-41f5-8aa3-5ffd8a6ed7ba" />
If we inspect the `request.widgets` attribute of the `QueryRequest` object, we
can see the following was sent through to the custom agent:
```python
>>> request.widgets
WidgetCollection(
primary=[
Widget(
uuid=UUID('68ab6973-ed1a-45aa-ab20-efd3e016dd48'),
origin='OpenBB API',
widget_id='management_team',
name='Management Team',
description='Details about the management team of a company, including name, title, and compensation.',
params=[
WidgetParam(
name='symbol',
type='ticker',
description='The symbol of the asset, e.g. AAPL,GOOGL,MSFT',
default_value=None,
current_value='AAPL',
options=[]
)
],
metadata={
'source': 'Financial Modelling Prep',
'lastUpdated': 1746177646279
}
)
],
secondary=[
Widget(
uuid=UUID('bfa0aaaf-0b63-49b9-bb48-b13ef9db514b'),
origin='OpenBB API',
widget_id='eod_price',
name='Historical Stock Price',
description='Historical stock price data, including open, high, low, close, volume, etc.',
params=[
WidgetParam(
name='symbol',
type='ticker',
description='The symbol of the asset, e.g. AAPL,GOOGL,MSFT',
default_value=None,
current_value='AAPL',
options=[]
),
WidgetParam(
name='start_date',
type='date',
description='The start date of the historical data',
default_value='2023-05-02',
current_value='2023-05-02',
options=[]
)
],
metadata={
'source': 'Financial Modelling Prep',
'lastUpdated': 1746177655947
}
)
],
extra=[]
)
```
You can also see the parameter information of each widget in the `params` field
of the `Widget` object.
## Details
This section contains more specific technical details about how the various
components work together.
### Architecture
```plaintext
┌─────────────────────┐ ┌───────────────────────────────────────────┐
│ │ │ │
│ │ │ Agent │
│ │ │ (Backend) │
│ │ 1. HTTP POST │ │
│ OpenBB Workspace │ ───────────> │ ┌─────────────┐ ┌─────────────────┐ │
│ (Frontend) │ /query │ │ │ │ │ │
│ │ │ │ LLM │───>│ Function │ │
│ ┌───────────────┐ │ │ │ Processing │ │ Call │ │
│ │ Widget Data │ │ <─────────── │ │ │<───│ Processing │ │
│ │ Retrieval │ │ 2. Function │ │ │ │ │ │
│ └───────────────┘ │ Call SSE │ └─────────────┘ └─────────────────┘ │
│ ^ │ │ │
│ │ │ 3. HTTP POST │ │
│ └───────────│ ───────────> │ │
│ Execute & │ /query │ │
│ Return Results │ │ │
│ │ <─────────── │ │
│ │ 4. SSE │ │
│ │ (text chunks, │ │
│ │reasoning steps)│ │
└─────────────────────┘ └───────────────────────────────────────────┘
```
The architecture consists of two main components:
1. **OpenBB Workspace (Frontend)**: The user interface where queries are entered
2. **Agent (Backend)**: Programmed by you, handles the processing of queries, executing internal function calls, and returns answers
The frontend communicates with the backend via REST requests to the `query`
endpoint as defined in the `agent.json` schema.
### Function calling to OpenBB Workspace (to retrieve widget data)
When retrieving data from widgets on the OpenBB Workspace, your custom agent must
execute a **remote** function call, which gets interpreted by the OpenBB
Workspace. This is in contrast to **local** function calling, which is executed locally by the agent within its own runtime / environment.
Unlike local function calling, where the function is executed entirely on the
custom agent backend, a remote function call to the OpenBB Workspace is
partially executed on the OpenBB Workspace, and the results are sent back to the
custom agent backend.
Below is a timing diagram of how a remote function call to the OpenBB Workspace works:
```plaintext
OpenBB Workspace Custom Agent
│ │
│ 1. POST /query │
│ { │
│ messages: [...], │
│ widgets: {...} │
│ } │
│───────────────────────────────>│
│ │
│ 2. Function Call SSE │
│<───────────────────────────────│
│ (Connection then closed) │
│ │
│ 3. POST /query │
│ { │
│ messages: [ │
│ ...(original messages), │
│ function_call, │
│ function_call_result │
│ ], │
│ widgets: {...} │
│ } │
│───────────────────────────────>│
│ │
│ 4. SSEs (text chunks, │
│ reasoning steps, etc.) │
│<───────────────────────────────│
│ │
```
This is what happens "under-the-hood" when you yield from the `get_widget_data`
helper function, and close the connection: OpenBB Workspace executes the
function call (retrieving the widget data), and then sends a follow-up request
to the `query` endpoint of the agent, containing the function call and its
result.
| text/markdown | OpenBB Team | hello@openbb.finance | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pydantic<3.0.0,>=2.12.0",
"xxhash<4.0.0,>=3.5.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:18:44.489952 | openbb_ai-1.8.7.tar.gz | 20,408 | 52/a1/30dfa02f0a5be531716526d927bfb9740f51b78d314000862af6ebd80f91/openbb_ai-1.8.7.tar.gz | source | sdist | null | false | 4e07756ae2cea10027cb388645c37411 | 81197a1e5948c54a7718dcfb4a550eb798cce8df783b914dd19aa92639d0a84a | 52a130dfa02f0a5be531716526d927bfb9740f51b78d314000862af6ebd80f91 | null | [] | 241 |
2.4 | pingram-python | 0.1.0 | Official Python SDK for Pingram - Send notifications via Email, SMS, Push, In-App, and more | # Pingram Python SDK
Official Python SDK for Pingram. Send notifications via Email, SMS, Push, In-App, and more from your server-side Python code.
## Requirements
- Python 3.9+
- Dependencies: `httpx`, `pydantic`, `python-dateutil`, `typing-extensions` (installed automatically)
## Installation
```bash
pip install pingram-python
```
To install from source (e.g. from the [GitHub repo](https://github.com/notificationapi-com/serverless)):
```bash
pip install -e sdks/python
```
## Quick start
Use the **Pingram** client with your **API key**, then call `send()` or the namespaced APIs (`user`, `users`, `logs`, etc.).
```python
import asyncio
from pingram import Pingram, SenderPostBody, SenderPostBodyTo
async def main():
# API key (e.g. pingram_sk_...) or JWT; optional region ("us" | "eu" | "ca")
async with Pingram(api_key="pingram_sk_...") as client:
# Send a notification
body = SenderPostBody(
notification_id="your_notification_id",
to=SenderPostBodyTo(id="user_123"),
)
response = await client.send(sender_post_body=body)
print(response)
# Or use namespaced APIs (same as Node: client.user, client.users, client.logs, ...)
# user = await client.user.user_get_user(account_id="...", user_id="...")
# logs = await client.logs.logs_query_logs(...)
asyncio.run(main())
```
You can also pass a config dict: `Pingram({"api_key": "pingram_sk_...", "region": "eu"})`. For full API coverage, use `client.send`, `client.user`, `client.users`, `client.logs`, `client.templates`, `client.environments`, and the other APIs.
## Links
- [Documentation](https://www.pingram.io/docs/)
| text/markdown | Pingram | null | null | null | MIT | pingram, notificationapi, notification, sdk, email, sms, push, in-app | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"python-dateutil>=2.8.2",
"httpx>=0.28.1",
"pydantic>=2",
"typing-extensions>=4.7.1"
] | [] | [] | [] | [
"Repository, https://github.com/notificationapi-com/serverless"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T15:18:17.466981 | pingram_python-0.1.0.tar.gz | 102,885 | 04/d3/9471d9a658cc38923edaa9045bf28d51855c0dd9f5d5188a983a2c975f31/pingram_python-0.1.0.tar.gz | source | sdist | null | false | b234f323911ccd1288b49e4633deb912 | a9015739bfe6d05392deadc6dcb58c1a070bbaec0da742d88c29fc8e3950bb83 | 04d39471d9a658cc38923edaa9045bf28d51855c0dd9f5d5188a983a2c975f31 | null | [
"LICENSE"
] | 256 |
2.4 | biovault-beaver | 0.1.50 | A library for data visitation and eager execution of remote bioinformatics workflows. | # BioVault Beaver
A Python library for analyzing biological data and genetic variants.
## Installation
```bash
pip install biovault-beaver
```
## Usage
```python
import beaver
print(beaver.__version__)
```
## Development
Install in development mode:
```bash
pip install -e .
```
Run tests:
```bash
pytest
```
| text/markdown | Madhava Jay <madhava@openmined.org> | null | null | null | Apache-2.0 | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Program... | [] | null | null | <3.15,>=3.9 | [] | [] | [] | [
"blake3>=0.3.0",
"numpy",
"pyfory==0.13.2",
"pyyaml>=6.0",
"restrictedpython>=8.0",
"syftbox-sdk>=0.1.20",
"zstandard>=0.20.0",
"mypy>=1.11.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.8.0; extra == \"dev\"",
"vulture>=2.11; extra == ... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:18:14.168719 | biovault_beaver-0.1.50.tar.gz | 158,730 | 22/67/5744186c5c76b1213642e733d06d62f980a694325907e81d50541f24ca07/biovault_beaver-0.1.50.tar.gz | source | sdist | null | false | 5f65290f88d9572dfdfa5163a3555ed6 | 6f7203d83285b230c409ee45022e54d35bd979b96a9e6b00cecb6ef66623d66e | 22675744186c5c76b1213642e733d06d62f980a694325907e81d50541f24ca07 | null | [] | 302 |
2.4 | xapian-model | 0.3.1 | A generic Python ORM-like base class for building models backed by Xapiand | # xapian_model
A generic Python ORM-like base class for building models backed by [Xapiand](https://github.com/pber/xapiand), a distributed search engine. Part of the Dubalu Framework.
## Features
- **Fully async** — All Xapiand operations use `async`/`await` (powered by `pyxapiand>=2.1.0` and `httpx`).
- **BaseXapianModel** — Base class with attribute interception, save/delete operations, and template-based dynamic index naming.
- **Manager** — Descriptor-based manager providing `create()`, `get()`, and `filter()` query methods.
- **SearchResults** — Dataclass wrapping search results with total counts and aggregations.
- **Schema auto-provisioning** — Automatically provisions the schema on first write.
## Installation
```bash
pip install xapian-model
```
### Dependencies
Requires [pyxapiand](https://github.com/Dubalu-Development-Team/xapiand) 2.1.0+ (async client):
```bash
pip install "pyxapiand>=2.1.0"
```
## Quick Start
```python
import asyncio
from xapian_model.base import BaseXapianModel
class Product(BaseXapianModel):
INDEX_TEMPLATE = "products/{store_id}"
SCHEMA = {
"name": {"_type": "text"},
"price": {"_type": "float"},
"active": {"_type": "boolean", "_default": True},
}
async def main():
# Create a product
product = await Product.objects.create(store_id="store1", name="Widget", price=9.99)
# Retrieve by ID
product = await Product.objects.get(id="abc123", store_id="store1")
# Search
results = await Product.objects.filter(query="widget", store_id="store1", limit=10)
for item in results.results:
print(item.name, item.price)
# Update and save
product.price = 12.99
await product.save()
# Delete
await product.delete()
asyncio.run(main())
```
## Requirements
- Python 3.12+
- [pyxapiand](https://github.com/Dubalu-Development-Team/xapiand) >= 2.1.0
- [Xapiand](https://github.com/pber/xapiand) server
## License
[MIT](LICENSE) — Copyright (c) 2026 Dubalu International
| text/markdown | Dubalu International | null | null | null | null | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Topic :: Database :: Front-Ends"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"pyxapiand>=2.1.0",
"pytest; extra == \"test\"",
"pytest-asyncio; extra == \"test\"",
"pytest-cov; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/Dubalu-Development-Team/xapian_model",
"Repository, https://github.com/Dubalu-Development-Team/xapian_model"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T15:17:56.941908 | xapian_model-0.3.1.tar.gz | 9,472 | 13/c3/ffd752eab0d0e16b203a2edec2d0a76b312d0fe4e884cfb5fa3c3d9353a0/xapian_model-0.3.1.tar.gz | source | sdist | null | false | dcb70c02ec3ac4d27c2b0d7806e18f26 | f017da522130950754dd4fa35efedee0414d97f965eb3e39d0f520bca8addee3 | 13c3ffd752eab0d0e16b203a2edec2d0a76b312d0fe4e884cfb5fa3c3d9353a0 | MIT | [
"LICENSE"
] | 245 |
2.4 | m4-infra | 0.4.3 | Infrastructure for AI-assisted clinical research with EHR datasets | # M4: Infrastructure for AI-Assisted Clinical Research
<p align="center">
<img src="webapp/public/m4_logo_transparent.png" alt="M4 Logo" width="180"/>
</p>
<p align="center">
<strong>Give your AI agents clinical intelligence & access to MIMIC-IV, eICU, and more</strong>
</p>
<p align="center">
<a href="https://www.python.org/downloads/"><img alt="Python" src="https://img.shields.io/badge/Python-3.10+-blue?logo=python&logoColor=white"></a>
<a href="https://modelcontextprotocol.io/"><img alt="MCP" src="https://img.shields.io/badge/MCP-Compatible-green?logo=ai&logoColor=white"></a>
<a href="https://github.com/hannesill/m4/actions/workflows/tests.yaml"><img alt="Tests" src="https://github.com/hannesill/m4/actions/workflows/tests.yaml/badge.svg"></a>
</p>
M4 is infrastructure for AI-assisted clinical research. Initialize MIMIC-IV, eICU, or custom datasets as fast local databases (with optional BigQuery for cloud access). Your AI agents get specialized tools (MCP, Python API) and clinical knowledge (agent skills) to query and analyze them.
[Usage example – M4 MCP](https://claude.ai/share/93f26832-f298-4d1d-96e3-5608d7f0d7ad) | [Usage example – Code Execution](docs/M4_Code_Execution_Example.pdf)
> M4 builds on the [M3](https://github.com/rafiattrach/m3) project. Please [cite](#citation) their work when using M4!
## Why M4?
Clinical research shouldn't require mastering database schemas. Whether you're screening a hypothesis, characterizing a cohort, or running a multi-step survival analysis—you should be able to describe what you want and get clinically meaningful results.
M4 makes this possible by giving AI agents deep clinical knowledge:
**Understand clinical semantics.**
LLMs can write SQL, but have a harder time with (dataset-specific) clinical semantics. M4's comprehensive agent skills encode validated clinical concepts—so "find sepsis patients" produces clinically correct queries on any supported dataset.
**Work across modalities.**
Clinical research with M4 spans structured data, clinical notes, and (soon) waveforms and imaging. M4 dynamically selects tools based on what each dataset contains—query labs in MIMIC-IV, search discharge summaries in MIMIC-IV-Note, all through the same interface.
**Go beyond chat.**
Data exploration and simple research questions work great via MCP. But real research requires iteration: explore a cohort, compute statistics, visualize distributions, refine criteria. M4's Python API returns DataFrames that integrate with pandas, scipy, and matplotlib—turning your AI assistant into a research partner that can execute complete analysis workflows.
**Cross-dataset research.**
You should be able to ask for multi-dataset queries or cross-dataset comparisons. M4 makes this easier than ever as the AI can switch between your initialized datasets on its own, allowing it to do cross-dataset tasks for you.
**Interactive exploration.**
Some research tasks—like cohort definition—benefit from real-time visual feedback rather than iterative text queries. M4 Apps embed purpose-built UIs directly in your AI client, letting you drag sliders, toggle filters, and see instant results without leaving your workflow.
## Quickstart (3 steps)
### 1. Install uv
**macOS/Linux:**
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
```
**Windows (PowerShell):**
```powershell
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
```
### 2. Initialize M4
```bash
mkdir my-research && cd my-research
uv init && uv add m4-infra
source .venv/bin/activate # Windows: .venv\Scripts\activate
m4 init mimic-iv-demo
```
This downloads the free MIMIC-IV demo dataset (~16MB) and sets up a local DuckDB database.
### 3. Connect your AI client
**Claude Desktop:**
```bash
m4 config claude --quick
```
**Other clients (Cursor, LibreChat, etc.):**
```bash
m4 config --quick
```
Copy the generated JSON into your client's MCP settings, restart, and start asking questions!
<details>
<summary>Different setup options</summary>
* If you don't want to use uv, you can just run pip install m4-infra
* If you want to use Docker, look at <a href="docs/DEVELOPMENT.md">docs/DEVELOPMENT.md</a>
</details>
## Code Execution
For complex analysis that goes beyond simple queries, M4 provides a Python API that returns Python data types instead of formatted strings (e.g. pd.DataFrame for SQL queries). This transforms M4 from a query tool into a complete clinical data analysis environment.
```python
from m4 import set_dataset, execute_query, get_schema
set_dataset("mimic-iv")
# Get schema as a dict
schema = get_schema()
print(schema['tables']) # ['mimiciv_hosp.admissions', 'mimiciv_hosp.diagnoses_icd', ...]
# Query returns a pandas DataFrame
df = execute_query("""
SELECT icd_code, COUNT(*) as n
FROM mimiciv_hosp.diagnoses_icd
GROUP BY icd_code
ORDER BY n DESC
LIMIT 10
""")
# Use full pandas power: filter, join, compute statistics
df[df['n'] > 100].plot(kind='bar')
```
The API uses the same tools as the MCP server, so behavior is consistent. But instead of parsing text, you get DataFrames you can immediately analyze, visualize, or feed into downstream pipelines.
**When to use code execution:**
- Multi-step analyses where each query informs the next
- Large result sets (thousands of rows) that shouldn't flood your context
- Statistical computations, survival analysis, cohort characterization
- Building reproducible analysis notebooks
See [Code Execution Guide](docs/CODE_EXECUTION.md) for the full API reference and [this example session](docs/M4_Code_Execution_Example.pdf) for a walkthrough.
## Agent Skills
M4 ships with a set of skills that teach AI coding assistants clinical research patterns. Skills activate automatically when relevant—ask about "SOFA scores" or "sepsis cohorts" and Claude uses validated SQL from MIT-LCP repositories.
For the canonical list of bundled skills, see `src/m4/skills/SKILLS_INDEX.md`.
**Clinical skills:**
- **Severity Scores**: SOFA, APACHE III, SAPS-II, OASIS, LODS, SIRS
- **Sepsis**: Sepsis-3 cohort identification, suspected infection
- **Organ Failure**: KDIGO AKI staging
- **Measurements**: GCS calculation, baseline creatinine, vasopressor equivalents
- **Cohort Selection**: First ICU stay identification
- **Research Methodology**: Common research pitfalls and how to avoid them
**System skills:**
- **M4 Framework**: Python API usage, research workflow, skill creation guide
- **Data Structure**: MIMIC-IV table relationships, MIMIC-eICU mapping
**Supported tools:** Claude Code, Cursor, Cline, Codex CLI, Gemini CLI, GitHub Copilot
```bash
m4 skills # Interactive tool and skill selection
m4 skills --tools claude,cursor # Install all skills for specific tools
m4 skills --tools claude --tier validated # Only validated skills
m4 skills --tools claude --category clinical # Only clinical skills
m4 skills --tools claude --skills sofa-score,m4-api # Specific skills by name
m4 skills --list # Show installed skills with metadata
```
See [Skills Guide](docs/SKILLS.md) for the full list and how to create custom skills.
## M4 Apps
M4 Apps bring interactivity to clinical research. Instead of text-only responses, apps render interactive UIs directly in your AI client—ideal for tasks that benefit from real-time visual feedback.
**Cohort Builder**: Define patient cohorts with live filtering. Adjust age ranges, add diagnosis codes, and toggle clinical criteria while watching counts update instantly.
```
User: Help me build a cohort of elderly diabetic patients
Claude: [Launches Cohort Builder UI with interactive filters]
```
M4 Apps require a host that supports the MCP Apps protocol (like Claude Desktop). In other clients, you'll get text-based results instead.
See [M4 Apps Guide](docs/M4_APPS.md) for details on available apps and how they work.
## Example Questions
Once connected, try asking:
**Tabular data (mimic-iv, eicu):**
- *"What tables are available in the database?"*
- *"Show me the race distribution in hospital admissions"*
- *"Find all ICU stays longer than 7 days"*
- *"What are the most common lab tests?"*
**Derived concept tables (mimic-iv, after `m4 init-derived`):**
- *"What are the average SOFA scores for patients with sepsis?"*
- *"Show KDIGO AKI staging distribution across ICU stays"*
- *"Find patients on norepinephrine with SOFA > 10"*
- *"What is the 30-day mortality for patients with Charlson index > 5?"*
**Clinical notes (mimic-iv-note):**
- *"Search for notes mentioning diabetes"*
- *"List all notes for patient 10000032"*
- *"Get the full discharge summary for this patient"*
## Supported Datasets
| Dataset | Modality | Size | Access | Local | BigQuery | Derived Tables |
|---------|----------|------|--------|-------|----------|----------------|
| **mimic-iv-demo** | Tabular | 100 patients | Free | Yes | No | No |
| **mimic-iv** | Tabular | 365k patients | [PhysioNet credentialed](https://physionet.org/content/mimiciv/) | Yes | Yes | Yes (63 tables) |
| **mimic-iv-note** | Notes | 331k notes | [PhysioNet credentialed](https://physionet.org/content/mimic-iv-note/) | Yes | Yes | No |
| **eicu** | Tabular | 200k+ patients | [PhysioNet credentialed](https://physionet.org/content/eicu-crd/) | Yes | Yes | No |
These datasets are supported out of the box. However, it is possible to add any other custom dataset by following [these instructions](docs/CUSTOM_DATASETS.md).
Switch datasets or backends anytime:
```bash
m4 use mimic-iv # Switch to full MIMIC-IV
m4 backend bigquery # Switch to BigQuery (or duckdb)
m4 status # Show active dataset and backend
m4 status --all # List all available datasets
m4 status --derived # Show per-table derived materialization status
```
**Derived concept tables** (MIMIC-IV only):
```bash
m4 init-derived mimic-iv # Materialize ~63 derived tables (SOFA, sepsis3, KDIGO, etc.)
m4 init-derived mimic-iv --list # List available derived tables without materializing
```
After running `m4 init mimic-iv`, you are prompted whether to materialize derived tables. You can also run `m4 init-derived` separately at any time. Derived tables are created in the `mimiciv_derived` schema (e.g., `mimiciv_derived.sofa`) and are immediately queryable. The SQL is vendored from the [mimic-code](https://github.com/MIT-LCP/mimic-code) repository -- production-tested and DuckDB-compatible. BigQuery users already have these tables available via `physionet-data.mimiciv_derived` and do not need to run `init-derived`.
<details>
<summary><strong>Setting up MIMIC-IV or eICU (credentialed datasets)</strong></summary>
1. **Get PhysioNet credentials:** Complete the [credentialing process](https://physionet.org/settings/credentialing/) and sign the data use agreement for the dataset.
2. **Download the data:**
```bash
# For MIMIC-IV
wget -r -N -c -np --cut-dirs=2 -nH --user YOUR_USERNAME --ask-password \
https://physionet.org/files/mimiciv/3.1/ \
-P m4_data/raw_files/mimic-iv
# For eICU
wget -r -N -c -np --cut-dirs=2 -nH --user YOUR_USERNAME --ask-password \
https://physionet.org/files/eicu-crd/2.0/ \
-P m4_data/raw_files/eicu
```
The `--cut-dirs=2 -nH` flags ensure CSV files land directly in `m4_data/raw_files/mimic-iv/` rather than a nested `physionet.org/files/...` structure.
3. **Initialize:**
```bash
m4 init mimic-iv # or: m4 init eicu
```
This converts the CSV files to Parquet format and creates a local DuckDB database.
</details>
## Available Tools
M4 exposes these tools to your AI client. Tools are filtered based on the active dataset's modality.
**Dataset Management:**
| Tool | Description |
|------|-------------|
| `list_datasets` | List available datasets and their status |
| `set_dataset` | Switch the active dataset |
**Tabular Data Tools** (mimic-iv, mimic-iv-demo, eicu):
| Tool | Description |
|------|-------------|
| `get_database_schema` | List all available tables |
| `get_table_info` | Get column details and sample data |
| `execute_query` | Run SQL SELECT queries |
**Clinical Notes Tools** (mimic-iv-note):
| Tool | Description |
|------|-------------|
| `search_notes` | Full-text search with snippets |
| `get_note` | Retrieve a single note by ID |
| `list_patient_notes` | List notes for a patient (metadata only) |
## More Documentation
| Guide | Description |
|-------|-------------|
| [Architecture](docs/ARCHITECTURE.md) | Design philosophy, system overview, clinical semantics |
| [Code Execution](docs/CODE_EXECUTION.md) | Python API for programmatic access |
| [M4 Apps](docs/M4_APPS.md) | Interactive UIs for clinical research tasks |
| [Skills](docs/SKILLS.md) | Clinical and system skills for AI-assisted research |
| [Tools Reference](docs/TOOLS.md) | MCP tool documentation |
| [BigQuery Setup](docs/BIGQUERY.md) | Google Cloud for full datasets |
| [Custom Datasets](docs/CUSTOM_DATASETS.md) | Add your own PhysioNet datasets |
| [Development](docs/DEVELOPMENT.md) | Contributing, testing, code style |
| [OAuth2 Authentication](docs/OAUTH2_AUTHENTICATION.md) | Enterprise security setup |
## Roadmap
M4 is infrastructure for AI-assisted clinical research. Current priorities:
- **Clinical Semantics**
- More concept mappings (comorbidity indices, medication classes)
- Semantic search over clinical notes (beyond keyword matching)
- More agent skills that provide meaningful clinical knowledge
- **New Modalities**
- Waveforms (ECG, arterial blood pressure)
- Imaging (chest X-rays)
- **Clinical Research Agents**
- Skills and guardrails that enforce scientific integrity and best practices (documentation, etc.)
- Query logging and session export
- Result fingerprints for audit trails
## Troubleshooting
**"Parquet not found" error:**
```bash
m4 init mimic-iv-demo --force
```
**MCP client won't connect:**
Check client logs (Claude Desktop: Help → View Logs) and ensure the config JSON is valid.
**`m4` command opens GNU M4 instead of the CLI:**
On macOS/Linux, `m4` is a built-in system utility. Make sure your virtual environment is activated (`source .venv/bin/activate`) so that the correct `m4` binary is found first. Alternatively, use `uv run m4 [command]` to run within the project environment without activating it.
**Need to reconfigure:**
```bash
m4 config claude --quick # Regenerate Claude Desktop config
m4 config --quick # Regenerate generic config
```
## Citation
M4 builds on the M3 project. Please cite:
```bibtex
@article{attrach2025conversational,
title={Conversational LLMs Simplify Secure Clinical Data Access, Understanding, and Analysis},
author={Attrach, Rafi Al and Moreira, Pedro and Fani, Rajna and Umeton, Renato and Celi, Leo Anthony},
journal={arXiv preprint arXiv:2507.01053},
year={2025}
}
```
---
<p align="center">
<a href="https://github.com/hannesill/m4/issues">Report an Issue</a> ·
<a href="docs/DEVELOPMENT.md">Contribute</a>
</p>
| text/markdown | null | Hannes Ill <illh534@mit.edu> | null | Hannes Ill <illh534@mit.edu> | null | mcp, agents, clinical-data, clinical research, code execution, llm, medical, healthcare, duckdb, bigquery, mimic-iv | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Intended Audience :: Healthcare Industry",
"Topic :: Scientific/Engineering :: Medical Science Apps.",
"Topic :: Database :: Database Engines/Servers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.... | [] | null | null | >=3.10 | [] | [] | [] | [
"typer>=0.9.0",
"rich>=13.0.0",
"requests>=2.30.0",
"beautifulsoup4>=4.12.0",
"pandas>=2.0.0",
"fastmcp>=2.14.0",
"google-cloud-bigquery>=3.0.0",
"pyarrow>=10.0.0",
"db-dtypes>=1.0.0",
"sqlparse>=0.4.0",
"pyjwt[crypto]>=2.8.0",
"cryptography>=41.0.0",
"python-jose[cryptography]>=3.3.0",
"h... | [] | [] | [] | [
"Homepage, https://github.com/rafiattrach/m4",
"Repository, https://github.com/rafiattrach/m4",
"Documentation, https://github.com/rafiattrach/m4#readme",
"Issues, https://github.com/rafiattrach/m4/issues",
"Changelog, https://github.com/rafiattrach/m4/releases"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:17:46.316580 | m4_infra-0.4.3.tar.gz | 702,854 | 10/a8/81e7bd508b9b5c5de4a5c96632566085ead40070801c536e1f533bf0f094/m4_infra-0.4.3.tar.gz | source | sdist | null | false | 0b1a4937e414f016bfb35e46893253b0 | 293e2651a755726ed04a608e6cf294c6c5749e8c2d4383804764cf2b9a65b664 | 10a881e7bd508b9b5c5de4a5c96632566085ead40070801c536e1f533bf0f094 | MIT | [] | 244 |
2.4 | Werkzeug | 3.1.6 | The comprehensive WSGI web application library. | <div align="center"><img src="https://raw.githubusercontent.com/pallets/werkzeug/refs/heads/stable/docs/_static/werkzeug-name.svg" alt="" height="150"></div>
# Werkzeug
*werkzeug* German noun: "tool". Etymology: *werk* ("work"), *zeug* ("stuff")
Werkzeug is a comprehensive [WSGI][] web application library. It began as
a simple collection of various utilities for WSGI applications and has
become one of the most advanced WSGI utility libraries.
It includes:
- An interactive debugger that allows inspecting stack traces and
source code in the browser with an interactive interpreter for any
frame in the stack.
- A full-featured request object with objects to interact with
headers, query args, form data, files, and cookies.
- A response object that can wrap other WSGI applications and handle
streaming data.
- A routing system for matching URLs to endpoints and generating URLs
for endpoints, with an extensible system for capturing variables
from URLs.
- HTTP utilities to handle entity tags, cache control, dates, user
agents, cookies, files, and more.
- A threaded WSGI server for use while developing applications
locally.
- A test client for simulating HTTP requests during testing without
requiring running a server.
Werkzeug doesn't enforce any dependencies. It is up to the developer to
choose a template engine, database adapter, and even how to handle
requests. It can be used to build all sorts of end user applications
such as blogs, wikis, or bulletin boards.
[Flask][] wraps Werkzeug, using it to handle the details of WSGI while
providing more structure and patterns for defining powerful
applications.
[WSGI]: https://wsgi.readthedocs.io/en/latest/
[Flask]: https://www.palletsprojects.com/p/flask/
## A Simple Example
```python
# save this as app.py
from werkzeug.wrappers import Request, Response
@Request.application
def application(request: Request) -> Response:
return Response("Hello, World!")
if __name__ == "__main__":
from werkzeug.serving import run_simple
run_simple("127.0.0.1", 5000, application)
```
```
$ python -m app
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
```
## Donate
The Pallets organization develops and supports Werkzeug and other
popular packages. In order to grow the community of contributors and
users, and allow the maintainers to devote more time to the projects,
[please donate today][].
[please donate today]: https://palletsprojects.com/donate
## Contributing
See our [detailed contributing documentation][contrib] for many ways to
contribute, including reporting issues, requesting features, asking or answering
questions, and making PRs.
[contrib]: https://palletsprojects.com/contributing/
| text/markdown | null | null | null | Pallets <contact@palletsprojects.com> | null | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Web Environment",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Topic :: Internet :: WWW/HTTP :: Dynamic Content",
"Topic :: Internet :: WWW/HTTP :: WSGI",
"Topic :: Internet ::... | [] | null | null | >=3.9 | [] | [] | [] | [
"markupsafe>=2.1.1",
"watchdog>=2.3; extra == \"watchdog\""
] | [] | [] | [] | [
"Changes, https://werkzeug.palletsprojects.com/page/changes/",
"Chat, https://discord.gg/pallets",
"Documentation, https://werkzeug.palletsprojects.com/",
"Donate, https://palletsprojects.com/donate",
"Source, https://github.com/pallets/werkzeug/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:17:18.884849 | werkzeug-3.1.6.tar.gz | 864,736 | 61/f1/ee81806690a87dab5f5653c1f146c92bc066d7f4cebc603ef88eb9e13957/werkzeug-3.1.6.tar.gz | source | sdist | null | false | 4ce9c948613b9b823226c98e28b9004b | 210c6bede5a420a913956b4791a7f4d6843a43b6fcee4dfa08a65e93007d0d25 | 61f1ee81806690a87dab5f5653c1f146c92bc066d7f4cebc603ef88eb9e13957 | BSD-3-Clause | [
"LICENSE.txt"
] | 0 |
2.4 | cloud-optimized-dicom | 0.2.4 | A library for efficiently storing and interacting with DICOM files in the cloud | # Cloud Optimized DICOM
[](https://pypi.org/project/cloud-optimized-dicom/)
[](https://pypi.org/project/cloud-optimized-dicom/)
[](https://pypi.org/project/cloud-optimized-dicom/)
[](https://github.com/gradienthealth/cloud_optimized_dicom/actions/workflows/test.yml)
A library for efficiently storing and interacting with DICOM files in the cloud.
# Development Setup
## Prerequisites
- Python 3.11 or higher (Note: Python 3.14 is not yet supported due to build system compatibility issues)
- pip
## Installation
1. Clone the repository:
```bash
git clone <repository-url>
cd cloud_optimized_dicom
```
2. Create and activate a virtual environment:
```bash
python3.11 -m venv .venv
source .venv/bin/activate # On Windows: .venv\Scripts\activate
```
3. Install the package in editable mode:
```bash
pip install -e .
```
4. To install with development dependencies (includes pre-commit and test dependencies):
```bash
pip install -e ".[dev]"
```
5. Set up pre-commit hooks (required for development):
```bash
pre-commit install
```
Alternatively, to install only test dependencies without pre-commit:
```bash
pip install -e ".[test]"
```
## Running Tests
```bash
SISKIN_ENV_ENABLED=1 python -m unittest discover -v cloud_optimized_dicom.tests
```
## Project Structure
The project uses `pyproject.toml` for package configuration and dependency management. Key dependencies include:
- `pydicom3`: Custom fork of pydicom with namespace isolation
- `google-cloud-storage`: For cloud storage operations
- `zstandard`: For metadata compression (v2.0)
- `apache-beam[gcp]` (optional): For data processing pipelines — install with `pip install cloud-optimized-dicom[beam]`
# Concepts & Design Philosophy
## Hashed vs. regular study/series/instance UIDs
Depending on your use case, you may notice that instances have 2 getter methods for each UID:
1. standard: `{study/series/instance}_uid()`
2. hashed: `hashed_{study/series/instance}_uid()`.
If your use case is purely storage related (say you're a hospital using COD to store your data), you can just use the standard getters and not worry about hashing functionality at all.
If, however, your use case is de-identification related, you will likely be interested in COD's hashing functionality (outlined below).
### `CODObject` UIDs are used directly
For simplicity, only the `Instance` class deals with hashing.
The `CODObject` class itself has no notion of hashed versus standard UIDs.
The study/series UIDs provided to a `CODObject` on instantiation are the ones it uses directly, no querstions asked.
So, **if CODObject study/series UIDs are supposed to be hashed or otherwise modified, it is the responsibility of the user to supply the modified UIDs on instantiation**
### `Instance.uid_hash_func`
The Instance class has an argument called `uid_hash_func: Callable[[str], str] = None`.
This is expected to be a user-provided hash function that takes a string (the raw uid) and returns a string (the hashed uid).
By default (if unspecified), this function is `None`.
The existence of `uid_hash_func` (or lack thereof) is used in various key scenarios to decide whether hashed or standard UIDs will be used, including:
- determining whether an instance "belongs" to a cod object (has same study/series UIDs)
- choosing keys for UID related data in CODObject metadata dict (`deid_study_uid` vs. `study_uid`)
As a safety feature, if `instance.hashed_{study/series/instance}_uid()` is called but `instance.uid_hash_func` was not provided, a `ValueError` is raised.
## "Locking" as a race-case solution
### Motivation
Say there are multiple processes interacting with a COD datastore simultaneously.
These could be entirely separate processes, or one job with multiple workers.
In either case, what happens if they both attempt to modify the same `CODObject` at the same time?
To avoid the "first process gets overwritten by second process" outcome, we introduce the concept of "locking".
### Terminology & Concepts
A **lock** is just a file with a specific name (`.gradient.lock`).
**Acquiring a lock** means that the `CODObject` will upload a lock blob to the datastore and store its generation number. If the lock already exists, the `CODObject` will raise a `LockAcquisitionError`.
### Access Modes
`CODObject`s take a `mode` argument that controls locking and sync behavior:
- `mode="r"` -> Read-only. No lock is acquired. Write operations will raise a `WriteOperationInReadModeError`.
- `mode="w"` -> Write (overwrite). A lock is acquired automatically. Starts fresh with empty metadata/tar locally. Overwrites remote tar/metadata on sync.
- `mode="a"` -> Append. A lock is acquired automatically. Fetches remote tar if it exists. Appends to existing tar/metadata on sync.
Because `mode="w"` and `mode="a"` raise an error if the lock cannot be acquired (already exists), it is guaranteed that no other writing-enabled `CODObject` will be created on the same series while one already exists, thus avoiding the race condition where two workers attempt to create CODObjects with the same study/series UIDs.
### When is a lock necessary?
When the operation you are attempting involves actually modifying the COD datastore itself (example: ingesting new files), use `mode="w"` or `mode="a"`.
For read-only operations like exporting or reading data from COD, use `mode="r"` so your operation is not blocked if another process is writing to the datastore.
### Lock Release & Management
`CODObject` is designed to be used as a context manager.
When you enter a `with` statement, the lock will persist for the duration of the statement. On successful exit, changes are automatically synced and the lock is released.
```python
with CODObject(client=..., datastore_path=..., mode="w") as cod:
cod.append(instances)
# sync() called automatically, lock released
```
If an exception occurs in user code (before sync), the lock is **released** — only local state was affected, so the remote datastore is not corrupt:
```python
with CODObject(client=..., datastore_path=..., mode="w") as cod:
raise ValueError("test")
# lock is released; sync was skipped since no work reached the remote datastore
```
However, if the sync itself fails (meaning remote state may be partially written), the lock is deliberately left **hanging** to signal that the series may be corrupt and needs attention.
Locks are NOT automatically released when a `CODObject` goes out of scope. Always use a context manager (`with` statement) to ensure proper cleanup:
```python
# Incorrect: Lock persists indefinitely
cod = CODObject(client=..., datastore_path=..., mode="w")
del cod # Lock still exists remotely!
```
**It is YOUR responsibility as the user of this class to make sure your locks are released.**
## Instance URI management: `dicom_uri` vs `_original_path` vs `dependencies`
Two main principles govern how the `Instance` class manages URIs:
1. It should be as simple and straightforward as possible to instantiate an `Instance`
2. There should be a single source of truth for where dicom data is actually located at all times
In keeping with these, there are three different class variables designed to manage URIs:
- `dicom_uri`: where the actual dcm data is located at any given moment. This is the only argument required to instantiate an `Instance`,
and may change from what the user provided in order to accurately reflect the location of the dicom data (see example below)
- `_original_path`: private field automatically set to the same value as `dicom_uri` during `Instance` initialization.
- `dependencies`: (OPTIONAL) a user-defined list of URI strings that are related to this `Instance`, which theoretically could be deleted safely if the instance was synced to a COD Datastore
Because the actual location of dicom data changes throughout the ingestion process, `dicom_uri` changes to reflect this. Consider the following example:
1. User creates `instance = Instance(dicom_uri="gs://some-bucket/example.dcm")`.
At this point, `dicom_uri=_original_path="gs://some-bucket/example.dcm"`
2. User calls `instance.open()` to view the data. This causes the file to be fetched from its remote URI, and at this point `dicom_uri=path/to/a/local/temp/file/that/got/generated`.
However, `_original_path` will never change and still points to `gs://some-bucket/example.dcm`
3. User appends `instance` to a `CODObject`. After a successful append the instance will be located in the `CODObject`'s series-level tar on disk, so `dicom_uri=local/path/to/cod/series.tar://instances/{instance_uid}.dcm`.
4. User `sync`s the `CODObject` to the datastore. Because the instance still exists on disk in the local series tar, `instance.dicom_uri` does not change. However, in the remote COD datastore, the instance is recorded as having `dicom_uri="gs://cod/datastore/series.tar://instances/{instance_uid}.dcm"`
## `Hints`
Metadata about the DICOM file that can be used to validate the file.
Say for example you have run some sort of inventory report on a set of DICOM files, and you now know their `instance_uid` and `crc32c` hash.
When ingesting these files using COD, you can provide this information via the `Hints` argument.
COD can then use the `instance_uid` and hash to determine whether this new instance is a duplicate without ever having to actually fetch the file,
thus avoiding unncessary costs associated with "no-op" ingestions (if ingestion job were to be mistakenly run twice, for example).
To avoid corrupting the COD datastore in the case of incorrect `Hint` values,
information provided in `Hints` is validated when the instance is fetched (i.e. during ingestion if the instance is NOT a duplicate),
so that if user-provided hints are incorrect the COD datastore is not corupted.
## The need for `Instance.dependencies`
In most cases, `dicom_uri` will be the only dependency - the DICOM file is self-contained.
However, there are more complex cases to consider. Intelerad data, for example, may have `.dcm` and `.j2c` files that needed to be combined in order to create the true dicom P10 file.
In this case, `dicom_uri` is not meaningful in the context of deletion (it's likely a temp path on disk), and `dependencies` would be the `.dcm` and `.j2c` files.
After ingestion, one can conveniently delete these files by calling `Instance.delete_dependencies()`.
# Metadata format
COD supports two metadata formats: v1.0 (legacy) and v2.0 (current). The formats differ primarily in how DICOM metadata is stored and whether certain fields are explicitly indexed.
## Metadata v2.0 (Current)
Version 2.0 introduces several optimizations:
- **Compressed metadata**: DICOM metadata is zstandard-compressed and base64-encoded to reduce storage size (typically achieves 5-10x compression on JSON)
- **Explicit UID indexing**: Study, Series, and Instance UIDs are stored as top-level fields for faster querying without decompression
- **Explicit pixeldata flag**: `has_pixeldata` boolean stored at top level
- **Lazy decompression**: Metadata is only decompressed when accessed via `instance.metadata`
- **Smart caching**: Small metadata (compressed size < 1KB) is cached after first decompression
Instance metadata structure (within `cod.instances`):
```json
{
"instance_uid": "1.2.3.4.5",
"series_uid": "1.2.3.4",
"study_uid": "1.2.3",
"has_pixeldata": true,
"metadata": "<base64-encoded zstandard-compressed DICOM JSON dict>",
"uri": "gs://.../series.tar://instances/{instance_uid}.dcm",
"headers": {"start_byte": 123, "end_byte": 456},
"offset_tables": {"CustomOffsetTable": [...], "CustomOffsetTableLengths": [...]},
"crc32c": "the_blob_hash",
"size": 123,
"original_path": "path/where/this/file/was/originally/located",
"dependencies": ["path/to/a/dependency", ...],
"diff_hash_dupe_paths": ["path/to/a/duplicate", ...],
"version": "2.0",
"modified_datetime": "2024-01-01T00:00:00"
}
```
## Metadata v1.0 (Legacy)
Version 1.0 stores metadata uncompressed:
- **Uncompressed metadata**: Full DICOM JSON dict stored inline
- **UIDs parsed from metadata**: UIDs must be extracted from the metadata dict when needed
- **Pixeldata detection**: Presence of tag `7FE00010` in metadata indicates pixeldata
Instance metadata structure (within `cod.instances`):
```json
{
"metadata": {
"00080018": {"vr": "UI", "Value": ["1.2.3.4.5"]},
"0020000D": {"vr": "UI", "Value": ["1.2.3"]},
"0020000E": {"vr": "UI", "Value": ["1.2.3.4"]},
...
},
"uri": "gs://.../series.tar://instances/{instance_uid}.dcm",
"headers": {"start_byte": 123, "end_byte": 456},
"offset_tables": {"CustomOffsetTable": [...], "CustomOffsetTableLengths": [...]},
"crc32c": "the_blob_hash",
"size": 123,
"original_path": "path/where/this/file/was/originally/located",
"dependencies": ["path/to/a/dependency", ...],
"diff_hash_dupe_paths": ["path/to/a/duplicate", ...],
"version": "1.0",
"modified_datetime": "2024-01-01T00:00:00"
}
```
## Complete COD Object Structure
Both versions use the same overall structure:
```json
{
"deid_study_uid": "deid(StudyInstanceUID)",
"deid_series_uid": "deid(SeriesInstanceUID)",
"cod": {
"instances": {
"deid(SOPInstanceUID)": { /* instance metadata (v1 or v2 format) */ }
}
},
"thumbnail": {
"version": "1.0",
"uri": "studies/{deid(StudyInstanceUID)}/series/{deid(SeriesInstanceUID)}.(mp4|jpg)",
"thumbnail_index_to_instance_frame": [["deid(SOPInstanceUID)", frame_index], ...],
"instances": {
"deid(SOPInstanceUID)": {
"frames": [
{
"thumbnail_index": 0,
"anchors": {
"original_size": {"width": 100, "height": 200},
"thumbnail_upper_left": {"row": 0, "col": 10},
"thumbnail_bottom_right": {"row": 127, "col": 117}
}
}
]
}
}
},
"other": {}
}
```
| text/markdown | null | Cal Nightingale <cal@gradienthealth.io> | null | null | null | null | [
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <3.14,>=3.11 | [] | [] | [] | [
"smart-open==7.0.4",
"ratarmountcore==0.7.1",
"numpy",
"google-cloud-storage==2.19.0",
"filetype==1.2.0",
"pylibjpeg==2.0.1",
"pylibjpeg-libjpeg==2.3.0",
"pylibjpeg-openjpeg==2.4.0",
"pydicom3>=3.1.0",
"opencv-python-headless==4.11.0.86",
"ffmpeg-python==0.2.0",
"zstandard>=0.24.0",
"urllib3... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:17:14.463929 | cloud_optimized_dicom-0.2.4.tar.gz | 82,549 | 02/49/5374c53fb1a01d1d75c5cfaab8c7fdfc2d7e4205a195ec0cad21d33e07d5/cloud_optimized_dicom-0.2.4.tar.gz | source | sdist | null | false | b2c41970a985efa24002651b61dd0d11 | 5a5a106ec3a309a62ed287a338094b3eedff0f6bc5c606c641a65f5003b1b311 | 02495374c53fb1a01d1d75c5cfaab8c7fdfc2d7e4205a195ec0cad21d33e07d5 | MIT | [
"LICENSE"
] | 243 |
2.3 | giantkelp-ai | 0.1.8 | Universal AI Agent supporting multiple LLM providers (Anthropic, OpenAI, Gemini, Groq, DeepSeek) | # GiantKelp AI
<div align="center">
**Universal AI Agent supporting multiple LLM providers with a single, unified interface**
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
*Built by [GiantKelp](https://www.giantkelp.com/) - AI Agency in London*
</div>
---
## Overview
GiantKelp AI is a powerful, provider-agnostic Python library that gives you a unified interface to interact with multiple leading LLM providers. Write your code once and switch between providers seamlessly - no need to learn different APIs or refactor your codebase.
### Why GiantKelp AI?
- **🔄 Provider Flexibility**: Switch between Anthropic, OpenAI, Gemini, Groq, and DeepSeek without changing your code
- **🎯 Smart Model Selection**: Automatically use smart, fast, or reasoning models based on your needs
- **📄 Rich Media Support**: Handle text, images, and documents (PDFs) with the same simple interface
- **🌐 Web Search Integration**: Native web search capabilities where supported
- **🤖 Agent Teams**: Build sophisticated multi-agent systems with handoffs (optional)
- **⚡ Streaming Support**: Real-time response streaming across all providers
- **📊 Usage Tracking**: Optional Redis stream integration for token usage monitoring
- **🛡️ Production Ready**: Comprehensive error handling, logging, and type hints
---
## Supported Providers
| Provider | Text | Vision | Documents | Web Search | Reasoning |
|----------|------|--------|-----------|------------|-----------|
| **Anthropic (Claude)** | ✅ | ✅ | ✅ | ✅ | ✅ |
| **OpenAI** | ✅ | ✅ | ✅ | ✅ | ✅ |
| **Google Gemini** | ✅ | ✅ | ✅ | ✅ | ✅ |
| **Groq** | ✅ | ✅ | ❌ | ✅ | ✅ |
| **DeepSeek** | ✅ | ❌ | ❌ | ❌ | ✅ |
---
## Installation
### Basic Installation
```bash
pip install giantkelp-ai
```
### With Agent Support
```bash
pip install giantkelp-ai[agents]
```
### With Redis Usage Tracking
```bash
pip install giantkelp-ai redis
```
---
## Quick Start
```python
from giantkelp_ai import AIAgent
# Initialize with your preferred provider
agent = AIAgent(provider="anthropic")
# Get a response
response = agent.fast_completion("What is the capital of France?")
print(response) # "Paris is the capital of France."
```
### With Agent Naming (for usage tracking)
```python
# Name your agent for usage tracking and analytics
agent = AIAgent(provider="anthropic", agent_name="customer_support")
response = agent.smart_completion("Help me with my order")
```
---
## Configuration
### Environment Variables
Set your API keys as environment variables:
```bash
export ANTHROPIC_API_KEY="your-anthropic-key"
export OPENAI_API_KEY="your-openai-key"
export GEMINI_API_KEY="your-gemini-key"
export GROQ_API_KEY="your-groq-key"
export DEEPSEEK_API_KEY="your-deepseek-key"
# Optional global settings
export MAX_TOKENS=5000
export TEMPERATURE=0.1
```
### Using .env File
Create a `.env` file in your project root:
```env
ANTHROPIC_API_KEY=your-anthropic-key
OPENAI_API_KEY=your-openai-key
GEMINI_API_KEY=your-gemini-key
GROQ_API_KEY=your-groq-key
DEEPSEEK_API_KEY=your-deepseek-key
MAX_TOKENS=5000
TEMPERATURE=0.1
```
---
## Core Features
### 1. Text Completions
Choose from three model tiers for different use cases:
#### Fast Completion (Optimized for Speed)
```python
agent = AIAgent(provider="anthropic")
response = agent.fast_completion(
user_prompt="Translate 'hello' to Spanish",
system_prompt="You are a helpful translator",
max_tokens=100,
temperature=0.1
)
print(response) # "Hola"
```
#### Smart Completion (Balanced Performance)
```python
response = agent.smart_completion(
user_prompt="Explain quantum entanglement",
system_prompt="You are a physics professor",
max_tokens=500,
temperature=0.7
)
```
#### Reasoning Completion (Advanced Problem Solving)
```python
response = agent.reasoning_completion(
user_prompt="Solve this complex math problem: ...",
max_tokens=2000
)
```
### 2. Streaming Responses
Get real-time responses as they're generated:
```python
stream = agent.fast_completion(
user_prompt="Write a short story about a robot",
stream=True
)
for chunk in agent.normalize_stream(stream):
print(chunk, end="", flush=True)
```
### 3. JSON Output Mode
Request structured JSON responses:
```python
response = agent.fast_completion(
user_prompt="List 5 fruits with their colors",
json_output=True
)
print(response)
# {
# "fruits": [
# {"name": "apple", "color": "red"},
# {"name": "banana", "color": "yellow"},
# ...
# ]
# }
```
### 4. Image Analysis
Analyze images with vision-capable models:
```python
# From file path
response = agent.image_completion(
user_prompt="What objects are in this image?",
image="path/to/image.jpg",
file_path=True
)
# From base64 data
response = agent.image_completion(
user_prompt="Describe this image",
image=base64_image_data,
file_path=False
)
# Use smart model for complex analysis
response = agent.image_completion(
user_prompt="Analyze the composition and artistic style",
image="artwork.jpg",
smart_model=True
)
```
### 5. Document Processing
Process PDF documents with automatic text extraction:
```python
# Single document processing
response = agent.document_completion(
user_prompt="Summarize this document",
document="report.pdf",
smart_model=True
)
# Process each page independently
results = agent.document_completion(
user_prompt="Extract key points from each page",
document="multi-page-report.pdf",
split_into_pages=True
)
# Results is a dict: {1: "Page 1 summary", 2: "Page 2 summary", ...}
for page_num, summary in results.items():
print(f"Page {page_num}: {summary}")
```
### 6. Web Search
Perform real-time web searches (provider-dependent):
```python
# Basic web search
response = agent.web_search(
query="Latest developments in AI 2025",
scope="smart"
)
# With system prompt
response = agent.web_search(
query="Best practices for Python async programming",
system="You are a senior Python developer",
scope="fast"
)
# With location-based search
response = agent.web_search(
query="Local restaurants",
country_code="GB",
city="London",
scope="fast"
)
# With reasoning model
response = agent.web_search(
query="Compare the economic impacts of renewable energy",
scope="reasoning",
thinking_budget=5000 # Anthropic only
)
```
---
## Advanced Features
### Agent Teams with Handoffs
Build sophisticated multi-agent systems that can delegate tasks to specialized agents:
```python
agent = AIAgent(provider="anthropic")
# Create a team of specialized agents
agent.create_handoff_team([
{
"name": "triage",
"instructions": "You are a customer service triage agent. Route inquiries to the appropriate specialist.",
"type": "smart",
"handoffs_to": ["billing", "technical", "sales"]
},
{
"name": "billing",
"instructions": "You handle all billing and payment-related questions. Be clear and concise.",
"type": "fast",
"handoffs_to": ["escalation"]
},
{
"name": "technical",
"instructions": "You provide technical support and troubleshooting. Be detailed and helpful.",
"type": "fast",
"handoffs_to": ["escalation"]
},
{
"name": "sales",
"instructions": "You handle sales inquiries and product questions. Be persuasive and informative.",
"type": "fast"
},
{
"name": "escalation",
"instructions": "You handle complex issues requiring deep reasoning and nuanced judgment.",
"type": "reasoning"
}
])
# Run an agent
response = agent.run_agent(
user_prompt="I'm having trouble with my last payment",
agent_name="triage"
)
# The triage agent will automatically hand off to billing if needed
print(response)
```
### Creating Individual Agents
```python
# Create a single agent
support_agent = agent.create_agent_sdk_agent(
name="support",
instructions="You are a friendly customer support agent.",
agent_type="smart",
store=True
)
# Create agent with custom tools
from my_tools import calculator, database_query
analyst_agent = agent.create_agent_sdk_agent(
name="analyst",
instructions="You analyze data and provide insights.",
agent_type="reasoning",
tools=[calculator, database_query]
)
# List all agents
print(agent.list_agents()) # ['support', 'analyst']
# Get a specific agent
my_agent = agent.get_agent("support")
```
### Async Agent Execution
```python
import asyncio
async def main():
agent = AIAgent(provider="anthropic")
# Create agent
agent.create_agent_sdk_agent(
name="assistant",
instructions="You are a helpful assistant."
)
# Run asynchronously
response_coro = agent.run_agent(
user_prompt="What's the weather like?",
agent_name="assistant",
async_mode=True
)
response = await response_coro
print(response)
asyncio.run(main())
```
### Usage Tracking with Redis
Track token usage across all your AI agents by sending usage events to a Redis stream. This is useful for monitoring costs, analyzing usage patterns, and billing.
#### Setup
```python
from giantkelp_ai import AIAgent, configure_redis, RedisUsageConfig, is_redis_configured
# Configure Redis (call once at app startup)
configure_redis(RedisUsageConfig(
redis_url="redis://localhost:6379",
stream_key="myapp:ai_usage", # Redis stream key
client_id="my_application" # Identifies your app in usage events
))
# Verify configuration
if is_redis_configured():
print("Redis usage tracking enabled!")
```
#### Usage Events
Once configured, every completion automatically sends usage data to the Redis stream:
```python
# All completion types are tracked
agent = AIAgent(provider="anthropic", agent_name="support_bot")
# Text completions
response = agent.fast_completion("Hello!")
# Streaming completions (usage captured at end of stream)
stream = agent.smart_completion("Write a story", stream=True)
for chunk in agent.normalize_stream(stream):
print(chunk, end="")
# Image completions
response = agent.image_completion("Describe this", image="photo.jpg", file_path=True)
# Document completions
response = agent.document_completion("Summarize", document="report.pdf", file_path=True)
# Web search
response = agent.web_search("Latest AI news")
```
#### Event Data Structure
Each event in the Redis stream contains:
```json
{
"type": "usage_event",
"payload": {
"provider": "anthropic",
"model": "claude-haiku-4-5",
"input_tokens": 150,
"output_tokens": 250,
"agent_name": "support_bot",
"client_id": "my_application",
"message": "What is the capital of France?",
"timestamp": "2025-02-19T10:30:00.000Z"
}
}
```
Note: The `message` field contains the first 100 characters of the user prompt.
#### Reading Usage Events
```python
import redis
import json
client = redis.from_url("redis://localhost:6379")
# Get recent usage events
messages = client.xrevrange("myapp:ai_usage", count=10)
for msg_id, data in messages:
event = json.loads(data[b"job"])
payload = event["payload"]
print(f"Model: {payload['model']}, Tokens: {payload['input_tokens']} in / {payload['output_tokens']} out")
```
#### Environment Variables
You can also configure Redis via environment variables:
```bash
REDIS_HOST=localhost
REDIS_PORT=6379
REDIS_PASSWORD=your_password # Optional
```
---
## Model Selection Guide
### When to Use Each Model Tier
| Model Tier | Best For | Examples |
|-----------|----------|----------|
| **Fast** | Quick responses, simple tasks, high-volume requests | Translations, classifications, simple Q&A |
| **Smart** | Complex reasoning, detailed analysis, creative tasks | Content generation, code review, strategy |
| **Reasoning** | Deep problem-solving, multi-step reasoning, expert-level analysis | Research, mathematical proofs, complex debugging |
### Provider-Specific Models
```python
# Anthropic
agent = AIAgent(provider="anthropic")
# Fast: claude-haiku-4-5
# Smart: claude-sonnet-4-5
# Reasoning: claude-opus-4-1
# OpenAI
agent = AIAgent(provider="openai")
# Fast: gpt-4o-mini
# Smart: gpt-4o
# Reasoning: o3
# Gemini
agent = AIAgent(provider="gemini")
# Fast: gemini-2.5-flash
# Smart: gemini-2.5-pro
# Reasoning: gemini-2.5-pro
# Groq
agent = AIAgent(provider="groq")
# Fast: llama-3.1-8b-instant
# Smart: llama-3.3-70b-versatile
# Reasoning: llama-3.3-70b-versatile
# DeepSeek
agent = AIAgent(provider="deepseek")
# Fast: deepseek-chat
# Smart: deepseek-chat
# Reasoning: deepseek-reasoner
```
---
## Switching Providers
One of the key benefits of GiantKelp AI is provider flexibility:
```python
# Start with Anthropic
agent = AIAgent(provider="anthropic")
response1 = agent.smart_completion("Explain AI")
# Switch to OpenAI (same code!)
agent = AIAgent(provider="openai")
response2 = agent.smart_completion("Explain AI")
# Switch to Groq (same code!)
agent = AIAgent(provider="groq")
response3 = agent.smart_completion("Explain AI")
# All three work identically!
```
---
## Error Handling
GiantKelp AI provides comprehensive error handling:
```python
from giantkelp_ai import AIAgent
try:
agent = AIAgent(provider="anthropic")
response = agent.smart_completion("Hello")
except ValueError as e:
# Configuration or input errors
print(f"Configuration error: {e}")
except RuntimeError as e:
# API or operational errors
print(f"Runtime error: {e}")
except FileNotFoundError as e:
# File-related errors (images, documents)
print(f"File error: {e}")
except NotImplementedError as e:
# Feature not supported by provider
print(f"Feature not available: {e}")
```
---
## Logging and Debugging
Enable verbose logging for debugging:
```python
import logging
# Configure logging
logging.basicConfig(level=logging.INFO)
# Enable verbose mode
agent = AIAgent(provider="anthropic", verbose=True)
# Now all operations will be logged
response = agent.smart_completion("Test")
```
---
## Examples
### Example 1: Content Generation
```python
from giantkelp_ai import AIAgent
agent = AIAgent(provider="anthropic")
blog_post = agent.smart_completion(
user_prompt="Write a 300-word blog post about the future of AI in healthcare",
system_prompt="You are a professional medical technology writer",
max_tokens=500,
temperature=0.7
)
print(blog_post)
```
### Example 2: Image Analysis Pipeline
```python
from giantkelp_ai import AIAgent
import os
agent = AIAgent(provider="openai")
# Analyze multiple images
image_folder = "product_photos/"
analyses = []
for filename in os.listdir(image_folder):
if filename.endswith((".jpg", ".png")):
analysis = agent.image_completion(
user_prompt="Describe this product image for an e-commerce catalog",
image=os.path.join(image_folder, filename),
smart_model=True,
json_output=True
)
analyses.append({
"filename": filename,
"analysis": analysis
})
print(analyses)
```
### Example 3: Document Summarization
```python
from giantkelp_ai import AIAgent
agent = AIAgent(provider="gemini")
# Summarize a research paper
summary = agent.document_completion(
user_prompt="""
Provide a structured summary with:
1. Main findings
2. Methodology
3. Conclusions
4. Limitations
""",
document="research_paper.pdf",
smart_model=True,
max_tokens=1000
)
print(summary)
```
### Example 4: Multi-Provider Comparison
```python
from giantkelp_ai import AIAgent
providers = ["anthropic", "openai", "gemini", "groq"]
prompt = "What is the meaning of life?"
results = {}
for provider in providers:
try:
agent = AIAgent(provider=provider)
response = agent.fast_completion(prompt)
results[provider] = response
except Exception as e:
results[provider] = f"Error: {e}"
for provider, response in results.items():
print(f"\n{provider.upper()}:")
print(response)
```
### Example 5: Intelligent Customer Support
```python
from giantkelp_ai import AIAgent
agent = AIAgent(provider="anthropic")
# Create support team
agent.create_handoff_team([
{
"name": "receptionist",
"instructions": """
You are the first point of contact. Be warm and welcoming.
Understand the customer's needs and route them to the right specialist.
""",
"type": "fast",
"handoffs_to": ["technical", "billing", "general"]
},
{
"name": "technical",
"instructions": "You solve technical problems. Be patient and thorough.",
"type": "smart"
},
{
"name": "billing",
"instructions": "You handle billing inquiries. Be clear and accurate.",
"type": "fast"
},
{
"name": "general",
"instructions": "You handle general questions and provide information.",
"type": "fast"
}
])
# Handle customer inquiry
customer_message = "I'm having trouble logging into my account"
response = agent.run_agent(customer_message, agent_name="receptionist")
print(response)
```
---
## API Reference
### AIAgent Class
#### Constructor
```python
AIAgent(provider: str = "anthropic", verbose: bool = False, agent_name: str = "general")
```
**Parameters:**
- `provider` (str): LLM provider name - "anthropic", "openai", "gemini", "groq", or "deepseek"
- `verbose` (bool): Enable detailed logging
- `agent_name` (str): Name for this agent instance, used in usage tracking events (default: "general")
#### Methods
##### Text Completion Methods
**`fast_completion(user_prompt, system_prompt=None, max_tokens=None, temperature=None, stream=False, json_output=False)`**
Fast model completion for quick responses.
**`smart_completion(user_prompt, system_prompt=None, max_tokens=None, temperature=None, stream=False, json_output=False)`**
Smart model completion for complex tasks.
**`reasoning_completion(user_prompt, system_prompt=None, max_tokens=None, temperature=None, stream=False, json_output=False)`**
Reasoning model completion for advanced problem-solving.
**Parameters:**
- `user_prompt` (str): User's input text
- `system_prompt` (str, optional): System instructions
- `max_tokens` (int, optional): Maximum tokens to generate
- `temperature` (float, optional): Sampling temperature (0.0-1.0)
- `stream` (bool): Enable streaming responses
- `json_output` (bool): Request JSON formatted output
**Returns:** str or dict (if json_output=True) or stream object (if stream=True)
##### Image Analysis
**`image_completion(user_prompt, image, file_path=True, smart_model=False, system_prompt=None, max_tokens=None, temperature=None, stream=False, json_output=False)`**
Analyze images using vision-capable models.
**Parameters:**
- `user_prompt` (str): Question or instruction about the image
- `image` (str or bytes): Image file path or base64 data
- `file_path` (bool): True if image is a file path, False if base64
- `smart_model` (bool): Use smart model instead of fast
- Other parameters same as completion methods
**Returns:** str or dict or stream object
##### Document Processing
**`document_completion(user_prompt, document, file_path=True, smart_model=False, system_prompt=None, max_tokens=None, temperature=None, stream=False, json_output=False, split_into_pages=False)`**
Process PDF documents.
**Parameters:**
- `user_prompt` (str): Question or instruction about the document
- `document` (str or bytes): Document file path or bytes
- `file_path` (bool): True if document is a file path
- `smart_model` (bool): Use smart model instead of fast
- `split_into_pages` (bool): Process each page independently
- Other parameters same as completion methods
**Returns:** str or dict or stream object, or dict of page results if split_into_pages=True
##### Web Search
**`web_search(query, system=None, scope="fast", max_tokens=10000, temperature=None, max_results=20, thinking_budget=5000, country_code=None, city=None)`**
Perform real-time web searches.
**Parameters:**
- `query` (str): Search query
- `system` (str, optional): System prompt
- `scope` (str): "smart", "fast", or "reasoning"
- `max_tokens` (int): Maximum tokens
- `temperature` (float, optional): Sampling temperature
- `max_results` (int): Hint for number of results
- `thinking_budget` (int, optional): Thinking token budget (Anthropic only)
- `country_code` (str, optional): Country code for location-based search
- `city` (str, optional): City name for location-based search
**Returns:** str
##### Agent Methods
**`create_agent_sdk_agent(name, instructions, agent_type="smart", handoffs=[], store=True, **agent_kwargs)`**
Create an OpenAI Agents SDK agent.
**`create_handoff_team(team_config)`**
Create a team of agents with handoff relationships.
**`run_agent(user_prompt, agent=None, agent_name=None, async_mode=False, **runner_kwargs)`**
Execute a stored agent.
**`get_agent(name)`**
Retrieve a stored agent by name.
**`list_agents()`**
List all stored agents.
##### Utility Methods
**`normalize_stream(stream)`**
Normalize streaming responses to yield text chunks.
**`clean_json_output(text)`**
Parse and clean JSON output from LLM responses.
### Redis Usage Tracking Functions
#### configure_redis
```python
configure_redis(config: RedisUsageConfig) -> None
```
Configure Redis for usage tracking. Call once at application startup.
**Parameters:**
- `config` (RedisUsageConfig): Redis configuration object
#### RedisUsageConfig
```python
RedisUsageConfig(
redis_url: str,
stream_key: str = "giantkelp:usage",
client_id: str = "default"
)
```
**Parameters:**
- `redis_url` (str): Redis connection URL (e.g., "redis://localhost:6379" or "redis://:password@host:port")
- `stream_key` (str): Redis stream key for usage events (default: "giantkelp:usage")
- `client_id` (str): Identifier for your application in usage events (default: "default")
#### is_redis_configured
```python
is_redis_configured() -> bool
```
Check if Redis usage tracking is configured and connected.
**Returns:** True if Redis is configured and ready, False otherwise.
---
## Best Practices
### 1. Choose the Right Model Tier
```python
# Use fast for simple, high-volume tasks
summaries = [
agent.fast_completion(f"Summarize: {text}")
for text in texts
]
# Use smart for important, complex tasks
strategy = agent.smart_completion(
"Develop a market entry strategy for...",
max_tokens=2000
)
# Use reasoning for critical decisions
analysis = agent.reasoning_completion(
"Analyze the risks and opportunities of..."
)
```
### 2. Implement Proper Error Handling
```python
def safe_completion(agent, prompt):
try:
return agent.smart_completion(prompt)
except RuntimeError as e:
# Log and retry with different provider
logger.error(f"Provider failed: {e}")
backup_agent = AIAgent(provider="groq")
return backup_agent.smart_completion(prompt)
except Exception as e:
logger.error(f"Unexpected error: {e}")
return None
```
### 3. Use Streaming for Long Responses
```python
# Better user experience with streaming
stream = agent.smart_completion(
"Write a comprehensive guide to...",
stream=True
)
for chunk in agent.normalize_stream(stream):
print(chunk, end="", flush=True)
# Update UI in real-time
```
### 4. Leverage JSON Mode for Structured Data
```python
# Request structured output
user_data = agent.fast_completion(
f"Extract name, email, and phone from: {text}",
json_output=True
)
# Now you can use the structured data
send_email(user_data['email'])
```
### 5. Optimize Token Usage
```python
# Be specific with max_tokens
agent.fast_completion(
"Yes or no: Is this spam?",
max_tokens=5 # Only need a short answer
)
# Use appropriate temperature
agent.smart_completion(
"Generate creative story ideas",
temperature=0.9 # Higher for creativity
)
agent.fast_completion(
"What is 2+2?",
temperature=0.1 # Lower for factual answers
)
```
---
## Performance Tips
1. **Batch Processing**: Process multiple items in parallel when possible
2. **Caching**: Cache responses for repeated queries
3. **Provider Selection**: Choose providers based on your use case (cost, speed, capabilities)
4. **Model Tiering**: Use fast models for simple tasks, save smart/reasoning for complex ones
5. **Streaming**: Use streaming for long-form content to improve perceived performance
---
## Troubleshooting
### Common Issues
**Issue: "API key not found"**
```python
# Solution: Set environment variable
import os
os.environ['ANTHROPIC_API_KEY'] = 'your-key'
agent = AIAgent(provider="anthropic")
```
**Issue: "Vision not supported for X provider"**
```python
# Solution: Use a provider that supports vision
agent = AIAgent(provider="anthropic") # Supports vision
# or
agent = AIAgent(provider="openai") # Supports vision
```
**Issue: "Document processing failed"**
```python
# Solution: Check file exists and is a valid PDF
import os
if os.path.exists("document.pdf"):
response = agent.document_completion(
"Summarize",
"document.pdf"
)
```
**Issue: "Rate limit exceeded"**
```python
# Solution: Implement retry logic with exponential backoff
import time
def completion_with_retry(agent, prompt, max_retries=3):
for attempt in range(max_retries):
try:
return agent.fast_completion(prompt)
except RuntimeError as e:
if "rate limit" in str(e).lower():
wait = 2 ** attempt
time.sleep(wait)
else:
raise
raise RuntimeError("Max retries exceeded")
```
---
## Support
- **Email**: jonah@giantkelp.com
- **Website**: [giantkelp.com](https://www.giantkelp.com/)
---
## About GiantKelp
GiantKelp is an AI agency based in London, specializing in cutting-edge artificial intelligence solutions for businesses. We build intelligent systems that help organizations leverage the power of AI effectively.
**Visit us**: [www.giantkelp.com](https://www.giantkelp.com/)
---
<div align="center">
**[Website](https://www.giantkelp.com/)
</div> | text/markdown | Jonah | jonah@giantkelp.xyz | null | null | MIT | ai, llm, anthropic, openai, gemini, groq, deepseek, multi-provider | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Py... | [] | null | null | >=3.10 | [] | [] | [] | [
"openai<3.0.0,>=2.6.1",
"anthropic<0.73.0,>=0.72.0",
"google-genai<2.0.0,>=1.47.0",
"groq<0.34.0,>=0.33.0",
"pillow<13.0.0,>=12.0.0",
"pikepdf<11.0.0,>=10.0.0",
"pypdf2<4.0.0,>=3.0.1",
"pycountry<25.0.0,>=24.6.1",
"openai-agents<0.5.0,>=0.4.2",
"openai-agents[litellm]<0.5.0,>=0.4.2",
"redis<8.0.... | [] | [] | [] | [] | poetry/2.1.1 CPython/3.13.2 Darwin/24.5.0 | 2026-02-19T15:17:09.735311 | giantkelp_ai-0.1.8.tar.gz | 30,483 | 9b/4b/9ff469f55ae4d79cccc40a071c2ef2c40aeed73a23b62b83e6f8269949c0/giantkelp_ai-0.1.8.tar.gz | source | sdist | null | false | 792a9e7928ca9d3c1f31015537366f0a | 8680c8ceb0c4a1299b9b055cdeb3a096ec68afef2364e8cd9415f925892ccbea | 9b4b9ff469f55ae4d79cccc40a071c2ef2c40aeed73a23b62b83e6f8269949c0 | null | [] | 236 |
2.4 | feagi-bv | 2.2.1 | Brain Visualizer runtime package for FEAGI (meta-package) | # feagi-bv
Python package that bundles **Brain Visualizer** binaries with a simple launcher API.
## Installation
**Most users should install the full FEAGI package instead:**
```bash
pip install feagi # Includes feagi-core + feagi-bv automatically
```
**Only install feagi-bv directly if:**
- You already have `feagi-core` installed
- You're building custom tooling
```bash
pip install feagi-bv # Requires feagi-core separately
```
This will automatically install the correct platform-specific package for your system:
- `feagi-bv-linux` on Linux
- `feagi-bv-macos` on macOS
- `feagi-bv-windows` on Windows
## Usage
```python
from feagi_bv import BrainVisualizer
# Create and configure BV launcher
bv = BrainVisualizer()
bv.load_config("feagi_configuration.toml")
# Start BV process
pid = bv.start()
print(f"Brain Visualizer running (PID: {pid})")
```
## Version Mapping
**`feagi-bv` version = BrainVisualizer binary version**
```bash
pip install feagi-bv==2.0.3
# ↑ Installs BrainVisualizer v2.0.3 binaries
```
## Architecture
This is a meta-package that installs platform-specific binaries:
- **feagi-bv-linux**: Linux x86_64 binaries (~50-70 MB)
- **feagi-bv-macos**: macOS universal binaries (~150-200 MB)
- **feagi-bv-windows**: Windows x86_64 binaries (~50-70 MB)
Only the binaries for your platform are downloaded.
## Dependencies
- `feagi-core>=2.1.0` - FEAGI SDK (core package)
- `toml>=0.10.2` - Configuration parsing
## Links
- [Brain Visualizer](https://github.com/feagi/brain-visualizer)
- [FEAGI](https://github.com/Neuraville/FEAGI-2.0)
- [Documentation](https://docs.feagi.org)
| text/markdown | null | "Neuraville Inc." <feagi@neuraville.com> | null | null | Apache-2.0 | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scie... | [] | null | null | >=3.10 | [] | [] | [] | [
"feagi-core>=2.1.1",
"toml>=0.10.2",
"feagi-bv-linux>=2.2.1"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:16:57.804811 | feagi_bv-2.2.1-py3-none-any.whl | 4,143 | 10/e5/c210fdb441e7df3d76f1029a50f3bcab6f09297b554c06860b46716b472e/feagi_bv-2.2.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 3a653c1857c06f331c51c02eddf4d2d3 | 8ff06587ede5943fd7a1b0f7ec78874726dc4732edef6680dd9efb16a42d8711 | 10e5c210fdb441e7df3d76f1029a50f3bcab6f09297b554c06860b46716b472e | null | [] | 174 |
2.4 | feagi-bv-windows | 2.2.1 | Brain Visualizer binaries for Windows (part of feagi-bv) | # feagi-bv-windows
Brain Visualizer binaries for Windows x86_64.
This package is automatically installed when you run `pip install feagi-bv` on Windows.
**Do not install directly** - use `pip install feagi-bv` instead.
| text/markdown | null | "Neuraville Inc." <feagi@neuraville.com> | null | null | Apache-2.0 | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: Microsoft :: Windows",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming... | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:16:47.738842 | feagi_bv_windows-2.2.1-py3-none-any.whl | 78,263,180 | 0b/43/999f904e05b893ae91337c1e4d582377f80835eb19a9963ac59d03d1efca/feagi_bv_windows-2.2.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 7fb6b68738cb8c6f2d05f9eac7c0bb3a | 9e938819e00345992b5276fda9943ac7a7dd521f156bf2528d745c9b1fd5a959 | 0b43999f904e05b893ae91337c1e4d582377f80835eb19a9963ac59d03d1efca | null | [] | 137 |
2.4 | feagi-bv-linux | 2.2.1 | Brain Visualizer binaries for Linux (part of feagi-bv) | # feagi-bv-linux
Brain Visualizer binaries for Linux x86_64.
This package is automatically installed when you run `pip install feagi-bv` on Linux.
**Do not install directly** - use `pip install feagi-bv` instead.
| text/markdown | null | "Neuraville Inc." <feagi@neuraville.com> | null | null | Apache-2.0 | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Langu... | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:16:37.777100 | feagi_bv_linux-2.2.1-py3-none-any.whl | 53,416,006 | 53/6c/a450bc01fd9b3ad4ede84afe72e71c4530c69bfa2cb298ee291efe7b60ae/feagi_bv_linux-2.2.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 18c4a0eccbb86f703a4625b77fc8dfc1 | 81af088e9011f8555b420463e6686639a264399982e8e98a2cc70b3446f2c224 | 536ca450bc01fd9b3ad4ede84afe72e71c4530c69bfa2cb298ee291efe7b60ae | null | [] | 178 |
2.4 | py2many | 0.8 | Python to Rust, C++, Go, Zig, Mojo & More - Universal Python Transpiler | # py2many: Python to Rust, C++, Go, Zig, Mojo & More - Universal Python Transpiler


**Convert Python code to Rust, C++, Go, Zig, Julia, Nim, Dart, and other languages automatically**
py2many is a powerful Python transpiler that converts Python source code into multiple statically-typed programming languages. Transform your Python code to Rust for performance, C++ for systems programming, Go for concurrency, or Kotlin for mobile development.
## Why Convert Python to Other Languages
**Performance**: Python is popular and easy to program in, but has poor runtime
performance. Transpiling Python to Rust, C++, or Go can dramatically improve execution speed
while maintaining the development experience of Python.
**Security**: Writing security-sensitive code in low-level languages like C is error-prone and could
lead to privilege escalation. With py2many, you can write secure code in Python, verify it
with unit tests, then transpile to a safer systems language like Rust.
**Cross-platform Development**: Accelerate Python code by transpiling
it into native [extensions](https://github.com/adsharma/py2many/issues/62) or standalone applications.
**Mobile & Systems Programming**: While Swift and Kotlin dominate mobile app development,
there's no universal solution for sharing lower-level library code between platforms.
py2many provides an alternative to Kotlin Mobile Multiplatform (KMM) by letting you
write once in Python and deploy to multiple targets.
**Learning Tool**: It's an excellent educational tool for learning new programming languages
by comparing Python implementations with their transpiled equivalents.
## Supported Languages & Status
**Primary Focus**: **Python to Rust** conversion with the most mature feature set and active development.
**Production Ready**: **Python to C++** transpilation (C++14 historically supported, C++17+ required for advanced features).
**Beta Support**: Python to Julia, Python to Kotlin, Python to Nim, Python to Go, Python to Dart, Python to V, and Python to D transpilation.
**Type Inference**: py2many can also emit enhanced Python 3 code with inferred type annotations
and syntax improvements for better code analysis.
## Python to Rust Example
See how py2many converts Python code to idiomatic Rust:
**Original Python code:**
```python
def fib(i: int) -> int:
if i == 0 or i == 1:
return 1
return fib(i - 1) + fib(i - 2)
# Demonstrate overflow handling
def add(i: i32, j: i32):
return i + j
```
**Transpiled Rust code:**
```rust
fn fib(i: i32) -> i32 {
if i == 0 || i == 1 {
return 1;
}
return (fib((i - 1)) + fib((i - 2)));
}
// return type is i64
pub fn add(i: i32, j: i32) -> i64 {
return ((i as i64) + (j as i64)) as i64;
}
```
**More Examples**: View transpiled code for all supported languages at:
https://github.com/adsharma/py2many/tree/main/tests/expected (fib*)
## Quick Start: Convert Python to Rust, C++, Go & More
**Requirements:**
- Python 3.8+
**Installation:**
```sh
pip3 install --user # installs to $HOME/.local
```
OR
```sh
sudo pip3 install # installs systemwide
```
**Usage Examples:**
Convert Python to different languages:
```sh
# Python to Rust
py2many --rust tests/cases/fib.py
# Python to C++
py2many --cpp tests/cases/fib.py
# Python to Go
py2many --go tests/cases/fib.py
# Python to Kotlin
py2many --kotlin tests/cases/fib.py
# Python to Julia
py2many --julia tests/cases/fib.py
# Python to Nim
py2many --nim tests/cases/fib.py
# Python to Dart
py2many --dart tests/cases/fib.py
# Python to D
py2many --dlang tests/cases/fib.py
```
**Compiling Transpiled Code:**
```sh
# Compile C++
clang tests/expected/fib.cpp
# Run Rust
./scripts/rust-runner.sh run tests/expected/fib.rs
# Run D
dmd -run tests/cases/fib.d
```
**Language-Specific Tools:**
py2many integrates with language-specific formatters and tools:
- `rustfmt` for Rust code formatting
- Language-specific standard libraries and external dependencies
For detailed setup instructions for each target language, see `.github/workflows/main.yml`.
## Key Features
- **Multi-Language Support**: Convert Python to 8+ programming languages
- **Type Inference**: Automatically infer and convert Python types to target language types
- **Performance Optimization**: Generate optimized code for systems programming languages
- **Cross-Platform**: Works on Linux, macOS, and Windows
- **Open Source**: MIT licensed with active community development
- **Educational**: Compare Python implementations with transpiled code to learn new languages
## Use Cases
- **Performance-Critical Applications**: Convert Python algorithms to Rust or C++ for speed
- **Systems Programming**: Transform Python prototypes to systems languages
- **Mobile Development**: Convert Python logic to Kotlin for Android development
- **WebAssembly**: Transpile Python to Rust for WASM deployment
- **Embedded Systems**: Convert Python code to C++ or Rust for resource-constrained environments
- **Cross-Platform Libraries**: Write once in Python, deploy to multiple language ecosystems
## Project History
Based on Julian Konchunas' [pyrs](http://github.com/konchunas/pyrs).
Based on Lukas Martinelli [Py14](https://github.com/lukasmartinelli/py14)
and [Py14/python-3](https://github.com/ProgVal/py14/tree/python-3) branch by Valentin
Lorentz.
# Contributing
See [CONTRIBUTING.md](https://github.com/adsharma/py2many/blob/main/CONTRIBUTING.md)
for how to test your changes and contribute to this project.
| text/markdown | Arun Sharma | null | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Rust",
"Programming Language :: C++",
"Programming Language :: Go",
"Programming Language :: Kotlin",
"Topic :: Software Development :: Compilers",
"Topic :... | [] | https://github.com/adsharma/py2many | null | >=3.8 | [] | [] | [] | [
"argparse_dataclass",
"importlib-resources; python_version < \"3.9\" and extra == \"test\"",
"pytest; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"black; extra == \"test\"",
"astpretty; extra == \"test\"",
"jgo; extra == \"test\"",
"mlx_llm; sys_platform == \"darwin\" and extra == \"llm\"",
... | [] | [] | [] | [
"Homepage, https://github.com/adsharma/py2many"
] | twine/6.2.0 CPython/3.13.3 | 2026-02-19T15:15:44.148424 | py2many-0.8-py3-none-any.whl | 165,678 | ef/fb/ae57aa812b7755e9a83afd27c1408bd243f45e1d631a14f6947add262782/py2many-0.8-py3-none-any.whl | py3 | bdist_wheel | null | false | 72745f7d35411fb92882b6229e45e114 | 11220932d779a3feb441e63c8e5312bfd34f48a3d23da661511690647e2153b0 | effbae57aa812b7755e9a83afd27c1408bd243f45e1d631a14f6947add262782 | null | [
"LICENSE"
] | 127 |
2.4 | bandeira | 0.1.0 | Official Python client SDK for Bandeira feature flag service | # Bandeira Python SDK
Official Python client SDK for [Bandeira](https://github.com/felipekafuri/bandeira), a self-hosted feature flag service.
## Install
```bash
pip install bandeira
```
## Usage
```python
from bandeira import BandeiraClient, Config, Context
client = BandeiraClient(Config(
url="http://localhost:8080",
token="your-client-token",
))
client.start()
if client.is_enabled("my-flag", Context(user_id="user-123")):
# feature is on
pass
client.close()
```
| text/markdown | Felipe Kafuri | null | null | null | null | bandeira, feature-flags, feature-toggles, sdk | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.27"
] | [] | [] | [] | [
"Repository, https://github.com/felipekafuri/bandeira-sdks"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:15:42.129277 | bandeira-0.1.0.tar.gz | 5,210 | 67/e8/5c74782c1edcb3b521007215f0cf650f9a7a1c1a620122b3084eff65deec/bandeira-0.1.0.tar.gz | source | sdist | null | false | 94237584e639a33e200f0913d4cf990e | 1ce4c2ce8d0fde2d50650befd8ba01965631641208c6c4006b94d21301890858 | 67e85c74782c1edcb3b521007215f0cf650f9a7a1c1a620122b3084eff65deec | MIT | [] | 235 |
2.4 | fastapi-fsp | 0.5.2 | Filter, Sort, and Paginate (FSP) utilities for FastAPI + SQLModel | # fastapi-fsp
Filter, Sort, and Paginate (FSP) utilities for FastAPI + SQLModel.
fastapi-fsp helps you build standardized list endpoints that support:
- Filtering on arbitrary fields with rich operators (eq, ne, lt, lte, gt, gte, in, between, like/ilike, null checks, contains/starts_with/ends_with)
- OR filters for searching across multiple columns with a single search term
- Sorting by field (asc/desc)
- Pagination with page/per_page and convenient HATEOAS links
It is framework-friendly: you declare it as a FastAPI dependency and feed it a SQLModel/SQLAlchemy Select query and a Session.
## Installation
Using uv (recommended):
```
# create & activate virtual env with uv
uv venv
. .venv/bin/activate
# add runtime dependency
uv add fastapi-fsp
```
Using pip:
```
pip install fastapi-fsp
```
## Quick start
Below is a minimal example using FastAPI and SQLModel.
```python
from typing import Optional
from fastapi import Depends, FastAPI
from sqlmodel import Field, SQLModel, Session, create_engine, select
from fastapi_fsp.fsp import FSPManager
from fastapi_fsp.models import PaginatedResponse
class HeroBase(SQLModel):
name: str = Field(index=True)
secret_name: str
age: Optional[int] = Field(default=None, index=True)
class Hero(HeroBase, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
class HeroPublic(HeroBase):
id: int
engine = create_engine("sqlite:///database.db", connect_args={"check_same_thread": False})
SQLModel.metadata.create_all(engine)
app = FastAPI()
def get_session():
with Session(engine) as session:
yield session
@app.get("/heroes/", response_model=PaginatedResponse[HeroPublic])
def read_heroes(*, session: Session = Depends(get_session), fsp: FSPManager = Depends(FSPManager)):
query = select(Hero)
return fsp.generate_response(query, session)
```
Run the app and query:
- Pagination: `GET /heroes/?page=1&per_page=10`
- Sorting: `GET /heroes/?sort_by=name&order=asc`
- Filtering: `GET /heroes/?field=age&operator=gte&value=21`
The response includes data, meta (pagination, filters, sorting), and links (self, first, next, prev, last).
## Query parameters
Pagination:
- page: integer (>=1), default 1
- per_page: integer (1..100), default 10
Sorting:
- sort_by: the field name, e.g., `name`
- order: `asc` or `desc`
Filtering (two supported formats):
1) Simple (triplets repeated in the query string):
- field: the field/column name, e.g., `name`
- operator: one of
- eq, ne
- lt, lte, gt, gte
- in, not_in (comma-separated values)
- between (two comma-separated values)
- like, not_like
- ilike, not_ilike (if backend supports ILIKE)
- is_null, is_not_null
- contains, starts_with, ends_with (translated to LIKE patterns)
- value: raw string value (or list-like comma-separated depending on operator)
Examples (simple format):
- `?field=name&operator=eq&value=Deadpond`
- `?field=age&operator=between&value=18,30`
- `?field=name&operator=in&value=Deadpond,Rusty-Man`
- `?field=name&operator=contains&value=man`
- Chain multiple filters by repeating the triplet: `?field=age&operator=gte&value=18&field=name&operator=ilike&value=rust`
2) Indexed format (useful for clients that handle arrays of objects):
- Use keys like `filters[0][field]`, `filters[0][operator]`, `filters[0][value]`, then increment the index for additional filters (`filters[1][...]`, etc.).
Example (indexed format):
```
?filters[0][field]=age&filters[0][operator]=gte&filters[0][value]=18&filters[1][field]=name&filters[1][operator]=ilike&filters[1][value]=joy
```
Notes:
- Both formats are equivalent; the indexed format takes precedence if present.
- If any filter is incomplete (missing operator or value in the indexed form, or mismatched counts of simple triplets), the API responds with HTTP 400.
## Filtering on Computed Fields
You can filter (and sort) on SQLAlchemy `hybrid_property` fields that have a SQL expression defined. This enables filtering on calculated or derived values at the database level.
### Defining a Computed Field
```python
from typing import ClassVar, Optional
from sqlalchemy import func
from sqlalchemy.ext.hybrid import hybrid_property
from sqlmodel import Field, SQLModel
class HeroBase(SQLModel):
name: str = Field(index=True)
secret_name: str
age: Optional[int] = Field(default=None)
full_name: ClassVar[str] # Required: declare as ClassVar for Pydantic
@hybrid_property
def full_name(self) -> str:
"""Python-level implementation (used on instances)."""
return f"{self.name}-{self.secret_name}"
@full_name.expression
def full_name(cls):
"""SQL-level implementation (used in queries)."""
return func.concat(cls.name, "-", cls.secret_name)
class Hero(HeroBase, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
class HeroPublic(HeroBase):
id: int
full_name: str # Include in response model
```
### Querying Computed Fields
Once defined, you can filter and sort on the computed field like any regular field:
```
# Filter by computed field
GET /heroes/?field=full_name&operator=eq&value=Spider-Man
GET /heroes/?field=full_name&operator=ilike&value=%man
GET /heroes/?field=full_name&operator=contains&value=Spider
# Sort by computed field
GET /heroes/?sort_by=full_name&order=asc
# Combine with other filters
GET /heroes/?field=full_name&operator=starts_with&value=Spider&field=age&operator=gte&value=21
```
### Requirements
- The `hybrid_property` must have an `.expression` decorator that returns a valid SQL expression
- The field should be declared as `ClassVar[type]` in the SQLModel base class to work with Pydantic
- Only computed fields with SQL expressions are supported; Python-only properties cannot be filtered at the database level
## OR Filters (Multi-Column Search)
OR filters let you search across multiple columns with a single search term — ideal for powering a table search input in your frontend.
### Query Parameters
Use `search` and `search_fields` to search across columns with OR logic:
```
GET /heroes/?search=john&search_fields=name,secret_name,email
```
This generates: `WHERE name ILIKE '%john%' OR secret_name ILIKE '%john%' OR email ILIKE '%john%'`
Combine with regular AND filters:
```
GET /heroes/?search=john&search_fields=name,email&field=deleted&operator=eq&value=false
```
This generates: `WHERE (name ILIKE '%john%' OR email ILIKE '%john%') AND deleted = false`
### Programmatic API
Use `CommonFilters.multi_field_search()` for server-side search:
```python
from fastapi_fsp import CommonFilters
@app.get("/heroes/")
def read_heroes(session: Session = Depends(get_session), fsp: FSPManager = Depends(FSPManager)):
or_groups = CommonFilters.multi_field_search(
fields=["name", "secret_name"],
term="john",
match_type="contains", # or "starts_with", "ends_with"
)
fsp.with_or_filters(or_groups)
return fsp.generate_response(select(Hero), session)
```
Or build OR groups with the `FilterBuilder`:
```python
from fastapi_fsp import FilterBuilder
or_group = (
FilterBuilder()
.where("name").contains("john")
.where("email").contains("john")
.build_or_group()
)
fsp.with_or_filters([or_group])
```
Or create `OrFilterGroup` objects directly:
```python
from fastapi_fsp import OrFilterGroup, Filter, FilterOperator
group = OrFilterGroup(filters=[
Filter(field="name", operator=FilterOperator.CONTAINS, value="john"),
Filter(field="email", operator=FilterOperator.CONTAINS, value="john"),
])
fsp.with_or_filters([group])
```
### Response
When OR filters are active, they appear in the response meta:
```json
{
"meta": {
"or_filters": [
{
"filters": [
{"field": "name", "operator": "contains", "value": "john"},
{"field": "email", "operator": "contains", "value": "john"}
]
}
]
}
}
```
## FilterBuilder API
For programmatic filter creation, use the fluent `FilterBuilder` API:
```python
from fastapi_fsp import FilterBuilder
# Instead of manually creating Filter objects:
# filters = [
# Filter(field="age", operator=FilterOperator.GTE, value="30"),
# Filter(field="city", operator=FilterOperator.EQ, value="Chicago"),
# ]
# Use the builder pattern:
filters = (
FilterBuilder()
.where("age").gte(30)
.where("city").eq("Chicago")
.where("active").eq(True)
.where("tags").in_(["python", "fastapi"])
.where("created_at").between("2024-01-01", "2024-12-31")
.build()
)
# Use with FSPManager
@app.get("/heroes/")
def read_heroes(session: Session = Depends(get_session), fsp: FSPManager = Depends(FSPManager)):
additional_filters = FilterBuilder().where("deleted").eq(False).build()
fsp.with_filters(additional_filters)
return fsp.generate_response(select(Hero), session)
```
### Available FilterBuilder Methods
| Method | Description |
|--------|-------------|
| `.eq(value)` | Equal to |
| `.ne(value)` | Not equal to |
| `.gt(value)` | Greater than |
| `.gte(value)` | Greater than or equal |
| `.lt(value)` | Less than |
| `.lte(value)` | Less than or equal |
| `.like(pattern)` | Case-sensitive LIKE |
| `.ilike(pattern)` | Case-insensitive LIKE |
| `.in_(values)` | IN list |
| `.not_in(values)` | NOT IN list |
| `.between(low, high)` | BETWEEN range |
| `.is_null()` | IS NULL |
| `.is_not_null()` | IS NOT NULL |
| `.starts_with(prefix)` | Starts with (case-insensitive) |
| `.ends_with(suffix)` | Ends with (case-insensitive) |
| `.contains(substring)` | Contains (case-insensitive) |
## Common Filter Presets
For frequently used filter patterns, use `CommonFilters`:
```python
from fastapi_fsp import CommonFilters
# Active (non-deleted) records
filters = CommonFilters.active() # deleted=false
# Recent records (last 7 days)
filters = CommonFilters.recent(days=7)
# Date range
filters = CommonFilters.date_range(start=datetime(2024, 1, 1), end=datetime(2024, 12, 31))
# Records created today
filters = CommonFilters.today()
# Null checks
filters = CommonFilters.not_null("email")
filters = CommonFilters.is_null("deleted_at")
# Search
filters = CommonFilters.search("name", "john", match_type="contains")
# Combine presets
filters = CommonFilters.active() + CommonFilters.recent(days=30)
```
## Configuration
Customize FSPManager behavior with `FSPConfig`:
```python
from fastapi_fsp import FSPConfig, FSPPresets
# Custom configuration
config = FSPConfig(
max_per_page=50,
default_per_page=20,
strict_mode=True, # Raise errors for unknown fields
max_page=100,
allow_deep_pagination=False,
)
# Or use presets
config = FSPPresets.strict() # strict_mode=True
config = FSPPresets.limited_pagination(max_page=50) # Limit deep pagination
config = FSPPresets.high_volume(max_per_page=500) # High-volume APIs
# Apply configuration
@app.get("/heroes/")
def read_heroes(session: Session = Depends(get_session), fsp: FSPManager = Depends(FSPManager)):
fsp.apply_config(config)
return fsp.generate_response(select(Hero), session)
```
### Strict Mode
When `strict_mode=True`, FSPManager raises HTTP 400 errors for unknown filter/sort fields:
```python
# With strict_mode=True, this raises HTTP 400:
# GET /heroes/?field=unknown_field&operator=eq&value=test
# Error: "Unknown field 'unknown_field'. Available fields: age, id, name, secret_name"
```
## Convenience Methods
### from_model()
Simplify common queries with `from_model()`:
```python
@app.get("/heroes/")
def read_heroes(session: Session = Depends(get_session), fsp: FSPManager = Depends(FSPManager)):
# Instead of:
# query = select(Hero)
# return fsp.generate_response(query, session)
# Use:
return fsp.from_model(Hero, session)
# Async version
@app.get("/heroes/")
async def read_heroes(session: AsyncSession = Depends(get_session), fsp: FSPManager = Depends(FSPManager)):
return await fsp.from_model_async(Hero, session)
```
### Method Chaining
Chain configuration methods:
```python
@app.get("/heroes/")
def read_heroes(session: Session = Depends(get_session), fsp: FSPManager = Depends(FSPManager)):
return (
fsp
.with_filters(CommonFilters.active())
.apply_config(FSPPresets.strict())
.generate_response(select(Hero), session)
)
```
## Response model
```
{
"data": [ ... ],
"meta": {
"pagination": {
"total_items": 42,
"per_page": 10,
"current_page": 1,
"total_pages": 5
},
"filters": [
{"field": "name", "operator": "eq", "value": "Deadpond"}
],
"or_filters": [
{
"filters": [
{"field": "name", "operator": "contains", "value": "john"},
{"field": "email", "operator": "contains", "value": "john"}
]
}
],
"sort": {"sort_by": "name", "order": "asc"}
},
"links": {
"self": "/heroes/?page=1&per_page=10",
"first": "/heroes/?page=1&per_page=10",
"next": "/heroes/?page=2&per_page=10",
"prev": null,
"last": "/heroes/?page=5&per_page=10"
}
}
```
`filters` and `or_filters` are `null` when not active.
## Development
This project uses uv as the package manager.
- Create env and sync deps:
```
uv venv
. .venv/bin/activate
uv sync --dev
```
- Run lint and format checks:
```
uv run ruff check .
uv run ruff format --check .
```
- Run tests:
```
uv run pytest -q
```
- Build the package:
```
uv build
```
## CI/CD and Releases
GitHub Actions workflows are included:
- CI (lint + tests) runs on pushes and PRs.
- Release: pushing a tag matching `v*.*.*` runs tests, builds, and publishes to PyPI using `PYPI_API_TOKEN` secret.
To release:
1. Update the version in `pyproject.toml`.
2. Push a tag, e.g. `git tag v0.1.1 && git push origin v0.1.1`.
3. Ensure the repository has `PYPI_API_TOKEN` secret set (an API token from PyPI).
## License
MIT License. See LICENSE.
| text/markdown | null | Evert Jan Stamhuis <ej@fromejdevelopment.nl> | null | null | MIT | api, fastapi, filtering, pagination, sorting, sqlmodel | [
"Development Status :: 3 - Alpha",
"Framework :: FastAPI",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Progra... | [] | null | null | >=3.12 | [] | [] | [] | [
"fastapi>=0.121.1",
"python-dateutil>=2.9.0.post0",
"sqlmodel>=0.0.27"
] | [] | [] | [] | [
"Homepage, https://github.com/fromej-dev/fastapi-fsp",
"Repository, https://github.com/fromej-dev/fastapi-fsp",
"Issues, https://github.com/fromej-dev/fastapi-fsp/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T15:15:07.261045 | fastapi_fsp-0.5.2.tar.gz | 87,499 | e3/a2/bf4b80db1e139db4c37a06cb4ffc1ed82c22a95c051bf22a2785bdd4114a/fastapi_fsp-0.5.2.tar.gz | source | sdist | null | false | af2818541814721d50f42dd8862c6a4a | f30e069b75853425f19879d5241f8109fd8f6a236be13fb06de73e111c4331f6 | e3a2bf4b80db1e139db4c37a06cb4ffc1ed82c22a95c051bf22a2785bdd4114a | null | [
"LICENSE"
] | 225 |
2.4 | pylmcf | 0.9.4 | Python bindings for Network Simplex algorithm from LEMON library | ## pylmcf: Python bindings for Min Cost Flow algorithm from LEMON graph library
### Overview
`pylmcf` provides Python bindings for the Min Cost Flow algorithm implemented in the [LEMON graph library](https://lemon.cs.elte.hu/trac/lemon). It enables efficient network flow optimization in Python applications. It is used by [wnet](https://github.com/michalsta/wnet) (a Python package enabling the efficient computation of Wasserstein and Truncated Wassersten distance between multidimensional distributions) and [wnetalign](https://github.com/michalsta/wnetalign) (A Python package enabling efficient alignment of MS or NMR spectra)
### Features
- Fast min cost flow computation using C++ backend
- Easy-to-use Python API
- Supports directed graphs, capacities, costs, and supplies/demands
### Installation
```bash
pip install pylmcf
```
### Usage
```python
import numpy as np
import pylmcf
# Create a graph with 3 nodes, labelled 0, 1, 2, and edges 0->1, 0->2, 1->2
no_nodes = 3
node_supply = np.array([5, 0, -5])
edge_starts = np.array([0, 0, 1])
edge_ends = np.array([1, 2, 2])
edge_costs = np.array([1, 3, 5])
edge_capacities = np.array([1, 2, 3])
G = pylmcf.Graph(3, edge_starts, edge_ends)
G.set_node_supply(node_supply)
G.set_edge_costs(edge_costs)
G.set_edge_capacities(edge_capacities)
G.show()
# Run the Min Cost Flow algorithm
G.solve()
# Retrieve the flow values
G.result()
# returns: np.array([1, 2, 1]))
# Retrieve the total cost of the flow
G.total_cost()
# == 12
```
### Requirements
- Python 3.7+
### Licence
pylmcf is published under Boost licence.
LEMON (which resides in src/pylmcf/cpp/lemon subdirectory) is also covered by Boost licence.
### References
- [LEMON Graph Library](https://lemon.cs.elte.hu/trac/lemon)
- [wnet package](https://github.com/michalsta/wnet)
- [wnetalign package](https://github.com/michalsta/wnetalign)
- [Min Cost Flow Problem](https://en.wikipedia.org/wiki/Minimum-cost_flow_problem) | text/markdown | null | =?utf-8?q?Micha=C5=82_Startek?= <michal.startek@mimuw.edu.pl> | null | =?utf-8?q?Micha=C5=82_Startek?= <michal.startek@mimuw.edu.pl> | null | network simplex, minimum cost flow, lemon, graph algorithms | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent",
"Topic :: Scientific/Engineering :: Mathematics",
"Topic :: Software Development :: Libraries :: Python Modules",
"Development Status :: 4 - Beta"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy",
"networkx; extra == \"extras\"",
"matplotlib; extra == \"extras\"",
"pytest; extra == \"pytest\"",
"networkx; extra == \"pytest\""
] | [] | [] | [] | [
"Homepage, https://github.com/michalsta/pylmcf",
"Repository, https://github.com/michalsta/pylmcf.git"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:14:08.136238 | pylmcf-0.9.4.tar.gz | 63,180 | be/a8/5d3df3a761f43482658eec383173ce6c58b3027a14380ea397529cdec88f/pylmcf-0.9.4.tar.gz | source | sdist | null | false | 44a1eda0e7845dadce78098baa2eb6ef | 8d81b5bd28418f8cc0e6f9f7272b53efafcc649ebf82ec4c63ee345f73430411 | bea85d3df3a761f43482658eec383173ce6c58b3027a14380ea397529cdec88f | BSL-1.0 | [
"LICENCE"
] | 5,262 |
2.4 | pytensor | 2.38.0 | Optimizing compiler for evaluating mathematical expressions on CPUs and GPUs. | .. image:: https://cdn.rawgit.com/pymc-devs/pytensor/main/doc/images/PyTensor_RGB.svg
:height: 100px
:alt: PyTensor logo
:align: center
|Tests Status| |Coverage|
|Project Name| is a Python library that allows one to define, optimize, and
efficiently evaluate mathematical expressions involving multi-dimensional arrays.
It provides the computational backend for `PyMC <https://github.com/pymc-devs/pymc>`__.
Features
========
- A hackable, pure-Python codebase
- Extensible graph framework suitable for rapid development of custom operators and symbolic optimizations
- Implements an extensible graph transpilation framework that currently provides
compilation via C, `JAX <https://github.com/google/jax>`__, and `Numba <https://github.com/numba/numba>`__
- Contrary to PyTorch and TensorFlow, PyTensor maintains a static graph which can be modified in-place to
allow for advanced optimizations
Getting started
===============
.. code-block:: python
import pytensor
from pytensor import tensor as pt
# Declare two symbolic floating-point scalars
a = pt.dscalar("a")
b = pt.dscalar("b")
# Create a simple example expression
c = a + b
# Convert the expression into a callable object that takes `(a, b)`
# values as input and computes the value of `c`.
f_c = pytensor.function([a, b], c)
assert f_c(1.5, 2.5) == 4.0
# Compute the gradient of the example expression with respect to `a`
dc = pytensor.grad(c, a)
f_dc = pytensor.function([a, b], dc)
assert f_dc(1.5, 2.5) == 1.0
# Compiling functions with `pytensor.function` also optimizes
# expression graphs by removing unnecessary operations and
# replacing computations with more efficient ones.
v = pt.vector("v")
M = pt.matrix("M")
d = a/a + (M + a).dot(v)
pytensor.dprint(d)
# Add [id A]
# ├─ ExpandDims{axis=0} [id B]
# │ └─ True_div [id C]
# │ ├─ a [id D]
# │ └─ a [id D]
# └─ dot [id E]
# ├─ Add [id F]
# │ ├─ M [id G]
# │ └─ ExpandDims{axes=[0, 1]} [id H]
# │ └─ a [id D]
# └─ v [id I]
f_d = pytensor.function([a, v, M], d)
# `a/a` -> `1` and the dot product is replaced with a BLAS function
# (i.e. CGemv)
pytensor.dprint(f_d)
# Add [id A] 5
# ├─ [1.] [id B]
# └─ CGemv{inplace} [id C] 4
# ├─ AllocEmpty{dtype='float64'} [id D] 3
# │ └─ Shape_i{0} [id E] 2
# │ └─ M [id F]
# ├─ 1.0 [id G]
# ├─ Add [id H] 1
# │ ├─ M [id F]
# │ └─ ExpandDims{axes=[0, 1]} [id I] 0
# │ └─ a [id J]
# ├─ v [id K]
# └─ 0.0 [id L]
See `the PyTensor documentation <https://pytensor.readthedocs.io/en/latest/>`__ for in-depth tutorials.
Installation
============
The latest release of |Project Name| can be installed from PyPI using ``pip``:
::
pip install pytensor
Or via conda-forge:
::
conda install -c conda-forge pytensor
The current development branch of |Project Name| can be installed from GitHub, also using ``pip``:
::
pip install git+https://github.com/pymc-devs/pytensor
Background
==========
PyTensor is a fork of `Aesara <https://github.com/aesara-devs/aesara>`__, which is a fork of `Theano <https://github.com/Theano/Theano>`__.
Contributing
============
We welcome bug reports and fixes and improvements to the documentation.
For more information on contributing, please see the
`contributing guide <https://pytensor.readthedocs.io/en/latest/dev_start_guide.html>`__.
A good place to start contributing is by looking through the issues
`here <https://github.com/pymc-devs/pytensor/issues>`__.
.. |Project Name| replace:: PyTensor
.. |Tests Status| image:: https://github.com/pymc-devs/pytensor/workflows/Tests/badge.svg
:target: https://github.com/pymc-devs/pytensor/actions?query=workflow%3ATests+branch%3Amain
.. |Coverage| image:: https://codecov.io/gh/pymc-devs/pytensor/branch/main/graph/badge.svg?token=WVwr8nZYmc
:target: https://codecov.io/gh/pymc-devs/pytensor
| text/x-rst | null | pymc-devs <pymc.devs@gmail.com> | null | null | null | pytensor, math, numerical, symbolic, blas, numpy, autodiff, differentiation | [
"Development Status :: 6 - Mature",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"Intended Audience :: Developers",
"Programming Language :: Python",
"Topic :: Software Development :: Code Generators",
"Topic :: Software Development :: Compilers",
"Topic :: Scientific/Eng... | [] | null | null | <3.15,>=3.11 | [] | [] | [] | [
"setuptools>=59.0.0",
"scipy<2,>=1",
"numpy>=2.0",
"numba<1,>0.57",
"filelock>=3.15",
"etuples",
"logical-unification",
"miniKanren",
"cons",
"pytensor[jax]; extra == \"complete\"",
"pytensor[numba]; extra == \"complete\"",
"pytensor[complete]; extra == \"development\"",
"pytensor[tests]; ex... | [] | [] | [] | [
"homepage, https://github.com/pymc-devs/pytensor",
"repository, https://github.com/pymc-devs/pytensor",
"documentation, https://pytensor.readthedocs.io/en/latest/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:13:57.431484 | pytensor-2.38.0.tar.gz | 4,858,140 | 45/9b/80affeea41684ff3b4d7b0ac0ccb90d2dc1aa03facb771fed056f98fdc3e/pytensor-2.38.0.tar.gz | source | sdist | null | false | 544352798de22171d3dddd98f9687a82 | 657f0d808ac2c247535ab9d8c5d27c98fb1b20a5f2d6716c1daed4630ad473f8 | 459b80affeea41684ff3b4d7b0ac0ccb90d2dc1aa03facb771fed056f98fdc3e | BSD-3-Clause | [
"LICENSE.txt"
] | 5,646 |
2.4 | answerrocket-client | 0.2.103 | Python client for interacting with AnswerRocket's skill API | # AnswerRocket Skill API Client
This is a client library for interacting with an AnswerRocket instance.
## Installation
`pip install answerrocket-client`
## Use
```
from answer_rocket import AnswerRocketClient
arc = AnswerRocketClient(url='https://your-answerrocket-instance.com', token='<your_api_token>')
# test that the config is valid
arc.can_connect()
# Get a resource file. When running in an AnswerRocket instance, this call will fetch a customized version of the resource if one has been created.
import json
some_resource = json.loads(arc.config.get_artifact('path/to/my/file.json'))
# to run SQL, get the database ID from an AnswerRocket environment
table_name = "my_table"
sql = "SELECT sum(my_measure) from "+table_name
database_id = "my_database_id"
execute_sql_query_result = arc.data.execute_sql_query(database_id, sql, 100)
if execute_sql_query_result.success:
print(execute_sql_query_result.df)
else:
print(execute_sql_query_result.error)
print(execute_sql_query_result.code)
# language model calls use the configured settings from the connected Max instance (except for the secret key)
success, model_reply = arc.chat.completion(messages = "hakuna")
if success:
# the reply is the full value of the LLM's return object
reply = model_reply["choices"][0]["message"]["content"]
print(f"** {reply} **")
else:
# error reply is a description of the exception
print("Error: "+model_reply)
# chat conversations and streaming replies are supported
messages = [
{ "role":"system",
"content":"You are an efficient assistant helping a business user answer questions about data."},
{ "role":"user",
"content":"Can you tell me the average of 150,12,200,54,24 and 32? are any of these outliers? Explain why."}
]
def display_streaming_result(str):
print(str,end="", flush=True)
success, reply = arc.chat.completion(messages = messages, stream_callback=display_streaming_result)
```
Notes:
- both the token and instance URL can be provided via the AR_TOKEN and AR_URL env vars instead, respectively. This is recommended to avoid accidentally committing a dev api token in your skill code. API token is available through the AnswerRocket UI for authenticated users.
- when running outside of an AnswerRocket installation such as during development, make sure the openai key is set before importing answer_rocket, like os.environ['OPENAI_API_KEY'] = openai_completion_key. Get this key from OpenAI.
# Working on the SDK
## Setup
This repository contains a .envrc file for use with direnv. With that installed you should have a separate python interpreter that direnv's hook will activate for you when you cd into this repository.
Once you have direnv set up and activating inside the repo, just `make` to install dev dependencies and get started.
## Finding things in the codebase
The main point of contact with users of this sdk is `AnswerRocketClient` in `answer_rocket/client.py`. That is, it is what users will import and initialize. Different categories of utilities can be grouped into modules in whatever way is most convenient, but they should be exposed via the client rather than through a separate import so that utilities for authentication, etc., can be reused.
The client hits an sdk-specific GraphQL API on its target AnswerRocket server. There is a `graphql/schema.py` with generated python types for what queries are available. When needed it can be regenerated with the `generate-gql-schema` makefile target. See the Makefile for details.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10.7 | [] | [] | [] | [
"sgqlc",
"pandas>=1.5.1",
"typing-extensions",
"pytest; extra == \"test\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:13:54.981091 | answerrocket_client-0.2.103.tar.gz | 60,301 | 66/ec/a91805be6f645c197ebac01746bcd7dc328c510b644ef7c79fbb382d8e85/answerrocket_client-0.2.103.tar.gz | source | sdist | null | false | 12168efbb0aa2ae8fe31710364f8ed4f | 3466b1764c4aa7de969d904eb5349a541eea63b64bfd0211f9adc45343a32d29 | 66eca91805be6f645c197ebac01746bcd7dc328c510b644ef7c79fbb382d8e85 | null | [] | 554 |
2.4 | ytmedia | 0.4.0 | Download MP4 (video+audio) and MP3 from YouTube at the highest possible quality | # ytmedia
Download MP4 (video + audio) and MP3 from YouTube at the highest possible quality, powered by [yt-dlp](https://github.com/yt-dlp/yt-dlp).
---
## Installation
```bash
pip install ytmedia
```
Or install from source (for development):
```bash
git clone https://github.com/yourusername/ytmedia
cd ytmedia
pip install -e .
```
---
## Quick Setup
After installing, check your environment and install any missing dependencies:
```bash
# Check what's installed
ytmedia doctor
# Install missing dependencies interactively
ytmedia install-deps
```
> **Note:** For best quality (1080p/4K), Node.js is recommended.
> Install from [nodejs.org](https://nodejs.org) if you don't have it.
---
## Requirements
- Python 3.10+
- ffmpeg — required for 1080p/4K and MP3 conversion (`ytmedia install-deps` can set this up)
- Node.js (recommended) — for full YouTube format support
---
## Usage
### As a Python library
```python
from ytmedia import download_mp4, download_mp3, download_playlist_mp4, get_info
from ytmedia import DownloadResult, DependencyMissing, DownloadFailed
# Download best quality MP4 (video + audio)
result = download_mp4("https://youtu.be/xxxx")
print(result.path) # Path to saved file
print(result.resolution) # e.g. '1080p'
print(result.audio_codec) # e.g. 'aac'
# Download MP4 capped at 1080p
result = download_mp4("https://youtu.be/xxxx", resolution="1080")
# Download to a specific folder
result = download_mp4("https://youtu.be/xxxx", output_dir="./videos")
# Download MP4 without audio (video only)
result = download_mp4("https://youtu.be/xxxx", audio=False)
# Download MP3 at 320kbps
result = download_mp3("https://youtu.be/xxxx")
# Download MP3 at a lower bitrate
result = download_mp3("https://youtu.be/xxxx", quality="192", output_dir="./music")
# Download an entire playlist as MP4
playlist = download_playlist_mp4("https://youtube.com/playlist?list=xxxx")
print(playlist) # PlaylistResult(12/12 downloaded, 0 failed)
# Get video metadata without downloading
info = get_info("https://youtu.be/xxxx")
print(info["title"], info["duration"])
```
### Error handling
```python
from ytmedia import download_mp4, DependencyMissing, DownloadFailed, YtMediaError
try:
result = download_mp4("https://youtu.be/xxxx")
print(f"Saved to {result.path}")
except DependencyMissing as e:
print(f"Missing: {e.dependency}") # e.g. 'ffmpeg'
except DownloadFailed as e:
print(f"Download failed: {e}")
except YtMediaError as e:
print(f"Error: {e}")
```
### Environment checks
```python
from ytmedia import has_ffmpeg, has_js_runtime, get_missing_dependencies
# Quick checks — cached, no repeated PATH probing
if not has_ffmpeg():
print("ffmpeg not found — run: ytmedia install-deps")
missing = get_missing_dependencies()
if missing:
print(f"Missing dependencies: {missing}")
```
### As a CLI tool
After installation, the `ytmedia` command is available globally:
```bash
# Check environment
ytmedia doctor
# Install missing dependencies
ytmedia install-deps
# Download MP4 (best quality)
ytmedia mp4 https://youtu.be/xxxx
# Download MP4 at 1080p into a specific folder
ytmedia mp4 https://youtu.be/xxxx -r 1080 -o ./videos
# Download MP4 without audio
ytmedia mp4 https://youtu.be/xxxx --no-audio
# Download MP3 at 320kbps
ytmedia mp3 https://youtu.be/xxxx
# Download MP3 at 192kbps into a specific folder
ytmedia mp3 https://youtu.be/xxxx -q 192 -o ./music
# Download an entire playlist
ytmedia playlist https://youtube.com/playlist?list=xxxx
# Print video metadata
ytmedia info https://youtu.be/xxxx
# Show full yt-dlp logs (for troubleshooting)
ytmedia mp4 https://youtu.be/xxxx --debug
```
#### CLI options
| Flag | Description | Default |
|---|---|---|
| `-o`, `--output` | Output directory | `./downloads` |
| `-r`, `--resolution` | Max video height e.g. `1080`, `720` | `best` |
| `-q`, `--quality` | MP3 bitrate in kbps e.g. `320`, `192` | `320` |
| `--no-audio` | Download MP4 without audio track | off |
| `--debug` | Show full yt-dlp internal logs | off |
---
## Notes
- URLs containing `&list=` (e.g. from YouTube autoplay) are treated as single-video downloads
by default. Use `ytmedia playlist <url>` or pass `allow_playlist=True` in Python to download
the full playlist.
- MP4 audio is re-encoded to **AAC** during the merge step, ensuring compatibility with
Windows Media Player, QuickTime, and mobile devices.
- Without ffmpeg, `download_mp4(audio=True)` raises `DependencyMissing`. Run
`ytmedia install-deps` to fix.
- MP3 conversion always requires ffmpeg.
---
## License
MIT
| text/markdown | Rei WuZen | null | null | null | MIT | youtube, download, mp4, mp3, yt-dlp, video, audio | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Topic :: Multimedia :: Video",
"Topic :: Multimedia :: Sound/Audio"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"yt-dlp>=2024.1.0",
"yt-dlp-ejs",
"static-ffmpeg>=2.5; extra == \"ffmpeg\"",
"static-ffmpeg>=2.5; extra == \"all\"",
"yt-dlp-ejs; extra == \"all\""
] | [] | [] | [] | [
"Homepage, https://github.com/yourusername/ytmedia",
"Issues, https://github.com/yourusername/ytmedia/issues"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-19T15:13:51.042296 | ytmedia-0.4.0.tar.gz | 13,842 | 1b/21/d12b5ca0a23f376488baf768e93227ccbc8218338c93f5dadcb475871ea5/ytmedia-0.4.0.tar.gz | source | sdist | null | false | 4e8661c014d560eacea6ffd88c08594f | 0944cdd0b9146be89d1b0d27c12ddd7370e338170c1c4ac69b44ae8fd9188486 | 1b21d12b5ca0a23f376488baf768e93227ccbc8218338c93f5dadcb475871ea5 | null | [
"LICENSE"
] | 226 |
2.4 | syftbox-sdk | 0.1.21 | Python bindings for the syftbox-sdk Rust library | # syftbox-sdk Python bindings
Python bindings for the `syftbox-sdk` Rust library, built with [PyO3](https://pyo3.rs/) and packaged via [maturin](https://www.maturin.rs/).
## Building and installing
```bash
# from the repository root
cd python
maturin develop # or `maturin build` to create wheels under target/wheels/
```
If you prefer pip:
```bash
cd python
pip install .
```
## Usage
```python
import syftbox_sdk as syft
url = syft.SyftURL.parse("syft://user@example.com/public/data/file.yaml")
print(url.to_http_relay_url("syftbox.net"))
cfg = syft.load_runtime("user@example.com")
print(cfg.data_dir)
app = syft.SyftBoxApp("/tmp/data", "user@example.com", "my_app")
print(app.list_endpoints())
```
| text/markdown; charset=UTF-8; variant=GFM | OpenMined | null | null | null | Apache-2.0 | null | [
"Programming Language :: Rust",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent"
] | [] | null | null | <3.14,>=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/OpenMined/syftbox-sdk"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:13:40.069545 | syftbox_sdk-0.1.21.tar.gz | 141,806 | 56/4b/6306d66590555dd807b5f5aefa7ac6b0918897333c9450db649793a7e698/syftbox_sdk-0.1.21.tar.gz | source | sdist | null | false | 14b0e177ca1ea866f2474d0ba134e8ac | 978b11bd44f0282eaf338b6dad05c0737bcf2a2db2ab742e5225e4024629ed65 | 564b6306d66590555dd807b5f5aefa7ac6b0918897333c9450db649793a7e698 | null | [] | 665 |
2.1 | mortm | 4.6.57 | 旋律生成、コード推定、マルチタスクな音楽生成を行うライブラリ | <div align="center">
<img src="asset/concept2.png" width="100%" alt="MORTM Structure"/>
<h1>MORTM: Metric-Oriented Rhythmic Transformer for Music Generation</h1>
<p>
<b>Takaaki Nagoshi</b>
</p>
<p>
<em>Project.MORTM Research Group</em>
</p>
<a href="https://github.com/Ayato964/mortm/blob/master/LICENSE">
<img alt="License" src="https://img.shields.io/badge/License-MIT-blue?style=flat-square">
</a>
<img alt="Version" src="https://img.shields.io/badge/Version-4.5-orange?style=flat-square">
<img alt="PyTorch" src="https://img.shields.io/badge/PyTorch-2.0%2B-EE4C2C?style=flat-square&logo=pytorch">
<img alt="Status" src="https://img.shields.io/badge/Status-Research_Preview-success?style=flat-square">
</div>
<div align="center">
<br>
<a href="./README_ja.md"><img src="https://img.shields.io/badge/ドキュメント-日本語-white?style=for-the-badge&logo=ja" alt="Japanese"/></a>
<a href="./README.md"><img src="https://img.shields.io/badge/Document-English-blue?style=for-the-badge&logo=en" alt="English"/></a>
</div>
---
## Abstract
Autoregressive models based on the Transformer architecture have achieved remarkable success in symbolic music generation. However, maintaining long-term structural coherence and rhythmic consistency remains a significant challenge, as standard tokenization methods often neglect the hierarchical nature of musical time.
We present **MORTM (Metric-Oriented Rhythmic Transformer for Music)**, a novel framework that explicitly models metric structures through a bar-centric tokenization strategy. Version 4.5 introduces a scalable **Sparse Mixture of Experts (MoE)** architecture and **FlashAttention-2** integration, enabling efficient training on extended contexts. Furthermore, we propose a **Reinforcement Learning from Music Feedback (RLMF)** pipeline using Proximal Policy Optimization (PPO), where the generator is aligned with stylistic objectives defined by a BERT-based reward model (BERTM).
---
## 1. Key Contributions
* **Metric-Oriented Tokenization**: A specialized vocabulary and encoding scheme that encapsulates musical events within a metric grid, enforcing bar-level structural integrity.
* **Sparse Mixture of Experts (MoE)**: Implementation of Top-2 gating MoE layers to decouple model capacity from inference cost, allowing for massive parameter scaling.
* **Efficient Long-Context Modeling**: Integration of **FlashAttention-2** and relative positional embeddings (**ALiBi/RoPE**) to handle extended musical sequences with linear memory complexity.
* **Reinforcement Learning Alignment**: A complete PPO-based RLHF pipeline that fine-tunes the autoregressive policy using rewards derived from a bidirectional discriminator (BERTM).
* **Multimodal Scalability**: Extensions for audio spectrogram modeling (**V_MORTM**) and piano-roll vision processing (**MORTM Live**).
---
## 2. Architecture
MORTM is built upon a decoder-only Transformer backbone, optimized for the nuances of symbolic music data.
### 2.1 Sparse Mixture of Experts (MoE)
To enhance the model's representational power without incurring prohibitive computational costs, we replace standard Feed-Forward Networks (FFNs) with MoE layers in selected blocks.
- **Routing Mechanism**: A learnable gating network routes each token to the Top-$k$ experts (default $k=2$).
- **Expert Specialization**: This allows different experts to specialize in distinct musical textures (e.g., rhythmic accompaniment vs. melodic phrasing).
### 2.2 Attention Mechanism
We employ **FlashAttention-2** to accelerate the attention computation.
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Combined with **Rotary Positional Embeddings (RoPE)**, the model effectively captures relative timing dependencies across thousands of tokens.
### 2.3 Reward Modeling (BERTM)
**BERTM (Bidirectional Encoder Representations for Music)** acts as a critic. Pre-trained on masked language modeling (MLM) and fine-tuned for genre/quality classification, it provides scalar rewards that guide the PPO training phase.
---
## 3. Installation & Prerequisites
This research code is implemented in PyTorch. For optimal performance, especially with FlashAttention-2, an NVIDIA GPU (Ampere architecture or newer) is recommended.
```bash
# Clone the repository
git clone [https://github.com/Ayato964/mortm.git](https://github.com/Ayato964/mortm.git)
cd mortm
# Install core dependencies
pip install torch torchvision torchaudio --index-url [https://download.pytorch.org/whl/cu118](https://download.pytorch.org/whl/cu118)
pip install flash-attn --no-build-isolation
# Install project requirements
pip install -r requirements.txt
| text/markdown | Nagoshi Takaaki | nagoshi@kthrlab.jp | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/Ayato964 | null | >=3.0 | [] | [] | [] | [] | [] | [] | [] | [] | twine/5.1.1 CPython/3.12.4 | 2026-02-19T15:13:16.699448 | mortm-4.6.57.tar.gz | 81,856 | 0c/d3/4cb784f15addd5ac78549b5aba12e436c2cc7022c878a5f410df96b847a1/mortm-4.6.57.tar.gz | source | sdist | null | false | 2209b7e5fdd74ac119d2391bce5c4f41 | 0b46dd578e9f7576d75b30daac9eed138c7be388ea41c803d45aecb403020e7d | 0cd34cb784f15addd5ac78549b5aba12e436c2cc7022c878a5f410df96b847a1 | null | [] | 239 |
2.4 | deisa-ray | 0.0.6 | In Situ Analytics with Ray backend | # Dask-on-Ray Enabled In Situ Analytics
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"dask[dataframe]==2025.5.0",
"numpy",
"ray[default]==2.48.0",
"torch>=2.10.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.8 | 2026-02-19T15:12:42.303899 | deisa_ray-0.0.6.tar.gz | 33,081 | 71/0b/4e107c3d33ae8216b963c59410fae81f1232d60183301c37fcbafba2fde7/deisa_ray-0.0.6.tar.gz | source | sdist | null | false | 5870a8e52883de415fab446365b3522c | fd02058a0f635efd9af92af787e44c78ca15dcdce6d5cb496978e17938131f48 | 710b4e107c3d33ae8216b963c59410fae81f1232d60183301c37fcbafba2fde7 | null | [] | 228 |
2.4 | ykutil | 0.0.20 | A continuously updates repository of utility functions. | # A vast range of python utils
This continuously updates with more utils that I add.
## Installation
+ `pip install ykutil`
+ Or clone this repo and `pip install -e .`
# Overview of all implemented utilities
Here is an overview of what utilities are implemented at this point.
## Basic python tools
### List Utilities
- `list_rindex(li, x)`: Find the last index of `x` in `li`.
- `list_split(li, max_len, min_len=None)`: Split `li` into sublists of length `max_len`.
- `split_multi(lists, max_len, progress=False, min_len=None)`: Split multiple lists into sublists.
- `list_multiply(elem_list, mul_list)`: Multiply elements of `elem_list` by corresponding elements in `mul_list`.
- `list_squeeze(l)`: Recursively squeeze single-element lists.
- `list_flip(lst)`: Flip list values based on max and min values.
- `chunk_list(lst, n)`: Yield consecutive chunks of size `n` from `lst`.
- `flatten(li)`: Flatten a list of lists.
- `unique_n_times(lst, n, invalid_filter=set(), verbose=False, comboer=None, shuffle=False)`: Get indices of the first `n` occurrences of each unique element in `lst`.
- `make_list_unique(seq)`: Remove duplicates from list.
- `all_sublist_matches(lst, sublst)`: Find all sublist matches.
- `removesuffixes(lst, suffix)`: Remove suffixes from a list.
- `approx_list_split(lst, n_splits)`: Split a list in n_splits parts of about equal length.
### String Utilities
- `multify_text(text, roles)`: Format text with multiple roles.
- `naive_regex_escape(some_str)`: Escape regex metacharacters in a string.
- `str_find_all(string, sub)`: Find all occurrences of `sub` in `string`.
- `re_line_matches(string, regex)`: Find line matches for a regex pattern.
### Dictionary Utilities
- `transpose_li_of_dict(lidic)`: Transpose a list of dictionaries.
- `transpose_dict_of_li(d)`: Transpose a dictionary of lists.
- `dict_percentages(d)`: Convert dictionary values to percentages.
- `recursed_dict_percentages(d)`: Recursively convert dictionary values to percentages.
- `recursed_merge_percent_stats(lst, weights=None)`: Merge percentage statistics recursively.
- `recursed_sum_up_stats(lst)`: Sum up statistics recursively.
- `dict_without(d, without)`: Return a dictionary without specified keys.
### General Utilities
- `identity(x)`: Return `x`.
- `index_of_sublist_match(haystack, needle)`: Find the index of a sublist match.
- `nth_index(lst, value, n)`: Find the nth occurrence of a value in a list.
- `update_running_avg(old_avg, old_weight, new_avg, new_weight=1)`: Update a running average.
- `all_equal(iterable, force_value=None)`: Check if all elements in an iterable are equal.
- `approx_number_split(n, n_splits)`: Split a number into a list of close integers that sum ut to the number.
- `anyin(haystack, needles)`: Predicate to check if any element from needles is in haystack
## Huggingface datasets utilities
### Dataset Description
- `describe_dataset(ds, tokenizer=None, show_rows=(0, 3))`: Print metadata, columns, number of rows, and example rows of a dataset.
### Dataset Visualization
- `colorcode_dataset(dd, tk, num_start=5, num_end=6, data_key="train", fname=None, beautify=True)`: Color-code and print dataset entries with optional beautification.
- `colorcode_entry(token_ds_path, fname=None, tokenizer_path="mistralai/Mistral-7B-v0.1", num_start=0, num_end=1, beautify=True)`: Load a dataset from disk and color-code its entries.
## Huggingface transformers utilities
### Tokenization
- `batch_tokenization(tk, texts, batch_size, include_offsets=False, **tk_args)`: Tokenize large batches of texts.
- `tokenize_instances(tokenizer, instances)`: Tokenize a sequence of instances.
- `flat_encode(tokenizer, inputs, add_special_tokens=False)`: Flatten and encode inputs.
- `get_token_begins(encoding)`: Get the beginning positions of tokens.
- `tokenize(tk_name, text)`: Tokenize a text using a specified tokenizer.
- `untokenize(tk_name, tokens)`: Decode tokens using a specified tokenizer.
### Generation
- `generate_different_sequences(model, context, sequence_bias_add, sequence_bias_decay, generation_args, num_generations)`: Generate different sequences with bias adjustments.
- `TokenStoppingCriteria(delimiter_token)`: Stopping criteria based on a delimiter token.
### Offsets and Spans
- `obtain_offsets(be, str_lengths=None)`: Obtain offsets from a batch encoding.
- `transform_with_offsets(offsets, spans, include_left=True, include_right=True)`: Transform spans using offsets.
- `regex_tokens_using_offsets(offsets, text, regex, include_left=True, include_right=True)`: Find tokens matching a regex using offsets.
### Tokenizer Utilities
- `find_tokens_with_str(tokenizer, string)`: Find tokens containing a specific string.
- `load_tk_with_pad_tk(model_path)`: Load a tokenizer and set the pad token if not set.
### Data Collation
- `DataCollatorWithPadding`: A data collator that pads sequences to the same length.
### Chat Template
- `dict_from_chat_template(chat_template_str, tk_type="llama3")`: Convert a chat template string to a dictionary.
### Training and Evaluation
- `train_eval_and_get_metrics(trainer, checkpoint=None)`: Train a model, evaluate it, and return the metrics.
### Model Utilities
- `print_trainable_parameters(model_args, model)`: Print the number of trainable parameters in the model.
- `print_parameters_by_dtype(model)`: Print the number of parameters by data type.
- `smart_tokenizer_and_embedding_resize(special_tokens_dict, tokenizer, model)`: Resize tokenizer and embedding.
- `find_all_linear_names(model, bits=32)`: Find all linear layer names in the model.
## Torch utilities
### Tensor Operations
- `rolling_window(a, size)`: Create a rolling window view of the input tensor.
- `find_all_subarray_poses(arr, subarr, end=False, roll_window=None)`: Find all positions of a subarray within an array.
- `tensor_in(needles, haystack)`: Check if elements of one tensor are in another tensor.
- `pad_along_dimension(tensors, dim, pad_value=0)`: Pad a list of tensors along a specified dimension.
### Model Utilities
- `disable_gradients(model)`: Disable gradients for all parameters in a model.
### Memory Management
- `print_memory_info()`: Print CUDA memory information.
- `free_cuda_memory()`: Free CUDA memory by collecting garbage and emptying the cache.
### Device Management
- `get_max_memory_and_device_map(max_memory_mb)`: Get the maximum memory and device map for distributed settings.
## Transformer Heads Utilities
### Sequence Log Probability
- `compute_seq_log_probability(model, pre_seq_tokens, post_seq_tokens)`: Compute the log probability of a sequence given a model and token sequences.
## LLM API Utilities
### Image Utilities
- `local_image_to_data_url(image_path)`: Encode a local image into a data URL.
### Message Utilities
- `human_readable_parse(messages)`: Parse messages into a human-readable format.
### Model Wrappers
- `ModelWrapper`: A wrapper class for models to handle completions and structured completions.
- `AzureModelWrapper`: A specialized wrapper for Azure OpenAI models with cost computation.
## Executable
### Bulk Rename
- `do_bulk_rename()`: Execute bulk renaming of files.
### JSON Beautification
- `beautify_json(json_str)`: Beautify a JSON string.
- `do_beautify_json()`: Command-line interface for beautifying a JSON string.
### Dataset Description
- `describe_dataset(ds_name, tokenizer_name=None, show_rows=(0, 3))`: Describe a dataset with optional tokenization.
- `do_describe_dataset()`: Command-line interface for describing a dataset.
### Tokenization
- `tokenize(tk, text)`: Tokenize a text using a specified tokenizer.
- `do_tokenize()`: Command-line interface for tokenizing a text.
### Untokenization
- `untokenize(tk, tokens)`: Decode tokens using a specified tokenizer.
- `do_untokenize()`: Command-line interface for untokenizing tokens.
### Dataset Color Coding
- `colorcode_entry(token_ds_path, fname=None, tokenizer_path="mistralai/Mistral-7B-v0.1", num_start=0, num_end=1, beautify=True)`: Load a dataset from disk and color-code its entries.
- `do_colorcode_dataset()`: Command-line interface for color-coding a dataset.
## Python Data Modelling Utilities
- `summed_stat_dc(datas, avg_keys=(), weight_attr="num_examples")`: Summarize statistics from a list of dataclass instances.
- `undefaultdict(d, do_copy=False)`: Convert defaultdict to dict recursively.
- `stringify_tuple_keys(d)`: Convert tuple keys in a dictionary to strings.
- `Serializable`: A base class to make dataclasses JSON serializable and hashable.
- `sortedtuple(sort_fun, fixed_len=None)`: Create a sorted tuple type with a custom sorting function.
## Statistics tools
- `Statlogger`: A class for logging and updating statistics.
- `Welfords`: A class for Welford's online algorithm for computing mean and variance.
## Pretty print tools
### Object description
- `describe_recursive(l, types, lengths, arrays, dict_keys, depth=0)`: Recursively describe the structure of a list or tuple.
- `describe_list(l, no_empty=True)`: Describe the structure of a list or tuple.
- `describe_array(arr)`: Describe the properties of a numpy array or torch tensor.
### Logging Utilities
- `add_file_handler(file_path)`: Add a file handler to the logger.
- `log(*messages, level=logging.INFO)`: Log messages with a specified logging level.
## Miscellaneous
### PEFT Utilities
- `load_maybe_peft_model_tokenizer(model_path, device_map="auto", quantization_config=None, flash_attn="flash_attention_2", only_inference=True)`: Load a PEFT model and tokenizer, with optional quantization and flash attention.
### Pandera Utilities
- `empty_dataframe_from_model(Model)`: Create an empty DataFrame from a Pandera DataFrameModel.
### Multiprocessing Utilities
- `starmap_with_kwargs(pool, fn, args_iter, kwargs_iter)`: Apply a function to arguments and keyword arguments in parallel using a pool.
- `apply_args_and_kwargs(fn, args, kwargs)`: Apply a function to arguments and keyword arguments.
- `run_in_parallel(func, list_ordered_kwargs, num_workers, extra_kwargs={})`: Run a function in parallel with specified arguments and number of workers.
### Constants
- `IGNORE_INDEX`: Constant for ignore index.
- `DEFAULT_PAD_TOKEN`: Default padding token.
- `SPACE_TOKENIZERS`: Tuple of space tokenizers.
### Configuration Utilities
- `from_file(cls, config_file, **argmod)`: Load a configuration from a file and apply modifications.
### Accelerate Tools
- `gather_dict(d, strict=False)`: Gather a dictionary across multiple processes.
### Types Utilities
- `describe_type(o)`: Pretty print the type of an object
- `T and U`: TypeVars ready to use
| text/markdown | null | Yannik Keller <yannik@kelnet.de> | null | null | MIT License | util | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"tqdm",
"accelerate; extra == \"all\"",
"bitsandbytes; extra == \"all\"",
"datasets; extra == \"all\"",
"openai; extra == \"all\"",
"pandera; extra == \"all\"",
"peft; extra == \"all\"",
"torch; extra == \"all\"",
"transformer-heads; extra == \"all\"",
"transformers; extra == \"all\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:12:31.335830 | ykutil-0.0.20.tar.gz | 39,767 | 8b/f8/db7c291ecafa7bcec209caf9379c38d96432341b6e222bc347a5cb49083a/ykutil-0.0.20.tar.gz | source | sdist | null | false | 447cc7c25e3c9be41121122b3d877482 | 6318f39ead1232eeb915e4b86966bed61e60256ceb47cdfdbf126ebbd441996a | 8bf8db7c291ecafa7bcec209caf9379c38d96432341b6e222bc347a5cb49083a | null | [] | 232 |
2.4 | opswald | 0.0.1 | The immutable audit trail for AI agents | # Opswald
The immutable audit trail for AI agents.
🚧 Coming soon. Join the waitlist at [opswald.com](https://opswald.com)
| text/markdown | null | Opswald <hello@opswald.com> | null | null | MIT | ai, agents, audit, observability, compliance | [] | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://opswald.com",
"Repository, https://github.com/opswald/opswald"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T15:12:17.467139 | opswald-0.0.1.tar.gz | 1,291 | bc/52/52bb1117f1f8ac8a74410dc461d3769035cccba44bbd60a527ad97a7e957/opswald-0.0.1.tar.gz | source | sdist | null | false | b061d731a3ca4635de7140af5a95eb0c | e82e00919a56bbad980c7cbfbe2e508325f084286d677d3244db264237743767 | bc5252bb1117f1f8ac8a74410dc461d3769035cccba44bbd60a527ad97a7e957 | null | [] | 234 |
2.4 | Daniel2013 | 4 | verb 4 here | v2:we add now a math test
| text/markdown | null | Daniel <danielipopopopopo@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.7 | 2026-02-19T15:12:13.974251 | daniel2013-4.tar.gz | 4,851 | ee/41/f576ffe868e633f846330462c040c56914614e2bb751f430a4517c7bc615/daniel2013-4.tar.gz | source | sdist | null | false | 4cf66f62bff068cffd424f40c0d425ba | b07e1cac37725885845fee03cdc771c476137343c953a4360512173d0d917ad1 | ee41f576ffe868e633f846330462c040c56914614e2bb751f430a4517c7bc615 | null | [] | 0 |
2.3 | nautobot-bgp-models | 3.0.1 | Nautobot BGP Models App | # BGP Models
<p align="center">
<img src="https://raw.githubusercontent.com/nautobot/nautobot-app-bgp-models/develop/docs/images/icon-nautobot-bgp-models.png" class="logo" height="200px">
<br>
<a href="https://github.com/nautobot/nautobot-app-bgp-models/actions"><img src="https://github.com/nautobot/nautobot-app-bgp-models/actions/workflows/ci.yml/badge.svg?branch=main"></a>
<a href="https://docs.nautobot.com/projects/bgp-models/en/latest/"><img src="https://readthedocs.org/projects/nautobot-plugin-bgp-models/badge/"></a>
<a href="https://pypi.org/project/nautobot-bgp-models/"><img src="https://img.shields.io/pypi/v/nautobot-bgp-models"></a>
<a href="https://pypi.org/project/nautobot-bgp-models/"><img src="https://img.shields.io/pypi/dm/nautobot-bgp-models"></a>
<br>
An <a href="https://networktocode.com/nautobot-apps/">App</a> for <a href="https://nautobot.com/">Nautobot</a>.
</p>
## Overview
An app for [Nautobot](https://github.com/nautobot/nautobot), extending the core models with BGP-specific models. They enable modeling and management of BGP peerings, whether or not the peer device is present in Nautobot.
> The initial development of this app was sponsored by Riot Games, Inc.
### Screenshots
More screenshots can be found in the [Using the App](https://docs.nautobot.com/projects/bgp-models/en/latest/user/app_use_cases/) page in the documentation. Here's a quick overview of some of the app's added functionality:
## Try it out!
This App is installed in the Nautobot Community Sandbox found over at [demo.nautobot.com](https://demo.nautobot.com/)!
> For a full list of all the available always-on sandbox environments, head over to the main page on [networktocode.com](https://www.networktocode.com/nautobot/sandbox-environments/).
## Documentation
Full documentation for this App can be found over on the [Nautobot Docs](https://docs.nautobot.com) website:
- [User Guide](https://docs.nautobot.com/projects/bgp-models/en/latest/user/app_overview/) - Overview, Using the App, Getting Started.
- [Administrator Guide](https://docs.nautobot.com/projects/bgp-models/en/latest/admin/install/) - How to Install, Configure, Upgrade, or Uninstall the App.
- [Developer Guide](https://docs.nautobot.com/projects/bgp-models/en/latest/dev/contributing/) - Extending the App, Code Reference, Contribution Guide.
- [Release Notes / Changelog](https://docs.nautobot.com/projects/bgp-models/en/latest/admin/release_notes/).
- [Frequently Asked Questions](https://docs.nautobot.com/projects/bgp-models/en/latest/user/faq/).
### Contributing to the Documentation
You can find all the Markdown source for the App documentation under the [`docs`](https://github.com/nautobot/nautobot-app-bgp-models/tree/develop/docs) folder in this repository. For simple edits, a Markdown capable editor is sufficient: clone the repository and edit away.
If you need to view the fully-generated documentation site, you can build it with [MkDocs](https://www.mkdocs.org/). A container hosting the documentation can be started using the `invoke` commands (details in the [Development Environment Guide](https://docs.nautobot.com/projects/bgp-models/en/latest/dev/dev_environment/#docker-development-environment)) on [http://localhost:8001](http://localhost:8001). Using this container, as your changes to the documentation are saved, they will be automatically rebuilt and any pages currently being viewed will be reloaded in your browser.
Any PRs with fixes or improvements are very welcome!
## Questions
For any questions or comments, please check the [FAQ](https://docs.nautobot.com/projects/bgp-models/en/latest/user/faq/) first. Feel free to also swing by the [Network to Code Slack](https://networktocode.slack.com/) (channel `#nautobot`), sign up [here](http://slack.networktocode.com/) if you don't have an account.
| text/markdown | Network to Code, LLC | opensource@networktocode.com | null | null | Apache-2.0 | nautobot, nautobot-app, nautobot-plugin | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"... | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"nautobot<4.0.0,>=3.0.0",
"netutils<2.0.0,>=1.6.0",
"toml<0.11.0,>=0.10.2"
] | [] | [] | [] | [
"Documentation, https://docs.nautobot.com/projects/bgp-models/en/latest/",
"Homepage, https://github.com/nautobot/nautobot-app-bgp-models",
"Repository, https://github.com/nautobot/nautobot-app-bgp-models"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:12:04.146276 | nautobot_bgp_models-3.0.1.tar.gz | 3,058,364 | 9b/0a/08506b7b677f819436dc64f19ebe93778a42aa2934947bdbefc208d2718c/nautobot_bgp_models-3.0.1.tar.gz | source | sdist | null | false | b68ac34484c0697be89658f284356801 | de823a6a78fcb485f2205073c858533f4b262ef862a1c2fba82c60c23eeb3ab9 | 9b0a08506b7b677f819436dc64f19ebe93778a42aa2934947bdbefc208d2718c | null | [] | 4,212 |
2.4 | hpc-runner | 0.7.0 | Unified HPC job submission across multiple schedulers | # hpc-runner
**Unified HPC job submission across multiple schedulers**
Write your jobs once, run them on any cluster - SGE, Slurm, PBS, or locally for testing.
## Features
- **Unified CLI** - Same commands work across SGE, Slurm, PBS
- **Python API** - Programmatic job submission with dependencies and pipelines
- **Auto-detection** - Automatically finds your cluster's scheduler
- **Interactive TUI** - Monitor jobs with a terminal dashboard
- **Job Dependencies** - Chain jobs with afterok, afterany, afternotok
- **Array Jobs** - Batch processing with throttling support
- **Virtual Environment Handling** - Automatic venv activation on compute nodes
- **Module Integration** - Load environment modules in job scripts
- **Dry-run Mode** - Preview generated scripts before submission
## Installation
```bash
pip install hpc-runner
```
Or with uv:
```bash
uv pip install hpc-runner
```
## Quick Start
### CLI
```bash
# Basic job submission
hpc run python train.py
# With resources
hpc run --cpu 4 --mem 16G --time 4:00:00 "python train.py"
# GPU job
hpc run --queue gpu --cpu 4 --mem 32G "python train.py --epochs 100"
# Preview without submitting
hpc run --dry-run --cpu 8 "make -j8"
# Interactive session
hpc run --interactive bash
# Array job
hpc run --array 1-100 "python process.py --task-id \$SGE_TASK_ID"
# Wait for completion
hpc run --wait python long_job.py
```
### Python API
```python
from hpc_runner import Job
# Create and submit a job
job = Job(
command="python train.py",
cpu=4,
mem="16G",
time="4:00:00",
queue="gpu",
)
result = job.submit()
# Wait for completion
status = result.wait()
print(f"Exit code: {result.returncode}")
# Read output
print(result.read_stdout())
```
### Job Dependencies
```python
from hpc_runner import Job
# First job
preprocess = Job(command="python preprocess.py", cpu=8, mem="32G")
result1 = preprocess.submit()
# Second job runs after first succeeds
train = Job(command="python train.py", cpu=4, mem="48G", queue="gpu")
train.after(result1, type="afterok")
result2 = train.submit()
```
### Pipelines
```python
from hpc_runner import Pipeline
with Pipeline("ml_workflow") as p:
p.add("python preprocess.py", name="preprocess", cpu=8)
p.add("python train.py", name="train", depends_on=["preprocess"], queue="gpu")
p.add("python evaluate.py", name="evaluate", depends_on=["train"])
results = p.submit()
p.wait()
```
## Scheduler Support
| Scheduler | Status | Notes |
|-----------|--------|-------|
| SGE | Fully implemented | qsub, qstat, qdel, qrsh |
| Local | Fully implemented | Run as subprocess (for testing) |
| Slurm | Planned | sbatch, squeue, scancel |
| PBS | Planned | qsub, qstat, qdel |
### Auto-detection Priority
1. `HPC_SCHEDULER` environment variable
2. SGE (`SGE_ROOT` or `qstat` available)
3. Slurm (`sbatch` available)
4. PBS (`qsub` with PBS)
5. Local fallback
## Configuration
hpc-runner uses TOML configuration files. Location priority:
1. `--config /path/to/config.toml`
2. `./hpc-runner.toml`
3. `./pyproject.toml` under `[tool.hpc-runner]`
4. Git repository root `hpc-runner.toml`
5. `~/.config/hpc-runner/config.toml`
6. Package defaults
### Example Configuration
```toml
[defaults]
cpu = 1
mem = "4G"
time = "1:00:00"
inherit_env = true
[schedulers.sge]
parallel_environment = "smp"
memory_resource = "mem_free"
purge_modules = true
[types.gpu]
queue = "gpu"
resources = [{name = "gpu", value = 1}]
[types.interactive]
queue = "interactive"
time = "8:00:00"
```
Use named job types:
```bash
hpc run --job-type gpu "python train.py"
```
### SGE Configuration
SGE clusters vary widely in how resources are named. The `[schedulers.sge]`
section lets you match your site's conventions without touching job definitions.
**How job fields map to SGE flags:**
| Job Field | SGE Flag | Configurable Via |
|-----------|----------|------------------|
| `cpu` | `-pe <pe_name> <slots>` | `parallel_environment` |
| `mem` | `-l <resource>=<value>` | `memory_resource` |
| `time` | `-l <resource>=<value>` | `time_resource` |
| `queue` | `-q <queue>` | direct |
| `resources` | `-l <name>=<value>` | direct |
**Full `[schedulers.sge]` reference:**
```toml
[schedulers.sge]
# Resource naming -- these must match your site's SGE configuration
parallel_environment = "smp" # PE name for CPU slots (some sites use "mpi", "threaded", etc.)
memory_resource = "mem_free" # Memory resource name (common alternatives: "h_vmem", "virtual_free")
time_resource = "h_rt" # Time limit resource name (commonly "h_rt")
# Output handling
merge_output = true # Merge stderr into stdout (-j y)
# Module system
purge_modules = true # Run 'module purge' before loading job modules
silent_modules = false # Suppress module command output (-s flag)
module_init_script = "" # Path to module init script (auto-detected if empty)
# Environment
expand_makeflags = true # Expand $NSLOTS in MAKEFLAGS for parallel make
unset_vars = [] # Environment variables to unset in jobs
# e.g. ["https_proxy", "http_proxy"]
```
**Fully populated config example:**
```toml
[defaults]
scheduler = "auto"
cpu = 1
mem = "4G"
time = "1:00:00"
queue = "batch.q"
use_cwd = true
inherit_env = true
stdout = "hpc.%N.%J.out"
modules = ["gcc/12.2", "python/3.11"]
resources = [
{ name = "scratch", value = "20G" }
]
[schedulers.sge]
parallel_environment = "smp"
memory_resource = "mem_free"
time_resource = "h_rt"
merge_output = true
purge_modules = true
silent_modules = false
expand_makeflags = true
unset_vars = ["https_proxy", "http_proxy"]
[tools.python]
cpu = 4
mem = "16G"
time = "4:00:00"
queue = "short.q"
modules = ["-", "python/3.11"] # leading "-" replaces the list instead of merging
resources = [
{ name = "tmpfs", value = "8G" }
]
[types.interactive]
queue = "interactive.q"
time = "8:00:00"
cpu = 2
mem = "8G"
[types.gpu]
queue = "gpu.q"
cpu = 8
mem = "64G"
time = "12:00:00"
resources = [
{ name = "gpu", value = 1 }
]
```
This config can also be embedded in `pyproject.toml` under `[tool.hpc-runner]`.
## TUI Monitor
Launch the interactive job monitor:
```bash
hpc monitor
```
Key bindings:
- `q` - Quit
- `r` - Refresh
- `u` - Toggle user filter (my jobs / all)
- `/` - Search
- `Enter` - View job details
- `Tab` - Switch tabs
## CLI Reference
```
hpc run [OPTIONS] COMMAND
Options:
--job-name TEXT Job name
--cpu INTEGER Number of CPUs
--mem TEXT Memory (e.g., 16G, 4096M)
--time TEXT Time limit (e.g., 4:00:00)
--queue TEXT Queue/partition name
--directory PATH Working directory
--module TEXT Module to load (repeatable)
--array TEXT Array spec (e.g., 1-100, 1-100%5)
--depend TEXT Job dependencies
--inherit-env Inherit environment (default: true)
--no-inherit-env Don't inherit environment
--interactive Run interactively (qrsh/srun)
--local Run locally (no scheduler)
--dry-run Show script without submitting
--wait Wait for completion
--keep-script Keep job script for debugging
-h, --help Show help
Other commands:
hpc status [JOB_ID] Check job status
hpc cancel JOB_ID Cancel a job
hpc monitor Interactive TUI
hpc config show Show active configuration
```
## Development
```bash
# Setup environment
source sourceme
source sourceme --clean # Clean rebuild
# Run tests
pytest
pytest -v
pytest -k "test_job"
# Type checking
mypy src/hpc_runner
# Linting
ruff check src/hpc_runner
ruff format src/hpc_runner
```
## License
MIT License - see LICENSE file for details.
| text/markdown | Shareef Jalloq | null | null | null | null | cluster, hpc, job-submission, pbs, sge, slurm | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"P... | [] | null | null | >=3.10 | [] | [] | [] | [
"jinja2>=3.0",
"rich-click>=1.7",
"textual>=6.11",
"tomli>=2.0; python_version < \"3.11\"",
"build; extra == \"all\"",
"furo>=2024.0.0; extra == \"all\"",
"hatch-vcs; extra == \"all\"",
"mypy>=1.19; extra == \"all\"",
"pre-commit; extra == \"all\"",
"pytest-asyncio; extra == \"all\"",
"pytest-co... | [] | [] | [] | [
"Homepage, https://github.com/sjalloq/hpc-runner",
"Repository, https://github.com/sjalloq/hpc-runner"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T15:11:52.076656 | hpc_runner-0.7.0.tar.gz | 107,378 | 22/06/eb895e8e196bb83141c1277980870cf6e64b53d566a2dc1b28cd33159049/hpc_runner-0.7.0.tar.gz | source | sdist | null | false | dd19c5b158e62190b8346a3661ee69a3 | 6e8e5ede07cf07e4db69340728a6e3afa01ac769c8e54f0c76103e2fb7561df9 | 2206eb895e8e196bb83141c1277980870cf6e64b53d566a2dc1b28cd33159049 | MIT | [] | 234 |
2.4 | UncountablePythonSDK | 0.0.152 | Uncountable SDK | # Uncountable Python SDK
## Documentation
[https://uncountableinc.github.io/uncountable-python-sdk/](https://uncountableinc.github.io/uncountable-python-sdk/)
## Installation
Install from PyPI:
```console
pip install UncountablePythonSDK
```
| text/markdown | null | null | null | null | null | uncountable, sdk, api, uncountable-sdk | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Topic :: Software Development",
"Topic :: Utilities",
"Typing :: Typed"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"aiotus==1.*",
"aiohttp==3.*",
"requests==2.*",
"SQLAlchemy>=1.4.0",
"APScheduler==3.*",
"python-dateutil==2.*",
"shelljob==0.*",
"PyYAML==6.*",
"google-api-python-client==2.*",
"tqdm==4.*",
"pysftp==0.*",
"opentelemetry-api==1.*",
"opentelemetry-exporter-otlp-proto-common==1.*",
"opentele... | [] | [] | [] | [
"Homepage, https://github.com/uncountableinc/uncountable-python-sdk",
"Repository, https://github.com/uncountableinc/uncountable-python-sdk.git",
"Issues, https://github.com/uncountableinc/uncountable-python-sdk/issues"
] | twine/6.1.0 CPython/3.13.2 | 2026-02-19T15:11:42.642747 | uncountablepythonsdk-0.0.152.tar.gz | 255,954 | 09/da/ef5a29fb7db6c917d2e5c38ff208f9981ecf5b9b09abd76fe74a74f06b82/uncountablepythonsdk-0.0.152.tar.gz | source | sdist | null | false | 730e291ab3105f3fa160a585a31aaf8f | a736c86a17cc5135d45d993bf437755acfe8e68355cc19a7d12c16e516fd8fab | 09daef5a29fb7db6c917d2e5c38ff208f9981ecf5b9b09abd76fe74a74f06b82 | null | [] | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.