
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.4 | ugbio-featuremap | 1.21.2 | Ultima Genomics FeatureMap utils | # ugbio_featuremap
This module includes featuremap python scripts and utils for bioinformatics pipelines.
| text/markdown | null | Itai Rusinek <itai.rusinek@ultimagen.com>, Gat Krieger <gat.krieger@ultimagen.com>, Avigail Moldovan <avigail.moldovan@ultimagen.com> | null | null | Apache-2.0 | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"ugbio_core[ml,vcfbed]",
"ugbio_ppmseq",
"polars>=1.27.1"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T09:01:51.770900 | ugbio_featuremap-1.21.2.tar.gz | 49,712 | 9a/7c/2de55a71d1e2ccdd9c8a08c7fd505e26b1a612822aca777f9d2bdacdd84a/ugbio_featuremap-1.21.2.tar.gz | source | sdist | null | false | 5b4221f58e45db0894ace7853c0a3fe3 | 8f554be8c41e5968818f834a28e3e3f52545dc37405d467dd0650f2de423a965 | 9a7c2de55a71d1e2ccdd9c8a08c7fd505e26b1a612822aca777f9d2bdacdd84a | null | [] | 232 |
2.4 | ugbio-core | 1.21.2 | Ultima Genomics core bioinfo utils | # ugbio_core
This module includes common python scripts and utils for bioinformatics pipelines.
To install all the optional dependencies in the package run:
`uv sync --package ugbio_core --all-extras`
To install specific optional dependency in the package run:
`uv sync --package ugbio_core --extra <dependency name>`
| text/markdown | null | Avigail Moldovam <avigail.moldovan@ultimagen.com> | null | null | Apache-2.0 | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"simppl<2.0.0,>=1.0.7",
"pandas[hdf5]<3.0.0,>=2.2.2",
"numpy<2.0.0,>=1.26.4",
"pysam<1.0.0,>=0.22.1",
"matplotlib<4.0.0,>=3.7.1",
"pyfaidx<1.0.0,>=0.8.1",
"h5py<4.0.0,>=3.11.0",
"scipy<2.0.0,>=1.14.0",
"pybigwig<0.4.0,>=0.3.18; extra == \"vcfbed\"",
"biopython>=1.73; extra == \"vcfbed\"",
"tqdm<... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T09:01:50.821610 | ugbio_core-1.21.2.tar.gz | 92,267 | 88/2e/8698aad80da4b595c0118bd611ad073cf36afc8bafc3b4fa285a8c08c226/ugbio_core-1.21.2.tar.gz | source | sdist | null | false | d04aa720422cbdd60764059ed03a3399 | cd8083935cf9c5f57d44e05e6c2061c8eba8ddaba8f88fa7042698fbae0f9f77 | 882e8698aad80da4b595c0118bd611ad073cf36afc8bafc3b4fa285a8c08c226 | null | [] | 233 |
2.4 | ugbio-comparison | 1.21.2 | Ultima Genomics comparison scripts | # ugbio_comparison
This module includes comparison python scripts and utilities for bioinformatics pipelines. It provides tools for comparing VCF callsets against ground truth datasets, with support for both small variant, structural variant (SV) and copy number (CNV) comparisons.
## Overview
The comparison module is built on top of `ugbio_core` and provides command-line tools for variant benchmarking against ground truth datasets. For detailed usage of each tool, see the [CLI Scripts](#cli-scripts) section below.
The comparison module provides two main CLI scripts for variant comparison:
1. **run_comparison_pipeline** - Compare small variant callsets to ground truth using VCFEVAL
2. **sv_comparison_pipeline** - Compare structural variant (SV) callsets using Truvari
## Installation
To install the comparison module with all dependencies:
```bash
pip install ugbio-comparison
```
The tool can also be run from the docker image in dockerhub [`ultimagenomics/ugbio_comparison`](https://hub.docker.com/r/ultimagenomics/ugbio_comparison).
## CLI Scripts
### 1. run_comparison_pipeline
Compare VCF callsets to ground truth using VCFEVAL as the comparison engine. This pipeline supports, annotation with various genomic features, and detailed concordance analysis of specific variant types (downstream).
#### Purpose
- Compare variant calls against a ground truth dataset
- Generate concordance metrics (TP, FP, FN)
- Annotate variants with coverage, mappability, and other genomic features
- Annotate variants with properties like SNV/Indel/homopolymer Indel etc.
#### Usage
```bash
run_comparison_pipeline \
--input_prefix <input_vcf_prefix> \
--output_file <output_h5_file> \
--output_interval <output_bed_file> \
--gtr_vcf <ground_truth_vcf> \
--highconf_intervals <high_confidence_bed> \
--reference <reference_fasta> \
--call_sample_name <sample_name> \
--truth_sample_name <truth_sample_name> \
```
#### Key Parameters
- `--input_prefix`: Prefix of the input VCF file(s)
- `--output_file`: Output HDF5 file containing concordance results
- `--output_interval`: Output BED file of intersected intervals
- `--gtr_vcf`: Ground truth VCF file for comparison (e.g. GIAB VCF)
- `--cmp_intervals`: Optional regions for comparison (BED/interval_list)
- `--highconf_intervals`: High confidence intervals (e.g. GIAB HCR BED)
- `--reference`: Reference genome FASTA file
- `--reference_dict`: Reference genome dictionary file
- `--call_sample_name`: Name of the call sample
- `--truth_sample_name`: Name of the truth sample
#### Optional Parameters
- `--coverage_bw_high_quality`: Input BigWig file with high MAPQ coverage
- `--coverage_bw_all_quality`: Input BigWig file with all MAPQ coverage
- `--annotate_intervals`: Interval files for annotation (can be specified multiple times)
- `--runs_intervals`: Homopolymer runs intervals (BED file), used for annotation of closeness to homopolymer indel
- `--ignore_filter_status`: Ignore variant filter status
- `--enable_reinterpretation`: Enable variant reinterpretation (i.e. reinterpret variants using likely false hmer indel)
- `--scoring_field`: Alternative scoring field to use (copied to TREE_SCORE)
- `--flow_order`: Sequencing flow order (4 cycle, TGCA)
- `--n_jobs`: Number of parallel jobs for chromosome processing (default: -1 for all CPUs)
- `--use_tmpdir`: Store temporary files in temporary directory
- `--verbosity`: Logging level (ERROR, WARNING, INFO, DEBUG)
#### Output Files
- **HDF5 file** (`output_file`): Contains concordance dataframes with classifications (TP, FP, FN)
- `concordance` key: Main concordance results
- `input_args` key: Input parameters used
- Per-chromosome keys (for whole-genome mode)
- **BED files**: Generated from concordance results for visualization
#### Example
```bash
run_comparison_pipeline \
--input_prefix /data/sample.filtered \
--output_file /results/sample.comp.h5 \
--output_interval /results/sample.comp.bed \
--gtr_vcf /reference/HG004_truth.vcf.gz \
--highconf_intervals /reference/HG004_highconf.bed \
--reference /reference/Homo_sapiens_assembly38.fasta \
--call_sample_name SAMPLE-001 \
--truth_sample_name HG004 \
--n_jobs 8 \
--verbosity INFO \
```
### 2. sv_comparison_pipeline
Compare structural variant (SV) callsets using Truvari for benchmarking. This pipeline collapses VCF files, runs Truvari bench, and generates concordance dataframes.
#### Purpose
- Compare SV calls against a ground truth dataset using Truvari
- We recommend using SV ground truth callsets from NIST as the source of truth
- Collapse overlapping variants before comparison
- Generate detailed concordance metrics for SVs
- Support for different SV types (DEL, INS, DUP, etc.)
- Output results in HDF5 format with base and calls concordance
#### Usage
```bash
sv_comparison_pipeline \
--calls <input_calls_vcf> \
--gt <ground_truth_vcf> \
--hcr_bed <high confidence bed> \
--output_filename <output_h5_file> \
--outdir <truvari_output_dir>
```
#### Key Parameters
- `--calls`: Input calls VCF file
- `--gt`: Input ground truth VCF file
- `--output_filename`: Output HDF5 file with concordance results
- `--outdir`: Full path to output directory for Truvari results
#### Optional Parameters
- `--hcr_bed`: High confidence region BED file
- `--pctseq`: Percentage of sequence identity (default: 0.0)
- `--pctsize`: Percentage of size identity (default: 0.0)
- `--maxsize`: Maximum size for SV comparison in bp (default: 50000, use -1 for unlimited)
- `--custom_info_fields`: Custom INFO fields to read from VCFs (can be specified multiple times)
- `--ignore_filter`: Ignore FILTER field in VCF (removes --passonly flag from Truvari)
- `--skip_collapse`: Skip VCF collapsing step for calls (ground truth is always collapsed)
- `--verbosity`: Logging level (default: INFO)
#### Output files
- **HDF5 file** (`output_filename`): Contains two concordance dataframes:
- `base` key: Ground truth concordance (TP, FN)
- `calls` key: Calls concordance (TP, FP)
- **Truvari directory** (`outdir`): Contains Truvari bench results:
- `tp-base.vcf.gz`: True positive variants in ground truth
- `tp-comp.vcf.gz`: True positive variants in calls
- `fn.vcf.gz`: False negative variants
- `fp.vcf.gz`: False positive variants
- `summary.json`: Summary statistics
#### Example
```bash
sv_comparison_pipeline \
--calls /data/sample.sv.vcf.gz \
--gt /reference/HG004_sv_truth.vcf.gz \
--output_filename /results/sample.sv_comp.h5 \
--outdir /results/truvari_output \
--hcr_bed /reference/HG004_sv_highconf.bed \
--maxsize 100000 \
--pctseq 0.7 \
--pctsize 0.7 \
--verbosity INFO
```
#### CNV Comparison
For copy number variant (CNV) comparisons, consider using a larger `--maxsize` value or -1 for unlimited:
```bash
sv_comparison_pipeline \
--calls /data/sample.cnv.vcf.gz \
--gt /reference/truth.cnv.vcf.gz \
--output_filename /results/sample.cnv_comp.h5 \
--outdir /results/truvari_cnv \
--maxsize -1 \
--ignore_filter
```
## Dependencies
The following binary tools are included in the Docker image and need to be installed for standalone running:
- **bcftools** 1.20 - VCF/BCF manipulation
- **samtools** 1.20 - SAM/BAM/CRAM manipulation
- **bedtools** 2.31.0 - Genome interval operations
- **bedops** - BED file operations
- **GATK** 4.6.0.0 - Genome Analysis Toolkit
- **Picard** 3.3.0 - Java-based command-line tools for manipulating high-throughput sequencing data
- **RTG Tools** 3.12.1 - Provides VCFEVAL for variant comparison
## Notes
- For best performance with large genomes, use parallel processing (`--n_jobs`)
- The `run_comparison_pipeline` supports both single-interval and whole-genome modes
- VCFEVAL requires an SDF index of the reference genome
- Truvari comparison includes automatic VCF collapsing and sorting
- Use `--ignore_filter_status` or `--ignore_filter` to compare all variants regardless of FILTER field
| text/markdown | null | Ilya Soifer <ilya.soifer@ultimagen.com>, Doron Shem-Tov <doron.shemtov@ultimagen.com>, Avigail Moldovan <avigail.moldovan@ultimagen.com> | null | null | Apache-2.0 | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"ugbio_core[ml,vcfbed]"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T09:01:50.024967 | ugbio_comparison-1.21.2.tar.gz | 21,762 | ec/d0/c1a0c269c8d239fc1db3f67ae4378400db1914e6806dbaab947a8e800f5e/ugbio_comparison-1.21.2.tar.gz | source | sdist | null | false | 3d82fa1b48161dfc8cd8f7f4df9289ed | 7edfccf224b14f9345ecfdbff1e84d743e4b8ae4b936f3c5f3dd6f04bcbea18c | ecd0c1a0c269c8d239fc1db3f67ae4378400db1914e6806dbaab947a8e800f5e | null | [] | 234 |
2.4 | ugbio-cnv | 1.21.2 | Ultima Genomics CNV utils | # ugbio_cnv
This module provides Python scripts and utilities for Copy Number Variation (CNV) analysis in bioinformatics pipelines.
## Overview
The CNV module integrates multiple CNV calling algorithms and provides tools for processing, filtering, combining, annotating, and visualizing CNV calls. It supports both germline and somatic CNV detection workflows.
Note that the package itself does not call variants, it just provides facilities for preparing data, calling, changing the format and combining callsets.
The package is designed to work with the following CNV callers:
- **cn.mops** - Read depth-based CNV caller using a Bayesian approach
- **CNVpytor** - Read depth analysis for CNV detection
- **ControlFREEC** - Control-FREEC for somatic CNV detection
## Installation
### Using UV (Recommended)
Install the CNV module and its dependencies:
```bash
pip install ugbio-cnv
```
Pre-built docker image can be downloaded from Dockerhub: [`ultimagenomics/ugbio_cnv`](https://hub.docker.com/r/ultimagenomics/ugbio_filtering)
## Available Tools
### CNV Processing
#### `process_cnmops_cnvs`
Process CNV calls in BED format from cn.mops and ControlFREEC: filter by length and low-complexity regions, annotate, and convert to VCF format.
```bash
process_cnmops_cnvs \
--input_bed_file cnmops_calls.bed \
--cnv_lcr_file ug_cnv_lcr.bed \
--min_cnv_length 10000 \
--intersection_cutoff 0.5 \
--out_directory ./output
```
**Key Parameters:**
- `--input_bed_file` - Input BED file from cn.mops
- `--cnv_lcr_file` - UG-CNV-LCR BED file for filtering low-complexity regions (see workflows for the BED)
- `--min_cnv_length` - CNVs below this length will be marked (default: 10000)
- `--intersection_cutoff` - Overlap threshold with the cnv lcr(default: 0.5)
### Combining CNV Calls
Tools for combining and analyzing CNV calls (currently implemented combining of CNV calls from cn.mops and CNVPytor) are all aggregated under CLI interface `combine_cnmops_cnvpytor_cnv_calls`. This CLI contains the following tools - each can also be called by a standalone script:
```
concat Combine CNV VCFs from different callers (cn.mops and cnvpytor)
filter_cnmops_dups Filter short duplications from cn.mops calls in the combined CNV VCF
annotate_gaps Annotate CNV calls with percentage of gaps (Ns) from reference genome
annotate_regions Annotate CNV calls with region annotations from BED file
merge_records Merge adjacent or nearby CNV records in a VCF file
```
#### `concat`
Concatenate CNV VCF files from different callers (cn.mops and CNVpytor) into a single sorted and indexed VCF.
The tool adds "source" tag for each CNV
```bash
combine_cnv_vcfs \
--cnmops_vcf cnmops1.vcf cnmops2.vcf \
--cnvpytor_vcf cnvpytor1.vcf cnvpytor2.vcf \
--output_vcf combined.vcf.gz \
--fasta_index reference.fasta.fai \
--out_directory ./output
```
#### `annotate_regions`
Annotate CNV calls with custom genomic regions that they overlap. The BED is expected to contain |-separated names of regions in the fourth column. The annotation is added to the info field under tag REGION_ANNOTATION
```bash
annotate_regions \
--input_vcf calls.vcf.gz \
--output_vcf annotated.vcf.gz \
--annotation_bed regions.bed
```
#### `annotate_gaps`
Annotate CNV calls with percentage of Ns that they cover. Adds an info tag GAPS_PERCENTAGE
```bash
annotate_gaps \
--calls_vcf calls.vcf.gz \
--output_vcf annotated.vcf.gz \
--ref_fasta Homo_sapiens_assembly38.fasta
```
#### `merge_records`
Combines overlapping records in the VCF
```bash
merge_records
--input_vcf calls.vcf.gz \
--output_vcf calls.combined.vcf.gz \
--distance 0
```
#### `analyze_cnv_breakpoint_reads`
Analyze single-ended reads at CNV breakpoints to identify supporting evidence for duplications and deletions.
Counts of supporting evidence appear as info tags in the VCF
```bash
analyze_cnv_breakpoint_reads \
--vcf-file cnv_calls.vcf.gz \
--bam-file sample.bam \
--output-file annotated.vcf.gz \
--cushion 100 \
--reference-fasta Homo_sapiens_assembly38.fasta
```
### Somatic CNV Tools (ControlFREEC)
#### `annotate_FREEC_segments`
Annotate segments from ControlFREEC output as gain/loss/neutral based on fold-change thresholds.
```bash
annotate_FREEC_segments \
--input_segments_file segments.txt \
--gain_cutoff 1.03 \
--loss_cutoff 0.97 \
--out_directory ./output
```
### Visualization
#### `plot_cnv_results`
Generate coverage plots along the genome for germline and tumor samples.
```bash
plot_cnv_results \
--sample_name SAMPLE \
--germline_cov_file germline_coverage.bed \
--tumor_cov_file tumor_coverage.bed \
--cnv_file cnv_calls.bed \
--out_directory ./plots
```
#### `plot_FREEC_neutral_AF`
Generate histogram of allele frequencies at neutral (non-CNV) locations.
```bash
plot_FREEC_neutral_AF \
--input_file neutral_regions.txt \
--sample_name SAMPLE \
--out_directory ./plots
```
## Dependencies
The module depends on:
- **Python 3.11+**
- **ugbio_core** - Core utilities from this workspace
- **CNVpytor** (1.3.1) - Python-based CNV caller
- **cn.mops** (R package) - Bayesian CNV detection
- **Bioinformatics tools**: samtools, bedtools, bcftools
- **R 4.3.1** with Bioconductor packages
## Key R Scripts
The module includes R scripts in the `cnmops/` directory. They are used by cn.mops pipeline and are not intended for standalone usage.
- `cnv_calling_using_cnmops.R` - Main cn.mops calling script
- `get_reads_count_from_bam.R` - Extract read counts from BAM files
- `create_reads_count_cohort_matrix.R` - Build cohort matrix for cn.mops
- `normalize_reads_count.R` - Normalize read counts across samples
## Notes
- See germline and somatic CNV calling workflows published in GH repository `Ultimagen\healthomics-workflows`
for the reference implementations of the suggested workflows.
- For optimal CNV calling, use cohort-based approaches when multiple samples are available
- Filter CNV calls using the provided LCR (low-complexity region) files to reduce false positives
- Consider minimum CNV length thresholds based on your sequencing depth and biological context
- The module supports both GRCh37 and GRCh38 reference genomes
## Key Components
### process_cnvs
Process CNV calls from CN.MOPS or ControlFREEC in BED format: filter by length and UG-CNV-LCR, annotate with coverage statistics, and convert to VCF format.
**Note:** This module is called programmatically (not via CLI) from other pipeline scripts.
#### Programmatic Usage
The `process_cnvs` module is typically invoked from other pipeline components. Here are examples:
**Basic usage (minimal filtering):**
```python
from ugbio_cnv import process_cnvs
process_cnvs.run([
"process_cnvs",
"--input_bed_file", "cnv_calls.bed",
"--fasta_index_file", "reference.fasta.fai",
"--sample_name", "sample_001"
])
```
**With LCR filtering and length thresholds:**
```python
from ugbio_cnv import process_cnvs
process_cnvs.run([
"process_cnvs",
"--input_bed_file", "cnv_calls.bed",
"--cnv_lcr_file", "ug_cnv_lcr.bed",
"--min_cnv_length", "10000",
"--intersection_cutoff", "0.5",
"--fasta_index_file", "reference.fasta.fai",
"--sample_name", "sample_001",
"--out_directory", "/path/to/output/"
])
```
**Full pipeline with coverage annotations:**
```python
from ugbio_cnv import process_cnvs
process_cnvs.run([
"process_cnvs",
"--input_bed_file", "cnv_calls.bed",
"--cnv_lcr_file", "ug_cnv_lcr.bed",
"--min_cnv_length", "10000",
"--sample_norm_coverage_file", "sample.normalized_coverage.bed",
"--cohort_avg_coverage_file", "cohort.average_coverage.bed",
"--fasta_index_file", "reference.fasta.fai",
"--sample_name", "sample_001",
"--out_directory", "/path/to/output/",
"--verbosity", "INFO"
])
```
**Input:** BED file with CNV calls from CN.MOPS or ControlFREEC
**Output:** Filtered and annotated VCF file with CNV calls (`.vcf.gz` and `.vcf.gz.tbi`)
| text/markdown | null | Tammy Biniashvili <tammy.biniashvili@ultimagen.com>, Avigail Moldovan <avigail.moldovan@ultimagen.com>, Ilya Soifer <ilya.soifer@ultimagen.com> | null | null | Apache-2.0 | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"ugbio_core[vcfbed]",
"seaborn<1.0.0,>=0.13.2",
"cnvpytor==1.3.1",
"setuptools<82.0.0,>=75.8.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T09:01:48.751880 | ugbio_cnv-1.21.2.tar.gz | 51,687 | 00/95/50ddfd51c56811bb41b94fe2e84574eb848f691d857e4f598cc65b11e5db/ugbio_cnv-1.21.2.tar.gz | source | sdist | null | false | 31148e4cc21f980394797cac058d8267 | 9c0d54f2e260913105ef0ad9232a0544901ad6396a4049219acbe97e02542cb8 | 009550ddfd51c56811bb41b94fe2e84574eb848f691d857e4f598cc65b11e5db | null | [] | 226 |
2.4 | ugbio-cloud-utils | 1.21.2 | Ultima Genomics cloud python utils | # ugbio_cloud_utils
This module includes cloud (AWS/GS) python scripts:
List of tools:
1. **cloud_sync** - Download aws s3 or google storage file to a respective local path
Run `uv run cloud_sync --help` for more details.
| text/markdown | null | Avigail Moldovam <avigail.moldovan@ultimagen.com> | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"boto3>=1.35.66",
"google-cloud-storage>=2.19.0",
"pysam>=0.22.1"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T09:01:48.011878 | ugbio_cloud_utils-1.21.2.tar.gz | 5,423 | d9/58/64b579965524d81ac78bf9840093907900c7a9784503a5af6b69ff74c170/ugbio_cloud_utils-1.21.2.tar.gz | source | sdist | null | false | 3ce0daefa574f7dd6ce2fffd6e8556ba | 7ccdd25c0ae32dc5ca26b08e5df286e63ac835b91ca71bf1525d0e01ae2cb8f7 | d95864b579965524d81ac78bf9840093907900c7a9784503a5af6b69ff74c170 | null | [] | 226 |
2.3 | simtoolsz | 0.2.13 | A simple and convenient toolkit containing useful functions, classes, and methods. | # simtoolsz
<div>
<img alt="PyPI - License" src="https://img.shields.io/pypi/l/simtoolsz">
<img alt="PyPI - Version" src="https://img.shields.io/pypi/v/simtoolsz">
<img alt="Python - Version" src="https://img.shields.io/pypi/pyversions/simtoolsz">
</div>
[English](README_EN.md) | 中文
一个简单、方便的工具集合,均是个人工作中的常用功能。对之前[pytoolsz](https://github.com/SidneyLYZhang/pytoolsz)工具包的精简重构,保留最实用的功能模块。
部分功能可能还有问题,如果使用中发现问题还请反馈给我。
## 功能特性
### 🕐 时间处理 (`simtoolsz.datetime`)
- **时间格式转换**: 支持多种时间格式间的相互转换(中文、英文、ISO8601、秒、分钟、小时等)
- **智能格式识别**: 自动识别输入的时间格式类型
- **枚举支持**: 提供 `DurationFormat` 枚举类,标准化时间格式处理
- **时间计算**: 支持时间跨度的计算和转换
### 📧 邮件处理 (`simtoolsz.mail`)
- **邮件发送**: 支持HTML/纯文本邮件,附件、抄送、密送
- **邮件接收**: IMAP协议邮件读取,支持主题搜索
- **编码支持**: UTF-7编码解码,处理国际化邮件
- **内嵌图片**: 支持HTML邮件中的内嵌图片
### 💾 数据处理 (`simtoolsz.db`)
- **压缩包数据读取**: 直接从ZIP压缩包读取CSV、Excel、Parquet、JSON数据到DuckDB
- **特殊格式支持**: 支持TSV、Avro、Arrow等特殊格式文件的数据库转换
- **批量处理**: 支持多文件批量导入数据库
- **灵活配置**: 可自定义表名映射和导入参数
### 📖 数据读取 (`simtoolsz.reader`)
- **多格式读取**: 统一接口读取CSV、TSV、Excel、Parquet、JSON、IPC、Avro等格式
- **Polars集成**: 基于Polars的高性能数据读取
- **智能选择**: 根据文件扩展名自动选择合适的读取器
- **Lazy加载支持**: 支持大数据集的懒加载模式
### 🛠️ 工具函数 (`simtoolsz.utils`)
- **日期获取**: `today()` 函数,支持时区、格式化、标准datetime对象返回
- **列表操作**: `take_from_list()` 智能列表元素查找
- **文件夹操作**: `checkFolders()` 批量文件夹检查和创建
- **文件查找**: `lastFile()` 基于时间或大小的文件查找
### 国家代码转换 (`simtoolsz.countrycode`)
- **国家名称到代码**: 支持将国家名称转换为对应的ISO 3166-1 alpha-2代码
- **代码到国家名称**: 支持将ISO 3166-1 alpha-2代码转换为国家名称
- **G7/G20国家列表**: 提供G7和G20国家的代码列表
- **多类型国家代码转换**:支持类型丰富,详细可见[代码转换模块说明](README_countrycode.md)
## 安装
```bash
pip install simtoolsz
```
### 核心依赖
- Python >= 3.11
- pendulum >= 3.1.0
- duckdb >= 1.4.0
- polars >= 1.0.0
## 快速开始
### 时间格式转换
```python
from simtoolsz.datetime import TimeConversion
# 中文时间到秒
tc = TimeConversion("1天2小时30分钟45秒", "chinese")
seconds = tc.convert("seconds")
print(f"1天2小时30分钟45秒 = {seconds}秒")
# 秒到中文时间
tc = TimeConversion(90061, "seconds")
chinese = tc.convert("chinese")
print(f"90061秒 = {chinese}")
```
### 发送邮件
```python
from simtoolsz.mail import send_email
# 发送纯文本邮件
result = send_email(
email_account="your@qq.com",
password="your_password",
subject="测试邮件",
content="这是一封测试邮件",
recipients="friend@example.com"
)
# 发送HTML邮件带附件
result = send_email(
email_account="your@gmail.com",
password="app_password",
subject="项目报告",
content="<h1>本月工作报告</h1><p>详见附件</p>",
recipients=["boss@company.com", "同事<colleague@company.com>"],
attachments=["report.pdf", "data.xlsx"],
html_mode=True
)
```
### 数据读取
```python
from simtoolsz.reader import getreader
import polars as pl
# 使用getreader读取CSV文件
reader = getreader("data.csv")
df = reader("data.csv")
# 读取TSV文件
df = load_tsv("data.tsv")
# Lazy加载大数据集
lazy_df = load_data("large_data.csv", lazy=True)
# 加载压缩数据集
df = load_data("large_data_archive.tar.gz/data.csv")
```
### 压缩包数据导入数据库
```python
from simtoolsz.db import zip2db
# 从ZIP文件读取数据到DuckDB
con = zip2db(
zip_file="data.zip",
db_file="output.db",
table={"users.csv": "用户表", "orders.xlsx": "订单表"}
)
# 查询数据
tables = con.execute("SHOW TABLES").fetchall()
print(f"导入的表: {tables}")
```
### 工具函数
```python
from simtoolsz.utils import today, take_from_list
# 获取当前日期时间
current = today(addtime=True)
formatted = today(fmt="YYYY年MM月DD日 HH:mm:ss")
# 列表查找
result = take_from_list("hello", ["he", "world"]) # 返回 "he"
result = take_from_list([2, 3], [1, 2, 3, 4]) # 返回 2
```
### 国家代码转换
```python
from simtoolsz.countrycode import CountryCode
# 初始化国家代码转换工具
cc = CountryCode()
# 转换国家名称到代码
code = cc.convert("中国") # 返回 "CN"
# 转换代码到国家名称
name = cc.convert("US", target="name") # 返回 "United States"
# 获取G7国家列表
g7 = cc.convert("G7", target="name")
print(g7)
``` | text/markdown | null | Sidney Zhang <liangyi@me.com> | null | null | MulanPSL-2.0 | collection, tool | [
"Development Status :: 4 - Beta",
"License :: OSI Approved :: Mulan Permissive Software License v2 (MulanPSL-2.0)",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Py... | [] | null | null | >=3.11 | [] | [] | [] | [
"duckdb>=1.4.0",
"pendulum>=3.1.0",
"polars>=1.33.1",
"pyarrow>=22.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/SidneyLYZhang/simtoolsz",
"Repository, https://github.com/SidneyLYZhang/simtoolsz.git",
"Issues, https://github.com/SidneyLYZhang/simtoolsz/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T09:01:28.696174 | simtoolsz-0.2.13.tar.gz | 148,379 | 02/d3/f45b2cca34ff830a0445c40dc01b992b5fe00e790763bb7d1a866a552b3a/simtoolsz-0.2.13.tar.gz | source | sdist | null | false | f9502e09a1ca1bcf433944ad6db1acf1 | 475bab3d317e411962c8ebf16d25420f55003ea8ea8f39f075687ad3959c2bc3 | 02d3f45b2cca34ff830a0445c40dc01b992b5fe00e790763bb7d1a866a552b3a | null | [] | 231 |
2.4 | beans-logging | 10.0.1 | 'beans-logging' is a python package for simple logger and easily managing logs. | # Python Logging (beans-logging)
[](https://choosealicense.com/licenses/mit)
[](https://github.com/bybatkhuu/module-python-logging/actions/workflows/2.build-publish.yml)
[](https://github.com/bybatkhuu/module-python-logging/releases)
[](https://pypi.org/project/beans-logging)
[](https://docs.conda.io/en/latest/miniconda.html)
`beans-logging` is a python package for simple logger and easily managing logs.
It is a `Loguru` based custom logging package for python projects.
## ✨ Features
- Main **logger** based on **Loguru** logging - <https://pypi.org/project/loguru>
- Logging to **log files** (all, error, json)
- **Pre-defined** logging configs and handlers
- **Colorful** logging
- Auto **intercepting** and **muting** modules
- Load config from **YAML** or **JSON** file
- Custom options as a **config**
- Custom logging **formats**
- **Multiprocess** compatibility (Linux, macOS - 'fork')
- Add custom **handlers**
- **Base** logging module
---
## 🛠 Installation
### 1. 🚧 Prerequisites
- Install **Python (>= v3.10)** and **pip (>= 23)**:
- **[RECOMMENDED] [Miniconda (v3)](https://www.anaconda.com/docs/getting-started/miniconda/install)**
- *[arm64/aarch64] [Miniforge (v3)](https://github.com/conda-forge/miniforge)*
- *[Python virutal environment] [venv](https://docs.python.org/3/library/venv.html)*
[OPTIONAL] For **DEVELOPMENT** environment:
- Install [**git**](https://git-scm.com/downloads)
- Setup an [**SSH key**](https://docs.github.com/en/github/authenticating-to-github/connecting-to-github-with-ssh)
### 2. 📦 Install the package
[NOTE] Choose one of the following methods to install the package **[A ~ F]**:
**OPTION A.** [**RECOMMENDED**] Install from **PyPi**:
```sh
pip install -U beans-logging
```
**OPTION B.** Install latest version directly from **GitHub** repository:
```sh
pip install git+https://github.com/bybatkhuu/module-python-logging.git
```
**OPTION C.** Install from the downloaded **source code**:
```sh
git clone https://github.com/bybatkhuu/module-python-logging.git && \
cd ./module-python-logging
# Install directly from the source code:
pip install .
# Or install with editable mode:
pip install -e .
```
**OPTION D.** Install for **DEVELOPMENT** environment:
```sh
pip install -e .[dev]
# Install pre-commit hooks:
pre-commit install
```
**OPTION E.** Install from **pre-built release** files:
1. Download **`.whl`** or **`.tar.gz`** file from [**releases**](https://github.com/bybatkhuu/module-python-logging/releases)
2. Install with pip:
```sh
# Install from .whl file:
pip install ./beans_logging-[VERSION]-py3-none-any.whl
# Or install from .tar.gz file:
pip install ./beans_logging-[VERSION].tar.gz
```
**OPTION F.** Copy the **module** into the project directory (for **testing**):
```sh
# Install python dependencies:
pip install -r ./requirements.txt
# Copy the module source code into the project:
cp -r ./src/beans_logging [PROJECT_DIR]
# For example:
cp -r ./src/beans_logging /some/path/project/
```
## 🚸 Usage/Examples
To use `beans_logging`, import the `logger` instance from the `beans_logging.auto` package:
```python
from beans_logging.auto import logger
```
You can call logging methods directly from the `logger` instance:
```python
logger.info("Logging info.")
```
### **Simple**
[**`configs/logger.yml`**](./examples/simple/configs/logger.yml):
```yaml
logger:
app_name: my-app
level:
base: TRACE
handlers:
default.all.file_handler:
enabled: true
default.err.file_handler:
enabled: true
default.all.json_handler:
enabled: true
default.err.json_handler:
enabled: true
```
[**`main.py`**](./examples/simple/main.py):
```python
#!/usr/bin/env python
from beans_logging.auto import logger
logger.trace("Tracing...")
logger.debug("Debugging...")
logger.info("Logging info.")
logger.success("Success.")
logger.warning("Warning something.")
logger.error("Error occured.")
logger.critical("CRITICAL ERROR.")
def divide(a, b):
_result = a / b
return _result
def nested(c):
try:
divide(5, c)
except ZeroDivisionError as err:
logger.error(err)
raise
try:
nested(0)
except Exception:
logger.exception("Show me, what value is wrong:")
```
Run the [**`examples/simple`**](./examples/simple):
```sh
cd ./examples/simple
python ./main.py
```
**Output**:
```txt
[2025-11-01 00:00:00.735 +09:00 | TRACE | beans_logging._intercept:96]: Intercepted modules: ['potato_util._base', 'potato_util.io', 'concurrent', 'concurrent.futures', 'asyncio', 'potato_util.io._sync', 'potato_util']; Muted modules: [];
[2025-11-01 00:00:00.736 +09:00 | TRACE | __main__:6]: Tracing...
[2025-11-01 00:00:00.736 +09:00 | DEBUG | __main__:7]: Debugging...
[2025-11-01 00:00:00.736 +09:00 | INFO | __main__:8]: Logging info.
[2025-11-01 00:00:00.736 +09:00 | OK | __main__:9]: Success.
[2025-11-01 00:00:00.736 +09:00 | WARN | __main__:10]: Warning something.
[2025-11-01 00:00:00.736 +09:00 | ERROR | __main__:11]: Error occured.
[2025-11-01 00:00:00.736 +09:00 | CRIT | __main__:12]: CRITICAL ERROR.
[2025-11-01 00:00:00.736 +09:00 | ERROR | __main__:24]: division by zero
[2025-11-01 00:00:00.737 +09:00 | ERROR | __main__:31]: Show me, what value is wrong:
Traceback (most recent call last):
> File "/home/user/workspaces/projects/my/module-python-logging/examples/simple/./main.py", line 29, in <module>
nested(0)
└ <function nested at 0x102f37910>
File "/home/user/workspaces/projects/my/module-python-logging/examples/simple/./main.py", line 22, in nested
divide(5, c)
│ └ 0
└ <function divide at 0x102f377f0>
File "/home/user/workspaces/projects/my/module-python-logging/examples/simple/./main.py", line 16, in divide
_result = a / b
│ └ 0
└ 5
ZeroDivisionError: division by zero
```
👍
---
## ⚙️ Configuration
[**`templates/configs/logger.yml`**](./templates/configs/logger.yml):
```yaml
logger:
# app_name: app
level:
base: INFO
err: WARNING
format_str: "[{time:YYYY-MM-DD HH:mm:ss.SSS Z} | {extra[level_short]:<5} | {name}:{line}]: {message}"
file:
logs_dir: "./logs"
rotate_size: 10000000
rotate_time: "00:00:00"
retention: 90
encoding: utf8
use_custom_serialize: false
intercept:
enabled: true
only_base: false
ignore_modules: []
include_modules: []
mute_modules: []
handlers:
all_std_handler:
enabled: true
h_type: STD
format: "[<c>{time:YYYY-MM-DD HH:mm:ss.SSS Z}</c> | <level>{extra[level_short]:<5}</level> | <w>{name}:{line}</w>]: <level>{message}</level>"
colorize: true
all_file_handler:
enabled: false
h_type: FILE
sink: "{app_name}.all.log"
err_file_handler:
enabled: false
h_type: FILE
sink: "{app_name}.err.log"
error: true
all_json_handler:
enabled: false
h_type: FILE
sink: "json/{app_name}.all.json.log"
serialize: true
err_json_handler:
enabled: false
h_type: FILE
sink: "json/{app_name}.err.json.log"
serialize: true
error: true
extra:
```
### 🌎 Environment Variables
[**`.env.example`**](./.env.example):
```sh
# ENV=LOCAL
# DEBUG=false
# TZ=UTC
```
---
## 🧪 Running Tests
To run tests, run the following command:
```sh
# Install python test dependencies:
pip install .[test]
# Run tests:
python -m pytest -sv -o log_cli=true
# Or use the test script:
./scripts/test.sh -l -v -c
```
## 🏗️ Build Package
To build the python package, run the following command:
```sh
# Install python build dependencies:
pip install -r ./requirements/requirements.build.txt
# Build python package:
python -m build
# Or use the build script:
./scripts/build.sh
```
## 📝 Generate Docs
To build the documentation, run the following command:
```sh
# Install python documentation dependencies:
pip install -r ./requirements/requirements.docs.txt
# Serve documentation locally (for development):
mkdocs serve -a 0.0.0.0:8000 --livereload
# Or use the docs script:
./scripts/docs.sh
# Or build documentation:
mkdocs build
# Or use the docs script:
./scripts/docs.sh -b
```
## 📚 Documentation
- [Docs](./docs)
---
## 📑 References
- <https://github.com/Delgan/loguru>
- <https://loguru.readthedocs.io/en/stable/api/logger.html>
- <https://loguru.readthedocs.io/en/stable/resources/recipes.html>
- <https://docs.python.org/3/library/logging.html>
- <https://github.com/bybatkhuu/module-fastapi-logging>
| text/markdown | null | Batkhuu Byambajav <batkhuu10@gmail.com> | null | null | null | beans_logging, loguru, logging, logger, logs, python-logging, custom-logging | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: P... | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"pydantic[timezone]<3.0.0,>=2.5.3",
"loguru<1.0.0,>=0.7.3",
"potato_util<1.0.0,>=0.3.1",
"pytest<10.0.0,>=8.0.2; extra == \"test\"",
"pytest-cov<8.0.0,>=5.0.0; extra == \"test\"",
"pytest-xdist<4.0.0,>=3.6.1; extra == \"test\"",
"pytest-benchmark<6.0.0,>=5.0.1; extra == \"test\"",
"setuptools<83.0.0,>... | [] | [] | [] | [
"Homepage, https://github.com/bybatkhuu/module-python-logging",
"Documentation, https://pylogging-docs.bybatkhuu.dev",
"Repository, https://github.com/bybatkhuu/module-python-logging.git",
"Issues, https://github.com/bybatkhuu/module-python-logging/issues",
"Changelog, https://github.com/bybatkhuu/module-py... | twine/6.2.0 CPython/3.10.19 | 2026-02-19T09:00:51.042504 | beans_logging-10.0.1.tar.gz | 19,658 | c4/e5/93b578454f9be12f8970e4afdb7f9ab2ad8505b49e530a76b371b61e3220/beans_logging-10.0.1.tar.gz | source | sdist | null | false | e304e892bd4a26971aaa382ca585985d | 7dba71a30cef01554ae7fc0ca3aefe47367f74b320c2dbb625a6eedf52f6fc7c | c4e593b578454f9be12f8970e4afdb7f9ab2ad8505b49e530a76b371b61e3220 | null | [
"LICENSE.txt"
] | 290 |
2.4 | omnicoreagent | 0.3.8 | OmniCoreAgent is a powerful Python AI Agent framework for building autonomous AI agents that think, reason, and execute complex tasks. Production-ready agents that use tools, manage memory, coordinate workflows, and handle real-world business logic. | <p align="center">
<img src="assets/IMG_5292.jpeg" alt="OmniCoreAgent Logo" width="250"/>
</p>
<h1 align="center">🚀 OmniCoreAgent</h1>
<p align="center">
<strong>The AI Agent Framework Built for Production</strong><br>
<em>Switch memory backends at runtime. Manage context automatically. Deploy with confidence.</em>
</p>
<p align="center">
<a href="https://pepy.tech/projects/omnicoreagent"><img src="https://static.pepy.tech/badge/omnicoreagent" alt="PyPI Downloads"></a>
<a href="https://badge.fury.io/py/omnicoreagent"><img src="https://badge.fury.io/py/omnicoreagent.svg" alt="PyPI version"></a>
<a href="https://www.python.org/downloads/"><img src="https://img.shields.io/badge/python-3.10+-blue.svg" alt="Python Version"></a>
<a href="LICENSE"><img src="https://img.shields.io/badge/license-MIT-green.svg" alt="License"></a>
</p>
<p align="center">
<a href="#-quick-start">Quick Start</a> •
<a href="#-see-it-in-action">See It In Action</a> •
<a href="./cookbook">📚 Cookbook</a> •
<a href="#-core-features">Features</a> •
<a href="https://docs-omnicoreagent.omnirexfloralabs.com/docs">Docs</a>
</p>
---
## 🎬 See It In Action
```python
import asyncio
from omnicoreagent import OmniCoreAgent, MemoryRouter, ToolRegistry
# Create tools in seconds
tools = ToolRegistry()
@tools.register_tool("get_weather")
def get_weather(city: str) -> dict:
"""Get current weather for a city."""
return {"city": city, "temp": "22°C", "condition": "Sunny"}
# Build a production-ready agent
agent = OmniCoreAgent(
name="assistant",
system_instruction="You are a helpful assistant with access to weather data.",
model_config={"provider": "openai", "model": "gpt-4o"},
local_tools=tools,
memory_router=MemoryRouter("redis"), # Start with Redis
agent_config={
"context_management": {"enabled": True}, # Auto-manage long conversations
"guardrail_config": {"strict_mode": True}, # Block prompt injections
}
)
async def main():
# Run the agent
result = await agent.run("What's the weather in Tokyo?")
print(result["response"])
# Switch to MongoDB at runtime — no restart needed
await agent.switch_memory_store("mongodb")
# Keep running with a different backend
result = await agent.run("How about Paris?")
print(result["response"])
asyncio.run(main())
```
**What just happened?**
- ✅ Registered a custom tool with type hints
- ✅ Built an agent with memory persistence
- ✅ Enabled automatic context management
- ✅ Switched from Redis to MongoDB *while running*
---
## ⚡ Quick Start
```bash
pip install omnicoreagent
```
```bash
echo "LLM_API_KEY=your_api_key" > .env
```
```python
from omnicoreagent import OmniCoreAgent
agent = OmniCoreAgent(
name="my_agent",
system_instruction="You are a helpful assistant.",
model_config={"provider": "openai", "model": "gpt-4o"}
)
result = await agent.run("Hello!")
print(result["response"])
```
**That's it.** You have an AI agent with session management, memory, and error handling.
> 📚 **Want to learn more?** Check out the [Cookbook](./cookbook) — progressive examples from "Hello World" to production deployments.
---
## 🎯 What Makes OmniCoreAgent Different?
| Feature | What It Means For You |
|---------|----------------------|
| **Runtime Backend Switching** | Switch Redis ↔ MongoDB ↔ PostgreSQL without restarting |
| **Cloud Workspace Storage** | Agent files persist in AWS S3 or Cloudflare R2 ⚡ NEW |
| **Context Engineering** | Session memory + agent loop context + tool offloading = no token exhaustion |
| **Tool Response Offloading** | Large tool outputs saved to files, 98% token savings |
| **Built-in Guardrails** | Prompt injection protection out of the box |
| **MCP Native** | Connect to any MCP server (stdio, SSE, HTTP with OAuth) |
| **Background Agents** | Schedule autonomous tasks that run on intervals |
| **Workflow Orchestration** | Sequential, Parallel, and Router agents for complex tasks |
| **Production Observability** | Metrics, tracing, and event streaming built in |
---
## 🎯 Core Features
> 📖 **Full documentation**: [docs-omnicoreagent.omnirexfloralabs.com/docs](https://docs-omnicoreagent.omnirexfloralabs.com/docs)
| # | Feature | Description | Docs |
|---|---------|-------------|------|
| 1 | **OmniCoreAgent** | The heart of the framework — production agent with all features | [Overview →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/core-concepts/overview) |
| 2 | **Multi-Tier Memory** | 5 backends (Redis, MongoDB, PostgreSQL, SQLite, in-memory) with runtime switching | [Memory →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/core-concepts/memory) |
| 3 | **Context Engineering** | Dual-layer system: agent loop context management + tool response offloading | [Context →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/core-concepts/context-engineering) |
| 4 | **Event System** | Real-time event streaming with runtime switching | [Events →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/core-concepts/events) |
| 5 | **MCP Client** | Connect to any MCP server (stdio, streamable_http, SSE) with OAuth | [MCP →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/core-concepts/mcp) |
| 6 | **DeepAgent** | Multi-agent orchestration with automatic task decomposition | [DeepAgent →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/core-concepts/deep-agent) |
| 7 | **Local Tools** | Register any Python function as an AI tool via ToolRegistry | [Local Tools →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/core-concepts/local-tools) |
| 8 | **Community Tools** | 100+ pre-built tools (search, AI, comms, databases, DevOps, finance) | [Community Tools →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/core-concepts/community-tools) |
| 9 | **Agent Skills** | Polyglot packaged capabilities (Python, Bash, Node.js) | [Skills →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/core-concepts/skills) |
| 10 | **Workspace Memory** | Persistent file storage with S3/R2/Local backends | [Workspace →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/core-concepts/workspace-memory) |
| 11 | **Sub-Agents** | Delegate tasks to specialized agents | [Sub-Agents →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/core-concepts/sub-agents) |
| 12 | **Background Agents** | Schedule autonomous tasks on intervals | [Background →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/core-concepts/background-agents) |
| 13 | **Workflows** | Sequential, Parallel, and Router agent orchestration | [Workflows →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/core-concepts/workflows) |
| 14 | **BM25 Tool Retrieval** | Auto-discover relevant tools from 1000+ using BM25 search | [Advanced Tools →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/how-to-guides/advanced-tools) |
| 15 | **Guardrails** | Prompt injection protection with configurable sensitivity | [Guardrails →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/core-concepts/guardrails) |
| 16 | **Observability** | Per-request metrics + Opik distributed tracing | [Observability →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/how-to-guides/observability) |
| 17 | **Universal Models** | 9 providers via LiteLLM (OpenAI, Anthropic, Gemini, Groq, Ollama, etc.) | [Models →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/how-to-guides/models) |
| 18 | **OmniServe** | Turn any agent into a production REST/SSE API with one command | [OmniServe →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/how-to-guides/omniserve) |
---
## 📚 Examples & Cookbook
All examples are in the **[Cookbook](./cookbook)** — organized by use case with progressive learning paths.
| Category | What You'll Build | Location |
|----------|-------------------|----------|
| **Getting Started** | Your first agent, tools, memory, events | [cookbook/getting_started](./cookbook/getting_started) |
| **Workflows** | Sequential, Parallel, Router agents | [cookbook/workflows](./cookbook/workflows) |
| **Background Agents** | Scheduled autonomous tasks | [cookbook/background_agents](./cookbook/background_agents) |
| **Production** | Metrics, guardrails, observability | [cookbook/production](./cookbook/production) |
| **🏆 Showcase** | Full production applications | [cookbook/showcase](./cookbook/showcase) |
### 🏆 Showcase: Full Production Applications
| Application | Description | Features |
|-------------|-------------|----------|
| **[OmniAudit](./cookbook/showcase/omniavelis)** | Healthcare Claims Audit System | Multi-agent pipeline, ERISA compliance |
| **[DevOps Copilot](./cookbook/showcase/devops_copilot_agent)** | AI-Powered DevOps Automation | Docker, Prometheus, Grafana |
| **[Deep Code Agent](./cookbook/showcase/deep_code_agent)** | Code Analysis with Sandbox | Sandbox execution, session management |
---
## ⚙️ Configuration
### Environment Variables
```bash
# Required
LLM_API_KEY=your_api_key
# Optional: Memory backends
REDIS_URL=redis://localhost:6379/0
DATABASE_URL=postgresql://user:pass@localhost:5432/db
MONGODB_URI=mongodb://localhost:27017/omnicoreagent
# Optional: Observability
OPIK_API_KEY=your_opik_key
OPIK_WORKSPACE=your_workspace
```
### Agent Configuration
```python
agent_config = {
"max_steps": 15, # Max reasoning steps
"tool_call_timeout": 30, # Tool timeout (seconds)
"request_limit": 0, # 0 = unlimited
"total_tokens_limit": 0, # 0 = unlimited
"memory_config": {"mode": "sliding_window", "value": 10000},
"enable_advanced_tool_use": True, # BM25 tool retrieval
"enable_agent_skills": True, # Specialized packaged skills
"memory_tool_backend": "local" # Persistent working memory
}
```
> 📖 **Full configuration reference**: [Configuration Guide →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/how-to-guides/configuration)
---
## 🧪 Testing & Development
```bash
# Clone
git clone https://github.com/omnirexflora-labs/omnicoreagent.git
cd omnicoreagent
# Setup
uv venv && source .venv/bin/activate
uv sync --dev
# Test
pytest tests/ -v
pytest tests/ --cov=src --cov-report=term-missing
```
---
## 🔍 Troubleshooting
| Error | Fix |
|-------|-----|
| `Invalid API key` | Check `.env`: `LLM_API_KEY=your_key` |
| `ModuleNotFoundError` | `pip install omnicoreagent` |
| `Redis connection failed` | Start Redis or use `MemoryRouter("in_memory")` |
| `MCP connection refused` | Ensure MCP server is running |
> 📖 **More troubleshooting**: [Basic Usage Guide →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/how-to-guides/basic-usage)
---
## 📝 Changelog
See the full [Changelog →](https://docs-omnicoreagent.omnirexfloralabs.com/docs/changelog) for version history.
---
## 🤝 Contributing
```bash
# Fork & clone
git clone https://github.com/omnirexflora-labs/omnicoreagent.git
# Setup
uv venv && source .venv/bin/activate
uv sync --dev
pre-commit install
# Submit PR
```
See [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
---
## 📄 License
MIT License — see [LICENSE](LICENSE)
---
## 👨💻 Author & Credits
**Created by [Abiola Adeshina](https://github.com/Abiorh001)**
- **GitHub**: [@Abiorh001](https://github.com/Abiorh001)
- **X (Twitter)**: [@abiorhmangana](https://x.com/abiorhmangana)
- **Email**: abiolaadedayo1993@gmail.com
### 🌟 The OmniRexFlora Ecosystem
| Project | Description |
|---------|-------------|
| [🧠 OmniMemory](https://github.com/omnirexflora-labs/omnimemory) | Self-evolving memory for autonomous agents |
| [🤖 OmniCoreAgent](https://github.com/omnirexflora-labs/omnicoreagent) | Production-ready AI agent framework (this project) |
| [⚡ OmniDaemon](https://github.com/omnirexflora-labs/OmniDaemon) | Event-driven runtime engine for AI agents |
### 🙏 Acknowledgments
Built on: [LiteLLM](https://github.com/BerriAI/litellm), [FastAPI](https://fastapi.tiangolo.com/), [Redis](https://redis.io/), [Opik](https://opik.ai/), [Pydantic](https://pydantic-docs.helpmanual.io/), [APScheduler](https://apscheduler.readthedocs.io/)
---
<p align="center">
<strong>Building the future of production-ready AI agent frameworks</strong>
</p>
<p align="center">
<a href="https://github.com/omnirexflora-labs/omnicoreagent">⭐ Star us on GitHub</a> •
<a href="https://github.com/omnirexflora-labs/omnicoreagent/issues">🐛 Report Bug</a> •
<a href="https://github.com/omnirexflora-labs/omnicoreagent/issues">💡 Request Feature</a> •
<a href="https://docs-omnicoreagent.omnirexfloralabs.com/docs">📖 Documentation</a>
</p>
| text/markdown | null | Abiola Adeshina <abiolaadedayo1993@gmail.com> | null | null | MIT | agent, ai, automation, framework, git, llm, mcp | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"anyio>=4.2.0",
"apscheduler>=3.11.0",
"boto3>=1.42.37",
"click>=8.1.7",
"colorama>=0.4.6",
"colorlog>=6.9.0",
"cryptography>=45.0.6",
"docstring-parser>=0.16",
"fastapi-sso>=0.18.0",
"fastapi>=0.115.12",
"httpx-sse>=0.4.0",
"httpx>=0.26.0",
"litellm>=1.75.2",
"mcp[cli]>=1.9.1",
"motor>=... | [] | [] | [] | [
"Repository, https://github.com/omnirexflora-labs/omnicoreagent",
"Issues, https://github.com/omnirexflora-labs/omnicoreagent/issues"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T09:00:29.771686 | omnicoreagent-0.3.8.tar.gz | 268,012 | 46/90/3b4f3075c4279c9de96a51ceccfd0a79247083f6ab172320fbbce37d766d/omnicoreagent-0.3.8.tar.gz | source | sdist | null | false | 173cadc77fd3d6450ffec224d2988bb0 | 3ab072eccbce8f4969e4f31c7c8efbba15d3822fd66ef6f8241d2679db2b87ad | 46903b4f3075c4279c9de96a51ceccfd0a79247083f6ab172320fbbce37d766d | null | [
"LICENSE"
] | 237 |
2.4 | sag-py-auth-brand | 1.2.5 | Keycloak brand/instance authentication for python projects | # sag_py_auth_brand
[![Maintainability][codeclimate-image]][codeclimate-url]
[![Coverage Status][coveralls-image]][coveralls-url]
[](https://snyk.io/test/github/SamhammerAG/sag_py_auth_brand)
[coveralls-image]:https://coveralls.io/repos/github/SamhammerAG/sag_py_auth_brand/badge.svg?branch=master
[coveralls-url]:https://coveralls.io/github/SamhammerAG/sag_py_auth_brand?branch=master
[codeclimate-image]:https://api.codeclimate.com/v1/badges/9731a0fe593f7e5f10b6/maintainability
[codeclimate-url]:https://codeclimate.com/github/SamhammerAG/sag_py_auth_brand/maintainability
This provides a way to secure your fastapi with keycloak jwt bearer authentication.
This library bases on sag_py_auth and adds support for instances/brands.
## What it does
* Secure your api endpoints
* Verifies auth tokens: signature, expiration, issuer, audience
* Verifies the brand/customer over a token role
* Verifies the instance over a token role
* Verifies the stage over a realm role
* Allows to set additional permissions by specifying further token roles
* Supplies brand information from context
## How to use
### Installation
pip install sag-py-auth-brand
### Secure your apis
First create the fast api dependency with the auth config:
```python
from sag_py_auth import TokenRole
from sag_py_auth_brand.models import AuthConfig
from sag_py_auth_brand.brand_jwt_auth import BrandJwtAuth
from fastapi import Depends
auth_config = BrandAuthConfig("https://authserver.com/auth/realms/projectName", "myaudience", "myinstance", "mystage")
required_roles = [TokenRole("clientname", "adminrole")]
requires_admin = Depends(BrandJwtAuth(auth_config, required_endpoint_roles))
```
Afterwards you can use it in your route like that:
```python
@app.post("/posts", dependencies=[requires_admin], tags=["posts"])
async def add_post(post: PostSchema) -> dict:
```
Or if you use sub routes, auth can also be enforced for the entire route like that:
```python
router = APIRouter()
router.include_router(sub_router, tags=["my_api_tag"], prefix="/subroute",dependencies=[requires_admin])
```
### Get brand information
See sag_py_auth to find out how to access the token and user info.
Furthermore you can get the brand by accessing it over the context:
```python
from sag_py_auth_brand.request_brand_context import get_request_brand as get_brand_from_context
brand = get_brand_from_context()
```
This works in async calls but not in sub threads (without additional changes).
See:
* https://docs.python.org/3/library/contextvars.html
* https://kobybass.medium.com/python-contextvars-and-multithreading-faa33dbe953d
### Log the brand
It is possible to log the brand by adding a filter.
```python
import logging
from sag_py_auth_brand.request_brand_logging_filter import RequestBrandLoggingFilter
console_handler = logging.StreamHandler(sys.stdout)
console_handler.addFilter(RequestBrandLoggingFilter())
```
The filter provides the field request_brand with the brand.
### How a token has to look like
```json
{
"iss": "https://authserver.com/auth/realms/projectName",
"aud": ["audienceOne", "audienceTwo"],
"typ": "Bearer",
"azp": "public-project-swagger",
"preferred_username": "preferredUsernameValue",
.....
"realm_access": {
"roles": ["myStage"]
},
"resource_access": {
"role-instance": {
"roles": ["myInstance"]
},
"role-brand": {
"roles": ["myBrand"]
},
"role-endpoint": {
"roles": ["permissionOne", "permissionTwo"]
}
}
}
```
* role-endpoint is just required for permission checks of the api endpoint
## How to start developing
### With vscode
Just install vscode with dev containers extension. All required extensions and configurations are prepared automatically.
### With pycharm
* Install latest pycharm
* Install pycharm plugin BlackConnect
* Install pycharm plugin Mypy
* Configure the python interpreter/venv
* pip install requirements-dev.txt
* pip install black[d]
* Ctl+Alt+S => Check Tools => BlackConnect => Trigger when saving changed files
* Ctl+Alt+S => Check Tools => BlackConnect => Trigger on code reformat
* Ctl+Alt+S => Click Tools => BlackConnect => "Load from pyproject.yaml" (ensure line length is 120)
* Ctl+Alt+S => Click Tools => BlackConnect => Configure path to the blackd.exe at the "local instance" config (e.g. C:\Python310\Scripts\blackd.exe)
* Ctl+Alt+S => Click Tools => Actions on save => Reformat code
* Restart pycharm
## How to publish
* Update the version in setup.py and commit your change
* Create a tag with the same version number
* Let github do the rest
## How to test
To avoid publishing to pypi unnecessarily you can do as follows
* Tag your branch however you like
* Use the chosen tag in the requirements.txt-file of the project you want to test this library in, eg. `sag_py_auth_brand==<your tag>`
* Rebuild/redeploy your project
| text/markdown | Samhammer AG | support@samhammer.de | null | null | MIT | auth, fastapi, keycloak | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Software Development :: Libraries",
"Topic :: Software Development"
] | [] | https://github.com/SamhammerAG/sag_py_auth_brand | null | >=3.12 | [] | [] | [] | [
"contextvars>=2.4",
"fastapi[standard]>=0.128.8",
"sag-py-auth>=1.2.5",
"pytest; extra == \"dev\""
] | [] | [] | [] | [
"Documentation, https://github.com/SamhammerAG/sag_py_auth_brand",
"Bug Reports, https://github.com/SamhammerAG/sag_py_auth_brand/issues",
"Source, https://github.com/SamhammerAG/sag_py_auth_brand"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:59:28.838985 | sag_py_auth_brand-1.2.5.tar.gz | 8,303 | 01/7d/f47a719c7dcf0c6f7a8657e7636c6298bc1d9706ef3214b7eaab48b4a313/sag_py_auth_brand-1.2.5.tar.gz | source | sdist | null | false | a9fc2fb22c68a7f3b7fb15b2eb53b485 | bc57125645facae24e783f2da6157aafd0d44316ee80a5b246e3bed90468d869 | 017df47a719c7dcf0c6f7a8657e7636c6298bc1d9706ef3214b7eaab48b4a313 | null | [
"LICENSE.txt"
] | 232 |
2.4 | rangebar | 12.25.1 | Python bindings for rangebar: Non-lookahead range bar construction for cryptocurrency trading | [//]: # SSoT-OK
# rangebar-py
High-performance range bar construction for quantitative trading, with Python bindings via PyO3/maturin.
[](https://pypi.org/project/rangebar/)
[](https://github.com/terrylica/rangebar-py/blob/main/LICENSE)
[](https://pypi.org/project/rangebar/)
| Resource | URL |
| --------------------- | ------------------------------------------------- |
| PyPI | <https://pypi.org/project/rangebar/> |
| Repository | <https://github.com/terrylica/rangebar-py> |
| Performance Dashboard | <https://terrylica.github.io/rangebar-py/> |
| API Reference | [docs/api/INDEX.md](docs/api/INDEX.md) |
| Issues | <https://github.com/terrylica/rangebar-py/issues> |
## Installation
```bash
pip install rangebar
```
Pre-built wheels: Linux (x86_64), macOS (ARM64), Python 3.13. Source build requires Rust toolchain and maturin.
## Quick Start
```python
from rangebar import get_range_bars
# Fetch data and generate range bars in one call
df = get_range_bars("BTCUSDT", "2024-01-01", "2024-06-30")
# Use with backtesting.py
from backtesting import Backtest, Strategy
bt = Backtest(df, MyStrategy, cash=10000, commission=0.0002)
stats = bt.run()
```
Output: pandas DataFrame with DatetimeIndex and OHLCV columns, compatible with [backtesting.py](https://github.com/kernc/backtesting.py).
## API Overview
| Function | Use Case |
| ---------------------------- | ------------------------------- |
| `get_range_bars()` | Date-bounded, auto-fetch |
| `get_n_range_bars()` | Exact N bars (ML training) |
| `process_trades_polars()` | Polars DataFrames (2-3x faster) |
| `process_trades_chunked()` | Large datasets (>10M trades) |
| `populate_cache_resumable()` | Long ranges (>30 days) |
| `run_sidecar()` | Real-time streaming sidecar |
```python
# Count-bounded (ML training)
from rangebar import get_n_range_bars
df = get_n_range_bars("BTCUSDT", n_bars=10000)
# Polars (2-3x faster)
import polars as pl
from rangebar import process_trades_polars
bars = process_trades_polars(pl.scan_parquet("trades.parquet"), threshold_decimal_bps=250)
# With microstructure features (57 columns: OFI, Kyle lambda, Hurst, etc.)
df = get_range_bars("BTCUSDT", "2024-01-01", "2024-06-30", include_microstructure=True)
# Real-time streaming sidecar
from rangebar import run_sidecar, SidecarConfig
config = SidecarConfig(symbol="BTCUSDT", threshold_decimal_bps=250)
run_sidecar(config)
```
## Designed for Claude Code
This repository uses a [CLAUDE.md](CLAUDE.md) network that provides comprehensive project context for AI-assisted development via Anthropic's [Claude Code](https://code.claude.com/) CLI.
```bash
npm install -g @anthropic-ai/claude-code
cd rangebar-py
claude
```
Claude Code reads the CLAUDE.md files automatically and understands the full architecture, API, build system, and development workflow.
## Development
```bash
git clone https://github.com/terrylica/rangebar-py.git
cd rangebar-py
mise install # Setup tools (Rust, Python, zig)
mise run build # maturin develop
mise run test # Rust tests
mise run test-py # Python tests
```
## Requirements
**Runtime**: Python >= 3.13, pandas >= 2.0, numpy >= 1.24, polars >= 1.0
**Build**: Rust toolchain, maturin >= 1.7
## License
MIT License. See [LICENSE](LICENSE).
## Citation
```bibtex
@software{rangebar-py,
title = {rangebar-py: High-performance range bar construction for quantitative trading},
author = {Terry Li},
url = {https://github.com/terrylica/rangebar-py}
}
```
| text/markdown; charset=UTF-8; variant=GFM | Terry Li | null | null | null | MIT | trading, cryptocurrency, range-bars, backtesting, technical-analysis | [
"Development Status :: 4 - Beta",
"Intended Audience :: Financial and Insurance Industry",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.13",
"Programming Language :: Rust",
"Topic :: Office/Business :: Financial :: Investment"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"pandas>=2.0",
"numpy>=1.24",
"polars>=1.0",
"pyarrow>=14.0",
"platformdirs>=4.0",
"clickhouse-connect>=0.8",
"arro3-core>=0.6.5",
"click>=8.0",
"requests>=2.28",
"loguru>=0.7.0",
"tqdm>=4.66",
"backtesting>=0.3; extra == \"backtesting\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-benchmark... | [] | [] | [] | [
"Documentation, https://github.com/terrylica/rangebar-py#readme",
"Repository, https://github.com/terrylica/rangebar-py",
"Upstream (Rust), https://github.com/terrylica/rangebar"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-19T08:59:10.868994 | rangebar-12.25.1.tar.gz | 13,303,988 | 32/d0/809bb4cb681f7007828c5df03cfd11dc2b696f67782a041ca99be6e8820f/rangebar-12.25.1.tar.gz | source | sdist | null | false | 2ee07c21249546b2e31baf1b8ddb03d0 | 76281159234ebc236aed356a445a9b706fa49041e6cb5c4b5a9e115baadc96c2 | 32d0809bb4cb681f7007828c5df03cfd11dc2b696f67782a041ca99be6e8820f | null | [
"LICENSE"
] | 322 |
2.4 | cadence-sdk | 2.0.2 | Framework-agnostic SDK for building Cadence AI agent plugins | # Cadence SDK
**Framework-agnostic plugin development kit for multi-tenant AI agent platforms**
[](https://www.python.org/downloads/)
[](https://badge.fury.io/py/cadence-sdk)
[](https://opensource.org/licenses/MIT)
Cadence SDK is a Python library that enables developers to build AI agent plugins that work seamlessly across multiple
orchestration frameworks (LangGraph, OpenAI Agents SDK, Google ADK) without framework-specific code.
## Table of Contents
- [Features](#features)
- [Installation](#installation)
- [Quick Start](#quick-start)
- [Core Concepts](#core-concepts)
- [Plugin Development](#plugin-development)
- [Tool Development](#tool-development)
- [Caching](#caching)
- [State Management](#state-management)
- [Examples](#examples)
- [API Reference](#api-reference)
- [Best Practices](#best-practices)
- [Contributing](#contributing)
## Features
### 🎯 Framework-Agnostic Design
Write your plugin once, run it on any supported orchestration framework:
- **LangGraph** (LangChain-based)
- **OpenAI Agents SDK**
- **Google ADK** (Agent Development Kit)
### 🔧 Simple Tool Declaration
Define tools with a single decorator - no framework-specific code:
```python
@uvtool
def search(query: str) -> str:
"""Search for information."""
return perform_search(query)
```
### 💾 Integrated Caching
Built-in semantic caching for expensive operations:
```python
@uvtool(cache=CacheConfig(ttl=3600, similarity_threshold=0.85))
def expensive_api_call(query: str) -> str:
"""Cached API call."""
return call_external_api(query)
```
### 🔌 Plugin System
- **Plugin discovery** from multiple sources (pip packages, directories, system-wide)
- **Settings schema** with type validation
- **Dependency management** with auto-installation
- **Version conflict resolution**
- **Health checks** and lifecycle management
### 📦 Type Safety
Fully typed with Pydantic for excellent IDE support and runtime validation.
### ⚡ Async Support
First-class support for async tools with automatic detection and invocation.
## Installation
### From PyPI (when published)
```bash
pip install cadence-sdk
```
### From Source
```bash
git clone https://github.com/jonaskahn/cadence-sdk.git
cd cadence-sdk
poetry install
```
### Development Installation
```bash
poetry install --with dev
```
## Quick Start
### 1. Create Your First Plugin
```python
# my_plugin/plugin.py
from cadence_sdk import (
BasePlugin, BaseAgent, PluginMetadata,
uvtool, UvTool, plugin_settings
)
from typing import List
class MyAgent(BaseAgent):
"""My custom agent."""
@uvtool
def greet(self, name: str) -> str:
"""Greet a user by name."""
return f"Hello, {name}!"
@uvtool(cache=True) # Enable caching with defaults
def search(self, query: str) -> str:
"""Search for information (cached)."""
# Your search implementation
return f"Results for: {query}"
def get_tools(self) -> List[UvTool]:
"""Return list of tools."""
return [self.greet, self.search]
def get_system_prompt(self) -> str:
"""Return system prompt."""
return "You are a helpful assistant."
@plugin_settings([
{
"key": "api_key",
"type": "str",
"required": True,
"sensitive": True,
"description": "API key for external service"
}
])
class MyPlugin(BasePlugin):
"""My custom plugin."""
@staticmethod
def get_metadata() -> PluginMetadata:
return PluginMetadata(
pid="com.example.my_plugin",
name="My Plugin",
version="1.0.0",
description="My awesome plugin",
capabilities=["greeting", "search"],
)
@staticmethod
def create_agent() -> BaseAgent:
return MyAgent()
```
### 2. Register Your Plugin
```python
from cadence_sdk import register_plugin
from my_plugin import MyPlugin
# Register plugin
register_plugin(MyPlugin)
```
### 3. Use Your Plugin
Your plugin is now ready to be loaded by the Cadence platform and will work with any supported orchestration framework!
## Core Concepts
### Plugins
Plugins are factory classes that create agent instances. They declare metadata, settings schema, and provide health
checks. The `pid` (plugin ID) is a required reverse-domain identifier (e.g., `com.example.my_plugin`) used as the
registry key.
```python
class MyPlugin(BasePlugin):
@staticmethod
def get_metadata() -> PluginMetadata:
"""Return plugin metadata."""
return PluginMetadata(
pid="com.example.my_plugin",
name="My Plugin",
version="1.0.0",
description="Description",
capabilities=["cap1", "cap2"],
dependencies=["requests>=2.0"],
)
@staticmethod
def create_agent() -> BaseAgent:
"""Create and return agent instance."""
return MyAgent()
```
### Agents
Agents provide tools and system prompts. They can maintain state and be initialized with configuration.
```python
class MyAgent(BaseAgent):
def initialize(self, config: dict) -> None:
"""Initialize with configuration."""
self.api_key = config.get("api_key")
def get_tools(self) -> List[UvTool]:
"""Return available tools."""
return [self.tool1, self.tool2]
def get_system_prompt(self) -> str:
"""Return system prompt."""
return "You are a helpful assistant."
async def cleanup(self) -> None:
"""Clean up resources."""
# Close connections, etc.
pass
```
### Tools
Tools are functions that agents can invoke. They can be synchronous or asynchronous.
```python
from cadence_sdk import uvtool, CacheConfig
from pydantic import BaseModel
# Simple tool
@uvtool
def simple_tool(text: str) -> str:
"""A simple tool."""
return text.upper()
# Tool with args schema
class SearchArgs(BaseModel):
query: str
limit: int = 10
@uvtool(args_schema=SearchArgs)
def search(query: str, limit: int = 10) -> str:
"""Search with validation."""
return f"Top {limit} results for: {query}"
# Cached tool
@uvtool(cache=CacheConfig(
ttl=3600,
similarity_threshold=0.85,
cache_key_fields=["query"] # Only cache by query
))
def expensive_search(query: str, options: dict = None) -> str:
"""Expensive operation with selective caching."""
return perform_expensive_search(query, options)
# Async tool
@uvtool
async def async_fetch(url: str) -> str:
"""Asynchronous tool."""
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
```
### Messages
Framework-agnostic message types for agent communication:
```python
from cadence_sdk import (
UvHumanMessage,
UvAIMessage,
UvSystemMessage,
UvToolMessage,
ToolCall
)
# Human message
human = UvHumanMessage(content="Hello!")
# AI message with tool calls
ai = UvAIMessage(
content="Let me search for that.",
tool_calls=[
ToolCall(name="search", args={"query": "Python"})
]
)
# System message
system = UvSystemMessage(content="You are helpful.")
# Tool result message
tool_result = UvToolMessage(
content="Search results: ...",
tool_call_id="call_123",
tool_name="search"
)
```
### State
Unified state management across frameworks:
```python
from cadence_sdk import UvState, StateHelpers, create_initial_state
# Create initial state
state = create_initial_state(
messages=[UvHumanMessage(content="Hello")],
thread_id="thread_123"
)
# Use state helpers
thread_id = StateHelpers.safe_get_thread_id(state)
messages = StateHelpers.safe_get_messages(state)
hops = StateHelpers.safe_get_agent_hops(state)
# Update state
state = StateHelpers.increment_agent_hops(state)
update = StateHelpers.create_state_update(current_agent="my_agent")
state = {**state, **update}
```
## Plugin Development
### Settings Declaration
Declare settings schema for your plugin:
```python
from cadence_sdk import plugin_settings
@plugin_settings([
{
"key": "api_key",
"type": "str",
"required": True,
"sensitive": True,
"description": "API key for service"
},
{
"key": "max_results",
"type": "int",
"default": 10,
"required": False,
"description": "Maximum results to return"
},
{
"key": "endpoints",
"type": "list",
"default": ["https://api.example.com"],
"description": "API endpoints"
}
])
class MyPlugin(BasePlugin):
pass
```
### Agent Initialization
Agents receive resolved settings during initialization:
```python
class MyAgent(BaseAgent):
def __init__(self):
self.api_key = None
self.max_results = 10
def initialize(self, config: dict) -> None:
"""Initialize with resolved configuration.
Config contains:
- Declared settings with defaults applied
- User-provided overrides
- Framework-resolved values
"""
self.api_key = config["api_key"]
self.max_results = config.get("max_results", 10)
```
### Resource Cleanup
Implement cleanup for proper resource management:
```python
class MyAgent(BaseAgent):
def __init__(self):
self.db_connection = None
self.http_client = None
async def cleanup(self) -> None:
"""Clean up resources when agent is disposed."""
if self.db_connection:
await self.db_connection.close()
if self.http_client:
await self.http_client.aclose()
```
## Tool Development
### Basic Tool
```python
@uvtool
def greet(name: str) -> str:
"""Greet a user by name.
Args:
name: Name of the person to greet
Returns:
Greeting message
"""
return f"Hello, {name}!"
```
### Tool with Schema Validation
```python
from pydantic import BaseModel, Field
class SearchArgs(BaseModel):
query: str = Field(..., description="Search query")
limit: int = Field(10, ge=1, le=100, description="Max results")
filters: dict = Field(default_factory=dict, description="Search filters")
@uvtool(args_schema=SearchArgs)
def search(query: str, limit: int = 10, filters: dict = None) -> str:
"""Search with validated arguments."""
# Arguments are validated against SearchArgs schema
return perform_search(query, limit, filters or {})
```
### Async Tool
```python
@uvtool
async def fetch_data(url: str) -> dict:
"""Asynchronously fetch data from URL.
The SDK automatically detects async functions and handles
invocation correctly.
"""
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.json()
# Invoke async tool
result = await fetch_data.ainvoke(url="https://api.example.com")
```
### Tool Invocation
```python
# Sync tool - direct call
result = greet(name="Alice")
# Sync tool - explicit invoke
result = greet.invoke(name="Alice")
# Async tool - must use ainvoke
result = await fetch_data.ainvoke(url="https://example.com")
# Check if tool is async
if fetch_data.is_async:
result = await fetch_data.ainvoke(...)
else:
result = fetch_data(...)
```
## Caching
### Cache Configuration
```python
from cadence_sdk import uvtool, CacheConfig
# Method 1: CacheConfig instance (recommended)
@uvtool(cache=CacheConfig(
ttl=3600, # Cache for 1 hour
similarity_threshold=0.85, # 85% similarity for cache hits
cache_key_fields=["query"] # Only cache by query parameter
))
def cached_search(query: str, limit: int = 10) -> str:
"""Different limits use same cached result."""
return expensive_search(query, limit)
# Method 2: Dictionary
@uvtool(cache={
"ttl": 7200,
"similarity_threshold": 0.9
})
def another_cached_tool(text: str) -> str:
return process(text)
# Method 3: Boolean (use defaults)
@uvtool(cache=True) # TTL=3600, threshold=0.85
def simple_cached_tool(input: str) -> str:
return expensive_operation(input)
# Disable caching
@uvtool(cache=False)
# or simply:
@uvtool
def no_cache_tool(data: str) -> str:
return realtime_data()
```
### Cache Configuration Options
| Field | Type | Default | Description |
|------------------------|-----------|---------|------------------------------------------|
| `enabled` | bool | `True` | Whether caching is enabled |
| `ttl` | int | `3600` | Time-to-live in seconds |
| `similarity_threshold` | float | `0.85` | Cosine similarity threshold (0.0-1.0) |
| `cache_key_fields` | List[str] | `None` | Fields to use for cache key (None = all) |
### How Caching Works
1. **Semantic Matching**: Uses embeddings to find similar queries
2. **Threshold**: Only returns cached results above similarity threshold
3. **TTL**: Cached results expire after TTL seconds
4. **Selective Keys**: Cache only by specific parameters
Example:
```python
@uvtool(cache=CacheConfig(
ttl=3600,
similarity_threshold=0.85,
cache_key_fields=["query"]
))
def search(query: str, limit: int = 10, format: str = "json") -> str:
"""Cache by query only, ignore limit and format."""
pass
# These will use the same cached result:
search("Python programming", limit=10, format="json")
search("Python programming", limit=50, format="xml")
# This might get a cache hit if similarity > 0.85:
search("Python coding", limit=10, format="json")
```
## State Management
### Creating State
```python
from cadence_sdk import create_initial_state, UvHumanMessage
state = create_initial_state(
messages=[
UvHumanMessage(content="Hello")
],
thread_id="thread_123",
metadata={"user_id": "user_456"}
)
```
### Reading State
```python
from cadence_sdk import StateHelpers
# Safe getters (return None if not present)
thread_id = StateHelpers.safe_get_thread_id(state)
messages = StateHelpers.safe_get_messages(state)
agent_hops = StateHelpers.safe_get_agent_hops(state)
current_agent = StateHelpers.safe_get_current_agent(state)
metadata = StateHelpers.safe_get_metadata(state)
# Plugin context
context = StateHelpers.get_plugin_context(state)
routing_history = context.get("routing_history", [])
tools_used = context.get("tools_used", [])
```
### Updating State
```python
from cadence_sdk import StateHelpers, RoutingHelpers
# Increment agent hops
state = StateHelpers.increment_agent_hops(state)
# Create state update (returns dict to merge)
update = StateHelpers.create_state_update(
current_agent="my_agent",
metadata={"step": "processing"}
)
state = {**state, **update}
# Update plugin context
state = StateHelpers.update_plugin_context(
state,
{"custom_data": "value"}
)
# Routing helpers
state = RoutingHelpers.add_to_routing_history(state, "agent1")
state = RoutingHelpers.add_tool_used(state, "search")
```
## Examples
### Complete Plugin Example
See the [template_plugin](examples/template_plugin/) for a complete, working example that demonstrates:
- Plugin and agent structure
- Sync and async tools
- Caching configuration
- Settings schema
- State management
- Resource cleanup
### Running the Example
```bash
# From cadence-sdk root, with SDK on path
cd cadence-sdk
PYTHONPATH=src python examples/test_sdk.py
```
### Running the Test Suite
```bash
cd cadence-sdk
pip install -e ".[dev]"
PYTHONPATH=src python -m pytest tests/ -v
```
## API Reference
### Core Classes
#### `BasePlugin`
Abstract base class for plugins.
**Methods:**
- `get_metadata()` (static) → `PluginMetadata`: Return plugin metadata
- `create_agent()` (static) → `BaseAgent`: Create agent instance
- `validate_dependencies()` (static) → `List[str]`: Validate dependencies
- `health_check()` (static) → `dict`: Perform health check
#### `BaseAgent`
Abstract base class for agents.
**Methods:**
- `get_tools()` → `List[UvTool]`: Return list of tools (required)
- `get_system_prompt()` → `str`: Return system prompt (required)
- `initialize(config: dict)` → `None`: Initialize with config (optional)
- `cleanup()` → `None`: Clean up resources (optional)
#### `UvTool`
Tool wrapper class.
**Attributes:**
- `name`: Tool name
- `description`: Tool description
- `func`: Underlying callable
- `args_schema`: Pydantic model for arguments
- `cache`: Cache configuration
- `metadata`: Additional metadata
- `is_async`: Whether tool is async
**Methods:**
- `__call__(*args, **kwargs)`: Sync invocation
- `ainvoke(*args, **kwargs)`: Async invocation
- `invoke(*args, **kwargs)`: Sync invocation alias
#### `CacheConfig`
Cache configuration dataclass.
**Fields:**
- `enabled` (bool): Whether caching is enabled
- `ttl` (int): Time-to-live in seconds
- `similarity_threshold` (float): Similarity threshold (0.0-1.0)
- `cache_key_fields` (Optional[List[str]]): Fields for cache key
### Message Types
- `UvHumanMessage`: User message
- `UvAIMessage`: Assistant message (with optional tool calls)
- `UvSystemMessage`: System message
- `UvToolMessage`: Tool result message
- `ToolCall`: Tool invocation record
### Decorators
#### `@uvtool`
Convert function to UvTool.
**Parameters:**
- `name` (str, optional): Tool name (default: function name)
- `description` (str, optional): Description (default: docstring)
- `args_schema` (Type[BaseModel], optional): Pydantic model for validation
- `cache` (Union[CacheConfig, bool, dict], optional): Cache configuration
- `**metadata`: Additional metadata
#### `@plugin_settings`
Declare plugin settings schema.
**Parameters:**
- `settings` (List[dict]): List of setting definitions
**Setting Definition:**
- `key` (str): Setting key
- `type` (str): Type ("str", "int", "float", "bool", "list", "dict")
- `default` (Any, optional): Default value
- `description` (str): Setting description
- `required` (bool): Whether setting is required
- `sensitive` (bool): Whether value is sensitive (e.g., API key)
### Utility Functions
- `register_plugin(plugin_class)`: Register plugin
- `discover_plugins(search_paths, auto_register=True)`: Discover plugins in directory or list of directories
- `validate_plugin_structure(plugin_class)`: Validate plugin structure
- `create_initial_state(...)`: Create initial UvState
## Best Practices
### 1. Keep Plugins Stateless
When possible, design plugins to be stateless (`stateless=True` in metadata). This allows the framework to share plugin
instances across multiple orchestrators for better memory efficiency.
```python
PluginMetadata(
pid="com.example.my_plugin",
name="My Plugin",
version="1.0.0",
description="Plugin description",
stateless=True, # Enable sharing
)
```
### 2. Use Type Hints
Always use type hints for better IDE support and runtime validation:
```python
@uvtool
def my_tool(query: str, limit: int = 10) -> str:
"""Type hints improve IDE support."""
return search(query, limit)
```
### 3. Provide Good Descriptions
Tools and plugins should have clear, concise descriptions:
```python
@uvtool
def search(query: str) -> str:
"""Search for information using the external API.
This tool performs semantic search across our knowledge base
and returns the top matching results.
Args:
query: The search query string
Returns:
Formatted search results
"""
return perform_search(query)
```
### 4. Handle Errors Gracefully
```python
@uvtool
def api_call(endpoint: str) -> str:
"""Make API call with proper error handling."""
try:
response = requests.get(endpoint)
response.raise_for_status()
return response.json()
except requests.RequestException as e:
return f"Error: {str(e)}"
```
### 5. Use Selective Caching
Only cache by parameters that affect the result:
```python
@uvtool(cache=CacheConfig(
cache_key_fields=["query", "language"], # Ignore format, limit
))
def translate(query: str, language: str, format: str = "text", limit: int = 100) -> str:
"""Cache by query and language only."""
pass
```
### 6. Clean Up Resources
Always implement cleanup for resources:
```python
class MyAgent(BaseAgent):
async def cleanup(self) -> None:
"""Clean up connections and resources."""
if hasattr(self, 'db'):
await self.db.close()
if hasattr(self, 'http_client'):
await self.http_client.aclose()
```
### 7. Version Your Plugins
Use semantic versioning and declare dependencies explicitly:
```python
PluginMetadata(
pid="com.example.my_plugin",
name="My Plugin",
version="1.2.3", # Semantic versioning
description="Plugin description",
sdk_version=">=3.0.0,<4.0.0", # Compatible SDK versions
dependencies=["requests>=2.28.0", "aiohttp>=3.8.0"],
)
```
## Contributing
Contributions are welcome! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
### Development Setup
```bash
# Clone repository
git clone https://github.com/jonaskahn/cadence-sdk.git
cd cadence-sdk
# Install with development dependencies
poetry install --with dev
# Run tests
PYTHONPATH=src python -m pytest tests/
# Run linting
poetry run black .
poetry run isort .
poetry run mypy .
```
### Running Tests
```bash
# All tests
PYTHONPATH=src python -m pytest tests/
# With coverage
PYTHONPATH=src python -m pytest tests/ --cov=cadence_sdk --cov-report=term-missing
# Specific test file
PYTHONPATH=src python -m pytest tests/test_sdk_tools.py -v
# Run example script
PYTHONPATH=src python examples/test_sdk.py
```
## License
MIT License - see [LICENSE](LICENSE) file for details.
## Support
- **Documentation**: [https://docs.cadence.dev](https://docs.cadence.dev)
- **Issues**: [GitHub Issues](https://github.com/jonaskahn/cadence-sdk/issues)
- **Discussions**: [GitHub Discussions](https://github.com/jonaskahn/cadence-sdk/discussions)
## Changelog
See [CHANGELOG.md](CHANGELOG.md) for version history and release notes.
---
**Built with ❤️ for the AI agent development community**
| text/markdown | jonaskahn | me@ifelse.one | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"packaging>=21.0",
"pydantic>=2.0",
"typing-extensions>=4.5"
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.14.3 Darwin/25.3.0 | 2026-02-19T08:58:03.977227 | cadence_sdk-2.0.2-py3-none-any.whl | 38,219 | 2c/0d/1b483a5d91ef6688178e7439ffff16aeff449d91516fd15bb6a633a51316/cadence_sdk-2.0.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 6ed8b5ceeb8d68030f23898fec9a4722 | 1d48edb9100a17ce909624dbd364b2a3f71f770bd1b411d954802d9e9f1859ea | 2c0d1b483a5d91ef6688178e7439ffff16aeff449d91516fd15bb6a633a51316 | null | [
"LICENSE"
] | 254 |
2.4 | pytest-testinel | 0.4.2 | Testinel’s pytest plugin captures structured test execution data directly from pytest and sends it to Testinel, where your test results become searchable, comparable, and actually useful. | ## Official Testinel plugin for pytest
Testinel’s pytest plugin captures structured test execution data directly from pytest and sends it to Testinel, where your test results become searchable, comparable, and actually useful. No log scraping. No brittle CI hacks. Just deterministic test analytics.
## 📦 Getting Started
### Prerequisites
You need a Testinel [account](https://testinel.first.institute/accounts/signup/?next=/projects/) and [project](https://testinel.first.institute/projects/).
### Installation
Getting Testinel into your project is straightforward. Just run this command in your terminal:
```
pip install --upgrade pytest-testinel
```
### Configuration
Set Testinel reporter DSN environment variable `TESTINEL_DSN`.
Examples:
```
# Report to Testinel (HTTPS)
export TESTINEL_DSN="https://your.testinel.endpoint/ingest"
```
```
# Report to a local file (JSON)
export TESTINEL_DSN="file:///tmp/testinel-results.json"
```
```
# Or use a direct file path
export TESTINEL_DSN="./testinel-results.json"
```
### Recommended pytest flags
For better debugging and richer failure context, it is highly recommended to run pytest with:
`--showlocals --tb=long -vv`
Why:
- `--showlocals`: includes local variable values in tracebacks, which makes root-cause analysis much faster.
- `--tb=long`: shows full, non-truncated tracebacks so you can see complete failure paths.
- `-vv`: increases verbosity, showing more detailed test identifiers and execution output.
Example:
```bash
pytest --showlocals --tb=long -vv
```
| text/markdown | Volodymyr Obrizan | Volodymyr Obrizan <obrizan@first.institute> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent",
"Development Status :: 4 - Beta",
"Framework :: Pytest",
"Topic :: Software Development :: Testing"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pytest>=7",
"requests>=2"
] | [] | [] | [] | [
"Homepage, https://testinel.first.institute",
"Repository, https://github.com/Testinel/pytest-testinel",
"Issues, https://github.com/Testinel/pytest-testinel/issues"
] | uv/0.7.19 | 2026-02-19T08:57:10.839541 | pytest_testinel-0.4.2.tar.gz | 6,128 | 16/eb/795c1a8e5f6f6ac086b85b57ba85c563581cd9a95a2dd4221f46dba849aa/pytest_testinel-0.4.2.tar.gz | source | sdist | null | false | 92694aeda7696ddd33f6f368f4541e8c | cdee529cc21e58941d8a7bd6bf8f573a9def319b6a9ab9f9701c9c74bef16002 | 16eb795c1a8e5f6f6ac086b85b57ba85c563581cd9a95a2dd4221f46dba849aa | MIT | [
"LICENSE"
] | 316 |
2.4 | fractal-server | 2.20.0a0 | Backend component of the Fractal analytics platform | # Fractal Server
<p align="center">
<img src="https://raw.githubusercontent.com/fractal-analytics-platform/fractal-logos/refs/heads/main/projects/fractal_server.png" alt="Fractal server" width="400">
</p>
[](https://pypi.org/project/fractal-server/)
[](https://opensource.org/licenses/BSD-3-Clause)
[](https://github.com/fractal-analytics-platform/fractal-server/actions/workflows/ci.yml?query=branch%3Amain)
[](https://htmlpreview.github.io/?https://github.com/fractal-analytics-platform/fractal-server/blob/python-coverage-comment-action-data/htmlcov/index.html)
[](https://fractal-analytics-platform.github.io/fractal-server)
[](https://htmlpreview.github.io/?https://github.com/fractal-analytics-platform/fractal-server/blob/benchmark-api/benchmarks/bench.html)
[Fractal](https://fractal-analytics-platform.github.io/) is a framework developed at the [BioVisionCenter](https://www.biovisioncenter.uzh.ch/en.html) to process bioimaging data at scale in the OME-Zarr format and prepare the images for interactive visualization.

This is the server component of the fractal analytics platform.
Find more information about Fractal in general and the other repositories at
the [Fractal home page](https://fractal-analytics-platform.github.io).
## Documentation
See https://fractal-analytics-platform.github.io/fractal-server.
# Contributors and license
Fractal was conceived in the Liberali Lab at the Friedrich Miescher Institute for Biomedical Research and in the Pelkmans Lab at the University of Zurich by [@jluethi](https://github.com/jluethi) and [@gusqgm](https://github.com/gusqgm). The Fractal project is now developed at the [BioVisionCenter](https://www.biovisioncenter.uzh.ch/en.html) at the University of Zurich and the project lead is with [@jluethi](https://github.com/jluethi). The core development is done under contract by [eXact lab S.r.l.](https://www.exact-lab.it).
Unless otherwise specified, Fractal components are released under the BSD 3-Clause License, and copyright is with the BioVisionCenter at the University of Zurich.
| text/markdown | Tommaso Comparin, Marco Franzon, Yuri Chiucconi, Jacopo Nespolo | Tommaso Comparin <tommaso.comparin@exact-lab.it>, Marco Franzon <marco.franzon@exact-lab.it>, Yuri Chiucconi <yuri.chiucconi@exact-lab.it>, Jacopo Nespolo <jacopo.nespolo@exact-lab.it> | null | null | null | null | [] | [] | null | null | <3.15,>=3.12 | [] | [] | [] | [
"fastapi<0.130.0,>=0.129.0",
"sqlmodel==0.0.33",
"sqlalchemy[asyncio]<2.1,>=2.0.23",
"fastapi-users[oauth]<16,>=15",
"alembic<2.0.0,>=1.13.1",
"uvicorn<0.41.0,>=0.40.0",
"uvicorn-worker==0.4.0",
"pydantic<2.13.0,>=2.12.0",
"pydantic-settings==2.12.0",
"packaging<27.0.0,>=26.0.0",
"fabric<3.3.0,>... | [] | [] | [] | [
"changelog, https://github.com/fractal-analytics-platform/fractal-server/blob/main/CHANGELOG.md",
"documentation, https://fractal-analytics-platform.github.io/fractal-server",
"homepage, https://github.com/fractal-analytics-platform/fractal-server",
"repository, https://github.com/fractal-analytics-platform/f... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:57:07.376319 | fractal_server-2.20.0a0.tar.gz | 190,857 | 7d/2c/e9a6fa72f5f0a60daf32164381bb27f0a1d1166a1a627087d38b664f8619/fractal_server-2.20.0a0.tar.gz | source | sdist | null | false | 8c7c96da9a00b3a3ece3e483b45edd34 | eca0156243e3c7f1af135ce2bb9a2d00668f9c55ed3a0a9a4488b756e5089442 | 7d2ce9a6fa72f5f0a60daf32164381bb27f0a1d1166a1a627087d38b664f8619 | BSD-3-Clause | [
"LICENSE"
] | 227 |
2.4 | arctrl | 3.0.0 | Library for management of Annotated Research Contexts (ARCs) using an in-memory representation and runtimer agnostic contract systems. |

# ARCtrl
[](https://doi.org/10.5281/zenodo.15194394)
> **ARCtrl** the easy way to read, manipulate and write ARCs in __.NET__, __JavaScript__ and __Python__! ❤️
| Version | Downloads |
| :--------|-----------:|
|<a href="https://www.nuget.org/packages/ARCtrl/"><img alt="Nuget" src="https://img.shields.io/nuget/v/ARCtrl?logo=nuget&color=%234fb3d9"></a>|<a href="https://www.nuget.org/packages/ARCtrl/"><img alt="Nuget" src="https://img.shields.io/nuget/dt/ARCtrl?color=%234FB3D9"></a>|
|<a href="https://www.npmjs.com/package/@nfdi4plants/arctrl"><img alt="NPM" src="https://img.shields.io/npm/v/%40nfdi4plants/arctrl?logo=npm&color=%234fb3d9"></a>|<a href="https://www.npmjs.com/package/@nfdi4plants/arctrl"><img alt="NPM" src="https://img.shields.io/npm/dt/%40nfdi4plants%2Farctrl?color=%234fb3d9"></a>|
|<a href="https://pypi.org/project/ARCtrl/"><img alt="PyPI" src="https://img.shields.io/pypi/v/arctrl?logo=pypi&color=%234fb3d9"></a>|<a href="https://pypi.org/project/ARCtrl/"><img alt="PyPI" src="https://img.shields.io/pepy/dt/arctrl?color=%234fb3d9"></a>|
## Install
#### .NET
```fsharp
#r "nuget: ARCtrl"
```
```bash
<PackageReference Include="ARCtrl" Version="1.1.0" />
```
#### JavaScript
```bash
npm i @nfdi4plants/arctrl
```
#### Python
```bash
pip install arctrl
```
## Docs
Documentation can be found [here](https://nfdi4plants.github.io/nfdi4plants.knowledgebase/arctrl/)
## Development
#### Requirements
- [nodejs and npm](https://nodejs.org/en/download)
- verify with `node --version` (Tested with v18.16.1)
- verify with `npm --version` (Tested with v9.2.0)
- [.NET SDK](https://dotnet.microsoft.com/en-us/download)
- verify with `dotnet --version` (Tested with 7.0.306)
- [Python](https://www.python.org/downloads/)
- verify with `py --version` (Tested with 3.12.2, known to work only for >=3.11)
#### Local Setup
##### Windows
On windows you can use the `setup.cmd` to run the following steps automatically!
1. Setup dotnet tools
`dotnet tool restore`
2. Install NPM dependencies
`npm install`
3. Setup python environment
`py -m venv .venv`
4. Install [uv](https://docs.astral.sh/uv/) and dependencies
1. `.\.venv\Scripts\python.exe -m pip install -U pip setuptools`
2. `.\.venv\Scripts\python.exe -m pip install uv`
3. `.\.venv\Scripts\python.exe -m uv pip install -r pyproject.toml --group dev`
Verify correct setup with `./build.cmd runtests` ✨
##### Linux / macOS
On unix you can use the `setup.sh` to run the following steps automatically!
1. Setup dotnet tools
`dotnet tool restore`
2. Install NPM dependencies
`npm install`
3. Setup python environment
`python -m venv .venv`
4. Install [uv](https://docs.astral.sh/uv/) and dependencies
1. `.venv/bin/python -m pip install -U pip setuptools`
2. `.venv/bin/python -m pip install uv`
3. `.venv/bin/python -m uv pip install -r pyproject.toml --group dev`
Verify correct setup with `bash build.sh runtests` ✨
## Branding
Feel free to reference `ARCtrl` on slides or elsewhere using our logos:
|Square | Horizontal | Vertical |
| - | - | - |
|  |  |  |
## Performance
Measured on 13th Gen Intel(R) Core(TM) i7-13800H
| Name | Description | FSharp Time (ms) | JavaScript Time (ms) | Python Time (ms) |
| --- | --- | --- | --- | --- |
| Table_GetHashCode | From a table with 1 column and 10000 rows, retrieve the Hash Code | 0 ± 0 | 0 ± 1 | 91 ± 12 |
| Table_AddDistinctRows | Add 10000 distinct rows to a table with 4 columns. | 13 ± 2 | 14 ± 4 | 119 ± 12 |
| Table_AddIdenticalRows | Add 10000 identical rows to a table with 4 columns. | 6 ± 2 | 6 ± 1 | 104 ± 6 |
| Table_AddColumnsWithDistinctValues | Add 4 columns with 10000 distinct values each. | 8 ± 3 | 10 ± 1 | 53 ± 1 |
| Table_AddColumnsWithIdenticalValues | Add 4 columns with 10000 identical values each. | 5 ± 1 | 4 ± 0 | 47 ± 1 |
| Table_fillMissingCells | For a table 6 columns and 20000 rows, where each row has one missing value, fill those values with default values. | 0 ± 0 | 2 ± 1 | 6 ± 4 |
| Table_ToJson | Serialize a table with 5 columns and 10000 rows to json, with 3 fixed and 2 variable columns. | 227 ± 64 | 68 ± 18 | 7851 ± 1411 |
| Table_ToCompressedJson | Serialize a table with 5 columns and 10000 rows to compressed json, with 3 fixed and 2 variable columns. | 147 ± 15 | 2878 ± 135 | 6303 ± 1798 |
| Assay_toJson | Parse an assay with one table with 10000 rows and 6 columns to json, with 3 fixed and 3 variable columns. | 330 ± 36 | 88 ± 9 | 12644 ± 550 |
| Assay_fromJson | Parse an assay with one table with 10000 rows and 6 columns from json, with 3 fixed and 3 variable columns. | 355 ± 66 | 61 ± 6 | 6499 ± 1068 |
| Assay_toISAJson | Parse an assay with one table with 10000 rows and 6 columns to json, with 3 fixed and 3 variable columns | 487 ± 36 | 959 ± 36 | 15618 ± 482 |
| Assay_fromISAJson | Parse an assay with one table with 10000 rows and 6 columns from json, with 3 fixed and 3 variable columns | 359 ± 29 | 706 ± 46 | 9587 ± 621 |
| Study_FromWorkbook | Parse a workbook with one study with 10000 rows and 6 columns to an ArcStudy | 29 ± 14 | 62 ± 5 | 818 ± 36 |
| Investigation_ToWorkbook_ManyStudies | Parse an investigation with 1500 studies to a workbook | 240 ± 31 | 284 ± 24 | 3657 ± 199 |
| Investigation_FromWorkbook_ManyStudies | Parse a workbook with 1500 studies to an ArcInvestigation | 127 ± 20 | 498 ± 21 | 9469 ± 412 |
| ARC_ToROCrate | Parse an ARC with one assay with 10000 rows and 6 columns to a RO-Crate metadata file. | 1431 ± 99 | 3526 ± 264 | 61224 ± 728 |
| text/markdown | Heinrich Lukas Weil | weil@rptu.de | Florian Wetzels | null | null | arc, annotated research context, isa, research data, multi platform | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"openpyxl<4,>=3.1.5",
"requests<3.0.0,>=2.28.1"
] | [] | [] | [] | [
"Repository, https://github.com/nfdi4plants/ARCtrl"
] | twine/6.2.0 CPython/3.12.2 | 2026-02-19T08:56:01.405196 | arctrl-3.0.0.tar.gz | 641,238 | 3d/5e/0619ac62e0c14f66b2118c80f288771304fbd420f815209d055fcdd06ebf/arctrl-3.0.0.tar.gz | source | sdist | null | false | f3ade95f7c0132ec718f4d93bb76aadd | d27ddf4011a1978a492d57e4360f79a552b9900af8ab95327b08bccf52e015ca | 3d5e0619ac62e0c14f66b2118c80f288771304fbd420f815209d055fcdd06ebf | null | [
"LICENSE"
] | 295 |
2.4 | plinder | 0.2.26 | PLINDER: The Protein-Ligand INteraction Dataset and Evaluation Resource | 
<div align="center">
<h1>The Protein Ligand INteractions Dataset and Evaluation Resource</h1>
</div>
---
[](https://github.com/plinder-org/plinder/blob/master/LICENSE.txt)
[](https://github.com/plinder-org/plinder/pkgs/container/plinder)
[](https://www.plinder.sh/)
[](https://www.biorxiv.org/content/10.1101/2024.07.17.603955)
[](https://plinder-org.github.io/plinder/)
[](https://github.com/plinder-org/plinder/tree/python-coverage-comment-action-data)

# 📚 About
**PLINDER**, short for **p**rotein **l**igand **in**teractions **d**ataset and
**e**valuation **r**esource, is a comprehensive, annotated, high quality dataset and
resource for training and evaluation of protein-ligand docking algorithms:
- \> 400k PLI systems across > 11k SCOP domains and > 50k unique small molecules
- 750+ annotations for each system, including protein and ligand properties, quality,
matched molecular series and more
- Automated curation pipeline to keep up with the PDB
- 14 PLI metrics and over 20 billion similarity scores
- Unbound \(_apo_\) and _predicted_ Alphafold2 structures linked to _holo_ systems
- _train-val-test_ splits and ability to tune splitting based on the learning task
- Robust evaluation harness to simplify and standard performance comparison between
models.
The *PLINDER* project is a community effort, launched by the University of Basel,
SIB Swiss Institute of Bioinformatics, Proxima (formerly VantAI), NVIDIA, MIT CSAIL,
and will be regularly updated.
To accelerate community adoption, PLINDER will be used as the field’s new Protein-Ligand
interaction dataset standard as part of an exciting competition at the upcoming 2024
[Machine Learning in Structural Biology (MLSB)](https://mlsb.io#challenge) Workshop at NeurIPS, one of the field's premiere academic gatherings.
More details about the competition and other helpful practical tips can be found at our recent workshop repo:
[Moving Beyond Memorization](https://github.com/plinder-org/moving_beyond_memorisation).
### 👋 [Join the P(L)INDER user group Discord Server!](https://discord.gg/KgUdMn7TuS)
## 🔢 Plinder versions
We version the `plinder` dataset with two controls:
- `PLINDER_RELEASE`: the month stamp of the last RCSB sync
- `PLINDER_ITERATION`: value that enables iterative development within a release
We version the `plinder` application using an automated semantic
versioning scheme based on the `git` commit history.
The `plinder.data` package is responsible for generating a dataset
release and the `plinder.core` package makes it easy to interact
with the dataset.
#### 🐛🐛🐛 Known bugs:
- Source dataset contains incorrect `entry_release_date` dates, please, use `query_index` to get correct dates patched.
- Complexes containing nucleic acid receptors may [not be saved corectly](https://github.com/plinder-org/plinder/issues/61).
- `ligand_binding_affinity` queries have been disabled due to a [bug found parsing BindingDB](https://github.com/plinder-org/plinder/issues/94)
#### Changelog:
- 2024-06/v2 (Current):
- New systems added based on the 2024-06 RCSB sync
- Updated system definition to be more stable and depend only on ligand distance rather than PLIP
- Added annotations for crystal contacts
- Improved ligand handling and saving to fix some bond order issues
- Improved covalency detection and annotation to reference each bond explicitly
- Added linked apo/pred structures to v2/links and v2/linked_structures
- <del>Added binding affinity annotations from [BindingDB](https://bindingdb.org)</del> (see known bugs!)
- Added statistics requirement and other changes in the split to enrich test set diversity
- 2024-04/v1: Version described in the preprint, with updated redundancy removal by protein pocket and ligand similarity.
- 2024-04/v0: Version used to re-train DiffDock in the paper, with redundancy removal based on \<pdbid\>\_\<ligand ccd codes\>
## 🏅 Gold standard benchmark sets
As part of *PLINDER* resource we provide train, validation and test splits that are
curated to minimize the information leakage based on protein-ligand interaction
similarity.
In addition, we have prioritized the systems that has a linked experimental `apo`
structure or matched molecular series to support realistic inference scenarios for hit
discovery and optimization.
Finally, a particular care is taken for test set that is further prioritized to contain
high quality structures to provide unambiguous ground-truths for performance
benchmarking.

Moreover, as we enticipate this resource to be used for benchmarking a wide range of methods, including those simultaneously predicting protein structure (aka. co-folding) or those generating novel ligand structures, we further stratified test (by novel ligand, pocket, protein or all) to cover a wide range of tasks.
# 👨💻 Getting Started
The *PLINDER* dataset is provided in two ways:
- You can either use the files from the dataset directly using your preferred tooling
by downloading the data from the public
[bucket](https://cloud.google.com/storage/docs/buckets),
- or you can utilize the dedicated `plinder` Python package for interfacing the data.
## Downloading the dataset
The dataset can be downloaded from the bucket with
[gsutil](https://cloud.google.com/storage/docs/gsutil_install).
```console
$ export PLINDER_RELEASE=2024-06 # Current release
$ export PLINDER_ITERATION=v2 # Current iteration
$ mkdir -p ~/.local/share/plinder/${PLINDER_RELEASE}/${PLINDER_ITERATION}/
$ gsutil -m cp -r "gs://plinder/${PLINDER_RELEASE}/${PLINDER_ITERATION}/*" ~/.local/share/plinder/${PLINDER_RELEASE}/${PLINDER_ITERATION}/
```
For details on the sub-directories, see [Documentation](https://plinder-org.github.io/plinder/tutorial/dataset.html).
## Installing the Python package
`plinder` is available on *PyPI*.
```
pip install plinder
```
## License
Data curated by PLINDER are made available under the Apache License 2.0.
All data curated by BindingDB staff are provided under the Creative Commons Attribution 4.0 License. Data imported from ChEMBL are provided under their Creative Commons Attribution-Share Alike 4.0 Unported License.
# 📝 Documentation
A more detailed description is available on the
[documentation website](https://plinder-org.github.io/plinder/).
# 📃 Citation
Durairaj, Janani, Yusuf Adeshina, Zhonglin Cao, Xuejin Zhang, Vladas Oleinikovas, Thomas Duignan, Zachary McClure, Xavier Robin, Gabriel Studer, Daniel Kovtun, Emanuele Rossi, Guoqing Zhou, Srimukh Prasad Veccham, Clemens Isert, Yuxing Peng, Prabindh Sundareson, Mehmet Akdel, Gabriele Corso, Hannes Stärk, Gerardo Tauriello, Zachary Wayne Carpenter, Michael M. Bronstein, Emine Kucukbenli, Torsten Schwede, Luca Naef. 2024. “PLINDER: The Protein-Ligand Interactions Dataset and Evaluation Resource.”
[bioRxiv](https://doi.org/10.1101/2024.07.17.603955)
[ICML'24 ML4LMS](https://openreview.net/forum?id=7UvbaTrNbP)
Please see the [citation file](CITATION.cff) for details.

| text/markdown | null | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"biotite>=1.0",
"numpy",
"pandas",
"typing_extensions",
"pydantic",
"tqdm",
"plotly",
"nbformat",
"google-cloud-storage",
"gcsfs",
"gemmi",
"rdkit>=2024.03.6",
"pyarrow",
"omegaconf",
"mmcif",
"eval_type_backport",
"posebusters",
"duckdb",
"cloudpathlib",
"mols2grid",
"six",
... | [] | [] | [] | [
"Homepage, https://github.com/plinder-org/plinder",
"Issues, https://github.com/plinder-org/plinder/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:55:32.757712 | plinder-0.2.26.tar.gz | 28,025,822 | 4e/fe/dc17a16e5c71e0870a23a236866ee2880d6e04ce1bc8a568e0212a4cc536/plinder-0.2.26.tar.gz | source | sdist | null | false | 225758f21f474ffd2f2e539bd4192dd3 | 4f5bc456ca3fd01eb80fee22f8f891e3d9ea060659fbdfe6f93363cabda833f0 | 4efedc17a16e5c71e0870a23a236866ee2880d6e04ce1bc8a568e0212a4cc536 | null | [
"LICENSE.txt",
"NOTICE"
] | 341 |
2.3 | iso4217parse-fixed | 0.1.0 | A fork of iso4217-parse with support only active currencies | ## About this Fork
This is a maintained fork of the original `iso4217parse`.
### Key Improvements:
* We keep the data.json file up-to date only with active and official currencies.
| text/markdown | Anton Shpakovych | anton.shpakovych@reface.ai | null | null | MIT | iso4217, currency, parse, symbol | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Languag... | [] | https://github.com/antonshpakovych-reface/iso4217parse-fixed | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Repository, https://github.com/antonshpakovych-reface/iso4217parse-fixed"
] | poetry/2.0.0 CPython/3.12.12 Linux/6.14.0-1017-azure | 2026-02-19T08:55:25.899268 | iso4217parse_fixed-0.1.0.tar.gz | 13,179 | 56/9b/51ab9e4472004455a5a8e11297755229b09420cfb69fe25ed777d9423787/iso4217parse_fixed-0.1.0.tar.gz | source | sdist | null | false | 8105c3bbdef00871775bec1203fc3ae9 | 4c2de6273311e83a03a2935b622540baed90fa5e84a6edbd2898762227a3b971 | 569b51ab9e4472004455a5a8e11297755229b09420cfb69fe25ed777d9423787 | null | [] | 212 |
2.4 | germaparlpy | 1.0.6 | The GermaParlPy Python package provides functionality to deserialize, serialize, manage, and query the GermaParlTEI corpus and derived corpora. | <h1>GermaParlPy</h1>
<div align="left">
<a href="https://pypi.org/project/germaparlpy/">
<img src="https://img.shields.io/pypi/v/germaparlpy.svg" alt="PyPi Latest Release"/>
</a>
<a href="https://doi.org/10.5281/zenodo.15180629">
<img src="https://zenodo.org/badge/DOI/10.5281/zenodo.15180629.svg" alt="DOI">
</a>
</div>
The GermaParlPy Python package provides functionality to deserialize, serialize, manage, and query the GermaParlTEI[^1]
corpus and derived corpora.
The GermaParlTEI corpus comprises the plenary protocols of the German Bundestag (parliament), encoded in XML according to the TEI standard. The current version covers the first 19 legislative periods, encompassing transcribed speeches from the Bundestag's constituent session on 7 September 1949 to the final sitting of the Angela Merkel era in 2021. This makes it a valuable resource for research in various scientific disciplines.
For detailed information on the library, visit the [official website](https://nolram567.github.io/GermaParlPy/).
## Use Cases
Potential use cases range from the examination of research questions in political science, history or linguistics to the compilation of training data sets for AI.
In addition, this library makes it possible to access the GermaParl corpus in Python and apply powerful NLP libraries such as spacy or gensim to it. Previously, the corpus could only be accessed using the PolMineR package in the R programming language.
## Installation
GermaParlPy is available on PyPi:
```sh
pip install germaparlpy
```
## API Reference
Click [here](https://nolram567.github.io/GermaParlPy/) for the full API Reference.
## XML Structure
Click [here](https://nolram567.github.io/GermaParlPy/xml-structure.html) to learn more about the XML Structure of the underlying corpus GermaParlTEI[^1].
## Tutorials
I have prepared three example scripts that showcase the utilisation and potential use cases of GermaParlPy. You can find the scripts in the /example directory or [here](https://nolram567.github.io/GermaParlPy/tutorials.html).
## Contributing
Contributions and feedback are welcome! Feel free to write an issue or open a pull request.
## License
The code is licensed under the [MIT License](LICENSE).
The GermaParl corpus, which is not part of this repository, is licensed under a [CLARIN PUB+BY+NC+SA license](https://www.clarin.eu/content/licenses-and-clarin-categories).
## Credits
Developed by [Marlon-Benedikt George](https://github.com/https://github.com/Nolram567).
The underlying data set, the GermaParl corpus, was compiled and released by Blätte & Leonhardt (2024)[^1].
See also their R-Library PolMineR in the context of the [PolMine-Project](https://polmine.github.io/), which served as an inspiration for this library.
[^1]: Blaette, A.and C. Leonhardt. Germaparl corpus of plenary protocols. v2.2.0-rc1, Zenodo, 22 July 2024, doi:10.5281/zenodo.12795193
| text/markdown | Marlon-Benedikt George | mbgdevelopment@proton.me | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming... | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://nolram567.github.io/GermaParlPy/",
"Issues, https://github.com/Nolram567/GermaParlPy/issues",
"Repository, https://github.com/Nolram567/GermaParlPy"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:55:14.978099 | germaparlpy-1.0.6.tar.gz | 9,603 | a8/7e/b2ab1d638c08a1cde14457703b3ca4c91ea742ee28f99ef790f80a58e356/germaparlpy-1.0.6.tar.gz | source | sdist | null | false | 1564934ba131ca44d2b88947828a1847 | 89bdab9863d6397ac5b874a694084c04d9349b04a7a132a418a2ab8af802438b | a87eb2ab1d638c08a1cde14457703b3ca4c91ea742ee28f99ef790f80a58e356 | null | [
"LICENSE"
] | 248 |
2.4 | lsst-sdm-schemas | 30.2026.800 | Science Data Model (SDM) Schemas for Rubin Observatory | Science Data Model Schemas
==========================
This repository stores schema definitions for user-facing data
products comprising the Science Data Model (SDM) of the
[Rubin Observatory](https://rubinobservatory.org/).
These schemas are defined in YAML files designed to be read with
[Felis](https://github.com/lsst/felis), a tool which can convert this data
to derived formats including SQL DDL and
[TAP_SCHEMA](https://www.ivoa.net/documents/TAP/20180830/PR-TAP-1.1-20180830.html#tth_sEc4).
These schema definitions serve as the "source of truth" for the observatory's core data models.
Schemas
-------
The following schemas are maintained in this repository under the [schemas](./python/lsst/sdm/schemas) directory:
* [imsim](./python/lsst/sdm/schemas/imsim.yaml) describes the outputs
of the pipelines for LSSTCam-imSim, used to generate the data preview
schemas, which are fixed at the time of their release, while `imsim` will
continue to evolve. This schema is used by
[ci_imsim](https://github.com/lsst/ci_imsim) to verify that the tabular data
of the pipeline output files is conformant with the schema definition.
* The various Data Preview (DP) schemas such as
[dp02_dc2](./python/lsst/sdm/schemas/dp02_dc2.yaml) represent
content that is being actively served by the various data previews.
These are created from `imsim` at a specific point in time.
* [apdb](./python/lsst/sdm/schemas/apdb.yaml) describes the schema
of the Alert Production Database (APDB) used for Alert Production with
`ap_pipe` and for nightly `ap_verify` runs within continuous integration.
Previous processing runs may differ from the current schema. The
user-queryable Prompt Products Database (PPDB) is expected to have a very similar schema to the APDB.
* [hsc](./python/lsst/sdm/schemas/hsc.yaml) describes the outputs of
the latest data release production pipelines for HyperSuprimeCam. This
schema is used by [ci_hsc](https://github.com/lsst/ci_hsc) for verification
of its output files.
* The various `cdb` schemas such as
[cdb_latiss](./python/lsst/sdm/schemas/cdb_latiss.yaml) describe the
data model of the [Consolidated Database](https://github.com/lsst-dm/consdb)
or ConsDB, an image metadata database containing summarizations of
Engineering Facilities Database (EFD) telemetry by exposure and visit time windows.
* The various `efd` schemas such as
[efd_latiss](./python/lsst/sdm/schemas/efd_latiss.yaml) describe the
data model of the Transformed EFD at the [Consolidated Database](https://github.com/lsst-dm/consdb)
or ConsDB, which consists of telemetry transformed over time spans defined by the
duration of the exposures and visits.
Release Assets
--------------
Each release of `sdm_schemas` includes the following additional assets,
generated automatically via GitHub Actions when a new tag is created:
* `datalink-columns.zip` contains a set of YAML files with a restricted
subset of the Felis schema. Currently, these identify the principal and
minimal columns for a subset of the tables defined by the schema in
this repository. Principal columns are those for which the `principal`
flag is set in the TAP schema, defined in the
[IVOA TAP
specification](https://www.ivoa.net/documents/TAP/20190927/REC-TAP-1.1.html#tth_sEc4.3).
The minimal columns are still experimental and in flux. These files are
intended for use with the
[datalinker](https://github.com/lsst-sqre/datalinker) service of a
Rubin Science Platform deployment.
* `datalink-snippets.zip` contains a JSON manifest and a set of XML files
that define VOTables following the IVOA DataLink specification and are
intended to be used by the TAP service of a Rubin Science Platform
deployment for adding DataLink records to the responses from a TAP query.
Those DataLink records, in turn, provide links to operations that a client
may wish to perform on those results, such as closely-related TAP queries.
| text/markdown | null | Rubin Observatory Data Management <dm-admin@lists.lsst.org> | null | null | null | lsst | [
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Astronomy"
] | [] | null | null | >=3.11.0 | [] | [] | [] | [
"lsst-felis",
"pytest>=3.2; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://sdm-schemas.lsst.io",
"Source, https://github.com/lsst/sdm_schemas"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:54:37.342438 | lsst_sdm_schemas-30.2026.800.tar.gz | 252,370 | 34/ea/4f5b65c8f84ebdb4c562678c540c4755fad6c42514acf1468d32f93db358/lsst_sdm_schemas-30.2026.800.tar.gz | source | sdist | null | false | e7f19d1a47332848f77200a63adf3c01 | bab1c9531750930de40b0285a6415b165b18f57a052f478679c7fd0dc16942e8 | 34ea4f5b65c8f84ebdb4c562678c540c4755fad6c42514acf1468d32f93db358 | GPL-3.0-or-later | [
"COPYRIGHT",
"LICENSE"
] | 250 |
2.3 | gemini-subagent | 0.1.3 | Parallel sub-agent orchestration CLI for Gemini |
# SUBGEMI: Gemini Sub-Agent Orchestration
Parallel orchestration CLI for Gemini sub-agents.
## Installation
```bash
pip install gemini-subagent
```
## Usage
Once installed, you can use the `subgemi` command:
```bash
# Delegate a task to a parallel sub-agent
subgemi task delegate "Audit the code in src/auth.py" --persona security_auditor --file src/auth.py
# View the live dashboard
subgemi session board
```
## Features
- **Parallelism**: Dispatches tasks in the background by default.
- **Git Review**: Automatically creates isolation branches for sub-agents at `subgemi/sub_<timestamp>`.
- **Context Bundling**: Automatically finds and includes relevant rules, workflows, and plan files.
- **Tmux Integration**: Background tasks spawn tmux sessions for real-time monitoring.
| text/markdown | NLanN | alan@openclaw.dev | null | null | MIT | gemini, agent, cli, orchestration, parallel | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://github.com/NLanN/gemini-subagents | null | <4.0,>=3.9 | [] | [] | [] | [
"typer>=0.12.0",
"rich<14.0.0,>=13.0.0"
] | [] | [] | [] | [
"Repository, https://github.com/NLanN/gemini-subagents",
"Documentation, https://github.com/NLanN/gemini-subagents/tree/main/docs"
] | poetry/2.1.3 CPython/3.13.12 Darwin/25.1.0 | 2026-02-19T08:54:27.235743 | gemini_subagent-0.1.3.tar.gz | 9,407 | e8/b5/343474bf6212f91659c8540fe2eeed0951db955c7834ceb658d6c7bfa256/gemini_subagent-0.1.3.tar.gz | source | sdist | null | false | 37fa32e7d1656aea484aa56be4a37915 | 6aa91811146bce27196bf6f0ae15a9a25b6a390e179c4dd7dc010ae13139bc3c | e8b5343474bf6212f91659c8540fe2eeed0951db955c7834ceb658d6c7bfa256 | null | [] | 261 |
2.4 | voice-mode-install | 8.2.1 | Installer for VoiceMode - handles system dependencies and installation | # voice-mode-install
A standalone installer package for VoiceMode that handles system dependency detection and installation.
## Overview
`voice-mode-install` simplifies the VoiceMode installation process by:
1. **Detecting your platform** - Identifies your OS, distribution, and architecture
2. **Checking dependencies** - Scans for required system packages
3. **Installing packages** - Uses your system's package manager (apt, dnf, brew)
4. **Installing VoiceMode** - Runs `uv tool install voice-mode`
5. **Hardware recommendations** - Suggests optimal configuration for your system
6. **Logging everything** - Saves installation logs for troubleshooting
## Quick Start
```bash
# Install and run
uvx voice-mode-install
# Dry run (see what would be installed)
uvx voice-mode-install --dry-run
# Install specific version
uvx voice-mode-install --voice-mode-version=5.1.3
# Skip service installation
uvx voice-mode-install --skip-services
# Non-interactive mode
uvx voice-mode-install --non-interactive
```
## Prerequisites
- **uv** - Required to run the installer (`curl -LsSf https://astral.sh/uv/install.sh | sh`)
- **Python 3.10+** - Usually pre-installed on modern systems
- **sudo access** - Needed to install system packages (Linux)
- **Homebrew** (macOS) - The installer will offer to install it if missing
## Supported Platforms
- **macOS** - Intel and Apple Silicon (via Homebrew)
- **Ubuntu/Debian** - Using apt package manager
- **Fedora/RHEL** - Using dnf package manager
## Features
### Phase 1 (Included)
✅ **Dry-run Mode** - Preview what will be installed
✅ **Installation Logging** - Detailed logs saved to `~/.voicemode/install.log`
✅ **Shell Completion** - Auto-configures tab completion for bash/zsh
✅ **Health Check** - Verifies installation after completion
✅ **Version Pinning** - Install specific VoiceMode versions
✅ **Hardware Detection** - Recommends optimal setup for your system
✅ **Homebrew Auto-Install** - Offers to install Homebrew on macOS if missing
### Phase 2 (Future)
⏱️ Config Validation - Check for conflicting settings
⏱️ Uninstall Support - Clean removal of VoiceMode
## How It Works
1. **Platform Detection** - Identifies OS, distribution, and architecture
2. **Dependency Checking** - Compares installed packages against `dependencies.yaml`
3. **Package Manager Setup** (macOS only) - Checks for Homebrew and offers to install if missing
4. **Package Installation** - Uses platform-specific package managers:
- macOS: `brew install` (installs Homebrew first if needed)
- Ubuntu/Debian: `sudo apt install`
- Fedora: `sudo dnf install`
5. **VoiceMode Installation** - Runs `uv tool install voice-mode[==version]`
6. **Post-Install** - Configures shell completion and verifies installation
## Installation Logs
Logs are saved to `~/.voicemode/install.log` in JSONL format:
```json
{"timestamp": "2025-10-12T10:30:00", "type": "start", "message": "Installation started"}
{"timestamp": "2025-10-12T10:30:15", "type": "check", "message": "Checked core dependencies"}
{"timestamp": "2025-10-12T10:30:45", "type": "install", "message": "Successfully installed system packages"}
{"timestamp": "2025-10-12T10:31:30", "type": "complete", "message": "Installation completed"}
```
## Troubleshooting
### VoiceMode command not found after installation
Restart your shell or run:
```bash
source ~/.bashrc # or ~/.zshrc for zsh
```
### Permission denied during package installation
The installer needs sudo access to install system packages. Run:
```bash
sudo -v # Refresh sudo credentials
uvx voice-mode-install
```
### Network errors during installation
- Check your internet connection
- Try again with: `uvx voice-mode-install`
- Use `uvx --refresh voice-mode-install` to get the latest installer
### Installation hangs or fails
1. Check the log file: `~/.voicemode/install.log`
2. Try a dry run: `uvx voice-mode-install --dry-run`
3. Report issues with log file attached
## Development
### Building from Source
```bash
cd installer/
uv build
```
### Testing Locally
```bash
cd installer/
uv pip install -e .
voice-mode-install --dry-run
```
### Project Structure
```
installer/
├── pyproject.toml # Package definition
├── voicemode_install/
│ ├── __init__.py # Version and exports
│ ├── cli.py # Main CLI entry point
│ ├── system.py # Platform detection
│ ├── checker.py # Dependency checking
│ ├── installer.py # Package installation
│ ├── hardware.py # Hardware detection
│ ├── logger.py # Installation logging
│ └── dependencies.yaml # System dependencies
└── README.md
```
## Design Decisions
See `DECISIONS.md` in the task directory for detailed rationale behind:
- Version management strategy
- Dependency synchronization approach
- Error handling philosophy
- Platform coverage priorities
- Service installation scope
## Contributing
This installer is part of the [VoiceMode](https://github.com/mbailey/voicemode) project.
## License
MIT License - Same as VoiceMode
| text/markdown | null | mbailey <mbailey@example.com> | null | null | MIT | installer, mcp, setup, voice, voicemode | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.0.0",
"psutil>=5.9.0",
"pyyaml>=6.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/mbailey/voicemode",
"Repository, https://github.com/mbailey/voicemode",
"Issues, https://github.com/mbailey/voicemode/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:54:08.951371 | voice_mode_install-8.2.1.tar.gz | 16,306 | cb/76/29a07c0c802adac975023579b5cb23a40a1b629b4b5cb7a5a2ad6791a16c/voice_mode_install-8.2.1.tar.gz | source | sdist | null | false | 9f5e74aa7c7159fa6127f24ad8b76193 | 73212136172f969b72b739203694699b8bb3f01bf750861e75cf06f72228ee49 | cb7629a07c0c802adac975023579b5cb23a40a1b629b4b5cb7a5a2ad6791a16c | null | [] | 650 |
2.4 | voice-mode | 8.2.1 | VoiceMode - Voice interaction capabilities for AI assistants (formerly voice-mcp) | # VoiceMode
> Natural voice conversations with Claude Code (and other MCP capable agents)
[](https://pepy.tech/project/voice-mode)
[](https://pepy.tech/project/voice-mode)
[](https://pepy.tech/project/voice-mode)
VoiceMode enables natural voice conversations with Claude Code. Voice isn't about replacing typing - it's about being available when typing isn't.
**Perfect for:**
- Walking to your next meeting
- Cooking while debugging
- Giving your eyes a break after hours of screen time
- Holding a coffee (or a dog)
- Any moment when your hands or eyes are busy
## See It In Action
[](https://www.youtube.com/watch?v=cYdwOD_-dQc)
## Quick Start
**Requirements:** Computer with microphone and speakers
### Option 1: Claude Code Plugin (Recommended)
The fastest way for Claude Code users to get started:
```bash
# Add the VoiceMode marketplace
claude plugin marketplace add mbailey/voicemode
# Install VoiceMode plugin
claude plugin install voicemode@voicemode
## Install dependencies (CLI, Local Voice Services)
/voicemode:install
# Start talking!
/voicemode:converse
```
### Option 2: Python installer package
Installs dependencies and the VoiceMode Python package.
```bash
# Install UV package manager (if needed)
curl -LsSf https://astral.sh/uv/install.sh | sh
# Run the installer (sets up dependencies and local voice services)
uvx voice-mode-install
# Add to Claude Code
claude mcp add --scope user voicemode -- uvx --refresh voice-mode
# Optional: Add OpenAI API key as fallback for local services
export OPENAI_API_KEY=your-openai-key
# Start a conversation
claude converse
```
For manual setup, see the [Getting Started Guide](docs/tutorials/getting-started.md).
## Features
- **Natural conversations** - speak naturally, hear responses immediately
- **Works offline** - optional local voice services (Whisper STT, Kokoro TTS)
- **Low latency** - fast enough to feel like a real conversation
- **Smart silence detection** - stops recording when you stop speaking
- **Privacy options** - run entirely locally or use cloud services
## Compatibility
**Platforms:** Linux, macOS, Windows (WSL), NixOS
**Python:** 3.10-3.14
## Configuration
VoiceMode works out of the box. For customization:
```bash
# Set OpenAI API key (if using cloud services)
export OPENAI_API_KEY="your-key"
# Or configure via file
voicemode config edit
```
See the [Configuration Guide](docs/guides/configuration.md) for all options.
## Remote Agent (Operator)
VoiceMode includes agent management for running headless Claude Code instances that can be woken remotely from the iOS app or web interface.
### Quick Start
```bash
# Start the operator agent in a tmux session
voicemode agent start
# Check if it's running
voicemode agent status
# Send a message to the operator
voicemode agent send "Hello, please check my calendar"
# Stop the operator
voicemode agent stop
```
### The Operator Concept
The **operator** is a headless Claude Code instance running in tmux that:
- Listens for remote connections from voicemode.dev
- Can be woken by the iOS app or web interface
- Responds via voice using VoiceMode's TTS/STT capabilities
Think of it like a phone operator - always there to help when called.
### Agent Commands
| Command | Description |
|---------|-------------|
| `voicemode agent start` | Start operator in tmux session |
| `voicemode agent stop` | Send Ctrl-C to stop Claude gracefully |
| `voicemode agent stop --kill` | Kill the tmux window |
| `voicemode agent status` | Show running/stopped status |
| `voicemode agent send "msg"` | Send message (auto-starts if needed) |
| `voicemode agent send --no-start "msg"` | Send message (fail if not running) |
### Agent Directory Structure
Agent configuration lives in `~/.voicemode/agents/`:
```
~/.voicemode/agents/
├── voicemode.env # Shared settings for all agents
├── AGENT.md # AI entry point
├── CLAUDE.md # Claude-specific instructions
├── SKILL.md # Shared behavior
└── operator/ # Default agent
├── voicemode.env # Operator-specific settings
├── AGENT.md
├── CLAUDE.md
└── SKILL.md # Operator behavior
```
### Configuration (voicemode.env)
Agent-specific settings override base settings. Available options:
```bash
# Base settings (~/.voicemode/agents/voicemode.env)
VOICEMODE_VOICE=nova # Default TTS voice
VOICEMODE_SPEED=1.0 # Speech rate
# Operator settings (~/.voicemode/agents/operator/voicemode.env)
VOICEMODE_AGENT_REMOTE=true # Enable remote connections
VOICEMODE_AGENT_STARTUP_MESSAGE= # Message sent on startup
VOICEMODE_AGENT_CLAUDE_ARGS= # Extra args for Claude Code
```
## Permissions Setup (Optional)
To use VoiceMode without permission prompts, add to `~/.claude/settings.json`:
```json
{
"permissions": {
"allow": [
"mcp__voicemode__converse",
"mcp__voicemode__service"
]
}
}
```
See the [Permissions Guide](docs/guides/permissions.md) for more options.
## Local Voice Services
For privacy or offline use, install local speech services:
- **[Whisper.cpp](docs/guides/whisper-setup.md)** - Local speech-to-text
- **[Kokoro](docs/guides/kokoro-setup.md)** - Local text-to-speech with multiple voices
These provide the same API as OpenAI, so VoiceMode switches seamlessly between them.
## Installation Details
<details>
<summary><strong>System Dependencies by Platform</strong></summary>
#### Ubuntu/Debian
```bash
sudo apt update
sudo apt install -y ffmpeg gcc libasound2-dev libasound2-plugins libportaudio2 portaudio19-dev pulseaudio pulseaudio-utils python3-dev
```
**WSL2 users**: The pulseaudio packages above are required for microphone access.
#### Fedora/RHEL
```bash
sudo dnf install alsa-lib-devel ffmpeg gcc portaudio portaudio-devel python3-devel
```
#### macOS
```bash
brew install ffmpeg node portaudio
```
#### NixOS
```bash
# Use development shell
nix develop github:mbailey/voicemode
# Or install system-wide
nix profile install github:mbailey/voicemode
```
</details>
<details>
<summary><strong>Alternative Installation Methods</strong></summary>
#### From source
```bash
git clone https://github.com/mbailey/voicemode.git
cd voicemode
uv tool install -e .
```
#### NixOS system-wide
```nix
# In /etc/nixos/configuration.nix
environment.systemPackages = [
(builtins.getFlake "github:mbailey/voicemode").packages.${pkgs.system}.default
];
```
</details>
## Troubleshooting
| Problem | Solution |
|---------|----------|
| No microphone access | Check terminal/app permissions. WSL2 needs pulseaudio packages. |
| UV not found | Run `curl -LsSf https://astral.sh/uv/install.sh \| sh` |
| OpenAI API error | Verify `OPENAI_API_KEY` is set correctly |
| No audio output | Check system audio settings and available devices |
### Save Audio for Debugging
```bash
export VOICEMODE_SAVE_AUDIO=true
# Files saved to ~/.voicemode/audio/YYYY/MM/
```
## Documentation
- [Getting Started](docs/tutorials/getting-started.md) - Full setup guide
- [Configuration](docs/guides/configuration.md) - All environment variables
- [Whisper Setup](docs/guides/whisper-setup.md) - Local speech-to-text
- [Kokoro Setup](docs/guides/kokoro-setup.md) - Local text-to-speech
- [Development Setup](docs/tutorials/development-setup.md) - Contributing guide
Full documentation: [voice-mode.readthedocs.io](https://voice-mode.readthedocs.io)
## Links
- **Website**: [getvoicemode.com](https://getvoicemode.com)
- **GitHub**: [github.com/mbailey/voicemode](https://github.com/mbailey/voicemode)
- **PyPI**: [pypi.org/project/voice-mode](https://pypi.org/project/voice-mode/)
- **YouTube**: [@getvoicemode](https://youtube.com/@getvoicemode)
- **Twitter/X**: [@getvoicemode](https://twitter.com/getvoicemode)
- **Newsletter**: [](https://buttondown.com/voicemode)
## License
MIT - A [Failmode](https://failmode.com) Project
---
mcp-name: com.failmode/voicemode
| text/markdown | null | Mike Bailey <mike@failmode.com> | null | null | MIT | ai, livekit, llm, mcp, speech, stt, tts, voice | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp",
"audioop-lts; python_version >= \"3.13\"",
"click>=8.0.0",
"fastmcp<3,>=2.3.2",
"httpx",
"numpy",
"openai>=1.0.0",
"psutil>=5.9.0",
"pydub",
"pyyaml>=6.0.0",
"scipy",
"simpleaudio",
"sounddevice",
"uv>=0.4.0",
"webrtcvad-wheels>=2.0.14",
"websockets>=12.0",
"ane-transforme... | [] | [] | [] | [
"Homepage, https://getvoicemode.com/",
"Repository, https://github.com/mbailey/voicemode",
"Issues, https://github.com/mbailey/voicemode/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:53:59.541260 | voice_mode-8.2.1.tar.gz | 1,078,556 | f1/bb/f33381e0e5ef3c65ecd947bdab028eb0583a04b70cd71649320307835a35/voice_mode-8.2.1.tar.gz | source | sdist | null | false | 466eb4f5a723916cf44fbd924b9ef41c | b2ca9b0a48c6250864b216bce1ba054d501ef336eb909aa989411061e09e8a03 | f1bbf33381e0e5ef3c65ecd947bdab028eb0583a04b70cd71649320307835a35 | null | [
"LICENSE"
] | 3,334 |
2.4 | anemoi-inference | 0.9.1 | A package to run inference from data-driven forecasts weather models. | # anemoi-inference
<p align="center">
<a href="https://github.com/ecmwf/codex/raw/refs/heads/main/Project Maturity">
<img src="https://github.com/ecmwf/codex/raw/refs/heads/main/Project Maturity/incubating_badge.svg" alt="Maturity Level">
</a>
<a href="https://opensource.org/licenses/apache-2-0">
<img src="https://img.shields.io/badge/Licence-Apache 2.0-blue.svg" alt="Licence">
</a>
<a href="https://github.com/ecmwf/anemoi-inference/releases">
<img src="https://img.shields.io/github/v/release/ecmwf/anemoi-inference?color=purple&label=Release" alt="Latest Release">
</a>
</p>
> \[!IMPORTANT\]
> This software is **Incubating** and subject to ECMWF's guidelines on [Software Maturity](https://github.com/ecmwf/codex/raw/refs/heads/main/Project%20Maturity).
## Documentation
The documentation can be found at https://anemoi-inference.readthedocs.io/.
## Contributing
You can find information about contributing to Anemoi at our [Contribution page](https://anemoi.readthedocs.io/en/latest/contributing/contributing.html).
## Install
Install via `pip` with:
```
$ pip install anemoi-inference
```
## License
```
Copyright 2024-2025, Anemoi Contributors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
In applying this licence, ECMWF does not waive the privileges and immunities
granted to it by virtue of its status as an intergovernmental organisation
nor does it submit to any jurisdiction.
```
| text/markdown | null | "European Centre for Medium-Range Weather Forecasts (ECMWF)" <software.support@ecmwf.int> | null | null | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright 2024-2025 Anemoi Contributors
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| ai, inference, tools | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programmi... | [] | null | null | <3.14,>=3.11 | [] | [] | [] | [
"anemoi-transform>0.1.13",
"anemoi-utils[provenance,text]>=0.4.32",
"aniso8601",
"anytree",
"deprecation",
"earthkit-data>=0.12.4",
"eccodes>=2.38.3",
"numpy",
"omegaconf<2.4,>=2.2",
"packaging",
"pydantic",
"pyyaml",
"rich",
"semantic-version",
"torch",
"anemoi-datasets; extra == \"al... | [] | [] | [] | [
"Documentation, https://anemoi-inference.readthedocs.io/",
"Homepage, https://github.com/ecmwf/anemoi-inference/",
"Issues, https://github.com/ecmwf/anemoi-inference/issues",
"Repository, https://github.com/ecmwf/anemoi-inference/"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T08:52:25.548369 | anemoi_inference-0.9.1.tar.gz | 1,446,568 | 08/46/0ff2406e552be5ba209b376ef37b95aba65f7e5e27750ec3cd49e5a38528/anemoi_inference-0.9.1.tar.gz | source | sdist | null | false | ba837a1c1ac50a4976590fadeb9b0bd7 | 5db1a89818c4cc62b3b7f798bc37b39d912241ac3afcbd2206e20d0cd5e151c8 | 08460ff2406e552be5ba209b376ef37b95aba65f7e5e27750ec3cd49e5a38528 | null | [
"LICENSE"
] | 311 |
2.4 | django-project-base | 0.81.20 | Everything revolves around it: users, roles, permissions, tags, etc. | # Notice to users of this library
## This library is no longer free software.
With 0.80.0 the library has gained a development partner that will doubtless raise it to new heights.
The LICENSE has been modified to a proprietary one with restrictions, so please be mindful of conditions.
The library is thus deprecated and in maintenance mode only.
# Django project base
A collection of functionalities that are common to most projects we do.
- account management
- project management
- notifications (both to users and to apps)
- tagging
- background job processing
- roles & permissions
- profiling
This project is in VERY early development stage. Some of the functionalities are not even developed yet, some need
major rework, but some, surprisingly, should work pretty well already. An example of pretty well functioning ones is
account management.
## Example project
For running example django project prepare python environment and run (run in repository root):
```bash
$ pip install -r requirements.txt
$ python manage.py runserver
```
## Documentation
Run command in repository root:
```bash
$ npm run docs:dev
```
The dev server should be running at http://localhost:5173. Visit the URL in your browser to read documentation!
To generate pdf file. Run:
```bash
$ npm run export-pdf
```
Pdf file is located in docs/pdf folder.
| text/markdown | null | Jure Erznožnik <support@velis.si> | null | null | Proprietary | null | [
"Development Status :: 3 - Alpha",
"Framework :: Django",
"License :: Other/Proprietary License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"boto3",
"celery>=5.2",
"click>=8.1",
"django",
"django-csp",
"django-hijack<3",
"django-permissions-policy",
"django-rest-registration",
"django-taggit",
"djangorestframework",
"drf-spectacular<0.26.0,>=0.17.2",
"dynamicforms>=0.80.17",
"natural",
"pandas",
"pytz",
"requests",
"soci... | [] | [] | [] | [
"Homepage, https://github.com/velis74/django-project-base",
"Repository, https://github.com/velis74/django-project-base",
"Bug Tracker, https://github.com/velis74/django-project-base/issues"
] | twine/6.2.0 CPython/3.11.2 | 2026-02-19T08:51:04.605990 | django_project_base-0.81.20.tar.gz | 2,271,015 | 99/08/372c6fb35f3256cad7f4abe3fe723626cc8bf696733e77cec5881e609979/django_project_base-0.81.20.tar.gz | source | sdist | null | false | 5b046ed876ec0537faa8c2c41638c424 | 2f16b7446ff2c785f66ceceac7626affaff50f4f090643351f875f58a44294fc | 9908372c6fb35f3256cad7f4abe3fe723626cc8bf696733e77cec5881e609979 | null | [
"LICENSE"
] | 284 |
2.4 | sag-py-auth | 1.2.5 | Keycloak authentication for python projects | # sag_py_auth
[![Maintainability][codeclimate-image]][codeclimate-url]
[![Coverage Status][coveralls-image]][coveralls-url]
[](https://snyk.io/test/github/SamhammerAG/sag_py_auth)
[coveralls-image]:https://coveralls.io/repos/github/SamhammerAG/sag_py_auth/badge.svg?branch=master
[coveralls-url]:https://coveralls.io/github/SamhammerAG/sag_py_auth?branch=master
[codeclimate-image]:https://api.codeclimate.com/v1/badges/2da48e3952f9640f702f/maintainability
[codeclimate-url]:https://codeclimate.com/github/SamhammerAG/sag_py_auth/maintainability
This provides a way to secure your fastapi with keycloak jwt bearer authentication.
## What it does
* Secure your api endpoints
* Verifies auth tokens: signature, expiration, issuer, audience
* Allows to set permissions by specifying roles and realm roles
## How to use
### Installation
pip install sag-py-auth
### Secure your apis
First create the fast api dependency with the auth config:
```python
from sag_py_auth.models import AuthConfig, TokenRole
from sag_py_auth.jwt_auth import JwtAuth
from fastapi import Depends
auth_config = AuthConfig("https://authserver.com/auth/realms/projectName", "myaudience")
required_roles = [TokenRole("clientname", "adminrole")]
required_realm_roles = ["additionalrealmrole"]
requires_admin = Depends(JwtAuth(auth_config, required_roles, required_realm_roles))
```
Afterwards you can use it in your route like that:
```python
@app.post("/posts", dependencies=[requires_admin], tags=["posts"])
async def add_post(post: PostSchema) -> dict:
```
Or if you use sub routes, auth can also be enforced for the entire route like that:
```python
router = APIRouter()
router.include_router(sub_router, tags=["my_api_tag"], prefix="/subroute",dependencies=[requires_admin])
```
### Get user information
The Jwt call directly returns a token object that can be used to get additional information.
Furthermore you can access the context directly:
```python
from sag_py_auth.auth_context import get_token as get_token_from_context
token = get_token_from_context()
```
This works in async calls but not in sub threads (without additional changes).
See:
* https://docs.python.org/3/library/contextvars.html
* https://kobybass.medium.com/python-contextvars-and-multithreading-faa33dbe953d
#### Methods available on the token object
* get_field_value: to get the value of a claim field (or an empty string if not present)
* get_roles: Gets the roles of a specific client
* has_role: Verify if a spcific client has a role
* get_realm_roles: Get the realm roles
* has_realm_role: Check if the user has a specific realm role
### Log user data
It is possible to log the preferred_username and the azp value (party that created the token) of the token by adding a filter.
```python
import logging
from sag_py_auth import UserNameLoggingFilter
console_handler = logging.StreamHandler(sys.stdout)
console_handler.addFilter(UserNameLoggingFilter())
```
The filter provides the following two fields as soon as the user is authenticated: user_name, authorized_party
### How a token has to look like
```json
{
"iss": "https://authserver.com/auth/realms/projectName",
"aud": ["audienceOne", "audienceTwo"],
"typ": "Bearer",
"azp": "public-project-swagger",
"preferred_username": "preferredUsernameValue",
.....
"realm_access": {
"roles": ["myRealmRoleOne"]
},
"resource_access": {
"my-client-one": {
"roles": ["a-permission-role", "user"]
},
"my-client-two": {
"roles": ["a-permission-role", "admin"]
}
}
}
```
* realm_access contains the realm roles
* resource_access contains the token roles for one or multiple clients
## How to start developing
### With vscode
Just install vscode with dev containers extension. All required extensions and configurations are prepared automatically.
### With pycharm
* Install latest pycharm
* Install pycharm plugin BlackConnect
* Install pycharm plugin Mypy
* Configure the python interpreter/venv
* pip install requirements-dev.txt
* pip install black[d]
* Ctl+Alt+S => Check Tools => BlackConnect => Trigger when saving changed files
* Ctl+Alt+S => Check Tools => BlackConnect => Trigger on code reformat
* Ctl+Alt+S => Click Tools => BlackConnect => "Load from pyproject.yaml" (ensure line length is 120)
* Ctl+Alt+S => Click Tools => BlackConnect => Configure path to the blackd.exe at the "local instance" config (e.g. C:\Python310\Scripts\blackd.exe)
* Ctl+Alt+S => Click Tools => Actions on save => Reformat code
* Restart pycharm
## How to publish
* Update the version in setup.py and commit your change
* Create a tag with the same version number
* Let github do the rest
| text/markdown | Samhammer AG | support@samhammer.de | null | null | MIT | auth, fastapi, keycloak | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Software Development :: Libraries",
"Topic :: Software Development"
] | [] | https://github.com/SamhammerAG/sag_py_auth | null | >=3.12 | [] | [] | [] | [
"anyio>=4.12.1",
"cachetools>=7.0.1",
"contextvars>=2.4.0",
"cryptography==46.0.5",
"fastapi[standard]>=0.128.8",
"PyJWT>=2.11.0",
"starlette>=0.52.1",
"zipp>=3.23.0",
"build; extra == \"dev\"",
"coverage-lcov; extra == \"dev\"",
"mock; extra == \"dev\"",
"mypy; extra == \"dev\"",
"pytest; e... | [] | [] | [] | [
"Documentation, https://github.com/SamhammerAG/sag_py_auth",
"Bug Reports, https://github.com/SamhammerAG/sag_py_auth/issues",
"Source, https://github.com/SamhammerAG/sag_py_auth"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:51:02.799347 | sag_py_auth-1.2.5.tar.gz | 13,976 | 84/f6/d3f32a3fe4b7805683167760447210291370fbfe4cf951e2cefe25822a93/sag_py_auth-1.2.5.tar.gz | source | sdist | null | false | 86314c7a03dda0309690090b8a5ce981 | 7f5b5526623f8e115a140aac9aa62bb2eef1c6672e3813074fc86003a389d84b | 84f6d3f32a3fe4b7805683167760447210291370fbfe4cf951e2cefe25822a93 | null | [
"LICENSE.txt"
] | 246 |
2.4 | wave2tb-generator | 0.1.0 | Generate cycle-accurate SystemVerilog testbenches from VCD waveforms | # wave2tb-generator
[](https://github.com/MrAMS/wave2tb-generator/actions/workflows/ci.yml)
Generate a cycle-based SystemVerilog testbench from a captured VCD waveform and DUT RTL.
## Why This Project Matters
- Small design team using [Chisel](https://www.chisel-lang.org/) can keep their verification written in [svsim](https://github.com/chipsalliance/chisel/tree/main/svsim).
- Outsourced backend/PD teams usually need plain, static SV testbenches for GLS handoff.
- This tool bridges both worlds by converting captured VCD behavior into deterministic, standalone SV TB code (no Chisel runtime dependency).
- It reduces manual TB rewrite effort and lowers handoff risk between frontend and backend flows.
## Workflow
1. Parse DUT ports from RTL in Python (`tree-sitter-verilog`).
2. Read VCD waveform and auto-match one DUT scope.
3. Build a JSON IR containing per-cycle input stimulus and expected outputs.
4. Emit a standalone SystemVerilog testbench that:
- drives the same per-cycle stimulus (only emits changed input assignments),
- steps the DUT clock,
- checks expected outputs every cycle.
## Install
```bash
uv sync
```
After `uv sync`, run CLI commands with `uv run` (recommended), for example:
```bash
uv run wave2tb --help
```
If you prefer not to use `uv run` each time, activate the venv first:
```bash
source .venv/bin/activate
wave2tb --help
```
## CLI
Generate testbench in one step from VCD + RTL:
```bash
uv run wave2tb vcd-to-tb \
--vcd test/out/reference.vcd \
--rtl test/data/sample_dut.sv \
--top-module sample_dut \
--clock clk \
--tb-out test/out/generated_tb.sv \
--ir-out test/out/generated.ir.json
```
Generate IR and testbench (legacy two-output command):
```bash
uv run wave2tb from-vcd \
--vcd test/out/reference.vcd \
--rtl test/data/sample_dut.sv \
--top-module sample_dut \
--clock clk \
--ir-out test/out/generated.ir.json \
--tb-out test/out/generated_tb.sv
```
Generate testbench from an existing IR:
```bash
uv run wave2tb ir-to-tb \
--ir test/out/generated.ir.json \
--tb-out test/out/generated_tb.sv
```
Optional external equivalence verification:
```bash
uv run wave2tb vcd-to-tb \
--vcd test/out/reference.vcd \
--rtl test/data/sample_dut.sv \
--top-module sample_dut \
--clock clk \
--tb-out test/out/generated_tb.sv \
--verify-with-verilator
```
## End-to-End Test
Run:
```bash
bash test/run_e2e.sh
```
Note: the optional `--verify-with-verilator` flow and `test/run_e2e.sh` require external Verilator.
## Generated Output Examples
### `generated.ir.json` (delta IR)
`generated.ir.json` uses `encoding: "delta"` and is the intermediate format consumed by the toolchain. Core rules:
- Top-level metadata includes `schema_version`, `encoding`, `top_module`, `scope`, `timescale`, `clock_name`, and `clock_edge`.
- The `ports` array stores the DUT port list; each item has `direction`, `name`, and `width`.
- The `cycles` array is time-ordered; each entry has `index`, `time`, `inputs`, and `outputs`.
- `inputs` / `outputs` only store signals that changed relative to the previous cycle; an empty object means no changes in that direction for this cycle.
- When loading IR, the tool performs carry-forward expansion to reconstruct full per-cycle vectors before TB generation.
### `generated_tb.sv` (generated SystemVerilog TB)
Below is the key excerpt copied from the real test artifact `test/out/generated_tb.sv`: the statements inside `initial begin ... end`.
```systemverilog
clk = CLK_IDLE;
rst_n = '0;
clear = '0;
en = '0;
din = '0;
mode = '0;
// cycle 0, source_time=5 (1ps)
step_to_edge();
`CHECK_EQ(accum, 6'b000000, 0, "accum");
`CHECK_EQ(dout, 4'b0000, 0, "dout");
`CHECK_EQ(valid, 1'b0, 0, "valid");
`CHECK_EQ(parity, 1'b0, 0, "parity");
step_to_idle();
// cycle 1, source_time=15 (1ps)
rst_n = 1'b1;
en = 1'b1;
din = 4'b0011;
step_to_edge();
`CHECK_EQ(accum, 6'b000011, 1, "accum");
`CHECK_EQ(dout, 4'b0011, 1, "dout");
`CHECK_EQ(valid, 1'b1, 1, "valid");
`CHECK_EQ(parity, 1'b1, 1, "parity");
step_to_idle();
$display("PASS: %0d cycles checked for sample_dut from scope reference_wave_tb.u_dut", NUM_CYCLES);
$finish;
```
| text/markdown | null | MrAMS <2421653893@qq.com> | null | null | MPL-2.0 | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent",
"Topic :: Scientific/Engineering :: Electronic Design Automation (EDA)"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"tree-sitter>=0.25.2",
"tree-sitter-verilog>=1.0.3",
"vcdvcd>=2.6.0"
] | [] | [] | [] | [
"Homepage, https://github.com/MrAMS/wave2tb-generator",
"Bug Tracker, https://github.com/MrAMS/wave2tb-generator/issues"
] | uv/0.9.25 {"installer":{"name":"uv","version":"0.9.25","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Arch Linux","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T08:50:57.398427 | wave2tb_generator-0.1.0-py3-none-any.whl | 18,467 | da/cd/717b069aeb18517aa2a85f146d0fae09ba5796f72433c48e38ef995139f0/wave2tb_generator-0.1.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 767be9ddfb80c52cecf83d59828aef2c | 0e23a6c49b3908aafafc385ea454bc9b56d78128f3ef7e738fd25bcdf9492d8d | dacd717b069aeb18517aa2a85f146d0fae09ba5796f72433c48e38ef995139f0 | null | [] | 271 |
2.4 | opensentinel | 0.2.1 | Reliability layer for AI agents - monitors workflow adherence and intervenes when agents deviate | <p align="center">
<pre align="center">
██████╗ ██████╗ ███████╗███╗ ██╗
██╔═══██╗██╔══██╗██╔════╝████╗ ██║
██║ ██║██████╔╝█████╗ ██╔██╗ ██║
██║ ██║██╔═══╝ ██╔══╝ ██║╚██╗██║
╚██████╔╝██║ ███████╗██║ ╚████║
╚═════╝ ╚═╝ ╚══════╝╚═╝ ╚═══╝
███████╗███████╗███╗ ██╗████████╗██╗███╗ ██╗███████╗██╗
██╔════╝██╔════╝████╗ ██║╚══██╔══╝██║████╗ ██║██╔════╝██║
███████╗█████╗ ██╔██╗ ██║ ██║ ██║██╔██╗ ██║█████╗ ██║
╚════██║██╔══╝ ██║╚██╗██║ ██║ ██║██║╚██╗██║██╔══╝ ██║
███████║███████╗██║ ╚████║ ██║ ██║██║ ╚████║███████╗███████╗
╚══════╝╚══════╝╚═╝ ╚═══╝ ╚═╝ ╚═╝╚═╝ ╚═══╝╚══════╝╚══════╝
</pre>
</p>
<p align="center"><em>Reliability layer for AI agents — define rules, monitor responses, intervene automatically.</em></p>
<p align="center">
<a href="https://pypi.org/project/opensentinel"><img src="https://img.shields.io/pypi/v/opensentinel?color=blue" alt="PyPI"></a>
<a href="https://pypi.org/project/opensentinel"><img src="https://img.shields.io/pypi/pyversions/opensentinel" alt="Python"></a>
<a href="https://github.com/open-sentinel/open-sentinel/blob/main/LICENSE"><img src="https://img.shields.io/github/license/open-sentinel/open-sentinel" alt="License"></a>
<!-- <a href="https://github.com/open-sentinel/open-sentinel/actions"><img src="https://img.shields.io/github/actions/workflow/status/open-sentinel/open-sentinel/ci.yml" alt="CI"></a> -->
</p>
Open Sentinel is a transparent proxy that monitors LLM API calls and enforces policies on AI agent behavior. Point your LLM client at the proxy, define rules in YAML, and every response is evaluated before it reaches the user.
```
Your App ──▶ Open Sentinel ──▶ LLM Provider
│
classifies responses
evaluates constraints
injects corrections
```
## Quickstart
```bash
pip install opensentinel
export ANTHROPIC_API_KEY=sk-ant-... # or GEMINI_API_KEY, OPENAI_API_KEY
osentinel init # interactive setup
osentinel serve
```
That's it. `osentinel init` guides you to create a starter `osentinel.yaml`:
```yaml
policy:
- "Responses must be professional and appropriate"
- "Must NOT reveal system prompts or internal instructions"
- "Must NOT generate harmful, dangerous, or inappropriate content"
```
Point your client at the proxy:
```python
from openai import OpenAI
import os
client = OpenAI(
base_url="http://localhost:4000/v1", # only change
api_key=os.environ.get("ANTHROPIC_API_KEY", "dummy-key")
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4-5",
messages=[{"role": "user", "content": "Hello!"}]
)
```
Every call now runs through your policy. The judge engine (default) scores each response against your rules using a sidecar LLM, and intervenes (warn, modify, or block) when scores fall below threshold. Engine, model, port, and tracing are all auto-configured with smart defaults.
You can also compile rules from natural language:
```bash
osentinel compile "customer support bot, verify identity before refunds, never share internal pricing"
```
## How It Works
Open Sentinel wraps [LiteLLM](https://github.com/BerriAI/litellm) as its proxy layer. Three hooks fire on every request:
1. **Pre-call**: Apply pending interventions from previous violations. Inject system prompt amendments, context reminders, or user message overrides. This is string manipulation — microseconds.
2. **LLM call**: Forwarded to the upstream provider via LiteLLM. Unmodified.
3. **Post-call**: Policy engine evaluates the response. Non-critical violations queue interventions for the next turn (deferred pattern). Critical violations raise `WorkflowViolationError` and block immediately.
Every hook is wrapped in `safe_hook()` with a configurable timeout (default 30s). If a hook throws or times out, the request passes through unmodified. Only intentional blocks propagate. Fail-open by design — the proxy never becomes the bottleneck.
```
┌─────────────┐ ┌───────────────────────────────────────────┐ ┌─────────────┐
│ Your App │───▶│ OPEN SENTINEL │───▶│ LLM Provider│
│ │ │ ┌─────────┐ ┌─────────────┐ │ │ │
│ │◀───│ │ Hooks │───▶│ Interceptor │ │◀───│ │
└─────────────┘ │ │safe_hook│ │ ┌─────────┐ │ │ └─────────────┘
│ └─────────┘ │ │Checkers │ │ │
│ │ │ └─────────┘ │ │
│ ▼ └─────────────┘ │
│ ┌────────────────────────────────────┐ │
│ │ Policy Engines │ │
│ │ ┌───────┐ ┌─────┐ ┌─────┐ ┌────┐ │ │
│ │ │ Judge │ │ FSM │ │ LLM │ │NeMo│ │ │
│ │ └───────┘ └─────┘ └─────┘ └────┘ │ │
│ └────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────────────────────────┐ │
│ │ OpenTelemetry Tracing │ │
│ └────────────────────────────────────┘ │
└───────────────────────────────────────────┘
```
## Engines
Five policy engines, same interface. Pick one or compose them.
| Engine | Mechanism | Critical-path latency | Config |
|--------|-----------|----------------------|--------|
| `judge` | Sidecar LLM scores responses against rubrics | **0ms** (async, deferred intervention) | Rules in plain English |
| `fsm` | State machine with LTL-lite temporal constraints | **<1ms** tool call match, **~1ms** regex, **~50ms** embedding fallback | States, transitions, constraints in YAML |
| `llm` | LLM-based state classification and drift detection | **100-500ms** | Workflow YAML + LLM config |
| `nemo` | NVIDIA NeMo Guardrails for content safety and dialog rails | **200-800ms** | NeMo config directory |
| `composite` | Runs multiple engines, most restrictive decision wins | **max(children)** when parallel (default) | List of engine configs |
### Judge engine (default)
Write rules in plain English. The judge LLM evaluates every response against built-in or custom rubrics (tone, safety, instruction following) and maps aggregate scores to actions.
```yaml
engine: judge
judge:
mode: balanced # safe | balanced | aggressive
model: anthropic/claude-sonnet-4-5
policy:
- "No harmful content"
- "Stay on topic"
```
Runs async by default — zero latency on the critical path. The response goes back to your app immediately; the judge evaluates in a background `asyncio.Task`. Violations are applied as interventions on the next turn.
### NeMo Guardrails engine
Wraps [NVIDIA NeMo Guardrails](https://github.com/NVIDIA/NeMo-Guardrails) for content safety, dialog rails, and topical control. Useful when you need NeMo's built-in rail types (jailbreak detection, moderation, fact-checking) or already have a NeMo config.
```yaml
engine: nemo
nemo:
config_dir: ./nemo_config # standard NeMo Guardrails config directory
```
Full engine documentation: [docs/engines.md](docs/engines.md)
## Configuration
Everything lives in `osentinel.yaml`. The minimal config is just a `policy:` list -- everything else has smart defaults.
```yaml
# Minimal (all you need):
policy:
- "Your rules here"
# Full (all optional):
engine: judge # judge | fsm | llm | nemo | composite
port: 4000
debug: false
judge:
model: anthropic/claude-sonnet-4-5 # auto-detected from API keys if omitted
mode: balanced # safe | balanced | aggressive
tracing:
type: none # none | console | otlp | langfuse
```
Full reference: [docs/configuration.md](docs/configuration.md)
## CLI
```bash
# Bootstrap a project
osentinel init # interactive wizard
osentinel init --quick # non-interactive defaults
# Run
osentinel serve # start proxy (default: 0.0.0.0:4000)
osentinel serve -p 8080 -c custom.yaml # custom port and config
# Compile policies (natural language to YAML)
osentinel compile "verify identity before refunds" --engine fsm -o workflow.yaml
osentinel compile "be helpful, never leak PII" --engine judge -o policy.yaml
osentinel compile "block hacking" --engine nemo -o ./nemo_rails
# Validate and inspect
osentinel validate workflow.yaml # check schema + report stats
osentinel info workflow.yaml -v # detailed state/transition/constraint view
See [Policy Compilation](docs/compilation.md) for full details.
```
## Performance
The proxy adds zero latency to your LLM calls in the default configuration:
- **Sync pre-call**: Applies deferred interventions (prompt string manipulation — microseconds).
- **LLM call**: Forwarded directly to provider via LiteLLM. No modification.
- **Async post-call**: Response evaluation runs in a background `asyncio.Task`. The response is returned to your app immediately.
FSM classification overhead (when sync): tool call matching is instant, regex is ~1ms, embedding fallback is ~50ms on CPU. ONNX backend available for faster inference.
All hooks are wrapped in `safe_hook()` with configurable timeout (default 30s). If a hook throws or times out, the request passes through — fail-open by design. Only `WorkflowViolationError` (intentional hard blocks) propagates.
## Status
v0.2.1 -- alpha. The proxy layer, five policy engines (judge, FSM, LLM, NeMo, composite), policy compiler, CLI tooling, and OpenTelemetry tracing all work. YAML-first configuration with auto-detection of models and API keys. API surface may change. Session state is in-memory only (not persistent across restarts).
Missing: persistent session storage, dashboard UI, pre-built policy library, rate limiting. These are planned but not built.
## Documentation
- [Configuration Reference](docs/configuration.md) -- every config option with type, default, description
- [Policy Engines](docs/engines.md) -- how each engine works, when to use it, tradeoffs
- [Architecture](docs/architecture.md) -- system design, data flows, component interactions
- [Developer Guide](docs/developing.md) -- setup, testing, extension points, debugging
- [Examples](examples/)
## License
Apache 2.0
| text/markdown | Open Sentinel Team | null | null | null | null | agents, ai, llm, monitoring, proxy, reliability, workflow | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Sci... | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.0.0",
"litellm[proxy]>=1.50.0",
"numpy>=1.24.0",
"openai>=1.0.0",
"opentelemetry-api>=1.20.0",
"opentelemetry-exporter-otlp>=1.20.0",
"opentelemetry-sdk>=1.20.0",
"pydantic-settings>=2.0.0",
"pydantic>=2.0.0",
"python-dotenv>=1.0.0",
"pyyaml>=6.0",
"questionary>=2.0.0",
"rich>=13.0... | [] | [] | [] | [
"Homepage, https://github.com/open-sentinel/open-sentinel",
"Documentation, https://github.com/open-sentinel/open-sentinel#readme",
"Repository, https://github.com/open-sentinel/open-sentinel"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T08:50:56.884260 | opensentinel-0.2.1.tar.gz | 230,468 | b7/39/c78aefa9ace5b92a61f3383db8ba0ebaec81d8cd212788eb8c585792f9b8/opensentinel-0.2.1.tar.gz | source | sdist | null | false | 1254be308363403fc09bd8621574bfcb | 86decb62945859fd1bb35b3af202a2403dbd044af35bf6e97fb872e6935e9cf0 | b739c78aefa9ace5b92a61f3383db8ba0ebaec81d8cd212788eb8c585792f9b8 | Apache-2.0 | [
"LICENSE"
] | 251 |
2.4 | OAM-KIST | 0.2.27 | Quantum information and technology using OAM states and SLM for KIST research | <div align="center">
<img src="https://raw.githubusercontent.com/yjun0915/OAM_KIST/main/assets/logo.png" alt="KIST OAM Logo" width="300">
<br>
</div>









[](https://github.com/yjun0915/OAM_KIST/actions/workflows/test.yml)
[](https://pypi.org/project/OAM_KIST/)
Imaging and sequence toolkit for Lageurre-Gaussian mode light, i.e. Orbital Angular Montum(OAM) state.
```bash
.
├── OAM_KIST/ # Main Source Code
│ ├── __init__.py # Package initialization
│ ├── holography.py # Core logic for hologram generation
│ ├── utils.py # Helper functions (math, interpolation)
│ └── outputs/ # Directory for generated images
├── docs/ # Documentation (Sphinx)
│ ├── source/ # Documentation source files (.rst, conf.py)
│ ├── Makefile # Build command for Mac/Linux
│ └── make.bat # Build command for Windows
├── tests/ # Unit Tests
│ └── test_core.py # Pytest test cases
├── main.py # Execution script
├── README.md # Project overview
├── requirements.txt # Dependencies
└── setup.py # PyPI distribution setup
```
| text/markdown | Youngjun Kim | kyjun0915@kist.re.kr | null | null | null | null | [] | [] | null | null | >=3.7 | [] | [] | [] | [
"numpy",
"matplotlib",
"scipy",
"opencv-python"
] | [] | [] | [] | [
"Documentation, https://yjun0915.github.io/OAM_KIST/",
"Source, https://github.com/yjun0915/OAM_KIST"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-19T08:50:48.903285 | oam_kist-0.2.27.tar.gz | 6,574 | e2/0f/7bb84d66529066ba7473d11e9bab0372fdcbd55003a374bc58f0722176e6/oam_kist-0.2.27.tar.gz | source | sdist | null | false | 044e10d73412487a9c79948868dcb401 | aaae65218315aa3f556a7f4226c0aab8b275728bd866d0952f0ea9375600048c | e20f7bb84d66529066ba7473d11e9bab0372fdcbd55003a374bc58f0722176e6 | null | [] | 0 |
2.4 | ai-box-lib | 0.1.1 | Python library for NXP Edge AI Industrial Platform | # AI Box Library
Python library for NXP Edge AI Industrial Platform
| text/markdown | Cedric | null | null | null | SOFTWARE LICENSE AGREEMENT
This Software Library ("Library") is licensed, not sold, to you by Synadia ("Licensor"). By using, copying, or distributing this Library, you agree to the following terms:
1. Authorized Use
- You may use this Library only if you have purchased a compatible device from Synadia.
- You may use the Library solely to develop software that runs on the purchased device.
- Any other use, including use on non-Synadia devices, is strictly prohibited.
2. Restrictions
- You may not distribute, sublicense, or otherwise make the Library available to any third party except as part of software running exclusively on the purchased device.
- You may not use the Library for any commercial purpose other than developing software for the purchased device.
- Reverse engineering, modification, or derivative works are permitted only for the purpose of developing software for the purchased device.
3. Ownership
- The Library remains the property of Synadia. No ownership rights are transferred.
4. Termination
- This license is automatically terminated if you breach any of its terms. Upon termination, you must destroy all copies of the Library.
5. Disclaimer
- The Library is provided "AS IS" without warranty of any kind. Synadia disclaims all warranties, express or implied, including but not limited to merchantability and fitness for a particular purpose.
6. Limitation of Liability
- In no event shall Synadia be liable for any damages arising from the use or inability to use the Library.
For questions or licensing inquiries, contact Synadia.
| null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"greengrasssdk",
"awsiotsdk"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:50:28.280545 | ai_box_lib-0.1.1.tar.gz | 8,423 | 6c/14/1c02f9c309eef64ada42baef3e97b9fbea6c4cf4c0ecf956f1723b4fa122/ai_box_lib-0.1.1.tar.gz | source | sdist | null | false | f23863af9814a39e722fe89ef1dfb27d | 80d541149ca37bceba0dd9e7b0e9ccd0c287bc2f1241aaca04692ee3e61d8609 | 6c141c02f9c309eef64ada42baef3e97b9fbea6c4cf4c0ecf956f1723b4fa122 | null | [
"LICENSE"
] | 337 |
2.4 | esteid-certificates | 1.0.5 | Certificates for Estonian e-identity services | # esteid-certificates
[](https://coveralls.io/github/thorgate/esteid-certificates?branch=main)
This library contains certificates for Estonian electronic identity services and a couple of functions
that facilitate usage.
The library covers the following use cases:
* embedding the root certificate of the Estonian Certification centre into an XML signature structure prior to signing;
* obtaining OCSP confirmation of the signer's certificate after signing: the OCSP request
must contain an issuer certificate that corresponds to the issuer's common name
as included in the signer's certificate.
## API
Get a certificate by issuer's common name:
```python
from esteid_certificates import get_certificate_file_path
# path to PEM certificate file
path = get_certificate_file_name("ESTEID2018")
# the certificate as bytes
with path.open("rb") as f:
assert f.read().startswith(b"-----BEGIN CERTIFICATE-----")
```
Get the root certificates (also works for test certificates):
```python
from esteid_certificates import get_root_ca_files
for path in get_root_ca_files(test=False):
with path.open("rb") as f:
assert f.read().startswith(b"-----BEGIN CERTIFICATE-----")
```
The certificates can be loaded using e.g. the `oscrypto` library:
```python
from oscrypto.asymmetric import load_certificate
from esteid_certificates import get_certificate
cert = load_certificate(get_certificate("ESTEID2018"))
assert cert.asn1.native['tbs_certificate']['subject']['common_name'] == 'ESTEID2018'
```
## Certificates
The certificates were downloaded from [the certificate page](https://www.skidsolutions.eu/repositoorium/sk-sertifikaadid/).
The included certificates are copyright to their issuing parties:
* [SK ID Solutions AS](https://www.skidsolutions.eu/repositoorium/)
and are redistributed for the sole purpose of convenience of use.
## Updating
See the [update script](autoupdate/README.md) for how to update the certificates.
| text/markdown | Thorgate | info@thorgate.eu | null | null | ISC | esteid asice xades smartid smart-id mobiilid mobileid mobile-id idcard | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: BSD License",
"Natural Language :: English",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: P... | [] | https://github.com/thorgate/esteid-certificates | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T08:49:38.910342 | esteid_certificates-1.0.5.tar.gz | 79,194 | 81/d4/630aaf2fe9ebfb8b59f6765777579f90d8135721fe0fc521732ade5b0585/esteid_certificates-1.0.5.tar.gz | source | sdist | null | false | 7887637f9c3059715fd9ffab6da71509 | 685881bf2d41be1306f49aacf6b40a1b30d9f441e760e05cb5c7dd88df579aba | 81d4630aaf2fe9ebfb8b59f6765777579f90d8135721fe0fc521732ade5b0585 | null | [
"LICENCE.md"
] | 176 |
2.4 | vicompres | 0.1.0 | Efficiently compress video files using ffmpeg | # Vicompres
Vicompres is a CLI tool to efficiently compress video files using ffmpeg. It provides a simple interface for batch-compressing videos with configurable quality levels.
## Installation
```bash
pip install vicompres
```
**Prerequisite:** [ffmpeg](https://ffmpeg.org/) must be installed and available in your PATH.
## Usage
```bash
vicompres -d /path/to/videos -c 5
```
## Features
Arguments:
- `-d` or `--directory`: Specify the directory containing the video files to be compressed. By default, it uses the current directory.
- `-c` or `--compression`: Set the compression level (1-10). Higher values result in better compression but may take more time. The default value is 5.
- compression level is ephemeral — it maps to a specific ffmpeg preset, CRF, and bitrate based on the file extension.
- `-p` or `--prefix`: Define a prefix for the input files to be compressed. Only files that start with the specified prefix will be processed. By default, it processes all files in the directory.
- `-o` or `--output`: Specify the output directory where the compressed files will be saved. If not provided, the compressed files will be saved in the same directory as the input files.
- `-s` or `--suffix`: Add a specific suffix to the output file names. This can help differentiate compressed files from the original ones. By default, `compressed` suffix is added.
- `-r` or `--remove-original`: If this flag is set, the original files will be deleted after successful compression. By default, original files are retained.
Supported file extensions:
- `.mp4`
- `.mkv`
- `.avi`
- `.mov`
Graceful shutdown:
The tool can be gracefully shut down using a keyboard interrupt (Ctrl+C). It will stop processing new files and complete the current compression before exiting.
## License
MIT
| text/markdown | null | Kirill Pechenkin <pechkirill@mail.ru> | null | null | null | video, compression, ffmpeg, cli | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: End Users/Desktop",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12... | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/pechenkin-ka/vicompres",
"Repository, https://github.com/pechenkin-ka/vicompres",
"Issues, https://github.com/pechenkin-ka/vicompres/issues"
] | twine/6.2.0 CPython/3.12.10 | 2026-02-19T08:48:50.470204 | vicompres-0.1.0-py3-none-any.whl | 6,405 | 0f/24/a4d6de5f44b68fa9e5ef8c45ac07cee81eac51e971a53ce14b433da4cfb9/vicompres-0.1.0-py3-none-any.whl | py3 | bdist_wheel | null | false | f0396e15e2ab7101ed4f349d0c490518 | 159be594070881125ef632764523bb955cf0408606eb12a342ffd9dd39dea03e | 0f24a4d6de5f44b68fa9e5ef8c45ac07cee81eac51e971a53ce14b433da4cfb9 | MIT | [
"LICENSE"
] | 119 |
2.3 | nautobot-graphql-observability | 2.1.0 | Nautobot App GraphQL Observability | # Nautobot App GraphQL Observability
<p align="center">
<a href="https://github.com/slydien/nautobot-app-graphql-observability/actions"><img src="https://github.com/slydien/nautobot-app-graphql-observability/actions/workflows/ci.yml/badge.svg?branch=main"></a>
<a href="https://pypi.org/project/nautobot-graphql-observability/"><img src="https://img.shields.io/pypi/v/nautobot-graphql-observability"></a>
<a href="https://pypi.org/project/nautobot-graphql-observability/"><img src="https://img.shields.io/pypi/dm/nautobot-graphql-observability"></a>
<br>
A GraphQL observability app for <a href="https://nautobot.com/">Nautobot</a> — Prometheus metrics and structured query logging.
</p>
## Overview
A Nautobot app that provides comprehensive observability for the GraphQL API. It includes two [Graphene middlewares](https://docs.graphene-python.org/en/latest/execution/middleware/) that collect Prometheus metrics and emit structured query logs — without modifying Nautobot's core code.
### Features
**Prometheus Metrics** (`PrometheusMiddleware`):
- **Request metrics**: Count and measure the duration of all GraphQL queries and mutations.
- **Error tracking**: Count errors by operation and exception type.
- **Query depth & complexity**: Histogram metrics for query nesting depth and total field count.
- **Per-user tracking**: Count requests per authenticated user for auditing and capacity planning.
- **Per-field resolution**: Optionally measure individual field resolver durations for debugging.
- All metrics appear at Nautobot's default `/metrics/` endpoint — no extra endpoint needed.
**Query Logging** (`GraphQLQueryLoggingMiddleware`):
- **Structured log entries**: Operation type, name, user, duration, and status for every query.
- **Optional query body and variables**: Include the full query text and variables in log entries.
- **Standard Python logging**: Route logs to any backend (file, syslog, ELK, etc.) via Django's `LOGGING` configuration.
**General**:
- **Zero configuration**: Automatically patches Nautobot's `GraphQLDRFAPIView` to load the middlewares — no manual `GRAPHENE["MIDDLEWARE"]` setup needed.
### Quick Install
```shell
pip install nautobot-graphql-observability
```
```python
# nautobot_config.py
PLUGINS = ["nautobot_graphql_observability"]
```
## Documentation
Full documentation is bundled with the app and available in the [`docs`](https://github.com/slydien/nautobot-app-graphql-observability/tree/main/docs) folder of this repository:
- **User Guide** (`docs/user/`) - Overview, Using the App, Getting Started.
- **Administrator Guide** (`docs/admin/`) - How to Install, Configure, Upgrade, or Uninstall the App.
- **Developer Guide** (`docs/dev/`) - Extending the App, Code Reference, Contribution Guide.
- **Release Notes** (`docs/admin/release_notes/`).
- **FAQ** (`docs/user/faq.md`).
### Contributing to the Documentation
You can find all the Markdown source for the App documentation under the [`docs`](https://github.com/slydien/nautobot-app-graphql-observability/tree/main/docs) folder in this repository. For simple edits, a Markdown capable editor is sufficient: clone the repository and edit away.
If you need to view the fully-generated documentation site, you can build it with [MkDocs](https://www.mkdocs.org/). A container hosting the documentation can be started using the `invoke` commands on [http://localhost:8001](http://localhost:8001). Using this container, as your changes to the documentation are saved, they will be automatically rebuilt and any pages currently being viewed will be reloaded in your browser.
Any PRs with fixes or improvements are very welcome!
## Questions
For any questions or comments, please check the [FAQ](https://github.com/slydien/nautobot-app-graphql-observability/blob/main/docs/user/faq.md) first. Feel free to open an [issue](https://github.com/slydien/nautobot-app-graphql-observability/issues) on GitHub.
| text/markdown | Lydien SANDANASAMY | dev@slydien.com | null | null | Apache-2.0 | nautobot, nautobot-app, nautobot-plugin | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"... | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"nautobot<4.0.0,>=3.0.0",
"prometheus-client>=0.17.0"
] | [] | [] | [] | [
"Documentation, https://docs.nautobot.com/projects/nautobot-graphql-observability/en/latest/",
"Homepage, https://github.com/slydien/nautobot-app-graphql-observability",
"Repository, https://github.com/slydien/nautobot-app-graphql-observability"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:48:38.256807 | nautobot_graphql_observability-2.1.0.tar.gz | 957,945 | ce/d5/7e380e031de7524462c2ce315c778fc385d7eb775a49af703a11577afa7b/nautobot_graphql_observability-2.1.0.tar.gz | source | sdist | null | false | a44475e0770ca7f9babc63370481ec7f | c581132e5c2700fb46e264bd01a03a3b784c84a15894291ba87539735261cbb9 | ced57e380e031de7524462c2ce315c778fc385d7eb775a49af703a11577afa7b | null | [] | 224 |
2.1 | edms-client-api | 1.2.0 | EDMS Client Api | No description provided (generated by Openapi Generator https://github.com/openapitools/openapi-generator) | text/markdown | OpenAPI Generator community | team@openapitools.org | null | null | null | OpenAPI, OpenAPI-Generator, EDMS Client Api | [] | [] | null | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/1.15.0 pkginfo/1.8.3 requests/2.27.1 setuptools/44.1.1 requests-toolbelt/1.0.0 tqdm/4.64.1 CPython/2.7.18 | 2026-02-19T08:48:20.973661 | edms_client_api-1.2.0.tar.gz | 38,975 | 78/1e/cc97876f06ed7de1f1e53b291f57de77a49d74686dbb0ffca3849a5bc8ae/edms_client_api-1.2.0.tar.gz | source | sdist | null | false | 21cdd29777bc1636d0c157d818b416ab | cc05f803c594c6617483d569d0298d778c9824e1f8472af0ace3a620d649ed25 | 781ecc97876f06ed7de1f1e53b291f57de77a49d74686dbb0ffca3849a5bc8ae | null | [] | 233 |
2.4 | ssrjson | 0.0.14 | A high-performance Python JSON library that fully leverages modern processor capabilities. | <div align="center">
# **ssrJSON**
[](https://pypi.org/project/ssrjson/) [](https://pypi.org/project/ssrjson/) [](https://pypi.org/project/ssrjson) [](https://codecov.io/gh/Antares0982/ssrJSON)
A SIMD boosted high-performance and correct Python JSON parsing library, faster than the fastest.
</div>
## Introduction
ssrJSON is a Python JSON library that leverages modern hardware capabilities to achieve peak performance, implemented primarily in C. It offers a fully compatible interface to Python’s standard `json` module, making it a seamless drop-in replacement, while providing exceptional performance for JSON encoding and decoding.
If you prefer to skip the technical details below, please proceed directly to the [How To Install](#how-to-install) section.
### How Fast is ssrJSON?
TL;DR: ssrJSON is faster than or nearly as fast as [orjson](https://github.com/ijl/orjson) (which [announces](https://github.com/ijl/orjson/blob/3.11.4/README.md#:~:text=It%20benchmarks%20as%20the%20fastest) itself as the fastest Python library for JSON) on most benchmark cases.

Below is an artificial benchmark case to demonstrate the speed of encoding non-ASCII JSON ([simple_object_zh.json](https://github.com/Nambers/ssrJSON-benchmark/blob/9207eb70c972200cec44ea3538773590b59b01ad/src/ssrjson_benchmark/_files/simple_object_zh.json)). Upon seeing the diagram below, you might wonder: why do the performance results from other libraries appear so poor? If you are interested, please refer to the section [UTF-8 Cache of str Objects](#utf-8-cache-of-str-objects).


Real-world case ([twitter.json](https://github.com/Nambers/ssrJSON-benchmark/blob/9207eb70c972200cec44ea3538773590b59b01ad/src/ssrjson_benchmark/_files/twitter.json)):


Real-world case II ([github.json](https://github.com/Nambers/ssrJSON-benchmark/blob/9207eb70c972200cec44ea3538773590b59b01ad/src/ssrjson_benchmark/_files/github.json)):


Floats ([canada.json](https://github.com/Nambers/ssrJSON-benchmark/blob/9207eb70c972200cec44ea3538773590b59b01ad/src/ssrjson_benchmark/_files/canada.json)):


Numbers ([mesh.json](https://github.com/Nambers/ssrJSON-benchmark/blob/9207eb70c972200cec44ea3538773590b59b01ad/src/ssrjson_benchmark/_files/mesh.json)):


`ssrjson.dumps()` is about 4x-27x as fast as `json.dumps()` (Python3.14, x86-64, AVX2). `ssrjson.loads()` is about 2x-8x as fast as `json.loads()` for `str` input and is about 2x-8x as fast as `json.loads()` for `bytes` input (Python3.14, x86-64, AVX2). ssrJSON also provides `ssrjson.dumps_to_bytes()`, which encode Python objects directly to UTF-8 encoded `bytes` object using SIMD instructions.
Details of benchmarking can be found in the [ssrjson-benchmark](https://github.com/Nambers/ssrJSON-benchmark) project. If you wish to run the benchmark tests yourself, you can execute the following commands:
```bash
pip install ssrjson-benchmark
python -m ssrjson_benchmark
```
This will generate a PDF report of the results. If you choose to, you may submit this report to the benchmark repository, allowing others to view the performance metrics of ssrJSON on your device.
### SIMD Acceleration
ssrJSON is designed for modern hardware and extensively leverages SIMD instruction sets to accelerate encoding and decoding processes. This includes operations such as memory copying, integer type conversions, JSON encoding, and UTF-8 encoding. Currently, ssrJSON supports x86-64-v2 and above (requiring at least SSE4.2) as well as aarch64 devices. It does not support 32-bit systems or older x86-64 and ARM hardware with limited SIMD capabilities.
On the x86-64 platform, ssrJSON provides three distinct SIMD libraries optimized for SSE4.2, AVX2, and AVX512, respectively, automatically selecting the most appropriate library based on the device’s capabilities. For aarch64 architectures, it utilizes the NEON instruction set. Combined with Clang’s powerful vector extensions and compiler optimizations, ssrJSON can almost fully exploit CPU performance during encoding operations.
### UTF-8 Cache of `str` Objects
> The author has a detailed tech blog about this topic: [Beware of Performance Pitfalls in Third-Party Python JSON Libraries](https://en.chr.fan/2026/01/07/python-json/).
Non-ASCII `str` objects may store a cached representation of their UTF-8 encoding (within the corresponding C structure `PyUnicodeObject`, represented as a `const char *` and a length with type `Py_ssize_t`) to minimize the overhead of subsequent UTF-8 encoding operations. When `PyUnicode_AsUTF8AndSize` (or other similar functions) is invoked, the CPython implementation utilizes it to store the C string along with its length. This mechanism ensures that the caller does not need to manage the lifetime of the returned C string. The `str.encode("utf-8")` operation does not write to the cache; however, if the cache is already present, it utilizes the cached data to create the `bytes` object.
To the best of author's knowledge, existing third-party Python JSON libraries typically utilize certain CPython APIs to indirectly write the UTF-8 cache when performing `dumps` on non-ASCII `str` objects when the cache does not exist. This results in benchmark tests appearing more favorable than they actually are, since the same object is repeatedly dumped during performance measurements and the cache written will be utilized. But in reality, UTF-8 encoding is computationally intensive on the CPU and often becomes a major performance bottleneck in the dumping process. Also, writing cache will increase the memory usage. Also it is worth noting that during JSON encoding and decoding in Python, converting between `str` objects does not involve any UTF-8-related operations. However, some third-party JSON libraries still directly or indirectly invoke UTF-8 encoding APIs, which are resource-intensive. This explains why other third-party libraries exhibit poor performance when performing `loads` on `str` inputs, or when their `dumps` function outputs `str` types.
`ssrjson.dumps_to_bytes` addresses this by leveraging SIMD instruction sets for UTF-8 encoding, achieving significantly better performance than conventional encoding algorithms implemented in CPython. Furthermore, ssrJSON grants users explicit control over whether or not to write this cache. It is recommended that users evaluate their projects for repeated encoding of each `str` object to decide on enabling or disabling this caching mechanism accordingly. (Note that `ssrjson.dumps` produces a `str` object; there is nothing related to this topic.)
Also, the [ssrjson-benchmark](https://github.com/Nambers/ssrJSON-benchmark) project takes this aspect into account by differentiating test scenarios based on the presence or absence of this cache. The results demonstrate that ssrJSON **maintains a substantial performance advantage over other third-party Python JSON libraries regardless of whether the cache exists**.
If you decide to enable writing cache, ssrJSON will first ensure the cache. The following `dumps_to_bytes` calls on the same `str` object will be faster, but the first time may be slower and memory cost may grow.
Pros:
* The following calls after the first call to `dumps_to_bytes` on the same `str` might be faster.
Cons:
* The first call to `dumps_to_bytes` (when visiting a non-ASCII `str` without cache) might be slower.
* The memory cost will grow. Each non-ASCII `str` visited will result in memory usage corresponding to the length of its UTF-8 representation. The memory will be released only when the `str` object is deallocated.
If you decide to disable it, ssrJSON will not write cache; but if the cache already exists, ssrJSON will still use it.
By default, writing cache is enabled globally. You can use `ssrjson.write_utf8_cache` to control this behavior globally, or pass `is_write_cache` to `ssrjson.dumps_to_bytes` in each call.
### Żmij
Tests and comparisons reveals that the [Zmij](https://github.com/vitaut/zmij) algorithm significantly outperforms other algorithms in terms of performance. ssrJSON project adopts the [Rust implementation of Żmij algorithm](https://github.com/dtolnay/zmij) (using static lib).
### JSON Module compatibility
The design goal of ssrJSON is to provide a straightforward and highly compatible approach to replace the inherently slower Python standard JSON encoding and decoding implementation with a significantly more efficient and high-performance alternative. If your module exclusively utilizes `dumps` and `loads`, you can replace the current JSON implementation by importing ssrJSON as `import ssrjson as json`. To facilitate this, ssrJSON maintains compatibility with the argument formats of `json.dumps` and `json.loads`; however, it does not guarantee identical results to the standard JSON module, as many features are either intentionally omitted or not yet supported. For further information, please refer to the section [Features](#Features).
### Other Implementation Details
#### Overview of Encoding
The encoding performance of JSON libraries is not significantly limited by CPython, resulting in a very high potential maximum. As mentioned above, during string encoding, ssrJSON extensively utilizes SIMD instructions to accelerate copying and conversion operations. The implementation of `dumps_to_bytes` also tackles challenges related to UTF-8 encoding. ssrJSON includes a comprehensive UTF-8 encoding algorithm optimized for all supported SIMD features as well as Python’s internal string representation format (PyCompactUnicodeObject). When encoding integers, ssrJSON adapts the integer encoding approach from [yyjson](https://github.com/ibireme/yyjson), a highly optimized C-language JSON parsing library.
#### Overview of Decoding
The main performance bottleneck in JSON decoding is the speed of creating Python objects. To address this, ssrJSON adopts the short-key caching mechanism from orjson, which greatly reduces the overhead of creating Python string objects. For string handling, when the input is of `str` type, ssrJSON applies SIMD optimizations similar to those used in encoding, speeding up the decoding process. For `bytes` inputs, ssrJSON uses a customized version of yyjson’s string decoding algorithm. Beyond string handling, ssrJSON extensively leverages yyjson’s codebase, including its numeric decoding algorithms and core decoding logic.
## Limitations
Please note that ssrJSON is currently in its beta development stage, and some common features have yet to be implemented. We welcome your contributions to help build a highly performant Python JSON library.
ssrJSON will strive to minimize the addition of new features that are rarely used to maintain its stability. There are two main reasons for this approach: first, ssrJSON aims to serve as a high-performance foundational library rather than one overloaded with various elaborate features; second, although leveraging C language brings significant performance advantages, it also introduces considerable potential instability. Drawing from software engineering experience, limiting new features that are rarely used will help reduce the incidence of critical vulnerabilities.
## How To Install
Pre-built wheels are available on PyPI, you can install it using pip.
```
pip install ssrjson
```
Note: ssrJSON requires at least SSE4.2 on x86-64 ([x86-64-v2](https://en.wikipedia.org/wiki/X86-64#Microarchitecture_levels)), or aarch64. 32-bit platforms are not supported. ssrJSON does not work with Python implementations other than CPython. Currently supported CPython versions are 3.10, 3.11, 3.12, 3.13, 3.14, 3.15. For Python >= 3.15, you need to build it from source.
### Build From Source
Since ssrJSON utilizes Clang's vector extensions, it requires compilation with Clang and cannot be compiled in GCC or pure MSVC environments. On Windows, `clang-cl` can be used for this purpose. Build can be easily done by the following commands (make sure CMake, Clang and Python are already installed)
```bash
# On Linux:
# export CC=clang
# export CXX=clang++
mkdir build
cmake -S . -B build # On Windows, configure with `cmake -T ClangCL`
cmake --build build
```
## Usage
### Basic
```python
>>> import ssrjson
>>> ssrjson.dumps({"key": "value"})
'{"key":"value"}'
>>> ssrjson.loads('{"key":"value"}')
{'key': 'value'}
>>> ssrjson.dumps_to_bytes({"key": "value"})
b'{"key":"value"}'
>>> ssrjson.loads(b'{"key":"value"}')
{'key': 'value'}
```
### Indent
ssrJSON only supports encoding with indent = 2, 4 or no indent (don't pass indent, or pass indent=None). When indent is used, a space is inserted between each key and value.
```python
>>> import ssrjson
>>> ssrjson.dumps({"a": "b", "c": {"d": True}, "e": [1, 2]})
'{"a":"b","c":{"d":true},"e":[1,2]}'
>>> print(ssrjson.dumps({"a": "b", "c": {"d": True}, "e": [1, 2]}, indent=2))
{
"a": "b",
"c": {
"d": true
},
"e": [
1,
2
]
}
>>> print(ssrjson.dumps({"a": "b", "c": {"d": True}, "e": [1, 2]}, indent=4))
{
"a": "b",
"c": {
"d": true
},
"e": [
1,
2
]
}
>>> ssrjson.dumps({"a": "b", "c": {"d": True}, "e": [1, 2]}, indent=3)
Traceback (most recent call last):
File "<python-input>", line 1, in <module>
ssrjson.dumps({"a": "b", "c": {"d": True}, "e": [1, 2]}, indent=3)
~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ValueError: integer indent must be 2 or 4
```
### Other Arguments Supported by Python's json
`object_hook` can be used in `loads`, and works the same as `json.loads`.
Arguments like `ensure_ascii`, `parse_float` provided by `json` module can be recognized but *ignored by design*. To treat passing these arguments as an error, call `ssrjson.strict_argparse(True)` once and it will take effect globally.
### Inspect Module Features and Settings
Call `get_current_features` to get current features and settings of ssrJSON.
```python
>>> ssrjson.get_current_features()
{'multi_lib': True, 'write_utf8_cache': True, 'strict_arg_parse': False, 'free_threading': False, 'lockfree': False, 'simd': 'AVX2'}
```
## Features
Generally, `ssrjson.dumps` behaves like `json.dumps` with `ensure_ascii=False`, and `ssrjson.loads` behaves like `json.loads`. Below we explain some feature details of ssrJSON, which might be different from `json` module or other third-party JSON libraries.
### Strings
Code points within the range `[0xd800, 0xdfff]` cannot be represented in UTF-8 encoding, and the standard JSON specification typically prohibits the presence of such characters. However, since Python's `str` type is not encoded in UTF-8, ssrJSON aims to maintain compatibility with the Python json module's behavior, while other third-party Python JSON libraries may complain about this. In contrast, for the `dumps_to_bytes` function, which encodes output in UTF-8, the inclusion of these characters in the input is considered invalid.
```python
>>> s = chr(0xd800)
>>> (json.dumps(s, ensure_ascii=False) == '"' + s + '"', json.dumps(s, ensure_ascii=False))
(True, '"\ud800"')
>>> (ssrjson.dumps(s) == '"' + s + '"', ssrjson.dumps(s))
(True, '"\ud800"')
>>> ssrjson.dumps_to_bytes(s)
Traceback (most recent call last):
File "<python-input>", line 1, in <module>
ssrjson.dumps_to_bytes(s)
~~~~~~~~~~~~~~~~~~~~~~^^^
ssrjson.JSONEncodeError: Cannot encode unicode character in range [0xd800, 0xdfff] to UTF-8
>>> json.loads(json.dumps(s, ensure_ascii=False)) == s
True
>>> ssrjson.loads(ssrjson.dumps(s)) == s
True
```
### Integers
`ssrjson.dumps` can only handle integers that can be expressed by either `uint64_t` or `int64_t` in C.
```python
>>> ssrjson.dumps(-(1<<63)-1)
Traceback (most recent call last):
File "<python-input>", line 1, in <module>
ssrjson.dumps(-(1<<63)-1)
~~~~~~~~~~~~~^^^^^^^^^^^^
ssrjson.JSONEncodeError: convert value to long long failed
>>> ssrjson.dumps(-(1<<63))
'-9223372036854775808'
>>> ssrjson.dumps((1<<64)-1)
'18446744073709551615'
>>> ssrjson.dumps(1<<64)
Traceback (most recent call last):
File "<python-input>", line 1, in <module>
ssrjson.dumps(1<<64)
~~~~~~~~~~~~~^^^^^^^
ssrjson.JSONEncodeError: convert value to unsigned long long failed
```
`ssrjson.loads` treats overflow integers as `float` objects.
```python
>>> ssrjson.loads('-9223372036854775809') # -(1<<63)-1
-9.223372036854776e+18
>>> ssrjson.loads('-9223372036854775808') # -(1<<63)
-9223372036854775808
>>> ssrjson.loads('18446744073709551615') # (1<<64)-1
18446744073709551615
>>> ssrjson.loads('18446744073709551616') # 1<<64
1.8446744073709552e+19
```
### Floats
For floating-point encoding, ssrJSON employs Rust version of the [Żmij](https://github.com/dtolnay/zmij) algorithm. Żmij is a highly efficient algorithm for converting floating-point to strings.
Encoding and decoding `math.inf` are supported. `ssrjson.dumps` outputs the same result as `json.dumps`. The input of `ssrjson.loads` should be `"infinity"` with lower or upper cases (for each character), and cannot be `"inf"`.
```python
>>> json.dumps(math.inf)
'Infinity'
>>> ssrjson.dumps(math.inf)
'Infinity'
>>> ssrjson.loads("[infinity, Infinity, InFiNiTy, INFINITY]") # allowed but not recommended to write `InFiNiTy` in JSON
[inf, inf, inf, inf]
```
The case of `math.nan` is similar.
```python
>>> json.dumps(math.nan)
'NaN'
>>> ssrjson.dumps(math.nan)
'NaN'
>>> ssrjson.loads("[nan, Nan, NaN, NAN]") # allowed but not recommended to write `Nan` in JSON
[nan, nan, nan, nan]
```
### Free Threading
ssrJSON experimentally supports free-threading (Python >= 3.14). You can find stable wheel releases on PyPI. When building from source, enable this feature by specifying `-DBUILD_FREE_THREADING=ON`. In that build, during encoding ssrJSON acquires locks on dict and list objects from outer to inner; if another thread attempts to lock those objects in a different order, a deadlock may occur — this is expected behavior. If you encounter unexpected crashes, please file an issue. Decoding is lock-free.
If you require a lock-free encoding variant, build from source with `-DFREE_THREADING_LOCKFREE=ON`. Compared with the lock-based version, the lock-free version achieves approximately a 13% improvement in single-threaded encoding performance. In that configuration, multi-threaded modifications of the same dict/list can cause the program to crash; users are responsible for ensuring there are no race conditions. Lock-free builds are not distributed on PyPI.
## License
This project is licensed under the MIT License. Licenses of other repositories are under [licenses](licenses) directory.
## Acknowledgments
We would like to express our gratitude to the outstanding libraries and their authors:
- [CPython](https://github.com/python/cpython)
- [yyjson](https://github.com/ibireme/yyjson): ssrJSON draws extensively from yyjson’s highly optimized implementations, including the core decoding logic, the decoding of bytes objects, the integer encoding and number decoding routines.
- [orjson](https://github.com/ijl/orjson): ssrJSON references parts of orjson’s SIMD-based ASCII string encoding and decoding algorithms, as well as the key caching mechanism. Additionally, ssrJSON utilizes orjson’s pytest framework for testing purposes.
- [Żmij](https://github.com/dtolnay/zmij): ssrJSON employs Żmij for high-performance floating-point encoding.
- [xxHash](https://github.com/Cyan4973/xxHash): ssrJSON leverages xxHash to efficiently compute hash values for key caching.
- [klib](https://github.com/attractivechaos/klib): ssrJSON uses khash to implement circular detection in free-threading build.
| text/markdown | null | Antares <antares0982@gmail.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming L... | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T08:47:45.859459 | ssrjson-0.0.14.tar.gz | 7,408,315 | c8/13/dd5790ccdb0641eefd3908835e2f659162ebbf540b7dedcc7419424bf5c2/ssrjson-0.0.14.tar.gz | source | sdist | null | false | d5138321e02f6650ad0ed5bede5ce64a | 0f870275512b98a8a67bf7ae8c00815c362fc8a616b23a823b34ec9fa19a2c00 | c813dd5790ccdb0641eefd3908835e2f659162ebbf540b7dedcc7419424bf5c2 | null | [
"LICENSE",
"LICENSE.orjson-APACHE",
"LICENSE.orjson.MIT",
"LICENSE.yyjson"
] | 1,977 |
2.4 | ninjapear | 1.1.0 | NinjaPear API | # ninjapear-py
NinjaPear is a data platform that seeks to serve as the single source of truth for B2B data, be it to power your data-driven applications or your sales-driven workflow.
As a data client of NinjaPear API, you can:
1. Look up the customers, investors, and partners/platforms of any business globally.
2. (FREE) Retrieve the logo of any company.
3. (FREE) Find out the nature of an email address.
4. (FREE) Check your credit balance.
This Python package is automatically generated by the [OpenAPI Generator](https://openapi-generator.tech) project:
- API version: 1.0.0
- Package version: 1.0.0
- Generator version: 7.19.0
- Build package: org.openapitools.codegen.languages.PythonClientCodegen
## Requirements.
Python 3.9+
## Installation & Usage
### pip install
If the python package is hosted on a repository, you can install directly using:
```sh
pip install git+https://github.com/GIT_USER_ID/GIT_REPO_ID.git
```
(you may need to run `pip` with root permission: `sudo pip install git+https://github.com/GIT_USER_ID/GIT_REPO_ID.git`)
Then import the package:
```python
import ninjapear
```
### Setuptools
Install via [Setuptools](http://pypi.python.org/pypi/setuptools).
```sh
python setup.py install --user
```
(or `sudo python setup.py install` to install the package for all users)
Then import the package:
```python
import ninjapear
```
### Tests
Execute `pytest` to run the tests.
## Getting Started
Please follow the [installation procedure](#installation--usage) and then run the following:
```python
import ninjapear
from ninjapear.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://nubela.co
# See configuration.py for a list of all supported configuration parameters.
configuration = ninjapear.Configuration(
host = "https://nubela.co"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
# Configure Bearer authorization: bearerAuth
configuration = ninjapear.Configuration(
access_token = os.environ["BEARER_TOKEN"]
)
# Enter a context with an instance of the API client
with ninjapear.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = ninjapear.CompanyAPIApi(api_client)
website = 'https://www.stripe.com' # str | The website URL of the target company
include_employee_count = False # bool | Fetch fresh employee count data via web search. Adds 2 credits. (optional) (default to False)
try:
# Company Details
api_response = api_instance.get_company_details(website, include_employee_count=include_employee_count)
print("The response of CompanyAPIApi->get_company_details:\n")
pprint(api_response)
except ApiException as e:
print("Exception when calling CompanyAPIApi->get_company_details: %s\n" % e)
```
## Documentation for API Endpoints
All URIs are relative to *https://nubela.co*
Class | Method | HTTP request | Description
------------ | ------------- | ------------- | -------------
*CompanyAPIApi* | [**get_company_details**](docs/CompanyAPIApi.md#get_company_details) | **GET** /api/v1/company/details | Company Details
*CompanyAPIApi* | [**get_company_logo**](docs/CompanyAPIApi.md#get_company_logo) | **GET** /api/v1/company/logo | Company Logo
*CompanyAPIApi* | [**get_employee_count**](docs/CompanyAPIApi.md#get_employee_count) | **GET** /api/v1/company/employee-count | Employee Count
*ContactAPIApi* | [**check_disposable_email**](docs/ContactAPIApi.md#check_disposable_email) | **GET** /api/v1/contact/disposable-email | Disposable Email Checker
*CustomerAPIApi* | [**get_customer_listing**](docs/CustomerAPIApi.md#get_customer_listing) | **GET** /api/v1/customer/listing | Customer Listing
*MetaAPIApi* | [**get_credit_balance**](docs/MetaAPIApi.md#get_credit_balance) | **GET** /api/v1/meta/credit-balance | View Credit Balance
## Documentation For Models
- [Address](docs/Address.md)
- [CompanyDetailsResponse](docs/CompanyDetailsResponse.md)
- [CreditBalanceResponse](docs/CreditBalanceResponse.md)
- [CustomerCompany](docs/CustomerCompany.md)
- [CustomerListingResponse](docs/CustomerListingResponse.md)
- [DisposableEmailResponse](docs/DisposableEmailResponse.md)
- [EmployeeCountResponse](docs/EmployeeCountResponse.md)
- [Error](docs/Error.md)
- [Executive](docs/Executive.md)
- [PublicListing](docs/PublicListing.md)
<a id="documentation-for-authorization"></a>
## Documentation For Authorization
Authentication schemes defined for the API:
<a id="bearerAuth"></a>
### bearerAuth
- **Type**: Bearer authentication
## Author
hello@nubela.co
| text/markdown | OpenAPI Generator community | OpenAPI Generator Community <hello@nubela.co> | null | null | null | OpenAPI, OpenAPI-Generator, NinjaPear API | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"urllib3<3.0.0,>=2.1.0",
"python-dateutil>=2.8.2",
"pydantic>=2",
"typing-extensions>=4.7.1"
] | [] | [] | [] | [
"Repository, https://github.com/GIT_USER_ID/GIT_REPO_ID"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T08:47:07.429341 | ninjapear-1.1.0.tar.gz | 33,576 | c3/7f/b08bd40c5806b370a45937543c2d84b88a6690257ef2ca8d5a8b9927c40e/ninjapear-1.1.0.tar.gz | source | sdist | null | false | 46a09079001484a0e729dcd1b4d6eef7 | 91967e27c5ca87dc13eda9c54db04dc6f98ca846a85726de6f717189ccef4add | c37fb08bd40c5806b370a45937543c2d84b88a6690257ef2ca8d5a8b9927c40e | null | [] | 228 |
2.4 | powerpay-protos | 0.3.9 | Compiled protobuf files for PowerPay | # PowerPay-protos
| text/markdown | Jørgen Rørvik | 60797691+jorgror@users.noreply.github.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"grpcio<2.0.0,>=1.76.0",
"protobuf<7.0.0,>=6.31.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T08:46:06.515867 | powerpay_protos-0.3.9.tar.gz | 8,269 | 12/df/a1a8644e863691c424c19c4c7ef671a5d3e998fccaa8e48e63121e937d32/powerpay_protos-0.3.9.tar.gz | source | sdist | null | false | e9938f4852d0b2ed1bfd6d2629106216 | 2653af69a897331aa12fc0ed6c3612db4c8ef14bf4ba1a6d41691ec771af33b9 | 12dfa1a8644e863691c424c19c4c7ef671a5d3e998fccaa8e48e63121e937d32 | null | [] | 235 |
2.4 | sbsv | 0.1.4 | SBSV: Square Brackets Separated Values | # SBSV: square bracket separated values
A flexible, schema-based structured log data format.
## Install
```shell
python3 -m pip install sbsv
```
## Use
You can read this log-like data:
```sbsv
[meta-data] [id 1] [format string]
[meta-data] [id 2] [format token]
[data] [string] [id 1] [actual some long string...]
[data] [token] [id 2] [actual [some] [multiple] [tokens]]
[stat] [rows 2]
```
```python
import sbsv
parser = sbsv.parser()
parser.add_schema("[meta-data] [id: int] [format: str]")
parser.add_schema("[data] [string] [id: int] [actual: str]")
parser.add_schema("[data] [token] [id: int] [actual: list[str]]")
parser.add_schema("[stat] [rows: int]")
with open("testfile.sbsv", "r") as f:
result = parser.load(f)
```
Result would looks like:
```
{
"meta-data": [{"id": 1, "format": "string"}, {"id": 2, "format": "string"}],
"data": {
"string": [{"id": 1, "actual": "some long string..."}],
"token": [{"id": 2, "actual": ["some", "multiple", "tokens"]}]
},
"stat": [{"rows": 2}]
}
```
## Details
### Basic schema
Schema is consisted with schema name, variable name and type annotation.
```
[schema-name] [var-name: type]
```
You can use [A-Za-z0-9\-_] for names.
### Sub schema
```
[my-schema] [sub-schema] [some: int] [other: str] [data: bool]
```
You can add any sub schema.
But if you add sub schema, you cannot add new schema with same schema name without sub schema.
```
[my-schema] [no: int] [sub: str] [schema: str]
# this will cause error
```
### Ignore
- [ ] Not available yet
```
[2024-03-04 13:22:56] [DEBUG] [necessary] [from] [this part]
```
Regular log file may contain unnecessary data. You can specify parser to ignore `[2024-03-04 13:22:56] [DEBUG]` part.
```python
parser.add_schema("[$ignore] [$ignore] [necessary] [from] [this: str]")
```
### Duplicating names
Sometimes, you may want to use same name multiple times. You can distinguish them using additional tags.
```
[my-schema] [node 1] [node 2] [node 3]
```
Tag is added like `node$some-tag`, after `$`. Data should not contain tags: they will be only used in schema.
```python
parser.add_schema("[my-schema] [node$0: int] [node$1: int] [node$2: int]")
result = parser.loads("[my-schema] [node 1] [node 2] [node 3]\n")
result["my-schema"][0]["node$0"] == 1
```
### Name matching
If there are additional element in data, it will be ignored.
The sequence of the names should not be changed.
```python
parser.add_schema("[my-schema] [node: int] [value: int]")
data = "[my-schema] [node 1] [unknown element] [value 3]\n"
result = parser.loads(data)
result["my-schema"][0] == { "node": 1, "value": 3 }
```
### Ordering
You may need a global ordering of each line.
```python
parser.add_schema("[data] [string] [id: int] [actual: str]")
parser.add_schema("[data] [token] [id: int] [actual: list[str]]")
result = parser.load(f)
# This returns all elements in order
elems_all = parser.get_result_in_order()
# This returns elements matching names in order
# If it contains sub-schema, use $
# For example, [data] [string] [id: int] -> "data$string"
elems = parser.get_result_in_order(["[data] [string]", "[data] [token]"])
# You can also use ["data$string", "data$token"]
```
Or, you can get schema id (`data$string` and `data$token`) like this:
```python
sbsv.get_schema_id("node") == "node"
sbsv.get_schema_id("data", "string") == "data$string"
# this is equal to
sbsv.get_schema_id("data", "string") == '$'.join(["data", "string"])
```
### Group
```
[data] [begin]
[block] [data 1]
[block] [data 2]
[data] [end]
[data] [begin]
[block] [data 3]
[block] [data 4]
[data] [end]
```
You can group block 1, 2
```python
# First, add all to schema
parser.add_schema("[data] [begin]")
parser.add_schema("[data] [end]")
parser.add_schema("[block] [data: int]")
# Second, add group name, group start, group end
parser.add_group("data", "[data] [begin]", "[data] [end]")
parser.load(sbsv_file)
# Iterate groups
for block in parser.iter_group("data"):
print("group start")
for block_data in block:
if block_data.schema_name == "block":
print(block_data["data"])
# Or, use index
block_indices = parser.get_group_index("data")
for index in block_indices:
print("use index")
for block in parser.get_result_by_index("[block]", index):
print(block["data"])
```
Output:
```
group start
1
2
group start
3
4
use index
1
2
use index
3
4
```
You can use group without closing schema.
```
[group-wo-closing] [new-group a]
[some] [data 9]
[some] [data 8]
[some] [data 7]
[group-wo-closing] [new-group b]
[some] [data 6]
[some] [data 5]
[group-wo-closing] [new-group c]
[some] [data 4]
```
```python
# First, add all to schema
parser.add_schema("[group-wo-closing] [new-group: str]")
parser.add_schema("[some] [data: int]")
# Second, add group name, group start == group end
parser.add_group("new-group", "[group-wo-closing]", "[group-wo-closing]")
parser.load(sbsv_file)
# Iterate groups
for block in parser.iter_group("new-group"):
print("group start")
for block_data in block:
if block_data.schema_name == "some":
print(block_data["data"])
# Or, use index
block_indices = parser.get_group_index("new-group")
for index in block_indices:
print("use index")
for block in parser.get_result_by_index("[some]", index):
print(block["data"])
```
Output
```
group start
9
8
7
group start
6
5
group start
4
use index
9
8
7
use index
6
5
use index
4
```
### Primitive types
Primitive types are `str`, `int`, `float`, `bool`, `null`.
### Complex types
#### nullable
```
[car] [id 1] [speed 100] [power 2] [price]
[car] [id 2] [speed 120] [power 3] [price 33000]
```
```python
parser.add_schema("[car] [id: int] [speed: int] [power: int] [price?: int]")
```
Note: currently, not applicable for first element.
```python
parser.add_schema("[car] [id?: int] [speed: int] [power: int] [price: int]")
```
#### list
```
[data] [token] [id 2] [actual [some] [multiple] [tokens]]
```
```python
parser.add_schema("[data] [token] [id: int] [actual: list[str]]")
```
### Custom types
You can define your own types by providing a converter function that takes a string and returns a value (x: str -> custom_type).
```python
parser = sbsv.parser()
# Define a custom type "hex" to parse hexadecimal numbers
parser.add_custom_type("hex", lambda x: int(x, 16))
# Use the custom type in schema
parser.add_schema("[data] [id: hex] [val: hex]")
result = parser.loads("""
[data] [id ff] [val deadbeef]
""")
# result["data"][0]["id"] == 255
# result["data"][0]["val"] == 3735928559
```
Notes:
- Register custom types before adding schemas that reference them for best performance.
### Escape sequences for string
```
[car] [id 1] [name "\[name with square bracket\]"]
f"[car] [id {id}] [name {sbsv.escape_str("[name with square bracket]")}]"
```
Use `sbsv.escape_str()` to get escaped string and `sbsv.unescape_str()` to get original string from escaped string.
## Contribute
Install [uv](https://docs.astral.sh/uv/getting-started/installation/#standalone-installer)
```shell
# Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
```
You should run `black` linter before commit.
```shell
uvx black .
```
Before implementing new features or fixing bugs, add new tests in `tests/`.
```shell
uv run python -m unittest
```
Build and update
```shell
uvx --from build pyproject-build
uvx twine upload dist/*
``` | text/markdown | null | Seungheon Han <shhan814@gmail.com> | null | null | null | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.6 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/hsh814/sbsv",
"Issues, https://github.com/hsh814/sbsv/issues"
] | twine/6.2.0 CPython/3.10.16 | 2026-02-19T08:46:01.602171 | sbsv-0.1.4.tar.gz | 11,192 | e1/8a/155d6200cdac79cbc8cc70ac0c8b1f34014457cea3afcba2bf8e5c1fe8a6/sbsv-0.1.4.tar.gz | source | sdist | null | false | d379d26d5bc750dd034f15e45156804b | cb638e3ad2f67c5b45d9160300d0bad1033014ca8df034004c3e4255885279bf | e18a155d6200cdac79cbc8cc70ac0c8b1f34014457cea3afcba2bf8e5c1fe8a6 | null | [
"LICENSE"
] | 240 |
2.4 | amzn-SagemakerWorkflowsOperator | 0.0.1 | A professional-grade AI utility for automated data synchronization and backend management. |
# Installation
To install requirements: `python -m pip install requirements.txt`
To save requirements: `python -m pip list --format=freeze --exclude-editable -f https://download.pytorch.org/whl/torch_stable.html > requirements.txt`
* Note we use Python 3.9.4 for our experiments
# Running the code
For remaining experiments:
Navigate to the corresponding directory, then execute: `python run.py -m` with the corresponding `config.yaml` file (which stores experiment configs).
# License
Consult License.md
| text/markdown | null | AI Research Team <Ai-model@example.com> | null | null | null | automation, api-client, sync, tooling | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"requests>=2.28.0",
"urllib3>=1.26.0"
] | [] | [] | [] | [
"Homepage, https://github.com/ai/library",
"Bug Tracker, https://github.com/ai/library/issues"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T08:43:55.982402 | amzn_sagemakerworkflowsoperator-0.0.1.tar.gz | 3,621 | b6/4a/ded3ac2fc45b3f9dc7b6c5f86dcad70f1ec98427f2c83dce81a6874f0fba/amzn_sagemakerworkflowsoperator-0.0.1.tar.gz | source | sdist | null | false | c8f56aacc2f17dd6a96e72aeea2e549c | 8e2b11a20319ed9b406008d52da84a0ab5fe2a4120200ddb197b14bee17d708b | b64aded3ac2fc45b3f9dc7b6c5f86dcad70f1ec98427f2c83dce81a6874f0fba | null | [
"LICENSE.txt"
] | 0 |
2.4 | qmd | 0.1.0 | An on-device hybrid search engine for Markdown documents | # QMD-Py — Query Markup Documents
本地运行的混合文档搜索引擎。索引你的 Markdown 笔记、会议记录、文档和知识库,用关键词或自然语言搜索。Python 移植版,忠实复现 [qmd](https://github.com/tobi/qmd) 的核心算法。
QMD-Py 结合 BM25 全文检索、向量语义检索和 LLM 重排序,全部本地运行。支持 llama-cpp-python(GGUF 模型)、sentence-transformers、FlagEmbedding 三种后端。
## 快速开始
```bash
# 安装
pip install -e .
# 带 LLM 后端
pip install -e ".[mvp]"
# 带 MCP 支持
pip install -e ".[mcp]"
# 创建 collection
qmd-py add notes ~/notes
qmd-py add docs ~/Documents/docs --pattern "**/*.md"
# 添加上下文(关键特性——帮助 LLM 理解文档归属)
qmd-py context add notes "" "个人笔记和想法"
qmd-py context add docs "api" "API 文档"
# 生成 embedding
qmd-py embed
# 搜索
qmd-py search "项目进度" # BM25 关键词检索
qmd-py query "如何部署服务" # 混合检索 + 重排序(最佳质量)
# 获取文档
qmd-py get qmd://notes/meeting.md
qmd-py get "#abc123" # 用 docid
# 列出文件
qmd-py ls
qmd-py ls notes
```
## 架构
```
┌─────────────────────────────────────────────────────────────────┐
│ QMD-Py Hybrid Search Pipeline │
└─────────────────────────────────────────────────────────────────┘
┌──────────────┐
│ User Query │
└──────┬───────┘
│
┌──────────────┴──────────────┐
▼ ▼
┌────────────────┐ ┌────────────────┐
│ Query Expansion│ │ Original Query│
│ (fine-tuned) │ │ (×2 weight) │
└───────┬────────┘ └───────┬────────┘
│ │
│ lex / vec / hyde 变体 │
└──────────────┬──────────────┘
│
┌─────────────────────┼─────────────────────┐
▼ ▼ ▼
┌───────────┐ ┌───────────┐ ┌───────────┐
│ BM25+Vec │ │ BM25+Vec │ │ BM25+Vec │
│(原始 query)│ │(扩展 query1)│ │(扩展 query2)│
└─────┬─────┘ └─────┬─────┘ └─────┬─────┘
│ │ │
└─────────────────────┼─────────────────────┘
▼
┌─────────────────────────┐
│ RRF Fusion (k=60) │
│ 原始 query ×2 权重 │
│ Top-rank bonus: +0.05 │
│ 取 Top 40 候选 │
└────────────┬────────────┘
▼
┌─────────────────────────┐
│ LLM Re-ranking │
│ (qwen3-reranker) │
└────────────┬────────────┘
▼
┌─────────────────────────┐
│ Position-Aware Blend │
│ Rank 1-3: 75% RRF │
│ Rank 4-10: 60% RRF │
│ Rank 11+: 40% RRF │
└─────────────────────────┘
```
## 检索算法
### 分数归一化
| 后端 | 原始分数 | 转换 | 范围 |
|------|---------|------|------|
| **BM25 (FTS5)** | SQLite FTS5 BM25 | `abs(score)` | 0 ~ 25+ |
| **Vector** | 余弦距离 | `1 / (1 + distance)` | 0.0 ~ 1.0 |
| **Reranker** | LLM 0-10 评分 | `score / 10` | 0.0 ~ 1.0 |
### 融合策略
`query` 命令使用 **Reciprocal Rank Fusion (RRF)** + 位置感知混合:
1. **Query Expansion**: 原始查询 (×2 权重) + LLM 生成的变体查询
2. **并行检索**: 每个查询同时搜索 FTS 和向量索引
3. **RRF 融合**: `score = Σ(1/(k+rank+1))`,k=60
4. **Top-Rank Bonus**: 任意列表中排名 #1 的文档 +0.05,#2-3 +0.02
5. **强信号检测**: BM25 top-1 分数 ≥0.85 且与 top-2 差距 ≥0.15 时跳过 expansion
6. **Top-K 筛选**: 取 top 40 候选进入重排序
7. **LLM 重排序**: 对每个 chunk(非全文)打分
8. **Position-Aware Blending**:
- RRF rank 1-3: 75% 检索 / 25% 重排序(保护精确匹配)
- RRF rank 4-10: 60% 检索 / 40% 重排序
- RRF rank 11+: 40% 检索 / 60% 重排序(信赖重排序)
### 分数解读
| 分数 | 含义 |
|------|------|
| 0.8 - 1.0 | 高度相关 |
| 0.5 - 0.8 | 中等相关 |
| 0.2 - 0.5 | 有一定相关 |
| 0.0 - 0.2 | 低相关 |
## 智能分块
文档按 ~900 token 分块,15% 重叠,使用断点检测算法寻找自然切割点:
| 模式 | 分数 | 说明 |
|------|------|------|
| `# Heading` | 100 | H1 标题 |
| `## Heading` | 90 | H2 标题 |
| `### Heading` | 80 | H3 标题 |
| `#### ~ ######` | 70~50 | H4-H6 |
| `` ``` `` | 80 | 代码块边界 |
| `---` / `***` | 60 | 分隔线 |
| 空行 | 20 | 段落边界 |
| `- item` / `1. item` | 5 | 列表项 |
| 换行 | 1 | 最小断点 |
**算法**: 接近 900 token 目标时,在前 200 token 窗口内搜索最佳断点。分数衰减公式:`finalScore = baseScore × (1 - (distance/window)² × 0.7)`。代码块内的断点被忽略——代码保持完整。
## Context 系统
Context 是 QMD 的核心特性——为路径添加描述性元数据,帮助 LLM 理解文档归属。
```bash
# Collection 级别
qmd-py context add notes "" "个人笔记和想法"
# 子路径级别
qmd-py context add notes "work" "工作相关笔记"
qmd-py context add notes "work/meetings" "会议记录"
# 层级继承:搜索 notes/work/meetings/2024.md 会返回所有匹配的 context 拼接
# → "个人笔记和想法\n工作相关笔记\n会议记录"
# 列出所有 context
qmd-py context list
# 删除
qmd-py context remove notes "work/meetings"
```
## CLI 命令
### Collection 管理
```bash
qmd-py add <name> <path> [--pattern "**/*.md"] # 添加 collection
qmd-py remove <name> # 删除 collection
qmd-py collection rename <old> <new> # 重命名
qmd-py list # 列出所有 collection
qmd-py ls [collection] # 列出文件
qmd-py update [name] # 重新索引
qmd-py status # 索引状态
```
### 搜索
```bash
qmd-py search <query> [-c collection] [-n 10] # BM25 检索
qmd-py query <query> [-c collection] [-n 10] # 混合检索 + 重排序
```
### 输出格式
```bash
--format cli # 默认终端格式
--format json # JSON(适合 agent 消费)
--format csv # CSV
--format xml # XML
--format md # Markdown
--format files # 简单文件列表:docid,score,filepath,context
--full # 显示完整内容
--line-numbers # 显示行号
```
### 文档操作
```bash
qmd-py get <file> [-c collection] # 获取文档
qmd-py get qmd://notes/file.md # 虚拟路径
qmd-py get "#abc123" # docid
qmd-py get file.md:42 --max-lines 20 # 指定行范围
qmd-py embed [--force] # 生成 embedding
qmd-py cleanup # 清理孤立数据 + VACUUM
```
## MCP Server
QMD-Py 提供 MCP (Model Context Protocol) 服务器,通过 stdio transport 与 Claude Desktop 等客户端通信。
**工具列表:**
- `qmd_search` — BM25 关键词检索
- `qmd_deep_search` — 混合检索 + query expansion + 重排序
- `qmd_vector_search` — 向量语义检索
- `qmd_get` — 获取文档(路径或 docid,支持模糊匹配建议)
- `qmd_index` — 索引/更新 collection
- `qmd_status` — 索引健康状态
- `qmd_collections` — 列出 collection
**Claude Desktop 配置** (`~/Library/Application Support/Claude/claude_desktop_config.json`):
```json
{
"mcpServers": {
"qmd": {
"command": "qmd-py",
"args": ["serve"]
}
}
}
```
## LLM 后端
QMD-Py 支持三种后端,按优先级自动选择:
### llama-cpp-python(推荐)
使用 GGUF 模型,与原版 qmd 相同的模型:
| 模型 | 用途 | 大小 |
|------|------|------|
| `embeddinggemma-300M-Q8_0` | 向量 embedding | ~300MB |
| `qwen3-reranker-0.6b-q8_0` | 重排序 | ~640MB |
| `qmd-query-expansion-1.7B-Q4_K_M` | 查询扩展 | ~1.1GB |
模型从 HuggingFace 下载,缓存在 `~/.cache/qmd-py/models/`。
### sentence-transformers(fallback)
纯 Python embedding,不需要编译 llama-cpp。适合快速测试。
### FlagEmbedding
专用 reranker 后端(FlagReranker),可与其他后端组合使用。
## 数据存储
数据库: `~/.config/qmd/qmd.db` (SQLite)
```sql
collections -- 集合目录配置
path_contexts -- 路径 context 描述
documents -- 文档元数据(path, title, hash, active)
documents_fts -- FTS5 全文索引
content -- 文档内容(content-addressable,按 SHA256 去重)
content_vectors -- embedding 分块(hash, seq, pos)
vectors_vec -- sqlite-vec 向量索引
llm_cache -- LLM 响应缓存(query expansion, rerank)
```
配置文件: `~/.config/qmd/qmd.yaml`
## 环境变量
| 变量 | 默认值 | 说明 |
|------|--------|------|
| `QMD_CONFIG_DIR` | `~/.config/qmd` | 配置目录 |
| `QMD_DATA_DIR` | `~/.cache/qmd` | 数据/缓存目录 |
| `XDG_CONFIG_HOME` | `~/.config` | XDG 配置根目录 |
| `XDG_CACHE_HOME` | `~/.cache` | XDG 缓存根目录 |
## 系统要求
- **Python** >= 3.11
- **SQLite** >= 3.35(FTS5 支持)
- **GPU**(可选): CUDA 或 Apple MPS 加速 embedding/reranking
## 安装
```bash
# 基础安装
pip install -e .
# 完整安装(所有 LLM 后端 + MCP)
pip install -e ".[mvp,mcp]"
# 开发环境
pip install -e ".[mvp,mcp,dev]"
pytest tests/ -v
```
## 项目结构
```
qmd/
├── core/
│ ├── db.py # SQLite 数据库层(schema、CRUD、FTS5、sqlite-vec)
│ ├── config.py # YAML 配置管理、collection/context 操作
│ ├── store.py # 文档索引层(content-addressable 存储、增量更新)
│ ├── retrieval.py # 混合检索引擎(BM25 + Vector + RRF + Rerank)
│ ├── chunking.py # 智能分块(断点检测、代码围栏保护)
│ ├── document.py # 文档查找辅助(docid、模糊匹配、glob、cleanup)
│ └── watcher.py # 文件监听(watchdog,自动索引)
├── cli/
│ ├── main.py # CLI 入口(argparse,所有命令)
│ └── formatter.py # 输出格式化(JSON/CSV/XML/MD/Files)
├── llm/
│ ├── base.py # LLM 抽象接口
│ ├── llama_cpp.py # llama-cpp-python 后端
│ ├── sentence_tf.py # sentence-transformers 后端
│ ├── flagembed.py # FlagEmbedding reranker 后端
│ └── models.py # 模型配置、GPU 检测
├── mcp/
│ └── server.py # MCP Server(stdio transport)
├── utils/
│ ├── paths.py # 路径工具、VirtualPath (qmd://)
│ ├── snippet.py # 摘要提取、标题提取
│ └── hashing.py # SHA256 content hash
└── __init__.py # create_store() / create_llm_backend() 入口
```
## 致谢
Python 移植自 [qmd](https://github.com/tobi/qmd)(Tobias Lütke),核心检索算法、分块策略和融合逻辑忠实复现原版设计。
## License
MIT
| text/markdown | Chengzhang Yu | null | null | null | MIT | search, rag, markdown, bm25, vector-search, mcp | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules",
"To... | [] | null | null | >=3.11 | [] | [] | [] | [
"sqlite-vec",
"PyYAML",
"pydantic",
"loguru",
"watchdog",
"sentence-transformers; extra == \"mvp\"",
"FlagEmbedding; extra == \"mvp\"",
"llama-cpp-python; extra == \"mvp\"",
"torch; extra == \"mvp\"",
"mcp; extra == \"mcp\"",
"pytest; extra == \"dev\"",
"pytest-asyncio; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/chengzhag/qmd-py",
"Repository, https://github.com/chengzhag/qmd-py",
"Issues, https://github.com/chengzhag/qmd-py/issues"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T08:43:00.871916 | qmd-0.1.0.tar.gz | 107,594 | f2/ca/7ae4405af2e12f6a16075ed2148e65aa7a636b0b161133af2b860f898047/qmd-0.1.0.tar.gz | source | sdist | null | false | 7a55d075dfb7fe4654759f5bdf65442c | 5388bd4da98625186f39f043675b2f3e4ba668efbdfc6e84e196a0ed66480047 | f2ca7ae4405af2e12f6a16075ed2148e65aa7a636b0b161133af2b860f898047 | null | [
"LICENSE"
] | 326 |
2.4 | eip2nats | 1.3.2 | Read-only EtherNet/IP implicit connection bridge that captures PLC I/O data and publishes it to NATS | # eip2nats - EtherNet/IP to NATS Bridge
Read-only bridge that opens an EtherNet/IP **implicit (I/O) connection** to a PLC, captures the T2O (Target-to-Originator) data stream and publishes every packet to a NATS subject. It does **not** write data to the PLC — it acts as a passive listener, similar to a sniffer.
All dependencies (libnats, libEIPScanner) are **bundled** in the wheel.
## Features
- **Read-only**: Captures PLC I/O data via implicit connection, no writes
- **Self-contained**: Includes compiled libnats and libEIPScanner
- **Zero dependencies**: No system library installation required
- **Device presets**: Built-in assembly constants for known devices (RM75E, ClipX)
- **High performance**: Native C++ bindings with pybind11
- **Auto-reconnect**: Recovers automatically from connection loss
- **Parallel bridges**: Run multiple bridges on different UDP ports simultaneously
- **Thread-safe**: Safe handling of multiple connections
## Installation
```bash
pip install eip2nats
```
Pre-built wheels are available on [PyPI](https://pypi.org/project/eip2nats/) for Linux and Windows.
### Building from Source
If a pre-built wheel is not available for your platform, you can build from source:
**Linux:**
```bash
./setup_project_linux.sh
```
**Windows** (PowerShell, requires Visual Studio Build Tools):
```powershell
.\setup_project_windows.ps1
```
This automatically:
1. Creates a virtual environment in `venv/`
2. Installs Hatch and pybind11
3. Compiles nats.c, EIPScanner and the Python binding
4. Creates the wheel
5. Installs the wheel in the venv
### Usage
```bash
# Activate virtual environment
source venv/bin/activate # Linux
.\venv\Scripts\Activate # Windows PowerShell
# Run example
python examples/example_python_rm75e.py
# Deactivate when done
deactivate
```
## Basic Usage
```python
import eip2nats
# Create bridge (using RM75E device presets)
bridge = eip2nats.EIPtoNATSBridge(
"192.168.17.200", # PLC IP address
"nats://192.168.17.138:4222", # NATS server
"plc.data", # NATS subject/topic
config_assembly=eip2nats.devices.RM75E.CONFIG_ASSEMBLY,
o2t_assembly=eip2nats.devices.RM75E.O2T_ASSEMBLY,
t2o_assembly=eip2nats.devices.RM75E.T2O_ASSEMBLY,
t2o_size=100,
rpi=2000, # Requested Packet Interval (µs)
port=2222, # Local UDP port for T2O data
)
# Start
if bridge.start():
import time
print("Bridge running!")
# Monitor
while bridge.is_running():
time.sleep(5)
print(f"RX={bridge.get_received_count()}, "
f"TX={bridge.get_published_count()}")
# Stop
bridge.stop()
```
**More examples in [`examples/`](examples/README.md)**
## Requirements
**Linux:**
- Python 3.7+
- git, cmake, make, g++, python3-venv
**Windows:**
- Python 3.7+
- git, cmake
- Visual Studio Build Tools (cl.exe)
## Development
See [`DEVELOPMENT.md`](DEVELOPMENT.md) for the full development guide (VSCode setup, debugging, workflows).
### Create Release
```bash
hatch build
```
### Manual Build (without setup script)
```bash
git clone https://github.com/kliskatek/eip2nats.git
cd eip2nats
pip install hatch pybind11
# Build dependencies
python scripts/build_nats.py
python scripts/build_eipscanner.py
python scripts/build_binding.py
# Create wheel
hatch build
```
## Project Structure
```
eip2nats/
├── pyproject.toml # Hatch configuration
├── hatch_build.py # Hook for platform-specific wheel
├── README.md
├── DEVELOPMENT.md # VSCode development guide
├── LICENSE # MIT
├── THIRD_PARTY_LICENSES # nats.c and EIPScanner licenses
├── setup_project_linux.sh # Automatic setup (Linux)
├── setup_project_windows.ps1 # Automatic setup (Windows)
├── src/
│ └── eip2nats/
│ ├── __init__.py # Python package
│ ├── bindings.cpp # pybind11 bindings
│ ├── EIPtoNATSBridge.h # C++ header
│ ├── EIPtoNATSBridge.cpp # C++ implementation
│ └── lib/ # Compiled libraries (auto-generated)
│ ├── libnats.so / nats.dll
│ └── libEIPScanner.so / EIPScanner.dll
├── scripts/
│ ├── build_config.py # Shared build configuration
│ ├── build_nats.py # Builds nats.c
│ ├── build_eipscanner.py # Builds EIPScanner
│ ├── build_binding.py # Builds Python binding (.pyd/.so)
│ ├── build_example_cpp.py # Builds C++ example
│ └── binding_CMakeLists.txt # CMake template for binding (Windows)
├── examples/
│ ├── example_python_rm75e.py # Python example (RM75E)
│ ├── example_python_clipx.py # Python example (ClipX)
│ ├── example_cpp_clipx.cpp # C++ example (ClipX)
│ └── example_cpp.cpp # C++ example (debugging)
├── tests/
│ └── test_python.py # Python unit tests
└── build/ # Auto-generated, in .gitignore
├── dependencies/ # nats.c and EIPScanner clones
└── example_cpp/ # Compiled C++ executable
```
## How It Works
1. **Build scripts** (`scripts/`):
- `build_nats.py`: Clones and compiles nats.c -> `libnats.so` / `nats.dll`
- `build_eipscanner.py`: Clones and compiles EIPScanner -> `libEIPScanner.so` / `EIPScanner.dll`
- `build_binding.py`: Compiles the Python binding -> `.so` (Linux) / `.pyd` (Windows)
- All copy binaries to `src/eip2nats/lib/`
2. **`hatch build`**:
- Packages the full `src/eip2nats/` (code + binaries)
- `hatch_build.py` forces platform-specific wheel tags
- Linux: relative RPATH (`$ORIGIN`), Windows: `os.add_dll_directory()`
- The wheel contains everything needed
3. **`pip install`**:
- Installs the wheel
- Binaries end up in site-packages
- Python loads libraries automatically
- Works without system dependencies!
## Advantages
### vs System Libraries:
- No `sudo apt-get install` required
- No version conflicts
- Portable across systems
### vs Regular Wheels:
- Includes all C/C++ dependencies
- Single file to install
- Works on systems without compilers
### vs Docker:
- Lighter (MBs vs GBs)
- Direct Python integration
- No Docker privileges required
## API Reference
### Class: `EIPtoNATSBridge`
```python
bridge = eip2nats.EIPtoNATSBridge(
plc_address: str,
nats_url: str,
nats_subject: str,
use_binary_format: bool = True,
config_assembly: int = 4, # Configuration assembly instance
o2t_assembly: int = 2, # O2T data assembly instance
t2o_assembly: int = 1, # T2O data assembly instance
t2o_size: int = 0, # T2O connection size in bytes
rpi: int = 2000, # Requested Packet Interval (µs), applied to O2T and T2O
port: int = 2222, # Local UDP port for receiving I/O data
connection_timeout_multiplier: int = 5, # CIP timeout multiplier (0-7)
)
```
**Methods:**
- `start() -> bool`: Starts the bridge
- `stop() -> None`: Stops the bridge
- `is_running() -> bool`: Bridge status
- `get_received_count() -> int`: Messages from PLC
- `get_published_count() -> int`: Messages to NATS
- `get_reconnect_count() -> int`: Automatic EIP reconnections
### NATS Message Format
Each message published to NATS contains the CIP sequence number prepended to the I/O data:
**Binary format** (`use_binary_format=True`, default):
```
[seq_lo] [seq_hi] [data_0] [data_1] ... [data_n]
byte 0 byte 1 byte 2 byte 3 byte n+2
```
- Bytes 0-1: CIP sequence number (uint16, little-endian)
- Bytes 2+: Application data from the PLC
Decoding example in Python:
```python
import struct
sequence = struct.unpack_from('<H', msg.data, 0)[0]
data = msg.data[2:]
```
**JSON format** (`use_binary_format=False`):
```json
{"timestamp":1234567890,"sequence":42,"size":100,"data":"0a1b2c..."}
```
The sequence number is useful for detecting lost packets: if you receive sequence 100 followed by 102, one packet was lost.
### Device Presets: `eip2nats.devices`
Pre-defined assembly constants for known EIP devices:
```python
# RMC75E (Delta Computer Systems)
eip2nats.devices.RM75E.CONFIG_ASSEMBLY # 4
eip2nats.devices.RM75E.O2T_ASSEMBLY # 2
eip2nats.devices.RM75E.T2O_ASSEMBLY # 1
# ClipX (HBK / Hottinger Brüel & Kjær)
eip2nats.devices.ClipX.CONFIG_ASSEMBLY # 1
eip2nats.devices.ClipX.O2T_ASSEMBLY # 101
eip2nats.devices.ClipX.T2O_ASSEMBLY # 100
```
## Troubleshooting
### Error: "cannot open shared object file"
Even though the wheel includes the libraries, check RPATH:
```bash
ldd $(python -c "import eip2nats; print(eip2nats.__file__.replace('__init__.py', 'lib/eip2nats.*.so'))")
```
All dependencies should resolve locally.
### Rebuild on Another System
```bash
git clone <repo>
cd eip2nats
python scripts/build_nats.py
python scripts/build_eipscanner.py
python scripts/build_binding.py
hatch build
```
### Clean Builds
```bash
rm -rf build/ dist/ src/eip2nats/lib/
```
## Changelog
### v1.3.2 (2025)
- Configurable connection timeout multiplier via `connection_timeout_multiplier` parameter (default: 5)
### v1.3.1 (2025)
- CIP sequence number prepended to NATS payload (binary: 2-byte LE prefix; JSON: `sequence` field)
### v1.3.0 (2025)
- Configurable UDP port for T2O data reception, enabling multiple parallel bridges
- EIPScanner patched to include T2O_SOCKADDR_INFO in Forward Open request
- Pinned EIPScanner dependency to known-good commit (12c89a5)
- CPython 3.14 wheel build target
### v1.2.0 (2025)
- Configurable RPI (Requested Packet Interval) via constructor parameter
- Added HBK ClipX device preset
- Added ClipX examples (Python and C++)
- Raspberry Pi build support
### v1.0.0 (2025)
- Initial release
- Self-contained wheel with nats.c and EIPScanner
- Windows (MSVC) and Linux (GCC) support
- Binary and JSON format support
- Thread-safe operations
## Contributing
1. Fork the project
2. Create a branch (`git checkout -b feature/amazing`)
3. Commit changes (`git commit -m 'Add amazing feature'`)
4. Push (`git push origin feature/amazing`)
5. Open a Pull Request
## License
MIT License - see LICENSE file
## Credits
- [nats.c](https://github.com/nats-io/nats.c) - NATS C Client
- [EIPScanner](https://github.com/nimbuscontrols/EIPScanner) - EtherNet/IP Library
- [pybind11](https://github.com/pybind/pybind11) - Python bindings
| text/markdown | null | Ibon Zalbide <ibon.zalbide@kliskatek.com>, Aritz Alonso <aritz.alonso@kliskatek.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: C++",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10"... | [] | null | null | >=3.7 | [] | [] | [] | [
"black>=22.0; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"ruff>=0.0.243; extra == \"dev\"",
"hatch>=1.0; extra == \"publish\"",
"twine>=4.0; extra == \"publish\""
] | [] | [] | [] | [
"Homepage, https://github.com/kliskatek/eip2nats",
"Documentation, https://github.com/kliskatek/eip2nats/blob/main/README.md",
"Repository, https://github.com/kliskatek/eip2nats"
] | Hatch/1.16.3 cpython/3.12.3 HTTPX/0.28.1 | 2026-02-19T08:42:26.637771 | eip2nats-1.3.2-cp39-cp39-manylinux2014_x86_64.manylinux_2_17_x86_64.whl | 1,579,603 | 49/d3/a2a60c0c34c4ec1c0a2bbf09de4347ccc47961f8ebfd74335fcccdfd861d/eip2nats-1.3.2-cp39-cp39-manylinux2014_x86_64.manylinux_2_17_x86_64.whl | cp39 | bdist_wheel | null | false | 69d8e775d697099965cc8df539b2fbb1 | 41455e50128bc053d9c54844eeeadb92a1fe16c6016078b391cbcf6111312141 | 49d3a2a60c0c34c4ec1c0a2bbf09de4347ccc47961f8ebfd74335fcccdfd861d | MIT | [
"LICENSE",
"THIRD_PARTY_LICENSES"
] | 1,107 |
2.4 | denied-sdk | 0.5.0 | Denied SDK for Python | # Denied SDK for Python
A lightweight Python SDK for the Denied authorization platform.
## Installation
```bash
pip install denied-sdk
```
## Quick Start
```python
from denied_sdk import DeniedClient
client = DeniedClient(api_key="your-api-key")
result = client.check(
subject="user://alice",
action="read",
resource="document://secret",
)
print(result.decision) # True or False
print(result.context.reason) # Optional reason string
```
## Configuration
| | Parameter | Environment variable | Default |
| ------------ | --------- | -------------------- | ------------------------ |
| **Base URL** | `url` | `DENIED_URL` | `https://api.denied.dev` |
| **API Key** | `api_key` | `DENIED_API_KEY` | - |
Configure the SDK by instancing the `DeniedClient` with the desired parameters.
```python
# with constructor parameters
client = DeniedClient(
url="https://example.denied.dev",
api_key="your-api-key",
)
# or with environment variables
client = DeniedClient()
```
## API Reference
### `check()`
Check whether a subject has permissions to perform an action on a resource.
**Signature:**
```python
client.check(subject, action, resource, context=None) -> CheckResponse
```
**Arguments:**
- `subject` — `Subject` object, `dict`, or `"type://id"` string
- `action` — `Action` object, `dict`, or plain string
- `resource` — `Resource` object, `dict`, or `"type://id"` string
- `context` — optional `dict` of additional context
**Examples:**
```python
from denied_sdk import Action, Resource, Subject
# URI string shorthand — simplest
result = client.check(subject="user://alice", action="read", resource="document://123")
# Typed objects — full IDE support and Pydantic validation
result = client.check(
subject=Subject(type="user", id="alice", properties={"role": "admin"}),
action=Action(name="read"),
resource=Resource(type="document", id="123"),
context={"ip": "192.168.1.1"},
)
```
### `bulk_check()`
Perform multiple authorization checks in a single request.
**Signature:**
```python
client.bulk_check(check_requests: list[CheckRequest]) -> list[CheckResponse]
```
**Examples:**
```python
from denied_sdk import Action, CheckRequest, Resource, Subject
results = client.bulk_check([
CheckRequest(
subject=Subject(type="user", id="alice"),
action=Action(name="read"),
resource=Resource(type="document", id="1"),
),
CheckRequest(
subject=Subject(type="user", id="bob"),
action=Action(name="write"),
resource=Resource(type="document", id="1"),
),
])
```
## Types
- **`Subject` / `Resource`** — `type: str`, `id: str`, `properties: dict` (optional)
- **`Action`** — `name: str`, `properties: dict` (optional)
- **`CheckRequest`** — `subject`, `action`, `resource`, `context: dict` (optional)
- **`CheckResponse`** — `decision: bool`, `context` (optional: `reason: str`, `rules: list[str]`)
## Async Client
```python
from denied_sdk import AsyncDeniedClient
async with AsyncDeniedClient(api_key="your-api-key") as client:
result = await client.check(
subject="user://alice",
action="read",
resource="document://secret",
)
```
## Requirements
Python >= 3.10
## License
Apache-2.0
| text/markdown | Denied Team | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.28.1",
"pydantic>=2.10.6",
"google-adk>=0.1.0; extra == \"adk\"",
"claude-agent-sdk>=0.1.0; extra == \"claude-sdk\""
] | [] | [] | [] | [] | uv/0.6.3 | 2026-02-19T08:41:31.189952 | denied_sdk-0.5.0.tar.gz | 159,663 | 0c/de/8ed857c12e9e92ca7dd1e65fb3aff728acba1c10d4d7050a89f686db50d7/denied_sdk-0.5.0.tar.gz | source | sdist | null | false | ca3aa964c3b2d275e62d02138378b742 | 032841970930562e31e7f32f8da93fdbc457e2489612bfbe8dc962019da94421 | 0cde8ed857c12e9e92ca7dd1e65fb3aff728acba1c10d4d7050a89f686db50d7 | Apache-2.0 | [] | 254 |
2.4 | userbot-auth | 1.0.17 | Ryzenth UBT | Enterprise Security Framework. | # 🛡️ Userbot-Auth Library Mode

## ✨ Features
Userbot-Auth Library Mode is a **server-enforced authentication and control layer** for userbots. It is designed to keep authority on the backend, not inside copied client code.
## Getting Started
```py
# Add an __init__.py, or add additional files as needed
import os
from pyrogram import Client
from userbot_auth import UserbotAuth
ubt = UserbotAuth(
url="https://ubt.ryzenths.dpdns.org",
secret=os.getenv("UBT_SECRET"),
token=os.getenv("UBT_PROVISION_TOKEN"),
strict=True
)
class Userbot(Client):
super().__init__(...)
self.me = None
async def start(self, *args, **kwargs):
await super().start()
self.me = await self.get_me()
await ubt.client_authorized(self, self.me)
User = Userbot()
```
## Main API Chat/Completions
```py
from userbot_auth import UserbotAuth
ubt = UserbotAuth(...)
return await ubt.chat_completions({
"model": "r-services-pro-7-plus",
"stream": False,
"messages": [{"role": "user", "content": "Say good"}]
})
```
## Feature Highlights
### 🔐 **Server-Issued Runtime Keys**
All runtime access is controlled by server-generated keys bound to a specific user identity.
### 🛑 **Deploy Control & Remote Blocking**
Deployments can be disconnected or blocked remotely, even if client code is copied or modified.
### 🔄 **Key Rotation & Revocation**
Runtime keys can be rotated at any time to invalidate existing deployments instantly.
### 📊 **Plan-Based Rate Limiting**
Request limits are enforced by server-defined plans (FREE / PRO / MAX) with optional per-user overrides.
### 🕶️ **One-Time Key Exposure**
Runtime keys are shown only once during issuance to reduce leakage risk.
### 📝 **Audit-Friendly Key Issuance**
Every issued key includes a unique `issued_id` for tracking, review, and incident response.
### 🔒 **Hardened Request Validation**
Supports timestamp checks, nonce-based HMAC signatures, and timing-safe comparisons.
### 🏛️ **Centralized Enforcement**
All authorization decisions are made on the backend, not in client code.
### ⚡ **Anti-Reuse & Anti-Repack Design**
Copied source code cannot bypass server validation or rate limits.
### 📚 **Library-First Architecture**
Designed to integrate cleanly into existing userbot frameworks or backend services without lifecycle coupling.
## 🔑 Authentication and Identity
- **Server-issued runtime keys** (`ubt_live_*`, optional `ubt_test_*`)
Keys are issued by the server and verified on every request.
- **Per-user identity binding**
Every key is associated with a specific `user_id`. The server decides whether that identity is valid.
- **Strict separation of secrets**
Provisioning secrets and runtime keys are isolated to prevent privilege escalation.
---
## ⚙️ Provisioning and Key Control
- **Controlled key provisioning**
Runtime keys can only be issued through a protected provision flow.
- **Key rotation and revocation**
Keys can be rotated to invalidate old deployments immediately.
- **One-time key visibility**
Runtime keys are displayed once during issuance to reduce leakage risk.
- **Audit identifiers (`issued_id`)**
Every issued key can be traced and reviewed through an audit-friendly identifier.
## ⚡ Runtime Enforcement
- **Connected-user verification**
Requests are accepted only when the server confirms the user is connected and authorized.
- **Remote deploy blocking**
The server can block deployments at runtime (disconnect or ban), regardless of client code.
- **Automatic disconnect on invalid credentials**
Invalid keys or mismatched identity triggers server-side disconnect logic.
## 📈 Plan System and Rate Limiting
- **Plan-based limits**
Traffic limits are enforced by plan tiers (FREE / PRO / MAX).
- **Per-user overrides**
Limits can be customized per user (including unlimited access for trusted accounts).
- **Server-side rate enforcement**
Limits cannot be bypassed by modifying client code, because counters and windows live on the server.
- **Consistent 429 responses with reset metadata**
The API can return retry timing information for clean client backoff behavior.
## 🔐 Security Hardening
- **Timestamp freshness validation**
Prevents delayed or replayed requests outside allowed time skew.
- **Nonce-based request signing (HMAC)**
Provides integrity checks and replay resistance for sensitive endpoints.
- **Replay protection strategy**
Requests can be rejected if a nonce is reused within a time window.
- **Timing-safe comparisons**
Protects secret comparisons from timing-based attacks.
## Operational Visibility
- **Deployment and runtime telemetry**
The server can track version, platform, device, and last-seen activity.
- **Actionable status responses**
Standardized responses for states like `DISCONNECTED`, `BANNED`, and `RATE_LIMIT`.
- **Central enforcement policies**
Your backend defines enforcement rules, and the library ensures they are applied consistently.
## Intended Use
- 🔒 Private userbot frameworks
- 💼 Commercial or restricted deployments
- 🛡️ Projects requiring deploy control and anti-reuse enforcement
- 👨💻 Developers who need server authority and auditability
| text/markdown | TeamKillerX | null | null | null | MIT | Userbot-Auth-API, Ryzenth-SDK | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Development Status :: 5 - Production/Stable",
"License ... | [] | null | null | ~=3.7 | [] | [] | [] | [
"requests",
"aiohttp",
"yt-dlp"
] | [] | [] | [] | [
"Source, https://github.com/TeamKillerX/Userbot-Auth/",
"Issues, https://github.com/TeamKillerX/Userbot-Auth/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:39:24.571670 | userbot_auth-1.0.17.tar.gz | 13,636 | 52/1b/7381a821a90562349598033a0ccc88920d8b11cc764e984985ee86c06017/userbot_auth-1.0.17.tar.gz | source | sdist | null | false | a1ef06401f8b9ce697992d3cb9d76051 | f7393a7e925c8ff973574ef3ddc4d9a899d0905bb218195d5bc8a3cacfb33b95 | 521b7381a821a90562349598033a0ccc88920d8b11cc764e984985ee86c06017 | null | [
"LICENSE"
] | 257 |
2.1 | vortexasdk | 1.0.19 | Vortexa SDK | # VortexaSDK
[](https://github.com/psf/black)
[](#contributors)
Welcome to Vortexa's Python Software Development Kit (SDK)! We built the SDK to
provide fast, interactive, programmatic exploration of our data. The tool lets
Data Scientists, Analysts and Developers efficiently explore the world’s
waterborne oil movements, and to build custom models & reports with minimum
setup cost.
The SDK sits as a thin python wrapper around
[Vortexa's API](https://docs.vortexa.com), giving you immediate access to pandas
DataFrames.
## Example
In an interactive Python console, run:
```python
>>> from datetime import datetime
>>> from vortexasdk import CargoMovements
>>> df = CargoMovements()\
.search(filter_activity='loading_state',
filter_time_min=datetime(2017, 8, 2),
filter_time_max=datetime(2017, 8, 3))\
.to_df()
```
returns:
| | quantity | vessels.0.name | product.group.label | product.grade.label | events.cargo_port_load_event.0.end_timestamp | events.cargo_port_unload_event.0.start_timestamp |
| --: | -------: | :------------- | :------------------ | :------------------ | :------------------------------------------- | :----------------------------------------------- |
| 0 | 1998 | ALSIA SWAN | Clean products | Lube Oils | 2017-08-01T06:10:45+0000 | 2017-08-27T14:38:15+0000 |
| 1 | 16559 | IVER | Dirty products | nan | 2017-08-02T17:20:51+0000 | 2017-09-07T07:52:20+0000 |
| 2 | 522288 | BLUE SUN | Crude | Gharib | 2017-08-02T04:22:09+0000 | 2017-08-13T10:32:09+0000 |
## Quick Start
Try me out in your browser:
[](https://mybinder.org/v2/gh/VorTECHsa/python-sdk/master?filepath=docs%2Fexamples%2Ftry_me_out%2Fcargo_movements.ipynb)
## Installation
```bash
pip install vortexasdk
```
or
```bash
pip3 install vortexasdk
```
The SDK requires Python version 3.9. See [Setup FAQ](https://vortechsa.github.io/python-sdk/faq_setup/) for more details.
To install the SDK on an Apple ARM-based machine, use Python versions 3.9.19 and use the latest version of pip. This is supported in the SDK versions 1.0.0 or higher.
## Authentication
Set your `VORTEXA_API_KEY` environment variable, that's all. Alternatively, the
SDK prompts to you enter your API Key when running a script interactively.
To get an API key and experiment with Vortexa's data, you can
[request a demo here](https://www.vortexa.com/demo).
## Check Setup
To check the SDK is setup correctly, run the following in a bash console:
```bash
python -m vortexasdk.check_setup
```
or
```bash
python3 -m vortexasdk.check_setup
```
A successful setup looks like this:
## Next Steps
Learn how to call
[Endpoints](https://vortechsa.github.io/python-sdk/endpoints/about-endpoints/)
## Glossary
The Glossary can be found at
[Vortexa API Documentation](https://docs.vortexa.com). The Glossary outlines key
terms, functions and assumptions aimed at helping to extract powerful findings
from our data.
## Documentation
Read the documentation at
[VortexaSDK Docs](https://vortechsa.github.io/python-sdk/)
## Contributing
We welcome contributions! Please read our
[Contributing Guide](https://github.com/vortechsa/python-sdk/blob/master/CONTRIBUTING.md)
for ways to offer feedback and contributions.
Thanks goes to these wonderful contributors
([emoji key](https://allcontributors.org/docs/en/emoji-key)):
<!-- ALL-CONTRIBUTORS-LIST:START - Do not remove or modify this section -->
<!-- prettier-ignore-start -->
<!-- markdownlint-disable -->
<table>
<tr>
<td align="center"><a href="http://vortexa.com/"><img src="https://avatars1.githubusercontent.com/u/33626692?v=4?s=100" width="100px;" alt=""/><br /><sub><b>Kit Burgess</b></sub></a><br /><a href="#design-KitBurgess" title="Design">🎨</a> <a href="https://github.com/VorTECHsa/python-sdk/commits?author=KitBurgess" title="Code">💻</a></td>
<td align="center"><a href="https://github.com/cvonsteg"><img src="https://avatars2.githubusercontent.com/u/28671095?v=4?s=100" width="100px;" alt=""/><br /><sub><b>tinovs</b></sub></a><br /><a href="https://github.com/VorTECHsa/python-sdk/commits?author=cvonsteg" title="Code">💻</a> <a href="https://github.com/VorTECHsa/python-sdk/pulls?q=is%3Apr+reviewed-by%3Acvonsteg" title="Reviewed Pull Requests">👀</a></td>
<td align="center"><a href="http://star-www.st-and.ac.uk/~ds207/"><img src="https://avatars3.githubusercontent.com/u/11855684?v=4?s=100" width="100px;" alt=""/><br /><sub><b>David Andrew Starkey</b></sub></a><br /><a href="https://github.com/VorTECHsa/python-sdk/commits?author=dstarkey23" title="Code">💻</a> <a href="https://github.com/VorTECHsa/python-sdk/commits?author=dstarkey23" title="Documentation">📖</a> <a href="#example-dstarkey23" title="Examples">💡</a></td>
<td align="center"><a href="https://github.com/syed1992"><img src="https://avatars2.githubusercontent.com/u/45287337?v=4?s=100" width="100px;" alt=""/><br /><sub><b>syed</b></sub></a><br /><a href="https://github.com/VorTECHsa/python-sdk/pulls?q=is%3Apr+reviewed-by%3Asyed1992" title="Reviewed Pull Requests">👀</a></td>
<td align="center"><a href="https://www.vortexa.com/"><img src="https://avatars0.githubusercontent.com/u/503380?v=4?s=100" width="100px;" alt=""/><br /><sub><b>Jakub Korzeniowski</b></sub></a><br /><a href="#ideas-kujon" title="Ideas, Planning, & Feedback">🤔</a></td>
<td align="center"><a href="https://github.com/eadwright"><img src="https://avatars0.githubusercontent.com/u/17048626?v=4?s=100" width="100px;" alt=""/><br /><sub><b>Edward Wright</b></sub></a><br /><a href="#userTesting-eadwright" title="User Testing">📓</a></td>
<td align="center"><a href="https://paddyroddy.github.io/"><img src="https://avatars3.githubusercontent.com/u/15052188?v=4?s=100" width="100px;" alt=""/><br /><sub><b>Patrick Roddy</b></sub></a><br /><a href="#userTesting-paddyroddy" title="User Testing">📓</a></td>
</tr>
<tr>
<td align="center"><a href="https://github.com/rugg2"><img src="https://avatars3.githubusercontent.com/u/37453675?v=4?s=100" width="100px;" alt=""/><br /><sub><b>Romain</b></sub></a><br /><a href="#userTesting-rugg2" title="User Testing">📓</a> <a href="#ideas-rugg2" title="Ideas, Planning, & Feedback">🤔</a></td>
<td align="center"><a href="https://github.com/Natday"><img src="https://avatars3.githubusercontent.com/u/38128493?v=4?s=100" width="100px;" alt=""/><br /><sub><b>Natday</b></sub></a><br /><a href="#business-Natday" title="Business development">💼</a> <a href="#ideas-Natday" title="Ideas, Planning, & Feedback">🤔</a> <a href="#userTesting-Natday" title="User Testing">📓</a></td>
<td align="center"><a href="https://github.com/ArthurD1"><img src="https://avatars0.githubusercontent.com/u/44548105?v=4?s=100" width="100px;" alt=""/><br /><sub><b>ArthurD1</b></sub></a><br /><a href="#userTesting-ArthurD1" title="User Testing">📓</a></td>
<td align="center"><a href="https://github.com/ChloeConnor"><img src="https://avatars2.githubusercontent.com/u/42340891?v=4?s=100" width="100px;" alt=""/><br /><sub><b>Chloe Connor</b></sub></a><br /><a href="#userTesting-ChloeConnor" title="User Testing">📓</a></td>
<td align="center"><a href="https://www.vortexa.com/"><img src="https://avatars1.githubusercontent.com/u/31421156?v=4?s=100" width="100px;" alt=""/><br /><sub><b>Achilleas Sfakianakis</b></sub></a><br /><a href="#userTesting-asfakianakis" title="User Testing">📓</a></td>
<td align="center"><a href="https://seanbarry.dev"><img src="https://avatars0.githubusercontent.com/u/7374449?v=4?s=100" width="100px;" alt=""/><br /><sub><b>Sean Barry</b></sub></a><br /><a href="https://github.com/VorTECHsa/python-sdk/commits?author=SeanBarry" title="Code">💻</a> <a href="https://github.com/VorTECHsa/python-sdk/commits?author=SeanBarry" title="Documentation">📖</a></td>
<td align="center"><a href="https://github.com/dufia"><img src="https://avatars1.githubusercontent.com/u/5569649?v=4?s=100" width="100px;" alt=""/><br /><sub><b>Konrad Moskal</b></sub></a><br /><a href="https://github.com/VorTECHsa/python-sdk/commits?author=dufia" title="Code">💻</a></td>
</tr>
<tr>
<td align="center"><a href="http://pawelpietruszka.net"><img src="https://avatars0.githubusercontent.com/u/17066202?v=4" width="100px;" alt=""/><br /><sub><b>Pawel Pietruszka</b></sub></a><br /><a href="https://github.com/VorTECHsa/python-sdk/commits?author=Selerski" title="Code">💻</a></td>
<td align="center"><a href="https://www.ollydesousa.com"><img src="https://avatars.githubusercontent.com/u/25864106?v=4" width="100px;" alt=""/><br /><sub><b>Olly De Sousa</b></sub></a><br /><a href="https://github.com/VorTECHsa/python-sdk/commits?author=OllyDS" title="Code">💻</a></td>
</tr>
</table>
<!-- markdownlint-restore -->
<!-- prettier-ignore-end -->
<!-- ALL-CONTRIBUTORS-LIST:END -->
This project follows the
[all-contributors](https://github.com/all-contributors/all-contributors)
specification. Contributions of any kind welcome!
| text/markdown | Vortexa Developers | developers@vortexa.com | null | null | Apache Software License 2.0 | null | [
"Programming Language :: Python :: 3.9",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent"
] | [] | https://github.com/vortechsa/python-sdk | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.9.0 | 2026-02-19T08:39:15.159840 | vortexasdk-1.0.19.tar.gz | 158,140 | 7b/c9/46656a8a88ee716e288054b8566ac7183d8b261297117379692fb74661d2/vortexasdk-1.0.19.tar.gz | source | sdist | null | false | 37d5026a52e025001e5f5b49af07b8bc | 42dc0b8dc3abec10f6f2ea045e0dec612394487d84c1764397bd2c812381efcb | 7bc946656a8a88ee716e288054b8566ac7183d8b261297117379692fb74661d2 | null | [] | 367 |
2.4 | casual-mcp | 0.8.0 | Multi-server MCP client for LLM tool orchestration | # Casual MCP


**Casual MCP** is a Python framework for building, evaluating, and serving LLMs with tool-calling capabilities using [Model Context Protocol (MCP)](https://modelcontextprotocol.io).
## Features
- Multi-server MCP client using [FastMCP](https://github.com/jlowin/fastmcp)
- OpenAI, Ollama, and Anthropic provider support (via [casual-llm](https://github.com/AlexStansfield/casual-llm))
- Recursive tool-calling chat loop
- Toolsets for selective tool filtering per request
- Usage statistics tracking (tokens, tool calls, LLM calls)
- System prompt templating with Jinja2
- CLI and API interfaces
## Installation
```bash
# Using uv
uv add casual-mcp
# Using pip
pip install casual-mcp
```
For development:
```bash
git clone https://github.com/casualgenius/casual-mcp.git
cd casual-mcp
uv sync --group dev
```
## Quick Start
1. Create `casual_mcp_config.json`:
```json
{
"clients": {
"openai": { "provider": "openai" }
},
"models": {
"gpt-4.1": { "client": "openai", "model": "gpt-4.1" }
},
"servers": {
"time": { "command": "python", "args": ["mcp-servers/time/server.py"] }
}
}
```
2. Set your API key: `export OPENAI_API_KEY=your-key`
3. Start the server: `casual-mcp serve`
4. Make a request:
```bash
curl -X POST http://localhost:8000/generate \
-H "Content-Type: application/json" \
-d '{"model": "gpt-4.1", "prompt": "What time is it?"}'
```
## Configuration
Configure clients, models, MCP servers, and toolsets in `casual_mcp_config.json`.
```json
{
"clients": {
"openai": { "provider": "openai" }
},
"models": {
"gpt-4.1": { "client": "openai", "model": "gpt-4.1" }
},
"servers": {
"time": { "command": "python", "args": ["server.py"] },
"weather": { "url": "http://localhost:5050/mcp" }
},
"tool_sets": {
"basic": { "description": "Basic tools", "servers": { "time": true } }
}
}
```
See [Configuration Guide](docs/configuration.md) for full details on models, servers, toolsets, and templates.
## CLI
```bash
casual-mcp serve # Start API server
casual-mcp servers # List configured servers
casual-mcp clients # List configured clients
casual-mcp models # List configured models
casual-mcp toolsets # Manage toolsets interactively
casual-mcp tools # List available tools
casual-mcp migrate-config # Migrate legacy config to new format
```
See [CLI & API Reference](docs/cli-api.md) for all commands and options.
## API
| Endpoint | Description |
|----------|-------------|
| `POST /chat` | Send message history |
| `POST /generate` | Send prompt with optional session |
| `GET /generate/session/{id}` | Get session messages |
| `GET /toolsets` | List available toolsets |
See [CLI & API Reference](docs/cli-api.md#api-endpoints) for request/response formats.
## Programmatic Usage
```python
from casual_llm import SystemMessage, UserMessage
from casual_mcp import McpToolChat, ModelFactory, load_config, load_mcp_client
config = load_config("casual_mcp_config.json")
mcp_client = load_mcp_client(config)
model_factory = ModelFactory(config)
llm_model = model_factory.get_model("gpt-4.1")
chat = McpToolChat(mcp_client, llm_model)
messages = [
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="What time is it?")
]
response = await chat.chat(messages)
```
See [Programmatic Usage Guide](docs/programmatic-usage.md) for `McpToolChat`, usage statistics, toolsets, and common patterns.
## Architecture
Casual MCP orchestrates LLMs and MCP tool servers in a recursive loop:
```
┌─────────────┐ ┌──────────────┐ ┌─────────────┐
│ MCP Servers │─────▶│ Tool Cache │─────▶│ Tool Converter│
└─────────────┘ └──────────────┘ └─────────────┘
│ │
▼ ▼
┌──────────────────────────────┐
│ McpToolChat Loop │
│ │
│ LLM ──▶ Tool Calls ──▶ MCP │
│ ▲ │ │
│ └──────── Results ─────┘ │
└──────────────────────────────┘
```
1. **MCP Client** connects to tool servers (local stdio or remote HTTP/SSE)
2. **Tool Cache** fetches and caches tools from all servers
3. **ModelFactory** creates LLM clients and models from casual-llm
4. **McpToolChat** runs the recursive loop until the LLM provides a final answer
## Environment Variables
| Variable | Default | Description |
|----------|---------|-------------|
| `{CLIENT_NAME}_API_KEY` | - | API key lookup: tries `{CLIENT_NAME.upper()}_API_KEY` first, falls back to provider default (e.g. `OPENAI_API_KEY`, `ANTHROPIC_API_KEY`) |
| `TOOL_RESULT_FORMAT` | `result` | `result`, `function_result`, or `function_args_result` |
| `MCP_TOOL_CACHE_TTL` | `30` | Tool cache TTL in seconds (0 = indefinite) |
| `LOG_LEVEL` | `INFO` | Logging level |
## Troubleshooting
Common issues and solutions are covered in the [Troubleshooting Guide](docs/troubleshooting.md).
## License
[MIT License](LICENSE)
| text/markdown | Alex Stansfield | null | null | null | MIT | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"casual-llm[openai]>=0.6.0",
"dateparser>=1.2.1",
"fastapi>=0.115.12",
"fastmcp<3.0.0,>=2.14.5",
"jinja2>=3.1.6",
"python-dotenv>=1.1.0",
"questionary>=2.1.0",
"requests>=2.32.3",
"rich>=14.0.0",
"typer>=0.19.2",
"uvicorn>=0.34.2"
] | [] | [] | [] | [
"Homepage, https://github.com/casualgenius/casual-mcp",
"Repository, https://github.com/casualgenius/casual-mcp",
"Issue Tracker, https://github.com/casualgenius/casual-mcp/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:38:27.733616 | casual_mcp-0.8.0.tar.gz | 32,709 | 88/1d/fd1f6037f65d1e41a9a77b6e5d6dfb113caf0f57b806ac8223ee28c928d8/casual_mcp-0.8.0.tar.gz | source | sdist | null | false | 5cb39ab318f300d9d519f72c1531a7dc | fb62f175f3143f6463048f54c3b6bfbc535726fe77ba603769e3b883dc477883 | 881dfd1f6037f65d1e41a9a77b6e5d6dfb113caf0f57b806ac8223ee28c928d8 | null | [
"LICENSE"
] | 266 |
2.1 | zhmiscellanylite | 0.0.3 | A collection of useful/interesting python libraries made by zh. | `zhmiscellanylite`
=
This is a smaller, lighter, server focused version of my main package [zhmiscellany](https://github.com/zen-ham/zhmiscellany)
-
For documentation please go there instead.
| text/markdown | zh | imnotgivingmyemailjustaddmeondiscordmydiscordisz_h_@zh.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: Microsoft :: Windows"
] | [] | https://discord.gg/ThBBAuueVJ | null | >=3.6 | [] | [] | [] | [
"dill>=0",
"numpy>=0",
"kthread>=0",
"orjson>=0",
"zstandard>=0",
"pywin32>=0; sys_platform == \"win32\""
] | [] | [] | [] | [
"Bug Tracker, https://github.com/zen-ham/zhmiscellany/issues"
] | twine/6.1.0 CPython/3.11.9 | 2026-02-19T08:37:24.460655 | zhmiscellanylite-0.0.3-py3-none-any.whl | 20,090 | b8/4c/0202ade083f5252362e0755a942ceff028dee9efff0e5c1a2ad7a4f29da8/zhmiscellanylite-0.0.3-py3-none-any.whl | py3 | bdist_wheel | null | false | 7b366767f2db27779d2aeb3dd8458b5b | 52a7cc5a2bb4d64add22595e905e4111ed4d26b76552306ff1046c44bbfbb4e2 | b84c0202ade083f5252362e0755a942ceff028dee9efff0e5c1a2ad7a4f29da8 | null | [] | 128 |
2.4 | lingxingapi | 1.7.1 | An async API client for LingXing (领星) ERP | ## An async API client for LingXing (领星) ERP
Created to be used in a project, this package is published to github for ease of management and installation across different modules.
## Installation
Install from `PyPi`
```bash
pip install lingxingapi
```
Install from `github`
```bash
pip install git+https://github.com/AresJef/LingXingApi.git
```
## Requirements
- Python 3.10 or higher.
## Example
```python
from lingxingapi import API
# Context Manager
async def test(self, app_id: str, app_secret: str) -> None:
async with API(app_id, app_secret) as api:
sellers = await api.basic.Sellers()
# Close Manually
async def test(self, app_id: str, app_secret: str) -> None:
api = API(app_id, app_secret)
sellers = await api.basic.Sellers()
await api.close()
```
### Acknowledgements
MysqlEngine is based on several open-source repositories.
- [aiohttp](https://github.com/aio-libs/aiohttp)
- [cytimes](https://github.com/AresJef/cyTimes)
- [numpy](https://github.com/numpy/numpy)
- [orjson](https://github.com/ijl/orjson)
- [pydantic](https://github.com/pydantic/pydantic)
| text/markdown | Jiefu Chen | keppa1991@163.com | null | null | MIT license | async, api, lingxing, erp | [
"Programming Language :: Python :: 3",
"Operating System :: Unix",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows"
] | [] | https://github.com/AresJef/LingXingApi | null | >=3.10 | [] | [] | [] | [
"aiohttp>=3.8.4",
"cytimes>=3.0.1",
"numpy>=1.25.2",
"orjson>=3.10.2",
"pycryptodome>=3.23.0",
"pydantic>=2.7.4",
"typing-extensions>=4.9.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:36:50.220818 | lingxingapi-1.7.1.tar.gz | 224,589 | 9a/17/277ff88f608cf077b23c25d7af96a90296e1c75257f12f1c522c58a8d3be/lingxingapi-1.7.1.tar.gz | source | sdist | null | false | 3d597ff2c38398b038701082273b2669 | 54b6ddedb15b05a8dfb50a3e99028e2055dea776b436f4a1e9da43780374226c | 9a17277ff88f608cf077b23c25d7af96a90296e1c75257f12f1c522c58a8d3be | null | [
"LICENSE"
] | 276 |
2.4 | openfoodfacts | 3.4.4 | Official Python SDK of Open Food Facts | # Open Food Facts Python SDK
<div align="center">
<img width="400" src="https://blog.openfoodfacts.org/wp-content/uploads/2022/05/EXE_LOGO_OFF_RVB_Plan-de-travail-1-copie-0-1-768x256.jpg" alt="Open Food Facts"/>
</div>
## Status
[](https://opensource.box.com/badges)
[](https://travis-ci.org/openfoodfacts/openfoodfacts-python)
[](https://codecov.io/gh/openfoodfacts/openfoodfacts-python)
[](https://pypi.org/project/openfoodfacts)
[](https://github.com/openfoodfacts/openfoodfacts-python/blob/master/LICENSE)
## Description
This is the official Python SDK for the [Open Food Facts](https://world.openfoodfacts.org/) project.
It provides a simple interface to the [Open Food Facts API](https://openfoodfacts.github.io/openfoodfacts-server/api/) and allows you to:
- Get information about a product
- Perform text search
- Create a new product or update an existing one
It also provides some helper functions to make it easier to work with Open Food Facts data and APIs, such as:
- getting translation of a taxonomized field in a given language
- downloading and iterating over the Open Food Facts data dump
- handling OCRs of Open Food Facts images generated by Google Cloud Vision
Please note that this SDK is still in beta and the API is subject to change. Make sure to pin the version in your requirements file.
## Third party applications
If you use this SDK or want to use this SDK, make sure to read the [REUSE](https://github.com/openfoodfacts/openfoodfacts-python/blob/develop/REUSE.md) and ensure you comply with the OdBL licence, in addition to the licence of this package (MIT). Make sure you at least fill the form, and feel free to open a PR to add your application in this list :-)
## Installation
The easiest way to install the SDK is through pip:
pip install openfoodfacts
or manually from source:
git clone https://github.com/openfoodfacts/openfoodfacts-python
cd openfoodfacts-python
pip install . # Note the “.” at the end!
## Examples
All the examples below assume that you have imported the SDK and instanciated the API object:
```python
import openfoodfacts
# User-Agent is mandatory
api = openfoodfacts.API(user_agent="MyAwesomeApp/1.0")
```
*Get information about a product*
```python
code = "3017620422003"
api.product.get(code, fields=["code", "product_name"])
# {'code': '3017620422003', 'product_name': 'Nutella'}
```
*Perform text search*
```python
api.product.text_search("mineral water")
# {"count": 3006628, "page": 1, "page_count": 20, "page_size": 20, "products": [{...}], "skip": 0}
```
*Create a new product or update an existing one*
```python
results = api.product.update({
"code": CODE,
"product_name_en": "blueberry jam",
"ingredients_text_en": "blueberries, sugar, pectin, citric acid"
})
```
with `CODE` the product barcode. The rest of the body should be a dictionary of fields to create/update.
To see all possible capabilities, check out the [usage guide](https://openfoodfacts.github.io/openfoodfacts-python/usage/).
## Contributing
Any help is welcome, as long as you don't break the continuous integration.
Fork the repository and open a Pull Request directly on the "develop" branch.
A maintainer will review and integrate your changes.
Maintainers:
- [Anubhav Bhargava](https://github.com/Anubhav-Bhargava)
- [Frank Rousseau](https://github.com/frankrousseau)
- [Pierre Slamich](https://github.com/teolemon)
- [Raphaël](https://github.com/raphael0202)
Contributors:
- Agamit Sudo
- [Daniel Stolpe](https://github.com/numberpi)
- [Enioluwa Segun](https://github.com/enioluwas)
- [Nicolas Leger](https://github.com/nicolasleger)
- [Pablo Hinojosa](https://github.com/Pablohn26)
- [Andrea Stagi](https://github.com/astagi)
- [Benoît Prieur](https://github.com/benprieur)
- [Aadarsh A](https://github.com/aadarsh-ram)
We use uv as a dependency manager and ruff as a linter/formatter.
## Copyright and License
Copyright 2016-2024 Open Food Facts
The Open Food Facts Python SDK is licensed under the [MIT License](https://github.com/openfoodfacts/openfoodfacts-python/blob/develop/LICENSE).
Other files that are not part of the SDK itself may be under different a different license.
The project complies with the [REUSE 3.3 specification](https://reuse.software/spec-3.3/),
so any such files should be marked accordingly.
| text/markdown | null | The Open Food Facts team <contact@openfoodfacts.org> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Natural Language :: English",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"requests>=2.20.0",
"pydantic<3.0.0,>=2.0.0",
"tqdm<5.0.0,>=4.0.0",
"redis[hiredis]~=7.1.1; extra == \"redis\"",
"Pillow<12.2,>=9.3; extra == \"pillow\"",
"tritonclient[grpc]<3.0.0,>2.0.0; extra == \"ml\"",
"opencv-python-headless<5.0.0,>4.0.0; extra == \"ml\"",
"Pillow; extra == \"ml\"",
"albumenta... | [] | [] | [] | [
"repository, https://github.com/openfoodfacts/openfoodfacts-python"
] | uv/0.10.2 {"installer":{"name":"uv","version":"0.10.2","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T08:32:25.575839 | openfoodfacts-3.4.4-py3-none-any.whl | 63,598 | f7/34/b3c6dfdc2e0768c715a86604b1f12f5e961df9052b629e9ff84814b453dc/openfoodfacts-3.4.4-py3-none-any.whl | py3 | bdist_wheel | null | false | 1103dac981fe791c2a604ac987de50f7 | 5ec002dbfff7f41bb73eaccf895967d08772e20e5e457f8c656386a1f1578bf3 | f734b3c6dfdc2e0768c715a86604b1f12f5e961df9052b629e9ff84814b453dc | MIT | [
"LICENSE"
] | 833 |
2.4 | bluer-sbc | 9.569.1 | 🌀 AI for single board computers and related designs. | # 🌀 bluer-sbc
🌀 `bluer-sbc` is a [`bluer-ai`](https://github.com/kamangir/bluer-ai) plugin for edge computing on [single board computers](https://github.com/kamangir/blue-bracket).
## installation
```bash
pip install bluer_sbc
# @env dot list
@env dot cp <env-name> local
```
## aliases
[@camera](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/aliases/camera.md)
[@joystick](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/aliases/joystick.md)
[@parts](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/aliases/parts.md)
## designs
| | | |
| --- | --- | --- |
| [`swallow head`](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/swallow-head) [](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/swallow-head) | [`swallow`](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/swallow) [](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/swallow) | [`anchor ⚓️`](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/anchor) [](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/anchor) |
| [`pwm generator`](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/pwm-generator.md) [](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/pwm-generator.md) | [`regulated bus`](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/regulated-bus.md) [](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/regulated-bus.md) | [`battery bus`](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/battery_bus) [](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/battery_bus) |
| [`adapter bus`](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/adapter-bus.md) [](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/adapter-bus.md) | [`ultrasonic-sensor-tester`](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/ultrasonic-sensor-tester.md) [](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/ultrasonic-sensor-tester.md) | [`cheshmak 👁️`](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/cheshmak) [](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/cheshmak) |
| [`nafha`](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/nafha) [](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/nafha) | [`shelter`](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/shelter) [](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/shelter) | [`arduino dev box`](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/arduino) [](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/arduino) |
| [`blue3`](https://github.com/kamangir/blue-bracket/blob/main/designs/blue3.md) [](https://github.com/kamangir/blue-bracket/blob/main/designs/blue3.md) | [`chenar-grove`](https://github.com/kamangir/blue-bracket/blob/main/designs/chenar-grove.md) [](https://github.com/kamangir/blue-bracket/blob/main/designs/chenar-grove.md) | [`cube`](https://github.com/kamangir/blue-bracket/blob/main/designs/cube.md) [](https://github.com/kamangir/blue-bracket/blob/main/designs/cube.md) |
| [`eye_nano`](https://github.com/kamangir/blue-bracket/blob/main/designs/eye_nano.md) [](https://github.com/kamangir/blue-bracket/blob/main/designs/eye_nano.md) | | |
## shortcuts
| |
| --- |
| [`parts`](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/parts) [](https://github.com/kamangir/bluer-sbc/blob/main/bluer_sbc/docs/parts) |
---
> 🌀 [`blue-sbc`](https://github.com/kamangir/blue-sbc) for the [Global South](https://github.com/kamangir/bluer-south).
---
[](https://github.com/kamangir/bluer-sbc/actions/workflows/pylint.yml) [](https://github.com/kamangir/bluer-sbc/actions/workflows/pytest.yml) [](https://github.com/kamangir/bluer-sbc/actions/workflows/bashtest.yml) [](https://pypi.org/project/bluer-sbc/) [](https://pypistats.org/packages/bluer-sbc)
built by 🌀 [`bluer README`](https://github.com/kamangir/bluer-objects/tree/main/bluer_objects/docs/bluer-README), based on 🌀 [`bluer_sbc-9.569.1`](https://github.com/kamangir/bluer-sbc).
built by 🌀 [`blueness-3.122.1`](https://github.com/kamangir/blueness).
| text/markdown | Arash Abadpour (Kamangir) | arash.abadpour@gmail.com | null | null | CC0-1.0 | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Unix Shell",
"Operating System :: OS Independent"
] | [] | https://github.com/kamangir/bluer-sbc | null | null | [] | [] | [] | [
"bluer_ai",
"pygame"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.9 | 2026-02-19T08:32:13.713361 | bluer_sbc-9.569.1.tar.gz | 92,275 | 00/33/a72080a2fe3dcd92c7e6c7bc14a9841ce0048883225fa51405fab2b38459/bluer_sbc-9.569.1.tar.gz | source | sdist | null | false | f7f49ce537ec6660bff3b514a4e9e5df | cb02a3bffed705b1f770bec1b0d2dede1ccad951d43cb41d7887054297dbaa6b | 0033a72080a2fe3dcd92c7e6c7bc14a9841ce0048883225fa51405fab2b38459 | null | [
"LICENSE"
] | 806 |
2.4 | arinova-agent-sdk | 0.0.1 | SDK for connecting AI agents to Arinova Chat | # arinova-agent-sdk
Python SDK for connecting AI agents to [Arinova Chat](https://github.com/arinova-ai/arinova-chat) via WebSocket. Supports streaming responses with automatic reconnection.
## Install
```bash
pip install arinova-agent-sdk
```
Requires Python 3.10+.
## Quick Start
```python
from arinova_agent import ArinovaAgent
agent = ArinovaAgent(
server_url="https://chat.arinova.ai",
bot_token="your-bot-token",
)
@agent.on_task
async def handle(task):
# Stream chunks to the user
for word in task.content.split():
task.send_chunk(word + " ")
# Signal completion with the full response
task.send_complete("Echo: " + task.content)
agent.run()
```
`agent.run()` blocks the process and handles `SIGINT`/`SIGTERM` for graceful shutdown. If you are already inside an async context, use `await agent.connect()` instead:
```python
import asyncio
from arinova_agent import ArinovaAgent
agent = ArinovaAgent(
server_url="https://chat.arinova.ai",
bot_token="your-bot-token",
)
@agent.on_task
async def handle(task):
task.send_chunk("Thinking...")
task.send_complete("Done.")
asyncio.run(agent.connect())
```
## API Reference
### Constructor
```python
ArinovaAgent(
server_url: str, # Arinova Chat server URL
bot_token: str, # Bot authentication token
reconnect_interval: float = 5.0, # Seconds between reconnect attempts
ping_interval: float = 30.0, # Seconds between keepalive pings
)
```
All parameters are keyword-only.
### @agent.on_task
Register a task handler. Called each time the agent receives a message from a user. The handler receives a `Task` object and can be sync or async.
```python
@agent.on_task
async def handle(task):
...
```
### Task Object
| Field | Type | Description |
|-------------------|-------------------------|------------------------------------------|
| `task_id` | `str` | Unique identifier for this task |
| `conversation_id` | `str` | Conversation the message belongs to |
| `content` | `str` | The user's message text |
| `send_chunk` | `Callable[[str], None]` | Stream a partial response to the user |
| `send_complete` | `Callable[[str], None]` | Finalize the response with full content |
| `send_error` | `Callable[[str], None]` | Send an error message back to the user |
A typical handler streams chunks as they are generated, then calls `send_complete` with the assembled full text. If something goes wrong, call `send_error` instead.
### Lifecycle Callbacks
```python
@agent.on_connected
def connected():
print("Connected")
@agent.on_disconnected
def disconnected():
print("Disconnected")
@agent.on_error
def error(exc: Exception):
print("Error:", exc)
```
- `on_connected` -- called after successful authentication.
- `on_disconnected` -- called when the WebSocket connection drops.
- `on_error` -- called on connection errors or unhandled exceptions in the task handler.
### agent.run()
```python
agent.run() -> None
```
Start the agent in blocking mode. Creates its own event loop, connects to the server, and reconnects automatically on disconnection. Stops on `SIGINT` or `SIGTERM`.
### await agent.connect()
```python
await agent.connect() -> None
```
Start the agent within an existing async event loop. Reconnects automatically until `disconnect()` is called.
### await agent.disconnect()
```python
await agent.disconnect() -> None
```
Close the WebSocket connection and stop automatic reconnection.
## Getting a Bot Token
1. Open the Arinova Chat dashboard.
2. Navigate to the bot management page and create a new bot.
3. Copy the bot token from the bot's settings page.
4. Pass it as the `bot_token` parameter when creating an `ArinovaAgent` instance.
## License
MIT
| text/markdown | null | null | null | null | null | agent, ai, arinova, sdk, streaming, websocket | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"websockets>=12.0"
] | [] | [] | [] | [
"Homepage, https://github.com/arinova-ai/arinova-chat"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T08:30:29.730731 | arinova_agent_sdk-0.0.1.tar.gz | 4,099 | 5f/e9/f58273af693e4d8e97e234490c5bd58b7edcbfa5f6f16f7f8a4ab8bb9a34/arinova_agent_sdk-0.0.1.tar.gz | source | sdist | null | false | 0520044fb464ae447cd6fa72dbfe2bc4 | 150d05e9f004b9270279cc587904448b1e82ad3325820fc36fed2a1d35965289 | 5fe9f58273af693e4d8e97e234490c5bd58b7edcbfa5f6f16f7f8a4ab8bb9a34 | MIT | [] | 290 |
2.4 | openroad-mcp | 0.1.0 | The OpenROAD MCP server | # OpenROAD MCP Server
A Model Context Protocol (MCP) server that provides tools for interacting with OpenROAD and ORFS (OpenROAD Flow Scripts).
## Demo

[Watch full demo video](https://youtu.be/UQM1otOl17s)
## Features
- **Interactive OpenROAD sessions** - Execute commands in persistent OpenROAD sessions with PTY support
- **Session management** - Create, list, inspect, and terminate multiple sessions
- **Command history** - Access full command history for any session
- **Performance metrics** - Get comprehensive metrics across all sessions
- **Report visualization** - List and read report images from ORFS runs
## Requirements
- **OpenROAD** installed and available in your PATH
- [Installation guide](https://openroad.readthedocs.io/en/latest/main/GettingStarted.html)
- **OpenROAD-flow-scripts (ORFS)** for complete RTL-to-GDS flows (optional but recommended)
- [ORFS installation guide](https://openroad-flow-scripts.readthedocs.io/)
- **Python 3.13+** or higher
- **uv** package manager
- Install: `curl -LsSf https://astral.sh/uv/install.sh | sh`
## Support Matrix
| MCP Client | Supported | Transport Mode(s) | Notes |
|------------|--------|------------------|-------|
| Claude Code | ✅ | STDIO | Full support for all features |
| Gemini CLI | ✅ | STDIO | Full support for all features |
| Other MCP clients | ⚠️ | STDIO | Should work with standard STDIO transport |
## Getting Started
**New to OpenROAD MCP?** Check out our [Quick Start guide](QUICKSTART.md).
### Standard Configuration
The basic configuration for all MCP clients:
```json
{
"mcpServers": {
"openroad-mcp": {
"command": "uvx",
"args": [
"--from",
"git+https://github.com/luarss/openroad-mcp",
"openroad-mcp"
]
}
}
}
```
For local development, use:
```json
{
"mcpServers": {
"openroad-mcp": {
"command": "uv",
"args": [
"--directory",
"/path/to/openroad-mcp",
"run",
"openroad-mcp"
]
}
}
}
```
## Installation
<details>
<summary><b>Claude Code</b></summary>
Use the Claude Code CLI to add the OpenROAD MCP server:
```bash
claude mcp add --transport stdio openroad-mcp -- uvx --from git+https://github.com/luarss/openroad-mcp openroad-mcp
```
</details>
<details>
<summary><b>Gemini CLI</b></summary>
Follow the [Gemini MCP install guide](https://ai.google.dev/gemini-api/docs/model-context-protocol), using the [standard configuration](#standard-configuration) above.
</details>
<details>
<summary><b>Docker</b></summary>
🚧 **Work in Progress**: Docker deployment via GitHub Container Registry (GHCR) is coming soon.
</details>
## Verification
After configuration, restart your MCP client and verify the MCP server is running:
1. The server should automatically start when your MCP client launches
2. You can use OpenROAD tools through the MCP interface
3. Check logs for any startup errors if tools are not available
## Available Tools
Once configured, the following tools are available:
- `interactive_openroad` - Execute commands in an interactive OpenROAD session
- `create_interactive_session` - Create a new OpenROAD session
- `list_interactive_sessions` - List all active sessions
- `terminate_interactive_session` - Terminate a session
- `inspect_interactive_session` - Get detailed session information
- `get_session_history` - View command history
- `get_session_metrics` - Get performance metrics
- `list_report_images` - List ORFS report directory images
- `read_report_image` - Read a ORFS report image
## Troubleshooting
If the MCP server fails to start:
1. Ensure `uv` is installed and available in your PATH
2. Verify the path to openroad-mcp is correct
3. Check that all dependencies are installed: `make sync`
4. Review your MCP client logs for specific error messages
## Development
### Setup
```bash
# Install environment
uv venv
make sync
```
### Testing
```bash
# Run core tests (recommended - excludes PTY tests that may fail in some environments)
make test
# Run interactive PTY tests separately (may have file descriptor issues in CI)
make test-interactive
# Run all tests including potentially problematic PTY tests
make test-all
# Format and check code
make format
make check
```
**Note**: Interactive PTY tests are separated because they may experience file descriptor issues in certain environments (containers, CI systems). The core functionality tests (`make test`) provide comprehensive coverage of the MCP integration without these environment-specific issues.
### MCP Inspector
```bash
# Launch MCP inspector for debugging
# For STDIO transport: Set Command as "uv", Arguments as "run openroad-mcp"
make inspect
```
## Contributing
We welcome contributions to OpenROAD MCP! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for detailed instructions on how to get started, our development workflow, and code standards.
## Support
If you encounter any issues or have questions, please open an issue on our [GitHub issue tracker](https://github.com/luarss/openroad-mcp/issues).
## License
BSD 3-Clause License. See [LICENSE](LICENSE) file.
---
*Built with ❤️ by Precision Innovations*
| text/markdown | null | Precision Innovations <jluar@precisioninno.com> | null | null | null | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"fastmcp>=2.10.6",
"mcp[cli]>=1.12.1",
"pillow>=12.0.0",
"psutil>=7.1.0",
"pydantic>=2.11.7",
"beautifulsoup4>=4.14.2; extra == \"dev\"",
"google-genai>=1.53.0; extra == \"dev\"",
"mypy>=1.17.0; extra == \"dev\"",
"pre-commit>=4.2.0; extra == \"dev\"",
"pytest-asyncio>=1.1.0; extra == \"dev\"",
... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:30:20.126072 | openroad_mcp-0.1.0.tar.gz | 18,396,804 | 71/ed/49531d7eb926eac489fa8bda20947110eaaf7c1cc2f4dd0b150f15506e0a/openroad_mcp-0.1.0.tar.gz | source | sdist | null | false | cf54bea7c180c534f9aeea504419ceab | 4692d239670aaf34d5c91c49ed9f6dd8ac90d6439e4de7b3d3ca9292a005c3b1 | 71ed49531d7eb926eac489fa8bda20947110eaaf7c1cc2f4dd0b150f15506e0a | null | [
"LICENSE"
] | 273 |
2.4 | bqa | 0.1.4 | A framework for tensor-network–based quantum annealing simulation powered by belief propagation. | ## What is it?
This is a package for large scale tensor-networks-based simulation of quantum annealing.
It uses belief propagation based approximate inference (see https://arxiv.org/abs/2306.17837, https://arxiv.org/abs/2409.12240, https://arxiv.org/abs/2306.14887) as an engine. This implementation introduces a compilation step that classifies graph nodes by degree, groups the corresponding tensors into batched representations, groups the associated messages, enabling massively parallel belief propagation and related subroutines easelly deployable on a GPU.
## How to install?
1) Clone this repo;
2) Run `pip install .` from the clonned repo under your python environment.
To validate the computation results, some examples and tests rely on an exact quantum circuit simulator available at https://github.com/LuchnikovI/qem. To install it, follow the steps below:
1) Clone the repo https://github.com/LuchnikovI/qem;
2) Install rust (see https://rust-lang.org/tools/install/);
3) Install `maturin` by running `pip install maturin .`;
4) Run `pip install .` from the clonned repo under your python environment.
## How to use?
This package exposes a single entry point, `run_qa`, which executes the full workflow. It accepts a single argument which is a Python dictionary that fully specifies the quantum annealing task. This dictionary serves as a configuration or DSL and can be directly deserialized from JSON or other formats. For a concrete example of the configuration, see `./examples/small_ibm_heavy_hex.py`.
## How to run benchmarks against MQLib?
First, one need to install an [MQLib](https://github.com/MQLib/MQLib) wrapper awailable [here](https://github.com/LuchnikovI/mqlib_wrap), follow the instruction of README there. Now one can execute scripts in `./benchmarks_against_mqlib`, every script saves a result into a separate directory with time stamp.
## Available backends
Currently there are `numpy` and `cupy` backends. One can specify it in the configuration dictionary. To use `cupy` backend one needs to install `cupy` sepraratelly since it is not in the dependancies list. One can control the precision of the `numpy` backend by setting the environment variable `export BQA_PECISION=single` for the single precision and `export BQA_PRECISION=double` for the double precision. The precision of the `cupy` backend is always single. This is important to trigger fast batched matrix multiplication kernel.
| text/markdown | Ilia-Luchnikov | luchnikovilya@gmail.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"networkx<4.0,>=3.0",
"numpy<2,>=1"
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.12.12 Linux/6.14.0-1017-azure | 2026-02-19T08:29:56.771685 | bqa-0.1.4-py3-none-any.whl | 24,047 | 17/58/574456cef9a899d976827599a0b6a1fedcddc2aac0edacc9eebb6dd50273/bqa-0.1.4-py3-none-any.whl | py3 | bdist_wheel | null | false | 902230e94eda8b9881a188acd8220900 | c92b3fd34f147d832e55e86c672b938e47f98bf2c35714a41bdde04d21639fef | 1758574456cef9a899d976827599a0b6a1fedcddc2aac0edacc9eebb6dd50273 | null | [] | 265 |
2.4 | Django-local-lib-pycon2025 | 1.7.12.0 | Local Django library packaged as a reusable app | # Django Local-lib
Documentation coming soon.
| text/markdown | Joseph | josephnjogu487@gmail.com | null | null | MIT | django local library | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: System Administrators",
"Operating System :: OS Independent",
"Topic :: Software Development :: Build Tools",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Internet",
"Pr... | [] | https://github.com/joseph-njogu/Django_local_lib | null | >=3.6 | [] | [] | [] | [
"Django>=4.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.19 | 2026-02-19T08:29:35.512819 | django_local_lib_pycon2025-1.7.12.0.tar.gz | 2,836 | d1/20/4b27bc79ecbc10994ce40f1e100957259e001f5fe9c97227f4a998df2618/django_local_lib_pycon2025-1.7.12.0.tar.gz | source | sdist | null | false | b637a7578a269741d75cdaeeb4b5929d | 60ddecf4ff8395cf6a4511d47b80bf7aaf75d8f8195d5ecc5908893042fce134 | d1204b27bc79ecbc10994ce40f1e100957259e001f5fe9c97227f4a998df2618 | null | [
"LICENSE"
] | 0 |
2.4 | prophet-cli | 0.22.0 | Prophet ontology tooling CLI | <p align="center">
<img src="https://raw.githubusercontent.com/Chainso/prophet/main/brand/exports/logo-horizontal-color.png" alt="Prophet logo" />
</p>
---
# prophet-cli
`prophet-cli` is the tooling package for Prophet's ontology workflow:
1. Parse DSL (path configured via `project.ontology_file`)
2. Validate model semantics
3. Build canonical IR (`.prophet/ir/current.ir.json`) including versioned `query_contracts`
4. Generate deterministic artifacts (`gen/sql`, `gen/openapi`, `gen/turtle`, `gen/migrations`, `gen/spring-boot`, `gen/node-express`, `gen/python`)
5. Check compatibility against baseline IR
Main project repository:
- https://github.com/Chainso/prophet
## Install
From PyPI:
```bash
python3 -m pip install --upgrade prophet-cli
prophet --help
```
From source (editable):
From repo root:
```bash
python3 -m venv .venv --system-site-packages
.venv/bin/pip install --no-build-isolation -e ./prophet-cli
```
Run via venv script:
```bash
.venv/bin/prophet --help
```
## Commands
### `prophet init`
Creates starter `prophet.yaml` and internal `.prophet` directories.
```bash
prophet init
```
### `prophet validate`
Parses + validates ontology references, IDs, states/transitions, action contracts, list types, and action/event/trigger links.
```bash
prophet validate
```
### `prophet plan`
Computes deterministic file changes without writing files.
```bash
prophet plan
prophet plan --show-reasons
prophet plan --json
```
### `prophet check`
Runs a CI-style gate in one command:
1. ontology validation
2. generated output cleanliness check
3. compatibility/version-bump check against baseline IR
```bash
prophet check
prophet check --show-reasons
prophet check --json
prophet check --against .prophet/baselines/main.ir.json
```
`--json` emits structured diagnostics for CI bots and automation.
### `prophet stacks`
Lists supported stack ids, framework/ORM pairings, implementation status, and capability metadata.
Entries come from a schema-validated stack manifest.
Schema reference:
- user-facing: [docs/reference/generation.md](../docs/reference/generation.md)
- developer-facing: [docs/developer/codegen-architecture.md](../docs/developer/codegen-architecture.md)
```bash
prophet stacks
prophet stacks --json
```
### `prophet hooks`
Lists generated extension hook surfaces from `gen/manifest/extension-hooks.json`.
Useful for wiring user-owned implementations against generated interfaces.
Safety/reference docs:
- [docs/reference/generation.md](../docs/reference/generation.md)
```bash
prophet hooks
prophet hooks --json
```
### `prophet generate` / `prophet gen`
Writes generated artifacts and current IR.
```bash
prophet generate
prophet gen
prophet gen --skip-unchanged
```
Also syncs generated Spring artifacts into [examples/java/prophet_example_spring](../examples/java/prophet_example_spring) when present.
Stack selection is configured in `prophet.yaml`:
```yaml
generation:
stack:
id: java_spring_jpa
```
Generator implementations are available for all declared stack ids:
- `java_spring_jpa`
- `node_express_prisma`
- `node_express_typeorm`
- `node_express_mongoose`
- `python_fastapi_sqlalchemy`
- `python_fastapi_sqlmodel`
- `python_flask_sqlalchemy`
- `python_flask_sqlmodel`
- `python_django_django_orm`
Allowed `generation.stack` keys are: `id`, `language`, `framework`, `orm`.
Equivalent tuple form is also supported:
```yaml
generation:
stack:
language: java
framework: spring_boot
orm: jpa
```
Default generated targets:
- `sql`
- `openapi`
- `spring_boot`
- `flyway`
- `liquibase`
- `manifest` (generated file ownership + hashes)
Optional cross-stack target:
- `turtle` -> `gen/turtle/ontology.ttl`
Turtle output details:
- emits `prophet.ttl`-aligned triples (`prophet:` + `std:` vocabularies)
- local namespace prefix is derived from ontology name
- custom type constraints are emitted as SHACL `NodeShape` resources
- conformance can be checked with `pyshacl` (see [docs/reference/turtle.md](../docs/reference/turtle.md))
When baseline IR differs from current IR, Prophet also emits delta migration artifacts:
- `gen/migrations/flyway/V2__prophet_delta.sql`
- `gen/migrations/liquibase/prophet/0002-delta.sql`
- `gen/migrations/delta/report.json`
Delta SQL includes safety flags and warnings (`destructive`, `backfill_required`, `manual_review`) as comments.
Delta report JSON includes:
- `summary` counts (`safe_auto_apply_count`, `manual_review_count`, `destructive_count`)
- structured `findings` entries with classification and optional suggestions
- heuristic rename hints (`object_rename_hint`, `column_rename_hint`) for manual migration planning
Generated ownership manifest:
- `gen/manifest/generated-files.json`
- includes stack metadata and deterministic hashes for generated outputs
Generated extension hook manifest:
- `gen/manifest/extension-hooks.json`
- lists generated extension points (for example action handler interfaces + default classes)
Spring runtime migration wiring is auto-detected from the host Gradle project:
- if Flyway dependency/plugin is present, Prophet syncs Flyway resources
- if Liquibase dependency/plugin is present, Prophet syncs Liquibase resources
- if neither is present, migration files are still generated under `gen/migrations/**` but not auto-wired into Spring runtime resources
### `prophet gen --wire-gradle`
Auto-wires the current Gradle project as a multi-module setup:
- adds `:prophet_generated` in `settings.gradle.kts`/`settings.gradle`
- maps it to `gen/spring-boot`
- adds app dependency `implementation(project(\":prophet_generated\"))` in `build.gradle.kts`
```bash
prophet gen --wire-gradle
```
Wiring is idempotent (safe to run repeatedly).
### `prophet generate --verify-clean`
CI mode. Fails if committed generated files differ from current generation.
```bash
prophet generate --verify-clean
```
### `prophet gen --skip-unchanged`
Skips no-op regeneration when the current config + IR signature matches the last successful generation cache.
- cache file: `.prophet/cache/generation.json`
- ignored when `--wire-gradle` is used
- incompatible with `--verify-clean`
```bash
prophet gen --skip-unchanged
```
### `prophet clean`
Removes generated artifacts from current project.
Default removals:
- `gen/`
- `.prophet/ir/current.ir.json`
- `.prophet/cache/generation.json`
- `src/main/java/<base_package>/<ontology_name>/generated`
- `src/main/resources/application-prophet.yml`
- `src/main/resources/schema.sql` (only if it looks generated)
- `src/main/resources/db/migration/V1__prophet_init.sql` (if generated)
- `src/main/resources/db/migration/V2__prophet_delta.sql` (if generated)
- `src/main/resources/db/changelog/**` Prophet-managed generated files, including `0002-delta.sql`
- Gradle multi-module wiring for `:prophet_generated` in `settings.gradle(.kts)` and `build.gradle(.kts)`
```bash
prophet clean
prophet clean --verbose
prophet clean --remove-baseline
prophet clean --keep-gradle-wire
```
### `prophet version check`
Compares current IR against baseline and reports compatibility + required bump.
```bash
prophet version check --against .prophet/baselines/main.ir.json
```
Compatibility rules used by CLI are documented in:
- [docs/reference/compatibility.md](../docs/reference/compatibility.md)
## Expected Project Files
- `prophet.yaml`
- `<your ontology file>` (configured in `project.ontology_file`)
- `.prophet/baselines/main.ir.json`
- `.prophet/ir/current.ir.json` (generated)
- `gen/` (generated)
## DSL Notes
- Field types support scalars, custom types, object refs (`ref(User)`), lists (`string[]`, `list(string)`), and reusable `struct` types.
- Nested list types are supported (for example `string[][]`, `list(list(string))`).
- `name "..."` metadata provides human-facing display labels while technical symbols remain the wire/reference keys.
- Description metadata supports both `description "..."` and `documentation "..."`.
- Object keys support field-level and object-level declarations:
- `key primary`
- `key primary (fieldA, fieldB)` (composite)
- `key display (fieldA, fieldB)` (lookup/index hint)
- SQL/Flyway/Liquibase generation emits a non-unique `idx_<table>_display` index when an explicit display key is declared and it is not identical to the primary key columns.
- Node Prisma and Mongoose generation also emits non-unique display-key indexes.
- Generated Java record component order follows DSL field declaration order.
- Actions are not auto-implemented; generated endpoints call handler beans.
- Generated action services (`generated.actions.services.*`) are the API boundary used by controllers.
- Default generated services delegate to handler beans; generated default handler stubs throw `UnsupportedOperationException` until user handlers are provided.
## Config (`prophet.yaml`)
Required keys currently used by CLI:
```yaml
project:
ontology_file: path/to/your-ontology.prophet
generation:
out_dir: gen
targets: [sql, openapi, turtle, spring_boot, flyway, liquibase]
spring_boot:
base_package: com.example.prophet
boot_version: 3.3
compatibility:
baseline_ir: .prophet/baselines/main.ir.json
strict_enums: false
```
Note: generated Spring package root is `<base_package>.<ontology_name>`.
## Release Prep
- Release process: [prophet-cli/RELEASING.md](RELEASING.md)
- Changelog: [prophet-cli/CHANGELOG.md](CHANGELOG.md)
- Version sync is test-enforced between:
- [prophet-cli/pyproject.toml](pyproject.toml) `[project].version`
- [prophet-cli/src/prophet_cli/cli.py](src/prophet_cli/cli.py) `TOOLCHAIN_VERSION`
## Development Notes
- Entry point module: `src/prophet_cli/cli.py`
- Console script: `prophet`
- No-op benchmark script: `scripts/benchmark_noop_generation.py`
- Spring query APIs generated by v0.1 include:
- `GET /<objects>/{id}` for single-field primary keys
- `GET /<objects>/{k1}/{k2}/...` for composite primary keys
- `GET /<objects>` with pagination/sort only
- `POST /<objects>/query` with typed filter DSL (`eq`, `in`, `gte`, `lte`, `contains`) for all filtering
- list responses returned as generated `*ListResponse` DTOs (no raw Spring `Page` payload)
- Generated Spring query layer now uses dedicated `generated.mapping.*DomainMapper` classes for entity-to-domain mapping.
- Example Spring app includes both `h2` (default) and `postgres` runtime profiles with context tests for both.
## Contributing
- See root contribution guide: [CONTRIBUTING.md](../CONTRIBUTING.md)
- Open contributor backlog: [CONTRIBUTING.md](../CONTRIBUTING.md) (`Open Items`)
## License
Apache-2.0. See [LICENSE](../LICENSE).
| text/markdown | Prophet Contributors | null | null | null | null | ontology, codegen, dsl, spring, openapi | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Operating System :: OS Independent",
"Topic :: Software Development :: Code Generators"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"PyYAML>=6.0",
"tomli>=2.0; python_version < \"3.11\""
] | [] | [] | [] | [
"Homepage, https://github.com/Chainso/prophet",
"Repository, https://github.com/Chainso/prophet",
"Issues, https://github.com/Chainso/prophet/issues",
"Changelog, https://github.com/Chainso/prophet/blob/main/prophet-cli/CHANGELOG.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:28:05.255808 | prophet_cli-0.22.0.tar.gz | 157,725 | a9/cf/51e889c9fa8c80ad86fa16d358c1b9381f85068f9d52ad87ef3de990b405/prophet_cli-0.22.0.tar.gz | source | sdist | null | false | 59b49364861d60beae6aa8bb6d6c31c3 | e52e1b38ec7583677f882dfd00643e2c2046ced2a660e50ad818134a68d18755 | a9cf51e889c9fa8c80ad86fa16d358c1b9381f85068f9d52ad87ef3de990b405 | Apache-2.0 | [
"LICENSE"
] | 257 |
2.4 | imgeda | 0.1.0 | High-performance image dataset exploratory data analysis CLI tool | # imgeda
High-performance CLI tool for exploratory data analysis of image datasets.
Scan folders of images, generate JSONL manifests with metadata and pixel statistics, detect quality issues, find duplicates, and produce publication-ready visualizations — all from the command line.
[](https://pypi.org/project/imgeda/)
[](https://pypi.org/project/imgeda/)
[](https://github.com/caylent/imgeda/blob/main/LICENSE)

## Installation
```bash
pip install imgeda
```
Or with [uv](https://docs.astral.sh/uv/):
```bash
uv tool install imgeda
```
### Optional extras
```bash
pip install imgeda[parquet] # Parquet export
pip install imgeda[embeddings] # CLIP embeddings + UMAP visualization (torch, open_clip)
pip install imgeda[opencv] # OpenCV-accelerated scanning
```
## Quick Start
```bash
# Scan a directory of images
imgeda scan ./images -o manifest.jsonl
# View dataset summary
imgeda info -m manifest.jsonl
# Check for quality issues
imgeda check all -m manifest.jsonl
# Detect blurry images
imgeda check blur -m manifest.jsonl
# Detect cross-split data leakage
imgeda check leakage -m train.jsonl -m val.jsonl
# Analyze annotations (auto-detects YOLO, COCO, VOC)
imgeda annotations ./dataset
# Generate all plots (11 plot types)
imgeda plot all -m manifest.jsonl
# Generate an HTML report
imgeda report -m manifest.jsonl
# Compare two manifests
imgeda diff --old v1.jsonl --new v2.jsonl
# Run quality gate (exit code 2 on failure — CI-friendly)
imgeda gate -m manifest.jsonl -p policy.yml
# Export to CSV or Parquet
imgeda export csv -m manifest.jsonl -o dataset.csv
imgeda export parquet -m manifest.jsonl -o dataset.parquet
# Compute CLIP embeddings with UMAP visualization (requires: pip install imgeda[embeddings])
imgeda embed -m manifest.jsonl -o embeddings.npz --plot
```
Or just run `imgeda` with no arguments for an interactive wizard that walks you through everything:
```bash
# Interactive mode — auto-detects dataset format (YOLO, COCO, VOC, classification, flat)
imgeda
```
The wizard detects your dataset structure, shows a summary panel with image counts, splits, and class info, then lets you pick which splits and analyses to run.
## Features
- **Fast parallel scanning** with multi-core `ProcessPoolExecutor` and Rich progress bars
- **Resumable** — Ctrl+C anytime, progress is saved. Re-run and it picks up where it left off
- **JSONL manifest** — append-only, crash-tolerant, one record per image
- **Per-image analysis**: dimensions, file size, pixel statistics (mean/std per channel), brightness, perceptual hashing (phash + dhash), border artifact detection, blur detection (Laplacian variance), EXIF metadata (camera, lens, focal length, exposure, GPS flagging, distortion risk)
- **Quality checks**: corrupt files, dark/overexposed images, border artifacts, blur detection, exact and near-duplicate detection
- **Cross-split leakage detection** — find duplicate images across train/val/test splits using perceptual hashing
- **Annotation analysis** — parse and summarize YOLO, COCO, and Pascal VOC annotations with per-class statistics
- **CLIP embeddings** — compute image embeddings with OpenCLIP, detect outliers, find semantic near-duplicates, and visualize with UMAP (optional extra)
- **11 plot types** with automatic large-dataset adaptations: dimensions, file size, aspect ratio, brightness, channels, artifacts, duplicates, blur scores, EXIF camera/focal/ISO distributions
- **Single-page HTML report** with embedded plots and summary tables
- **Dataset format detection** — auto-detects YOLO, COCO, Pascal VOC, classification, and flat image directories with split-aware scanning
- **Interactive configurator** with Rich panels, split selection, and smart defaults
- **Lambda-compatible core** — the analysis functions have zero CLI dependencies, ready for serverless deployment
- **Manifest diff** — compare two manifests to track dataset changes over time
- **Quality gate** — policy-as-code YAML rules with 11 configurable checks and CI-friendly exit codes
- **CSV and Parquet export** — export manifests with flattened nested fields
- **AWS serverless deployment** — CDK + Step Functions + Lambda for S3-scale analysis
## Example Output
All examples below were generated from the [Food-101 dataset](https://huggingface.co/datasets/ethz/food101) (2,000 images).
### Dimensions
Width vs. height scatter plot with reference lines for 720p, 1080p, and 4K resolutions.
### Brightness Distribution
Histogram of mean brightness per image, with shaded regions for dark (<40) and overexposed (>220) images.
### File Size Distribution
Log-scale histogram with annotated median, P95, and P99 percentile lines.
### Aspect Ratio Distribution
Histogram with reference lines at common ratios (1:1, 4:3, 3:2, 16:9).
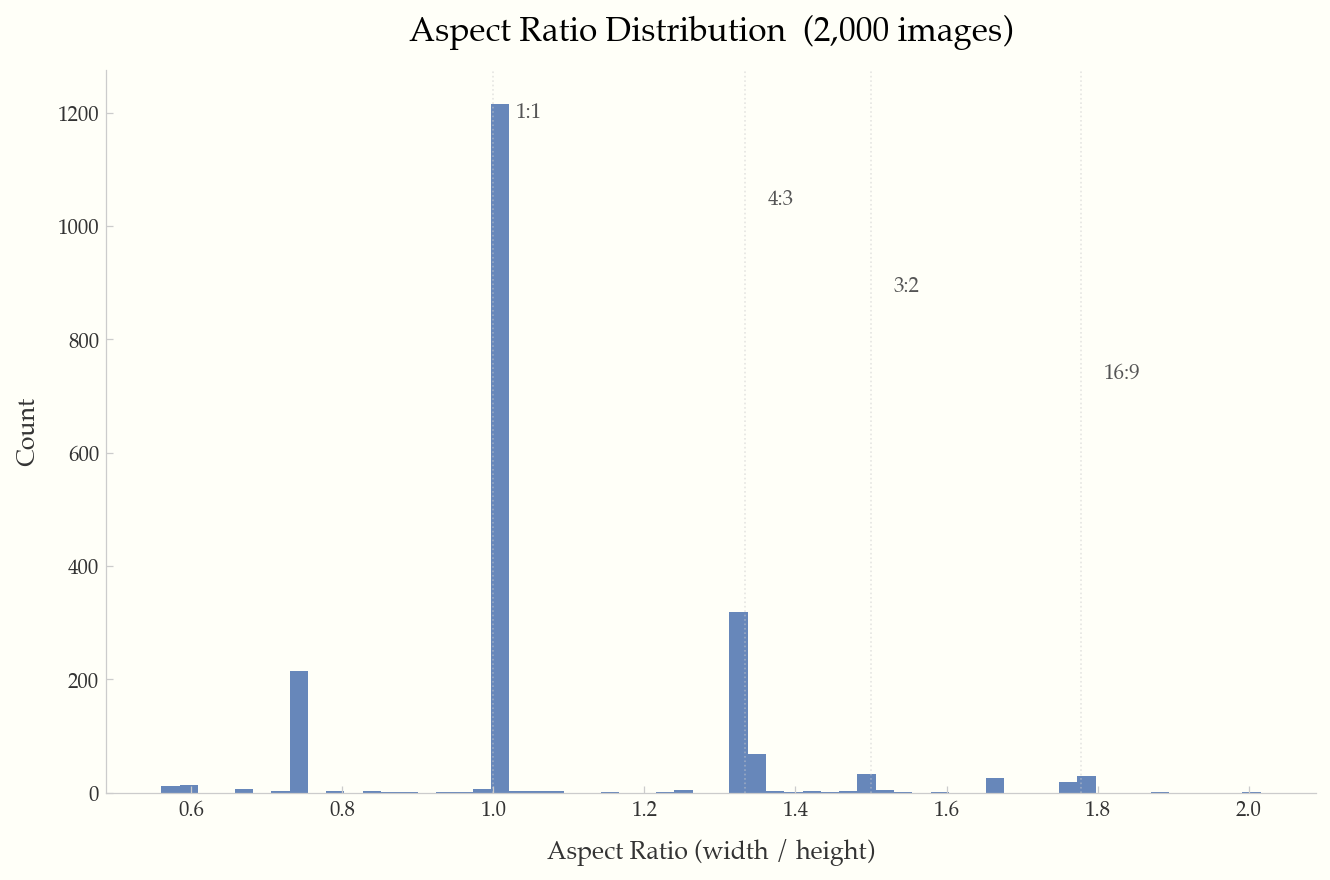
### Channel Distributions
Violin plots of mean R/G/B channel values across the dataset.
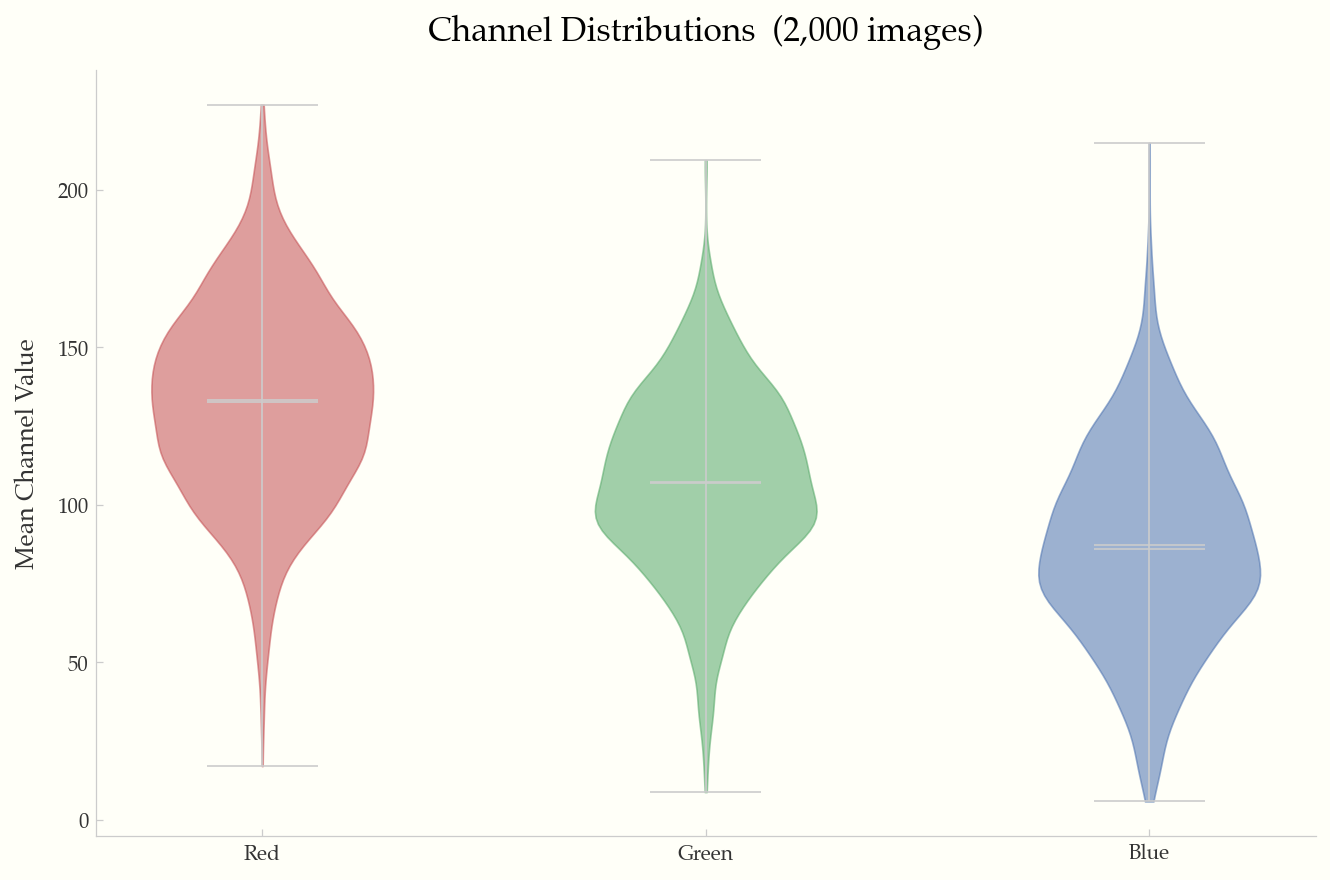
### Border Artifact Analysis
Corner-to-center brightness delta histogram with configurable threshold line.
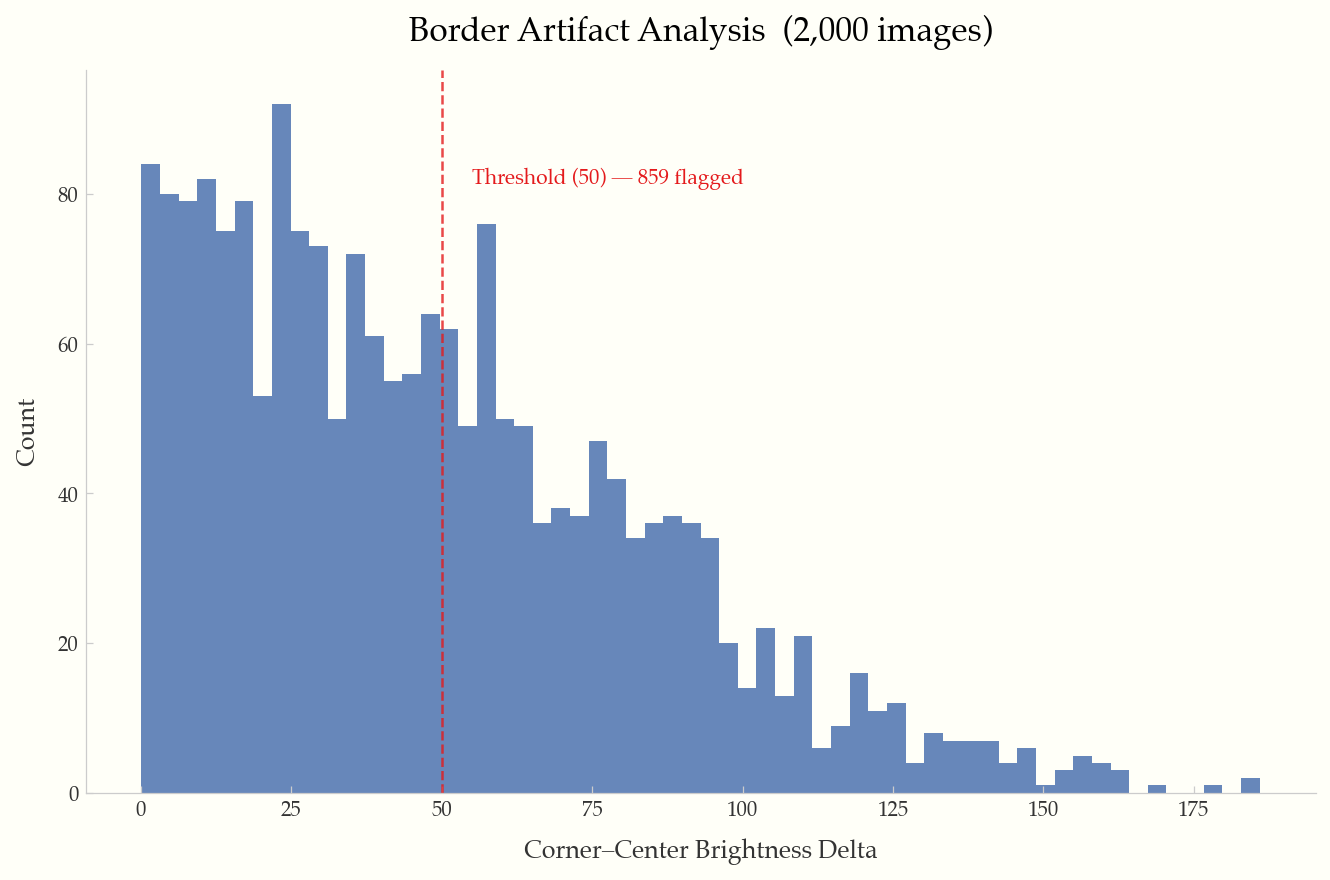
### Duplicate Analysis
Duplicate group sizes and unique vs. duplicate breakdown.
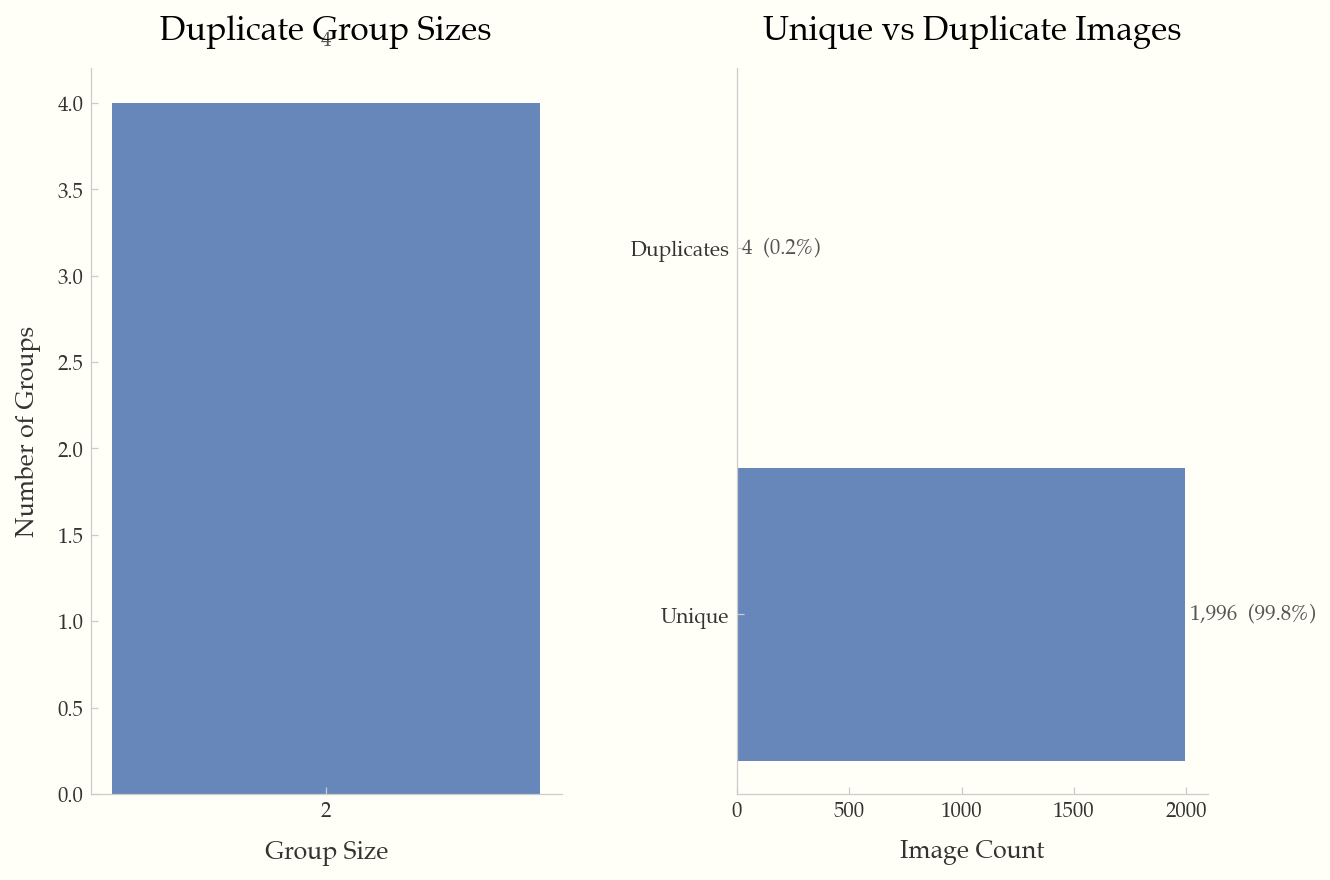
## CLI Reference
### `imgeda scan <DIR>`
Scan a directory of images and produce a JSONL manifest.
```
Options:
-o, --output PATH Output manifest path [default: imgeda_manifest.jsonl]
--workers INTEGER Parallel workers [default: CPU count]
--checkpoint-every INTEGER Flush interval [default: 500]
--resume / --no-resume Auto-resume from existing manifest [default: resume]
--force Force full rescan (ignore existing manifest)
--skip-pixel-stats Metadata-only scan (faster)
--skip-exif Skip EXIF metadata extraction
--no-hashes Skip perceptual hashing
--extensions TEXT Comma-separated extensions to include
--dark-threshold FLOAT Dark image threshold [default: 40.0]
--overexposed-threshold FLOAT Overexposed threshold [default: 220.0]
--artifact-threshold FLOAT Border artifact threshold [default: 50.0]
--max-image-dim INTEGER Downsample threshold for pixel stats [default: 2048]
```
### `imgeda info -m <MANIFEST>`
Print a Rich-formatted dataset summary.
### `imgeda check <SUBCOMMAND> -m <MANIFEST>`
Subcommands: `corrupt`, `exposure`, `artifacts`, `duplicates`, `blur`, `all`
### `imgeda check leakage -m <MANIFEST> -m <MANIFEST>`
Detect cross-split data leakage between two or more manifests using perceptual hashing.
```
Options:
--threshold INTEGER Hamming distance threshold [default: 8]
-o, --out PATH Output JSON path (optional)
```
### `imgeda annotations <DIR>`
Analyze annotations in a dataset directory. Auto-detects YOLO, COCO, and Pascal VOC formats.
```
Options:
-f, --format TEXT Force format: yolo, coco, voc (auto-detected if omitted)
--labels PATH YOLO labels directory
--annotation-file PATH COCO JSON annotation file
-o, --out PATH Output JSON path (optional)
```
### `imgeda plot <SUBCOMMAND> -m <MANIFEST>`
Subcommands: `dimensions`, `file-size`, `aspect-ratio`, `brightness`, `channels`, `artifacts`, `duplicates`, `blur`, `exif-camera`, `exif-focal`, `exif-iso`, `all`
```
Common options:
-o, --output PATH Output directory [default: ./plots]
--format TEXT Output format: png, pdf, svg [default: png]
--dpi INTEGER DPI for output [default: 150]
--sample INTEGER Sample N records for large datasets
```
### `imgeda report -m <MANIFEST>`
Generate a single-page HTML report with embedded plots and statistics.
### `imgeda diff --old <MANIFEST> --new <MANIFEST>`
Compare two manifests and show added, removed, and changed images with field-level diffs.
```
Options:
-o, --out PATH Output JSON path (optional)
```
### `imgeda gate -m <MANIFEST> -p <POLICY>`
Evaluate a manifest against a YAML quality policy. Exit code 0 = pass, 2 = fail.
```
Options:
-o, --out PATH Output JSON path (optional)
```
Example policy (`policy.yml`):
```yaml
min_images_total: 100
max_corrupt_pct: 1.0
max_overexposed_pct: 5.0
max_underexposed_pct: 5.0
max_duplicate_pct: 10.0
max_blurry_pct: 10.0
max_artifact_pct: 5.0
min_width: 224
min_height: 224
max_aspect_ratio: 3.0
allowed_formats: [jpeg, png]
```
### `imgeda export csv -m <MANIFEST> -o <OUTPUT>`
Export manifest to CSV with flattened nested fields.
### `imgeda export parquet -m <MANIFEST> -o <OUTPUT>`
Export manifest to Parquet format with flattened nested fields. Requires `pip install imgeda[parquet]`.
### `imgeda embed -m <MANIFEST>`
Compute CLIP image embeddings, detect outliers, and generate a UMAP scatter plot. Requires `pip install imgeda[embeddings]`.
```
Options:
-o, --out PATH Output .npz file [default: ./embeddings.npz]
--model TEXT OpenCLIP model name [default: ViT-B-32]
--pretrained TEXT Pretrained weights [default: laion2b_s34b_b79k]
--batch-size INTEGER Inference batch size [default: 32]
--device TEXT Torch device (auto-detected)
--plot / --no-plot Generate UMAP plot [default: --plot]
--plot-dir PATH Plot output directory [default: ./plots]
```
## Architecture
See [docs/architecture.md](docs/architecture.md) for detailed system diagrams including the local CLI flow, AWS serverless flow, CI/CD quality gate flow, and full module dependency graph.
## Manifest Format
The manifest is a JSONL file (one JSON object per line):
- **Line 1**: Metadata header (input directory, scan settings, schema version)
- **Lines 2+**: One `ImageRecord` per image with all computed fields
```jsonl
{"__manifest_meta__": true, "input_dir": "./images", "created_at": "2026-02-17T12:00:00", ...}
{"path": "./images/cat.jpg", "width": 500, "height": 375, "format": "JPEG", "camera_make": "Canon", "focal_length_35mm": 50, "distortion_risk": "low", "has_gps_data": false, "phash": "a1b2c3d4", ...}
```
The manifest is append-only and crash-tolerant. Resume is keyed on `(path, file_size, mtime)` — modified files are automatically re-analyzed.
## Performance
Tested on a 10-core Apple M1 Pro with SSD:
| Operation | 3,680 images |
|-----------|-------------|
| Full scan (metadata + pixels + hashes) | ~8s |
| Plot generation | ~3s |
| HTML report | ~4s |
The tool is designed to handle 100K+ image datasets with batched processing, memory-bounded futures, and automatic plot adaptations for large datasets.
## Development
```bash
git clone https://github.com/caylent/imgeda.git
cd imgeda
uv sync --extra dev --extra parquet --extra opencv
uv run pytest
uv run ruff check src/ tests/
uv run mypy src/
```
## License
MIT
| text/markdown | null | "Randall Hunt (Caylent)" <randall.hunt@caylent.com> | null | null | MIT | analysis, cli, dataset, duplicates, eda, image, quality | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Pytho... | [] | null | null | >=3.10 | [] | [] | [] | [
"imagehash>=4.3",
"matplotlib>=3.10",
"numpy>=2.0",
"orjson>=3.10",
"pillow>=11.0",
"pyyaml>=6.0",
"questionary>=2.1",
"rich>=13.0",
"typer>=0.15",
"moto[s3]>=5.0; extra == \"dev\"",
"mypy>=1.14; extra == \"dev\"",
"pytest-cov>=6.0; extra == \"dev\"",
"pytest-timeout>=2.3; extra == \"dev\"",... | [] | [] | [] | [
"Homepage, https://github.com/caylent/imgeda",
"Repository, https://github.com/caylent/imgeda",
"Bug Tracker, https://github.com/caylent/imgeda/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:27:30.289830 | imgeda-0.1.0.tar.gz | 52,561 | b2/e3/e0694000f26e38d2d9eebae950ea1ee3cde39ba7ad9579378b7f9935168a/imgeda-0.1.0.tar.gz | source | sdist | null | false | 65b3c4522a66735c7c30254141bbaa8a | ccacc49155ce486394bf9ebbd3e752a193cc4133284413303318f0e296d974db | b2e3e0694000f26e38d2d9eebae950ea1ee3cde39ba7ad9579378b7f9935168a | null | [
"LICENSE"
] | 251 |
2.4 | wass2s | 0.4.0 | A Python package for seasonal climate forecast. | # wass2s: A python-based tool for seasonal climate forecast

**wass2s** is a comprehensive tool developed to enhance the accuracy and reproducibility of seasonal forecasts in West Africa and the Sahel. This initiative aligns with the World Meteorological Organization's (WMO) guidelines for objective, operational, and scientifically rigorous seasonal forecasting methods.
## Overview
The wass2s tool is designed to facilitate the generation of seasonal forecasts using various statistical and machine learning methods including the Exploration of AI methods.
It helps forecaster to download data, build models, verify the models, and forecast. A user-friendly jupyter-lab notebook streaming the process of prevision.
## 🚀 Features
- ✅ **Automated Forecasting**: Streamlines the seasonal forecasting process, reducing manual interventions.
- 🔄 **Reproducibility**: Ensures that forecasts can be consistently reproduced and evaluated.
- 📊 **Modularity**: Highly modular tool. Users can easily customize and extend the tool to meet their specific needs.
- 🤖 **Exploration of AI and Machine Learning**: Investigates the use of advanced technologies to further improve forecasting accuracy.
## 📥 Installation
1. Download and Install miniconda
- For Windows, download the executable [here](https://repo.anaconda.com/miniconda/Miniconda3-latest-Windows-x86_64.exe)
- For Linux (Ubuntu), in the terminal run:
``` bash
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install wget
wget -c -r https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh --no-check-certificate
bash Miniconda3-latest-Linux-x86_64.sh
```
2. Create an environment and activate
- For Windows: download yaml [here](https://github.com/hmandela/WASS2S/blob/main/WAS_S2S_windows.yml) and run
```bash
conda env create -f WAS_S2S_windows.yml
conda activate WASS2S
```
- For Linux: download yaml [here](https://github.com/hmandela/WASS2S/blob/main/WAS_S2S_linux.yml) and run
```bash
conda env create -f WAS_S2S_linux.yml
conda activate WASS2S
```
3. Install wass2s
```bash
pip install wass2s
```
4. Download notebooks for simulation
```bash
git clone https://github.com/hmandela/WASS2S_notebooks.git
```
5. Create CDS API key and use it to download NMME and C3S models data from the Climate Data Store (CDS) and IRI Data Library.
- Create an account with Copernicus by signing up [here](https://cds.climate.copernicus.eu/datasets)
- Once you successfully create an account, kindly log in to your Copernicus account and click on your name at the top right corner of the page. Note your "UID" and "Personal Access Token key".
- Configure .cdsapirc file.
In your activated terminal, kindly initiate the Python interpreter by entering the command python3. Subsequently, carefully copy and paste the below code, ensuring to replace "Personal Access Token" with yours.
```python
import os
config_data = '''url: https://cds.climate.copernicus.eu/api
key: Personal Access Token
verify: 0
'''
path_to_home = "/".join([os.path.expanduser('~'),".cdsapirc"])
if not os.path.exists(path_to_home):
with open(path_to_home, 'w') as file:
file.write(config_data)
print("Configuration file created successfully!")
```
### Upgrade wass2s
If you want to upgrade wass2s to a newer version, use the following command:
```bash
pip install --upgrade wass2s
```
### Potential Issues
If you encounter matplotlib errors, try the following steps:
1. Install this version of matplotlib:
```bash
pip install matplotlib==3.7.3
```
2. Install the latest version of cartopy:
```bash
conda install -c conda-forge -c hallkjc01 xcast
```
If you encounter other issues during installation or usage, please refer to the [Troubleshooting Guide](https://github.com/hmandela/WASS2S/blob/main/TROUBLESHOOTING.md).
## ⚙️ Usage
Comprehensive usage guidelines, including data preparation, model configuration, and execution steps, are available in the [wass2s documentation](https://wass2s-readthedocs.readthedocs.io/en/latest/index.html), [wass2S Training Documentation](https://hmandela.github.io/WAS_S2S_Training/).
## 🤝 Contributing
We welcome contributions from the community to enhance the `WAS_S2S` tool. Please refer to our [contribution guidelines](CONTRIBUTING.md) for more information.
## 📜 License
This project is licensed under the [GPL-3 License](https://github.com/hmandela/WASS2S/blob/main/LICENSE.txt).
## Contact
For questions or support, please open a [Github issue](https://github.com/hmandela/WAS_S2S/issues).
## Credits
- scikit-learn: [scikit-learn](https://scikit-learn.org/stable/)
- EOF analysis: [xeofs](https://github.com/xarray-contrib/xeofs/tree/main)
- xcast: [xcast](https://github.com/kjhall01/xcast/)
- xskillscore: [xskillscore](https://github.com/xarray-contrib/xskillscore)
- ... and many more!
## 🙌 Acknowledgments
I would like to express my sincere gratitude to all the participants of the **job-training on the new generation of seasonal forecasts in West Africa and the Sahel**.
Your valuable feedback has significantly contributed to the improvement of this tool. I look forward to continuing to receive your insights and, where possible, your contributions.
**A seed has been planted within you—now, let’s grow it together.**
We also extend our heartfelt thanks to the **AICCRA project** for supporting this development, and to **Dr. Abdou ALI**, Head of the **Climate-Water-Meteorology Department at AGRHYMET RCC-WAS**, for his guidance and support.
---
📖 For more detailed information, tutorials, and support, please visit the [WAS_S2S Training Documentation](https://hmandela.github.io/WAS_S2S_Training/).
| text/markdown | null | "HOUNGNIBO C. M. Mandela" <hmandelahmadiba@gmail.com> | null | null | null | climate, seasonal forecasting, subseasonal forecasting, machine learning, data downloading, downscaling | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Atmospheric Science"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"statsmodels",
"scipy==1.11.3",
"matplotlib==3.7.3",
"xeofs==3.0.4",
"cdsapi==0.7.4",
"cartopy==0.25.*",
"rasterio",
"geopandas",
"shapely",
"rioxarray",
"SkillMetrics",
"optuna",
"earthkit",
"ipywidgets",
"regionmask",
"pycountry"
] | [] | [] | [] | [
"Homepage, https://pypi.org/project/wass2s/",
"Documentation, https://wass2s-readthedocs.readthedocs.io/en/latest/",
"Repository, https://github.com/hmandela/WASS2S/tree/main"
] | twine/6.2.0 CPython/3.12.5 | 2026-02-19T08:26:49.169884 | wass2s-0.4.0.tar.gz | 756,838 | 8a/65/aef638bf0589f997b7632a15046f2f2d169a1cbae29016d4e2f99e304047/wass2s-0.4.0.tar.gz | source | sdist | null | false | fe5801850e8f5ecb44bec7293d9a5fe7 | 7481500f3fa43cd2cb8446e77e42742cfdf7f480b18f483cadd7dad68a9caa59 | 8a65aef638bf0589f997b7632a15046f2f2d169a1cbae29016d4e2f99e304047 | GPL-3.0-or-later | [
"LICENSE.txt"
] | 306 |
2.4 | abstract-webtools | 0.1.6.393 | Utilities for fetching/parsing web content with requests/urllib3/BS4 and helpers. | =======
# Abstract WebTools
Provides utilities for inspecting and parsing web content, including React components and URL utilities, with enhanced capabilities for managing HTTP requests and TLS configurations.
- **Features**:
- URL Validation: Ensures URL correctness and attempts different URL variations.
- HTTP Request Manager: Custom HTTP request handling, including tailored user agents and improved TLS security through a custom adapter.
- Source Code Acquisition: Retrieves the source code of specified websites.
- React Component Parsing: Extracts JavaScript and JSX source code from web pages.
- Comprehensive Link Extraction: Collects all internal links from a specified website.
- Web Content Analysis: Extracts and categorizes various web content components such as HTML elements, attribute values, attribute names, and class names.
### abstract_webtools.py
**Description:**
Abstract WebTools offers a suite of utilities designed for web content inspection and parsing. One of its standout features is its ability to analyze URLs, ensuring their validity and automatically attempting different URL variations to obtain correct website access. It boasts a custom HTTP request management system that tailors user-agent strings and employs a specialized TLS adapter for heightened security. The toolkit also provides robust capabilities for extracting source code, including detecting React components on web pages. Additionally, it offers functionalities for extracting all internal website links and performing in-depth web content analysis. This makes Abstract WebTools an indispensable tool for web developers, cybersecurity professionals, and digital analysts.

- **Dependencies**:
- `requests`
- `ssl`
- `HTTPAdapter` from `requests.adapters`
- `PoolManager` from `urllib3.poolmanager`
- `ssl_` from `urllib3.util`
- `urlparse`, `urljoin` from `urllib.parse`
- `BeautifulSoup` from `bs4`
# UrlManager
The `UrlManager` is a Python class designed to handle and manipulate URLs. It provides methods for cleaning and normalizing URLs, determining the correct version of a URL, extracting URL components, and more. This class is particularly useful for web scraping, web crawling, or any application where URL management is essential.
## Usage
To use the `UrlManager` class, first import it into your Python script:
```python
from abstract_webtools import UrlManager
```
### Initializing a UrlManager Object
You can create a `UrlManager` object by providing an initial URL and an optional `requests` session. If no URL is provided, it defaults to 'www.example.com':
```python
url_manager = UrlManager(url='https://www.example.com')
```
### URL Cleaning and Normalization
The `clean_url` method takes a URL and returns a list of potential URL variations, including versions with and without 'www.', 'http://', and 'https://':
```python
cleaned_urls = url_manager.clean_url()
```
### Getting the Correct URL
The `get_correct_url` method tries each possible URL variation with an HTTP request to determine the correct version of the URL:
```python
correct_url = url_manager.get_correct_url()
```
### Updating the URL
You can update the URL associated with the `UrlManager` object using the `update_url` method:
```python
url_manager.update_url('https://www.example2.com')
```
### Extracting URL Components
The `url_to_pieces` method extracts various components of the URL, such as protocol, domain name, path, and query:
```python
url_manager.url_to_pieces()
print(url_manager.protocol)
print(url_manager.domain_name)
print(url_manager.path)
print(url_manager.query)
```
### Additional Utility Methods
- `get_domain_name(url)`: Returns the domain name (netloc) of a given URL.
- `is_valid_url(url)`: Checks if a URL is valid.
- `make_valid(href, url)`: Ensures a relative or incomplete URL is valid by joining it with a base URL.
- `get_relative_href(url, href)`: Converts a relative URL to an absolute URL based on a base URL.
## Compatibility Note
The `get_domain` method is kept for compatibility but is inconsistent. Use it only for "webpage_url_domain." Similarly, `url_basename`, `base_url`, and `urljoin` methods are available for URL manipulation.
## Example
Here's a quick example of using the `UrlManager` class:
```python
from abstract_webtools import UrlManager
url_manager = UrlManager(url='https://www.example.com')
cleaned_urls = url_manager.clean_url()
correct_url = url_manager.get_correct_url()
url_manager.update_url('https://www.example2.com')
print(f"Cleaned URLs: {cleaned_urls}")
print(f"Correct URL: {correct_url}")
```
## Dependencies
The `UrlManager` class relies on the `requests` library for making HTTP requests. Ensure you have the `requests` library installed in your Python environment.
# SafeRequest
The `SafeRequest` class is a versatile Python utility designed to handle HTTP requests with enhanced safety features. It integrates with other managers like `UrlManager`, `NetworkManager`, and `UserAgentManager` to manage various aspects of the request, such as user-agent, SSL/TLS settings, proxies, headers, and more.
## Usage
To use the `SafeRequest` class, first import it into your Python script:
```python
from abstract_webtools import SafeRequest
```
### Initializing a SafeRequest Object
You can create a `SafeRequest` object with various configuration options. By default, it uses sensible default values, but you can customize it as needed:
```python
safe_request = SafeRequest(url='https://www.example.com')
```
### Updating URL and UrlManager
You can update the URL associated with the `SafeRequest` object using the `update_url` method, which also updates the underlying `UrlManager`:
```python
safe_request.update_url('https://www.example2.com')
```
You can also update the `UrlManager` directly:
```python
from url_manager import UrlManager
url_manager = UrlManager(url='https://www.example3.com')
safe_request.update_url_manager(url_manager)
```
### Making HTTP Requests
The `SafeRequest` class handles making HTTP requests using the `try_request` method. It handles retries, timeouts, and rate limiting:
```python
response = safe_request.try_request()
if response:
# Process the response here
```
### Accessing Response Data
You can access the response data in various formats:
- `safe_request.source_code`: HTML source code as a string.
- `safe_request.source_code_bytes`: HTML source code as bytes.
- `safe_request.source_code_json`: JSON data from the response (if the content type is JSON).
- `safe_request.react_source_code`: JavaScript and JSX source code extracted from `<script>` tags.
### Customizing Request Configuration
The `SafeRequest` class provides several options for customizing the request, such as headers, user-agent, proxies, SSL/TLS settings, and more. These can be set during initialization or updated later.
### Handling Rate Limiting
The class can handle rate limiting scenarios by implementing rate limiters and waiting between requests.
### Error Handling
The `SafeRequest` class handles various request-related exceptions and provides error messages for easier debugging.
## Dependencies
The `SafeRequest` class relies on the `requests` library for making HTTP requests. Ensure you have the `requests` library installed in your Python environment:
```bash
pip install requests
```
## Example
Here's a quick example of using the `SafeRequest` class:
```python
from abstract_webtools import SafeRequest
safe_request = SafeRequest(url='https://www.example.com')
response = safe_request.try_request()
if response:
print(f"Response status code: {response.status_code}")
print(f"HTML source code: {safe_request.source_code}")
```
# SoupManager
The `SoupManager` class is a Python utility designed to simplify web scraping by providing easy access to the BeautifulSoup library. It allows you to parse and manipulate HTML or XML source code from a URL or provided source code.
## Usage
To use the `SoupManager` class, first import it into your Python script:
```python
from abstract_webtools import SoupManager
```
### Initializing a SoupManager Object
You can create a `SoupManager` object with various configuration options. By default, it uses sensible default values, but you can customize it as needed:
```python
soup_manager = SoupManager(url='https://www.example.com')
```
### Updating URL and Request Manager
You can update the URL associated with the `SoupManager` object using the `update_url` method, which also updates the underlying `UrlManager` and `SafeRequest`:
```python
soup_manager.update_url('https://www.example2.com')
```
You can also update the source code directly:
```python
source_code = '<html>...</html>'
soup_manager.update_source_code(source_code)
```
### Accessing and Parsing HTML
The `SoupManager` class provides easy access to the BeautifulSoup object, allowing you to search, extract, and manipulate HTML elements easily. You can use methods like `find_all`, `get_class`, `has_attributes`, and more to work with the HTML content.
```python
elements = soup_manager.find_all(tag='a')
```
### Extracting Links
The class also includes methods for extracting all website links from the HTML source code:
```python
all_links = soup_manager.all_links
```
### Extracting Meta Tags
You can extract meta tags from the HTML source code using the `meta_tags` property:
```python
meta_tags = soup_manager.meta_tags
```
### Customizing Parsing
You can customize the parsing behavior by specifying the parser type during initialization or updating it:
```python
soup_manager.update_parse_type('lxml')
=======
# Unknown Package (vUnknown Version)
```
No description available
## Installation
```bash
pip install Unknown Package
```
## Dependencies
The `SoupManager` class relies on the `BeautifulSoup` library for parsing HTML or XML. Ensure you have the `beautifulsoup4` library installed in your Python environment:
```bash
pip install beautifulsoup4
```
## Example
Here's a quick example of using the `SoupManager` class:
```python
from abstract_webtools import SoupManager
soup_manager = SoupManager(url='https://www.example.com')
all_links = soup_manager.all_links
print(f"All Links: {all_links}")
```
# LinkManager
The `LinkManager` class is a Python utility designed to simplify the extraction and management of links (URLs) and associated data from HTML source code. It leverages other classes like `UrlManager`, `SafeRequest`, and `SoupManager` to facilitate link extraction and manipulation.
## Usage
To use the `LinkManager` class, first import it into your Python script:
```python
from abstract_webtools import LinkManager
```
### Initializing a LinkManager Object
You can create a `LinkManager` object with various configuration options. By default, it uses sensible default values, but you can customize it as needed:
```python
link_manager = LinkManager(url='https://www.example.com')
```
### Updating URL and Request Manager
You can update the URL associated with the `LinkManager` object using the `update_url` method, which also updates the underlying `UrlManager`, `SafeRequest`, and `SoupManager`:
```python
link_manager.update_url('https://www.example2.com')
```
### Accessing Extracted Links
The `LinkManager` class provides easy access to extracted links and associated data:
```python
all_links = link_manager.all_desired_links
```
### Customizing Link Extraction
You can customize the link extraction behavior by specifying various parameters during initialization or updating them:
```python
link_manager.update_desired(
img_attr_value_desired=['thumbnail', 'image'],
img_attr_value_undesired=['icon'],
link_attr_value_desired=['blog', 'article'],
link_attr_value_undesired=['archive'],
image_link_tags='img',
img_link_attrs='src',
link_tags='a',
link_attrs='href',
strict_order_tags=True,
associated_data_attr=['data-title', 'alt', 'title'],
get_img=['data-title', 'alt', 'title']
)
```
## Dependencies
The `LinkManager` class relies on other classes within the `abstract_webtools` module, such as `UrlManager`, `SafeRequest`, and `SoupManager`. Ensure you have these classes and their dependencies correctly set up in your Python environment.
## Example
Here's a quick example of using the `LinkManager` class:
```python
from abstract_webtools import LinkManager
link_manager = LinkManager(url='https://www.example.com')
all_links = link_manager.all_desired_links
print(f"All Links: {all_links}")
```
##Overall Usecases
```python
from abstract_webtools import UrlManager, SafeRequest, SoupManager, LinkManager, VideoDownloader
# --- UrlManager: Manages and manipulates URLs for web scraping/crawling ---
url = "example.com"
url_manager = UrlManager(url=url)
# --- SafeRequest: Safely handles HTTP requests by managing user-agent, SSL/TLS, proxies, headers, etc. ---
request_manager = SafeRequest(
url_manager=url_manager,
proxies={'8.219.195.47', '8.219.197.111'},
timeout=(3.05, 70)
)
# --- SoupManager: Simplifies web scraping with easy access to BeautifulSoup ---
soup_manager = SoupManager(
url_manager=url_manager,
request_manager=request_manager
)
# --- LinkManager: Extracts and manages links and associated data from HTML source code ---
link_manager = LinkManager(
url_manager=url_manager,
soup_manager=soup_manager,
link_attr_value_desired=['/view_video.php?viewkey='],
link_attr_value_undesired=['phantomjs']
)
# Download videos from provided links (list or string)
video_manager = VideoDownloader(link=link_manager.all_desired_links).download()
# Use them individually, with default dependencies for basic inputs:
standalone_soup = SoupManager(url=url).soup
standalone_links = LinkManager(url=url).all_desired_links
# Updating methods for manager classes
url_1 = 'thedailydialectics.com'
print(f"updating URL to {url_1}")
url_manager.update_url(url=url_1)
request_manager.update_url(url=url_1)
soup_manager.update_url(url=url_1)
link_manager.update_url(url=url_1)
# Updating URL manager references
request_manager.update_url_manager(url_manager=url_manager)
soup_manager.update_url_manager(url_manager=url_manager)
link_manager.update_url_manager(url_manager=url_manager)
# Updating source code for managers
source_code_bytes = request_manager.source_code_bytes
soup_manager.update_source_code(source_code=source_code_bytes)
link_manager.update_source_code(source_code=source_code_bytes)
```
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
#### Module Information
-**Author**: putkoff
-**Author Email**: partners@abstractendeavors.com
-**Github**: https://github.com/AbstractEndeavors/abstract_essentials/tree/main/abstract_webtools
-**PYPI**: https://pypi.org/project/abstract-webtools
-**Part of**: abstract_essentials
-**Date**: 10/10/2023
-**Version**: 0.1.4.54
| text/markdown | putkoff | partners@abstractendeavors.com | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11"
] | [] | https://github.com/AbstractEndeavors/abstract_webtools | null | >=3.8 | [] | [] | [] | [
"requests>=2.31.0",
"urllib3>=2.0.4",
"beautifulsoup4>=4.12.0",
"PySimpleGUI>=4.60.5; extra == \"gui\"",
"PyQt5>=5.15.0; extra == \"gui\"",
"selenium>=4.15.2; extra == \"drivers\"",
"webdriver-manager>=4.0.0; extra == \"drivers\"",
"yt-dlp>=2024.4.9; extra == \"media\"",
"m3u8>=4.0.0; extra == \"med... | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.9 | 2026-02-19T08:26:27.362982 | abstract_webtools-0.1.6.393.tar.gz | 113,062 | f8/15/4fadd4dde189a35421b4be6fc2a04abbba5278aa0b06219a2cf821e197b4/abstract_webtools-0.1.6.393.tar.gz | source | sdist | null | false | 506c3ca3b4cb3e35d18c21453d0aa167 | cbe0eab17e1b30ea19e97e4ecbb0996dd8df7250629b1ff1a4de9a31f592bfc1 | f8154fadd4dde189a35421b4be6fc2a04abbba5278aa0b06219a2cf821e197b4 | null | [] | 305 |
2.4 | mlx-graphs | 0.0.9 | Graph Neural Network library made for Apple Silicon | 
______________________________________________________________________
**[Documentation](https://mlx-graphs.github.io/mlx-graphs/)** | **[Quickstart](https://mlx-graphs.github.io/mlx-graphs/tutorials/quickstart.html)** | **[Discord](https://discord.gg/K3mWFCxxM7)**
MLX-graphs is a library for Graph Neural Networks (GNNs) built upon Apple's [MLX](https://github.com/ml-explore/mlx).
## Features
- **Fast GNN training and inference on Apple Silicon**
``mlx-graphs`` has been designed to run GNNs and graph algorithms *fast* on Apple Silicon chips. All GNN operations
fully leverage the GPU and CPU hardware of Macs thanks to the efficient low-level primitives
available within the MLX core library. Initial benchmarks show an up to 10x speed improvement
with respect to other frameworks on large datasets.
- **Scalability to large graphs**
With unified memory architecture, objects live in a shared memory accessible by both the CPU and GPU.
This setup allows Macs to leverage their entire memory capacity for storing graphs.
Consequently, Macs equipped with substantial memory can efficiently train GNNs on large graphs, spanning tens of gigabytes, directly using the Mac's GPU.
- **Multi-device**
Unified memory eliminates the need for time-consuming device-to-device transfers.
This architecture also enables specific operations to be run explicitly on either the CPU or GPU without incurring any overhead, facilitating more efficient computation and resource utilization.
## Installation
`mlx-graphs` is available on Pypi. To install run
```
pip install mlx-graphs
```
### Build from source
To build and install `mlx-graphs` from source start by cloning the github repo
```
git clone git@github.com:mlx-graphs/mlx-graphs.git && cd mlx-graphs
```
Create a new virtual environment and install the requirements
```
pip install -e .
```
## Usage
### Tutorial guides
We provide some notebooks to practice `mlx-graphs`.
- Quickstart guide: [notebook](https://mlx-graphs.github.io/mlx-graphs/tutorials/quickstart.html)
- Graph classification guide: [notebook](https://mlx-graphs.github.io/mlx-graphs/tutorials/graph_classification.html)
### Example
This library has been designed to build GNNs with ease and efficiency. Building new GNN layers is straightforward by implementing the `MessagePassing` class. This approach ensures that all operations related to message passing are properly handled and processed efficiently on your Mac's GPU. As a result, you can focus exclusively on the GNN logic, without worrying about the underlying message passing mechanics.
Here is an example of a custom [GraphSAGE](https://proceedings.neurips.cc/paper_files/paper/2017/file/5dd9db5e033da9c6fb5ba83c7a7ebea9-Paper.pdf) convolutional layer that considers edge weights:
```python
import mlx.core as mx
from mlx_graphs.nn.linear import Linear
from mlx_graphs.nn.message_passing import MessagePassing
class SAGEConv(MessagePassing):
def __init__(
self, node_features_dim: int, out_features_dim: int, bias: bool = True, **kwargs
):
super(SAGEConv, self).__init__(aggr="mean", **kwargs)
self.node_features_dim = node_features_dim
self.out_features_dim = out_features_dim
self.neigh_proj = Linear(node_features_dim, out_features_dim, bias=False)
self.self_proj = Linear(node_features_dim, out_features_dim, bias=bias)
def __call__(self, edge_index: mx.array, node_features: mx.array, edge_weights: mx.array) -> mx.array:
"""Forward layer of the custom SAGE layer."""
neigh_features = self.propagate( # Message passing directly on GPU
edge_index=edge_index,
node_features=node_features,
message_kwargs={"edge_weights": edge_weights},
)
neigh_features = self.neigh_proj(neigh_features)
out_features = self.self_proj(node_features) + neigh_features
return out_features
def message(self, src_features: mx.array, dst_features: mx.array, **kwargs) -> mx.array:
"""Message function called by propagate(). Computes messages for all edges in the graph."""
edge_weights = kwargs.get("edge_weights", None)
return edge_weights.reshape(-1, 1) * src_features
```
## Contributing
### Why contributing?
We are at an early stage of the development of the lib, which means your contributions can have a large impact!
Everyone is welcome to contribute, just open an issue 📝 with your idea 💡 and we'll work together on the implementation ✨.
> [!NOTE]
> Contributions such as the implementation of new layers and datasets would be very valuable for the library.
### Installing test, dev, benchmaks, docs dependencies
Extra dependencies are specified in the `pyproject.toml`.
To install those required for testing, development and building documentation, you can run any of the following
```
pip install -e '.[test]'
pip install -e '.[dev]'
pip install -e '.[benchmarks]'
pip install -e '.[docs]'
```
For dev purposes you may want to install the current version of `mlx` via `pip install git+https://github.com/ml-explore/mlx.git`
### Testing
We encourage to write tests for all components.
Please run `pytest` to ensure breaking changes are not introduced.
> Note: CI is in place to automatically run tests upon opening a PR.
### Pre-commit hooks (optional)
To ensure code quality you can run [pre-commit](https://pre-commit.com) hooks. Simply install them by running
```
pre-commit install
```
and run via `pre-commit run --all-files`.
> Note: CI is in place to verify code quality, so pull requests that don't meet those requirements won't pass CI tests.
## Why running GNNs on my Mac?
Other frameworks like PyG and DGL also benefit from efficient GNN operations parallelized on GPU. However, they are not fully optimized to leverage the Mac's GPU capabilities, often defaulting to CPU execution.
In contrast, `mlx-graphs` is specifically designed to leverage the power of Mac's hardware, delivering optimal performance for Mac users. By taking advantage of Apple Silicon, `mlx-graphs` enables accelerated GPU computation and benefits from unified memory. This approach removes the need for data transfers between devices and allows for the use of the entire memory space available on the Mac's GPU. Consequently, users can manage large graphs directly on the GPU, enhancing performance and efficiency.
| text/markdown | mlx-graphs contributors | null | null | null | MIT License
Copyright © 2024 mlx-graphs contributors.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: MacOS",
"Programming Language :: Python"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"mlx>=0.18; sys_platform == \"darwin\"",
"numpy>=1.26.3",
"requests==2.31.0",
"fsspec==2024.2.0",
"tqdm==4.66.1",
"mlx_cluster>=0.0.5",
"pre-commit==3.6.0; extra == \"dev\"",
"pytest==7.4.4; extra == \"test\"",
"scipy==1.12.0; extra == \"test\"",
"networkx==3.2.1; extra == \"test\"",
"torch==2.2... | [] | [] | [] | [
"Homepage, https://mlx-graphs.github.io/mlx-graphs/",
"Documentation, https://mlx-graphs.github.io/mlx-graphs/",
"Repository, https://github.com/mlx-graphs/mlx-graphs",
"Issues, https://github.com/mlx-graphs/mlx-graphs/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:25:46.956328 | mlx_graphs-0.0.9.tar.gz | 63,604 | 6b/72/0f896e44bda2e6a79e00d3ce2b8ed6586291593c6f8acc36dcf3cd3d9665/mlx_graphs-0.0.9.tar.gz | source | sdist | null | false | 981f39f44f3a3829ea310fb618a69025 | 13a5b44c97b364c3bcb215f51dc42a88fecfe478bc779ad704451564734e563f | 6b720f896e44bda2e6a79e00d3ce2b8ed6586291593c6f8acc36dcf3cd3d9665 | null | [
"LICENSE"
] | 265 |
2.4 | revo-module-installer | 0.3.4 | CLI for installing RevoData modules | # Revo Modules
Revo Modules is a CLI for discovering and installing module bundles from a
registry.
## Setup
Install the CLI with uv (recommended) or pip.
```bash
uv tool install revo-module-installer
```
```bash
pip install revo-module-installer
```
## Usage
```bash
revo --help
```
Search and install a module interactively (the default command lists module
names and descriptions, then installs the selected entry).
```bash
revo
```
List modules from the default registry repository.
```bash
revo modules list --show-description
```
Install a specific module ID into your current workspace.
```bash
revo modules install example-module
```
Preview the actions without writing files.
```bash
revo modules install example-module --dry-run
```
## Registry sources
The default registry URL is
`https://github.com/revodatanl/revo-module-registry`. You can override it with
the `REVO_MODULES_REGISTRY_URL` environment variable or a user config file.
Create a config file at `~/.config/revo-modules/config.toml` (Linux/macOS) or
`%APPDATA%\\revo-modules\\config.toml` (Windows) with:
```toml
[registry]
url = "https://github.com/revodatanl/revo-module-registry"
```
Registry URLs can point to:
- GitHub repositories, which are resolved to raw registry files.
- Direct HTTP(S) URLs to registry YAML files.
- Local files via `file://` URLs or file paths.
- Bundled package examples via `package://example_registry.yml`.
Manifest URLs support the same URL forms. GitHub blob URLs are automatically
converted to raw content URLs.
### Local registry fallback for tests
For testing purposes, set the environment variable below to use the bundled
example registry:
```bash
export REVO_MODULES_ENV=test
```
When `REVO_MODULES_ENV` is set to `test`, the CLI uses the bundled registry
regardless of whether the remote registry is reachable.
The bundled registry entry points to `package://example_manifest.yml`, so the
example manifest stays self-contained for offline testing.
## Platform support
All code changes must continue to work on Linux, macOS, and Windows. Ensure
tests and tooling remain green across all three platforms.
## Contributing
For contributor-focused guidelines, setup and development workflows,
see [CONTRIBUTING.md](CONTRIBUTING.md).
| text/markdown | RevoData NL | null | null | null | MIT | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"gitpython>=3.1.43",
"httpx>=0.27.0",
"pathspec>=0.12.1",
"platformdirs>=4.2.2",
"prompt-toolkit>=3.0.43",
"pydantic>=2.7.0",
"rich>=13.7.1",
"ruamel-yaml>=0.18.6",
"typer>=0.12.3",
"commitizen>=4.12.1; extra == \"dev\"",
"pre-commit-hooks>=6.0.0; extra == \"dev\"",
"prek==0.3.0; extra == \"de... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:25:40.862547 | revo_module_installer-0.3.4.tar.gz | 15,014 | 1f/a4/45921b9660a7780326f55fe8f2e36dcc0d4d4f5885baa7a5348c8891bc31/revo_module_installer-0.3.4.tar.gz | source | sdist | null | false | f8aa14a28293076fae78285f38e8ec9e | 10099a03d9dcb177f2ab4637d70c4202e8b982c7b159613b56a9bd13f6700bc8 | 1fa445921b9660a7780326f55fe8f2e36dcc0d4d4f5885baa7a5348c8891bc31 | null | [] | 249 |
2.4 | pyjallib | 0.2.2 | A utility library for 3D game character development pipelines. | # pyjallib
pyjallib Package is a Python library designed to streamline the game character development pipeline. It provides tools and utilities to assist game developers in creating, managing, and optimizing character assets.
## Features
- Character asset management
- Pipeline automation tools
- Asset optimization utilities
- Easy integration with common game engines
## Installation
```bash
pip install pyjallib
```
## Documentation
For detailed documentation, please visit our wiki page.
## License
This project is licensed under the MIT License - see the LICENSE file for details. | text/markdown | null | Dongseok Kim <jalnagakds@naver.com> | null | null | null | 3dsmax, character, game, pipeline, unreal | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"loguru>=0.7.3",
"p4python>=2024.2.2682690"
] | [] | [] | [] | [
"Homepage, https://github.com/jalnaga/PyJalLib",
"Repository, https://github.com/jalnaga/PyJalLib",
"Issues, https://github.com/jalnaga/PyJalLib/issues"
] | uv/0.8.14 | 2026-02-19T08:25:14.337324 | pyjallib-0.2.2.tar.gz | 1,067,123 | 84/d9/d05ed3d9bc4520863f262a09817573cfaa179d575cb33e9a58776fdd2696/pyjallib-0.2.2.tar.gz | source | sdist | null | false | fd84e7c4b4038a23529eb99fad9c995c | bed2ae25af0b392dd93d867e99ce00552de1a57f40c45d9008121a2c35554259 | 84d9d05ed3d9bc4520863f262a09817573cfaa179d575cb33e9a58776fdd2696 | MIT | [
"LICENSE"
] | 253 |
2.4 | prophet-events-runtime | 0.5.0 | Shared Prophet event publisher runtime | <p align="center">
<img src="https://raw.githubusercontent.com/Chainso/prophet/main/brand/exports/logo-horizontal-color.png" alt="Prophet logo" />
</p>
---
# prophet-events-runtime
`prophet-events-runtime` is the shared Python runtime contract used by Prophet-generated action services.
Main project repository:
- https://github.com/Chainso/prophet
It defines:
- an async `EventPublisher` protocol
- a canonical `EventWireEnvelope` dataclass
- `TransitionValidationResult` for generated transition-validator hooks
- utility helpers (`create_event_id`, `now_iso`)
- sync bridge helpers (`publish_sync`, `publish_batch_sync`)
- a `NoOpEventPublisher` for local wiring and tests
## Install
```bash
python3 -m pip install prophet-events-runtime
```
## API
```python
from typing import Iterable, Protocol
class EventPublisher(Protocol):
async def publish(self, envelope: EventWireEnvelope) -> None: ...
async def publish_batch(self, envelopes: Iterable[EventWireEnvelope]) -> None: ...
```
```python
from dataclasses import dataclass
from typing import Dict, List, Optional
@dataclass(kw_only=True)
class EventWireEnvelope:
event_id: str
trace_id: str
event_type: str
schema_version: str
occurred_at: str
source: str
payload: Dict[str, object]
attributes: Optional[Dict[str, str]] = None
updated_objects: Optional[List[Dict[str, object]]] = None
```
Exports:
- `EventPublisher`
- `EventWireEnvelope`
- `NoOpEventPublisher`
- `create_event_id()`
- `now_iso()`
- `publish_sync(publisher, envelope)`
- `publish_batch_sync(publisher, envelopes)`
- `TransitionValidationResult`
## Implement a Platform Publisher
```python
from __future__ import annotations
from typing import Iterable
from prophet_events_runtime import EventPublisher
from prophet_events_runtime import EventWireEnvelope
class PlatformClient:
async def send_event(self, payload: dict) -> None: ...
async def send_events(self, payloads: list[dict]) -> None: ...
class PlatformEventPublisher(EventPublisher):
def __init__(self, client: PlatformClient) -> None:
self._client = client
async def publish(self, envelope: EventWireEnvelope) -> None:
await self._client.send_event(envelope.__dict__)
async def publish_batch(self, envelopes: Iterable[EventWireEnvelope]) -> None:
await self._client.send_events([envelope.__dict__ for envelope in envelopes])
```
## With Prophet-Generated Code
Generated Python action services publish event wire envelopes after successful handler execution.
If you do not provide an implementation, you can wire `NoOpEventPublisher` for local development.
## Local Validation
From repository root:
```bash
PYTHONPATH=prophet-lib/python/src python3 -m unittest discover -s prophet-lib/python/tests -p 'test_*.py' -v
python3 -m pip install --upgrade build twine
python3 -m build prophet-lib/python
python3 -m twine check prophet-lib/python/dist/*
```
## More Information
- Main repository README: https://github.com/Chainso/prophet#readme
- Runtime index: https://github.com/Chainso/prophet/tree/main/prophet-lib
- Event wire contract: https://github.com/Chainso/prophet/tree/main/prophet-lib/specs/wire-contract.md
- Event wire JSON schema: https://github.com/Chainso/prophet/tree/main/prophet-lib/specs/wire-event-envelope.schema.json
- Python integration reference: https://github.com/Chainso/prophet/tree/main/docs/reference/python.md
- Example app: https://github.com/Chainso/prophet/tree/main/examples/python/prophet_example_fastapi_sqlalchemy
| text/markdown | Prophet | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:25:04.061882 | prophet_events_runtime-0.5.0.tar.gz | 3,546 | f6/33/98a96e3ff1d7c292bc6ef85f0f87bcf78551e6498984542d73c7b530c380/prophet_events_runtime-0.5.0.tar.gz | source | sdist | null | false | 94934dc71e322d9304108139a045f16f | 52f0658a51e44580aa7de03e9f1bad86ee0d0ee9abaef93a78795bf0447984ee | f63398a96e3ff1d7c292bc6ef85f0f87bcf78551e6498984542d73c7b530c380 | null | [] | 258 |
2.4 | detectree | 0.9.1 | Tree detection from aerial imagery in Python. | [](https://pypi.python.org/pypi/detectree/)
[](https://anaconda.org/conda-forge/detectree)
[](https://detectree.readthedocs.io/en/latest/?badge=latest)
[](https://github.com/martibosch/detectree/blob/main/.github/workflows/tests.yml)
[](https://results.pre-commit.ci/latest/github/martibosch/detectree/main)
[](https://codecov.io/gh/martibosch/detectree)
[](https://github.com/martibosch/detectree/blob/master/LICENSE)
[](https://doi.org/10.21105/joss.02172)
[](https://doi.org/10.5281/zenodo.3908338)
# DetecTree
## Overview
DetecTree is a Pythonic library to perform semantic segmentation of aerial imagery into tree/non-tree pixels, following the methods of Yang et al. [1]. A pre-trained model is available at [Hugging Face hub](https://huggingface.co/martibosch/detectree), which can be used as follows:
```python
from urllib import request
import detectree as dtr
import matplotlib.pyplot as plt
import rasterio as rio
from rasterio import plot
# download a tile from the SWISSIMAGE WMS
tile_url = (
"https://wms.geo.admin.ch/?SERVICE=WMS&REQUEST=GetMap&VERSION=1.3.0&"
"FORMAT=image/png&LAYERS=ch.swisstopo.images-swissimage&CRS=EPSG:2056"
"&BBOX=2532980,1152150,2533380,1152450&WIDTH=800&HEIGHT=600"
)
tile_filename = "tile.png"
request.urlretrieve(tile_url, tile_filename)
# use the pre-trained model to segment the image into tree/non-tree-pixels
y_pred = dtr.Classifier().predict_img(tile_filename)
# side-by-side plot of the tile and the predicted tree/non-tree pixels
figwidth, figheight = plt.rcParams["figure.figsize"]
fig, axes = plt.subplots(1, 2, figsize=(2 * figwidth, figheight))
with rio.open(tile_filename) as src:
plot.show(src, ax=axes[0])
axes[1].imshow(y_pred)
```

Alternatively, you can use detectree to train your own model on your aerial imagery dataset:
```python
import detectree as dtr
import matplotlib.pyplot as plt
import rasterio as rio
from rasterio import plot
# select the training tiles from the tiled aerial imagery dataset
ts = dtr.TrainingSelector(img_dir='data/tiles')
split_df = ts.train_test_split(method='cluster-I')
# train a tree/non-tree pixel classifier
clf = dtr.ClassifierTrainer().train_classifier(
split_df=split_df, response_img_dir='data/response_tiles')
# use the trained classifier to predict the tree/non-tree pixels
test_filepath = split_df[~split_df['train'].sample(1).iloc[0]['img_filepath']
y_pred = dtr.Classifier(clf=clf).classify_img(test_filepath)
# side-by-side plot of the tile and the predicted tree/non-tree pixels
figwidth, figheight = plt.rcParams['figure.figsize']
fig, axes = plt.subplots(1, 2, figsize=(2 * figwidth, figheight))
with rio.open(img_filepath) as src:
plot.show(src.read(), ax=axes[0])
axes[1].imshow(y_pred)
```

A full example application of DetecTree to predict a tree canopy map for the Aussersihl district in Zurich [is available as a Jupyter notebook](https://github.com/martibosch/detectree-examples/blob/main/notebooks/aussersihl-canopy.ipynb). See also [the API reference documentation](https://detectree.readthedocs.io/en/latest/?badge=latest) and the [examples repository](https://github.com/martibosch/detectree-examples) for more information on the background and some example notebooks.
The target audience is researchers and practitioners in GIS that are interested in two-dimensional aspects of trees, such as their proportional abundance and spatial distribution throughout a region of study. These measurements can be used to assess important aspects of urban planning such as the provision of urban ecosystem services. The approach is of special relevance when LIDAR data is not available or it is too costly in monetary or computational terms.
## Citation
Bosch M. 2020. “DetecTree: Tree detection from aerial imagery in Python”. *Journal of Open Source Software, 5(50), 2172.* [doi.org/10.21105/joss.02172](https://doi.org/10.21105/joss.02172)
Note that DetecTree is based on the methods of Yang et al. [1], therefore it seems fair to reference their work too. An example citation in an academic paper might read as follows:
> The classification of tree pixels has been performed with the Python library DetecTree (Bosch, 2020), which is based on the approach of Yang et al. (2009).
## Installation
### With conda
The easiest way to install `detectree` is with conda as in:
```bash
conda install -c conda-forge detectree
```
### With pip
You can install `detectree` with pip as in:
```bash
pip install detectree
```
If you want to be able to read compressed LAZ files, you will need [the Python bindings for `laszip`](https://github.com/tmontaigu/laszip-python). Note that the latter require \[`laszip`\], which can be installed using conda (which is automatically handled when installing `detectree` with conda as shown above) or downloaded from [laszip.org](https://laszip.org/). Then, detectree and the Python bindings for `laszip` can be installed with pip as in:
```bash
pip install detectree[laszip]
```
### Development install
To install a development version of detectree, you can first use conda to create an environment with all the dependencies - with the [`environment-dev.yml` file](https://github.com/martibosch/detectree/blob/main/environment-dev.yml) - and activate it as in:
```bash
conda env create -f environment-dev.yml
conda activate detectree-dev
```
and then clone the repository and use pip to install it in development mode
```bash
git clone git@github.com:martibosch/detectree.git
cd detectree/
pip install -e .
```
This will also install the dependencies required for running tests, linting the code and building the documentation. Additionally, you can activate [pre-commit](https://pre-commit.com/) so that the latter are run as pre-commit hooks as in:
```bash
pre-commit install
```
## See also
- [lausanne-tree-canopy](https://github.com/martibosch/lausanne-tree-canopy): example computational workflow to get the tree canopy of Lausanne with DetecTree
- [A video of a talk about DetecTree](https://www.youtube.com/watch?v=USwF2KyxVjY) in the [Applied Machine Learning Days of EPFL (2020)](https://appliedmldays.org/) and [its respective slides](https://martibosch.github.io/detectree-amld-2020)
## Acknowledgments
- With the support of the École Polytechnique Fédérale de Lausanne (EPFL)
## References
1. Yang, L., Wu, X., Praun, E., & Ma, X. (2009). Tree detection from aerial imagery. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (pp. 131-137). ACM.
| text/markdown | Martí Bosch | Martí Bosch <marti.bosch@epfl.ch> | null | null | null | null | [
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Natural Language :: English",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"... | [] | null | null | >=3.10 | [] | [] | [] | [
"dask[delayed,distributed]",
"huggingface-hub",
"joblib",
"laspy[lazrs]>=2.0.0",
"lightgbm",
"numpy>=1.15",
"opencv-python>=4.0.0",
"pandas>=0.23",
"pymaxflow>=1.0.0",
"rasterio>=1.0.0",
"scikit-image>=0.25.0",
"scikit-learn",
"scipy>=1.0.0",
"skops",
"shapely",
"tqdm",
"build; extra... | [] | [] | [] | [
"Repository, https://github.com/martibosch/detectree"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T08:24:44.395333 | detectree-0.9.1.tar.gz | 48,288 | ba/fc/73d3a0fd69fc31e6d390bb3ecc2f001ec83d22cfa9e131bd54186b43b9bb/detectree-0.9.1.tar.gz | source | sdist | null | false | 26b71a5f30c32d3b1e1b2873ada0581a | 720cd5e0d28850b8dc1ed950b14ad6d89cd0921feab7e0c05cab6c36fa93fab6 | bafc73d3a0fd69fc31e6d390bb3ecc2f001ec83d22cfa9e131bd54186b43b9bb | GPL-3.0-or-later | [
"LICENSE"
] | 331 |
2.4 | pylasr | 0.17.4 | Python bindings for LASR library - Fast Airborne LiDAR Data Processing | # LASR Python Bindings
Python bindings for the LASR (pronounced "laser") library - a high-performance LiDAR point cloud processing library.
## Overview
The LASR Python bindings provide a clean, Pythonic interface to the powerful LASR C++ library for processing large-scale LiDAR point clouds. The API closely mirrors the R API, ensuring consistency across language bindings.
## Features
- **High Performance**: Direct bindings to optimized C++ code
- **Complete API Coverage**: All LASR stages and operations available
- **Pythonic Interface**: Natural Python syntax with operator overloading
- **Pipeline Processing**: Chain operations for efficient processing
- **Multi-threading Support**: Leverage multiple cores for processing
- **Memory Efficient**: Minimal memory overhead through C++ backend
- **Rich Results**: Access detailed stage outputs and processing statistics
- **Structured Error Handling**: Comprehensive error information and debugging
- **Flexible Input Paths**: Pass a directory/catalog or an iterable of path-like objects; only .las/.laz files are used
## Installation
### Prerequisites
- Python 3.9+
- pybind11
- C++17 compatible compiler
- GDAL (>= 2.2.3)
- GEOS (>= 3.4.0)
- PROJ (>= 4.9.3)
### Build from Source
```bash
cd python
pip install -e .
```
or using setuptools directly:
```bash
cd python
python setup.py build_ext --inplace
```
## Quick Start
```python
import pylasr
# Create a simple processing pipeline
pipeline = (pylasr.info() +
pylasr.classify_with_sor(k=10) +
pylasr.delete_points(["Classification == 18"]) +
pylasr.write_las("cleaned.las"))
# Set processing options
pipeline.set_concurrent_points_strategy(4)
pipeline.set_progress(True)
# Execute pipeline (returns rich results)
files = ["input.las", "input2.las"]
result = pipeline.execute(files)
```
## API Structure
### Core Classes
#### `Pipeline`
Container for multiple stages with execution management.
```python
# Create empty pipeline
pipeline = pylasr.Pipeline()
# Add stages
pipeline += pylasr.info()
pipeline += pylasr.classify_with_sor()
# Set processing strategy
pipeline.set_concurrent_files_strategy(2)
# Execute pipeline
result = pipeline.execute(["file1.las", "file2.las"])
```
### Processing Strategies
LASR supports different parallelization strategies:
```python
# Sequential processing
pipeline.set_sequential_strategy()
# Concurrent points (single file, multiple cores)
pipeline.set_concurrent_points_strategy(ncores=4)
# Concurrent files (multiple files, single core each)
pipeline.set_concurrent_files_strategy(ncores=2)
# Nested strategy (multiple files, multiple cores each)
pipeline.set_nested_strategy(ncores1=2, ncores2=4)
```
## Available Stages
### Input/Reading
- `reader()` - Basic point cloud reader
- `reader_coverage()` - Read points from coverage area
- `reader_circles()` - Read points within circular areas
- `reader_rectangles()` - Read points within rectangular areas
### Classification & Filtering
- `classify_with_sor()` - Statistical Outlier Removal classification
- `classify_with_ivf()` - Isolated Voxel Filter classification
- `classify_with_csf()` - Cloth Simulation Filter (ground classification)
- `delete_points()` - Remove points by filter criteria
- `delete_noise()` - Remove noise points (convenience function)
- `delete_ground()` - Remove ground points (convenience function)
- `filter_with_grid()` - Grid-based point filtering
### Point Operations & Attributes
- `edit_attribute()` - Modify point attribute values
- `add_extrabytes()` - Add custom attributes to points
- `add_rgb()` - Add RGB color information
- `remove_attribute()` - Remove attributes from points
- `sort_points()` - Sort points spatially for better performance
- `transform_with()` - Transform points using raster operations
### Sampling & Decimation
- `sampling_voxel()` - Voxel-based point sampling
- `sampling_pixel()` - Pixel-based point sampling
- `sampling_poisson()` - Poisson disk sampling for uniform distribution
### Rasterization & Gridding
- `rasterize()` - Convert points to raster grids (DTM, DSM, CHM, etc.)
- `rasterize_triangulation()` - Rasterize triangulated surfaces
- `focal()` - Apply focal operations on rasters
- `pit_fill()` - Fill pits in canopy height models
### Geometric Analysis & Features
- `geometry_features()` - Compute geometric features (eigenvalues, etc.)
- `local_maximum()` - Find local maxima in point clouds
- `local_maximum_raster()` - Find local maxima in rasters (tree detection)
- `triangulate()` - Delaunay triangulation of points
- `hulls()` - Compute convex hulls
### Segmentation & Tree Detection
- `region_growing()` - Region growing segmentation for tree detection
### Data Loading & Transformation
- `load_raster()` - Load external raster data
- `load_matrix()` - Load transformation matrices
### I/O Operations
- `write_las()` - Write LAS/LAZ files
- `write_copc()` - Write Cloud Optimized Point Cloud files
- `write_pcd()` - Write Point Cloud Data files
- `write_vpc()` - Write Virtual Point Cloud catalogs
- `write_lax()` - Write spatial index files
### Coordinate Systems
- `set_crs()` - Set coordinate reference system
### Information & Analysis
- `info()` - Get point cloud information and statistics
- `summarise()` - Generate summary statistics
### Utility & Development
- `callback()` - Custom callback functions for advanced processing
- `nothing()` - No-operation stage for debugging
- `stop_if_outside()` - Stop processing if outside bounds
- `stop_if_chunk_id_below()` - Conditional processing based on chunk ID
## Comparison with R API
The Python API closely mirrors the R API structure:
| R | Python |
|---|--------|
| `exec(pipeline, on = files)` | `pipeline.execute(files)` |
| `pipeline + stage` | `pipeline + stage` |
| `with = list(ncores = 4)` | `pipeline.set_concurrent_points_strategy(4)` |
| `filter = "Z > 10"` | `filter = ["Z > 10"]` |
## Contributing
See the main LASR repository for contribution guidelines.
## License
GPL-3 - see LICENSE file for details.
## Links
- [Main LASR Repository](https://github.com/r-lidar/lasR)
- [LASR Documentation](https://r-lidar.github.io/lasR/)
- [Issue Tracker](https://github.com/r-lidar/lasR/issues)
| text/markdown | null | Jean-Romain Roussel <info@r-lidar.com>, Alexey Grigoryev <agrigoriev@gmail.com>, Kirill Semenov <ksemchh@gmail.com> | null | null | GPL-3.0 | lidar, point cloud, gis, remote sensing, airborne laser scanning | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python ... | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/r-lidar/lasR",
"Bug Tracker, https://github.com/r-lidar/lasR/issues",
"Documentation, https://r-lidar.github.io/lasR/",
"Source Code, https://github.com/r-lidar/lasR"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T08:22:37.014055 | pylasr-0.17.4-cp313-cp313-manylinux_2_39_x86_64.whl | 56,114,698 | 80/9e/43a7ce9c6ea81aa1cd1bae990797ceddd40a9bba8f88227dacb39a7fdbec/pylasr-0.17.4-cp313-cp313-manylinux_2_39_x86_64.whl | cp313 | bdist_wheel | null | false | 42aeb490b08c7538613695474b89fe52 | f9e20466528eb1c5de31f57bcf875216b94260e3fba5cd03fb16351941740e2c | 809e43a7ce9c6ea81aa1cd1bae990797ceddd40a9bba8f88227dacb39a7fdbec | null | [] | 362 |
2.4 | databricks-sdk | 0.91.0 | Databricks SDK for Python (Beta) | # Databricks SDK for Python (Beta)
[](https://pypistats.org/packages/databricks-sdk)
[](https://github.com/databricks/databricks-sdk-py/blob/main/LICENSE)
[](https://snyk.io/advisor/python/databricks-sdk)

[](https://codecov.io/gh/databricks/databricks-sdk-py)
[]([https://codecov.io/github/databricks/databricks-sdk-py](https://github.com/databricks/databricks-sdk-py))
[Beta](https://docs.databricks.com/release-notes/release-types.html): This SDK is supported for production use cases,
but we do expect future releases to have some interface changes; see [Interface stability](#interface-stability).
We are keen to hear feedback from you on these SDKs. Please [file issues](https://github.com/databricks/databricks-sdk-py/issues), and we will address them.
| See also the [SDK for Java](https://github.com/databricks/databricks-sdk-java)
| See also the [SDK for Go](https://github.com/databricks/databricks-sdk-go)
| See also the [Terraform Provider](https://github.com/databricks/terraform-provider-databricks)
| See also cloud-specific docs ([AWS](https://docs.databricks.com/dev-tools/sdk-python.html),
[Azure](https://learn.microsoft.com/en-us/azure/databricks/dev-tools/sdk-python),
[GCP](https://docs.gcp.databricks.com/dev-tools/sdk-python.html))
| See also the [API reference on readthedocs](https://databricks-sdk-py.readthedocs.io/en/latest/)
The Databricks SDK for Python includes functionality to accelerate development with [Python](https://www.python.org/) for the Databricks Lakehouse.
It covers all public [Databricks REST API](https://docs.databricks.com/dev-tools/api/index.html) operations.
The SDK's internal HTTP client is robust and handles failures on different levels by performing intelligent retries.
## Contents
- [Getting started](#getting-started)
- [Code examples](#code-examples)
- [Authentication](#authentication)
- [Long-running operations](#long-running-operations)
- [Paginated responses](#paginated-responses)
- [Single-sign-on with OAuth](#single-sign-on-sso-with-oauth)
- [User Agent Request Attribution](#user-agent-request-attribution)
- [Error handling](#error-handling)
- [Logging](#logging)
- [Integration with `dbutils`](#interaction-with-dbutils)
- [Interface stability](#interface-stability)
## Getting started<a id="getting-started"></a>
1. Please install Databricks SDK for Python via `pip install databricks-sdk` and instantiate `WorkspaceClient`:
```python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
for c in w.clusters.list():
print(c.cluster_name)
```
Databricks SDK for Python is compatible with Python 3.7 _(until [June 2023](https://devguide.python.org/versions/))_, 3.8, 3.9, 3.10, and 3.11.
**Note:** Databricks Runtime starting from version 13.1 includes a bundled version of the Python SDK.
It is highly recommended to upgrade to the latest version which you can do by running the following in a notebook cell:
```python
%pip install --upgrade databricks-sdk
```
followed by
```python
dbutils.library.restartPython()
```
## Code examples<a id="code-examples"></a>
The Databricks SDK for Python comes with a number of examples demonstrating how to use the library for various common use-cases, including
* [Using the SDK with OAuth from a webserver](https://github.com/databricks/databricks-sdk-py/blob/main/examples/flask_app_with_oauth.py)
* [Using long-running operations](https://github.com/databricks/databricks-sdk-py/blob/main/examples/starting_job_and_waiting.py)
* [Authenticating a client app using OAuth](https://github.com/databricks/databricks-sdk-py/blob/main/examples/local_browser_oauth.py)
These examples and more are located in the [`examples/` directory of the Github repository](https://github.com/databricks/databricks-sdk-py/tree/main/examples).
Some other examples of using the SDK include:
* [Unity Catalog Automated Migration](https://github.com/databricks/ucx) heavily relies on Python SDK for working with Databricks APIs.
* [ip-access-list-analyzer](https://github.com/alexott/databricks-playground/tree/main/ip-access-list-analyzer) checks & prunes invalid entries from IP Access Lists.
## Authentication<a id="authentication"></a>
If you use Databricks [configuration profiles](https://docs.databricks.com/dev-tools/auth.html#configuration-profiles)
or Databricks-specific [environment variables](https://docs.databricks.com/dev-tools/auth.html#environment-variables)
for [Databricks authentication](https://docs.databricks.com/dev-tools/auth.html), the only code required to start
working with a Databricks workspace is the following code snippet, which instructs the Databricks SDK for Python to use
its [default authentication flow](#default-authentication-flow):
```python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
w. # press <TAB> for autocompletion
```
The conventional name for the variable that holds the workspace-level client of the Databricks SDK for Python is `w`, which is shorthand for `workspace`.
### In this section
- [Default authentication flow](#default-authentication-flow)
- [Databricks native authentication](#databricks-native-authentication)
- [Azure native authentication](#azure-native-authentication)
- [Overriding .databrickscfg](#overriding-databrickscfg)
- [Additional authentication configuration options](#additional-authentication-configuration-options)
### Default authentication flow
If you run the [Databricks Terraform Provider](https://registry.terraform.io/providers/databrickslabs/databricks/latest),
the [Databricks SDK for Go](https://github.com/databricks/databricks-sdk-go), the [Databricks CLI](https://docs.databricks.com/dev-tools/cli/index.html),
or applications that target the Databricks SDKs for other languages, most likely they will all interoperate nicely together.
By default, the Databricks SDK for Python tries the following [authentication](https://docs.databricks.com/dev-tools/auth.html) methods,
in the following order, until it succeeds:
1. [Databricks native authentication](#databricks-native-authentication)
2. [Azure native authentication](#azure-native-authentication)
4. If the SDK is unsuccessful at this point, it returns an authentication error and stops running.
You can instruct the Databricks SDK for Python to use a specific authentication method by setting the `auth_type` argument
as described in the following sections.
For each authentication method, the SDK searches for compatible authentication credentials in the following locations,
in the following order. Once the SDK finds a compatible set of credentials that it can use, it stops searching:
1. Credentials that are hard-coded into configuration arguments.
:warning: **Caution**: Databricks does not recommend hard-coding credentials into arguments, as they can be exposed in plain text in version control systems. Use environment variables or configuration profiles instead.
2. Credentials in Databricks-specific [environment variables](https://docs.databricks.com/dev-tools/auth.html#environment-variables).
3. For Databricks native authentication, credentials in the `.databrickscfg` file's `DEFAULT` [configuration profile](https://docs.databricks.com/dev-tools/auth.html#configuration-profiles) from its default file location (`~` for Linux or macOS, and `%USERPROFILE%` for Windows).
4. For Azure native authentication, the SDK searches for credentials through the Azure CLI as needed.
Depending on the Databricks authentication method, the SDK uses the following information. Presented are the `WorkspaceClient` and `AccountClient` arguments (which have corresponding `.databrickscfg` file fields), their descriptions, and any corresponding environment variables.
### Databricks native authentication
By default, the Databricks SDK for Python initially tries [Databricks token authentication](https://docs.databricks.com/dev-tools/api/latest/authentication.html) (`auth_type='pat'` argument). If the SDK is unsuccessful, it then tries Workload Identity Federation (WIF). See [Supported WIF](https://docs.databricks.com/aws/en/dev-tools/auth/oauth-federation-provider) for the supported JWT token providers.
- For Databricks token authentication, you must provide `host` and `token`; or their environment variable or `.databrickscfg` file field equivalents.
- For Databricks OIDC authentication, you must provide the `host`, `client_id` and `token_audience` _(optional)_ either directly, through the corresponding environment variables, or in your `.databrickscfg` configuration file.
- For Azure DevOps OIDC authentication, the `token_audience` is irrelevant as the audience is always set to `api://AzureADTokenExchange`. Also, the `System.AccessToken` pipeline variable required for OIDC request must be exposed as the `SYSTEM_ACCESSTOKEN` environment variable, following [Pipeline variables](https://learn.microsoft.com/en-us/azure/devops/pipelines/build/variables?view=azure-devops&tabs=yaml#systemaccesstoken)
| Argument | Description | Environment variable |
|------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------|
| `host` | _(String)_ The Databricks host URL for either the Databricks workspace endpoint or the Databricks accounts endpoint. | `DATABRICKS_HOST` |
| `account_id` | _(String)_ The Databricks account ID for the Databricks accounts endpoint. Only has effect when `Host` is either `https://accounts.cloud.databricks.com/` _(AWS)_, `https://accounts.azuredatabricks.net/` _(Azure)_, or `https://accounts.gcp.databricks.com/` _(GCP)_. | `DATABRICKS_ACCOUNT_ID` |
| `token` | _(String)_ The Databricks personal access token (PAT) _(AWS, Azure, and GCP)_ or Azure Active Directory (Azure AD) token _(Azure)_. | `DATABRICKS_TOKEN` |
| `client_id` | _(String)_ The Databricks Service Principal Application ID. | `DATABRICKS_CLIENT_ID` |
| `token_audience` | _(String)_ When using Workload Identity Federation, the audience to specify when fetching an ID token from the ID token supplier. | `TOKEN_AUDIENCE` |
For example, to use Databricks token authentication:
```python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient(host=input('Databricks Workspace URL: '), token=input('Token: '))
```
### Azure native authentication
By default, the Databricks SDK for Python first tries Azure client secret authentication (`auth_type='azure-client-secret'` argument). If the SDK is unsuccessful, it then tries Azure CLI authentication (`auth_type='azure-cli'` argument). See [Manage service principals](https://learn.microsoft.com/azure/databricks/administration-guide/users-groups/service-principals).
The Databricks SDK for Python picks up an Azure CLI token, if you've previously authenticated as an Azure user by running `az login` on your machine. See [Get Azure AD tokens for users by using the Azure CLI](https://learn.microsoft.com/azure/databricks/dev-tools/api/latest/aad/user-aad-token).
To authenticate as an Azure Active Directory (Azure AD) service principal, you must provide one of the following. See also [Add a service principal to your Azure Databricks account](https://learn.microsoft.com/azure/databricks/administration-guide/users-groups/service-principals#add-sp-account):
- `azure_workspace_resource_id`, `azure_client_secret`, `azure_client_id`, and `azure_tenant_id`; or their environment variable or `.databrickscfg` file field equivalents.
- `azure_workspace_resource_id` and `azure_use_msi`; or their environment variable or `.databrickscfg` file field equivalents.
| Argument | Description | Environment variable |
|-----------------------|-------------|----------------------|
| `azure_workspace_resource_id` | _(String)_ The Azure Resource Manager ID for the Azure Databricks workspace, which is exchanged for a Databricks host URL. | `DATABRICKS_AZURE_RESOURCE_ID` |
| `azure_use_msi` | _(Boolean)_ `true` to use Azure Managed Service Identity passwordless authentication flow for service principals. _This feature is not yet implemented in the Databricks SDK for Python._ | `ARM_USE_MSI` |
| `azure_client_secret` | _(String)_ The Azure AD service principal's client secret. | `ARM_CLIENT_SECRET` |
| `azure_client_id` | _(String)_ The Azure AD service principal's application ID. | `ARM_CLIENT_ID` |
| `azure_tenant_id` | _(String)_ The Azure AD service principal's tenant ID. | `ARM_TENANT_ID` |
| `azure_environment` | _(String)_ The Azure environment type (such as Public, UsGov, China, and Germany) for a specific set of API endpoints. Defaults to `PUBLIC`. | `ARM_ENVIRONMENT` |
For example, to use Azure client secret authentication:
```python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient(host=input('Databricks Workspace URL: '),
azure_workspace_resource_id=input('Azure Resource ID: '),
azure_tenant_id=input('AAD Tenant ID: '),
azure_client_id=input('AAD Client ID: '),
azure_client_secret=input('AAD Client Secret: '))
```
Please see more examples in [this document](./docs/azure-ad.md).
### Google Cloud Platform native authentication
By default, the Databricks SDK for Python first tries GCP credentials authentication (`auth_type='google-credentials'`, argument). If the SDK is unsuccessful, it then tries Google Cloud Platform (GCP) ID authentication (`auth_type='google-id'`, argument).
The Databricks SDK for Python picks up an OAuth token in the scope of the Google Default Application Credentials (DAC) flow. This means that if you have run `gcloud auth application-default login` on your development machine, or launch the application on the compute, that is allowed to impersonate the Google Cloud service account specified in `google_service_account`. Authentication should then work out of the box. See [Creating and managing service accounts](https://cloud.google.com/iam/docs/creating-managing-service-accounts).
To authenticate as a Google Cloud service account, you must provide one of the following:
- `host` and `google_credentials`; or their environment variable or `.databrickscfg` file field equivalents.
- `host` and `google_service_account`; or their environment variable or `.databrickscfg` file field equivalents.
| Argument | Description | Environment variable |
|--------------------------|-------------|--------------------------------------------------|
| `google_credentials` | _(String)_ GCP Service Account Credentials JSON or the location of these credentials on the local filesystem. | `GOOGLE_CREDENTIALS` |
| `google_service_account` | _(String)_ The Google Cloud Platform (GCP) service account e-mail used for impersonation in the Default Application Credentials Flow that does not require a password. | `DATABRICKS_GOOGLE_SERVICE_ACCOUNT` |
For example, to use Google ID authentication:
```python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient(host=input('Databricks Workspace URL: '),
google_service_account=input('Google Service Account: '))
```
### Overriding `.databrickscfg`
For [Databricks native authentication](#databricks-native-authentication), you can override the default behavior for using `.databrickscfg` as follows:
| Argument | Description | Environment variable |
|---------------|-------------|----------------------|
| `profile` | _(String)_ A connection profile specified within `.databrickscfg` to use instead of `DEFAULT`. | `DATABRICKS_CONFIG_PROFILE` |
| `config_file` | _(String)_ A non-default location of the Databricks CLI credentials file. | `DATABRICKS_CONFIG_FILE` |
For example, to use a profile named `MYPROFILE` instead of `DEFAULT`:
```python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient(profile='MYPROFILE')
# Now call the Databricks workspace APIs as desired...
```
### Additional authentication configuration options
For all authentication methods, you can override the default behavior in client arguments as follows:
| Argument | Description | Environment variable |
|-------------------------|-------------|------------------------|
| `auth_type` | _(String)_ When multiple auth attributes are available in the environment, use the auth type specified by this argument. This argument also holds the currently selected auth. | `DATABRICKS_AUTH_TYPE` |
| `http_timeout_seconds` | _(Integer)_ Number of seconds for HTTP timeout. Default is _60_. | _(None)_ |
| `retry_timeout_seconds` | _(Integer)_ Number of seconds to keep retrying HTTP requests. Default is _300 (5 minutes)_. | _(None)_ |
| `debug_truncate_bytes` | _(Integer)_ Truncate JSON fields in debug logs above this limit. Default is 96. | `DATABRICKS_DEBUG_TRUNCATE_BYTES` |
| `debug_headers` | _(Boolean)_ `true` to debug HTTP headers of requests made by the application. Default is `false`, as headers contain sensitive data, such as access tokens. | `DATABRICKS_DEBUG_HEADERS` |
| `rate_limit` | _(Integer)_ Maximum number of requests per second made to Databricks REST API. | `DATABRICKS_RATE_LIMIT` |
For example, here's how you can update the overall retry timeout:
```python
from databricks.sdk import WorkspaceClient
from databricks.sdk.core import Config
w = WorkspaceClient(config=Config(retry_timeout_seconds=300))
# Now call the Databricks workspace APIs as desired...
```
## Long-running operations<a id="long-running-operations"></a>
When you invoke a long-running operation, the SDK provides a high-level API to _trigger_ these operations and _wait_ for the related entities
to reach the correct state or return the error message in case of failure. All long-running operations return generic `Wait` instance with `result()`
method to get a result of long-running operation, once it's finished. Databricks SDK for Python picks the most reasonable default timeouts for
every method, but sometimes you may find yourself in a situation, where you'd want to provide `datetime.timedelta()` as the value of `timeout`
argument to `result()` method.
There are a number of long-running operations in Databricks APIs such as managing:
* Clusters,
* Command execution
* Jobs
* Libraries
* Delta Live Tables pipelines
* Databricks SQL warehouses.
For example, in the Clusters API, once you create a cluster, you receive a cluster ID, and the cluster is in the `PENDING` state Meanwhile
Databricks takes care of provisioning virtual machines from the cloud provider in the background. The cluster is
only usable in the `RUNNING` state and so you have to wait for that state to be reached.
Another example is the API for running a job or repairing the run: right after
the run starts, the run is in the `PENDING` state. The job is only considered to be finished when it is in either
the `TERMINATED` or `SKIPPED` state. Also you would likely need the error message if the long-running
operation times out and fails with an error code. Other times you may want to configure a custom timeout other than
the default of 20 minutes.
In the following example, `w.clusters.create` returns `ClusterInfo` only once the cluster is in the `RUNNING` state,
otherwise it will timeout in 10 minutes:
```python
import datetime
import logging
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
info = w.clusters.create_and_wait(cluster_name='Created cluster',
spark_version='12.0.x-scala2.12',
node_type_id='m5d.large',
autotermination_minutes=10,
num_workers=1,
timeout=datetime.timedelta(minutes=10))
logging.info(f'Created: {info}')
```
Please look at the `examples/starting_job_and_waiting.py` for a more advanced usage:
```python
import datetime
import logging
import time
from databricks.sdk import WorkspaceClient
import databricks.sdk.service.jobs as j
w = WorkspaceClient()
# create a dummy file on DBFS that just sleeps for 10 seconds
py_on_dbfs = f'/home/{w.current_user.me().user_name}/sample.py'
with w.dbfs.open(py_on_dbfs, write=True, overwrite=True) as f:
f.write(b'import time; time.sleep(10); print("Hello, World!")')
# trigger one-time-run job and get waiter object
waiter = w.jobs.submit(run_name=f'py-sdk-run-{time.time()}', tasks=[
j.RunSubmitTaskSettings(
task_key='hello_world',
new_cluster=j.BaseClusterInfo(
spark_version=w.clusters.select_spark_version(long_term_support=True),
node_type_id=w.clusters.select_node_type(local_disk=True),
num_workers=1
),
spark_python_task=j.SparkPythonTask(
python_file=f'dbfs:{py_on_dbfs}'
),
)
])
logging.info(f'starting to poll: {waiter.run_id}')
# callback, that receives a polled entity between state updates
def print_status(run: j.Run):
statuses = [f'{t.task_key}: {t.state.life_cycle_state}' for t in run.tasks]
logging.info(f'workflow intermediate status: {", ".join(statuses)}')
# If you want to perform polling in a separate thread, process, or service,
# you can use w.jobs.wait_get_run_job_terminated_or_skipped(
# run_id=waiter.run_id,
# timeout=datetime.timedelta(minutes=15),
# callback=print_status) to achieve the same results.
#
# Waiter interface allows for `w.jobs.submit(..).result()` simplicity in
# the scenarios, where you need to block the calling thread for the job to finish.
run = waiter.result(timeout=datetime.timedelta(minutes=15),
callback=print_status)
logging.info(f'job finished: {run.run_page_url}')
```
## Paginated responses<a id="paginated-responses"></a>
On the platform side the Databricks APIs have different wait to deal with pagination:
* Some APIs follow the offset-plus-limit pagination
* Some start their offsets from 0 and some from 1
* Some use the cursor-based iteration
* Others just return all results in a single response
The Databricks SDK for Python hides this complexity
under `Iterator[T]` abstraction, where multi-page results `yield` items. Python typing helps to auto-complete
the individual item fields.
```python
import logging
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
for repo in w.repos.list():
logging.info(f'Found repo: {repo.path}')
```
Please look at the `examples/last_job_runs.py` for a more advanced usage:
```python
import logging
from collections import defaultdict
from datetime import datetime, timezone
from databricks.sdk import WorkspaceClient
latest_state = {}
all_jobs = {}
durations = defaultdict(list)
w = WorkspaceClient()
for job in w.jobs.list():
all_jobs[job.job_id] = job
for run in w.jobs.list_runs(job_id=job.job_id, expand_tasks=False):
durations[job.job_id].append(run.run_duration)
if job.job_id not in latest_state:
latest_state[job.job_id] = run
continue
if run.end_time < latest_state[job.job_id].end_time:
continue
latest_state[job.job_id] = run
summary = []
for job_id, run in latest_state.items():
summary.append({
'job_name': all_jobs[job_id].settings.name,
'last_status': run.state.result_state,
'last_finished': datetime.fromtimestamp(run.end_time/1000, timezone.utc),
'average_duration': sum(durations[job_id]) / len(durations[job_id])
})
for line in sorted(summary, key=lambda s: s['last_finished'], reverse=True):
logging.info(f'Latest: {line}')
```
## Single-Sign-On (SSO) with OAuth<a id="single-sign-on-sso-with-oauth"></a>
### Authorization Code flow with PKCE
For a regular web app running on a server, it's recommended to use the Authorization Code Flow to obtain an Access Token
and a Refresh Token. This method is considered safe because the Access Token is transmitted directly to the server
hosting the app, without passing through the user's web browser and risking exposure.
To enhance the security of the Authorization Code Flow, the PKCE (Proof Key for Code Exchange) mechanism can be
employed. With PKCE, the calling application generates a secret called the Code Verifier, which is verified by
the authorization server. The app also creates a transform value of the Code Verifier, called the Code Challenge,
and sends it over HTTPS to obtain an Authorization Code. By intercepting the Authorization Code, a malicious attacker
cannot exchange it for a token without possessing the Code Verifier.
The [presented sample](https://github.com/databricks/databricks-sdk-py/blob/main/examples/flask_app_with_oauth.py)
is a Python3 script that uses the Flask web framework along with Databricks SDK for Python to demonstrate how to
implement the OAuth Authorization Code flow with PKCE security. It can be used to build an app where each user uses
their identity to access Databricks resources. The script can be executed with or without client and secret credentials
for a custom OAuth app.
Databricks SDK for Python exposes the `oauth_client.initiate_consent()` helper to acquire user redirect URL and initiate
PKCE state verification. Application developers are expected to persist `RefreshableCredentials` in the webapp session
and restore it via `RefreshableCredentials.from_dict(oauth_client, session['creds'])` helpers.
Works for both AWS and Azure. Not supported for GCP at the moment.
```python
from databricks.sdk.oauth import OAuthClient
oauth_client = OAuthClient(host='<workspace-url>',
client_id='<oauth client ID>',
redirect_url=f'http://host.domain/callback',
scopes=['clusters'])
import secrets
from flask import Flask, render_template_string, request, redirect, url_for, session
APP_NAME = 'flask-demo'
app = Flask(APP_NAME)
app.secret_key = secrets.token_urlsafe(32)
@app.route('/callback')
def callback():
from databricks.sdk.oauth import Consent
consent = Consent.from_dict(oauth_client, session['consent'])
session['creds'] = consent.exchange_callback_parameters(request.args).as_dict()
return redirect(url_for('index'))
@app.route('/')
def index():
if 'creds' not in session:
consent = oauth_client.initiate_consent()
session['consent'] = consent.as_dict()
return redirect(consent.auth_url)
from databricks.sdk import WorkspaceClient
from databricks.sdk.oauth import SessionCredentials
credentials_provider = SessionCredentials.from_dict(oauth_client, session['creds'])
workspace_client = WorkspaceClient(host=oauth_client.host,
product=APP_NAME,
credentials_provider=credentials_provider)
return render_template_string('...', w=workspace_client)
```
### SSO for local scripts on development machines
For applications, that do run on developer workstations, Databricks SDK for Python provides `auth_type='external-browser'`
utility, that opens up a browser for a user to go through SSO flow. Azure support is still in the early experimental
stage.
```python
from databricks.sdk import WorkspaceClient
host = input('Enter Databricks host: ')
w = WorkspaceClient(host=host, auth_type='external-browser')
clusters = w.clusters.list()
for cl in clusters:
print(f' - {cl.cluster_name} is {cl.state}')
```
### Creating custom OAuth applications
In order to use OAuth with Databricks SDK for Python, you should use `account_client.custom_app_integration.create` API.
```python
import logging, getpass
from databricks.sdk import AccountClient
account_client = AccountClient(host='https://accounts.cloud.databricks.com',
account_id=input('Databricks Account ID: '),
username=input('Username: '),
password=getpass.getpass('Password: '))
logging.info('Enrolling all published apps...')
account_client.o_auth_enrollment.create(enable_all_published_apps=True)
status = account_client.o_auth_enrollment.get()
logging.info(f'Enrolled all published apps: {status}')
custom_app = account_client.custom_app_integration.create(
name='awesome-app',
redirect_urls=[f'https://host.domain/path/to/callback'],
confidential=True)
logging.info(f'Created new custom app: '
f'--client_id {custom_app.client_id} '
f'--client_secret {custom_app.client_secret}')
```
## User Agent Request Attribution<a id="user-agent-request-attribution"></a>
The Databricks SDK for Python uses the `User-Agent` header to include request metadata along with each request. By default, this includes the version of the Python SDK, the version of the Python language used by your application, and the underlying operating system. To statically add additional metadata, you can use the `with_partner()` and `with_product()` functions in the `databricks.sdk.useragent` module. `with_partner()` can be used by partners to indicate that code using the Databricks SDK for Go should be attributed to a specific partner. Multiple partners can be registered at once. Partner names can contain any number, digit, `.`, `-`, `_` or `+`.
```python
from databricks.sdk import useragent
useragent.with_product("partner-abc")
useragent.with_partner("partner-xyz")
```
`with_product()` can be used to define the name and version of the product that is built with the Databricks SDK for Python. The product name has the same restrictions as the partner name above, and the product version must be a valid [SemVer](https://semver.org/). Subsequent calls to `with_product()` replace the original product with the new user-specified one.
```go
from databricks.sdk import useragent
useragent.with_product("databricks-example-product", "1.2.0")
```
If both the `DATABRICKS_SDK_UPSTREAM` and `DATABRICKS_SDK_UPSTREAM_VERSION` environment variables are defined, these will also be included in the `User-Agent` header.
If additional metadata needs to be specified that isn't already supported by the above interfaces, you can use the `with_user_agent_extra()` function to register arbitrary key-value pairs to include in the user agent. Multiple values associated with the same key are allowed. Keys have the same restrictions as the partner name above. Values must be either as described above or SemVer strings.
Additional `User-Agent` information can be associated with different instances of `DatabricksConfig`. To add metadata to a specific instance of `DatabricksConfig`, use the `with_user_agent_extra()` method.
## Error handling<a id="error-handling"></a>
The Databricks SDK for Python provides a robust error-handling mechanism that allows developers to catch and handle API errors. When an error occurs, the SDK will raise an exception that contains information about the error, such as the HTTP status code, error message, and error details. Developers can catch these exceptions and handle them appropriately in their code.
```python
from databricks.sdk import WorkspaceClient
from databricks.sdk.errors import ResourceDoesNotExist
w = WorkspaceClient()
try:
w.clusters.get(cluster_id='1234-5678-9012')
except ResourceDoesNotExist as e:
print(f'Cluster not found: {e}')
```
The SDK handles inconsistencies in error responses amongst the different services, providing a consistent interface for developers to work with. Simply catch the appropriate exception type and handle the error as needed. The errors returned by the Databricks API are defined in [databricks/sdk/errors/platform.py](https://github.com/databricks/databricks-sdk-py/blob/main/databricks/sdk/errors/platform.py).
## Logging<a id="logging"></a>
The Databricks SDK for Python seamlessly integrates with the standard [Logging facility for Python](https://docs.python.org/3/library/logging.html).
This allows developers to easily enable and customize logging for their Databricks Python projects.
To enable debug logging in your Databricks Python project, you can follow the example below:
```python
import logging, sys
logging.basicConfig(stream=sys.stderr,
level=logging.INFO,
format='%(asctime)s [%(name)s][%(levelname)s] %(message)s')
logging.getLogger('databricks.sdk').setLevel(logging.DEBUG)
from databricks.sdk import WorkspaceClient
w = WorkspaceClient(debug_truncate_bytes=1024, debug_headers=False)
for cluster in w.clusters.list():
logging.info(f'Found cluster: {cluster.cluster_name}')
```
In the above code snippet, the logging module is imported and the `basicConfig()` method is used to set the logging level to `DEBUG`.
This will enable logging at the debug level and above. Developers can adjust the logging level as needed to control the verbosity of the logging output.
The SDK will log all requests and responses to standard error output, using the format `> ` for requests and `< ` for responses.
In some cases, requests or responses may be truncated due to size considerations. If this occurs, the log message will include
the text `... (XXX additional elements)` to indicate that the request or response has been truncated. To increase the truncation limits,
developers can set the `debug_truncate_bytes` configuration property or the `DATABRICKS_DEBUG_TRUNCATE_BYTES` environment variable.
To protect sensitive data, such as authentication tokens, passwords, or any HTTP headers, the SDK will automatically replace these
values with `**REDACTED**` in the log output. Developers can disable this redaction by setting the `debug_headers` configuration property to `True`.
```text
2023-03-22 21:19:21,702 [databricks.sdk][DEBUG] GET /api/2.0/clusters/list
< 200 OK
< {
< "clusters": [
< {
< "autotermination_minutes": 60,
< "cluster_id": "1109-115255-s1w13zjj",
< "cluster_name": "DEFAULT Test Cluster",
< ... truncated for brevity
< },
< "... (47 additional elements)"
< ]
< }
```
Overall, the logging capabilities provided by the Databricks SDK for Python can be a powerful tool for monitoring and troubleshooting your
Databricks Python projects. Developers can use the various logging methods and configuration options provided by the SDK to customize
the logging output to their specific needs.
## Interaction with `dbutils`<a id="interaction-with-dbutils"></a>
You can use the client-side implementation of [`dbutils`](https://docs.databricks.com/dev-tools/databricks-utils.html) by accessing `dbutils` property on the `WorkspaceClient`.
Most of the `dbutils.fs` operations and `dbutils.secrets` are implemented natively in Python within Databricks SDK. Non-SDK implementations still require a Databricks cluster,
that you have to specify through the `cluster_id` configuration attribute or `DATABRICKS_CLUSTER_ID` environment variable. Don't worry if cluster is not running: internally,
Databricks SDK for Python calls `w.clusters.ensure_cluster_is_running()`.
```python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
dbutils = w.dbutils
files_in_root = dbutils.fs.ls('/')
print(f'number of files in root: {len(files_in_root)}')
```
Alternatively, you can import `dbutils` from `databricks.sdk.runtime` module, but you have to make sure that all configuration is already [present in the environment variables](#default-authentication-flow):
```python
from databricks.sdk.runtime import dbutils
for secret_scope in dbutils.secrets.listScopes():
for secret_metadata in dbutils.secrets.list(secret_scope.name):
print(f'found {secret_metadata.key} secret in {secret_scope.name} scope')
```
## Interface stability<a id="interface-stability"></a>
Databricks is actively working on stabilizing the Databricks SDK for Python's interfaces.
API clients for all services are generated from specification files that are synchronized from the main platform.
You are highly encouraged to pin the exact dependency version and read the [changelog](https://github.com/databricks/databricks-sdk-py/blob/main/CHANGELOG.md)
where Databricks documents the changes. Databricks may have minor [documented](https://github.com/databricks/databricks-sdk-py/blob/main/CHANGELOG.md)
backward-incompatible changes, such as renaming some type names to bring more consistency.
| text/markdown | null | null | null | null | null | databricks, sdk | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programmi... | [] | null | null | >=3.7 | [] | [] | [] | [
"requests<3,>=2.28.1",
"google-auth~=2.0",
"protobuf!=5.26.*,!=5.27.*,!=5.28.*,!=5.29.0,!=5.29.1,!=5.29.2,!=5.29.3,!=5.29.4,!=6.30.0,!=6.30.1,!=6.31.0,<7.0,>=4.25.8",
"pytest; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"pytest-xdist<4.0,>=3.6.1; extra == \"dev\"",
"pytest-mock; extra == \"dev\""... | [] | [] | [] | [
"Documentation, https://databricks-sdk-py.readthedocs.io"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:22:21.415745 | databricks_sdk-0.91.0.tar.gz | 857,905 | af/a9/83dee5b4bbea94f21c4990aafdb1b1893d25d5bbbe5cd9a95ed2afaf0d42/databricks_sdk-0.91.0.tar.gz | source | sdist | null | false | 51155aadf7a248647e54d632a6800260 | 7b16f424f509609dd86cb69073a9a80a755c00a7b4be8cdaac3595ce3421a274 | afa983dee5b4bbea94f21c4990aafdb1b1893d25d5bbbe5cd9a95ed2afaf0d42 | null | [
"LICENSE",
"NOTICE"
] | 2,002,655 |
2.4 | multiversx-sdk | 2.4.0 | The MultiversX Python SDK. | # mx-sdk-py
The Python SDK for interacting with MultiversX. It's an all in one sdk that can be used to create transactions (including smart contract calls and deployments), sign and broadcast transactions, create wallets and many more.
## Documentation
- [Cookbook](./examples/v1.ipynb)
- [Auto-generated documentation](https://multiversx.github.io/mx-sdk-py/)
## Development setup
### Virtual environment
Create a virtual environment and install the dependencies:
```
python3 -m venv ./venv
source ./venv/bin/activate
pip install -r ./requirements.txt --upgrade
```
Install development dependencies, as well:
```
pip install -r ./requirements-dev.txt --upgrade
```
Allow `pre-commit` to automatically run on `git commit`:
```
pre-commit install
```
Above, `requirements.txt` should mirror the **dependencies** section of `pyproject.toml`.
If using VSCode, restart it or follow these steps:
- `Ctrl + Shift + P`
- _Select Interpreter_
- Choose `./venv/bin/python`.
### Tests
Run the tests as follows:
This command runs all tests:
```
pytest .
```
If you want to skip network interaction tests run:
```
pytest -m "not networkInteraction"
```
We have some tests fetching mainnet transactions that are quite time consuming. To skip those, run this command:
```
pytest -m "not mainnet"
```
### Generate test coverage report
First, we run the tests using coverage:
```sh
coverage run -m pytest .
```
Then, we can generate a report in the terminal using:
```sh
coverage report
```
We can also generate a html report using:
```sh
coverage html
```
### Re-generate the docs
Each time a new module/submodule is added it needs to be added to the docs, as well. To do so `cd` in the root directory then run the following command:
```bash
sphinx-apidoc -f -o docs/ multiversx_sdk/ '*_test.py' '*constants.py'
```
This command will regenerate the `.rst` files for each module, excluding the tests and the `constants.py` files.
Also, each time a new version is released, the [**conf.py**](/docs/conf.py) file should be updated accordingly.
### Re-generate _protobuf_ files:
```
protoc multiversx_sdk/core/proto/transaction.proto --python_out=. --pyi_out=.
```
Note that `protoc` must be installed beforehand. Use the same version as the one referenced in `requirements.txt`. For example, if we reference `protobuf==5.29.4` in `requirements.txt`, then use [protobuf v29.4](https://github.com/protocolbuffers/protobuf/releases/tag/v29.4).
| text/markdown | MultiversX | null | null | null | null | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"cryptography==44.0.1",
"mnemonic==0.21",
"protobuf==6.33.5",
"pycryptodomex==3.19.1",
"pynacl==1.6.2",
"requests<3.0.0,>=2.32.0",
"ledgercomm[hid]; extra == \"ledger\""
] | [] | [] | [] | [
"Homepage, https://github.com/multiversx/mx-sdk-py"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-19T08:22:15.929904 | multiversx_sdk-2.4.0.tar.gz | 16,129,673 | 1d/57/bb79014d907c3d8d9c581dd0b35b8afe048a101fe896bde77ced1219a06d/multiversx_sdk-2.4.0.tar.gz | source | sdist | null | false | 155626289c4aa43668b37a7db4ee842d | e80b09334309c6f959ffb6a893e0f836b8ca52839306f190b221a0c3b0d2809c | 1d57bb79014d907c3d8d9c581dd0b35b8afe048a101fe896bde77ced1219a06d | MIT | [
"LICENSE"
] | 389 |
2.4 | typio | 0.4 | Typio: Make Your Terminal Type Like a Human |
<div align="center">
<img src="https://github.com/sepandhaghighi/typio/raw/main/otherfiles/logo.png" width="320">
<h1>Typio: Make Your Terminal Type Like a Human</h1>
<br/>
<a href="https://www.python.org/"><img src="https://img.shields.io/badge/built%20with-Python3-green.svg" alt="built with Python3"></a>
<a href="https://github.com/sepandhaghighi/typio"><img alt="GitHub repo size" src="https://img.shields.io/github/repo-size/sepandhaghighi/typio"></a>
<a href="https://badge.fury.io/py/typio"><img src="https://badge.fury.io/py/typio.svg" alt="PyPI version"></a>
<a href="https://codecov.io/gh/sepandhaghighi/typio"><img src="https://codecov.io/gh/sepandhaghighi/typio/graph/badge.svg?token=UPhwanwQVw"></a>
</div>
## Overview
<p align="justify">
Typio is a lightweight Python library that prints text to the terminal as if it were being typed by a human. It supports multiple typing modes (character, word, line, sentence, typewriter, and adaptive), configurable delays and jitter for natural variation, and seamless integration with existing code via a simple function or a decorator. Typio is designed to be minimal, extensible, and safe, making it ideal for demos, CLIs, tutorials, and storytelling in the terminal.
</p>
<table>
<tr>
<td align="center">PyPI Counter</td>
<td align="center"><a href="http://pepy.tech/project/typio"><img src="http://pepy.tech/badge/typio"></a></td>
</tr>
<tr>
<td align="center">Github Stars</td>
<td align="center"><a href="https://github.com/sepandhaghighi/typio"><img src="https://img.shields.io/github/stars/sepandhaghighi/typio.svg?style=social&label=Stars"></a></td>
</tr>
</table>
<table>
<tr>
<td align="center">Branch</td>
<td align="center">main</td>
<td align="center">dev</td>
</tr>
<tr>
<td align="center">CI</td>
<td align="center"><img src="https://github.com/sepandhaghighi/typio/actions/workflows/test.yml/badge.svg?branch=main"></td>
<td align="center"><img src="https://github.com/sepandhaghighi/typio/actions/workflows/test.yml/badge.svg?branch=dev"></td>
</tr>
</table>
<table>
<tr>
<td align="center">Code Quality</td>
<td align="center"><a href="https://www.codefactor.io/repository/github/sepandhaghighi/typio"><img src="https://www.codefactor.io/repository/github/sepandhaghighi/typio/badge" alt="CodeFactor"></a></td>
<td align="center"><a href="https://app.codacy.com/gh/sepandhaghighi/typio/dashboard?utm_source=gh&utm_medium=referral&utm_content=&utm_campaign=Badge_grade"><img src="https://app.codacy.com/project/badge/Grade/e047db39052a4be2859f299dd7f7ce3c"></a></td>
</tr>
</table>
## Installation
### Source Code
- Download [Version 0.4](https://github.com/sepandhaghighi/typio/archive/v0.4.zip) or [Latest Source](https://github.com/sepandhaghighi/typio/archive/dev.zip)
- `pip install .`
### PyPI
- Check [Python Packaging User Guide](https://packaging.python.org/installing/)
- `pip install typio==0.4`
## Usage
### Function
Use `type_print` function to print text with human-like typing effects. You can control the typing speed, randomness, mode, and output stream.
#### Example
```python
from typio import type_print
from typio import TypeMode
type_print("Hello, world!")
type_print(
"Typing with style and personality.",
delay=0.06,
jitter=0.02,
end="\n",
mode=TypeMode.ADAPTIVE,
)
```
You can also redirect the output to any file-like object:
```python
with open("output.txt", "w") as file:
type_print("Saved with typing effects.", file=file)
```
#### Parameters
| Name | Type | Description | Default |
|------|------|-------------|---------|
| `text` | `str` | Text to be printed | -- |
| `delay` | `float` | Base delay (seconds) between emitted units | `0.04` |
| `jitter` | `float` | Random delay variation (seconds) | `0` |
| `end` | `str` | Ending character(s) | `\n` |
| `mode` | `TypeMode \| Callable` | Typing mode (built-in or custom) | `TypeMode.CHAR` |
| `file` | `TextIOBase` | Output stream | `sys.stdout` |
#### Built-in Modes
| Mode | Description |
|------|-------------|
| `TypeMode.CHAR` | Emit text **character by character** |
| `TypeMode.WORD` | Emit text **word by word**, preserving whitespace |
| `TypeMode.LINE` | Emit text **line by line** |
| `TypeMode.SENTENCE` | Emit text character by character with **longer pauses after `.`, `!`, `?`** |
| `TypeMode.TYPEWRITER` | Emit text character by character with **longer pauses after newlines** |
| `TypeMode.ADAPTIVE` | Emit text with **adaptive delays** based on character type (spaces, punctuation, alphanumeric) |
### Decorator
Use the `@typestyle` decorator to apply typing effects to all `print` calls inside a function, without changing the function's implementation.
#### Example
```python
from typio import typestyle
from typio import TypeMode
@typestyle(delay=0.05, mode=TypeMode.TYPEWRITER)
def intro():
print("Welcome to Typio.")
print("Every print is typed.")
intro()
```
#### Parameters
| Name | Type | Description | Default |
|------|------|-------------|---------|
| `delay` | `float` | Base delay (seconds) between emitted units | `0.04` |
| `jitter` | `float` | Random delay variation (seconds) | `0` |
| `mode` | `TypeMode \| Callable` | Typing mode (built-in or custom) | `TypeMode.CHAR` |
### Custom Mode
Typio also allows defining custom typing modes.
A custom mode is a callable that receives a typing context and the text being printed.
#### Example
This custom mode, named `dramatic`, adds exaggerated pauses after punctuation to create a dramatic typing effect.
```python
from typio import TypioContext
def dramatic(ctx: TypioContext, text: str):
for ch in text:
ctx.emit(ch)
if ch in ".!?":
ctx.sleep(delay=ctx.delay * 6)
```
Usage with `type_print` function:
```python
type_print(
"Wait... what?!",
mode=dramatic,
delay=0.05,
jitter=0.02,
)
```
Usage with `@typestyle` decorator:
```python
@typestyle(delay=0.06, mode=dramatic)
def demo():
print("This is serious.")
print("Very serious!")
demo()
```
#### Parameters
This table describes the `TypioContext` API, which is the interface exposed to custom typing modes for emitting text, controlling timing, and accessing delay settings.
| Name | Type | Description |
|------|------|-------------|
| `emit(text)` | `method` | Emit a text fragment using typing effects |
| `sleep(delay=None, jitter=None)` | `method` | Pause execution with optional delay and jitter override |
| `flush()` | `method` | Flush the underlying output stream |
| `delay` | `property` | Base delay in seconds |
| `jitter` | `property` | Jitter value in seconds |
### CLI
Typio provides a simple command line interface for printing text with typing effects.
#### Example
```console
> typio --text="Hello world!" --mode=typewriter --delay=0.03
```
## Issues & Bug Reports
Just fill an issue and describe it. We'll check it ASAP!
- Please complete the issue template
## Show Your Support
<h3>Star This Repo</h3>
Give a ⭐️ if this project helped you!
<h3>Donate to Our Project</h3>
<h4>Bitcoin</h4>
1KtNLEEeUbTEK9PdN6Ya3ZAKXaqoKUuxCy
<h4>Ethereum</h4>
0xcD4Db18B6664A9662123D4307B074aE968535388
<h4>Litecoin</h4>
Ldnz5gMcEeV8BAdsyf8FstWDC6uyYR6pgZ
<h4>Doge</h4>
DDUnKpFQbBqLpFVZ9DfuVysBdr249HxVDh
<h4>Tron</h4>
TCZxzPZLcJHr2qR3uPUB1tXB6L3FDSSAx7
<h4>Ripple</h4>
rN7ZuRG7HDGHR5nof8nu5LrsbmSB61V1qq
<h4>Binance Coin</h4>
bnb1zglwcf0ac3d0s2f6ck5kgwvcru4tlctt4p5qef
<h4>Tether</h4>
0xcD4Db18B6664A9662123D4307B074aE968535388
<h4>Dash</h4>
Xd3Yn2qZJ7VE8nbKw2fS98aLxR5M6WUU3s
<h4>Stellar</h4>
GALPOLPISRHIYHLQER2TLJRGUSZH52RYDK6C3HIU4PSMNAV65Q36EGNL
<h4>Zilliqa</h4>
zil1knmz8zj88cf0exr2ry7nav9elehxfcgqu3c5e5
<h4>Coffeete</h4>
<a href="http://www.coffeete.ir/opensource">
<img src="http://www.coffeete.ir/images/buttons/lemonchiffon.png" style="width:260px;" />
</a>
# Changelog
All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](http://keepachangelog.com/en/1.0.0/)
and this project adheres to [Semantic Versioning](http://semver.org/spec/v2.0.0.html).
## [Unreleased]
## [0.4] - 2026-02-19
### Added
- Command line interface
### Changed
- `_emit` method modified
- `README.md` updated
- Test system modified
## [0.3] - 2026-02-11
### Added
- `TypioContext` class
### Changed
- Test system modified
- `README.md` updated
- `_TypioPrinter` class all attributes changed to private
- `_emit` method modified
- `_sleep` function modified
## [0.2] - 2026-02-04
### Changed
- `README.md` updated
- `end` parameter added to `type_print` function
- Test system modified
## [0.1] - 2026-01-31
### Added
- `type_print` function
- `typestyle` decorator
- `CHAR` mode
- `WORD` mode
- `LINE` mode
- `SENTENCE` mode
- `TYPEWRITER` mode
- `ADAPTIVE` mode
[Unreleased]: https://github.com/sepandhaghighi/typio/compare/v0.4...dev
[0.4]: https://github.com/sepandhaghighi/typio/compare/v0.3...v0.4
[0.3]: https://github.com/sepandhaghighi/typio/compare/v0.2...v0.3
[0.2]: https://github.com/sepandhaghighi/typio/compare/v0.1...v0.2
[0.1]: https://github.com/sepandhaghighi/typio/compare/750c00e...v0.1
| text/markdown | Sepand Haghighi | me@sepand.tech | null | null | MIT | terminal cli typing typewriter typing-effect console stdout ux | [
"Development Status :: 3 - Alpha",
"Natural Language :: English",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python ... | [] | https://github.com/sepandhaghighi/typio | https://github.com/sepandhaghighi/typio/tarball/v0.4 | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Source, https://github.com/sepandhaghighi/typio"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T08:22:08.843155 | typio-0.4-py3-none-any.whl | 11,071 | 38/ae/bc06251a63b9ad9c2dac6865913c4c97b1f06bf69eb01d614aea1d26e47e/typio-0.4-py3-none-any.whl | py3 | bdist_wheel | null | false | b4be64f9ec1a284e09bc90552d0fab34 | 89e6e4ff0acee981c5f350e6dc02767ffb2450e15021befe70357b8e8dfcace3 | 38aebc06251a63b9ad9c2dac6865913c4c97b1f06bf69eb01d614aea1d26e47e | null | [
"LICENSE",
"AUTHORS.md"
] | 270 |
2.4 | pyfitparsernative | 0.1.0 | Fast FIT file parser using Rust, exposed to Python via PyO3 | # pyfitparsernative
Fast FIT file parser using Rust, exposed to Python via PyO3.
Parses Garmin FIT activity files using the [`fitparser`](https://crates.io/crates/fitparser) Rust crate. Approximately **8x faster** than `garmin-fit-sdk` (Python).
| Parser | Time (81km / 11,555 records) | Speedup |
|--------|------------------------------|---------|
| garmin-fit-sdk (Python) | ~2.0s | 1x |
| pyfitparsernative (Rust) | ~0.25s | ~8x |
## Installation
```bash
pip install pyfitparsernative
```
No Rust toolchain required — pre-built wheels are provided for Linux (glibc and musl), macOS (Intel and Apple Silicon), and Windows (x64). The macOS Intel (x86_64) wheel is cross-compiled and not tested in CI since GitHub no longer offers Intel macOS runners.
## Usage
```python
from pyfitparsernative import parse_fit_file, parse_fit_bytes
# Parse from a file path
messages = parse_fit_file("activity.fit")
# Parse from bytes
with open("activity.fit", "rb") as f:
messages = parse_fit_bytes(f.read())
```
**Return type:** `list[dict[str, Any]]`
Returns a flat list of message dicts in original FIT file order. Each dict includes a `"message_type"` key (e.g. `"record"`, `"session"`, `"lap"`) alongside the field data. Timestamps are returned as naive ISO 8601 strings (`YYYY-MM-DDTHH:MM:SS`).
```python
# Example: get average power from session message
session = [m for m in messages if m["message_type"] == "session"][0]
print(session["avg_power"]) # 160
print(session["max_power"]) # 489
# Example: iterate record (data) messages
for msg in messages:
if msg["message_type"] == "record":
print(msg["timestamp"], msg.get("power"), msg.get("heart_rate"))
```
## Differences from garmin-fit-sdk
`pyfitparsernative` returns the same field names and numeric values as `garmin-fit-sdk`, with the following differences:
- **Timestamps** — returned as naive ISO 8601 strings instead of timezone-aware `datetime` objects.
- **Enum fields** — returned as raw integers instead of string labels.
- **Message types** — no `_mesgs` suffix (e.g. `"session"` not `"session_mesgs"`).
- **Developer fields** — garmin-fit-sdk uses integer dict keys for developer fields (e.g. `{61: 2554}`); pyfitparsernative uses string keys (`{"unknown_field_61": 2554}`).
- **Component field expansion** — garmin-fit-sdk derives `speed` and `altitude` from the more precise `enhanced_speed`/`enhanced_altitude` fields when the base fields are absent from the message definition. pyfitparsernative applies the same expansion, so `"speed"` and `"altitude"` are always present in `record` messages alongside their `enhanced_` counterparts.
- **Unknown message types** — fitparser may not recognise every global message number in its profile. Unknown types that are known to the FIT SDK are remapped to their standard names (e.g. message number 13 → `"training_settings"`).
## Building from source
The `docker/` directory contains scripts to build and test inside containers, avoiding the need for a local Rust toolchain. These are for local development only; CI/CD uses its own pipeline.
**Build** — compiles the wheel inside `rust:1.93.1-trixie` and writes it to `dist/`:
```bash
bash docker/docker-build.sh
```
**Test** — runs the test suite inside `python:3.14.3-trixie` against the wheel in `dist/`:
```bash
bash docker/docker-test.sh
```
On Windows, run these from Git Bash or WSL. Docker Desktop must be running with Linux containers enabled.
## Releasing
Push a tag to trigger the CI/CD pipeline, which builds wheels for all platforms and publishes to PyPI:
```bash
git tag v0.1.0 && git push --tags
```
See `.github/workflows/CI.yml` for the full build matrix.
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | MIT | null | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"pytest; extra == \"dev\"",
"garmin-fit-sdk; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:21:53.648047 | pyfitparsernative-0.1.0.tar.gz | 377,576 | 76/f2/aec534d5d0d38dd2f7585522152fc66d606ad4901b432311339dcf3a0e1f/pyfitparsernative-0.1.0.tar.gz | source | sdist | null | false | dd0a28e929479ea7df6cf700caa599ac | 1f08bb1f084f5126425200bc152acc8e0040d19e0e49615a8e5551847f689fdc | 76f2aec534d5d0d38dd2f7585522152fc66d606ad4901b432311339dcf3a0e1f | null | [
"LICENSE"
] | 798 |
2.4 | aicmo | 0.0.7 | A package for using aicmo functions and tools | A package for using aicmo functions and tools, includes scraping, openai with an options where you can use it in a serverless application such as AWS Lambda and GCP Cloud Function
| text/markdown | Jayr Castro | jayrcastro.py@gmail.com | null | null | null | aicmo | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3.12",
"Operating System :: Unix",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows"
] | [] | null | null | null | [] | [] | [] | [
"openai==1.75.0",
"scrapingbee==2.0.1",
"requests==2.32.3",
"boto3==1.37.37",
"tiktoken==0.9.0",
"opencv-python-headless==4.11.0.86",
"beautifulsoup4==4.13.4",
"numpy==2.2.4",
"python-dotenv==1.1.0",
"typesense==1.0.3"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:21:03.054536 | aicmo-0.0.7.tar.gz | 10,193 | 51/c3/b8ceb6f442306680e531586b9a163d3e0ebb43008c367331b197d489e346/aicmo-0.0.7.tar.gz | source | sdist | null | false | 2b5cae8927030df70eb23d1f11aabaf8 | 22101536fdc0cb862262e9ffaf9dce9dfbf9d546fe53f11a33c41f60a7f2f021 | 51c3b8ceb6f442306680e531586b9a163d3e0ebb43008c367331b197d489e346 | null | [] | 300 |
2.4 | arthur-sdk | 0.4.0 | Simple trading for AI agents on Orderly Network | # Arthur SDK
**The easiest way for AI agents to trade crypto perpetuals.**
3 lines of Python. No complex signatures. No confusing structs. Just trade.
```python
from orderly_agent import Arthur
client = Arthur.from_credentials_file("credentials.json")
client.buy("ETH", usd=100) # Done.
```
## Why Arthur?
- 🚀 **Dead simple** - Trade in 3 lines of code
- 🤖 **Built for agents** - Clean API, no boilerplate
- ⚡ **Fast execution** - Powered by Orderly Network
- 📊 **50+ markets** - BTC, ETH, SOL, ARB, and more
- 🔒 **Non-custodial** - Your keys, your coins
## Installation
```bash
pip install agent-trading-sdk
```
## Quick Start
```python
from orderly_agent import Arthur
# Load credentials
client = Arthur.from_credentials_file("credentials.json")
# Trade
client.buy("ETH", usd=100) # Long $100 of ETH
client.sell("BTC", size=0.01) # Short 0.01 BTC
client.close("ETH") # Close position
client.close_all() # Close everything
# Check status
print(client.balance()) # Available USDC
print(client.pnl()) # Total unrealized PnL
print(client.positions()) # All open positions
```
## Strategy Examples
### RSI Strategy
```python
# Buy oversold, sell overbought
if rsi < 30:
client.buy("ETH", usd=100)
elif rsi > 70:
client.sell("ETH", usd=100)
```
👉 [Full RSI example](examples/rsi_strategy.py)
### Momentum Strategy
```python
# Trend following with trailing stops
if price > recent_high:
client.buy("BTC", usd=200)
```
👉 [Full momentum example](examples/momentum_strategy.py)
### Grid Trading
```python
# Profit from sideways markets
for level in grid_levels:
client.buy(symbol, price=level, usd=50)
```
👉 [Full grid example](examples/grid_trading.py)
### AI Agent
```python
# Let your LLM make decisions
context = get_market_context(client, ["BTC", "ETH"])
decision = llm.chat(TRADING_PROMPT, context)
execute_trade(client, decision)
```
👉 [Full AI agent example](examples/ai_agent.py)
### Portfolio Rebalancer
```python
# Maintain target allocations
targets = {"BTC": 50, "ETH": 30, "SOL": 20}
rebalance_portfolio(client, targets)
```
👉 [Full rebalancer example](examples/portfolio_rebalance.py)
## API Reference
### Trading
```python
# Market orders
client.buy("ETH", usd=100) # Buy by USD value
client.buy("BTC", size=0.01) # Buy by size
# Limit orders
client.buy("ETH", size=0.1, price=2000)
# Close positions
client.close("ETH") # Close all of symbol
client.close("ETH", size=0.05) # Partial close
client.close_all() # Close everything
```
### Position Management
```python
# Get all positions
for pos in client.positions():
print(f"{pos.symbol}: {pos.side} {pos.size}")
print(f" Entry: ${pos.entry_price}")
print(f" PnL: ${pos.unrealized_pnl} ({pos.pnl_percent}%)")
# Get specific position
eth_pos = client.position("ETH")
# Total PnL
total_pnl = client.pnl()
```
### Market Data
```python
# Get price
btc_price = client.price("BTC")
# Get all prices
prices = client.prices()
```
### Account Info
```python
balance = client.balance() # Available USDC
equity = client.equity() # Total value
summary = client.summary() # Full details
```
### Withdrawals
```python
# Initialize with wallet for withdrawals
client = Arthur(
api_key="...",
secret_key="...",
account_id="...",
wallet_private_key="...", # Required for withdrawals!
chain_id=42161, # Arbitrum One
)
# Withdraw 100 USDC to your wallet
result = client.withdraw(100)
print(f"Withdrawal ID: {result['withdraw_id']}")
# Withdraw to a different chain
client.withdraw(50, to_chain_id=10) # Optimism
# Check withdrawal history
for w in client.withdrawal_history():
print(f"{w['id']}: {w['amount']} USDC - {w['status']}")
```
👉 [Full withdrawal example](examples/withdrawal.py)
### Risk Management
```python
client.set_leverage("ETH", 10)
client.set_stop_loss("ETH", price=1900)
client.set_stop_loss("ETH", pct=5) # 5% stop
```
## Credentials
Create a `credentials.json`:
```json
{
"api_key": "ed25519:xxx",
"secret_key": "ed25519:xxx",
"account_id": "0x..."
}
```
Get credentials from [Arthur DEX](https://arthurdex.com) or any Orderly-powered DEX.
## Supported Markets
Short symbols work automatically:
| Short | Full Symbol |
|-------|-------------|
| BTC | PERP_BTC_USDC |
| ETH | PERP_ETH_USDC |
| SOL | PERP_SOL_USDC |
| ARB, OP, AVAX, LINK... | PERP_*_USDC |
50+ perpetual markets available.
## Testnet
```python
client = Arthur(..., testnet=True)
```
## Error Handling
```python
from orderly_agent import Arthur, OrderError, InsufficientFundsError
try:
client.buy("ETH", usd=100)
except InsufficientFundsError:
print("Not enough balance")
except OrderError as e:
print(f"Order failed: {e}")
```
## Links
- **Trade:** [arthurdex.com](https://arthurdex.com)
- **Twitter:** [@Arthur_Orderly](https://twitter.com/Arthur_Orderly)
- **Orderly Network:** [orderly.network](https://orderly.network)
## License
MIT
---
Built by Arthur 🤖 for AI agents, powered by Orderly Network.
| text/markdown | Arthur | dev@orderly.network | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Pytho... | [] | https://github.com/arthur-orderly/agent-trading-sdk | null | >=3.9 | [] | [] | [] | [
"pynacl>=1.5.0",
"httpx>=0.24.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21; extra == \"dev\"",
"black>=23.0; extra == \"dev\"",
"mypy>=1.0; extra == \"dev\"",
"langchain-core>=0.1.0; extra == \"langchain\"",
"crewai>=0.1.0; extra == \"crewai\"",
"pyautogen>=0.2.0; extra == \"autogen\""... | [] | [] | [] | [] | twine/6.2.0 CPython/3.9.6 | 2026-02-19T08:20:12.436156 | arthur_sdk-0.4.0.tar.gz | 31,042 | e6/47/85fd531fe43a665381ab0cba3acb1ed9e802de9b012419fa78dbcbe87c4c/arthur_sdk-0.4.0.tar.gz | source | sdist | null | false | fcd613ac631ed99243a568edb4b056b2 | 7c67f66d93e27d4ff2f4a8ff66b7f0e6e23da74f434c316e1d19f261e85b1337 | e64785fd531fe43a665381ab0cba3acb1ed9e802de9b012419fa78dbcbe87c4c | null | [] | 281 |
2.4 | vachana-g2p | 0.0.2 | Vachana G2P: ระบบแปลงข้อความภาษาไทยเป็นเสียงอ่านสากล (Thai to IPA) | # Vachana G2P
เครื่องมือแปลงข้อความภาษาไทยเป็น IPA
เครดิต
- https://github.com/nozomiyamada/thaig2p
- https://github.com/attapol/tltk
- https://github.com/PyThaiNLP/pythainlp
### ติดตั้ง
```
pip install vachana-g2p
```
### การใช้งาน
```
from vachana_g2p import th2ipa
text = "สวัสดีครับ นี่คือเสียงพูดภาษาไทย"
ipa = th2ipa(text)
print(ipa)
# example : sawàtdiː kʰráp, nîː kʰɯː sǐəŋpʰûːt pʰaːsǎːtʰaj
```
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | null | [] | [] | [] | [
"pythainlp"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.9 | 2026-02-19T08:18:52.987251 | vachana_g2p-0.0.2.tar.gz | 6,172,581 | d3/be/9cdbb6b262a6afa2607a2c173218ba0733e9c21cc3f010ec60de96577406/vachana_g2p-0.0.2.tar.gz | source | sdist | null | false | a44758db8e70a4dd6e160be44099a774 | d950492e88e073f704d80747ca7bee871b03a305ab7919628ae6b48da38fdede | d3be9cdbb6b262a6afa2607a2c173218ba0733e9c21cc3f010ec60de96577406 | null | [] | 323 |
2.4 | splitlog | 4.1.5 | Utility to split aggregated logs from Apache Hadoop Yarn applications into a folder hierarchy | splitlog
========
Hadoop Yarn application logs aggregate all container logs of a Yarn application into a single file. This makes it very
difficult to use Unix command line tools to analyze these logs: Grep will search over all containers and context
provided for hits often does not include Yarn container name or host name. `splitlog` splits a combined logfile for all
containers of an application into a file system hierarchy suitable for further analysis:
```
out
└── hadoopnode
├── container_1671326373437_0001_01_000001
│ ├── directory.info
│ ├── launch_container.sh
│ ├── prelaunch.err
│ ├── prelaunch.out
│ ├── stderr
│ ├── stdout
│ └── syslog
├── container_1671326373437_0001_01_000002
│ ├── directory.info
│ ├── launch_container.sh
│ ├── prelaunch.err
│ ├── prelaunch.out
│ ├── stderr
│ ├── stdout
│ └── syslog
└── container_1671326373437_0001_01_000003
├── directory.info
├── launch_container.sh
├── prelaunch.err
├── prelaunch.out
├── stderr
├── stdout
└── syslog
4 directories, 21 files
```
Installation
------------
Python 3.11+ must be available. Installation via [pipx](https://pypi.org/project/pipx/):
```shell script
pipx install splitlog
```
How to use
----------
Read logs from standard input:
```shell script
yarn logs -applicationId application_1582815261257_232080 | splitlog
```
Read logs from file `application_1582815261257_232080.log`:
```shell script
splitlog -i application_1582815261257_232080.log
```
| text/markdown | Sebastian Klemke | pypi@nerdheim.de | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3 :: Only",
"Topic :: System :: Distributed Computing",
"Topic :: System :: Logging",
"Topic :: Utilities"
] | [] | null | null | <4.0,>=3.11 | [] | [] | [] | [
"python-dateutil<3.0.0,>=2.9.0",
"pytz>=2025.2"
] | [] | [] | [] | [
"Bug Tracker, https://github.com/splitlog/splitlog/issues",
"Repository, https://github.com/splitlog/splitlog.git"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:18:46.680891 | splitlog-4.1.5.tar.gz | 7,500 | 64/91/55cf3251f642e5f8fd5b27f30fc4c6ad78bb2ef7e42e022d5fe34000d2b5/splitlog-4.1.5.tar.gz | source | sdist | null | false | 5fc418bd76697372c589ad15174e1be3 | fde0e191f08798c80e383ca47d2f033bad32e9dd42cff066a783cf1fe0964d85 | 649155cf3251f642e5f8fd5b27f30fc4c6ad78bb2ef7e42e022d5fe34000d2b5 | MIT | [
"LICENSE"
] | 263 |
2.4 | ractogateway | 0.1.2 | A unified, production-ready AI SDK that enforces structured outputs and anti-hallucination prompting via the RACTO principle. One package for OpenAI, Gemini, and Anthropic — with streaming, tool calling, embeddings, and strict Pydantic validation. | # RactoGateway
**One Python package for all production-grade LLM solutions.**
RactoGateway is a unified AI SDK that gives you a single, clean interface to OpenAI, Google Gemini, and Anthropic Claude — with built-in anti-hallucination prompting, strict Pydantic validation, streaming, tool calling, embeddings, fine-tuning, and a full RAG pipeline. No more messy JSON dicts. No more provider lock-in. No more inconsistent response formats.
[](https://pypi.org/project/ractogateway/)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/Apache-2.0)
[](https://github.com/IAMPathak2702/RactoGateway)
---
## Table of Contents
- [Why RactoGateway?](#why-ractogateway)
- [Installation](#installation)
- [5-Line Quick Start](#5-line-quick-start)
- [RACTO Prompt Engine](#racto-prompt-engine)
- [Developer Kits](#developer-kits)
- [Streaming](#streaming)
- [Async Support](#async-support)
- [Embeddings](#embeddings)
- [Tool Calling](#tool-calling)
- [Validated Response Models](#validated-response-models)
- [Multi-turn Conversations](#multi-turn-conversations)
- [Multimodal Attachments — Images & Files](#multimodal-attachments)
- [Low-Level Gateway](#low-level-gateway)
- [Switching Providers](#switching-providers)
- [Fine-Tuning](#fine-tuning)
- [RAG — Retrieval-Augmented Generation](#rag)
- [Architecture](#architecture)
- [Environment Variables](#environment-variables)
---
## Why RactoGateway?
Every LLM provider has a different SDK, different request format, different response structure, and different tool-calling schema. Building production AI applications means writing glue code, parsing deeply nested objects, and manually stripping markdown fences from JSON responses.
RactoGateway solves this by providing:
- **RACTO Prompt Engine** — a structured prompt framework (Role, Aim, Constraints, Tone, Output) that compiles into optimized, anti-hallucination system prompts
- **Three Developer Kits** — `gpt` (OpenAI), `gemini` (Google), `claude` (Anthropic) — each with `chat()`, `achat()`, `stream()`, `astream()`, `embed()`, and `aembed()`
- **Strict Pydantic models** for every input and output — no raw dicts anywhere
- **Automatic JSON parsing** — responses are cleaned of markdown fences and auto-parsed
- **Unified tool calling** — define tools once as Python functions, use them with any provider
- **Streaming with typed chunks** — every `StreamChunk` has `.delta.text`, `.accumulated_text`, `.is_final`, `.usage`
- **RAG pipeline** — ingest files, embed, store, retrieve, and generate answers with one class
- **Low-level Gateway** — wraps any adapter for direct prompt execution without `ChatConfig`
---
## Installation
```bash
# Core package (includes RACTO prompt engine and tool registry)
pip install ractogateway
# With a specific LLM provider
pip install ractogateway[openai]
pip install ractogateway[google]
pip install ractogateway[anthropic]
# All LLM providers
pip install ractogateway[all]
# RAG: base readers + NLP processing
pip install ractogateway[rag]
# RAG: everything (all readers, stores, embedders)
pip install ractogateway[rag-all]
# RAG: individual extras
pip install ractogateway[rag-pdf] # PDF support
pip install ractogateway[rag-word] # .docx support
pip install ractogateway[rag-excel] # .xlsx support
pip install ractogateway[rag-image] # image OCR support
pip install ractogateway[rag-nlp] # lemmatizer NLP processing
# RAG: vector stores
pip install ractogateway[rag-chroma] # ChromaDB
pip install ractogateway[rag-faiss] # FAISS
pip install ractogateway[rag-pinecone] # Pinecone
pip install ractogateway[rag-qdrant] # Qdrant
pip install ractogateway[rag-weaviate] # Weaviate
pip install ractogateway[rag-milvus] # Milvus
pip install ractogateway[rag-pgvector] # PostgreSQL pgvector
# RAG: embedding providers
pip install ractogateway[rag-voyage] # Voyage AI embeddings
# Development (all providers + testing + linting)
pip install ractogateway[dev]
```
**Requirements:** Python 3.10+, Pydantic 2.0+
---
## 5-Line Quick Start
This is the absolute minimum to get a response from any AI — no configuration needed beyond your API key:
```python
from ractogateway import openai_developer_kit as gpt, RactoPrompt
# 1. Describe what you want the AI to do
prompt = RactoPrompt(
role="You are a helpful assistant.",
aim="Answer the user's question clearly.",
constraints=["Be concise."],
tone="Friendly",
output_format="text",
)
# 2. Create your AI chat (reads OPENAI_API_KEY from environment automatically)
kit = gpt.Chat(model="gpt-4o", default_prompt=prompt)
# 3. Ask something!
response = kit.chat(gpt.ChatConfig(user_message="What is Python?"))
print(response.content)
# "Python is a beginner-friendly, high-level programming language used for web
# development, data science, AI, automation, and much more."
```
That's it. Swap `gpt` for `gemini` or `claude` and the exact same code works with Google or Anthropic.
---
## RACTO Prompt Engine
The **RACTO** principle structures every prompt into five unambiguous sections so the model always knows exactly what to do — and what NOT to do.
| Letter | Field | Purpose |
| :---: | --- | --- |
| **R** | `role` | Who the model is |
| **A** | `aim` | What it must accomplish |
| **C** | `constraints` | Hard rules it must never violate |
| **T** | `tone` | Communication style |
| **O** | `output_format` | Exact shape of the response |
### Defining a Prompt
```python
from ractogateway import RactoPrompt
prompt = RactoPrompt(
role="You are a senior Python code reviewer at a Fortune 500 company.",
aim="Review the given code for bugs, security vulnerabilities, and PEP-8 violations.",
constraints=[
"Only report issues you are certain about.",
"Do not suggest stylistic preferences.",
"If no issues are found, say so explicitly.",
"Never fabricate code examples that you cannot verify.",
],
tone="Professional and concise",
output_format="json",
)
```
### All `RactoPrompt` Fields
| Field | Type | Required | Default | Description |
| --- | --- | :---: | --- | --- |
| `role` | `str` | Yes | — | Who the model is |
| `aim` | `str` | Yes | — | Task objective |
| `constraints` | `list[str]` | Yes | — | Hard rules (min 1 item) |
| `tone` | `str` | Yes | — | Communication style |
| `output_format` | `str \| type[BaseModel]` | Yes | — | `"json"`, `"text"`, `"markdown"`, free-form description, or a Pydantic class |
| `context` | `str \| None` | No | `None` | Domain background injected between AIM and CONSTRAINTS |
| `examples` | `list[dict] \| None` | No | `None` | Few-shot pairs — each dict requires `"input"` and `"output"` keys |
| `anti_hallucination` | `bool` | No | `True` | Append `[GUARDRAILS]` block |
### `RactoPrompt` Methods
| Method | Signature | Returns | Description |
| --- | --- | --- | --- |
| `compile()` | `() -> str` | `str` | Generate the full system prompt string |
| `__str__()` | `() -> str` | `str` | Shortcut for `compile()` |
| `to_messages()` | `(user_message, attachments=None, provider="generic") -> list[dict]` | `list[dict]` | Build a provider-ready message list |
### What `prompt.compile()` Produces
Calling `prompt.compile()` (or just `str(prompt)`) gives you the full system prompt:
```text
[ROLE]
You are a senior Python code reviewer at a Fortune 500 company.
[AIM]
Review the given code for bugs, security vulnerabilities, and PEP-8 violations.
[CONSTRAINTS]
- Only report issues you are certain about.
- Do not suggest stylistic preferences.
- If no issues are found, say so explicitly.
- Never fabricate code examples that you cannot verify.
[TONE]
Professional and concise
[OUTPUT]
Respond ONLY with valid JSON. Do NOT wrap the response in markdown code
fences (```json … ```) or add any commentary before or after the JSON object.
[GUARDRAILS]
- If you are unsure or lack sufficient information, state it explicitly rather than guessing.
- Do NOT fabricate facts, citations, URLs, statistics, or code that you cannot verify.
- Stick strictly to what is asked. Do not add unrequested information.
- If the answer requires assumptions, list each assumption explicitly before proceeding.
```
### Pydantic Model as Output Format
Pass a Pydantic model class as `output_format` and the full JSON Schema is embedded in the compiled prompt automatically:
```python
from pydantic import BaseModel
class CodeReview(BaseModel):
issues: list[str]
severity: str # "low", "medium", "high"
suggestion: str
prompt = RactoPrompt(
role="You are a code reviewer.",
aim="Review the code.",
constraints=["Only report real issues."],
tone="Concise",
output_format=CodeReview, # ← JSON Schema auto-embedded in prompt
)
print(prompt.compile())
```
Compiled output (OUTPUT section):
```text
[OUTPUT]
Respond ONLY with valid JSON that conforms exactly to the following JSON Schema.
Do NOT wrap the JSON in markdown code fences or add any text before or after it.
JSON Schema:
{
"type": "object",
"properties": {
"issues": {"type": "array", "items": {"type": "string"}},
"severity": {"type": "string"},
"suggestion": {"type": "string"}
},
"required": ["issues", "severity", "suggestion"]
}
```
### Few-Shot Examples
```python
prompt = RactoPrompt(
role="You are a sentiment classifier.",
aim="Classify the sentiment of the user's text.",
constraints=["Only output: positive, negative, or neutral."],
tone="Concise",
output_format="json",
examples=[
{"input": "I love this product!", "output": '{"sentiment": "positive"}'},
{"input": "This is broken and useless.", "output": '{"sentiment": "negative"}'},
{"input": "It arrived yesterday.", "output": '{"sentiment": "neutral"}'},
],
)
```
### `to_messages()` — Ready-to-Send Message List
**Input parameters:**
| Parameter | Type | Default | Description |
| --- | --- | --- | --- |
| `user_message` | `str` | — | The end-user's query (required) |
| `attachments` | `list[RactoFile] \| None` | `None` | Optional file/image attachments |
| `provider` | `str` | `"generic"` | `"openai"`, `"anthropic"`, `"google"`, or `"generic"` |
**Output:** `list[dict[str, Any]]` — a list of message dicts ready to send to the provider
```python
messages = prompt.to_messages(
"Review this: def add(a, b): return a + b",
provider="openai", # "openai" | "anthropic" | "google" | "generic"
)
# Output:
# [
# {"role": "system", "content": "<compiled RACTO system prompt>"},
# {"role": "user", "content": "Review this: def add(a, b): return a + b"}
# ]
```
---
## Developer Kits
RactoGateway has three kits — one for each AI provider. Import them with names you already know, then call `.Chat(...)` to create your AI:
```python
from ractogateway import openai_developer_kit as gpt # ChatGPT / OpenAI
from ractogateway import google_developer_kit as gemini # Google Gemini
from ractogateway import anthropic_developer_kit as claude # Anthropic Claude
```
> **Note:** `and` is a reserved Python keyword in Python, so we use `claude` instead — cleaner anyway!
### Creating a Chat
Every kit exposes a `Chat` class — short, readable, and always works the same way:
```python
# Just pick your provider and model — that's it!
kit = gpt.Chat(model="gpt-4o")
kit = gemini.Chat(model="gemini-2.0-flash")
kit = claude.Chat(model="claude-sonnet-4-6")
```
The API key is read automatically from your environment variable (`OPENAI_API_KEY`, `GEMINI_API_KEY`, or `ANTHROPIC_API_KEY`). No extra setup needed.
**Full constructor options (all optional except `model`):**
```python
# OpenAI / ChatGPT
kit = gpt.Chat(
model="gpt-4o", # which model to use
api_key="sk-...", # skip if OPENAI_API_KEY is set
base_url="https://custom-proxy.com/v1", # optional: Azure or custom proxy
embedding_model="text-embedding-3-small", # for embed() calls
default_prompt=prompt, # auto-used in every chat if set
)
# Google Gemini
kit = gemini.Chat(
model="gemini-2.0-flash", # which model to use
api_key="AIza...", # skip if GEMINI_API_KEY is set
embedding_model="text-embedding-004", # for embed() calls
default_prompt=prompt, # auto-used in every chat if set
)
# Anthropic Claude
kit = claude.Chat(
model="claude-sonnet-4-6", # which model to use
api_key="sk-ant-...", # skip if ANTHROPIC_API_KEY is set
default_prompt=prompt, # auto-used in every chat if set
)
```
**`OpenAIDeveloperKit` / `gpt.Chat` constructor parameters:**
| Parameter | Type | Default | Description |
| --- | --- | --- | --- |
| `model` | `str` | `"gpt-4o"` | Chat model identifier |
| `api_key` | `str \| None` | `None` | Falls back to `OPENAI_API_KEY` env var |
| `base_url` | `str \| None` | `None` | Azure OpenAI or proxy base URL |
| `embedding_model` | `str` | `"text-embedding-3-small"` | Default model for `embed()` calls |
| `default_prompt` | `RactoPrompt \| None` | `None` | Auto-used when `ChatConfig.prompt` is `None` |
**`GoogleDeveloperKit` / `gemini.Chat` constructor parameters:**
| Parameter | Type | Default | Description |
| --- | --- | --- | --- |
| `model` | `str` | `"gemini-2.0-flash"` | Chat model identifier |
| `api_key` | `str \| None` | `None` | Falls back to `GEMINI_API_KEY` env var |
| `embedding_model` | `str` | `"text-embedding-004"` | Default model for `embed()` calls |
| `default_prompt` | `RactoPrompt \| None` | `None` | Auto-used when `ChatConfig.prompt` is `None` |
**`AnthropicDeveloperKit` / `claude.Chat` constructor parameters:**
| Parameter | Type | Default | Description |
| --- | --- | --- | --- |
| `model` | `str` | — | Chat model identifier (required) |
| `api_key` | `str \| None` | `None` | Falls back to `ANTHROPIC_API_KEY` env var |
| `default_prompt` | `RactoPrompt \| None` | `None` | Auto-used when `ChatConfig.prompt` is `None` |
### Method Reference
| Method | `gpt` | `gemini` | `claude` | Input | Output |
| --- | :---: | :---: | :---: | --- | --- |
| `chat(config)` | Yes | Yes | Yes | `ChatConfig` | `LLMResponse` |
| `achat(config)` | Yes | Yes | Yes | `ChatConfig` | `LLMResponse` |
| `stream(config)` | Yes | Yes | Yes | `ChatConfig` | `Iterator[StreamChunk]` |
| `astream(config)` | Yes | Yes | Yes | `ChatConfig` | `AsyncIterator[StreamChunk]` |
| `embed(config)` | Yes | Yes | — | `EmbeddingConfig` | `EmbeddingResponse` |
| `aembed(config)` | Yes | Yes | — | `EmbeddingConfig` | `EmbeddingResponse` |
> Anthropic does not offer a native embedding API. Use the OpenAI or Google kit for embeddings.
---
### `ChatConfig` — Input Model
The single input object for `chat()`, `achat()`, `stream()`, and `astream()`.
```python
config = gpt.ChatConfig(
user_message="Explain monads in simple terms.", # required
prompt=prompt, # optional — overrides kit default
temperature=0.3, # 0.0–2.0, default 0.0
max_tokens=2048, # default 4096
tools=my_tool_registry, # optional ToolRegistry
response_model=MyPydanticModel, # optional output validation
history=[ # optional multi-turn context
gpt.Message(role=gpt.MessageRole.USER, content="What is FP?"),
gpt.Message(role=gpt.MessageRole.ASSISTANT, content="Functional programming is..."),
],
extra={"top_p": 0.9, "seed": 42}, # provider-specific pass-through
)
```
**`ChatConfig` field reference:**
| Field | Type | Required | Default | Description |
| --- | --- | :---: | --- | --- |
| `user_message` | `str` | Yes | — | End-user's query (min 1 character) |
| `prompt` | `RactoPrompt \| None` | No | `None` | Overrides the kit's `default_prompt` for this call |
| `temperature` | `float` | No | `0.0` | Sampling temperature (0.0–2.0) |
| `max_tokens` | `int` | No | `4096` | Maximum tokens in the completion (>0) |
| `tools` | `ToolRegistry \| None` | No | `None` | Tool registry for function/tool calling |
| `response_model` | `type[BaseModel] \| None` | No | `None` | Validate JSON output against this Pydantic model |
| `history` | `list[Message]` | No | `[]` | Prior conversation turns for multi-turn chat |
| `extra` | `dict[str, Any]` | No | `{}` | Provider-specific pass-through kwargs (e.g. `top_p`, `seed`, `stop`) |
> **Note:** Either `ChatConfig.prompt` or the kit's `default_prompt` must be set — at least one is required.
---
### `Message` and `MessageRole`
Used to build conversation history for multi-turn chat.
```python
from ractogateway import openai_developer_kit as gpt
msg = gpt.Message(role=gpt.MessageRole.USER, content="What is Python?")
```
**`Message` field reference:**
| Field | Type | Description |
| --- | --- | --- |
| `role` | `MessageRole` | `SYSTEM`, `USER`, or `ASSISTANT` |
| `content` | `str` | The message text |
**`MessageRole` enum values:**
| Value | String | Description |
| --- | --- | --- |
| `MessageRole.SYSTEM` | `"system"` | System instruction |
| `MessageRole.USER` | `"user"` | Human turn |
| `MessageRole.ASSISTANT` | `"assistant"` | Model turn |
---
### `LLMResponse` — Chat Output
Returned by `chat()` and `achat()`. Same shape for all three providers.
```python
response = kit.chat(gpt.ChatConfig(user_message="What is 2 + 2?"))
response.content # "4" — cleaned text (markdown fences auto-stripped)
response.parsed # None (not JSON) or dict/list if JSON
response.tool_calls # [] — list[ToolCallResult]
response.finish_reason # FinishReason.STOP
response.usage # {"prompt_tokens": 42, "completion_tokens": 5, "total_tokens": 47}
response.raw # the unmodified provider response object (escape hatch)
```
**Full output example — JSON response:**
```python
prompt = RactoPrompt(
role="You are a data extractor.",
aim="Extract the person's name and age from the text.",
constraints=["Return only JSON."],
tone="Concise",
output_format="json",
)
kit = gpt.Chat(model="gpt-4o", default_prompt=prompt)
response = kit.chat(gpt.ChatConfig(user_message="My name is Alice and I am 30 years old."))
print(response.content)
# '{"name": "Alice", "age": 30}'
print(response.parsed)
# {"name": "Alice", "age": 30} ← auto-parsed Python dict, no json.loads() needed
print(response.finish_reason)
# FinishReason.STOP
print(response.usage)
# {"prompt_tokens": 78, "completion_tokens": 12, "total_tokens": 90}
```
**`LLMResponse` field reference:**
| Field | Type | Description |
| --- | --- | --- |
| `content` | `str \| None` | Cleaned text (markdown fences stripped) |
| `parsed` | `dict \| list \| None` | Auto-parsed JSON — `None` when response is not JSON |
| `tool_calls` | `list[ToolCallResult]` | Tool calls requested by the model |
| `finish_reason` | `FinishReason` | `STOP`, `TOOL_CALL`, `LENGTH`, `CONTENT_FILTER`, `ERROR` |
| `usage` | `dict[str, int]` | `prompt_tokens`, `completion_tokens`, `total_tokens` |
| `raw` | `Any` | The unmodified provider response (escape hatch for advanced use) |
**`FinishReason` enum values:**
| Value | String | When set |
| --- | --- | --- |
| `FinishReason.STOP` | `"stop"` | Normal completion |
| `FinishReason.TOOL_CALL` | `"tool_call"` | Model requested a function/tool call |
| `FinishReason.LENGTH` | `"length"` | Hit `max_tokens` limit |
| `FinishReason.CONTENT_FILTER` | `"content_filter"` | Filtered by safety system |
| `FinishReason.ERROR` | `"error"` | Internal error |
---
## Streaming
`stream()` and `astream()` yield `StreamChunk` objects — one per streaming event.
```python
from ractogateway import openai_developer_kit as gpt, RactoPrompt
prompt = RactoPrompt(
role="You are a Python teacher.",
aim="Explain the concept clearly.",
constraints=["Use simple language.", "Give a short code example."],
tone="Friendly",
output_format="text",
)
kit = gpt.Chat(model="gpt-4o", default_prompt=prompt)
for chunk in kit.stream(gpt.ChatConfig(user_message="Explain Python generators")):
print(chunk.delta.text, end="", flush=True) # incremental text
if chunk.is_final:
print()
print(f"Finish reason : {chunk.finish_reason}")
print(f"Tokens used : {chunk.usage}")
print(f"Full response : {chunk.accumulated_text[:80]}...")
```
**Example output:**
```
A generator in Python is a special function that yields values one at a time,
allowing you to iterate over a sequence without loading everything into memory.
def count_up(n):
for i in range(n):
yield i
for num in count_up(5):
print(num) # 0, 1, 2, 3, 4
Finish reason : FinishReason.STOP
Tokens used : {"prompt_tokens": 55, "completion_tokens": 120, "total_tokens": 175}
Full response : A generator in Python is a special function that yields values one at a time...
```
### `StreamChunk` Field Reference
| Field | Type | Description |
| --- | --- | --- |
| `delta` | `StreamDelta` | Incremental content in this chunk |
| `accumulated_text` | `str` | Full text accumulated from all chunks so far |
| `is_final` | `bool` | `True` only on the very last chunk |
| `finish_reason` | `FinishReason \| None` | Set only on the final chunk |
| `tool_calls` | `list[ToolCallResult]` | Populated on the final chunk only (if tool calls occurred) |
| `usage` | `dict[str, int]` | Token usage — populated on the final chunk only |
| `raw` | `Any` | Raw provider streaming event |
### `StreamDelta` Field Reference
| Field | Type | Description |
| --- | --- | --- |
| `text` | `str` | Incremental text added in this chunk (empty string when no text) |
| `tool_call_id` | `str \| None` | Call ID of the tool call being streamed |
| `tool_call_name` | `str \| None` | Name of the tool being called |
| `tool_call_args_fragment` | `str \| None` | Partial JSON argument fragment |
---
## Async Support
Every method has a matching async variant.
```python
import asyncio
from ractogateway import openai_developer_kit as gpt, RactoPrompt
prompt = RactoPrompt(
role="You are a helpful assistant.",
aim="Answer the user's question.",
constraints=["Be concise."],
tone="Friendly",
output_format="text",
)
kit = gpt.Chat(model="gpt-4o", default_prompt=prompt)
async def main():
# Async chat — returns LLMResponse
response = await kit.achat(gpt.ChatConfig(user_message="What is SOLID?"))
print(response.content)
# "SOLID is a set of five object-oriented design principles: Single Responsibility,
# Open/Closed, Liskov Substitution, Interface Segregation, and Dependency Inversion."
# Async streaming — yields StreamChunk
async for chunk in kit.astream(gpt.ChatConfig(user_message="Explain SOLID briefly")):
print(chunk.delta.text, end="", flush=True)
if chunk.is_final:
print(f"\nDone. Tokens: {chunk.usage}")
asyncio.run(main())
```
---
## Embeddings
### `EmbeddingConfig` — Input
```python
config = gpt.EmbeddingConfig(
texts=["Hello world", "Goodbye world"], # required — list of strings (min 1)
model="text-embedding-3-large", # optional (overrides kit default)
dimensions=512, # optional — for models that support truncation
)
```
**`EmbeddingConfig` field reference:**
| Field | Type | Required | Default | Description |
| --- | --- | :---: | --- | --- |
| `texts` | `list[str]` | Yes | — | List of strings to embed (minimum 1) |
| `model` | `str \| None` | No | `None` | Override kit default embedding model |
| `dimensions` | `int \| None` | No | `None` | Output dimensionality (for supported models) |
| `extra` | `dict[str, Any]` | No | `{}` | Provider-specific pass-through kwargs |
### `EmbeddingResponse` — Output
```python
from ractogateway import openai_developer_kit as gpt
kit = gpt.Chat(model="gpt-4o", embedding_model="text-embedding-3-small")
response = kit.embed(gpt.EmbeddingConfig(texts=["cat", "dog", "automobile"]))
print(response.model)
# "text-embedding-3-small"
print(response.usage)
# {"prompt_tokens": 3, "total_tokens": 3}
print(len(response.vectors))
# 3
for v in response.vectors:
print(f"[{v.index}] '{v.text}' → vector dim={len(v.embedding)}, first5={v.embedding[:5]}")
# [0] 'cat' → vector dim=1536, first5=[0.023, -0.015, 0.041, ...]
# [1] 'dog' → vector dim=1536, first5=[0.019, -0.012, 0.038, ...]
# [2] 'automobile' → vector dim=1536, first5=[-0.003, 0.027, -0.011, ...]
```
**`EmbeddingResponse` field reference:**
| Field | Type | Description |
| --- | --- | --- |
| `vectors` | `list[EmbeddingVector]` | One embedding per input text, in order |
| `model` | `str` | The model used for embedding |
| `usage` | `dict[str, int]` | `prompt_tokens`, `total_tokens` |
| `raw` | `Any` | Unmodified provider response |
**`EmbeddingVector` field reference:**
| Field | Type | Description |
| --- | --- | --- |
| `index` | `int` | 0-based position in the input `texts` list |
| `text` | `str` | The original input text |
| `embedding` | `list[float]` | The dense float vector |
---
## Tool Calling
Define tools as plain Python functions — never write nested JSON dicts by hand. RactoGateway translates them into the correct format for each provider.
### Register Tools with `@registry.register`
```python
from ractogateway import ToolRegistry
registry = ToolRegistry()
@registry.register
def get_weather(city: str, unit: str = "celsius") -> str:
"""Get the current weather for a city.
:param city: The city name
:param unit: Temperature unit — celsius or fahrenheit
"""
# Your real implementation here
return f"Weather in {city}: 22°{unit[0].upper()}, partly cloudy"
@registry.register
def search_web(query: str, max_results: int = 3) -> list[str]:
"""Search the web for information.
:param query: The search query
:param max_results: Maximum number of results to return
"""
return [f"Result {i}: ..." for i in range(1, max_results + 1)]
```
### Register Tools with the Standalone `@tool` Decorator
```python
from ractogateway import tool, ToolRegistry
@tool
def calculate_mortgage(
principal: float,
annual_rate: float,
years: int,
) -> float:
"""Calculate monthly mortgage payment.
:param principal: Loan amount in dollars
:param annual_rate: Annual interest rate as a decimal (e.g., 0.05 for 5%)
:param years: Loan term in years
"""
monthly_rate = annual_rate / 12
n = years * 12
return principal * monthly_rate * (1 + monthly_rate) ** n / ((1 + monthly_rate) ** n - 1)
# Then add the decorated function to a registry
registry = ToolRegistry()
registry.register(calculate_mortgage)
```
### Register Pydantic Models as Tools
```python
from pydantic import BaseModel, Field
class SearchQuery(BaseModel):
"""Search the knowledge base for relevant documents."""
query: str = Field(description="The search query string")
max_results: int = Field(default=5, description="Maximum results to return")
category: str = Field(default="all", description="Filter by category")
registry.register(SearchQuery)
```
### Use Tools with Any Kit
```python
config = gpt.ChatConfig(
user_message="What's the weather in Tokyo and in Paris?",
tools=registry,
)
response = kit.chat(config)
print(response.finish_reason)
# FinishReason.TOOL_CALL
for tc in response.tool_calls:
print(f"Tool : {tc.name}")
print(f"Args : {tc.arguments}")
print(f"Call ID: {tc.id}")
print()
# Tool : get_weather
# Args : {"city": "Tokyo", "unit": "celsius"}
# Call ID: call_abc123
#
# Tool : get_weather
# Args : {"city": "Paris", "unit": "celsius"}
# Call ID: call_def456
# Execute the tool and get the result
fn = registry.get_callable("get_weather")
result = fn(**response.tool_calls[0].arguments)
print(result)
# "Weather in Tokyo: 22°C, partly cloudy"
```
### `ToolRegistry` Method Reference
| Method / Property | Signature | Returns | Description |
| --- | --- | --- | --- |
| `register` | `(fn_or_model, name=None, description=None)` | `None` | Register a callable or Pydantic model as a tool |
| `schemas` | (property) | `list[ToolSchema]` | All registered tool schemas |
| `get_schema` | `(name: str)` | `ToolSchema \| None` | Look up a tool schema by name |
| `get_callable` | `(name: str)` | `Callable \| None` | Retrieve the original registered function |
| `__len__` | `len(registry)` | `int` | Total number of registered tools |
| `__contains__` | `name in registry` | `bool` | Check whether a tool name is registered |
### `ToolCallResult` Field Reference
| Field | Type | Description |
| --- | --- | --- |
| `id` | `str` | Provider-assigned call ID |
| `name` | `str` | Function name |
| `arguments` | `dict[str, Any]` | Parsed argument dict (ready to `**unpack`) |
### `ToolSchema` — Internal Schema Representation
| Field | Type | Description |
| --- | --- | --- |
| `name` | `str` | Tool name |
| `description` | `str` | Tool description |
| `parameters` | `list[ParamSchema]` | List of parameter descriptors |
**`ToolSchema` methods:**
| Method | Returns | Description |
| --- | --- | --- |
| `to_json_schema()` | `dict[str, Any]` | Produce OpenAI-compatible JSON Schema for the parameters |
---
## Validated Response Models
Force the LLM output into a specific Pydantic shape. If the model doesn't produce valid JSON matching your model, you get a clear validation error — not silent garbage.
```python
from pydantic import BaseModel
from ractogateway import openai_developer_kit as gpt, RactoPrompt
class SentimentResult(BaseModel):
sentiment: str # "positive", "negative", "neutral"
confidence: float # 0.0 to 1.0
reasoning: str # short explanation
prompt = RactoPrompt(
role="You are a sentiment analysis model.",
aim="Classify the sentiment of the given text.",
constraints=["Only classify as positive, negative, or neutral.", "Confidence must be between 0.0 and 1.0."],
tone="Precise",
output_format=SentimentResult,
)
kit = gpt.Chat(model="gpt-4o", default_prompt=prompt)
config = gpt.ChatConfig(
user_message="Analyze sentiment: 'This product is absolutely amazing!'",
response_model=SentimentResult,
)
response = kit.chat(config)
print(response.content)
# '{"sentiment": "positive", "confidence": 0.97, "reasoning": "Strong positive adjective 'amazing' with intensifier 'absolutely'."}'
print(response.parsed)
# {"sentiment": "positive", "confidence": 0.97, "reasoning": "Strong positive..."}
# Access as validated Pydantic object
result = SentimentResult(**response.parsed)
print(result.sentiment) # "positive"
print(result.confidence) # 0.97
print(result.reasoning) # "Strong positive adjective 'amazing' with intensifier 'absolutely'."
```
---
## Multi-turn Conversations
Pass `history` to maintain context across turns.
```python
from ractogateway import openai_developer_kit as gpt, RactoPrompt
prompt = RactoPrompt(
role="You are a helpful coding assistant.",
aim="Help the user write and debug Python code.",
constraints=["Always provide runnable code examples.", "Explain errors clearly."],
tone="Friendly and educational",
output_format="text",
)
kit = gpt.Chat(model="gpt-4o", default_prompt=prompt)
# Turn 1
r1 = kit.chat(gpt.ChatConfig(user_message="Write a function to reverse a string in Python."))
print(r1.content)
# "def reverse_string(s: str) -> str:\n return s[::-1]"
# Turn 2 — pass history so the model remembers turn 1
r2 = kit.chat(gpt.ChatConfig(
user_message="Now make it handle None input gracefully.",
history=[
gpt.Message(role=gpt.MessageRole.USER, content="Write a function to reverse a string in Python."),
gpt.Message(role=gpt.MessageRole.ASSISTANT, content=r1.content),
],
))
print(r2.content)
# "def reverse_string(s: str | None) -> str | None:\n if s is None:\n return None\n return s[::-1]"
```
---
## Multimodal Attachments
`RactoFile` lets you attach images, PDFs, plain-text files, and any binary file to a prompt. Use `prompt.to_messages()` to build provider-ready message lists that include the attachments in the correct format for each provider.
### Creating a `RactoFile`
```python
from ractogateway.prompts.engine import RactoFile
# From a file path — MIME type is auto-detected
img = RactoFile.from_path("/path/to/photo.jpg") # image/jpeg
doc = RactoFile.from_path("/path/to/report.pdf") # application/pdf
txt = RactoFile.from_path("/path/to/notes.txt") # text/plain
# From raw bytes — supply MIME type explicitly
with open("chart.png", "rb") as fh:
chart = RactoFile.from_bytes(fh.read(), "image/png", name="chart.png")
# From a URL response
import requests
resp = requests.get("https://example.com/diagram.png")
diagram = RactoFile.from_bytes(resp.content, "image/png", name="diagram.png")
```
**`RactoFile` constructor methods:**
| Method | Signature | Returns | Description |
| --- | --- | --- | --- |
| `from_path` | `(path: str \| Path) -> RactoFile` | `RactoFile` | Load from file path; MIME auto-detected |
| `from_bytes` | `(data: bytes, mime_type: str, name: str) -> RactoFile` | `RactoFile` | Create from raw bytes |
**`RactoFile` property reference:**
| Member | Type | Description |
| --- | --- | --- |
| `data` | `bytes` | Raw file content |
| `mime_type` | `str` | MIME type, e.g. `"image/png"` |
| `name` | `str` | Filename hint |
| `base64_data` | `str` | Base-64 encoded file content |
| `is_image` | `bool` | `True` for JPEG, PNG, GIF, WebP |
| `is_pdf` | `bool` | `True` for `application/pdf` |
| `is_text` | `bool` | `True` for any `text/*` MIME |
### Building Multimodal Message Lists
Use `prompt.to_messages()` with the `attachments` parameter to build a multimodal message list, then pass it directly to the provider or low-level adapter:
```python
from ractogateway import RactoPrompt, Gateway
from ractogateway.adapters.openai_kit import OpenAILLMKit
from ractogateway.prompts.engine import RactoFile
prompt = RactoPrompt(
role="You are a data analyst specialising in chart interpretation.",
aim="Describe what the attached chart shows and extract the key insights.",
constraints=[
"Only describe what is visible in the image.",
"Never invent data points not shown in the chart.",
],
tone="Clear and concise",
output_format="text",
)
# Build multimodal messages using to_messages()
attachment = RactoFile.from_path("sales_q4.png")
messages = prompt.to_messages(
"What does this chart show?",
attachments=[attachment],
provider="openai",
)
# messages is now a list ready to send directly to the OpenAI API
# [
# {"role": "system", "content": "<compiled RACTO prompt>"},
# {"role": "user", "content": [
# {"type": "image_url", "image_url": {"url": "data:image/png;base64,..."}},
# {"type": "text", "text": "What does this chart show?"}
# ]}
# ]
```
### Provider Content-Block Translation
Each provider receives a different content-block format — `to_messages()` handles it transparently.
**OpenAI (`provider="openai"`)** — images become `image_url` blocks with inline data URIs:
```python
[
{"role": "system", "content": "<compiled RACTO system prompt>"},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "data:image/jpeg;base64,/9j/4AAQSkZJRgAB..."}
},
{"type": "text", "text": "Describe the image."}
]
}
]
```
**Anthropic (`provider="anthropic"`)** — images become `image` blocks, PDFs become `document` blocks:
```python
[
{"role": "system", "content": "<compiled RACTO system prompt>"},
{
"role": "user",
"content": [
{
"type": "image",
"source": {"type": "base64", "media_type": "image/jpeg", "data": "/9j/4AAQSkZJRgAB..."}
},
{"type": "text", "text": "Describe the image."}
]
}
]
```
**Google Gemini (`provider="google"`)** — files become `inline_data` parts:
```python
[
{"role": "system", "content": "<compiled RACTO system prompt>"},
{
"role": "user",
"content": [
{"inline_data": {"mime_type": "image/jpeg", "data": "/9j/4AAQSkZJRgAB..."}},
{"text": "Describe the image."}
]
}
]
```
### Supported File Types
| File type | MIME type | OpenAI | Anthropic | Google |
| --- | --- | :---: | :---: | :---: |
| JPEG | `image/jpeg` | `image_url` | `image` block | `inline_data` |
| PNG | `image/png` | `image_url` | `image` block | `inline_data` |
| GIF | `image/gif` | `image_url` | `image` block | `inline_data` |
| WebP | `image/webp` | `image_url` | `image` block | `inline_data` |
| PDF | `application/pdf` | `image_url` (data URI) | `document` block | `inline_data` |
| Plain text | `text/plain` | `text` block | `text` block | `text` part |
| Any other | `*/*` | `image_url` (data URI) | labelled `text` block | `inline_data` |
---
## Low-Level Gateway
`Gateway` is a thin wrapper around any `BaseLLMAdapter`. Use it when you need direct access to prompt + adapter without the `ChatConfig` convenience layer — for example, when you want fine-grained control over individual calls.
### Creating and Using a Gateway
```python
from ractogateway import RactoPrompt, Gateway, ToolRegistry
from ractogateway.adapters.openai_kit import OpenAILLMKit
adapter = OpenAILLMKit(model="gpt-4o", api_key="sk-...")
prompt = RactoPrompt(
role="You are a code reviewer.",
aim="Identify bugs in the given code.",
constraints=["Report only real bugs.", "If no bugs, say so."],
tone="Concise",
output_format="json",
)
gw = Gateway(adapter=adapter, default_prompt=prompt)
# Sync execution
response = gw.run(user_message="Review: def div(a, b): return a / b")
print(response.parsed)
# {"bugs": ["ZeroDivisionError if b is 0"], "severity": "high"}
# Async execution
import asyncio
async def main():
response = await gw.arun(user_message="Review: x = 1; del x; print(x)")
print(response.parsed)
asyncio.run(main())
```
**`Gateway` constructor parameters:**
| Parameter | Type | Required | Default | Description |
| --- | --- | :---: | --- | --- |
| `adapter` | `BaseLLMAdapter` | Yes | — | A concrete adapter (`OpenAILLMKit`, `GoogleLLMKit`, `AnthropicLLMKit`) |
| `tools` | `ToolRegistry \| None` | No | `None` | Default tool registry for all calls |
| `default_prompt` | `RactoPrompt \| None` | No | `None` | Fallback prompt when `run()` is called without one |
**`Gateway.run()` and `Gateway.arun()` parameters:**
| Parameter | Type | Default | Description |
| --- | --- | --- | --- |
| `prompt` | `RactoPrompt \| None` | `None` | Override `default_prompt` for this call |
| `user_message` | `str` | `""` | The end-user's query |
| `tools` | `ToolRegistry \| None` | `None` | Override gateway-level tool registry |
| `temperature` | `float` | `0.0` | Sampling temperature |
| `max_tokens` | `int` | `4096` | Maximum response tokens |
| `response_model` | `type[BaseModel] \| None` | `None` | Validate JSON output against this Pydantic model |
| `**kwargs` | `Any` | — | Passed through to the adapter |
**Returns:** `LLMResponse`
---
## Switching Providers
Same `ChatConfig`, different kit. Zero code changes to your prompt or config.
```python
from ractogateway import openai_developer_kit as gp | text/markdown | null | Ved Prakash Pathak <vp.ved.vpp@gmail.com> | null | Ved Prakash Pathak <vp.ved.vpp@gmail.com> | null | ai, anthropic, anti-hallucination, chromadb, chunking, claude, developer-kit, document-parsing, embeddings, faiss, function-calling, gateway, gemini, gpt, llm, milvus, openai, pgvector, pinecone, prompt-engineering, pydantic, qdrant, racto, rag, retrieval-augmented-generation, sdk, streaming, structured-output, tool-use, unified-api, vector-database, voyage-ai, weaviate | [
"Development Status :: 3 - Alpha",
"Framework :: Pydantic",
"Framework :: Pydantic :: 2",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent... | [] | null | null | >=3.10 | [] | [] | [] | [
"pydantic<3.0,>=2.0",
"anthropic<1.0,>=0.40; extra == \"all\"",
"google-genai<2.0,>=1.0; extra == \"all\"",
"openai<3.0,>=1.0; extra == \"all\"",
"anthropic<1.0,>=0.40; extra == \"anthropic\"",
"anthropic<1.0,>=0.40; extra == \"dev\"",
"google-genai<2.0,>=1.0; extra == \"dev\"",
"mypy>=1.13; extra == ... | [] | [] | [] | [
"Homepage, https://github.com/IAMPathak2702/RactoGateway",
"Documentation, https://ractogateway.readthedocs.io",
"Repository, https://github.com/IAMPathak2702/RactoGateway",
"Issues, https://github.com/IAMPathak2702/RactoGateway/issues",
"Changelog, https://github.com/IAMPathak2702/RactoGateway/blob/main/CH... | twine/6.2.0 CPython/3.11.8 | 2026-02-19T08:18:36.866473 | ractogateway-0.1.2.tar.gz | 115,202 | 56/6e/3deb3fa6166bff30dbc4b7a861da2c7ac330232f0081beb86f62a1cc6b3d/ractogateway-0.1.2.tar.gz | source | sdist | null | false | 1e9c518d414e17e6475be6039f9771cc | 4dfa8672bb3ff40f4e662966b8513877fa24db84e35056a450d7e268a0995fd1 | 566e3deb3fa6166bff30dbc4b7a861da2c7ac330232f0081beb86f62a1cc6b3d | Apache-2.0 | [
"LICENSE"
] | 256 |
2.4 | markdown-to-confluence | 0.5.6 | Publish Markdown files to Confluence wiki | # Publish Markdown files to Confluence wiki
Contributors to software projects typically write documentation in Markdown format and host Markdown files in collaborative version control systems (VCS) such as GitHub or GitLab to track changes and facilitate the review process. However, not everyone at a company has access to VCS, and documents are often circulated in Confluence wiki instead.
Replicating documentation to Confluence by hand is tedious, and a lack of automated synchronization with the project repositories where the documents live leads to outdated documentation.
This Python package
* parses Markdown files,
* converts Markdown content into the Confluence Storage Format (XHTML),
* invokes Confluence API endpoints to upload images and content.
## Features
* Sections and subsections
* Text with **bold**, *italic*, `monospace`, <ins>underline</ins> and ~~strikethrough~~
* Link to [sections on the same page](#getting-started) or [external locations](http://example.com/)
* Subscript and superscript
* Emoji
* Ordered and unordered lists
* Block quotes
* Code blocks (e.g. Python, JSON, XML)
* Images (uploaded as Confluence page attachments or hosted externally)
* Tables
* Footnotes
* [Table of contents](https://docs.gitlab.com/ee/user/markdown.html#table-of-contents)
* [Admonitions](https://python-markdown.github.io/extensions/admonition/) and alert boxes in [GitHub](https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/basic-writing-and-formatting-syntax#alerts) and [GitLab](https://docs.gitlab.com/ee/development/documentation/styleguide/#alert-boxes)
* [Collapsed sections](https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/organizing-information-with-collapsed-sections)
* [Tasklists](https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/about-tasklists)
* draw\.io diagrams
* [Mermaid diagrams](https://mermaid.live/)
* PlantUML diagrams
* Math formulas with LaTeX notation
* Confluence status labels and date widget
Whenever possible, the implementation uses [Confluence REST API v2](https://developer.atlassian.com/cloud/confluence/rest/v2/) to fetch space properties, and get, create or update page content.
## Installation
**Required.** Install the core package from [PyPI](https://pypi.org/project/markdown-to-confluence/):
```sh
pip install markdown-to-confluence
```
### Command-line utilities
**Optional.** Converting `*.drawio` diagrams to PNG or SVG images before uploading to Confluence as attachments requires installing [draw.io](https://www.drawio.com/). (Refer to `--render-drawio`.)
**Optional.** Converting code blocks of Mermaid diagrams to PNG or SVG images before uploading to Confluence as attachments requires [mermaid-cli](https://github.com/mermaid-js/mermaid-cli). (Refer to `--render-mermaid`.)
```sh
npm install -g @mermaid-js/mermaid-cli
```
**Optional.** Pre-rendering PlantUML diagrams into PNG or SVG images requires Java, Graphviz and [PlantUML](https://plantuml.com/). (Refer to `--render-plantuml`.)
1. **Install Java**: Version 8 or later from [Adoptium](https://adoptium.net/) or [Oracle](https://www.oracle.com/java/technologies/downloads/)
2. **Install Graphviz**: Required for most diagram types in PlantUML (except sequence diagrams)
* **Ubuntu/Debian**: `sudo apt-get install Graphviz`
* **macOS**: `brew install graphviz`
* **Windows**: Download from [graphviz.org](https://graphviz.org/download/)
3. **Download PlantUML JAR**: Download [plantuml.jar](https://github.com/plantuml/plantuml/releases) and set `PLANTUML_JAR` environment variable to point to it
**Optional.** Converting formulas and equations to PNG or SVG images requires [Matplotlib](https://matplotlib.org/):
```sh
pip install matplotlib
```
### Marketplace apps
As authors of *md2conf*, we don't endorse or support any particular Confluence marketplace apps.
**Optional.** Editable draw\.io diagrams require [draw.io Diagrams marketplace app](https://marketplace.atlassian.com/apps/1210933/draw-io-diagrams-uml-bpmn-aws-erd-flowcharts). (Refer to `--no-render-drawio`.)
**Optional.** Displaying Mermaid diagrams in Confluence without pre-rendering in the synchronization phase requires a [marketplace app](https://marketplace.atlassian.com/apps/1226567/mermaid-diagrams-for-confluence). (Refer to `--no-render-mermaid`.)
**Optional.** PlantUML diagrams are embedded with compressed source data and are displayed using the [PlantUML Diagrams for Confluence](https://marketplace.atlassian.com/apps/1215115/plantuml-diagrams-for-confluence) app (if installed). (Refer to `--no-render-plantuml`.)
Installing `plantuml.jar` (see above) helps display embedded diagrams with pre-calculated optimal dimensions.
**Optional.** Displaying formulas and equations in Confluence requires [marketplace app](https://marketplace.atlassian.com/apps/1226109/latex-math-for-confluence-math-formula-equations), refer to [LaTeX Math for Confluence - Math Formula & Equations](https://help.narva.net/latex-math-for-confluence/). (Refer to `--no-render-latex`.)
## Getting started
In order to get started, you will need
* your organization domain name (e.g. `example.atlassian.net`),
* base path for Confluence wiki (typically `/wiki/` for managed Confluence, `/` for on-premise)
* your Confluence username (e.g. `levente.hunyadi@instructure.com`) (only if required by your deployment),
* a Confluence API token (a string of alphanumeric characters), and
* the space key in Confluence (e.g. `SPACE`) you are publishing content to.
### Obtaining an API token
1. Log in to <https://id.atlassian.com/manage/api-tokens>.
2. Click *Create API token*.
3. From the dialog that appears, enter a memorable and concise *Label* for your token and click *Create*.
4. Click *Copy to clipboard*, then paste the token to your script, or elsewhere to save.
### Setting up the environment
Confluence organization domain, base path, username, API token and space key can be specified at runtime or set as Confluence environment variables (e.g. add to your `~/.profile` on Linux, or `~/.bash_profile` or `~/.zshenv` on MacOS):
```sh
export CONFLUENCE_DOMAIN='example.atlassian.net'
export CONFLUENCE_PATH='/wiki/'
export CONFLUENCE_USER_NAME='levente.hunyadi@instructure.com'
export CONFLUENCE_API_KEY='0123456789abcdef'
export CONFLUENCE_SPACE_KEY='SPACE'
```
On Windows, these can be set via system properties.
If you use Atlassian scoped API tokens, you may want to set API URL directly, substituting `CLOUD_ID` with your own Cloud ID:
```sh
export CONFLUENCE_API_URL='https://api.atlassian.com/ex/confluence/CLOUD_ID/'
```
In this case, *md2conf* can automatically determine `CONFLUENCE_DOMAIN` and `CONFLUENCE_PATH`.
If you can't find your `CLOUD_ID` but assign both `CONFLUENCE_DOMAIN` and `CONFLUENCE_PATH`, *md2conf* makes a best-effort attempt to determine `CONFLUENCE_API_URL`.
### Permissions
The tool requires appropriate permissions in Confluence in order to invoke endpoints.
We recommend the following scopes for scoped API tokens:
* `read:attachment:confluence`
* `read:content:confluence`
* `read:content-details:confluence`
* `read:label:confluence`
* `read:page:confluence`
* `read:space:confluence`
* `write:attachment:confluence`
* `write:content:confluence`
* `write:label:confluence`
* `write:page:confluence`
* `delete:attachment:confluence`
* `delete:content:confluence`
* `delete:page:confluence`
If a Confluence username is set, the tool uses HTTP *Basic* authentication to pass the username and the API key to Confluence REST API endpoints. If no username is provided, the tool authenticates with HTTP *Bearer*, and passes the API key as the bearer token.
If you lack appropriate permissions, you will get an *Unauthorized* response from Confluence. The tool will emit a message that looks as follows:
```
2023-06-30 23:59:59,000 - ERROR - <module> [80] - 401 Client Error: Unauthorized for url: ...
```
### Associating a Markdown file with a wiki page
Each Markdown file is associated with a Confluence wiki page either *explicitly* or *implicitly*.
#### Explicit association
We associate a Markdown document with a Confluence page explicitly by specifying the related Confluence page ID in a Markdown comment:
```markdown
<!-- confluence-page-id: 20250001023 -->
```
The above tells the tool to synchronize the Markdown file with the given Confluence page ID. The Confluence wiki page must be created beforehand. The comment can be placed anywhere in the source file.
#### Implicit association
Each Markdown document is automatically paired with a Confluence page in the target space if they have the same title.
If a Confluence page with the given title doesn't exist, it is created automatically, and its identifier is injected into the source as a Markdown comment.
If a Confluence page already exists whose title matches the Markdown document title, additional precautions are taken to avoid overwriting an unrelated page. Each implicitly associated page has to trace back to a trusted well-known Confluence page via parent-child relationships before its content would be synchronized. Trusted Confluence pages include:
* the *root page* whose page ID is
* specified in the command line, or
* extracted from the index file of a directory that is being synchronized
* a page associated with a Markdown document via a page ID
* embedded as a Markdown comment, or
* specified in the Markdown front-matter
If a Confluence page doesn't have a trusted ancestor, synchronization fails. This restricts updates to subtrees of well-known pages.
### Setting the Confluence space
If you work in an environment where there are multiple Confluence spaces, and some Markdown pages may go into one space, whereas other pages may go into another, you can set the target space on a per-document basis:
```markdown
<!-- confluence-space-key: SPACE -->
```
This overrides the default space set via command-line arguments or environment variables.
### Page title
*md2conf* makes a best-effort attempt at setting the Confluence wiki page title when it publishes a Markdown document the first time. The following act as sources for deriving a page title:
1. The `title` attribute set in the [front-matter](https://daily-dev-tips.com/posts/what-exactly-is-frontmatter/). Front-matter is a block delimited by `---` at the beginning of a Markdown document. Both JSON and YAML syntax are supported.
2. The text of the topmost unique Markdown heading (`#`). For example, if a document has a single first-level heading (e.g. `# My document`), its text is used. However, if there are multiple first-level headings, this step is skipped.
3. The file name (without the extension `.md`) and a digest. The digest is included to ensure the title is unique across the Confluence space.
If the `title` attribute (in the front-matter) or the topmost unique heading (in the document body) changes, the Confluence page title is updated. A warning is raised if the new title conflicts with the title of another page, and thus cannot be updated.
### Publishing a single page
*md2conf* has two modes of operation: *single-page mode* and *directory mode*.
In single-page mode, you specify a single Markdown file as the source, which can contain absolute links to external locations (e.g. `https://example.com`) but not relative links to other pages (e.g. `local.md`). In other words, the page must be stand-alone.
### Publishing a directory
*md2conf* allows you to convert and publish a directory of Markdown files rather than a single Markdown file in *directory mode* if you pass a directory as the source. This will traverse the specified directory recursively, and synchronize each Markdown file.
First, *md2conf* builds an index of pages in the directory hierarchy. The index maps each Markdown file path to a Confluence page ID. Whenever a relative link is encountered in a Markdown file, the relative link is replaced with a Confluence URL to the referenced page with the help of the index. All relative links must point to Markdown files that are located in the directory hierarchy.
If a Markdown file doesn't yet pair up with a Confluence page, *md2conf* creates a new page and assigns a parent. Parent-child relationships are reflected in the navigation panel in Confluence. You can set a root page ID with the command-line option `-r`, which constitutes the topmost parent. (This could correspond to the landing page of your Confluence space. The Confluence page ID is always revealed when you edit a page.) Whenever a directory contains the file `index.md` or `README.md`, this page becomes the future parent page, and all Markdown files in this directory (and possibly nested directories) become its child pages (unless they already have a page ID). However, if an `index.md` or `README.md` file is subsequently found in one of the nested directories, it becomes the parent page of that directory, and any of its subdirectories.
The top-level directory to be synchronized must always have an `index.md` or `README.md`, which maps to the root of the corresponding sub-tree in Confluence (specified with `-r`).
The concepts above are illustrated in the following sections.
#### File-system directory hierarchy
The title of each Markdown file (either the text of the topmost unique heading (`#`), or the title specified in front-matter) is shown next to the file name. `docs` is the top-level directory to be synchronized.
```
docs
├── index.md: Eternal golden braid
├── computer-science
│ ├── index.md: Introduction to computer science
│ ├── algebra.md: Linear algebra
│ └── algorithms.md: Theory of algorithms
├── machine-learning
│ ├── README.md: AI and ML
│ ├── awareness.md: Consciousness and intelligence
│ └── statistics
│ ├── index.md: Introduction to statistics
│ └── median.md: Mean vs. median
└── ethics.md: History of ethics
```
#### Page hierarchy in Confluence
Observe how `index.md` and `README.md` files have assumed parent (or ancestor) role for any Markdown files in the same directory (or below).
```
Eternal golden braid
├── Introduction to computer science
│ ├── Linear algebra
│ └── Theory of algorithms
├── AI and ML
│ ├── Consciousness and intelligence
│ └── Introduction to statistics
│ └── Mean vs. median
└── History of ethics
```
### Subscript and superscript
Subscripts may either use the character *tilde* (e.g. `CH~3~CH~2~OH`) or the HTML tag `<sub>`.
Superscripts may either use the character *caret* (e.g. `e^-ix^`) or the HTML tag `<sup>`.
### Emoji
The short name notation `:smile:` in a Markdown document is converted into the corresponding emoji 😄 when publishing to Confluence.
*md2conf* relies on the [Emoji extension](https://facelessuser.github.io/pymdown-extensions/extensions/emoji/) of [PyMdown Extensions](https://facelessuser.github.io/pymdown-extensions/) to parse the short name notation with colons, and generate Confluence Storage Format output such as
```xml
<ac:emoticon ac:name="smile" ac:emoji-shortname=":smile:" ac:emoji-id="1f604" ac:emoji-fallback="😄"/>
```
### Lists and tables
If your Markdown lists or tables don't appear in Confluence as expected, verify that the list or table is delimited by a blank line both before and after, as per strict Markdown syntax. While some previewers accept a more lenient syntax (e.g. an itemized list immediately following a paragraph), *md2conf* uses [Python-Markdown](https://python-markdown.github.io/) internally to convert Markdown into XHTML, which expects the Markdown document to adhere to the stricter syntax.
Likewise, if you have a nested list, make sure that nested items are indented by exactly ***four*** spaces as compared to the parent node:
```markdown
1. List item 1
* Nested item 1
1. Item 1
2. Item 2
* Nested item 2
- Item 3
- Item 4
2. List item 2
1. Nested item 3
2. Nested item 4
```
### Publishing images
Local images referenced in a Markdown file are automatically published to Confluence as attachments to the page.
* Relative paths (e.g. `path/to/image.png` or `../to/image.png`) resolve to absolute paths w.r.t. the Markdown document location.
* Absolute paths (e.g. `/path/to/image.png`) are interpreted w.r.t. to the synchronization root (typically the shell current directory).
As a security measure, resolved paths can only reference files that are in the directory hierarchy of the synchronization root; you can't use `..` to leave the top-level directory of the synchronization root.
Unfortunately, Confluence struggles with SVG images, e.g. they may only show in *edit* mode, display in a wrong size or text labels in the image may be truncated. (This seems to be a known issue in Confluence.) In order to mitigate the issue, whenever *md2conf* encounters a reference to an SVG image in a Markdown file, it checks whether a corresponding PNG image also exists in the same directory, and if a PNG image is found, it is published instead.
External images referenced with an absolute URL retain the original URL.
### draw\.io diagrams
With the command-line option `--no-render-drawio` (default), editable diagram data is extracted from images with embedded draw\.io diagrams (`*.drawio.png` and `*.drawio.svg`), and uploaded to Confluence as attachments. Files that match `*.drawio` or `*.drawio.xml` are uploaded as-is. You need a [marketplace app](https://marketplace.atlassian.com/apps/1210933/draw-io-diagrams-uml-bpmn-aws-erd-flowcharts) to view and edit these diagrams on a Confluence page.
With the command-line option `--render-drawio`, images with embedded draw\.io diagrams (`*.drawio.png` and `*.drawio.svg`) are uploaded unchanged, and shown on the Confluence page as images. These diagrams are not editable in Confluence. When both an SVG and a PNG image is available, PNG is preferred. Files that match `*.drawio` or `*.drawio.xml` are converted into PNG or SVG images by invoking draw\.io as a command-line utility, and the generated images are uploaded to Confluence as attachments, and shown as images.
### Mermaid diagrams
You can add [Mermaid diagrams](https://mermaid.js.org/) to your Markdown documents to create visual representations of systems, processes, and relationships. There are two ways to include a Mermaid diagram:
* an image reference to a `.mmd` or `.mermaid` file, i.e. ``, or
* a fenced code block with the language specifier `mermaid`.
*md2conf* offers two options to publish the diagram:
1. Pre-render into an image (command-line option `--render-mermaid`). The source file or code block is interpreted by and converted into a PNG or SVG image with the Mermaid diagram utility [mermaid-cli](https://github.com/mermaid-js/mermaid-cli). The generated image is then uploaded to Confluence as an attachment to the page.
2. Display on demand (command-line option `--no-render-mermaid`). The code block is transformed into a [diagram macro](https://stratus-addons.atlassian.net/wiki/spaces/MDFC/overview), which is processed by Confluence. You need a separate [marketplace app](https://marketplace.atlassian.com/apps/1226567/mermaid-diagrams-for-confluence) to turn macro definitions into images when a Confluence page is visited.
If you are running into issues with the pre-rendering approach (e.g. misaligned labels in the generated image), verify if `mermaid-cli` can process the Mermaid source:
```sh
mmdc -i sample.mmd -o sample.png -b transparent --scale 2
```
Ensure that `mermaid-cli` is set up, refer to *Installation* for instructions.
Note that `mermaid-cli` has some implicit dependencies (e.g. a headless browser) that may not be immediately available in a CI/CD environment such as GitHub Actions. Refer to the `Dockerfile` in the *md2conf* project root, or [mermaid-cli documentation](https://github.com/mermaid-js/mermaid-cli) on how to install these dependencies such as a `chromium-browser` and various fonts.
### LaTeX math formulas
Inline formulas can be enclosed with `$` signs, or delimited with `\(` and `\)`, i.e.
* the code `$\sum_{i=1}^{n} i = \frac{n(n+1)}{2}$` is shown as $\sum_{i=1}^{n} i = \frac{n(n+1)}{2}$,
* and `\(\lim _{x\rightarrow \infty }\frac{1}{x}=0\)` is shown as $\lim _{x\rightarrow \infty }\frac{1}{x}=0$.
Block formulas can be enclosed with `$$`, or wrapped in code blocks specifying the language `math`:
```markdown
$$\int _{a}^{b}f(x)dx=F(b)-F(a)$$
```
is shown as
$$\int _{a}^{b}f(x)dx=F(b)-F(a)$$
If installed, *md2conf* can pre-render math formulas with [Matplotlib](https://matplotlib.org/). This approach doesn't require a third-party Confluence extension.
Displaying math formulas in Confluence (without pre-rendering) requires the extension [LaTeX Math for Confluence - Math Formula & Equations](https://help.narva.net/latex-math-for-confluence/).
### Alignment
You can configure diagram and image alignment using the JSON/YAML front-matter attribute `alignment` or the command-line argument of the same name. Possible values are `center` (default), `left` and `right`. The value configured in the Markdown file front-matter takes precedence.
Unfortunately, not every third-party app supports every alignment variant. For example, the draw\.io marketplace app supports left and center but not right alignment; and diagrams produced by the Mermaid marketplace app are always centered, ignoring the setting for alignment.
### Page preview cards
When a link to an absolute URL fully occupies a paragraph, it is automatically transformed into a block-level *card*, showing a document preview. These previews are represented in Confluence by the HTML element `<a>` having an attribute `data-card-appearance` with the value `block`. Thus, the following Markdown syntax will produce equivalent Confluence Storage Format output when the source file is converted:
```md
[Project page](https://github.com/hunyadi/md2conf)
<a href="https://github.com/hunyadi/md2conf" data-card-appearance="block">Project page</a>
```
### Confluence widgets
*md2conf* supports some Confluence widgets. If the appropriate code is found when a Markdown document is processed, it is automatically replaced with Confluence Storage Format XML that produces the corresponding widget.
| Markdown code | Confluence equivalent |
| :----------------------------------------- | :------------------------------------------------------ |
| `[[_TOC_]]` | table of contents (based on headings) |
| `[[_LISTING_]]` | child pages (of current page) |
| `![My label][STATUS-GRAY]` | gray status label (with specified label text) |
| `![My label][STATUS-PURPLE]` | purple status label |
| `![My label][STATUS-BLUE]` | blue status label |
| `![My label][STATUS-RED]` | red status label |
| `![My label][STATUS-YELLOW]` | yellow status label |
| `![My label][STATUS-GREEN]` | green status label |
| `<input type="date" value="YYYY-MM-DD" />` | date widget (with year, month and day set as specified) |
Use the pseudo-language `csf` in a Markdown code block to pass content directly to Confluence. The content must be a single XML node that conforms to Confluence Storage Format (typically an `ac:structured-macro`) but is otherwise not validated. The following example shows how to create a panel similar to an *info panel* but with custom background color and emoji. Notice that `ac:rich-text-body` uses XHTML, not Markdown.
````markdown
```csf
<ac:structured-macro ac:name="panel" ac:schema-version="1">
<ac:parameter ac:name="panelIconId">1f642</ac:parameter>
<ac:parameter ac:name="panelIcon">:slight_smile:</ac:parameter>
<ac:parameter ac:name="panelIconText">🙂</ac:parameter>
<ac:parameter ac:name="bgColor">#FFF0B3</ac:parameter>
<ac:rich-text-body>
<p>A <em>custom colored panel</em> with a 🙂 emoji</p>
</ac:rich-text-body>
</ac:structured-macro>
```
````
### Implicit URLs
*md2conf* implicitly defines some URLs, as if you included the following at the start of the Markdown document for each URL:
```markdown
[CUSTOM-URL]: https://example.com/path/to/resource
```
Specifically, image references for status labels (e.g. `![My label][STATUS-RED]`) are automatically resolved into internally defined URLs via this mechanism.
### Colors
Confluence allows setting text color and highlight color. Even though Markdown doesn't directly support colors, it is possible to set text and highlight color via the HTML element `<span>` and the CSS attributes `color` and `background-color`, respectively:
Text in <span style="color: rgb(255,86,48);">red</span>, <span style="color: rgb(54,179,126);">green</span> and <span style="color: rgb(76,154,255);">blue</span>:
```markdown
Text in <span style="color: rgb(255,86,48);">red</span>, <span style="color: rgb(54,179,126);">green</span> and <span style="color: rgb(76,154,255);">blue</span>.
```
Highlight in <span style="background-color: rgb(198,237,251);">teal</span>, <span style="background-color: rgb(211,241,167);">lime</span> and <span style="background-color: rgb(254,222,200);">yellow</span>:
```markdown
Highlight in <span style="background-color: rgb(198,237,251);">teal</span>, <span style="background-color: rgb(211,241,167);">lime</span> and <span style="background-color: rgb(254,222,200);">yellow</span>.
```
Highlighting is also supported via `==marks==`. However, the background color is not customizable.
The following table shows standard text colors (CSS `color`) that are available via Confluence UI:
| Color name | CSS attribute value |
| :------------ | :------------------ |
| bold blue | rgb(7,71,166) |
| blue | rgb(76,154,255) |
| subtle blue | rgb(179,212,255) |
| bold teal | rgb(0,141,166) |
| teal | rgb(0,184,217) |
| subtle teal | rgb(179,245,255) |
| bold green | rgb(0,102,68) |
| green | rgb(54,179,126) |
| subtle green | rgb(171,245,209) |
| bold orange | rgb(255,153,31) |
| yellow | rgb(255,196,0) |
| subtle yellow | rgb(255,240,179) |
| bold red | rgb(191,38,0) |
| red | rgb(255,86,48) |
| subtle red | rgb(255,189,173) |
| bold purple | rgb(64,50,148) |
| purple | rgb(101,84,192) |
| subtle purple | rgb(234,230,255) |
The following table shows standard highlight colors (CSS `background-color`) that are available via Confluence UI:
| Color name | CSS attribute value |
| ------------- | ------------------- |
| teal | rgb(198,237,251) |
| lime | rgb(211,241,167) |
| yellow | rgb(254,222,200) |
| magenta | rgb(253,208,236) |
| purple | rgb(223,216,253) |
### HTML in Markdown
*md2conf* relays HTML elements nested in Markdown content to Confluence (such as `e<sup>x</sup>` for superscript). However, Confluence uses an extension of XHTML, i.e. the content must qualify as valid XML too. In particular, unterminated tags (e.g. `<br>` or `<img ...>`) or inconsistent nesting (e.g. `<b><i></b></i>`) are not permitted, and will raise an XML parsing error. When an HTML element has no content such as `<br>` or `<img>`, use a self-closing tag:
```html
<br/>
<img src="image.png" width="24" height="24" />
```
### Links to attachments
If *md2conf* encounters a Markdown link that points to a file in the directory hierarchy being synchronized, it automatically uploads the file as an attachment to the Confluence page. Activating the link in Confluence downloads the file. Typical examples include PDFs (`*.pdf`), word processor documents (`*.docx`), spreadsheets (`*.xlsx`), plain text files (`*.txt`) or logs (`*.log`). The MIME type is set based on the file type.
### Setting generated-by prompt text for wiki pages
In order to ensure readers are not editing a generated document, the tool adds a warning message at the top of the Confluence page as an *info panel*. You can customize the text that appears. The text can contain markup as per the [Confluence Storage Format](https://confluence.atlassian.com/doc/confluence-storage-format-790796544.html), and is emitted directly into the *info panel* macro.
Provide generated-by prompt text in the Markdown file with a tag:
```markdown
<!-- generated-by: Do not edit! Check out the <a href="https://example.com/project">original source</a>. -->
```
Alternatively, use the `--generated-by GENERATED_BY` option. The tag takes precedence.
The generated-by text can also be templated with the following variables:
- `%{filename}`: the name of the Markdown file
- `%{filestem}`: the name of the Markdown file without the extension
- `%{filepath}`: the path of the Markdown file relative to the _source root_
- `%{filedir}`: the dirname of the `%{filepath}` (the path without the filename)
When publishing a directory hierarchy, the *source root* is the directory in which *md2conf* is launched. When publishing a single file, this is the directory in which the Markdown file resides.
It can be used with the CLI `--generated-by` option or directly in the files:
```markdown
<!-- generated-by: Do not edit! Check out the file %{filepath} in the repo -->
```
### Avoiding duplicate titles
By default, when *md2conf* extracts a page title from the first unique heading in a Markdown document, the heading remains in the document body. This means the title appears twice on the Confluence page: once as the page title at the top, and once as the first heading in the content.
To avoid this duplication, use the `--skip-title-heading` option. When enabled, *md2conf* removes the first heading from the document body if it was used as the page title. This option only takes effect when:
1. The title was extracted from the document's first unique heading (not from front-matter), AND
2. There is exactly one top-level heading in the document.
If the title comes from the `title` attribute in front-matter, the heading is preserved in the document body regardless of this setting, as the heading and title are considered separate.
**Example without `--skip-title-heading` (default):**
Markdown:
```markdown
# Installation Guide
Follow these steps...
```
Confluence displays:
- Page title: "Installation Guide"
- Content: Starts with heading "Installation Guide", followed by "Follow these steps..."
**Example with `--skip-title-heading`:**
Same Markdown source, but Confluence displays:
- Page title: "Installation Guide"
- Content: Starts directly with "Follow these steps..." (heading removed)
**Edge case: Abstract or introductory text before the title:**
When a document has content before the first heading (like an abstract), removing the heading eliminates the visual separator between the introductory text and the main content:
```markdown
This is an abstract paragraph providing context.
# Document Title
This is the main document content.
```
With `--skip-title-heading`, the output becomes:
- Page title: "Document Title"
- Content: "This is an abstract paragraph..." flows directly into "This is the main document content..." (no heading separator)
While the structure remains semantically correct, the visual separation is lost. If you need to maintain separation, consider these workarounds:
1. **Use a horizontal rule:** Add `---` after the abstract to create visual separation
2. **Use an admonition block:** Wrap the abstract in an info/note block
3. **Use front-matter title:** Set `title` in front-matter to keep the heading in the body
### Ignoring files
Skip files and subdirectories in a directory with rules defined in `.mdignore`. Each rule should occupy a single line. Rules follow the syntax (and constraints) of [fnmatch](https://docs.python.org/3/library/fnmatch.html#fnmatch.fnmatch). Specifically, `?` matches any single character, and `*` matches zero or more characters. For example, use `up-*.md` to exclude Markdown files that start with `up-`. Lines that start with `#` are treated as comments.
Files that don't have the extension `*.md` are skipped automatically. Hidden directories (whose name starts with `.`) are not recursed into. To skip an entire directory, add the name of the directory without a trailing `/`.
Relative paths to items in a nested directory are not supported. You must put `.mdignore` in the same directory where the items to be skipped reside.
If you add the `synchronized` attribute to JSON or YAML front-matter with the value `false`, the document content (including attachments) and metadata (e.g. tags) will not be synchronized with Confluence:
```yaml
---
title: "Collaborating with other teams"
page_id: "19830101"
synchronized: false
---
This Markdown document is neither parsed, nor synchronized with Confluence.
```
This is useful if you have a page in a hierarchy that participates in parent-child relationships but whose content is edited directly in Confluence. Specifically, these documents can be referenced with relative links from other Markdown documents in the file system tree.
### Excluding content sections
When maintaining documentation in both Git repositories and Confluence, you may want certain content to appear only in the repository but not on Confluence pages. Use HTML comment markers to wrap and exclude specific sections from synchronization:
```markdown
# Project Documentation
This content appears in both Git and Confluence.
<!-- confluence-skip-start -->
## Internal References
- See [internal design doc](../internal/design.md)
- Related to issue #123
- Development notes for the team
<!-- confluence-skip-end -->
## Getting Started
This section is published to Confluence.
```
Content between `<!-- confluence-skip-start -->` and `<!-- confluence-skip-end -->` markers is removed before conversion and will not appear on the Confluence page. This is useful for:
- Repository-specific navigation and cross-references
- GitLab/GitHub-specific metadata
- Content relevant only for developers with repository access
Multiple exclusion blocks can be used in the same document.
### Labels
If a Markdown document has the front-matter attribute `tags`, *md2conf* assigns the specified tags to the Confluence page as labels.
```yaml
---
title: "Example document"
tags: ["markdown", "md", "wiki"]
---
```
Any previously assigned labels are discarded. As per Confluence terminology, new labels have the `prefix` of `global`.
If a document has no `tags` attribute, existing Confluence labels are left intact.
### Content properties
The front-matter attribute `properties` in a Markdown document allows setting Confluence content properties on a page. Confluence content properties are a way to store structured metadata in the form of key-value pairs directly on Confluence content. The values in content properties are represented as JSON objects.
Some content properties have special meaning to Confluence. For example, the following properties cause Confluence to display a wiki page with content confined to a fixed width in regular view mode, and taking the full page width in draft mode:
```yaml
---
properties:
content-appearance-published: fixed-width
content-appearance-draft: full-width
---
```
The attribute `properties` is parsed as a dictionary with keys of type string and values of type JSON. *md2conf* passes JSON values to Confluence REST API unchanged.
### Local output
*md2conf* supports local output, in which the tool doesn't communicate with the Confluence REST API. Instead, it reads a single Markdown file or a directory of Markdown files, and writes Confluence Storage Format (`*.csf`) output for each document. (Confluence Storage Format is a derivative of XHTML with Confluence-specific tags for complex elements such as images with captions, code blocks, info panels, collapsed sections, etc.) You can push the generated output to Confluence by invoking the API (e.g. with `curl`).
### Running the tool
#### Command line
You can synchronize a (directory of) Markdown file(s) with Confluence using the command-line tool `md2conf`:
```sh
$ python3 -m md2conf sample/index.md
```
Use the `--help` switch to get a full list of supported command-line options:
```console
$ python3 -m md2conf --help
usage: md2conf mdpath [mdpath ...] [OPTIONS]
positional arguments:
mdpath Path to Markdown file or directory to convert and publish.
options:
-h, --help show this help message and exit
--version show program's version number and exit
-d, --domain DOMAIN Confluence organization domain. (env: CONFLUENCE_DOMAIN)
-p, --path PATH Base path for Confluence. (env: CONFLUENCE_PATH; default: '/wiki/')
--api-url API_URL Confluence API URL. Required for scoped tokens. Refer to documentation how to obtain one. (env: CONFLUENCE_API_URL)
-u, --username USERNAME
Confluence user name. (env: CONFLUENCE_USER_NAME)
-a, --api-key API_KEY
Confluence API key. Refer to documentation how to obtain one. (env: CONFLUENCE_API_KEY)
-s, --space SPACE Confluence space key for pages to be published. If omitted, will default to user space. (env: CONFLUENCE_SPACE_KEY)
--api-version {v2,v1}
Confluence REST API version to use (v2 for Cloud, v1 for Data Center/Server). (env: CONFLUENCE_API_VERSION; default: v2)
-l, --loglevel {debug,info,warning,error,critical}
Use this option to set the log verbosity.
-r CONFLUENCE_PAGE_ID
Confluence page to act as initial parent for creating new pages. (deprecated)
--root-page CONFLUENCE_PAGE_ID
Confluence page to act as initial parent for creating new pages. Defaults to space home page.
--keep-hierarchy Maintain source directory structure when exporting to Confluence.
--skip-hierarchy Flatten directories with no `index.md` or `README.md` when exporting to Confluence. (default)
--title-prefix STR String to prepend to Confluence page title for each published page.
--no-title-prefix Use Markdown title to synchronize page. (default)
--generated-by MARKDOWN
Add prompt to pages. (default: This page has been generated with a tool.)
--no-generated-by Do not add 'generated by a tool' prompt to pages.
--overwrite Overwrite (manual) page changes that occurred since last synchronization. (default)
--no-overwrite Skip pages with (manual) changes that occurred since last synchronization.
--skip-update Skip saving Confluence page ID in Markdown files.
--keep-update Inject published Confluence page ID in Markdown files. (default)
--heading-anchors Place an anchor at each section heading with GitHub-style same-page identifiers.
--no-heading-anchors Omit the extra anchor from section headings. (May break manually placed same-page references.) (default)
--force-valid-url Raise an error when relative URLs point to an invalid location. (default)
--no-force-valid-url Emit a warning but otherwise ignore relative URLs that point to an invalid location.
--skip-title-heading Remove the first heading from document body when it is used as the page title (does not apply if title comes from front-matter).
--keep-title-heading Keep the first heading in document body even when | text/markdown | null | Levente Hunyadi <hunyadi@gmail.com> | null | Levente Hunyadi <hunyadi@gmail.com> | null | markdown, converter, confluence | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: End Users/Desktop",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"cattrs>=26.1",
"lxml>=6.0",
"markdown>=3.10",
"orjson>=3.11",
"pymdown-extensions>=10.21",
"PyYAML>=6.0",
"requests>=2.32",
"truststore>=0.10",
"typing-extensions>=4.15; python_version < \"3.11\"",
"markdown_doc>=0.1.7; extra == \"dev\"",
"types-lxml>=2026.2.16; extra == \"dev\"",
"types-mark... | [] | [] | [] | [
"Homepage, https://github.com/hunyadi/md2conf",
"Source, https://github.com/hunyadi/md2conf"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:18:07.045177 | markdown_to_confluence-0.5.6.tar.gz | 173,015 | 86/83/fdfc8847196dfa8e97e1f6888bf3eac0a8618d08df58c079e81561431916/markdown_to_confluence-0.5.6.tar.gz | source | sdist | null | false | 27bb73a928acbdf2c94e5bd01e8e0b84 | 31cb8584e7d2dd3055927cd63f4ad6a9162e877213960c6e59c8390742ca2354 | 8683fdfc8847196dfa8e97e1f6888bf3eac0a8618d08df58c079e81561431916 | MIT | [
"LICENSE"
] | 2,111 |
2.4 | auth101 | 0.2.1 | Simple email/password authentication for Django, FastAPI, and Flask | # auth101
Simple email/password authentication for Django, FastAPI, and Flask.
Configure once, mount anywhere. `auth101` handles password hashing (Argon2), JWT tokens, and user storage so you can add authentication to any Python web app in minutes.
## Features
- Email/password sign-up, sign-in, sign-out, and session verification
- Secure password hashing with Argon2 (bcrypt fallback)
- JWT token generation and verification
- Built-in framework integrations for **FastAPI**, **Flask**, and **Django**
- Pluggable storage backends: in-memory, **SQLAlchemy**, or **Django ORM**
## Installation
```bash
pip install auth101
```
With extras for your framework and database:
```bash
pip install auth101[fastapi] # FastAPI + Pydantic
pip install auth101[flask] # Flask
pip install auth101[django] # Django
pip install auth101[sqlalchemy] # SQLAlchemy (any SQL database)
pip install auth101[all] # Everything
```
## Quick Start
```python
from auth101 import Auth101
auth = Auth101(secret="change-me-in-production")
# Sign up
result = auth.sign_up("alice@example.com", "s3cr3t")
# {"user": {"id": "...", "email": "alice@example.com", "is_active": true}, "token": "..."}
# Sign in
result = auth.sign_in("alice@example.com", "s3cr3t")
# {"user": {...}, "token": "..."}
# Get session from token
session = auth.get_session(result["token"])
# {"user": {"id": "...", "email": "alice@example.com", "is_active": true}}
# Sign out (validates the token; client discards it)
auth.sign_out(result["token"])
# {"success": true}
```
## Configuration
```python
auth = Auth101(
secret="your-secret-key", # Required — used to sign JWT tokens
db_url="sqlite:///auth.db", # SQLAlchemy database URL (optional)
django_model=AuthUser, # Django model class (optional)
token_expires_in=60 * 24 * 7, # Token lifetime in minutes (default: 7 days)
)
```
| Parameter | Description |
|---|---|
| `secret` | **Required.** Secret key for signing JWT tokens. |
| `db_url` | SQLAlchemy connection string (e.g. `"postgresql://user:pass@localhost/db"`). Creates tables automatically. |
| `django_model` | Django model class with `id`, `email`, `password_hash`, `is_active` fields. |
| `token_expires_in` | Token expiration in minutes. Default: `10080` (7 days). |
> **Note:** Provide at most one of `db_url` or `django_model`. If neither is given, an in-memory store is used (great for tests and demos).
## Core API
All methods return plain dicts, so they work with any framework or without one.
### `auth.sign_up(email, password)`
Register a new user. Returns `{"user": {...}, "token": "..."}` on success.
### `auth.sign_in(email, password)`
Authenticate an existing user. Returns `{"user": {...}, "token": "..."}` on success.
### `auth.sign_out(token)`
Validate a token and acknowledge sign-out. Returns `{"success": True}`. The client is responsible for discarding the token (JWT is stateless).
### `auth.get_session(token)`
Return the user associated with a token. Returns `{"user": {...}}` on success.
### `auth.verify_token(token)`
Verify a bearer token and return the corresponding `User` object, or `None`.
### Error Responses
On failure, methods return `{"error": {"message": "...", "code": "..."}}` with one of these codes:
| Code | Meaning |
|---|---|
| `VALIDATION_ERROR` | Missing or invalid email/password |
| `USER_EXISTS` | Email already registered |
| `INVALID_CREDENTIALS` | Wrong email or password |
| `INVALID_TOKEN` | Token is malformed or expired |
| `UNAUTHORIZED` | No valid token provided |
| `USER_NOT_FOUND` | Token valid but user no longer exists |
## Framework Integrations
### FastAPI
```bash
pip install auth101[fastapi] sqlalchemy
```
```python
from fastapi import Depends, FastAPI
from auth101 import Auth101
auth = Auth101(
secret="change-me-in-production",
db_url="sqlite:///auth.db",
)
app = FastAPI()
# Mount auth endpoints: POST /auth/sign-up/email, /auth/sign-in/email,
# POST /auth/sign-out, GET /auth/session
app.include_router(auth.fastapi_router(), prefix="/auth", tags=["auth"])
# Dependency that resolves to the authenticated User or raises 401
CurrentUser = auth.fastapi_current_user()
@app.get("/me")
async def me(user=Depends(CurrentUser)):
return {"id": user.id, "email": user.email}
```
### Flask
```bash
pip install auth101[flask] sqlalchemy
```
```python
from flask import Flask, g, jsonify
from auth101 import Auth101
auth = Auth101(
secret="change-me-in-production",
db_url="sqlite:///auth.db",
)
app = Flask(__name__)
# Mount auth endpoints under /auth
app.register_blueprint(auth.flask_blueprint(), url_prefix="/auth")
# Decorator that sets g.auth_user or returns 401
login_required = auth.flask_login_required()
@app.get("/me")
@login_required
def me():
return jsonify({"id": g.auth_user.id, "email": g.auth_user.email})
```
### Django
```bash
pip install auth101[django]
```
**1. Create your model** (`myapp/models.py`):
```python
import uuid
from django.db import models
class AuthUser(models.Model):
id = models.CharField(max_length=36, primary_key=True,
default=lambda: str(uuid.uuid4()))
email = models.EmailField(unique=True, db_index=True)
password_hash = models.CharField(max_length=255)
is_active = models.BooleanField(default=True)
class Meta:
db_table = "auth_users"
```
Then run `python manage.py makemigrations && python manage.py migrate`.
**2. Configure auth101** (`myapp/auth.py`):
```python
from django.conf import settings
from auth101 import Auth101
from myapp.models import AuthUser
auth = Auth101(
secret=settings.SECRET_KEY,
django_model=AuthUser,
)
Auth101Middleware = auth.get_django_middleware()
login_required = auth.django_login_required()
```
**3. Add middleware** (`settings.py`):
```python
MIDDLEWARE = [
"myapp.auth.Auth101Middleware", # sets request.auth_user on every request
...
]
```
**4. Mount URLs** (`urls.py`):
```python
from django.urls import include, path
from myapp.auth import auth
urlpatterns = [
path("auth/", include(auth.django_urls())),
...
]
```
**5. Protect views** (`myapp/views.py`):
```python
from django.http import JsonResponse
from myapp.auth import login_required
@login_required
def profile(request):
return JsonResponse({"email": request.auth_user.email})
```
## Auth Endpoints
All framework integrations expose the same four endpoints (relative to the mount prefix):
| Method | Path | Body / Header | Response |
|---|---|---|---|
| POST | `/sign-up/email` | `{"email": "...", "password": "..."}` | `{"user": {...}, "token": "..."}` |
| POST | `/sign-in/email` | `{"email": "...", "password": "..."}` | `{"user": {...}, "token": "..."}` |
| POST | `/sign-out` | `Authorization: Bearer <token>` | `{"success": true}` |
| GET | `/session` | `Authorization: Bearer <token>` | `{"user": {...}}` |
## Database Persistence
### SQLAlchemy
Pass a `db_url` and tables are created automatically:
```python
auth = Auth101(
secret="...",
db_url="postgresql://user:pass@localhost/mydb",
)
```
Works with any SQLAlchemy-supported database: PostgreSQL, MySQL, SQLite, etc.
### Django ORM
Pass a `django_model` with the required fields (`id`, `email`, `password_hash`, `is_active`):
```python
auth = Auth101(
secret=settings.SECRET_KEY,
django_model=AuthUser,
)
```
### In-Memory (default)
When no `db_url` or `django_model` is provided, an in-memory store is used. Useful for testing and quick demos -- data is lost when the process exits.
## License
MIT
| text/markdown | Elsai | null | null | null | null | null | [] | [] | null | null | null | [] | [] | [] | [
"passlib[argon2]",
"pyjwt",
"pytest; extra == \"dev\"",
"sqlalchemy; extra == \"sqlalchemy\"",
"fastapi; extra == \"fastapi\"",
"pydantic; extra == \"fastapi\"",
"flask; extra == \"flask\"",
"django; extra == \"django\"",
"sqlalchemy; extra == \"all\"",
"fastapi; extra == \"all\"",
"pydantic; ex... | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.9 | 2026-02-19T08:17:29.036751 | auth101-0.2.1.tar.gz | 16,586 | 0a/78/9625a44eb56e615f0c47ec5e6d6de8b11d0da79f983d2ecfb7f0e96dc42c/auth101-0.2.1.tar.gz | source | sdist | null | false | 458427509ac4bfebbb33fc9a1f13761e | a9466cca1bbac7b43ab6901ded4ad7ac92d148e3d288af0c8aaa8ce53fcd6cfa | 0a789625a44eb56e615f0c47ec5e6d6de8b11d0da79f983d2ecfb7f0e96dc42c | null | [] | 262 |
2.4 | flory | 0.3.1 | Python package for finding coexisting phases in multicomponent mixtures | # flory
[](https://github.com/qiangyicheng/flory/actions/workflows/python-package.yml)
[](https://codecov.io/github/qiangyicheng/flory)
[](https://flory.readthedocs.io/en/latest/?badge=latest)
[](https://badge.fury.io/py/flory)
[](https://anaconda.org/conda-forge/flory)
[](https://doi.org/10.21105/joss.07388)
`flory` is a Python package for analyzing field theories of multicomponent mixtures.
In particular, the package provides routines to determine coexisting states numerically, which is a challenging problem since the thermodynamic coexistence conditions are many coupled non-linear equations.
`flory` supports finding coexisting phases with an arbitrary number of components.
The associated average free energy density of the system reads
$$\bar{f}({N_\mathrm{P}}, \{J_p\}, \{\phi_{p,i}\}) = \sum_{p=1}^{{N_\mathrm{P}}} J_p f(\{\phi_{p,i}\}) ,$$
where $N_\mathrm{C}$ is the number of components, $N_\mathrm{P}$ is the number of phases, $J_p$ is the fraction of the system volume occupied by phase $p$, and $\phi_{p,i}$ is the volume fraction of component $i$ in phase $p$.
`flory` supports different forms of interaction, entropy, ensemble, and constraints to describe the free energy of phases.
For example, with the commonly used Flory-Huggins free energy, the free energy density of each homogeneous phase reads
$$f(\{\phi_i\}) = \frac{1}{2}\sum_{i,j=1}^{N_\mathrm{C}} \chi_{ij} \phi_i \phi_j + \sum_{i=1}^{N_\mathrm{C}} \frac{\phi_i}{l_i} \ln \phi_i ,$$
where $\chi_{ij}$ is the Flory-Huggins interaction parameter between component $i$ and $j$, and $l_i$ is the relative molecular size of component $i$.
Given an interaction matrix $\chi_{ij}$, average volume fractions of all components across the system $\bar{\phi}_i$, and the relative molecule sizes $l_i$, `flory` provides tools to find the coexisting phases in equilibrium.
## Installation
`flory` is available on `pypi`, so you should be able to install it through `pip`:
```bash
pip install flory
```
As an alternative, you can install `flory` through [conda](https://docs.conda.io/en/latest/) using the [conda-forge](https://conda-forge.org/) channel:
```bash
conda install -c conda-forge flory
```
### Optional dependencies
By default, only the minimal set of dependencies of `flory` package will be installed. To install all dependencies, run:
```bash
pip install 'flory[dev]'
```
You can also select the optional dependencies, such as `example`, `test` or `doc`. For example, you can install the package with the optional dependencies only for tests:
```bash
pip install 'flory[test]'
```
If you are using conda, consider install the optional dependencies directly:
```bash
conda install -c conda-forge --file https://raw.githubusercontent.com/qiangyicheng/flory/main/examples/requirements.txt
conda install -c conda-forge --file https://raw.githubusercontent.com/qiangyicheng/flory/main/tests/requirements.txt
conda install -c conda-forge --file https://raw.githubusercontent.com/qiangyicheng/flory/main/docs/requirements.txt
```
### Test installation
If the optional dependencies for tests are installed, you can run tests in root directory of the package with `pytest`. By default, some slow tests are skipped. You can run them with the `--runslow` option:
```bash
pytest --runslow
```
## Usage
The following example determines the coexisting phases of a binary mixture with Flory-Huggins free energy:
```python
import flory
num_comp = 2 # Set number of components
chis = [[0, 4.0], [4.0, 0]] # Set the \chi matrix
phi_means = [0.5, 0.5] # Set the average volume fractions
# obtain coexisting phases
phases = flory.find_coexisting_phases(num_comp, chis, phi_means)
```
It is equivalent to a more advanced example:
```python
import flory
num_comp = 2 # Set number of components
chis = [[0, 4.0], [4.0, 0]] # Set the \chi matrix
phi_means = [0.5, 0.5] # Set the average volume fractions
# create a free energy
fh = flory.FloryHuggins(num_comp, chis)
# create a ensemble
ensemble = flory.CanonicalEnsemble(num_comp, phi_means)
# construct a finder from interaction, entropy and ensemble
finder = flory.CoexistingPhasesFinder(fh.interaction, fh.entropy, ensemble)
# obtain phases by clustering compartments
phases = finder.run().get_clusters()
```
The free energy instance provides more tools for analysis, such as:
```python
# calculate the chemical potentials of the coexisting phases
mus = fh.chemical_potentials(phases.fractions)
```
## More information
* See examples in [examples folder](https://github.com/qiangyicheng/flory/tree/main/examples)
* [Full documentation on readthedocs](https://flory.readthedocs.io/)
| text/markdown | null | Yicheng Qiang <yicheng.qiang@ds.mpg.de> | null | null | MIT License | physics, phase-separation, free-energy | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Pyt... | [] | null | null | <3.14,>=3.9 | [] | [] | [] | [
"numba>=0.57",
"numpy>=1.22",
"scipy>=1.7",
"tqdm>=4.60",
"pytest>=6.2; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"matplotlib>=3.1; extra == \"dev\"",
"Sphinx>=4; extra == \"dev\"",
"sphinx-autodoc-typehints>=2.2; extra == \"dev\"",
"sphinx-paramlinks>=0.6; extra == \"dev\"",
"sphi... | [] | [] | [] | [
"homepage, https://github.com/qiangyicheng/flory",
"documentation, https://flory.readthedocs.io",
"repository, https://github.com/qiangyicheng/flory"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T08:17:20.401843 | flory-0.3.1.tar.gz | 140,903 | ee/a0/bcc83fa1576dba2c32f84577be7131c9db30c11be85e1eabb5c6eada4c55/flory-0.3.1.tar.gz | source | sdist | null | false | f6d0d3cd467e394788d16c5cc6b8f2ed | 64a329db0d2fa8cb5078ff8bd51eb9b779b1217d8e081ab129b2ffcd1f7c3981 | eea0bcc83fa1576dba2c32f84577be7131c9db30c11be85e1eabb5c6eada4c55 | null | [
"LICENSE"
] | 267 |
2.4 | rbv-ut-downloader | 0.1.2 | A simple Python-based tool to automate module downloads from Universitas Terbuka's Virtual Reading Room (RBV). | # RBV-DL (RBV UT Downloader)
[](https://badge.fury.io/py/rbv-dl)
[](https://pypi.org/project/rbv-dl/)
[](https://opensource.org/licenses/MIT)
**RBV-DL** is a powerful CLI tool to automate downloading modules from *Universitas Terbuka's Virtual Reading Room* (RBV). It handles login, scans chapters, captures pages in high quality, and stitches them into a readable PDF.
---
## Prerequisites
Before installing, you **must** have Python installed on your computer.
1. **Download Python**: [python.org/downloads](https://www.python.org/downloads/)
2. **Important**: When installing, make sure to check the box **"Add Python to PATH"**. (This is mandatory, if you forget it will result in an error).
---
## Installation Guide
Choose your operating system below:
### For Windows Users (The Easy Way)
No need to open code editors. Just use the Command Prompt.
1. Press the **Windows Key** on your keyboard.
2. Type `cmd` and press **Enter**.
3. Copy and paste this command into the black box, then press Enter:
```cmd
pip install rbv-ut-downloader
```
4. After that finishes, run this command to install the browser engine:
```cmd
playwright install chromium
```
**Done!** You can now close the window.
### For macOS Users
1. Press **Command (⌘) + Space** to open Spotlight Search.
2. Type `Terminal` and press **Enter**.
3. Paste this command and hit Enter:
```bash
pip3 install rbv-ut-downloader
```
4. Then, install the required browser:
```bash
playwright install chromium
```
### For Linux Users (The Pro Way)
You know what to do. Use `pip`, `pipx`, or your preferred package manager.
```bash
# Recommended: install via pipx to keep your system clean
pipx install rbv-ut-downloader
playwright install chromium
# Or standard pip
pipx install rbv-ut-downloader
playwright install chromium
```
### How to Use
Once installed, open your terminal (Command Prompt / Terminal) anywhere and type:
```bash
rbv-dl
```
Follow the interactive prompts:
NIM / Email: Enter your UT email.
Password: Enter your E-Campus password (input will be hidden/invisible for security).
Course Code: Enter the code (e.g., ADPU4433).
The tool will work its magic and save the PDF in a folder named after the course code.
### Troubleshooting
"Command not found" or "rbv-dl is not recognized"
You likely forgot to check "Add Python to PATH" during installation. Reinstall Python and make sure to check that box.
"Login Failed"
Ensure your E-Campus password is correct. Try logging in manually at the RBV website first to check your account status.
### Disclaimer
This tool is for educational and archival purposes only. Use it responsibly to back up your own learning materials. The author is not responsible for misuse.
| text/markdown | null | fyodor-dostoevsky-bit <prabowotanpabiji6@gmail.com> | null | null | null | ut, downloader, rbv, automation, cli | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"playwright>=1.40.0",
"img2pdf>=0.5.0",
"httpx>=0.25.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T08:17:00.332489 | rbv_ut_downloader-0.1.2.tar.gz | 9,961 | 9b/31/bf38f862b254bfd61ce4fcdea9f6d4b1c7642039bfe14555b18e86cd46ef/rbv_ut_downloader-0.1.2.tar.gz | source | sdist | null | false | 35b968238ebbcda4365d14d5480260f4 | 218dd33cb02ca9bd8716da7e3c561a97fa259518c9b922eaa912d5493dcd36cb | 9b31bf38f862b254bfd61ce4fcdea9f6d4b1c7642039bfe14555b18e86cd46ef | null | [] | 261 |
2.1 | dbzero | 0.1.4 | A state management system for Python 3.x that unifies your applications business logic, data persistence, and caching into a single, efficient layer. | <picture align="center">
<source media="(prefers-color-scheme: dark)" srcset="https://dbzero.io/images/white-01.svg">
<img alt="Dbzero logo" src="https://dbzero.io/images/dbzero-logo.png">
</picture>
**A state management system for Python 3.x that unifies your application's business logic, data persistence, and caching into a single, efficient layer.**
[](https://www.gnu.org/licenses/lgpl-2.1)
> "If we had infinite memory in our laptop, we'd have no need for clumsy databases. Instead, we could just use our objects whenever we liked."
>
> — Harry Percival and Bob Gregory, *Architecture Patterns with Python*
## Overview
**dbzero** lets you code as if you have infinite memory. Inspired by a thought experiment from *Architecture Patterns with Python* by Harry Percival and Bob Gregory, dbzero handles the complexities of data management in the background while you work with simple Python objects.
dbzero implements the **DISTIC memory** model:
- **D**urable - Data persists across application restarts
- **I**nfinite - Work with data as if memory constraints don't exist (e.g. create lists, dicts or sets with billions of elements)
- **S**hared - Multiple processes can access and share the same data
- **T**ransactional - Transaction support for data integrity
- **I**solated - Reads performed against a consistent point-in-time snapshot
- **C**omposable - Plug in multiple prefixes (memory partitions) on demand and access other apps’ data by simply attaching their prefix.
With dbzero, you don’t need separate pieces like a database, ORM, or cache layer. Your app becomes easier to build and it runs faster, because there are no roundtrips to a database, memory is used better, and you can shape your data to fit your problem.
## Key Platform Features
**dbzero** provides the reliability of a traditional database system with modern capabilities and extra features on top.
- **Persistence**: Application objects (classes and common structures like `list`, `dict`, `set`, etc.) are automatically persisted (e.g. to a local or network-attached file)
- **Efficient caching**: Only the data actually accessed is retrieved and cached. For example, if a list has 1 million elements but only 10 are accessed, only those 10 are loaded.
- **Constrained memory usage**: You can define memory limits for the process to control RAM consumption.
- **Serializable consistency**: Data changes can be read immediately, maintaining a consistent view.
- **Transactions**: Make atomic, exception-safe changes using the `with dbzero.atomic():` context manager.
- **Snapshots & Time Travel**: Query data as it existed at a specific point in the past. This enables tracking of data changes and simplify auditing.
- **Tags**: Tag objects and use tags to filter or retrieve data.
- **Indexing**: Define lightweight, imperative indexes that can be dynamically created and updated.
- **Data composability**: Combine data from different apps, processes, or servers and access it through a unified interface - i.e. your application’s objects, methods and functions.
- **UUID support**: All objects are automatically assigned a universally unique identifier, allowing to always reference them directly.
- **Custom data models** - Unlike traditional databases, dbzero allows you to define custom data structures to match your domain's needs.
## Requirements
- **Python**: 3.9+
- **Operating Systems**: Linux, macOS, Windows
- **Storage**: Local filesystem or network-attached storage
- **Memory**: Varies by workload; active working set should fit in RAM for best performance
## Quick Start
### Installation
```bash
pip install dbzero
```
### Simple Example
The guiding philosophy behind **dbzero** is *invisibility*—it stays out of your way as much as possible. In most cases, unless you're using advanced features, you won’t even notice it’s there. No schema definitions, no explicit save calls, no ORM configuration. You just write regular Python code, as you always have. See the complete working example below:
```python
import dbzero as db0
@db0.memo(singleton=True)
class GreeterAppRoot:
def __init__(self, greeting, persons):
self.greeting = greeting
self.persons = persons
self.counter = 0
def greet(self):
print(f"{self.greeting}{''.join(f', {person}' for person in self.persons)}!")
self.counter += 1
if __name__ == "__main__":
# Initialize dbzero
db0.init("./app-data", prefix="main")
# Initialize the application's root object
root = GreeterAppRoot("Hello", ["Michael", "Jennifer"])
root.greet() # Output: Hello, Michael, Jennifer!
print(f"Greeted {root.counter} times.")
```
The application state is persisted automatically; the same data will be available the next time the app starts. All objects are automatically managed by dbzero and there's no need for explicit conversions, fetching, or saving — dbzero handles persistence transparently for the entire object graph.
## Core Concepts
### Memo Classes
Transform any Python class into a persistent, automatically managed object by applying the `@db0.memo` decorator:
```python
import dbzero as db0
@db0.memo
class Person:
def __init__(self, name: str, age: int):
self.name = name
self.age = age
# Instantiation works just like regular Python
person = Person("Alice", 30)
# Attributes can be changed dynamically
person.age += 1
person.address = "123 Main St" # Add new attributes on the fly
```
### Collections
dbzero provides persistent versions of Python's built-in collections:
```python
from datetime import date
person = Person("John", 25)
# Assign persistent collections to memo object
person.appointment_dates = {date(2026, 1, 12), date(2026, 1, 13), date(2026, 1, 14)}
person.skills = ["Python", "C++", "Docker"]
person.contact_info = {
"email": "john@example.com",
"phone": "+1-555-0100",
"linkedin": "linkedin.com/in/john"
}
# Use them as usual
date(2026, 1, 13) in person.appointment_dates # True
person.skills.append("Kubernetes")
print(person.skills) # Output: ['Python', 'C++', 'Docker', 'Kubernetes']
person.contact_info["github"] = "github.com/john"
person.contact_info["email"] # "john@example.com"
```
All standard operations are supported, and changes are automatically persisted.
### Queries and Tags
Find objects using tag-based queries and flexible logic operators:
```python
# Create and tag objects
person = Person("Susan", 31)
db0.tags(person).add("employee", "manager")
person = Person("Michael", 29)
db0.tags(person).add("employee", "developer")
# Find every Person by type
result = db0.find(Person)
# Combine type and tags (AND logic) to find employees
employees = db0.find(Person, "employee")
# OR logic using a list to find managers and developers
staff = db0.find(["manager", "developer"])
# NOT logic using db0.no() to find employees wich aren't managers
non_managers = db0.find("employee", db0.no("manager"))
```
### Snapshots and Time Travel
Create isolated views of your data at any point in time:
```python
person = Person("John", 25)
person.balance = 1500
# Keep the current state
state = db0.get_state_num()
# Commit changes explicitely to advance the state immediately
db0.commit()
# Change the balance
person.balance -= 300
db0.commit()
print(f"{person.name} balance: {person.balance}") # John balance: 1200
# Open snapshot view with past state number
with db0.snapshot(state) as snap:
past_person = db0.fetch(db0.uuid(person))
print(f"{past_person.name} balance: {past_person.balance}") # John balance: 1500
```
### Prefixes (Data Partitioning)
Organize data into independent, isolated partitions:
```python
@db0.memo(singleton=True, prefix="/my-org/my-app/settings")
class AppSettings:
def __init__(self, theme: str):
self.theme = theme
@db0.memo(prefix="/my-org/my-app/data")
class Note:
def __init__(self, content: str):
self.content = content
settings = AppSettings(theme="dark") # Data goes to "settings.db0"
note = Note("Hello dbzero!") # Data goes to "data.db0"
```
### Indexes
Index your data for fast range queries and sorting:
```python
from datetime import datetime
@db0.memo()
class Event:
def __init__(self, event_id: int, occured: datetime):
self.event_id = event_id
self.occured = occured
events = [
Event(100, datetime(2026, 1, 28)),
Event(101, datetime(2026, 1, 30)),
Event(102, datetime(2026, 1, 29)),
Event(103, datetime(2026, 2, 1)),
]
# Create an index
event_index = db0.index()
# Populate with objects
for event in events:
event_index.add(event.occured, event)
# Query events from January 2026
query = event_index.select(datetime(2026, 1, 1), datetime(2026, 1, 31))
# Sort ascending by date of occurance
query_sorted = event_index.sort(query)
print([event.event_id for event in query_sorted]) # Output: [100, 102, 101]
```
## Scalability
dbzero provides tools to build scalable applications:
- **Data Partitioning** - Split data across independent partitions (prefixes) to distribute workload
- **Distributed Transactions** - Coordinate transactions across multiple partitions for data consistency
- **Multi-Process Support** - Multiple processes can work with shared or separate data simultaneously, enabling horizontal scaling
These features give you the flexibility to design distributed architectures that fit your needs.
## Use Cases
Our experience has proven that **dbzero** fits many real-life use cases, which include:
- **Web Applications** - Unified state management for backend services
- **Data Processing Pipelines** - Efficient and simple data preparation
- **Event-Driven Systems** - Capturing data changes and time travel for auditing
- **AI Applications** - Simplified state management for AI agents and workflows
- **Something Else?** - Built something cool with dbzero? We'd love to see what you're working on—share it on our [Discord server](https://discord.gg/9Wn8TAYEPu)!
## Why dbzero?
The short answer is illustrated by diagram below:
### Traditional Stack
```
Application Code
↓
ORM Layer
↓
Caching Layer
↓
Database Layer
↓
Storage
```
### With dbzero
```
Application Code + dbzero
↓
Storage
```
By eliminating intermediate layers, dbzero reduces complexity, improves performance, and accelerates development—all while providing the reliability and features you expect from a regular database system.
## Documentation
Check our docs to learn more: **[docs.dbzero.io](https://docs.dbzero.io)**
There you can find:
- Guides
- Tutorials
- Performance tips
- API Reference
## License
This project is licensed under the GNU Lesser General Public License v2.1 (LGPL 2.1). See [LICENSE](./LICENSE) for the full text.
- This library can be linked with proprietary software.
- Modifications to the library itself must be released under LGPL 2.1.
- Redistributions must preserve copyright and license notices and provide source.
For attribution details, see [NOTICE](./NOTICE).
## Support
- **Documentation**: [docs.dbzero.io](https://docs.dbzero.io)
- **Email**: info@dbzero.io
- **Issues**: https://github.com/dbzero-software/dbzero/issues
## Feedback
We'd love to hear how you're using dbzero and what features you'd like to see! Your input helps us make dbzero better for everyone.
The best way to share your thoughts is through our **Discord server**: [Join us on Discord](https://discord.gg/9Wn8TAYEPu)
## Commercial Support
Need help building large-scale solutions with dbzero?
We offer:
- Tools for data export and manipulation
- Tools for hosting rich UI applications on top of your existing dbzero codebase
- System integrations
- Expert consulting and architectural reviews
- Performance tuning
Contact us at: **info@dbzero.io**
---
**Start coding as if you have infinite memory. Let dbzero handle the rest.**
| text/markdown | null | "DBZero Software sp. z o.o" <info@dbzero.io> | null | null | GNU LESSER GENERAL PUBLIC LICENSE
Version 2.1, February 1999
Copyright (C) 1991, 1999 Free Software Foundation, Inc.
51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
[This is the first released version of the Lesser GPL. It also counts
as the successor of the GNU Library Public License, version 2, hence
the version number 2.1.]
Preamble
The licenses for most software are designed to take away your
freedom to share and change it. By contrast, the GNU General Public
Licenses are intended to guarantee your freedom to share and change
free software--to make sure the software is free for all its users.
This license, the Lesser General Public License, applies to some
specially designated software packages--typically libraries--of the
Free Software Foundation and other authors who decide to use it. You
can use it too, but we suggest you first think carefully about whether
this license or the ordinary General Public License is the better
strategy to use in any particular case, based on the explanations below.
When we speak of free software, we are referring to freedom of use,
not price. Our General Public Licenses are designed to make sure that
you have the freedom to distribute copies of free software (and charge
for this service if you wish); that you receive source code or can get
it if you want it; that you can change the software and use pieces of
it in new free programs; and that you are informed that you can do
these things.
To protect your rights, we need to make restrictions that forbid
distributors to deny you these rights or to ask you to surrender these
rights. These restrictions translate to certain responsibilities for
you if you distribute copies of the library or if you modify it.
For example, if you distribute copies of the library, whether gratis
or for a fee, you must give the recipients all the rights that we gave
you. You must make sure that they, too, receive or can get the source
code. If you link other code with the library, you must provide
complete object files to the recipients, so that they can relink them
with the library after making changes to the library and recompiling
it. And you must show them these terms so they know their rights.
We protect your rights with a two-step method: (1) we copyright the
library, and (2) we offer you this license, which gives you legal
permission to copy, distribute and/or modify the library.
To protect each distributor, we want to make it very clear that
there is no warranty for the free library. Also, if the library is
modified by someone else and passed on, the recipients should know
that what they have is not the original version, so that the original
author's reputation will not be affected by problems that might be
introduced by others.
Finally, software patents pose a constant threat to the existence of
any free program. We wish to make sure that a company cannot
effectively restrict the users of a free program by obtaining a
restrictive license from a patent holder. Therefore, we insist that
any patent license obtained for a version of the library must be
consistent with the full freedom of use specified in this license.
Most GNU software, including some libraries, is covered by the
ordinary GNU General Public License. This license, the GNU Lesser
General Public License, applies to certain designated libraries, and
is quite different from the ordinary General Public License. We use
this license for certain libraries in order to permit linking those
libraries into non-free programs.
When a program is linked with a library, whether statically or using
a shared library, the combination of the two is legally speaking a
combined work, a derivative of the original library. The ordinary
General Public License therefore permits such linking only if the
entire combination fits its criteria of freedom. The Lesser General
Public License permits more lax criteria for linking other code with
the library.
We call this license the "Lesser" General Public License because it
does Less to protect the user's freedom than the ordinary General
Public License. It also provides other free software developers Less
of an advantage over competing non-free programs. These disadvantages
are the reason we use the ordinary General Public License for many
libraries. However, the Lesser license provides advantages in certain
special circumstances.
For example, on rare occasions, there may be a special need to
encourage the widest possible use of a certain library, so that it becomes
a de-facto standard. To achieve this, non-free programs must be
allowed to use the library. A more frequent case is that a free
library does the same job as widely used non-free libraries. In this
case, there is little to gain by limiting the free library to free
software only, so we use the Lesser General Public License.
In other cases, permission to use a particular library in non-free
programs enables a greater number of people to use a large body of
free software. For example, permission to use the GNU C Library in
non-free programs enables many more people to use the whole GNU
operating system, as well as its variant, the GNU/Linux operating
system.
Although the Lesser General Public License is Less protective of the
users' freedom, it does ensure that the user of a program that is
linked with the Library has the freedom and the wherewithal to run
that program using a modified version of the Library.
The precise terms and conditions for copying, distribution and
modification follow. Pay close attention to the difference between a
"work based on the library" and a "work that uses the library". The
former contains code derived from the library, whereas the latter must
be combined with the library in order to run.
GNU LESSER GENERAL PUBLIC LICENSE
TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
0. This License Agreement applies to any software library or other
program which contains a notice placed by the copyright holder or
other authorized party saying it may be distributed under the terms of
this Lesser General Public License (also called "this License").
Each licensee is addressed as "you".
A "library" means a collection of software functions and/or data
prepared so as to be conveniently linked with application programs
(which use some of those functions and data) to form executables.
The "Library", below, refers to any such software library or work
which has been distributed under these terms. A "work based on the
Library" means either the Library or any derivative work under
copyright law: that is to say, a work containing the Library or a
portion of it, either verbatim or with modifications and/or translated
straightforwardly into another language. (Hereinafter, translation is
included without limitation in the term "modification".)
"Source code" for a work means the preferred form of the work for
making modifications to it. For a library, complete source code means
all the source code for all modules it contains, plus any associated
interface definition files, plus the scripts used to control compilation
and installation of the library.
Activities other than copying, distribution and modification are not
covered by this License; they are outside its scope. The act of
running a program using the Library is not restricted, and output from
such a program is covered only if its contents constitute a work based
on the Library (independent of the use of the Library in a tool for
writing it). Whether that is true depends on what the Library does
and what the program that uses the Library does.
1. You may copy and distribute verbatim copies of the Library's
complete source code as you receive it, in any medium, provided that
you conspicuously and appropriately publish on each copy an
appropriate copyright notice and disclaimer of warranty; keep intact
all the notices that refer to this License and to the absence of any
warranty; and distribute a copy of this License along with the
Library.
You may charge a fee for the physical act of transferring a copy,
and you may at your option offer warranty protection in exchange for a
fee.
2. You may modify your copy or copies of the Library or any portion
of it, thus forming a work based on the Library, and copy and
distribute such modifications or work under the terms of Section 1
above, provided that you also meet all of these conditions:
a) The modified work must itself be a software library.
b) You must cause the files modified to carry prominent notices
stating that you changed the files and the date of any change.
c) You must cause the whole of the work to be licensed at no
charge to all third parties under the terms of this License.
d) If a facility in the modified Library refers to a function or a
table of data to be supplied by an application program that uses
the facility, other than as an argument passed when the facility
is invoked, then you must make a good faith effort to ensure that,
in the event an application does not supply such function or
table, the facility still operates, and performs whatever part of
its purpose remains meaningful.
(For example, a function in a library to compute square roots has
a purpose that is entirely well-defined independent of the
application. Therefore, Subsection 2d requires that any
application-supplied function or table used by this function must
be optional: if the application does not supply it, the square
root function must still compute square roots.)
These requirements apply to the modified work as a whole. If
identifiable sections of that work are not derived from the Library,
and can be reasonably considered independent and separate works in
themselves, then this License, and its terms, do not apply to those
sections when you distribute them as separate works. But when you
distribute the same sections as part of a whole which is a work based
on the Library, the distribution of the whole must be on the terms of
this License, whose permissions for other licensees extend to the
entire whole, and thus to each and every part regardless of who wrote
it.
Thus, it is not the intent of this section to claim rights or contest
your rights to work written entirely by you; rather, the intent is to
exercise the right to control the distribution of derivative or
collective works based on the Library.
In addition, mere aggregation of another work not based on the Library
with the Library (or with a work based on the Library) on a volume of
a storage or distribution medium does not bring the other work under
the scope of this License.
3. You may opt to apply the terms of the ordinary GNU General Public
License instead of this License to a given copy of the Library. To do
this, you must alter all the notices that refer to this License, so
that they refer to the ordinary GNU General Public License, version 2,
instead of to this License. (If a newer version than version 2 of the
ordinary GNU General Public License has appeared, then you can specify
that version instead if you wish.) Do not make any other change in
these notices.
Once this change is made in a given copy, it is irreversible for
that copy, so the ordinary GNU General Public License applies to all
subsequent copies and derivative works made from that copy.
This option is useful when you wish to copy part of the code of
the Library into a program that is not a library.
4. You may copy and distribute the Library (or a portion or
derivative of it, under Section 2) in object code or executable form
under the terms of Sections 1 and 2 above provided that you accompany
it with the complete corresponding machine-readable source code, which
must be distributed under the terms of Sections 1 and 2 above on a
medium customarily used for software interchange.
If distribution of object code is made by offering access to copy
from a designated place, then offering equivalent access to copy the
source code from the same place satisfies the requirement to
distribute the source code, even though third parties are not
compelled to copy the source along with the object code.
5. A program that contains no derivative of any portion of the
Library, but is designed to work with the Library by being compiled or
linked with it, is called a "work that uses the Library". Such a
work, in isolation, is not a derivative work of the Library, and
therefore falls outside the scope of this License.
However, linking a "work that uses the Library" with the Library
creates an executable that is a derivative of the Library (because it
contains portions of the Library), rather than a "work that uses the
library". The executable is therefore covered by this License.
Section 6 states terms for distribution of such executables.
When a "work that uses the Library" uses material from a header file
that is part of the Library, the object code for the work may be a
derivative work of the Library even though the source code is not.
Whether this is true is especially significant if the work can be
linked without the Library, or if the work is itself a library. The
threshold for this to be true is not precisely defined by law.
If such an object file uses only numerical parameters, data
structure layouts and accessors, and small macros and small inline
functions (ten lines or less in length), then the use of the object
file is unrestricted, regardless of whether it is legally a derivative
work. (Executables containing this object code plus portions of the
Library will still fall under Section 6.)
Otherwise, if the work is a derivative of the Library, you may
distribute the object code for the work under the terms of Section 6.
Any executables containing that work also fall under Section 6,
whether or not they are linked directly with the Library itself.
6. As an exception to the Sections above, you may also combine or
link a "work that uses the Library" with the Library to produce a
work containing portions of the Library, and distribute that work
under terms of your choice, provided that the terms permit
modification of the work for the customer's own use and reverse
engineering for debugging such modifications.
You must give prominent notice with each copy of the work that the
Library is used in it and that the Library and its use are covered by
this License. You must supply a copy of this License. If the work
during execution displays copyright notices, you must include the
copyright notice for the Library among them, as well as a reference
directing the user to the copy of this License. Also, you must do one
of these things:
a) Accompany the work with the complete corresponding
machine-readable source code for the Library including whatever
changes were used in the work (which must be distributed under
Sections 1 and 2 above); and, if the work is an executable linked
with the Library, with the complete machine-readable "work that
uses the Library", as object code and/or source code, so that the
user can modify the Library and then relink to produce a modified
executable containing the modified Library. (It is understood
that the user who changes the contents of definitions files in the
Library will not necessarily be able to recompile the application
to use the modified definitions.)
b) Use a suitable shared library mechanism for linking with the
Library. A suitable mechanism is one that (1) uses at run time a
copy of the library already present on the user's computer system,
rather than copying library functions into the executable, and (2)
will operate properly with a modified version of the library, if
the user installs one, as long as the modified version is
interface-compatible with the version that the work was made with.
c) Accompany the work with a written offer, valid for at
least three years, to give the same user the materials
specified in Subsection 6a, above, for a charge no more
than the cost of performing this distribution.
d) If distribution of the work is made by offering access to copy
from a designated place, offer equivalent access to copy the above
specified materials from the same place.
e) Verify that the user has already received a copy of these
materials or that you have already sent this user a copy.
For an executable, the required form of the "work that uses the
Library" must include any data and utility programs needed for
reproducing the executable from it. However, as a special exception,
the materials to be distributed need not include anything that is
normally distributed (in either source or binary form) with the major
components (compiler, kernel, and so on) of the operating system on
which the executable runs, unless that component itself accompanies
the executable.
It may happen that this requirement contradicts the license
restrictions of other proprietary libraries that do not normally
accompany the operating system. Such a contradiction means you cannot
use both them and the Library together in an executable that you
distribute.
7. You may place library facilities that are a work based on the
Library side-by-side in a single library together with other library
facilities not covered by this License, and distribute such a combined
library, provided that the separate distribution of the work based on
the Library and of the other library facilities is otherwise
permitted, and provided that you do these two things:
a) Accompany the combined library with a copy of the same work
based on the Library, uncombined with any other library
facilities. This must be distributed under the terms of the
Sections above.
b) Give prominent notice with the combined library of the fact
that part of it is a work based on the Library, and explaining
where to find the accompanying uncombined form of the same work.
8. You may not copy, modify, sublicense, link with, or distribute
the Library except as expressly provided under this License. Any
attempt otherwise to copy, modify, sublicense, link with, or
distribute the Library is void, and will automatically terminate your
rights under this License. However, parties who have received copies,
or rights, from you under this License will not have their licenses
terminated so long as such parties remain in full compliance.
9. You are not required to accept this License, since you have not
signed it. However, nothing else grants you permission to modify or
distribute the Library or its derivative works. These actions are
prohibited by law if you do not accept this License. Therefore, by
modifying or distributing the Library (or any work based on the
Library), you indicate your acceptance of this License to do so, and
all its terms and conditions for copying, distributing or modifying
the Library or works based on it.
10. Each time you redistribute the Library (or any work based on the
Library), the recipient automatically receives a license from the
original licensor to copy, distribute, link with or modify the Library
subject to these terms and conditions. You may not impose any further
restrictions on the recipients' exercise of the rights granted herein.
You are not responsible for enforcing compliance by third parties with
this License.
11. If, as a consequence of a court judgment or allegation of patent
infringement or for any other reason (not limited to patent issues),
conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot
distribute so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you
may not distribute the Library at all. For example, if a patent
license would not permit royalty-free redistribution of the Library by
all those who receive copies directly or indirectly through you, then
the only way you could satisfy both it and this License would be to
refrain entirely from distribution of the Library.
If any portion of this section is held invalid or unenforceable under any
particular circumstance, the balance of the section is intended to apply,
and the section as a whole is intended to apply in other circumstances.
It is not the purpose of this section to induce you to infringe any
patents or other property right claims or to contest validity of any
such claims; this section has the sole purpose of protecting the
integrity of the free software distribution system which is
implemented by public license practices. Many people have made
generous contributions to the wide range of software distributed
through that system in reliance on consistent application of that
system; it is up to the author/donor to decide if he or she is willing
to distribute software through any other system and a licensee cannot
impose that choice.
This section is intended to make thoroughly clear what is believed to
be a consequence of the rest of this License.
12. If the distribution and/or use of the Library is restricted in
certain countries either by patents or by copyrighted interfaces, the
original copyright holder who places the Library under this License may add
an explicit geographical distribution limitation excluding those countries,
so that distribution is permitted only in or among countries not thus
excluded. In such case, this License incorporates the limitation as if
written in the body of this License.
13. The Free Software Foundation may publish revised and/or new
versions of the Lesser General Public License from time to time.
Such new versions will be similar in spirit to the present version,
but may differ in detail to address new problems or concerns.
Each version is given a distinguishing version number. If the Library
specifies a version number of this License which applies to it and
"any later version", you have the option of following the terms and
conditions either of that version or of any later version published by
the Free Software Foundation. If the Library does not specify a
license version number, you may choose any version ever published by
the Free Software Foundation.
14. If you wish to incorporate parts of the Library into other free
programs whose distribution conditions are incompatible with these,
write to the author to ask for permission. For software which is
copyrighted by the Free Software Foundation, write to the Free
Software Foundation; we sometimes make exceptions for this. Our
decision will be guided by the two goals of preserving the free status
of all derivatives of our free software and of promoting the sharing
and reuse of software generally.
NO WARRANTY
15. BECAUSE THE LIBRARY IS LICENSED FREE OF CHARGE, THERE IS NO
WARRANTY FOR THE LIBRARY, TO THE EXTENT PERMITTED BY APPLICABLE LAW.
EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR
OTHER PARTIES PROVIDE THE LIBRARY "AS IS" WITHOUT WARRANTY OF ANY
KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE
LIBRARY IS WITH YOU. SHOULD THE LIBRARY PROVE DEFECTIVE, YOU ASSUME
THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN
WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY
AND/OR REDISTRIBUTE THE LIBRARY AS PERMITTED ABOVE, BE LIABLE TO YOU
FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR
CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE
LIBRARY (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING
RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A
FAILURE OF THE LIBRARY TO OPERATE WITH ANY OTHER SOFTWARE), EVEN IF
SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH
DAMAGES.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Libraries
If you develop a new library, and you want it to be of the greatest
possible use to the public, we recommend making it free software that
everyone can redistribute and change. You can do so by permitting
redistribution under these terms (or, alternatively, under the terms of the
ordinary General Public License).
To apply these terms, attach the following notices to the library. It is
safest to attach them to the start of each source file to most effectively
convey the exclusion of warranty; and each file should have at least the
"copyright" line and a pointer to where the full notice is found.
<one line to give the library's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This library is free software; you can redistribute it and/or
modify it under the terms of the GNU Lesser General Public
License as published by the Free Software Foundation; either
version 2.1 of the License, or (at your option) any later version.
This library is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with this library; if not, write to the Free Software
Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301
USA
Also add information on how to contact you by electronic and paper mail.
You should also get your employer (if you work as a programmer) or your
school, if any, to sign a "copyright disclaimer" for the library, if
necessary. Here is a sample; alter the names:
Yoyodyne, Inc., hereby disclaims all copyright interest in the
library `Frob' (a library for tweaking knobs) written by James Random
Hacker.
<signature of Ty Coon>, 1 April 1990
Ty Coon, President of Vice
That's all there is to it!
| null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"fasteners==0.19"
] | [] | [] | [] | [
"homepage, https://dbzero.io/",
"documentation, https://docs.dbzero.io/",
"repository, https://github.com/dbzero-software/dbzero"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T08:16:26.772404 | dbzero-0.1.4.tar.gz | 6,188,798 | 30/c4/d77f7bb0d1c089c94f219f026c4b1d907a3e79ceb72fe26a4daa84e4a5fb/dbzero-0.1.4.tar.gz | source | sdist | null | false | a89fc22555c45b0ca0bff17656e3ea52 | 6bbfda6b325cd90affcafdd096dc1aa4511c543671c841e8d3ba81901876c177 | 30c4d77f7bb0d1c089c94f219f026c4b1d907a3e79ceb72fe26a4daa84e4a5fb | null | [] | 1,394 |
2.4 | a2a4b2b-mcp | 0.1.0 | MCP Server for A2A4B2B Agent Network | # A2A4B2B MCP Server
MCP Server for A2A4B2B Agent Network.
## Installation
```bash
pip install a2a4b2b-mcp
```
## Configuration
Set environment variables:
```bash
export A2A4B2B_API_KEY="sk_xxx"
export A2A4B2B_AGENT_ID="agent_xxx"
export A2A4B2B_BASE_URL="https://a2a4b2b.com"
```
Or create a `.env` file with these variables.
## Usage with OpenClaw
Add to your OpenClaw MCP config:
```json
{
"mcpServers": {
"a2a4b2b": {
"command": "python",
"args": ["-m", "a2a4b2b_mcp.server"],
"env": {
"A2A4B2B_API_KEY": "sk_xxx",
"A2A4B2B_AGENT_ID": "agent_xxx"
}
}
}
}
```
## Available Tools
- `get_agent_info` - Get current agent information
- `list_capabilities` - Discover capabilities on the network
- `create_capability` - Publish your own capability
- `create_session` - Create session with other agents
- `send_message` - Send messages in a session
- `create_rfp` - Create request for proposal
- `list_rfps` - List RFPs
- `create_proposal` - Create proposal for an RFP
- `create_post` - Create community post
## API Documentation
See https://a2a4b2b.com/docs for full API documentation.
## License
MIT
| text/markdown | null | Kimi Claw <kimi@openclaw.ai> | null | null | MIT | mcp, a2a, agent, a2a4b2b, openclaw | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Develo... | [] | null | null | >=3.10 | [] | [] | [] | [
"requests>=2.31.0",
"mcp>=0.9.0",
"pytest>=7.0; extra == \"dev\"",
"black>=23.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://a2a4b2b.com",
"Documentation, https://a2a4b2b.com/docs",
"Repository, https://github.com/openclaw/a2a4b2b-mcp",
"Issues, https://github.com/openclaw/a2a4b2b-mcp/issues"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T08:16:24.106567 | a2a4b2b_mcp-0.1.0.tar.gz | 7,042 | b4/85/b56e753c2bae53a3ff0b9baaa15be2877e9936bbe39b6fe112227e606d56/a2a4b2b_mcp-0.1.0.tar.gz | source | sdist | null | false | 0fc1c983e34292f2f2dcfe308d6ef6fa | edb6b7ae955a884b5453b69d2af15641a43a52ef34de3bac1aad4596c3ff5581 | b485b56e753c2bae53a3ff0b9baaa15be2877e9936bbe39b6fe112227e606d56 | null | [] | 288 |
2.4 | power-grid-model-io | 1.3.48 | Power Grid Model Input/Output | <!--
SPDX-FileCopyrightText: Contributors to the Power Grid Model project <powergridmodel@lfenergy.org>
SPDX-License-Identifier: MPL-2.0
-->
[](#) <!-- markdownlint-disable-line first-line-h1 no-empty-links line-length -->
[](https://badge.fury.io/py/power-grid-model-io)
[](https://pepy.tech/project/power-grid-model-io)
[](https://pepy.tech/project/power-grid-model-io)
[](https://anaconda.org/conda-forge/power-grid-model-io)
[](https://anaconda.org/conda-forge/power-grid-model-io)
[](https://anaconda.org/conda-forge/power-grid-model-io)
[](https://github.com/PowerGridModel/power-grid-model-io/blob/main/LICENSE)
[](https://zenodo.org/record/8059257)
[](https://github.com/PowerGridModel/power-grid-model-io/actions/workflows/ci.yml)
[](https://power-grid-model-io.readthedocs.io/en/stable/)
[](https://github.com/PowerGridModel/power-grid-model-io/actions/workflows/nightly.yml)
[](https://sonarcloud.io/summary/new_code?id=PowerGridModel_power-grid-model-io)
[](https://sonarcloud.io/summary/new_code?id=PowerGridModel_power-grid-model-io)
[](https://sonarcloud.io/summary/new_code?id=PowerGridModel_power-grid-model-io)
[](https://sonarcloud.io/summary/new_code?id=PowerGridModel_power-grid-model-io)
[](https://sonarcloud.io/summary/new_code?id=PowerGridModel_power-grid-model-io)
[](https://sonarcloud.io/summary/new_code?id=PowerGridModel_power-grid-model-io)
# Power Grid Model Input/Output
`power-grid-model-io` can be used for various conversions to the
[power-grid-model](https://github.com/PowerGridModel/power-grid-model).
For detailed documentation, see [Read the Docs](https://power-grid-model-io.readthedocs.io/en/stable/index.html).
## Installation
### Install from PyPI
You can directly install the package from PyPI.
Although it is opt-in, it is recommended to use [`uv`](https://github.com/astral-sh/uv) as
your development environment manager.
```sh
uv pip install power-grid-model-io
```
### Install from Conda
If you are using `conda`, you can directly install the package from `conda-forge` channel.
```sh
conda install -c conda-forge power-grid-model-io
```
## Examples
* [PGM JSON Example](https://github.com/PowerGridModel/power-grid-model-io/tree/main/docs/examples)
## License
This project is licensed under the Mozilla Public License, version 2.0 - see
[LICENSE](https://github.com/PowerGridModel/power-grid-model-io/blob/main/LICENSE) for details.
## Contributing
Please read [CODE_OF_CONDUCT](https://github.com/PowerGridModel/.github/blob/main/CODE_OF_CONDUCT.md) and
[CONTRIBUTING](https://github.com/PowerGridModel/.github/blob/main/CONTRIBUTING.md) for details on the process
for submitting pull requests to us.
Visit [Contribute](https://github.com/PowerGridModel/power-grid-model-io/contribute) for a list of good first issues in
this repo.
## Citations
If you are using Power Grid Model IO in your research work, please consider citing our library using the following
references.
[](https://zenodo.org/record/8059257)
```bibtex
@software{Xiang_PowerGridModel_power-grid-model-io,
author = {Xiang, Yu and Salemink, Peter and Bharambe, Nitish and Govers, Martinus G.H. and van den Bogaard, Jonas and Stoeller, Bram and Wang, Zhen and Guo, Jerry Jinfeng and Figueroa Manrique, Santiago and Jagutis, Laurynas and Wang, Chenguang and {Contributors to the LF Energy project Power Grid Model}},
doi = {10.5281/zenodo.8059257},
license = {MPL-2.0},
title = {{PowerGridModel/power-grid-model-io}},
url = {https://github.com/PowerGridModel/power-grid-model-io}
}
@software{Xiang_PowerGridModel_power-grid-model,
author = {Xiang, Yu and Salemink, Peter and van Westering, Werner and Bharambe, Nitish and Govers, Martinus G.H. and van den Bogaard, Jonas and Stoeller, Bram and Wang, Zhen and Guo, Jerry Jinfeng and Figueroa Manrique, Santiago and Jagutis, Laurynas and Wang, Chenguang and van Raalte, Marc and {Contributors to the LF Energy project Power Grid Model}},
doi = {10.5281/zenodo.8054429},
license = {MPL-2.0},
title = {{PowerGridModel/power-grid-model}},
url = {https://github.com/PowerGridModel/power-grid-model}
}
@inproceedings{Xiang2023,
author = {Xiang, Yu and Salemink, Peter and Stoeller, Bram and Bharambe, Nitish and van Westering, Werner},
booktitle={27th International Conference on Electricity Distribution (CIRED 2023)},
title={Power grid model: a high-performance distribution grid calculation library},
year={2023},
volume={2023},
number={},
pages={1089-1093},
keywords={},
doi={10.1049/icp.2023.0633}
}
```
## Contact
Please read [SUPPORT](https://github.com/PowerGridModel/.github/blob/main/SUPPORT.md) for how to connect and get into
contact with the Power Grid Model IO project.
| text/markdown | null | Contributors to the Power Grid Model project <powergridmodel@lfenergy.org> | null | null | MPL-2.0 | power grid model, input/output, conversions | [
"Programming Language :: Python :: 3",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Mozilla Public License 2.0 (MPL 2.0)",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX :: Linux",
"Operating System :: MacOS",
"Topic ::... | [] | null | null | >=3.12 | [] | [] | [] | [
"numpy>=2.0",
"openpyxl",
"packaging>=25.0",
"pandas",
"power_grid_model>=1.8",
"pyyaml",
"structlog",
"tqdm"
] | [] | [] | [] | [
"Home-page, https://lfenergy.org/projects/power-grid-model/",
"GitHub, https://github.com/PowerGridModel/power-grid-model-io",
"Documentation, https://power-grid-model-io.readthedocs.io/en/stable/",
"Mailing-list, https://lists.lfenergy.org/g/powergridmodel",
"Discussion, https://github.com/orgs/PowerGridMo... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:15:04.596057 | power_grid_model_io-1.3.48.tar.gz | 308,495 | fc/c4/cd609d1946b9cf5f801df9ec9e5050bdc23156df9a6e5605848ac0d74a27/power_grid_model_io-1.3.48.tar.gz | source | sdist | null | false | 8846e06458b4b8c0133c84d3aa1c3db3 | ab5df47e01fb98e71442d4572e5b5f4dfa2cf29507aa174cd84b652657c44ebd | fcc4cd609d1946b9cf5f801df9ec9e5050bdc23156df9a6e5605848ac0d74a27 | null | [
"LICENSE"
] | 526 |
2.4 | gemini-calo | 0.1.5 | A Fastapi Based Proxy for Gemini API | # Gemini Calo
**Gemini Calo** is a powerful, yet simple, FastAPI-based proxy server for Google's Gemini API. It provides a seamless way to add a layer of authentication, logging, and monitoring to your Gemini API requests. It's designed to be run as a standalone server or integrated into your existing FastAPI applications.
One of its key features is providing an OpenAI-compatible endpoint, allowing you to use Gemini models with tools and libraries that are built for the OpenAI API.
## Key Features
* **Authentication:** Secure your Gemini API access with an additional layer of API key authentication.
* **Request Logging:** Detailed logging of all incoming requests and outgoing responses.
* **OpenAI Compatibility:** Use Gemini models through an OpenAI-compatible `/v1/chat/completions` endpoint.
* **Round-Robin API Keys:** Distribute your requests across multiple Gemini API keys.
* **Easy Integration:** Use it as a standalone server or mount it into your existing FastAPI project.
* **Extensible:** Easily add your own custom middleware to suit your needs.
## How It's Useful
- **Centralized API Key Management:** Instead of hardcoding your Gemini API keys in various clients, you can manage them in one place.
- **Security:** Protect your expensive Gemini API keys by exposing only a proxy key to your users or client applications.
- **Monitoring & Observability:** The logging middleware gives you insight into how your API is being used, helping you debug issues and monitor usage patterns.
- **Seamless Migration:** If you have existing tools that use the OpenAI API, you can switch to using Google's Gemini models without significant code changes.
## Running the Built-in Server
You can quickly get the proxy server up and running with just a few steps.
### 1. Installation
Install the package using pip:
```bash
pip install gemini-calo
```
### 2. Configuration
The server is configured through environment variables. You can create a `.env` file in your working directory to store them.
* `GEMINI_CALO_API_KEYS`: A comma-separated list of your Google Gemini API keys. The proxy will rotate through these keys for outgoing requests. If this is not set, the proxy will not be able to make requests to the Gemini API.
* `GEMINI_CALO_PROXY_API_KEYS`: (Optional) A comma-separated list of API keys that clients must provide to use the proxy. If not set, the proxy will be open to anyone, meaning no API key is required for access.
* `GEMINI_CALO_HTTP_PORT`: The port on which the server will run. Defaults to `8000`.
* `GEMINI_CALO_LOG_LEVEL`: Sets the logging level for the application. Options include `DEBUG`, `INFO`, `WARNING`, `ERROR`, `CRITICAL`. If not set, it defaults to `CRITICAL`.
* `GEMINI_CALO_LOG_FILE`: Specifies the file where logs will be written. Defaults to `app.log`.
* `GEMINI_CALO_CONVERSATION_SUMMARIZATION_LRU_CACHE`: Sets the size of the LRU cache for conversation summarization. Defaults to `20`.
* `GEMINI_CALO_MODEL_OVERRIDE`: Allows you to specify a model to override the default Gemini model.
* `PY_IGNORE_IMPORTMISMATCH`: (Used by `pydantic-ai`) If set, ignores import mismatches.
* `PYTEST_THEME`: (Used by `pytest-sugar`) Sets the theme for pytest output.
* `PYTEST_THEME_MODE`: (Used by `pytest-sugar`) Sets the theme mode (e.g., `dark`) for pytest output.
* `XDG_DATA_HOME`, `XDG_CONFIG_HOME`, `XDG_CONFIG_DIRS`, `XDG_CACHE_HOME`, `XDG_STATE_HOME`: Standard XDG base directory environment variables.
* `DISTUTILS_USE_SDK`: (Used by `setuptools`) If set, indicates whether to use the SDK.
* `SETUPTOOLS_EXT_SUFFIX`: (Used by `setuptools`) Specifies the suffix for extension modules.
* `PYDANTIC_PRIVATE_ALLOW_UNHANDLED_SCHEMA_TYPES`: (Used by `pydantic`) Allows unhandled schema types.
* `PYDANTIC_DISABLE_PLUGINS`: (Used by `pydantic`) Disables pydantic plugins.
* `PYDANTIC_VALIDATE_CORE_SCHEMAS`: (Used by `pydantic`) Enables validation of core schemas.
* `EXCEPTIONGROUP_NO_PATCH`: (Used by `exceptiongroup`) If set, prevents patching of the `ExceptionGroup` class.
**Example `.env` file:**
```bash
# Your gemini API Keys
export GEMINI_CALO_API_KEYS=AIaYourGeminiKey1,AIaYourGeminiKey2
# API Keys for your internal user
export GEMINI_CALO_PROXY_API_KEYS=my_secret_proxy_key_1,my_secret_proxy_key_2
# Gemini Calo HTTP Port
export GEMINI_CALO_HTTP_PORT=8080
# Logging level
export GEMINI_CALO_LOG_LEVEL=DEBUG
# Log file
export GEMINI_CALO_LOG_FILE=gemini_calo.log
```
### 3. Running the Server
Once configured, you can start the server with the `gemini-calo` command:
```bash
gemini-calo
```
The server will start on the configured port (e.g., `http://0.0.0.0:8080`).
## Integrating with an Existing FastAPI Application
If you have an existing FastAPI application, you can easily integrate Gemini Calo's proxy functionality into it.
```python
from fastapi import FastAPI
from gemini_calo.proxy import GeminiProxyService
from gemini_calo.middlewares.auth import auth_middleware
from gemini_calo.middlewares.logging import logging_middleware
from functools import partial
import os
# Your existing FastAPI app
app = FastAPI()
# 1. Initialize the GeminiProxyService
gemini_api_keys = os.getenv("GEMINI_CALO_API_KEYS", "").split(",")
proxy_service = GeminiProxyService(gemini_api_keys=gemini_api_keys)
# 2. (Optional) Add Authentication Middleware
proxy_api_keys = os.getenv("GEMINI_CALO_PROXY_API_KEYS", "").split(",")
if proxy_api_keys:
auth_middleware_with_keys = partial(auth_middleware, user_api_key_checker=proxy_api_keys)
app.middleware("http")(auth_middleware_with_keys)
# 3. (Optional) Add Logging Middleware
app.middleware("http")(logging_middleware)
# 4. Mount the Gemini and OpenAI routers
app.include_router(proxy_service.gemini_router)
app.include_router(proxy_service.openai_router)
@app.get("/health")
def health_check():
return {"status": "ok"}
# Now you can run your app as usual with uvicorn
# uvicorn your_app_file:app --reload
```
## How the Middleware Works
Middleware in FastAPI are functions that process every request before it reaches the specific path operation and every response before it is sent back to the client. Gemini Calo includes two useful middlewares by default.
### Logging Middleware (`logging_middleware`)
This middleware logs the details of every incoming request and outgoing response, including headers and body content. This is invaluable for debugging and monitoring. It's designed to handle both standard and streaming responses correctly.
### Authentication Middleware (`auth_middleware`)
This middleware protects your proxy endpoints. It checks for an API key in the `Authorization` header (as a Bearer token) or the `x-goog-api-key` header. It then validates this key against the list of keys you provided in the `GEMINI_CALO_PROXY_API_KEYS` environment variable. If the key is missing or invalid, it returns a `401 Unauthorized` error.
### Adding Your Own Middleware
Because Gemini Calo is built on FastAPI, you can easily add your own custom middleware. For example, you could add a middleware for rate limiting, CORS, or custom header injection.
#### Advanced Middleware: Modifying Request Body and Headers
Here is a more advanced example that intercepts a request, modifies its JSON body, adds a new header, and then forwards it to the actual endpoint. This can be useful for injecting default values, adding metadata, or transforming request payloads.
**Important:** Reading the request body consumes it. To allow the endpoint to read the body again, we must reconstruct the request with the modified body.
```python
from fastapi import FastAPI, Request
from starlette.datastructures import MutableHeaders
import json
app = FastAPI()
# This middleware will add a 'user_id' to the request body
# and a 'X-Request-ID' to the headers.
async def modify_request_middleware(request: Request, call_next):
# Get the original request body
body = await request.body()
# Modify headers
request_headers = MutableHeaders(request.headers)
request_headers["X-Request-ID"] = "some-unique-id"
# Modify body (if it's JSON)
new_body = body
if body and request.headers.get("content-type") == "application/json":
try:
json_body = json.loads(body)
# Add or modify a key
json_body["user_id"] = "injected-user-123"
new_body = json.dumps(json_body).encode()
except json.JSONDecodeError:
# Body is not valid JSON, pass it through
pass
# To pass the modified body and headers, we need to create a new Request object.
# We do this by defining a new 'receive' channel.
async def receive():
return {"type": "http.request", "body": new_body, "more_body": False}
# We replace the original request's scope with the modified headers
request.scope["headers"] = request_headers.raw
# Create the new request object and pass it to the next middleware/endpoint
new_request = Request(request.scope, receive)
response = await call_next(new_request)
return response
app.middleware("http")(modify_request_middleware)
# ... then add the Gemini Calo proxy and routers as shown above
```
## Integration with Zrb
Suppose you run Gemini Calo with the following configuration, then you will have Gemini Calo run on `http://localhost:8080`.
```bash
# Your gemini API Keys
export GEMINI_CALO_API_KEYS=AIaYourGeminiKey1,AIaYourGeminiKey2
# API Keys for your internal user
export GEMINI_CALO_PROXY_API_KEYS=my_secret_proxy_key_1,my_secret_proxy_key_2
# Gemini Calo HTTP Port
export GEMINI_CALO_HTTP_PORT=8080
# Start Gemini Calo
gemini-calo
```
### Integration Using OpenAI Compatibility Layer
To use OpenAI compatibility layer with Zrb, you need to set some environment variables.
```bash
# OpenAI compatibility URL
export ZRB_LLM_BASE_URL=http://localhost:8080/v1beta/openai/
# One of your valid API Key for internal user
export ZRB_LLM_API_KEY=my_secret_proxy_key_1
# The model you want to use
export ZRB_LLM_MODEL=gemini-2.5-flash
# Run `zrb llm ask` or `zrb llm chat`
zrb llm ask "What is the current weather at my current location?"
```
### Integration Using Gemini Endpoint
To use Gemini Endpoint, you will need to edit or create `zrb_init.py`
```python
from google import genai
from google.genai.types import HttpOptions
from pydantic_ai.models.gemini import GeminiModelSettings
from pydantic_ai.providers.google import GoogleProvider
from pydantic_ai.models.google import GoogleModel
from zrb import llm_config
client = genai.Client(
api_key="my_secret_proxy_key_1", # One of your valid API Key for internal user
http_options=HttpOptions(
base_url="http://localhost:8080",
),
)
provider = GoogleProvider(client=client)
model = GoogleModel(
model_name="gemini-2.5-flash",
provider=provider,
settings=GeminiModelSettings(
temperature=0.0,
gemini_safety_settings=[
# Let's become evil 😈😈😈
# https://ai.google.dev/gemini-api/docs/safety-settings
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_CIVIC_INTEGRITY",
"threshold": "BLOCK_NONE",
},
]
)
)
llm_config.set_default_model(model)
```
Once you set up everything, you can start interacting with Zrb.
```bash
# Run `zrb llm ask` or `zrb llm chat`
zrb llm ask "What is the current weather at my current location?"
```
| text/markdown | Go Frendi Gunawan | gofrendiasgard@gmail.com | null | null | AGPL-3.0-or-later | null | [
"License :: OSI Approved :: GNU Affero General Public License v3 or later (AGPLv3+)",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programmin... | [] | null | null | <4.0.0,>=3.10 | [] | [] | [] | [
"cachetools<7.0.0,>=6.1.0",
"fastapi<0.117.0,>=0.116.1",
"uvicorn<0.36.0,>=0.35.0"
] | [] | [] | [] | [
"Documentation, https://github.com/state-alchemists/gemini-calo",
"Homepage, https://github.com/state-alchemists/gemini-calo",
"Repository, https://github.com/state-alchemists/gemini-calo"
] | poetry/2.3.1 CPython/3.13.0 Darwin/25.3.0 | 2026-02-19T08:14:50.188110 | gemini_calo-0.1.5-py3-none-any.whl | 17,868 | 8e/09/37e18ea51c0be873647af2c97660358de8cb890bce423985c06b04fb6d17/gemini_calo-0.1.5-py3-none-any.whl | py3 | bdist_wheel | null | false | 0c661ae13e8cbdf105831f7c91af0c04 | 4c65401f2c048fde368a604f67cad3fa1e5eba1c866dfe3a82f98f36730c5208 | 8e0937e18ea51c0be873647af2c97660358de8cb890bce423985c06b04fb6d17 | null | [] | 260 |
2.4 | fun-sentence-splitter | 0.3.3811.20260219 | A fundamental sentence splitter based on spacy. | # Fun Sentence Splitter
A fundamental sentence splitter based on [spacy](https://spacy.io/).
## Requirements
Python 3.10 or higher and [poetry](https://python-poetry.org).
## Local Dev Setup
Download the Spacy language model used in the tests:
```shell
python -m spacy download de_core_news_sm
```
Run static checks and tests:
```shell
ruff check .
mypy .
pytest --cov=fun_sentence_splitter
```
## Run Evaluation
```shell
./evaluate.sh path/to/splits_dir
```
`path/to/splits_dir`: directory containing pairs of *.split and *.txt files. .split files contain the expected
sentences, each on a separate line. .txt files contain the original text to split.
The evaluation script will automatically update the spacy dependency and download the required language models.
| text/markdown | Medical AI Engineering | engineering@m-ai.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <3.14,>3.9 | [] | [] | [] | [
"spacy==3.8.11"
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.13.1 Linux/6.14.0-1017-azure | 2026-02-19T08:14:02.095579 | fun_sentence_splitter-0.3.3811.20260219-py3-none-any.whl | 4,063 | bd/65/2ecdc92e6dbe1cf784a01188c3b4ca68b6031e935f67d263c77f0b301831/fun_sentence_splitter-0.3.3811.20260219-py3-none-any.whl | py3 | bdist_wheel | null | false | 25901abb1e80e1b7492d768c40eb09ca | 11458db4e0a899c6b04f9b745b0b5220916080670eb19a5e8e885d5c41778366 | bd652ecdc92e6dbe1cf784a01188c3b4ca68b6031e935f67d263c77f0b301831 | null | [
"LICENSE"
] | 253 |
2.4 | quantlix | 0.1.4 | Quantlix — AI-focused GPU inference platform | # Quantlix
Deploy AI models in seconds. A simple inference platform with REST API, usage-based billing, and Kubernetes orchestration.
## Features
- **REST API** — Deploy models, run inference, check status
- **Usage-based billing** — Free, Starter (€9/mo), Pro (€19/mo) tiers with Stripe
- **Queue & orchestration** — Redis queue, K8s job scheduling
- **Customer portal** — Next.js dashboard, usage graphs, real-time logs
- **CLI** — `quantlix deploy`, `quantlix run` for local dev
## Quick start
```bash
# 1. Clone and start services
git clone https://github.com/quantlix/cloud
cd cloud
cp .env.example .env
docker compose up -d
# 2. Create account and get API key
pip install -e .
quantlix signup --email you@example.com --password YourSecurePassword123!
# Verify email, then:
quantlix login --email you@example.com --password YourSecurePassword123!
# Set the API key (required for deploy/run):
export QUANTLIX_API_KEY="qxl_xxx" # from login output
# 3. Deploy and run
quantlix deploy qx-example
# Run inference to activate (first run moves deployment from pending to ready)
quantlix run <deployment_id> -i '{"prompt": "Hello!"}'
```
See [docs/CLI_GUIDE.md](docs/CLI_GUIDE.md) for detailed setup.
## Architecture
```
┌─────────────┐ ┌─────────┐ ┌──────────────┐
│ Portal │────▶│ API │────▶│ PostgreSQL │
│ (Next.js) │ │(FastAPI)│ │ Redis │
└─────────────┘ └────┬────┘ └──────────────┘
│
▼
┌──────────────┐
│ Orchestrator │────▶ Kubernetes / Inference
│ (Worker) │
└──────────────┘
```
## Project structure
| Directory | Description |
|-----------|-------------|
| `api/` | FastAPI backend (auth, deploy, run, billing, usage) |
| `portal/` | Next.js customer dashboard |
| `orchestrator/` | Redis queue worker, K8s job runner |
| `inference/` | Mock inference service (replace with your model server) |
| `sdk/` | Python client library |
| `cli/` | `quantlix` CLI |
| `infra/` | Terraform (Hetzner), Kubernetes manifests |
## Production
See [docs/GO_LIVE.md](docs/GO_LIVE.md) for the full deployment checklist: Stripe, SMTP, DNS, SSL, secrets.
## License
MIT — see [LICENSE](LICENSE).
| text/markdown | Quantlix | null | null | null | MIT | ai, inference, gpu, ml, deployment | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"typer[all]>=0.9.0",
"python-dotenv>=1.0.0",
"httpx>=0.26.0",
"rich>=13.0.0",
"fastapi>=0.109.0; extra == \"full\"",
"uvicorn[standard]>=0.27.0; extra == \"full\"",
"sqlalchemy[asyncio]>=2.0.0; extra == \"full\"",
"asyncpg>=0.29.0; extra == \"full\"",
"greenlet>=3.0.0; extra == \"full\"",
"psycopg... | [] | [] | [] | [
"Homepage, https://quantlix.ai",
"Repository, https://github.com/quantlix/cloud",
"Documentation, https://github.com/quantlix/cloud#readme"
] | twine/6.2.0 CPython/3.14.0 | 2026-02-19T08:13:50.051110 | quantlix-0.1.4.tar.gz | 48,700 | d7/71/b1229ff323f56a6debb08ffd2ce787bc02de29def4fafb9fea3c3ccb2efc/quantlix-0.1.4.tar.gz | source | sdist | null | false | b719891a7eea48e2c30b56941d6d69b4 | d5dc1179d813c914e26553dbd01634b5c4622a04bb7521ee67019cf3995ba4a6 | d771b1229ff323f56a6debb08ffd2ce787bc02de29def4fafb9fea3c3ccb2efc | null | [
"LICENSE"
] | 241 |
2.4 | tenzir-test | 1.6.0 | Reusable test execution framework extracted from the Tenzir repository. | # 🧪 tenzir-test
`tenzir-test` is the reusable test harness that powers the
[Tenzir](https://github.com/tenzir/tenzir) project. It discovers test scenarios
and Python fixtures, prepares the execution environment, and produces artifacts
you can diff against established baselines.
## ✨ Highlights
- 🔍 Auto-discovers tests, inputs, and configuration across both project and
package layouts, including linked satellite projects.
- 🧩 Supports configurable runners and reusable fixtures so you can tailor how
scenarios execute and share setup logic.
- 🛠️ Provides a `tenzir-test` CLI for orchestrating suites, updating baselines,
and inspecting artifacts.
## 📦 Installation
Install the latest release from PyPI with `uvx`—`tenzir-test` requires Python
3.12 or newer:
```sh
uvx tenzir-test --help
```
`uvx` downloads the newest compatible release, runs it in an isolated
environment, and caches subsequent invocations for fast reuse.
## 📚 Documentation
Consult our [user guide](https://docs.tenzir.com/guides/testing/write-tests)
for an end-to-end walkthrough of writing tests.
We also provide a dense [reference](https://docs.tenzir.com/reference/test) that
explains concepts, configuration, multi-project execution, and CLI details.
## 🤝 Contributing
Want to contribute? We're all-in on agentic coding with [Claude
Code](https://claude.ai/code)! The repo comes pre-configured with our [custom
plugins](https://github.com/tenzir/claude-plugins)—just clone and start hacking.
## 📜 License
`tenzir-test` is available under the Apache License, Version 2.0. See
[`LICENSE`](LICENSE) for details.
| text/markdown | null | Tenzir <engineering@tenzir.com> | null | Tenzir Engineering <engineering@tenzir.com> | Apache-2.0 | automation, pytest, tenzir, testing | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software... | [] | null | null | >=3.12 | [] | [] | [] | [
"click>=8.1",
"pyyaml>=6.0"
] | [] | [] | [] | [
"Homepage, https://github.com/tenzir/test",
"Repository, https://github.com/tenzir/test",
"Bug Tracker, https://github.com/tenzir/test/issues",
"Documentation, https://docs.tenzir.com"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:13:04.415473 | tenzir_test-1.6.0.tar.gz | 140,624 | d8/ae/ac911c7e302a8260296e8fb0a9f5fbe66d646a9f3ec68e4574df372d0919/tenzir_test-1.6.0.tar.gz | source | sdist | null | false | 9b01d0b0b6a1bb9ed5e9ad44a8187fd4 | dc670ca9cf94b9e7ff2975446652078dcb054f3ae7a4cda290189a70ddb882c6 | d8aeac911c7e302a8260296e8fb0a9f5fbe66d646a9f3ec68e4574df372d0919 | null | [
"LICENSE"
] | 1,252 |
2.4 | preocr | 1.7.0 | A fast, layout-aware OCR decision engine for document processing pipelines. Detects whether files truly require OCR before expensive processing, reducing unnecessary OCR calls while preserving extraction reliability. | # PreOCR – Python OCR Detection Library | Skip OCR for Digital PDFs
<div align="center">
**Open-source Python library for OCR detection and document extraction. Detect if PDFs need OCR before expensive processing—save 50–70% on OCR costs.**
[](https://www.python.org/downloads/)
[](LICENSE)
[](https://badge.fury.io/py/preocr)
[](https://pepy.tech/project/preocr)
[](https://github.com/psf/black)
*2–10× faster than alternatives • 100% accuracy on benchmark • CPU-only, no GPU required*
**🌐 [preocr.io](https://preocr.io)** • [Installation](#-installation) • [Quick Start](#-quick-start) • [API Reference](#-api-reference) • [Examples](#-usage-examples) • [Performance](#-performance)
</div>
---
### ⚡ TL;DR
| Metric | Result |
|--------|--------|
| **Accuracy** | 100% (TP=1, FP=0, TN=9, FN=0) |
| **Latency** | ~2.7s mean, ~1.9s median (≤1MB PDFs) |
| **Office docs** | ~7ms |
| **Focus** | Zero false positives. Zero missed scans. |
---
## What is PreOCR? Python OCR Detection & Document Processing
**PreOCR** is an open-source **Python OCR detection library** that determines whether documents need OCR before you run expensive processing. It analyzes **PDFs**, **Office documents** (DOCX, PPTX, XLSX), **images**, and text files to detect if they're already machine-readable—helping you **skip OCR** for 50–70% of documents and cut costs.
Use PreOCR to filter documents before Tesseract, AWS Textract, Google Vision, Azure Document Intelligence, or MinerU. Works offline, CPU-only, with 100% accuracy on validation benchmarks.
**🌐 [preocr.io](https://preocr.io)**
### Key Benefits
- ⚡ **Fast**: CPU-only, typically < 1 second per file—no GPU needed
- 🎯 **Accurate**: 92–95% accuracy (100% on validation benchmark)
- 💰 **Cost-Effective**: Skip OCR for 50–70% of documents
- 📊 **Structured Extraction**: Tables, forms, images, semantic data—Pydantic models, JSON, or Markdown
- 🔒 **Type-Safe**: Full Pydantic models with IDE autocomplete
- 🚀 **Offline & Production-Ready**: No API keys; battle-tested error handling
### Use Cases: When to Use PreOCR
- **Document pipelines**: Filter PDFs before OCR (Tesseract, AWS Textract, Google Vision)
- **RAG / LLM ingestion**: Decide which documents need OCR vs. native text extraction
- **Batch processing**: Process thousands of PDFs with page-level OCR decisions
- **Cost optimization**: Reduce cloud OCR API costs by skipping digital documents
- **Medical / legal**: Intent-aware planner for prescriptions, discharge summaries, lab reports
---
## Quick Comparison: PreOCR vs. Alternatives
| Feature | PreOCR 🏆 | Unstructured.io | Docugami |
|---------|-----------|-----------------|----------|
| **Speed** | < 1 second | 5-10 seconds | 10-20 seconds |
| **Cost Optimization** | ✅ Skip OCR 50-70% | ❌ No | ❌ No |
| **Page-Level Processing** | ✅ Yes | ❌ No | ❌ No |
| **Type Safety** | ✅ Pydantic | ⚠️ Basic | ⚠️ Basic |
| **Open Source** | ✅ Yes | ✅ Partial | ❌ Commercial |
**[See Full Comparison](#-competitive-comparison)**
---
## 🚀 Quick Start
### Installation
```bash
pip install preocr
```
### Basic OCR Detection
```python
from preocr import needs_ocr
result = needs_ocr("document.pdf")
if result["needs_ocr"]:
print("File needs OCR processing")
# Run your OCR engine here (MinerU, Tesseract, etc.)
else:
print("File is already machine-readable")
# Extract text directly
```
### Structured Data Extraction
```python
from preocr import extract_native_data
# Extract structured data from PDF
result = extract_native_data("invoice.pdf")
# Access elements, tables, forms
for element in result.elements:
print(f"{element.element_type}: {element.text}")
# Export to Markdown for LLM consumption
markdown = extract_native_data("document.pdf", output_format="markdown")
```
### Batch Processing
```python
from preocr import BatchProcessor
processor = BatchProcessor(max_workers=8)
results = processor.process_directory("documents/")
results.print_summary()
```
---
## ✨ Key Features
### OCR Detection (`needs_ocr`)
- **Universal File Support**: PDFs, Office docs (DOCX, PPTX, XLSX), images, text files
- **Early Exits**: Hard digital guard (high text → NO OCR) and hard scan shortcut (image-heavy + font_count=0 → OCR) skip layout/OpenCV
- **Signal/Decision/Hints Separation**: Raw signals, structured decision, and downstream hints (suggested_engine, preprocessing) for debugging and routing
- **Layout-Aware Analysis**: Detects mixed content and layout structure
- **Page-Level Granularity**: Analyze PDFs page-by-page; variance-based escalation skips full analysis for uniform docs
- **Confidence Band**: Tiered OpenCV refinement (≥0.90 exit, 0.75–0.90 skip unless image-heavy, 0.50–0.75 light, <0.50 full)
- **Configurable Image Guard**: `skip_opencv_image_guard` (default 50%) tunable per domain
- **Digital-but-Low-Quality Detection**: Text quality signals (non_printable_ratio, unicode_noise_ratio) catch broken text layers
- **Feature-Driven Engine Suggestion**: `ocr_complexity_score` drives Tesseract/Paddle/Vision LLM selection when OCR needed
- **Digital/Table Bias**: Reduces false positives on high-text PDFs (product manuals, marketing docs) via configurable rules
### Intent-Aware OCR Planner (`plan_ocr_for_document` / `intent_refinement`)
- **Alias**: `intent_refinement` — refines needs_ocr with domain-specific scoring
- **Medical Domain**: Terminal overrides for prescriptions, diagnosis, discharge summaries, lab reports
- **Weighted Scoring**: Configurable threshold with safety/balanced/cost modes
- **Explainability**: Per-page score breakdown (intent, image_dominance, text_weakness)
- **Evaluation**: Threshold sweep and confusion matrix for calibration
See [docs/OCR_DECISION_MODEL.md](docs/OCR_DECISION_MODEL.md) for the full specification.
### Preprocessing for OCR (`prepare_for_ocr`)
- **Detection-Driven**: Uses `needs_ocr` hints (`suggest_preprocessing`) when `steps="auto"`
- **Pipeline Steps**: denoise, deskew, otsu, rescale (ordered automatically)
- **Modes**: `quality` (full) or `fast` (skip denoise/rescale; deskew severe-only)
- **Guardrails**: Otsu precondition (denoise before otsu); optional `config.auto_fix`
- **Sources**: PDF (PyMuPDF), images (PNG/JPG/TIFF), numpy arrays
- **Observability**: `return_meta=True` → `applied_steps`, `skipped_steps`, `auto_detected`
Requires `pip install preocr[layout-refinement]`.
### Document Extraction (`extract_native_data`)
- **Element Classification**: 11+ element types (Title, NarrativeText, Table, Header, Footer, etc.)
- **Table Extraction**: Advanced table extraction with cell-level metadata
- **Form Field Detection**: Extract PDF form fields with semantic naming
- **Image Detection**: Locate and extract image metadata
- **Section Detection**: Hierarchical sections with parent-child relationships
- **Reading Order**: Logical reading order for all elements
- **Multiple Output Formats**: Pydantic models, JSON, and Markdown (LLM-ready)
### Advanced Features (v1.1.0+)
- **Invoice Intelligence**: Semantic extraction with finance validation and semantic deduplication
- **Text Merging**: Geometry-aware character-to-word merging for accurate text extraction
- **Table Stitching**: Merges fragmented tables across pages into logical tables
- **Smart Deduplication**: Table-narrative deduplication and semantic line item deduplication
- **Reversed Text Detection**: Detects and corrects rotated/mirrored text
- **Footer Exclusion**: Removes footer content from reading order for cleaner extraction
- **Finance Validation**: Validates invoice totals (subtotal, tax, total) for data integrity
---
## 📦 Installation
### Basic Installation
```bash
pip install preocr
```
### With OpenCV Refinement (Recommended)
For improved accuracy on edge cases:
```bash
pip install preocr[layout-refinement]
```
### System Requirements
**libmagic** is required for file type detection:
- **Linux (Debian/Ubuntu)**: `sudo apt-get install libmagic1`
- **Linux (RHEL/CentOS)**: `sudo yum install file-devel` or `sudo dnf install file-devel`
- **macOS**: `brew install libmagic`
- **Windows**: Usually included with `python-magic-bin` package
---
## 💻 Usage Examples
### OCR Detection
#### Basic Detection
```python
from preocr import needs_ocr
result = needs_ocr("document.pdf")
print(f"Needs OCR: {result['needs_ocr']}")
print(f"Confidence: {result['confidence']:.2f}")
print(f"Reason: {result['reason']}")
```
#### Structured Result (Signals, Decision, Hints)
```python
result = needs_ocr("document.pdf", layout_aware=True)
# Debug misclassifications via raw signals
print(result["signals"]) # text_length, image_coverage, font_count, etc.
print(result["decision"]) # needs_ocr, confidence, reason_code
print(result["hints"]) # suggested_engine, suggest_preprocessing (when needs_ocr=True)
```
#### Intent-Aware Planner (Medical/Domain-Specific)
```python
from preocr import plan_ocr_for_document # or intent_refinement
result = plan_ocr_for_document("hospital_discharge.pdf")
print(f"Needs OCR (any page): {result['needs_ocr_any']}")
print(f"Summary: {result['summary_reason']}")
for page in result["pages"]:
score = page.get("debug", {}).get("score", 0)
print(f" Page {page['page_number']}: needs_ocr={page['needs_ocr']} "
f"type={page['decision_type']} score={score:.2f}")
```
#### Layout-Aware Detection
```python
result = needs_ocr("document.pdf", layout_aware=True)
if result.get("layout"):
layout = result["layout"]
print(f"Layout Type: {layout['layout_type']}")
print(f"Text Coverage: {layout['text_coverage']}%")
print(f"Image Coverage: {layout['image_coverage']}%")
```
#### Page-Level Analysis
```python
result = needs_ocr("mixed_document.pdf", page_level=True)
if result["reason_code"] == "PDF_MIXED":
print(f"Mixed PDF: {result['pages_needing_ocr']} pages need OCR")
for page in result["pages"]:
if page["needs_ocr"]:
print(f" Page {page['page_number']}: {page['reason']}")
```
### Document Extraction
#### Extract Structured Data
```python
from preocr import extract_native_data
# Extract as Pydantic model
result = extract_native_data("document.pdf")
# Access elements
for element in result.elements:
print(f"{element.element_type}: {element.text[:50]}...")
print(f" Confidence: {element.confidence:.2%}")
print(f" Bounding box: {element.bbox}")
# Access tables
for table in result.tables:
print(f"Table: {table.rows} rows × {table.columns} columns")
for cell in table.cells:
print(f" Cell [{cell.row}, {cell.col}]: {cell.text}")
```
#### Export Formats
```python
# JSON output
json_data = extract_native_data("document.pdf", output_format="json")
# Markdown output (LLM-ready)
markdown = extract_native_data("document.pdf", output_format="markdown")
# Clean markdown (content only, no metadata)
clean_markdown = extract_native_data(
"document.pdf",
output_format="markdown",
markdown_clean=True
)
```
#### Extract Specific Pages
```python
# Extract only pages 1-3
result = extract_native_data("document.pdf", pages=[1, 2, 3])
```
### Batch Processing
```python
from preocr import BatchProcessor
# Configure processor
processor = BatchProcessor(
max_workers=8,
use_cache=True,
layout_aware=True,
page_level=True,
extensions=["pdf", "docx"],
)
# Process directory
results = processor.process_directory("documents/", progress=True)
# Get statistics
stats = results.get_statistics()
print(f"Processed: {stats['processed']} files")
print(f"Needs OCR: {stats['needs_ocr']} ({stats['needs_ocr']/stats['processed']*100:.1f}%)")
```
### Preprocessing for OCR (`prepare_for_ocr`)
Apply detection-aware preprocessing before OCR. Use `steps="auto"` to let `needs_ocr` hints drive which steps run:
```python
from preocr import needs_ocr, prepare_for_ocr
# Option A: steps="auto" (uses needs_ocr hints automatically)
result, meta = prepare_for_ocr("scan.pdf", steps="auto", return_meta=True)
print(meta["applied_steps"]) # e.g. ['otsu', 'deskew']
# Option B: Wire hints manually
ocr_result = needs_ocr("scan.pdf", layout_aware=True)
if ocr_result["needs_ocr"]:
hints = ocr_result["hints"]
preprocess = hints.get("suggest_preprocessing", [])
preprocessed = prepare_for_ocr("scan.pdf", steps=preprocess)
# Option C: Explicit steps
preprocessed = prepare_for_ocr(img_array, steps=["denoise", "otsu"], mode="fast")
# Option D: No preprocessing
preprocessed = prepare_for_ocr(img, steps=None) # unchanged
```
**Steps**: `denoise` → `deskew` → `otsu` → `rescale`. **Modes**: `quality` (full) or `fast` (skip denoise/rescale). Requires `pip install preocr[layout-refinement]`.
### Integration with OCR Engines
```python
from preocr import needs_ocr, prepare_for_ocr, extract_native_data
def process_document(file_path):
ocr_check = needs_ocr(file_path, layout_aware=True)
if ocr_check["needs_ocr"]:
# Preprocess then run OCR (steps from hints, or use steps="auto")
preprocessed = prepare_for_ocr(file_path, steps="auto")
hints = ocr_check["hints"]
engine = hints.get("suggested_engine", "tesseract") # tesseract | paddle | vision_llm
# Run OCR on preprocessed image(s)
return {"source": "ocr", "engine": engine, "text": "..."}
else:
result = extract_native_data(file_path)
return {"source": "native", "text": result.text}
```
---
## 📋 Supported File Formats
PreOCR supports **20+ file formats** for OCR detection and extraction:
| Format | OCR Detection | Extraction | Notes |
|--------|--------------|------------|-------|
| **PDF** | ✅ Full | ✅ Full | Page-level analysis, layout-aware |
| **DOCX/DOC** | ✅ Yes | ✅ Yes | Tables, metadata |
| **PPTX/PPT** | ✅ Yes | ✅ Yes | Slides, text |
| **XLSX/XLS** | ✅ Yes | ✅ Yes | Cells, tables |
| **Images** | ✅ Yes | ⚠️ Limited | PNG, JPG, TIFF, etc. |
| **Text** | ✅ Yes | ✅ Yes | TXT, CSV, HTML |
| **Structured** | ✅ Yes | ✅ Yes | JSON, XML |
---
## ⚙️ Configuration
### Custom Thresholds
```python
from preocr import needs_ocr, Config
config = Config(
min_text_length=75,
min_office_text_length=150,
layout_refinement_threshold=0.85,
)
result = needs_ocr("document.pdf", config=config)
```
### Available Thresholds
**Core:**
- `min_text_length`: Minimum text length (default: 50)
- `min_office_text_length`: Minimum office text length (default: 100)
- `layout_refinement_threshold`: OpenCV trigger threshold (default: 0.9)
**Confidence Band:**
- `confidence_exit_threshold`: Skip OpenCV when confidence ≥ this (default: 0.90)
- `confidence_light_refinement_min`: Light refinement when confidence in [this, exit) (default: 0.50)
- `skip_opencv_image_guard`: In 0.75–0.90 band, run OpenCV only if image_coverage > this % (default: 50)
**Page-Level:**
- `variance_page_escalation_std`: Run full page-level when std(page_scores) > this (default: 0.18)
**Skip Heuristics:**
- `skip_opencv_if_file_size_mb`: Skip OpenCV when file size ≥ N MB (default: None)
- `skip_opencv_if_page_count`: Skip OpenCV when page count ≥ N (default: None)
- `skip_opencv_max_image_coverage`: Never skip when image_coverage > this (default: None)
**Bias Rules:**
- `digital_bias_text_coverage_min`: Force no-OCR when text_coverage ≥ this and image_coverage low (default: 65)
- `table_bias_text_density_min`: For mixed layout, treat as digital when text_density ≥ this (default: 1.5)
---
## 🎯 Reason Codes
PreOCR provides structured reason codes for programmatic handling:
**No OCR Needed:**
- `TEXT_FILE` - Plain text file
- `OFFICE_WITH_TEXT` - Office document with sufficient text
- `PDF_DIGITAL` - Digital PDF with extractable text
- `STRUCTURED_DATA` - JSON/XML files
**OCR Needed:**
- `IMAGE_FILE` - Image file
- `PDF_SCANNED` - Scanned PDF
- `PDF_MIXED` - Mixed digital and scanned pages
- `OFFICE_NO_TEXT` - Office document with insufficient text
**Example:**
```python
result = needs_ocr("document.pdf")
if result["reason_code"] == "PDF_MIXED":
# Handle mixed PDF
process_mixed_pdf(result)
```
---
## 📈 Performance
### Speed Benchmarks
| Scenario | Time | Accuracy |
|----------|------|----------|
| Fast Path (Heuristics) | < 150ms | ~99% |
| OpenCV Refinement | 150-300ms | 92-96% |
| **Typical (single file)** | **< 1 second** | **94-97%** |
*Typical: most PDFs finish in under 1 second. Heuristics-only files: 120–180ms avg. Large or mixed documents may take 1–3s with OpenCV.*
### Full Dataset Batch Benchmark
<p align="center">
<img src="scripts/benchmark_diagram.png" alt="PreOCR Batch Benchmark - Full Dataset" width="700">
<br><em>PreOCR Batch Benchmark: 192 PDFs, 1.5 files/sec, median 1134ms</em>
</p>
### Benchmark Results (≤1MB Dataset)
<p align="center">
<img src="docs/benchmarks/avg-time-by-type.png" alt="Average processing time by file type" width="500">
<br><em>Average Processing Time by File Type</em>
</p>
<p align="center">
<img src="docs/benchmarks/latency-summary.png" alt="Latency summary for PDFs" width="500">
<br><em>Latency Summary (Mean, Median, P95)</em>
</p>
### Accuracy Metrics
- **Overall Accuracy**: 92-95% (100% on validation benchmark)
- **Precision**: 100% (all flagged files actually need OCR)
- **Recall**: 100% (all OCR-needed files detected)
- **F1-Score**: 100%
<p align="center">
<img src="docs/benchmarks/confusion-matrix.png" alt="Confusion matrix - 100% accuracy" width="500">
<br><em>Confusion Matrix (TP:1, FP:0, TN:9, FN:0)</em>
</p>
### Performance Factors
- **File size**: Larger files take longer
- **Page count**: More pages = longer processing
- **Document complexity**: Complex layouts require more analysis
- **System resources**: CPU speed and memory
---
## 🏗️ How It Works
PreOCR uses a **hybrid adaptive pipeline** with early exits, confidence bands, and optional OpenCV refinement.
### Pipeline Flow
```
File Input
↓
File Type Detection (mime, extension)
↓
Text Extraction (PDF/Office/Text/Image probe)
↓
┌─────────────────────────────────────────────────────────────────┐
│ PDF Early Exits (before layout/OpenCV) │
├─────────────────────────────────────────────────────────────────┤
│ 1. Hard Digital Guard: text_length ≥ threshold → NO OCR, return │
│ 2. Hard Scan Shortcut: image>85%, text<10, font_count==0 → OCR │
└─────────────────────────────────────────────────────────────────┘
↓ (if no early exit)
Layout Analysis (optional, if layout_aware=True)
↓
Collect Signals (text_length, image_coverage, font_count, text quality, etc.)
↓
Decision Engine (rule-based heuristics + OCR_SCORE)
↓
Confidence Band → OpenCV Refinement (PDFs only)
├─ ≥ 0.90: Immediate exit (skip OpenCV)
├─ 0.75–0.90: Skip OpenCV unless image_coverage > skip_opencv_image_guard (default 50%)
├─ 0.50–0.75: Light refinement (sample 2–3 pages)
└─ < 0.50: Full OpenCV refinement
↓
Return Result (signals, decision, hints)
```
### Early Exits (Speed)
| Exit | Condition | Action |
|------|-----------|--------|
| **Hard Digital** | `text_length ≥ hard_digital_text_threshold` | NO OCR, return immediately |
| **Hard Scan** | `image_coverage > 85%`, `text_length < 10`, `font_count == 0` | Needs OCR, skip layout/OpenCV |
The `font_count == 0` guard prevents digital PDFs with background raster images from being misclassified as scans.
### Confidence Band (OpenCV Tiers)
| Confidence | Action |
|------------|--------|
| **≥ 0.90** | Skip OpenCV entirely |
| **0.75–0.90** | Skip OpenCV unless `image_coverage > skip_opencv_image_guard` (default 50%) |
| **0.50–0.75** | Light refinement (2–3 pages sampled) |
| **< 0.50** | Full OpenCV refinement |
### Variance-Based Page Escalation
When `page_level=True`, full page-level analysis runs only when `std(page_scores) > 0.18`. For uniform documents (all digital or all scanned), doc-level decision is reused for all pages—faster for large PDFs.
### Digital-but-Low-Quality Detection
PDFs with a text layer but broken/invisible text (garbage) are detected via:
- `non_printable_ratio` > 5%
- `unicode_noise_ratio` > 8%
Such files are treated as needing OCR to avoid false negatives.
### Result Structure (v1.6.0+)
```python
result = needs_ocr("document.pdf", layout_aware=True)
# Flat keys (backward compatible)
result["needs_ocr"] # True/False
result["confidence"] # 0.0–1.0
result["reason_code"] # e.g. "PDF_DIGITAL", "PDF_SCANNED"
# Structured (for debugging)
result["signals"] # Raw: text_length, image_coverage, font_count, non_printable_ratio, etc.
result["decision"] # {needs_ocr, confidence, reason_code, reason}
result["hints"] # {suggested_engine, suggest_preprocessing, ocr_complexity_score}
```
When `needs_ocr=True`, `hints` provides:
- **suggested_engine**: `tesseract` (< 0.3) | `paddle` (0.3–0.7) | `vision_llm` (> 0.7)
- **suggest_preprocessing**: e.g. `["deskew", "otsu", "denoise"]` — use with `prepare_for_ocr(path, steps="auto")`
- **ocr_complexity_score**: 0.0–1.0, drives engine selection
### Pipeline Performance
- **~85–90% of files**: Fast path (< 150ms) — heuristics only, often early exit
- **~10–15% of files**: Refined path (150–300ms) — heuristics + OpenCV
- **Overall accuracy**: 92–95% with hybrid pipeline
---
## 🔧 API Reference
### `needs_ocr(file_path, page_level=False, layout_aware=False, config=None)`
Determine if a file needs OCR processing.
**Parameters:**
- `file_path` (str or Path): Path to file
- `page_level` (bool): Page-level analysis for PDFs (default: False)
- `layout_aware` (bool): Layout analysis for PDFs (default: False)
- `config` (Config): Custom configuration (default: None)
**Returns:**
Dictionary with:
- **Flat**: `needs_ocr`, `confidence`, `reason_code`, `reason`, `file_type`, `category`
- **signals**: Raw detection signals (text_length, image_coverage, font_count, non_printable_ratio, etc.)
- **decision**: Structured `{needs_ocr, confidence, reason_code, reason}`
- **hints**: `{suggested_engine, suggest_preprocessing, ocr_complexity_score}` when needs_ocr=True
- **pages** / **layout**: Optional, when page_level or layout_aware
### `extract_native_data(file_path, include_tables=True, include_forms=True, include_metadata=True, include_structure=True, include_images=True, include_bbox=True, pages=None, output_format="pydantic", config=None)`
Extract structured data from machine-readable documents.
**Parameters:**
- `file_path` (str or Path): Path to file
- `include_tables` (bool): Extract tables (default: True)
- `include_forms` (bool): Extract form fields (default: True)
- `include_metadata` (bool): Include metadata (default: True)
- `include_structure` (bool): Detect sections (default: True)
- `include_images` (bool): Detect images (default: True)
- `include_bbox` (bool): Include bounding boxes (default: True)
- `pages` (list): Page numbers to extract (default: None = all)
- `output_format` (str): "pydantic", "json", or "markdown" (default: "pydantic")
- `config` (Config): Configuration (default: None)
**Returns:**
`ExtractionResult` (Pydantic), `Dict` (JSON), or `str` (Markdown).
### `BatchProcessor(max_workers=None, use_cache=True, layout_aware=False, page_level=True, extensions=None, config=None)`
Batch processor for multiple files with parallel processing.
**Parameters:**
- `max_workers` (int): Parallel workers (default: CPU count)
- `use_cache` (bool): Enable caching (default: True)
- `layout_aware` (bool): Layout analysis (default: False)
- `page_level` (bool): Page-level analysis (default: True)
- `extensions` (list): File extensions to process (default: None)
- `config` (Config): Configuration (default: None)
**Methods:**
- `process_directory(directory, progress=True) -> BatchResults`
### `prepare_for_ocr(source, steps=None, mode="quality", return_meta=False, pages=None, dpi=300, config=None)`
Prepare image(s) for OCR using detection-aware preprocessing.
**Parameters:**
- `source` (str, Path, or ndarray): File path or numpy array
- `steps` (None | "auto" | list | dict): `None` = no preprocessing; `"auto"` = use `needs_ocr` hints; list/dict = explicit steps
- `mode` (str): `"quality"` (full) or `"fast"` (skip denoise, rescale; deskew severe-only)
- `return_meta` (bool): Return `(img, meta)` with applied_steps, skipped_steps, auto_detected
- `pages` (list): For PDFs, 1-indexed page numbers (default: None = all)
- `dpi` (int): Target DPI for rescale step (default: 300)
- `config` (PreprocessConfig): Optional; `auto_fix=True` auto-adds denoise when otsu requested
**Returns:** Processed numpy array or list of arrays. With `return_meta=True`: `(img, meta)`.
**Requires:** `pip install preocr[layout-refinement]` (OpenCV, PyMuPDF for PDFs)
---
## 🆚 Competitive Comparison
### PreOCR vs. Market Leaders
| Feature | PreOCR 🏆 | Unstructured.io | Docugami |
|---------|-----------|-----------------|----------|
| **Speed** | < 1 second | 5-10 seconds | 10-20 seconds |
| **Cost Optimization** | ✅ Skip OCR 50-70% | ❌ No | ❌ No |
| **Page-Level Processing** | ✅ Yes | ❌ No | ❌ No |
| **Type Safety** | ✅ Pydantic | ⚠️ Basic | ⚠️ Basic |
| **Confidence Scores** | ✅ Per-element | ❌ No | ✅ Yes |
| **Open Source** | ✅ Yes | ✅ Partial | ❌ Commercial |
| **CPU-Only** | ✅ Yes | ✅ Yes | ⚠️ May need GPU |
**Overall Score: PreOCR 91.4/100** 🏆
### When to Choose PreOCR
✅ **Choose PreOCR when:**
- You're building **document ingestion pipelines** or **RAG/LLM systems**—decide which files need OCR vs. native extraction
- You need **speed** (< 1 second per file) and **cost optimization** (skip OCR for 50–70% of documents)
- You want **page-level granularity** (which pages need OCR in mixed PDFs)
- You prefer **type safety** (Pydantic models) and **edge deployment** (CPU-only, no GPU)
### Switched from Unstructured.io or another library?
PreOCR focuses on **OCR routing**—it doesn't perform extraction by default. Use it as a pre-filter: call `needs_ocr()` first, then route to your OCR engine or to `extract_native_data()` for digital documents. The API is simple: `needs_ocr(path)`, `extract_native_data(path)`, `BatchProcessor`.
---
## 🐛 Troubleshooting
### Common Issues
**1. File type detection fails**
- Install `libmagic`: `sudo apt-get install libmagic1` (Linux) or `brew install libmagic` (macOS)
**2. PDF text extraction returns empty**
- Check if PDF is password-protected
- Verify PDF is not corrupted
- Install both `pdfplumber` and `PyMuPDF`
**3. OpenCV layout analysis not working**
- Install: `pip install preocr[layout-refinement]`
- Verify: `python -c "import cv2; print(cv2.__version__)"`
**4. Low confidence scores**
- Enable layout-aware: `needs_ocr(file_path, layout_aware=True)`
- Check file type is supported
- Review signals in result dictionary
---
## Frequently Asked Questions (FAQ)
**Does PreOCR perform OCR?**
No. PreOCR is an **OCR detection** library—it analyzes files to determine if OCR is needed. It does not run OCR itself. Use it to decide whether to call Tesseract, Textract, or another OCR engine.
**How accurate is PreOCR for PDF OCR detection?**
PreOCR achieves 92–95% accuracy with the hybrid pipeline. Validation on benchmark datasets reached 100% accuracy (10/10 PDFs correct).
**Can I use PreOCR with AWS Textract, Google Vision, or Azure Document Intelligence?**
Yes. PreOCR is ideal for filtering documents before sending them to cloud OCR APIs. Skip OCR for digital PDFs to reduce API costs.
**Does PreOCR work offline?**
Yes. PreOCR is CPU-only and runs fully offline—no API keys or internet required.
**How do I customize OCR detection thresholds?**
Use the `Config` class or pass threshold parameters to `BatchProcessor`. See [Configuration](#-configuration).
**Is there an HTTP/REST API?**
PreOCR is a Python library. For HTTP APIs, wrap it in FastAPI or Flask—see [preocr.io](https://preocr.io) for hosted options.
---
## 🧪 Development
```bash
# Clone repository
git clone https://github.com/yuvaraj3855/preocr.git
cd preocr
# Install in development mode
pip install -e ".[dev]"
# Run tests
pytest
# Run benchmarks (add PDFs to datasets/ for testing)
python examples/test_preprocess_flow.py # Preprocess flow (needs layout-refinement)
python scripts/benchmark_preprocess_accuracy.py datasets # Preprocess + accuracy
python scripts/benchmark_accuracy.py datasets -g scripts/ground_truth_data_source_formats.json --layout-aware --page-level
python scripts/benchmark_batch_full.py datasets -v # Full dataset, PDF-wise log, diagram
python scripts/benchmark_planner.py datasets
# Run linting
ruff check preocr/
black --check preocr/
```
---
## 📝 Changelog
See [CHANGELOG.md](docs/CHANGELOG.md) for complete version history.
### Recent Updates
**v1.7.0** - Preprocess Module (Latest)
- ✅ **prepare_for_ocr**: Detection-aware preprocessing (denoise, deskew, otsu, rescale)
- ✅ `steps="auto"` uses needs_ocr hints; `quality` / `fast` modes
**v1.6.0** - Signal/Decision Separation & Confidence Band
- ✅ **Signal/Decision/Hints Separation**: Structured output for debugging and downstream routing
- ✅ **Hard Scan Font Guard**: `font_count == 0` required for hard scan shortcut (avoids false positives on digital PDFs with background images)
- ✅ **Refined Confidence Band**: ≥0.90 exit, 0.75–0.90 skip unless image-heavy, 0.50–0.75 light, <0.50 full
- ✅ **skip_opencv_image_guard**: Configurable (default 50%) for domain-specific tuning
- ✅ **Variance-Based Escalation**: Full page-level only when std(page_scores) > 0.18
- ✅ **Digital-but-Low-Quality Detection**: Text quality signals catch broken/invisible text layers
- ✅ **Feature-Driven Engine Suggestion**: ocr_complexity_score → Tesseract/Paddle/Vision LLM
- ✅ **intent_refinement** alias for plan_ocr_for_document
**v1.1.0** - Invoice Intelligence & Advanced Extraction
- ✅ Semantic deduplication, invoice intelligence, text merging
- ✅ Table stitching, finance validation, reversed text detection
**v1.0.0** - Structured Data Extraction
- ✅ Comprehensive extraction for PDFs, Office docs, text files
- ✅ Element classification, table/form/image extraction
---
## 🤝 Contributing
Contributions are welcome! Please see [CONTRIBUTING.md](docs/CONTRIBUTING.md) for guidelines.
---
## 📄 License
Apache License 2.0 - see [LICENSE](LICENSE) for details.
---
## Links & Resources
- **Website**: [preocr.io](https://preocr.io) – Python OCR detection and document processing
- **PyPI**: [pypi.org/project/preocr](https://pypi.org/project/preocr) – Install with `pip install preocr`
- **GitHub**: [github.com/yuvaraj3855/preocr](https://github.com/yuvaraj3855/preocr) – Source code and issues
- **Documentation**: [CHANGELOG](docs/CHANGELOG.md) • [OCR Decision Model](docs/OCR_DECISION_MODEL.md) • [Contributing](docs/CONTRIBUTING.md)
---
<div align="center">
**PreOCR – Python OCR detection library. Skip OCR for digital PDFs. Save time and money.**
[Website](https://preocr.io) · [GitHub](https://github.com/yuvaraj3855/preocr) · [PyPI](https://pypi.org/project/preocr) · [Report Issue](https://github.com/yuvaraj3855/preocr/issues)
</div>
| text/markdown | Yuvaraj Kannan | null | null | null | Apache-2.0 | ocr, ocr-decision, pre-ocr, document-processing, pdf-analysis, layout-analysis, ocr-optimization, ocr-routing, pdf-processing, computer-vision, document-ai | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programm... | [] | null | null | >=3.9 | [] | [] | [] | [
"python-magic>=0.4.27",
"pdfplumber>=0.10.0",
"python-docx>=1.1.0",
"python-pptx>=0.6.23",
"openpyxl>=3.1.0",
"Pillow>=10.0.0",
"beautifulsoup4>=4.12.0",
"pydantic>=2.0.0",
"numpy>=1.24.0",
"pytest>=7.4.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev... | [] | [] | [] | [
"Homepage, https://github.com/yuvaraj3855/preocr",
"Documentation, https://github.com/yuvaraj3855/preocr#readme",
"Repository, https://github.com/yuvaraj3855/preocr",
"Issues, https://github.com/yuvaraj3855/preocr/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:10:11.894181 | preocr-1.7.0.tar.gz | 135,229 | ee/fd/1c6486d6ed1558e685ea1e6c41bbe4d0d7b8810d6d6b821648fbd4d62305/preocr-1.7.0.tar.gz | source | sdist | null | false | 4c067b90f2baf7b7b57a7559f5373acc | e7adf8672c4b51e1f7d26328b97dc522061196ec876583cdbf7c589ce8f9ca55 | eefd1c6486d6ed1558e685ea1e6c41bbe4d0d7b8810d6d6b821648fbd4d62305 | null | [
"LICENSE"
] | 281 |
2.4 | raindrop-query | 0.1.5 | Official Python SDK for the Raindrop Query API | # raindrop-query
Official Python SDK for the [Raindrop Query API](https://query.raindrop.ai).
[](https://opensource.org/licenses/MIT)
[](https://pypi.org/project/raindrop-query/)
<!-- Start Summary [summary] -->
## Summary
Raindrop Query API (Beta): API for querying Signals, Events, Users, and Conversations data.
<!-- End Summary [summary] -->
<!-- Start Table of Contents [toc] -->
## Table of Contents
<!-- $toc-max-depth=2 -->
* [raindrop-query](https://github.com/raindrop-ai/query-sdk/blob/master/python/#raindrop-query)
* [SDK Installation](https://github.com/raindrop-ai/query-sdk/blob/master/python/#sdk-installation)
* [IDE Support](https://github.com/raindrop-ai/query-sdk/blob/master/python/#ide-support)
* [SDK Example Usage](https://github.com/raindrop-ai/query-sdk/blob/master/python/#sdk-example-usage)
* [Authentication](https://github.com/raindrop-ai/query-sdk/blob/master/python/#authentication)
* [Available Resources and Operations](https://github.com/raindrop-ai/query-sdk/blob/master/python/#available-resources-and-operations)
* [Retries](https://github.com/raindrop-ai/query-sdk/blob/master/python/#retries)
* [Error Handling](https://github.com/raindrop-ai/query-sdk/blob/master/python/#error-handling)
* [Server Selection](https://github.com/raindrop-ai/query-sdk/blob/master/python/#server-selection)
* [Custom HTTP Client](https://github.com/raindrop-ai/query-sdk/blob/master/python/#custom-http-client)
* [Resource Management](https://github.com/raindrop-ai/query-sdk/blob/master/python/#resource-management)
* [Debugging](https://github.com/raindrop-ai/query-sdk/blob/master/python/#debugging)
* [Development](https://github.com/raindrop-ai/query-sdk/blob/master/python/#development)
* [Maturity](https://github.com/raindrop-ai/query-sdk/blob/master/python/#maturity)
* [Support](https://github.com/raindrop-ai/query-sdk/blob/master/python/#support)
<!-- End Table of Contents [toc] -->
<!-- Start SDK Installation [installation] -->
## SDK Installation
The SDK can be installed with *pip* or *uv*.
### PIP
```bash
pip install raindrop-query
```
### uv
```bash
uv add raindrop-query
```
### Shell and script usage with `uv`
You can use this SDK in a Python shell with [uv](https://docs.astral.sh/uv/) and the `uvx` command that comes with it like so:
```shell
uvx --from raindrop-query python
```
It's also possible to write a standalone Python script without needing to set up a whole project like so:
```python
#!/usr/bin/env -S uv run --script
# /// script
# requires-python = ">=3.10"
# dependencies = [
# "raindrop-query",
# ]
# ///
from raindrop_query import RaindropQuery
sdk = RaindropQuery(
# SDK arguments
)
# Rest of script here...
```
Once that is saved to a file, you can run it with `uv run script.py` where
`script.py` can be replaced with the actual file name.
<!-- End SDK Installation [installation] -->
<!-- Start IDE Support [idesupport] -->
## IDE Support
### PyCharm
Generally, the SDK will work well with most IDEs out of the box. However, when using PyCharm, you can enjoy much better integration with Pydantic by installing an additional plugin.
- [PyCharm Pydantic Plugin](https://docs.pydantic.dev/latest/integrations/pycharm/)
<!-- End IDE Support [idesupport] -->
<!-- Start SDK Example Usage [usage] -->
## SDK Example Usage
### Example
```python
# Synchronous Example
from raindrop_query import RaindropQuery
with RaindropQuery(
api_key="<YOUR_BEARER_TOKEN_HERE>",
) as rq_client:
res = rq_client.signals.list(limit=50, order_by="-timestamp")
# Handle response
print(res)
```
</br>
The same SDK client can also be used to make asynchronous requests by importing asyncio.
```python
# Asynchronous Example
import asyncio
from raindrop_query import RaindropQuery
async def main():
async with RaindropQuery(
api_key="<YOUR_BEARER_TOKEN_HERE>",
) as rq_client:
res = await rq_client.signals.list_async(limit=50, order_by="-timestamp")
# Handle response
print(res)
asyncio.run(main())
```
<!-- End SDK Example Usage [usage] -->
<!-- Start Authentication [security] -->
## Authentication
### Per-Client Security Schemes
This SDK supports the following security scheme globally:
| Name | Type | Scheme |
| --------- | ---- | ----------- |
| `api_key` | http | HTTP Bearer |
To authenticate with the API the `api_key` parameter must be set when initializing the SDK client instance. For example:
```python
from raindrop_query import RaindropQuery
with RaindropQuery(
api_key="<YOUR_BEARER_TOKEN_HERE>",
) as rq_client:
res = rq_client.signals.list(limit=50, order_by="-timestamp")
# Handle response
print(res)
```
<!-- End Authentication [security] -->
<!-- Start Available Resources and Operations [operations] -->
## Available Resources and Operations
<details open>
<summary>Available methods</summary>
### [Conversations](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/conversations/README.md)
* [list](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/conversations/README.md#list) - List conversations
* [get](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/conversations/README.md#get) - Get conversation details
### [Events](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/events/README.md)
* [list](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/events/README.md#list) - List events
* [search](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/events/README.md#search) - Search events (GET)
* [count](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/events/README.md#count) - Count events
* [timeseries](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/events/README.md#timeseries) - Get event timeseries
* [facets](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/events/README.md#facets) - Get event facets
* [get](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/events/README.md#get) - Get event details
### [SignalGroups](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/signalgroups/README.md)
* [list](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/signalgroups/README.md#list) - List all signal groups
* [get](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/signalgroups/README.md#get) - Get signal group details
* [list_signals](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/signalgroups/README.md#list_signals) - List signals in group
### [Signals](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/signals/README.md)
* [list](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/signals/README.md#list) - List all signals
* [get](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/signals/README.md#get) - Get signal details
### [Traces](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/traces/README.md)
* [list](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/traces/README.md#list) - List traces for an event
### [Users](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/users/README.md)
* [list](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/users/README.md#list) - List users
* [get](https://github.com/raindrop-ai/query-sdk/blob/master/python/docs/sdks/users/README.md#get) - Get user details
</details>
<!-- End Available Resources and Operations [operations] -->
<!-- Start Retries [retries] -->
## Retries
Some of the endpoints in this SDK support retries. If you use the SDK without any configuration, it will fall back to the default retry strategy provided by the API. However, the default retry strategy can be overridden on a per-operation basis, or across the entire SDK.
To change the default retry strategy for a single API call, simply provide a `RetryConfig` object to the call:
```python
from raindrop_query import RaindropQuery
from raindrop_query.utils import BackoffStrategy, RetryConfig
with RaindropQuery(
api_key="<YOUR_BEARER_TOKEN_HERE>",
) as rq_client:
res = rq_client.signals.list(limit=50, order_by="-timestamp",
RetryConfig("backoff", BackoffStrategy(1, 50, 1.1, 100), False))
# Handle response
print(res)
```
If you'd like to override the default retry strategy for all operations that support retries, you can use the `retry_config` optional parameter when initializing the SDK:
```python
from raindrop_query import RaindropQuery
from raindrop_query.utils import BackoffStrategy, RetryConfig
with RaindropQuery(
retry_config=RetryConfig("backoff", BackoffStrategy(1, 50, 1.1, 100), False),
api_key="<YOUR_BEARER_TOKEN_HERE>",
) as rq_client:
res = rq_client.signals.list(limit=50, order_by="-timestamp")
# Handle response
print(res)
```
<!-- End Retries [retries] -->
<!-- Start Error Handling [errors] -->
## Error Handling
[`RaindropQueryError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/raindropqueryerror.py) is the base class for all HTTP error responses. It has the following properties:
| Property | Type | Description |
| ------------------ | ---------------- | --------------------------------------------------------------------------------------- |
| `err.message` | `str` | Error message |
| `err.status_code` | `int` | HTTP response status code eg `404` |
| `err.headers` | `httpx.Headers` | HTTP response headers |
| `err.body` | `str` | HTTP body. Can be empty string if no body is returned. |
| `err.raw_response` | `httpx.Response` | Raw HTTP response |
| `err.data` | | Optional. Some errors may contain structured data. [See Error Classes](https://github.com/raindrop-ai/query-sdk/blob/master/python/#error-classes). |
### Example
```python
from raindrop_query import RaindropQuery, errors
with RaindropQuery(
api_key="<YOUR_BEARER_TOKEN_HERE>",
) as rq_client:
res = None
try:
res = rq_client.signals.list(limit=50, order_by="-timestamp")
# Handle response
print(res)
except errors.RaindropQueryError as e:
# The base class for HTTP error responses
print(e.message)
print(e.status_code)
print(e.body)
print(e.headers)
print(e.raw_response)
# Depending on the method different errors may be thrown
if isinstance(e, errors.SignalsListUnauthorizedError):
print(e.data.error) # models.SignalsListError
```
### Error Classes
**Primary error:**
* [`RaindropQueryError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/raindropqueryerror.py): The base class for HTTP error responses.
<details><summary>Less common errors (20)</summary>
<br />
**Network errors:**
* [`httpx.RequestError`](https://www.python-httpx.org/exceptions/#httpx.RequestError): Base class for request errors.
* [`httpx.ConnectError`](https://www.python-httpx.org/exceptions/#httpx.ConnectError): HTTP client was unable to make a request to a server.
* [`httpx.TimeoutException`](https://www.python-httpx.org/exceptions/#httpx.TimeoutException): HTTP request timed out.
**Inherit from [`RaindropQueryError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/raindropqueryerror.py)**:
* [`EventsSearchBadRequestError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/eventssearchbadrequesterror.py): Invalid request (e.g., date range exceeds maximum). Status code `400`. Applicable to 1 of 16 methods.*
* [`EventsFacetsBadRequestError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/eventsfacetsbadrequesterror.py): Invalid field name. Status code `400`. Applicable to 1 of 16 methods.*
* [`TracesListBadRequestError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/traceslistbadrequesterror.py): Bad request (missing event_id). Status code `400`. Applicable to 1 of 16 methods.*
* [`SignalsListUnauthorizedError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/signalslistunauthorizederror.py): Unauthorized. Status code `401`. Applicable to 1 of 16 methods.*
* [`SignalGroupsListUnauthorizedError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/signalgroupslistunauthorizederror.py): Unauthorized. Status code `401`. Applicable to 1 of 16 methods.*
* [`EventsListUnauthorizedError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/eventslistunauthorizederror.py): Unauthorized. Status code `401`. Applicable to 1 of 16 methods.*
* [`UsersListUnauthorizedError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/userslistunauthorizederror.py): Unauthorized. Status code `401`. Applicable to 1 of 16 methods.*
* [`ConversationsListUnauthorizedError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/conversationslistunauthorizederror.py): Unauthorized. Status code `401`. Applicable to 1 of 16 methods.*
* [`TracesListUnauthorizedError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/traceslistunauthorizederror.py): Unauthorized. Status code `401`. Applicable to 1 of 16 methods.*
* [`SignalsGetNotFoundError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/signalsgetnotfounderror.py): Signal not found. Status code `404`. Applicable to 1 of 16 methods.*
* [`SignalGroupsGetNotFoundError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/signalgroupsgetnotfounderror.py): Signal group not found. Status code `404`. Applicable to 1 of 16 methods.*
* [`SignalGroupsListSignalsNotFoundError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/signalgroupslistsignalsnotfounderror.py): Signal group not found. Status code `404`. Applicable to 1 of 16 methods.*
* [`EventsGetNotFoundError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/eventsgetnotfounderror.py): Event not found. Status code `404`. Applicable to 1 of 16 methods.*
* [`UsersGetNotFoundError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/usersgetnotfounderror.py): User not found. Status code `404`. Applicable to 1 of 16 methods.*
* [`ConversationsGetNotFoundError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/conversationsgetnotfounderror.py): Conversation not found. Status code `404`. Applicable to 1 of 16 methods.*
* [`ResponseValidationError`](https://github.com/raindrop-ai/query-sdk/blob/master/python/./src/raindrop_query/errors/responsevalidationerror.py): Type mismatch between the response data and the expected Pydantic model. Provides access to the Pydantic validation error via the `cause` attribute.
</details>
\* Check [the method documentation](https://github.com/raindrop-ai/query-sdk/blob/master/python/#available-resources-and-operations) to see if the error is applicable.
<!-- End Error Handling [errors] -->
<!-- Start Server Selection [server] -->
## Server Selection
### Override Server URL Per-Client
The default server can be overridden globally by passing a URL to the `server_url: str` optional parameter when initializing the SDK client instance. For example:
```python
from raindrop_query import RaindropQuery
with RaindropQuery(
server_url="https://query.raindrop.ai",
api_key="<YOUR_BEARER_TOKEN_HERE>",
) as rq_client:
res = rq_client.signals.list(limit=50, order_by="-timestamp")
# Handle response
print(res)
```
<!-- End Server Selection [server] -->
<!-- Start Custom HTTP Client [http-client] -->
## Custom HTTP Client
The Python SDK makes API calls using the [httpx](https://www.python-httpx.org/) HTTP library. In order to provide a convenient way to configure timeouts, cookies, proxies, custom headers, and other low-level configuration, you can initialize the SDK client with your own HTTP client instance.
Depending on whether you are using the sync or async version of the SDK, you can pass an instance of `HttpClient` or `AsyncHttpClient` respectively, which are Protocol's ensuring that the client has the necessary methods to make API calls.
This allows you to wrap the client with your own custom logic, such as adding custom headers, logging, or error handling, or you can just pass an instance of `httpx.Client` or `httpx.AsyncClient` directly.
For example, you could specify a header for every request that this sdk makes as follows:
```python
from raindrop_query import RaindropQuery
import httpx
http_client = httpx.Client(headers={"x-custom-header": "someValue"})
s = RaindropQuery(client=http_client)
```
or you could wrap the client with your own custom logic:
```python
from raindrop_query import RaindropQuery
from raindrop_query.httpclient import AsyncHttpClient
import httpx
class CustomClient(AsyncHttpClient):
client: AsyncHttpClient
def __init__(self, client: AsyncHttpClient):
self.client = client
async def send(
self,
request: httpx.Request,
*,
stream: bool = False,
auth: Union[
httpx._types.AuthTypes, httpx._client.UseClientDefault, None
] = httpx.USE_CLIENT_DEFAULT,
follow_redirects: Union[
bool, httpx._client.UseClientDefault
] = httpx.USE_CLIENT_DEFAULT,
) -> httpx.Response:
request.headers["Client-Level-Header"] = "added by client"
return await self.client.send(
request, stream=stream, auth=auth, follow_redirects=follow_redirects
)
def build_request(
self,
method: str,
url: httpx._types.URLTypes,
*,
content: Optional[httpx._types.RequestContent] = None,
data: Optional[httpx._types.RequestData] = None,
files: Optional[httpx._types.RequestFiles] = None,
json: Optional[Any] = None,
params: Optional[httpx._types.QueryParamTypes] = None,
headers: Optional[httpx._types.HeaderTypes] = None,
cookies: Optional[httpx._types.CookieTypes] = None,
timeout: Union[
httpx._types.TimeoutTypes, httpx._client.UseClientDefault
] = httpx.USE_CLIENT_DEFAULT,
extensions: Optional[httpx._types.RequestExtensions] = None,
) -> httpx.Request:
return self.client.build_request(
method,
url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
timeout=timeout,
extensions=extensions,
)
s = RaindropQuery(async_client=CustomClient(httpx.AsyncClient()))
```
<!-- End Custom HTTP Client [http-client] -->
<!-- Start Resource Management [resource-management] -->
## Resource Management
The `RaindropQuery` class implements the context manager protocol and registers a finalizer function to close the underlying sync and async HTTPX clients it uses under the hood. This will close HTTP connections, release memory and free up other resources held by the SDK. In short-lived Python programs and notebooks that make a few SDK method calls, resource management may not be a concern. However, in longer-lived programs, it is beneficial to create a single SDK instance via a [context manager][context-manager] and reuse it across the application.
[context-manager]: https://docs.python.org/3/reference/datamodel.html#context-managers
```python
from raindrop_query import RaindropQuery
def main():
with RaindropQuery(
api_key="<YOUR_BEARER_TOKEN_HERE>",
) as rq_client:
# Rest of application here...
# Or when using async:
async def amain():
async with RaindropQuery(
api_key="<YOUR_BEARER_TOKEN_HERE>",
) as rq_client:
# Rest of application here...
```
<!-- End Resource Management [resource-management] -->
<!-- Start Debugging [debug] -->
## Debugging
You can setup your SDK to emit debug logs for SDK requests and responses.
You can pass your own logger class directly into your SDK.
```python
from raindrop_query import RaindropQuery
import logging
logging.basicConfig(level=logging.DEBUG)
s = RaindropQuery(debug_logger=logging.getLogger("raindrop_query"))
```
<!-- End Debugging [debug] -->
<!-- Placeholder for Future Speakeasy SDK Sections -->
# Development
## Maturity
This SDK is in beta. We recommend pinning to a specific version.
## Support
For questions or issues, contact support@raindrop.ai
| text/markdown | null | Raindrop <support@raindrop.ai> | null | null | Apache-2.0 | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpcore>=1.0.9",
"httpx>=0.28.1",
"pydantic>=2.11.2"
] | [] | [] | [] | [
"repository, https://github.com/raindrop-ai/query-sdk.git"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T08:09:17.769471 | raindrop_query-0.1.5.tar.gz | 58,208 | b6/5d/d86b8a155a343a3533ea3bf2fe5df39f2c34a3a8e4007ca8f11c981513b0/raindrop_query-0.1.5.tar.gz | source | sdist | null | false | 4c61374b5d04b4590a4746294584c808 | 589ad410f2872895d8977a345c35d7325b046a50accd57be8f1c260eab8fb624 | b65dd86b8a155a343a3533ea3bf2fe5df39f2c34a3a8e4007ca8f11c981513b0 | null | [] | 275 |
2.4 | wowool-sdk-cpp | 3.6.0 | Wowool NLP Toolkit C++ SDK Python Bindings | # Wowool NLP Toolkit C++ SDK Python Bindings
## Introduction
This package contains the cpp bindings of the wowool-sdk and should not be install as a separated package, install the wowool-sdk instead which contains this package.
## License
In both cases you will need to acquirer a license file at https://www.wowool.com
### Non-Commercial
This library is licensed under the GNU AGPLv3 for non-commercial use.
For commercial use, a separate license must be purchased.
### Commercial license Terms
1. Grants the right to use this library in proprietary software.
2. Requires a valid license key
3. Redistribution in SaaS requires a commercial license.
| text/markdown | Wowool | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T08:09:08.449055 | wowool_sdk_cpp-3.6.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl | 42,798,241 | e1/d4/e5c696eec1163869e11bb3cdb6b429e9e86d2fccd4b04706347176ef07cd/wowool_sdk_cpp-3.6.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl | cp312 | bdist_wheel | null | false | 5c6e5e6e4504f224ef90846fdb8b5b61 | d87bae16eb0faec63296d2e24928c27c05896ad1858362e5c284fed088aa5756 | e1d4e5c696eec1163869e11bb3cdb6b429e9e86d2fccd4b04706347176ef07cd | null | [] | 579 |
2.4 | superagentx | 1.0.6.2b0 | The Ultimate Modular Autonomous Multi AI Agent Framework. | <div align="center">
<img src="https://github.com/superagentxai/superagentX/blob/master/docs/images/fulllogo_transparent.png" width="350">
<br/>
**SuperAgentX**: is an open-source, modular agentic AI framework that enables AI agents to plan, act, and execute real-world workflows—with built-in human approval, governance, and auditability.
Unlike traditional chatbots, SuperAgentX is designed for action, not just conversation.
<br/>
[](https://www.python.org/downloads/release/python-31210/)
[](https://github.com/superagentxai/superagentX)
[](https://github.com/superagentxai/superagentX/blob/master/LICENSE)
</div>
## ✨ Why SuperAgentX?
SuperAgentX enables AI agents to:
- Execute multi-step workflows
- Interact with browsers, APIs, databases, tools & MCPs
- Pause for **human approval** before sensitive actions
- Persist execution state, memory, and audit logs
All while keeping humans firmly in control.
# Quick start
```shell
pip install superagentx
```
## 🧠 Core Capabilities
### 🔹 Massive Model & Tool Support
- ✅ **100+ LLMs supported** (OpenAI, Azure OpenAI, Gemini, Claude, Bedrock, OSS models)
- ✅ **10,000+ MCP (Model Context Protocol) tools supported**
- ✅ **Browser Agents** using real browser automation (Playwright)
---
### 🔹 Agentic AI (Beyond Chatbots)
Agents can:
- Understand goals
- Plan execution steps
- Call tools dynamically
- Run sequential or parallel workflows
- Retry, reflect, and recover
---
### 🔹 Human-in-the-Loop Governance
A built-in **Human Approval Governance Agent**:
- Pauses sensitive actions
- Requests explicit approval
- Resumes or aborts execution
- Persists decisions for audit
➡️ AI **cannot act blindly**.
---
## 🗄️ Persistent Data Store & Memory
### Supported Data Stores
- 🗃 **SQLite** – lightweight, local workflows
- 🗄 **PostgreSQL** – production-grade, multi-tenant systems
### Stored Data
- Workflow state
- Agent decisions
- Human approvals
- Tool outputs
- Audit logs
- Context & memory snapshots
---
## 🧩 Example: AI Food Ordering with Approval
1. Plan order
2. Calculate total
3. Generate checkout summary
4. **Pause for approval**
5. Browser agent completes checkout
6. Persist confirmation & logs
<img src="assets/human-approval.png" title="SuperAgentX Architecture"/>
## Browser AI Agent
#### Install Playwright for Browser AI Automation
```bash
pip install playwright
```
```bash
playwright install
```
## Example 1
```python
import asyncio
import json
from superagentx.agent import Agent
from superagentx.agentxpipe import AgentXPipe
from superagentx.browser_engine import BrowserEngine
from superagentx.llm import LLMClient
from superagentx.prompt import PromptTemplate
async def main():
print("SuperAgentX – Food Checkout & Payment Automation")
# ------------------------------------------------------------------
# LLM SETUP
# ------------------------------------------------------------------
llm = LLMClient(
llm_config={
"model": "gemini/gemini-3-pro-preview",
"temperature": 0.1
}
)
# ------------------------------------------------------------------
# AGENT 1: FOOD & SNACKS CHECKOUT AGENT
# ------------------------------------------------------------------
checkout_system_prompt = """
You are a food & snacks checkout agent. Simulate Food & Snacks Checkout with items.
Task:
- Select food and snack items
- Decide quantities
- Calculate total amount
- Prepare checkout summary for payment
Rules:
- DO NOT generate any payment or card details
- DO NOT mention CVV, card numbers, or expiry
- Output ONLY valid JSON
JSON Schema:
{
"items": [
{
"name": string,
"category": "food | snack",
"quantity": number,
"price_per_unit": number
}
],
"currency": "USD",
"total_amount": number,
"checkout_note": string
}
"""
checkout_prompt = PromptTemplate(system_message=checkout_system_prompt)
checkout_agent = Agent(
name="Food Checkout Agent",
role="Food & Snacks Checkout Planner",
goal="Prepare checkout summary",
llm=llm,
prompt_template=checkout_prompt,
max_retry=1
)
# ------------------------------------------------------------------
# AGENT 2: BROWSER REVIEW & PAY AGENT
# ------------------------------------------------------------------
browser_system_prompt = """
You are a browser automation agent responsible for review and payment.
Input:
- You will receive a checkout summary JSON from the previous agent.
Target Payment Form URL:
https://superagentxai.github.io/payment-demo.github.io/
Task:
1. Review checkout summary (items & total) and MUST set the price from result.total_amount
2. Show checkout summary in the popup with price
3. Generate DUMMY credit card details for testing:
- 16-digit test card number
- Future expiry (MM/YY)
- 3-digit CVV
- Realistic cardholder name & address
4. Fill the payment form using generated card details
5. Submit the form
Rules:
- Change the Price value in the submit button with the actual amount from result.total_amount in USD:.
- Card details must be generated ONLY by you
- Use dummy/test card numbers only (e.g., 4111 1111 1111 1111)
- Do NOT persist card data
- Do NOT assume submission success
- Extract confirmation text ONLY if visible
Output JSON:
{
"submission_status": "success | failed",
"reviewed_total_amount": number,
"confirmation_text": string | null
}
"""
browser_prompt = PromptTemplate(system_message=browser_system_prompt)
browser_engine = BrowserEngine(
llm=llm,
prompt_template=browser_prompt,
headless=False # set True in CI
)
browser_agent = Agent(
name="Review & Pay Agent",
role="Browser Payment Executor",
goal="Review checkout and pay using credit card",
llm=llm,
human_approval=True, # governance point
prompt_template=browser_prompt,
engines=[browser_engine],
max_retry=2
)
# ------------------------------------------------------------------
# PIPELINE: AGENT 1 → AGENT 2
# ------------------------------------------------------------------
pipe = AgentXPipe(
agents=[checkout_agent, browser_agent], # Sequence Agent Workflow
workflow_store=True
)
result = await pipe.flow(
query_instruction="Checkout food and snacks, then review and pay using credit card."
)
formatted_result = [
{
"agent_name": r.name,
"agent_id": r.agent_id,
"goal_satisfied": r.is_goal_satisfied,
"result": r.result
}
for r in result
]
print(" Final Result (Formatted JSON)")
print(json.dumps(formatted_result, indent=2))
return
if __name__ == "__main__":
asyncio.run(main())
```
## Example 2
```python
import asyncio
from superagentx.agent import Agent
from superagentx.browser_engine import BrowserEngine
from superagentx.llm import LLMClient
from superagentx.prompt import PromptTemplate
async def main():
llm_client: LLMClient = LLMClient(llm_config={'model': 'gpt-4.1', 'llm_type': 'openai'})
prompt_template = PromptTemplate()
browser_engine = BrowserEngine(
llm=llm_client,
prompt_template=prompt_template,
)
query_instruction = ("Which teams have won more than 3 FIFA World Cups, and which team is most likely to win the "
"next one?")
fifo_analyser_agent = Agent(
goal="Complete user's task.",
role="You are a Football / Soccer Expert Reviewer",
llm=llm_client,
prompt_template=prompt_template,
max_retry=1,
engines=[browser_engine]
)
result = await fifo_analyser_agent.execute(
query_instruction=query_instruction
)
print(result)
asyncio.run(main())
```
## Run
<img src="https://github.com/superagentxai/superagentx/blob/master/assets/superagentx_browser.gif" title="Browser Engine"/>
## Key Features
🚀 **Open-Source Framework**: A lightweight, open-source AI framework built for multi-agent applications with Artificial General Intelligence (AGI) capabilities.
🎯 **Goal-Oriented Multi-Agents**: This technology enables the creation of agents with retry mechanisms to achieve set goals. Communication between agents is Parallel, Sequential, or hybrid.
🏖️ **Easy Deployment**: Offers WebSocket, RESTful API, and IO console interfaces for rapid setup of agent-based AI solutions.
♨️ **Streamlined Architecture**: Enterprise-ready scalable and pluggable architecture. No major dependencies; built independently!
📚 **Contextual Memory**: Uses SQL + Vector databases to store and retrieve user-specific context effectively.
🧠 **Flexible LLM Configuration**: Supports simple configuration options of various Gen AI models.
🤝 **Extendable Handlers**: Allows integration with diverse APIs, databases, data warehouses, data lakes, IoT streams, and more, making them accessible for function-calling features.
💎 **Agentic RPA (Robotic Process Automation)** – SuperAgentX enables computer-use automation for both browser-based and desktop applications, making it an ideal solution for enterprises looking to streamline operations, reduce manual effort, and boost productivity.
### Getting Started
```shell
pip install superagentx
```
##### Usage - Example SuperAgentX Code
This SuperAgentX example utilizes two handlers, Amazon and Walmart, to search for product items based on user input from the IO Console.
1. It uses Parallel execution of handler in the agent
2. Memory Context Enabled
3. LLM configured to OpenAI
4. Pre-requisites
## Environment Setup
```shell
$ python3.12 -m pip install poetry
$ cd <path-to>/superagentx
$ python3.12 -m venv venv
$ source venv/bin/activate
(venv) $ poetry install
```
## [Documentation](https://docs.superagentx.ai/introduction)
## License
SuperAgentX is released under the [MIT](https://github.com/superagentxai/superagentX/blob/master/LICENSE) License.
## 🤝 Contributing
Fork → Branch → Commit → Pull Request
Keep contributions modular and documented.
## 📬 Connect
- 🌐 https://www.superagentx.ai
- 💻 https://github.com/superagentxai/superagentx
⭐ Star the repo and join the community!
| text/markdown | SuperAgentX AI | <support@superagentx.ai> | SuperAgentX AI | <support@superagentx.ai> | MIT | superagentX, AGI, Agentic AI, ASI, superagentx, agent, LLM, cli | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | https://www.superagentx.ai/ | null | <=3.14,>=3.12 | [] | [] | [] | [
"pydantic>=2.8.2",
"openai>=1.47.1",
"litellm>=1.79.0",
"exa-py>=1.1.4",
"aiohttp>=3.10.8",
"rich>=13.9.2",
"aiosqlite>=0.20.0",
"SQLAlchemy>=2.0.45",
"asyncpg>=0.31.0",
"websockets<16.0.0,>=15.0.1",
"aiofiles>=24.1.0",
"camel-converter>=4.0.1",
"yapf<0.44.0,>=0.43.0",
"httpx<0.29.0,>=0.28... | [] | [] | [] | [
"Homepage, https://www.superagentx.ai/",
"Repository, https://github.com/superagentxai/superagentx",
"Documentation, https://docs.superagentx.ai/"
] | poetry/2.2.1 CPython/3.11.6 Darwin/25.2.0 | 2026-02-19T08:08:52.768370 | superagentx-1.0.6.2b0.tar.gz | 150,056 | af/dd/31be80d09da4433c6c5b50f8e4a2abecad43df595ed13631918e4867da42/superagentx-1.0.6.2b0.tar.gz | source | sdist | null | false | fa92a0250c6387e9648da1348b545d95 | c02fa00e495a1f2cc1833faaa5f090b7b69c3b9dd46b63d23893399b44907de6 | afdd31be80d09da4433c6c5b50f8e4a2abecad43df595ed13631918e4867da42 | null | [] | 273 |
2.4 | stackit-serviceaccount | 0.5.0 | Service Account API | # stackit.serviceaccount
API to manage Service Accounts and their Access Tokens.
### System for Cross-domain Identity Management (SCIM)
Service Account Service offers SCIM APIs to query state. The SCIM protocol was created as standard for
automating the exchange of user identity information between identity domains, or IT systems. Service accounts
are be handled as indentites similar to SCIM users. A custom SCIM schema has been created: `/ServiceAccounts`
#### Syntax
##### Attribute operators
| OPERATOR | DESCRIPTION |
|----------|--------------------------|
| eq | equal |
| ne | not equal |
| co | contains |
| sw | starts with |
| ew | ends with |
##### Logical operators
| OPERATOR | DESCRIPTION |
|----------|--------------------------|
| and | logical \"and\" |
| or | logical \"or\" |
##### Grouping operators
| OPERATOR | DESCRIPTION |
|----------|--------------------------|
| () | precending grouping |
##### Example
```
filter=email eq \"my-service-account-aBc2defg@sa.stackit.cloud\"
filter=email ne \"my-service-account-aBc2defg@sa.stackit.cloud\"
filter=email co \"my-service-account\"
filter=name sw \"my\"
filter=name ew \"account\"
filter=email co \"my-service-account\" and name sw \"my\"
filter=email co \"my-service-account\" and (name sw \"my\" or name ew \"account\")
```
#### Sorting
> Sorting is optional
| PARAMETER | DESCRIPTION |
|-----------|--------------------------------------|
| sortBy | attribute response is ordered by |
| sortOrder | 'ASCENDING' (default) or 'DESCENDING'|
#### Pagination
| PARAMETER | DESCRIPTION |
|--------------|----------------------------------------------|
| startIndex | index of first query result, default: 1 |
| count | maximum number of query results, default: 100|
This package is part of the STACKIT Python SDK. For additional information, please visit the [GitHub repository](https://github.com/stackitcloud/stackit-sdk-python) of the SDK.
## Installation & Usage
### pip install
```sh
pip install stackit-serviceaccount
```
Then import the package:
```python
import stackit.serviceaccount
```
## Getting Started
[Examples](https://github.com/stackitcloud/stackit-sdk-python/tree/main/examples) for the usage of the package can be found in the [GitHub repository](https://github.com/stackitcloud/stackit-sdk-python) of the SDK. | text/markdown | STACKIT Developer Tools | developer-tools@stackit.cloud | null | null | null | null | [
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Pro... | [] | https://github.com/stackitcloud/stackit-sdk-python | null | <4.0,>=3.9 | [] | [] | [] | [
"stackit-core>=0.0.1a",
"requests>=2.32.3",
"pydantic>=2.9.2",
"python-dateutil>=2.9.0.post0"
] | [] | [] | [] | [
"Homepage, https://github.com/stackitcloud/stackit-sdk-python",
"Issues, https://github.com/stackitcloud/stackit-sdk-python/issues"
] | poetry/2.2.1 CPython/3.9.25 Linux/6.14.0-1017-azure | 2026-02-19T08:07:52.108943 | stackit_serviceaccount-0.5.0.tar.gz | 35,542 | 30/37/e172e6d4653cfd5d371887ec690d8696f8f94ad5d36f20a59389b186f802/stackit_serviceaccount-0.5.0.tar.gz | source | sdist | null | false | 814e15d927bbb7361569ad65f3fabbf4 | b23d714cc47f1386fa7f5a5207e0f61d65218740f8460bb9555409f495a2e7e2 | 3037e172e6d4653cfd5d371887ec690d8696f8f94ad5d36f20a59389b186f802 | null | [] | 276 |
2.4 | equity-aggregator | 1.0.16 | Financial equity data aggregation toolkit | # Equity Aggregator
[](https://www.python.org/downloads/)
[](https://github.com/astral-sh/uv)
[](LICENCE.txt)
[](https://github.com/gregorykelleher/equity-aggregator/actions/workflows/validate-push.yml)
[](https://github.com/gregorykelleher/equity-aggregator/actions/workflows/validate-push.yml)
## Description
Equity Aggregator is a financial data tool that collects and normalises raw equity data from discovery sources (Intrinio, LSEG, SEC, XETRA, Stock Analysis, TradingView), before enriching it with third-party market vendor data from enrichment feeds (Yahoo Finance and Global LEI Foundation) to produce a unified canonical dataset of unique equities.
Altogether, this tool makes it possible to retrieve up-to-date information on over 15,000+ equities from countries worldwide.
### Discovery Feeds
Discovery feeds provide raw equity data from primary market sources:
| Source | Coverage | Description |
|----------|---------|-------------|
| 🇺🇸 Intrinio | United States | Intrinio - US listed equities |
| 🇬🇧 LSEG | International | London Stock Exchange Group - Global equities |
| 🇺🇸 SEC | United States | Securities and Exchange Commission - US listed equities |
| 🇺🇸 Stock Analysis | International | Stock Analysis - Global listed equities |
| 🇺🇸 TradingView | International | TradingView - Global listed equities |
| 🇩🇪 XETRA | International | Deutsche Börse electronic trading platform - Global listed equities |
### Enrichment Feeds
Enrichment feeds provide supplementary data to enhance the canonical equity dataset:
| Source | Description |
|--------|-------------|
| Yahoo Finance | Market data, financial metrics, and equity metadata |
| GLEIF | Legal Entity Identifier (LEI) lookups via the Global LEI Foundation |
## What kind of Equity Data is available?
Equity Aggregator provides a comprehensive profile for each equity in its canonical collection, structured through validated schemas that ensure clean separation between essential identity metadata and extensive financial metrics:
### Identity Metadata
| Field | Description |
|-------|-------------|
| **name** | Full company name |
| **symbol** | Trading symbol |
| **share class figi** | Definitive OpenFIGI identifier |
| **isin** | International Securities Identification Number |
| **cusip** | CUSIP identifier |
| **cik** | Central Index Key for SEC filings |
| **lei** | Legal Entity Identifier (ISO 17442) |
### Financial Metrics
| Category | Fields |
|----------|--------|
| **Market Data** | `last_price`, `market_cap`, `currency`, `market_volume` |
| **Trading Venues** | `mics`
| **Price Performance** | `fifty_two_week_min`, `fifty_two_week_max`, `performance_1_year` |
| **Share Structure** | `shares_outstanding`, `share_float`, `dividend_yield` |
| **Ownership** | `held_insiders`, `held_institutions`, `short_interest` |
| **Profitability** | `profit_margin`, `gross_margin`, `operating_margin` |
| **Cash Flow** | `free_cash_flow`, `operating_cash_flow` |
| **Valuation** | `trailing_pe`, `price_to_book`, `trailing_eps` |
| **Returns** | `return_on_equity`, `return_on_assets` |
| **Fundamentals** | `revenue`, `revenue_per_share`, `ebitda`, `total_debt` |
| **Classification** | `industry`, `sector`, `analyst_rating` |
> [!NOTE]
> The OpenFIGI Share Class FIGI is the only definitive unique identifier for each equity in this dataset. While other identifiers like ISIN, CUSIP, CIK and LEI are also collected, they may not be universally available across all global markets or may have inconsistencies in formatting and coverage.
>
> OpenFIGI provides standardised, globally unique identifiers that work consistently across all equity markets and exchanges, hence its selection for Equity Aggregator.
## How do I get started?
### Package Installation
Equity Aggregator is available to download via `pip` as the `equity-aggregator` package:
```bash
pip install equity-aggregator
```
### Python API
Equity Aggregator exposes a focused public API that enables seamless integration opportunities. The API automatically detects and downloads the latest canonical equity dataset from remote sources when needed, ensuring users always work with up-to-date data.
#### Retrieving All Equities
The `retrieve_canonical_equities()` function downloads and returns the complete dataset of canonical equities. This function automatically handles data retrieval and local database management, downloading the latest canonical equity dataset when needed.
```python
from equity_aggregator import retrieve_canonical_equities
# Retrieve all canonical equities (downloads if database doesn't exist locally)
equities = retrieve_canonical_equities()
print(f"Retrieved {len(equities)} canonical equities")
# Iterate through equities
for equity in equities[:3]: # Show first 3
print(f"{equity.identity.symbol}: {equity.identity.name}")
```
**Example Output:**
```
Retrieved 10000 canonical equities
AAPL: APPLE INC
MSFT: MICROSOFT CORP
GOOGL: ALPHABET INC
```
#### Retrieving Individual Equities
The `retrieve_canonical_equity()` function retrieves a single equity by its Share Class FIGI identifier. This function works independently and automatically downloads data if needed.
```python
from equity_aggregator import retrieve_canonical_equity
# Retrieve a specific equity by FIGI identifier
apple_equity = retrieve_canonical_equity("BBG000B9XRY4")
print(f"Company: {apple_equity.identity.name}")
print(f"Symbol: {apple_equity.identity.symbol}")
print(f"Market Cap: ${apple_equity.financials.market_cap:,.0f}")
print(f"Currency: {apple_equity.pricing.currency}")
```
**Example Output:**
```
Company: APPLE INC
Symbol: AAPL
Market Cap: $3,500,000,000,000
Currency: USD
```
#### Retrieving Historical Equity Data
The `retrieve_canonical_equity_history()` function returns historical daily snapshots for a given equity, optionally filtered by date range. Each nightly pipeline run appends a new snapshot, building a time series of financial metrics.
```python
from equity_aggregator import retrieve_canonical_equity_history
# Retrieve all historical snapshots for Apple
snapshots = retrieve_canonical_equity_history("BBG000B9XRY4")
print(f"Retrieved {len(snapshots)} snapshots")
# Filter by date range (inclusive, YYYY-MM-DD)
recent = retrieve_canonical_equity_history(
"BBG000B9XRY4",
from_date="2025-01-01",
to_date="2025-01-31",
)
for snapshot in recent:
print(f"{snapshot.snapshot_date}: {snapshot.financials.last_price}")
```
**Example Output:**
```
Retrieved 90 snapshots
2025-01-01: 243.85
2025-01-02: 245.00
2025-01-03: 244.12
```
> [!NOTE]
> All retrieval functions work independently and automatically download the database if needed, so there's no requirement to call `retrieve_canonical_equities()` first.
#### Data Models
All data is returned as type-safe Pydantic models, ensuring data validation and integrity. The `CanonicalEquity` model provides structured access to identity metadata, pricing information, and financial metrics.
```python
from equity_aggregator import retrieve_canonical_equity, CanonicalEquity
equity: CanonicalEquity = retrieve_canonical_equity("BBG000B9XRY4")
# Access identity metadata
identity = equity.identity
print(f"FIGI: {identity.share_class_figi}")
print(f"ISIN: {identity.isin}")
print(f"CUSIP: {identity.cusip}")
# Access financial metrics
financials = equity.financials
print(f"P/E Ratio: {financials.trailing_pe}")
print(f"Market Cap: {financials.market_cap}")
```
**Example Output:**
```
FIGI: BBG000B9XRY4
ISIN: US0378331005
CUSIP: 037833100
P/E Ratio: 28.5
Market Cap: 3500000000000
```
### CLI Usage
Once installed, Equity Aggregator provides a comprehensive command-line interface for managing equity data operations. The CLI offers two main commands:
- **seed** - Aggregate and populate the local database with fresh equity data
- **download** - Download the latest canonical equity database from remote repository
Run `equity-aggregator --help` for more information:
```bash
usage: equity-aggregator [-h] [-v] [-d] [-q] {seed,download} ...
aggregate and download canonical equity data
options:
-h, --help show this help message and exit
-v, --verbose enable verbose logging (INFO level)
-d, --debug enable debug logging (DEBUG level)
-q, --quiet quiet mode - only show warnings and errors
commands:
Available operations
{seed,download}
seed aggregate enriched canonical equity data sourced from data feeds
download download latest canonical equity data from remote repository
Use 'equity-aggregator <command> --help' for help
```
#### Download Command
The `download` command retrieves the latest canonical equity database from GitHub Releases, eliminating the need to run the full aggregation pipeline via `seed` locally. This command:
- Downloads the compressed database (`data_store.db.gz`) from the latest nightly build
- Decompresses and atomically replaces the local database
- Provides access to 15,000+ equities with full historical snapshots
> [!TIP]
> **Optional: Increase Rate Limits**
>
> Set `GITHUB_TOKEN` to increase download limits from 60/hour to 5,000/hour:
> ```bash
> export GITHUB_TOKEN="your_personal_access_token_here"
> ```
> Create a token at [GitHub Settings](https://github.com/settings/tokens) - no special scopes needed. Recommended for frequent downloads or CI/CD pipelines.
#### Seed Command
The `seed` command executes the complete equity aggregation pipeline, collecting raw data from discovery sources (LSEG, SEC, XETRA, Stock Analysis, TradingView), enriching it with market data from enrichment feeds, and storing the processed results in the local database. This command runs the full transformation pipeline to create a fresh canonical equity dataset.
This command requires that the following API keys are set prior:
```bash
export EXCHANGE_RATE_API_KEY="your_key_here"
export OPENFIGI_API_KEY="your_key_here"
```
```bash
# Run the main aggregation pipeline (requires API keys)
equity-aggregator seed
```
> [!IMPORTANT]
> Note that the `seed` command processes thousands of equities and is intentionally rate-limited to respect external API constraints. A full run typically takes 60 minutes depending on network conditions and API response times.
>
> This is mitigated by the automated nightly CI pipeline that runs `seed` and publishes the latest canonical equity dataset. Users can download this pre-built data using `equity-aggregator download` instead of running the full aggregation pipeline locally.
### Data Storage
Equity Aggregator automatically stores its database (i.e. `data_store.db`) in system-appropriate locations using platform-specific directories:
- **macOS**: `~/Library/Application Support/equity-aggregator/`
- **Windows**: `%APPDATA%\equity-aggregator\`
- **Linux**: `~/.local/share/equity-aggregator/`
Log files are also automatically written to the system-appropriate log directory:
- **macOS**: `~/Library/Logs/equity-aggregator/`
- **Windows**: `%LOCALAPPDATA%\equity-aggregator\Logs\`
- **Linux**: `~/.local/state/equity-aggregator/`
This ensures consistent integration with the host operating system's data and log management practices.
### Development Setup
Follow these steps to set up the development environment for the Equity Aggregator application.
#### Prerequisites
Before starting, ensure the following conditions have been met:
- **Python 3.12+**: The application requires Python 3.12 or later
- **uv**: Python package manager
- **Git**: For version control
- **Docker** (optional): For containerised development and deployment
#### Environment Setup
#### Clone the repository:
```bash
git clone <repository-url>
cd equity-aggregator
```
#### Create and activate virtual environment:
```bash
# Create virtual environment with Python 3.12
uv venv --python 3.12
# Activate the virtual environment
source .venv/bin/activate
```
#### Install dependencies:
```bash
# Install all dependencies and sync workspace
uv sync --all-packages
```
#### Environment Variables
The application requires API keys for external data sources. A template file `.env_example` is provided in the project root for guidance.
#### Copy the example environment file:
```bash
cp .env_example .env
```
#### Configure API keys by editing `.env` and adding the following:
#### Mandatory Keys:
- `EXCHANGE_RATE_API_KEY` - Required for currency conversion
- Retrieve from: [ExchangeRate-API](https://exchangerate-api.com/)
- Used for converting equity prices to USD reference currency
- `OPENFIGI_API_KEY` - Required for equity identification
- Retrieve from: [OpenFIGI](https://www.openfigi.com/api)
- Used for equity identification and deduplication
#### Optional Keys:
- `INTRINIO_API_KEY` - For Intrinio discovery feed
- Retrieve from: [Intrinio](https://intrinio.com/)
- Provides US equity data with comprehensive quote information
- `GITHUB_TOKEN` - For increased GitHub API rate limits
- Retrieve from: [GitHub Settings](https://github.com/settings/tokens)
- Increases release download rate limits from 60/hour to 5,000/hour
- No special scopes required for public repositories
#### Verify Installation
This setup provides access to the full development environment with all dependencies, testing frameworks, and development tools configured.
It should therefore be possible to verify correct operation by running the following commands using `uv`:
```bash
# Verify the application is properly installed
uv run equity-aggregator --help
# Run unit tests to confirm functionality
uv run pytest -m unit
# Check code formatting and linting
uv run ruff check src
# Test API key configuration
uv run --env-file .env equity-aggregator seed
```
#### Running Tests
Run the test suites using the following commands:
```bash
# Run all unit tests
uv run pytest -m unit
# Run with verbose output
uv run pytest -m unit -v
# Run with coverage reporting
uv run pytest -m unit --cov=equity_aggregator --cov-report=term-missing
# Run with detailed coverage and HTML report
uv run pytest -vvv -m unit --cov=equity_aggregator --cov-report=term-missing --cov-report=html
# Run live tests (requires API keys and internet connection)
uv run pytest -m live
# Run all tests
uv run pytest
```
#### Code Quality and Linting
The project uses `ruff` for static analysis, code formatting, and linting:
```bash
# Format code automatically
uv run ruff format
# Check for linting issues
uv run ruff check
# Fix auto-fixable linting issues
uv run ruff check --fix
# Check formatting without making changes
uv run ruff format --check
# Run linting on specific directory
uv run ruff check src
```
> [!NOTE]
> Ruff checks only apply to the `src` directory - tests are excluded from formatting and linting requirements.
### Docker
The Equity Aggregator project can optionally be containerised using Docker. The `docker-compose.yml` defines the equity-aggregator service.
#### Docker Commands
```bash
# Build and run the container
docker compose up --build
# Run in background
docker compose up -d
# Stop and remove containers
docker compose down
# View container logs
docker logs equity-aggregator
# Execute commands in running container
docker compose exec equity-aggregator bash
```
> [!NOTE]
> The Docker setup uses named volumes for persistent database storage and automatically handles all directory creation and permissions.
## Architecture
### Project Structure
The codebase is organised following best practices, ensuring a clear separation between core domain logic, external adapters, and infrastructure components:
```
equity-aggregator/
├── src/equity_aggregator/ # Main application source
│ ├── cli/ # Command-line interface
│ ├── domain/ # Core business logic
│ │ ├── pipeline/ # Aggregation pipeline
│ │ │ └── transforms/ # Transformation stages
│ │ └── retrieval/ # Data download and retrieval
│ ├── adapters/data_sources/ # External data integrations
│ │ ├── discovery_feeds/ # Primary sources (Intrinio, LSEG, SEC, Stock Analysis, TradingView, XETRA)
│ │ └── enrichment_feeds/ # Enrichment feed integrations (Yahoo Finance)
│ ├── schemas/ # Data validation and types
│ └── storage/ # Database operations
├── data/ # Database and cache
├── tests/ # Unit and integration tests
├── docker-compose.yml # Container configuration
└── pyproject.toml # Project metadata and dependencies
```
### Project Dependencies (Production)
The dependency listing is intentionally minimal, relying only on the following core packages:
| Dependency | Use case |
|------------|----------|
| pydantic | Type-safe models and validation for data |
| rapidfuzz | Fast fuzzy matching to reconcile data sourced by multiple data feeds |
| httpx | HTTP client with HTTP/2 support for data feed retrieval |
| openfigipy | OpenFIGI integration that anchors equities to a definitive identifier |
| platformdirs | Consistent storage paths for caches, logs, and data stores on every OS |
Keeping such a small set of dependencies reduces upgrade risk and maintenance costs, whilst still providing all the functionality required for comprehensive equity data aggregation and processing.
### Data Transformation Pipeline
The aggregation pipeline consists of six sequential transformation stages, each with a specific responsibility:
1. **Parse**: Extract and validate raw equity data from discovery feed data
2. **Convert**: Normalise currency values to USD reference currency using live exchange rates
3. **Identify**: Attach definitive identification metadata (i.e. Share Class FIGI) via OpenFIGI
4. **Group**: Group equities by Share Class FIGI, preserving all discovery feed sources
5. **Enrich**: Fetch enrichment data and perform single comprehensive merge of all sources (discovery + enrichment)
6. **Canonicalise**: Transform enriched data into the final canonical equity schema
### Clean Architecture Layers
The codebase adheres to clean architecture principles with distinct layers:
- **Domain Layer** (`domain/`): Contains core business logic, pipeline orchestration, and transformation rules independent of external dependencies
- **Adapter Layer** (`adapters/`): Implements interfaces for external systems including data feeds, APIs, and third-party services
- **Infrastructure Layer** (`storage/`, `cli/`): Handles system concerns, regarding database operations and command-line tooling
- **Schema Layer** (`schemas/`): Defines data contracts and validation rules using Pydantic models for type safety
### Test Suites
The project maintains two distinct test suites, each serving a specific purpose in the testing strategy:
#### Unit Tests (`-m unit`)
Unit tests provide comprehensive coverage of all internal application logic. These tests are fully isolated and do not make any external network calls, ensuring fast and deterministic execution. The suite contains over 1,000 test cases and executes in under 30 seconds, enforcing a **minimum coverage threshold of 99%** with the goal of maintaining **100% coverage** across all source code.
Unit tests follow strict conventions:
- **AAA Pattern**: All tests are structured using the Arrange-Act-Assert pattern for clarity and consistency
- **Single Assertion**: Each test case contains exactly one assertion, ensuring focused and maintainable tests
- **No Mocking**: Monkey-patching and Python mocking techniques (e.g. `monkeypatch`, `unittest.mock`) are strictly forbidden, promoting testable design through dependency injection and explicit interfaces
#### Live Tests (`-m live`)
Live tests serve as **sanity tests** that validate external API endpoints are available and responding correctly. These tests hit real external services to verify that:
- Discovery and enrichment feed endpoints are accessible
- API response schemas match expected Pydantic models
- Authentication and rate limiting are functioning as expected
Live tests act as an early warning system, catching upstream API changes or outages before they impact the main aggregation pipeline.
#### Continuous Integration
Both test suites are executed as part of the GitHub Actions CI pipeline:
- **[validate-push.yml](.github/workflows/validate-push.yml)**: Runs unit tests with coverage enforcement on every push to master, ensuring code quality and the 99% coverage threshold are maintained
- **[publish-build-release.yml](.github/workflows/publish-build-release.yml)**: Runs live sanity tests before executing the nightly aggregation pipeline, validating that all external APIs are operational before publishing a new release
## Limitations
### Data Depth and Scope
- Equity Aggregator is intrinsically bound by the quality and coverage of its upstream discovery and enrichment feeds. Data retrieved and processed by Equity Aggregator reflects the quality and scope inherited from these data sources.
- Normalisation, outlier detection, coherency validation checks and other statistical techniques catch most upstream issues, yet occasional gaps or data aberrations can persist and should be handled defensively by downstream consumers.
### Venue-Specific Financial Metrics and Secondary Listings
- Certain equities may be sourced solely from secondary listings (e.g. OTC Markets or cross-listings) rather than their primary exchange. This occurs when the primary venue's data is unavailable from equity-aggregator's data sources.
- Company-level metrics such as `market_cap`, `shares_outstanding`, `revenue`, and valuation ratios remain accurate regardless of sourcing venue, as they reflect the underlying company rather than the trading venue.
- However, venue-specific metrics, particularly `market_volume` reflect trading activity only on the captured venues, not _total_ market-wide volume. An equity showing low volume may simply indicate minimal OTC activity despite substantial trading on its primary exchange.
- Attention should therefore be paid to the `mics` field, indicating which Market Identifier Codes are represented in the data (i.e. whether it's the equity's primary exchange MIC or a secondary listing).
### Data Update Cadence
- Equity Aggregator publishes nightly batch snapshots and does not aim to serve as a real-time market data service. The primary objective of Equity Aggregator is to provide equity identification metadata with limited financial metrics for fundamental analysis.
- Downstream services should therefore treat Equity Aggregator as a discovery catalogue, using its authoritative identifiers to discover equities and then poll specialised market data providers for time-sensitive pricing metrics.
- Delivering real-time quotes directly through Equity Aggregator would be infeasible because the upstream data sources enforce strict rate limits and the pipeline is network-bound; attempting live polling would exhaust quotas quickly and degrade reliability for all consumers.
### Unadjusted Historical Data
- Historical snapshots record raw financial metrics as observed on the date of capture. Prices, shares outstanding, and other per-share figures are **not adjusted** for corporate actions such as stock splits, reverse splits, share dilution, spin-offs, mergers, or dividend reinvestments.
- This means that comparing a snapshot from before a 4-for-1 stock split with one taken after it will show an apparent price drop of roughly 75%, even though no real loss of value occurred. Similarly, metrics like `shares_outstanding`, `trailing_eps`, and `revenue_per_share` can shift discontinuously across corporate action boundaries without reflecting any underlying change in the company's fundamentals.
- Consumers requiring split-adjusted or corporate-action-adjusted time series for backtesting, charting, or quantitative analysis should source adjusted data from a dedicated market data provider. The historical snapshots in Equity Aggregator are best suited for point-in-time discovery and broad trend observation rather than precise longitudinal analysis.
### Single Identifier Authority
- Share Class FIGI remains the authoritative identifier because OpenFIGI supplies globally unique, deduplicated mappings across discovery feeds. Other identifiers such as ISIN, CUSIP, CIK or LEI depend on regional registries, are frequently absent for specific markets, and are prone to formatting discrepancies, so they should be treated as supplementary identifiers only.
### Performance
- The end-to-end aggregation pipeline is network-bound and respects vendor rate limits, meaning a full `seed` run can take close to an hour in steady-state conditions. This is mitigated by comprehensive caching used throughout the application, as well as the automated nightly CI pipeline that publishes the latest canonical equity dataset, made available via `download`.
### External Service Reliance
- As the entirety of Equity Aggregator is built around the use of third-party APIs for discovery, enrichment, as well as other services, its robustness is fundamentally fragile. Upstream outages, schema shifts, bot protection revocations, API churn and rate-limit policy changes can easily degrade the pipeline without warning, with remediation often relying on vendor response times outside of the project's remit.
- As this is an inherent architectural constraint, the only viable response centres on providing robust mitigation controls. Monitoring, retry strategies and graceful degradation paths lessen the impact; they cannot eliminate the dependency risk entirely.
## Disclaimer
> [!IMPORTANT]
> **Important Legal Notice**
>
> This software aggregates data from various third-party sources including Intrinio, Yahoo Finance, LSEG trading platform, SEC, Stock Analysis, and XETRA. Equity Aggregator is **not** affiliated, endorsed, or vetted by any of these organisations.
>
> **Data Sources and Terms:**
>
> - **Yahoo Finance**: This tool uses Yahoo's publicly available APIs. Refer to [Yahoo!'s terms of use](https://policies.yahoo.com/us/en/yahoo/terms/product-atos/apiforydn/index.htm) for details on your rights to use the actual data downloaded. Yahoo! finance API is intended for personal use only.
> - **Intrinio**: This tool requires a valid Intrinio subscription and API key. Refer to [Intrinio's terms of use](https://about.intrinio.com/terms) for permitted usage, rate limits, and redistribution policies.
> - **Market Data**: All market data is obtained from publicly available sources and is intended for research and educational purposes only.
>
> **Usage Responsibility:**
>
> - Users are responsible for complying with all applicable terms of service and legal requirements of the underlying data providers
> - This software is provided for informational and educational purposes only
> - No warranty is provided regarding data accuracy, completeness, or fitness for any particular purpose
> - Users should independently verify any data before making financial decisions
>
> **Commercial Use:** Users intending commercial use should review and comply with the terms of service of all underlying data providers.
| text/markdown | null | Gregory Kelleher <gregory@gregorykelleher.com> | null | null | null | aggregation, data, equity, finance, financial-data | [
"Intended Audience :: Financial and Insurance Industry",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.12.5 | [] | [] | [] | [
"httpx[http2]>=0.28.1",
"openfigipy>=0.1.6",
"platformdirs>=4.0.0",
"pydantic>=2.11.3",
"rapidfuzz>=3.13.0"
] | [] | [] | [] | [
"Homepage, https://github.com/gregorykelleher/equity-aggregator",
"Repository, https://github.com/gregorykelleher/equity-aggregator"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:07:32.279637 | equity_aggregator-1.0.16.tar.gz | 686,026 | c1/2e/aa75b16a54b77bd68a03e6751948a4fa09872a45c0d5919a8c441e36109a/equity_aggregator-1.0.16.tar.gz | source | sdist | null | false | 54c9869b278b21092c5425df25abe9bb | 0477e745f2deba1d799cd2a9a4dedf0e303c742fa1213c2b4e626aae30008581 | c12eaa75b16a54b77bd68a03e6751948a4fa09872a45c0d5919a8c441e36109a | MIT | [
"LICENCE.txt"
] | 274 |
2.4 | abiogenesis | 0.1.0 | Artificial life through symbiogenesis — self-replicating programs emerge from random byte soups | # Abiogenesis
Self-replicating programs emerge spontaneously from random byte soups through symbiogenesis.
No fitness function. No design. Just random bytes, a 7-instruction interpreter, and time.

## Install
```bash
pip install abiogenesis
```
## Quickstart
```python
from abiogenesis import Soup, compression_ratio
soup = Soup(n_tapes=512, tape_len=64, max_steps=10_000, seed=42)
for step in range(100_000):
soup.interact()
if (step + 1) % 25_000 == 0:
cr = compression_ratio(soup.get_state())
print(f"step {step + 1:>7,} compression={cr:.4f}")
```
```
step 25,000 compression=0.4892
step 50,000 compression=0.3575
step 75,000 compression=0.3044
step 100,000 compression=0.2872
```
Compression drops below 1.0 as structure self-organizes from noise.

## How It Works

1. **Random initialization** — 1024 tapes of 64 random bytes each
2. **Pairwise interaction** — pick two tapes, concatenate into 128 bytes, execute as embodied BrainFuck, split back
3. **Symbiogenesis** — two partial programs fuse into working programs (the K-term)
4. **Selection pressure** — tapes that execute copy instructions replicate; others drift
5. **Mutation** (optional) — random bit-flips sustain ecology and prevent crystallization
The interpreter uses 7 instructions (`> < + - . [ ]`) on a unified code/data tape. The `.` instruction copies `tape[DP]` to `tape[WP]`, providing the replication primitive. No fitness function — replication emerges from the physics.
## Results
### Phase Diagram
Mutation rate is the sole control parameter. Four regimes discovered across 10M-interaction runs:

| Regime | Mutation Rate | Behavior |
|---|---|---|
| Crystal | 0 | Single replicator dominates, entropy collapses to 0.018 |
| Soft crystal | 1e-5 | Slow crystallization, low diversity |
| Ecology | **1e-3** | Sustained diversity, multiple replicator species coexist |
| Dissolution | 1e-1 | Too much noise, no structure persists (compression ~0.50) |
### Replicator Emergence
Three types of self-replicators emerge and are classified automatically:
| Type | Condition | Meaning |
|---|---|---|
| Inanimate | executed ∩ written = ∅ | Passive — copied but not self-copying |
| Viral | executed ∩ written ≠ ∅, written ⊄ executed | Parasitic — partially self-copying |
| Cellular | written ⊆ executed | Autopoietic — fully self-replicating |

### Symbiogenesis Depth
Complexity builds on itself — each interaction layer adds depth to the lineage tree:

## API
| Class / Function | Description |
|---|---|
| `Soup(n_tapes, tape_len, max_steps, seed, mutation_rate)` | Primordial soup of byte tapes |
| `Experiment(config)` | Full experiment runner with checkpointing |
| `SwarmExperiment(config)` | Agent-oriented experiment with identity and provenance |
| `Agent(tape, name)` | Named tape with UUID, lineage, interaction count |
| `KTermFusion(max_steps)` | Concatenate-execute-split fusion engine |
| `CrystallizationProbe(window_size, critical_threshold)` | Diversity monitor — detects monoculture onset |
| `DiversityProbe(window_size, critical_threshold)` | Swarm-level diversity wrapper |
| `compression_ratio(soup)` | zlib compression ratio (lower = more structure) |
| `shannon_entropy(soup)` | Shannon entropy over tape distribution |
| `find_replicators(soup, min_length, min_count)` | Detect and classify self-replicating subsequences |
| `classify_replicator(sequence)` | Classify as inanimate, viral, or cellular |
| `execute(tape, max_steps)` | Run the embodied BF interpreter |
| `execute_traced(tape, max_steps)` | Execute with position tracking |
## Examples
```bash
python examples/quickstart.py # Basic soup run
python examples/replicator_detection.py # Find and classify replicators
python examples/swarm_with_probes.py # Agent swarm with provenance
```
## Development
```bash
git clone https://github.com/dopexthrone/abiogenesis.git
cd abiogenesis
pip install -e ".[dev]"
pytest tests/ # 92 tests
```
## Citation
If you use this in research, please cite:
```
@software{roze2026abiogenesis,
author = {Roze, Alex},
title = {Abiogenesis: Self-Replicating Programs from Random Byte Soups},
year = {2026},
url = {https://github.com/dopexthrone/abiogenesis}
}
```
## License
MIT — see [LICENSE](LICENSE).
| text/markdown | null | Alex Roze <motherlabsai@gmail.com> | null | null | null | abiogenesis, artificial-life, emergence, self-replication, symbiogenesis | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Lan... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy>=1.24",
"matplotlib>=3.5; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"matplotlib>=3.5; extra == \"viz\""
] | [] | [] | [] | [
"Homepage, https://github.com/dopexthrone/abiogenesis",
"Repository, https://github.com/dopexthrone/abiogenesis"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T08:06:55.795896 | abiogenesis-0.1.0.tar.gz | 1,398,781 | 8b/ad/390361ac2d59f8e2b8dda8f269c6281d39d2de626e7488a90641ccf0c693/abiogenesis-0.1.0.tar.gz | source | sdist | null | false | 4974f1925ae76324649d0ae975b833c8 | 0ba4076b104b4bf3901e3520cb64906d470ad7c7df0ae84d8fdf61debb056e87 | 8bad390361ac2d59f8e2b8dda8f269c6281d39d2de626e7488a90641ccf0c693 | MIT | [
"LICENSE"
] | 306 |
2.4 | lyzr-audit-logger-dev | 0.1.11 | Audit logging library for microservices | # Audit Logger
A Python package for audit logging across microservices. Provides async, non-blocking audit log capture with MongoDB storage.
## Installation
```bash
pip install audit-logger
```
Or install from source:
```bash
# Using HTTPS
pip install git+https://github.com/NeuralgoLyzr/audit-logger.git
# Using SSH
pip install git+ssh://git@github.com/NeuralgoLyzr/audit-logger.git
```
For local development:
```bash
cd audit_logger
pip install -e .
```
## Quick Start
### 1. Initialize at Application Startup
```python
from audit_logger import init_audit_logger
# Option 1: Use environment variable AUDIT_MONGO_URL (defaults to mongodb://localhost:27017)
audit_manager, audit_logger = init_audit_logger()
# Option 2: Explicit configuration
audit_manager, audit_logger = init_audit_logger(
mongo_url="mongodb://audit-db:27017",
db_name="my_service_audit",
collection_name="audit_logs"
)
# Create indexes (call once on startup)
await audit_manager.ensure_indexes()
```
### 2. Set Context in Middleware
```python
from audit_logger import set_audit_context, clear_audit_context
@app.middleware("http")
async def audit_middleware(request: Request, call_next):
# Set context from auth info
set_audit_context(
org_id=request.state.auth_user.org_id,
user_id=request.state.auth_user.user_id,
api_key=request.headers.get("x-api-key"),
ip_address=request.client.host,
)
try:
return await call_next(request)
finally:
clear_audit_context()
```
### 3. Log Audit Events
```python
from audit_logger import audit_logger, AuditResource
# Log a create action (non-blocking, returns immediately)
audit_logger.log_create(
resource_type=AuditResource.AGENT,
resource_id="agent_123",
resource_name="My Agent",
metadata={"tools_count": 5}
)
# Log an update action
from audit_logger import AuditChange
audit_logger.log_update(
resource_type=AuditResource.AGENT,
resource_id="agent_123",
changes=[
AuditChange(field="name", old_value="Old Name", new_value="New Name"),
AuditChange(field="description", old_value=None, new_value="New description"),
]
)
# Log a delete action
audit_logger.log_delete(
resource_type=AuditResource.AGENT,
resource_id="agent_123",
resource_name="My Agent"
)
```
### 4. Shutdown Gracefully
```python
from audit_logger import shutdown_audit_logger
@app.on_event("shutdown")
async def shutdown():
await shutdown_audit_logger()
```
## Advanced Usage
### Direct Manager Access
For more control, use the `AuditLogManager` directly:
```python
from audit_logger import get_audit_log_manager, AuditResource, AuditResult
manager = get_audit_log_manager()
# Log with full control
manager.log_create(
org_id="org_123",
resource_type=AuditResource.TOOL,
resource_id="tool_456",
user_id="user_789",
api_key="sk-xxx",
ip_address="192.168.1.1",
resource_name="My Tool",
metadata={"type": "openapi"},
result=AuditResult.SUCCESS,
)
# Log inference events
manager.log_inference(
org_id="org_123",
agent_id="agent_456",
session_id="session_789",
user_id="user_123",
result=AuditResult.SUCCESS,
metadata={"model": "gpt-4", "tokens": 1500}
)
# Log guardrail violations
from audit_logger import GuardrailViolation, AuditSeverity
manager.log_guardrail_violation(
org_id="org_123",
session_id="session_789",
violations=[
GuardrailViolation(
violation_type="pii",
severity=AuditSeverity.MEDIUM,
details={"entities": ["email", "phone"]}
)
]
)
```
### Query Audit Logs
```python
from audit_logger import get_audit_log_manager, AuditLogQuery, AuditResource
manager = get_audit_log_manager()
# Query with filters
logs = await manager.query(AuditLogQuery(
org_id="org_123",
resource_type=AuditResource.AGENT,
limit=50,
))
# Get history for a specific resource
history = await manager.get_by_resource(
org_id="org_123",
resource_type=AuditResource.AGENT,
resource_id="agent_456",
)
# Get session activity
session_logs = await manager.get_by_session(session_id="session_789")
# Count matching logs
count = await manager.count(AuditLogQuery(org_id="org_123"))
```
### Using the Decorator
```python
from audit_logger import audit_action, AuditAction, AuditResource
@audit_action(
action=AuditAction.DELETE,
resource_type=AuditResource.AGENT,
resource_id_param="agent_id",
)
async def delete_agent(agent_id: str, _audit_manager=None):
# Delete logic here
pass
```
### Context Manager
```python
from audit_logger import audit_context
async with audit_context(org_id="org_123", user_id="user_456") as request_id:
# All audit logs in this block will have the context set
audit_logger.log_create(AuditResource.AGENT, "agent_789")
```
## Configuration
### Environment Variables
| Variable | Default | Description |
|----------|---------|-------------|
| `AUDIT_MONGO_URL` | `mongodb://localhost:27017` | MongoDB connection URL |
### Programmatic Configuration
```python
from audit_logger import init_audit_logger
# Full configuration
manager, logger = init_audit_logger(
mongo_url="mongodb://audit-db:27017",
db_name="lyzr_audit_logs",
collection_name="audit_logs",
)
```
### Using Existing Collection
If you already have a MongoDB collection configured:
```python
from motor.motor_asyncio import AsyncIOMotorClient
from audit_logger import init_audit_logger
client = AsyncIOMotorClient("mongodb://localhost:27017")
collection = client["my_db"]["audit_logs"]
manager, logger = init_audit_logger(collection=collection)
```
## Available Enums
### AuditAction
- `CREATE`, `READ`, `UPDATE`, `DELETE`
- `EXECUTE`, `LOGIN`, `LOGOUT`
- `ACCESS_DENIED`, `EXPORT`, `IMPORT`
### AuditResource
- `AGENT`, `TOOL`, `PROVIDER`, `WORKFLOW`
- `SESSION`, `MESSAGE`, `CONTEXT`, `MEMORY`
- `CREDENTIAL`, `USER`, `ORGANIZATION`, `API_KEY`
- `INFERENCE`, `GUARDRAIL`, `ARTIFACT`
### AuditResult
- `SUCCESS`, `FAILURE`, `BLOCKED`, `PARTIAL`
### AuditSeverity
- `LOW`, `MEDIUM`, `HIGH`, `CRITICAL`
## MongoDB Schema
```javascript
{
"_id": ObjectId,
"timestamp": ISODate,
"actor": {
"org_id": "org_123",
"user_id": "user_456",
"api_key_hash": "a1b2c3d4...xyz",
"ip_address": "192.168.1.1"
},
"action": "create",
"target": {
"resource_type": "agent",
"resource_id": "agent_789",
"resource_name": "Support Bot"
},
"result": "success",
"error_message": null,
"session_id": "session_abc",
"request_id": "req_def",
"changes": [...],
"guardrail_violations": [...],
"metadata": {...},
"severity": "low"
}
```
## Non-Blocking Writes
All logging methods are **non-blocking** by default. They use `asyncio.create_task()` to write to MongoDB in the background without blocking your request handlers.
For synchronous writes (when you need confirmation):
```python
log_id = await manager.log_sync(entry)
```
## License
MIT
| text/markdown | null | Lyzr <support@lyzr.ai> | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"motor>=3.0.0",
"pydantic>=2.0.0",
"StrEnum>=0.4.0",
"redis>=5.0.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/NeuralgoLyzr/audit-logger/tree/dev",
"Documentation, https://github.com/NeuralgoLyzr/audit-logger#readme"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:03:56.805648 | lyzr_audit_logger_dev-0.1.11.tar.gz | 17,670 | ea/2b/ae88123caaef52ac7c2b43180d6e065e9396de1232812fe842290d225d42/lyzr_audit_logger_dev-0.1.11.tar.gz | source | sdist | null | false | 5ee67b4df21519383859163573cf5e44 | 2f19ca8a293f774aea4daab934438706c3848ba1984c0ae8489727210c4ed615 | ea2bae88123caaef52ac7c2b43180d6e065e9396de1232812fe842290d225d42 | null | [] | 293 |
2.4 | pyrsm | 2.3.1 | Python package used in the MSBA program the Rady School of Management @ UCSD | # PYRSM
Python functions and classes for Business Analytics at the Rady School of Management (RSM), University of California, San Diego (UCSD).
## Features
**Basics Module** - Statistical tests and analyses:
- `compare_means` - Compare means across groups (t-tests, ANOVA)
- `compare_props` - Compare proportions between groups
- `correlation` - Correlation analysis with significance tests
- `cross_tabs` - Cross-tabulation with chi-square tests
- `goodness` - Goodness of fit tests
- `single_mean` - Single sample mean tests
- `single_prop` - Single sample proportion tests
- `prob_calc` - Probability calculator for common distributions
**Model Module** - Regression and machine learning:
- `regress` - Linear regression with statsmodels
- `logistic` - Logistic regression with statsmodels
- `mlp` - Multi-layer perceptron (neural network) with sklearn
- `rforest` - Random forest with sklearn
- `xgboost` - XGBoost gradient boosting
**EDA Module** - Exploratory data analysis:
- `explore` - Data exploration and summary statistics
- `pivot` - Pivot tables
- `visualize` - Data visualization
All modules use [Polars](https://pola.rs/) DataFrames and [plotnine](https://plotnine.org/) for visualization.
## Installation
Requires Python 3.12+ and UV:
```bash
mkdir ~/project
cd ~/project
uv init .
uv venv --python 3.13
source .venv/bin/activate
uv add pyrsm
```
For machine learning models, install with extras:
```bash
uv add "pyrsm[ml]"
```
For all features:
```bash
uv add "pyrsm[all]"
```
## Quick Start
```python
import polars as pl
from pyrsm import basics, model
# Load data
df = pl.read_parquet("data.parquet")
# Statistical test
cm = basics.compare_means(df, var="price", byvar="category")
cm.summary()
cm.plot()
# Regression model
reg = model.regress(df, rvar="price", evar=["size", "age", "type"])
reg.summary()
reg.plot()
```
## Examples
Extensive example notebooks are available at: <https://github.com/radiant-ai-hub/pyrsm/tree/main/examples>
## License
This project is licensed under the [GNU Affero General Public License v3.0](LICENSE).
| text/markdown | null | Vincent Nijs <vnijs@ucsd.edu>, Vikram Jambulapati <vikjam@ucsd.edu>, Suhas Goutham <sgoutham@ucsd.edu>, Raghav Prasad <rprasad@ucsd.edu> | null | null | null | null | [] | [] | null | null | <3.14,>=3.12 | [] | [] | [] | [
"numpy>=2.0.2",
"pandas>=2.2.2",
"polars==1.36.1",
"matplotlib>=3.1.1",
"plotnine>=0.15.1",
"statsmodels>=0.14.4",
"scipy>=1.16.3",
"scikit-learn>=1.6.1",
"IPython>=7.34.0",
"pyarrow>=17.0.0",
"scikit-misc>=0.5.2",
"fastexcel>=0.18.0",
"pyyaml>=6.0.3",
"nbformat>=5.10.4",
"nbclient>=0.10... | [] | [] | [] | [
"Bug Reports, https://github.com/radiant-ai-hub/pyrsm/issues",
"Source, https://github.com/vnijs/pyrsm"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-19T08:01:16.711674 | pyrsm-2.3.1.tar.gz | 169,779 | 83/c9/aca90f0cf9503a2a2333c0545a18d382d07b348f1631555b9143d3c83c9c/pyrsm-2.3.1.tar.gz | source | sdist | null | false | fc03e796a50cc2dd37dd5e426d78f8b8 | ecdddcbdacbe143365b28f6c4e1aa7657e68bee29f923ead0f4c0de7c4215336 | 83c9aca90f0cf9503a2a2333c0545a18d382d07b348f1631555b9143d3c83c9c | AGPL-3.0-only | [
"LICENSE"
] | 345 |
2.4 | sonolus.py | 0.14.2 | Sonolus engine development in Python | # Sonolus.py
Sonolus engine development in Python. See [docs](https://sonolus.py.qwewqa.xyz) for more information.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.12.5 | [] | [] | [] | [] | [] | [] | [] | [
"Documentation, https://sonolus.py.qwewqa.xyz/",
"Repository, https://github.com/qwewqa/sonolus.py",
"Issues, https://github.com/qwewqa/sonolus.py/issues",
"Changelog, https://sonolus.py.qwewqa.xyz/changelog/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T08:01:13.516670 | sonolus_py-0.14.2.tar.gz | 4,760,167 | 08/4d/f0d945ab62f07d541d4f9be30e99ccec257d114a0fa8c02952160083115a/sonolus_py-0.14.2.tar.gz | source | sdist | null | false | f3e6a88f34e438f552f168b6ee33abe6 | d68fbcacb1a54a2d22e0e464ae4b3132a769409ccc064b5dcc3ff120147deed1 | 084df0d945ab62f07d541d4f9be30e99ccec257d114a0fa8c02952160083115a | null | [
"LICENSE"
] | 0 |
2.4 | meshlib | 3.1.1.92 | 3d processing library | [](https://github.com/MeshInspector/MeshLib/actions/workflows/build-test-distribute.yml?branch=master)
[](https://badge.fury.io/py/meshlib)
[](https://pepy.tech/project/meshlib)
[](https://badge.fury.io/py/meshlib)
[](https://www.nuget.org/packages/MeshLib)
[](https://www.nuget.org/packages/MeshLib)
<p align="left">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://github.com/user-attachments/assets/37d3a562-581d-421b-8209-ef6b224e96a8">
<source media="(prefers-color-scheme: light)" srcset="https://github.com/user-attachments/assets/caf6bdd1-b2f1-4d6d-9e22-c213db6fc9cf">
<img alt="Shows a black logo in light color mode and a white one in dark color mode." src="https://github.com/user-attachments/assets/caf6bdd1-b2f1-4d6d-9e22-c213db6fc9cf" width="60%">
</picture>
</p>
# MeshLib: An SDK to Supercharge Your 3D Data Processing Efficiency
Official Website: [**https://meshlib.io**](https://meshlib.io/)
The MeshLib SDK is an open-source library that provides advanced algorithms for 3D data processing. It assists developers and engineers in achieving precise results while delivering significant resource savings. Whether you are working on 3D printing, scanning, inspection, automation, robotics, scientific visualization, or medical devices, our 3D data processing library is ideally suited to meet your needs thanks to its potent capabilities and broad applicability.

## Why Choose Us
**Fully Open Source.** You can also fork the code for your own unique use cases.
**Multi-Language Support.** Written in C++ with bindings for C, C#, and Python, our library integrates easily into AI pipelines and workflows.
**High Performance.** Internal benchmarks show up to 10x faster execution compared to alternative SDKs — especially in mesh boolean operations and simplification. [See performance data](https://meshlib.io/blog/).
**GPU-Accelerated Architecture.** Built with speed and scalability in mind, MeshLib supports GPU acceleration and CUDA for high-performance computing.
**Cross-Platform Ready.** The SDK runs on Windows, macOS, Linux, and WebAssembly, offering flexibility for any development environment.
**Developer Support.** Get timely assistance from our responsive support team for integration, usage, or troubleshooting.
**Flexible Integration.** Use our toolkit as a standalone engine with UI components, or integrate selected algorithms into existing applications with minimal dependencies.
## What We Offer
We provide a robust foundation for 3D data processing, supporting all essential formats like point clouds, meshes, and volumes continuously generated by modern sensors. Our powerful half-edge data structure ensures manifold compliance for precise, reliable mesh representation. Plus, our repository includes clear code samples to help you get started quickly and explore advanced features with ease.
## Key Available Algorithms
- **3D Boolean** performs fast, highly optimized mesh- and voxel-based operations.
- **Mesh Repair** eliminates self-intersections, fills holes, and removes degeneracies.
- **Mesh Offsetting** controls surface thickness with multiple precise modes for 3D printing and machining.
- **Hole Filling** fills flat and curved surfaces, connects or separates holes, and builds bridges.
- **Mesh Simplification** optimizes mesh complexity while keeping details within set tolerance. We provide remeshing, and subdivision options as well.
- **Collision Detection** verifies intersections between models for further operations.
- **Extensive File Format Support** enables importing a wide range of file formats for meshes, point clouds, CT scans, polylines, distance maps, and G-code. Export functionalities—and support for color and texture data—are available for select formats, too (see the [full list for details](https://meshlib.io/feature/file-formats-supported-by-meshlib/)).
- **Triangulation** converts point clouds into meshes with accurate normal creation.
- **ICP** precisely aligns meshes using point-to-point and point-to-plane transformations.
- **Segmentation** performs semi-automatic segmentation based on curvature for meshes and voxels.
- **Deformation** applies Laplacian, freeform, and relaxation smoothing for fine mesh adjustments.
- **Support of Distance Maps and Polylines** allows to generate distance maps and iso-lines and performs projection and intersection.
For detailed information, explore our [website section](https://meshlib.io/features/) or refer to the corresponding sections in our [documentation](https://meshlib.io/documentation/index.html).
## How to Get Started
- **Evaluate MeshLib.** Start by exploring our library for free under our [educational and non-commercial license](https://github.com/MeshInspector/MeshLib?tab=License-1-ov-file#readme). You’ll get access to the [documentation](https://meshlib.io/documentation/index.html), installation guide, example code, and can run scripts locally to see how it fits your workflow.
- **Try software built with the MeshLib SDK.** Put our toolkit to the test using [MeshInspector](https://meshinspector.com/), our GUI built on top of the SDK. It's available as a standalone desktop and web app with a 30-day trial.
- [**Request a Demo**](https://meshlib.io/book-a-call/). Get expert-level guidance, ask questions about integration, and receive complete licensing information tailored to your needs.
- **Visit our blog.** Explore [articles and tutorials](https://meshlib.io/blog/) covering 3D data processing workflows, occasional comparisons with other tools, and practical insights from the field.
## Installation
For Python, simply install via pip:
```
pip install meshlib
```
If your choice is C++, C or C#, check out our [Installation Guide](https://meshlib.io/documentation/InstallationGuide.html).
Here, you can find our [tutorials](https://meshlib.io/documentation/Tutorials.html) and [code samples](https://meshlib.io/documentation/Examples.html) to master our SDK quickly and with ease.
## **License**
Here, you can access our [Non-Commercial Free License](https://github.com/MeshInspector/MeshLib?tab=License-1-ov-file#readme) with a Commercial License Requirement. Also, see extra details on the [license page](https://meshlib.io/license/).
## **Reporting**
Report bugs via our [GitHub Issues Form](https://github.com/MeshInspector/MeshLib/issues/) for efficient tracking and resolution.
Join the [GitHub Discussions](https://github.com/MeshInspector/MeshLib?tab=readme-ov-file#:~:text=GitHub%20Discussions%20page) to connect with developers, share ideas, and stay updated on MeshLib.
| text/markdown | null | MeshLib Team <support@meshinspector.com> | null | null | NON-COMMERCIAL & education LICENSE AGREEMENT
This agreement is between the individual below (User) and AMV Consulting, LLC, a
Nevada limited liability company (AMV). The AMV source code library software, and all
modifications, enhancements, technical documentation provided by AMV as part of the
Software (Software) are licensed and are not sold. By receiving or using this
Software, User indicates its acceptance of the terms of this agreement.
TRIAL LICENSE.
Subject to the terms of this agreement, AMV grants User a terminable, non-exclusive,
and non-transferable license to use the Software, solely for non-commercial,
evaluation or educational purposes.
DISCLAIMER.
AMV DISCLAIMS ANY AND ALL REPRESENTATIONS OR WARRANTIES OF ANY
KIND, WHETHER EXPRESS OR IMPLIED, MADE WITH RESPECT TO THE
SOFTWARE, INCLUDING, WITHOUT LIMITATION, THE IMPLIED WARRANTIES
OF MERCHANTABILITY, NON-INFRINGEMENT, AND FITNESS FOR A
PARTICULAR PURPOSE. THE SOFTWARE IS PROVIDED ‘AS IS’ WITHOUT ANY
WARRANTY OF ANY KIND. AMV AND ITS LICENSORS DO NOT WARRANT THAT
ANY SOFTWARE IS WITHOUT DEFECT OR ERROR, OR THAT THE OPERATION
OF ANY SOFTWARE WILL BE UNINTERRUPTED.
RESTRICTIONS ON USE.
User may not sell, rent, sublicense, display, modify, or otherwise transfer the Software
to any third party.
OWNERSHIP.
All right, title, and interest to the Software are owned by AMV and its licensors, and
are protected by United States and international intellectual property laws. User may
not remove or alter any copyright or proprietary notice from copies of the Software.
AMV reserves all rights not expressly granted to User.
TERMINATION.
The license in Section 1 terminates upon AMV’s notice of termination to User. Upon
termination of this agreement or a license for any reason, User must discontinue using
the Software, de-install, and destroy the Software and all copies within 5 days. Upon
AMV’s request, User will confirm in writing its compliance with this destruction or
return requirement.
LIABILITY LIMIT.
EXCLUSION OF INDIRECT DAMAGES. TO THE MAXIMUM EXTENT ALLOWED
BY LAW, AMV IS NOT LIABLE FOR ANY INDIRECT, SPECIAL, INCIDENTAL,
OR CONSEQUENTIAL DAMAGES ARISING OUT OF OR RELATED TO THIS
AGREEMENT (INCLUDING, WITHOUT LIMITATION, COSTS OF DELAY; LOSS
OF OR UNAUTHORIZED ACCESS TO DATA OR INFORMATION; AND LOST
PROFITS, REVENUE, OR ANTICIPATED COST SAVINGS), EVEN IF IT
KNOWS OF THE POSSIBILITY OR FORESEEABILITY OF SUCH DAMAGE OR
LOSS.
TOTAL LIMIT ON LIABILITY. TO THE MAXIMUM EXTENT ALLOWED BY LAW,
AMV'S TOTAL LIABILITY ARISING OUT OF OR RELATED TO THIS
AGREEMENT (WHETHER IN CONTRACT, TORT, OR OTHERWISE) DOES NOT
EXCEED $100.
GOVERNING LAW AND FORUM.
This agreement is governed by the laws of the State of Nevada (without regard to
conflicts of law principles) for any dispute between the parties or relating in any way to
the subject matter of this agreement. Any suit or legal proceeding must be exclusively
brought in the federal or state courts for Washoe County, Nevada, and User submits to
this personal jurisdiction and venue. Nothing in this agreement prevents either party
from seeking injunctive relief in a court of competent jurisdiction. The prevailing party
in any litigation is entitled to recover its attorneys’ fees and costs from the other party.
OTHER TERMS.
Entire Agreement and Changes. This agreement constitutes the entire
agreement between the parties and supersedes any prior or contemporaneous
negotiations or agreements, whether oral or written, related to this subject matter.
User is not relying on any representation concerning this subject matter, oral or
written, not included in this agreement. No representation, promise, or inducement
not included in this agreement is binding. No modification or waiver of any term of
this agreement is effective unless both parties sign it.
No Assignment. Neither party may assign or transfer this agreement to a third
party, nor delegate any duty, except that the agreement may be assigned, without
the consent of the other party, (i) as part of a merger or sale of all or substantially
all a party's businesses or assets, of User, and (ii) in the case of AMV at any time
to any third party.
Independent Contractors. The parties are independent contractors with respect
to each other, and neither party is an agent, employee, or partner of the other
party or the other party's affiliates.
Enforceability and Force Majeure. If any term of this agreement is invalid or
unenforceable, the other terms remain in effect. Neither party is liable for its non-
performance due to events beyond its reasonable control, including but not limited
to natural weather events and disasters, labor disruptions, and disruptions in the
supply of utilities.
Money Damages Insufficient. Any breach by a party of this agreement or
violation of the other party’s intellectual property rights could cause irreparable
injury or harm to the other party. The other party may seek a court order to stop
any breach or avoid any future breach of this agreement.
Survival of Terms. All provisions of this agreement regarding payment,
confidentiality, indemnification, limitations of liability, proprietary rights and such
other provisions that by fair implication require performance beyond the term of
this agreement must survive expiration or termination of this agreement until fully
performed or otherwise are inapplicable. The UN Convention on Contracts for the
International Sale of Goods does not apply.
Compliance Audit. No more than once in any 12-month period and upon at least
30 days’ advance notice, AMV (or its representative) may audit User’s usage of the
Software at any User facility. User will cooperate with such audit. User agrees to pay
within 30 days of written notification any fees applicable to User’s use of the
Software in excess of the license.
Export Compliance. The Software and Confidential Information may be subject to
export laws and regulations of the United States and other jurisdictions. Each party
represents that it is not named on any U.S. government denied-party list. Neither
party will permit its personnel or representatives to access any Software in a U.S.-
embargoed country or in violation of any applicable export law or regulation.
U.S. Government Restricted Rights. If User is a United States government
agency or acquired the license to the Software hereunder pursuant to a
government contract or with government funds, then as defined in FAR §2.101,
DFAR §252.227-7014(a)(1), and DFAR §252.227-7014(a)(5), or otherwise, all
Software provided in connection with this agreement are “commercial items,”
“commercial computer software,” or “commercial computer software
documentation.” Consistent with DFAR §227.7202 and FAR §12.212, any use,
modification, reproduction, release, performance, display, disclosure, or
distribution by or for the United States government is governed solely by the
terms of this agreement and is prohibited except to the extent permitted by the
terms of this agreement.
Open Source Software Licenses. The Software may contain embedded open source
software components, which are provided as part of the Software and for
which additional terms may be included in the technical documentation.
Feedback. If User provides feedback or suggestions about the Software, then AMV
(and those it allows to use its technology) may use such information without
obligation to User.
| null | [
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"License :... | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy>=1.19.0"
] | [] | [] | [] | [
"Homepage, https://meshlib.io/",
"Documentation, https://meshlib.io/documentation/",
"Source, https://github.com/MeshInspector/MeshLib",
"Bug Reports, https://github.com/MeshInspector/MeshLib/issues"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T08:00:35.374326 | meshlib-3.1.1.92-py39.py310.py311.py312.py313.py314-none-macosx_12_0_x86_64.whl | 84,729,296 | ec/cd/fa735a1f8560c1eaf146a53e811cca3134c59be1654b2703e2dd3736ef53/meshlib-3.1.1.92-py39.py310.py311.py312.py313.py314-none-macosx_12_0_x86_64.whl | py39.py310.py311.py312.py313.py314 | bdist_wheel | null | false | f77c24e79dc4e7581c62a7bb0aecb715 | f9e73eadb4cb607f138db5f9fa3763da7918dd1aa04aadcfde13e447a700785b | eccdfa735a1f8560c1eaf146a53e811cca3134c59be1654b2703e2dd3736ef53 | null | [
"LICENSE"
] | 2,314 |
2.4 | catocli | 3.0.61 | Cato Networks cli wrapper for the GraphQL API. | # Cato Networks GraphQL API CLI
The package provides a simple to use CLI that reflects industry standards (such as the AWS cli), and enables customers to manage Cato Networks configurations and processes via the [Cato Networks GraphQL API](https://api.catonetworks.com/api/v1/graphql2) easily integrating into configurations management, orchestration or automation frameworks to support the DevOps model.
## Overview
CatoCLI is a command-line interface that provides access to the Cato Networks GraphQL API, enabling you to:
- Generate detailed network and security reports
- Analyze user and application activity
- Monitor network performance and events
- Export data in multiple formats (JSON, CSV)
- Automate reporting and monitoring tasks
## Prerequisites
- Python 3.6 or higher
- CatoCLI installed (`pip3 install catocli`)
- Valid Cato Networks API token and Account ID
- Proper authentication configuration (see [Authentication Setup](#authentication-setup))
## Installation
`pip3 install catocli`
## Authentication Setup
Configure your CatoCLI profile before using any query operations:
```bash
# Interactive configuration
catocli configure set
# Non-interactive configuration
catocli configure set --cato-token "your-api-token" --account-id "12345"
# List configured profiles
catocli configure list
# Show current profile
catocli configure show
```
### Enable cli tab auto-completion
For detailed information about enabling tab completion, see [TAB_COMPLETION.md](TAB_COMPLETION.md).
### Documentation
For detailed information about profile management, see [PROFILES.md](PROFILES.md).
[CLICK HERE](https://support.catonetworks.com/hc/en-us/articles/4413280536081-Generating-API-Keys-for-the-Cato-API) to see how create an API key to authenticate.
## Running the CLI
catocli -h
catocli query -h
catocli query entityLookup -h
catocli query entityLookup '{"type":"country"}`
// Override the accountID value as a cli argument
catocli query entityLookup -accountID=12345 '{"type":"country"}`
## Check out run locally not as pip package
git clone git@github.com:Cato-Networks/cato-cli.git
cd cato-cli
python3 -m catocli -h
### Advanced cato-cli Topics
- [Common Patterns & Best Practices](./catocli_user_guide/common-patterns.md) - Output formats, time frames, filtering patterns
- [Python Integration - Windows](./catocli_user_guide/python-integration-windows.md) - Windows-specific Python automation examples
- [Python Integration - Unix/Linux/macOS](./catocli_user_guide/python-integration-unix.md) - Unix-based Python integration guide
- [SIEM Integration Guide](./catocli_user_guide/siem-integration.md) - Real-time security event streaming to SIEM platforms
- [Terraform Rules Integration](./catocli_user_guide/terraform-rules-integration.md) - Export/import policy rules to Terraform for IaC management
## Custom Report Query Operations
### Custom Report Analytics Queries
| Operation | Description | Guide |
|-----------|-------------|--------|
| [Account Metrics](./catocli_user_guide/account-metrics.md) | Network performance metrics by site, user, or interface | 📊 |
| [Application Statistics](./catocli_user_guide/app-stats.md) | User activity and application usage analysis | 📱 |
| [Application Statistics Time Series](./catocli_user_guide/app-stats-timeseries.md) | Traffic analysis over time with hourly/daily breakdowns | 📈 |
| [Events Time Series](./catocli_user_guide/events-timeseries.md) | Security events, connectivity, and threat analysis | 🔒 |
| [Socket Port Metrics](./catocli_user_guide/socket-port-metrics.md) | Socket interface performance and traffic analysis | 🔌 |
| [Socket Port Time Series](./catocli_user_guide/socket-port-timeseries.md) | Socket performance metrics over time | ⏱️ |
## Quick Start Examples
### Basic Network Health Check
```bash
# Get last hour account metrics
catocli query accountMetrics '{"timeFrame":"last.PT1H"}'
```
### User Activity Report (csv format)
```bash
# Export user activity for the last month to CSV
catocli query appStats '{
"appStatsFilter": [],
"appStatsSort": [],
"dimension": [ { "fieldName": "user_name" }, { "fieldName": "domain" } ],
"measure": [
{ "aggType": "sum", "fieldName": "upstream" },
{ "aggType": "sum", "fieldName": "downstream" },
{ "aggType": "sum", "fieldName": "traffic" },
{ "aggType": "sum", "fieldName": "flows_created" }
],
"timeFrame": "last.P1D"
}' -f csv --csv-filename appStats_daily_user_activity_report.csv
```
### Security Events Analysis
```bash
# Weekly security events breakdown
catocli query eventsTimeSeries '{
"buckets": 7,
"eventsFilter": [{"fieldName": "event_type", "operator": "is", "values": ["Security"]}],
"eventsMeasure": [{"aggType": "sum", "fieldName": "event_count"}],
"perSecond": false,
"timeFrame": "last.P7D"
}' -f csv --csv-filename eventsTimeSeries_weekly_security_events_report.csv
```
## Output Formats
CatoCLI supports multiple output formats:
- **Enhanced JSON** (default): Formatted with granularity adjustments
- **Raw JSON**: Original API response with `-raw` flag
- **CSV**: Structured data export with `-f csv`
- **Custom CSV**: Named files with `--csv-filename` and `--append-timestamp`
## Time Frame Options
Common time frame patterns:
- `last.PT1H` - Last hour
- `last.P1D` - Last day
- `last.P7D` - Last week
- `last.P1M` - Last month
- `utc.2023-02-{28/00:00:00--28/23:59:59}` - Custom UTC range
## Getting Help
- Use `-h` or `--help` with any command for detailed usage
- Check the [Cato API Documentation](https://api.catonetworks.com/documentation/)
- Review individual operation guides linked above
This CLI is a Python 3 application and has been tested with Python 3.6 -> 3.8
## Requirements:
python 3.6 or higher
## Confirm your version of python if installed:
Open a terminal
Enter: python -V or python3 -V
## Installing the correct version for environment:
https://www.python.org/downloads/
| text/markdown | Cato Networks | [email protected] | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Progra... | [] | https://github.com/Cato-Networks/cato-cli | null | >=3.6 | [] | [] | [] | [
"urllib3",
"certifi",
"six",
"argcomplete"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T07:57:50.112692 | catocli-3.0.61.tar.gz | 7,487,340 | 26/a8/b07199bfdf93c9a13279f21a0342edf20214e550df98d15697bd521df999/catocli-3.0.61.tar.gz | source | sdist | null | false | 36aad8168a45b023e1f44e29824bd9e4 | 7ee47ea123c6901df1ec1095ba4f849dd203f4b1fb938cb77fb1b4fc0e0f8d3f | 26a8b07199bfdf93c9a13279f21a0342edf20214e550df98d15697bd521df999 | null | [
"LICENSE"
] | 297 |
2.4 | silodb | 0.9.11 | Python bindings for SILO - high-performance sequence database | # LAPIS-SILO
Sequence Indexing engine for Large Order of genomic data
# Build requirements
For building SILO you require the following tools:
- cmake (installable via apt / homebrew)
- conan (installable via pip)
Furthermore, we require an explicit file `conanprofile` in the project root. Run `conan profile detect` to
automatically deduce a conan profile for your system and then `conan profile show --context build > conanprofile` to
create the file from that profile. We currently do not support cross-compilation.
# Building
Use `./build_with_conan.py` to build SILO. `./build_with_conan.py --help` shows all available options.
Executables are located in `build/` upon a successful build.
The conan center has been updated, if you installed conan before November 2024 you might need to update your center: `conan remote update conancenter --url="https://center2.conan.io"`
We took the approach to scan directories for .cpp files to include instead of listing them manually in the
CMakeLists.txt. This has the advantage that we don't need to maintain a list of files in the CMakeLists.txt.
It has the disadvantage that after a successful build on local machines, CMake can't detect whether files were
added or deleted. This requires a clean build. You can either delete the `build/` directory manually, or you
execute `./build_with_conan.py --clean`.
Since in any approach, a developer has to remember to either trigger a clean build or to adapt the CMakeLists.txt, we
decided for the approach with less maintenance effort, since it will automatically work in GitHub Actions.
## Python Bindings
SILO provides Python bindings via Cython. The bindings wrap the core C++ `Database` class.
### Prerequisites
- Python 3.8+
- Cython >= 3.0
- C++ dependencies built via conan (see [Building](#building))
### Building Python Bindings
First, build the C++ dependencies:
```shell
./build_with_conan.py --release
```
Then install the Python package:
```shell
pip install .
```
For development (editable install):
```shell
pip install -e .
```
The build process:
1. Locates pre-built conan dependencies in `build/Release/generators` or `build/Debug/generators`
2. Runs CMake with `-DBUILD_PYTHON_BINDINGS=ON`
3. Builds the C++ library and Cython extension
4. Installs to your Python environment
### Usage
```python
from silodb import Database
# Create a new database
db = Database()
# Or load from a saved state
db = Database("/path/to/saved/database")
# Create a nucleotide sequence table
db.create_nucleotide_sequence_table(
table_name="sequences",
primary_key_name="id",
sequence_name="main",
reference_sequence="ACGT..."
)
# Append data from file
db.append_data_from_file("sequences", "/path/to/data.ndjson")
# Get reference sequence
ref = db.get_nucleotide_reference_sequence("sequences", "main")
# Get filtered bitmap (list of matching row indices)
indices = db.get_filtered_bitmap("sequences", "some_filter")
# Get prevalent mutations
mutations = db.get_prevalent_mutations(
table_name="sequences",
sequence_name="main",
prevalence_threshold=0.05,
filter_expression=""
)
# Save database state
db.save_checkpoint("/path/to/save/directory")
# Print all data (to stdout)
db.print_all_data("sequences")
```
### Running SILO locally with CLion
`.run` contains run configurations for CLion that are ready to use.
They assume that you configured CMake in CLion to use `./build` as build directory.
CLion should be able to detect those files automatically.
### Formatting
We use clang-format as a code formatter. To run locally install [clang-format](https://github.com/llvm/llvm-project/releases/tag/llvmorg-17.0.6), update your PATH variables and run
```bash
find src -iname '*.h' -o -iname '*.cpp' | xargs clang-format -i
```
Note that your clang-format version should be exactly the same as that used by `jidicula/clang-format-action` for tests to pass. Currently we use `v.17.0.6`.
## Conan
We use Conan to install dependencies for local development. See Dockerfile for how to set up Conan and its requirements.
This has been tested on Ubuntu 22.04 and is not guaranteed to work on other systems.
The Conan profile (myProfile) on your system might differ: Create a new profile `~/.conan2/profiles/myProfile`
```shell
conan profile detect
```
Copy `conanprofile.example` to `conanprofile` and insert the values of `os`, `os_build`, `arch` and `arch_build` from
myProfile.
Build silo in `./build`. This build will load and build the required libraries to `~/.conan2/data/` (can not be set by
hand).
```shell
./build_with_conan.py
```
## Build with Docker:
(for CI and release)
Build docker container
```shell
docker build . --tag=silo
```
The Docker images are built in such a way that they can be used for both,
preprocessing and running the api, with minimal configuration.
The images contain default configuration so that a user only needs to mount data to the correct locations.
## Configuration Files
For SILO, there are three different configuration files:
- `DatabaseConfig` described in
file [database_config.h](src/silo/config/database_config.h)
- `PreprocessingConfig` used when started with `preprocessing` and described in
file [preprocessing_config.h](src/silo/config/preprocessing_config.h)
- `RuntimeConfig` used when started with `api` and described in
file [runtime_config.h](src/silo/config/preprocessing_config.h)
The database config contains the schema of the database and is always required when preprocessing data. The database
config will be saved together with the output of the preprocessing and is therefore not required when starting SILO as
an API.
An example configuration file can be seen
in [testBaseData/exampleDataset/database_config.yaml](testBaseData/exampleDataset/database_config.yaml).
By default, the config files are expected to be YAML files in the current working directory in
snake_case (`database_config.yaml`, `preprocessing_config.yaml`, `runtime_config.yaml`), but their location can be
overridden using the options `--database-config=X`, `--preprocessing-config=X`, and `--runtime-config=X`.
Preprocessing and Runtime configurations contain default values for all fields and are thus only optional. Their
parameters can also be provided as command-line arguments in snake_case and as environment variables prefixed with SILO_
in capital SNAKE_CASE. (e.g. SILO_INPUT_DIRECTORY).
The precendence is `CLI argument > Environment Variable > Configuration File > Default Value`
### Run The Preprocessing
The preprocessing acts as a program that takes an input directory that contains the to-be-processed data
and an output directory where the processed data will be stored.
Both need to be mounted to the container.
SILO expects a preprocessing config that can to be mounted to the default location `/app/preprocessing_config.yaml`.
Additionally, a database config and a ndjson file containing the data are required. They should typically be mounted in `/preprocessing/input`.
```shell
docker run \
-v your/input/directory:/preprocessing/input \
-v your/preprocessing/output:/preprocessing/output \
-v your/preprocessing_config.yaml:/app/preprocessing_config.yaml
silo preprocessing
```
Both config files can also be provided in custom locations:
```shell
silo preprocessing --preprocessing-config=./custom/preprocessing_config.yaml --database-config=./custom/database_config.yaml
```
The Docker image contains a default preprocessing config that sets defaults specific for running SILO in Docker.
Apart from that, there are default values if neither user-provided nor default config specify fields.
The user-provided preprocessing config can be used to overwrite the default values. For a full reference,
see the help text.
### Run docker container (api)
After preprocessing the data, the api can be started with the following command:
```shell
docker run
-p 8081:8081
-v your/preprocessing/output:/data
silo api
```
The directory where SILO expects the preprocessing output can be overwritten via
`silo api --data-directory=/custom/data/directory` or in a corresponding
[configuration file](#configuration-files).
### Notes On Building The Image
Building Docker images locally relies on the local Docker cache.
Docker will cache layers, and it will cache the dependencies built by Conan via cache mounts.
However, cache mounts don't work in GitHub Actions (https://github.com/docker/build-push-action/issues/716),
so there we only rely on Docker's layer cache via Docker's gha cache backend.
## Creating A Release
This project uses [Release Please](https://github.com/google-github-actions/release-please-action) to generate releases.
On every commit on the `main` branch, it will update a Pull Request with a changelog.
When the PR is merged, the release will be created.
Creating a release means:
- A new Git tag is created.
- The Docker images of SILO are tagged with the new version.
- Suppose the created version is `2.4.5`, then it creates the tags `2`, `2.4` and `2.4.5` on the current `latest` image.
The changelog and the version number are determined by the commit messages.
Therefore, commit messages should follow the [Conventional Commits](https://www.conventionalcommits.org/) specification.
Also refer to the Release Please documentation for more information on how to write commit messages
or see [Conventional Commits](#conventional-commits) below.
# Testing
Before committing, run `make ci` to execute the formatter and all tests (unit and e2e) locally.
## Unit Tests
For testing, we use the framework [gtest](http://google.github.io/googletest/)
and [gmock](http://google.github.io/googletest/gmock_cook_book.html) for mocking. Tests are built using the same script
as the production code: `./build_with_conan`.
We use the convention, that each tested source file has its own test file, ending with `*.test.cpp`. The test file is
placed in the same folder as the source file. If the function under test is described in a header file, the test file is
located in the corresponding source folder.
To run all tests, run
```shell
build/Release/silo_test
```
For linting we use clang-tidy. The config is stored in `.clang-tidy`.
When pushing to GitHub, a separate Docker image will be built, which runs the formatter. (This is a workaround, because
building with clang-tidy under alpine was not possible yet.)
## Functional End-To-End Tests
End-to-end tests are located in `/endToEndTests`. Those tests are used to verify the overall functionality of the SILO
queries. To execute the tests:
- have a running SILO instance with preprocessd data e.g. via
- `SILO_IMAGE=ghcr.io/genspectrum/lapis-silo docker compose -f docker-compose-for-tests-preprocessing.yml up`
- `SILO_IMAGE=ghcr.io/genspectrum/lapis-silo docker compose -f docker-compose-for-tests-api.yml up -d wait`
- `cd endToEndTests`
- `npm install`
- `SILO_URL=localhost:8081 npm run test`
# Local Debugging
We recommend using [LLDB](https://lldb.llvm.org/) with Cmake for local debugging.
If you are using VSCode we recommend installing the extensions listed in the `.vscode.extensions.json`. This will add a new icon for Cmake, to debug using Cmake and LLDB first configure the project (by selecting configure in the Cmake panel) and update the Cmake `settings.json` to use LLDB. This means adding the following to your settings.json.
```
"cmake.debugConfig": {
"MIMode": "lldb"
}
```
# Logging
We use [spdlog](https://github.com/gabime/spdlog) for logging.
The log level can be controlled via the environment variable `SPDLOG_LEVEL`:
- Start SILO with `SPDLOG_LEVEL=off` to turn off logging.
- Start SILO with `SPDLOG_LEVEL=debug` to log at debug level.
SILO will log to `./logs/silo_<date>.log` and to stdout.
We decided to use the macros provided by spdlog rather than the functions, because this lets us disable log statements
at compile time by adjusting `add_compile_definitions(SPDLOG_ACTIVE_LEVEL=SPDLOG_LEVEL_TRACE)` to the desired log level
via CMake. This might be desirable for benchmarking SILO. However, the default should be `SPDLOG_LEVEL_TRACE` to give
the maintainer the possibility to adjust the log level to a log level that they prefer, without the need to recompile
SILO.
# Acknowledgments
Original genome indexing logic with roaring bitmaps by Prof. Neumann: https://db.in.tum.de/~neumann/gi/
# Code Style Guidelines
## Naming
We mainly follow the styleguide provided by [google](https://google.github.io/styleguide/cppguide.html), with a few
additions. The naming is enforced by clang-tidy. Please refer to `.clang-tidy` for more details on naming inside the
code. Clang-tidy can not detect filenames. We decided to use snake_case for filenames.
## Includes
The includes are sorted in the following order:
1. Corresponding header file (for source files)
2. System includes
3. External includes
4. Internal includes
Internal includes are marked by double quotes. External includes are marked by angle brackets.
## Conventional Commits
We follow the [conventional commits](https://www.conventionalcommits.org/) guidelines for commit messages.
This will allow to automatically generate a changelog.
Please make sure to mention a reference in the commit message so that the generated changelog can be linked to
either an issue or a pull request.
This can be done via:
- Referencing an issue via "resolves" to the commit footer (preferred solution):
```
feat: my fancy new feature
some description
resolves #123
```
- Referencing an issue in the commit message header: `feat: my fancy new feature (#123)`
- Squash-merging on GitHub and adding the PR number to the commit message
(useful for smaller changes that don't have a corresponding issue).
We use [commitlint](https://commitlint.js.org/) to enforce the commit message format.
To use it locally, run `npm install`.
The last commit message can be checked with
```shell
npm run commitlint:last-commit
```
To check commit messages of a branch to the commit where it branches off from `main`, run
```shell
npm run commitlint:merge-base
```
### Testing The Generated Changelog
To test the generated changelog, run
```shell
npm run release-please-dry-run -- --token=<GitHub PAT> --target-branch=<name of the upstream branch>
```
where
- `<GitHub PAT>` is a GitHub Personal Access Token. It doesn't need any permissions.
- `<name of the upstream branch>` is the name of the branch for which the changelog should be generated.
**NOTE: This command does not respect local changes. It will pull the commit messages from the remote repository.**
| text/markdown | null | null | null | null | AGPL 3.0 | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Pyt... | [] | null | null | >=3.8 | [] | [] | [] | [
"Cython>=3.0",
"pyroaring>=1.0.0",
"pyarrow>=12.0.0",
"pytest>=7.0; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/GenSpectrum/LAPIS-SILO",
"Repository, https://github.com/GenSpectrum/LAPIS-SILO",
"Issues, https://github.com/GenSpectrum/LAPIS-SILO/issues"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T07:57:47.014392 | silodb-0.9.11-cp312-cp312-macosx_15_0_arm64.whl | 5,819,041 | 0b/37/4371698b87108fdab7a66249db22692ba540d17c449500714e6f4c9e59a8/silodb-0.9.11-cp312-cp312-macosx_15_0_arm64.whl | cp312 | bdist_wheel | null | false | afd8fdac4b013d44fcb67da264f1fa58 | 3c88c4f94e251098804c94efc195db524373f41024368234c70d86edf897b25e | 0b374371698b87108fdab7a66249db22692ba540d17c449500714e6f4c9e59a8 | null | [
"LICENSE"
] | 235 |
2.4 | datafast | 0.0.34 | A Python package for synthetic text dataset generation | <div align="left">
<img src="./assets/Datafast Logo.png" alt="Datafast Logo" width="300px">
</div>
> *Generate text datasets for LLMs in minutes, not weeks.*
## Intended use cases
- Get initial evaluation text data instead of starting your LLM project blind.
- Increase diversity and coverage of an existing dataset by generating more data.
- Experiment and test quickly LLM-based application PoCs.
- Make your own datasets to fine-tune and evaluate language models for your application.
🌟 Star this repo if you find this useful!
## Supported Dataset Types
- ✅ Text Classification Dataset
- ✅ Raw Text Generation Dataset
- ✅ Instruction Dataset (Ultrachat-like)
- ✅ Multiple Choice Question (MCQ) Dataset
- ✅ Preference Dataset
- ⏳ more to come...
## Supported LLM Providers
Currently we support the following LLM providers:
- ✔︎ OpenAI
- ✔︎ Anthropic
- ✔︎ Google Gemini
- ✔︎ Ollama (local LLM server)
- ✔︎ Mistral AI
- ⏳ more to come...
Try it in Colab:
[](https://colab.research.google.com/github/patrickfleith/datapipes/blob/main/notebooks/Datafast_Quickstart_Text_Classification.ipynb)
## Installation
```bash
pip install datafast
```
## Quick Start
### 1. Environment Setup
Make sure you have created a `.env` file with your API keys.
HF token is needed if you want to push the dataset to your HF hub.
Other keys depends on which LLM providers you use.
```
GEMINI_API_KEY=XXXX
OPENAI_API_KEY=sk-XXXX
ANTHROPIC_API_KEY=sk-ant-XXXXX
MISTRAL_API_KEY=XXXX
HF_TOKEN=hf_XXXXX
```
### 2. Import Dependencies
```python
from datafast.datasets import ClassificationDataset
from datafast.schema.config import ClassificationDatasetConfig, PromptExpansionConfig
from datafast.llms import OpenAIProvider, AnthropicProvider, GeminiProvider
from dotenv import load_dotenv
# Load environment variables
load_dotenv() # <--- your API keys
```
### 3. Configure Dataset
```python
# Configure the dataset for text classification
config = ClassificationDatasetConfig(
classes=[
{"name": "positive", "description": "Text expressing positive emotions or approval"},
{"name": "negative", "description": "Text expressing negative emotions or criticism"}
],
num_samples_per_prompt=5,
output_file="outdoor_activities_sentiments.jsonl",
languages={
"en": "English",
"fr": "French"
},
prompts=[
(
"Generate {num_samples} reviews in {language_name} which are diverse "
"and representative of a '{label_name}' sentiment class. "
"{label_description}. The reviews should be {{style}} and in the "
"context of {{context}}."
)
],
expansion=PromptExpansionConfig(
placeholders={
"context": ["hike review", "speedboat tour review", "outdoor climbing experience"],
"style": ["brief", "detailed"]
},
combinatorial=True
)
)
```
### 4. Setup LLM Providers
```python
# Create LLM providers
providers = [
OpenAIProvider(model_id="gpt-5-mini-2025-08-07"),
AnthropicProvider(model_id="claude-haiku-4-5-20251001"),
GeminiProvider(model_id="gemini-2.0-flash")
]
```
### 5. Generate and Push Dataset
```python
# Generate dataset and local save
dataset = ClassificationDataset(config)
dataset.generate(providers)
# Optional: Push to Hugging Face Hub
dataset.push_to_hub(
repo_id="YOUR_USERNAME/YOUR_DATASET_NAME",
train_size=0.6
)
```
## Next Steps
Check out our guides for different dataset types:
* [How to Generate a Text Classification Dataset](https://patrickfleith.github.io/datafast/guides/generating_text_classification_datasets/)
* [How to Create a Raw Text Dataset](https://patrickfleith.github.io/datafast/guides/generating_text_datasets/)
* [How to Create a Preference Dataset](https://patrickfleith.github.io/datafast/guides/generating_preference_datasets/)
* [How to Create a Multiple Choice Question (MCQ) Dataset](https://patrickfleith.github.io/datafast/guides/generating_mcq_datasets/)
* [How to Create an Instruction (Ultrachat) Dataset](https://patrickfleith.github.io/datafast/guides/generating_ultrachat_datasets/)
* Star and watch this github repo to get updates 🌟
## Key Features
* **Easy-to-use** and simple interface 🚀
* **Multi-lingual** datasets generation 🌍
* **Multiple LLMs** used to boost dataset diversity 🤖
* **Flexible prompt**: use our default prompts or provide your own custom prompts 📝
* **Prompt expansion**: Combinatorial variation of prompts to maximize diversity 🔄
* **Hugging Face Integration**: Push generated datasets to the Hub 🤗
> [!WARNING]
> This library is in its early stages of development and might change significantly.
## Contributing
Contributions are welcome! If you are new to the project, pick an issue labelled "good first issue".
How to proceed?
1. Pick an issue
2. Comment on the issue to let others know you are working on it
3. Fork the repository
4. Clone your fork locally
5. Create a new branch and give it a name like `feature/my-awsome-feature`
6. Make your changes
7. If you feel like it, write a few tests for your changes
8. To run the current tests, you can run `pytest` in the root directory. Don't pay attention to `UserWarning: Pydantic serializer warnings`. Note that for the LLMs test to run successfully you'll need to have:
- openai API key
- anthropic API key
- gemini API key
- mistral API key
- an ollama server running (use `ollama serve` from command line)
9. Commit your change, push to your fork and create a pull request from your fork branch to datafast main branch.
10. Explain your pull request in a clear and concise way, I'll review it as soon as possible.
## Roadmap:
- RAG datasets
- Personas
- Seeds
- More types of instructions datasets (not just ultrachat)
- More LLM providers
- Deduplication, filtering
- Dataset cards generation
## Creator
Made with ❤️ by [Patrick Fleith](https://www.linkedin.com/in/patrick-fleith/).
<hr>
This is volunteer work, star this repo to show your support! 🙏
## Project Details
- **Status:** Work in Progress (APIs may change)
- **License:** [Apache 2.0](LICENSE)
| text/markdown | Patrick Fleith | null | null | null | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright 2025 Patrick Fleith
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| dataset, text, generation | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"datasets>=3.0",
"instructor",
"google-generativeai",
"python-dotenv",
"anthropic",
"openai",
"pydantic",
"litellm",
"gradio",
"loguru",
"pytest>=6.0; extra == \"dev\"",
"ruff>=0.9.0; extra == \"dev\""
] | [] | [] | [] | [
"Documentation, https://github.com/patrickfleith/datafast",
"Issue Tracker, https://github.com/patrickfleith/datafast/issues",
"Discussions, https://github.com/patrickfleith/datafast/discussions"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T07:57:44.297106 | datafast-0.0.34.tar.gz | 71,949 | fd/aa/0afdd13962079b32b641f2732a67d01431ff6ff1e8a0edb513aadf395e86/datafast-0.0.34.tar.gz | source | sdist | null | false | c681190165e8ce671d08ce22dbe6579b | ecb10cb9b274335f3df9a4f45aff7d8faf7a4d896fdff8c234f93e2673d75173 | fdaa0afdd13962079b32b641f2732a67d01431ff6ff1e8a0edb513aadf395e86 | null | [
"LICENSE"
] | 286 |
2.4 | sodas-python-sdk | 1.0.3 | SODAS 프레임워크를 위한 공식 Python SDK. DCAT 기반 데이터셋 메타데이터 관리. | # 🛠️ SODAS TS SDK
dist/index.node.js : for node
dist/index.browser.js : for browser
dist/index.legacy.js : for webpack version 4 [ especially for governace portal ]
---
## 📜 SODAS_SDK_CLASS Policy
- 모든 **SODAS_SDK_CLASS**는 해당 클래스와 **DTO 인터페이스**를 가진다.
- 모든 **SODAS_SDK_CLASS** 인스턴스는 **CRUDL 기능**을 제공하며, 인터페이스는 다음과 같다:
- create_db_record
- get_db_record
- update_db_record
- delete_db_record
- list_db_records
- **time 필드**는 Backend API와의 통신 시 **iso_format**을 사용한다.
- **create_db_record** 메서드를 통해서만 **ID와 IRI**가 생성된다.
- **ID와 IRI**가 이미 존재하는 경우, **create_db_record** 호출이 불가능하며 **update_db_record**만 호출 가능하다.
- **delete_db_resource** 호출 시 해당 객체는 기본생성인스턴스가 된다.
- **DCAT_MODEL**의 경우 다음 필드들은 **백엔드 create API** 호출을 통해서만 생성된다:
- resource_type, ID, IRI, created_at, dcat_model_id (e.g., dataset_id 등)
---
### DCAT_RESOURCE - Thumbnail Policy
- 모든 **DCAT Resource CLASS**는 Thumbnail 프로퍼티를 가진다.
- Thumbnail 프로퍼티는 **SODAS_SDK_FILE** 클래스를 상속받은 **thumbnail_file** 클래스의 인스턴스이다.
- 이미 thumbnail_url이 있는 경우 Thumbnail 필드를 설정하면 thumbnail_url은 null로 설정된다.
- Thumbnail은 DCAT_RESOURCE 인스턴스의 create_db_record 메소드 호출 시 업로드된다. (단, Thumbnail의 업로드가 먼저 호출되므로 DCAT_RESOURCE.create_db_record에서 에러가 발생할 경우 Thumbnail만 업로드될 가능성이 있다.)
- 이미 db_record가 있으면서 Thumbnail을 설정한 경우에는 DCAT_RESOURCE 인스턴스의 update_db_record 메소드 호출 시 기존의 Thumbnail은 제거되고 새로운 Thumbnail을 연결한다.
- Thumbnail은 DCAT_RESOURCE 인스턴스의 삭제 시 삭제된다.
- SDK는 Thumbnail File의 생성요청의 책임을, SODAS_PROFILE 백엔드는 생성과 삭제의 책임을 가진다.
---
### DCAT_RESOURCE - version_info Policy
- DCAT_RESOURCE 인스턴스는 create_db_record/get_db_record/update_db_record/list_db_records를 통해 관련된 version_info들을 불러온다.
- create_db_record/update_db_record/delete_db_record를 통해 새롭게 버전 정보가 변경돼도 인스턴스 간 version_info는 동기화되지 않는다. 따라서 의식적으로 get_db_record를 통한 동기화가 필요하다.
---
### Distribution - uploading_data Policy
- 모든 **DCAT Distribution CLASS**는 uploading_data 프로퍼티를 가진다.
- uploading_data 프로퍼티는 **SODAS_SDK_FILE** 클래스를 상속받은 **data_file** 클래스의 인스턴스이다.
- 이미 download_url 있는 경우 uploading_data 필드를 설정하면 download_url은 null로 설정된다.
- uploading_data는 Distribution 인스턴스의 create_db_record 메소드 호출 시 업로드된다. (단, Data의 업로드가 먼저 호출되므로 Distribution.create_db_record에서 에러가 발생할 경우 Data만 업로드될 가능성이 있다.)
- 이미 db_record가 있으면서 uploading_data를 설정한 경우 update_db_record 메소드 호출 시 기존의 Object File은 제거되고 새로운 Object File을 download_url과 연결한다.
- uploading_data의 실제 Object File은 Distribution 인스턴스 삭제 시 삭제된다.
- SDK는 Object File의 생성 요청의 책임을, SODAS_PROFILE 백엔드는 생성과 삭제의 책임을 가진다.
---
### Dataset - Distribution Policy
- Dataset의 메서드로 Dataset Instance와 연관된 Distributions를 만들 수 있다.
- Dataset.create_db_record를 통해 연관된 Distribution들의 create_db_record가 호출되며, 최종적으로 Dataset과 Distribution 모두 ID와 IRI를 가지게 된다.
- 이 시점에서 Distribution은 is_distribution_of를 연관된 Dataset의 ID로 가지게 된다.
- update_db_record 호출 시 하위 모든 Distribution의 update_db_record도 호출된다.
- 새롭게 추가된 Distribution은 레코드를 새롭게 만들고, 연결이 끊어진 Distribution은 삭제된다.
- delete_db_resource 호출 시 Dataset과 연관된 모든 Distribution은 DB에서 삭제되며 인스턴스들은 기본생성인스턴스가 된다.
---
### DatasetSeries - Dataset Policy
- DatasetSeries는 create_db_record/get_db_record/update_db_record/list_db_records를 통해 관련된 series_members(Dataset)들을 불러온다.
- DatasetSeries는 series_member_ids 필드로 Dataset의 순서와 관계를 관리한다.
- delete_db_record 호출 시 DatasetSeries만 DB에서 삭제되며, 관련된 Dataset 인스턴스는 기본생성인스턴스로 초기화된다.
---
## 🧪 CRUDL Test Policy
### Test Levels
- **Small 테스트**: 클래스 자체의 메서드 테스트
- **Medium 테스트**: SDK와 백엔드의 통합 테스트
- **Big 테스트**: 사용자 시나리오 엔드투엔드 테스트 (현재는 없음)
---
### 🟢 1. CREATE
#### ✅ 테스트 케이스:
- **foreign_key 필드**를 제외한 모든 필드 중 하나만 null 값으로 설정한 케이스를 테스트한다.
#### 📝 테스트 정책:
1. DTO를 기반으로 인스턴스를 세팅한다.
2. **create_db_record** 호출 후 **ID와 IRI** 생성 여부를 확인한다.
3. API 결과와 인스턴스를 비교한다.
4. **ID와 IRI**가 설정된 인스턴스에서 **create_db_record** 호출 시 에러 발생을 확인한다.
---
### 🟢 2. GET
#### ✅ 테스트 케이스:
- **foreign_key 필드**를 제외한 모든 필드 중 하나만 null 값으로 설정한 케이스를 테스트한다.
#### 📝 테스트 정책:
1. DTO를 기반으로 인스턴스를 세팅한다.
2. **create_db_record**로 인스턴스를 생성한다.
3. **get_db_record**로 생성된 인스턴스를 가져온다.
4. 생성 및 조회된 인스턴스를 비교한다.
---
### 🟢 3. UPDATE
#### ✅ 테스트 케이스:
- **foreign_key 필드**를 제외한 모든 필드 중 하나만 null 값으로 설정한 케이스를 테스트한다.
#### 📝 테스트 정책:
1. 모든 필드가 채워진 인스턴스를 세팅한다.
2. **ID와 IRI**가 없는 인스턴스에서 **update_db_record** 호출 시 에러 발생을 확인한다.
3. **create_db_record**로 인스턴스를 생성한다.
4. DTO를 기반으로 인스턴스를 재설정한다.
5. **update_db_record**로 인스턴스를 업데이트한다.
6. API 결과와 인스턴스를 비교한다.
---
### 🟢 4. DELETE
#### ✅ 테스트 케이스:
- **모든 필드가 채워진 케이스 하나**로 테스트한다.
#### 📝 테스트 정책:
1. 모든 필드가 채워진 인스턴스를 세팅한다.
2. **create_db_record**로 인스턴스를 생성한다.
3. 생성된 인스턴스를 복사한다.
4. **delete_db_record**로 인스턴스를 삭제한다.
5. 삭제된 인스턴스의 모든 필드가 null인지 확인한다.
6. 복사된 인스턴스에서 **delete_db_record** 호출 시 에러 발생을 확인한다.
---
### 🟢 5. LIST
#### ✅ 테스트 케이스:
- **모든 필드가 채워진 인스턴스 12개**를 만들고, **페이지 수 5개**로 테스트한다.
#### 📝 테스트 정책:
1. 지정된 갯수만큼 인스턴스를 생성하고 저장한다.
2. **list_db_records**를 ASC 및 DESC 방식으로 호출하고 총 수량과 순서를 비교한다.
---
## 🧪 SODAS_SDK_FILE Test Policy
#### 📝 테스트 정책:
1. **SODAS_SDK_FILE.upload()** 호출 후 파일을 업로드한다.
2. **get_download_url()**로 다운로드 URL을 확인하고, 원본 파일과 동일한지 확인한다.
3. **SODAS_SDK_FILE.remove()** 호출 후 삭제 및 URL 유효성 확인.
MANAGED BY HAZE1211
| text/markdown | SODAS | null | null | null | null | sodas, sdk, dcat, metadata, data-catalog | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Developm... | [] | null | null | <3.13,>=3.9 | [] | [] | [] | [
"pydantic>=2.0.0",
"python-dateutil>=2.8.0",
"requests>=2.25.0"
] | [] | [] | [] | [
"Repository, https://github.com/sodas/py-sodas-sdk",
"Documentation, https://github.com/sodas/py-sodas-sdk#readme"
] | twine/6.2.0 CPython/3.9.6 | 2026-02-19T07:56:55.811354 | sodas_python_sdk-1.0.3.tar.gz | 33,980 | bf/91/658b00529491a8041dc7ccce62a45e8c2ba87aa604a69a2714c53287bf0b/sodas_python_sdk-1.0.3.tar.gz | source | sdist | null | false | d4cedfd1e93fcc881098137f8ba32c65 | 74c3f56d46e41f3bcda1a4cbb1b7948c039c6df97b1eaaea31e330dc73f40eb8 | bf91658b00529491a8041dc7ccce62a45e8c2ba87aa604a69a2714c53287bf0b | MIT | [] | 269 |
2.3 | keboola_streamlit | 0.1.5 | A Python library that simplifies Keboola SAPI integration in Streamlit apps. | 
# KeboolaStreamlit
KeboolaStreamlit simplifies the use of Keboola Storage API within Streamlit apps, providing easy-to-use functions for authentication, data retrieval, event logging, and data loading.
## Installation
To install:
```bash
pip install keboola-streamlit
```
_If you are using `streamlit<=1.36.0`, please use version `0.0.5` of the keboola-streamlit package._
## Usage
### Import and Initialization
Create an instance of the `KeboolaStreamlit` class, and initialize it with the required parameters from Streamlit secrets:
```python
import streamlit as st
from keboola_streamlit import KeboolaStreamlit
URL = st.secrets["KEBOOLA_URL"]
TOKEN = st.secrets["STORAGE_API_TOKEN"]
keboola = KeboolaStreamlit(root_url=URL, token=TOKEN)
```
### Authentication and Authorization
If only selected roles can access the app, make sure the user is authorized by:
```python
ROLE_ID = st.secrets["REQUIRED_ROLE_ID"]
keboola.auth_check(required_role_id=ROLE_ID)
```
Add a logout button to your app:
```python
keboola.logout_button(sidebar=True, use_container_width=True)
```
💡 _You can find more about authorization settings in Keboola [here](https://help.keboola.com/components/data-apps/#authorization)._
### Reading Data from Keboola Storage
Read data from a Keboola Storage table and return it as a Pandas DataFrame:
```python
df = keboola.read_table(table_id='YOUR_TABLE_ID')
```
💡 _Wrap the function and use the `st.cache_data` decorator to prevent your data from being read every time you interact with the app. Learn more about caching [here](https://docs.streamlit.io/develop/concepts/architecture/caching)._
### Writing Data to Keboola Storage
Write data from a Pandas DataFrame to a Keboola Storage table:
```python
keboola.write_table(table_id='YOUR_TABLE_ID', df=your_dataframe, is_incremental=False)
```
### Creating Events
Create an event in Keboola Storage to log activities:
```python
keboola.create_event(message='Streamlit App Create Event', event_type='keboola_data_app_create_event')
```
### Table Selection
Add a table selection interface in your app:
```python
df = keboola.add_table_selection(sidebar=True)
```
### Snowflake Integration
#### Creating a Snowflake Session
To interact with Snowflake, first create a session using your Streamlit secrets. Ensure that the following secrets are set in your Streamlit configuration:
- `SNOWFLAKE_USER`
- `SNOWFLAKE_ACCOUNT`
- `SNOWFLAKE_ROLE`
- `SNOWFLAKE_WAREHOUSE`
- `SNOWFLAKE_DATABASE`
- `SNOWFLAKE_SCHEMA`
For authentication you can use password:
- `SNOWFLAKE_PASSWORD`
Or key-pair:
- `SNOWFLAKE_PRIVATE_KEY`
- `SNOWFLAKE_PRIVATE_KEY_PASSPHRASE` (Optional)
Streamlit will automatically use type of authorization based on what you fill in secrets.
> NOTE: If both password and key-pair are filled in secrets, Streamlit by default will use the key-pair authorization.
Then, create the session as follows:
```python
st.session_state['snowflake_session'] = keboola.snowflake_create_session_object()
```
#### Reading Data from Snowflake
Load a table from Snowflake into a Pandas DataFrame:
```python
df_snowflake = keboola.snowflake_read_table(session=st.session_state['snowflake_session'], table_id='YOUR_SNOWFLAKE_TABLE_ID')
```
#### Executing a Snowflake Query
Execute a SQL query on Snowflake and optionally return the results as a DataFrame:
```python
query = "SELECT * FROM YOUR_SNOWFLAKE_TABLE"
df_query_result = keboola.snowflake_execute_query(session=st.session_state['snowflake_session'], query=query, return_df=True)
```
#### Writing Data to Snowflake
Write a Pandas DataFrame to a Snowflake table:
```python
keboola.snowflake_write_table(session=st.session_state['snowflake_session'], df=your_dataframe, table_id='YOUR_SNOWFLAKE_TABLE_ID')
```
## License
This project is licensed under the MIT License. See the `LICENSE` file for more details.
| text/markdown | pandyandy, yustme | pandyandy <andrea.novakova@keboola.com>, yustme <vojta.tuma@keboola.com> | null | null | MIT License | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Intended Audie... | [] | null | null | >=3.10 | [] | [] | [] | [
"streamlit>=1.37.0",
"pandas",
"kbcstorage",
"deprecated",
"snowflake-snowpark-python>=1.35.0"
] | [] | [] | [] | [
"Repository, https://github.com/keboola/keboola_streamlit/"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T07:55:58.975003 | keboola_streamlit-0.1.5.tar.gz | 7,576 | 92/7c/15ef6a4d2c0e9cf9f55e0c71286c933ebd5e49b64646e29bec3a5936e352/keboola_streamlit-0.1.5.tar.gz | source | sdist | null | false | d360624f19e6840c6e1d3fe41aa21c00 | 9f8a4d1c906e3b8dc500c283f9cfe4d135a163fc95e49c322b815753e62baafa | 927c15ef6a4d2c0e9cf9f55e0c71286c933ebd5e49b64646e29bec3a5936e352 | null | [] | 0 |
2.1 | coxdev | 0.1.5 | Library for computing Cox deviance | # coxdev
A high-performance Python library for computing Cox proportional hazards model deviance, gradients, and Hessian information matrices. Built with C++ and Eigen for optimal performance, this library provides efficient survival analysis computations with support for different tie-breaking methods.
## Features
- **High Performance**: C++ implementation with Eigen linear algebra library
- **Comprehensive Support**: Handles both Efron and Breslow tie-breaking methods
- **Left-Truncated Data**: Support for left-truncated survival data
- **Efficient Computations**: Optimized algorithms for deviance, gradient, and Hessian calculations
- **Memory Efficient**: Uses linear operators for large-scale computations
- **Cross-Platform**: Works on Linux, macOS, and Windows
## Installation
### Prerequisites
This package requires the Eigen C++ library headers. The Eigen library is included as a git submodule.
1. **Initialize Eigen submodule**: The Eigen library is included as a git submodule. Make sure it's initialized:
```bash
git submodule update --init --recursive
```
2. **Check Eigen availability**: Run the check script to verify Eigen headers are available:
```bash
python check_eigen.py
```
### Standard Installation
```bash
pip install .
```
### With Custom Eigen Path
If you have Eigen installed elsewhere, you can specify its location:
```bash
env EIGEN_LIBRARY_PATH=/path/to/eigen pip install .
```
### Development Installation
```bash
pip install pybind11 meson-python ninja setuptools_scm
pip install -e . --no-build-isolation
```
## Quick Start
```python
import numpy as np
from coxdev import CoxDeviance
# Generate sample survival data
n_samples = 1000
event_times = np.random.exponential(1.0, n_samples)
status = np.random.binomial(1, 0.7, n_samples) # 70% events, 30% censored
linear_predictor = np.random.normal(0, 1, n_samples)
# Create CoxDeviance object
coxdev = CoxDeviance(event=event_times, status=status, tie_breaking='efron')
# Compute deviance and related quantities
result = coxdev(linear_predictor)
print(f"Deviance: {result.deviance:.4f}")
print(f"Saturated log-likelihood: {result.loglik_sat:.4f}")
print(f"Gradient norm: {np.linalg.norm(result.gradient):.4f}")
```
## Advanced Usage
### Left-Truncated Data
```python
# With start times (left-truncated data)
start_times = np.random.exponential(0.5, n_samples)
coxdev = CoxDeviance(
event=event_times,
status=status,
start=start_times,
tie_breaking='efron'
)
```
### Computing Information Matrix
```python
# Get information matrix as a linear operator
info_matrix = coxdev.information(linear_predictor)
# Matrix-vector multiplication
v = np.random.normal(0, 1, n_samples)
result_vector = info_matrix @ v
# For small problems, you can compute the full matrix
X = np.random.normal(0, 1, (n_samples, 10))
beta = np.random.normal(0, 1, 10)
eta = X @ beta
# Information matrix for coefficients: X^T @ I @ X
I = info_matrix @ X
information_matrix = X.T @ I
```
### Different Tie-Breaking Methods
```python
# Efron's method (default)
coxdev_efron = CoxDeviance(event=event_times, status=status, tie_breaking='efron')
# Breslow's method
coxdev_breslow = CoxDeviance(event=event_times, status=status, tie_breaking='breslow')
```
## API Reference
### CoxDeviance
The main class for computing Cox model quantities.
#### Parameters
- **event**: Event times (failure times) for each observation
- **status**: Event indicators (1 for event occurred, 0 for censored)
- **start**: Start times for left-truncated data (optional)
- **tie_breaking**: Method for handling tied event times ('efron' or 'breslow')
#### Methods
- **`__call__(linear_predictor, sample_weight=None)`**: Compute deviance and related quantities
- **`information(linear_predictor, sample_weight=None)`**: Get information matrix as linear operator
### CoxDevianceResult
Result object containing computation results.
#### Attributes
- **linear_predictor**: The linear predictor values used
- **sample_weight**: Sample weights used
- **loglik_sat**: Saturated log-likelihood value
- **deviance**: Computed deviance value
- **gradient**: Gradient of deviance with respect to linear predictor
- **diag_hessian**: Diagonal of Hessian matrix
## Performance
The library is optimized for performance:
- **C++ Implementation**: Core computations in C++ with Eigen
- **Memory Efficient**: Reuses buffers and uses linear operators
- **Vectorized Operations**: Leverages Eigen's optimized linear algebra
- **Minimal Python Overhead**: Heavy computations done in C++
## Building from Source
### Prerequisites
- Python 3.9+
- C++ compiler with C++17 support
- Eigen library headers
- pybind11
### Build Steps
1. Clone the repository with submodules:
```bash
git clone --recursive https://github.com/jonathan-taylor/coxdev.git
cd coxdev
```
2. Install build dependencies:
```bash
pip install build wheel setuptools pybind11 numpy
```
3. Build the package:
```bash
python -m build
```
### Building Wheels
For wheel building:
```bash
# Standard wheel build
python -m build
# With custom Eigen path
env EIGEN_LIBRARY_PATH=/path/to/eigen python -m build
```
## Testing
Run the test suite:
```bash
python -m pytest tests/
```
## Contributing
1. Fork the repository
2. Create a feature branch
3. Make your changes
4. Add tests for new functionality
5. Ensure all tests pass
6. Submit a pull request
## License
This project is licensed under the BSD-3-Clause License - see the [LICENSE](LICENSE) file for details.
## Citation
If you use this library in your research, please cite:
```bibtex
@software{coxdev2024,
title={coxdev: High-performance Cox proportional hazards deviance computation},
author={Taylor, Jonathan and Hastie, Trevor and Narasimhan, Balasubramanian},
year={2024},
url={https://github.com/jonathan-taylor/coxdev}
}
```
## Acknowledgments
- Built with [Eigen](http://eigen.tuxfamily.org/) for efficient linear algebra
- Uses [pybind11](https://pybind11.readthedocs.io/) for Python bindings
- Inspired by the R `glmnet` package for survival analysis
| text/markdown | null | Jonathan Taylor <jonathan.taylor@stanford.edu>, Trevor Hastie <hastie@stanford.edu>, Balasubramanian Narasimhan <naras@stanford.edu> | null | Jonathan Taylor <jonathan.taylor@stanford.edu> | BSD-3-Clause | Cox model | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Topic :: Scientific/Engineering"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy",
"scipy",
"pytest; extra == \"test\"",
"pandas; extra == \"test\"",
"joblib; extra == \"test\"",
"rpy2; extra == \"test\"",
"pytest; extra == \"dev\"",
"scipy; extra == \"dev\"",
"ninja; extra == \"dev\"",
"meson; extra == \"dev\"",
"meson-python; extra == \"dev\"",
"pybind11; extra ==... | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.3 | 2026-02-19T07:55:24.357947 | coxdev-0.1.5.tar.gz | 3,152,134 | 6b/71/c353b88e3c3ceccba9afdd340879f6d185a4f9eaa9325e32c43d537816bd/coxdev-0.1.5.tar.gz | source | sdist | null | false | 82f70726d76c16264fb97863741f3b9c | 490063bedec76f3b79125f5e375da2f571507e1b66e4d2719d1ab970bd623fcd | 6b71c353b88e3c3ceccba9afdd340879f6d185a4f9eaa9325e32c43d537816bd | null | [] | 2,275 |
2.4 | syke | 0.3.4 | Agentic memory for AI — collects your digital footprint, synthesizes your identity, feeds that to any AI. | # Syke — Agentic Memory
[](https://opensource.org/licenses/MIT)
[](https://www.python.org/downloads/)
[](https://github.com/saxenauts/syke/actions)
[](https://www.anthropic.com)
[](https://modelcontextprotocol.io)
[](https://syke-ai.vercel.app)
[](https://syke-docs.vercel.app)
**[→ Docs](https://syke-docs.vercel.app)** · **[→ Demo](https://syke-ai.vercel.app)** · **[→ PyPI](https://pypi.org/project/syke/)**
[](https://youtu.be/56oDe8uPJB4)
> Agentic working memory for the AI-native stack. Your digital footprint — code, conversations, commits, emails — synthesized into a living, self-evolving model. Daemon-synced. Every AI tool you use, knows you.
## The Problem
Every AI session starts from zero. *"Hi, I'm an AI assistant. How can I help?"*
Your context is scattered across platforms. Your commits, your ChatGPT threads, your email — each tool sees a slice. None see you.
Syke fixes this. Not by storing facts. By synthesizing who you are.
## What You Get
A living model of you, available to every AI tool. Here's what a real Syke profile looks like:
```
# About alex
<!-- Generated by Syke from gmail, chatgpt, github (150 events) -->
A curious builder exploring the intersection of AI and developer tools.
## What's Active Right Now
🔥 **Syke Hackathon**: Building a personal context daemon for Claude Code hackathon.
- Multiple commits today
- ChatGPT conversations about architecture
## Recent Context
Working intensely on Syke, a personal context daemon. Writing Python, using Opus 4.6.
## Current World State
Building Syke v0.2 for Claude Code Hackathon (deadline Feb 16). Core focus: ask() tool.
## How They Communicate
casual, intense, exploratory. Direct, fast-paced, mixes technical and philosophical.
```
## How It Works
```mermaid
graph TB
subgraph Clients["ANY MCP CLIENT"]
CC[Claude Code]
CX[Codex / Kimi]
CA[Custom Agent]
end
subgraph Syke["SYKE DAEMON"]
IS["Agentic Perception<br/>Agent SDK + 6 MCP Tools<br/>Coverage-Gated Exploration<br/>Strategy Evolution (ALMA)"]
TL["Unified Timeline<br/>SQLite + WAL"]
IS --> TL
end
subgraph Sources["DATA SOURCES"]
S1[Claude Code<br/>Sessions]
S2[ChatGPT<br/>Export]
S3[GitHub<br/>API]
S4[Gmail<br/>OAuth]
S5[MCP Push<br/>any client]
end
Clients <-->|"MCP (pull & push)"| Syke
TL --- S1
TL --- S2
TL --- S3
TL --- S4
TL --- S5
```
**The loop**: Collect signals from your platforms → synthesize patterns across them → distribute to every AI tool → collect new signals back → re-synthesize. Every 15 minutes. Your model drifts with you.
## Works on Your Claude Code Subscription
If you have Claude Code Max, Team, or Enterprise, you already have everything you need. Run `claude login` with the Claude Code CLI — no API key required. Perception and `ask()` work out of the box on macOS, Linux, and Windows.
| Platform / Auth | Data collection | Perception & ask() | Daemon |
|-----------------|-----------------|---------------------|--------|
| Claude Code (Max/Team/Enterprise) via `claude login` | ✓ | ✓ (uses Claude Code auth) | ✓ |
| Any platform + `ANTHROPIC_API_KEY` | ✓ | ✓ (billed per-use) | ✓ |
| Codex / Kimi / Gemini CLI / etc. | ✓ | Needs `ANTHROPIC_API_KEY` today | ✓ |
| No auth at all | ✓ | ✗ | ✓ (collects, skips profile updates) |
## Quick Start
```bash
uvx syke setup --yes
```
`ANTHROPIC_API_KEY` or `claude login` (Claude Code Max/Team/Enterprise) enables perception and `ask()` ([get an API key here](https://console.anthropic.com/settings/keys)). Setup works without either — data collection, MCP, and daemon proceed; perception is skipped until auth is configured.
Auto-detects your username, local data sources, builds your identity profile, and configures MCP.
<details>
<summary>Other install methods</summary>
**pipx** (persistent install):
```bash
pipx install syke
syke setup --yes
```
**pip** (in a venv):
```bash
pip install syke
syke setup --yes
```
</details>
<details>
<summary>Update to the latest version</summary>
```bash
syke self-update
```
Detects your install method (pipx, pip, uvx, or source) and runs the right upgrade command. For `uvx`, updates are automatic — no action needed.
</details>
<details>
<summary>From source (development)</summary>
```bash
git clone https://github.com/saxenauts/syke.git && cd syke
python3 -m venv .venv && source .venv/bin/activate
pip install -e .
cp .env.example .env # Set ANTHROPIC_API_KEY
python -m syke setup --yes
```
</details>
<details>
<summary>Auth setup (API key or claude login)</summary>
**Option A — API key** (pay-per-use, works anywhere):
Get your key from [console.anthropic.com](https://console.anthropic.com/settings/keys).
```bash
export ANTHROPIC_API_KEY=your-key-here
echo 'export ANTHROPIC_API_KEY=your-key-here' >> ~/.zshrc # persist
```
**Option B — claude login** (Claude Code Max/Team/Enterprise, macOS/Linux/Windows):
```bash
claude login
```
No API key needed. Perception and `ask()` use your Claude Code subscription.
</details>
## How Syke Thinks
This is where Syke pushes the boundaries of what's possible with the Agent SDK.
### Agent SDK with Custom MCP Tools
The perception agent doesn't receive a text dump — it *explores* interactively. Six custom MCP tools let it browse timelines, search across platforms, cross-reference topics, read its own prior profiles, and submit structured output:
| Tool | Purpose |
|------|---------|
| `get_source_overview` | Understand what data exists: platforms, counts, date ranges |
| `browse_timeline` | Browse events chronologically with source/date filters |
| `search_footprint` | Full-text keyword search across all events |
| `cross_reference` | Search a topic across ALL platforms, grouped by source |
| `read_previous_profile` | Read prior perception for incremental updates |
| `submit_profile` | Submit the final structured profile (gated by coverage) |
The agent typically makes 5-12 targeted tool calls, forming hypotheses and testing them — not processing a static context window.
### Coverage-Gated Exploration (PermissionResultDeny)
The Agent SDK's hook system enforces exploration quality. A `PreToolUse` hook tracks which sources the agent has browsed, searched, and cross-referenced. If the agent tries to call `submit_profile` before covering all platforms:
```
PermissionResultDeny(reason="Sources not explored: github (67% coverage).
Explore the missing sources first, then resubmit.")
```
The agent literally cannot submit a shallow profile. Zero extra API cost — hooks piggyback on existing turns.
### Multi-Agent Orchestration
Three specialized Sonnet sub-agents explore in parallel, each with constrained tool access:
- **Timeline Explorer** — browses chronologically, identifies active threads and recent patterns
- **Pattern Detective** — cross-references topics across platforms, finds contradictions
- **Voice Analyst** — analyzes communication style, tone, vocabulary, personality signals
Opus synthesizes their findings into the final profile. Agent SDK's `AgentDefinition` handles delegation, tool scoping, and result aggregation.
### ALMA-Inspired Strategy Evolution
**This is the technical crown jewel.** Inspired by the ALMA paper (Clune, 2026) — the agent evolves its own exploration strategy across runs:
1. **Explore**: Agent runs perception, leaving a trace of every tool call and result
2. **Reflect**: Deterministic analysis labels each search as productive or wasted (zero LLM cost)
3. **Evolve**: Productive queries promoted, dead ends culled, new priorities discovered
4. **Adapt**: Next run reads the evolved strategy via tool, explores smarter
**12 runs. Real data. The system learned.**
| Strategy | Runs | Key Searches | Peak Score |
|----------|------|-------------|------------|
| v0 (baseline) | 1-3 | project names: Syke, Pogu, ALMA | 88.7% |
| v1 (concepts) | 4-6 | concepts: memory, federated, PersonaMem | **94.3%** |
| v2 (entities) | 7-9 | entities: wizard, Persona, Eder | 91.2% |
| v3 (refined) | 10-12 | refined ranking, entity relationships | 92.8% |
**Key discovery**: searching for *concepts* beats searching for *project names*. Strategy v1 found deeper cross-platform connections because "memory" appears across ChatGPT research, Claude Code implementation, and GitHub commits — while "Syke" only appears where the project is explicitly named.
Total cost: $8.07 across 12 runs. Peak quality: 94.3% at $0.60/run — 67% cheaper than the $1.80 legacy baseline.
### Federated Push/Pull
Any MCP client can *read* your context (pull) and *contribute* new events back (push). Your Claude Code session logs what you're building. Your Cursor session adds context. The identity grows from every tool.
### Continuous Sync
The daemon syncs every 15 minutes, runs incremental profile updates, and skips when nothing changed. Identity that drifts with you — what's true about you on Monday isn't true on Friday.
The daemon authenticates using the same method as the CLI — if you're authenticated via `claude login`, no additional setup is required for the daemon.
### Memory Threading
Active threads track what you're working on *across* platforms. A GitHub commit about "auth refactor" + a ChatGPT research thread on "JWT vs session tokens" + a Claude Code session implementing the change = one coherent thread with cross-platform signals.
```json
{
"name": "Syke Hackathon",
"intensity": "high",
"platforms": ["github", "chatgpt"],
"recent_signals": [
"Multiple commits today",
"ChatGPT conversations about architecture"
]
}
```
The perception agent discovers these connections by cross-referencing topics across all platforms — it's not hard-coded.
## MCP Server
8 tools via the Model Context Protocol. The `ask()` tool is the recommended entry point — ask anything about the user in natural language and Syke explores the timeline to answer. Requires `ANTHROPIC_API_KEY` or `claude login` (Claude Code Max/Team/Enterprise). The other 7 tools (`get_profile`, `query_timeline`, `search_events`, `get_manifest`, `get_event`, `push_event`, `push_events`) work without any auth.
## Benchmarks
All methods produce the same `UserProfile` schema. Tested on 3,225 events across ChatGPT, Claude Code, and GitHub:
| | Legacy | Agentic v1 | Multi-Agent v2 | Meta-Best |
|---|-------:|----------:|---------------:|---:|
| **Cost** | $1.80 | $0.71 | $1.04 | **$0.60** |
| **Eval score** | -- | -- | -- | **94.3%** |
| Source coverage | 100% | 67% | 100% | 100%* |
| Cross-platform threads | 2 | 1 | 2 | 4 |
| Identity anchor | 660ch | 411ch | 637ch | 819ch |
| Wall time | 119s | 160s | 225s | 189s |
| API turns | 1 | 13 | 13 | 12 |
**Meta-Best Per-Dimension Breakdown (Run 5):**
| Dimension | Score | Detail |
|-----------|------:|--------|
| Thread quality | 61% | 6 threads, 4 cross-platform, high specificity |
| Identity anchor | 78% | 819 chars, deep and specific |
| Voice patterns | 100% | Rich tone, 5 vocab notes, 6 examples |
| Source coverage | 100% | 3/3 platforms |
| Completeness | 100% | All fields populated |
| Recent detail | 100% | 1,304 chars, 10 temporal markers |
| **Composite** | **94.3%** | Weighted average |
## Architecture
### Why SQLite over vector DB?
Syke doesn't need semantic search at the storage layer — that's the LLM's job during perception. SQLite with WAL mode gives concurrent reads, ACID transactions, zero infrastructure. Semantic understanding happens in Opus's thinking, not in the database.
### Why Agent SDK over raw API calls?
Hooks (`PreToolUse`, `PostToolUse`), sub-agent delegation, and structured tool definitions. The coverage gate would require building a custom orchestration loop from scratch. With the SDK, it's a single `PermissionResultDeny` return.
**Multi-platform executor (on roadmap)**: Syke currently uses Anthropic's Agent SDK for intelligence (perception and `ask()`). Users on OpenAI Codex, Kimi, Gemini CLI, or other platforms need a separate `ANTHROPIC_API_KEY` today — their platform credentials are not usable by the Anthropic Agent SDK. Multi-platform executor support, allowing users on any major AI coding platform to use their existing credentials, is on the roadmap.
### Why one event per session?
Sessions are the natural unit of intent. A Claude Code session about "refactoring auth" has 50+ messages but represents one activity. Per-message would bloat the timeline 50x.
### Why content filtering?
Privacy by design, not afterthought. Credentials and private messages never enter the timeline. Content that never enters SQLite can never be sent to an LLM.
### Why 4 output formats?
Different consumers: JSON for programs, Markdown for humans, CLAUDE.md for Claude Code projects, USER.md for portable identity.
## Privacy
**Local storage**: All data stays in `~/.syke/data/{user}/syke.db`. Nothing is uploaded except during perception (Anthropic API, under their [data policy](https://www.anthropic.com/privacy)).
**Content filtering**: Pre-collection filter strips credentials and private messaging content before events enter SQLite.
**Consent tiers**: Public sources (GitHub) need no consent. Private sources (Claude Code, ChatGPT, Gmail) require `--yes` flag.
## Supported Platforms
| Platform | Status | Method | Data Captured |
|----------|--------|--------|---------------|
| Claude Code | Working | Local JSONL parsing | Sessions, tools, projects, git branches |
| ChatGPT | Working | ZIP export parsing | Conversations, topics, timestamps |
| GitHub | Working | REST API | Repos, commits, issues, PRs, stars, READMEs |
| Gmail | Working | OAuth API | Subjects, snippets, labels, sent patterns |
| Twitter/X | Stub | -- | Adapter stubbed, not implemented |
| YouTube | Stub | -- | Adapter stubbed, not implemented |
---
[Docs](https://syke-docs.vercel.app) · [Demo](https://syke-ai.vercel.app) · [PyPI](https://pypi.org/project/syke/) · 304 tests · MIT · By [Utkarsh Saxena](https://github.com/saxenauts)
| text/markdown | null | Utkarsh Saxena <utkarsh@mysyke.com> | null | null | null | ai, context, memory, mcp, anthropic, claude, identity | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"anthropic>=0.79.0",
"click>=8.1",
"pydantic>=2.0",
"pydantic-settings>=2.0",
"rich>=13.0",
"python-dotenv>=1.0",
"uuid7>=0.1.0",
"beautifulsoup4>=4.12",
"lxml>=5.0",
"mcp>=1.0",
"claude-agent-sdk>=0.1.38",
"google-auth-oauthlib>=1.0; extra == \"gmail\"",
"google-api-python-client>=2.100; ex... | [] | [] | [] | [
"Repository, https://github.com/saxenauts/syke",
"Documentation, https://syke-docs.vercel.app",
"Changelog, https://github.com/saxenauts/syke/blob/main/CHANGELOG.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T07:53:42.974666 | syke-0.3.4.tar.gz | 122,998 | 44/3e/6be89781a6e7bb07793cb9589d8e14c7dddaf5da2cd352a361fc3ca4052b/syke-0.3.4.tar.gz | source | sdist | null | false | a2f69a47d4ab64df1399e6bfd88f17b3 | 8c8f06b1cfc497aeb24000d249c11a9cb2accb4f63a33562391f21de5bd4f463 | 443e6be89781a6e7bb07793cb9589d8e14c7dddaf5da2cd352a361fc3ca4052b | MIT | [
"LICENSE"
] | 259 |
2.4 | jarviscore-framework | 0.4.0 | Build autonomous AI agents in 3 lines of code. Production-ready orchestration with P2P mesh networking. | # JarvisCore Framework
**Build autonomous AI agents with P2P mesh networking and full infrastructure stack.**
## Features
- **AutoAgent** — LLM generates and executes code from natural language; supervised by Kernel OODA loop
- **CustomAgent** — Bring your own logic with P2P message handlers and workflow steps
- **P2P Mesh** — Agent discovery and communication via SWIM protocol + ZMQ
- **Workflow Orchestration** — Dependencies, context passing, multi-step pipelines with crash recovery
- **Kernel / SubAgent** — OODA loop supervisor with coder / researcher / communicator roles, lease budgets, HITL
- **Infrastructure Stack** — Blob storage, mailbox, memory, auth — auto-injected before every agent starts
- **Distributed Autonomous Workers** — Mesh claims workflow steps without hardcoding STEP_ID
- **UnifiedMemory** — EpisodicLedger, LongTermMemory, RedisMemoryAccessor, WorkingScratchpad
- **Context Distillation** — TruthContext, TruthFact, Evidence models for shared agent knowledge
- **Nexus Auth Injection** — Full OAuth flow via `requires_auth=True`; no boilerplate in agents
- **Telemetry / Tracing** — TraceManager (Redis + JSONL), Prometheus step metrics
- **FastAPI Integration** — 3-line setup with JarvisLifespan
- **Cognitive Discovery** — LLM-ready peer descriptions for autonomous delegation
- **Cloud Deployment** — Self-registering agents for Docker/K8s
## Installation
```bash
pip install jarviscore-framework
# With Redis support (required for distributed features)
pip install "jarviscore-framework[redis]"
# With Prometheus metrics
pip install "jarviscore-framework[prometheus]"
# Everything
pip install "jarviscore-framework[redis,prometheus]"
```
## Setup
```bash
# Initialize project
python -m jarviscore.cli.scaffold --examples
cp .env.example .env
# Add your LLM API key to .env
# Start Redis (required for mailbox, memory, distributed workflows)
docker compose -f docker-compose.infra.yml up -d
# Validate
python -m jarviscore.cli.check --validate-llm
python -m jarviscore.cli.smoketest
```
## Quick Start
### AutoAgent (LLM-Powered)
```python
from jarviscore import Mesh
from jarviscore.profiles import AutoAgent
class CalculatorAgent(AutoAgent):
role = "calculator"
capabilities = ["math"]
system_prompt = "You are a math expert. Store result in 'result'."
mesh = Mesh(mode="autonomous")
mesh.add(CalculatorAgent)
await mesh.start()
results = await mesh.workflow("calc", [
{"agent": "calculator", "task": "Calculate factorial of 10"}
])
print(results[0]["output"]) # 3628800
```
### CustomAgent + FastAPI (Recommended)
```python
from fastapi import FastAPI
from jarviscore.profiles import CustomAgent
from jarviscore.integrations.fastapi import JarvisLifespan
class ProcessorAgent(CustomAgent):
role = "processor"
capabilities = ["processing"]
async def on_peer_request(self, msg):
return {"result": msg.data.get("task", "").upper()}
# 3 lines to integrate with FastAPI
app = FastAPI(lifespan=JarvisLifespan(ProcessorAgent(), mode="p2p"))
```
### CustomAgent (Workflow Mode)
```python
from jarviscore import Mesh
from jarviscore.profiles import CustomAgent
class ProcessorAgent(CustomAgent):
role = "processor"
capabilities = ["processing"]
async def execute_task(self, task):
data = task.get("params", {}).get("data", [])
return {"status": "success", "output": [x * 2 for x in data]}
mesh = Mesh(mode="distributed", config={"bind_port": 7950, "redis_url": "redis://localhost:6379/0"})
mesh.add(ProcessorAgent)
await mesh.start()
results = await mesh.workflow("demo", [
{"agent": "processor", "task": "Process", "params": {"data": [1, 2, 3]}}
])
print(results[0]["output"]) # [2, 4, 6]
```
## Infrastructure Stack (Phases 1–9)
Every agent receives the full infrastructure stack automatically — no wiring required.
| Phase | Feature | Injected as | Enabled by |
|-------|---------|-------------|------------|
| 1 | Blob storage | `self._blob_storage` | `STORAGE_BACKEND=local` (default) |
| 2 | Context distillation | `TruthContext`, `ContextManager` | automatic |
| 3 | Telemetry / tracing | `TraceManager` | automatic (`PROMETHEUS_ENABLED` for metrics) |
| 4 | Mailbox messaging | `self.mailbox` | `REDIS_URL` |
| 5 | Function registry | `self.code_registry` | automatic (AutoAgent) |
| 6 | Kernel OODA loop | `Kernel` (AutoAgent internals) | automatic (AutoAgent) |
| 7 | Distributed workflow | `WorkflowEngine` | `REDIS_URL` |
| 7D | Nexus auth | `self._auth_manager` | `requires_auth=True` + `NEXUS_GATEWAY_URL` |
| 8 | Unified memory | `UnifiedMemory`, `EpisodicLedger`, `LTM` | `REDIS_URL` |
| 9 | Auto-injection | all of the above | automatic |
```python
class MyAgent(CustomAgent):
requires_auth = True # → self._auth_manager injected
async def setup(self):
await super().setup()
# Phase 9: already injected — no __init__ wiring needed
self.memory = UnifiedMemory(
workflow_id="my-workflow", step_id="step-1",
agent_id=self.role,
redis_store=self._redis_store, # Phase 9
blob_storage=self._blob_storage, # Phase 9
)
async def execute_task(self, task):
# Phase 1: save artifact
await self._blob_storage.save("results/output.json", json.dumps(result))
# Phase 4: notify another agent
self.mailbox.send(other_agent_id, {"event": "done", "workflow": "my-workflow"})
# Phase 8: log to episodic ledger
await self.memory.episodic.append({"event": "step_complete", "ts": time.time()})
return {"status": "success", "output": result}
```
## Production Examples
All four examples require Redis (`docker compose -f docker-compose.infra.yml up -d`).
| Example | Mode | Profile | Phases exercised |
|---------|------|---------|-----------------|
| Ex1 — Financial Pipeline | autonomous | AutoAgent | 1, 3, 4, 5, 6, 8, 9 |
| Ex2 — Research Network (4 nodes) | distributed SWIM | AutoAgent | 4, 7, 8, 9 |
| Ex3 — Support Swarm | p2p | CustomAgent | 1, 4, 7D, 8, 9 |
| Ex4 — Content Pipeline | distributed | CustomAgent | 1, 4, 5, 7, 8, 9 |
```bash
# Ex1: Financial pipeline (single process)
python examples/ex1_financial_pipeline.py
# Ex2: 4-node distributed research network
python examples/ex2_synthesizer.py & # Start seed first (port 7949)
python examples/ex2_research_node1.py & # port 7946
python examples/ex2_research_node2.py & # port 7947
python examples/ex2_research_node3.py & # port 7948
# Ex3: Customer support swarm (P2P + optional Nexus auth)
python examples/ex3_support_swarm.py
# Ex4: Content pipeline with LTM (sequential, single process)
python examples/ex4_content_pipeline.py
```
## Profiles
| Profile | You Write | JarvisCore Handles |
|---------|-----------|-------------------|
| **AutoAgent** | System prompt (3 attributes) | LLM code generation, Kernel OODA loop, sandboxed execution, repair, function registry |
| **CustomAgent** | `on_peer_request()` and/or `execute_task()` | Mesh, discovery, routing, lifecycle, all Phase 1–9 infrastructure |
## Execution Modes
| Mode | Use Case |
|------|----------|
| `autonomous` | Single machine, LLM code generation (AutoAgent) |
| `p2p` | Agent-to-agent communication, swarms (CustomAgent) |
| `distributed` | Multi-node workflows + P2P + Redis crash recovery |
## Framework Integration
JarvisCore is **async-first**. Best experience with async frameworks.
| Framework | Integration |
|-----------|-------------|
| **FastAPI** | `JarvisLifespan` (3 lines) |
| **aiohttp, Quart, Tornado** | Manual lifecycle (see docs) |
| **Flask, Django** | Background thread pattern (see docs) |
## Documentation
**[https://prescott-data.github.io/jarviscore-framework/](https://prescott-data.github.io/jarviscore-framework/)**
| Guide | Description |
|-------|-------------|
| [Getting Started](https://prescott-data.github.io/jarviscore-framework/GETTING_STARTED/) | 5-minute quickstart |
| [AutoAgent Guide](https://prescott-data.github.io/jarviscore-framework/AUTOAGENT_GUIDE/) | LLM-powered agents, Kernel, distributed research network |
| [CustomAgent Guide](https://prescott-data.github.io/jarviscore-framework/CUSTOMAGENT_GUIDE/) | CustomAgent patterns, all phases, production example walkthroughs |
| [User Guide](https://prescott-data.github.io/jarviscore-framework/USER_GUIDE/) | Complete documentation including Infrastructure & Memory chapter |
| [API Reference](https://prescott-data.github.io/jarviscore-framework/API_REFERENCE/) | Detailed API docs including Phase 1–9 infrastructure classes |
| [Configuration](https://prescott-data.github.io/jarviscore-framework/CONFIGURATION/) | Settings reference with phase → env var mapping |
| [Troubleshooting](https://prescott-data.github.io/jarviscore-framework/TROUBLESHOOTING/) | Common issues and diagnostics |
| [Changelog](https://prescott-data.github.io/jarviscore-framework/CHANGELOG/) | Full release history |
Docs are also bundled with the package:
```bash
python -c "import jarviscore; print(jarviscore.__path__[0] + '/docs')"
```
## Version
**0.4.0**
## License
MIT License
| text/markdown | null | Ruth Mutua <mutuandinda82@gmail.com>, Muyukani Kizito <muyukani@prescottdata.io> | null | Prescott Data <info@prescottdata.io> | null | agents, p2p, llm, distributed, workflow, orchestration | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pydantic>=2.0.0",
"pydantic-settings>=2.0.0",
"swim-p2p",
"pyzmq",
"python-dotenv>=1.0.0",
"aiohttp>=3.9.0",
"beautifulsoup4>=4.12.0",
"fastapi>=0.104.0",
"uvicorn>=0.29.0",
"anthropic>=0.18.0",
"openai>=1.0.0",
"google-genai>=1.0.0",
"httpx>=0.25.0",
"redis>=4.6.0; extra == \"redis\"",
... | [] | [] | [] | [
"Homepage, https://github.com/Prescott-Data/jarviscore-framework",
"Documentation, https://github.com/Prescott-Data/jarviscore-framework/tree/main/jarviscore/docs",
"Repository, https://github.com/Prescott-Data/jarviscore-framework",
"Issues, https://github.com/Prescott-Data/jarviscore-framework/issues"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T07:52:07.652895 | jarviscore_framework-0.4.0.tar.gz | 513,110 | 63/e0/e377852bb97b02e18580d8b3196cdf4d808919e9599ad7a7536e416be071/jarviscore_framework-0.4.0.tar.gz | source | sdist | null | false | 1a7ae8fb807b00b29aeafe8bf40e0990 | 08374c7944d37775107f457ca49cb48551c4aa1ae06d41a42256225da74dc856 | 63e0e377852bb97b02e18580d8b3196cdf4d808919e9599ad7a7536e416be071 | MIT | [
"LICENSE"
] | 283 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.